

【跨模态智能分析】人物关系检测、指代表达、指代分割
主要内容来自于 北京航空航天大学 刘偲 老师在 CSIG 云讲堂的报告《跨模态智能分析》
人物交互关系检测:Parallel point detection and matching
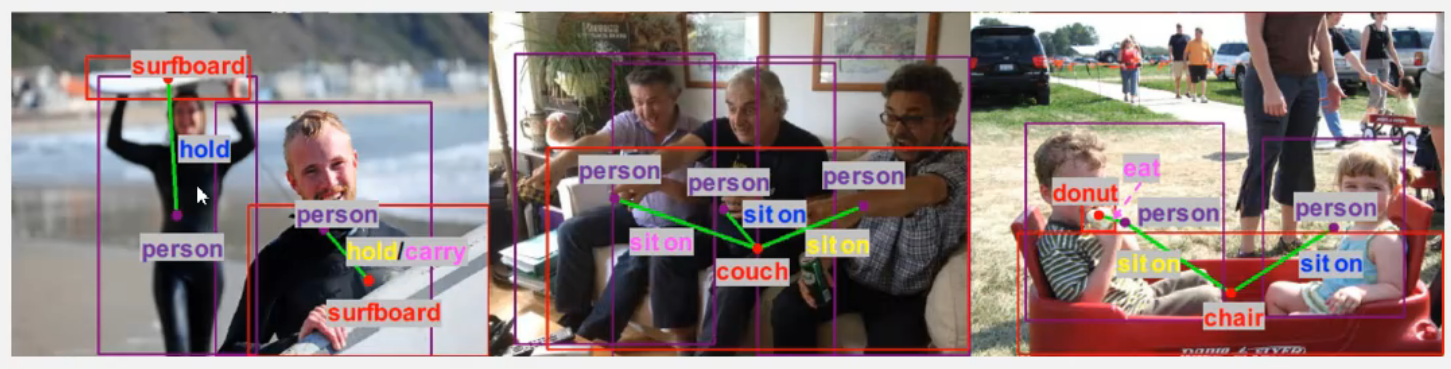
近年来,在目标检测和识别领域取得了较大进展。 但是,要了解场景中的情况,还需要认识到人类如何与周围物体互动。比如下面中间的图,有一个 couch,还有很多人,就知道这些人和 couch 的关系是 sit on。
传统方法都是采用 two-stage 的方法,先用 faster-rcnn 检测出来很多个 bounding box,然后把任意两个 box 配对,就有 C(n^2) 个 pair, 然后把所有的 pair 送到一个分类网络中,判断这些 box 之间是不是有关系?如果有关系,是哪一种关系?
但这样的话,就带来一个挑战问题:算法复杂度高,无法实习应用。
因此,提出了下面的方法:
PPDM: Parallel point detection and matching for real-time human-object interaction detection. CVPR 2020.
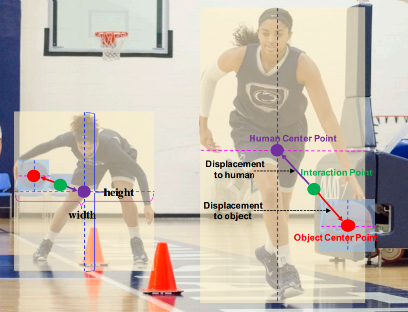
这个方法主要是提出了一个 interaction point,就是下图中的绿点,同时可以定位到主语和宾语。这就是 point detection branch,相当于定位到三个点。
第二个阶段,是 point matching branch。对这个图来说,可能有多个人,可能有多个球,这样就要确认到底是哪个人在打哪个球,把对应的人和球找到。
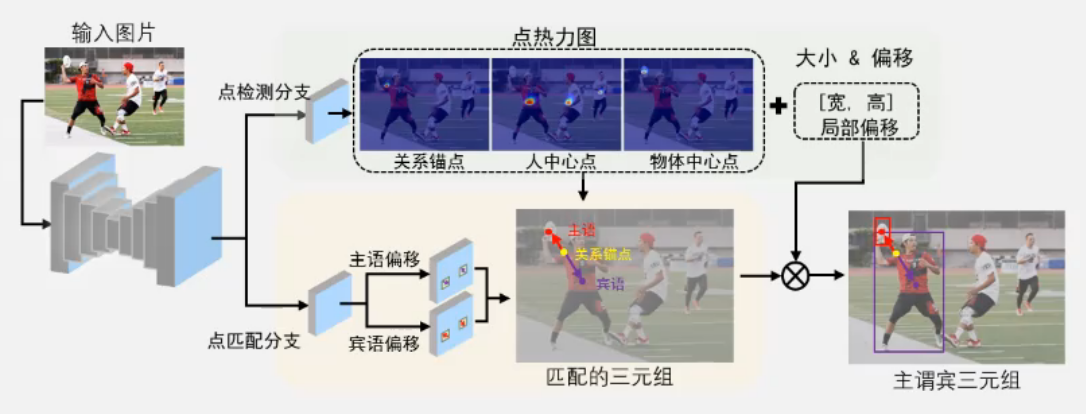
方法框架和常规的方法不一样,分为两个并行的 branch,上面分支是点检测,下面分支是点匹配,两个 branch 是可以并行的,因此,可以达到近实时的处理效果。
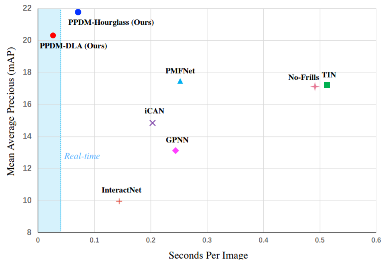
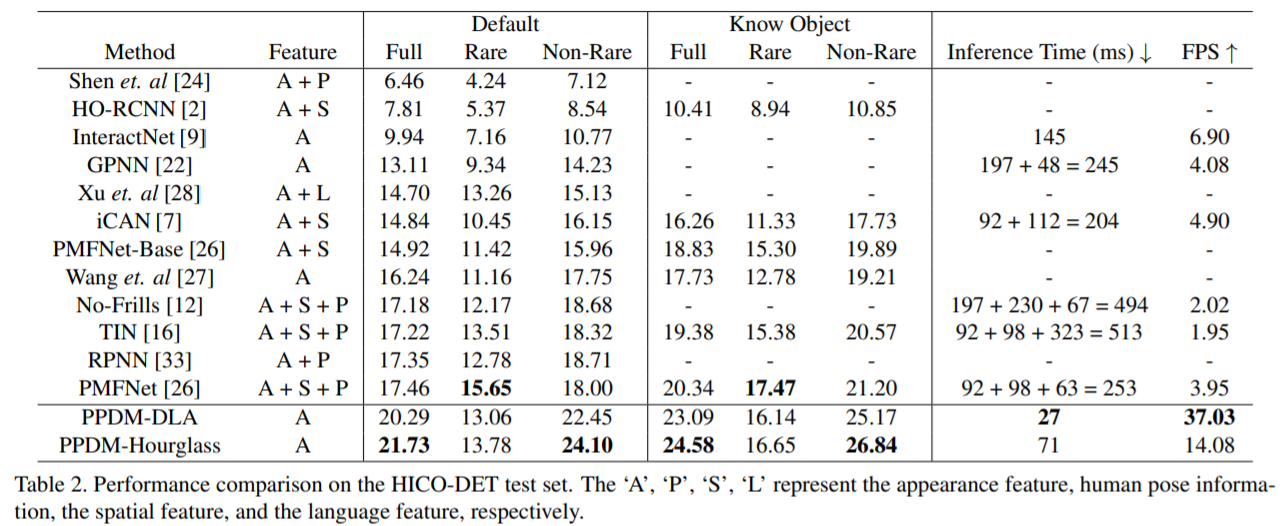
下图是一个实验结果,纵轴是精度,横轴是每张图片的耗时,可以看到,该方法的精度是非常高的,同时速度也是最快的。这个方法也是第一个可以做到实时的方法。
下图是在 HICO-DET数据集上的一个结果,可以看出,该方法的精度非常高,同时,速度可以达到每秒37帧。
指代表达
A Real-time cross-modality correlation filtering method for referring expression comprehension, CVPR 2020
指代表达是要做下面的事,提供一句话“拿着白色飞盘的红衣男子”,然后在图中画一个框,把这个人找到。这个和一般的目标定位不一样,因为里面有“红色衣服”这样的属性,还有“拿着白色飞盘”这样的动作,要深刻的理解图像才能找到对象,这个任务会非常难。

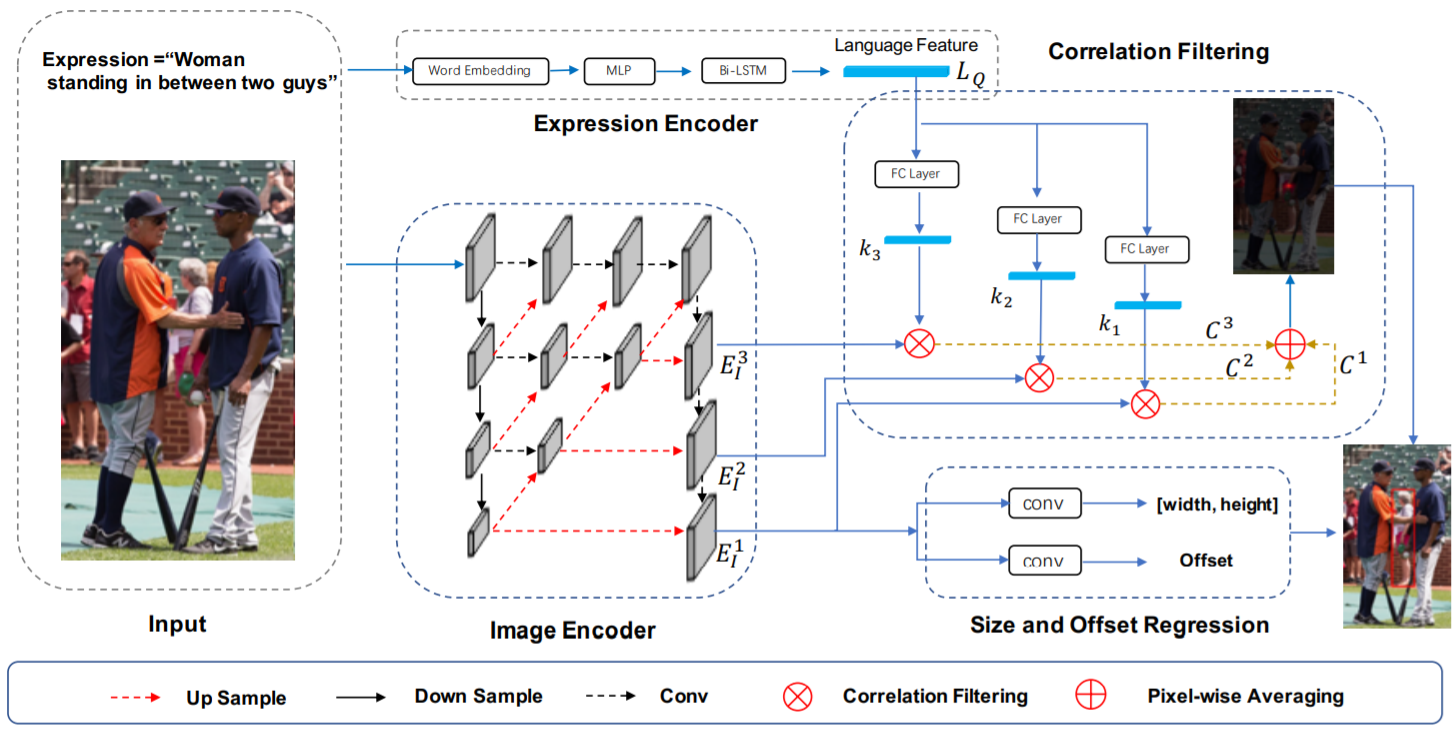
这个方法是怎么做的呢?首先有一个文本的理角,有一个 expression encoder,然后得到一个文本的特征。然后对图像提取特征,这里是一个非常 general 的做法,就是提取 multiscale 的特征。
接着把本文的特征看作一个 kernel ,来和图像的 feature map 做卷积,最后得到一个输出,得到 woman 在哪里。然后通过前面的图像信息来计算 size 和 offset。得而得到最终的结果。
下面是在各个数据集上的实验结果对比,可以看到,该方法是大幅的超越了 state-of-the-art。

下面是视化的实验结果,可以看到检测的结果还是非常神奇。绿色的是 ground truth,绿色的是本方法的结果,蓝色的是 MAttNet 的结果。

后续工作:指代分割
Referring image segmentation via cross-modal progressive comprehension, CVPR 2020
Linguistic structure guided context modeling for referring image segmentation, ECCV 2020
是在上一个工作的基础上做一个分割。

从动机上来看,主要是依照人类的做法。首先,人会在图像中找到一些实体,比如说人,飞盘等等。第二步,做一个关系推理,知道其他人不是我们的目标,只有拿着白色飞盘的人是我们的目标。相当于“飞盘”给人一个强化,最后得到最终结果。
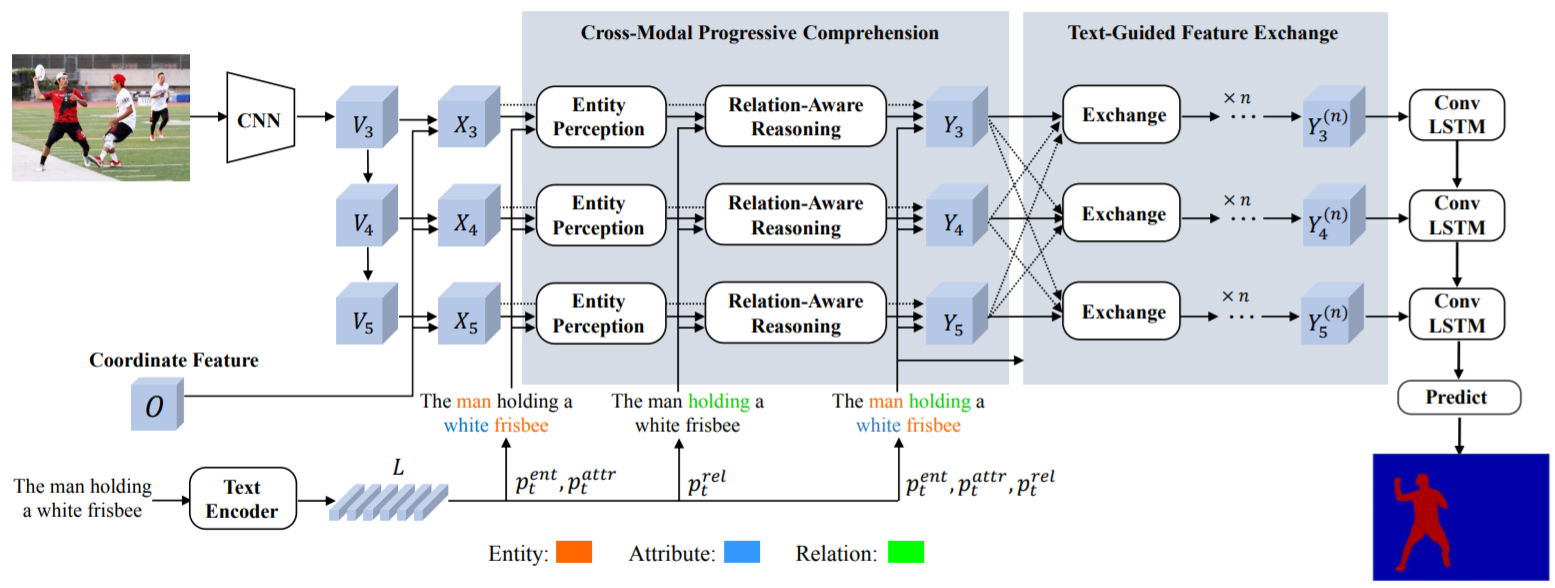
该方法的 framework 如下。首先提取文本特征,然后,提取多尺度的图像特征,同时还会结合 “坐标特征”。
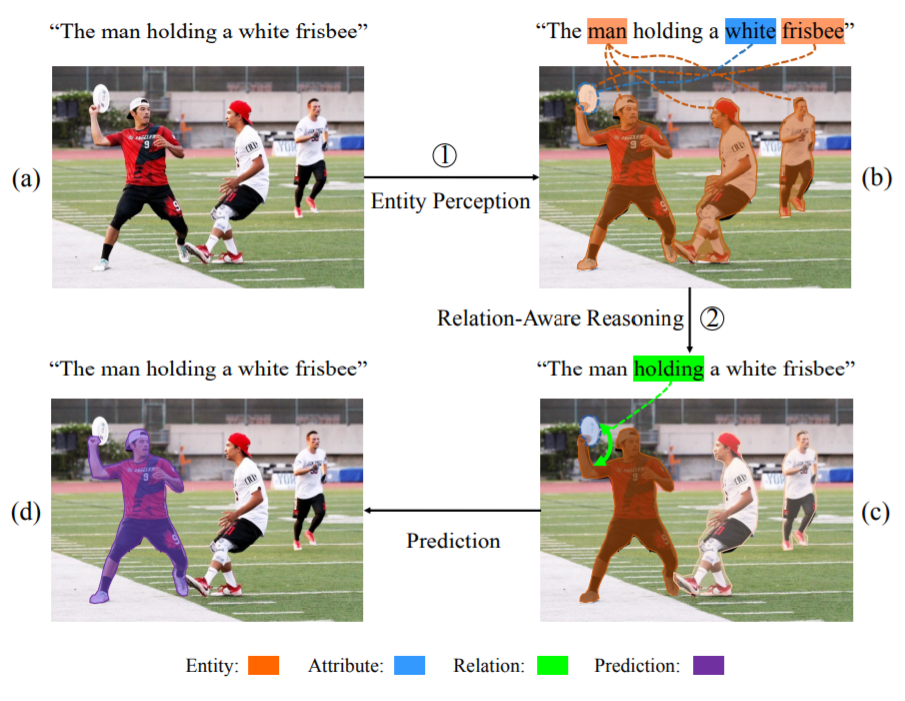
接下来是 entity perception,就是定位到所有的实体。接下来是进行关系推理,利用动作来强化我们感兴趣的目标。这里相当于是模拟了人的一个感知过程。
最后,text-guided feature exchange 是不同层特征的融合,这里融合主要是可以综合利用不同层的信息,最后得到一个分割的结果。
因为关系的推理是非常重要的一环,下面重点说下这部分:
entity perception: 视觉特征 \(X\) 和文本特征 \(q\) 使用双线性融合。
relation-aware reasoning:多模态全连接的图 \(G\) 被构建起来,每一个节点对应了图像中的一个区域。使用 GCN 最重要的是两点,你的点是怎么定义的,你的边及权重是如何定义的。每一个目标就是一个节点,然后使用一个 attention 机制,来强调动作。

该方法在4个数据集上,都取得到 state-of-the-art 的效果。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号