
Elastic学习之旅 (7) 聚合分析
 Elastic除搜索之外,还提供针对ES数据的统计分析功能,具有较高的实时性。通过聚合,我们可以得到一个数据的概览,它是分析和总结全套的数据,而不是寻找单个文档。
Elastic除搜索之外,还提供针对ES数据的统计分析功能,具有较高的实时性。通过聚合,我们可以得到一个数据的概览,它是分析和总结全套的数据,而不是寻找单个文档。
上一篇:ES的Query DSL
什么是ES的聚合
Elastic除搜索之外,还提供针对ES数据的统计分析功能,具有较高的实时性。
通过聚合,我们可以得到一个数据的概览,它是分析和总结全套的数据,而不是寻找单个文档。
例如,我们可以通过聚合得到一个旅游网站的以下数据:
-
地区A 和 地区B 的客房数量
-
不同的价格区间,可以预定的经济性酒店和舒适型酒店的数量
使用ES聚合,我们只需要一条语句,就可以从ES得到分析的结果,无需在客户端去实现。在Kibana中,大量的可视化报表其实都是采用了ES的聚合分析来得到的数据结果。
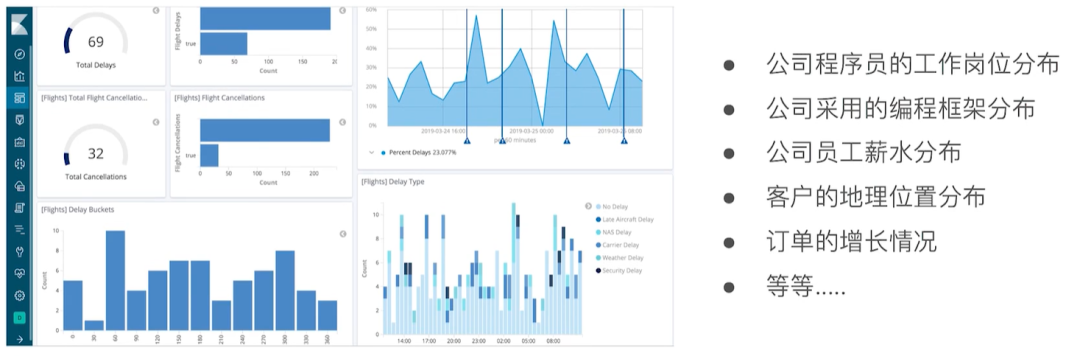
ES聚合的分类
ES中常见的聚合有如下几类:
-
Bucket Aggregation - 一些列满足特定条件的文档集合
-
Metric Aggregation - 一些数学运算,可以对文档字段进行统计分析
-
Pipeline Aggregation - 对其他的聚合结果进行二次聚合
-
Matrix Aggregation - 支持对多个字段的操作并提供一个结果矩阵
那么,接下来,我们就一起来看看最常用的Bucket & Metric聚合。
Bucket & Metric
这里我们直接用我们都很熟悉的SQL语句来理解Bucket和Metric:
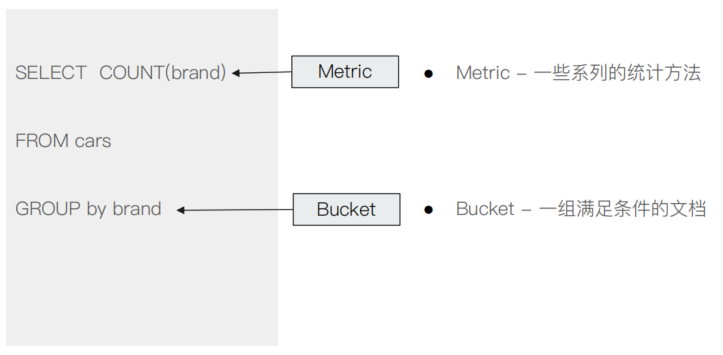
Metric就类似于SQL中的一些聚合函数方法,主要对数据集进行计算。
大多数Metric是数学计算,仅仅输出一个值,如:min / max / sum / avg / cardinality
少部分Metric支持输出多个数值,如:stats / percentiles / percentile_ranks
Bucket就类似于SQL中对数据进行分组,主要指满足一定条件的文档集合。
我们可以借助Bucket实现数据的分桶,例如可以实现酒店的高档、中档和低档的分桶,也可以在高档的分组下再分为好评、中评和差评三个分桶。
ES中提供了多种类型的Bucket,例如 Term & Range,可以让我们轻松地实现时间 / 年龄区间 / 地理位置的分桶。
下面我们来看一个Bucket的例子:
查看航班目的地的统计信息
分桶字段:DestCountry (目的地)
// 按照字段的Terms进行分桶 GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "flight_dest": { "terms": { "field": "DestCountry" } } } }
统计结果如下图所示:

可以从结果图中看出,ES返回了以航班目的地为分组的的Buckets(分桶),IT(意大利)的航班有2371次,US(美丽国)的航班有1987次...
下面我们来看一个加入Metirc的例子:
查看航班目的地的统计信息,并增加均价、最高价 和 最低价的统计
这里我们就可以使用ES提供的数学计算Metrics了
GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "flight_dest": { "terms": { "field": "DestCountry" }, "aggs": { // 自定义名字为 avaerage_price "average_price": { // 使用 avg metric "avg": { "field": "AvgTicketPrice" } }, // 自定义名字为 max_price "max_price": { // 使用 max metric "max": { "field": "AvgTicketPrice" } }, // 自定义名字为 min_price "min_price": { // 使用 min metric "min": { "field": "AvgTicketPrice" } } } } } }
统计结果如下图所示:
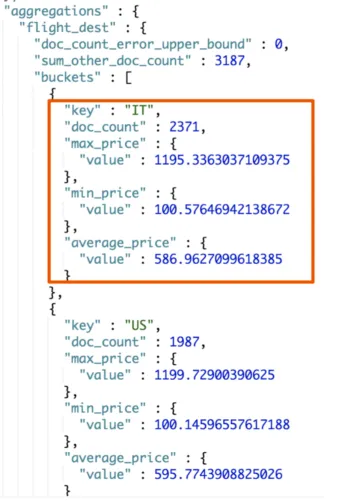
可以从结果图中看出,ES在之前分组统计的基础上,还把平均价格、最高价和最低价都统计出来了。
相信到这里,你已经初步了解基本的统计分析了。
聚合嵌套
如果想要在上面的聚合统计基础之上,再做进一步的详细分析,我们就可以使用聚合嵌套。
还是以上面的示例为基础,我们想要:
查看航班目的地的统计信息,平均票价,以及天气情况。
天气情况是基于之前对航班目的地的聚合统计的基础之上,做的二次聚合,类似于在第一个Bucket中再分几个Bucket,这个就是聚合嵌套。
GET kibana_sample_data_flights/_search { "size": 0, "aggs": { "flight_dest": { "terms": { "field": "DestCountry" }, "aggs": { "average_price": { "avg": { "field": "AvgTicketPrice" } }, // 聚合嵌套 "weather": { "terms": { "field": "DestWeather" } } } } } }
统计结果如下图所示:

可以看到,ES在以航班目的地为分组的Bucket下,又为我们分出了多个Bucket,这些嵌套的Bucket就是我们想要统计的天气情况。比如,图中航班目的地为CN(中国)的天气情况中,Sunny(晴朗)天气的记录有209条,而Rain(下雨)天气的记录有207条。
小结
本篇,我们了解了ElasticSearch的聚合的概念,以及两个重要的聚合 Bucket & Metric。通过一个查询实例,我们了解了如何使用 Bucket & Metric 进行最基本的统计分析,ES的聚合还支持嵌套,还是很强大的!
参考资料
极客时间,阮一鸣,《ElasticSearch核心技术与实战》



 浙公网安备 33010602011771号
浙公网安备 33010602011771号