
MySQL核心知识学习之路(5)
作为一个后端工程师,想必没有人没用过数据库,跟我一起复习一下MySQL吧,本文是我学习《MySQL实战45讲》的总结笔记的第五篇,总结了MySQL索引相关的实践使用问题。
上一篇:MySQL核心知识学习之路(4)
1 普通索引与唯一索引如何选择?
先说结论
查询性能对比上普通索引和唯一索引差别不大。
更新性能对比上普通索引可以使用Change Buffer机制提高性能(前提:在业务层面保证数据唯一)。唯一索引则每次都需要判断是否违反唯一约束,因此每次都需要从内存中找到对应数据页,如果不在内存中则需要从磁盘读取出来,因此效率较低。
因此,如果业务可以接受,从性能角度出发,建议优先考虑普通索引。
关于Change Buffer机制
Change Buffer是一种特殊的数据结构,它的过程如下:
(1)在对数据变更时,如果数据所在的数据页不在内存中的话,就先将更新操作记录在Change Buffer中,不需要从磁盘中读出数据页。
(2)Change Buffer中的数据会最终更新到原数据页,这个操作称之为Merge。
MySQL中进行Merge操作的时机包括:
-
当目标数据页加载到内存中的时候,会先执行Change Buffer中的Merge操作。
-
系统后台线程会定期执行Merge操作。
-
MySQL正常关闭(shutdown)时也会执行Merge操作。
使用Change Buffer的优点在于:将数据页从磁盘中读入内存涉及随机IO访问,是数据库中成本最高的操作之一,Change Buffer可以有效减少随机IO读操作,从而提升性能。
下图展示了一个带有Change Buffer的工作流程,假设我们向表t插入了两行记录,其中一行记录在Page1(已经在内存中),另一行记录在Page2(不在内存中,需要写入到磁盘)。
insert into t(id,k) values(id1,k1),(id2,k2);
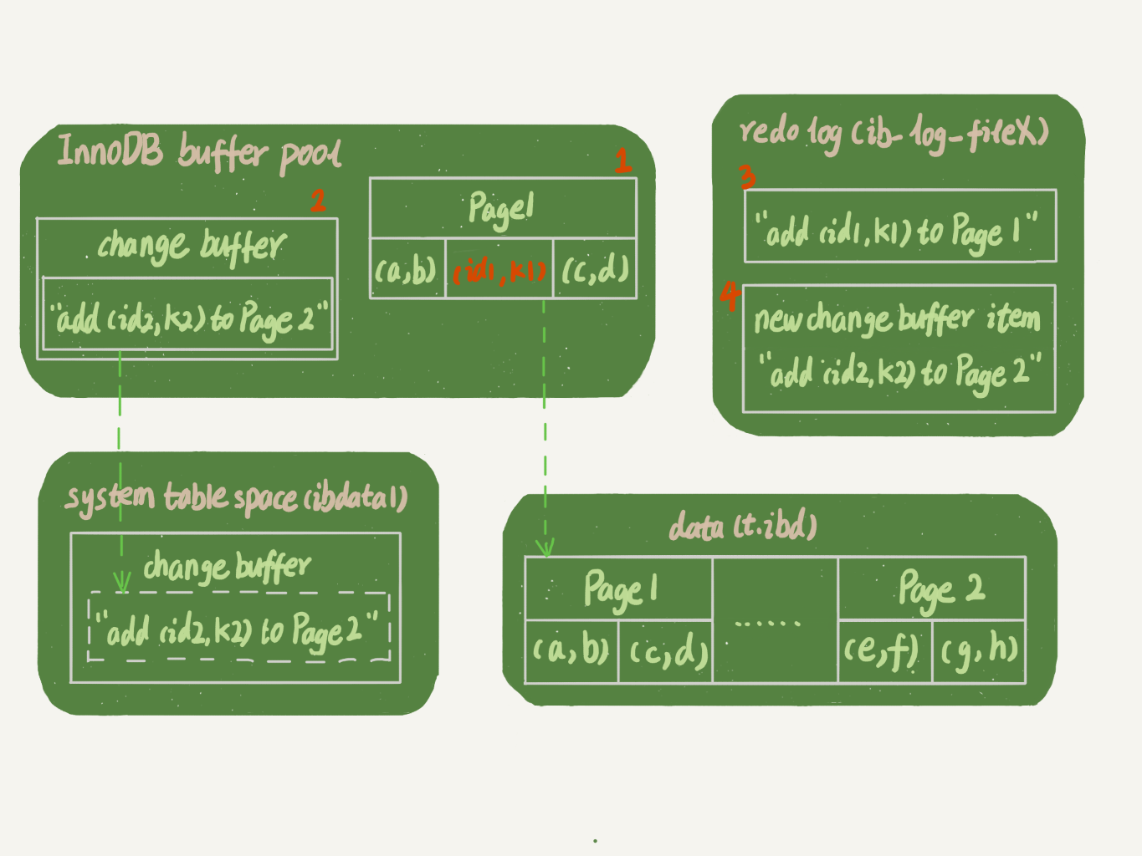
图片来源:林晓斌《MySQL实战45讲》
Change Buffer的适用场景在于:写多读少的场景,数据页在写完以后不会被马上访问到。
Change Buffer不适用的场景:写少读多的场景,数据页写完后立马会被查询到,会立即出发merge操作,因此随机IO访问的次数不会减少。
Change Buffer与Redo log的对比:Redo log主要节省的是随机写磁盘的IO消耗(转为顺序写),而Change Buffer主要节省的是随机读磁盘的IO消耗。
2 为何MySQL有时候会选错索引?
MySQL中,在索引建立之后,一条语句可能会命中多个索引,这时,索引的选择就会交由 优化器来选择合适的索引。优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。
不过,MySQL中有时候会选错索引,导致查询性能较差,主要会出现在以下场景中。
场景1:由于索引统计信息不准确导致
解决办法:使用 analyze table 命令重新统计索引信息。
原因:MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。索引统计(cardinality列)信息不够准确,会导致MySQL优化器无法准确判断选择。
补充:MySQL优化器对于索引的选择,基于索引基数(cardinality)与表中数据行数(n_row_in_table)的比值,即索引选择性:
索引选择性=索引基数/数据行
cardinality非常关键,表示索引中不重复记录的预估值。需要注意的是cardinality是一个预估值,而不是一个准确值。基本上用户也不可能得到一个准确的值。在实际应用中,这个基数越大,索引的区分度越好。
我们可以使用 show index 方法,看到一个索引的基数。

场景2:优化器误判导致
解决办法A:应用端使用 force index 强行选择一个索引。
select * from t force index(a) where a between 10000 and 20000;
解决办法B:修改语句引导MySQL使用期望的索引。此方法不具备通用性。
解决办法C:新增更合适的索引 或 删除误用的索引。此方法是一个绕过问题的思路。
3 如何给字符串字段加索引?
简单粗暴:直接创建完整索引
直接创建完整索引,可能比较占用空间
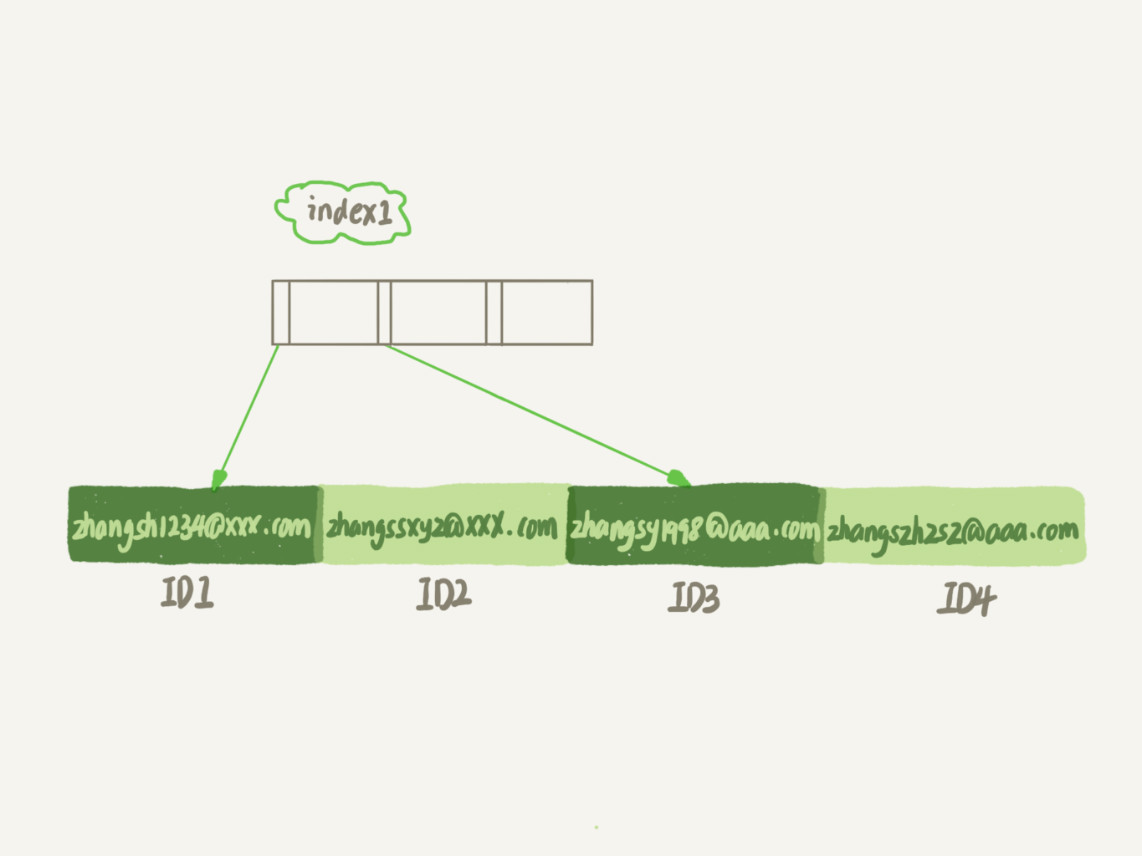
图片来源:林晓斌《MySQL实战45讲》
前缀索引:节省空间的方式
创建前缀索引,比较节省空间,但会增加查询扫描次数,并且不能使用覆盖索引。比如下图就展示了一个截取了email前六位的前缀索引。
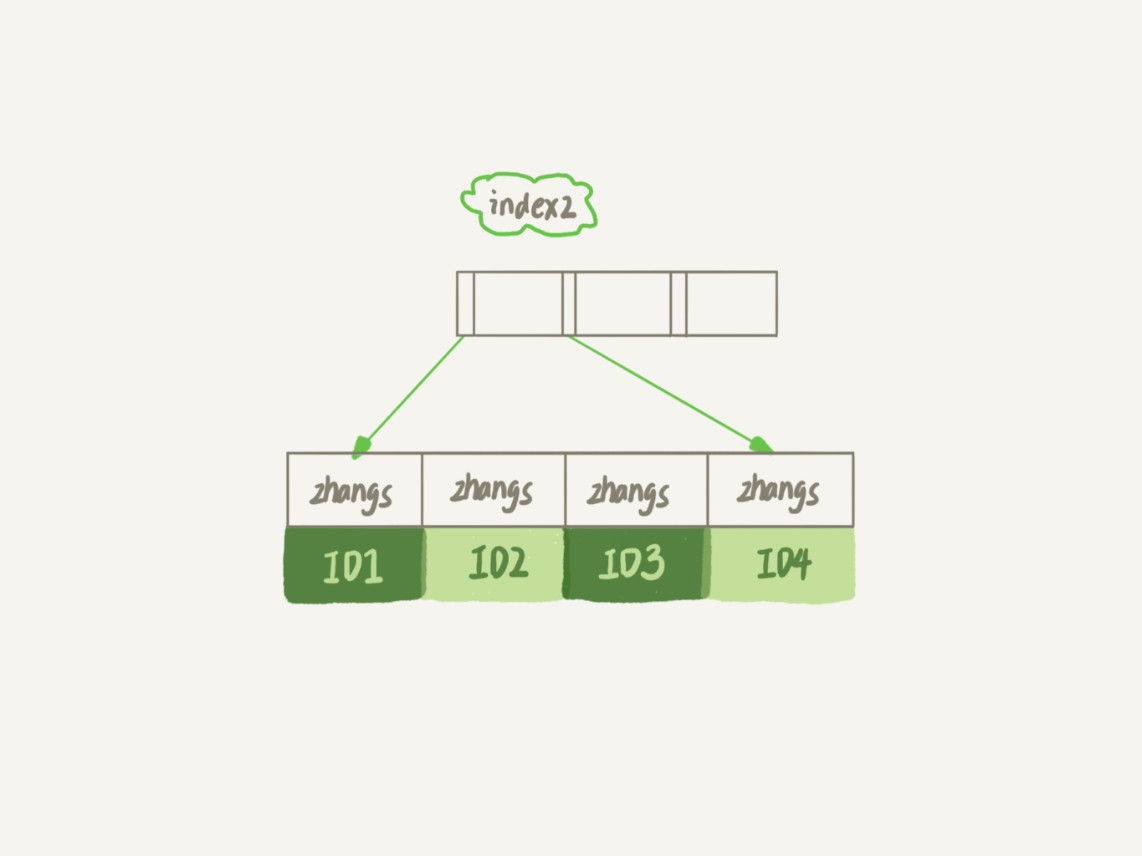
图片来源:林晓斌《MySQL实战45讲》
此方式需要判断出前缀的合适长度,根据业务来定,主要看区分度。
示例:
select count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6
from SUser;
倒序存储
倒序存储,再创建前缀索引,用于绕过字符串本身前缀的区分度不够的问题。
此方式适用于前缀区分度不高但后缀区分度高的场景,目的是提高索引的区分度。但此方式不支持范围扫描。
示例:
select field_list from t where id_card = reverse('input_id_card_string');
Hash字段索引
创建hash字段索引,查询性能稳定,但有额外的存储和计算消耗。
此方式不支持范围扫描。
示例:
select field_list from t
where id_card_crc=crc32('input_id_card_string')
and id_card='input_id_card_string';
4 小结
本文总结了MySQL的索引相关的实践使用问题,包括普通索引和唯一索引如何选择,MySQL为什么有时候会选错索引,怎么给字符串字段加索引。
参考资料
林晓斌(丁奇),《MySQL实战45讲》
👇扫码订阅《MySQL实战45讲》




 浙公网安备 33010602011771号
浙公网安备 33010602011771号