
卷积层中的特征冗余
随着CNN在手机终端部署的越来越多,很多研究人员在研究如何降低神经网络的计算量。同时,大家都观察到一个现象,feature map 中的冗余是 CNN 的重要特点。
下图是 ResNet50 中的 feature map,可以看到很多的 feature map 是很相似的,比如图中标出的红、绿、蓝三组,这也说明 feature map 中存在较多的冗余。下面分析下相关的三个工作:

GhostNet,CVPR 2020
华为在 CVPR 2020 发表的 GhostNet (论文:https://arxiv.org/pdf/1911.11907.pdf)没有去除冗余特征,而是采用一种比传统卷积更轻量化的方法来生成冗余特征。通过“少量传统卷积计算”+“轻量的冗余特征生成器”的方式,既能减少网络的整体计算量,又能保证网络的精度。
作者提出了用于代替传统卷积层的Ghost module。Ghost module 如下图所示,包括两次卷积:

第一次卷积: 假设output中的通道数为 init_channels * ratio,那么第一次卷积生成 init_channels 个 feature map
第二次卷积: 每个 feature map 通过映射生成 ratio-1 个新的 feature map,这样会生成 init_channels * (ratio-1)个 feature map 。最后,把第一次卷积和第二次卷积得到的 feature map 拼接在一起,得到 output。
代码如下所示:
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
# 第一次卷积:得到通道数为init_channels,是输出的 1/ratio
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential())
# 第二次卷积:注意有个参数groups,为分组卷积
# 每个feature map被卷积成 raito-1 个新的 feature map
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
# 第一次卷积得到的 feature map,被作为 identity
# 和第二次卷积的结果拼接在一起
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
在实际应用中,作者构建了 Ghost Bottleneck,如下图所示。其中包含2个Ghost module,第1个Ghost module用于扩充特征的通道数,第2个Ghost module用于减少特征的通道数。

Split to be slim,IJCAI 2020
这是一篇 IJCAI 2020 的论文,在这个论文中,作者认为,卷积得到的 feature map 存在大量的冗余信息。因此,可以选择一些有代表性的 feature map 表达目标的本征特征,剩余的只需要补充一些细节信息。
作者提出了一个 SPConv 的模块,用来降低常规卷积中的冗余信息。在该模块中,所有的输入通道按比例α分为两部分:representative部分用 k x k 的卷积提取重要信息;redundant部分用 1x1 的卷积补充细节信息。如下图所示:
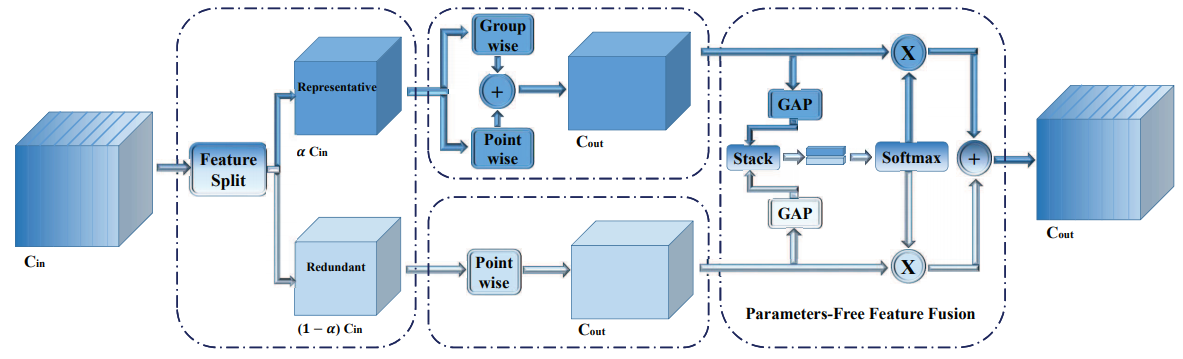
作者还认为,representative 部分仍可能存在冗余,因此,可以进一步拆分。因此,作者使用使用group-wise和point-wise卷积分别处理,再将结果融合。
对于得到的上下两个分支的特征,使用了类似 SKNet 的处理方式进行融合(这里是比较熟悉的 self-attention),得到最终的输出特征。
Tied Block Convolution
这篇论文是Berkeley 的 Xudong Wang 博士20年9月放在 arxiv 上的论文。作者同样指出,在卷积当中, feature map 的冗余比较高。作者提出了 Tied Block Convolution (TBC)。
TBC 和 group conv 比较像,首先回顾一下 group conv :如果输入 feature map 的通道数是 \(c_i\),输出的 feature map 通道数是 \(c_o\),卷积核大小为 \(k\times k\) ,分为 \(G\) 组做卷积,那么参数量为:\(c_i\times c_o \times k \times k / G\)。
TBC 通过在不同组间重用 kernel 来减少滤波器的有效数量。直观来说,TBC 把特征为 \(B\) 组做卷积,但是这 \(B\) 组的 kernel 是完全相同的 ( group conv 里,各组的 kernel 是不同的)。这样,TBC 的参数量就是 \(c_i \times c_o \times k\times k / (B\times B)\) 。参数量进一步降低了。
作者认为 TBC 与 group conv 相比有三个优势:1、参数降低了; 2、更加容易在GPU 上并行; 3、每一组 filter 都应用于所有输入通道,可以更好的建模跨通道的依赖关系。
目前能想到的有这三个工作,再有类似的,随时想到再继续补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号