RealPython-中文系列教程-十六-
RealPython 中文系列教程(十六)
原文:RealPython
Python sleep():如何在代码中添加时间延迟
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 sleep()编写一个 Python 正常运行时间 Bot
你曾经需要让你的 Python 程序等待什么吗?大多数时候,您会希望代码尽可能快地执行。但是有时候让你的代码休眠一会儿实际上是对你最有利的。
例如,您可以使用 Python sleep()调用来模拟程序中的延迟。也许您需要等待文件上传或下载,或者等待图形加载或绘制到屏幕上。您甚至可能需要在调用 web API 或查询数据库之间暂停。在你的程序中添加 Python sleep() 调用可以帮助你解决这些问题,甚至更多!
在本教程中,您将学习如何使用添加 Python sleep()调用
time.sleep()- 装修工
- 线
- Async IO
- 图形用户界面
本文面向希望增长 Python 知识的中级开发人员。如果这听起来像你,那么让我们开始吧!
免费奖励: ,它向您展示了三种高级装饰模式和技术,您可以用它们来编写更干净、更 Python 化的程序。
添加 Python sleep()调用time.sleep()
Python 内置了让程序休眠的支持。 time模块有一个函数 sleep() ,你可以用它来暂停执行你指定的任意秒数的调用线程。
这里有一个如何使用time.sleep()的例子:
>>> import time >>> time.sleep(3) # Sleep for 3 seconds如果在控制台中运行这段代码,那么在 REPL 中输入新语句之前,应该会有一段延迟。
注:在 Python 3.5 中,核心开发者对
time.sleep()的行为做了些许改动。新的 Pythonsleep()系统调用将至少持续您指定的秒数,即使睡眠被信号中断。但是,如果信号本身引发了异常,这就不适用。你可以通过使用 Python 的
timeit模块来测试睡眠持续多长时间:$ python3 -m timeit -n 3 "import time; time.sleep(3)" 3 loops, best of 5: 3 sec per loop在这里,您运行带有
-n参数的timeit模块,它告诉timeit运行后面的语句的次数。您可以看到timeit运行了该语句 3 次,最佳运行时间是 3 秒,这是所期望的。默认情况下,
timeit运行代码的次数是一百万次。如果您使用默认的-n运行上面的代码,那么每次迭代 3 秒,您的终端将会挂起大约 34 天!timeit模块有几个其他的命令行选项,你可以在它的文档中查看。让我们创造一些更真实的东西。系统管理员需要知道他们的一个网站何时关闭。您希望能够定期检查网站的状态代码,但不能经常查询 web 服务器,否则会影响性能。进行这种检查的一种方法是使用 Python
sleep()系统调用:import time import urllib.request import urllib.error def uptime_bot(url): while True: try: conn = urllib.request.urlopen(url) except urllib.error.HTTPError as e: # Email admin / log print(f'HTTPError: {e.code} for {url}') except urllib.error.URLError as e: # Email admin / log print(f'URLError: {e.code} for {url}') else: # Website is up print(f'{url} is up') time.sleep(60) if __name__ == '__main__': url = 'http://www.google.com/py' uptime_bot(url)这里您创建了
uptime_bot(),它将一个 URL 作为它的参数。然后,该函数尝试用urllib打开该 URL。如果有一个HTTPError或URLError,那么程序会捕捉到它并打印出错误。(在实际环境中,您可能会记录错误,并向网站管理员或系统管理员发送电子邮件。)如果没有错误发生,那么您的代码将显示一切正常。不管发生什么,你的程序都会休眠 60 秒。这意味着你每分钟只能访问一次网站。此示例中使用的 URL 是错误的,因此它将每分钟向您的控制台输出一次以下内容:
HTTPError: 404 for http://www.google.com/py继续更新代码,使用一个已知良好的网址,如
http://www.google.com。然后,您可以重新运行它,以查看它是否成功工作。您也可以尝试更新代码来发送电子邮件或记录错误。关于如何做到这一点的更多信息,请查看使用 Python 发送电子邮件的和登录 Python 的。用 decorator添加 Python
sleep()调用有时,您需要重试一个失败的功能。这种情况的一个常见用例是当您因为服务器繁忙而需要重试文件下载时。您通常不希望过于频繁地向服务器发出请求,所以在每个请求之间添加一个 Python
sleep()调用是可取的。我亲身经历的另一个用例是,我需要在自动化测试期间检查用户界面的状态。用户界面的加载速度可能比平时快或慢,这取决于我运行测试的计算机。这会改变我的程序正在验证的时候屏幕上的内容。
在这种情况下,我可以告诉程序休眠一会儿,然后在一两秒钟后重新检查。这可能意味着通过测试和失败测试之间的差别。
在这两种情况下,您都可以使用一个装饰器来添加一个 Python
sleep()系统调用。如果你不熟悉装饰者,或者如果你想重温他们,那么看看 Python 装饰者的初级读本。让我们看一个例子:import time import urllib.request import urllib.error def sleep(timeout, retry=3): def the_real_decorator(function): def wrapper(*args, **kwargs): retries = 0 while retries < retry: try: value = function(*args, **kwargs) if value is None: return except: print(f'Sleeping for {timeout} seconds') time.sleep(timeout) retries += 1 return wrapper return the_real_decorator是你的装潢师。它接受一个
timeout值和它应该接受的次数retry,默认为 3。在sleep()内部是另一个函数the_real_decorator(),它接受修饰函数。最后,最里面的函数
wrapper()接受您传递给修饰函数的参数和关键字参数。这就是奇迹发生的地方!您使用一个while循环来重试调用该函数。如果有异常,那么您调用time.sleep(),递增retries计数器,并尝试再次运行该函数。现在重写
uptime_bot()来使用你的新装饰器:@sleep(3) def uptime_bot(url): try: conn = urllib.request.urlopen(url) except urllib.error.HTTPError as e: # Email admin / log print(f'HTTPError: {e.code} for {url}') # Re-raise the exception for the decorator raise urllib.error.HTTPError except urllib.error.URLError as e: # Email admin / log print(f'URLError: {e.code} for {url}') # Re-raise the exception for the decorator raise urllib.error.URLError else: # Website is up print(f'{url} is up') if __name__ == '__main__': url = 'http://www.google.com/py' uptime_bot(url)这里,你用 3 秒的
sleep()来修饰uptime_bot()。您还删除了原来的while循环,以及旧的调用sleep(60)。装潢师现在负责这个。您所做的另一个更改是在异常处理块中添加了一个
raise。这是为了让装修工正常工作。您可以编写装饰器来处理这些错误,但是由于这些异常只适用于urllib,您最好保持装饰器的原样。这样,它将与更广泛的功能一起工作。注意:如果你想温习一下 Python 中的异常处理,那么请查看 Python 异常:简介。
你可以对你的室内设计师做一些改进。如果它用尽了重试次数,仍然失败,那么您可以让它重新引发上一个错误。装饰者还会在最后一次失败后等待 3 秒钟,这可能是您不希望发生的事情。请随意尝试这些作为练习!
用线程添加 Python
sleep()调用有时候,你可能想给一个线程添加一个 Python
sleep()调用。也许您正在针对生产环境中有数百万条记录的数据库运行迁移脚本。您不想造成任何停机,但是也不想等待过长的时间来完成迁移,所以您决定使用线程。注意:线程是 Python 中进行并发的一种方法。您可以同时运行多个线程来增加应用程序的吞吐量。如果你不熟悉 Python 中的线程,那么请查看Python 中的线程介绍。
为了防止客户注意到任何类型的速度下降,每个线程都需要运行一小段时间,然后休眠。有两种方法可以做到这一点:
- 像以前一样使用
time.sleep()。- 使用
threading模块中的Event.wait()。我们先来看一下
time.sleep()。使用
time.sleep()Python 日志食谱展示了一个使用
time.sleep()的好例子。Python 的logging模块是线程安全的,所以在这个练习中,它比print()语句更有用一些。以下代码基于此示例:import logging import threading import time def worker(arg): while not arg["stop"]: logging.debug("worker thread checking in") time.sleep(1) def main(): logging.basicConfig( level=logging.DEBUG, format="%(relativeCreated)6d %(threadName)s %(message)s" ) info = {"stop": False} thread = threading.Thread(target=worker, args=(info,)) thread_two = threading.Thread(target=worker, args=(info,)) thread.start() thread_two.start() while True: try: logging.debug("Checking in from main thread") time.sleep(0.75) except KeyboardInterrupt: info["stop"] = True logging.debug('Stopping') break thread.join() thread_two.join() if __name__ == "__main__": main()这里,您使用 Python 的
threading模块来创建两个线程。您还创建了一个日志记录对象,它将把threadName记录到 stdout 中。接下来,启动两个线程,并不时地从主线程启动一个循环来记录日志。你用KeyboardInterrupt来捕捉用户按下Ctrl+C。尝试在您的终端上运行上面的代码。您应该会看到类似如下的输出:
0 Thread-1 worker thread checking in 1 Thread-2 worker thread checking in 1 MainThread Checking in from main thread 752 MainThread Checking in from main thread 1001 Thread-1 worker thread checking in 1001 Thread-2 worker thread checking in 1502 MainThread Checking in from main thread 2003 Thread-1 worker thread checking in 2003 Thread-2 worker thread checking in 2253 MainThread Checking in from main thread 3005 Thread-1 worker thread checking in 3005 MainThread Checking in from main thread 3005 Thread-2 worker thread checking in当每个线程运行然后休眠时,日志输出被打印到控制台。既然您已经尝试了一个示例,您将能够在自己的代码中使用这些概念。
使用
Event.wait()
threading模块提供了一个Event(),你可以像time.sleep()一样使用它。然而,Event()有一个额外的好处,那就是响应速度更快。这样做的原因是,当事件被设置时,程序将立即跳出循环。使用time.sleep(),您的代码将需要等待 Pythonsleep()调用完成,然后线程才能退出。这里你想使用
wait()的原因是因为wait()是非阻塞,而time.sleep()是阻塞。这意味着当您使用time.sleep()时,您将阻止主线程继续运行,同时等待sleep()调用结束。wait()解决了这个问题。你可以在 Python 的线程文档中了解更多关于这一切是如何工作的。下面是如何用
Event.wait()添加一个 Pythonsleep()调用:import logging import threading def worker(event): while not event.isSet(): logging.debug("worker thread checking in") event.wait(1) def main(): logging.basicConfig( level=logging.DEBUG, format="%(relativeCreated)6d %(threadName)s %(message)s" ) event = threading.Event() thread = threading.Thread(target=worker, args=(event,)) thread_two = threading.Thread(target=worker, args=(event,)) thread.start() thread_two.start() while not event.isSet(): try: logging.debug("Checking in from main thread") event.wait(0.75) except KeyboardInterrupt: event.set() break if __name__ == "__main__": main()在这个例子中,您创建了
threading.Event()并将其传递给worker()。(回想一下,在前面的例子中,您传递了一个字典。)接下来,你设置你的循环来检查event是否被设置。如果不是,那么您的代码会打印一条消息,并在再次检查之前等待一段时间。要设置事件,可以按Ctrl+C。一旦事件被设置,worker()将返回,循环将中断,程序结束。注意:如果你想了解更多关于字典的知识,那么就来看看 Python 中的字典。
仔细看看上面的代码块。你如何给每个工作线程分配不同的睡眠时间?你能搞清楚吗?请自行解决这个练习!
使用异步 IO 添加 Python
sleep()调用在 3.4 版本中,Python 增加了异步功能,从那以后,这个特性集一直在积极地扩展。异步编程是一种并行编程,允许你一次运行多个任务。当一个任务完成时,它会通知主线程。
asyncio是一个模块,允许您异步添加 Pythonsleep()调用。如果你不熟悉 Python 异步编程的实现,那么看看 Python 中的异步 IO:完整演练和 Python 并发&并行编程。这里有一个来自 Python 自己的文档的例子:
import asyncio async def main(): print('Hello ...') await asyncio.sleep(1) print('... World!') # Python 3.7+ asyncio.run(main())在这个例子中,您运行
main(),让它在两次print()调用之间休眠一秒钟。这里有一个来自
asyncio文档的协程和任务部分的更有说服力的例子:import asyncio import time async def output(sleep, text): await asyncio.sleep(sleep) print(text) async def main(): print(f"Started: {time.strftime('%X')}") await output(1, 'First') await output(2, 'Second') await output(3, 'Third') print(f"Ended: {time.strftime('%X')}") # Python 3.7+ asyncio.run(main())在这段代码中,您创建了一个名为
output()的工作器,它接收到sleep的秒数和要打印出来的text。然后,使用 Python 的await关键字等待output()代码运行。这里需要await,因为output()已经被标记为async函数,所以你不能像调用普通函数一样调用它。当您运行这段代码时,您的程序将执行
await3 次。代码将等待 1 秒、2 秒和 3 秒,总等待时间为 6 秒。您也可以重写代码,使任务并行运行:import asyncio import time async def output(text, sleep): while sleep > 0: await asyncio.sleep(1) print(f'{text} counter: {sleep} seconds') sleep -= 1 async def main(): task_1 = asyncio.create_task(output('First', 1)) task_2 = asyncio.create_task(output('Second', 2)) task_3 = asyncio.create_task(output('Third', 3)) print(f"Started: {time.strftime('%X')}") await task_1 await task_2 await task_3 print(f"Ended: {time.strftime('%X')}") if __name__ == '__main__': asyncio.run(main())现在你正在使用任务的概念,你可以用
create_task()来完成它。当您在asyncio中使用任务时,Python 将异步运行任务。因此,当您运行上面的代码时,它应该在总共 3 秒内完成,而不是 6 秒。使用 GUI添加 Python
sleep()调用命令行应用程序并不是唯一需要添加 Python
sleep()调用的地方。当你创建一个图形用户界面(GUI) 时,你偶尔会需要添加延迟。例如,您可能创建一个 FTP 应用程序来下载数百万个文件,但是您需要在批处理之间添加一个sleep()调用,这样您就不会使服务器陷入困境。GUI 代码将在一个名为事件循环的主线程中运行所有的处理和绘图。如果您在 GUI 代码中使用
time.sleep(),那么您将阻塞它的事件循环。从用户的角度来看,应用程序可能会冻结。当应用程序使用这种方法休眠时,用户将无法与应用程序进行交互。(在 Windows 上,您甚至可能会收到一个关于您的应用程序现在如何无响应的警告。)幸运的是,除了
time.sleep()还有其他方法可以使用。在接下来的几节中,您将学习如何在 Tkinter 和 wxPython 中添加 Pythonsleep()调用。睡在 Tkinter
tkinter是 Python 标准库的一部分。如果您在 Linux 或 Mac 上使用的是预装版本的 Python,则可能无法使用它。如果你得到了一个ImportError,那么你需要考虑如何将它添加到你的系统中。但是如果你自己安装 Python,那么tkinter应该已经可以用了。首先,我们来看一个使用
time.sleep()的例子。运行这段代码,看看当你以错误的方式添加 Pythonsleep()调用时会发生什么:import tkinter import time class MyApp: def __init__(self, parent): self.root = parent self.root.geometry("400x400") self.frame = tkinter.Frame(parent) self.frame.pack() b = tkinter.Button(text="click me", command=self.delayed) b.pack() def delayed(self): time.sleep(3) if __name__ == "__main__": root = tkinter.Tk() app = MyApp(root) root.mainloop()运行完代码后,按下 GUI 中的按钮。在等待
sleep()完成的过程中,该按钮将持续三秒钟。如果应用程序有其他按钮,那么你将无法点击它们。您也不能在应用程序睡眠时关闭它,因为它不能响应 close 事件。为了让
tkinter正常睡眠,你需要使用after():import tkinter class MyApp: def __init__(self, parent): self.root = parent self.root.geometry("400x400") self.frame = tkinter.Frame(parent) self.frame.pack() self.root.after(3000, self.delayed) def delayed(self): print('I was delayed') if __name__ == "__main__": root = tkinter.Tk() app = MyApp(root) root.mainloop()这里您创建了一个 400 像素宽 400 像素高的应用程序。它上面没有小部件。它只会显示一个框架。然后,调用
self.root.after(),其中self.root是对Tk()对象的引用。after()需要两个参数:
- 休眠的毫秒数
- 睡眠结束时要调用的方法
在这种情况下,您的应用程序将在 3 秒钟后将一个字符串打印到 stdout。你可以把
after()看作是time.sleep()的tkinter版本,但是它也增加了在睡眠结束后调用函数的能力。您可以使用该功能来改善用户体验。通过添加 Python
sleep()调用,您可以让应用程序看起来加载得更快,然后在启动后启动一些运行时间更长的进程。这样,用户就不必等待应用程序打开。睡在 wxPython
wxPython 和 Tkinter 之间有两个主要区别:
- wxPython 有更多的小部件。
- wxPython 的目标是在所有平台上都具有原生的外观和感觉。
Python 中没有包含 wxPython 框架,所以您需要自己安装它。如果你不熟悉 wxPython,那么看看如何用 wxPython 构建一个 Python GUI 应用程序。
在 wxPython 中,可以使用
wx.CallLater()添加一个 Pythonsleep()调用:import wx class MyFrame(wx.Frame): def __init__(self): super().__init__(parent=None, title='Hello World') wx.CallLater(4000, self.delayed) self.Show() def delayed(self): print('I was delayed') if __name__ == '__main__': app = wx.App() frame = MyFrame() app.MainLoop()这里,你直接子类化
wx.Frame,然后调用wx.CallLater()。该函数采用与 Tkinter 的after()相同的参数:
- 休眠的毫秒数
- 睡眠结束时要调用的方法
运行这段代码时,您应该会看到一个没有任何小部件的空白小窗口。4 秒钟后,您将看到字符串
'I was delayed'被打印到 stdout。使用
wx.CallLater()的好处之一是它是线程安全的。您可以在线程中使用该方法来调用主 wxPython 应用程序中的函数。结论
通过本教程,您已经获得了一项可添加到 Python 工具箱中的有价值的新技术!您知道如何添加延迟来调整应用程序的速度,并防止它们耗尽系统资源。您甚至可以使用 Python
sleep()调用来帮助您的 GUI 代码更有效地重绘。这将为您的客户带来更好的用户体验!概括地说,您已经学习了如何使用以下工具添加 Python
sleep()调用:
time.sleep()- 装修工
- 线
asyncio- Tkinter
- wxPython
现在,您可以利用您所学到的知识,开始让您的代码休眠了!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 使用 sleep()编写一个 Python 正常运行时间 Bot***
Python 中的套接字编程(指南)
套接字和套接字 API 用于通过网络发送消息。它们提供了一种进程间通信(IPC) 的形式。该网络可以是计算机的逻辑本地网络,也可以是物理连接到外部网络的网络,它自己连接到其他网络。一个明显的例子是互联网,你通过你的 ISP 连接到互联网。
在本教程中,您将创建:
- 一个简单的套接字服务器和客户端
- 同时处理多个连接的改进版本
- 一个服务器-客户端应用程序,其功能就像一个成熟的套接字应用程序,拥有自己的自定义头和内容
在本教程结束时,您将了解如何使用 Python 的套接字模块中的主要函数和方法来编写您自己的客户端-服务器应用程序。您将知道如何使用自定义类在端点之间发送消息和数据,您可以在自己的应用程序中构建和利用这些消息和数据。
本教程中的示例需要 Python 3.6 或更高版本,并且已经使用 Python 3.10 进行了测试。为了充分利用本教程,最好下载源代码,并在阅读时放在手边以供参考:
获取源代码: 点击此处获取源代码,您将在本教程的示例中使用。
网络和套接字是很大的主题。关于他们的文字已经写了很多。如果您是套接字或网络的新手,如果您对所有的术语和内容感到不知所措,这是完全正常的。
但是不要气馁。这个教程是给你的!和任何 Python 相关的东西一样,你可以一次学一点点。将这篇文章加入书签,当你准备好下一部分时再回来。
背景
插座有着悠久的历史。它们的使用起源于 1971 年的 ARPANET ,后来成为 1983 年发布的伯克利软件分发(BSD)操作系统中的 API,名为伯克利套接字。
当互联网随着万维网在 20 世纪 90 年代起飞时,网络编程也是如此。Web 服务器和浏览器并不是唯一利用新连接的网络和使用套接字的应用程序。各种类型和规模的客户机-服务器应用程序开始广泛使用。
今天,尽管 socket API 所使用的底层协议已经发展了多年,并且开发了新的协议,但是低级 API 仍然保持不变。
最常见的套接字应用程序类型是客户端-服务器应用程序,其中一方充当服务器并等待来自客户端的连接。这是您将在本教程中创建的应用程序类型。更具体地说,您将关注用于互联网套接字的套接字 API,有时称为 Berkeley 或 BSD 套接字。还有 Unix 域套接字,只能用于同一个主机上的进程之间的通信。
套接字 API 概述
Python 的套接字模块提供了与 Berkeley 套接字 API 的接口。这是您将在本教程中使用的模块。
该模块中的主要套接字 API 函数和方法是:
socket().bind().listen().accept().connect().connect_ex().send().recv().close()Python 提供了一个方便且一致的 API,它直接映射到系统调用,即它们的 C 语言对应物。在下一节中,您将学习如何一起使用它们。
作为其标准库的一部分,Python 也有一些类,使得使用这些低级套接字函数更加容易。尽管本教程没有涉及到,但是您可以查看一下 socketserver 模块,这是一个网络服务器框架。还有许多模块可以实现更高级别的互联网协议,如 HTTP 和 SMTP。有关概述,请参见互联网协议和支持。
TCP 套接字
您将使用
socket.socket()创建一个套接字对象,将套接字类型指定为socket.SOCK_STREAM。当您这样做时,使用的默认协议是传输控制协议(TCP) 。这是一个很好的默认设置,可能也是您想要的。为什么应该使用 TCP?传输控制协议(TCP):
- 可靠:网络中丢弃的数据包由发送方检测并重新发送。
- 有有序的数据传递:应用程序按照发送方写入的顺序读取数据。
相比之下,用
socket.SOCK_DGRAM创建的用户数据报协议(UDP) 套接字是不可靠的,接收方读取的数据可能与发送方写入的数据不一致。为什么这很重要?网络是一个尽最大努力的传递系统。不能保证您的数据会到达目的地,也不能保证您会收到发送给您的内容。
网络设备(如路由器和交换机)的可用带宽有限,并且有其固有的系统限制。它们有 CPU、内存、总线和接口包缓冲区,就像你的客户机和服务器一样。TCP 让您不必担心数据包丢失、无序数据到达以及其他在网络通信时不可避免会出现的陷阱。
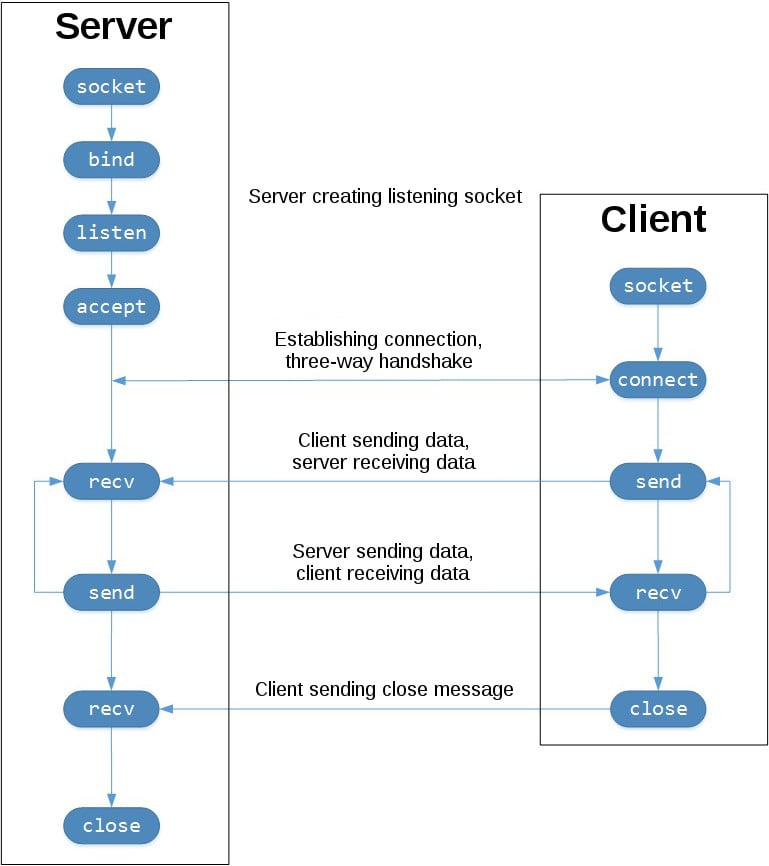
为了更好地理解这一点,请查看 TCP 的套接字 API 调用序列和数据流:
TCP Socket Flow ([Image source](https://commons.wikimedia.org/wiki/File:InternetSocketBasicDiagram_zhtw.png)) 左边的列代表服务器。右手边是客户端。
从左上角的列开始,注意服务器为设置“监听”套接字而进行的 API 调用:
socket().bind().listen().accept()监听套接字顾名思义就是这样做的。它监听来自客户端的连接。当客户机连接时,服务器调用
.accept()来接受或完成连接。客户机调用
.connect()来建立到服务器的连接,并启动三次握手。握手步骤很重要,因为它确保连接的每一端在网络中都是可到达的,换句话说,客户端可以到达服务器,反之亦然。可能只有一台主机、客户机或服务器可以到达另一台。中间是往返部分,通过调用
.send()和.recv()在客户机和服务器之间交换数据。在底部,客户端和服务器关闭各自的套接字。
回显客户端和服务器
现在您已经对 socket API 以及客户机和服务器如何通信有了一个大致的了解,您已经准备好创建您的第一个客户机和服务器了。您将从一个简单的实现开始。服务器将简单地把它收到的任何信息回显给客户机。
回声服务器
这是服务器:
# echo-server.py import socket HOST = "127.0.0.1" # Standard loopback interface address (localhost) PORT = 65432 # Port to listen on (non-privileged ports are > 1023) with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() conn, addr = s.accept() with conn: print(f"Connected by {addr}") while True: data = conn.recv(1024) if not data: break conn.sendall(data)注意:现在不要担心理解上面的一切。这几行代码中有很多内容。这只是一个起点,因此您可以看到一个运行中的基本服务器。
在本教程的最后有一个参考部分,其中有更多的信息和其他资源的链接。在整个教程中,您还可以找到这些和其他有用的链接。
好的,那么 API 调用中到底发生了什么?
socket.socket()创建一个支持上下文管理器类型的 socket 对象,因此您可以在with语句中使用它。没必要给s.close()打电话:with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: pass # Use the socket object without calling s.close().传递给
socket()的参数是常量,用于指定地址族和套接字类型。AF_INET是 IPv4 的互联网地址族。SOCK_STREAM是 TCP 的套接字类型,该协议将用于在网络中传输消息。
.bind()方法用于将套接字与特定的网络接口和端口号相关联:# echo-server.py # ... with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) # ...传递给
.bind()的值取决于套接字的地址族。在本例中,您使用的是socket.AF_INET(IPv4)。因此它期望一个二元组:(host, port)。
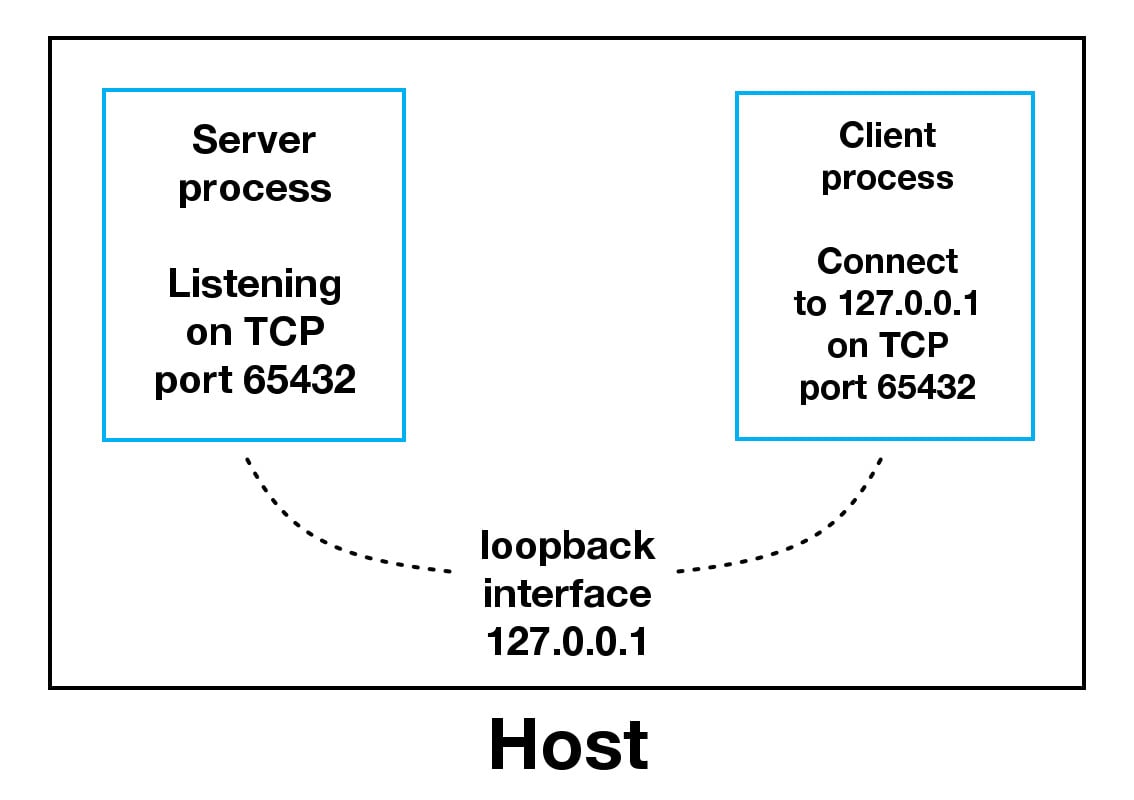
host可以是主机名、 IP 地址或空字符串。如果使用 IP 地址,host应该是 IPv4 格式的地址字符串。IP 地址127.0.0.1是回送接口的标准 IPv4 地址,因此只有主机上的进程能够连接到服务器。如果传递空字符串,服务器将接受所有可用 IPv4 接口上的连接。
port表示接受来自客户端的连接的 TCP 端口号。应该是从1到65535的整数,因为0是保留的。如果端口号小于1024,一些系统可能需要超级用户权限。这里有一个关于使用主机名和
.bind()的注意事项:“如果在 IPv4/v6 套接字地址的主机部分使用主机名,程序可能会显示不确定的行为,因为 Python 使用从 DNS 解析返回的第一个地址。根据 DNS 解析和/或主机配置的结果,套接字地址将被不同地解析为实际的 IPv4/v6 地址。对于确定性行为,请在主机部分使用数字地址。(来源)
稍后你会在使用主机名中了解到更多。现在,只要理解当使用主机名时,根据名称解析过程返回的内容,您可能会看到不同的结果。这些结果可能是任何东西。第一次运行应用程序时,您可能会得到地址
10.1.2.3。下一次,你得到一个不同的地址,192.168.0.1。第三次,你可以得到172.16.7.8,以此类推。在服务器示例中,
.listen()使服务器能够接受连接。它使服务器成为一个“监听”套接字:# echo-server.py # ... with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() conn, addr = s.accept() # ...
.listen()方法有一个backlog参数。它指定在拒绝新连接之前,系统允许的未接受连接数。从 Python 3.5 开始,它是可选的。如果未指定,则选择默认的backlog值。如果您的服务器同时收到大量连接请求,增加
backlog值可能会有所帮助,因为它设置了挂起连接的最大队列长度。最大值取决于系统。比如在 Linux 上,参见/proc/sys/net/core/somaxconn。
.accept()方法阻止的执行,并等待传入的连接。当客户端连接时,它返回一个表示连接的新套接字对象和一个保存客户端地址的元组。元组将包含用于 IPv4 连接的(host, port)或用于 IPv6 的(host, port, flowinfo, scopeid)。有关元组值的详细信息,请参见参考部分的套接字地址族。需要理解的一件事是,您现在有了一个来自
.accept()的新 socket 对象。这很重要,因为它是您将用来与客户端通信的套接字。它不同于服务器用来接受新连接的监听套接字:# echo-server.py # ... with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() conn, addr = s.accept() with conn: print(f"Connected by {addr}") while True: data = conn.recv(1024) if not data: break conn.sendall(data)在
.accept()提供客户端套接字对象conn后,无限while循环用于循环阻塞调用到conn.recv()。它读取客户端发送的任何数据,并使用conn.sendall()将其回显。如果
conn.recv()返回一个空的bytes对象b'',则表示客户端关闭了连接,循环终止。with语句与conn一起使用,自动关闭程序块末端的插座。回显客户端
现在让我们来看看客户端:
# echo-client.py import socket HOST = "127.0.0.1" # The server's hostname or IP address PORT = 65432 # The port used by the server with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((HOST, PORT)) s.sendall(b"Hello, world") data = s.recv(1024) print(f"Received {data!r}")与服务器相比,客户端非常简单。它创建一个套接字对象,使用
.connect()连接到服务器,并调用s.sendall()发送它的消息。最后,它调用s.recv()来读取服务器的回复,然后打印它。运行 Echo 客户端和服务器
在本节中,您将运行客户机和服务器,查看它们的行为并检查发生了什么。
注意:如果你在从命令行运行例子或你自己的代码时有困难,请阅读我如何使用 Python 制作我自己的命令行命令?或如何运行你的 Python 脚本。如果你使用的是 Windows,请查看 Python Windows FAQ 。
打开终端或命令提示符,导航到包含脚本的目录,确保路径上安装了 Python 3.6 或更高版本,然后运行服务器:
$ python echo-server.py您的终端将会挂起。这是因为服务器在
.accept()被阻止,或者暂停:# echo-server.py # ... with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.bind((HOST, PORT)) s.listen() conn, addr = s.accept() with conn: print(f"Connected by {addr}") while True: data = conn.recv(1024) if not data: break conn.sendall(data)它正在等待客户端连接。现在,打开另一个终端窗口或命令提示符并运行客户端:
$ python echo-client.py Received b'Hello, world'在服务器窗口中,您应该会注意到如下内容:
$ python echo-server.py Connected by ('127.0.0.1', 64623)在上面的输出中,服务器打印了从
s.accept()返回的addr元组。这是客户端的 IP 地址和 TCP 端口号。端口号64623,在您的机器上运行时很可能会有所不同。查看插座状态
要查看主机上套接字的当前状态,请使用
netstat。它在 macOS、Linux 和 Windows 上默认可用。下面是启动服务器后 macOS 的 netstat 输出:
$ netstat -an Active Internet connections (including servers) Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 0 127.0.0.1.65432 *.* LISTEN注意
Local Address是127.0.0.1.65432。如果echo-server.py使用了HOST = ""而不是HOST = "127.0.0.1",netstat 会显示:$ netstat -an Active Internet connections (including servers) Proto Recv-Q Send-Q Local Address Foreign Address (state) tcp4 0 0 *.65432 *.* LISTEN
Local Address是*.65432,这意味着所有支持该地址族的可用主机接口都将用于接受传入的连接。在这个例子中,在对socket()的调用中使用了socket.AF_INET(IP v4)。你可以在Proto一栏看到这个:tcp4。上面的输出被裁剪成只显示 echo 服务器。您可能会看到更多的输出,这取决于您运行它的系统。需要注意的是列
Proto、Local Address和(state)。在上面的最后一个示例中,netstat 显示 echo 服务器正在所有接口的端口 65432 上使用 IPv4 TCP 套接字(tcp4),并且它处于监听状态(LISTEN)。另一种方法是使用
lsof(列出打开的文件)来访问它以及其他有用的信息。默认情况下,它在 macOS 上可用,如果尚未安装,可以使用您的软件包管理器安装在 Linux 上:$ lsof -i -n COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME Python 67982 nathan 3u IPv4 0xecf272 0t0 TCP *:65432 (LISTEN)当与
-i选项一起使用时,lsof给出了开放互联网套接字的COMMAND、PID(进程 ID)和USER(用户 ID)。以上是 echo 服务器流程。
netstat和lsof有很多选项可用,并且根据运行它们的操作系统而有所不同。查看man页面或文档。他们绝对值得花一点时间去了解。你会得到回报的。在 macOS 和 Linux 上,使用man netstat和man lsof。对于 Windows,使用netstat /?。当试图连接到没有监听套接字的端口时,您会遇到以下常见错误:
$ python echo-client.py Traceback (most recent call last): File "./echo-client.py", line 9, in <module> s.connect((HOST, PORT)) ConnectionRefusedError: [Errno 61] Connection refused指定的端口号不正确,或者服务器没有运行。或者可能是路径中有防火墙阻挡了连接,这很容易被忘记。您也可能会看到错误
Connection timed out。添加允许客户端连接到 TCP 端口的防火墙规则!在参考部分有一个常见错误的列表。
通信故障
现在,您将进一步了解客户端和服务器是如何相互通信的:
使用回环接口(IPv4 地址
127.0.0.1或 IPv6 地址::1)时,数据永远不会离开主机或接触外部网络。在上图中,环回接口包含在主机内部。这代表了环回接口的内部性质,并表明通过该接口的连接和数据都位于主机本地。这就是为什么您还会听到环回接口和 IP 地址127.0.0.1或::1被称为“本地主机”应用程序使用环回接口与主机上运行的其它进程进行通信,以实现安全性和与外部网络的隔离。因为它是内部的,只能从主机内部访问,所以不会暴露。
如果您有一个使用自己的私有数据库的应用服务器,就可以看到这一点。如果它不是其他服务器使用的数据库,它可能被配置为仅侦听环回接口上的连接。如果是这种情况,网络上的其他主机就无法连接到它。
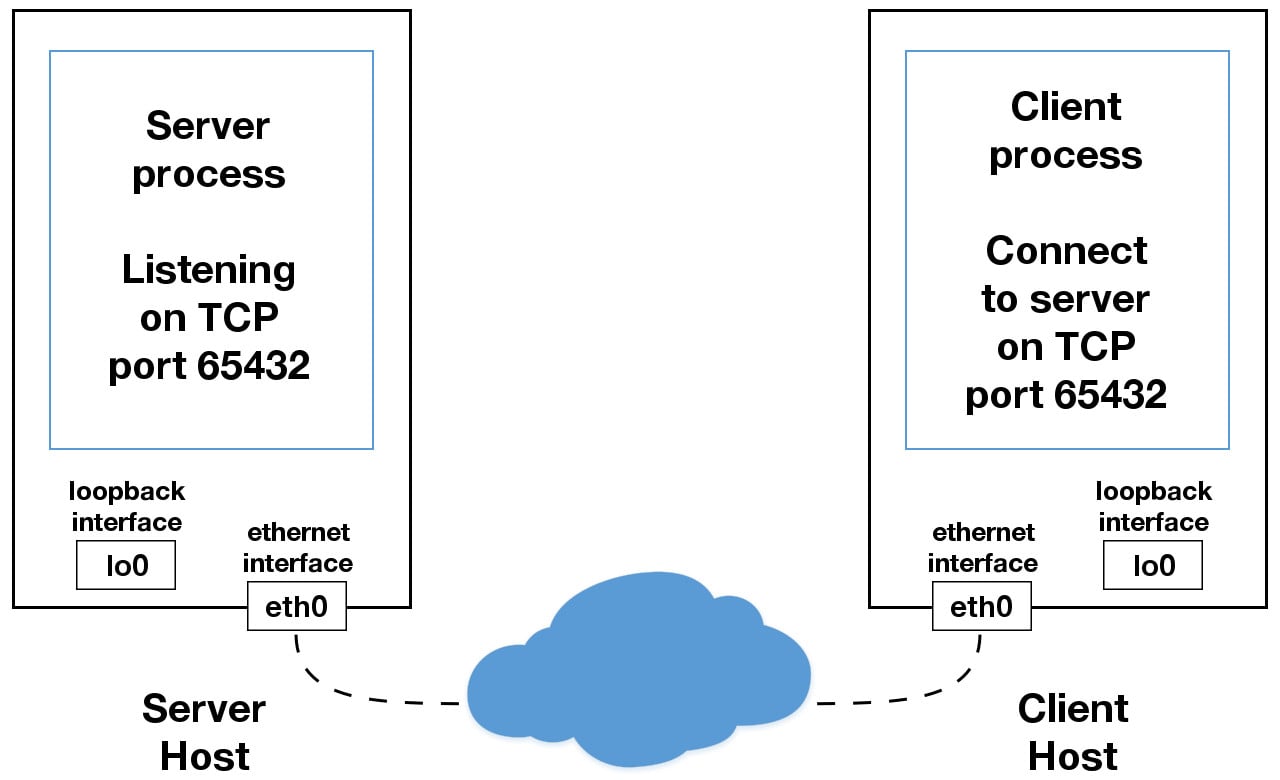
当您在应用程序中使用除
127.0.0.1或::1之外的 IP 地址时,它可能被绑定到一个连接到外部网络的以太网接口。这是您通往“本地主机”王国之外的其他主机的网关:
在外面要小心。这是一个肮脏、残酷的世界。在冒险离开“localhost”的安全范围之前,请务必阅读使用主机名一节有一个安全注意事项适用于即使你不使用主机名,但只使用 IP 地址。
处理多个连接
echo 服务器肯定有其局限性。最大的一个就是只服务一个客户,然后退出。echo 客户端也有这个限制,但是还有一个额外的问题。当客户端使用
s.recv()时,可能只会从b'Hello, world'返回一个字节b'H':# echo-client.py # ... with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((HOST, PORT)) s.sendall(b"Hello, world") data = s.recv(1024) print(f"Received {data!r}")上面使用的
1024的bufsize自变量是一次要接收的最大数据量。并不意味着.recv()会返回1024字节。
.send()方法也是如此。它返回发送的字节数,这可能小于传入的数据的大小。您负责检查这个并根据需要多次调用.send()来发送所有数据:“应用程序负责检查所有数据是否都已发送;如果只传输了部分数据,应用程序需要尝试传递剩余的数据。(来源)
在上面的例子中,您通过使用
.sendall()避免了这样做:与 send()不同,此方法继续从字节发送数据,直到所有数据都已发送或出现错误。成功时返回。(来源)
在这一点上你有两个问题:
- 如何同时处理多个连接?
- 你需要调用
.send()和.recv()直到所有的数据都被发送或接收。你能做什么?有许多方法可以实现并发。一种流行的方法是使用异步 I/O 。
asyncio在 Python 3.4 中被引入标准库。传统的选择是使用线程。并发的问题是很难做到正确。有许多微妙之处需要考虑和防范。所有需要做的就是让其中的一个显现出来,你的应用程序可能会突然以不那么微妙的方式失败。
这并不是要吓退你学习和使用并发编程。如果您的应用需要扩展,如果您想要使用多个处理器或一个内核,这是必要的。然而,对于本教程,您将使用比线程更传统、更容易推理的东西。你要用系统调用的祖师爷:
.select()。
.select()方法允许您在多个套接字上检查 I/O 完成情况。因此,您可以调用.select()来查看哪些插座的 I/O 已经准备好进行读写。但这是 Python,所以还有更多。您将使用标准库中的选择器模块,以便使用最有效的实现,而不管您运行的是什么操作系统:“该模块支持基于选择模块原语的高级高效 I/O 多路复用。我们鼓励用户使用这个模块,除非他们希望对所使用的操作系统级原语进行精确控制。”(来源)
然而,通过使用
.select(),你不能同时运行。也就是说,根据您的工作量,这种方法可能仍然非常快。这取决于您的应用程序在处理请求时需要做什么,以及它需要支持的客户端数量。
asyncio使用单线程协同多任务和一个事件循环来管理任务。使用.select(),您将编写自己版本的事件循环,尽管更加简单和同步。当使用多线程时,即使你有并发性,你现在也必须使用 GIL (全局解释器锁)和 CPython 和 PyPy 。这有效地限制了您可以并行完成的工作量。这就是说使用
.select()可能是一个非常好的选择。不要觉得你必须使用asyncio、线程或者最新的异步库。通常,在网络应用程序中,您的应用程序无论如何都是受 I/O 限制的:它可能在本地网络上等待,等待网络另一端的端点,等待磁盘写入,等等。如果您从启动 CPU 绑定工作的客户端收到请求,请查看 concurrent.futures 模块。它包含类 ProcessPoolExecutor ,该类使用一个进程池来异步执行调用。
如果您使用多个进程,操作系统能够调度您的 Python 代码在多个处理器或内核上并行运行,而无需 GIL。有关想法和灵感,请参见 PyCon talk 约翰·里斯-用 AsyncIO 和多处理技术思考 GIL 之外的世界- PyCon 2018 。
在下一节中,您将看到解决这些问题的服务器和客户机的例子。他们使用
.select()来同时处理多个连接,并根据需要多次调用.send()和.recv()。多连接客户端和服务器
在接下来的两节中,您将使用从选择器模块创建的
selector对象创建一个处理多个连接的服务器和客户机。多连接服务器
首先,将注意力转向多连接服务器。第一部分设置监听套接字:
# multiconn-server.py import sys import socket import selectors import types sel = selectors.DefaultSelector() # ... host, port = sys.argv[1], int(sys.argv[2]) lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) lsock.bind((host, port)) lsock.listen() print(f"Listening on {(host, port)}") lsock.setblocking(False) sel.register(lsock, selectors.EVENT_READ, data=None)这个服务器和 echo 服务器最大的区别就是调用
lsock.setblocking(False)来配置非阻塞模式的套接字。对这个插座的呼叫将不再被阻塞。当它与sel.select()一起使用时,正如您将在下面看到的,您可以等待一个或多个套接字上的事件,然后在准备就绪时读写数据。
sel.register()为您感兴趣的事件向sel.select()注册要监控的套接字。对于监听套接字,您需要读取事件:selectors.EVENT_READ。为了在套接字中存储您想要的任意数据,您将使用
data。在.select()返回的时候返回。您将使用data来跟踪套接字上发送和接收的内容。接下来是事件循环:
# multiconn-server.py # ... try: while True: events = sel.select(timeout=None) for key, mask in events: if key.data is None: accept_wrapper(key.fileobj) else: service_connection(key, mask) except KeyboardInterrupt: print("Caught keyboard interrupt, exiting") finally: sel.close()
sel.select(timeout=None)阻塞,直到有套接字为 I/O 做好准备。它返回元组列表,每个套接字一个。每个元组包含一个key和一个mask。key是一个包含fileobj属性的选择键namedtuple。key.fileobj是 socket 对象,mask是就绪操作的事件屏蔽。如果
key.data是None,那么你知道它来自监听套接字,你需要接受连接。您将调用自己的accept_wrapper()函数来获取新的套接字对象,并向选择器注册它。你一会儿就会看到。如果
key.data不是None,那么您知道这是一个已经被接受的客户端套接字,您需要服务它。然后用key和mask作为参数调用service_connection(),这就是你在套接字上操作所需要的一切。下面是您的
accept_wrapper()函数的作用:# multiconn-server.py # ... def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print(f"Accepted connection from {addr}") conn.setblocking(False) data = types.SimpleNamespace(addr=addr, inb=b"", outb=b"") events = selectors.EVENT_READ | selectors.EVENT_WRITE sel.register(conn, events, data=data) # ...因为监听套接字是为事件
selectors.EVENT_READ注册的,所以它应该准备好读取。你调用sock.accept()然后调用conn.setblocking(False)将插座置于非阻塞模式。记住,这是这个版本服务器的主要目标,因为你不希望它阻塞。如果它阻塞了,那么整个服务器将停止运行,直到它返回。这意味着即使服务器没有积极工作,其他套接字也会等待。这是您不希望您的服务器处于的可怕的“挂起”状态。
接下来,使用
SimpleNamespace创建一个对象来保存希望包含在套接字中的数据。因为您想知道客户端连接何时准备好进行读写,所以这两个事件都用按位 OR 操作符来设置:# multiconn-server.py # ... def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print(f"Accepted connection from {addr}") conn.setblocking(False) data = types.SimpleNamespace(addr=addr, inb=b"", outb=b"") events = selectors.EVENT_READ | selectors.EVENT_WRITE sel.register(conn, events, data=data) # ...然后,
events掩码、套接字和数据对象被传递给sel.register()。现在看一下
service_connection(),看看当客户端连接准备好时是如何处理的:# multiconn-server.py # ... def service_connection(key, mask): sock = key.fileobj data = key.data if mask & selectors.EVENT_READ: recv_data = sock.recv(1024) # Should be ready to read if recv_data: data.outb += recv_data else: print(f"Closing connection to {data.addr}") sel.unregister(sock) sock.close() if mask & selectors.EVENT_WRITE: if data.outb: print(f"Echoing {data.outb!r} to {data.addr}") sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:] # ...这是简单多连接服务器的核心。
key是从.select()返回的namedtuple,包含套接字对象(fileobj)和数据对象。mask包含已经准备好的事件。如果套接字准备好读取,那么
mask & selectors.EVENT_READ将评估为True,因此sock.recv()被调用。任何读取的数据都被附加到data.outb中,以便以后发送。注意
else:块,检查是否没有接收到数据:# multiconn-server.py # ... def service_connection(key, mask): sock = key.fileobj data = key.data if mask & selectors.EVENT_READ: recv_data = sock.recv(1024) # Should be ready to read if recv_data: data.outb += recv_data else: print(f"Closing connection to {data.addr}") sel.unregister(sock) sock.close() if mask & selectors.EVENT_WRITE: if data.outb: print(f"Echoing {data.outb!r} to {data.addr}") sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:] # ...如果没有收到数据,这意味着客户端已经关闭了它们的套接字,所以服务器也应该关闭。但是别忘了在关闭前调用
sel.unregister(),这样就不再被.select()监控了。当套接字准备好写入时,对于健康的套接字来说总是这样,存储在
data.outb中的任何接收到的数据都使用sock.send()回显到客户端。然后,发送的字节将从发送缓冲区中删除:# multiconn-server.py # ... def service_connection(key, mask): # ... if mask & selectors.EVENT_WRITE: if data.outb: print(f"Echoing {data.outb!r} to {data.addr}") sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:] # ...
.send()方法返回发送的字节数。然后,这个数字可以与.outb缓冲器上的片符号一起使用,以丢弃发送的字节。多连接客户端
现在来看看多连接客户端,
multiconn-client.py。它与服务器非常相似,但是它不是监听连接,而是通过start_connections()启动连接:# multiconn-client.py import sys import socket import selectors import types sel = selectors.DefaultSelector() messages = [b"Message 1 from client.", b"Message 2 from client."] def start_connections(host, port, num_conns): server_addr = (host, port) for i in range(0, num_conns): connid = i + 1 print(f"Starting connection {connid} to {server_addr}") sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setblocking(False) sock.connect_ex(server_addr) events = selectors.EVENT_READ | selectors.EVENT_WRITE data = types.SimpleNamespace( connid=connid, msg_total=sum(len(m) for m in messages), recv_total=0, messages=messages.copy(), outb=b"", ) sel.register(sock, events, data=data) # ...
num_conns从命令行读取,是创建到服务器的连接数。就像服务器一样,每个套接字都设置为非阻塞模式。您使用
.connect_ex()而不是.connect(),因为.connect()会立即引发一个BlockingIOError异常。.connect_ex()方法最初返回一个错误指示器、errno.EINPROGRESS,而不是引发一个会干扰正在进行的连接的异常。一旦连接完成,套接字就准备好进行读写,并由.select()返回。在设置好套接字后,使用
SimpleNamespace创建您想要用套接字存储的数据。客户端发送给服务器的消息是使用messages.copy()复制的,因为每个连接都会调用socket.send()并修改列表。跟踪客户机需要发送、已经发送和已经接收的内容所需的一切,包括消息中的总字节数,都存储在对象data中。检查从服务器的
service_connection()对客户端版本所做的更改:def service_connection(key, mask): sock = key.fileobj data = key.data if mask & selectors.EVENT_READ: recv_data = sock.recv(1024) # Should be ready to read if recv_data: - data.outb += recv_data + print(f"Received {recv_data!r} from connection {data.connid}") + data.recv_total += len(recv_data) - else: - print(f"Closing connection {data.connid}") + if not recv_data or data.recv_total == data.msg_total: + print(f"Closing connection {data.connid}") sel.unregister(sock) sock.close() if mask & selectors.EVENT_WRITE: + if not data.outb and data.messages: + data.outb = data.messages.pop(0) if data.outb: - print(f"Echoing {data.outb!r} to {data.addr}") + print(f"Sending {data.outb!r} to connection {data.connid}") sent = sock.send(data.outb) # Should be ready to write data.outb = data.outb[sent:]除了一个重要的区别之外,基本上是一样的。客户端跟踪它从服务器收到的字节数,以便它可以关闭自己的连接。当服务器检测到这种情况时,它也会关闭自己的连接。
注意,通过这样做,服务器依赖于表现良好的客户端:服务器期望客户端在完成发送消息后关闭其连接端。如果客户端没有关闭,服务器将保持连接打开。在一个实际的应用程序中,您可能希望在您的服务器中通过实现一个超时来防止客户端连接在一定时间后没有发送请求时累积。
运行多连接客户端和服务器
现在是时候运行
multiconn-server.py和multiconn-client.py了。他们都使用命令行参数。您可以不带参数运行它们来查看选项。对于服务器,传递
host和port号:$ python multiconn-server.py Usage: multiconn-server.py <host> <port>对于客户端,还要向服务器传递要创建的连接数,
num_connections:$ python multiconn-client.py Usage: multiconn-client.py <host> <port> <num_connections>以下是监听端口 65432 上的环回接口时的服务器输出:
$ python multiconn-server.py 127.0.0.1 65432 Listening on ('127.0.0.1', 65432) Accepted connection from ('127.0.0.1', 61354) Accepted connection from ('127.0.0.1', 61355) Echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61354) Echoing b'Message 1 from client.Message 2 from client.' to ('127.0.0.1', 61355) Closing connection to ('127.0.0.1', 61354) Closing connection to ('127.0.0.1', 61355)下面是客户端创建到上面服务器的两个连接时的输出:
$ python multiconn-client.py 127.0.0.1 65432 2 Starting connection 1 to ('127.0.0.1', 65432) Starting connection 2 to ('127.0.0.1', 65432) Sending b'Message 1 from client.' to connection 1 Sending b'Message 2 from client.' to connection 1 Sending b'Message 1 from client.' to connection 2 Sending b'Message 2 from client.' to connection 2 Received b'Message 1 from client.Message 2 from client.' from connection 1 Closing connection 1 Received b'Message 1 from client.Message 2 from client.' from connection 2 Closing connection 2太好了!现在您已经运行了多连接客户机和服务器。在下一节中,您将进一步研究这个例子。
应用客户端和服务器
与开始时相比,多连接客户机和服务器的例子无疑是一个改进。然而,现在您可以再走一步,在最终实现中解决前面的
multiconn示例的缺点:应用程序客户机和服务器。您需要一个适当处理错误的客户机和服务器,以便其他连接不受影响。显然,如果没有捕获到异常,您的客户机或服务器不应该崩溃。这是到目前为止您不必担心的事情,因为为了简洁和清晰起见,示例有意省略了错误处理。
既然您已经熟悉了基本的 API、非阻塞套接字和
.select(),那么您可以添加一些错误处理,并解决房间里的大象问题,这些示例已经对您隐藏在那边的大窗帘后面。还记得介绍中提到的自定义类吗?这就是你接下来要探索的。首先,您将解决这些错误:
所有错误都会引发异常。可以引发无效参数类型和内存不足情况的正常异常;从 Python 3.3 开始,与套接字或地址语义相关的错误会引发
OSError或它的一个子类。”(来源)所以,你需要做的一件事就是抓住
OSError。与错误相关的另一个重要考虑是超时。您会在文档的很多地方看到对它们的讨论。超时会发生,是一种所谓的正常错误。主机和路由器重新启动,交换机端口坏了,电缆坏了,电缆被拔掉了,你能想到的都有。您应该为这些和其他错误做好准备,在代码中处理它们。房间里的大象呢?正如套接字类型
socket.SOCK_STREAM所暗示的,当使用 TCP 时,您正在从连续的字节流中读取。这就像从磁盘上的文件中读取数据,但是你是从网络上读取字节。然而,与阅读文件不同,这里没有f.seek()。换句话说,你不能重新定位套接字指针(如果有的话),也不能移动数据。
当字节到达你的套接字时,会涉及到网络缓冲区。一旦你读了它们,它们需要被保存在某个地方,否则你就会把它们扔掉。再次调用
.recv()读取套接字中可用的下一个字节流。你将从插槽中读取数据。因此,您需要调用
.recv()和将数据保存在缓冲区中,直到您读取了足够的字节,以获得对您的应用程序有意义的完整消息。由您来定义并跟踪消息边界的位置。就 TCP 套接字而言,它只是向网络发送和从网络接收原始字节。它不知道这些原始字节是什么意思。
这就是为什么您需要定义一个应用层协议。什么是应用层协议?简单地说,您的应用程序将发送和接收消息。这些消息的格式是您的应用程序的协议。
换句话说,您为这些消息选择的长度和格式定义了应用程序的语义和行为。这与您在上一段中学到的关于从套接字读取字节的内容直接相关。当你用
.recv()读取字节时,你需要跟上读取了多少字节,并找出消息边界在哪里。你怎么能这样做?一种方法是总是发送固定长度的消息。如果它们总是一样大,那就简单了。当你将这个字节数读入缓冲区时,你就知道你得到了一条完整的消息。
然而,对于需要使用填充符来填充的小消息,使用固定长度的消息是低效的。此外,您仍然面临着如何处理不适合一条消息的数据的问题。
在本教程中,您将学习一种通用方法,这种方法被许多协议使用,包括 HTTP。您将为消息添加前缀头,它包括内容长度以及您需要的任何其他字段。这样做,你只需要跟上标题。阅读完邮件头后,您可以对其进行处理,以确定邮件内容的长度。有了内容长度,您就可以读取该字节数来使用它。
您将通过创建一个可以发送和接收包含文本或二进制数据的消息的自定义类来实现这一点。您可以为自己的应用程序改进和扩展这个类。最重要的是,你将能够看到一个如何做到这一点的例子。
在开始之前,您需要了解一些关于套接字和字节的知识。正如您之前了解到的,当通过套接字发送和接收数据时,您发送和接收的是个原始字节。
如果您接收数据,并希望在将其解释为多个字节(例如一个 4 字节的整数)的上下文中使用它,那么您需要考虑到它可能不是您的机器的 CPU 所固有的格式。另一端的客户机或服务器的 CPU 可能使用不同的字节顺序。如果是这种情况,那么您需要在使用它之前将其转换为您的主机的本机字节顺序。
这种字节顺序被称为 CPU 的字节序。详见参考部分的字节顺序。您可以通过利用 Unicode 作为您的消息头并使用 UTF-8 编码来避免这个问题。由于 UTF-8 使用 8 位编码,因此不存在字节排序问题。
你可以在 Python 的编码和 Unicode 文档中找到解释。请注意,这仅适用于文本标题。您将使用在消息头中定义的显式类型和编码来发送内容,即消息有效负载。这将允许你以任何格式传输你想要的任何数据(文本或二进制)。
使用
sys.byteorder可以很容易地确定你的机器的字节顺序。例如,您可能会看到这样的内容:$ python -c 'import sys; print(repr(sys.byteorder))' 'little'如果你在一个虚拟机上运行这个程序,这个虚拟机模拟了一个大端 CPU (PowerPC ),那么会发生这样的事情:
$ python -c 'import sys; print(repr(sys.byteorder))' 'big'在这个示例应用程序中,您的应用层协议将报头定义为采用 UTF-8 编码的 Unicode 文本。对于消息中的实际内容,即消息负载,如果需要,您仍然需要手动交换字节顺序。
这将取决于您的应用程序以及它是否需要处理来自具有不同字节序的机器的多字节二进制数据。您可以通过添加额外的头并使用它们传递参数来帮助您的客户端或服务器实现二进制支持,类似于 HTTP。
如果这还没有意义,不要担心。在下一节中,您将看到所有这些是如何工作和组合在一起的。
应用协议报头
现在,您将完全定义协议头。协议头是:
- 可变长度文本
- 编码为 UTF-8 的 Unicode
- 使用 JSON 序列化的 Python 字典
协议报头字典中所需的报头或子报头如下:
名字 描述 byteorder机器的字节顺序(使用 sys.byteorder)。您的应用程序可能不需要这样做。content-length内容的长度,以字节为单位。 content-type有效负载中的内容类型,例如, text/json或binary/my-binary-type。content-encoding内容使用的编码,例如, utf-8表示 Unicode 文本,binary表示二进制数据。这些头通知接收者消息有效载荷中的内容。这允许您发送任意数据,同时提供足够的信息,以便接收方能够正确解码和解释内容。因为头在字典中,所以可以根据需要通过插入键值对来添加额外的头。
发送应用消息
还有一点问题。你有一个变长的头,很好看也很灵活,但是用
.recv()读的时候怎么知道头的长度呢?当您之前学习使用
.recv()和消息边界时,您还学习了固定长度的头可能是低效的。确实如此,但是您将使用一个小的 2 字节固定长度的头作为包含其长度的 JSON 头的前缀。您可以将此视为发送消息的混合方法。实际上,您通过首先发送消息头的长度来引导消息接收过程。这使得你的接收者很容易解构信息。
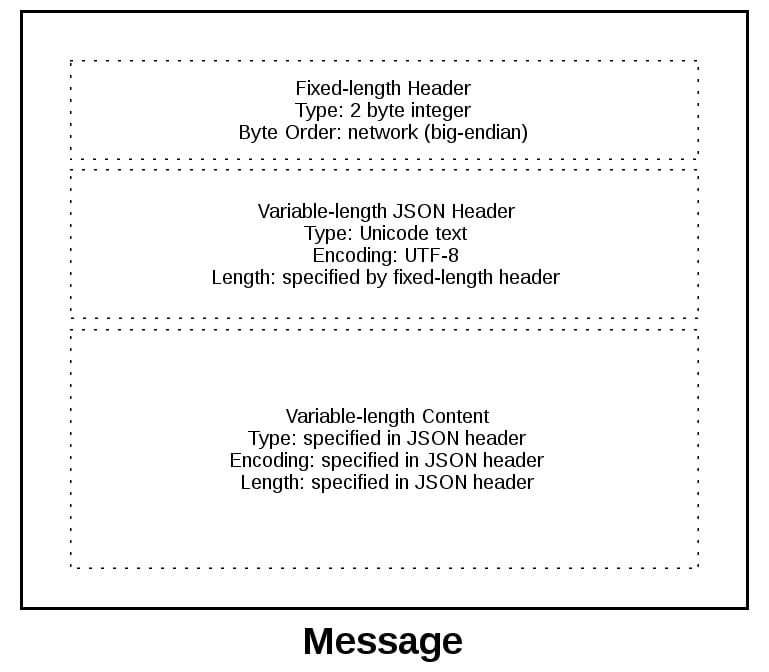
为了让您更好地了解邮件格式,请完整查看邮件:
消息以两个字节的固定长度报头开始,这是网络字节顺序中的一个整数。这是下一个头的长度,可变长度的 JSON 头。一旦你用
.recv()读取了两个字节,那么你知道你可以把这两个字节作为一个整数来处理,然后在解码 UTF-8 JSON 头之前读取这个字节数。JSON 头包含一个附加头的字典。其中一个是
content-length,它是消息内容的字节数(不包括 JSON 头)。一旦你调用了.recv()并读取了content-length字节,那么你就到达了一个消息边界,这意味着你已经读取了一条完整的消息。应用程序消息类别
最后,回报!在本节中,您将学习
Message类,并了解当读写事件在套接字上发生时,它是如何与.select()一起使用的。这个示例应用程序反映了客户机和服务器可以合理使用的消息类型。在这一点上,你远远超出了玩具回声客户端和服务器!
为了保持简单,并演示在实际应用程序中如何工作,这个例子使用了一个实现基本搜索特性的应用程序协议。客户端发送一个搜索请求,服务器查找匹配项。如果客户端发送的请求没有被识别为搜索,服务器会认为这是一个二进制请求,并返回一个二进制响应。
在阅读了以下部分、运行了示例并对代码进行了实验之后,您将会看到事情是如何工作的。然后,您可以使用
Message类作为起点,并修改它供您自己使用。这个应用程序离
multiconn客户机和服务器的例子并不远。事件循环代码在app-client.py和app-server.py中保持不变。您要做的是将消息代码移动到一个名为Message的类中,并添加方法来支持头部和内容的读取、写入和处理。这是使用类的一个很好的例子。正如您之前所学的,您将在下面看到,使用套接字涉及到保持状态。通过使用类,您可以将所有的状态、数据和代码捆绑在一个有组织的单元中。当启动或接受连接时,会为客户端和服务器中的每个套接字创建一个类的实例。
对于包装器和实用程序方法,客户端和服务器端的类基本相同。它们以下划线开头,比如
Message._json_encode()。这些方法简化了类的使用。他们通过允许其他方法保持更短的时间和支持干原则来帮助其他方法。服务器的
Message类的工作方式与客户端的基本相同,反之亦然。不同之处在于,客户端启动连接并发送请求消息,然后处理服务器的响应消息。相反,服务器等待连接,处理客户端的请求消息,然后发送响应消息。看起来是这样的:
步骤 端点 操作/消息内容 one 客户 发送包含请求内容的 MessageTwo 计算机网络服务器 接收并处理客户请求 Messagethree 计算机网络服务器 发送包含响应内容的 Messagefour 客户 接收并处理服务器响应 Message下面是文件和代码布局:
应用 文件 密码 计算机网络服务器 app-server.py服务器的主脚本 计算机网络服务器 libserver.py服务器的 Message类客户 app-client.py客户端的主脚本 客户 libclient.py客户端的 Message类消息入口点
理解
Message类是如何工作的可能是一个挑战,因为它的设计中有一个方面可能不是很明显。为什么?管理状态。在创建了一个
Message对象之后,它与一个套接字相关联,该套接字使用selector.register()来监控事件:# app-server.py # ... def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print(f"Accepted connection from {addr}") conn.setblocking(False) message = libserver.Message(sel, conn, addr) sel.register(conn, selectors.EVENT_READ, data=message) # ...注意:本节中的一些代码示例来自服务器的主脚本和
Message类,但是本节和讨论同样适用于客户端。当客户端版本不同时,您会收到警告。当套接字上的事件准备好时,它们由
selector.select()返回。然后,您可以使用key对象上的data属性获取对消息对象的引用,并调用Message中的方法:# app-server.py # ... try: while True: events = sel.select(timeout=None) for key, mask in events: if key.data is None: accept_wrapper(key.fileobj) else: message = key.data try: message.process_events(mask) # ... # ...看看上面的事件循环,你会看到
sel.select()在驾驶座上。它正在阻塞,在循环的顶端等待事件。它负责在套接字上准备好处理读写事件时唤醒。这意味着,间接地,它也负责调用方法.process_events()。这就是为什么.process_events()是切入点。下面是
.process_events()方法的作用:# libserver.py # ... class Message: def __init__(self, selector, sock, addr): # ... # ... def process_events(self, mask): if mask & selectors.EVENT_READ: self.read() if mask & selectors.EVENT_WRITE: self.write() # ...那就好:
.process_events()简单。它只能做两件事:调用.read()和.write()。这就是管理状态的由来。如果另一个方法依赖于具有特定值的状态变量,那么它们将只从
.read()和.write()被调用。这使得事件进入套接字进行处理时,逻辑尽可能简单。您可能想混合使用一些方法来检查当前状态变量,并根据它们的值调用其他方法来处理
.read()或.write()之外的数据。最终,这可能会被证明过于复杂,难以管理和跟上。您应该明确地修改该类以适应您自己的需要,以便它最适合您,但是如果您保持状态检查和对依赖于该状态的方法的调用(如果可能的话)到
.read()和.write()方法,您可能会得到最好的结果。现在看
.read()。这是服务器的版本,但是客户端的版本是一样的。它只是使用了不同的方法名,.process_response()而不是.process_request():# libserver.py # ... class Message: # ... def read(self): self._read() if self._jsonheader_len is None: self.process_protoheader() if self._jsonheader_len is not None: if self.jsonheader is None: self.process_jsonheader() if self.jsonheader: if self.request is None: self.process_request() # ...首先调用
._read()方法。它调用socket.recv()从套接字读取数据,并将其存储在接收缓冲区中。记住,当调用
socket.recv()时,组成完整消息的所有数据可能还没有到达。socket.recv()可能需要再次调用。这就是为什么在调用处理消息的适当方法之前,要对消息的每个部分进行状态检查。在方法处理它的消息部分之前,它首先检查以确保足够的字节已经被读入接收缓冲区。如果有,它会处理各自的字节,从缓冲区中删除它们,并将其输出写入下一个处理阶段使用的变量。因为消息有三个组成部分,所以有三个状态检查和
process方法调用:
消息组件 方法 输出 固定长度标题 process_protoheader()self._jsonheader_lenJSON 标题 process_jsonheader()self.jsonheader内容 process_request()self.request接下来,来看看
.write()。这是服务器的版本:# libserver.py # ... class Message: # ... def write(self): if self.request: if not self.response_created: self.create_response() self._write() # ...
.write()方法首先检查一个request。如果一个已经存在,但还没有创建响应,则调用.create_response()。.create_response()方法设置状态变量response_created并将响应写入发送缓冲区。如果发送缓冲区中有数据,
._write()方法调用socket.send()。记住,当调用
socket.send()时,发送缓冲区中的所有数据可能还没有排队等待传输。套接字的网络缓冲区可能已满,可能需要再次调用socket.send()。这就是为什么有国家检查。.create_response()方法应该只被调用一次,但是预计._write()需要被调用多次。
.write()的客户端版本类似:# libclient.py # ... class Message: def __init__(self, selector, sock, addr, request): # ... def write(self): if not self._request_queued: self.queue_request() self._write() if self._request_queued: if not self._send_buffer: # Set selector to listen for read events, we're done writing. self._set_selector_events_mask("r") # ...因为客户端发起到服务器的连接并首先发送请求,所以检查状态变量
_request_queued。如果一个请求没有被排队,它调用.queue_request()。queue_request()方法创建请求并将其写入发送缓冲区。它还设置了状态变量_request_queued,这样它只被调用一次。就像服务器一样,如果发送缓冲区中有数据,
._write()就会调用socket.send()。客户端版本
.write()的显著区别是最后一次检查请求是否已经排队。这将在客户端主脚本一节中详细解释,但是这样做的原因是告诉selector.select()停止监视套接字的写事件。如果请求已经排队,并且发送缓冲区是空的,那么您就完成了写操作,并且您只对读事件感兴趣。没有理由被通知套接字是可写的。总结这一节,考虑这样一个想法:这一节的主要目的是解释
selector.select()通过方法.process_events()调用Message类,并描述状态是如何被管理的。这很重要,因为在连接的生命周期中会多次调用
.process_events()。因此,请确保任何只应调用一次的方法要么自己检查状态变量,要么由方法设置的状态变量由调用方检查。服务器主脚本
在服务器的主脚本
app-server.py中,从命令行读取参数,这些参数指定要监听的接口和端口:$ python app-server.py Usage: app-server.py <host> <port>例如,要监听端口
65432上的环回接口,请输入:$ python app-server.py 127.0.0.1 65432 Listening on ('127.0.0.1', 65432)使用空字符串
<host>监听所有接口。在创建套接字之后,使用选项
socket.SO_REUSEADDR调用socket.setsockopt():# app-server.py # ... host, port = sys.argv[1], int(sys.argv[2]) lsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # Avoid bind() exception: OSError: [Errno 48] Address already in use lsock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) lsock.bind((host, port)) lsock.listen() print(f"Listening on {(host, port)}") lsock.setblocking(False) sel.register(lsock, selectors.EVENT_READ, data=None) # ...设置该插座选项可避免错误
Address already in use。当在连接处于 TIME_WAIT 状态的端口上启动服务器时,您会看到这种情况。例如,如果服务器主动关闭了一个连接,它将保持在
TIME_WAIT状态两分钟或更长时间,这取决于操作系统。如果您试图在TIME_WAIT状态到期之前再次启动服务器,那么您将得到一个Address already in use的OSError异常。这是一种安全措施,确保网络中任何延迟的数据包都不会被发送到错误的应用程序。事件循环捕捉任何错误,以便服务器可以保持运行并继续运行:
# app-server.py # ... try: while True: events = sel.select(timeout=None) for key, mask in events: if key.data is None: accept_wrapper(key.fileobj) else: message = key.data try: message.process_events(mask) except Exception: print( f"Main: Error: Exception for {message.addr}:\n" f"{traceback.format_exc()}" ) message.close() except KeyboardInterrupt: print("Caught keyboard interrupt, exiting") finally: sel.close()当一个客户端连接被接受时,一个
Message对象被创建:# app-server.py # ... def accept_wrapper(sock): conn, addr = sock.accept() # Should be ready to read print(f"Accepted connection from {addr}") conn.setblocking(False) message = libserver.Message(sel, conn, addr) sel.register(conn, selectors.EVENT_READ, data=message) # ...
Message对象与对sel.register()的调用中的套接字相关联,并且最初被设置为仅监视读取事件。一旦请求被读取,您将修改它只监听写事件。在服务器中采用这种方法的一个优点是,在大多数情况下,当套接字是健康的并且没有网络问题时,它将总是可写的。
如果您告诉
sel.register()也监视EVENT_WRITE,那么事件循环将立即唤醒并通知您这是一种情况。然而,在这一点上,没有理由醒来并调用插座上的.send()。没有要发送的响应,因为请求尚未处理。这将消耗和浪费宝贵的 CPU 周期。服务器消息类别
在消息入口点一节中,您了解了当套接字事件通过
.process_events()准备好时Message对象是如何被调用的。现在,您将了解在套接字上读取数据以及消息的一部分准备好由服务器处理时会发生什么。服务器的消息类在
libserver.py里,是你之前下载的源代码的一部分。您也可以通过单击下面的链接下载代码:获取源代码: 点击此处获取源代码,您将在本教程的示例中使用。
这些方法按照处理消息的顺序出现在类中。
当服务器已经读取了至少两个字节时,可以处理固定长度的报头:
# libserver.py # ... class Message: def __init__(self, selector, sock, addr): # ... # ... def process_protoheader(self): hdrlen = 2 if len(self._recv_buffer) >= hdrlen: self._jsonheader_len = struct.unpack( ">H", self._recv_buffer[:hdrlen] )[0] self._recv_buffer = self._recv_buffer[hdrlen:] # ...固定长度的报头是网络中的 2 字节整数,或大端字节顺序。它包含 JSON 头的长度。您将使用 struct.unpack() 来读取值,对其进行解码,并将其存储在
self._jsonheader_len中。在处理完它所负责的消息片段后,.process_protoheader()将其从接收缓冲区中删除。就像固定长度的头一样,当接收缓冲区中有足够的数据来包含 JSON 头时,也可以对它进行处理:
# libserver.py # ... class Message: # ... def process_jsonheader(self): hdrlen = self._jsonheader_len if len(self._recv_buffer) >= hdrlen: self.jsonheader = self._json_decode( self._recv_buffer[:hdrlen], "utf-8" ) self._recv_buffer = self._recv_buffer[hdrlen:] for reqhdr in ( "byteorder", "content-length", "content-type", "content-encoding", ): if reqhdr not in self.jsonheader: raise ValueError(f"Missing required header '{reqhdr}'.") # ...调用方法
self._json_decode()将 JSON 头解码并反序列化到字典中。因为 JSON 头被定义为采用 UTF-8 编码的 Unicode,所以在调用中对utf-8进行了硬编码。结果被保存到self.jsonheader。在处理完它所负责的消息片段后,process_jsonheader()将其从接收缓冲区中删除。接下来是消息的实际内容或有效载荷。由
self.jsonheader中的 JSON 头描述。当content-length字节在接收缓冲器中可用时,可以处理请求:# libserver.py # ... class Message: # ... def process_request(self): content_len = self.jsonheader["content-length"] if not len(self._recv_buffer) >= content_len: return data = self._recv_buffer[:content_len] self._recv_buffer = self._recv_buffer[content_len:] if self.jsonheader["content-type"] == "text/json": encoding = self.jsonheader["content-encoding"] self.request = self._json_decode(data, encoding) print(f"Received request {self.request!r} from {self.addr}") else: # Binary or unknown content-type self.request = data print( f"Received {self.jsonheader['content-type']} " f"request from {self.addr}" ) # Set selector to listen for write events, we're done reading. self._set_selector_events_mask("w") # ...将消息内容保存到
data变量后,.process_request()将其从接收缓冲区中删除。然后,如果内容类型是 JSON,.process_request()对其进行解码和反序列化。如果不是,这个示例应用程序假设它是一个二进制请求,并简单地打印内容类型。
.process_request()做的最后一件事是修改选择器,只监控写事件。在服务器的主脚本app-server.py中,套接字最初被设置为仅监视读取事件。现在这个请求已经被完全处理了,你不再对阅读感兴趣了。现在可以创建响应并将其写入套接字。当套接字可写时,从
.write()调用.create_response():# libserver.py # ... class Message: # ... def create_response(self): if self.jsonheader["content-type"] == "text/json": response = self._create_response_json_content() else: # Binary or unknown content-type response = self._create_response_binary_content() message = self._create_message(**response) self.response_created = True self._send_buffer += message根据内容类型,通过调用其他方法来创建响应。在这个示例应用程序中,当
action == 'search'时,对 JSON 请求进行简单的字典查找。对于您自己的应用程序,您可以定义在这里调用的其他方法。在创建响应消息之后,状态变量
self.response_created被设置,使得.write()不再调用.create_response()。最后,响应被附加到发送缓冲区。这被._write()看到并通过._write()发送。需要解决的一个棘手问题是如何在响应写完后关闭连接。您可以在方法
._write()中调用.close():# libserver.py # ... class Message: # ... def _write(self): if self._send_buffer: print(f"Sending {self._send_buffer!r} to {self.addr}") try: # Should be ready to write sent = self.sock.send(self._send_buffer) except BlockingIOError: # Resource temporarily unavailable (errno EWOULDBLOCK) pass else: self._send_buffer = self._send_buffer[sent:] # Close when the buffer is drained. The response has been sent. if sent and not self._send_buffer: self.close() # ...尽管它有些隐蔽,但考虑到
Message类只处理每个连接的一条消息,这是一个可以接受的折衷。写完响应后,服务器就没什么可做的了。它已经完成了它的工作。客户端主脚本
在客户端的主脚本
app-client.py中,从命令行读取参数,并用于创建请求和启动与服务器的连接:$ python app-client.py Usage: app-client.py <host> <port> <action> <value>这里有一个例子:
$ python app-client.py 127.0.0.1 65432 search needle在从命令行参数创建了表示请求的字典之后,主机、端口和请求字典被传递给
.start_connection():# app-client.py # ... def start_connection(host, port, request): addr = (host, port) print(f"Starting connection to {addr}") sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock.setblocking(False) sock.connect_ex(addr) events = selectors.EVENT_READ | selectors.EVENT_WRITE message = libclient.Message(sel, sock, addr, request) sel.register(sock, events, data=message) # ...为服务器连接创建一个套接字,并使用
request字典创建一个Message对象。与服务器一样,
Message对象与调用sel.register()中的套接字相关联。但是,对于客户端,套接字最初被设置为针对读取和写入事件进行监控。一旦请求被写入,您将修改它只监听读事件。这种方法为您提供了与服务器相同的优势:不浪费 CPU 周期。请求发出后,您不再对写事件感兴趣,所以没有理由唤醒并处理它们。
客户端消息类别
在消息入口点一节中,您了解了当套接字事件通过
.process_events()准备好时如何调用消息对象。现在,您将了解在套接字上读写数据以及客户端准备好处理消息之后会发生什么。客户端的消息类在
libclient.py里,是你之前下载的源代码的一部分。您也可以通过单击下面的链接下载代码:获取源代码: 点击此处获取源代码,您将在本教程的示例中使用。
这些方法按照处理消息的顺序出现在类中。
客户端的第一个任务是对请求进行排队:
# libclient.py # ... class Message: # ... def queue_request(self): content = self.request["content"] content_type = self.request["type"] content_encoding = self.request["encoding"] if content_type == "text/json": req = { "content_bytes": self._json_encode(content, content_encoding), "content_type": content_type, "content_encoding": content_encoding, } else: req = { "content_bytes": content, "content_type": content_type, "content_encoding": content_encoding, } message = self._create_message(**req) self._send_buffer += message self._request_queued = True # ...根据命令行传递的内容,用于创建请求的字典位于客户端的主脚本
app-client.py中。当创建一个Message对象时,请求字典作为一个参数传递给该类。请求消息被创建并附加到发送缓冲区,然后被发现并通过
._write()发送。状态变量self._request_queued被设置,使得.queue_request()不再被调用。发送请求后,客户端等待服务器的响应。
客户端读取和处理消息的方法与服务器端相同。当从套接字读取响应数据时,
process头方法被调用:.process_protoheader()和.process_jsonheader()。不同之处在于最后的
process方法的命名,以及它们处理响应而不是创建响应的事实:.process_response()、._process_response_json_content()和._process_response_binary_content()。最后,但肯定不是最不重要的,是最后一次召集
.process_response():# libclient.py # ... class Message: # ... def process_response(self): # ... # Close when response has been processed self.close() # ...消息类摘要
为了总结您对
Message类的学习,有必要提及一些关于一些支持方法的重要注意事项。该类引发的任何异常都由事件循环中的主脚本在
except子句中捕获:# app-client.py # ... try: while True: events = sel.select(timeout=1) for key, mask in events: message = key.data try: message.process_events(mask) except Exception: print( f"Main: Error: Exception for {message.addr}:\n" f"{traceback.format_exc()}" ) message.close() # Check for a socket being monitored to continue. if not sel.get_map(): break except KeyboardInterrupt: print("Caught keyboard interrupt, exiting") finally: sel.close()注意台词:
message.close()。这是一条非常重要的线,原因不止一个!它不仅确保套接字是关闭的,而且
message.close()还将套接字从.select()的监控中移除。这极大地简化了类中的代码并降低了复杂性。如果有异常或者你自己明确提出了一个,你知道.close()会负责清理。方法
Message._read()和Message._write()也包含一些有趣的东西:# libclient.py # ... class Message: # ... def _read(self): try: # Should be ready to read data = self.sock.recv(4096) except BlockingIOError: # Resource temporarily unavailable (errno EWOULDBLOCK) pass else: if data: self._recv_buffer += data else: raise RuntimeError("Peer closed.") # ...注意
except BlockingIOError:行。
._write()方法也有一个。这些行很重要,因为它们捕捉到一个临时错误,并使用pass跳过它。暂时的错误是当套接字阻塞时,例如,如果它正在等待网络或连接的另一端,也称为它的对等方。通过用
pass捕捉并跳过异常,.select()将最终触发一个新的调用,您将获得另一个读取或写入数据的机会。运行应用客户端和服务器
在所有这些艰苦的工作之后,是时候找点乐子,进行一些搜索了!
在这些例子中,您将运行服务器,以便它通过为参数
host传递一个空字符串来监听所有接口。这将允许您运行客户端并从另一个网络上的虚拟机进行连接。它模拟大端 PowerPC 机器。首先,启动服务器:
$ python app-server.py '' 65432 Listening on ('', 65432)现在运行客户端并输入一个搜索。看看你能否找到他:
$ python app-client.py 10.0.1.1 65432 search morpheus Starting connection to ('10.0.1.1', 65432) Sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 41}{"action": "search", "value": "morpheus"}' to ('10.0.1.1', 65432) Received response {'result': 'Follow the white rabbit. 🐰'} from ('10.0.1.1', 65432) Got result: Follow the white rabbit. 🐰 Closing connection to ('10.0.1.1', 65432) ```py 您可能会注意到终端正在运行一个使用 Unicode (UTF-8)文本编码的 shell,所以上面的输出用表情符号打印得很好。 现在看看你是否能找到小狗:$ python app-client.py 10.0.1.1 65432 search 🐶
Starting connection to ('10.0.1.1', 65432)
Sending b'\x00d{"byteorder": "big", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"action": "search", "value": "\xf0\x9f\x90\xb6"}' to ('10.0.1.1', 65432)
Received response {'result': '🐾 Playing ball! 🏐'} from ('10.0.1.1', 65432)
Got result: 🐾 Playing ball! 🏐
Closing connection to ('10.0.1.1', 65432)注意在`sending`行中通过网络为请求发送的字节串。如果你寻找用十六进制打印的代表小狗表情符号的字节:`\xf0\x9f\x90\xb6`,就更容易看出来。如果你的终端使用的是编码为 UTF-8 的 Unicode,你可以通过[输入表情符号](https://support.apple.com/en-us/HT201586)进行搜索。 这表明您正在通过网络发送原始字节,它们需要由接收方解码才能正确解释。这就是为什么您不辞辛苦地创建一个包含内容类型和编码的头。 以下是上述两个客户端连接的服务器输出:Accepted connection from ('10.0.2.2', 55340)
Received request {'action': 'search', 'value': 'morpheus'} from ('10.0.2.2', 55340)
Sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 43}{"result": "Follow the white rabbit. \xf0\x9f\x90\xb0"}' to ('10.0.2.2', 55340)
Closing connection to ('10.0.2.2', 55340)Accepted connection from ('10.0.2.2', 55338)
Received request {'action': 'search', 'value': '🐶'} from ('10.0.2.2', 55338)
Sending b'\x00g{"byteorder": "little", "content-type": "text/json", "content-encoding": "utf-8", "content-length": 37}{"result": "\xf0\x9f\x90\xbe Playing ball! \xf0\x9f\x8f\x90"}' to ('10.0.2.2', 55338)
Closing connection to ('10.0.2.2', 55338)查看`sending`行,了解写入客户端套接字的字节。这是服务器的响应消息。 如果`action`参数是除了`search`之外的任何参数,您也可以测试向服务器发送二进制请求:$ python app-client.py 10.0.1.1 65432 binary 😃
Starting connection to ('10.0.1.1', 65432)
Sending b'\x00|{"byteorder": "big", "content-type": "binary/custom-client-binary-type", "content-encoding": "binary", "content-length": 10}binary\xf0\x9f\x98\x83' to ('10.0.1.1', 65432)
Received binary/custom-server-binary-type response from ('10.0.1.1', 65432)
Got response: b'First 10 bytes of request: binary\xf0\x9f\x98\x83'
Closing connection to ('10.0.1.1', 65432)因为请求的`content-type`不是`text/json`,所以服务器将其视为自定义二进制类型,并且不执行 JSON 解码。它只是打印出`content-type`,并将前十个字节返回给客户端:$ python app-server.py '' 65432
Listening on ('', 65432)
Accepted connection from ('10.0.2.2', 55320)
Received binary/custom-client-binary-type request from ('10.0.2.2', 55320)
Sending b'\x00\x7f{"byteorder": "little", "content-type": "binary/custom-server-binary-type", "content-encoding": "binary", "content-length": 37}First 10 bytes of request: binary\xf0\x9f\x98\x83' to ('10.0.2.2', 55320)
Closing connection to ('10.0.2.2', 55320)## 故障排除 不可避免的是,有些事情会失败,你会不知道该怎么做。别担心,每个人都会这样。希望在本教程、您的调试器和您最喜欢的搜索引擎的帮助下,您能够重新开始使用源代码部分。 如果没有,你的第一站应该是 Python 的[套接字模块](https://docs.python.org/3/library/socket.html)文档。确保您阅读了您调用的每个函数或方法的所有文档。此外,通读下面的[参考](#reference)部分以获取想法。特别是,检查[错误](#errors)部分。 有时候,并不全是关于源代码。源代码可能是正确的,它只是另一台主机、客户机或服务器。也可能是网络。可能是路由器、防火墙或其他网络设备在扮演中间人的角色。 对于这类问题,其他工具是必不可少的。下面是一些工具和实用程序,可能会有所帮助,或者至少提供一些线索。 [*Remove ads*](/account/join/) ### 乒 `ping`将通过发送 [ICMP](https://en.wikipedia.org/wiki/Internet_Control_Message_Protocol) 回应请求来检查主机是否存活并连接到网络。它直接与操作系统的 TCP/IP 协议栈通信,因此它独立于主机上运行的任何应用程序工作。 下面是在 macOS 上运行 ping 的示例:$ ping -c 3 127.0.0.1
PING 127.0.0.1 (127.0.0.1): 56 data bytes
64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=0.058 ms
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.165 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.164 ms--- 127.0.0.1 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.058/0.129/0.165/0.050 ms请注意输出末尾的统计数据。当您试图发现间歇性连接问题时,这很有帮助。比如有没有丢包?有多少延迟?可以查一下往返时间。 如果您和另一台主机之间有防火墙,ping 的回应请求可能不被允许。一些防火墙管理员实施了强制执行这一点的策略。这个想法是,他们不想让他们的主机被发现。如果是这种情况,并且您添加了防火墙规则来允许主机通信,那么请确保这些规则也允许 ICMP 在它们之间通过。 ICMP 是`ping`使用的协议,但它也是 TCP 和其他低层协议用来传递错误消息的协议。如果您遇到奇怪的行为或缓慢的连接,这可能是原因。 ICMP 消息由类型和代码标识。为了让你了解它们所携带的重要信息,这里有一些: | ICMP 类型 | ICMP 代码 | 描述 | | --- | --- | --- | | eight | Zero | 回应请求 | | Zero | Zero | 回音回复 | | three | Zero | 目标网络不可达 | | three | one | 无法到达目的主机 | | three | Two | 目标协议不可达 | | three | three | 目标端口不可达 | | three | four | 需要分段,并且设置了 DF 标志 | | Eleven | Zero | TTL 在传输中过期 | 有关碎片和 ICMP 消息的信息,请参见文章[路径 MTU 发现](https://en.wikipedia.org/wiki/Path_MTU_Discovery#Problems_with_PMTUD)。这是一个可能导致奇怪行为的例子。 ### netstat 在[查看套接字状态](#viewing-socket-state)一节中,您了解了如何使用`netstat`来显示关于套接字及其当前状态的信息。该实用程序可在 macOS、Linux 和 Windows 上使用。 该部分没有提到示例输出中的列`Recv-Q`和`Send-Q`。这些列将向您显示网络缓冲区中的字节数,这些字节排队等待传输或接收,但由于某种原因还没有被远程或本地应用程序读取或写入。 换句话说,字节在操作系统的队列中的网络缓冲区中等待。一个原因可能是应用程序受到 CPU 的限制,或者无法调用`socket.recv()`或`socket.send()`并处理字节。或者可能存在影响通信的网络问题,如拥塞或网络硬件或电缆故障。 为了演示这一点,并看看在看到错误之前可以发送多少数据,您可以尝试一个连接到测试服务器并重复调用`socket.send()`的测试客户机。测试服务器从不调用`socket.recv()`。它只是接受连接。这会导致服务器上的网络缓冲区被填满,最终在客户端引发错误。 首先,启动服务器:$ python app-server-test.py 127.0.0.1 65432
Listening on ('127.0.0.1', 65432)然后运行客户端,查看错误是什么:$ python app-client-test.py 127.0.0.1 65432 binary test
Error: socket.send() blocking io exception for ('127.0.0.1', 65432):
BlockingIOError(35, 'Resource temporarily unavailable')下面是客户端和服务器仍在运行时的`netstat`输出,客户端多次打印出上面的错误消息:$ netstat -an | grep 65432
Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED
tcp4 0 0 127.0.0.1.65432 . LISTEN第一个条目是服务器(`Local Address`的端口是 65432):Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 408300 0 127.0.0.1.65432 127.0.0.1.53225 ESTABLISHED注意`Recv-Q` : `408300`。 第二个条目是客户端(`Foreign Address`有端口 65432):Proto Recv-Q Send-Q Local Address Foreign Address (state)
tcp4 0 269868 127.0.0.1.53225 127.0.0.1.65432 ESTABLISHED注意`Send-Q` : `269868`。 客户端确实试图写入字节,但是服务器没有读取它们。这导致服务器的网络缓冲区队列在接收端填满,而客户端的网络缓冲区队列在发送端填满。 ### 窗户 如果你使用 Windows,有一套实用程序你一定要看看,如果你还没有的话: [Windows Sysinternals](https://docs.microsoft.com/en-us/sysinternals/) 。 其中一个就是`TCPView.exe`。TCPView 是 Windows 的图形化`netstat`。除了地址、端口号和套接字状态,它还会显示发送和接收的数据包和字节数的运行总数。像 Unix 实用程序`lsof`一样,您也可以获得进程名和 ID。检查其他显示选项的菜单。 [](https://files.realpython.com/media/tcpview.53c115c8b061.png) ### Wireshark 有时候你需要看看网络上发生了什么。忘记应用程序日志说了什么,或者从库调用返回的值是什么。您希望看到网络上实际发送或接收的内容。就像调试器一样,当您需要查看它时,没有替代品。 [Wireshark](https://www.wireshark.org/) 是一款网络协议分析器和流量捕获应用,运行于 macOS、Linux 和 Windows 等平台。有一个名为`wireshark`的 GUI 版本和一个名为`tshark`的基于文本的终端版本。 运行流量捕获是观察应用程序在网络上的行为并收集其发送和接收内容、频率和数量的证据的好方法。您还可以看到客户端或服务器何时关闭或中止连接或停止响应。此信息在您进行故障诊断时非常有用。 网上有许多好的教程和其他资源,将带您了解使用 Wireshark 和 TShark 的基本知识。 以下是在环回接口上使用 Wireshark 捕获流量的示例: [](https://files.realpython.com/media/wireshark.529c058891dc.png) 这里是上面使用`tshark`显示的同一个例子:$ tshark -i lo0 'tcp port 65432'
Capturing on 'Loopback'
1 0.000000 127.0.0.1 → 127.0.0.1 TCP 68 53942 → 65432 [SYN] Seq=0 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=0 SACK_PERM=1
2 0.000057 127.0.0.1 → 127.0.0.1 TCP 68 65432 → 53942 [SYN, ACK] Seq=0 Ack=1 Win=65535 Len=0 MSS=16344 WS=32 TSval=940533635 TSecr=940533635 SACK_PERM=1
3 0.000068 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
4 0.000075 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Window Update] 65432 → 53942 [ACK] Seq=1 Ack=1 Win=408288 Len=0 TSval=940533635 TSecr=940533635
5 0.000216 127.0.0.1 → 127.0.0.1 TCP 202 53942 → 65432 [PSH, ACK] Seq=1 Ack=1 Win=408288 Len=146 TSval=940533635 TSecr=940533635
6 0.000234 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=1 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
7 0.000627 127.0.0.1 → 127.0.0.1 TCP 204 65432 → 53942 [PSH, ACK] Seq=1 Ack=147 Win=408128 Len=148 TSval=940533635 TSecr=940533635
8 0.000649 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=149 Win=408128 Len=0 TSval=940533635 TSecr=940533635
9 0.000668 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [FIN, ACK] Seq=149 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
10 0.000682 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
11 0.000687 127.0.0.1 → 127.0.0.1 TCP 56 [TCP Dup ACK 6#1] 65432 → 53942 [ACK] Seq=150 Ack=147 Win=408128 Len=0 TSval=940533635 TSecr=940533635
12 0.000848 127.0.0.1 → 127.0.0.1 TCP 56 53942 → 65432 [FIN, ACK] Seq=147 Ack=150 Win=408128 Len=0 TSval=940533635 TSecr=940533635
13 0.001004 127.0.0.1 → 127.0.0.1 TCP 56 65432 → 53942 [ACK] Seq=150 Ack=148 Win=408128 Len=0 TSval=940533635 TSecr=940533635
^C13 packets captured接下来,您将获得更多的参考资料来支持您的套接字编程之旅! ## 参考 您可以将本节作为一般参考,其中包含附加信息和外部资源链接。 ### Python 文档 * Python 的[套接字模块](https://docs.python.org/3/library/socket.html) * Python 的 [Socket 编程 HOWTO](https://docs.python.org/3/howto/sockets.html#socket-howto) ### 错误 以下摘自 Python 的`socket`模块文档: > 所有错误都会引发异常。可以引发无效参数类型和内存不足情况的正常异常;从 Python 3.3 开始,与套接字或地址语义相关的错误会引发`OSError`或它的一个子类。”[(来源)](https://docs.python.org/3/library/socket.html) 以下是您在使用套接字时可能会遇到的一些常见错误: | 例外 | `errno`常数 | 描述 | | --- | --- | --- | | 阻塞误差 | EWOULDBLOCK | 资源暂时不可用。比如在非阻塞模式下,调用`.send()`时,对等体忙而不读,发送队列(网络缓冲区)已满。或者网络有问题。希望这只是暂时的。 | | OSError | EADDRINUSE | 地址已被使用。确保没有其他正在运行的进程使用相同的端口号,并且您的服务器正在设置套接字选项`SO_REUSEADDR` : `socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)`。 | | 连接恐怖 | econnreset(经济集) | 对等方重置了连接。远程进程崩溃或没有正确关闭其套接字,也称为不干净的关闭。或者网络路径中有防火墙或其他设备缺少规则或行为不当。 | | 超时错误 | ETIMEDOUT | 操作超时。对等方没有响应。 | | ConnectionRefusedError | 经济复兴 | 连接被拒绝。没有应用程序监听指定的端口。 | ### 套接字地址族 `socket.AF_INET`和`socket.AF_INET6`代表用于`socket.socket()`第一个参数的地址和协议族。使用地址的 API 期望它是某种格式,这取决于套接字是用`socket.AF_INET`还是`socket.AF_INET6`创建的。 | 地址族 | 草案 | 地址元组 | 描述 | | --- | --- | --- | --- | | `socket.AF_INET` | IPv4 | `(host, port)` | `host`是一个字符串,其主机名类似于`'www.example.com'`或者 IPv4 地址类似于`'10.1.2.3'`。`port`是一个整数。 | | `socket.AF_INET6` | IPv6 | `(host, port, flowinfo, scopeid)` | `host`是主机名类似于`'www.example.com'`或 IPv6 地址类似于`'fe80::6203:7ab:fe88:9c23'`的字符串。`port`是一个整数。`flowinfo`和`scopeid`代表 C 结构`sockaddr_in6`中的`sin6_flowinfo`和`sin6_scope_id`成员。 | 请注意下面来自 Python 的套接字模块文档中关于地址元组的`host`值的摘录: > 对于 IPv4 地址,接受两种特殊形式来代替主机地址:空字符串代表`INADDR_ANY`,字符串`'<broadcast>'`代表`INADDR_BROADCAST`。这种行为与 IPv6 不兼容,因此,如果您打算在 Python 程序中支持 IPv6,您可能需要避免这些行为。”[(来源)](https://docs.python.org/3/library/socket.html) 更多信息参见 Python 的 [Socket families 文档](https://docs.python.org/3/library/socket.html#socket-families)。 本教程使用 IPv4 套接字,但是如果您的网络支持,请尽可能尝试测试和使用 IPv6。一种简单的支持方法是使用函数 [socket.getaddrinfo()](https://docs.python.org/3/library/socket.html#socket.getaddrinfo) 。它将`host`和`port`参数转换成一个五元组序列,该序列包含创建连接到该服务的套接字所需的所有参数。`socket.getaddrinfo()`将理解并解释传入的 IPv6 地址和解析为 IPv6 地址的主机名,以及 IPv4。 以下示例返回到端口`80`上`example.org`的 TCP 连接的地址信息:
>>> socket.getaddrinfo("example.org", 80, proto=socket.IPPROTO_TCP)
[(<AddressFamily.AF_INET6: 10>, <SocketType.SOCK_STREAM: 1>,
6, '', ('2606:2800:220:1:248:1893:25c8:1946', 80, 0, 0)),
(<AddressFamily.AF_INET: 2>, <SocketType.SOCK_STREAM: 1>,
6, '', ('93.184.216.34', 80))]
```py
如果未启用 IPv6,您的系统上的结果可能会有所不同。上面返回的值可以通过传递给`socket.socket()`和`socket.connect()`来使用。在 Python 的套接字模块文档的[示例部分](https://docs.python.org/3/library/socket.html#example)中有一个客户端和服务器示例。
### 使用主机名
对于上下文,这一节主要适用于使用带有`.bind()`和`.connect()`或`.connect_ex()`的主机名,当您打算使用环回接口“localhost”时然而,它也适用于任何时候您使用主机名,并期望它解析到某个地址,并对您的应用程序有特殊的意义,影响其行为或假设。这与客户端使用主机名连接到由 DNS 解析的服务器(如 www.example.com)的典型场景形成对比。
以下摘自 Python 的`socket`模块文档:
> “如果在 IPv4/v6 套接字地址的主机部分使用主机名,程序可能会显示不确定的行为,因为 Python 使用从 DNS 解析返回的第一个地址。根据 DNS 解析和/或主机配置的结果,套接字地址将被不同地解析为实际的 IPv4/v6 地址。对于确定性行为,请在主机部分使用数字地址。[(来源)](https://docs.python.org/3/library/socket.html)
名称“ [localhost](https://en.wikipedia.org/wiki/Localhost) 的标准约定是将其解析为`127.0.0.1`或`::1`,即环回接口。在您的系统中,这种情况很有可能发生,但也有可能不发生。这取决于您的系统如何配置名称解析。正如所有的事情一样,总是有例外,并且不能保证使用名称“localhost”将连接到环回接口。
例如,在 Linux 上,请参见`man nsswitch.conf`,名称服务交换机配置文件。在 macOS 和 Linux 上另一个需要检查的地方是文件`/etc/hosts`。在 Windows 上,参见`C:\Windows\System32\drivers\etc\hosts`。`hosts`文件包含一个简单文本格式的名称到地址映射的静态表。 [DNS](https://en.wikipedia.org/wiki/Domain_Name_System) 完全是拼图的另一块。
有趣的是,截至 2018 年 6 月,有一个 RFC 草案[让“localhost”成为 localhost](https://tools.ietf.org/html/draft-ietf-dnsop-let-localhost-be-localhost-02) ,它讨论了使用“localhost”名称的约定、假设和安全性。
需要理解的重要一点是,当您在应用程序中使用主机名时,返回的地址实际上可以是任何内容。如果您有一个安全敏感的应用程序,不要对名称做任何假设。根据您的应用程序和环境,这可能是您关心的问题,也可能不是。
**注意:**安全预防措施和最佳实践仍然适用,即使您的应用程序不是显式安全敏感的。如果您的应用程序访问网络,它应该得到保护和维护。这至少意味着:
* 定期应用系统软件更新和安全补丁,包括 Python。你正在使用任何第三方库吗?如果是这样的话,请确保检查并更新这些信息。
* 如果可能,使用专用的或基于主机的防火墙来限制仅连接到受信任的系统。
* 配置了哪些 DNS 服务器?你信任他们和他们的管理员吗?
* 确保在调用处理请求数据的其他代码之前,对请求数据进行尽可能多的清理和验证。为此使用模糊测试,并定期运行它们。
不管您是否使用主机名,如果您的应用程序需要通过加密和认证来支持安全连接,那么您可能会希望考虑使用 [TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security) 。这是一个独立的主题,超出了本教程的范围。参见 Python 的 [ssl 模块文档](https://docs.python.org/3/library/ssl.html)开始。这与您的 web 浏览器用来安全连接到网站的协议相同。
由于要考虑接口、IP 地址和名称解析,因此存在许多可变因素。你该怎么办?如果您没有网络申请审核流程,可以参考以下建议:
| 应用 | 使用 | 建议 |
| --- | --- | --- |
| 计算机网络服务器 | 环回接口 | 使用 IP 地址,如`127.0.0.1`或`::1`。 |
| 计算机网络服务器 | 以太网接口 | 使用 IP 地址,如`10.1.2.3`。要支持多个接口,请对所有接口/地址使用空字符串。请参见上面的安全说明。 |
| 客户 | 环回接口 | 使用 IP 地址,如`127.0.0.1`或`::1`。 |
| 客户 | 以太网接口 | 为了一致性和不依赖名称解析,请使用 IP 地址。对于典型情况,使用主机名。请参见上面的安全说明。 |
对于客户端或服务器,如果您需要验证您正在连接的主机,请考虑使用 TLS。
### 阻止通话
暂时挂起应用程序的套接字函数或方法是阻塞调用。例如,`.accept()`、`.connect()`、`.send()`、`.recv()` block,表示不立即返回。阻塞调用必须等待系统调用(I/O)完成,然后才能返回值。所以你,调用者,被阻塞,直到他们完成或超时或其他错误发生。
阻塞套接字调用可以设置为非阻塞模式,这样它们会立即返回。如果你这样做了,那么你至少需要重构或重新设计你的应用程序来处理套接字操作。
因为调用会立即返回,所以数据可能没有准备好。被调用方正在网络上等待,还没有时间完成它的工作。如果是这种情况,那么当前状态就是`errno`值`socket.EWOULDBLOCK`。[支持非阻塞模式。setblocking()](https://docs.python.org/3/library/socket.html#socket.socket.setblocking) 。
默认情况下,套接字总是以阻塞模式创建。参见[套接字超时注释](https://docs.python.org/3/library/socket.html#notes-on-socket-timeouts)了解三种模式的描述。
### 关闭连接
关于 TCP 要注意的一件有趣的事情是,客户端或服务器关闭它们这边的连接而另一边保持打开是完全合法的。这被称为“半开”连接。这是应用程序的决定是否是可取的。总的来说,不是。在这种状态下,已关闭连接端的一端无法再发送数据。他们只能接收它。
这种方法不一定被推荐,但是作为一个例子,HTTP 使用一个名为“Connection”的头,用于标准化应用程序应该如何关闭或保持打开的连接。有关详细信息,请参见 RFC 7230 中的第 6.3 节“超文本传输协议(HTTP/1.1):消息语法和路由”。
在设计和编写应用程序及其应用层协议时,最好先弄清楚您希望如何关闭连接。有时这很明显也很简单,或者需要一些初始的原型和测试。这取决于应用程序以及如何处理消息循环及其预期数据。只要确保套接字在完成工作后总是及时关闭即可。
### 字节顺序
参见[维基百科关于字节序](https://en.wikipedia.org/wiki/Endianness)的文章,了解不同 CPU 如何在内存中存储字节顺序的详细信息。当解释单个字节时,这不是问题。但是,当您处理作为单个值读取和处理的多个字节时,例如一个 4 字节的整数,如果您与使用不同字节顺序的机器通信,那么字节顺序需要颠倒。
字节顺序对于表示为多字节序列的文本字符串也很重要,比如 Unicode。除非你总是使用真正的、严格的 ASCII 码并控制客户端和服务器的实现,否则你最好使用 Unicode 编码,比如 UTF-8 或支持 T2 字节顺序标记(BOM)的编码。
明确定义应用层协议中使用的编码非常重要。您可以通过强制所有文本都是 UTF 8 或使用指定编码的“内容编码”头来做到这一点。这使您的应用程序不必检测编码,如果可能的话,您应该避免这样做。
当涉及存储在文件或数据库中的数据,并且没有指定其编码的元数据时,这就成了问题。当数据传输到另一个端点时,它必须尝试检测编码。关于讨论,请参见[维基百科的 Unicode 文章](https://en.wikipedia.org/wiki/Unicode),其中引用了 [RFC 3629: UTF-8,一种 ISO 10646](https://tools.ietf.org/html/rfc3629#page-6) 的转换格式:
> 然而,UTF-8 标准 RFC 3629 建议在使用 UTF-8 的协议中禁止字节顺序标记,但是讨论了这可能不可行的情况。此外,UTF-8 对可能的模式有很大的限制(例如,高位设置不能有任何单独的字节),这意味着应该可以在不依赖 BOM 的情况下将 UTF-8 与其他字符编码区分开来。”[(来源)](https://en.wikipedia.org/wiki/Unicode)
从中得出的结论是,如果应用程序处理的数据可能会发生变化,就要始终存储该数据所使用的编码。换句话说,如果编码不总是 UTF-8 或其他带有 BOM 的编码,尝试以某种方式将编码存储为元数据。然后,您可以在报头中发送该编码和数据,以告诉接收方它是什么。
TCP/IP 中使用的字节排序是 [big-endian](https://en.wikipedia.org/wiki/Endianness#Big) ,被称为网络顺序。网络顺序用于表示协议栈较低层的整数,如 IP 地址和端口号。Python 的套接字模块包括将整数与网络和主机字节顺序相互转换的函数:
| 功能 | 描述 |
| --- | --- |
| `socket.ntohl(x)` | 将 32 位正整数从网络字节顺序转换为主机字节顺序。在主机字节顺序与网络字节顺序相同的机器上,这是不可行的;否则,它执行 4 字节交换操作。 |
| `socket.ntohs(x)` | 将 16 位正整数从网络字节顺序转换为主机字节顺序。在主机字节顺序与网络字节顺序相同的机器上,这是不可行的;否则,它执行 2 字节交换操作。 |
| `socket.htonl(x)` | 将 32 位正整数从主机字节顺序转换为网络字节顺序。在主机字节顺序与网络字节顺序相同的机器上,这是不可行的;否则,它执行 4 字节交换操作。 |
| `socket.htons(x)` | 将 16 位正整数从主机字节顺序转换为网络字节顺序。在主机字节顺序与网络字节顺序相同的机器上,这是不可行的;否则,它执行 2 字节交换操作。 |
您还可以使用格式字符串使用 [struct 模块](https://docs.python.org/3/library/struct.html)打包和解包二进制数据:
import struct
network_byteorder_int = struct.pack('>H', 256)
python_int = struct.unpack('>H', network_byteorder_int)[0]
## 结论
您在本教程中涉及了很多内容!网络和套接字是很大的主题。如果您是网络或套接字的新手,不要被所有的术语和首字母缩略词吓倒。
为了理解所有东西是如何一起工作的,有很多部分需要熟悉。然而,就像 Python 一样,当你开始了解各个部分并花更多时间使用它们时,它会变得更有意义。
**在本教程中,您:**
* 查看了 Python 的`socket`模块中的**低级套接字 API** ,并了解了如何使用它来创建客户机-服务器应用程序
* 使用一个`selectors`对象构建了一个能够处理**多个连接**的客户端和服务器
* 创建您自己的**自定义类**,并将其用作应用层协议,以在端点之间交换消息和数据
从这里开始,您可以使用您的自定义类,并在它的基础上学习和帮助创建您自己的套接字应用程序更容易和更快。
要查看示例,您可以单击下面的链接:
**获取源代码:** [点击此处获取源代码,您将在本教程的示例中使用](https://realpython.com/bonus/python-sockets-source-code/)。
恭喜你坚持到最后!现在,您已经可以在自己的应用程序中使用套接字了。祝您的套接字开发之旅好运。**********
# 如何在 Python 中使用 sorted()和 sort()
> 原文:<https://realpython.com/python-sort/>
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: [**用 Python 排序数据**](/courses/python-sorting-data/)
在某些时候,所有程序员都必须编写代码来对项目或数据进行排序。排序对于应用程序中的用户体验至关重要,无论是按时间戳对用户最近的活动进行排序,还是按姓氏的字母顺序排列电子邮件收件人列表。Python 排序功能提供了强大的特性,可以进行基本排序或在粒度级别定制排序。
在本指南中,您将学习如何在不同的[数据结构](https://realpython.com/python-data-structures/)中对各种类型的数据进行排序,定制顺序,并使用 Python 中两种不同的排序方法。
**本教程结束时,你将知道如何:**
* 在数据结构上实现基本的 Python 排序和排序
* 区分`sorted()`和`.sort()`
* 根据独特的要求在代码中自定义复杂的排序顺序
对于本教程,你需要对[列表和元组](https://realpython.com/python-lists-tuples/)以及[集合](https://realpython.com/python-sets/)有一个基本的了解。这些数据结构将在本教程中使用,并将对它们执行一些基本操作。此外,本教程使用 Python 3,因此如果您使用 Python 2,本教程中的示例输出可能会略有不同。
**免费下载:** [从 Python 技巧中获取一个示例章节:这本书](https://realpython.com/bonus/python-tricks-sample-pdf/)用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
## 用`sorted()` 对数值进行排序
要开始使用 Python 排序,首先要了解如何对数字数据和[字符串](https://realpython.com/python-strings/)数据进行排序。
[*Remove ads*](/account/join/)
### 分类编号
您可以使用 Python 通过使用`sorted()`来对列表进行排序。在这个例子中,定义了一个整数列表,然后用`numbers` [变量](https://realpython.com/python-variables/)作为参数调用`sorted()`:
>>>
```py
>>> numbers = [6, 9, 3, 1]
>>> sorted(numbers)
[1, 3, 6, 9]
>>> numbers
[6, 9, 3, 1]
这段代码的输出是一个新的排序列表。打印原始变量时,初始值不变。
这个例子展示了sorted()的四个重要特征:
- 不必定义函数
sorted()。这是一个内置函数,在 Python 的标准安装中可用。 - 没有附加参数的
sorted()以升序对numbers中的值进行排序,即从最小到最大。 - 原始的
numbers变量没有改变,因为sorted()提供了排序的输出,并且没有就地改变原始值。 - 当调用
sorted()时,它提供一个有序列表作为返回值。
这最后一点意味着sorted()可以用在一个列表上,并且输出可以立即赋给一个变量:
>>> numbers = [6, 9, 3, 1] >>> numbers_sorted = sorted(numbers) >>> numbers_sorted [1, 3, 6, 9] >>> numbers [6, 9, 3, 1]在这个例子中,现在有一个新的变量
numbers_sorted存储了sorted()的输出。您可以通过在
sorted()上调用help()来确认所有这些观察结果。可选参数key和reverse将在后面的教程中介绍:
>>> # Python 3
>>> help(sorted)
Help on built-in function sorted in module builtins:
sorted(iterable, /, *, key=None, reverse=False)
Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customize the sort order, and the
reverse flag can be set to request the result in descending order.
技术细节:如果您正在从 Python 2 过渡,并且熟悉它的同名功能,那么您应该知道 Python 3 中的几个重要变化:
- Python 3 的
sorted()没有cmp参数。相反,只有key用于引入定制排序逻辑。 key和reverse必须作为关键字参数传递,不像在 Python 2 中,它们可以作为位置参数传递。
如果你需要将 Python 2 的cmp函数转换成key函数,那么就去看看functools.cmp_to_key()。本教程不会涵盖任何使用 Python 2 的例子。
sorted()可以非常相似地用于元组和集合:
>>> numbers_tuple = (6, 9, 3, 1) >>> numbers_set = {5, 5, 10, 1, 0} >>> numbers_tuple_sorted = sorted(numbers_tuple) >>> numbers_set_sorted = sorted(numbers_set) >>> numbers_tuple_sorted [1, 3, 6, 9] >>> numbers_set_sorted [0, 1, 5, 10]注意即使输入是一个集合和一个元组,输出也是一个列表,因为
sorted()根据定义返回一个新列表。如果返回的对象需要匹配输入类型,则可以将其转换为新类型。如果试图将结果列表转换回集合,请小心,因为根据定义,集合是无序的:
>>> numbers_tuple = (6, 9, 3, 1)
>>> numbers_set = {5, 5, 10, 1, 0}
>>> numbers_tuple_sorted = sorted(numbers_tuple)
>>> numbers_set_sorted = sorted(numbers_set)
>>> numbers_tuple_sorted
[1, 3, 6, 9]
>>> numbers_set_sorted
[0, 1, 5, 10]
>>> tuple(numbers_tuple_sorted)
(1, 3, 6, 9)
>>> set(numbers_set_sorted)
{0, 1, 10, 5}
转换为set时的numbers_set_sorted值没有像预期的那样排序。另一个变量,numbers_tuple_sorted,保留了排序的顺序。
排序字符串
类型的排序类似于列表和元组等其他可迭代对象。下面的例子显示了sorted()如何遍历传递给它的值中的每个字符,并在输出中对它们进行排序:
>>> string_number_value = '34521' >>> string_value = 'I like to sort' >>> sorted_string_number = sorted(string_number_value) >>> sorted_string = sorted(string_value) >>> sorted_string_number ['1', '2', '3', '4', '5'] >>> sorted_string [' ', ' ', ' ', 'I', 'e', 'i', 'k', 'l', 'o', 'o', 'r', 's', 't', 't']
sorted()将把一个str当作一个列表,遍历每个元素。在str中,每个元素代表str中的每个字符。sorted()不会区别对待一个句子,它会对每个字符进行排序,包括空格。
.split()可以改变这种行为并清理输出,.join()可以把它们全部放回一起。我们将很快介绍输出的具体顺序以及为什么会这样:
>>> string_value = 'I like to sort'
>>> sorted_string = sorted(string_value.split())
>>> sorted_string
['I', 'like', 'sort', 'to']
>>> ' '.join(sorted_string)
'I like sort to'
这个例子中的原始句子被转换成一个单词列表,而不是将其作为一个str。该列表然后被排序和组合以再次形成一个str而不是一个列表。
Python 排序的局限性和陷阱
值得注意的是,在使用 Python 对整数以外的值进行排序时,会出现一些限制和奇怪的行为。
具有不可比数据类型的列表不能是sorted()
有些数据类型仅仅使用sorted()是无法相互比较的,因为它们差异太大。如果您试图在包含不可比数据的列表上使用sorted(),Python 将返回一个错误。在本例中,同一列表中的一个 None 和一个int由于不兼容而无法排序:
>>> mixed_types = [None, 0] >>> sorted(mixed_types) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'int' and 'NoneType'这个错误说明了为什么 Python 不能对给它的值进行排序。它试图通过使用小于运算符(
<)来确定哪个值在排序顺序中较低,从而对值进行排序。您可以通过手动比较这两个值来复制此错误:
>>> None < 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'NoneType' and 'int'
当您试图在不使用sorted()的情况下比较两个不可比较的值时,会抛出相同的TypeError。
如果列表中的值可以比较并且不会抛出TypeError,那么列表就可以排序。这可以防止对具有本质上不可排序的值的可迭代项进行排序,并产生可能没有意义的输出。
比如数字1应该在单词apple之前吗?然而,如果 iterable 包含的整数和字符串组合都是数字,那么可以通过使用列表理解将它们转换为可比较的数据类型:
>>> mixed_numbers = [5, "1", 100, "34"] >>> sorted(mixed_numbers) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: '<' not supported between instances of 'str' and 'int' >>> # List comprehension to convert all values to integers >>> [int(x) for x in mixed_numbers] [5, 1, 100, 34] >>> sorted([int(x) for x in mixed_numbers]) [1, 5, 34, 100]
mixed_numbers中的每个元素都调用了int()来将任何str值转换为int值。然后调用sorted(),它可以成功地比较每个元素,并提供一个排序后的输出。Python 也可以隐式地将一个值转换成另一种类型。在下面的例子中,
1 <= 0的求值是假语句,所以求值的输出将是False。数字1可以转换为True作为bool类型,而0转换为False。尽管列表中的元素看起来不同,但它们都可以被转换成布尔值 (
True或False),并使用sorted()进行相互比较:
>>> similar_values = [False, 0, 1, 'A' == 'B', 1 <= 0]
>>> sorted(similar_values)
[False, 0, False, False, 1]
'A' == 'B'和1 <= 0被转换为False并在有序输出中返回。
这个例子说明了排序的一个重要方面:排序稳定性。在 Python 中,当您对相等的值进行排序时,它们将在输出中保持其原始顺序。即使1移动了,所有其他的值都是相等的,所以它们保持它们相对于彼此的原始顺序。在下面的示例中,所有值都被视为相等,并将保留其原始位置:
>>> false_values = [False, 0, 0, 1 == 2, 0, False, False] >>> sorted(false_values) [False, 0, 0, False, 0, False, False]如果检查原始顺序和排序后的输出,您会看到
1 == 2被转换为False,所有排序后的输出都是原始顺序。对字符串排序时,大小写很重要
sorted()可用于字符串列表,按升序对值进行排序,默认情况下按字母顺序排列:
>>> names = ['Harry', 'Suzy', 'Al', 'Mark']
>>> sorted(names)
['Al', 'Harry', 'Mark', 'Suzy']
然而,Python 使用每个字符串中第一个字母的 Unicode 码位来确定升序排序。这意味着sorted()不会将名字Al和al视为相同。这个例子使用ord()返回每个字符串中第一个字母的 Unicode 码位:
>>> names_with_case = ['harry', 'Suzy', 'al', 'Mark'] >>> sorted(names_with_case) ['Mark', 'Suzy', 'al', 'harry'] >>> # List comprehension for Unicode Code Point of first letter in each word >>> [(ord(name[0]), name[0]) for name in sorted(names_with_case)] [(77, 'M'), (83, 'S'), (97, 'a'), (104, 'h')]
name[0]正在返回sorted(names_with_case)的每个元素的第一个字符,ord()正在提供 Unicode 码位。尽管在字母表中a在M之前,但是M的码位在a之前,所以排序后的输出首先是M。如果第一个字母相同,那么
sorted()将使用第二个字符来确定顺序,如果第三个字符相同,则使用第三个字符,依此类推,直到字符串结束:
>>> very_similar_strs = ['hhhhhd', 'hhhhha', 'hhhhhc','hhhhhb']
>>> sorted(very_similar_strs)
['hhhhha', 'hhhhhb', 'hhhhhc', 'hhhhhd']
除了最后一个字符,very_similar_strs的每个值都是相同的。sorted()会比较字符串,由于前五个字符相同,所以输出会以第六个字符为基础。
包含相同值的字符串将按从短到长的顺序排序,因为较短的字符串没有可与较长的字符串进行比较的元素:
>>> different_lengths = ['hhhh', 'hh', 'hhhhh','h'] >>> sorted(different_lengths) ['h', 'hh', 'hhhh', 'hhhhh']最短的字符串
h排在最前面,最长的字符串hhhhh排在最后。使用带有
reverse参数的sorted()如
sorted()的help()文档所示,有一个名为reverse的可选关键字参数,它将根据分配给它的布尔值改变排序行为。如果reverse被指定为True,那么排序将按降序进行:
>>> names = ['Harry', 'Suzy', 'Al', 'Mark']
>>> sorted(names)
['Al', 'Harry', 'Mark', 'Suzy']
>>> sorted(names, reverse=True)
['Suzy', 'Mark', 'Harry', 'Al']
排序逻辑保持不变,这意味着姓名仍然按其首字母排序。但是输出已经反转,关键字reverse设置为True。
分配False时,排序将保持升序。使用True或False可以使用前面的任何例子来查看反向的行为:
>>> names_with_case = ['harry', 'Suzy', 'al', 'Mark'] >>> sorted(names_with_case, reverse=True) ['harry', 'al', 'Suzy', 'Mark'] >>> similar_values = [False, 1, 'A' == 'B', 1 <= 0] >>> sorted(similar_values, reverse=True) [1, False, False, False] >>> numbers = [6, 9, 3, 1] >>> sorted(numbers, reverse=False) [1, 3, 6, 9]
sorted()带着key的论调
sorted()最强大的组件之一是名为key的关键字参数。该参数需要一个函数传递给它,该函数将用于排序列表中的每个值,以确定结果顺序。为了演示一个基本的例子,让我们假设对一个特定列表进行排序的要求是列表中字符串的长度,从最短到最长。返回字符串长度的函数
len()将与key参数一起使用:
>>> word = 'paper'
>>> len(word)
5
>>> words = ['banana', 'pie', 'Washington', 'book']
>>> sorted(words, key=len)
['pie', 'book', 'banana', 'Washington']
得到的顺序是一个从最短到最长的字符串顺序的列表。列表中每个元素的长度由len()决定,然后按升序返回。
当情况不同时,让我们回到前面按首字母排序的例子。key可以通过将整个字符串转换成小写来解决这个问题:
>>> names_with_case = ['harry', 'Suzy', 'al', 'Mark'] >>> sorted(names_with_case) ['Mark', 'Suzy', 'al', 'harry'] >>> sorted(names_with_case, key=str.lower) ['al', 'harry', 'Mark', 'Suzy']输出值没有被转换成小写,因为
key没有操作原始列表中的数据。在排序期间,传递给key的函数在每个元素上被调用,以确定排序顺序,但是原始值将出现在输出中。当您使用带有
key参数的函数时,有两个主要限制。首先,传递给
key的函数中所需参数的数量必须是 1。下面的示例显示了一个带两个参数的加法函数的定义。当在数字列表的
key中使用该函数时,它会失败,因为它缺少第二个参数。在排序过程中,每次调用add()时,它每次只接收列表中的一个元素:
>>> def add(x, y):
... return x + y
...
>>> values_to_add = [1, 2, 3]
>>> sorted(values_to_add, key=add)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: add() missing 1 required positional argument: 'y'
第二个限制是与key一起使用的函数必须能够处理 iterable 中的所有值。例如,您有一个用字符串表示的数字列表,将在sorted()中使用,而key将尝试使用int将它们转换成数字。如果 iterable 中的值不能转换为整数,那么函数将失败:
>>> values_to_cast = ['1', '2', '3', 'four'] >>> sorted(values_to_cast, key=int) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: invalid literal for int() with base 10: 'four'每个数值作为一个
str可以转换成int,但是four不能。这导致一个ValueError被引发,并解释four不能被转换为int,因为它是无效的。
key功能非常强大,因为几乎任何内置或用户定义的函数都可以用来操纵输出顺序。如果排序要求是根据每个字符串中的最后一个字母对 iterable 排序(如果这个字母是相同的,那么使用下一个字母),那么可以定义一个函数,然后在排序中使用。下面的例子定义了一个函数,该函数反转传递给它的字符串,然后该函数被用作
key的参数:
>>> def reverse_word(word):
... return word[::-1]
...
>>> words = ['banana', 'pie', 'Washington', 'book']
>>> sorted(words, key=reverse_word)
['banana', 'pie', 'book', 'Washington']
word[::-1] slice 语法用于反转字符串。每个元素都将应用reverse_word(),排序顺序将基于倒排单词中的字符。
您可以使用在key参数中定义的 lambda函数,而不是编写一个独立的函数。
lambda是一个匿名函数,它:
- 必须内联定义
- 没有名字
- 不能包含语句
- 将像函数一样执行
在下面的例子中,key被定义为一个没有名字的lambda,lambda采用的参数是x,x[::-1]是将对参数执行的操作:
>>> words = ['banana', 'pie', 'Washington', 'book'] >>> sorted(words, key=lambda x: x[::-1]) ['banana', 'pie', 'book', 'Washington']在每个元素上调用
x[::-1],并反转单词。反转后的输出将用于排序,但仍会返回原始单词。如果需求改变,顺序也应该颠倒,那么可以在
key参数旁边使用reverse关键字:
>>> words = ['banana', 'pie', 'Washington', 'book']
>>> sorted(words, key=lambda x: x[::-1], reverse=True)
['Washington', 'book', 'pie', 'banana']
当您需要根据属性对class对象进行排序时,函数也很有用。如果你有一组学生,需要按照他们的最终成绩从高到低进行排序,那么可以使用一个lambda从class那里获得grade属性:
>>> from collections import namedtuple >>> StudentFinal = namedtuple('StudentFinal', 'name grade') >>> bill = StudentFinal('Bill', 90) >>> patty = StudentFinal('Patty', 94) >>> bart = StudentFinal('Bart', 89) >>> students = [bill, patty, bart] >>> sorted(students, key=lambda x: getattr(x, 'grade'), reverse=True) [StudentFinal(name='Patty', grade=94), StudentFinal(name='Bill', grade=90), StudentFinal(name='Bart', grade=89)]这个例子使用
namedtuple来产生具有name和grade属性的类。lambda在每个元素上调用getattr(),并返回grade的值。
reverse设置为True使升序输出翻转为降序,最高等级先排序。当您在
sorted()上利用key和reverse关键字参数时,排序的可能性是无限的。当你为一个小函数使用一个基本的lambda时,代码可以保持简洁,或者你可以写一个全新的函数,导入它,并在关键参数中使用它。用
.sort()对数值进行排序名称非常相似的
.sort()与内置的sorted()有很大不同。它们完成的事情或多或少是一样的,但是list.sort()的help()文档强调了.sort()和sorted()之间的两个最关键的区别:
>>> # Python2
Help on method_descriptor:
sort(...)
L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*;
cmp(x, y) -> -1, 0, 1
>>> # Python3
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE*
首先,sort 是list类的一个方法,只能用于列表。它不是传递了 iterable 的内置函数。
第二,.sort()返回None并就地修改值。让我们来看看这两种代码差异的影响:
>>> values_to_sort = [5, 2, 6, 1] >>> # Try to call .sort() like sorted() >>> sort(values_to_sort) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'sort' is not defined >>> # Try to use .sort() on a tuple >>> tuple_val = (5, 1, 3, 5) >>> tuple_val.sort() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'tuple' object has no attribute 'sort' >>> # Sort the list and assign to new variable >>> sorted_values = values_to_sort.sort() >>> print(sorted_values) None >>> # Print original variable >>> print(values_to_sort) [1, 2, 5, 6]在这个代码示例中,
.sort()的运行方式与sorted()相比有一些非常显著的不同:
.sort()没有有序输出,所以对新变量的赋值只传递了一个None类型。values_to_sort列表已经更改到位,不以任何方式维持原有顺序。这些行为上的差异使得
.sort()和sorted()在代码中绝对不可互换,如果其中一个被错误地使用,它们会产生意想不到的结果。
.sort()具有与sorted()相同的key和reverse可选关键字参数,产生相同的健壮功能。在这里,您可以按第三个单词的第二个字母对短语列表进行排序,并反向返回列表:
>>> phrases = ['when in rome',
... 'what goes around comes around',
... 'all is fair in love and war'
... ]
>>> phrases.sort(key=lambda x: x.split()[2][1], reverse=True)
>>> phrases
['what goes around comes around', 'when in rome', 'all is fair in love and war']
在此示例中,使用了一个lambda来执行以下操作:
- 将每个短语分成一个单词列表
- 找到第三个元素,或者这个例子中的单词
- 找出这个单词的第二个字母
什么时候用sorted()什么时候用.sort()
你已经看到了sorted()和.sort()的区别,但是什么时候用哪个呢?
假设即将有一场 5k 比赛:第一届年度 Python 5k。来自比赛的数据需要被捕获和分类。需要捕获的数据是跑步者的围兜号码和完成比赛所用的秒数:
>>> from collections import namedtuple >>> Runner = namedtuple('Runner', 'bibnumber duration')随着赛跑者越过终点线,每个
Runner将被添加到一个名为runners的列表中。在 5 公里赛跑中,并非所有选手都同时冲过起跑线,所以第一个冲过终点线的人可能并不是最快的人:
>>> runners = []
>>> runners.append(Runner('2528567', 1500))
>>> runners.append(Runner('7575234', 1420))
>>> runners.append(Runner('2666234', 1600))
>>> runners.append(Runner('2425234', 1490))
>>> runners.append(Runner('1235234', 1620))
>>> # Thousands and Thousands of entries later...
>>> runners.append(Runner('2526674', 1906))
每一次跑步者越过终点线,他们的号码和他们的总持续时间(以秒计)就会被添加到runners中。
现在,负责处理结果数据的尽职的程序员看到这个列表,知道前 5 名最快的参与者是获得奖励的获胜者,其余的跑步者将按最快时间排序。
不需要根据各种属性进行多种类型的排序。这份名单的规模是合理的。没有提到将列表存储在某个地方。只需按持续时间排序,抓住持续时间最短的五名参与者:
>>> runners.sort(key=lambda x: getattr(x, 'duration')) >>> top_five_runners = runners[:5]程序员选择在
key参数中使用lambda来从每个跑步者那里获得duration属性,并使用.sort()对runners进行排序。runners排序后,前 5 个元素存储在top_five_runners中。任务完成!比赛总监过来告诉程序员,由于 Python 的当前版本是 3.7,他们决定每 37 个冲过终点线的人将获得一个免费的运动包。
此时,程序员开始冒汗,因为跑步者的列表已经被不可逆转地改变了。没有办法恢复跑步者的原始名单,按照他们完成的顺序,找到每第三十七个人。
如果您正在处理重要数据,并且原始数据需要恢复的可能性极小,那么
.sort()不是最佳选择。如果数据是副本,如果它是不重要的工作数据,如果没有人会介意丢失它,因为它可以被检索,那么.sort()可能是一个不错的选择。或者,可以使用
sorted()并使用相同的lambda对跑步者进行分类:
>>> runners_by_duration = sorted(runners, key=lambda x: getattr(x, 'duration'))
>>> top_five_runners = runners_by_duration[:5]
在这个使用sorted()的场景中,最初的跑步者列表仍然是完整的,没有被覆盖。找到每 37 个人中穿过终点线的即席要求可以通过与原始值交互来实现:
>>> every_thirtyseventh_runners = runners[::37]
every_thirtyseventh_runners是通过使用runners上的列表片语法中的步幅创建的,它仍然包含跑步者穿过终点线的原始顺序。如何在 Python 中排序:结论
如果将
.sort()和sorted()与可选关键字参数reverse和key一起正确使用,它们可以提供您需要的排序顺序。当涉及到输出和就地修改时,两者都有非常不同的特征,所以请确保您考虑过任何将使用
.sort()的应用程序功能或程序,因为它可能会不可挽回地覆盖数据。对于热衷于寻找排序挑战的 Pythonistas 来说,可以尝试在排序中使用更复杂的数据类型:嵌套的 iterables。此外,您可以随意深入研究内置的开源 Python 代码实现,并阅读 Python 中使用的名为 Timsort 的排序算法。如果你想对字典进行排序,那么看看对 Python 字典进行排序:值、键等等。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用 Python 排序数据******
Python 语音识别终极指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 进行语音识别
您是否想过如何在您的 Python 项目中添加语音识别?如果有,那就继续读下去吧!这比你想象的要容易。
像亚马逊 Alexa 这样的语音功能产品的巨大成功已经证明,在可预见的未来,某种程度的语音支持将是家用技术的一个重要方面,这远远不是一种时尚。如果你仔细想想,原因是显而易见的。将语音识别集成到您的 Python 应用程序中,可以提供很少技术可以比拟的交互性和可访问性。
仅可访问性的改进就值得考虑。语音识别允许老年人、身体和视力受损者快速、自然地与最先进的产品和服务进行交互,无需 GUI!
最重要的是,在 Python 项目中包含语音识别非常简单。在本指南中,您将了解如何做到这一点。您将了解到:
- 语音识别的工作原理,
- PyPI 上有哪些软件包;和
- 如何安装和使用 SpeechRecognition 包——一个功能齐全且易于使用的 Python 语音识别库。
最后,您将把您所学到的知识应用到一个简单的“猜单词”游戏中,看看它是如何组合在一起的。
免费奖励: 单击此处下载一个 Python 语音识别示例项目,该项目具有完整的源代码,您可以将其用作自己的语音识别应用程序的基础。
语音识别的工作原理——概述
在我们开始用 Python 进行语音识别的基础知识之前,让我们花点时间来讨论一下语音识别是如何工作的。完整的讨论可以写一本书,所以我不会在这里用所有的技术细节来烦你。事实上,这一部分并不是本教程其余部分的先决条件。如果你想直奔主题,那就直接跳到前面。
语音识别源于 20 世纪 50 年代早期贝尔实验室的研究。早期的系统仅限于单个说话者,并且词汇量有限,大约只有十几个单词。现代语音识别系统与古代的系统相比已经有了很大的进步。它们可以识别来自多个说话者的语音,并拥有多种语言的大量词汇。
语音识别的第一个组成部分当然是语音。语音必须通过麦克风从物理声音转换为电信号,然后通过模数转换器转换为数字数据。一旦数字化,几个模型可以用来转录音频到文本。
大多数现代语音识别系统依赖于所谓的隐马尔可夫模型 (HMM)。这种方法基于这样一种假设,即当在足够短的时间尺度(比如 10 毫秒)上观察时,语音信号可以合理地近似为一个平稳过程,即统计特性不随时间变化的过程。
在典型的 HMM 中,语音信号被分成 10 毫秒的片段。每个碎片的功率谱本质上是信号功率与频率的函数关系图,它被映射到一个称为倒谱系数的实数向量上。这个向量的维数通常很小,有时低至 10,尽管更精确的系统可能有 32 或更高的维数。HMM 的最终输出是这些向量的序列。
为了将语音解码成文本,向量组与一个或多个音素匹配——语音的基本单位。这种计算需要训练,因为音素的声音因说话者而异,甚至因同一说话者的不同话语而异。然后应用一种特殊的算法来确定产生给定音素序列的最可能的单词。
可以想象,这整个过程在计算上可能是昂贵的。在许多现代语音识别系统中,神经网络用于简化语音信号,在 HMM 识别之前使用特征变换和维度缩减技术。语音活动检测器(VAD)也用于将音频信号减少到可能包含语音的部分。这防止识别器浪费时间分析信号的不必要部分。
幸运的是,作为一名 Python 程序员,您不必担心这些。许多语音识别服务可以通过 API 在线使用,其中许多服务提供了Python SDK。
挑选一个 Python 语音识别包
PyPI 上有一些用于语音识别的包。其中一些包括:
其中一些软件包——如 wit 和 apai——提供内置功能,如用于识别说话者意图的自然语言处理,这超出了基本的语音识别。其他的,比如 google-cloud-speech,只专注于语音到文本的转换。
有一个软件包在易用性方面非常突出:SpeechRecognition。
识别语音需要音频输入,而 SpeechRecognition 使检索这种输入变得非常容易。SpeechRecognition 无需从头开始编写访问麦克风和处理音频文件的脚本,只需几分钟就能让您启动并运行。
SpeechRecognition 库充当几种流行的语音 API 的包装器,因此非常灵活。其中之一——Google Web Speech API——支持一个默认的 API 键,该键被硬编码到 SpeechRecognition 库中。这意味着你可以不用注册服务就可以开始工作。
SpeechRecognition 包的灵活性和易用性使其成为任何 Python 项目的绝佳选择。然而,并不能保证支持它所包装的每个 API 的每个特性。您需要花一些时间研究可用的选项,看看演讲识别功能是否适用于您的特定情况。
所以,既然您已经确信应该试用 SpeechRecognition,下一步就是在您的环境中安装它。
安装语音识别功能
SpeechRecognition 与 Python 2.6、2.7 和 3.3+兼容,但是对于 Python 2 需要一些额外的安装步骤。对于本教程,我假设您使用的是 Python 3.3+。
您可以使用 pip 从终端安装 SpeechRecognition:
$ pip install SpeechRecognition安装后,您应该通过打开解释器会话并键入以下命令来验证安装:
>>> import speech_recognition as sr
>>> sr.__version__
'3.8.1'
注意:您获得的版本号可能会有所不同。在撰写本文时,最新的版本是 3.8.1。
继续并保持此会话打开。你很快就会开始使用它。
如果你需要做的只是处理现有的音频文件,那么演讲识别将开箱即用。然而,特定的用例需要一些依赖关系。值得注意的是,捕捉麦克风输入需要 PyAudio 包。
随着阅读的深入,您将会看到您需要哪些依赖项。现在,让我们深入研究一下这个包的基础知识。
Recognizer类
SpeechRecognition 的所有神奇之处都发生在Recognizer类上。
当然,Recognizer实例的主要目的是识别语音。每个实例都带有各种设置和功能,用于识别来自音频源的语音。
创建一个Recognizer实例很容易。在当前的解释器会话中,只需键入:
>>> r = sr.Recognizer()每个
Recognizer实例都有七种方法,用于使用各种 API 识别来自音频源的语音。这些是:
recognize_bing(): 微软必应演讲recognize_google(): 谷歌网络语音 APIrecognize_google_cloud(): 谷歌云语音——需要安装谷歌云语音包recognize_houndify(): 用 SoundHound 来形容recognize_ibm(): IBM 语音转文字recognize_sphinx(): CMU 狮身人面像 -需要安装 PocketSphinxrecognize_wit(): Wit.ai在这七个引擎中,只有
recognize_sphinx()离线使用 CMU 狮身人面像引擎。其他六个都需要互联网连接。对每个 API 的特性和优点的全面讨论超出了本教程的范围。因为 SpeechRecognition 为 Google Web Speech API 提供了一个默认的 API 键,所以您可以马上开始使用它。因此,我们将在本指南中使用 Web 语音 API。其他六个 API 都需要使用 API 密钥或用户名/密码组合进行身份验证。欲了解更多信息,请查阅演讲人认知文档。
注意:speech recognition 提供的默认密钥仅用于测试目的,谷歌可能随时撤销该密钥。在产品中使用谷歌网络语音 API 不是一个好主意。即使有一个有效的 API 密匙,你也将被限制在每天只有 50 个请求,并且没有办法提高这个配额。幸运的是,SpeechRecognition 的界面对于每个 API 几乎都是相同的,因此您今天所学的内容将很容易转化为现实世界的项目。
如果 API 不可达,每个
recognize_*()方法将抛出一个speech_recognition.RequestError异常。对于recognize_sphinx()来说,这可能是由于 Sphinx 安装缺失、损坏或不兼容造成的。对于其他六种方法,如果达到配额限制、服务器不可用或没有互联网连接,可能会抛出RequestError。好了,闲聊够了。让我们把手弄脏吧。继续尝试在您的解释器会话中调用
recognize_google()。
>>> r.recognize_google()
发生了什么事?
您可能会看到类似这样的内容:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: recognize_google() missing 1 required positional argument: 'audio_data'
你可能已经猜到会发生这种情况。从无到有怎么可能认识到什么?
Recognizer类的所有七个recognize_*()方法都需要一个audio_data参数。在每种情况下,audio_data必须是 SpeechRecognition 的AudioData类的一个实例。
创建AudioData实例有两种方法:从音频文件或麦克风录制的音频。音频文件比较容易上手,所以我们先来看看。
使用音频文件
继续之前,您需要下载一个音频文件。我用来入门的那个“harvard.wav”,可以在这里找到。确保将它保存到运行 Python 解释器会话的同一目录中。
SpeechRecognition 通过其便利的AudioFile类使处理音频文件变得简单。这个类可以用音频文件的路径初始化,并提供一个上下文管理器接口来读取和处理文件的内容。
支持的文件类型
目前,SpeechRecognition 支持以下文件格式:
- WAV:必须是 PCM/LPCM 格式
- AIFF
- AIFF-C
- FLAC:必须是原生 FLAC 格式;不支持 OGG-FLAC
如果你在基于 x-86 的 Linux、macOS 或 Windows 上工作,你应该能够毫无问题地处理 FLAC 文件。在其他平台上,您需要安装 FLAC 编码器,并确保您可以访问flac命令行工具。如果适用于您,您可以在这里找到更多信息。
使用record()从文件中捕获数据
在您的解释器会话中键入以下内容,以处理“harvard.wav”文件的内容:
>>> harvard = sr.AudioFile('harvard.wav') >>> with harvard as source: ... audio = r.record(source) ...上下文管理器打开文件并读取其内容,将数据存储在名为
source.的AudioFile实例中,然后record()方法将整个文件中的数据记录到一个AudioData实例中。您可以通过检查audio的类型来确认这一点:
>>> type(audio)
<class 'speech_recognition.AudioData'>
您现在可以调用recognize_google()来尝试识别音频中的任何语音。根据您的互联网连接速度,您可能需要等待几秒钟才能看到结果。
>>> r.recognize_google(audio) 'the stale smell of old beer lingers it takes heat to bring out the odor a cold dip restores health and zest a salt pickle taste fine with ham tacos al Pastore are my favorite a zestful food is the hot cross bun'恭喜你!您刚刚转录了您的第一个音频文件!
如果你想知道“harvard.wav”文件中的短语来自哪里,它们是哈佛句子的例子。这些短语由 IEEE 于 1965 年发布,用于电话线的语音清晰度测试。今天,它们仍然用于 VoIP 和蜂窝测试。
哈佛的句子由 72 个 10 个短语组成。你可以在 Open Speech Repository 网站上找到这些短语的免费录音。录音有英语、汉语普通话、法语和印地语版本。它们为测试您的代码提供了极好的免费资料来源。
用
offset和duration捕捉片段如果您只想在文件中捕获一部分语音,该怎么办?
record()方法接受一个duration关键字参数,该参数在指定的秒数后停止记录。例如,以下代码捕获文件前四秒钟的任何语音:
>>> with harvard as source:
... audio = r.record(source, duration=4)
...
>>> r.recognize_google(audio)
'the stale smell of old beer lingers'
在with块中使用的record()方法总是在文件流中向前移动。这意味着,如果您录制一次四秒钟,然后再次录制四秒钟,第二次将返回前四秒钟之后的四秒钟音频。
>>> with harvard as source: ... audio1 = r.record(source, duration=4) ... audio2 = r.record(source, duration=4) ... >>> r.recognize_google(audio1) 'the stale smell of old beer lingers' >>> r.recognize_google(audio2) 'it takes heat to bring out the odor a cold dip'注意
audio2包含了文件中第三个短语的一部分。当指定持续时间时,录音可能会在短语中间停止,甚至在单词中间停止,这可能会影响转录的准确性。稍后会有更多的介绍。除了指定记录持续时间之外,还可以使用
offset关键字参数为record()方法指定一个特定的起点。该值表示从文件开始到开始记录之前要忽略的秒数。要仅捕获文件中的第二个短语,您可以从 4 秒钟的偏移开始记录,比如说,3 秒钟。
>>> with harvard as source:
... audio = r.record(source, offset=4, duration=3)
...
>>> r.recognize_google(audio)
'it takes heat to bring out the odor'
如果您事先知道文件中的语音结构,那么offset和duration关键字参数对于分割音频文件非常有用。然而,匆忙使用它们会导致糟糕的转录。要查看这种效果,请在您的解释器中尝试以下操作:
>>> with harvard as source: ... audio = r.record(source, offset=4.7, duration=2.8) ... >>> r.recognize_google(audio) 'Mesquite to bring out the odor Aiko'通过在 4.7 秒开始记录,您错过了短语“需要加热才能带出气味”开头的“it t”部分,因此 API 只得到“akes heat”,它与“Mesquite”匹配。
同样,在录音的结尾,你听到了“a co”,这是第三个短语“冷浸恢复健康和热情”的开头这与 API 中的“Aiko”相匹配。
还有一个原因,你可能会得到不准确的转录。噪音!上面的例子工作得很好,因为音频文件相当干净。在现实世界中,除非您有机会事先处理音频文件,否则您不能期望音频是无噪声的。
噪声对语音识别的影响
噪音是生活的现实。所有的录音都有一定程度的噪音,未经处理的噪音会破坏语音识别应用的准确性。
要了解噪声如何影响语音识别,请在此下载“jackhammer.wav”文件。像往常一样,确保将它保存到解释器会话的工作目录中。
这份文件有一句话“旧啤酒的陈腐气味挥之不去”,背景是一个响亮的手提钻。
当你试图转录这个文件时会发生什么?
>>> jackhammer = sr.AudioFile('jackhammer.wav')
>>> with jackhammer as source:
... audio = r.record(source)
...
>>> r.recognize_google(audio)
'the snail smell of old gear vendors'
太离谱了。
那么你如何处理这个问题呢?您可以尝试使用Recognizer类的adjust_for_ambient_noise()方法。
>>> with jackhammer as source: ... r.adjust_for_ambient_noise(source) ... audio = r.record(source) ... >>> r.recognize_google(audio) 'still smell of old beer vendors'这让你离真正的短语更近了一点,但它仍然不完美。此外,短语开头缺少“the”。这是为什么呢?
adjust_for_ambient_noise()方法读取文件流的第一秒,并将识别器校准到音频的噪声级别。因此,在您调用record()来捕获数据之前,流的这一部分就被消耗掉了。您可以使用
duration关键字参数调整adjust_for_ambient_noise()用于分析的时间范围。该参数采用以秒为单位的数值,默认情况下设置为 1。尝试将该值降低到 0.5。
>>> with jackhammer as source:
... r.adjust_for_ambient_noise(source, duration=0.5)
... audio = r.record(source)
...
>>> r.recognize_google(audio)
'the snail smell like old Beer Mongers'
好吧,那让你在短语的开始有了“the ”,但是现在你有一些新的问题了!有时不可能消除噪声的影响——信号噪声太大,无法成功处理。这份档案就是这样。
如果您发现自己经常遇到这些问题,您可能需要对音频进行一些预处理。这可以通过音频编辑软件或者可以对文件应用过滤器的 Python 包(比如 SciPy )来完成。关于这一点的详细讨论超出了本教程的范围——如果你感兴趣,可以看看艾伦·唐尼的 Think DSP 一书。现在,请注意,音频文件中的环境噪声可能会导致问题,为了最大限度地提高语音识别的准确性,必须解决这个问题。
当处理有噪声的文件时,查看实际的 API 响应会很有帮助。大多数 API 返回一个包含许多可能转写的 JSON 字符串。recognize_google()方法将总是返回最有可能的转录,除非你强迫它给你完整的响应。
您可以通过将recognize_google()方法的show_all关键字参数设置为True.来做到这一点
>>> r.recognize_google(audio, show_all=True) {'alternative': [ {'transcript': 'the snail smell like old Beer Mongers'}, {'transcript': 'the still smell of old beer vendors'}, {'transcript': 'the snail smell like old beer vendors'}, {'transcript': 'the stale smell of old beer vendors'}, {'transcript': 'the snail smell like old beermongers'}, {'transcript': 'destihl smell of old beer vendors'}, {'transcript': 'the still smell like old beer vendors'}, {'transcript': 'bastille smell of old beer vendors'}, {'transcript': 'the still smell like old beermongers'}, {'transcript': 'the still smell of old beer venders'}, {'transcript': 'the still smelling old beer vendors'}, {'transcript': 'musty smell of old beer vendors'}, {'transcript': 'the still smell of old beer vendor'} ], 'final': True}如您所见,
recognize_google()返回一个带有键'alternative'的字典,指向一个可能的抄本列表。该响应的结构可能因 API 而异,主要用于调试。到目前为止,您已经对演讲识别包的基本知识有了很好的了解。您已经看到了如何从一个音频文件创建一个
AudioFile实例,并使用record()方法从文件中捕获数据。您学习了如何使用record()的offset和duration关键字参数来记录文件片段,并且体验了噪声对转录准确性的不利影响。现在是有趣的部分。让我们从转录静态音频文件过渡到通过接受麦克风输入来使您的项目具有交互性。
使用麦克风
要使用 SpeechRecognizer 访问您的麦克风,您必须安装 PyAudio 软件包。继续并关闭您当前的解释器会话,让我们这样做。
安装 PyAudio
安装 PyAudio 的过程会因您的操作系统而异。
Debian Linux
如果你在基于 Debian 的 Linux 上(比如 Ubuntu),你可以用
apt安装 PyAudio:$ sudo apt-get install python-pyaudio python3-pyaudio一旦安装完毕,你可能仍然需要运行
pip install pyaudio,尤其是如果你正在一个虚拟环境中工作。苹果电脑
对于 macOS 来说,首先你需要用 Homebrew 安装 PortAudio,然后用
pip安装 PyAudio:$ brew install portaudio $ pip install pyaudio窗户
在 Windows 上,可以用
pip安装 PyAudio:$ pip install pyaudio测试安装
一旦安装了 PyAudio,就可以从控制台测试安装。
$ python -m speech_recognition请确定您的默认麦克风已打开且未静音。如果安装工作正常,您应该会看到如下内容:
A moment of silence, please... Set minimum energy threshold to 600.4452854381937 Say something!Go ahead and play around with it a little bit by speaking into your microphone and seeing how well SpeechRecognition transcribes your speech.
注意:如果你在 Ubuntu 上,得到一些像“ALSA lib …未知 PCM”这样的时髦输出,参考这一页关于抑制这些信息的提示。这个输出来自与 Ubuntu 一起安装的 ALSA 软件包——而不是 SpeechRecognition 或 PyAudio。实际上,这些消息可能表明您的 ALSA 配置有问题,但是根据我的经验,它们不会影响您代码的功能。他们大多令人讨厌。
Microphone类打开另一个解释器会话并创建识别器类的一个实例。
>>> import speech_recognition as sr
>>> r = sr.Recognizer()
现在,您将使用默认的系统麦克风,而不是使用音频文件作为源。您可以通过创建一个Microphone类的实例来访问它。
>>> mic = sr.Microphone()如果您的系统没有默认麦克风(例如在 Raspberry Pi 上),或者您想要使用默认麦克风之外的麦克风,您将需要通过提供设备索引来指定使用哪个麦克风。您可以通过调用
Microphone类的list_microphone_names()静态方法来获得麦克风名称的列表。
>>> sr.Microphone.list_microphone_names()
['HDA Intel PCH: ALC272 Analog (hw:0,0)',
'HDA Intel PCH: HDMI 0 (hw:0,3)',
'sysdefault',
'front',
'surround40',
'surround51',
'surround71',
'hdmi',
'pulse',
'dmix',
'default']
请注意,您的输出可能与上面的示例不同。
麦克风的设备索引是其名称在由list_microphone_names().返回的列表中的索引。例如,给定上面的输出,如果您想要使用名为“front”的麦克风,它在列表中的索引为 3,您将创建一个麦克风实例,如下所示:
>>> # This is just an example; do not run >>> mic = sr.Microphone(device_index=3)不过,对于大多数项目,您可能会想要使用默认的系统麦克风。
使用
listen()捕捉麦克风输入既然您已经准备好了一个
Microphone实例,那么是时候捕获一些输入了。就像
AudioFile类一样,Microphone是一个上下文管理器。您可以使用with块中的Recognizer类的listen()方法来捕获来自麦克风的输入。该方法将音频源作为其第一个参数,并记录来自该源的输入,直到检测到无声。
>>> with mic as source:
... audio = r.listen(source)
...
一旦你执行了with块,试着对着你的麦克风说“hello”。稍等片刻,让解释器提示符再次显示。一旦"> > >"提示返回,您就可以识别语音了。
>>> r.recognize_google(audio) 'hello'如果提示音不再出现,您的麦克风很可能拾取了太多的环境噪音。您可以使用
Ctrl+C来中断该过程,以获得您的提示。要处理环境噪声,您需要使用
Recognizer类的adjust_for_ambient_noise()方法,就像您在尝试理解嘈杂的音频文件时所做的那样。由于来自麦克风的输入远不如来自音频文件的输入可预测,因此在您收听麦克风输入时,最好这样做。
>>> with mic as source:
... r.adjust_for_ambient_noise(source)
... audio = r.listen(source)
...
运行上述代码后,等待一秒钟让adjust_for_ambient_noise()完成它的工作,然后试着对着麦克风说“hello”。同样,在尝试识别语音之前,您必须等待解释器提示返回。
回想一下adjust_for_ambient_noise()分析音源一秒钟。如果这对你来说太长了,你可以用关键字参数duration来调整它。
演讲者识别文档建议使用不少于 0.5 秒的持续时间。在某些情况下,您可能会发现持续时间长于默认值一秒会产生更好的结果。您需要的最小值取决于麦克风的周围环境。不幸的是,这些信息在开发过程中通常是未知的。根据我的经验,一秒钟的默认持续时间对于大多数应用程序来说已经足够了。
处理无法识别的语音
尝试在 interpeter 中键入前面的代码示例,并在麦克风中制造一些难以理解的噪音。您应该得到类似这样的响应:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/david/real_python/speech_recognition_primer/venv/lib/python3.5/site-packages/speech_recognition/__init__.py", line 858, in recognize_google
if not isinstance(actual_result, dict) or len(actual_result.get("alternative", [])) == 0: raise UnknownValueError()
speech_recognition.UnknownValueError
API 无法匹配文本的音频会引发一个UnknownValueError异常。你应该总是用 try和except块包装对 API 的调用来处理这个异常。
注意:要抛出异常,你可能需要付出比预期更多的努力。API 非常努力地转录任何声音。对我来说,即使是简短的咕哝声也会被翻译成“怎么样”这样的词。咳嗽、拍手和咂嘴都会引发异常。
综合起来:一个“猜单词”游戏
现在,您已经看到了使用 SpeechRecognition 软件包识别语音的基本知识,让我们将您新学到的知识用于编写一个小游戏,从列表中随机选择一个单词,并给用户三次猜测该单词的机会。
以下是完整的脚本:
import random
import time
import speech_recognition as sr
def recognize_speech_from_mic(recognizer, microphone):
"""Transcribe speech from recorded from `microphone`.
Returns a dictionary with three keys:
"success": a boolean indicating whether or not the API request was
successful
"error": `None` if no error occured, otherwise a string containing
an error message if the API could not be reached or
speech was unrecognizable
"transcription": `None` if speech could not be transcribed,
otherwise a string containing the transcribed text
"""
# check that recognizer and microphone arguments are appropriate type
if not isinstance(recognizer, sr.Recognizer):
raise TypeError("`recognizer` must be `Recognizer` instance")
if not isinstance(microphone, sr.Microphone):
raise TypeError("`microphone` must be `Microphone` instance")
# adjust the recognizer sensitivity to ambient noise and record audio
# from the microphone
with microphone as source:
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
# set up the response object
response = {
"success": True,
"error": None,
"transcription": None
}
# try recognizing the speech in the recording
# if a RequestError or UnknownValueError exception is caught,
# update the response object accordingly
try:
response["transcription"] = recognizer.recognize_google(audio)
except sr.RequestError:
# API was unreachable or unresponsive
response["success"] = False
response["error"] = "API unavailable"
except sr.UnknownValueError:
# speech was unintelligible
response["error"] = "Unable to recognize speech"
return response
if __name__ == "__main__":
# set the list of words, maxnumber of guesses, and prompt limit
WORDS = ["apple", "banana", "grape", "orange", "mango", "lemon"]
NUM_GUESSES = 3
PROMPT_LIMIT = 5
# create recognizer and mic instances
recognizer = sr.Recognizer()
microphone = sr.Microphone()
# get a random word from the list
word = random.choice(WORDS)
# format the instructions string
instructions = (
"I'm thinking of one of these words:\n"
"{words}\n"
"You have {n} tries to guess which one.\n"
).format(words=', '.join(WORDS), n=NUM_GUESSES)
# show instructions and wait 3 seconds before starting the game
print(instructions)
time.sleep(3)
for i in range(NUM_GUESSES):
# get the guess from the user
# if a transcription is returned, break out of the loop and
# continue
# if no transcription returned and API request failed, break
# loop and continue
# if API request succeeded but no transcription was returned,
# re-prompt the user to say their guess again. Do this up
# to PROMPT_LIMIT times
for j in range(PROMPT_LIMIT):
print('Guess {}. Speak!'.format(i+1))
guess = recognize_speech_from_mic(recognizer, microphone)
if guess["transcription"]:
break
if not guess["success"]:
break
print("I didn't catch that. What did you say?\n")
# if there was an error, stop the game
if guess["error"]:
print("ERROR: {}".format(guess["error"]))
break
# show the user the transcription
print("You said: {}".format(guess["transcription"]))
# determine if guess is correct and if any attempts remain
guess_is_correct = guess["transcription"].lower() == word.lower()
user_has_more_attempts = i < NUM_GUESSES - 1
# determine if the user has won the game
# if not, repeat the loop if user has more attempts
# if no attempts left, the user loses the game
if guess_is_correct:
print("Correct! You win!".format(word))
break
elif user_has_more_attempts:
print("Incorrect. Try again.\n")
else:
print("Sorry, you lose!\nI was thinking of '{}'.".format(word))
break
让我们稍微分解一下。
recognize_speech_from_mic()函数将Recognizer和Microphone实例作为参数,并返回一个包含三个键的字典。第一个关键字"success"是一个布尔值,它指示 API 请求是否成功。第二个键"error",或者是 None ,或者是指示 API 不可用或者语音不可理解的错误消息。最后,"transcription"键包含麦克风录制的音频的转录。
该函数首先检查recognizer和microphone参数的类型是否正确,如果其中一个无效,则引发一个TypeError:
if not isinstance(recognizer, sr.Recognizer):
raise TypeError('`recognizer` must be `Recognizer` instance')
if not isinstance(microphone, sr.Microphone):
raise TypeError('`microphone` must be a `Microphone` instance')
然后使用listen()方法记录麦克风输入:
with microphone as source:
recognizer.adjust_for_ambient_noise(source)
audio = recognizer.listen(source)
每次调用recognize_speech_from_mic()函数时,adjust_for_ambient_noise()方法用于校准识别器以改变噪声条件。
接下来,recognize_google()被调用来转录录音中的任何讲话。一个try...except块用于捕捉RequestError和UnknownValueError异常并相应地处理它们。API 请求的成功、任何错误消息和转录的语音都存储在response字典的success、error和transcription键中,由recognize_speech_from_mic()函数返回。
response = {
"success": True,
"error": None,
"transcription": None
}
try:
response["transcription"] = recognizer.recognize_google(audio)
except sr.RequestError:
# API was unreachable or unresponsive
response["success"] = False
response["error"] = "API unavailable"
except sr.UnknownValueError:
# speech was unintelligible
response["error"] = "Unable to recognize speech"
return response
您可以通过将上述脚本保存到一个名为“guessing_game.py”的文件中并在解释器会话中运行以下命令来测试recognize_speech_from_mic()函数:
>>> import speech_recognition as sr >>> from guessing_game import recognize_speech_from_mic >>> r = sr.Recognizer() >>> m = sr.Microphone() >>> recognize_speech_from_mic(r, m) {'success': True, 'error': None, 'transcription': 'hello'} >>> # Your output will vary depending on what you say游戏本身非常简单。首先,声明单词列表、允许猜测的最大数量和提示限制:
WORDS = ['apple', 'banana', 'grape', 'orange', 'mango', 'lemon'] NUM_GUESSES = 3 PROMPT_LIMIT = 5接下来,创建一个
Recognizer和Microphone实例,并从WORDS中选择一个随机单词:recognizer = sr.Recognizer() microphone = sr.Microphone() word = random.choice(WORDS)在打印一些指令并等待 3 秒钟后,使用一个
for循环来管理每个用户猜测所选单词的尝试。在for循环中的第一件事是另一个for循环,它最多提示用户PROMPT_LIMIT次猜测,每次都试图用recognize_speech_from_mic()函数识别输入,并将返回的字典存储到本地变量guess。如果
guess的"transcription"键不是None,则用户的语音被转录,内部循环以break结束。如果语音未被转录并且"success"键被设置为False,则出现 API 错误,并且循环再次以break终止。否则,API 请求成功,但语音无法识别。警告用户并重复for循环,给用户当前尝试的另一次机会。for j in range(PROMPT_LIMIT): print('Guess {}. Speak!'.format(i+1)) guess = recognize_speech_from_mic(recognizer, microphone) if guess["transcription"]: break if not guess["success"]: break print("I didn't catch that. What did you say?\n")一旦内部
for循环终止,就会检查guess字典中的错误。如果发生任何错误,显示错误信息,用break终止外部for循环,这将结束程序执行。if guess['error']: print("ERROR: {}".format(guess["error"])) break如果没有任何错误,转录将与随机选择的单词进行比较。string 对象的
lower()方法用于确保猜测与所选单词的更好匹配。API 可以将与单词“apple”匹配的语音返回为“Apple”或“Apple”,并且任何一个响应都应该算作正确答案。如果猜测正确,用户获胜,游戏终止。如果用户是不正确的,并且有任何剩余的尝试,外部的
for循环重复,并且检索新的猜测。否则,用户输掉游戏。guess_is_correct = guess["transcription"].lower() == word.lower() user_has_more_attempts = i < NUM_GUESSES - 1 if guess_is_correct: print('Correct! You win!'.format(word)) break elif user_has_more_attempts: print('Incorrect. Try again.\n') else: print("Sorry, you lose!\nI was thinking of '{}'.".format(word)) break运行时,输出如下所示:
I'm thinking of one of these words: apple, banana, grape, orange, mango, lemon You have 3 tries to guess which one. Guess 1\. Speak! You said: banana Incorrect. Try again. Guess 2\. Speak! You said: lemon Incorrect. Try again. Guess 3\. Speak! You said: Orange Correct! You win!概述和其他资源
在本教程中,您已经看到了如何安装 SpeechRecognition 包并使用它的
Recognizer类来轻松识别来自文件(使用record())和麦克风输入(使用listen().)的语音。您还看到了如何使用record()方法的offset和duration关键字参数来处理音频文件的片段。您已经看到了噪声对转录准确性的影响,并且已经学习了如何使用
adjust_for_ambient_noise().调整Recognizer实例对环境噪声的敏感度,还学习了Recognizer实例可能抛出哪些异常——对于糟糕的 API 请求使用RequestError,对于难以理解的语音使用UnkownValueError——以及如何使用try...except块处理这些异常。语音识别是一个很深的课题,您在这里学到的知识只是皮毛。如果您有兴趣了解更多,这里有一些额外的资源。
免费奖励: 单击此处下载一个 Python 语音识别示例项目,该项目具有完整的源代码,您可以将其用作自己的语音识别应用程序的基础。
有关演讲识别包的更多信息,请访问:
一些有趣的互联网资源:
- 麦克风背后:与计算机对话的科学。一部关于谷歌语音处理的短片。
- 语音识别的历史透视。美国计算机协会的通报(2014 年)。这篇文章对语音识别技术的发展进行了深入的学术探讨。
- 语音识别技术的过去、现在和未来Clark Boyd 在初创公司。这篇博客文章介绍了语音识别技术的概况,以及对未来的一些思考。
一些关于语音识别的好书:
- 机器中的声音:构建理解语音的计算机,Pieraccini,麻省理工学院出版社(2012)。一本通俗易懂的大众读物,涵盖了语音处理的历史和现代进展。
- 语音识别基础,Rabiner 和 Juang,Prentice Hall (1993)。贝尔实验室的研究人员 Rabiner 在设计第一批商业上可行的语音识别器方面发挥了重要作用。这本书已经有 20 多年的历史了,但是很多基本原理还是一样的。
- 自动语音识别:一种深度学习的方法,于邓,施普林格(2014)。俞和邓是微软公司的研究人员,他们都在语音处理领域非常活跃。这本书涵盖了许多现代方法和前沿研究,但不适合数学胆小的人。
附录:识别非英语语言的语音
在本教程中,我们一直在识别英语语音,这是 SpeechRecognition 软件包中每个
recognize_*()方法的默认语言。然而,识别其他语言的语音是完全可能的,而且很容易实现。要识别不同语言的语音,请将
recognize_*()方法的language关键字参数设置为对应于所需语言的字符串。大多数方法都接受 BCP-47 语言标签,比如'en-US'代表美式英语,或者'fr-FR'代表法语。例如,以下代码识别音频文件中的法语语音:import speech_recognition as sr r = sr.Recognizer() with sr.AudioFile('path/to/audiofile.wav') as source: audio = r.record(source) r.recognize_google(audio, language='fr-FR')只有以下方法接受
language关键字参数:
recognize_bing()recognize_google()recognize_google_cloud()recognize_ibm()recognize_sphinx()要找出你正在使用的 API 支持哪些语言标签,你必须查阅相应的文档。
recognize_google()接受的标签列表可以在这个栈溢出回答中找到。立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 进行语音识别******
Python SQL 库简介
所有软件应用程序都与数据交互,最常见的是通过 T2 数据库管理系统(DBMS)与数据交互。一些编程语言附带了可以用来与 DBMS 交互的模块,而另一些则需要使用第三方包。在本教程中,您将探索您可以使用的不同的 Python SQL 库。您将开发一个简单的应用程序来与 SQLite、MySQL 和 PostgreSQL 数据库进行交互。
在本教程中,您将学习如何:
- 使用 Python SQL 库将连接到不同的数据库管理系统
- 与 SQLite、MySQL 和 PostgreSQL 数据库进行交互
- 使用 Python 应用程序执行常见数据库查询
- 使用 Python 脚本开发跨不同数据库的应用程序
为了从本教程中获得最大收益,您应该具备基本的 Python、SQL 和使用数据库管理系统的知识。您还应该能够用 Python 下载和导入包,并且知道如何在本地或远程安装和运行不同的数据库服务器。
免费 PDF 下载: Python 3 备忘单
了解数据库模式
在本教程中,您将为一个社交媒体应用程序开发一个非常小的数据库。该数据库将由四个表组成:
userspostscommentslikes数据库模式的高级图表如下所示:
因为一个用户可以喜欢很多帖子,所以
users和posts都有一个一对多关系。同样,一个用户可以发表许多评论,一篇文章也可以有多条评论。因此,users和posts也将与comments表有一对多的关系。这也适用于likes表,因此users和posts都将与likes表有一对多的关系。使用 Python SQL 库连接到数据库
在通过 Python SQL 库与任何数据库交互之前,您必须将连接到该数据库。在本节中,您将看到如何从 Python 应用程序中连接到 SQLite 、 MySQL 和 PostgreSQL 数据库。
注意:在执行 MySQL 和 PostgreSQL 数据库部分的脚本之前,您需要启动并运行 MySQL 和 PostgreSQL 服务器。要快速了解如何启动 MySQL 服务器,请查看启动 Django 项目的 MySQL 部分。要了解如何在 PostgreSQL 中创建数据库,请查看使用 Python 防止 SQL 注入攻击中的设置数据库部分。
建议您创建三个不同的 Python 文件,这样三个数据库各有一个。您将在相应的文件中为每个数据库执行脚本。
SQLite
SQLite 可能是用 Python 应用程序连接到的最直接的数据库,因为你不需要安装任何外部 Python SQL 模块来这样做。默认情况下,您的 Python 安装包含一个名为
sqlite3的 Python SQL 库,您可以使用它与 SQLite 数据库进行交互。此外,SQLite 数据库是无服务器的和独立的,因为它们从一个文件中读取和写入数据。这意味着,与 MySQL 和 PostgreSQL 不同,您甚至不需要安装和运行 SQLite 服务器来执行数据库操作!
下面是在 Python 中如何使用
sqlite3连接到 SQLite 数据库:1import sqlite3 2from sqlite3 import Error 3 4def create_connection(path): 5 connection = None 6 try: 7 connection = sqlite3.connect(path) 8 print("Connection to SQLite DB successful") 9 except Error as e: 10 print(f"The error '{e}' occurred") 11 12 return connection下面是这段代码的工作原理:
- 行 1 和 2 导入
sqlite3和模块的Error类。- 第 4 行定义了一个接受 SQLite 数据库路径的函数
.create_connection()。- 第 7 行使用来自
sqlite3模块的.connect(),并将 SQLite 数据库路径作为参数。如果数据库存在于指定位置,则建立到数据库的连接。否则,将在指定位置创建新的数据库,并建立连接。- 第 8 行打印成功数据库连接的状态。
- 第 9 行捕捉任何异常,如果
.connect()未能建立连接,可能会抛出异常。- 第 10 行显示控制台中的错误信息。
sqlite3.connect(path)返回一个connection对象,该对象又由create_connection()返回。这个connection对象可以用来在 SQLite 数据库上执行查询。以下脚本创建了到 SQLite 数据库的连接:connection = create_connection("E:\\sm_app.sqlite")一旦您执行了上面的脚本,您将会看到在根目录中创建了一个数据库文件
sm_app.sqlite。请注意,您可以更改位置以匹配您的设置。MySQL
与 SQLite 不同,没有默认的 Python SQL 模块可以用来连接 MySQL 数据库。相反,您需要为 MySQL 安装一个 Python SQL 驱动程序,以便在 Python 应用程序中与 MySQL 数据库进行交互。一个这样的司机就是
mysql-connector-python。可以用pip下载这个 Python SQL 模块:$ pip install mysql-connector-python注意,MySQL 是一个基于服务器的数据库管理系统。一个 MySQL 服务器可以有多个数据库。与 SQLite 不同,在 SQLite 中创建连接相当于创建数据库,而 MySQL 数据库创建数据库的过程分为两步:
- 建立到 MySQL 服务器的连接。
- 执行一个单独的查询来创建数据库。
定义一个连接到 MySQL 数据库服务器并返回连接对象的函数:
1import mysql.connector 2from mysql.connector import Error 3 4def create_connection(host_name, user_name, user_password): 5 connection = None 6 try: 7 connection = mysql.connector.connect( 8 host=host_name, 9 user=user_name, 10 passwd=user_password 11 ) 12 print("Connection to MySQL DB successful") 13 except Error as e: 14 print(f"The error '{e}' occurred") 15 16 return connection 17 18connection = create_connection("localhost", "root", "")在上面的脚本中,您定义了一个接受三个参数的函数
create_connection():
- 主机名
- 用户名
- 用户密码
mysql.connectorPython SQL 模块包含一个方法.connect(),您可以在第 7 行使用它来连接 MySQL 数据库服务器。一旦建立了连接,connection对象就被返回给调用函数。最后,在第 18 行,用主机名、用户名和密码调用create_connection()。到目前为止,你只建立了联系。数据库尚未创建。为此,您将定义另一个接受两个参数的函数
create_database():
connection是您要与之交互的数据库服务器的connection对象。query是创建数据库的查询。这个函数是这样的:
def create_database(connection, query): cursor = connection.cursor() try: cursor.execute(query) print("Database created successfully") except Error as e: print(f"The error '{e}' occurred")要执行查询,可以使用
cursor对象。要执行的query以字符串的格式传递给cursor.execute()。在 MySQL 数据库服务器中为您的社交媒体应用程序创建一个名为
sm_app的数据库:create_database_query = "CREATE DATABASE sm_app" create_database(connection, create_database_query)现在您已经在数据库服务器上创建了一个数据库
sm_app。然而,create_connection()返回的connection对象连接到 MySQL 数据库服务器。您需要连接到sm_app数据库。为此,您可以对create_connection()进行如下修改:1def create_connection(host_name, user_name, user_password, db_name): 2 connection = None 3 try: 4 connection = mysql.connector.connect( 5 host=host_name, 6 user=user_name, 7 passwd=user_password, 8 database=db_name 9 ) 10 print("Connection to MySQL DB successful") 11 except Error as e: 12 print(f"The error '{e}' occurred") 13 14 return connection您可以在第 8 行看到,
create_connection()现在接受了一个名为db_name的额外参数。此参数指定要连接的数据库的名称。调用此函数时,可以传入要连接的数据库的名称:connection = create_connection("localhost", "root", "", "sm_app")上面的脚本成功地调用了
create_connection()并连接到了sm_app数据库。PostgreSQL
像 MySQL 一样,没有默认的 Python SQL 库可以用来与 PostgreSQL 数据库交互。而是需要安装一个第三方 Python SQL 驱动来与 PostgreSQL 交互。PostgreSQL 的一个 Python SQL 驱动程序是
psycopg2。在您的终端上执行以下命令来安装psycopg2Python SQL 模块:$ pip install psycopg2与 SQLite 和 MySQL 数据库一样,您将定义
create_connection()来连接您的 PostgreSQL 数据库:import psycopg2 from psycopg2 import OperationalError def create_connection(db_name, db_user, db_password, db_host, db_port): connection = None try: connection = psycopg2.connect( database=db_name, user=db_user, password=db_password, host=db_host, port=db_port, ) print("Connection to PostgreSQL DB successful") except OperationalError as e: print(f"The error '{e}' occurred") return connection使用
psycopg2.connect()从 Python 应用程序中连接到 PostgreSQL 服务器。然后,您可以使用
create_connection()创建到 PostgreSQL 数据库的连接。首先,您将使用以下字符串与默认数据库postgres建立连接:connection = create_connection( "postgres", "postgres", "abc123", "127.0.0.1", "5432" )接下来,您必须在默认的
postgres数据库中创建数据库sm_app。您可以在 PostgreSQL 中定义一个函数来执行任何 SQL 查询。下面,您定义create_database()在 PostgreSQL 数据库服务器中创建一个新的数据库:def create_database(connection, query): connection.autocommit = True cursor = connection.cursor() try: cursor.execute(query) print("Query executed successfully") except OperationalError as e: print(f"The error '{e}' occurred") create_database_query = "CREATE DATABASE sm_app" create_database(connection, create_database_query)一旦运行上面的脚本,您将在 PostgreSQL 数据库服务器中看到
sm_app数据库。在对
sm_app数据库执行查询之前,您需要连接到它:connection = create_connection( "sm_app", "postgres", "abc123", "127.0.0.1", "5432" )一旦执行了上面的脚本,就会与位于
postgres数据库服务器中的sm_app数据库建立连接。这里,127.0.0.1是指数据库服务器主机 IP 地址,5432是指数据库服务器的端口号。创建表格
在上一节中,您看到了如何使用不同的 Python SQL 库连接到 SQLite、MySQL 和 PostgreSQL 数据库服务器。您在所有三台数据库服务器上创建了
sm_app数据库。在本节中,您将看到如何在这三个数据库中创建表。如前所述,您将创建四个表:
userspostscommentslikes您将从 SQLite 开始。
SQLite
要在 SQLite 中执行查询,请使用
cursor.execute()。在本节中,您将定义一个使用该方法的函数execute_query()。您的函数将接受connection对象和一个查询字符串,您将把它传递给cursor.execute()。
.execute()可以执行任何以字符串形式传递给它的查询。在本节中,您将使用这个方法来创建表。在接下来的小节中,您将使用相同的方法来执行更新和删除查询。注意:这个脚本应该在您为 SQLite 数据库创建连接的同一个文件中执行。
这是您的函数定义:
def execute_query(connection, query): cursor = connection.cursor() try: cursor.execute(query) connection.commit() print("Query executed successfully") except Error as e: print(f"The error '{e}' occurred")这段代码试图执行给定的
query,并在必要时打印一条错误消息。接下来,编写您的查询:
create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ); """这意味着创建一个包含以下五列的表
users:
idnameagegendernationality最后,您将调用
execute_query()来创建表格。您将传入在上一节中创建的connection对象,以及包含创建表查询的create_users_table字符串:execute_query(connection, create_users_table)以下查询用于创建
posts表:create_posts_table = """ CREATE TABLE IF NOT EXISTS posts( id INTEGER PRIMARY KEY AUTOINCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) ); """由于
users和posts之间存在一对多的关系,您可以在posts表中看到一个外键user_id,它引用了users表中的id列。执行以下脚本来创建posts表:execute_query(connection, create_posts_table)最后,您可以用下面的脚本创建
comments和likes表:create_comments_table = """ CREATE TABLE IF NOT EXISTS comments ( id INTEGER PRIMARY KEY AUTOINCREMENT, text TEXT NOT NULL, user_id INTEGER NOT NULL, post_id INTEGER NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ create_likes_table = """ CREATE TABLE IF NOT EXISTS likes ( id INTEGER PRIMARY KEY AUTOINCREMENT, user_id INTEGER NOT NULL, post_id integer NOT NULL, FOREIGN KEY (user_id) REFERENCES users (id) FOREIGN KEY (post_id) REFERENCES posts (id) ); """ execute_query(connection, create_comments_table) execute_query(connection, create_likes_table)您可以看到在 SQLite 中创建表与使用原始 SQL 非常相似。您所要做的就是将查询存储在一个字符串变量中,然后将该变量传递给
cursor.execute()。MySQL
您将使用
mysql-connector-pythonPython SQL 模块在 MySQL 中创建表。就像使用 SQLite 一样,您需要将您的查询传递给cursor.execute(),它是通过调用connection对象上的.cursor()返回的。您可以创建另一个接受connection和query字符串的函数execute_query():1def execute_query(connection, query): 2 cursor = connection.cursor() 3 try: 4 cursor.execute(query) 5 connection.commit() 6 print("Query executed successfully") 7 except Error as e: 8 print(f"The error '{e}' occurred")在第 4 行,您将
query传递给cursor.execute()。现在您可以使用这个函数创建您的
users表:create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id INT AUTO_INCREMENT, name TEXT NOT NULL, age INT, gender TEXT, nationality TEXT, PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_users_table)与 SQLite 相比,MySQL 中实现外键关系的查询略有不同。此外,MySQL 使用
AUTO_INCREMENT关键字(与 SQLiteAUTOINCREMENT关键字相比)来创建列,当插入新记录时,这些列的值会自动递增。下面的脚本创建了
posts表,该表包含一个外键user_id,该外键引用了users表的id列:create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id INT AUTO_INCREMENT, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER NOT NULL, FOREIGN KEY fk_user_id (user_id) REFERENCES users(id), PRIMARY KEY (id) ) ENGINE = InnoDB """ execute_query(connection, create_posts_table)类似地,要创建
comments和likes表,可以将相应的CREATE查询传递给execute_query()。PostgreSQL
像 SQLite 和 MySQL 数据库一样,
psycopg2.connect()返回的connection对象包含一个cursor对象。您可以使用cursor.execute()在 PostgreSQL 数据库上执行 Python SQL 查询。定义一个功能
execute_query():def execute_query(connection, query): connection.autocommit = True cursor = connection.cursor() try: cursor.execute(query) print("Query executed successfully") except OperationalError as e: print(f"The error '{e}' occurred")您可以使用此函数在 PostgreSQL 数据库中创建表、插入记录、修改记录和删除记录。
现在在
sm_app数据库中创建users表:create_users_table = """ CREATE TABLE IF NOT EXISTS users ( id SERIAL PRIMARY KEY, name TEXT NOT NULL, age INTEGER, gender TEXT, nationality TEXT ) """ execute_query(connection, create_users_table)可以看到在 PostgreSQL 中创建
users表的查询与 SQLite 和 MySQL 略有不同。这里,关键字SERIAL用于创建自动递增的列。回想一下,MySQL 使用了关键字AUTO_INCREMENT。此外,外键引用也以不同的方式指定,如下面创建
posts表的脚本所示:create_posts_table = """ CREATE TABLE IF NOT EXISTS posts ( id SERIAL PRIMARY KEY, title TEXT NOT NULL, description TEXT NOT NULL, user_id INTEGER REFERENCES users(id) ) """ execute_query(connection, create_posts_table)要创建
comments表,您必须为comments表编写一个CREATE查询,并将其传递给execute_query()。创建likes表的过程是相同的。您只需修改CREATE查询来创建likes表,而不是comments表。插入记录
在上一节中,您看到了如何通过使用不同的 Python SQL 模块在 SQLite、MySQL 和 PostgreSQL 数据库中创建表。在本节中,您将看到如何将记录插入到您的表中。
SQLite
要将记录插入 SQLite 数据库,您可以使用与创建表相同的
execute_query()函数。首先,您必须将您的INSERT INTO查询存储在一个字符串中。然后,可以将connection对象和query字符串传递给execute_query()。让我们将五条记录插入到users表中:create_users = """ INSERT INTO users (name, age, gender, nationality) VALUES ('James', 25, 'male', 'USA'), ('Leila', 32, 'female', 'France'), ('Brigitte', 35, 'female', 'England'), ('Mike', 40, 'male', 'Denmark'), ('Elizabeth', 21, 'female', 'Canada'); """ execute_query(connection, create_users)因为您将
id列设置为自动递增,所以您不需要为这些users指定id列的值。users表将从1到5用id值自动填充这五个记录。现在将六条记录插入到
posts表中:create_posts = """ INSERT INTO posts (title, description, user_id) VALUES ("Happy", "I am feeling very happy today", 1), ("Hot Weather", "The weather is very hot today", 2), ("Help", "I need some help with my work", 2), ("Great News", "I am getting married", 1), ("Interesting Game", "It was a fantastic game of tennis", 5), ("Party", "Anyone up for a late-night party today?", 3); """ execute_query(connection, create_posts)值得一提的是,
posts表的user_id列是引用users表的id列的外键。这意味着user_id列必须包含一个值,即users表的id列中已经存在。如果它不存在,那么您会看到一个错误。类似地,以下脚本将记录插入到
comments和likes表中:create_comments = """ INSERT INTO comments (text, user_id, post_id) VALUES ('Count me in', 1, 6), ('What sort of help?', 5, 3), ('Congrats buddy', 2, 4), ('I was rooting for Nadal though', 4, 5), ('Help with your thesis?', 2, 3), ('Many congratulations', 5, 4); """ create_likes = """ INSERT INTO likes (user_id, post_id) VALUES (1, 6), (2, 3), (1, 5), (5, 4), (2, 4), (4, 2), (3, 6); """ execute_query(connection, create_comments) execute_query(connection, create_likes)在这两种情况下,您都将您的
INSERT INTO查询存储为一个字符串,并使用execute_query()执行它。MySQL
从 Python 应用程序向 MySQL 数据库插入记录有两种方法。第一种方法类似于 SQLite。您可以将
INSERT INTO查询存储在一个字符串中,然后使用cursor.execute()来插入记录。在前面,您定义了一个用于插入记录的包装函数
execute_query()。您现在可以使用同样的函数将记录插入到 MySQL 表中。以下脚本使用execute_query()将记录插入到users表中:create_users = """ INSERT INTO `users` (`name`, `age`, `gender`, `nationality`) VALUES ('James', 25, 'male', 'USA'), ('Leila', 32, 'female', 'France'), ('Brigitte', 35, 'female', 'England'), ('Mike', 40, 'male', 'Denmark'), ('Elizabeth', 21, 'female', 'Canada'); """ execute_query(connection, create_users)第二种方法使用
cursor.executemany(),它接受两个参数:
- 查询字符串,包含要插入的记录的占位符
- 列表中的 为您想要插入的记录
看看下面的例子,它将两条记录插入到
likes表中:sql = "INSERT INTO likes ( user_id, post_id ) VALUES ( %s, %s )" val = [(4, 5), (3, 4)] cursor = connection.cursor() cursor.executemany(sql, val) connection.commit()选择哪种方法将记录插入 MySQL 表取决于您自己。如果你是 SQL 专家,那么你可以使用
.execute()。如果您不太熟悉 SQL,那么使用.executemany()可能更简单。使用这两种方法中的任何一种,您都可以成功地将记录插入到posts、comments和likes表中。PostgreSQL
在上一节中,您看到了将记录插入 SQLite 数据库表的两种方法。第一个使用 SQL 字符串查询,第二个使用
.executemany()。psycopg2遵循第二种方法,尽管.execute()用于执行基于占位符的查询。您将带有占位符和记录列表的 SQL 查询传递给
.execute()。列表中的每条记录都将是一个元组,其中元组值对应于数据库表中的列值。下面是如何将用户记录插入 PostgreSQL 数据库的users表中:users = [ ("James", 25, "male", "USA"), ("Leila", 32, "female", "France"), ("Brigitte", 35, "female", "England"), ("Mike", 40, "male", "Denmark"), ("Elizabeth", 21, "female", "Canada"), ] user_records = ", ".join(["%s"] * len(users)) insert_query = ( f"INSERT INTO users (name, age, gender, nationality) VALUES {user_records}" ) connection.autocommit = True cursor = connection.cursor() cursor.execute(insert_query, users)上面的脚本创建了一个列表
users,其中包含五个元组形式的用户记录。接下来,创建一个占位符字符串,它包含五个占位符元素(%s),对应于五个用户记录。占位符字符串与将记录插入到users表中的查询连接在一起。最后,查询字符串和用户记录被传递给.execute()。上面的脚本成功地将五条记录插入到users表中。看看另一个将记录插入 PostgreSQL 表的例子。以下脚本将记录插入到
posts表中:posts = [ ("Happy", "I am feeling very happy today", 1), ("Hot Weather", "The weather is very hot today", 2), ("Help", "I need some help with my work", 2), ("Great News", "I am getting married", 1), ("Interesting Game", "It was a fantastic game of tennis", 5), ("Party", "Anyone up for a late-night party today?", 3), ] post_records = ", ".join(["%s"] * len(posts)) insert_query = ( f"INSERT INTO posts (title, description, user_id) VALUES {post_records}" ) connection.autocommit = True cursor = connection.cursor() cursor.execute(insert_query, posts)您可以用同样的方法将记录插入到
comments和likes表中。选择记录
在本节中,您将看到如何使用不同的 Python SQL 模块从数据库表中选择记录。特别是,您将看到如何在 SQLite、MySQL 和 PostgreSQL 数据库上执行
SELECT查询。SQLite
要使用 SQLite 选择记录,您可以再次使用
cursor.execute()。然而,在你完成这些之后,你需要调用.fetchall()。该方法返回一个元组列表,其中每个元组都映射到检索到的记录中的相应行。为了简化这个过程,您可以创建一个函数
execute_read_query():def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except Error as e: print(f"The error '{e}' occurred")该函数接受
connection对象和SELECT查询,并返回选中的记录。
SELECT现在让我们从
users表中选择所有记录:select_users = "SELECT * from users" users = execute_read_query(connection, select_users) for user in users: print(user)在上面的脚本中,
SELECT查询从users表中选择所有用户。这被传递给execute_read_query(),后者返回来自users表的所有记录。然后记录被遍历并打印到控制台。注意:不建议在大型表上使用
SELECT *,因为这会导致大量 I/O 操作,从而增加网络流量。上述查询的输出如下所示:
(1, 'James', 25, 'male', 'USA') (2, 'Leila', 32, 'female', 'France') (3, 'Brigitte', 35, 'female', 'England') (4, 'Mike', 40, 'male', 'Denmark') (5, 'Elizabeth', 21, 'female', 'Canada')同样,您可以使用下面的脚本从
posts表中检索所有记录:select_posts = "SELECT * FROM posts" posts = execute_read_query(connection, select_posts) for post in posts: print(post)输出如下所示:
(1, 'Happy', 'I am feeling very happy today', 1) (2, 'Hot Weather', 'The weather is very hot today', 2) (3, 'Help', 'I need some help with my work', 2) (4, 'Great News', 'I am getting married', 1) (5, 'Interesting Game', 'It was a fantastic game of tennis', 5) (6, 'Party', 'Anyone up for a late-night party today?', 3)结果显示了
posts表中的所有记录。
JOIN您还可以执行涉及
JOIN操作的复杂查询,从两个相关的表中检索数据。例如,以下脚本返回用户 id 和名称,以及这些用户发布的帖子的描述:select_users_posts = """ SELECT users.id, users.name, posts.description FROM posts INNER JOIN users ON users.id = posts.user_id """ users_posts = execute_read_query(connection, select_users_posts) for users_post in users_posts: print(users_post)以下是输出结果:
(1, 'James', 'I am feeling very happy today') (2, 'Leila', 'The weather is very hot today') (2, 'Leila', 'I need some help with my work') (1, 'James', 'I am getting married') (5, 'Elizabeth', 'It was a fantastic game of tennis') (3, 'Brigitte', 'Anyone up for a late night party today?')你也可以通过实现多个
JOIN操作符从三个相关的表中选择数据。以下脚本返回所有帖子,以及帖子上的评论和发表评论的用户的姓名:select_posts_comments_users = """ SELECT posts.description as post, text as comment, name FROM posts INNER JOIN comments ON posts.id = comments.post_id INNER JOIN users ON users.id = comments.user_id """ posts_comments_users = execute_read_query( connection, select_posts_comments_users ) for posts_comments_user in posts_comments_users: print(posts_comments_user)输出如下所示:
('Anyone up for a late night party today?', 'Count me in', 'James') ('I need some help with my work', 'What sort of help?', 'Elizabeth') ('I am getting married', 'Congrats buddy', 'Leila') ('It was a fantastic game of tennis', 'I was rooting for Nadal though', 'Mike') ('I need some help with my work', 'Help with your thesis?', 'Leila') ('I am getting married', 'Many congratulations', 'Elizabeth')从输出中可以看到,
.fetchall()没有返回列名。要返回列名,可以使用cursor对象的.description属性。例如,以下列表返回上述查询的所有列名:cursor = connection.cursor() cursor.execute(select_posts_comments_users) cursor.fetchall() column_names = [description[0] for description in cursor.description] print(column_names)输出如下所示:
['post', 'comment', 'name']您可以看到给定查询的列名。
WHERE现在,您将执行一个
SELECT查询来返回帖子,以及帖子收到的赞的总数:select_post_likes = """ SELECT description as Post, COUNT(likes.id) as Likes FROM likes, posts WHERE posts.id = likes.post_id GROUP BY likes.post_id """ post_likes = execute_read_query(connection, select_post_likes) for post_like in post_likes: print(post_like)输出如下所示:
('The weather is very hot today', 1) ('I need some help with my work', 1) ('I am getting married', 2) ('It was a fantastic game of tennis', 1) ('Anyone up for a late night party today?', 2)通过使用
WHERE子句,您能够返回更具体的结果。MySQL
在 MySQL 中选择记录的过程与在 SQLite 中选择记录的过程完全相同。可以用
cursor.execute()后跟.fetchall()。下面的脚本创建了一个包装器函数execute_read_query(),您可以用它来选择记录:def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except Error as e: print(f"The error '{e}' occurred")现在从
users表中选择所有记录:select_users = "SELECT * FROM users" users = execute_read_query(connection, select_users) for user in users: print(user)输出将类似于您在 SQLite 中看到的。
PostgreSQL
使用
psycopg2Python SQL 模块从 PostgreSQL 表中选择记录的过程类似于使用 SQLite 和 MySQL。同样,您将使用cursor.execute()后跟.fetchall()从 PostgreSQL 表中选择记录。以下脚本从users表中选择所有记录,并将它们打印到控制台:def execute_read_query(connection, query): cursor = connection.cursor() result = None try: cursor.execute(query) result = cursor.fetchall() return result except OperationalError as e: print(f"The error '{e}' occurred") select_users = "SELECT * FROM users" users = execute_read_query(connection, select_users) for user in users: print(user)同样,输出将与您之前看到的类似。
更新表格记录
在上一节中,您看到了如何从 SQLite、MySQL 和 PostgreSQL 数据库中选择记录。在本节中,您将介绍使用 SQLite、PostgresSQL 和 MySQL 的 Python SQL 库更新记录的过程。
SQLite
在 SQLite 中更新记录非常简单。您可以再次使用
execute_query()。例如,您可以用2的id来更新文章的描述。首先,SELECT本帖描述:select_post_description = "SELECT description FROM posts WHERE id = 2" post_description = execute_read_query(connection, select_post_description) for description in post_description: print(description)您应该会看到以下输出:
('The weather is very hot today',)以下脚本更新了描述:
update_post_description = """ UPDATE posts SET description = "The weather has become pleasant now" WHERE id = 2 """ execute_query(connection, update_post_description)现在,如果您再次执行
SELECT查询,您应该会看到以下结果:('The weather has become pleasant now',)输出已更新。
MySQL
MySQL 中用
mysql-connector-python更新记录的过程也是sqlite3Python SQL 模块的翻版。您需要将字符串查询传递给cursor.execute()。例如,下面的脚本用2的id更新了帖子的描述:update_post_description = """ UPDATE posts SET description = "The weather has become pleasant now" WHERE id = 2 """ execute_query(connection, update_post_description)同样,您使用了包装函数
execute_query()来更新文章描述。PostgreSQL
PostgreSQL 的更新查询类似于 SQLite 和 MySQL。您可以使用上述脚本来更新 PostgreSQL 表中的记录。
删除表格记录
在本节中,您将看到如何使用 SQLite、MySQL 和 PostgreSQL 数据库的 Python SQL 模块删除表记录。由于三个数据库的
DELETE查询是相同的,所以删除记录的过程对于所有三个数据库是统一的。SQLite
您可以再次使用
execute_query()从 SQLite 数据库中删除记录。您所要做的就是将connection对象和要删除的记录的字符串查询传递给execute_query()。然后,execute_query()将使用connection创建一个cursor对象,并将字符串查询传递给cursor.execute(),后者将删除记录。例如,尝试删除带有
5的id的注释:delete_comment = "DELETE FROM comments WHERE id = 5" execute_query(connection, delete_comment)现在,如果您从
comments表中选择所有记录,您会看到第五条注释已经被删除。MySQL
MySQL 中的删除过程也类似于 SQLite,如下例所示:
delete_comment = "DELETE FROM comments WHERE id = 2" execute_query(connection, delete_comment)这里,您从 MySQL 数据库服务器中的
sm_app数据库的comments表中删除了第二条注释。PostgreSQL
PostgreSQL 的删除查询也类似于 SQLite 和 MySQL。您可以使用
DELETE关键字编写一个删除查询字符串,然后将查询和connection对象传递给execute_query()。这将从 PostgreSQL 数据库中删除指定的记录。结论
在本教程中,您已经学习了如何使用三个常见的 Python SQL 库。
sqlite3、mysql-connector-python和psycopg2允许您将 Python 应用程序分别连接到 SQLite、MySQL 和 PostgreSQL 数据库。现在你可以:
- 与 SQLite、MySQL 或 PostgreSQL 数据库进行交互
- 使用三个不同的 Python SQL 模块
- 在 Python 应用程序中对各种数据库执行 SQL 查询
然而,这只是冰山一角!还有用于对象关系映射的 Python SQL 库,比如 SQLAlchemy 和 Django ORM,它们在 Python 中实现了数据库交互任务的自动化。在我们的 Python 数据库部分的其他教程中,你会学到更多关于这些库的知识。*******
Python 平方根函数
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python 中的平方根函数
你想解一个二次方程吗?也许你需要计算直角三角形一边的长度。对于这类方程和更多的方程,Python 的平方根函数,
sqrt(),可以帮助你快速准确地计算出你的解。到本文结束时,您将了解到:
- 平方根是什么
- 如何使用 Python 的平方根函数,
sqrt()- 什么时候
sqrt()在现实世界中有用让我们开始吧!
Python 中途站:本教程是一个快速和实用的方法来找到你需要的信息,所以你会很快回到你的项目!
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
数学中的平方根
在代数中,一个平方、 x ,是一个数、 n 乘以自身的结果: x = n
您可以使用 Python 计算平方:

>>> n = 5
>>> x = n ** 2
>>> x
25
Python **运算符用于计算一个数的幂。在这种情况下,5 的平方或 5 的 2 次方是 25。
那么,平方根是数字 n ,当乘以它自身时,产生平方, x 。
在这个例子中, n 的平方根是 5。
25 是一个完美正方形的例子。完美平方是整数值的平方:
>>> 1 ** 2 1 >>> 2 ** 2 4 >>> 3 ** 2 9当你在初级代数课上学习乘法表时,你可能已经记住了一些完美的正方形。
如果给你一个小正方,计算或记忆它的平方根可能足够简单。但是对于大多数其他的方块来说,这种计算可能会变得有点乏味。通常,当你没有计算器时,一个估计就足够了。
幸运的是,作为一名 Python 开发者,您确实有一个计算器,即 Python 解释器!
Python 平方根函数
Python 标准库中的
math模块,可以帮助你在代码中处理数学相关的问题。它包含许多有用的功能,如remainder()和factorial()。还包括 Python 平方根函数、sqrt()。您将从导入
math开始:
>>> import math
这就够了!你现在可以使用math.sqrt()来计算平方根。
有一个简单明了的界面。
它有一个参数x,它(正如您之前看到的)代表您试图计算平方根的平方。在前面的例子中,这应该是25。
sqrt()的返回值是x的平方根,作为浮点数。在本例中,这将是5.0。
让我们来看一些如何(以及如何不)使用sqrt()的例子。
正数的平方根
可以传递给sqrt()的一种参数是正数。这既包括 int 又包括 float 类型。
例如,您可以使用sqrt()求解49的平方根:
>>> math.sqrt(49) 7.0返回值是作为浮点数的
7.0(49的平方根)。除了整数,您还可以传递
float值:
>>> math.sqrt(70.5)
8.396427811873332
您可以通过计算平方根的倒数来验证平方根的准确性:
>>> 8.396427811873332 ** 2 70.5零的平方根
偶数
0是传递给 Python 平方根函数的有效平方:
>>> math.sqrt(0)
0.0
虽然您可能不需要经常计算零的平方根,但是您可能会将一个变量传递给sqrt(),而您实际上并不知道它的值。所以,很高兴知道在这些情况下它可以处理零。
负数的平方根
任何实数的平方不能为负。这是因为只有当一个因子为正,另一个为负时,负乘积才是可能的。根据定义,正方形是一个数和它本身的乘积,所以不可能有负的实数正方形:
>>> math.sqrt(-25) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: math domain error如果你试图给
sqrt()传递一个负数,那么你会得到一个ValueError,因为负数不在可能的实数范围内。相反,负数的平方根需要是复数,这超出了 Python 平方根函数的范围。现实世界中的平方根
要查看 Python 平方根函数的实际应用,让我们转向网球运动。
想象一下,世界上速度最快的球员之一拉斐尔·纳达尔刚刚从后角打了一个正手球,底线在网球场的边线上:
现在,假设他的对手回击了一记吊球(这种球会使球变短,几乎没有向前的动力)到另一个边线与球网相遇的对角:
纳达尔必须跑多远才能触到球?
你可以从规则网球场的尺寸确定底线是 27 英尺长,边线(在网的一边)是 39 英尺长。所以,本质上,这归结为求解直角三角形的斜边:
利用几何学中一个很有价值的方程勾股定理,我们知道 a + b = c ,其中 a 和 b 是直角三角形的腿, c 是斜边。
因此,我们可以通过重新排列方程来求解 c 来计算纳达尔必须跑的距离:
您可以使用 Python 平方根函数求解该方程:

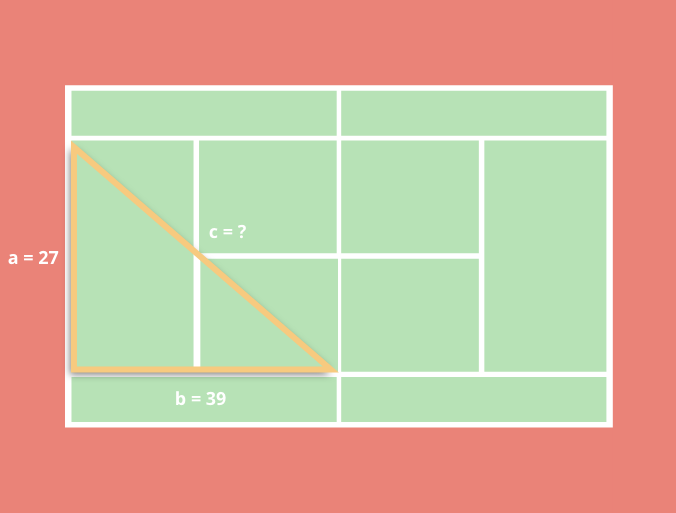
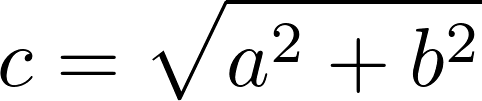
>>> a = 27
>>> b = 39
>>> math.sqrt(a ** 2 + b ** 2)
47.43416490252569
所以,纳达尔必须跑大约 47.4 英尺(14.5 米),才能触到球并保住分。
结论
恭喜你!现在,您已经了解了 Python 平方根函数的所有内容。
您已经完成了:
- 平方根简介
- Python 平方根函数的来龙去脉,
sqrt() - 使用真实世界示例的
sqrt()的实际应用
知道如何使用sqrt()只是成功的一半。理解何时使用它是另一个问题。现在,您已经知道了这两者,那么就去应用您新掌握的 Python 平方根函数吧!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解:Python 中的平方根函数***
Python 统计基础:如何描述数据
在大数据和人工智能的时代,数据科学和机器学习已经成为很多科技领域的必备。处理数据的一个必要方面是描述、总结和可视化表示数据的能力。 Python 统计库是全面、流行和广泛使用的工具,将帮助您处理数据。
在本教程中,您将学习:
- 你可以用什么数字量来描述和总结你的数据集
- 如何用纯 Python 实现计算描述性统计
- 如何使用可用的 Python 库获得描述性统计数据
- 如何可视化您的数据集
免费附赠: ,你可以以此为基础制作自己的剧情和图形。
了解描述性统计
描述性统计是关于数据的描述和汇总。它使用两种主要方法:
- 定量方法用数字描述和总结数据。
- 视觉方法用图表、曲线图、直方图和其他图形说明数据。
您可以对一个或多个数据集或变量应用描述性统计。当你描述和总结一个单一变量时,你是在进行单变量分析。当你搜索一对变量之间的统计关系时,你正在做一个双变量分析。类似地,多元分析同时涉及多个变量。
措施类型
在本教程中,您将了解描述性统计中的以下测量类型:
- 中心趋势告诉你数据的中心。有用的度量包括平均值、中值和众数。
- 可变性告诉你数据的分布情况。有用的度量包括方差和标准差。
- 相关性或联合可变性告诉您数据集中一对变量之间的关系。有用的度量包括协方差和相关系数。
您将学习如何使用 Python 理解和计算这些测量值。
人口和样本
在统计学中,群体是你感兴趣的所有元素或项目的集合。人口通常很庞大,这使得他们不适合收集和分析数据。这就是为什么统计学家通常试图通过选择和检查人口中有代表性的子集来对人口做出一些结论。
群体的这个子集被称为样本。理想的情况是,样本应在令人满意的程度上保留人口的基本统计特征。这样,您将能够使用样本来收集关于人口的结论。
离群值
异常值是一个数据点,它与取自样本或总体的大部分数据有显著不同。离群值有许多可能的原因,但这里有一些可以帮助您开始:
- 数据的自然变化
- 被观察系统行为的变化
- 数据收集中的错误
数据收集错误是异常值的一个特别突出的原因。例如,测量仪器或程序的局限性可能意味着无法获得正确的数据。其他错误可能是由计算错误、数据污染、人为错误等造成的。
离群值没有精确的数学定义。您必须依靠经验、关于感兴趣主题的知识和常识来确定数据点是否是异常值以及如何处理它。
选择 Python 统计库
有许多 Python 统计库可供您使用,但在本教程中,您将了解一些最流行和最广泛使用的统计库:
-
Python 的
statistics是内置的用于描述性统计的 Python 库。如果数据集不太大或者不能依赖于导入其他库,可以使用它。 -
NumPy 是一个用于数值计算的第三方库,为处理一维及多维数组而优化。它的主类型是名为
ndarray的数组类型。这个库包含许多用于统计分析的例程。 -
SciPy 是基于 NumPy 的科学计算第三方库。与 NumPy 相比,它提供了更多的功能,包括用于统计分析的
scipy.stats。 -
熊猫 是基于 NumPy 的数值计算第三方库。擅长用
Series对象处理带标签的一维(1D)数据,用DataFrame对象处理二维(2D)数据。 -
Matplotlib 是数据可视化的第三方库。它与 NumPy,SciPy 和 Pandas 结合使用效果很好。
注意,在很多情况下,Series和 DataFrame 对象可以用来代替 NumPy 数组。通常,您可能只是将它们传递给一个 NumPy 或 SciPy 统计函数。另外,您可以通过调用 .values 或 .to_numpy() 从一个Series或DataFrame对象中获取未标记的数据。
Python 统计库入门
内置的 Python statistics库拥有相对较少的最重要的统计函数。官方文件是找到细节的宝贵资源。如果您仅限于纯 Python,那么 Python statistics库可能是正确的选择。
开始学习 NumPy 的一个好地方是官方的用户指南,尤其是快速入门和基础知识部分。官方参考可以帮助你刷新对具体数字概念的记忆。当你阅读本教程时,你可能想看看统计部分和官方参考。
注:
要了解关于 NumPy 的更多信息,请查看以下资源:
如果你想学习熊猫,那么官方入门页面是一个很好的开始。数据结构的介绍可以帮助你了解基本的数据类型Series和DataFrame。同样,优秀的官方入门教程旨在给你足够的信息,开始在实践中有效地使用熊猫。
注:
要了解更多关于熊猫的信息,请查看以下资源:
matplotlib有一个全面的官方用户指南,你可以用它来深入了解使用该库的细节。Matplotlib的剖析对于想要开始使用matplotlib及其相关库的初学者来说是一个极好的资源。
注:
要了解有关数据可视化的更多信息,请查看以下资源:
- 使用 Matplotlib 进行 Python 绘图(指南)
- Python 直方图绘制:NumPy,Matplotlib,Pandas & Seaborn
- 使用散景在 Python 中进行交互式数据可视化
- 熊猫图:面向初学者的 Python 数据可视化
让我们开始使用这些 Python 统计库吧!
计算描述性统计数据
首先导入您需要的所有包:
>>> import math >>> import statistics >>> import numpy as np >>> import scipy.stats >>> import pandas as pd这些都是 Python 统计数据计算所需的包。通常,您不会使用 Python 的内置
math包,但在本教程中它会很有用。稍后,您将导入matplotlib.pyplot进行数据可视化。让我们创建一些数据来使用。您将从包含一些任意数字数据的 Python 列表开始:
>>> x = [8.0, 1, 2.5, 4, 28.0]
>>> x_with_nan = [8.0, 1, 2.5, math.nan, 4, 28.0]
>>> x
[8.0, 1, 2.5, 4, 28.0]
>>> x_with_nan
[8.0, 1, 2.5, nan, 4, 28.0]
现在你有了列表x和x_with_nan。它们几乎相同,不同之处在于x_with_nan包含一个nan值。理解 Python 统计例程在遇到 非数字值(nan ) 时的行为很重要。在数据科学中,丢失值是常见的,您通常会用nan来替换它们。
注:你怎么得到一个nan值?
在 Python 中,可以使用以下任意一种:
您可以互换使用所有这些功能:
>>> math.isnan(np.nan), np.isnan(math.nan) (True, True) >>> math.isnan(y_with_nan[3]), np.isnan(y_with_nan[3]) (True, True)可以看到功能都是等价的。但是,请记住,比较两个
nan值是否相等会返回False。换句话说,math.nan == math.nan就是False!现在,创建对应于
x和x_with_nan的np.ndarray和pd.Series对象:
>>> y, y_with_nan = np.array(x), np.array(x_with_nan)
>>> z, z_with_nan = pd.Series(x), pd.Series(x_with_nan)
>>> y
array([ 8\. , 1\. , 2.5, 4\. , 28\. ])
>>> y_with_nan
array([ 8\. , 1\. , 2.5, nan, 4\. , 28\. ])
>>> z
0 8.0
1 1.0
2 2.5
3 4.0
4 28.0
dtype: float64
>>> z_with_nan
0 8.0
1 1.0
2 2.5
3 NaN
4 4.0
5 28.0
dtype: float64
你现在有两个 NumPy 数组(y和y_with_nan)和两只熊猫Series ( z和z_with_nan)。所有这些都是 1D 值序列。
注意:虽然你将在本教程中使用列表,但是请记住,在大多数情况下,你可以以同样的方式使用元组。
您可以选择为z和z_with_nan中的每个值指定一个标签。
集中趋势的度量
集中趋势的测量值显示数据集的中心或中间值。关于什么被认为是数据集的中心,有几种定义。在本教程中,您将学习如何识别和计算这些集中趋势的度量:
- 平均
- 加权平均数
- 几何平均值
- 调和平均值
- 中位数
- 方式
平均值
样本平均值,也称为样本算术平均值或简称为平均值,是一个数据集中所有项目的算术平均值。数据集𝑥的平均值在数学上表示为σᵢ𝑥ᵢ/𝑛,其中𝑖 = 1,2,…,𝑛.换句话说,它是所有𝑥ᵢ元素的总和除以数据集𝑥.中的项目数
下图显示了一个样本的平均值,包含五个数据点:
绿点代表数据点 1、2.5、4、8 和 28。红色虚线是他们的平均值,或者说(1 + 2.5 + 4 + 8 + 28) / 5 = 8.7。
你可以用纯 Python 使用 sum() 和 len() 计算平均值,不需要导入库:
>>> mean_ = sum(x) / len(x) >>> mean_ 8.7尽管这很简洁,但您也可以应用内置的 Python 统计函数:
>>> mean_ = statistics.mean(x)
>>> mean_
8.7
>>> mean_ = statistics.fmean(x)
>>> mean_
8.7
您已经从内置的 Python statistics库中调用了函数 mean() 和 fmean() ,并获得了与使用纯 Python 相同的结果。fmean()是在 Python 3.8 中引入的,作为mean()的更快替代。它总是返回一个浮点数。
但是,如果您的数据中有nan值,那么statistics.mean()和statistics.fmean()将返回nan作为输出:
>>> mean_ = statistics.mean(x_with_nan) >>> mean_ nan >>> mean_ = statistics.fmean(x_with_nan) >>> mean_ nan这个结果与
sum()的行为一致,因为sum(x_with_nan)也返回nan。如果用 NumPy,那么就可以用
np.mean()得到平均值:
>>> mean_ = np.mean(y)
>>> mean_
8.7
在上面的例子中,mean()是一个函数,但是你也可以使用相应的方法 .mean() :
>>> mean_ = y.mean() >>> mean_ 8.7NumPy 的函数
mean()和方法.mean()返回与statistics.mean()相同的结果。当您的数据中有nan值时也是如此:
>>> np.mean(y_with_nan)
nan
>>> y_with_nan.mean()
nan
结果你通常不需要得到一个nan值。如果你喜欢忽略nan值,那么你可以使用 np.nanmean() :
>>> np.nanmean(y_with_nan) 8.7
nanmean()简单地忽略所有的nan值。如果您将它应用到没有nan值的数据集,它将返回与mean()相同的值。
pd.Series对象也有方法.mean():
>>> mean_ = z.mean()
>>> mean_
8.7
如您所见,它的用法与 NumPy 的用法相似。但是,熊猫的.mean()默认忽略nan值:
>>> z_with_nan.mean() 8.7这种行为是可选参数
skipna默认值的结果。您可以更改此参数来修改行为。加权平均值
加权平均值,也称为加权算术平均值或加权平均值,是算术平均值的推广,使您能够定义每个数据点对结果的相对贡献。
您为数据集𝑥的每个数据点𝑥ᵢ定义一个权重𝑤ᵢ ,其中𝑖 = 1,2,…,𝑛和𝑛是𝑥.的项目数然后,你将每个数据点乘以相应的权重,将所有乘积求和,将得到的和除以权重之和:σᵢ(𝑤ᵢ𝑥ᵢ)/σᵢ𝑤ᵢ.
注:方便(通常情况下)所有权重都是非负,𝑤ᵢ ≥ 0,并且它们的和等于 1,或者σᵢ𝑤ᵢ= 1。
当您需要包含以给定相对频率出现的项目的数据集的平均值时,加权平均值非常方便。例如,假设有一个集合,其中 20%的项目等于 2,50%的项目等于 4,其余 30%的项目等于 8。你可以这样计算这样一个集合的平均值:
>>> 0.2 * 2 + 0.5 * 4 + 0.3 * 8
4.8
在这里,你将频率和权重考虑在内。用这种方法,你不需要知道项目的总数。
通过将sum()与 range() 或 zip() 结合,可以在纯 Python 中实现加权平均:
>>> x = [8.0, 1, 2.5, 4, 28.0] >>> w = [0.1, 0.2, 0.3, 0.25, 0.15] >>> wmean = sum(w[i] * x[i] for i in range(len(x))) / sum(w) >>> wmean 6.95 >>> wmean = sum(x_ * w_ for (x_, w_) in zip(x, w)) / sum(w) >>> wmean 6.95同样,这是一个干净优雅的实现,不需要导入任何库。
但是,如果您有大型数据集,那么 NumPy 可能会提供更好的解决方案。您可以使用
np.average()来获得 NumPy 数组或 PandasSeries的加权平均值:
>>> y, z, w = np.array(x), pd.Series(x), np.array(w)
>>> wmean = np.average(y, weights=w)
>>> wmean
6.95
>>> wmean = np.average(z, weights=w)
>>> wmean
6.95
结果与纯 Python 实现的情况相同。您也可以在普通的列表和元组上使用这种方法。
另一种解决方案是使用基于元素的乘积w * y与 np.sum() 或 .sum() :
>>> (w * y).sum() / w.sum() 6.95就是这样!你已经计算了加权平均值。
但是,如果数据集包含
nan值,请小心:
>>> w = np.array([0.1, 0.2, 0.3, 0.0, 0.2, 0.1])
>>> (w * y_with_nan).sum() / w.sum()
nan
>>> np.average(y_with_nan, weights=w)
nan
>>> np.average(z_with_nan, weights=w)
nan
本例中,average()返回nan,与np.mean()一致。
调和平均值
调和平均值是数据集中所有项目的倒数的平均值的倒数:𝑛/σᵢ(1/𝑥ᵢ),其中𝑖 = 1,2,…,𝑛和𝑛是数据集中的项目数𝑥.调和平均值的纯 Python 实现的一个变体是:
>>> hmean = len(x) / sum(1 / item for item in x) >>> hmean 2.7613412228796843和同样数据
x的算术平均值相差很大,你算出来是 8.7。你也可以用
statistics.harmonic_mean()来计算这个测度:
>>> hmean = statistics.harmonic_mean(x)
>>> hmean
2.7613412228796843
上面的例子展示了statistics.harmonic_mean()的一个实现。如果数据集中有一个nan值,那么它将返回nan。如果至少有一个0,那么它将返回0。如果您至少提供一个负数,那么您将得到 statistics.StatisticsError :
>>> statistics.harmonic_mean(x_with_nan) nan >>> statistics.harmonic_mean([1, 0, 2]) 0 >>> statistics.harmonic_mean([1, 2, -2]) # Raises StatisticsError当你使用这种方法时,请记住这三种情况!
计算调和平均值的第三种方法是使用
scipy.stats.hmean():
>>> scipy.stats.hmean(y)
2.7613412228796843
>>> scipy.stats.hmean(z)
2.7613412228796843
同样,这是一个非常简单的实现。然而,如果你的数据集包含nan、0、负数,或者除了正数之外的任何数字,那么你将得到一个 ValueError !
几何平均值
几何平均值是数据集𝑥:ⁿ√(πᵢ𝑥ᵢ中所有𝑛元素𝑥ᵢ乘积的𝑛-th 根,其中𝑖 = 1,2,…,𝑛.下图说明了数据集的算术平均值、调和平均值和几何平均值:
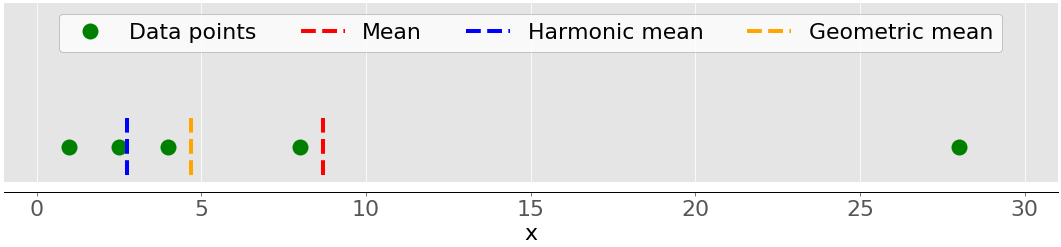
绿点再次表示数据点 1、2.5、4、8 和 28。红色虚线是平均值。蓝色虚线是调和平均值,黄色虚线是几何平均值。
您可以在纯 Python 中实现几何平均,如下所示:
>>> gmean = 1 >>> for item in x: ... gmean *= item ... >>> gmean **= 1 / len(x) >>> gmean 4.677885674856041如您所见,在这种情况下,几何平均值与同一个数据集
x的算术平均值(8.7)和调和平均值(2.76)显著不同。Python 3.8 引入了
statistics.geometric_mean(),将所有值转换为浮点数,并返回其几何平均值:
>>> gmean = statistics.geometric_mean(x)
>>> gmean
4.67788567485604
您已经获得了与上一个示例相同的结果,但是舍入误差很小。
如果您传递带有nan值的数据,那么statistics.geometric_mean()将像大多数类似的函数一样运行并返回nan:
>>> gmean = statistics.geometric_mean(x_with_nan) >>> gmean nan的确,这与
statistics.mean()、statistics.fmean()、statistics.harmonic_mean()的行为是一致的。如果你的数据中有一个零或负数,那么statistics.geometric_mean()将提高statistics.StatisticsError。你也可以用
scipy.stats.gmean()得到几何平均数:
>>> scipy.stats.gmean(y)
4.67788567485604
>>> scipy.stats.gmean(z)
4.67788567485604
您获得了与纯 Python 实现相同的结果。
如果数据集中有nan个值,那么gmean()将返回nan。如果至少有一个0,那么它将返回0.0并给出警告。如果您至少提供一个负数,那么您将得到nan和警告。
中位数
样本中值是排序数据集的中间元素。数据集可以按升序或降序排序。如果数据集的元素𝑛数是奇数,则中值是中间位置的值:0.5(𝑛 + 1)。如果𝑛是偶数,则中位数是中间两个值的算术平均值,即 0.5𝑛和 0.5𝑛 + 1 位置上的项目。
例如,如果您有数据点 2、4、1、8 和 9,则中值为 4,位于排序数据集(1、2、4、8、9)的中间。如果数据点是 2、4、1 和 8,则中位数是 3,这是排序序列(2 和 4)的两个中间元素的平均值。下图说明了这一点:
数据点是绿点,紫线显示每个数据集的中位数。上部数据集(1、2.5、4、8 和 28)的中值为 4。如果从较低的数据集中移除异常值 28,则中值变为 2.5 和 4 之间的算术平均值,即 3.25。
下图显示了数据点 1、2.5、4、8 和 28 的平均值和中值:
同样,平均值是红色虚线,而中间值是紫色线。
平均值和中值行为之间的主要差异与数据集异常值或极端值有关。平均值受异常值的影响很大,但中值仅轻微或根本不依赖于异常值。请考虑下图:
上面的数据集再次包含项目 1、2.5、4、8 和 28。它的平均值是 8.7,中位数是 5,正如你之前看到的。下面的数据集显示了移动最右边的值为 28 的点时的情况:
- 如果你增加它的值(向右移动),那么平均值会上升,但是中间值不会改变。
- 如果你减少它的值(向左移动),那么均值会下降,但是中值会保持不变,直到移动点的值大于等于 4。
您可以通过比较平均值和中值来检测数据中的异常值和不对称性。是平均值还是中值对你更有用取决于你特定问题的背景。
以下是中间值的许多可能的纯 Python 实现之一:
>>> n = len(x) >>> if n % 2: ... median_ = sorted(x)[round(0.5*(n-1))] ... else: ... x_ord, index = sorted(x), round(0.5 * n) ... median_ = 0.5 * (x_ord[index-1] + x_ord[index]) ... >>> median_ 4该实现的两个最重要的步骤如下:
- 排序数据集的元素
- 在排序的数据集中寻找中间元素
用
statistics.median()可以得到中位数:
>>> median_ = statistics.median(x)
>>> median_
4
>>> median_ = statistics.median(x[:-1])
>>> median_
3.25
x的排序版本是[1, 2.5, 4, 8.0, 28.0],所以中间的元素是4。x[:-1]的排序版本,没有最后一项28.0的x,是[1, 2.5, 4, 8.0]。现在,有两个中间元素,2.5和4。他们的平均成绩是3.25。
median_low() 和 median_high() 是 Python statistics库中又两个与中位数相关的函数。它们总是从数据集中返回一个元素:
- 如果元素的数量是奇数,那么有一个中间值,所以这些函数的行为就像
median()。 - 如果元素个数是偶数,那么有两个中间值。在这种情况下,
median_low()返回较低的中间值,median_high()返回较高的中间值。
您可以像使用median()一样使用这些函数:
>>> statistics.median_low(x[:-1]) 2.5 >>> statistics.median_high(x[:-1]) 4同样,
x[:-1]的排序版本是[1, 2.5, 4, 8.0]。中间的两个元素是2.5(低)和4(高)。与 Python
statistics库中的大多数其他函数不同,当数据点中存在nan值时,median()、median_low()和median_high()不会返回nan:
>>> statistics.median(x_with_nan)
6.0
>>> statistics.median_low(x_with_nan)
4
>>> statistics.median_high(x_with_nan)
8.0
小心这种行为,因为它可能不是你想要的!
也可以用 np.median() 得到中位数:
>>> median_ = np.median(y) >>> median_ 4.0 >>> median_ = np.median(y[:-1]) >>> median_ 3.25您已经获得了与
statistics.median()和np.median()相同的值。但是,如果数据集中有一个
nan值,那么np.median()发出RuntimeWarning并返回nan。如果这种行为不是您想要的,那么您可以使用nanmedian()来忽略所有的nan值:
>>> np.nanmedian(y_with_nan)
4.0
>>> np.nanmedian(y_with_nan[:-1])
3.25
获得的结果与将statistics.median()和np.median()应用于数据集x和y的结果相同。
熊猫Series对象有默认忽略nan值的 .median() 方法:
>>> z.median() 4.0 >>> z_with_nan.median() 4.0
.median()的行为与熊猫身上的.mean()一致。您可以使用可选参数skipna来改变这种行为。模式
采样模式是数据集中出现频率最高的值。如果没有一个这样的值,那么这个集合就是多模态,因为它有多个模态值。例如,在包含点 2、3、2、8 和 12 的集合中,数字 2 是众数,因为它出现两次,不像其他项目只出现一次。
这是如何用纯 Python 获得模式的:
>>> u = [2, 3, 2, 8, 12]
>>> mode_ = max((u.count(item), item) for item in set(u))[1]
>>> mode_
2
您使用u.count()来获得每个条目在u中出现的次数。出现次数最多的项目是模式。注意,你不必使用set(u)。相反,您可以用u来代替它,并遍历整个列表。
注: set(u)返回一个 Python 集合,集合u中的所有唯一项。您可以使用这个技巧来优化对较大数据的处理,尤其是当您希望看到大量重复数据时。
可以用 statistics.mode() 和 statistics.multimode() 获得模式:
>>> mode_ = statistics.mode(u) >>> mode_ >>> mode_ = statistics.multimode(u) >>> mode_ [2]如您所见,
mode()返回单个值,而multimode()返回包含结果的列表。不过,这并不是这两个函数之间的唯一区别。如果有多个模态值,那么mode()引发StatisticsError,而multimode()返回包含所有模态的列表:
>>> v = [12, 15, 12, 15, 21, 15, 12]
>>> statistics.mode(v) # Raises StatisticsError
>>> statistics.multimode(v)
[12, 15]
您应该特别注意这种情况,并且在选择这两种功能时要小心。
statistics.mode()和statistics.multimode()将nan值作为常规值处理,并可以返回nan作为模态值:
>>> statistics.mode([2, math.nan, 2]) 2 >>> statistics.multimode([2, math.nan, 2]) [2] >>> statistics.mode([2, math.nan, 0, math.nan, 5]) nan >>> statistics.multimode([2, math.nan, 0, math.nan, 5]) [nan]在上面的第一个例子中,数字
2出现了两次,并且是模态值。在第二个示例中,nan是模态值,因为它出现了两次,而其他值只出现了一次。注:
statistics.multimode()在 Python 3.8 中介绍。也可以用
scipy.stats.mode()得到模式:
>>> u, v = np.array(u), np.array(v)
>>> mode_ = scipy.stats.mode(u)
>>> mode_
ModeResult(mode=array([2]), count=array([2]))
>>> mode_ = scipy.stats.mode(v)
>>> mode_
ModeResult(mode=array([12]), count=array([3]))
这个函数返回带有模态值的对象以及它出现的次数。如果数据集中有多个模态值,那么只返回最小的值。
您可以用点标记的 NumPy 数组来获取模式及其出现次数:
>>> mode_.mode array([12]) >>> mode_.count array([3])这段代码使用
.mode返回数组v中最小的众数(12),使用.count返回众数(3)。scipy.stats.mode()也可以灵活使用nan值。它允许您用可选参数nan_policy定义期望的行为。该参数可以采用值'propagate'、'raise'(错误)或'omit'。熊猫
Series对象具有方法.mode(),该方法可以很好地处理多模态值,并在默认情况下忽略nan值:
>>> u, v, w = pd.Series(u), pd.Series(v), pd.Series([2, 2, math.nan])
>>> u.mode()
0 2
dtype: int64
>>> v.mode()
0 12
1 15
dtype: int64
>>> w.mode()
0 2.0
dtype: float64
如您所见,.mode()返回一个保存所有模态值的新的pd.Series。如果你想让.mode()考虑nan的值,那么只需传递可选参数dropna=False。
可变性测量
集中趋势的度量不足以描述数据。您还需要量化数据点分布的可变性的度量。在本节中,您将学习如何识别和计算以下可变性度量:
- 差异
- 标准偏差
- 歪斜
- 百分位数
- 范围
差异
样本方差量化了数据的分布。它用数字显示数据点离平均值有多远。您可以用数学方法将带有𝑛元素的数据集𝑥的样本方差表示为𝑠=σᵢ(𝑥ᵢmean(𝑥)/(𝑛1),其中𝑖 = 1,2,…,𝑛,mean 是的样本均值。如果你想更深入地理解为什么用𝑛1 而不是𝑛来除和,那么你可以更深入地研究贝塞尔的修正。
下图说明了在描述数据集时考虑差异的重要性:
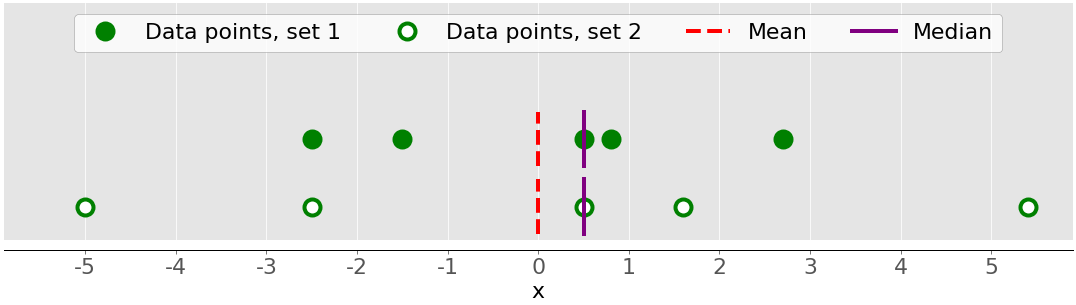
该图中有两个数据集:
- 绿点:该数据集具有较小的方差或与平均值的较小平均差。它还具有较小的范围或最大和最小项目之间的较小差异。
- 白点:该数据集具有较大的方差或与均值的较大平均差。它还具有更大的范围或最大和最小项目之间的更大差异。
请注意,这两个数据集具有相同的平均值和中值,尽管它们看起来明显不同。无论是平均值还是中位数都无法描述这种差异。这就是为什么你需要可变性的度量。
以下是使用纯 Python 计算样本方差的方法:
>>> n = len(x) >>> mean_ = sum(x) / n >>> var_ = sum((item - mean_)**2 for item in x) / (n - 1) >>> var_ 123.19999999999999这种方法是足够的,并且很好地计算样本方差。然而,更简短、更优雅的解决方案是调用现有的函数
statistics.variance():
>>> var_ = statistics.variance(x)
>>> var_
123.2
你已经获得了与上面相同的方差结果。variance()可以避免计算平均值,如果你提供平均值作为第二个参数:statistics.variance(x, mean_)。
如果你的数据中有nan个值,那么statistics.variance()将返回nan:
>>> statistics.variance(x_with_nan) nan这种行为与 Python
statistics库中的mean()和大多数其他函数一致。
>>> var_ = np.var(y, ddof=1)
>>> var_
123.19999999999999
>>> var_ = y.var(ddof=1)
>>> var_
123.19999999999999
指定参数ddof=1非常重要。这就是如何将的自由度增量设置为1。此参数允许正确计算𝑠,分母为(𝑛1)而不是𝑛.
如果数据集中有nan个值,那么np.var()和.var()将返回nan:
>>> np.var(y_with_nan, ddof=1) nan >>> y_with_nan.var(ddof=1) nan这与
np.mean()和np.average()一致。如果你想跳过nan值,那么你应该使用np.nanvar():
>>> np.nanvar(y_with_nan, ddof=1)
123.19999999999999
np.nanvar()忽略nan值。这还需要你指定ddof=1。
pd.Series对象有默认跳过nan值的 .var() 方法:
>>> z.var(ddof=1) 123.19999999999999 >>> z_with_nan.var(ddof=1) 123.19999999999999它也有参数
ddof,但是它的默认值是1,所以可以省略。如果您想要与nan值相关的不同行为,那么使用可选参数skipna。您可以像计算样本方差一样计算总体方差。但是,您必须在分母中使用𝑛,而不是𝑛1:σᵢ(𝑥ᵢmean(𝑥))/𝑛.在这种情况下,𝑛是整个人口中的项目数。您可以获得与样本方差相似的总体方差,但有以下区别:
- 在纯 Python 实现中用
n替换(n - 1)。- 用
statistics.pvariance()代替statistics.variance()。- 如果使用 NumPy 或 Pandas,指定参数
ddof=0。在 NumPy 中,可以省略ddof,因为它的默认值是0。请注意,无论何时计算方差,您都应该知道您是在处理一个样本还是整个总体!
标准偏差
样本标准差是数据分布的另一个度量。它与样本方差有关,因为标准差𝑠是样本方差的正平方根。标准差通常比方差更方便,因为它与数据点具有相同的单位。一旦得到方差,就可以用纯 Python 计算标准差:
>>> std_ = var_ ** 0.5
>>> std_
11.099549540409285
虽然这种解决方案可行,但是您也可以使用 statistics.stdev() :
>>> std_ = statistics.stdev(x) >>> std_ 11.099549540409287当然,结果和以前一样。像
variance(),stdev()不计算平均值,如果你明确地提供它作为第二个参数:statistics.stdev(x, mean_)。你可以用几乎相同的方法得到 NumPy 的标准差。可以使用函数
std()和相应的方法.std()来计算标准差。如果数据集中有nan值,那么它们将返回nan。要忽略nan值,应该使用np.nanstd()。使用 NumPy 中的std()、.std()和nanstd(),就像使用var()、.var()和nanvar()一样:
>>> np.std(y, ddof=1)
11.099549540409285
>>> y.std(ddof=1)
11.099549540409285
>>> np.std(y_with_nan, ddof=1)
nan
>>> y_with_nan.std(ddof=1)
nan
>>> np.nanstd(y_with_nan, ddof=1)
11.099549540409285
不要忘记将 delta 自由度设置为1!
pd.Series对象也有默认跳过nan的 .std() 方法:
>>> z.std(ddof=1) 11.099549540409285 >>> z_with_nan.std(ddof=1) 11.099549540409285参数
ddof默认为1,可以省略。同样,如果您想区别对待nan值,那么应用参数skipna。总体标准差是指总体。它是人口方差的正平方根。您可以像计算样本标准差一样计算它,但有以下区别:
- 求纯 Python 实现中人口方差的平方根。
- 用
statistics.pstdev()代替statistics.stdev()。- 如果使用 NumPy 或 Pandas,指定参数
ddof=0。在 NumPy 中,可以省略ddof,因为它的默认值是0。如您所见,在 Python、NumPy 和 Pandas 中,您可以用与确定方差几乎相同的方式来确定标准差。您使用不同但相似的函数和方法,并使用相同的参数。
偏斜度
样本偏斜度测量数据样本的不对称度。
偏斜度有几种数学定义。计算具有𝑛元素的数据集𝑥的偏度的一个常用表达式是(𝑛/((𝑛-1)(𝑛-2))(σᵢ(𝑥ᵢ-mean(𝑥))/(𝑛𝑠)。更简单的表达式是σᵢ(𝑥ᵢmean(𝑥))𝑛/((𝑛1)(𝑛2)𝑠),其中𝑖 = 1,2,…,𝑛,mean(是)的样本均值。这样定义的偏度称为调整后的费希尔-皮尔逊标准化矩系数。
上图显示了两个非常对称的数据集。换句话说,他们的点离平均值有相似的距离。相比之下,下图显示了两个不对称的集合:
第一组用绿点表示,第二组用白点表示。通常,负偏度值表示在左侧有一个优势尾部,你可以在第一组中看到。正偏度值对应的是右边更长或更粗的尾巴,你可以在第二组中看到。如果偏斜度接近 0(例如,在 0.5 和 0.5 之间),则数据集被认为是完全对称的。
一旦计算出数据集的大小
n、样本均值mean_和标准差std_,就可以用纯 Python 获得样本偏斜度:
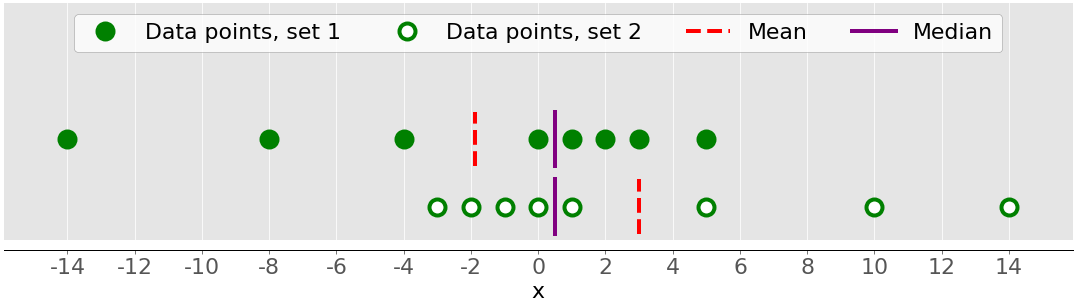
>>> x = [8.0, 1, 2.5, 4, 28.0]
>>> n = len(x)
>>> mean_ = sum(x) / n
>>> var_ = sum((item - mean_)**2 for item in x) / (n - 1)
>>> std_ = var_ ** 0.5
>>> skew_ = (sum((item - mean_)**3 for item in x)
... * n / ((n - 1) * (n - 2) * std_**3))
>>> skew_
1.9470432273905929
偏斜度为正,所以x有一个右侧尾部。
也可以用 scipy.stats.skew() 计算样本偏度:
>>> y, y_with_nan = np.array(x), np.array(x_with_nan) >>> scipy.stats.skew(y, bias=False) 1.9470432273905927 >>> scipy.stats.skew(y_with_nan, bias=False) nan获得的结果与纯 Python 实现相同。参数
bias被设置为False以启用对统计偏差的校正。可选参数nan_policy可以取值'propagate'、'raise'或'omit'。它允许你控制如何处理nan值。熊猫
Series对象具有方法.skew(),该方法也返回数据集的偏斜度:
>>> z, z_with_nan = pd.Series(x), pd.Series(x_with_nan)
>>> z.skew()
1.9470432273905924
>>> z_with_nan.skew()
1.9470432273905924
像其他方法一样,.skew()默认忽略nan值,因为可选参数skipna的默认值。
百分位数
样本𝑝百分位是数据集中的元素,使得数据集中元素的𝑝%小于或等于该值。此外,元素的(100)𝑝)%大于或等于该值。如果数据集中有两个这样的元素,那么样本𝑝百分位数就是它们的算术平均值。每个数据集有三个四分位数,它们是将数据集分成四个部分的百分点:
- 第一个四分位数是样本的第 25 个百分位数。它从数据集的其余部分中划分出大约 25%的最小项目。
- 第二个四分位数是样本的第 50 百分位或中位数。大约 25%的项目位于第一和第二四分位数之间,另外 25%位于第二和第三四分位数之间。
- 第三个四分位数是样本的第 75 个百分位数。它从数据集的其余部分中划分出大约 25%的最大项目。
每个零件都有大约相同数量的项目。如果你想把你的数据分成几个区间,那么你可以使用 statistics.quantiles() :
>>> x = [-5.0, -1.1, 0.1, 2.0, 8.0, 12.8, 21.0, 25.8, 41.0] >>> statistics.quantiles(x, n=2) [8.0] >>> statistics.quantiles(x, n=4, method='inclusive') [0.1, 8.0, 21.0]在这个例子中,
8.0是x的中位数,而0.1和21.0分别是样本的第 25 和第 75 个百分位数。参数n定义了产生的等概率百分位数,而method决定了如何计算它们。注:
statistics.quantiles()在 Python 3.8 中介绍。您还可以使用
np.percentile()来确定数据集中的任何样本百分比。例如,这是如何找到第 5 个和第 95 个百分位数的方法:
>>> y = np.array(x)
>>> np.percentile(y, 5)
-3.44
>>> np.percentile(y, 95)
34.919999999999995
percentile()需要几个参数。您必须提供数据集作为第一个参数,百分位值作为第二个参数。数据集可以是 NumPy 数组、列表、元组或类似数据结构的形式。百分比可以是 0 到 100 之间的一个数字,就像上面的例子一样,但它也可以是一个数字序列:
>>> np.percentile(y, [25, 50, 75]) array([ 0.1, 8\. , 21\. ]) >>> np.median(y) 8.0这段代码一次性计算第 25、50 和 75 个百分点。如果百分比值是一个序列,那么
percentile()返回一个 NumPy 数组和结果。第一条语句返回四分位数数组。第二个语句返回中间值,因此您可以确认它等于第 50 个百分位数,即8.0。如果要忽略
nan值,那么用np.nanpercentile()代替:
>>> y_with_nan = np.insert(y, 2, np.nan)
>>> y_with_nan
array([-5\. , -1.1, nan, 0.1, 2\. , 8\. , 12.8, 21\. , 25.8, 41\. ])
>>> np.nanpercentile(y_with_nan, [25, 50, 75])
array([ 0.1, 8\. , 21\. ])
这就是你避免nan值的方法。
NumPy 在 quantile() 和 nanquantile() 中也为你提供了非常相似的功能。如果您使用它们,那么您需要将分位数值作为 0 到 1 之间的数字而不是百分点来提供:
>>> np.quantile(y, 0.05) -3.44 >>> np.quantile(y, 0.95) 34.919999999999995 >>> np.quantile(y, [0.25, 0.5, 0.75]) array([ 0.1, 8\. , 21\. ]) >>> np.nanquantile(y_with_nan, [0.25, 0.5, 0.75]) array([ 0.1, 8\. , 21\. ])结果和前面的例子一样,但是这里你的参数在 0 和 1 之间。换句话说,你通过了
0.05而不是5,通过了0.95而不是95。
pd.Series对象有方法.quantile():
>>> z, z_with_nan = pd.Series(y), pd.Series(y_with_nan)
>>> z.quantile(0.05)
-3.44
>>> z.quantile(0.95)
34.919999999999995
>>> z.quantile([0.25, 0.5, 0.75])
0.25 0.1
0.50 8.0
0.75 21.0
dtype: float64
>>> z_with_nan.quantile([0.25, 0.5, 0.75])
0.25 0.1
0.50 8.0
0.75 21.0
dtype: float64
.quantile()还需要你提供分位数值作为自变量。该值可以是 0 到 1 之间的数字,也可以是一系列数字。在第一种情况下,.quantile()返回一个标量。在第二种情况下,它返回一个保存结果的新的Series。
范围
数据的范围是数据集中最大和最小元素之间的差值。用 np.ptp() 功能可以得到:
>>> np.ptp(y) 46.0 >>> np.ptp(z) 46.0 >>> np.ptp(y_with_nan) nan >>> np.ptp(z_with_nan) 46.0如果 NumPy 数组中有
nan个值,这个函数将返回nan。如果你使用一个熊猫Series对象,那么它将返回一个数字。或者,您可以使用内置的 Python、 NumPy 或 Pandas 函数和方法来计算序列的最大值和最小值:
- 来自 Python 标准库的
max()和min()- 来自 NumPy 的
amax()和amin()nanmax()和nanmin()从 NumPy 忽略nan值- 来自 NumPy 的
.max()和.min().max()和.min()来自熊猫默认忽略nan值以下是如何使用这些例程的一些示例:
>>> np.amax(y) - np.amin(y)
46.0
>>> np.nanmax(y_with_nan) - np.nanmin(y_with_nan)
46.0
>>> y.max() - y.min()
46.0
>>> z.max() - z.min()
46.0
>>> z_with_nan.max() - z_with_nan.min()
46.0
这就是你得到数据范围的方法。
四分位数间距是第一个四分位数和第三个四分位数之间的差值。一旦你计算出四分位数,你就可以得到它们的差值:
>>> quartiles = np.quantile(y, [0.25, 0.75]) >>> quartiles[1] - quartiles[0] 20.9 >>> quartiles = z.quantile([0.25, 0.75]) >>> quartiles[0.75] - quartiles[0.25] 20.9请注意,您访问的是带有标签
0.75和0.25的熊猫Series对象中的值。描述性统计概要
SciPy 和 Pandas 提供了有用的例程,可以通过一个函数或方法调用快速获得描述性统计数据。可以这样使用 scipy.stats.describe() :
>>> result = scipy.stats.describe(y, ddof=1, bias=False)
>>> result
DescribeResult(nobs=9, minmax=(-5.0, 41.0), mean=11.622222222222222, variance=228.75194444444446, skewness=0.9249043136685094, kurtosis=0.14770623629658886)
您必须提供数据集作为第一个参数。参数可以是 NumPy 数组、列表、元组或类似的数据结构。您可以省略ddof=1,因为这是默认值,并且只在计算方差时才起作用。您可以通过bias=False来强制校正偏斜度,并通过峰度来校正统计偏差。
注:可选参数nan_policy可以取值'propagate'(默认)、'raise'(错误)、或'omit'。该参数允许您控制有nan值时发生的情况。
describe()返回包含以下描述性统计信息的对象:
nobs:数据集中观察值或元素的数量minmax:数据集的最小值和最大值的元组mean:你的数据集的均值variance:你的数据集的方差skewness:数据集的偏斜度kurtosis:你的数据集的峰度
您可以使用点符号访问特定值:
>>> result.nobs 9 >>> result.minmax[0] # Min -5.0 >>> result.minmax[1] # Max 41.0 >>> result.mean 11.622222222222222 >>> result.variance 228.75194444444446 >>> result.skewness 0.9249043136685094 >>> result.kurtosis 0.14770623629658886使用 SciPy,只需一次函数调用就能获得数据集的描述性统计摘要。
熊猫有类似的功能,如果不是更好的话。
Series对象有方法.describe():
>>> result = z.describe()
>>> result
count 9.000000
mean 11.622222
std 15.124548
min -5.000000
25% 0.100000
50% 8.000000
75% 21.000000
max 41.000000
dtype: float64
它返回一个新的Series,包含以下内容:
count: 数据集中的元素数量mean: 你的数据集的均值std: 数据集的标准差min和max: 数据集的最小值和最大值25%、50%、75%: 数据集的四分位数
如果您希望得到的Series对象包含其他百分点,那么您应该指定可选参数percentiles的值。您可以通过标签访问result的每个项目:
>>> result['mean'] 11.622222222222222 >>> result['std'] 15.12454774346805 >>> result['min'] -5.0 >>> result['max'] 41.0 >>> result['25%'] 0.1 >>> result['50%'] 8.0 >>> result['75%'] 21.0这就是如何使用 Pandas 通过一个方法调用获得一个
Series对象的描述性统计数据。数据对之间相关性的度量
您经常需要检查数据集中两个变量的对应元素之间的关系。假设有两个变量,𝑥和𝑦,有相同数量的元素,𝑛.让𝑥的𝑥₁对应𝑦的𝑦₁,𝑥的𝑥₂对应𝑦的𝑦₂,等等。然后你可以说有𝑛对的对应元素:(𝑥₁,𝑦₁),(𝑥₂,𝑦₂),等等。
您将看到数据对之间的相关性的以下度量:
- 当𝑥的较大值对应于𝑦的较大值时,正相关存在,反之亦然。
- 当𝑥的较大值对应于𝑦的较小值时,负相关存在,反之亦然。
- 如果没有这种明显的关系,则存在弱相关性或无相关性。
下图显示了负相关、弱相关和正相关的示例:
左边带红点的图显示负相关。中间带绿点的图显示弱相关性。最后,右边的蓝点图显示了正相关。
注意:当处理一对变量之间的相关性时,有一件重要的事情你应该永远记住,那就是相关性不是因果关系的量度或指标,而只是关联性!
测量数据集之间相关性的两个统计量是协方差和相关系数。让我们定义一些数据来使用这些度量。您将创建两个 Python 列表,并使用它们来获得相应的 NumPy 数组和 Pandas
Series:
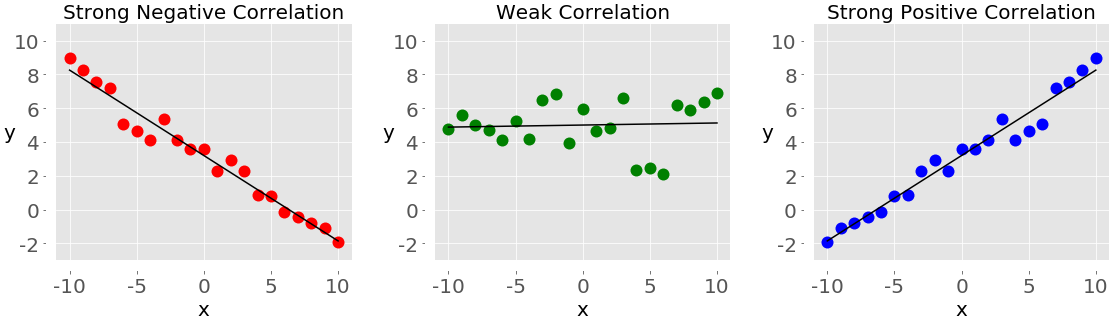
>>> x = list(range(-10, 11))
>>> y = [0, 2, 2, 2, 2, 3, 3, 6, 7, 4, 7, 6, 6, 9, 4, 5, 5, 10, 11, 12, 14]
>>> x_, y_ = np.array(x), np.array(y)
>>> x__, y__ = pd.Series(x_), pd.Series(y_)
既然有了这两个变量,就可以开始探索它们之间的关系了。
协方差
样本协方差是一种量化一对变量之间关系的强度和方向的方法:
- 如果相关性为正,那么协方差也为正。更强的关系对应于更高的协方差值。
- 如果相关性为负,那么协方差也为负。更强的关系对应于协方差的更低(或更高)的绝对值。
- 如果相关性弱,那么协方差接近于零。
变量𝑥和𝑦的协方差在数学上定义为𝑠ˣʸ=σᵢ(𝑥ᵢ-mean(𝑥))(𝑦ᵢ-mean(𝑦)/(1),其中,均值是样本均值因此,两个相同变量的协方差实际上是方差:𝑠ˣˣ=σᵢ(𝑥ᵢmean(𝑥)/(𝑛1)=(𝑠ˣ)和𝑠ʸʸ=σᵢ(𝑦ᵢmean(𝑦)/(1)=(1)。
这是在纯 Python 中计算协方差的方法:
>>> n = len(x) >>> mean_x, mean_y = sum(x) / n, sum(y) / n >>> cov_xy = (sum((x[k] - mean_x) * (y[k] - mean_y) for k in range(n)) ... / (n - 1)) >>> cov_xy 19.95首先,你得找到
x和y的平均值。然后,应用协方差的数学公式。NumPy 有函数
cov(),返回协方差矩阵:
>>> cov_matrix = np.cov(x_, y_)
>>> cov_matrix
array([[38.5 , 19.95 ],
[19.95 , 13.91428571]])
注意cov()有可选参数bias,默认为False,和ddof,默认为None。它们的默认值适用于获取样本协方差矩阵。协方差矩阵的左上元素是x和x的协方差,或者是x的方差。同样,右下元素是y和y的协方差,或者是y的方差。您可以查看这是不是真的:
>>> x_.var(ddof=1) 38.5 >>> y_.var(ddof=1) 13.914285714285711如你所见,
x和y的方差分别等于cov_matrix[0, 0]和cov_matrix[1, 1]。协方差矩阵的另外两个元素是相等的,并且表示
x和y之间的实际协方差:
>>> cov_xy = cov_matrix[0, 1]
>>> cov_xy
19.95
>>> cov_xy = cov_matrix[1, 0]
>>> cov_xy
19.95
您已经用np.cov()获得了与纯 Python 相同的协方差值。
熊猫Series有方法 .cov() 可以用来计算协方差:
>>> cov_xy = x__.cov(y__) >>> cov_xy 19.95 >>> cov_xy = y__.cov(x__) >>> cov_xy 19.95这里,您在一个
Series对象上调用.cov(),并将另一个对象作为第一个参数传递。相关系数
相关系数或皮尔逊积差相关系数用符号𝑟.表示系数是数据间相关性的另一种度量。你可以把它想成一个标准化的协方差。以下是一些重要的事实:
- 值𝑟 > 0 表示正相关。
- 值𝑟 < 0 表示负相关。
- 值 r = 1 是𝑟.的最大可能值它对应于变量之间完美的正线性关系。
- 值 r = 1 是𝑟.的最小可能值它对应于变量之间完美的负线性关系。
- 值 r ≈ 0 ,或者𝑟在零附近时,意味着变量之间的相关性弱。
相关系数的数学公式是𝑟 = 𝑠ˣʸ / (𝑠ˣ𝑠ʸ),其中𝑠ˣ和𝑠ʸ分别是𝑥和𝑦的标准差。如果你有数据集
x和y的均值(mean_x和mean_y)和标准差(std_x、std_y),以及它们的协方差cov_xy,那么你可以用纯 Python 计算相关系数:
>>> var_x = sum((item - mean_x)**2 for item in x) / (n - 1)
>>> var_y = sum((item - mean_y)**2 for item in y) / (n - 1)
>>> std_x, std_y = var_x ** 0.5, var_y ** 0.5
>>> r = cov_xy / (std_x * std_y)
>>> r
0.861950005631606
你已经得到了代表相关系数的变量r。
scipy.stats具有计算相关系数的例程 pearsonr() 和 𝑝-value :
>>> r, p = scipy.stats.pearsonr(x_, y_) >>> r 0.861950005631606 >>> p 5.122760847201171e-07
pearsonr()返回包含两个数字的元组。第一个是𝑟,第二个是𝑝-value.类似于协方差矩阵的情况,可以应用
np.corrcoef(),以x_和y_为自变量,得到相关系数矩阵:
>>> corr_matrix = np.corrcoef(x_, y_)
>>> corr_matrix
array([[1\. , 0.86195001],
[0.86195001, 1\. ]])
左上角的元素是x_和x_之间的相关系数。右下方的元素是y_和y_之间的相关系数。他们的价值观等于1.0。其他两个元素相等,代表x_和y_之间的实际相关系数:
>>> r = corr_matrix[0, 1] >>> r 0.8619500056316061 >>> r = corr_matrix[1, 0] >>> r 0.861950005631606当然,结果和用纯 Python 和
pearsonr()是一样的。你可以用
scipy.stats.linregress()得到相关系数:
>>> scipy.stats.linregress(x_, y_)
LinregressResult(slope=0.5181818181818181, intercept=5.714285714285714, rvalue=0.861950005631606, pvalue=5.122760847201164e-07, stderr=0.06992387660074979)
linregress()取x_和y_,进行线性回归,返回结果。slope和intercept定义回归线的方程,而rvalue是相关系数。要访问linregress()结果中的特定值,包括相关系数,使用点符号:
>>> result = scipy.stats.linregress(x_, y_) >>> r = result.rvalue >>> r 0.861950005631606这就是你如何进行线性回归,并获得相关系数。
熊猫
Series有计算相关系数的方法.corr():
>>> r = x__.corr(y__)
>>> r
0.8619500056316061
>>> r = y__.corr(x__)
>>> r
0.861950005631606
您应该在一个Series对象上调用.corr(),并将另一个对象作为第一个参数传递。
使用 2D 数据
统计学家经常使用 2D 数据。以下是 2D 数据格式的一些示例:
NumPy 和 SciPy 提供了处理 2D 数据的综合方法。Pandas 有专门处理 2D 标签数据的类DataFrame。
坐标轴
首先创建一个 2D NumPy 数组:
>>> a = np.array([[1, 1, 1], ... [2, 3, 1], ... [4, 9, 2], ... [8, 27, 4], ... [16, 1, 1]]) >>> a array([[ 1, 1, 1], [ 2, 3, 1], [ 4, 9, 2], [ 8, 27, 4], [16, 1, 1]])现在您有了一个 2D 数据集,将在本节中使用。您可以像对 1D 数据一样对其应用 Python 统计函数和方法:
>>> np.mean(a)
5.4
>>> a.mean()
5.4
>>> np.median(a)
2.0
>>> a.var(ddof=1)
53.40000000000001
如您所见,您可以获得数组a中所有数据的统计数据(如平均值、中值或方差)。有时,这种行为是您想要的,但在某些情况下,您会想要为 2D 数组的每一行或每一列计算这些量。
到目前为止,您使用的函数和方法都有一个可选参数,名为 axis ,这对于处理 2D 数据是必不可少的。axis可以取以下任何值:
axis=None表示计算统计数组中的所有数据。上面的例子是这样工作的。这种行为通常是 NumPy 中的默认行为。axis=0表示计算所有行的统计数据,即数组的每一列。这种行为通常是 SciPy 统计函数的默认行为。axis=1表示计算所有列的统计数据,即数组的每一行。
让我们看看axis=0和np.mean()的行动:
>>> np.mean(a, axis=0) array([6.2, 8.2, 1.8]) >>> a.mean(axis=0) array([6.2, 8.2, 1.8])上面的两条语句返回新的 NumPy 数组,其中包含每列的平均值
a。在这个例子中,第一列的平均值是6.2。第二列有平均值8.2,而第三列有1.8。如果您提供
axis=1到mean(),那么您将得到每一行的结果:
>>> np.mean(a, axis=1)
array([ 1., 2., 5., 13., 6.])
>>> a.mean(axis=1)
array([ 1., 2., 5., 13., 6.])
如你所见,第一行的a是平均值1.0,第二行是2.0,依此类推。
注意:您可以将这些规则扩展到多维数组,但这超出了本教程的范围。请随意自己深入这个话题!
参数axis与其他 NumPy 函数和方法的工作方式相同:
>>> np.median(a, axis=0) array([4., 3., 1.]) >>> np.median(a, axis=1) array([1., 2., 4., 8., 1.]) >>> a.var(axis=0, ddof=1) array([ 37.2, 121.2, 1.7]) >>> a.var(axis=1, ddof=1) array([ 0., 1., 13., 151., 75.])您已经得到了数组
a的所有列(axis=0)和行(axis=1)的中位数和样本方差。当您使用 SciPy 统计函数时,这非常相似。但是请记住,在这种情况下,
axis的默认值是0:
>>> scipy.stats.gmean(a) # Default: axis=0
array([4\. , 3.73719282, 1.51571657])
>>> scipy.stats.gmean(a, axis=0)
array([4\. , 3.73719282, 1.51571657])
如果您省略axis或提供axis=0,那么您将得到所有行的结果,也就是每一列的结果。例如,a的第一列的几何平均值为4.0,以此类推。
如果您指定了axis=1,那么您将得到所有列的计算结果,也就是每行的计算结果:
>>> scipy.stats.gmean(a, axis=1) array([1\. , 1.81712059, 4.16016765, 9.52440631, 2.5198421 ])本例中第一行
a的几何平均值为1.0。第二排大约是1.82,依此类推。如果您想要整个数据集的统计数据,那么您必须提供
axis=None:
>>> scipy.stats.gmean(a, axis=None)
2.829705017016332
数组a中所有项的几何平均值约为2.83。
通过使用 scipy.stats.describe() 对 2D 数据进行一次函数调用,就可以获得 Python 统计数据摘要。它的工作原理类似于 1D 阵列,但是您必须小心使用参数axis:
>>> scipy.stats.describe(a, axis=None, ddof=1, bias=False) DescribeResult(nobs=15, minmax=(1, 27), mean=5.4, variance=53.40000000000001, skewness=2.264965290423389, kurtosis=5.212690982795767) >>> scipy.stats.describe(a, ddof=1, bias=False) # Default: axis=0 DescribeResult(nobs=5, minmax=(array([1, 1, 1]), array([16, 27, 4])), mean=array([6.2, 8.2, 1.8]), variance=array([ 37.2, 121.2, 1.7]), skewness=array([1.32531471, 1.79809454, 1.71439233]), kurtosis=array([1.30376344, 3.14969121, 2.66435986])) >>> scipy.stats.describe(a, axis=1, ddof=1, bias=False) DescribeResult(nobs=3, minmax=(array([1, 1, 2, 4, 1]), array([ 1, 3, 9, 27, 16])), mean=array([ 1., 2., 5., 13., 6.]), variance=array([ 0., 1., 13., 151., 75.]), skewness=array([0\. , 0\. , 1.15206964, 1.52787436, 1.73205081]), kurtosis=array([-3\. , -1.5, -1.5, -1.5, -1.5]))当您提供
axis=None时,您将获得所有数据的摘要。大多数结果都是标量。如果设置了axis=0或者省略了它,那么返回值就是每一列的摘要。因此,大多数结果是具有与列数相同的项数的数组。如果您设置了axis=1,那么describe()将返回所有行的摘要。您可以从带有点符号的摘要中获得特定值:
>>> result = scipy.stats.describe(a, axis=1, ddof=1, bias=False)
>>> result.mean
array([ 1., 2., 5., 13., 6.])
这就是您如何通过一个函数调用来查看 2D 数组的统计信息摘要。
DataFrames
类DataFrame是基本的 Pandas 数据类型之一。使用起来非常舒服,因为它有行和列的标签。使用数组a并创建一个DataFrame:
>>> row_names = ['first', 'second', 'third', 'fourth', 'fifth'] >>> col_names = ['A', 'B', 'C'] >>> df = pd.DataFrame(a, index=row_names, columns=col_names) >>> df A B C first 1 1 1 second 2 3 1 third 4 9 2 fourth 8 27 4 fifth 16 1 1实际上,列名很重要,应该是描述性的。行的名称有时会自动指定为
0、1等等。您可以用参数index显式地指定它们,不过如果您愿意,也可以省略index。
DataFrame方法与Series方法非常相似,尽管行为不同。如果调用不带参数的 Python 统计方法,那么DataFrame将返回每一列的结果:
>>> df.mean()
A 6.2
B 8.2
C 1.8
dtype: float64
>>> df.var()
A 37.2
B 121.2
C 1.7
dtype: float64
您得到的是一个保存结果的新的Series。在这种情况下,Series保存每一列的平均值和方差。如果您想要每一行的结果,那么只需指定参数axis=1:
>>> df.mean(axis=1) first 1.0 second 2.0 third 5.0 fourth 13.0 fifth 6.0 dtype: float64 >>> df.var(axis=1) first 0.0 second 1.0 third 13.0 fourth 151.0 fifth 75.0 dtype: float64结果是一个
Series,每一行都有期望的数量。标签'first'、'second'等指的是不同的行。您可以像这样隔离
DataFrame的每一列:
>>> df['A']
first 1
second 2
third 4
fourth 8
fifth 16
Name: A, dtype: int64
现在,您有了一个Series对象形式的列'A',您可以应用适当的方法:
>>> df['A'].mean() 6.2 >>> df['A'].var() 37.20000000000001这就是获得单个列的统计数据的方法。
有时,您可能想使用一个
DataFrame作为 NumPy 数组,并对它应用一些函数。通过.values或.to_numpy()可以从DataFrame获取所有数据:
>>> df.values
array([[ 1, 1, 1],
[ 2, 3, 1],
[ 4, 9, 2],
[ 8, 27, 4],
[16, 1, 1]])
>>> df.to_numpy()
array([[ 1, 1, 1],
[ 2, 3, 1],
[ 4, 9, 2],
[ 8, 27, 4],
[16, 1, 1]])
df.values和df.to_numpy()给出了一个 NumPy 数组,其中包含来自DataFrame的所有项目,没有行和列标签。请注意,df.to_numpy()更加灵活,因为您可以指定项目的数据类型,以及您是想要使用现有数据还是复制它。
像Series,DataFrame对象具有方法 .describe() ,该方法返回另一个DataFrame,其中包含所有列的统计汇总:
>>> df.describe() A B C count 5.00000 5.000000 5.00000 mean 6.20000 8.200000 1.80000 std 6.09918 11.009087 1.30384 min 1.00000 1.000000 1.00000 25% 2.00000 1.000000 1.00000 50% 4.00000 3.000000 1.00000 75% 8.00000 9.000000 2.00000 max 16.00000 27.000000 4.00000该摘要包含以下结果:
count: 每列的项目数mean: 各列的意思std: 标准差min和max: 最小值和最大值25%、50%、75%: 百分位如果您希望得到的
DataFrame对象包含其他百分点,那么您应该指定可选参数percentiles的值。您可以像这样访问摘要的每个项目:
>>> df.describe().at['mean', 'A']
6.2
>>> df.describe().at['50%', 'B']
3.0
这就是如何通过一个 Pandas 方法调用在一个Series对象中获得描述性的 Python 统计数据。
可视化数据
除了计算数字量(如平均值、中值或方差)之外,您还可以使用可视化方法来呈现、描述和汇总数据。在本节中,您将了解如何使用以下图表直观地展示您的数据:
- 箱线图
- 直方图
- 饼图
- 条形图
- X-Y 图
- 热图
是一个非常方便且广泛使用的库,尽管它不是唯一可用于此目的的 Python 库。可以像这样导入它:
>>> import matplotlib.pyplot as plt >>> plt.style.use('ggplot')现在,您已经将
matplotlib.pyplot导入并准备好使用。第二条语句通过选择颜色、线宽和其他样式元素来设置绘图的样式。如果你对默认的样式设置满意,你可以省略这些。注意:这个部分主要关注表示数据的,并且将样式设置保持在最低限度。你会看到从
matplotlib.pyplot到所用例程的官方文档的链接,所以你可以探索这里看不到的选项。您将使用伪随机数来获取要处理的数据。你不需要了解随机数就能理解这一部分。你只需要一些任意的数字,伪随机发生器就是一个获取它们的便捷工具。模块
np.random生成伪随机数数组:
- 正态分布数字由
np.random.randn()生成。- 均匀分布的整数用
np.random.randint()生成。NumPy 1.17 引入了另一个用于伪随机数生成的模块。要了解更多信息,请查看官方文档。
箱线图
箱线图是一个非常好的工具,可以直观地表示给定数据集的描述性统计数据。它可以显示范围、四分位数范围、中位数、众数、异常值和所有四分位数。首先,创建一些数据,用箱线图来表示:
>>> np.random.seed(seed=0)
>>> x = np.random.randn(1000)
>>> y = np.random.randn(100)
>>> z = np.random.randn(10)
第一条语句用 seed() 设置 NumPy 随机数发生器的种子,这样每次运行代码都能得到相同的结果。您不必设置种子,但是如果您不指定这个值,那么您每次都会得到不同的结果。
其他语句用正态分布的伪随机数生成三个 NumPy 数组。x是指有 1000 项的数组,y有 100 项,z包含 10 项。现在你已经有了要处理的数据,你可以应用 .boxplot() 来得到方框图:
fig, ax = plt.subplots()
ax.boxplot((x, y, z), vert=False, showmeans=True, meanline=True,
labels=('x', 'y', 'z'), patch_artist=True,
medianprops={'linewidth': 2, 'color': 'purple'},
meanprops={'linewidth': 2, 'color': 'red'})
plt.show()
.boxplot()的参数定义如下:
x是你的数据。vert在False时将绘图方向设置为水平。默认方向是垂直的。showmeans显示了True时你的数据的均值。meanline代表当True时的意思为一条线。默认表示是一个点。labels: 你的数据的标签。patch_artist决定了如何绘制图形。medianprops表示代表中线的属性。meanprops表示代表平均值的线或点的性质。
还有其他参数,但是它们的分析超出了本教程的范围。
上面的代码生成了这样一幅图像:
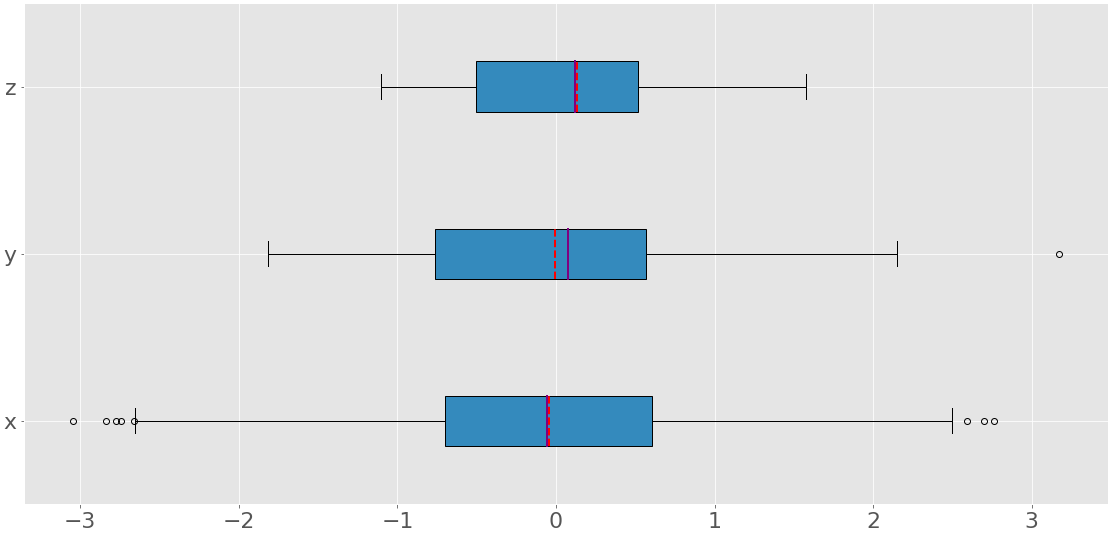
你可以看到三个方框图。它们中的每一个都对应于单个数据集(x、y或z),并显示以下内容:
- 平均值为红色虚线。
- 中值为紫线。
- 第一个四分位数是蓝色矩形的左边缘。
- 第三个四分位数是蓝色矩形的右边缘。
- 四分位范围是蓝色矩形的长度。
- 范围包含从左到右的所有内容。
- 离群值是左右两边的点。
一个方框图可以在一个图形中显示如此多的信息!
直方图
直方图在数据集中有大量唯一值时特别有用。直方图将排序后的数据集中的值划分为区间,也称为箱。通常,所有的箱子都是等宽的,尽管这不是必须的。面元的下限和上限的值被称为面元边缘。
频率是对应于每个仓的单个值。它是值位于条柱边缘之间的数据集元素的数量。按照惯例,除了最右边的箱子,所有箱子都是半开的。它们包括等于下限的值,但不包括等于上限的值。最右边的库是封闭的,因为它包括两个边界。如果使用条柱边 0、5、10 和 15 划分数据集,则有三个条柱:
- 第一个和最左边的容器包含大于或等于 0 且小于 5 的值。
- 第二个框包含大于或等于 5 且小于 10 的值。
- 第三个和最右边的容器包含大于或等于 10 且小于或等于 15 的值。
函数 np.histogram() 是获取直方图数据的便捷方式:
>>> hist, bin_edges = np.histogram(x, bins=10) >>> hist array([ 9, 20, 70, 146, 217, 239, 160, 86, 38, 15]) >>> bin_edges array([-3.04614305, -2.46559324, -1.88504342, -1.3044936 , -0.72394379, -0.14339397, 0.43715585, 1.01770566, 1.59825548, 2.1788053 , 2.75935511])它接受包含您的数据和箱数(或边数)的数组,并返回两个 NumPy 数组:
hist包含每个 bin 对应的频率或项数。bin_edges包含面元的边缘或边界。
histogram()算什么,.hist()可以图形化地显示:fig, ax = plt.subplots() ax.hist(x, bin_edges, cumulative=False) ax.set_xlabel('x') ax.set_ylabel('Frequency') plt.show()
.hist()的第一个参数是你的数据序列。第二个参数定义了容器的边缘。第三个选项禁止使用累积值创建直方图。上面的代码生成了这样一个图形:
您可以在水平轴上看到容器边缘,在垂直轴上看到频率。
如果您提供参数
cumulative=True到.hist(),就有可能获得带有累积项数的直方图:fig, ax = plt.subplots() ax.hist(x, bin_edges, cumulative=True) ax.set_xlabel('x') ax.set_ylabel('Frequency') plt.show()这段代码产生了下图:
它显示带有累积值的直方图。第一个和最左边的容器的频率是该容器中的项目数。第二容器的频率是第一和第二容器中项目数量的总和。其他箱遵循相同的模式。最后,最后一个和最右边的 bin 的频率是数据集中的项目总数(在本例中为 1000)。也可以在后台使用
matplotlib直接绘制带有pd.Series.hist()的直方图。饼状图
饼图用少量标签和给定的相对频率表示数据。即使有无法订购的标签(如名义数据),它们也能很好地工作。饼图是一个分成多个部分的圆形。每个切片对应于来自数据集的单个不同标签,并且具有与该标签相关联的相对频率成比例的面积。
让我们定义与三个标签相关的数据:
>>> x, y, z = 128, 256, 1024
现在,用 .pie() 创建一个饼状图:
fig, ax = plt.subplots()
ax.pie((x, y, z), labels=('x', 'y', 'z'), autopct='%1.1f%%')
plt.show()
.pie()的第一个参数是你的数据,第二个是对应标签的顺序。autopct定义了图上显示的相对频率的格式。你会得到一个类似这样的图:
饼图显示x为圆圈的最小部分,y为第二大部分,然后z为最大部分。百分比表示每个值与其总和相比的相对大小。
条形图
条形图也显示了对应于给定标签或离散数值的数据。它们可以显示来自两个数据集的数据对。一组项目是标签,另一组对应的项目是它们的频率。可选地,它们也可以显示与频率相关的误差。
条形图显示称为条的平行矩形。每个条对应于单个标签,并且具有与其标签的频率或相对频率成比例的高度。让我们生成三个数据集,每个数据集有 21 个项目:
>>> x = np.arange(21) >>> y = np.random.randint(21, size=21) >>> err = np.random.randn(21)你用
np.arange()得到x,或者从0到20的连续整数数组。您将使用它来表示标签。y是一个均匀分布的随机整数数组,也在0和20之间。这个数组将代表频率。err包含正态分布的浮点数,为误差。这些值是可选的。如果需要竖条,您可以使用
.bar()创建条形图;如果需要横条,您可以使用.barh()创建条形图:fig, ax = plt.subplots()) ax.bar(x, y, yerr=err) ax.set_xlabel('x') ax.set_ylabel('y') plt.show()该代码应产生下图:
红色条的高度对应于频率
y,而黑线的长度显示误差err。如果不想包含错误,则省略.bar()的参数yerr。X-Y 坐标图
x-y 图或散点图代表来自两个数据集的数据对。水平 x 轴显示来自集合
x的值,而垂直 y 轴显示来自集合y的相应值。您可以选择包括回归线和相关系数。让我们生成两个数据集并用scipy.stats.linregress()进行线性回归:
>>> x = np.arange(21)
>>> y = 5 + 2 * x + 2 * np.random.randn(21)
>>> slope, intercept, r, *__ = scipy.stats.linregress(x, y)
>>> line = f'Regression line: y={intercept:.2f}+{slope:.2f}x, r={r:.2f}'
数据集x也是一个从 0 到 20 的整数数组。y被计算为被一些随机噪声扭曲的x的线性函数。
linregress返回几个值。你需要回归线的slope和intercept,以及相关系数r。然后你可以应用 .plot() 得到 x-y 坐标图:
fig, ax = plt.subplots()
ax.plot(x, y, linewidth=0, marker='s', label='Data points')
ax.plot(x, intercept + slope * x, label=line)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.legend(facecolor='white')
plt.show()
上面代码的结果如下图所示:
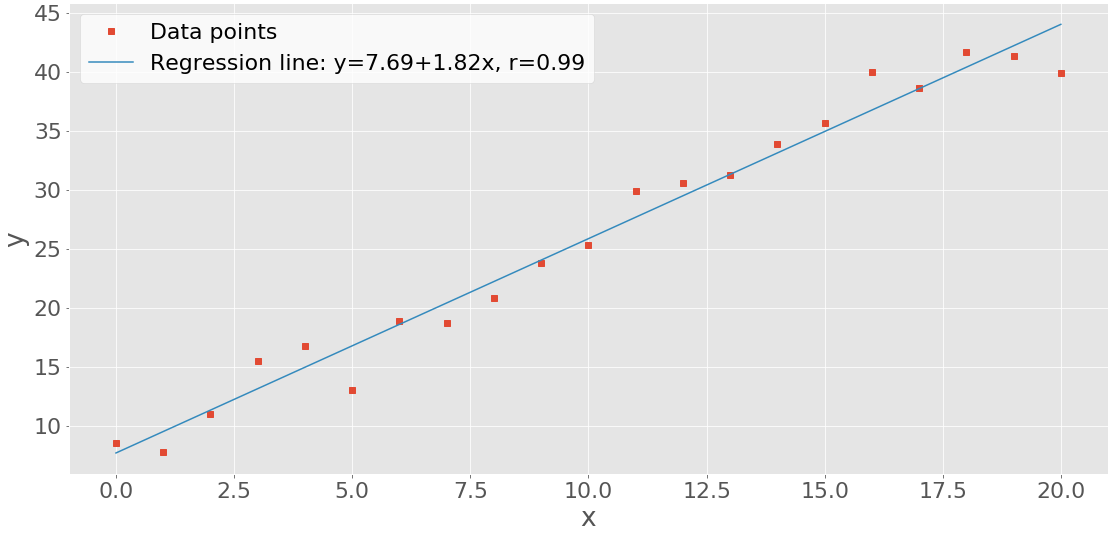
您可以看到红色正方形的数据点(x-y 对),以及蓝色回归线。
热图
一个热图可以用来直观地显示一个矩阵。颜色代表矩阵的数字或元素。热图对于说明协方差和相关矩阵特别有用。您可以使用 .imshow() 为协方差矩阵创建热图:
matrix = np.cov(x, y).round(decimals=2)
fig, ax = plt.subplots()
ax.imshow(matrix)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, matrix[i, j], ha='center', va='center', color='w')
plt.show()
这里,热图包含标签'x'和'y'以及协方差矩阵中的数字。你会得到这样一个数字:
黄色区域代表矩阵中最大的元素130.34,而紫色区域对应最小的元素38.5。中间的蓝色方块与值69.9相关联。
您可以按照相同的逻辑获得相关系数矩阵的热图:
matrix = np.corrcoef(x, y).round(decimals=2)
fig, ax = plt.subplots()
ax.imshow(matrix)
ax.grid(False)
ax.xaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.yaxis.set(ticks=(0, 1), ticklabels=('x', 'y'))
ax.set_ylim(1.5, -0.5)
for i in range(2):
for j in range(2):
ax.text(j, i, matrix[i, j], ha='center', va='center', color='w')
plt.show()
结果如下图所示:
黄色代表数值1.0,紫色显示0.99。
结论
现在,您已经了解了描述和汇总数据集的数量,以及如何在 Python 中计算它们。用纯 Python 代码可以得到描述性统计数据,但这很少是必要的。通常,您会使用一些专门为此目的而创建的库:
- 使用 Python 的
statistics进行最重要的 Python 统计函数。 - 使用 NumPy 高效处理数组。
- 使用 SciPy 为 NumPy 数组执行额外的 Python 统计例程。
- 使用 Pandas 处理带标签的数据集。
- 使用 Matplotlib 将数据可视化为曲线图、图表和直方图。
在大数据和人工智能时代,你必须知道如何计算描述性统计量。现在你已经准备好深入数据科学和机器学习的世界了!如果你有任何问题或意见,请写在下面的评论区。**********
如何检查 Python 字符串是否包含子串
如果您是编程新手,或者来自 Python 之外的编程语言,您可能正在寻找在 Python 中检查一个字符串是否包含另一个字符串的最佳方法。
当您处理来自文件的文本内容时,或者在收到用户输入后,识别这样的子字符串会很方便。根据子字符串是否存在,您可能希望在程序中执行不同的操作。
在本教程中,您将关注处理这项任务的最 Pythonic 化的方法,使用成员操作符in 。此外,您将学习如何为相关但不同的用例识别正确的字符串方法。
最后,您还将学习如何在 pandas 列中查找子字符串。如果您需要搜索 CSV 文件中的数据,这很有帮助。您可以使用您将在下一节学习的方法,但是如果您正在使用表格数据,最好将数据加载到 pandas 数据框架中,然后在 pandas 中搜索子字符串。
免费下载: 单击此处下载示例代码,您将使用它来检查字符串是否包含子字符串。
如何确认一个 Python 字符串包含另一个字符串
如果需要检查一个字符串是否包含子串,使用 Python 的成员操作符in。在 Python 中,这是确认字符串中子串存在的推荐方法:
>>> raw_file_content = """Hi there and welcome. ... This is a special hidden file with a SECRET secret. ... I don't want to tell you The Secret, ... but I do want to secretly tell you that I have one.""" >>> "secret" in raw_file_content True
in成员操作符为您提供了一种快速、易读的方法来检查一个子串是否存在于一个字符串中。您可能会注意到,这一行代码读起来几乎像英语。注意:如果要检查子串是否是字符串中的而不是,那么可以使用
not in:
>>> "secret" not in raw_file_content
False
因为子串"secret"出现在raw_file_content中,所以not in操作符返回False。
当使用in时,表达式返回一个布尔值:
True如果 Python 找到了子串False如果 Python 没有找到子串
您可以在条件语句中使用这种直观的语法在您的代码中做出决定:
>>> if "secret" in raw_file_content: ... print("Found!") ... Found!在这个代码片段中,您使用成员操作符来检查
"secret"是否是raw_file_content的子串。如果是,那么您将向终端打印一条消息。任何缩进的代码只有在您检查的 Python 字符串包含您提供的子字符串时才会执行。注意: Python 认为空字符串总是作为任何其他字符串的子串,所以检查字符串中的空字符串会返回
True:
>>> "" in "secret"
True
这可能令人惊讶,因为 Python 认为em tty 字符串为 false ,但是记住这种极端情况是有帮助的。
如果您只需要检查一个 Python 字符串是否包含子串,那么成员操作符in是您最好的朋友。
但是,如果你想知道更多关于子串的信息呢?如果您通读存储在raw_file_content中的文本,那么您会注意到子字符串不止一次出现,甚至出现在不同的变体中!
Python 找到了这些事件中的哪一个?大写有区别吗?子字符串在文本中出现的频率是多少?这些子串的位置在哪里?如果你需要这些问题的答案,请继续阅读。
通过消除大小写敏感性来概括您的检查
Python 字符串区分大小写。如果您提供的子字符串与文本中的同一个单词使用不同的大写字母,Python 将找不到它。例如,如果您在原文的标题大小写版本上检查小写单词"secret",成员操作符 check 返回False:
>>> title_cased_file_content = """Hi There And Welcome. ... This Is A Special Hidden File With A Secret Secret. ... I Don't Want To Tell You The Secret, ... But I Do Want To Secretly Tell You That I Have One.""" >>> "secret" in title_cased_file_content False尽管单词 secret 在标题文本
title_cased_file_content中多次出现,但它从未以小写形式出现。这就是为什么用成员资格操作符执行的检查会返回False。Python 在提供的文本中找不到全小写的字符串"secret"。人类对待语言的方式与计算机不同。这就是为什么在 Python 中检查一个字符串是否包含子串时,通常会忽略大小写。
您可以通过将整个输入文本转换为小写来概括您的子字符串检查:
>>> file_content = title_cased_file_content.lower()
>>> print(file_content)
hi there and welcome.
this is a special hidden file with a secret secret.
i don't want to tell you the secret,
but i do want to secretly tell you that i have one.
>>> "secret" in file_content
True
将输入文本转换为小写是一种常见的方式,因为人类认为只有大小写不同的单词才是同一个单词,而计算机不会。
注意:在下面的例子中,您将继续使用小写版本的文本file_content。
如果您使用原始字符串(raw_file_content)或大写字符串(title_cased_file_content),那么您会得到不同的结果,因为它们不是小写的。在您完成示例时,请随意尝试一下!
既然您已经将字符串转换为小写,以避免由区分大小写引起的意外问题,那么是时候进一步挖掘和了解更多关于子字符串的内容了。
了解有关子字符串的更多信息
成员操作符in是描述性检查字符串中是否有子串的好方法,但是它并没有提供更多的信息。它非常适合条件检查——但是如果您需要了解更多关于子字符串的信息,该怎么办呢?
Python 提供了许多额外的字符串方法,允许您检查字符串包含多少个目标子字符串,根据复杂的条件搜索子字符串,或者在文本中定位子字符串的索引。
在这一节中,您将讨论一些额外的字符串方法,这些方法可以帮助您了解更多关于子字符串的信息。
注意:你可能见过下面这些用来检查一个字符串是否包含子串的方法。这是可能的——但是它们不应该被用于这个目的!
编程是一项创造性的活动,你总能找到不同的方法来完成同一项任务。但是,为了提高代码的可读性,最好按照您正在使用的语言的意图来使用方法。
通过使用in,您确认了字符串包含子字符串。但是你没有得到子串所在的的的任何信息。
如果您需要知道子串出现在字符串中的什么位置,那么您可以在 string 对象上使用.index():
>>> file_content = """hi there and welcome. ... this is a special hidden file with a secret secret. ... i don't want to tell you the secret, ... but i do want to secretly tell you that i have one.""" >>> file_content.index("secret") 59当您在字符串上调用
.index()并将子字符串作为参数传递给它时,您将获得子字符串第一次出现的第一个字符的索引位置。注意:如果 Python 找不到子串,那么
.index()会引发一个ValueError异常。但是,如果您想找到子字符串的其他出现,该怎么办呢?
.index()方法还接受第二个参数,该参数可以定义从哪个索引位置开始查找。因此,通过传递特定的索引位置,可以跳过已经识别的子字符串:
>>> file_content.index("secret", 60)
66
当您传递一个超过子串第一次出现的起始索引时,Python 会从那里开始搜索。在这种情况下,您会得到另一个匹配,而不是一个ValueError。
这意味着文本不止一次包含子字符串。但是多久一次呢?
您可以使用描述性和惯用的 Python 代码使用.count()快速得到您的答案:
>>> file_content.count("secret") 4您在小写字符串上使用了
.count(),并将子字符串"secret"作为参数传递。Python 统计了子串在字符串中出现的频率,并返回答案。该文本包含子字符串四次。但是这些子串是什么样子的呢?您可以检查所有的子字符串,方法是在默认的单词边界处拆分您的文本,并使用
for循环将单词打印到您的终端:
>>> for word in file_content.split():
... if "secret" in word:
... print(word)
...
secret
secret.
secret,
secretly
在这个例子中,您使用 .split() 将空白处的文本分成字符串,Python 将这些字符串打包成一个列表。然后遍历这个列表,在每个字符串上使用in,看看它是否包含子串"secret"。
注意:除了打印子字符串之外,您还可以将它们保存在一个新的列表中,例如通过使用带有条件表达式的列表理解:
>>> [word for word in file_content.split() if "secret" in word] ['secret', 'secret.', 'secret,', 'secretly']在这种情况下,您只从包含子字符串的单词中构建一个列表,这实质上是过滤文本。
既然您可以检查 Python 识别的所有子字符串,您可能会注意到 Python 并不关心子字符串
"secret"之后是否有任何字符。无论单词后面是空格还是标点符号,它都会找到该单词。它甚至可以找到像"secretly"这样的单词。知道这一点很好,但是如果想要对子串检查施加更严格的条件,该怎么办呢?
使用正则表达式查找带有条件的子字符串
您可能只想匹配出现的子串和标点符号,或者识别包含子串和其他字母的单词,例如
"secretly"。对于这种需要更复杂的字符串匹配的情况,您可以将正则表达式或 regex 与 Python 的
re模块一起使用。例如,如果您想查找以
"secret"开头但后面至少还有一个字母的所有单词,那么您可以使用 regex 单词字符 (\w),后面跟着加量词 (+):
>>> import re
>>> file_content = """hi there and welcome.
... this is a special hidden file with a secret secret.
... i don't want to tell you the secret,
... but i do want to secretly tell you that i have one."""
>>> re.search(r"secret\w+", file_content)
<re.Match object; span=(128, 136), match='secretly'>
re.search()函数返回匹配条件的子串及其起始和结束索引位置——而不仅仅是True!
然后,您可以通过Match对象上的方法来访问这些属性,用m表示:
>>> m = re.search(r"secret\w+", file_content) >>> m.group() 'secretly' >>> m.span() (128, 136)这些结果为您继续处理匹配的子字符串提供了很大的灵活性。
例如,您可以只搜索后跟逗号(
,)或句点(.)的子字符串:
>>> re.search(r"secret[\.,]", file_content)
<re.Match object; span=(66, 73), match='secret.'>
您的文本中有两个潜在匹配项,但您只匹配了符合您的查询的第一个结果。当您使用re.search()时,Python 再次只找到的第一个匹配。如果您想让符合某个条件的"secret"的所有提及会怎样?
要使用re查找所有匹配,您可以使用re.findall():
>>> re.findall(r"secret[\.,]", file_content) ['secret.', 'secret,']通过使用
re.findall(),您可以在您的文本中找到该模式的所有匹配。Python 将所有匹配作为字符串保存在一个列表中。当您使用捕获组时,您可以通过将该部分括在括号中来指定您想要在列表中保留的匹配部分:
>>> re.findall(r"(secret)[\.,]", file_content)
['secret', 'secret']
通过将秘密括在括号中,您定义了一个单独的捕获组。 findall()函数返回匹配捕获组的字符串列表,只要模式中正好有一个捕获组。通过在秘密周围加上括号,你成功的去掉了标点符号!
注意:记住,子串"secret"在您的文本中出现了四次,通过使用re,您过滤出了两个您根据特殊条件匹配的特定出现。
将re.findall()与匹配组一起使用是从文本中提取子字符串的有效方法。但是你只得到一个字符串的列表,这意味着你已经丢失了你在使用re.search()时可以访问的索引位置。
如果你想保留这些信息,那么re可以给你一个迭代器中的所有匹配:
>>> for match in re.finditer(r"(secret)[\.,]", file_content): ... print(match) ... <re.Match object; span=(66, 73), match='secret.'> <re.Match object; span=(103, 110), match='secret,'>当您使用
re.finditer()并将搜索模式和文本内容作为参数传递给它时,您可以访问包含子字符串的每个Match对象,以及它的开始和结束索引位置。您可能会注意到标点符号出现在这些结果中,即使您仍然使用捕获组。这是因为一个
Match对象的字符串表示显示了整个匹配,而不仅仅是第一个捕获组。但是
Match对象是一个强大的信息容器,就像您之前看到的那样,您可以挑选出您需要的信息:
>>> for match in re.finditer(r"(secret)[\.,]", file_content):
... print(match.group(1))
...
secret
secret
通过调用 .group() 并指定您想要的第一个捕获组,您从每个匹配的子串中选择了不带标点的单词 secret 。
当您使用正则表达式时,您可以使用子串匹配进行更详细的描述。除了检查一个字符串是否包含另一个字符串,您还可以根据复杂的条件搜索子字符串。
注意:如果你想学习更多关于使用捕获组和组成更复杂的正则表达式模式的知识,那么你可以深入研究 Python 中的正则表达式。
如果您需要有关子字符串的信息,或者如果您在文本中找到子字符串后需要继续使用它们,那么使用带有re的正则表达式是一个很好的方法。但是如果您正在处理表格数据呢?为此,你会求助于熊猫。
在熊猫数据帧列中查找子串
如果您处理的数据不是来自纯文本文件或用户输入,而是来自 CSV 文件或 Excel 表格,那么您可以使用上面讨论的相同方法。
然而,有一种更好的方法来识别列中的哪些单元格包含子串:您将使用熊猫!在本例中,您将使用一个包含虚假公司名称和标语的 CSV 文件。如果您想继续工作,可以下载下面的文件:
免费下载: 单击此处下载示例代码,您将使用它来检查字符串是否包含子字符串。
当你在 Python 中处理表格数据时,通常最好先把它加载到一个熊猫DataFrame 中:
>>> import pandas as pd >>> companies = pd.read_csv("companies.csv") >>> companies.shape (1000, 2) >>> companies.head() company slogan 0 Kuvalis-Nolan revolutionize next-generation metrics 1 Dietrich-Champlin envisioneer bleeding-edge functionalities 2 West Inc mesh user-centric infomediaries 3 Wehner LLC utilize sticky infomediaries 4 Langworth Inc reinvent magnetic networks在这个代码块中,您将一个包含一千行虚假公司数据的 CSV 文件加载到 pandas DataFrame 中,并使用
.head()检查了前五行。将数据加载到 DataFrame 中后,可以快速查询整个 pandas 列来筛选包含子字符串的条目:
>>> companies[companies.slogan.str.contains("secret")]
company slogan
7 Maggio LLC target secret niches
117 Kub and Sons brand secret methodologies
654 Koss-Zulauf syndicate secret paradigms
656 Bernier-Kihn secretly synthesize back-end bandwidth
921 Ward-Shields embrace secret e-commerce
945 Williamson Group unleash secret action-items
您可以在 pandas 列上使用 .str.contains() ,并将子串作为参数传递给它,以过滤包含子串的行。
注意:索引操作符([])和属性操作符(.)提供了获取数据帧的单个列或片的直观方法。
然而,如果您正在处理与性能有关的生产代码,pandas 建议使用优化的数据访问方法来索引和选择数据。
当你使用.str.contains()并且需要更复杂的匹配场景时,你也可以使用正则表达式!您只需要传递一个符合 regex 的搜索模式作为 substring 参数:
>>> companies[companies.slogan.str.contains(r"secret\w+")] company slogan 656 Bernier-Kihn secretly synthesize back-end bandwidth在这个代码片段中,您使用了之前使用的相同模式,只匹配包含秘密的单词,但是继续使用一个或多个单词字符(
\w+)。这个假数据集中只有一家公司似乎在秘密运营*!您可以编写任何复杂的正则表达式模式,并将其传递给
.str.contains(),以便从 pandas 列中切割出您分析所需的行。结论
就像一个坚持不懈的寻宝者,你找到了每一个
"secret",不管它藏得多好!在这个过程中,您了解到在 Python 中检查字符串是否包含子串的最佳方式是使用in成员操作符。您还学习了如何描述性地使用另外两个字符串方法,它们经常被误用来检查子字符串:
.count()统计子串在字符串中出现的次数.index()获取子串开头的索引位置之后,您探索了如何使用正则表达式和 Python 的
re模块中的一些函数根据更高级的条件查找子字符串。最后,您还学习了如何使用 DataFrame 方法
.str.contains()来检查 pandas DataFrame 中的哪些条目包含子串。现在,您知道了在 Python 中处理子字符串时如何选择最惯用的方法。继续使用最具描述性的方法,你会写出令人愉悦的代码,让别人很快就能理解。
免费下载: 单击此处下载示例代码,您将使用它来检查字符串是否包含子字符串。****
Python 字符串格式化最佳实践
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 字符串格式化技巧&最佳实践
还记得 Python 的禅,以及“在 Python 中应该有一种显而易见的方法来做某事”吗?当您发现在 Python 中有四种主要的方法来进行字符串格式化时,您可能会感到困惑。
在本教程中,您将学习 Python 中字符串格式化的四种主要方法,以及它们的优缺点。对于如何在自己的程序中选择最佳的通用字符串格式化方法,您还将获得一个简单的经验法则。
让我们直接开始吧,因为我们有很多要谈的。为了有一个简单的玩具例子来做实验,让我们假设你已经有了下面的变量(或者常数,真的):
>>> errno = 50159747054
>>> name = 'Bob'
基于这些变量,您想要生成一个包含简单错误消息的输出字符串:
'Hey Bob, there is a 0xbadc0ffee error!'这个错误可能真的会破坏一个开发人员的周一早晨…但是我们在这里讨论字符串格式。所以我们开始工作吧。
#1“旧样式”字符串格式(%运算符)
Python 中的字符串有一个独特的内置操作,可以用
%操作符访问。这使您可以非常容易地进行简单的位置格式化。如果你曾经在 C 中使用过printf风格的函数,你会立刻意识到它是如何工作的。这里有一个简单的例子:
>>> 'Hello, %s' % name
"Hello, Bob"
我在这里使用%s格式说明符来告诉 Python 在哪里替换用字符串表示的name的值。
还有其他格式说明符可以让您控制输出格式。例如,可以将数字转换为十六进制表示法,或者添加空白填充来生成格式良好的表格和报告。(参见 Python 文档:“printf 风格的字符串格式化”。)
在这里,您可以使用%x格式说明符将int值转换为字符串,并将其表示为十六进制数:
>>> '%x' % errno 'badc0ffee'如果您想在单个字符串中进行多次替换,“旧样式”字符串格式语法会稍有变化。因为
%操作符只接受一个参数,所以您需要将右边包装在一个元组中,就像这样:
>>> 'Hey %s, there is a 0x%x error!' % (name, errno)
'Hey Bob, there is a 0xbadc0ffee error!'
如果将映射传递给%操作符,也可以在格式字符串中通过名称引用变量替换:
>>> 'Hey %(name)s, there is a 0x%(errno)x error!' % { ... "name": name, "errno": errno } 'Hey Bob, there is a 0xbadc0ffee error!'这使得您的格式字符串更容易维护,也更容易在将来修改。您不必担心要确保传入值的顺序与格式字符串中引用值的顺序相匹配。当然,缺点是这种技术需要更多的输入。
我相信您一定想知道为什么这种
printf样式的格式被称为“旧样式”字符串格式。它在技术上被 Python 3 中的“新风格”格式所取代,我们接下来会谈到这一点。#2“新样式”字符串格式(
str.format)Python 3 引入了一种新的方法来进行字符串格式化,这种方法后来也被移植回 Python 2.7。这种“新样式”的字符串格式去掉了
%-操作符的特殊语法,使字符串格式的语法更加规则。格式化现在由在字符串对象上调用.format()来处理。您可以使用
format()进行简单的位置格式化,就像您可以使用“旧样式”格式化一样:
>>> 'Hello, {}'.format(name)
'Hello, Bob'
或者,您可以通过名称引用变量替换,并按照您想要的任何顺序使用它们。这是一个非常强大的特性,因为它允许在不改变传递给format()的参数的情况下重新排列显示顺序:
>>> 'Hey {name}, there is a 0x{errno:x} error!'.format( ... name=name, errno=errno) 'Hey Bob, there is a 0xbadc0ffee error!'这也表明将
int变量格式化为十六进制字符串的语法已经改变。现在您需要通过添加一个:x后缀来传递一个格式规范。格式字符串语法变得更加强大,而不会使简单的用例变得复杂。仔细阅读 Python 文档中的这个字符串格式化迷你语言是值得的。在 Python 3 中,这种“新样式”的字符串格式优于
%样式的格式。虽然“旧风格”格式已经被弱化,但它并没有被弃用。最新版本的 Python 仍然支持它。根据关于 Python 开发电子邮件列表和的讨论,关于 Python 开发 bug 追踪器、%的这个问题——格式化将会持续很长时间。尽管如此,Python 3 的官方文档并不完全推荐“旧风格”的格式,也没有过多地提及它:
这里描述的格式化操作展示了导致许多常见错误的各种怪癖(比如不能正确显示元组和字典)。使用较新的格式化字符串或 str.format()接口有助于避免这些错误。这些替代方案还提供了更强大、更灵活、更可扩展的文本格式化方法。”(来源)
这就是为什么我个人会努力坚持使用
str.format来开发新代码。从 Python 3.6 开始,还有另一种方法来格式化字符串。我会在下一节告诉你所有的事情。#3 字符串插值/ f 字符串(Python 3.6+)
Python 3.6 增加了一种新的字符串格式化方法,称为格式化字符串文字或“f-strings”。这种格式化字符串的新方法允许您在字符串常量中使用嵌入式 Python 表达式。下面是一个简单的例子,让您感受一下这个特性:
>>> f'Hello, {name}!'
'Hello, Bob!'
正如您所看到的,这给字符串常量加上了前缀字母“f”——因此命名为“f-strings”这种新的格式语法非常强大。因为可以嵌入任意的 Python 表达式,所以甚至可以用它做内联算术。看看这个例子:
>>> a = 5 >>> b = 10 >>> f'Five plus ten is {a + b} and not {2 * (a + b)}.' 'Five plus ten is 15 and not 30.'格式化字符串是 Python 解析器的一个特性,它将 f 字符串转换成一系列字符串常量和表达式。然后将它们连接起来,组成最后一串。
假设您有以下包含 f 字符串的
greet()函数:
>>> def greet(name, question):
... return f"Hello, {name}! How's it {question}?"
...
>>> greet('Bob', 'going')
"Hello, Bob! How's it going?"
当您反汇编该函数并检查幕后发生的情况时,您会看到函数中的 f 字符串被转换成类似于以下内容的形式:
>>> def greet(name, question): ... return "Hello, " + name + "! How's it " + question + "?"真正的实现比这稍微快一点,因为它使用了
BUILD_STRING操作码作为优化。但是功能上它们是一样的:
>>> import dis
>>> dis.dis(greet)
2 0 LOAD_CONST 1 ('Hello, ')
2 LOAD_FAST 0 (name)
4 FORMAT_VALUE 0
6 LOAD_CONST 2 ("! How's it ")
8 LOAD_FAST 1 (question)
10 FORMAT_VALUE 0
12 LOAD_CONST 3 ('?')
14 BUILD_STRING 5
16 RETURN_VALUE
字符串文字也支持str.format()方法的现有格式字符串语法。这使您可以解决我们在前两节中讨论过的相同的格式问题:
>>> f"Hey {name}, there's a {errno:#x} error!" "Hey Bob, there's a 0xbadc0ffee error!"Python 新的格式化字符串文字类似于 JavaScript 在 ES2015 中添加的模板文字。我认为它们是 Python 的一个很好的补充,我已经开始在我的日常工作中使用它们了。您可以在我们的深度 Python f-strings 教程中了解更多关于格式化字符串的信息。
#4 模板字符串(标准库)
这里还有一个 Python 中的字符串格式化工具:模板字符串。这是一种更简单、功能更弱的机制,但在某些情况下,这可能正是您想要的。
让我们来看一个简单的问候示例:
>>> from string import Template
>>> t = Template('Hey, $name!')
>>> t.substitute(name=name)
'Hey, Bob!'
您在这里看到我们需要从 Python 的内置string模块导入Template类。模板字符串不是核心语言特性,但它们是由标准库中的 string模块提供的。
另一个区别是模板字符串不允许格式说明符。因此,为了让前面的错误字符串示例生效,您需要手动将int错误号转换成十六进制字符串:
>>> templ_string = 'Hey $name, there is a $error error!' >>> Template(templ_string).substitute( ... name=name, error=hex(errno)) 'Hey Bob, there is a 0xbadc0ffee error!'效果很好。
那么什么时候应该在 Python 程序中使用模板字符串呢?在我看来,使用模板字符串的最佳时机是在处理程序用户生成的格式化字符串时。由于降低了复杂性,模板字符串是更安全的选择。
其他字符串格式化技术的更复杂的格式化微型语言可能会给程序带来安全漏洞。例如,格式字符串有可能访问你的程序中的任意变量。
这意味着,如果恶意用户可以提供格式字符串,他们就有可能泄漏密钥和其他敏感信息!这里有一个简单的概念证明,说明这种攻击可能如何针对您的代码:
>>> # This is our super secret key:
>>> SECRET = 'this-is-a-secret'
>>> class Error:
... def __init__(self):
... pass
>>> # A malicious user can craft a format string that
>>> # can read data from the global namespace:
>>> user_input = '{error.__init__.__globals__[SECRET]}'
>>> # This allows them to exfiltrate sensitive information,
>>> # like the secret key:
>>> err = Error()
>>> user_input.format(error=err)
'this-is-a-secret'
看看一个假想的攻击者是如何通过从一个恶意的格式字符串中访问__globals__字典来提取我们的秘密字符串的?可怕吧。模板字符串关闭了这个攻击媒介。如果您正在处理从用户输入生成的格式字符串,这使它们成为更安全的选择:
>>> user_input = '${error.__init__.__globals__[SECRET]}' >>> Template(user_input).substitute(error=err) ValueError: "Invalid placeholder in string: line 1, col 1"应该使用哪种字符串格式化方法?
我完全理解在 Python 中有这么多选择来格式化你的字符串会让人感到很困惑。这是一个很好的提示,来展示我为您整理的这张便捷的流程图信息图:
Python String Formatting Rule of Thumb (Image: [Click to Tweet](https://twitter.com/intent/tweet/?text=Python%20String%20Formatting%20Rule%20of%20Thumb&url=https://realpython.com/python-string-formatting/)) 这个流程图是基于我在编写 Python 时应用的经验法则:
Python 字符串格式化的经验法则:如果你的格式字符串是用户提供的,使用模板字符串(#4) 来避免安全问题。否则,如果你在 Python 3.6+上,使用文字字符串插值/f 字符串(#3) ,如果你不是,使用“新样式”str.format (#2) 。
关键要点
- 也许令人惊讶的是,在 Python 中处理字符串格式的方法不止一种。
- 每种方法都有各自的优缺点。您的用例将影响您应该使用哪种方法。
- 如果你在决定使用哪种字符串格式化方法时有困难,试试我们的 Python 字符串格式化经验法则。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: Python 字符串格式化技巧&最佳实践***
在 Python 中拆分、连接和连接字符串
原文:https://realpython.com/python-string-split-concatenate-join/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的拆分、串联、连接字符串
生活中很少有保证:死亡、税收、程序员需要处理字符串。字符串可以有多种形式。它们可以是非结构化的文本、用户名、产品描述、数据库列名,或者任何我们用语言描述的东西。
由于字符串数据几乎无处不在,当涉及到字符串时,掌握交易工具很重要。幸运的是,Python 使得字符串操作变得非常简单,尤其是与其他语言甚至更老版本的 Python 相比。
在本文中,你将学习一些最基本的字符串操作:拆分、连接和连接。你不仅将学会如何使用这些工具,还将对它们的工作原理有更深的理解。
参加测验:通过我们的交互式“Python 中字符串的拆分、连接和联接”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
拆分字符串
在 Python 中,字符串被表示为
str对象,这些对象是不可变的:这意味着内存中表示的对象不能被直接改变。这两个事实可以帮助你学习(然后记住)如何使用.split()。您猜到字符串的这两个特性与 Python 中的拆分功能有什么关系了吗?如果您猜测
.split()是一个 实例方法 ,因为字符串是一种特殊的类型,那么您就猜对了!在其他一些语言中(比如 Perl),原始字符串作为独立的.split()函数的输入,而不是字符串本身调用的方法。注意:调用字符串方法的方式
像
.split()这样的字符串方法在这里主要显示为在字符串上调用的实例方法。它们也可以被称为静态方法,但这并不理想,因为它更“罗嗦”为了完整起见,这里有一个例子:# Avoid this: str.split('a,b,c', ',')与首选用途相比,这种方法体积庞大且不实用:
# Do this instead: 'a,b,c'.split(',')关于 Python 中实例、类和静态方法的更多信息,请查看我们的深度教程。
字符串不变性呢?这应该提醒你,字符串方法不是就地操作,而是它们在内存中返回一个新的对象。
注:就地操作
就地操作是直接改变调用它们的对象的操作。一个常见的例子是在列表上使用的
.append()方法:当你在一个列表上调用.append()时,该列表通过将.append()的输入添加到同一个列表中而被直接改变。无参数分割
在深入探讨之前,我们先看一个简单的例子:
>>> 'this is my string'.split()
['this', 'is', 'my', 'string']
这实际上是一个.split()调用的特例,我选择它是因为它简单。如果没有指定任何分隔符,.split()会将任何空格作为分隔符。
对.split()的裸调用的另一个特性是,它会自动删除开头和结尾的空白,以及连续的空白。比较调用以下不带分隔符参数的字符串上的.split()和使用' '作为分隔符参数的情况:
>>> s = ' this is my string ' >>> s.split() ['this', 'is', 'my', 'string'] >>> s.split(' ') ['', 'this', '', '', 'is', '', 'my', 'string', '']首先要注意的是,这展示了 Python 中字符串的不变性:对
.split()的后续调用处理原始字符串,而不是第一次调用.split()的列表结果。您应该看到的第二件事——也是最主要的一件事——是简单的
.split()调用提取了句子中的单词,并丢弃了任何空白。指定分隔符
另一方面,
.split(' '),就更加字面了。当有前导或尾随分隔符时,您将得到一个空字符串,您可以在结果列表的第一个和最后一个元素中看到它。如果有多个连续的分隔符(例如“this”和“is”之间以及“is”和“my”之间),第一个分隔符将被用作分隔符,随后的分隔符将作为空字符串进入结果列表。
注:
.split()调用中的分隔符虽然上面的例子使用单个空格字符作为输入到
.split()的分隔符,但是您并不局限于用作分隔符的字符类型或字符串长度。唯一的要求是您的分隔符是一个字符串。你可以使用从"..."到"separator"的任何东西。用最大分割限制分割
.split()还有一个可选参数叫做maxsplit。默认情况下,.split()会在被调用时进行所有可能的拆分。然而,当您给maxsplit赋值时,将只进行给定数量的分割。使用我们之前的示例字符串,我们可以看到maxsplit在运行:
>>> s = "this is my string"
>>> s.split(maxsplit=1)
['this', 'is my string']
正如您在上面看到的,如果您将maxsplit设置为1,第一个空白区域被用作分隔符,其余的被忽略。让我们做些练习来检验一下到目前为止我们所学的一切。
给一个负数作为maxsplit参数会怎么样?
.split()将在所有可用的分隔符上分割字符串,这也是当maxsplit未设置时的默认行为。
您最近收到了一个格式非常糟糕的逗号分隔值(CSV)文件。您的工作是将每一行提取到一个列表中,列表中的每个元素代表该文件的列。是什么让它格式不好?“地址”字段包含多个逗号,但需要在列表中表示为单个元素!
假设您的文件已经作为以下多行字符串加载到内存中:
Name,Phone,Address
Mike Smith,15554218841,123 Nice St, Roy, NM, USA
Anita Hernandez,15557789941,425 Sunny St, New York, NY, USA
Guido van Rossum,315558730,Science Park 123, 1098 XG Amsterdam, NL
您的输出应该是一个列表列表:
[
['Mike Smith', '15554218841', '123 Nice St, Roy, NM, USA'],
['Anita Hernandez', '15557789941', '425 Sunny St, New York, NY, USA'],
['Guido van Rossum', '315558730', 'Science Park 123, 1098 XG Amsterdam, NL']
]
每个内部列表代表我们感兴趣的 CSV 的行,而外部列表将它们放在一起。
这是我的解决方案。有几种方法可以解决这个问题。重要的是,您使用了带有所有可选参数的.split(),并获得了预期的输出:
input_string = """Name,Phone,Address
Mike Smith,15554218841,123 Nice St, Roy, NM, USA
Anita Hernandez,15557789941,425 Sunny St, New York, NY, USA
Guido van Rossum,315558730,Science Park 123, 1098 XG Amsterdam, NL"""
def string_split_ex(unsplit):
results = []
# Bonus points for using splitlines() here instead,
# which will be more readable
for line in unsplit.split('\n')[1:]:
results.append(line.split(',', maxsplit=2))
return results
print(string_split_ex(input_string))
我们在这里调用.split()两次。第一种用法可能看起来有点吓人,但是不要担心!我们会一步一步来,你会习惯这些表达方式。让我们再来看看第一个.split()呼叫:unsplit.split('\n')[1:]。
第一个元素是unsplit,它只是指向你的输入字符串的变量。然后我们有我们的.split()呼叫:.split('\n')。在这里,我们拆分一个叫做换行符的特殊字符。
\n是做什么的?顾名思义,它告诉正在读取字符串的任何东西,它后面的每个字符都应该显示在下一行。在像我们的input_string这样的多行字符串中,每行的末尾都有一个隐藏的\n。
最后一部分可能是新的:[1:]。到目前为止,这条语句在内存中给了我们一个新的列表,并且[1:]看起来像一个列表索引符号,它确实是——有点像!这个扩展的索引符号给了我们一个列表片。在这种情况下,我们获取索引1处的元素及其之后的所有内容,丢弃索引0处的元素。
总之,我们遍历一个字符串列表,其中每个元素表示多行输入字符串中除第一行之外的每一行。
在每个字符串中,我们使用,作为拆分字符再次调用.split(),但是这一次我们使用maxsplit只拆分前两个逗号,保持地址不变。然后,我们将该调用的结果附加到名副其实的results数组中,并将其返回给调用者。
串联和连接字符串
另一个基本的字符串操作与拆分字符串相反:字符串连接。如果你没见过这个词,不用担心。这只是“粘在一起”的一种花哨说法
用+运算符连接
有几种方法可以做到这一点,这取决于你想要达到的目标。最简单也是最常见的方法是使用加号(+)将多个字符串加在一起。只需在想要连接的任意多的字符串之间放置一个+:
>>> 'a' + 'b' + 'c' 'abc'为了与数学主题保持一致,您也可以将字符串相乘来重复它:
>>> 'do' * 2
'dodo'
记住,字符串是不可变的!如果您连接或重复存储在变量中的字符串,您必须将新字符串赋给另一个变量才能保留它。
>>> orig_string = 'Hello' >>> orig_string + ', world' 'Hello, world' >>> orig_string 'Hello' >>> full_sentence = orig_string + ', world' >>> full_sentence 'Hello, world'如果我们没有不可变的字符串,
full_sentence将会输出'Hello, world, world'。另一点需要注意的是,Python 不做隐式字符串转换。如果你试图将一个字符串和一个非字符串类型连接起来,Python 会抛出一个
TypeError:
>>> 'Hello' + 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: must be str, not int
这是因为您只能将字符串与其他字符串连接起来,如果您来自像 JavaScript 这样试图进行隐式类型转换的语言,这可能是一种新的行为。
用.join() 在 Python 中从列表到字符串
还有另一种更强大的方法将字符串连接在一起。在 Python 中,你可以用join()方法从一个列表变成一个字符串。
这里的常见用例是,当您有一个由字符串组成的 iterable(如列表)时,您希望将这些字符串组合成一个字符串。和.split()、.join()一样,是一个字符串实例方法。如果你所有的字符串都在一个 iterable 中,你在哪个上面调用.join()?
这是一个有点棘手的问题。请记住,当您使用.split()时,您是在想要拆分的字符串或字符上调用它。相反的操作是.join(),所以您可以在想要用来将字符串的 iterable 连接在一起的字符串或字符上调用它:
>>> strings = ['do', 're', 'mi'] >>> ','.join(strings) 'do,re,mi'在这里,我们用逗号(
,)连接strings列表的每个元素,并在其上调用.join()而不是strings列表。如何使输出文本更具可读性?
你可以做的一件事是增加间距:
>>> strings = ['do', 're', 'mi']
>>> ', '.join(strings)
'do, re, mi'
通过在连接字符串中添加一个空格,我们极大地提高了输出的可读性。这是您在连接字符串以提高可读性时应该始终牢记的事情。
.join()的聪明之处在于,它将你的“joiner”插入到你想要连接的 iterable 的字符串之间,而不是仅仅在 iterable 的每个字符串的末尾添加 joiner。这意味着如果你传递一个大小为1的 iterable,你将看不到你的 joiner:
>>> 'b'.join(['a']) 'a'使用我们的网页抓取教程,你已经建立了一个伟大的天气抓取工具。但是,它在列表的列表中加载字符串信息,每个列表都包含您要写入 CSV 文件的唯一一行信息:
[ ['Boston', 'MA', '76F', '65% Precip', '0.15 in'], ['San Francisco', 'CA', '62F', '20% Precip', '0.00 in'], ['Washington', 'DC', '82F', '80% Precip', '0.19 in'], ['Miami', 'FL', '79F', '50% Precip', '0.70 in'] ]您的输出应该是如下所示的单个字符串:
""" Boston,MA,76F,65% Precip,0.15in San Francisco,CA,62F,20% Precip,0.00 in Washington,DC,82F,80% Precip,0.19 in Miami,FL,79F,50% Precip,0.70 in """对于这个解决方案,我使用了 list comprehension,这是 Python 的一个强大特性,允许您快速构建列表。如果你想学习更多关于它们的知识,可以看看这篇伟大的文章,它涵盖了 Python 中所有可用的理解。
下面是我的解决方案,从一个列表列表开始,以一个字符串结束:
input_list = [ ['Boston', 'MA', '76F', '65% Precip', '0.15 in'], ['San Francisco', 'CA', '62F', '20% Precip', '0.00 in'], ['Washington', 'DC', '82F', '80% Precip', '0.19 in'], ['Miami', 'FL', '79F', '50% Precip', '0.70 in'] ] # We start with joining each inner list into a single string joined = [','.join(row) for row in input_list] # Now we transform the list of strings into a single string output = '\n'.join(joined) print(output)这里我们使用
.join()不是一次,而是两次。首先,我们在列表理解中使用它,它将每个内部列表中的所有字符串组合成一个字符串。接下来,我们用我们之前看到的换行符\n连接这些字符串。最后,我们简单地打印结果,这样我们就可以验证它是否如我们所期望的那样。将所有这些联系在一起
虽然对 Python 中最基本的字符串操作(拆分、连接和连接)的概述到此结束,但仍有大量的字符串方法可以让您更轻松地操作字符串。
一旦你掌握了这些基本的字符串操作,你可能想学习更多。幸运的是,我们有许多很棒的教程来帮助您完全掌握 Python 支持智能字符串操作的特性:
参加测验:通过我们的交互式“Python 中字符串的拆分、连接和联接”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的拆分、串联、连接字符串******
Python 中的字符串和字符数据
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的字符串和字符数据
在 Python 中关于基本数据类型的教程中,您学习了如何定义包含字符数据序列的字符串:对象。处理字符数据是编程的一部分。这是一个罕见的应用程序,至少在某种程度上不需要操作字符串。
下面是你将在本教程中学到的: Python 提供了一组丰富的操作符、函数和方法来处理字符串。完成本教程后,您将知道如何访问和提取部分字符串,并且熟悉可用于操作和修改字符串数据的方法。
还将向您介绍另外两个用于表示原始字节数据的 Python 对象,即
bytes和bytearray类型。参加测验:通过我们的交互式“Python 字符串和字符数据”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
字符串操作
以下部分重点介绍了可用于处理字符串的运算符、方法和函数。
字符串运算符
在关于 Python 中的操作符和表达式的教程中,您已经看到了应用于数值操作数的操作符
+和*。这两个运算符也可以应用于字符串。
+操作员
+操作符连接字符串。它返回由连接在一起的操作数组成的字符串,如下所示:
>>> s = 'foo'
>>> t = 'bar'
>>> u = 'baz'
>>> s + t
'foobar'
>>> s + t + u
'foobarbaz'
>>> print('Go team' + '!!!')
Go team!!!
*操作员
*操作符创建一个字符串的多个副本。如果s是一个字符串,而n是一个整数,则以下任一表达式都会返回一个由s的n串联副本组成的字符串:
s * n
T1】
以下是两种形式的示例:
>>> s = 'foo.' >>> s * 4 'foo.foo.foo.foo.' >>> 4 * s 'foo.foo.foo.foo.'乘数操作数
n必须是整数。您可能认为它必须是正整数,但有趣的是,它可以是零或负,在这种情况下,结果是一个空字符串:
>>> 'foo' * -8
''
如果你要创建一个字符串变量并通过赋值'foo' * -8将其初始化为空字符串,任何人都会认为你有点愚蠢。但这是可行的。
in操作员
Python 还提供了可用于字符串的成员运算符。如果第一个操作数包含在第二个操作数中,则in运算符返回True,否则返回False:
>>> s = 'foo' >>> s in 'That\'s food for thought.' True >>> s in 'That\'s good for now.' False还有一个
not in操作符,它的作用正好相反:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
内置字符串函数
正如你在关于 Python 中的基本数据类型的教程中所看到的,Python 提供了许多内置于解释器中并且总是可用的函数。以下是一些使用字符串的示例:
| 功能 | 描述 |
|---|---|
chr() |
将整数转换为字符 |
ord() |
将字符转换为整数 |
len() |
返回字符串的长度 |
str() |
返回对象的字符串表示形式 |
下面将更全面地探讨这些问题。
ord(c)
返回给定字符的整数值。
在最基本的层面上,计算机将所有信息存储为数字。为了表示字符数据,使用将每个字符映射到其代表数字的转换方案。
常用的最简单的方案叫做 ASCII 。它涵盖了您可能最习惯使用的常见拉丁字符。对于这些字符,ord(c)返回字符c的 ASCII 值:
>>> ord('a') 97 >>> ord('#') 35就目前而言,ASCII 是很好的。但是,世界上有许多不同的语言在使用,数字媒体中出现了无数的符号和字形。可能需要用计算机代码表示的全套字符远远超过你通常看到的普通拉丁字母、数字和符号。
Unicode 是一个雄心勃勃的标准,它试图为每一种可能的语言、每一种可能的平台上的每一个可能的字符提供一个数字代码。Python 3 广泛支持 Unicode,包括允许字符串中包含 Unicode 字符。
更多信息:参见 Python 文档中的 Unicode &字符编码:无痛指南和 Python 的 Unicode 支持。
只要您停留在通用字符的领域,ASCII 和 Unicode 之间的实际差别就很小。但是
ord()函数也将为 Unicode 字符返回数值:
>>> ord('€')
8364
>>> ord('∑')
8721
chr(n)
返回给定整数的字符值。
chr()与ord()相反。给定一个数值n,chr(n)返回一个表示对应于n的字符的字符串:
>>> chr(97) 'a' >>> chr(35) '#'
chr()也处理 Unicode 字符:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
len(s)
返回字符串的长度。
用len(),可以检查 Python 字符串长度。len(s)返回s中的字符数:
>>> s = 'I am a string.' >>> len(s) 14
str(obj)返回对象的字符串表示形式。
几乎 Python 中的任何对象都可以呈现为字符串。
str(obj)返回对象obj的字符串表示:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('foo')
'foo'
字符串索引
通常在编程语言中,可以使用数字索引或键值直接访问有序数据集中的单个项目。这个过程被称为索引。
在 Python 中,字符串是字符数据的有序序列,因此可以用这种方式进行索引。字符串中的单个字符可以通过指定字符串名称后跟方括号中的数字([])来访问。
Python 中的字符串索引是从零开始的:字符串中的第一个字符有索引0,下一个有索引1,依此类推。最后一个字符的索引将是字符串长度减一。
例如,字符串'foobar'的索引示意图如下所示:
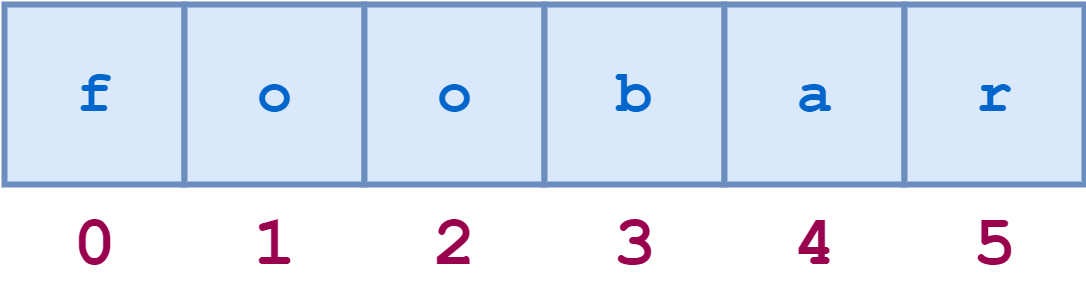
单个字符可以通过索引访问,如下所示:
>>> s = 'foobar' >>> s[0] 'f' >>> s[1] 'o' >>> s[3] 'b' >>> len(s) 6 >>> s[len(s)-1] 'r'试图在字符串末尾之外进行索引会导致错误:
>>> s[6]
Traceback (most recent call last):
File "<pyshell#17>", line 1, in <module>
s[6]
IndexError: string index out of range
字符串索引也可以用负数指定,在这种情况下,索引从字符串的末尾向后开始:-1表示最后一个字符,-2表示倒数第二个字符,依此类推。下图显示了字符串'foobar'的正负索引:
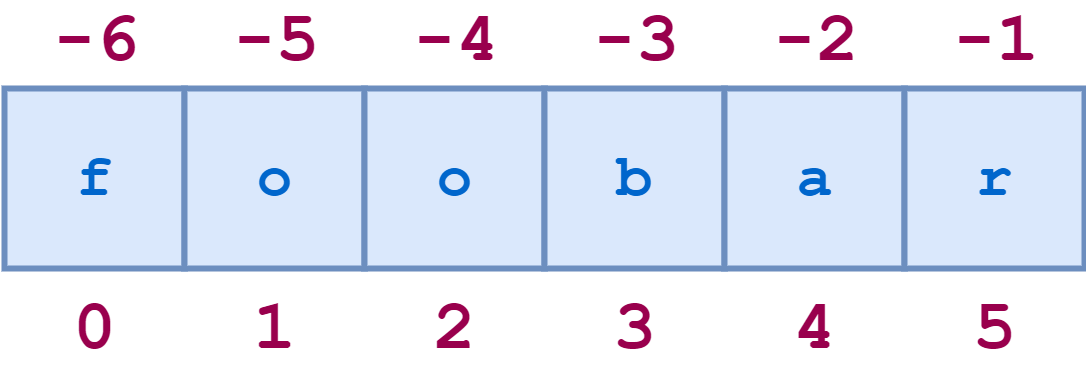
下面是一些负指数的例子:
>>> s = 'foobar' >>> s[-1] 'r' >>> s[-2] 'a' >>> len(s) 6 >>> s[-len(s)] 'f'试图用字符串开头以外的负数进行索引会导致错误:
>>> s[-7]
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
s[-7]
IndexError: string index out of range
对于任何非空字符串s,s[len(s)-1]和s[-1]都返回最后一个字符。没有任何索引对空字符串有意义。
字符串切片
Python 还允许一种从字符串中提取子字符串的索引语法,称为字符串切片。如果s是一个字符串,则形式为s[m:n]的表达式返回从位置m开始的s部分,直到但不包括位置n:
>>> s = 'foobar' >>> s[2:5] 'oba'记住:字符串索引是从零开始的。字符串中的第一个字符的索引为
0。这适用于标准索引和切片。同样,第二个索引指定了结果中不包含的第一个字符——上例中的字符
'r'(s[5])。这看起来有点不直观,但它产生的结果是有意义的:表达式s[m:n]将返回长度为n - m个字符的子串,在本例中是5 - 2 = 3。如果省略第一个索引,切片将从字符串的开头开始。因此,
s[:m]和s[0:m]是等价的:
>>> s = 'foobar'
>>> s[:4]
'foob'
>>> s[0:4]
'foob'
类似地,如果您像在s[n:]中一样省略第二个索引,切片将从第一个索引延伸到字符串的末尾。这是更麻烦的s[n:len(s)]的一个很好的、简洁的替代方案:
>>> s = 'foobar' >>> s[2:] 'obar' >>> s[2:len(s)] 'obar'对于任意字符串
s和任意整数n(0 ≤ n ≤ len(s)),s[:n] + s[n:]将等于s:
>>> s = 'foobar'
>>> s[:4] + s[4:]
'foobar'
>>> s[:4] + s[4:] == s
True
省略这两个索引将返回完整的原始字符串。字面上。它不是副本,而是对原始字符串的引用:
>>> s = 'foobar' >>> t = s[:] >>> id(s) 59598496 >>> id(t) 59598496 >>> s is t True如果切片中的第一个索引大于或等于第二个索引,Python 将返回一个空字符串。如果您正在寻找一个空字符串,这是另一种生成空字符串的混淆方法:
>>> s[2:2]
''
>>> s[4:2]
''
负索引也可以与切片一起使用。-1表示最后一个字符,-2表示倒数第二个字符,以此类推,就像简单的索引一样。下图显示了如何使用正负索引从字符串'foobar'中切分出子字符串'oob':
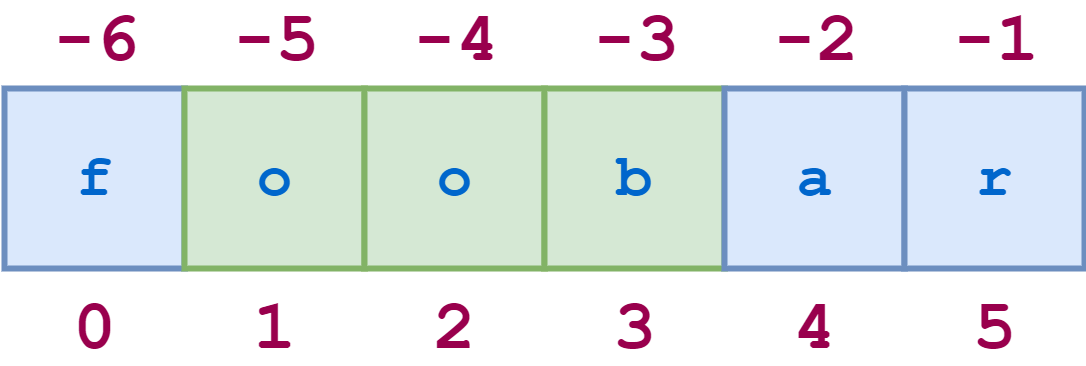
下面是相应的 Python 代码:
>>> s = 'foobar' >>> s[-5:-2] 'oob' >>> s[1:4] 'oob' >>> s[-5:-2] == s[1:4] True在字符串片段中指定步幅
还有一个切片语法的变体需要讨论。添加一个额外的
:和第三个索引指定一个步幅(也称为一个步长),它指示在检索片段中的每个字符后要跳跃多少个字符。比如对于字符串
'foobar',切片0:6:2从第一个字符开始,到最后一个字符结束(整个字符串),每隔一个字符跳过一个。如下图所示:
String Indexing with Stride 类似地,
1:6:2指定一个从第二个字符(索引1)开始到最后一个字符结束的片段,并且步距值2再次导致每隔一个字符被跳过:
Another String Indexing with Stride 说明性的 REPL 代码如下所示:
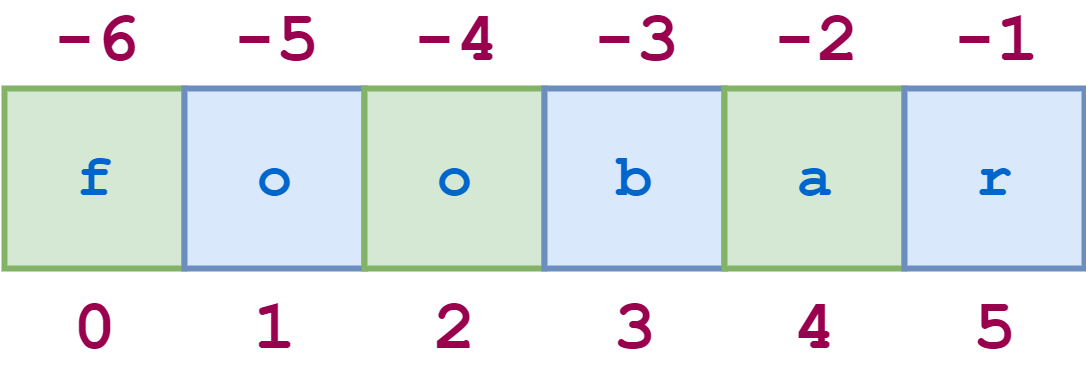
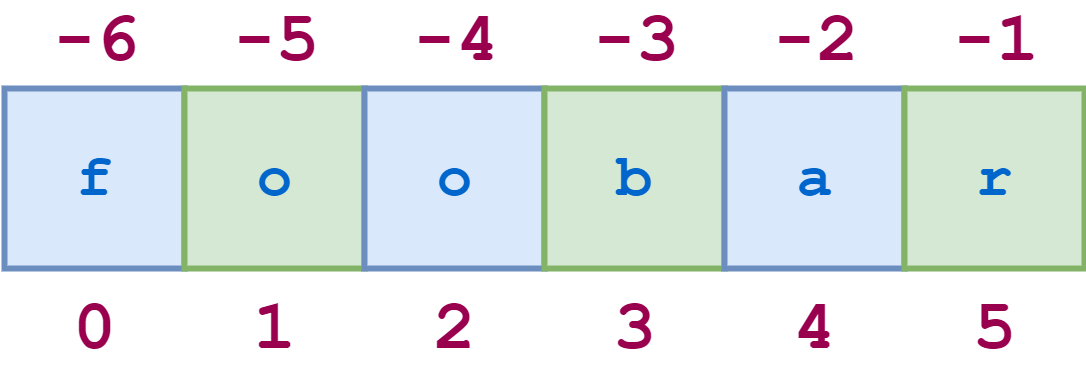
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
与任何切片一样,第一个和第二个索引可以省略,分别默认为第一个和最后一个字符:
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::5] '11111' >>> s[4::5] '55555'您也可以指定一个负的步幅值,在这种情况下,Python 会在字符串中后退。在这种情况下,起始/第一个索引应该大于结束/第二个索引:
>>> s = 'foobar'
>>> s[5:0:-2]
'rbo'
在上面的例子中,5:0:-2表示“从最后一个字符开始,后退2,直到但不包括第一个字符。”
当您向后步进时,如果省略了第一个和第二个索引,默认情况会以直观的方式反转:第一个索引默认为字符串的结尾,第二个索引默认为开头。这里有一个例子:
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::-5] '55555'这是反转字符串的常见范例:
>>> s = 'If Comrade Napoleon says it, it must be right.'
>>> s[::-1]
'.thgir eb tsum ti ,ti syas noelopaN edarmoC fI'
将变量插入字符串
在 Python 版中,引入了一种新的字符串格式化机制。这个特性被正式命名为格式化字符串文字,但更常用的是它的昵称 f-string 。
f-strings 提供的格式化功能非常广泛,这里不会详细介绍。如果你想了解更多,你可以看看真正的 Python 文章 Python 3 的 f-Strings:一个改进的字符串格式化语法(指南)。在本系列的后面还有一个关于格式化输出的教程,深入探讨了 f 字符串。
f 弦的一个简单特性是变量插值,你可以马上开始使用。您可以直接在 f 字符串中指定变量名,Python 会用相应的值替换该名称。
例如,假设您想要显示算术计算的结果。您可以用一个简单的print()语句来实现,用逗号分隔数值和字符串:
>>> n = 20 >>> m = 25 >>> prod = n * m >>> print('The product of', n, 'and', m, 'is', prod) The product of 20 and 25 is 500但是这很麻烦。要使用 f 弦完成同样的事情:
- 直接在字符串的左引号前指定小写
f或大写F。这告诉 Python 它是 f 字符串而不是标准字符串。- 在花括号(
{})中指定任何要插值的变量。使用 f 弦重新转换,上面的例子看起来更清晰:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'The product of {n} and {m} is {prod}')
The product of 20 and 25 is 500
Python 的三种引用机制中的任何一种都可以用来定义 f 字符串:
>>> var = 'Bark' >>> print(f'A dog says {var}!') A dog says Bark! >>> print(f"A dog says {var}!") A dog says Bark! >>> print(f'''A dog says {var}!''') A dog says Bark!修改字符串
一言以蔽之,不能。字符串是 Python 认为不可变的数据类型之一,这意味着不能被改变。事实上,到目前为止,您看到的所有数据类型都是不可变的。(Python 确实提供可变的数据类型,您很快就会看到这一点。)
像这样的语句会导致错误:
>>> s = 'foobar'
>>> s[3] = 'x'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 'x'
TypeError: 'str' object does not support item assignment
事实上,没有必要修改字符串。您通常可以通过生成原始字符串的副本来轻松完成您想要的操作,该副本中包含了所需的更改。在 Python 中有很多方法可以做到这一点。这里有一种可能性:
>>> s = s[:3] + 'x' + s[4:] >>> s 'fooxar'还有一个内置的字符串方法来实现这一点:
>>> s = 'foobar'
>>> s = s.replace('b', 'x')
>>> s
'fooxar'
请继续阅读关于内置字符串方法的更多信息!
内置字符串方法
您在 Python 中的变量教程中了解到 Python 是一种高度面向对象的语言。Python 程序中的每一项数据都是一个对象。
您还熟悉函数:可以调用来执行特定任务的可调用过程。
方法类似于函数。方法是一种与对象紧密关联的特殊类型的可调用过程。像函数一样,调用方法来执行不同的任务,但它是在特定的对象上调用的,并且在执行期间知道其目标对象。
调用对象上的方法的语法如下:
obj.foo(<args>)
这将调用对象obj上的方法.foo()。<args>指定传递给方法的参数(如果有的话)。
在面向对象编程的讨论中,您将会深入探讨如何定义和调用方法。目前,我们的目标是展示 Python 支持的一些更常用的对字符串对象进行操作的内置方法。
在以下方法定义中,方括号([])中指定的参数是可选的。
案例转换
该组中的方法对目标字符串执行大小写转换。
s.capitalize()
将目标字符串大写。
s.capitalize()返回s的副本,其中第一个字符转换为大写,所有其他字符转换为小写:
>>> s = 'foO BaR BAZ quX' >>> s.capitalize() 'Foo bar baz qux'非字母字符不变:
>>> s = 'foo123#BAR#.'
>>> s.capitalize()
'Foo123#bar#.'
s.lower()
将字母字符转换为小写。
s.lower()返回s的副本,其中所有字母字符都转换为小写:
>>> 'FOO Bar 123 baz qUX'.lower() 'foo bar 123 baz qux'
s.swapcase()交换字母字符的大小写。
s.swapcase()返回s的副本,其中大写字母字符被转换为小写字母,反之亦然:
>>> 'FOO Bar 123 baz qUX'.swapcase()
'foo bAR 123 BAZ Qux'
s.title()
将目标字符串转换为“标题大小写”
s.title()返回s的副本,其中每个单词的第一个字母转换为大写,其余字母为小写:
>>> 'the sun also rises'.title() 'The Sun Also Rises'这个方法使用一个相当简单的算法。它不试图区分重要和不重要的单词,也不优雅地处理撇号、所有格或缩写词:
>>> "what's happened to ted's IBM stock?".title()
"What'S Happened To Ted'S Ibm Stock?"
s.upper()
将字母字符转换为大写。
s.upper()返回s的副本,其中所有字母字符都转换为大写:
>>> 'FOO Bar 123 baz qUX'.upper() 'FOO BAR 123 BAZ QUX'查找并替换
这些方法提供了在目标字符串中搜索指定子字符串的各种方法。
该组中的每个方法都支持可选的
<start>和<end>参数。这些被解释为字符串切片:该方法的动作被限制在目标字符串的一部分,从字符位置<start>开始,一直到但不包括字符位置<end>。如果指定了<start>,但没有指定<end>,则该方法适用于从<start>到字符串末尾的目标字符串部分。
s.count(<sub>[, <start>[, <end>]])统计子字符串在目标字符串中的出现次数。
s.count(<sub>)返回子串<sub>在s中非重叠出现的次数:
>>> 'foo goo moo'.count('oo')
3
如果指定了<start>和<end>,则计数被限制为子串中出现的次数:
>>> 'foo goo moo'.count('oo', 0, 8) 2
s.endswith(<suffix>[, <start>[, <end>]])确定目标字符串是否以给定的子字符串结尾。
如果
s以指定的<suffix>结束,则s.endswith(<suffix>)返回True,否则返回False;
>>> 'foobar'.endswith('bar')
True
>>> 'foobar'.endswith('baz')
False
比较仅限于由<start>和<end>指示的子串,如果它们被指定:
>>> 'foobar'.endswith('oob', 0, 4) True >>> 'foobar'.endswith('oob', 2, 4) False
s.find(<sub>[, <start>[, <end>]])在目标字符串中搜索给定的子字符串。
您可以使用
.find()来查看 Python 字符串是否包含特定的子字符串。s.find(<sub>)返回在s中找到子串<sub>的最低索引:
>>> 'foo bar foo baz foo qux'.find('foo')
0
如果没有找到指定的子字符串,该方法返回-1:
>>> 'foo bar foo baz foo qux'.find('grault') -1如果指定了
<start>和<end>,则搜索被限制在由它们指示的子串中:
>>> 'foo bar foo baz foo qux'.find('foo', 4)
8
>>> 'foo bar foo baz foo qux'.find('foo', 4, 7)
-1
s.index(<sub>[, <start>[, <end>]])
在目标字符串中搜索给定的子字符串。
这个方法与.find()相同,除了如果没有找到<sub>它会引发一个异常,而不是返回-1:
>>> 'foo bar foo baz foo qux'.index('grault') Traceback (most recent call last): File "<pyshell#0>", line 1, in <module> 'foo bar foo baz foo qux'.index('grault') ValueError: substring not found
s.rfind(<sub>[, <start>[, <end>]])在目标字符串中搜索从末尾开始的给定子字符串。
s.rfind(<sub>)返回在s中找到子串<sub>的最高索引:
>>> 'foo bar foo baz foo qux'.rfind('foo')
16
与.find()一样,如果没有找到子串,则返回-1:
>>> 'foo bar foo baz foo qux'.rfind('grault') -1如果指定了
<start>和<end>,则搜索被限制在由它们指示的子串中:
>>> 'foo bar foo baz foo qux'.rfind('foo', 0, 14)
8
>>> 'foo bar foo baz foo qux'.rfind('foo', 10, 14)
-1
s.rindex(<sub>[, <start>[, <end>]])
在目标字符串中搜索从末尾开始的给定子字符串。
这个方法与.rfind()相同,除了如果没有找到<sub>它会引发一个异常,而不是返回-1:
>>> 'foo bar foo baz foo qux'.rindex('grault') Traceback (most recent call last): File "<pyshell#1>", line 1, in <module> 'foo bar foo baz foo qux'.rindex('grault') ValueError: substring not found
s.startswith(<prefix>[, <start>[, <end>]])确定目标字符串是否以给定的子字符串开头。
当使用 Python
.startswith()方法时,如果s以指定的<suffix>开始,则s.startswith(<suffix>)返回True,否则返回False:
>>> 'foobar'.startswith('foo')
True
>>> 'foobar'.startswith('bar')
False
比较仅限于由<start>和<end>指示的子串,如果它们被指定:
>>> 'foobar'.startswith('bar', 3) True >>> 'foobar'.startswith('bar', 3, 2) False字符分类
该组中的方法根据字符串包含的字符对字符串进行分类。
s.isalnum()确定目标字符串是否由字母数字字符组成。
如果
s为非空且所有字符均为字母数字(字母或数字),则s.isalnum()返回True,否则返回False:
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
s.isalpha()
确定目标字符串是否由字母字符组成。
如果s非空且所有字符都是字母,则s.isalpha()返回True,否则False:
>>> 'ABCabc'.isalpha() True >>> 'abc123'.isalpha() False
s.isdigit()确定目标字符串是否由数字字符组成。
您可以使用
.isdigit()Python 方法来检查您的字符串是否仅由数字组成。如果s非空且所有字符均为数字,则s.isdigit()返回True,否则返回False:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
s.isidentifier()
确定目标字符串是否是有效的 Python 标识符。
根据语言定义,如果s是有效的 Python 标识符,则s.isidentifier()返回True,否则返回False:
>>> 'foo32'.isidentifier() True >>> '32foo'.isidentifier() False >>> 'foo$32'.isidentifier() False注意:
.isidentifier()将为匹配 Python 关键字的字符串返回True,即使这实际上不是有效的标识符:
>>> 'and'.isidentifier()
True
您可以使用一个名为iskeyword()的函数来测试一个字符串是否匹配一个 Python 关键字,这个函数包含在一个名为keyword的模块中。一种可行的方法如下所示:
>>> from keyword import iskeyword >>> iskeyword('and') True如果你真的想确保一个字符串作为一个有效的 Python 标识符,你应该检查一下
.isidentifier()是True并且iskeyword()是False。参见 Python 模块和包——简介阅读更多关于 Python 模块的内容。
s.islower()确定目标字符串的字母字符是否为小写。
如果
s非空,并且包含的所有字母字符都是小写,则s.islower()返回True,否则返回False。非字母字符被忽略:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
s.isprintable()
确定目标字符串是否完全由可打印字符组成。
如果s为空或者它包含的所有字母字符都可以打印,则s.isprintable()返回True。如果s包含至少一个不可打印的字符,它将返回False。非字母字符被忽略:
>>> 'a\tb'.isprintable() False >>> 'a b'.isprintable() True >>> ''.isprintable() True >>> 'a\nb'.isprintable() False注意:如果
s是空字符串,这是唯一返回True的.isxxxx()方法。所有其他的返回空字符串的False。
s.isspace()确定目标字符串是否由空白字符组成。
如果
s非空且所有字符都是空白字符,则s.isspace()返回True,否则返回False。最常见的空白字符是空格
' '、制表符'\t'和换行符'\n':
>>> ' \t \n '.isspace()
True
>>> ' a '.isspace()
False
然而,还有一些其他的 ASCII 字符符合空白条件,如果考虑 Unicode 字符,还有很多超出空白的字符:
>>> '\f\u2005\r'.isspace() True(
'\f'和'\r'是 ASCII 换页符和回车符的转义序列;'\u2005'是 Unicode 四行空格的转义序列。)
s.istitle()确定目标字符串是否区分大小写。
s.istitle()返回True如果s非空,则每个单词的第一个字母字符大写,每个单词的其他字母字符小写。否则返回False:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
注意:下面是 Python 文档对.istitle()的描述,如果你觉得这样更直观的话:“大写字符只能跟在无大小写字符后面,小写字符只能跟在有大小写字符后面。”
s.isupper()
确定目标字符串的字母字符是否为大写。
如果s非空,并且包含的所有字母字符都是大写,则s.isupper()返回True,否则返回False。非字母字符被忽略:
>>> 'ABC'.isupper() True >>> 'ABC1$D'.isupper() True >>> 'Abc1$D'.isupper() False字符串格式化
该组中的方法修改或增强字符串的格式。
s.center(<width>[, <fill>])将字段中的字符串居中。
s.center(<width>)返回一个由位于宽度为<width>的字段中心的s组成的字符串。默认情况下,填充由 ASCII 空格字符组成:
>>> 'foo'.center(10)
' foo '
如果指定了可选的<fill>参数,它将被用作填充字符:
>>> 'bar'.center(10, '-') '---bar----'如果
s已经至少与<width>一样长,则返回不变:
>>> 'foo'.center(2)
'foo'
s.expandtabs(tabsize=8)
展开字符串中的选项卡。
s.expandtabs()用空格替换每个制表符('\t')。默认情况下,填充空格时假设每八列有一个制表位:
>>> 'a\tb\tc'.expandtabs() 'a b c' >>> 'aaa\tbbb\tc'.expandtabs() 'aaa bbb c'
tabsize是一个可选的关键字参数,用于指定可选的制表位列:
>>> 'a\tb\tc'.expandtabs(4)
'a b c'
>>> 'aaa\tbbb\tc'.expandtabs(tabsize=4)
'aaa bbb c'
s.ljust(<width>[, <fill>])
将字段中的字符串左对齐。
s.ljust(<width>)返回由宽度为<width>的字段中左对齐的s组成的字符串。默认情况下,填充由 ASCII 空格字符组成:
>>> 'foo'.ljust(10) 'foo '如果指定了可选的
<fill>参数,它将被用作填充字符:
>>> 'foo'.ljust(10, '-')
'foo-------'
如果s已经至少与<width>一样长,则返回不变:
>>> 'foo'.ljust(2) 'foo'
s.lstrip([<chars>])修剪字符串中的前导字符。
s.lstrip()返回s的副本,其中左端的所有空白字符都被删除:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> '\t\nfoo\t\nbar\t\nbaz'.lstrip()
'foo\t\nbar\t\nbaz'
如果指定了可选的<chars>参数,它是一个指定要删除的字符集的字符串:
>>> 'http://www.realpython.com'.lstrip('/:pth') 'www.realpython.com'
s.replace(<old>, <new>[, <count>])替换字符串中出现的子字符串。
在 Python 中,要从字符串中删除一个字符,可以使用 Python string
.replace()方法。s.replace(<old>, <new>)返回一个s的副本,所有出现的子串<old>都被替换为<new>:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault')
'grault bar grault baz grault qux'
如果指定了可选的<count>参数,从s的左端开始,最多执行<count>次替换:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault', 2) 'grault bar grault baz foo qux'
s.rjust(<width>[, <fill>])将字段中的字符串右对齐。
s.rjust(<width>)返回由宽度为<width>的字段中右对齐的s组成的字符串。默认情况下,填充由 ASCII 空格字符组成:
>>> 'foo'.rjust(10)
' foo'
如果指定了可选的<fill>参数,它将被用作填充字符:
>>> 'foo'.rjust(10, '-') '-------foo'如果
s已经至少与<width>一样长,则返回不变:
>>> 'foo'.rjust(2)
'foo'
s.rstrip([<chars>])
修剪字符串中的尾随字符。
s.rstrip()返回从右端删除所有空白字符的s的副本:
>>> ' foo bar baz '.rstrip() ' foo bar baz' >>> 'foo\t\nbar\t\nbaz\t\n'.rstrip() 'foo\t\nbar\t\nbaz'如果指定了可选的
<chars>参数,它是一个指定要删除的字符集的字符串:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
s.strip([<chars>])
从字符串的左端和右端去除字符。
s.strip()本质上相当于连续调用s.lstrip()和s.rstrip()。如果没有<chars>参数,它将删除开头和结尾的空格:
>>> s = ' foo bar baz\t\t\t' >>> s = s.lstrip() >>> s = s.rstrip() >>> s 'foo bar baz'与
.lstrip()和.rstrip()一样,可选的<chars>参数指定要删除的字符集:
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
注意:当一个字符串方法的返回值是另一个字符串时,通常情况下,可以通过链接调用来连续调用方法:
>>> ' foo bar baz\t\t\t'.lstrip().rstrip() 'foo bar baz' >>> ' foo bar baz\t\t\t'.strip() 'foo bar baz' >>> 'www.realpython.com'.lstrip('w.moc').rstrip('w.moc') 'realpython' >>> 'www.realpython.com'.strip('w.moc') 'realpython'
s.zfill(<width>)用零填充左边的字符串。
s.zfill(<width>)将左侧填充有'0'字符的s的副本返回给指定的<width>:
>>> '42'.zfill(5)
'00042'
如果s包含前导符号,则在插入零后,它仍位于结果字符串的左边缘:
>>> '+42'.zfill(8) '+0000042' >>> '-42'.zfill(8) '-0000042'如果
s已经至少与<width>一样长,则返回不变:
>>> '-42'.zfill(3)
'-42'
.zfill()对于数字的字符串表示最有用,但是 Python 仍然乐意用零填充不是数字的字符串:
>>> 'foo'.zfill(6) '000foo'在字符串和列表之间转换
该组中的方法通过将对象粘贴在一起形成一个字符串,或者通过将字符串拆分成多个部分,在字符串和某种复合数据类型之间进行转换。
这些方法操作或返回 iterables ,这是一个通用的 Python 术语,表示对象的顺序集合。在接下来的关于明确迭代的教程中,您将更详细地探索 iterables 的内部工作方式。
这些方法中的许多要么返回列表,要么返回元组。这是两个相似的复合数据类型,是 Python 中可迭代对象的原型示例。它们将在下一个教程中介绍,所以您很快就会了解它们!在此之前,只需将它们视为值的序列。列表用方括号(
[])括起来,元组用圆括号(())括起来。有了这些介绍,让我们看看最后一组字符串方法。
s.join(<iterable>)串联 iterable 中的字符串。
s.join(<iterable>)返回连接由s分隔的<iterable>中的对象得到的字符串。请注意,
.join()是在分隔符字符串s上调用的。<iterable>也必须是一个字符串对象序列。一些示例代码应该有助于澄清。在下面的例子中,分隔符
s是字符串', ',而<iterable>是字符串值的列表:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
结果是由逗号分隔的列表对象组成的单个字符串。
在下一个示例中,<iterable>被指定为单个字符串值。当字符串值用作 iterable 时,它被解释为字符串的单个字符的列表:
>>> list('corge') ['c', 'o', 'r', 'g', 'e'] >>> ':'.join('corge') 'c:o:r:g:e'因此,
':'.join('corge')的结果是由用':'分隔的'corge'中的每个字符组成的字符串。此示例失败,因为
<iterable>中的一个对象不是字符串:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
不过,这是可以补救的:
>>> '---'.join(['foo', str(23), 'bar']) 'foo---23---bar'正如您将很快看到的,Python 中的许多复合对象可以被解释为 iterables,并且
.join()对于从它们创建字符串特别有用。
s.partition(<sep>)基于分隔符分割字符串。
s.partition(<sep>)在字符串<sep>第一次出现时拆分s。返回值是由三部分组成的元组,包括:
s在<sep>之前的部分<sep>本身<sep>之后的s部分这里有几个
.partition()的例子:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
如果在s中没有找到<sep>,则返回的元组包含s,后跟两个空字符串:
>>> 'foo.bar'.partition('@@') ('foo.bar', '', '')记住:列表和元组会在下一个教程中介绍。
s.rpartition(<sep>)基于分隔符分割字符串。
s.rpartition(<sep>)的功能与s.partition(<sep>)完全相同,除了s在<sep>的最后一次出现而不是第一次出现时被分割:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
s.rsplit(sep=None, maxsplit=-1)
将一个字符串拆分成子字符串列表。
如果没有参数,s.rsplit()将s分割成由任何空白序列分隔的子字符串,并将子字符串作为列表返回:
>>> 'foo bar baz qux'.rsplit() ['foo', 'bar', 'baz', 'qux'] >>> 'foo\n\tbar baz\r\fqux'.rsplit() ['foo', 'bar', 'baz', 'qux']如果指定了
<sep>,它将被用作分割的分隔符:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
(如果用值 None 指定<sep>,字符串由空白分隔,就像根本没有指定<sep>。)
当<sep>被显式指定为分隔符时,s中的连续分隔符被假定为分隔空字符串,将返回:
>>> 'foo...bar'.rsplit(sep='.') ['foo', '', '', 'bar']然而,当省略
<sep>时,情况并非如此。在这种情况下,连续的空白字符被组合成一个分隔符,结果列表将不会包含空字符串:
>>> 'foo\t\t\tbar'.rsplit()
['foo', 'bar']
如果指定了可选的关键字参数<maxsplit>,则从s的右端开始,最多执行这么多次分割:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=1) ['www.realpython', 'com']
<maxsplit>的默认值是-1,这意味着应该执行所有可能的分割——就像完全省略了<maxsplit>一样:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=-1)
['www', 'realpython', 'com']
>>> 'www.realpython.com'.rsplit(sep='.')
['www', 'realpython', 'com']
s.split(sep=None, maxsplit=-1)
将一个字符串拆分成子字符串列表。
s.split()的行为与s.rsplit()完全一样,除了如果指定了<maxsplit>,分割从s的左端而不是右端开始计数:
>>> 'www.realpython.com'.split('.', maxsplit=1) ['www', 'realpython.com'] >>> 'www.realpython.com'.rsplit('.', maxsplit=1) ['www.realpython', 'com']如果没有指定
<maxsplit>,则.split()和.rsplit()无法区分。
s.splitlines([<keepends>])在行边界断开字符串。
s.splitlines()将s拆分成行,并在列表中返回它们。以下任何字符或字符序列都被视为构成了一条线边界:
换码顺序 性格;角色;字母 \n新行 \r回车 \r\n回车+换行 \v或\x0b线条制表 \f或\x0c换页 \x1c文件分隔符 \x1d组分隔符 \x1e记录分离器 \x85下一行(C1 控制代码) \u2028Unicode 行分隔符 \u2029Unicode 段落分隔符 下面是一个使用几种不同行分隔符的示例:
>>> 'foo\nbar\r\nbaz\fqux\u2028quux'.splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
如果字符串中存在连续的行边界字符,则假定它们分隔空行,这些空行将出现在结果列表中:
>>> 'foo\f\f\fbar'.splitlines() ['foo', '', '', 'bar']如果指定了可选的
<keepends>参数并且该参数为真,则结果字符串中会保留线条边界:
>>> 'foo\nbar\nbaz\nqux'.splitlines(True)
['foo\n', 'bar\n', 'baz\n', 'qux']
>>> 'foo\nbar\nbaz\nqux'.splitlines(1)
['foo\n', 'bar\n', 'baz\n', 'qux']
bytes物体
bytes对象是操作二进制数据的核心内置类型之一。bytes对象是单个字节值的不可变序列。一个bytes对象中的每个元素都是一个在0到255范围内的小整数。
定义一个文字bytes对象
bytes文字的定义方式与字符串文字相同,只是增加了一个'b'前缀:
>>> b = b'foo bar baz' >>> b b'foo bar baz' >>> type(b) <class 'bytes'>与字符串一样,您可以使用单引号、双引号或三引号机制中的任何一种:
>>> b'Contains embedded "double" quotes'
b'Contains embedded "double" quotes'
>>> b"Contains embedded 'single' quotes"
b"Contains embedded 'single' quotes"
>>> b'''Contains embedded "double" and 'single' quotes'''
b'Contains embedded "double" and \'single\' quotes'
>>> b"""Contains embedded "double" and 'single' quotes"""
b'Contains embedded "double" and \'single\' quotes'
在bytes文字中只允许 ASCII 字符。任何大于127的字符值都必须使用适当的转义序列来指定:
>>> b = b'foo\xddbar' >>> b b'foo\xddbar' >>> b[3] 221 >>> int(0xdd) 221可以在
bytes文字上使用'r'前缀来禁止处理转义序列,就像字符串一样:
>>> b = rb'foo\xddbar'
>>> b
b'foo\\xddbar'
>>> b[3]
92
>>> chr(92)
'\\'
用内置的bytes()函数定义一个bytes对象
bytes()函数也创建了一个bytes对象。返回哪种类型的bytes对象取决于传递给函数的参数。可能的形式如下所示。
bytes(<s>, <encoding>)
从字符串创建一个
bytes对象。
bytes(<s>, <encoding>)将字符串<s>转换为bytes对象,根据指定的<encoding>使用str.encode():
>>> b = bytes('foo.bar', 'utf8') >>> b b'foo.bar' >>> type(b) <class 'bytes'>技术说明:在这种形式的
bytes()函数中,<encoding>参数是必需的。“编码”是指将字符转换为整数值的方式。值"utf8"表示 Unicode 转换格式 UTF-8 ,这是一种可以处理所有可能的 Unicode 字符的编码。UTF-8 也可以通过指定"UTF8"、"utf-8"或"UTF-8"表示<encoding>。更多信息参见 Unicode 文档。只要您处理的是常见的拉丁字符,UTF-8 将为您提供良好的服务。
bytes(<size>)创建一个由空(
0x00)字节组成的bytes对象。
bytes(<size>)定义了一个指定<size>的bytes对象,必须是正整数。产生的bytes对象被初始化为空(0x00)字节:
>>> b = bytes(8)
>>> b
b'\x00\x00\x00\x00\x00\x00\x00\x00'
>>> type(b)
<class 'bytes'>
bytes(<iterable>)
从 iterable 创建一个
bytes对象。
bytes(<iterable>)从由<iterable>生成的整数序列中定义一个bytes对象。<iterable>必须是一个 iterable,它生成一个在0 ≤ n ≤ 255范围内的整数序列n:
>>> b = bytes([100, 102, 104, 106, 108]) >>> b b'dfhjl' >>> type(b) <class 'bytes'> >>> b[2] 104对
bytes对象的操作像字符串一样,
bytes对象支持常见的序列操作:
in和not in操作符:
```py
>>> b = b'abcde'
>>> b'cd' in b
True
>>> b'foo' not in b
True`
```
-
串联(
+)和复制(*)运算符:>>> b = b'abcde' >>> b + b'fghi' b'abcdefghi' >>> b * 3 b'abcdeabcdeabcde'`>>> b = b'abcde' >>> b[2] 99 >>> b[1:3] b'bc'` -
内置函数:
>>> len(b) 5 >>> min(b) 97 >>> max(b) 101`
>>> b = b'foo,bar,foo,baz,foo,qux'
>>> b.count(b'foo')
3
>>> b.endswith(b'qux')
True
>>> b.find(b'baz')
12
>>> b.split(sep=b',')
[b'foo', b'bar', b'foo', b'baz', b'foo', b'qux']
>>> b.center(30, b'-')
b'---foo,bar,foo,baz,foo,qux----'
但是,请注意,当这些操作符和方法在一个bytes对象上被调用时,操作数和参数也必须是bytes对象:
>>> b = b'foo.bar' >>> b + '.baz' Traceback (most recent call last): File "<pyshell#72>", line 1, in <module> b + '.baz' TypeError: can't concat bytes to str >>> b + b'.baz' b'foo.bar.baz' >>> b.split(sep='.') Traceback (most recent call last): File "<pyshell#74>", line 1, in <module> b.split(sep='.') TypeError: a bytes-like object is required, not 'str' >>> b.split(sep=b'.') [b'foo', b'bar']虽然一个
bytes对象的定义和表示是基于 ASCII 文本的,但它实际上表现得像一个不可变的小整数序列,范围在0到255之间,包括这两个值。这就是为什么来自bytes对象的单个元素显示为整数:
>>> b = b'foo\xddbar'
>>> b[3]
221
>>> hex(b[3])
'0xdd'
>>> min(b)
97
>>> max(b)
221
尽管一个切片显示为一个bytes对象,即使它只有一个字节长:
>>> b[2:3] b'c'您可以使用内置的
list()函数将bytes对象转换成整数列表:
>>> list(b)
[97, 98, 99, 100, 101]
十六进制数通常用于指定二进制数据,因为两个十六进制数字直接对应一个字节。bytes类支持两种额外的方法,这两种方法有助于十六进制数字串之间的相互转换。
bytes.fromhex(<s>)
返回一个由一串十六进制值构成的
bytes对象。
bytes.fromhex(<s>)返回将<s>中的每对十六进制数字转换成相应的字节值后得到的bytes对象。<s>中的十六进制数字对可以选择性地用空白分隔,空白被忽略:
>>> b = bytes.fromhex(' aa 68 4682cc ') >>> b b'\xaahF\x82\xcc' >>> list(b) [170, 104, 70, 130, 204]注意:这个方法是一个类方法,不是一个对象方法。它被绑定到
bytes类,而不是bytes对象。在接下来的关于面向对象编程的教程中,你会更深入地了解类、对象以及它们各自的方法之间的区别。现在,只需注意这个方法是在bytes类上调用的,而不是在对象b上调用的。
b.hex()从一个
bytes对象返回一串十六进制值。
b.hex()返回将bytes对象b转换成一串十六进制数字对的结果。也就是说,它与.fromhex()相反:
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'\xaahF\x82\xcc'
>>> b.hex()
'aa684682cc'
>>> type(b.hex())
<class 'str'>
注意:与.fromhex()相对,.hex()是对象方法,不是类方法。因此,它是在bytes类的对象上调用的,而不是在类本身上。
bytearray物体
Python 支持另一种称为bytearray的二进制序列类型。bytearray物体与bytes物体非常相似,尽管有些不同:
-
Python 中没有定义
bytearray文字的专用语法,比如可以用来定义bytes对象的'b'前缀。一个bytearray对象总是使用bytearray()内置函数创建的:>>> ba = bytearray('foo.bar.baz', 'UTF-8') >>> ba bytearray(b'foo.bar.baz') >>> bytearray(6) bytearray(b'\x00\x00\x00\x00\x00\x00') >>> bytearray([100, 102, 104, 106, 108]) bytearray(b'dfhjl')`>>> ba = bytearray('foo.bar.baz', 'UTF-8') >>> ba bytearray(b'foo.bar.baz') >>> ba[5] = 0xee >>> ba bytearray(b'foo.b\xeer.baz') >>> ba[8:11] = b'qux' >>> ba bytearray(b'foo.b\xeer.qux')`
一个bytearray对象也可以直接由一个bytes对象构成:
>>> ba = bytearray(b'foo') >>> ba bytearray(b'foo')结论
本教程深入介绍了 Python 为字符串处理提供的许多不同机制,包括字符串操作符、内置函数、索引、切片和内置方法。你还被介绍给了
bytes和bytearray类型的人。这些类型是您已经检查过的第一批复合类型——由一组较小的部分构建而成。Python 提供了几种复合内置类型。在下一篇教程中,您将探索两个最常用的:列表和元组。
参加测验:通过我们的交互式“Python 字符串和字符数据”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*« Operators and Expressions in PythonStrings in PythonLists and Tuples in Python »
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解:Python 中的字符串和字符数据********
子流程模块:用 Python 包装程序
如果你曾经想简化你的命令行脚本或者在命令行应用程序中使用 Python——或者任何相关的应用程序——那么 Python
subprocess模块可以帮助你。从运行 shell 命令和命令行应用程序到启动 GUI 应用程序,Pythonsubprocess模块可以提供帮助。本教程结束时,您将能够:
- 理解 Python
subprocess模块如何与操作系统交互- 发布外壳命令,如
ls或dir- 将输入送入一个流程,并使用其输出。
- 使用
subprocess时处理错误- 通过考虑实际例子,理解
subprocess的用例在本教程中,在进入
subprocess模块和实验示例之前,您将获得一个高级心智模型,用于理解流程、子流程和 Python。之后,您将开始探索 shell 并学习如何利用 Python 的subprocess和基于 Windows 和 UNIX 的shell 和系统。具体来说,您将涉及与进程、管道和错误处理的通信。注意:
subprocess不是 GUI 自动化模块,也不是实现并发的一种方式。对于 GUI 自动化,你可能想看看 PyAutoGUI 。关于并发性,请看一下本教程中与subprocess相关的模块部分。一旦你有了基础,你将会探索一些如何利用 Python 的
subprocess的实用想法。您还将通过实验底层的Popen()构造函数来尝试 Python 的subprocess的高级用法。源代码: 点击这里下载免费的源代码,您将使用它来熟悉 Python
subprocess模块。流程和子流程
首先,您可能想知道为什么 Python
subprocess模块名称中有一个sub。到底什么是过程呢?在本节中,您将回答这些问题。你将获得一个思考过程的高级心智模型。如果你已经熟悉了流程,那么你可能想直接跳到 Pythonsubprocess模块的基本用法。进程和操作系统
每当你使用计算机时,你总是在和程序互动。进程是操作系统对正在运行的程序的抽象。所以,使用计算机总是涉及到过程。开始菜单、应用程序栏、命令行解释器、文本编辑器、浏览器等等——每个应用程序都包含一个或多个进程。
一个典型的操作系统会报告数百甚至数千个正在运行的进程,稍后您将了解这些进程。然而,中央处理单元(CPU)通常只有少量内核,这意味着它们只能同时运行少量指令。因此,您可能想知道成千上万的进程是如何同时运行的。
简而言之,操作系统是一个了不起的多任务处理系统——它必须如此。CPU 是计算机的大脑,但它以纳秒的时间尺度运行。计算机的大多数其他组件都比 CPU 慢得多。例如,一个磁性硬盘的读取时间比一个典型的 CPU 操作要长几千倍。
如果一个进程需要在硬盘上写东西,或者等待远程服务器的响应,那么 CPU 会在大部分时间处于空闲状态。多任务处理让 CPU 忙个不停。
操作系统在多任务处理方面如此出色的部分原因是它的组织性也非常好。操作系统在进程表或进程控制块中跟踪进程。在这个表中,您会发现进程的文件句柄,安全上下文,对其地址空间的引用,等等。
进程表允许操作系统随意放弃一个特定的进程,因为它拥有在以后返回并继续该进程所需的所有信息。一个进程在执行过程中可能会被中断成千上万次,但是操作系统总是会在返回时找到它停止的确切位置。
然而,一个操作系统不会启动成千上万个进程。你熟悉的许多过程都是由你开始的。在下一节中,您将研究一个进程的生命周期。
流程寿命
考虑如何从命令行启动 Python 应用程序。这是您的命令行进程启动 Python 进程的一个实例:
启动另一个进程的进程被称为父进程,新进程被称为子进程。父进程和子进程通常独立运行。有时,子节点从父节点继承特定的资源或上下文。
正如您在进程和操作系统中了解到的,关于进程的信息保存在一个表中。每个进程都跟踪其父进程,这使得进程层次结构可以表示为一棵树。在下一节的中,您将探索您系统的流程树。
注意:创建进程的精确机制因操作系统而异。简要概述一下,维基百科关于流程管理的文章中有一小段是关于流程创建的。
有关 Windows 机制的更多细节,请查看 win32 API 文档页面上的创建进程
在基于 UNIX 的系统上,通常通过使用
fork()复制当前进程,然后用exec()系列函数之一替换子进程来创建进程。流程及其子流程之间的父子关系并不总是相同的。有时这两个过程会共享特定的资源,比如输入和输出,但有时不会。有时子进程比父进程生存时间长。子进程比父进程长寿会导致孤儿或僵尸进程,尽管关于这些的更多讨论超出了本教程的范围。
当一个进程完成运行时,它通常会结束。每个进程在退出时都应该返回一个整数。这个整数被称为返回码或退出状态。零是成功的同义词,而任何其他值都被认为是失败。不同的整数可以用来表示进程失败的原因。
就像您可以从 Python 中的函数返回值一样,一旦进程退出,操作系统也希望它返回一个整数。这就是为什么规范的 C
main()函数通常返回一个整数:// minimal_program.c int main(){ return 0; }这个例子显示了使用
gcc编译文件所需的最少 C 代码,并且没有任何警告。它有一个返回整数的main()函数。当这个程序运行时,操作系统将把它的执行解释为成功,因为它返回零。那么,现在您的系统上正在运行哪些进程呢?在下一节中,您将探索一些可以用来查看系统进程树的工具。当可视化
subprocess模块如何工作时,能够看到哪些进程正在运行以及它们是如何构造的将会很方便。系统上的活动进程
您可能很想知道现在系统上正在运行什么进程。为此,您可以使用特定于平台的实用程序来跟踪它们:
- 视窗
** Linux + macOS**有许多工具可用于 Windows,但有一个工具很容易设置,速度很快,并且会毫不费力地向您展示进程树,这就是 Process Hacker 。
您可以通过进入下载页面或使用巧克力来安装 Process Hacker:
PS> choco install processhacker打开应用程序,您应该立即看到流程树。
PowerShell 可以使用的本地命令之一是
Get-Process,它在命令行中列出了活动的进程。tasklist是一个命令提示符实用程序,它也能做到这一点。微软官方版本的 Process Hacker 是 Sysinternals 工具的一部分,即进程监视器和进程浏览器。您还会得到 PsList ,这是一个命令行实用程序,类似于 UNIX 上的
pstree。您可以通过进入下载页面或使用 Chocolatey 来安装 Sysinternals:PS> choco install sysinternals您也可以使用更基本但经典的任务管理器—通过按下
Win+X并选择任务管理器来访问。对于基于 UNIX 的系统,有许多命令行实用程序可供选择:
top:经典的进程和资源监视器,通常默认安装。一旦运行,要查看树视图,也叫森林视图,按Shift+V。森林视图可能无法在默认的 macOStop上运行。htop:更高级更人性化的top版本。atop:另一个版本的top,有更多的信息,但更具技术性。bpytop:视觉效果不错的top的 Python 实现。pstree:专门探索流程树的实用程序。在 macOS 上,您的实用程序中也有活动监视器应用程序。在查看菜单中,如果您选择所有流程,分层次选择,您应该能够看到您的流程树。
您还可以探索 Python psutil 库,它允许您在基于 Windows 和 UNIX 的系统上检索运行的进程信息。
跨系统的进程跟踪的一个通用属性是,每个进程都有一个进程标识号,或 PID ,这是一个唯一的整数,用于在操作系统的上下文中标识该进程。您会在上面列出的大多数实用程序中看到这个数字。
除了 PID 之外,通常还可以看到资源使用情况,比如特定进程正在使用的 CPU 的百分比和 RAM 的数量。如果一个程序占用了你所有的资源,这就是你要找的信息。
进程的资源利用率对于开发或调试使用
subprocess模块的脚本很有用,即使您不需要 PID,或者关于代码本身中进程正在使用什么资源的任何信息。在使用即将出现的示例时,考虑打开流程树的表示,以查看新流程的弹出。现在,您已经对流程有了一个大致的了解。在整个教程中,您将深化您的心智模型,但现在是时候看看如何使用 Python
subprocess模块启动您自己的流程了。Python
subprocess模块概述Python
subprocess模块用于启动子流程。这些进程可以是从 GUI 应用程序到 shell 的任何东西。流程的父子关系就是subprocess名称中的子的来源。当您使用subprocess时,Python 是创建新的子流程的父流程。新的子进程是什么,由您决定。Python
subprocess最初是为 Python 2.4 提出并接受作为使用os模块的替代方案。一些有文档记录的更改发生在 3.8 之后。本文中的例子是用 Python 3.10.4 测试的,但是你只需要 3.8+就可以完成本教程。你与 Python
subprocess模块的大部分交互将通过run()函数来完成。这个阻塞功能将启动一个进程,等待直到新进程退出,然后继续。文档推荐使用
run()来处理它能处理的所有情况。对于需要更多控制的边缘情况,可以使用Popen类。Popen是整个subprocess模块的底层类。subprocess模块中的所有函数都是围绕Popen()构造函数及其实例方法的便利包装器。在本教程快结束的时候,你将深入到Popen类。注意:如果你正试图决定你是否需要
subprocess,看看上决定你的任务是否需要subprocess的部分。你可能会遇到其他类似
call()check_call()check_output()的函数,但这些都属于 Python 3.5 及更早版本的更老的subprocessAPI 。这三个函数所做的一切都可以用新的run()函数来复制。旧的 API 主要是为了向后兼容,在本教程中不会涉及。在
subprocess模块中也有相当多的冗余,这意味着有各种方法来实现相同的最终目标。在本教程中,您不会探索所有的变化。不过,你会发现,一些强健的技术应该会让你走在正确的道路上。Python
subprocess模块的基本用法在这一节中,您将看到一些演示
subprocess模块用法的最基本的例子。您将从探索一个带有run()函数的基本命令行定时器程序开始。如果您想按照示例进行操作,那么创建一个新文件夹。所有的例子和程序都可以保存在这个文件夹中。在命令行中导航到这个新创建的文件夹,为后面的示例做准备。本教程中的所有代码都是标准的 Python 库——不需要外部依赖——所以不需要虚拟环境。
定时器示例
为了掌握 Python
subprocess模块,您将需要一个运行和试验的基本程序。为此,您将使用一个用 Python 编写的程序:# timer.py from argparse import ArgumentParser from time import sleep parser = ArgumentParser() parser.add_argument("time", type=int) args = parser.parse_args() print(f"Starting timer of {args.time} seconds") for _ in range(args.time): print(".", end="", flush=True) sleep(1) print("Done!")计时器程序使用
argparse接受一个整数作为参数。整数代表定时器在退出前应该等待的秒数,程序使用sleep()来实现。它将播放一个小动画,代表过去的每一秒,直到它退出:https://player.vimeo.com/video/715636109?background=1
这并不多,但关键是它作为一个跨平台的进程运行了几秒钟,你可以很容易地修补。您将使用
subprocess调用它,就好像它是一个单独的可执行文件。注意:用 Python
subprocess模块调用 Python 程序没有多大意义——通常不需要其他 Python 模块在单独的进程中,因为你可以直接导入它们。对于本教程中的大多数示例,您将使用 Python 程序的主要原因是它们是跨平台的,并且您很可能已经安装了 Python!
您可能会认为启动一个新的进程是实现并发的一个好方法,但这不是
subprocess模块的预期用例。也许你需要的是其他致力于并发的 Python 模块,在后面的章节中会有介绍。
subprocess模块主要用于调用 Python 之外的和程序。但是,如您所见,如果您愿意,也可以调用 Python!有关subprocess用例的更多讨论,请查看部分,其中对此进行了更深入的讨论,或者稍后的示例之一。好了,准备好开始吧!一旦准备好
timer.py程序,打开一个 Python 交互会话,用subprocess调用计时器:
>>> import subprocess
>>> subprocess.run(["python", "timer.py", "5"])
Starting timer of 5 seconds
.....Done!
CompletedProcess(args=['python', 'timer.py', '5'], returncode=0)
使用这段代码,您应该已经看到了在 REPL 中播放的动画。您导入了subprocess,然后调用了run()函数,将字符串列表作为惟一的参数。这是run()功能的args参数。
在执行run()时,定时器进程开始,您可以实时看到它的输出。一旦完成,它返回一个 CompletedProcess 类的实例。
在命令行上,您可能习惯于用单个字符串启动程序:
$ python timer.py 5
然而,使用run(),您需要将命令作为一个序列传递,如run()示例所示。序列中的每一项都代表一个令牌,用于系统调用来启动一个新的进程。
注意:调用run()不同于在命令行上调用程序。run()函数发出一个系统调用,放弃了对 shell 的需求。您将在后面的部分中讨论与 shell 的交互。
Shells 通常会进行自己的标记化,这就是为什么您只需在命令行上将命令写成一个长字符串。但是,使用 Python subprocess模块,您必须手动将命令分解成标记。例如,可执行文件的名称、标志和参数都是一个令牌。
注意:如果你需要,你可以使用 shlex 模块来帮助你,只是要记住它是为 POSIX 兼容系统设计的,可能在 Windows 环境下不能很好地工作:
>>> import shlex >>> shlex.split("python timer.py 5") ['python', 'timer.py', '5'] >>> subprocess.run(shlex.split("python timer.py 5")) Starting timer of 5 seconds .....Done! CompletedProcess(args=['python', 'timer.py', '5'], returncode=0)
split()函数将一个典型的命令分成所需的不同令牌。当不清楚如何分割具有特殊字符(如空格)的更复杂的命令时,shlex模块可以派上用场:
>>> shlex.split("echo 'Hello, World!'")
['echo', 'Hello, World!']
您会注意到,包含空格的消息被保存为单个标记,不再需要额外的引号。外壳上额外的引号用于将令牌分组在一起,但是因为subprocess使用序列,所以应该将哪些部分解释为一个令牌总是很明确的。
现在您已经熟悉了使用 Python subprocess模块启动新进程的一些基本知识,接下来您将看到您可以运行任何类型的进程,而不仅仅是 Python 或基于文本的程序。
使用subprocess运行任何应用
有了subprocess,你不再局限于基于文本的应用程序,比如 shell。只要您知道想要运行的程序的确切名称或路径,您就可以使用“开始”菜单或应用程序栏调用任何应用程序:
***>>>
>>> subprocess.run(["notepad"])
CompletedProcess(args=['notepad'], returncode=0)
>>> subprocess.run(["gedit"]) CompletedProcess(args=['gedit'], returncode=0)根据您的 Linux 发行版,您可能有不同的文本编辑器,比如
kate、leafpad、kwrite或enki。
>>> subprocess.run(["open", "-e"])
CompletedProcess(args=['open', '-e'], returncode=0)
这些命令应该会打开一个文本编辑器窗口。通常CompletedProcess不会被返回,直到你关闭编辑器窗口。然而,在 macOS 的情况下,因为你需要运行启动器进程 open 来启动文本编辑,CompletedProcess会立即返回。
启动器进程负责启动一个特定的进程,然后结束。有时程序,如网络浏览器,内置了这些功能。启动器进程的机制超出了本教程的范围,但是可以说它们能够操纵操作系统的进程树来重新分配父子关系。
注意:有许多问题你可能一开始会找subprocess来解决,但之后你会找到一个特定的模块或库来帮你解决。这倾向于成为subprocess的主题,因为它是一个相当低级的实用程序。
你可能想用subprocess做的事情的一个例子是打开一个网页浏览器到一个特定的页面。然而,为此,最好使用 Python 模块 webbrowser 。webbrowser模块使用subprocess,但是处理你可能遇到的所有挑剔的跨平台和浏览器差异。
话又说回来,subprocess可能是一个非常有用的工具,可以快速完成某件事。如果你不需要一个完整的库,那么subprocess可以成为你的瑞士军刀。这完全取决于您的用例。关于这个话题的更多讨论将在晚些时候进行。
您已经使用 Python 成功启动了新流程!这是最基本的。接下来,您将仔细查看从run()返回的CompletedProcess对象。
CompletedProcess对象
当您使用run()时,返回值是CompletedProcess类的一个实例。顾名思义,run()只在子进程结束后返回对象。它有各种有用的属性,比如用于流程的args和returncode。
为了清楚地看到这一点,您可以将run()的结果赋给一个变量,然后访问它的属性,例如.returncode:
>>> import subprocess >>> completed_process = subprocess.run(["python", "timer.py"]) usage: timer.py [-h] time timer.py: error: the following arguments are required: time >>> completed_process.returncode 2该流程有一个指示失败的返回代码,但是它没有引发异常T5】。通常,当一个
subprocess进程失败时,您总是希望引发一个异常,这可以通过传入一个check=True参数来实现:
>>> completed_process = subprocess.run(
... ["python", "timer.py"],
... check=True ... )
...
usage: timer.py [-h] time
timer.py: error: the following arguments are required: time
Traceback (most recent call last):
...
subprocess.CalledProcessError: Command '['python', 'timer.py']' returned
non-zero exit status 2.
有各种各样的方法来处理失败,其中一些将在下一节中介绍。现在需要注意的重要一点是,如果进程失败,run()不一定会引发异常,除非您已经传入了一个check=True参数。
CompletedProcess还有一些与输入/输出(I/O) 相关的属性,您将在与进程通信一节中更详细地介绍这些属性。不过,在与进程通信之前,您将学习如何在使用subprocess编码时处理错误。
subprocess异常情况
正如您之前看到的,即使一个进程退出并返回一个代表失败的代码,Python 也不会引发异常。对于subprocess模块的大多数用例来说,这并不理想。如果一个过程失败了,你通常会想办法处理它,而不仅仅是继续下去。
许多subprocess用例涉及到简短的个人脚本,你可能不会花太多时间,或者至少不应该在上花太多时间。如果你正在修改这样的脚本,那么你会希望subprocess尽早失败。
CalledProcessError为非零退出代码
如果一个进程返回一个非零的退出代码,你应该把它解释为一个失败的进程。与您可能期望的相反,Python 模块subprocess不会而会在非零退出代码时自动引发异常。一个失败的进程通常不是你希望你的程序悄悄忽略的,所以你可以传递一个check=True参数给run()来引发一个异常:
>>> completed_process = subprocess.run( ... ["python", "timer.py"], ... check=True ... ) ... usage: timer.py [-h] time timer.py: error: the following arguments are required: time Traceback (most recent call last): ... subprocess.CalledProcessError: Command '['python', 'timer.py']' returned non-zero exit status 2.一旦子流程运行到非零返回代码,就会引发
CalledProcessError。如果你正在开发一个简短的个人脚本,那么这可能对你来说已经足够好了。如果您想更优雅地处理错误,那么请继续阅读关于异常处理的章节。需要记住的一点是,
CalledProcessError并不适用于可能会无限期挂起和阻塞您的执行的进程。为了防止这种情况,您需要利用timeout参数。
TimeoutExpired对于耗时过长的过程有时进程表现不佳,它们可能花费太长时间或无限期挂起。为了处理这些情况,使用
run()函数的timeout参数总是一个好主意。向
run()传递一个timeout=1参数将导致该函数关闭进程,并在一秒钟后引发一个TimeoutExpired错误:
>>> import subprocess
>>> subprocess.run(["python", "timer.py", "5"], timeout=1)
Starting timer of 5 seconds
.Traceback (most recent call last):
...
subprocess.TimeoutExpired: Command '['python', 'timer.py', '5']' timed out
after 1.0 seconds
在本例中,输出了计时器动画的第一个点,但是子流程在完成之前关闭了。
另一种可能发生的错误是,该程序在特定系统上不存在,这引发了最后一种错误。
FileNotFoundError对于不存在的程序
您将看到的最后一种异常是FileNotFoundError,如果您试图调用目标系统上不存在的程序,就会引发该异常:
>>> import subprocess >>> subprocess.run(["now_you_see_me"]) Traceback (most recent call last): ... FileNotFoundError: The system cannot find the file specified这种类型的错误无论如何都会出现,所以您不需要为
FileNotFoundError传递任何参数。这些是您在使用 Python
subprocess模块时会遇到的主要异常。对于许多用例,知道异常并确保使用timeout和check参数就足够了。这是因为如果子流程失败了,那么这通常意味着您的脚本失败了。然而,如果您有一个更复杂的程序,那么您可能希望更优雅地处理错误。例如,您可能需要在很长一段时间内调用许多进程。为此,您可以使用
try…except结构。异常处理的例子
这里有一段代码展示了使用
subprocess时需要处理的主要异常:import subprocess try: subprocess.run( ["python", "timer.py", "5"], timeout=10, check=True ) except FileNotFoundError as exc: print(f"Process failed because the executable could not be found.\n{exc}") except subprocess.CalledProcessError as exc: print( f"Process failed because did not return a successful return code. " f"Returned {exc.returncode}\n{exc}" ) except subprocess.TimeoutExpired as exc: print(f"Process timed out.\n{exc}")这个片段向您展示了如何处理由
subprocess模块引发的三个主要异常的示例。既然您已经使用了基本形式的
subprocess并处理了一些异常,那么是时候熟悉如何与 shell 交互了。用
subprocess介绍 Shell 和基于文本的程序
subprocess模块的一些最受欢迎的用例是与基于文本的程序交互,通常在 shell 上可用。这就是为什么在这一节中,您将开始探索与基于文本的程序交互时涉及的所有活动部分,并且可能会问您是否需要 shell!shell 通常与命令行界面或 CLI 同义,但这个术语并不完全准确。实际上有两个独立的过程构成了典型的命令行体验:
- 解释器,通常被认为是整个 CLI。常见的解释器是 Linux 上的 Bash、macOS 上的 Zsh 或 Windows 上的 PowerShell。在本教程中,解释器将被称为外壳。
- 界面,在窗口中显示解释器的输出,并将用户的按键发送给解释器。该接口是一个独立于外壳的进程,有时被称为终端模拟器。
当在命令行上时,通常认为您是在直接与 shell 交互,但实际上您是在与接口交互。该接口负责将您的命令发送到 shell,并将 shell 的输出显示给您。
记住这个重要的区别,是时候把你的注意力转向
run()实际上在做什么了。人们通常认为调用run()在某种程度上与在终端界面中键入命令是一样的,但是有重要的区别。虽然所有的新进程都是用相同的系统调用创建的,但是进行系统调用的上下文是不同的。
run()函数可以直接进行系统调用,而不需要通过 shell 来实现:https://player.vimeo.com/video/715635882?background=1
事实上,许多被认为是外壳程序的程序,比如 Git ,实际上只是不需要外壳就能运行的基于文本的程序。在 UNIX 环境中尤其如此,所有熟悉的实用程序如
ls、rm、grep和cat实际上都是可以直接调用的独立的可执行文件:
>>> # Linux or macOS
>>> import subprocess
>>> subprocess.run(["ls"])
timer.py
CompletedProcess(args=['ls'], returncode=0)
但是,有一些工具是专门针对 shells 的。在像 PowerShell 这样的 Windows Shells 中,查找嵌入到 shell 中的工具要常见得多,像ls这样的命令是 shell 本身的部分,而不是像在 UNIX 环境中那样单独的可执行文件:
>>> # Windows >>> import subprocess >>> subprocess.run(["ls"]) Traceback (most recent call last): ... FileNotFoundError: [WinError 2] The system cannot find the file specified在 PowerShell 中,
ls是Get-ChildItem的默认别名,但是调用它也不行,因为Get-ChildItem不是一个单独的可执行文件——它是 PowerShell 本身的部分。许多基于文本的程序可以独立于 shell 运行,这一事实可能会让您想知道是否可以省去中间过程——即 shell——并直接将
subprocess用于通常与 shell 相关联的基于文本的程序。用例为外壳
subprocess和您可能希望用
Python子进程模块调用 shell 有几个常见原因:
- 当您知道某些命令只能通过 shell 使用时,这在 Windows 中更常见
- 当您有使用特定 shell 编写 shell 脚本的经验时,您会希望在主要使用 Python 的同时利用您的能力来完成某些任务
- 当您继承了一个大型 shell 脚本,该脚本可能做 Python 做不到的事情,但是用 Python 重新实现需要很长时间
这不是一个详尽的列表!
您可以使用 shell 来包装程序或进行一些文本处理。然而,与 Python 相比,语法可能非常晦涩。使用 Python,文本处理工作流更容易编写,更容易维护,通常更具性能,并且可以跨平台启动。所以很值得考虑不带壳去。
然而,经常发生的情况是,您没有时间或者不值得花力气用 Python 重新实现现有的 shell 脚本。在这种情况下,将
subprocess用于一些松散的 Python 并不是一件坏事!使用
subprocess本身的常见原因本质上类似于使用带有subprocess的 shell:注意:黑盒可能是一个可以免费使用的程序,但是它的源代码是不可用的,所以没有办法知道它到底做了什么,也没有办法修改它的内部。
类似地,白盒可以是一个程序,它的源代码是可用的,但不能被修改。它也可能是一个你可以改变其源代码的程序,但是它的复杂性意味着你要花很长时间才能理解它并能够改变它。
在这些情况下,你可以使用
subprocess来包装不同透明度的盒子,绕过任何改变或重新实现 Python 的需要。通常你会发现对于
subprocess用例,会有一个专用的库来完成这个任务。在本教程的后面,您将研究一个创建 Python 项目的脚本,该脚本包含一个虚拟环境和一个完全初始化的 Git 存储库。然而, Cookiecutter 和 Copier 库已经存在。即使特定的库可能能够完成你的任务,用
subprocess做一些事情仍然是值得的。首先,对你来说,执行你已经知道如何做的事情可能比学习一个新的库要快得多。此外,如果您正在与朋友或同事共享这个脚本,那么如果您的脚本是纯 Python 的,没有任何其他依赖性,尤其是如果您的脚本需要在服务器或嵌入式系统这样的最小环境中运行,这将非常方便。
然而,如果您使用
subprocess而不是pathlib来读写 Bash 中的一些文件,您可能需要考虑学习如何使用 Python 来读写。学习如何读写文件并不需要很长时间,对于这样一个普通的任务来说,这绝对是值得的。至此,是时候熟悉基于 Windows 和 UNIX 的系统上的 shell 环境了。
基于 UNIX 的 shell中
subprocess的基本用法要使用
run()运行 shell 命令,args应该包含您想要使用的 shell、指示您想要它运行特定命令的标志,以及您要传入的命令:
>>> import subprocess
>>> subprocess.run(["bash", "-c", "ls /usr/bin | grep pycode"])
pycodestyle
pycodestyle-3
pycodestyle-3.10
CompletedProcess(args=['bash', '-c', 'ls /usr/bin | grep pycode'], returncode=0)
这里演示了一个常见的 shell 命令。它使用通过管道传输到grep的ls来过滤一些条目。对于这种操作,shell 非常方便,因为您可以利用管道操作符(|)。稍后你将更详细地介绍管道。
你可以用你选择的外壳替换bash。-c标志代表命令,但是根据您使用的 shell 可能会有所不同。这几乎与添加shell=True参数时发生的情况完全相同:
>>> subprocess.run(["ls /usr/bin | grep pycode"], shell=True) pycodestyle pycodestyle-3 pycodestyle-3.10 CompletedProcess(args=['ls /usr/bin | grep pycode'], returncode=0)
shell=True参数在幕后使用["sh", "-c", ...],所以它几乎相当于前面的例子。注意:在基于 UNIX 的系统上,
shshell 传统上是 Bourne shell 。也就是说,Bourne shell 现在已经相当老了,所以许多操作系统都使用sh作为链接到 Bash 或 Dash 。这通常不同于与您交互的终端界面所使用的 shell。例如,从 macOS Catalina 开始,你会在命令行应用上发现的默认 shell 已经从 Bash 变成了 Zsh ,然而
sh仍然经常指向 Bash。同样,在 Ubuntu 上,sh指向 Dash,但是您通常在命令行应用程序上与之交互的默认仍然是 Bash。因此,在您的系统上调用
sh可能会产生与本教程中不同的 shell。尽管如此,这些例子应该仍然有效。你会注意到,
"-c"后面的符号应该是一个包含所有空格的符号。在这里,您将控制权交给 shell 来解析命令。如果要包含更多的标记,这将被解释为传递给 shell 可执行文件的更多选项,而不是在 shell 中运行的附加命令。Windows shell中
subprocess的基本用法在这一节中,您将介绍在 Windows 环境中使用
subprocessshell 的基本方法。要使用
run()运行 shell 命令,args应该包含您想要使用的 shell、指示您想要它运行特定命令的标志,以及您要传入的命令:
>>> import subprocess
>>> subprocess.run(["pwsh", "-Command", "ls C:\RealPython"])
Directory: C:\RealPython
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a--- 09/05/22 10:41 237 basics.py
-a--- 18/05/22 17:28 486 hello_world.py
CompletedProcess(args=['pwsh', '-Command', 'ls'], returncode=0)
注意pwsh和pwsh.exe都是工作的。如果你没有 PowerShell Core,那么你可以调用powershell或者powershell.exe。
你会注意到,"-Command"后面的符号应该是一个包含所有空格的符号。在这里,您将控制权交给 shell 来解析命令。如果要包含更多的标记,这将被解释为传递给 shell 可执行文件的更多选项,而不是在 shell 中运行的附加命令。
如果需要命令提示符,那么可执行文件是cmd或cmd.exe,表示后面的令牌是命令的标志是/c:
>>> import subprocess >>> subprocess.run(["cmd", "/c", "dir C:\RealPython"]) Volume in drive C has no label. Volume Serial Number is 0000-0000 Directory of C:\RealPython 30/03/22 23:01 <DIR> . 30/03/22 23:01 <DIR> .. 09/05/22 10:41 237 basics.py 18/05/22 17:28 486 hello_world.py最后一个例子完全等同于用
shell=True调用run()。换句话说,使用shell=True参数就像将"cmd"和"/c"添加到您的参数列表中。注意: Windows 的发展与基于 UNIX 的系统有很大不同。最广为人知的 shell 是 Windows 命令提示符,它现在是一个遗留的 shell。命令提示符是为了模拟 Windows 之前的 MS-DOS 环境。许多 shell 脚本或批处理
.bat脚本就是为这种环境编写的,它们至今仍在使用。带有
Shell参数的run()函数几乎总是使用命令提示符结束。subprocess模块使用 WindowsCOMSPEC环境变量,该变量在几乎所有情况下都会指向命令提示符cmd.exe。到目前为止,有如此多的程序将COMSPEC等同于cmd.exe,以至于改变它会在意想不到的地方造成很多破坏!所以一般不建议换COMSPEC。此时,您应该知道一个重要的安全问题,如果您的 Python 程序中有面向用户的元素,不管是什么操作系统,您都应该注意这个问题。这是一个不仅限于
subprocess的漏洞。相反,它可以用于许多不同的领域。安全警告
如果在任何时候你计划获取用户输入并以某种方式将其转换为对
subprocess的调用,那么你必须非常小心注入攻击。也就是说,要考虑到潜在的恶意行为者。如果你只是让人们在你的机器上运行代码,有很多方法会导致混乱。举一个非常简单的例子,您获取用户输入,未经过滤就将其发送到在 shell 上运行的子流程:
- 视窗
** Linux + macOS*# unsafe_program.py import subprocess # ... subprocess.run(["pwsh", "-Command", f"ls {input()}"]) # ...# unsafe_program.py import subprocess # ... subprocess.run(["bash", "-c", f"ls {input()}"]) # ...你可以想象预期的用例是包装
ls并向其添加一些东西。所以预期的用户行为是提供一个类似"/home/realpython/"的路径。然而,如果恶意行为者意识到发生了什么,他们几乎可以执行任何他们想要的代码。举下面的例子,但是要小心这个:
- 视窗
** Linux + macOS**>
C:\RealPython; echo 'You could've been hacked: rm -Recurse -Force C:\'
/home/realpython/; echo 'You could've been hacked: rm -rf /*'再次,当心!这些看起来无辜的行可以尝试删除系统上的一切!在这种情况下,恶意部分在引号中,所以它不会运行,但是如果引号不在那里,您就有麻烦了。这样做的关键部分是用相关的标志调用
rm来递归地删除所有文件、文件夹和子文件夹,它将强制删除完成。通过添加分号,它可以将echo和潜在的rm作为完全独立的命令运行,分号充当命令分隔符,允许通常多行代码在一行上运行。运行这些恶意命令会对文件系统造成不可修复的损坏,并且需要重新安装操作系统。所以,要小心!
幸运的是,操作系统不允许你对一些特别重要的文件这样做。在基于 UNIX 的系统中,
rm命令需要使用sudo,或者在 Windows 中以管理员身份运行才能完全成功地破坏。不过,该命令在停止之前可能会删除很多重要的内容。所以,确保如果你正在动态地构建用户输入来馈入一个
subprocess调用,那么你要非常小心!有了这个警告,接下来您将讨论如何使用命令的输出和将命令链接在一起——简而言之,如何在进程启动后与它们进行通信。与进程的通信
您已经使用了
subprocess模块来执行程序并向 shell 发送基本命令。但是仍然缺少一些重要的东西。对于许多您可能希望使用subprocess的任务,您可能希望稍后在 Python 代码中动态发送输入或使用输出。为了与您的流程进行通信,您首先应该了解一些关于流程一般是如何通信的,然后您将看两个例子来理解这些概念。
标准输入/输出流
一个流在最基本的情况下代表了一系列的元素,这些元素并不是一次都可用的。当你从一个文件中读取字符和行时,你正在以文件对象的形式处理一个流,它最基本的是一个文件描述符。文件描述符通常用于流。所以,术语流、文件和类文件互换使用并不罕见。
当进程初始化时,有三个特殊的流供进程使用。流程执行以下操作:
- 读取输入的
stdin- 写入
stdout以获得通用输出- 写入
stderr进行错误报告这些是标准流——用于进程通信的跨平台模式。
有时子进程从父进程继承这些流。当您在 REPL 中使用
subprocess.run()并能够看到命令的输出时,就会发生这种情况。Python 解释器的stdout由子流程继承。当您在 REPL 环境中时,您会看到一个命令行界面过程,包括三个标准 I/O 流。该接口有一个 shell 进程作为子进程,它本身有一个 Python REPL 作为子进程。在这种情况下,除非您另外指定,
stdin来自键盘,而stdout和stderr显示在屏幕上。接口、外壳和 REPL 共享流:
您可以将标准 I/O 流视为字节分配器。子流程填充
stdout和stderr,你填充stdin。然后你读取stdout和stderr中的字节,子进程从stdin读取。与分配器一样,您可以在
stdin链接到子进程之前存储它。当需要时,子进程将从stdin中读取数据。但是,一旦进程从流中读取数据,字节就会被分配。你不能回头再读一遍:https://player.vimeo.com/video/715635931?background=1
这三个流或文件是与您的进程通信的基础。在下一节中,您将通过获得一个幻数生成器程序的输出开始看到这一点。
幻数生成器示例
通常,当使用
subprocess模块时,您会希望将输出用于某些事情,而不仅仅是像您到目前为止所做的那样显示输出。在这一节中,您将使用一个幻数生成器来输出一个幻数。想象一下,幻数生成器是某个晦涩难懂的程序,一个黑匣子,在你的工作岗位上由几代系统管理员继承而来。它输出一个你秘密计算所需的幻数。您将从
subprocess的stdout中读取并在您的包装 Python 程序中使用它:# magic_number.py from random import randint print(randint(0, 1000))好吧,没那么神奇。也就是说,你感兴趣的不是这个神奇的数字生成器——有趣的是与一个带有
subprocess的假想黑盒进行交互。为了获取数字生成器的输出供以后使用,您可以向run()传递一个capture_output=True参数:
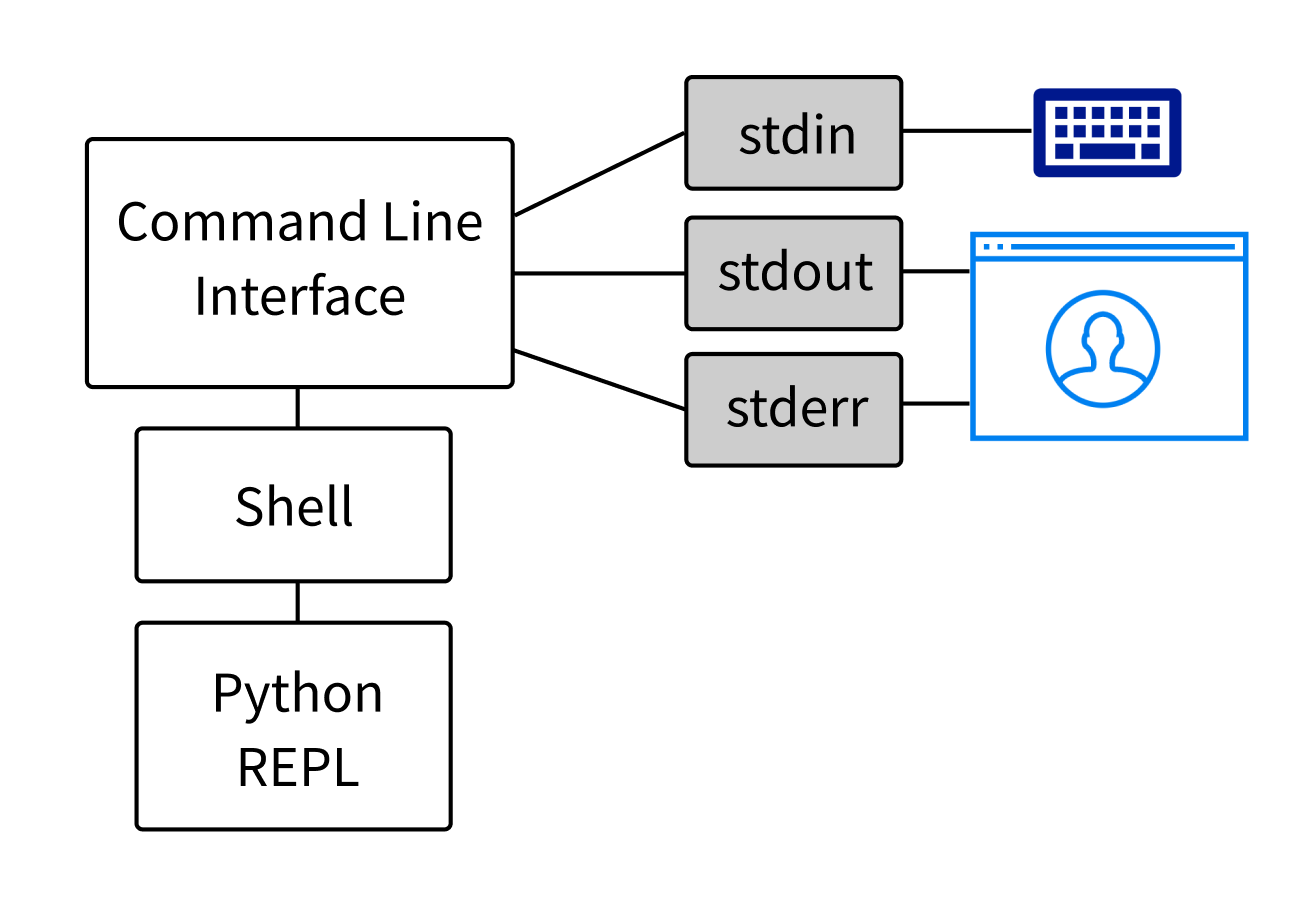
>>> import subprocess
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... )
>>> magic_number_process.stdout
b'769\n'
将True的一个capture_output参数传递给run()使得流程的输出在已完成的流程对象的.stdout属性中可用。你会注意到它是作为一个字节对象返回的,所以在读取它的时候需要注意编码。
还要注意的是,CompletedProcess的.stdout属性不再是一个流。该流已经被读取,并作为字节对象存储在.stdout属性中。
有了输出,您可以使用多个子流程来获取值,并在代码中对它们进行操作:
>>> import subprocess >>> sum( ... int( ... subprocess.run( ... ["python", "magic_number.py"], capture_output=True ... ).stdout ... ) ... for _ in range(2) ... ) 1085在本例中,您启动了两个幻数进程,获取两个幻数,然后将它们相加。目前,您依赖于由
int()构造函数对 bytes 对象的自动解码。不过,在下一节中,您将学习如何显式解码和编码。标准流的解码
进程以字节为单位进行通信,你有几种不同的方法来处理这些字节的编码和解码。在表面之下,
subprocess有几种进入 文本模式 的方法。文本模式意味着
subprocess将尝试处理编码本身。为此,它需要知道使用什么字符编码。在subprocess中,大多数选项都会尝试使用默认编码。然而,你通常想要明确使用什么编码来防止将来很难发现的错误。您可以为 Python 传递一个
text=True参数来使用默认编码处理编码。但是,如前所述,使用encoding参数显式指定编码总是更安全,因为并非所有系统都使用几乎通用 UTF-8 :
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True, encoding="utf-8"
... )
...
>>> magic_number_process.stdout
'647\n'
如果在文本模式下,CompletedProcess上的.stdout属性现在是一个字符串而不是一个字节对象。
您还可以通过直接调用stdout属性上的.decode()方法来解码返回的字节,根本不需要文本模式:
>>> magic_number_process = subprocess.run( ... ["python", "magic_number.py"], capture_output=True ... ) ... >>> magic_number_process.stdout.decode("utf-8") '72\n'还有其他方法可以让
run()进入文本模式。您也可以为errors或universal_newlines设置一个True值,这也会将run()置于文本模式。这似乎是多余的,但是这大部分是为了向后兼容,因为subprocess模块已经改变了很多年。现在您已经知道了如何读取和解码进程的输出,是时候看看如何写入进程的输入了。
反应游戏示例
在本节中,您将使用
subprocess与命令行游戏进行交互。这是一个用来测试人类反应时间的基本程序。不过,凭借您对标准 I/O 流的了解,您将能够破解它!游戏的源代码利用了time和random模块:# reaction_game.py from time import perf_counter, sleep from random import random print("Press enter to play") input() print("Ok, get ready!") sleep(random() * 5 + 1) print("go!") start = perf_counter() input() end = perf_counter() print(f"You reacted in {(end - start) * 1000:.0f} milliseconds!\nGoodbye!")程序启动,要求用户按 enter 键,然后在一段随机的时间后会要求用户再次按 enter 键。它测量从消息出现到用户按回车键的时间,或者至少游戏开发者是这么认为的:
https://player.vimeo.com/video/715635604?background=1
input()函数将从stdin开始读取,直到它到达一个新行,这意味着在这个上下文中的Enter击键。它返回从stdin开始使用的所有内容,除了换行符。有了这些知识,你就可以用subprocess来和这个游戏互动了:
>>> import subprocess
>>> process = subprocess.run(
... ["python", "reaction_game.py"], input="\n\n", encoding="utf-8"
... )
...
Press enter to play
Ok, get ready!
go!
You reacted in 0 milliseconds!
Goodbye!
0 毫秒的反应时间!还不错!考虑到人类的平均反应时间大约是 270 毫秒,你的程序绝对是超人的。注意,游戏对输出进行舍入,所以 0 毫秒并不意味着它是瞬时的。
传递给run()的input参数是由两个换行符组成的字符串。encoding参数设置为utf-8,使run()进入文本模式。这为它建立了接收你给它的输入的过程。
在程序开始之前,stdin被存储起来,等待程序使用它所包含的换行符。消耗一个新行来开始游戏,消耗下一个新行来反应go!。
现在你已经知道发生了什么——也就是说stdin可以被储存——你可以不用subprocess自己编写程序。如果你开始游戏,然后按几下 Enter ,这将为stdin储存几个换行符,程序将在到达input()行时自动使用这些换行符。所以你的反应时间实际上只是反应游戏执行start = time()和消耗输入的时间:
https://player.vimeo.com/video/715635649?background=1
游戏开发者明白了这一点,并发誓要发布另一个版本来防范这一漏洞。同时,您将在subprocess的引擎盖下看得更远一点,并了解它如何连接标准 I/O 流。
管道和外壳
要真正理解子流程和流的重定向,您确实需要理解管道以及它们是什么。例如,如果您想将两个进程连接在一起,将一个stdout输入到另一个进程的stdin中,这一点尤其正确。在这一部分,你将掌握管道以及如何在subprocess模块中使用它们。
管道介绍
管道,或称管道,是一种特殊的流,它不是像大多数文件那样只有一个文件句柄,而是有两个。一个句柄是只读的,另一个是只写的。这个名字非常具有描述性——管道用于将字节流从一个进程传输到另一个进程。它也是缓冲的,所以一个进程可以写入它,它会保存这些字节,直到它被读取,就像分配器一样。
您可能习惯于在命令行上看到管道,正如您在 shell 的部分所做的那样:
$ ls /usr/bin | grep python
这个命令告诉 shell 创建一个ls进程来列出/usr/bin中的所有文件。管道操作员(|)告诉 shell 从ls流程的stdout创建一个管道,并将其送入grep流程的stdin。grep进程过滤掉所有不包含字符串python的行。
Windows 没有grep,但是相同命令的大致等效如下:
PS> ls "C:\Program Files" | Out-String -stream | Select-String windows
然而,在 Windows PowerShell 上,事情的工作方式非常不同。正如您在本教程的 Windows shell 部分中了解到的,不同的命令不是独立的可执行文件。因此,PowerShell 在内部将一个命令的输出重定向到另一个命令,而不启动新的进程。
注意:如果你没有使用基于 UNIX 的操作系统,但有 Windows 10 或以上版本,那么你实际上有使用基于 UNIX 的操作系统的权利!看看Linux 的 Windows 子系统,它将让你接触到一个全功能的 Linux shell。
您可以在 PowerShell 上为不同的进程使用管道,尽管深入研究其中的复杂之处超出了本教程的范围。有关 PowerShell 管道的更多信息,请查看文档。因此,对于其余的管道示例,将只使用基于 UNIX 的示例,因为两个系统的基本机制是相同的。不管怎样,它们在 Windows 上并不常见。
如果您想让 shell 负责将进程相互连接,那么您可以将整个字符串作为命令传递给subprocess:
>>> import subprocess >>> subprocess.run(["sh" , "-c", "ls /usr/bin | grep python"]) python3 python3-config python3.8 python3.8-config ... CompletedProcess(...)这样,您可以让您选择的 shell 负责将一个进程传送到另一个进程,而不是尝试用 Python 重新实现。在某些情况下,这是一个完全正确的选择。
稍后在教程中,你也会发现不能直接用
run()来管进程。为此,你需要更复杂的Popen()。在本教程快结束时,实际的管道在中演示,用管道将两个过程连接在一起。无论您是否打算用
subprocess模块将一个进程通过管道传输到另一个进程中,subprocess模块在幕后大量使用管道。
subprocess的管道Python
subprocess模块广泛使用管道与其启动的进程进行交互。在前面的例子中,您使用了capture_output参数来访问stdout:
>>> import subprocess
>>> magic_number_process = subprocess.run(
... ["python", "magic_number.py"], capture_output=True
... )
>>> magic_number_process.stdout
b'769\n'
capture_output=True相当于将stdout和stderr参数显式设置为subprocess.PIPE常数:
>>> import subprocess >>> magic_number_process = subprocess.run( ... ["python", "magic_number.py"], ... stdout=subprocess.PIPE, ... stderr=subprocess.PIPE ... ) ... >>> magic_number_process.stdout b'769\n'
PIPE常数没什么特别的。它只是一个数字,向subprocess表明应该创建一个管道。然后,该函数创建一个管道链接到子流程的stdout,然后该函数将这个管道读入CompletedProcess对象的stdout属性。到了一个CompletedProcess的时候,它不再是一个管道,而是一个可以多次访问的 bytes 对象。注意:管道缓冲器的容量有限。根据您运行的系统,如果您计划在缓冲区中保存大量数据,您可能会很容易遇到这个限制。要解决这个限制,您可以使用普通文件。
您还可以将一个文件对象传递给任何一个标准流参数:
>>> from tempfile import TemporaryFile
>>> with TemporaryFile() as f:
... ls_process = subprocess.run(["python", "magic_number.py"], stdout=f)
... f.seek(0)
... print(f.read().decode("utf-8"))
...
0
554
然而,你不能将一个字节对象或一个字符串直接传递给stdin参数。它需要像文件一样。
注意,首先返回的0来自对 seek() 的调用,该调用返回新的流位置,在这种情况下是流的开始。
input参数与capture_output参数相似,都是快捷方式。使用input参数将创建一个缓冲区来存储input的内容,然后将该文件链接到新进程,作为它的stdin。
在subprocess内部用管道实际连接两个进程是你不能用run()做做的事情。相反,您可以将管道工作委托给 shell,就像您在前面的使用subprocess 介绍基于 Shell 和文本的程序一节中所做的那样。
如果你需要链接不同的进程而不把任何工作委托给 shell,那么你可以用底层的Popen()构造函数来做这件事。您将在稍后的部分中讲述Popen()。不过,在下一节中,您将使用run()模拟一个管道,因为在大多数情况下,直接链接进程并不重要。
管道模拟用run()
虽然您不能通过使用run()函数用管道将两个进程链接在一起,至少在没有将它委托给 shell 的情况下,您可以通过明智地使用stdout属性来模拟管道。
如果您在基于 UNIX 的系统上,几乎所有典型的 shell 命令都是独立的可执行文件,那么您可以将第二个进程的input设置为第一个CompletedProcess的.stdout属性:
>>> import subprocess >>> ls_process = subprocess.run(["ls", "/usr/bin"], stdout=subprocess.PIPE) >>> grep_process = subprocess.run( ... ["grep", "python"], input=ls_process.stdout, stdout=subprocess.PIPE ... ) >>> print(grep_process.stdout.decode("utf-8")) python3 python3-config python3.8 python3.8-config ...这里
ls的CompletedProcess对象的.stdout属性被设置为grep_process的input。重要的是设置为input而不是stdin。这是因为.stdout属性不是一个类似文件的对象。它是一个 bytes 对象,所以不能作为stdin的参数。或者,您也可以直接操作文件,将它们设置为标准流参数。使用文件时,将文件对象作为参数设置为
stdin,而不是使用input参数:
>>> import subprocess
>>> from tempfile import TemporaryFile
>>> with TemporaryFile() as f:
... ls_process = subprocess.run(["ls", "/usr/bin"], stdout=f)
... f.seek(0)
... grep_process = subprocess.run(
... ["grep", "python"], stdin=f, stdout=subprocess.PIPE
... )
...
0 # from f.seek(0)
>>> print(grep_process.stdout.decode("utf-8"))
python3
python3-config
python3.8
python3.8-config
...
正如您在上一节中了解到的,对于 Windows PowerShell,这样做没有太大意义,因为大多数时候,这些实用程序是 PowerShell 本身的一部分。因为您不需要处理单独的可执行文件,管道就变得不那么必要了。然而,如果需要做类似的事情,管道的模式仍然是相同的。
随着大多数工具的出现,现在是时候考虑一下subprocess的一些实际应用了。
实用创意
当你想用 Python 解决一个问题时,有时subprocess模块是最简单的方法,即使它可能不是最正确的。
使用subprocess通常很难跨平台工作,并且它有固有的危险。但是即使它可能涉及一些马虎的 Python ,使用subprocess可能是解决问题的一个非常快速有效的方法。
如前所述,对于大多数你可以想象用subprocess完成的任务,通常会有一个专用于该特定任务的库。这个库几乎肯定会使用subprocess,开发者会努力让代码变得可靠,并覆盖所有可能使使用subprocess变得困难的极端情况。
因此,即使存在专用的库,使用subprocess通常会更简单,尤其是如果您处于需要限制依赖关系的环境中。
在接下来的部分中,您将探索一些实用的想法。
创建新项目:示例
假设您经常需要创建新的本地项目,每个项目都有一个虚拟环境,并被初始化为 T2 Git 库。你可以去找专门从事这项工作的 Cookiecutter 图书馆,这是个不错的主意。
然而,使用 Cookiecutter 意味着学习 Cookiecutter。假设您没有太多时间,并且您的环境非常小——您真正能指望的只有 Git 和 Python。在这些情况下,subprocess可以快速为您设置项目:
# create_project.py
from argparse import ArgumentParser
from pathlib import Path
import subprocess
def create_new_project(name):
project_folder = Path.cwd().absolute() / name
project_folder.mkdir()
(project_folder / "README.md").touch()
with open(project_folder / ".gitignore", mode="w") as f:
f.write("\n".join(["venv", "__pycache__"]))
commands = [
[
"python",
"-m",
"venv",
f"{project_folder}/venv",
],
["git", "-C", project_folder, "init"],
["git", "-C", project_folder, "add", "."],
["git", "-C", project_folder, "commit", "-m", "Initial commit"],
]
for command in commands:
try:
subprocess.run(command, check=True, timeout=60)
except FileNotFoundError as exc:
print(
f"Command {command} failed because the process "
f"could not be found.\n{exc}"
)
except subprocess.CalledProcessError as exc:
print(
f"Command {command} failed because the process "
f"did not return a successful return code.\n{exc}"
)
except subprocess.TimeoutExpired as exc:
print(f"Command {command} timed out.\n {exc}")
if __name__ == "__main__":
parser = ArgumentParser()
parser.add_argument("project_name", type=str)
args = parser.parse_args()
create_new_project(args.project_name)
这是一个命令行工具,您可以调用它来启动项目。它将负责创建一个README.md文件和一个.gitignore文件,然后运行一些命令来创建一个虚拟环境,初始化一个 git 存储库,并执行您的第一次提交。它甚至是跨平台的,选择使用pathlib来创建文件和文件夹,这抽象了操作系统的差异。
用 Cookiecutter 能做到吗?你能用 GitPython 做git部分吗?你能使用venv模块来创建虚拟环境吗?对所有人都是。但是,如果你只是需要一些快速和肮脏的东西,使用你已经知道的命令,那么只使用subprocess可能是一个伟大的选择。
更改扩展属性
如果你使用 Dropbox,你可能不知道有一种方法可以在同步时忽略文件。例如,您可以将虚拟环境保存在项目文件夹中,并使用 Dropbox 来同步代码,但将虚拟环境保存在本地。
也就是说,这不像添加一个.dropboxignore文件那么简单。相反,它涉及到向文件添加特殊属性,这可以从命令行完成。这些属性在类 UNIX 系统和 Windows 之间是不同的:
PS> Set-Content -Path `
'C:\Users\yourname\Dropbox\YourFileName.pdf' `
-Stream com.dropbox.ignored -Value 1
$ attr -s com.dropbox.ignored -V 1 \
/home/yourname/Dropbox/YourFileName.pdf
$ xattr -w com.dropbox.ignored 1 \
/Users/yourname/Dropbox/YourFileName.pdf
有一些基于 UNIX 的项目,如 dropboxignore ,使用 shell 脚本来使忽略文件和文件夹变得更容易。代码相对复杂,在 Windows 上也不行。
有了subprocess模块,您可以很容易地包装不同的 shell 命令,以实现您自己的实用程序:
# dropbox_ignore.py
import platform
from pathlib import Path
from subprocess import run, DEVNULL
def init_shell():
print("initializing shell")
system = platform.system()
print(f"{system} detected")
if system == "Linux":
return Bash_shell()
elif system == "Windows":
return Pwsh_shell()
elif system == "Darwin":
raise NotImplementedError
class Pwsh_shell():
def __init__(self) -> None:
try:
run(["pwsh", "-V"], stdout=DEVNULL, stderr=DEVNULL)
self.shell = "pwsh"
except FileNotFoundError as exc:
print("Powershell Core not installed, falling back to PowerShell")
self.shell = "powershell"
@staticmethod
def _make_string_path_list(paths: list[Path]) -> str:
return "', '".join(str(path).replace("'", "`'") for path in paths)
def ignore_folders(self, paths: list[Path]) -> None:
path_list = self._make_string_path_list(paths)
command = (
f"Set-Content -Path '{path_list}' "
f"-Stream com.dropbox.ignored -Value 1"
)
run([self.shell, "-NoProfile", "-Command", command], check=True)
print("Done!")
class Bash_shell():
@staticmethod
def _make_string_path_list(paths: list[Path]) -> str:
return "' '".join(str(path).replace("'", "\\'") for path in paths)
def ignore_folders(self, paths: list[Path]) -> None:
path_list = self._make_string_path_list(paths)
command = (
f"for f in '{path_list}'\n do\n "
f"attr -s com.dropbox.ignored -V 1 $f\ndone"
)
run(["bash", "-c", command], check=True)
print("Done!")
这是作者的dottropbox ignore资源库的一个简化片段。init_shell()函数使用 platform 模块检测操作系统,并返回一个对象,该对象是特定于系统的外壳的抽象。该代码没有在 macOS 上实现该行为,所以如果它检测到它正在 macOS 上运行,就会引发一个NotImplementedError。
shell 对象允许你调用一个带有一列 pathlib Path 对象的.ignore_folders()方法来设置 Dropbox 忽略那些文件。
在Pwsh_shell类上,构造函数测试 PowerShell 核心是否可用,如果不可用,将退回到较旧的 Windows PowerShell,默认安装在 Windows 10 上。
在下一节中,您将回顾在决定是否使用subprocess时需要记住的一些其他模块。
与subprocess关联的 Python 模块
当决定某个任务是否适合subprocess时,有一些相关的模块你可能想知道。
在subprocess存在之前,你可以使用os.system()来运行命令。然而,就像以前使用os的许多东西一样,标准库模块已经取代了os,所以它主要在内部使用。几乎没有任何自己使用os的用例。
有一个官方文档页面,在这里你可以查看一些用os完成任务的老方法,并学习如何用subprocess做同样的事情。
人们可能会认为subprocess可以用于并发,在简单的情况下,确实可以。但是,按照草率的 Python 哲学,很可能只是快速地拼凑一些东西。如果您想要更健壮的东西,那么您可能想要开始查看multiprocessing模块。
根据你正在尝试的任务,你也许可以用 asyncio 或 threading 模块来完成它。如果所有东西都是用 Python 写的,那么这些模块可能是你的最佳选择。
asyncio模块也有一个高级 API 来创建和管理子流程,所以如果您想要对非 Python 并行流程有更多的控制,这可能是一个不错的选择。
现在是时候深入subprocess并探索底层的Popen类及其构造函数了。
Popen类
如上所述,整个subprocess模块的底层类是Popen类和Popen()构造函数。subprocess中的每个函数调用幕后的Popen()构造函数。使用Popen()构造函数可以让您对新启动的子流程进行更多的控制。
简单总结一下,run()基本上就是Popen()类的构造函数,一些设置,然后在新初始化的Popen对象上调用 .communicate() 方法。.communicate()方法是一种阻塞方法,一旦进程结束,它就返回stdout和stderr数据。
Popen的名字来自一个类似的 UNIX 命令,代表管道打开。该命令创建一个管道,然后启动一个调用 shell 的新进程。然而,subprocess模块不会自动调用 shell。
run()函数是一个阻塞函数,这意味着不可能与进程进行动态交互。然而,Popen()构造函数启动了一个新的进程并继续,让进程以并行方式运行。
你之前入侵的反应游戏的开发者发布了他们游戏的新版本,在这个版本中,你不能通过加载带有换行符的stdin来作弊:
# reaction_game_v2.py
from random import choice, random
from string import ascii_lowercase
from time import perf_counter, sleep
print(
"A letter will appear on screen after a random amount of time,\n"
"when it appears, type the letter as fast as possible "
"and then press enter\n"
)
print("Press enter when you are ready")
input()
print("Ok, get ready!")
sleep(random() * 5 + 2)
target_letter = choice(ascii_lowercase)
print(f"=====\n= {target_letter} =\n=====\n")
start = perf_counter()
while True:
if input() == target_letter:
break
else:
print("Nope! Try again.")
end = perf_counter()
print(f"You reacted in {(end - start) * 1000:.0f} milliseconds!\nGoodbye!")
现在程序会显示一个随机字符,你需要按下那个字符让游戏记录你的反应时间:
https://player.vimeo.com/video/715635705?background=1
该怎么办呢?首先,你需要掌握在基本命令中使用Popen(),然后你会找到另一种方法来开发反应游戏。
使用Popen()
使用Popen()构造函数在外观上与使用run()非常相似。如果有一个论点你可以传递给run(),那么你通常可以传递给Popen()。最根本的区别是它不是一个阻塞调用——它不是等到进程结束,而是并行运行进程。因此,如果您想读取新进程的输出,就需要考虑这种非阻塞特性:
# popen_timer.py
import subprocess
from time import sleep
with subprocess.Popen(
["python", "timer.py", "5"], stdout=subprocess.PIPE
) as process:
def poll_and_read():
print(f"Output from poll: {process.poll()}")
print(f"Output from stdout: {process.stdout.read1().decode('utf-8')}")
poll_and_read()
sleep(3)
poll_and_read()
sleep(3)
poll_and_read()
这个程序调用上下文管理器中的定时器进程,并将stdout分配给一个管道。然后在Popen对象上运行 .poll() 方法,并读取其stdout。
.poll()方法是检查进程是否仍在运行的基本方法。如果是,那么.poll()返回None。否则,它将返回进程的退出代码。
然后程序使用 .read1() 尝试读取.stdout可用的尽可能多的字节。
注意:如果您将Popen对象置于文本模式,然后在.stdout上调用.read(),那么对.read()的调用将被阻塞,直到它到达一个新行。在这种情况下,换行符将与定时器程序的结尾一致。在这种情况下,这种行为是不可取的。
要读取当时可用的尽可能多的字节,不考虑换行符,您需要使用.read1()来读取。需要注意的是.read1()只在字节流上可用,所以你需要确保手动处理编码,不要使用文本模式。
这个程序的输出首先打印出None,因为这个过程还没有完成。然后程序打印出目前为止stdout中可用的内容,这是开始消息和动画的第一个字符。
三秒钟后,计时器还没有结束,所以你再次得到None,还有动画的另外两个角色。又过了三秒,这个过程结束了,所以.poll()产生了0,你得到了动画的最终角色和Done!:
Output from poll: None
Output from stdout: Starting timer of 5 seconds
.
Output from poll: None
Output from stdout: ..
Output from poll: 0
Output from stdout: ..Done!
在这个例子中,您已经看到了Popen()构造函数的工作方式与run()非常不同。在大多数情况下,你不需要这种细粒度的控制。也就是说,在接下来的部分中,您将看到如何将一个进程连接到另一个进程,以及如何破解新的反应游戏。
用管道将两个过程连接在一起
正如在前一节中提到的,如果你需要用管道将进程连接在一起,你需要使用Popen()构造函数。这主要是因为run()是一个阻塞调用,所以当下一个进程开始时,第一个进程已经结束,这意味着您不能直接链接到它的stdout。
该程序将仅针对 UNIX 系统进行演示,因为 Windows 中的管道远不常见,正如在模拟管道一节中提到的:
# popen_pipe.py
import subprocess
ls_process = subprocess.Popen(["ls", "/usr/bin"], stdout=subprocess.PIPE)
grep_process = subprocess.Popen(
["grep", "python"], stdin=ls_process.stdout, stdout=subprocess.PIPE
)
for line in grep_process.stdout:
print(line.decode("utf-8").strip())
在本例中,两个进程并行启动。它们通过一个公共管道连接在一起,for循环负责读取stdout处的管道以输出这些行。
需要注意的一个关键点是,与返回一个CompletedProcess对象的run()相反,Popen()构造函数返回一个Popen对象。CompletedProcess的标准流属性指向字节对象或字符串,但是Popen对象的相同属性指向实际流。这允许您在进程运行时与它们进行通信。
但是,是否真的需要将进程通过管道连接到另一个进程,则是另一回事了。问问你自己,用 Python 协调这个过程并专门使用run()是否会损失很多。不过,有些情况下你真的需要Popen,比如破解新版的反应时间游戏。
与流程动态交互
既然您知道可以使用Popen()在流程运行时动态地与流程交互,那么是时候将这一知识再次用于开发反应时间游戏了:
# reaction_game_v2_hack.py
import subprocess
def get_char(process):
character = process.stdout.read1(1)
print(
character.decode("utf-8"),
end="",
flush=True, # Unbuffered print
)
return character.decode("utf-8")
def search_for_output(strings, process):
buffer = ""
while not any(string in buffer for string in strings):
buffer = buffer + get_char(process)
with subprocess.Popen(
[
"python",
"-u", # Unbuffered stdout and stderr
"reaction_game_v2.py",
],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
) as process:
process.stdin.write(b"\n")
process.stdin.flush()
search_for_output(["==\n= ", "==\r\n= "], process)
target_char = get_char(process)
stdout, stderr = process.communicate(
input=f"{target_char}\n".encode("utf-8"), timeout=10
)
print(stdout.decode("utf-8"))
有了这个脚本,您就完全控制了进程的缓冲,这就是为什么您将诸如-u这样的参数传递给 Python 进程,将flush=True传递给print()。这些参数是为了确保不会发生额外的缓冲。
该脚本通过使用一个函数来工作,该函数将通过从进程的stdout中一次抓取一个字符来搜索字符串列表中的一个。当每个字符出现时,脚本将搜索字符串。
注意:为了在基于 Windows 和 UNIX 的系统上都能工作,需要搜索两个字符串:或者是"==\n= "或者是"==\r\n= "。Windows 系统需要 Windows 风格的回车和典型的换行符。
在脚本找到一个目标字符串(在本例中是目标字母之前的字符序列)后,它将获取下一个字符,并将该字母写入进程的stdin,后跟一个换行符:
https://player.vimeo.com/video/715635790?background=1
在 1 毫秒的时间里,它不像最初的黑客那样好,但它仍然是非常超人的。干得好!
抛开所有这些乐趣不谈,使用Popen与流程交互可能非常棘手,并且容易出错。首先,在求助于Popen()构造函数之前,看看是否可以独占使用run()。
如果你真的需要在这个层次上与流程交互, asyncio 模块有一个高层 API 来创建和管理子流程。
asyncio子流程功能旨在用于更复杂的subprocess应用,您可能需要编排各种流程。例如,如果您正在执行许多图像、视频或音频文件的复杂处理,可能会出现这种情况。如果你在这个水平上使用subprocess,那么你可能正在建造一个图书馆。
结论
您已经完成了进入 Python subprocess模块的旅程。您现在应该能够决定subprocess是否适合您的问题。您还应该能够决定是否需要调用 shell。除此之外,您应该能够运行子流程并与其输入和输出进行交互。
您还应该能够开始探索使用Popen()构造函数进行流程操作的可能性。
一路走来,你已经:
- 大致了解了流程
- 从初级到高级
subprocess的用法 - 了解如何在使用
run()时引发和处理错误 - 熟悉shell以及它们在 Windows 和类 UNIX 系统上的复杂性
- 通过实际例子探究了
subprocess用于的用例 - 了解标准的输入/输出流以及如何与它们进行交互
- 开始与管道搏斗,包括外壳和
subprocess - 查看了
Popen()构造函数,并将其用于一些高级进程通信
现在,您已经准备好将各种可执行文件纳入 Pythonic 的影响范围了!
源代码: 点击这里下载免费的源代码,您将使用它来熟悉 Python subprocess模块。*************************
Python 的 sum():对值求和的 python 方式
Python 的内置函数sum()是一种高效且的 python 式方法来对一系列数值求和。将几个数字相加是许多计算中常见的中间步骤,因此对于 Python 程序员来说,sum()是一个非常方便的工具。
作为一个额外的有趣用例,您可以使用sum()连接列表和元组,这在您需要简化列表列表时会很方便。
在本教程中,您将学习如何:
- 使用通用技术和工具手工计算数值总和
- 使用 Python 的
sum()高效地将几个数值相加 - 用
sum()连接列表和元组 - 用
sum()处理常见的求和问题 - 为
sum()中的参数使用合适的值 - 在
sum()和之间选择替代工具来求和并连接对象
这些知识将帮助您使用sum()或其他替代和专门的工具有效地处理和解决代码中的求和问题。
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
理解求和问题
将数值相加是编程中相当常见的问题。例如,假设您有一个数字列表[1,2,3,4,5],并希望将它们相加以计算它们的总和。使用标准算术,您将做类似这样的事情:
1 + 2 + 3 + 4 + 5 = 15
就数学而言,这个表达式非常简单。它会引导您完成一系列简短的加法运算,直到您找到所有数字的总和。
手动进行这种特殊的计算是可能的,但是想象一下在其他一些情况下这可能是不可能的。如果您有一个特别长的数字列表,手动添加可能效率低下且容易出错。如果你甚至不知道列表中有多少项,会发生什么?最后,设想一个场景,您需要添加的项目数量动态或不可预测地变化。
在这种情况下,无论你有一长串或短串的数字,Python 对于解决求和问题都非常有用。
如果你想通过从头开始创建自己的解决方案来对数字求和,那么你可以尝试使用一个 for循环:
>>> numbers = [1, 2, 3, 4, 5] >>> total = 0 >>> for number in numbers: ... total += number ... >>> total 15这里,首先创建
total,并将其初始化为0。这个变量作为一个累加器工作,你在其中存储中间结果直到你得到最终结果。循环遍历numbers,并通过使用增加赋值累加每个连续值来更新total。你也可以在一个函数中包装
for循环。这样,您可以为不同的列表重用代码:
>>> def sum_numbers(numbers):
... total = 0
... for number in numbers:
... total += number
... return total
...
>>> sum_numbers([1, 2, 3, 4, 5])
15
>>> sum_numbers([])
0
在sum_numbers()中,您将一个可迭代——具体来说,是一个数值列表——作为一个参数,然后返回输入列表中值的总和。如果输入列表为空,那么函数返回0。这个for循环就是你之前看到的那个。
也可以用递归代替迭代。递归是一种函数式编程技术,在这种技术中,函数在其自己的定义中被调用。换句话说,递归函数在循环中调用自己:
>>> def sum_numbers(numbers): ... if len(numbers) == 0: ... return 0 ... return numbers[0] + sum_numbers(numbers[1:]) ... >>> sum_numbers([1, 2, 3, 4, 5]) 15当你定义一个递归函数时,你有陷入无限循环的风险。为了防止这种情况,您需要定义一个停止递归的基本用例和一个调用函数并开始隐式循环的递归用例。
在上面的例子中,基本情况意味着零长度列表的总和是
0。递归情况意味着总和是第一个值numbers[0],加上其余值的总和numbers[1:]。因为递归情况在每次迭代中使用较短的序列,所以当numbers是一个零长度列表时,您可能会遇到基本情况。作为最终结果,您得到了输入列表中所有条目的总和,numbers。注意:在这个例子中,如果你不检查一个空的输入列表(你的基本情况),那么
sum_numbers()将永远不会进入一个无限的递归循环。当您的numbers列表长度达到0时,代码试图从空列表中访问一个项目,这将引发一个IndexError并中断循环。使用这种实现,你永远不会从这个函数中得到一个和。你每次都会得到一个
IndexError。Python 中对一列数字求和的另一种选择是从
functools中使用reduce()。要获得一系列数字的总和,您可以将operator.add或适当的lambda函数作为第一个参数传递给reduce():
>>> from functools import reduce
>>> from operator import add
>>> reduce(add, [1, 2, 3, 4, 5])
15
>>> reduce(add, [])
Traceback (most recent call last):
...
TypeError: reduce() of empty sequence with no initial value
>>> reduce(lambda x, y: x + y, [1, 2, 3, 4, 5])
15
你可以调用reduce()加一个还原,或者折叠,function加一个iterable作为参数。然后reduce()使用输入函数处理iterable并返回一个累积值。
在第一个例子中,归约函数是add(),它取两个数并将它们相加。最终结果是输入iterable中数字的总和。作为一个缺点,reduce()用空iterable调用时会引出一个 TypeError 。
在第二个例子中,reduction 函数是一个返回两个数相加的lambda函数。
由于像这样的求和在编程中很常见,所以每次需要对一些数字求和时都要编写一个新函数,这是一项重复的工作。此外,使用reduce()并不是最容易理解的解决方案。
Python 提供了一个专用的内置函数来解决这个问题。该功能被方便地称为 sum() 。因为它是一个内置函数,你可以直接在你的代码中使用它,而不需要导入任何东西。
Python 的sum() 入门
可读性是 Python 哲学背后最重要的原则之一。当对一列值求和时,想象你要求一个循环做什么。您希望它循环遍历一些数字,将它们累积在一个中间变量中,并返回最终的和。然而,你或许可以想象一个不需要循环的可读性更好的求和版本。你想让 Python 取一些数字,然后把它们加起来。
现在想想reduce()是如何求和的。使用reduce()可能比基于循环的解决方案可读性更差,也更不直接。
这就是为什么 Python 2.3 添加了sum()作为内置函数,为求和问题提供 Python 式的解决方案。亚历克斯·马尔泰利贡献了这个函数,它现在是对一系列值求和的首选语法:
>>> sum([1, 2, 3, 4, 5]) 15 >>> sum([]) 0哇!很整洁,不是吗?它读起来像简单的英语,清楚地传达了你在输入列表上执行的动作。使用
sum()比使用for循环或reduce()调用更具可读性。与reduce()不同,sum()不会在你提供一个空的 iterable 时抛出TypeError。相反,它可以理解地返回0。您可以使用以下两个参数调用
sum():
iterable是必选参数,可以容纳任何 Python iterable。iterable 通常包含数值,但也可以包含列表或元组。start是可选参数,可以保存初始值。然后将该值添加到最终结果中。默认为0。在内部,
sum()从左到右将start加上iterable中的值相加。输入iterable中的值通常是数字,但是您也可以使用列表和元组。可选参数start可以接受一个数字、列表或元组,这取决于传递给iterable的内容。它不能带一个字符串。在接下来的两节中,您将学习在代码中使用
sum()的基本知识。
iterable所需参数:接受任何 Python iterable 作为它的第一个参数使得
sum()通用、可重用并且多态。由于这个特性,您可以将sum()与列表、元组、集、range对象和字典一起使用:
>>> # Use a list
>>> sum([1, 2, 3, 4, 5])
15
>>> # Use a tuple
>>> sum((1, 2, 3, 4, 5))
15
>>> # Use a set
>>> sum({1, 2, 3, 4, 5})
15
>>> # Use a range
>>> sum(range(1, 6))
15
>>> # Use a dictionary
>>> sum({1: "one", 2: "two", 3: "three"})
6
>>> sum({1: "one", 2: "two", 3: "three"}.keys())
6
在所有这些例子中,sum()计算输入 iterable 中所有值的算术和,而不考虑它们的类型。在两个字典示例中,对sum()的两个调用都返回输入字典的键的总和。第一个例子默认情况下对键求和,第二个例子对键求和是因为输入字典上的 .keys() 调用。
如果您的字典在其值中存储了数字,并且您想要对这些值求和而不是对键求和,那么您可以使用 .values() 来实现这一点,就像在.keys()示例中一样。
你也可以使用sum()和列表理解作为论元。下面是一个计算一系列值的平方和的示例:
>>> sum([x ** 2 for x in range(1, 6)]) 55Python 2.4 在语言中增加了生成器表达式。同样,当您使用生成器表达式作为参数时,
sum()会按预期工作:
>>> sum(x ** 2 for x in range(1, 6))
55
这个例子展示了处理求和问题的一个最重要的技巧。它在一行代码中提供了一个优雅、易读、高效的解决方案。
start可选参数:
第二个也是可选的参数start,允许您提供一个值来初始化求和过程。当您需要按顺序处理累积值时,此参数很方便:
>>> sum([1, 2, 3, 4, 5], 100) # Positional argument 115 >>> sum([1, 2, 3, 4, 5], start=100) # Keyword argument 115这里,您提供一个初始值
100到start。实际效果是sum()将这个值添加到输入 iterable 中值的累积和中。注意,您可以提供start作为位置参数或关键字参数。后一种选择更加清晰易读。如果你不给
start提供一个值,那么它默认为0。默认值0确保了返回输入值总和的预期行为。对数值求和
sum()的主要目的是提供一种将数值相加的 Pythonic 方式。到目前为止,您已经看到了如何使用函数对整数求和。此外,您可以将sum()与任何其他数字 Python 类型一起使用,例如float、complex、decimal.Decimal和fractions.Fraction。下面是几个对不同数值类型的值使用
sum()的例子:
>>> from decimal import Decimal
>>> from fractions import Fraction
>>> # Sum floating-point numbers
>>> sum([10.2, 12.5, 11.8])
34.5
>>> sum([10.2, 12.5, 11.8, float("inf")])
inf
>>> sum([10.2, 12.5, 11.8, float("nan")])
nan
>>> # Sum complex numbers
>>> sum([3 + 2j, 5 + 6j])
(8+8j)
>>> # Sum Decimal numbers
>>> sum([Decimal("10.2"), Decimal("12.5"), Decimal("11.8")])
Decimal('34.5')
>>> # Sum Fraction numbers
>>> sum([Fraction(51, 5), Fraction(25, 2), Fraction(59, 5)])
Fraction(69, 2)
在这里,您首先将sum()与浮点数一起使用。当您在调用float("inf")和float("nan")中使用特殊符号inf和nan时,值得注意函数的行为。第一个符号代表一个无穷大的值,所以sum()返回inf。第二个符号代表 NaN(非数字)值。由于不能将数字和非数字相加,结果得到nan。
其他例子对complex、Decimal和Fraction数的可迭代项求和。在所有情况下,sum()使用适当的数值类型返回结果的累积和。
串联序列
尽管sum()主要用于操作数值,但是您也可以使用该函数来连接序列,比如列表和元组。为此,您需要为start提供一个合适的值:
>>> num_lists = [[1, 2, 3], [4, 5, 6]] >>> sum(num_lists, start=[]) [1, 2, 3, 4, 5, 6] >>> # Equivalent concatenation >>> [1, 2, 3] + [4, 5, 6] [1, 2, 3, 4, 5, 6] >>> num_tuples = ((1, 2, 3), (4, 5, 6)) >>> sum(num_tuples, start=()) (1, 2, 3, 4, 5, 6) >>> # Equivalent concatenation >>> (1, 2, 3) + (4, 5, 6) (1, 2, 3, 4, 5, 6)在这些例子中,您使用
sum()来连接列表和元组。这是一个有趣的特性,您可以使用它来扁平化一个列表列表或一个元组。这些例子工作的关键要求是为start选择一个合适的值。例如,如果你想连接列表,那么start需要保存一个列表。在上面的例子中,
sum()在内部执行连接操作,所以它只处理那些支持连接的序列类型,字符串除外:
>>> num_strs = ["123", "456"]
>>> sum(num_strs, "0")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: sum() can't sum strings [use ''.join(seq) instead]
当您试图使用sum()来连接字符串时,您会得到一个TypeError。正如异常消息所建议的,在 Python 中应该使用 str.join() 来连接字符串。稍后当您到达使用sum() 的替代物的部分时,您将看到使用这种方法的例子。
用 Python 的sum()练习
到目前为止,您已经学习了使用sum()的基本知识。您已经学习了如何使用这个函数将数值相加,以及连接序列,如列表和元组。
在这一节中,您将看到更多关于何时以及如何在代码中使用sum()的例子。通过这些实际的例子,您将了解到,当您执行计算时,这个内置函数是非常方便的,因为您需要将计算一系列数字的和作为中间步骤。
您还将了解到sum()在处理列表和元组时会很有帮助。您将看到的一个特殊例子是当您需要展平一系列列表时。
计算累计金额
您要编写的第一个例子是关于如何利用start参数对数值的累积列表求和。
假设你正在开发一个系统来管理一个给定产品在几个不同销售点的销售。每天,您都会从每个销售点获得一份售出单位报告。您需要系统地计算累计金额,以了解整个公司在一周内销售了多少台设备。要解决这个问题,可以使用sum():
>>> cumulative_sales = 0 >>> monday = [50, 27, 42] >>> cumulative_sales = sum(monday, start=cumulative_sales) >>> cumulative_sales 119 >>> tuesday = [12, 32, 15] >>> cumulative_sales = sum(tuesday, start=cumulative_sales) >>> cumulative_sales 178 >>> wednesday = [20, 24, 42] >>> cumulative_sales = sum(wednesday, start=cumulative_sales) >>> cumulative_sales 264 ...通过使用
start,您可以设置一个初始值来初始化总和,这允许您将连续的单位添加到先前计算的小计中。在这个周末,你会得到公司的总销售量。计算样本的平均值
sum()的另一个实际使用案例是在做进一步计算之前,将其作为中间计算。例如,假设您需要计算一个数值样本的算术平均值和。算术平均值,也称为平均值,是样本中数值的总和除以数值的个数,即个数据点。如果你有样本[2,3,4,2,3,6,4,2]并且你想手工计算算术平均值,那么你可以解这个运算:
(2 + 3 + 4 + 2 + 3 + 6 + 4 + 2) / 8 = 3.25
如果你想通过使用 Python 来加速这个过程,你可以把它分成两部分。计算的第一部分,也就是把数字加在一起,是
sum()的任务。操作的下一部分是除以 8,使用样本中的数字计数。要计算你的除数,可以用len():
>>> data_points = [2, 3, 4, 2, 3, 6, 4, 2]
>>> sum(data_points) / len(data_points)
3.25
这里,对sum()的调用计算样本中数据点的总和。接下来,您使用len()来获得数据点的数量。最后,执行所需的除法来计算样本的算术平均值。
实际上,您可能希望将此代码转换为具有一些附加功能的函数,例如描述性名称和空样本检查:
>>> # Python >= 3.8 >>> def average(data_points): ... if (num_points := len(data_points)) == 0: ... raise ValueError("average requires at least one data point") ... return sum(data_points) / num_points ... >>> average([2, 3, 4, 2, 3, 6, 4, 2]) 3.25 >>> average([]) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 3, in average ValueError: average requires at least one data point在
average()中,首先检查输入样本是否有数据点。如果没有,那么您将引发一个带有描述性消息的ValueError。在这个例子中,您使用 walrus 操作符将数据点的数量存储在变量num_points中,这样您就不需要再次调用len()。返回语句计算样本的算术平均值,并将其发送回调用代码。注:计算一个数据样本的均值是统计和数据分析中的常见操作。Python 标准库提供了一个名为
statistics的便捷模块来处理这类计算。在
statistics模块中,你会发现一个名为mean()的函数:
>>> from statistics import mean
>>> mean([2, 3, 4, 2, 3, 6, 4, 2])
3.25
>>> mean([])
Traceback (most recent call last):
...
statistics.StatisticsError: mean requires at least one data point
statistics.mean()函数的行为与您之前编写的average()函数非常相似。当你用一个数值样本调用mean()时,你将得到输入数据的算术平均值。当您将一个空列表传递给mean()时,您将获得一个statistics.StatisticsError。
请注意,当您使用适当的样本调用average()时,您将获得期望的平均值。如果你用一个空样本调用average(),那么你会得到一个预期的ValueError。
求两个序列的点积
使用sum()可以解决的另一个问题是寻找两个等长数值序列的点积。点积是输入序列中每对值的乘积的代数和。例如,如果您有序列(1,2,3)和(4,5,6),那么您可以使用加法和乘法手动计算它们的点积:
1 × 4 + 2 × 5 + 3 × 6 = 32
要从输入序列中提取连续的值对,可以使用 zip() 。然后,您可以使用生成器表达式将每对值相乘。最后,sum()可以对乘积求和:
>>> x_vector = (1, 2, 3) >>> y_vector = (4, 5, 6) >>> sum(x * y for x, y in zip(x_vector, y_vector)) 32使用
zip(),您可以用每个输入序列的值生成一个元组列表。生成器表达式在每个元组上循环,同时将先前由zip()排列的连续值对相乘。最后一步是使用sum()将产品加在一起。上面例子中的代码是有效的。然而,点积是为长度相等的序列定义的,那么如果提供不同长度的序列会发生什么呢?在这种情况下,
zip()会忽略最长序列中的额外值,从而导致不正确的结果。为了处理这种可能性,您可以将对
sum()的调用包装在一个自定义函数中,并提供对输入序列长度的适当检查:
>>> def dot_product(x_vector, y_vector):
... if len(x_vector) != len(y_vector):
... raise ValueError("Vectors must have equal sizes")
... return sum(x * y for x, y in zip(x_vector, y_vector))
...
>>> dot_product((1, 2, 3), (4, 5, 6))
32
>>> dot_product((1, 2, 3, 4), (5, 6, 3))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 3, in dot_product
ValueError: Vectors must have equal sizes
这里,dot_product()以两个序列为自变量,返回它们对应的点积。如果输入序列具有不同的长度,那么该函数产生一个ValueError。
将功能嵌入到自定义函数中允许您重用代码。它还让您有机会描述性地命名该函数,以便用户只需阅读其名称就能知道该函数的用途。
展平列表列表
平整列表列表是 Python 中的一项常见任务。假设您有一个列表列表,需要将它展平为一个包含原始嵌套列表中所有项目的列表。在 Python 中,你可以使用几种方法中的任何一种来展平列表。例如,您可以使用一个for循环,如以下代码所示:
>>> def flatten_list(a_list): ... flat = [] ... for sublist in a_list: ... flat += sublist ... return flat ... >>> matrix = [ ... [1, 2, 3], ... [4, 5, 6], ... [7, 8, 9], ... ] >>> flatten_list(matrix) [1, 2, 3, 4, 5, 6, 7, 8, 9]在
flatten_list()内部,循环遍历包含在a_list中的所有嵌套列表。然后,它使用一个增强的赋值操作(+=)在flat中将它们连接起来。因此,您将获得一个包含原始嵌套列表中所有项目的平面列表。但是坚持住!在本教程中,你已经学会了如何使用
sum()来连接序列。你能像上面的例子一样使用这个特性来展平列表吗?是啊!方法如下:
>>> matrix = [
... [1, 2, 3],
... [4, 5, 6],
... [7, 8, 9],
... ]
>>> sum(matrix, [])
[1, 2, 3, 4, 5, 6, 7, 8, 9]
真快!单行代码和matrix现在是一个平面列表。然而,使用sum()似乎不是最快的解决方案。
任何包含串联的解决方案的一个重要缺点是,在幕后,每个中间步骤都会创建一个新列表。就内存使用而言,这可能是相当浪费的。最终返回的列表只是在每一轮连接中创建的所有列表中最近创建的列表。相反,使用列表理解可以确保您只创建和返回一个列表:
>>> def flatten_list(a_list): ... return [item for sublist in a_list for item in sublist] ... >>> matrix = [ ... [1, 2, 3], ... [4, 5, 6], ... [7, 8, 9], ... ] >>> flatten_list(matrix) [1, 2, 3, 4, 5, 6, 7, 8, 9]这个新版本的
flatten_list()在内存使用方面效率更高,浪费更少。然而,嵌套的理解可能难以阅读和理解。使用
.append()可能是展平列表列表的可读性最强的方法:
>>> def flatten_list(a_list):
... flat = []
... for sublist in a_list:
... for item in sublist:
... flat.append(item)
... return flat
...
>>> matrix = [
... [1, 2, 3],
... [4, 5, 6],
... [7, 8, 9],
... ]
>>> flatten_list(matrix)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
在这个版本的flatten_list()中,阅读您代码的人可以看到函数在a_list中的每个sublist上迭代。在第一个for循环中,它遍历sublist中的每个item,最终用.append()填充新的flat列表。就像前面的理解一样,这个解决方案在这个过程中只创建一个列表。这种解决方案的一个优点是可读性很强。
使用sum()的替代品
正如您已经了解到的,sum()通常有助于处理数值。然而,在处理浮点数时,Python 提供了一个替代工具。在 math 中,您会发现一个名为 fsum() 的函数,它可以帮助您提高浮点计算的总体精度。
在一个任务中,您可能希望连接或链接几个可重复项,以便可以将它们作为一个整体使用。对于这种场景,可以看看 itertools 模块的功能 chain() 。
您可能还需要一个任务来连接字符串列表。在本教程中,您已经了解到无法使用sum()来连接字符串。这个函数不是为字符串连接而构建的。最 Pythonic 化的替代就是使用 str.join() 。
浮点数求和:math.fsum()
如果您的代码经常用sum()对浮点数求和,那么您应该考虑使用math.fsum()来代替。这个函数比sum()更仔细地执行浮点计算,这提高了计算的精度。
根据其文档,fsum()“通过跟踪多个中间部分和来避免精度损失。”文档提供了以下示例:
>>> from math import fsum >>> sum([.1, .1, .1, .1, .1, .1, .1, .1, .1, .1]) 0.9999999999999999 >>> fsum([.1, .1, .1, .1, .1, .1, .1, .1, .1, .1]) 1.0用
fsum(),你得到一个更精确的结果。然而,你应该注意到fsum()并没有解决浮点运算中的表示错误。以下示例揭示了这一限制:
>>> from math import fsum
>>> sum([0.1, 0.2])
0.30000000000000004
>>> fsum([0.1, 0.2])
0.30000000000000004
在这些示例中,两个函数返回相同的结果。这是因为无法用二进制浮点精确表示值0.1和0.2:
>>> f"{0.1:.28f}" '0.1000000000000000055511151231' >>> f"{0.2:.28f}" '0.2000000000000000111022302463'然而,与
sum()不同的是,当您将非常大的数字和非常小的数字相加时,fsum()可以帮助您减少浮点误差传播:
>>> from math import fsum
>>> sum([1e-16, 1, 1e16])
1e+16
>>> fsum([1e-16, 1, 1e16])
1.0000000000000002e+16
>>> sum([1, 1, 1e100, -1e100] * 10_000)
0.0
>>> fsum([1, 1, 1e100, -1e100] * 10_000)
20000.0
哇!第二个例子相当令人惊讶,完全击败了sum()。有了sum(),你得到的结果是0.0。这与你用fsum()得到的20000.0的正确结果相差甚远。
用itertools.chain() 串联可重复项
如果您正在寻找一个方便的工具来连接或链接一系列可重复项,那么可以考虑使用来自itertools的chain()。这个函数可以接受多个可迭代对象,并构建一个迭代器,从第一个产生项目,从第二个产生项目,以此类推,直到它穷尽所有的输入可迭代对象:
>>> from itertools import chain >>> numbers = chain([1, 2, 3], [4, 5, 6], [7, 8, 9]) >>> numbers <itertools.chain object at 0x7f0d0f160a30> >>> next(numbers) 1 >>> next(numbers) 2 >>> list(chain([1, 2, 3], [4, 5, 6], [7, 8, 9])) [1, 2, 3, 4, 5, 6, 7, 8, 9]当您调用
chain()时,您从输入 iterables 中获得一个 iterator。在本例中,您使用next()从numbers访问连续的项目。如果您想使用列表,那么您可以使用list()来使用迭代器并返回一个常规的 Python 列表。
chain()也是在 Python 中展平列表列表的一个好选项:
>>> from itertools import chain
>>> matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
>>> list(chain(*matrix))
[1, 2, 3, 4, 5, 6, 7, 8, 9]
要用chain()展平一个列表列表,需要使用可迭代解包操作符 ( *)。该操作符解包所有输入的可迭代对象,以便chain()可以处理它们并生成相应的迭代器。最后一步是调用list()来构建所需的平面列表。
用str.join()和连接字符串
正如你已经看到的,sum()没有连接或加入字符串。如果您需要这样做,那么 Python 中首选且最快的工具是str.join()。此方法将一系列字符串作为参数,并返回一个新的串联字符串:
>>> greeting = ["Hello,", "welcome to", "Real Python!"] >>> " ".join(greeting) 'Hello, welcome to Real Python!'使用
.join()是连接字符串的最有效的方式。这里,您使用一个字符串列表作为参数,并从输入中构建一个单独的字符串。注意.join()在连接过程中使用调用方法的字符串作为分隔符。在这个例子中,您在由一个空格字符(" ")组成的字符串上调用.join(),所以来自greeting的原始字符串在您的最终字符串中由空格分隔。结论
现在可以使用 Python 的内置函数
sum()将多个数值相加在一起。这个函数提供了一种有效的、可读的、Pythonic 式的方法来解决代码中的求和问题。如果您正在处理需要对数值求和的数学计算,那么sum()可以成为您的救命稻草。在本教程中,您学习了如何:
- 使用通用技术和工具对数值求和
- 使用 Python 的
sum()有效地添加几个数值- 使用
sum()连接序列- 用
sum()处理常见的求和问题- 为
sum()中的的iterable和start参数使用合适的值- 在
sum()和之间选择替代工具来求和并连接对象有了这些知识,您现在能够以一种 Pythonic 式的、可读的、高效的方式将多个数值相加。*****
使用 Python super()增强您的类
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python super() 为你的类增压
虽然 Python 不是纯粹的面向对象语言,但它足够灵活和强大,允许您使用面向对象的范例构建应用程序。Python 实现这一点的方法之一是支持继承,它用
super()做到了这一点。在本教程中,您将了解以下内容:
- Python 中的继承概念
- Python 中的多重继承
super()功能的工作原理- 单一继承中的
super()函数是如何工作的- 多重继承中的
super()函数是如何工作的免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 的
super()函数概述如果你有面向对象语言的经验,你可能已经熟悉了
super()的功能。如果没有,不要害怕!虽然官方文档是相当技术性的,但在高层次上
super()让你可以从继承它的子类中访问超类中的方法。单独返回超类的临时对象,然后允许你调用超类的方法。
你为什么想做这些?虽然可能性受到您的想象力的限制,但一个常见的用例是构建扩展先前构建的类的功能的类。
用
super()调用先前构建的方法可以让您不必在子类中重写这些方法,并允许您用最少的代码更改换出超类。
super()在单继承如果你不熟悉面向对象的编程概念,继承可能是一个陌生的术语。继承是面向对象编程中的一个概念,其中一个类从另一个类派生(或者继承)属性和行为,而不需要再次实现它们。
至少对我来说,看代码时更容易理解这些概念,所以让我们编写描述一些形状的类:
class Rectangle: def __init__(self, length, width): self.length = length self.width = width def area(self): return self.length * self.width def perimeter(self): return 2 * self.length + 2 * self.width class Square: def __init__(self, length): self.length = length def area(self): return self.length * self.length def perimeter(self): return 4 * self.length这里有两个类似的类:
Rectangle和Square。您可以按如下方式使用它们:
>>> square = Square(4)
>>> square.area()
16
>>> rectangle = Rectangle(2,4)
>>> rectangle.area()
8
在本例中,您有两个相互关联的形状:正方形是一种特殊的矩形。然而,代码没有反映这种关系,因此代码本质上是重复的。
通过使用继承,您可以减少编写的代码量,同时反映矩形和正方形之间的真实关系:
class Rectangle:
def __init__(self, length, width):
self.length = length
self.width = width
def area(self):
return self.length * self.width
def perimeter(self):
return 2 * self.length + 2 * self.width
# Here we declare that the Square class inherits from the Rectangle class
class Square(Rectangle):
def __init__(self, length):
super().__init__(length, length)
这里,您已经使用了super()来调用Rectangle类的__init__(),允许您在Square类中使用它而无需重复代码。下面是更改后保留的核心功能:
>>> square = Square(4) >>> square.area() 16在这个例子中,
Rectangle是超类,Square是子类。因为
Square和Rectangle.__init__()方法是如此的相似,你可以简单的通过使用super()从Square调用超类的.__init__()方法(Rectangle.__init__())。这将设置.length和.width属性,即使您只需向Square构造函数提供一个length参数。当您运行它时,即使您的
Square类没有显式实现它,对.area()的调用将使用超类中的.area()方法并打印16。Square类从Rectangle类继承了类.area()。注意:要了解更多关于 Python 中的继承和面向对象概念,请务必查看继承和组合:Python OOP 指南和Python 3 中的面向对象编程(OOP)。
super()能为你做什么?那么
super()在单一继承中能为你做些什么呢?像在其他面向对象的语言中一样,它允许你在子类中调用超类的方法。这种方法的主要用例是扩展继承方法的功能。
在下面的例子中,您将创建一个继承自
Square的类Cube,并扩展.area()的功能(通过Square继承自Rectangle类)来计算Cube实例的表面积和体积:class Square(Rectangle): def __init__(self, length): super().__init__(length, length) class Cube(Square): def surface_area(self): face_area = super().area() return face_area * 6 def volume(self): face_area = super().area() return face_area * self.length既然您已经构建了这些类,让我们来看看边长为
3的立方体的表面积和体积:
>>> cube = Cube(3)
>>> cube.surface_area()
54
>>> cube.volume()
27
注意:注意,在我们上面的例子中,super()不会单独为您进行方法调用:您必须调用代理对象本身的方法。
这里您已经为Cube类实现了两个方法:.surface_area()和.volume()。这两种计算都依赖于计算单个面的面积,因此,与其重新实现面积计算,不如使用super()来扩展面积计算。
还要注意的是,Cube类定义没有.__init__()。因为Cube从Square继承而来,并且.__init__()对Cube和对Square并没有什么不同,所以你可以跳过对它的定义,超类的.__init__()(Square)将被自动调用。
super()返回一个委托对象给父类,所以你直接在上面调用你想要的方法:super().area()。
这不仅让我们不必重写面积计算,还允许我们在一个位置改变内部的.area()逻辑。当你有许多继承自一个超类的子类时,这尤其方便。
一次super()深潜
在进入多重继承之前,让我们快速了解一下super()的机制。
虽然上面(和下面)的例子不带任何参数调用super(),但是super()也可以带两个参数:第一个参数是子类,第二个参数是该子类的实例对象。
首先,让我们看两个例子,使用已经显示的类,展示操作第一个变量可以做什么:
class Rectangle:
def __init__(self, length, width):
self.length = length
self.width = width
def area(self):
return self.length * self.width
def perimeter(self):
return 2 * self.length + 2 * self.width
class Square(Rectangle):
def __init__(self, length):
super(Square, self).__init__(length, length)
在 Python 3 中,super(Square, self)调用相当于无参数的super()调用。第一个参数指向子类Square,而第二个参数指向一个Square对象,在本例中是self。您也可以用其他类调用super():
class Cube(Square):
def surface_area(self):
face_area = super(Square, self).area()
return face_area * 6
def volume(self):
face_area = super(Square, self).area()
return face_area * self.length
在这个例子中,你将Square设置为super()的子类参数,而不是Cube。这使得super()开始在实例层次结构中Square之上的一个级别搜索匹配方法(在本例中为.area()),在本例中为Rectangle。
在这个具体的例子中,行为没有改变。但是想象一下,Square也实现了一个.area()函数,你想确保Cube没有使用它。以这种方式调用super()允许您这样做。
注意:虽然我们正在对super()的参数进行大量的修改,以探索它在引擎盖下是如何工作的,但我建议不要经常这样做。
推荐使用对super()的无参数调用,这对于大多数用例来说已经足够了,并且需要定期改变搜索层次可能表明存在更大的设计问题。
第二个参数呢?请记住,这是一个对象,它是用作第一个参数的类的实例。举个例子,isinstance(Cube, Square)必须返回True。
通过包含一个实例化的对象,super()返回一个绑定的方法:一个绑定到对象的方法,它为该方法提供对象的上下文,比如任何实例属性。如果没有包含这个参数,那么返回的方法只是一个函数,与对象的上下文无关。
有关绑定方法、未绑定方法和函数的更多信息,请阅读 Python 文档的描述符系统。
注意:从技术上来说,super()不返回方法。它返回一个代理对象。这是一个对象,它将调用委托给正确的类方法,而无需为此创建额外的对象。
super()在多重继承中
现在您已经学习了关于super()和单一继承的概述和一些例子,接下来将向您介绍展示多重继承如何工作以及super()如何实现该功能的概述和一些例子。
多重继承概述
还有另一个用例super()非常出色,这个用例不像单一继承场景那样常见。除了单一继承,Python 还支持多重继承,在多重继承中,一个子类可以从多个不一定相互继承的超类中继承(也称为兄弟类)。
我是一个非常视觉化的人,我发现图表对于理解这样的概念非常有帮助。下图显示了一个非常简单的多重继承场景,其中一个类继承自两个不相关的(兄弟)超类:

为了更好地说明多重继承,这里有一些代码供您试用,展示了如何用一个Triangle和一个Square构建一个正金字塔(一个正方形底的金字塔):
class Triangle:
def __init__(self, base, height):
self.base = base
self.height = height
def area(self):
return 0.5 * self.base * self.height
class RightPyramid(Triangle, Square):
def __init__(self, base, slant_height):
self.base = base
self.slant_height = slant_height
def area(self):
base_area = super().area()
perimeter = super().perimeter()
return 0.5 * perimeter * self.slant_height + base_area
注意:术语倾斜高度可能不熟悉,尤其是如果你已经有一段时间没有上过几何课或做过金字塔了。
倾斜高度是从一个物体(如金字塔)底部的中心到其表面到该物体顶点的高度。你可以在 WolframMathWorld 了解更多关于倾斜高度的信息。
这个例子声明了一个Triangle类和一个从Square和Triangle继承的RightPyramid类。
您将看到另一个.area()方法,它使用super(),就像在单一继承中一样,目的是让它达到在Rectangle类中定义的.perimeter()和.area()方法。
注意:你可能注意到上面的代码还没有使用任何从Triangle类继承的属性。后面的例子将充分利用从Triangle和Square的继承。
然而,问题是两个超类(Triangle和Square)都定义了一个.area()。花点时间想想当你在RightPyramid上调用.area()时会发生什么,然后试着像下面这样调用它:
>> pyramid = RightPyramid(2, 4) >> pyramid.area() Traceback (most recent call last): File "shapes.py", line 63, in <module> print(pyramid.area()) File "shapes.py", line 47, in area base_area = super().area() File "shapes.py", line 38, in area return 0.5 * self.base * self.height AttributeError: 'RightPyramid' object has no attribute 'height'你猜到 Python 会尝试调用
Triangle.area()了吗?这是因为一种叫做方法决议顺序的东西。注意:我们怎么会注意到
Triangle.area()被调用,而不是我们希望的Square.area()?如果您查看回溯的最后一行(在AttributeError之前),您会看到对特定代码行的引用:return 0.5 * self.base * self.height你可能在几何课上见过这个三角形的面积公式。否则,如果你像我一样,你可能已经向上滚动到
Triangle和Rectangle类定义,并在Triangle.area()中看到相同的代码。方法解析顺序
方法解析顺序(或 MRO )告诉 Python 如何搜索继承的方法。这在您使用
super()时很方便,因为 MRO 会告诉您 Python 将在哪里寻找您用super()调用的方法,以及以什么顺序。每个类都有一个
.__mro__属性,允许我们检查顺序,所以让我们这样做:
>>> RightPyramid.__mro__
(<class '__main__.RightPyramid'>, <class '__main__.Triangle'>,
<class '__main__.Square'>, <class '__main__.Rectangle'>,
<class 'object'>)
这告诉我们,方法将首先在Rightpyramid中搜索,然后在Triangle中搜索,然后在Square中搜索,然后在Rectangle中搜索,如果什么都没有找到,那么在所有类都源自的object中搜索。
这里的问题是解释器在Square和Rectangle之前在Triangle中搜索.area(),一找到Triangle中的.area(),Python 就调用它而不是你想要的那个。因为Triangle.area()期望有一个.height和一个.base属性,Python 抛出了一个AttributeError。
幸运的是,您可以控制 MRO 的构建方式。只需更改RightPyramid类的签名,您就可以按照您想要的顺序进行搜索,并且这些方法将正确解析:
class RightPyramid(Square, Triangle):
def __init__(self, base, slant_height):
self.base = base
self.slant_height = slant_height
super().__init__(self.base)
def area(self):
base_area = super().area()
perimeter = super().perimeter()
return 0.5 * perimeter * self.slant_height + base_area
注意,RightPyramid用来自Square类的.__init__()部分初始化。这允许.area()按照设计在对象上使用.length。
现在,您可以构建一个金字塔,检查 MRO,并计算表面积:
>>> pyramid = RightPyramid(2, 4) >>> RightPyramid.__mro__ (<class '__main__.RightPyramid'>, <class '__main__.Square'>, <class '__main__.Rectangle'>, <class '__main__.Triangle'>, <class 'object'>) >>> pyramid.area() 20.0你可以看到 MRO 现在是你所期望的样子,而且多亏了
.area()和.perimeter(),你还可以检查金字塔的区域。不过,这里还有一个问题。为了简单起见,我在这个例子中做错了几件事:第一件,也可以说是最重要的一件事,就是我有两个不同的类,它们有相同的方法名和签名。
这导致了方法解析的问题,因为在 MRO 列表中遇到的第一个实例
.area()将被调用。当你在多重继承中使用
super()时,设计你的类来与合作是必要的。其中一部分是通过确保方法签名是唯一的(无论是使用方法名还是方法参数),来确保您的方法是唯一的,以便在 MRO 中得到解析。在这种情况下,为了避免彻底检查您的代码,您可以将
Triangle类的.area()方法重命名为.tri_area()。这样,面积方法可以继续使用类属性,而不是采用外部参数:class Triangle: def __init__(self, base, height): self.base = base self.height = height super().__init__() def tri_area(self): return 0.5 * self.base * self.height让我们继续在
RightPyramid类中使用它:class RightPyramid(Square, Triangle): def __init__(self, base, slant_height): self.base = base self.slant_height = slant_height super().__init__(self.base) def area(self): base_area = super().area() perimeter = super().perimeter() return 0.5 * perimeter * self.slant_height + base_area def area_2(self): base_area = super().area() triangle_area = super().tri_area() return triangle_area * 4 + base_area这里的下一个问题是,代码不像对
Square对象那样有委托的Triangle对象,所以调用.area_2()会给我们一个AttributeError,因为.base和.height没有任何值。要解决这个问题,您需要做两件事:
所有用
super()调用的方法都需要调用该方法的超类版本。这意味着您需要将super().__init__()添加到Triangle和Rectangle的.__init__()方法中。重新设计所有的
.__init__()调用,取一个关键字字典。参见下面的完整代码。class Rectangle: def __init__(self, length, width, **kwargs): self.length = length self.width = width super().__init__(**kwargs) def area(self): return self.length * self.width def perimeter(self): return 2 * self.length + 2 * self.width # Here we declare that the Square class inherits from # the Rectangle class class Square(Rectangle): def __init__(self, length, **kwargs): super().__init__(length=length, width=length, **kwargs) class Cube(Square): def surface_area(self): face_area = super().area() return face_area * 6 def volume(self): face_area = super().area() return face_area * self.length class Triangle: def __init__(self, base, height, **kwargs): self.base = base self.height = height super().__init__(**kwargs) def tri_area(self): return 0.5 * self.base * self.height class RightPyramid(Square, Triangle): def __init__(self, base, slant_height, **kwargs): self.base = base self.slant_height = slant_height kwargs["height"] = slant_height kwargs["length"] = base super().__init__(base=base, **kwargs) def area(self): base_area = super().area() perimeter = super().perimeter() return 0.5 * perimeter * self.slant_height + base_area def area_2(self): base_area = super().area() triangle_area = super().tri_area() return triangle_area * 4 + base_area这段代码中有许多重要的不同之处:
**
kwargs在某些地方被修改(比如RightPyramid.__init__())😗*这将允许这些对象的用户仅使用对该特定对象有意义的参数来实例化它们。在
**kwargs之前设置命名参数:这个你可以在RightPyramid.__init__()里看到。这产生了一个整洁的效果,将那个键从**kwargs字典中弹出,这样当它在object类的 MRO 末尾结束时,**kwargs是空的。注意:跟踪
kwargs的状态在这里可能很棘手,所以这里有一个按顺序排列的.__init__()调用表,显示了拥有那个调用的类,以及那个调用期间kwargs的内容:
班级 命名参数 kwargsRightPyramidbase,slant_heightSquarelengthbase,heightRectanglelength,widthbase,heightTrianglebase,height现在,当您使用这些更新的类时,您会看到:
>>> pyramid = RightPyramid(base=2, slant_height=4)
>>> pyramid.area()
20.0
>>> pyramid.area_2()
20.0
有用!您已经使用super()成功地导航了一个复杂的类层次结构,同时使用继承和组合以最小的重新实现创建了新的类。
多重继承选择
如您所见,多重继承非常有用,但也会导致非常复杂的情况和难以阅读的代码。也很少有对象从多个其他对象继承所有东西。
如果你看到自己开始使用多重继承和复杂的类层次结构,那就值得问问自己,是否可以通过使用组合而不是继承来实现更干净、更容易理解的代码。因为本文关注的是继承,所以我不会过多地讨论组合以及如何在 Python 中使用它。幸运的是,Real Python 已经发布了一个关于 Python 继承和组合的深度指南,它将让你立刻成为 OOP 专家。
还有另一种技术可以帮助您避开多重继承的复杂性,同时仍然提供许多好处。这种技术的形式是一个专门的简单的类,叫做 mixin 。
mixin 作为一种继承工作,但是与其定义“是-a”关系,不如说它定义了“包含-a”关系可能更准确。使用 mix-in,您可以编写一个可以直接包含在任意数量的其他类中的行为。
下面,您将看到一个使用VolumeMixin为我们的 3D 对象赋予特定功能的简短示例——在本例中,是体积计算:
class Rectangle:
def __init__(self, length, width):
self.length = length
self.width = width
def area(self):
return self.length * self.width
class Square(Rectangle):
def __init__(self, length):
super().__init__(length, length)
class VolumeMixin:
def volume(self):
return self.area() * self.height
class Cube(VolumeMixin, Square):
def __init__(self, length):
super().__init__(length)
self.height = length
def face_area(self):
return super().area()
def surface_area(self):
return super().area() * 6
在这个例子中,代码被修改为包含一个名为VolumeMixin的 mixin。mixin 然后被Cube使用,并赋予Cube计算其体积的能力,如下所示:
>>> cube = Cube(2) >>> cube.surface_area() 24 >>> cube.volume() 8这个 mixin 可以以同样的方式在任何其他类中使用,这些类具有为其定义的区域,并且公式
area * height返回正确的体积。一个
super()回顾在本教程中,你学习了如何用
super()来增强你的类。您的旅程从回顾单一继承开始,然后展示了如何使用super()轻松调用超类方法。然后,您学习了多重继承在 Python 中是如何工作的,以及将
super()与多重继承结合起来的技术。您还了解了 Python 如何使用方法解析顺序(MRO)解析方法调用,以及如何检查和修改 MRO 以确保在适当的时间调用适当的方法。有关 Python 中面向对象编程和使用
super()的更多信息,请查看以下资源:立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python super() 为你的类增压***
Python 测试入门
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 PyTest 测试驱动开发
本教程是为那些已经用 Python 写了一个很棒的应用程序但还没有写任何测试的人准备的。
用 Python 进行测试是一个很大的话题,可能会很复杂,但并不一定很难。您可以通过几个简单的步骤开始为您的应用程序创建简单的测试,然后在此基础上进行构建。
在本教程中,您将学习如何创建一个基本的测试,执行它,并在您的用户之前找到错误!您将了解可用于编写和执行测试、检查应用程序性能,甚至查找安全问题的工具。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
测试您的代码
有很多方法可以测试你的代码。在本教程中,您将从最基本的步骤开始学习技术,并朝着高级方法前进。
自动测试与手动测试
好消息是,您可能已经在没有意识到的情况下创建了一个测试。还记得您第一次运行和使用应用程序的时候吗?你检查过这些特性并尝试使用它们了吗?这就是所谓的探索性测试,也是手工测试的一种形式。
探索性测试是一种没有计划的测试形式。在探索性测试中,您只是在探索应用程序。
要有一套完整的手动测试,您需要做的就是列出您的应用程序具有的所有特性、它可以接受的不同类型的输入以及预期的结果。现在,每次你对你的代码进行修改时,你都需要检查列表上的每一项。
听起来没什么意思,是吧?
这就是自动化测试的用武之地。自动化测试是由脚本而不是人来执行您的测试计划(您想要测试的应用程序部分、您想要测试它们的顺序以及预期的响应)。Python 已经提供了一套工具和库来帮助您为应用程序创建自动化测试。我们将在本教程中探索这些工具和库。
单元测试与集成测试
测试领域并不缺少术语,现在您已经知道了自动化测试和手动测试之间的区别,是时候更深入一层了。
想想你可能如何测试汽车上的灯。你可以打开灯(被称为测试步骤),走到车外或请朋友检查灯是否打开(被称为测试断言)。测试多个组件被称为集成测试。
想想为了让一个简单的任务产生正确的结果,需要正确工作的所有事情。这些组件就像是你的应用程序的一部分,所有你写的类、函数和模块。
集成测试的一个主要挑战是当集成测试没有给出正确的结果时。如果不能确定系统的哪个部分出现故障,就很难诊断问题。如果灯没有打开,那么可能是灯泡坏了。电池没电了吗?交流发电机呢?车的电脑是不是出故障了?
如果你有一辆时髦的汽车,它会告诉你什么时候你的灯泡坏了。它使用一种形式的单元测试来做到这一点。
单元测试是一个较小的测试,它检查单个组件是否以正确的方式运行。单元测试有助于您隔离应用程序中的问题,并更快地修复它。
您刚刚看到了两种类型的测试:
- 集成测试检查应用程序中的组件是否可以相互操作。
- 单元测试检查应用程序中的一个小组件。
您可以用 Python 编写集成测试和单元测试。为了编写内置函数
sum()的单元测试,您需要对照已知的输出来检查sum()的输出。例如,下面是如何检查数字
(1, 2, 3)的sum()是否等于6:
>>> assert sum([1, 2, 3]) == 6, "Should be 6"
这不会在 REPL 上输出任何内容,因为值是正确的。
如果来自sum()的结果不正确,这将失败,并显示AssertionError和消息"Should be 6"。使用错误的值再次尝试断言语句,以查看AssertionError:
>>> assert sum([1, 1, 1]) == 6, "Should be 6" Traceback (most recent call last): File "<stdin>", line 1, in <module> AssertionError: Should be 6在 REPL 中,您会看到凸起的
AssertionError,因为sum()的结果与6不匹配。不是在 REPL 上测试,而是将它放入一个名为
test_sum.py的新 Python 文件中,并再次执行它:def test_sum(): assert sum([1, 2, 3]) == 6, "Should be 6" if __name__ == "__main__": test_sum() print("Everything passed")现在您已经编写了一个测试用例,一个断言,和一个入口点(命令行)。现在,您可以在命令行中执行此操作:
$ python test_sum.py Everything passed可以看到成功的结果,
Everything passed。在 Python 中,
sum()接受任何 iterable 作为它的第一个参数。你用一个列表来测试。现在也用一个元组进行测试。用下面的代码创建一个名为test_sum_2.py的新文件:def test_sum(): assert sum([1, 2, 3]) == 6, "Should be 6" def test_sum_tuple(): assert sum((1, 2, 2)) == 6, "Should be 6" if __name__ == "__main__": test_sum() test_sum_tuple() print("Everything passed")当你执行
test_sum_2.py时,脚本会给出一个错误,因为(1, 2, 2)的sum()是5,而不是6。脚本的结果给出了错误消息、代码行和回溯:$ python test_sum_2.py Traceback (most recent call last): File "test_sum_2.py", line 9, in <module> test_sum_tuple() File "test_sum_2.py", line 5, in test_sum_tuple assert sum((1, 2, 2)) == 6, "Should be 6" AssertionError: Should be 6在这里,您可以看到代码中的一个错误如何在控制台上给出一个错误,并提供一些关于错误位置和预期结果的信息。
注意:可以同时记录和测试你的代码,同时确保你的代码和它的记录保持同步。查看 Python 的 doctest:立刻记录并测试你的代码以了解更多。
以这种方式编写测试对于简单的检查来说是可以的,但是如果不止一个测试失败了呢?这就是试车员的用武之地。测试运行程序是一个特殊的应用程序,设计用于运行测试、检查输出,并为您提供调试和诊断测试和应用程序的工具。
选择测试跑步者
Python 有许多可用的测试程序。Python 标准库中内置的那个叫做
unittest。在本教程中,您将使用unittest测试用例以及unittest测试运行器。unittest的原则很容易移植到其他框架。三个最受欢迎的测试跑步者是:
unittestnose或nose2pytest根据您的需求和经验水平选择最佳的测试跑步者非常重要。
unittest
unittest从 2.1 版本开始就已经内置到 Python 标准库中。您可能会在商业 Python 应用程序和开源项目中看到它。包含测试框架和测试运行程序。
unittest对编写和执行测试有一些重要的要求。
unittest要求:
- 您将测试作为方法放入类中
- 您在
unittest.TestCase类中使用了一系列特殊的断言方法,而不是内置的assert语句要将前面的例子转换成一个
unittest测试用例,您必须:
- 从标准库中导入
unittest- 创建一个名为
TestSum的类,它继承自TestCase类- 通过添加
self作为第一个参数,将测试函数转换成方法- 更改断言以在
TestCase类上使用self.assertEqual()方法- 将命令行入口点改为调用
unittest.main()按照这些步骤,用下面的代码创建一个新文件
test_sum_unittest.py:import unittest class TestSum(unittest.TestCase): def test_sum(self): self.assertEqual(sum([1, 2, 3]), 6, "Should be 6") def test_sum_tuple(self): self.assertEqual(sum((1, 2, 2)), 6, "Should be 6") if __name__ == '__main__': unittest.main()如果在命令行执行,您将看到一次成功(用
.表示)和一次失败(用F表示):$ python test_sum_unittest.py .F ====================================================================== FAIL: test_sum_tuple (__main__.TestSum) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_sum_unittest.py", line 9, in test_sum_tuple self.assertEqual(sum((1, 2, 2)), 6, "Should be 6") AssertionError: Should be 6 ---------------------------------------------------------------------- Ran 2 tests in 0.001s FAILED (failures=1)您已经使用
unittest测试运行器执行了两个测试。注意:如果你正在编写需要同时在 Python 2 和 3 中执行的测试用例,要小心。在 Python 2.7 及以下版本中,
unittest被称为unittest2。如果你简单地从unittest中导入,你将会在 Python 2 和 3 之间得到具有不同特性的不同版本。要了解更多关于
unittest的信息,你可以浏览单元测试文档。
nose您可能会发现,随着时间的推移,当您为您的应用程序编写数百甚至数千个测试时,理解和使用来自
unittest的输出变得越来越困难。
nose兼容任何使用unittest框架编写的测试,并且可以作为unittest测试运行程序的替代。作为开源应用的nose的开发落后了,一个叫做nose2的分支被创建了。如果你是从零开始,建议你使用nose2而不是nose。要开始使用
nose2,从 PyPI 安装nose2并在命令行上执行它。nose2将尝试在您当前的目录中发现所有名为test*.py的测试脚本和从unittest.TestCase继承的测试用例;$ pip install nose2 $ python -m nose2 .F ====================================================================== FAIL: test_sum_tuple (__main__.TestSum) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_sum_unittest.py", line 9, in test_sum_tuple self.assertEqual(sum((1, 2, 2)), 6, "Should be 6") AssertionError: Should be 6 ---------------------------------------------------------------------- Ran 2 tests in 0.001s FAILED (failures=1)您刚刚从
nose2测试运行程序中执行了您在test_sum_unittest.py中创建的测试。nose2提供了许多命令行标志来过滤您执行的测试。要了解更多信息,你可以浏览 Nose 2 文档。
pytest
pytest支持unittest测试用例的执行。pytest的真正优势来自于编写pytest测试用例。pytest测试用例是一个 Python 文件中的一系列函数,以名称test_开始。
pytest还有其他一些很棒的功能:
- 支持内置的
assert语句,而不是使用特殊的self.assert*()方法- 支持测试用例的过滤
- 从上次失败的测试重新运行的能力
- 一个由数百个插件组成的生态系统,用于扩展功能
为
pytest编写的TestSum测试用例示例如下所示:def test_sum(): assert sum([1, 2, 3]) == 6, "Should be 6" def test_sum_tuple(): assert sum((1, 2, 2)) == 6, "Should be 6"您已经放弃了
TestCase、任何对类的使用以及命令行入口点。更多信息可以在 Pytest 文档网站上找到。
编写您的第一个测试
让我们将您到目前为止所学到的东西结合起来,测试相同需求的简单实现,而不是测试内置的
sum()函数。创建一个新的项目文件夹,并在其中创建一个名为
my_sum的新文件夹。在my_sum中,创建一个名为__init__.py的空文件。创建__init__.py文件意味着my_sum文件夹可以作为一个模块从父目录导入。您的项目文件夹应该如下所示:
project/ │ └── my_sum/ └── __init__.py打开
my_sum/__init__.py并创建一个名为sum()的新函数,它接受一个 iterable(一个列表、元组或集合)并将值相加:def sum(arg): total = 0 for val in arg: total += val return total这个代码示例创建一个名为
total的变量,遍历arg中的所有值,并将它们添加到total。一旦 iterable 用完,它就返回结果。在哪里写测试
要开始编写测试,您可以简单地创建一个名为
test.py的文件,它将包含您的第一个测试用例。因为该文件将需要能够导入您的应用程序以便能够测试它,所以您希望将test.py放在包文件夹之上,这样您的目录树将看起来像这样:project/ │ ├── my_sum/ │ └── __init__.py | └── test.py您会发现,随着您添加越来越多的测试,您的单个文件将变得混乱和难以维护,因此您可以创建一个名为
tests/的文件夹,并将测试拆分成多个文件。按照惯例,要确保每个文件都以test_开头,这样所有的测试运行者都会认为 Python 文件包含了要执行的测试。一些非常大的项目根据它们的目的或用途将测试分成更多的子目录。注意:如果你的应用是单个脚本怎么办?
您可以使用内置的
__import__()函数导入脚本的任何属性,比如类、函数和变量。代替from my_sum import sum,你可以写如下:target = __import__("my_sum.py") sum = target.sum使用
__import__()的好处是不用把项目文件夹变成包,可以指定文件名。如果您的文件名与任何标准库包冲突,这也很有用。例如,math.py会与math模块发生冲突。如何构建一个简单的测试
在开始编写测试之前,您需要首先做出几个决定:
- 你想测试什么?
- 你写的是单元测试还是集成测试?
那么测试的结构应该大致遵循这个工作流程:
- 创建您的输入
- 执行被测试的代码,捕获输出
- 将输出与预期结果进行比较
对于这个应用程序,您正在测试
sum()。在sum()中有许多行为可以检查,例如:
- 它能对一列整数求和吗?
- 它能对一个元组或集合求和吗?
- 它能对一个浮点数列表求和吗?
- 当你给它提供一个错误的值,比如单个整数或者一个字符串,会发生什么?
- 当其中一个值为负时会发生什么?
最简单的测试是一个整数列表。使用以下 Python 代码创建一个文件
test.py:import unittest from my_sum import sum class TestSum(unittest.TestCase): def test_list_int(self): """ Test that it can sum a list of integers """ data = [1, 2, 3] result = sum(data) self.assertEqual(result, 6) if __name__ == '__main__': unittest.main()此代码示例:
从您创建的
my_sum包中导入sum()定义一个名为
TestSum的新测试用例类,它继承自unittest.TestCase定义一个测试方法
.test_list_int(),用于测试整数列表。方法.test_list_int()将:
- 用一列数字
(1, 2, 3)声明一个变量data- 将
my_sum.sum(data)的结果赋给一个result变量- 通过使用
unittest.TestCase类上的.assertEqual()方法断言result的值等于6定义一个命令行入口点,它运行
unittest测试运行程序.main()如果你不确定
self是什么或者.assertEqual()是如何定义的,你可以用 Python 3 面向对象编程来温习你的面向对象编程。如何写断言
编写测试的最后一步是根据已知的响应来验证输出。这被称为断言。关于如何编写断言,有一些通用的最佳实践:
- 确保测试是可重复的,并多次运行测试,以确保每次都给出相同的结果
- 尝试断言与您的输入数据相关的结果,例如检查结果是否是
sum()示例中值的实际总和有很多方法可以断言变量的值、类型和存在性。以下是一些最常用的方法:
方法 等于 .assertEqual(a, b)a == b.assertTrue(x)bool(x) is True.assertFalse(x)bool(x) is False.assertIs(a, b)a is b.assertIsNone(x)x is None.assertIn(a, b)a in b.assertIsInstance(a, b)isinstance(a, b)
.assertIs()、.assertIsNone()、.assertIn()、.assertIsInstance()都有相反的方法,命名为.assertIsNot(),以此类推。副作用
当你写测试时,通常不像查看函数的返回值那么简单。通常,执行一段代码会改变环境中的其他东西,比如类的属性、文件系统中的文件或者数据库中的值。这些被称为副作用,是测试的重要组成部分。在将副作用包含在您的断言列表中之前,决定是否正在测试它。
如果你发现你想要测试的代码单元有很多副作用,你可能违反了单一责任原则。违反单一责任原则意味着这段代码做了太多的事情,重构会更好。遵循单一责任原则是设计代码的一个很好的方法,它易于为可靠的应用程序编写可重复的简单单元测试。
执行您的第一个测试
现在您已经创建了第一个测试,您想要执行它。当然,您知道它会通过,但是在您创建更复杂的测试之前,您应该检查您是否能够成功地执行测试。
执行测试运行程序
执行测试代码、检查断言并在控制台中给出测试结果的 Python 应用程序被称为测试运行程序。
在
test.py的底部,您添加了这一小段代码:if __name__ == '__main__': unittest.main()这是命令行入口点。意思是如果你在命令行运行
python test.py单独执行脚本,它会调用unittest.main()。这通过发现这个文件中从unittest.TestCase继承的所有类来执行测试运行器。这是执行
unittest测试运行程序的许多方法之一。当您有一个名为test.py的测试文件时,调用python test.py是一个很好的开始方式。另一种方法是使用
unittest命令行。试试这个:$ python -m unittest test这将通过命令行执行相同的测试模块(名为
test)。您可以提供附加选项来更改输出。其中之一是
-v表示冗长。尝试下一步:$ python -m unittest -v test test_list_int (test.TestSum) ... ok ---------------------------------------------------------------------- Ran 1 tests in 0.000s这执行了
test.py中的一个测试,并将结果打印到控制台。详细模式列出了它首先执行的测试的名称,以及每个测试的结果。您可以使用以下命令请求自动发现,而不是提供包含测试的模块的名称:
$ python -m unittest discover这将在当前目录中搜索任何名为
test*.py的文件,并尝试测试它们。一旦您有了多个测试文件,只要您遵循
test*.py命名模式,您就可以通过使用-s标志和目录名来提供目录名:$ python -m unittest discover -s tests将在一个测试计划中运行所有测试,并给出结果。
最后,如果您的源代码不在根目录中,而是包含在子目录中,例如在一个名为
src/的文件夹中,您可以告诉unittest在哪里执行测试,以便它可以正确地导入带有-t标志的模块:$ python -m unittest discover -s tests -t src
unittest会切换到src/目录,扫描tests目录下的所有test*.py文件,并执行。了解测试输出
这是一个非常简单的例子,一切都通过了,所以现在您将尝试一个失败的测试并解释输出。
应该能够接受其他数字类型的列表,比如分数。
在
test.py文件的顶部,添加一条导入语句,从标准库中的fractions模块导入Fraction类型:from fractions import Fraction现在添加一个测试,其断言预期值不正确,在本例中预期 1/4、1/4 和 2/5 之和为 1:
import unittest from my_sum import sum class TestSum(unittest.TestCase): def test_list_int(self): """ Test that it can sum a list of integers """ data = [1, 2, 3] result = sum(data) self.assertEqual(result, 6) def test_list_fraction(self): """ Test that it can sum a list of fractions """ data = [Fraction(1, 4), Fraction(1, 4), Fraction(2, 5)] result = sum(data) self.assertEqual(result, 1) if __name__ == '__main__': unittest.main()如果使用
python -m unittest test再次执行测试,您应该会看到以下输出:$ python -m unittest test F. ====================================================================== FAIL: test_list_fraction (test.TestSum) ---------------------------------------------------------------------- Traceback (most recent call last): File "test.py", line 21, in test_list_fraction self.assertEqual(result, 1) AssertionError: Fraction(9, 10) != 1 ---------------------------------------------------------------------- Ran 2 tests in 0.001s FAILED (failures=1)在输出中,您将看到以下信息:
第一行显示了所有测试的执行结果,一个失败(
F),一个通过(.)。
FAIL条目显示了关于失败测试的一些细节:
- 测试方法名称(
test_list_fraction)- 测试模块(
test)和测试用例(TestSum)- 对故障线路的追溯
- 带有预期结果(
1)和实际结果(Fraction(9, 10))的断言的详细信息请记住,您可以通过将
-v标志添加到python -m unittest命令来将额外的信息添加到测试输出中。从 PyCharm 运行您的测试
如果您使用的是 PyCharm IDE,您可以按照以下步骤运行
unittest或pytest:
- 在项目工具窗口中,选择
tests目录。- 在上下文菜单中,选择
unittest的运行命令。例如,选择运行‘我的测试中的单元测试…’。这将在测试窗口中执行
unittest,并在 PyCharm 中给出结果:
更多信息请访问 PyCharm 网站。
从 Visual Studio 代码运行测试
如果您使用的是 Microsoft Visual Studio 代码集成开发环境,Python 插件内置了对
unittest、nose和pytest执行的支持。如果你已经安装了 Python 插件,你可以通过打开命令面板用
Ctrl+Shift+P并输入“Python test”来设置你的测试的配置。您将看到一系列选项:
选择调试所有单元测试,VSCode 会提示配置测试框架。点击 cog 选择测试跑步者(
unittest)和主目录(.)。设置完成后,您将在窗口底部看到测试的状态,并且您可以通过单击这些图标快速访问测试日志并再次运行测试:
这表明测试正在执行,但是其中一些测试失败了。
测试像 Django 和 Flask 这样的 Web 框架
如果您使用流行的框架(如 Django 或 Flask)为 web 应用程序编写测试,那么在编写和运行测试的方式上会有一些重要的不同。
为什么它们不同于其他应用程序
想想您将在 web 应用程序中测试的所有代码。路线、视图和模型都需要大量的导入和关于正在使用的框架的知识。
这类似于教程开始时的汽车测试:你必须启动汽车的计算机,然后才能运行像检查车灯这样的简单测试。
Django 和 Flask 都提供了一个基于
unittest的测试框架,让这一切变得简单。您可以继续以您一直学习的方式编写测试,但是执行它们会稍有不同。如何使用 Django 测试运行器
Django
startapp模板将在您的应用程序目录中创建一个tests.py文件。如果还没有,可以用以下内容创建它:from django.test import TestCase class MyTestCase(TestCase): # Your test methods到目前为止,与示例的主要区别在于,您需要从
django.test.TestCase而不是unittest.TestCase继承。这些类有相同的 API,但是 DjangoTestCase类设置了所有需要测试的状态。要执行您的测试套件,您可以使用
manage.py test,而不是在命令行使用unittest:$ python manage.py test如果你想要多个测试文件,用一个名为
tests的文件夹替换tests.py,在里面插入一个名为__init__.py的空文件,然后创建你的test_*.py文件。姜戈会发现并执行这些。更多信息请访问 Django 文档网站。
如何使用
unittest和烧瓶Flask 要求导入应用程序,然后设置为测试模式。您可以实例化一个测试客户端,并使用该测试客户端向应用程序中的任何路由发出请求。
所有的测试客户端实例化都是在测试用例的
setUp方法中完成的。在下面的示例中,my_app是应用程序的名称。如果你不知道setUp是做什么的,不要担心。您将在更高级的测试场景部分了解到这一点。测试文件中的代码应该如下所示:
import my_app import unittest class MyTestCase(unittest.TestCase): def setUp(self): my_app.app.testing = True self.app = my_app.app.test_client() def test_home(self): result = self.app.get('/') # Make your assertions然后您可以使用
python -m unittest discover命令来执行测试用例。更多信息请访问烧瓶文档网站。
更高级的测试场景
在开始为应用程序创建测试之前,请记住每个测试的三个基本步骤:
- 创建您的输入
- 执行代码,捕获输出
- 将输出与预期结果进行比较
为输入创建一个静态值(如字符串或数字)并不总是那么容易。有时,您的应用程序将需要一个类或上下文的实例。那你会怎么做?
您作为输入创建的数据被称为 fixture 。创建装置并重复使用它们是常见的做法。
如果你运行相同的测试,每次传递不同的值,并期望得到相同的结果,这就是所谓的参数化。
处理预期故障
早些时候,当你列出测试
sum()的场景时,出现了一个问题:当你给它提供一个错误的值,比如单个整数或字符串,会发生什么?在这种情况下,您会期望
sum()抛出一个错误。当它抛出错误时,会导致测试失败。有一种特殊的方法来处理预期的错误。您可以使用
.assertRaises()作为上下文管理器,然后在with块中执行测试步骤:import unittest from my_sum import sum class TestSum(unittest.TestCase): def test_list_int(self): """ Test that it can sum a list of integers """ data = [1, 2, 3] result = sum(data) self.assertEqual(result, 6) def test_list_fraction(self): """ Test that it can sum a list of fractions """ data = [Fraction(1, 4), Fraction(1, 4), Fraction(2, 5)] result = sum(data) self.assertEqual(result, 1) def test_bad_type(self): data = "banana" with self.assertRaises(TypeError): result = sum(data) if __name__ == '__main__': unittest.main()只有当
sum(data)引发TypeError时,这个测试用例才会通过。您可以用您选择的任何异常类型替换TypeError。隔离应用程序中的行为
在本教程的前面,您已经学习了什么是副作用。副作用使得单元测试更加困难,因为每次运行测试时,它可能会给出不同的结果,或者更糟的是,一个测试可能会影响应用程序的状态,导致另一个测试失败!
有一些简单的技术可以用来测试应用程序中有许多副作用的部分:
- 重构代码以遵循单一责任原则
- 模仿任何方法或函数调用来消除副作用
- 对应用程序的这一部分使用集成测试而不是单元测试
如果你不熟悉嘲讽,请看 Python CLI 测试中一些很棒的例子。
编写集成测试
到目前为止,您主要学习了单元测试。单元测试是构建可预测的稳定代码的好方法。但是最终,您的应用程序需要在启动时工作!
集成测试是对应用程序的多个组件进行测试,以检查它们是否能协同工作。集成测试可能需要通过以下方式扮演应用程序的消费者或用户:
- 调用 HTTP REST API
- 调用 Python API
- 调用 web 服务
- 运行命令行
每种类型的集成测试都可以按照输入、执行和断言模式,以与单元测试相同的方式编写。最显著的区别是集成测试一次检查更多的组件,因此会比单元测试有更多的副作用。此外,集成测试将需要更多的设备,比如数据库、网络套接字或配置文件。
这就是为什么将单元测试和集成测试分开是一个好的实践。创建集成所需的装置(如测试数据库)和测试用例本身通常比单元测试需要更长的时间来执行,因此您可能只想在推向生产之前运行集成测试,而不是在每次提交时运行一次。
分离单元测试和集成测试的一个简单方法就是将它们放在不同的文件夹中:
project/ │ ├── my_app/ │ └── __init__.py │ └── tests/ | ├── unit/ | ├── __init__.py | └── test_sum.py | └── integration/ ├── __init__.py └── test_integration.py有许多方法可以只执行一组选定的测试。可以将指定源目录标志
-s添加到unittest discover中,其路径包含测试:$ python -m unittest discover -s tests/integration
unittest将为您提供tests/integration目录中所有测试的结果。测试数据驱动的应用程序
许多集成测试将需要像数据库这样的后端数据以特定的值存在。例如,您可能希望有一个测试来检查数据库中超过 100 个客户的应用程序是否正确显示,或者即使产品名称以日语显示,订单页面是否正常工作。
这些类型的集成测试将依赖于不同的测试设备,以确保它们是可重复的和可预测的。
一个好的方法是将测试数据存储在集成测试文件夹中的一个名为
fixtures的文件夹中,以表明它包含测试数据。然后,在您的测试中,您可以加载数据并运行测试。如果数据由 JSON 文件组成,下面是这种结构的一个例子:
project/ │ ├── my_app/ │ └── __init__.py │ └── tests/ | └── unit/ | ├── __init__.py | └── test_sum.py | └── integration/ | ├── fixtures/ | ├── test_basic.json | └── test_complex.json | ├── __init__.py └── test_integration.py在您的测试用例中,您可以使用
.setUp()方法从一个已知路径的 fixture 文件中加载测试数据,并针对该测试数据执行许多测试。记住,在一个 Python 文件中可以有多个测试用例,而unittestdiscovery 将同时执行这两个测试用例。每组测试数据可以有一个测试用例:import unittest class TestBasic(unittest.TestCase): def setUp(self): # Load test data self.app = App(database='fixtures/test_basic.json') def test_customer_count(self): self.assertEqual(len(self.app.customers), 100) def test_existence_of_customer(self): customer = self.app.get_customer(id=10) self.assertEqual(customer.name, "Org XYZ") self.assertEqual(customer.address, "10 Red Road, Reading") class TestComplexData(unittest.TestCase): def setUp(self): # load test data self.app = App(database='fixtures/test_complex.json') def test_customer_count(self): self.assertEqual(len(self.app.customers), 10000) def test_existence_of_customer(self): customer = self.app.get_customer(id=9999) self.assertEqual(customer.name, u"バナナ") self.assertEqual(customer.address, "10 Red Road, Akihabara, Tokyo") if __name__ == '__main__': unittest.main()如果您的应用程序依赖于来自远程位置的数据,比如一个远程 API ,您将希望确保您的测试是可重复的。因为 API 离线或者有一个连接问题而导致测试失败可能会减慢开发速度。在这种情况下,最好将远程设备存储在本地,这样就可以调用它们并发送给应用程序。
requests库有一个名为responses的免费包,它提供了创建响应夹具并将它们保存在测试文件夹中的方法。在他们的 GitHub 页面上找到更多。多种环境下的测试
到目前为止,您已经使用具有一组特定依赖关系的虚拟环境测试了 Python 的单个版本。您可能想要检查您的应用程序是否在多个版本的 Python 上工作,或者是否在一个包的多个版本上工作。Tox 是一个在多种环境中自动测试的应用程序。
安装 Tox
通过
pip可以在 PyPI 上安装 Tox 软件包:$ pip install tox现在您已经安装了 Tox,需要对它进行配置。
为您的依赖项配置 Tox
Tox 是通过项目目录中的配置文件进行配置的。Tox 配置文件包含以下内容:
- 为了执行测试而运行的命令
- 执行前需要的任何附加包
- 要测试的目标 Python 版本
您不必学习 Tox 配置语法,而是可以通过运行 quickstart 应用程序来提前开始:
$ tox-quickstartTox 配置工具将询问您这些问题,并创建一个类似于
tox.ini中的文件:[tox] envlist = py27, py36 [testenv] deps = commands = python -m unittest discover在运行 Tox 之前,它要求您的应用程序文件夹中有一个包含安装包的步骤的
setup.py文件。如果你还没有,你可以在继续之前按照这个指南来创建一个setup.py。或者,如果您的项目不在 PyPI 上发布,您可以通过在标题
[tox]下的tox.ini文件中添加下面一行来跳过这个要求:[tox] envlist = py27, py36 skipsdist=True如果您没有创建一个
setup.py,并且您的应用程序有一些来自 PyPI 的依赖项,您将需要在[testenv]部分下的许多行中指定这些依赖项。例如,Django 将要求:[testenv] deps = django一旦你完成了这个阶段,你就可以运行测试了。
您现在可以执行 Tox,它将创建两个虚拟环境:一个用于 Python 2.7,一个用于 Python 3.6。Tox 目录名为
.tox/。在.tox/目录中,Tox 将针对每个虚拟环境执行python -m unittest discover。您可以通过在命令行中调用 Tox 来运行此过程:
$ toxTox 将输出您在各种环境下的测试结果。第一次运行时,Tox 需要一点时间来创建虚拟环境,但是一旦创建了虚拟环境,第二次执行就会快得多。
正在执行 Tox
Tox 的输出非常简单。它为每个版本创建一个环境,安装您的依赖项,然后运行测试命令。
还有一些额外的命令行选项需要记住。
仅运行单一环境,如 Python 3.6:
$ tox -e py36重新创建虚拟环境,以防您的依赖关系发生变化或站点包损坏:
$ tox -r运行 Tox,减少详细输出:
$ tox -q使用更详细的输出运行 Tox:
$ tox -v有关 Tox 的更多信息可在 Tox 文档网站上找到。
自动化测试的执行
到目前为止,您一直通过运行命令来手动执行测试。当您做出更改并将它们提交到一个像 Git 这样的源代码控制存储库时,有一些工具可以自动执行测试。自动化测试工具通常被称为 CI/CD 工具,代表“持续集成/持续部署”他们可以运行您的测试,编译和发布任何应用程序,甚至将它们部署到生产环境中。
Travis CI 是众多可用 CI()服务之一。
Travis CI 与 Python 配合得很好,现在您已经创建了所有这些测试,您可以在云中自动执行它们了!Travis CI 对 GitHub 和 GitLab 上的任何开源项目都是免费的,对私人项目也是收费的。
首先,登录网站,使用您的 GitHub 或 GitLab 凭据进行认证。然后用以下内容创建一个名为
.travis.yml的文件:language: python python: - "2.7" - "3.7" install: - pip install -r requirements.txt script: - python -m unittest discover该配置指示 Travis CI:
- 针对 Python 2.7 和 3.7 进行测试(您可以用您选择的任何版本替换这些版本。)
- 安装您在
requirements.txt中列出的所有软件包(如果您没有任何依赖项,您应该删除这一部分。)- 运行
python -m unittest discover运行测试一旦您提交并推送了这个文件,Travis CI 将在您每次推送远程 Git 存储库时运行这些命令。你可以在他们的网站上查看结果。
接下来是什么
既然您已经学习了如何创建测试、执行测试、将测试包含到项目中,甚至自动执行测试,那么随着您的测试库的增长,您可能会发现有一些高级的技术非常方便。
在你的应用中引入 Linters】
Tox 和 Travis CI 配置了测试命令。您在本教程中一直使用的测试命令是
python -m unittest discover。您可以在所有这些工具中提供一个或多个命令,这个选项使您能够添加更多的工具来提高应用程序的质量。
一种这样的应用被称为棉绒。一个过客会看着你的代码并对它进行评论。它可以给你提示你所犯的错误,纠正尾随空格,甚至预测你可能引入的错误。
关于 linters 的更多信息,请阅读 Python 代码质量教程。
被动的林挺用
flake8与根据 PEP 8 规范来评论你的代码风格的流行短评是
flake8。您可以使用
pip安装flake8:$ pip install flake8然后,您可以对单个文件、文件夹或模式运行
flake8:$ flake8 test.py test.py:6:1: E302 expected 2 blank lines, found 1 test.py:23:1: E305 expected 2 blank lines after class or function definition, found 1 test.py:24:20: W292 no newline at end of file您将看到
flake8发现的代码错误和警告列表。
flake8可以在命令行上配置,也可以在项目的配置文件中配置。如果您想忽略某些规则,比如上面显示的E305,您可以在配置中设置它们。flake8将检查项目文件夹中的一个.flake8文件或一个setup.cfg文件。如果您决定使用 Tox,您可以将flake8配置部分放在tox.ini中。这个例子忽略了
.git和__pycache__目录以及E305规则。此外,它将最大行长度设置为 90 而不是 80 个字符。您可能会发现,79 个字符的默认行宽约束对于测试来说非常有限,因为它们包含长方法名、带有测试值的字符串文字以及其他可能更长的数据。通常将测试的行长度设置为最多 120 个字符:[flake8] ignore = E305 exclude = .git,__pycache__ max-line-length = 90或者,您可以在命令行上提供这些选项:
$ flake8 --ignore E305 --exclude .git,__pycache__ --max-line-length=90配置选项的完整列表可在文档网站上获得。
您现在可以将
flake8添加到您的配置项配置中。对于 Travis CI,这将如下所示:matrix: include: - python: "2.7" script: "flake8"Travis 将读取
.flake8中的配置,如果出现任何林挺错误,构建就会失败。确保将flake8依赖项添加到您的requirements.txt文件中。带有代码格式化程序的主动林挺
是一个被动的提示:它建议修改,但是你必须去修改代码。更积极的方法是代码格式化程序。代码格式化程序将自动更改您的代码,以满足一系列样式和布局实践。
是一个非常无情的格式化者。它没有任何配置选项,它有一个非常具体的风格。这使得它非常适合作为一个嵌入工具放在您的测试管道中。
注意:
black需要 Python 3.6+。您可以通过 pip 安装
black:$ pip install black然后在命令行运行
black,提供想要格式化的文件或目录:$ black test.py保持你的测试代码整洁
在编写测试时,您可能会发现,与常规应用程序相比,您最终会更多地复制和粘贴代码。测试有时会非常重复,但这绝不是让您的代码变得松散和难以维护的理由。
随着时间的推移,你将在你的测试代码中开发大量的技术债务,如果你的应用程序有重大的变化,需要改变你的测试,这可能是一个比必要的更麻烦的任务,因为你构建它们的方式。
编写测试时尽量遵循干原则:Don tREPE atYyourself。
测试夹具和函数是产生易于维护的测试代码的好方法。此外,可读性也很重要。考虑在你的测试代码上部署一个类似
flake8的林挺工具:$ flake8 --max-line-length=120 tests/测试变更之间的性能下降
在 Python 中有很多方法可以对代码进行基准测试。标准库提供了
timeit模块,它可以对函数进行多次计时,并给出发行版。这个例子将执行test()100 次,然后print()输出:def test(): # ... your code if __name__ == '__main__': import timeit print(timeit.timeit("test()", setup="from __main__ import test", number=100))如果你决定使用
pytest作为测试运行器,另一个选择是pytest-benchmark插件。这提供了一个名为benchmark的pytest夹具。你可以给benchmark()传递任何一个可调用的函数,它会把这个函数的时间记录到pytest的结果中。您可以使用
pip从 PyPI 安装pytest-benchmark:$ pip install pytest-benchmark然后,您可以添加一个测试,该测试使用 fixture 并传递要执行的 callable:
def test_my_function(benchmark): result = benchmark(test)执行
pytest将会给出基准测试结果:
更多信息请访问文档网站。
测试应用程序中的安全缺陷
您希望在应用程序上运行的另一个测试是检查常见的安全错误或漏洞。
您可以使用
pip从 PyPI 安装bandit:$ pip install bandit然后,您可以传递带有
-r标志的应用程序模块的名称,它会给出一个摘要:$ bandit -r my_sum [main] INFO profile include tests: None [main] INFO profile exclude tests: None [main] INFO cli include tests: None [main] INFO cli exclude tests: None [main] INFO running on Python 3.5.2 Run started:2018-10-08 00:35:02.669550 Test results: No issues identified. Code scanned: Total lines of code: 5 Total lines skipped (#nosec): 0 Run metrics: Total issues (by severity): Undefined: 0.0 Low: 0.0 Medium: 0.0 High: 0.0 Total issues (by confidence): Undefined: 0.0 Low: 0.0 Medium: 0.0 High: 0.0 Files skipped (0):与
flake8一样,bandit标记的规则是可配置的,如果您希望忽略任何规则,您可以将以下部分添加到您的setup.cfg文件中,并提供选项:[bandit] exclude: /test tests: B101,B102,B301更多细节可在 GitHub 网站获得。
结论
Python 通过内置验证应用程序是否按设计运行所需的命令和库,使测试变得容易。开始使用 Python 进行测试并不复杂:您可以使用
unittest并编写小的、可维护的方法来验证您的代码。随着您对测试的了解越来越多,您的应用程序越来越多,您可以考虑切换到其他测试框架之一,比如
pytest,并开始利用更高级的特性。感谢您的阅读。我希望你有一个没有 bug 的 Python 未来!
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 PyTest 测试驱动开发*********
用 Python 递归思考
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用 Python 递归思考
“在我介绍给孩子们的所有想法中,递归是特别能够引起兴奋反应的一个想法。”
— 西蒙·派珀特,头脑风暴
Image: [xkcd.com](https://www.xkcd.com/1739) (生活中以及计算机科学中的)问题常常看起来很大,很可怕。但是如果我们不断地解决它们,通常我们可以把它们分解成更小的块,小到足以解决问题。这是递归思维的本质,我在这篇文章中的目的是向你,我亲爱的读者,提供从这个递归观点处理问题所必需的概念工具。
通过掌握递归函数和递归数据结构等概念,我们将一起学习如何在 Python 程序中使用递归。我们还将讨论在递归期间维护状态,以及通过缓存结果来避免重新计算。这将会非常有趣。向前向上!
亲爱的 Pythonic 圣诞老人……
我意识到作为 Pythonistas 的同伴,我们在这里都是同意的成年人,但孩子们似乎更好地探索递归之美。所以让我们暂时不要像成年人一样,讨论一下我们如何使用递归来帮助圣诞老人。
你有没有想过圣诞礼物是怎么送的?我当然有,而且我相信圣诞老人有一张他循环经过的房子的清单。他去一所房子,放下礼物,吃了饼干和牛奶,然后去名单上的下一所房子。因为这个传递礼物的算法是基于一个显式的循环结构,所以它被称为迭代算法。
用 Python 实现的迭代提交算法;
houses = ["Eric's house", "Kenny's house", "Kyle's house", "Stan's house"] def deliver_presents_iteratively(): for house in houses: print("Delivering presents to", house)





>>> deliver_presents_iteratively()
Delivering presents to Eric's house
Delivering presents to Kenny's house
Delivering presents to Kyle's house
Delivering presents to Stan's house
但我同情圣诞老人。在他这个年龄,他不应该自己送所有的礼物。我提出了一个算法,他可以用这个算法在他的小精灵之间分配送礼物的工作:
- Appoint an elf and give him all the work.
- Assign titles and responsibilities according to the number of houses the elves are responsible for:
> 1He is a manager who can appoint two elves and distribute work among them.= 1He is a worker, and he must send gifts to the house assigned to him.
这是递归算法的典型结构。如果当前的问题代表一个简单的案例,那就解决它。如果不是,把它分成子问题,并对它们应用同样的策略。
用 Python 实现的递归礼物递送算法;
houses = ["Eric's house", "Kenny's house", "Kyle's house", "Stan's house"]
# Each function call represents an elf doing his work
def deliver_presents_recursively(houses):
# Worker elf doing his work
if len(houses) == 1:
house = houses[0]
print("Delivering presents to", house)
# Manager elf doing his work
else:
mid = len(houses) // 2
first_half = houses[:mid]
second_half = houses[mid:]
# Divides his work among two elves
deliver_presents_recursively(first_half)
deliver_presents_recursively(second_half)
>>> deliver_presents_recursively(houses) Delivering presents to Eric's house Delivering presents to Kenny's house Delivering presents to Kyle's house Delivering presents to Stan's housePython 中的递归函数
现在我们对递归有了一些直觉,让我们介绍递归函数的正式定义。递归函数是通过自引用表达式根据自身定义的函数。
这意味着函数将继续调用自身并重复其行为,直到满足某个条件返回一个结果。所有的递归函数共享一个由两部分组成的公共结构:基格和递归格。
为了演示这个结构,让我们编写一个计算
n!的递归函数:
将原始问题分解成同一问题的更简单的实例。这是递归情况:
n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3 x 2 x 1 n! = n x (n−1)!`随着大问题被分解成一个个越来越不复杂的问题,这些子问题最终一定会变得非常简单,不需要进一步细分就可以解决。这是基本情况:
n! = n x (n−1)! n! = n x (n−1) x (n−2)! n! = n x (n−1) x (n−2) x (n−3)! ⋅ ⋅ n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3! n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3 x 2! n! = n x (n−1) x (n−2) x (n−3) ⋅⋅⋅⋅ x 3 x 2 x 1!`这里,
1!是我们的基本情况,它等于1。用 Python 实现的用于计算
n!的递归函数:def factorial_recursive(n): # Base case: 1! = 1 if n == 1: return 1 # Recursive case: n! = n * (n-1)! else: return n * factorial_recursive(n-1)
>>> factorial_recursive(5)
120
在幕后,每个递归调用都向调用堆栈添加一个堆栈帧(包含其执行上下文),直到我们到达基本情况。然后,随着每个调用返回其结果,堆栈开始展开:

保持状态
在处理递归函数时,请记住每个递归调用都有自己的执行上下文,因此为了在递归期间保持状态,您必须:
- 通过每个递归调用来线程化状态,以便当前状态是当前调用的执行上下文的一部分
- 将状态保持在全局范围内
一次演示应该能让事情变得更清楚。让我们用递归来计算1 + 2 + 3 ⋅⋅⋅⋅ + 10。我们要维护的状态是(当前正在加的数,到目前为止的累计数)。
下面是如何通过在每个递归调用中使用线程来实现的(例如,将更新后的当前状态作为参数传递给每个递归调用):
def sum_recursive(current_number, accumulated_sum):
# Base case
# Return the final state
if current_number == 11:
return accumulated_sum
# Recursive case
# Thread the state through the recursive call
else:
return sum_recursive(current_number + 1, accumulated_sum + current_number)
# Pass the initial state >>> sum_recursive(1, 0) 55
下面是如何通过将状态保持在全局范围来维护状态:
# Global mutable state current_number = 1 accumulated_sum = 0 def sum_recursive(): global current_number global accumulated_sum # Base case if current_number == 11: return accumulated_sum # Recursive case else: accumulated_sum = accumulated_sum + current_number current_number = current_number + 1 return sum_recursive()
>>> sum_recursive()
55
我更喜欢在每个递归调用中线程化状态,因为我发现全局可变状态是邪恶的,但这将在以后讨论。
Python 中的递归数据结构
如果一个数据结构可以用它自身的一个更小的版本来定义,那么它就是递归的。列表是递归数据结构的一个例子。让我来演示一下。假设您只有一个空列表,您可以对它执行的唯一操作是:
# Return a new list that is the result of
# adding element to the head (i.e. front) of input_list
def attach_head(element, input_list):
return [element] + input_list
使用空列表和attach_head操作,你可以生成任何列表。例如,让我们生成[1, 46, -31, "hello"]:
attach_head(1, # Will return [1, 46, -31, "hello"]
attach_head(46, # Will return [46, -31, "hello"]
attach_head(-31, # Will return [-31, "hello"]
attach_head("hello", [])))) # Will return ["hello"]
[1, 46, -31, 'hello']

-
从一个空列表开始,您可以通过递归地应用
attach_head函数来生成任何列表,因此列表数据结构可以递归地定义为:+---- attach_head(element, smaller list) list = + +---- empty list` -
递归也可以看作是自引用的函数合成。我们将一个函数应用于一个参数,然后将结果作为一个参数传递给同一个函数的第二个应用程序,依此类推。用自己反复作曲
attach_head和attach_head反复调用自己是一样的。
列表不是唯一的递归数据结构。其他例子还包括集合,树,字典等。
递归数据结构和递归函数形影不离。递归函数的结构通常可以根据它作为输入的递归数据结构的定义来建模。让我通过递归计算列表中所有元素的总和来演示这一点:
def list_sum_recursive(input_list):
# Base case
if input_list == []:
return 0
# Recursive case
# Decompose the original problem into simpler instances of the same problem
# by making use of the fact that the input is a recursive data structure
# and can be defined in terms of a smaller version of itself
else:
head = input_list[0]
smaller_list = input_list[1:]
return head + list_sum_recursive(smaller_list)
>>> list_sum_recursive([1, 2, 3]) 6幼稚递归是幼稚的
斐波那契数列最初是由意大利数学家斐波那契在十三世纪定义的,用来模拟兔子数量的增长。斐波那契推测,从第一年的一对兔子开始,某一年出生的兔子对的数量等于前两年每年出生的兔子对的数量。
为了计算第 n 年出生的兔子数量,他定义了递归关系:
Fn = Fn-1 + Fn-2基本情况是:
F0 = 0 and F1 = 1让我们编写一个递归函数来计算第 n 个斐波那契数:
def fibonacci_recursive(n): print("Calculating F", "(", n, ")", sep="", end=", ") # Base case if n == 0: return 0 elif n == 1: return 1 # Recursive case else: return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
>>> fibonacci_recursive(5)
Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1),
Calculating F(0), Calculating F(1), Calculating F(2), Calculating F(1), Calculating F(0),
Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0), Calculating F(1),
5
天真地遵循第 n 个斐波那契数的递归定义是相当低效的。从上面的输出可以看出,我们不必要地重新计算了值。让我们通过缓存每次斐波那契计算 F k 的结果来尝试改进fibonacci_recursive:
from functools import lru_cache
@lru_cache(maxsize=None)
def fibonacci_recursive(n):
print("Calculating F", "(", n, ")", sep="", end=", ")
# Base case
if n == 0:
return 0
elif n == 1:
return 1
# Recursive case
else:
return fibonacci_recursive(n-1) + fibonacci_recursive(n-2)
>>> fibonacci_recursive(5) Calculating F(5), Calculating F(4), Calculating F(3), Calculating F(2), Calculating F(1), Calculating F(0), 5
lru_cache是缓存结果的装饰器。因此,我们通过在试图计算值之前显式检查该值来避免重新计算。关于lru_cache需要记住的一点是,因为它使用字典来缓存结果,所以函数的位置和关键字参数(在字典中充当键)必须是可散列的。讨厌的细节
>>> import sys
>>> sys.getrecursionlimit()
3000
如果你有一个需要深度递归的程序,请记住这个限制。
此外,Python 的可变数据结构不支持结构化共享,所以像对待不可变数据结构一样对待它们将会对您的空间和 GC(垃圾收集)效率产生负面影响,因为您将会不必要地复制大量可变对象。例如,我使用这种模式来分解列表并对其进行递归:
>>> input_list = [1, 2, 3] >>> head = input_list[0] >>> tail = input_list[1:] >>> print("head --", head) head -- 1 >>> print("tail --", tail) tail -- [2, 3]为了清楚起见,我这样做是为了简化事情。请记住,tail 是通过复制创建的。在大型列表上递归地这么做可能会对您的空间和 GC 效率产生负面影响。
鳍
我曾经在一次面试中被要求解释递归。我拿了一张纸,两面都写了
Please turn over。面试官没有理解这个笑话,但是既然你已经读了这篇文章,希望你能理解🙂快乐的蟒蛇!参考文献
立即观看本教程有真实 Python 团队创建的相关视频课程。和写好的教程一起看,加深理解: 用 Python 递归思考**
Thonny:初学者友好的 Python 编辑器
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Thonny:初学友好的 Python 编辑器
你是一个 Python 初学者,正在寻找一个可以支持你学习的工具吗?这篇文章送给你!每个程序员都需要一个写代码的地方。本文将讨论一个名为 Thonny 的令人敬畏的工具,它将使您能够在一个初学者友好的环境中开始使用 Python。
在这篇文章中,你将了解到:
- 如何在电脑上安装 Thonny
- 如何浏览 Thonny 的用户界面以使用其内置功能
- 如何使用 Thonny 编写和运行您的代码
- 如何使用 Thonny 调试您的代码
到本文结束时,您将对 Thonny 中的开发工作流感到舒适,并准备好将其用于您的 Python 学习。
那么什么是 Thonny 呢?很棒的问题!
Thonny 是一个免费的 Python 集成开发环境(IDE) ,它是专门为初学 Python 的人设计的。具体来说,它有一个内置的调试器,可以在您遇到讨厌的错误时提供帮助,并且它提供了通过表达式求值的能力,以及其他非常棒的功能。
免费样章: ,获得实用的 Python 编程技巧。
安装 Thonny
本文假设您的计算机上安装了 Python 3。如果没有,请查看 Python 3 安装&设置。
网页下载
可以通过访问 Thonny 网站经由网络浏览器访问网络下载。进入页面后,您会在右上角看到一个浅灰色框,如下所示:
找到灰框后,单击适用于您的操作系统的链接。本教程假设您已经下载了版本 3.0.1。
命令行下载
您也可以通过系统的命令行安装 Thonny。在 Windows 上,你可以通过启动一个名为命令提示符的程序来做到这一点,而在 macOS 和 Linux 上,你可以启动一个名为终端的程序。完成后,输入以下命令:
$ pip install thonny用户界面
让我们确保你明白 Thonny 能提供什么。将 Thonny 想象成一个工作室,在这里您将创建令人惊叹的 Python 项目。你的工作室里有一个工具箱,里面有许多工具,可以让你成为摇滚明星皮托尼斯塔。在本节中,您将了解 UI 的每个特性,这些特性将帮助您使用 Thonny 工具箱中的每个工具。
代码编辑器和 Shell
现在你已经安装了 Thonny,打开应用程序。您应该会看到一个窗口,顶部有几个图标,还有两个白色区域:
请注意窗口的两个主要部分。顶部是您的代码编辑器,在这里您将编写所有的代码。下半部分是您的 Shell,在这里您可以看到代码的输出。
图标
在顶部你会看到几个图标。让我们来探究一下它们各自的功能。您将看到下面的图标图像,每个图标上方都有一个字母。我们将使用这些字母来谈论每个图标:
从左到右,下面是图像中每个图标的描述。
答:纸张图标允许您创建新文件。通常在 Python 中,你想把你的程序分成不同的文件。在本教程的后面部分,您将使用该按钮在 Thonny 中创建您的第一个程序!
B: 打开文件夹图标允许你打开一个已经存在于你电脑上的文件。如果您回到以前工作过的程序,这可能会很有用。
C: 软盘图标允许你保存你的代码。尽早并经常按这个。稍后您将使用它来保存您的第一个 Thonny Python 程序。
D: 播放图标允许你运行你的代码。记住你写的代码是要被执行的。运行您的代码意味着您在告诉 Python,“按照我告诉您的去做!”(换句话说,“通读我的代码,执行我写的东西。”)
bug 图标允许你调试你的代码。当你写代码时,不可避免地会遇到错误。bug 是问题的另一种说法。错误可能以多种形式出现,有时出现在你使用不适当的语法时,有时出现在你的逻辑不正确时。
Thonny 的 bug 按钮通常用于发现和调查 bug。在教程的后面部分,您将会用到它。顺便说一句,如果你想知道为什么它们被称为虫子,还有一个有趣的关于它是如何产生的故事!
箭头图标允许你一步一步地运行你的程序。当你调试时,或者换句话说,当你试图在你的代码中找到那些讨厌的 bug 时,这是非常有用的。这些图标在您按下 bug 图标后使用。您会注意到,当您点击每个箭头时,一个黄色高亮条将指示 Python 当前正在评估的行或部分:
- 箭头告诉 Python 前进一大步,意思是跳到下一行或下一个代码块。
- 箭头告诉 Python 迈出一小步,意思是深入到表达式的每个部分。
- 箭头告诉 Python 退出调试器。
I: 恢复图标允许你从调试模式返回到播放模式。这在您不想一步一步地遍历代码,而是希望程序结束运行的情况下非常有用。
J:stop 图标允许你停止运行你的代码。比方说,如果您的代码运行了一个打开新窗口的程序,而您想要停止该程序,这可能特别有用。在本教程的后面部分,您将使用停止图标。
我们试试吧!
准备好用 Thonny 编写您的第一个官方 Python 程序:
在代码编辑器中输入以下代码:
print("Hello World")`单击播放按钮运行您的程序。
在 Shell 窗口中查看输出。
再次单击“播放”按钮,它会再次显示“你好”。
恭喜你!您现在已经完成了您在 Thonny 的第一个程序!你应该看到
Hello world!印在外壳里面,也就是所谓的控制台。这是因为您的程序告诉 Python 打印这个短语,控制台是您看到这个执行的输出的地方。其他用户界面特性
要查看 Thonny 提供的更多其他功能,请导航到菜单栏并选择视图下拉菜单。您应该看到 Shell 旁边有一个复选标记,这就是您在 Thonny 的应用程序窗口中看到 Shell 部分的原因:
让我们探索一些其他的产品,特别是那些对 Pythonista 初学者有用的产品:
帮助:如果你想了解更多关于与 Thonny 合作的信息,你可以选择帮助视图。目前这一节提供了更多关于以下主题的阅读:逐步运行程序,如何安装第三方包,或者使用科学 Python 包。
变量:这个特性可能非常有价值。Python 中的变量是您在代码中定义的值。变量可以是数字、字符串,或者其他复杂的数据结构。此部分允许您查看分配给程序中所有变量的值。
助手:当你遇到异常或其他类型的错误时,助手会给你有用的提示。
随着你技能的提高,其他功能也会变得有用。一旦你对 Thonny 更熟悉了,就去看看吧!
代码编辑器
现在你对 UI 有了了解,让我们用 Thonny 再写一个小程序。在本节中,您将了解 Thonny 的特性,这些特性将有助于指导您完成开发工作流程。
写一些代码
在代码编辑器(UI 的顶部)中,添加以下函数:
def factorial(num): if num == 1: return 1 else: return num * factorial(num - 1) print(factorial(3))保存您的代码
在我们继续之前,让我们保存您的程序。上一次,按下播放按钮后,系统会提示您这样做。你也可以点击蓝色的软盘图标或进入菜单栏选择文件 > 保存来完成此操作。我们称这个程序为
factorial.py。运行您的代码
为了运行您的代码,找到并按下播放图标。输出应该如下所示:
调试您的代码
要真正理解这个函数在做什么,请尝试 step 特性。通过该函数执行一些大大小小的步骤,看看发生了什么。请记住,您可以通过按箭头图标来完成此操作:
如你所见,这些步骤将显示计算机如何评估代码的每一部分。每个弹出窗口就像一张草稿纸,计算机用它来计算代码的每一部分。如果没有这个令人敬畏的特性,这可能很难被概念化——但是现在你已经得到它了!
停止运行您的代码
到目前为止,这个程序还不需要点击停止图标,特别是因为它一执行
print()就会退出。尝试将传递给阶乘函数的数字增加到100:def factorial(num): if num == 1: return 1 else: return num * factorial(num - 1) print(factorial(100))然后单步执行该函数。过一会儿,你会发现你会点击很长时间才能到达终点。这是使用停止按钮的好时机。“停止”按钮对于停止有意或无意持续运行的程序非常有用。
在代码中查找语法错误
现在你有一个简单的程序,让我们打破它!通过在阶乘程序中故意创建一个错误,您将能够看到 Thonny 是如何处理这些类型的问题的。
我们将创建所谓的语法错误。一个语法错误是一个表明你的代码语法不正确的错误。换句话说,你的代码没有按照正确的方式编写 Python。当 Python 注意到这个错误时,它会显示一个语法错误来抱怨你的无效代码。
在 print 语句上面,我们再添加一个 print 语句,上面写着
print("The factorial of 100 is:")。现在让我们继续创建语法错误。在第一条 print 语句中,删除第二个引号,在另一条语句中,删除第二个括号。当你这样做的时候,你应该看到 Thonny 会突出显示你的
SyntaxErrors。缺少的引用以绿色突出显示,缺少的括号以灰色显示:
对于初学者来说,这是一个很好的资源,可以帮助你在写作时发现任何打字错误。开始编程时,一些最常见和最令人沮丧的错误是缺少引号和不匹配的括号。
如果您打开了助手视图,您还会注意到,当您调试时,它会给出一条有用的消息,指引您正确的方向:
随着你对 Thonny 越来越熟悉,助手会成为帮助你摆脱困境的有用工具!
软件包管理器
随着您继续学习 Python,下载一个 Python 包在您的代码中使用会非常有用。这允许你使用别人在你的程序中编写的代码。
考虑一个例子,你想在你的代码中做一些计算。与其编写自己的计算器,你可能想使用一个名为
simplecalculator的第三方包。为了做到这一点,您将使用 Thonny 的包管理器。软件包管理器将允许您安装您的程序需要使用的软件包。具体来说,它允许您向工具箱中添加更多工具。Thonny 具有处理与其他 Python 解释器冲突的内在优势。
要访问软件包管理器,进入菜单栏并选择工具 > 管理软件包… 这将弹出一个带有搜索字段的新窗口。在该字段中键入
simplecalculator并点击搜索按钮。输出应该类似于以下内容:
继续点击安装来安装这个包。您将看到一个弹出的小窗口,显示安装软件包时系统的日志。一旦完成,您就可以在代码中使用
simplecalculator了!在下一节中,您将使用
simplecalculator包以及您在本教程中学到的一些其他技能来创建一个简单的计算器程序。检查你的理解能力
到目前为止你已经了解了很多关于 Thonny 的事情!以下是你学到的东西:
- 在哪里编写代码
- 如何保存您的代码
- 如何运行您的代码
- 如何阻止您的代码运行
- 在哪里看到您的代码执行
- 如何发现
SyntaxErrors- 如何安装第三方软件包
让我们检查一下你对这些概念的理解。
现在您已经安装了
simplecalculator,让我们创建一个使用这个包的简单程序。您还将利用这个机会来检查您是否理解了到目前为止在教程中所学的一些 UI 和开发特性。第 1 部分:创建一个文件,添加一些代码,理解代码
在第 1 部分中,您将创建一个文件,并向其中添加一些代码!尽最大努力去挖掘代码实际在做什么。如果你卡住了,检查一下深入观察窗口。让我们开始吧:
- 创建一个新文件。
- 将以下代码添加到您的 Thonny 代码编辑器中:
1from calculator.simple import SimpleCalculator 2 3my_calculator = SimpleCalculator() 4my_calculator.run('2 * 2') 5print(my_calculator.lcd)这段代码将把
2 * 2的结果打印到主 UI 中的 Thonny Shell。要了解代码的每个部分在做什么,请查看下面的深入了解部分。
第 1 行:这段代码将库
calculator导入到名为simplecalculator的包中。从这个库中,我们从名为simple.py的文件中导入名为SimpleCalculator的类。你可以在这里看到代码。第 2 行:这是代码块后面的一个空行,一般是首选样式。在本文中阅读更多关于 Python 代码质量的内容。
第 3 行:这里我们创建了一个类
SimpleCalculator的实例,并将其赋给一个名为my_calculator的变量。这可以用来运行不同的计算器。如果你是新手,你可以在这里学习更多关于面向对象编程的知识。第 4 行:这里我们让计算器通过调用
run()并以字符串形式传入表达式来运行运算2 * 2。第 5 行:这里我们打印计算的结果。您会注意到,为了获得最新的计算结果,我们必须访问名为
lcd的属性。太好了!现在您已经确切地知道了您的计算器代码在做什么,让我们继续运行这段代码吧!
第 2 部分:保存文件,查看变量,运行代码
现在是保存和运行代码的时候了。在本节中,您将使用我们之前讨论过的两个图标:
- 将新文件另存为
calculations.py。- 打开变量窗口,记下列出的两个变量。你应该看到
SimpleCalculator和my_calculator。本节还让您深入了解每个变量所指向的值。- 运行您的代码!您应该在输出中看到
4.0:
干得好!接下来,您将探索 Thonny 的调试器如何帮助您更好地理解这段代码。
其他优秀的初学者功能
随着您对 Thonny 越来越熟悉,本节中的特性将会非常方便。
调试
使用您的
calculations.py脚本,您将使用调试器来调查发生了什么。将calculations.py中的代码更新为以下内容:from calculator.simple import SimpleCalculator def create_add_string(x, y): '''Returns a string containing an addition expression.''' return 'x + y' my_calculator = SimpleCalculator() my_calculator.run(create_add_string(2, 2)) print(my_calculator.lcd)点击保存图标保存该版本。
您会注意到代码有一个名为
create_add_string()的新函数。如果你对 Python 函数不熟悉,请在这个令人敬畏的真正的 Python 课程中学习更多!当您检查这个函数时,您可能会注意到为什么这个脚本不能像预期的那样工作。如果没有,那也没关系!Thonny 将帮助您了解到底发生了什么,并粉碎这一错误!继续运行你的程序,看看会发生什么。Shell 输出应该如下所示:
>>> %Run calculations.py 0哦不!现在你可以看到你的程序中有一个错误。答案应该是 4!接下来,您将使用 Thonny 的调试器来查找 bug。
我们试试吧!
现在我们的程序中有了一个 bug,这是一个使用 Thonny 调试功能的好机会:
单击窗口顶部的 bug 图标。这将进入调试器模式。
您应该看到 import 语句被突出显示。单击中间的黄色小箭头图标。继续按这个按钮,看看调试器是如何工作的。您应该注意到,它突出显示了 Python 评估您的程序所采取的每个步骤。一旦点击
create_add_string(),您应该会看到一个新窗口弹出。仔细检查弹出窗口。您应该会看到它显示了 x 和 y 的值。持续按下小步骤图标,直到您看到 Python 将返回到您的程序的值。它会被封装在一个浅蓝色的盒子里:
哦不!有只虫子!看起来 Python 将返回一个包含字母
x和y(意为'x + y'的字符串,而不是像'2 + 2'那样包含这些变量的值的字符串,这正是计算器所期望的。)每次你看到一个浅蓝色的框,你可以认为这是 Python 用它们的值一步一步地替换子表达式。弹出窗口可以被认为是 Python 用来计算这些值的一张草稿纸。继续浏览程序,看看这个 bug 如何导致0的计算。这里的错误与字符串格式有关。如果您不熟悉字符串格式,请查看这篇关于 Python 字符串格式最佳实践的文章。在
create_add_string()、中,应该使用 f 字符串格式化方法。将此函数更新为:def create_add_string(x, y): '''Returns a string containing an addition expression.''' return f'{x} + {y}'`再次运行您的程序。您应该会看到以下输出:
>>> %Run calculations.py 4.0`成功!您刚刚演示了分步调试器如何帮助您找到代码中的问题!接下来,您将了解一些其他有趣的 Thonny 功能。
变量范围高亮显示
Thonny 提供了变量突出显示,以提醒您相同的名称并不总是意味着相同的变量。为了使该功能工作,在菜单栏上,转到 Thonny > 首选项,并确保选中高亮匹配姓名。
注意在下面的代码片段中,
create_add_string()现在有了一个名为my_calculator的新变量,尽管这与第 10 行和第 11 行的my_calculator不同。你应该能看出来,因为 Thonny 强调了引用同一事物的变量。函数中的这个my_calculator只存在于该函数的范围内,这就是为什么当光标在第 10 行的另一个my_calculator变量上时,它没有被高亮显示:
这个特性真的可以帮助你避免打字错误和理解你的变量的范围。
代码完成
Thonny 还为 API 提供代码完成功能。注意在下面的快照中,按下
Tab键显示了random库中可用的方法:
当您使用库并且不想查看文档来查找方法或属性名时,这可能非常有用。
从事一个已经存在的项目
现在您已经了解了 Thonny 的基本特性,让我们来探索如何使用它来处理一个已经存在的项目。
在您的电脑上找到一个文件
在电脑上打开一个文件就像在菜单栏中选择文件 > 打开一样简单,然后使用浏览器导航到该文件。您也可以使用屏幕顶部的打开文件夹图标来完成此操作。
如果你有一个本地安装的
requirements.txt文件和pip,你可以从 Thonny 系统 Shell 中pip install它们。如果你没有安装 pip,记住你可以使用软件包管理器来安装它:$ pip install -r requirements.txt参与 Github 的一个项目
既然您是 Thonny 专家,您可以使用它来完成真实 Python 课程 1:Python 简介中的练习:
导航到名为的真实 Python GitHub repo 第一册-练习。
点击绿色按钮克隆或下载并选择下载 Zip 。
单击打开的文件夹图标导航并查找下载的文件。你应该找到一个名为
book1-exercises1的文件夹。打开其中一个文件,开始工作!
这很有用,因为 GitHub 上有很多很酷的项目!
结论
完成 Thonny 的教程真是太棒了!
您现在可以开始使用 Thonny 编写、调试和运行 Python 代码了!如果你喜欢 Thonny,你可能也会喜欢我们在Python ide 和代码编辑器(指南)中列出的其他一些 ide。
Thonny 正在积极维护中,并且一直在添加新功能。有几个很棒的新功能目前处于测试阶段,可以在 Thonny 的博客上找到。Thonny 的主要开发工作在爱沙尼亚塔尔图大学的计算机科学研究所进行,同时还有来自世界各地的贡献者。
立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: Thonny:初学友好的 Python 编辑器******
Python 时间模块初学者指南
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 掌握 Python 内置的时间模块
Python
time模块提供了许多用代码表示时间的方式,比如对象、数字和字符串。除了表示时间之外,它还提供了其他功能,比如在代码执行过程中等待,以及测量代码的效率。本文将带您了解
time中最常用的函数和对象。本文结束时,你将能够:
- 理解处理日期和时间的核心概念,如纪元、时区和夏令时
- 用浮点数、元组和
struct_time表示代码中的时间- 在不同的时间表示之间转换
- 暂停线程执行
- 使用
perf_counter()测量代码性能您将从学习如何使用浮点数来表示时间开始。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
用秒处理 Python 时间
在应用程序中管理 Python 时间概念的方法之一是使用一个浮点数来表示自一个时代开始(即从某个起点开始)以来经过的秒数。
让我们更深入地了解这意味着什么,为什么它有用,以及如何在应用程序中使用它来实现基于 Python time 的逻辑。
纪元
在上一节中,您了解了可以用一个浮点数来管理 Python 时间,该浮点数表示自纪元开始以来经过的时间。
韦氏词典将一个时代定义为:
- 一个固定的时间点,从该点开始计算一系列的年份
- 以给定的日期为基础计算出来的时间记数法
这里要把握的重要概念是,在处理 Python 时间时,您考虑的是由起点标识的一段时间。在计算中,你称这个起点为纪元。
那么,纪元就是你衡量时间流逝的起点。
例如,如果您将纪元定义为 UTC 1970 年 1 月 1 日的午夜 Windows 和大多数 UNIX 系统上定义的纪元——那么您可以将 UTC 1970 年 1 月 2 日的午夜表示为从该纪元开始的
86400秒。这是因为一分钟有 60 秒,一小时有 60 分钟,一天有 24 小时。UTC 时间 1970 年 1 月 2 日仅是纪元后的第一天,因此您可以应用基础数学得出结果:












>>> 60 * 60 * 24
86400
同样重要的是要注意,您仍然可以表示纪元之前的时间。秒数将会是负数。
例如,您可以将 UTC 1969 年 12 月 31 日的午夜(使用 1970 年 1 月 1 日的纪元)表示为-86400秒。
虽然 UTC 1970 年 1 月 1 日是一个常见的纪元,但它不是计算中使用的唯一纪元。事实上,不同的操作系统、文件系统和 API 有时使用不同的纪元。
正如您之前看到的,UNIX 系统将纪元定义为 1970 年 1 月 1 日。另一方面,Win32 API 将纪元定义为1601 年 1 月 1 日。
您可以使用time.gmtime()来确定您系统的纪元:
>>> import time >>> time.gmtime(0) time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)在本文的整个过程中,您将了解到
gmtime()和struct_time。现在,只要知道你可以使用time来发现使用这个功能的纪元。既然您已经更多地了解了如何使用 epoch 以秒为单位测量时间,那么让我们来看看 Python 的
time模块,看看它提供了哪些功能来帮助您这样做。以秒为单位的浮点数形式的 Python 时间
首先,
time.time()返回自纪元以来经过的秒数。返回值是一个浮点数,表示小数秒:
>>> from time import time
>>> time()
1551143536.9323719
你在你的机器上得到的数字可能非常不同,因为被认为是纪元的参考点可能非常不同。
延伸阅读: Python 3.7 引入了 time_ns() ,返回一个整数值,表示自纪元以来经过的相同时间,但以纳秒而不是秒为单位。
以秒为单位测量时间非常有用,原因有很多:
- 你可以用一个浮点数来计算两个时间点之间的差值。
- float 很容易被序列化,这意味着它可以被存储用于数据传输,并在另一端完整无缺地输出。
然而,有时您可能希望看到用字符串表示的当前时间。为此,您可以将从time()获得的秒数传递给time.ctime()。
以秒为单位的 Python 时间,作为表示本地时间的字符串
正如您之前看到的,您可能想要将 Python 时间(表示为自纪元以来经过的秒数)转换为一个字符串。您可以使用ctime()来完成:
>>> from time import time, ctime >>> t = time() >>> ctime(t) 'Mon Feb 25 19:11:59 2019'这里,您已经以秒为单位将当前时间记录到变量
t中,然后将t作为参数传递给ctime(),后者返回相同时间的字符串表示。技术细节:根据
ctime()的定义,表示从纪元开始的秒的参数是可选的。如果没有传递参数,那么默认情况下,ctime()使用time()的返回值。所以,你可以简化上面的例子:
>>> from time import ctime
>>> ctime()
'Mon Feb 25 19:11:59 2019'
由ctime()返回的时间的字符串表示,也称为时间戳,被格式化为以下结构:
- 星期几:
Mon(Monday) - 一年中的月份:
Feb(February) - 一月中的某一天:
25 - 小时、分钟和秒,使用 24 小时制符号:
19:11:59 - 年份:
2019
前面的示例显示了从美国中南部地区的计算机捕获的特定时刻的时间戳。但是,假设你住在澳大利亚的悉尼,你在同一时刻执行了同样的命令。
您将看到以下内容,而不是上面的输出:
>>> from time import time, ctime >>> t = time() >>> ctime(t) 'Tue Feb 26 12:11:59 2019'注意,时间戳的
day of week、day of month和hour部分与第一个例子不同。这些输出是不同的,因为由
ctime()返回的时间戳取决于您的地理位置。注意:虽然时区的概念是相对于您的物理位置而言的,但您可以在计算机的设置中修改时区,而无需实际搬迁。
依赖于你的物理位置的时间表示被称为本地时间,并利用了一个被称为 T2 时区的概念。
注意:因为本地时间与您的语言环境相关,所以时间戳通常会考虑特定于语言环境的细节,比如字符串中元素的顺序以及日期和月份缩写的翻译。
ctime()忽略这些细节。让我们更深入地研究一下时区的概念,以便更好地理解 Python 时间表示。
了解时区
时区是世界上符合标准时间的区域。时区是由它们相对于协调世界时(UTC)的偏移量来定义的,并且可能包括夏令时(我们将在本文后面更详细地介绍)。
有趣的事实:如果你的母语是英语,你可能会奇怪为什么“协调世界时”的缩写是 UTC,而不是更明显的 CUT。然而,如果你的母语是法语,你会称之为“Temps Universel Coordonné”,这意味着不同的缩写:TUC。
最终,国际电信联盟和国际天文学联盟达成妥协,将 UTC 作为官方缩写,这样,无论何种语言,缩写都是相同的。
UTC 和时区
UTC 是世界上所有时间同步(或协调)的时间标准。它本身不是一个时区,而是一个定义时区的卓越标准。
UTC 时间是利用参考地球自转的天文时间和原子钟精确测量的。
然后,时区由它们与 UTC 的偏移量来定义。例如,在北美和南美,中部时区(CT)比 UTC 晚五六个小时,因此使用 UTC-5:00 或 UTC-6:00 表示法。
另一方面,澳大利亚的悉尼属于澳大利亚东部时区(AET),比 UTC 早十或十一个小时(UTC+10:00 或 UTC+11:00)。
这种差异(UTC-6:00 到 UTC+10:00)是您在前面的示例中从
ctime()的两个输出中观察到的差异的原因:
- 中部时间(CT):
'Mon Feb 25 19:11:59 2019'- 澳大利亚东部时间(AET):
'Tue Feb 26 12:11:59 2019'这些时间正好相隔 16 个小时,这与上面提到的时区偏移是一致的。
您可能想知道为什么 CT 会比 UTC 晚五或六个小时,或者为什么 AET 会比 UTC 早十或十一个小时。这是因为世界上的一些地区,包括这些时区的部分地区,采用夏令时。
夏令时
夏季通常比冬季有更多的日照时间。因此,一些地区在春季和夏季实行夏令时(DST ),以更好地利用这些时间。
对于实行夏令时的地方,他们的时钟会在春天开始时向前跳一小时(实际上慢了一小时)。然后,在秋季,时钟将被重置为标准时间。
在时区表示法中,字母 S 和 D 代表标准时间和夏令时:
- 中部标准时间
- 澳大利亚东部夏令时(AEDT)
当您用本地时间表示时间戳时,考虑 DST 是否适用总是很重要的。
ctime()表示夏令时。因此,前面列出的输出差异更准确,如下所示:
- 中部标准时间(CST):
'Mon Feb 25 19:11:59 2019'- 澳大利亚东部夏令时(AEDT):
'Tue Feb 26 12:11:59 2019'使用数据结构处理 Python 时间
现在您已经牢牢掌握了许多基本的时间概念,包括纪元、时区和 UTC,让我们来看看使用 Python
time模块表示时间的更多方法。作为元组的 Python 时间
不使用数字来表示 Python 时间,可以使用另一种原始数据结构:一个元组。
通过抽象一些数据并使其更具可读性,tuple 允许您更轻松地管理时间。
当您将时间表示为元组时,元组中的每个元素都对应于一个特定的时间元素:
- 年
- 整数形式的月份,范围在 1(1 月)和 12(12 月)之间
- 一月中的某一天
- 整数形式的小时,范围从 0(上午 12 点)到 23(晚上 11 点)
- 分钟
- 第二
- 整数形式的星期几,范围在 0(星期一)到 6(星期日)之间
- 一年中的某一天
- 以整数表示的夏令时,值如下:
1是夏令时。0是标准时间。-1不详。使用您已经学过的方法,您可以用两种不同的方式表示相同的 Python 时间:
>>> from time import time, ctime
>>> t = time()
>>> t
1551186415.360564
>>> ctime(t)
'Tue Feb 26 07:06:55 2019'
>>> time_tuple = (2019, 2, 26, 7, 6, 55, 1, 57, 0)
在这种情况下,t和time_tuple都表示相同的时间,但是元组为处理时间组件提供了更易读的接口。
技术细节:实际上,如果您以秒为单位查看由time_tuple表示的 Python 时间(您将在本文后面看到如何操作),您会看到它解析为1551186415.0而不是1551186415.360564。
这是因为元组没有表示小数秒的方法。
虽然 tuple 为使用 Python time 提供了一个更易于管理的接口,但是还有一个更好的对象:struct_time。
Python 时间作为对象
tuple 结构的问题是它看起来仍然像一串数字,尽管它比单个基于秒的数字组织得更好。
struct_time通过利用来自 Python 的collections模块的 NamedTuple 将元组的数字序列与有用的标识符相关联,提供了一个解决方案:
>>> from time import struct_time >>> time_tuple = (2019, 2, 26, 7, 6, 55, 1, 57, 0) >>> time_obj = struct_time(time_tuple) >>> time_obj time.struct_time(tm_year=2019, tm_mon=2, tm_mday=26, tm_hour=7, tm_min=6, tm_sec=55, tm_wday=1, tm_yday=57, tm_isdst=0)技术细节:如果你来自另一种语言,术语
struct和object可能会相互对立。在 Python 中,没有叫做
struct的数据类型。相反,一切都是对象。然而,
struct_time这个名字来源于基于 C 的时间库,其中的数据类型实际上是一个struct。其实 Python 的
time模块,也就是用 C 实现的,通过包含头文件times.h直接使用了这个struct。现在,您可以使用属性名而不是索引来访问
time_obj的特定元素:
>>> day_of_year = time_obj.tm_yday
>>> day_of_year
57
>>> day_of_month = time_obj.tm_mday
>>> day_of_month
26
除了struct_time的可读性和可用性之外,了解它也很重要,因为它是 Python time模块中许多函数的返回类型。
将 Python 时间(秒)转换为对象
既然您已经看到了使用 Python 时间的三种主要方式,那么您将学习如何在不同的时间数据类型之间进行转换。
时间数据类型之间的转换取决于时间是 UTC 时间还是本地时间。
协调世界时
纪元使用 UTC 而不是时区来定义。因此,自纪元以来经过的秒数不会因您的地理位置而变化。
然而,struct_time就不一样了。Python 时间的对象表示可能会也可能不会考虑您的时区。
有两种方法可以将表示秒的浮点数转换成struct_time:
- 协调世界时。亦称 COORDINATED UNIVERSAL TIME
- 当地时间
为了将 Python 时间浮点转换成基于 UTC 的struct_time,Python time模块提供了一个名为gmtime()的函数。
您已经在本文中看到过一次gmtime():
>>> import time >>> time.gmtime(0) time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=1, tm_isdst=0)您使用这个调用来发现您系统的纪元。现在,你有了一个更好的基础来理解这里到底发生了什么。
gmtime()将从纪元开始经过的秒数转换为 UTC 中的struct_time。在这种情况下,您已经将0作为秒数传递,这意味着您正在尝试查找 UTC 中的纪元本身。注意:注意属性
tm_isdst被设置为0。此属性表示时区是否使用夏令时。UTC 从不订阅 DST,因此在使用gmtime()时,该标志将始终为0。正如您之前看到的,
struct_time不能表示小数秒,因此gmtime()忽略参数中的小数秒:
>>> import time
>>> time.gmtime(1.99)
time.struct_time(tm_year=1970, tm_mon=1, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=1, tm_wday=3, tm_yday=1, tm_isdst=0)
请注意,即使你经过的秒数非常接近2,但是.99的小数秒被简单地忽略了,如tm_sec=1所示。
gmtime()的secs参数是可选的,这意味着您可以不带任何参数调用gmtime()。这样做将提供 UTC 的当前时间:
>>> import time >>> time.gmtime() time.struct_time(tm_year=2019, tm_mon=2, tm_mday=28, tm_hour=12, tm_min=57, tm_sec=24, tm_wday=3, tm_yday=59, tm_isdst=0)有趣的是,这个函数在
time中没有反函数。相反,你必须在 Python 的calendar模块中寻找一个名为timegm()的函数:
>>> import calendar
>>> import time
>>> time.gmtime()
time.struct_time(tm_year=2019, tm_mon=2, tm_mday=28, tm_hour=13, tm_min=23, tm_sec=12, tm_wday=3, tm_yday=59, tm_isdst=0)
>>> calendar.timegm(time.gmtime())
1551360204
timegm()获取一个 tuple(或struct_time,因为它是 tuple 的子类)并返回从 epoch 开始的相应秒数。
历史脉络:如果你对timegm()为什么不在time感兴趣,可以查看 Python 第 6280 期的讨论。
简而言之,它最初被添加到calendar是因为time紧跟 C 的时间库(在time.h中定义),其中不包含匹配函数。上述问题提出了将timegm()移动或复制到time的想法。
然而,随着datetime库的进步,time.timegm()的补丁实现中的不一致性,以及如何处理calendar.timegm()的问题,维护者拒绝了这个补丁,鼓励使用datetime来代替。
使用 UTC 在编程中很有价值,因为它是一种标准。您不必担心 DST、时区或地区信息。
也就是说,在很多情况下,您会希望使用当地时间。接下来,您将看到如何将秒转换为本地时间,这样您就可以这样做了。
当地时间
在您的应用程序中,您可能需要使用本地时间而不是 UTC。Python 的time模块提供了一个函数,用于从名为localtime()的纪元以来经过的秒数中获取本地时间。
localtime()的签名类似于gmtime(),因为它采用了一个可选的secs参数,使用您的本地时区来构建一个struct_time:
>>> import time >>> time.time() 1551448206.86196 >>> time.localtime(1551448206.86196) time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=7, tm_min=50, tm_sec=6, tm_wday=4, tm_yday=60, tm_isdst=0)注意
tm_isdst=0。由于 DST 与当地时间有关,tm_isdst将在0和1之间变化,这取决于 DST 是否适用于给定时间。由于tm_isdst=0,夏令时不适用于 2019 年 3 月 1 日。2019 年的美国,夏令时从 3 月 10 日开始。因此,为了测试 DST 标志是否会正确更改,您需要向
secs参数添加 9 天的秒数。要计算这一点,您需要将一天中的秒数(86,400)乘以 9 天:
>>> new_secs = 1551448206.86196 + (86400 * 9)
>>> time.localtime(new_secs)
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=10, tm_hour=8, tm_min=50, tm_sec=6, tm_wday=6, tm_yday=69, tm_isdst=1)
现在,你会看到struct_time显示的日期是 2019 年 3 月 10 日tm_isdst=1。另外,请注意,tm_hour也提前跳到了8,而不是前面示例中的7,这是因为采用了夏令时。
从 Python 3.3 开始,struct_time还包含了两个在确定struct_time时区时有用的属性:
tm_zonetm_gmtoff
起初,这些属性依赖于平台,但是从 Python 3.6 开始,它们在所有平台上都可用。
首先,tm_zone存储当地时区:
>>> import time >>> current_local = time.localtime() >>> current_local.tm_zone 'CST'在这里,您可以看到
localtime()返回一个时区设置为CST(中部标准时间)的struct_time。正如您之前看到的,您还可以根据两条信息辨别时区,即 UTC 偏移量和 DST(如果适用):
>>> import time
>>> current_local = time.localtime()
>>> current_local.tm_gmtoff
-21600
>>> current_local.tm_isdst
0
在这种情况下,你可以看到current_local比代表格林威治标准时间的 GMT 晚了21600秒。GMT 是没有 UTC 偏移的时区:UTC 00:00。
21600秒除以秒每小时(3600)表示current_local时间为GMT-06:00(或UTC-06:00)。
您可以使用 GMT 偏移量加上 DST 状态来推断出标准时间的current_local是UTC-06:00,它对应于中部标准时区。
和gmtime()一样,调用localtime()时可以忽略secs参数,它会在一个struct_time中返回当前当地时间:
>>> import time >>> time.localtime() time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=8, tm_min=34, tm_sec=28, tm_wday=4, tm_yday=60, tm_isdst=0)与
gmtime()不同,localtime()的反函数确实存在于 Pythontime模块中。让我们来看看它是如何工作的。将本地时间对象转换为秒
您已经看到了如何使用
calendar.timegm()将 UTC 时间对象转换成秒。要将本地时间转换成秒,您将使用mktime()。
mktime()要求您传递一个名为t的参数,该参数采用普通 9 元组或表示本地时间的struct_time对象的形式:
>>> import time
>>> time_tuple = (2019, 3, 10, 8, 50, 6, 6, 69, 1)
>>> time.mktime(time_tuple)
1552225806.0
>>> time_struct = time.struct_time(time_tuple)
>>> time.mktime(time_struct)
1552225806.0
记住t必须是表示本地时间的元组,而不是 UTC,这一点很重要:
>>> from time import gmtime, mktime >>> # 1 >>> current_utc = time.gmtime() >>> current_utc time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=14, tm_min=51, tm_sec=19, tm_wday=4, tm_yday=60, tm_isdst=0) >>> # 2 >>> current_utc_secs = mktime(current_utc) >>> current_utc_secs 1551473479.0 >>> # 3 >>> time.gmtime(current_utc_secs) time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=20, tm_min=51, tm_sec=19, tm_wday=4, tm_yday=60, tm_isdst=0)注意:对于这个例子,假设当地时间是
March 1, 2019 08:51:19 CST。这个例子说明了为什么使用本地时间
mktime()而不是 UTC 很重要:
不带参数的
gmtime()使用 UTC 返回一个struct_time。current_utc显示March 1, 2019 14:51:19 UTC。因为CST is UTC-06:00很准确,所以 UTC 应该比当地时间早 6 个小时。
mktime()试图返回秒数,期望是本地时间,但是您却传递了current_utc。所以,它没有理解current_utc是 UTC 时间,而是假设你指的是March 1, 2019 14:51:19 CST。然后使用
gmtime()将这些秒转换回 UTC,这会导致不一致。现在时间是March 1, 2019 20:51:19 UTC。出现这种差异的原因是,mktime()预计当地时间。因此,转换回 UTC 会将当地时间再增加 6 个小时。众所周知,使用时区非常困难,因此了解 UTC 和本地时间之间的差异以及处理这两种时间的 Python 时间函数对您的成功非常重要。
将 Python 时间对象转换为字符串
虽然使用元组很有趣,但有时最好使用字符串。
时间的字符串表示,也称为时间戳,有助于提高时间的可读性,对于构建直观的用户界面尤其有用。
有两个 Python
time函数可用于将time.struct_time对象转换为字符串:
asctime()strftime()你将从学习
asctime()开始。
asctime()您使用
asctime()将时间元组或struct_time转换为时间戳:
>>> import time
>>> time.asctime(time.gmtime())
'Fri Mar 1 18:42:08 2019'
>>> time.asctime(time.localtime())
'Fri Mar 1 12:42:15 2019'
gmtime()和localtime()分别为 UTC 和本地时间返回struct_time实例。
您可以使用asctime()将struct_time转换成时间戳。asctime()的工作方式与ctime()类似,您在本文前面已经了解过,只是您传递的不是浮点数,而是一个元组。甚至这两个函数的时间戳格式也是相同的。
与ctime()一样,asctime()的参数是可选的。如果您没有将时间对象传递给asctime(),那么它将使用当前的本地时间:
>>> import time >>> time.asctime() 'Fri Mar 1 12:56:07 2019'和
ctime()一样,它也忽略了语言环境信息。
asctime()最大的缺点之一是它的格式不灵活。strftime()通过允许你格式化你的时间戳来解决这个问题。
strftime()您可能会发现来自
ctime()和asctime()的字符串格式不适合您的应用程序。相反,您可能希望以对用户更有意义的方式格式化字符串。其中一个例子是,如果您希望在字符串中显示您的时间,并考虑区域设置信息。
要格式化字符串,给定一个
struct_time或 Python 时间元组,可以使用strftime(),它代表“字符串格式时间”
strftime()需要两个参数:
format指定字符串中时间元素的顺序和形式。t是可选的时间元组。要格式化一个字符串,可以使用指令。指令是以指定特定时间元素的
%开头的字符序列,例如:
%d: 一月中的某一天%m: 一年中的月份%Y: 年份例如,您可以使用 ISO 8601 标准输出当地时间的日期,如下所示:
>>> import time
>>> time.strftime('%Y-%m-%d', time.localtime())
'2019-03-01'
延伸阅读:虽然使用 Python time 表示日期是完全有效且可接受的,但您也应该考虑使用 Python 的datetime模块,它提供了快捷方式和更健壮的框架来处理日期和时间。
例如,您可以使用datetime简化 ISO 8601 格式的日期输出:
>>> from datetime import date >>> date(year=2019, month=3, day=1).isoformat() '2019-03-01'要了解更多关于使用 Python
datetime模块的信息,请查看使用 Python datetime 处理日期和时间的正如您之前看到的,使用
strftime()而不是asctime()的一个很大的好处是它能够呈现利用特定于地区的信息的时间戳。例如,如果您想以一种区域敏感的方式表示日期和时间,您不能使用
asctime():
>>> from time import asctime
>>> asctime()
'Sat Mar 2 15:21:14 2019'
>>> import locale
>>> locale.setlocale(locale.LC_TIME, 'zh_HK') # Chinese - Hong Kong
'zh_HK'
>>> asctime()
'Sat Mar 2 15:58:49 2019'
请注意,即使以编程方式更改了您的语言环境,asctime()仍然会以与以前相同的格式返回日期和时间。
技术细节: LC_TIME是日期和时间格式的区域设置类别。根据您的系统不同,locale参数'zh_HK'可能会有所不同。
然而,当您使用strftime()时,您会发现它考虑了地区:
>>> from time import strftime, localtime >>> strftime('%c', localtime()) 'Sat Mar 2 15:23:20 2019' >>> import locale >>> locale.setlocale(locale.LC_TIME, 'zh_HK') # Chinese - Hong Kong 'zh_HK' >>> strftime('%c', localtime()) '六 3/ 2 15:58:12 2019' 2019'这里,您成功地利用了地区信息,因为您使用了
strftime()。注意:
%c是适用于地区的日期和时间的指令。如果时间元组没有传递给参数
t,那么默认情况下strftime()会使用localtime()的结果。因此,您可以通过删除可选的第二个参数来简化上面的示例:
>>> from time import strftime
>>> strftime('The current local datetime is: %c')
'The current local datetime is: Fri Mar 1 23:18:32 2019'
这里,您使用了默认时间,而不是将自己的时间作为参数传递。另外,请注意,format参数可以由格式化指令以外的文本组成。
延伸阅读:查看strftime()可获得的指令的完整列表。
Python time模块还包括将时间戳转换回struct_time对象的逆向操作。
将 Python 时间字符串转换为对象
当您处理与日期和时间相关的字符串时,将时间戳转换为时间对象是非常有价值的。
要将时间字符串转换成struct_time,您可以使用strptime(),它代表“字符串解析时间”:
>>> from time import strptime >>> strptime('2019-03-01', '%Y-%m-%d') time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=4, tm_yday=60, tm_isdst=-1)
strptime()的第一个参数必须是您想要转换的时间戳。第二个参数是时间戳所在的format。
format参数是可选的,默认为'%a %b %d %H:%M:%S %Y'。因此,如果您有这种格式的时间戳,您不需要将它作为参数传递:
>>> strptime('Fri Mar 01 23:38:40 2019')
time.struct_time(tm_year=2019, tm_mon=3, tm_mday=1, tm_hour=23, tm_min=38, tm_sec=40, tm_wday=4, tm_yday=60, tm_isdst=-1)
因为一个struct_time有 9 个关键的日期和时间组件,strptime()必须为那些它不能从string解析的组件提供合理的默认值。
在前面的例子中,tm_isdst=-1。这意味着strptime()无法通过时间戳确定它是否代表夏令时。
现在您知道了如何以多种方式使用time模块处理 Python 时间和日期。然而,除了简单地创建时间对象、获取 Python 时间字符串和使用自纪元以来经过的秒数之外,time还有其他用途。
暂停执行
一个非常有用的 Python 时间函数是 sleep() ,它将线程的执行暂停一段指定的时间。
例如,您可以暂停程序执行 10 秒钟,如下所示:
>>> from time import sleep, strftime >>> strftime('%c') 'Fri Mar 1 23:49:26 2019' >>> sleep(10) >>> strftime('%c') 'Fri Mar 1 23:49:36 2019'你的程序将打印第一个格式化的
datetime字符串,然后暂停 10 秒,最后打印第二个格式化的datetime字符串。您也可以将小数秒传递给
sleep():
>>> from time import sleep
>>> sleep(0.5)
对于测试或者让你的程序因为任何原因而等待是有用的,但是你必须小心不要停止你的生产代码,除非你有很好的理由这样做。
在 Python 3.5 之前,发送给你的进程的信号可以中断sleep()。但是,在 3.5 和更高版本中,sleep()将总是至少在指定的时间内暂停执行,即使进程收到信号。
仅仅是一个 Python 时间函数,它可以帮助你测试你的程序并使它们更加健壮。
测量性能
你可以使用time来衡量你的程序的性能。
这样做的方法是使用perf_counter(),顾名思义,它提供了一个高分辨率的性能计数器来测量短距离的时间。
要使用perf_counter(),您需要在代码开始执行之前以及代码执行完成之后放置一个计数器:
>>> from time import perf_counter >>> def longrunning_function(): ... for i in range(1, 11): ... time.sleep(i / i ** 2) ... >>> start = perf_counter() >>> longrunning_function() >>> end = perf_counter() >>> execution_time = (end - start) >>> execution_time 8.201258441999926首先,
start捕捉调用函数之前的瞬间。end捕捉函数返回后的瞬间。该函数的总执行时间为(end - start)秒。技术细节: Python 3.7 引入了
perf_counter_ns(),其工作原理与perf_counter()相同,但使用纳秒而非秒。
perf_counter()(或perf_counter_ns())是使用一次执行来测量代码性能的最精确的方法。然而,如果你试图精确地测量代码片段的性能,我推荐使用 Pythontimeit模块。
timeit专门多次运行代码,以获得更准确的性能分析,并帮助您避免过于简化您的时间测量以及其他常见的陷阱。结论
恭喜你!现在,您已经为使用 Python 处理日期和时间打下了良好的基础。
现在,您能够:
- 使用一个浮点数来处理时间,表示从纪元开始经过的秒数
- 使用元组和
struct_time对象管理时间- 在秒、元组和时间戳字符串之间转换
- 暂停 Python 线程的执行
- 使用
perf_counter()测量性能除此之外,您还学习了一些关于日期和时间的基本概念,例如:
- 世
- 协调世界时。亦称 COORDINATED UNIVERSAL TIME
- 时区
- 夏令时
现在,是时候将您新学到的 Python time 知识应用到现实世界的应用程序中了!
延伸阅读
如果您想继续学习更多关于在 Python 中使用日期和时间的知识,请查看以下模块:
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 掌握 Python 内置的时间模块********
Python 计时器函数:监控代码的三种方式
虽然许多开发人员认为 Python 是一种有效的编程语言,但纯 Python 程序可能比编译语言(如 C 、Rust 和 Java )中的程序运行得更慢。在本教程中,你将学习如何使用一个 Python 定时器来监控你的程序运行的速度。
在本教程中,你将学习如何使用:
time.perf_counter()用 Python 来度量时间- 类保持状态
- 上下文管理器处理代码块
- 装饰者定制一个功能
您还将获得关于类、上下文管理器和装饰器如何工作的背景知识。当您探索每个概念的示例时,您会受到启发,在代码中使用其中的一个或几个来计时代码执行,以及在其他应用程序中。每种方法都有其优点,您将根据具体情况学习使用哪种方法。另外,您将拥有一个工作的 Python 计时器,可以用来监控您的程序!
Decorators Q &文字记录: 点击此处获取我们 Python decorators Q &的 25 页聊天记录,这是真实 Python 社区 Slack 中的一个会话,我们在这里讨论了常见的 decorator 问题。
Python 定时器
首先,您将看到一些在整个教程中使用的示例代码。稍后,您将向该代码添加一个 Python 计时器来监控其性能。您还将学习一些最简单的方法来测量这个例子的运行时间。
Python 定时器功能
如果你查看 Python 内置的
time模块,你会注意到几个可以测量时间的函数:Python 3.7 引入了几个新的函数,像
thread_time(),以及上面所有函数的纳秒版本,以_ns后缀命名。比如perf_counter_ns()就是perf_counter()的纳秒版本。稍后您将了解更多关于这些函数的内容。现在,请注意文档中对perf_counter()的描述:返回性能计数器的值(以秒为单位),即具有最高可用分辨率来测量短时间的时钟。(来源)
首先,您将使用
perf_counter()创建一个 Python 定时器。稍后,您将把它与其他 Python 计时器函数进行比较,并了解为什么perf_counter()通常是最佳选择。示例:下载教程
为了更好地比较向代码中添加 Python 计时器的不同方法,在本教程中,您将对同一代码示例应用不同的 Python 计时器函数。如果您已经有了想要度量的代码,那么您可以自由地跟随示例。
本教程中您将使用的示例是一个简短的函数,它使用
realpython-reader包下载 Real Python 上的最新教程。要了解更多关于真正的 Python Reader 及其工作原理,请查看如何将开源 Python 包发布到 PyPI 。您可以使用pip在您的系统上安装realpython-reader:$ python -m pip install realpython-reader然后,你可以导入这个包作为
reader。您将把这个例子存储在一个名为
latest_tutorial.py的文件中。代码由一个函数组成,该函数下载并打印 Real Python 的最新教程:1# latest_tutorial.py 2 3from reader import feed 4 5def main(): 6 """Download and print the latest tutorial from Real Python""" 7 tutorial = feed.get_article(0) 8 print(tutorial) 9 10if __name__ == "__main__": 11 main()处理大部分艰难的工作:
- 三号线从
realpython-reader进口feed。该模块包含从真实 Python 提要下载教程的功能。- 第 7 行从 Real Python 下载最新教程。数字
0是一个偏移量,其中0表示最近的教程,1是以前的教程,依此类推。- 第 8 行将教程打印到控制台。
- 运行脚本时,第 11 行调用
main()。当您运行此示例时,您的输出通常如下所示:
$ python latest_tutorial.py # Python Timer Functions: Three Ways to Monitor Your Code While many developers recognize Python as an effective programming language, pure Python programs may run more slowly than their counterparts in compiled languages like C, Rust, and Java. In this tutorial, you'll learn how to use a Python timer to monitor how quickly your programs are running. [ ... ] ## Read the full article at https://realpython.com/python-timer/ » * * *根据您的网络,代码可能需要一段时间运行,因此您可能希望使用 Python 计时器来监控脚本的性能。
你的第一个 Python 定时器
现在,您将使用
time.perf_counter()向示例添加一个基本的 Python 计时器。同样,这是一个性能计数器,非常适合为你的代码计时。
perf_counter()以秒为单位测量从某个未指定的时刻开始的时间,这意味着对函数的单次调用的返回值是没有用的。然而,当您查看对perf_counter()的两次调用之间的差异时,您可以计算出两次调用之间经过了多少秒:
>>> import time
>>> time.perf_counter()
32311.48899951
>>> time.perf_counter() # A few seconds later
32315.261320793
在这个例子中,你给perf_counter()打了两个电话,几乎相隔 4 秒。您可以通过计算两个输出之间的差异来确认这一点:32315.26 - 32311.49 = 3.77。
现在,您可以将 Python 计时器添加到示例代码中:
1# latest_tutorial.py
2
3import time 4from reader import feed
5
6def main():
7 """Print the latest tutorial from Real Python"""
8 tic = time.perf_counter() 9 tutorial = feed.get_article(0)
10 toc = time.perf_counter() 11 print(f"Downloaded the tutorial in {toc - tic:0.4f} seconds") 12
13 print(tutorial)
14
15if __name__ == "__main__":
16 main()
注意,在下载教程之前和之后都要调用perf_counter()。然后,通过计算两次调用之间的差异,打印下载教程所用的时间。
注意:在第 11 行,字符串前的f表示这是一个 f 字符串,这是一种格式化文本字符串的便捷方式。:0.4f是一个格式说明符,表示数字toc - tic应该打印为一个有四位小数的十进制数。
有关 f 字符串的更多信息,请查看 Python 3 的 f 字符串:一种改进的字符串格式化语法。
现在,当您运行该示例时,您将看到教程开始之前所用的时间:
$ python latest_tutorial.py
Downloaded the tutorial in 0.6721 seconds # Python Timer Functions: Three Ways to Monitor Your Code
[ ... ]
就是这样!您已经讲述了为自己的 Python 代码计时的基础知识。在本教程的其余部分,您将了解如何将 Python 计时器封装到一个类、一个上下文管理器和一个装饰器中,以使它更加一致和方便使用。
一个 Python 定时器类
回头看看您是如何将 Python 计时器添加到上面的示例中的。注意,在下载教程之前,您至少需要一个变量(tic)来存储 Python 定时器的状态。稍微研究了一下代码之后,您可能还会注意到,添加这三个突出显示的行只是为了计时!现在,您将创建一个与您手动调用perf_counter()相同的类,但是以一种更加可读和一致的方式。
在本教程中,您将创建并更新Timer,这个类可以用来以几种不同的方式为您的代码计时。带有一些额外特性的最终代码也可以在 PyPI 上以codetiming的名字获得。您可以像这样在您的系统上安装它:
$ python -m pip install codetiming
你可以在本教程后面的部分找到更多关于codetiming的信息,Python 计时器代码。
理解 Python 中的类
类是面向对象编程的主要构件。一个类本质上是一个模板,你可以用它来创建对象。虽然 Python 并不强迫你以面向对象的方式编程,但类在这种语言中无处不在。为了快速证明,研究 time模块:
>>> import time >>> type(time) <class 'module'> >>> time.__class__ <class 'module'>
type()返回对象的类型。这里你可以看到模块实际上是从一个module类创建的对象。您可以使用特殊属性.__class__来访问定义对象的类。事实上,Python 中的几乎所有东西都是一个类:
>>> type(3)
<class 'int'>
>>> type(None)
<class 'NoneType'>
>>> type(print)
<class 'builtin_function_or_method'>
>>> type(type)
<class 'type'>
在 Python 中,当您需要对需要跟踪特定状态的东西建模时,类非常有用。一般来说,一个类是称为属性的属性和称为方法的行为的集合。关于类和面向对象编程的更多背景知识,请查看 Python 3 中的面向对象编程(OOP)或官方文档。
创建 Python 定时器类
类有利于跟踪状态。在一个Timer类中,你想要记录一个计时器何时开始计时,以及从那时起已经过了多长时间。对于Timer的第一个实现,您将添加一个._start_time属性,以及.start()和.stop()方法。将以下代码添加到名为timer.py的文件中:
1# timer.py
2
3import time
4
5class TimerError(Exception):
6 """A custom exception used to report errors in use of Timer class"""
7
8class Timer:
9 def __init__(self):
10 self._start_time = None
11
12 def start(self):
13 """Start a new timer"""
14 if self._start_time is not None:
15 raise TimerError(f"Timer is running. Use .stop() to stop it")
16
17 self._start_time = time.perf_counter()
18
19 def stop(self):
20 """Stop the timer, and report the elapsed time"""
21 if self._start_time is None:
22 raise TimerError(f"Timer is not running. Use .start() to start it")
23
24 elapsed_time = time.perf_counter() - self._start_time
25 self._start_time = None
26 print(f"Elapsed time: {elapsed_time:0.4f} seconds")
这里发生了一些不同的事情,所以花点时间一步一步地浏览代码。
在第 5 行,您定义了一个TimerError类。(Exception)符号意味着TimerError 从另一个名为Exception的类继承了。Python 使用这个内置的类进行错误处理。您不需要给TimerError添加任何属性或方法,但是拥有一个自定义错误会让您更加灵活地处理Timer内部的问题。更多信息,请查看 Python 异常:简介。
Timer本身的定义从第 8 行开始。当您第一次创建或实例化一个来自类的对象时,您的代码调用特殊方法.__init__()。在Timer的第一个版本中,您只初始化了._start_time属性,它将用于跟踪您的 Python 定时器的状态。当计时器不运行时,它的值为None。一旦定时器开始运行,._start_time会跟踪定时器的启动时间。
注意:._start_time的下划线 ( _)前缀是 Python 约定。它表明._start_time是一个内部属性,用户不应该操纵Timer类。
当您调用.start()来启动一个新的 Python 计时器时,您首先检查计时器是否已经运行。然后你将当前值存储在._start_time中。
另一方面,当您调用.stop()时,您首先检查 Python 计时器是否正在运行。如果是的话,那么你可以计算出perf_counter()的当前值和你存储在._start_time中的值之间的差值。最后,您重置._start_time以便计时器可以重新启动,并打印经过的时间。
下面是使用Timer的方法:
>>> from timer import Timer >>> t = Timer() >>> t.start() >>> t.stop() # A few seconds later Elapsed time: 3.8191 seconds将这个与之前的例子进行比较,在那里你直接使用了
perf_counter()。代码的结构相当相似,但是现在代码更清晰了,这是使用类的好处之一。通过仔细选择您的类、方法和属性名,您可以使您的代码非常具有描述性!使用 Python 定时器类
现在将
Timer应用到latest_tutorial.py。您只需要对之前的代码做一些修改:# latest_tutorial.py from timer import Timer from reader import feed def main(): """Print the latest tutorial from Real Python""" t = Timer() t.start() tutorial = feed.get_article(0) t.stop() print(tutorial) if __name__ == "__main__": main()请注意,该代码与您之前使用的代码非常相似。除了使代码更具可读性之外,
Timer还负责将经过的时间打印到控制台,这使得记录花费的时间更加一致。当您运行代码时,您将得到几乎相同的输出:$ python latest_tutorial.py Elapsed time: 0.6462 seconds # Python Timer Functions: Three Ways to Monitor Your Code [ ... ]打印从
Timer开始经过的时间可能是一致的,但是这种方式似乎不是很灵活。在下一节中,您将看到如何定制您的类。增加更多便利性和灵活性
到目前为止,您已经了解了当您想要封装状态并确保代码中行为一致时,类是合适的。在本节中,您将为 Python 计时器增加更多的便利性和灵活性:
- 在报告花费的时间时,使用适应性文本和格式
- 将灵活的日志应用到屏幕、日志文件或程序的其他部分
- 创建一个 Python 计时器,它可以在几次调用中累计 T1
- 构建一个 Python 定时器的信息表示
首先,看看如何定制用于报告花费时间的文本。在前面的代码中,文本
f"Elapsed time: {elapsed_time:0.4f} seconds"被硬编码为.stop()。您可以使用实例变量为类增加灵活性,实例变量的值通常作为参数传递给.__init__(),并存储为self属性。为了方便起见,您还可以提供合理的默认值。要添加
.text作为一个Timer实例变量,您可以在timer.py中这样做:# timer.py def __init__(self, text="Elapsed time: {:0.4f} seconds"): self._start_time = None self.text = text请注意,默认文本
"Elapsed time: {:0.4f} seconds"是作为常规字符串给出的,而不是 f 字符串。你不能在这里使用 f-string,因为 f-string 立即计算,当你实例化Timer时,你的代码还没有计算运行时间。注意:如果你想用一个 f-string 来指定
.text,那么你需要用双花括号来转义实际运行时间将替换的花括号。一个例子就是
f"Finished {task} in {{:0.4f}} seconds"。如果task的值是"reading",那么这个 f 字符串将被评估为"Finished reading in {:0.4f} seconds"。在
.stop()中,您使用.text作为模板,使用.format()来填充模板:# timer.py def stop(self): """Stop the timer, and report the elapsed time""" if self._start_time is None: raise TimerError(f"Timer is not running. Use .start() to start it") elapsed_time = time.perf_counter() - self._start_time self._start_time = None print(self.text.format(elapsed_time))更新到
timer.py后,您可以按如下方式更改文本:
>>> from timer import Timer
>>> t = Timer(text="You waited {:.1f} seconds")
>>> t.start()
>>> t.stop() # A few seconds later
You waited 4.1 seconds
接下来,假设您不只是想在控制台上打印一条消息。也许您想保存您的时间测量值,以便可以将它们存储在数据库中。您可以通过从.stop()返回elapsed_time的值来实现这一点。然后,调用代码可以选择忽略该返回值或保存它供以后处理。
也许你想将Timer集成到你的日志程序中。为了支持来自Timer的日志或其他输出,您需要更改对print()的调用,以便用户可以提供他们自己的日志功能。这可以类似于您之前定制文本的方式来完成:
1# timer.py
2
3# ...
4
5class Timer:
6 def __init__(
7 self,
8 text="Elapsed time: {:0.4f} seconds",
9 logger=print 10 ):
11 self._start_time = None
12 self.text = text
13 self.logger = logger 14
15 # Other methods are unchanged
16
17 def stop(self):
18 """Stop the timer, and report the elapsed time"""
19 if self._start_time is None:
20 raise TimerError(f"Timer is not running. Use .start() to start it")
21
22 elapsed_time = time.perf_counter() - self._start_time
23 self._start_time = None
24
25 if self.logger: 26 self.logger(self.text.format(elapsed_time)) 27
28 return elapsed_time
您没有直接使用print(),而是在第 13 行创建了另一个实例变量self.logger,它应该引用一个以字符串作为参数的函数。除了print(),你还可以在文件对象上使用类似 logging.info() 或者.write()的函数。还要注意第 25 行的if测试,它允许您通过logger=None完全关闭打印。
下面是两个展示新功能的例子:
>>> from timer import Timer >>> import logging >>> t = Timer(logger=logging.warning) >>> t.start() >>> t.stop() # A few seconds later WARNING:root:Elapsed time: 3.1610 seconds 3.1609658249999484 >>> t = Timer(logger=None) >>> t.start() >>> value = t.stop() # A few seconds later >>> value 4.710851433001153当您在交互式 shell 中运行这些示例时,Python 会自动打印返回值。
您将添加的第三个改进是累积时间测量值的能力。例如,当你在一个循环中调用一个慢速函数时,你可能想这样做。您将使用一个字典以命名计时器的形式添加更多的功能,该字典跟踪您代码中的每个 Python 计时器。
假设您正在将
latest_tutorial.py扩展为一个latest_tutorials.py脚本,该脚本下载并打印来自 Real Python 的十个最新教程。以下是一种可能的实现方式:# latest_tutorials.py from timer import Timer from reader import feed def main(): """Print the 10 latest tutorials from Real Python""" t = Timer(text="Downloaded 10 tutorials in {:0.2f} seconds") t.start() for tutorial_num in range(10): tutorial = feed.get_article(tutorial_num) print(tutorial) t.stop() if __name__ == "__main__": main()代码循环遍历从 0 到 9 的数字,并将它们用作
feed.get_article()的偏移参数。当您运行该脚本时,您会将大量信息打印到您的控制台:$ python latest_tutorials.py # Python Timer Functions: Three Ways to Monitor Your Code [ ... The text of the tutorials ... ] Downloaded 10 tutorials in 0.67 seconds这段代码的一个微妙问题是,您不仅要测量下载教程所花费的时间,还要测量 Python 将教程打印到屏幕上所花费的时间。这可能没那么重要,因为与下载时间相比,打印时间可以忽略不计。尽管如此,在这种情况下,有一种方法可以精确地确定你所追求的是什么,这将是一件好事。
注意:下载十个教程所花的时间和下载一个教程所花的时间差不多。这不是你代码中的错误!相反,
reader在第一次调用get_article()时缓存真正的 Python 提要,并在以后的调用中重用这些信息。有几种方法可以在不改变当前
Timer.实现的情况下解决这个问题。然而,支持这个用例将会非常有用,你只需要几行代码就可以做到。首先,您将引入一个名为
.timers的字典作为Timer上的类变量,这意味着Timer的所有实例将共享它。您可以通过在任何方法之外定义它来实现它:class Timer: timers = {}可以直接在类上或通过类的实例来访问类变量:
>>> from timer import Timer
>>> Timer.timers
{}
>>> t = Timer()
>>> t.timers
{}
>>> Timer.timers is t.timers
True
在这两种情况下,代码都返回相同的空类字典。
接下来,您将向 Python 计时器添加可选名称。您可以将该名称用于两个不同的目的:
- 在代码中查找经过的时间
- 累积同名的个计时器
要向 Python 计时器添加名称,需要对timer.py再做两处修改。首先,Timer应该接受name作为参数。第二,当定时器停止时,经过的时间应该加到.timers:
1# timer.py
2
3# ...
4
5class Timer:
6 timers = {} 7
8 def __init__(
9 self,
10 name=None, 11 text="Elapsed time: {:0.4f} seconds",
12 logger=print,
13 ):
14 self._start_time = None
15 self.name = name 16 self.text = text
17 self.logger = logger
18
19 # Add new named timers to dictionary of timers 20 if name: 21 self.timers.setdefault(name, 0) 22
23 # Other methods are unchanged
24
25 def stop(self):
26 """Stop the timer, and report the elapsed time"""
27 if self._start_time is None:
28 raise TimerError(f"Timer is not running. Use .start() to start it")
29
30 elapsed_time = time.perf_counter() - self._start_time
31 self._start_time = None
32
33 if self.logger:
34 self.logger(self.text.format(elapsed_time))
35 if self.name: 36 self.timers[self.name] += elapsed_time 37
38 return elapsed_time
注意,在向.timers添加新的 Python 定时器时,使用了.setdefault()。这是一个很棒的特性,它只在name还没有在字典中定义的情况下设置值。如果name已经在.timers中使用,则该值保持不变。这允许您累积几个计时器:
>>> from timer import Timer >>> t = Timer("accumulate") >>> t.start() >>> t.stop() # A few seconds later Elapsed time: 3.7036 seconds 3.703554293999332 >>> t.start() >>> t.stop() # A few seconds later Elapsed time: 2.3449 seconds 2.3448921170001995 >>> Timer.timers {'accumulate': 6.0484464109995315}您现在可以重新访问
latest_tutorials.py,并确保只计算下载教程所花费的时间:# latest_tutorials.py from timer import Timer from reader import feed def main(): """Print the 10 latest tutorials from Real Python""" t = Timer("download", logger=None) for tutorial_num in range(10): t.start() tutorial = feed.get_article(tutorial_num) t.stop() print(tutorial) download_time = Timer.timers["download"] print(f"Downloaded 10 tutorials in {download_time:0.2f} seconds") if __name__ == "__main__": main()重新运行该脚本将给出与前面类似的输出,尽管现在您只是对教程的实际下载进行计时:
$ python latest_tutorials.py # Python Timer Functions: Three Ways to Monitor Your Code [ ... The text of the tutorials ... ] Downloaded 10 tutorials in 0.65 seconds你将对
Timer做的最后一个改进是,当你交互地使用它时,它会提供更多的信息。尝试以下方法:
>>> from timer import Timer
>>> t = Timer()
>>> t
<timer.Timer object at 0x7f0578804320>
最后一行是 Python 表示对象的默认方式。虽然您可以从中收集一些信息,但通常不是很有用。相反,最好能看到类似于Timer的名字,或者它将如何报告时间的信息。
在 Python 3.7 中,数据类被添加到标准库中。这些为您的类提供了一些便利,包括更丰富的表示字符串。
注意:数据类仅包含在 Python 3.7 及更高版本中。然而,Python 3.6 的 PyPI 上有一个反向端口。
您可以使用pip来安装它:
$ python -m pip install dataclasses
更多信息请参见 Python 3.7+(指南)中的数据类。
使用@dataclass装饰器将 Python 定时器转换成数据类。在本教程的后面,你会学到更多关于装饰师的知识。现在,你可以把这看作是告诉 PythonTimer是一个数据类的符号:
1# timer.py
2
3import time
4from dataclasses import dataclass, field
5from typing import Any, ClassVar
6
7# ...
8
9@dataclass
10class Timer:
11 timers: ClassVar = {}
12 name: Any = None
13 text: Any = "Elapsed time: {:0.4f} seconds"
14 logger: Any = print
15 _start_time: Any = field(default=None, init=False, repr=False)
16
17 def __post_init__(self):
18 """Initialization: add timer to dict of timers"""
19 if self.name:
20 self.timers.setdefault(self.name, 0)
21
22 # The rest of the code is unchanged
这段代码取代了您之前的.__init__()方法。请注意数据类如何使用看起来类似于您在前面看到的用于定义所有变量的类变量语法的语法。事实上,.__init__()是根据类定义中的注释变量自动为数据类创建的。
要使用数据类,您需要对变量进行注释。您可以使用该注释将类型提示添加到代码中。如果你不想使用类型提示,那么你可以用Any来注释所有的变量,就像上面所做的一样。您将很快学会如何向数据类添加实际的类型提示。
以下是关于Timer数据类的一些注意事项:
-
第 9 行:
@dataclass装饰器将Timer定义为一个数据类。 -
第 11 行:数据类需要特殊的
ClassVar注释来指定.timers是一个类变量。 -
第 12 到 14 行:
.name、.text、.logger将被定义为Timer上的属性,其值可以在创建Timer实例时指定。它们都有给定的默认值。 -
第 15 行:回想一下
._start_time是一个特殊的属性,用于跟踪 Python 定时器的状态,但是它应该对用户隐藏。利用dataclasses.field(),你说._start_time应该从.__init__()和Timer的表象中去掉。 -
第 17 到 20 行:除了设置实例属性,您还可以使用特殊的
.__post_init__()方法进行任何需要的初始化。在这里,您使用它将命名计时器添加到.timers。
新的Timer数据类的工作方式与之前的常规类一样,只是它现在有了一个很好的表示:
>>> from timer import Timer >>> t = Timer() >>> t Timer(name=None, text='Elapsed time: {:0.4f} seconds', logger=<built-in function print>) >>> t.start() >>> t.stop() # A few seconds later Elapsed time: 6.7197 seconds 6.719705373998295现在你有了一个非常简洁的版本
Timer,它是一致的、灵活的、方便的、信息丰富的!您也可以将本节中所做的许多改进应用到项目中的其他类型的类中。在结束这一部分之前,重新看看目前的完整源代码。您会注意到在代码中添加了类型提示,以获得额外的文档:
# timer.py from dataclasses import dataclass, field import time from typing import Callable, ClassVar, Dict, Optional class TimerError(Exception): """A custom exception used to report errors in use of Timer class""" @dataclass class Timer: timers: ClassVar[Dict[str, float]] = {} name: Optional[str] = None text: str = "Elapsed time: {:0.4f} seconds" logger: Optional[Callable[[str], None]] = print _start_time: Optional[float] = field(default=None, init=False, repr=False) def __post_init__(self) -> None: """Add timer to dict of timers after initialization""" if self.name is not None: self.timers.setdefault(self.name, 0) def start(self) -> None: """Start a new timer""" if self._start_time is not None: raise TimerError(f"Timer is running. Use .stop() to stop it") self._start_time = time.perf_counter() def stop(self) -> float: """Stop the timer, and report the elapsed time""" if self._start_time is None: raise TimerError(f"Timer is not running. Use .start() to start it") # Calculate elapsed time elapsed_time = time.perf_counter() - self._start_time self._start_time = None # Report elapsed time if self.logger: self.logger(self.text.format(elapsed_time)) if self.name: self.timers[self.name] += elapsed_time return elapsed_time使用类创建 Python 计时器有几个好处:
- 可读性:如果你仔细选择类名和方法名,你的代码读起来会更自然。
- 一致性:如果你将属性和行为封装到属性和方法中,你的代码会更容易使用。
- 灵活性:如果您使用带有默认值的属性,而不是硬编码的值,您的代码将是可重用的。
这个类非常灵活,您几乎可以在任何想要监控代码运行时间的情况下使用它。然而,在接下来的部分中,您将学习如何使用上下文管理器和装饰器,这对于定时代码块和函数来说更加方便。
Python 定时器上下文管理器
您的 Python
Timer类已经取得了很大的进步!与你创建的第一个Python 定时器相比,你的代码已经变得相当强大了。然而,仍然有一些样板代码是使用您的Timer所必需的:
- 首先,实例化该类。
- 在你想要计时的代码块之前调用
.start()。- 代码块后调用
.stop()。幸运的是,Python 有一个在代码块前后调用函数的独特构造:上下文管理器**。在本节中,您将了解什么是上下文管理器和 Python 的
with语句,以及如何创建自己的上下文管理器。然后您将扩展Timer,这样它也可以作为上下文管理器工作。最后,您将看到使用Timer作为上下文管理器如何简化您的代码。**### 理解 Python 中的上下文管理器
上下文管理器成为 Python 的一部分已经有很长时间了。它们是由 PEP 343 在 2005 年提出的,并在 Python 2.5 中首次实现。您可以通过使用
with关键字来识别代码中的上下文管理器:with EXPRESSION as VARIABLE: BLOCK
EXPRESSION是返回上下文管理器的 Python 表达式。上下文管理器可选地绑定到名称VARIABLE。最后,BLOCK是任何常规的 Python 代码块。上下文管理器将保证你的程序在BLOCK之前调用一些代码,在BLOCK执行之后调用另一些代码。后者会发生,即使BLOCK引发异常。上下文管理器最常见的用途可能是处理不同的资源,比如文件、锁和数据库连接。在您使用完资源后,上下文管理器将用于释放和清理资源。下面的例子通过打印包含冒号的行揭示了
timer.py的基本结构。更重要的是,它展示了在 Python 中打开文件的通用习语:
>>> with open("timer.py") as fp:
... print("".join(ln for ln in fp if ":" in ln))
...
class TimerError(Exception):
class Timer:
timers: ClassVar[Dict[str, float]] = {}
name: Optional[str] = None
text: str = "Elapsed time: {:0.4f} seconds"
logger: Optional[Callable[[str], None]] = print
_start_time: Optional[float] = field(default=None, init=False, repr=False)
def __post_init__(self) -> None:
if self.name is not None:
def start(self) -> None:
if self._start_time is not None:
def stop(self) -> float:
if self._start_time is None:
if self.logger:
if self.name:
请注意,文件指针fp从未被显式关闭,因为您使用了open()作为上下文管理器。您可以确认fp已经自动关闭:
>>> fp.closed True在本例中,
open("timer.py")是一个返回上下文管理器的表达式。该上下文管理器被绑定到名称fp。上下文管理器在print()执行期间有效。这一行代码块在fp的上下文中执行。
fp是上下文管理器是什么意思?从技术上讲,这意味着fp实现了上下文管理器协议。Python 语言下有许多不同的协议。您可以将协议视为一个契约,它规定了您的代码必须实现哪些特定的方法。上下文管理器协议由两种方法组成:
- 进入与上下文管理器相关的上下文时,调用
.__enter__()。- 退出与上下文管理器相关的上下文时,调用
.__exit__()。换句话说,要自己创建一个上下文管理器,需要编写一个实现
.__enter__()和.__exit__()的类。不多不少。试试你好,世界!上下文管理器示例:# greeter.py class Greeter: def __init__(self, name): self.name = name def __enter__(self): print(f"Hello {self.name}") return self def __exit__(self, exc_type, exc_value, exc_tb): print(f"See you later, {self.name}")
Greeter是上下文管理器,因为它实现了上下文管理器协议。你可以这样使用它:
>>> from greeter import Greeter
>>> with Greeter("Akshay"):
... print("Doing stuff ...")
...
Hello Akshay
Doing stuff ...
See you later, Akshay
首先,注意如何在你做事情之前调用.__enter__(),而在之后调用.__exit__()。在这个简化的例子中,您没有引用上下文管理器。在这种情况下,您不需要给上下文管理器起一个带有as的名字。
接下来,注意.__enter__()如何返回self。.__enter__()的返回值被as绑定。在创建上下文管理器时,通常希望从.__enter__()返回self。您可以按如下方式使用返回值:
>>> from greeter import Greeter >>> with Greeter("Bethan") as grt: ... print(f"{grt.name} is doing stuff ...") ... Hello Bethan Bethan is doing stuff ... See you later, Bethan最后,
.__exit__()带三个参数:exc_type、exc_value和exc_tb。这些用于上下文管理器中的错误处理,它们反映了sys.exc_info()的返回值。如果在执行代码块时发生了异常,那么您的代码会调用带有异常类型、异常实例和回溯对象的
.__exit__()。通常,您可以在上下文管理器中忽略这些,在这种情况下,会在重新引发异常之前调用.__exit__():
>>> from greeter import Greeter
>>> with Greeter("Rascal") as grt:
... print(f"{grt.age} does not exist")
...
Hello Rascal
See you later, Rascal Traceback (most recent call last):
File "<stdin>", line 2, in <module>
AttributeError: 'Greeter' object has no attribute 'age'
您可以看到"See you later, Rascal"被打印出来,尽管代码中有一个错误。
现在您知道了什么是上下文管理器,以及如何创建自己的上下文管理器。如果你想更深入,那么在标准库中查看 contextlib 。它包括定义新的上下文管理器的方便方法,以及现成的上下文管理器,您可以使用它们来关闭对象、抑制错误,甚至什么都不做!更多信息,请查看上下文管理器和 Python 的with语句。
创建 Python 定时器上下文管理器
您已经看到了上下文管理器一般是如何工作的,但是它们如何帮助处理计时代码呢?如果您可以在代码块之前和之后运行某些函数,那么您就可以简化 Python 计时器的工作方式。到目前为止,在为代码计时时,您需要显式调用.start()和.stop(),但是上下文管理器可以自动完成这项工作。
同样,对于作为上下文管理器工作的Timer,它需要遵守上下文管理器协议。换句话说,它必须实现.__enter__()和.__exit__()来启动和停止 Python 定时器。所有必要的功能都已经可用,所以不需要编写太多新代码。只需将以下方法添加到您的Timer类中:
# timer.py
# ...
@dataclass
class Timer:
# The rest of the code is unchanged
def __enter__(self):
"""Start a new timer as a context manager"""
self.start()
return self
def __exit__(self, *exc_info):
"""Stop the context manager timer"""
self.stop()
Timer现在是上下文管理器。实现的重要部分是当进入上下文时,.__enter__()调用.start()启动 Python 定时器,当代码离开上下文时,.__exit__()使用.stop()停止 Python 定时器。尝试一下:
>>> from timer import Timer >>> import time >>> with Timer(): ... time.sleep(0.7) ... Elapsed time: 0.7012 seconds您还应该注意两个更微妙的细节:
.__enter__()返回self,Timer实例,允许用户使用as将Timer实例绑定到变量。例如,with Timer() as t:将创建指向Timer对象的变量t。
.__exit__()期望三个参数带有关于在上下文执行期间发生的任何异常的信息。在您的代码中,这些参数被打包到一个名为exc_info的元组中,然后被忽略,这意味着Timer不会尝试任何异常处理。
.__exit__()在这种情况下不做任何错误处理。尽管如此,上下文管理器的一个重要特性是,无论上下文如何退出,它们都保证调用.__exit__()。在以下示例中,您通过除以零故意制造了一个误差:
>>> from timer import Timer
>>> with Timer():
... for num in range(-3, 3):
... print(f"1 / {num} = {1 / num:.3f}")
...
1 / -3 = -0.333
1 / -2 = -0.500
1 / -1 = -1.000
Elapsed time: 0.0001 seconds Traceback (most recent call last):
File "<stdin>", line 3, in <module>
ZeroDivisionError: division by zero
请注意,Timer打印出运行时间,即使代码崩溃。可以检查和抑制.__exit__()中的错误。更多信息参见文档。
使用 Python 定时器上下文管理器
现在您将学习如何使用Timer上下文管理器来为真正的 Python 教程下载计时。回想一下您之前是如何使用Timer的:
# latest_tutorial.py
from timer import Timer
from reader import feed
def main():
"""Print the latest tutorial from Real Python"""
t = Timer()
t.start()
tutorial = feed.get_article(0)
t.stop()
print(tutorial)
if __name__ == "__main__":
main()
您正在为呼叫feed.get_article()计时。您可以使用上下文管理器使代码更短、更简单、更易读:
# latest_tutorial.py
from timer import Timer
from reader import feed
def main():
"""Print the latest tutorial from Real Python"""
with Timer(): tutorial = feed.get_article(0)
print(tutorial)
if __name__ == "__main__":
main()
这段代码实际上和上面的代码做的一样。主要的区别在于,您没有定义无关变量t,这使得您的名称空间更加清晰。
运行该脚本应该会得到一个熟悉的结果:
$ python latest_tutorial.py
Elapsed time: 0.71 seconds # Python Timer Functions: Three Ways to Monitor Your Code
[ ... ]
将上下文管理器功能添加到 Python 计时器类中有几个好处:
- 省力:你只需要一行额外的代码来计时一段代码的执行。
- 可读性:调用上下文管理器是可读的,您可以更清楚地可视化您正在计时的代码块。
使用Timer作为上下文管理器几乎和直接使用.start()和.stop()一样灵活,而且样板代码更少。在下一节中,您将学习如何使用Timer作为装饰器。这将使监控完整函数的运行时变得更加容易。
一个 Python 定时器装饰器
你的Timer课现在很全能。然而,有一个用例您可以进一步简化它。假设您想要跟踪代码库中一个给定函数所花费的时间。使用上下文管理器,您有两种不同的选择:
-
每次调用函数时使用
Timer:with Timer("some_name"): do_something()`如果你在很多地方调用
do_something(),那么这将变得很繁琐,很难维护。 -
将函数中的代码包装在上下文管理器中:
def do_something(): with Timer("some_name"): ...`只需要在一个地方添加
Timer,但是这给do_something()的整个定义增加了一级缩进。
更好的解决方案是使用Timer作为装饰器。装饰器是用来修改函数和类的行为的强大构造。在这一节中,您将了解装饰器是如何工作的,如何将Timer扩展为装饰器,以及这将如何简化计时功能。关于装饰者的更深入的解释,请参见【Python 装饰者入门。
理解 Python 中的装饰者
一个装饰器是一个包装另一个函数来修改其行为的函数。这种技术是可行的,因为函数是 Python 中的一级对象。换句话说,函数可以赋给变量,也可以用作其他函数的参数,就像任何其他对象一样。这为您提供了很大的灵活性,并且是 Python 几个最强大特性的基础。
作为第一个例子,您将创建一个什么都不做的装饰器:
def turn_off(func):
return lambda *args, **kwargs: None
首先,注意turn_off()只是一个常规函数。使它成为装饰器的是,它将一个函数作为唯一的参数,并返回一个函数。您可以使用turn_off()来修改其他功能,如下所示:
>>> print("Hello") Hello >>> print = turn_off(print) >>> print("Hush") >>> # Nothing is printed第
print = turn_off(print)行用turn_off()修饰符修饰打印语句。实际上,它用由turn_off()返回的lambda *args, **kwargs: None代替了print()。 lambda 语句表示一个除了返回None之外什么也不做的匿名函数。要定义更多有趣的装饰器,你需要了解内部函数。一个内部函数是定义在另一个函数内部的函数。内部函数的一个常见用途是创建函数工厂:
def create_multiplier(factor): def multiplier(num): return factor * num return multiplier
multiplier()是一个内部函数,定义在create_multiplier()内部。请注意,您可以访问multiplier()内的factor,而create_multiplier()外的multiplier()没有定义:
>>> multiplier
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'multiplier' is not defined
相反,您可以使用create_multiplier()来创建新的乘数函数,每个函数都基于不同的因子:
>>> double = create_multiplier(factor=2) >>> double(3) 6 >>> quadruple = create_multiplier(factor=4) >>> quadruple(7) 28同样,您可以使用内部函数来创建装饰器。记住,装饰器是一个返回函数的函数:
1def triple(func): 2 def wrapper_triple(*args, **kwargs): 3 print(f"Tripled {func.__name__!r}") 4 value = func(*args, **kwargs) 5 return value * 3 6 return wrapper_triple
triple()是一个装饰器,因为它是一个期望函数func()作为其唯一参数并返回另一个函数wrapper_triple()的函数。注意triple()本身的结构:
- 第 1 行开始定义
triple(),并期望一个函数作为参数。- 第 2 到 5 行定义了内部函数
wrapper_triple()。- 第 6 行返回
wrapper_triple()。这种模式普遍用于定义装饰者。有趣的部分发生在内部函数中:
- 第 2 行开始定义
wrapper_triple()。这个函数将取代triple()修饰的函数。参数是*args和**kwargs,它们收集您传递给函数的任何位置和关键字参数。这给了你在任何函数上使用triple()的灵活性。- 第 3 行打印出被修饰函数的名称,并注意到
triple()已经被应用于它。- 第 4 行调用
func(),triple()修饰过的功能。它将传递给wrapper_triple()的所有参数。- 第 5 行将
func()的返回值三倍并返回。试试吧!
knock()是返回单词Penny的函数。看看如果增加三倍会发生什么:
>>> def knock():
... return "Penny! "
...
>>> knock = triple(knock)
>>> result = knock()
Tripled 'knock'
>>> result
'Penny! Penny! Penny! '
将一个文本字符串乘以一个数字是一种重复形式,所以Penny重复三次。装饰发生在knock = triple(knock)。
一直重复knock感觉有点笨拙。相反, PEP 318 引入了一个更方便的语法来应用装饰器。下面的knock()定义与上面的定义相同:
>>> @triple ... def knock(): ... return "Penny! " ... >>> result = knock() Tripled 'knock' >>> result 'Penny! Penny! Penny! '符号用来应用装饰符。在这种情况下,
@triple意味着triple()被应用于紧随其后定义的函数。标准库中定义的少数装饰者之一是
@functools.wraps。在定义自己的装饰者时,这一条非常有用。因为装饰者有效地用一个函数替换了另一个函数,所以他们给你的函数制造了一个微妙的问题:
>>> knock
<function triple.<locals>.wrapper_triple at 0x7fa3bfe5dd90>
@triple修饰knock(),然后被wrapper_triple()内部函数替换,正如上面的输出所证实的。这也将替换名称、文档字符串和其他元数据。通常,这不会有太大的效果,但会使自省变得困难。
有时,修饰函数必须有正确的元数据。@functools.wraps解决了这个问题:
import functools
def triple(func):
@functools.wraps(func) def wrapper_triple(*args, **kwargs):
print(f"Tripled {func.__name__!r}")
value = func(*args, **kwargs)
return value * 3
return wrapper_triple
使用这个新的@triple定义,元数据被保留:
>>> @triple ... def knock(): ... return "Penny! " ... >>> knock <function knock at 0x7fa3bfe5df28>请注意,
knock()现在保持其正确的名称,即使在装饰之后。在定义装饰器时使用@functools.wraps是一种好的形式。您可以为大多数装饰者使用的蓝图如下:import functools def decorator(func): @functools.wraps(func) def wrapper_decorator(*args, **kwargs): # Do something before value = func(*args, **kwargs) # Do something after return value return wrapper_decorator要查看更多关于如何定义 decorator 的例子,请查看 Python Decorators 入门教程中列出的例子。
创建 Python 计时器装饰器
在这一节中,您将学习如何扩展您的 Python 计时器,以便您也可以将它用作装饰器。然而,作为第一个练习,您将从头开始创建一个 Python 计时器装饰器。
基于上面的蓝图,您只需要决定在调用修饰函数之前和之后做什么。这类似于在进入和退出上下文管理器时要做什么的考虑。您希望在调用修饰函数之前启动 Python 计时器,并在调用完成后停止 Python 计时器。您可以定义一个
@timer装饰者,如下所示:import functools import time def timer(func): @functools.wraps(func) def wrapper_timer(*args, **kwargs): tic = time.perf_counter() value = func(*args, **kwargs) toc = time.perf_counter() elapsed_time = toc - tic print(f"Elapsed time: {elapsed_time:0.4f} seconds") return value return wrapper_timer注意
wrapper_timer()与您为计时 Python 代码建立的早期模式有多么相似。您可以如下应用@timer:
>>> @timer
... def latest_tutorial():
... tutorial = feed.get_article(0)
... print(tutorial)
...
>>> latest_tutorial()
# Python Timer Functions: Three Ways to Monitor Your Code
[ ... ]
Elapsed time: 0.5414 seconds
回想一下,您还可以将装饰器应用于先前定义的函数:
>>> feed.get_article = timer(feed.get_article)因为
@在定义函数时适用,所以在这些情况下需要使用更基本的形式。使用装饰器的一个好处是你只需要应用一次,它每次都会计算函数的时间:
>>> tutorial = feed.get_article(0)
Elapsed time: 0.5512 seconds
做这项工作。然而,在某种意义上,你又回到了起点,因为@timer没有Timer的任何灵活性或便利性。你也能让你的Timer类表现得像一个装饰者吗?
到目前为止,您已经将 decorators 用作应用于其他函数的函数,但这并不完全正确。装饰者必须是可召唤者。Python 中有很多可调用类型。您可以通过在自己的类中定义特殊的.__call__()方法来使自己的对象可调用。以下函数和类的行为类似:
>>> def square(num): ... return num ** 2 ... >>> square(4) 16 >>> class Squarer: ... def __call__(self, num): ... return num ** 2 ... >>> square = Squarer() >>> square(4) 16这里,
square是一个可调用的实例,可以平方数字,就像第一个例子中的square()函数一样。这为您提供了一种向现有的
Timer类添加装饰功能的方法:# timer.py import functools # ... @dataclass class Timer: # The rest of the code is unchanged def __call__(self, func): """Support using Timer as a decorator""" @functools.wraps(func) def wrapper_timer(*args, **kwargs): with self: return func(*args, **kwargs) return wrapper_timer
.__call__()利用Timer已经是一个上下文管理器的事实来利用您已经在那里定义的便利。确定你也在timer.py上方导入functools。您现在可以使用
Timer作为装饰器:
>>> @Timer(text="Downloaded the tutorial in {:.2f} seconds")
... def latest_tutorial():
... tutorial = feed.get_article(0)
... print(tutorial)
...
>>> latest_tutorial()
# Python Timer Functions: Three Ways to Monitor Your Code
[ ... ]
Downloaded the tutorial in 0.72 seconds
在结束这一部分之前,要知道有一种更直接的方法可以将 Python 计时器变成装饰器。您已经看到了上下文管理器和装饰器之间的一些相似之处。它们通常都用于在执行给定代码之前和之后做一些事情。
基于这些相似性,标准库中定义了一个 mixin 类,称为 ContextDecorator 。您可以简单地通过继承ContextDecorator来为您的上下文管理器类添加装饰功能:
from contextlib import ContextDecorator
# ...
@dataclass
class Timer(ContextDecorator):
# Implementation of Timer is unchanged
当你以这种方式使用ContextDecorator时,没有必要自己实现.__call__(),所以你可以安全地从Timer类中删除它。
使用 Python 计时器装饰器
接下来,您将最后一次重做latest_tutorial.py示例,使用 Python 定时器作为装饰器:
1# latest_tutorial.py
2
3from timer import Timer
4from reader import feed
5
6@Timer() 7def main():
8 """Print the latest tutorial from Real Python"""
9 tutorial = feed.get_article(0)
10 print(tutorial)
11
12if __name__ == "__main__":
13 main()
如果您将这个实现与没有任何计时的原始实现进行比较,那么您会注意到唯一的区别是第 3 行Timer的导入和第 6 行@Timer()的应用。使用 decorators 的一个显著优点是它们通常很容易应用,正如你在这里看到的。
然而,装饰器仍然适用于整个函数。这意味着除了下载时间之外,您的代码还考虑了打印教程所需的时间。最后一次运行脚本:
$ python latest_tutorial.py
# Python Timer Functions: Three Ways to Monitor Your Code
[ ... ]
Elapsed time: 0.69 seconds
运行时间输出的位置是一个信号,表明您的代码也在考虑打印所花费的时间。正如您在这里看到的,您的代码在教程的之后打印了经过的时间。
当您使用Timer作为装饰器时,您会看到与使用上下文管理器类似的优势:
- 你只需要一行额外的代码来计时一个函数的执行。
- 可读性:当您添加装饰器时,您可以更清楚地注意到您的代码将为函数计时。
- 一致性:你只需要在定义函数的时候添加装饰器。每次调用时,您的代码都会持续计时。
然而,装饰器不像上下文管理器那样灵活。您只能将它们应用于完整的功能。可以在已经定义的函数中添加装饰器,但是这有点笨拙,也不太常见。
Python 定时器代码
您可以展开下面的代码块来查看 Python 计时器的最终源代码:
# timer.py
import time
from contextlib import ContextDecorator
from dataclasses import dataclass, field
from typing import Any, Callable, ClassVar, Dict, Optional
class TimerError(Exception):
"""A custom exception used to report errors in use of Timer class"""
@dataclass
class Timer(ContextDecorator):
"""Time your code using a class, context manager, or decorator"""
timers: ClassVar[Dict[str, float]] = {}
name: Optional[str] = None
text: str = "Elapsed time: {:0.4f} seconds"
logger: Optional[Callable[[str], None]] = print
_start_time: Optional[float] = field(default=None, init=False, repr=False)
def __post_init__(self) -> None:
"""Initialization: add timer to dict of timers"""
if self.name:
self.timers.setdefault(self.name, 0)
def start(self) -> None:
"""Start a new timer"""
if self._start_time is not None:
raise TimerError(f"Timer is running. Use .stop() to stop it")
self._start_time = time.perf_counter()
def stop(self) -> float:
"""Stop the timer, and report the elapsed time"""
if self._start_time is None:
raise TimerError(f"Timer is not running. Use .start() to start it")
# Calculate elapsed time
elapsed_time = time.perf_counter() - self._start_time
self._start_time = None
# Report elapsed time
if self.logger:
self.logger(self.text.format(elapsed_time))
if self.name:
self.timers[self.name] += elapsed_time
return elapsed_time
def __enter__(self) -> "Timer":
"""Start a new timer as a context manager"""
self.start()
return self
def __exit__(self, *exc_info: Any) -> None:
"""Stop the context manager timer"""
self.stop()
GitHub 上的 codetiming库中也有该代码。
您可以将代码保存到一个名为timer.py的文件中,然后导入到您的程序中,这样您就可以自己使用代码了:
>>> from timer import Timer
Timer在 PyPI 上也有,所以更简单的选择是使用pip安装它:$ python -m pip install codetiming注意 PyPI 上的包名是
codetiming。在安装软件包和导入Timer时,您都需要使用这个名称:
>>> from codetiming import Timer
除了名字和的一些额外特性,codetiming.Timer的工作方式与timer.Timer完全一样。总而言之,你可以用三种不同的方式使用Timer:
-
作为类:
t = Timer(name="class") t.start() # Do something t.stop()` -
作为上下文管理器:
with Timer(name="context manager"): # Do something` -
作为一名装饰师:
@Timer(name="decorator") def stuff(): # Do something`
这种 Python 计时器主要用于监控代码在单个关键代码块或函数上花费的时间。在下一节中,如果您想要优化代码,您将得到一个备选方案的快速概述。
其他 Python 定时器函数
使用 Python 为代码计时有很多选择。在本教程中,您已经学习了如何创建一个灵活方便的类,您可以用几种不同的方式来使用它。在 PyPI 上快速搜索显示已经有许多项目提供 Python 定时器解决方案。
在本节中,您将首先了解标准库中用于测量时间的不同函数,包括为什么perf_counter()更好。然后,您将探索优化代码的替代方法,而Timer并不适合。
使用替代的 Python 定时器函数
在本教程中,您一直在使用perf_counter()来进行实际的时间测量,但是 Python 的time库附带了其他几个也可以测量时间的函数。以下是一些备选方案:
拥有多个函数的一个原因是 Python 将时间表示为一个float。浮点数本质上是不准确的。您可能以前见过这样的结果:
>>> 0.1 + 0.1 + 0.1 0.30000000000000004 >>> 0.1 + 0.1 + 0.1 == 0.3 FalsePython 的
float遵循浮点运算的 IEEE 754 标准,试图用 64 位表示所有浮点数。因为浮点数有无限多种,你不可能用有限的位数全部表示出来。IEEE 754 规定了一个系统,在这个系统中,您可以表示的数字密度是变化的。你越接近一,你能代表的数字就越多。对于更大的数字,你可以表达的数字之间有更多的空间。当你用一个
float来表示时间时,这会产生一些后果。考虑一下
time()。这个函数的主要目的是表示现在的实际时间。这是从给定时间点开始的秒数,称为时期。time()返回的数字相当大,这意味着可用的数字较少,分辨率受到影响。具体来说,time()无法测量纳秒的差异:
>>> import time
>>> t = time.time()
>>> t
1564342757.0654016
>>> t + 1e-9
1564342757.0654016
>>> t == t + 1e-9
True
一纳秒是十亿分之一秒。注意,给t加一纳秒不会影响结果。另一方面,perf_counter()使用某个未定义的时间点作为其历元,允许其使用较小的数字,从而获得更好的分辨率:
>>> import time >>> p = time.perf_counter() >>> p 11370.015653846 >>> p + 1e-9 11370.015653847 >>> p == p + 1e-9 False这里,您会注意到在
p上增加一纳秒实际上会影响结果。有关如何使用time()的更多信息,请参见Python 时间模块的初学者指南。用
float表示时间的挑战是众所周知的,所以 Python 3.7 引入了一个新的选项。每个time测量函数现在都有一个相应的_ns函数,它返回纳秒数作为int,而不是秒数作为float。例如,time()现在有了一个纳秒级的对应物,叫做time_ns():
>>> import time
>>> time.time_ns()
1564342792866601283
在 Python 中整数是无限的,所以这允许time_ns()永远给出纳秒级的分辨率。类似地,perf_counter_ns()是perf_counter()的纳秒变体:
>>> import time >>> time.perf_counter() 13580.153084446 >>> time.perf_counter_ns() 13580765666638因为
perf_counter()已经提供了纳秒级的分辨率,所以使用perf_counter_ns()的优势更少。注意:
perf_counter_ns()仅在 Python 3.7 及更高版本中可用。在本教程中,你已经在你的Timer类中使用了perf_counter()。这样,您也可以在旧版本的 Python 上使用Timer。有关
time中_ns函数的更多信息,请查看 Python 3.7 中的新功能。
time中有两个函数不测量睡眠花费的时间。这些是process_time()和thread_time(),在某些设置中很有用。然而,对于Timer,您通常想要测量花费的全部时间。上面列表中的最后一个函数是monotonic()。这个名字暗示这个函数是一个单调计时器,是一个永远不能向后移动的 Python 计时器。所有这些功能都是单调的,只有
time()除外,如果调整系统时间,它可以倒退。在某些系统上,monotonic()与perf_counter()的功能相同,可以互换使用。然而,情况并非总是如此。您可以使用time.get_clock_info()获得关于 Python 定时器函数的更多信息:
>>> import time
>>> time.get_clock_info("monotonic")
namespace(adjustable=False, implementation='clock_gettime(CLOCK_MONOTONIC)',
monotonic=True, resolution=1e-09)
>>> time.get_clock_info("perf_counter")
namespace(adjustable=False, implementation='clock_gettime(CLOCK_MONOTONIC)',
monotonic=True, resolution=1e-09)
在您的系统上,结果可能有所不同。
PEP 418 描述了引入这些功能背后的一些基本原理。它包括以下简短描述:
time.monotonic(): Timeout and scheduling, not affected by system clock update.time.perf_counter(): benchmark test, the most accurate short-period clock.time.process_time(): profiling, CPU time of the process ( source )
可以看出,perf_counter()通常是 Python 计时器的最佳选择。
用timeit 估算运行时间
假设您试图从代码中挤出最后一点性能,并且您想知道将列表转换为集合的最有效方法。您希望使用set()和设置的文字{...}进行比较。为此,您可以使用 Python 计时器:
>>> from timer import Timer >>> numbers = [7, 6, 1, 4, 1, 8, 0, 6] >>> with Timer(text="{:.8f}"): ... set(numbers) ... {0, 1, 4, 6, 7, 8} 0.00007373 >>> with Timer(text="{:.8f}"): ... {*numbers} ... {0, 1, 4, 6, 7, 8} 0.00006204这个测试似乎表明 set literal 可能会稍微快一些。然而,这些结果是相当不确定的,如果您重新运行代码,您可能会得到非常不同的结果。那是因为你只试了一次代码。例如,您可能很不走运,在您的计算机正忙于其他任务时运行该脚本。
更好的方法是使用
timeit标准库。它旨在精确测量小代码片段的执行时间。虽然您可以作为常规函数从 Python 导入和调用timeit.timeit(),但是使用命令行接口通常更方便。您可以对两个变量计时,如下所示:$ python -m timeit --setup "nums = [7, 6, 1, 4, 1, 8, 0, 6]" "set(nums)" 2000000 loops, best of 5: 163 nsec per loop $ python -m timeit --setup "nums = [7, 6, 1, 4, 1, 8, 0, 6]" "{*nums}" 2000000 loops, best of 5: 121 nsec per loop
timeit多次自动调用您的代码,以消除噪声测量。来自timeit的结果证实了 set literal 比set()快。注意:在可以下载文件或访问数据库的代码上使用
timeit时要小心。由于timeit会自动调用你的程序几次,你可能会无意中向服务器发送垃圾请求!最后, IPython 交互外壳和 Jupyter 笔记本通过
%timeit魔法命令对此功能提供了额外的支持:
In [1]: numbers = [7, 6, 1, 4, 1, 8, 0, 6]
In [2]: %timeit set(numbers)
171 ns ± 0.748 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
In [3]: %timeit {*numbers}
147 ns ± 2.62 ns per loop (mean ± std. dev. of 7 runs, 10000000 loops each)
同样,测量表明使用 set 文字更快。在 Jupyter 笔记本中,您还可以使用%%timeit cell-magic 来测量运行整个电池的时间。
用评测器寻找代码中的瓶颈
timeit非常适合对特定的代码片段进行基准测试。然而,用它来检查程序的所有部分并定位哪个部分花费的时间最多是非常麻烦的。相反,你可以使用一个分析器。
cProfile 是一个可以随时从标准库中访问的剖析器。您可以通过多种方式使用它,尽管通常最直接的方式是将其用作命令行工具:
$ python -m cProfile -o latest_tutorial.prof latest_tutorial.py
该命令在剖析打开的情况下运行latest_tutorial.py。按照-o选项的指定,将cProfile的输出保存在latest_tutorial.prof中。输出数据是二进制格式,需要专门的程序来理解它。同样,Python 在标准库中有一个选项!在您的.prof文件上运行 pstats 模块会打开一个交互式概要统计浏览器:
$ python -m pstats latest_tutorial.prof
Welcome to the profile statistics browser.
latest_tutorial.prof% help
Documented commands (type help <topic>):
========================================
EOF add callees callers help quit read reverse sort stats strip
要使用pstats,您可以在提示符下键入命令。这里您可以看到集成的帮助系统。通常你会使用sort和stats命令。要获得更清晰的输出,strip可能很有用:
latest_tutorial.prof% strip latest_tutorial.prof% sort cumtime latest_tutorial.prof% stats 10
1393801 function calls (1389027 primitive calls) in 0.586 seconds
Ordered by: cumulative time
List reduced from 1443 to 10 due to restriction <10>
ncalls tottime percall cumtime percall filename:lineno(function)
144/1 0.001 0.000 0.586 0.586 {built-in method builtins.exec}
1 0.000 0.000 0.586 0.586 latest_tutorial.py:3(<module>)
1 0.000 0.000 0.521 0.521 contextlib.py:71(inner)
1 0.000 0.000 0.521 0.521 latest_tutorial.py:6(read_latest_tutorial)
1 0.000 0.000 0.521 0.521 feed.py:28(get_article)
1 0.000 0.000 0.469 0.469 feed.py:15(_feed)
1 0.000 0.000 0.469 0.469 feedparser.py:3817(parse)
1 0.000 0.000 0.271 0.271 expatreader.py:103(parse)
1 0.000 0.000 0.271 0.271 xmlreader.py:115(parse)
13 0.000 0.000 0.270 0.021 expatreader.py:206(feed)
该输出显示总运行时间为 0.586 秒。它还列出了代码花费时间最多的十个函数。这里你已经按累计时间(cumtime)排序,这意味着当给定的函数调用另一个函数时,你的代码计算时间。
您可以看到您的代码几乎所有的时间都花在了latest_tutorial模块中,尤其是在read_latest_tutorial()中。虽然这可能是对您已经知道的东西的有用确认,但是发现您的代码实际花费时间的地方通常更有意思。
总时间(tottime)列表示代码在一个函数中花费的时间,不包括在子函数中的时间。您可以看到,上面的函数都没有真正花时间来做这件事。为了找到代码花费时间最多的地方,发出另一个sort命令:
latest_tutorial.prof% sort tottime latest_tutorial.prof% stats 10
1393801 function calls (1389027 primitive calls) in 0.586 seconds
Ordered by: internal time
List reduced from 1443 to 10 due to restriction <10>
ncalls tottime percall cumtime percall filename:lineno(function)
59 0.091 0.002 0.091 0.002 {method 'read' of '_ssl._SSLSocket'}
114215 0.070 0.000 0.099 0.000 feedparser.py:308(__getitem__)
113341 0.046 0.000 0.173 0.000 feedparser.py:756(handle_data)
1 0.033 0.033 0.033 0.033 {method 'do_handshake' of '_ssl._SSLSocket'}
1 0.029 0.029 0.029 0.029 {method 'connect' of '_socket.socket'}
13 0.026 0.002 0.270 0.021 {method 'Parse' of 'pyexpat.xmlparser'}
113806 0.024 0.000 0.123 0.000 feedparser.py:373(get)
3455 0.023 0.000 0.024 0.000 {method 'sub' of 're.Pattern'}
113341 0.019 0.000 0.193 0.000 feedparser.py:2033(characters)
236 0.017 0.000 0.017 0.000 {method 'translate' of 'str'}
你现在可以看到,latest_tutorial.py实际上大部分时间都在使用套接字或者处理 feedparser 内部的数据。后者是用于解析教程提要的真正 Python 阅读器的依赖项之一。
您可以使用pstats来了解您的代码在哪里花费了大部分时间,然后尝试优化您发现的任何瓶颈。您还可以使用该工具来更好地理解代码的结构。例如,命令callees和callers将显示给定的函数调用了哪些函数,以及哪些函数被调用了。
您还可以研究某些功能。通过使用短语timer过滤结果,检查Timer导致了多少开销:
latest_tutorial.prof% stats timer
1393801 function calls (1389027 primitive calls) in 0.586 seconds
Ordered by: internal time
List reduced from 1443 to 8 due to restriction <'timer'>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.000 0.000 timer.py:13(Timer)
1 0.000 0.000 0.000 0.000 timer.py:35(stop)
1 0.000 0.000 0.003 0.003 timer.py:3(<module>)
1 0.000 0.000 0.000 0.000 timer.py:28(start)
1 0.000 0.000 0.000 0.000 timer.py:9(TimerError)
1 0.000 0.000 0.000 0.000 timer.py:23(__post_init__)
1 0.000 0.000 0.000 0.000 timer.py:57(__exit__)
1 0.000 0.000 0.000 0.000 timer.py:52(__enter__)
幸运的是,Timer只会产生最小的开销。完成调查后,使用quit离开pstats浏览器。
对于一个更强大的界面到配置文件数据,检查出 KCacheGrind 。它使用自己的数据格式,但是您可以使用 pyprof2calltree 转换来自cProfile的数据:
$ pyprof2calltree -k -i latest_tutorial.prof
该命令将转换latest_tutorial.prof并打开 KCacheGrind 来分析数据。
最后一个选项是 line_profiler 。cProfile可以告诉你你的代码在哪个函数中花费的时间最多,但是它不能让你知道在那个函数中哪个行是最慢的。这就是line_profiler可以帮助你的地方。
注意:您还可以分析代码的内存消耗。这超出了本教程的范围。但是,如果您需要监控程序的内存消耗,您可以查看 memory-profiler 。
请注意,行分析需要时间,并且会给运行时增加相当多的开销。正常的工作流程是首先使用cProfile来确定要调查哪些函数,然后对这些函数运行line_profiler。line_profiler不是标准库的一部分,所以你应该首先按照安装说明来设置它。
在运行分析器之前,您需要告诉它要分析哪些函数。您可以通过在源代码中添加一个@profile装饰器来做到这一点。例如,为了对Timer.stop()进行概要分析,您可以在timer.py中添加以下内容:
@profile def stop(self) -> float:
# The rest of the code is unchanged
请注意,您没有在任何地方导入profile。相反,当您运行探查器时,它会自动添加到全局命名空间中。不过,在完成分析后,您需要删除这一行。否则你会得到一个NameError。
接下来,使用kernprof运行分析器,它是line_profiler包的一部分:
$ kernprof -l latest_tutorial.py
该命令自动将 profiler 数据保存在一个名为latest_tutorial.py.lprof的文件中。您可以使用line_profiler查看这些结果:
$ python -m line_profiler latest_tutorial.py.lprof
Timer unit: 1e-06 s
Total time: 1.6e-05 s
File: /home/realpython/timer.py
Function: stop at line 35
# Hits Time PrHit %Time Line Contents
=====================================
35 @profile
36 def stop(self) -> float:
37 """Stop the timer, and report the elapsed time"""
38 1 1.0 1.0 6.2 if self._start_time is None:
39 raise TimerError(f"Timer is not running. ...")
40
41 # Calculate elapsed time
42 1 2.0 2.0 12.5 elapsed_time = time.perf_counter() - self._start_time
43 1 0.0 0.0 0.0 self._start_time = None
44
45 # Report elapsed time
46 1 0.0 0.0 0.0 if self.logger:
47 1 11.0 11.0 68.8 self.logger(self.text.format(elapsed_time))
48 1 1.0 1.0 6.2 if self.name:
49 1 1.0 1.0 6.2 self.timers[self.name] += elapsed_time
50
51 1 0.0 0.0 0.0 return elapsed_time
首先,注意这个报告中的时间单位是微秒(1e-06 s)。通常,最容易查看的数字是%Time,它告诉您代码在每一行中花费在函数中的时间占总时间的百分比。在这个例子中,您可以看到您的代码在第 47 行花费了几乎 70%的时间,这是格式化和打印计时器结果的行。
结论
在本教程中,您已经尝试了几种不同的方法来将 Python 计时器添加到代码中:
-
您使用了一个类来保存状态并添加一个用户友好的界面。类非常灵活,直接使用
Timer可以完全控制如何以及何时调用计时器。 -
您使用了一个上下文管理器来为代码块添加特性,并且如果必要的话,在之后进行清理。上下文管理器使用起来很简单,添加
with Timer()可以帮助你在视觉上更清楚地区分你的代码。 -
您使用了一个装饰器来为函数添加行为。Decorators 简洁而引人注目,使用
@Timer()是监控代码运行时的一种快捷方式。
您还了解了在对代码进行基准测试时为什么应该选择time.perf_counter()而不是time.time(),以及在优化代码时有哪些其他选择。
现在您可以在自己的代码中添加 Python 计时器函数了!在日志中记录程序运行的速度有助于监控脚本。对于类、上下文管理器和装饰器一起很好地发挥作用的其他用例,你有什么想法吗?在下面留下评论吧!
资源
要更深入地了解 Python 计时器函数,请查看以下资源:
codetiming是 PyPI 上可用的 Python 定时器。time.perf_counter()是用于精确计时的性能计数器。timeit是一个比较代码片段运行时的工具。cProfile是一个在脚本和程序中寻找瓶颈的剖析器。pstats是一个查看分析器数据的命令行工具。- KCachegrind 是查看 profiler 数据的 GUI。
line_profiler是一个用于测量单独代码行的分析器。memory-profiler是一个用于监控内存使用情况的分析器。************
Python 和 TOML:新的好朋友
原文:# t0]https://realython . com/python-toml/
TOML——Tom 显而易见的最小语言——是一种相当新的配置文件格式,Python 社区在过去几年里已经接受了这种格式。TOML 在 Python 生态系统中扮演着重要的角色。许多您喜欢的工具依赖于 TOML 进行配置,当您构建和发布自己的包时,您将使用pyproject.toml。
在本教程中,你会学到更多关于 TOML 的知识以及如何使用它。特别是,您将:
- 学习并理解 TOML 的语法
- 使用
tomli和tomllib来解析 TOML 文档 - 使用
tomli_w到将数据结构写成 TOML - 当你需要对你的 TOML 文件有更多的控制时,使用
tomlkit
在 Python 3.11 中,一个新的 TOML 解析模块被添加到 Python 的标准库中。稍后在本教程中,你将学习如何使用这个新模块。如果你想了解更多关于tomllib为什么被加入 Python 的信息,那么看看配套教程, Python 3.11 预览:TOML 和tomllibT5。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
使用 TOML 作为配置格式
TOML 是汤姆的显而易见的最小语言的缩写,并以它的创造者汤姆·普雷斯顿-沃纳的名字谦逊地命名。它被明确设计成一种配置文件格式,应该“易于解析成各种语言的数据结构”(来源)。
在这一节中,您将开始考虑配置文件,并看看 TOML 带来了什么。
配置和配置文件
配置几乎是任何应用程序或系统的重要组成部分。它允许你在不改变源代码的情况下改变设置或行为。有时,您将使用配置来指定连接到另一个服务(如数据库或云存储)所需的信息。其他时候,您将使用配置设置来允许用户自定他们对项目的体验。
为您的项目使用一个配置文件是将您的代码与其设置分开的一个好方法。它还鼓励您意识到系统的哪些部分是真正可配置的,为您提供了一个在源代码中命名神奇值的工具。现在,考虑一个假想的井字游戏的配置文件:
player_x_color = blue player_o_color = green board_size = 3 server_url = https://tictactoe.example.com/
您可以直接在源代码中编写这种代码。但是,通过将设置移动到一个单独的文件中,您可以实现一些目标:
- 你给值一个明确的名字。
- 你提供这些值更多的可见性。
- 你使得改变这些值变得更简单。
更仔细地看看您假设的配置文件。这些值在概念上是不同的。颜色是您的框架可能支持更改的值。换句话说,如果您将blue替换为red,那么在代码中不会有任何特殊处理。您甚至可以考虑是否值得通过您的前端向您的最终用户公开此配置。
然而,电路板尺寸可以配置,也可以不配置。井字游戏是在一个三乘三的格子上玩的。不确定你的逻辑是否还适用于其他尺寸的电路板。将该值保存在配置文件中仍然是有意义的,这既是为了给该值命名,也是为了使其可见。
最后,在部署应用程序时,项目 URL 通常是必不可少的。这不是一个普通用户会改变的事情,但是一个超级用户可能想把你的游戏重新部署到一个不同的服务器上。
为了更清楚地了解这些不同的用例,您可能希望在您的配置中添加一些组织。一种流行的选择是将您的配置分成附加文件,每个文件处理不同的问题。另一个选择是以某种方式对配置值进行分组。例如,您可以按如下方式组织假设的配置文件:
[user] player_x_color = blue player_o_color = green [constant] board_size = 3 [server] url = https://tictactoe.example.com
文件的组织使得每个配置项的角色更加清晰。您还可以向配置文件添加注释,并向任何想对其进行更改的人提供说明。
注意:配置文件的实际格式对于这个讨论并不重要。上述原则与您如何指定配置值无关。碰巧的是,到目前为止你看到的例子都可以被 Python 的 ConfigParser 类解析。
您可以通过多种方式来指定配置。Windows 传统上使用 INI 文件,它类似于上面的配置文件。Unix 系统也依赖于纯文本、人类可读的配置文件,尽管不同服务之间的实际格式有所不同。
随着时间的推移,越来越多的应用程序开始使用定义良好的格式,如 XML 、 JSON 或 YAML 来满足它们的配置需求。这些格式被设计成数据交换或串行化格式,通常用于计算机通信。
另一方面,配置文件通常是由人编写或编辑的。许多开发人员在更新他们的 Visual Studio 代码设置时对 JSON 严格的逗号规则感到失望,或者在建立云服务时对 YAML 的嵌套缩进感到失望。尽管它们无处不在,但这些文件格式并不是最容易手写的。
汤姆:汤姆明显的最小语言
TOML 是一种相当新的格式。第一个格式规范版本 0.1.0 于 2013 年发布。从一开始,它就专注于成为人类可读的最小配置文件格式。根据 TOML 的网页,TOML 的目标如下:
TOML 的目标是成为一种最小化的配置文件格式,由于明显的语义,这种格式易于阅读。TOML 被设计成明确地将映射到散列表。TOML 应该容易解析成各种语言的数据结构。(来源,重点添加)
当您阅读本教程时,您将会看到 TOML 是如何达到这些目标的。不过,很明显,TOML 在其短暂的生命周期中变得非常流行。越来越多的 Python 工具,包括 Black 、 pytest 、 mypy 和 isort ,都使用 TOML 进行配置。对于大多数流行的编程语言来说,TOML 解析器是可用的。
回忆一下上一小节中的配置。用 TOML 表达它的一种方法如下:
[user] player_x.color = "blue" player_o.color = "green" [constant] board_size = 3 [server] url = "https://tictactoe.example.com"
在下一节的中,您将了解更多关于 TOML 格式的细节。现在,试着自己阅读和解析这些信息。注意,和早前没太大区别。最大的变化是在一些值中添加了引号(")。
TOML 的语法受到传统配置文件的启发。与 Windows INI 文件和 Unix 配置文件相比,它的一个主要优势是 TOML 有一个规范,它精确地说明了 TOML 文档中允许的内容以及不同的值应该如何解释。规范在 2021 年初达到 1.0.0 版本后稳定成熟。
相比之下,INI 格式没有正式的规范。相反,有许多变体和方言,其中大部分是由一个实现定义的。Python 附带了对标准库中读取 INI 文件的支持。虽然ConfigParser相当宽松,但它并不支持所有类型的 INI 文件。
TOML 和许多传统格式的另一个区别是 TOML 值有类型。在上面的例子中,"blue"被解释为一个字符串,而3是一个数字。对 TOML 的一个潜在的批评是,编写 TOML 的人需要知道类型。在更简单的格式中,这个责任在于程序员解析配置。
TOML 不是像 JSON 或 YAML 那样的数据序列化格式。换句话说,您不应该试图将一般数据存储在 TOML 中以便以后恢复。TOML 在几个方面有限制:
- 所有键都被解释为字符串。你不能轻易使用,比如说,一个数字作为密钥。
- TOML 没有空类型。
- 一些空白很重要,这会降低压缩 TOML 文档大小的效率。
即使 TOML 是一把好锤子,但并不是所有的数据文件都是钉子。您应该主要使用 TOML 进行配置。
TOML 模式验证
在下一节中,您将更深入地研究 TOML 语法。在那里,您将了解一些 TOML 文件的语法要求。然而,在实践中,给定的 TOML 文件也可能带有一些非语法要求。
这些是模式需求。例如,您的井字游戏应用程序可能要求配置文件包含服务器 URL。另一方面,播放器颜色可以是可选的,因为应用程序定义了默认颜色。
目前,TOML 不包括一种可以在 TOML 文档中指定必填和可选字段的模式语言。有几个提议存在,尽管还不清楚它们中的任何一个是否会很快被接受。
在简单的应用程序中,您可以手动验证 TOML 配置。比如可以使用结构模式匹配,这是在 Python 3.10 中引入的。假设您已经将配置解析成 Python,并将其命名为config。然后,您可以按如下方式检查其结构:
match config:
case {
"user": {"player_x": {"color": str()}, "player_o": {"color": str()}}, "constant": {"board_size": int()}, "server": {"url": str()}, }:
pass
case _:
raise ValueError(f"invalid configuration: {config}")
第一个case语句详细说明了您期望的结构。如果config匹配,那么你使用 pass 继续你的代码。否则,您会引发一个错误。
如果您的 TOML 文档更复杂,这种方法可能不太适用。如果想提供好的错误消息,还需要做更多的工作。更好的替代方法是使用 pydantic ,它利用类型注释在运行时进行数据验证。pydantic 的一个优点是它内置了精确而有用的错误消息。
还有一些工具可以利用针对 JSON 等格式的现有模式验证。例如, Taplo 是一个 TOML 工具包,可以根据 JSON 模式验证 TOML 文档。Taplo 也可用于 Visual Studio 代码,捆绑到更好的 TOML 扩展中。
在本教程的其余部分中,您不必担心模式验证。相反,您将更加熟悉 TOML 语法,并了解您可以使用的所有不同的数据类型。稍后,您将看到如何在 Python 中与 TOML 交互的示例,并且您将探索 TOML 非常适合的一些用例。
了解 TOML:键值对
TOML 是围绕键值对构建的,这些键值对可以很好地映射到哈希表数据结构。TOML 值有不同的类型。每个值必须具有以下类型之一:
此外,您可以使用表和表数组作为组织几个键值对的集合。在本节的剩余部分,您将了解到更多关于所有这些的内容,以及如何在 TOML 中指定它们。
注意: TOML 支持与 Python 相同语法的注释。散列符号(#)将该行的其余部分标记为注释。使用注释可以使您的配置文件更容易理解,便于您和您的用户使用。
在本教程中,您将看到 TOML 的所有不同元素。然而,一些细节和边缘情况将被掩盖。如果你对细则感兴趣,请查阅文档。
如前所述,键值对是 TOML 文档中的基本构件。您用一个<key> = <value>语法指定它们,其中键用等号与值分开。以下是具有一个键值对的有效 TOML 文档:
greeting = "Hello, TOML!"
在这个例子中,greeting是键,而"Hello, TOML!"是值。值有类型。在本例中,该值是一个文本字符串。您将在下面的小节中了解不同的值类型。
键总是被解释为字符串,即使引号没有将它们括起来。考虑下面的例子:
greeting = "Hello, TOML!" 42 = "Life, the universe, and everything"
这里,42是一个有效的键,但是它被解释为一个字符串,而不是一个数字。通常,你要使用光杆键。这些密钥仅由 ASCII 字母和数字以及下划线和破折号组成。所有这样的键都可以不用引号,就像上面的例子一样。
TOML 文档必须用 UTF-8 Unicode 编码。这让你在表达自己的价值观时有很大的灵活性。尽管对空键有限制,但是在拼写键时也可以使用 Unicode。然而,这是有代价的。要使用 Unicode 键,必须在它们周围加上引号:
"realpython.com" = "Real Python" "blåbærsyltetøy" = "blueberry jam" "Tom Preston-Werner" = "creator"
所有这些键都包含裸键中不允许的字符:点(.)、挪威语字符(å、æ和ø)和一个空格。您可以在任何键周围使用引号,但是一般来说,您希望坚持使用不使用或不需要引号的简单键。
点(.)在 TOML 键中起着特殊的作用。您可以在未加引号的键中使用点,但在这种情况下,它们会通过在每个点处拆分带点的键来触发分组。考虑下面的例子:
player_x.symbol = "X" player_x.color = "purple"
这里,您指定了两个点键。因为它们都以player_x开始,所以键symbol和color将被组合在一个名为player_x的部分中。当你开始探索表时,你会学到更多关于点键的知识。
接下来,把注意力转向价值观。在下一节中,您将了解 TOML 中最基本的数据类型。
字符串、数字和布尔值
TOML 对基本数据类型使用熟悉的语法。从 Python 中,您可以识别字符串、整数、浮点数和布尔值:
string = "Text with quotes" integer = 42 float = 3.11 boolean = true
TOML 和 Python 最直接的区别就是 TOML 的布尔值是小写的:true和false。
一个 TOML 字符串通常应该使用双引号(")。在字符串内部,可以借助反斜杠对特殊字符进行转义:"\u03c0 is less than four"。这里,\u03c0表示带有 codepoint U+03c0 的 Unicode 字符,恰好是希腊字母π。该字符串将被解释为"π is less than four"。
还可以使用单引号(')指定 TOML 字符串。单引号字符串被称为文字字符串,其行为类似于 Python 中的原始字符串。在文字字符串中没有任何东西被转义和解释,所以'\u03c0 is the Unicode codepoint of π'从文字\u03c0字符开始。
最后,还可以使用三重引号 ( """或''')来指定 TOML 字符串。三重引号字符串允许您在多行上编写一个字符串,类似于 Python 多行字符串:
partly_zen = """
Flat is better than nested.
Sparse is better than dense.
"""
基本字符串中不允许出现控制字符,包括文字换行符。不过,您可以使用\n来表示基本字符串中的换行符。如果要将字符串格式化为多行,必须使用多行字符串。您也可以使用三重引号文字字符串。除了多行之外,这是在文字字符串中包含单引号的唯一方法:'''Use '\u03c0' to represent π'''。
注意:在 Python 代码中创建 TOML 文档时要小心特殊字符,因为 Python 也会解释这些特殊字符。例如,下面是一个有效的 TOML 文档:
numbers = "one\ntwo\nthree"
在这里,numbers的值是一个分成三行的字符串。您可以尝试用 Python 表示同一个文档,如下所示:
>>> 'numbers = "one\ntwo\nthree"' 'numbers = "one\ntwo\nthree"'这是行不通的,因为 Python 解析了
\n字符并创建了一个无效的 TOML 文档。您需要让特殊字符远离 Python,例如使用原始字符串:
>>> r'numbers = "one\ntwo\nthree"'
'numbers = "one\\ntwo\\nthree"'
该字符串表示与原始文档相同的 TOML 文档。
TOML 中的数字要么是整数,要么是浮点数。整数代表整数,被指定为普通的数字字符。与 Python 中一样,您可以使用下划线来增强可读性:
number = 42 negative = -8 large = 60_481_729
浮点数代表十进制数,包括整数部分、代表小数点的点和小数部分。浮点数可以使用科学记数法来表示非常小或非常大的数字。TOML 还支持特殊的浮点值,比如无穷大和非数字(NaN) :
number = 3.11 googol = 1e100 mole = 6.22e23 negative_infinity = -inf not_a_number = nan
注意,TOML 规范要求整数至少要表示为 64 位有符号整数。Python 处理任意大的整数,但是只有大约 19 位数的整数才能保证在所有的 TOML 实现中工作。
注意: TOML 是一种配置文件格式,不是编程语言。不支持类似1 + 2的表达式,只支持文字数字。
非负整数值也可以分别用前缀0x、0o或0b表示为十六进制、八进制或二进制值。例如,0xffff00是十六进制表示,0b00101010是二进制表示。
布尔值表示为true和false。这些必须是小写的。
TOML 还包括几种时间和日期类型。但是,在探索这些之前,您将看到如何使用表来组织和结构化您的键值对。
表格
您已经了解了 TOML 文档由一个或多个键值对组成。当用编程语言表示时,这些应该存储在一个散列表数据结构中。在 Python 中,这将是一个字典或另一个类似于字典的数据结构。为了组织键值对,可以使用表。
TOML 支持三种不同的指定表格的方式。您将很快看到这些例子。最终结果将是相同的,与您如何表示您的表无关。尽管如此,不同的表确实有稍微不同的用例:
- 在大多数情况下,使用带有标题的常规表。
- 当您需要指定一些与其父表紧密相关的键值对时,使用点状键表。
- 将内联表仅用于最多有三个键值对的非常小的表,其中的数据构成了一个明确定义的实体。
不同的表格表示通常是可以互换的。您应该默认使用常规表,只有当您认为这样可以提高配置的可读性或阐明您的意图时,才切换到点键表或内联表。
这些不同的表格类型在实践中看起来如何?从普通桌子开始。它们是通过在键值对上方添加一个表头来定义的。头是一个没有值的键,用方括号([])括起来。您之前遇到的以下示例定义了三个表:
[user] player_x.color = "blue" player_o.color = "green" [constant] board_size = 3 [server] url = "https://tictactoe.example.com"
突出显示的三行是表格标题。它们指定了三个表,分别命名为user、constant和server。表的内容或值是列在标题下面和下一个标题上面的所有键值对。例如,constant和server各包含一个嵌套的键值对。
你也可以在上面的配置中找到虚线键表。在user中,您有以下内容:
[user] player_x.color = "blue" player_o.color = "green"
键中的句点或点(.)创建一个由点之前的键部分命名的表。您也可以通过嵌套常规表来表示配置的相同部分:
[user] [user.player_x] color = "blue" [user.player_o] color = "green"
缩进在 TOML 中并不重要。这里用它来表示表格的嵌套。您可以看到,user表包含两个子表,player_x和player_o。每个子表都包含一个键值对。
注意:你可以任意深度的嵌套 TOML 表。例如,player.x.color.name这样的键或表头表示color表中的name和player表中的x。
请注意,您需要在嵌套表的标题中使用点键,并命名所有中间表。这使得 TOML 头规范相当冗长。例如,在 JSON 或 YAML 的类似规范中,您只需指定子表的名称,而不必重复外部表的名称。同时,这使得 TOML 非常显式,在深度嵌套的结构中更难迷失方向。
现在,您将在user桌面上扩展一点,为每个玩家添加一个标签或符号。您将用三种不同的形式来表示这个表,首先只使用常规表,然后使用点键表,最后使用内联表。您还没有看到后者,所以这将是对内联表以及如何表示它们的介绍。
从嵌套的常规表格开始:
[user] [user.player_x] symbol = "X" color = "blue" [user.player_o] symbol = "O" color = "green"
这种表示非常清楚地表明,你有两个不同的球员表。您不需要显式定义只包含子表而不包含任何常规键的表。在前面的例子中,您可以删除线[user]。
将嵌套表与点键配置进行比较:
[user] player_x.symbol = "X" player_x.color = "blue" player_o.symbol = "O" player_o.color = "green"
这比上面的嵌套表更短更简洁。然而,结构现在不太清楚了,在您意识到在user中嵌套了两个玩家表之前,您需要花费一些精力来解析这些键。当您有几个嵌套表,每个表有一个键时,点键表会更有用,就像前面的例子中只有color个子键一样。
接下来,您将使用内联表格来表示user:
[user] player_x = { symbol = "X", color = "blue" } player_o = { symbol = "O", color = "green" }
内联表是用花括号({})定义的,用逗号分隔的键值对。在这个例子中,内联表带来了可读性和紧凑性的良好平衡,因为玩家表的分组变得清晰。
不过,您应该谨慎地使用内联表,主要是在这种情况下,一个表代表一个小型的、定义良好的实体,比如一个播放器。与常规表格相比,内联表格被有意地限制。特别是,内联表必须写在 TOML 文件中的一行上,并且不能使用像结尾逗号这样的便利。
在结束 TOML 中的表之旅之前,您将简要地看一下几个小问题。一般来说,您可以按任何顺序定义您的表,并且您应该努力以一种对您的用户有意义的方式来排列您的配置。
TOML 文档由一个包含所有其他表和键值对的无名根表表示。您在 TOML 配置的顶部,在任何表头之前编写的键-值对直接存储在根表中:
title = "Tic-Tac-Toe" [constant] board_size = 3
在这个例子中,title是根表中的一个键,constant是嵌套在根表中的一个表,board_size是constant表中的一个键。
请注意,一个表包括所有写在它的表头和下一个表头之间的键值对。实际上,这意味着您必须在属于该表的键值对下定义嵌套子表。考虑这份文件:
[user] [user.player_x] color = "blue" [user.player_o] color = "green" background_color = "white"
缩进表明background_color应该是user表中的一个键。但是,TOML 忽略缩进,只检查表头。在这个例子中,background_color是user.player_o表的一部分。要纠正这一点,background_color应该在嵌套表之前定义:
[user] background_color = "white" [user.player_x] color = "blue" [user.player_o] color = "green"
在这种情况下,background_color是user中的一个键。如果你使用点键表,那么你可以更自由地使用任何顺序的键:
[user] player_x.color = "blue" player_o.color = "green" background_color = "white"
现在除了[user]之外没有显式的表头,所以background_color将是user表中的一个键。
您已经了解了 TOML 中的基本数据类型,以及如何使用表来组织数据。在接下来的小节中,您将看到可以在 TOML 文档中使用的最终数据类型。
时间和日期
TOML 支持直接在文档中定义时间和日期。您可以在四种不同的表示法之间进行选择,每种表示法都有其特定的用例:
- 偏移日期时间是一个带有时区信息的时间戳,代表特定的时刻。
- 本地日期时间是没有时区信息的时间戳。
- 本地日期是没有任何时区信息的日期。你通常用它来代表一整天。
- 本地时间是具有任何日期或时区信息的时间。您使用本地时间来表示一天中的某个时间。
TOML 基于 RFC 3339 来表示时间和日期。本文档定义了一种时间和日期格式,通常用于表示互联网上的时间戳。一个完整定义的时间戳应该是这样的:2021-01-12T01:23:45.654321+01:00。时间戳由几个字段组成,由不同的分隔符分隔:
| 田 | 例子 | 细节 |
|---|---|---|
| 年 | 2021 |
|
| 月 | 01 |
从01(1 月)到12(12 月)的两位数 |
| 一天 | 12 |
两位数,十位以下用零填充 |
| 小时 | 01 |
从00到23的两位数 |
| 分钟 | 23 |
从00到59的两位数 |
| 第二 | 45 |
从00到59的两位数 |
| 微秒 | 654321 |
从000000到999999的六位数字 |
| 抵消 | +01:00 |
时区相对于 UTC 的偏移量,Z代表 UTC |
偏移日期时间是包含偏移信息的时间戳。本地日期时间是不包括这个的时间戳。本地时间戳也称为简单时间戳。
在 TOML 中,微秒字段对于所有日期时间和时间类型都是可选的。您还可以用空格替换分隔日期和时间的T。在这里,您可以看到每种时间戳相关类型的示例:
offset_date-time = 2021-01-12 01:23:45+01:00 offset_date-time_utc = 2021-01-12 00:23:45Z local_date-time = 2021-01-12 01:23:45 local_date = 2021-01-12 local_time = 01:23:45 local_time_with_us = 01:23:45.654321
注意,不能用引号将时间戳值括起来,因为这会将它们转换成文本字符串。
这些不同的时间和日期类型为您提供了相当大的灵活性。如果您有这些没有涵盖的用例—例如,如果您想要指定一个像1 day这样的时间间隔—那么您可以使用字符串并使用您的应用程序来正确地处理它们。
TOML 支持的最后一种数据类型是数组。这些允许您在一个列表中组合其他几个值。请继续阅读,了解更多信息。
数组
TOML 数组表示一个有序的值列表。您使用方括号([])来指定它们,以便它们类似于 Python 的列表:
packages = ["tomllib", "tomli", "tomli_w", "tomlkit"]
在这个例子中,packages的值是一个包含四个字符串元素的数组:"tomllib"、"tomli"、"tomli_w"和"tomlkit"。
注:你会学到更多关于 tomllib , tomli , tomli_w , tomlkit 的知识,以及它们在 Python 的 TOML 版图中所扮演的角色,在本教程后面的的实际章节中。
您可以在数组中使用任何 TOML 数据类型,包括其他数组,并且一个数组可以包含不同的数据类型。您可以在几行中指定一个数组,并且可以在数组的最后一个元素后使用尾随逗号。以下所有示例都是有效的 TOML 数组:
potpourri = ["flower", 1749, { symbol = "X", color = "blue" }, 1994-02-14] skiers = ["Thomas", "Bjørn", "Mika"] players = [ { symbol = "X", color = "blue", ai = true }, { symbol = "O", color = "green", ai = false }, ]
这定义了三个数组。potpourri是包含四个不同数据类型元素的数组,而skiers是包含三个字符串的数组。最后一个数组players修改了前面的例子,将两个内联表格表示为一个数组中的元素。注意players是在四行中定义的,在最后一个行内表格后面有一个可选的逗号。
最后一个例子展示了创建表格数组的一种方法。您可以将内联表格放在方括号内。但是,正如您之前看到的,内联表的伸缩性不好。如果您想要表示一个表的数组,其中的表比较大,那么您应该使用不同的语法。
一般来说,您应该通过在双方括号([[]])内编写表格标题来表达表格的数组。语法不一定漂亮,但相当有效。您可以用下面的例子来表示players:
[[players]] symbol = "X" color = "blue" ai = true [[players]] symbol = "O" color = "green" ai = false
这个表格数组相当于您上面编写的内联表格数组。双方括号定义了一个表格数组,而不是一个常规的表格。您需要为数组中的每个嵌套表重复数组名称。
作为一个更广泛的例子,考虑下面的 TOML 文档摘录,该文档列出了一个测验应用程序的问题:
[python] label = "Python" [[python.questions]] question = "Which built-in function can get information from the user" answers = ["input"] alternatives = ["get", "print", "write"] [[python.questions]] question = "What's the purpose of the built-in zip() function" answers = ["To iterate over two or more sequences at the same time"] alternatives = [ "To combine several strings into one", "To compress several files into one archive", "To get information from the user", ]
在这个例子中,python表有两个键,label和questions。questions的值是一个包含两个元素的表格数组。每个元素是一个带有三个键的表格:question、answers和alternatives。
您现在已经看到了 TOML 必须提供的所有数据类型。除了简单的数据类型,如字符串、数字、布尔值、时间和日期,您还可以用表和数组来组合和组织您的键和值。在这篇概述中,您忽略了一些细节和边缘情况。你可以在 TOML 规范中了解所有细节。
在接下来的章节中,当您学习如何在 Python 中使用 TOML 时,您会变得更加实际。您将了解如何读写 TOML 文档,并探索如何组织您的应用程序来有效地使用配置文件。
用 Python 加载 TOML】
是时候把手弄脏了。在本节中,您将启动 Python 解释器并将 TOML 文档加载到 Python 中。您已经看到了 TOML 格式的主要用例是配置文件。这些通常是手工编写的,因此在这一节中,您将了解如何使用 Python 读取这样的配置文件,并在您的项目中使用它们。
用tomli和tomllib 读取 TOML 文件
自从 TOML 规范在 2013 年首次出现以来,已经有几个包可以使用这种格式。随着时间的推移,这些包中的一些变得不可维护。一些曾经流行的库不再兼容最新版本的 TOML。
在本节中,您将使用一个相对较新的包,名为 tomli 及其兄弟包 tomllib 。当您只想将一个 TOML 文档加载到 Python 中时,这些是很好的库。在以后的章节中,您还将探索tomlkit。该包为桌面带来了更高级的功能,并为您开辟了一些新的使用案例。
注意:在 Python 3.11 中,TOML 支持被添加到 Python 标准库中。新的tomllib模块可以帮助你读取和解析 TOML 文档。关于添加库的动机和原因详见 Python 3.11 预览版:TOML 和tomllib 。
这个新的tomllib模块实际上是通过将现有的tomli库复制到 CPython 代码库中而创建的。这样做的结果是,你可以在 Python 版本 3.7 、 3.8 、 3.9 和 3.10 上使用tomli作为兼容的后端口。
按照下面的说明,你将学会如何使用tomli。如果你使用的是 Python 3.11,那么你可以跳过tomli的安装,用tomllib替换任何提到tomli的代码。
是时候探索如何读取 TOML 文件了。首先创建以下 TOML 文件,并将其另存为tic_tac_toe.toml:
# tic_tac_toe.toml [user] player_x.color = "blue" player_o.color = "green" [constant] board_size = 3 [server] url = "https://tictactoe.example.com"
这与您在上一节中使用的配置相同。接下来,使用 pip 将tomli安装到您的虚拟环境中:
(venv) $ python -m pip install tomli
tomli模块只公开了两个函数:load()和loads()。您可以使用它们分别从 file 对象和 string 加载 TOML 文档。首先使用load()读取您在上面创建的文件:
>>> import tomli >>> with open("tic_tac_toe.toml", mode="rb") as fp: ... config = tomli.load(fp) ...你首先打开文件,使用一个上下文管理器来处理可能出现的任何问题。重要的是,您需要通过指定
mode="rb"以二进制模式打开文件。这允许tomli正确处理您的 TOML 文件的编码。您将 TOML 配置存储在一个名为
config的变量中。继续探索它的内容:
>>> config
{'user': {'player_x': {'color': 'blue'}, 'player_o': {'color': 'green'}},
'constant': {'board_size': 3},
'server': {'url': 'https://tictactoe.example.com'}}
>>> config["user"]["player_o"]
{'color': 'green'}
>>> config["server"]["url"]
'https://tictactoe.example.com'
在 Python 中,TOML 文档被表示为字典。TOML 文件中的所有表和子表都显示为config中的嵌套字典。您可以通过跟踪嵌套字典中的键来挑选单个值。
如果您已经将 TOML 文档表示为字符串,那么您可以使用loads()代替load()。可以把函数名后面的s看作是字符串的助记符。以下示例解析存储为toml_str的 TOML 文档:
>>> import tomli >>> toml_str = """ ... offset_date-time_utc = 2021-01-12 00:23:45Z ... potpourri = ["flower", 1749, { symbol = "X", color = "blue" }, 1994-02-14] ... """ >>> tomli.loads(toml_str) {'offset_date-time_utc': datetime.datetime(2021, 1, 12, 0, 23, 45, tzinfo=datetime.timezone.utc), 'potpourri': ['flower', 1749, {'symbol': 'X', 'color': 'blue'}, datetime.date(1994, 2, 14)]}同样,您将生成一个字典,其中的键和值对应于 TOML 文档中的键值对。注意,TOML 时间和日期类型由 Python 的
datetime类型表示,TOML 数组被转换成 Python 列表。您可以看到,正如预期的那样,在.tzinfo属性中表示的时区信息被附加到了offset_date-time_utc。注意:偏移日期时间是具有指定时区的日期时间。将时区添加到
datetime意味着您提供了足够的信息来描述一个确切的时刻,这在许多处理真实世界数据的应用程序中非常重要。看看 Python 3.9:很酷的新特性供你尝试阅读更多关于 Python 如何处理时区的信息,并查看 Python 3.9 版本中添加的
zoneinfo模块。
load()和loads()都将 TOML 文档转换成 Python 字典,并且可以互换使用。选择最适合您的使用情形的一个。作为最后一个例子,您将结合loads()和pathlib来重建井字游戏配置示例:
>>> from pathlib import Path
>>> import tomli
>>> tomli.loads(Path("tic_tac_toe.toml").read_text(encoding="utf-8")) {'user': {'player_x': {'color': 'blue'}, 'player_o': {'color': 'green'}},
'constant': {'board_size': 3},
'server': {'url': 'https://tictactoe.example.com'}}
load()和loads()的一个区别是当你使用后者时,你使用常规的字符串而不是字节。在这种情况下,tomli假设您已经正确处理了编码。
注:这些例子都用了tomli。然而,如上所述,如果您使用的是 Python 3.11 或更新版本,您可以用tomllib替换任何提到tomli的代码。
你可能想在你的应用程序中自动执行这个决定。您可以通过将下面一行添加到您的requirements.txt依赖项规范中来实现这一点:
tomli >= 1.1.0 ; python_version < "3.11"
这将确保tomli只安装在 3.11 之前的 Python 版本上。此外,您应该用一个稍微复杂一点的咒语替换您导入的tomli:
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
这段代码将首先尝试导入tomllib。如果失败,它将导入tomli,但是将tomli模块的别名改为tomllib名称。由于这两个库是兼容的,你现在可以在你的代码中引用tomllib,它将在所有 Python 版本 3.7 和更高版本上工作。
您已经开始使用 Python 加载并解析了您的第一个 TOML 文档。在下一小节中,您将更仔细地查看 TOML 数据类型和来自tomli的输出之间的对应关系。
比较 TOML 类型和 Python 类型
在前一小节中,您加载了一些 TOML 文档,并学习了tomli和tomllib如何表示,例如,将 TOML 字符串表示为 Python 字符串,将 TOML 数组表示为 Python 列表。TOML 规范没有明确定义 Python 应该如何表示 TOML 对象,因为这超出了它的范围。然而,TOML 规范提到了对其自身类型的一些要求。例如:
- TOML 文件必须是有效的 UTF-8 编码的 Unicode 文档。
- 应该无损地接受和处理任意 64 位有符号整数(从−2^63 到 2^63−1)。
- 浮点应该实现为 IEEE 754 二进制 64 值。
总的来说,TOML 的需求与 Python 的相应类型的实现匹配得很好。Python 通常在处理文件时默认使用 UTF-8,一个 Python float 遵循 IEEE 754。Python 的int 类实现了任意精度的整数,可以处理所需的范围和更大的数字。
对于像tomli和tomllib这样的基本库,TOML 的数据类型和 Python 的数据类型之间的映射是相当自然的。您可以在tomllib的文档中找到以下换算表:
| 汤姆 | 计算机编程语言 |
|---|---|
| 线 | str |
| 整数 | int |
| 漂浮物 | float |
| 布尔型 | bool |
| 桌子 | dict |
| 偏移日期时间 | datetime.datetime ( .tzinfo是datetime.timezone的一个实例) |
| 当地日期时间 | datetime.datetime ( .tzinfo是None) |
| 当地日期 | datetime.date |
| 当地时间 | datetime.time |
| 排列 | list |
所有的 Python 数据类型要么是内置的,要么是标准库中 datetime 的一部分。重申一下,并不要求 TOML 类型必须映射到本地 Python 类型。这是tomli和tomllib选择实现的便利。
仅使用标准类型也是一种限制。实际上,您只能表示值,而不能表示 TOML 文档中编码的其他信息,如注释或缩进。您的 Python 表示也没有区分在常规表或内联表中定义的值。
在许多用例中,这个元信息是不相关的,所以不会丢失任何东西。然而,有时这很重要。例如,如果您试图在现有的 TOML 文件中插入一个表格,那么您不希望所有的注释都消失。稍后你会了解到tomlkit。这个库将 TOML 类型表示为定制的 Python 对象,这些对象保留了恢复完整的 TOML 文档所必需的信息。
load()和loads()函数有一个参数,可以用来定制 TOML 解析。您可以向parse_float提供一个参数来指定应该如何解析浮点数。默认实现满足了使用 64 位浮点数的要求,这通常精确到大约 16 位有效数字。
但是,如果您的应用程序依赖于非常精确的数字,16 位数字可能不够。作为例子,考虑天文学中使用的儒略日的概念。这是一个时间戳的表示,它是一个计数自 6700 多年前的儒略历开始以来的天数的数字。例如,UTC 时间 2022 年 7 月 11 日中午是儒略日 2,459,772。
天文学家有时需要在非常小的时间尺度上工作,比如纳秒甚至皮秒。要以纳秒的精度表示一天中的时间,在小数的小数点后需要大约 14 位数字。例如,UTC 时间 2022 年 7 月 11 日下午 2:01,表示为具有纳秒精度的儒略日,即 245。58661 . 86768678671
像这样的数字,既有很大的值,又精确到许多小数位,不太适合表示为浮点数。如果你用tomli读这个儒略日,你会损失多少精度?打开 REPL,体验一下:
>>> import tomli >>> ts = tomli.loads("ts = 2_459_772.084027777777778")["ts"] >>> ts 2459772.084027778 >>> seconds = (ts - int(ts)) * 86_400 >>> seconds 7260.000009834766 >>> seconds - 7260 9.834766387939453e-06首先使用
tomli解析儒略日,挑选出值,并将其命名为ts。您可以看到ts的值被截断了几个小数位。为了弄清楚截断的效果有多糟糕,您计算由ts的小数部分表示的秒数,并将其与 7260 进行比较。整数儒略日代表某一天的中午。下午 2:01 是中午之后的两小时零一分钟,两小时零一分钟等于 7260 秒,所以
seconds - 7260向您展示了您的解析引入了多大的误差。在这种情况下,您的时间戳大约有 10 微秒的误差。这听起来可能不多,但在许多天文应用中,信号以光速传播。在这种情况下,10 微秒可能会导致大约 3 公里的误差!
这个问题的一个常见解决方案是不将非常精确的时间戳存储为儒略日。取而代之的是许多具有更高精度的变体。然而,您也可以通过使用 Python 的
Decimal类来修复您的示例,该类提供任意精度的十进制数。回到你的 REPL,重复上面的例子:
>>> import tomli
>>> from decimal import Decimal
>>> ts = tomli.loads(
... "ts = 2_459_772.084027777777778",
... parse_float=Decimal, ... )["ts"]
>>> ts
Decimal('2459772.084027777777778')
>>> seconds = (ts - int(ts)) * 86_400
>>> seconds
Decimal('7260.000000000019200')
>>> seconds - 7260
Decimal('1.9200E-11')
现在,剩下的小误差来自你的原始表示,大约是 19 皮秒,相当于光速下的亚厘米误差。
当你知道你需要精确的浮点数时,你可以使用Decimal。在更具体的用例中,您还可以将数据存储为字符串,并在读取 TOML 文件后解析应用程序中的字符串。
到目前为止,您已经看到了如何用 Python 读取 TOML 文件。接下来,您将讨论如何将配置文件合并到您自己的项目中。
在项目中使用配置文件
您有一个项目,其中包含一些您想要提取到配置文件中的设置。回想一下,配置可以通过多种方式改进您的代码库:
- 它命名价值观和概念。
- 它为特定值提供了更多可见性。
- 它使得改变的值更简单。
配置文件可以帮助您了解源代码,并增加用户与应用程序交互的灵活性。您知道如何阅读基于 TOML 的配置文件,但是如何在您的项目中使用它呢?
特别是,你如何确保配置文件只被解析一次,你如何从不同的模块访问配置?
原来 Python 的导入系统已经支持这两个开箱即用的特性。当您导入一个模块时,它会被缓存以备后用。换句话说,如果您将您的配置包装在一个模块中,您知道该配置将只被读取一次,即使您从几个地方导入该模块。
是时候举个具体的例子了。调用前面的tic_tac_toe.toml配置文件:
# tic_tac_toe.toml [user] player_x.color = "blue" player_o.color = "green" [constant] board_size = 3 [server] url = "https://tictactoe.example.com"
创建一个名为config/的目录,并将tic_tac_toe.toml保存在该目录中。另外,在config/中创建一个名为__init__.py的空文件。您的小型目录结构应该如下所示:
config/
├── __init__.py
└── tic_tac_toe.toml
名为__init__.py的文件在 Python 中起着特殊的作用。它们将包含目录标记为包。此外,在__init__.py中定义的名字通过包公开。您将很快看到这在实践中意味着什么。
现在,向__init__.py添加代码以读取配置文件:
# __init__.py
import pathlib
import tomli
path = pathlib.Path(__file__).parent / "tic_tac_toe.toml"
with path.open(mode="rb") as fp:
tic_tac_toe = tomli.load(fp)
像前面一样,使用load()读取 TOML 文件,并将 TOML 数据存储到名称tic_tac_toe中。你使用 pathlib 和特殊的 __file__ 变量来设置path,TOML 文件的完整路径。实际上,这指定了 TOML 文件存储在与__init__.py文件相同的目录中。
通过从config/的父目录启动 REPL 会话来试用您的小软件包:
>>> import config >>> config.path PosixPath('/home/realpython/config/tic_tac_toe.toml') >>> config.tic_tac_toe {'user': {'player_x': {'color': 'blue'}, 'player_o': {'color': 'green'}}, 'constant': {'board_size': 3}, 'server': {'url': 'https://tictactoe.example.com'}}您可以检查配置的路径并访问配置本身。要读取特定值,可以使用常规项目访问:
>>> config.tic_tac_toe["server"]["url"]
'https://tictactoe.example.com'
>>> config.tic_tac_toe["constant"]["board_size"]
3
>>> config.tic_tac_toe["user"]["player_o"]
{'color': 'green'}
>>> config.tic_tac_toe["user"]["player_o"]["color"]
'green'
现在,您可以通过将config/目录复制到您的项目中,并用您自己的设置替换井字游戏配置,来将配置集成到您现有的项目中。
在代码文件中,您可能希望为配置导入设置别名,以便更方便地访问您的设置:
>>> from config import tic_tac_toe as CFG >>> CFG["user"]["player_x"]["color"] 'blue'在这里,您可以在导入过程中将配置命名为
CFG,这使得访问配置设置既高效又易读。这个菜谱为您提供了一种在您自己的项目中使用配置的快速而可靠的方法。
将 Python 对象转储为 TOML
您现在知道如何用 Python 读取 TOML 文件了。怎么能反其道而行之呢?TOML 文档通常是手写的,因为它们主要用作配置。尽管如此,有时您可能需要将嵌套字典转换成 TOML 文档。
在这一节中,您将从手工编写一个基本的 TOML 编写器开始。然后,您会看到哪些工具已经可用,并使用第三方的
tomli_w库将您的数据转储到 TOML。将字典转换为 TOML
回想一下您之前使用的井字游戏配置。您可以将其稍加修改的版本表示为嵌套的 Python 字典:
{ "user": { "player_x": {"symbol": "X", "color": "blue", "ai": True}, "player_o": {"symbol": "O", "color": "green", "ai": False}, "ai_skill": 0.85, }, "board_size": 3, "server": {"url": "https://tictactoe.example.com"}, }在这一小节中,您将编写一个简化的 TOML 编写器,它能够将本词典编写为 TOML 文档。你不会实现 TOML 的所有特性。特别是,您忽略了一些值类型,如时间、日期和表格数组。您也没有处理需要加引号的键或多行字符串。
尽管如此,您的实现将处理 TOML 的许多典型用例。在下一小节中,您将看到如何使用一个库来处理规范的其余部分。打开编辑器,创建一个名为
to_toml.py的新文件。首先,编写一个名为
_dumps_value()的助手函数。该函数将接受某个值,并基于值类型返回其 TOML 表示。您可以通过isinstance()检查来实现这一点:# to_toml.py def _dumps_value(value): if isinstance(value, bool): return "true" if value else "false" elif isinstance(value, (int, float)): return str(value) elif isinstance(value, str): return f'"{value}"' elif isinstance(value, list): return f"[{', '.join(_dumps_value(v) for v in value)}]" else: raise TypeError(f"{type(value).__name__} {value!r} is not supported")您为布尔值返回
true或false,并在字符串两边加上双引号。如果你的值是一个列表,你可以通过递归调用_dumps_value()来创建一个 TOML 数组。如果你正在使用 Python 3.10 或更新版本,那么你可以用一个match…case语句来替换你的isinstance()检查。接下来,您将添加处理这些表的代码。您的 main 函数循环遍历一个字典,并将每个条目转换成一个键值对。如果值碰巧是一个字典,那么您将添加一个表头并递归地填写该表:
# to_toml.py # ... def dumps(toml_dict, table=""): toml = [] for key, value in toml_dict.items(): if isinstance(value, dict): table_key = f"{table}.{key}" if table else key toml.append(f"\n[{table_key}]\n{dumps(value, table_key)}") else: toml.append(f"{key} = {_dumps_value(value)}") return "\n".join(toml)为了方便起见,可以使用一个列表,在添加表或键值对时跟踪它们。在返回之前,将这个列表转换成一个字符串。
除了前面提到的限制,这个函数中还隐藏着一个微妙的错误。考虑一下如果您尝试转储前面的示例会发生什么:
>>> import to_toml
>>> config = {
... "user": {
... "player_x": {"symbol": "X", "color": "blue", "ai": True},
... "player_o": {"symbol": "O", "color": "green", "ai": False},
... "ai_skill": 0.85,
... },
... "board_size": 3,
... "server": {"url": "https://tictactoe.example.com"},
... }
>>> print(to_toml.dumps(config))
[user]
[user.player_x]
symbol = "X"
color = "blue"
ai = true
[user.player_o]
symbol = "O"
color = "green"
ai = false
ai_skill = 0.85 board_size = 3
[server]
url = "https://tictactoe.example.com"
请特别注意突出显示的行。看起来ai_skill和board_size是user.player_o表中的键。但根据原始数据,它们应该分别是user和根表的成员。
问题是没有办法标记 TOML 表的结束。相反,常规键必须列在任何子表之前。修复代码的一种方法是对字典项进行排序,使字典值排在所有其他值之后。按如下方式更新您的函数:
# to_toml.py
# ...
def dumps(toml_dict, table=""):
def tables_at_end(item): _, value = item return isinstance(value, dict)
toml = []
for key, value in sorted(toml_dict.items(), key=tables_at_end): if isinstance(value, dict):
table_key = f"{table}.{key}" if table else key
toml.append(f"\n[{table_key}]\n{dumps(value, table_key)}")
else:
toml.append(f"{key} = {_dumps_value(value)}")
return "\n".join(toml)
实际上,tables_at_end()为所有非字典值返回False或0,为所有字典值返回True,T3 相当于1。使用它作为排序关键字可以确保嵌套字典在其他类型的值之后被处理。
现在,您可以重做上面的示例。当您将结果打印到您的终端屏幕时,您将看到下面的 TOML 文档:
board_size = 3 [user] ai_skill = 0.85 [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false [server] url = "https://tictactoe.example.com"
这里,board_size作为根表的一部分列在顶部,这是意料之中的。另外,ai_skill现在是user中的一个键,就像它应该的那样。
尽管 TOML 不是一种复杂的格式,但是在创建自己的 TOML 编写器时,您需要考虑一些细节。您不再继续这个任务,而是转而研究如何使用现有的库将数据转储到 TOML 中。
用tomli_w 编写 TOML 文档
在本节中,您将使用 tomli_w 库。顾名思义,tomli_w与tomli有关。它有两个功能,dump()和dumps(),其设计或多或少与load()和loads()相反。
注意:Python 3.11 中新增的tomllib库不包括 dump()和dumps(),也没有tomllib_w。相反,你可以使用tomli_w在 Python 3.7 以后的所有版本上编写 TOML。
您必须将tomli_w安装到您的虚拟环境中,然后才能使用它:
(venv) $ python -m pip install tomli_w
现在,尝试重复上一小节中的示例:
>>> import tomli_w >>> config = { ... "user": { ... "player_x": {"symbol": "X", "color": "blue", "ai": True}, ... "player_o": {"symbol": "O", "color": "green", "ai": False}, ... "ai_skill": 0.85, ... }, ... "board_size": 3, ... "server": {"url": "https://tictactoe.example.com"}, ... } >>> print(tomli_w.dumps(config)) board_size = 3 [user] ai_skill = 0.85 [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false [server] url = "https://tictactoe.example.com"毫无疑问:
tomli_w编写了与您在上一节中手写的dumps()函数相同的 TOML 文档。此外,第三方库支持您没有实现的所有功能,包括时间和日期、内联表格和表格数组。
dumps()写入可以继续处理的字符串。如果您想将新的 TOML 文档直接存储到磁盘,那么您可以调用dump()来代替。与load()一样,您需要传入一个以二进制模式打开的文件指针。继续上面的例子:
>>> with open("tic-tac-toe-config.toml", mode="wb") as fp:
... tomli_w.dump(config, fp)
...
这将把config数据结构存储到文件tic-tac-toe-config.toml中。查看一下您新创建的文件:
# tic-tac-toe-config.toml board_size = 3 [user] ai_skill = 0.85 [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false [server] url = "https://tictactoe.example.com"
您可以在需要的地方找到所有熟悉的表和键值对。
tomli和tomli_w都很基本,功能有限,同时实现了对 TOML v1.0.0 的完全支持。一般来说,只要它们兼容,您就可以通过 TOML 往返处理您的数据结构:
>>> import tomli, tomli_w >>> data = {"fortytwo": 42} >>> tomli.loads(tomli_w.dumps(data)) == data True在这里,您确认您能够在第一次转储到 TOML 然后加载回 Python 之后恢复
data。注意:不应该使用 TOML 进行数据序列化的一个原因是有许多数据类型不受支持。例如,如果您有一个带数字键的字典,那么
tomli_w理所当然地拒绝将它转换成 TOML:
>>> import tomli, tomli_w
>>> data = {1: "one", 2: "two"}
>>> tomli.loads(tomli_w.dumps(data)) == data
Traceback (most recent call last):
...
TypeError: 'int' object is not iterable
这个错误消息不是很有描述性,但是问题是 TOML 不支持像1和2这样的非字符串键。
之前,您已经了解到tomli会丢弃评论。此外,您无法在字典中区分由load()或loads()返回的文字字符串、多行字符串和常规字符串。总的来说,这意味着当您解析一个 TOML 文档并将其写回时,您会丢失一些元信息:
>>> import tomli, tomli_w >>> toml_data = """ ... [nested] # Not necessary ... ... [nested.table] ... string = "Hello, TOML!" ... weird_string = '''Literal ... Multiline''' ... """ >>> print(tomli_w.dumps(tomli.loads(toml_data))) [nested.table] string = "Hello, TOML!" weird_string = "Literal\n Multiline"TOML 内容保持不变,但是您的输出与您传入的完全不同!父表
nested没有明确地包含在输出中,注释也不见了。此外,nested.table中的等号不再对齐,weird_string也不再表示为多行字符串。注意:您可以使用
multiline_strings参数来指示tomli_w在适当的时候使用多行字符串。总之,
tomli_w是编写 TOML 文档的一个很好的选择,只要您不需要对输出进行很多控制。在下一节中,您将使用tomlkit,如果需要的话,它会给您更多的控制权。您将从头开始创建一个专用的 TOML 文档对象,而不是简单地将字典转储到 TOML。创建新的 TOML 文档
你知道如何用
tomli和tomli_w快速读写 TOML 文档。您还注意到了tomli_w的一些局限性,尤其是在格式化生成的 TOML 文件时。在这一节中,您将首先探索如何格式化 TOML 文档,使它们更易于用户使用。然后,您将尝试另一个名为
tomlkit的库,您可以用它来完全控制您的 TOML 文档。TOML 文档的格式和样式
一般来说,空白在 TOML 文件中会被忽略。您可以利用这一点来使您的配置文件组织良好、易读和直观。此外,散列符号(
#)将该行的其余部分标记为注释。自由地使用它们。没有针对 TOML 文档的样式指南,也就是说 PEP 8 是针对 Python 代码的样式指南。然而,规范确实包含了一些建议,同时也为你留下了一些风格方面的选择。
TOML 中的一些特性非常灵活。例如,您可以任意顺序定义表格。因为表名是完全限定的,所以您甚至可以在父表之前定义子表。此外,键周围的空白被忽略。标题
[nested.table]和[ nested . table]从同一个嵌套表开始。TOML 规范中的建议可以总结为不要滥用灵活性。保持你对一致性和可读性的关注,你和你的用户会更开心!
要查看样式选项列表,您可以根据个人偏好做出合理的选择,请查看 Taplo 格式化程序可用的配置选项。以下是一些你可以思考的问题:
- 缩进子表还是只依靠表头来表示结构?
- 在每个表中对齐键-值对中的等号还是始终坚持在等号的每一侧留一个空格?
- 将长数组分割成多行还是总是将它们集中在一行?
- 在多行数组的最后一个值后添加一个尾随逗号或让它保持空白?
- 对表和键按语义或按字母顺序排序?
每一个选择都取决于个人品味,所以请随意尝试,找到你觉得舒服的东西。
尽管如此,努力保持一致还是有好处的。为了保持一致性,您可以在项目中使用类似于 Taplo 的格式化程序,并将其配置文件包含在您的版本控制中。你也可以将集成到你的编辑器中。
回头看看上面的问题。如果使用
tomli_w编写 TOML 文档,那么唯一可以选择的问题就是如何对表和键进行排序。如果你想更好地控制你的文档,那么你需要一个不同的工具。在下一小节中,您将开始关注tomlkit,它赋予您更多的权力和责任。用
tomlkit从头开始创建 TOMLTOML Kit 最初是为诗歌项目打造的。作为其依赖性管理的一部分,poem 操作
pyproject.toml文件。然而,由于这个文件用于多种用途,诗歌必须保留文件中的风格和注释。在这一小节中,您将使用
tomlkit从头开始创建一个 TOML 文档,以便使用它的一些功能。首先,您需要将软件包安装到您的虚拟环境中:(venv) $ python -m pip install tomlkit你可以从确认
tomlkit比tomli和tomli_w更强大开始。重复前面的往返示例,注意所有的格式都保留了下来:
>>> import tomlkit
>>> toml_data = """
... [nested] # Not necessary
... ... [nested.table]
... string = "Hello, TOML!"
... weird_string = '''Literal
... Multiline'''
... """
>>> print(tomlkit.dumps(tomlkit.loads(toml_data)))
[nested] # Not necessary
[nested.table]
string = "Hello, TOML!"
weird_string = '''Literal
Multiline'''
>>> tomlkit.dumps(tomlkit.loads(toml_data)) == toml_data
True
你可以像前面一样使用loads()和dumps()——load()和dump()来读写 TOML。但是,现在所有的字符串类型、缩进、注释和对齐方式都保留了下来。
为了实现这一点,tomlkit使用了定制的数据类型,其行为或多或少类似于您的本地 Python 类型。稍后你会学到更多关于这些数据类型的知识。首先,您将看到如何从头开始创建一个 TOML 文档:
>>> from tomlkit import comment, document, nl, table >>> toml = document() >>> toml.add(comment("Written by TOML Kit")) >>> toml.add(nl()) >>> toml.add("board_size", 3)一般来说,你需要通过调用
document()来创建一个 TOML 文档实例。然后,您可以使用.add()向这个文档添加不同的对象,比如注释、换行符、键值对和表格。注意:调用
.add()返回更新后的对象。在本节的示例中您不会看到这一点,因为额外的输出会分散示例流的注意力。稍后您将看到如何利用这一设计,并将几个调用链接到一起.add()。你可以使用上面的
dump()或dumps()将toml转换成一个实际的 TOML 文档,或者你可以使用.as_string()方法:
>>> print(toml.as_string())
# Written by TOML Kit
board_size = 3
在本例中,您开始重新创建之前使用过的井字游戏配置的各个部分。注意输出中的每一行如何对应到代码中的一个.add()方法。首先是注释,然后是代表空行的nl(),然后是键值对。
继续您的示例,添加几个表格:
>>> player_x = table() >>> player_x.add("symbol", "X") >>> player_x.add("color", "blue") >>> player_x.comment("Start player") >>> toml.add("player_x", player_x) >>> player_o = table() >>> player_o.update({"symbol": "O", "color": "green"}) >>> toml["player_o"] = player_o您可以通过调用
table()来创建表格,并向其中添加内容。创建了一个表格后,就可以将它添加到 TOML 文档中。您可以坚持使用.add()来组合您的文档,但是这个例子也展示了一些添加内容的替代方法。例如,您可以使用.update()直接从字典中添加键和值。当您将文档转换为 TOML 字符串时,它将如下所示:
>>> print(toml.as_string())
# Written by TOML Kit
board_size = 3
[player_x] # Start player
symbol = "X"
color = "blue"
[player_o]
symbol = "O"
color = "green"
将此输出与您用来创建文档的命令进行比较。如果您正在创建一个具有固定结构的 TOML 文档,那么将文档写成一个 TOML 字符串并用tomlkit加载它可能更容易。然而,您在上面看到的命令在动态组合配置时为您提供了很大的灵活性。
在下一节中,您将更深入地研究tomlkit,看看如何使用它来更新现有的配置。
更新现有的 TOML 文档
假设您已经花了一些时间将一个组织良好的配置和良好的注释放在一起,指导您的用户如何更改它。然后一些其他的应用程序出现并把它的配置存储在同一个文件中,同时破坏你精心制作的艺术品。
这可能是将您的配置保存在一个其他人不会接触到的专用文件中的一个理由。然而,有时使用公共配置文件也很方便。 pyproject.toml 文件就是这样一个通用文件,尤其是对于开发和构建包时使用的工具。
在这一节中,您将深入了解tomlkit如何表示 TOML 对象,以及如何使用这个包来更新现有的 TOML 文件。
将 TOML 表示为tomlkit对象
在前面,您看到了tomli和tomllib将 TOML 文档解析成本地 Python 类型,如字符串、整数和字典。你已经看到一些迹象表明tomlkit是不同的。现在,是时候仔细看看tomlkit如何表示一个 TOML 文档了。
首先,复制并保存下面的 TOML 文件为tic-tac-toe-config.toml:
# tic-tac-toe-config.toml board_size = 3 [user] ai_skill = 0.85 # A number between 0 (random) and 1 (expert) [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false # Settings used when deploying the application [server] url = "https://tictactoe.example.com"
打开 REPL 会话并用tomlkit加载此文档:
>>> import tomlkit >>> with open("tic-tac-toe-config.toml", mode="rt", encoding="utf-8") as fp: ... config = tomlkit.load(fp) ... >>> config {'board_size': 3, 'user': {'ai_skill': 0.85, 'player_x': { ... }}} >>> type(config) <class 'tomlkit.toml_document.TOMLDocument'>使用
load()从文件中加载 TOML 文档。看config的时候,第一眼就像一本字典。然而,深入挖掘,你会发现这是一种特殊的TOMLDocument类型。注意:与
tomli不同,tomlkit希望你以文本模式打开文件。你还应该记得指定文件应该使用utf-8编码来打开。这些自定义数据类型的行为或多或少类似于您的本地 Python 类型。例如,您可以使用方括号(
[])访问文档中的子表和值,就像字典一样。继续上面的例子:
>>> config["user"]["player_o"]["color"]
'green'
>>> type(config["user"]["player_o"]["color"])
<class 'tomlkit.items.String'>
>>> config["user"]["player_o"]["color"].upper()
'GREEN'
尽管这些值也是特殊的tomlkit数据类型,但是您可以像处理普通的 Python 类型一样处理它们。例如,您可以使用.upper()字符串方法。
特殊数据类型的一个优点是,它们允许您访问关于文档的元信息,包括注释和缩进:
>>> config["user"]["ai_skill"] 0.85 >>> config["user"]["ai_skill"].trivia.comment '# A number between 0 (random) and 1 (expert)' >>> config["user"]["player_x"].trivia.indent ' '例如,您可以通过
.trivia访问器恢复注释和缩进信息。正如您在上面看到的,您可以将这些特殊对象视为本地 Python 对象。事实上,他们从本地的同类那里继承了 T2。但是,如果您真的需要,您可以使用
.unwrap()将它们转换成普通的 Python:
>>> config["board_size"] ** 2
9
>>> isinstance(config["board_size"], int)
True
>>> config["board_size"].unwrap()
3
>>> type(config["board_size"].unwrap())
<class 'int'>
在调用了.unwrap()之后,3现在是一个普通的 Python 整数。总之,这个调查让你对tomlkit如何能够保持 TOML 文档的风格有了一些了解。
在下一小节中,您将了解如何使用tomlkit数据类型来定制 TOML 文档,而不影响现有的样式。
无损读写 TOML】
您知道tomlkit表示使用定制类的 TOML 文档,并且您已经看到如何从头开始创建这些对象,以及如何读取现有的 TOML 文档。在这一小节中,您将加载一个现有的 TOML 文件,并在将其写回磁盘之前对其进行一些更改。
首先加载您在上一小节中使用的同一个 TOML 文件:
>>> import tomlkit >>> with open("tic-tac-toe-config.toml", mode="rt", encoding="utf-8") as fp: ... config = tomlkit.load(fp) ...正如您之前看到的,
config现在是一个TOMLDocument。您可以使用.add()向其中添加新元素,就像您从头开始创建文档时一样。但是,您不能使用.add()来更新现有键的值:
>>> config.add("app_name", "Tic-Tac-Toe")
{'board_size': 3, 'app_name': 'Tic-Tac-Toe', 'user': { ... }}
>>> config["user"].add("ai_skill", 0.6)
Traceback (most recent call last):
...
KeyAlreadyPresent: Key "ai_skill" already exists.
你试图降低人工智能的技能,这样你就有一个更容易对付的对手。但是,你不能用.add()做到这一点。相反,您可以分配新值,就像config是一个常规字典一样:
>>> config["user"]["ai_skill"] = 0.6 >>> print(config["user"].as_string()) ai_skill = 0.6 # A number between 0 (random) and 1 (expert) [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false当您像这样更新一个值时,
tomlkit仍然会注意保留样式和注释。如你所见,关于ai_skill的评论没有被改动。部分
tomlkit支持所谓的流畅界面。实际上,这意味着像.add()这样的操作会返回更新后的对象,这样你就可以在其上链接另一个对.add()的调用。当您需要构造包含多个字段的表时,可以利用这一点:
>>> from tomlkit import aot, comment, inline_table, nl, table
>>> player_data = [
... {"user": "gah", "first_name": "Geir Arne", "last_name": "Hjelle"},
... {"user": "tompw", "first_name": "Tom", "last_name": "Preston-Werner"},
... ]
>>> players = aot()
>>> for player in player_data:
... players.append(
... table()
... .add("username", player["user"])
... .add("name",
... inline_table()
... .add("first", player["first_name"])
... .add("last", player["last_name"])
... )
... )
...
>>> config.add(nl()).add(comment("Players")).add("players", players)
在本例中,您创建了一个包含球员信息的表数组。首先用aot()构造函数创建一个空的表数组。然后循环遍历玩家数据,将每个玩家添加到数组中。
您使用方法链接来创建每个玩家表。实际上,您的调用是table().add().add(),它将两个元素添加到一个新表中。最后,在配置的底部,在一个简短的注释下面添加新的玩家表数组。
对配置的更新完成后,您现在可以将它写回同一个文件:
>>> with open("tic-tac-toe-config.toml", mode="wt", encoding="utf-8") as fp: ... tomlkit.dump(config, fp)打开
tic-tac-toe-config.toml,注意你的更新已经包含在内。与此同时,原有的风格得以保留:# tic-tac-toe-config.toml board_size = 3 app_name = "Tic-Tac-Toe" [user] ai_skill = 0.6 # A number between 0 (random) and 1 (expert) [user.player_x] symbol = "X" color = "blue" ai = true [user.player_o] symbol = "O" color = "green" ai = false # Settings used when deploying the application [server] url = "https://tictactoe.example.com" # Players [[players]] username = "gah" name = {first = "Geir Arne", last = "Hjelle"} [[players]] username = "tompw" name = {first = "Tom", last = "Preston-Werner"}请注意,
app_name已经被添加,user.ai_skill的值已经被更新,players表的数组已经被附加到您的配置的末尾。您已经成功地以编程方式更新了您的配置。结论
这是您对 TOML 格式以及如何在 Python 中使用它的广泛探索的结束。您已经看到了一些使 TOML 成为一种灵活方便的配置文件格式的特性。同时,您还发现了一些限制其在其他应用程序(如数据序列化)中使用的局限性。
在本教程中,您已经:
- 了解了 TOML 语法及其支持的数据类型
- 用
tomli和tomllib解析 TOML 文档- 用
tomli_w编写 TOML 文档- 无损的用
tomlkit更新了的 TOML 文件您是否有需要方便配置的应用程序?汤姆可能就是你要找的人。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。**********
了解 Python 回溯
*立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 充分利用 Python 回溯
当代码中出现异常时,Python 会打印一个回溯。如果你是第一次看到回溯输出,或者你不知道它在告诉你什么,那么回溯输出可能有点让人不知所措。但是 Python traceback 提供了丰富的信息,可以帮助您诊断和修复代码中引发异常的原因。理解 Python 回溯提供的信息对于成为更好的 Python 程序员至关重要。
本教程结束时,你将能够:
- 理解你看到的下一个追溯
- 认识一些更常见的追溯
- 成功记录回溯,同时仍然处理异常
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
什么是 Python 回溯?
回溯是一份报告,其中包含代码中特定点的函数调用。回溯有很多名字,包括栈跟踪、栈回溯、回溯等等。在 Python 中,使用的术语是回溯。
当你的程序导致一个异常时,Python 会打印当前的回溯来帮助你知道哪里出错了。下面是一个说明这种情况的例子:
# example.py def greet(someone): print('Hello, ' + someon) greet('Chad')这里,
greet()用参数someone调用。然而,在greet()中,没有使用那个变量名称。反而在print()调用中被拼错为someon。注意:本教程假设您理解 Python 异常。如果你不熟悉或者只是想复习一下,那么你应该看看 Python 异常:简介。
当您运行此程序时,您将获得以下回溯:
$ python example.py Traceback (most recent call last): File "/path/to/example.py", line 4, in <module> greet('Chad') File "/path/to/example.py", line 2, in greet print('Hello, ' + someon) NameError: name 'someon' is not defined这个回溯输出包含了诊断问题所需的所有信息。回溯输出的最后一行告诉您引发了什么类型的异常,以及关于该异常的一些相关信息。回溯的前几行指出了导致引发异常的代码。
在上面的回溯中,异常是一个
NameError,这意味着有一个对某个名称(变量、函数、类)的引用还没有被定义。在这种情况下,引用的名称是someon。这种情况下的最后一行有足够的信息来帮助您解决问题。在代码中搜索名字
someon,这是一个拼写错误,将为您指出正确的方向。然而,通常你的代码要复杂得多。如何解读 Python 回溯?
当您试图确定代码中出现异常的原因时,Python traceback 包含大量有用的信息。在本节中,您将通过不同的回溯来理解回溯中包含的不同信息。
Python 回溯概述
每个 Python 回溯都有几个重要的部分。下图突出显示了各个部分:
在 Python 中,最好从下往上读回溯:
蓝框:回溯的最后一行是错误信息行。它包含引发的异常名称。
绿框:异常名称后是错误信息。此消息通常包含有助于理解引发异常的原因的信息。
黄色框:追溯的更高部分是从下到上移动的各种函数调用,从最近到最近。这些呼叫由每个呼叫的两行条目表示。每个调用的第一行包含诸如文件名、行号和模块名之类的信息,所有这些信息都指定了在哪里可以找到代码。
红色下划线:这些调用的第二行包含实际执行的代码。
在命令行中执行代码时的回溯输出和在 REPL 中运行代码时的回溯输出有一些不同。下面是在 REPL 中执行的上一节中的相同代码以及由此产生的回溯输出:

>>> def greet(someone):
... print('Hello, ' + someon)
...
>>> greet('Chad')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in greet
NameError: name 'someon' is not defined
注意,代替文件名的是"<stdin>"。这是有意义的,因为您是通过标准输入来键入代码的。此外,已执行的代码行不会显示在回溯中。
注意:如果你习惯于在其他编程语言中看到堆栈跟踪,那么你会注意到 Python 回溯相比之下的主要区别。大多数其他语言将异常打印在顶部,然后从上到下,从最近调用到最近调用。
已经有人说过了,但只是重申一下,Python 回溯应该从下往上读。这非常有帮助,因为回溯被打印出来,并且您的终端(或者您正在读取回溯的任何地方)通常在输出的底部结束,这给了您开始读取回溯的完美位置。
具体追溯演练
查看一些特定的回溯输出将有助于您更好地理解和了解回溯会给您提供什么信息。
下面的示例中使用了下面的代码来说明 Python 回溯所提供的信息:
# greetings.py
def who_to_greet(person):
return person if person else input('Greet who? ')
def greet(someone, greeting='Hello'):
print(greeting + ', ' + who_to_greet(someone))
def greet_many(people):
for person in people:
try:
greet(person)
except Exception:
print('hi, ' + person)
这里,who_to_greet()接受一个值,person,要么返回它,要么提示返回一个值。
然后,greet()取一个要问候的名字,someone,和一个可选的greeting值,调用 print() 。who_to_greet()也通过传入的someone值被调用。
最后,greet_many()将迭代people的列表并调用greet()。如果调用greet()引发了异常,则打印一个简单的备份问候。
只要提供了正确的输入,这段代码没有任何会导致异常的错误。
如果您将对greet()的调用添加到greetings.py的底部,并指定一个它不期望的关键字参数(例如greet('Chad', greting='Yo'),那么您将得到以下回溯:
$ python example.py
Traceback (most recent call last):
File "/path/to/greetings.py", line 19, in <module>
greet('Chad', greting='Yo')
TypeError: greet() got an unexpected keyword argument 'greting'
同样,使用 Python 回溯,最好向后工作,向上移动输出。从回溯的最后一行开始,您可以看到异常是一个TypeError。异常类型后面的消息,冒号后面的所有内容,为您提供了一些有用的信息。它告诉你greet()是用一个它没有预料到的关键字参数调用的。未知的参数名称也给你:greting。
向上移动,您可以看到导致异常的那一行。在本例中,是我们添加到greetings.py底部的greet()调用。
下一行给出了代码所在文件的路径、可以找到代码的文件的行号以及代码所在的模块。在这种情况下,因为我们的代码没有使用任何其他 Python 模块,所以我们在这里只看到了<module>,这意味着这是正在执行的文件。
使用不同的文件和不同的输入,您可以看到回溯确实为您指出了找到问题的正确方向。如果您正在跟进,从greetings.py的底部删除有问题的greet()调用,并将以下文件添加到您的目录中:
# example.py
from greetings import greet
greet(1)
在这里,您已经设置了另一个 Python 文件,该文件导入您之前的模块greetings.py,并从中使用greet()。如果你现在运行example.py,会发生以下情况:
$ python example.py
Traceback (most recent call last):
File "/path/to/example.py", line 3, in <module>
greet(1)
File "/path/to/greetings.py", line 5, in greet
print(greeting + ', ' + who_to_greet(someone))
TypeError: must be str, not int
在这种情况下引发的异常又是一个TypeError,但是这一次这个消息没有那么有用。它告诉你,在代码的某个地方,它期望处理一个字符串,但是给定的是一个整数。
向上移动,您会看到执行的代码行。然后是代码的文件和行号。然而,这一次,我们得到的不是<module>,而是正在执行的函数的名称greet()。
移到下一个执行的代码行,我们看到有问题的greet()调用传入了一个整数。
有时,在引发异常后,另一段代码会捕获该异常并导致异常。在这些情况下,Python 将按照接收的顺序输出所有异常回溯,再次以最近引发的异常回溯结束。
由于这可能有点令人困惑,这里有一个例子。将对greet_many()的调用添加到greetings.py的底部:
# greetings.py
...
greet_many(['Chad', 'Dan', 1])
这应该会打印出对这三个人的问候。但是,如果您运行这段代码,您将看到一个输出多个回溯的示例:
$ python greetings.py
Hello, Chad
Hello, Dan
Traceback (most recent call last):
File "greetings.py", line 10, in greet_many
greet(person)
File "greetings.py", line 5, in greet
print(greeting + ', ' + who_to_greet(someone))
TypeError: must be str, not int
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "greetings.py", line 14, in <module>
greet_many(['Chad', 'Dan', 1])
File "greetings.py", line 12, in greet_many
print('hi, ' + person)
TypeError: must be str, not int
注意上面输出中以During handling开始的高亮行。在所有回溯之间,你会看到这条线。它的信息非常清楚,当您的代码试图处理前一个异常时,另一个异常出现了。
注意:Python 3 中增加了显示之前异常回溯的特性。在 Python 2 中,您将只能获得最后一个异常的回溯。
你以前见过前面的异常,当你用一个整数调用greet()时。因为我们在要问候的人的列表中添加了一个1,所以我们可以期待相同的结果。然而,函数greet_many()将greet()调用包装在try和except块中。万一greet()导致一个异常被引发,greet_many()想要打印一个默认的问候。
这里重复了greetings.py的相关部分:
def greet_many(people):
for person in people:
try:
greet(person)
except Exception:
print('hi, ' + person)
因此,当greet()因为错误的整数输入而导致TypeError时,greet_many()会处理这个异常并尝试打印一个简单的问候。在这里,代码最终导致另一个类似的异常。它仍在尝试添加一个字符串和一个整数。
查看所有回溯输出可以帮助您了解异常的真正原因。有时,当您看到最后一个异常被引发,以及它导致的回溯时,您仍然看不到哪里出了问题。在这些情况下,转到前面的异常通常会让您更好地了解根本原因。
Python 中有哪些常见的回溯?
在编程时,知道如何在程序引发异常时读取 Python 回溯会非常有帮助,但是知道一些更常见的回溯也可以加快您的过程。
以下是您可能遇到的一些常见异常,它们出现的原因和含义,以及您可以在它们的回溯中找到的信息。
AttributeError
当您试图访问一个没有定义属性的对象的属性时,就会引发AttributeError。Python 文档定义了何时引发此异常:
当属性引用或赋值失败时引发。(来源)
下面是一个AttributeError被提升的例子:
>>> an_int = 1 >>> an_int.an_attribute Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'int' object has no attribute 'an_attribute'一个
AttributeError的错误信息行告诉您,特定的对象类型,在本例中为int,没有被访问的属性,在本例中为an_attribute。看到错误消息行中的AttributeError可以帮助您快速识别您试图访问哪个属性以及到哪里去修复它。大多数情况下,得到这个异常表明您可能正在使用一个不是您所期望的类型的对象:
>>> a_list = (1, 2)
>>> a_list.append(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple' object has no attribute 'append'
在上面的例子中,你可能期望a_list是 list 类型,它有一个叫做 .append() 的方法。当您收到AttributeError异常,并看到它是在您试图调用.append()时引发的,这告诉您您可能没有处理您所期望的对象类型。
通常,当您期望从函数或方法调用中返回一个特定类型的对象时,就会发生这种情况,而您最终得到了一个类型为 None 的对象。在这种情况下,错误信息行将显示为AttributeError: 'NoneType' object has no attribute 'append'。
ImportError
当一个导入语句出错时,就会引发ImportError。如果你试图导入的模块找不到,或者如果你试图从一个不存在的模块中导入一些东西,你就会得到这个异常,或者它的子类ModuleNotFoundError。Python 文档定义了何时引发此异常:
当 import 语句在尝试加载模块时遇到问题时引发。当
from ... import中的“from list”有一个找不到的名称时也会引发。(来源)
下面是一个ImportError和ModuleNotFoundError被提升的例子:
>>> import asdf Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'asdf' >>> from collections import asdf Traceback (most recent call last): File "<stdin>", line 1, in <module> ImportError: cannot import name 'asdf'在上面的例子中,您可以看到试图导入一个不存在的模块
asdf,导致了ModuleNotFoundError。当试图从一个存在的模块collections中导入一个不存在的东西asdf时,这会导致一个ImportError。回溯底部的错误信息行告诉您哪一项不能被导入,在两种情况下都是asdf。
IndexError当你试图从一个序列中检索一个索引时,比如一个
list或者一个tuple,而这个索引在序列中找不到时,就会引发IndexError。Python 文档定义了何时引发此异常:当序列下标超出范围时引发。(来源)
这里有一个引发
IndexError的例子:
>>> a_list = ['a', 'b']
>>> a_list[3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
一个IndexError的错误信息行并没有给你太多的信息。你可以看到你有一个序列引用是out of range和序列的类型是什么,在这种情况下是list。这些信息与其余的回溯信息结合起来,通常足以帮助您快速确定如何修复问题。
KeyError
与IndexError类似,当您试图访问一个不在映射中的键(通常是一个dict)时,就会引发KeyError。把这个当做IndexError但是对于字典来说。Python 文档定义了何时引发此异常:
在现有键集中找不到映射(字典)键时引发。(来源)
下面是一个KeyError被提升的例子:
>>> a_dict['b'] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'b'
KeyError的错误信息行给出了找不到的键。这不是很多,但结合其余的追溯,通常足以修复问题。要深入了解
KeyError,请看一下 Python KeyError 异常以及如何处理它们。
NameError当你引用了一个变量、模块、类、函数或者其他一些你的代码中没有定义的名字时,就会引发
NameError。Python 文档定义了何时引发此异常:找不到本地或全局名称时引发。(来源)
在下面的代码中,
greet()接受一个参数person。但是在函数本身中,这个参数被拼错成了persn:
>>> def greet(person):
... print(f'Hello, {persn}')
>>> greet('World')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 2, in greet
NameError: name 'persn' is not defined
NameError回溯的错误信息行给出了缺少的名字。在上面的例子中,它是传入函数的一个拼写错误的变量或参数。
如果是您拼错的参数,也会引发一个NameError:
>>> def greet(persn): ... print(f'Hello, {person}') >>> greet('World') Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in greet NameError: name 'person' is not defined在这里,看起来你好像没有做错什么。回溯中执行和引用的最后一行看起来不错。如果您发现自己处于这种情况,那么要做的事情就是仔细检查您的代码,看看在哪里使用和定义了
person变量。在这里,您可以很快看到参数名称拼写错误。
SyntaxError当您的代码中有不正确的 Python 语法时,会引发
SyntaxError。Python 文档定义了何时引发此异常:当分析器遇到语法错误时引发。(来源)
下面,问题是在函数定义行的末尾缺少了一个冒号。在 Python REPL 中,按 enter 键后会立即出现此语法错误:
>>> def greet(person)
File "<stdin>", line 1
def greet(person)
^
SyntaxError: invalid syntax
SyntaxError的错误信息行只告诉你代码的语法有问题。查看上面的行可以找到有问题的行,通常还有一个^(插入符号)指向问题点。这里,函数的def语句中缺少冒号。
同样,使用SyntaxError回溯,常规的第一行Traceback (most recent call last):会丢失。这是因为当 Python 试图解析代码时会引发SyntaxError,而这些行实际上并没有被执行。
TypeError
当你的代码试图用一个对象做一些不能做的事情时,比如试图将一个字符串加到一个整数上,或者在一个长度没有定义的对象上调用len(),就会引发TypeError。Python 文档定义了何时引发此异常:
当操作或函数应用于不适当类型的对象时引发。(来源)
下面是几个被引发的TypeError的例子:
>>> 1 + '1' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str' >>> '1' + 1 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: must be str, not int >>> len(1) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: object of type 'int' has no len()以上所有引发
TypeError的例子都会导致一个包含不同消息的错误消息行。它们中的每一个都能很好地告诉你哪里出了问题。前两个示例尝试将字符串和整数相加。然而,它们有细微的不同:
- 第一个是尝试将一个
str添加到一个int中。- 第二个是尝试将一个
int添加到一个str中。错误信息行反映了这些差异。
最后一个例子试图在一个
int上调用len()。错误信息行告诉你,你不能用int这样做。
ValueError当对象的值不正确时会引发
ValueError。你可以认为这是因为索引的值不在序列的范围内而引发的IndexError,只有ValueError是针对更一般的情况。Python 文档定义了何时引发此异常:当操作或函数接收到类型正确但值不正确的参数,并且这种情况没有用更精确的异常(如
IndexError)来描述时引发。(来源)这里有两个
ValueError被加注的例子:
>>> a, b, c = [1, 2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 3, got 2)
>>> a, b = [1, 2, 3]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
这些示例中的ValueError错误信息行告诉您这些值到底有什么问题:
-
在第一个例子中,您试图解包太多的值。错误消息行甚至告诉您,您期望解包 3 个值,但是得到了 2 个值。
-
在第二个例子中,问题是你得到了太多的值,却没有足够的变量来将它们打包。
你如何记录回溯?
获得一个异常及其导致的 Python 回溯意味着您需要决定如何处理它。通常,修复代码是第一步,但有时问题出在意外或不正确的输入上。虽然在您的代码中提供这些情况是很好的,但有时通过记录回溯和做其他事情来隐藏异常也是有意义的。
下面是一个更真实的代码示例,它需要消除一些 Python 回溯。这个例子使用了 requests库。你可以在 Python 的请求库(指南)中找到更多关于它的信息:
# urlcaller.py
import sys
import requests
response = requests.get(sys.argv[1])
print(response.status_code, response.content)
这段代码运行良好。当您运行这个脚本时,给它一个 URL 作为命令行参数,它将调用这个 URL,然后打印 HTTP 状态代码和来自响应的内容。即使响应是 HTTP 错误状态,它也能工作:
$ python urlcaller.py https://httpbin.org/status/200
200 b''
$ python urlcaller.py https://httpbin.org/status/500
500 b''
但是,有时脚本要检索的 URL 不存在,或者主机服务器关闭了。在这些情况下,这个脚本现在将引发一个未被捕获的ConnectionError异常,并打印一个回溯:
$ python urlcaller.py http://thisurlprobablydoesntexist.com
...
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "urlcaller.py", line 5, in <module> response = requests.get(sys.argv[1]) File "/path/to/requests/api.py", line 75, in get
return request('get', url, params=params, **kwargs)
File "/path/to/requests/api.py", line 60, in request
return session.request(method=method, url=url, **kwargs)
File "/path/to/requests/sessions.py", line 533, in request
resp = self.send(prep, **send_kwargs)
File "/path/to/requests/sessions.py", line 646, in send
r = adapter.send(request, **kwargs)
File "/path/to/requests/adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='thisurlprobablydoesntexist.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7faf9d671860>: Failed to establish a new connection: [Errno -2] Name or service not known',))
这里的 Python 回溯可能很长,会引发许多其他异常,最终导致ConnectionError被requests本身引发。如果你向上追溯最后的异常,你可以看到问题都是从我们的代码的第 5 行urlcaller.py开始的。
如果您在 try和except块中包装违规行,捕捉适当的异常将允许您的脚本继续处理更多输入:
# urlcaller.py
...
try:
response = requests.get(sys.argv[1])
except requests.exceptions.ConnectionError:
print(-1, 'Connection Error')
else:
print(response.status_code, response.content)
上面的代码使用了一个带有try和except块的else子句。如果您不熟悉 Python 的这个特性,那么可以查看一下 Python 异常:简介中关于else子句的部分。
现在,当您运行带有 URL 的脚本时,将会产生一个ConnectionError,您将得到一个状态代码的-1,以及内容Connection Error:
$ python urlcaller.py http://thisurlprobablydoesntexist.com
-1 Connection Error
这很有效。然而,在大多数真实的系统中,您不希望只是消除异常和导致的回溯,而是希望记录回溯。记录回溯可以让你更好地理解程序中的错误。
注意:要了解更多关于 Python 日志系统的信息,请查看 Python 中的日志。
您可以通过导入 logging包,获得一个记录器,并在try和except块的except部分调用该记录器上的.exception(),在脚本中记录回溯。您的最终脚本应该类似于以下代码:
# urlcaller.py
import logging import sys
import requests
logger = logging.getLogger(__name__)
try:
response = requests.get(sys.argv[1])
except requests.exceptions.ConnectionError as e:
logger.exception() print(-1, 'Connection Error')
else:
print(response.status_code, response.content)
现在,当您为一个有问题的 URL 运行脚本时,它将打印预期的-1和Connection Error,但是它也将记录回溯:
$ python urlcaller.py http://thisurlprobablydoesntexist.com
...
File "/path/to/requests/adapters.py", line 516, in send
raise ConnectionError(e, request=request)
requests.exceptions.ConnectionError: HTTPConnectionPool(host='thisurlprobablydoesntexist.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7faf9d671860>: Failed to establish a new connection: [Errno -2] Name or service not known',))
-1 Connection Error
默认情况下,Python 会向标准错误(stderr)发送日志消息。这看起来好像我们根本没有抑制回溯输出。但是,如果您在重定向stderr时再次调用它,您可以看到日志记录系统正在工作,我们可以保存日志供以后使用:
$ python urlcaller.py http://thisurlprobablydoesntexist.com 2> my-logs.log
-1 Connection Error
结论
Python 回溯包含大量信息,可以帮助您找到 Python 代码中的错误。这些回溯看起来有点吓人,但是一旦你把它分解开来,看看它试图向你展示什么,它们会非常有帮助。一行一行地浏览一些回溯会让你更好地理解它们所包含的信息,并帮助你最大限度地利用它们。
运行代码时获得 Python 回溯输出是改进代码的机会。这是 Python 试图帮助你的一种方式。
既然您已经知道了如何阅读 Python traceback,那么您可以通过学习更多的工具和技术来诊断您的 traceback 输出所告诉您的问题。Python 内置的 traceback模块可以用来处理和检查回溯。当您需要从回溯输出中获取更多信息时,traceback模块会很有帮助。学习更多关于调试 Python 代码的一些技术和在空闲状态下调试的方法也会有所帮助。
立即观看**本教程有真实 Python 团队创建的相关视频课程。与书面教程一起观看,加深您的理解: 充分利用 Python 回溯******
Python 类型检查(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 类型检查
在本指南中,您将了解 Python 类型检查。传统上,Python 解释器以灵活但隐含的方式处理类型。Python 的最新版本允许您指定显式类型提示,不同的工具可以使用这些提示来帮助您更高效地开发代码。
在本教程中,您将了解以下内容:
- 类型批注和类型提示
- 向代码中添加静态类型,包括您的代码和他人的代码
- 运行静态类型检查器
- 在运行时强制类型
这是一个全面的指南,将涵盖很多领域。如果您只想快速浏览一下 Python 中的类型提示是如何工作的,并看看类型检查是否会包含在您的代码中,您不需要阅读全部内容。两个部分 Hello Types 和利弊将让您体验类型检查是如何工作的,以及它何时有用的建议。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
类型系统
所有的编程语言都包括某种类型的类型系统,该系统形式化了它可以处理的对象类别以及如何处理这些类别。例如,类型系统可以定义数字类型,用42作为数字类型对象的一个例子。
动态打字
Python 是一种动态类型语言。这意味着 Python 解释器只在代码运行时进行类型检查,并且允许变量的类型在其生命周期内改变。以下虚拟示例演示了 Python 具有动态类型:
>>> if False: ... 1 + "two" # This line never runs, so no TypeError is raised ... else: ... 1 + 2 ... 3 >>> 1 + "two" # Now this is type checked, and a TypeError is raised TypeError: unsupported operand type(s) for +: 'int' and 'str'在第一个例子中,分支
1 + "two"从不运行,所以它从不进行类型检查。第二个例子显示,当对1 + "two"求值时,它会产生一个TypeError,因为在 Python 中不能将整数和字符串相加。接下来,让我们看看变量是否可以改变类型:
>>> thing = "Hello"
>>> type(thing)
<class 'str'>
>>> thing = 28.1
>>> type(thing)
<class 'float'>
type()返回对象的类型。这些例子证实了thing的类型是允许改变的,Python 在它改变时正确地推断出了类型。
静态打字
动态类型的对立面是静态类型。静态类型检查是在不运行程序的情况下执行的。在大多数静态类型语言中,例如 C 和 Java ,这是在编译程序时完成的。
对于静态类型,通常不允许变量改变类型,尽管可能存在将变量转换为不同类型的机制。
让我们看一个静态类型语言的简单例子。考虑下面的 Java 片段:
String thing; thing = "Hello";
第一行声明变量名thing在编译时被绑定到String类型。该名称永远不能反弹到另一种类型。在第二行中,thing被赋值。它永远不能被赋予一个不是String对象的值。例如,如果你稍后说thing = 28.1f,编译器会因为不兼容的类型而抛出一个错误。
Python 将永远保持动态类型语言的地位。然而, PEP 484 引入了类型提示,这使得对 Python 代码进行静态类型检查成为可能。
与大多数其他静态类型语言中类型的工作方式不同,类型提示本身不会导致 Python 强制类型。顾名思义,类型提示只是建议类型。还有其他一些工具,你将在后面看到它们使用类型提示来执行静态类型检查。
鸭子打字
另一个在谈论 Python 时经常用到的术语是 duck typing 。这个绰号来自短语“如果它走路像鸭子,叫声像鸭子,那么它一定是一只鸭子”(或及其任何变体)。
Duck typing 是一个与动态类型相关的概念,在动态类型中,对象的类型或类没有它定义的方法重要。使用 duck 类型,你根本不用检查类型。相反,您需要检查给定方法或属性的存在。
例如,您可以在任何定义了.__len__()方法的 Python 对象上调用len():
>>> class TheHobbit: ... def __len__(self): ... return 95022 ... >>> the_hobbit = TheHobbit() >>> len(the_hobbit) 95022注意,对
len()的调用给出了.__len__()方法的返回值。事实上,len()的实现本质上相当于如下:def len(obj): return obj.__len__()为了调用
len(obj),对obj唯一真正的约束是它必须定义一个.__len__()方法。否则,对象可以是不同的类型,如str、list、dict或TheHobbit。当使用结构子类型对 Python 代码进行静态类型检查时,Duck 类型有所支持。稍后你会学到更多关于鸭子打字的知识。
你好类型
在本节中,您将看到如何向函数添加类型提示。以下函数通过添加适当的大写字母和装饰线将文本字符串转换为标题:
def headline(text, align=True): if align: return f"{text.title()}\n{'-' * len(text)}" else: return f" {text.title()} ".center(50, "o")默认情况下,该函数返回带有下划线的左对齐标题。通过将
align标志设置为False,您可以选择将标题居中,并环绕一行o:
>>> print(headline("python type checking"))
Python Type Checking
--------------------
>>> print(headline("python type checking", align=False))
oooooooooooooo Python Type Checking oooooooooooooo
现在是我们第一次类型提示的时候了!要将有关类型的信息添加到函数中,只需如下注释其参数和返回值:
def headline(text: str, align: bool = True) -> str:
...
text: str语法规定text参数应该是str类型。类似地,可选的align参数应该具有类型bool,默认值为True。最后,-> str符号指定headline()将返回一个字符串。
- 对冒号使用常规规则,即冒号前没有空格,冒号后有一个空格:
text: str。 - 将参数注释与默认值
align: bool = True组合时,请在=符号周围使用空格。 - 在
->箭头周围使用空格:def headline(...) -> str。
像这样添加类型提示没有运行时效果:它们只是提示,本身并不强制执行。例如,如果我们对align参数使用了错误的类型(不可否认,它的名字很糟糕),代码仍然可以运行,没有任何问题或警告:
>>> print(headline("python type checking", align="left")) Python Type Checking --------------------注意:这看似可行的原因是字符串
"left"比较起来像真值。使用align="center"不会有预期的效果,因为"center"也是真实的。为了捕捉这种错误,您可以使用静态类型检查器。也就是说,这是一个检查代码类型的工具,而不是传统意义上的实际运行。
您可能已经在编辑器中内置了这样的类型检查器。例如 PyCharm 会立即给你一个警告:
不过最常用的类型检查工具是 Mypy 。一会儿你会得到一个关于 Mypy 的简短介绍,稍后你会了解更多关于它如何工作的。
如果您的系统上还没有 Mypy,您可以使用
pip安装它:$ pip install mypy将以下代码放在名为
headlines.py的文件中:1# headlines.py 2 3def headline(text: str, align: bool = True) -> str: 4 if align: 5 return f"{text.title()}\n{'-' * len(text)}" 6 else: 7 return f" {text.title()} ".center(50, "o") 8 9print(headline("python type checking")) 10print(headline("use mypy", align="center"))这基本上与您之前看到的代码相同:
headline()的定义和两个使用它的例子。现在对这段代码运行 Mypy:
$ mypy headlines.py headlines.py:10: error: Argument "align" to "headline" has incompatible type "str"; expected "bool"根据类型提示,Mypy 能够告诉我们在第 10 行使用了错误的类型。
要修复代码中的问题,您应该更改传入的参数
align的值。您也可以将align标志重命名为一个不太容易混淆的名称:1# headlines.py 2 3def headline(text: str, centered: bool = False) -> str: 4 if not centered: 5 return f"{text.title()}\n{'-' * len(text)}" 6 else: 7 return f" {text.title()} ".center(50, "o") 8 9print(headline("python type checking")) 10print(headline("use mypy", centered=True))在这里,您已经将
align更改为centered,并且在调用headline()时正确地使用了一个布尔值来表示centered。代码现在通过了 Mypy:$ mypy headlines.py Success: no issues found in 1 source file成功消息确认没有检测到类型错误。旧版本的 Mypy 通过不显示任何输出来表明这一点。此外,当您运行代码时,您会看到预期的输出:
$ python headlines.py Python Type Checking -------------------- oooooooooooooooooooo Use Mypy oooooooooooooooooooo第一个标题靠左对齐,而第二个标题居中。
利弊
上一节让您初步了解了 Python 中的类型检查。您还看到了向代码中添加类型的一个好处:类型提示帮助捕捉某些错误。其他优势包括:
类型提示帮助记录你的代码。传统上,如果你想记录函数参数的预期类型,你会使用文档字符串。这是可行的,但是由于没有文档字符串的标准(尽管有 PEP 257 ,它们不能被容易地用于自动检查。
类型提示改进 ide 和 linters 。它们使得对代码进行静态推理变得更加容易。这反过来允许 ide 提供更好的代码完成和类似的特性。通过类型标注,PyCharm 知道
text是一个字符串,并可以基于此给出具体建议:
T4】
类型提示帮助你构建和维护一个更干净的架构。编写类型提示的行为迫使你考虑程序中的类型。虽然 Python 的动态特性是它的一大优点,但意识到依赖 duck 类型、重载方法或多返回类型是一件好事。
当然,静态类型检查并不全是桃子和奶油。还有一些你应该考虑的缺点:
类型提示需要开发人员花费时间和精力来添加。尽管花更少的时间调试可能会有回报,但你会花更多的时间输入代码。
类型提示在现代 python中效果最好。注释是在 Python 3.0 中引入的,在 Python 2.7 中可以使用类型的注释。尽管如此,像变量注释和推迟类型提示的评估这样的改进意味着使用 Python 3.6 甚至 Python 3.7 进行类型检查会有更好的体验。
稍后你将了解
typing模块,以及在大多数情况下当你添加类型提示时它是如何必要的。导入模块必然要花一些时间,但是要花多少时间呢?为了了解这一点,创建两个文件:
empty_file.py应该是一个空文件,而import_typing.py应该包含以下行:import typing在 Linux 上,使用
perf实用程序很容易检查typing导入需要多少时间:$ perf stat -r 1000 python3.6 import_typing.py Performance counter stats for 'python3.6 import_typing.py' (1000 runs): [ ... extra information hidden for brevity ... ] 0.045161650 seconds time elapsed ( +- 0.77% )所以运行
import typing.py脚本大约需要 45 毫秒。当然,这并不是花在导入typing上的所有时间。其中一些是启动 Python 解释器的开销,所以让我们比较一下在空文件上运行 Python:$ perf stat -r 1000 python3.6 empty_file.py Performance counter stats for 'python3.6 empty_file.py' (1000 runs): [ ... extra information hidden for brevity ... ] 0.028077845 seconds time elapsed ( +- 0.49% )根据这个测试,在 Python 3.6 中,
typing模块的导入大约需要 17 毫秒。Python 3.7 中宣传的改进之一是更快的启动。让我们看看结果是否不同:
$ perf stat -r 1000 python3.7 import_typing.py [...] 0.025979806 seconds time elapsed ( +- 0.31% ) $ perf stat -r 1000 python3.7 empty_file.py [...] 0.020002505 seconds time elapsed ( +- 0.30% )事实上,一般启动时间减少了大约 8 毫秒,导入
typing的时间从 17 毫秒减少到大约 6 毫秒——几乎快了 3 倍。使用
timeit其他平台上也有类似的工具。Python 本身带有标准库中的
timeit模块。通常,我们会直接使用timeit作为上面的计时。然而,timeit很难确定可靠的导入时间,因为 Python 擅长于只导入模块一次。考虑下面的例子:$ python3.6 -m timeit "import typing" 10000000 loops, best of 3: 0.134 usec per loop当你得到一个结果时,你应该怀疑这个结果:0.1 微秒比
perf测得的要快 100000 倍以上!timeit实际做的是运行import typing语句 3000 万次,而 Python 实际上只导入了typing一次。为了获得合理的结果,您可以告诉
timeit只运行一次:$ python3.6 -m timeit -n 1 -r 1 "import typing" 1 loops, best of 1: 9.77 msec per loop $ python3.7 -m timeit -n 1 -r 1 "import typing" 1 loop, best of 1: 1.97 msec per loop这些结果与上述
perf的结果处于同一等级。然而,由于这些只是基于代码的一次执行,它们不如基于多次运行的那些可靠。这两种情况下的结论都是导入
typing需要几毫秒。对于您编写的大多数程序和脚本来说,这可能不是问题。新的
importtime选项在 Python 3.7 中,还有一个新的命令行选项,可以用来计算导入需要多少时间。使用
-X importtime您将得到一份关于所有进口的报告:$ python3.7 -X importtime import_typing.py import time: self [us] | cumulative | imported package [ ... some information hidden for brevity ... ] import time: 358 | 358 | zipimport import time: 2107 | 14610 | site import time: 272 | 272 | collections.abc import time: 664 | 3058 | re import time: 3044 | 6373 | typing这显示了类似的结果。导入
typing大约需要 6 毫秒。如果你仔细阅读报告,你会注意到大约一半的时间花在导入typing所依赖的collections.abc和re模块上。那么,您应该在自己的代码中使用静态类型检查吗?这不是一个全有或全无的问题。幸运的是,Python 支持逐步输入的概念。这意味着您可以逐渐将类型引入到代码中。没有类型提示的代码将被静态类型检查器忽略。因此,您可以开始向关键组件添加类型,并且只要它为您增加价值就继续下去。
看看上面的利弊列表,你会注意到添加类型对你正在运行的程序或程序的用户没有任何影响。类型检查是为了让开发人员的生活更好、更方便。
关于是否向项目中添加类型的一些经验法则是:
如果你刚刚开始学习 Python,你可以放心地等待类型提示,直到你有了更多的经验。
类型提示在简短的抛弃型脚本中没有增加什么价值。
在将被其他人使用的库中,尤其是那些在 PyPI 上发布的库,类型提示增加了很多价值。使用您的库的其他代码需要这些类型提示来进行正确的类型检查。使用类型提示的项目示例参见
cursive_re、black、我们自己的 Real Python Reader 和 Mypy 本身。在较大的项目中,类型提示有助于理解类型如何在代码中流动,强烈推荐使用。在与他人合作的项目中更是如此。
在他的优秀文章Python 中类型提示的状态中,Bernát Gábor 建议“只要单元测试值得编写,就应该使用类型提示事实上,类型提示在你的代码中扮演着类似于测试的角色:它们帮助你作为开发者写出更好的代码。
希望您现在已经了解了 Python 中的类型检查是如何工作的,以及您是否想在自己的项目中使用它。
在本指南的其余部分,我们将更详细地介绍 Python 类型系统,包括如何运行静态类型检查器(特别关注 Mypy),如何在没有类型提示的情况下键入使用库的检查代码,以及如何在运行时使用注释。
注释
注释是在 Python 3.0 中引入的,最初没有任何特定的用途。它们只是一种将任意表达式与函数参数和返回值关联起来的方法。
几年后, PEP 484 基于 Jukka Lehtosalo 在他的博士项目 Mypy 上所做的工作,定义了如何在 Python 代码中添加类型提示。添加类型提示的主要方式是使用批注。随着类型检查变得越来越普遍,这也意味着注释应该主要用于类型提示。
接下来的部分解释了注释如何在类型提示的上下文中工作。
功能注释
对于函数,您可以注释参数和返回值。这是按如下方式完成的:
def func(arg: arg_type, optarg: arg_type = default) -> return_type: ...对于参数,语法是
argument: annotation,而返回类型使用-> annotation进行注释。请注意,注释必须是有效的 Python 表达式。下面的简单示例向计算圆周的函数添加注释:
import math def circumference(radius: float) -> float: return 2 * math.pi * radius运行代码时,您还可以检查注释。它们存储在函数的一个特殊的
.__annotations__属性中:

>>> circumference(1.23)
7.728317927830891
>>> circumference.__annotations__
{'radius': <class 'float'>, 'return': <class 'float'>}
有时你可能会对 Mypy 如何解释你的类型提示感到困惑。对于那些情况,有特殊的 Mypy 表达式:reveal_type()和reveal_locals()。您可以在运行 Mypy 之前将这些添加到您的代码中,Mypy 将忠实地报告它推断出了哪些类型。例如,将下面的代码保存到reveal.py:
1# reveal.py
2
3import math
4reveal_type(math.pi) 5
6radius = 1
7circumference = 2 * math.pi * radius
8reveal_locals()
接下来,通过 Mypy 运行这段代码:
$ mypy reveal.py
reveal.py:4: error: Revealed type is 'builtins.float'
reveal.py:8: error: Revealed local types are:
reveal.py:8: error: circumference: builtins.float
reveal.py:8: error: radius: builtins.int
即使没有任何注释,Mypy 也能正确地推断出内置的类型math.pi,以及我们的局部变量radius和circumference。
注意:reveal 表达式仅仅是一个帮助你添加类型和调试类型提示的工具。如果你试图以 Python 脚本的形式运行reveal.py文件,它会因NameError而崩溃,因为reveal_type()不是 Python 解释器已知的函数。
如果 Mypy 说“Name ' reveal_locals'未定义”,您可能需要更新您的 Mypy 安装。reveal_locals()表达式在 Mypy 版本 0.610 及更高版本中可用。
变量注释
在前一节的circumference()的定义中,您只注释了参数和返回值。您没有在函数体中添加任何注释。通常情况下,这就足够了。
然而,有时类型检查器也需要帮助来确定变量的类型。变量注释在 PEP 526 中定义,并在 Python 3.6 中引入。语法与函数参数注释的语法相同:
pi: float = 3.142
def circumference(radius: float) -> float:
return 2 * pi * radius
变量pi已经用float类型提示进行了注释。
注意:静态类型的检查器更能判断出3.142是一个浮点数,所以在这个例子中pi的注释是不必要的。随着您对 Python 类型系统的了解越来越多,您将会看到更多变量注释的相关示例。
变量的注释存储在模块级__annotations__字典中:
>>> circumference(1) 6.284 >>> __annotations__ {'pi': <class 'float'>}你可以注释一个变量,而不用给它赋值。这将注释添加到
__annotations__字典中,而变量仍未定义:
>>> nothing: str
>>> nothing
NameError: name 'nothing' is not defined
>>> __annotations__
{'nothing': <class 'str'>}
因为没有给nothing赋值,所以还没有定义名称nothing。
键入注释
如前所述,注释是在 Python 3 中引入的,它们还没有被移植到 Python 2 中。这意味着如果你正在编写需要支持传统 Python 的代码,你不能使用注释。
相反,您可以使用类型注释。这些是特殊格式的注释,可用于添加与旧代码兼容的类型提示。要在函数中添加类型注释,您需要执行如下操作:
import math
def circumference(radius):
# type: (float) -> float return 2 * math.pi * radius
类型注释只是注释,所以它们可以在任何版本的 Python 中使用。
类型注释由类型检查器直接处理,因此这些类型在__annotations__字典中不可用:
>>> circumference.__annotations__ {}类型注释必须以
type:开始,并且与函数定义在同一行或下一行。如果你想用几个参数注释一个函数,你可以用逗号分隔每个类型:def headline(text, width=80, fill_char="-"): # type: (str, int, str) -> str return f" {text.title()} ".center(width, fill_char) print(headline("type comments work", width=40))您还可以将每个参数写在单独的一行上,并带有自己的注释:
1# headlines.py 2 3def headline( 4 text, # type: str 5 width=80, # type: int 6 fill_char="-", # type: str 7): # type: (...) -> str 8 return f" {text.title()} ".center(width, fill_char) 9 10print(headline("type comments work", width=40))通过 Python 和 Mypy 运行示例:
$ python headlines.py ---------- Type Comments Work ---------- $ mypy headlines.py Success: no issues found in 1 source file如果你有错误,比如你碰巧在第 10 行用
width="full"调用了headline(),Mypy 会告诉你:$ mypy headline.py headline.py:10: error: Argument "width" to "headline" has incompatible type "str"; expected "int"还可以向变量添加类型注释。这与向参数添加类型注释的方式类似:
pi = 3.142 # type: float在本例中,
pi将作为一个浮点变量进行类型检查。所以,打注释还是打注释?
向自己的代码中添加类型提示时,应该使用批注还是类型注释?简而言之:能用注释就用注释,不能用就用类型注释。
注释提供了更简洁的语法,使类型信息更接近于您的代码。它们也是官方推荐的书写类型提示的方式,以后会进一步开发和适当维护。
类型注释更加冗长,可能会与代码中其他类型的注释冲突,比如 linter 指令。但是,它们可以用在不支持注释的代码库中。
还有第三个隐藏选项:存根文件。稍后,当我们讨论向第三方库添加类型时,你会了解到这些。
存根文件可以在任何版本的 Python 中工作,代价是必须维护第二组文件。一般来说,如果不能更改原始源代码,您只希望使用存根文件。
使用 Python 类型,第 1 部分
到目前为止,你只在类型提示中使用了像
str、float和bool这样的基本类型。Python 类型系统非常强大,支持多种更复杂的类型。这是必要的,因为它需要能够合理地模拟 Python 的动态鸭类型化特性。在这一节中,您将学习更多关于这种类型系统的知识,同时实现一个简单的纸牌游戏。您将看到如何指定:
在短暂地了解了一些类型理论之后,你将会看到在 Python 中用指定类型的更多方法。你可以在这里找到本节的代码示例。
例子:一副牌
以下示例显示了一副普通(法式)纸牌的实现:
1# game.py 2 3import random 4 5SUITS = "♠ ♡ ♢ ♣".split() 6RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split() 7 8def create_deck(shuffle=False): 9 """Create a new deck of 52 cards""" 10 deck = [(s, r) for r in RANKS for s in SUITS] 11 if shuffle: 12 random.shuffle(deck) 13 return deck 14 15def deal_hands(deck): 16 """Deal the cards in the deck into four hands""" 17 return (deck[0::4], deck[1::4], deck[2::4], deck[3::4]) 18 19def play(): 20 """Play a 4-player card game""" 21 deck = create_deck(shuffle=True) 22 names = "P1 P2 P3 P4".split() 23 hands = {n: h for n, h in zip(names, deal_hands(deck))} 24 25 for name, cards in hands.items(): 26 card_str = " ".join(f"{s}{r}" for (s, r) in cards) 27 print(f"{name}: {card_str}") 28 29if __name__ == "__main__": 30 play()每张牌都被表示为一组表示花色和等级的字符串。这副牌被表示为一列卡片。创建一副常规的 52 张扑克牌,并随意洗牌。
deal_hands()向四名玩家分发一副牌。最后,
play()玩游戏。截至目前,它只准备了一个纸牌游戏,通过建立一个洗牌甲板和分发卡给每个球员。以下是典型的输出:$ python game.py P4: ♣9 ♢9 ♡2 ♢7 ♡7 ♣A ♠6 ♡K ♡5 ♢6 ♢3 ♣3 ♣Q P1: ♡A ♠2 ♠10 ♢J ♣10 ♣4 ♠5 ♡Q ♢5 ♣6 ♠A ♣5 ♢4 P2: ♢2 ♠7 ♡8 ♢K ♠3 ♡3 ♣K ♠J ♢A ♣7 ♡6 ♡10 ♠K P3: ♣2 ♣8 ♠8 ♣J ♢Q ♡9 ♡J ♠4 ♢8 ♢10 ♠9 ♡4 ♠Q随着我们的进展,您将看到如何将这个例子扩展到一个更有趣的游戏中。
序列和映射
让我们给我们的纸牌游戏添加类型提示。换句话说,让我们注释函数
create_deck()、deal_hands()和play()。第一个挑战是您需要注释复合类型,比如用于表示卡片组的列表和用于表示卡片本身的元组。对于像
str、float和bool这样的简单类型,添加类型提示就像使用类型本身一样简单:
>>> name: str = "Guido"
>>> pi: float = 3.142
>>> centered: bool = False
对于复合类型,您也可以这样做:
>>> names: list = ["Guido", "Jukka", "Ivan"] >>> version: tuple = (3, 7, 1) >>> options: dict = {"centered": False, "capitalize": True}然而,这并没有真正说明全部情况。
names[2]、version[0]、options["centered"]的类型会是什么?在这个具体案例中,你可以看到它们分别是str、int和bool。然而,类型提示本身并没有给出这方面的信息。相反,你应该使用在
typing模块中定义的特殊类型。这些类型添加了用于指定复合类型的元素类型的语法。您可以编写以下内容:
>>> from typing import Dict, List, Tuple
>>> names: List[str] = ["Guido", "Jukka", "Ivan"]
>>> version: Tuple[int, int, int] = (3, 7, 1)
>>> options: Dict[str, bool] = {"centered": False, "capitalize": True}
请注意,这些类型都以大写字母开头,并且都使用方括号来定义项目类型:
names是一串字符串version是由三个整数组成的三元组options是一个将字符串映射为布尔值的字典
typing模块包含更多的复合类型,包括Counter、Deque、FrozenSet、NamedTuple和Set。此外,该模块还包括其他类型,您将在后面的章节中看到。
让我们回到纸牌游戏。一张卡由两个字符串的元组表示。你可以把这个写成Tuple[str, str],那么这副牌的类型就变成了List[Tuple[str, str]]。因此你可以将create_deck()注释如下:
8def create_deck(shuffle: bool = False) -> List[Tuple[str, str]]:
9 """Create a new deck of 52 cards"""
10 deck = [(s, r) for r in RANKS for s in SUITS]
11 if shuffle:
12 random.shuffle(deck)
13 return deck
除了返回值之外,您还向可选的shuffle参数添加了bool类型。
注意:元组和列表的注释不同。
元组是不可变的序列,通常由固定数量的可能不同类型的元素组成。例如,我们将一张牌表示为花色和等级的元组。一般来说,你为一个 n 元组写Tuple[t_1, t_2, ..., t_n]。
列表是一个可变的序列,通常由未知数量的相同类型的元素组成,例如卡片列表。无论列表中有多少元素,注释中只有一种类型:List[t]。
在很多情况下,你的函数会期待某种类型的序列,并不真正关心它是一个列表还是一个元组。在这些情况下,您应该在注释函数参数时使用typing.Sequence:
from typing import List, Sequence
def square(elems: Sequence[float]) -> List[float]:
return [x**2 for x in elems]
使用Sequence是使用 duck 类型的一个例子。一个Sequence是支持len()和.__getitem__()的任何东西,独立于它的实际类型。
类型别名
当使用嵌套类型(如卡片组)时,类型提示可能会变得相当模糊。你可能需要盯着List[Tuple[str, str]]看一会儿,然后才能发现它与我们描述的一副牌相匹配。
现在考虑如何注释deal_hands():
15def deal_hands(
16 deck: List[Tuple[str, str]]
17) -> Tuple[
18 List[Tuple[str, str]],
19 List[Tuple[str, str]],
20 List[Tuple[str, str]],
21 List[Tuple[str, str]],
22]:
23 """Deal the cards in the deck into four hands"""
24 return (deck[0::4], deck[1::4], deck[2::4], deck[3::4])
太可怕了!
回想一下,类型注释是正则 Python 表达式。这意味着您可以通过将类型别名赋给新变量来定义自己的类型别名。例如,您可以创建Card和Deck类型别名:
from typing import List, Tuple
Card = Tuple[str, str]
Deck = List[Card]
Card现在可以用在类型提示或新类型别名的定义中,就像上面例子中的Deck。
使用这些别名,deal_hands()的注释变得更加易读:
15def deal_hands(deck: Deck) -> Tuple[Deck, Deck, Deck, Deck]:
16 """Deal the cards in the deck into four hands"""
17 return (deck[0::4], deck[1::4], deck[2::4], deck[3::4])
类型别名对于使您的代码及其意图更加清晰非常有用。同时,可以检查这些别名以了解它们代表什么:
>>> from typing import List, Tuple >>> Card = Tuple[str, str] >>> Deck = List[Card] >>> Deck typing.List[typing.Tuple[str, str]]注意,当打印
Deck时,它显示它是一个 2 元组字符串列表的别名。没有返回值的函数
你可能知道没有显式返回的函数仍然返回
None:
>>> def play(player_name):
... print(f"{player_name} plays")
...
>>> ret_val = play("Jacob")
Jacob plays
>>> print(ret_val)
None
虽然这些函数在技术上返回一些东西,但是返回值是没有用的。您应该通过使用None作为返回类型来添加类型提示:
1# play.py
2
3def play(player_name: str) -> None:
4 print(f"{player_name} plays")
5
6ret_val = play("Filip")
注释有助于捕捉那些试图使用无意义返回值的微妙错误。Mypy 会给你一个有用的警告:
$ mypy play.py
play.py:6: error: "play" does not return a value
请注意,明确说明函数不返回任何内容不同于不添加有关返回值的类型提示:
# play.py
def play(player_name: str):
print(f"{player_name} plays")
ret_val = play("Henrik")
在后一种情况下,Mypy 没有关于返回值的信息,因此它不会生成任何警告:
$ mypy play.py
Success: no issues found in 1 source file
作为一个更奇特的例子,请注意,您还可以注释那些永远不会正常返回的函数。这是用 NoReturn 完成的:
from typing import NoReturn
def black_hole() -> NoReturn:
raise Exception("There is no going back ...")
由于black_hole()总是引发异常,它将永远不会正确返回。
示例:玩一些牌
让我们回到我们的卡牌游戏例子。在这个游戏的第二个版本中,我们像以前一样给每个玩家发一手牌。然后选择一个开始玩家,玩家轮流出牌。不过,游戏中并没有什么规则,所以玩家只会随机出牌:
1# game.py
2
3import random
4from typing import List, Tuple
5
6SUITS = "♠ ♡ ♢ ♣".split()
7RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split()
8
9Card = Tuple[str, str]
10Deck = List[Card]
11
12def create_deck(shuffle: bool = False) -> Deck:
13 """Create a new deck of 52 cards"""
14 deck = [(s, r) for r in RANKS for s in SUITS]
15 if shuffle:
16 random.shuffle(deck)
17 return deck
18
19def deal_hands(deck: Deck) -> Tuple[Deck, Deck, Deck, Deck]:
20 """Deal the cards in the deck into four hands"""
21 return (deck[0::4], deck[1::4], deck[2::4], deck[3::4])
22
23def choose(items):
24 """Choose and return a random item"""
25 return random.choice(items)
26
27def player_order(names, start=None):
28 """Rotate player order so that start goes first"""
29 if start is None:
30 start = choose(names)
31 start_idx = names.index(start)
32 return names[start_idx:] + names[:start_idx]
33
34def play() -> None:
35 """Play a 4-player card game"""
36 deck = create_deck(shuffle=True)
37 names = "P1 P2 P3 P4".split()
38 hands = {n: h for n, h in zip(names, deal_hands(deck))}
39 start_player = choose(names)
40 turn_order = player_order(names, start=start_player)
41
42 # Randomly play cards from each player's hand until empty
43 while hands[start_player]:
44 for name in turn_order:
45 card = choose(hands[name])
46 hands[name].remove(card)
47 print(f"{name}: {card[0] + card[1]:<3} ", end="")
48 print()
49
50if __name__ == "__main__":
51 play()
注意,除了改变play(),我们还增加了两个需要类型提示的新函数:choose()和player_order()。在讨论如何向它们添加类型提示之前,这里有一个运行游戏的输出示例:
$ python game.py
P3: ♢10 P4: ♣4 P1: ♡8 P2: ♡Q
P3: ♣8 P4: ♠6 P1: ♠5 P2: ♡K
P3: ♢9 P4: ♡J P1: ♣A P2: ♡A
P3: ♠Q P4: ♠3 P1: ♠7 P2: ♠A
P3: ♡4 P4: ♡6 P1: ♣2 P2: ♠K
P3: ♣K P4: ♣7 P1: ♡7 P2: ♠2
P3: ♣10 P4: ♠4 P1: ♢5 P2: ♡3
P3: ♣Q P4: ♢K P1: ♣J P2: ♡9
P3: ♢2 P4: ♢4 P1: ♠9 P2: ♠10
P3: ♢A P4: ♡5 P1: ♠J P2: ♢Q
P3: ♠8 P4: ♢7 P1: ♢3 P2: ♢J
P3: ♣3 P4: ♡10 P1: ♣9 P2: ♡2
P3: ♢6 P4: ♣6 P1: ♣5 P2: ♢8
在这个例子中,玩家P3被随机选为开始玩家。依次,每个玩家出一张牌:首先是P3,然后是P4,然后是P1,最后是P2。只要手里还有牌,玩家们就继续打牌。
Any类型
choose()对名字列表和卡片列表(以及任何其他序列)都有效。为此添加类型提示的一种方法是:
import random
from typing import Any, Sequence
def choose(items: Sequence[Any]) -> Any:
return random.choice(items)
这或多或少意味着:items是一个序列,可以包含任何类型的项目,choose()将返回一个任何类型的项目。不幸的是,这并没有那么有用。考虑下面的例子:
1# choose.py
2
3import random
4from typing import Any, Sequence
5
6def choose(items: Sequence[Any]) -> Any:
7 return random.choice(items)
8
9names = ["Guido", "Jukka", "Ivan"]
10reveal_type(names)
11
12name = choose(names)
13reveal_type(name)
虽然 Mypy 会正确地推断出names是一个字符串列表,但是由于使用了Any类型,该信息在调用choose()后会丢失:
$ mypy choose.py
choose.py:10: error: Revealed type is 'builtins.list[builtins.str*]'
choose.py:13: error: Revealed type is 'Any'
你很快就会看到更好的方法。不过,首先让我们从理论上看一下 Python 类型系统,以及Any所扮演的特殊角色。
类型理论
本教程主要是一个实践指南,我们将仅仅触及支撑 Python 类型提示的理论的表面。要了解更多细节,PEP 483 是一个很好的起点。如果你想回到实际例子,请随意跳到下一节。
子类型
一个重要的概念是亚型。形式上,如果以下两个条件成立,我们说类型T是U的子类型:
- 来自
T的每个值也在U类型的值集中。 - 来自
U类型的每个函数也在T类型的函数集中。
这两个条件保证了即使类型T与U不同,T类型的变量也可以一直伪装成U。
具体的例子,考虑T = bool和U = int。bool类型只有两个值。通常这些被表示为True和False,但是这些名字分别只是整数值1和0的别名:
>>> int(False) 0 >>> int(True) 1 >>> True + True 2 >>> issubclass(bool, int) True因为 0 和 1 都是整数,所以第一个条件成立。上面你可以看到布尔可以加在一起,但是它们也可以做整数能做的任何事情。这是上面的第二个条件。换句话说,
bool是int的一个子类型。子类型的重要性在于一个子类型可以一直伪装成它的超类型。例如,以下代码类型检查是否正确:
def double(number: int) -> int: return number * 2 print(double(True)) # Passing in bool instead of int子类型和子类有些关系。事实上,所有子类都对应于子类型,而
bool是int的子类型,因为bool是int的子类。但是,也有子类型不对应子类。例如,int是float的子类,但是int不是float的子类。协变、逆变和不变
在复合类型中使用子类型会发生什么?例如,
Tuple[bool]是Tuple[int]的子类型吗?答案取决于复合类型,以及该类型是协变、逆变还是不变。这是一个很快的技术问题,所以让我们举几个例子:
Tuple是协变的。这意味着它保留了其条目类型的类型层次:Tuple[bool]是Tuple[int]的子类型,因为bool是int的子类型。
List不变。不变类型对于子类型没有任何保证。虽然List[bool]的所有值都是List[int]的值,但是您可以将int附加到List[int]而不是List[bool]。换句话说,子类型的第二个条件不成立,List[bool]不是List[int]的子类型。
Callable在论证中是逆变的。这意味着它颠倒了类型层次结构。稍后你会看到Callable如何工作,但是现在把Callable[[T], ...]看作一个函数,它唯一的参数是类型T。一个Callable[[int], ...]的例子是上面定义的double()函数。逆变意味着如果在bool上运行的函数是预期的,那么在int上运行的函数将是可接受的。一般来说,你不需要直截了当地表达。但是,您应该意识到子类型和复合类型可能并不简单和直观。
渐进分型和一致分型
前面我们提到 Python 支持逐步类型化,在这里你可以逐步向你的 Python 代码添加类型提示。逐步打字基本上是通过
Any类型实现的。不知何故,
Any位于子类型的类型层次结构的顶部和底部。任何类型的行为就好像它是Any的子类型,而Any的行为就好像它是任何其他类型的子类型。看上面子类型的定义,这是不太可能的。相反,我们谈论一致的类型。如果
T是U的子类型或者T或U是Any,则T类型与U类型一致。类型检查器只抱怨不一致的类型。因此,要点是您永远不会看到由
Any类型引起的类型错误。这意味着您可以使用
Any显式地退回到动态类型,描述过于复杂而无法在 Python 类型系统中描述的类型,或者描述复合类型中的项。例如,一个带有字符串键的字典可以将任何类型作为它的值,它可以被注释Dict[str, Any]。但是请记住,如果你使用
Any,静态类型检查器实际上不会做任何类型检查。使用 Python 类型,第 2 部分
让我们回到我们的实际例子。回想一下,您试图注释一般的
choose()函数:import random from typing import Any, Sequence def choose(items: Sequence[Any]) -> Any: return random.choice(items)使用
Any的问题是你会不必要的丢失类型信息。你知道如果你传递一个字符串列表给choose(),它会返回一个字符串。下面您将看到如何使用类型变量来表达这一点,以及如何处理:类型变量
类型变量是一种特殊的变量,可以根据具体情况采用任何类型。
让我们创建一个类型变量,它将有效地封装
choose()的行为:1# choose.py 2 3import random 4from typing import Sequence, TypeVar 5 6Choosable = TypeVar("Choosable") 7 8def choose(items: Sequence[Choosable]) -> Choosable: 9 return random.choice(items) 10 11names = ["Guido", "Jukka", "Ivan"] 12reveal_type(names) 13 14name = choose(names) 15reveal_type(name)必须使用来自
typing模块的TypeVar定义类型变量。使用时,类型变量涵盖所有可能的类型,并尽可能采用最具体的类型。在这个例子中,name现在是一个str:$ mypy choose.py choose.py:12: error: Revealed type is 'builtins.list[builtins.str*]' choose.py:15: error: Revealed type is 'builtins.str*'考虑其他几个例子:
1# choose_examples.py 2 3from choose import choose 4 5reveal_type(choose(["Guido", "Jukka", "Ivan"])) 6reveal_type(choose([1, 2, 3])) 7reveal_type(choose([True, 42, 3.14])) 8reveal_type(choose(["Python", 3, 7])前两个例子应该有类型
str和int,但是后两个呢?单个列表项有不同的类型,在这种情况下,Choosable类型变量会尽力适应:$ mypy choose_examples.py choose_examples.py:5: error: Revealed type is 'builtins.str*' choose_examples.py:6: error: Revealed type is 'builtins.int*' choose_examples.py:7: error: Revealed type is 'builtins.float*' choose_examples.py:8: error: Revealed type is 'builtins.object*'正如你已经看到的,
bool是int的一个子类型,而int又是float的一个子类型。所以在第三个例子中,choose()的返回值肯定是可以被认为是一个float的值。在最后一个例子中,str和int之间没有子类型关系,所以关于返回值最好的说法是它是一个对象。请注意,这些示例都没有引发类型错误。有没有办法告诉类型检查器
choose()应该同时接受字符串和数字,但不能同时接受两者?您可以通过列出可接受的类型来约束类型变量:
1# choose.py 2 3import random 4from typing import Sequence, TypeVar 5 6Choosable = TypeVar("Choosable", str, float) 7 8def choose(items: Sequence[Choosable]) -> Choosable: 9 return random.choice(items) 10 11reveal_type(choose(["Guido", "Jukka", "Ivan"])) 12reveal_type(choose([1, 2, 3])) 13reveal_type(choose([True, 42, 3.14])) 14reveal_type(choose(["Python", 3, 7]))现在
Choosable只能是str或者float,Mypy 会注意到最后一个例子是错误的:$ mypy choose.py choose.py:11: error: Revealed type is 'builtins.str*' choose.py:12: error: Revealed type is 'builtins.float*' choose.py:13: error: Revealed type is 'builtins.float*' choose.py:14: error: Revealed type is 'builtins.object*' choose.py:14: error: Value of type variable "Choosable" of "choose" cannot be "object"还要注意,在第二个例子中,类型被认为是
float,即使输入列表只包含int对象。这是因为Choosable仅限于字符串和浮动,而int是float的一个子类型。在我们的卡牌游戏中,我们希望限制
choose()用于str和Card:Choosable = TypeVar("Choosable", str, Card) def choose(items: Sequence[Choosable]) -> Choosable: ...我们简单提到过
Sequence既代表列表又代表元组。正如我们所提到的,Sequence可以被认为是一个 duck 类型,因为它可以是任何实现了.__len__()和.__getitem__()的对象。鸭子类型和协议
回想一下引言中的以下例子:
def len(obj): return obj.__len__()
len()可以返回任何实现了.__len__()方法的对象的长度。我们如何给len()添加类型提示,尤其是obj参数?答案隐藏在学术术语结构子类型的背后。对类型系统进行分类的一种方式是根据它们是名义还是结构:
在一个标称系统中,类型之间的比较是基于名字和声明的。Python 类型系统大多是名义上的,因为它们的子类型关系,可以用一个
int来代替一个float。在一个结构系统中,类型之间的比较是基于结构的。您可以定义一个结构类型
Sized,它包括定义.__len__()的所有实例,而不管它们的名义类型。正在进行的工作是通过 PEP 544 为 Python 带来一个成熟的结构类型系统,其目的是增加一个叫做协议的概念。PEP 544 的大部分已经在 Mypy 中实现了。
协议指定了一个或多个必须实现的方法。例如,所有定义
.__len__()的类都满足typing.Sized协议。因此,我们可以将len()注释如下:from typing import Sized def len(obj: Sized) -> int: return obj.__len__()在
typing模块中定义的协议的其他例子包括Container、Iterable、Awaitable和ContextManager。您也可以定义自己的协议。这是通过从
Protocol继承并定义协议期望的函数签名(带有空函数体)来完成的。下面的例子展示了如何实现len()和Sized:from typing_extensions import Protocol class Sized(Protocol): def __len__(self) -> int: ... def len(obj: Sized) -> int: return obj.__len__()在撰写本文时,对自定义协议的支持仍处于试验阶段,只能通过
typing_extensions模块获得。这个模块必须通过做pip install typing-extensions从 PyPI 显式安装。
Optional类型Python 中一个常见的模式是使用
None作为参数的默认值。这样做通常是为了避免可变缺省值的问题,或者用一个标记值来标记特殊行为。在卡片示例中,
player_order()函数使用None作为start的标记值,表示如果没有给出开始玩家,则应该随机选择:27def player_order(names, start=None): 28 """Rotate player order so that start goes first""" 29 if start is None: 30 start = choose(names) 31 start_idx = names.index(start) 32 return names[start_idx:] + names[:start_idx]这给类型提示带来的挑战是一般来说
start应该是一个字符串。但是,它也可能采用特殊的非字符串值None。为了注释这样的参数,您可以使用
Optional类型:from typing import Sequence, Optional def player_order( names: Sequence[str], start: Optional[str] = None ) -> Sequence[str]: ...
Optional类型简单地说,变量要么具有指定的类型,要么是None。指定相同内容的等效方式是使用Union类型:Union[None, str]注意,当使用
Optional或Union时,你必须注意当你操作变量时,变量具有正确的类型。在示例中,这是通过测试start is None是否。不这样做将导致静态类型错误以及可能的运行时错误:1# player_order.py 2 3from typing import Sequence, Optional 4 5def player_order( 6 names: Sequence[str], start: Optional[str] = None 7) -> Sequence[str]: 8 start_idx = names.index(start) 9 return names[start_idx:] + names[:start_idx]Mypy 告诉您,您没有考虑到
start是None的情况:$ mypy player_order.py player_order.py:8: error: Argument 1 to "index" of "list" has incompatible type "Optional[str]"; expected "str"注意:使用
None作为可选参数非常普遍,以至于 Mypy 会自动处理它。Mypy 假设默认参数None表示可选参数,即使类型提示没有明确这样说。您可以使用以下内容:def player_order(names: Sequence[str], start: str = None) -> Sequence[str]: ...如果您不希望 Mypy 做出这样的假设,您可以使用
--no-implicit-optional命令行选项关闭它。例子:游戏的对象(ive)
让我们重写纸牌游戏,使其更加面向对象。这将允许我们讨论如何正确地注释类和方法。
将我们的纸牌游戏或多或少地直接翻译成使用了
Card、Deck、Player和Game类的代码,看起来如下所示:1# game.py 2 3import random 4import sys 5 6class Card: 7 SUITS = "♠ ♡ ♢ ♣".split() 8 RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split() 9 10 def __init__(self, suit, rank): 11 self.suit = suit 12 self.rank = rank 13 14 def __repr__(self): 15 return f"{self.suit}{self.rank}" 16 17class Deck: 18 def __init__(self, cards): 19 self.cards = cards 20 21 @classmethod 22 def create(cls, shuffle=False): 23 """Create a new deck of 52 cards""" 24 cards = [Card(s, r) for r in Card.RANKS for s in Card.SUITS] 25 if shuffle: 26 random.shuffle(cards) 27 return cls(cards) 28 29 def deal(self, num_hands): 30 """Deal the cards in the deck into a number of hands""" 31 cls = self.__class__ 32 return tuple(cls(self.cards[i::num_hands]) for i in range(num_hands)) 33 34class Player: 35 def __init__(self, name, hand): 36 self.name = name 37 self.hand = hand 38 39 def play_card(self): 40 """Play a card from the player's hand""" 41 card = random.choice(self.hand.cards) 42 self.hand.cards.remove(card) 43 print(f"{self.name}: {card!r:<3} ", end="") 44 return card 45 46class Game: 47 def __init__(self, *names): 48 """Set up the deck and deal cards to 4 players""" 49 deck = Deck.create(shuffle=True) 50 self.names = (list(names) + "P1 P2 P3 P4".split())[:4] 51 self.hands = { 52 n: Player(n, h) for n, h in zip(self.names, deck.deal(4)) 53 } 54 55 def play(self): 56 """Play a card game""" 57 start_player = random.choice(self.names) 58 turn_order = self.player_order(start=start_player) 59 60 # Play cards from each player's hand until empty 61 while self.hands[start_player].hand.cards: 62 for name in turn_order: 63 self.hands[name].play_card() 64 print() 65 66 def player_order(self, start=None): 67 """Rotate player order so that start goes first""" 68 if start is None: 69 start = random.choice(self.names) 70 start_idx = self.names.index(start) 71 return self.names[start_idx:] + self.names[:start_idx] 72 73if __name__ == "__main__": 74 # Read player names from command line 75 player_names = sys.argv[1:] 76 game = Game(*player_names) 77 game.play()现在让我们向代码中添加类型。
方法的类型提示
首先,方法的类型提示与函数的类型提示非常相似。唯一的区别是,
self参数不需要注释,因为它总是一个类实例。Card类的类型很容易添加:6class Card: 7 SUITS = "♠ ♡ ♢ ♣".split() 8 RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split() 9 10 def __init__(self, suit: str, rank: str) -> None: 11 self.suit = suit 12 self.rank = rank 13 14 def __repr__(self) -> str: 15 return f"{self.suit}{self.rank}"请注意,
.__init__()方法应该总是将None作为其返回类型。作为类型的类
类和类型之间有对应关系。例如,
Card类的所有实例一起构成了Card类型。要使用类作为类型,只需使用类的名称。例如,
Deck本质上由一系列Card对象组成。您可以对此进行如下注释:17class Deck: 18 def __init__(self, cards: List[Card]) -> None: 19 self.cards = cardsMypy 能够将注释中对
Card的使用与Card类的定义联系起来。但是,当您需要引用当前正在定义的类时,这就不那么简单了。例如,
Deck.create()类方法返回一个类型为Deck的对象。然而,你不能简单地添加-> Deck,因为Deck类还没有完全定义。相反,您可以在注释中使用字符串。这些字符串只能由类型检查器稍后进行评估,因此可以包含自身引用和前向引用。
.create()方法应该为其类型使用这样的字符串文字:20class Deck: 21 @classmethod 22 def create(cls, shuffle: bool = False) -> "Deck": 23 """Create a new deck of 52 cards""" 24 cards = [Card(s, r) for r in Card.RANKS for s in Card.SUITS] 25 if shuffle: 26 random.shuffle(cards) 27 return cls(cards)注意,
Player类也将引用Deck类。然而这没有问题,因为Deck是在Player之前定义的:34class Player: 35 def __init__(self, name: str, hand: Deck) -> None: 36 self.name = name 37 self.hand = hand通常在运行时不使用注释。这为推迟注释的评估的想法插上了翅膀。该建议不是将注释作为 Python 表达式进行评估并存储它们的值,而是存储注释的字符串表示,并仅在需要时对其进行评估。
这样的功能计划成为仍在神话中的 Python 4.0 的标准。然而,在 Python 3.7 和更高版本中,可以通过
__future__导入获得前向引用:from __future__ import annotations class Deck: @classmethod def create(cls, shuffle: bool = False) -> Deck: ...有了
__future__导入,你甚至可以在定义Deck之前使用Deck来代替"Deck"。返回
self或cls如上所述,您通常不应该注释
self或cls参数。部分来说,这是不必要的,因为self指向该类的一个实例,所以它将拥有该类的类型。在Card示例中,self具有隐式类型Card。此外,显式添加该类型会很麻烦,因为该类还没有定义。您必须使用字符串语法,self: "Card"。不过,有一种情况下,您可能想要注释
self或cls。考虑一下,如果你有一个超类,其他类从它继承,并且它有返回self或cls的方法,会发生什么:1# dogs.py 2 3from datetime import date 4 5class Animal: 6 def __init__(self, name: str, birthday: date) -> None: 7 self.name = name 8 self.birthday = birthday 9 10 @classmethod 11 def newborn(cls, name: str) -> "Animal": 12 return cls(name, date.today()) 13 14 def twin(self, name: str) -> "Animal": 15 cls = self.__class__ 16 return cls(name, self.birthday) 17 18class Dog(Animal): 19 def bark(self) -> None: 20 print(f"{self.name} says woof!") 21 22fido = Dog.newborn("Fido") 23pluto = fido.twin("Pluto") 24fido.bark() 25pluto.bark()虽然代码运行没有问题,但 Mypy 会标记一个问题:
$ mypy dogs.py dogs.py:24: error: "Animal" has no attribute "bark" dogs.py:25: error: "Animal" has no attribute "bark"问题是,即使继承的
Dog.newborn()和Dog.twin()方法将返回一个Dog,注释却说它们返回一个Animal。在这种情况下,您需要更加小心,以确保注释是正确的。返回类型应该匹配
self的类型或者cls的实例类型。这可以通过使用类型变量来完成,这些变量跟踪实际传递给self和cls的内容:# dogs.py from datetime import date from typing import Type, TypeVar TAnimal = TypeVar("TAnimal", bound="Animal") class Animal: def __init__(self, name: str, birthday: date) -> None: self.name = name self.birthday = birthday @classmethod def newborn(cls: Type[TAnimal], name: str) -> TAnimal: return cls(name, date.today()) def twin(self: TAnimal, name: str) -> TAnimal: cls = self.__class__ return cls(name, self.birthday) class Dog(Animal): def bark(self) -> None: print(f"{self.name} says woof!") fido = Dog.newborn("Fido") pluto = fido.twin("Pluto") fido.bark() pluto.bark()在这个例子中有一些事情需要注意:
类型变量
TAnimal用于表示返回值可能是Animal的子类的实例。我们指定
Animal是TAnimal的上界。指定bound意味着TAnimal将仅仅是Animal或者它的一个子类。这是正确限制允许的类型所必需的。
typing.Type[]构造是type()的等价类型。您需要注意,class 方法需要一个类,并返回该类的一个实例。注释
*args和**kwargs在游戏的面向对象版本中,我们增加了在命令行命名玩家的选项。这是通过在节目名称后列出播放器名称来实现的:
$ python game.py GeirArne Dan Joanna Dan: ♢A Joanna: ♡9 P1: ♣A GeirArne: ♣2 Dan: ♡A Joanna: ♡6 P1: ♠4 GeirArne: ♢8 Dan: ♢K Joanna: ♢Q P1: ♣K GeirArne: ♠5 Dan: ♡2 Joanna: ♡J P1: ♠7 GeirArne: ♡K Dan: ♢10 Joanna: ♣3 P1: ♢4 GeirArne: ♠8 Dan: ♣6 Joanna: ♡Q P1: ♣Q GeirArne: ♢J Dan: ♢2 Joanna: ♡4 P1: ♣8 GeirArne: ♡7 Dan: ♡10 Joanna: ♢3 P1: ♡3 GeirArne: ♠2 Dan: ♠K Joanna: ♣5 P1: ♣7 GeirArne: ♠J Dan: ♠6 Joanna: ♢9 P1: ♣J GeirArne: ♣10 Dan: ♠3 Joanna: ♡5 P1: ♣9 GeirArne: ♠Q Dan: ♠A Joanna: ♠9 P1: ♠10 GeirArne: ♡8 Dan: ♢6 Joanna: ♢5 P1: ♢7 GeirArne: ♣4这是通过在实例化时解包并传入
sys.argv到Game()来实现的。.__init__()方法使用*names将给定的名称打包到一个元组中。关于类型注释:即使
names是一组字符串,你也应该只注释每个名字的类型。换句话说,你应该使用str而不是Tuple[str]:46class Game: 47 def __init__(self, *names: str) -> None: 48 """Set up the deck and deal cards to 4 players""" 49 deck = Deck.create(shuffle=True) 50 self.names = (list(names) + "P1 P2 P3 P4".split())[:4] 51 self.hands = { 52 n: Player(n, h) for n, h in zip(self.names, deck.deal(4)) 53 }类似地,如果您有一个接受
**kwargs的函数或方法,那么您应该只注释每个可能的关键字参数的类型。可调用内容
函数在 Python 中是一级对象。这意味着您可以将函数用作其他函数的参数。这也意味着您需要能够添加表示函数的类型提示。
函数,以及 lambdas,方法和类都是用
typing.Callable表示的。参数和返回值的类型通常也被表示出来。例如,Callable[[A1, A2, A3], Rt]代表一个带有三个参数的函数,这三个参数的类型分别是A1、A2和A3。函数的返回类型是Rt。在下面的示例中,函数
do_twice()调用给定函数两次,并打印返回值:1# do_twice.py 2 3from typing import Callable 4 5def do_twice(func: Callable[[str], str], argument: str) -> None: 6 print(func(argument)) 7 print(func(argument)) 8 9def create_greeting(name: str) -> str: 10 return f"Hello {name}" 11 12do_twice(create_greeting, "Jekyll")注意第 5 行中对
do_twice()的func参数的注释。它说func应该是一个带有一个字符串参数的可调用函数,它也返回一个字符串。这种可调用的一个例子是第 9 行定义的create_greeting()。大多数可调用类型都可以用类似的方式进行注释。然而,如果你需要更多的灵活性,可以看看回调协议和扩展可调用类型。
示例:心形
让我们以一个完整的红心游戏的例子来结束。你可能已经从其他计算机模拟中知道这个游戏了。以下是规则的简要回顾:
四名玩家每人有 13 张牌。
持有♣2 的玩家开始第一轮,必须与♣2.对战
玩家轮流玩牌,如果可能的话,跟随领头的花色。
在领先花色中打出最高牌的玩家赢得该墩牌,并成为下一回合的开始玩家。
在之前的一墩牌中已经用过♡之前,玩家不能以♡打头。
在所有的牌都打出后,如果玩家拿到某些牌,他们就会得到分数:
- ♠Q 得了 13 分
- 每个♡得 1 分
一场游戏持续几轮,直到一名玩家获得 100 分或更多。得分最少的玩家获胜。
更多详情可在网上找到。
在这个例子中,没有多少你还没有看到的新的类型概念。因此,我们不会详细讨论这段代码,而是将它作为带注释代码的一个例子。
您可以从 GitHub 下载这段代码和其他示例:
# hearts.py from collections import Counter import random import sys from typing import Any, Dict, List, Optional, Sequence, Tuple, Union from typing import overload class Card: SUITS = "♠ ♡ ♢ ♣".split() RANKS = "2 3 4 5 6 7 8 9 10 J Q K A".split() def __init__(self, suit: str, rank: str) -> None: self.suit = suit self.rank = rank @property def value(self) -> int: """The value of a card is rank as a number""" return self.RANKS.index(self.rank) @property def points(self) -> int: """Points this card is worth""" if self.suit == "♠" and self.rank == "Q": return 13 if self.suit == "♡": return 1 return 0 def __eq__(self, other: Any) -> Any: return self.suit == other.suit and self.rank == other.rank def __lt__(self, other: Any) -> Any: return self.value < other.value def __repr__(self) -> str: return f"{self.suit}{self.rank}" class Deck(Sequence[Card]): def __init__(self, cards: List[Card]) -> None: self.cards = cards @classmethod def create(cls, shuffle: bool = False) -> "Deck": """Create a new deck of 52 cards""" cards = [Card(s, r) for r in Card.RANKS for s in Card.SUITS] if shuffle: random.shuffle(cards) return cls(cards) def play(self, card: Card) -> None: """Play one card by removing it from the deck""" self.cards.remove(card) def deal(self, num_hands: int) -> Tuple["Deck", ...]: """Deal the cards in the deck into a number of hands""" return tuple(self[i::num_hands] for i in range(num_hands)) def add_cards(self, cards: List[Card]) -> None: """Add a list of cards to the deck""" self.cards += cards def __len__(self) -> int: return len(self.cards) @overload def __getitem__(self, key: int) -> Card: ... @overload def __getitem__(self, key: slice) -> "Deck": ... def __getitem__(self, key: Union[int, slice]) -> Union[Card, "Deck"]: if isinstance(key, int): return self.cards[key] elif isinstance(key, slice): cls = self.__class__ return cls(self.cards[key]) else: raise TypeError("Indices must be integers or slices") def __repr__(self) -> str: return " ".join(repr(c) for c in self.cards) class Player: def __init__(self, name: str, hand: Optional[Deck] = None) -> None: self.name = name self.hand = Deck([]) if hand is None else hand def playable_cards(self, played: List[Card], hearts_broken: bool) -> Deck: """List which cards in hand are playable this round""" if Card("♣", "2") in self.hand: return Deck([Card("♣", "2")]) lead = played[0].suit if played else None playable = Deck([c for c in self.hand if c.suit == lead]) or self.hand if lead is None and not hearts_broken: playable = Deck([c for c in playable if c.suit != "♡"]) return playable or Deck(self.hand.cards) def non_winning_cards(self, played: List[Card], playable: Deck) -> Deck: """List playable cards that are guaranteed to not win the trick""" if not played: return Deck([]) lead = played[0].suit best_card = max(c for c in played if c.suit == lead) return Deck([c for c in playable if c < best_card or c.suit != lead]) def play_card(self, played: List[Card], hearts_broken: bool) -> Card: """Play a card from a cpu player's hand""" playable = self.playable_cards(played, hearts_broken) non_winning = self.non_winning_cards(played, playable) # Strategy if non_winning: # Highest card not winning the trick, prefer points card = max(non_winning, key=lambda c: (c.points, c.value)) elif len(played) < 3: # Lowest card maybe winning, avoid points card = min(playable, key=lambda c: (c.points, c.value)) else: # Highest card guaranteed winning, avoid points card = max(playable, key=lambda c: (-c.points, c.value)) self.hand.cards.remove(card) print(f"{self.name} -> {card}") return card def has_card(self, card: Card) -> bool: return card in self.hand def __repr__(self) -> str: return f"{self.__class__.__name__}({self.name!r}, {self.hand})" class HumanPlayer(Player): def play_card(self, played: List[Card], hearts_broken: bool) -> Card: """Play a card from a human player's hand""" playable = sorted(self.playable_cards(played, hearts_broken)) p_str = " ".join(f"{n}: {c}" for n, c in enumerate(playable)) np_str = " ".join(repr(c) for c in self.hand if c not in playable) print(f" {p_str} (Rest: {np_str})") while True: try: card_num = int(input(f" {self.name}, choose card: ")) card = playable[card_num] except (ValueError, IndexError): pass else: break self.hand.play(card) print(f"{self.name} => {card}") return card class HeartsGame: def __init__(self, *names: str) -> None: self.names = (list(names) + "P1 P2 P3 P4".split())[:4] self.players = [Player(n) for n in self.names[1:]] self.players.append(HumanPlayer(self.names[0])) def play(self) -> None: """Play a game of Hearts until one player go bust""" score = Counter({n: 0 for n in self.names}) while all(s < 100 for s in score.values()): print("\nStarting new round:") round_score = self.play_round() score.update(Counter(round_score)) print("Scores:") for name, total_score in score.most_common(4): print(f"{name:<15} {round_score[name]:>3} {total_score:>3}") winners = [n for n in self.names if score[n] == min(score.values())] print(f"\n{' and '.join(winners)} won the game") def play_round(self) -> Dict[str, int]: """Play a round of the Hearts card game""" deck = Deck.create(shuffle=True) for player, hand in zip(self.players, deck.deal(4)): player.hand.add_cards(hand.cards) start_player = next( p for p in self.players if p.has_card(Card("♣", "2")) ) tricks = {p.name: Deck([]) for p in self.players} hearts = False # Play cards from each player's hand until empty while start_player.hand: played: List[Card] = [] turn_order = self.player_order(start=start_player) for player in turn_order: card = player.play_card(played, hearts_broken=hearts) played.append(card) start_player = self.trick_winner(played, turn_order) tricks[start_player.name].add_cards(played) print(f"{start_player.name} wins the trick\n") hearts = hearts or any(c.suit == "♡" for c in played) return self.count_points(tricks) def player_order(self, start: Optional[Player] = None) -> List[Player]: """Rotate player order so that start goes first""" if start is None: start = random.choice(self.players) start_idx = self.players.index(start) return self.players[start_idx:] + self.players[:start_idx] @staticmethod def trick_winner(trick: List[Card], players: List[Player]) -> Player: lead = trick[0].suit valid = [ (c.value, p) for c, p in zip(trick, players) if c.suit == lead ] return max(valid)[1] @staticmethod def count_points(tricks: Dict[str, Deck]) -> Dict[str, int]: return {n: sum(c.points for c in cards) for n, cards in tricks.items()} if __name__ == "__main__": # Read player names from the command line player_names = sys.argv[1:] game = HeartsGame(*player_names) game.play()以下是代码中需要注意的几点:
对于难以用
Union或类型变量表达的类型关系,可以使用@overload装饰器。参见Deck.__getitem__()中的示例和文档中的更多信息。子类对应于子类型,因此在任何需要使用
Player的地方都可以使用HumanPlayer。当子类从超类重新实现方法时,类型注释必须匹配。参见
HumanPlayer.play_card()中的示例。开始游戏时,你控制第一个玩家。输入数字以选择要玩的牌。下面是一个玩游戏的例子,突出显示的线条显示了玩家做出选择的位置:
$ python hearts.py GeirArne Aldren Joanna Brad Starting new round: Brad -> ♣2 0: ♣5 1: ♣Q 2: ♣K (Rest: ♢6 ♡10 ♡6 ♠J ♡3 ♡9 ♢10 ♠7 ♠K ♠4) GeirArne, choose card: 2 GeirArne => ♣K Aldren -> ♣10 Joanna -> ♣9 GeirArne wins the trick 0: ♠4 1: ♣5 2: ♢6 3: ♠7 4: ♢10 5: ♠J 6: ♣Q 7: ♠K (Rest: ♡10 ♡6 ♡3 ♡9) GeirArne, choose card: 0 GeirArne => ♠4 Aldren -> ♠5 Joanna -> ♠3 Brad -> ♠2 Aldren wins the trick ... Joanna -> ♡J Brad -> ♡2 0: ♡6 1: ♡9 (Rest: ) GeirArne, choose card: 1 GeirArne => ♡9 Aldren -> ♡A Aldren wins the trick Aldren -> ♣A Joanna -> ♡Q Brad -> ♣J 0: ♡6 (Rest: ) GeirArne, choose card: 0 GeirArne => ♡6 Aldren wins the trick Scores: Brad 14 14 Aldren 10 10 GeirArne 1 1 Joanna 1 1静态类型检查
到目前为止,您已经了解了如何向代码中添加类型提示。在本节中,您将了解更多关于如何实际执行 Python 代码的静态类型检查。
Mypy 项目
Mypy 由 Jukka Lehtosalo 于 2012 年左右在剑桥攻读博士学位期间创立。Mypy 最初被设想为具有无缝动态和静态类型的 Python 变体。参见 2012 年芬兰 PyCon 上 Jukka 的幻灯片,了解 Mypy 最初愿景的示例。
这些原创想法中的大部分仍然在 Mypy 项目中发挥着重要作用。事实上,“无缝动态和静态类型化”的口号仍然在 Mypy 的主页上醒目可见,并且很好地描述了在 Python 中使用类型提示的动机。
2012 年以来最大的变化就是 Mypy 不再是 Python 的变种。在其第一个版本中,Mypy 是一种独立的语言,除了类型声明之外,它与 Python 兼容。按照吉多·范·罗苏姆的建议,Mypy 被改写成使用注释。今天,Mypy 是一个静态类型检查器,用于常规的Python 代码。
运行 Mypy
首次运行 Mypy 之前,必须安装该程序。使用
pip最容易做到这一点:$ pip install mypy安装 Mypy 后,您可以将其作为常规命令行程序运行:
$ mypy my_program.py在您的
my_program.pyPython 文件上运行 Mypy 将检查它的类型错误,而不实际执行代码。对代码进行类型检查时,有许多可用的选项。由于 Mypy 仍处于非常活跃的开发阶段,命令行选项很容易在不同版本之间发生变化。您应该参考 Mypy 的帮助来了解哪些设置是您的版本的默认设置:
$ mypy --help usage: mypy [-h] [-v] [-V] [more options; see below] [-m MODULE] [-p PACKAGE] [-c PROGRAM_TEXT] [files ...] Mypy is a program that will type check your Python code. [... The rest of the help hidden for brevity ...]此外, Mypy 命令行文档在线有很多信息。
让我们看看一些最常见的选项。首先,如果你使用的是没有类型提示的第三方包,你可能想让 Mypy 关于这些的警告静音。这可以通过
--ignore-missing-imports选项来完成。以下示例使用 Numpy 计算并打印几个数字的余弦值:
1# cosine.py 2 3import numpy as np 4 5def print_cosine(x: np.ndarray) -> None: 6 with np.printoptions(precision=3, suppress=True): 7 print(np.cos(x)) 8 9x = np.linspace(0, 2 * np.pi, 9) 10print_cosine(x)注意
np.printoptions()只在 Numpy 的 1.15 及以后版本才有。运行此示例会将一些数字打印到控制台:$ python cosine.py [ 1\. 0.707 0\. -0.707 -1\. -0.707 -0\. 0.707 1\. ]这个例子的实际输出并不重要。然而,你应该注意到参数
x在第 5 行用np.ndarray进行了注释,因为我们想要打印一个完整的数字数组的余弦值。您可以像往常一样对这个文件运行 Mypy:
$ mypy cosine.py cosine.py:3: error: No library stub file for module 'numpy' cosine.py:3: note: (Stub files are from https://github.com/python/typeshed)这些警告可能不会马上让你明白,但是你很快就会了解到存根和排版。您基本上可以将警告理解为 Mypy,表示 Numpy 包不包含类型提示。
在大多数情况下,第三方包中缺少类型提示并不是您想烦恼的事情,因此您可以隐藏这些消息:
$ mypy --ignore-missing-imports cosine.py Success: no issues found in 1 source file如果您使用
--ignore-missing-import命令行选项,Mypy 将不会尝试跟踪或警告任何丢失的导入。这可能有点过分,因为它也忽略了实际的错误,比如拼错了包的名字。处理第三方包的两种侵入性较小的方法是使用类型注释或配置文件。
在上面这个简单的例子中,您可以通过向包含导入的行添加类型注释来消除
numpy警告:3import numpy as np # type: ignore文字
# type: ignore告诉 Mypy 忽略 Numpy 的导入。如果您有几个文件,在配置文件中跟踪要忽略的导入可能会更容易。Mypy 读取当前目录中名为
mypy.ini的文件(如果存在的话)。该配置文件必须包含一个名为[mypy]的部分,并且可能包含[mypy-module]形式的模块特定部分。以下配置文件将忽略 Numpy 缺少类型提示:
# mypy.ini [mypy] [mypy-numpy] ignore_missing_imports = True在配置文件中可以指定许多选项。也可以指定一个全局配置文件。更多信息参见文档。
添加存根
Python 标准库中的所有包都有类型提示。然而,如果你使用第三方软件包,你已经看到情况可能会有所不同。
下面的例子使用解析包进行简单的文本解析。要继续学习,您应该首先安装 Parse:
$ pip install parse解析可以用来识别简单的模式。这里有一个小程序,它会尽力找出你的名字:
1# parse_name.py 2 3import parse 4 5def parse_name(text: str) -> str: 6 patterns = ( 7 "my name is {name}", 8 "i'm {name}", 9 "i am {name}", 10 "call me {name}", 11 "{name}", 12 ) 13 for pattern in patterns: 14 result = parse.parse(pattern, text) 15 if result: 16 return result["name"] 17 return "" 18 19answer = input("What is your name? ") 20name = parse_name(answer) 21print(f"Hi {name}, nice to meet you!")主要流程在最后三行中定义:询问您的姓名,解析答案,并打印问候。第 14 行调用了
parse包,试图根据第 7-11 行列出的模式之一找到一个名字。该程序可按如下方式使用:
$ python parse_name.py What is your name? I am Geir Arne Hi Geir Arne, nice to meet you!请注意,即使我回答了
I am Geir Arne,程序也认为I am不是我名字的一部分。让我们在程序中添加一个小错误,看看 Mypy 是否能够帮助我们检测到它。将第 16 行从
return result["name"]改为return result。这将返回一个parse.Result对象,而不是包含名字的字符串。接下来在程序上运行 Mypy:
$ mypy parse_name.py parse_name.py:3: error: Cannot find module named 'parse' parse_name.py:3: note: (Perhaps setting MYPYPATH or using the "--ignore-missing-imports" flag would help)Mypy 打印出与您在上一节中看到的错误类似的错误:它不知道
parse包。您可以尝试忽略导入:$ mypy parse_name.py --ignore-missing-imports Success: no issues found in 1 source file不幸的是,忽略导入意味着 Mypy 无法发现我们程序中的 bug。更好的解决方案是向解析包本身添加类型提示。由于 Parse 是开源的,你实际上可以向源代码添加类型并发送一个 pull 请求。
或者,您可以在一个存根文件中添加类型。存根文件是一个文本文件,它包含方法和函数的签名,但不包含它们的实现。它们的主要功能是向由于某种原因不能更改的代码添加类型提示。为了展示这是如何工作的,我们将为解析包添加一些存根。
首先,您应该将所有的存根文件放在一个公共目录中,并将
MYPYPATH环境变量设置为指向这个目录。在 Mac 和 Linux 上,您可以如下设置MYPYPATH:$ export MYPYPATH=/home/gahjelle/python/stubs您可以通过将该行添加到您的
.bashrc文件来永久设置该变量。在 Windows 上你可以点击开始菜单,搜索环境变量来设置MYPYPATH。接下来,在存根目录中创建一个名为
parse.pyi的文件。它必须以您正在添加类型提示的包命名,并带有一个.pyi后缀。暂时将该文件留空。然后再次运行 Mypy:$ mypy parse_name.py parse_name.py:14: error: Module has no attribute "parse"如果您已经正确设置了所有内容,您应该会看到这个新的错误消息。Mypy 使用新的
parse.pyi文件来确定在parse包中哪些函数是可用的。由于存根文件是空的,Mypy 假设parse.parse()不存在,然后给出您在上面看到的错误。下面的例子没有为整个
parse包添加类型。相反,它显示了您需要添加的类型提示,以便 Mypy 对您使用的parse.parse()进行类型检查:# parse.pyi from typing import Any, Mapping, Optional, Sequence, Tuple, Union class Result: def __init__( self, fixed: Sequence[str], named: Mapping[str, str], spans: Mapping[int, Tuple[int, int]], ) -> None: ... def __getitem__(self, item: Union[int, str]) -> str: ... def __repr__(self) -> str: ... def parse( format: str, string: str, evaluate_result: bool = ..., case_sensitive: bool = ..., ) -> Optional[Result]: ...省略号
...是文件的一部分,应该完全按照上面的写法。存根文件应该只包含变量、属性、函数和方法的类型提示,所以实现应该被省略,并由...标记代替。最终,Mypy 能够发现我们引入的 bug:
$ mypy parse_name.py parse_name.py:16: error: Incompatible return value type (got "Result", expected "str")这直接指向第 16 行,以及我们返回一个
Result对象而不是名称字符串的事实。把return result改回return result["name"],再次运行 Mypy,看它开心不。排版的
您已经看到了如何使用存根来添加类型提示,而无需更改源代码本身。在上一节中,我们向第三方解析包添加了一些类型提示。现在,如果每个人都需要为他们正在使用的所有第三方软件包创建自己的存根文件,这将不会非常有效。
Typeshed 是一个 Github 库,包含 Python 标准库的类型提示,以及许多第三方包。Typeshed 包含在 Mypy 中,所以如果您使用的包已经在 Typeshed 中定义了类型提示,类型检查就可以了。
您还可以向已排版的提供类型提示。不过要确保首先获得软件包所有者的许可,特别是因为他们可能会在源代码本身中添加类型提示——这是首选的方法。
其他静态类型检查器
在本教程中,我们主要关注使用 Mypy 进行类型检查。然而,在 Python 生态系统中还有其他静态类型检查器。
这个 PyCharm 编辑器自带类型检查器。如果您使用 PyCharm 编写 Python 代码,将会自动进行类型检查。
脸书研制出了 柴堆 。它的目标之一是快速和高效。虽然有一些不同,但 Pyre 的功能与 Mypy 非常相似。如果您有兴趣尝试 Pyre,请参见文档。
此外,谷歌还创造了 Pytype 。这个类型检查器的工作方式也与 Mypy 基本相同。除了检查带注释的代码,Pytype 还支持对不带注释的代码进行类型检查,甚至自动向代码添加注释。更多信息参见快速入门文档。
在运行时使用类型
最后要注意的是,在 Python 程序执行期间,也可以在运行时使用类型提示。Python 可能永远不会支持运行时类型检查。
然而,类型提示在运行时可以在
__annotations__字典中找到,如果您愿意,您可以使用它们来进行类型检查。在您开始编写自己的强制类型包之前,您应该知道已经有几个包在为您做这件事了。看看 Enforce , Pydantic ,或者 Pytypes 的一些例子。类型提示的另一个用途是将 Python 代码翻译成 C 语言,并对其进行编译以进行优化。流行的 Cython 项目使用混合 C/Python 语言编写静态类型的 Python 代码。然而,从 0.27 版本开始,Cython 也支持类型注释。最近, Mypyc 项目已经面世。虽然还没有准备好用于一般用途,但它可以将一些带类型注释的 Python 代码编译成 C 扩展。
结论
Python 中的类型提示是一个非常有用的特性,没有它你也能快乐地生活。类型提示并不能让你写出任何不使用类型提示就无法写出的代码。相反,使用类型提示可以让您更容易推理代码,找到细微的错误,并维护一个干净的体系结构。
在本教程中,您了解了 Python 中的类型提示是如何工作的,以及渐进类型化如何使 Python 中的类型检查比许多其他语言中的类型检查更加灵活。您已经看到了使用类型提示的一些优点和缺点,以及如何使用批注或类型注释将它们添加到代码中。最后,您看到了 Python 支持的许多不同类型,以及如何执行静态类型检查。
有很多资源可以让你了解更多关于 Python 中静态类型检查的知识。PEP 483 和 PEP 484 给出了很多关于 Python 中如何实现类型检查的背景知识。 Mypy 文档有一个很棒的参考部分详细介绍了所有可用的不同类型。
立即观看本教程有真实 Python 团队创建的相关视频课程。配合文字教程一起看,加深理解: Python 类型检查*********

 浙公网安备 33010602011771号
浙公网安备 33010602011771号