
Elastic学习之旅 (8) 深入词项和全文搜索
 相信很多童鞋和我一样,有点傻傻分不清Term查询和全文查询的区别,那么今天我们就来一起梳理一下。通过了解ElasticSearch的Term和全文查询的基本概念及其特点,利用这些特点在指定的场景会有是事半功倍的效果!
相信很多童鞋和我一样,有点傻傻分不清Term查询和全文查询的区别,那么今天我们就来一起梳理一下。通过了解ElasticSearch的Term和全文查询的基本概念及其特点,利用这些特点在指定的场景会有是事半功倍的效果!
相信很多童鞋和我一样,有点傻傻分不清Term查询和全文查询的区别,那么今天我们就来一起梳理一下。
基于Term的查询
Term(词项)是ES中表达语义的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term。
ES中Term Query包含了:
Term Query / Range Query / Exist Query / Prefix Query / Wildcard Query
ES中Term的特点:
特点1:在ES中,Term查询对输入不做分词。换句话说,它会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分 - 例如“Apple Store”。
可能上面有点难理解,现在我们通过一个实例来理解。
首先,我们先插入几条示例数据:
POST /products/_bulk { "index":{"_id":1}} { "productID": "XHDK-A-1293-#fJ3", "desc":"iPhone"} { "index":{"_id":2}} { "productID": "KDKE-B-9947-#kL5", "desc":"iPad"} { "index":{"_id":3}} { "productID": "J0DL-X-1937-#pV7", "desc":"MBP"}
然后,我们通过以下Term Query查询desc为iPhone的记录:
POST /products/_search { "query":{ "term": { "desc": { "value": "iPhone" } } } }
当你执行这条查询后,你会发现,ES居然没有查到这条记录,明明我们刚刚插入的就是它啊!
别急,这恰恰是因为Term查询不对输入做分词,会将输入作为一个整体,进而导致我们搜索不到。
我们进一步将上面的查询改为以下方式就可以查询到记录:将iPhone改为全小写的iphone即可。
POST /products/_search { "query":{ "term": { "desc": { "value": "iphone" } } } }
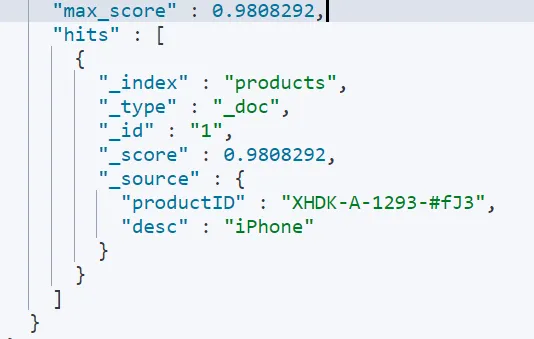
同时,如果我们想实现一个精确匹配,我们可以使用term的keyword关键字来实现,如下查询所示:精确匹配一个productID。这也说明,在ES中通过keyword关键字查询,它也不会做分词处理。
POST /products/_search { "query":{ "term": { "productID.keyword": { "value": "XHDK-A-1293-#fJ3" } } } }
我们还会发现,Term查询会返回一个算分:0.9808292,代表匹配的精准度。
特点2:可以使用Constant Score将查询转换成一个Filtering,避免算分,并利用缓存,提高性能。
刚刚提到ES会在倒排索引中进行相关性算分,这在一定程度上会带来一些查询上的开销。我们可以通过ConstantScore将Query转成Filter,来避免相关性算分的开销,还可以有效利用缓存,提高查询的效率!
POST /products/_search { "explain": true, "query": { "constant_score": { "filter": { "term": { "productID.keyword": { "value": "XHDK-A-1293-#fJ3" } } } } } }
查询结果显示也可以证明它会跳过算分步骤:

基于全文的查询
基于全文的查询,ES提供了以下Query(我们在第6篇Query DSL中学习的就是全文查询):
Match Query / Match Phrase Query / Query String Query
基于全文的查询具有以下的特点:
特点1:索引和搜索时都会进行分词,查询字符串先传到一个合适的分词器,然后生成一个待查询的词项列表。
特点2:查询会对每个词项进行底层的查询,再将结果进行合并,还会为每个文档生成一个算分。
针对这两个特点,我们通过一个示例来串一下:
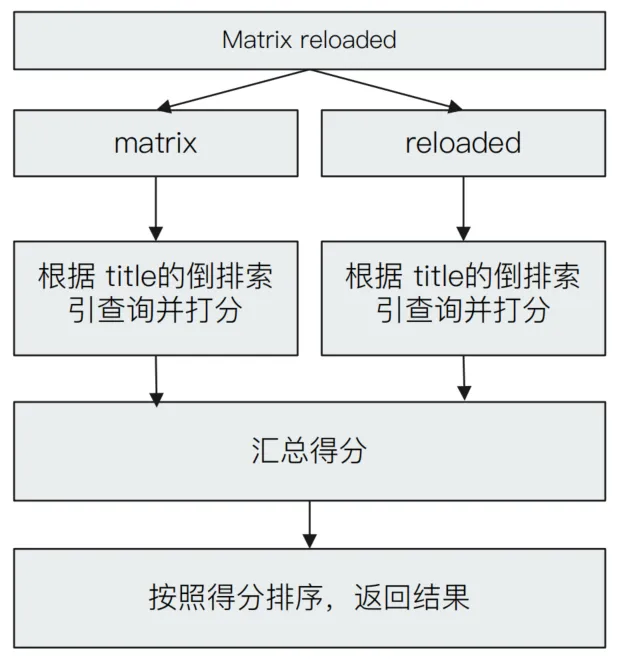
例如,查询“Matrix reloaded”,会查到包括Matrix或者reload的所有结果。
首先,构建一个Match Query:
POST /movies/_search { "query": { "match": { "title": { "query": "Matrix reloaded" } } } }
ES会返回title字段中包括Matrix 或者 reloaded的所有记录:

其次,如果你希望查询title字段中同时包含Matrix reloaded,那你可以修改默认的operator为AND来提高精准度:
POST /movies/_search { "profile": "true", "query": { "match": { "title": { "query": "Matrix reloaded", "operator": "AND" } } } }
然后,如果你希望查询的是只要出现Matrix 和 reloaed,其中间可以间隔一些单词,那么你也可以使用match phrase 和 slop参数设置分词出现的最大间隔距离:
POST /movies/_search { "profile": "true", "query": { "match_phrase": { "title": { "query": "Matrix reloaded", "slop": 1 } } } }
最后,这个基于全文的查询在ES中的基本查询过程如下所示:
小结
本篇,我们了解了ElasticSearch的Term和全文查询的基本概念及其特点,利用这些特点在指定的场景会有是事半功倍的效果!
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号