sharding:谁都能读懂的分库、分表、分区
本文通过大量图片来分析和描述分库、分表以及数据库分区是怎样进行的。
1.sharding前的初始数据分布
在本文中,我打算用高考考生相关信息作为实验数据。请无视表的字段是否符合现实,也请无视表的设计是否符合范式。
3张表:
- 考生表,存放全国所有高考考生信息,假设34个省、(直辖)市、(自治区、特别行政)区共3000W考生
- 学科表,分文理科,共9门课程(语文、数学、英语、历史、地理、政治、物理、化学、生物)
- 成绩表,存过全国所有考生所有学科成绩,每个学生6门成绩,共1.8亿条成绩数据
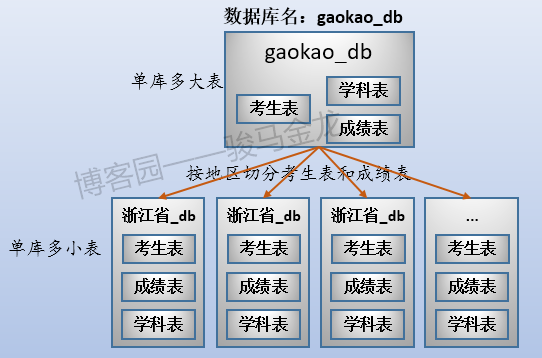
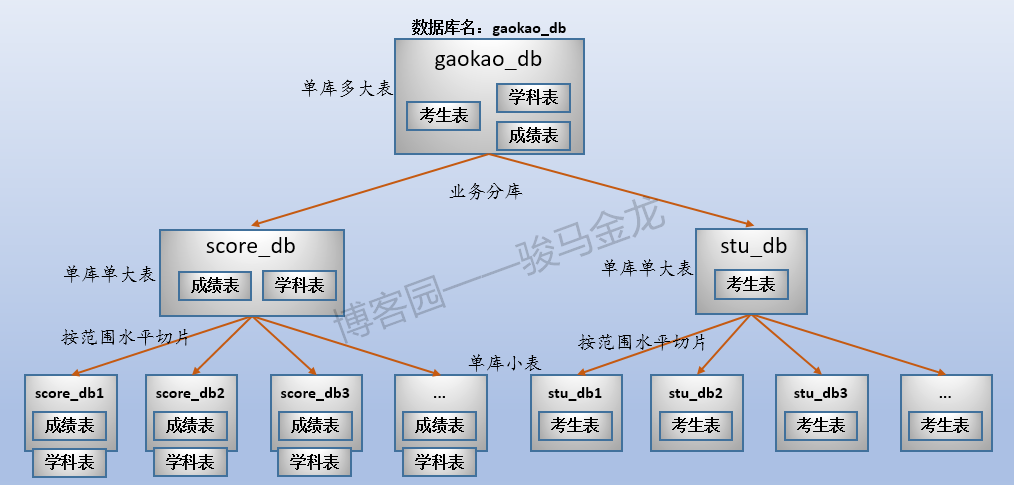
三张表放在名为"gaokao_db"的库中。所以,它们的结构如下:
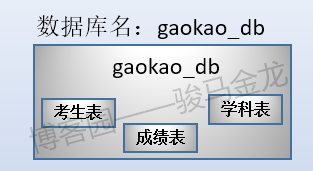
这三张表的大致存储方式如下:
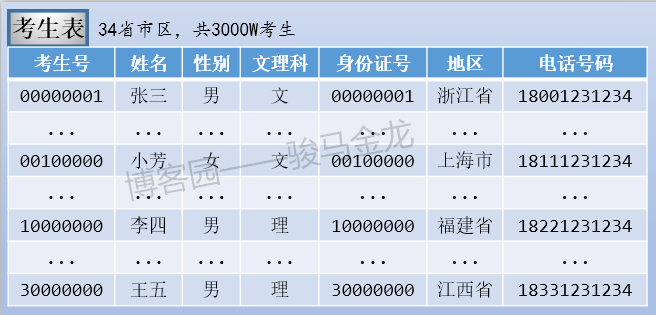
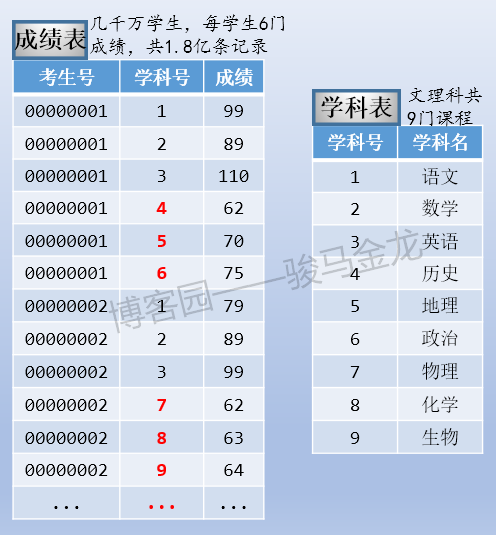
这个时候数据存储方式是单库多表。
2.业务分库
业务分库:按业务将不同表放进不同库。每个库可以放在不同数据库服务器上。
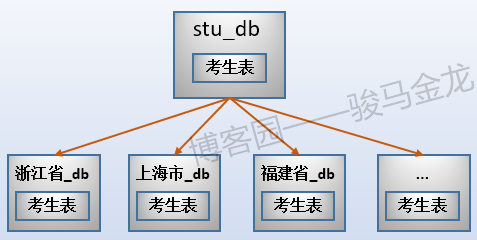
例如,在这里将原始数据库gaokao_db中的3个表分开放进两个数据库中,stu_db存放考生表,score_db存放成绩表。
还有一张学科表放在哪呢?对于那些很小、无需进行切片的表,可以将多个这样的表共同放在同一个库中,也可以根据联接特性将其分开放置在常与之进行联接的库中。在此处,学科表很小,没必要单独占用一个库甚至数据库服务器,且由于学科表只会和成绩表进行联接,所以将其放在score_db库中。
业务分库如下图:
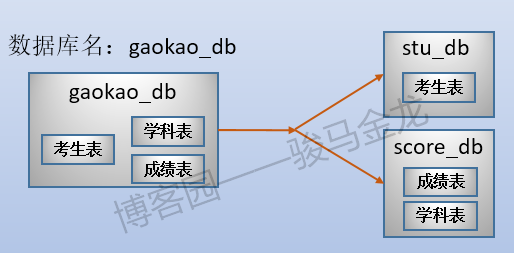
stu_db和score_db可以放在同一数据库服务器上,也可以放在不同数据库服务器上,从而在整体上减轻系统的压力。但是,如果这两个库放在不同服务器上,因为跨数据库实例,将没法对stu_db和score_db中的表进行join操作。
一般来说,对于可预见的、不断增长的数据,业务分库可能最先进行的sharding。
3.垂直切分
垂直切分:将一个表按照字段分成多表,每个表存储一部分字段。表可以放在不同存储设备上。
其实,在最初设计数据库的时候,因为是关系型数据库,或多或少都会去遵守一些设计范式。当设计的数据库表满足第一范式、第二范式、第三范式等等范式要求时,其实就已经进行了所谓的垂直切分。
即使按照范式设计了数据库表,但有些表是宽表,有很多可能很少使用的字段,这些字段可能是按照稀疏列进行管理的,也可能是大BLOB后大text字段。此外,表中的字段还可以划分为"热门字段和冷门字段",例如本文示例中,相比考生号、姓名、所属地区使用频繁程度,考生电话号码可能很少使用、身份证号也很少使用,所以这两个字段是冷门字段。
所以,当表数据量很大时,即使满足了范式要求,还是可以强行将表按字段切开,将热门字段、冷门字段分开放置在不同库中,这些库可以放在不同的存储设备上,避免IO争抢。
如下图:
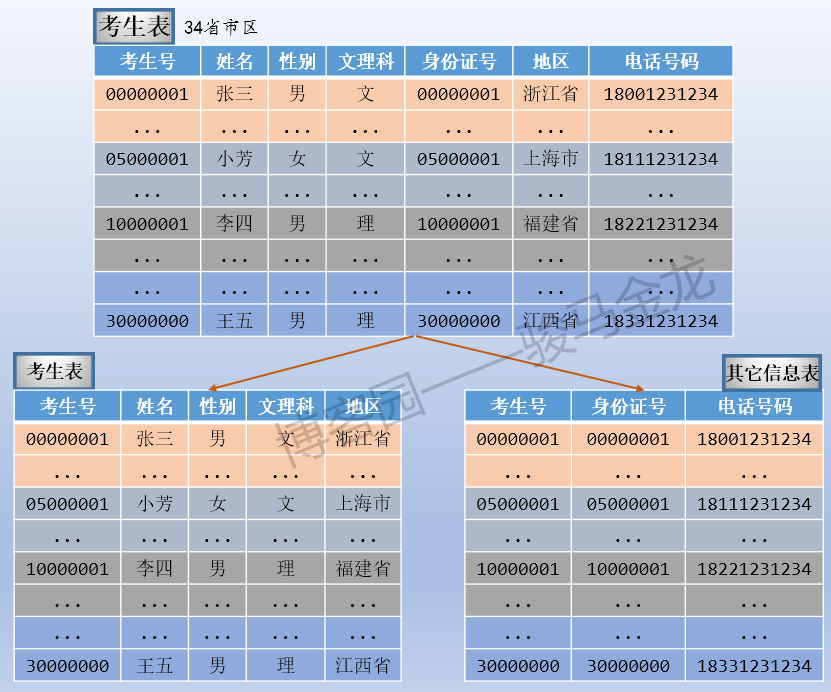
注意,垂直切分后的表,要能进行关联,所以在此处的其它信息表中加上了考生号字段。
垂直切分其实是更深一步的范式设计,或者反范式设计。垂直切分带来的性能提升,主要集中在热门数据的操作效率上,而且磁盘争用情况减少。但如果想要将两个表中的数据再次联合起来,性能将比垂直切分前差的多。
另外,有很多人将业务分库当作垂直切分,其实这都不重要,重要的是知道各种手段是干嘛的。不过在本文以及我后面的文章,将认为业务分库和垂直切分是不同sharding的分类。
4.水平切分
水平切分:将大表按条件切分到不同表中。每个表存储一部分满足条件的行。
水平切分通常有几种常用的切分方式:
- 直接按字段条件切分
- 取模后切分
- 按月份、季度、年份切分,或者称之为按范围切分
水平切分对性能提升非常大,不仅可以避开服务器资源争用,还减小了索引大小以及每个库维护的表数据量。
4.1 按字段条件进行切分
例如本文的示例中,按照考生所属地区对考生表进行水平切分,这是按照字段条件进行切分。
如下图,因为有34个省、市、区,所以分成34个考生表,每个考生表都放在地区命名的库中。各库可放在同一数据库服务器,也可以放在不同数据库服务器。例如,某些省市区的考生数量少,可以将多个这样的库放在同一个数据库服务器上,而山东、江西等高考大省,因为考生数量多,可以单独放在同一个数据库服务器上。
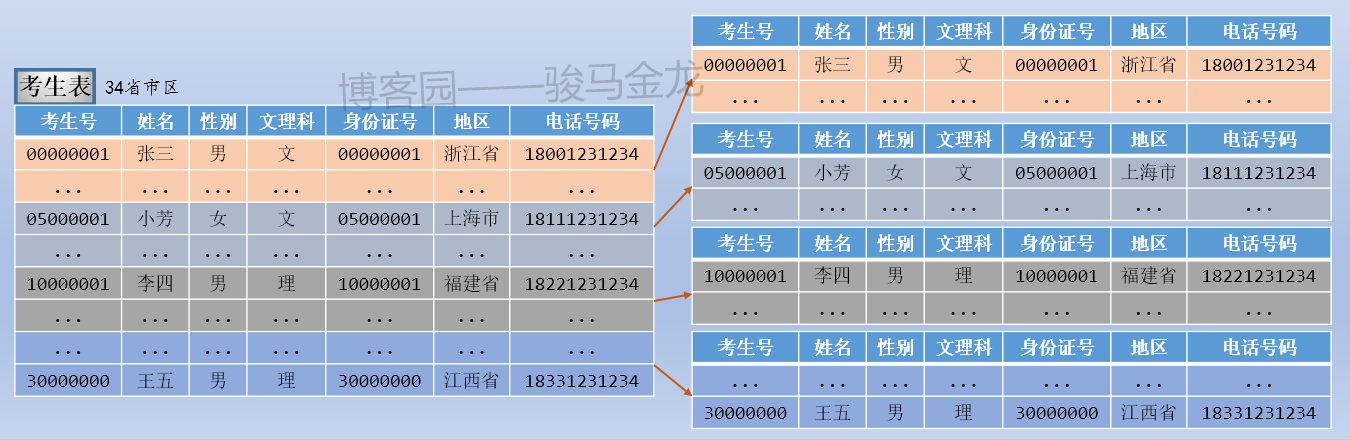
注意上述按字段条件进行水平切分时,表名不变,创建新的按地区命名的库,将各地区的表放置在对应的库中。
通常,按照字段条件进行水平切分时,其它表也很有可能也按这个条件进行切分,使得满足条件的表都放在同一个库中,这样能保证正常的join操作。
例如,上面切分了考生表,还可以切分成绩表,让同一个地区的考生表、成绩表放在同一个库中(所以,不能将考生表、成绩表进行业务分库)。
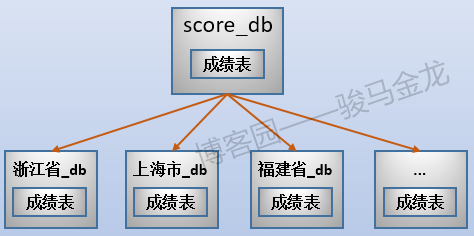
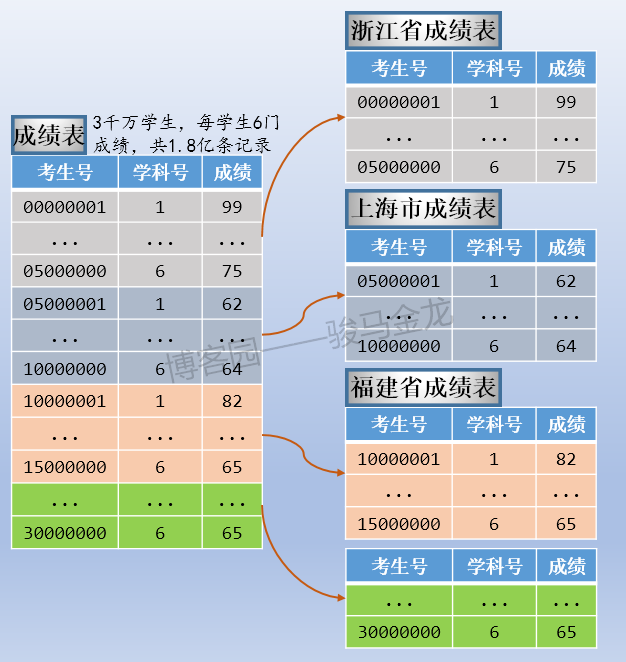
这样切分后,整个数据的分布情况如下:
4.2 按范围进行切分
对于上面的成绩表,如果在此之前已经进行了业务分库,就无法让成绩表、考生表同时按照地区进行水平切分。这时可以进行范围切分,最常见的范围切分是按月份、季度、年份进行切分。
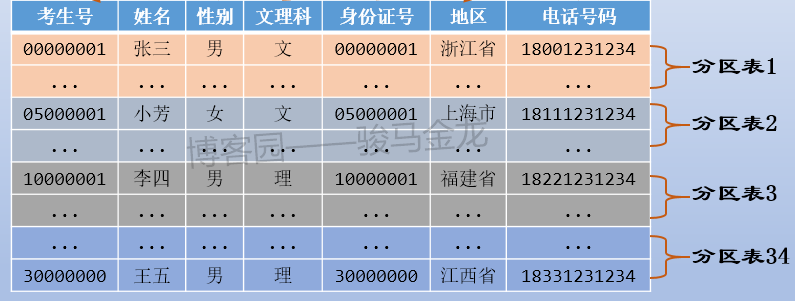
例如,本文示例的成绩表,可以按考生号范围切片,可按考生号取模后切片,也可按学科类别切片。例如,按考生号范围切片,每张表500W考生共3000W条成绩数据,共切成6片。
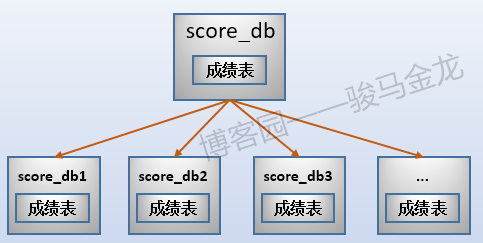
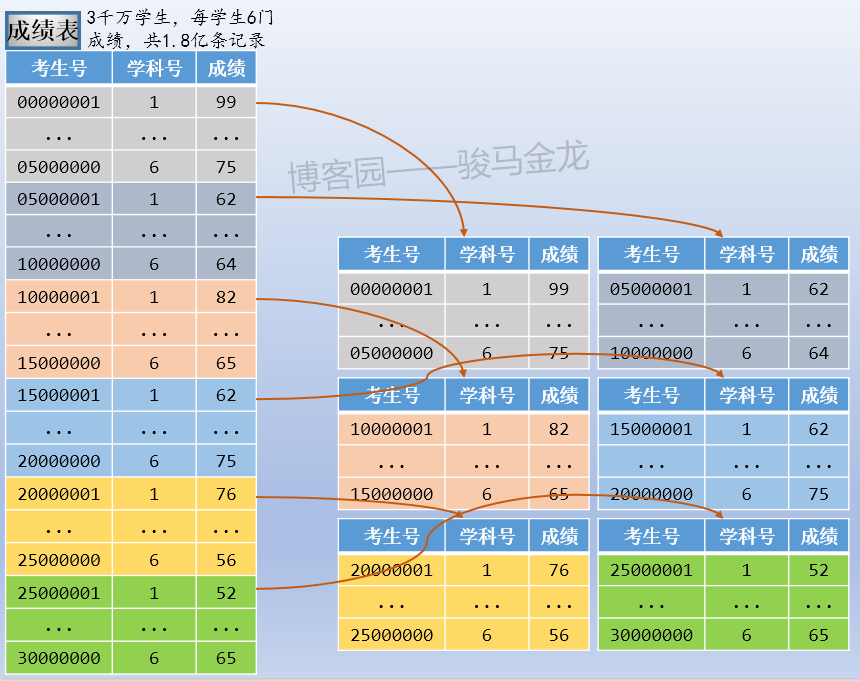
注意按照范围(或者取模、年份、月份、季度等)切片后,数据库的命名。这些库可以放在同一个数据库服务器上,也可以放在不同数据库服务器上。
如果对成绩表按照范围(或者取模、年份、月份、季度等)切片后,最好对考生表也按照同样的切分方式进行切片。举个反例很容易理解,这里的成绩表按照范围切分了,但是考生表按照地区切分,这两类库的名称之间将失去对应关系,对于数据维护来说可能会增加很大的难度。
按照这种模式的水平切分后,整个数据的分布情况如下(假设考生表也按范围切片):
4.3 取模切分
取模是对数值或能转换为数值的字段进行取模,要切分成几片,就除几。
例如,按照取模切分的方式,将本文的考生表切分成6片。于是:
00000001 % 6 = 1 --> 放进stu_1库
00000002 % 6 = 2 --> 放进stu_2库
00000003 % 6 = 3 --> 放进stu_3库
00000004 % 6 = 4 --> 放进stu_4库
00000005 % 6 = 5 --> 放进stu_5库
00000006 % 6 = 0 --> 放进stu_0库
...
00000101 % 6 = 5 --> 放进stu_5库
00000102 % 6 = 0 --> 放进stu_0库
00000103 % 6 = 1 --> 放进stu_1库
00000104 % 6 = 2 --> 放进stu_2库
00000105 % 6 = 3 --> 放进stu_3库
00000106 % 6 = 4 --> 放进stu_4库
...
注意,取模切片后的表名仍然为考生表,这些考生表放在对应的库里,这些库可以单独放在一个数据库服务器上,也可以多个库一起放在同一个数据库服务器上。
5.数据库分区
数据库分区:将大表进行分区,不同分区可以放置在不同存储设备上,这些分区在逻辑上组成一个大表,对客户端透明
- 分区方式和水平切片是类似的,分区方式也和水平切片方式类似,如范围切片,取模切片等
- 数据库分区是数据库自身的特性,切片则是外部强制手段控制完成的
- 数据库分区无法将分区跨库,更不能跨数据库服务器,但能保存在不同数据文件从而放置在不同存储设备上
- 数据库分区是数据库的特性,数据完整性、一致性等实现起来很方便,这一切都是数据库自身保证的
例如,对考生表按照地区进行分区。
在数据库切片流行之前,对大表的处理方式就是划分分区表。数据库分区相比于切片,最大的缺点在于无法跨库、跨服务器,所以在某些方面的压力得到不缓解。
6.分库、分表带来的问题
因为分库、分表可以将大表切分成多个片段,每次检索时可以只检索一小个片段,且因为这些片段可以分开存放在不同存储设备、不同数据库服务器上,它的整体性能得到了很大的提高。但是,随之而来不少问题。最主要集中在以下几个方面。
1.分库分表本身的复杂性
分库分表的方式可以在开发端通过代码来实现,也可以在app和数据库中间使用中间件来实现(如mycat),还可以直接使用分布式数据库(如TiDB、OceanBase)替代传统关系型数据库。无论是哪一种方案,学习成本、维护成本都有一段阵痛时期。
2.分库分表让数据库系统架构变得复杂
特别是添加中间件的方式,毕竟在app和数据库中间多了一层,这一层不能出现单点故障。
3.跨节点join问题
当进行了业务分库,或者其它切片方式将库放置在不同数据库实例上时,因为跨了实例,将无法进行join操作。
4.扩容和数据迁移艰难
对于那些以范围、取模方式做水平切分的大表,扩容以及扩容时的数据迁移很艰难。需要解决几个问题:
- 扩容到多少节点比较满足自己的期望。
- 扩容时,哪些数据需要从旧节点清洗掉,哪些数据需要从旧节点迁移到新节点。
- 如何实现在线迁移。
例如原本按照4个节点取模分片,现在出现了瓶颈,想要扩容成6个节点。
第一个问题,从4个节点扩容为6个节点,在整体上大致能提升50%的性能。
第二个问题和第三个问题。看如下数据分布情况
扩容前 扩容后
0 % 4 = 0 0 % 6 = 0
1 % 4 = 1 1 % 6 = 1
2 % 4 = 2 2 % 6 = 2
3 % 4 = 3 3 % 6 = 3
4 % 4 = 0 4 % 6 = 4 -> 从0节点迁移到4节点
5 % 4 = 1 5 % 6 = 5 -> 从1节点迁移到5节点
6 % 4 = 2 6 % 6 = 0 -> 从2节点迁移到0节点
7 % 4 = 3 7 % 6 = 1 -> 从3节点迁移到1节点
8 % 4 = 0 8 % 6 = 2 -> 从0节点迁移到2节点
9 % 4 = 1 9 % 6 = 3 -> 从1节点迁移到3节点
10 % 4 = 2 10 % 6 = 4 -> 从2节点迁移到4节点
11 % 4 = 3 11 % 6 = 5 -> 从3节点迁移到5节点
12 % 4 = 0 12 % 6 = 0
13 % 4 = 1 13 % 6 = 1
14 % 4 = 2 14 % 6 = 2
15 % 4 = 3 15 % 6 = 3
16 % 4 = 0 16 % 6 = 4 -> 从0节点迁移到4节点
可见,每12条数据就要从旧节点迁移8条数据,而且这8掉数据还是在各个节点之间交叉迁移。这使得数据迁移非常复杂,不是想加几个节点就加几个节点,让扩容变得不再随心所欲。一种比较好的解决方案是双倍扩容,例如从4节点扩容为8节点。
扩容前 扩容后
0 % 4 = 0 0 % 8 = 0
1 % 4 = 1 1 % 8 = 1
2 % 4 = 2 2 % 8 = 2
3 % 4 = 3 3 % 8 = 3
4 % 4 = 0 4 % 8 = 4 -> 从0节点迁移到4节点
5 % 4 = 1 5 % 8 = 5 -> 从1节点迁移到5节点
6 % 4 = 2 6 % 8 = 6 -> 从2节点迁移到6节点
7 % 4 = 3 7 % 8 = 7 -> 从3节点迁移到7节点
8 % 4 = 0 8 % 8 = 0
9 % 4 = 1 9 % 8 = 1
10 % 4 = 2 10 % 8 = 2
11 % 4 = 3 11 % 8 = 3
12 % 4 = 0 12 % 8 = 4 -> 从0节点迁移到4节点
13 % 4 = 1 13 % 8 = 5 -> 从1节点迁移到5节点
14 % 4 = 2 14 % 8 = 6 -> 从2节点迁移到6节点
15 % 4 = 3 15 % 8 = 7 -> 从3节点迁移到7节点
16 % 4 = 0 16 % 8 = 0
这样每8条数据迁移4条,且需要迁移的数据不会在各节点之间交叉。这样迁移要方便的的,而且性能提升100%。但是因为要迁移的数据量较大,迁移速度较慢,而且每次扩容都采取双倍扩容,必须要考虑服务器成本。
还有一种比较流行的"业务双写"迁移法。相比于双倍扩容法,它仍然很复杂。它的迁移过程大概是这样的:
- 加入新节点。
- 将业务写入过程按照旧规则和新规则同时写到新旧节点(业务双写)。例如4节点扩容到6节点时,id=2000的数据(假设之前没有该数据)将同时写入到0节点和2节点,id=2003将同时写入3节点和5节点。
- 迁移旧数据。
- 应用新规则,将新节点向外提供服务。
- 清洗旧数据。
双写能保证迁移数据的过程仍然持续在线提供服务。但是,那些已存在的旧数据迁移仍然较为复杂,需要仔细琢磨要迁移哪些数据,以及迁移到哪个节点,这点必须把控好。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号