
python编程中的circular import问题
循环引入,circular import是编程语言中常见的问题,在C语言中我们可以使用宏定义来处理,在c++语言中我们可以使用宏定义和类的预定义等方式来解决,那么在python编程中呢?
其实在python编程语言中出现circular import的时候还是毕竟少的,主要原因是python用来开发较大、较复杂的项目的场景有限,这一点不像C、C++等语言,但是随着AI领域的兴起python语言作为几乎是唯一的选择慢慢的应用多了起来。与此同时如网络编程、图形设计等中小规模的开发场景也开始逐渐选择python语言了,毕竟python语言的用户多了以后一些适合python的中小级别项目也会更倾向选择使用python语言开发了,但是随着python开发的项目大了起来以后这个circular import问题也就开始常见起来了。
=====================================
给出一个circular import的典型例子:
x2.py
print("this is x2.file, in ") import x3 def f1(): print("x2.f1") def f2(): x3.f3() f2() print("this is x2.file, out ")
x3.py
print("this is x3.file, in") import x2 def f3(): print("x3.f3") def f4(): x2.f1() f4() print("this is x3.file, out")
运行结果:

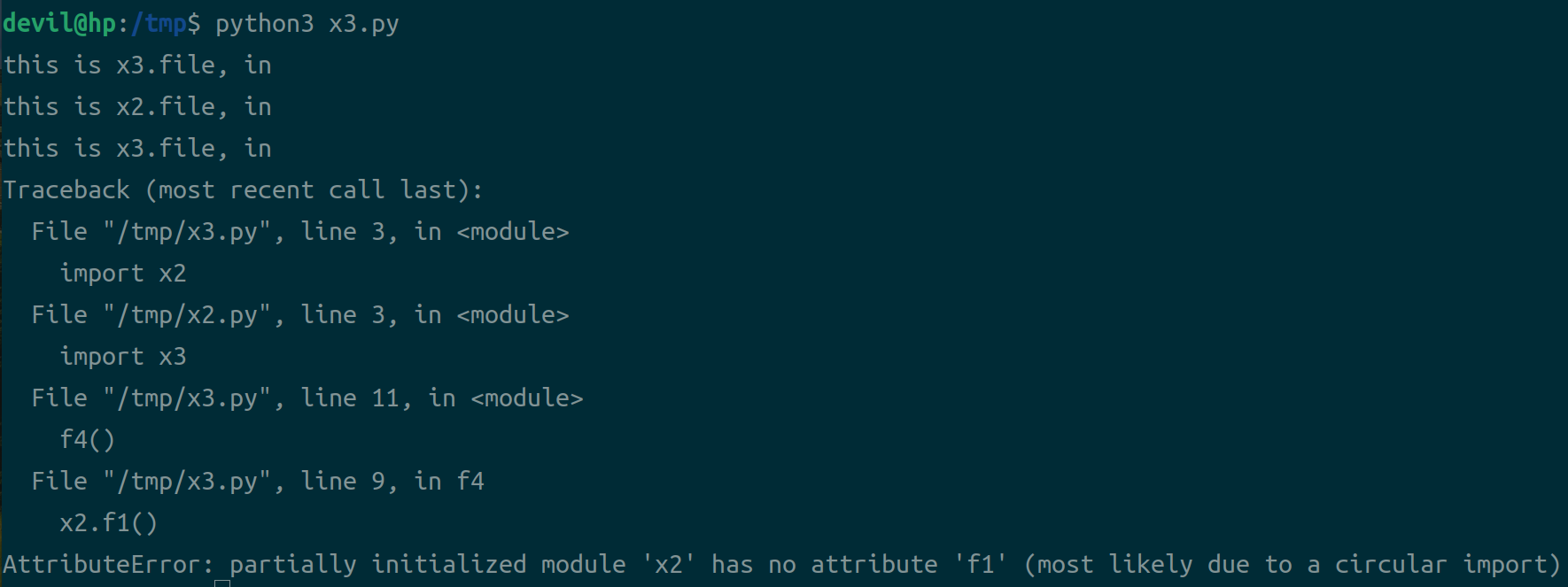
从上面的代码运行我们可以知道circle import问题其实简单的说就是一个python的module文件运行到import语句时跳转到了另一个module文件并执行该module文件,跳转到的module文件又import了原先没有运行完的module文件,但是由于原module文件已经加入到了引入模块中不会再次import了并且由于是执行被中断后跳转到现在的module中导致并没有完整的运行完。换句话说,跳转后的module文件查询已引入的模块发现原module已经被引入(但是此时的原module并没有完全引入)就不会再重新引入原模块,但是此时跳转后的module又调用了原模块中的变量,而由于原模块并没有完整引入因此该变量并不能成功调用,此时就会包circle import的错误。
知道了circle import 问题出现的原理,那么像上面的例子我们完全可以通过简单的修改import的位置来解决,给出修改后的文件:
x2.py
print("this is x2.file, in ") def f1(): print("x2.f1") import x3 def f2(): x3.f3() f2() print("this is x2.file, out ")
x3.py
print("this is x3.file, in") def f3(): print("x3.f3") import x2 def f4(): x2.f1() f4() print("this is x3.file, out")
运行结果:

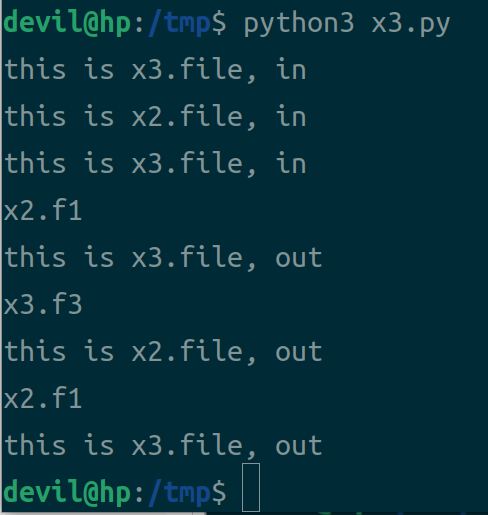
可以看到对于circle import,只要解决对未初始化变量的调用就会解决报错问题,像上面的例子就是通过修改import的时机来解决的,但是在实际coding中出现circle import的情况都很复杂,对于不同情况也都需要不同的解决方法,但是基本准则就是解决对未初始化变量的调用。
-----------------------------------------------------
另外说一下,不论使用什么coding技巧对于出现circular import的python代码最终的必杀技就是代码重构,不过由于这样做时间损耗比较大所以不大万不得已还是不建议的。
在某些情况下可以使用稍稍修改来解决,在网上找到了一个针对两个文件内相互调用对方文件下的类来声明本文件下变量的解决方法:
https://www.bilibili.com/video/BV1E54y1R7wm/?vd_source=f1d0f27367a99104c397918f0cf362b7
=====================================
为了更详细的研究一下python中的circle import问题写了几个小DEMO,并把代码上传到网上,具体见:
https://gitee.com/devilmaycry812839668/circle_import_python
先进入到 circle_import_python_1 文件夹,看下文件:

文件内容:
main.py
import xyz
xyz.py
print("this is xyz.py file, in") import submodule submodule.s = submodule.s+1 def fun(): print("........ xyz.fun") print("submodule.s: ", submodule.s) print("this is xyz.py file, out")
submodule/__init__.py
print("this is __init__, in") s = 0 import submodule.x import submodule.y print("this is __init__, out")
submodule/x.py
print("this is x.py file, in") print("this is x.py file, out")
submodule/y.py
print("this is y.py file, in") import xyz xyz.fun() print("this is y.py file, out")
在 circle_import_python_1 文件夹下执行:
python3 xyz.py
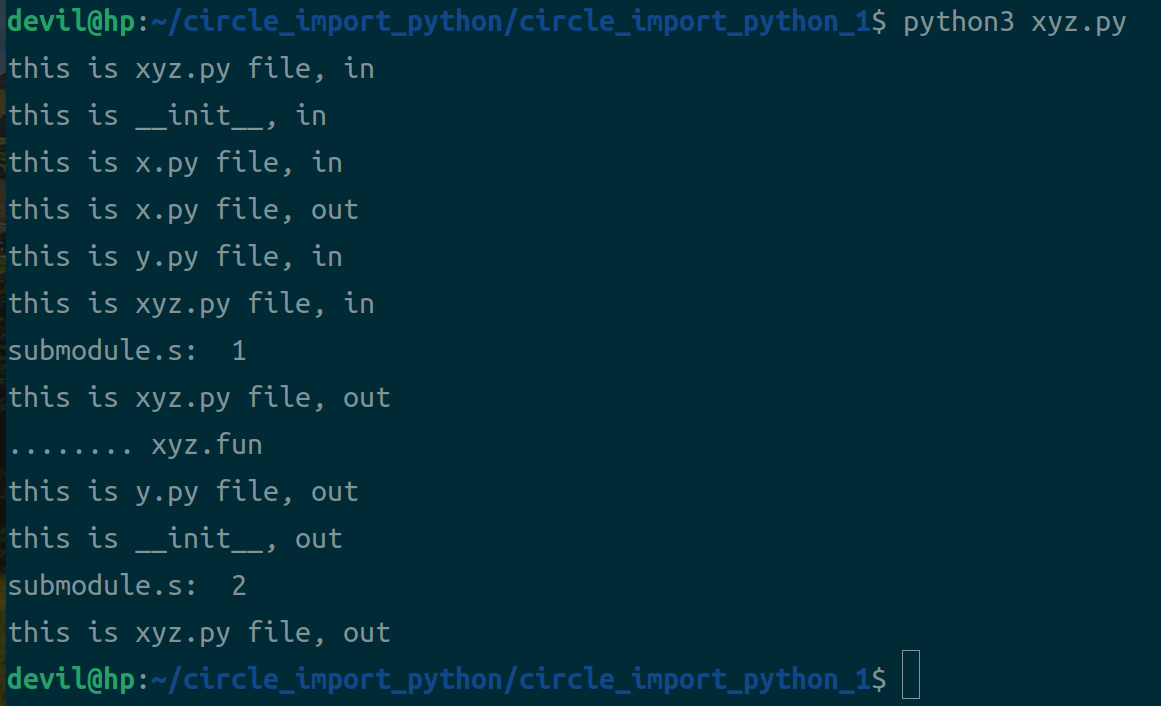
--------------------------------------------
python3 main.py
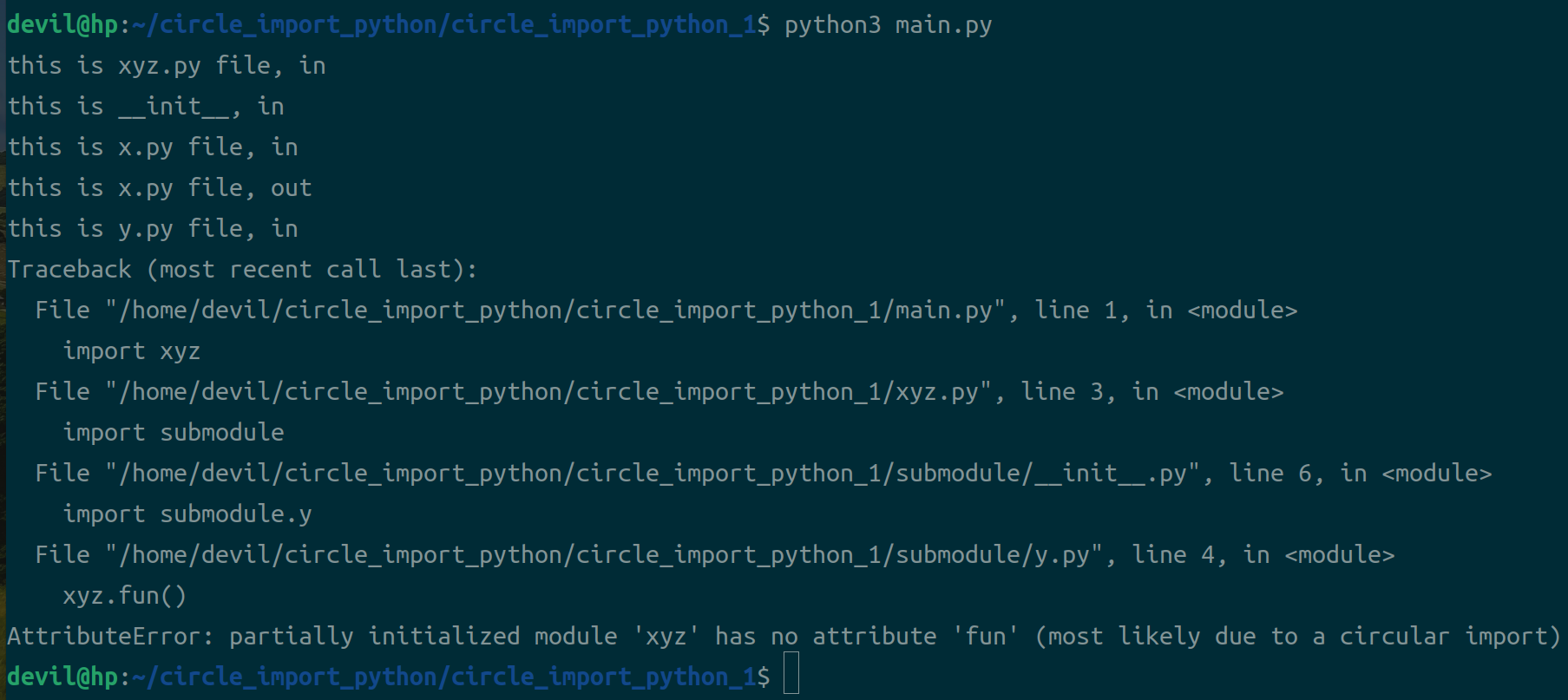
python3 main.py 时,xyz模块在main.py中被执行所以在y.py中import xyz时就不会被再次执行,但是此时main.py中对xyz模块的执行并没有完成因此y.py中调用xyz.fun就会由于未初始化而报错。
python3 xyz.py 时,xyz模块作为启动模块不会在启动时加入到已经在已经import的模块的路径集合中,所以在y.py中import xyz时就会被再次执行,这时再次跳转到xyz.py文件中,而由于y.py已经加入到已经import的模块的路径集合中,因此此时执行xyz.py模块可以顺利的对xyz.fun初始化,然后xyz执行完重新回到y.py中执行对xyz.fun的调用就不会报circle import的错误。
----------------------------------------------
从上面的circle_import_python_1的例子我们可以知道:
(python程序运行时会维护一个已经import的模块的路径集合,每次执行import语句时都会判断该模块是否已经在已经import的模块的路径集合中,如果不在才执行,如果已经存在则不执行)
1. 如果python程序以非交互的方式启动,那么启动文件(module)是不会加入到模块引入路径的,因此如果在其他模块中重新import启动文件那么就可能使启动文件被运行两次:一次是启动程序时作为启动文件,此时并没有加入import模块路径中;一次是在其他模块中被import,然后加入到import模块路径中。就如上面的submodule.s的最后输出数值为2。
(回答一个问题,python中有没有可能一个模块被重复执行两次?会的,如果这个模块是作为启动模块存在的,并且在其他模块中还import这个模块则这个模块会被执行两次)
2. 当import一个package里面的模块时都是要判断这个package的__init__.py模块是否被加入到import模块路径中,如果没有加入到已经import的模块的路径集合中则执行该__init__.py并加入到已经import的模块的路径集合中,只有package中的__init__.py被执行过才可以import该package下的模块。
3. 在一个module中执行import语句,如果判断需要import的模块并不在已经import的模块的路径集合中则会中断在现在的module中的运行并跳转到需要import的那个模块中运行,只有当import的那个模块执行结束才会恢复现模块的执行。
-------------------------------------------------------
对circle_import_python_1进行下修改,得到circle_import_python_2 代码,修改的地方在submodule/__init__.py中的s=0的声明位置,我们将submodule/__init__.py中的s=0的声明位置放在import语句后。
修改后的 submodule/__init__.py :
print("this is __init__, in") import submodule.x import submodule.y s = 0 print("this is __init__, out")
执行:
python3 xyz.py
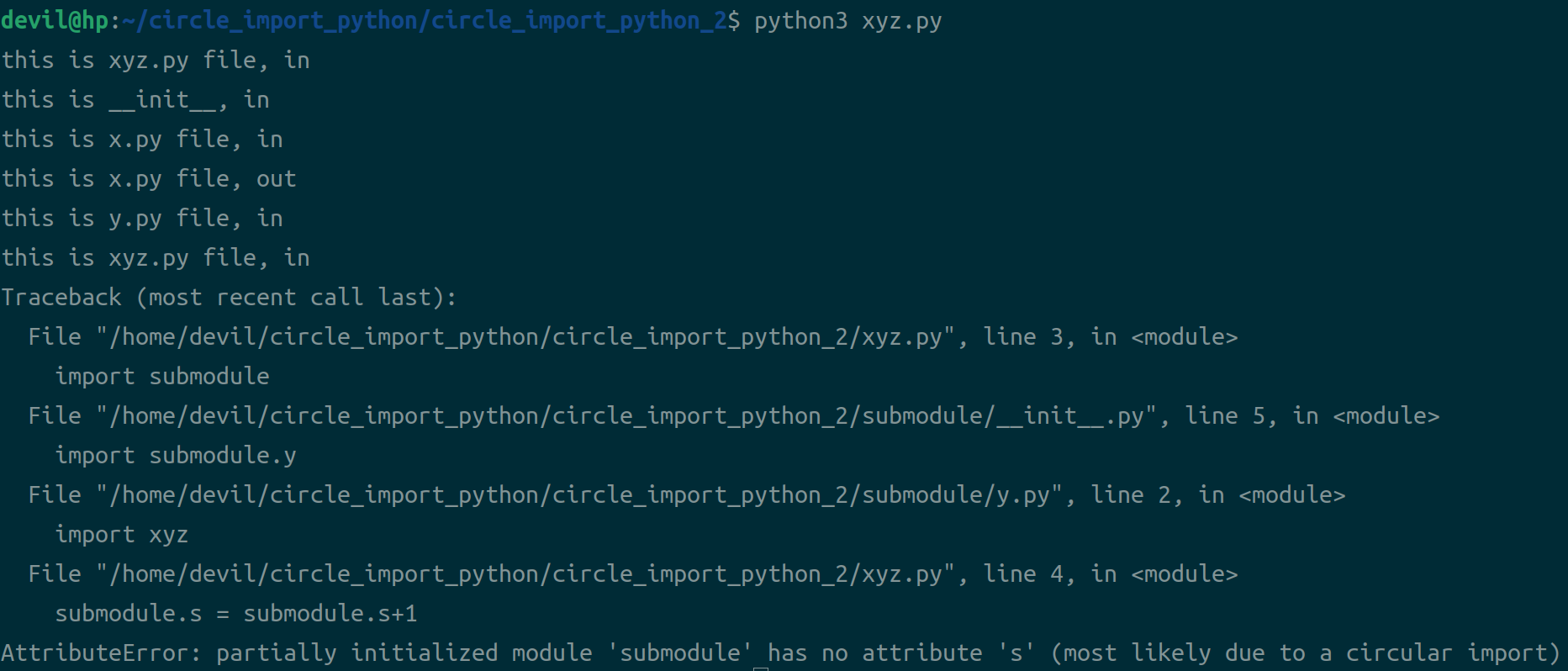
可以看到同样也是报circle import错误。在python中如果项目大了起来出现circle import的机会就会增多,知道circle import出现的原理我们就可以根据实际情况来进行应对。就先前面说的,一旦出现circle import如果实在没有办法解决可以选择最后的方法,就是代码重构,不过重构的话一个是需要较大的时间耗费,一个就是会影响原代码的逻辑结构、影响代码风格。
可以说,对于circle import问题最好的解决方法就是在coding时对模块的层级做到较好的计划,在coding时有较好的规范可以很好的避免circle import问题的出现,不过在有些情况下该问题又难以通过改善coding规范的方法来解决(当然可以通过重构的方法来解决,不过需要尽量避免重构),给出以下的例子,参见:
https://www.bilibili.com/video/BV1E54y1R7wm/?vd_source=f1d0f27367a99104c397918f0cf362b7
参照上面视频中的代码重新写了各类似的代码,上传在:
x_class.py
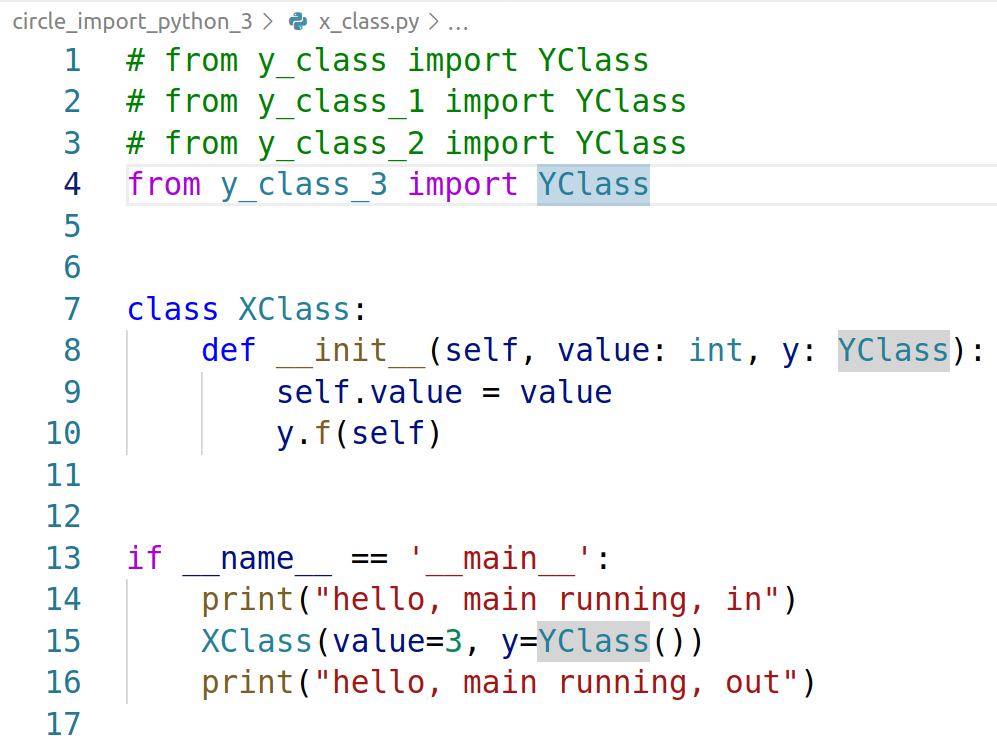
y_class_3.py

对这个 typing.TYPE_CHECKING 个人理解的不是很多,个人的理解是 typing.TYPE_CHECKING 在编译时为true,在运行时为false。因此在编译时可以正常通过,在代码编辑时可以被识别出类型并给出很好的提示信息(value: int),而在执行时由于 typing.TYPE_CHECKING 为false,所以在执行时并不会执行import class语句因此不会造成circle import的错误。
而在y_class_1.py和y_class_2.py中虽然可以通过编译及运行,但是在代码编辑时还是会提示类型无法识别:
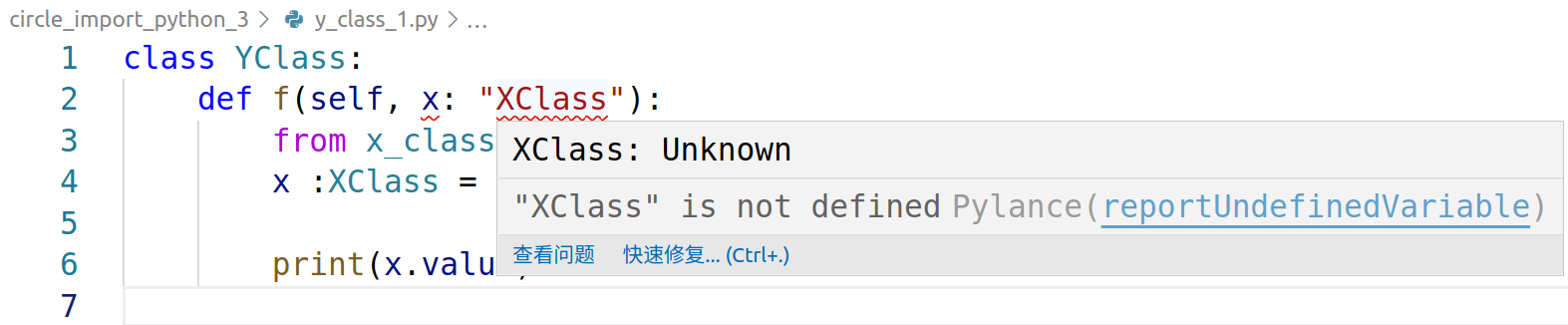

可以看到y_class_1.py和y_class_2.py中所使用的方法可以起到对程序员的提示功能,但是并不被IDE所识别,y_class_3.py中所使用的typing.TYPE_CHECKING方法为python的原生支持语法可以被IDE所识别。
------------------------------------------------------------------
typing.TYPE_CHECKING 的使用方法:
https://docs.python.org/zh-cn/3/library/typing.html?highlight=type_check#typing.TYPE_CHECKING
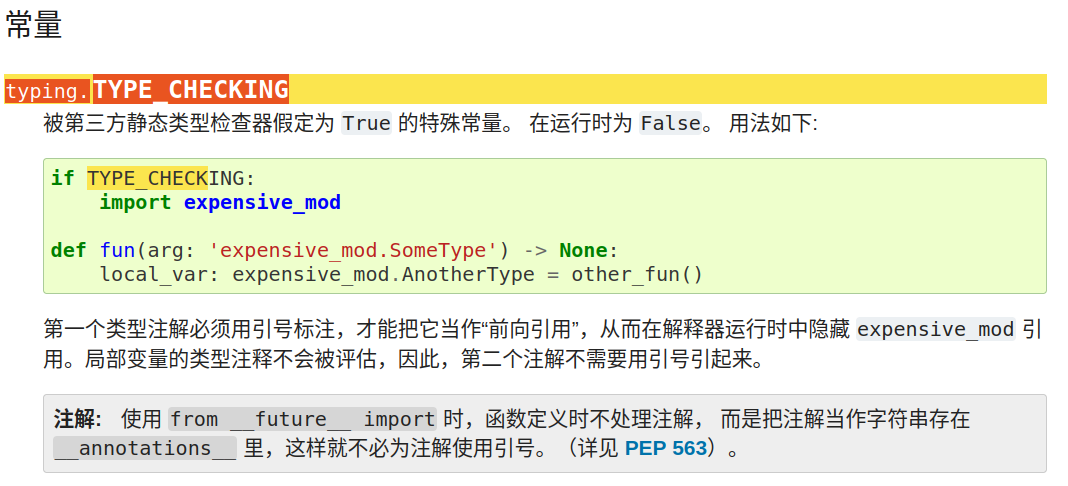
我们知道python语言在执行时是一边编译一边执行的,我们也可以这样理解,那就是python在执行一段代码之前是需要先对其进行编译的,编译好才会执行。python语言在编译时是不考虑对象和变量类型的,也就是不会去检查对象和变量类型的,至于会不会出现类型错误都是在执行的时候才会发现,python的该种特性导致在coding时是不会显示的声明类型的,这样不利于人类对代码的理解,说白了就是这样的代码在review的时候谁也搞不懂这个代码原先设计的含义是什么。为此python语言的解决方法就是大量的编写说明文档doc,但是doc的编写很耗费时间十分的不讨coding人员的喜爱,为此就出现了python语言的注解(typing下的annotation),说白了就是为python语言中的对象标记出类型,这个类型并不像c++、java语言那样提供给编译器使用而是只工程序员理解代码含义的,这一特性可以很好的减少doc文档的体量也便于理解。
而在 circle_import_python_3 的例子中就是因为使用了注解(typing下的annotation)从而造成了circle import的问题,针对这种情况下的circle import问题python官方给出了typing.TYPE_CHECKING的解决方法,该方法在代码静态编辑的时候可以被pylance等第三方类型检查工具读取出typing.TYPE_CHECKING的值为true,以使执行import语句可执行从而保证编译成功,但是在代码执行的时候typing.TYPE_CHECKING的值为false,从而避免了circle import错误的出现。
=====================================
相关:
posted on 2022-07-05 17:12 Angry_Panda 阅读(1804) 评论(1) 编辑 收藏 举报


