摘要: 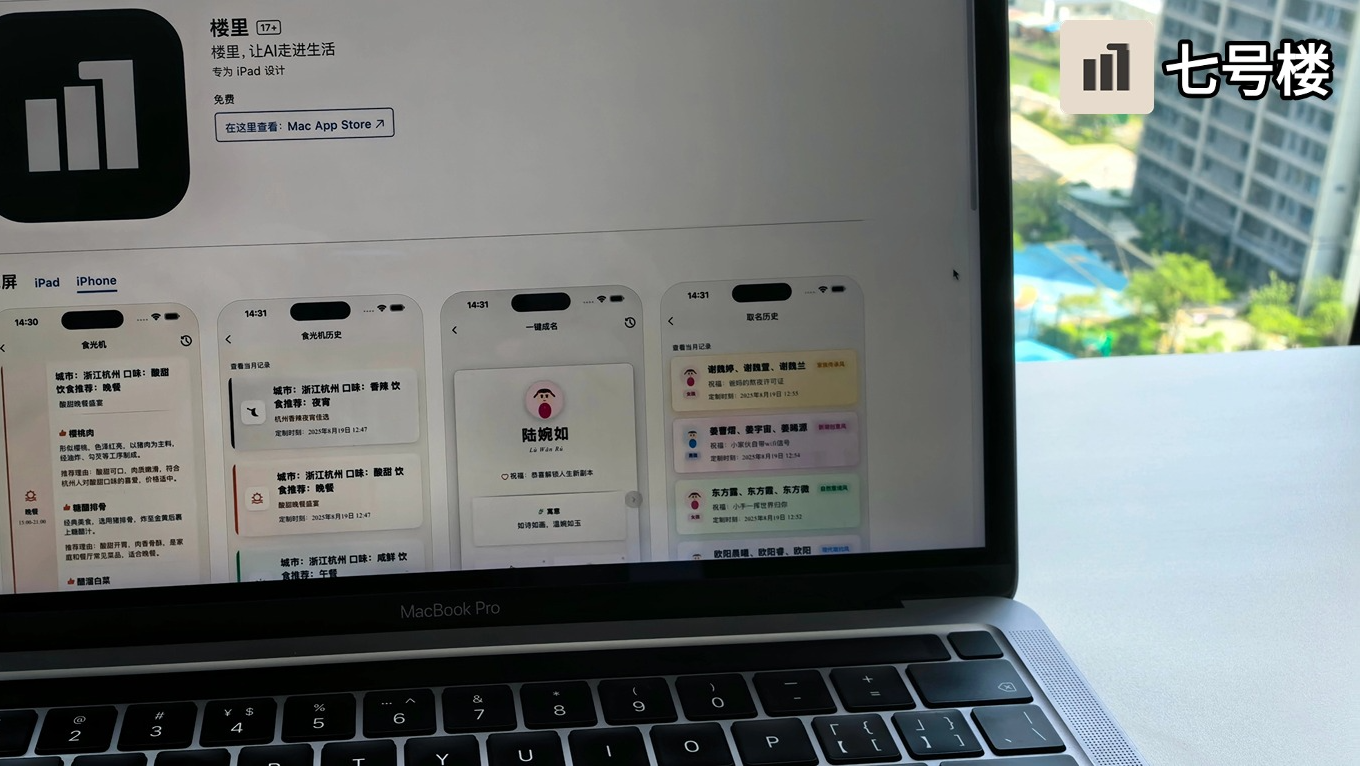 无论是结果还是时间线,都不符合最初的预期,产品的用户数没有过百,第一个阶段没有在八月下旬结束,心态也并非不急不躁,这就是不装不演的真实现状。 阅读全文
无论是结果还是时间线,都不符合最初的预期,产品的用户数没有过百,第一个阶段没有在八月下旬结束,心态也并非不急不躁,这就是不装不演的真实现状。 阅读全文
无论是结果还是时间线,都不符合最初的预期,产品的用户数没有过百,第一个阶段没有在八月下旬结束,心态也并非不急不躁,这就是不装不演的真实现状。 阅读全文
posted @ 2025-09-05 09:38
七号楼
阅读(658)
评论(3)
推荐(7)
无论是结果还是时间线,都不符合最初的预期,产品的用户数没有过百,第一个阶段没有在八月下旬结束,心态也并非不急不躁,这就是不装不演的真实现状。 阅读全文
 不知道大家在提问大模型的时候,有没有碰到过这种情况。并不是每一个问题,它都能答上来。甚至有时候它会瞎编一些答案,一本正经地胡说八道。这种情况,通常被称为大模型的幻觉。因为大模型所有的认知,都是通过模型训练得来的。恰巧你提的问题,在它的认知范围外,它就无法正确地回答你。在早期,大模型遇到这种情况可能会分析得头头是道,但最终答非所问。但现在,它会实打实地回复它不知道。 阅读全文
不知道大家在提问大模型的时候,有没有碰到过这种情况。并不是每一个问题,它都能答上来。甚至有时候它会瞎编一些答案,一本正经地胡说八道。这种情况,通常被称为大模型的幻觉。因为大模型所有的认知,都是通过模型训练得来的。恰巧你提的问题,在它的认知范围外,它就无法正确地回答你。在早期,大模型遇到这种情况可能会分析得头头是道,但最终答非所问。但现在,它会实打实地回复它不知道。 阅读全文
 使用AI Studio编程工具,相同的模型版本,但是效果有了质的提升,在社媒上很多亮眼的开发案例,实际都是基于AI Studio生成。 阅读全文
使用AI Studio编程工具,相同的模型版本,但是效果有了质的提升,在社媒上很多亮眼的开发案例,实际都是基于AI Studio生成。 阅读全文
 八月初代码就开发好了,然后就是一轮测试和验收。八月中旬,开始打包提交到AppStore审核。结果磕磕绊绊,踩了一路的坑。起初天真地以为打包上传,只要有手就行。结果整个流程像是“九九八十一难”豪华套餐。 阅读全文
八月初代码就开发好了,然后就是一轮测试和验收。八月中旬,开始打包提交到AppStore审核。结果磕磕绊绊,踩了一路的坑。起初天真地以为打包上传,只要有手就行。结果整个流程像是“九九八十一难”豪华套餐。 阅读全文
 年初DeepSeek爆火,Manus紧随其后也莫名火了。不过当时Manus算是黑红体,因为它一夜成名的时候,大部分用户压根就用不上。 阅读全文
年初DeepSeek爆火,Manus紧随其后也莫名火了。不过当时Manus算是黑红体,因为它一夜成名的时候,大部分用户压根就用不上。 阅读全文
 在接入并适配业务的过程中,不断的调整和优化提示词,见识到大模型各种场景下的文本能力,也让自己反思AI方向的能力不足。 阅读全文
在接入并适配业务的过程中,不断的调整和优化提示词,见识到大模型各种场景下的文本能力,也让自己反思AI方向的能力不足。 阅读全文
 往事如风,一周就过去了。上周在Figma里指点江山,这周在前端代码里卑微搬砖。 阅读全文
往事如风,一周就过去了。上周在Figma里指点江山,这周在前端代码里卑微搬砖。 阅读全文
 第一款尝试的产品自然是AI方向,此前不具备专业的产品经验,所以只能更多的依赖大模型的能力。 阅读全文
第一款尝试的产品自然是AI方向,此前不具备专业的产品经验,所以只能更多的依赖大模型的能力。 阅读全文
 IP地址一般分为两种,IPV4和IPV6,相应的计算方式也有差异,以国家维度来参考,每个国家都有对应的网段范围,计算网段中的最小和最大IP地址的对应数值,然后对比请求的IP地址。 阅读全文
IP地址一般分为两种,IPV4和IPV6,相应的计算方式也有差异,以国家维度来参考,每个国家都有对应的网段范围,计算网段中的最小和最大IP地址的对应数值,然后对比请求的IP地址。 阅读全文
 这里不由的在反思一个问题,既然DeepSeekV3能写出这种页面,那么是不是我写的提示词不行,所以让DeepSeek自己来写提示词,会不会更靠谱? 阅读全文
这里不由的在反思一个问题,既然DeepSeekV3能写出这种页面,那么是不是我写的提示词不行,所以让DeepSeek自己来写提示词,会不会更靠谱? 阅读全文
 Tab,Tab,再来一次 Tab 在当今AI工具横飞的时代,用一款好用的AI编码工具会让你的效率成倍增长。 上篇我们刚试过国内的Trae工具写了一个简单的demo,表现的中规中矩吧。Trae可以尝试写一些简单的应用。 今天我们来玩一玩Cursor,刚打开cursor的官网,是这么介绍的: AI代码编 阅读全文
Tab,Tab,再来一次 Tab 在当今AI工具横飞的时代,用一款好用的AI编码工具会让你的效率成倍增长。 上篇我们刚试过国内的Trae工具写了一个简单的demo,表现的中规中矩吧。Trae可以尝试写一些简单的应用。 今天我们来玩一玩Cursor,刚打开cursor的官网,是这么介绍的: AI代码编 阅读全文
 从2024年2025年,不断的有各种AI工具会在自媒体中火起来,号称各种效率王炸,而在AI是否会替代打工人的话题中,程序员又首当其冲。 阅读全文
从2024年2025年,不断的有各种AI工具会在自媒体中火起来,号称各种效率王炸,而在AI是否会替代打工人的话题中,程序员又首当其冲。 阅读全文
 人工智能行业在2024年称得上是浑浑噩噩,大模型的能力没有出现跳跃式的迭代,而产品层面没有出现杀手级应用,下半年更是有新闻频频爆出,AI赛道的多家公司有放弃大模型训练的打算。在这种背景下,DeepSeek发布的模型“炸穿”了国内外。 阅读全文
人工智能行业在2024年称得上是浑浑噩噩,大模型的能力没有出现跳跃式的迭代,而产品层面没有出现杀手级应用,下半年更是有新闻频频爆出,AI赛道的多家公司有放弃大模型训练的打算。在这种背景下,DeepSeek发布的模型“炸穿”了国内外。 阅读全文
 生存压力下,做项目时间和成本是最重视的维度,抛开什么AI和各种工具加持,节省编程时间最有效的办法就是:拿现成的,最好只改个端口号。 阅读全文
生存压力下,做项目时间和成本是最重视的维度,抛开什么AI和各种工具加持,节省编程时间最有效的办法就是:拿现成的,最好只改个端口号。 阅读全文
 使用Java的Graphics2D类,绘制业务需要的图形模板,然后在具体流程中填充数据,并且将图形存储起来。 阅读全文
使用Java的Graphics2D类,绘制业务需要的图形模板,然后在具体流程中填充数据,并且将图形存储起来。 阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号