
【CVPR2022】Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation

【CVPR2022】Multi-Scale High-Resolution Vision Transformer for Semantic
Segmentation 代码:https://github.com/facebookresearch/HRViT
核心思想和主要方法
这个论文的核心思想就是将 HRNet 和 Transformer 相结合,同时,为了应用于密集预测任务,提出了避免计算复杂度过高的解决方案。
网络的整体架构如下图所示,可以看出整体结构和 HRNet 基本上是一样的,只是将其中的卷积层用 Transformer block 来代替。Transformer block 有 attention 和 FFN 两个基本结构,下面分别介绍两个部分作者的改进工作。
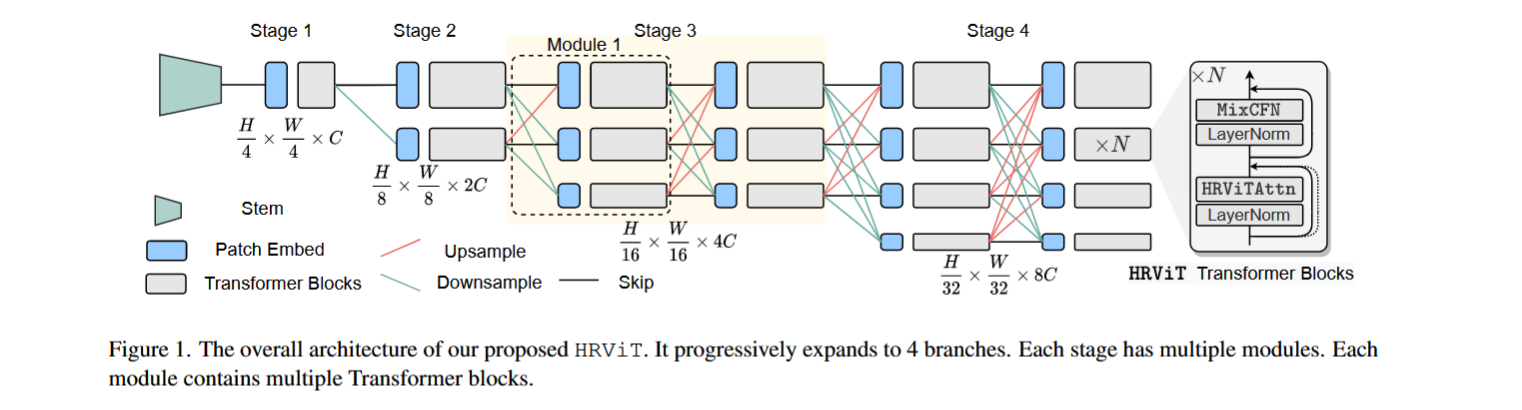
HRViTAttn
作者提出了 HRViTAttn ,结构如下图所示。Attention 复杂度最高的部分就是 Q 和 K 的矩阵相似度的计算,每个像素都参与计算相似度复杂度过高。因此,作者将从一开始就将通道分为两半,上面一半做行注意力,下面一半做列注意力。
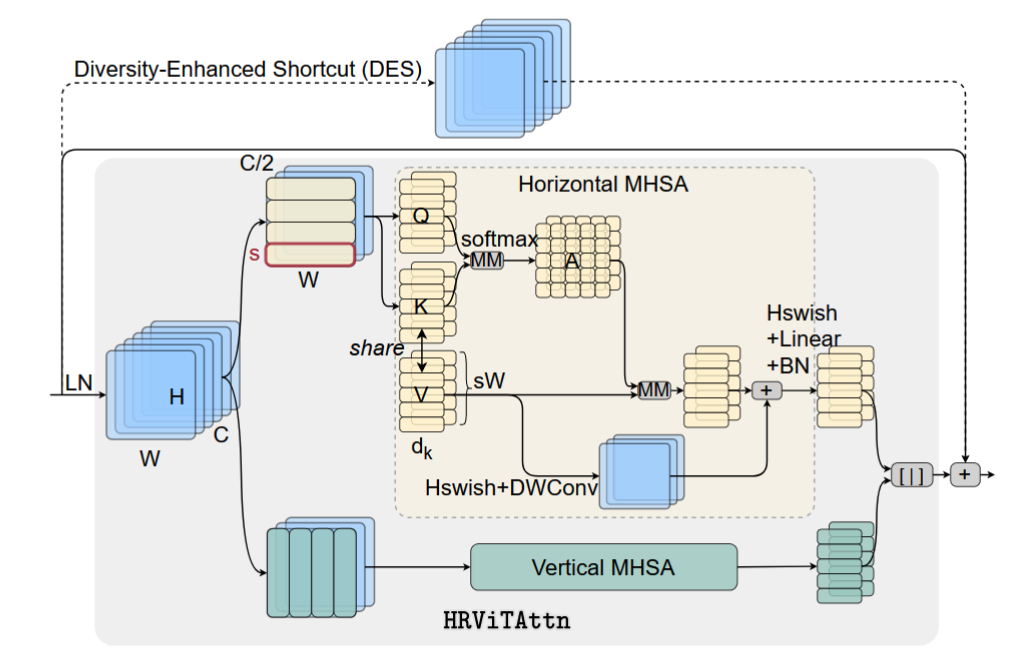
- s行为一个token,每个 token 的特征为 \(s \times W\) 或者 \(s \times H\),同时,相似度矩阵就为 \(s \times s\) 了,相似度的计算就简化了。(这里的处理方法和 Restormer 类似,大家可以回顾);
- 正常得到 K,Q,V时,需要三个 1x1 卷积,这里作者只使用了两个,K 和 V 是共享的,又进一步简化了计算;
- V 额外使用了 Hardwith 激活函数和 DWConv 处理,作者解释是增加了归纳偏置。
- 添加了一个 diversity-enhanced shortcut,这里是受了 NeurIPS2021 论文 Augmented Shortcuts for Vision Transformers 的启发,非常类似。
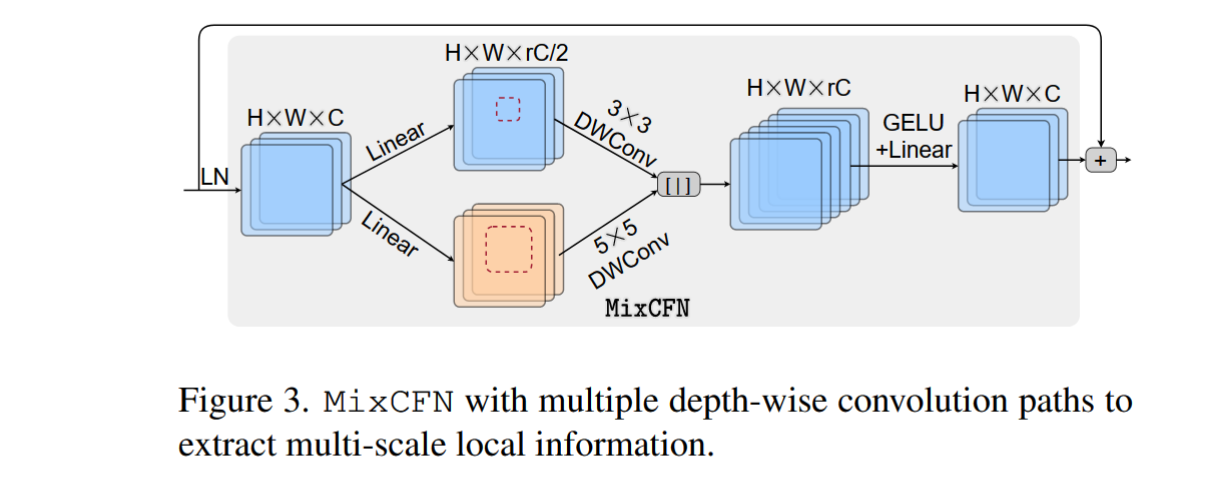
MixCFN
作者提出的 MixCFN 和大多数的 FFN 类似,都是先升维,后降维。不同的地方就是为了增强多尺度特征的提取,作者使用了 3X3 卷积和 5X5 卷积,如下图所示。
实验设计与分析
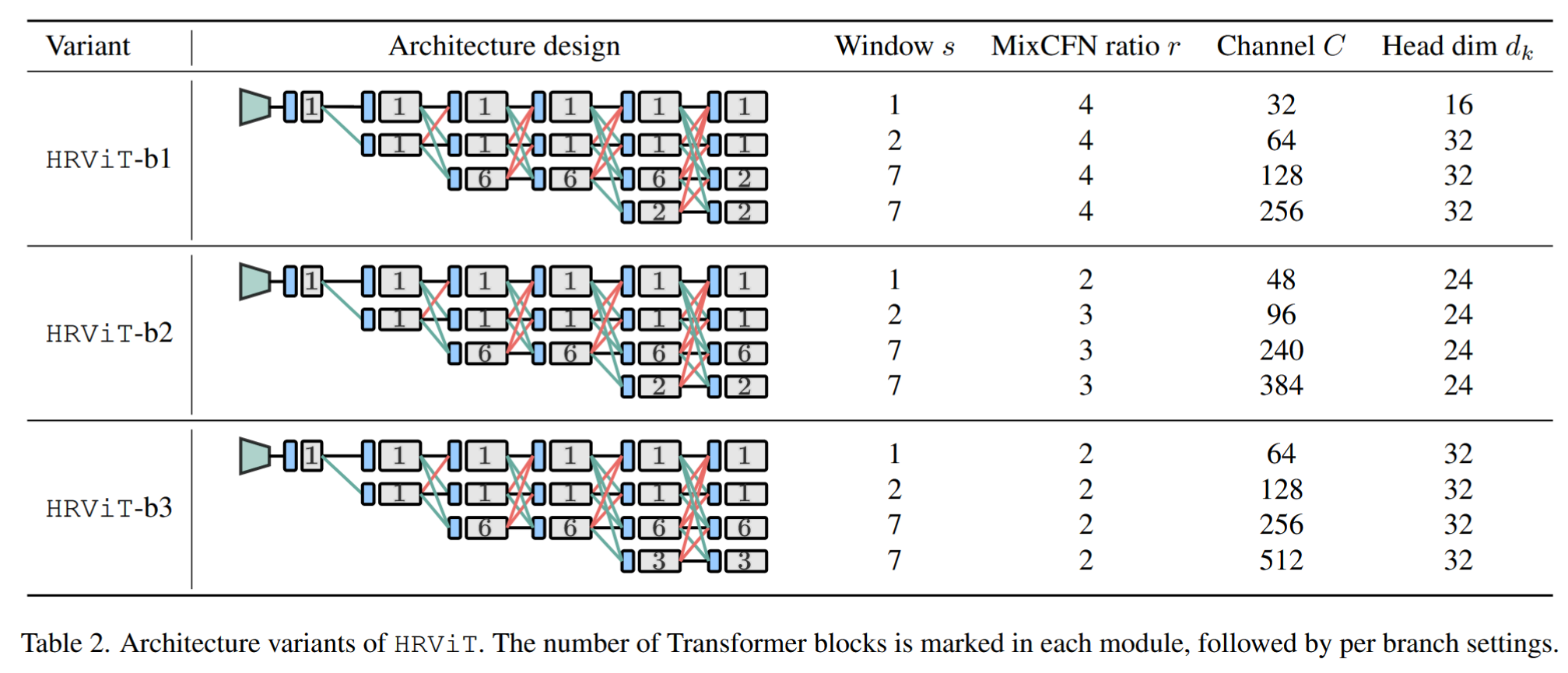
作者构建了网络的三个变体,具体如下表所示。
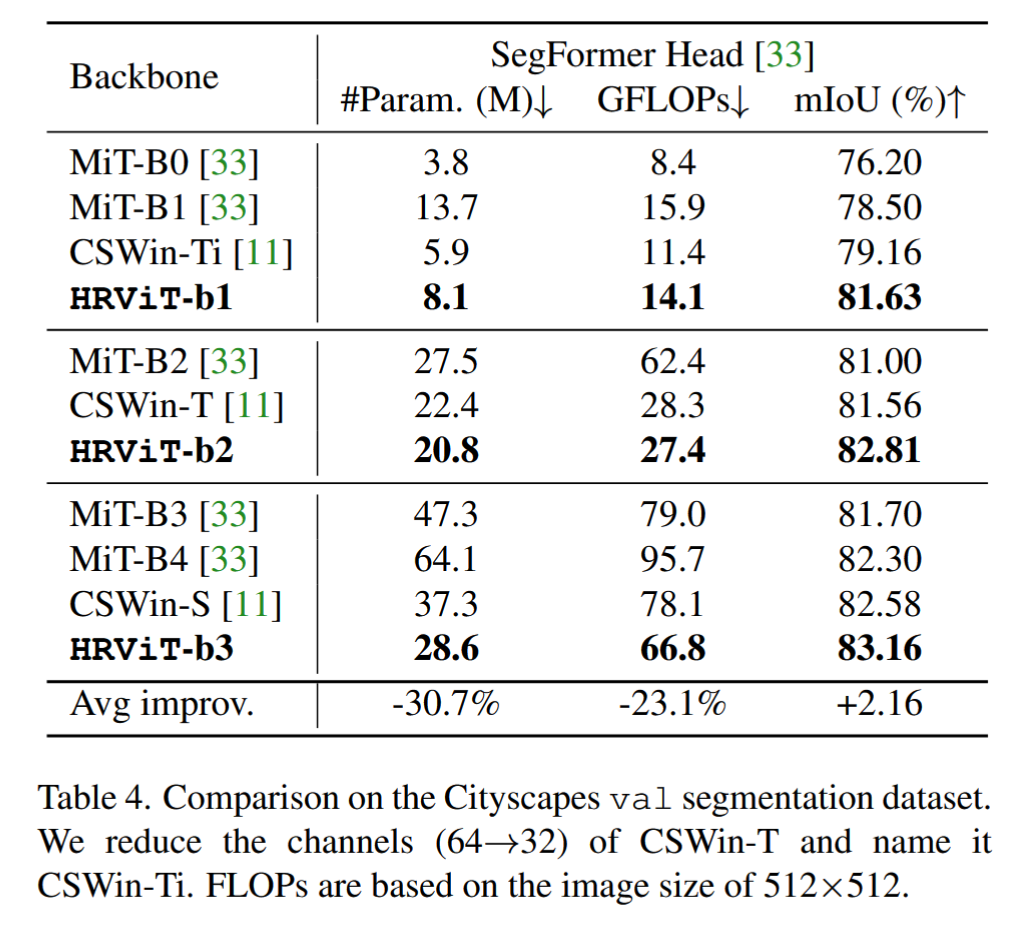
在Cityscapes 数据集上的分割结果如下表所示,与MiT和CSWin两个SoTA ViT Backbone相比,HRViT的mIoU平均提高了+2.16,参数减少了30.7%,计算量减少了22.3%。
其它实验可以参考作者论文,这里不过多介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号