linux: 删除列重复的行
如下图所示:
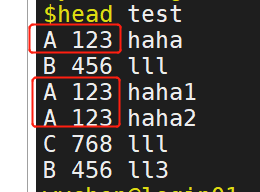
第一列和第二列在好多行中重复了,现只想保留非重复的行:达到以下目的:
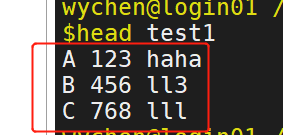
则可以使用以下命令:
sort test -k 1,2 | awk '!i[$1,$2]++' > test1
本文来自博客园,作者:橙子牛奶糖(陈文燕),转载请注明原文链接:https://www.cnblogs.com/chenwenyan/p/16083200.html


如下图所示:
第一列和第二列在好多行中重复了,现只想保留非重复的行:达到以下目的:
则可以使用以下命令:
sort test -k 1,2 | awk '!i[$1,$2]++' > test1
本文来自博客园,作者:橙子牛奶糖(陈文燕),转载请注明原文链接:https://www.cnblogs.com/chenwenyan/p/16083200.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号