【转载】 深究强化学习在谷歌芯片布局上的应用
论文:
https://www.nature.com/articles/s41586-021-03544-w.pdf
谷歌论文:
《 A graph placement methodology for fast chip design》
=================================================================
Chip Placement with Deep Reinforcement Learning
电路板制作流程
在讲解芯片布局之前,我们先了解电路板的大致制作流程,这和芯片设计有一定类比性,可帮助建立概念。
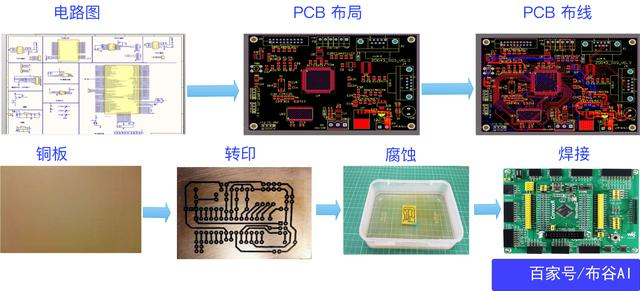
1,按照设计好的PCB板,对铜板进行热转印;腐蚀之后,保留需要的芯片、电阻等元件引脚及走线信息。
2,PCB布局就是排放电路图中各芯片、电阻电容等元件的位置。
3,PCB布线就是布置各元件之间的连线。
芯片制作流程
下图是intel cpu的制作流程:

1,与电路板制作类似,不过是在晶圆上制作各种晶体管。
2,光刻类似电路板制作的热转印,将事先设计好的芯片布局布线图案(掩膜),通过紫外线刻在晶圆上;被“卡脖子”的5nm光刻机指的就是这里。
芯片布局
《Chip Placement with Deep Reinforcement Learning》尝试通过深度强化学习的方法,解决芯片布局的问题,类比于电路板制作的PCB元件布局;注意只包括布局,不包括布线。
芯片布局包含两部分,一是标准单元(standard cells)的布局,如NAND(与非门)、NOR(或非门)、XOR(异或门)等逻辑门,二是宏(macros)的布局,触发器、算术逻辑单元、硬件暂存器等预定义逻辑模块。
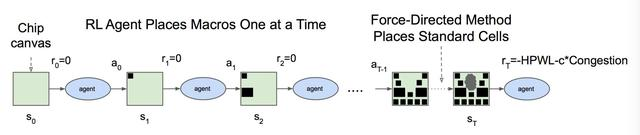
宏的布局就是论文算法要解决的问题,标准单元的布局采用分组聚类(hMETIS)和力导引(force-directed)的传统方法。
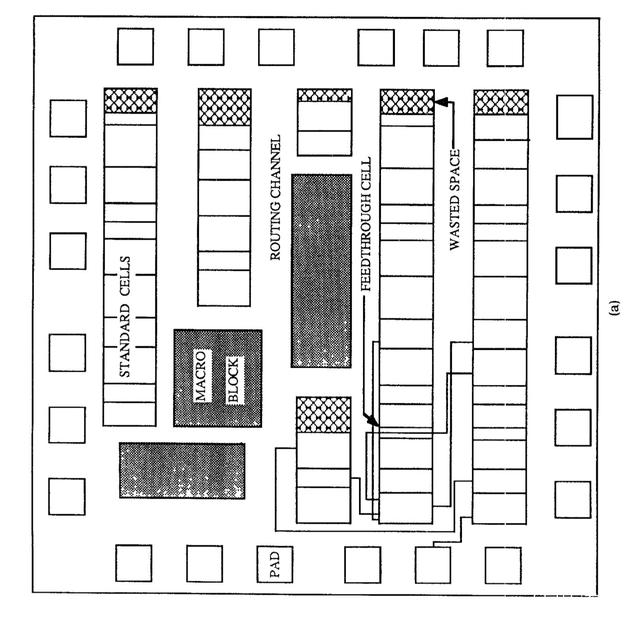
布局宏(macros)
问题描述为给定芯片的netlist,将宏放置到128X128的晶圆画布(canvas)上,以使芯片的PPA(能耗、性能和面积)最小;netlist是一张图(Graph),描述电路图中各节点(宏或标准单元)的连接关系。
采用PPO:近端策略优化深度强化学习算法来建模宏布局。
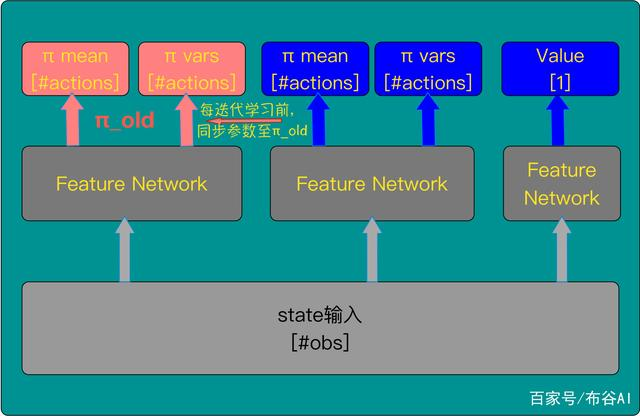
模型结构
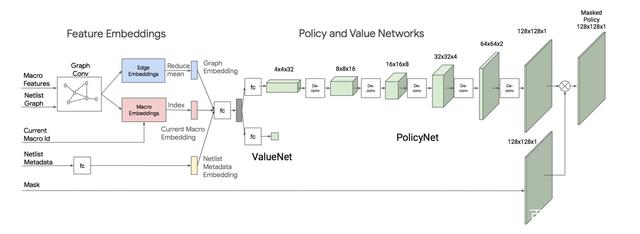
1,基于PPO结构,由Policy π(.|s) 和 state-value V(s)网络构成。
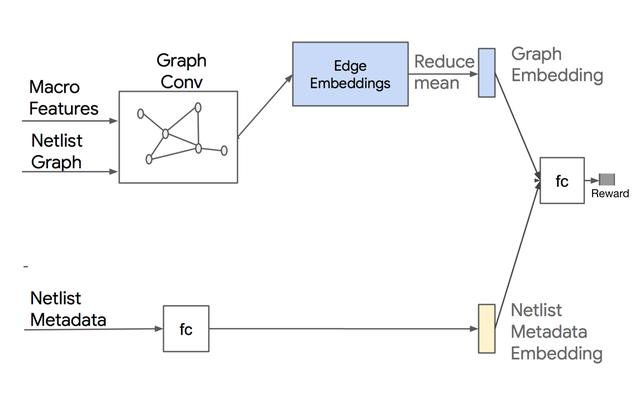
2,输入State包含所有宏的Graph Embedding、当前要放置的宏的Id、netlist metadata(比如连线、宏标准单元等数量等netlist基础信息)、Mask信息(表达不能被放置的Grid位置)。
3,Policy π(.|s)采用转置卷积(如下图一种升维方法),最终Actions动作空间输出为128X128X1,与画布大小一致,表达的是画布上每一个Grid。
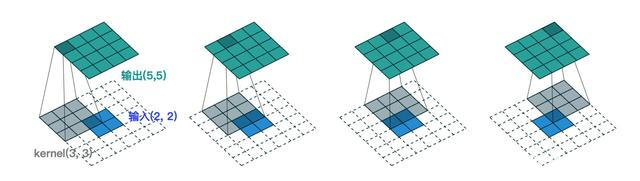
4,注意这个宏布局过程按照顺序逐个摆放,对于Policy π(.|s)来说,是一种无放回的采样;此处引入Mask作为Filter,Policy每次只能从Mask之外的Grids采样。
5,Mask一方面包含已经布局的Grid,同时也包含不满足Density约束的Grid; Density约束为了防止布局过于稠密,引起重叠。
6,Policy采样采取的是贪心方法,每次选择概率最大的Grid,这个和PPO本身是有所区别。
7,即时Reward表征芯片PPA,当芯片布局完成,给出最终奖赏,其它步骤都是0。直接通过EDA Tool获得Reward,环境反馈时间比较长,这是强化学习在真实应用场景中的一个常见困难。 采用如下布线长度和布线阻塞进行近似:
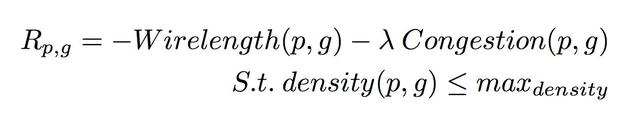
布线长度Wirelength通过HPWL方法进行估计。
Graph Embedding
Netlist Graph,通过GCN网络,同时输出Edge Embeddings和Node Embeddings。
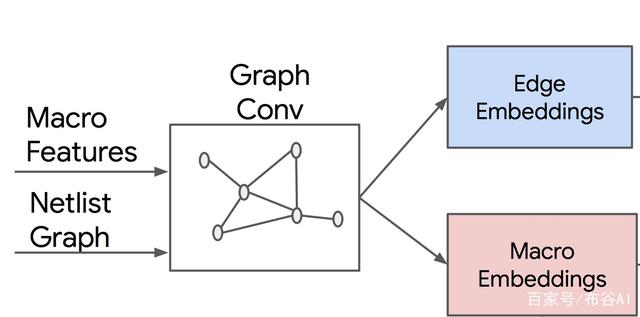
GCN是CNN在图结构上的应用,输入为node features和 邻接矩阵,如本例中的Macro Features和Netlist adjacency。架构如下:
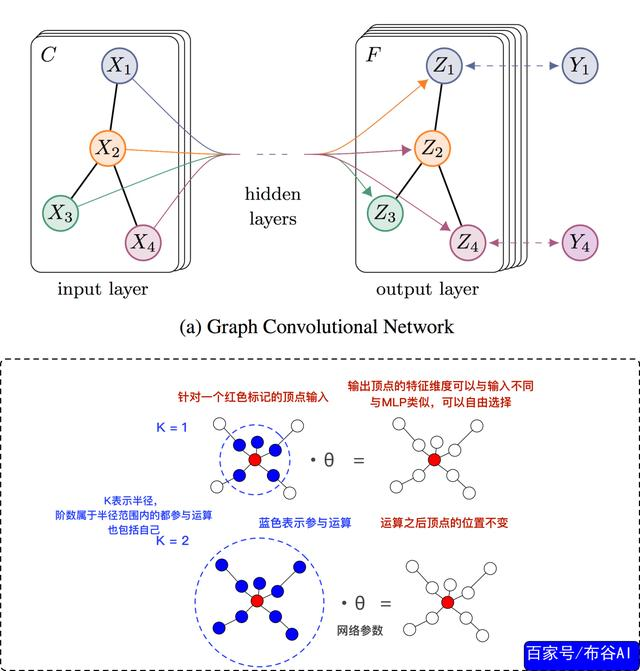
类比于CNN中的Kernel,GCN Kernel中大小K表达距离目标节点的半径。如上,比如k=1,表达只考虑距离(阶)目标节点小于等于1的节点,也包括自身。
经过GCN网络之后,就能得到最后的节点特征向量即node embeddings,本例中网络参数更新方式为:

训练Graph Embedding的数据与即时Reward模型数据一致,应该也可以在训练Reward模型时一并更新Graph Embedding参数,或者fine-tuning方式。
预训练Policy Network ( 存疑 ???)
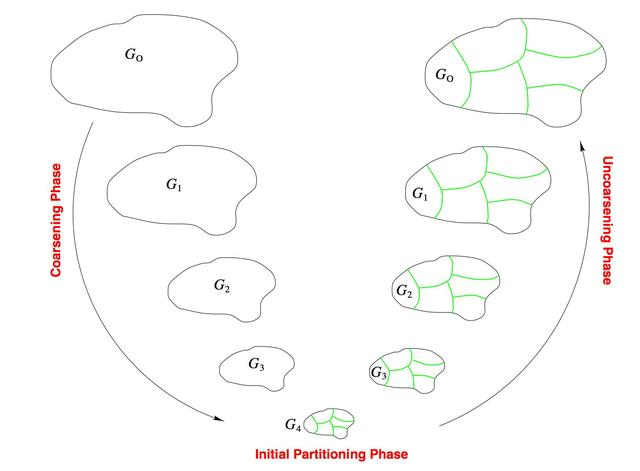
2,簇之间采用力导引(force-directed)方法。
总结
深度强化学习PPO应用于芯片宏布局中,提高了芯片设计效率。谷歌论文展示了高超的工程实践技艺,通过Graph Embedding、预训练等深度学习策略,以及丰富的先验知识,使学习约束到有限的时间内,整套解决问题的方案非常值得借鉴。
======================================================
posted on 2022-05-08 15:13 Angry_Panda 阅读(1070) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号