数据分析(2)——数据的类型和尺度
数据(data)是事实或观察的结果,是对客观事物的逻辑归纳,是用于表示客观事物的未经加工的的原始素材……在计算机系统中,数据以二进制信息单元0,1的形式表示(百度百科)
后半句看懂了,至于前半句,还是忘记比较好。
简单地说,任何事物的结果都是数据,注意是结果,不是过程,过程是一个动作,是驱动结果的行为。
更简单一点,用任何媒体记录的东西都是数据,比如一本书中的文字,一张光盘中的信息,当然了,程序员们也许第一个想到的是数据库中的数据。

假设有客户发了一条微信:
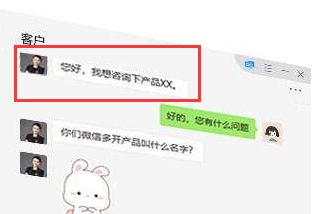
通常管这叫“信息”,那么信息和数据有什么区别?
假设你在另一个手机上恢复和某人的聊天记录,你管这个叫什么?叫“历史数据”对吧,所以说,数据是信息的集合。通常把某一类数据叫做数据集,比如图片数据集,聊天记录数据集。实际上这些名词没必要区分得那么详细,这些概念通常都很直白,不会弄错,即使弄错了也没关系,你管数据集叫信息集也不影响理解。
人是很善于分类的,什么事情都要分分类,最近比较热门的分类是垃圾分类:

23种设计模式还分成5、7、11三类:

对于天天打交道的数据,也少不了要分分类。大体上,数据可以分为结构化数据和非结构化数据,对于结构化数据的每一维度,还可以根据类型和尺度进一步划分。
结构化和非结构化
结构化数据指能够用行列存储,有严格维度划分的数据,科学家的实验数据,关系型数据库的表记录,都是结构化数据。
与结构化对应的是非结构化数据,比如某个系统产生的日志,一封邮件,一张图片,一段视频,一段微信聊天记录……可见世界上的大部分数据都是非结构化数据。
显然结构化数据更易于分析和处理,实际上大部分统计学模型和机器学习模型都只能使用格式化数据,很多时候,在面对非格式化数据时,不得不将其转换成结构化数据。
对于一条非格式化数据,首先能够提取出的信息是数据的大小,当然,大小的度量根据数据集的不同可能会有所差异。
来看一下美团上对苏州松鹤楼的评价:
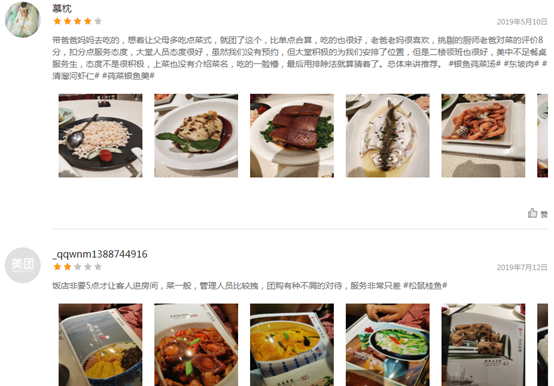

第一条评论的文字比较多,其他大多数评论都很短,这符合常理,毕竟大多数人都很懒。
“带爸爸妈妈去吃的,想着让父母多吃点菜式,就团了这个,比单点合算,吃的也很好,老爸老妈很喜欢,挑剔的厨师老爸对菜的评价8分,扣分点服务态度,大堂人员态度很好,虽然我们没有预约,但大堂积极的为我们安排了位置,但是二楼领班也很好,美中不足餐桌服务生,态度不是很积极,上菜也没有介绍菜名,吃的一脸懵,最后用排除法就算猜着了。总体来讲推荐。 #银鱼莼菜汤# #东坡肉# #清溜河虾仁# #莼菜银鱼羹#”
这条评论有194个字(包括标点),松鹤楼共有274人评论,平均评论是21个字,在没有大量重复语句的前提下,差不多可以认定这条品论是精品评论了。
接下来对评论进行分词解析:
1 mport pandas as pd 2 from jieba.analyse import ChineseAnalyzer 3 4 content = '带爸爸妈妈去吃的,想着让父母多吃点菜式,就团了这个,比单点合算,吃的也很好,老爸老妈很喜欢,挑剔的厨师老爸对菜的评价8分,扣分点服务态度,大堂人员态度很好,虽然我们没有预约,但大堂积极的为我们安排了位置,但是二楼领班也很好,美中不足餐桌服务生,态度不是很积极,上菜也没有介绍菜名,吃的一脸懵,最后用排除法就算猜着了。总体来讲推荐。' \ 5 '#银鱼莼菜汤# #东坡肉# #清溜河虾仁# #莼菜银鱼羹#' 6 length = len(content) 7 print('length =', length) 8 9 segments = [] 10 analyzer = ChineseAnalyzer() 11 # 进行中文分词 12 for word in analyzer(content): 13 segments.append({'word': word.text, 'count': 1}) 14 15 df = pd.DataFrame(segments) 16 # 词频统计 17 word_feq = df.groupby('word')['count'].sum() 18 # 按count降序排序,取出现次数最多的前30个词 19 word_feq_n = word_feq.sort_values(ascending=False)[:30] 20 print(word_feq_n)
使用'ChineseAnalyzer'时可能出现:ImportError: cannot import name 'ChineseAnalyzer',安装whoosh即可:pop install whoosh
代码先对这条评论进行分词,再统计词频最高的前30个词,结果如下:
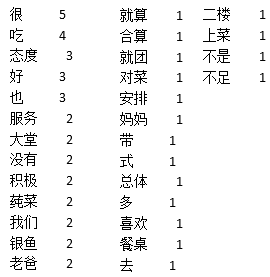
其中“好”、“积极”、“合算”、“喜欢”这类正面的词共出现了5次,“不足”出现了1次,说明用顾客对本次用餐还是比较满意的。评论中出现了“我们”、“爸爸”、“妈妈”,说明该顾客是多人用餐。“态度”、”菜”、 “上菜”都出现了,通常来说,如果态度和菜比较差,顾客不会用“不足”来评价,最可能的不足是“上菜”。
根据这些分析,可以得到格式化数据:

对于后三个字段,简单地用2表示好,1表示一般,0表示差。
借助类似的方法,我们可以将非结构化数据转换成结构化数据,从而挖掘出更多的信息。
定性和定类
对于结构化数据来说,某一列的类型可分为定量数据和定性数据。如果能够参与加减乘除这类运算,那么这个数据就是定量数据,否则是定性数据。
看起来很简单,比如某个企业的员工信息:

姓名这类文本类型肯定是定性数据。年龄可以相减,得到的年龄差是有意义的,是定量数据;学号、性别、电话,虽然也是数字,但是进行减法没有任何意义,因此也是定性数据。对于定量数据来说,可以计算这一维度的平均数、最大值、最小值等信息。
4个尺度
比定性和定量更进一步,根据每一列参与数学运算的程度,结构化数据的一列可归为4个尺度之一:定类尺度、定序尺度、定距尺度、定比尺度。
每个维度的数据都有一个测度中心,它是一个描述数据趋势的数值,也被称为数据平衡点,平均数是常用的测度中心。
定类尺度
定类尺度主要包含文字和类别数据,比如姓名、订单号、产品类别、发货地址等,这类数据通常是字符串格式,无法参与加减乘除这类数学运算。
两种数学运算可能适合定类尺度——等式运算和包含运算,比如我们可以比较几个订单的发货地址是否相同,或者产品是否隶属于某个大类之下。
有些数据虽然可以用数字表示,但仍然属于定类尺度,比如电话号码,对电话号进行加减乘除和除了等式之外的大小比较都是毫无意义的。
很明显,定类尺度无法使用均值、中位数,但是可以通过统计的方式计算定类尺度数据的众数,因此定类尺度的测度中心是数据的众数。
(关于中位数和众数,可参考 关于平均数)
定序尺度
定类尺度数据无法按照自然属性排序,而定序尺度数据可以支持大小比较运算,从而对数据进行排序。这里的排序,指对数据进行大小比较是有意义的前提下进行的排序,而不是指程序上的asc和desc。
定序尺度不能进行乘除运算,这容易理解,但是很多数资料上说定序尺度不能进行加减法运算(减法和加法是一回事,a-b相当于a+(-b)),并把这一点作为判断定序尺度的依据,这就不容易理解了,需要换一种容易判定的方式。
我们经常看到企业的人员的学历统计图:

上图是某个互联网公司的人员学历,分为大专、本科、博士、硕士4个等级,可以编号为1、2、3、4。学历的排序是有意义的,但是学历相减呢?或许也是有意义的,3-1=2,4-2=2,两个2都表示学历的等级差,但这个等级差是否有用就值得商榷了,你能马上联想到什么地方需要这个差值吗?因此我们说,判断定序尺度的依据之一是:数据并不一定是不能相减,只是相减后的差值很少有(或根本没有)明确的用途。另一个依据是,定序尺度通常用中位数而不是均值作为测度中心。上图的中位数是2,表示本科占了大多数;而均值可能是2.1,它并没有一个明确的类别。因此HR在介绍时会说:“我们公司的平均学历是本科”,而不是说:“我们公司的平均学历比本科高那么一丢丢。
定距尺度
定距尺度除了具备定序尺度的特征外,还可以进行有意义的加减法运算。
上海近20年11月份的平均气温、某个企业员工的年龄,这些都是定距尺度,两个定距尺度的差是有意义的,并且很常用:去年11月的平均气温比今年高了2℃,老李比小王大10岁。显然,定距尺度数据可以使用均值作为测度中心。
对于给定的数据集来说,我们往往想了解数据的波动性,此时需要用到标准差:

其中r是均值,N是数据总量。
下表示2个射击运动员5轮射击后的数据:

均值是都9.5,似乎而二者实力相当。但通过观察数据会发现,甲是发挥型选手,成绩波动较大,可以打出“超级环”,也会打出大失水准的“低级环”;相反,乙的发挥比较稳定,总是与平均成绩接近。
每一次射击的成绩均会产生波动,用每一次射击的得分减去平均成绩表示本次波动,得到了下面的数据:

现在可以计算出二人的总体波动了:
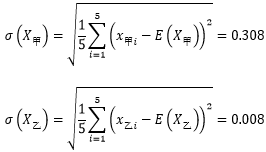
可以看出,乙的波动远远小于甲的波动,说明乙的稳定性更高。
关于标准差和数据波动的更多信息,可参考:方差、均方差和协方差
能否使用标准差也可以作为定序尺度和定距尺度的参考判定依据之一。对于人类的智商来说,平均智商通常使用中位数,而且计算智商的波动是没有意义的,因此智商属于定序尺度。当然,智商也许会出现波动,比如看见美女智商下降70%,但这属于玄学问题了。
定比尺度
定比尺度数据是最牛的一种,处理定距尺度的特性外,还可以进行乘除运算,同时还具有绝对或自然的起点,即存在可以作为比较的共同起点或基数。
收入和存款是典型定比尺度,我们经常说某某的收入是自己的2倍。
定比尺度和定距尺度也很微妙,关键还是看乘除法是否有明确的意义。比如考试分数,0分可以作为自然的起点,但是我们通常直说A比B高了30分,而不说A比B的分数高一倍,因此分数是用来确定两人之间的距离的,而不是比例。我家的面积是100平米,同学家是200平米,同学家比我家的面积大一倍,面积是定比尺度。
作者:我是8位的
出处:https://mp.weixin.qq.com/s/XJROL6iAFZ5XuFNq4WT86g
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注作者公众号“我是8位的”



 浙公网安备 33010602011771号
浙公网安备 33010602011771号