

【ECCV2020】Image Inpainting via a Mutual Encoder-Decoder with Feature Equalizations
论文:https://arxiv.org/abs/2007.06929
代码:https://github.com/KumapowerLIU/Rethinking-Inpainting-MEDFE
论文的解读选自刘虹雨的在极市平台的文章,值得注意的是,这个工作在今年2月份也宣传过,论文的题目及内容有相应调整。
当前的双阶段image inpainting需要在第一阶段得到一个 coarse 的图像,在这个图像上结构已经修复的不错,在此基础上再修复图像的纹理细节。但是, 这些方法的结果中 structure 和 texture 往往不一致。如下图所示:

Visual comparison on the Paris StreetView dataset. GT is the ground truth image. The proposed inpainting method is effffective to reduce blur and artifacts within and around the hole regions, which are brought by inconsistent structure and texture features.
为了解决这一问题,作者提出了一个 mutual encoder-decoder,同时从CNN中学习结构 和 纹理 特征。网络结构如下图所示:
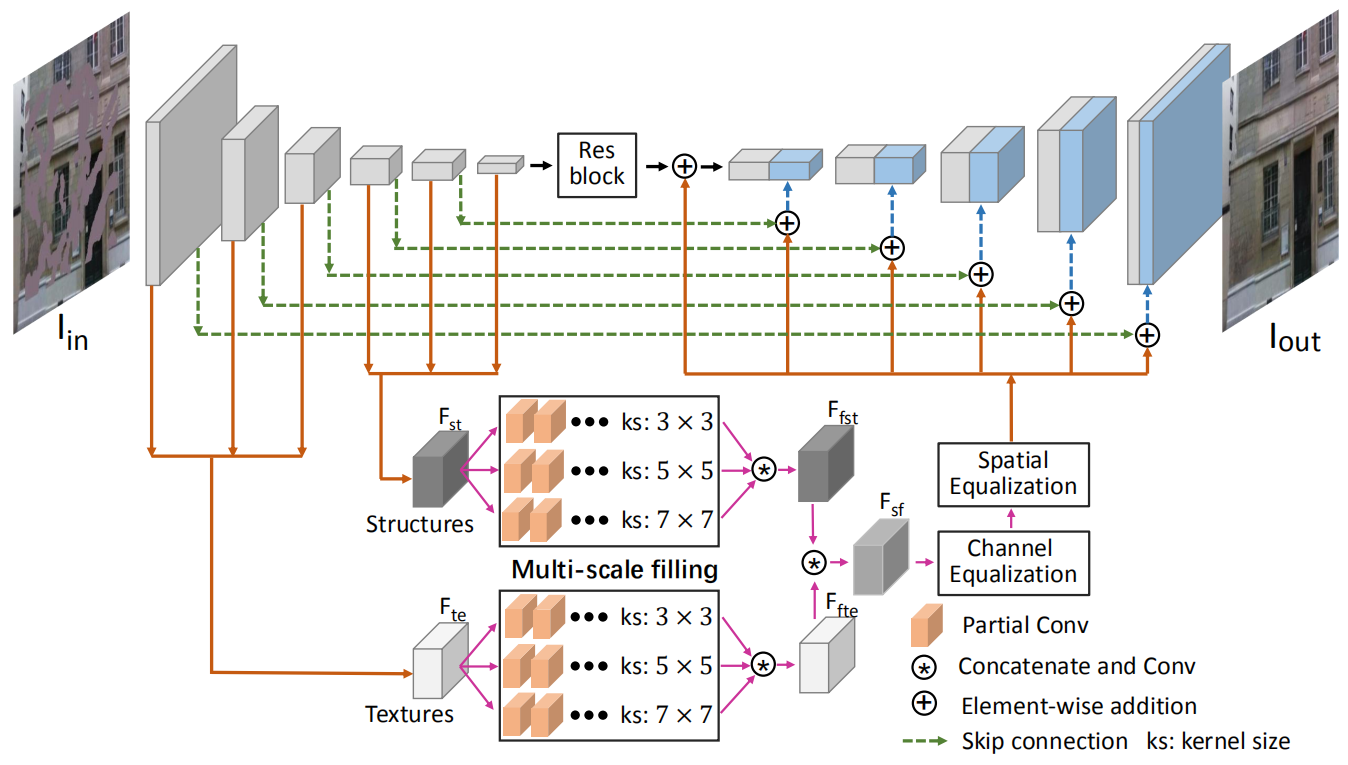
作者认为:越深的卷积层代表着结构信息(高级语义信息),越浅的卷积层代表纹理以及细节信息(低层级信息)。因此,将编码器的特征分成两个部分,前3层代表纹理信息,后3层代表结构信息,前三层和后三层分别 integrate 起来变成32×32×256大小的卷积。其中 \(F_{te}\) 代表前三层的 integrated features 也就是充满纹理的特征, \(F_{st}\) 代表后三层的 integrated features 也就是充满结构信息的特征。
-
如何去修复这些 feature 的孔洞区域? 将 \(F_{st}\) 和 \(F_{te}\) 分别通过多尺度修复模块来修复孔洞区域,具体来说多尺度修复由三个不同卷积大小的partial conv 组成,他们的kernel size分别是3,5,7。 \(F_{st}\) 和 \(F_{te}\) 经过多尺度修复模块后就是\(F_{fst}\) 和 \(F_{fte}\) .
-
那么如何能够保证这些 feature 能够真正关注纹理或者结构呢? 这里用了最简单的constrain,将 \(F_{fst}\) 和 \(F_{fte}\) 用1×1的卷积映射到RGB( \(F_{fst}\) 映射后的图为 \(I_{ost}\) , \(F_{fte}\) 映射后的图为 \(I_{ote}\))并跟 ground truth 计算 L1 loss,其中 \(I_{ost}\) 的 ground truth 是结构图 \(I_{st}\) ,这张结构图是将原图通过edge-perserving filter 处理后抹去纹理生成的,而 \(I_{ost}\) 的ground truth就是原图( \(I_{gt}\), 有纹理和细节的图)。这种constrain如下所示:
\[L_{rst}= || I_{ost}-I_{st}|| \]\[L_{rte}=||I_{ote}-I_{gt}|| \]
这样,解码器包括两个流:结构流 和 纹理流,分别通过多尺度修复进行inpainting,同时分别有自己的 constrain 保证填充效果,并促进每个流关注纹理或者结构。
这时又产生一个新的问题,如何将\(F_{fst}\) 和 \(F_{fte}\) 融合成一张完整的图呢?作者将二者拼接,同时使用 1x1 的卷积处理得到一个简单融合的 \(F_{st}\),接着通过特征均衡化来实现更好的融合。特称均衡化包括两个维度的均衡,一个是channel上的一个是spatial上的,其中channel上的均衡通过SE-block实现,因为其中的attention值是由 \(F_{sf}\) 得到,而 \(F_{sf}\) 已经包含了结构和纹理的特征信息,所以这些attention是由结构和纹理信息一起得来从而保证了均衡化。在spatial上,作者提出了双边激活函数 bilateral propagation activation function (BPA).
BPA是从 edge-perserving image smoothing (双边滤波) 中得到的启发,下面回顾下双边波滤。在数字图像处理中我们都学过,高斯滤波的结果可以模糊图像,但是容易丢失边缘细节信息。双边滤波是在其基础上,叠加了像素值的考虑,对于保留图像中的边缘更有效。
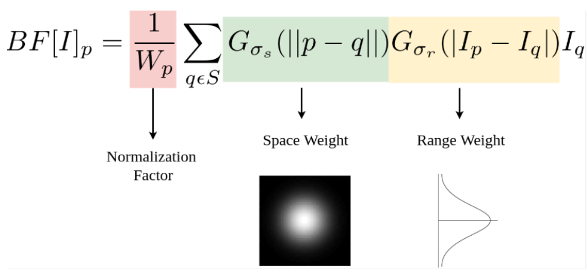
双边滤波可以理解为包含两个部分:一个为空间分支(spatial),即以前的高斯滤滤; 另一个为灰度分支(range),考虑当前点与模板中心点的灰度差的绝对值。
在图像的平坦区域,像素值变化小,此时空间域权重起主要作用,相当于对图像进行高斯模糊。
在图像的边缘区域,像素值变化较大的点灰度分支权重较大。当前点灰度值如果与模板中心点灰度差值较大,即使离中心点距离远,仍然权重较大,这样就保护了边缘信息。
一个形象的图如下所示,在边缘上,使用了像素差权重,所以较好的保留了图像中的边缘信息。

现在回到论文中的双边注意力机制,如下图所示。可以从图中看到,右边为 spatial 分支,当前特征点是通过全图所有特征点融合生成,每个特征点的weight是通过高斯分布来计算,近大远小。左边为 range 分支,可以理解为局部的注意力机制(3X3邻域),中心点由周围3邻域里的9个点融合得到,特征点的 weight 通过与中心像素的点积得到。
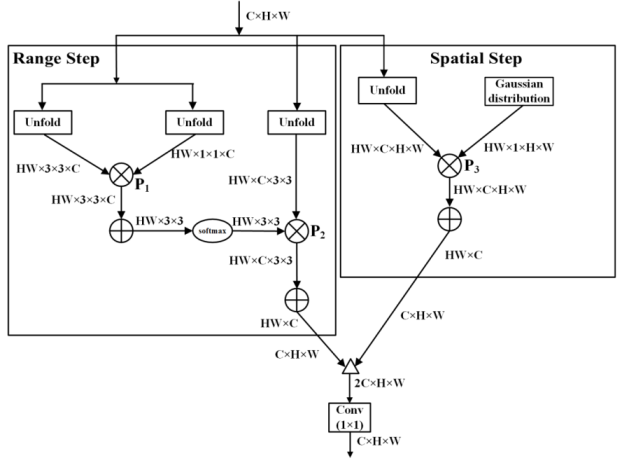
总体来说,在这个双边注意力模块中,当前点的特征由周围3x3邻域以及全局的点加权组成,保证了全局与局部信息的一致性,从而保证了填充的内容连贯,同时与背具有较好的一致性。
实验结果不多说,大家可以参考作者论文。有趣的是,论文的损失函数包括很多个部分组成,需要留意下。作者做了两个 ablation study,在第一个实验中,考虑了网络纹理分支 和 结构分支 的作用。只用结构分支图像的细节不好,只用纹理分支图像的结构不好。作者的方法同时结合了 结构 和 纹理 信息,效果最好。

同时,在另一组 ablation study 中,作者分析了特征均衡化的作用。如果把论文最特色的双边注意力机制去掉,就是相当于使用了“Non-local aggregation”,但生成的图像仍有模糊现象。但是作者方法通过特征均衡化,保证了全局与局部信息的一致性,效果是最好的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号