
【ARXIV2203】Efficient Long-Range Attention Network for Image Super-resolution

【ARXIV2203】Efficient Long-Range Attention Network for Image Super-resolution
1、研究动机
尽管Transformer已经“主宰”了CV领域,在图像修复领域也有较多应用。但是Transformer中的自注意力计算量代价过于昂贵,同时某些操作对于超分而言可能是冗余的,这就限制了自注意力的计算范围,进而限制了超分性能。
本文提出了一种用于图像超分的高效长程距离网络ELAN(Efficient Long-range Attention Network),该模型架构如下所示,核心是 ELAB 模块,下面对这个模块进行详细介绍。
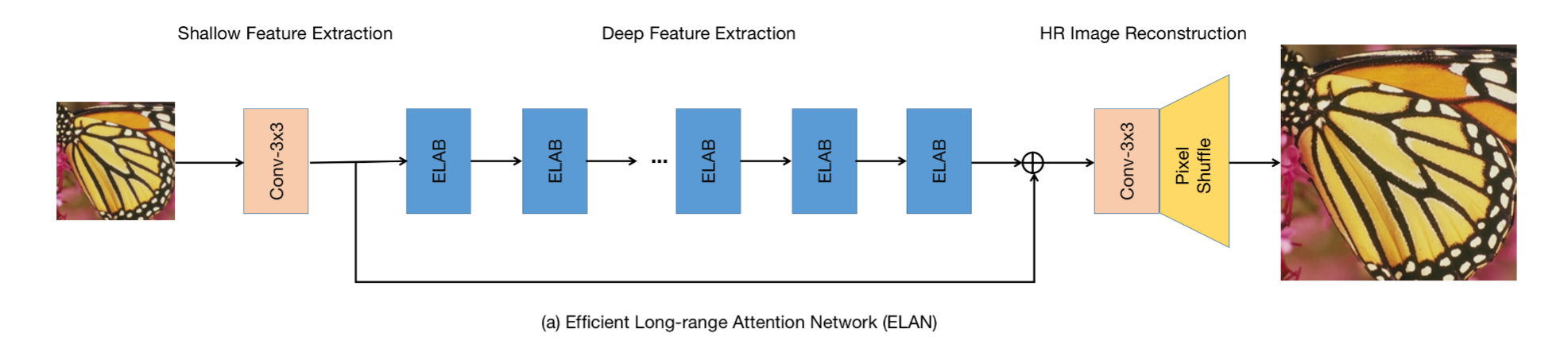
2、ELAB模块
ELAB模块包括两个关键部分: 局部特征提取 和 GMSA。
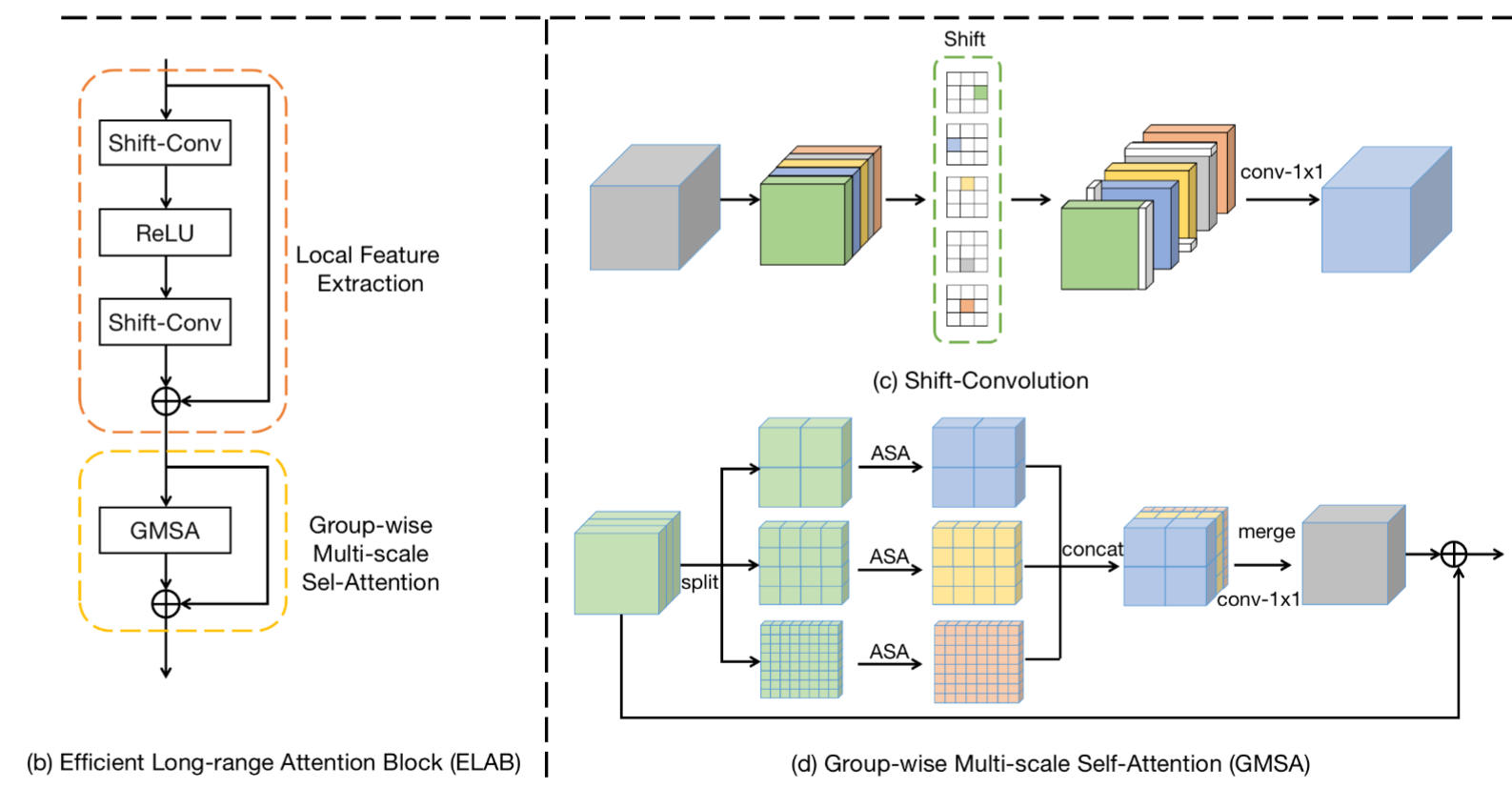
(1)局部特征提取
局部特征提取采用两个shift-conv+ReLU组合进行处理。具体来说,shift-conv由四个shift操作与卷积1x1卷积组成,shift操作则旨在对输入特征进行上下左右移位,然后将所得五组特征送入后接 1x1 卷积进行降维与信息聚合。无需引入额外可学习参数与计算量, shift-conv可以获得与(3x3卷积)相同的感受野与 1x1 卷积相当的计算量。
(2)GMSA
Group-wise multi-scale self-attention, GMSA 首先将输入特征分成K组,然后对不同组在不同窗口尺寸上执行自注意力,最后采用 1x1 卷积对不同组特征进行信息聚合。

注意力计算时使用了改进方法ASA,如上图所示,主要改进的地方为:
- 将LN替换为BN,作者认为LN对于推理并不友好,BN不仅可以稳定训练同时在推理阶段可以合并进卷积产生加速效果。
- 原来的自注意力需要要三个1X1卷积,这里进行了合并,只需要两个了。其中,L x M x M = H x W。是在局部窗口里计算注意力,M x M 是窗口的数量。
为了进一步加速计算,作者提出了 shared attention : 第i个自注意力模块的注意力图直接被同尺度后接n个自注意力模块复用。通过这种方式,我们可以避免2n个reshape与n个 1x1 卷积。作者发现:所提共享注意力机制仅导致轻微性能下降,但它可以在推理阶段节省大量的计算资源。
实验部分可以参考作者论文,这里不再过多介绍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号