使用Apriori进行关联分析(二)
摘要:
 大型超市有海量交易数据,我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是如何找出商品的隐藏关联,从而打包促销,以增加营业收入。其中最经典的案例就是关于尿不湿和啤酒的故事。怎样在繁杂的数据中寻找到数据之间的隐藏关系?当然可以使用穷举法,但代价高昂,所以需要使用更加智能的方法在合理时间内找到答案。Apriori就是其中的一种关联分析算法。本文是Apriori的第二篇,介绍如何在频繁项集的基础上挖掘关联规则。 阅读全文
大型超市有海量交易数据,我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是如何找出商品的隐藏关联,从而打包促销,以增加营业收入。其中最经典的案例就是关于尿不湿和啤酒的故事。怎样在繁杂的数据中寻找到数据之间的隐藏关系?当然可以使用穷举法,但代价高昂,所以需要使用更加智能的方法在合理时间内找到答案。Apriori就是其中的一种关联分析算法。本文是Apriori的第二篇,介绍如何在频繁项集的基础上挖掘关联规则。 阅读全文
大型超市有海量交易数据,我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是如何找出商品的隐藏关联,从而打包促销,以增加营业收入。其中最经典的案例就是关于尿不湿和啤酒的故事。怎样在繁杂的数据中寻找到数据之间的隐藏关系?当然可以使用穷举法,但代价高昂,所以需要使用更加智能的方法在合理时间内找到答案。Apriori就是其中的一种关联分析算法。本文是Apriori的第二篇,介绍如何在频繁项集的基础上挖掘关联规则。 阅读全文
posted @ 2017-08-29 22:32 我是8位的 阅读(4666) 评论(1) 推荐(1)
 大型超市有海量交易数据,我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是如何找出商品的隐藏关联,从而打包促销,以增加营业收入。其中最经典的案例就是关于尿不湿和啤酒的故事。怎样在繁杂的数据中寻找到数据之间的隐藏关系?当然可以使用穷举法,但代价高昂,所以需要使用更加智能的方法在合理时间内找到答案。Apriori就是其中的一种关联分析算法。本文是Apriori的第一篇。
大型超市有海量交易数据,我们可以通过聚类算法寻找购买相似物品的人群,从而为特定人群提供更具个性化的服务。但是对于超市来讲,更有价值的是如何找出商品的隐藏关联,从而打包促销,以增加营业收入。其中最经典的案例就是关于尿不湿和啤酒的故事。怎样在繁杂的数据中寻找到数据之间的隐藏关系?当然可以使用穷举法,但代价高昂,所以需要使用更加智能的方法在合理时间内找到答案。Apriori就是其中的一种关联分析算法。本文是Apriori的第一篇。  上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,本文介绍了如何使用反函数和高斯函数进行加权,以及加权后的计算过程
上篇文章中提到为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重,本文介绍了如何使用反函数和高斯函数进行加权,以及加权后的计算过程 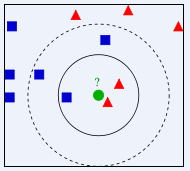 上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别。k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的一类。假设一个样本空间被分为几类,然后给定一个待分类的特征数据,通过计算距离该数据的最近的k个样本来判断这个数据属于哪一类。如果距离待分类属性最近的k个类大多数都属于某一个特定的类,那么这个待分类的数据也就属于这个类。
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别。k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的一类。假设一个样本空间被分为几类,然后给定一个待分类的特征数据,通过计算距离该数据的最近的k个样本来判断这个数据属于哪一类。如果距离待分类属性最近的k个类大多数都属于某一个特定的类,那么这个待分类的数据也就属于这个类。  本文主要介绍使用pillow对图像进行简单处理,进而引出图像处理与手写识别的关系。
本文主要介绍使用pillow对图像进行简单处理,进而引出图像处理与手写识别的关系。  朴素贝叶斯分类是基于贝叶斯概率的思想,假设属性之间相互独立,求得各特征的概率,最后取较大的一个作为预测结果(为了消弱罕见特征对最终结果的影响,通常会为概率加入权重,在比较时加入阈值)。
朴素贝叶斯分类是基于贝叶斯概率的思想,假设属性之间相互独立,求得各特征的概率,最后取较大的一个作为预测结果(为了消弱罕见特征对最终结果的影响,通常会为概率加入权重,在比较时加入阈值)。  AdbBoost是adaptive boosting的缩写,是众多Boosting算法中较为流行的一种。
AdaBoost算法针对不同的训练集训练同一个(使用相同算法)基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器)。理论证明,只要每个弱分类器分类能力比随机猜测要好,当其个数趋向于无穷个数时,强分类器的错误率将趋向于零。这点可以用直观感觉判断,只要每个分类器的正确率比错误率稍高一点点,当分类器足够多的时候,正确的数量就会压倒错误的数量。
AdbBoost是adaptive boosting的缩写,是众多Boosting算法中较为流行的一种。
AdaBoost算法针对不同的训练集训练同一个(使用相同算法)基本分类器(弱分类器),然后把这些在不同训练集上得到的分类器集合起来,构成一个更强的最终的分类器(强分类器)。理论证明,只要每个弱分类器分类能力比随机猜测要好,当其个数趋向于无穷个数时,强分类器的错误率将趋向于零。这点可以用直观感觉判断,只要每个分类器的正确率比错误率稍高一点点,当分类器足够多的时候,正确的数量就会压倒错误的数量。 
 浙公网安备 33010602011771号
浙公网安备 33010602011771号