
MobileNetV1 解读
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017
谷歌公司
ResNet,网络已经达到152层,模型大小动辄300MB+。巨大的存储和计算开销,严重限制了CNN在手机端的应用,谷歌为此于2017年设计了轻量级网络MobileNetV1,其核心是把普通卷积拆分为 Depthwise 和 Pointwise 两部分。
一般来说,输入卷积的通道数如果是Ci,输出的通道数如果是Co,卷积核大小为 kxk,那么卷积的参数量就是 Ci x Co x k x k。 如下图所示,卷积核大小为3x3,参数量为:3x4x3x3=108。
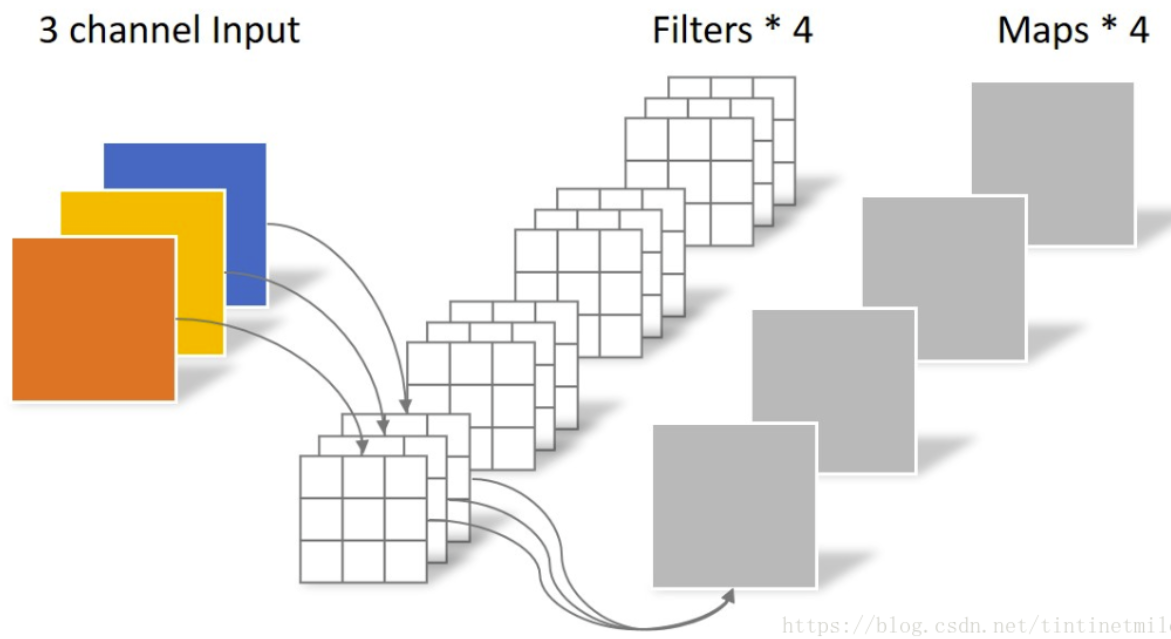
为了降低卷积中的参数,谷歌研究人员提出将常规卷积拆分为 Depthwise 和 Pointwise 两部分。
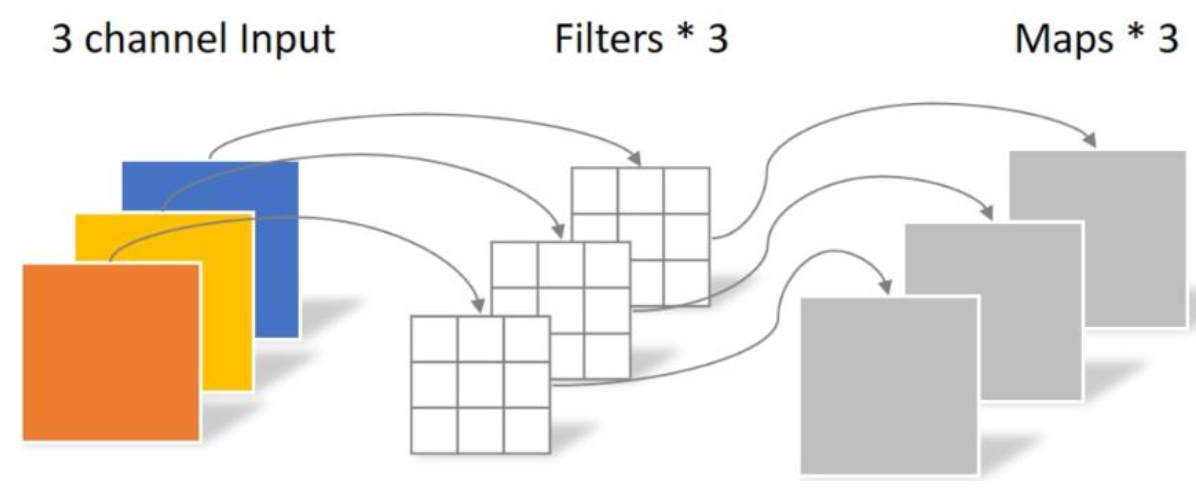
Depthwise: 处理上述图像,分为三组处理,卷积核的数量与输入的通道数相同(即组数),所以经过运算生成三个 feature map,卷积的参数为:3x3x3=27。 Depthwise没有充分利用不同通道上相同位置的信息,因此需要 Pointwise 来将这些特征重新整合。
Pointwise: 卷积核尺寸为 1x1x通道数。其实是将 Depthwise 的结果逐像素加权融合。但是,这里有几个 filter 输出就有几个通道。如下图所示,参数量为:1x1x3x4=12。
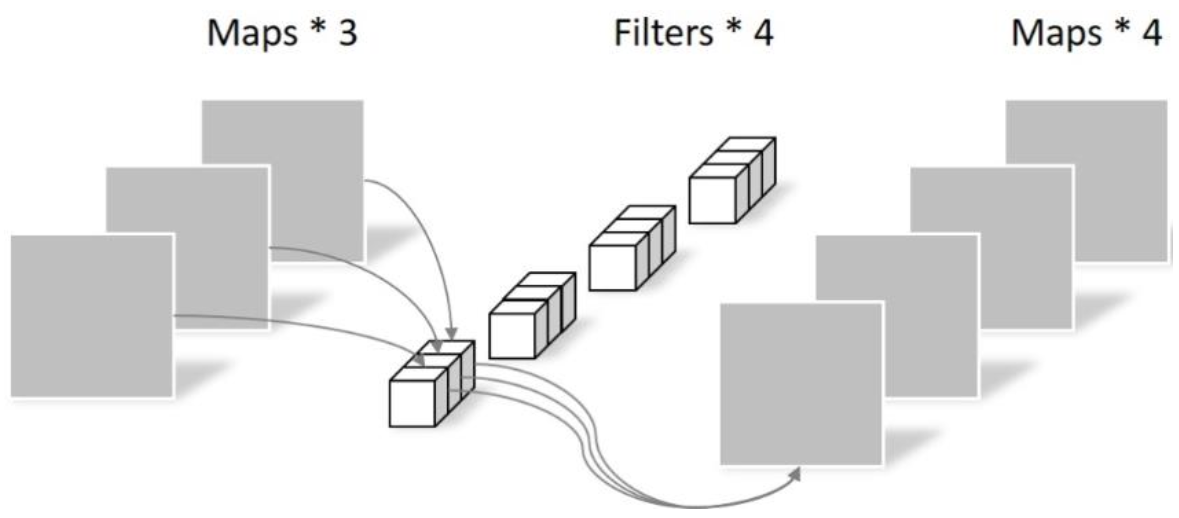
因此,现在通过 Depthwise 和 Pointwise 操作,卷积参数量为:27+12 = 39,显著小于原来的 108。
Pytorch代码如下:
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3,
stride=stride, padding=1, groups=in_planes, bias=False)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1,
stride=1, padding=0, bias=False)
MobileNetV1 的网络架构为(注意观察最后的输出部分):
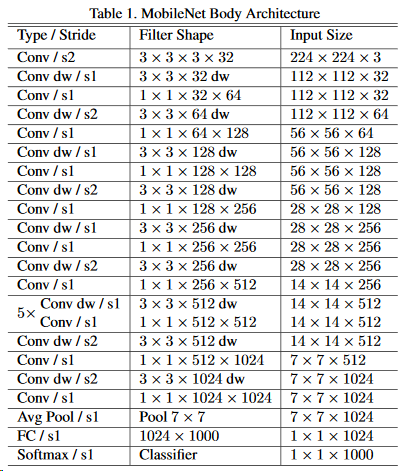
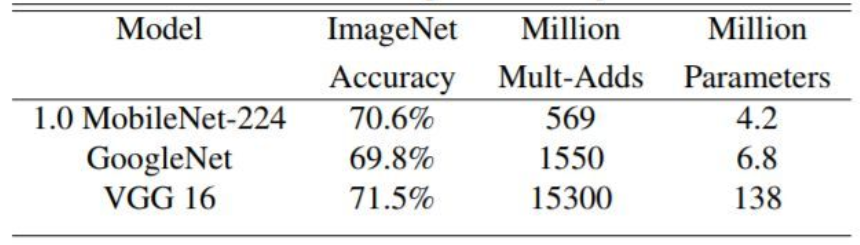
作者还做实验与 GoogleNet,VGG16 进行了比较,可以看到准确率相当的情况下,参数量显著降低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号