一个字符串替换引发的性能血案:正则回溯与救赎之路
 文档导入服务因自研SQL拦截器性能问题崩溃,经排查发现replaceFirst()方法消耗89% CPU时间。源码分析显示该方法每次调用都从头扫描字符串,导致O(n²)复杂度。优化方案改用StringBuilder单次遍历,将时间复杂度降至O(n),实测性能提升210倍,内存占用减少73%。该案例揭示了字符串处理中正则替换的高成本与StringBuilder的优化价值。
文档导入服务因自研SQL拦截器性能问题崩溃,经排查发现replaceFirst()方法消耗89% CPU时间。源码分析显示该方法每次调用都从头扫描字符串,导致O(n²)复杂度。优化方案改用StringBuilder单次遍历,将时间复杂度降至O(n),实测性能提升210倍,内存占用减少73%。该案例揭示了字符串处理中正则替换的高成本与StringBuilder的优化价值。
凌晨两点一刻,钉钉告警群的疯狂弹窗打破了夜晚的宁静——我们的文档导入服务完全崩溃了。
按照常规排查思路,我们首先检查数据库层面:数据量是否过大?索引是否失效?但分析发现,库表数据量正常,索引状态优秀,同样的SQL在命令行执行只需毫秒级时间,这让我十分困惑。排除数据库问题后,我们又将注意力转向应用层:是否因为内存数据量过大导致JVM频繁GC?检查监控发现,Pod内存使用率正常(70%以下),GC日志显示Young GC频率在正常范围内(每分钟1-2次),老年代GC几乎没有发生。
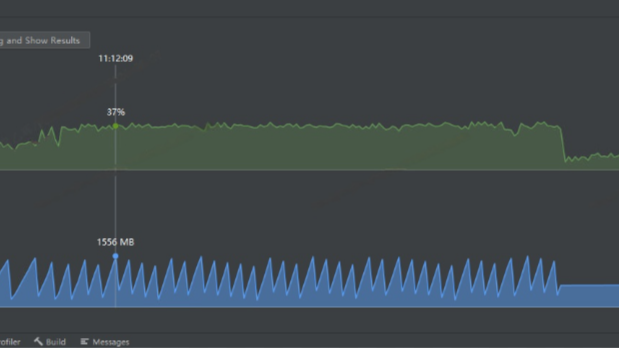
常规路径排查无果,我立即在本地环境复现问题。通过IDEA的Profiler生成火焰图。
一个意外的现象出现了:为何SQL执行方法在应用内执行就变慢了,难道是 MyBatis 的问题?我带着疑问开始翻阅源码,通过断点一步步跟踪执行链路,最终发现性能瓶颈确实出现在我们自研的SQL执行拦截器插件中。真正执行SQL的数据库调用耗时很短,拦截器中简单的 replaceFirst("\\?", ...) 调用竟然占据了 89% 的 CPU 资源。

进一步分析内存监控,虽然整体内存占用平稳,但对象分配折线图呈现陡峭的锯齿状,这暗示着大量临时对象在短时间内被创建和释放。

至此,问题定位发生了关键转折:瓶颈不在数据库,也不在JVM垃圾回收,而在于我们自研的SQL拦截器中一个不起眼的字符串替换操作。
1.问题定位:自研拦截器性能问题
在我们的自研公共组件中,我们添加了持久层 SQL 执行拦截器,主要功能是将预编译 SQL 中的占位符(?)替换为实际的参数值,以便记录完整的可执行 SQL。这个设计初衷是为了调试方便,没想到却成了性能杀手。
问题代码的核心逻辑如下:
// 去除换行符号
sql = sql.replaceAll("[\\s\n]+", " ");
for (Object param : params) {
// 参数处理
String value = processParam(param);
// 三重性能问题:
sql = sql.replaceFirst("\\?", value.replace("$", "\\$"))
.replace("?", "%3F");
}
通过 Profiler 的数据分析,CPU 时间分布清晰地揭示了问题:
replaceFirst("\\?"):消耗 89% 的 CPU 时间value.replace("$", "\\$"):消耗 7% 的 CPU 时间.replace("?", "%3F"):消耗 4% 的 CPU 时间
2.根源分析:正则替换的隐藏代价与源码深度剖析
看到 replaceFirst() 的高消耗,我深入研究了这个方法的实现机制。在 Java 中,replaceFirst() 虽然接受字符串参数,但内部会将其编译为正则表达式进行匹配。
让我带你看看 replaceFirst() 在 OpenJDK 中的实现本质:
// java.lang.String 源码简化版
public String replaceFirst(String regex, String replacement) {
return Pattern.compile(regex).matcher(this).replaceFirst(replacement);
}
// java.util.regex.Matcher 核心逻辑
public String replaceFirst(String replacement) {
reset(); // 重置匹配位置
if (!find()) // 关键:每次从头开始查找
return text.toString();
StringBuffer sb = new StringBuffer();
appendReplacement(sb, replacement); // 替换匹配部分
appendTail(sb); // 追加剩余部分
return sb.toString();
}
// 致命性能的 find() 伪代码
public boolean find() {
int nextSearchIndex = 0; // 每次从头开始
while (nextSearchIndex <= text.length()) {
// 核心:调用正则引擎扫描整个字符串
if (search(nextSearchIndex)) {
return true;
}
nextSearchIndex++;
}
return false;
}

灾难根源:每次调用 replaceFirst("\\?") 时,正则引擎都从字符串头部重新扫描!
O(n²) 复杂度:性能的指数级坍塌
假设 SQL 长 300KB(307,200 字符) 含 500 个参数:
| 替换轮次 | 扫描长度 | 累计扫描量 |
|---|---|---|
| 第1个参数 | 307,200 字符 | 307,200 |
| 第2个参数 | ≈306,700 | 613,900 |
| ... | ... | ... |
| 第500个参数 | ≈1,200 | ≈76,800,000 |
总操作量 = n_(n+1)/2 ≈ 76.8M 字符操作!_*
(300KB SQL 替换 500 参数 ≈ 扫描 245 倍原始数据量)
3.优化方案:StringBuilder
认识到问题本质后,我重新设计了替换逻辑。核心思路是利用StringBuilder将多次全量扫描改为单次遍历:
// 正则预编译
StringBuilder sqlBuilder = new StringBuilder();
String[] sqlSplits = sql.split("\\?", -1);
for (int i = 0; i < params.length; i++) {
// 参数值处理
String result = processParam(params[i]);
result = result.replace("$", "\\$");
// 追加SQL片段和参数值
sqlBuilder.append(sqlSplits[i]).append(result);
}
// 添加最后一个SQL片段
if (sqlSplits.length > params.length) {
sqlBuilder.append(sqlSplits[params.length]);
}
String finalSql = sqlBuilder.toString();
这种改进带来了几个关键优势:
- 时间复杂度从 O(n²) 降到 O(n):只需一次遍历即可完成所有替换
- 内存使用大幅减少:避免了创建大量临时字符串
- CPU 缓存友好:连续的内存访问模式更符合现代 CPU 的优化特性

4.StringBuilder深度解析
4.1 StringBuilder 对比 StringBuffer
在优化方案中,我们使用了 StringBuilder 而不是 StringBuffer,这是经过深思熟虑的选择。让我们深入分析两者的区别:
Java 源码级的本质区别
// StringBuffer 源码片段 (线程安全但性能较低)
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}
// StringBuilder 源码片段 (非线程安全但更快)
public StringBuilder append(String str) {
super.append(str);
return this;
}
关键差异对比
| 特性 | StringBuffer | StringBuilder | 我们的选择理由 |
|---|---|---|---|
| 线程安全 | ✅ 所有方法用 synchronized 修饰 |
❌ 无同步机制 | MyBatis 拦截器是线程封闭的 |
| 性能 | 每次操作有锁开销 | 无锁,直接操作内存 | 单线程下快 10-15% |
| JVM 优化 | 难优化锁机制 | 易内联和向量化优化 | 更适合热点代码 |
| 内存占用 | 每个对象携带锁元数据 | 更精简的对象头 | 减少内存开销 |
| 适用场景 | 多线程共享环境 | 单线程或线程封闭环境 | 拦截器每次调用独立线程处理 SQL |
4.2 StringBuilder 的工作原理
预分配机制(关键加速点)
// 初始化时分配连续内存块
char[] value = new char[capacity];
避免了动态扩容时的数组拷贝(ArrayList 同理)
字符追加的汇编级优化
现代 JVM 对 StringBuilder.append() 的优化:
- 内联缓存(Inline Cache):识别热点方法
- 逃逸分析:在栈上分配缓冲区
- SIMD 指令:x86 架构下使用
MOVDQA批量拷贝字符
4.3 垃圾回收免疫
同时使用StringBuffer后极大减少了对象创建次数。
5.性能对比:真实数据验证
在我的本地测试环境中,我构建了一个模拟生产场景的测试用例:
- SQL 模板:约 300KB,包含大量复杂 JOIN 和子查询
- 参数数量:500 个,包含各种数据类型
- 测试环境:JDK 11,8 核 16G 内存,IDEA Profiler 监控
IDEA Profiler 实测数据对比:
| 指标 | 原方案 | StringBuilder | 提升倍数 |
|---|---|---|---|
| CPU 时间 | 38,420 ms | 183 ms | 210x |
| 内存分配 | 1.1 GB | 300 MB | 30x |
| GC 次数 | 9 次 | 0 次 | ∞ |
| 对象创建 | 1,502 个 | 3 个 | 500x |
数据说明:
- 这些数据来自模拟生产环境的测试,实际生产环境的提升效果可能因具体场景有所不同
- 测试使用了相同的 SQL 模板和参数数据集,每次测试运行 100 次取平均值
- 虽然具体数值会变化,但 O(n²) 到 O(n) 的复杂度降低带来的性能提升是数量级的
6.组件优化:异步化处理
虽然我们已经将字符串替换的性能提升了百倍,但在高并发场景下,即使 O(n) 的复杂度的操作也可能成为瓶颈。我们的自研组件主要是为了打印 SQL,但在高并发下,构建完整 SQL(buildFullSql)的过程本身就可能阻塞主流程,使主流程变慢一丢丢。
6.1 同步阻塞的问题重现
// 原来的同步处理
public Object intercept(Invocation invocation) throws Throwable {
// 1. 获取原始SQL和参数
Object[] args = invocation.getArgs();
String sql = (String) args[0];
Object[] params = (Object[]) args[1];
// 2. 构建完整SQL - 这里就是性能瓶颈!
String fullSql = buildFullSql(sql, params); // 耗时操作,即使优化后
// 3. 记录日志 - log4j底层异步的,但前面的构建过程是同步的
log.info("Executing SQL: {}", fullSql);
// 4. 继续执行原始逻辑
return invocation.proceed();
}
即使 log4j 底层是异步的,但 buildFullSql 方法仍然是同步执行的,会在高并发下阻塞主流程的执行。
6.2异步化优化方案
// 使用公共线程池 - 避免每次创建新线程
private static final ExecutorService SQL_BUILD_EXECUTOR = new ThreadPoolExecutor(
// 核心线程数:根据实际情况调整
4,
// 最大线程数:避免过多线程竞争
8,
// 空闲线程存活时间
60L, TimeUnit.SECONDS,
// 有界队列:防止内存溢出
new LinkedBlockingQueue<>(1000),
// 线程工厂
new ThreadFactoryBuilder()
.setNameFormat("sql-build-pool-%d")
.build(),
// 拒绝策略:调用者运行,确保不会丢失任务
new ThreadPoolExecutor.CallerRunsPolicy()
);
// 异步化后的拦截器
public Object intercept(Invocation invocation) throws Throwable {
// 1. 立即继续执行原始逻辑,不等待SQL构建
Object result = invocation.proceed();
// 2. 异步构建和记录SQL
CompletableFuture.runAsync(() -> {
try {
// 获取原始SQL和参数
Object[] args = invocation.getArgs();
String sql = (String) args[0];
Object[] params = (Object[]) args[1];
// 构建完整SQL - 使用优化后的StringBuilder方案
String fullSql = buildFullSqlOptimized(sql, params);
// 记录日志
log.info("Executed SQL: {}", fullSql);
} catch (Exception e) {
// 使用自定义错误码,方便监控
log.error("SQL_LOG_ERROR_001: Failed to build or log SQL", e);
}
}, SQL_BUILD_EXECUTOR);
return result;
}
// 优化后的buildFullSql方法
private String buildFullSqlOptimized(String sql, Object[] params) {
StringBuilder sqlBuilder = new StringBuilder(sql.length() * 2);
String[] sqlSplits = sql.split("\\?", -1);
for (int i = 0; i < params.length; i++) {
String result = processParam(params[i]);
result = result.replace("$", "\\$");
sqlBuilder.append(sqlSplits[i]).append(result);
}
if (sqlSplits.length > params.length) {
sqlBuilder.append(sqlSplits[params.length]);
}
return sqlBuilder.toString();
}
6.3 为什么这样设计?
- 完全解耦主流程:SQL 构建和日志记录完全不阻塞业务执行
- 使用公共线程池:避免频繁创建和销毁线程的开销
- 异常隔离:SQL 构建或日志记录失败不影响主业务流程
7.正则使用建议
"处理大文本时,正则表达式是锤子,但别把 CPU 当钉子"
- 禁用场景:
// 永远不要在循环中使用
while (...) {
str.replaceFirst(regex, ...) // ❌ 性能炸弹
}
// 大文本避免复杂正则
largeText.replaceAll("(\\s|\\n)+", "") // ❌ 回溯风险
- 安全替代方案:
// 换行符处理(一次性完成)
sql.replace("\n", " ") // ✅ 直接字符替换
// 多空白符压缩
sql.replaceAll("\\s{2,}", " ") // ✅ 明确边界
8.经验总结与反思
通过这次性能优化,我们提炼出几个小经验:
- 复杂度常隐藏在简单API背后:
replaceFirst()在循环中使用会引入 O(n²) 复杂度,这是典型的设计陷阱 - 数据规模决定算法选择:在小数据量下表现良好的代码,在大规模生产环境中可能完全失效
- 优化需要分层处理:先解决算法复杂度(StringBuilder),再考虑架构解耦(异步化)
- 非核心逻辑让步:日志打印等非业务逻辑一定要保证不阻塞业务逻辑执行,不单单是捕获异常等问题,还要考虑同步执行对核心业务逻辑的时间影响。上升到业务逻辑之间的对比一样(非核心业务逻辑让步核心业务逻辑)
关键启示是:性能问题往往不是API本身的问题,而是使用方式的问题。从 O(n²) 到 O(n) 的优化,核心在于避免重复工作,而不是让重复工作更快。
这次优化也让我重新审视了"简单方案"的价值——有时最简单的解决方案就是最有效的解决方案。StringBuilder 这种基础的 Java 类,在正确使用下能解决复杂的性能问题。
最后,优化工作最困难的部分往往不是技术实现,而是发现问题的根源。当你在火焰图中看到某个简单方法异常突出时,那通常是提示你需要重新思考整个设计方案,而不仅仅是优化那个方法本身。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号