隐马尔可夫模型(一)
隐马尔可夫模型
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。
马尔可夫过程
先来看一个例子。假设几个月大的宝宝每天做三件事:玩(兴奋状态)、吃(饥饿状态)、睡(困倦状态),这三件事按下图所示的方向转移:

这就是一个简单的马尔可夫过程。需要注意的是,这和确定性系统不同,每个转移都是有概率的,宝宝的状态是经常变化的,而且会任意在两个状态间切换:

上图中箭头表示从一个状态到切换到另一个状态的概率,吃饱后睡觉的概率是0.7。
从上图中可以看出,一个状态的转移只依赖于之前的n个状态,当n取1时就是马尔可夫假设。由此得出马尔可夫链的定义:
马尔可夫链是随机变量 S1, … , St 的一个数列(状态集),这些变量的范围,即他们所有可能取值的集合,被称为“状态空间”,而 St 的值则是在时间 t 的状态。如果 St+1 对于过去状态的条件概率分布仅是 St 的一个函数,则:

这里小 x 为过程中的某个状态。上面这个等式称为马尔可夫假设。
上述函数可以这样理解:在已知“现在”的条件下,“将来”不依赖于“过去”;或“将来”仅依赖于已知的“现在”。即St+1只于St有关,与St-n, 1<n<t无关。
一个含有 N 个状态的马尔可夫链有 N2 个状态转移。每一个转移的概率叫做状态转移概率 (state transition probability),就是从一个状态转移到另一个状态的概率。这所有的 N2 个概率可以用一个状态转移矩阵来表示:

这个矩阵表示,如果在t时间时宝宝的状态是吃,则在t+1时间状态是玩、吃、睡的概率分别为(0.2、0.1、0.7)。

矩阵的每一行的数据累加和为1。
隐马尔可夫模型
在很多时候,马尔可夫过程不足以描述我们发现的问题,例如我们并不能直接知晓宝宝的状态是饿了或者困了,但是可以通过宝宝的其他行为推测。如果宝宝哭闹,可能是饿了;如果无精打采,则可能是困了。由此我们将产生两个状态集,一个是可观测的状态集O和一个隐藏状态集S,我们的目的之一是借由可观测状态预测隐藏状态,为了简化描述,将“玩”这个状态去掉,让宝宝每天除了吃就是睡,这也是大多数家长共同的愿望,模型如下:
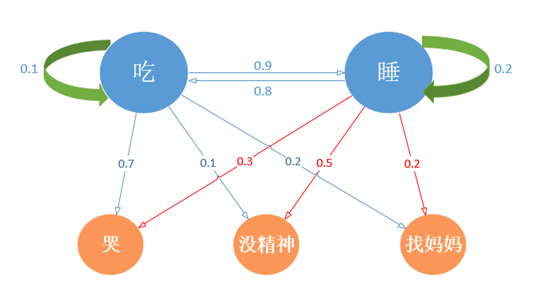
由此得到O={Ocry,Otired,Ofind},S={Seat,Szzz}。宝宝在“吃(饥饿)”状态下表现出哭、没精神、找妈妈三种可观察行为的概率分别是(0.7,0.1,0.2)。
上面的例子中,可以观察到的状态序列和隐藏的状态序列是概率相关的。于是我们可以将这种类型的过程建模为有一个隐藏的马尔科夫过程和一个与这个隐藏马尔科夫过程概率相关的并且可以观察到的状态集合。这就是隐马尔可夫模型。
隐马尔可夫模型 (Hidden Markov Model,HMM) 是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。
通过转移矩阵,我们知道怎样表示P(St+1=m|St=n),怎样表示P(Ot|S)呢(观测到的状态相当于对隐藏的真实状态的一种估计)?在HMM中我们使用另一个矩阵:

该矩阵被称为混淆矩阵。矩阵行代表隐藏状态,列代表可观测的状态,矩阵每一行概率值的和为1。其中第1行第1列,P(Ot=cry|Pt=eat)=0.7,宝宝在饿了时,哭的概率是0.7。
混淆矩阵可视为马尔可夫模型的另一个假设,独立性假设:假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其它观测状态无关。

HMM模型的形式定义
一个 HMM 可用一个5元组 { N, M, π,A,B } 表示,其中:
- N 表示隐藏状态的数量,我们要么知道确切的值,要么猜测该值;
- M 表示可观测状态的数量,可以通过训练集获得;
- π={πi} 为初始状态概率;代表的是刚开始的时候各个隐藏状态的发生概率;
- A={aij}为隐藏状态的转移矩阵;N*N维矩阵,代表的是第一个状态到第二个状态发生的概率;
- B={bij}为混淆矩阵,N*M矩阵,代表的是处于某个隐状态的条件下,某个观测发生的概率。
在状态转移矩阵和混淆矩阵中的每个概率都是时间无关的,即当系统演化时,这些矩阵并不随时间改变。对于一个 N 和 M 固定的 HMM 来说,用 λ={π, A, B } 表示 HMM 参数。
问题求解
假设有一个已知的HMM模型:

在该模型中,初始化概率π={Seat=0.3,Szzz=0.7};隐藏状态N=2;可观测状态M=3;转移矩阵和混淆矩阵分别是:

现在我们要解决3个问题:
1.模型评估问题(概率计算问题)
已知整个模型,宝宝的行为依次是哭 -> 没精神 –>找妈妈,计算产生这些行为的概率。
即:
已知模型参数,计算某一给定可观察状态序列的概率。即在已知一个观察序列,和模型λ=(A,B,π}的条件下,观察序列O的概率,即P(O|λ}。
对应算法:向前算法、向后算法
2.解码问题(预测问题)
已知整个模型,宝宝的行为依次是哭 -> 没精神 –>找妈妈,计算这三个行为下,宝宝的状态最可能是什么。
即:
已知模型参数和可观察状态序列,怎样选择一个状态序列S={S1,S2,…,ST},能最好的解释观测序列O。
对应算法:维特比算法
3.参数评估问题(属于非监督学习算法)
通过宝宝的行为,哭、没精神、找妈妈,来确定宝宝的状态转换概率。
数据集仅有观测序列,如何调整模型参数 λ=(π, A, B), 使得P(O|λ)最大
对应算法:鲍姆-韦尔奇算法
本文主要解决问题1和问题2,从中可以看到马尔可夫假设(上文提到的公式1和2)简化了概率计算(问题3后续补充)。
遍历法
求解问题1。
遍历法也是典型的穷举法,实现较为简单,罗列可能情况后将其相加即可。共有3种可观察状态,每个可观察状态对应2种隐藏状态,共有23 = 8中可能的情况。其中一种:
P(Seat1, Seat2, Seat3,Ocry1,Otired2,Ofind3)
= P(Seat1)·P(Ocry1)·P(Seat2)·P(Otired2)·P(Seat3)·P(Ofind3)
= (0.3×0.7)×(0.1×0.1)×(0.1×0.2)
= 0.000042
上式中的下标的数字表示时间,下标在观测点和隐藏点都比较少的时候,遍历法最为有效(因为简单),一旦节点数增加,计算量将急剧增大。
向前算法(Forward Algorithm)
求解问题1。
向前算法是在时间 t=1的时候,一步一步往前计算。
其背后的马尔可夫概率公式:
P(W1,W2) = P(W1)P(W2|W1)
P(W1,W2,W3) = P(W1,W2)P(W3|W1,W2)
P(W1,W2,…,Wn) = P(W1,W2,…,Wn-1)P(Wn|W1,W2,…,Wn-1)
1.计算当t=1时,发生Cry这一行为的概率:
P(Ocry,Seat) = P(Seat)P(Ocry|Seat) =0.3×0.7=0.21
P(Ocry,Szzz) = P(Szzz)P(Ocry|Szzz) =0.7×0.3=0.21
2.计算当t=2时,发生Tired这一行为的概率:
根据马尔可夫假设,P(Ot=2)仅与St=1有关,下一天的行为概率是由前一天的状态计算而来,如果St=2=Seat2:
P(Ocry1,Otired2,Seat2)
= P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Seat2)+ P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Seat2)
=[P(Ocry1,Seat1)P(Seat2|Seat1)+P(Ocry1,Szzz1)P(Seat2|Szzz1)]·P(Otired2|Seat2)
= [0.21×0.1+0.21×0.8]×0.1
= 0.0189
如果St=2=Szzz2:
P(Ocry1,Otired2,Szzz2)
= P(Ocry1,Seat1)P(Szzz2|Seat1)P(Otired2|Szzz2)+P(Ocry1,Szzz1)P(Szzz2|Szzz1)P(Otired2|Szzz2)
= [P(Ocry1,Seat1)P(Szzz2|Seat1)+ P(Ocry1,Seat1)P(Szzz2|Seat1)]·P(Otired2|Szzz2)
= [0.21×0.9+0.21×0.2]×0.5
= 0.1155
3.计算当t=3时,发生Find这一行为的概率:
如果St=3=Seat3,
P(Ocry1,Otired2,Ofind3,Seat3)
= P(Ocry1,Otired2,Seat2)P(Seat3| Seat2)P(Ofind3|Seat3)+
P(Ocry1,Otired2,Szzz2)P(Seat3| Szzz2)P(Ofind3|Seat3)
= [P(Ocry1,Otired2,Seat2)P(Seat3| Seat2)+
P(Ocry1,Otired2,Szzz2)P(Seat3| Szzz2)]·P(Ofind3|Seat3)
= [0.0189×0.1+0.1155×0.8]×0.2
= 0.018858
如果St=3=Szzz3,
P(Ocry1,Otired2,Ofind3,Seat3)
= P(Ocry1,Otired2,Seat2)P(Szzz3| Seat2)P(Ofind3|Szzz3)+
P(Ocry1,Otired2,Szzz2)P(Szzz3| Szzz2)P(Ofind3|Szzz3)
= [P(Ocry1,Otired2,Seat2)P(Szzz3| Seat2)+
P(Ocry1,Otired2,Szzz2)P(Szzz3| Szzz2)]·P(Ofind3|Szzz3)
= [0.0189×0.9+0.1155×0.2]×0.2
= 0.008022
综上,
P(Ocry1,Otired2,Ofind3)
= P(Ocry1,Otired2,Ofind3,Seat3)+ P(Ocry1,Otired2,Ofind3,Szzz3)
= 0.018858+0.049602
= 0.06848
维特比算法(Viterbi Algorithm)
参照百度百科:
维特比算法的基础可以概括成下面三点:
- 如果概率最大的路径p(或者说最短路径)经过某个点,比如途中的X22,那么这条路径上的起始点S到X22的这段子路径Q,一定是S到X22之间的最短路径。否则,用S到X22的最短路径R替代Q,便构成一条比P更短的路径,这显然是矛盾的。证明了满足最优性原理。
- 从S到E的路径必定经过第i个时刻的某个状态,假定第i个时刻有k个状态,那么如果记录了从S到第i个状态的所有k个节点的最短路径,最终的最短路径必经过其中一条,这样,在任意时刻,只要考虑非常有限的最短路即可。
- 结合以上两点,假定当我们从状态i进入状态i+1时,从S到状态i上各个节的最短路径已经找到,并且记录在这些节点上,那么在计算从起点S到第i+1状态的某个节点Xi+1的最短路径时,只要考虑从S到前一个状态i所有的k个节点的最短路径,以及从这个节点到Xi+1,j的距离即可。
在本例中,维特比算法实际上是从t=1时刻开始,不断向后计算,寻找概率最大的路径。
1.计算t=1时刻Ocry发生的概率:
δ11 = P(Ocry,Seat) = P(Seat)P(Ocry|Seat)=0.3×0.7=0.21
δ12 = P(Ocry,Szzz) = P(Szzz)P(Ocry|Szzz)=0.7×0.3=0.21
2.计算t=2时刻Otired发生的概率:
δ21 =max(P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Seat2),P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Seat2))
= max(P(Ocry1,Seat1)P(Seat2|Seat1), P(Ocry1,Szzz1)P(Seat2|Szzz1))·P(Otired2|Seat2)
= max(δ11 P(Seat2|Seat1), δ12 P(Seat2|Szzz1)) ·P(Otired2|Seat2)
= max(0.21×0.1,0.21×0.8)×0.1
= 0.0168
S21 = eat
δ22 = max(P(Ocry1,Seat1)P(Seat2|Seat1)P(Otired2|Szzz2),P(Ocry1,Szzz1)P(Seat2|Szzz1)P(Otired2|Szzz2))
= max(δ11 P(Szzz2|Seat1), δ12 P(Szzz2|Szzz1)) ·P(Otired2|Szzz2)
= max(0.21×0.9,0.21×0.2)×0.5
= 0.0945
S22 = zzz
3.计算t=3时刻Ofind发生的概率:
δ31 = max(δ21P(Seat3|Seat2), δ22P(Seat3|Szzz2)) ·P(Ofind3|Seat3)
=max(0.0168×0.1, 0.0189×0.8)×0.2
=0.003024
S31 = eat
δ32 = max(δ21P(Szzz3|Seat2), δ22P(Szzz3|Szzz2)) ·P(Ofind3|Szzz3)
=max(0.0168×0.9, 0.0189×0.2)×0.2
=0.003024
S32 = zzz
4.回溯,每一步的最大概率:
max(δ11,δ12), max(δ21,δ22), max(δ31,δ32)
对应的状态:eat or zzz, zzz, eat or zzz
语音识别
以下内容整理自吴军的《数学之美》
当我们观测到语音信号 o1,o2,o3 时,我们要根据这组信号推测出发送的句子 s1,s2,s3。显然,我们应该在所有可能的句子中找最有可能性的一个。用数学语言来描述,就是在已知 o1,o2,o3,…的情况下,求使得条件概率P (s1,s2,s3,…|o1,o2,o3….) 达到最大值的那个句子 s1,s2,s3,…

其中

独立性假设

马尔可夫假设

由此可以看出,语音识别正好符合HMM模型。
出处:微信公众号 "我是8位的"
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号