Flux 和 Mono 、reactor实战 (史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
前言
响应式编程用的是越来越多,尤其是在移动端 安卓的应用上边。
在Java后台服务开发中, 响应式编程用的不是太广泛,主要原因是, 响应式编程需要一个完整的生态, 包括数据库、缓存、中间件,都需要配套的响应式组件。 但是这点,其实很多并没有。
但是,随着 SpringCloud Gateway 的火爆, 响应式编程又变成了 不可回避, 不得不去学习的技术。
如果要做 SpringCloud Gateway 的开发, 就必须掌握一些响应式编程的知识。 由于最近在做 spring cloud gateway相关的开发工作, 所以:
把响应式编程Flux 和 Mono 的知识梳理一下,形成了此文。
并且,此文会不断完善。
姊妹篇:关于 SpringCloud Gateway 简介
SpringCloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
SpringCloud Gateway 作为 Spring Cloud 生态系统中的网关,目标是替代 Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuul 2.0以上最新高性能版本进行集成,仍然还是使用的Zuul 2.0之前的非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
Spring Cloud Gateway 的目标,不仅提供统一的路由方式,并且基于 Filter 链的方式提供了网关基本的功能,例如:安全,监控/指标,和限流。
有关 Spring Cloud Gateway 响应式编程的实战, 具体请参考本文姊妹篇:
特别说明:
Spring Cloud Gateway 底层使用了高性能的通信框架Netty。
Netty 是高性能中间件的通讯底座, rocketmq 、seata、nacos 、sentinel 、redission 、dubbo 等太多、太多的的大名鼎鼎的中间件,无一例外都是基于netty。
可以毫不夸张的说: netty 是进入大厂、走向高端 的必备技能。
要想深入了解springcloud gateway ,最好是掌握netty 编程。
有关 netty学习 具体请参见机工社出版 、尼恩的畅销书: 《Java高并发核心编程卷 1》
响应式编程概述
背景知识
为了应对高并发服务器端开发场景,在2009 年,微软提出了一个更优雅地实现异步编程的方式——Reactive Programming,我们称之为响应式编程。随后,Netflix 和LightBend 公司提供了RxJava 和Akka Stream 等技术,使得Java 平台也有了能够实现响应式编程的框架。
在2017 年9 月28 日,Spring 5 正式发布。Spring 5 发布最大的意义在于,它将响应式编程技术的普及向前推进了一大步。而同时,作为在背后支持Spring 5 响应式编程的框架Spring Reactor,也进入了里程碑式的3.1.0 版本。
什么是响应式编程
响应式编程是一种面向数据流和变化传播的编程范式。这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
响应式编程基于reactor(Reactor 是一个运行在 Java8 之上的响应式框架)的思想,当你做一个带有一定延迟的才能够返回的io操作时,不会阻塞,而是立刻返回一个流,并且订阅这个流,当这个流上产生了返回数据,可以立刻得到通知并调用回调函数处理数据。
电子表格程序就是响应式编程的一个例子。单元格可以包含字面值或类似"=B1+C1"的公式,而包含公式的单元格的值会依据其他单元格的值的变化而变化。
响应式传播核心特点之一:变化传播:一个单元格变化之后,会像多米诺骨牌一样,导致直接和间接引用它的其他单元格均发生相应变化。
基于Java8实现观察者模式
Observable类:此类表示可观察对象,或模型视图范例中的“数据”。
它可以被子类实现以表示应用程序想要观察的对象。
//想要观察的对象 ObserverDemo
public class ObserverDemo extends Observable {
public static void main(String[] args) {
ObserverDemo observerDemo = new ObserverDemo();
//添加观察者
observerDemo.addObserver((o,arg)->{
System.out.println("数据发生变化A");
});
observerDemo.addObserver((o,arg)->{
System.out.println("数据发生变化B");
});
observerDemo.setChanged();//将此Observable对象标记为已更改
observerDemo.notifyObservers();//如果该对象发生了变化,则通知其所有观察者
}
}
启动程序测试:

创建一个Observable
rxjava中,可以使用Observable.create() 该方法接收一个Obsubscribe对象
Observable<Integer> observable = Observable.create(new Observable.OnSubscribe<Integer>() {
@Override
public void call(Subscriber<? super Integer> subscriber) {
}
});
来个例子:
Observable<Integer> observable=Observable.create(new Observable.OnSubscribe<Integer>() {
@Override
public void call(Subscriber<? super Integer> subscriber) {
for(int i=0;i<5;i++){
subscriber.onNext(i);
}
subscriber.onCompleted();
}
});
//Observable.subscribe(Observer),Observer订阅了Observable
Subscription subscribe = observable.subscribe(new Observer<Integer>() {
@Override
public void onCompleted() {
Log.e(TAG, "完成");
}
@Override
public void onError(Throwable e) {
Log.e(TAG, "异常");
}
@Override
public void onNext(Integer integer) {
Log.e(TAG, "接收Obsverable中发射的值:" + integer);
}
});
输出:
接收Obsverable中发射的值:0
接收Obsverable中发射的值:1
接收Obsverable中发射的值:2
接收Obsverable中发射的值:3
接收Obsverable中发射的值:4
从上面的例子可以看出,在Observer订阅了Observable后,
Observer作为OnSubscribe中call方法的参数传入,从而调用了Observer的相关方法
基于 Reactor 实现
Reactor 是一个运行在 Java8 之上满足 Reactice 规范的响应式框架,它提供了一组响应式风格的 API。
Reactor 有两个核心类: Flux<T> 和 Mono<T>,这两个类都实现 Publisher 接口。
- Flux 类似 RxJava 的 Observable,它可以触发零到多个事件,并根据实际情况结束处理或触发错误。
- Mono 最多只触发一个事件,所以可以把 Mono 用于在异步任务完成时发出通知。

Flux 和 Mono 都是数据流的发布者,使用 Flux 和 Mono 都可以发出三种数据信号:元素值,错误信号,完成信号;错误信号和完成信号都代表终止信号,终止信号用于告诉订阅者数据流结束了,错误信号终止数据流同时把错误信息传递给订阅者。
三种信号的特点:
- 错误信号和完成信号都是终止信号,不能共存
- 如果没有发送任何元素值,而是直接发送错误或者完成信号,表示是空数据流
- 如果没有错误信号,也没有完成信号,表示是无限数据流
引入依赖
<dependency>
<groupId>org.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>1.1.6.RELEASE</version>
</dependency>
just 和 subscribe方法
just():创建Flux序列,并声明指定数据流
subscribe():订阅Flux序列,只有进行订阅后才回触发数据流,不订阅就什么都不会发生
public class TestReactor {
public static void main(String[] args) {
//just():创建Flux序列,并声明数据流,
Flux<Integer> integerFlux = Flux.just(1, 2, 3, 4);//整形
//subscribe():订阅Flux序列,只有进行订阅后才回触发数据流,不订阅就什么都不会发生
integerFlux.subscribe(System.out::println);
Flux<String> stringFlux = Flux.just("hello", "world");//字符串
stringFlux.subscribe(System.out::println);
//fromArray(),fromIterable()和fromStream():可以从一个数组、Iterable 对象或Stream 对象中创建Flux序列
Integer[] array = {1,2,3,4};
Flux.fromArray(array).subscribe(System.out::println);
List<Integer> integers = Arrays.asList(array);
Flux.fromIterable(integers).subscribe(System.out::println);
Stream<Integer> stream = integers.stream();
Flux.fromStream(stream).subscribe(System.out::println);
}
}
启动测试:

响应流的特点
要搞清楚这两个概念,必须说一下响应流规范。它是响应式编程的基石。他具有以下特点:
-
响应流必须是无阻塞的。
-
响应流必须是一个数据流。
-
它必须可以异步执行。
-
并且它也应该能够处理背压。
-
即时响应性: 只要有可能, 系统就会及时地做出响应。 即时响应是可用性和实用性的基石, 而更加重要的是,即时响应意味着可以快速地检测到问题并且有效地对其进行处理。 即时响应的系统专注于提供快速而一致的响应时间, 确立可靠的反馈上限, 以提供一致的服务质量。 这种一致的行为转而将简化错误处理、 建立最终用户的信任并促使用户与系统作进一步的互动。
-
回弹性:系统在出现失败时依然保持即时响应性。 这不仅适用于高可用的、 任务关键型系统——任何不具备回弹性的系统都将会在发生失败之后丢失即时响应性。 回弹性是通过复制、 遏制、 隔离以及委托来实现的。 失败的扩散被遏制在了每个组件内部, 与其他组件相互隔离, 从而确保系统某部分的失败不会危及整个系统,并能独立恢复。 每个组件的恢复都被委托给了另一个(外部的)组件, 此外,在必要时可以通过复制来保证高可用性。 (因此)组件的客户端不再承担组件失败的处理。
-
弹性: 系统在不断变化的工作负载之下依然保持即时响应性。 反应式系统可以对输入(负载)的速率变化做出反应,比如通过增加或者减少被分配用于服务这些输入(负载)的资源。 这意味着设计上并没有争用点和中央瓶颈, 得以进行组件的分片或者复制, 并在它们之间分布输入(负载)。 通过提供相关的实时性能指标, 反应式系统能支持预测式以及反应式的伸缩算法。 这些系统可以在常规的硬件以及软件平台上实现成本高效的弹性。
-
消息驱动:反应式系统依赖异步的消息传递,从而确保了松耦合、隔离、位置透明的组件之间有着明确边界。 这一边界还提供了将失败作为消息委托出去的手段。 使用显式的消息传递,可以通过在系统中塑造并监视消息流队列, 并在必要时应用回压, 从而实现负载管理、 弹性以及流量控制。 使用位置透明的消息传递作为通信的手段, 使得跨集群或者在单个主机中使用相同的结构成分和语义来管理失败成为了可能。 非阻塞的通信使得接收者可以只在活动时才消耗资源, 从而减少系统开销。
Publisher/Flux和Mono
由于响应流的特点,我们不能再返回一个简单的POJO对象来表示结果了。必须返回一个类似Java中的Future的概念,在有结果可用时通知消费者进行消费响应。
Reactive Stream规范中这种被定义为Publisher
PublisherSubscriber<? super T>的需求推送元素。
一个Publisher
下面这个Excel计算就能说明一些Publisher

A1-A9就可以看做Publisher
A10-A13分别是求和函数SUM(A1:A9)、平均函数AVERAGE(A1:A9)、最大值函数MAX(A1:A9)、最小值函数MIN(A1:A9),
A10-A13可以看作订阅者Subscriber。
假如说我们没有A10-A13,那么A1-A9就没有实际意义,它们并不产生计算。
这也是响应式的一个重要特点:当没有订阅时发布者什么也不做。而Flux和Mono都是Publisher
Publishersubscribe方法,允许消费者在有结果可用时进行消费。
如果没有消费者Publisher
Publisher
Flux
Flux 是一个发出(emit)0-N个元素组成的异步序列的PublisheronComplete信号或者onError信号所终止。
在响应流规范中存在三种给下游消费者调用的方法 onNext, onComplete, 和onError。下面这张图表示了Flux的抽象模型:
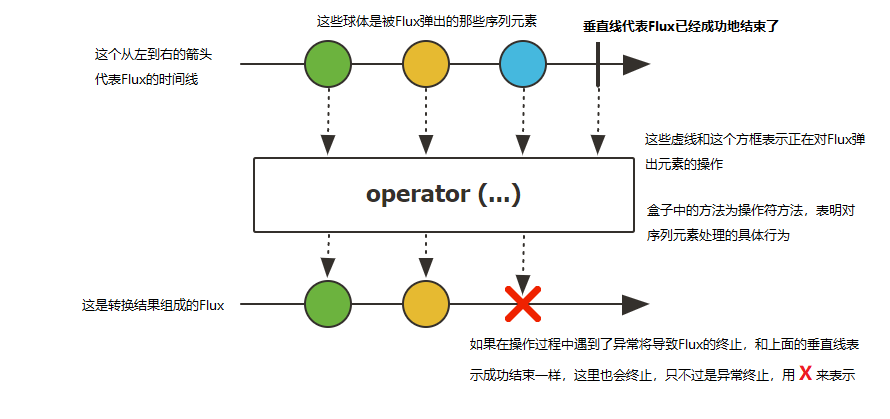
以上的的讲解对于初次接触反应式编程的依然是难以理解的,所以这里有一个循序渐进的理解过程。
有些类比并不是很妥当,但是对于你循序渐进的理解这些新概念还是有帮助的。
传统数据处理
我们在平常是这么写的:
public List<ClientUser> allUsers() {
return Arrays.asList(new ClientUser("felord.cn", "reactive"),
new ClientUser("Felordcn", "Reactor"));
}
我们通过迭代返回值List来get这些元素进行再处理(消费),不管有没有消费者, 菜品都会生产出来。
流式数据处理
在Java 8中我们可以改写为流的表示:
public Stream<ClientUser> allUsers() {
return Stream.of(new ClientUser("felord.cn", "reactive"),
new ClientUser("Felordcn", "Reactor"));
}
反应式数据处理
在Reactor中我们又可以改写为Flux表示:
public Flux<ClientUser> allUsers(){
return Flux.just(new ClientUser("felord.cn", "reactive"),
new ClientUser("Felordcn", "Reactor"));
}
这时候食客来了,发生了订阅,厨师才开始做。
Flux 的创建Demo
Flux ints = Flux.range(1, 4);
Flux seq1 = Flux.just("bole1", "bole2", "bole3");
List iterable = Arrays.asList("bole_01", "bole_02", "bole_03");
Flux seq2 = Flux.fromIterable(iterable);
seq2.subscribe(i -> System.out.println(i));
Mono
Mono 是一个发出(emit)0-1个元素的PublisheronComplete信号或者onError信号所终止。
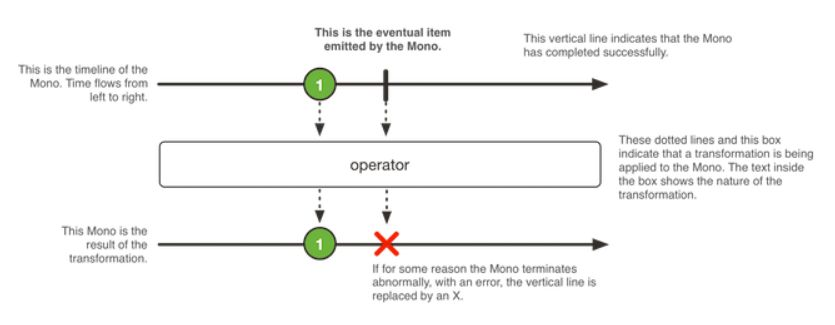
mono 整体和Flux差不多,只不过这里只会发出0-1个元素。也就是说不是有就是没有。
象Flux一样,我们来看看Mono的演化过程以帮助理解。
传统数据处理
public ClientUser currentUser () {
return isAuthenticated ? new ClientUser("felord.cn", "reactive") : null;
}
直接返回符合条件的对象或者null`。
Optional的处理方式
public Optional<ClientUser> currentUser () {
return isAuthenticated ? Optional.of(new ClientUser("felord.cn", "reactive"))
: Optional.empty();
}
这个Optional我觉得就有反应式的那种味儿了,当然它并不是反应式。当我们不从返回值Optional取其中具体的对象时,我们不清楚里面到底有没有,但是Optional是一定客观存在的,不会出现NPE问题。
反应式数据处理
public Mono<ClientUser> currentUser () {
return isAuthenticated ? Mono.just(new ClientUser("felord.cn", "reactive"))
: Mono.empty();
}
和Optional有点类似的机制,当然Mono不是为了解决NPE问题的,它是为了处理响应流中单个值(也可能是Void)而存在的。
Mono的创建Demo
Mono data = Mono.just("bole");
Mono noData = Mono.empty();
m.subscribe(i -> System.out.println(i));
Flux和Mono总结
Flux和Mono是Java反应式中的重要概念,但是很多同学包括我在开始都难以理解它们。这其实是规定了两种流式范式,这种范式让数据具有一些新的特性,比如基于发布订阅的事件驱动,异步流、背压等等。另外数据是推送(Push)给消费者的以区别于平时我们的拉(Pull)模式。同时我们可以像Stream Api一样使用类似map、flatmap等操作符(operator)来操作它们。
函数编程
反应式编程,常常和函数式编程结合,这就是让大家困扰的地方
函数编程接口
| 接口函数名 | 说明 |
|---|---|
| BiConsumer | 表示接收两个输入参数和不返回结果的操作。 |
| BiFunction | 表示接受两个参数,并产生一个结果的函数。 |
| BinaryOperator | 表示在相同类型的两个操作数的操作,生产相同类型的操作数的结果。 |
| BiPredicate | 代表两个参数谓词(布尔值函数)。 |
| BooleanSupplier | 代表布尔值结果的提供者。 |
| Consumer | 表示接受一个输入参数和不返回结果的操作。 |
| DoubleBinaryOperator | 代表在两个double值操作数的运算,并产生一个double值结果。 |
| DoubleConsumer | 表示接受一个double值参数,不返回结果的操作。 |
| DoubleFunction | 表示接受double值参数,并产生一个结果的函数。 |
| DoublePredicate | 代表一个double值参数谓词(布尔值函数)。 |
| DoubleSupplier | 表示表示接受double值参数,并产生一个结果的函数。值结果的提供者。 |
| DoubleToIntFunction | 表示接受一个double值参数,不返回结果的操作。 |
| DoubleFunction | 表示接受double值参数,并产生一个结果的函数。 |
| DoublePredicate | 代表一个double值参数谓词(布尔值函数)。 |
| DoubleSupplier | DoubleToIntFunction |
| DoubleToIntFunction | 表示接受double值参数,并产生一个int值结果的函数。 |
| DoubleToLongFunction | 表示上产生一个double值结果的单个double值操作数的操作。 |
| Function | 代表接受一个double值参数,并产生一个long值结果的函数。 |
| DoubleUnaryOperator | 表示上产生一个double值结果的单个double值操作数的操作。 |
| Function | 表示接受一个参数,并产生一个结果的函数。 |
| IntConsumer | 表示接受单个int值的参数并没有返回结果的操作。 |
| IntFunction | 表示接受一个int值参数,并产生一个结果的函数。 |
| IntPredicate | 表示一个整数值参数谓词(布尔值函数)。 |
| IntSupplier | 代表整型值的结果的提供者。 |
| IntToLongFunction | 表示接受一个int值参数,并产生一个long值结果的函数。 |
| IntUnaryOperator | 表示产生一个int值结果的单个int值操作数的运算。 |
| LongBinaryOperator | 表示在两个long值操作数的操作,并产生一个ObjLongConsumer值结果。 |
| LongFunction | 表示接受long值参数,并产生一个结果的函数。 |
| LongPredicate | 代表一个long值参数谓词(布尔值函数)。 |
| LongSupplier | 表示long值结果的提供者。 |
| LongToDoubleFunction | 表示接受double参数,并产生一个double值结果的函数。 |
| LongToIntFunction | 表示接受long值参数,并产生一个int值结果的函数。 |
| LongUnaryOperator | 表示上产生一个long值结果单一的long值操作数的操作。 |
| ObjDoubleConsumer | 表示接受对象值和double值参数,并且没有返回结果的操作。 |
| ObjIntConsumer | 表示接受对象值和整型值参数,并返回没有结果的操作。 |
| ObjLongConsumer | 表示接受对象值和整型值参数,并返回没有结果的操作。 |
| ObjLongConsumer | 表示接受对象值和double值参数,并且没有返回结果的操作。 |
| ObjIntConsumer | 表示接受对象值和整型值参数,并返回没有结果的操作。 |
| ObjLongConsumer | 表示接受对象的值和long值的说法,并没有返回结果的操作。 |
| Predicate | 代表一个参数谓词(布尔值函数)。 |
| Supplier | 表示一个提供者的结果。 |
| ToDoubleBiFunction | 表示接受两个参数,并产生一个double值结果的功能。 |
| ToDoubleFunction | 代表一个产生一个double值结果的功能。 |
| ToIntBiFunction | 表示接受两个参数,并产生一个int值结果的函数。 |
| ToIntFunction | 代表产生一个int值结果的功能。 |
| ToLongBiFunction | 表示接受两个参数,并产生long值结果的功能。 |
| ToLongFunction | 代表一个产生long值结果的功能。 |
| UnaryOperator | 表示上产生相同类型的操作数的结果的单个操作数的操作。 |
常用函数编程示例
Consumer 一个输入 无输出
Product product=new Product();
//类名+静态方法 一个输入T 没有输出
Consumer consumer1 = Product->Product.nameOf(product);//lambda
consumer1.accept(product);
Consumer consumer = Product::nameOf;//方法引用
consumer.accept(product);
Funtion<T,R> 一个输入 一个输出
//对象+方法 一个输入T 一个输出R
Function<Integer, Integer> function = product::reduceStock;
System.out.println("剩余库存:" + function.apply(10));
//带参数的构造函数
Function<Integer,Product> function1=Product::new;
System.out.println("新对象:" +function1.apply(200));
Predicate 一个输入T, 一个输出 Boolean
//Predicate 一个输入T 一个输出Boolean
Predicate predicate= i -> product.isEnough(i);//lambda
System.out.println("库存是否足够:"+predicate.test(100));
Predicate predicate1= product::isEnough;//方法引用
System.out.println("库存是否足够:"+predicate1.test(100));
UnaryOperator 一元操作符 输入输出都是T
//一元操作符 输入和输出T
UnaryOperator integerUnaryOperator =product::reduceStock;
System.out.println("剩余库存:" + integerUnaryOperator.apply(20));
IntUnaryOperator intUnaryOperator = product::reduceStock;
System.out.println("剩余库存:" + intUnaryOperator.applyAsInt(30));
Supplier 没有输入 只有输出
//无参数构造函数
Supplier supplier = Product::new;
System.out.println("创建新对象:" + supplier.get());
Supplier supplier1=()->product.getStock();
System.out.println("剩余库存:" + supplier1.get());
BiFunction 二元操作符 两个输入<T,U> 一个输出
//类名+方法
BiFunction<Product, Integer, Integer> binaryOperator = Product::reduceStock;
System.out.println(" 剩余库存(BiFunction):" + binaryOperator.apply(product, 10));
BinaryOperator 二元操作符 ,二个输入 一个输出
//BinaryOperator binaryOperator1=(x,y)->product.reduceStock(x,y);
BinaryOperator binaryOperator1=product::reduceStock;
System.out.println(" 剩余库存(BinaryOperator):" +binaryOperator1.apply(product.getStock(),10));
Flux类中的静态方法:
简单的创建方法
just():
可以指定序列中包含的全部元素。创建出来的Flux序列在发布这些元素之后会自动结束
fromArray(),fromIterable(),fromStream():
可以从一个数组,Iterable对象或Stream对象中穿件Flux对象
empty():
创建一个不包含任何元素,只发布结束消息的序列
error(Throwable error):
创建一个只包含错误消息的序列
never():
传建一个不包含任务消息通知的序列
range(int start, int count):
创建包含从start起始的count个数量的Integer对象的序列
interval(Duration period)和interval(Duration delay, Duration period):
创建一个包含了从0开始递增的Long对象的序列。其中包含的元素按照指定的间隔来发布。除了间隔时间之外,还可以指定起始元素发布之前的延迟时间
intervalMillis(long period)和intervalMillis(long delay, long period):
与interval()方法相同,但该方法通过毫秒数来指定时间间隔和延迟时间
例子
Flux.just("Hello", "World").subscribe(System.out::println);
Flux.fromArray(new Integer[]{1, 2, 3}).subscribe(System.out::println);
Flux.empty().subscribe(System.out::println);
Flux.range(1, 10).subscribe(System.out::println);
Flux.interval(Duration.of(10, ChronoUnit.SECONDS)).subscribe(System.out::println);
Flux.intervalMillis(1000).subscirbe(System.out::println);
复杂的序列创建 generate()
当序列的生成需要复杂的逻辑时,则应该使用generate()或create()方法。
generate()方法通过同步和逐一的方式来产生Flux序列。
序列的产生是通过调用所提供的的SynchronousSink对象的next(),complete()和error(Throwable)方法来完成的。
逐一生成的含义是在具体的生成逻辑中,next()方法只能最多被调用一次。
在某些情况下,序列的生成可能是有状态的,需要用到某些状态对象,此时可以使用
generate(Callable<S> stateSupplier, BiFunction<S, SynchronousSink<T>, S> generator),
其中stateSupplier用来提供初始的状态对象。
在进行序列生成时,状态对象会作为generator使用的第一个参数传入,可以在对应的逻辑中对改状态对象进行修改以供下一次生成时使用。
Flux.generate(sink -> {
sink.next("Hello");
sink.complete();
}).subscribe(System.out::println);
final Random random = new Random();
Flux.generate(ArrayList::new, (list, sink) -> {
int value = random.nextInt(100);
list.add(value);
sink.next(value);
if( list.size() ==10 )
sink.complete();
return list;
}).subscribe(System.out::println);
复杂的序列创建 create()
create()方法与generate()方法的不同之处在于所使用的是FluxSink对象。
FluxSink支持同步和异步的消息产生,并且可以在一次调用中产生多个元素。
Flux.create(sink -> {
for(int i = 0; i < 10; i ++)
sink.next(i);
sink.complete();
}).subscribe(System.out::println);
Mono静态方法
Mono类包含了与Flux类中相同的静态方法:just(),empty()和never()等。
除此之外,Mono还有一些独有的静态方法:
fromCallable(),fromCompletionStage(),fromFuture(),fromRunnable()和fromSupplier():分别从Callable,CompletionStage,CompletableFuture,Runnable和Supplier中创建Mono
delay(Duration duration)和delayMillis(long duration):创建一个Mono序列,在指定的延迟时间之后,产生数字0作为唯一值
ignoreElements(Publisher
justOrEmpty(Optional<? extends T> data)和justOrEmpty(T data):从一个Optional对象或可能为null的对象中创建Mono。只有Optional对象中包含之或对象不为null时,Mono序列才产生对应的元素
Mono.fromSupplier(() -> "Hello").subscribe(System.out::println);
Mono.justOrEmpty(Optional.of("Hello")).subscribe(System.out::println);
Mono.create(sink -> sink.success("Hello")).subscribte(System.out::println);
操作符
操作符buffer和bufferTimeout
这两个操作符的作用是把当前流中的元素收集到集合中,并把集合对象作为流中的新元素。
在进行收集时可以指定不同的条件:所包含的元素的最大数量或收集的时间间隔。方法buffer()仅使用一个条件,而bufferTimeout()可以同时指定两个条件。
指定时间间隔时可以使用Duration对象或毫秒数,即使用bufferMillis()或bufferTimeoutMillis()两个方法。
除了元素数量和时间间隔外,还可以通过bufferUntil和bufferWhile操作符来进行收集。这两个操作符的参数时表示每个集合中的元素索要满足的条件的Predicate对象。
bufferUntil会一直收集直到Predicate返回true。
使得Predicate返回true的那个元素可以选择添加到当前集合或下一个集合中;bufferWhile则只有当Predicate返回true时才会收集。一旦为false,会立即开始下一次收集。
Flux.range(1, 100).buffer(20).subscribe(System.out::println);
Flux.intervalMillis(100).bufferMillis(1001).take(2).toStream().forEach(System.out::println);
Flux.range(1, 10).bufferUntil(i -> i%2 == 0).subscribe(System.out::println);
Flux.range(1, 10).bufferWhile(i -> i%2 == 0).subscribe(System.out::println);
操作符Filter
对流中包含的元素进行过滤,只留下满足Predicate指定条件的元素。
Flux.range(1, 10).filter(i -> i%2 == 0).subscribe(System.out::println);
操作符zipWith
zipWith操作符把当前流中的元素与另一个流中的元素按照一对一的方式进行合并。在合并时可以不做任何处理,由此得到的是一个元素类型为Tuple2的流;也可以通过一个BiFunction函数对合并的元素进行处理,所得到的流的元素类型为该函数的返回值。
Flux.just("a", "b").zipWith(Flux.just("c", "d")).subscribe(System.out::println);
Flux.just("a", "b").zipWith(Flux.just("c", "d"), (s1, s2) -> String.format("%s-%s", s1, s2)).subscribe(System.out::println);
操作符take
take系列操作符用来从当前流中提取元素。提取方式如下:
take(long n),take(Duration timespan)和takeMillis(long timespan):按照指定的数量或时间间隔来提取
takeLast(long n):提取流中的最后N个元素
takeUntil(Predicate<? super T> predicate) :提取元素直到Predicate返回true
takeWhile(Predicate<? super T> continuePredicate):当Predicate返回true时才进行提取
takeUntilOther(Publisher<?> other):提取元素知道另外一个流开始产生元素
Flux.range(1, 1000).take(10).subscribe(System.out::println);
Flux.range(1, 1000).takeLast(10).subscribe(System.out::println);
Flux.range(1, 1000).takeWhile(i -> i < 10).subscribe(System.out::println);
Flux.range(1, 1000).takeUntil(i -> i == 10).subscribe(System.out::println);
操作符reduce和reduceWith
reduce和reduceWith操作符对流中包含的所有元素进行累计操作,得到一个包含计算结果的Mono序列。累计操作是通过一个BiFunction来表示的。在操作时可以指定一个初始值。若没有初始值,则序列的第一个元素作为初始值。
Flux.range(1, 100).reduce((x, y) -> x + y).subscribe(System.out::println);
Flux.range(1, 100).reduceWith(() -> 100, (x + y) -> x + y).subscribe(System.out::println);
操作符merge和mergeSequential
merge和mergeSequential操作符用来把多个流合并成一个Flux序列。merge按照所有流中元素的实际产生序列来合并,而mergeSequential按照所有流被订阅的顺序,以流为单位进行合并。
Flux.merge(Flux.intervalMillis(0, 100).take(5), Flux.intervalMillis(50, 100).take(5)).toStream().forEach(System.out::println);
Flux.mergeSequential(Flux.intervalMillis(0, 100).take(5), Flux.intervalMillis(50, 100).take(5)).toStream().forEach(System.out::println);
操作符flatMap和flatMapSequential
flatMap和flatMapSequential操作符把流中的每个元素转换成一个流,再把所有流中的元素进行合并。flatMapSequential和flatMap之间的区别与mergeSequential和merge是一样的。
Flux.just(5, 10).flatMap(x -> Flux.intervalMillis(x * 10, 100).take(x)).toStream().forEach(System.out::println);
操作符concatMap
concatMap操作符的作用也是把流中的每个元素转换成一个流,再把所有流进行合并。concatMap会根据原始流中的元素顺序依次把转换之后的流进行合并,并且concatMap堆转换之后的流的订阅是动态进行的,而flatMapSequential在合并之前就已经订阅了所有的流。
Flux.just(5, 10).concatMap(x -> Flux.intervalMillis(x * 10, 100).take(x)).toStream().forEach(System.out::println);
操作符combineLatest
combineLatest操作符把所有流中的最新产生的元素合并成一个新的元素,作为返回结果流中的元素。只要其中任何一个流中产生了新的元素,合并操作就会被执行一次,结果流中就会产生新的元素。
Flux.combineLatest(Arrays::toString, Flux.intervalMillis(100).take(5), Flux.intervalMillis(50, 100).take(5)).toStream().forEach(System.out::println);
消息处理
当需要处理Flux或Mono中的消息时,可以通过subscribe方法来添加相应的订阅逻辑。
在调用subscribe方法时可以指定需要处理的消息类型。
Flux.just(1, 2).concatWith(Mono.error(new IllegalStateException())).subscribe(System.out::println, System.err::println);
Flux.just(1, 2).concatWith(Mono.error(new IllegalStateException())).onErrorReturn(0).subscribe(System.out::println);
第2种可以通过switchOnError()方法来使用另外的流来产生元素。
Flux.just(1, 2).concatWith(Mono.error(new IllegalStateException())).switchOnError(Mono.just(0)).subscribe(System.out::println);
第三种是通过onErrorResumeWith()方法来根据不同的异常类型来选择要使用的产生元素的流。
Flux.just(1, 2).concatWith(Mono.error(new IllegalArgumentException())).onErrorResumeWith(e -> {
if(e instanceof IllegalStateException)
return Mono.just(0);
else if(e instanceof IllegalArgumentException)
return Mono.just(-1);
return Mono.epmty();
}).subscribe(System,.out::println);
当出现错误时还可以使用retry操作符来进行重试。重试的动作是通过重新订阅序列来实现的。在使用retry操作时还可以指定重试的次数。
Flux.just(1, 2).concatWith(Mono.error(new IllegalStateException())).retry(1).subscrible(System.out::println);
调度器Scheduler
通过调度器可以指定操作执行的方式和所在的线程。有以下几种不同的调度器实现
当前线程,通过Schedulers.immediate()方法来创建
单一的可复用的线程,通过Schedulers.single()方法来创建
使用弹性的线程池,通过Schedulers.elastic()方法来创建。线程池中的线程是可以复用的。当所需要时,新的线程会被创建。若一个线程闲置时间太长,则会被销毁。该调度器适用于I/O操作相关的流的处理
使用对并行操作优化的线程池,通过Schedulers.parallel()方法来创建。其中的线程数量取决于CPU的核的数量。该调度器适用于计算密集型的流的处理
使用支持任务调度的调度器,通过Schedulers.timer()方法来创建
从已有的ExecutorService对象中创建调度器,通过Schedulers.fromExecutorService()方法来创建
通过publishOn()和subscribeOn()方法可以切换执行操作调度器。publishOn()方法切换的是操作符的执行方式,而subscribeOn()方法切换的是产生流中元素时的执行方式
Flux.create(sink -> {
sink.next(Thread.currentThread().getName());
sink.complete();
}).publishOn(Schedulers.single())
.map(x -> String.format("[%s] %s", Thread.currentThread().getName(), x))
.publishOn(Schedulers.elastic())
.map(x -> String.format("[%s] %s", Thread.currentThread().getName(), x))
.subscribeOn(Schedulers.parallel())
.toStream()
.forEach(System.out::println);
测试
StepVerifier的作用是可以对序列中包含的元素进行逐一验证。通过StepVerifier.create()方法对一个流进行包装之后再进行验证。expectNext()方法用来声明测试时所期待的流中的下一个元素的值,而verifyComplete()方法则验证流是否正常结束。verifyError()来验证流由于错误而终止。
StepVerifier.create(Flux.just(a, b)).expectNext("a").expectNext("b").verifyComplete();
使用StepVerifier.withVirtualTime()方法可以创建出使用虚拟时钟的SteoVerifier。通过thenAwait(Duration)方法可以让虚拟时钟前进。
StepVerifier.withVirtualTime(() -> Flux.interval(Duration.ofHours(4), Duration.ofDays(1)).take(2))
.expectSubscription()
.expectNoEvent(Duration.ofHours(4))
.expectNext(0L)
.thenAwait(Duration.ofDays(1))
.expectNext(1L)
.verifyComplete();
TestPublisher的作用在于可以控制流中元素的产生,甚至是违反反应流规范的情况。通过create()方法创建一个新的TestPublisher对象,然后使用next()方法来产生元素,使用complete()方法来结束流。
final TestPublisher<String> testPublisher = TestPublisher.creater();
testPublisher.next("a");
testPublisher.next("b");
testPublisher.complete();
StepVerifier.create(testPublisher)
.expectNext("a")
.expectNext("b")
.expectComplete();
调试
在调试模式启用之后,所有的操作符在执行时都会保存额外的与执行链相关的信息。当出现错误时,这些信息会被作为异常堆栈信息的一部分输出。
Hooks.onOperator(providedHook -> providedHook.operatorStacktrace());
也可以通过checkpoint操作符来对特定的流处理链来启用调试模式。
Flux.just(1, 0).map(x -> 1/x).checkpoint("test").subscribe(System.out::println);
日志记录
可以通过添加log操作把流相关的事件记录在日志中,
Flux.range(1, 2).log("Range").subscribe(System.out::println);
冷热序列
冷序列的含义是不论订阅者在何时订阅该序列,总是能收到序列中产生的全部消息。热序列是在持续不断的产生消息,订阅者只能获取到在其订阅之后产生的消息。
final Flux<Long> source = Flux.intervalMillis(1000).take(10).publish.autoConnect();
source.subscribe();
Thread.sleep(5000);
source.toStream().forEach(System.out::println);
ServerWebExchange交换机
ServerWebExchange与过滤器的关系:
Spring Cloud Gateway同zuul类似,有“pre”和“post”两种方式的filter。
客户端的请求先经过“pre”类型的filter,然后将请求转发到具体的业务服务,收到业务服务的响应之后,再经过“post”类型的filter处理,最后返回响应到客户端。
引用Spring Cloud Gateway官网上的一张图:

与zuul不同的是,filter除了分为“pre”和“post”两种方式的filter外,在Spring Cloud Gateway中,filter从作用范围可分为另外两种,
一种是针对于单个路由的gateway filter,它在配置文件中的写法同predict类似;
一种是针对于所有路由的global gateway filer。
现在从作用范围划分的维度来讲解这两种filter。
我们在使用Spring Cloud Gateway的时候,注意到过滤器(包括GatewayFilter、GlobalFilter和过滤器链GatewayFilterChain)。
Spring Cloud Gateway根据作用范围划分为GatewayFilter和GlobalFilter,二者区别如下:
- GatewayFilter : 需要通过spring.cloud.routes.filters 配置在具体路由下,只作用在当前路由上或通过spring.cloud.default-filters配置在全局,作用在所有路由上
- GlobalFilter : 全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过GatewayFilterAdapter包装成GatewayFilterChain可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上。
Spring Cloud Gateway框架内置的GlobalFilter如下:

上图中每一个GlobalFilter都作用在每一个router上,能够满足大多数的需求。
但是如果遇到业务上的定制,可能需要编写满足自己需求的GlobalFilter。
过滤器都依赖到ServerWebExchange:
public interface GlobalFilter {
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
public interface GatewayFilter extends ShortcutConfigurable {
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}
public interface GatewayFilterChain {
Mono<Void> filter(ServerWebExchange exchange);
}
这里的设计和Servlet中的Filter是相似的,
当前过滤器可以决定是否执行下一个过滤器的逻辑,由GatewayFilterChain#filter()是否被调用来决定。
而ServerWebExchange就相当于当前请求和响应的上下文。
ServerWebExchange实例不单存储了Request和Response对象,还提供了一些扩展方法,如果想实现改造请求参数或者响应参数,就必须深入了解ServerWebExchange。
理解ServerWebExchange
先看ServerWebExchange的注释:
Contract for an HTTP request-response interaction.
Provides access to the HTTP request and response and also exposes additional server-side processing related properties and features such as request attributes.
翻译一下大概是:
ServerWebExchange是一个HTTP请求-响应交互的契约。提供对HTTP请求和响应的访问,并公开额外的服务器端处理相关属性和特性,如请求属性。
其实,ServerWebExchange命名为服务网络交换器,存放着重要的请求-响应属性、请求实例和响应实例等等,有点像Context的角色。
ServerWebExchange接口
ServerWebExchange接口的所有方法:
public interface ServerWebExchange {
// 日志前缀属性的KEY,值为org.springframework.web.server.ServerWebExchange.LOG_ID
// 可以理解为 attributes.set("org.springframework.web.server.ServerWebExchange.LOG_ID","日志前缀的具体值");
// 作用是打印日志的时候会拼接这个KEY对饮的前缀值,默认值为""
String LOG_ID_ATTRIBUTE = ServerWebExchange.class.getName() + ".LOG_ID";
String getLogPrefix();
// 获取ServerHttpRequest对象
ServerHttpRequest getRequest();
// 获取ServerHttpResponse对象
ServerHttpResponse getResponse();
// 返回当前exchange的请求属性,返回结果是一个可变的Map
Map<String, Object> getAttributes();
// 根据KEY获取请求属性
@Nullable
default <T> T getAttribute(String name) {
return (T) getAttributes().get(name);
}
// 根据KEY获取请求属性,做了非空判断
@SuppressWarnings("unchecked")
default <T> T getRequiredAttribute(String name) {
T value = getAttribute(name);
Assert.notNull(value, () -> "Required attribute '" + name + "' is missing");
return value;
}
// 根据KEY获取请求属性,需要提供默认值
@SuppressWarnings("unchecked")
default <T> T getAttributeOrDefault(String name, T defaultValue) {
return (T) getAttributes().getOrDefault(name, defaultValue);
}
// 返回当前请求的网络会话
Mono<WebSession> getSession();
// 返回当前请求的认证用户,如果存在的话
<T extends Principal> Mono<T> getPrincipal();
// 返回请求的表单数据或者一个空的Map,只有Content-Type为application/x-www-form-urlencoded的时候这个方法才会返回一个非空的Map -- 这个一般是表单数据提交用到
Mono<MultiValueMap<String, String>> getFormData();
// 返回multipart请求的part数据或者一个空的Map,只有Content-Type为multipart/form-data的时候这个方法才会返回一个非空的Map -- 这个一般是文件上传用到
Mono<MultiValueMap<String, Part>> getMultipartData();
// 返回Spring的上下文
@Nullable
ApplicationContext getApplicationContext();
// 这几个方法和lastModified属性相关
boolean isNotModified();
boolean checkNotModified(Instant lastModified);
boolean checkNotModified(String etag);
boolean checkNotModified(@Nullable String etag, Instant lastModified);
// URL转换
String transformUrl(String url);
// URL转换映射
void addUrlTransformer(Function<String, String> transformer);
// 注意这个方法,方法名是:改变,这个是修改ServerWebExchange属性的方法,返回的是一个Builder实例,Builder是ServerWebExchange的内部类
default Builder mutate() {
return new DefaultServerWebExchangeBuilder(this);
}
interface Builder {
// 覆盖ServerHttpRequest
Builder request(Consumer<ServerHttpRequest.Builder> requestBuilderConsumer);
Builder request(ServerHttpRequest request);
// 覆盖ServerHttpResponse
Builder response(ServerHttpResponse response);
// 覆盖当前请求的认证用户
Builder principal(Mono<Principal> principalMono);
// 构建新的ServerWebExchange实例
ServerWebExchange build();
}
}
ServerWebExchange#mutate()方法
注意到ServerWebExchange#mutate()方法,ServerWebExchange实例可以理解为不可变实例,
如果我们想要修改它,需要通过mutate()方法生成一个新的实例,例如这样:
public class CustomGlobalFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
// 这里可以修改ServerHttpRequest实例
ServerHttpRequest newRequest = ...
ServerHttpResponse response = exchange.getResponse();
// 这里可以修改ServerHttpResponse实例
ServerHttpResponse newResponse = ...
// 构建新的ServerWebExchange实例
ServerWebExchange newExchange = exchange.mutate().request(newRequest).response(newResponse).build();
return chain.filter(newExchange);
}
}
ServerHttpRequest接口
ServerHttpRequest实例是用于承载请求相关的属性和请求体,
Spring Cloud Gateway中底层使用Netty处理网络请求,通过追溯源码,
可以从ReactorHttpHandlerAdapter中得知ServerWebExchange实例中持有的ServerHttpRequest实例的具体实现是ReactorServerHttpRequest。
之所以列出这些实例之间的关系,是因为这样比较容易理清一些隐含的问题,例如:
ReactorServerHttpRequest的父类AbstractServerHttpRequest中初始化内部属性headers的时候把请求的HTTP头部封装为只读的实例:
public AbstractServerHttpRequest(URI uri, @Nullable String contextPath, HttpHeaders headers) {
this.uri = uri;
this.path = RequestPath.parse(uri, contextPath);
this.headers = HttpHeaders.readOnlyHttpHeaders(headers);
}
// HttpHeaders类中的readOnlyHttpHeaders方法,
// ReadOnlyHttpHeaders屏蔽了所有修改请求头的方法,直接抛出UnsupportedOperationException
public static HttpHeaders readOnlyHttpHeaders(HttpHeaders headers) {
Assert.notNull(headers, "HttpHeaders must not be null");
if (headers instanceof ReadOnlyHttpHeaders) {
return headers;
}
else {
return new ReadOnlyHttpHeaders(headers);
}
}
所以, 不能直接从ServerHttpRequest实例中直接获取请求头HttpHeaders实例并且进行修改。
ServerHttpRequest接口如下:
public interface HttpMessage {
// 获取请求头,目前的实现中返回的是ReadOnlyHttpHeaders实例,只读
HttpHeaders getHeaders();
}
public interface ReactiveHttpInputMessage extends HttpMessage {
// 返回请求体的Flux封装
Flux<DataBuffer> getBody();
}
public interface HttpRequest extends HttpMessage {
// 返回HTTP请求方法,解析为HttpMethod实例
@Nullable
default HttpMethod getMethod() {
return HttpMethod.resolve(getMethodValue());
}
// 返回HTTP请求方法,字符串
String getMethodValue();
// 请求的URI
URI getURI();
}
public interface ServerHttpRequest extends HttpRequest, ReactiveHttpInputMessage {
// 连接的唯一标识或者用于日志处理标识
String getId();
// 获取请求路径,封装为RequestPath对象
RequestPath getPath();
// 返回查询参数,是只读的MultiValueMap实例
MultiValueMap<String, String> getQueryParams();
// 返回Cookie集合,是只读的MultiValueMap实例
MultiValueMap<String, HttpCookie> getCookies();
// 远程服务器地址信息
@Nullable
default InetSocketAddress getRemoteAddress() {
return null;
}
// SSL会话实现的相关信息
@Nullable
default SslInfo getSslInfo() {
return null;
}
// 修改请求的方法,返回一个建造器实例Builder,Builder是内部类
default ServerHttpRequest.Builder mutate() {
return new DefaultServerHttpRequestBuilder(this);
}
interface Builder {
// 覆盖请求方法
Builder method(HttpMethod httpMethod);
// 覆盖请求的URI、请求路径或者上下文,这三者相互有制约关系,具体可以参考API注释
Builder uri(URI uri);
Builder path(String path);
Builder contextPath(String contextPath);
// 覆盖请求头
Builder header(String key, String value);
Builder headers(Consumer<HttpHeaders> headersConsumer);
// 覆盖SslInfo
Builder sslInfo(SslInfo sslInfo);
// 构建一个新的ServerHttpRequest实例
ServerHttpRequest build();
}
}
注意:
ServerHttpRequest或者说HttpMessage接口提供的获取请求头方法HttpHeaders getHeaders();
返回结果是一个只读的实例,具体是ReadOnlyHttpHeaders类型,
如果要修改ServerHttpRequest实例,那么需要这样做:
ServerHttpRequest request = exchange.getRequest();
ServerHttpRequest newRequest = request.mutate().header("key","value").path("/myPath").build();
ServerHttpResponse接口
ServerHttpResponse实例是用于承载响应相关的属性和响应体,
Spring Cloud Gateway中底层使用Netty处理网络请求,通过追溯源码,可以从ReactorHttpHandlerAdapter中得知ServerWebExchange实例中持有的ServerHttpResponse实例的具体实现是ReactorServerHttpResponse。
之所以列出这些实例之间的关系,是因为这样比较容易理清一些隐含的问题,例如:
// ReactorServerHttpResponse的父类
public AbstractServerHttpResponse(DataBufferFactory dataBufferFactory, HttpHeaders headers) {
Assert.notNull(dataBufferFactory, "DataBufferFactory must not be null");
Assert.notNull(headers, "HttpHeaders must not be null");
this.dataBufferFactory = dataBufferFactory;
this.headers = headers;
this.cookies = new LinkedMultiValueMap<>();
}
public ReactorServerHttpResponse(HttpServerResponse response, DataBufferFactory bufferFactory) {
super(bufferFactory, new HttpHeaders(new NettyHeadersAdapter(response.responseHeaders())));
Assert.notNull(response, "HttpServerResponse must not be null");
this.response = response;
}
可知ReactorServerHttpResponse构造函数初始化实例的时候,存放响应Header的是HttpHeaders实例,也就是响应Header是可以直接修改的。
ServerHttpResponse接口如下:
public interface HttpMessage {
// 获取响应Header,目前的实现中返回的是HttpHeaders实例,可以直接修改
HttpHeaders getHeaders();
}
public interface ReactiveHttpOutputMessage extends HttpMessage {
// 获取DataBufferFactory实例,用于包装或者生成数据缓冲区DataBuffer实例(创建响应体)
DataBufferFactory bufferFactory();
// 注册一个动作,在HttpOutputMessage提交之前此动作会进行回调
void beforeCommit(Supplier<? extends Mono<Void>> action);
// 判断HttpOutputMessage是否已经提交
boolean isCommitted();
// 写入消息体到HTTP协议层
Mono<Void> writeWith(Publisher<? extends DataBuffer> body);
// 写入消息体到HTTP协议层并且刷新缓冲区
Mono<Void> writeAndFlushWith(Publisher<? extends Publisher<? extends DataBuffer>> body);
// 指明消息处理已经结束,一般在消息处理结束自动调用此方法,多次调用不会产生副作用
Mono<Void> setComplete();
}
public interface ServerHttpResponse extends ReactiveHttpOutputMessage {
// 设置响应状态码
boolean setStatusCode(@Nullable HttpStatus status);
// 获取响应状态码
@Nullable
HttpStatus getStatusCode();
// 获取响应Cookie,封装为MultiValueMap实例,可以修改
MultiValueMap<String, ResponseCookie> getCookies();
// 添加响应Cookie
void addCookie(ResponseCookie cookie);
}
这里可以看到除了响应体比较难修改之外,其他的属性都是可变的。
ServerWebExchangeUtils和上下文属性
ServerWebExchangeUtils里面存放了很多静态公有的字符串KEY值
(这些字符串KEY的实际值是org.springframework.cloud.gateway.support.ServerWebExchangeUtils. + 下面任意的静态公有KEY),
这些字符串KEY值一般是用于ServerWebExchange的属性(Attribute,见上文的ServerWebExchange#getAttributes()方法)的KEY,这些属性值都是有特殊的含义,在使用过滤器的时候如果时机适当可以直接取出来使用,下面逐个分析。
PRESERVE_HOST_HEADER_ATTRIBUTE:是否保存Host属性,值是布尔值类型,写入位置是PreserveHostHeaderGatewayFilterFactory,使用的位置是NettyRoutingFilter,作用是如果设置为true,HTTP请求头中的Host属性会写到底层Reactor-Netty的请求Header属性中。CLIENT_RESPONSE_ATTR:保存底层Reactor-Netty的响应对象,类型是reactor.netty.http.client.HttpClientResponse。CLIENT_RESPONSE_CONN_ATTR:保存底层Reactor-Netty的连接对象,类型是reactor.netty.Connection。URI_TEMPLATE_VARIABLES_ATTRIBUTE:PathRoutePredicateFactory解析路径参数完成之后,把解析完成后的占位符KEY-路径Path映射存放在ServerWebExchange的属性中,KEY就是URI_TEMPLATE_VARIABLES_ATTRIBUTE。CLIENT_RESPONSE_HEADER_NAMES:保存底层Reactor-Netty的响应Header的名称集合。GATEWAY_ROUTE_ATTR:用于存放RoutePredicateHandlerMapping中匹配出来的具体的路由(org.springframework.cloud.gateway.route.Route)实例,通过这个路由实例可以得知当前请求会路由到下游哪个服务。GATEWAY_REQUEST_URL_ATTR:java.net.URI类型的实例,这个实例代表直接请求或者负载均衡处理之后需要请求到下游服务的真实URI。GATEWAY_ORIGINAL_REQUEST_URL_ATTR:java.net.URI类型的实例,需要重写请求URI的时候,保存原始的请求URI。GATEWAY_HANDLER_MAPPER_ATTR:保存当前使用的HandlerMapping具体实例的类型简称(一般是字符串"RoutePredicateHandlerMapping")。GATEWAY_SCHEME_PREFIX_ATTR:确定目标路由URI中如果存在schemeSpecificPart属性,则保存该URI的scheme在此属性中,路由URI会被重新构造,见RouteToRequestUrlFilter。GATEWAY_PREDICATE_ROUTE_ATTR:用于存放RoutePredicateHandlerMapping中匹配出来的具体的路由(org.springframework.cloud.gateway.route.Route)实例的ID。WEIGHT_ATTR:实验性功能(此版本还不建议在正式版本使用)存放分组权重相关属性,见WeightCalculatorWebFilter。ORIGINAL_RESPONSE_CONTENT_TYPE_ATTR:存放响应Header中的ContentType的值。HYSTRIX_EXECUTION_EXCEPTION_ATTR:Throwable的实例,存放的是Hystrix执行异常时候的异常实例,见HystrixGatewayFilterFactory。GATEWAY_ALREADY_ROUTED_ATTR:布尔值,用于判断是否已经进行了路由,见NettyRoutingFilter。GATEWAY_ALREADY_PREFIXED_ATTR:布尔值,用于判断请求路径是否被添加了前置部分,见PrefixPathGatewayFilterFactory。
ServerWebExchangeUtils提供的上下文属性用于Spring Cloud Gateway的ServerWebExchange组件处理请求和响应的时候,内部一些重要实例或者标识属性的安全传输和使用,使用它们可能存在一定的风险,
因为没有人可以确定在版本升级之后,原有的属性KEY或者VALUE是否会发生改变,如果评估过风险或者规避了风险之后,可以安心使用。
例如我们在做请求和响应日志(类似Nginx的Access Log)的时候,可以依赖到GATEWAY_ROUTE_ATTR,因为我们要打印路由的目标信息。举个简单例子:
@Slf4j
@Component
public class AccessLogFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String path = request.getPath().pathWithinApplication().value();
HttpMethod method = request.getMethod();
// 获取路由的目标URI
URI targetUri = exchange.getAttribute(ServerWebExchangeUtils.GATEWAY_REQUEST_URL_ATTR);
InetSocketAddress remoteAddress = request.getRemoteAddress();
return chain.filter(exchange.mutate().build()).then(Mono.fromRunnable(() -> {
ServerHttpResponse response = exchange.getResponse();
HttpStatus statusCode = response.getStatusCode();
log.info("请求路径:{},客户端远程IP地址:{},请求方法:{},目标URI:{},响应码:{}",
path, remoteAddress, method, targetUri, statusCode);
}));
}
}
修改请求体
修改请求体是一个比较常见的需求。
例如我们使用Spring Cloud Gateway实现网关的时候,要实现一个功能:
把存放在请求头中的JWT解析后,提取里面的用户ID,然后写入到请求体中。
我们简化这个场景,假设我们把userId明文存放在请求头中的accessToken中,请求体是一个JSON结构:
{
"serialNumber": "请求流水号",
"payload" : {
// ... 这里是有效载荷,存放具体的数据
}
}
我们需要提取accessToken,也就是userId插入到请求体JSON中如下:
{
"userId": "用户ID",
"serialNumber": "请求流水号",
"payload" : {
// ... 这里是有效载荷,存放具体的数据
}
}
这里为了简化设计,用全局过滤器GlobalFilter实现,实际需要结合具体场景考虑:
@Slf4j
@Component
public class ModifyRequestBodyGlobalFilter implements GlobalFilter {
private final DataBufferFactory dataBufferFactory = new NettyDataBufferFactory(ByteBufAllocator.DEFAULT);
@Autowired
private ObjectMapper objectMapper;
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
String accessToken = request.getHeaders().getFirst("accessToken");
if (!StringUtils.hasLength(accessToken)) {
throw new IllegalArgumentException("accessToken");
}
// 新建一个ServerHttpRequest装饰器,覆盖需要装饰的方法
ServerHttpRequestDecorator decorator = new ServerHttpRequestDecorator(request) {
@Override
public Flux<DataBuffer> getBody() {
Flux<DataBuffer> body = super.getBody();
InputStreamHolder holder = new InputStreamHolder();
body.subscribe(buffer -> holder.inputStream = buffer.asInputStream());
if (null != holder.inputStream) {
try {
// 解析JSON的节点
JsonNode jsonNode = objectMapper.readTree(holder.inputStream);
Assert.isTrue(jsonNode instanceof ObjectNode, "JSON格式异常");
ObjectNode objectNode = (ObjectNode) jsonNode;
// JSON节点最外层写入新的属性
objectNode.put("userId", accessToken);
DataBuffer dataBuffer = dataBufferFactory.allocateBuffer();
String json = objectNode.toString();
log.info("最终的JSON数据为:{}", json);
dataBuffer.write(json.getBytes(StandardCharsets.UTF_8));
return Flux.just(dataBuffer);
} catch (Exception e) {
throw new IllegalStateException(e);
}
} else {
return super.getBody();
}
}
};
// 使用修改后的ServerHttpRequestDecorator重新生成一个新的ServerWebExchange
return chain.filter(exchange.mutate().request(decorator).build());
}
private class InputStreamHolder {
InputStream inputStream;
}
}
测试一下:
// HTTP
POST /order/json HTTP/1.1
Host: localhost:9090
Content-Type: application/json
accessToken: 10086
Accept: */*
Cache-Control: no-cache
Host: localhost:9090
accept-encoding: gzip, deflate
content-length: 94
Connection: keep-alive
cache-control: no-cache
{
"serialNumber": "请求流水号",
"payload": {
"name": "doge"
}
}
// 日志输出
最终的JSON数据为:{"serialNumber":"请求流水号","payload":{"name":"doge"},"userId":"10086"}
最重要的是用到了ServerHttpRequest装饰器ServerHttpRequestDecorator,主要覆盖对应获取请求体数据缓冲区的方法即可,至于怎么处理其他逻辑需要自行考虑,这里只是做一个简单的示范。
一般的代码逻辑如下:
ServerHttpRequest request = exchange.getRequest();
ServerHttpRequestDecorator requestDecorator = new ServerHttpRequestDecorator(request) {
@Override
public Flux<DataBuffer> getBody() {
// 拿到承载原始请求体的Flux
Flux<DataBuffer> body = super.getBody();
// 这里通过自定义方式生成新的承载请求体的Flux
Flux<DataBuffer> newBody = ...
return newBody;
}
}
return chain.filter(exchange.mutate().request(requestDecorator).build());
修改响应体
修改响应体的需求也是比较常见的,具体的做法和修改请求体差不多。
例如我们想要实现下面的功能:第三方服务请求经过网关,原始报文是密文,我们需要在网关实现密文解密,然后把解密后的明文路由到下游服务,下游服务处理成功响应明文,需要在网关把明文加密成密文再返回到第三方服务。
现在简化整个流程,用AES加密算法,统一密码为字符串"throwable",假设请求报文和响应报文明文如下:
// 请求密文
{
"serialNumber": "请求流水号",
"payload" : "加密后的请求消息载荷"
}
// 请求明文(仅仅作为提示)
{
"serialNumber": "请求流水号",
"payload" : "{\"name:\":\"doge\"}"
}
// 响应密文
{
"code": 200,
"message":"ok",
"payload" : "加密后的响应消息载荷"
}
// 响应明文(仅仅作为提示)
{
"code": 200,
"message":"ok",
"payload" : "{\"name:\":\"doge\",\"age\":26}"
}
为了方便一些加解密或者编码解码的实现,需要引入Apache的commons-codec类库:
<dependency>
<groupId>commons-codec</groupId>
<artifactId>commons-codec</artifactId>
<version>1.12</version>
</dependency>
这里定义一个全局过滤器专门处理加解密,实际上最好结合真实的场景决定是否适合全局过滤器,这里只是一个示例:
// AES加解密工具类
public enum AesUtils {
// 单例
X;
private static final String PASSWORD = "throwable";
private static final String KEY_ALGORITHM = "AES";
private static final String SECURE_RANDOM_ALGORITHM = "SHA1PRNG";
private static final String DEFAULT_CIPHER_ALGORITHM = "AES/ECB/PKCS5Padding";
public String encrypt(String content) {
try {
Cipher cipher = Cipher.getInstance(DEFAULT_CIPHER_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, provideSecretKey());
return Hex.encodeHexString(cipher.doFinal(content.getBytes(StandardCharsets.UTF_8)));
} catch (Exception e) {
throw new IllegalArgumentException(e);
}
}
public byte[] decrypt(String content) {
try {
Cipher cipher = Cipher.getInstance(DEFAULT_CIPHER_ALGORITHM);
cipher.init(Cipher.DECRYPT_MODE, provideSecretKey());
return cipher.doFinal(Hex.decodeHex(content));
} catch (Exception e) {
throw new IllegalArgumentException(e);
}
}
private SecretKey provideSecretKey() {
try {
KeyGenerator keyGen = KeyGenerator.getInstance(KEY_ALGORITHM);
SecureRandom secureRandom = SecureRandom.getInstance(SECURE_RANDOM_ALGORITHM);
secureRandom.setSeed(PASSWORD.getBytes(StandardCharsets.UTF_8));
keyGen.init(128, secureRandom);
return new SecretKeySpec(keyGen.generateKey().getEncoded(), KEY_ALGORITHM);
} catch (Exception e) {
throw new IllegalArgumentException(e);
}
}
}
// EncryptionGlobalFilter
@Slf4j
@Component
public class EncryptionGlobalFilter implements GlobalFilter, Ordered {
@Autowired
private ObjectMapper objectMapper;
@Override
public int getOrder() {
return -2;
}
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
ServerHttpRequest request = exchange.getRequest();
// 响应体
ServerHttpResponse response = exchange.getResponse();
DataBufferFactory bufferFactory = exchange.getResponse().bufferFactory();
ServerHttpRequestDecorator requestDecorator = processRequest(request, bufferFactory);
ServerHttpResponseDecorator responseDecorator = processResponse(response, bufferFactory);
return chain.filter(exchange.mutate().request(requestDecorator).response(responseDecorator).build());
}
private ServerHttpRequestDecorator processRequest(ServerHttpRequest request, DataBufferFactory bufferFactory) {
Flux<DataBuffer> body = request.getBody();
DataBufferHolder holder = new DataBufferHolder();
body.subscribe(dataBuffer -> {
int len = dataBuffer.readableByteCount();
holder.length = len;
byte[] bytes = new byte[len];
dataBuffer.read(bytes);
DataBufferUtils.release(dataBuffer);
String text = new String(bytes, StandardCharsets.UTF_8);
JsonNode jsonNode = readNode(text);
JsonNode payload = jsonNode.get("payload");
String payloadText = payload.asText();
byte[] content = AesUtils.X.decrypt(payloadText);
String requestBody = new String(content, StandardCharsets.UTF_8);
log.info("修改请求体payload,修改前:{},修改后:{}", payloadText, requestBody);
rewritePayloadNode(requestBody, jsonNode);
DataBuffer data = bufferFactory.allocateBuffer();
data.write(jsonNode.toString().getBytes(StandardCharsets.UTF_8));
holder.dataBuffer = data;
});
HttpHeaders headers = new HttpHeaders();
headers.putAll(request.getHeaders());
headers.remove(HttpHeaders.CONTENT_LENGTH);
return new ServerHttpRequestDecorator(request) {
@Override
public HttpHeaders getHeaders() {
int contentLength = holder.length;
if (contentLength > 0) {
headers.setContentLength(contentLength);
} else {
headers.set(HttpHeaders.TRANSFER_ENCODING, "chunked");
}
return headers;
}
@Override
public Flux<DataBuffer> getBody() {
return Flux.just(holder.dataBuffer);
}
};
}
private ServerHttpResponseDecorator processResponse(ServerHttpResponse response, DataBufferFactory bufferFactory) {
return new ServerHttpResponseDecorator(response) {
@SuppressWarnings("unchecked")
@Override
public Mono<Void> writeWith(Publisher<? extends DataBuffer> body) {
if (body instanceof Flux) {
Flux<? extends DataBuffer> flux = (Flux<? extends DataBuffer>) body;
return super.writeWith(flux.map(buffer -> {
CharBuffer charBuffer = StandardCharsets.UTF_8.decode(buffer.asByteBuffer());
DataBufferUtils.release(buffer);
JsonNode jsonNode = readNode(charBuffer.toString());
JsonNode payload = jsonNode.get("payload");
String text = payload.toString();
String content = AesUtils.X.encrypt(text);
log.info("修改响应体payload,修改前:{},修改后:{}", text, content);
setPayloadTextNode(content, jsonNode);
return bufferFactory.wrap(jsonNode.toString().getBytes(StandardCharsets.UTF_8));
}));
}
return super.writeWith(body);
}
};
}
private void rewritePayloadNode(String text, JsonNode root) {
try {
JsonNode node = objectMapper.readTree(text);
ObjectNode objectNode = (ObjectNode) root;
objectNode.set("payload", node);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
private void setPayloadTextNode(String text, JsonNode root) {
try {
ObjectNode objectNode = (ObjectNode) root;
objectNode.set("payload", new TextNode(text));
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
private JsonNode readNode(String in) {
try {
return objectMapper.readTree(in);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
private class DataBufferHolder {
DataBuffer dataBuffer;
int length;
}
}
先准备一份密文:
Map<String, Object> json = new HashMap<>(8);
json.put("serialNumber", "请求流水号");
String content = "{\"name\": \"doge\"}";
json.put("payload", AesUtils.X.encrypt(content));
System.out.println(new ObjectMapper().writeValueAsString(json));
// 输出
{"serialNumber":"请求流水号","payload":"144e3dc734743f5709f1adf857bca473da683246fd612f86ac70edeb5f2d2729"}
模拟请求:
POST /order/json HTTP/1.1
Host: localhost:9090
accessToken: 10086
Content-Type: application/json
User-Agent: PostmanRuntime/7.13.0
Accept: */*
Cache-Control: no-cache
Postman-Token: bda07fc3-ea1a-478c-b4d7-754fe6f37200,634734d9-feed-4fc9-ba20-7618bd986e1c
Host: localhost:9090
cookie: customCookieName=customCookieValue
accept-encoding: gzip, deflate
content-length: 104
Connection: keep-alive
cache-control: no-cache
{
"serialNumber": "请求流水号",
"payload": "FE49xzR0P1cJ8a34V7ykc9poMkb9YS+GrHDt618tJyk="
}
// 响应结果
{
"serialNumber": "请求流水号",
"payload": "oo/K1igg2t/S8EExkBVGWOfI1gAh5pBpZ0wyjNPW6e8=" # <--- 解密后:{"name":"doge","age":26}
}
遇到的问题:
- 必须实现
Ordered接口,返回一个小于-1的order值,这是因为NettyWriteResponseFilter的order值为-1,我们需要覆盖返回响应体的逻辑,自定义的GlobalFilter必须比NettyWriteResponseFilter优先执行。 - 网关每次重启之后,第一个请求总是无法从原始的
ServerHttpRequest读取到有效的Body,准确来说出现的现象是NettyRoutingFilter调用ServerHttpRequest#getBody()的时候获取到一个空的对象,导致空指针;奇怪的是从第二个请求开始就能正常调用。笔者把**Spring Cloud Gateway**的版本降低到**Finchley.SR3**,**Spring Boot**的版本降低到**2.0.8.RELEASE**,问题不再出现,初步确定是**Spring Cloud Gateway**版本升级导致的兼容性问题或者是BUG。
最重要的是用到了ServerHttpResponse装饰器ServerHttpResponseDecorator,主要覆盖写入响应体数据缓冲区的部分,至于怎么处理其他逻辑需要自行考虑,这里只是做一个简单的示范。一般的代码逻辑如下:
ServerHttpResponse response = exchange.getResponse();
ServerHttpResponseDecorator responseDecorator = new ServerHttpResponseDecorator(response) {
@Override
public Mono<Void> writeWith(Publisher<? extends DataBuffer> body) {
if (body instanceof Flux) {
Flux<? extends DataBuffer> flux = (Flux<? extends DataBuffer>) body;
return super.writeWith(flux.map(buffer -> {
// buffer就是原始的响应数据的缓冲区
// 下面处理完毕之后返回新的响应数据的缓冲区即可
return bufferFactory.wrap(...);
}));
}
return super.writeWith(body);
}
};
return chain.filter(exchange.mutate().response(responseDecorator).build());
参考文献
https://blog.csdn.net/wpc2018/article/details/122634049
https://www.jianshu.com/p/7d80b94068b3
https://blog.csdn.net/yhj_911/article/details/119540000
http://bjqianye.cn/detail/6845.html
https://blog.csdn.net/hao134838/article/details/110824092
https://blog.csdn.net/hao134838/article/details/110824092
https://blog.csdn.net/weixin_34096182/article/details/91436704
https://blog.csdn.net/fly910905/article/details/121682625

 浙公网安备 33010602011771号
浙公网安备 33010602011771号