摘要:  本文收集了一些目前为止仅有DeepSeek满血版可以正确答复的“简单问题”,以供测试和验证自己所使用的模型是满血版DeepSeek还是残血版的DeepSeek。有两点需要提示:各大厂商模型可以联网更新,本问题集有一定的时效性;部分数学和推理类问题,跟temperature参数的设定有关,temperature参数设置的越低,回答越严谨。 阅读全文
本文收集了一些目前为止仅有DeepSeek满血版可以正确答复的“简单问题”,以供测试和验证自己所使用的模型是满血版DeepSeek还是残血版的DeepSeek。有两点需要提示:各大厂商模型可以联网更新,本问题集有一定的时效性;部分数学和推理类问题,跟temperature参数的设定有关,temperature参数设置的越低,回答越严谨。 阅读全文
本文收集了一些目前为止仅有DeepSeek满血版可以正确答复的“简单问题”,以供测试和验证自己所使用的模型是满血版DeepSeek还是残血版的DeepSeek。有两点需要提示:各大厂商模型可以联网更新,本问题集有一定的时效性;部分数学和推理类问题,跟temperature参数的设定有关,temperature参数设置的越低,回答越严谨。 阅读全文
posted @ 2025-02-28 16:34
DECHIN
阅读(3071)
评论(0)
推荐(0)
摘要: 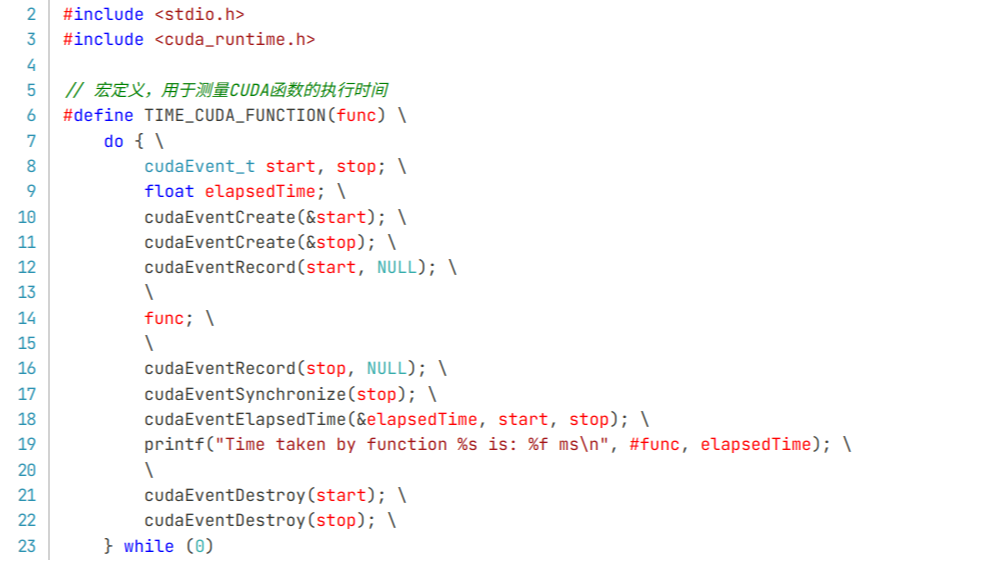 这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。 阅读全文
这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。 阅读全文
这篇文章主要介绍了一个CUDA入门的技术:使用CUDA头文件写一个专门用于CUDA函数运行时长统计的宏,这样就可以统计目标Kernel函数的运行时长。可以直接在CUDA中打印相应的数值,也可以回传到Cython或者Python中进行打印。 阅读全文
posted @ 2025-02-28 09:45
DECHIN
阅读(572)
评论(0)
推荐(0)
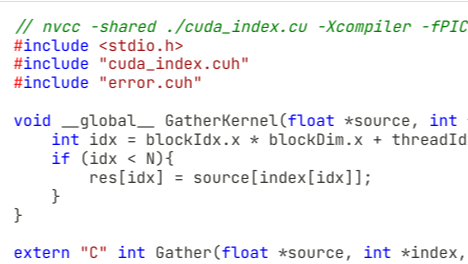 本文使用了Cython作为封装函数,封装一个CUDA C实现的Gather算子,然后通过Python去调用,用这种方法实现一个比较Pythonic的CUDA Gather函数的实现和调用。
本文使用了Cython作为封装函数,封装一个CUDA C实现的Gather算子,然后通过Python去调用,用这种方法实现一个比较Pythonic的CUDA Gather函数的实现和调用。  本文主要介绍了在CUDA编程的实践中,增加一个异常捕获的宏模块,以保障CUDA项目结果的准确性。主要代码内容参考了樊哲勇所著的《CUDA编程基础与实践》,是一本很好的CUDA编程入门书籍。
本文主要介绍了在CUDA编程的实践中,增加一个异常捕获的宏模块,以保障CUDA项目结果的准确性。主要代码内容参考了樊哲勇所著的《CUDA编程基础与实践》,是一本很好的CUDA编程入门书籍。  本文介绍了一种将Hugging Face上bin格式的大模型文件,在线转换为safetensors文件格式,然后下载到本地的方法。
本文介绍了一种将Hugging Face上bin格式的大模型文件,在线转换为safetensors文件格式,然后下载到本地的方法。  对于本地模型的加载来说,除了使用KTransformer等工具进行指令集层面的优化之外,还可以调整模型加载层数,做一个简单的优化。这里提供了一个num_gpu和num_ctx参数调整的策略,实测Tokens性能最大可优化10倍左右。
对于本地模型的加载来说,除了使用KTransformer等工具进行指令集层面的优化之外,还可以调整模型加载层数,做一个简单的优化。这里提供了一个num_gpu和num_ctx参数调整的策略,实测Tokens性能最大可优化10倍左右。  为了方便本地大模型部署和迁移,本文提供了一个关于Ollama的模型本地迁移的方法。由于直接从Ollama Hub下载下来的模型,或者是比较大的GGUF模型文件,往往会被切分成多个,而文件名在Ollama的路径中又被执行了sha256散列变换。因此我们需要从索引文件中获取相应的文件名,再进行模型本地迁移。
为了方便本地大模型部署和迁移,本文提供了一个关于Ollama的模型本地迁移的方法。由于直接从Ollama Hub下载下来的模型,或者是比较大的GGUF模型文件,往往会被切分成多个,而文件名在Ollama的路径中又被执行了sha256散列变换。因此我们需要从索引文件中获取相应的文件名,再进行模型本地迁移。  本文介绍了两种智能编程的方案,一种是使用Cursor结合远程API形式的智能化自动编程,另一种方案是VSCode插件结合本地部署的Ollama模型来进行智能编程。用户可以根据自己的需求来选择一种合适的交互方案,总体来说智能化、自动化的编程已经近在眼前了。
本文介绍了两种智能编程的方案,一种是使用Cursor结合远程API形式的智能化自动编程,另一种方案是VSCode插件结合本地部署的Ollama模型来进行智能编程。用户可以根据自己的需求来选择一种合适的交互方案,总体来说智能化、自动化的编程已经近在眼前了。  本文主要介绍的是国产高性能大模型加载工具KTransformer的安装方法。之所以是使用方法,是因为该工具对本地的硬件条件还是有一定的要求。如果是型号过于老旧的显卡,有可能出现TORCH_USE_CUDA_DSA相关的一个报错。而这个问题只能通过换显卡来解决,所以作者本地并未完全测试成功,只是源码安装方法和Docker安装方法经过确认没有问题。
本文主要介绍的是国产高性能大模型加载工具KTransformer的安装方法。之所以是使用方法,是因为该工具对本地的硬件条件还是有一定的要求。如果是型号过于老旧的显卡,有可能出现TORCH_USE_CUDA_DSA相关的一个报错。而这个问题只能通过换显卡来解决,所以作者本地并未完全测试成功,只是源码安装方法和Docker安装方法经过确认没有问题。  这篇文章主要介绍了llama.cpp这一大模型工具的使用。因为已经使用Ollama来run大模型,因此仅介绍了llama.cpp在HF模型转GGUF模型中的应用,及其在大模型量化中的使用。大模型的参数量化技术,使得我们可以在本地有限预算的硬件条件下,也能够运行DeepSeek的蒸馏模型。
这篇文章主要介绍了llama.cpp这一大模型工具的使用。因为已经使用Ollama来run大模型,因此仅介绍了llama.cpp在HF模型转GGUF模型中的应用,及其在大模型量化中的使用。大模型的参数量化技术,使得我们可以在本地有限预算的硬件条件下,也能够运行DeepSeek的蒸馏模型。  这篇文章主要介绍了通过使用PageAssist,来使得本地部署的DeepSeek模型可以联网搜索的方案。
这篇文章主要介绍了通过使用PageAssist,来使得本地部署的DeepSeek模型可以联网搜索的方案。 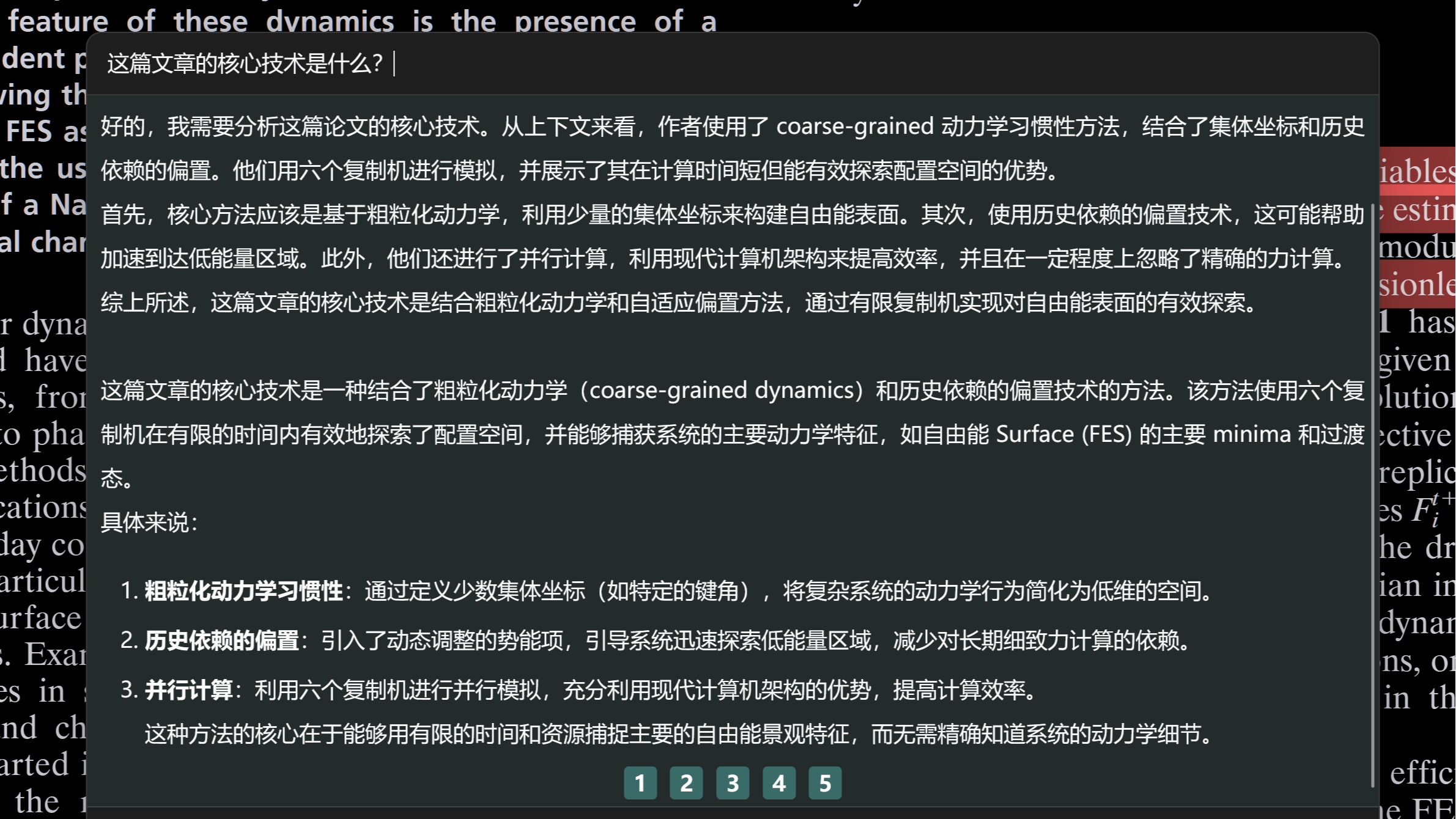 这篇文章介绍了一种在Zotero科研文献阅读管理软件中,使用Awesome GPT插件配置Ollama-DeepSeek文本生成模型+BAAI-bgeM3嵌入模型,来解析和理解科研论文的一种方法。借此可以简化一部分繁杂的论文学习过程,也许可以提升科学研究的效率。
这篇文章介绍了一种在Zotero科研文献阅读管理软件中,使用Awesome GPT插件配置Ollama-DeepSeek文本生成模型+BAAI-bgeM3嵌入模型,来解析和理解科研论文的一种方法。借此可以简化一部分繁杂的论文学习过程,也许可以提升科学研究的效率。 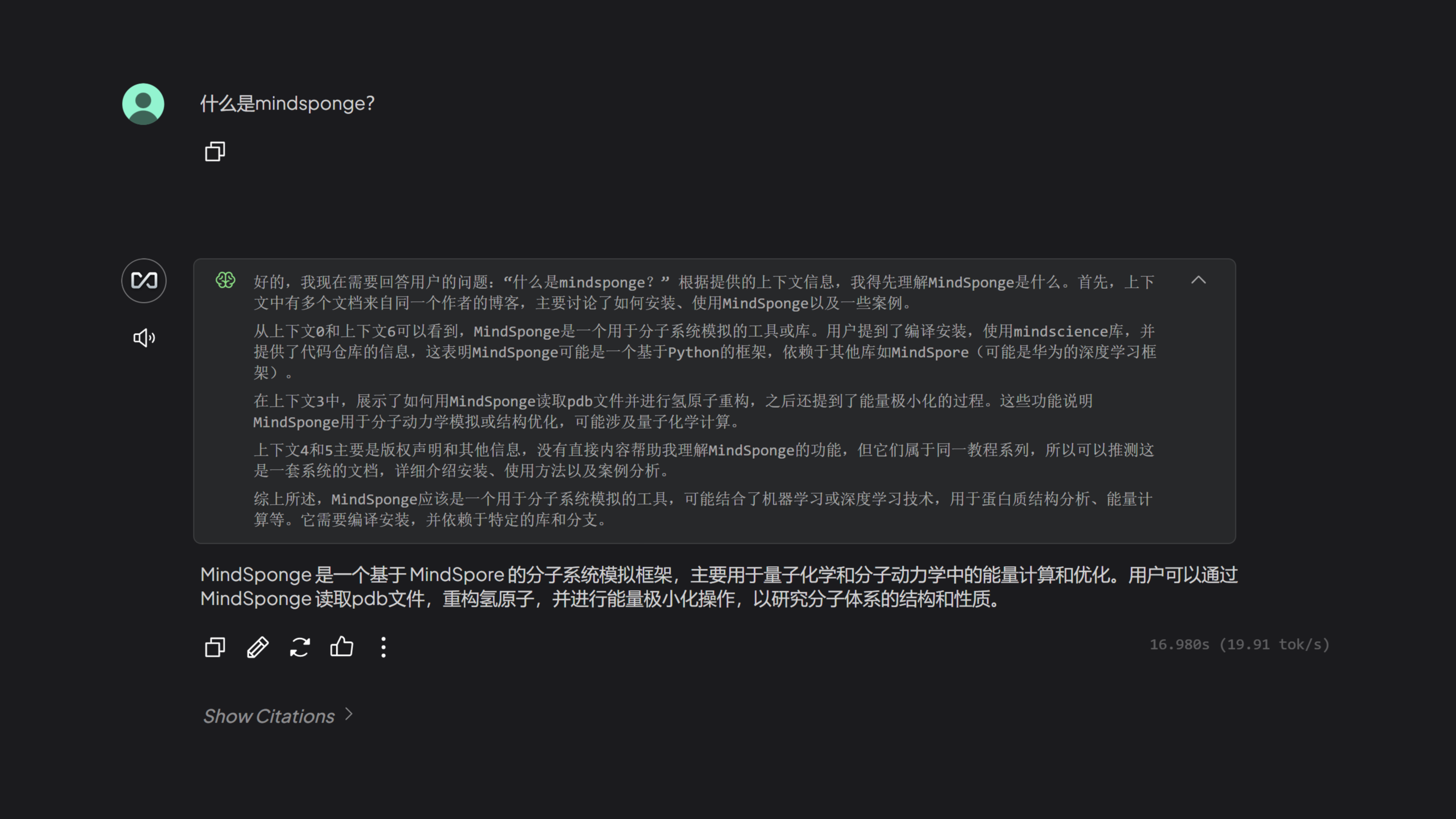 大模型之大,可以训练我们所有人日常生活学习工作可能使用到的所有知识。但是完整的大模型,要实现一个本地化的部署,可能是有点困难,因此才有了大模型的蒸馏技术。蒸馏之后大模型可能会损失大多数的行业知识,而我们可以通过本地知识库构建的方法,在本地构建一个私有的专业大模型。
大模型之大,可以训练我们所有人日常生活学习工作可能使用到的所有知识。但是完整的大模型,要实现一个本地化的部署,可能是有点困难,因此才有了大模型的蒸馏技术。蒸馏之后大模型可能会损失大多数的行业知识,而我们可以通过本地知识库构建的方法,在本地构建一个私有的专业大模型。 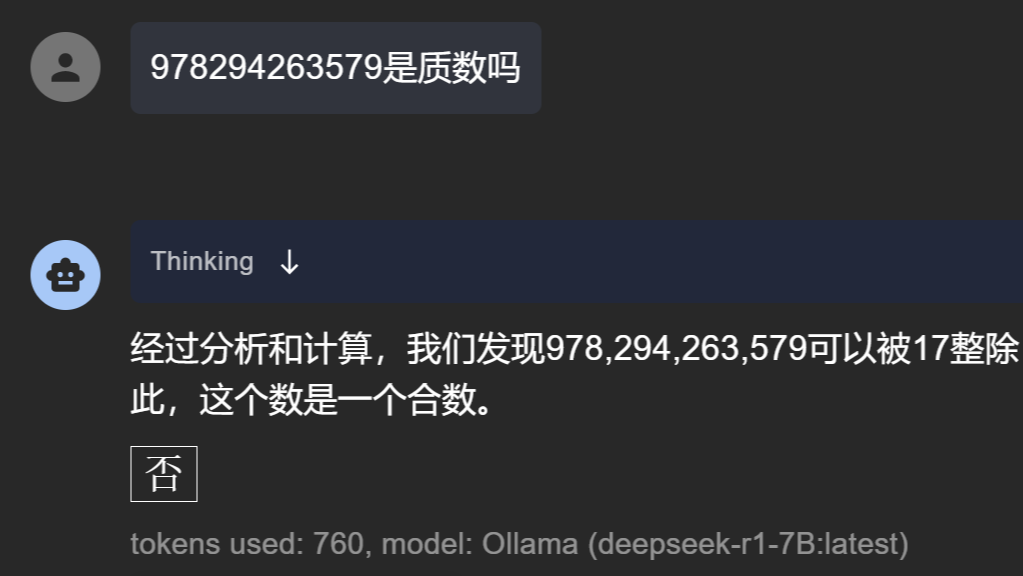 本文介绍了一个可以相比之下更快速的在本地部署DeepSeek的方法,除了在上一篇博客中介绍的从Github或者Github加速网站获取Ollama之外,还可以通过从国内的其他大模型文件平台下载模型文件,来加速本地模型的构建。
本文介绍了一个可以相比之下更快速的在本地部署DeepSeek的方法,除了在上一篇博客中介绍的从Github或者Github加速网站获取Ollama之外,还可以通过从国内的其他大模型文件平台下载模型文件,来加速本地模型的构建。 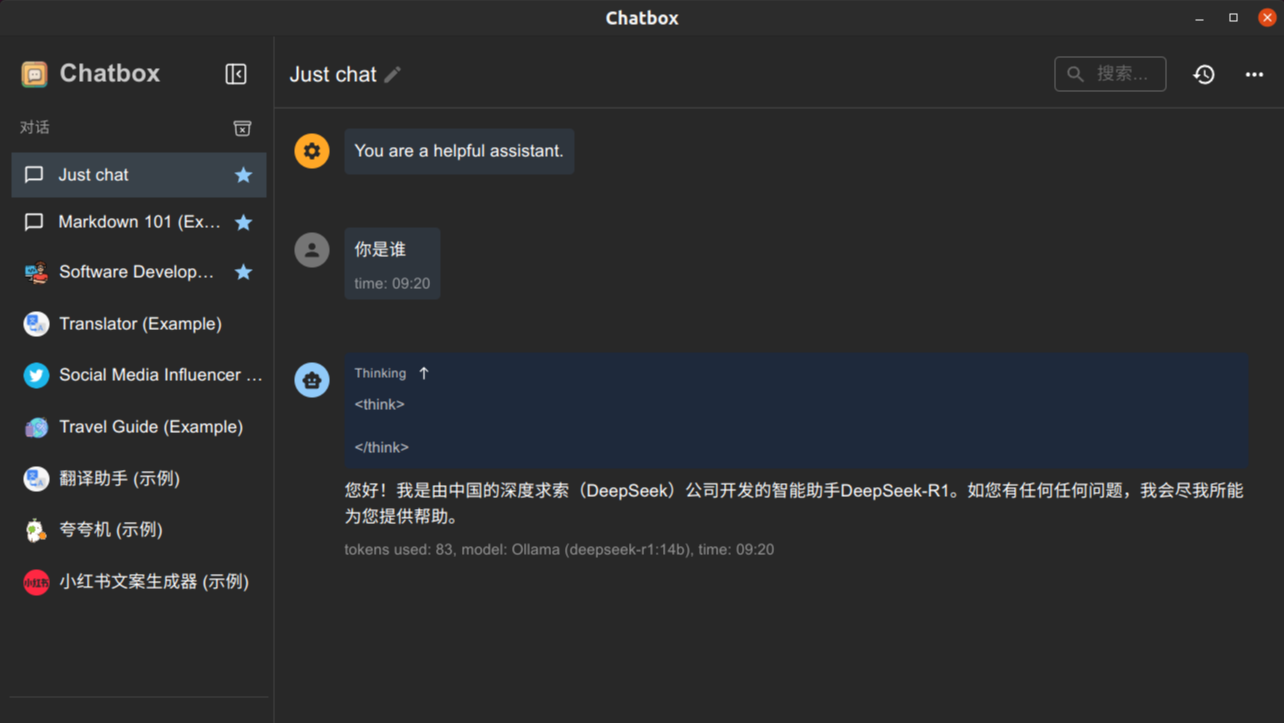 本文介绍了通过Ollama在Ubuntu Linux平台上部署DeepSeek本地大模型的方法,并且可以使用ChatBox调用本地Ollama API进行本地对话或者是远程对话。
本文介绍了通过Ollama在Ubuntu Linux平台上部署DeepSeek本地大模型的方法,并且可以使用ChatBox调用本地Ollama API进行本地对话或者是远程对话。  浙公网安备 33010602011771号
浙公网安备 33010602011771号