


tensorflow预定义经典卷积神经网络和数据集tf.keras.applications
自己开发了一个股票软件,功能很强大,需要的点击下面的链接获取:
https://www.cnblogs.com/bclshuai/p/11380657.html
1.1 tensorflow预定义经典卷积神经网络和数据集
1.1.1 预定义模型tf.keras.applications
tensorflow有很多已经定义好的模型,而且模型参数已经训练过,可以直接下载模型参数文件,载入参数,使用模型。预定义模型在tf.keras.applications。
# This file is MACHINE GENERATED! Do not edit. # Generated by: tensorflow/python/tools/api/generator/create_python_api.py script. """Keras Applications are canned architectures with pre-trained weights. """ from __future__ import print_function as _print_function import sys as _sys from . import densenet from . import efficientnet from . import imagenet_utils from . import inception_resnet_v2 from . import inception_v3 from . import mobilenet from . import mobilenet_v2 from . import nasnet from . import resnet from . import resnet50 from . import resnet_v2 from . import vgg16 from . import vgg19 from . import xception from tensorflow.python.keras.applications.densenet import DenseNet121 from tensorflow.python.keras.applications.densenet import DenseNet169 from tensorflow.python.keras.applications.densenet import DenseNet201 from tensorflow.python.keras.applications.efficientnet import EfficientNetB0 from tensorflow.python.keras.applications.efficientnet import EfficientNetB1 from tensorflow.python.keras.applications.efficientnet import EfficientNetB2 from tensorflow.python.keras.applications.efficientnet import EfficientNetB3 from tensorflow.python.keras.applications.efficientnet import EfficientNetB4 from tensorflow.python.keras.applications.efficientnet import EfficientNetB5 from tensorflow.python.keras.applications.efficientnet import EfficientNetB6 from tensorflow.python.keras.applications.efficientnet import EfficientNetB7 from tensorflow.python.keras.applications.inception_resnet_v2 import InceptionResNetV2 from tensorflow.python.keras.applications.inception_v3 import InceptionV3 from tensorflow.python.keras.applications.mobilenet import MobileNet from tensorflow.python.keras.applications.mobilenet_v2 import MobileNetV2 from tensorflow.python.keras.applications.nasnet import NASNetLarge from tensorflow.python.keras.applications.nasnet import NASNetMobile from tensorflow.python.keras.applications.resnet import ResNet101 from tensorflow.python.keras.applications.resnet import ResNet152 from tensorflow.python.keras.applications.resnet import ResNet50 from tensorflow.python.keras.applications.resnet_v2 import ResNet101V2 from tensorflow.python.keras.applications.resnet_v2 import ResNet152V2 from tensorflow.python.keras.applications.resnet_v2 import ResNet50V2 from tensorflow.python.keras.applications.vgg16 import VGG16 from tensorflow.python.keras.applications.vgg19 import VGG19 from tensorflow.python.keras.applications.xception import Xception del _print_function
预定模型种类说明
可以在官网查看https://keras.io/zh/applications/
|
|
|
|
|
|
|
|
模型 |
大小 |
Top-1 准确率 |
Top-5 准确率 |
参数数量 |
深度 |
|
88 MB |
0.790 |
0.945 |
22,910,480 |
126 |
|
|
528 MB |
0.713 |
0.901 |
138,357,544 |
23 |
|
|
549 MB |
0.713 |
0.900 |
143,667,240 |
26 |
|
|
98 MB |
0.749 |
0.921 |
25,636,712 |
- |
|
|
171 MB |
0.764 |
0.928 |
44,707,176 |
- |
|
|
232 MB |
0.766 |
0.931 |
60,419,944 |
- |
|
|
98 MB |
0.760 |
0.930 |
25,613,800 |
- |
|
|
171 MB |
0.772 |
0.938 |
44,675,560 |
- |
|
|
232 MB |
0.780 |
0.942 |
60,380,648 |
- |
|
|
96 MB |
0.777 |
0.938 |
25,097,128 |
- |
|
|
170 MB |
0.787 |
0.943 |
44,315,560 |
- |
|
|
92 MB |
0.779 |
0.937 |
23,851,784 |
159 |
|
|
215 MB |
0.803 |
0.953 |
55,873,736 |
572 |
|
|
16 MB |
0.704 |
0.895 |
4,253,864 |
88 |
|
|
14 MB |
0.713 |
0.901 |
3,538,984 |
88 |
|
|
33 MB |
0.750 |
0.923 |
8,062,504 |
121 |
|
|
57 MB |
0.762 |
0.932 |
14,307,880 |
169 |
|
|
80 MB |
0.773 |
0.936 |
20,242,984 |
201 |
|
|
23 MB |
0.744 |
0.919 |
5,326,716 |
- |
|
|
343 MB |
0.825 |
0.960 |
88,949,818 |
1.1.2 数据集tensorflow_datasets
(1)安装方式,可以打开anaconda界面,用命令行去添加,也可以直接在pycharm里面为环境添加。
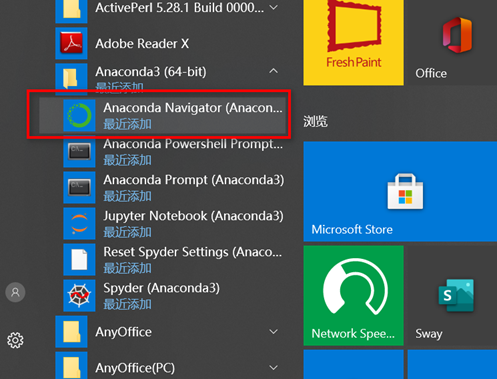
输入activate tensoflow 激活环境
然后输入pip install tensorflow_datasets 安装数据集库
(2)或者在pycharm里面安装库
点击pycharm工程的file-》setting
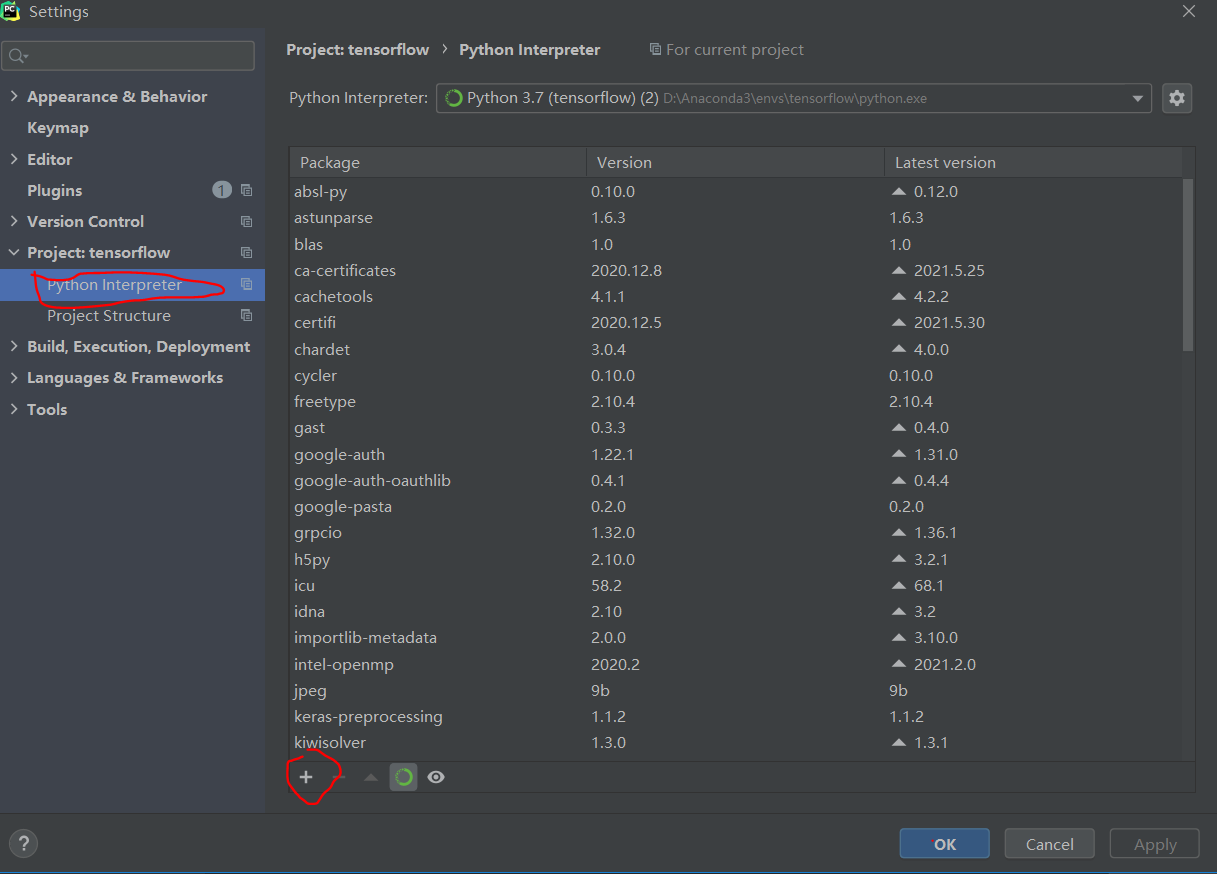
在输入框内输入tensorflow_datasets,出现安装库,然后选中列表中的tensorflow_datasets,点击左下角的install Package
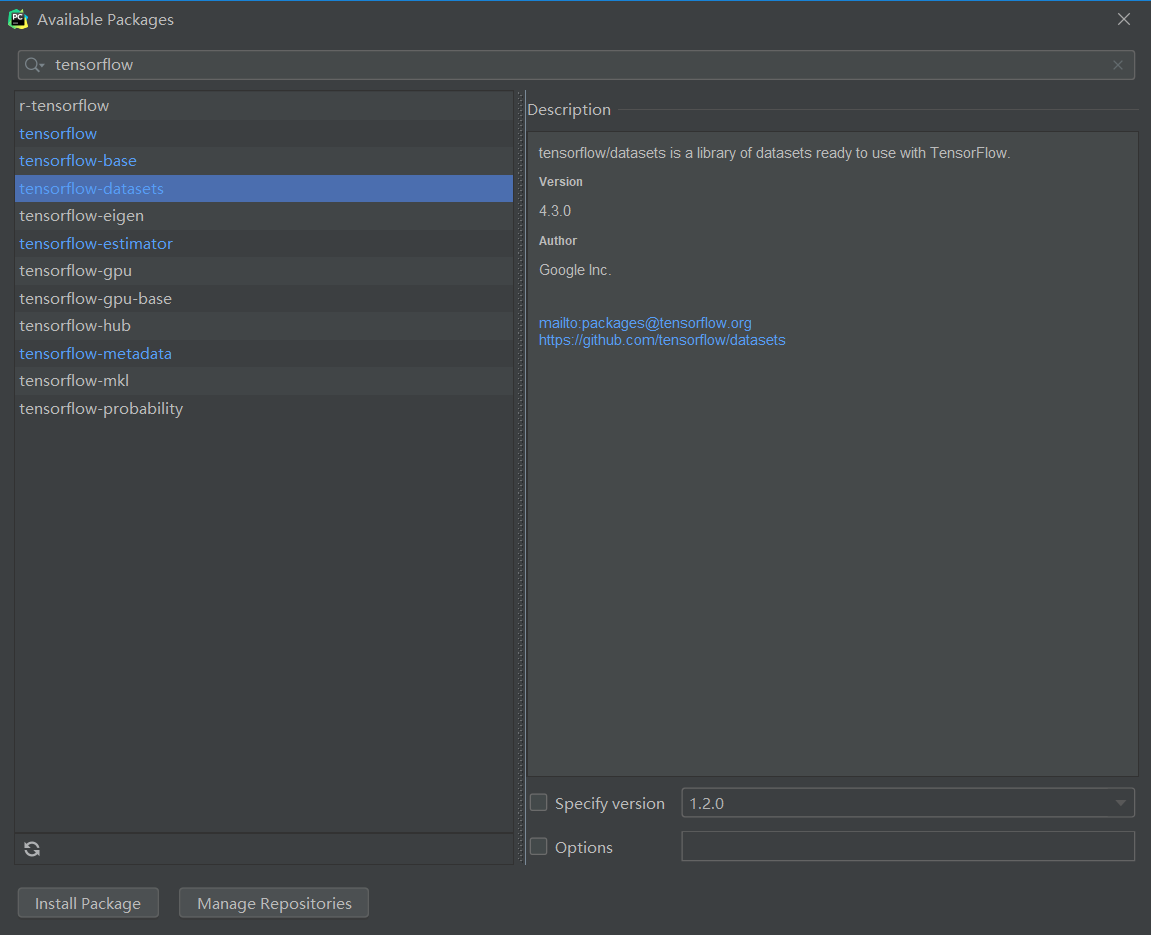
之后再py文件中输入import tensorflow_datasets as dataset就可以使用数据集了。
(3)运行出现HDF5库和h5py版本不匹配的问题
安装完成后开始编译下载数据,出现如下错误
h5py is running against HDF5 1.10.5 when it was built against 1.10.6, this may cause problems
因为下载数据用到的HDF5和h5py的版本冲突不匹配,可以在anaconda中先输入pip uninstall h5py 然后再输入pip install h5py。下载最新版本的h5py,问题解决。
(4)tensorflow_datasets 包含的数据集名称
可以用下面的语句打印显示
import tensorflow_datasets as data
print(data.list_builders())#打印显示所有的数据集名称,用load加载
['abstract_reasoning', 'accentdb', 'aeslc', 'aflw2k3d', 'ag_news_subset', 'ai2_arc', 'ai2_arc_with_ir', 'amazon_us_reviews', 'anli', 'arc', 'bair_robot_pushing_small', 'bccd', 'beans', 'big_patent', 'bigearthnet', 'billsum', 'binarized_mnist', 'binary_alpha_digits', 'blimp', 'bool_q', 'c4', 'caltech101', 'caltech_birds2010', 'caltech_birds2011', 'cars196', 'cassava', 'cats_vs_dogs', 'celeb_a', 'celeb_a_hq', 'cfq', 'cherry_blossoms', 'chexpert', 'cifar10', 'cifar100', 'cifar10_1', 'cifar10_corrupted', 'citrus_leaves', 'cityscapes', 'civil_comments', 'clevr', 'clic', 'clinc_oos', 'cmaterdb', 'cnn_dailymail', 'coco', 'coco_captions', 'coil100', 'colorectal_histology', 'colorectal_histology_large', 'common_voice', 'coqa', 'cos_e', 'cosmos_qa', 'covid19sum', 'crema_d', 'curated_breast_imaging_ddsm', 'cycle_gan', 'd4rl_mujoco_ant', 'd4rl_mujoco_halfcheetah', 'dart', 'davis', 'deep_weeds', 'definite_pronoun_resolution', 'dementiabank', 'diabetic_retinopathy_detection', 'div2k', 'dmlab', 'dolphin_number_word', 'downsampled_imagenet', 'drop', 'dsprites', 'dtd', 'duke_ultrasound', 'e2e_cleaned', 'efron_morris75', 'emnist', 'eraser_multi_rc', 'esnli', 'eurosat', 'fashion_mnist', 'flic', 'flores', 'food101', 'forest_fires', 'fuss', 'gap', 'geirhos_conflict_stimuli', 'gem', 'genomics_ood', 'german_credit_numeric', 'gigaword', 'glue', 'goemotions', 'gpt3', 'gref', 'groove', 'gtzan', 'gtzan_music_speech', 'hellaswag', 'higgs', 'horses_or_humans', 'howell', 'i_naturalist2017', 'imagenet2012', 'imagenet2012_corrupted', 'imagenet2012_real', 'imagenet2012_subset', 'imagenet_a', 'imagenet_r', 'imagenet_resized', 'imagenet_v2', 'imagenette', 'imagewang', 'imdb_reviews', 'irc_disentanglement', 'iris', 'kitti', 'kmnist', 'lambada', 'lfw', 'librispeech', 'librispeech_lm', 'libritts', 'ljspeech', 'lm1b', 'lost_and_found', 'lsun', 'lvis', 'malaria', 'math_dataset', 'mctaco', 'mlqa', 'mnist', 'mnist_corrupted', 'movie_lens', 'movie_rationales', 'movielens', 'moving_mnist', 'multi_news', 'multi_nli', 'multi_nli_mismatch', 'natural_questions', 'natural_questions_open', 'newsroom', 'nsynth', 'nyu_depth_v2', 'ogbg_molpcba', 'omniglot', 'open_images_challenge2019_detection', 'open_images_v4', 'openbookqa', 'opinion_abstracts', 'opinosis', 'opus', 'oxford_flowers102', 'oxford_iiit_pet', 'para_crawl', 'patch_camelyon', 'paws_wiki', 'paws_x_wiki', 'pet_finder', 'pg19', 'piqa', 'places365_small', 'plant_leaves', 'plant_village', 'plantae_k', 'qa4mre', 'qasc', 'quac', 'quickdraw_bitmap', 'race', 'radon', 'reddit', 'reddit_disentanglement', 'reddit_tifu', 'resisc45', 'robonet', 'rock_paper_scissors', 'rock_you', 's3o4d', 'salient_span_wikipedia', 'samsum', 'savee', 'scan', 'scene_parse150', 'schema_guided_dialogue', 'scicite', 'scientific_papers', 'sentiment140', 'shapes3d', 'siscore', 'smallnorb', 'snli', 'so2sat', 'speech_commands', 'spoken_digit', 'squad', 'stanford_dogs', 'stanford_online_products', 'star_cfq', 'starcraft_video', 'stl10', 'story_cloze', 'sun397', 'super_glue', 'svhn_cropped', 'tao', 'ted_hrlr_translate', 'ted_multi_translate', 'tedlium', 'tf_flowers', 'the300w_lp', 'tiny_shakespeare', 'titanic', 'trec', 'trivia_qa', 'tydi_qa', 'uc_merced', 'ucf101', 'vctk', 'vgg_face2', 'visual_domain_decathlon', 'voc', 'voxceleb', 'voxforge', 'waymo_open_dataset', 'web_nlg', 'web_questions', 'wider_face', 'wiki40b', 'wiki_bio', 'wiki_table_questions', 'wiki_table_text', 'wikiann', 'wikihow', 'wikipedia', 'wikipedia_toxicity_subtypes', 'wine_quality', 'winogrande', 'wmt13_translate', 'wmt14_translate', 'wmt15_translate', 'wmt16_translate', 'wmt17_translate', 'wmt18_translate', 'wmt19_translate', 'wmt_t2t_translate', 'wmt_translate', 'wordnet', 'wsc273', 'xnli', 'xquad', 'xsum', 'xtreme_pawsx', 'xtreme_xnli', 'yelp_polarity_reviews', 'yes_no', 'youtube_vis']
1.1.3 预定义模型和数据集使用实例
import tensorflow as tf import tensorflow_datasets as data #(3)定义训练参数和模型对象,数据集对象 num_epochs = 5 batch_size = 19#一批数据的数量 learning_rate = 0.001#学习率 #根据第一个参数名称来下载数据集 print(data.list_builders())#打印显示所有的数据集名称,用load加载 dataset = data.load("tf_flowers",split=data.Split.TRAIN,as_supervised=True)#创建数据源对象,下载数据 dataset=dataset.map(lambda img,label:(tf.image.resize(img,(224,224))/255.0,label)).shuffle(1024).batch(batch_size) model = tf.keras.applications.MobileNetV2(weights=None,classes=5)#创建模型 optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)#创建优化器,用于参数学习优化 #开始训练参数 #arryindex=np.arange(num_batches) #arryloss=np.zeros(num_batches) #通过梯度下降法对模型参数进行训练,优化模型 for e in range(num_epochs): for images,labels in dataset: with tf.GradientTape() as tape: label_pred=model(images,trainable=True) # 计算损失函数 loss = tf.keras.losses.sparse_categorical_crossentropy(y_true=labels, y_pred=label_pred) # 计算损失函数的均方根值,表示误差大小 loss = tf.reduce_mean(loss) print("第%d次训练后:误差%f" % (batch_index, loss.numpy())) grads = tape.gradient(loss, model.variables) # 将梯度值调整模型参数 print(label_pred) optimizer.apply_gradients(grads_and_vars=zip(grads, model.variables))
运行下载数据出现断开连接的错误
Connection broken: ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None)"
网上因为下载数据太多,时间超时,远程主机以为是受到攻击,自动断开。没找到解决方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号