

架构设计 | 高并发流量削峰,共享资源加锁机制
一、高并发简介
在互联网的业务架构中,高并发是最难处理的业务之一,常见的使用场景:秒杀,抢购,订票系统;高并发的流程中需要处理的复杂问题非常多,主要涉及下面几个方面:
- 流量管理,逐级承接削峰;
- 网关控制,路由请求,接口熔断;
- 并发控制机制,资源加锁;
- 分布式架构,隔离服务和数据库;
高并发业务核心还是流量控制,控制流量下沉速度,或者控制承接流量的容器大小,多余的直接溢出,这是相对复杂的流程。其次就是多线程并发下访问共享资源,该流程需要加锁机制,避免数据写出现错乱情况。
二、秒杀场景
1、预抢购业务
活动未正式开始,先进行活动预约,先把一部分流量收集和控制起来,在真正秒杀的时间点,很多数据可能都已经预处理好了,可以很大程度上削减系统的压力。有了一定预约流量还可以提前对库存系统做好准备,一举两得。
场景:活动预约,定金预约,高铁抢票预购。
2、分批抢购
分批抢购和抢购的场景实现的机制是一致的,只是在流量上缓解了很多压力,秒杀10W件库存和秒杀100件库存系统的抗压不是一个级别。如果秒杀10W件库存,系统至少承担多于10W几倍的流量冲击,秒杀100件库存,体系可能承担几百或者上千的流量就结束了。下面流量削峰会详解这里的策略机制。
场景:分时段多场次抢购,高铁票分批放出。
3、实时秒杀
最有难度的场景就是准点实时的秒杀活动,假如10点整准时抢1W件商品,在这个时间点前后会涌入高并发的流量,刷新页面,或者请求抢购的接口,这样的场景处理起来是最复杂的。
- 首先系统要承接住流量的涌入;
- 页面的不断刷新要实时加载;
- 高并发请求的流量控制加锁等;
- 服务隔离和数据库设计的系统保护;
场景:618准点抢购,双11准点秒杀,电商促销秒杀。
三、流量削峰
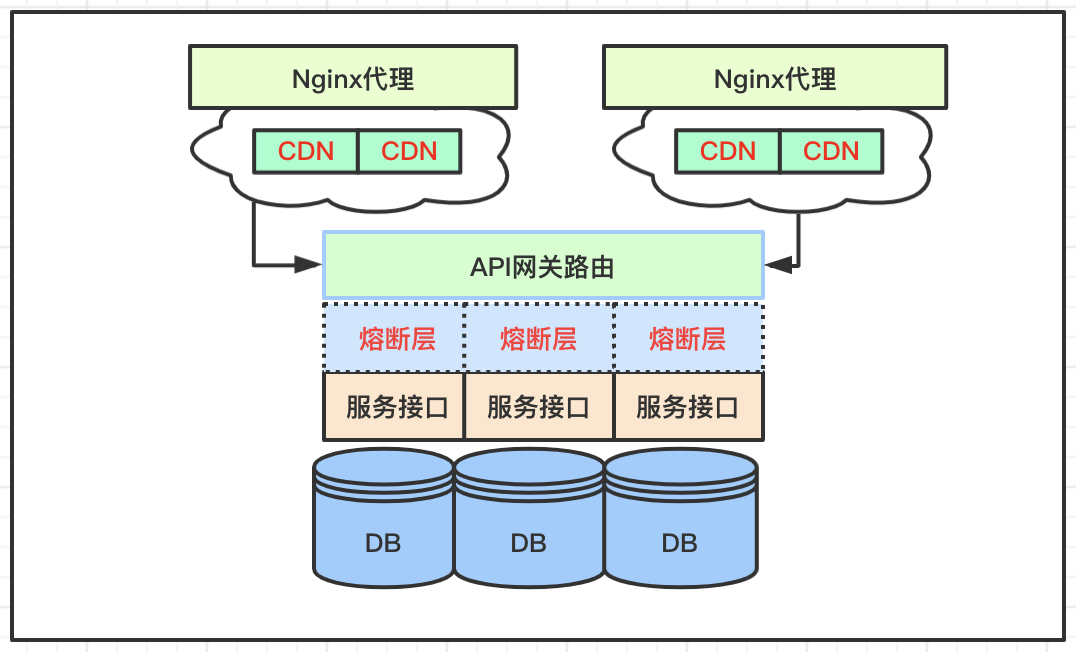
1、Nginx代理
Nginx是一个高性能的HTTP和反向代理web服务器,经常用在集群服务中做统一代理层和负载均衡策略,也可以作为一层流量控制层,提供两种限流方式,一是控制速率,二是控制并发连接数。
基于漏桶算法,提供限制请求处理速率能力;限制IP的访问频率,流量突然增大时,超出的请求将被拒绝;还可以限制并发连接数。
高并发的秒杀场景下,经过Nginx层的各种限制策略,可以控制流量在一个相对稳定的状态。
2、CDN节点
CDN静态文件的代理节点,秒杀场景的服务有这样一个操作特点,活动倒计时开始之前,大量的用户会不断的刷新页面,这时候静态页面可以交给CDN层面代理,分担数据服务接口的压力。
CDN层面也可以做一层限流,在页面内置一层策略,假设有10W用户点击抢购,可以只放行1W的流量,其他的直接提示活动结束即可,这也是常用的手段之一。
话外之意:平时参与的抢购活动,可能你的请求根本没有到达数据接口层面,就极速响应商品已抢完,自行意会吧。
3、网关控制
网关层面处理服务接口路由,一些校验之外,最主要的是可以集成一些策略进入网关,比如经过上述层层的流量控制之后,请求已经接近核心的数据接口,这时在网关层面内置一些策略控制:如果活动是想激活老用户,网关层面快速判断用户属性,老用户会放行请求;如果活动的目的是拉新,则放行更多的新用户。
经过这些层面的控制,剩下的流量已经不多了,后续才真正开始执行抢购的数据操作。
话外之意:如果有10W人参加抢购活动,真正下沉到底层的抢购流量可能就1W,甚至更少,在分散到集群服务中处理。
4、并发熔断
在分布式服务的接口中,还有最精细的一层控制,对于一个接口在单位之间内控制请求处理的数量,这个基于接口的响应时间综合考虑,响应越快,单位时间内的并发量就越高,这里逻辑不难理解。
言外之意:流量经过层层控制,数据接口层面分担的压力已经不大,这时候就是面对秒杀业务中的加锁问题了。
四、分布式加锁
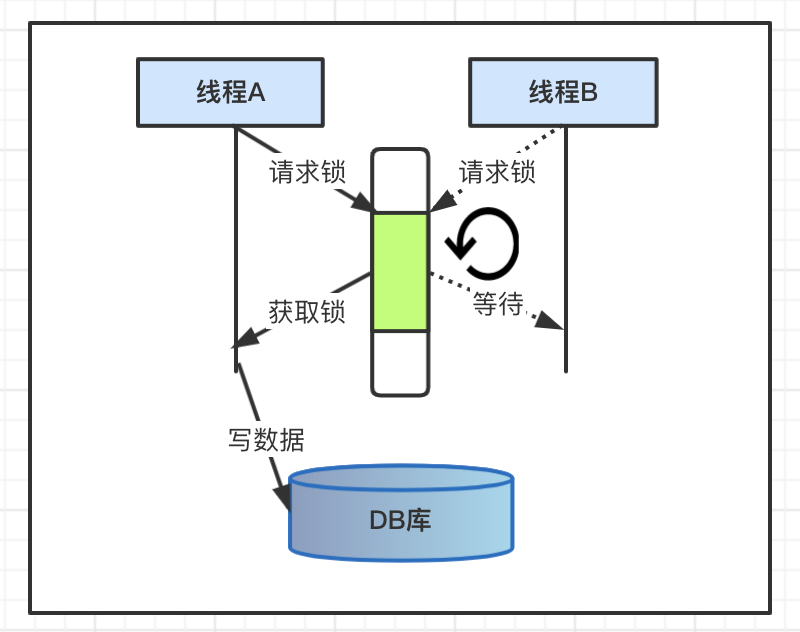
1、悲观锁
机制描述
所有请求的线程必须在获取锁之后,才能执行数据库操作,并且基于序列化的模式,没有获取锁的线程处于等待状态,并且设定重试机制,在单位时间后再次尝试获取锁,或者直接返回。
过程图解
Redis基础命令
SETNX:加锁的思路是,如果key不存在,将key设置为value如果key已存在,则 SETNX 不做任何动作。并且可以给key设置过期时间,过期后其他线程可以继续尝试锁获取机制。
借助Redis的该命令模拟锁的获取动作。
代码实现
这里基于Redis实现的锁获取和释放机制。
import org.springframework.stereotype.Component;
import redis.clients.jedis.Jedis;
import javax.annotation.Resource;
@Component
public class RedisLock {
@Resource
private Jedis jedis ;
/**
* 获取锁
*/
public boolean getLock (String key,String value,long expire){
try {
String result = jedis.set( key, value, "nx", "ex", expire);
return result != null;
} catch (Exception e){
e.printStackTrace();
}finally {
if (jedis != null) jedis.close();
}
return false ;
}
/**
* 释放锁
*/
public boolean unLock (String key){
try {
Long result = jedis.del(key);
return result > 0 ;
} catch (Exception e){
e.printStackTrace();
}finally {
if (jedis != null) jedis.close();
}
return false ;
}
}
这里基于Jedis的API实现,这里提供一份配置文件。
@Configuration
public class RedisConfig {
@Bean
public JedisPoolConfig jedisPoolConfig (){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig() ;
jedisPoolConfig.setMaxIdle(8);
jedisPoolConfig.setMaxTotal(20);
return jedisPoolConfig ;
}
@Bean
public JedisPool jedisPool (@Autowired JedisPoolConfig jedisPoolConfig){
return new JedisPool(jedisPoolConfig,"127.0.0.1",6379) ;
}
@Bean
public Jedis jedis (@Autowired JedisPool jedisPool){
return jedisPool.getResource() ;
}
}
问题描述
在实际的系统运行期间可能出现如下情况:线程01获取锁之后,进程被挂起,后续该执行的没有执行,锁失效后,线程02又获取锁,在数据库更新后,线程01恢复,此时在持有锁之后的状态,继续执行后就会容易导致数据错乱问题。
这时候就需要引入锁版本概念的,假设线程01获取锁版本1,如果没有执行,线程02获取锁版本2,执行之后,通过锁版本的比较,线程01的锁版本过低,数据更新就会失败。
CREATE TABLE `dl_data_lock` (
`id` INT (11) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`inventory` INT (11) DEFAULT '0' COMMENT '库存量',
`lock_value` INT (11) NOT NULL DEFAULT '0' COMMENT '锁版本',
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 COMMENT = '锁机制表';
说明:lock_value就是记录锁版本,作为控制数据更新的条件。
<update id="updateByLock">
UPDATE dl_data_lock SET inventory=inventory-1,lock_value=#{lockVersion}
WHERE id=#{id} AND lock_value <#{lockVersion}
</update>
说明:这里的更新操作,不但要求线程获取锁,还会判断线程锁的版本不能低于当前更新记录中的最新锁版本。
2、乐观锁
机制描述
乐观锁大多是基于数据记录来控制,在更新数据库的时候,基于前置的查询条件判断,如果查询出来的数据没有被修改,则更新操作成功,如果前置的查询结果作为更新的条件不成立,则数据写失败。
过程图解
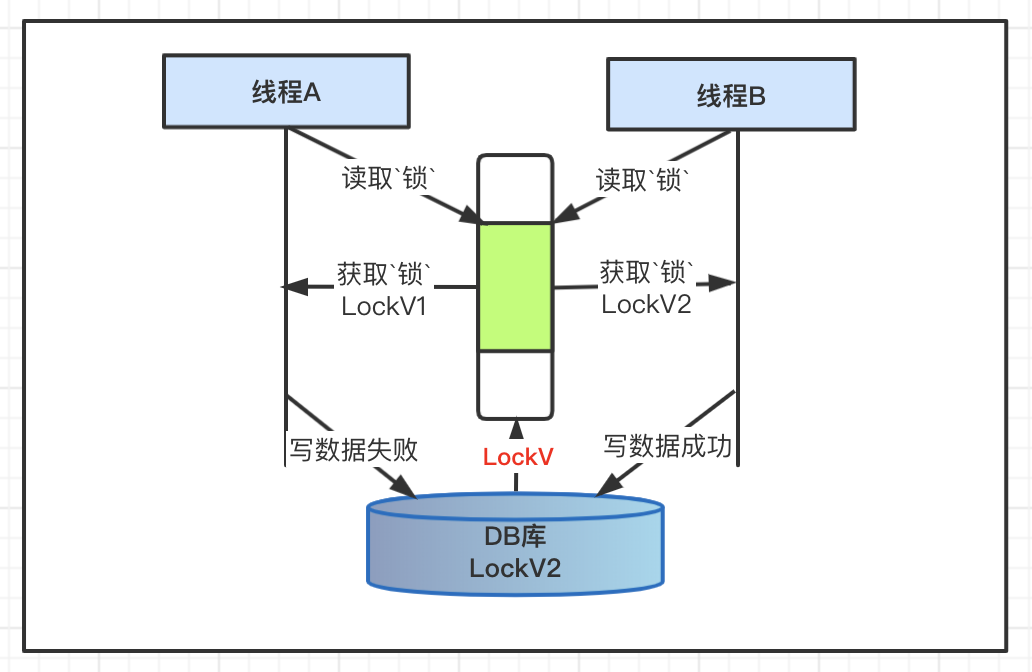
代码实现
业务流程,先查询要更新的记录,然后把读取的列,作为更新条件。
@Override
public Boolean updateByInventory(Integer id) {
DataLockEntity dataLockEntity = dataLockMapper.getById(id);
if (dataLockEntity != null){
return dataLockMapper.updateByInventory(id,dataLockEntity.getInventory())>0 ;
}
return false ;
}
例如如果要把库存更新,就把读取的库存数据作为更新条件,如果读取库存是100,在更新的时候库存变了,则更新条件自然不能成立。
<update id="updateByInventory">
UPDATE dl_data_lock SET inventory=inventory-1 WHERE id=#{id} AND inventory=#{inventory}
</update>
五、分布式服务
1、服务保护
在处理高并发的秒杀场景时,经常出现服务挂掉场景,常见某些APP的营销页面,出现活动火爆页面丢失的提示情况,但是不影响整体应用的运行,这就是服务的隔离和保护机制。
基于分布式的服务结构可以把高并发的业务服务独立出来,不会因为秒杀服务挂掉影响整体的服务,导致服务雪崩的场景。
2、数据库保护
数据库保护和服务保护是相辅相成的,分布式服务架构下,服务和数据库是对应的,理论上秒杀服务对应的就是秒杀数据库,不会因为秒杀库挂掉,导致整个数据库宕机。
六、源代码地址
GitHub·地址
https://github.com/cicadasmile/data-manage-parent
GitEE·地址
https://gitee.com/cicadasmile/data-manage-parent

 浙公网安备 33010602011771号
浙公网安备 33010602011771号