炸裂了…京东一面索命40问,过了就50W+(京东面试真题)
文章很长,且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 :《尼恩技术圣经+高并发系列PDF》 ,帮你 实现技术自由,完成职业升级, 薪酬猛涨!加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
炸裂了…京东一面索命40问,过了就50W+(京东面试真题)
说在前面
在40岁老架构师尼恩的(50+)读者社群中,经常有小伙伴,需要面试京东、阿里、 百度、头条、美团等大厂。
下面是一个小伙伴成功拿到通过了京东一次技术面试,最终,小伙伴通过后几面技术拷问、灵魂拷问,最终拿到offer。
从这些题目来看:京东的面试,偏重底层知识和原理,大家来看看吧。
现在把面试真题和参考答案收入咱们的宝典,大家看看,收个京东Offer需要学点啥?
当然对于中高级开发来说,这些面试题,也有参考意义。
这里把题目以及参考答案,收入咱们的《尼恩Java面试宝典》 V83版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到公众号【技术自由圈】获取
本文目录
- 炸裂了…京东一面索命40问,过了就50W+(京东面试真题)
- 说在前面
- 本文目录
- 京东一面索命40问
- 1、聊聊五种 IO 模型
- 2、说说什么是一致性
- 3、说说什么是隔离性
- 4、说说MySQL的隔离级别
- 5、说说每个隔离级别是如何解决
- 6、MySQL要加上nextkey锁,语句该怎么写
- 7、说说Java的内存模型,垃圾回收
- 8、实现分布式锁,Zookeeper 和 Redis 哪种更好?
- 9、说一下分布式锁实现
- 10、了解hystrix么?说一下它的工作原理?
- 11、说说NIO和IO有什么区别
- 12、说说NIO和AIO的区别
- 13、Spring的aop怎么实现?Spring的aop有哪些实现方式
- 14、说说动态代理的实现方式和区别
- 15、聊聊索引在哪些场景下会失效?
- 16、怎么查看系统负载
- 17、分布式 id 生成方案有哪些?什么是雪花算法?
- 18、Linux中,查找磁盘上最大的文件的命令
- 19、Linux中,如何查看系统日志文件
- 20、聊聊事务隔离级别,以及可重复读实现原理
- 21、os进程间怎么通信?
- 22、os有使用哪些数据结构?
- 23、说说对Linux的了解
- 24、TCP和UDP的区别?
- 25、HTTP和HTTPS的区别?
- 26、HTTPS的TLS握手过程?
- 27、GC了解吗?
- 28、说说Java有哪些锁?
- 29、Lock和synchronized有啥区别?
- 30、synchronized一定会阻塞吗?
- 31、说说偏向锁、轻量锁级、重量级锁是什么锁?
- 32、线程池有哪些参数?
- 33、说说RocketMQ的消息生产消费过程?
- 34、说说生产者的负载均衡?
- 35、说说消息的reput过程?
- 36、说说RocketMQ的ConsumeQueue消息的格式?
- 37、3PC、2PC、CAP是啥?
- 38、RocketMQ是AP还是CP?
- 39、RocketMQ的Broker宕机会怎样?
- 40、有看过选主过程的源码吗?简述一下
- 尼恩说在最后
- 技术自由的实现路径 PDF:
- 获取11个技术圣经PDF:
京东一面索命40问
1、聊聊五种 IO 模型
一、什么是 IO
IO 全程 Input/Output,即数据的读取(接收)或写入(发送)操作,针对不同的数据存储媒介,大致可以分为网络 IO 和磁盘 IO 两种。
而在 Linux 系统中,为了保证系统安全,操作系统将虚拟内存划分为内核空间和用户空间两部分。因此用户进程无法直接操作IO设备资源,需要通过系统调用完成对应的IO操作。
即此时一个完整的 IO 操作将经历一下两个阶段:用户空间 <-> 内核空间 <-> 设备空间。

二、五种 IO 模型
1.同步阻塞 IO
同步阻塞IO(Blocking IO) 指的是用户进程(或线程)主动发起,需要等待内核 IO 操作彻底完成后才返回到用户空间的 IO 操作。在 IO 操作过程中,发起 IO 请求的用户进程处于阻塞状态。

2.同步非阻塞 IO
同步非阻塞IO(Non-Blocking IO,NIO) 指的是用户进程主动发起,不需要等待内核 IO 操作彻底完成就能立即返回用户空间的 IO 操作。在 IO 操作过程中,发起 IO 请求的用户进程处于非阻塞状态。

1)当数据 Ready 之后,用户线程仍然会进入阻塞状态,直到数据复制完成,并不是绝对的非阻塞。
2)NIO 实时性好,内核态数据没有 Ready 会立即返回,但频繁的轮询内核,会占用大量的 CPU 资源,降低效率。
3.IO 多路复用
IO 多路复用(IO Multiplexing) 实际上就解决了 NIO 中的频繁轮询 CPU 的问题,并且引入一种新的 select 系统调用。
复用 IO 的基本思路就是通过 slect 调用来监控多 fd(文件描述符),来达到不必为每个 fd 创建一个对应的监控线程的目的,从而减少线程资源创建的开销。一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核就能够将文件描述符的就绪状态返回给用户进程(或者线程),用户空间可以根据文件描述符的就绪状态进行相应的 IO 系统调用。
IO 多路复用(IO Multiplexing)属于一种经典的 Reactor 模式实现,有时也称为异步阻塞 IO。

4.异步 IO
异步IO(Asynchronous IO,AIO) 指的是用户空间的线程变成被动接收者,而内核空间成为主动调用者。在异步 IO 模型中,当用户线程收到通知时,数据已经被内核读取完毕并放在用户缓冲区内,内核在 IO 完成后通知用户线程直接使用即可。而此处说的 AIO 通常是一种异步非阻塞 IO。

5.信号驱动 IO
当进程发起一个 IO 操作,会向内核注册一个信号处理函数,然后进程返回不阻塞;当内核数据就绪时会发送一个信号给进程,进程便在信号处理函数中调用 IO 读取数据。
信号驱动 IO 不同于 AIO 的是依旧存在阻塞状态,即用户进程获取到数据就绪信号后阻塞进行 IO 操作。
2、说说什么是一致性
一、不同的一致性
我们在不同的地方见到过一致性的概念,总结大概分为以下几类:
- ACID里的一致性
- 多副本的一致性
- CAP理论的一致性
- 一致性哈希
二、ACID里的一致性
1.最常见的定义是:事务的一致性是指系统从一个正确的状态,迁移到另一个正确的状态。
指的是事务前后的正确性是一致的。
Consistency ensures that a transaction can only bring the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades,triggers, and any combination thereof. This prevents database corruption by an illegal transaction, but does not guarantee that a transaction is correct.
2.“ensuring the consistency is the responsibility of user, not DBMS.”, "DBMS assumes that consistency holds for each transaction。
指的是对业务中和数据库中约束的检查,业务上的合理性,只靠AID手段不容易检查出逻辑性的问题来。比如转账操作中,账户金额不能为负数,这是业务逻辑上的要求,用一致性来保证。
3.This(Consistency)does not guarantee correctness of the transaction in all ways the application programmer might have wanted (that is the responsibility of application-level code) but merely that any programming errors cannot result in the violation of any defined database constraints.[1]
三、多副本一致性
某些数据保存了多个副本,所有副本内容相同。
四、CAP理论中的一致性
整个分布式系统在对外的反馈上,与一台单机完全一样,不会因为分布式导致对外行为的前后冲突。
五、一致性哈希
一种哈希算法,指将存储节点和数据都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题。
对比非一致性哈希(普通的哈希),映射时如果节点发生变化,需要重新计算所有数据的映射值。
六、线性一致性、外部一致性、最终一致性的区别
这三个都是分布式系统的一致性级别
线性一致性:强一致性,侧重于单个key的场景
外部一致性:事务在数据库内的执行序列不能违背外部观察到的顺序,更侧重于对比传统数据库系统的内部一致性。
最终一致性:弱一致性。
40岁老架构师尼恩提示:分布式事务是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题17:分布式事务面试题》PDF,该专题对分布式事务有一个系统化、体系化、全面化的介绍。
如果要把分布式事务写入简历,可以找尼恩指导
3、说说什么是隔离性
一、事务的四大特性:
1.原子性(Atomicity)
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,这和前面两篇博客介绍事务的功能是一样的概念,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
2.一致性(Consistency)
一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
3.隔离性(Isolation)
隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。
关于事务的隔离性数据库提供了多种隔离级别,稍后会介绍到。
4.持久性(Durability)
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
二、隔离性:
多个线程都开启事务操作数据库中的数据时,数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性,在介绍数据库提供的各种隔离级别之前,我们先看看如果不考虑事务的隔离性,会发生的几种问题:
1.脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B)
update account set money=money - 100 where name=’A’;
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
2.不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
3.虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
现在来看看MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
40岁老架构师尼恩提示:分布式事务是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题17:分布式事务面试题》PDF,该专题对分布式事务有一个系统化、体系化、全面化的介绍。
如果要把分布式事务写入简历,可以找尼恩指导。
4、说说MySQL的隔离级别
在SQL标准中定义了四种隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
1)Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
2)Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是mysql默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一条select语句可能返回不同结果。
3)Repeatable Read(可重读)
这是mysql的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
4)Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争,因此使用该隔离级别会造成数据库性能的显著下降。
5、说说每个隔离级别是如何解决
在数据库中,事务隔离级别确定了事务中读取和写入操作的执行顺序。下面是每个隔离级别是如何解决数据冲突的。
- READ UNCOMMITTED:读取未提交。当事务读取其他事务未提交的数据时,可能会发生数据冲突。解决方法是在读取未提交的数据时需要等待,直到所有事务都已提交。
- READ COMMITTED:读取已提交。当事务读取其他事务已提交的数据时,不会发生数据冲突。解决方法是在读取已提交的数据时,可以保证读取到的数据是一致的。
- REPEATABLE READ:可重复读。当事务读取其他事务已提交的数据时,可能会发生数据冲突。解决方法是在读取已提交的数据时,需要等待,直到所有事务都已提交,或者在事务提交后再读取数据,可以保证数据的一致性。
- SERIALIZABLE:串行化。当事务需要访问同一条数据时,需要按照事务提交的顺序进行访问,否则会发生数据冲突。解决方法是在事务提交时,必须保证所有操作都已完成,否则会回滚事务。
总之,隔离级别越高,数据的一致性越高,但是性能越差。在实际应用中,需要根据不同的业务需求选择合适的隔离级别。
6、MySQL要加上nextkey锁,语句该怎么写
在MySQL中,要使用next-key锁,可以使用以下语句示例:
SELECT * FROM table_name WHERE column_name = 'value' FOR UPDATE
在上述示例中,你需要将table_name替换为你要查询的表名,column_name替换为你要查询的列名,value替换为你要匹配的值。
使用FOR UPDATE语句可以确保在查询期间对所选行应用next-key锁,以防止其他事务对这些行进行修改。
请注意,next-key锁是在InnoDB存储引擎中实现的,默认情况下它是开启的。确保你的表使用了InnoDB引擎,以便使用next-key锁。
7、说说Java的内存模型,垃圾回收
一、内存模型
JDK8的内存模型
在Java中所有的垃圾收集问题几乎都是针对堆内存空间完成的,但是要想充分理解垃圾的收集流程,必须首先掌握Java堆内存的最初内存模型组成。如图1所示:

内存模型的变化
JDK1.8以前提共用永久代,而从JDK1.8后永久代被替换为元空间(MetaSpace)。在JDK1.8之前,HotSpot都在努力改变永久代的存储位置,例如,在JDK1.6时提供有永久代,到了JDK1.7时又将永久代的部分操作移交给了堆内存,而在JDK1.8时使用元空间代替了永久代。
JDK 1.8之前的内存模型如图2所示。

可以发现,在JDK1.8之前都会提供有永久代,此部分内存是不受GC控制的。在最初的设计中,都将方法区保存在了永久代,所以一旦方法执行中出现了内存不足的情况,将会抛出:“OutOfMemoryError:PermGen space”错误。同时Oracle也在考虑将HotSpot与JRockit(此虚拟机不存在永久代)两个虚拟机合二为一,所以此内存空间被元空间所替代。
二、垃圾收集流程
在整个Java內存模型中,主要有3块内存区:年轻代(Young)、老年代(Tenured)、元空间(MetaSpace),同时还会有几块动态调整的内存伸缩区(当几个内存区空间不足时动态扩充)。而JVM的内存回收就是对这几块空间的回收处理操作,对于内存分配与GC的执行流程如图3所示。

上图中的垃圾回收主要是针对年轻代(Eden+Survivor)与老年代(Tenured)完成的。
具体流程如下:
- 当使用关键字new创建一个新对象时,JVM会将新对象保存在Eden区,此时需要判断Eden区是否有空余空间。
-
如果没有,则会执行“MinorGC(年轻代GC)”。
-
如果有,则直接将新对象保存在Edeti区之内;
-
执行完“MinorGC”后会清除不活跃的对象,从而释放Eden区的内存空间,随后对Eden空间再次判断。
-
如果此时Eden区的空间依然不足,则会将部分活跃对象保存在Survivor区。
-
如果此时剩余空间可以直接容纳新对象,则会直接为新对象申请内存空间;
-
-
由于Survivor区也有对象会存储在内,所以在保存Eden区发送来的对象前首先需要判断其空间是否充足。
-
如果Suivivor有足够的空余空间,则直接保存Eden区晋升的对象。此时Eden区空间得到释放,随后可以在Eden区为新的对象申请内存空间。
-
如果Survivor区空间不足,则需要将Survivor区的部分活跃对象保存到Tenured区。
-
-
Tenured区如果有足够的内存空间,则会将Survivor区发送来的对象进行保存。
-
如果此时Tenured区的内存空间也已经满了,则将执行“FullGC”(完全GC或称为MajorGC,其包括年轻代和老年代,相当于使用“Runtime.getRuntime().gc()”处理)以释放年轻代和老年代中保存的不活跃对象。
-
如果在释放后有足够的内存空间,Survivor将保存Eden发送来的对象,这样就可以在Eden区内有足够的内存保存新的对象。
-
-
此时,如果老年代的内存区也己经被占满,则会抛出“OutOfMemoryError(OOM错误)”,程序将中断运行。
可见,Java在每次创建对象时如果发现内存不足都会自动向其他区域延伸。为了提高性能,在实际应用中可能会开辟尽量大的内存空间,以实现更加合理的GC控制。
8、实现分布式锁,Zookeeper 和 Redis 哪种更好?
一、zookeeper实现分布式锁方案
a.争抢锁,只有一个人能获得锁
b.获得锁,客户端出现问题,临时节点(session)
c.锁被释放,删除,如何通知其他客户端
c-1: 主动轮询,心跳:弊端:延迟,压力
c-2: watch: 解决延迟问题。 弊端:压力
c-3: sequence+watch:watch 前一个,最小的获得锁,一旦最小的释放了锁,成本:zk只需要给第二个发时间回调
二、Redis实现分布式锁方案
a.使用setnx()方法,获取锁信息
b.设置过期时间,防止客户端down机,造成死锁
c.多线程(守护线程),监控锁,业务还未处理完,锁过期,自动延期
三、对比zookeeper与redis分布式锁的实现方案
3.1 从获得锁的速度上,redis的速度优于zookeeper
3.2 从方案实现的角度,zookeeper实现相对redis简单,zookeeper只管获取锁和回调,redis还要增加线程对锁进行监控。
四、Zookeeper分布式锁的具体实现
public class ZKUtils {
private static ZooKeeper zk;
private static String address = "192.168.7.230:2181,192.168.7.240:2180,192.168.7.71:2181/testDistributeLock";
private static DefaultWatch watch = new DefaultWatch();
private static CountDownLatch init = new CountDownLatch(1);
public static ZooKeeper getZK(){
try {
zk = new ZooKeeper(address,1000,watch);
watch.setCc(init);
init.await();
} catch (Exception e) {
e.printStackTrace();
}
return zk;
}
}
public class WatchCallBack implements Watcher, AsyncCallback.StringCallback ,AsyncCallback.Children2Callback ,AsyncCallback.StatCallback {
ZooKeeper zk ;
String threadName;
CountDownLatch cc = new CountDownLatch(1);
String pathName;
public String getPathName() {
return pathName;
}
public void setPathName(String pathName) {
this.pathName = pathName;
}
public String getThreadName() {
return threadName;
}
public void setThreadName(String threadName) {
this.threadName = threadName;
}
public ZooKeeper getZk() {
return zk;
}
public void setZk(ZooKeeper zk) {
this.zk = zk;
}
public void tryLock(){
try {
System.out.println(threadName + " create....");
// if(zk.getData("/"))
zk.create("/lock",threadName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL,this,"abc");
cc.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void unLock(){
try {
zk.delete(pathName,-1);
System.out.println(threadName + " over work....");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
@Override
public void process(WatchedEvent event) {
//如果第一个哥们,那个锁释放了,其实只有第二个收到了回调事件!!
//如果,不是第一个哥们,某一个,挂了,也能造成他后边的收到这个通知,从而让他后边那个跟去watch挂掉这个哥们前边的。。。
switch (event.getType()) {
case None:
break;
case NodeCreated:
break;
case NodeDeleted:
zk.getChildren("/",false,this ,"sdf");
break;
case NodeDataChanged:
break;
case NodeChildrenChanged:
break;
}
}
@Override
public void processResult(int rc, String path, Object ctx, String name) {
if(name != null ){
System.out.println(threadName +" create node : " + name );
pathName = name ;
zk.getChildren("/",false,this ,"sdf");
}
}
//getChildren call back
@Override
public void processResult(int rc, String path, Object ctx, List<String> children, Stat stat) {
//一定能看到自己前边的。。
// System.out.println(threadName+"look locks.....");
// for (String child : children) {
// System.out.println(child);
// }
Collections.sort(children);
int i = children.indexOf(pathName.substring(1));
//是不是第一个
if(i == 0){
//yes
System.out.println(threadName +" i am first....");
try {
zk.setData("/",threadName.getBytes(),-1);
cc.countDown();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}else{
//no
zk.exists("/"+children.get(i-1),this,this,"sdf");
}
}
@Override
public void processResult(int rc, String path, Object ctx, Stat stat) {
//偷懒
}
}
public class TestDistributeLock {
ZooKeeper zk ;
@Before
public void conn (){
zk = ZKUtils.getZK();
}
@After
public void close (){
try {
zk.close();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Test
public void lock(){
for (int i = 0; i < 10; i++) {
new Thread(){
@Override
public void run() {
WatchCallBack watchCallBack = new WatchCallBack();
watchCallBack.setZk(zk);
String threadName = Thread.currentThread().getName();
watchCallBack.setThreadName(threadName);
//每一个线程:
//抢锁
watchCallBack.tryLock();
//干活
System.out.println(threadName+" working...");
// try {
// Thread.sleep(1000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
//释放锁
watchCallBack.unLock();
}
}.start();
}
while(true){
}
}
}
40岁老架构师尼恩提示:分布式锁是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题15:分布式锁面试题》PDF,该专题对分布式锁有一个系统化、体系化、全面化的介绍。
如果要把分布式锁写入简历,可以找尼恩指导。
9、说一下分布式锁实现
一、什么是分布式锁
在一个进程中,多线程去竞争资源时,可以通过synchronized或者Lock锁进行同步执行,保证多线程情况下,资源的调用是安全的,那么多进程中或者多节点机器中如何去保证对相同资源的调用是安全的,此时就引出了分布式锁解决方案。分布式锁就是用来保证在分布式系统中对共享资源调用时保证其一致性。
二、分布式锁实现
在实现分布式锁过程中需要考虑如下几点:
- 加锁和释放锁的原理
- 怎么保证一次只有一个节点拿到锁
- 锁的可重入性
- 怎么预防死锁问题
- 没有获得锁的节点应该怎么处理
需要实现分布式锁,就得借助于第三方软件,比如数据库、Redis、ZooKeeper等,本文就分别从这三种软件着手,来看看是怎样的实现过程。
1、基于Mysql的分布式锁
数据库中我们可以通过主键唯一性特点来进行加锁和解锁过程,主键唯一性就表示当前节点中只能有一个节点创建成功,其余的都是得到创建异常,那么创建成功的节点就表示获得了锁,其余节点只能等待获得锁。此时保证了第一步和第二步,那么怎么实现锁的可重入性呢?此时我们可以增加一列来存储当前节点的当前线程信息(可以用节点的应用名称+ip+线程名),重入次数加上一个计数器,因为数据库没有一个过期时间的设置,所以需要开启一个定时任务去判断当前锁是不是已经过期。所以我们还需要一个更新时间。
表如下:
DROP TABLE IF EXISTS `locks`;
CREATE TABLE `locks` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`lock_key` varchar(255) NOT NULL COMMENT '需要锁定的资源',
`repeat_key` varchar(255) NOT NULL COMMENT '可重入标识',
`repeat_time` int(11) DEFAULT NULL COMMENT '重入次数',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `lock_key` (`lock_key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
代码实现如下,
import javax.sql.DataSource;
import java.io.Closeable;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.concurrent.TimeUnit;
/**
* Created by Administrator on 2022/1/13.
*/
public class MyLockFromMysql implements MyLock{
private DataSource dataSource;
public MyLockFromMysql(DataSource dataSource) {
this.dataSource = dataSource;
}
@Override
public void lock(String key) {
if (!tryLock(key)){
throw new RuntimeException();
}
}
@Override
public void unlock(String key) {
String repeatKey= getRepeatKey();
if (hasRepeatLock(key,repeatKey)){
updateLock(key,repeatKey,-1);
}else if (!deleteLock(key,repeatKey)){
throw new RuntimeException();
}
}
@Override
public boolean tryLock(String key) {
String repeatKey= getRepeatKey();
if (hasLock(key,repeatKey)){
return updateLock(key,repeatKey,1);
}
for (;;){
if (addLock(key,repeatKey)){
break;
}
try {
Thread.sleep(100);
} catch (InterruptedException e) {
}
}
return true;
}
private String getRepeatKey() {
String host= "";
try {
host = InetAddress.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
return host+Thread.currentThread().getName();//采用节点ip+线程名来做重入判断
}
/**
* 根据key和repeatKey判断当前是否已经获得锁
* @param key 锁定的资源
* @param repeatKey 可重入标识
* @return
*/
private boolean hasLock(String key,String repeatKey){
Connection connection=null;
PreparedStatement statement=null;
ResultSet rs=null;
try {
connection=dataSource.getConnection();
statement=connection.prepareStatement("SELECT repeat_time FROM locks WHERE lock_key=? AND repeat_key=?");
statement.setString(1,key);
statement.setString(2,repeatKey);
rs=statement.executeQuery();
return rs.next();
} catch (Exception e) {
return false;
}finally {
close(rs);
close(statement);
close(connection);
}
}
/**
* 判断当前是否有重入锁
* @param key
* @param repeatKey
* @return
*/
private boolean hasRepeatLock(String key,String repeatKey){
Connection connection=null;
PreparedStatement statement=null;
ResultSet rs=null;
try {
connection=dataSource.getConnection();
statement=connection.prepareStatement("SELECT repeat_time FROM locks WHERE lock_key=? AND repeat_key=? AND repeat_time>1 ");
statement.setString(1,key);
statement.setString(2,repeatKey);
rs=statement.executeQuery();
return rs.next();
} catch (Exception e) {
return false;
}finally {
close(rs);
close(statement);
close(connection);
}
}
/**
* 如果当前线程没有获得锁直接添加一条数据去竞争锁
* @param key 锁定的资源
* @param repeatKey 可重入标识
* @return
*/
private boolean addLock(String key,String repeatKey){
Connection connection=null;
PreparedStatement statement=null;
try {
connection=dataSource.getConnection();
statement=connection.prepareStatement("INSERT INTO locks (lock_key,repeat_key,repeat_time,update_time) VALUES (?,?,1,now())");
statement.setString(1,key);
statement.setString(2,repeatKey);
return statement.executeUpdate()>0;
} catch (Exception e) {
return false;
}finally {
close(statement);
close(connection);
}
}
private boolean updateLock(String key,String repeatKey,int upDown){
Connection connection=null;
PreparedStatement statement=null;
try {
connection=dataSource.getConnection();
statement=connection.prepareStatement("UPDATE locks set repeat_time=repeat_time+?,update_time=now() WHERE lock_key=? AND repeat_key=?");
statement.setInt(1,upDown);
statement.setString(2,key);
statement.setString(3,repeatKey);
return statement.executeUpdate()>0;
} catch (Exception e) {
return false;
}finally {
close(statement);
close(connection);
}
}
private boolean deleteLock(String key,String repeatKey){
Connection connection=null;
PreparedStatement statement=null;
try {
connection=dataSource.getConnection();
statement=connection.prepareStatement("DELETE FROM locks WHERE lock_key=?");
statement.setString(1,key);
return statement.executeUpdate()>0;
} catch (Exception e) {
e.printStackTrace();
return false;
}finally {
close(statement);
close(connection);
}
}
private void close(AutoCloseable close){
if (close!=null){
try {
close.close();
} catch (Exception e) {
}
}
}
}
以上代码只是简单的去实现了用mysql来做分布式锁的过程(性能不是太友好,也会存在很多问题),逻辑就是通过设定需要锁定的资源为主键,加锁的时候往数据库中添加数据,此时只会有添加成功的节点会获得锁,当调用完成之后删掉数据,也就是表明释放锁。针对重入锁,采用了一个重入key和重入次数两个字段来实现重入,如果当前节点已经获得锁,需要再次获得锁的时候,直接对次数+1操作,释放锁的时候做-1操作。当为1的时候再释放就需要删除节点。
其中的缺点也可想而知:
- 获得锁节点,不能正确的释放锁,那么锁记录就会一直存在数据库中,其它节点就不能获得锁,此时就需要人工干预
- 高并发时,会给系统和数据库系统带来压力
- 没有唤醒操作,其它线程只能是循环去获得锁
2、基于Redis实现分布式锁
Redis中有一个setnx命令,这个命令key不存在添加成功放回1,存在返回0,所以采用redis实现分布式锁就是基于这个命令来实现,也就是只有在创建成功放回1的节点就是获得锁的节点,释放锁的时候,删除该节点即可,redis中可以采用过期时间策略来保证,客户端释放锁失败后,也能在规定时间内释放锁,锁的可重入性在于value的设计过程,value我们可以保存当前节点的唯一标识和可重入次数。
简单代码如下所示:
import com.alibaba.fastjson.JSONObject;
import redis.clients.jedis.Jedis;
import java.net.InetAddress;
import java.net.UnknownHostException;
/**
* Created by Administrator on 2022/1/14.
*/
public class MyLockForRedis implements MyLock {
private final long TIME_WAIT=50L;
@Override
public void lock(String key) {
tryLock(key);
}
@Override
public void unlock(String key) {
Jedis redis=new Jedis("127.0.0.1",6379);
String json=redis.get(key);
LockValue lockValue= JSONObject.parseObject(json,LockValue.class);
if (getRepeatKeyV().equals(lockValue.getRepeatKey())){
if (lockValue.getTime()>1){
lockValue.setTime(lockValue.getTime()-1);
redis.set(key,JSONObject.toJSONString(lockValue));
}else {
redis.del(key);
}
}
redis.close();
}
@Override
public boolean tryLock(String key) {
Jedis redis=new Jedis("127.0.0.1",6379);
try {
for (;;){
if ("OK".equals(redis.set(key,JSONObject.toJSONString(new LockValue()),"NX","EX",200000))){
return true;
}else {
String json=redis.get(key);
LockValue lockValue= JSONObject.parseObject(json,LockValue.class);
if (lockValue!=null&&getRepeatKeyV().equals(lockValue.getRepeatKey())){
lockValue.setTime(lockValue.getTime()+1);
redis.set(key,JSONObject.toJSONString(lockValue));
return true;
}
}
try {
Thread.sleep(TIME_WAIT);
} catch (InterruptedException e) {
}
}
}finally {
redis.close();
}
}
private static class LockValue{
private int time=1;
private String repeatKey=getRepeatKeyV();
public int getTime() {
return time;
}
public void setTime(int time) {
this.time = time;
}
public String getRepeatKey() {
return repeatKey;
}
public void setRepeatKey(String repeatKey) {
this.repeatKey = repeatKey;
}
@Override
public String toString() {
return "{time=" + time +", repeatKey=\"" + repeatKey+ "\"}";
}
}
private static String getRepeatKeyV() {
String host= "";
try {
host = InetAddress.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
return host+Thread.currentThread().getName();//采用节点ip+线程名来做重入判断
}
}
以上只是简单的去实现了基于Redis的分布式锁功能(肯定存在很多问题),其中value保存的是json格式的数据来实现锁的可重入性,这里就会存在一个性能的开销(不断的解析json格式),这里存在一个问题是过期时间的设置,如果我们设置的是10,如果某节点获得锁之后,执行的很慢超过了十秒,此时别的节点就可以获得锁,一种解决方案就是在获得锁的节点中开启一个线程去更新锁的过期时间,当节点执行完成之后关掉这个线程,如果获取锁的节点宕机之后,也可以通过过期时间来解决。
3、基于Zookeeper实现分布式锁
ZooKeeper中实现分布式锁方式有两种方案:
- 创建临时节点,多个客户端同时去创建相同节点,只能一个创建成功,其余的都会创建失败,那么创建成功的节点就获得锁,失败的就继续等待释放锁
- 创建临时有序节点,每个客户端都去创建一个临时有序节点,然后获取到所有节点,判断自己是不是最小的节点,如果是则获得锁,否则监听自己前一个节点锁的释放。
基于这种方式实现的分布式锁,可以查看Curator客户端连接中的InterProcessMutex实现,它的实现逻辑就是通过创建临时顺序子节点,具体实现过程如下:
- 首先在InterProcessMutex中维护一个ConcurrentMap集合,集合的键值是当前线程,值是LockData(他是由当前线程,锁路径、以及重入次数组成)
- 获取锁时,先从集合中取出当前的LockData,如果存在说明当前线程已经获取锁,只需要重入次数加1操作,否则就尝试获得锁
- 尝试获得锁时,先创建属于自己的临时顺序节点,然后先获取到当前锁中所有的顺序子节点(排序后的),然后判断当前节点是否是最小节点,如果是则获取锁,返回,否则找到前一个节点,然后在前一个节点上注册一个wathcer,然后调用wait方法进行阻塞(如果设置的等待时间为负数,表示当前节点没有获得锁时,立即退出,然后会删除当前节点)
- 当前节点释放锁时,当前节点就会收到watcher通知,然后调用notifyAll()方法进行唤醒,此时当前节点再次去竞争锁
- 当前获得锁之后,会把当前节点和LockData保存在集合中,用来处理重入性
- 锁释放,根据当前节点线程找到需要释放的路径(不存在抛出异常),然后先判断当前的重入性,如果大于0,表示当前是重入锁,否则如果等于0,则进行锁的释放,小于0 ,抛出异常
- 锁的释放过程就是,删除当前节点,从集合中移除当前线程,然后移除watcher
40岁老架构师尼恩提示:分布式锁是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题15:分布式锁面试题》PDF,该专题对分布式锁有一个系统化、体系化、全面化的介绍。
如果要把分布式锁写入简历,可以找尼恩指导。
10、了解hystrix么?说一下它的工作原理?
一、流程图
下面的图片显示了一个请求在hystrix中的流程图。

1.构造一个HystrixCommand或者HystrixObservableCommand对象
第一步是创建一个HystrixCommand或者HystrixObservableCommand对象来执行依赖请求。创建时需要传递相应的参数。
如果请求只返回一个单一值,使用HystrixCommand。
HystrixCommand command = new HystrixCommand(arg1, arg2);
如果希望返回一个Observable来监听多个值,使用HystrixObservableCommand。
HystrixObservableCommand command = new HystrixObservableCommand(arg1, arg2);
2.执行命令
有四种方法来执行命令(前面两种只对HystrixCommand有用,HystrixObservableCommand没有相应的方法)。
- execute-阻塞,阻塞直到收到调用的返回值(或者抛出异常)
- queue 返回一个future,可以通过future来获取调用的返回值。
- observe 监听一个调用返回的Observable对象。
- toObservable 返回一个Observable,当监听该Observable后hystrix命令将会执行并返回结果。
K value = command.execute();
Future<K> fValue = command.queue();
Observable<K> ohValue = command.observe(); //hot observable
Observable<K> ocValue = command.toObservable(); //cold observab
同步调用execute本质是调用了queue().get().queue() ,而queue本质上调用了toObservable().toBlocking().toFuture().本质上都是通过rxjava的Observable实现。
3.是否使用缓存
如果开启缓存,请求首先会返回缓存中的结果。
4.是否开启熔断
当运行hystrix命令时,会判断是否熔断,如果已经熔断,hystrix将不会执行命令,而是直接执行fallback。等熔断关闭了,在执行命令。
5.线程/队列/信号量是否已满
如果线程或队列(非线程池模式下是信号量)已满,将不会执行命令,而是直接执行fallback。
6.HystrixObservableCommand.construct() or HystrixCommand.run()
hystrix通过一下两种方式来调用依赖:
HystrixObservableCommand.construct() :返回一个Observable,发射多个值。
HystrixCommand.run():返回一个单一值,或抛异常。
如果HystrixCommand.run()或HystrixObservableCommand.construct() 发送超时,则执行的相应线程将会抛出TimeoutException的异常。然后执行fallback流程。并且丢弃run或construst的返回值。
注意,hystrix没有办法强制停止线程执行,hysrix能做的最好方式是抛出InterruptedException。如果hystrix执行的方法没有相应InterruptedException,那么它会继续执行,但是用户的已经收到TimeoutException异常。大多是的http client不回响应InterruptedException,确保正确配置了链接的timeout时间。
如果执行方法成功,hystrix会记录日志、上报metrics,然后返回执行结果。
7.熔断器计算
hystrix在成功、失败、拒绝、timeout时会上报到熔断器模块,熔断器会计算当前的熔断状态。熔断器使用一个状态来表示当前是否被熔断,一旦熔断所有的请求将不回执行命令直到熔断恢复。
8.执行fallback
当命令执行失败时,hystrix会执行fallback:当run或construct方法抛出异常;当熔断器被熔断;当线程池/队列/信号量使用完;当timeout。
通过fallback可以优雅降级,通过静态逻辑返回一个结果。如果你想要在fallback中执行依赖调用,那么必须把这个依赖封装成一个HystrixCommand或者HystrixObservableCommand。HystrixCommand中通过fallback方法来返回一个单一值,HystrixObservableCommand通过resumeWithFallback来返回一个 Observable来返回一个或多个值。hystrix将会把返回值返回给调用方。
如果不实现fallback方法,或者执行fallback方法抛出异常,hystrix仍然会返回一个Observable,但该Observable不会发射数据,而是直接执行error。通过onerror通知,告诉调用方失败结果。fallback不存在或者fallback执行失败,不同的方法将会有不同的表现:
execute,抛出一个异常。
queue,返回一个future,但是调用get方法时,将会抛出异常。
observe,返回一个Observable,一旦被监听会立即调用监听者的onError方法。
toObservable,返回一个Observable,一旦被监听会立即调用监听者的onError方法。
9.返回成功结果
如果hystrix命令执行成功,它将会返回一个Observable,根据调用的方法,Observable将会被转换成响应结果:

- execute-通过queue获取一个future,然后通过future对象的get方法获取一个值。
- queue-通过toObservable获取一个Observable对象,然后通过toBlocking方法获得一个Future.
- observe-返回Observable对象,当监听该Observable会把所有消息重新发送一边。
- toObservable-返回Observable对象,当监听该Observable,开始执行命令。
二、熔断器
下面的图表展示了HystrixCommand和HystrixObservableCommand与HystrixCircuitBreaker交互的流程,以及HystrixCircuitBreaker的原理。

熔断器开关条件:
- 如果请求量到达了指定值(HystrixCommandProperties.circuitBreakerRequestVolumeThreshold)
- 如果异常比率超过了指定值(HystrixCommandProperties.circuitBreakerErrorThresholdPercentage)
- 则,熔断器将状态设置为OPEN.
- 之后所有请求都会被直接熔断。
- 在经过指定窗口期(HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds)后,状态将会被设置为HALF-OPEN,如果该请求失败了,状态重新被设置为OPEN并且等待下一个窗口期,如果请求成功了,状态设置为CLOSE。
三、隔离
hystrix使用了舱壁隔离模式来隔离和限制各个请求。

线程和线程池
第三方依赖在独立的线程池中执行,这样可以隔离调用线程(tomcat线程池)实现异步调用。
hystrix为每个依赖服务调用使用独立池。

在依赖调用能够快速失败或者可以一直运行良好的情况下,也可以不使用线程池来执行调用。
hystrix选择使用线程池有一下原因:
- 很多应用执行大量的第三方调用,这些第三方服务由不同的团队维护。
- 每一个服务有它自己的依赖包
- 这些依赖包时刻都可能变化。
- 依赖包对调用方来说是黑盒的。

四、请求缓存
HystrixCommand和HystrixObservableCommand实现了缓存机制,通过指定一个cache key,它们能够在一个请求范围内对运行结果进行缓存以便下次使用。下面是在一个请求中两个线程执行同一个请求的流程:

使用缓存的好处
- 线程池会隔离每一个依赖,避免他们相互影响,从而保护了整个系统
- 某几个依赖服务失败后,只要整个系统正常运行,那么恢复起来也很快。
- 通过线程池可以实现异步操作。
总之,通过线程池来隔离依赖服务可以很优雅的隔离那些经常发生变化的依赖服务从而保护整个系统的运行。
线程池的缺点
线程池的主要缺点就是增加了额外的计算资源,每一个命令的执行都需要系统进行调度。netflix基于线程池不会耗费大量计算资源而决定使用这样的设计。
线程池花费
hystrix计算了通过线程池执行construct和run的延时。Netflix API 每天使用线程池方式处理上百亿的请求,每一个API都有40多个线程池,每个线程池中有5~20个线程。线图显示了一个QPS为60的HystrixCommand在线程池模式下的执行性能

平均请求,线程池几乎没有什么花费。
90th%,线程池花费3ms
99th%,线程池花费达到了9ms。但是线程池的增长远远小于整个请求的延时增长。超过90th%的花费对于大多数的Netflix使用场景来说是可接受的。
信号量
也可以使用信号量来限制每个依赖的并发数量。他可以对依赖服务降级,但不能监听timeout,如果我们对依赖服务的调用确认不会出现timeout情况,我们也可以使用这中方式。
HystrixCommand和HystrixObservableCommand在下面两个地方支持使用信号量。
- 降级方法fallback:当Hystrix执行fallback方法时,总是会通过信号量检查并发量。
- 执行方法:如果设置了execution.isolation.strategy为SEMAPHORE,Hystrix将会使用信号量来控制并发数。
可以通过动态的配置来设置并发数。尽可能设置合适的并发数,不可设置过大的并发数,这样将导致无法起保护作用。
五、请求合并
通过使用HystrixCollapser可以实现合并多个请求批量执行。下面的图标显示了使用请求合并和不是请求合并,他们的线程迟和连接情况:

使用请求合并可以减少线程数和并发连接数,并且不需要使用这额外的工作。请求合并有两种作用域,全局作用域会合并全局内的同一个HystrixCommand请求,请求作用域只会合并同一个请求内的同一个HystrixCommand请求。但是请求合并会增加请求的延时。

六、缓存
一个请求对同一个Hystrix Command调用可以避免重复执行。
对于一些延时比较低的,不需要检测timeout的依赖,我们也可以使用信号量控制方式来做隔离,减少额外的花费。
这个功能对于多人协作开发的大型的项目非常有用。据一个例子,在一个请求中,多个地方需要使用用户的Account对象。
Account account = new UserGetAccount(accountId).execute();
//or
Observable<Account> accountObservable = new UserGetAccount(accountId).observe();
Hystrix将会执行run方法一次,两个线程都会接收到各自内容相同的Account对象。当执行第一次run方法后,结果将会被缓存起来,当在同一个请求执行同一个命令时,会直接使用缓存值。
减少线程重复执行。
因为缓存是在执行run或者construct方法前进行判断的,所以可以减少run和construct的调用。如果Hystrix没有实现缓存功能,那么每个调用都需要执行construct或者run方法。
11、说说NIO和IO有什么区别
一、概述
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
NIO和IO的主要区别,下表总结了Java IO和NIO之间的主要区别:
| 类型 | IO | NIO |
|---|---|---|
| 流类型 | 面向流 | 面向缓冲 |
| 是否阻塞 | 阻塞IO | 非阻塞IO |
| 有无选择器 | 无 | 选择器 |
真正的了解NIO一定要看Netty,Netty是NIO里用的最好的框架。
二、IO与NIO区别详解
1.面向流与面向缓冲
Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,因为它们没有被缓存在任何地方,所以,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2.阻塞与非阻塞IO
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write() 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道channel。
3.选择器(Selectors)
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
4.NIO和IO适用场景
NIO是为弥补传统IO的不足而诞生的,但是尺有所短寸有所长,NIO也有缺点,因为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那么就会有一个问题,在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕,如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。所以每次数据处理之前都要检测缓冲区数据。
那么NIO和IO各适用的场景是什么呢?
如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。
而如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
三、Java NIO 总览
Java NIO的三个核心基础组件:Channels、Buffers、Selectors。其余的诸如Pipe,FileLcok都是在使用以上三个核心组件时帮助更好使用的工具类。
12、说说NIO和AIO的区别
NIO(New IO)和AIO(Asynchronous I/O)都是基于内存缓存的通道与传输机制,可以直接读写本地文件和网络通道,不需要经过文件系统和网络协议栈。两者的主要区别如下:
1.数据通信方式不同
NIO基于通道和传输机制,IO基于文件和网络协议栈。在NIO中,通道可以是TCP通道、UDP通道等,而IO只能是TCP通道。
2.对内存的使用不同
NIO对内存进行了缓存和重用,使得NIO程序可以高效地读写内存中的数据。IO没有使用内存缓存机制,每次读写都需要使用文件和网络协议栈。
3.事件驱动模型不同
NIO采用了事件驱动模型,程序可以根据IO事件进行读写操作。IO则采用了同步阻塞模型,需要等待操作完成才能返回结果。
4.应用场景不同
NIO适用于需要高并发、高吞吐量的场景,例如Web服务器、IM应用等。IO适用于需要低延迟、高可靠性的场景,例如数据库、文件系统等。
因此,虽然NIO和AIO都是基于内存缓存的通道与传输机制,但是两者的数据通信方式、对内存的使用、事件驱动模型和应用场景有很大的不同。对于需要高并发和高吞吐量的应用,使用NIO是一个不错的选择;而对于需要低延迟和高可靠性的应用,则可以使用AIO。
13、Spring的aop怎么实现?Spring的aop有哪些实现方式
AOP(Aspect Oriented Programming)面向切面编程,通过预编译方式和运行期动态代理实现程序功能的横向多模块统一控制的一种技术。通俗点,就是在不改变系统原本业务功能的前提下,对系统的功能进行横向扩展。
一、AOP的相关概念
- 横切关注点:对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点
- Aspect(切面):通常是一个类,里面可以定义切入点和通知
- JointPoint(连接点):程序执行过程中明确的点,一般是方法的调用。被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
- Advice(通知):AOP在特定的切入点上执行的增强处理,有before(前置)、after(后置)、afterReturning(最终)、afterThrowing(异常)、around(环绕)
- Pointcut(切入点):就是带有通知的连接点,在程序中主要体现为书写切入点表达式
- weave(织入):将切面应用到目标对象并导致代理对象创建的过程
- introduction(引入):在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
- AOP代理(AOP Proxy):AOP框架创建的对象,代理就是目标对象的加强。Spring中的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类
- 目标对象(Target Object): 包含连接点的对象。也被称作被通知或被代理对象。
二、使用AOP的三大方式
- 方式一:使用原生Spring API接口
- 方式二:自定义切面类
- 方式三:注解方式
方式一:使用原生Spring API接口
创建UserService接口,包含4个方法,并创建UserServiceImpl类实现该接口。
public interface UserService {
public void add();
public void delete();
public void update();
public void select();
}
123456
public class UserServiceImpl implements UserService {
public void add() {
System.out.println("增加了一个用户");
}
public void delete() {
System.out.println("删除了一个用户");
}
public void select() {
System.out.println("查询了一个用户");
}
public void update() {
System.out.println("修改了一个用户");
}
}
创建Log类,实现MethodBeforeAdvice接口,在这里可以进行一些自定义操作,比如向控制台输出一句话,还可以利用反射机制获得该方法的一些信息,必须方法名等,这是另外两大方法所不具备的优点,该切面方法会放在切入点方法调用之前调用。
import org.springframework.aop.MethodBeforeAdvice;
import java.lang.reflect.Method;
public class Log implements MethodBeforeAdvice {
//method:要执行的目标对象的方法
//args:参数
//target:目标对象
public void before(Method method, Object[] args, Object target) throws Throwable {
System.out.println(target.getClass().getName()+"的"+method.getName()+"被执行了");
}
}
创建AfterLog类,实现AfterReturningAdvice接口,在这里可以进行一些自定义操作,比如向控制台输出一句话,还可以利用反射机制获得该方法的一些信息,必须方法名等,这是另外两大方法所不具备的优点,该切面方法会放在切入点方法调用之前调用。
import org.springframework.aop.AfterReturningAdvice;
import java.lang.reflect.Method;
public class AfterLog implements AfterReturningAdvice {
//returnValue:返回值
public void afterReturning(Object returnValue, Method method, Object[] args, Object target) throws Throwable {
System.out.println("执行了"+method.getName()+"方法,返回结果为:"+returnValue);
}
}
在xml配置文件中的标签中应加上对应的aop地址,创建相应bean,对aop进行配置,并导入aop的约束。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!--注册bean -->
<bean id="userService" class="com.kuang.service.UserServiceImpl"/>
<bean id="log" class="com.kuang.log.Log"/>
<bean id="afterLog" class="com.kuang.log.AfterLog"/>
<!-- 方式一:使用原生Spring API接口-->
<!-- 配置aop:需要导入aop的约束-->
<aop:config>
<!-- 切入点:execution:表达式,execution(要执行的位置)-->
<aop:pointcut id="poinicut" expression="execution(* com.kuang.service.UserServiceImpl.*(..))"/>
<!--执行环绕增加 -->
<aop:advisor advice-ref="log" pointcut-ref="poinicut"/>
<aop:advisor advice-ref="afterLog" pointcut-ref="poinicut"/>
</aop:config>
com.kuang.service.UserServiceImpl.(…)指切入点为UserServiceImpl类中的所有方法。
运行结果:
com.kuang.service.UserServiceImpl的add被执行了
增加了一个用户
执行了add方法,返回结果为:null
方式二:自定义切面类
创建自定义切面类DiyPointCut,里面包含一些自定义的切面方法。
public class DiyPointCut {
public void before(){
System.out.println("===========方法执行前==========");
}
public void after(){
System.out.println("===========方法执行后==========");
}
}
在applicationContext.xml文件中的aop配置为:
<!-- 方式二:自定义类-->
<bean id="diy" class="com.kuang.diy.DiyPointCut"/>
<aop:config>
<!-- 自定义切面,ref要引用的类-->
<aop:aspect ref="diy">
<!--切入点 -->
<aop:pointcut id="point" expression="execution(* com.kuang.service.UserServiceImpl.*(..))"/>
<!--通知 -->
<aop:before method="before" pointcut-ref="point"/>
<aop:after method="after" pointcut-ref="point"/>
</aop:aspect>
</aop:config>
运行结果
=========== 方法执行前 ==========
增加了一个用户
=========== 方法执行后==========
方式三:注解方式
建立一个切面方法类(AnnotationPointCut),里面包含一些切面方法,比如before、after、aroud等。
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
//方式三:使用注解方式实现AOP
@Aspect//标注这个类是一个切面
public class AnnotationPointCut {
@Before("execution(* com.kuang.service.UserServiceImpl.*(..))")
public void before(){
System.out.println("==========方法执行前==========");
}
@After("execution(* com.kuang.service.UserServiceImpl.*(..))")
public void after(){
System.out.println("==========方法执行后==========");
}
@Around("execution(* com.kuang.service.UserServiceImpl.*(..))")
public void around(ProceedingJoinPoint jp) throws Throwable{
System.out.println("环绕前");
Object proceed=jp.proceed();
System.out.println("环绕后");
}
}
在applicationContext.xml配置文件中对aop进行配置
<!-- 方式三:注解方式-->
<bean id="annotationPointCut" class="com.kuang.diy.AnnotationPointCut"/>
<!--开启注解支持 -->
<aop:aspectj-autoproxy/>
运行结果
环绕前
========== 方法执行前==========
增加了一个用户
环绕后
========== 方法执行后==========
这里注意aroud与before、after方法的执行顺序:
环绕前—>方法执行前—>增加了一个用户—>环绕后—>方法执行后
总结
- 使用原生的spring AIP接口,代码较为复杂,但可以在切面方法中利用反射机制获得切入点方法的相关信息,比如获得切入点方法的方法名。
- 使用自定义切面类的方法,简单易懂。
- 使用注解的方式,方便便捷,大大简化了xml配置文件中aop代码,只需要开启注解即可
- 最重要的是:AOP思想可以与动态代理相结合,在本例中有所体现,UserServiceImpl类实现了UserService接口,我们可以在UserServiceImpl类中对UserService接口中的方法进行扩展,再结合AOP思想,可以极大的方便我们的日常开发。
14、说说动态代理的实现方式和区别
动态代理是一种在运行时创建代理对象的方式,它可以在不修改原始类的情况下,为其添加额外的功能。在Java中,有两种常见的动态代理实现方式:基于接口的动态代理和基于类的动态代理。
-
基于接口的动态代理:
- 实现方式:基于接口的动态代理是通过Java的
java.lang.reflect.Proxy类实现的。该类提供了一个newProxyInstance()方法,通过传入目标类的接口、一个InvocationHandler对象和类加载器来创建代理对象。 - 实现原理:在运行时,当调用代理对象的方法时,实际上会被转发到
InvocationHandler对象的invoke()方法中。在invoke()方法中,可以执行一些前置或后置操作,并最终调用目标对象的方法。 - 适用场景:基于接口的动态代理适用于目标对象实现了接口的情况。
- 实现方式:基于接口的动态代理是通过Java的
-
基于类的动态代理:
- 实现方式:基于类的动态代理是通过使用第三方库(如CGLIB)来实现的。该库通过生成目标类的子类来创建代理对象。
- 实现原理:在运行时,当调用代理对象的方法时,实际上会被转发到子类中重写的方法中。在重写的方法中,可以执行一些前置或后置操作,并最终调用目标对象的方法。
- 适用场景:基于类的动态代理适用于目标对象没有实现接口的情况。
区别:
- 基于接口的动态代理要求目标对象实现接口,而基于类的动态代理可以代理任何类,无论是否实现接口。
- 基于接口的动态代理是通过Java标准库实现的,而基于类的动态代理需要使用第三方库。
- 基于接口的动态代理创建的代理对象是一个实现了目标接口的实例,而基于类的动态代理创建的代理对象是目标类的子类。
- 基于接口的动态代理执行效率相对较高,而基于类的动态代理执行效率较低。
总体而言,基于接口的动态代理更加灵活,并且是Java官方支持的方式;而基于类的动态代理在某些场景下更加方便,尤其是对于没有实现接口的类。
15、聊聊索引在哪些场景下会失效?
索引在以下场景下可能会失效:
-
使用函数或表达式进行查询:如果在查询条件中使用了函数或表达式,例如
WHERE UPPER(column_name) = 'VALUE',索引可能无法起作用,因为函数或表达式的结果无法直接匹配索引中的值。 -
对索引列进行类型转换:如果在查询条件中对索引列进行了类型转换,例如
WHERE CAST(column_name AS VARCHAR) = 'value',索引可能无法起作用,因为类型转换后的值无法直接匹配索引中的数据类型。 -
使用模糊查询:当使用模糊查询操作符(如
LIKE)进行搜索时,如果搜索模式以通配符开头(例如LIKE '%value'),则索引可能无法起作用,因为通配符开头的模式无法利用索引的有序性。 -
列的基数太低:如果索引列的基数(不同值的数量)非常低,即使使用了索引,数据库优化器可能会认为全表扫描更快,从而选择不使用索引。
-
数据量过小:当表中的数据量非常小(例如只有几行)时,使用索引进行查询可能会比全表扫描更慢,因为额外的索引查找开销可能会抵消使用索引的好处。
-
范围查询:对于一些范围查询(例如
BETWEEN、>、<等),索引可能会失效,因为范围查询需要扫描多个索引节点,而不是单个等值匹配。 -
隐式类型转换:如果在查询条件中进行了隐式类型转换,例如将字符串与数字进行比较,索引可能无法起作用,因为隐式转换可能导致索引列的值与查询条件不匹配。
-
复合索引中未使用第一个列:对于复合索引,如果查询条件没有使用到索引的第一个列,那么索引可能会失效。
要确保索引的有效使用,需要根据具体的查询场景和数据特点来设计和优化索引。
16、怎么查看系统负载
一、uptime
一种简单的方法是通过命令 "uptime" 来查看系统负载。这个命令会输出系统启动以来的总时间和系统当前的负载状态。
例如,如果系统负载较高,你可以看到类似下面的输出:
load average: 1.24 1.24 1.24
这个输出表示在过去1分钟、5分钟和15分钟内,系统的负载状态分别为1.24、1.24和1.24。
二、top
另外,一些图形化界面的系统管理工具也可以提供系统负载的图表,让你更直观地了解系统的负载状态。例如,在Linux系统中,你可以使用 "top" 命令来查看系统负载,如下所示:
top
这个命令会以字符界面的形式显示系统当前的进程和系统资源的使用情况,包括CPU、内存、磁盘等。你可以根据需要使用 "Ctrl+C" 退出命令。
17、分布式 id 生成方案有哪些?什么是雪花算法?
分布式ID生成方案是在分布式系统中生成唯一ID的一种解决方案,常见的分布式ID生成方案包括:
-
UUID(Universally Unique Identifier):UUID是一种由128位数字组成的标识符,通常以32个十六进制数字表示。它可以在不同系统和多个节点之间生成唯一ID,但由于其长度较长,不适合作为数据库索引或URL参数。
-
数据库自增ID:通过数据库的自增主键生成ID,保证了递增和唯一性。但在分布式系统中,需要使用分布式锁或其他机制来保证生成的ID的唯一性。
-
基于Redis或ZooKeeper的分布式ID生成器:使用Redis或ZooKeeper等分布式存储系统作为中心化的ID生成器,利用其原子性操作和分布式特性来保证生成的ID的唯一性。
-
Twitter的Snowflake算法:Snowflake算法是一种基于时间戳、机器ID和序列号的分布式ID生成算法。它使用了一个64位的整数,其中包含了时间戳、机器ID和序列号,并且保证了生成的ID在分布式系统中的唯一性和有序性。
雪花算法是Twitter开源的一种分布式ID生成算法,它是基于Snowflake算法实现的。雪花算法使用了一个64位的整数,其中包含了时间戳、机器ID、数据中心ID和序列号。具体来说:
- 符号位:1位,固定为0。
- 时间戳:41位,精确到毫秒级,可以支持约69年的时间戳。
- 数据中心ID和机器ID:10位,分别用于标识数据中心和机器,可以支持1024个数据中心和每个数据中心1024台机器。
- 序列号:12位,用于解决在同一毫秒内生成ID时的并发冲突问题,支持每个节点每毫秒最多生成4096个ID。
通过雪花算法生成的ID既能保证在分布式系统中的唯一性,又能保证ID的有序性(按照时间戳递增)。雪花算法非常适合高并发环境下的分布式ID生成需求。
40岁老架构师尼恩提示:分布式id是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见尼恩的《10Wqps推送中台实操》,该专题对分布式id有一个系统化、体系化、全面化的介绍。
如果要把推送中台写入简历,可以找尼恩指导。
18、Linux中,查找磁盘上最大的文件的命令
在 Linux 中,可以使用 du 命令来查找磁盘上最大的文件。具体命令如下:
du -sh * | sort -rh | head -n 1
这个命令的含义是:
du命令用于显示指定目录或文件的磁盘使用情况;-s选项表示只显示指定目录或文件的总大小;-h选项表示以人类可读的方式显示大小(例如,将字节转换为 KB、MB、GB 等);*表示查找当前目录下的所有文件和目录;|符号用于将前面的命令输出作为后面命令的输入;sort命令用于对输入进行排序;-r选项表示按照降序排序;-h选项表示按照人类可读的方式排序;head命令用于显示前几行结果,这里设置为只显示一行结果;-n n选项表示显示前 n 行结果。
19、Linux中,如何查看系统日志文件
在 Linux 中,可以使用 cat、less、tail、grep 等命令来查看系统日志文件。
以下是一些常用的命令:
cat /var/log/messages:显示系统消息日志文件的内容;less /var/log/messages:分页显示系统消息日志文件的内容;tail -f /var/log/messages:实时显示系统消息日志文件的最后几行内容;grep "error" /var/log/messages:查找包含 "error" 字符串的系统消息日志文件的内容;sudo journalctl -u sshd.service:查看 SSHD 服务的日志文件。
40岁老架构师尼恩提示:Linux是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题22:Linux面试题》PDF,该专题对Linux有一个系统化、体系化、全面化的介绍。
如果要把Linux相关实战写入简历,可以找尼恩指导
20、聊聊事务隔离级别,以及可重复读实现原理
事务隔离级别是数据库管理系统中用来控制并发访问数据的一种机制。常见的事务隔离级别包括读未提交(Read Uncommitted)、读已提交(Read Committed)、可重复读(Repeatable Read)和串行化(Serializable)。
在可重复读隔离级别下,事务在执行期间看到的数据是一致的,即使其他事务对数据进行了修改。这是通过多版本并发控制(MVCC)实现的。下面是可重复读实现原理的简要说明:
-
事务开始时,会为每个读取的数据行创建一个快照(Snapshot),该快照会记录当前数据行的状态。
-
在事务执行期间,其他事务对数据行进行修改不会影响当前事务的快照数据。
-
当前事务读取数据时,会使用快照数据而不是实时数据。
-
当前事务对数据进行修改时,会在修改的数据行上创建一个新的版本,并更新快照数据。
-
如果其他事务在当前事务执行期间对数据行进行修改,并且修改的数据行版本晚于当前事务的快照版本,则当前事务会回滚并重新执行。
通过使用快照和版本控制,可重复读隔离级别可以保证事务在执行期间看到一致的数据。
需要注意的是,不同的数据库管理系统可能会有不同的实现方式,但基本原理是相似的。同时,可重复读隔离级别也可能导致幻读问题,即在同一事务中多次执行相同的查询,但结果集不一致。为了解决幻读问题,可以使用更高级别的隔离级别,如串行化。
21、os进程间怎么通信?
在操作系统中,进程间通信(Inter-Process Communication,IPC)是指不同进程之间进行数据交换和共享资源的过程。常见的进程间通信方式包括以下几种:
- 管道(Pipe):管道是一种半双工的通信方式,数据只能单向流动,且只能在具有亲缘关系的进程间使用。管道分为匿名管道和命名管道两种。
- 消息队列(Message Queue):消息队列是一种消息的链表,存放在内核中并由消息队列标识符标识。发送进程将消息放入消息队列中,接收进程从消息队列中取出消息进行处理。
- 共享内存(Shared Memory):共享内存是最快的 IPC 方式,它允许多个进程访问同一块内存空间,因此可以实现数据的共享。但是,由于多个进程同时读写同一块内存空间可能会导致数据不一致的问题,所以需要加锁来保证数据的同步性。
- 信号量(Semaphore):信号量是一个计数器,可以用来控制多个进程对共享资源的访问。当一个进程需要访问共享资源时,它会请求信号量,如果信号量的值大于0,则该进程可以获得访问权;否则,该进程需要等待其他进程释放信号量。
- 套接字(Socket):套接字是一种网络编程中的通信方式,可以在不同的主机之间进行通信。套接字提供了一种可靠的、高效的、全双工的通信机制,可以用于实现不同进程之间的通信。
22、os有使用哪些数据结构?
操作系统中常用的数据结构包括:
-
数组(Array):是一种线性数据结构,用于存储相同类型的元素。数组在内存中是连续的一段空间,可以通过下标来访问其中的元素。
-
链表(Linked List):是一种非线性数据结构,由一系列节点组成,每个节点包含一个数据元素和指向下一个节点的指针。链表可以动态地添加或删除节点,但访问某个节点的时间复杂度为O(n)。
-
栈(Stack):是一种后进先出(LIFO)的数据结构,用于存储函数调用时的局部变量、表达式的计算结果等信息。栈中的元素只能从栈顶进行插入和删除操作。
-
队列(Queue):是一种先进先出(FIFO)的数据结构,用于实现生产者-消费者模型。队列中的元素按照先进先出的顺序排列,可以进行入队和出队操作。
-
树(Tree):是一种非线性数据结构,由若干个节点组成,每个节点包含一个数据元素和若干个子节点。树可以分为二叉树、平衡树、B+树等多种类型。
除了以上常见的数据结构,操作系统中还使用了其他一些特殊的数据结构,如散列表、红黑树、图等。这些数据结构在操作系统的实现中发挥着重要的作用。
23、说说对Linux的了解
Linux是一种操作系统内核,它是由一些志愿者开发的,具有开放源代码的特点。Linux系统在全球范围内被广泛应用于各种不同的领域,例如服务器、工作站、嵌入式系统等。
Linux系统的优势包括:
- 开放源代码:Linux系统的源代码是开放的,这意味着用户可以根据需要自由地修改和扩展Linux系统。
- 稳定性高:Linux系统的稳定性非常高,它的稳定性和安全性已经得到了广泛的验证和认可。
- 安全性高:Linux系统的安全性也非常高,它具有多种安全保护措施,例如访问控制、权限管理、病毒防范等。
- 可定制性强:Linux系统的可定制性非常强,用户可以根据需要自由地定制Linux系统的功能和外观。
- 性能优良:Linux系统具有非常优良的性能,它可以快速地处理大量的数据和任务。
应用场景:
- 服务器:Linux系统是最常用的服务器操作系统之一,例如Apache、MySQL、PHP等都是基于Linux系统的。
- 嵌入式系统:Linux系统可以应用于各种嵌入式设备中,例如移动设备、物联网设备等。
- 工作站:Linux系统也是一种非常流行的工作站操作系统,例如Ubuntu、Fedora等。
注意事项:
- 尽量避免在标准输入、标准输出和标准错误输出中使用"/"字符。
- 在配置网络设备时,需要注意设备的型号、驱动程序等问题。
- 在安装和配置Linux系统时,需要注意权限和用户管理等问题。
24、TCP和UDP的区别?
一、TCP和UDP是什么?
TCP:
传输控制协议(TCP,Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793 定义。
UDP:
Internet 协议集支持一个无连接的传输协议,该协议称为用户数据报协议(UDP,User Datagram Protocol)。UDP 为应用程序提供了一种无需建立连接就可以发送封装的 IP 数据包的方法。RFC 768 描述了 UDP。
二、TCP和UDP有什么区别?
1.TCP和UDP区别总结
TCP与UDP区别总结:
- TCP面向连接,通过三次握手建立连接,四次挥手接除连接;UDP是无连接的,即发送数据之前不需要建立连接,这种方式为UDP带来了高效的传输效率,但也导致无法确保数据的发送成功。
- TCP是可靠的通信方式。通过TCP连接传送的数据,TCP通过超时重传、 数据校验等方式来确保数据无差错,不丢失,不重复,且按序到达;而UDP由于无需连接的原因,将会以最大速度进行传输,但不保证可靠交付,也就是会出现丢失、重复等等问题。
- TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流,由于连接的问题,当网络出现波动时,连接可能出现响应问题;UDP是面向报文的,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低。
- 每一条TCP连接只能是点到点的;而UDP不建立连接,所以可以支持一对一,一对多,多对一和多对多的交互通信,也就是可以同时接受多个人的包。
- TCP需要建立连接,首部开销20字节相比8个字节的UDP显得比较大。
- TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。
2.TCP三次握手和四次挥手
1)TCP三次握手
三次握手是TCP用来确保连接可靠建立的方式:
- 第一次握手: A给B发短信说:“B,你现在有空吗?”
- 第二次握手: B此时收到了A的信息,然后对A说: “ 我有空,你呢?有空吗? ”
- 第三次握手: A此时收到了B的确认信息,然后说:“我也有空,那我跟你说个事。”
在三次握手之后,A和B都能确定这么一件事: 双方的通信可以流畅的进行。 这样,双方就可以开始进行正常的对话了。
2)TCP四次挥手
四次挥手是TCP用来确保连接可靠关闭的方式:
- 第一次挥手: A给B发短信说:“B,我要准备吃饭了?”
- 第二次挥手: B此时收到了A的信息,然后先对A说: “ 我知道了。”
- 第三次挥手: B对A说到: “ 我也要准备吃饭了。”然后放下了手机,
- 第四次挥手: A此时收到了B的确认信息,然后想B发一个包说:“好的,我知道了。”这时才放下手机去吃饭,
在四次挥手之后,A和B都能确定这么一件事: 双方的通信可以正常关闭。 这样,双方就可以确定对方已经完全知晓自己确认要关闭连接。
3.TCP维护可靠的通信方式
- 数据分片:在发送端对用户数据进行分片,在接收端进行重组,由TCP确定分片的大小并控制分片和重组;
- 到达确认:接收端接收到分片数据时,根据分片数据序号向发送端发送一个确认包;
- 超时重发:发送方在发送分片后计时,若超时却没有收到相应的确认包,将会重发对应的分片;
- 滑动窗口:TCP连接双方的接收缓冲空间大小都固定,接收端只能接受缓冲区能接纳的数据。
- 失序处理:TCP的接收端需要重新排序接收到的数据。
- 重复处理:如果传输的TCP分片出现重复,TCP的接收端需要丢弃重复的数据。
- 数据校验:TCP通过保持它首部和数据的检验和来检测数据在传输过程中的任何变化。
4.TCP和UDP使用场景
1)UDP 使用场景:
因此UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务,随时都可以发送数据,处理简单且高效。
所以主要使用在以下场景:
- 包总量较小的通信(DNS、SNMP)
- 视频、音频等多媒体通信(即时通信)
QQ就是使用的UDP协议。 - 广播通信
主要是一切追求速度的场景上
2)TCP 使用场景:
TCP 使用场景:相对于 UDP,TCP 实现了数据传输过程中的各种控制,可以进行丢包时的重发控制,还可以对次序乱掉的分包进行顺序控制。在对可靠性要求较高的情况下,可以使用 TCP,即不考虑 UDP 的时候,都可以选择 TCP。
特别是需要可靠连接,比如付费、加密数据等等方向都需要依靠TCP
总结
面向连接的TCP与无连接的UDP将是网络协议中不可或缺的重要知识点,TCP 和 UDP是TCP/IP 中有两个具有代表性的传输层协议,也是常年常考题型。
40岁老架构师尼恩提示:TCP/IP协议是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩Java面试宝典-专题10:TCPIP协议》PDF,该专题对TCP/IP协议有一个系统化、体系化、全面化的介绍。
如果要把TCP/IP实战写入简历,可以找尼恩指导
25、HTTP和HTTPS的区别?
一、什么是HTTP?
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。HTTP是客户端浏览器或其他程序与Web服务器之间的应用层通信协议。
二、什么是HTTPS?
HTTPS(全称:Hyper Text Transfer Protocol over Secure Socket Layer 或 Hypertext Transfer Protocol Secure,超文本传输安全协议),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。它是一个URI scheme(抽象标识符体系),句法类同http体系。用于安全的HTTP数据传输。
三、HTTP与HTTPS有什么区别?
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
-
https需要到证书机构申请证书。
-
http是超文本传输协议,信息是明文传输,https则是通过ssl加密传输协议。
-
http和https使用的是完全不同的连接方式,前者默认端口是80,后者默认是443。
四、HTTPS有什么用?
在描述HTTPS有什么用之前,先来了解什么是HTTPS证书(即SSL证书)。
简单来说,SSL证书 = HTTPS +证书 +域名。HTTPS证书(即SSL证书)。HTTPS证书是颁发给标识互联网域名的数字证书,证书作用为建立SSL加密通道。结合HTTPS证书,来描述HTTPS,更容易理解HTTPS的作用。将SSL证书安装在网站服务器上,可实现网站身份验证和数据加密传输双重功能。
A:安全上的作用
1)实现加密传输
用户通过http协议访问网站时,浏览器和服务器之间是明文传输,安装SSL证书后,使用Https协议加密访问网站,可激活客户端浏览器到网站服务器之间的"SSL加密通道"(SSL协议),实现高强度双向加密传输,防止传输数据被泄露或篡改。
2)认证服务器真实身份(防钓鱼)
钓鱼欺诈网站泛滥,用户如何识别网站是钓鱼网站还是安全网站?网站部署全球信任的SSL证书后,浏览器内置安全机制,实时查验证书状态,通过浏览器向用户展示网站认证信息,让用户轻松识别网站真实身份,防止钓鱼网站仿冒。
B:提升企业形象
谷歌在2014年宣布,他们将考虑将https作为一个轻量级的因素,以鼓励网络安全。即使在Google的建议之外,那些切换到SSL的站点也经常发现客户认为他们的站点更真实。该网站还受到更多保护,免受第三方可能造成的损害。最近,谷歌警告Chrome用户,网络浏览器将开始重新标记仍在http上的网站:“从2017年10月开始,Chrome将在另外两种情况下显示‘不安全’警告。”
C:提升SEO搜索权重
重要的是要注意,从切换到HTTPS,谷歌,百度搜索引擎已经提示了其权重。百度已明确表示https配置作为排名因素,而且是出于网站安全的角度,那么我们也应该引起足够的重视,这可能并不需要花费太多的精力去解决这个事情但是能为SEO优化带来很好的效果!
26、HTTPS的TLS握手过程?
我们知道,https就是http+ssl/tls,而http又是建立在tcp/ip之上的,所以浏览器和服务器使用https协议传输时,先用tcp/ip协议三次握手建立连接,再用ssl/tls协议握手确定算法密钥等,然后才是加密传输应用数据,最后tcp/ip四次挥手断开连接。
TLS协议分为TLS记录协议以及TLS握手协议。TLS记录协议负责对消息的压缩、加密以及数据认证。TSL握手协议则是生成共享密钥以及交换证书,其中共享密钥是为了支持TLS记录协议的加密传输,而交换证书是通信双方进行认证。
TLS握手协议的握手过程如下图所示:

具体步骤:
-
ClientHello:客户端向服务器发送"ClientHello"消息,这些消息主要包含:可用版本号、当前时间、客户端随机数、会话ID、可用密码套件清单(对称和非对称加密的组合清单)、可用的压缩方式清单。客户端提供可用版本号、密码套件清单、压缩方式清单让服务器选择。是因为不同型号版本浏览器不同,所能支持的算法也不同,需要和服务器进行协商。当前时间在TLS中基本没用到,随机数可以被后续步骤用到。
-
ServerHello:服务器端会响应客户端,发送"ServerHello"消息,具体内容有:使用的版本号、当前时间、服务器随机数、会话ID、使用的密码套件、使用的压缩方式。即,服务器发送本次传输使用的版本号、密码套件、压缩方式给客户端。生成的随机数后续会用到,该随机数生成与浏览器的随机数无关。
-
Cretificate:服务器发送证书给客户端,首先发送服务器证书,接收按顺序发送服务器证书签名的认证机构证书。匿名通信则会省略此步骤。
-
ServerKeyExchange:服务器发送密钥参数给客户端,比如RSA公钥的参数N和E以及散列值等
-
CeritificateRequest:服务器发送服务器能理解的证书类型清单和认证机构清单给客户端。服务器请求对客户端进行认证,当不使用客户端认证,服务器不会发送此消息。
-
ServerHelloDone:服务器发送问候结束消息给客户端,代表服务器从ServerHello之后的一系列消息的结束。
-
Cretificate:客户端向服务器发送证书,此步骤需要服务器发送了证书认证请求(第五步骤CeritificateRequest),否则客户端不会发送证书给服务器。
-
ClientKeyExchange:客户端发送非对称加密算法的预备主密码给服务器,服务器和客户端可以根据预备主密码计算出相同的主密码,根据主密码生成 对称加密的密钥、消息认真码的密钥、对称密码CBC模式中的初始化向量IV。
-
CretificateVerify:客户端将主密码、握手协议消息的散列值以及自己的数字签名发送给服务器,向服务器证明自己持有客户端证书的私钥。此步骤仅当服务器发送了证书认证请求(第五步骤CeritificateRequest)才会进行,否则客户端不会向服务器发送自己的证明信息。
-
ChangeCipherSpec:客户端会向服务器发送切换密码消息,声明之后,服务器和客户端会同时切换密码。这个消息仅限于变更密码才会发出,实际上,这个消息不是握手协议消息,是密码变更协议的消息。
-
Finished:客户端发送握手协议结束消息给服务器,通过这个消息,可以确认客户端握手协议和密码套件切换是否正确结束。
-
ChangeCipherSpec:服务端发送切换密码消息给客服端。
-
Finished:服务器发送握手协议结束消息给客户端,这一消息会通过确定好的密码套件来加密传输。
-
切换到应用数据协议:以上步骤完成后,客户端和服务器会使用应用数据协议和TLS记录协议进行密码通信。
可以看到,握手协议完成了以下操作:
-
客户端获得了服务器的公钥,完成了服务器认证。
-
服务器获得了客户端的公钥,完成了客户端认证(当需要认证客户端时)。
-
客户端和服务器生成了密码通信中使用的共享密钥。
-
客户端和服务器生成了消息认证码中使用的共享密钥。
以上握手协议是TLS握手协议的一部分,TLS握手协议还包括:密码变更协议、警告协议、应用数据协议。
密码变更协议:客户端和服务器修改密码前分别发出 ChangeCipherSpec 消息表明要切换密码,并发送Finished 消息 确认切换密码结束。
警告协议:发生错误时通知通信对象,握手协议过程中异常、消息认证码错误等,都会使用该协议。
应用数据协议:用于通信对象之间传输应用数据,当TLS加密http时,请求和响应就会通过TLS的应用数据协议和TLS记录协议来进行传送。
27、GC了解吗?
一、定义
GC(Garbage Collection)是Java虚拟机(JVM)垃圾回收器提供的一种用于在空闲时间不定时回收无任何对象引用的对象占据的内存空间的一种机制。
二、作用
垃圾回收机制的引入可以有效的防止内存泄露、保证内存的有效使用,也减轻了 Java 程序员的对内存管理的工作量。
三、回收什么?
在JVM内存模型中,有三个是不需要进行垃圾回收的:程序计数器、JVM栈、本地方法栈。因为它们的生命周期是和线程同步的,随着线程的销毁,它们占用的内存会自动释放,所以只有方法区和堆需要进行GC

垃圾收集器在对垃圾进行回收前,确定有哪些对象是“死亡”状态,在对他们进行回收
四、判断方法
引用计数算法(Reference Counting):堆中每个对象实例都有一个引用计数。当一个对象被创建时,就将该对象实例分配给一个变量,该变量计数设置为1。当任何其它变量被赋值为这个对象的引用时,计数加1(a = b,则b引用的对象实例的计数器+1),但当一个对象实例的某个引用超过了生命周期或者被设置为一个新值时,对象实例的引用计数器减1。任何引用计数器为0的对象实例可以被当作垃圾收集。当一个对象实例被垃圾收集时,它引用的任何对象实例的引用计数器减1。
可达性算法(根搜索算法GC Roots Tracing):从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点,无用的节点将会被判定为是可回收的对象。
GC ROOT对象:a) 虚拟机栈中引用的对象(栈帧中的本地变量表);b) 方法区中类静态属性引用的对象;c) 方法区中常量引用的对象;d) 本地方法栈中JNI(Native方法)引用的对象。
对象死亡(被回收)前的最后一次挣扎:通过可达性分析,那些不可达的对象并不是立即被销毁,他们还有被拯救的机会。如果要回收一个不可达的对象,要经历两次标记过程。首先是第一次标记,并判断对象是否覆写了 finalize 方法,如果没有覆写,则直接进行第二次标记并被回收。如果对象在finalize()方法中重新与引用链建立了关联关系,那么将会逃离本次回收,继续存活。
五、什么时候进行回收?
- 会在cpu空闲的时候自动进行回收
- 在堆内存存储满了之后
- 主动调用System.gc()后尝试进行回收
六、怎么回收?
垃圾收集算法、垃圾收集器
在介绍收集算法之前先给出一个术语:Stop-the-world(STW).意味着 JVM由于要执行GC而停止了应用程序的执行,并且这种情形会在任何一种GC算法中发生。当Stop-the-world发生时,除了GC所需的线程以外,所有线程都处于等待状态直到GC任务完成。
七、垃圾收集算法
-
标记-清除(Mark-Sweep):从根集合(GC Roots)进行扫描,对存活的对象进行标记,标记完毕后,再扫描整个空间中未被标记的对象,进行回收,此算法一般没有虚拟机采用。(效率低,产生不连续内存碎片)
-
复制(Copying):将内存分成两块容量大小相等的区域,每次只使用其中一块,当这一块内存用完了,就将所有存活对象复制到另一块内存空间,然后清除前一块内存空间。(复制代价高,适合新生代,浪费空间)
-
标记-整理(Mark-Compact):在完成标记之后,它不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存。不会产生内存碎片,但是依旧移动对象的成本。(适合老年代)
-
分代收集算法:分代收集算法是目前大部分JVM的垃圾收集器采用的算法。它的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),在堆区之外还有一个代就是永久代(Permanet Generation)。
在文章开头,已经说了垃圾回收机制主要负责回收方法区和堆的垃圾。方法区也叫做永久代。Java堆就包括新生代和老年代两部分
注意:在JDK 1.8中已经移除了永久代,改为元空间

工作流程如下:
-
所有新生成的对象都放在Eden,当 Eden区快要满了,触发Minor GC,把存活对象复制到 Survivor0区,清空 Eden 区;
-
Eden区被清空后,继续对外提供堆内存;当 Eden 区再次被填满,又触发Minor GC,对 Eden区和 S0 区同时进行垃圾回收,把存活对象放入 S1区,同时清空 Eden 区和S0区;
-
不断重复上面的步骤,每进行一次垃圾回收存活的对象年龄就会加1,默认临界值为15;
-
当到达临界年龄,对象就会被复制到老年代;
-
当老年代的被占满,无法再进入对象时,就会进行一次Full GC,也就是新生代、老年代都进行回收,这个垃圾回收的时间比较长。
八、垃圾收集器
新生代收集器:Serial,ParNew,Parallel Scavenge
老年代收集器:CMS,Serial Old,Parallel Old
Serial收集器:新生代单线程收集器,标记和清理都是单线程,优点是简单高效。是client级别默认的GC方式,可以通过-XX:+UseSerialGC来强制指定。
Serial Old收集器:老年代单线程收集器,Serial收集器的老年代版本。
ParNew收集器:新生代收集器,可以认为是Serial收集器的多线程版本,在多核CPU环境下有着比Serial更好的表现。
Parallel Scavenge收集器:并行收集器,追求高吞吐量,高效利用CPU。吞吐量一般为99%, 吞吐量= 用户线程时间/(用户线程时间+GC线程时间)。适合后台应用等对交互相应要求不高的场景。是server级别默认采用的GC方式,可用-XX:+UseParallelGC来强制指定,用-XX:ParallelGCThreads=4来指定线程数。
Parallel Old收集器:Parallel Scavenge收集器的老年代版本,并行收集器,吞吐量优先。
CMS(Concurrent Mark Sweep)收集器:高并发、低停顿,追求最短GC回收停顿时间,cpu占用比较高,响应时间快,停顿时间短,多核cpu 追求高响应时间的选择。
28、说说Java有哪些锁?
一、悲观锁和乐观锁
悲观锁:当前线程去操作数据的时候,总是认为别的线程会去修改数据,所以每次操作数据的时候都会上锁,别的线程去操作数据的时候就会阻塞,比如synchronized;
乐观锁:当前线程每次去操作数据的时候都认为别人不会修改,更新的时候会判断别人是否会去更新数据,通过版本来判断,如果数据被修改了就拒绝更新,例如cas是乐观锁,但是严格来说并不是锁,通过原子性来保证数据的同步,例如数据库的乐观锁,通过版本控制来实现,cas不会保证线程同步,乐观的认为在数据更新期间没有其他线程影响
总结:悲观锁适合写操作多的场景,乐观锁适合读操作多的场景,乐观锁的吞吐量会比悲观锁高
二、公平锁和非公平锁
公平锁:有多个线程按照申请锁的顺序来获取锁,就是说,如果一个线程组里面,能够保证每个线程都能拿到锁,例如:ReentrantLock(使用的同步队列FIFO)
非公平锁:获取锁的方式是随机的,保证不了每个线程都能拿到锁,会存在有的线程饿死,一直拿不到锁,例如:synchronized,ReentrantLock
总结:非公平锁性能高于公平锁,更能重复利用CPU的时间
三、可重入锁和不可重入锁
可重入锁:也叫递归锁,在外层使用锁之后,在内层仍然可以使用,并且不会产生死锁
不可重入锁:在当前线程执行某个方法已经获取了该锁,那么在方法中尝试再次获取锁时,就会获取不到被阻塞
总结:可重入锁能一定程度的避免死锁,例如:synchronized,ReentrantLock
四、自旋锁
自旋锁:一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环,任何时刻最多只能有一个执行单元获得锁
总结:不会发生线程状态的切换,一直处于用户态,减少了线程上下文切换的消耗,缺点是循环会消耗CPU
五、共享锁和独享锁
共享锁:也叫读锁,可以查看数据,但是不能修改和删除的一种数据锁,加锁后其他的用户可以并发读取,但不能修改、增加、删除数据,该锁可被多个线程持有,用于资源数据共享
独享锁:也叫排它锁、写锁、独占锁、独享锁,该锁每一次只能被一个线程所持有,加锁后任何线程试图再次加锁都会被阻塞,直到当前线程解锁。例如:线程A对data加上排它锁后,则其他线程不能再对data加任何类型的锁,获得互斥锁的线程既能读数据又能修改数据
29、Lock和synchronized有啥区别?
一、作用
lock 和 synchronized 都是 Java 中去用来解决线程安全问题的一个工具,是Java中两种用来实现线程同步的方式。
二、来源
sychronized 是 Java 中的一个关键字,它可以修饰方法和代码块。当一个线程访问一个对象的同步方法或同步代码块时,其他线程不能访问这个对象的其他同步方法或同步代码块。
lock 是 java.util.concurrent.locks 包里的一个接口,这个接口有很多实现类,其中就包括我们最常用的 ReentrantLock(可重入锁)。它提供了更多的灵活性,比如可以尝试获取锁而不会阻塞线程、可以重试获取锁的次数以及可以提供公平锁和非公平锁。
三、锁的力度
sychronized 可以通过两种方式去控制锁的力度:
- 把
sychronized关键字修饰在方法层面。 - 修饰在代码块上。
锁对象的不同:
锁对象为静态对象或者是class对象,那这个锁属于全局锁。
锁对象为普通实例对象,那这个锁的范围取决于这个实例的生命周期。
lock锁的力度是通过lock()与unlock()两个方法决定的。在两个方法之间的代码能保证其线程安全。lock的作用域取决于lock实例的生命周期。
四、灵活性
lock锁比sychronized的灵活性更高。
lock可以自主的去决定什么时候加锁与释放锁。只需要调用lock 的lock()和unlock()这两个方法就可以。
sychronized 由于是一个关键字,所以他无法实现非阻塞竞争锁的方法,一个线程获取锁之后,其他锁只能等待那个线程释放之后才能有获取锁的机会。
五、公平锁与非公平锁
(1)公平锁:
多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死。
- 缺点:吞吐量低,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销大。
(2)非公平锁:
多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,最终饿死。
lock提供了公平锁和非公平锁两种机制(默认非公平锁)。
PS:sychronized是非公平锁。
六、异常是否释放锁
synchronized锁的释放是被动的,当sychronized同步代码块执行结束或者出现异常的时候才会被释放。
lock锁发生异常的时候,不会主动释放占有的锁,必须手动unlock()来释放,所以我们一般都是将同步代码块放进try-catch里面,finally中写入unlock()方法,避免死锁发生。
七、判断是否能获取锁
synchronized不能。
lock提供了非阻塞竞争锁的方法trylock(),返回值是Boolean类型。它表示的是用来尝试获取锁:成功获取则返回true;获取失败则返回false,这个方法无论如何都会立即返回。
八、调度方式
synchronized使用的是object对象本身的wait、notify、notifyAll方法,而lock使用的是Condition进行线程之间的调度。
九、是否能中断
synchronized只能等待锁的释放,不能响应中断。
lock等待锁过程中可以用interrupt()来中断。
十、性能
如果竞争不激烈,性能差不多;竞争激烈时,lock的性能会更好。
lock锁还能使用readwritelock实现读写分离,提高多线程的读操作效率。
十一、sychronized锁升级
synchronized 代码块是由一对 monitorenter/monitorexit 指令实现的。Monitor的实现完全是依靠操作系统内部的互斥锁,因为需要进行用户态到内核态的切换,所以同步操作是一个无差别的重量级操作。
所以现在JVM提供了三种不同的锁:偏向锁、轻量级锁、重量级锁。
(1)偏向锁:
当没有竞争出现时,默认使用偏向锁。线程会利用 CAS 操作在对象头上设置线程 ID ,以表示对象偏向当前线程。
目的:在很多应用场景中,大部分对象生命周期最多会被一个线程锁定,使用偏向锁可以降低无竞争时的开销。
(2)轻量级锁:
JVM比较当前线程的 threadID 和 Java 对象头中的threadID是否一致,如果不一致(比如线程2要竞争锁对象),那么需要查看 Java 对象头中记录的线程1是否存活(偏向锁不会主动释放因此还是存储的线程1的 threadID):
- 如果没有存活,那么锁对象还是为偏向锁(对象头中的
threadID为线程2的); - 如果存活,那么撤销偏向锁,升级为轻量级锁。
当有其他线程想访问加了轻量级锁的资源时,会使用 自旋锁 优化,来进行资源访问。
目的:竞争锁对象的线程不多,而且线程持有锁的时间也不长的情景。因为阻塞线程需要CPU从用户态转到内核态,开销大,如果刚刚阻塞不久这个锁就被释放了,就得不偿失了,因此这个时候就干脆不阻塞这个线程,让它自旋这等待锁释放。
(3)重量级锁:
如果自旋失败,很大概率再进行一次自旋,如果也是失败,因此直接升级成 重量级锁 ,进行线程阻塞,减少cpu消耗。
当锁升级为重量级锁后,未抢到锁的线程都会被阻塞,进入阻塞队列。
30、synchronized一定会阻塞吗?
synchronized关键字并不一定会阻塞线程。synchronized关键字用于实现Java中的同步机制,它可以应用于方法或代码块。当一个线程获得了某个对象的锁时(通过synchronized关键字),其他线程如果想要获取该对象的锁,就会被阻塞,直到持有锁的线程释放锁。
但是,如果一个线程尝试获取一个对象的锁时,如果锁没有被其他线程持有,那么该线程会立即获得锁,而不会被阻塞。因此,synchronized关键字只会在获取锁时可能导致线程阻塞,而不是一定会阻塞线程。
另外需要注意的是,synchronized关键字还可以用于静态方法和类级别的锁定,这时锁定的是整个类而不是对象。在这种情况下,如果一个线程获取了类级别的锁,其他线程也会被阻塞,直到持有锁的线程释放锁。
总结起来,synchronized关键字的阻塞行为取决于锁的可用性,如果锁可用,线程会立即获取锁而不被阻塞;如果锁不可用,线程会被阻塞直到锁可用。
31、说说偏向锁、轻量锁级、重量级锁是什么锁?
在Java中,锁是用于实现线程同步的机制。为了提高多线程程序的性能,Java引入了偏向锁、轻量级锁和重量级锁等不同级别的锁。
-
偏向锁(Biased Locking):
偏向锁是为了在无竞争的情况下减少锁的开销而引入的机制。当一个线程访问一个同步块并获取锁时,锁会被标记为偏向锁,并且记录下持有锁的线程ID。当该线程再次进入同步块时,无需进行任何同步操作,直接获取锁。只有当其他线程尝试获取该锁时,偏向锁才会升级为轻量级锁。 -
轻量级锁(Lightweight Locking):
轻量级锁是为了在竞争不激烈的情况下减少锁的开销而引入的机制。当一个线程尝试获取一个已经被偏向锁持有的锁时,会尝试将锁升级为轻量级锁。升级的过程中,会使用CAS(Compare and Swap)操作来尝试获取锁。如果获取成功,线程就可以进入临界区,执行同步操作。如果获取失败,表示有其他线程竞争锁,锁会膨胀为重量级锁。 -
重量级锁(Heavyweight Locking):
重量级锁是最传统的锁实现方式,它使用操作系统的互斥量来实现线程的同步。当一个线程尝试获取一个已经被轻量级锁持有的锁时,如果获取失败,锁就会膨胀为重量级锁。膨胀为重量级锁的过程中,其他线程会被阻塞,进入等待状态,直到持有锁的线程释放锁。
总的来说,偏向锁和轻量级锁都是为了在竞争不激烈的情况下减少锁的开销,提高程序性能。只有在竞争激烈的情况下,锁才会膨胀为重量级锁,使用操作系统的互斥量来实现线程同步。
一、内存布局对应对应的锁状态

锁状态的变化结论

二、偏向锁
- 偏向锁是一种针对加锁操作的优化手段。
- 在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,因此为了消除数据在无竞争情况下锁重入(CAS操作)的开销而引入偏向锁。
- 对于没有锁竞争的场合,偏向锁有很好的优化效果。
- JVM启用了偏向锁模式:jdk6之后默认开启
- 新创建对象的Mark Word中的Thread Id为0,说明此时处于可偏向但未偏向任何线程,也叫做匿名偏向状态(anonymously biased)。
偏向锁延迟偏向
- HotSpot 虚拟机在启动后开启偏向锁模式默认在4s后。
- 为了减少初始化时间,JVM默认延时加载偏向锁。
//关闭延迟开启偏向锁
-XX:BiasedLockingStartupDelay=0
//禁止偏向锁
-XX:-UseBiasedLocking

- 上图的代码可以验证:从无锁变为偏向锁(4秒)
偏向锁在无竞争的时候一直是偏向锁
public static void main(String[] args) throws InterruptedException {
log.debug(Thread.currentThread().getName() + "最开始的状态。。。\n"
+ ClassLayout.parseInstance(new Object()).toPrintable());
// HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(4000);
Object obj = new Object();
new Thread(new Runnable() {
@Override
public void run() {
log.debug(
Thread.currentThread().getName() + "开始执行准备获取锁。。。\n" + ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj) {
log.debug(Thread.currentThread().getName() + "获取锁执行中。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName() + "释放锁。。。\n" + ClassLayout.parseInstance(obj).toPrintable());
}
}, "thread1").start();
Thread.sleep(5000);
log.debug(Thread.currentThread().getName() + "结束状态。。。\n" + ClassLayout.parseInstance(obj).toPrintable());
}
- 执行结果
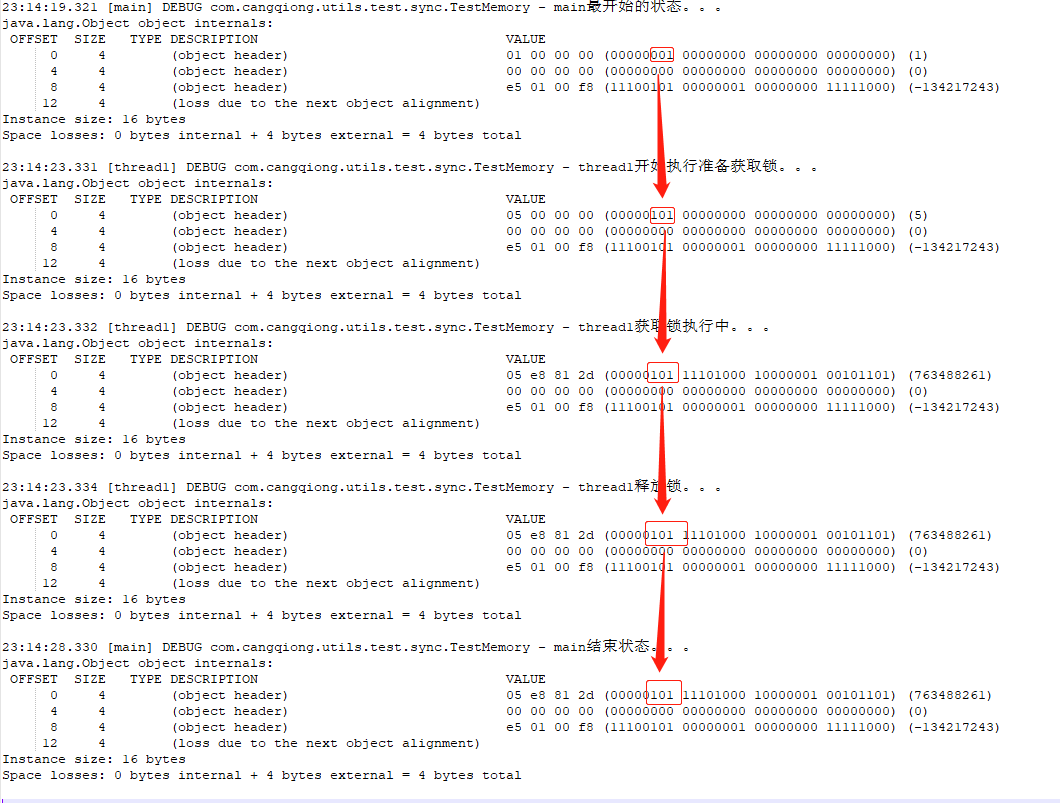
- 从结果可以看出:无锁状态经过4秒变为偏向锁,之后的的状态一直是偏向锁!
- 在进入同步代码块后,锁的偏向线程由0变为具体的线程。
在同步代码块外调用hashCode()方法

- 进入同步代码块后锁升级为轻量级锁
- 当对象可偏向(线程ID为0)时,MarkWord将变成未锁定状态,并只能升级成轻量锁。
在同步代码块内调用hashCode()方法

- 直接升级为重量级锁
- 当对象正处于偏向锁时,调用HashCode将使偏向锁强制升级成重量锁。
偏向锁撤销:自己验证wait和notify
- 调用锁对象的obj.hashCode()或System.identityHashCode(obj)方法会导致该对象的偏向锁被撤销。
- 因为对于一个对象,其HashCode只会生成一次并保存,偏向锁是没有地方保存hashcode的。
- 轻量级锁会在锁记录中记录 hashCode。
- 重量级锁会在 Monitor 中记录 hashCode。
- 当对象可偏向(线程ID为0)时,MarkWord将变成未锁定状态,并只能升级成轻量锁。
- 当对象正处于偏向锁时,调用HashCode将使偏向锁强制升级成重量锁。
- 偏向锁状态执行obj.notify() 会升级为轻量级锁。
- 调用obj.wait(timeout) 会升级为重量级锁。
三、轻量级锁
- 倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段,此时Mark Word 的结构也变为轻量级锁的结构。
- 轻量级锁所适应的场景是线程交替执行同步块的场合,如果存在同一时间多个线程访问同一把锁的场合,就会导致轻量级锁膨胀为重量级锁。
- 轻量级锁在降级的时候直接变为无锁状态!(查看之前在同步代码块外调用hashCode()方法)
模拟竞争不激烈的场景
@Slf4j
public class TestMemory {
public static void main(String[] args) throws InterruptedException {
log.debug(Thread.currentThread().getName() + "最开始的状态。。。\n"
+ ClassLayout.parseInstance(new Object()).toPrintable());
// HotSpot 虚拟机在启动后有个 4s 的延迟才会对每个新建的对象开启偏向锁模式
Thread.sleep(4000);
Object obj = new Object();
Thread thread1 = new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName() + "开始执行thread1。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj) {
log.debug(Thread.currentThread().getName() + "获取锁执行中thread1。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName() + "释放锁thread1。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
}, "thread1");
thread1.start();
// 控制线程竞争时机
Thread.sleep(1);
Thread thread2 = new Thread(new Runnable() {
@Override
public void run() {
log.debug(Thread.currentThread().getName() + "开始执行thread2。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
synchronized (obj) {
log.debug(Thread.currentThread().getName() + "获取锁执行中thread2。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
log.debug(Thread.currentThread().getName() + "释放锁thread2。。。\n"
+ ClassLayout.parseInstance(obj).toPrintable());
}
}, "thread2");
thread2.start();
Thread.sleep(5000);
log.debug(Thread.currentThread().getName() + "结束状态。。。\n" + ClassLayout.parseInstance(obj).toPrintable());
}
}
竞争不激烈的场景的运行结果

四、重量级锁
- 轻量级锁经过一次自选如果没有获取到锁,直接膨胀为重量级锁。
- 重量级锁是基于 Monitor 机制,并且在 Monitor 中记录 hashCode
模拟竞争激烈的场景
- 去掉不激烈的场景中的以下代码就是竞争激烈的场景
// 控制线程竞争时机
Thread.sleep(1);
竞争激烈的场景的运行结果

32、线程池有哪些参数?
线程池的7大参数包括:corePoolSize、maximumPoolSize、keepAliveTime、TimeUnit、workQueue、threadFactory和handler。
- corePoolSize:线程池核心线程大小,即线程池中会维护一个最小的线程数量,即使这些线程处理空闲状态,他们也不会被销毁,除非设置了allowCoreThreadTimeOut。这里的最小线程数量即是corePoolSize。任务提交到线程池后,首先会检查当前线程数是否达到了corePoolSize,如果没有达到的话,则会创建一个新线程来处理这个任务。
- maximumPoolSize:线程池最大线程数量。当任务队列满了之后,新来的任务就会在这里等待执行。如果超过了maximunPoolSize个任务在队列中等待,那么就会抛出RejectedExecutionException异常。
- keepAliveTime:线程空闲时间,也就是当一个线程处于空闲状态时,它会在这段时间内不会被回收。默认情况下是60秒。
- TimeUnit:keepAliveTime的时间单位,可以是毫秒(ms)、秒(s)等等。
- workQueue:工作队列类型。Java提供了几种不同的队列类型供选择,包括ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue等等。
- threadFactory:自定义线程工厂类。如果不指定这个参数,则使用默认的ThreadFactory实现。
- handler:拒绝策略。当任务无法被分配给正在运行的线程时,就会抛出RejectedExecutionException异常。Java提供了几种不同的拒绝策略可供选择,包括AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy等等。
在使用 ThreadPoolExecutor 创建线程池时所设置的 7 个参数,如以下源码所示:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//...
}
参数1:corePoolSize
核心线程数:是指线程池中长期存活的线程数。
这就好比古代大户人家,会长期雇佣一些“长工”来给他们干活,这些人一般比较稳定,无论这一年的活多活少,这些人都不会被辞退,都是长期生活在大户人家的。
参数2:maximumPoolSize
最大线程数:线程池允许创建的最大线程数量,当线程池的任务队列满了之后,可以创建的最大线程数。
这是古代大户人家最多可以雇佣的人数,比如某个节日或大户人家有人过寿时,因为活太多,仅靠“长工”是完不成任务,这时就会再招聘一些“短工”一起来干活,这个最大线程数就是“长工”+“短工”的总人数,也就是招聘的人数不能超过 maximumPoolSize。
注意事项
最大线程数 maximumPoolSize 的值不能小于核心线程数 corePoolSize,否则在程序运行时会报 IllegalArgumentException 非法参数异常,如下图所示:

参数3:keepAliveTime
空闲线程存活时间,当线程池中没有任务时,会销毁一些线程,销毁的线程数=maximumPoolSize(最大线程数)-corePoolSize(核心线程数)。
还是以大户人家为例,当大户人家比较忙的时候就会雇佣一些“短工”来干活,但等干完活之后,不忙了,就会将这些“短工”辞退掉,而 keepAliveTime 就是用来描述没活之后,短工可以在大户人家待的(最长)时间。
参数4:TimeUnit
时间单位:空闲线程存活时间的描述单位,此参数是配合参数 3 使用的。
参数 3 是一个 long 类型的值,比如参数 3 传递的是 1,那么这个 1 表示的是 1 天?还是 1 小时?还是 1 秒钟?是由参数 4 说了算的。
TimeUnit 有以下 7 个值:
-
TimeUnit.DAYS:天
-
TimeUnit.HOURS:小时
-
TimeUnit.MINUTES:分
-
TimeUnit.SECONDS:秒
-
TimeUnit.MILLISECONDS:毫秒
-
TimeUnit.MICROSECONDS:微妙
-
TimeUnit.NANOSECONDS:纳秒
参数5:BlockingQueue
阻塞队列:线程池存放任务的队列,用来存储线程池的所有待执行任务。
它可以设置以下几个值:
-
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
-
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
-
SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
-
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
-
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
-
LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
-
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
比较常用的是 LinkedBlockingQueue,线程池的排队策略和 BlockingQueue 息息相关。
参数6:ThreadFactory
线程工厂:线程池创建线程时调用的工厂方法,通过此方法可以设置线程的优先级、线程命名规则以及线程类型(用户线程还是守护线程)等。
线程工厂的使用示例如下:
public static void main(String[] args) {
// 创建线程工厂
ThreadFactory threadFactory = new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
// 创建线程池中的线程
Thread thread = new Thread(r);
// 设置线程名称
thread.setName("Thread-" + r.hashCode());
// 设置线程优先级(最大值:10)
thread.setPriority(Thread.MAX_PRIORITY);
//......
return thread;
}
};
// 创建线程池
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(10, 10, 0,
TimeUnit.SECONDS, new LinkedBlockingQueue<>(),
threadFactory); // 使用自定义的线程工厂
threadPoolExecutor.submit(new Runnable() {
@Override
public void run() {
Thread thread = Thread.currentThread();
System.out.println(String.format("线程:%s,线程优先级:%d",
thread.getName(), thread.getPriority()));
}
});
}
以上程序的执行结果如下:

从上述执行结果可以看出,自定义线程工厂起作用了,线程的名称和线程的优先级都是通过线程工厂设置的。
参数7:RejectedExecutionHandler
拒绝策略:当线程池的任务超出线程池队列可以存储的最大值之后,执行的策略。
默认的拒绝策略有以下 4 种:
- AbortPolicy:拒绝并抛出异常。
- CallerRunsPolicy:使用当前调用的线程来执行此任务。
- DiscardOldestPolicy:抛弃队列头部(最旧)的一个任务,并执行当前任务。
- DiscardPolicy:忽略并抛弃当前任务。
线程池的默认策略是 AbortPolicy 拒绝并抛出异常。
33、说说RocketMQ的消息生产消费过程?
RocketMQ 消息生产消费过程如下:
- 生产者向 RocketMQ 发送消息,消息会被封装到一个
Message对象中,并放入到topic的queue中。 - Producer 通过
producerGroup向 Broker 发送消息,Broker 会将消息发送到所属的topic的queue中。 - 消费者从 Broker 中拉取消息,消息会被封装到一个
Message对象中,并从topic的queue中取出。 - 消费者通过
consumerGroup从 Broker 中拉取消息,并在消费者自己的messageListener中处理消息。
下面是用 Java 实现的 RocketMQ 消息生产消费过程的示例代码:
public class RocketMQProducer {
public static void main(String[] args) throws Exception {
// 创建生产者
Producer producer = new DefaultMQProducer("my-project-namespace");
// 创建消息
Message message = new Message("TopicTest", "TagA", "Hello World".getBytes());
// 发送消息到消息队列
producer.send(message);
// 关闭生产者
producer.close();
}
}
public class RocketMQConsumer {
public static void main(String[] args) throws Exception {
// 创建消费者
Consumer consumer = new DefaultMQPushConsumer("my-project-namespace");
// 设置消费者组名称
consumer.setConsumerGroup("ConsumerGroup");
// 创建消息监听器
MessageListenerOrderly messageListener = new MessageListenerOrderly();
consumer.subscribe("TopicTest", "*");
consumer.setMessageListener(messageListener);
// 启动消费者
consumer.start();
// 关闭消费者
consumer.shutdown();
}
static class MessageListenerOrderly implements MessageListener {
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
// 处理消息
System.out.println("Received Message: " + new String(msgs.get(0).getBody()));
// 返回消费者消费状态
return ConsumeOrderlyStatus.SUCCESS;
}
}
}
在以上示例代码中,我们使用 DefaultMQProducer 和 DefaultMQPushConsumer 来创建生产者和消费者。我们使用 send() 方法将消息发送到消息队列中,使用 subscribe() 方法订阅消息主题,使用 setMessageListener() 方法设置消费者监听器,在监听器中实现 consumeMessage() 方法来处理消息。在 consumeMessage() 方法中,我们可以对消息进行业务处理,并将处理结果返回给消费者。
在以上示例代码中,我们还使用了 MessageExt 类来封装消息,它包含了消息的主题、消息内容、消息类型等信息。在使用 consumeMessage() 方法处理消息时,我们需要实现 MessageListener 接口,并实现 consumeMessage() 方法来处理消息。
在实际应用中,我们还需要考虑消息的发送顺序、消息的重试等问题,可以使用 RocketMQ 提供的一些高级特性来实现,例如:发送消息时设置 Priority,使用 TransactionManager 进行事务管理,使用 BrokerSelector 选择合适的 Broker 等。
40岁老架构师尼恩提示:RocketMQ是既是面试的绝对重点,也是面试的绝对难点,建议大家有一个深入和详细的掌握,具体的内容请参见《尼恩RocketMQ四部曲》,该专题对RocketMQ有一个系统化、体系化、全面化的介绍。
如果要把RocketMQ实战写入简历,可以找尼恩指导
34、说说生产者的负载均衡?
生产者的负载均衡是指在多个Broker之间分配消息,以确保每个Broker处理的消息量大致相等。RocketMQ提供了多种负载均衡策略,包括以下几种:
- 轮询(RoundRobin):将消息依次发送到不同的Broker上,每个Broker处理的消息量大致相等。
- 随机(Random):将消息随机发送到不同的Broker上,每个Broker处理的消息量可能不相等。
- 最少连接(LeastConnections):将消息发送到当前连接数最少的Broker上,以确保每个Broker处理的消息量大致相等。
- 一致性哈希(ConsistentHash):根据消息的key值计算哈希值,将消息发送到对应的Broker上,以确保每个Broker处理的消息量大致相等。
在RocketMQ中,可以通过设置ProducerConfig对象的loadBalancePolicy属性来选择负载均衡策略。例如,使用轮询策略可以这样设置:
DefaultMQProducer producer = new DefaultMQProducer("producer_group");
producer.setNamesrvAddr("localhost:9876");
producer.setLoadBalancePolicy("roundrobin"); // 设置负载均衡策略为轮询
producer.start();
35、说说消息的reput过程?
在RocketMQ中,消息的reput过程是指对消息的可靠性和一致性进行保障的过程。RocketMQ是一个分布式消息队列系统,用于实现高可靠性、高吞吐量的消息传递。
消息的reput过程在RocketMQ中包括以下几个步骤:
-
消息发送:消息的发送者将消息发送到RocketMQ的生产者。
-
消息持久化:生产者将消息持久化到本地磁盘,以保证消息的可靠性。消息会被写入消息日志文件(Commit Log)和索引文件(Index File)。
-
主从同步:消息在主节点持久化后,会通过主从同步机制将消息复制到从节点。这样可以保证即使主节点宕机,消息仍然可以在从节点上访问。
-
消息复制:消息在主从同步后,会在从节点上进行消息复制。从节点会将消息写入本地的消息日志文件和索引文件。
-
消息消费:消费者从RocketMQ的消费者端订阅消息,并从Broker拉取消息进行消费。消费者可以设置消息的消费模式,包括集群模式和广播模式。
-
消息确认:消费者消费消息后,会向Broker发送消息确认(ACK)。Broker收到消息确认后会更新消息的消费进度,并标记消息为已消费。
-
消息重试:如果消费者在消费过程中出现异常或者超时,RocketMQ会进行消息重试。消息重试机制会根据配置的重试次数和重试间隔进行消息的重新消费。
-
消息顺序:RocketMQ还支持消息的顺序消费。在顺序消费模式下,消息会按照发送顺序进行消费,保证消息的顺序性。
需要注意的是,RocketMQ的消息reput过程是基于分布式架构的,通过主从同步和消息复制机制保证消息的可靠性和一致性。同时,RocketMQ还提供了丰富的配置选项和监控工具,以便对消息的reput过程进行监控和调优。
36、说说RocketMQ的ConsumeQueue消息的格式?
在RocketMQ中,ConsumeQueue是用于存储消息消费进度的数据结构。它是基于文件的存储方式,每个主题(Topic)都有一个对应的ConsumeQueue文件。
ConsumeQueue文件由多个逻辑队列(Logical Queue)组成,每个逻辑队列对应一个消息队列(Message Queue)。逻辑队列中存储了消息的索引信息,包括消息在CommitLog文件中的偏移量(offset)和消息的大小。
ConsumeQueue文件由两部分组成:索引文件(Index File)和位图文件(BitMap File)。
1. 索引文件(Index File):
索引文件用于记录每个消息队列的消息索引信息。它包含了每个消息的偏移量和消息的存储时间戳。索引文件按照消息的存储时间戳进行排序,方便快速查找特定时间范围内的消息。
2. 位图文件(BitMap File):
位图文件用于记录消息队列中每个消息的消费状态。每个消息占用一个位,0表示未消费,1表示已消费。通过位图文件,可以快速判断消息是否已经被消费。
ConsumeQueue中的消息格式如下:
+---------------------+---------------------+
| Offset | CommitLogOffset |
| (8字节) | (8字节) |
+---------------------+---------------------+
| Size | TagsCode |
| (4字节) | (8字节) |
+---------------------+---------------------+
| StoreTimestamp | ConsumeTimestamp |
| (8字节) | (8字节) |
+---------------------+---------------------+
- Offset:消息在CommitLog文件中的偏移量。
- CommitLogOffset:消息在CommitLog文件中的物理偏移量。
- Size:消息的大小。
- TagsCode:消息的标签编码。
- StoreTimestamp:消息的存储时间戳。
- ConsumeTimestamp:消息的消费时间戳。
通过解析ConsumeQueue文件,RocketMQ可以快速定位消息的位置,提高消息的消费效率。
37、3PC、2PC、CAP是啥?
- 3PC原理:3PC(Three-Processor Code)是一种多处理器并行编程模型,在这个模型中,有三个基本的程序执行单位:线程、进程和中断处理程序。线程是执行单个任务的最小单位,进程是一个执行单元,它可以拥有自己的地址空间,中断处理程序是处理硬件中断请求的一种机制。通过使用线程来实现并行计算,可以有效地利用多个处理器的能力。
- 2PC原理:2PC(Two-Processor Code)是一种基于时间片轮转的多处理器并行编程模型。在这个模型中,有两个基本的程序执行单位:线程和进程。线程轮流使用 CPU,进程则按照一定的时间片轮流执行。线程和进程的切换由操作系统控制,并且时间片的长度是一定的。通过使用时间片轮转的方式,可以有效地利用多个处理器的能力。
- CAP原理:CAP原理是指在分布式系统中,对于一个分区容忍性的系统,必须同时满足 C(Consistency)、A(Availability)和P(Partition Tolerance)三个属性。这三个属性中,C 属性表示数据的一致性,即在整个系统中,所有节点看到的数据都是一致的;A 属性表示系统的可用性,即在出现故障时,整个系统必须能够继续运行;P 属性表示分区容忍性,即在系统中出现节点故障或者通信异常时,整个系统仍然能够继续运行。
- 区别: 3PC和2PC都是多处理器并行编程模型,但是在实现方式上有所不同。3PC是基于线程的并行,而2PC是基于时间片轮转的并行。在使用场景上,3PC适用于计算密集型任务,2PC适用于时间敏感型任务。
CAP原理主要是针对分布式系统中的一致性、可用性和分区容忍性进行的讨论。在分布式系统中,这三个属性是相互制约的,必须根据实际情况进行权衡。
38、RocketMQ是AP还是CP?
RocketMQ是一个开源的分布式消息中间件,它的设计目标是提供高吞吐量、低延迟、高可用性和可伸缩性的消息传递解决方案。
在分布式系统中,一般会使用CAP原则来描述系统的特性。CAP原则指的是一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),它表明在分布式系统中,无法同时满足一致性、可用性和分区容错性这三个特性,只能在其中选择两个。
根据CAP原则,RocketMQ被归类为AP(可用性和分区容错性)系统。这意味着在RocketMQ中,当网络分区发生时,它会保证可用性和分区容错性,即消息仍然可以进行传递和消费,但在某些情况下可能会出现数据不一致的情况。
RocketMQ通过主从复制和消息冗余机制来保证高可用性和可靠性。它使用了主题(Topic)和队列(Queue)的概念来组织消息,消息被写入到主题中,然后根据配置的队列数量进行分布式存储。当一个消息被发送到RocketMQ集群时,它会被复制到多个Broker节点上的队列中,以确保消息的可靠性和高可用性。
总结起来,RocketMQ是一个AP系统,它在可用性和分区容错性方面提供了强大的支持,但在某些情况下可能会出现数据不一致的情况。
39、RocketMQ的Broker宕机会怎样?
当RocketMQ的Broker宕机时,会对消息传递的可用性和可靠性产生一定的影响。下面是宕机时的一些可能情况和处理方式:
-
主节点宕机:RocketMQ的Broker节点通常以主从复制的方式运行,当主节点宕机时,集群中的其他节点会自动选举一个新的主节点来接管工作。这个过程通常是自动完成的,不需要人工干预。在选举完成之前,消息的写入和消费可能会受到一定的影响,但一旦选举完成,系统将恢复正常。
-
所有节点宕机:如果RocketMQ的所有Broker节点都宕机,消息的写入和消费将无法进行。在这种情况下,需要将Broker节点恢复或重新启动,以使系统恢复正常运行。
-
部分节点宕机:如果RocketMQ集群中的部分Broker节点宕机,其他正常运行的节点仍然可以接收消息并提供服务。但是,由于部分节点宕机,整个集群的可用性和吞吐量可能会受到影响。一旦宕机的节点恢复正常,系统将重新平衡负载并恢复正常运行。
为了减少Broker宕机对消息传递的影响,可以采取以下措施:
-
配置高可用性:通过使用主从复制模式,将消息复制到多个Broker节点上,以确保即使其中一个节点宕机,仍然可以从其他节点获取消息。
-
监控和自动恢复:使用监控系统来实时监测Broker节点的状态,一旦宕机,可以自动触发恢复机制,例如自动选举新的主节点。
-
数据备份和恢复:定期备份Broker节点上的数据,以便在宕机后能够快速恢复数据并重新启动节点。
总的来说,RocketMQ对Broker宕机情况有一定的容错和恢复机制,可以保证消息传递的可用性和可靠性。然而,对于关键业务场景,建议采取适当的高可用性和容灾措施,以确保系统的稳定性和可靠性。
40、有看过选主过程的源码吗?简述一下
RocketMQ是一个开源项目,您可以在Apache RocketMQ的官方GitHub仓库( https://github.com/apache/RocketMQ )中找到完整的源代码。
以下是选主过程的源码简要描述:
-
首先,当一个Broker节点启动时,它会执行
org.apache.RocketMQ.broker.BrokerController类中的initialize()方法,该方法用于初始化Broker节点的各个组件。 -
在
initialize()方法中,会执行org.apache.RocketMQ.broker.BrokerController类中的registerBrokerAll()方法,该方法用于向NameServer注册Broker节点的相关信息。 -
在
registerBrokerAll()方法中,会执行org.apache.RocketMQ.namesrv.processor.RegisterBrokerProcessor类中的processRequest()方法,该方法用于处理Broker节点注册的请求。 -
在
processRequest()方法中,会执行org.apache.RocketMQ.namesrv.routeinfo.RouteInfoManager类中的registerBroker()方法,该方法用于将Broker节点的信息存储在内存中,并定期将这些信息持久化到磁盘上的文件中。 -
当一个Master节点宕机或失去连接时,NameServer会检测到这个变化,并将Master节点对应的Topic和队列信息标记为不可用。
-
Slave节点会通过与NameServer的交互,获取到Master节点宕机的信息。具体的代码逻辑可以在
org.apache.RocketMQ.client.impl.factory.MQClientInstance类中的updateTopicRouteInfoFromNameServer()方法中找到。 -
Slave节点会尝试与其他可用的Master节点建立连接,并请求成为宕机Master节点的Slave节点。
-
如果其他Master节点同意将该Slave节点作为自己的Slave节点,那么该Slave节点将成为新的Master节点的Slave节点。具体的代码逻辑可以在
org.apache.RocketMQ.broker.BrokerController类中的slaveSynchronize()方法中找到。 -
新的Master节点会将自己的写入操作同步给所有的Slave节点,以保证数据的一致性。具体的代码逻辑可以在
org.apache.RocketMQ.store.DefaultMessageStore类中的doDispatch()方法中找到。 -
一旦宕机的Master节点恢复正常,它会尝试重新成为Master节点,而原来的Slave节点则会转变为它的Slave节点。具体的代码逻辑可以在
org.apache.RocketMQ.broker.BrokerController类中的rebalanceService()方法中找到。
尼恩说在最后
在尼恩的(50+)读者社群中,很多、很多小伙伴需要进大厂、拿高薪。
尼恩团队,会持续结合一些大厂的面试真题,给大家梳理一下学习路径,看看大家需要学点啥?
前面用多篇文章,给大家介绍阿里、百度、字节、滴滴的真题:
《炸裂了…京东一面索命40问,过了就50W+(京东面试真题)》
《问麻了…阿里一面索命27问,过了就60W+(阿里面试真题)》
《百度狂问3小时,大厂offer到手,小伙真狠!(百度面试真题)》
《饿了么太狠:面个高级Java,抖这多硬活、狠活(饿了么面试真题)》
《字节狂问一小时,小伙offer到手,太狠了!(字节面试真题)》
《收个滴滴Offer:从小伙三面经历,看看需要学点啥?(滴滴面试真题)》
这些真题,都会收入到 史上最全、持续升级的 PDF电子书 《尼恩Java面试宝典》。
本文收录于 《尼恩Java面试宝典》 V83版。
基本上,把尼恩的 《尼恩Java面试宝典》吃透,大厂offer很容易拿到滴。另外,下一期的 大厂面经大家有啥需求,可以发消息给尼恩。
技术自由的实现路径 PDF:
实现你的 响应式 自由:
这是老版本 《Flux、Mono、Reactor 实战(史上最全)》
实现你的 spring cloud 自由:
《Spring cloud Alibaba 学习圣经》 PDF
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
实现你的 linux 自由:
实现你的 网络 自由:
《网络三张表:ARP表, MAC表, 路由表,实现你的网络自由!!》
实现你的 分布式锁 自由:
实现你的 王者组件 自由:
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
实现你的 面试题 自由:
获取11个技术圣经PDF:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号