Sharding-JDBC 实战(史上最全)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录 博客园版 为您奉上珍贵的学习资源 :
免费赠送 :《尼恩Java面试宝典》 持续更新+ 史上最全 + 面试必备 2000页+ 面试必备 + 大厂必备 +涨薪必备
免费赠送 经典图书:《Java高并发核心编程(卷1)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷2)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《Java高并发核心编程(卷3)加强版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 经典图书:《尼恩Java面试宝典 最新版》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Sharding-JDBC 实战(史上最全)
在开始 Sharding-JDBC分库分表具体实战之前,
必要先了解分库分表的一些核心概念。
分库分表的背景:
传统的将数据集中存储⾄单⼀数据节点的解决⽅案,在性能、可⽤性和运维成本这三⽅⾯已经难于满⾜互联⽹的海量数据场景。
随着业务数据量的增加,原来所有的数据都是在一个数据库上的,网络IO及文件IO都集中在一个数据库上的,因此CPU、内存、文件IO、网络IO都可能会成为系统瓶颈。
当业务系统的数据容量接近或超过单台服务器的容量、QPS/TPS接近或超过单个数据库实例的处理极限等,
此时,往往是采用垂直和水平结合的数据拆分方法,把数据服务和数据存储分布到多台数据库服务器上。
容量瓶颈:
从性能⽅⾯来说,由于关系型数据库⼤多采⽤ B+ 树类型的索引,
数据量超过一定大小,B+Tree 索引的高度就会增加,而每增加一层高度,整个索引扫描就会多一次 IO 。
在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降;
一般的存储容量是多少呢? 请参见 3 高架构秒杀部分内容。
吞吐量瓶颈:
同时,⾼并发访问请求也使得集中式数据库成为系统的最⼤瓶颈。
一般的吞吐量是多少呢? 请参见 3 高架构秒杀部分内容。
在传统的关系型数据库⽆法满⾜互联⽹场景需要的情况下,将数据存储⾄原⽣⽀持分布式的 NoSQL 的尝试越来越多。
但 NoSQL 并不能包治百病,而关系型数据库的地位却依然不可撼动。
如果进行sql、nosql数据库的选型呢? 请参见 推送中台架构部分的内容。
分治模式在存储领域的落地
分治模式在存储领域的使用:数据分⽚
数据分⽚指按照某个维度将存放在单⼀数据库中的数据, 分散地存放⾄多个数据库或表中以达到提升性能瓶颈以及可⽤性的效果。
数据分⽚的有效⼿段是对关系型数据库进⾏分库和分表。
分库能够⽤于有效的分散对数据库单点的访问量;
分库的合理的时机, 请参见 3 高架构秒杀部分内容。
分表能够⽤于有效的数据量超过可承受阈值而产⽣的查询瓶颈, 解决MySQL 单表性能问题
分表的合理的时机, 请参见 3 高架构秒杀部分内容。
使⽤多主多从的分⽚⽅式,可以有效的避免数据单点,从而提升数据架构的可⽤性。
通过分库和分表进⾏数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进⾏疏导应对⾼访问量,是应对⾼并发和海量数据系统的有效⼿段。
数据分⽚的拆分⽅式⼜分为垂直分⽚和⽔平分⽚。
分库分表的问题
分库导致的事务问题
不过,由于目前采用柔性事务居多,实际上,分库的事务性能也是很高的,有关柔性事务,请参见疯狂创客圈的专题博文:
Sharding-JDBC简介
Sharding-JDBC 是当当网开源的适用于微服务的分布式数据访问基础类库,完整的实现了分库分表,读写分离和分布式主键功能,并初步实现了柔性事务。
从 2016 年开源至今,在经历了整体架构的数次精炼以及稳定性打磨后,如今它已积累了足够的底蕴。
官方的网址如下:
http://shardingsphere.apache.org/index_zh.html
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar这3款相互独立的产品组成。
他们均提供标准化的数据分片、分布式事务 和 数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款相互独立,却又能够混合部署配合使用的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
Apache ShardingSphere 5.x 版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。 目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。 开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
Sharding-JDBC的优势
Sharding-JDBC直接封装JDBC API,可以理解为增强版的JDBC驱动,旧代码迁移成本几乎为零:
- 可适用于任何基于Java的ORM框架,如JPA、Hibernate、Mybatis、Spring JDBC Template或直接使用JDBC。
- 可基于任何第三方的数据库连接池,如DBCP、C3P0、 BoneCP、Druid等。
- 理论上可支持任意实现JDBC规范的数据库。虽然目前仅支持MySQL,但已有支持Oracle、SQLServer等数据库的计划。
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
与常见开源产品对比
下表仅列出在数据库分片领域非常有影响力的几个项目:

通过以上表格可以看出,Cobar(MyCat)属于中间层方案,在应用程序和MySQL之间搭建一层Proxy。
中间层介于应用程序与数据库间,需要做一次转发,而基于JDBC协议并无额外转发,直接由应用程序连接数据库,性能上有些许优势。这里并非说明中间层一定不如客户端直连,除了性能,需要考虑的因素还有很多,中间层更便于实现监控、数据迁移、连接管理等功能。
Cobar-Client、TDDL和Sharding-JDBC均属于客户端直连方案。
此方案的优势在于轻便、兼容性、性能以及对DBA影响小。其中Cobar-Client的实现方式基于ORM(Mybatis)框架,其兼容性与扩展性不如基于JDBC协议的后两者。

目前常用的就是Cobar(MyCat)与Sharding-JDBC两种方案
MyCAT
MyCAT是社区爱好者在阿里cobar基础上进行二次开发,解决了cobar当时存 在的一些问题,并且加入了许多新的功能在其中。目前MyCAT社区活 跃度很高,
目前已经有一些公司在使用MyCAT。
总体来说支持度比 较高,也会一直维护下去,发展到目前的版本,已经不是一个单纯的MySQL代理了,
它的后端可以支持MySQL, SQL Server, Oracle, DB2, PostgreSQL等主流数据库,也支持MongoDB这种新型NoSQL方式的存储,未来还会支持更多类型的存储。
MyCAT是一个强大的数据库中间件,不仅仅可以用作读写分离,以及分表分库、容灾管理,而且可以用于多租户应用开发、云平台基础设施,让你的架构具备很强的适应性和灵活性,
借助于即将发布的MyCAT只能优化模块,系统的数据访问瓶颈和热点一目了然,
根据这些统计分析数据,你可以自动或手工调整后端存储,将不同的表隐射到不同存储引擎上,而整个应用的代码一行也不用改变。
MyCAT是在Cobar基础上发展的版本,两个显著提高:
-
后端由BIO改为NIO,并发量有大幅提高;
-
增加了对Order By, Group By, Limit等聚合功能
(虽然Cobar也可以支持Order By, Group By, Limit语法,但是结果没有进行聚合,只是简单返回给前端,聚合功能还是需要业务系统自己完成, 适用于有专门团队维护的大型企业、或者大团队。)
Sharding-JDBC
Sharding-JDBC定位为轻量Java框架,使用客户端直连数据库,以jar包形式提供服务,无proxy代理层,无需额外部署,无其他依赖,DBA也无需改变原有的运维方式。
所以 ,适用于中小企业、或者中小团队。
Sharding-JDBC分片策略灵活,可支持等号、between、in等多维度分片,也可支持多分片键。
SQL解析功能完善,支持聚合、分组、排序、limit、or等查询,并支持Binding Table以及笛卡尔积表查询。
Sharding-JDBC 功能列表
- 分库 & 分表
- 读写分离
- 分布式主键
高并发数据分片的两大工作
一般情况下,开发维度的数据分片,大多是以水平切分模式(水平分库、分表)为基础来说的,
垂直分片主要在于 运维维度,或者 或者做存储的深级改造的时候。
数据分片的工作
简单来说,数据分片的工作分为两大工作 :
第一大工作:分片的拆分
es 的数据分片的背后原理
参见视频
rediscluster的数据分片的背后原理
表的拆分:
将一张大表 t_order ,拆分生成数个表结构完全一致的小表 t_order_0、t_order_1、···、t_order_n,
每张小表,只存储大表中的一部分数据,
第二大工作:分片的路由
当执行一条SQL时,会通过 路由策略 , 将数据route(路由)到不同的分片内。
面临的问题:
-
分片建的选择
-
分片策略的选择
-
分片算法的选择
什么是数据分片?
按照分片规则把数据分到若干个shard、partition当中

主要的分片算法
range 分片
一种是按照 range 来分,就是每个片,一段连续的数据,这个一般是按比如时间范围/数据范围来的,但是这种一般较少用,因为很容易发生数据倾斜,大量的流量都打在最新的数据上了。
比如,安装数据范围分片,把1到100个数字,要保存在3个节点上
按照顺序分片,把数据平均分配三个节点上
- 1号到33号数据保存到节点1上
- 34号到66号数据保存到节点2上
- 67号到100号数据保存到节点3上

ID取模分片
此种分片规则将数据分成n份(通常dn节点也为n),从而将数据均匀的分布于各个表中,或者各节点上。
扩容方便。
ID取模分片常用在关系型数据库的设计
具体请参见 秒杀视频的 亿级库表架构设计
hash 哈希分布
使用hash 算法,获取key的哈希结果,再按照规则进行分片,这样可以保证数据被打散,同时保证数据分布的比较均匀
哈希分布方式分为三个分片方式:
- 哈希取余分片
- 一致性哈希分片
- 虚拟槽分片
哈希取余模分片
例如1到100个数字,对每个数字进行哈希运算,然后对每个数的哈希结果除以节点数进行取余,余数为1则保存在第1个节点上,余数为2则保存在第2个节点上,余数为0则保存在第3个节点,这样可以保证数据被打散,同时保证数据分布的比较均匀
比如有100个数据,对每个数据进行hash运算之后,与节点数进行取余运算,根据余数不同保存在不同的节点上

哈希取余分片是非常简单的一种分片方式
哈希取模分片有一个问题
即当增加或减少节点时,原来节点中的80%的数据会进行迁移操作,对所有数据重新进行分布
哈希取余分片,建议使用多倍扩容的方式,例如以前用3个节点保存数据,扩容为比以前多一倍的节点即6个节点来保存数据,这样只需要适移50%的数据。
数据迁移之后,第一次无法从缓存中读取数据,必须先从数据库中读取数据,然后回写到缓存中,然后才能从缓存中读取迁移之后的数据

哈希取余分片优点:
- 配置简单:对数据进行哈希,然后取余
哈希取余分片缺点:
- 数据节点伸缩时,导致数据迁移
- 迁移数量和添加节点数据有关,建议翻倍扩容
一致性哈希分片
一致性哈希原理:
将所有的数据当做一个token环,
token环中的数据范围是0到2的32次方。
然后为每一个数据节点分配一个token范围值,这个节点就负责保存这个范围内的数据。

对每一个key进行hash运算,被哈希后的结果在哪个token的范围内,则按顺时针去找最近的节点,这个key将会被保存在这个节点上。

一致性哈希分片的节点扩容
在下面的图中:
-
有4个key被hash之后的值在在n1节点和n2节点之间,按照顺时针规则,这4个key都会被保存在n2节点上
-
如果在n1节点和n2节点之间添加n5节点,当下次有key被hash之后的值在n1节点和n5节点之间,这些key就会被保存在n5节点上面了
下图的例子里,添加n5节点之后:
- 数据迁移会在n1节点和n2节点之间进行
- n3节点和n4节点不受影响
- 数据迁移范围被缩小很多
同理,如果有1000个节点,此时添加一个节点,受影响的节点范围最多只有千分之2。所以,一致性哈希一般用在节点比较多的时候,节点越多,扩容时受影响的节点范围越少

分片方式:哈希 + 顺时针(优化取余)
一致性哈希分片优点:
- 一致性哈希算法解决了分布式下数据分布问题。比如在缓存系统中,通过一致性哈希算法把缓存键映射到不同的节点上,由于算法中虚拟节点的存在,哈希结果一般情况下比较均匀。
- 节点伸缩时,只影响邻近节点,但是还是有数据迁移
“但没有一种解决方案是银弹,能适用于任何场景。所以实践中一致性哈希算法有哪些缺陷,或者有哪些场景不适用呢?”
一致性哈希分片缺点:
一致性哈希在大批量的数据场景下负载更加均衡,但是在数据规模小的场景下,会出现单位时间内某个节点完全空闲的情况出现。
虚拟槽分片 (范围分片的变种)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
虚拟槽分片 ,可以理解为范围分片的变种, hash取模分片+范围分片, 把hash值取余数分为n段,一个段给一个节点负责

es的数据分片两大工作
Shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。
分片的数量只能在索引创建前指定,并且索引创建后不能更改。(why,大家可以独立思考一下!)
分片配置建议:
每个分片大小不要超过30G,硬盘条件好的话,不建议超过100G.
(官方推荐,每个shard的数据量应该在20GB - 50GB)。
总而言之,每个分片都是一个Lucene实例,当查询请求打到ES后,ES会把请求转发到每个shard上分别进行查询,最终进行汇总。
这时候,shard越少,产生的额外开销越少
路由机制
一条数据是如何落地到对应的shard上的?
当索引一个文档的时候,文档会被存储到一个主分片中。
Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?

es的路由过程是根据下面这个算法决定的:
shard_num = hash(_routing) % num_primary_shards
其中 _routing是一个可变值,默认是文档的 _id 的值 ,也可以设置成一个自定义的值。Elasticsearch文档的ID(类似于关系数据库中的自增ID),
_routing 通过 hash 函数生成一个数字,然后这个数字再除以 num_of_primary_shards (主分片的数量)后得到余数 。
这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:
因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
假设你有一个100个分片的索引。当一个请求在集群上执行时会发生什么呢?
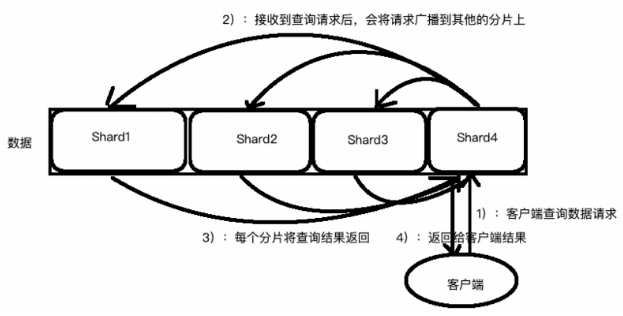
1. 这个搜索的请求会被发送到一个节点
2. 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
3. 每个分片执行这个搜索查询并返回结果
4. 结果在通道节点上合并、排序并返回给用户
rediscluster的数据分片两大工作
虚拟槽分片 ( hash取模分片+范围分片的混血)
Redis Cluster在设计中没有使用一致性哈希(Consistency Hashing),而是使用数据分片引入哈希槽(hash slot)来实现;
虚拟槽分片是Redis Cluster采用的分片方式.
在该分片方式中:
- 首先 预设虚拟槽,每个槽为一个hash值,每个node负责一定槽范围。
- 每一个值都是key的hash值取余,每个槽映射一个数据子集,一般比节点数大
Redis Cluster中预设虚拟槽的范围为0到16383

3个节点的Redis集群虚拟槽分片结果:
[root@localhost redis-cluster]# docker exec -it redis-cluster_redis1_1 redis-cli --cluster check 172.18.8.164:6001
172.18.8.164:6001 (c4cfd72f...) -> 0 keys | 5461 slots | 1 slaves.
172.18.8.164:6002 (c15a7801...) -> 0 keys | 5462 slots | 1 slaves.
172.18.8.164:6003 (3fe7628d...) -> 0 keys | 5461 slots | 1 slaves.
[OK] 0 keys in 3 masters.
0.00 keys per slot on average.
>>> Performing Cluster Check (using node 172.18.8.164:6001)
M: c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd 172.18.8.164:6001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: a212e28165b809b4c75f95ddc986033c599f3efb 172.18.8.164:6006
slots: (0 slots) slave
replicates 3fe7628d7bda14e4b383e9582b07f3bb7a74b469
M: c15a7801623ee5ebe3cf952989dd5a157918af96 172.18.8.164:6002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 5e74257b26eb149f25c3d54aef86a4d2b10269ca 172.18.8.164:6004
slots: (0 slots) slave
replicates c4cfd72f7cbc22cd81b701bd4376fabbe3d162bd
S: 8fb7f7f904ad1c960714d8ddb9ad9bca2b43be1c 172.18.8.164:6005
slots: (0 slots) slave
replicates c15a7801623ee5ebe3cf952989dd5a157918af96
M: 3fe7628d7bda14e4b383e9582b07f3bb7a74b469 172.18.8.164:6003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
虚拟槽分片的路由机制:
1.把16384槽按照节点数量进行平均分配,由节点进行管理
2.对每个key按照CRC16规则进行hash运算
3.把hash结果对16383进行取模
4.把余数发送给Redis节点
5.节点接收到数据,验证是否在自己管理的槽编号的范围
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中
需要注意的是:Redis Cluster的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。
当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
shardingjdbc的数据分片两大工作
第一大工作:分片的拆分
表的拆分:
将一张大表 t_order ,拆分生成数个表结构完全一致的小表 t_order_0、t_order_1、···、t_order_n,
每张小表,只存储大表中的一部分数据,
例子:user表的数据分片

例子:order表的数据分片

第二大工作:分片的路由
当执行一条SQL时,会通过 路由策略 , 将数据route(路由)到不同的分片内。
-
数据源的路由
-
表的路由
面临的问题:
- 分片key的选择
- 分片策略的选择
- 分片算法的选择
核心概念
分片键
⽤于分⽚的字段,是将数据库(表)⽔平拆分的关键字段。
在对表中的数据进行分片时,首先要选出一个分片键(Shard Key),即用户可以通过这个字段进行数据的水平拆分。
例:
将订单表中的订单主键的尾数取模分⽚,则订单主键为分⽚字段。
执行表的选择
我们将 t_order 表分片以后,当执行一条 SQL 时,通过对字段 order_id 取模的方式来决定要执行的表, 这条数据该在哪个数据库中的哪个表中执行,此时 order_id 字段就是分片健。

执行库的选择(数据源的选择)
这样以来同一个订单的相关数据就会存在同一个数据库表中,大幅提升数据检索的性能,
说明
-
除了使用单个字段作为分片件, sharding-jdbc 还支持根据多个字段作为分片健进行分片。
-
SQL 中如果⽆分⽚字段,将执⾏全路由,性能较差。
数据节点
数据节点是分库分表中一个不可再分的最小数据单元(表),它由数据源名称和数据表组成,
例如上图中 ds1.t_user_0 就表示一个数据节点。
逻辑表
逻辑表是指一组具有相同逻辑和数据结构表的总称。
比如我们将订单表 t_order 拆分成 t_order_0 ··· t_order_9 等 10 张表。
此时我们会发现分库分表以后数据库中已不在有 t_order 这张表,取而代之的是 t_order_n,但我们在代码中写 SQL 依然按 t_order 来写。
此时 t_order 就是这些拆分表的逻辑表。
例如上图中 t_user 就表示一个数据节点。
真实表(物理表)
真实表也就是上边提到的 t_order_n 数据库中真实存在的物理表。
例如上图中 t_user _0就表示一个真实表。
分片策略
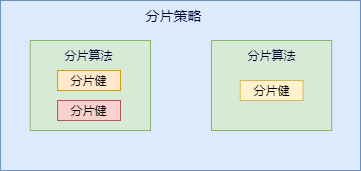
分片策略是一种抽象的概念,实际分片操作的是由分片算法和分片健来完成的。
真正可⽤于分⽚操作的是分⽚键 + 分⽚算法,也就是分⽚策略。

为什么要这么设计,是出于分⽚算法的独⽴性,将其独⽴抽离。
ShardingSphere-JDBC考虑更多的灵活性,把分片算法单独抽象出来,方便开发者扩展;
标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。
RangeShardingAlgorithm 用于处理BETWEEN AND, >, <,>=,<= 条件分片,
RangeShardingAlgorithm 是可选的, 如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。

复合分片策略
复合分片策略对应 ComplexShardingStrategy。
同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。
不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。
ComplexShardingStrategy ⽀持多分⽚键,由于多分⽚键之间的关系复杂,因此并未进⾏过多的封装,而是直接将分⽚键值组合以及分⽚操作符透传⾄分⽚算法,完全由应⽤开发者实现,提供最⼤的灵活度。
表达式分片策略(inline内联分片策略)
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。
这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
t_order_$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。
强制分片策略(Hint 暗示分片策略)
Hint 分片策略,通过指定分片健而非从 SQL 中提取分片健的方式进行分片的策略。
对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片策略 。
前面的分片策略都是解析 SQL 语句, 提取分片建和分片值,并根据设置的分片算法进行分片。
Hint 分片算法 指定分⽚值而⾮从 SQL 中提取,而是手工设置的⽅式,进⾏分⽚的策略。
例:内部系统,按照员⼯登录主键分库,而数据库中并⽆此字段。
不分⽚策略
对应 NoneShardingStrategy。不分⽚的策略。
这种严格来说不算是一种分片策略了。
只是ShardingSphere也提供了这么一个配置。
分片算法
上边我们提到可以用分片健取模的规则分片,但这只是比较简单的一种,
在实际开发中我们还希望用 >=、<=、>、<、BETWEEN 和 IN 等条件作为分片规则,自定义分片逻辑,这时就需要用到分片策略与分片算法。
从执行 SQL 的角度来看,分库分表可以看作是一种路由机制,把 SQL 语句路由到我们期望的数据库或数据表中并获取数据,分片算法可以理解成一种路由规则。
咱们先捋一下它们之间的关系,分片策略只是抽象出的概念,它是由分片算法和分片健组合而成,分片算法做具体的数据分片逻辑。
分库、分表的分片策略配置是相对独立的,可以各自使用不同的策略与算法,每种策略中可以是多个分片算法的组合,每个分片算法可以对多个分片健做逻辑判断。
sharding-jdbc 提供了多种分片算法:
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用Hint行分片的场景;
精确分片算法 PreciseShardingAlgorithm
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,
需要配合 StandardShardingStrategy 使⽤。
范围分片算法 RangeShardingAlgorithm
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要需要配合 StandardShardingStrategy 使⽤。
复合分片算法 ComplexKeysShardingAlgorithm
对应 ComplexKeysShardingAlgorithm,⽤于处理使⽤ 多键作为分⽚键 进⾏分⽚的场景,
(多个字段作为分片键),同时获取到多个分片健的值,根据多个字段处理业务逻辑。
包含多个分⽚键的逻辑较复杂,需要应⽤开发者⾃⾏处理其中的复杂度。
需要配合 ComplexShardingStrategy 使⽤。
需要在复合分片策略(ComplexShardingStrategy )下使用。
Hint 分片算法 HintShardingAlgorithm
Hint 分片算法(HintShardingAlgorithm)稍有不同
前面的算法(如StandardShardingAlgorithm)都是解析 SQL 语句, 提取分片值,并根据设置的分片算法进行分片。
Hint 分片算法 指定分⽚值而⾮从 SQL 中提取,而是手工设置的⽅式,进⾏分⽚的策略。
对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片算法 。
就需要通过 Java API 等方式 指定 分片值,这也叫强制路由、或者说 暗示路由。
例: 内部系统,按照员⼯登录主键分库,而数据库中并⽆此字段。
SQL Hint ⽀持通过 Java API 和 SQL 注释(待实现)两种⽅式使⽤。
ShardingJDBC的分片策略
整个ShardingJDBC 分库分表的核心就是在于**配置 分片策略+分片算法 **。
我们的这些实战都是使用的inline分片算法,即提供一个分片键和一个分片表达式来制定分片算法。
这种方式配置简单,功能灵活,是分库分表最佳的配置方式,并且对于绝大多数的分库分片场景来说,都已经非常好用了。
但是,如果针对一些更为复杂的分片策略,例如多分片键、按范围分片等场景,inline分片算法就有点力不从心了。
所以,我们还需要学习下ShardingSphere提供的其他几种分片策略。
ShardingSphere目前提供了一共五种分片策略:
-
NoneShardingStrategy 不分片
-
InlineShardingStrategy
InlineShardingStrategy
最常用的分片方式
实现方式:
按照分片表达式来进行分片。
实战:JavaAPI使用InlineShardingStrategy 实战
Inline内联分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;\
- 内联分片策略:
对应InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现;
Inline内联分片配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
InlineShardingStrategyConfiguration
Inline内联分片实战
有了以上相关基础概念,接下来针对每种分片策略做一个简单的实战,
在实战前首先准备好库和表;
具体请参见视频,和配套源码
准备真实数据源
分别准备两个库:ds0、ds1;然后每个库分别包含4个表
CREATE TABLE `t_user_0` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_1` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_2` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
CREATE TABLE `t_user_3` (`user_id` bigInt NOT NULL, `name` VARCHAR(45) NULL, PRIMARY KEY (`user_id`));
我们这里有两个数据源,这里都使用java代码的方式来配置:
@Before
public void buildShardingDataSource() throws SQLException {
/*
* 1. 数据源集合:dataSourceMap
* 2. 分片规则:shardingRuleConfig
*
*/
DataSource druidDs1 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
DataSource druidDs2 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
// 添加数据源.
// 两个数据源ds_0和ds_1
dataSourceMap.put("ds0",druidDs1);
dataSourceMap.put("ds1", druidDs2);
/**
* 需要构建表规则
* 1. 指定逻辑表.
* 2. 配置实际节点》
* 3. 指定主键字段.
* 4. 分库和分表的规则》
*
*/
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//消息表分片规则
TableRuleConfiguration userShardingRuleConfig = userShardingRuleConfig();
shardingRuleConfig.getTableRuleConfigs().add(userShardingRuleConfig);
// 多数据源一定要指定默认数据源
// 只有一个数据源就不需要
shardingRuleConfig.setDefaultDataSourceName("ds0");
Properties p = new Properties();
//打印sql语句,生产环境关闭
p.setProperty("sql.show", Boolean.TRUE.toString());
dataSource= ShardingDataSourceFactory.createDataSource(
dataSourceMap, shardingRuleConfig, p);
}
这里配置的两个数据源都是普通的数据源,最后会把dataSourceMap交给ShardingDataSourceFactory管理;
表规则配置
表规则配置类TableRuleConfiguration,包含了五个要素:
逻辑表、真实数据节点、数据库分片策略、数据表分片策略、分布式主键生成策略;
/**
* 消息表的分片规则
*/
protected TableRuleConfiguration userShardingRuleConfig() {
String logicTable = USER_LOGIC_TB;
//获取实际的 ActualDataNodes
String actualDataNodes = "ds$->{0..1}.t_user_$->{0..1}";
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(logicTable, actualDataNodes);
//设置分表策略
// inline 模式
ShardingStrategyConfiguration tableShardingStrategy =
new InlineShardingStrategyConfiguration("user_id", "t_user_$->{user_id % 2}");
//自定义模式
// TableShardingAlgorithm tableShardingAlgorithm = new TableShardingAlgorithm();
// ShardingStrategyConfiguration tableShardingStrategy = new StandardShardingStrategyConfiguration("user_id", tableShardingAlgorithm);
tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);
// 配置分库策略(Groovy表达式配置db规则)
// inline 模式
ShardingStrategyConfiguration dsShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}");
//自定义模式
// DsShardingAlgorithm dsShardingAlgorithm = new DsShardingAlgorithm();
// ShardingStrategyConfiguration dsShardingStrategy = new StandardShardingStrategyConfiguration("user_id", dsShardingAlgorithm);
tableRuleConfig.setDatabaseShardingStrategyConfig(dsShardingStrategy);
tableRuleConfig.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "user_id"));
return tableRuleConfig;
}
-
逻辑表:这里配置的逻辑表就是t_user,对应的物理表有t_user_0,t_user_1;
-
真实数据节点:这里使用行表达式进行配置的,简化了配置;上面的配置就相当于配置了:
db0 ├── t_user_0 └── t_user_1 db1 ├── t_user_0 └── t_user_1 -
数据库分片策略:
这里的库分片策略就是上面介绍的五种类型,
这里使用的InlineShardingStrategy,需要设置 内联表达式,groovy表达式;
//设置分表策略 // inline 模式 ShardingStrategyConfiguration tableShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "t_user_$->{user_id % 2}"); //自定义模式 // TableShardingAlgorithm tableShardingAlgorithm = new TableShardingAlgorithm(); // ShardingStrategyConfiguration tableShardingStrategy = new StandardShardingStrategyConfiguration("user_id", tableShardingAlgorithm); tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);这里的shardingValue就是user_id对应的真实值,每次和2取余;availableTargetNames可选择就是{ds0,ds1};看余数和哪个库能匹配上就表示路由到哪个库;
-
数据表分片策略:指定的分片键(order_id)和分库策略不一致,其他都一样;
-
分布式主键生成策略:ShardingSphere-JDBC提供了多种分布式主键生成策略,后面详细介绍,这里使用雪花算法;
groovy语法说明
行表达式的使⽤⾮常直观,只需要在配置中使⽤ ${ expression } 或 $->{ expression } 标识 行表达式即可。
⽬前⽀持数据节点和分⽚算法这两个部分的配置。
行表达式的内容使⽤的是 Groovy 的语法,Groovy 能够⽀持的所有操作, 行表达式均能够⽀持。例如:
${begin..end} 表⽰范围区间
${[unit1, unit2, unit_x]} 表⽰枚举值
行表达式中如果出现连续多个 ${ expression } 或 $->{ expression } 表达式,整个表达式最终的结果将会根据每个表达式的结果进笛卡尔组合。
例如,以下⾏表达式: ${['online', 'offline']}_table${1..3}
最终会解析为:
online_table1, online_table2, online_table3, offline_table1, offline_table2,offline_table3
配置数据节点时对于均匀分布的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order0
└── t_order1
用行表达式可以简化为:
db${0..1}.t_order${0..1}
或者
db$->{0..1}.t_order$->{0..1}
对于⾃定义的数据节点,如果数据结构如下:
db0
├── t_order0
└── t_order1
db1
├── t_order2
├── t_order3
└── t_order4
用行表达式可以简化为:
db0.t_order${0..1},db1.t_order${2..4}
或者
db0.t_order$->{0..1},db1.t_order$->{2..4}
配置分片规则
配置分片规则ShardingRuleConfiguration,包括多种配置规则:
表规则配置、绑定表配置、广播表配置、默认数据源名称、默认数据库分片策略、默认表分片策略、默认主键生成策略、主从规则配置、加密规则配置;
- 表规则配置 tableRuleConfigs:也就是上面配置的库分片策略和表分片策略,也是最常用的配置;
- 绑定表配置 bindingTableGroups:指分⽚规则⼀致的主表和⼦表;绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将⼤⼤提升;
- 广播表配置 broadcastTables:所有的分⽚数据源中都存在的表,表结构和表中的数据在每个数据库中均完全⼀致。适⽤于数据量不⼤且需要与海量数据的表进⾏关联查询的场景;
- 默认数据源名称 defaultDataSourceName:未配置分片的表将通过默认数据源定位;
- 默认数据库分片策略 defaultDatabaseShardingStrategyConfig:表规则配置可以设置数据库分片策略,如果没有配置可以在这里面配置默认的;
- 默认表分片策略 defaultTableShardingStrategyConfig:表规则配置可以设置表分片策略,如果没有配置可以在这里面配置默认的;
- 默认主键生成策略 defaultKeyGeneratorConfig:表规则配置可以设置主键生成策略,如果没有配置可以在这里面配置默认的;内置UUID、SNOWFLAKE生成器;
- 主从规则配置 masterSlaveRuleConfigs:用来实现读写分离的,可配置一个主表多个从表,读面对多个从库可以配置负载均衡策略;
- 加密规则配置 encryptRuleConfig:提供了对某些敏感数据进行加密的功能,提供了⼀套完整、安全、透明化、低改造成本的数据加密整合解决⽅案;
实战:数据插入
以上准备好,就可以操作数据库了,这里执行插入操作:
/**
* 新增测试.
*
*/
@Test
public void testInsertUser() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "insert into t_user(name) values('name-0001')";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
preparedStatement.execute();
sql = "insert into t_user(name) values('name-0002')";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
通过以上配置的真实数据源、分片规则以及属性文件创建分片数据源ShardingDataSource;
接下来就可以像使用单库单表一样操作分库分表了,sql中可以直接使用逻辑表,分片算法会根据具体的值就行路由处理;
经过路由最终:奇数入ds1.t_user_1,偶数入ds0.t_user_0;
实战:数据查询
以上准备好,就可以操作数据库了,这里执行查询操作:
/**
* 新增测试.
*
*/
@Test
public void testSelectUser() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "select * from t_user where user_id=10000";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
ResultSet resultSet= preparedStatement.executeQuery();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
实战:Properties配置InlineShardingStrategy 实战
通过 Properties 配置来使用 InlineShardingStrategy
配置参数:
inline.shardingColumn 分片键;
inline.algorithmExpression 分片表达式
配置实例
spring.shardingsphere.datasource.names=ds0,ds1
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.filters=com.alibaba.druid.filter.stat.StatFilter,com.alibaba.druid.wall.WallFilter,com.alibaba.druid.filter.logging.Log4j2Filter
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://cdh1:3306/sharding_db1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
spring.shardingsphere.datasource.ds0.password=123456
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.maxActive=20
spring.shardingsphere.datasource.ds0.initialSize=1
spring.shardingsphere.datasource.ds0.maxWait=60000
spring.shardingsphere.datasource.ds0.minIdle=1
spring.shardingsphere.datasource.ds0.timeBetweenEvictionRunsMillis=60000
spring.shardingsphere.datasource.ds0.minEvictableIdleTimeMillis=300000
spring.shardingsphere.datasource.ds0.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.ds0.testWhileIdle=true
spring.shardingsphere.datasource.ds0.testOnBorrow=false
spring.shardingsphere.datasource.ds0.testOnReturn=false
spring.shardingsphere.datasource.ds0.poolPreparedStatements=true
spring.shardingsphere.datasource.ds0.maxOpenPreparedStatements=20
spring.shardingsphere.datasource.ds0.connection-properties=druid.stat.merggSql=ture;druid.stat.slowSqlMillis=5000
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.filters=com.alibaba.druid.filter.stat.StatFilter,com.alibaba.druid.wall.WallFilter,com.alibaba.druid.filter.logging.Log4j2Filter
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://cdh1:3306/sharding_db2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.password=123456
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.maxActive=20
spring.shardingsphere.datasource.ds1.initialSize=1
spring.shardingsphere.datasource.ds1.maxWait=60000
spring.shardingsphere.datasource.ds1.minIdle=1
spring.shardingsphere.datasource.ds1.timeBetweenEvictionRunsMillis=60000
spring.shardingsphere.datasource.ds1.minEvictableIdleTimeMillis=300000
spring.shardingsphere.datasource.ds1.validationQuery=SELECT 1 FROM DUAL
spring.shardingsphere.datasource.ds1.testWhileIdle=true
spring.shardingsphere.datasource.ds1.testOnBorrow=false
spring.shardingsphere.datasource.ds1.testOnReturn=false
spring.shardingsphere.datasource.ds1.poolPreparedStatements=true
spring.shardingsphere.datasource.ds1.maxOpenPreparedStatements=20
spring.shardingsphere.datasource.ds1.connection-properties=druid.stat.merggSql=ture;druid.stat.slowSqlMillis=5000
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds$->{0..1}.t_user_$->{0..1}
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.table-strategy.inline.algorithm-expression=t_user_$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_user.key-generator.props.worker.id=123
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
spring.shardingsphere.sharding.binding-tables[0]=t_order,t_user
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=t_config
spring.shardingsphere.sharding.tables.t_config.key-generator.column=id
spring.shardingsphere.sharding.tables.t_config.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_config.key-generator.props.worker.id=123
行表达式分片策略的测试用例
@Test
public void testAddSomeUser() {
for (int i = 0; i < 10; i++) {
User dto = new User();
dto.setName("user_" + i);
//增加用户
entityService.addUser(dto);
}
}
@Test
public void testSelectAllUser() {
//增加用户
List<User> all = entityService.selectAllUser();
System.out.println(all);
}
@Test
public void testSelectAll() {
entityService.selectAll();
}
行表达式分片策略的问题
行表达式分片策略(InlineShardingStrategy),在配置中使用 Groovy 表达式,提供对 SQL语句中的 = 和 IN 的分片操作支持,它只支持单分片健。
行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。
它的配置相当简洁,这种分片策略利用inline.algorithm-expression书写表达式。
比如:ds-$->{order_id % 2} 表示对 order_id 做取模计算,$ 是个通配符用来承接取模结果,最终计算出分库ds-0 ··· ds-n,整体来说比较简单。
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{user_id % 2}
优势:
相当简洁
行表达式分片策略的问题:
不能支持 范围分片
范围分片 用于处理含有
BETWEEN AND、>,>=,<=,<的分片处理。
具体演示,请参见视频
实战: JavaAPI使用StandardShardingStrategy
标准分片策略的使用场景
使用场景:SQL 语句中有>,>=, <=,<,=,IN 和 BETWEEN AND 操作符,都可以应用此分片策略。
标准分片策略(StandardShardingStrategy),它只支持对单个分片健(字段)为依据的分库分表,
并提供了两种分片算法 PreciseShardingAlgorithm(精准分片)和 RangeShardingAlgorithm(范围分片)。
其中,精准分片算法是必须实现的算法,用于 SQL 含有 = 和 IN 的分片处理;
范围分片算法是非必选的,用于处理含有 BETWEEN AND 、>,>=, <=,<的分片处理。
一旦我们没配置范围分片算法,而 SQL 中又用到
BETWEEN AND或者like等,那么 SQL 将按全库、表路由的方式逐一执行,查询性能会很差需要特别注意。
实战准备
有了以上相关基础概念,接下来针对每种分片策略做一个简单的实战,
在实战前首先准备好库和表;
具体请参见视频,和配套源码
精准分片用于处理含有= 、in的分片处理。
范围分片 用于处理含有 BETWEEN AND 、>,>=, <=,<的分片处理。
表规则配置
表规则配置类TableRuleConfiguration,包含了五个要素:
逻辑表、真实数据节点、数据库分片策略、数据表分片策略、分布式主键生成策略;
/**
* 表的分片规则
*/
protected TableRuleConfiguration userShardingRuleConfig() {
String logicTable = USER_LOGIC_TB;
//获取实际的 ActualDataNodes
String actualDataNodes = "ds$->{0..1}.t_user_$->{0..1}";
// 两个表达式的 笛卡尔积
//ds0.t_user_0
//ds1.t_user_0
//ds0.t_user_1
//ds1.t_user_1
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(logicTable, actualDataNodes);
//设置分表策略
// inline 模式
// ShardingStrategyConfiguration tableShardingStrategy =
// new InlineShardingStrategyConfiguration("user_id", "t_user_$->{user_id % 2}");
//自定义模式
TablePreciseShardingAlgorithm tablePreciseShardingAlgorithm =
new TablePreciseShardingAlgorithm();
/* RouteInfinityRangeShardingAlgorithm tableRangeShardingAlg =
new RouteInfinityRangeShardingAlgorithm();
*/
RangeOrderShardingAlgorithm tableRangeShardingAlg =
new RangeOrderShardingAlgorithm();
PreciseOrderShardingAlgorithm preciseOrderShardingAlgorithm =
new PreciseOrderShardingAlgorithm();
ShardingStrategyConfiguration tableShardingStrategy =
new StandardShardingStrategyConfiguration("user_id",
preciseOrderShardingAlgorithm);
tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);
// 配置分库策略(Groovy表达式配置db规则)
// inline 模式
// ShardingStrategyConfiguration dsShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}");
//自定义模式
DsPreciseShardingAlgorithm dsPreciseShardingAlgorithm = new DsPreciseShardingAlgorithm();
RangeOrderShardingAlgorithm dsRangeShardingAlg =
new RangeOrderShardingAlgorithm();
ShardingStrategyConfiguration dsShardingStrategy =
new StandardShardingStrategyConfiguration("user_id",
preciseOrderShardingAlgorithm);
tableRuleConfig.setDatabaseShardingStrategyConfig(dsShardingStrategy);
tableRuleConfig.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "user_id"));
return tableRuleConfig;
}
数据库分片策略 StandardShardingStrategyConfiguration
ShardingStrategyConfiguration dsShardingStrategy =
new StandardShardingStrategyConfiguration("user_id",
dsPreciseShardingAlgorithm);
这里的shardingValue就是user_id对应的真实值,每次和2取余;availableTargetNames可选择就是{ds0,ds1};看余数和哪个库能匹配上就表示路由到哪个库;
-
数据表分片策略:指定的分片键(order_id)和分库策略不一致,其他都一样;
-
分布式主键生成策略:ShardingSphere-JDBC提供了多种分布式主键生成策略,后面详细介绍,这里使用雪花算法;
测试用例
以上准备好,就可以操作数据库了,这里执行插入操作:
@Test
public void testSelectUserIn() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "select * from t_user where user_id in (10,11,23)";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
ResultSet resultSet = preparedStatement.executeQuery();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
通过以上配置的真实数据源、分片规则以及属性文件创建分片数据源ShardingDataSource;
接下来就可以像使用单库单表一样操作分库分表了,sql中可以直接使用逻辑表,分片算法会根据具体的值就行路由处理;
以上使用了最常见的精确分片算法,下面继续看一下其他几种分片算法;
实战: JavaAPI使用RangeShardingAlgorithm实战1
分片算法与分片值
四大分片算法
- 精确分片算法 PreciseShardingAlgorithm
精确分片算法(PreciseShardingAlgorithm)用于单个字段作为分片键,SQL中有 = 与 IN 等条件的分片,
需要配合 StandardShardingStrategy 使⽤。
- 范围分片算法 RangeShardingAlgorithm
范围分片算法(RangeShardingAlgorithm)用于单个字段作为分片键,SQL中有 BETWEEN AND、>、<、>=、<= 等条件的分片,需要需要配合 StandardShardingStrategy 使⽤。
- 复合分片算法 ComplexKeysShardingAlgorithm
对应 ComplexKeysShardingAlgorithm,⽤于处理使⽤ 多键作为分⽚键 进⾏分⽚的场景,
(多个字段作为分片键),同时获取到多个分片健的值,根据多个字段处理业务逻辑。
包含多个分⽚键的逻辑较复杂,需要应⽤开发者⾃⾏处理其中的复杂度。
需要配合 ComplexShardingStrategy 使⽤。
需要在复合分片策略(ComplexShardingStrategy )下使用。
- Hint 分片算法 HintShardingAlgorithm
Hint 分片算法(HintShardingAlgorithm)稍有不同
前面的算法(如StandardShardingAlgorithm)都是解析 SQL 语句, 提取分片值,并根据设置的分片算法进行分片。
Hint 分片算法 指定分⽚值而⾮从 SQL 中提取,而是手工设置的⽅式,进⾏分⽚的策略。
对于分⽚值⾮ SQL 决定,不是来自于分片建,甚至连分片建都没有 ,而由其他外置条件决定的场景,可使⽤Hint 分片算法 。
就需要通过 Java API 等方式 指定 分片值,这也叫强制路由、或者说 暗示路由。
例: 内部系统,按照员⼯登录主键分库,而数据库中并⽆此字段。
四大分片值
SQL Hint ⽀持通过 Java API 和 SQL 注释(待实现)两种⽅式使⽤。
ShardingSphere-JDBC针对每种分片算法都提供了相应的ShardingValue,具体包括:
- PreciseShardingValue
- RangeShardingValue
- ComplexKeysShardingValue
- HintShardingValue
范围分片算法
用在区间查询/范围查询的时候,比如下面的查询SQL:
select * from t_user where user_id between 10 and 20
以上两个区间值10、20会直接保存到RangeShardingValue中,做库路由时,所以会访问两个库;
参考的代码如下(以下代码,视频中有详细介绍):
public final class RangeOrderShardingAlgorithm implements RangeShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Integer> shardingValue) {
Collection<String> result = new HashSet<>(2);
for (int i = shardingValue.getValueRange().lowerEndpoint(); i <= shardingValue.getValueRange().upperEndpoint(); i++) {
for (String each : availableTargetNames) {
System.out.println("shardingValue = " + shardingValue.getValueRange() + " target = " + each + " shardingValue.getValue() % 2) = " + i % 2);
if (each.endsWith(String.valueOf(i % 2))) {
result.add(each);
}
}
}
return result;
}
}
测试用例:
@Test
public void testSelectUserBetween() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "select * from t_user where user_id between 10 and 20 ";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
ResultSet resultSet = preparedStatement.executeQuery();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
实战: JavaAPI使用RangeShardingAlgorithm实战2
异常:range unbounded on this side
用上面的算法,执行下面的测试用例,会抛出 异常:range unbounded on this side
可以执行下面的用例,看看异常的效果
@Test
public void testSelectUserBigThan() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "select * from t_user where user_id > 10000";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
ResultSet resultSet = preparedStatement.executeQuery();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
异常的原因
以上两个区间值是没有边界的,执行获取上边界时,RangeShardingValue会抛出异常
既然没有边界,直接做全路由
对没有边界的范围分片进行路由
用在区间查询/范围查询的时候,比如下面的查询SQL:
select * from t_user where user_id > 10000
参考的代码如下(以下代码,视频中有详细介绍):
public final class RouteInfinityRangeShardingAlgorithm implements RangeShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(final Collection<String> availableTargetNames, final RangeShardingValue<Integer> shardingValue) {
Collection<String> result = new HashSet<>();
result.addAll(availableTargetNames);
return result;
}
}
Properties配置StandardShardingStrategy 实战
通过 Properties 配置来使用 StandardShardingStrategy
配置参数:
-
standard.sharding-column 分片键;
-
standard.precise-algorithm-class-name 精确分片算法类名;
-
standard.range-algorithm-class-name 范围分片算法类名
参数standard.precise-algorithm-class-name 说明:
standard.precise-algorithm-class-name 指向一个实现了PreciseShardingAlgorithm接口的java实现类,
io.shardingsphere.api.algorithm.sharding.standard.PreciseShardingAlgorithm
此java实现类提供按照 = 或者 IN 逻辑的精确分片
参数standard.range-algorithm-class-name 说明:
指向一个实现了 io.shardingsphere.api.algorithm.sharding.standard.RangeShardingAlgorithm接口的java类名,
此java实现类提供按照 Between 条件进行的范围分片。
示例: com.crazymaker.springcloud.message.core.PreciseShardingAlgorithm
参数补充说明:
StandardShardingStrategy的两大内嵌算法中:精确分片算法是必须提供的,而范围分片算法则是可选的。
配置实例
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order_$->{0..1}
#spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression=t_order_$->{user_id % 2}
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_order.table-strategy.standard.precise-algorithm-class-name=com.crazymaker.springcloud.sharding.jdbc.demo.core.TablePreciseShardingAlgorithmDemo
spring.shardingsphere.sharding.tables.t_order.key-generator.column=order_id
spring.shardingsphere.sharding.tables.t_order.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_order.key-generator.props.worker.id=123
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.precise-algorithm-class-name=com.crazymaker.springcloud.sharding.jdbc.demo.core.DsPreciseShardingAlgorithmDemo
spring.shardingsphere.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
#spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.tables.t_order.database-strategy.inline.algorithm-expression=ds$->{user_id % 2}
就写这么多,更加详细的内容,请参见视频
ComplexShardingStrategy复合分片策略实战
内联分片、标准分片 策略的不足:
只有一个分片建
问题: 多个分片键参与分片路由,咋整?
ComplexSharding分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;
-
标准分片策略:对应
StandardShardingStrategy类,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法,PreciseShardingAlgorithm是必须的,RangeShardingAlgorithm可选的;public final class StandardShardingStrategy implements ShardingStrategy { private final String shardingColumn; private final PreciseShardingAlgorithm preciseShardingAlgorithm; private final RangeShardingAlgorithm rangeShardingAlgorithm; } -
复合分片策略:对应
ComplexShardingStrategy类,提供ComplexKeysShardingAlgorithm分片算法;public final class ComplexShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final ComplexKeysShardingAlgorithm shardingAlgorithm; }可以发现支持多个分片键;
-
Hint分片策略:对应
HintShardingStrategy类,通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略;提供HintShardingAlgorithm分片算法;public final class HintShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final HintShardingAlgorithm shardingAlgorithm; } -
内联分片策略:对应
InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现; -
不分片策略:对应
NoneShardingStrategy类,不分片策略;
ComplexSharding分片策略配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
StandardShardingStrategyConfigurationComplexShardingStrategyConfigurationHintShardingStrategyConfigurationInlineShardingStrategyConfigurationNoneShardingStrategyConfiguration
/**
* Complex sharding strategy configuration.
*/
@Getter
public final class ComplexShardingStrategyConfiguration implements ShardingStrategyConfiguration {
private final String shardingColumns;
private final ComplexKeysShardingAlgorithm shardingAlgorithm;
public ComplexShardingStrategyConfiguration(
final String shardingColumns,
final ComplexKeysShardingAlgorithm shardingAlgorithm) {
Preconditions.checkArgument(!Strings.isNullOrEmpty(shardingColumns), "ShardingColumns is required.");
Preconditions.checkNotNull(shardingAlgorithm, "ShardingAlgorithm is required.");
this.shardingColumns = shardingColumns;
this.shardingAlgorithm = shardingAlgorithm;
}
}
ComplexSharding分片算法
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用Hint行分片的场景;
以上所有的算法类都是接口类,具体实现交给开发者自己;
自定义ComplexSharding分片算法
问题: 多个分片键参与分片路由,咋整?
user_id,和oder_id 参与分片
分片算法如下:
public class SimpleComplexKeySharding implements ComplexKeysShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
ComplexKeysShardingValue<Long> shardingValue) {
Map<String, Collection<Long>> map = shardingValue.getColumnNameAndShardingValuesMap();
Collection<Long> userIds = map.get("user_id");
Collection<Long> orderIds = map.get("order_id");
List<String> result = new ArrayList<>();
// user_id,order_id分片键进行分表
for (Long userId : userIds) {
for (Long orderId : orderIds) {
Long innerShardingValue = userId + orderId;
Long suffix = innerShardingValue % 2;
for (String each : availableTargetNames) {
System.out.println("innerShardingValue = " + innerShardingValue + " target = " + each + " innerShardingValue % 2 = " + suffix);
if (each.endsWith(suffix + "")) {
result.add(each);
}
}
}
}
return result;
}
}
通过代码使用ComplexSharding复合分片算法
可以同时使用多个分片键,比如可以同时使用user_id和order_id作为分片键;
orderTableRuleConfig.setDatabaseShardingStrategyConfig(
new ComplexShardingStrategyConfiguration("order_id,user_id", new SimpleComplexKeySharding()));
orderTableRuleConfig.setTableShardingStrategyConfig(
new ComplexShardingStrategyConfiguration("order_id,user_id", new SimpleComplexKeySharding()));
如上在配置分库分表策略时,指定了两个分片键,用逗号隔开;
使用属性进行配置
支持多分片键的复杂分片策略。
配置参数:
complex.sharding-columns 分片键(多个);
complex.algorithm-class-name 分片算法实现类。
配置参数:
shardingColumn指定多个分片列。
algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm接口的java类名。提供按照多个分片列进行综合分片的算法。
具体的介绍,请参见视频
测试用例与执行
参见视频
HintShardingStrategy强制(暗示)分片策略实战
问题: 在一些应用场景中,分片值并不存在于 SQL,而存在于外部业务逻辑,咋整?
问题2:根据外部值分片,咋整?
eg:
我要根据 月份分片,或者根据 小时分片
我要根据 心情 分片
简单来理解
这个分片策略,简单来理解就是说,他的分片键不再跟SQL语句相关联,而是用程序另行指定。
对于一些复杂的情况,例如select count(*) from (select userid from t_user where userid in (1,3,5,7,9)) 这样的SQL语句,就没法通过SQL语句来指定一个分片键。
暗示策略与前面的策略之不同:
- 前面的策略提取分片键列与值并进行分片是 Apache ShardingSphere 对 SQL 零侵入的实现方式。
若 SQL 语句中没有分片条件,则无法进行分片,需要全路由。
在一些应用场景中,分片条件并不存在于 SQL,而存在于外部业务逻辑。
- 暗示策略需要提供一种通过外部指定分片值的方式,在 Apache ShardingSphere 中叫做 Hint。
暗示分片值算法如下:
可以通过编程的方式向 HintManager 中添加分片值,该分片值仅在当前线程内生效;然后通过 hint暗示策略+hint暗示算法分片
分片策略算法
ShardingSphere-JDBC在分片策略上分别引入了分片算法、分片策略两个概念,
当然在分片的过程中分片键也是一个核心的概念;在此可以简单的理解分片策略 = 分片算法 + 分片键;
至于为什么要这么设计,应该是ShardingSphere-JDBC考虑更多的灵活性,把分片算法单独抽象出来,方便开发者扩展;
分片算法
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用外部值分片的场景;
以上所有的算法类都是接口类,具体实现交给开发者自己;
分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;
-
Hint分片策略:对应
HintShardingStrategy类,通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略;提供HintShardingAlgorithm分片算法;public final class HintShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final HintShardingAlgorithm shardingAlgorithm; } -
内联分片策略:对应
InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现; -
不分片策略:对应
NoneShardingStrategy类,不分片策略;
分片策略配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
StandardShardingStrategyConfigurationComplexShardingStrategyConfigurationHintShardingStrategyConfiguration外部值分片InlineShardingStrategyConfigurationNoneShardingStrategyConfiguration
自定义HintShardingAlgorithm分片算法
问题:根据外部值分片,咋整?
我要根据 月份分片,或者根据 小时分片
我要根据 心情 分片
分片算法如下:
public class SimpleHintShardingAlgorithmDemo implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
HintShardingValue<Integer> hintShardingValue) {
Collection<String> result = new HashSet<>(2);
Collection<Integer> values = hintShardingValue.getValues();
for (String each : availableTargetNames) {
for (int shardingValue : values) {
System.out.println("shardingValue = " + shardingValue + " target = " + each + " shardingValue % 2 = " + shardingValue % 2);
if (each.endsWith(String.valueOf(shardingValue % 2))) {
result.add(each);
}
}
}
return result;
}
}
使用代码进行配置
// 设置库表分片策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new HintShardingStrategyConfiguration(new SimpleHintShardingAlgorithmDemo()));
orderTableRuleConfig.setTableShardingStrategyConfig(new HintShardingStrategyConfiguration(new SimpleHintShardingAlgorithmDemo()));
使用属性进行配置
-
配置参数:hint.algorithm-class-name 分片算法实现类。
-
实现方式:
algorithmClassName指向一个实现了org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm接口的java类名。
示例:com.roy.shardingDemo.algorithm.MyHintShardingAlgorithm在这个算法类中,同样是需要分片键的。而分片键的指定是通过HintManager.addDatabaseShardingValue方法(分库)和HintManager.addTableShardingValue(分表)来指定。
使用时要注意,这个分片键是线程隔离的,只在当前线程有效,所以通常建议使用之后立即关闭,或者用try资源方式打开。
在代码使用HintManager进行暗示
在一些应用场景中,分片条件并不存在于 SQL,而存在于外部业务逻辑;
问题:根据外部值分片,咋整?
我要根据 月份分片,或者根据 小时分片
我要根据 心情 分片
可以通过编程的方式向 HintManager 中添加分片值,该分片值仅在当前线程内生效;
@Test
public void testAddSomeOrderByMonth() {
for (int month = 1; month <= 12; month++) {
final int index = month;
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("当前月份 = " + index);
HintManager hintManager = HintManager.getInstance();
hintManager.addTableShardingValue("t_order", index);
hintManager.addDatabaseShardingValue("t_order", index);
Order dto = new Order();
dto.setUserId(704733680467685377L);
//增加订单
entityService.addOrder(dto);
}
}).start();
}
}
测试用例与执行
参见视频
Hint实现机制
Apache ShardingSphere 使用 ThreadLocal 管理分片键值。 可以通过编程的方式向 HintManager 中添加分片条件,该分片条件仅在当前线程内生效。
除了通过编程的方式使用强制分片路由,Apache ShardingSphere 还可以通过 SQL 中的特殊注释的方式引用 Hint,使开发者可以采用更加透明的方式使用该功能。
指定了强制分片路由的 SQL 将会无视原有的分片逻辑,直接路由至指定的真实数据节点。
切记:
涉及到ThreadLocal 线程局部变量的,执行完后用完记得清理哦。免得污染后面的执行,尤其在线程池的场景中。
Session的使用,也是类似的。
Hint分片策略的优势和劣势
场景优势:
可以程序指定分片值
性能优势:
Hint分片策略并没有完全按照SQL解析树来构建分片策略,是绕开了SQL解析的,
所有对某些比较复杂的语句,Hint分片策略性能有可能会比较好,仅仅是可能,还需要是分析源码。
使用限制
Hint路由在使用时有非常多的限制:
-- 不支持UNION SELECT * FROM t_order1 UNION SELECT * FROM t_order2 INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? -- 不支持多层子查询 SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?)) -- 不支持函数计算。ShardingSphere只能通过SQL字面提取用于分片的值 SELECT * FROM t_order WHERE to_date(create_time, 'yyyy-mm-dd') = '2019-01-01';
从这里也能看出,即便有了ShardingSphere框架,分库分表后对于SQL语句的支持依然是非常脆弱的。
NoneShardingStrategyConfiguration不分片策略实战
不分片,怎么配置呢
分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;
- 不分片策略:对应
NoneShardingStrategy类,不分片策略;
分片策略配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
- NoneShardingStrategyConfiguration
使用代码进行配置
配置NoneShardingStrategyConfiguration即可:
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new NoneShardingStrategyConfiguration());
orderTableRuleConfig.setTableShardingStrategyConfig(new NoneShardingStrategyConfiguration());
使用属性进行配置
参见视频
这样数据会插入每个库每张表,可以理解为广播表
实战:广播表原理与实操
什么是广播表:
存在于所有的数据源中的表,表结构和表中的数据在每个数据库中均完全一致。
一般是为字典表或者配置表 t_config,
某个表一旦被配置为广播表,只要修改某个数据库的广播表,所有数据源中广播表的数据都会跟着同步。
存在这样的情况:表结构和表中的数据在每个数据库中完全一致,如字典表,那么这时候应该怎么办?广播表这时候就应运而生了。
定义:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中完全一致。
适用:数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
广播表需要满足如下:
(1)在每个数据库表都存在该表以及表结构都一样。
(2)当保存的时候,每个数据库都会插入相同的数据。
使用代码进行配置
配置NoneShardingStrategyConfiguration即可:
//广播表配置如下;
// shardingRuleConfig.getBroadcastTables().add("t_config");
使用属性进行配置
spring.shardingsphere.sharding.broadcast-tables=t_config
具体的演示,请参见视频
广播表的效果
运行结果如下:
添加记录时,在ds0和ds1都会保存1条相同的数据。
当查询的时候,会随机的选择一个数据源进行查询。
添加
[main] INFO ShardingSphere-SQL - Logic SQL: insert into t_config (status, id) values (?, ?)
[main] INFO ShardingSphere-SQL - SQLStatement: InsertStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@61be6051, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@13c18bba), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@13c18bba, columnNames=[status, id], insertValueContexts=[InsertValueContext(parametersCount=2, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=42, stopIndex=42, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=45, stopIndex=45, parameterMarkerIndex=1)], parameters=[UN_KNOWN, 1])], generatedKeyContext=Optional.empty)
[main] INFO ShardingSphere-SQL - Actual SQL: ds0 ::: insert into t_config (status, id) values (?, ?) ::: [UN_KNOWN, 1]
[main] INFO ShardingSphere-SQL - Actual SQL: ds1 ::: insert into t_config (status, id) values (?, ?) ::: [UN_KNOWN, 1]
查询
[main] INFO o.h.h.i.QueryTranslatorFactoryInitiator - HHH000397: Using ASTQueryTranslatorFactory
[main] INFO ShardingSphere-SQL - Logic SQL: select configenti0_.id as id1_0_, configenti0_.status as status2_0_ from t_config configenti0_ limit ?
[main] INFO ShardingSphere-SQL - SQLStatement: SelectStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.SelectStatement@784212, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@5ac646b3), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@5ac646b3, projectionsContext=ProjectionsContext(startIndex=7, stopIndex=66, distinctRow=false, projections=[ColumnProjection(owner=configenti0_, name=id, alias=Optional[id1_0_]), ColumnProjection(owner=configenti0_, name=status, alias=Optional[status2_0_])]), groupByContext=org.apache.shardingsphere.sql.parser.binder.segment.select.groupby.GroupByContext@24b38e8f, orderByContext=org.apache.shardingsphere.sql.parser.binder.segment.select.orderby.OrderByContext@5cf072ea, paginationContext=org.apache.shardingsphere.sql.parser.binder.segment.select.pagination.PaginationContext@1edac3b4, containsSubquery=false)
[main] INFO ShardingSphere-SQL - Actual SQL: ds1 ::: select configenti0_.id as id1_0_, configenti0_.status as status2_0_ from t_config configenti0_ limit ? ::: [3]
[ConfigBean(id=1, status=UN_KNOWN), ConfigBean(id=704836248892059648, status=UN_KNOWN0), ConfigBean(id=704836250150350849, status=UN_KNOWN1)]
实战:绑定表
绑定表:那些分片规则一致的主表和子表。
比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。
那绑定表存在的意义是啥呢?
通常在我们的业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。
如果不配置绑定表关系,会出现笛卡尔积关联查询,将产生如下四条 SQL。
没有绑定表的效果
[main] INFO ShardingSphere-SQL - Logic SQL: SELECT a.* FROM `t_order` a left join `t_user` b on a.user_id=b.user_id where a.user_id=?
....
[main] INFO ShardingSphere-SQL - Actual SQL: ds1 ::: SELECT a.* FROM `t_order_1` a left join `t_user_1` b on a.user_id=b.user_id where a.user_id=? ::: [704733680467685377]
[main] INFO ShardingSphere-SQL - Actual SQL: ds1 ::: SELECT a.* FROM `t_order_1` a left join `t_user_0` b on a.user_id=b.user_id where a.user_id=? ::: [704733680467685377]
[order_id: 704786564605521921, user_id: 704733680467685377, status: NotPayed, order_id: 704786564697796609, ....]
有绑定表的效果
[main] INFO ShardingSphere-SQL - Logic SQL: SELECT a.* FROM `t_order` a left join `t_user` b on a.user_id=b.user_id where a.user_id=?
[main] INFO ShardingSphere-SQL - SQLStatement: SelectStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.SelectStatement@4247093b, tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7074da1d), tablesContext=org.apache.shardingsphere.sql.parser.binder.segment.table.TablesContext@7074da1d, projectionsContext=ProjectionsContext(startIndex=7, stopIndex=9, distinctRow=false, projections=[ShorthandProjection(owner=Optional[a], actualColumns=[ColumnProjection(owner=a, name=order_id, alias=Optional.empty), ColumnProjection(owner=a, name=user_id, alias=Optional.empty), ColumnProjection(owner=a, name=status, alias=Optional.empty)])]), groupByContext=org.apache.shardingsphere.sql.parser.binder.segment.select.groupby.GroupByContext@5bdb6ea8, orderByContext=org.apache.shardingsphere.sql.parser.binder.segment.select.orderby.OrderByContext@3e55eeb9, paginationContext=org.apache.shardingsphere.sql.parser.binder.segment.select.pagination.PaginationContext@44a13699, containsSubquery=false)
[main] INFO ShardingSphere-SQL - Actual SQL: ds1 ::: SELECT a.* FROM `t_order_1` a left join `t_user_1` b on a.user_id=b.user_id where a.user_id=? ::: [704733680467685377]
[order_id: 704786564605521921, user_id: 704733680467685377, status: NotPayed, order_id: 704786564697796609, user_id: 704733680467685377, status: NotPayed, order_id: 704786564790071297, user_id: 704733680467685377, .....]
shardingjdbc 的sql执行流程
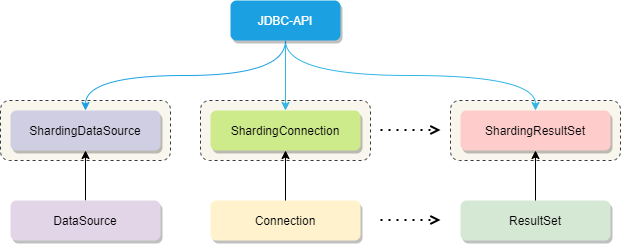
shardingjdbc 对原有的 DataSource、Connection 等接口扩展成 ShardingDataSource、ShardingConnection,
而对外暴露的分片操作接口与 JDBC 规范中所提供的接口完全一致,只要你熟悉 JDBC 就可以轻松应用 Sharding-JDBC 来实现分库分表。
一张表经过分库分表后被拆分成多个子表,并分散到不同的数据库中,
在不修改原业务 SQL 的前提下,Sharding-JDBC 就必须对 SQL进行一些改造才能正常执行。
大致的执行流程:SQL 解析 -> 查询优化 -> SQL 路由 -> SQL 改写 -> SQL 执⾏ -> 结果归并 六步组成,一起瞅瞅每个步骤做了点什么。
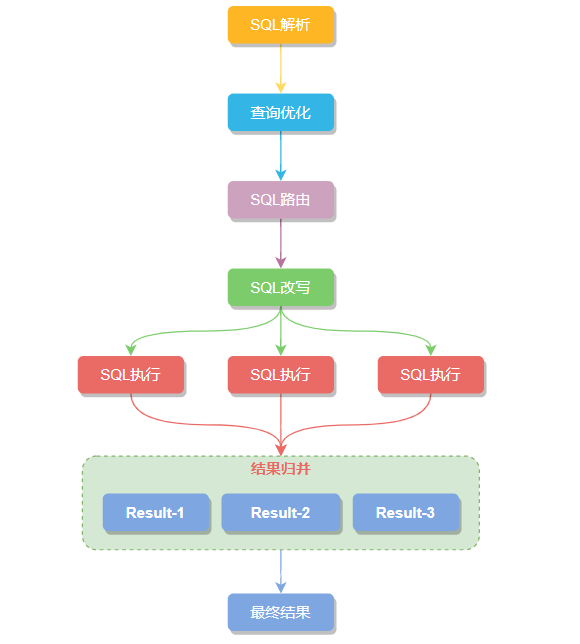
SQL解析
接着语法解析会将拆分后的SQL转换为抽象语法树,通过对抽象语法树遍历,提炼出分片所需的上下文,
上下文包含查询字段信息(Field)、表信息(Table)、查询条件(Condition)、排序信息(Order By)、分组信息(Group By)以及分页信息(Limit)等,并标记出 SQL中有可能需要改写的位置。
例如,以下 SQL:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
SQL 解析引擎
相对于其他编程语⾔,SQL 是⽐较简单的。不过,它依然是⼀⻔完善的编程语⾔,因此对 SQL 的语法进⾏解析,与解析其他编程语⾔(如:Java 语⾔、C 语⾔、Go 语⾔等)并⽆本质区别。
功能点
• 提供独立的 SQL 解析功能
• 可以非常方便的对语法规则进行扩充和修改 (使用了 ANTLR)
• 支持多种方言的 SQL 解析
| 数据库 | 支持状态 |
|---|---|
| MySQL | 支持,完善 |
| PostgreSQL | 支持,完善 |
| SQLServer | 支持 |
| Oracle | 支持 |
| SQL92 | 支持 |
- 历史
SQL 解析作为分库分表类产品的核心,其性能和兼容性是最重要的衡量指标。ShardingSphere 的 SQL 解 析器经历了 3 代产品的更新迭代。
第一代 SQL 解析器为了追求性能与快速实现,在 1.4.x 之前的版本使用 Druid 作为 SQL 解析器。经实际 测试,它的性能远超其它解析器。
第二代 SQL 解析器从 1.5.x 版本开始,ShardingSphere 采用完全自研的 SQL 解析引擎。由于目的不同, ShardingSphere 并不需要将 SQL 转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它 采用对 SQL 半理解的方式,仅提炼数据分片需要关注的上下文,因此 SQL 解析的性能和兼容性得到了进 一步的提高。
第三代 SQL 解析器从 3.0.x 版本开始,尝试使用 ANTLR 作为 SQL 解析引擎的生成器,并采用 Visit 的方 式从 AST 中获取 SQL Statement。从 5.0.x 版本开始,解析引擎的架构已完成重构调整,同时通过将第一 次解析的得到的 AST 放入缓存,方便下次直接获取相同 SQL 的解析结果,来提高解析效率。
因此官方建 议用戶采用 PreparedStatement 这种 SQL 预编译的方式来提升性能。
抽象语法树
解析过程分为词法解析和语法解析。词法解析器⽤于将 SQL 拆解为不可再分的原⼦符号,称为 Token。并根据不同数据库⽅⾔所提供的字典,将其归类为关键字,表达式,字⾯量和操作符。再使⽤语法解析器将 SQL 转换为抽象语法树。
SQL 改写
将基于逻辑表开发的SQL改写成可以在真实数据库中可以正确执行的语句。比如查询 t_order 订单表,我们实际开发中 SQL是按逻辑表 t_order 写的。
SELECT * FROM t_order
但分库分表以后真实数据库中 t_order 表就不存在了,而是被拆分成多个子表 t_order_n 分散在不同的数据库内,还按原SQL执行显然是行不通的,这时需要将分表配置中的逻辑表名称改写为路由之后所获取的真实表名称。
SELECT * FROM t_order_n
SQL执行
将路由和改写后的真实 SQL 安全且高效发送到底层数据源执行。但这个过程并不是简单的将 SQL 通过JDBC 直接发送至数据源执行,而是平衡数据源连接创建以及内存占用所产生的消耗,它会自动化的平衡资源控制与执行效率。
结果归并
将从各个数据节点获取的多数据结果集,合并成一个大的结果集并正确的返回至请求客户端,称为结果归并。
而我们SQL中的排序、分组、分页和聚合等语法,均是在归并后的结果集上进行操作的。
shardingjdbc 的SQL 路由原理
SQL 路由通过解析分片上下文,匹配到用户配置的分片策略,并生成路由路径。
简单点理解就是可以根据我们配置的分片策略计算出 SQL该在哪个库的哪个表中执行,
而SQL路由又根据有无分片健区分出 分片路由 和 广播路由。
有分⽚键的路由叫分片路由,细分为直接路由、标准路由和笛卡尔积路由这3种类型。
DQL、DML、DDL、DCL、TCL、DAL
一、DDL (Data Definition Language) 数据库定义语言
用于创建、改变、删除对象的SQL语句统称:DDL。
1. Create
create命令用于创建对象如:表、索引、存储过程、触发器、函数等。
create table tblEmployee(
Id int primary key identity(1,1) not null,
Name nvarchar(50) ,
Gender nvarchar(50) ,
Salary int ,
DepartmentId int ,
);
2. Alter
Alter命令用于创建数据库和对象。
3. Drop
Drop命令用于从数据库中删除对象。
4. Truncate
Truncate表命令用户移除表中所有的记录,包括所分配的空间(不可恢复)
5. Rename
Rename用于重命名对象
6. Comment
// -> 单行 Comments, /* --多行 Comments-- */ 用户注释SQL
二、DML(Data Manipulation Language) 数据库操作语言
用于操作数据库(insert、modify、delete)的SQL命令,统称:DML
1. Insert
2. Modify、update
3. Delete
三、DQL (Data Query Language) 数据库查询语言
用于从数据库检索数据的SQL命令,统称:DQL, 所以,所有的select语句都属于DQL
select
四、DCL(Data Control Language) 数据库控制语言
用于在数据库访问中控制访问限制的SQL命令统称:DCL
1. Grant
授权
2. Revoke
取消授权
五、TCL(Transaction Control Language) 事务控制语言
用于控制数据库冲突的SQL 统称为TCL。 如:
1. Commit
提交事务,并使已对数据库进行的所有修改称为永久性。
2. Rollback
回滚用户的事务,并撤销正在进行的所有未提交的事务。
3. Save Point
保存回滚点。
4. Set Transaction
INNODB存储引擎提供的事务隔离级别READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ和SERIALIZABLLE.
六 dal
DESCRIBE
直接路由(暗示路由)
直接路由是通过使用 HintAPI 直接将 SQL路由到指定⾄库表的一种分⽚方式,而且直接路由可以⽤于分⽚键不在SQL中的场景,还可以执⾏包括⼦查询、⾃定义函数等复杂情况的任意SQL。
比如根据 t_order_id 字段为条件查询订单,此时希望在不修改SQL的前提下,加上 user_id作为分片条件就可以使用直接路由。
直接路由需要通过 Hint(使用 HintAPI 直接指定路由至库表)方式指定分片值,
不需要提取分片键值,并且 是只分库不分表的前提下,则可以避免 SQL 解析。
因此它的兼容性最好,可以执行包 括子查询、自定义函数等复杂情况的任意 SQL。直接路由还可以用于分片键不在 SQL 中的场景。例如,设 置用于数据库分片的值为 3
hintManager.setDatabaseShardingValue(3);
假如路由算法为 value % 2,当一个逻辑库 t_order 对应 2 个真实库 t_order_0 和 t_order_1 时, 路由后 SQL 将在 t_order_1 上执行。
标准路由
标准路由是最推荐也是最为常⽤的分⽚⽅式,它的适⽤范围是不包含关联查询或仅包含绑定表之间关联查询的SQL。
-
当 SQL分片健的运算符为
=时,路由结果将落⼊单库(表),路由策略返回的是单个的目标。 -
当分⽚运算符是
BETWEEN或IN等范围时,路由结果则不⼀定落⼊唯⼀的库(表),因此⼀条逻辑SQL最终可能被拆分为多条⽤于执⾏的真实SQL。
如果按照 order_id 的奇数和偶数进行数据分片,一个单表查询的 SQL 如下:
SELECT * FROM t_order where t_order_id in (1,2)
SQL路由处理后
SELECT * FROM t_order_0 where t_order_id in (1,2)
SELECT * FROM t_order_1 where t_order_id in (1,2)
绑定表的关联查询与单表查询复杂度和性能相当。
举例说明,如果一个包含绑定表的关联查询的 SQL 如 下:
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_ id IN (1, 2);
那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
可以看到,SQL 拆分的数目与单表是一致的。
笛卡尔积路由
笛卡尔路由是由非绑定表之间的关联查询产生的,查询性能较低尽量避免走此路由模式。
笛卡尔路由是最复杂的情况,它无法根据绑定表的关系定位分片规则,因此非绑定表之间的关联查询需 要拆解为笛卡尔积组合执行。
如果上个示例中的 SQL 并未配置绑定表关系,那么路由的结果应为:
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
笛卡尔路由查询性能较低,需谨慎使用。
广播路由
无分⽚键的路由又叫做广播路由,可以划分为全库表路由、全库路由、 全实例路由、单播路由和阻断路由这 5种类型。
全库路由
全库路由⽤于处理对数据库的操作,包括⽤于库设置的 SET 类型的数据库管理命令,以及 TCL 这样的事务控制语句。
在这种情况下,会根据逻辑库的名字遍历所有符合名字匹配的真实库,并在真实库中执⾏该命令,例如:
SET autocommit=0;
在 t_order 中执⾏,t_order 有 2 个真实库。
则实际会在 t_order_0 和 t_order_1 上都执⾏这个命令。
全库表路由
全库表路由⽤于处理对数据库中与其逻辑表相关的所有真实表的操作,主要包括不带分⽚键的 DQL 和DML,以及 DDL 等。例如:
SELECT * FROM t_order WHERE good_prority IN (1, 10);
则会遍历所有数据库中的所有表,逐⼀匹配逻辑表和真实表名,能够匹配得上则执⾏。路由后成为
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_1 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
全实例路由
全实例路由是针对数据库实例的 DCL 操作(设置或更改数据库用户或角色权限),
比如:创建一个用户 order ,这个命令将在所有的真实库实例中执行,以此确保 order 用户可以正常访问每一个数据库实例。
CREATE USER order@127.0.0.1 identified BY '程序员内点事';
⽆论⼀个实例中包含多少个 Schema,每个数据库的实例只执⾏⼀次。例如:
CREATE USER customer@127.0.0.1 identified BY '123';
这个命令将在所有的真实数据库实例中执⾏,以确保 customer ⽤⼾可以访问每⼀个实例。
单播路由
单播路由用来获取某一真实表信息,比如获得表的描述信息:
DESCRIBE t_order;
t_order 的真实表是 t_order_0 ···· t_order_n,他们的描述结构相完全同,我们只需在任意的真实表执行一次就可以。
阻断路由
⽤来屏蔽SQL对数据库的操作,例如:
USE order_db;
这个命令不会在真实数据库中执⾏,因为 ShardingSphere 采⽤的是逻辑 Schema(数据库的组织和结构) ⽅式,所以无需将切换数据库的命令发送⾄真实数据库中。
问题:分库分表时,分片键怎么选择

这个是小伙伴刚提出来的内容
我从减少倾斜和提高性能的角度,用3个案例,说明了一下,具体请参见视频。
问题:分库的join怎么解决

首先看是那种 join。
JOIN的含大致分为左连接,右连接,内连接,外连接,自然连接。
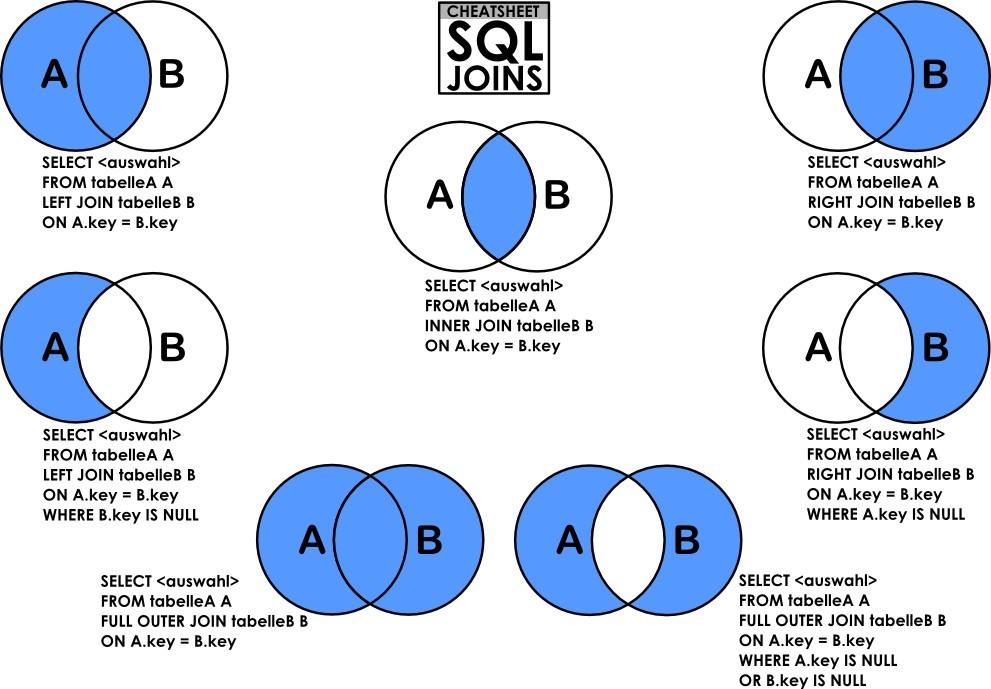
笛卡尔积
JOIN首先要理解笛卡尔积。
笛卡尔积就是将A表的每一条记录与B表的每一条记录强行拼在一起。所以,如果A表有n条记录,B表有m条记录,笛卡尔积产生的结果就会产生n*m条记录。
内连接:INNER JOIN
内连接INNER JOIN是最常用的连接操作。从数学的角度讲就是求两个表的交集,从笛卡尔积的角度讲就是从笛卡尔积中挑出ON子句条件成立的记录。
左连接:LEFT JOIN
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据。
从笛卡尔积的角度讲,就是先从笛卡尔积中挑出ON子句条件成立的记录,然后加上左表中剩余的记录
右连接:RIGHT JOIN
同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。
从笛卡尔积的角度描述,右连接就是从笛卡尔积中挑出ON子句条件成立的记录,然后加上右表中剩余的记录
常用的是左外连接
/**
* 根据用户查询 order
*
* @return
*/
@Query(nativeQuery = true,
value = "SELECT a.* FROM `t_order` a left join `t_user` b on a.user_id=b.user_id where a.user_id=?1")
List<OrderEntity> selectOrderOfUserId(long userId);
/**
* 根据用户查询 order
*
* @return
*/
@Query(nativeQuery = true,
value = "SELECT a.* FROM `t_order` a left join `t_user` b on a.user_id=b.user_id ")
List<OrderEntity> selectOrderOfUser();
回答:分库的join怎么解决:
-
就是一般用左外连接,
-
两个表用相同的分片建,
-
并且进行表绑定,防止产生数据源实例内的笛卡尔积路由。
-
使得join的时候,一个分片内部的数据,在分片内部完成 join操作,再由shardingjdbc完成 结果的归并。
-
从而得到最终的结果。
连环问:分库分表后,模糊条件查询怎么处理?
上面提到的都是条件中有sharding column的SQL执行。
但是,总有一些查询条件是不包含sharding column的,同时,我们也不可能为了这些请求量并不高的查询,无限制的冗余分库分表。
那么这些查询条件中没有sharding column的SQL怎么处理?
而在移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的。
比如
-
用户表:支付宝8亿,微信10亿。CITIC对公140万,对私8700万。
-
订单表:美团每天几千万,淘宝历史订单百亿、千亿。
目前绝大部分公司的核心数据都是:以RDBMS存储为主,NoSQL/NewSQL存储为辅!
-
RDBMS互联网公司又以MySQL为主
-
NoSQL比较具有代表性的是MongoDB,es
-
NewSQL比较具有代表性的是TiDB。
但是,MySQL单表可以存储10亿级数据,具体的原因,前面视频已经具体分析
但是,行业认可的,MySQL单表容量在1KW以下, 所以必然要分库分表
回顾一下,sharding 核心的步骤是:
SQL解析,重写,路由,执行,结果归并。
以sharding-jdbc为例,有多少个分库分表,就要并发路由到多少个分库分表中执行,然后对结果进行合并。
更有甚者,尤其是有些模糊条件查询,或者上十个条件筛选。
这种条件查询相对于有sharding column的条件查询性能很明显会下降很多。
多sharding column最好不要使用,建议采用 单sharding column + es + HBase的索引与存储隔离的架构。
索引与存储隔离的架构
例如有sharding column的查询走分库分表,一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。

HBase特点:
所有字段的全量数据保存到HBase中,Hadoop体系下的HBase存储能力是海量的,
rowkey查询速度快,快如闪电(可以优化到50Wqps甚至更高)。
es特点:
es的多条件检索能力非常强大。可能参与条件检索的字段索引到ES中。
这个方案把es和HBase的优点发挥的淋漓尽致,同时又规避了它们的缺点,可以说是一个扬长避免的最佳实践。
这就是经典的ES+HBase组合方案,即索引与数据存储隔离的方案。
它们之间的交互大概是这样的:
-
先根据用户输入的条件去es查询获取符合过滤条件的rowkey值,
-
然后用rowkey值去HBase查询
交互图如下所示:

对于海量数据,且有一定的并发量的分库分表,绝不是引入某一个分库分表中间件就能解决问题,而是一项系统的工程。
需要分析整个表相关的业务,让合适的中间件做它最擅长的事情。
例如有sharding column的查询走分库分表,
一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。
biglog同步保障数据一致性的架构
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化, 使用es 做全文检索。
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。
这种数据同步的代码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。

数据的冷热分离
做了这么多事情后,后面还会有很多的工作要做,比如数据同步的一致性问题,
还有运行一段时间后,某些表的数据量慢慢达到单表瓶颈,这时候还需要做冷数据迁移。
问题:广播表是不是公共表

可以这么理解。
广播表,就是更新操作,覆盖所有分片, 查询操作,查一个分片即可。
分布式主键
数据分⽚后,不同数据节点⽣成全局唯⼀主键是非常棘⼿的问题,
同⼀个逻辑表(t_order)内的不同真实表(t_order_n)之间的⾃增键由于无法互相感知而产⽣重复主键。
尽管可通过设置⾃增主键 初始值 和 步长 的⽅式避免 ID 碰撞,但这样会使维护成本加大,乏完整性和可扩展性。
如果后去需要增加分片表的数量,要逐一修改分片表的步长,运维成本非常高,所以不建议这种方式。
为了让上手更加简单,ApacheShardingSphere 内置了 UUID、SNOWFLAKE 两种分布式主键⽣成器,
默认使⽤雪花算法(snowflake)⽣成 64bit 的⻓整型数据。
不仅如此它还抽离出分布式主键⽣成器的接口,⽅便我们实现⾃定义的⾃增主键⽣成算法。
实现动机
传统数据库软件开发中,主键⾃动⽣成技术是基本需求。而各个数据库对于该需求也提供了相应的⽀持,⽐如 MySQL 的⾃增键,Oracle 的⾃增序列等。
数据分⽚后,不同数据节点⽣成全局唯⼀主键是⾮常棘⼿的问题。
同⼀个逻辑表内的不同实际表之间的⾃增键由于⽆法互相感知而产⽣重复主键。
虽然可通过约束⾃增主键初始值和步⻓的⽅式避免碰撞,但需引⼊额外的运维规则,使解决⽅案缺乏完整性和可扩展性。
⽬前有许多第三⽅解决⽅案可以完美解决这个问题,如 UUID 等依靠特定算法⾃⽣成不重复键,或者通过引⼊主键⽣成服务等。
为了⽅⽤⼾使⽤、满⾜不同⽤⼾不同使⽤场景的需求,Apache ShardingSphere不仅提供了内置的分布式主键⽣成器,
例如 UUID 、SNOWFLAKE,
还抽离出分布式主键⽣成器的接口,⽅便⽤⼾⾃⾏实现⾃定义的⾃增主键⽣成器。
内置的主键⽣成器
UUID
采⽤ UUID.randomUUID() 的⽅式产⽣分布式主键。
SNOWFLAKE
在分⽚规则配置模块可配置每个表的主键⽣成策略,默认使⽤雪花算法(snowfl ake )⽣成 64bit 的⻓整型数据。
雪花算法是由 Twitter 公布的分布式主键⽣成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
实现原理
在同⼀个进程中,它⾸先是通过时间位保证不重复,如果时间相同则是通过序列位保证。同时由于时间位是单调递增的,且各个服务器如果⼤体做了时间同步,那么⽣成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插⼊的⾼效性。
例如 MySQL 的 Innodb 存储引擎的主键。
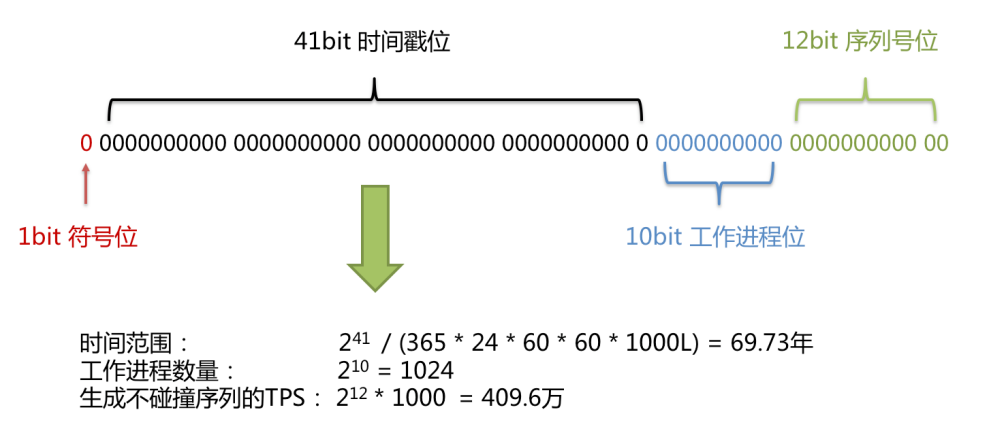
使⽤雪花算法⽣成的主键,⼆进制表⽰形式包含 4 部分,从⾼位到低位分表为:
- 1bit 符号位、
- 41bit 时间戳位、
- 10bit ⼯作进程位以及
- 12bit 序列号位。
符号位(1bit)
预留的符号位,恒为零。
时间戳位(41bit)
41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,⼀年所使⽤的毫秒数是:365 * 24 * 60 * 60 *1000。
通过计算可知:
Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L);
结果约等于 69.73 年。
Apache ShardingSphere 的雪花算法的时间纪元从 2016 年 11 ⽉ 1 ⽇零点开始,可以使⽤到 2086 年,
相信能满⾜绝⼤部分系统的要求。
⼯作进程位(10bit)
该标志在 Java 进程内是唯⼀的,如果是分布式应⽤部署应保证每个⼯作进程的 id 是不同的。该值默认为0,可通过属性设置。
序列号位(12bit)
该序列是⽤来在同⼀个毫秒内⽣成不同的 ID。
如果在这个毫秒内⽣成的数量超过 4096 (2 的 12 次幂),那么⽣成器会等待到下个毫秒继续⽣成。
雪花算法主键的详细结构⻅下图。
时钟回拨
服务器时钟回拨会导致产⽣重复序列,因此默认分布式主键⽣成器提供了⼀个最⼤容忍的时钟回拨毫秒数。
如果时钟回拨的时间超过最⼤容忍的毫秒数阈值,则程序报错;
如果在可容忍的范围内,默认分布式主键⽣成器会等待时钟同步到最后⼀次主键⽣成的时间后再继续⼯作。
最⼤容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
步长不均衡
导致数据倾斜
基因id算法
基本原理
业务:查询用户的所有订单、 查询订单详情。
字段:用户ID、订单ID。
普通水平切分:
根据订单ID切分则无法一次查询用户的所有订单;
根据用户ID切分则需要先查订单所属用户;
什么是分库基因?
通过uid分库,假设分为16个库,采用uid%16的方式来进行数据库路由,这里的uid%16,
其本质是uid的最后4个bit决定这行数据落在哪个库上,这4个bit,就是分库基因。
什么是基因法分库?

如上图所示,uid=666的用户发布了一条订单(666的二进制表示为:1010011010):
使用uid%16分库,决定这行数据要插入到哪个库中
分库基因是uid的最后4个bit,即1010
在生成tid时,先使用一种分布式ID生成算法生成前60bit(上图中绿色部分)
将分库基因加入到tid的最后4个bit(上图中粉色部分)
拼装成最终的64bit帖子tid(上图中蓝色部分)
这般,保证了同一个用户发布的所有订单的tid,都落在同一个库上,tid的最后4个bit都相同,
于是:
通过uid%16能够定位到库
通过tid%16也能定位到库
全局唯一ID也可以通过表自增位置和自增范围实现,比如用户ID哈希为 1 的表,自增位置为1,自增范围为 10。
代码实现
请参见视频配套源码
Shardingjdbc SPI与自定义主键
Java SPI是什么
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件。
系统设计的各个抽象,往往有很多不同的实现方案,
在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。
一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。
为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
Java SPI就是提供这样的一个机制:为某个接口寻找服务实现的机制。
有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。
整体机制图如下:

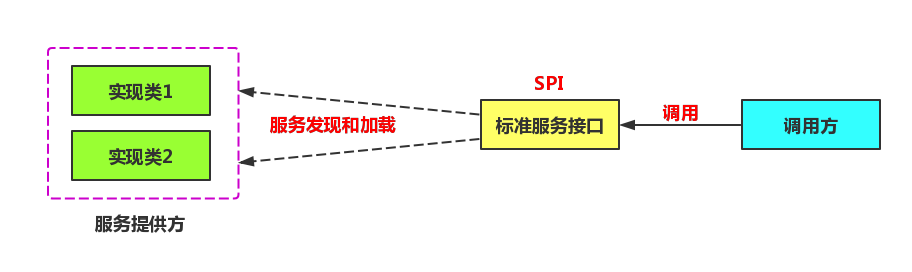
Java SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制。所以SPI的核心思想就是解耦。
Java SPI的约定
Java SPI使用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略
比较常见的例子:
- 数据库驱动加载接口实现类的加载
JDBC加载不同类型数据库的驱动 - 日志门面接口实现类加载
SLF4J加载不同提供商的日志实现类 - Spring
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等 - Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
Java SPI使用约定
要使用Java SPI,需要遵循如下约定:
- 1、当服务提供者提供了接口的一种具体实现后,在jar包的META-INF/services目录下创建一个以“接口全限定名”为命名的文件,内容为实现类的全限定名;
- 2、接口实现类所在的jar包放在主程序的classpath中;
- 3、主程序通过java.util.ServiceLoder动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM;
- 4、SPI的实现类必须携带一个不带参数的构造方法;
JavaSPI实战
首先,我们需要定义一个接口,SPI Service 接口
package com.crazymaker.springcloud.sharding.jdbc.demo.generator;
public interface IdGenerator
{
/**
* Next id long.
*
* @return the nextId
*/
Long nextId();
}
然后,定义两个实现类,也可以定义两个实现类
// 单机版 AtomicLong 类型的ID生成器
@Data
public class AtomicLongShardingKeyGeneratorSPIDemo implements IdGenerator {
private AtomicLong atomicLong = new AtomicLong(0);
@Override
public Long nextId() {
return atomicLong.incrementAndGet();
}
}
最后,要在ClassPath路径下配置添加一个文件:
- 文件名字是接口的全限定类名
- 内容是实现类的全限定类名
- 多个实现类用换行符分隔。
SPI配置文件位置,文件路径如下:

内容就是实现类的全限定类名:
com.crazymaker.springcloud.sharding.jdbc.demo.generator.AtomicLongShardingKeyGeneratorSPIDemo
测试
然后我们就可以通过ServiceLoader.load或者Service.providers方法拿到实现类的实例。
Service.providers包位于sun.misc.Service,ServiceLoader.load包位于java.util.ServiceLoader。
@Test
public void testGenIdByProvider() {
Iterator<IdGenerator> providers = Service.providers(IdGenerator.class);
while (providers.hasNext()) {
IdGenerator generator = providers.next();
for (int i = 0; i < 100; i++) {
Long id = generator.nextId();
System.out.println("id = " + id);
}
}
}
@Test
public void testGenIdByServiceLoader() {
ServiceLoader<IdGenerator> serviceLoaders = ServiceLoader.load(IdGenerator.class);
Iterator<IdGenerator> iterator = serviceLoaders.iterator();
while (iterator.hasNext()) {
IdGenerator generator = iterator.next();
for (int i = 0; i < 100; i++) {
Long id = generator.nextId();
System.out.println("id = " + id);
}
}
}
两种方式的输出结果是一致的:
可插拔架构
背景
在 Apache ShardingSphere 中,很多功能实现类的加载⽅式是通过 SPI(Service Provider Interface)注的⽅式完成的。SPI 是⼀种为了被第三⽅实现或扩展的 API,它可以⽤于实现框架扩展或组件替换。
挑战
可插拔架构对程序架构设计的要求⾮常⾼,需要将各个模块相互独⽴,互不感知,并且通过⼀个可插拔内核,以叠加的⽅式将各种功能组合使⽤。设计⼀套将功能开发完全隔离的架构体系,既可以最⼤限度的将开源社区的活⼒激发出来,也能够保障项⽬的质量。
Apache ShardingSphere 5.x 版本开始致⼒于可插拔架构,项⽬的功能组件能够灵活的以可插拔的⽅式进⾏扩展。⽬前,数据分⽚、读写分离、数据加密、影⼦库压测等功能,以及对 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的⽀持,均通过插件的⽅式织⼊项⽬。Apache ShardingSphere ⽬前已提供数⼗个 SPI 作为系统的扩展点,而且仍在不断增加中。
⽬标
让开发者能够像使⽤积木⼀样定制属于⾃⼰的独特系统,是 Apache ShardingSphere 可插拔架构的设计⽬标。
Apache ShardingSphere 可插拔架构提供了数⼗个基于 SPI 的扩展点。对于开发者来说,可以⼗分⽅便的对功能进⾏定制化扩展。
本章节将 Apache ShardingSphere 的 SPI 扩展点悉数列出。如⽆特殊需求,⽤⼾可以使⽤ Apache Shard-ingSphere 提供的内置实现;⾼级⽤⼾则可以参考各个功能模块的接口进⾏⾃定义实现。
基于类型的SPI机制
package org.apache.shardingsphere.spi;
import java.util.Properties;
/**
* Base algorithm SPI.
*/
public interface TypeBasedSPI {
/**
* Get algorithm type.
*
* @return type
*/
String getType();
/**
* Get properties.
*
* @return properties of algorithm
*/
Properties getProperties();
/**
* Set properties.
*
* @param properties properties of algorithm
*/
void setProperties(Properties properties);
}
分布式主键扩展点
自定义主键实战
package com.crazymaker.springcloud.sharding.jdbc.demo.generator;
import lombok.Data;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
// 单机版 AtomicLong 类型的ID生成器
@Data
public class AtomicLongShardingKeyGenerator implements ShardingKeyGenerator {
private AtomicLong atomicLong = new AtomicLong(0);
private Properties properties = new Properties();
@Override
public Comparable<?> generateKey() {
return atomicLong.incrementAndGet();
}
@Override
public String getType() {
//声明类型
return "DemoAtomicLongID";
}
}
使用实例
@Test
public void testGenIdByShardingServiceLoader() {
ShardingKeyGeneratorServiceLoader serviceLoader = new ShardingKeyGeneratorServiceLoader();
ShardingKeyGenerator keyGenerator= serviceLoader.newService("DemoAtomicLongID" ,new Properties());
for (int i = 0; i < 100; i++) {
Long id = (Long) keyGenerator.generateKey();
System.out.println("id = " + id);
}
}
演示和源码介绍:
请参见视频
ShardingSphere的SQL使用限制
参见官网文档:
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/
文档中
详细列出了非常多ShardingSphere目前版本支持和不支持的SQL类型。
这些需要关注。
支持的SQL
| SQL | 必要条件 |
|---|---|
| SELECT * FROM tbl_name | |
| SELECT * FROM tbl_name WHERE (col1 = ? or col2 = ?) and col3 = ? | |
| SELECT * FROM tbl_name WHERE col1 = ? ORDER BY col2 DESC LIMIT ? | |
| SELECT COUNT(*), SUM(col1), MIN(col1), MAX(col1), AVG(col1) FROM tbl_name WHERE col1 = ? | |
| SELECT COUNT(col1) FROM tbl_name WHERE col2 = ? GROUP BY col1 ORDER BY col3 DESC LIMIT ?, ? | |
| INSERT INTO tbl_name (col1, col2,…) VALUES (?, ?, ….) | |
| INSERT INTO tbl_name VALUES (?, ?,….) | |
| INSERT INTO tbl_name (col1, col2, …) VALUES (?, ?, ….), (?, ?, ….) | |
| INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? | INSERT表和SELECT表必须为相同表或绑定表 |
| REPLACE INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? | REPLACE表和SELECT表必须为相同表或绑定表 |
| UPDATE tbl_name SET col1 = ? WHERE col2 = ? | |
| DELETE FROM tbl_name WHERE col1 = ? | |
| CREATE TABLE tbl_name (col1 int, …) | |
| ALTER TABLE tbl_name ADD col1 varchar(10) | |
| DROP TABLE tbl_name | |
| TRUNCATE TABLE tbl_name | |
| CREATE INDEX idx_name ON tbl_name | |
| DROP INDEX idx_name ON tbl_name | |
| DROP INDEX idx_name | |
| SELECT DISTINCT * FROM tbl_name WHERE col1 = ? | |
| SELECT COUNT(DISTINCT col1) FROM tbl_name | |
| SELECT subquery_alias.col1 FROM (select tbl_name.col1 from tbl_name where tbl_name.col2=?) subquery_alias |
不支持的SQL
| SQL | 不支持原因 |
|---|---|
| INSERT INTO tbl_name (col1, col2, …) VALUES(1+2, ?, …) | VALUES语句不支持运算表达式 |
| INSERT INTO tbl_name (col1, col2, …) SELECT * FROM tbl_name WHERE col3 = ? | SELECT子句暂不支持使用*号简写及内置的分布式主键生成器 |
| REPLACE INTO tbl_name (col1, col2, …) SELECT * FROM tbl_name WHERE col3 = ? | SELECT子句暂不支持使用*号简写及内置的分布式主键生成器 |
| SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2 | UNION |
| SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2 | UNION ALL |
| SELECT SUM(DISTINCT col1), SUM(col1) FROM tbl_name | 详见DISTINCT支持情况详细说明 |
| SELECT * FROM tbl_name WHERE to_date(create_time, ‘yyyy-mm-dd’) = ? | 会导致全路由 |
| (SELECT * FROM tbl_name) | 暂不支持加括号的查询 |
| SELECT MAX(tbl_name.col1) FROM tbl_name | 查询列是函数表达式时,查询列前不能使用表名;若查询表存在别名,则可使用表的别名 |
DISTINCT支持情况详细说明
支持的SQL
| SQL |
|---|
| SELECT DISTINCT * FROM tbl_name WHERE col1 = ? |
| SELECT DISTINCT col1 FROM tbl_name |
| SELECT DISTINCT col1, col2, col3 FROM tbl_name |
| SELECT DISTINCT col1 FROM tbl_name ORDER BY col1 |
| SELECT DISTINCT col1 FROM tbl_name ORDER BY col2 |
| SELECT DISTINCT(col1) FROM tbl_name |
| SELECT AVG(DISTINCT col1) FROM tbl_name |
| SELECT SUM(DISTINCT col1) FROM tbl_name |
| SELECT COUNT(DISTINCT col1) FROM tbl_name |
| SELECT COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1 |
| SELECT COUNT(DISTINCT col1 + col2) FROM tbl_name |
| SELECT COUNT(DISTINCT col1), SUM(DISTINCT col1) FROM tbl_name |
| SELECT COUNT(DISTINCT col1), col1 FROM tbl_name GROUP BY col1 |
| SELECT col1, COUNT(DISTINCT col1) FROM tbl_name GROUP BY col1 |
不支持的SQL
| SQL | 不支持原因 |
|---|---|
| SELECT SUM(DISTINCT tbl_name.col1), SUM(tbl_name.col1) FROM tbl_name | 查询列是函数表达式时,查询列前不能使用表名;若查询表存在别名,则可使用表的别名 |
ShardingJdbc数据分片开发总结
作为一个开发者,ShardingJdbc可以帮我们屏蔽底层的细节,
让我们在面对分库分表的场景下,可以像使用单库单表一样简单;
分片策略算法
ShardingSphere-JDBC在分片策略上分别引入了分片算法、分片策略两个概念,
当然在分片的过程中分片键也是一个核心的概念;在此可以简单的理解分片策略 = 分片算法 + 分片键;
至于为什么要这么设计,应该是ShardingSphere-JDBC考虑更多的灵活性,把分片算法单独抽象出来,方便开发者扩展;
分片算法
提供了抽象分片算法类:ShardingAlgorithm,根据类型又分为:精确分片算法、区间分片算法、复合分片算法以及Hint分片算法;
- 精确分片算法:对应
PreciseShardingAlgorithm类,主要用于处理=和IN的分片; - 区间分片算法:对应
RangeShardingAlgorithm类,主要用于处理BETWEEN AND,>,<,>=,<=分片; - 复合分片算法:对应
ComplexKeysShardingAlgorithm类,用于处理使用多键作为分片键进行分片的场景; - Hint分片算法:对应
HintShardingAlgorithm类,用于处理使用Hint行分片的场景;
以上所有的算法类都是接口类,具体实现交给开发者自己;
分片策略
分片策略基本和上面的分片算法对应,包括:标准分片策略、复合分片策略、Hint分片策略、内联分片策略、不分片策略;
-
标准分片策略:对应
StandardShardingStrategy类,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法,PreciseShardingAlgorithm是必须的,RangeShardingAlgorithm可选的;public final class StandardShardingStrategy implements ShardingStrategy { private final String shardingColumn; private final PreciseShardingAlgorithm preciseShardingAlgorithm; private final RangeShardingAlgorithm rangeShardingAlgorithm; } -
复合分片策略:对应
ComplexShardingStrategy类,提供ComplexKeysShardingAlgorithm分片算法;public final class ComplexShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final ComplexKeysShardingAlgorithm shardingAlgorithm; }可以发现支持多个分片键;
-
Hint分片策略:对应
HintShardingStrategy类,通过 Hint 指定分片值而非从 SQL 中提取分片值的方式进行分片的策略;提供HintShardingAlgorithm分片算法;public final class HintShardingStrategy implements ShardingStrategy { @Getter private final Collection<String> shardingColumns; private final HintShardingAlgorithm shardingAlgorithm; } -
内联分片策略:对应
InlineShardingStrategy类,没有提供分片算法,路由规则通过表达式来实现; -
不分片策略:对应
NoneShardingStrategy类,不分片策略;
分片策略配置类
在使用中我们并没有直接使用上面的分片策略类,ShardingSphere-JDBC分别提供了对应策略的配置类包括:
StandardShardingStrategyConfigurationComplexShardingStrategyConfigurationHintShardingStrategyConfigurationInlineShardingStrategyConfigurationNoneShardingStrategyConfiguration
实战步骤总结
有了以上相关基础概念,接下来针对每种分片策略做一个简单的实战,在实战前首先准备好库和表;
准备
分别准备两个库:ds0、ds1;然后每个库分别包含两个表:t_order0,t_order1;
CREATE TABLE `t_order0` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`order_id` bigint(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
准备真实数据源
我们这里有两个数据源,这里都使用java代码的方式来配置:
/**
* 通过ShardingDataSourceFactory 构建分片数据源
*
* @return
* @throws SQLException
*/
@Before
public void buildShardingDataSource() throws SQLException {
/*
* 1. 数据源集合:dataSourceMap
* 2. 分片规则:shardingRuleConfig
* 3. 属性:properties
*
*/
DataSource druidDs1 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db1?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
DataSource druidDs2 = buildDruidDataSource(
"jdbc:mysql://cdh1:3306/sharding_db2?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=true&serverTimezone=UTC",
"root", "123456");
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
// 添加数据源.
// 两个数据源ds_0和ds_1
dataSourceMap.put("ds0",druidDs1);
dataSourceMap.put("ds1", druidDs2);
/**
* 需要构建表规则
* 1. 指定逻辑表.
* 2. 配置实际节点》
* 3. 指定主键字段.
* 4. 分库和分表的规则》
*
*/
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
//step2:分片规则
TableRuleConfiguration userShardingRuleConfig = userShardingRuleConfig();
shardingRuleConfig.getTableRuleConfigs().add(userShardingRuleConfig);
// 多数据源一定要指定默认数据源
// 只有一个数据源就不需要
shardingRuleConfig.setDefaultDataSourceName("ds0");
Properties properties = new Properties();
//打印sql语句,生产环境关闭
properties.setProperty("sql.show", Boolean.TRUE.toString());
dataSource= ShardingDataSourceFactory.createDataSource(
dataSourceMap, shardingRuleConfig, properties);
}
这里配置的两个数据源都是普通的数据源,最后会把dataSourceMap交给ShardingDataSourceFactory管理;
表规则配置
表规则配置类TableRuleConfiguration,包含了五个要素:逻辑表、真实数据节点、数据库分片策略、数据表分片策略、分布式主键生成策略;
/**
* 表的分片规则
*/
protected TableRuleConfiguration userShardingRuleConfig() {
String logicTable = USER_LOGIC_TB;
//获取实际的 ActualDataNodes
String actualDataNodes = "ds$->{0..1}.t_user_$->{0..1}";
// 两个表达式的 笛卡尔积
//ds0.t_user_0
//ds1.t_user_0
//ds0.t_user_1
//ds1.t_user_1
TableRuleConfiguration tableRuleConfig = new TableRuleConfiguration(logicTable, actualDataNodes);
//设置分表策略
// inline 模式
// ShardingStrategyConfiguration tableShardingStrategy =
// new InlineShardingStrategyConfiguration("user_id", "t_user_$->{user_id % 2}");
//自定义模式
TablePreciseShardingAlgorithm tablePreciseShardingAlgorithm =
new TablePreciseShardingAlgorithm();
RouteInfinityRangeShardingAlgorithm routeInfinityRangeShardingAlgorithm =
new RouteInfinityRangeShardingAlgorithm();
RangeOrderShardingAlgorithm tableRangeShardingAlg =
new RangeOrderShardingAlgorithm();
PreciseOrderShardingAlgorithm preciseOrderShardingAlgorithm =
new PreciseOrderShardingAlgorithm();
ShardingStrategyConfiguration tableShardingStrategy =
new StandardShardingStrategyConfiguration("user_id",
preciseOrderShardingAlgorithm,
routeInfinityRangeShardingAlgorithm);
tableRuleConfig.setTableShardingStrategyConfig(tableShardingStrategy);
// 配置分库策略(Groovy表达式配置db规则)
// inline 模式
// ShardingStrategyConfiguration dsShardingStrategy = new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}");
//自定义模式
DsPreciseShardingAlgorithm dsPreciseShardingAlgorithm = new DsPreciseShardingAlgorithm();
RangeOrderShardingAlgorithm dsRangeShardingAlg =
new RangeOrderShardingAlgorithm();
ShardingStrategyConfiguration dsShardingStrategy =
new StandardShardingStrategyConfiguration("user_id",
preciseOrderShardingAlgorithm,
routeInfinityRangeShardingAlgorithm);
tableRuleConfig.setDatabaseShardingStrategyConfig(dsShardingStrategy);
tableRuleConfig.setKeyGeneratorConfig(new KeyGeneratorConfiguration("SNOWFLAKE", "user_id"));
return tableRuleConfig;
}
-
逻辑表:这里配置的逻辑表就是t_user,对应的物理表有t_user_0,t_user_1;
-
真实数据节点:这里使用行表达式进行配置的,简化了配置;上面的配置就相当于配置了:
db0 ├── t_user_0 └── t_user_1 db1 ├── t_user_0 └── t_user_1 -
数据库分片策略:这里的库分片策略就是上面介绍的五种类型,这里使用的
StandardShardingStrategyConfiguration,需要指定分片键和分片算法,这里使用的是精确分片算法;public final class PreciseOrderShardingAlgorithm implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(final Collection<String> availableTargetNames, final PreciseShardingValue<Long> shardingValue) { for (String each : availableTargetNames) { System.out.println("shardingValue = " + shardingValue.getValue()+ " target = " + each + " shardingValue.getValue() % 2) = " + shardingValue.getValue() % 2L); if (each.endsWith(String.valueOf(shardingValue.getValue() % 2L))) { return each; } } return null; } }这里的shardingValue就是user_id对应的真实值,每次和2取余;availableTargetNames可选择就是{ds0,ds1};看余数和哪个库能匹配上就表示路由到哪个库;
-
数据表分片策略:指定的分片键(order_id)和分库策略不一致,其他都一样;
-
分布式主键生成策略:ShardingSphere-JDBC提供了多种分布式主键生成策略,后面详细介绍,这里使用雪花算法;
配置分片规则
配置分片规则ShardingRuleConfiguration,包括多种配置规则:表规则配置、绑定表配置、广播表配置、默认数据源名称、默认数据库分片策略、默认表分片策略、默认主键生成策略、主从规则配置、加密规则配置;
- 表规则配置 tableRuleConfigs:也就是上面配置的库分片策略和表分片策略,也是最常用的配置;
- 绑定表配置 bindingTableGroups:指分⽚规则⼀致的主表和⼦表;绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将⼤⼤提升;
- 广播表配置 broadcastTables:所有的分⽚数据源中都存在的表,表结构和表中的数据在每个数据库中均完全⼀致。适⽤于数据量不⼤且需要与海量数据的表进⾏关联查询的场景;
- 默认数据源名称 defaultDataSourceName:未配置分片的表将通过默认数据源定位;
- 默认数据库分片策略 defaultDatabaseShardingStrategyConfig:表规则配置可以设置数据库分片策略,如果没有配置可以在这里面配置默认的;
- 默认表分片策略 defaultTableShardingStrategyConfig:表规则配置可以设置表分片策略,如果没有配置可以在这里面配置默认的;
- 默认主键生成策略 defaultKeyGeneratorConfig:表规则配置可以设置主键生成策略,如果没有配置可以在这里面配置默认的;内置UUID、SNOWFLAKE生成器;
- 主从规则配置 masterSlaveRuleConfigs:用来实现读写分离的,可配置一个主表多个从表,读面对多个从库可以配置负载均衡策略;
- 加密规则配置 encryptRuleConfig:提供了对某些敏感数据进行加密的功能,提供了⼀套完整、安全、透明化、低改造成本的数据加密整合解决⽅案;
数据插入
以上准备好,就可以操作数据库了,这里执行插入操作:
/**
* 新增测试.
*
*/
@Test
public void testInsertUser() throws SQLException {
/*
* 1. 需要到DataSource
* 2. 通过DataSource获取Connection
* 3. 定义一条SQL语句.
* 4. 通过Connection获取到PreparedStament.
* 5. 执行SQL语句.
* 6. 关闭连接.
*/
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "insert into t_user(name) values('name-0001')";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
preparedStatement.execute();
sql = "insert into t_user(name) values('name-0002')";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.execute();
// * 6. 关闭连接.
preparedStatement.close();
connection.close();
}
通过以上配置的真实数据源、分片规则以及属性文件创建分片数据源ShardingDataSource;
接下来就可以像使用单库单表一样操作分库分表了,sql中可以直接使用逻辑表,分片算法会根据具体的值就行路由处理;
经过路由最终:奇数入ds1.t_user_1,偶数入ds0.t_user_0;
分片算法
上面的介绍的精确分片算法中,通过PreciseShardingValue来获取当前分片键值,ShardingSphere-JDBC针对每种分片算法都提供了相应的ShardingValue,具体包括:
- PreciseShardingValue
- RangeShardingValue
- ComplexKeysShardingValue
- HintShardingValue
主从复制&读写分离
对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
搭建的Mysql主从集群
设置前注意下面几点:
1)要保证同步服务期间之间的网络联通。即能相互ping通,能使用对方授权信息连接到对方数据库(防火墙开放3306端口)。
2)关闭selinux。
3)同步前,双方数据库中需要同步的数据要保持一致。这样,同步环境实现后,再次更新的数据就会如期同步了。如果主库是新库,忽略此步。
创建目录
把尼恩提供的 配置文件、编排文件整体复制到 cdn2 虚拟机的 目录下:
docker-compose.yml文件如下
version: '3.5'
services:
mysql-master:
container_name: mysql-master
image: mysql:5.7.31
restart: always
ports:
- 3340:3306
privileged: true
volumes:
- ./mysql-master/log:/var/log/mysql
- ./mysql-master/conf/my.cnf:/etc/mysql/my.cnf
- ./mysql-master/data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: "123456"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci',
'--max_connections=3000'
]
networks:
mysql-canal-network:
aliases:
- mysql-master
mysql-slave:
container_name: mysql-slave
image: mysql:5.7.31
restart: always
ports:
- 3341:3306
privileged: true
volumes:
- ./mysql-slave/log:/var/log/mysql
- ./mysql-slave/conf/my.cnf:/etc/mysql/my.cnf
- ./mysql-slave/data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: "123456"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci',
'--max_connections=3000'
]
networks:
mysql-canal-network:
aliases:
- mysql-slave
networks:
mysql-canal-network:
name: mysql-canal-network
driver: bridge
1. 主master配置文件my.cnf
vim msql-master/volumes/conf/my.cnf
[mysqld]
# [必须]服务器唯一ID,默认是1,一般取IP最后一段
server-id=1
# [必须]启用二进制日志
log-bin=mysql-bin
# 复制过滤:也就是指定哪个数据库不用同步(mysql库一般不同步)
binlog-ignore-db=mysql
# 设置需要同步的数据库 binlog_do_db = 数据库名;
# 如果是多个同步库,就以此格式另写几行即可。
# 如果不指明对某个具体库同步,表示同步所有库。除了binlog-ignore-db设置的忽略的库
# binlog_do_db = test #需要同步test数据库。
# 确保binlog日志写入后与硬盘同步
sync_binlog = 1
# 跳过所有的错误,继续执行复制操作
slave-skip-errors = all
温馨提示:在主服务器上最重要的二进制日志设置是sync_binlog,这使得mysql在每次提交事务的时候把二进制日志的内容同步到磁盘上,即使服务器崩溃也会把事件写入日志中。
sync_binlog这个参数是对于MySQL系统来说是至关重要的,他不仅影响到Binlog对MySQL所带来的性能损耗,而且还影响到MySQL中数据的完整性。对于``"sync_binlog"``参数的各种设置的说明如下:
sync_binlog=0,当事务提交之后,MySQL不做fsync之类的磁盘同步指令刷新binlog_cache中的信息到磁盘,而让Filesystem自行决定什么时候来做同步,或者cache满了之后才同步到磁盘。
sync_binlog=n,当每进行n次事务提交之后,MySQL将进行一次fsync之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。
在MySQL中系统默认的设置是sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候的性能是最好的,但是风险也是最大的。因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。而当设置为“1”的时候,是最安全但是性能损耗最大的设置。因为当设置为1的时候,即使系统Crash,也最多丢失binlog_cache中未完成的一个事务,对实际数据没有任何实质性影响。
从以往经验和相关测试来看,对于高并发事务的系统来说,“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
2. 从slave配置文件my.cnf
每个slave都需要设置server_id,且一个集群中所有的server_id不能够被重复。
每个slave只能有一个Master,但每个Master可以有多个Slave(MySQL 5.7开始出现多源复制,就是允许Slave有多个Master)。
vim msql-slave/volumes/conf/my.cnf
[mysqld]
# [必须]服务器唯一ID,默认是1,一般取IP最后一段
server-id=2
# 如果想实现 主-从(主)-从 这样的链条式结构,需要设置:
# log-slave-updates 只有加上它,从前一台机器上同步过来的数据才能同步到下一台机器。
# 设置需要同步的数据库,主服务器上不限定数据库,在从服务器上限定replicate-do-db = 数据库名;
# 如果不指明同步哪些库,就去掉这行,表示所有库的同步(除了ignore忽略的库)。
# replicate-do-db = test;
# 不同步test数据库 可以写多个例如 binlog-ignore-db = mysql,information_schema
replicate-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-bin
log-bin-index=mysql-bin.index
## relay_log配置中继日志
#relay_log=edu-mysql-relay-bin
## 还可以设置一个log保存周期:
#expire_logs_days=14
# 跳过所有的错误,继续执行复制操作
slave-skip-errors = all
启动服务mysql主从集群
rm -rf /home/docker-compose/mysqlmasterslave
cp -rf /vagrant/3G-middleware/mysqlmasterslave /home/docker-compose/
cd /home/docker-compose/
chmod 777 -R /home/docker-compose/mysqlmasterslave
chmod 644 /home/docker-compose/mysqlmasterslave/master/my.cnf
chmod 644 /home/docker-compose/mysqlmasterslave/slave/my.cnf
chown -R mysql:mysql /home/docker-compose/mysqlmasterslave/slave/bin-log
chown -R mysql:mysql /home/docker-compose/mysqlmasterslave/master/bin-log
cd mysqlmasterslave
docker-compose up
docker-compose --compatibility up -d
docker-compose logs -f
docker-compose down
tail -30 /home/docker-compose/mysqlmasterslave/master/log/mysql/error.log
tail -f /home/docker-compose/mysqlmasterslave/master/log/mysql/error.log
有关docker环境的学习,请参考疯狂创客圈 总目录

查询服务ip地址
从上面的信息里获取服务创建的网络名称mysql-canal-network
docker network inspect mysql-canal-network
"Containers": {
"4714af786aa835a8b6eca35e123e9f4d7f4cdd7099f329d17ba5e513e8cbd59b": {
"Name": "mysql-master",
"EndpointID": "b14745f5abc126aef1b534e43f3eb99d0afec6ab8ba92c7edc162f52eb5d0662",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"8573f0faeea2259995db260fa7d4cba4d5fd363752ef24aef825bec237a0df7f": {
"Name": "mysql-slave",
"EndpointID": "369bca8b3d30c19b2fae71e648b6ff5c73583dcb2aa73f0380cc3410dd018114",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
},
查到结果
mysql-master ip为 172.18.0.3
mysql-slave ip为 172.18.0.2
进入主mysql服务
docker exec -it mysql-master bash
mysql -uroot -p123456
#查看server_id是否生效
mysql> show variables like '%server_id%';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| server_id | 3306 |
| server_id_bits | 32 |
+----------------+-------+
2 rows in set (0.00 sec)
#看master信息 File 和 Position, 从服务上要用
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000004 | 154 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
给root开 远程权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
grant replication slave,replication client on *.* to 'slave'@'%' identified by "123456";
flush privileges;
#开权限
grant replication slave,replication client on *.* to 'slave'@'%' identified by "123456";
flush privileges;
进入从slave服务
docker exec -it mysql-slave bash
mysql -uroot -p123456
show variables like '%server_id%';
#查看server_id是否生效
mysql> show variables like '%server_id%';
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| server_id | 2 |
| server_id_bits | 32 |
+----------------+-------+
建立主从关系
change master to master_host='mysql-master',master_user='slave',master_password='123456',master_port=3306,master_log_file='bin-log.000003', master_log_pos=1346,master_connect_retry=30;
mysql> change master to master_host='mysql-master',master_user='slave',master_password='123456',master_port=3306,master_log_file='bin-log.000003', master_log_pos=154,master_connect_retry=30;
Query OK, 0 rows affected, 2 warnings (0.24 sec)
在从库上,启动 slave线程
mysql> start slave;
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-master
Master_User: slave
Master_Port: 3306
Connect_Retry: 30
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 610
Relay_Log_File: ed93d4a41e0f-relay-bin.000002
Relay_Log_Pos: 776
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 610
Relay_Log_Space: 990
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3306
Master_UUID: 3c1efb5d-a1e9-11ec-ad17-0242ac120002
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
连接主mysql参数说明:
**master_port**:Master的端口号,指的是容器的端口号
**master_user**:用于数据同步的用户
**master_password**:用于同步的用户的密码
**master_log_file**:指定 Slave 从哪个日志文件开始复制数据,即上文中提到的 File 字段的值
**master_log_pos**:从哪个 Position 开始读,即上文中提到的 Position 字段的值
**master_connect_retry**:如果连接失败,重试的时间间隔,单位是秒,默认是60秒
上面看到,有两个Yes,说明已经成功了
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
设置从服务器slave为只读模式
在从服务器slave上操作
SHOW VARIABLES LIKE '%read_only%'; #查看只读状态
SET GLOBAL super_read_only=1; #super权限的用户只读状态 1.只读 0:可写
SET GLOBAL read_only=1; #普通权限用户读状态 1.只读 0:可写
到此已经设置成功了,下面就可以测试一下,已经可以主从同步了
从服务器上的常用操作
docker exec -it mysql-slave bash
mysql -uroot -p123456
stop slave;
start slave;
show slave status;
show slave status \G;
reset slave;
drop user canal;
drop database ...;
tail -30 /home/docker-compose/mysqlmasterslave/master/log/mysql/error.log
数据源准备
在cdh1节点的主库创建表
[]( https://img-blog.csdnimg.cn/20210101220214565.png?x-oss-process=image/watermark ,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2NyYXp5bWFrZXJjaXJjbGU=,size_16,color_FFFFFF,t_70)
脚本如下:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for t_user_0
-- ----------------------------
DROP TABLE IF EXISTS `t_user_0`;
CREATE TABLE `t_user_0` (
`id` bigint(20) NULL DEFAULT NULL,
`name` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
DROP TABLE IF EXISTS `t_user_1`;
CREATE TABLE `t_user_1` (
`id` bigint(20) NULL DEFAULT NULL,
`name` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
确保cdh2节点的从库也有以上两个表:
[]( https://img-blog.csdnimg.cn/20210101220505503.png?x-oss-process=image/watermark ,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2NyYXp5bWFrZXJjaXJjbGU=,size_16,color_FFFFFF,t_70)
注意:主库创建的表,会自动复制到从库
binlog(归档日志)
名称:归档日志(二进制日志)
作用:用于复制,在主从复制中,从库利用主库上的binlog进行重播,实现主从同步。
用于的基于时间点的数据还原,主要是用于增量数据还原。
内容:逻辑格式的日志,可以简单认为就是执行过的事务中的sql语句。
binlog记录了对MySQL数据库执行更改的所有操作,不包括SELECT和SHOW这类操作,主要作用是用于数据库的主从复制及数据的增量恢复
使用mysqldump备份时,只是对一段时间的数据进行全备,但是如果备份后突然发现数据库服务器故障,这个时候就要用到binlog的日志了
mysqldump 全量备份 + mysqlbinlog 二进制日志增量备份
存在一个完全备份,生产环境一般凌晨某个时刻进行全备
mysqldump -uroot -p --default-character-set=gbk --single-transaction -F -B school |gzip > /backup/school_$(date +%F).sql.gz
恢复增量备份
mysqlbinlog -d school mysql-bin.000004 > db-bin.sql
mysql -uroot -p111111 db < db-bin.sql
要开启 mysql log-bin 日志功能,
[mysqld]
datadir=/var/lib/mysql/data
log-bin=mysql-bin
server-id=1
binlog格式有三种:STATEMENT,ROW,MIXED
- STATEMENT模式:binlog里面记录的就是SQL语句的原文。优点是并不需要记录每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致
- ROW模式:不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了,解决了STATEMENT模式下出现master-slave中的数据不一致。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨
- MIXED模式:以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式
binlog 持久化策略
在进行事务的过程中,首先会把binlog 写入到binlog cache中(因为写入到cache中会比较快,一个事务通常会有多个操作,避免每个操作都直接写磁盘导致性能降低),事务最终提交的时候再吧binlog 写入到磁盘中。当然事务在最终commit的时候binlog是否马上写入到磁盘中是由参数 sync_binlog 配置来决定的。
1、sync_binlog=0 的时候,表示每次提交事务binlog不会马上写入到磁盘,而是先写到page cache,相对于磁盘写入来说写page cache要快得多,不过在Mysql 崩溃的时候会有丢失日志的风险。
2、sync_binlog=1 的时候,表示每次提交事务都会执行 fsync 写入到磁盘 ;
3、sync_binlog的值大于1 的时候,表示每次提交事务都 先写到page cach,只有等到积累了N个事务之后才fsync 写入到磁盘,同样在此设置下Mysql 崩溃的时候会有丢失N个事务日志的风险。
很显然三种模式下,sync_binlog=1 是强一致的选择,选择0或者N的情况下在极端情况下就会有丢失日志的风险,具体选择什么模式还是得看系统对于一致性的要求。
redo log(重做日志)
名称: 重做日志
作用:确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
内容:物理格式的日志,记录的是物理数据页面的修改的信息,其redo log是顺序写入redo log file的物理文件中去的。
MySQL整体来看就有两块:
-
一块是Server层,主要做的是MySQL功能层面的事情;比如 binlog是 Server层也有自己的日志
-
还有一块是引擎层,负责存储相关的具体事宜。比如,redo log是InnoDB引擎特有的日志,
MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM所改良。虽然性能极佳,但却有一个缺点:不支持事务处理(transaction)。
redo log的来源
redo log 是属于引擎层(innodb)的日志,它的设计目标是支持innodb的“事务”的特性,事务ACID特性分别是原子性、一致性、隔离性、持久性, 一致性是事务的最终追求的目标,隔离性、原子性、持久性是达成一致性目标的手段,隔离性是通过锁机制来实现的。
而事务的原子性和持久性则是通过redo log 和undo log来保障的。
redo log 能保证对于已经COMMIT的事务产生的数据变更,即使是系统宕机崩溃也可以通过它来进行数据重做,达到数据的一致性,这也就是事务持久性的特征,一旦事务成功提交后,只要修改的数据都会进行持久化,不会因为异常、宕机而造成数据错误或丢失,所以解决异常、宕机而可能造成数据错误或丢是redo log的核心职责。
什么是 WAL
MySQL里常说的WAL技术,全称是Write Ahead Log,即当事务提交时,先写redo log,再修改页。
WAL(Write Ahead Log)预写日志,是数据库系统中常见的一种手段,用于保证数据操做的原子性和持久性。
在计算机科学中,预写式日志(Write-ahead logging,缩写 WAL)是关系数据库系统中用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在使用 WAL 的系统中,全部的修改在提交以前都要先写入 log 文件中。
log 文件中一般包括 redo 和 undo 信息。
这样作的目的能够经过一个例子来讲明。
假设一个程序在执行某些操做的过程当中机器掉电了。在重新启动时,若是使用了 WAL,程序就能够检查 log 文件,并对忽然掉电时计划执行的操做内容跟实际上执行的操做内容进行比较。在这个比较的基础上,程序就能够决定是撤销已作的操做仍是继续完成已作的操做,或者是保持原样。
预写式日志(Write-ahead logging,缩写 WAL),当有一条记录需要更新的时候,InnoDB会先把记录写到redo log里面,并更新Buffer Pool的page,这个时候更新操作就算完成了
Buffer Pool是物理页的缓存,对InnoDB的任何修改操作都会首先在Buffer Pool的page上进行,然后这样的页将被标记为脏页并被放到专门的Flush List上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,循环使用,从头开始写,写到末尾就又回到开头循环写(顺序写,节省了随机写磁盘的IO消耗)
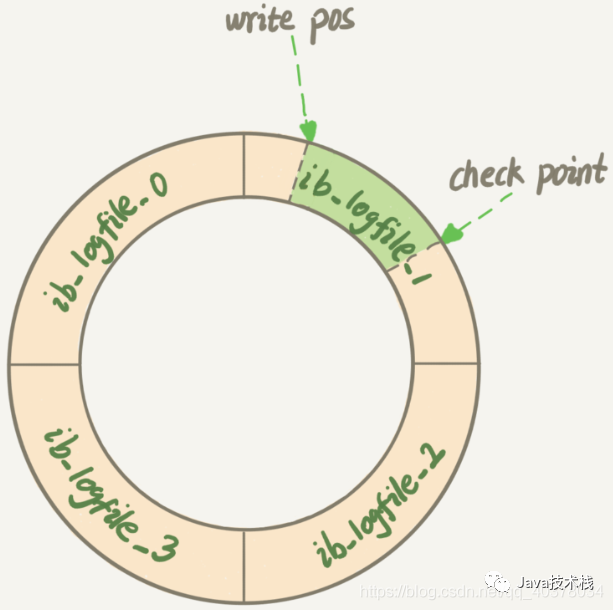
Write Pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。
Check Point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
Write Pos和Check Point之间空着的部分,可以用来记录新的操作。如果Write Pos追上Check Point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把Check Point推进一下
当数据库发生宕机时,数据库不需要重做所有的日志,因为Check Point之前的页都已经刷新回磁盘,只需对Check Point后的redo log进行恢复,从而缩短了恢复的时间
当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Check Point,将脏页刷新回磁盘。
InnoDB首先将redo log放入到redo log buffer,然后按一定频率将其刷新到redo log file
下列三种情况下会将redo log buffer刷新到redo log file:
-
Master Thread每一秒将redo log buffer刷新到redo log file
-
每个事务提交时会将redo log buffer刷新到redo log file
-
当redo log缓冲池剩余空间小于1/2时,会将redo log buffer刷新到redo log file
两阶段提交
将redo log的写入拆成了两个步骤:prepare和commit,这就是两阶段提交
update T set c=c+1 where ID=2;
执行器和InnoDB引擎在执行这个update语句时的内部流程:
- 执行器先找到引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据也本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回
- 执行器拿到引擎给的行数据,把这个值加上1,得到新的一行数据,再调用引擎接口写入这行新数据
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务
- 执行器生成这个操作的binlog,并把binlog写入磁盘
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交状态,更新完成
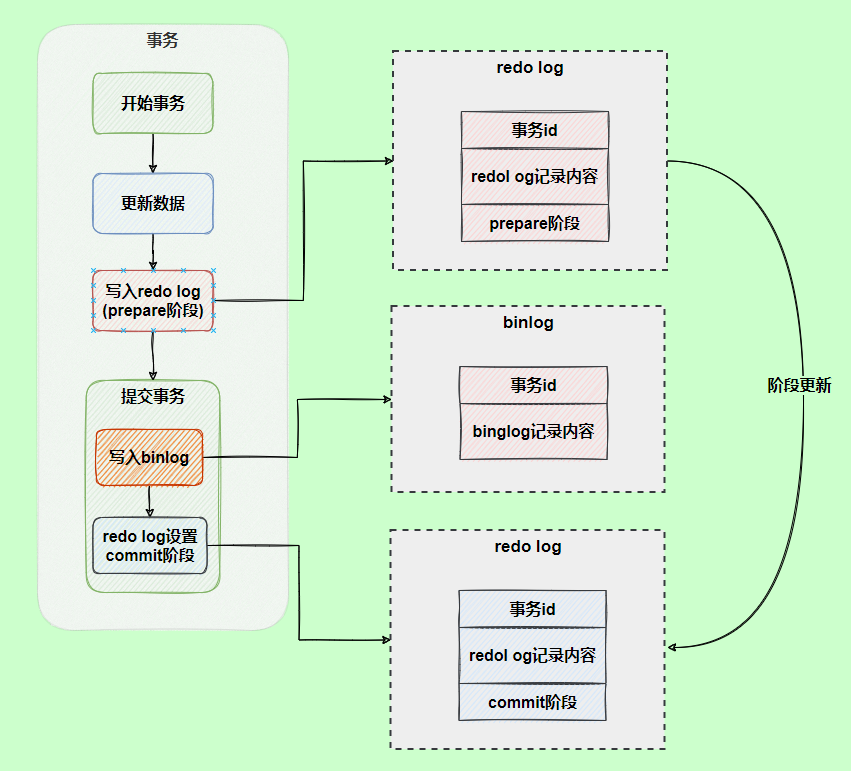
两阶段提交的原因
两阶段提交,是为了binlog和redolog两分日志之间的逻辑一致。
redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。
如果不用两阶段提交,那么有两种可能:
- 要么就是先写完 redo log 再写 binlog,
- 或者采用反过来的顺序。
可能造成的问题:
update 语句来做例子。
假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash崩溃,会出现什么情况呢?
1. 先写 redo log 后写 binlog。
假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。
由于,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。
但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。
因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。
然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
2. 先写 binlog 后写 redo log。
如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。
但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。
所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
redolog 写入策略
redo 占用的空间是一定的,并不会无线增大(可以通过参数设置),写入的时候是进顺序写的,所以写入的性能比较高。
当redo log空间满了之后又会从头开始以循环的方式进行覆盖式的写入。
在写入redo log的时候也有一个redo log buffer,日志什么时候会刷到磁盘是通过innodb_flush_log_at_trx_commit 参数决定。
innodb_flush_log_at_trx_commit=0 ,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
innodb_flush_log_at_trx_commit=1,表示每次事务提交时都将 redo log 直接持久化到磁盘;
innodb_flush_log_at_trx_commit=2,表示每次事务提交时都只是把 redo log 写到 page cache。
除了上面几种机制外,还有其它两种情况会把redo log buffer中的日志刷到磁盘。
1、定时处理:有线程会定时(每隔 1 秒)把redo log buffer中的数据刷盘。
2、根据空间处理:redo log buffer 占用到了一定程度( innodb_log_buffer_size 设置的值一半)占,这个时候也会把redo log buffer中的数据刷盘。
redo log&Write-Ahead 的本质
一个事务要修改多张表的多条记录,多条记录分布在不同的Page里面,
对应到磁盘的不同位置。如果每个事务都直接写磁盘,一次事务提交就要多次磁盘的随机I/O,性能达不到要求。
怎么办呢?
不写磁盘,在内存中进行事务提交。然后再通过后台线程,异步地把内存中的数据写入到磁盘中。
但有个问题:
机器宕机,内存中的数据还没来得及刷盘,数据就丢失了。
为此,就有了Write-ahead Log的思路:
先在内存中提交事务,然后写日志(所谓的Write-ahead Log),然后后台任务把内存中的数据异步刷到磁盘。
是顺序地在尾部Append,从而也就避免了一个事务发生多次磁盘随机 I/O 的问题。
明明是先在内存中提交事务,后写的日志,为什么叫作Write-Ahead呢?
这里的Ahead,其实是指相对于真正的数据刷到磁盘,因为是先写的日志,后把内存数据刷到磁盘,所以叫Write-Ahead Log。
redo log和binlog日志的不同
binlog是逻辑记录,格式为row模式
比如update tb_user set age =18 where name ='赵白' ,如果这条语句修改了三条记录的话,那么binlog记录就是
UPDATE `db_test`.`tb_user` WHERE @1=5 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
UPDATE `db_test`.`tb_user` WHERE @1=6 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
UPDATE `db_test`.`tb_user` WHERE @1=7 @2='赵白' @3=91 @4='1543571201' SET @1=5 @2='赵白' @3=18 @4='1543571201'
redo log是物理记录
上面的修改语句,在redo log里面记录得可能就是下面的形式。
把表空间10、页号5、偏移量为10处的值更新为18。
把表空间11、页号1、偏移量为2处的值更新为18。
把表空间12、页号2、偏移量为9处的值更新为18。
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用
- redo log是物理日志,记录的是在某个数据上做了什么修改;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如给ID=2这一行的c字段加1
- redo log是循环写的,空间固定会用完;binlog是可以追加写入的,binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
undo log
名称:回滚日志
作用:保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
内容:逻辑格式的日志,根据每行记录进行记录。
在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的,这一点是不同于redo log的。
undo log与redo log的不同
undo日志用于记录事务开始前的状态,用于事务失败时的回滚操作;
redo日志记录事务执行后的状态,用来恢复未写入data file的已成功事务更新的数据。
例如:
某一事务的事务序号为T1,其对数据c进行修改,设c的原值是0,修改后的值为1,
那么Undo日志为<T1, c, 0>,
Redo日志为<T1, c, 1>。
redo log 是也属于引擎层(innodb)的日志,从上面的redo log介绍中我们就已经知道了,
redo log 和undo log的核心是为了保证innodb事务机制中的持久性和原子性,事务提交成功由redo log保证数据持久性,
而事务可以进行回滚从而保证事务操作原子性则是通过undo log 来保证的。
要对事务数据回滚到历史的数据状态,所以我们也能猜到undo log是保存的是数据的历史版本,通过历史版本让数据在任何时候都可以回滚到某一个事务开始之前的状态。
undo log除了进行事务回滚的日志外还有一个作用,就是为数据库提供MVCC多版本数据读的功能。
undo log物理文件:
MySQL5.6之前,位于数据文件目录中,undo表空间位于共享表空间的回滚段中,共享表空间的默认的名称是ibdata,位于数据文件目录中。
MySQL5.6之后,undo表空间可以配置成独立的文件,但是提前需要在配置文件中配置,完成数据库初始化后生效且不可改变undo log文件的个数
redo、undo、binlog三大log的生成流程与crash崩溃恢复
当我们执行 update T set c=c+1 where ID=1; 的时候大致流程如下:
1、从磁盘读取到id=1的记录,放到内存。
2、修改内存中的记录。
3、记录undo log 日志。
4、记录redo log (预提交状态)
5、记录binlog
6、提交事务,写入redo log (commit状态)
我们根据上面的流程来看,如果在上面的某一个阶段数据库崩溃,如何恢复数据。
1、在第一步、第二步、第三步执行时据库崩溃:因为这个时候数据还没有发生任何变化,所以没有任何影响,不需要做任何操作。
2、在第四步修改内存中的记录时数据库崩溃:因为此时事务没有commit,所以这里要进行数据回滚,所以这里会通过undo log进行数据回滚。
3、第五步写入binlog时数据库崩溃:这里和第四步一样的逻辑,此时事务没有commit,所以这里要进行数据回滚,会通过undo log进行数据回滚。
binlog不存在事务记录,那么这种情况事务还未提交成功,redo log 也没有commit标记,所以会对数据进行回滚。
4、执行第六步事务提交时数据库崩溃:如果数据库在这个阶段崩溃,那其实事务还是没有提交成功,但是这里并不能像之前一样对数据进行回滚,因为在提交事务前,binlog可能成功写入磁盘了,所以这里要根据两种情况来做决定。
一种情况,binlog不存在事务记录,那么这种情况事务还未提交成功,redo log 也没有commit标记,所以会对数据进行回滚。
一种情况, 是binlog存在数据记录,而binlog写入后,那么依赖于binlog的其它扩展业务(比如:从库已经同步了日志进行数据的变更)数据就已经产生了,如果这里进行数据回滚,那么势必就会造成主从数据的不一致。此时不能回滚,怎么办呢。
如果把 innodb_flush_log_at_trx_commit 设置成 1,那么 redo log 在 prepare 阶段就要持久化一次,崩溃恢复逻辑是要依赖于 prepare 的 redo log,再加上 binlog 来恢复的。
结合binlog的状态,进行redo。
如果binlog存在事务记录:那么就"认为"事务已经提交了,这里可以根据binlog对数据进行重做。其实这个阶段发生崩溃了,最终的事务是没提交成功的,这里应该对数据进行回滚。
binlog主从复制原理

从库B和主库A之间维持了一个长连接。主库A内部有一个线程,专门用于服务从库B的这个长连接。
一个事务日志同步的完整过程如下:
- 在从库B上通过change master命令,设置主库A的IP、端口、用户名、密码,以及要从哪个位置开始请求binlog,这个位置包含文件名和日志偏移量
- 在从库B上执行start slave命令,这时从库会启动两个线程,就是图中的I/O线程和SQL线程。其中I/O线程负责与主库建立连接
- 主库A校验完用户名、密码后,开始按照从库B传过来的位置,从本地读取binlog,发给B
- 从库B拿到binlog后,写到本地文件,称为中继日志 relay log
- SQL线程读取中继日志 relay log,解析出日志里的命令,并执行
由于多线程复制方案的引入,SQL线程演化成了多个线程
主从复制不是完全实时地进行同步,而是异步实时。
主从服务之间的延时较大
这中间存在主从服务之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。
应该怎么优化,缩短回放时间?
MySQL使用单线程回放RelayLog。
多线程并行回放RelayLog可以缩短时间。
slave_parallel_type='LOGICAL_CLOCK'
slave_parallel_workers=8
Sharding-JDBC实现读写分离
sharding-jdbc实现读写分离技术的思路比较简洁,不支持类似主库双写或多写这样的特性,但目前来看,已经可以满足一般的业务需求了。
提供了一主多从的读写分离配置,可独立使用,也可配合分库分表使用。
使用Sharding-JDBC配置读写分离,优点在于数据源完全有Sharding托管,写操作自动执行master库,读操作自动执行slave库。不需要程序员在程序中关注这个实现了。
spring.main.allow-bean-definition-overriding=true
spring.shardingsphere.datasource.names=master,slave
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/db_master?characterEncoding=utf-8
spring.shardingsphere.datasource.master.username=
spring.shardingsphere.datasource.master.password=
spring.shardingsphere.datasource.slave.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave.url=jdbc:mysql://localhost:3306/db_slave?characterEncoding=utf-8
spring.shardingsphere.datasource.slave.username=
spring.shardingsphere.datasource.slave.password=
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
spring.shardingsphere.masterslave.name=dataSource
spring.shardingsphere.masterslave.master-data-source-name=master
spring.shardingsphere.masterslave.slave-data-source-names=slave
spring.shardingsphere.props.sql.show=true
参数解读:
load-balance-algorithm-type 用于配置从库负载均衡算法类型,可选值:ROUND_ROBIN(轮询),RANDOM(随机)
props.sql.show=true 在执行SQL时,会打印SQL,并显示执行库的名称
Java API主从配置
分别给ds0和ds1准备从库:ds01和ds11,分别配置主从同步;读写分离配置如下:
List<String> slaveDataSourceNames1 = new ArrayList<String>();
slaveDataSourceNames1.add("ds11");
MasterSlaveRuleConfiguration masterSlaveRuleConfiguration1 = new MasterSlaveRuleConfiguration("ds1", "ds1",
slaveDataSourceNames1);
shardingRuleConfig.getMasterSlaveRuleConfigs().add(masterSlaveRuleConfiguration1);
这样在执行查询操作的时候会自动路由到从库,实现读写分离;
MasterSlaveRuleConfiguration
在上面章节介绍分片规则的时候,其中有说到主从规则配置,其目的就是用来实现读写分离的,核心配置类:MasterSlaveRuleConfiguration:
public final class MasterSlaveRuleConfiguration implements RuleConfiguration {
private final String name;
private final String masterDataSourceName;
private final List<String> slaveDataSourceNames;
private final LoadBalanceStrategyConfiguration loadBalanceStrategyConfiguration;
}
- name:配置名称,当前使用的4.1.0版本,这里必须是主库的名称;
- masterDataSourceName:主库数据源名称;
- slaveDataSourceNames:从库数据源列表,可以配置一主多从;
- LoadBalanceStrategyConfiguration:面对多个从库,读取的时候会通过负载算法进行选择;
主从负载算法类:MasterSlaveLoadBalanceAlgorithm,实现类包括:随机和循环;
- ROUND_ROBIN:实现类
RoundRobinMasterSlaveLoadBalanceAlgorithm - RANDOM:实现类
RandomMasterSlaveLoadBalanceAlgorithm
问题: 读写分离架构中经常出现,那就是读延迟的问题如何解决?
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,也就是说数据还没复制到从节点,你就已经去从节点读取了,肯定读不到。
mysql5.7 的主从复制是多线程了,意味着速度会变快,但是不一定能保证百分百马上读取到,这个问题我们可以有两种方式解决:
(1)业务层面妥协,是否操作完之后马上要进行读取
(2)对于操作完马上要读出来的,且业务上不能妥协的,我们可以对于这类的读取直接走主库,当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,可以让用户在使用的时候指定要不要走主库进行读取。
在读取前使用下面的方式进行设置就可以了:
public List<UserInfo> getList() {
//默认的查询
// * 2. 通过DataSource获取Connection
Connection connection = dataSource.getConnection();
// * 3. 定义一条SQL语句.
// 注意:******* sql语句中 使用的表是 上面代码中定义的逻辑表 *******
String sql = "select * from t_user where user_id between 10 and 20 ";
// * 4. 通过Connection获取到PreparedStament.
PreparedStatement preparedStatement = connection.prepareStatement(sql);
// * 5. 执行SQL语句.
ResultSet resultSet = preparedStatement.executeQuery();
//如果结果集为空,做一次兜底的方案
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
// * 5. 执行SQL语句.
ResultSet resultSet = preparedStatement.executeQuery();
return this.list();
}
通过canal接收二进制日志,通过rocketmq同步到redis+es+hbase
canal [kə'næl],译意为水道/管道/沟渠.
canal 主要用途是基于 MySQL 数据库增量日志解析,提供增量数据 订阅 和 消费。
canal 应该是阿里云DTS(Data Transfer Service)的开源版本,开源地址:
https://github.com/alibaba/canal 。
伪装的mysqlslave, dump协议
回放线程不一样, 而是 进行转发, socket,也可以发送rocketmq
canal的工作原理
-
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump请求;
-
mysql master收到dump请求,开始推送binary log给slave(也就是canal);
-
canal解析binary log对象(原始为byte流);
-
canal将解析后的对象,根据业务场景,分发到比如 MySQL 、RocketMQ 或者 ES 中。
canal使用场景
在很多业务情况下,我们都会在系统中加入redis缓存做查询优化, 使用es 做全文检索 ,hbase /mongdb做海量存储。
canal rocketmq redis
如果数据库数据发生更新,这时候就需要在业务代码中写一段同步更新redis的代码。
这种数据同步的代码跟业务代码糅合在一起会不太优雅,能不能把这些数据同步的代码抽出来形成一个独立的模块呢,答案是可以的。
canal即可作为MySQL binlog增量订阅消费组件+MQ消息队列将增量数据更新到redis
Redis缓存和MySQL数据一致性解决方案
延时双删策略
异步更新缓存(基于订阅binlog的延迟更新机制)
…
canal rocketmq es+hbase /mongdb
canal即可作为MySQL binlog增量订阅消费组件+MQ消息队列将增量数据更新到es
基于canal的数据一致性的环境搭建
master 为 canal 创建专用账号,并且授权
登录mysql输入以下命令,canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限
docker exec -it mysql-master bash
mysql -uroot -p123456
CREATE USER canal IDENTIFIED BY 'canal';
grant select, replication slave,replication client on *.* to 'canal'@'%' identified by "canal";
flush privileges;
创建数据库
USE `canal_manager`;
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for canal_adapter_config
-- ----------------------------
DROP TABLE IF EXISTS `canal_adapter_config`;
CREATE TABLE `canal_adapter_config` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`category` varchar(45) NOT NULL,
`name` varchar(45) NOT NULL,
`status` varchar(45) DEFAULT NULL,
`content` text NOT NULL,
`modified_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
省略.....
启动cannel服务
rm -rf /home/docker-compose/canal
cp -rf /vagrant/3G-middleware/canal /home/docker-compose/
cd /home/docker-compose/
chmod 777 -R canal
cd canal
docker-compose --compatibility up -d
docker-compose logs -f
docker-compose down
mysql/5.7.31
docker save mysql:5.7.31 -o /vagrant/3G-middleware/mysql.5.7.31.tar
docker save registry.cn-hangzhou.aliyuncs.com/zhengqing/canal-server:v1.1.5 -o /vagrant/3G-middleware/canal-server.v1.1.5.tar
docker save registry.cn-hangzhou.aliyuncs.com/zhengqing/canal-admin:v1.1.5 -o /vagrant/3G-middleware/canal-admin.v1.1.5.tar
访问canal admin 并且配置实例 / Instance
在浏览器上面输入 hostip:9089 即可进入到管理页面,如果使用的默认的配置信息,用户名入”admin”,密码输入”123456”即可访问首页。
canal amin 123456
http://cdh2:18089
rocketmq
http://cdh2:19001
通过配置文件对canal进行配置
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
# set this value to 'true' means that when binlog pos not found, skip to latest.
# WARN: pls keep 'false' in production env, or if you know what you want.
canal.auto.reset.latest.pos.mode = false
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ Properties #############
##################################################
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
canal.aliyun.uid=
canal.mq.flatMessage = true
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
canal.mq.database.hash = true
canal.mq.send.thread.size = 30
canal.mq.build.thread.size = 8
##################################################
######### Kafka #############
##################################################
kafka.bootstrap.servers = 127.0.0.1:6667
kafka.acks = all
kafka.compression.type = none
kafka.batch.size = 16384
kafka.linger.ms = 1
kafka.max.request.size = 1048576
kafka.buffer.memory = 33554432
kafka.max.in.flight.requests.per.connection = 1
kafka.retries = 0
kafka.kerberos.enable = false
kafka.kerberos.krb5.file = "../conf/kerberos/krb5.conf"
kafka.kerberos.jaas.file = "../conf/kerberos/jaas.conf"
##################################################
######### RocketMQ #############
##################################################
rocketmq.producer.group = canal_producer
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host =
rabbitmq.virtual.host =
rabbitmq.exchange =
rabbitmq.username =
rabbitmq.password =
rabbitmq.deliveryMode =
访问canal admin 并且配置实例 / Instance
在浏览器上面输入 hostip:9089 即可进入到管理页面,如果使用的默认的配置信息,用户名入”admin”,密码输入”123456”即可访问首页。
canal amin 123456
http://cdh2:18089
rocketmq
http://cdh2:19001
访问canal-admin,可以看到自动出现了一个Server,可在此页面进行Server的配置、修改、启动、查看log等操作
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=mysql-master:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=canal_log
# dynamic topic route by schema or table regex
# canal.mq.dynamicTopic=test.user,student\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
canal.mq.partitionsNum=3
canal.mq.partitionHash=test.users:uid,.*\\..*
##################################################
######### MQ #############
##################################################
canal.mq.servers = 192.168.56.122:9876
#canal.mq.servers = rmqnamesrv:9876
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = canal_producer
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
去Instance列表新增Instance,可选择载入模版进行修改,可参考上文中的canal相关配置文件修改
点击侧边栏的Instance管理,选择新建 Instance,选择那个唯一的主机,再点击载入模板,修改下面的一些参数:
实例名称随便填一个就行。
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
#canal.admin.register.auto = true
#canal.admin.register.cluster =
#canal.admin.register.name =
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
# canal.serverMode = tcp
canal.serverMode = RocketMQ
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
canal.instance.filter.dml.insert = false
canal.instance.filter.dml.update = false
canal.instance.filter.dml.delete = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
rocketmq.producer.group = canal_producers
rocketmq.enable.message.trace = false
rocketmq.customized.trace.topic =
rocketmq.namespace =
#rocketmq.namesrv.addr = 127.0.0.1:9876
#rocketmq.namesrv.addr = 192.168.56.122:9876
rocketmq.namesrv.addr = rmqnamesrv:9876
rocketmq.retry.times.when.send.failed = 0
rocketmq.vip.channel.enabled = false
rocketmq.tag =
创建好的新实例默认是停止状态,将其启动。
从master 查看从节点
select * from information_schema.processlist as p where p.command = 'Binlog Dump';
mysql> select * from information_schema.processlist as p where p.command = 'Binlog Dump';
+----+-------+----------------------------------------+------+-------------+-------+---------------------------------------------------------------+------+
| ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO |
+----+-------+----------------------------------------+------+-------------+-------+---------------------------------------------------------------+------+
| 80 | canal | canal-server.mysql-canal-network:44699 | NULL | Binlog Dump | 315 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 3 | slave | mysql-slave.mysql-canal-network:43428 | NULL | Binlog Dump | 18133 | Master has sent all binlog to slave; waiting for more updates | NULL |
+----+-------+----------------------------------------+------+-------------+-------+---------------------------------------------------------------+------+
2 rows in set (0.01 sec)
基于canal+rocketmq的数据一致性的实操
SnowFlake时钟回拨问题
SnowFlake很好,分布式、去中心化、无第三方依赖。
但它并不是完美的,由于SnowFlake强依赖时间戳,所以时间的变动会造成SnowFlake的算法产生错误。
时钟回拨:最常见的问题就是时钟回拨导致的ID重复问题,在SnowFlake算法中并没有什么有效的解法,仅是抛出异常。时钟回拨涉及两种情况①实例停机→时钟回拨→实例重启→计算ID ②实例运行中→时钟回拨→计算ID
手动配置:另一个就是workerId(机器ID)是需要部署时手动配置,而workerId又不能重复。几台实例还好,一旦实例达到一定量级,管理workerId将是一个复杂的操作。
ntp导致的时钟回拨
我们的服务器时间校准一般是通过ntp进程去校准的。但由于校准这个动作,会导致时钟跳跃变化的现象。
而这种情况里面,往往回拨最能引起我们的困扰,回拨如下所示:
时钟回拨改进避免
ID生成器一旦不可用,可能造成所有数据库相关新增业务都不可用,影响太大。所以时钟回拨的问题必须解决。
造成时钟回拨的原因多种多样,可能是闰秒回拨,可能是NTP同步,还可能是服务器时间手动调整。总之就是时间回到了过去。针对回退时间的多少可以进行不同的策略改进。
一般有以下几种方案:
- 少量服务器部署ID生成器实例,关闭NTP服务器,严格管理服务器。这种方案不需要从代码层面解决,完全人治。
- 针对回退时间断的情况,如闰秒回拨仅回拨了1s,可以在代码层面通过判断暂停一定时间内的ID生成器使用。虽然少了几秒钟可用时间,但时钟正常后,业务即可恢复正常。
if (refusedSeconds <= 5) {
try {
//时间偏差大小小于5ms,则等待两倍时间
wait(refusedSeconds << 1);//wait
} catch (InterruptedException e) {
e.printStackTrace();
}
currentSecond = getCurrentSecond();
}else {//时钟回拨较大
//用其他策略修复时钟问题
}
实例启动后,改用内存生成时间。
该方案为baidu开源的UidGenerator使用的方案,由于实例启动后,时间不再从服务器获取,所以不管服务器时钟如何回拨,都影响不了SnowFlake的执行。
如下代码中lastSecond变量是一个AtomicLong类型,用以代替系统时间
List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());
以上2和3都是解决时钟实例运行中→时钟回拨→计算ID的情况。
而实例停机→时钟回拨→实例重启→计算ID的情况,可以通过实例启动的时候,采用未使用过的workerId来完成。
只要workerId和此前生成ID的workerId不一致,即便时间戳有误,所生成的ID也不会重复。
UidGenerator采取的就是这种方案,但这种方案又必须依赖一个存储中心,不管是redis、mysql、zookeeper都可以,但必须存储着此前使用过的workerId,不能重复。
尤其是在分布式部署Id生成器的情况下,更要注意用一个存储中心解决此问题。
UidGenerator代码可上Githubhttps://github.com/zer0Black/uid-generator查看
本文持续优化中
有问题,大家可以直接找尼恩, 联系方式请参见 疯狂创客圈 总目录。
参考文档:
https://www.jianshu.com/p/d3c1ee5237e5
https://www.cnblogs.com/zer0black/p/12323541.html?ivk_sa=1024320u
https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/
https://blog.csdn.net/free_ant/article/details/111461606
https://www.jianshu.com/p/46b42f7f593c
https://blog.csdn.net/yangguosb/article/details/78772730
https://blog.csdn.net/youanyyou/article/details/121005680
https://www.cnblogs.com/huanshilang/p/12055296.html
https://www.cnblogs.com/haima/p/14341903.html
https://www.cnblogs.com/wilburxu/p/7229642.html
https://zhuanlan.zhihu.com/p/213770128

 浙公网安备 33010602011771号
浙公网安备 33010602011771号