深度学习框架中的“自动求导”原理是什么?
深度学习这个概念已经火了好些年了,前些年刚开始的时候大家都不清除那些深度学习的框架是什么原理,in other words,大家都是只知道用这些深度学习框架,但是没有几个人真的了解这个框架的原理是什么,不过随着这几年开源的相关资料越来越多,慢慢的这也不是当年的什么高深秘密了,当年所有的深度学习框架都被外国产品所垄断,今天国内的公司开发的深度学习框架如:mindspore、paddle等等已经很多了,而且更神奇的是很多个人或者开源团体也都有推出的深度学习框架了,更神奇的是有的甚至就几个研究生一起鼓捣鼓捣也能搞出个深度学习框架,这就十分神奇了,因此本文就探讨下深度学习框架的核心原理——“自动求导机制”到底是个什么东西???
刚开始使用深度学习框架时十分惊叹于深度学习框架的自动求导功能,可以说深度学习框架的本质就是自动求导的高性能计算,而这种对于任何操作都可以自动求得其倒数的能力更是核心。其实在本篇post开始之前我对这个自动求导的一个假想是两个可能,第一个可能就是深度学习框架其实是把所有的操作的导数公式已经预先写好,然后在进行深度学习求导时自动调用并结合链式法则即可,不过这种想法后来想想感觉比较不靠谱,主要原因就是把所有的操作都手动写导数计算方式这个工作量太大,不是很现实,于是就有了第二种假想;第二种假想,深度学习框架的自动求导其实是使用了某种估计的计算方法,比如计算y=f(x)中在x0时的dy/dx,那么分别计算x0+delta时的y+,以及计算x0-delta时的y-,然后通过计算(y+ - y-)/(2*delta)就可以估计出导数,但是该种方式本身每次运行的计算又比较大,而且对于这个导数估计的精度又是难以确定的,考虑了这两种方式的不足后就更加感觉深度学习框架中的autograd的实现是极为黑科技的。本身在学校几年前读phd的时候导师要向国家申请国家级的项目来研发一个自主的深度学习框架,由于自己这书读的十分的无望再加上整个实验室的人不管是发几个A的人基本都是只会fusion code,这个事情也就是无疾而终了,不过这也更加深了我对这个autograd的好奇,毕竟这个深度学习框架主要的技术内容就是autograd了。
各种机缘下有了再已经下autograd的想法,于是在网上找了下资料,从tensorflow的函数自动求导是如何实现的?中突然发现原来深度学习中的autograd居然真的是使用hard code的方式把求导方法保存下来的,这个实际操作居然和自己曾经的一个假想十分靠近了,只不过深度学习中并不是将一些函数的求导方法hard code的方式写入框架中,而是使用将各种算子的求导方式hard code到框架中,而且在进行链式求导时是把这些一个求导链条中的算子的求导数值组合计算的,看来自己当年的头脑风暴还是沾些边的。其实深度学习框架的求导核心就是两个操作,第一个就是将每个算子的求导方法hard code到框架中;第二个就是使用链式法制把这些算子的导数合成我们要求解的导数,而这个过程中何如构建和优化链式法则中各算子的导数就是一个关键点了。
为了直观的了解如何通过hard code算子求导公式后利用链式法则自动求导,可以看下tensorflow的函数自动求导是如何实现的?中的例子:

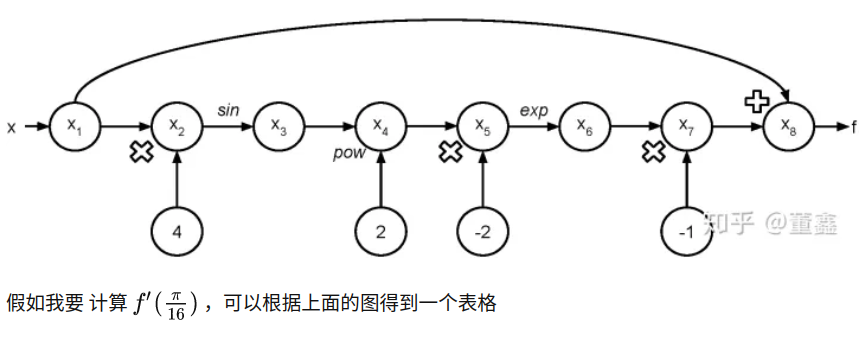
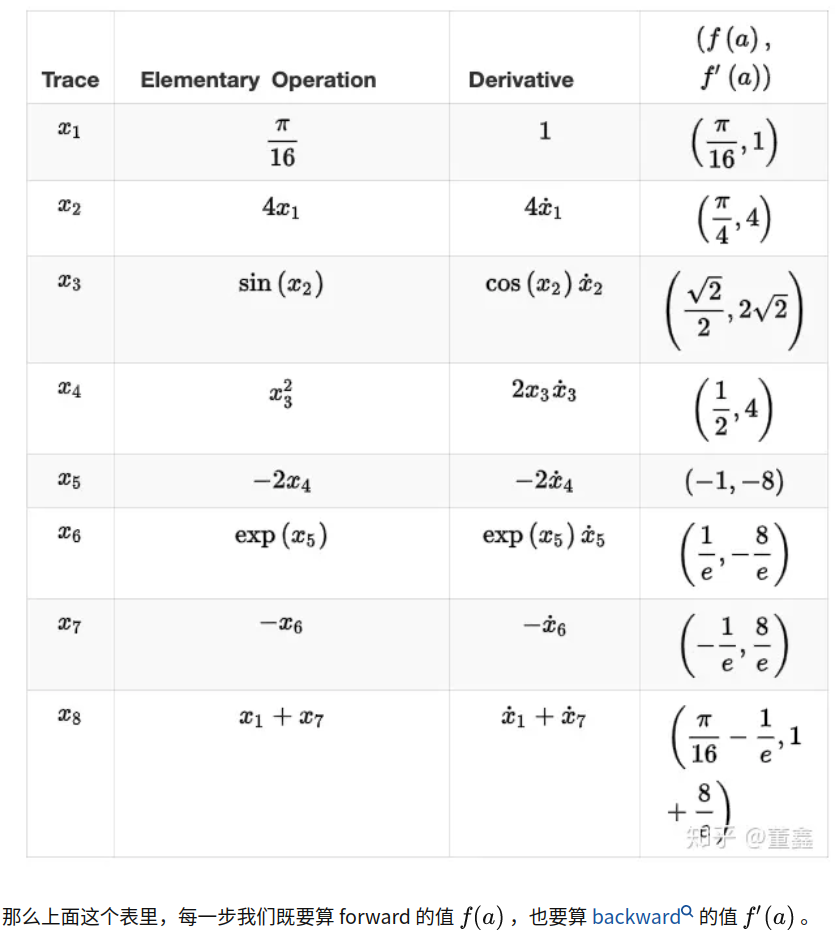
--------------------------------------------------------
其实看到这里很多人基本可以在脑海中对深度学习框架的自动求导机制有个大致的图案了。
在神经网络自动求导的设计与实现中给出了神经网络前向计算和后向计算的示意图:
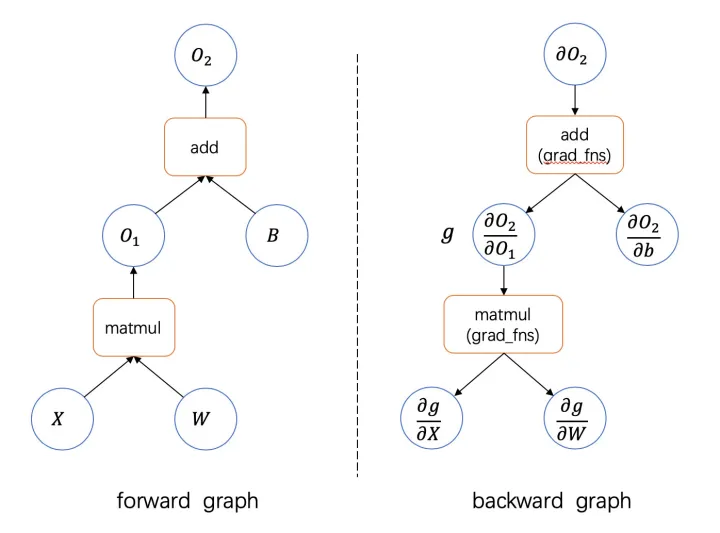
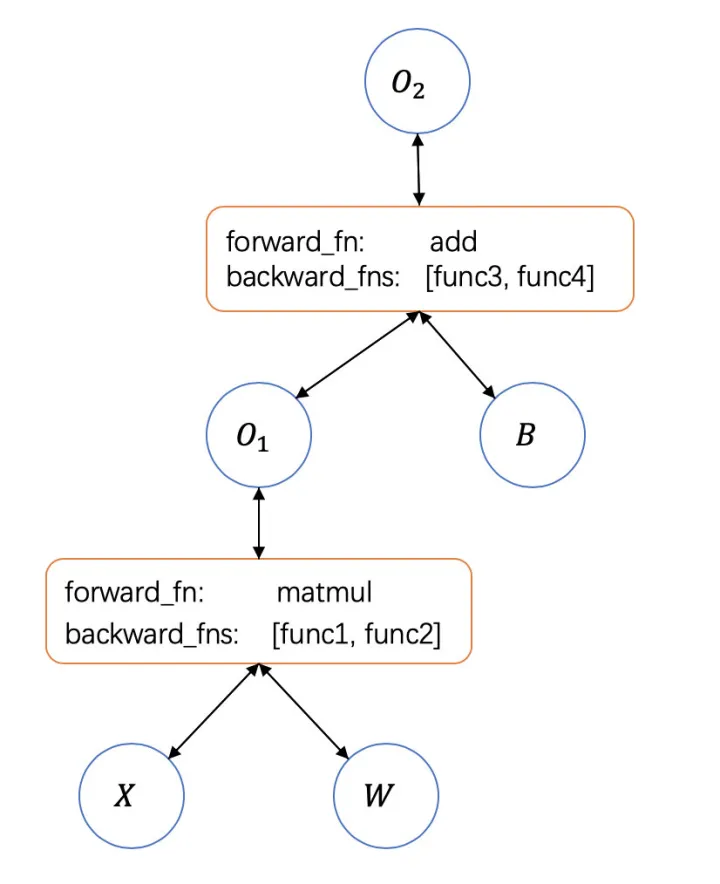
从这个示意图中我们可以知道如果在前向计算时的每个算子的导数都被记录下来,并且可以记录每个算子的反向传输时下个算子的导数函数(backward function),那么我们就可以使用计算机自动计算出导数。
当前常见的深度学习框架分别为pytorch代表的动态计算图和tensorflow的静态计算图。动态计算图就是在运行前向计算时动态的构建计算图(这个计算图就是为了反传时寻找将各个算子的导数利用链式法则连乘所用的),而静态构建计算图则时在前向传播之前就将整个计算图构建好。动态计算图的优点就是设计简单,在构建图时可以使用python语言做循环控制和判断,缺点就是对计算图的优化往往不足,不过JIT技术现在也可以很好的解决动态构建计算图时的优化问题了。静态计算图在前向传播之前将计算图构建完成,可以使用编译的思想对整个反传时的计算图进行很好的优化,提高反传计算效率,缺点就是在构建计算图时不能使用python控制语句,而且编程难度也有一定提高。为了方便理解,本文以及后续的post都是在动态图的情况下进行讨论(动态图和静态图原理都是一样的,区别就是对反传的优化方式上,因为这里不涉及对反传的计算效率优化,因此以动态图作为template可以有简洁的作用)。
前面说了,实现autograd的主要两个key point,一个是算子的反传函数的编写;一个是计算图的构建。对于深度学习框架来说,好像是构建计算图的部分十分重要,但是实际这部分工作量并不大,好的计算图构建方式只不过是优化的更加好些,而算子反传部分往往才是工作量最多的地方。
动手设计实现一个深度学习框架中给出了一个toy版的深度学习框架代码,之所以说是toy版本,因为这个library并没有实现全部的基本功能,只是实现了比较简单的一些功能,不过作为学习之用还是不错的,给出具体的代码地址:
https://github.com/borgwang/tinynn-autograd
=======================================================
参考:
https://pytorch-cn.readthedocs.io/zh/latest/notes/autograd/
posted on 2022-11-17 19:29 Angry_Panda 阅读(913) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号