RealPython-中文系列教程-十八-
RealPython 中文系列教程(十八)
原文:RealPython
使用 Python zip()函数进行并行迭代
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 的 zip()函数 并行迭代
Python 的zip()函数创建了一个迭代器,它将聚合两个或更多可迭代对象的元素。您可以使用结果迭代器快速一致地解决常见的编程问题,比如创建字典。在本教程中,您将发现 Python zip()函数背后的逻辑,以及如何使用它来解决现实世界中的问题。
本教程结束时,您将学会:
zip()如何在 Python 3 和 Python 2 中工作- 如何使用 Python
zip()函数进行并行迭代 - 如何使用
zip()动态地创建字典
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
了解 Python zip()函数
zip()在内置命名空间中可用。如果您使用dir()来检查__builtins__,那么您会在列表的末尾看到zip():
>>> dir(__builtins__) ['ArithmeticError', 'AssertionError', 'AttributeError', ..., 'zip']您可以看到
'zip'是可用对象列表中的最后一个条目。根据官方文档,Python 的
zip()函数表现如下:返回元组的迭代器,其中第 i 个元组包含来自每个参数序列或可迭代对象的第 i 个元素。当最短的输入 iterable 用尽时,迭代器停止。使用一个可迭代的参数,它返回一个 1 元组的迭代器。如果没有参数,它将返回一个空迭代器。(来源)
在本教程的剩余部分,您将解开这个定义。在研究代码示例时,您会看到 Python zip 操作的工作方式就像包或牛仔裤上的物理拉链一样。拉链两侧的互锁齿对被拉到一起以闭合开口。事实上,这个直观的类比对于理解
zip()来说是完美的,因为这个功能是以物理拉链命名的!在 Python 中使用
zip()Python 的
zip()函数定义为zip(*iterables)。该函数将 iterables 作为参数,并返回一个迭代器。这个迭代器生成一系列元组,其中包含来自每个 iterable 的元素。zip()可以接受任何类型的 iterable,比如文件、列表、元组、字典、集合等等。传递
n个参数如果将
zip()与n参数一起使用,那么函数将返回一个迭代器,生成长度为n的元组。要了解这一点,请看下面的代码块:
>>> numbers = [1, 2, 3]
>>> letters = ['a', 'b', 'c']
>>> zipped = zip(numbers, letters)
>>> zipped # Holds an iterator object
<zip object at 0x7fa4831153c8>
>>> type(zipped)
<class 'zip'>
>>> list(zipped)
[(1, 'a'), (2, 'b'), (3, 'c')]
这里,您使用zip(numbers, letters)创建一个迭代器,该迭代器产生形式为(x, y)的元组。在这种情况下,x值取自numbers,而y值取自letters。注意 Python zip()函数是如何返回迭代器的。要检索最终的列表对象,需要使用list()来消耗迭代器。
如果你正在处理像列表、元组或字符串这样的序列,那么你的 iterables 肯定会从左到右被求值。这意味着元组的结果列表将采用[(numbers[0], letters[0]), (numbers[1], letters[1]),..., (numbers[n], letters[n])]的形式。然而,对于其他类型的可重复项(如集合,您可能会看到一些奇怪的结果:
>>> s1 = {2, 3, 1} >>> s2 = {'b', 'a', 'c'} >>> list(zip(s1, s2)) [(1, 'a'), (2, 'c'), (3, 'b')]在这个例子中,
s1和s2是set对象,它们的元素没有任何特定的顺序。这意味着zip()返回的元组将包含随机配对的元素。如果你打算将 Pythonzip()函数用于像集合这样的无序可重复项,那么这一点需要记住。不传递参数
您也可以不带任何参数调用
zip()。在这种情况下,您将简单地得到一个空迭代器:
>>> zipped = zip()
>>> zipped
<zip object at 0x7f196294a488>
>>> list(zipped)
[]
在这里,您调用没有参数的zip(),所以您的zipped 变量持有一个空迭代器。如果您使用list()来使用迭代器,那么您也会看到一个空列表。
您也可以尝试强制空迭代器直接产生一个元素。在这种情况下,你会得到一个StopIteration 异常:
>>> zipped = zip() >>> next(zipped) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration当您在
zipped上调用next()时,Python 会尝试检索下一项。然而,由于zipped持有一个空迭代器,所以没有东西可以取出,所以 Python 引发了一个StopIteration异常。传递一个参数
Python 的
zip()函数也可以只接受一个参数。结果将是一个迭代器,产生一系列 1 项元组:
>>> a = [1, 2, 3]
>>> zipped = zip(a)
>>> list(zipped)
[(1,), (2,), (3,)]
这可能不是那么有用,但它仍然有效。也许你能找到一些zip()这种行为的用例!
正如您所看到的,您可以调用 Python zip()函数,使用任意多的输入可重复项。结果元组的长度将始终等于作为参数传递的 iterables 的数量。下面是一个包含三个可迭代项的示例:
>>> integers = [1, 2, 3] >>> letters = ['a', 'b', 'c'] >>> floats = [4.0, 5.0, 6.0] >>> zipped = zip(integers, letters, floats) # Three input iterables >>> list(zipped) [(1, 'a', 4.0), (2, 'b', 5.0), (3, 'c', 6.0)]这里,您用三个 iterables 调用 Python
zip()函数,所以得到的元组每个都有三个元素。传递长度不等的参数
当你使用 Python
zip()函数时,注意你的 iterables 的长度是很重要的。作为参数传入的 iterables 可能长度不同。在这些情况下,
zip()输出的元素数量将等于最短的的长度。任何更长的 iterables 中的剩余元素将被zip()完全忽略,正如你在这里看到的:
>>> list(zip(range(5), range(100)))
[(0, 0), (1, 1), (2, 2), (3, 3), (4, 4)]
由于5是第一个(也是最短的) range() 对象的长度,zip()输出一个五元组列表。第二个range()对象仍有 95 个不匹配的元素。这些都被zip()忽略了,因为没有更多来自第一个range()对象的元素来完成配对。
如果尾随或不匹配的值对你很重要,那么你可以用 itertools.zip_longest() 代替zip()。使用这个函数,丢失的值将被替换为传递给fillvalue参数的值(默认为 None )。迭代将继续,直到最长的可迭代次数用完:
>>> from itertools import zip_longest >>> numbers = [1, 2, 3] >>> letters = ['a', 'b', 'c'] >>> longest = range(5) >>> zipped = zip_longest(numbers, letters, longest, fillvalue='?') >>> list(zipped) [(1, 'a', 0), (2, 'b', 1), (3, 'c', 2), ('?', '?', 3), ('?', '?', 4)]在这里,您使用
itertools.zip_longest()生成五个元组,其中包含来自letters、numbers和longest的元素。只有当longest耗尽时,迭代才会停止。numbers和letters中缺失的元素用问号?填充,这是你用fillvalue指定的。自从 Python 3.10 ,
zip()有了一个新的可选关键字参数叫做strict,它是通过 PEP 618 引入的——给 zip 添加可选的长度检查。这个参数的主要目标是提供一种安全的方式来处理长度不等的可重复项。
strict的缺省值是False,这确保了zip()保持向后兼容,并且具有与它在旧 Python 3 版本中的行为相匹配的缺省行为:
>>> # Python >= 3.10
>>> list(zip(range(5), range(100)))
[(0, 0), (1, 1), (2, 2), (3, 3), (4, 4)]
在 Python >= 3.10 中,调用zip()而不将默认值更改为strict仍然会给出一个五元组列表,忽略第二个range()对象中不匹配的元素。
或者,如果您将strict设置为True,那么zip()将检查您作为参数提供的输入可重复项是否具有相同的长度,如果不相同,将引发 ValueError :
>>> # Python >= 3.10 >>> list(zip(range(5), range(100), strict=True)) Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: zip() argument 2 is longer than argument 1当您需要确保函数只接受等长的可重复项时,
zip()的这个新特性非常有用。将strict设置为True会使期望等长可重复项的代码更加安全,确保对调用者代码的错误更改不会导致数据无声地丢失。比较 Python 3 中的
zip()和 2 中的Python 的
zip()函数在该语言的两个版本中工作方式不同。在 Python 2 中,zip()返回元组的list。产生的list被截断为最短输入 iterable 的长度。如果你调用zip()而没有参数,那么你得到一个空的list作为回报:
>>> # Python 2
>>> zipped = zip(range(3), 'ABCD')
>>> zipped # Hold a list object
[(0, 'A'), (1, 'B'), (2, 'C')]
>>> type(zipped)
<type 'list'>
>>> zipped = zip() # Create an empty list
>>> zipped
[]
在这种情况下,您对 Python zip()函数的调用返回在值C处截断的元组列表。当你调用没有参数的zip()时,你得到一个空的list。
然而,在 Python 3 中,zip()返回一个迭代器。该对象按需生成元组,并且只能被遍历一次。一旦最短的输入 iterable 用尽,迭代以一个StopIteration异常结束。如果没有给zip()提供参数,那么函数返回一个空迭代器:
>>> # Python 3 >>> zipped = zip(range(3), 'ABCD') >>> zipped # Hold an iterator <zip object at 0x7f456ccacbc8> >>> type(zipped) <class 'zip'> >>> list(zipped) [(0, 'A'), (1, 'B'), (2, 'C')] >>> zipped = zip() # Create an empty iterator >>> zipped <zip object at 0x7f456cc93ac8> >>> next(zipped) Traceback (most recent call last): File "<input>", line 1, in <module> next(zipped) StopIteration这里,您对
zip()的调用返回一个迭代器。第一次迭代在C被截断,第二次迭代导致StopIteration异常。在 Python 3 中,您还可以通过将返回的迭代器封装在对list()的调用中来模拟zip()的 Python 2 行为。这将遍历迭代器并返回一个元组列表。如果您经常使用 Python 2,那么请注意将
zip()与长输入 iterables 一起使用会无意中消耗大量内存。在这些情况下,考虑使用itertools.izip(*iterables)来代替。这个函数创建了一个迭代器,它聚集了每个可迭代对象的元素。它产生了与 Python 3 中的zip()相同的效果:
>>> # Python 2
>>> from itertools import izip
>>> zipped = izip(range(3), 'ABCD')
>>> zipped
<itertools.izip object at 0x7f3614b3fdd0>
>>> list(zipped)
[(0, 'A'), (1, 'B'), (2, 'C')]
在这个例子中,您调用itertools.izip()来创建一个迭代器。当您用list()消费返回的迭代器时,您会得到一个元组列表,就像您在 Python 3 中使用zip()一样。当最短的输入 iterable 用尽时,迭代停止。
如果您真的需要编写在 Python 2 和 Python 3 中行为相同的代码,那么您可以使用如下技巧:
try:
from itertools import izip as zip
except ImportError:
pass
在这里,如果在itertools中izip()可用,那么您将知道您在 Python 2 中,并且izip()将使用别名zip被导入。否则,你的程序会抛出一个ImportError,你就知道你在 Python 3 中了。(这里的 pass语句只是一个占位符。)
有了这个技巧,您可以在整个代码中安全地使用 Python zip()函数。运行时,您的程序将自动选择并使用正确的版本。
到目前为止,您已经了解了 Python 的zip()函数是如何工作的,并了解了它的一些最重要的特性。现在是时候卷起袖子开始编写真实世界的例子了!
在多个可迭代对象上循环
在多个可迭代对象上循环是 Python 的zip()函数最常见的用例之一。如果您需要遍历多个列表、元组或任何其他序列,那么您很可能会求助于zip()。本节将向您展示如何使用zip()来同时迭代多个可迭代对象。
并行遍历列表
Python 的zip()函数允许你在两个或更多的可迭代对象上并行迭代。由于zip()生成元组,您可以在 for循环的头中解包这些元组:
>>> letters = ['a', 'b', 'c'] >>> numbers = [0, 1, 2] >>> for l, n in zip(letters, numbers): ... print(f'Letter: {l}') ... print(f'Number: {n}') ... Letter: a Number: 0 Letter: b Number: 1 Letter: c Number: 2在这里,您遍历由
zip()返回的一系列元组,并将元素解包到l和n。当你组合zip()、for循环、元组解包时,你可以得到一个有用的python 式习语,用于一次遍历两个或更多的 iterables。您也可以在一个
for循环中遍历两个以上的 iterables。考虑下面的例子,它有三个输入项:
>>> letters = ['a', 'b', 'c']
>>> numbers = [0, 1, 2]
>>> operators = ['*', '/', '+']
>>> for l, n, o in zip(letters, numbers, operators):
... print(f'Letter: {l}')
... print(f'Number: {n}')
... print(f'Operator: {o}')
...
Letter: a
Number: 0
Operator: *
Letter: b
Number: 1
Operator: /
Letter: c
Number: 2
Operator: +
在这个例子中,您使用带有三个 iterables 的zip()来创建并返回一个迭代器,该迭代器生成 3 项元组。这使您可以一次遍历所有三个可迭代对象。对于 Python 的zip()函数,可以使用的 iterables 的数量没有限制。
注意:如果你想更深入地研究 Python for循环,请查看Python“for”循环(确定迭代)。
并行遍历字典
在 Python 3.6 及更高版本中,字典是有序集合,这意味着它们保持其元素被引入的相同顺序。如果您利用了这个特性,那么您可以使用 Python zip()函数以一种安全和一致的方式遍历多个字典:
>>> dict_one = {'name': 'John', 'last_name': 'Doe', 'job': 'Python Consultant'} >>> dict_two = {'name': 'Jane', 'last_name': 'Doe', 'job': 'Community Manager'} >>> for (k1, v1), (k2, v2) in zip(dict_one.items(), dict_two.items()): ... print(k1, '->', v1) ... print(k2, '->', v2) ... name -> John name -> Jane last_name -> Doe last_name -> Doe job -> Python Consultant job -> Community Manager这里,您并行迭代
dict_one和dict_two。在这种情况下,zip()用两个字典中的条目生成元组。然后,您可以解包每个元组并同时访问两个字典的条目。注意:如果你想更深入地研究字典迭代,请查看如何在 Python 中迭代字典。
注意,在上面的例子中,从左到右的求值顺序是有保证的。还可以使用 Python 的
zip()函数并行遍历集合。然而,你需要考虑到,与 Python 3.6 中的字典不同,集合不会保持它们的元素有序。如果你忘记了这个细节,你的程序的最终结果可能并不完全是你想要的或期望的。解压缩序列
在新 Pythonistas 的论坛中经常出现一个问题:“如果有一个
zip()函数,那么为什么没有一个unzip()函数做相反的事情?”Python 中之所以没有
unzip()函数,是因为zip()的反义词是……嗯,zip()。你还记得 Pythonzip()函数就像一个真正的拉链一样工作吗?到目前为止,示例已经向您展示了 Python 如何压缩关闭的内容。那么,如何解压 Python 对象呢?假设您有一个元组列表,并希望将每个元组的元素分成独立的序列。为此,您可以将
zip()与解包操作符*一起使用,如下所示:
>>> pairs = [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')]
>>> numbers, letters = zip(*pairs)
>>> numbers
(1, 2, 3, 4)
>>> letters
('a', 'b', 'c', 'd')
这里,您有一个包含某种混合数据的元组list。然后,使用解包操作符*解压数据,创建两个不同的列表(numbers和letters)。
并行排序
排序是编程中常见的操作。假设你想合并两个列表,同时对它们进行排序。为此,您可以将zip()与 .sort() 一起使用,如下所示:
>>> letters = ['b', 'a', 'd', 'c'] >>> numbers = [2, 4, 3, 1] >>> data1 = list(zip(letters, numbers)) >>> data1 [('b', 2), ('a', 4), ('d', 3), ('c', 1)] >>> data1.sort() # Sort by letters >>> data1 [('a', 4), ('b', 2), ('c', 1), ('d', 3)] >>> data2 = list(zip(numbers, letters)) >>> data2 [(2, 'b'), (4, 'a'), (3, 'd'), (1, 'c')] >>> data2.sort() # Sort by numbers >>> data2 [(1, 'c'), (2, 'b'), (3, 'd'), (4, 'a')]在这个例子中,首先用
zip()合并两个列表,并对它们进行排序。请注意data1是如何按照letters排序的,而data2是如何按照numbers排序的。您也可以同时使用
sorted()和zip()来获得类似的结果:
>>> letters = ['b', 'a', 'd', 'c']
>>> numbers = [2, 4, 3, 1]
>>> data = sorted(zip(letters, numbers)) # Sort by letters
>>> data
[('a', 4), ('b', 2), ('c', 1), ('d', 3)]
在这种情况下,sorted()遍历由zip()生成的迭代器,并通过letters对条目进行排序,这一切都是一气呵成的。这种方法会快一点,因为你只需要两个函数调用:zip()和sorted()。
使用sorted(),你还可以编写一段更通用的代码。这将允许你排序任何种类的序列,而不仅仅是列表。
成对计算
可以使用 Python zip()函数进行一些快速计算。假设您在电子表格中有以下数据:
| 元素/月份 | 一月 | 二月 | 三月 |
|---|---|---|---|
| 销售总额 | Fifty-two thousand | Fifty-one thousand | Forty-eight thousand |
| 生产成本 | Forty-six thousand eight hundred | Forty-five thousand nine hundred | Forty-three thousand two hundred |
你将使用这些数据来计算你的月利润。zip()可以为您提供一种快速的计算方式:
>>> total_sales = [52000.00, 51000.00, 48000.00] >>> prod_cost = [46800.00, 45900.00, 43200.00] >>> for sales, costs in zip(total_sales, prod_cost): ... profit = sales - costs ... print(f'Total profit: {profit}') ... Total profit: 5200.0 Total profit: 5100.0 Total profit: 4800.0在这里,您通过从
sales中减去costs来计算每个月的利润。Python 的zip()函数结合正确的数据对进行计算。您可以推广这个逻辑,用zip()返回的对进行任何复杂的计算。构建字典
Python 的字典是一种非常有用的数据结构。有时,您可能需要从两个不同但密切相关的序列中构建一个字典。实现这一点的一个方便方法是同时使用
dict()和zip()。例如,假设您从表单或数据库中检索一个人的数据。现在,您拥有以下数据列表:
>>> fields = ['name', 'last_name', 'age', 'job']
>>> values = ['John', 'Doe', '45', 'Python Developer']
有了这些数据,您需要创建一个字典来进行进一步的处理。在这种情况下,您可以将dict()与zip()一起使用,如下所示:
>>> a_dict = dict(zip(fields, values)) >>> a_dict {'name': 'John', 'last_name': 'Doe', 'age': '45', 'job': 'Python Developer'}在这里,您创建了一个结合了两个列表的字典。
zip(fields, values)返回一个生成 2 项元组的迭代器。如果您在这个迭代器上调用dict(),那么您将构建您需要的字典。fields的元素成为字典的键,values的元素代表字典中的值。您也可以通过组合
zip()和dict.update()来更新现有的字典。假设约翰换了工作,你需要更新字典。您可以执行如下操作:
>>> new_job = ['Python Consultant']
>>> field = ['job']
>>> a_dict.update(zip(field, new_job))
>>> a_dict
{'name': 'John', 'last_name': 'Doe', 'age': '45', 'job': 'Python Consultant'}
这里,dict.update()用您使用 Python 的zip()函数创建的键值元组更新字典。使用这种技术,您可以很容易地覆盖job的值。
结论
在本教程中,你已经学会了如何使用 Python 的zip()函数。zip()可以接收多个 iterables 作为输入。它返回一个迭代器,该迭代器可以从每个参数生成带有成对元素的元组。当您需要在一个循环中处理多个可迭代对象并同时对它们的项执行一些操作时,结果迭代器会非常有用。
现在您可以:
- 在 Python 3 和 Python 2 中都使用
zip()函数 - 循环遍历多个 iterables 并对它们的项目并行执行不同的操作
- 通过将两个输入的可重复项压缩在一起,动态创建和更新字典
您还编写了一些例子,可以作为使用 Python 的zip()函数实现自己的解决方案的起点。当您深入探索zip()时,请随意修改这些示例!
立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 用 Python 的 zip()函数 并行迭代******
Python Zip 导入:快速分发模块和包
Python 允许你直接通过 Zip imports 从 ZIP 文件导入代码。这个有趣的内置特性使您能够压缩 Python 代码以供分发。如果您经常使用 Zip 文件中的 Python 代码,ZIP 导入也会有所帮助。在这两种情况下,学习创建可导入的 ZIP 文件并从中导入代码将是一项很有价值的技能。
即使您的日常工作流程不涉及包含 Python 代码的 Zip 文件,您仍然可以通过本教程探索 ZIP 导入来学习一些有趣的新技能。
在本教程中,您将学习:
- 什么是 Zip 导入
- 何时在代码中使用 Zip 导入
- 如何用
zipfile创建可导入的压缩文件 - 如何使您的 ZIP 文件对导入代码可用
您还将学习如何使用zipimport模块从 ZIP 文件中动态导入代码,而无需将它们添加到 Python 的模块搜索路径中。为此,您将编写一个从 ZIP 文件加载 Python 代码的最小插件系统。
为了从本教程中获得最大收益,你应该事先了解 Python 的导入系统是如何工作的。你还应该知道用zipfile操作 ZIP 文件的基本知识,用操作文件,使用 with语句。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
了解 Python Zip 导入
从 Python 2.3 开始,可以从 ZIP 文件里面导入模块和包。这个特性被称为 Zip imports ,当您需要将一个完整的包作为单个文件分发时,这是非常有用的,这是它最常见的用例。
PEP 273 引入了 Zip 导入作为内置特性。这个特性被 Python 社区广泛认为是必备的,因为分发几个独立的.py、.pyc和.pyo文件并不总是合适和有效的。
Zip 导入可以简化共享和分发代码的过程,这样您的同事和最终用户就不必四处摸索,试图将文件提取到正确的位置来让代码工作。
注意:从 Python 3.5 开始,.pyo文件扩展名不再使用。详见 PEP 488 。
PEP 302 增加了一系列的导入挂钩 ,为 Zip 导入提供内置支持。如果你想从一个 ZIP 文件中导入模块和包,那么你只需要这个文件出现在 Python 的模块搜索路径中。
模块搜索路径是目录和 ZIP 文件的列表。它住在 sys.path 。当您在代码中运行 import 语句时,Python 会自动搜索列表中的项目。
在接下来的几节中,您将学习如何使用不同的 Python 工具和技术创建准备导入的 ZIP 文件。您还将了解一些将这些文件添加到当前 Python 的模块搜索路径中的方法。最后,您将深入研究zipimport,它是在幕后支持 Zip 导入特性的模块。
创建您自己的可导入 ZIP 文件
Zip 导入允许您将组织在几个模块和包中的代码作为单个文件快速分发。在创建可导入的 ZIP 文件时,Python 已经帮你搞定了。来自标准库的 zipfile 模块包含一个名为 ZipFile 的类,用于操作 ZIP 文件。它还包含了一个更专业的类,叫做 PyZipFile ,可以方便地创建可导入的 ZIP 文件。
PyZipFile让您快速高效地将 Python 代码捆绑到 ZIP 文件中。该类继承自ZipFile,因此它共享同一个基本接口。但是,这些类别之间有两个主要区别:
PyZipFile的初始化器带有一个名为optimize的可选参数,它允许你在归档之前通过编译成字节码来优化 Python 代码。PyZipFile类提供了一个名为.writepy()的方法,该方法接受 Python 模块或包作为参数,并将其添加到目标 ZIP 文件中。
如果optimize是其默认值-1,那么输入的.py文件会自动编译成.pyc文件,然后添加到目标档案中。为什么会这样?通过跳过编译步骤,打包.pyc文件而不是原始的.py文件使得导入过程更加有效。在接下来的章节中,您将了解到关于这个主题的更多信息。
在接下来的两节中,您将亲自动手创建自己的包含模块和包的可导入 ZIP 文件。
将 Python 模块捆绑成 ZIP 文件
在这一节中,您将使用PyZipFile.writepy()将一个.py文件编译成字节码,并将生成的.pyc文件添加到一个 ZIP 存档中。要试用.writepy(),假设您有一个hello.py模块:
"""Print a greeting message."""
# hello.py
def greet(name="World"):
print(f"Hello, {name}! Welcome to Real Python!")
这个模块定义了一个名为greet()的函数,它将name作为参数,将友好的问候信息打印到屏幕上。
现在假设您想将这个模块打包成一个 ZIP 文件,以便以后导入。为此,您可以运行以下代码:
>>> import zipfile >>> with zipfile.PyZipFile("hello.zip", mode="w") as zip_module: ... zip_module.writepy("hello.py") ... >>> with zipfile.PyZipFile("hello.zip", mode="r") as zip_module: ... zip_module.printdir() ... File Name Modified Size hello.pyc 2021-10-18 05:40:04 313运行这段代码后,您将在当前工作目录中拥有一个
hello.zip文件。对zip_module上的.writepy()的调用自动将hello.py编译成hello.pyc,并存储在底层的 ZIP 文件hello.zip中。这就是为什么.printdir()显示hello.pyc而不是你原来的hello.py文件。这种自动编译确保了高效的导入过程。注意:
PyZipFile类默认不压缩你的 Python 模块和包。它只是将它们存储在一个 ZIP 文件容器中。如果你想压缩你的源文件,你需要通过PyZipFile的compression参数显式地提供一个压缩方法。目前,Python 支持 Deflate 、 bzip2 和 LZMA 压缩方法。在本教程中,您将依赖于默认值
compression、、ZIP_STORED、,这意味着您的源文件不会被压缩。压缩源文件会影响导入操作的性能,您将在本教程的后面部分了解到这一点。您也可以使用任何常规的文件归档器手动将
.py和.pyc文件打包成 ZIP 文件。如果生成的档案包含没有相应的.pyc文件的.py文件,那么 Python 将在您第一次从特定的 ZIP 文件导入时编译它们。Python 不会修改底层的 ZIP 文件来添加新编译的
.pyc文件。所以下次运行导入时,Python 会再次编译代码。这种行为会使导入过程变慢。您还可以将一个目录作为第一个参数传递给
.writepy()。如果输入目录不是 Python 包,那么该方法扫描它寻找.py文件,将它们编译成.pyc文件,并将这些.pyc文件添加到目标 ZIP 文件的顶层。扫描步骤不是递归的,这意味着不扫描子目录中的源文件。您可以通过将
PyZipFile的optimize参数设置为以下值之一来进一步调整编译过程:
价值 最佳化 0不执行任何优化 1删除 assert语句2删除 assert语句和文档字符串有了这些值,当
.writepy()在归档之前将.py文件编译成.pyc文件时,您可以微调您想要使用的优化级别。到目前为止,您已经学习了如何将一个或多个模块捆绑到一个 ZIP 文件中。在日常编码中,您可能还需要压缩一个完整的 Python 包。您将在下一节中学习如何做到这一点。
将 Python 包打包成 ZIP 文件
还可以通过使用
PyZipFile及其.writepy()方法将 Python 包捆绑到 ZIP 文件中。正如您已经了解到的,如果您将一个常规目录作为第一个参数传递给.writepy(),那么该方法将扫描目录中的.py文件,编译它们,并将相应的.pyc文件添加到结果 ZIP 文件中。另一方面,如果输入目录是一个 Python 包,那么
.writepy()编译所有的.py文件,并将它们添加到 ZIP 文件中,保持包的内部结构。要使用 Python 包来尝试
.writepy(),创建一个新的hello/目录,并将您的hello.py文件复制到其中。然后添加一个空的__init__.py模块,把目录变成一个包。您最终应该得到以下结构:hello/ | ├── __init__.py └── hello.py现在假设您想要将这个包打包成一个 ZIP 文件,以便分发。如果是这种情况,那么您可以运行以下代码:
>>> import zipfile
>>> with zipfile.PyZipFile("hello_pkg.zip", mode="w") as zip_pkg:
... zip_pkg.writepy("hello")
...
>>> with zipfile.PyZipFile("hello_pkg.zip", mode="r") as zip_pkg:
... zip_pkg.printdir()
...
File Name Modified Size
hello/__init__.pyc 2021-10-18 05:56:00 110
hello/hello.pyc 2021-10-18 05:56:00 319
对.writepy()的调用以hello包为参数,在其中搜索.py文件,编译成.pyc文件,最后添加到目标 ZIP 文件中,保持相同的包结构。
了解 Zip 导入的局限性
当您使用 Zip 文件分发 Python 代码时,您需要考虑 ZIP 导入的一些限制:
- 无法加载动态文件,如
.pyd、.dll、.so、。
*** 从.py文件中导入代码意味着性能妥协。* 如果解压缩库不可用,从压缩文件导入代码将会失败。*
*您可以在 ZIP 存档中包含任何类型的文件。然而,当您的用户从这些档案中导入代码时,只读取了.py、.pyw、.pyc和.pyo文件。从动态文件中导入代码是不可能的,比如.pyd、.dll和.so,如果它们存在于 ZIP 文件中。比如,你不能从 ZIP 存档中加载用 C 编写的共享库和扩展模块。
您可以通过从 ZIP 文件中提取动态模块,将它们写入文件系统,然后加载它们的代码来解决这个限制。然而,这意味着您需要创建临时文件并处理可能的错误和安全风险,这可能会使事情变得复杂。
正如您在本教程前面所学的,Zip 导入也可能意味着性能的降低。如果您的档案包含.py模块,那么 Python 将编译它们以满足导入。但是,它不会保存相应的.pyc文件。这种行为可能会降低导入操作的性能。
最后,如果你需要从一个压缩的 ZIP 文件中导入代码,那么 zlib 必须在你的工作环境中可用以进行解压缩。如果这个库不可用,从压缩的归档文件中导入代码会失败,并显示一个丢失的zlib消息。此外,解压缩步骤会给导入过程增加额外的性能开销。出于这些原因,您将在本教程中使用未压缩的 ZIP 文件。
从 ZIP 文件导入 Python 代码
到目前为止,您已经学会了如何创建自己的可导入 ZIP 文件以供分发。现在假设您在另一端,并且您正在获得带有 Python 模块和包的 ZIP 文件。如何从它们那里导入代码呢?在本节中,您将获得这个问题的答案,并了解如何使 ZIP 文件可用于导入其内容。
为了让 Python 从 ZIP 文件导入代码,该文件必须在 Python 的模块搜索路径中可用,该路径存储在sys.path中。这个模块级变量包含一个由指定模块搜索路径的字符串组成的列表。path的内容包括:
- 包含您正在运行的脚本的目录
- 当前目录,如果你已经交互式地运行了解释器
PYTHONPATH环境变量中的目录,如果设置的话- 取决于您的特定 Python 安装的目录列表
- 该目录中列出了任意路径的配置文件(
.pth文件)
下表指出了几种将 ZIP 文件添加到sys.path的方法:
| [计]选项 | 目标代码或解释程序 |
|---|---|
list.insert()、list.append()和list.extend()方法 |
您正在编写和运行的 Python 代码 |
PYTHONPATH环境变量 |
您系统上运行的每个 Python 解释器 |
一个 Python 路径配置文件,或.pth文件 |
包含.pth文件的 Python 解释器 |
在接下来的部分中,您将探索这三种向sys.path添加项目的方法,这样您就可以使您的 ZIP 文件可用于导入它们的内容。
动态使用sys.path进行 Zip 导入
因为sys.path是一个list对象,所以可以通过使用常规的list方法从 Python 代码中操纵它。一般来说,要向list对象添加新项目,可以使用.insert()、、或.extend()。
通常,您将使用.insert(0, item)从您的 Python 代码向sys.path添加新项目。以这种方式调用.insert()会在列表的开头插入item,确保新添加的条目优先于已有的条目。在名字冲突可能发生的时候,让item在开头使你能够隐藏现有的模块和包。
现在假设您需要将包含您的hello.py模块的hello.zip文件添加到您当前 Python 的sys.path中。在这种情况下,您可以运行下面示例中的代码。注意,为了在您的机器上运行这个例子,您需要提供到hello.zip的正确路径:
>>> import sys >>> # Insert the hello.zip into sys.path >>> sys.path.insert(0, "/path/to/hello.zip") >>> sys.path[0] '/path/to/hello.zip' >>> # Import and use the code >>> import hello >>> hello.greet("Pythonista") Hello, Pythonista! Welcome to Real Python!一旦你将
hello.zip的路径添加到你的sys.path中,那么你就可以从hello.py中导入对象,就像对待任何常规模块一样。如果像
hello_pkg.zip一样,您的 ZIP 文件包含 Python 包,那么您也可以将它添加到sys.path中。在这种情况下,导入应该是包相关的:
>>> import sys
>>> sys.path.insert(0, "/path/to/hello_pkg.zip")
>>> from hello import hello
>>> hello.greet("Pythonista")
Hello, Pythonista! Welcome to Real Python!
因为您的代码现在在一个包中,所以您需要从hello包中导入hello模块。然后您可以像往常一样访问greet()功能。
向sys.path添加项目的另一个选项是使用.append()。此方法将单个对象作为参数,并将其添加到基础列表的末尾。重启您的 Python 交互式会话,并运行提供hello.zip路径的代码:
>>> import sys >>> sys.path.append("/path/to/hello.zip") >>> # The hello.zip file is at the end of sys.path >>> sys.path[-1] '/path/to/hello.zip' >>> from hello import greet >>> greet("Pythonista") Hello, Pythonista! Welcome to Real Python!这种技术的工作原理类似于使用
.insert()。然而,ZIP 文件的路径现在位于sys.path的末尾。如果列表中前面的任何一项包含一个名为hello.py的模块,那么 Python 将从该模块导入,而不是从您新添加的hello.py模块导入。你也可以循环使用
.append()来添加几个文件到sys.path,或者你可以只使用.extend()。该方法接受 iterable 项,并将其内容添加到基础列表的末尾。和.append()一样,记住.extend()会把你的文件添加到sys.path的末尾,所以现有的名字可以隐藏你的 ZIP 文件中的模块和包。使用
PYTHONPATH进行系统范围的 Zip 导入在某些情况下,您可能需要一个给定的 ZIP 文件,以便从计算机上运行的任何脚本或程序中导入其内容。在这些情况下,您可以使用
PYTHONPATH环境变量让 Python 在您运行解释器时自动将您的档案加载到sys.path中。
PYTHONPATH使用与PATH环境变量相同的格式,由os.pathsep分隔的目录路径列表。在 Unix 系统上,比如 Linux 和 macOS,这个函数返回一个冒号(:),而在 Windows 上,它返回一个分号(;)。例如,如果您在 Linux 或 macOS 上,那么您可以通过运行以下命令将您的
hello.zip文件添加到PYTHONPATH:$ export PYTHONPATH="$PYTHONPATH:/path/to/hello.zip"该命令将
/path/to/hello.zip添加到当前的PYTHONPATH中,并导出它,以便它在当前的终端会话中可用。注意:上面的命令导出了一个定制版本的
PYTHONPATH,其中包含了到hello.zip的路径。该变量的自定义版本仅在当前命令行会话中可用,一旦关闭该会话,该版本将会丢失。如果您正在运行 Bash 作为您当前的 shell ,那么您可以通过将以下代码添加到您的
.bashrc文件中,使这个自定义版本的PYTHONPATH可用于您的所有命令行会话:# .bashrc if [ -f /path/to/hello.zip ]; then export PYTHONPATH="$PYTHONPATH:/path/to/hello.zip" fi这段代码检查
hello.zip是否存在于您的文件系统中。如果是,那么它将文件添加到PYTHONPATH变量并导出它。因为每次启动新的命令行实例时,Bash 都会运行这个文件,所以定制的PYTHONPATH将在每个会话中可用。现在您可以发出
python命令来运行解释器。一旦你到达那里,像往常一样检查sys.path的内容:
>>> import sys
>>> sys.path
[..., '/path/to/hello.zip', ...]
酷!您的hello.zip文件在列表中。从这一点开始,您将能够像在上一节中一样从hello.py导入对象。来吧,试一试!
在上面的输出中需要注意的重要一点是,你的hello.zip文件不在sys.path的开头,这意味着根据 Python 如何处理其模块搜索路径,较早出现的同名模块将优先于你的hello模块。
要在 Windows 系统上向PYTHONPATH添加项目,您可以在cmd.exe窗口中执行命令:
C:\> set PYTHONPATH=%PYTHONPATH%;C:\path\to\hello.zip
该命令将C:\path\to\hello.zip添加到 Windows 机器上PYTHONPATH变量的当前内容中。要检查它,在同一个命令提示符会话中运行 Python 解释器,并像以前一样查看sys.path的内容。
注意:同样,您用上面的命令设置的PYTHONPATH变量将只在您当前的终端会话中可用。要在 Windows 上永久设置PYTHONPATH变量,学习如何在 Windows 中添加 PYTHONPATH
将目录和 ZIP 文件添加到PYTHONPATH环境变量中,可以让您在终端会话下运行的任何 Python 解释器都可以使用这些条目。最后,需要注意的是 Python 会忽略PYTHONPATH中列出的不存在的目录和 ZIP 文件,所以请密切关注。
使用.pth文件进行首选范围的 zip 导入
有时,只有在运行特定的 Python 解释器时,您可能希望从给定的 ZIP 文件中导入代码。当您的项目使用该 ZIP 文件中的代码,并且您不希望该代码可用于您的其他项目时,这是非常有用的。
Python 的路径配置文件允许你用自定义的目录和 ZIP 文件来扩展给定解释器的sys.path。
路径配置文件使用.pth文件扩展名,可以保存目录和 ZIP 文件的路径列表,每行一个。每次运行提供.pth文件的 Python 解释器时,这个路径列表都会被添加到sys.path中。
Python 的.pth文件有一个简单明了的格式:
- 每行必须包含一个路径条目。
- 空行和以数字符号(
#)开头的行被跳过。 - 执行以
import开头的行。
一旦你有了一个合适的.pth文件,你需要把它复制到一个站点目录中,这样 Python 就可以找到它并加载它的内容。要获得当前 Python 环境的站点目录,可以从 site 模块中调用 getusersitepackages() 。如果您在当前机器上没有管理员权限,那么您可以使用位于 site.USER_SITE 的用户站点目录。
注意:用户网站目录可能不在您的个人文件夹中。如果这是您的情况,那么请按照所需的路径结构随意创建它。
例如,以下命令为 Ubuntu 上的全系统 Python 3 解释器创建了一个hello.pth路径配置文件:
$ sudo nano /usr/lib/python3/dist-packages/hello.pth
该命令创建hello.pth,使用 GNU nano 文本编辑器作为root。在那里,输入你的hello.zip文件的路径。按 Ctrl + X ,然后按 Y ,最后按 Enter 保存文件。现在,当您再次启动系统 Python 解释器时,这个 ZIP 文件将在sys.path中可用:
>>> import sys >>> sys.path [..., '/path/to/hello.zip', ...]就是这样!从这一点开始,只要使用系统范围的 Python 解释器,就可以从
hello.py导入对象。同样,当 Python 读取和加载给定的
.pth文件的内容时,不存在的目录和 ZIP 文件不会被添加到sys.path中。最后,.pth文件中的重复条目只添加一次到sys.path。探索 Python 的
zipimport:Zip 导入背后的工具你已经在不知不觉中使用了标准库中的
zipimport模块。在幕后,当一个sys.path项包含一个 ZIP 文件的路径时,Python 的内置导入机制会自动使用这个模块。在这一节中,您将通过一个实际的例子学习zipimport是如何工作的,以及如何在您的代码中显式地使用它。了解
zipimport的基础知识
zipimport的主要成分是zipimporter。这个类将 ZIP 文件的路径作为参数,并创建一个导入器实例。下面是一个如何使用zipimporter及其一些属性和方法的例子:
>>> from zipimport import zipimporter
>>> importer = zipimporter("/path/to/hello.zip")
>>> importer.is_package("hello")
False
>>> importer.get_filename("hello")
'/path/to/hello.zip/hello.pyc'
>>> hello = importer.load_module("hello")
>>> hello.__file__
'/path/to/hello.zip/hello.pyc'
>>> hello.greet("Pythonista")
Hello, Pythonista! Welcome to Real Python!
在这个例子中,首先从zipimport导入zipimporter。然后您创建一个带有您的hello.zip文件路径的zipimporter实例。
zipimporter类提供了几个有用的属性和方法。例如,如果输入名称是一个包,则 .is_package() 返回True,否则返回False。 .get_filename() 方法返回归档文件中给定模块的路径( .__file__ )。
如果您想将模块的名称放入当前的名称空间,那么您可以使用.load_module(),它返回对输入模块的引用。有了这个引用,您就可以像往常一样从模块中访问任何代码对象。
用zipimport 构建一个插件系统
如上所述,Python 内部使用zipimport从 ZIP 文件加载代码。您还了解了本模块提供的工具,您可以在一些实际的编码情况下使用。例如,假设您想要实现一个定制的插件系统,其中每个插件都位于自己的 ZIP 文件中。您的代码应该在给定的文件夹中搜索 ZIP 文件,并自动导入插件的功能。
要实际体验这个例子,您将实现两个玩具插件,它们接受一条消息和一个标题,并在您的默认 web 浏览器和一个 Tkinter 消息框中显示它们。每个插件都应该在自己的目录中,在一个叫做plugin.py的模块中。这个模块应该实现插件的功能,并提供一个 main() 函数作为插件的入口点。
继续创建一个名为web_message/的文件夹,其中包含一个plugin.py文件。在您最喜欢的代码编辑器或 IDE 中打开文件,并为 web 浏览器插件键入以下代码:
"""A plugin that displays a message using webbrowser."""
# web_message/plugin.py
import tempfile
import webbrowser
def main(text, title="Alert"):
with tempfile.NamedTemporaryFile(
mode="w", suffix=".html", delete=False
) as home:
html = f"""
<html>
<head>
<title>{title}</title>
</head>
<body>
<h1>
{text} </h1>
</body>
</html>
"""
home.write(html)
path = "file://" + home.name
webbrowser.open(path)
这段代码中的main()函数接受一条text消息和一个窗口title。然后在一个with语句中创建一个 NamedTemporaryFile 。该文件将包含一个在页面上显示title和text的最小 HTML 文档。要在默认的 web 浏览器中打开这个文件,可以使用webbrowser.open()。
下一个插件提供了类似的功能,但是使用了Tkinter工具包。这个插件的代码也应该存在于一个名为plugin.py的模块中。您可以将该模块放在文件系统中一个名为tk_message/的目录下:
"""A plugin that displays a message using Tkinter."""
# tk_message/plugin.py
import tkinter
from tkinter import messagebox
def main(text, title="Alert"):
root = tkinter.Tk()
root.withdraw()
messagebox.showinfo(title, text)
遵循与网络浏览器插件相同的模式,main()使用text和title。在这种情况下,该函数创建一个 Tk 实例来保存插件的顶层窗口。但是,您不需要显示那个窗口,只需要一个消息框。所以,你使用.withdraw()来隐藏根窗口,然后调用messagebox上的.showinfo()来显示一个带有输入text和title的对话框。
现在您需要将每个插件打包到它自己的 ZIP 文件中。为此,在包含web_message/和tk_message/文件夹的目录中启动一个 Python 交互会话,并运行以下代码:
>>> import zipfile >>> plugins = ("web_message", "tk_message") >>> for plugin in plugins: ... with zipfile.PyZipFile(f"{plugin}.zip", mode="w") as zip_plugin: ... zip_plugin.writepy(plugin) ...下一步是为你的插件系统创建一个根文件夹。该文件夹必须包含一个
plugins/目录,其中包含新创建的 ZIP 文件。您的目录应该是这样的:rp_plugins/ │ ├── plugins/ │ │ │ ├── tk_message.zip │ └── web_message.zip │ └── main.py在
main.py中,您将为您的插件系统放置客户端代码。继续用下面的代码填充main.py:1# main.py 2 3import zipimport 4from pathlib import Path 5 6def load_plugins(path): 7 plugins = [] 8 for zip_plugin in path.glob("*.zip"): 9 importer = zipimport.zipimporter(zip_plugin) 10 plugin_module = importer.load_module("plugin") 11 plugins.append(getattr(plugin_module, "main")) 12 return plugins 13 14if __name__ == "__main__": 15 path = Path("plugins/") 16 plugins = load_plugins(path) 17 for plugin in plugins: 18 plugin("Hello, World!", "Greeting!")下面是这段代码的逐行工作方式:
- 第 3 行导入
zipimport从相应的 ZIP 文件中动态加载你的插件。- 第 4 行导入
pathlib来管理系统路径。- 第 6 行定义了
load_plugins(),它获取包含插件档案的目录的路径。- 第 7 行创建一个空列表来保存当前的插件。
- 第 8 行定义了一个
for循环,它遍历插件目录中的.zip文件。- 第 9 行为系统中的每个插件创建一个
zipimporter实例。- 第 10 行从每个插件的 ZIP 文件中加载
plugin模块。- 第 11 行将每个插件的
main()函数添加到plugins列表中。- 第 12 行T3】将
plugins列表返回给调用者。第 14 到 18 行调用
load_plugins()来生成当前可用插件列表,并循环执行它们。如果您从命令行运行
main.py脚本,那么您首先会得到一个 Tkinter 消息框,显示Hello, World!消息和Greeting!标题。关闭该窗口后,您的 web 浏览器将在新页面上显示相同的消息和标题。来吧,试一试!结论
Python 可以直接从 ZIP 文件导入代码,如果它们在模块搜索路径中可用的话。这个特性被称为 Zip 导入。您可以利用 Zip 导入将模块和包捆绑到一个归档文件中,这样您就可以快速有效地将它们分发给最终用户。
如果您经常将 Python 代码捆绑到 ZIP 文件中,并且需要在日常任务中使用这些代码,那么您也可以利用 Zip 导入。
在本教程中,您学习了:
- 什么是 Zip 导入
- 何时以及如何使用 Zip 导入
- 如何用
zipfile构建可导入的压缩文件- 如何使 ZIP 文件对导入机制可用
您还编写了一个关于如何用
zipimport构建一个最小插件系统的实践示例。通过这个例子,您学习了如何用 Python 从 ZIP 文件中动态导入代码。*******Python 的 zipapp:构建可执行的 Zip 应用程序
Python Zip 应用程序是一个快速而又酷的选择,您可以将可执行的应用程序捆绑并分发到一个单独的准备运行的文件中,这将使您的最终用户体验更加愉快。如果您想了解 Python 应用程序以及如何使用标准库中的
zipapp创建它们,那么本教程就是为您准备的。您将能够创建 Python Zip 应用程序,作为向最终用户和客户分发您的软件产品的一种快速且可访问的方式。
在本教程中,您将学习:
- 什么是 Python Zip 应用程序
- Zip 应用程序如何工作内部
- 如何用
zipapp****构建 Python Zip 应用- 什么是独立的 Python Zip 应用程序以及如何创建它们
- 如何使用命令行工具手动创建 Python Zip 应用程序
**您还将了解一些用于创建 Zip 应用程序的第三方库,它们克服了
zipapp的一些限制。为了更好地理解本教程,你需要知道如何构造 Python 应用程序布局、运行 Python 脚本、构建 Python 包,使用 Python 虚拟环境,以及使用
pip安装和管理依赖关系。您还需要熟练使用命令行或终端。免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
Python Zip 应用入门
Python 生态系统中最具挑战性的问题之一是找到一种有效的方法来分发可执行的应用程序,如图形用户界面(GUI) 和命令行界面(CLI) 程序。
编译后的编程语言,比如 C 、 C++ 、 Go ,可以生成你可以直接在不同操作系统和架构上运行的可执行文件。这种能力使您可以轻松地向最终用户分发软件。
然而,Python 不是那样工作的。Python 是一种解释语言,这意味着你需要一个合适的 Python 解释器来运行你的应用程序。没有直接的方法生成一个不需要解释器就能运行的独立的可执行文件。
有许多解决方案可以解决这个问题。你会发现诸如 PyInstaller 、 py2exe 、 py2app 、 Nuitka 等工具。这些工具允许您创建可分发给最终用户的自包含可执行应用程序。然而,设置这些工具可能是一个复杂且具有挑战性的过程。
有时候你不需要额外的复杂性。你只需要从一个脚本或者一个小程序中构建一个可执行的应用程序,这样你就可以快速的把它分发给你的终端用户。如果您的应用程序足够小,并且使用纯 Python 代码,那么使用一个 Python Zip 应用程序就足够了。
什么是 Python Zip 应用程序?
PEP 441——改进 Python ZIP 应用程序支持围绕 Python Zip 应用程序形成了概念、术语和规范。这种类型的应用程序由一个使用 ZIP 文件格式的文件组成,其中包含 Python 可以作为程序执行的代码。这些应用程序依靠 Python 从 ZIP 文件中运行代码的能力,这些 ZIP 文件的根目录下有一个
__main__.py模块,它作为一个入口点脚本工作。从版本 2.6 和 3.0 开始,Python 已经能够从 ZIP 文件运行脚本。实现这一目标的步骤非常简单。您只需要一个 ZIP 文件,其根目录下有一个
__main__.py模块。然后你可以把那个文件传递给 Python,Python 把它添加到sys.path并把__main__.py作为一个程序执行。在sys.path中保存应用程序的档案允许你通过 Python 的导入系统访问它的代码。举个简单的例子,假设你在一个类似于 Unix 的操作系统上,比如 Linux 或者 macOS,你运行下面的命令:
$ echo 'print("Hello, World!")' > __main__.py $ zip hello.zip __main__.py adding: __main__.py (stored 0%) $ python ./hello.zip Hello, World!您使用
echo命令创建一个包含代码print("Hello, World!")的__main__.py文件。然后你使用zip命令将__main__.py存档到hello.zip。一旦你完成了这些,你就可以通过将文件名作为参数传递给python命令来运行hello.zip了。为了完善 Python Zip 应用程序的内部结构,您需要一种方法来告诉操作系统如何执行它们。ZIP 文件格式允许您在 ZIP 存档文件的开头添加任意数据。Python Zip 应用程序利用该特性在应用程序的归档中包含一个标准的 Unix she bang 行:
#!/usr/bin/env python3在 Unix 系统上,这一行告诉操作系统使用哪个程序来执行手头的文件,这样您就可以直接运行文件,而无需使用
python命令。在 Windows 系统上,Python 启动器正确理解 shebang 行并为您运行 Zip 应用程序。即使使用 shebang 行,也可以通过将应用程序的文件名作为参数传递给
python命令来执行 Python Zip 应用程序。总之,要构建 Python Zip 应用程序,您需要:
- 一个使用标准 ZIP 文件格式并在其根包含一个
__main__.py模块的档案- 一个可选的 shebang 行,指定适当的 Python 解释器来运行应用程序
除了
__main__.py模块,您的应用程序的 ZIP 文件可以包含 Python 模块和包以及任何其他任意文件。但是,只有.py、.pyc和.pyo文件可以通过导入系统直接使用。换句话说,您可以将.pyd、.so和.dll文件打包到您的应用程序文件中,但是除非您将它们解压缩到您的文件系统中,否则您将无法使用它们。注意:无法执行存储在 ZIP 文件中的
.pyd、.so和.dll文件的代码是操作系统的限制。这个限制使得创建运送和使用.pyd、.so和.dll文件的 Zip 应用程序变得困难。Python 生态系统充满了用 C 或 C++编写的有用的库和工具,以保证速度和效率。即使您可以将这些库捆绑到一个 Zip 应用程序的归档文件中,您也不能从那里直接使用它们。您需要将这个库解压缩到您的文件系统中,然后从这个新位置访问它的组件。
PEP 441 提议将
.pyz和.pyzw作为 Python Zip 应用的文件扩展名。.pyz扩展标识控制台或命令行应用程序,而.pyzw扩展指窗口或 GUI 应用程序。在 Unix 系统上,如果您更喜欢 CLI 应用程序的简单命令名,可以删除
.pyz扩展名。在 Windows 上,.pyz和.pyzw文件是可执行文件,因为 Python 解释器将它们注册为可执行文件。为什么使用 Python Zip 应用程序?
假设你有一个程序,你的团队在他们的内部工作流程中经常使用它。该程序已经从一个单文件脚本发展成为一个拥有多个包、模块和文件的成熟应用程序。
此时,一些团队成员努力安装和设置每个新版本。他们不断要求您提供一种更快、更简单的方式来设置和运行程序。在这种情况下,您应该考虑创建一个 Python Zip 应用程序,将您的程序捆绑到一个文件中,并作为一个准备运行的应用程序分发给您的同事。
Python Zip 应用程序是发布软件的绝佳选择,您必须将这些软件作为单个可执行文件进行分发。这也是一种使用非正式渠道分发软件的便捷方式,例如通过计算机网络发送或托管在 FTP 服务器上。
Python Zip 应用程序是以现成的格式打包和分发 Python 应用程序的方便快捷的方式,可以让您的最终用户的生活更加愉快。
如何构建 Python Zip 应用程序?
正如您已经了解到的,Python Zip 应用程序由一个标准 Zip 文件组成,该文件包含一个
__main__.py模块,该模块作为应用程序的入口点。当您运行应用程序时,Python 会自动将其容器(ZIP 文件本身)添加到sys.path中,这样__main__.py就可以从塑造应用程序的模块和包中导入对象。要构建 Python Zip 应用程序,您可以运行以下常规步骤:
- 创建包含
__main__.py模块的应用程序源目录。- 压缩应用程序的源目录。
- 添加一个可选的 Unix shebang 行来定义运行应用程序的解释器。
- 使应用程序的 ZIP 文件可执行。此步骤仅适用于类似 Unix 的操作系统。
这些步骤非常简单,运行起来也很快。有了它们,如果您拥有所需的工具和知识,您可以在几分钟内手动构建一个 Python Zip 应用程序。然而,Python 标准库为您提供了更方便、更快捷的解决方案。
PEP 441 提议在标准库中增加一个名为
zipapp的新模块。这个模块方便了 Zip 应用程序的创建,它从 Python 3.5 开始就可用了。在本教程中,您将关注使用
zipapp创建 Python Zip 应用程序。然而,您还将学习如何使用不同的工具手动运行整个系列的步骤。这些额外的知识可以帮助您更深入地理解创建 Python Zip 应用程序的整个过程。如果您使用的是低于 3.5 的 Python 版本,这也会很有帮助。设置 Python Zip 应用程序
到目前为止,您已经了解了什么是 Python Zip 应用程序,如何构建它们,为什么使用它们,以及创建它们时需要遵循的步骤。你已经准备好开始建造你自己的了。不过,首先,您需要有一个用于 Python Zip 应用程序的功能性应用程序或脚本。
对于本教程,您将使用一个名为
reader的示例应用程序,它是一个最小的 web 提要阅读器,从 真实 Python 提要中读取最新的文章和资源。接下来,您应该将
reader的存储库克隆到您的本地机器上。在您选择的工作目录中打开命令行,并运行以下命令:$ git clone https://github.com/realpython/reader.git该命令将
reader存储库的全部内容下载到当前目录下的reader/文件夹中。注意:如果你不熟悉 Git 和 GitHub ,请查看Git 和 GitHub 介绍给 Python 开发者。
一旦克隆了存储库,就需要安装应用程序的依赖项。首先,你应该创建一个 Python 虚拟环境。继续运行以下命令:
$ cd reader/ $ python3 -m venv ./venv $ source venv/bin/activate这些命令在
reader/目录中创建和激活一个新的 Python 虚拟环境,该目录是reader项目的根目录。注意:要在 Windows 上创建和激活虚拟环境,您可以运行以下命令:
C:\> python -m venv venv C:\> venv\Scripts\activate.bat如果你在一个不同的平台上,那么你可能需要查看 Python 的官方文档关于创建虚拟环境。
现在您可以使用
pip安装reader的依赖项:(venv) $ python -m pip install feedparser html2text importlib_resources运行上面的命令将在您的活动 Python 虚拟环境中安装应用程序的所有依赖项。
注:自 Python 3.7 起,
importlib_resources在标准库中可用为importlib.resources。所以,如果你使用的是高于或等于 3.7 的版本,你不需要安装这个库。只需在定义了reader包的__init__.py文件中修改相应的导入。下面是一个使用
reader从 Real Python 获取最新文章、课程、播客剧集和其他学习资源的例子:(venv) $ python -m reader The latest tutorials from Real Python (https://realpython.com/) 0 The Django Template Language: Tags and Filters 1 Pass by Reference in Python: Best Practices 2 Using the "and" Boolean Operator in Python ...由于
reader在提要中列出了 30 个最新的学习资源,因此您的输出会有所不同。每个学习资源都有一个 ID 号。要从这些学习资源中获取一个项目的内容,您可以将相应的 ID 号作为命令行参数传递给reader:(venv) $ python -m reader 2 Using the "and" Boolean Operator in Python Python has three Boolean operators, or **logical operators** : `and`, `or`, and `not`. You can use them to check if certain conditions are met before deciding the execution path your programs will follow. In this tutorial, you'll learn about the `and` operator and how to use it in your code. ...该命令使用 Python 中的“and”布尔运算符将文章的部分内容打印到使用 Markdown 文本格式的屏幕上。您可以通过更改 ID 号来阅读任何可用的内容。
注意:
reader如何工作的细节与本教程无关。如果你对实现感兴趣,那么看看如何向 PyPI 发布开源 Python 包。特别是,你可以阅读名为的部分,快速浏览代码。要从
reader存储库创建一个 Zip 应用程序,您将主要使用reader/文件夹。该文件夹具有以下结构:reader/ | ├── config.cfg ├── feed.py ├── __init__.py ├── __main__.py └── viewer.py从
reader/目录中要注意的最重要的事实是,它包括一个__main__.py文件。这个文件使您能够像以前一样使用python -m reader命令来执行这个包。拥有一个
__main__.py文件提供了创建 Python Zip 应用程序所需的入口点脚本。在这个例子中,__main__.py文件在reader包中。如果您使用这个目录结构创建您的 Zip 应用程序,那么您的应用程序将不会运行,因为__main__.py将无法从reader导入对象。要解决这个问题,将
reader包复制到一个名为realpython/的外部目录,并将__main__.py文件放在其根目录下。然后删除运行python -m reader产生的__pycache__/文件夹,就像你之前做的那样。您最终应该得到以下目录结构:realpython/ │ ├── reader/ │ ├── __init__.py │ ├── config.cfg │ ├── feed.py │ └── viewer.py │ └── __main__.py有了这个新的目录结构,您就可以用
zipapp创建您的第一个 Python Zip 应用程序了。这就是你在下一节要做的。用
zipapp构建 Python Zip 应用程序要创建您的第一个 Python Zip 应用程序,您将使用
zipapp。这个模块实现了一个用户友好的命令行界面,它提供了用一个命令构建一个完整的 Zip 应用程序所需的选项。你也可以通过模块的 Python API 从你的代码中使用zipapp,它主要由一个单一的函数组成。在接下来的两节中,您将了解使用
zipapp构建 Zip 应用程序的两种方法。从命令行使用
zipapp
zipapp的命令行界面简化了将 Python 应用程序打包成 ZIP 文件的过程。在内部,zipapp通过运行您之前学习的步骤,从源代码创建一个 Zip 应用程序。要从命令行运行
zipapp,您应该使用以下命令语法:$ python -m zipapp <source> [OPTIONS]如果
source是一个目录,那么这个命令从该目录的内容创建一个 Zip 应用程序。如果source是一个文件,那么这个文件应该是一个包含应用程序代码的 ZIP 文件。然后,输入 ZIP 文件的内容被复制到目标应用程序档案中。下面是
zipapp接受的命令行选项的总结:
选择 描述 -o <output_filename>或--output=<output_filename>将 Zip 应用程序写入名为 output_filename的文件。此选项使用您提供的输出文件名。如果你不提供这个选项,那么zipapp使用带有.pyz扩展名的source的名字。-p <interpreter>或--python=<interpreter>将 shebang 行添加到应用程序的存档中。如果你在一个 POSIX 系统上,那么 zipapp使应用程序的归档文件可执行。如果您不提供此选项,那么您的应用程序的存档将不会有 shebang,也不会是可执行的。-m <main_function>或--main=<main_function>生成并写入一个适当的执行 main_function的__main__.py文件。main_function参数的形式应该是"package.module:callable"。如果你已经有一个__main__.py模块,你不需要这个选项。-c或--compress使用 Deflate 压缩方法压缩 source的内容。默认情况下,zipapp只存储source的内容而不压缩它,这可以让你的应用程序运行得更快。此表提供了对
zipapp命令行选项的简要描述。有关每个选项的具体行为的更多细节,请查看官方文档。现在您已经知道了从命令行使用
zipapp的基本知识,是时候构建readerZip 应用程序了。返回终端窗口,运行以下命令:(venv) $ python -m zipapp realpython/ \ -o realpython.pyz \ -p "/usr/bin/env python3"在这个命令中,您将
realpython/目录设置为 Zip 应用程序的源。使用-o选项,您可以为应用程序的档案提供一个名称realpython.pyz。最后,-p选项让您设置解释器,zipapp将使用它来构建 shebang 行。就是这样!现在,您将在当前目录中拥有一个
realpython.pyz文件。稍后您将学习如何执行该文件。为了展示
zipapp的-m和--main命令行选项,假设您决定更改reader项目布局并将__main__.py重命名为cli.py,同时将文件移回reader包。继续创建您的realpython/目录的副本,并进行建议的更改。之后,realpython/的文案应该是这样的:realpython_copy/ │ └── reader/ ├── __init__.py ├── cli.py ├── config.cfg ├── feed.py └── viewer.py目前,您的应用程序的源目录没有一个
__main__.py模块。zipapp的-m命令行选项允许你自动生成:$ python -m zipapp realpython_copy/ \ -o realpython.pyz \ -p "/usr/bin/env python3" \ -m "reader.cli:main"该命令使用带有
"reader.cli:main"的-m选项作为参数。这个输入值告诉zipappZip 应用程序可调用的入口点是reader包中cli.py模块的main()。生成的
__main__.py文件包含以下内容:# -*- coding: utf-8 -*- import reader.cli reader.cli.main()然后,这个
__main__.py文件与您的应用程序源代码一起打包成一个名为realpython.pyz的 ZIP 存档文件。使用 Python 代码中的
zipappPython 的
zipapp也有一个应用编程接口(API) ,你可以从你的 Python 代码中使用它。这个 API 主要由一个名为create_archive()的函数组成。使用该函数,您可以快速创建 Python Zip 应用程序:
>>> import zipapp
>>> zipapp.create_archive(
... source="realpython/",
... target="realpython.pyz",
... interpreter="/usr/bin/env python3",
... )
这个对create_archive()的调用需要一个名为source的第一个参数,它代表您的 Zip 应用程序的源代码。第二个参数,target,保存应用程序存档的文件名。最后,interpreter保存解释器来构建并作为 shebang 行添加到应用程序的 ZIP 存档中。
以下是create_archive()可以提出的论点的总结:
source可以带以下对象:- 现有源目录的基于字符串的路径
- 引用现有源目录的类似于路径的对象
- 现有 Zip 应用程序归档的基于字符串的路径
- 引用现有 Zip 应用程序档案的类似路径的对象
- 一个类似于文件的对象被打开用于读取并指向一个现有的 Zip 应用程序档案
target接受以下对象:- 目标 Zip 应用程序文件的基于字符串的路径
- 目标 Zip 应用程序文件的类似路径的对象
interpreter指定一个 Python 解释器,作为 shebang 行写在生成的应用程序归档文件的开头。省略此参数会导致没有 shebang 行,也没有应用程序的执行权限。main指定zipapp将用作目标归档入口点的可调用文件的名称。当您没有一个__main__.py文件时,您为main提供一个值。filter采用一个布尔值函数,如果源目录中的给定文件应该被添加到最终的 Zip 应用程序文件中,该函数应该返回True。compressed接受一个决定是否要压缩源文件的布尔值。
这些参数中的大多数在zipapp的命令行界面中都有等价的选项。上面的例子只使用了前三个参数。根据您的具体需要,您也可以使用其他参数。
运行 Python Zip 应用程序
到目前为止,您已经学习了如何从命令行和 Python 代码使用zipapp创建 Python Zip 应用程序。现在是时候运行你的realpython.pyz应用程序了,以确保它能正常工作。
如果您在一个类似 Unix 的系统上,那么您可以通过执行以下命令来运行您的应用程序:
(venv) $ ./realpython.pyz
The latest tutorials from Real Python (https://realpython.com/)
0 The Django Template Language: Tags and Filters
1 Pass by Reference in Python: Best Practices
2 Using the "and" Boolean Operator in Python
...
酷!有用!现在,您有了一个可以快速与朋友和同事共享的应用程序文件。
您不再需要从命令行调用 Python 来运行应用程序。因为您的 Zip 应用程序档案文件在开头有一个 shebang 行,所以操作系统将自动使用您的活动 Python 解释器来运行目标档案文件的内容。
注意:为了让您的应用程序运行,您需要在 Python 环境中安装所有必需的依赖项。否则,你会得到一个ImportError。
如果您在 Windows 上,那么您的 Python 安装应该已经注册了.pyz和.pyzw文件,并且应该能够运行它们:
C:\> .\realpython.pyz
The latest tutorials from Real Python (https://realpython.com/)
0 The Django Template Language: Tags and Filters
1 Pass by Reference in Python: Best Practices
2 Using the "and" Boolean Operator in Python
...
本教程中使用的reader应用程序有一个命令行界面,所以从命令行或终端窗口运行它是有意义的。然而,如果你有一个图形用户界面应用程序,那么你将能够从你最喜欢的文件管理器中运行它,就像你通常运行可执行程序一样。
同样,您可以通过调用适当的 Python 解释器来执行任何 Zip 应用程序,并将应用程序的文件名作为参数:
$ python3 realpython.pyz
The latest tutorials from Real Python (https://realpython.com/)
0 The Django Template Language: Tags and Filters
1 Pass by Reference in Python: Best Practices
2 Using the "and" Boolean Operator in Python
...
在这个例子中,您使用系统 Python 3.x 安装来运行realpython.pyz。如果您的系统上有许多 Python 版本,那么您可能需要更具体一些,使用类似于python3.9 realpython.pyz的命令。
注意,无论您使用什么解释器,您都需要安装应用程序的依赖项。否则,您的应用程序将会失败。不满足依赖关系是 Python Zip 应用程序的常见问题。要解决这种恼人的情况,您可以创建一个独立的应用程序,这是下一节的主题。
使用zipapp 创建独立的 Python Zip 应用程序
您还可以使用zipapp来创建独立的 Python Zip 应用程序。这种类型的应用程序将其所有依赖项捆绑到应用程序的 ZIP 文件中。这样,您的最终用户只需要一个合适的 Python 解释器来运行应用程序。他们不需要担心依赖性。
要创建一个独立的 Python Zip 应用程序,首先需要使用pip将其依赖项安装到源目录中。继续创建一个名为realpython_sa/的realpython/目录的副本。然后运行以下命令来安装应用程序的依赖项:
(venv) $ python -m pip install feedparser html2text importlib_resources \
--target realpython_sa/
这个命令使用带有--target选项的pip install来安装reader的所有依赖项。pip的文档说这个选项允许你将包安装到一个目标目录中。在本例中,该目录必须是您的应用程序的源目录,realpython_sa/。
注意:如果你的应用程序有一个requirements.txt文件,那么你可以通过一个快捷方式来安装依赖项。
您可以改为运行以下命令:
(venv) $ python -m pip install \
-r requirements.txt \ --target app_directory/
使用这个命令,您可以将应用程序的requirements.txt文件中列出的所有依赖项安装到app_directory/文件夹中。
一旦将reader的依赖项安装到realpython_sa/中,就可以随意删除pip创建的*.dist-info目录。这些目录包含几个带有元数据的文件,pip用它们来管理相应的包。既然你不再需要这些信息,你可以把它们扔掉。
这个过程的最后一步是像往常一样使用zipapp构建 Zip 应用程序:
(venv) $ python -m zipapp realpython_sa/ \
-p "/usr/bin/env python3" \
-o realpython_sa.pyz \
-c
该命令在realpython_sa.pyz中生成一个独立的 Python Zip 应用程序。要运行这个应用程序,您的最终用户只需要在他们的机器上安装一个合适的 Python 3 解释器。与常规的 Zip 应用程序相比,这种应用程序的优势在于您的最终用户不需要安装任何依赖项来运行应用程序。来吧,试一试!
在上面的例子中,您使用了zipapp的-c选项来压缩realpython_sa/的内容。对于具有许多依赖项、占用大量磁盘空间的应用程序来说,这个选项相当方便。
手动创建 Python Zip 应用程序
正如您已经了解到的,从 Python 3.5 开始,zipapp就在标准库中可用。如果您使用的是低于这个版本的 Python,那么您仍然可以手动构建您的 Python Zip 应用程序,而不需要zipapp。
在接下来的两节中,您将学习如何使用 Python 标准库中的 zipfile 创建一个 Zip 应用程序。您还将学习如何使用一些命令行工具来完成相同的任务。
使用 Python 的zipfile
您已经有了包含reader应用程序源文件的realpython/目录。从该目录手动构建 Python Zip 应用程序的下一步是将其归档到一个 Zip 文件中。为此,你可以使用zipfile。这个模块提供了创建、读取、写入、添加和列出 ZIP 文件内容的便利工具。
下面的代码展示了如何使用zipfile.ZipFile和一些其他工具创建reader Zip 应用程序。例如,代码依靠 pathlib 和 stat 来读取源目录的内容,并对结果文件设置执行权限:
# build_app.py
import pathlib
import stat
import zipfile
app_source = pathlib.Path("realpython/")
app_filename = pathlib.Path("realpython.pyz")
with open(app_filename, "wb") as app_file:
# 1\. Prepend a shebang line shebang_line = b"#!/usr/bin/env python3\n"
app_file.write(shebang_line)
# 2\. Zip the app's source with zipfile.ZipFile(app_file, "w") as zip_app:
for file in app_source.rglob("*"):
member_file = file.relative_to(app_source)
zip_app.write(file, member_file)
# 3\. Make the app executable (POSIX systems only) current_mode = app_filename.stat().st_mode
exec_mode = stat.S_IEXEC
app_filename.chmod(current_mode | exec_mode)
这段代码运行所需的三个步骤,最终得到一个成熟的 Python Zip 应用程序。第一步是在应用程序文件中添加一个 shebang 行。它使用 with语句中的 open() 创建一个文件对象(app_file)来处理应用程序。然后调用.write()在app_file的开头写 shebang 行。
注意:如果你在 Windows 上,你应该在 UTF-8 中编码 shebang 行。如果你在一个 POSIX 系统上,比如 Linux 和 macOS,你应该用 sys.getfilesystemencoding() 返回的任何文件系统编码对它进行编码。
第二步使用嵌套的with语句中的 ZipFile 压缩应用程序的源目录内容。for循环使用pathlib.Path.rglob()遍历realpython/中的文件,并将它们写入zip_app。注意.rglob()通过目标文件夹app_source递归搜索文件和目录。
最终 ZIP 存档中每个文件的文件名member_file需要相对于应用程序的源目录,以确保应用程序 ZIP 文件的内部结构与源文件的结构realpython/相匹配。这就是为什么你在上面的例子中使用pathlib.Path.relative_to()。
最后,第三步使用 pathlib.Path.chmod() 使应用程序的文件可执行。为此,首先使用 pathlib.Path.stat() 获取文件的当前模式,然后使用按位或运算符(|)将该模式与 stat.S_IEXEC 结合起来。注意,这个步骤只对 POSIX 系统有影响。
运行完这些步骤后,您的realpython.pyz应用程序就可以运行了。请从命令行尝试一下。
使用 Unix 命令行工具
如果您使用的是类 Unix 系统,比如 Linux 和 macOS,那么您也可以在命令行中使用特定的工具来运行上一节中的三个步骤。例如,您可以使用zip命令压缩应用程序源目录的内容:
$ cd realpython/
$ zip -r ../realpython.zip *
在这个例子中,你先将 cd 放入realpython/目录。然后使用带有-r选项的zip命令将realpython/的内容压缩到realpython.zip中。该选项递归遍历目标目录。
注意:另一个选择是从命令行使用 Python 的zipfile。
为此,从realpython/目录外运行以下命令:
$ python -m zipfile --create realpython.zip realpython/*
zipfile的--create命令行选项允许您从源目录创建一个 ZIP 文件。追加到realpython/目录的星号(*)告诉zipfile将该目录的内容放在生成的 ZIP 文件的根目录下。
下一步是将 shebang 行添加到 ZIP 文件realpython.zip,并将其保存为realpython.pyz。为此,您可以在管道中使用echo和 cat 命令:
$ cd ..
$ echo '#!/usr/bin/env python3' | cat - realpython.zip > realpython.pyz
cd ..命令让你退出realpython/。echo命令将'#!/usr/bin/env python3'发送到标准输出。管道字符(|)将标准输出的内容传递给cat命令。然后cat将标准输出(-)与realpython.zip的内容连接起来。最后,大于号(>)将cat输出重定向到realpython.pyz文件。
最后,您可能希望使用 chmod 命令使应用程序的文件可执行:
$ chmod +x realpython.pyz
这里,chmod给realpython.pyz增加了执行权限(+x)。现在,您已经准备好再次运行您的应用程序,这可以像往常一样从命令行完成。
使用第三方工具创建 Python 应用程序
在 Python 生态系统中,您会发现一些第三方库的工作方式与zipapp类似。它们提供了更多的特性,对探索这些特性很有帮助。在本节中,您将了解其中两个第三方库: pex 和 shiv 。
项目提供了一个创建 PEX 文件的工具。PEX 代表 Python 可执行文件,是一种存储自包含可执行 Python 虚拟环境的文件格式。pex工具用一个 shebang 行和一个__main__.py模块将这些环境打包成 ZIP 文件,这允许您直接执行生成的 PEX 文件。pex工具是对 PEP 441 中概述的思想的扩展。
要用pex创建一个可执行的应用程序,首先需要安装它:
(venv) $ python -m pip install pex
(venv) $ pex --help
pex [-o OUTPUT.PEX] [options] [-- arg1 arg2 ...]
pex builds a PEX (Python Executable) file based on the given specifications:
sources, requirements, their dependencies and other options.
Command-line options can be provided in one or more files by prefixing the
filenames with an @ symbol. These files must contain one argument per line.
...
pex工具提供了丰富的选项,允许你微调你的 PEX 文件。以下命令显示了如何为reader项目创建一个 PEX 文件:
(venv) $ pex realpython-reader -c realpython -o realpython.pex
这个命令在你的当前目录中创建realpython.pex。这个文件是用于reader的 Python 可执行文件。注意,pex处理reader的安装和所有来自 PyPI 的依赖项。在 PyPI 上可以获得名为realpython-reader的reader项目,这就是为什么您使用这个名称作为pex的第一个参数。
-c选项允许您定义应用程序将使用哪个控制台脚本。在这种情况下,控制台脚本是reader的setup.py文件中定义的realpython。-o选项指定输出文件。像往常一样,您可以从命令行执行./realpython.pex来运行应用程序。
由于.pex文件的内容在执行前被解压缩,PEX 应用程序解决了zipapp应用程序的限制,允许您执行来自.pyd、.so和.dll文件的代码。
需要注意的最后一个细节是pex在生成的 PEX 文件中创建和打包了一个 Python 虚拟环境。这种行为使您的 Zip 应用程序比用zipapp创建的常规应用程序大很多。
在本节中,您将学习的第二个工具是shiv。它是一个命令行工具,用于构建自包含的 Python Zip 应用程序,如 PEP 441 中所述。与zipapp相比,shiv的优势在于shiv会自动将应用程序的所有依赖项包含在最终文档中,并使它们在 Python 的模块搜索路径中可用。
要使用shiv,您需要从 PyPI 安装它:
(venv) $ python -m pip install shiv
(venv) $ shiv --help
Usage: shiv [OPTIONS] [PIP_ARGS]...
Shiv is a command line utility for building fully self-contained Python
zipapps as outlined in PEP 441, but with all their dependencies included!
...
--help选项显示了一个完整的使用信息,您可以通过检查来快速了解shiv是如何工作的。
要用shiv构建 Python Zip 应用程序,您需要一个可安装的 Python 应用程序,带有一个setup.py或pyproject.toml文件。幸运的是,GitHub 最初的reader项目满足了这个要求。回到包含克隆的reader/文件夹的目录,运行以下命令:
(venv) $ shiv -c realpython \
-o realpython.pyz reader/ \
-p "/usr/bin/env python3"
像pex工具一样,shiv有一个-c选项来定义应用程序的控制台脚本。-o和-p选项允许您分别提供输出文件名和合适的 Python 解释器。
注意:上面的命令按预期工作。然而,shiv (0.5.2)的当前版本让pip显示一条关于它如何构建包的反对消息。由于shiv 直接接受pip参数,所以可以将 --use-feature=in-tree-build 放在命令的末尾,这样shiv就可以安全地使用pip。
与zipapp不同,shiv允许您使用存储在应用程序档案中的.pyd、.so和.dll文件。为此,shiv在归档中包含了一个特殊的引导功能。这个函数将应用程序的依赖项解压到您的主文件夹的.shiv/目录中,并将它们添加到 Python 的sys.path目录中。
这个特性允许您创建独立的应用程序,其中包括部分用 C 和 C++编写的库,以提高速度和效率,例如 NumPy 。
结论
拥有一种快速有效的方法来分发 Python 可执行应用程序,可以在满足最终用户需求方面发挥重要作用。 Python Zip applications 为您捆绑和分发现成的应用程序提供了一个有效且可访问的解决方案。您可以使用 Python 标准库中的 zipapp 来快速创建自己的可执行 Zip 应用程序,并将它们传递给最终用户。
在本教程中,您学习了:
- 什么是 Python Zip 应用程序
- Zip 应用程序如何工作内部
- 如何用
zipapp构建自己的 Python Zip 应用 - 什么是独立 Zip 应用以及如何使用
pip和zipapp创建它们 - 如何使用命令行工具手动创建 Python Zip 应用程序
有了这些知识,您就可以快速创建 Python Zip 应用程序,作为向最终用户分发 Python 程序和脚本的便捷方式。*********
Python 的 zipfile:有效地操作你的 ZIP 文件
原文:# t0]https://realython . com/python-zipfile/
Python 的 zipfile 是一个标准的库模块,用来操作 ZIP 文件。这种文件格式是归档和压缩数字数据时广泛采用的行业标准。你可以用它来打包几个相关的文件。它还允许您减少文件的大小并节省磁盘空间。最重要的是,它促进了计算机网络上的数据交换。
作为 Python 开发人员或 DevOps 工程师,知道如何使用zipfile模块创建、读取、写入、填充、提取和列出 ZIP 文件是一项有用的技能。
在本教程中,您将学习如何:
- 用 Python 的
zipfile从 ZIP 文件中读取、写入和提取文件 - 使用
zipfile读取关于 ZIP 文件内容的元数据 - 使用
zipfile到操作现有 ZIP 文件中的成员文件 - 创建新的 ZIP 文件来归档和压缩文件
如果您经常处理 ZIP 文件,那么这些知识可以帮助您简化工作流程,自信地处理您的文件。
为了从本教程中获得最大收益,你应该知道处理文件,使用 with语句,用 pathlib 处理文件系统路径,以及处理类和面向对象编程的基础知识。
要获取您将用于编写本教程中的示例的文件和档案,请单击下面的链接:
获取资料: 单击此处获取文件和档案的副本,您将使用它们来运行本 zipfile 教程中的示例。
ZIP 文件入门
ZIP 文件是当今数字世界中众所周知的流行工具。这些文件相当流行,广泛用于计算机网络(尤其是互联网)上的跨平台数据交换。
您可以使用 ZIP 文件将常规文件打包成一个归档文件,压缩数据以节省磁盘空间,分发您的数字产品,等等。在本教程中,您将学习如何使用 Python 的zipfile模块操作 ZIP 文件。
因为关于 ZIP 文件的术语有时会令人困惑,所以本教程将遵循以下术语约定:
| 学期 | 意义 |
|---|---|
| ZIP 文件、ZIP 存档或存档 | 使用 ZIP 文件格式的物理文件 |
| 文件 | 一个普通的电脑文件 |
| 成员文件 | 作为现有 ZIP 文件一部分的文件 |
清楚地记住这些术语将有助于你在阅读接下来的章节时避免混淆。现在,您已经准备好继续学习如何在 Python 代码中有效地操作 ZIP 文件了!
什么是 ZIP 文件?
您可能已经遇到并使用过 ZIP 文件。没错,那些带.zip文件扩展名的到处都是!ZIP 文件,又称 ZIP 存档,是使用 ZIP 文件格式的文件。
PKWARE 是创建并首先实现这种文件格式的公司。该公司制定并维护了当前的格式规范,该规范公开发布,允许创建使用 ZIP 文件格式读写文件的产品、程序和进程。
ZIP 文件格式是一种跨平台、可互操作的文件存储和传输格式。它结合了无损数据压缩,文件管理,数据加密。
数据压缩不是将归档文件视为 ZIP 文件的必要条件。因此,您可以在 ZIP 存档中压缩或解压缩成员文件。ZIP 文件格式支持几种压缩算法,尽管最常见的是 Deflate 。该格式还支持用 CRC32 进行信息完整性检查。
尽管有其他类似的存档格式,如 RAR 文件和 T2 文件,ZIP 文件格式已经迅速成为高效数据存储和计算机网络数据交换的通用标准。
ZIP 文件到处都是。比如微软 Office 和 Libre Office 等办公套件都依赖 ZIP 文件格式作为它们的文档容器文件。这意味着.docx、.xlsx、.pptx、.odt、.ods、.odp文件实际上是包含组成每个文档的几个文件和文件夹的 ZIP 存档。其他使用 ZIP 格式的常见文件包括 .jar 、 .war 、 .epub 文件。
你可能对 GitHub 很熟悉,它使用 Git 为软件开发和版本控制提供 web 托管。当你下载软件到你的本地电脑时,GitHub 使用 ZIP 文件打包软件项目。例如,您可以下载 ZIP 文件形式的练习解决方案 for Python 基础知识:Python 3 实用介绍一书,或者您可以下载您选择的任何其他项目。
ZIP 文件允许您将文件聚合、压缩和加密到一个可互操作的便携式容器中。您可以传输 ZIP 文件,将它们分割成段,使它们能够自解压,等等。
为什么使用 ZIP 文件?
对于使用计算机和数字信息的开发人员和专业人员来说,知道如何创建、读取、写入和提取 ZIP 文件是一项有用的技能。除其他好处外,ZIP 文件允许您:
- 在不丢失信息的情况下,减小文件的大小及其存储要求
- 由于尺寸减小和单文件传输,提高了网络传输速度
- 将几个相关的文件打包在一起到一个归档中,以便高效管理
- 将您的代码打包到一个单独的归档文件中,以便分发
- 使用加密技术保护您的数据,这是当今的普遍要求
- 保证您信息的完整性避免对您数据的意外和恶意更改
如果您正在寻找一种灵活、可移植且可靠的方法来归档您的数字文件,这些功能使 ZIP 文件成为您的 Python 工具箱的有用补充。
Python 可以操作 ZIP 文件吗?
是啊!Python 有几个工具可以让你操作 ZIP 文件。其中一些工具在 Python 标准库中可用。它们包括使用特定压缩算法压缩和解压缩数据的低级库,如zlibbz2lzma其他。
Python 还提供了一个名为zipfile的高级模块,专门用于创建、读取、写入、提取和列出 ZIP 文件的内容。在本教程中,您将了解 Python 的zipfile以及如何有效地使用它。
用 Python 的zipfile 操作现有的 ZIP 文件
Python 的zipfile提供了方便的类和函数,允许您创建、读取、写入、提取和列出 ZIP 文件的内容。以下是zipfile支持的一些附加功能:
要知道zipfile确实有一些限制。例如,当前的数据解密功能可能相当慢,因为它使用纯 Python 代码。该模块无法处理加密 ZIP 文件的创建。最后,也不支持使用多磁盘 ZIP 文件。尽管有这些限制,zipfile仍然是一个伟大而有用的工具。继续阅读,探索它的能力。
打开 ZIP 文件进行读写
在zipfile模块中,你会找到 ZipFile 类。这个类的工作很像 Python 内置的 open() 函数,允许你使用不同的模式打开你的 ZIP 文件。默认为读取模式("r")。您也可以使用写入("w")、追加("a")和独占("x")模式。稍后,您将了解更多关于这些内容的信息。
ZipFile实现了上下文管理器协议,这样你就可以在 with语句中使用该类。该功能允许您快速打开并处理 ZIP 文件,而不用担心在完成工作后会关闭文件。
在编写任何代码之前,请确保您有一份将要使用的文件和归档的副本:
获取资料: 单击此处获取文件和档案的副本,您将使用它们来运行本 zipfile 教程中的示例。
为了准备好您的工作环境,将下载的资源放在您的主文件夹中名为python-zipfile/的目录中。将文件放在正确的位置后,移动到新创建的目录,并在那里启动一个 Python 交互式会话。
为了热身,您将从阅读名为sample.zip的 ZIP 文件开始。为此,您可以在阅读模式下使用ZipFile:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428
ZipFile初始化器的第一个参数可以是一个字符串,代表你需要打开的 ZIP 文件的路径。这个参数也可以接受类似文件的和类似路径的对象。在本例中,您使用基于字符串的路径。
ZipFile的第二个参数是一个单字母字符串,表示您将用来打开文件的模式。正如您在本节开始时了解到的,ZipFile可以根据您的需要接受四种可能的模式。mode位置参数默认为"r",如果想打开档案只读可以去掉。在
with语句里面,你在archive上调用.printdir()。archive变量现在保存了ZipFile本身的实例。这个函数提供了一种在屏幕上显示底层 ZIP 文件内容的快速方法。该函数的输出具有用户友好的表格格式,包含三个信息栏:
File NameModifiedSize如果您想在尝试打开一个有效的 ZIP 文件之前确保它,那么您可以将
ZipFile包装在一个try…except语句中,并捕捉任何BadZipFile异常:
>>> import zipfile
>>> try:
... with zipfile.ZipFile("sample.zip") as archive:
... archive.printdir()
... except zipfile.BadZipFile as error:
... print(error)
...
File Name Modified Size
hello.txt 2021-09-07 19:50:10 83
lorem.md 2021-09-07 19:50:10 2609
realpython.md 2021-09-07 19:50:10 428
>>> try:
... with zipfile.ZipFile("bad_sample.zip") as archive:
... archive.printdir()
... except zipfile.BadZipFile as error:
... print(error)
...
File is not a zip file
第一个例子成功地打开了sample.zip而没有引发BadZipFile异常。这是因为sample.zip有一个有效的 ZIP 格式。另一方面,第二个例子没有成功打开bad_sample.zip,因为这个文件不是一个有效的 ZIP 文件。
要检查有效的 ZIP 文件,您也可以使用 is_zipfile() 功能:
>>> import zipfile >>> if zipfile.is_zipfile("sample.zip"): ... with zipfile.ZipFile("sample.zip", "r") as archive: ... archive.printdir() ... else: ... print("File is not a zip file") ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 >>> if zipfile.is_zipfile("bad_sample.zip"): ... with zipfile.ZipFile("bad_sample.zip", "r") as archive: ... archive.printdir() ... else: ... print("File is not a zip file") ... File is not a zip file在这些例子中,您使用了一个带有
is_zipfile()的条件语句作为条件。这个函数接受一个filename参数,它保存文件系统中 ZIP 文件的路径。该参数可以接受字符串、类似文件或类似路径的对象。如果filename是一个有效的 ZIP 文件,该函数将返回True。否则,它返回False。现在假设您想使用
ZipFile将hello.txt添加到hello.zip档案中。为此,您可以使用写入模式("w")。这种模式打开一个 ZIP 文件进行写入。如果目标 ZIP 文件存在,那么"w"模式会截断它,并写入您传入的任何新内容。注意:如果你对现有文件使用
ZipFile,那么你应该小心使用"w"模式。您可以截断您的 ZIP 文件并丢失所有原始内容。如果目标 ZIP 文件不存在,那么
ZipFile会在您关闭归档时为您创建一个:
>>> import zipfile
>>> with zipfile.ZipFile("hello.zip", mode="w") as archive:
... archive.write("hello.txt")
...
运行这段代码后,在您的python-zipfile/目录中会有一个hello.zip文件。如果您使用.printdir()列出文件内容,那么您会注意到hello.txt会出现在那里。在这个例子中,你在ZipFile对象上调用 .write() 。这种方法允许您将成员文件写入 ZIP 存档。请注意,.write()的参数应该是一个现有的文件。
注意: ZipFile足够聪明,当你以写模式使用该类并且目标档案不存在时,它可以创建一个新的档案。但是,如果这些目录不存在,该类不会在目标 ZIP 文件的路径中创建新目录。
这解释了为什么下面的代码不起作用:
>>> import zipfile >>> with zipfile.ZipFile("missing/hello.zip", mode="w") as archive: ... archive.write("hello.txt") ... Traceback (most recent call last): ... FileNotFoundError: [Errno 2] No such file or directory: 'missing/hello.zip'因为目标
hello.zip文件路径中的missing/目录不存在,你得到一个FileNotFoundError异常。追加模式(
"a")允许您向现有的 ZIP 文件追加新成员文件。这种模式不会截断存档,因此其原始内容是安全的。如果目标 ZIP 文件不存在,那么"a"模式会为您创建一个新文件,然后将您作为参数传递的任何输入文件追加到.write()中。要尝试
"a"模式,继续将new_hello.txt文件添加到您新创建的hello.zip档案中:
>>> import zipfile
>>> with zipfile.ZipFile("hello.zip", mode="a") as archive:
... archive.write("new_hello.txt")
...
>>> with zipfile.ZipFile("hello.zip") as archive:
... archive.printdir()
...
File Name Modified Size
hello.txt 2021-09-07 19:50:10 83
new_hello.txt 2021-08-31 17:13:44 13
这里,您使用 append 模式将new_hello.txt添加到hello.zip文件中。然后运行.printdir()来确认这个新文件存在于 ZIP 文件中。
ZipFile还支持独占模式("x")。这种模式允许你独占创建新的 ZIP 文件,并向其中写入新的成员文件。当您想要创建一个新的 ZIP 文件而不覆盖现有文件时,您将使用独占模式。如果目标文件已经存在,那么你得到 FileExistsError 。
最后,如果您使用"w"、"a"或"x"模式创建一个 ZIP 文件,然后关闭归档文件而不添加任何成员文件,那么ZipFile会创建一个具有适当 ZIP 格式的空归档文件。
从 ZIP 文件读取元数据
你已经将.printdir()付诸行动。这是一个非常有用的方法,可以用来快速列出 ZIP 文件的内容。与.printdir()一起,ZipFile类提供了几种从现有 ZIP 文件中提取元数据的简便方法。
以下是这些方法的总结:
| 方法 | 描述 |
|---|---|
T2.getinfo(filename) |
返回一个包含由filename提供的成员文件信息的 ZipInfo 对象。注意,filename必须保存底层 ZIP 文件中目标文件的路径。 |
T2.infolist() |
返回一个列表中的 ZipInfo 对象,每个成员一个文件。 |
T2.namelist() |
返回包含基础存档中所有成员文件名称的列表。此列表中的名称是.getinfo()的有效参数。 |
使用这三个工具,您可以检索大量关于 ZIP 文件内容的有用信息。例如,看看下面的例子,它使用了.getinfo():
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... info = archive.getinfo("hello.txt") ... >>> info.file_size 83 >>> info.compress_size 83 >>> info.filename 'hello.txt' >>> info.date_time (2021, 9, 7, 19, 50, 10)正如您在上表中所了解到的,
.getinfo()将一个成员文件作为参数,并返回一个带有相关信息的ZipInfo对象。注意:
ZipInfo不打算直接实例化。当你调用.getinfo()和.infolist()方法时,它们会自动返回ZipInfo对象。然而,ZipInfo包含了一个名为.from_file()的类方法,如果你需要的话,它允许你显式地实例化这个类。
ZipInfo对象有几个属性,允许你检索关于目标成员文件的有价值的信息。例如,.file_size和.compress_size分别保存原始文件和压缩文件的大小,以字节为单位。该类还有一些其他有用的属性,如.filename和.date_time,它们返回文件名和上次修改日期。注意:默认情况下,
ZipFile不会对输入文件进行压缩以将其添加到最终的归档文件中。这就是为什么在上面的例子中,大小和压缩后的大小是相同的。在下面的压缩文件和目录部分,你会学到更多关于这个主题的知识。使用
.infolist(),您可以从给定档案中的所有文件中提取信息。下面是一个使用这种方法生成最小报告的例子,该报告包含关于您的sample.zip档案中所有成员文件的信息:
>>> import datetime
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... for info in archive.infolist():
... print(f"Filename: {info.filename}")
... print(f"Modified: {datetime.datetime(*info.date_time)}")
... print(f"Normal size: {info.file_size} bytes")
... print(f"Compressed size: {info.compress_size} bytes")
... print("-" * 20)
...
Filename: hello.txt
Modified: 2021-09-07 19:50:10
Normal size: 83 bytes
Compressed size: 83 bytes
--------------------
Filename: lorem.md
Modified: 2021-09-07 19:50:10
Normal size: 2609 bytes
Compressed size: 2609 bytes
--------------------
Filename: realpython.md
Modified: 2021-09-07 19:50:10
Normal size: 428 bytes
Compressed size: 428 bytes
--------------------
for循环遍历来自.infolist()的ZipInfo对象,检索每个成员文件的文件名、最后修改日期、正常大小和压缩大小。在本例中,您使用了 datetime 以人类可读的方式格式化日期。
注:上例改编自 zipfile — ZIP 存档访问。
如果您只需要对一个 ZIP 文件执行快速检查并列出其成员文件的名称,那么您可以使用.namelist():
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... for filename in archive.namelist(): ... print(filename) ... hello.txt lorem.md realpython.md因为这个输出中的文件名是
.getinfo()的有效参数,所以可以结合这两种方法来只检索关于所选成员文件的信息。例如,您可能有一个 ZIP 文件,其中包含不同类型的成员文件(
.docx、.xlsx、.txt等等)。不需要用.infolist()得到完整的信息,你只需要得到关于.docx文件的信息。然后您可以通过扩展名过滤文件,并只对您的.docx文件调用.getinfo()。来吧,试一试!读写成员文件
有时您有一个 ZIP 文件,需要读取给定成员文件的内容,而不需要提取它。为此,您可以使用
.read()。这个方法获取一个成员文件的name并将该文件的内容作为字节返回:
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... for line in archive.read("hello.txt").split(b"\n"):
... print(line)
...
b'Hello, Pythonista!'
b''
b'Welcome to Real Python!'
b''
b"Ready to try Python's zipfile module?"
b''
要使用.read(),需要打开 ZIP 文件进行读取或追加。注意.read()以字节流的形式返回目标文件的内容。在这个例子中,您使用.split()将流分成行,使用换行字符"\n"作为分隔符。因为.split()正在对一个字节对象进行操作,所以您需要在用作参数的字符串前添加一个前导b。
ZipFile.read()也接受名为pwd的第二个位置参数。此参数允许您提供读取加密文件的密码。要尝试这个特性,您可以依赖与本教程的材料一起下载的sample_pwd.zip文件:
>>> import zipfile >>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt", pwd=b"secret").split(b"\n"): ... print(line) ... b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b'' >>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt").split(b"\n"): ... print(line) ... Traceback (most recent call last): ... RuntimeError: File 'hello.txt' is encrypted, password required for extraction在第一个例子中,您提供密码
secret来读取您的加密文件。pwd参数接受 bytes 类型的值。如果您在没有提供所需密码的情况下对一个加密文件使用.read(),那么您会得到一个RuntimeError,正如您在第二个示例中注意到的。注意: Python 的
zipfile支持解密。但是,它不支持加密 ZIP 文件的创建。这就是为什么你需要使用一个外部文件归档来加密你的文件。一些流行的文件归档器包括 Windows 的 7z 和 WinRAR ,Linux 的 Ark 和 GNOME Archive Manager ,macOS 的 Archiver 。
对于大型加密 ZIP 文件,请记住,解密操作可能会非常慢,因为它是在纯 Python 中实现的。在这种情况下,考虑使用一个专门的程序来处理你的档案,而不是使用
zipfile。如果您经常使用加密文件,那么您可能希望避免每次调用
.read()或另一个接受pwd参数的方法时都提供解密密码。如果是这种情况,可以使用ZipFile.setpassword()来设置全局密码:
>>> import zipfile
>>> with zipfile.ZipFile("sample_pwd.zip", mode="r") as archive:
... archive.setpassword(b"secret")
... for file in archive.namelist():
... print(file)
... print("-" * 20)
... for line in archive.read(file).split(b"\n"):
... print(line)
...
hello.txt
--------------------
b'Hello, Pythonista!'
b''
b'Welcome to Real Python!'
b''
b"Ready to try Python's zipfile module?"
b''
lorem.md
--------------------
b'# Lorem Ipsum'
b''
b'Lorem ipsum dolor sit amet, consectetur adipiscing elit.
...
使用.setpassword(),您只需提供一次密码。ZipFile使用该唯一密码解密所有成员文件。
相比之下,如果 ZIP 文件的各个成员文件具有不同的密码,那么您需要使用.read()的pwd参数为每个文件提供特定的密码:
>>> import zipfile >>> with zipfile.ZipFile("sample_file_pwd.zip", mode="r") as archive: ... for line in archive.read("hello.txt", pwd=b"secret1").split(b"\n"): ... print(line) ... b'Hello, Pythonista!' b'' b'Welcome to Real Python!' b'' b"Ready to try Python's zipfile module?" b'' >>> with zipfile.ZipFile("sample_file_pwd.zip", mode="r") as archive: ... for line in archive.read("lorem.md", pwd=b"secret2").split(b"\n"): ... print(line) ... b'# Lorem Ipsum' b'' b'Lorem ipsum dolor sit amet, consectetur adipiscing elit. ...在这个例子中,您使用
secret1作为密码来读取hello.txt,使用secret2来读取lorem.md。要考虑的最后一个细节是,当您使用pwd参数时,您将覆盖您可能已经用.setpassword()设置的任何归档级密码。注意:在使用不支持的压缩方法的 ZIP 文件上调用
.read()会引发一个NotImplementedError。如果所需的压缩模块在 Python 安装中不可用,也会出现错误。如果您正在寻找一种更灵活的方式来读取成员文件,并创建和添加新的成员文件到一个档案,那么
ZipFile.open()是为您准备的。像内置的open()函数一样,这个方法实现了上下文管理器协议,因此它支持with语句:
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... with archive.open("hello.txt", mode="r") as hello:
... for line in hello:
... print(line)
...
b'Hello, Pythonista!\n'
b'\n'
b'Welcome to Real Python!\n'
b'\n'
b"Ready to try Python's zipfile module?\n"
在这个例子中,你打开hello.txt进行阅读。.open()的第一个参数是name,表示您想要打开的成员文件。第二个参数是模式,照常默认为"r"。ZipFile.open()也接受一个pwd参数来打开加密文件。该参数的工作原理与.read()中的等效pwd参数相同。
您也可以将.open()与"w"模式配合使用。此模式允许您创建一个新的成员文件,向其中写入内容,最后将文件追加到底层归档文件中,您应该在追加模式下打开该归档文件:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="a") as archive: ... with archive.open("new_hello.txt", "w") as new_hello: ... new_hello.write(b"Hello, World!") ... 13 >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.printdir() ... print("------") ... archive.read("new_hello.txt") ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 new_hello.txt 1980-01-01 00:00:00 13 ------ b'Hello, World!'在第一段代码中,您以追加模式(
"a")打开sample.zip。然后你通过用"w"模式调用.open()来创建new_hello.txt。这个函数返回一个类似文件的对象,支持.write(),允许你向新创建的文件中写入字节。注意:你需要给
.open()提供一个不存在的文件名。如果您使用的文件名已经存在于底层归档文件中,那么您将得到一个重复的文件和一个UserWarning异常。在这个例子中,你将
b'Hello, World!'写入new_hello.txt。当执行流退出内部的with语句时,Python 将输入字节写入成员文件。当外部的with语句退出时,Python 将new_hello.txt写入底层的 ZIP 文件sample.zip。第二段代码确认了
new_hello.txt现在是sample.zip的成员文件。在这个例子的输出中需要注意的一个细节是,.write()将新添加文件的Modified日期设置为1980-01-01 00:00:00,这是一个奇怪的行为,在使用这个方法时应该记住。以文本形式读取成员文件的内容
正如您在上一节中了解到的,您可以使用
.read()和.write()方法来读取和写入成员文件,而不需要从包含它们的 ZIP 存档中提取它们。这两种方法都专门处理字节。但是,当您有一个包含文本文件的 ZIP 存档时,您可能希望将它们的内容作为文本而不是字节来读取。至少有两种方法可以做到这一点。您可以使用:
因为
ZipFile.read()以字节的形式返回目标成员文件的内容,.decode()可以直接对这些字节进行操作。.decode()方法使用给定的字符编码格式将bytes对象解码成字符串。以下是如何使用
.decode()从sample.zip档案中的hello.txt文件中读取文本:
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... text = archive.read("hello.txt").decode(encoding="utf-8")
...
>>> print(text)
Hello, Pythonista!
Welcome to Real Python!
Ready to try Python's zipfile module?
在这个例子中,你以字节的形式读取hello.txt的内容。然后你调用.decode()将字节解码成一个字符串,使用 UTF-8 作为编码。要设置encoding参数,可以使用"utf-8"字符串。但是,您可以使用任何其他有效的编码,例如 UTF-16 或 cp1252 ,它们可以表示为不区分大小写的字符串。注意,"utf-8"是encoding参数对.decode()的默认值。
记住这一点很重要,您需要预先知道想要使用.decode()处理的任何成员文件的字符编码格式。如果您使用了错误的字符编码,那么您的代码将无法正确地将底层的字节解码成文本,并且您最终会得到大量无法辨认的字符。
从成员文件中读取文本的第二个选项是使用一个io.TextIOWrapper对象,它提供了一个缓冲的文本流。这次你需要使用.open()而不是.read()。下面是一个使用io.TextIOWrapper将hello.txt成员文件的内容作为文本流读取的例子:
>>> import io >>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... with archive.open("hello.txt", mode="r") as hello: ... for line in io.TextIOWrapper(hello, encoding="utf-8"): ... print(line.strip()) ... Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?在本例的内部
with语句中,您从您的sample.zip档案中打开了hello.txt成员文件。然后将生成的类似二进制文件的对象hello作为参数传递给io.TextIOWrapper。这通过使用 UTF-8 字符编码格式解码hello的内容来创建一个缓冲的文本流。因此,您可以直接从目标成员文件中获得文本流。就像使用
.encode()一样,io.TextIOWrapper类接受一个encoding参数。您应该始终为该参数指定一个值,因为默认文本编码取决于运行代码的系统,并且可能不是您试图解码的文件的正确值。从您的 ZIP 存档中提取成员文件
提取给定归档文件的内容是对 ZIP 文件最常见的操作之一。根据您的需要,您可能希望一次提取一个文件或一次提取所有文件。
ZipFile.extract()让你完成第一个任务。这个方法获取一个member文件的名称,并将其提取到一个由path指示的给定目录中。目的地path默认为当前目录:
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... archive.extract("new_hello.txt", path="output_dir/")
...
'output_dir/new_hello.txt'
现在new_hello.txt将在你的output_dir/目录中。如果目标文件名已经存在于输出目录中,那么.extract()会覆盖它而不要求确认。如果输出目录不存在,那么.extract()会为您创建一个。注意,.extract()返回解压文件的路径。
成员文件的名称必须是由.namelist()返回的文件的全名。它也可以是一个包含文件信息的ZipInfo对象。
您也可以对加密文件使用.extract()。在这种情况下,您需要提供必需的pwd参数或者用.setpassword()设置归档级别的密码。
当从一个档案中提取所有成员文件时,可以使用 .extractall() 。顾名思义,该方法将所有成员文件提取到目标路径,默认情况下是当前目录:
>>> import zipfile >>> with zipfile.ZipFile("sample.zip", mode="r") as archive: ... archive.extractall("output_dir/") ...运行这段代码后,
sample.zip的所有当前内容都将在您的output_dir/目录中。如果您将一个不存在的目录传递给.extractall(),那么这个方法会自动创建这个目录。最后,如果任何成员文件已经存在于目标目录中,那么.extractall()将会覆盖它们而不需要你的确认,所以要小心。如果您只需要从给定的档案中提取一些成员文件,那么您可以使用
members参数。该参数接受一个成员文件列表,该列表应该是手头存档中整个文件列表的子集。最后,和.extract()一样,.extractall()方法也接受一个pwd参数来提取加密文件。使用后关闭 ZIP 文件
有时,不使用
with语句打开给定的 ZIP 文件会很方便。在这些情况下,您需要在使用后手动关闭归档,以完成任何写入操作并释放获得的资源。为此,您可以在您的
ZipFile对象上调用.close():
>>> import zipfile
>>> archive = zipfile.ZipFile("sample.zip", mode="r")
>>> # Use archive in different parts of your code
>>> archive.printdir()
File Name Modified Size
hello.txt 2021-09-07 19:50:10 83
lorem.md 2021-09-07 19:50:10 2609
realpython.md 2021-09-07 19:50:10 428
new_hello.txt 1980-01-01 00:00:00 13
>>> # Close the archive when you're done
>>> archive.close()
>>> archive
<zipfile.ZipFile [closed]>
对.close()的调用会为您关闭archive。在退出你的程序之前,你必须呼叫.close()。否则,一些写操作可能无法执行。例如,如果您打开一个 ZIP 文件来追加("a")新的成员文件,那么您需要关闭归档文件来写入这些文件。
创建、填充和解压你自己的 ZIP 文件
到目前为止,您已经学习了如何使用现有的 ZIP 文件。您已经学会了通过使用不同的ZipFile模式来读取、写入和添加成员文件。您还学习了如何读取相关元数据以及如何提取给定 ZIP 文件的内容。
在这一节中,您将编写一些实用的例子,帮助您学习如何使用zipfile和其他 Python 工具从几个输入文件和整个目录创建 ZIP 文件。您还将学习如何使用zipfile进行文件压缩等等。
从多个常规文件创建一个 ZIP 文件
有时您需要从几个相关的文件创建一个 ZIP 存档。这样,您可以将所有文件放在一个容器中,以便通过计算机网络分发或与朋友或同事共享。为此,您可以创建一个目标文件列表,并使用ZipFile和一个循环将它们写入归档文件:
>>> import zipfile >>> filenames = ["hello.txt", "lorem.md", "realpython.md"] >>> with zipfile.ZipFile("multiple_files.zip", mode="w") as archive: ... for filename in filenames: ... archive.write(filename) ...在这里,您创建了一个
ZipFile对象,将所需的档案名称作为它的第一个参数。"w"模式允许您将成员文件写入最终的 ZIP 文件。
for循环遍历输入文件列表,并使用.write()将它们写入底层 ZIP 文件。一旦执行流退出了with语句,ZipFile会自动关闭存档,为您保存更改。现在您有了一个multiple_files.zip档案,其中包含了您的原始文件列表中的所有文件。从目录构建 ZIP 文件
将一个目录的内容捆绑到一个归档中是 ZIP 文件的另一个日常用例。Python 有几个工具可以和
zipfile一起使用来完成这个任务。例如,您可以使用pathlib到读取给定目录的内容。有了这些信息,您可以使用ZipFile创建一个容器档案。在
python-zipfile/目录下,有一个名为source_dir/的子目录,内容如下:source_dir/ │ ├── hello.txt ├── lorem.md └── realpython.md在
source_dir/中,你只有三个常规文件。因为目录不包含子目录,所以可以使用pathlib.Path.iterdir()直接迭代其内容。有了这个想法,下面是如何从source_dir/的内容构建一个 ZIP 文件:
>>> import pathlib
>>> import zipfile
>>> directory = pathlib.Path("source_dir/")
>>> with zipfile.ZipFile("directory.zip", mode="w") as archive:
... for file_path in directory.iterdir():
... archive.write(file_path, arcname=file_path.name)
...
>>> with zipfile.ZipFile("directory.zip", mode="r") as archive:
... archive.printdir()
...
File Name Modified Size
realpython.md 2021-09-07 19:50:10 428
hello.txt 2021-09-07 19:50:10 83
lorem.md 2021-09-07 19:50:10 2609
在这个例子中,你从你的源目录中创建一个 pathlib.Path 对象。第一个with语句创建一个准备写入的ZipFile对象。然后对.iterdir()的调用返回底层目录中条目的迭代器。
因为在source_dir/中没有任何子目录,所以.iterdir()函数只产生文件。for循环遍历文件并将它们写入存档。
在这种情况下,您将file_path.name传递给.write()的第二个参数。这个参数被称为arcname,它保存了结果档案中成员文件的名称。到目前为止,您看到的所有示例都依赖于默认值arcname,这是您作为第一个参数传递给.write()的相同文件名。
如果您没有将file_path.name传递给arcname,那么您的源目录将位于您的 ZIP 文件的根目录,根据您的需要,这也可以是一个有效的结果。
现在检查工作目录中的root_dir/文件夹。在这种情况下,您会发现以下结构:
root_dir/
│
├── sub_dir/
│ └── new_hello.txt
│
├── hello.txt
├── lorem.md
└── realpython.md
您有常用的文件和一个包含单个文件的子目录。如果你想创建一个具有相同内部结构的 ZIP 文件,那么你需要一个工具,让递归地遍历目录树中root_dir/下的。
下面是如何压缩一个完整的目录树,如上图所示,使用来自pathlib模块的zipfile和Path.rglob():
>>> import pathlib >>> import zipfile >>> directory = pathlib.Path("root_dir/") >>> with zipfile.ZipFile("directory_tree.zip", mode="w") as archive: ... for file_path in directory.rglob("*"): ... archive.write( ... file_path, ... arcname=file_path.relative_to(directory) ... ) ... >>> with zipfile.ZipFile("directory_tree.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size sub_dir/ 2021-09-09 20:52:14 0 realpython.md 2021-09-07 19:50:10 428 hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 sub_dir/new_hello.txt 2021-08-31 17:13:44 13在这个例子中,您使用
Path.rglob()递归遍历root_dir/下的目录树。然后,将每个文件和子目录写入目标 ZIP 存档。这一次,您使用
Path.relative_to()获得每个文件的相对路径,然后将结果传递给第二个参数.write()。这样,最终得到的 ZIP 文件的内部结构与原始源目录相同。同样,如果您希望您的源目录位于 ZIP 文件的根目录,您可以去掉这个参数。压缩文件和目录
如果您的文件占用了太多的磁盘空间,那么您可以考虑压缩它们。Python 的
zipfile支持几种流行的压缩方法。但是,默认情况下,该模块不会压缩您的文件。如果您想让您的文件更小,那么您需要显式地为ZipFile提供一个压缩方法。通常,您将使用术语存储的来指代未经压缩就写入 ZIP 文件的成员文件。这就是为什么
ZipFile的默认压缩方法被称为 ZIP_STORED ,它实际上指的是未压缩的成员文件,它们被简单地存储在包含的归档文件中。
compression方法是ZipFile初始化器的第三个参数。如果要在将文件写入 ZIP 存档文件时对其进行压缩,可以将该参数设置为下列常量之一:
常数 压缩法 所需模块 zipfile.ZIP_DEFLATED紧缩 zlibzipfile.ZIP_BZIP2Bzip2 bz2zipfile.ZIP_LZMA伊玛 lzma这些是您目前可以在
ZipFile中使用的压缩方法。不同的方法会养出一个NotImplementedError。从 Python 3.10 开始,zipfile没有额外的压缩方法。作为附加要求,如果您选择这些方法中的一种,那么 Python 安装中必须有支持它的压缩模块。否则,你会得到一个
RuntimeError异常,你的代码就会中断。当涉及到压缩文件时,
ZipFile的另一个相关参数是compresslevel。此参数控制您使用的压缩级别。使用 Deflate 方法,
compresslevel可以从0到9取整数。使用 Bzip2 方法,您可以从1到9传递整数。在这两种情况下,当压缩级别增加时,您将获得更高的压缩和更低的压缩速度。注意:PNG、JPG、MP3 等二进制文件已经使用了某种压缩方式。因此,将它们添加到 ZIP 文件中可能不会使数据变得更小,因为它已经被压缩到一定程度。
现在假设您想使用 Deflate 方法归档和压缩给定目录的内容,这是 ZIP 文件中最常用的方法。为此,您可以运行以下代码:
>>> import pathlib
>>> from zipfile import ZipFile, ZIP_DEFLATED
>>> directory = pathlib.Path("source_dir/")
>>> with ZipFile("comp_dir.zip", "w", ZIP_DEFLATED, compresslevel=9) as archive:
... for file_path in directory.rglob("*"):
... archive.write(file_path, arcname=file_path.relative_to(directory))
...
在这个例子中,您将9传递给compresslevel以获得最大的压缩。为了提供这个参数,您使用了一个关键字参数。你需要这么做,因为compresslevel不是ZipFile初始化器的第四个位置参数。
注意:ZipFile的初始化器接受第四个参数,称为allowZip64。这是一个布尔参数,告诉ZipFile为大于 4 GB 的文件创建扩展名为.zip64的 ZIP 文件。
运行这段代码后,您将在当前目录中拥有一个comp_dir.zip文件。如果您将该文件的大小与您原来的sample.zip文件的大小进行比较,那么您会注意到文件大小显著减小。
按顺序创建 ZIP 文件
按顺序创建 ZIP 文件可能是日常编程中的另一个常见需求。例如,您可能需要创建一个包含或不包含内容的初始 ZIP 文件,然后在新成员文件可用时立即追加它们。在这种情况下,您需要多次打开和关闭目标 ZIP 文件。
要解决这个问题,您可以在追加模式("a")中使用ZipFile,就像您已经做的那样。此模式允许您将新成员文件安全地附加到 ZIP 存档,而不会截断其当前内容:
>>> import zipfile >>> def append_member(zip_file, member): ... with zipfile.ZipFile(zip_file, mode="a") as archive: ... archive.write(member) ... >>> def get_file_from_stream(): ... """Simulate a stream of files.""" ... for file in ["hello.txt", "lorem.md", "realpython.md"]: ... yield file ... >>> for filename in get_file_from_stream(): ... append_member("incremental.zip", filename) ... >>> with zipfile.ZipFile("incremental.zip", mode="r") as archive: ... archive.printdir() ... File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428在这个例子中,
append_member()是一个函数,它将一个文件(member)附加到输入 ZIP 存档(zip_file)中。要执行此操作,该函数会在您每次调用它时打开和关闭目标归档。使用一个函数来执行这个任务允许您根据需要多次重用代码。
get_file_from_stream()函数是一个生成器函数,模拟要处理的文件流。同时,for循环使用append_number()将成员文件依次添加到incremental.zip中。如果您在运行完这段代码后检查您的工作目录,那么您会发现一个incremental.zip档案,包含您传递到循环中的三个文件。提取文件和目录
对 ZIP 文件执行的最常见的操作之一是将它们的内容提取到文件系统中的给定目录。您已经学习了使用
.extract()和.extractall()从归档中提取一个或所有文件的基础知识。作为一个额外的例子,回到你的
sample.zip文件。此时,归档包含四个不同类型的文件。你有两个.txt档和两个.md档。现在假设您只想提取.md文件。为此,您可以运行以下代码:
>>> import zipfile
>>> with zipfile.ZipFile("sample.zip", mode="r") as archive:
... for file in archive.namelist():
... if file.endswith(".md"):
... archive.extract(file, "output_dir/")
...
'output_dir/lorem.md'
'output_dir/realpython.md'
with语句打开sample.zip进行读取。该循环使用namelist()遍历归档中的每个文件,而条件语句检查文件名是否以扩展名.md结尾。如果是这样,那么使用.extract()将手头的文件提取到目标目录output_dir/。
从zipfile到探索附加类
到目前为止,你已经学习了ZipFile和ZipInfo,这是zipfile中可用的两个职业。这个模块还提供了另外两个类,在某些情况下会很方便。那些类是 zipfile.Path 和 zipfile.PyZipFile 。在接下来的两节中,您将学习这些类的基础知识和它们的主要特性。
在 ZIP 文件中查找Path
当你用你最喜欢的归档程序打开一个 ZIP 文件时,你会看到归档文件的内部结构。您可能在归档的根目录下有文件。您还可以拥有包含更多文件的子目录。归档文件看起来像文件系统中的一个普通目录,每个文件都位于一个特定的路径中。
zipfile.Path类允许您构造 path 对象来快速创建和管理给定 ZIP 文件中成员文件和目录的路径。该类有两个参数:
root接受一个 ZIP 文件,作为一个ZipFile对象或者一个物理 ZIP 文件的基于字符串的路径。at保存着特定成员文件的位置或归档内的目录。它默认为空字符串,代表归档文件的根目录。
以你的老朋友sample.zip为目标,运行下面的代码:
>>> import zipfile >>> hello_txt = zipfile.Path("sample.zip", "hello.txt") >>> hello_txt Path('sample.zip', 'hello.txt') >>> hello_txt.name 'hello.txt' >>> hello_txt.is_file() True >>> hello_txt.exists() True >>> print(hello_txt.read_text()) Hello, Pythonista! Welcome to Real Python! Ready to try Python's zipfile module?这段代码显示了
zipfile.Path实现了几个对pathlib.Path对象通用的特性。你可以用.name得到文件的名字。可以用.is_file()检查路径是否指向常规文件。您可以检查给定的文件是否存在于特定的 ZIP 文件中,等等。
Path还提供了一个.open()方法来使用不同的模式打开一个成员文件。例如,下面的代码打开hello.txt进行阅读:
>>> import zipfile
>>> hello_txt = zipfile.Path("sample.zip", "hello.txt")
>>> with hello_txt.open(mode="r") as hello:
... for line in hello:
... print(line)
...
Hello, Pythonista!
Welcome to Real Python!
Ready to try Python's zipfile module?
使用Path,您可以在给定的 ZIP 文件中快速创建一个指向特定成员文件的 path 对象,并使用.open()立即访问其内容。
就像使用pathlib.Path对象一样,您可以通过在zipfile.Path对象上调用 .iterdir() 来列出 ZIP 文件的内容:
>>> import zipfile >>> root = zipfile.Path("sample.zip") >>> root Path('sample.zip', '') >>> root.is_dir() True >>> list(root.iterdir()) [ Path('sample.zip', 'hello.txt'), Path('sample.zip', 'lorem.md'), Path('sample.zip', 'realpython.md') ]很明显,
zipfile.Path提供了许多有用的特性,您可以用它们来管理 ZIP 存档中的成员文件。用
PyZipFile构建可导入的 ZIP 文件
zipfile中另一个有用的类是PyZipFile。这个类非常类似于ZipFile,当您需要将 Python 模块和包打包成 ZIP 文件时,它尤其方便。与ZipFile的主要区别在于PyZipFile的初始化器带有一个名为optimize的可选参数,它允许你在归档之前通过编译成字节码来优化 Python 代码。
PyZipFile提供与ZipFile相同的接口,增加了.writepy()。这个方法可以将一个 Python 文件(.py)作为参数,并将其添加到底层的 ZIP 文件中。如果optimize是-1(默认),那么.py文件会自动编译成.pyc文件,然后添加到目标档案中。为什么会这样?从 2.3 版本开始,Python 解释器支持从 ZIP 文件导入 Python 代码,这一功能被称为 Zip 导入。这个功能相当方便。它允许你创建可导入的 ZIP 文件来分发你的模块和包作为一个单独的存档。
注意:还可以使用 ZIP 文件格式创建和分发 Python 可执行应用程序,也就是俗称的 Python Zip 应用程序。要了解如何创建它们,请查看 Python 的 zipapp:构建可执行的 Zip 应用程序。
当您需要生成可导入的 ZIP 文件时,
PyZipFile非常有用。打包.pyc文件而不是.py文件使得导入过程更加有效,因为它跳过了编译步骤。在
python-zipfile/目录中,有一个包含以下内容的hello.py模块:"""Print a greeting message.""" # hello.py def greet(name="World"): print(f"Hello, {name}! Welcome to Real Python!")这段代码定义了一个名为
greet()的函数,它将name作为一个参数,将一条问候消息打印到屏幕上。现在假设您想要将这个模块打包成一个 ZIP 文件,以便于分发。为此,您可以运行以下代码:
>>> import zipfile
>>> with zipfile.PyZipFile("hello.zip", mode="w") as zip_module:
... zip_module.writepy("hello.py")
...
>>> with zipfile.PyZipFile("hello.zip", mode="r") as zip_module:
... zip_module.printdir()
...
File Name Modified Size
hello.pyc 2021-09-13 13:25:56 311
在这个例子中,对.writepy()的调用自动将hello.py编译成hello.pyc,并存储在hello.zip中。当您使用.printdir()列出档案的内容时,这就变得很清楚了。
一旦将hello.py打包成一个 ZIP 文件,就可以使用 Python 的 import 系统从其包含的归档文件中导入这个模块:
>>> import sys >>> # Insert the archive into sys.path >>> sys.path.insert(0, "/home/user/python-zipfile/hello.zip") >>> sys.path[0] '/home/user/python-zipfile/hello.zip' >>> # Import and use the code >>> import hello >>> hello.greet("Pythonista") Hello, Pythonista! Welcome to Real Python!从 ZIP 文件导入代码的第一步是使该文件在
sys.path中可用。这个变量保存了一个字符串列表,该列表指定了 Python 对模块的搜索路径。要向sys.path添加新项目,可以使用.insert()。为了让这个示例工作,您需要更改占位符路径,并将路径传递给文件系统上的
hello.zip。一旦您的可导入 ZIP 文件出现在这个列表中,您就可以像对待常规模块一样导入代码了。最后,考虑工作文件夹中的
hello/子目录。它包含一个具有以下结构的小 Python 包:hello/ | ├── __init__.py └── hello.py
__init__.py模块将hello/目录变成一个 Python 包。hello.py模块就是你在上面的例子中使用的那个。现在假设您想将这个包打包成一个 ZIP 文件。如果是这种情况,您可以执行以下操作:
>>> import zipfile
>>> with zipfile.PyZipFile("hello.zip", mode="w") as zip_pkg:
... zip_pkg.writepy("hello")
...
>>> with zipfile.PyZipFile("hello.zip", mode="r") as zip_pkg:
... zip_pkg.printdir()
...
File Name Modified Size
hello/__init__.pyc 2021-09-13 13:39:30 108
hello/hello.pyc 2021-09-13 13:39:30 317
对.writepy()的调用以hello包为参数,在其中搜索.py文件,编译成.pyc文件,最后添加到目标 ZIP 文件hello.zip。同样,您可以按照之前学习的步骤从这个归档文件中导入您的代码:
>>> import sys >>> sys.path.insert(0, "/home/user/python-zipfile/hello.zip") >>> from hello import hello >>> hello.greet("Pythonista") Hello, Pythonista! Welcome to Real Python!因为您的代码现在在一个包中,所以您首先需要从
hello包中导入hello模块。然后您可以正常访问您的greet()功能。从命令行运行
zipfilePython 的
zipfile还提供了一个最小的命令行接口,允许你快速访问模块的主要功能。例如,您可以使用-l或--list选项来列出现有 ZIP 文件的内容:$ python -m zipfile --list sample.zip File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428 new_hello.txt 1980-01-01 00:00:00 13该命令显示的输出与对
sample.zip档案中的.printdir()的等效调用相同。现在假设您想要创建一个包含几个输入文件的新 ZIP 文件。在这种情况下,您可以使用
-c或--create选项:$ python -m zipfile --create new_sample.zip hello.txt lorem.md realpython.md $ python -m zipfile -l new_sample.zip File Name Modified Size hello.txt 2021-09-07 19:50:10 83 lorem.md 2021-09-07 19:50:10 2609 realpython.md 2021-09-07 19:50:10 428这个命令创建一个包含您的
hello.txt、lorem.md、realpython.md文件的new_sample.zip文件。如果您需要创建一个 ZIP 文件来归档整个目录,该怎么办?例如,您可能有自己的
source_dir/,它包含与上面例子相同的三个文件。您可以使用以下命令从该目录创建一个 ZIP 文件:$ python -m zipfile -c source_dir.zip source_dir/ $ python -m zipfile -l source_dir.zip File Name Modified Size source_dir/ 2021-08-31 08:55:58 0 source_dir/hello.txt 2021-08-31 08:55:58 83 source_dir/lorem.md 2021-08-31 09:01:08 2609 source_dir/realpython.md 2021-08-31 09:31:22 428使用这个命令,
zipfile将source_dir/放在生成的source_dir.zip文件的根目录下。像往常一样,您可以通过使用-l选项运行zipfile来列出归档内容。注意:当您从命令行使用
zipfile创建归档文件时,库在归档您的文件时隐式地使用Deflate 压缩算法。您还可以从命令行使用
-e或--extract选项提取给定 ZIP 文件的所有内容:$ python -m zipfile --extract sample.zip sample/运行这个命令后,您的工作目录中将会有一个新的
sample/文件夹。新文件夹将包含您的sample.zip档案中的当前文件。您可以从命令行使用
zipfile的最后一个选项是-t或--test。此选项允许您测试给定文件是否是有效的 ZIP 文件。来吧,试一试!使用其他库管理 ZIP 文件
Python 标准库中还有一些其他工具,可以用来在较低的级别上归档、压缩和解压缩文件。Python 的
zipfile在内部使用了其中一些,主要用于压缩目的。以下是其中一些工具的摘要:
组件 描述 T2 zlib允许使用 zlib 库进行压缩和解压缩 T2 bz2提供使用 Bzip2 压缩算法压缩和解压缩数据的接口 T2 lzma提供使用 LZMA 压缩算法压缩和解压缩数据的类和函数 与
zipfile不同,这些模块中的一些允许你压缩和解压缩来自内存和数据流的数据,而不是常规文件和存档。在 Python 标准库中,您还会找到
tarfile,它支持 TAR 归档格式。还有一个模块叫做gzip,它提供了一个压缩和解压缩数据的接口,类似于 GNU Gzip 程序的做法。例如,您可以使用
gzip创建一个包含一些文本的压缩文件:
>>> import gzip
>>> with gzip.open("hello.txt.gz", mode="wt") as gz_file:
... gz_file.write("Hello, World!")
...
13
一旦运行了这段代码,在当前目录中就会有一个包含压缩版本的hello.txt的hello.txt.gz档案。在hello.txt里面,你会找到文本Hello, World!。
不使用zipfile创建 ZIP 文件的一种快速高级方法是使用 shutil 。此模块允许您对文件和文件集合执行一些高级操作。说到归档操作,你有 make_archive() ,可以创建归档,比如 ZIP 或者 TAR 文件:
>>> import shutil >>> shutil.make_archive("shutil_sample", format="zip", root_dir="source_dir/") '/home/user/sample.zip'这段代码在您的工作目录中创建一个名为
sample.zip的压缩文件。这个 ZIP 文件将包含输入目录source_dir/中的所有文件。当你需要一种快速和高级的方式在 Python 中创建你的 ZIP 文件时,make_archive()函数是很方便的。结论
当你需要从 ZIP 档案中读取、写入、压缩、解压缩和提取文件时,Python 的
zipfile是一个方便的工具。ZIP 文件格式已经成为行业标准,允许你打包或者压缩你的数字数据。使用 ZIP 文件的好处包括将相关文件归档在一起、节省磁盘空间、便于通过计算机网络传输数据、捆绑 Python 代码以供分发等等。
在本教程中,您学习了如何:
- 使用 Python 的
zipfile来读取、写入和提取现有的 ZIP 文件- 用
zipfile阅读元数据关于你的 ZIP 文件的内容- 使用
zipfile到操作现有 ZIP 文件中的成员文件- 创建您自己的 ZIP 文件来归档和压缩您的数字数据
您还学习了如何在命令行中使用
zipfile来列出、创建和解压缩 ZIP 文件。有了这些知识,您就可以使用 ZIP 文件格式高效地归档、压缩和操作您的数字数据了。**********Python 3 中的面向对象编程(OOP)
原文:https://realpython.com/python3-object-oriented-programming/
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的面向对象编程(OOP)介绍
面向对象编程 (OOP)是一种通过将相关属性和行为捆绑到单独的对象中来构建程序的方法。在本教程中,您将学习 Python 中面向对象编程的基础知识。
从概念上讲,对象就像系统的组件。把一个程序想象成某种工厂装配线。在装配线的每一步,一个系统组件处理一些材料,最终将原材料转化为成品。
对象包含数据(如装配线上每个步骤的原材料或预处理材料)和行为(如每个装配线组件执行的操作)。
在本教程中,您将学习如何:
- 创建一个类,这就像是创建一个对象的蓝图
- 使用类来创建新对象
- 具有类继承的模型系统
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“面向对象编程(OOP)”一章。
这本书使用 Python 内置的 IDLE 编辑器来创建和编辑 Python 文件,并与 Python shell 进行交互,因此在整个教程中你会偶尔看到对 IDLE 的引用。但是,从您选择的编辑器和环境中运行示例代码应该没有问题。
免费奖励: 点击此处获取免费的 Python OOP 备忘单,它会为你指出最好的教程、视频和书籍,让你了解更多关于 Python 面向对象编程的知识。
Python 中的面向对象编程是什么?
面向对象编程是一种编程范式,它提供了一种结构化程序的方法,从而将属性和行为捆绑到单独的对象中。
例如,一个对象可以代表一个具有属性如姓名、年龄和地址以及行为如走路、说话、呼吸和跑步的人。或者它可以代表一封电子邮件,具有收件人列表、主题和正文等属性,以及添加附件和发送等行为。
换句话说,面向对象编程是一种对具体的、真实世界的事物建模的方法,如汽车,以及事物之间的关系,如公司和雇员、学生和教师等等。OOP 将现实世界中的实体建模为软件对象,这些对象有一些与之相关的数据,并且可以执行某些功能。
另一个常见的编程范例是过程化编程,它像菜谱一样构建程序,以函数和代码块的形式提供一组步骤,这些步骤按顺序流动以完成任务。
关键的一点是,在 Python 中,对象是面向对象编程的核心,不仅像在过程编程中一样表示数据,而且在程序的整体结构中也是如此。
在 Python 中定义一个类
原始的数据结构——像数字、字符串和列表——被设计用来表示简单的信息,比如一个苹果的价格、一首诗的名字或者你最喜欢的颜色。如果你想表现更复杂的东西呢?
例如,假设您想要跟踪某个组织中的员工。您需要存储每个员工的一些基本信息,比如他们的姓名、年龄、职位以及他们开始工作的年份。
一种方法是将每个雇员表示为一个列表:
kirk = ["James Kirk", 34, "Captain", 2265] spock = ["Spock", 35, "Science Officer", 2254] mccoy = ["Leonard McCoy", "Chief Medical Officer", 2266]这种方法有许多问题。
首先,它会使较大的代码文件更难管理。如果在声明
kirk列表的地方引用几行之外的kirk[0],你会记得索引为0的元素是雇员的名字吗?第二,如果不是每个雇员在列表中有相同数量的元素,它可能会引入错误。在上面的
mccoy列表中,缺少年龄,所以mccoy[1]将返回"Chief Medical Officer"而不是麦考伊博士的年龄。让这类代码更易于管理和维护的一个好方法是使用类。
类与实例
类用于创建用户定义的数据结构。类定义了名为方法的函数,这些方法标识了从类创建的对象可以对其数据执行的行为和动作。
在本教程中,您将创建一个
Dog类来存储一些关于单只狗的特征和行为的信息。一个类是应该如何定义的蓝图。它实际上不包含任何数据。
Dog类指定名字和年龄是定义狗的必要条件,但它不包含任何特定狗的名字或年龄。类是蓝图,而实例是从类构建的包含真实数据的对象。
Dog类的实例不再是蓝图。这是一只真正的狗,它有一个名字,像四岁的迈尔斯。换句话说,一个类就像一个表格或问卷。实例就像一个已经填写了信息的表单。就像许多人可以用他们自己的独特信息填写同一个表单一样,许多实例可以从单个类中创建。
如何定义一个类
所有的类定义都以关键字
class开始,后面是类名和冒号。缩进到类定义下面的任何代码都被认为是类体的一部分。下面是一个
Dog类的例子:class Dog: pass
Dog类的主体由一条语句组成:关键字pass。pass通常被用作占位符,表示代码最终的去向。它允许您在 Python 不抛出错误的情况下运行这段代码。注意: Python 类名按照惯例是用 CapitalizedWords 符号写的。例如,一个特定品种的狗(如杰克罗素梗)的类可以写成
JackRussellTerrier。
Dog类现在不是很有趣,所以让我们通过定义所有Dog对象应该具有的一些属性来稍微修饰一下它。有许多属性可供我们选择,包括名字、年龄、毛色和品种。为了简单起见,我们只使用姓名和年龄。所有
Dog对象必须具有的属性在一个叫做.__init__()的方法中定义。每次创建一个新的Dog对象,.__init__()通过分配对象的属性值来设置对象的初始状态。也就是说,.__init__()初始化该类的每个新实例。你可以给
.__init__()任意数量的参数,但是第一个参数总是一个叫做self的变量。当一个新的类实例被创建时,该实例被自动传递给.__init__()中的self参数,这样就可以在对象上定义新的属性。让我们用一个创建
.name和.age属性的.__init__()方法来更新Dog类:class Dog: def __init__(self, name, age): self.name = name self.age = age注意,
.__init__()方法的签名缩进了四个空格。该方法的主体缩进八个空格。这个缩进非常重要。它告诉 Python,.__init__()方法属于Dog类。在
.__init__()的主体中,有两条语句使用了self变量:
self.name = name创建一个名为name的属性,并赋予它name参数的值。self.age = age创建一个名为age的属性,并赋予它age参数的值。在
.__init__()中创建的属性称为实例属性。实例属性的值特定于类的特定实例。所有的Dog对象都有名称和年龄,但是name和age属性的值会根据Dog实例的不同而不同。另一方面,类属性是对所有类实例具有相同值的属性。您可以通过在
.__init__()之外给变量赋值来定义一个类属性。例如,下面的
Dog类有一个名为species的类属性,其值为"Canis familiaris":class Dog: # Class attribute species = "Canis familiaris" def __init__(self, name, age): self.name = name self.age = age类属性直接定义在类名的第一行下面,缩进四个空格。它们必须总是被赋予一个初始值。当创建类的实例时,会自动创建类属性并将其赋给初始值。
使用类属性为每个类实例定义应该具有相同值的属性。对于因实例而异的属性,请使用实例属性。
现在我们有了一个
Dog类,让我们创建一些狗吧!用 Python 实例化一个对象
打开 IDLE 的交互窗口,键入以下内容:
>>> class Dog:
... pass
这创建了一个没有属性或方法的新的Dog类。
从一个类创建一个新对象叫做实例化一个对象。您可以通过键入类名,后跟左括号和右括号来实例化一个新的Dog对象:
>>> Dog() <__main__.Dog object at 0x106702d30>您现在在
0x106702d30有了一个新的Dog对象。这个看起来很有趣的字母和数字串是一个内存地址,它指示了Dog对象在你的计算机内存中的存储位置。请注意,您在屏幕上看到的地址会有所不同。现在实例化第二个
Dog对象:
>>> Dog()
<__main__.Dog object at 0x0004ccc90>
新的Dog实例位于不同的内存地址。这是因为它是一个全新的实例,与您实例化的第一个Dog对象完全不同。
要从另一个角度看这个问题,请键入以下内容:
>>> a = Dog() >>> b = Dog() >>> a == b False在这段代码中,您创建了两个新的
Dog对象,并将它们分配给变量a和b。当您使用==运算符比较a和b时,结果是False。尽管a和b都是Dog类的实例,但它们在内存中代表两个不同的对象。类别和实例属性
现在创建一个新的
Dog类,它有一个名为.species的类属性和两个名为.name和.age的实例属性:
>>> class Dog:
... species = "Canis familiaris"
... def __init__(self, name, age):
... self.name = name
... self.age = age
要实例化这个Dog类的对象,您需要为name和age提供值。如果没有,Python 就会抛出一个TypeError:
>>> Dog() Traceback (most recent call last): File "<pyshell#6>", line 1, in <module> Dog() TypeError: __init__() missing 2 required positional arguments: 'name' and 'age'要将参数传递给
name和age参数,请将值放入类名后的括号中:
>>> buddy = Dog("Buddy", 9)
>>> miles = Dog("Miles", 4)
这创建了两个新的Dog实例——一个是九岁的狗 Buddy,另一个是四岁的狗 Miles。
Dog类的.__init__()方法有三个参数,那么为什么在示例中只有两个参数传递给它呢?
当实例化一个Dog对象时,Python 会创建一个新的实例,并将其传递给.__init__()的第一个参数。这实质上移除了self参数,因此您只需要担心name和age参数。
在您创建了Dog实例之后,您可以使用点符号来访问它们的实例属性:
>>> buddy.name 'Buddy' >>> buddy.age 9 >>> miles.name 'Miles' >>> miles.age 4您可以用同样的方式访问类属性:
>>> buddy.species
'Canis familiaris'
使用类来组织数据的一个最大的优点是实例保证具有您期望的属性。所有的Dog实例都有.species、.name和.age属性,所以您可以放心地使用这些属性,因为它们总是会返回值。
虽然属性被保证存在,但是它们的值可以被动态地改变:
>>> buddy.age = 10 >>> buddy.age 10 >>> miles.species = "Felis silvestris" >>> miles.species 'Felis silvestris'在这个例子中,您将
buddy对象的.age属性更改为10。然后你将miles对象的.species属性改为"Felis silvestris",这是一种猫。这使得迈尔斯成为一只非常奇怪的狗,但它是一条有效的蟒蛇!这里的关键是定制对象在默认情况下是可变的。如果一个对象可以动态改变,那么它就是可变的。例如,列表和字典是可变的,但是字符串和元组是不可变的。
实例方法
实例方法是定义在类内部的函数,只能从该类的实例中调用。就像
.__init__()一样,实例方法的第一个参数总是self。在空闲状态下打开一个新的编辑器窗口,键入下面的
Dog类:class Dog: species = "Canis familiaris" def __init__(self, name, age): self.name = name self.age = age # Instance method def description(self): return f"{self.name} is {self.age} years old" # Another instance method def speak(self, sound): return f"{self.name} says {sound}"这个
Dog类有两个实例方法:
.description()返回显示狗的名字和年龄的字符串。.speak()有一个名为sound的参数,返回一个包含狗的名字和狗发出的声音的字符串。将修改后的
Dog类保存到名为dog.py的文件中,按F5运行程序。然后打开交互式窗口并键入以下内容,查看实例方法的运行情况:
>>> miles = Dog("Miles", 4)
>>> miles.description()
'Miles is 4 years old'
>>> miles.speak("Woof Woof")
'Miles says Woof Woof'
>>> miles.speak("Bow Wow")
'Miles says Bow Wow'
在上面的Dog类中,.description()返回一个包含关于Dog实例miles信息的字符串。在编写自己的类时,最好有一个方法返回一个字符串,该字符串包含关于类实例的有用信息。然而,.description()并不是最蟒的做法。
当您创建一个list对象时,您可以使用print()来显示一个类似于列表的字符串:
>>> names = ["Fletcher", "David", "Dan"] >>> print(names) ['Fletcher', 'David', 'Dan']让我们看看当你
print()这个miles对象时会发生什么:
>>> print(miles)
<__main__.Dog object at 0x00aeff70>
当你print(miles)时,你会得到一个看起来很神秘的消息,告诉你miles是一个位于内存地址0x00aeff70的Dog对象。这条消息没什么帮助。您可以通过定义一个名为.__str__()的特殊实例方法来改变打印的内容。
在编辑器窗口中,将Dog类的.description()方法的名称改为.__str__():
class Dog:
# Leave other parts of Dog class as-is
# Replace .description() with __str__()
def __str__(self):
return f"{self.name} is {self.age} years old"
保存文件,按 F5 。现在,当你print(miles)时,你会得到一个更友好的输出:
>>> miles = Dog("Miles", 4) >>> print(miles) 'Miles is 4 years old'像
.__init__()和.__str__()这样的方法被称为 dunder 方法,因为它们以双下划线开始和结束。在 Python 中,有许多 dunder 方法可以用来定制类。虽然对于一本初级 Python 书籍来说,这是一个过于高级的主题,但是理解 dunder 方法是掌握 Python 中面向对象编程的重要部分。在下一节中,您将看到如何更进一步,从其他类创建类。
检查你的理解能力
展开下面的方框,检查您的理解程度:
创建一个具有两个实例属性的
Car类:
.color,它将汽车颜色的名称存储为一个字符串.mileage,以整数形式存储汽车的里程数然后实例化两个
Car对象——一辆行驶 20,000 英里的蓝色汽车和一辆行驶 30,000 英里的红色汽车——并打印出它们的颜色和里程。您的输出应该如下所示:The blue car has 20,000 miles. The red car has 30,000 miles.您可以展开下面的方框查看解决方案:
首先,创建一个具有
.color和.mileage实例属性的Car类:class Car: def __init__(self, color, mileage): self.color = color self.mileage = mileage
.__init__()的color和mileage参数被分配给self.color和self.mileage,这就创建了两个实例属性。现在您可以创建两个
Car实例:blue_car = Car(color="blue", mileage=20_000) red_car = Car(color="red", mileage=30_000)通过将值
"blue"传递给color参数并将20_000传递给mileage参数来创建blue_car实例。类似地,red_car用值"red"和30_000创建。要打印每个
Car对象的颜色和里程,您可以在包含两个对象的tuple上循环:for car in (blue_car, red_car): print(f"The {car.color} car has {car.mileage:,} miles")上述
for循环中的 f 字符串将.color和.mileage属性插入到字符串中,并使用:,格式说明符打印以千为单位分组并以逗号分隔的里程。最终输出如下所示:
The blue car has 20,000 miles. The red car has 30,000 miles.当你准备好了,你可以进入下一部分。
从 Python 中的其他类继承
继承是一个类继承另一个类的属性和方法的过程。新形成的类称为子类,子类派生的类称为父类。
注:本教程改编自 Python 基础知识:Python 实用入门 3 中“面向对象编程(OOP)”一章。如果你喜欢你正在阅读的东西,那么一定要看看这本书的其余部分。
子类可以重写或扩展父类的属性和方法。换句话说,子类继承父类的所有属性和方法,但也可以指定自己独有的属性和方法。
虽然这个类比并不完美,但是你可以把对象继承想象成类似于基因继承。
你可能从你母亲那里遗传了你的发色。这是你与生俱来的属性。假设你决定把头发染成紫色。假设你的母亲没有紫色的头发,你只是覆盖了你从你母亲那里继承的头发颜色属性。
从某种意义上说,你也从父母那里继承了你的语言。如果你的父母说英语,那么你也会说英语。现在想象你决定学习第二语言,比如德语。在这种情况下,您已经扩展了您的属性,因为您添加了一个您的父母没有的属性。
狗狗公园的例子
假设你在一个狗狗公园。公园里有很多不同品种的狗,都在从事各种狗的行为。
假设现在您想用 Python 类来建模 dog park。您在上一节中编写的
Dog类可以通过名字和年龄来区分狗,但不能通过品种来区分。您可以通过添加一个
.breed属性来修改编辑器窗口中的Dog类:class Dog: species = "Canis familiaris" def __init__(self, name, age, breed): self.name = name self.age = age self.breed = breed这里省略了前面定义的实例方法,因为它们对于本次讨论并不重要。
按
F5保存文件。现在,您可以通过在交互式窗口中实例化一群不同的狗来模拟狗公园:
>>> miles = Dog("Miles", 4, "Jack Russell Terrier")
>>> buddy = Dog("Buddy", 9, "Dachshund")
>>> jack = Dog("Jack", 3, "Bulldog")
>>> jim = Dog("Jim", 5, "Bulldog")
每种狗的行为都略有不同。例如,牛头犬低沉的叫声听起来像汪汪叫,但是腊肠犬的叫声更高,听起来更像 T2 吠声。
仅使用Dog类,每次在Dog实例上调用.speak()的sound参数时,必须提供一个字符串:
>>> buddy.speak("Yap") 'Buddy says Yap' >>> jim.speak("Woof") 'Jim says Woof' >>> jack.speak("Woof") 'Jack says Woof'向每个对
.speak()的调用传递一个字符串是重复且不方便的。此外,代表每个Dog实例发出的声音的字符串应该由它的.breed属性决定,但是这里您必须在每次调用它时手动将正确的字符串传递给.speak()。您可以通过为每种狗创建一个子类来简化使用
Dog类的体验。这允许您扩展每个子类继承的功能,包括为.speak()指定一个默认参数。父类 vs 子类
让我们为上面提到的三个品种分别创建一个子类:杰克罗素梗、腊肠犬和牛头犬。
作为参考,下面是
Dog类的完整定义:class Dog: species = "Canis familiaris" def __init__(self, name, age): self.name = name self.age = age def __str__(self): return f"{self.name} is {self.age} years old" def speak(self, sound): return f"{self.name} says {sound}"记住,要创建一个子类,你要创建一个有自己名字的新类,然后把父类的名字放在括号里。将以下内容添加到
dog.py文件中,以创建Dog类的三个新子类:class JackRussellTerrier(Dog): pass class Dachshund(Dog): pass class Bulldog(Dog): pass按
F5保存并运行文件。定义子类后,现在可以在交互窗口中实例化一些特定品种的狗:
>>> miles = JackRussellTerrier("Miles", 4)
>>> buddy = Dachshund("Buddy", 9)
>>> jack = Bulldog("Jack", 3)
>>> jim = Bulldog("Jim", 5)
子类的实例继承父类的所有属性和方法:
>>> miles.species 'Canis familiaris' >>> buddy.name 'Buddy' >>> print(jack) Jack is 3 years old >>> jim.speak("Woof") 'Jim says Woof'要确定给定对象属于哪个类,可以使用内置的
type():
>>> type(miles)
<class '__main__.JackRussellTerrier'>
如果你想确定miles是否也是Dog类的一个实例呢?你可以通过内置的isinstance()来实现:
>>> isinstance(miles, Dog) True注意
isinstance()有两个参数,一个对象和一个类。在上面的例子中,isinstance()检查miles是否是Dog类的实例,并返回True。
miles、buddy、jack和jim对象都是Dog实例,但是miles不是Bulldog实例,jack也不是Dachshund实例:
>>> isinstance(miles, Bulldog)
False
>>> isinstance(jack, Dachshund)
False
更一般地说,从子类创建的所有对象都是父类的实例,尽管它们可能不是其他子类的实例。
现在你已经为一些不同品种的狗创建了子类,让我们给每个品种赋予它自己的声音。
扩展父类的功能
由于不同品种的狗的叫声略有不同,所以您希望为它们各自的.speak()方法的sound参数提供一个默认值。为此,你需要在每个品种的类定义中覆盖.speak()。
要重写在父类上定义的方法,需要在子类上定义一个同名的方法。下面是JackRussellTerrier类的情况:
class JackRussellTerrier(Dog):
def speak(self, sound="Arf"):
return f"{self.name} says {sound}"
现在.speak()被定义在JackRussellTerrier类上,sound的默认参数被设置为"Arf"。
用新的JackRussellTerrier类更新dog.py并按 F5 保存并运行文件。现在,您可以在一个JackRussellTerrier实例上调用.speak(),而无需向sound传递参数:
>>> miles = JackRussellTerrier("Miles", 4) >>> miles.speak() 'Miles says Arf'有时狗会发出不同的叫声,所以如果迈尔斯生气了,你仍然可以用不同的声音呼叫
.speak():
>>> miles.speak("Grrr")
'Miles says Grrr'
关于类继承要记住的一点是,对父类的更改会自动传播到子类。只要被更改的属性或方法没有在子类中被重写,就会发生这种情况。
例如,在编辑器窗口中,更改由Dog类中的.speak()返回的字符串:
class Dog:
# Leave other attributes and methods as they are
# Change the string returned by .speak()
def speak(self, sound):
return f"{self.name} barks: {sound}"
保存文件并按 F5 。现在,当您创建一个名为jim的新的Bulldog实例时,jim.speak()返回新的字符串:
>>> jim = Bulldog("Jim", 5) >>> jim.speak("Woof") 'Jim barks: Woof'然而,在一个
JackRussellTerrier实例上调用.speak()不会显示新的输出样式:
>>> miles = JackRussellTerrier("Miles", 4)
>>> miles.speak()
'Miles says Arf'
有时完全重写父类的方法是有意义的。但是在这个实例中,我们不希望JackRussellTerrier类丢失任何可能对Dog.speak()的输出字符串格式进行的更改。
为此,您仍然需要在子类JackRussellTerrier上定义一个.speak()方法。但是不需要显式定义输出字符串,您需要使用传递给JackRussellTerrier.speak()的相同参数调用子类.speak()的内的Dog类的.speak() 。
您可以使用 super() 从子类的方法内部访问父类:
class JackRussellTerrier(Dog):
def speak(self, sound="Arf"):
return super().speak(sound)
当您在JackRussellTerrier中调用super().speak(sound)时,Python 会在父类Dog中搜索一个.speak()方法,并用变量sound调用它。
用新的JackRussellTerrier类更新dog.py。保存文件并按下 F5 ,这样您就可以在交互窗口中测试它了:
>>> miles = JackRussellTerrier("Miles", 4) >>> miles.speak() 'Miles barks: Arf'现在,当您调用
miles.speak()时,您将看到输出反映了Dog类中的新格式。注意:在上面的例子中,类的层次结构非常简单。
JackRussellTerrier类只有一个父类Dog。在现实世界的例子中,类的层次结构会变得非常复杂。不仅仅是在父类中搜索方法或属性。它遍历整个类层次结构,寻找匹配的方法或属性。如果不小心,
super()可能会有惊人的结果。检查你的理解能力
展开下面的方框,检查您的理解程度:
创建一个继承自
Dog类的GoldenRetriever类。给GoldenRetriever.speak()的sound参数一个默认值"Bark"。为您的父类Dog使用以下代码:class Dog: species = "Canis familiaris" def __init__(self, name, age): self.name = name self.age = age def __str__(self): return f"{self.name} is {self.age} years old" def speak(self, sound): return f"{self.name} says {sound}"您可以展开下面的方框查看解决方案:
创建一个名为
GoldenRetriever的类,它继承了Dog类并覆盖了.speak()方法:class GoldenRetriever(Dog): def speak(self, sound="Bark"): return super().speak(sound)
GoldenRetriever.speak()中的sound参数被赋予默认值"Bark"。然后用super()调用父类的.speak()方法,传递给sound的参数与GoldenRetriever类的.speak()方法相同。结论
在本教程中,您学习了 Python 中的面向对象编程(OOP)。大多数现代编程语言,如 Java 、 C# 、 C++ ,都遵循 OOP 原则,因此无论你的编程生涯走向何方,你在这里学到的知识都将适用。
在本教程中,您学习了如何:
- 定义一个类,它是一种对象的蓝图
- 从一个类中实例化一个对象
- 使用属性和方法来定义对象的属性和行为
- 使用继承从父类创建子类
- 使用
super()引用父类上的方法- 使用
isinstance()检查一个对象是否从另一个类继承如果你喜欢在这个例子中从 Python 基础知识:Python 3 实用介绍中学到的东西,那么一定要看看这本书的其余部分。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 中的面向对象编程(OOP)介绍*****
Python 3.10:很酷的新特性供您尝试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.10 中很酷的新特性
Python 3.10 出来了!自 2020 年 5 月以来,志愿者一直致力于新版本的工作,为您带来更好、更快、更安全的 Python。截至2021 年 10 月 4 日,第一个正式版本面世。
Python 的每个新版本都带来了大量的变化。你可以在文档中读到所有这些。在这里,您将了解到最酷的新功能。
在本教程中,您将了解到:
- 使用更有用、更精确的错误消息进行调试
- 使用结构模式匹配处理数据结构
- 添加可读性更强、更具体的类型提示
- 使用
zip()时检查序列的长度- 计算多变量统计
要自己尝试新功能,您需要运行 Python 3.10。可以从 Python 主页获取。或者,你可以使用 Docker 和最新的 Python 镜像。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
额外学习材料:查看真实 Python 播客第 81 集,了解 Python 3.10 技巧,并与真实 Python 团队成员进行讨论。
更好的错误消息
Python 经常被称赞为用户友好的编程语言。虽然这是真的,但 Python 的某些部分可以更友好。Python 3.10 提供了大量更精确、更有建设性的错误消息。在这一部分,您将看到一些最新的改进。完整列表可在文档中找到。
回想一下用 Python 编写你的第一个 Hello World 程序:
# hello.py print("Hello, World!)也许你创建了一个文件,给
print()添加了著名的调用,保存为hello.py。然后你运行这个程序,渴望称自己是一个真正的 Pythonista。然而,有些事情出错了:$ python hello.py File "/home/rp/hello.py", line 3 print("Hello, World!) ^ SyntaxError: EOL while scanning string literal代码中有一个
SyntaxError。EOL,那到底是什么意思?你回到你的代码,在盯着看了一会儿和搜索了一会儿之后,你意识到在你的字符串的末尾少了一个引号。Python 3.10 中最具影响力的改进之一是针对许多常见问题的更好、更精确的错误消息。如果您在 Python 3.10 中运行有问题的 Hello World,您将获得比 Python 早期版本更多的帮助:
$ python hello.py File "/home/rp/hello.py", line 3 print("Hello, World!) ^ SyntaxError: unterminated string literal (detected at line 3)错误信息仍然有点技术性,但是神秘的
EOL已经消失了。相反,消息告诉你你需要终止你的字符串!许多不同的错误信息都有类似的改进,您将在下面看到。一个
SyntaxError是一个错误,当你的代码被解析时,甚至在它开始执行之前。语法错误可能很难调试,因为解释器会提供不精确或者有时甚至是误导性的错误消息。以下代码缺少终止字典的花括号:1# unterminated_dict.py 2 3months = { 4 10: "October", 5 11: "November", 6 12: "December" 7 8print(f"{months[10]} is the tenth month")本应在第 7 行的右花括号丢失是一个错误。如果使用 Python 3.9 或更低版本运行此代码,您将看到以下错误消息:
File "/home/rp/unterminated_dict.py", line 8 print(f"{months[10]} is the tenth month") ^ SyntaxError: invalid syntax错误消息突出显示了第 8 行,但是第 8 行没有语法问题!如果你经历过 Python 中的语法错误,你可能已经知道诀窍是查看 Python 抱怨的那一行之前的行。在这种情况下,您要在第 7 行寻找丢失的右大括号。
在 Python 3.10 中,相同的代码显示了一个更有用、更精确的错误消息:
File "/home/rp/unterminated_dict.py", line 3 months = { ^ SyntaxError: '{' was never closed这直接将您指向有问题的字典,并允许您立即修复问题。
还有其他一些方法可以弄乱字典语法。一个典型的例子是忘记了其中一项后面的逗号:
1# missing_comma.py 2 3months = { 4 10: "October" 5 11: "November", 6 12: "December", 7}在这段代码中,第 4 行末尾缺少一个逗号。Python 3.10 就如何修复代码给了你一个清晰的建议:
File "/home/real_python/missing_comma.py", line 4 10: "October" ^^^^^^^^^ SyntaxError: invalid syntax. Perhaps you forgot a comma?您可以添加缺少的逗号,让您的代码立即备份并运行。
另一个常见的错误是在比较值时使用赋值运算符(
=)而不是等式比较运算符(==)。以前,这只会引起另一个invalid syntax消息。在 Python 的最新版本中,您会得到更多的建议:
>>> if month = "October":
File "<stdin>", line 1
if month = "October":
^^^^^^^^^^^^^^^^^
SyntaxError: invalid syntax. Maybe you meant '==' or ':=' instead of '='?
请注意 Python 3.10 错误消息中的另一个漂亮的改进。最后两个例子展示了 carets ( ^^^)是如何突出整个冒犯性的表达的。以前,单个插入符号(^)仅仅表示一个大概的位置。
现在,最后一个错误消息改进是,如果您拼错了属性或名称,属性和名称错误现在可以提供建议:
>>> import math >>> math.py AttributeError: module 'math' has no attribute 'py'. Did you mean: 'pi'? >>> pint NameError: name 'pint' is not defined. Did you mean: 'print'? >>> release = "3.10" >>> relaese NameError: name 'relaese' is not defined. Did you mean: 'release'?请注意,这些建议对内置名称和您自己定义的名称都有效,尽管它们可能不是在所有环境中都可用。如果你喜欢这类建议,看看 BetterErrorMessages ,它提供了更多类似的建议。
您在本节中看到的改进只是许多错误消息的一部分。新的 Python 将比以前更加用户友好,并且希望新的错误消息将节省您的时间和挫折。
结构模式匹配
Python 3.10 中最大的新特性,可能在争议和潜在影响方面,是结构模式匹配。它的引入有时被称为
switch ... case来到 Python,但是你会看到结构模式匹配比那要强大得多。您将看到三个不同的例子,它们共同强调了为什么这个特性被称为结构模式匹配,并向您展示了如何使用这个新特性:
- 检测和解构数据中不同的结构
- 使用不同种类的模式
- 匹配文字模式
结构化模式匹配是对 Python 语言的全面补充。为了让您体验如何在自己的项目中利用它,接下来的三小节将深入探讨一些细节。如果你愿意,你还会看到一些可以帮助你更深入探索的链接。
解构数据结构
结构模式匹配的核心是定义数据结构可以匹配的模式。在这一节中,您将学习一个实际的例子,在这个例子中,您将处理结构不同的数据,尽管它们的含义是相同的。您将定义几个模式,根据哪个模式匹配您的数据,您将适当地处理您的数据。
这一节对可能的模式的解释会稍微少一点。相反,它会试图给你一个可能性的印象。下一节将后退一步,更详细地解释这些模式。
是时候匹配你的第一个图案了!下面的例子使用了一个
match ... case块,通过从一个user数据结构中提取名字来查找用户的名字:
>>> user = {
... "name": {"first": "Pablo", "last": "Galindo Salgado"},
... "title": "Python 3.10 release manager",
... }
>>> match user: ... case {"name": {"first": first_name}}: ... pass
...
>>> first_name
'Pablo'
您可以在突出显示的行中看到工作中的结构模式匹配。user是一个有用户信息的小字典。case行指定了一个与user匹配的模式。在本例中,您正在寻找一个带有"name"键的字典,它的值是一个新字典。这个嵌套字典有一个名为"first"的键。对应的值被绑定到变量first_name。
举个实际的例子,假设您正在处理用户数据,而底层数据模型会随着时间的推移而变化。因此,您需要能够处理同一数据的不同版本。
在下一个例子中,您将使用来自 randomuser.me 的数据。这是一个生成随机用户数据的很好的 API,您可以在测试和开发过程中使用它。API 也是一个随着时间而改变的 API 的例子。你仍然可以访问 API 的旧版本。
您可以展开下面折叠的部分,查看如何使用 requests 通过 API 获得不同版本的用户数据:
您可以使用requests从 API 中获得一个随机用户,如下所示:
# random_user.py
import requests
def get_user(version="1.3"):
"""Get random users"""
url = f"https://randomuser.me/api/{version}/?results=1"
response = requests.get(url)
if response:
return response.json()["results"][0]
get_user()随机获取一个 JSON 格式的用户。注意version参数。在早期版本如"1.1"和当前版本"1.3"之间,返回数据的结构有了很大的变化,但是在每种情况下,实际的用户数据都包含在"results"数组内的一个列表中。该函数返回列表中的第一个也是唯一一个用户。
在撰写本文时,API 的最新版本是 1.3,数据具有以下结构:
{ "gender": "female", "name": { "title": "Miss", "first": "Ilona", "last": "Jokela" }, "location": { "street": { "number": 4473, "name": "Mannerheimintie" }, "city": "Harjavalta", "state": "Ostrobothnia", "country": "Finland", "postcode": 44879, "coordinates": { "latitude": "-6.0321", "longitude": "123.2213" }, "timezone": { "offset": "+5:30", "description": "Bombay, Calcutta, Madras, New Delhi" } }, "email": "ilona.jokela@example.com", "login": { "uuid": "632b7617-6312-4edf-9c24-d6334a6af52d", "username": "brownsnake482", "password": "biatch", "salt": "ofk518ZW", "md5": "6d589615ca44f6e583c85d45bf431c54", "sha1": "cd87c931d579bdff77af96c09e0eea82d1edfc19", "sha256": "6038ede83d4ce74116faa67fb3b1b2e6f6898e5749b57b5a0312bd46a539214a" }, "dob": { "date": "1957-05-20T08:36:09.083Z", "age": 64 }, "registered": { "date": "2006-07-30T18:39:20.050Z", "age": 15 }, "phone": "07-369-318", "cell": "048-284-01-59", "id": { "name": "HETU", "value": "NaNNA204undefined" }, "picture": { "large": "https://randomuser.me/api/portraits/women/28.jpg", "medium": "https://randomuser.me/api/portraits/med/women/28.jpg", "thumbnail": "https://randomuser.me/api/portraits/thumb/women/28.jpg" }, "nat": "FI" }
在不同版本之间变化的成员之一是"dob",出生日期。注意,在 1.3 版本中,这是一个有两个成员的 JSON 对象,"date"和"age"。
注意:默认情况下, randomuser.me 返回一个随机用户。通过将种子设置为310,您可以获得与本例中完全相同的用户:
url = f"https://randomuser.me/api/{version}/?results=1&seed=310"
通过将&seed=310添加到 URL 来设置种子。API 返回的完整对象还包含一些名为"info"的成员中的元数据。这些元数据将包括数据的版本以及用于创建随机用户的种子。
将上面的结果与 1.1 版本的随机用户进行比较:
{ "gender": "female", "name": { "title": "miss", "first": "ilona", "last": "jokela" }, "location": { "street": "7336 myllypuronkatu", "city": "kurikka", "state": "central ostrobothnia", "postcode": 53740 }, "email": "ilona.jokela@example.com", "login": { "username": "blackelephant837", "password": "sand", "salt": "yofk518Z", "md5": "b26367ea967600d679ee3e0b9bda012f", "sha1": "87d2910595acba5b8e8aa8b00a841bab08580e2f", "sha256": "73bd0d205d0dc83ae184ae222ff2e9de5ea4039119a962c4f97fabd5bbfa7aca" }, "dob": "1966-04-17 11:57:01", "registered": "2005-08-10 10:15:01", "phone": "04-636-931", "cell": "048-828-40-15", "id": { "name": "HETU", "value": "366-9204" }, "picture": { "large": "https://randomuser.me/api/portraits/women/24.jpg", "medium": "https://randomuser.me/api/portraits/med/women/24.jpg", "thumbnail": "https://randomuser.me/api/portraits/thumb/women/24.jpg" }, "nat": "FI" }
注意,在这个旧格式中,"dob"成员的值是一个普通的字符串。
在本例中,您将处理每个用户的出生日期(dob)信息。这些数据的结构在不同版本的随机用户 API 之间发生了变化:
# Version 1.1 "dob": "1966-04-17 11:57:01" # Version 1.3 "dob": {"date": "1957-05-20T08:36:09.083Z", "age": 64}
注意,在 1.1 版本中,出生日期被表示为一个简单的字符串,而在 1.3 版本中,它是一个 JSON 对象,有两个成员:"date"和"age"。假设您想要查找一个用户的年龄。根据数据的结构,您可能需要根据出生日期计算年龄,或者查找年龄(如果已经有年龄的话)。
注意:age的值在下载数据时是准确的。如果存储数据,这个值最终会过时。如果这是一个问题,您应该基于date计算当前年龄。
传统上,您会用一个if测试来检测数据的结构,可能是基于"dob"字段的类型。在 Python 3.10 中,您可以采用不同的方法。现在,您可以使用结构模式匹配来代替:
1# random_user.py (continued)
2
3from datetime import datetime
4
5def get_age(user):
6 """Get the age of a user"""
7 match user: 8 case {"dob": {"age": int(age)}}: 9 return age
10 case {"dob": dob}: 11 now = datetime.now()
12 dob_date = datetime.strptime(dob, "%Y-%m-%d %H:%M:%S")
13 return now.year - dob_date.year
match ... case构造是 Python 3.10 中的新特性,也是执行结构化模式匹配的方式。您从一个match语句开始,该语句指定了您想要匹配的内容。在这个例子中,这就是user数据结构。
一个或几个case语句跟在match后面。每一个case描述了一种模式,它下面的缩进块说明了如果有匹配会发生什么。在本例中:
-
第 8 行匹配一个带有
"dob"键的字典,其值是另一个带有名为"age"的整数(int)项的字典。age这个名字抓住了它的价值。 -
第 10 行匹配任何带有
"dob"键的字典。名字dob抓住了它的价值。
模式匹配的一个重要特征是最多匹配一个模式。因为第 10 行的模式匹配任何带有"dob"的字典,所以第 8 行更具体的模式排在最前面是很重要的。
注意:第 13 行的年龄计算不是很精确,因为它忽略了日期。您可以通过显式比较月份和日期来检查用户今年是否已经庆祝了生日,从而改进这一点。然而,更好的解决方案是使用 dateutil 包中的 relativedelta 。使用relativedelta可以直接计算年份。
在仔细研究模式的细节以及它们是如何工作的之前,试着用不同的数据结构调用get_age()来看看结果:
>>> import random_user >>> users11 = random_user.get_user(version="1.1") >>> random_user.get_age(users11) 55 >>> users13 = random_user.get_user(version="1.3") >>> random_user.get_age(users13) 64您的代码可以正确计算两个版本的用户数据的年龄,这两个版本的用户数据具有不同的出生日期。
仔细看看那些图案。第一个模式
{"dob": {"age": int(age)}},匹配版本 1.3 的用户数据:{ ... "dob": {"date": "1957-05-20T08:36:09.083Z", "age": 64}, ... }第一种模式是嵌套模式。外面的花括号表示需要一个带有键
"dob"的字典。对应的值应该是字典。这个嵌套字典必须匹配子模式{"age": int(age)}。换句话说,它需要一个整数值的"age"键。该值被绑定到名称age。第二种模式
{"dob": dob},匹配旧版本 1.1 的用户数据:{ ... "dob": "1966-04-17 11:57:01", ... }第二种模式比第一种模式简单。同样,花括号表示它将匹配一个字典。但是,任何带有
"dob"键的字典都会被匹配,因为没有指定其他限制。该键的值被绑定到名称dob。主要的收获是,您可以使用最熟悉的符号来描述数据的结构。然而,一个显著的变化是你可以使用像
dob和age这样的名字,它们还没有被定义。相反,当模式匹配时,来自数据的值被绑定到这些名称。在这个例子中,您已经探索了结构模式匹配的一些功能。在下一节中,您将更深入地了解细节。
使用不同种类的模式
您已经看到了如何使用模式有效地解开复杂数据结构的例子。现在,您将后退一步,看看构成这一新功能的构件。许多事情凑在一起使它起作用。事实上,有三个描述结构化模式匹配的 Python 增强提案(pep):
如果您对以下内容感兴趣,这些文档将为您提供大量背景和细节。
模式是结构模式匹配的核心。在本节中,您将了解一些不同种类的现有模式:
- 映射模式像字典一样匹配映射结构。
- 序列模式匹配序列结构,如元组和列表。
- 捕获模式将值绑定到名称。
- AS 模式将子模式的值绑定到名称。
- OR 模式匹配几个不同子模式中的一个。
- 通配符模式匹配任何内容。
- 类模式匹配类结构。
- 值模式匹配存储在属性中的值。
- 文字模式匹配文字值。
在前一节的示例中,您已经使用了其中的几个。特别是,您使用了映射模式来解开存储在字典中的数据。在本节中,您将了解其中一些是如何工作的。所有的细节都可以在上面提到的 PEPs 中找到。
一个捕获模式用于捕获一个模式的匹配,并将其绑定到一个名称。考虑下面的递归函数,它对一系列数字求和:
1def sum_list(numbers): 2 match numbers: 3 case []: 4 return 0 5 case [first, *rest]: 6 return first + sum_list(rest)第 3 行的第一个
case匹配空列表并返回0作为其总和。第 5 行的第二个case使用一个序列模式和两个捕获模式来匹配带有一个或多个元素的列表。列表中的第一个元素被捕获并绑定到名称first。第二种捕获模式*rest,使用解包语法来匹配任意数量的元素。rest将绑定到包含除第一个元素之外的所有numbers元素的列表。
sum_list()通过递归相加列表中的第一个数字和其余数字的和来计算数字列表的和。您可以按如下方式使用它:
>>> sum_list([4, 5, 9, 4])
22
4 + 5 + 9 + 4 的和被正确地计算为 22。作为一个练习,您可以尝试跟踪对sum_list()的递归调用,以确保您理解代码是如何对整个列表求和的。
注意:捕获模式本质上是给变量赋值。然而,一个限制是只允许未被删除的名字。换句话说,您不能使用一个捕获模式来直接分配给一个类或实例属性。
sum_list()处理对一列数字求和。观察如果你试图对任何不是列表的东西求和会发生什么:
>>> print(sum_list("4594")) None >>> print(sum_list(4594)) None将字符串或数字传递给
sum_list()会返回None。发生这种情况是因为没有匹配的模式,执行在match块之后继续。那正好是函数的结尾,所以sum_list()隐式返回None。不过,通常情况下,您希望在匹配失败时得到提醒。例如,您可以添加一个 catchall 模式作为最终案例,通过引发一个错误来处理这个问题。您可以使用下划线(
_)作为通配符模式,它可以匹配任何内容,而不必绑定到名称。您可以向sum_list()添加一些错误处理,如下所示:def sum_list(numbers): match numbers: case []: return 0 case [first, *rest]: return first + sum_list(rest) case _: wrong_type = numbers.__class__.__name__ raise ValueError(f"Can only sum lists, not {wrong_type!r}")最后的
case将匹配与前两个模式不匹配的任何内容。这将引发一个描述性错误,例如,如果您试图计算sum_list(4594)。当您需要提醒用户某些输入与预期不符时,这很有用。不过,你的模式仍然不是万无一失的。考虑一下,如果您尝试对一系列字符串求和,会发生什么情况:
>>> sum_list(["45", "94"])
TypeError: can only concatenate str (not "int") to str
基本情况返回0,因此求和只适用于可以用数字相加的类型。Python 不知道如何将数字和文本字符串相加。您可以使用类模式将您的模式限制为仅匹配整数:
def sum_list(numbers):
match numbers:
case []:
return 0
case [int(first), *rest]: return first + sum_list(rest)
case _:
raise ValueError(f"Can only sum lists of numbers")
在first前后添加int()可以确保只有值是整数时模式才匹配。不过,这可能限制太多了。您的函数应该能够将整数和浮点数相加,那么在您的模式中您怎么能允许这样呢?
为了检查几个子模式中是否至少有一个匹配,您可以使用一个或模式。OR 模式由两个或更多子模式组成,如果至少有一个子模式匹配,则模式匹配。当第一个元素是类型int或类型float时,您可以使用它来匹配:
def sum_list(numbers):
match numbers:
case []:
return 0
case [int(first) | float(first), *rest]: return first + sum_list(rest)
case _:
raise ValueError(f"Can only sum lists of numbers")
您可以使用管道符号(|)来分隔 OR 模式中的子模式。您的函数现在允许对一系列浮点数求和:
>>> sum_list([45.94, 46.17, 46.72]) 138.82999999999998在结构模式匹配中有很多能力和灵活性,甚至比你目前所看到的还要多。本概述中未涵盖的一些内容包括:
如果您感兴趣,也可以查看文档以了解更多关于这些特性的信息。在下一节中,您将了解文字模式和值模式。
匹配文字模式
文字模式是一种匹配文字对象的模式,比如显式字符串或数字。在某种意义上,这是最基本的一种模式,允许你模仿其他语言中的
switch ... case语句。以下示例匹配特定的名称:def greet(name): match name: case "Guido": print("Hi, Guido!") case _: print("Howdy, stranger!")第一个
case匹配文字字符串"Guido"。在这种情况下,只要name不是"Guido",就使用_作为通配符来打印通用问候。这种文字模式有时可以代替if ... elif ... else结构,并且可以扮演与其他一些语言中的switch ... case相同的角色。结构模式匹配的一个限制是不能直接匹配存储在变量中的值。假设您已经定义了
bdfl = "Guido"。像case bdfl:这样的图案不会与"Guido"相配。相反,这将被解释为匹配任何内容的捕获模式,并将该值绑定到bdfl,有效地覆盖旧值。但是,您可以使用一个值模式来匹配存储的值。值模式看起来有点像捕获模式,但是它使用了一个预先定义的带点的名称,该名称包含将要匹配的值。
注:一个带点的名字是一个名字里面带一个点(
.)。实际上,这将引用类的属性、类的实例、枚举或模块。例如,您可以使用一个枚举来创建这样的点名称:
import enum class Pythonista(str, enum.Enum): BDFL = "Guido" FLUFL = "Barry" def greet(name): match name: case Pythonista.BDFL: print("Hi, Guido!") case _: print("Howdy, stranger!")第一种情况现在使用一个值模式来匹配
Pythonista.BDFL,也就是"Guido"。请注意,您可以在值模式中使用任何带点的名称。例如,您可以使用常规类或模块来代替枚举。要查看如何使用文字模式的更大的例子,考虑一下 FizzBuzz 的游戏。这是一个数数游戏,你应该根据以下规则用单词替换一些数字:
- 你用 fizz 代替能被 3 整除的数字。
- 你用蜂音代替能被 5 整除的数字。
- 你用 fizzbuzz 替换能被 3 和 5 整除的数字。
FizzBuzz 有时用于在编程教育中引入条件句,并作为面试中的筛选问题。尽管解决方案很简单,乔尔·格鲁什已经写了一本关于不同游戏编程方式的完整的《T2》书。
Python 中的典型解决方案将如下使用
if ... elif ... else:def fizzbuzz(number): mod_3 = number % 3 mod_5 = number % 5 if mod_3 == 0 and mod_5 == 0: return "fizzbuzz" elif mod_3 == 0: return "fizz" elif mod_5 == 0: return "buzz" else: return str(number)
%运算符计算模数,你可以用它来测试整除性。即如果两个数 a 和 b 的 a 模数 b 为 0,那么 a 可被 b 整除。在
fizzbuzz()中,你计算number % 3和number % 5,然后用它们来测试 3 和 5 的整除性。请注意,您必须首先测试 3 和 5 的整除性。否则,能被 3 和 5 整除的数字将被"fizz"或"buzz"的情况所覆盖。您可以检查您的实现是否给出了预期的结果:
>>> fizzbuzz(3)
fizz
>>> fizzbuzz(14)
14
>>> fizzbuzz(15)
fizzbuzz
>>> fizzbuzz(92)
92
>>> fizzbuzz(65)
buzz
你可以自己确认 3 能被 3 整除,65 能被 5 整除,15 能被 3 和 5 整除,而 14 和 92 不能被 3 和 5 整除。
在一个if ... elif ... else结构中,你要多次比较一个或几个变量,使用模式匹配来重写是非常简单的。例如,您可以执行以下操作:
def fizzbuzz(number):
mod_3 = number % 3
mod_5 = number % 5
match (mod_3, mod_5):
case (0, 0):
return "fizzbuzz"
case (0, _):
return "fizz"
case (_, 0):
return "buzz"
case _:
return str(number)
您在mod_3和mod_5上都匹配。然后,每个case模式匹配相应值上的文字数字0或通配符_。
将这个版本与前一个版本进行比较和对比。注意图案(0, 0)如何对应于测试mod_3 == 0 and mod_5 == 0,而(0, _)如何对应于mod_3 == 0。
正如您在前面看到的,您可以使用 OR 模式来匹配几个不同的模式。例如,由于mod_3只能取值0、1和2,所以可以用case (1, 0) | (2, 0)代替case (_, 0)。记住(0, 0)已经讲过了。
注意:如果你一直在其他语言中使用switch ... case,你应该记得在 Python 的模式匹配中没有 fallthrough 。这意味着最多会执行一个case,即第一个匹配的case。这与 C 和 Java 等语言不同。您可以使用或模式来处理大部分失败的效果。
Python 核心开发者有意识地选择不在语言中包含switch ... case语句。然而,有一些第三方包可以做到,比如 switchlang ,它增加了一个switch命令,也适用于早期版本的 Python。
类型联合、别名和保护
可靠地说,每一个新的 Python 版本都会给静态类型系统带来一些改进。Python 3.10 也不例外。事实上,这个新版本附带了四个不同的关于打字的 pep:
- 人教版 604: 允许编写工会类型为
X | Y - PEP 613: 显式类型别名
- PEP 647: 自定义类型守卫
- PEP 612: 参数说明变量
PEP 604 可能是这些变化中应用最广泛的,但是在这一节中你将得到每个特性的简要概述。
您可以使用联合类型来声明一个变量可以有几种不同类型中的一种。例如,您已经能够键入 hint a 函数来计算一组数字、浮点数或整数的平均值,如下所示:
from typing import List, Union
def mean(numbers: List[Union[float, int]]) -> float:
return sum(numbers) / len(numbers)
注释List[Union[float, int]]意味着numbers应该是一个列表,其中每个元素要么是浮点数,要么是整数。这工作得很好,但是符号有点冗长。另外,你需要从typing导入List和Union。
注:mean()的实现看起来很简单,但实际上有几个的死角会失败。如果需要计算手段,就用 statistics.mean() 代替。
在 Python 3.10 中,可以用更简洁的float | int代替Union[float, int]。结合在类型提示中使用list而不是typing.List的能力,这是 Python 3.9 引入的。然后,您可以简化代码,同时保留所有类型信息:
def mean(numbers: list[float | int]) -> float:
return sum(numbers) / len(numbers)
现在,numbers的注释更容易阅读,并且作为一个额外的好处,你不需要从typing导入任何东西。
联合类型的一个特殊情况是当一个变量可以有一个特定的类型或者是None。您可以将这样的可选类型注释为Union[None, T],或者等效地,为某些类型T注释为 Optional[T] 。可选类型没有新的特殊语法,但是可以使用新的联合语法来避免导入typing.Optional:
address: str | None
在本例中,address可以是None或字符串。
您还可以在运行时在isinstance()或issubclass()测试中使用新的联合语法:
>>> isinstance("mypy", str | int) True >>> issubclass(str, int | float | bytes) False传统上,您使用元组一次测试几种类型——例如,
(str, int)而不是str | int。这种旧语法仍然有效。类型别名允许你快速定义新的别名来代替更复杂的类型声明。例如,假设你用一组花色和等级串和一副牌的列表来表示一张扑克牌。然后一副牌被提示为
list[tuple[str, str]]。为了简化类型注释,可以按如下方式定义类型别名:
Card = tuple[str, str] Deck = list[Card]这通常没问题。然而,类型检查器通常不可能知道这样的语句是类型别名还是普通全局变量的定义。为了帮助类型检查器,或者更确切地说,帮助类型检查器帮助您,您现在可以显式地注释类型别名:
from typing import TypeAlias Card: TypeAlias = tuple[str, str] Deck: TypeAlias = list[Card]添加
TypeAlias注释向类型检查者和任何阅读您代码的人阐明了意图。类型守卫用于缩小联合类型。下面的函数接受一个字符串或
None,但总是返回一组表示扑克牌的字符串:def get_ace(suit: str | None) -> tuple[str, str]: if suit is None: suit = "♠" return (suit, "A")突出显示的行作为类型保护,静态类型检查器能够意识到
suit在返回时必然是一个字符串。目前,类型检查器只能使用几种不同的构造以这种方式缩小联合类型。使用新的
typing.TypeGuard,您可以注释自定义函数,这些函数可用于缩小联合类型:from typing import Any, TypeAlias, TypeGuard Card: TypeAlias = tuple[str, str] Deck: TypeAlias = list[Card] def is_deck_of_cards(obj: Any) -> TypeGuard[Deck]: # Return True if obj is a deck of cards, otherwise False根据
obj是否代表Deck对象,is_deck_of_cards()应该返回True或False。然后,您可以使用 guard 函数,类型检查器将能够正确地缩小类型范围:def get_score(card_or_deck: Card | Deck) -> int: if is_deck_of_cards(card_or_deck): # Calculate score of a deck of cards ...在
if块内部,类型检查器知道card_or_deck实际上属于类型Deck。详见 PEP 647 。最后一个新的类型化特征是参数规格变量,它与类型变量相关。考虑一下装饰师的定义。一般来说,它看起来像下面这样:
import functools from typing import Any, Callable, TypeVar R = TypeVar("R") def decorator(func: Callable[..., R]) -> Callable[..., R]: @functools.wraps(func) def wrapper(*args: Any, **kwargs: Any) -> R: ... return wrapper注释意味着装饰器返回的函数是一个可调用的函数,带有一些参数和与传递给装饰器的函数相同的返回类型
R。函数头中的省略号 (...)正确地允许任意数量的参数,并且每个参数可以是任意类型。但是,没有验证返回的 callable 是否与传入的函数具有相同的参数。实际上,这意味着类型检查器不能正确地检查修饰函数。不幸的是,您不能使用
TypeVar作为参数,因为您不知道函数将有多少个参数。在 Python 3.10 中,你可以访问ParamSpec来正确地输入提示这些类型的调用。ParamSpec的工作方式与TypeVar相似,但同时代表几个参数。你可以如下重写你的装饰器来利用ParamSpec:import functools from typing import Callable, ParamSpec, TypeVar P = ParamSpec("P") R = TypeVar("R") def decorator(func: Callable[P, R]) -> Callable[P, R]: @functools.wraps(func) def wrapper(*args: P.args, **kwargs: P.kwargs) -> R: ... return wrapper注意,当你注释
wrapper()时,你也使用P。你也可以使用新的typing.Concatenate给ParamSpec添加类型。详情和示例参见文档和 PEP 612 。更严格的序列压缩
zip()是 Python 中的内置函数,可以组合多个序列中的元素。Python 3.10 引入了新的strict参数,它增加了一个运行时测试来检查所有被压缩的序列是否具有相同的长度。例如,考虑下面的乐高套装表:
名字 设定数目 片 卢浮宫 Twenty-one thousand and twenty-four Six hundred and ninety-five 对角巷 Seventy-five thousand nine hundred and seventy-eight Five thousand five hundred and forty-four 美国宇航局阿波罗土星五号 Ninety-two thousand one hundred and seventy-six One thousand nine hundred and sixty-nine 千年隼 Seventy-five thousand one hundred and ninety-two Seven thousand five hundred and forty-one 纽约市 Twenty-one thousand and twenty-eight Five hundred and ninety-eight 用普通 Python 表示这些数据的一种方法是将每一列作为一个列表。它可能看起来像这样:
>>> names = ["Louvre", "Diagon Alley", "Saturn V", "Millennium Falcon", "NYC"]
>>> set_numbers = ["21024", "75978", "92176", "75192", "21028"]
>>> num_pieces = [695, 5544, 1969, 7541, 598]
请注意,您有三个独立的列表,但是它们的元素之间存在隐式的对应关系。名字("Louvre")、第一套号("21024")和第一件数(695)都描述了第一套乐高积木。
注意: pandas 非常适合处理和操作这类表格数据。但是,如果您正在进行较小的计算,您可能不希望在项目中引入如此大的依赖性。
zip()可用于并行迭代这三个列表:
>>> for name, num, pieces in zip(names, set_numbers, num_pieces): ... print(f"{name} ({num}): {pieces} pieces") ... Louvre (21024): 695 pieces Diagon Alley (75978): 5544 pieces Saturn V (92176): 1969 pieces Millennium Falcon (75192): 7541 pieces NYC (21028): 598 pieces请注意每一行是如何从所有三个列表中收集信息并显示某个特定集合的信息的。这是一种非常常见的模式,在许多不同的 Python 代码中使用,包括标准库中的。
您还可以添加
list()来将所有三个列表的内容收集到一个元组的嵌套列表中:
>>> list(zip(names, set_numbers, num_pieces))
[('Louvre', '21024', 695),
('Diagon Alley', '75978', 5544),
('Saturn V', '92176', 1969),
('Millennium Falcon', '75192', 7541),
('NYC', '21028', 598)]
请注意嵌套列表与原始表非常相似。
使用zip()的负面影响是很容易引入难以发现的细微错误。请注意,如果您的列表中有一项缺失,会发生什么情况:
>>> set_numbers = ["21024", "75978", "75192", "21028"] # Saturn V missing >>> list(zip(names, set_numbers, num_pieces)) [('Louvre', '21024', 695), ('Diagon Alley', '75978', 5544), ('Saturn V', '75192', 1969), ('Millennium Falcon', '21028', 7541)]所有关于纽约市布景的信息都消失了!此外,土星五号和千年隼的设定数字是错误的。如果数据集较大,这种错误可能很难发现。即使你发现有问题,也不容易诊断和解决。
问题是您假设三个列表具有相同数量的元素,并且每个列表中的信息顺序相同。在
set_numbers被破坏后,这个假设不再成立。PEP 618 为
zip()引入了一个新的strict关键字参数,你可以用它来确认所有的序列都有相同的长度。在您的示例中,它会引发一个错误,提醒您列表已损坏:
>>> list(zip(names, set_numbers, num_pieces, strict=True)) Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: zip() argument 2 is shorter than argument 1
当迭代到达纽约市乐高集合时,第二个参数set_numbers已经用尽,而第一个参数names中仍有元素。您的代码会因错误而失败,而不是静静地给出错误的结果,您可以采取措施来查找并修复错误。
有些情况下,您希望组合长度不等的序列。展开下面的方框,查看zip()和itertools.zip_longest()如何处理这些问题:
跟随习语的将乐高积木分成两个一组:
>>> num_per_group = 2 >>> list(zip(*[iter(names)] * num_per_group)) [('Louvre', 'Diagon Alley'), ('Saturn V', 'Millennium Falcon')]一共有五套,一个不平均分成对的数。在这种情况下,
zip()的默认行为,即最后一个元素被删除,可能是有意义的。您也可以在这里使用strict=True,但是当您的列表不能被分成对时,这将会产生一个错误。第三个选项,在这种情况下可能是最好的,是使用来自itertools标准库中的zip_longest()。顾名思义,
zip_longest()组合序列,直到最长的序列用完。如果你用zip_longest()来划分乐高积木,纽约市没有任何配对就变得更加明显了:
>>> from itertools import zip_longest
>>> list(zip_longest(*[iter(names)] * num_per_group, fillvalue=""))
[('Louvre', 'Diagon Alley'),
('Saturn V', 'Millennium Falcon'),
('NYC', '')]
注意,'NYC'和一个空字符串一起出现在最后一个元组中。您可以使用fillvalue参数控制为缺失值填充什么。
虽然strict并没有给zip()增加任何新的功能,但是它可以帮助你避免那些难以发现的错误。
statistics模块中的新功能
随着 2014 年 Python 3.4 的发布, statistics 模块被添加到标准库中。statistics的目的是使的统计计算达到 Python 中图形计算器的级别。
注意: statistics不是为了提供专用的数值数据类型或全功能的统计建模而设计的。如果标准库不能满足您的需求,可以看看第三方包,如 NumPy 、 SciPy 、 pandas 、 statsmodels 、 PyMC3 、 scikit-learn 或 seaborn 。
Python 3.10 为statistics增加了一些多变量函数:
您可以使用每个函数来描述两个变量之间关系的某个方面。例如,假设您有一组博客文章的数据,即每篇博客文章的字数和每篇文章在一段时间内的浏览量:
>>> words = [7742, 11539, 16898, 13447, 4608, 6628, 2683, 6156, 2623, 6948] >>> views = [8368, 5901, 3978, 3329, 2611, 2096, 1515, 1177, 814, 467]你现在想调查字数和浏览量之间是否有任何(线性)关系。在 Python 3.10 中,可以用新的
correlation()函数计算words和views之间的相关性:
>>> import statistics
>>> statistics.correlation(words, views)
0.454180067865917
两个变量之间的相关性总是一个介于-1 和 1 之间的数。如果接近 0,那么它们之间几乎没有对应关系,而接近-1 或 1 的相关性表明这两个变量的行为倾向于相互跟随。在这个例子中,0.45 的相关性表明有一种趋势,即有更多单词的帖子有更多的浏览量,尽管这不是一个强有力的联系。
注意:俗话说相关性并不意味着因果关系记住这一点很重要。即使你发现两个变量密切相关,你也不能断定一个是另一个的原因。
还可以计算出words和views之间的协方差。协方差是两个变量之间联合可变性的另一个度量。可以用 covariance() 来计算:
>>> import statistics >>> statistics.covariance(words, views) 5292289.977777777与相关性相反,协方差是一个绝对度量。它应该在变量本身的可变性的背景下进行解释。实际上,你可以通过每个变量的标准差来归一化协方差,以恢复皮尔逊相关系数:
>>> import statistics
>>> cov = statistics.covariance(words, views)
>>> σ_words, σ_views = statistics.stdev(words), statistics.stdev(views)
>>> cov / (σ_words * σ_views)
0.454180067865917
请注意,这与您之前的相关系数完全匹配。
查看两个变量之间线性对应关系的第三种方式是通过简单的线性回归。你通过计算两个数字斜率和截距来做线性回归,这样(平方)误差在近似视图数量 = 斜率 × 字数 + 截距中最小化。
在 Python 3.10 中,可以使用 linear_regression() :
>>> import statistics >>> statistics.linear_regression(words, views) LinearRegression(slope=0.2424443064354672, intercept=1103.6954940247645)基于这种回归,一篇 10,074 字的帖子预计会有大约 0.2424 × 10074 + 1104 = 3546 次浏览。但是,正如你之前看到的,字数和浏览量之间的相关性相当弱。因此,你不应该期望这个预测非常准确。
LinearRegression对象是一个名为元组的。这意味着您可以解开斜率并直接截取:
>>> import statistics
>>> slope, intercept = statistics.linear_regression(words, views)
>>> slope * 10074 + intercept
3546.0794370556605
在这里,您使用slope和intercept来预测一篇 10,074 个单词的博客帖子的浏览量。
如果你做大量的统计分析,你仍然想使用一些更高级的包,比如 pandas 和 statsmodels。然而,随着 Python 3.10 中对statistics的新添加,您有机会更容易地进行基本分析,而无需引入第三方依赖。
其他非常酷的功能
到目前为止,您已经看到了 Python 3.10 中最大、最有影响力的新特性。在这一节中,您将看到新版本带来的其他一些变化。如果你对这个新版本的所有变化感到好奇,可以查看一下文档。
默认文本编码
打开文本文件时,用于解释字符的默认编码取决于系统。特别是使用了 locale.getpreferredencoding() 。在 Mac 和 Linux 上,这通常会返回"UTF-8",而在 Windows 上的结果更加多样。
因此,当您尝试打开文本文件时,应该始终指定一种编码:
with open("some_file.txt", mode="r", encoding="utf-8") as file:
... # Do something with file
如果没有明确指定编码,将使用首选的区域设置编码,并且您可能会遇到在一台计算机上可以读取的文件在另一台计算机上无法打开的情况。
Python 3.7 引入了 UTF-8 模式,它允许你强制你的程序使用独立于地区编码的 UTF-8 编码。您可以通过给python可执行文件提供-X utf8命令行选项或者通过设置PYTHONUTF8环境变量来启用 UTF-8 模式。
在 Python 3.10 中,您可以激活一个警告,在没有指定编码的情况下打开一个文本文件时向您发出警告。考虑下面的脚本,它没有指定编码:
# mirror.py
import pathlib
import sys
def mirror_file(filename):
for line in pathlib.Path(filename).open(mode="r"): print(f"{line.rstrip()[::-1]:>72}")
if __name__ == "__main__":
for filename in sys.argv[1:]:
mirror_file(filename)
该程序将一个或多个文本文件回显到控制台,但每一行都是相反的。在编码警告启用的情况下运行程序本身:
$ python -X warn_default_encoding mirror.py mirror.py
/home/rp/mirror.py:7: EncodingWarning: 'encoding' argument not specified
for line in pathlib.Path(filename).open(mode="r"): yp.rorrim #
bilhtap tropmi
sys tropmi
:)emanelif(elif_rorrim fed
:)"r"=edom(nepo.)emanelif(htaP.bilhtap ni enil rof
)"}27>:]1-::[)(pirtsr.enil{"f(tnirp
:"__niam__" == __eman__ fi
:]:1[vgra.sys ni emanelif rof
)emanelif(elif_rorrim
注意印在控制台上的EncodingWarning。命令行选项-X warn_default_encoding激活它。如果您在打开文件时指定了编码,例如encoding="utf-8",警告将会消失。
有时您希望使用用户定义的本地编码。您仍然可以通过显式使用encoding="locale"来这样做。然而,建议尽可能使用 UTF-8。你可以查看 PEP 597 了解更多信息。
异步迭代
异步编程是一个强大的编程范例,从版本 3.5 开始,Python 就提供了这种编程范例。你可以通过使用async关键字或者以.__a 开始的特殊方法来识别一个异步程序,比如 .__aiter__() 或者 .__aenter__() 。
Python 3.10 中新增了两个异步内置函数:aiter()和 anext() 。实际上,这些函数调用了.__aiter__()和.__anext__()特殊方法——类似于常规的iter()和next()——所以没有添加新功能。这些都是方便的函数,使您的代码更具可读性。
换句话说,在最新版本的 Python 中,以下语句——其中things是一个异步可迭代——是等价的:
>>> it = things.__aiter__() >>> it = aiter(things)无论哪种情况,
it最终都是一个异步迭代器。展开下面的方框,查看使用aiter()和anext()的完整示例:下面的程序计算几个文件中的行数。在实践中,您使用 Python 迭代文件的能力来计算行数。该脚本使用异步迭代来同时处理几个文件。
注意,运行这段代码之前需要安装带有
pip的第三方aiofiles包:# line_count.py import asyncio import sys import aiofiles async def count_lines(filename): """Count the number of lines in the given file""" num_lines = 0 async with aiofiles.open(filename, mode="r") as file: lines = aiter(file) while True: try: await anext(lines) num_lines += 1 except StopAsyncIteration: break print(f"{filename}: {num_lines}") async def count_all_files(filenames): """Asynchronously count lines in all files""" tasks = [asyncio.create_task(count_lines(f)) for f in filenames] await asyncio.gather(*tasks) if __name__ == "__main__": asyncio.run(count_all_files(filenames=sys.argv[1:]))
asyncio用于为每个文件名创建并运行一个异步任务。count_lines()异步打开一个文件,并使用aiter()和anext()遍历它,以计算行数。参见 PEP 525 了解更多关于异步迭代的信息。
上下文管理器语法
上下文管理器非常适合管理你的程序中的资源。然而,直到最近,它们的语法还包含了一个不常见的赘疣。你没有被允许使用括号来打断长
with语句,就像这样:with ( read_path.open(mode="r", encoding="utf-8") as read_file, write_path.open(mode="w", encoding="utf-8") as write_file, ): ...在 Python 的早期版本中,这会导致一个
invalid syntax错误消息。相反,如果您想要控制换行的位置,您需要使用反斜杠(\):with read_path.open(mode="r", encoding="utf-8") as read_file, \ write_path.open(mode="w", encoding="utf-8") as write_file: ...虽然在 Python 中带反斜杠的显式行延续是可能的,但 PEP 8 不鼓励它。黑色格式化工具完全避免了反斜杠。
在 Python 3.10 中,现在允许在
with语句周围添加括号,以满足您的需求。特别是如果你同时使用几个上下文管理器,就像上面的例子一样,这有助于提高代码的可读性。Python 的文档展示了这种新语法的一些其他可能性。一个小的有趣的事实:带括号的
with语句实际上在 CPython 的 3.9 版本中工作。随着 Python 3.9 中 PEG 解析器的引入,它们的实现几乎是免费的。之所以称之为 Python 3.10 特性,是因为在 Python 3.9 中使用 PEG 解析器是自愿的,而 Python 3.9 和旧的 LL(1)解析器不支持带括号的with语句。现代安全的 SSL
安全性很有挑战性!一个很好的经验法则是避免使用自己的安全算法,而是依赖已有的包。
Python 针对
hashlib、hmac、ssl标准库模块中暴露的不同密码特性,使用 OpenSSL 。您的系统可以管理 OpenSSL,或者 Python 安装程序可以包含 OpenSSL。Python 3.9 支持使用任何 OpenSSL 版本 1.0.2 LTS、1.1.0 和 1.1.1 LTS。OpenSSL 1.0.2 LTS 和 OpenSSL 1.1.0 都已过期,因此 Python 3.10 将只支持 OpenSSL 1.1.1 LTS,如下表所示:
openssl 版本 Python 3.9 Python 3.10 寿命结束 LTS ✔ 一千 2019 年 12 月 20 日 1.1.0 ✔ 一千 2019 年 9 月 10 日 LTS ✔ ✔ 2023 年 9 月 11 日 这种对旧版本支持的终止只会影响到您,如果您需要在旧操作系统上升级系统 Python 的话。如果你使用 macOS 或者 Windows,或者如果你安装来自 python.org 的 Python 或者使用 T2 的 Conda,你将不会看到任何变化。
不过, Ubuntu 18.04 LTS 用的是 OpenSSL 1.1.0,而红帽企业版 Linux (RHEL) 7 和 CentOS 7 都用的是 OpenSSL 1.0.2 LTS。如果你需要在这些系统上运行 Python 3.10,你应该考虑使用python.org或 Conda 安装程序自己安装。
放弃对旧版本 OpenSSL 的支持将使 Python 更加安全。这也将有助于 Python 开发人员,因为代码将更容易维护。最终,这将有助于您,因为您的 Python 体验将更加健壮。详见 PEP 644 。
关于你的 Python 解释器的更多信息
sys模块包含许多关于您的系统、当前 Python 运行时和当前正在执行的脚本的信息。比如,你可以用sys.path查询 Python 寻找模块的路径,用sys.modules查看在当前会话中已经导入的所有模块。在 Python 3.10 中,
sys有两个新属性。首先,您现在可以获得标准库中所有模块的名称列表:
>>> import sys
>>> len(sys.stdlib_module_names)
302
>>> sorted(sys.stdlib_module_names)[-5:]
['zipapp', 'zipfile', 'zipimport', 'zlib', 'zoneinfo']
在这里,您可以看到标准库中大约有 300 个模块,其中几个以字母z开头。请注意,只列出了顶级模块和包。像 importlib.metadata 这样的子包没有单独的条目。
你可能不会经常使用 sys.stdlib_module_names 。尽管如此,这个列表与类似的自省特性很好地结合在一起,比如 keyword.kwlist 和 sys.builtin_module_names 。
新属性的一个可能的用例是确定当前导入的哪些模块是第三方依赖项:
>>> import pandas as pd >>> import sys >>> {m for m in sys.modules if "." not in m} - sys.stdlib_module_names {'__main__', 'numpy', '_cython_0_29_24', 'dateutil', 'pytz', 'six', 'pandas', 'cython_runtime'}您可以通过查看
sys.modules中名称中没有点的名字来找到导入的顶级模块。通过将它们与标准库模块名称进行比较,您会发现numpy、dateutil、pandas是本例中导入的一些第三方模块。另一个新属性是
sys.orig_argv。这与sys.argv有关,它保存了在程序启动时赋予它的命令行参数。相比之下,sys.orig_argv列出了传递给python可执行文件本身的命令行参数。考虑下面的例子:# argvs.py import sys print(f"argv: {sys.argv}") print(f"orig_argv: {sys.orig_argv}")这个脚本回显了
orig_argv和argv列表。运行它以查看信息是如何捕获的:$ python -X utf8 -O argvs.py 3.10 --upgrade argv: ['argvs.py', '3.10', '--upgrade'] orig_argv: ['python', '-X', 'utf8', '-O', 'argvs.py', '3.10', '--upgrade']本质上,所有参数——包括 Python 可执行文件的名称——都以
orig_argv结尾。这与argv相反,后者只包含不被python本身处理的参数。同样,这个特性你不会经常用到。如果你的程序需要关心它是如何运行的,你通常最好依靠已经公开的信息,而不是试图解析这个列表。例如,只有当您的脚本没有使用优化标志
-O运行时,您才可以选择使用严格zip()模式,如下所示:list(zip(names, set_numbers, num_pieces, strict=__debug__))当解释器启动时,设置
__debug__标志。如果指定了-O或-OO运行python,则为False,否则为True。使用__debug__通常比"-O" not in sys.orig_argv或一些类似的构造更好。对于
sys.orig_argv来说,的一个激励用例是,你可以用它来生成一个新的 Python 进程,其命令行参数与你当前的进程相同或有所修改。未来注释
注解是在 Python 3 中引入的,为您提供了一种将元数据附加到变量、函数参数和返回值的方法。它们最常用于向代码中添加类型提示。
注释的一个挑战是它们必须是有效的 Python 代码。首先,这使得很难键入提示递归类。 PEP 563 引入了推迟注释评估,使得用尚未定义的名字进行注释成为可能。从 Python 3.7 开始,您可以使用
__future__导入来激活注释的延迟求值:from __future__ import annotations其意图是推迟评估将在将来的某个时候成为默认。在 2020 Python 语言峰会之后,决定在 Python 3.10 中实现这一点。
然而,在更多的测试之后,很明显,延迟评估对于在运行时使用注释的项目来说效果不好。FastAPI 和 T2 Pydantic 和 T4 的关键人物表达了他们的担忧。在最后一刻,我们决定为 Python 3.11 重新安排这些更改。
为了简化向未来行为的过渡,Python 3.10 也做了一些改变。最重要的是,新增了
inspect.get_annotations()功能。您应该调用这个函数在运行时访问注释:
>>> import inspect
>>> def mean(numbers: list[int | float]) -> float:
... return sum(numbers) / len(numbers)
...
>>> inspect.get_annotations(mean)
{'numbers': list[int | float], 'return': <class 'float'>}
查看注解最佳实践了解详情。
如何在运行时检测 Python 3.10
Python 3.10 是 Python 的第一个版本,拥有两位数的次要版本号。虽然这主要是一个有趣的事实,并表明 Python 3 已经存在了相当长的时间,但它也有一些实际的后果。
当你的代码需要在运行时基于 Python 的版本做一些特定的事情时,到目前为止,你已经完成了版本字符串的字典式的比较。虽然这从来都不是好的做法,但还是有可能做到以下几点:
# bad_version_check.py
import sys
# Don't do the following
if sys.version < "3.6":
raise SystemExit("Only Python 3.6 and above is supported")
在 Python 3.10 中,这段代码会引发SystemExit并停止你的程序。这是因为,作为字符串,"3.10"小于"3.6"。
比较版本号的正确方法是使用数字元组:
# good_version_check.py
import sys
if sys.version_info < (3, 6):
raise SystemExit("Only Python 3.6 and above is supported")
sys.version_info 是一个可以用来比较的元组对象。
如果您在代码中进行这种比较,您应该用 flake8-2020 检查您的代码,以确保您正确处理版本:
$ python -m pip install flake8-2020
$ flake8 bad_version_check.py good_version_check.py
bad_version_check.py:3:4: YTT103 `sys.version` compared to string
(python3.10), use `sys.version_info`
随着flake8-2020扩展被激活,你会得到一个关于用sys.version_info替换sys.version的建议。
那么,该不该升级到 Python 3.10 呢?
现在,您已经看到了 Python 最新版本中最酷的特性。现在的问题是你是否应该升级到 Python 3.10,如果是,你应该什么时候升级。考虑升级到 Python 3.10 时,需要考虑两个不同的方面:
- 您是否应该升级您的环境,以便使用 Python 3.10 解释器运行您的代码?
- 你应该使用 Python 3.10 的新特性来编写你的代码吗?
显然,如果您想测试结构化模式匹配或您在这里读到的任何其他很酷的新特性,您需要 Python 3.10。可以将最新版本与您当前的 Python 版本并行安装。一个简单的方法是使用像 pyenv 或 Conda 这样的环境管理器。你也可以使用 Docker 运行 Python 3.10,而不用在本地安装。
Python 3.10 已经通过了大约五个月的 beta 测试,所以开始使用它进行自己的开发应该不会有什么大问题。您可能会发现您的一些依赖项没有立即提供 Python 3.10 的轮子,这使得它们的安装更加麻烦。但是一般来说,使用最新的 Python 进行本地开发是相当安全的。
与往常一样,在升级生产环境之前,您应该小心谨慎。警惕测试你的代码在新版本上运行良好。特别是,你要留意那些被弃用的或被移除的特性。
您是否可以在代码中开始使用这些新特性取决于您的用户群和代码运行的环境。如果您能保证 Python 3.10 是可用的,那么使用新的联合类型语法或任何其他新特性都没有危险。
如果你分发的应用或库被其他人使用,你可能要保守一点。目前, Python 3.6 是官方支持的最老的 Python 版本。它将于 2021 年 12 月寿终正寝,之后 Python 3.7 将是支持的最低版本。
该文档包括一个关于将代码移植到 Python 3.10 的有用指南。查看更多详情!
结论
新 Python 版本的发布总是值得庆祝的。即使你不能马上开始使用这些新功能,它们也会在几年内广泛应用,成为你日常生活的一部分。
在本教程中,您已经看到了一些新功能,如:
- 更友好的错误消息
- 强大的结构模式匹配
- 类型提示改进
- 更安全的序列组合
- 新增统计功能
要了解更多 Python 3.10 技巧以及与真正的 Python 团队成员的讨论,请查看真正的 Python 播客第 81 集。
体验新功能的乐趣!请在下面的评论中分享你的经历。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.10 中很酷的新特性*********
Python 3.11 预览版:更好的错误消息
Python 3.11 将于 2022 年 10 月发布。尽管十月份还有几个月的时间,但您已经可以预览一些即将到来的特性,包括 Python 3.11 将如何提供更具可读性和可操作性的错误消息。
在本教程中,您将:
- 在你的电脑上安装 Python 3.11 Alpha,就在你当前安装的 Python 旁边
- 解释 Python 3.11 中改进的错误消息,学习更有效地调试你的代码
- 将这些改进与 Python 3.10 中的 PEG 解析器和更好的错误消息联系起来
- 探索提供增强错误消息的第三方包
- 测试 Python 3.11 中较小的改进,包括新的数学函数和更多的可读分数
Python 3.11 中还有许多其他的改进和特性。跟踪变更日志中的新内容以获得最新列表。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 3.11 Alpha
Python 的新版本在每年 10 月发布。代码是在发布日期前经过 17 个月的时间开发和测试的。新功能在 alpha 阶段实现,持续到五月,大约在最终发布前五个月。
大约每月一次在 alpha 阶段,Python 的核心开发者发布一个新的 alpha 版本来展示新特性,测试它们,并获得早期反馈。目前 Python 3.11 的最新版本是 3.11.0 alpha 5 ,发布于 2022 年 2 月 3 日。
注:本教程使用的是 Python 3.11 的第五个 alpha 版本。如果您使用更高版本,可能会遇到一些小的差异。然而,你可以期望你在这里学到的大部分内容在 alpha 和 beta 阶段以及 Python 3.11 的最终版本中保持不变。
Python 3.11 的第一个测试版计划于 2022 年 5 月 6 日发布。通常,在测试阶段不会添加新功能。相反,特性冻结和发布日期之间的时间被用来测试和固化代码。
很酷的新功能
Python 3.11 的一些最新亮点包括:
- 增强的错误消息,这将帮助你更有效地调试你的代码
- 异常组,允许程序同时引发和处理多个异常
- 优化,承诺使 Python 3.11 比以前的版本明显更快
- 静态类型的改进,这将让你更精确地注释你的代码
- TOML 支持,它允许你使用标准库解析 TOML 文档
Python 3.11 有很多值得期待的地方!要获得全面的概述,请查看 Python 3.11:供您尝试的酷新功能。您还可以在本系列的其他文章中更深入地研究上面列出的一些特性:
在本教程中,您将关注增强的错误报告如何通过让您更有效地调试代码来改善您的开发人员体验。您还将看到 Python 3.11 中其他一些更小的特性。
安装
要使用本教程中的代码示例,您需要在系统上安装 Python 3.11 版本。在这一节中,你将学习一些不同的方法来做到这一点:使用 Docker ,使用 pyenv ,或者从源安装。选择最适合您和您的系统的一个。
注意: Alpha 版本是即将推出的功能的预览。虽然大多数特性都可以很好地工作,但是您不应该在生产中依赖任何 Python 3.11 alpha 版本,也不应该依赖任何 bug 会带来严重后果的地方。
如果您可以在您的系统上访问 Docker ,那么您可以通过拉取并运行python:3.11-rc-slim Docker 镜像来下载最新版本的 Python 3.11:
$ docker pull python:3.11-rc-slim
Unable to find image 'python:3.11-rc-slim' locally
latest: Pulling from library/python
[...]
$ docker run -it --rm python:3.11-rc-slim
这会将您带入 Python 3.11 REPL。查看 Docker 中的运行 Python 版本,了解如何通过 Docker 使用 Python 的更多信息,包括如何运行脚本。
pyenv 工具非常适合管理系统上不同版本的 Python,如果你愿意,你可以用它来安装 Python 3.11 Alpha。它有两个不同的版本,一个用于 Windows,一个用于 Linux 和 macOS:
- 视窗
** Linux + macOS
**在 Windows 上,你可以使用 pyenv-win 。首先更新您的pyenv安装:
C:\> pyenv update
:: [Info] :: Mirror: https://www.python.org/ftp/python
[...]
进行更新可以确保您可以安装最新版本的 Python。你也可以手动更新pyenv。
在 Linux 和 macOS 上,可以使用 pyenv 。首先使用 pyenv-update 插件更新您的pyenv安装:
$ pyenv update
Updating /home/realpython/.pyenv...
[...]
进行更新可以确保您可以安装最新版本的 Python。如果不想用更新插件,可以手动更新pyenv。
使用pyenv install --list查看 Python 3.11 有哪些版本。然后,安装最新版本:
$ pyenv install 3.11.0a5
Downloading Python-3.11.0a5.tar.xz...
[...]
安装可能需要几分钟时间。一旦你的新 alpha 版本安装完毕,你就可以创建一个虚拟环境来玩它:
- 视窗
** Linux + macOS*
C:\> pyenv local 3.11.0a5
C:\> python -m venv venv
C:\> venv\Scripts\activate.bat
使用pyenv local激活您的 Python 3.11 版本,然后使用python -m venv设置虚拟环境。
$ pyenv virtualenv 3.11.0a5 311_preview
$ pyenv activate 311_preview
在 Linux 和 macOS 上,你使用 pyenv-virtualenv 插件来设置虚拟环境并激活它。
你也可以从python.org的预发布版本中安装 Python。选择最新预发布,向下滚动到页面底部的文件部分。下载并安装与您的系统对应的文件。更多信息参见 Python 3 安装&设置指南。
在本教程的其余部分,python3.11用于指示您应该启动 Python 3.11 可执行文件。具体如何运行取决于您如何安装它。如果你不确定的话,可以参考关于 Docker 、 pyenv 、虚拟环境或者从源码安装的相关教程。
Python 3.11 中更好的错误消息
从一开始,Python 就使用自制的、显式基本的 LL(1)解析器,带有单令牌前瞻,没有回溯能力。根据 Python 的创造者吉多·范·罗苏姆的说法,这是一个有意识的选择:
Python 的解析器生成器是……蹩脚的,但这反过来又是有意的——它是如此蹩脚,以至于无法阻止我发明难以编写解析器或难以被人类读者消除歧义的语法,而人类读者在 Python 的设计中总是排在第一位。(来源)
LL(1)解析器中的限制导致了几个变通办法,使 Python 的语法规则及其解析器生成变得复杂。最终,Guido 建议将 Python 的语法更新为具有无限前瞻和回溯的解析表达式语法(PEG) 。为 Python 3.9 创建了一个新的解析器。
Python 3.10 利用新的 PEG 解析器实现了结构模式匹配和更好的错误消息。这项工作在 Python 3.11 中继续进行,对 Python 的错误消息进行了更多的改进。
Python 3.11 面临的挑战
您将很快看到新的和改进的错误消息的例子。不过,首先,您会在 Python 3.10 或更早版本中犯一些错误,这样您就会理解当前的挑战。
假设你有一个数据集,里面有一些关于著名科学家的不一致数据。对于每个科学家,他们的名字、出生日期和死亡日期都被记录下来:
# scientists.py
scientists = [
{
"name": {"first": "Grace", "last": "Hopper"},
"birth": {"year": 1906, "month": 12, "day": 9},
"death": {"year": 1992, "month": 1, "day": 1},
},
{"name": {"first": "Euclid"}},
{"name": {"first": "Abu Nasr", "last": "Al-Farabi"}, "birth": None},
{
"name": {"first": "Srinivasa", "last": "Ramanujan"},
"birth": {"year": 1887},
"death": {"month": 4, "day": 26},
},
{
"name": {"first": "Ada", "last": "Lovelace"},
"birth": {"year": 1815},
"death": {"year": 1852},
},
{
"name": {"first": "Charles", "last": "Babbage"},
"birth": {"year": 1791, "month": 12, "day": 26},
"death": {"year": 1871, "month": 10, "day": 18},
},
]
注意,关于每个科学家的信息都记录在一个嵌套字典中,该字典有name、birth和death字段。但是,有些信息是不完整的。比如欧几里德只有一个名字,Ramanujan 缺少他的死亡年份。
为了处理这些数据,您决定创建一个名为 tuple 的和一个可以将嵌套字典转换为命名元组的函数:
1# scientists.py
2
3from typing import NamedTuple
4
5class Person(NamedTuple):
6 name: str
7 life_span: tuple
8
9def dict_to_person(info):
10 """Convert a dictionary to a Person object"""
11 return Person(
12 name=f"{info['name']['first']} {info['name']['last']}",
13 life_span=(info["birth"]["year"], info["death"]["year"]),
14 )
15
16scientists = ... # As above
Person将一个人的信息编辑成两个字段:name和life_span。您可以通过交互运行scientists.py来尝试一下:
$ python -i scientists.py
使用-i装载scientists.py并将你留在 REPL 继续你的探索。例如,您可以转换列出的第一位科学家格蕾丝·赫柏的信息:
>>> dict_to_person(scientists[0]) Person(name='Grace Hopper', life_span=(1906, 1992))请注意,您在
dict_to_person()中没有做任何验证或错误处理,所以当您试图处理一些数据不完整的科学家时,您会遇到问题。本节中的其余示例都是在 Python 3.10 上运行的,显示了一些模糊不清的错误消息。为了了解处理不完整数据时会发生什么,首先尝试转换关于欧几里德的信息:
>>> scientists[1]
{'name': {'first': 'Euclid'}}
>>> dict_to_person(scientists[1])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 12, in dict_to_person
name=f"{info['name']['first']} {info['name']['last']}", KeyError: 'last'
正确地说,错误消息指出您缺少last字段。你需要在回溯或编辑器中查看你的代码,看看last是否应该嵌套在name中。尽管如此,这种反馈是相当可行的。
接下来,考虑当你处理阿布·纳斯尔·阿尔·法拉比时会发生什么:
>>> scientists[2] {'name': {'first': 'Abu Nasr', 'last': 'Al-Farabi'}, 'birth': None} >>> dict_to_person(scientists[2]) Traceback (most recent call last): ... File "/home/realpython/scientists.py", line 13, in dict_to_person life_span=(info["birth"]["year"], info["death"]["year"]), TypeError: 'NoneType' object is not subscriptable在这种情况下,你被告知某个对象是
None,你正试图从中获取某个项目。从相关的代码中,你可以判断出info、info["birth"]或info["death"]中的任何一个一定是None,但是你没有办法知道是哪一个,直到你查看你的scientist字典。斯里尼瓦瑟·拉马努金的数据引发了一个类似的问题:
>>> scientists[3]
{'name': {'first': 'Srinivasa', 'last': 'Ramanujan'},
'birth': {'year': 1887},
'death': {'month': 4, 'day': 26}}
>>> dict_to_person(scientists[3])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]), KeyError: 'year'
在这种情况下,birth或death字段中缺少year。同样,您需要检查实际数据来确定错误。
当您的代码在一条语句中进行多次函数调用时,您可能会遇到一个不同但相似的问题。为了说明这一点,添加一个将一对字典转换为Person对象的函数:
# scientists.py
# ...
def convert_pair(first, second):
"""Convert two dictionaries to Person objects"""
return dict_to_person(first), dict_to_person(second)
# ...
注意,convert_pair()调用dict_to_person()两次,每个科学家一次。你可以用它来查看关于阿达·洛芙莱斯和查尔斯·巴贝奇的信息:
>>> convert_pair(scientists[4], scientists[5]) (Person(name='Ada Lovelace', life_span=(1815, 1852)), Person(name='Charles Babbage', life_span=(1791, 1871)))不出所料,您会得到一组代表科学家的
Person对象。接下来,看看如果你尝试将阿达·洛芙莱斯和斯里尼瓦瑟·拉马努金配对会发生什么:
>>> convert_pair(scientists[4], scientists[3])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 19, in convert_pair
return dict_to_person(first), dict_to_person(second) File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]), KeyError: 'year'
同样,你注意到year不见了,尽管你不能判断它是否与birth或death相关。另外,还有更多困惑:是第一次还是第二次调用dict_to_person()导致了 KeyError ?追溯不会告诉你。和以前一样,您需要手动跟踪输入数据,以真正理解错误的原因。
通过这些例子,您已经体验了 Python 3.10 和更早版本中错误消息的一些小麻烦。在这里,输入数据很少,您可以相当快地找出每个错误的原因。通常,您要处理更大的数据集和更复杂的代码,这使得挑战变得更加困难。
这种模糊错误消息的技术原因是 Python 在内部使用源代码中的一行作为程序中每个指令的引用,即使一行可以包含几个指令。这在 Python 3.11 中有所改变。
Python 3.11 中的改进
Python 3.11 改进了上一节中的所有错误消息。你可以在 PEP 657 中查看细节——包括回溯中的细粒度错误位置。Python 的错误消息,包括导致错误的函数调用,被称为回溯。在这一节中,您将了解更精确的错误消息如何帮助您进行调试。
要开始探索,请将scientists.py交互式加载到您的 Python 3.11 解释器中:
$ python3.11 --version
Python 3.11.0a5
$ python3.11 -i scientists.py
和上一节一样,这将您带入交互式 REPL,其中已经定义了scientists、dict_to_person()和convert_pair()。
只要信息格式良好,您仍然可以创建Person对象。但是,请观察如果遇到错误会发生什么:
>>> dict_to_person(scientists[0]) Person(name='Grace Hopper', life_span=(1906, 1992)) >>> scientists[1] {'name': {'first': 'Euclid'}} >>> dict_to_person(scientists[1]) Traceback (most recent call last): ... File "/home/realpython/scientists.py", line 12, in dict_to_person name=f"{info['name']['first']} {info['name']['last']}", ~~~~~~~~~~~~^^^^^^^^ KeyError: 'last'因为缺少了一个
last字段,所以仍然得到相同的KeyError。但是现在一个可见的标记指向源代码行中的确切位置,所以您可以立即看到last是嵌套在name中的一个预期字段。这已经是一种改进,因为您不需要如此仔细地研究错误消息。然而,在原始错误消息含糊不清的情况下,好处变得非常明显。现在,处理阿布·纳斯尔·阿尔·法拉比的数据:
>>> scientists[2]
{'name': {'first': 'Abu Nasr', 'last': 'Al-Farabi'}, 'birth': None}
>>> dict_to_person(scientists[2])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]), ~~~~~~~~~~~~~^^^^^^^^ TypeError: 'NoneType' object is not subscriptable
虽然消息'NoneType' object is not subscriptable没有告诉您数据结构的哪一部分恰好是None,但是标记清楚地表明了这一点。在这里,info["birth"]是None,所以你无法从中获得year物品。
注意如果info本身是None的区别:
>>> dict_to_person(None) Traceback (most recent call last): ... File "/home/realpython/scientists.py", line 12, in dict_to_person name=f"{info['name']['first']} {info['name']['last']}", ~~~~^^^^^^^^ TypeError: 'NoneType' object is not subscriptable现在,波浪号(
~)标记指示info是None,这在试图读取name时会导致错误,正如卡雷茨(^)指示的那样。相同的标记将区分出生和死亡年份:
>>> scientists[3]
{'name': {'first': 'Srinivasa', 'last': 'Ramanujan'},
'birth': {'year': 1887}, 'death': {'month': 4, 'day': 26}}
>>> dict_to_person(scientists[3])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]), ~~~~~~~~~~~~~^^^^^^^^ KeyError: 'year'
不需要研究数据。错误消息和新标记立即告诉您,death字段缺少关于年份的信息。
最后,注意当错误发生在嵌套函数调用中时,您将获得什么信息。再次将阿达·洛芙莱斯和斯里尼瓦瑟·拉马努金配对:
>>> convert_pair(scientists[4], scientists[3]) Traceback (most recent call last): ... File "/home/realpython/scientists.py", line 19, in convert_pair return dict_to_person(first), dict_to_person(second) ^^^^^^^^^^^^^^^^^^^^^^ File "/home/realpython/scientists.py", line 13, in dict_to_person life_span=(info["birth"]["year"], info["death"]["year"]), ~~~~~~~~~~~~~^^^^^^^^ KeyError: 'year'最后一条回溯消息仍然指向
death缺失year。但是,请注意,上面的回溯信息现在清楚地显示问题出在第二位科学家 Ramanujan 身上。如此示例所示,回溯标记被添加到回溯中的每一行代码中。错误消息中增加的清晰度将帮助您在问题出现时快速跟踪问题,以便您可以修复它们。
技术背景
标记一行中的哪一部分导致了错误,看起来似乎是一个快速而明显的改进。为什么 Python 之前没有包含这个?
为了理解技术细节,您应该对 CPython 如何运行您的源代码有所了解:
- 您的代码被标记化。
- 这些标记被解析成一棵抽象语法树(AST) 。
- AST 被转换成一个控制流图(CFG) 。
- CFG 被转换成字节码。
在运行时,Python 解释器只关心字节码,这是从源代码中删除的几个步骤。
标准库中的几个模块允许您窥视这个过程的幕后。例如,你可以使用
dis来反汇编字节码。记住convert_pair()的定义:17def convert_pair(first, second): 18 """Convert two dictionaries to Person objects""" 19 return dict_to_person(first), dict_to_person(second)如上所述,这段代码被标记化、解析,并最终转换成字节码。您可以按如下方式研究这个函数的字节码:
>>> import dis
>>> dis.dis(convert_pair)
17 0 RESUME 0
19 2 LOAD_GLOBAL 0 (dict_to_person)
4 LOAD_FAST 0 (first)
6 PRECALL_FUNCTION 1
8 CALL 0
10 LOAD_GLOBAL 0 (dict_to_person)
12 LOAD_FAST 1 (second)
14 PRECALL_FUNCTION 1
16 CALL 0
18 BUILD_TUPLE 2
20 RETURN_VALUE
这里每个指令的含义并不重要。只需注意最左边一列中的数字:17 和 19 是原始源代码的行号。您可以看到第 19 行已经被转换成十个字节码指令。如果这些指令中的任何一个失败了,Python 的早期版本只有足够的信息来断定错误发生在第 19 行的某个地方。
Python 3.11 为每个字节码指令引入了一个新的四位数元组。表示每条指令的起始行、结束行、起始列偏移和结束列偏移。您可以通过对代码对象调用新的 .co_positions() 方法来访问这些元组:
>>> list(convert_pair.__code__.co_positions()) [(17, 17, 0, 0), (19, 19, 11, 25), (19, 19, 26, 31), (19, 19, 11, 32), (19, 19, 11, 32), (19, 19, 34, 48), (19, 19, 49, 55), (19, 19, 34, 56), (19, 19, 34, 56), (19, 19, 11, 56), (19, 19, 4, 56)]例如,第一个
LOAD_GLOBAL指令具有位置(19, 19, 11, 25)。查看源代码的第 19 行。从 0 开始计数,你会发现d是这一行中的第 11 个字符。您发现列偏移量 11 到 25 对应于文本dict_to_person。将所有行号和列偏移量连接到源代码,并将它们与字节码指令相匹配,以创建下表:
字节码 源代码 简历 加载 _ 全局 dict_to_person快速加载 first预调用函数 dict_to_person(first)呼叫 dict_to_person(first)加载 _ 全局 dict_to_person快速加载 second预调用函数 dict_to_person(second)呼叫 dict_to_person(second)构建元组 dict_to_person(first), dict_to_person(second)返回值 return dict_to_person(first), dict_to_person(second)关于行号和列偏移量的新信息允许您的回溯更加详细。您已经看到 Python 3.11 中的内置回溯是如何利用这一点的。随着 Python 3.11 越来越广泛地被使用,一些第三方包可能也会使用这些信息。
注意:
.co_positions()方法不仅仅支持更好、更精确的错误消息。它还可以向其他类型的工具提供信息——比如 Coverage.py ,它测量你的代码的哪些部分被执行了。在运行时,存储这些偏移量会占用 Python 的缓存字节码文件和内存中的一些空间。如果这是一个问题,您可以通过设置
PYTHONNODEBUGRANGES环境变量或使用-X no_debug_ranges命令行选项来删除它们:$ python3.11 -X no_debug_ranges -i scientists.py自然地,关闭这些会删除回溯中添加的信息:
>>> dict_to_person(scientists[3])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]),
KeyError: 'year'
>>> list(convert_pair.__code__.co_positions())
[(17, None, None, None), (19, None, None, None), (19, None, None, None),
(19, None, None, None), (19, None, None, None), (19, None, None, None),
(19, None, None, None), (19, None, None, None), (19, None, None, None),
(19, None, None, None), (19, None, None, None)]
请注意,没有标记显示哪个字段丢失了year,并且.co_positions()只包含关于行号的信息。标有None的字段不存储在磁盘或内存中。
这样做的好处是您的.pyc文件更小,代码对象占用的内存空间也相应更少:
- 视窗
** Linux + macOS*
C:\> python3.11 -m py_compile scientists.py
C:\> dir __pycache__\scientists.cpython-311.pyc
[...]
1 File(s) 1,679 bytes
C:\> python3.11 -X no_debug_ranges -m py_compile scientists.py
C:\> dir __pycache__\scientists.cpython-311.pyc
[...]
1 File(s) 1,279 bytes
$ python3.11 -m py_compile scientists.py
$ wc -c __pycache__/scientists.cpython-311.pyc
1679 __pycache__/scientists.cpython-311.pyc
$ python3.11 -X no_debug_ranges -m py_compile scientists.py
$ wc -c __pycache__/scientists.cpython-311.pyc
1279 __pycache__/scientists.cpython-311.pyc
在这种情况下,您可以看到删除额外的信息节省了 400 个字节。通常情况下,这不会影响您的程序。当您在一个受限环境中运行时,您只需要考虑关闭这个信息,在这里您确实需要优化您的内存使用。
甚至更好的错误消息使用第三方库
有几个第三方包可以用来增强错误消息,包括 3.11 之前的 Python 版本。这些并不依赖于你到目前为止所了解到的改进。相反,它们是对这些开发的补充,您可以使用它们为自己建立一个更好的调试工作流。
better_exceptions 包将变量值的信息添加到回溯中。要试用它,你首先需要从 PyPI 安装它:
$ python -m pip install better_exceptions
在你自己的工作中有几种方法可以使用better_exceptions。例如,您可以使用环境变量来激活它:
- 视窗
** Linux + macOS*
C:\> set BETTER_EXCEPTIONS=1
C:\> python -i scientists.py
$ BETTER_EXCEPTIONS=1 python -i scientists.py
通过设置BETTER_EXCEPTIONS环境变量,您可以让包格式化您的回溯。关于调用better_exceptions的其他方式,可以参考文档。
既然已经设置了环境变量,请注意如果您调用convert_pair()并尝试将欧几里德与他自己配对会发生什么:
>>> convert_pair(scientists[1], scientists[1]) Traceback (most recent call last): ... File "/home/realpython/scientists.py", line 19, in convert_pair return dict_to_person(first), dict_to_person(second) │ │ │ └ {'name': {'first': 'Euclid'}} │ │ └ <function dict_to_person at 0x7fe2f2c0c040> │ └ {'name': {'first': 'Euclid'}} └ <function dict_to_person at 0x7fe2f2c0c040> File "/home/realpython/scientists.py", line 12, in dict_to_person name=f"{info['name']['first']} {info['name']['last']}", │ └ {'name': {'first': 'Euclid'}} └ {'name': {'first': 'Euclid'}} KeyError: 'last'请注意,回溯中的每个变量名都用其对应的值进行了注释。这使您可以快速判断出
KeyError的发生是因为欧几里德的信息缺少了last字段。注意:
better_exceptions的当前最新版本,版本 0.3.3,用自己的标记替换了 Python 3.11 的标记。换句话说,您在前面几节中学到的箭头不见了。希望未来版本的better_exceptions能够展示这两者。友好的 T2 项目提供了一种不同的追溯方式。它的原始目的是“让初学者更容易理解是什么导致程序产生回溯。”要自己尝试友好,用
pip安装:$ python -m pip install friendly正如文档所解释的,你可以在不同的环境中使用 Friendly,包括控制台、笔记本和编辑器。一个简单的选择是,在遇到错误后,您可以友好地开始:
>>> dict_to_person(scientists[2])
Traceback (most recent call last):
...
File "/home/realpython/scientists.py", line 13, in dict_to_person
life_span=(info["birth"]["year"], info["death"]["year"]),
~~~~~~~~~~~~~^^^^^^^^
TypeError: 'NoneType' object is not subscriptable
>>> from friendly import start_console >>> start_console()
友好的控制台充当常规 Python REPL 的包装器。您现在可以执行几个新命令,让您更深入地了解最近的错误:
>>> why() Subscriptable objects are typically containers from which you can retrieve item using the notation [...]. Using this notation, you attempted to retrieve an item from an object of type NoneType which is not allowed. Note: NoneType means that the object has a value of None. >>> what() A TypeError is usually caused by trying to combine two incompatible types of objects, by calling a function with the wrong type of object, or by trying to do an operation not allowed on a given type of object.
why()函数为您提供关于特定错误的信息,而what()为您遇到的错误添加一些背景信息,在本例中是一个TypeError。也可以试试where()、explain()、www()。注意:友好适用于 Python 3.11。然而,当使用 Python 的开发版本时,您可能会遇到一些库支持方面的问题。请记住,本节中使用的所有库也适用于旧版本的 Python。
最近的一个选择是 Rich ,它提供了对带注释的回溯的支持。要试用 Rich,您应该首先安装它:
$ python -m pip install rich您可以通过安装 Rich 的异常钩子来激活增强的回溯。如果遇到错误,您将得到一个彩色的、格式良好的回溯,其中包含所有可用变量的值的信息,以及发生错误的行的更多上下文信息:
>>> from rich import traceback
>>> traceback.install(show_locals=True)
<built-in function excepthook>
>>> dict_to_person(scientists[3])
╭───────────────── Traceback (most recent call last) ──────────────────╮
│ <stdin>:1 in <module> │
│ ╭───────────────────────────── locals ─────────────────────────────╮ │
│ │ __annotations__ = {} │ │
│ │ __builtins__ = <module 'builtins' (built-in)> │ │
│ │ __doc__ = None │ │
│ │ __loader__ = <_frozen_importlib_external.SourceFileLoader │ │
│ │ object at 0x7f933c7b05d0> │ │
│ │ __name__ = '__main__' │ │
│ │ __package__ = None │ │
│ │ __spec__ = None │ │
│ │ convert_pair = <function convert_pair at 0x7f933c628680> │ │
│ │ dict_to_person = <function dict_to_person at 0x7f933c837380> │ │
│ │ NamedTuple = <function NamedTuple at 0x7f933c615080> │ │
│ │ Person = <class '__main__.Person'> │ │
│ │ scientists = [ ... ] │ │
│ │ traceback = <module 'rich.traceback' from │ │
│ │ '/home/realpython/.pyenv/versions/311_preview/…│ │
│ ╰──────────────────────────────────────────────────────────────────╯ │
│ /home/realpython/scientists.py:13 in dict_to_person │
│ │
│ 10 │ """Convert a dictionary to a Person object""" │
│ 11 │ return Person( │
│ 12 │ │ name=f"{info['name']['first']} {info['name']['last']}", │
│ ❱ 13 │ │ life_span=(info["birth"]["year"], info["death"]["year"])│
│ 14 │ ) │
│ 15 │
│ 16 │
│ │
│ ╭──────────────────────────── locals ─────────────────────────────╮ │
│ │ info = { │ │
│ │ │ 'name': { │ │
│ │ │ │ 'first': 'Srinivasa', │ │
│ │ │ │ 'last': 'Ramanujan' │ │
│ │ │ }, │ │
│ │ │ 'birth': {'year': 1887}, │ │
│ │ │ 'death': {'month': 4, 'day': 26} │ │
│ │ } │ │
│ ╰─────────────────────────────────────────────────────────────────╯ │
╰──────────────────────────────────────────────────────────────────────╯
KeyError: 'year'
参见丰富的文档以获得更多信息和其他输出示例。
还有其他项目试图改进 Python 的回溯和错误信息。其中几个在用 Python 的异常钩子创建漂亮的回溯和在 Python Bytes 播客上讨论的中得到了强调。所有这些都适用于 Python 3.11 之前的版本。
其他新功能
在 Python 的每一个新版本中,少数几个特性获得了最多的关注。然而,Python 的大部分发展都是一小步一小步地发生的,通过在这里或那里添加一个功能,改进一些现有的功能,或者修复一个长期存在的错误。
Python 3.11 也不例外。本节展示了 Python 3.11 中一些较小的改进。
二的立方根和幂
math 模块包含基本的数学函数和常数。大多数都是类似的 C 函数的包装器。Python 3.11 给math增加了两个新函数:
类似于其他的math函数,这些是作为相应的 C 函数的包装器实现的。例如,您可以使用cbrt()来确认 Ramanujan 的观察结果,您可以用两种不同的方式将 1729 表示为两个立方体的和:
>>> import math >>> 1 + 1728 1729 >>> math.cbrt(1) 1.0 >>> math.cbrt(1728) 12.000000000000002 >>> 729 + 1000 1729 >>> math.cbrt(729) 9.000000000000002 >>> math.cbrt(1000) 10.0尽管有一些舍入误差,你注意到 1729 可以写成 1 + 12 或者 9 + 10 。换句话说,1729 可以表示为两个不同的立方数之和。
在 Python 的早期版本中,可以使用取幂(
**或math.pow())来计算立方根和 2 的幂。现在,cbrt()允许你在没有明确指定1/3的情况下找到立方根。同样,exp2()给你一个计算 2 的幂的捷径。在 Python 3.11 中,进行这些计算有几种选择:
>>> math.cbrt(729)
9.000000000000002
>>> 729**(1/3)
8.999999999999998
>>> math.pow(729, 1/3)
8.999999999999998
>>> math.exp2(16)
65536.0
>>> 2**16
65536
>>> math.pow(2, 16)
65536.0
注意,由于浮点表示错误,不同的方法可能会得到稍微不同的结果。特别是在 Windows 上,exp2()似乎比math.pow()更不准确。目前坚持旧的方法应该对你有好处。
当计算负数的立方根时,你也会得到不同的结果:
>>> math.cbrt(-8) -2.0 >>> (-8)**(1/3) (1.0000000000000002+1.7320508075688772j) >>> math.pow(-8, 1/3) Traceback (most recent call last): ... ValueError: math domain error任何数字都有三个立方根。对于实数,这些根中的一个将是实数,而另外两个根将是一对复数。
cbrt()返回主立方根,包括负数。取幂运算返回一个复数立方根,而math.pow()只处理整数指数的负数。分数中的下划线
从 Python 3.6 开始,Python 就支持在文字数字中添加下划线。通常,您使用下划线将大量数字分组,以使它们更具可读性:
>>> number = 60481729
>>> readable_number = 60_481_729
在这个例子中,number是大约 600 万还是 6000 万可能不是很明显。通过将数字分成三组,很明显readable_number大约是六千万。
请注意,这个特性是一种便利,可以让您的源代码更具可读性。下划线对计算或 Python 表示数字的方式没有影响,尽管您可以使用 f 字符串用下划线格式化数字:
>>> number == readable_number True >>> readable_number 60481729 >>> f"{number:_}" '60_481_729'注意 Python 并不关心你把下划线放在哪里。你应该小心,不要让它们最终增加混乱:
>>> confusing_number = 6_048_1729
confusing_number的价值也大约是六千万,但是你很容易认为它是六百万。如果您使用下划线来分隔千位,那么您应该知道在世界范围内有不同的惯例来对数字进行分组。
Python 可以用 fractions 模块准确地表示有理数。例如,您可以使用字符串文字指定 1729 的分数 6048,如下所示:
>>> from fractions import Fraction >>> print(Fraction("6048/1729")) 864/247出于某种原因,在 Python 3.11 之前,下划线不允许出现在
Fraction字符串参数中。现在,您也可以在指定分数时使用下划线:
>>> print(Fraction("6_048/1_729"))
864/247
和其他数字一样,Python 不关心下划线放在哪里。使用下划线来提高代码的可读性取决于您。
对象的灵活调用
operator 模块包含在使用 Python 的一些函数式编程特性时有用的函数。举个简单的例子,您可以使用operator.abs到按照绝对值对数字 -3、-2、-1、0、1、2 和 3 进行排序:
>>> sorted([-3, -2, -1, 0, 1, 2, 3], key=operator.abs) [0, -1, 1, -2, 2, -3, 3]通过指定
key,首先通过计算每个项目的绝对值来对列表进行排序。Python 3.11 在
operator上增加了call()。你可以使用call()来调用函数。例如,您可以按如下方式编写前面的示例:
>>> operator.call(sorted, [-3, -2, -1, 0, 1, 2, 3], key=operator.abs)
[0, -1, 1, -2, 2, -3, 3]
一般来说,像这样使用call()是没有用的。你应该坚持直接调用函数。一个可能的例外是当你调用被变量引用的函数时,因为添加call()可以使你的代码更加明确。
下一个例子展示了call()的一个更好的用例。你实现了一个可以用挪威语进行基本计算的计算器。它使用 parse 库解析文本字符串,然后使用call()执行正确的算术运算:
import operator
import parse
OPERATIONS = {
"pluss": operator.add, # Addition
"minus": operator.sub, # Subtraction
"ganger": operator.mul, # Multiplication
"delt på": operator.truediv, # Division
}
EXPRESSION = parse.compile("{operand1:g} {operation} {operand2:g}")
def calculate(text):
if (ops := EXPRESSION.parse(text)) and ops["operation"] in OPERATIONS:
operation = OPERATIONS[ops["operation"]]
return operator.call(operation, ops["operand1"], ops["operand2"])
OPERATIONS是一个映射,指定您的计算器理解哪些命令,并定义它们对应的功能。EXPRESSION是一个模板,定义了将要解析的文本字符串的种类。calculate()解析你的字符串,如果可以识别,就调用相关的操作。
注意:你可以返回operation(ops["operand1"], ops["operand2"])而不是使用operator.call()。
您可以使用calculate()进行挪威算术运算,如下所示:
>>> calculate("3 pluss 11") 14.0 >>> calculate("3 delt på 11") 0.2727272727272727你的计算器算出 3 加 11 等于 14,而 3 除以 11 大约是 0.27。
operator.call()类似于apply(),在 Python 2 中可用,随着参数解包的引入而失宠。call()让你在调用函数时更加灵活。然而,正如这些例子所示,您通常最好直接调用函数。结论
现在你已经看到了 Python 3.11 在 2022 年 10 月发布时将会带来什么。您已经了解了它的一些新特性,并探索了如何利用这些改进。
特别是,你已经:
- 在你的电脑上安装了 Python 3.11 Alpha
- 在 Python 3.11 中使用了增强的错误回溯功能,并用它们来更有效地调试你的代码
- 了解 Python 3.11 如何构建在 Python 3.10 的 PEG 解析器和之上,更好的错误消息
- 探索了第三方库如何让你的调试更加高效
- 尝试了 Python 3.11 中一些较小的改进,包括新的数学函数和更多的可读分数
试试 Python 3.11 中更好的错误消息!你怎么看待这些增强的回溯?在下面评论分享你的经验。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。*******************
Python 3.11 预览版:任务和异常组
Python 3.11 将于 2022 年 10 月发布。尽管十月份还有几个月的时间,但是您已经可以预览一些即将到来的特性,包括 Python 3.11 必须提供的新任务和异常组。任务组可以让您更好地组织异步代码,而异常组可以收集同时发生的几个错误,并让您以直接的方式处理它们。
在本教程中,您将:
- 在你的电脑上安装 Python 3.11 alpha,就在你当前安装的 Python 旁边
- 探索异常组如何组织几个不相关的错误
- 过滤器带有
except*和的异常组处理不同类型的错误- 使用任务组来设置你的异步代码
- 测试 Python 3.11 中较小的改进,包括异常注释和一个新的内部异常表示
Python 3.11 中还有许多其他的改进和特性。请查看变更日志中的新增内容,获取最新列表。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 3.11 Alpha
Python 的新版本在每年 10 月发布。代码是在发布日期前经过 17 个月的时间开发和测试的。新功能在 alpha 阶段实现,持续到五月,大约在最终发布前五个月。
大约每月一次在 alpha 阶段,Python 的核心开发者发布一个新的 alpha 版本来展示新特性,测试它们,并获得早期反馈。目前 Python 3.11 的最新 alpha 版本是 3.11.0a7 ,发布于 2022 年 4 月 5 日。
注:本教程使用的是 Python 3.11 的第七个 alpha 版本。如果您使用更高版本,可能会遇到一些小的差异。特别是,任务组实现的一些方面仍在讨论中。然而,你可以期望你在这里学到的大部分内容在 alpha 和 beta 阶段以及 Python 3.11 的最终版本中保持不变。
Python 3.11 的第一个 beta 版本即将发布,计划于 2022 年 5 月 6 日发布。通常,在测试阶段不会添加新功能。相反,特性冻结和发布日期之间的时间被用来测试和固化代码。
很酷的新功能
Python 3.11 的一些最新亮点包括:
- 异常组,允许程序同时引发和处理多个异常
- 任务组,改善你如何运行异步代码
- 增强的错误消息,这将帮助你更有效地调试你的代码
- 优化,承诺使 Python 3.11 比以前的版本明显更快
- 静态类型的改进,这将让你更精确地注释你的代码
- TOML 支持,它允许你使用标准库解析 TOML 文档
Python 3.11 有很多值得期待的地方!要获得全面的概述,请查看 Python 3.11:供您尝试的酷新功能。您还可以在本系列的其他文章中更深入地研究上面列出的一些特性:
在本教程中,您将关注异常组如何一次处理多个不相关的异常,以及该特性如何为任务组铺平道路,从而使 Python 中的并发编程更加方便。您还将看到 Python 3.11 中其他一些更小的特性。
安装
要使用本教程中的代码示例,您需要在系统上安装 Python 3.11 版本。在这一小节中,你将学习几种不同的方法:使用 Docker ,使用 pyenv ,或者从源安装。选择最适合您和您的系统的一个。
注意: Alpha 版本是即将推出的功能的预览。虽然大多数特性都可以很好地工作,但是您不应该在生产中依赖任何 Python 3.11 alpha 版本,也不应该依赖任何潜在错误会带来严重后果的地方。
如果您可以在您的系统上访问 Docker ,那么您可以通过拉取并运行
python:3.11-rc-slimDocker 镜像来下载最新版本的 Python 3.11:$ docker pull python:3.11-rc-slim Unable to find image 'python:3.11-rc-slim' locally latest: Pulling from library/python [...] $ docker run -it --rm python:3.11-rc-slim这会将您带入 Python 3.11 REPL。查看 Docker 中的运行 Python 版本,了解更多关于通过 Docker 使用 Python 的信息,包括如何运行脚本。
pyenv 工具非常适合管理系统上不同版本的 Python,如果你愿意,你可以用它来安装 Python 3.11 alpha。它有两个不同的版本,一个用于 Windows,一个用于 Linux 和 macOS。使用下面的切换器选择您的平台:
- 视窗
** Linux + macOS**在 Windows 上,你可以使用 pyenv-win 。首先更新您的
pyenv安装:PS> pyenv update :: [Info] :: Mirror: https://www.python.org/ftp/python [...]进行更新可以确保您可以安装最新版本的 Python。你也可以手动更新
pyenv。在 Linux 和 macOS 上,可以使用 pyenv 。首先使用
pyenv-update插件更新您的pyenv安装:$ pyenv update Updating /home/realpython/.pyenv... [...]进行更新可以确保您可以安装最新版本的 Python。如果不想用更新插件,可以手动更新
pyenv。使用
pyenv install --list查看 Python 3.11 有哪些版本。然后,安装最新版本:$ pyenv install 3.11.0a7 Downloading Python-3.11.0a7.tar.xz... [...]安装可能需要几分钟时间。一旦你的新 alpha 版本安装完毕,你就可以创建一个虚拟环境来玩它:
- 视窗
** Linux + macOS*PS> pyenv local 3.11.0a7 PS> python --version Python 3.11.0a7 PS> python -m venv venv PS> venv\Scripts\activate您使用
pyenv local激活您的 Python 3.11 版本,然后使用python -m venv设置虚拟环境。$ pyenv virtualenv 3.11.0a7 311_preview $ pyenv activate 311_preview (311_preview) $ python --version Python 3.11.0a7在 Linux 和 macOS 上,你使用
pyenv-virtualenv插件来设置虚拟环境并激活它。你也可以从python.org的预发布版本中安装 Python。选择最新预发布,向下滚动到页面底部的文件部分。下载并安装与您的系统对应的文件。更多信息参见 Python 3 安装&设置指南。
本教程中的许多示例将适用于旧版本的 Python,但一般来说,您应该使用 Python 3.11 可执行文件来运行它们。具体如何运行可执行文件取决于您的安装方式。如果您需要帮助,请参见关于 Docker 、 pyenv 、虚拟环境或从源安装的相关教程。
Python 3.11 中的异常组和
except*处理异常是编程的重要部分。有时错误是因为代码中的错误而发生的。在这些情况下,好的错误消息将帮助你有效地调试你的代码。其他时候,错误的发生并不是因为代码的错误。可能是用户试图打开一个损坏的文件,可能是网络中断,或者可能是数据库的身份验证丢失。
通常,一次只会发生一个错误。如果您的代码继续运行,可能会发生另一个错误。但是 Python 通常只会报告它遇到的第一个错误。但是,在某些情况下,一次报告几个错误是有意义的:
- 几个并发任务可能同时失败。
- 清理代码可能会导致它自己的错误。
- 代码可以尝试几种不同的方法,但都会引发异常。
在 Python 3.11 中,有了一个叫做异常组的新特性。它提供了一种将不相关的异常分组在一起的方法,并且提供了一种新的
except*语法来处理它们。详细描述见 PEP 654:异常组和except*。PEP 654 由 CPython 的核心开发者之一 Irit Katriel 编写并实现,得到了
asyncio维护者 Yury Selivanov 和前 BDFL 吉多·范·罗苏姆的支持。它是在 2021 年 5 月的 Python 语言峰会上提出并讨论的。本节将教您如何使用异常组。在下一节的中,您将看到一个并发代码的实际例子,它使用异常组来同时引发和处理几个任务的错误。
用
except处理常规异常在探索异常组之前,您将回顾 Python 中常规异常处理的工作方式。如果您已经习惯了用 Python 处理错误,那么在这一小节中您不会学到任何新东西。然而,这篇综述将作为您稍后将了解的异常组的对比。您将在本教程的这一小节中看到的所有内容都适用于 Python 3 的所有版本,包括 Python 3.10。
异常打破了程序的正常流程。如果出现异常,Python 会丢弃其他所有东西,寻找处理错误的代码。如果没有这样的处理程序,那么不管程序在做什么,程序都会停止。
您可以使用
raise关键字自己提出一个错误:
>>> raise ValueError(654)
Traceback (most recent call last):
...
ValueError: 654
在这里,你用描述 654 明确地提出了一个ValueError。你可以看到 Python 提供了一个回溯,它告诉你有一个未处理的错误。
有时,您会在代码中引发这样的错误,以表示出现了问题。然而,更常见的是遇到由 Python 本身或您正在使用的某个库引发的错误。例如,Python 不允许您添加一个字符串和一个整数,如果您尝试这样做,就会引发一个TypeError:
>>> "3" + 11 Traceback (most recent call last): ... TypeError: can only concatenate str (not "int") to str大多数异常都有描述,可以帮助您找出问题所在。在这种情况下,它告诉你,你的第二项也应该是字符串。
你用
try…except块来处理错误。有时,您使用这些只是记录错误并继续运行。其他时候,您设法从错误中恢复过来,或者计算一些替代值。一个短的
try…except块可能如下所示:
>>> try:
... raise ValueError(654)
... except ValueError as err:
... print(f"Got a bad value: {err}")
...
Got a bad value: 654
您可以通过在控制台上打印一条消息来处理ValueError异常。注意,因为您处理了错误,所以在这个例子中没有回溯。但是,不处理其他类型的错误:
>>> try: ... "3" + 11 ... except ValueError as err: ... print(f"Got a bad value: {err}") ... Traceback (most recent call last): ... TypeError: can only concatenate str (not "int") to str即使错误发生在
try…except块中,它也不会被处理,因为没有与TypeError匹配的except子句。您可以在一个块中处理几种错误:
>>> try:
... "3" + 11
... except ValueError as err:
... print(f"Got a bad value: {err}")
... except TypeError as err:
... print(f"Got bad types: {err}")
...
Got bad types: can only concatenate str (not "int") to str
这个例子将处理ValueError和TypeError异常。
异常在层级中定义。比如一个ModuleNotFoundError是一种ImportError,是一种Exception。
注意:因为大多数异常都是从Exception继承的,所以你可以通过只使用except Exception块来简化你的错误处理。这通常是个坏主意。您希望您的异常块尽可能具体,以避免意外错误的发生,并打乱您的错误处理。
匹配错误的第一个except子句将触发异常处理:
>>> try: ... import no_such_module ... except ImportError as err: ... print(f"ImportError: {err.__class__}") ... except ModuleNotFoundError as err: ... print(f"ModuleNotFoundError: {err.__class__}") ... ImportError: <class 'ModuleNotFoundError'>当你试图导入一个不存在的模块时,Python 会抛出一个
ModuleNotFoundError。然而,由于ModuleNotFoundError是一种ImportError,您的错误处理触发了except ImportError子句。请注意:
- 最多会触发一个
except子句- 匹配的第一个
except子句将被触发如果您以前处理过异常,这可能看起来很直观。然而,稍后您将看到异常组的行为有所不同。
虽然一次最多只有一个异常是活动的,但是可以将相关的异常链接起来。这种链接是由 PEP 3134 为 Python 3.0 引入的。例如,如果在处理错误时引发新的异常,观察会发生什么情况:
>>> try:
... "3" + 11
... except TypeError:
... raise ValueError(654)
...
Traceback (most recent call last):
...
TypeError: can only concatenate str (not "int") to str
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
...
ValueError: 654
注意第During handling of the above exception, another exception occurred行。在这一行之前有一个回溯,代表由您的代码引起的最初的TypeError。然后,在这条线下面有另一个回溯,代表您在处理TypeError时引发的新的ValueError。
如果您的错误处理代码中碰巧有问题,这种行为特别有用,因为您可以获得关于原始错误和错误处理程序中的错误的信息。
您也可以使用一个 raise … from语句将异常显式地链接在一起。虽然您可以使用链式异常一次引发几个异常,但请注意,该机制适用于相关的异常,特别是在处理另一个异常时发生的异常。
这不同于异常组被设计来处理的用例。异常组将不相关的异常组合在一起,也就是说它们彼此独立发生。当处理链式异常时,您只能捕捉和处理链中的最后一个错误。您将很快了解到,您可以在一个异常组中捕获所有的异常。
用ExceptionGroup 分组异常
在这一小节中,您将探索 Python 3.11 中可用的新的ExceptionGroup类。首先,注意一个ExceptionGroup也是一种Exception:
>>> issubclass(ExceptionGroup, Exception) True由于
ExceptionGroup是Exception的子类,您可以使用 Python 的常规异常处理来处理它。您可以用raise引发一个ExceptionGroup,尽管您可能不会经常这么做,除非您正在实现一些低级的库。用except ExceptionGroup抓一个ExceptionGroup也是可以的。然而,正如您将在的下一小节中了解到的,使用新的except*语法通常会更好。与大多数其他异常不同,异常组在初始化时有两个参数:
- 通常的描述
- 一系列子异常
子异常序列可以包括其他异常组,但不能为空:
>>> ExceptionGroup("one error", [ValueError(654)])
ExceptionGroup('one error', [ValueError(654)])
>>> ExceptionGroup("two errors", [ValueError(654), TypeError("int")])
ExceptionGroup('two errors', [ValueError(654), TypeError('int')])
>>> ExceptionGroup("nested",
... [
... ValueError(654),
... ExceptionGroup("imports",
... [
... ImportError("no_such_module"),
... ModuleNotFoundError("another_module"),
... ]
... ),
... ]
... )
ExceptionGroup('nested', [ValueError(654), ExceptionGroup('imports',
[ImportError('no_such_module'), ModuleNotFoundError('another_module')])])
>>> ExceptionGroup("no errors", [])
Traceback (most recent call last):
...
ValueError: second argument (exceptions) must be a non-empty sequence
在这个例子中,您正在实例化几个不同的异常组,这表明异常组可以包含一个异常、几个异常,甚至其他异常组。但是,异常组不允许为空。
您第一次遇到异常组很可能是它的回溯。例外组回溯被格式化以清楚地显示组内的结构。当您提出一个例外组时,您会看到一个回溯:
>>> raise ExceptionGroup("nested", ... [ ... ValueError(654), ... ExceptionGroup("imports", ... [ ... ImportError("no_such_module"), ... ModuleNotFoundError("another_module"), ... ] ... ), ... TypeError("int"), ... ] ... ) + Exception Group Traceback (most recent call last): | ... | ExceptionGroup: nested (3 sub-exceptions) +-+---------------- 1 ---------------- | ValueError: 654 +---------------- 2 ---------------- | ExceptionGroup: imports (2 sub-exceptions) +-+---------------- 1 ---------------- | ImportError: no_such_module +---------------- 2 ---------------- | ModuleNotFoundError: another_module +------------------------------------ +---------------- 3 ---------------- | TypeError: int +------------------------------------回溯列出了属于异常组所有异常。此外,以图形方式和通过列出每个组中有多少子异常来指示组内异常的嵌套树结构。
您之前已经了解到,
ExceptionGroup也是一个常规的 Python 异常。这意味着您可以用常规的except块捕获异常组:
>>> try:
... raise ExceptionGroup("group", [ValueError(654)])
... except ExceptionGroup:
... print("Handling ExceptionGroup")
...
Handling ExceptionGroup
这通常不是很有帮助,因为您更感兴趣的是嵌套在异常组中的错误。请注意,您不能直接处理这些问题:
>>> try: ... raise ExceptionGroup("group", [ValueError(654)]) ... except ValueError: ... print("Handling ValueError") ... + Exception Group Traceback (most recent call last): | ... | ExceptionGroup: group (1 sub-exception) +-+---------------- 1 ---------------- | ValueError: 654 +------------------------------------即使异常组包含一个
ValueError,你也不能用except ValueError来处理它。相反,您应该使用一种新的except*语法来处理异常组。您将在下一节了解这是如何工作的。用
except*过滤异常在 Python 的早期版本中,已经有人尝试处理多个错误。例如,流行的三重奏库包括一个
MultiError异常,它可以包装其他异常。然而,因为 Python 倾向于一次处理一个错误,所以处理MultiError异常的不如理想的。Python 3.11 中新的
except*语法使得同时处理几个错误更加方便。异常组有一些常规异常没有的属性和方法。特别是,您可以访问.exceptions来获得组中所有子异常的元组。例如,您可以将上一小节中的最后一个示例重写如下:
>>> try:
... raise ExceptionGroup("group", [ValueError(654)])
... except ExceptionGroup as eg:
... for err in eg.exceptions:
... if isinstance(err, ValueError):
... print("Handling ValueError")
... elif isinstance(err, TypeError):
... print("Handling TypeError")
...
Handling ValueError
一旦您捕获了一个ExceptionGroup,您就可以循环所有的子异常,并根据它们的类型来处理它们。虽然这是可能的,但很快就会变得很麻烦。还要注意,上面的代码不处理嵌套的异常组。
相反,您应该使用except*来处理异常组。您可以再次重写该示例:
>>> try: ... raise ExceptionGroup("group", [ValueError(654)]) ... except* ValueError: ... print("Handling ValueError") ... except* TypeError: ... print("Handling TypeError") ... Handling ValueError每个
except*子句处理一个异常组,它是原始异常组的子组,包含所有与给定错误类型匹配的异常。考虑稍微复杂一点的例子:
>>> try:
... raise ExceptionGroup(
... "group", [TypeError("str"), ValueError(654), TypeError("int")]
... )
... except* ValueError as eg:
... print(f"Handling ValueError: {eg.exceptions}")
... except* TypeError as eg:
... print(f"Handling TypeError: {eg.exceptions}")
...
Handling ValueError: (ValueError(654),)
Handling TypeError: (TypeError('str'), TypeError('int'))
注意,在这个例子中,两个except*子句都会触发。这不同于常规的except子句,在常规子句中,一次最多触发一个子句。
首先,从原始异常组中过滤出ValueError并进行处理。在被except* TypeError捕获之前,TypeError异常不会被处理。每个子句只触发一次,即使该类型有更多的异常。因此,您的处理代码必须处理异常组。
您可能最终只能部分处理异常组。例如,您可以只处理上一个示例中的ValueError:
>>> try: ... raise ExceptionGroup( ... "group", [TypeError("str"), ValueError(654), TypeError("int")] ... ) ... except* ValueError as eg: ... print(f"Handling ValueError: {eg.exceptions}") ... Handling ValueError: (ValueError(654),) + Exception Group Traceback (most recent call last): | ... | ExceptionGroup: group (2 sub-exceptions) +-+---------------- 1 ---------------- | TypeError: str +---------------- 2 ---------------- | TypeError: int +------------------------------------在这种情况下,
ValueError被处理。但是这在异常组中留下了两个未处理的错误。这些错误然后冒泡出来,并创建一个追溯。注意,ValueError不是回溯的一部分,因为它已经被处理了。你可以看到except*的行为与except不同:
- 可能会触发几个
except*子句。except*匹配错误的子句从例外组中删除该错误。与普通的
except相比,这是一个明显的变化,起初可能会感觉有点不直观。然而,这些变化使得处理多个并发错误变得更加方便。您可以手动拆分例外组,尽管您可能不需要这样做:
>>> eg = ExceptionGroup(
... "group", [TypeError("str"), ValueError(654), TypeError("int")]
... )
>>> eg
ExceptionGroup('group', [TypeError('str'), ValueError(654), TypeError('int')])
>>> value_errors, eg = eg.split(ValueError) >>> value_errors
ExceptionGroup('group', [ValueError(654)])
>>> eg
ExceptionGroup('group', [TypeError('str'), TypeError('int')])
>>> import_errors, eg = eg.split(ImportError) >>> print(import_errors)
None
>>> eg
ExceptionGroup('group', [TypeError('str'), TypeError('int')])
>>> type_errors, eg = eg.split(TypeError) >>> type_errors
ExceptionGroup('group', [TypeError('str'), TypeError('int')])
>>> print(eg)
None
您可以在异常组上使用.split()将它们分成两个新的异常组。第一组由与给定错误匹配的错误组成,而第二组由剩余的错误组成。如果任何一个组最终是空的,那么它们将被None替换。如果您想手动操作异常组,请参见 PEP 654 和文档了解更多信息。
异常组不会替换常规异常!相反,它们被设计用来处理特定的用例,在这种情况下,同时处理几个异常是有用的。库应该清楚地区分可以引发常规异常的函数和可以引发异常组的函数。
PEP 654 的作者建议将函数从引发异常改为引发异常组应被视为重大更改,因为任何使用该库的人都需要更新他们处理错误的方式。在下一节中,您将了解任务组。它们是 Python 3.11 中的新特性,是标准库中引发异常组的第一部分。
您已经看到,在常规的except块中处理异常组是可能的,但是很麻烦。也可以反其道而行之。except*可以处理常规异常:
>>> try: ... raise ValueError(654) ... except* ValueError as eg: ... print(type(eg), eg.exceptions) ... <class 'ExceptionGroup'> (ValueError(654),)即使您引发了一个单独的
ValueError异常,except*机制也会在处理它之前将异常包装在一个异常组中。理论上,这意味着你可以用except*替换你所有的except积木。实际上,这是个坏主意。异常组旨在处理多个异常。除非需要,否则不要使用它们!异常组是 Python 3.11 中的新增功能。但是,如果您使用的是旧版本的 Python,那么您可以使用
exceptiongroupbackport 来访问相同的功能。代替except*,反向端口使用exceptiongroup.catch()上下文管理器来处理多个错误。Python 3.11 中的异步任务组
在上一节中,您了解了异常组。你什么时候会使用它们?如上所述,异常组和
except*并不意味着取代常规异常和except。事实上,您很可能没有在自己的代码中引发异常组的良好用例。它们可能主要用在低级别的库中。随着 Python 3.11 越来越普及,您所依赖的包可能会开始产生异常组,因此您可能需要在应用程序中处理它们。
引入异常组的一个激励用例是处理并发代码中的错误。如果您同时运行几个任务,其中几个可能会遇到问题。直到现在,Python 还没有很好的方法来处理这个问题。几个异步库,像 Trio 、 AnyIO 和 Curio ,增加了一种多错误容器。但是如果没有语言支持,处理并发错误仍然很复杂。
如果你想看异常组及其在并发编程中的使用的视频演示,看看ukasz Langa 的演示异常组将如何改进 AsyncIO 中的错误处理。
在本节中,您将探索一个模拟同时分析几个文件的玩具示例。您将从一个基本的同步应用程序构建这个示例,在这个应用程序中,文件被按顺序分析,直到一个完整的异步工具使用新的 Python 3.11
asyncio任务组。其他异步库中也存在类似的任务组,但是新的实现首次使用异常组来平滑错误处理。您的第一个版本的分析工具将与旧版本的 Python 一起工作,但是您将需要 Python 3.11 来利用最终示例中的任务和异常组。
按顺序分析文件
在这一小节中,您将实现一个可以计算几个文件中的行数的工具。输出将会是动画的,这样您就可以很好地看到文件大小的分布情况。最终结果看起来会像这样:
您将扩展这个程序,探索异步编程的一些特性。虽然这个工具本身并不一定有用,但它很明确,因此您可以清楚地看到发生了什么,而且它很灵活,因此您可以引入几个异常,并通过异常组来处理它们。
Colorama 是一个库,可以让你更好地控制终端的输出。当程序计算不同文件中的行数时,您将使用它来创建动画。先用
pip安装:$ python -m pip install colorama顾名思义,Colorama 的主要用例是为您的终端添加颜色。但是,您也可以使用它在特定位置打印文本。将以下代码写入名为
count.py的文件中:# count.py import sys import time import colorama from colorama import Cursor colorama.init() def print_at(row, text): print(Cursor.POS(1, 1 + row) + str(text)) time.sleep(0.03) def count_lines_in_file(file_num, file_name): counter_text = f"{file_name[:20]:<20} " with open(file_name, mode="rt", encoding="utf-8") as file: for line_num, _ in enumerate(file, start=1): counter_text += "□" print_at(file_num, counter_text) print_at(file_num, f"{counter_text} ({line_num})") def count_all_files(file_names): for file_num, file_name in enumerate(file_names, start=1): count_lines_in_file(file_num, file_name) if __name__ == "__main__": count_all_files(sys.argv[1:])
print_at()功能是动画的核心。它使用 Colorama 的Cursor.POS()在终端的特定行或线打印一些文本。接下来,会让休眠一会儿,以创造动画效果。您使用
count_lines_in_file()来分析一个文件并制作动画。该函数打开一个文件并遍历它,一次一行。对于每一行,它向字符串添加一个框(□),并使用print_at()在同一行连续打印字符串。这将创建动画。最后,打印出总行数。注意:用 Colorama 定位终端光标是创建简单动画的快捷方式。然而,它确实扰乱了终端的正常流程,您可能会遇到一些文本被覆盖的问题。
通过在分析文件之前清空屏幕,并在结束时将光标设置在动画下方,您会有更流畅的体验。您可以通过在主块中添加如下内容来实现这一点:
# count.py # ... if __name__ == "__main__": print(colorama.ansi.clear_screen()) count_all_files(sys.argv[1:]) print(Cursor.POS(1, 1 + len(sys.argv)))您还可以在这里和在
print_at()中更改添加到Cursor.POS()的第二个参数的数字,以获得一个与您的终端设置相适应的行为。当您找到一个有效的数字时,您也应该在后面的示例中进行类似的定制。你程序的入口点是
count_all_files()。这将遍历您作为命令行参数提供的所有文件名,并对它们调用count_lines_in_file()。试试你的线计数器!您通过提供应该在命令行上分析的文件来运行程序。例如,您可以计算源代码中的行数,如下所示:
$ python count.py count.py count.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□ (28)这将计算
count.py中的行数。您应该创建几个其他文件,用于研究您的行计数器。这些文件中的一些会暴露出你目前没有做任何异常处理。您可以使用以下代码创建几个新文件:

>>> import pathlib
>>> import string
>>> chars = string.ascii_uppercase
>>> data = [c1 + c2 for c1, c2 in zip(chars[:13], chars[13:])]
>>> pathlib.Path("rot13.txt").write_text("\n".join(data))
38
>>> pathlib.Path("empty_file.txt").touch()
>>> bbj = [98, 108, 229, 98, 230, 114, 115, 121, 108, 116, 101, 116, 248, 121]
>>> pathlib.Path("not_utf8.txt").write_bytes(bytes(bbj))
14
您已经创建了三个文件:rot13.txt、empty_file.txt和not_utf8.txt。第一个文件包含在 ROT13 密码中相互映射的字母。第二个文件是一个完全空的文件,而第三个文件包含一些不是 UTF-8 编码的数据。您很快就会看到,最后两个文件会给您的程序带来问题。
要计算两个文件中的行数,需要在命令行中提供它们的名称:
$ python count.py count.py rot13.txt
count.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□ (28)
rot13.txt □□□□□□□□□□□□□ (13)
您用命令行提供的所有参数调用count_all_files()。然后,该函数对每个文件名进行循环。
如果您提供了一个不存在的文件名,那么您的程序将引发一个异常告诉您:
$ python count.py wrong_name.txt
Traceback (most recent call last):
...
FileNotFoundError: [Errno 2] No such file or directory: 'wrong_name.txt'
如果您尝试分析empty_file.txt或not_utf8.txt,也会发生类似的事情:
$ python count.py empty_file.txt
Traceback (most recent call last):
...
UnboundLocalError: cannot access local variable 'line_num' where it is
not associated with a value
$ python count.py not_utf8.txt
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 2:
invalid continuation byte
这两种情况都会产生错误。对于empty_file.txt,问题是line_num是通过迭代文件的行来定义的。如果文件中没有行,那么line_num没有被定义,当你试图访问它的时候会得到一个错误。not_utf8.txt的问题在于,你试图对不是 UTF 8 编码的东西进行 UTF 8 解码。
在接下来的小节中,您将使用这些错误来探索异常组如何帮助您改进错误处理。现在,观察如果您试图分析两个都产生错误的文件会发生什么:
$ python count.py not_utf8.txt empty_file.txt
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 2:
invalid continuation byte
请注意,只有对应于not_utf8.txt的第一个错误出现。这很自然,因为文件是按顺序分析的。这个错误发生在empty_file.txt打开之前很久。
同时分析文件
在这一小节中,您将重写程序以异步运行。这意味着对所有文件的分析是同时进行的,而不是按顺序进行的。看到更新后的程序运行很有启发性:

动画显示,所有文件中的行数是同时计算的,而不是像以前那样一次只计算一个文件中的行数。
通过使用async和await关键字将函数重写为异步协程,可以实现这种并发性。请注意,这个新版本仍然使用旧的异步实践,并且这个代码在 Python 3.7 和更高版本中是可运行的。在下一小节中,您将执行最后一步并使用新的任务组。
用以下代码创建一个名为count_gather.py的新文件:
# count_gather.py
import asyncio import sys
import colorama
from colorama import Cursor
colorama.init()
async def print_at(row, text):
print(Cursor.POS(1, 1 + row) + str(text))
await asyncio.sleep(0.03)
async def count_lines_in_file(file_num, file_name):
counter_text = f"{file_name[:20]:<20} "
with open(file_name, mode="rt", encoding="utf-8") as file:
for line_num, _ in enumerate(file, start=1):
counter_text += "□"
await print_at(file_num, counter_text) await print_at(file_num, f"{counter_text} ({line_num})")
async def count_all_files(file_names):
tasks = [ asyncio.create_task(count_lines_in_file(file_num, file_name)) for file_num, file_name in enumerate(file_names, start=1) ] await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(count_all_files(sys.argv[1:]))
如果您将这段代码与前一小节中的count.py进行比较,那么您会注意到,大多数更改只是将async添加到函数定义中,或者将await添加到函数调用中。async和awaitT5】关键字构成了 Python 做异步编程的 API。
注意: asyncio是 Python 标准库中包含的用于异步编程的库。不过 Python 的异步计算模型还是比较通用的,你可以用其他第三方库比如 Trio 和 Curio 代替asyncio。
或者,你可以使用第三方库,比如 uvloop 和 Quattro 。这些不是asyncio的替代品。相反,他们在此基础上增加了性能或额外的功能。
接下来,请注意count_all_files()发生了显著变化。不是顺序调用count_lines_in_file(),而是为每个文件名创建一个任务。每个任务都为count_lines_in_file()准备了相关的参数。所有的任务都收集在一个列表里,传递给 asyncio.gather() 。最后,count_all_files()是通过调用 asyncio.run() 发起的。
这里发生的是asyncio.run()创建了一个事件循环。任务由事件循环执行。在动画中,看起来所有文件都是同时分析的。然而,虽然这些行是同时计数的,但它们不是并行计数的。你的程序中只有一个线程,但是这个线程不断地切换它正在执行的任务。
异步编程有时被称为协作多任务,因为每个任务都主动放弃控制权,让其他任务运行。把await想象成代码中的一个标记,在那里你决定可以切换任务。在这个例子中,这主要是当代码在下一个动画步骤之前休眠的时候。
注意: 线程实现了类似的结果,但是使用了抢占式多任务,其中操作系统决定何时切换任务。异步编程通常比线程编程更容易推理,因为您知道任务何时会中断。参见使用并发性加速 Python 程序了解线程、异步编程和其他类型的并发性的比较。
在几个不同的文件上运行您的新代码,并观察它们是如何被并行分析的:
$ python count_gather.py count.py rot13.txt count_gather.py
count.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□ (28)
rot13.txt □□□□□□□□□□□□□ (13)
count_gather.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□ (31)
当你的文件在你的控制台中显示动画时,你会看到rot13.txt在其他任务之前完成。接下来,尝试分析您之前创建的一些麻烦的文件:
$ python count_gather.py not_utf8.txt empty_file.txt
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 2:
invalid continuation byte
即使现在同时分析了not_utf8.txt和empty_file.txt,您也只能看到其中一个产生的错误。正如您之前了解到的,常规的 Python 异常是一个接一个处理的,而asyncio.gather()受此限制。
注意:等待asyncio.gather()时可以用return_exceptions=True作为论元。这将从所有任务中收集异常,并在所有任务完成后将它们返回到一个列表中。然而,正确处理这些异常是很复杂的,因为它们没有使用 Python 正常的错误处理。
像 Trio 和 Curio 这样的第三方库做了一些特殊的错误处理,能够处理多个异常。例如,Trio 的 MultiError 包装了两个或多个异常,并提供了处理它们的上下文管理器。
更方便地处理多个错误正是异常组被设计来处理的用例之一。在您的计数器应用程序中,您会希望看到一个组,其中包含每个未被分析的文件的一个异常,并有一种简单的方法来处理它们。是时候给新的 Python 3.11 TaskGroup一个旋转了!
用任务组控制并发处理
任务组一直是asyncio的一个计划功能。Yuri Selivanov 在他在 PyBay 2018 上发表的演讲 asyncio:下一步是什么中提到它们是对 Python 3.8 的可能增强。其他图书馆也有类似的功能,包括三人托儿所、古玩任务组和夸特罗任务组。
实现花费这么多时间的主要原因是任务组需要同时正确处理几个异常。Python 3.11 中新的异常组特性也为包含异步任务组铺平了道路。它们最终由尤里·塞利万诺夫和吉多·范·罗苏姆实现,并在 Python 3.11.0a6 中发布
在这一小节中,您将重新实现您的计数器应用程序来使用asyncio.TaskGroup而不是asyncio.gather()。在下一小节中,您将使用except*来方便地处理您的应用程序可能引发的不同异常。
将以下代码放入名为count_taskgroup.py的文件中:
# count_taskgroup.py
import asyncio
import sys
import colorama
from colorama import Cursor
colorama.init()
async def print_at(row, text):
print(Cursor.POS(1, 1 + row) + str(text))
await asyncio.sleep(0.03)
async def count_lines_in_file(file_num, file_name):
counter_text = f"{file_name[:20]:<20} "
with open(file_name, mode="rt", encoding="utf-8") as file:
for line_num, _ in enumerate(file, start=1):
counter_text += "□"
await print_at(file_num, counter_text)
await print_at(file_num, f"{counter_text} ({line_num})")
async def count_all_files(file_names):
async with asyncio.TaskGroup() as tg: for file_num, file_name in enumerate(file_names, start=1): tg.create_task(count_lines_in_file(file_num, file_name))
if __name__ == "__main__":
asyncio.run(count_all_files(sys.argv[1:]))
将此与count_gather.py进行比较。您会注意到唯一的变化是在count_all_files()中如何创建任务。在这里,您使用上下文管理器创建任务组。之后,您的代码与count.py中最初的同步实现非常相似:
def count_all_files(file_names):
for file_num, file_name in enumerate(file_names, start=1):
count_lines_in_file(file_num, file_name)
在TaskGroup中创建的任务是并发运行的,类似于由asyncio.gather()运行的任务。只要您使用的是 Python 3.11,对文件计数的工作方式应该和以前一样:
$ python count_taskgroup.py count.py rot13.txt count_taskgroup.py
count.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□ (28)
rot13.txt □□□□□□□□□□□□□ (13)
count_taskgroup.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□□ (29)
不过,一个很大的改进是错误的处理方式。通过分析一些麻烦的文件来激发您的新代码:
$ python count_taskgroup.py not_utf8.txt empty_file.txt
+ Exception Group Traceback (most recent call last):
| ...
| ExceptionGroup: unhandled errors in a TaskGroup (2 sub-exceptions)
+-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "count_taskgroup.py", line 18, in count_lines_in_file
| for line_num, _ in enumerate(file, start=1):
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 2:
| invalid continuation byte
+---------------- 2 ----------------
| Traceback (most recent call last):
| File "count_taskgroup.py", line 21, in count_lines_in_file
| await print_at(file_num, f"{counter_text} ({line_num})")
| ^^^^^^^^
| UnboundLocalError: cannot access local variable 'line_num' where it is
| not associated with a value
+------------------------------------
注意,您会得到一个带有两个子异常的Exception Group Traceback,每个子异常对应一个未被分析的文件。这已经是对asyncio.gather()的改进了。在下一小节中,您将学习如何在代码中处理这些类型的错误。
Yuri Selivanov 指出,新的任务组比旧的任务组提供了更好的 API,因为任务组是“可组合的、可预测的和安全的”。此外,他指出,任务组:
- 运行一组嵌套任务。如果一个任务失败,所有其他仍在运行的任务都将被取消。
- 允许在计划嵌套任务之间执行代码(包括等待)。
- 多亏了 ExceptionGroups,所有的错误都被传播并可以被处理/报告。
尤里·谢利万诺夫 ( 来源)
在下一小节中,您将尝试在并发代码中处理和报告错误。
处理并发错误
您编写了一些有时会引发错误的并发代码。如何正确处理这些异常?您很快就会看到错误处理的例子。但是,首先,您将添加代码可能失败的另一种方式。
到目前为止,您在代码中看到的问题都是在文件分析开始之前出现的。为了模拟在分析过程中可能发生的错误,假设你的工具患有恐怖症,这意味着它不理智地害怕数字 13。在count_lines_in_file()中增加两行:
# count_taskgroup.py
# ...
async def count_lines_in_file(file_num, file_name):
counter_text = f"{file_name[:20]:<20} "
with open(file_name, mode="rt", encoding="utf-8") as file:
for line_num, _ in enumerate(file, start=1):
counter_text += "□"
await print_at(file_num, counter_text)
await print_at(file_num, f"{counter_text} ({line_num})")
if line_num == 13: raise RuntimeError("Files with thirteen lines are too scary!")
# ...
如果一个文件正好有 13 行,那么在分析结束时会产生一个RuntimeError。你可以通过分析rot13.txt来看这个的效果:
$ python count_taskgroup.py rot13.txt
rot13.txt □□□□□□□□□□□□□ (13)
+ Exception Group Traceback (most recent call last):
| ...
| ExceptionGroup: unhandled errors in a TaskGroup (1 sub-exception)
+-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "count_taskgroup.py", line 23, in count_lines_in_file
| raise RuntimeError("Files with thirteen lines are too scary!")
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| RuntimeError: Files with thirteen lines are too scary!
+------------------------------------
不出所料,你的新 triskaidekaphobic 代码在rot13.py的 13 行处停顿了。接下来,结合您之前看到的一个错误:
$ python count_taskgroup.py rot13.txt not_utf8.txt
rot13.txt □
+ Exception Group Traceback (most recent call last):
| ...
| ExceptionGroup: unhandled errors in a TaskGroup (1 sub-exception)
+-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "count_taskgroup.py", line 18, in count_lines_in_file
| for line_num, _ in enumerate(file, start=1):
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 2:
| invalid continuation byte
+------------------------------------
这一次,即使您知道两个文件都应该引发异常,也只报告一个错误。你只得到一个错误的原因是这两个问题会在不同的时间出现。任务组的一个特性是它们实现了一个取消范围。一旦某些任务失败,同一任务组中的其他任务就会被事件循环取消。
注:取消示波器是由三人组首创的。取消范围的最终实现以及它们将在asyncio中支持哪些功能仍在讨论中。以下示例适用于 Python 3.11.0a7,但在 Python 3.11 最终完成之前,情况可能仍会发生变化。
通常,有两种方法可以用来处理异步任务中的错误:
- 在协程中使用常规的
try…except块来处理问题。 - 使用任务组之外的新
try…except*模块来处理问题。
在第一种情况下,一个任务中的错误通常不会影响其他正在运行的任务。然而,在第二种情况下,一个任务中的错误将取消所有其他正在运行的任务。
自己尝试一下吧!首先,添加safe_count_lines_in_file(),它在您的协程中使用常规的异常处理:
# count_taskgroup.py
# ...
async def safe_count_lines_in_file(file_num, file_name):
try: await count_lines_in_file(file_num, file_name) except RuntimeError as err: await print_at(file_num, err)
async def count_all_files(file_names):
async with asyncio.TaskGroup() as tg:
for file_num, file_name in enumerate(file_names, start=1):
tg.create_task(safe_count_lines_in_file(file_num, file_name))
# ...
你也把count_all_files()改成称呼新的safe_count_lines_in_file()而不是count_lines_in_file()。在这个实现中,只要一个文件有 13 行,您只需处理引发的RuntimeError。
注意: safe_count_lines_in_file()不使用任务组的任何具体特性。你也可以使用类似的函数使count.py和count_gather.py更加健壮。
分析rot13.txt和其他一些文件,确认错误不再取消其他任务:
$ python count_taskgroup.py count.py rot13.txt count_taskgroup.py
count.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□ (28)
Files with thirteen lines are too scary!
count_taskgroup.py □□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□□ (37)
被处理的错误不会冒泡并影响其他任务。在本例中,count.py和count_taskgroup.py得到了正确分析,尽管对rot13.txt的分析失败了。
接下来,尝试使用except*来处理事后错误。例如,您可以将事件循环包装在一个try … except*块中:
# count_taskgroup.py
# ...
if __name__ == "__main__":
try: asyncio.run(count_all_files(sys.argv[1:]))
except* UnicodeDecodeError as eg: print("Bad encoding:", *[str(e)[:50] for e in eg.exceptions])
回想一下except*与异常组一起工作。在这种情况下,您循环遍历组中的UnicodeDecodeError异常,并将它们的前 50 个字符打印到控制台以记录它们。
与其他一些文件一起分析not_utf8.txt看看效果:
$ python count_taskgroup.py rot13.txt not_utf8.txt count.py
rot13.txt □
count.py □
Bad encoding: 'utf-8' codec can't decode byte 0xe5 in position 2
与前一个例子相反,即使您处理了UnicodeDecodeError,其他任务也会被取消。注意在rot13.txt和count.py中只计算一行。
注意:在count.py和count_gather.py示例中,您可以将对count_all_files()的调用包装在常规的try … except块中。然而,这将只允许您处理最多一个错误。相反,任务组可以报告所有错误:
$ python count_taskgroup.py not_utf8.txt count_taskgroup.py empty.txt
count_taskgroup.py □
Bad text: ["'utf-8' codec can't decode byte 0xe5 in position 2"] Empty file: ["cannot access local variable 'line_num' where it i"]
这个例子展示了在您扩展上一个例子中的代码来处理UnicodeDecodeError和UnboundLocalError之后,出现几个并发错误的结果。
如果您不处理引发的所有异常,那么未处理的异常仍然会导致您的程序因回溯而崩溃。要查看这一点,在您的分析中将count.py切换到empty_file.txt:
$ python count_taskgroup.py rot13.txt not_utf8.txt empty_file.txt
rot13.txt □
Bad encoding: 'utf-8' codec can't decode byte 0xe5 in position 2
+ Exception Group Traceback (most recent call last):
| ...
| ExceptionGroup: unhandled errors in a TaskGroup (1 sub-exception) +-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "count_taskgroup.py", line 21, in count_lines_in_file
| await print_at(file_num, f"{counter_text} ({line_num})")
| ^^^^^^^^
| UnboundLocalError: cannot access local variable 'line_num' where it is
| not associated with a value
+------------------------------------
你得到熟悉的UnboundLocalError。请注意,部分错误消息指出有一个未处理的子异常。在您处理的UnicodeDecodeError子异常的回溯中没有记录。
现在,您已经看到了一个使用任务组来改进异步应用程序的错误处理的示例,特别是能够轻松地处理同时发生的几个错误。异常组和任务组的结合使 Python 成为一种非常适合异步编程的语言。
其他新功能
在 Python 的每一个新版本中,少数几个特性获得了最多的关注。然而,Python 的大部分发展都是一小步一小步地发生的,通过在这里或那里添加一个功能,改进一些现有的功能,或者修复一个长期存在的错误。
Python 3.11 也不例外。本节展示了 Python 3.11 中一些较小的改进。
用自定义注释注释异常
现在,您可以向例外添加自定义注释。这是对 Python 中异常处理方式的又一次改进。异常注释是由扎克·哈特菲尔德-多兹在 PEP 678:用注释丰富异常中提出的。PEP 已经被接受,并且该提议的早期版本已经在 Python 3.11.0a3 到 Python 3.11.0a7 上实现
在这些 alpha 版本中,您可以在异常时将字符串分配给一个.__note__属性,如果错误没有得到处理,该信息将变得可用。这里有一个基本的例子:
>>> try: ... raise ValueError(678) ... except ValueError as err: ... err.__note__ = "Enriching Exceptions with Notes" ... raise ... Traceback (most recent call last): ... ValueError: 678 Enriching Exceptions with Notes您正在向
ValueError添加注释,然后再提升它。然后,您的注释会与常规错误消息一起显示在追溯的末尾。注意:本节的其余部分于 2022 年 5 月 9 日更新,以反映随着 Python 3.11.0b1 的发布而变得可用的异常注释特性的变化。
在讨论期间,PEP
.__note__的被更改为.__notes__,它可以包含几个注释。在跟踪单个笔记很重要的特定用例中,笔记列表会很有用。这方面的一个例子是国际化和注释的翻译。还有一个新的专用方法
.add_note(),可以用来添加这些注释。PEP 678 的完整实现在 Python 3.11 的首个测试版及以后版本中可用。接下来,您应该按如下方式编写前面的示例:
>>> try:
... raise ValueError(678)
... except ValueError as err:
... err.add_note("Enriching Exceptions with Notes") ... raise
...
Traceback (most recent call last):
...
ValueError: 678
Enriching Exceptions with Notes
您可以添加几个重复调用.add_note()的音符,并通过循环.__notes__来恢复它们。引发异常时,所有注释都将打印在追溯记录的下方:
>>> err = ValueError(678) >>> err.add_note("Enriching Exceptions with Notes") >>> err.add_note("Python 3.11") >>> err.__notes__ ['Enriching Exceptions with Notes', 'Python 3.11'] >>> for note in err.__notes__: ... print(note) ... Enriching Exceptions with Notes Python 3.11 >>> raise err Traceback (most recent call last): ... ValueError: 678 Enriching Exceptions with Notes Python 3.11新的异常注释也与异常组兼容。
用
sys.exception()引用活动异常在内部,Python 将异常表示为一个元组,其中包含关于异常类型、异常本身以及异常回溯的信息。这个在 Python 3.11 中改变了。现在,Python 将只在内部存储异常本身。类型和回溯都可以从异常对象派生。
一般来说,你不需要考虑这个变化,因为它都在引擎盖下。但是,如果您需要访问一个活动异常,您现在可以使用
sys模块中新的exception()函数:
>>> import sys
>>> try:
... raise ValueError("bpo-46328")
... except ValueError:
... print(f"Handling {sys.exception()}") ...
Handling bpo-46328
注意,你通常不会像上面那样在正常的错误处理中使用exception()。相反,在错误处理中使用的包装器库中使用它有时会很方便,但不能直接访问活动异常。在正常的错误处理中,您应该在except子句中命名您的错误:
>>> try: ... raise ValueError("bpo-46328") ... except ValueError as err: ... print(f"Handling {err}") ... Handling bpo-46328在 Python 3.11 之前的版本中,您可以从
sys.exc_info()中获得相同的信息:
>>> try:
... raise ValueError("bpo-46328")
... except ValueError:
... sys.exception() is sys.exc_info()[1] ...
True
的确,sys.exception()和sys.exc_info()[1]是一样的。这个新功能是由 Irit Katriel 在 bpo-46328 中添加的,尽管这个想法最初是在 PEP 3134 中提出的,可以追溯到 2005 年。
一致引用活动回溯
如前一小节所述,Python 的旧版本将异常表示为元组。您可以通过两种不同的方式访问追溯信息:
>>> import sys >>> try: ... raise ValueError("bpo-45711") ... except ValueError: ... exc_type, exc_value, exc_tb = sys.exc_info() ... exc_value.__traceback__ is exc_tb ... True注意,通过
exc_value和exc_tb访问回溯返回完全相同的对象。总的来说,这就是你想要的。然而,事实证明,有一个微妙的错误隐藏了一段时间。您可以在不更新exc_tb的情况下更新对exc_value的追溯。为了演示这一点,编写以下程序,该程序在异常处理期间更改回溯:
1# traceback_demo.py 2 3import sys 4import traceback 5 6def tb_last(tb): 7 frame, *_ = traceback.extract_tb(tb, limit=1) 8 return f"{frame.name}:{frame.lineno}" 9 10def bad_calculation(): 11 return 1 / 0 12 13def main(): 14 try: 15 bad_calculation() 16 except ZeroDivisionError as err: 17 err_tb = err.__traceback__ 18 err = err.with_traceback(err_tb.tb_next) 19 20 exc_type, exc_value, exc_tb = sys.exc_info() 21 print(f"{tb_last(exc_value.__traceback__) = }") 22 print(f"{tb_last(exc_tb) = }") 23 24if __name__ == "__main__": 25 main()您在第 18 行更改了活动异常的回溯。您很快就会看到,这不会更新 Python 3.10 和更早版本中异常元组的回溯部分。为了说明这一点,第 20 到 22 行比较了活动异常和回溯对象引用的回溯的最后一帧。
使用 Python 3.10 或更早版本运行此程序:
$ python traceback_demo.py tb_last(exc_value.__traceback__) = 'bad_calculation:11' tb_last(exc_tb) = 'main:15'这里需要注意的重要一点是,这两个行引用是不同的。活动异常指向更新的位置,即
bad_calculation()内的第 11 行,而回溯指向main()内的旧位置。在 Python 3.11 中,异常元组的回溯部分总是从异常本身读取。因此,不一致性消失了:
$ python3.11 traceback_demo.py tb_last(exc_value.__traceback__) = 'bad_calculation:11' tb_last(exc_tb) = 'bad_calculation:11'现在,访问回溯的两种方式给出了相同的结果。这修复了一个在 Python 中已经存在一段时间的 bug。不过,值得注意的是,这种不一致主要是学术上的。是的,旧的方法是错误的,但是它不太可能在实际代码中引起问题。
这个 bug 修复很有趣,因为它揭开了更大的帷幕。正如您在前一小节中了解到的,Python 的内部异常表示在 3.11 版中发生了变化。这一缺陷修复是这一变化的直接结果。
重构 Python 的异常是优化 Python 许多不同部分的更大努力的一部分。马克·香农已经启动了fast-cpython项目。简化例外只是该计划的想法之一。
您在本节中了解到的较小的改进举例说明了维护和开发编程语言的所有工作,而不仅仅是几个项目占据了大部分标题。您在这里学到的特性都与 Python 的异常处理相关。然而,还有许多其他的小变化也在发生。Python 3.11 中的新特性跟踪所有这些特性。
结论
在本教程中,您了解了 Python 3.11 将于 2022 年 10 月发布时带来的一些新功能。您已经看到了它的一些新特性,并探索了如何利用这些改进。
特别是,你已经:
- 在你的电脑上安装了Python 3.11 的 alpha 版本
- 探索了异常组以及如何使用它们来组织错误
- 使用
except*到过滤异常组和处理不同类型的错误- 重写您的异步代码以使用任务组来启动并发工作流
- 尝试了 Python 3.11 中一些较小的改进,包括异常注释和一个新的内部异常表示
试用 Python 3.11 中的任务和异常组!你有它们的用例吗?在下面评论分享你的经验。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。**************
Python 3.11:很酷的新特性供您尝试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.11 中很酷的新特性
Python 3.11 发布于2022 年 10 月 24 日。Python 的这个最新版本更快,也更用户友好。经过 17 个月的开发,它现在已经可以投入使用了。
和每个版本一样,Python 3.11 也有很多改进和变化。你可以在文档中看到它们的列表。在这里,您将探索最酷、最具影响力的新功能。
在本教程中,您将了解到新的特性和改进,例如:
- 更好的错误消息,提供更多信息的回溯
- 更快的代码执行得益于在更快的 CPython 项目中付出的巨大努力
- 简化异步代码工作的任务和异常组
- 几个新的类型特性改进了 Python 的静态类型支持
- 本地的 TOML 支持使用配置文件
如果你想尝试本教程中的任何例子,那么你需要使用 Python 3.11。Python 3 的安装&安装指南和如何安装 Python 的预发布版本?向您介绍向系统添加新版本 Python 的几个选项。
除了了解更多关于该语言的新特性,您还将获得一些关于升级到新版本之前需要考虑的事项的建议。单击以下链接下载演示 Python 3.11 新功能的代码示例:
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。
更多信息的错误回溯
Python 通常被认为是很好的初学者编程语言,它的可读语法和强大的数据结构。对所有人来说,尤其是对 Python 新手来说,一个挑战是如何解释 Python 遇到错误时显示的回溯。
在 Python 3.10 中,Python 的错误消息被大幅改进。同样,Python 3.11 的最令人期待的特性之一也将提升你的开发者体验。装饰性注释被添加到回溯中,可以帮助您更快地解释错误信息。
要查看增强回溯的快速示例,请将以下代码添加到名为
inverse.py的文件中:# inverse.py def inverse(number): return 1 / number print(inverse(0))你可以用
inverse()来计算一个数的乘逆。0没有乘法逆运算,所以当您运行它时,您的代码会产生一个错误:$ python inverse.py Traceback (most recent call last): File "/home/realpython/inverse.py", line 6, in <module> print(inverse(0)) ^^^^^^^^^^ File "/home/realpython/inverse.py", line 4, in inverse return 1 / number ~~^~~~~~~~ ZeroDivisionError: division by zero注意回溯中嵌入的
^和~符号。它们用于引导您注意导致错误的代码。像通常的回溯一样,你应该从底层开始,一步步向上。在这个例子中,ZeroDivisionError是由分割1 / number引起的。真正的罪魁祸首是召唤inverse(0),因为0没有逆。在发现错误方面获得这种额外的帮助是有用的。然而,如果您的代码更复杂,带注释的回溯甚至更强大。它们也许能够传达你以前无法从回溯本身获得的信息。
为了体会改进的回溯的威力,您将构建一个关于几个程序员的信息的小型解析器。假设您有一个名为
programmers.json的文件,其内容如下:[ {"name": {"first": "Uncle Barry"}}, { "name": {"first": "Ada", "last": "Lovelace"}, "birth": {"year": 1815}, "death": {"month": 11, "day": 27} }, { "name": {"first": "Grace", "last": "Hopper"}, "birth": {"year": 1906, "month": 12, "day": 9}, "death": {"year": 1992, "month": 1, "day": 1} }, { "name": {"first": "Ole-Johan", "last": "Dahl"}, "birth": {"year": 1931, "month": 10, "day": 12}, "death": {"year": 2002, "month": 6, "day": 29} }, { "name": {"first": "Guido", "last": "Van Rossum"}, "birth": {"year": 1956, "month": 1, "day": 31}, "death": null } ]注意,关于程序员的信息是相当不一致的。虽然关于格蕾丝·赫柏和奥利·约翰·达尔的信息是完整的,但是你遗漏了阿达·洛芙莱斯的出生日期和月份以及她的死亡年份。自然,你只有关于吉多·范·罗苏姆的出生信息。更重要的是,你只记录了巴里叔叔的名字。
您将创建一个可以包装这些信息的类。首先从 JSON 文件中读取信息:
# programmers.py import json import pathlib programmers = json.loads( pathlib.Path("programmers.json").read_text(encoding="utf-8") )您使用
pathlib读取 JSON 文件,使用json将信息解析到一个 Python 字典列表中。接下来,您将使用一个数据类来封装关于每个程序员的信息:
# programmers.py from dataclasses import dataclass # ... @dataclass class Person: name: str life_span: tuple[int, int] @classmethod def from_dict(cls, info): return cls( name=f"{info['name']['first']} {info['name']['last']}", life_span=(info["birth"]["year"], info["death"]["year"]), )每个
Person将有一个name和一个life_span属性。此外,您添加了一个方便的构造函数,它可以根据 JSON 文件中的信息和结构初始化Person。您还将添加一个可以一次性初始化两个
Person对象的函数:# programmers.py # ... def convert_pair(first, second): return Person.from_dict(first), Person.from_dict(second)
convert_pair()函数两次使用.from_dict()构造函数将一对程序员从 JSON 结构转换成Person对象。是时候探索您的代码了,尤其是看看一些回溯。运行带有
-i标志的程序,打开 Python 的交互式 REPL,其中包含所有可用的变量、类和函数:$ python -i programmers.py >>> Person.from_dict(programmers[2]) Person(name='Grace Hopper', life_span=(1906, 1992))Grace 的信息是完整的,因此您可以将她的全名和寿命信息封装到一个
Person对象中。要查看新的回溯功能,请尝试转换 Barry 叔叔:
>>> programmers[0]
{'name': {'first': 'Uncle Barry'}}
>>> Person.from_dict(programmers[0])
Traceback (most recent call last):
File "/home/realpython/programmers.py", line 17, in from_dict
name=f"{info['name']['first']} {info['name']['last']}",
~~~~~~~~~~~~^^^^^^^^
KeyError: 'last'
你得到一个 KeyError ,因为last不见了。虽然您可能记得last是name中的一个子字段,但是注释立即为您指出了这一点。
类似地,回想一下关于 Ada 的寿命信息是不完整的。您不能为她创建Person对象:
>>> programmers[1] { 'name': {'first': 'Ada', 'last': 'Lovelace'}, 'birth': {'year': 1815}, 'death': {'month': 11, 'day': 27} } >>> Person.from_dict(programmers[1]) Traceback (most recent call last): File "/home/realpython/programmers.py", line 18, in from_dict life_span=(info["birth"]["year"], info["death"]["year"]), ~~~~~~~~~~~~~^^^^^^^^ KeyError: 'year'您将获得另一个
KeyError,这次是因为year丢失了。在这种情况下,回溯比前面的例子更加有用。您有两个year子字段,一个用于birth,一个用于death。回溯注释会立即显示您缺少了死亡年份。圭多怎么样了?你只有关于他出生的信息:
>>> programmers[4]
{
'name': {'first': 'Guido', 'last': 'Van Rossum'},
'birth': {'year': 1956, 'month': 1, 'day': 31},
'death': None
}
>>> Person.from_dict(programmers[4])
Traceback (most recent call last):
File "/home/realpython/programmers.py", line 18, in from_dict
life_span=(info["birth"]["year"], info["death"]["year"]),
~~~~~~~~~~~~~^^^^^^^^
TypeError: 'NoneType' object is not subscriptable
在这种情况下,会产生一个TypeError。您可能以前见过这种'NoneType'类型的错误。众所周知,它们很难调试,因为不清楚哪个对象是意外的None。但是,从注释中,你会看到这个例子中的info["death"]是 None 。
在最后一个例子中,您将探索嵌套函数调用会发生什么。记住convert_pair()调用Person.from_dict()两次。现在,尝试将 Ada 和 Ole-Johan 配对:
>>> convert_pair(programmers[3], programmers[1]) Traceback (most recent call last): File "/home/realpython/programmers.py", line 24, in convert_pair return Person.from_dict(first), Person.from_dict(second) ^^^^^^^^^^^^^^^^^^^^^^^^ File "/home/realpython/programmers.py", line 18, in from_dict life_span=(info["birth"]["year"], info["death"]["year"]), ~~~~~~~~~~~~~^^^^^^^^ KeyError: 'year'试图封装 Ada 引发了与前面相同的
KeyError。但是,请注意来自convert_pair()内部的回溯。因为该函数调用了.from_dict()两次,所以通常需要花费一些精力来判断在处理first或second时是否出现了错误。在 Python 的最新版本中,您会立即发现这些问题是由second引起的。这些回溯使得 Python 3.11 中的调试比早期版本更容易。你可以在 Python 3.11 预览教程中看到更多的例子,更多关于如何实现回溯的信息,以及其他可以在调试中使用的工具,甚至更好的错误消息。更多技术细节,请看 PEP 657 。
作为 Python 开发人员,带注释的回溯将有助于提高您的工作效率。另一个令人兴奋的发展是 Python 3.11 是迄今为止最快的 Python 版本。
更快的代码执行
Python 以缓慢的语言著称。例如,Python 中的常规循环比 c 中的类似循环要慢几个数量级。通常程序员的生产力比代码执行时间更重要。
Python 也非常能够包装用更快的语言编写的库。例如,在 NumPy 中完成的计算比在纯 Python 中完成的类似计算要快得多。与开发代码的便利性相匹配,这使得 Python 成为数据科学领域的有力竞争者。
尽管如此,还是有一股力量推动核心 Python 语言变得更快。2020 年秋天,Mark Shannon 提出了一些可以在 Python 中实现的性能改进。被称为香农计划的提案非常雄心勃勃,希望在几个版本中将 Python 速度提高五倍。
微软已经加入进来,目前正在支持一组开发人员——包括马克·香农和 Python 的创造者吉多·范·罗苏姆——从事现在所知的更快的 CPython 项目。基于更快的 CPython 项目,Python 3.11 有很多改进。在这一节中,您将了解到专用自适应解释器。在后面的章节中,您还将了解到更快的启动时间和零成本异常。
描述了一个专门化的自适应解释器。主要思想是通过优化经常执行的操作来加速代码的运行。这类似于即时 (JIT)编译,除了它不影响编译。相反,Python 的字节码是动态适应或改变的。
注意: Python 代码在运行前被编译成字节码。字节码由比常规 Python 代码更多的基本指令组成,所以 Python 的每一行都被转换成几个字节码语句。
你可以用
dis来看看 Python 的字节码。例如,考虑一个可以从英尺转换为米的函数:
1>>> def feet_to_meters(feet):
2... return 0.3048 * feet
3...
您可以通过调用dis.dis()将这个函数反汇编成字节码:
>>> import dis >>> dis.dis(feet_to_meters) 1 0 RESUME 0 2 2 LOAD_CONST 1 (0.3048) 4 LOAD_FAST 0 (feet) 6 BINARY_OP 5 (*) 10 RETURN_VALUE每行显示一个字节码指令的信息。这五列分别是行号、字节地址、操作码名称、操作参数以及圆括号内参数的解释。
一般来说,写 Python 不需要了解字节码。不过,它可以帮助您理解 Python 内部是如何工作的。
字节码生成中增加了一个叫做加快的新步骤。这需要在运行时优化指令,并用自适应指令替换它们。每一条这样的指令都会考虑如何使用它,并且可能会相应地对进行特殊化。
一旦一个函数被调用了一定的次数,加速就开始了。在 CPython 3.11 中,这发生在八次调用之后。您可以通过调用
dis()并设置adaptive参数来观察解释器如何适应字节码。首先定义一个函数,用浮点数作为参数调用它七次:
>>> def feet_to_meters(feet):
... return 0.3048 * feet
...
>>> feet_to_meters(1.1)
0.33528
>>> feet_to_meters(2.2)
0.67056
>>> feet_to_meters(3.3)
1.00584
>>> feet_to_meters(4.4)
1.34112
>>> feet_to_meters(5.5)
1.6764000000000001
>>> feet_to_meters(6.6)
2.01168
>>> feet_to_meters(7.7)
2.34696
接下来,看看feet_to_meters()的字节码:
>>> import dis >>> dis.dis(feet_to_meters, adaptive=True) 1 0 RESUME 0 2 2 LOAD_CONST 1 (0.3048) 4 LOAD_FAST 0 (feet) 6 BINARY_OP 5 (*) 10 RETURN_VALUE你还不会观察到什么特别的东西。字节码的这个版本仍然与非自适应版本相同。当您第八次调用
feet_to_meters()时,情况会发生变化:
>>> feet_to_meters(8.8)
2.68224
>>> dis.dis(feet_to_meters, adaptive=True)
1 0 RESUME_QUICK 0
2 2 LOAD_CONST__LOAD_FAST 1 (0.3048) 4 LOAD_FAST 0 (feet)
6 BINARY_OP_MULTIPLY_FLOAT 5 (*) 10 RETURN_VALUE
现在,原来的几个说明已经被专门的取代了。例如,BINARY_OP已经被专门化为BINARY_OP_MULTIPLY_FLOAT,它在两个float数相乘时更快。
即使feet_to_meters()已经针对feet是一个float参数的情况进行了优化,它仍然通过退回到原始的字节码指令来正常工作于其他类型的参数。内部操作发生了变化,但是您的代码将与以前完全一样。
专用指令仍然是自适应的。再调用你的函数 52 次,但是现在用一个整数参数:
>>> for feet in range(52): ... feet_to_meters(feet) ... >>> dis.dis(feet_to_meters, adaptive=True) 1 0 RESUME_QUICK 0 2 2 LOAD_CONST__LOAD_FAST 1 (0.3048) 4 LOAD_FAST 0 (feet) 6 BINARY_OP_MULTIPLY_FLOAT 5 (*) 10 RETURN_VALUEPython 解释器仍然希望能够将两个
float数字相乘。当您用整数再次调用feet_to_meters()时,它会重新提交并转换回一个非专门化的自适应指令:
>>> feet_to_meters(52)
15.8496
>>> dis.dis(feet_to_meters, adaptive=True)
1 0 RESUME_QUICK 0
2 2 LOAD_CONST__LOAD_FAST 1 (0.3048)
4 LOAD_FAST 0 (feet)
6 BINARY_OP_ADAPTIVE 5 (*) 10 RETURN_VALUE
在这种情况下,字节码指令被改为BINARY_OP_ADAPTIVE而不是BINARY_OP_MULTIPLY_INT,因为其中一个操作符0.3048总是浮点数。
整数和浮点数之间的乘法比同类型数字之间的乘法更难优化。至少目前没有专门的指令来做float和int之间的乘法。
这个例子旨在让您对自适应专门化解释器的工作原理有所了解。一般来说,您不应该担心更改现有代码来利用它。您的大部分代码实际上会运行得更快。
也就是说,在一些情况下,您可以重构您的代码,以便更有效地进行专门化。Brandt Bucher 的 specialist 是一个可视化解释器如何处理你的代码的工具。教程展示了一个手工改进代码的例子。您可以在与我谈论 Python 播客上了解更多信息。
更快的 CPython 项目的几个重要准则是:
- 该项目不会对 Python 引入任何突破性的改变。
- 大多数代码的性能都应该得到提高。
在基准测试中,“CPython 3.11 平均比 CPython 3.10 快 25%”(来源)。然而,你应该更感兴趣的是 Python 3.11 在你的代码上的表现,而不是它在基准测试中的表现。展开下面的方框,了解如何衡量自己代码的性能:
一般来说,有三种方法可以用来衡量代码性能:
- 对程序中重要的小段代码进行基准测试。
- 剖析你的程序,找出可以改进的瓶颈。
- 监控整个程序的性能。
通常情况下,您希望完成所有这些任务。基准可以在你开发代码的时候帮助你在不同的实现之间选择。Python 内置了对带有 timeit 模块的微基准测试的支持。第三方的 richbench 工具对于基准函数来说是不错的。此外, pyperformance 是更快的 CPython 项目用来衡量改进的基准套件。
如果你需要加速你的程序,并且想弄清楚应该关注哪部分代码,那么代码分析器会很有用。Python 的标准库提供了 cProfile ,您可以用它来收集关于您的程序的统计数据,还提供了 pstats ,您可以用它来研究那些统计数据。
第三种方法,监控你的程序的运行时间,这是你应该对所有运行超过几秒钟的程序做的事情。最简单的方法是在您的日志消息中添加一个计时器。第三方的 codetiming 允许你这样做,例如通过给你的主函数添加一个装饰器。
让 Python 变得更快的一个可行且重要的方法是分享举例说明您的用例的基准。特别是如果你没有注意到 Python 3.11 中的加速,如果你能够分享你的代码,这对核心开发者来说是有帮助的。有关更多信息,请参见 Mark Shannon 的闪电演讲如何帮助提升 Python 的速度。
更快的 CPython 项目是一项正在进行的工作,已经有几项优化计划在 2023 年 10 月发布的 Python 3.12 中发布。你可以在 GitHub 上关注这个项目。要了解更多信息,您还可以查看以下讨论和演示:
- 跟我说说 Python:用 Guido 和 Mark 让 Python 更快
- 欧洲 Python 2022: 我们如何让 Python 3.11 更快马克·香农
- 跟我说说 Python:Python Perf:specialized,Adaptive Interpreter 与 Brandt Bucher
- PyCon 是:更快的 CPython 项目:我们怎样使 Python 3.11 更快【由 Pablo Galindo Salgado,西班牙语介绍]
更快的 CPython 是一个庞大的项目,涉及 Python 的所有部分。自适应专门化解释器就是其中的一部分。在本教程的后面,您将了解另外两种优化:更快的启动和零成本异常。
更好的异步任务语法
Python 中对异步编程的支持已经发展了很长时间。随着生成器的加入,Python 2 时代奠定了基础。Python 3.4 中最初增加了 asyncio 库,Python 3.5 中又跟进了async``await关键字。
这种开发在以后的版本中继续进行,对 Python 的异步功能进行了许多小的改进。在 Python 3.11 中,您可以使用任务组,它为运行和监控异步任务提供了更清晰的语法。
注意:如果您还不熟悉 Python 中的异步编程,那么您可以查阅以下资源开始学习:
您还可以在 Python 3.11 预览版:任务和异常组中了解关于异步任务组的更多细节。
asyncio库是 Python 标准库的一部分。然而,这并不是异步工作的唯一方式。有几个流行的第三方图书馆提供同样的功能,包括三重奏和古玩。此外,像 uvloop 、 AnyIO 、 Quattro 这样的包增强了asyncio更好的性能和更多的功能。
用asyncio运行几个异步任务的传统方式是用 create_task() 创建任务,然后用 gather() 等待它们。这就完成了任务,但是有点麻烦。
为了组织孩子的任务,Curio 引入了任务组,Trio 引入了托儿所作为替代。新的asyncio任务组深受这些的启发。
当您使用gather()组织异步任务时,部分代码通常如下所示:
tasks = [asyncio.create_task(run_some_task(param)) for param in params]
await asyncio.gather(*tasks)
在将任务传递给gather()之前,手动跟踪列表中的所有任务。通过等待gather(),你可以确保在继续前进之前完成每项任务。
对于任务组,等价的代码更加简单。不使用gather(),而是使用上下文管理器来定义任务等待的时间:
async with asyncio.TaskGroup() as tg:
for param in params:
tg.create_task(run_some_task(param))
您创建一个任务组对象,在本例中命名为tg,并使用它的.create_task()方法来创建新任务。
要查看完整的示例,请考虑下载几个文件的任务。您想下载一些历史 PEP 文档的文本,这些文档展示了 Python 的异步特性是如何发展的。为了提高效率,您将使用第三方库 aiohttp 来异步下载文件。
首先导入必要的库,记下存储每个 PEP 文本的库的 URL:
# download_peps_gather.py
import asyncio
import aiohttp
PEP_URL = (
"https://raw.githubusercontent.com/python/peps/master/pep-{pep:04d}.txt"
)
async def main(peps):
async with aiohttp.ClientSession() as session:
await download_peps(session, peps)
您添加了一个初始化一个aiohttp会话的main()函数来管理可能被重用的连接池。现在,您正在调用一个名为download_peps()的函数,而您还没有编写这个函数。该函数将为每个需要下载的 PEP 创建一个任务:
# download_peps_gather.py
# ...
async def download_peps(session, peps):
tasks = [asyncio.create_task(download_pep(session, pep)) for pep in peps]
await asyncio.gather(*tasks)
这符合您之前看到的模式。每个任务都由运行download_pep()组成,接下来您将对其进行定义。一旦你设置好所有的任务,你就把它们传递给gather()。
每个任务下载一个 PEP。您将添加几个print()呼叫,这样您就可以看到发生了什么:
# download_peps_gather.py
# ...
async def download_pep(session, pep):
print(f"Downloading PEP {pep}")
url = PEP_URL.format(pep=pep)
async with session.get(url, params={}) as response:
pep_text = await response.text()
title = pep_text.split("\n")[1].removeprefix("Title:").strip()
print(f"Downloaded PEP {pep}: {title}")
对于每个 PEP,您可以找到它自己的 URL 并使用session.get()下载它。一旦有了 PEP 的文本,就可以找到 PEP 的标题并将其打印到控制台。
最后,异步运行main():
# download_peps_gather.py
# ...
asyncio.run(main([492, 525, 530, 3148, 3156]))
您正在用 PEP 编号列表调用您的代码,所有这些都与 Python 中的异步特性相关。运行您的脚本,看看它是如何工作的:
$ python download_peps_gather.py
Downloading PEP 492
Downloading PEP 525
Downloading PEP 530
Downloading PEP 3148
Downloading PEP 3156
Downloaded PEP 3148: futures - execute computations asynchronously
Downloaded PEP 492: Coroutines with async and await syntax
Downloaded PEP 530: Asynchronous Comprehensions
Downloaded PEP 3156: Asynchronous IO Support Rebooted: the "asyncio" Module
Downloaded PEP 525: Asynchronous Generators
您可以看到所有的下载都是同时发生的,因为所有的任务都显示它们在任何任务报告完成之前开始下载 PEP。另外,请注意,任务是按照您定义的顺序启动的,pep 是按照数字顺序启动的。
相反,任务似乎是以随机的顺序完成的。对gather()的调用确保了所有的任务都在代码继续之前完成。
您可以更新您的代码来使用任务组而不是gather()。首先,将download_peps_gather.py复制到名为download_peps_taskgroup.py的新文件中。这些文件将非常相似。您只需要编辑download_peps()功能:
# download_peps_taskgroup.py
# ...
async def download_peps(session, peps):
async with asyncio.TaskGroup() as tg:
for pep in peps:
tg.create_task(download_pep(session, pep))
# ...
请注意,您的代码遵循示例之前概述的一般模式。首先在上下文管理器中建立一个任务组,然后使用该任务组创建子任务:每个 PEP 下载一个任务。运行更新后的代码,观察它的行为是否与早期版本相同。
当您处理几个异步任务时,一个挑战是它们中的任何一个都可能在任何时候引发错误。理论上,两个或更多的任务甚至可以同时引发一个错误。
像 Trio 和 Curio 这样的库已经用一种特殊的多错误对象处理了这个问题。这是可行的,但是有点麻烦,因为 Python 没有提供太多的内置支持。
为了正确支持任务组中的错误处理,Python 3.11 引入了异常组,用于跟踪几个并发错误。稍后在本教程中,你会学到更多关于他们的知识。
任务组使用异常组来提供比旧方法更好的错误处理支持。关于任务组的更深入的讨论,请参见 Python 3.11 预览版:任务和异常组。你可以在吉多·范·罗苏姆关于asyncio.Semaphore 的推理中了解更多的基本原理。
改进类型变量
Python 是一种动态类型语言,但是它通过可选的类型提示支持静态类型。Python 的静态类型系统的基础是在 2015 年 PEP 484 中定义的。从 Python 3.5 开始,每个 Python 版本都引入了几个与类型相关的新提议。
Python 3.11 宣布了五个与类型相关的 pep,创历史新高:
在这一节中,您将关注其中的两个:可变泛型和Self类型。要了解更多信息,请查看 PEP 文档和在这个 Python 3.11 预览版中输入的覆盖范围。
注意:除了 Python 版本之外,对类型化特性的支持还取决于您的类型检查器。例如,在 Python 3.11 发布时, mypy 不支持的几个新特性。
从开始,类型变量就已经是 Python 静态类型系统的一部分。你用它们来参数化通用类型。换句话说,如果您有一个列表,那么您可以使用类型变量来检查列表中项目的类型:
from typing import Sequence, TypeVar
T = TypeVar("T")
def first(sequence: Sequence[T]) -> T:
return sequence[0]
first()函数从一个序列类型中挑选出第一个元素,比如一个列表。不管序列元素的类型如何,代码都是一样的。尽管如此,您仍然需要跟踪元素类型,以便知道first()的返回类型。
类型变量正是这样做的。例如,如果您将一个整数列表传递给first(),那么在类型检查期间T将被设置为int。因此,类型检查器可以推断出对first()的调用返回了int。在这个例子中,列表被称为通用类型,因为它可以被其他类型参数化。
随着时间的推移,发展起来的一种模式试图解决引用当前类的类型提示问题。回忆一下之前的Person课:
# programmers.py
from dataclasses import dataclass
# ...
@dataclass
class Person:
name: str
life_span: tuple[int, int]
@classmethod
def from_dict(cls, info):
return cls(
name=f"{info['name']['first']} {info['name']['last']}",
life_span=(info["birth"]["year"], info["death"]["year"]),
)
.from_dict()构造函数返回一个Person对象。然而,不允许使用-> Person作为.from_dict()返回值的类型提示,因为Person类在你的代码中还没有完全定义。
此外,如果你被允许使用-> Person,那么这将不能很好地与继承一起工作。如果你创建了一个Person的子类,那么.from_dict()将返回那个子类,而不是一个Person对象。
这个挑战的一个解决方案是使用绑定到您的类的类型变量:
# programmers.py
# ...
from typing import Any, Type, TypeVar
TPerson = TypeVar("TPerson", bound="Person")
@dataclass
class Person:
name: str
life_span: tuple[int, int]
@classmethod
def from_dict(cls: Type[TPerson], info: dict[str, Any]) -> TPerson: return cls(
name=f"{info['name']['first']} {info['name']['last']}",
life_span=(info["birth"]["year"], info["death"]["year"]),
)
你指定了bound来确保TPerson永远只能是Person或者它的一个子类。这种模式是可行的,但是可读性不是特别好。它还迫使你注释self或cls,这通常是不必要的。
你现在可以使用新的 Self 类型来代替。它总是引用封装类,所以你不必手动定义一个类型变量。以下代码等效于前面的示例:
# programmers.py
# ...
from typing import Any, Self
@dataclass
class Person:
name: str
life_span: tuple[int, int]
@classmethod
def from_dict(cls, info: dict[str, Any]) -> Self: return cls(
name=f"{info['name']['first']} {info['name']['last']}",
life_span=(info["birth"]["year"], info["death"]["year"]),
)
可以从typing导入Self。你不需要创建一个类型变量或者注释cls。相反,您会注意到该方法返回了Self,它将引用Person。
关于如何使用Self的另一个例子,参见 Python 3.11 预览版。你也可以查看 PEP 673 了解更多详情。
类型变量的一个限制是它们一次只能代表一种类型。假设您有一个翻转二元元组顺序的函数:
# pair_order.py
def flip(pair):
first, second = pair
return (second, first)
这里,pair假设是一个有两个元素的元组。元素可以是不同的类型,因此需要两个类型变量来注释函数:
# pair_order.py
from typing import TypeVar
T0 = TypeVar("T0") T1 = TypeVar("T1")
def flip(pair: tuple[T0, T1]) -> tuple[T1, T0]:
first, second = pair
return (second, first)
这个写起来有点繁琐,不过还是可以的。注释是清晰易读的。如果您想要注释代码的变体,该变体适用于具有任意数量元素的元组,那么挑战就来了:
# tuple_order.py
def cycle(elements):
first, *rest = elements
return (*rest, first)
使用cycle(),将第一个元素移动到一个包含任意数量元素的元组的末尾。如果你传入一对元素,那么这相当于flip()。
想想你会如何注释cycle()。如果elements是一个有 n 个元素的元组,那么你需要 n 个类型变量。但是元素的数量可以是任意的,所以你不知道你需要多少类型变量。
PEP 646 引入 TypeVarTuple 来处理这个用例。一个TypeVarTuple可以代表任意数量的类型。因此,您可以用它来注释带有变量参数的泛型类型。
您可以向cycle()添加类型提示,如下所示:
# tuple_order.py
from typing import TypeVar, TypeVarTuple
T0 = TypeVar("T0") Ts = TypeVarTuple("Ts")
def cycle(elements: tuple[T0, *Ts]) -> tuple[*Ts, T0]:
first, *rest = elements
return (*rest, first)
TypeVarTuple将替换任意数量的类型,因此该注释将适用于具有一个、三个、十一个或任何其他数量元素的元组。
注意,Ts前面的星号(*)是语法的必要部分。它类似于你已经在代码中使用的解包语法,它提醒你Ts代表任意数量的类型。
引入类型变量元组的激励用例是注释多维数组的形状。你可以在这个 Python 3.11 预览版和 PEP 中了解更多关于这个例子的信息。
在结束关于类型提示的这一节之前,请记住静态类型结合了两种不同的工具:Python 语言和类型检查器。要使用新的输入功能,您的 Python 版本必须支持它们。此外,它们需要得到您的类型检查器的支持。
在 typing_extensions 包中,包括Self和TypeVarTuple在内的许多输入特性都被移植到了旧版本的 Python 中。在 Python 3.10 上,您可以使用 pip 将typing-extensions安装到您的虚拟环境中,然后实现最后一个示例,如下所示:
# tuple_order.py
from typing_extensions import TypeVar, TypeVarTuple, Unpack
T0 = TypeVar("T0")
Ts = TypeVarTuple("Ts")
def cycle(elements: tuple[T0, Unpack[Ts]]) -> tuple[Unpack[Ts], T0]:
first, *rest = elements
return (*rest, first)
只有 Python 3.11 才允许使用*Ts语法。一个在旧版本 Python 上工作的等价替代是Unpack[Ts]。即使你的代码可以在你的 Python 版本上运行,也不是所有的类型检查器都支持 TypeVarTuple。
支持 TOML 配置解析
TOML 是汤姆明显最小语言的简称。这是一种配置文件格式,在过去十年中变得很流行。当为包和项目指定元数据时,Python 社区已经将 TOML 作为首选格式。
TOML 被设计成易于人类阅读和计算机解析。你可以在 Python 和 TOML: New Best Friends 中了解配置文件格式本身。
虽然 TOML 已经被许多不同的工具使用了很多年,但是 Python 还没有内置的 TOML 支持。Python 3.11 中的变化是,当 tomllib 被添加到标准库中。这个新模块建立在流行的第三方库 tomli 之上,允许你解析 TOML 文件。
下面是一个名为units.toml的 TOML 文件的例子:
# units.toml [second] label = { singular = "second", plural = "seconds" } aliases = ["s", "sec", "seconds"] [minute] label = { singular = "minute", plural = "minutes" } aliases = ["min", "minutes"] multiplier = 60 to_unit = "second" [hour] label = { singular = "hour", plural = "hours" } aliases = ["h", "hr", "hours"] multiplier = 60 to_unit = "minute" [day] label = { singular = "day", plural = "days" } aliases = ["d", "days"] multiplier = 24 to_unit = "hour" [year] label = { singular = "year", plural = "years" } aliases = ["y", "yr", "years", "julian_year", "julian years"] multiplier = 365.25 to_unit = "day"
该文件包含几个部分,标题在方括号中。每个这样的部分在 TOML 中被称为一个表,它的标题被称为一个键。表格包含键值对。表格可以嵌套,这样值就是新的表格。在上面的例子中,你可以看到除了second之外的每个表都有相同的结构,有四个键:label、aliases、multiplier和to_unit。
值可以有不同的类型。在本例中,您可以看到四种数据类型:
label是一个内联表,类似于 Python 的字典。aliases是一个数组,类似于 Python 的 list。multiplier是一个数,可以是整数,也可以是浮点数。to_unit是一根弦。
TOML 支持更多的数据类型,包括布尔值和日期。请参见 Python 和 TOML:新的最好的朋友以深入了解该格式及其语法示例。
您可以使用tomllib来读取一个 TOML 文件:
>>> import tomllib >>> with open("units.toml", mode="rb") as file: ... units = tomllib.load(file) ... >>> units {'second': {'label': {'singular': 'second', 'plural': 'seconds'}, ... }}当使用
tomllib.load()时,你通过指定mode="rb"传入一个必须在二进制模式下打开的文件对象。或者,您可以用tomllib.loads()解析一个字符串:
>>> import tomllib
>>> import pathlib
>>> units = tomllib.loads(
... pathlib.Path("units.toml").read_text(encoding="utf-8")
... )
>>> units
{'second': {'label': {'singular': 'second', 'plural': 'seconds'}, ... }}
在这个例子中,首先使用 pathlib 将units.toml读入一个字符串,然后用loads()解析这个字符串。TOML 文件应该存储在一个 UTF-8 编码中。您应该明确地为指定编码,以确保您的代码在所有平台上都运行相同。
接下来,把注意力转向调用load()或loads()的结果。在上面的例子中,你可以看到units是一个嵌套的字典。情况总是这样:tomllib将 TOML 文档解析成 Python 字典。
在本节的其余部分,您将练习在 Python 中使用 TOML 数据。您将创建一个小的单元转换器,它解析您的 TOML 文件并使用生成的字典。
注意:如果你真的在做单位转换,那么你应该看看品脱。这个库可以在数百个单位之间转换,并且很好地集成到其他包中,比如 NumPy 。
将您的代码添加到名为units.py的文件中:
# units.py
import pathlib
import tomllib
# Read units from file
with pathlib.Path("units.toml").open(mode="rb") as file:
base_units = tomllib.load(file)
您希望能够通过名称或别名来查找每个单元。您可以通过复制单元信息来实现这一点,这样每个别名都可以用作字典键:
# units.py
# ...
units = {}
for unit, unit_info in base_units.items():
units[unit] = unit_info
for alias in unit_info["aliases"]:
units[alias] = unit_info
例如,您的units字典现在将有键second以及它的别名s、sec和seconds都指向second表。
接下来,您将定义to_baseunit(),它可以将 TOML 文件中的任何单元转换为其对应的基本单元。在本例中,基本单位始终是second。但是,您可以扩展该表,以包括以meter为基本单位的长度单位。
将to_baseunit()的定义添加到文件中:
# units.py
# ...
def to_baseunit(value, from_unit):
from_info = units[from_unit]
if "multiplier" not in from_info:
return (
value,
from_info["label"]["singular" if value == 1 else "plural"],
)
return to_baseunit(value * from_info["multiplier"], from_info["to_unit"])
您将to_baseunit()实现为一个递归函数。如果对应于from_unit的表不包含multiplier字段,那么您将该单元视为基本单元并返回其值和名称。另一方面,如果有一个multiplier字段,那么您转换到链中的下一个单元,并再次调用to_baseunit()。
启动你的 REPL 。然后,导入units并转换几个数字:
>>> import units >>> units.to_baseunit(7, "s") (7, 'seconds') >>> units.to_baseunit(3.11, "minutes") (186.6, 'seconds')在第一个例子中,
"s"被解释为second,因为它是一个别名。既然这是基地单位,7就原封不动地返回。在第二个例子中,"minutes"让您的函数在minute表中查找。它发现可以通过乘以60转换成second。转化链可能会更长:
>>> units.to_baseunit(14, "days")
(1209600, 'seconds')
>>> units.to_baseunit(1 / 12, "yr")
(2629800.0, 'seconds')
为了将"days"转换为其基本单位,您的函数首先将day转换为hour,然后将hour转换为minute,最后将minute转换为second。你发现十四天大约有 120 万秒,一年的十二分之一大约有 260 万秒。
注意:在这个例子中,您使用 TOML 文件来存储关于您的单元转换器所支持的单元的信息。您也可以通过将base_units定义为一个文字字典,将信息直接放入代码中。
但是,使用配置文件带来了几个与代码和数据分离相关的优点:
- 你的逻辑从你的数据中分离出来。
- 非开发者可以贡献到你的单元转换器中,而不需要接触——甚至不需要了解——Python 代码。
- 只需最少的努力,您就可以支持额外的单元配置文件。用户可以添加这些,以便在转换器中包含自定义单位。
您应该考虑为您使用的任何项目设置一个配置文件。
如前所述,tomllib基于tomli。如果你想在需要支持旧 Python 版本的代码中解析 TOML 文档,那么你可以安装tomli 并把它作为tomllib 的后端口,如下所示:
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
在 Python 3.11 上,这照常导入tomllib。在 Python 的早期版本中,导入会引发一个ModuleNotFoundError。在这里,您捕捉错误并导入tomli,同时将其别名化为名称tomllib,这样您的代码的其余部分就可以不变地工作。
你可以在 Python 3.11 预览版:TOML 和tomllib 中了解更多关于tomllib的内容。此外, PEP 680 概述了导致tomllib被添加到 Python 的讨论。
其他非常酷的功能
到目前为止,您已经了解了 Python 3.11 中最大的变化和改进。然而,还有更多的功能需要探索。在本节中,您将了解一些可能隐藏在标题下的新特性。它们包括更多的加速、对异常的更多修改以及对字符串格式的一点改进。
更快启动
更快的 CPython 项目的另一个令人兴奋的结果是更快的启动时间。运行 Python 脚本时,解释器初始化时会发生几件事。这导致即使是最简单的程序也需要几毫秒才能运行:
PS> Measure-Command {python -c "pass"}
...
TotalMilliseconds : 25.9823
$ time python -c "pass"
real 0m0,020s
user 0m0,012s
sys 0m0,008s
$ time python -c "pass"
python -c "pass"
0.02s user
0.01s system
90% cpu
0.024 total
您使用-c在命令行上直接传递一个程序。在这种情况下,您的整个程序由一个pass语句组成,它什么也不做。
在许多情况下,与运行代码所需的时间相比,启动程序所需的时间可以忽略不计。但是,在运行时间较短的脚本中,比如典型的命令行应用程序,启动时间可能会显著影响程序的性能。
作为一个具体的例子,考虑下面的脚本——受经典的 cowsay 程序的启发:
# snakesay.py
import sys
message = " ".join(sys.argv[1:])
bubble_length = len(message) + 2
print(
rf"""
{"_" * bubble_length} ( {message} )
{"‾" * bubble_length} \
\ __
\ [oo]
(__)\
λ \\
_\\__
(_____)_
(________)Oo°"""
)
在snakesay.py中,你从命令行中读到一条消息。然后,你在一个伴随着可爱的蛇的讲话泡泡里打印信息。现在,你可以让蛇说任何话:
$ python snakesay.py Faster startup!
_________________
( Faster startup! )
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
\
\ __
\ [oo]
(__)\
λ \\
_\\__
(_____)_
(________)Oo°
这是一个命令行应用程序的基本示例。像许多其他命令行应用程序一样,它运行速度很快。尽管如此,它还需要几毫秒才能运行。这种开销的很大一部分是在 Python 导入模块时发生的,甚至有些模块不是您自己显式导入的。
您可以使用 -X importtime选项来显示导入模块所用时间的概述:
$ python -X importtime -S snakesay.py Imports are faster!
import time: self [us] | cumulative | imported package
import time: 283 | 283 | _io
import time: 56 | 56 | marshal
import time: 647 | 647 | posix
import time: 587 | 1573 | _frozen_importlib_external
import time: 167 | 167 | time
import time: 191 | 358 | zipimport
import time: 90 | 90 | _codecs
import time: 561 | 651 | codecs
import time: 825 | 825 | encodings.aliases
import time: 1136 | 2611 | encodings
import time: 417 | 417 | encodings.utf_8
import time: 174 | 174 | _signal
import time: 56 | 56 | _abc
import time: 251 | 306 | abc
import time: 310 | 616 | io
_____________________
( Imports are faster! )
‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾
\
\ __
\ [oo]
(__)\
λ \\
_\\__
(_____)_
(________)Oo°
表中的数字以微秒为单位。注意最后一列中模块名称的格式。树形结构表明有几个顶级模块,这些模块导入其他模块。例如,io是顶级导入,而abc是由io导入的。
注意:你使用了上面的-S选项。根据文档,这将“禁用模块site的导入和它所需要的sys.path的站点相关操作”(源)。
对于这个简单的程序,-S使它运行得更快,因为需要的导入更少。然而,这不是一个可以在大多数脚本中使用的优化,因为您不能导入任何第三方库。
该示例在 Python 3.11 上运行。下表以微秒为单位将这些数字与使用 Python 3.10 运行相同命令进行了比较:
| 组件 | Python 3.11 | Python 3.10 | 加速 |
|---|---|---|---|
_frozen_importlib_external |
One thousand five hundred and seventy-three | Two thousand two hundred and fifty-five | 1.43 倍 |
zipimport |
Three hundred and fifty-eight | Five hundred and fifty-eight | 1.56 倍 |
encodings |
Two thousand six hundred and eleven | Three thousand and nine | 1.15 倍 |
encodings.utf_8 |
Four hundred and seventeen | Four hundred and nine | 0.98 倍 |
_signal |
One hundred and seventy-four | One hundred and seventy-three | 0.99x |
io |
Six hundred and sixteen | One thousand two hundred and sixteen | 1.97 倍 |
| 总计 | 5749 | 7620 | 1.33x |
您的数字会有所不同,但您应该会看到相同的模式。Python 3.11 的导入速度更快,这有助于 Python 程序更快地启动。
速度加快的一个重要原因是缓存的字节码是如何存储和读取的。正如您所了解的,Python 将源代码编译成由解释器运行的字节码。在长时间中,Python 将编译后的字节码存储在一个名为 __pycache__ 的目录中,以避免不必要的重新编译。
但是在 Python 的最新版本中,许多模块都被冻结了,并以一种更快的方式存储在内存中。你可以在文档中了解更多关于快速启动的信息。
零成本例外
Python 3.11 中异常的内部表示是不同的。异常对象更加轻量级,异常处理也发生了变化,因此只要不触发except子句,在try … except块中就几乎没有开销。
所谓的零成本异常是受 C++和 Java 等其他语言的启发。我们的目标是快乐之路——当没有出现异常时——实际上应该是免费的。处理异常仍然需要一些时间。
当源代码被编译成字节码时,通过让编译器创建跳转表来实现零成本异常。如果出现异常,将参考这些表。如果没有异常,那么try块中的代码就没有运行时开销。
回想一下您之前与合作的乘法逆运算示例。您添加了一些错误处理:
1>>> def inverse(number): 2... try: 3... return 1 / number 4... except ZeroDivisionError: 5... print("0 has no inverse") 6...如果你试图计算零的倒数,那么就会产生一个
ZeroDivisionError。在您的新实现中,您捕获这些错误并打印一条描述性消息。和以前一样,您使用dis来查看幕后的字节码:
>>> import dis
>>> dis.dis(inverse)
1 0 RESUME 0
2 2 NOP
3 4 LOAD_CONST 1 (1)
6 LOAD_FAST 0 (number)
8 BINARY_OP 11 (/)
12 RETURN_VALUE
>> 14 PUSH_EXC_INFO
4 16 LOAD_GLOBAL 0 (ZeroDivisionError)
28 CHECK_EXC_MATCH
30 POP_JUMP_FORWARD_IF_FALSE 19 (to 70)
32 POP_TOP
5 34 LOAD_GLOBAL 3 (NULL + print)
46 LOAD_CONST 2 ('0 has no inverse')
48 PRECALL 1
52 CALL 1
62 POP_TOP
64 POP_EXCEPT
66 LOAD_CONST 0 (None)
68 RETURN_VALUE
4 >> 70 RERAISE 0
>> 72 COPY 3
74 POP_EXCEPT
76 RERAISE 1
ExceptionTable:
4 to 10 -> 14 [0] 14 to 62 -> 72 [1] lasti 70 to 70 -> 72 [1] lasti
你不需要理解字节码的细节。但是,您可以将最左边一列中的数字与源代码中的行号进行比较。注意,第 2 行是try:,被翻译成单个 NOP 指令。这是一个无操作,它什么也不做。更有趣的是,反汇编的最后是一个异常表。这是解释器在需要处理异常时使用的跳转表。
在 Python 3.10 和更早的版本中,运行时有一点异常处理。例如,try语句被编译成包含指向第一个异常块的指针的 SETUP_FINALLY 指令。用跳转表替换它可以在异常没有出现时加速try块。
零成本异常很好地适应了一种的更容易请求宽恕而不是许可的代码风格,这种风格通常使用大量的try … except块。
异常组
之前,您学习了任务组以及它们如何能够同时处理几个错误。他们通过一个叫做异常组的新特性来做到这一点。
考虑异常组的一种方式是,它们是包装几个其他常规异常的常规异常。然而,尽管异常组在许多方面表现得像常规异常,但它们也支持特殊的语法,帮助您有效地处理每个包装的异常。
通过为例外组提供描述并列出它所包装的例外,可以创建例外组:
>>> ExceptionGroup("twice", [TypeError("int"), ValueError(654)]) ExceptionGroup('twice', [TypeError('int'), ValueError(654)])这里您已经创建了一个描述为
"twice"的异常组,它包装了一个TypeError和一个ValueError。如果一个异常组在没有被处理的情况下被引发,那么它会显示一个很好的回溯来说明错误的分组和嵌套:
>>> raise ExceptionGroup("twice", [TypeError("int"), ValueError(654)])
+ Exception Group Traceback (most recent call last):
| File "<stdin>", line 1, in <module>
| ExceptionGroup: twice (2 sub-exceptions)
+-+---------------- 1 ----------------
| TypeError: int
+---------------- 2 ----------------
| ValueError: 654
+------------------------------------
此错误消息说明引发了一个包含两个子异常的异常组。每个包装的异常都显示在它自己的面板中。
除了引入异常组之外,新版本的 Python 还添加了新的语法来有效地使用它们。你可以做except ExceptionGroup as eg并且循环eg中的每个错误。然而,这很麻烦。相反,你应该使用新的except*关键字:
>>> try: ... raise ExceptionGroup("twice", [TypeError("int"), ValueError(654)]) ... except* ValueError as err: ... print(f"handling ValueError: {err.exceptions}") ... except* TypeError as err: ... print(f"handling TypeError: {err.exceptions}") ... handling ValueError: (ValueError(654),) handling TypeError: (TypeError('int'),)与常规的
except语句相比,几个except*语句可以触发。在这个例子中,ValueError和TypeError都被处理了。异常组中未处理的异常将停止你的程序,并照常显示回溯。请注意,由
except*处理的错误被过滤出该组:
>>> try:
... raise ExceptionGroup("twice", [TypeError("int"), ValueError(654)])
... except* ValueError as err:
... print(f"handling ValueError: {err.exceptions}")
...
handling ValueError: (ValueError(654),)
+ Exception Group Traceback (most recent call last):
| File "<stdin>", line 2, in <module>
| ExceptionGroup: twice (1 sub-exception)
+-+---------------- 1 ----------------
| TypeError: int
+------------------------------------
你处理了ValueError,但是TypeError没有被触动。这反映在回溯中,这里的twice异常组现在只有一个子异常。
异常组和except*语法不会取代常规异常和普通的except。事实上,您可能不会有很多自己创建异常组的用例。相反,他们将主要由像asyncio这样的图书馆抚养。
用except*可以捕捉常规异常。尽管如此,在大多数情况下,你还是希望坚持使用普通的except,并且只对实际上可能引发异常组的代码使用except*。
要了解更多关于异常组如何工作、如何嵌套以及except*的全部功能,请参见 Python 3.11 预览版:任务和异常组。Python 的核心开发者之一 Irit Katriel 在 2021 年的 Python 语言峰会和 2022 年的 PyCon UK 上展示了异常组。
你可以在 PEP 654 中阅读更多关于异常组的动机和导致当前实现的讨论。
异常注释
常规异常的一个扩展是添加任意注释的能力。PEP 678 描述了如何使用这些注释在不同于最初引发异常的代码段中向异常添加信息。例如,像假设这样的测试库可以添加关于哪个测试失败的信息。
您可以使用.add_note()向任何异常添加注释,并通过检查.__notes__属性查看现有注释:
>>> err = ValueError(678) >>> err.add_note("Enriching Exceptions with Notes") >>> err.add_note("Python 3.11") >>> err.__notes__ ['Enriching Exceptions with Notes', 'Python 3.11'] >>> raise err Traceback (most recent call last): ... ValueError: 678 Enriching Exceptions with Notes Python 3.11如果出现错误,任何相关的注释都会打印在追溯的底部。
在下面的例子中,您将主循环包装在一个
try…except块中,该块为错误添加了一个时间戳。如果您需要将错误消息与程序的运行中的日志进行比较,这可能会很有用:# timestamped_errors.py from datetime import datetime def main(): inverse(0) def inverse(number): return 1 / number if __name__ == "__main__": try: main() except Exception as err: err.add_note(f"Raised at {datetime.now()}") raise正如你之前看到的,这个程序计算乘法逆运算。这里,您添加了一个简短的
main()函数,稍后您将调用它。您已经将对
main()的调用包装在一个try…except块中,该块捕捉任何Exception。虽然您通常希望更加具体,但是您在这里使用Exception来有效地为主程序碰巧引发的任何异常添加上下文。当您运行这段代码时,您将看到预期的
ZeroDivisionError。此外,您的回溯包含一个时间戳,可能有助于您的调试工作:$ python timestamped_errors.py Traceback (most recent call last): ... ZeroDivisionError: division by zero Raised at 2022-10-24 12:18:13.913838您可以使用相同的模式向您的异常添加其他有用的信息。更多信息参见这个 Python 3.11 预览版和 PEP 678 。
负零格式
使用浮点数进行计算时,您可能会遇到一个奇怪的概念,那就是负零。您可以观察到负零和常规零在您的 REPL 中呈现不同:
>>> -0.0
-0.0
>>> 0.0
0.0
正常情况下,只有一个零,它既不是正的也不是负的。然而,当允许符号零时,浮点数的表示更容易。在内部,数字用它们的符号和大小作为独立的量来表示。和其他数字一样,用正号或负号来表示零更简单。
Python 知道这两种表示是相等的:
>>> -0.0 == 0.0 True一般来说,你在计算中不需要担心负零。尽管如此,当您显示带有四舍五入的小负数的数据时,您可能会得到一些意外的结果:
>>> small = -0.00311
>>> f"A small number: {small:.2f}"
'A small number: -0.00'
通常,当一个数被四舍五入为零时,它将被表示为一个无符号的零。在这个例子中,当表示为 f 字符串时,小负数被四舍五入到两位小数。注意,在零之前显示一个负号。
PEP 682 对 f 弦和 str.format() 使用的格式迷你语言做了一个小的扩展。在 Python 3.11 中,可以在格式字符串中添加文字z。这将在格式化之前强制将任何零规范化为正零:
>>> small = -0.00311 >>> f"A small number: {small:z.2f}" 'A small number: 0.00'您已经向格式字符串
z.2f添加了一个z。这确保了负零不会渗透到面向用户的数据表示中。没电的电池
Python 早期的优势之一是它自带了包括 T1 在内的 T0 电池。这个有点神秘的短语用来指出编程语言本身包含了很多功能。例如,Python 是最早包含对列表、元组和字典等容器的高级支持的语言之一。
然而,真正的电池可以在 Python 的标准库中找到。这是 Python 的每个安装都包含的包的集合。例如,标准库包括以下功能:
总的来说,标准库由数百个模块组成:
>>> import sys
>>> len(sys.stdlib_module_names)
305
通过检查sys.stdlib_module_names可以看到标准库中有哪些模块。在早期,语言内置了如此强大的功能对 Python 来说是一个福音。
随着时间的推移,标准库的用处已经减少,主要是因为第三方模块的分发和安装变得更加方便。Python 的许多最受欢迎的特性现在都存在于主发行版之外。像 NumPy 和熊猫这样的数据科学库,像 Matplotlib 和 Bokeh 这样的可视化工具,像 Django 和 Flask 这样的 web 框架都是独立开发的。
PEP 594 描述了一项从标准库中移除废电池的计划。这个想法是不再相关的模块应该从标准库中删除。这将有助于 Python 的维护者将他们的精力集中在最需要的地方,从而获得最大的收益。此外,一个更精简的标准库使 Python 更适合替代平台,如微控制器或浏览器。
在这个版本的 Python 中,没有从标准库中删除任何模块。相反,在 Python 3.13 中,有几个很少使用的模块被标记为删除。在 Python 3.11 中,有问题的模块将开始发出警告:
>>> import imghdr <stdin>:1: DeprecationWarning: 'imghdr' is deprecated and slated for removal in Python 3.13如果您的代码开始发出这种警告,那么您应该开始考虑重写您的代码。在大多数情况下,会有更现代的选择。例如,如果你正在使用
imghdr,那么你可以重写你的代码来使用 python-magic 。在这里,您可以识别文件的类型:
>>> import imghdr
<stdin>:1: DeprecationWarning: 'imghdr' is deprecated and slated for
removal in Python 3.13 >>> imghdr.what("python-311.jpg")
'jpeg'
>>> import magic
>>> magic.from_file("python-311.jpg")
'JPEG image data, JFIF standard 1.02, precision 8, 1920x1080, components 3'
旧的、废弃的imghdr和第三方 python-magic 库都认为python-311.jpg代表 JPEG 图像文件。
注意:python-magic 包依赖于一个需要安装的 C 库。查看文档了解如何在你的操作系统上安装它的细节。
你可以在电池耗尽的 PEP 中找到一个包含所有废弃模块的列表。
那么,该不该升级到 Python 3.11 呢?
Python 3.11 中最酷的改进和新特性之旅到此结束。一个重要的问题是,是否应该升级到 Python 的新版本。如果是的话,什么时候是升级的最佳时机?
像往常一样,这类问题的答案是一清二楚的看情况!
Python 3.11 最大的胜利是对开发人员体验的改进:更好的错误消息和更快的代码执行。这些都是尽快升级你用于当地发展的环境的巨大激励。这也是风险最小的一种升级,因为您遇到的任何错误都应该影响有限。
速度的提高也是更新您的生产环境的一个很好的理由。但是,与往常一样,在更新环境时,您应该小心,因为在这些环境中,错误和错误可能会带来严重的后果。确保在运行交换机之前进行适当的测试。作为更快的 CPython 项目的一部分,新版本的内部变化比平时更大,范围更广。发布经理 Pablo Galindo Salgado 在的真实 Python 播客上讲述了这些变化是如何影响发布过程的。
新版本的一个常见问题是,您所依赖的一些第三方包可能在第一天就没有为新版本做好准备。对于 Python 3.11,像 NumPy 和 SciPy 这样的大软件包在发布之前就已经开始为 3.11 打包轮子了。希望这一次您不必等待您的依赖项为升级做好准备。
升级的另一个方面是何时应该开始利用新语法。如果你正在维护一个支持旧版本 Python 的库,那么你就不能在你的代码中使用TaskGroup()或者像except*这样的语法。尽管如此,对于任何使用 Python 3.11 的人来说,你的库会更快。
相反,如果您正在创建一个应用程序,在那里您控制它运行的环境,那么一旦您升级了环境,您将能够使用新的特性。
结论
Python 的新版本总是值得庆祝的,也是对来自世界各地的志愿者投入到这门语言中的所有努力的认可。
在本教程中,您已经看到了新的特性和改进,例如:
- 更好的错误消息,提供更多信息的回溯
- 更快的代码执行得益于在更快的 CPython 项目中付出的巨大努力
- 简化异步代码工作的任务和异常组
- 几个新的类型特性改进了 Python 的静态类型支持
- 本地的 TOML 支持使用配置文件
您可能无法立即利用所有功能。尽管如此,您应该努力在 Python 3.11 上测试您的代码,以确保您的代码是面向未来的。你注意到速度加快了吗?请在下面的评论中分享你的经历。
免费下载: 点击这里下载免费的示例代码,它展示了 Python 3.11 的一些新特性。
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.11 中很酷的新特性***********
Python 3.11 预览版:TOML 和 tomllib
Python 3.11 离最终发布越来越近,最终发布将在 2022 年 10 月。新版本目前正在进行 beta 测试,你可以自己安装它来预览和测试一些新功能,包括支持使用新的tomllib模块读取 TOML。
TOML 是一种配置文件格式,在 Python 生态系统中越来越流行。这是由采用pyproject.toml作为 Python 打包中的中央配置文件所驱动的。其他重要的工具,像黑色、 mypy 和 pytest 也使用 TOML 进行配置。
在本教程中,您将:
- 在你的电脑上安装 Python 3.11 测试版,就在你当前安装的 Python 旁边
- 熟悉 TOML 格式的基础知识
- 使用新的
tomllib模块读取 TOML 文件 - 用第三方库编写 TOML ,了解为什么这个功能没有包含在
tomllib的中 - 探索 Python 3.11 新的类型特性,包括
Self和LiteralString类型以及可变泛型
Python 3.11 中还有许多其他新特性和改进。查看变更日志中的新增内容以获得最新列表,并在 Real Python 上阅读其他 Python 3.11 预览版以了解其他特性。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。
Python 3.11 测试版
Python 的新版本在每年 10 月发布。代码是在发布日期前经过 17 个月的时间开发和测试的。新功能在 alpha 阶段实现。对于 Python 3.11,在 2021 年 10 月至 2022 年 4 月期间,共发布了七个 alpha 版本。
Python 3.11 的第一个 beta 版本发生在 2022 年 5 月 8 日凌晨。每个这样的预发布都由一个发布经理协调——目前是Pablo ga lindo Salgado——并将来自 Python 核心开发者和其他志愿者的数百个提交集合在一起。
这个版本也标志着新版本的功能冻结。换句话说,Python 3.11.0b1 中没有的新功能不会添加到 Python 3.11 中。相反,功能冻结和发布日期(2022 年 10 月 3 日)之间的时间用于测试和巩固代码。
大约每月一次在测试阶段,Python 的核心开发者发布一个新的测试版本,继续展示新特性,测试它们,并获得早期反馈。目前 Python 3.11 的最新测试版是 3.11.0b3 ,发布于2022 年6 月 1 日。
注:本教程使用的是 Python 3.11 的第三个 beta 版本。如果您使用更高版本,可能会遇到一些小的差异。然而,tomllib建立在一个成熟的库之上,你可以预期你在本教程中学到的东西将在 Python 3.11 的测试阶段和最终版本中保持不变。
如果你在维护你自己的 Python 包,那么测试阶段是一个重要的时期,你应该开始用新版本测试你的包。核心开发人员与社区一起,希望在最终发布之前找到并修复尽可能多的 bug。
很酷的新功能
Python 3.11 的一些亮点包括:
- 增强的错误消息,帮助您更有效地调试代码
- 任务和异常组,它们简化了异步代码的使用,并允许程序同时引发和处理多个异常
- TOML 支持,它允许你使用标准库解析 TOML 文档
- 静态类型改进,让你更精确地注释你的代码
- 优化,承诺让 Python 3.11 比以前的版本快很多
Python 3.11 有很多值得期待的地方!你已经可以在早期的 Python 3.11 预览版文章中读到关于增强的错误消息和任务和异常组。要获得全面的概述,请查看 Python 3.11:供您尝试的酷新功能。
在本教程中,您将关注如何使用新的tomllib库来读取和解析 TOML 文件。您还将看到 Python 3.11 中的一些打字改进。
安装
要使用本教程中的代码示例,您需要在系统上安装 Python 3.11 版本。在这一小节中,你将学习几种不同的方法:使用 Docker ,使用 pyenv ,或者从源安装。选择最适合您和您的系统的一个。
注意:测试版是即将推出的功能的预览。虽然大多数特性都可以很好地工作,但是你不应该依赖任何 Python 3.11 beta 版本的产品,或者任何潜在错误会带来严重后果的地方。
如果您可以在您的系统上访问 Docker ,那么您可以通过拉取并运行python:3.11-rc-slim Docker 镜像来下载最新版本的 Python 3.11:
$ docker pull python:3.11-rc-slim
3.11-rc-slim: Pulling from library/python
[...]
docker.io/library/python:3.11-rc-slim
$ docker run -it --rm python:3.11-rc-slim
这会将您带入 Python 3.11 REPL。查看 Docker 中的运行 Python 版本,了解更多关于通过 Docker 使用 Python 的信息,包括如何运行脚本。
pyenv 工具非常适合管理系统上不同版本的 Python,如果你愿意,你可以用它来安装 Python 3.11 beta。它有两个不同的版本,一个用于 Windows,一个用于 Linux 和 macOS。使用下面的切换器选择您的平台:
- 视窗
** Linux + macOS
**在 Windows 上,你可以使用 pyenv-win 。首先更新您的pyenv安装:
PS> pyenv update
:: [Info] :: Mirror: https://www.python.org/ftp/python
[...]
进行更新可以确保您可以安装最新版本的 Python。你也可以手动更新pyenv。
在 Linux 和 macOS 上,可以使用 pyenv 。首先使用 pyenv-update 插件更新您的pyenv安装:
$ pyenv update
Updating /home/realpython/.pyenv...
[...]
进行更新可以确保您可以安装最新版本的 Python。如果你不想使用更新插件,那么你可以手动更新pyenv。
使用pyenv install --list查看 Python 3.11 有哪些版本。然后,安装最新版本:
$ pyenv install 3.11.0b3
Downloading Python-3.11.0b3.tar.xz...
[...]
安装可能需要几分钟时间。一旦安装了新的测试版,你就可以创建一个虚拟环境,在这里你可以玩它:
- 视窗
** Linux + macOS*
PS> pyenv local 3.11.0b3
PS> python --version
Python 3.11.0b3
PS> python -m venv venv
PS> venv\Scripts\activate
您使用pyenv local激活您的 Python 3.11 版本,然后使用python -m venv设置虚拟环境。
$ pyenv virtualenv 3.11.0b3 311_preview
$ pyenv activate 311_preview
(311_preview) $ python --version
Python 3.11.0b3
在 Linux 和 macOS 上,你使用 pyenv-virtualenv 插件来设置虚拟环境并激活它。
你也可以从python.org的预发布版本中安装 Python。选择最新预发布,向下滚动到页面底部的文件部分。下载并安装与您的系统对应的文件。更多信息参见 Python 3 安装&设置指南。
本教程中的大多数示例都依赖于新特性,因此您应该使用 Python 3.11 可执行文件来运行它们。具体如何运行可执行文件取决于您的安装方式。如果你需要帮助,那么看看关于 Docker 、 pyenv 、虚拟环境或者从源码安装的相关教程。
tomllibPython 3.11 中的 TOML 解析器
Python 是一门成熟的语言。Python 的第一个公共版本发布于 30 多年前的 1991 年。Python 的许多独特特性,包括显式异常处理、对空白的依赖以及丰富的数据结构,如列表和字典,甚至在早期的就已经存在。
然而,Python 的第一个版本缺少的一个特性是共享社区包和模块的便捷方式。这并不奇怪。事实上,Python 和万维网几乎是同时发明的。1991 年底,全世界只有12 台网络服务器,而且没有一台是专门用于发布 Python 代码的。
随着时间的推移,Python 和 T2 互联网变得越来越流行。几个倡议旨在允许共享 Python 代码。这些特性有机地发展,导致 Python 与打包的关系有些混乱。
在过去的几十年里,这个问题已经通过几个打包 pep(Python 增强提案)得到了解决,对于库维护者和最终用户来说,情况已经有了很大的改善。
一个挑战是构建包依赖于执行一个setup.py文件,但是没有机制知道该文件依赖于哪些依赖项。这就产生了一种先有鸡还是先有蛋的问题,你需要运行setup.py来发现如何运行setup.py。
实际上,pip——Python 的包管理器——假设它应该使用 Setuptools 来构建包,并且 Setuptools 在你的计算机上是可用的。这使得使用像 Flit 和poems这样的替代构建系统变得更加困难。
为了解决这种情况, PEP 518 引入了 pyproject.toml 配置文件,它指定了 Python 项目构建依赖关系。2016 年接受了 PEP 518。当时,TOML 仍然是一种相当新的格式,而且 Python 或其标准库中没有对解析 TOML 的内置支持。
随着 TOML 格式的成熟和pyproject.toml文件的使用,Python 3.11 增加了对解析 TOML 文件的支持。在这一节中,您将了解更多关于什么是 TOML 格式,如何使用新的tomllib来解析 TOML 文档,以及为什么tomllib不支持编写 TOML 文件。
学习基本的 TOML
Tom Preston-Werner 先是宣布 Tom 的显而易见、极简的语言——俗称TOML——并于 2013 年发布了其规范的版本 0.1.0 。从一开始,TOML 的目标就是提供一种“最小化的配置文件格式,由于语义明显,易于阅读”( Source )。TOML 规范的稳定版本 1.0.0 于 2021 年 1 月发布。
TOML 文件是一个 UTF-8 编码的,区分大小写的文本文件。TOML 中的主要构件是键-值对,其中键与值用等号(=)隔开:
version = 3.11
在这个最小的 TOML 文档中,version是一个具有相应值3.11的键。TOML 中的值有类型。3.11解释为浮点数。您可以利用的其他基本类型有字符串、布尔值、整数和日期:
version = 3.11 release_manager = "Pablo Galindo Salgado" is_beta = true beta_release = 3 release_date = 2022-06-01
这个例子展示了其中的大部分类型。语法类似于 Python 的语法,除了有小写布尔和一个特殊的日期文字。在其基本形式中,TOML 键值对类似于 Python 变量赋值,因此它们应该看起来很熟悉。关于这些和其他相似之处的更多细节,请查看 TOML 文档。
从本质上讲,TOML 文档是键值对的集合。您可以通过将它们包装在数组和表中,为这些对添加一些结构。一个数组是一个值列表,类似于一个 Python list。一个表是一个键值对的嵌套集合,类似于 Python dict。
使用方括号将数组的元素括起来。表格从命名表格的[key]行开始:
[python] version = 3.11 release_manager = "Pablo Galindo Salgado" is_beta = true beta_release = 3 release_date = 2022-06-01 peps = [657, 654, 678, 680, 673, 675, 646, 659] [toml] version = 1.0 release_date = 2021-01-12
这个 TOML 文档可以用 Python 表示如下:
{
"python": {
"version": 3.11,
"release_manager": "Pablo Galindo Salgado",
"is_beta": True,
"beta_release": 3,
"release_date": datetime.date(2022, 6, 1),
"peps": [657, 654, 678, 680, 673, 675, 646, 659],
},
"toml": {
"version": 1.0,
"release_date": datetime.date(2021, 1, 12),
},
}
TOML 中的[python]键在 Python 中由字典中的"python"键表示,指向包含 TOML 部分中所有键值对的嵌套字典。TOML 表可以任意嵌套,一个 TOML 文档可以包含几个 TOML 表。
这就结束了对 TOML 语法的简短介绍。虽然 TOML 的设计有一个相当简单的语法,但是这里还有一些细节没有涉及到。要深入了解,请查看 Python 和 TOML:新的最好的朋友或 TOML 规范。
除了语法之外,您还应该考虑如何解释 TOML 文件中的值。TOML 文档通常用于配置。最终,其他一些应用程序会使用 TOML 文档中的信息。因此,该应用程序对 TOML 文件的内容有一些期望。这意味着一个 TOML 文档可能有两种不同的错误:
- 语法错误:TOML 文档不是有效的 TOML。TOML 解析器通常会捕捉到这一点。
- 模式错误:TOML 文档是有效的 TOML,但是它的结构不是应用程序所期望的。应用程序本身必须处理这个问题。
TOML 规范目前还不包括一种可以用来验证 TOML 文档结构的模式语言,尽管有几个提案存在。这种模式将检查给定的 TOML 文档是否包含给定用例的正确的表、键和值类型。
作为一个非正式模式的例子, PEP 517 和 PEP 518 说一个pyproject.toml文件应该定义build-system表,该表必须包括关键字requires和build-backend。此外,requires的值必须是字符串数组,而build-backend的值必须是字符串。下面是一个满足这个模式的 TOML 文档的示例:
# pyproject.toml [build-system] requires = ["setuptools>=61.0.0", "wheel"] build-backend = "setuptools.build_meta"
本例遵循 PEP 517 和 PEP 518 的要求。然而,验证通常由构建者前端完成。
注意:如果你想了解更多关于用 Python 构建自己的包的知识,请查看如何向 PyPI 发布开源 Python 包。
您可以自己检查这个验证。创建以下错误的pyproject.toml文件:
# pyproject.toml [build-system] requires = "setuptools>=61.0.0" backend = "setuptools.build_meta"
这是有效的 TOML,因此该文件可以被任何 TOML 解析器读取。但是,根据 PEPs 中的要求,它不是有效的build-system表。为了确认这一点,安装 build ,这是一个符合 PEP 517 的构建前端,并基于您的pyproject.toml文件执行构建:
(venv) $ python -m pip install build
(venv) $ python -m build
ERROR Failed to validate `build-system` in pyproject.toml:
`requires` must be an array of strings
错误消息指出requires必须是一个字符串数组,如 PEP 518 中所指定的。尝试其他版本的pyproject.toml文件,注意build为你做的其他验证。您可能需要在自己的应用程序中实现类似的验证。
到目前为止,您已经看到了一些 TOML 文档的例子,但是您还没有探索如何在您自己的项目中使用它们。在下一小节中,您将了解如何使用标准库中新的tomllib包来读取和解析 Python 3.11 中的 TOML 文件。
用tomllib读 TOML】
Python 3.11 在标准库中新增了一个模块,名为 tomllib 。您可以使用tomllib来读取和解析任何符合 TOML v1.0 的文档。在这一小节中,您将学习如何直接从文件和包含 TOML 文档的字符串中加载 TOML。
PEP 680 描述了tomllib和一些导致 TOML 支持被添加到标准库中的过程。在 Python 3.11 中包含tomllib的两个决定性因素是pyproject.toml在 Python 打包生态系统中扮演的核心角色,以及 TOML 规范将在 2021 年初达到 1.0 版本。
tomllib的实现或多或少是直接从的 tomli 中剽窃来的,他也是 PEP 680 的合著者之一。
tomllib模块非常简单,因为它只包含两个函数:
load()从文件中读取 TOML 文件。loads()从字符串中读取 TOML 文件。
您将首先看到如何使用tomllib来读取下面的pyproject.toml文件,它是 tomli 项目中相同文件的简化版本:
# pyproject.toml [build-system] requires = ["flit_core>=3.2.0,<4"] build-backend = "flit_core.buildapi" [project] name = "tomli" version = "2.0.1" # DO NOT EDIT THIS LINE MANUALLY. LET bump2version DO IT description = "A lil' TOML parser" requires-python = ">=3.7" readme = "README.md" keywords = ["toml"] [project.urls] "Homepage" = "https://github.com/hukkin/tomli" "PyPI" = "https://pypi.org/project/tomli"
复制该文档,并将其保存在本地文件系统上名为pyproject.toml的文件中。现在,您可以开始 REPL 会话,探索 Python 3.11 的 TOML 支持:
>>> import tomllib >>> with open("pyproject.toml", mode="rb") as fp: ... tomllib.load(fp) ... {'build-system': {'requires': ['flit_core>=3.2.0,<4'], 'build-backend': 'flit_core.buildapi'}, 'project': {'name': 'tomli', 'version': '2.0.1', 'description': "A lil' TOML parser", 'requires-python': '>=3.7', 'readme': 'README.md', 'keywords': ['toml'], 'urls': {'Homepage': 'https://github.com/hukkin/tomli', 'PyPI': 'https://pypi.org/project/tomli'}}}通过向函数传递一个文件指针,使用
load()来读取和解析 TOML 文件。注意,文件指针必须指向二进制流。确保这一点的一种方法是使用open()和mode="rb",其中b表示二进制模式。注意:根据 PEP 680 的规定,文件必须以二进制模式打开,这样
tomllib才能确保 UTF-8 编码在所有系统上都得到正确处理。将原始的 TOML 文档与生成的 Python 数据结构进行比较。文档由 Python 字典表示,其中所有的键都是字符串,TOML 中的不同表表示为嵌套字典。注意,原始文件中关于
version的注释被忽略,并且不是结果的一部分。您可以使用
loads()来加载已经用字符串表示的 TOML 文档。以下示例解析来自前面的子节的示例:
>>> import tomllib
>>> document = """
... [python]
... version = 3.11
... release_manager = "Pablo Galindo Salgado"
... is_beta = true
... beta_release = 3
... release_date = 2022-06-01
... peps = [657, 654, 678, 680, 673, 675, 646, 659]
... ... [toml]
... version = 1.0
... release_date = 2021-01-12
... """
>>> tomllib.loads(document)
{'python': {'version': 3.11,
'release_manager': 'Pablo Galindo Salgado',
'is_beta': True,
'beta_release': 3,
'release_date': datetime.date(2022, 6, 1),
'peps': [657, 654, 678, 680, 673, 675, 646, 659]},
'toml': {'version': 1.0,
'release_date': datetime.date(2021, 1, 12)}}
与load()类似,loads()返回一个字典。一般来说,表示基于基本的 Python 类型:str、float、int、bool,以及字典、列表和、datetime对象。tomllib文档包括一个转换表,它展示了如何用 Python 表示 TOML 类型。
如果您愿意,那么您可以使用loads()结合pathlib从文件中读取 TOML:
>>> import pathlib >>> import tomllib >>> path = pathlib.Path("pyproject.toml") >>> with path.open(mode="rb") as fp: ... from_load = tomllib.load(fp) ... >>> from_loads = tomllib.loads(path.read_text()) >>> from_load == from_loads True在这个例子中,你使用
load()和loads()来加载pyproject.toml。然后确认无论如何加载文件,Python 表示都是相同的。
load()和loads()都接受一个可选参数:parse_float。这允许您控制如何用 Python 解析和表示浮点数。默认情况下,它们被解析并存储为float对象,在大多数 Python 实现中,这些对象是 64 位的,精度为精度的大约 16 位十进制数字。另一种方法是,如果你需要用更精确的数字,用
decimal.Decimal代替:
>>> import tomllib
>>> from decimal import Decimal
>>> document = """
... small = 0.12345678901234567890
... large = 9999.12345678901234567890
... """
>>> tomllib.loads(document)
{'small': 0.12345678901234568,
'large': 9999.123456789011}
>>> tomllib.loads(document, parse_float=Decimal)
{'small': Decimal('0.12345678901234567890'),
'large': Decimal('9999.12345678901234567890')}
这里加载一个带有两个键值对的 TOML 文档。默认情况下,当使用load()或loads()时,您会损失一些精度。通过使用Decimal类,您可以保持输入的精确性。
如上所述,tomllib模块改编自流行的tomli模块。如果你想在需要支持旧版本 Python 的代码库上使用 TOML 和tomllib,那么你可以依靠tomli。为此,请在您的需求文件中添加以下行:
tomli >= 1.1.0 ; python_version < "3.11"
这将在 3.11 之前的 Python 版本上使用时安装tomli。在您的源代码中,您可以适当地使用tomllib或tomli和下面的导入:
try:
import tomllib
except ModuleNotFoundError:
import tomli as tomllib
这段代码将在 Python 3.11 和更高版本中导入tomllib。如果tomllib不可用,那么tomli被导入并别名为tomllib名。
您已经看到了如何使用tomllib来读取 TOML 文档。您可能想知道如何编写 TOML 文件。原来不能用tomllib写 TOML。请继续阅读,了解原因,并查看一些替代方案。
写入 toml〔t0〕
类似的现有库如json和pickle包括load()和dump()函数,后者用于写数据。dump()功能,以及相应的dumps(),被故意排除在tomllib之外。
根据 PEP 680 和围绕它的讨论,这样做有几个原因:
-
将
tomllib包含在标准库中的主要动机是为了能够读取生态系统中使用的 TOML 文件。 -
TOML 格式被设计成一种对人友好的配置格式,所以许多 TOML 文件都是手工编写的。
-
TOML 格式不是像 JSON 或 pickle 那样的数据序列化格式,所以没有必要完全与
json和pickleAPI 保持一致。 -
TOML 文档可能包含在写入文件时应该保留的注释和格式。这与将 TOML 表示为基本 Python 类型不兼容。
-
关于如何布局和格式化 TOML 文件有不同的观点。
-
没有一个核心开发人员表示有兴趣为
tomllib维护一个写 API。
一旦某些东西被添加到标准库中,就很难更改或删除,因为有人依赖它。这是一件好事,因为这意味着 Python 在很大程度上保持了向后兼容:在 Python 3.10 上运行的 Python 程序很少会在 Python 3.11 上停止工作。
另一个后果是,核心团队对添加新功能持保守态度。如果有明确的需求,可以在以后添加对编写 TOML 文档的支持。
不过,这不会让你空手而归。有几个第三方 TOML 编写器可用。tomllib文档提到了两个包:
tomli-w顾名思义就是可以写 TOML 文档的tomli的兄弟姐妹。这是一个简单的模块,没有很多选项来控制输出。tomlkit是一个强大的处理 TOML 文档的软件包,它支持读写。它保留注释、缩进和其他空白。TOML 工具包是为诗开发和使用的。
根据您的用例,其中一个包可能会满足您的 TOML 编写需求。
如果你不想仅仅为了写一个 TOML 文件而添加一个外部依赖,那么你也可以试着滚动你自己的 writer。以下示例显示了一个不完整的 TOML 编写器的示例。它不支持 TOML v1.0 的所有特性,但是它支持编写您之前看到的pyproject.toml示例:
# tomllib_w.py
from datetime import date
def dumps(toml_dict, table=""):
document = []
for key, value in toml_dict.items():
match value:
case dict():
table_key = f"{table}.{key}" if table else key
document.append(
f"\n[{table_key}]\n{dumps(value, table=table_key)}"
)
case _:
document.append(f"{key} = {_dumps_value(value)}")
return "\n".join(document)
def _dumps_value(value):
match value:
case bool():
return "true" if value else "false"
case float() | int():
return str(value)
case str():
return f'"{value}"'
case date():
return value.isoformat()
case list():
return f"[{', '.join(_dumps_value(v) for v in value)}]"
case _:
raise TypeError(
f"{type(value).__name__} {value!r} is not supported"
)
dumps()函数接受一个代表 TOML 文档的字典。它通过遍历字典中的键值对,将字典转换为字符串。你很快就会更仔细地了解细节。首先,您应该检查代码是否有效。打开 REPL 并导入dumps():
>>> from tomllib_w import dumps >>> print(dumps({"version": 3.11, "module": "tomllib_w", "stdlib": False})) version = 3.11 module = "tomllib_w" stdlib = false你用不同类型的值编写一个简单的字典。它们被正确地写成 TOML 类型:数字是普通的,字符串用双引号括起来,布尔值是小写的。
回头看看代码。大多数对 TOML 类型的序列化发生在助手函数
_dumps_value()中。它使用结构模式匹配基于value的类型构造不同种类的 TOML 字符串。主
dumps()函数与字典一起工作。它遍历每个键值对。如果值是另一个字典,那么它通过添加一个表头来构造一个 TOML 表,然后递归地调用自己来处理表中的键值对。如果值不是一个字典,那么_dumps_value()用于正确地将键-值对转换成 TOML。如上所述,这个编写器不支持完整的 TOML 规范。例如,它不支持 TOML 中可用的所有日期和时间类型,也不支持内嵌或数组表等嵌套结构。在字符串处理中也有一些不被支持的边缘情况。但是,对于许多应用程序来说,这已经足够了。
例如,您可以尝试加载并转储您之前使用的
pyproject.toml文件:
>>> import tomllib
>>> from tomllib_w import dumps
>>> with open("pyproject.toml", mode="rb") as fp:
... pyproject = tomllib.load(fp)
...
>>> print(dumps(pyproject))
[build-system]
requires = ["flit_core>=3.2.0,<4"]
build-backend = "flit_core.buildapi"
[project]
name = "tomli"
version = "2.0.1"
description = "A lil' TOML parser"
requires-python = ">=3.7"
readme = "README.md"
keywords = ["toml"]
[project.urls]
Homepage = "https://github.com/hukkin/tomli"
PyPI = "https://pypi.org/project/tomli"
这里你先用tomllib读pyproject.toml。然后使用自己的tomllib_w模块将 TOML 文档写回控制台。
如果你需要更好的支持来编写 TOML 文档,你可以扩展一下tomllib_w。然而,在大多数情况下,你应该依赖一个现有的包,比如tomli_w或者tomlkit。
虽然 Python 3.11 不支持编写 TOML 文件,但是包含的 TOML 解析器对许多项目都很有用。接下来,您可以将 TOML 用于您的配置文件,因为您知道在 Python 中读取它们将获得一流的支持。
其他新功能
TOML 支持当然值得庆祝,但是 Python 3.11 中也有一些小的改进。在很长一段时间里,Python 的类型检查领域已经出现了这样的增量变化。
PEP 484 引入了类型提示。它们从 Pyhon 3.5 开始就可用了,每一个新的 Python 版本都为静态类型系统增加了功能。在 PyCon US 2022 大会的主题演讲中,茹卡兹·兰加谈到了类型检查。
Python 3.11 接受了几个新的与类型相关的 pep。您将很快了解到更多关于Self类型、LiteralString类型和可变泛型的知识。
注意:类型检查增强有点特殊,因为它们依赖于您的 Python 版本和类型检查工具的版本。最新的测试版支持一些新的 Python 3.11 类型系统特性,但是还没有在所有的类型检查器中实现。
例如,你可以在他们的 GitHub 页面上监控 mypy 的对新功能的支持状态。
甚至还有一些新的与打字相关的特性,下面就不介绍了。 PEP 681 增加了@dataclass_transform 装饰器,可以标记语义类似于数据类的类。此外, PEP 655 允许您在类型化词典中标记必填和可选字段。
自身类型
PEP 673 引入了一个新的Self类型,它动态地引用当前的类。当您用返回类实例的方法实现类时,这很有用。考虑由极坐标表示的二维点的以下部分实现:
# polar_point.py
import math
from dataclasses import dataclass
@dataclass
class PolarPoint:
r: float
φ: float
@classmethod
def from_xy(cls, x, y):
return cls(r=math.hypot(x, y), φ=math.atan2(y, x))
您添加了.from_xy()构造函数,这样您就可以方便地从相应的笛卡尔坐标创建PolarPoint实例。
注意:属性名.r和.φ是特意选择来模仿公式中使用的数学符号。
一般来说,建议为属性使用更长更具描述性的名称。然而,有时候遵循你的问题领域的惯例也是有用的。如果你愿意的话,可以随意用.radius替换.r,用.phi或.angle替换.φ。
Python 源代码由默认编码在 UTF-8 中。然而,标识符像变量和属性不能使用完整的 Unicode 字母表。例如,在你的变量和属性名中,你必须远离和表情符号。
您可以按如下方式使用新类:
>>> from polar_point import PolarPoint >>> point = PolarPoint.from_xy(3, 4) >>> point PolarPoint(r=5.0, φ=0.9272952180016122) >>> from math import cos >>> point.r * cos(point.φ) 3.0000000000000004这里,首先创建一个表示笛卡尔点(3,4)的点。在极坐标中,这个点用半径
r= 5.0,角度φ≈ 0.927 来表示。您可以使用公式x = r * cos(φ)转换回笛卡尔x坐标。现在,您想给
.from_xy()添加类型提示。它返回一个PolarPoint对象。然而,在这一点上你不能直接使用PolarPoint作为注释,因为那个类还没有被完全定义。相反,您可以使用带引号的"PolarPoint"或者添加一个 PEP 563 future import,使推迟注释的求值。这两种变通方法都有其缺点,目前推荐的是用一个
TypeVar代替。这种方法即使在子类中也能工作,但是它很麻烦并且容易出错。使用新的
Self类型,您可以向您的类添加类型提示,如下所示:import math from dataclasses import dataclass from typing import Self @dataclass class PolarPoint: r: float φ: float @classmethod def from_xy(cls, x: float, y: float) -> Self: return cls(r=math.hypot(x, y), φ=math.atan2(y, x))注释
-> Self表明.from_xy()将返回当前类的一个实例。如果你创建了一个PolarPoint的子类,这也可以正常工作。工具箱中有了
Self类型,就可以更方便地使用类和面向对象的特性(如继承)向项目添加静态类型。任意文字字符串类型
Python 3.11 中的另一个新类型是
LiteralString。虽然这个名字可能会让你想起 Python 3.8 中添加的Literal,但是LiteralString的主要用例有点不同。要理解将它添加到类型系统的动机,首先退一步考虑字符串。一般来说,Python 不关心如何构造字符串:
>>> s1 = "Python"
>>> s2 = "".join(["P", "y", "t", "h", "o", "n"])
>>> s3 = input()
Python
>>> s1 == s2 == s3
True
在这个例子中,您以三种不同的方式创建字符串"Python"。首先,将它指定为一个文字字符串。接下来,将六个单字符字符串连接起来,形成字符串"Python"。最后,您使用 input() 从用户输入中读取字符串。
最后的测试显示每个字符串的值是相同的。在大多数应用程序中,您不需要关心特定的字符串是如何构造的。但是,有些时候您需要小心,尤其是在处理用户输入时。
不幸的是,针对数据库的攻击非常普遍。 Java Log4j 漏洞同样利用日志系统执行任意代码。
回到上面的例子。虽然s1和s3的值恰好相同,但是您对这两个字符串的信任应该是完全不同的。假设您需要构建一个 SQL 语句,从数据库中读取关于用户的信息:
>>> def get_user_sql(user_id): ... return f"SELECT * FROM users WHERE user_id = '{user_id}'" ... >>> user_id = "Bobby" >>> get_user_sql(user_id) "SELECT * FROM users WHERE user_id = 'Bobby'" >>> user_id = input() Robert'; DROP TABLE users; -- >>> get_user_sql(user_id) "SELECT * FROM users WHERE user_id = 'Robert'; DROP TABLE users; --'"这是对一个经典的 SQL 注入例子的改编。恶意用户可以利用编写任意 SQL 代码的能力进行破坏。如果最后一条 SQL 语句被执行,那么它将删除
users表。有许多机制可以抵御这类攻击。 PEP 675 名单上又多了一个。一种新的类型被添加到了
typing模块中:LiteralString是一种特殊的字符串类型,它是在您的代码中定义的。您可以使用
LiteralString来标记易受用户控制字符串攻击的函数。例如,执行 SQL 查询的函数可以注释如下:from typing import LiteralString def execute_sql(query: LiteralString): # ...类型检查器会特别注意在这个函数中作为
query传递的值的类型。以下字符串将全部被允许作为execute_sql的参数:
>>> execute_sql("SELECT * FROM users")
>>> table = "users"
>>> execute_sql("SELECT * FROM " + table)
>>> execute_sql(f"SELECT * FROM {table}")
最后两个例子没问题,因为query是从文字字符串构建的。如果字符串的所有部分都是按字面定义的,则该字符串仅被识别为LiteralString。例如,以下示例将无法通过类型检查:
>>> user_input = input() users >>> execute_sql("SELECT * FROM " + user_input)即使
user_input的值恰好与前面的table的值相同,类型检查器也会在这里产生一个错误。用户控制着user_input的值,并有可能将其更改为对您的应用程序不安全的值。如果您使用LiteralString标记这些易受攻击的函数,类型检查器将帮助您跟踪需要格外小心的情况。可变泛型类型
一个通用类型指定了一个用其他类型参数化的类型,例如一个字符串列表或一个由一个整数、一个字符串和另一个整数组成的元组。Python 使用方括号来参数化泛型。你把这两个例子分别写成
list[str]和tuple[int, str, int]。一个变量是一个接受可变数量参数的实体。例如,
print()在 Python 中是一个变量函数:
>>> print("abc", 123, "def")
abc 123 def
通过使用 *args和**kwargs 来捕获多个位置和关键字参数,您可以定义自己的变量函数。
如果你想指定你自己的类是泛型的,你可以使用typing.Generic。下面是一个向量的例子,也称为一维数组:
# vector.py
from typing import Generic, TypeVar
T = TypeVar("T")
class Vector(Generic[T]):
...
类型变量 T用作任何类型的替身。可以在类型注释中使用Vector,如下所示:
>>> from vector import Vector >>> position: Vector[float]
>>> from typing import NewType
>>> from vector import Vector
>>> Coordinate = NewType("Coordinate", float)
>>> Coordinate(3.11)
3.11
>>> type(Coordinate(3.11))
<class 'float'>
>>> position: Vector[Coordinate]
这里,Coordinate在运行时的行为类似于float,但是静态类型检查将区分Coordinate和float。
现在,假设您创建了一个更通用的数组类,它可以处理可变数量的维度。直到现在,还没有好的方法来指定这样的可变泛型。
PEP 646 引入 typing.TypeVarTuple 来处理这个用例。这些类型变量元组本质上是包装在元组中的任意数量的类型变量。您可以使用它们来定义任意维数的数组:
# ndarray.py
from typing import Generic, TypeVarTuple
Ts = TypeVarTuple("Ts")
class Array(Generic[*Ts]):
...
注意解包操作符(*)的使用。这是语法的必要部分,表明Ts代表可变数量的类型。
注意:在 3.11 之前的 Python 版本上可以从typing_extensions导入TypeVarTuple。然而,*Ts语法在这些版本上不起作用。作为等价的替代,你可以用 typing_extensions.Unpack 并写成Unpack[Ts]。
您可以使用NewType来标记数组中的尺寸,或者使用 Literal 来指定精确的形状:
>>> from typing import Literal, NewType >>> from ndarray import Array >>> Height = NewType("Height", int) >>> Width = NewType("Width", int) >>> Channels = NewType("Channels", int) >>> image: Array[Height, Width, Channels] >>> video_frame: Array[Literal[1920], Literal[1080], Literal[3]]您将
image标注为一个三维数组,其维度标记为Height、Width和Channels。您不需要指定这些维度的大小。第二个例子,video_frame,用文字值注释。实际上,这意味着video_frame必须是一个特定形状为 1920 × 1080 × 3 的数组。可变泛型的主要动机是对数组进行类型化,就像你在上面的例子中看到的那样。然而,也有其他用例。一旦工具到位, NumPy 和其他数组库计划实现可变泛型。
结论
在本教程中,您了解了 Python 3.11 中的一些新特性。虽然最终版本将于 2022 年 10 月发布,但你已经可以下载测试版并尝试新功能。在这里,您已经探索了新的
tomllib模块,并逐渐熟悉了 TOML 格式。您已经完成了以下操作:
- 在您的计算机上安装了 Python 3.11 测试版,就在您当前安装的 Python 旁边
- 使用新的
tomllib模块读取 TOML 文件- 用第三方库编写了 TOML 并创建了自己的函数来编写 TOML 的子集
- 探索 Python 3.11 新的类型特性,包括
Self和LiteralString类型以及可变泛型你已经在你的项目中使用 TOML 了吗?尝试新的 TOML 解析器,并在下面的评论中分享你的经验。
免费奖励: 掌握 Python 的 5 个想法,这是一个面向 Python 开发者的免费课程,向您展示将 Python 技能提升到下一个水平所需的路线图和心态。*************
Python 3.7:很酷的新特性供您尝试
python 3.7正式发布!这个新的 Python 版本自 2016 年 9 月开始开发,现在我们都开始享受核心开发者辛勤工作的成果。
Python 新版本带来了什么?虽然文档很好地概述了新特性,但本文将深入探讨一些最重要的新闻。其中包括:
- 通过新的内置
breakpoint()更容易访问调试器- 使用数据类创建简单的类
- 对模块属性的定制访问
- 改进了对类型提示的支持
- 更高精度的定时功能
更重要的是,Python 3.7 速度快。
在本文的最后几节,您将会读到更多关于这个速度的内容,以及 Python 3.7 的一些其他很酷的特性。您还将获得一些关于升级到新版本的建议。
breakpoint()内置虽然我们可能努力写出完美的代码,但简单的事实是我们从来没有这样做过。调试是编程的一个重要部分。Python 3.7 引入了新的内置函数
breakpoint()。这并没有给 Python 添加任何新的功能,但是它使得调试器的使用更加灵活和直观。假设您在文件
bugs.py中有以下错误代码:def divide(e, f): return f / e a, b = 0, 1 print(divide(a, b))运行代码会在
divide()函数中产生一个ZeroDivisionError。假设你想中断你的代码,进入divide()顶部的调试器。您可以通过在代码中设置一个所谓的“断点”来做到这一点:def divide(e, f): # Insert breakpoint here return f / e断点是代码内部的一个信号,表示执行应该暂时停止,以便您可以查看程序的当前状态。如何放置断点?在 Python 3.6 和更低版本中,您使用了这一行有点神秘的代码:
def divide(e, f): import pdb; pdb.set_trace() return f / e这里,
pdb是来自标准库的 Python 调试器。在 Python 3.7 中,您可以使用新的breakpoint()函数调用作为快捷方式:def divide(e, f): breakpoint() return f / e在后台,
breakpoint()是先导入pdb再给你调用pdb.set_trace()。明显的好处是breakpoint()更容易记忆,你只需要输入 12 个字符而不是 27 个。然而,使用breakpoint()的真正好处是它的可定制性。使用
breakpoint()运行您的bugs.py脚本:$ python3.7 bugs.py > /home/gahjelle/bugs.py(3)divide() -> return f / e (Pdb)脚本将在到达
breakpoint()时中断,并让您进入 PDB 调试会话。您可以键入c并点击Enter继续脚本。如果你想了解更多关于 PDB 和调试的知识,请参考内森·詹宁斯的 PDB 指南。现在,假设你认为你已经修复了这个错误。您希望再次运行脚本,但不在调试器中停止。当然,您可以注释掉
breakpoint()行,但是另一个选择是使用PYTHONBREAKPOINT环境变量。这个变量控制breakpoint()的行为,设置PYTHONBREAKPOINT=0意味着任何对breakpoint()的调用都被忽略:$ PYTHONBREAKPOINT=0 python3.7 bugs.py ZeroDivisionError: division by zero哎呀,看来你还是没有修复这个错误…
另一个选择是使用
PYTHONBREAKPOINT来指定一个除 PDB 之外的调试器。例如,要使用 PuDB (控制台中的一个可视化调试器),您可以:$ PYTHONBREAKPOINT=pudb.set_trace python3.7 bugs.py为此,您需要安装
pudb(pip install pudb)。不过 Python 会为你负责导入pudb。这样,您也可以设置您的默认调试器。只需将PYTHONBREAKPOINT环境变量设置为您喜欢的调试器。参见本指南了解如何在您的系统上设置环境变量。新的
breakpoint()函数不仅适用于调试器。一个方便的选择是在代码中简单地启动一个交互式 shell。例如,要启动 IPython 会话,可以使用以下命令:$ PYTHONBREAKPOINT=IPython.embed python3.7 bugs.py IPython 6.3.1 -- An enhanced Interactive Python. Type '?' for help. In [1]: print(e / f) 0.0你也可以创建自己的函数并让
breakpoint()调用它。下面的代码打印局部范围内的所有变量。将其添加到名为bp_utils.py的文件中:from pprint import pprint import sys def print_locals(): caller = sys._getframe(1) # Caller is 1 frame up. pprint(caller.f_locals)要使用该功能,如前所述设置
PYTHONBREAKPOINT,用<module>.<function>符号表示:$ PYTHONBREAKPOINT=bp_utils.print_locals python3.7 bugs.py {'e': 0, 'f': 1} ZeroDivisionError: division by zero正常情况下,
breakpoint()会被用来调用不需要参数的函数和方法。然而,也可以传递参数。将bugs.py中的breakpoint()行改为:breakpoint(e, f, end="<-END\n")注意:默认的 PDB 调试器将在这一行抛出一个
TypeError,因为pdb.set_trace()不接受任何位置参数。用伪装成
print()函数的breakpoint()运行这段代码,查看一个传递参数的简单示例:$ PYTHONBREAKPOINT=print python3.7 bugs.py 0 1<-END ZeroDivisionError: division by zero更多信息参见 PEP 553 以及
breakpoint()和sys.breakpointhook()的文档。数据类别
新的
dataclasses模块使得编写自己的类更加方便,因为像.__init__()、.__repr__()和.__eq__()这样的特殊方法是自动添加的。使用@dataclass装饰器,您可以编写如下代码:from dataclasses import dataclass, field @dataclass(order=True) class Country: name: str population: int area: float = field(repr=False, compare=False) coastline: float = 0 def beach_per_person(self): """Meters of coastline per person""" return (self.coastline * 1000) / self.population这九行代码代表了相当多的样板代码和最佳实践。考虑一下将
Country实现为一个常规类需要什么:一个.__init__()方法,一个repr,六个不同的比较方法以及一个.beach_per_person()方法。您可以展开下面的框来查看大约相当于数据类的Country的实现:class Country: def __init__(self, name, population, area, coastline=0): self.name = name self.population = population self.area = area self.coastline = coastline def __repr__(self): return ( f"Country(name={self.name!r}, population={self.population!r}," f" coastline={self.coastline!r})" ) def __eq__(self, other): if other.__class__ is self.__class__: return ( (self.name, self.population, self.coastline) == (other.name, other.population, other.coastline) ) return NotImplemented def __ne__(self, other): if other.__class__ is self.__class__: return ( (self.name, self.population, self.coastline) != (other.name, other.population, other.coastline) ) return NotImplemented def __lt__(self, other): if other.__class__ is self.__class__: return ((self.name, self.population, self.coastline) < ( other.name, other.population, other.coastline )) return NotImplemented def __le__(self, other): if other.__class__ is self.__class__: return ((self.name, self.population, self.coastline) <= ( other.name, other.population, other.coastline )) return NotImplemented def __gt__(self, other): if other.__class__ is self.__class__: return ((self.name, self.population, self.coastline) > ( other.name, other.population, other.coastline )) return NotImplemented def __ge__(self, other): if other.__class__ is self.__class__: return ((self.name, self.population, self.coastline) >= ( other.name, other.population, other.coastline )) return NotImplemented def beach_per_person(self): """Meters of coastline per person""" return (self.coastline * 1000) / self.population创建后,数据类就是普通类。例如,您可以以正常方式从数据类继承。数据类的主要目的是使编写健壮的类变得快速和容易,特别是主要存储数据的小类。
您可以像使用任何其他类一样使用
Country数据类:
>>> norway = Country("Norway", 5320045, 323802, 58133)
>>> norway
Country(name='Norway', population=5320045, coastline=58133)
>>> norway.area
323802
>>> usa = Country("United States", 326625791, 9833517, 19924)
>>> nepal = Country("Nepal", 29384297, 147181)
>>> nepal
Country(name='Nepal', population=29384297, coastline=0)
>>> usa.beach_per_person()
0.06099946957342386
>>> norway.beach_per_person()
10.927163210085629
注意,初始化类时使用所有字段.name、.population、.area和.coastline(尽管.coastline是可选的,如内陆尼泊尔的例子所示)。Country类有一个合理的 repr ,而定义方法的工作方式与普通类相同。
默认情况下,可以比较数据类是否相等。因为我们在@dataclass装饰器中指定了order=True,所以Country类也可以被排序:
>>> norway == norway True >>> nepal == usa False >>> sorted((norway, usa, nepal)) [Country(name='Nepal', population=29384297, coastline=0), Country(name='Norway', population=5320045, coastline=58133), Country(name='United States', population=326625791, coastline=19924)]对字段值进行排序,首先是
.name,然后是.population,依此类推。然而,如果您使用field(),您可以定制哪些字段将用于比较。在这个例子中,.area字段被排除在repr和比较之外。注:国家数据来自中情局世界概况,人口数字估计为 2017 年 7 月。
在你们预订下一次挪威海滩度假之前,这里是关于挪威气候的实况报道:“沿海地区气候温和,受北大西洋洋流影响;降水量增加,夏季更冷,内陆更冷;西海岸全年多雨。”
数据类做一些与
namedtuple相同的事情。然而,他们从attrs项目中获得了最大的灵感。参见我们的完整的数据类指南以获得更多的例子和进一步的信息,以及 PEP 557 的官方描述。模块属性定制
属性在 Python 中无处不在!虽然类属性可能是最著名的,但属性实际上可以放在任何东西上——包括函数和模块。Python 的几个基本特性被实现为属性:大部分自省功能、文档字符串和名称空间。模块内部的函数可以作为模块属性使用。
最常使用点符号来检索属性:
thing.attribute。然而,您也可以使用getattr()获得在运行时命名的属性:import random random_attr = random.choice(("gammavariate", "lognormvariate", "normalvariate")) random_func = getattr(random, random_attr) print(f"A {random_attr} random value: {random_func(1, 1)}")运行这段代码将会产生如下结果:
A gammavariate random value: 2.8017715125270618对于类,调用
thing.attr将首先寻找在thing上定义的attr。如果没有找到,那么调用特殊方法thing.__getattr__("attr")。(这是一种简化。详见本文。)方法.__getattr__()可用于定制对对象属性的访问。在 Python 3.7 之前,同样的定制不容易用于模块属性。然而, PEP 562 在模块上引入了
__getattr__(),以及相应的__dir__()功能。__dir__()特殊功能允许定制模块上调用T3 的结果。PEP 本身给出了一些如何使用这些函数的例子,包括向函数中添加弃用警告,以及延迟加载沉重的子模块。下面,我们将构建一个简单的插件系统,允许功能被动态地添加到一个模块中。这个例子利用了 Python 包。如果你需要关于软件包的复习,请参见本文。
创建一个新目录
plugins,并将以下代码添加到文件plugins/__init__.py:from importlib import import_module from importlib import resources PLUGINS = dict() def register_plugin(func): """Decorator to register plug-ins""" name = func.__name__ PLUGINS[name] = func return func def __getattr__(name): """Return a named plugin""" try: return PLUGINS[name] except KeyError: _import_plugins() if name in PLUGINS: return PLUGINS[name] else: raise AttributeError( f"module {__name__!r} has no attribute {name!r}" ) from None def __dir__(): """List available plug-ins""" _import_plugins() return list(PLUGINS.keys()) def _import_plugins(): """Import all resources to register plug-ins""" for name in resources.contents(__name__): if name.endswith(".py"): import_module(f"{__name__}.{name[:-3]}")在我们看这段代码做什么之前,在
plugins目录中再添加两个文件。首先来看看plugins/plugin_1.py:from . import register_plugin @register_plugin def hello_1(): print("Hello from Plugin 1")接下来,在文件
plugins/plugin_2.py中添加类似的代码:from . import register_plugin @register_plugin def hello_2(): print("Hello from Plugin 2") @register_plugin def goodbye(): print("Plugin 2 says goodbye")这些插件现在可以如下使用:
>>> import plugins
>>> plugins.hello_1()
Hello from Plugin 1
>>> dir(plugins)
['goodbye', 'hello_1', 'hello_2']
>>> plugins.goodbye()
Plugin 2 says goodbye
这可能看起来不那么具有革命性(很可能不是),但让我们看看这里实际发生了什么。通常情况下,为了能够调用plugins.hello_1(),hello_1()函数必须在plugins模块中定义,或者在plugins包的__init__.py中显式导入。在这里,两者都不是!
相反,hello_1()被定义在plugins包内的任意文件中,hello_1()通过使用@register_plugin 装饰器注册自己而成为plugins包的一部分。
差别是微妙的。不同于软件包规定哪些功能可用,单个功能将自己注册为软件包的一部分。这为您提供了一个简单的结构,您可以独立于代码的其余部分添加函数,而不必保留可用函数的集中列表。
让我们快速回顾一下__getattr__()在plugins/__init__.py代码中做了什么。当您请求plugins.hello_1()时,Python 首先在plugins/__init__.py文件中寻找一个hello_1()函数。因为不存在这样的函数,所以 Python 调用了__getattr__("hello_1")。记住__getattr__()函数的源代码:
def __getattr__(name):
"""Return a named plugin"""
try:
return PLUGINS[name] # 1) Try to return plugin
except KeyError:
_import_plugins() # 2) Import all plugins
if name in PLUGINS:
return PLUGINS[name] # 3) Try to return plugin again
else:
raise AttributeError( # 4) Raise error
f"module {__name__!r} has no attribute {name!r}"
) from None
__getattr__()包含以下步骤。下表中的数字对应于代码中的编号注释:
- 首先,该函数乐观地尝试从
PLUGINS字典中返回已命名的插件。如果名为name的插件存在并且已经被导入,这将会成功。 - 如果在
PLUGINS字典中没有找到指定的插件,我们确保所有的插件都被导入。 - 如果导入后可用,则返回指定的插件。
- 如果在导入所有插件后,插件不在
PLUGINS字典中,我们抛出一个AttributeError,表示name不是当前模块的属性(插件)。
然而,字典是如何填充的呢?_import_plugins()函数导入了plugins包中的所有 Python 文件,但似乎没有触及PLUGINS:
def _import_plugins():
"""Import all resources to register plug-ins"""
for name in resources.contents(__name__):
if name.endswith(".py"):
import_module(f"{__name__}.{name[:-3]}")
别忘了每个插件函数都是由@register_plugin装饰器装饰的。这个装饰器在插件被导入时被调用,并且是真正填充PLUGINS字典的那个。如果您手动导入其中一个插件文件,就会看到这种情况:
>>> import plugins >>> plugins.PLUGINS {} >>> import plugins.plugin_1 >>> plugins.PLUGINS {'hello_1': <function hello_1 at 0x7f29d4341598>}继续这个例子,注意在模块上调用
dir()也会导入剩余的插件:
>>> dir(plugins)
['goodbye', 'hello_1', 'hello_2']
>>> plugins.PLUGINS
{'hello_1': <function hello_1 at 0x7f29d4341598>,
'hello_2': <function hello_2 at 0x7f29d4341620>,
'goodbye': <function goodbye at 0x7f29d43416a8>}
dir()通常列出一个对象的所有可用属性。通常,在一个模块上使用dir()会产生类似这样的结果:
>>> import plugins >>> dir(plugins) ['PLUGINS', '__builtins__', '__cached__', '__doc__', '__file__', '__getattr__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_import_plugins', 'import_module', 'register_plugin', 'resources']虽然这可能是有用的信息,但我们更感兴趣的是公开可用的插件。在 Python 3.7 中,可以通过添加一个
__dir__()特殊函数来自定义在模块上调用dir()的结果。对于plugins/__init__.py,这个函数首先确定所有插件都已经导入,然后列出它们的名称:def __dir__(): """List available plug-ins""" _import_plugins() return list(PLUGINS.keys())在离开这个例子之前,请注意我们还使用了 Python 3.7 的另一个很酷的新特性。为了导入
plugins目录中的所有模块,我们使用了新的importlib.resources模块。这个模块提供了对模块和包内部的文件和资源的访问,而不需要__file__黑客(这并不总是有效)或者pkg_resources(这很慢)。importlib.resources的其他特点将在后面中强调。打字增强功能
类型提示和注释在 Python 3 系列版本中一直在不断发展。Python 的打字系统现在已经相当稳定了。尽管如此,Python 3.7 还是带来了一些改进:更好的性能、核心支持和前向引用。
Python 在运行时不做任何类型检查(除非你显式地使用像
enforce这样的包)。因此,向代码中添加类型提示不会影响其性能。不幸的是,这并不完全正确,因为大多数类型提示都需要
typing模块。typing模块是标准库中最慢的模块之一。 PEP 560 在 Python 3.7 中增加了一些对类型的核心支持,显著加快了typing模块的速度。这方面的细节一般来说没有必要知道。只需向后一靠,享受更高的性能。虽然 Python 的类型系统表达能力相当强,但有一个问题很让人头疼,那就是前向引用。在导入模块时,会计算类型提示,或者更一般的注释。因此,所有名称在使用之前必须已经定义。以下情况是不可能的:
class Tree: def __init__(self, left: Tree, right: Tree) -> None: self.left = left self.right = right运行代码会引发一个
NameError,因为在.__init__()方法的定义中还没有(完全)定义类Tree:Traceback (most recent call last): File "tree.py", line 1, in <module> class Tree: File "tree.py", line 2, in Tree def __init__(self, left: Tree, right: Tree) -> None: NameError: name 'Tree' is not defined为了克服这一点,您可能需要将
"Tree"写成字符串文字:class Tree: def __init__(self, left: "Tree", right: "Tree") -> None: self.left = left self.right = right原讨论见 PEP 484 。
在未来的 Python 4.0 中,这种所谓的向前引用将被允许。这将通过在明确要求之前不评估注释来处理。 PEP 563 描述了该提案的细节。在 Python 3.7 中,前向引用已经可以作为
__future__导入使用。您现在可以编写以下内容:from __future__ import annotations class Tree: def __init__(self, left: Tree, right: Tree) -> None: self.left = left self.right = right请注意,除了避免有些笨拙的
"Tree"语法之外,延迟的注释求值也将加速您的代码,因为不执行类型提示。mypy已经支持正向引用。到目前为止,注释最常见的用途是类型提示。尽管如此,您在运行时仍然可以完全访问注释,并且可以在您认为合适的时候使用它们。如果您直接处理注释,您需要显式地处理可能的前向引用。
让我们创建一些公认的愚蠢的例子来显示注释何时被求值。首先我们用老方法,所以注释在导入时被评估。让
anno.py包含以下代码:def greet(name: print("Now!")): print(f"Hello {name}")注意
name的标注是print()。这只是为了查看注释何时被求值。导入新模块:
>>> import anno
Now!
>>> anno.greet.__annotations__
{'name': None}
>>> anno.greet("Alice")
Hello Alice
如您所见,注释是在导入时进行评估的。注意,name以None结束注释,因为那是print()的返回值。
添加__future__导入以启用注释的延期评估:
from __future__ import annotations
def greet(name: print("Now!")):
print(f"Hello {name}")
导入此更新的代码将不会评估批注:
>>> import anno >>> anno.greet.__annotations__ {'name': "print('Now!')"} >>> anno.greet("Marty") Hello Marty注意,
Now!永远不会被打印,注释作为字符串保存在__annotations__字典中。为了评价注释,使用typing.get_type_hints()或eval():
>>> import typing
>>> typing.get_type_hints(anno.greet)
Now!
{'name': <class 'NoneType'>}
>>> eval(anno.greet.__annotations__["name"])
Now!
>>> anno.greet.__annotations__
{'name': "print('Now!')"}
注意到__annotations__字典从不更新,所以每次使用时都需要评估注释。
计时精度
在 Python 3.7 中, time模块获得了一些新功能,如 PEP 564 中所述。特别是增加了以下六个功能:
clock_gettime_ns(): 返回指定时钟的时间clock_settime_ns(): 设置指定时钟的时间monotonic_ns(): 返回不能倒退的相对时钟的时间(例如由于夏令时)perf_counter_ns():返回性能计数器的值,该计数器是一种专门用于测量短时间间隔的时钟process_time_ns(): 返回当前进程的系统和用户 CPU 时间之和(不包括睡眠时间)time_ns():返回自 1970 年 1 月 1 日以来的纳秒数
从某种意义上说,没有添加新的功能。每个函数都类似于一个没有_ns后缀的现有函数。不同之处在于,新函数返回纳秒数作为int,而不是秒数作为float。
对大多数应用来说,这些新的毫微秒函数和它们的旧对应物之间的差别是不明显的。然而,新函数更容易推理,因为它们依赖于int而不是float。浮点数本质上是不准确的:
>>> 0.1 + 0.1 + 0.1 0.30000000000000004 >>> 0.1 + 0.1 + 0.1 == 0.3 False这不是 Python 的问题,而是计算机需要用有限的位数表示无限的十进制数的结果。
Python
float遵循 IEEE 754 标准,使用 53 个有效位。结果是,任何大于大约 104 天(2⁵或大约 9 千万亿纳秒)的时间都不能用纳秒精度的浮点数表示。相比之下,Pythonint是无限的,因此整数纳秒的精度总是与时间值无关。例如,
time.time()返回自 1970 年 1 月 1 日以来的秒数。这个数字已经相当大了,所以这个数字的精度在微秒级。这个函数是其_ns版本中改进最大的一个。time.time_ns()的分辨率大约是的 3 倍比time.time()好。顺便问一下,纳秒是什么?从技术上讲,它是十亿分之一秒,或者如果你更喜欢科学记数法的话,是
1e-9秒。这些只是数字,并不真正提供任何直觉。想要更好的视觉帮助,请看格蕾丝·赫柏的纳秒的精彩演示。顺便说一句,如果你需要处理纳秒精度的日期时间,
datetime标准库不会满足你的要求。它只显式处理微秒:
>>> from datetime import datetime, timedelta
>>> datetime(2018, 6, 27) + timedelta(seconds=1e-6)
datetime.datetime(2018, 6, 27, 0, 0, 0, 1)
>>> datetime(2018, 6, 27) + timedelta(seconds=1e-9)
datetime.datetime(2018, 6, 27, 0, 0)
相反,你可以使用 astropy项目。它的 astropy.time 包使用两个float对象表示日期时间,这保证了“跨越宇宙年龄的亚纳秒精度”
>>> from astropy.time import Time, TimeDelta >>> Time("2018-06-27") <Time object: scale='utc' format='iso' value=2018-06-27 00:00:00.000> >>> t = Time("2018-06-27") + TimeDelta(1e-9, format="sec") >>> (t - Time("2018-06-27")).sec 9.976020010071807e-10最新版本的
astropy在 Python 3.5 及更高版本中可用。其他非常酷的功能
到目前为止,您已经看到了关于 Python 3.7 新特性的头条新闻。然而,还有许多其他的变化也很酷。在本节中,我们将简要介绍其中的一些。
字典的顺序是有保证的
Python 3.6 的 CPython 实现已经对字典进行了排序。( PyPy 也有这个。)这意味着字典中的条目按照它们被插入的顺序被迭代。第一个例子是使用 Python 3.5,第二个例子是使用 Python 3.6:
>>> {"one": 1, "two": 2, "three": 3} # Python <= 3.5
{'three': 3, 'one': 1, 'two': 2}
>>> {"one": 1, "two": 2, "three": 3} # Python >= 3.6
{'one': 1, 'two': 2, 'three': 3}
在 Python 3.6 中,这种排序只是实现dict的一个很好的结果。然而,在 Python 3.7 中,保留插入顺序的字典是语言规范的一部分。因此,现在可以在只支持 Python > = 3.7(或 CPython > = 3.6)的项目中依赖它。
“async”和“await”是关键词
Python 3.5 引入了带有async和await语法的协程。为了避免向后兼容的问题,async和await没有被添加到保留的关键字列表中。换句话说,仍然可以定义名为async和await的变量或函数。
在 Python 3.7 中,这不再可能:
>>> async = 1 File "<stdin>", line 1 async = 1 ^ SyntaxError: invalid syntax >>> def await(): File "<stdin>", line 1 def await(): ^ SyntaxError: invalid syntax
asyncio整容标准库最初是在 Python 3.4 中引入的,使用事件循环、协程和未来以现代方式处理并发性。下面是温柔介绍。
在 Python 3.7 中,
asyncio模块得到了的重大改进,包括许多新功能、对上下文变量的支持(参见下面的)和性能改进。特别值得注意的是asyncio.run(),它简化了从同步代码调用协程。使用asyncio.run(),你不需要显式创建事件循环。现在可以编写一个异步 Hello World 程序:import asyncio async def hello_world(): print("Hello World!") asyncio.run(hello_world())上下文变量
上下文变量是根据上下文可以有不同值的变量。它们类似于线程本地存储,其中每个执行线程可能有一个不同的变量值。然而,对于上下文变量,一个执行线程中可能有几个上下文。上下文变量的主要用例是在并发异步任务中跟踪变量。
下面的例子构造了三个上下文,每个上下文都有自己的值
name。greet()函数稍后能够在每个上下文中使用name的值:import contextvars name = contextvars.ContextVar("name") contexts = list() def greet(): print(f"Hello {name.get()}") # Construct contexts and set the context variable name for first_name in ["Steve", "Dina", "Harry"]: ctx = contextvars.copy_context() ctx.run(name.set, first_name) contexts.append(ctx) # Run greet function inside each context for ctx in reversed(contexts): ctx.run(greet)运行该脚本以相反的顺序问候史蒂夫、迪娜和哈利:
$ python3.7 context_demo.py Hello Harry Hello Dina Hello Steve导入带有
importlib.resources的数据文件打包 Python 项目时的一个挑战是决定如何处理项目资源,如项目所需的数据文件。有几个常用的选项:
- 硬编码数据文件的路径。
- 将数据文件放入包中,并使用
__file__找到它。- 使用
setuptools.pkg_resources访问数据文件资源。这些都有其缺点。第一种选择是不可移植的。使用
__file__更具可移植性,但是如果安装了 Python 项目,它可能会在 zip 中结束,并且没有__file__属性。第三种选择解决了这个问题,但不幸的是非常慢。比较好的解决方案是在标准库中新增
importlib.resources模块。它使用 Python 现有的导入功能来导入数据文件。假设您在 Python 包中有一个资源,如下所示:data/ │ ├── alice_in_wonderland.txt └── __init__.py注意
data需要是一个 Python 包。也就是说,目录需要包含一个__init__.py文件(可能是空的)。然后你可以如下阅读alice_in_wonderland.txt文件:
>>> from importlib import resources
>>> with resources.open_text("data", "alice_in_wonderland.txt") as fid:
... alice = fid.readlines()
...
>>> print("".join(alice[:7]))
CHAPTER I. Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, "and what is the use of a book," thought Alice "without pictures or
conversations?"
类似的 resources.open_binary() 功能也可用于以二进制模式打开文件。在前面的“插件作为模块属性”示例中,我们使用importlib.resources通过resources.contents()来发现可用的插件。更多信息,请参见巴里华沙 PyCon 2018 演讲。
在 Python 2.7 和 Python 3.4+中可以通过一个反向端口来使用importlib.resources。从pkg_resources迁移到importlib.resourcesT6 的指南可用。
开发者招数
Python 3.7 增加了几个针对开发人员的特性。你已经见过新的breakpoint()内置。此外,Python 解释器中增加了一些新的 -X命令行选项。
使用-X importtime,您可以很容易地知道脚本中的导入需要多少时间:
$ python3.7 -X importtime my_script.py
import time: self [us] | cumulative | imported package
import time: 2607 | 2607 | _frozen_importlib_external
...
import time: 844 | 28866 | importlib.resources
import time: 404 | 30434 | plugins
cumulative列显示导入的累计时间(以微秒计)。在这个例子中,导入plugins花费了大约 0.03 秒,其中大部分时间用于导入importlib.resources。self列显示不包括嵌套导入的导入时间。
您现在可以使用-X dev来激活“开发模式”开发模式将添加某些调试功能和运行时检查,这些功能被认为太慢,默认情况下无法启用。这些包括启用 faulthandler 来显示对严重崩溃的追溯,以及更多的警告和调试挂钩。
最后,-X utf8启用 UTF-8 模式。(参见 PEP 540 。)在这种模式下,UTF-8将被用于文本编码,而不管当前的语言环境。
优化
Python 的每个新版本都有一组优化。在 Python 3.7 中,有一些显著的加速,包括:
- 在标准库中调用许多方法的开销更少。
- 一般来说,方法调用要快 20%。
- Python 本身的启动时间减少了 10-30%。
- 导入
typing快 7 倍。
此外,还包括许多更专业的优化。详细概述见该列表。
所有这些优化的结果是 Python 3.7 更快。它简直是迄今为止发布的 CPython 的最快版本。
那么,我该不该升级?
先说简单的答案。如果您想尝试一下您在这里看到的任何新特性,那么您确实需要能够使用 Python 3.7。使用诸如 pyenv 或 Anaconda 之类的工具,可以很容易地同时安装多个版本的 Python。安装 Python 3.7 并试用它没有什么坏处。
现在,对于更复杂的问题。您是否应该将生产环境升级到 Python 3.7?您是否应该让自己的项目依赖于 Python 3.7 来利用这些新特性?
显而易见,在升级您的生产环境之前,您应该总是进行彻底的测试,Python 3.7 中很少有东西会破坏早期的代码(虽然async和await成为关键字就是一个例子)。如果你已经在使用现代 Python,升级到 3.7 应该会相当顺利。如果你想保守一点,你可能想等待第一个维护版本的发布——Python 3 . 7 . 1——暂定 2018 年 7 月的某个时间。
争论你应该只让你的项目 3.7 更难。Python 3.7 中的许多新特性要么可以作为 Python 3.6 的反向移植(数据类,importlib.resources),要么很方便(更快的启动和方法调用,更容易的调试,以及-X选项)。后者,您可以通过自己运行 Python 3.7 来利用,同时保持代码与 Python 3.6(或更低版本)兼容。
将你的代码锁定到 Python 3.7 的主要特性是模块上的 __getattr__()、类型提示中的前向引用,以及纳秒time函数。如果你真的需要这些,你应该继续前进,提高你的要求。否则,如果您的项目可以在 Python 3.6 上运行一段时间,它可能会对其他人更有用。
有关升级时需要注意的详细信息,请参见移植到 Python 3.7 指南。*****
Python 3.8:很酷的新特性供您尝试
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.8 中很酷的新特性
Python 最新版本发布!Python 3.8 自夏季以来一直有测试版,但在 2019 年【2019 月 14 日第一个正式版本已经准备好了。现在,我们都可以开始使用新功能,并从最新的改进中受益。
Python 3.8 带来了什么?文档很好地概述了新特性。然而,本文将更深入地讨论一些最大的变化,并向您展示如何利用 Python 3.8。
在这篇文章中,你将了解到:
- 使用赋值表达式简化一些代码结构
- 在您自己的函数中强制使用仅位置参数
- 指定更精确的类型提示
- 使用 f 字符串简化调试
除了少数例外,Python 3.8 包含了许多对早期版本的小改进。在本文的结尾,您将看到许多不太引人注目的变化,以及关于使 Python 3.8 比其前身更快的一些优化的讨论。最后,你会得到一些关于升级到新版本的建议。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
房间里的海象:赋值表达式
Python 3.8 最大的变化是引入了赋值表达式。它们是用一种新的符号(:=)写的。这种操作者通常被称为海象操作者,因为它像海象侧面的眼睛和长牙。
赋值表达式允许您在同一个表达式中赋值和返回值。例如,如果你想给一个变量赋值并且打印它的值,那么你通常会这样做:
>>> walrus = False >>> print(walrus) False在 Python 3.8 中,您可以使用 walrus 运算符将这两个语句合并为一个:
>>> print(walrus := True)
True
赋值表达式允许您将True赋值给walrus,并立即打印该值。但是请记住,没有它,海象运营商不会而不是做任何不可能的事情。它只是使某些构造更加方便,有时可以更清楚地传达代码的意图。
显示 walrus 操作符的一些优点的一个模式是 while循环,其中您需要初始化和更新一个变量。例如,下面的代码要求用户输入,直到他们键入quit:
inputs = list()
current = input("Write something: ")
while current != "quit":
inputs.append(current)
current = input("Write something: ")
这段代码不太理想。您在重复input()语句,不知何故,您需要将current添加到列表中,然后在之前向用户请求。更好的解决方案是建立一个无限的while循环,并使用break来停止循环:
inputs = list()
while True:
current = input("Write something: ")
if current == "quit":
break
inputs.append(current)
这段代码相当于上面的代码,但是避免了重复,并且以某种方式保持了更符合逻辑的顺序。如果使用赋值表达式,可以进一步简化这个循环:
inputs = list()
while (current := input("Write something: ")) != "quit":
inputs.append(current)
这将测试移回到while行,它应该在那里。然而,现在在那一行发生了几件事,所以要正确地阅读它需要更多的努力。对于 walrus 操作符何时有助于提高代码的可读性,请做出最佳判断。
PEP 572 描述了赋值表达式的所有细节,包括将它们引入语言的一些基本原理,以及如何使用 walrus 运算符的几个例子。
仅位置参数
内置函数float()可用于将文本串和数字转换为float对象。考虑下面的例子:
>>> float("3.8") 3.8 >>> help(float) class float(object) | float(x=0, /) | | Convert a string or number to a floating point number, if possible. [...]仔细看
float()的签名。注意参数后面的斜杠(/)。这是什么意思?注:关于
/符号的深入讨论,参见 PEP 457 -仅位置参数符号。原来,虽然
float()的一个参数被称为x,但是不允许使用它的名称:
>>> float(x="3.8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: float() takes no keyword arguments
当使用float()时,你只能通过位置指定参数,而不能通过关键字。在 Python 3.8 之前,这种仅位置的参数只可能用于内置函数。没有简单的方法来指定参数应该是位置性的——仅在您自己的函数中:
>>> def incr(x): ... return x + 1 ... >>> incr(3.8) 4.8 >>> incr(x=3.8) 4.8使用
*args可以模拟的仅位置参数,但是这不太灵活,可读性差,并且迫使您实现自己的参数解析。在 Python 3.8 中,可以使用/来表示它之前的所有参数都必须由位置指定。你可以重写incr()来只接受位置参数:
>>> def incr(x, /):
... return x + 1
...
>>> incr(3.8)
4.8
>>> incr(x=3.8)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: incr() got some positional-only arguments passed as
keyword arguments: 'x'
通过在x后添加/,您可以指定x是一个只有位置的参数。通过将常规参数放在斜杠后,可以将常规参数与仅限位置的参数组合在一起:
>>> def greet(name, /, greeting="Hello"): ... return f"{greeting}, {name}" ... >>> greet("Łukasz") 'Hello, Łukasz' >>> greet("Łukasz", greeting="Awesome job") 'Awesome job, Łukasz' >>> greet(name="Łukasz", greeting="Awesome job") Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: greet() got some positional-only arguments passed as keyword arguments: 'name'在
greet()中,斜线位于name和greeting之间。这意味着name是一个只有位置的参数,而greeting是一个可以通过位置或关键字传递的常规参数。乍一看,只有位置的参数似乎有点限制,并且违背了 Python 关于可读性重要性的口头禅。您可能会发现,仅有位置的参数改善代码的情况并不多见。
然而,在正确的情况下,只有位置的参数可以在设计函数时给你一些灵活性。首先,当参数有自然的顺序,但是很难给它们起一个好的、描述性的名字时,只有位置的参数是有意义的。
使用仅位置参数的另一个好处是可以更容易地重构函数。特别是,您可以更改参数的名称,而不必担心其他代码依赖于这些名称。
只有位置的参数很好地补充了只有关键字的参数。在 Python 3 的任何版本中,都可以使用星号(
*)指定仅关键字参数。*后的任何参数必须使用关键字指定:
>>> def to_fahrenheit(*, celsius):
... return 32 + celsius * 9 / 5
...
>>> to_fahrenheit(40)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: to_fahrenheit() takes 0 positional arguments but 1 was given
>>> to_fahrenheit(celsius=40)
104.0
celsius是一个只有关键字的参数,所以如果您试图在没有关键字的情况下基于位置来指定它,Python 会引发一个错误。
通过以/和*分隔的顺序指定,您可以组合仅位置、常规和仅关键字参数。在下面的示例中,text是仅位置参数,border是具有默认值的常规参数,width是具有默认值的仅关键字参数:
>>> def headline(text, /, border="♦", *, width=50): ... return f" {text} ".center(width, border) ...因为
text是位置唯一的,所以不能使用关键字text:
>>> headline("Positional-only Arguments")
'♦♦♦♦♦♦♦♦♦♦♦ Positional-only Arguments ♦♦♦♦♦♦♦♦♦♦♦♦'
>>> headline(text="This doesn't work!")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: headline() got some positional-only arguments passed as
keyword arguments: 'text'
另一方面,border既可以用关键字指定,也可以不用关键字指定:
>>> headline("Python 3.8", "=") '=================== Python 3.8 ===================' >>> headline("Real Python", border=":") ':::::::::::::::::: Real Python :::::::::::::::::::'最后,
width必须使用关键字指定:
>>> headline("Python", "🐍", width=38)
'🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍 Python 🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍🐍'
>>> headline("Python", "🐍", 38)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: headline() takes from 1 to 2 positional arguments
but 3 were given
```py
你可以在 [PEP 570](https://www.python.org/dev/peps/pep-0570/) 中读到更多关于位置唯一参数的内容。
[*Remove ads*](/account/join/)
## 更精确的类型
Python 的类型系统在这一点上已经相当成熟了。然而,在 Python 3.8 中,一些新特性被添加到了`typing`中,以允许更精确的输入:
* 文字类型
* 打字词典
* 最终对象
* 协议
Python 支持可选的**类型提示**,通常作为代码的注释:
def double(number: float) -> float:
return 2 * number
在这个例子中,你说`number`应该是一个`float`,`double()`函数也应该返回一个`float`。然而,Python 将这些注释视为*提示*。它们不会在运行时强制执行:
>>>
double(3.14)
6.28
double("I'm not a float")
"I'm not a floatI'm not a float"
`double()`愉快地接受`"I'm not a float"`作为参数,尽管那不是`float`。有[库可以在运行时使用类型](https://realpython.com/python-type-checking/#using-types-at-runtime),但这不是 Python 类型系统的主要用例。
相反,类型提示允许[静态类型检查器](https://realpython.com/python-type-checking/#other-static-type-checkers)对您的 Python 代码进行类型检查,而无需实际运行您的脚本。这让人想起编译器捕捉其他语言中的类型错误,如 [Java](https://www.java.com) 、 [Rust](https://www.rust-lang.org/) 和 [Crystal](https://crystal-lang.org/) 。此外,类型提示充当代码的[文档](https://realpython.com/documenting-python-code/),使其更容易阅读,以及[改进 IDE](https://realpython.com/python-type-checking/#pros-and-cons) 中的自动完成。
**注:**有几种静态类型的跳棋可供选择,包括 [Pyright](https://github.com/Microsoft/pyright) 、 [Pytype](https://google.github.io/pytype/) 和 [Pyre](https://pyre-check.org/) 。在本文中,您将使用 [Mypy](http://mypy-lang.org/) 。您可以使用 [`pip`](https://realpython.com/what-is-pip/) 从 [PyPI](https://pypi.org/project/mypy/) 安装 Mypy:
$ python -m pip install mypy
在某种意义上,Mypy 是 Python 的类型检查器的参考实现,并且正在 Jukka Lehtasalo 的领导下由 Dropbox 开发。Python 的创造者吉多·范·罗苏姆是 Mypy 团队的一员。
你可以在[原始 PEP 484](https://www.python.org/dev/peps/pep-0484/) 以及 [Python 类型检查(指南)](https://realpython.com/python-type-checking/)中找到更多关于 Python 中类型提示的信息。
Python 3.8 中已经接受并包含了四个关于类型检查的新 pep。你会看到每个例子的简短例子。
[PEP 586](https://www.python.org/dev/peps/pep-0586/) 介绍一下 **[`Literal`](https://docs.python.org/3.8/library/typing.html#typing.Literal)** 型。`Literal`有点特殊,代表一个或几个特定值。`Literal`的一个用例是能够精确地添加类型,当字符串参数被用来描述特定的行为时。考虑下面的例子:
draw_line.py
def draw_line(direction: str) -> None:
if direction == "horizontal":
... # Draw horizontal line
elif direction == "vertical":
... # Draw vertical line
else:
raise ValueError(f"invalid direction {direction!r}")
draw_line("up")
程序将通过静态类型检查,即使`"up"`是一个无效的方向。类型检查器只检查`"up"`是一个字符串。在这种情况下,更准确的说法是`direction`必须是字符串`"horizontal"`或字符串`"vertical"`。使用`Literal`,您可以做到这一点:
draw_line.py
from typing import Literal
def draw_line(direction: Literal["horizontal", "vertical"]) -> None:
if direction == "horizontal":
... # Draw horizontal line
elif direction == "vertical":
... # Draw vertical line
else:
raise ValueError(f"invalid direction {direction!r}")
draw_line("up")
通过将允许的值`direction`暴露给类型检查器,您现在可以得到关于错误的警告:
$ mypy draw_line.py
draw_line.py:15: error:
Argument 1 to "draw_line" has incompatible type "Literal['up']";
expected "Union[Literal['horizontal'], Literal['vertical']]"
Found 1 error in 1 file (checked 1 source file)
基本语法是`Literal[<literal>]`。例如,`Literal[38]`表示文字值 38。您可以使用`Union`来表示几个文字值中的一个:
Union[Literal["horizontal"], Literal["vertical"]]
由于这是一个相当常见的用例,您可以(并且可能应该)使用更简单的符号`Literal["horizontal", "vertical"]`来代替。在向`draw_line()`添加类型时,您已经使用了后者。如果仔细观察上面 Mypy 的输出,可以看到它在内部将更简单的符号翻译成了`Union`符号。
有些情况下,函数返回值的类型取决于输入参数。一个例子是`open()`,它可能根据`mode`的值返回一个文本字符串或一个字节数组。这可以通过[超载](https://mypy.readthedocs.io/en/latest/more_types.html#function-overloading)来处理。
下面的例子展示了一个计算器的框架,它可以以普通数字(`38`)或[罗马数字](http://code.activestate.com/recipes/81611-roman-numerals/) ( `XXXVIII`)的形式返回答案:
calculator.py
from typing import Union
ARABIC_TO_ROMAN = [(1000, "M"), (900, "CM"), (500, "D"), (400, "CD"),
(100, "C"), (90, "XC"), (50, "L"), (40, "XL"),
(10, "X"), (9, "IX"), (5, "V"), (4, "IV"), (1, "I")]
def _convert_to_roman_numeral(number: int) -> str:
"""Convert number to a roman numeral string"""
result = list()
for arabic, roman in ARABIC_TO_ROMAN:
count, number = divmod(number, arabic)
result.append(roman * count)
return "".join(result)
def add(num_1: int, num_2: int, to_roman: bool = True) -> Union[str, int]:
"""Add two numbers"""
result = num_1 + num_2
if to_roman:
return _convert_to_roman_numeral(result)
else:
return result
代码有正确的类型提示:`add()`的结果将是`str`或`int`。然而,通常调用这段代码时会使用文字`True`或`False`作为`to_roman`的值,在这种情况下,您会希望类型检查器准确推断出返回的是`str`还是`int`。这可以通过使用`Literal`和`@overload`来完成:
calculator.py
from typing import Literal, overload, Union
ARABIC_TO_ROMAN = [(1000, "M"), (900, "CM"), (500, "D"), (400, "CD"),
(100, "C"), (90, "XC"), (50, "L"), (40, "XL"),
(10, "X"), (9, "IX"), (5, "V"), (4, "IV"), (1, "I")]
def _convert_to_roman_numeral(number: int) -> str:
"""Convert number to a roman numeral string"""
result = list()
for arabic, roman in ARABIC_TO_ROMAN:
count, number = divmod(number, arabic)
result.append(roman * count)
return "".join(result)
@overload
def add(num_1: int, num_2: int, to_roman: Literal[True]) -> str: ...
@overload
def add(num_1: int, num_2: int, to_roman: Literal[False]) -> int: ...
def add(num_1: int, num_2: int, to_roman: bool = True) -> Union[str, int]:
"""Add two numbers"""
result = num_1 + num_2
if to_roman:
return _convert_to_roman_numeral(result)
else:
return result
添加的`@overload`签名将帮助您的类型检查器根据`to_roman`的文字值推断出`str`或`int`。注意省略号(`...`)是代码的一部分。它们代表重载签名中的函数体。
作为对`Literal`、 [PEP 591](https://www.python.org/dev/peps/pep-0591/) 的补充介绍 **[`Final`](https://docs.python.org/3.8/library/typing.html#typing.Final)** 。此限定符指定变量或属性不应被重新分配、重新定义或重写。以下是一个打字错误:
from typing import Final
ID: Final = 1
...
ID += 1
Mypy 将突出显示行`ID += 1`,并注意到您`Cannot assign to final name "ID"`。这为您提供了一种方法来确保代码中的常量永远不会改变它们的值。
此外,还有一个可以应用于类和方法的 **[`@final`](https://docs.python.org/3.8/library/typing.html#typing.final)** 装饰器。用`@final`修饰的[类](https://realpython.com/courses/python-decorators-101/)不能被子类化,而`@final`方法不能被子类覆盖:
from typing import final
@final
class Base:
...
class Sub(Base):
...
Mypy 将用错误消息`Cannot inherit from final class "Base"`标记这个例子。要了解更多关于`Final`和`@final`的信息,请参见 [PEP 591](https://www.python.org/dev/peps/pep-0591/) 。
第三个允许更具体类型提示的 PEP 是 [PEP 589](https://www.python.org/dev/peps/pep-0589/) ,它引入了 **[`TypedDict`](https://docs.python.org/3.8/library/typing.html#typing.TypedDict)** 。这可用于指定字典中键和值的类型,使用类似于键入的 [`NamedTuple`](https://docs.python.org/library/typing.html#typing.NamedTuple) 的符号。
传统上,词典都是用 [`Dict`](https://docs.python.org/library/typing.html#typing.Dict) 来注释的。问题是这只允许一种类型的键和一种类型的值,经常导致类似于`Dict[str, Any]`的注释。例如,考虑一个注册 Python 版本信息的字典:
py38 = {"version": "3.8", "release_year": 2019}
`version`对应的值是一个字符串,而`release_year`是一个整数。这不能用`Dict`来精确描述。使用新的`TypedDict`,您可以执行以下操作:
from typing import TypedDict
class PythonVersion(TypedDict):
version: str
release_year: int
py38 = PythonVersion(version="3.8", release_year=2019)
类型检查器将能够推断出`py38["version"]`具有类型`str`,而`py38["release_year"]`是一个`int`。在运行时,`TypedDict`是一个常规的`dict`,类型提示照常被忽略。您也可以将`TypedDict`纯粹用作注释:
py38: PythonVersion = {"version": "3.8", "release_year": 2019}
Mypy 会让你知道你的值是否有错误的类型,或者你是否使用了一个没有声明的键。更多例子见 [PEP 589](https://www.python.org/dev/peps/pep-0589/) 。
Mypy 支持 [**协议**](https://realpython.com/python-type-checking/#duck-types-and-protocols) 已经有一段时间了。然而,[官方验收](https://mail.python.org/archives/list/typing-sig@python.org/message/FDO4KFYWYQEP3U2HVVBEBR3SXPHQSHYR/)却发生在 2019 年 5 月。
协议是一种形式化 Python 对 duck 类型支持的方式:
> 当我看到一只像鸭子一样走路、像鸭子一样游泳、像鸭子一样嘎嘎叫的鸟时,我就把那只鸟叫做鸭子。([来源](https://en.wikipedia.org/wiki/Duck_test#History))
例如,Duck typing 允许您读取任何具有`.name`属性的对象上的`.name`,而不必真正关心对象的类型。打字系统支持这一点似乎有悖常理。通过[结构分型](https://en.wikipedia.org/wiki/Structural_type_system),还是有可能搞清楚鸭子分型的。
例如,您可以定义一个名为`Named`的协议,该协议可以识别具有`.name`属性的所有对象:
from typing import Protocol
class Named(Protocol):
name: str
def greet(obj: Named) -> None:
print(f"Hi {obj.name}")
这里,`greet()`接受任何对象,只要它定义了一个`.name`属性。有关协议的更多信息,请参见 [PEP 544](https://www.python.org/dev/peps/pep-0544/) 和[Mypy 文档](https://mypy.readthedocs.io/en/latest/protocols.html)。
[*Remove ads*](/account/join/)
## 使用 f 弦进行更简单的调试
f 弦是在 Python 3.6 中引入的,并且变得非常流行。这可能是 Python 库仅在 3.6 版及更高版本中受支持的最常见原因。f 字符串是格式化的字符串文字。你可以通过主角`f`认出来:
>>>
style = "formatted"
f"This is a {style} string"
'This is a formatted string'
当你使用 f 字符串时,你可以用花括号把变量甚至表达式括起来。然后,它们将在运行时被计算并包含在字符串中。一个 f 字符串中可以有多个表达式:
>>>
import math
r = 3.6
f"A circle with radius {r} has area {math.pi * r * r:.2f}"
'A circle with radius 3.6 has area 40.72'
在最后一个表达式`{math.pi * r * r:.2f}`中,还使用了格式说明符。格式说明符用冒号与表达式分开。
`.2f`表示该区域被格式化为具有 2 位小数的浮点数。格式说明符同 [`.format()`](https://docs.python.org/library/stdtypes.html#str.format) 。参见[官方文档](https://docs.python.org/library/string.html#format-specification-mini-language)获得允许格式说明符的完整列表。
在 Python 3.8 中,可以在 f 字符串中使用赋值表达式。只需确保用括号将赋值表达式括起来:
>>>
import math
r = 3.8
f"Diameter {(diam := 2 * r)} gives circumference {math.pi * diam:.2f}"
'Diameter 7.6 gives circumference 23.88'
然而,Python 3.8 中真正的新闻是新的调试说明符。您现在可以在表达式的末尾添加`=`,它将打印表达式及其值:
>>>
python = 3.8
f"{python=}"
'python=3.8'
这是一个简写,通常在交互工作或添加打印语句来调试脚本时最有用。在 Python 的早期版本中,您需要两次拼出变量或表达式才能获得相同的信息:
>>>
python = 3.7
f"python={python}"
'python=3.7'
您可以在`=`周围添加空格,并照常使用格式说明符:
>>>
name = "Eric"
f"{name = }"
"name = 'Eric'"
f"{name = :>10}"
'name = Eric'
`>10`格式说明符指出`name`应该在 10 个字符串内右对齐。`=`也适用于更复杂的表达式:
>>>
f"{name.upper()[::-1] = }"
"name.upper()[::-1] = 'CIRE'"
有关 f 字符串的更多信息,请参见 [Python 3 的 f 字符串:改进的字符串格式化语法(指南)](https://realpython.com/python-f-strings/)。
## Python 指导委员会
从技术上来说, [Python 的**治理**](https://www.python.org/dev/peps/pep-0013/) 并不是语言特性。然而,Python 3.8 是第一个不是在**仁慈的独裁统治**和[吉多·范·罗苏姆](https://gvanrossum.github.io/)下开发的版本。Python 语言现在由五个核心开发者组成的**指导委员会**管理:
* [巴里华沙](https://twitter.com/pumpichank)
* 布雷特·卡农
* [卡罗尔心甘情愿](https://twitter.com/WillingCarol)
* [圭多·范罗斯](https://twitter.com/gvanrossum)
* 尼克·科格兰
Python 的新治理模型之路是自组织中一项有趣的研究。吉多·范·罗苏姆在 20 世纪 90 年代初创造了 Python,并被亲切地称为 Python 的[**【BDFL】**](https://en.wikipedia.org/wiki/Benevolent_dictator_for_life)**。这些年来,越来越多关于 Python 语言的决定是通过 [**Python 增强提案** (PEPs)](https://www.python.org/dev/peps/pep-0001/) 做出的。尽管如此,Guido 还是对任何新的语言特性拥有最终决定权。*
*在关于[任务表达](#the-walrus-in-the-room-assignment-expressions)的漫长讨论之后,圭多[于 2018 年 7 月宣布](https://mail.python.org/pipermail/python-committers/2018-July/005664.html)他将从 BDFL 的角色中退休(这次是真正的)。他故意没有指定继任者。相反,他要求核心开发人员团队找出 Python 今后应该如何治理。
幸运的是,PEP 流程已经很好地建立起来了,所以使用 PEP 来讨论和决定新的治理模型是很自然的。在 2018 年秋季,[提出了几种模式](https://www.python.org/dev/peps/pep-8000/),包括[选举新的 BDFL](https://www.python.org/dev/peps/pep-8010/) (更名为亲切的裁判影响决策官:圭多),或者转向基于共识和投票的[社区模式](https://www.python.org/dev/peps/pep-8012/),没有集中的领导。2018 年 12 月,[指导委员会型号](https://www.python.org/dev/peps/pep-8016/)在核心开发者中投票选出。
[](https://files.realpython.com/media/steering_council.1aae31a91dad.jpg)
<figcaption class="figure-caption text-center">The Python Steering Council at PyCon 2019\. From left to right: Barry Warsaw, Brett Cannon, Carol Willing, Guido van Rossum, and Nick Coghlan (Image: Geir Arne Hjelle)</figcaption>
指导委员会由 Python 社区的五名成员组成,如上所列。在 Python 的每一个主要版本发布后,都会选举一个新的指导委员会。换句话说,Python 3.8 发布后会有一次选举。
虽然这是一次公开选举,但预计首届指导委员会的大部分成员(如果不是全部的话)将会改选。指导委员会拥有广泛的权力来决定 Python 语言,但是应该尽可能少的行使这些权力。
你可以在 [PEP 13](https://www.python.org/dev/peps/pep-0013/) 中阅读关于新治理模式的所有信息,而决定新模式的过程在 [PEP 8000](https://www.python.org/dev/peps/pep-8000/) 中描述。欲了解更多信息,请参见 [PyCon 2019 主题演讲](https://pyvideo.org/pycon-us-2019/python-steering-council-keynote-pycon-2019.html),并聆听 Brett Cannon 在[与我谈论 Python](https://talkpython.fm/episodes/show/209/inside-python-s-new-governance-model)和[Changelog 播客](https://changelog.com/podcast/348)上的演讲。你可以在 [GitHub](https://github.com/python/steering-council) 上关注指导委员会的更新。
[*Remove ads*](/account/join/)
## 其他非常酷的功能
到目前为止,您已经看到了关于 Python 3.8 新特性的头条新闻。然而,还有许多其他的变化也很酷。在本节中,您将快速浏览其中一些。
### `importlib.metadata`
Python 3.8 中的标准库中新增了一个模块: [`importlib.metadata`](https://importlib-metadata.readthedocs.io) 。通过此模块,您可以访问 Python 安装中已安装包的相关信息。与它的同伴模块[`importlib.resources`](https://realpython.com/python37-new-features/#importing-data-files-with-importlibresources)`importlib.metadata`一起,改进了老款 [`pkg_resources`](https://setuptools.readthedocs.io/en/latest/pkg_resources.html) 的功能。
举个例子,你可以得到一些关于 [`pip`](https://realpython.com/courses/what-is-pip/) 的信息:
>>>
from importlib import metadata
metadata.version("pip")
'19.2.3'
pip_metadata = metadata.metadata("pip")
list(pip_metadata)
['Metadata-Version', 'Name', 'Version', 'Summary', 'Home-page', 'Author',
'Author-email', 'License', 'Keywords', 'Platform', 'Classifier',
'Classifier', 'Classifier', 'Classifier', 'Classifier', 'Classifier',
'Classifier', 'Classifier', 'Classifier', 'Classifier', 'Classifier',
'Classifier', 'Classifier', 'Requires-Python']
pip_metadata["Home-page"]
'https://pip.pypa.io/'
pip_metadata["Requires-Python"]
'>=2.7,!=3.0.,!=3.1.,!=3.2.,!=3.3.,!=3.4.*'
len(metadata.files("pip"))
668
目前安装的`pip`版本是 19.2.3。`metadata()`提供您在 [PyPI](https://pypi.org/project/pip/) 上看到的大部分信息。例如,你可以看到这个版本的`pip`需要 Python 2.7,或者 Python 3.5 或更高版本。使用`files()`,您将获得组成`pip`包的所有文件的列表。在这种情况下,有将近 700 个文件。
`files()`返回一个 [`Path`](https://realpython.com/python-pathlib/) 对象的[列表](https://realpython.com/python-lists-tuples/)。这些给了你一个方便的方法来查看一个包的源代码,使用`read_text()`。以下示例从 [`realpython-reader`](https://pypi.org/project/realpython-reader/) 包中打印出`__init__.py`:
>>>
[p for p in metadata.files("realpython-reader") if p.suffix == ".py"]
[PackagePath('reader/init.py'), PackagePath('reader/main.py'),
PackagePath('reader/feed.py'), PackagePath('reader/viewer.py')]
init_path = _[0] # Underscore access last returned value in the REPL
print(init_path.read_text()) """Real Python feed reader
Import the feed module to work with the Real Python feed:
from reader import feed
feed.get_titles()
['Logging in Python', 'The Best Python Books', ...]
See https://github.com/realpython/reader/ for more information
"""
Version of realpython-reader package
version = "1.0.0"
...
您还可以访问软件包相关性:
>>>
metadata.requires("realpython-reader")
['feedparser', 'html2text', 'importlib-resources', 'typing']
列出一个包的依赖关系。您可以看到,`realpython-reader`在后台使用 [`feedparser`](https://pypi.org/project/feedparser/) 来读取和解析文章提要。
PyPI 上有一个对早期版本 Python 有效的`importlib.metadata` [的反向移植。您可以使用`pip`安装它:](https://pypi.org/project/importlib-metadata/)
$ python -m pip install importlib-metadata
您可以在代码中使用 PyPI 反向端口,如下所示:
try:
from importlib import metadata
except ImportError:
import importlib_metadata as metadata
...
有关`importlib.metadata`的更多信息,请参见[文档](https://importlib-metadata.readthedocs.io)
### 新的和改进的`math`和`statistics`功能
Python 3.8 对现有的标准库包和模块进行了许多改进。`math`在标准库中有一些新的功能。`math.prod()`的工作方式与内置的`sum()`类似,但对于乘法运算:
>>>
import math
math.prod((2, 8, 7, 7))
784
2 * 8 * 7 * 7
784
这两种说法是等价的。当你已经将因子存储在一个 iterable 中时,将会更容易使用。
另一个新功能是`math.isqrt()`。可以用`isqrt()`求[平方根](https://realpython.com/python-square-root-function/)的整数部分:
>>>
import math
math.isqrt(9)
3
math.sqrt(9)
3.0
math.isqrt(15)
3
math.sqrt(15)
3.872983346207417
9 的平方根是 3。可以看到`isqrt()`返回一个整数结果,而 [`math.sqrt()`](https://realpython.com/python-square-root-function/) 总是返回一个`float`。15 的平方根差不多是 3.9。请注意,`isqrt()` [将答案截断到下一个整数](https://realpython.com/python-rounding/#truncation),在本例中为 3。
最后,你现在可以更容易地使用标准库中的 *n* 维点和向量。用`math.dist()`可以求出两点之间的距离,用`math.hypot()`可以求出一个矢量的长度:
>>>
import math
point_1 = (16, 25, 20)
point_2 = (8, 15, 14)
math.dist(point_1, point_2)
14.142135623730951
math.hypot(*point_1)
35.79106033634656
math.hypot(*point_2)
22.02271554554524
这使得使用标准库处理点和向量变得更加容易。然而,如果你要对点或向量做很多计算,你应该检查一下 [NumPy](https://realpython.com/numpy-array-programming/) 。
`statistics`模块还有几个新功能:
* [`statistics.fmean()`](https://docs.python.org/3.8/library/statistics.html#statistics.fmean) 计算`float`数字的平均值。
* [`statistics.geometric_mean()`](https://docs.python.org/3.8/library/statistics.html#statistics.geometric_mean) 计算`float`个数字的几何平均值。
* [`statistics.multimode()`](https://docs.python.org/3.8/library/statistics.html#statistics.multimode) 查找序列中出现频率最高的值。
* [`statistics.quantiles()`](https://docs.python.org/3.8/library/statistics.html#statistics.quantiles) 计算分割点,将数据等概率分割成 *n 个*连续区间。
以下示例显示了正在使用的函数:
>>>
import statistics
data = [9, 3, 2, 1, 1, 2, 7, 9]
statistics.fmean(data)
4.25
statistics.geometric_mean(data)
3.013668912157617
statistics.multimode(data)
[9, 2, 1]
statistics.quantiles(data, n=4)
[1.25, 2.5, 8.5]
在 Python 3.8 中,有一个新的 [`statistics.NormalDist`](https://docs.python.org/3.8/library/statistics.html#statistics.NormalDist) 类,使得[使用高斯正态分布](https://docs.python.org/3.8/library/statistics.html#normaldist-examples-and-recipes)更加方便。
要看使用`NormalDist`的例子,可以试着比较一下新`statistics.fmean()`和传统`statistics.mean()`的速度:
>>>
import random
import statistics
from timeit import timeit
Create 10,000 random numbers
data = [random.random() for _ in range(10_000)]
Measure the time it takes to run mean() and fmean()
t_mean = [timeit("statistics.mean(data)", number=100, globals=globals())
... for _ in range(30)]
t_fmean = [timeit("statistics.fmean(data)", number=100, globals=globals())
... for _ in range(30)]
Create NormalDist objects based on the sampled timings
n_mean = statistics.NormalDist.from_samples(t_mean)
n_fmean = statistics.NormalDist.from_samples(t_fmean)
Look at sample mean and standard deviation
n_mean.mean, n_mean.stdev
(0.825690647733245, 0.07788573997674526)
n_fmean.mean, n_fmean.stdev
(0.010488564966666065, 0.0008572332785645231)
Calculate the lower 1 percentile of mean
n_mean.quantiles(n=100)[0]
0.6445013221202459
在这个例子中,您使用 [`timeit`](https://docs.python.org/library/timeit.html) 来测量`mean()`和`fmean()`的执行时间。为了获得可靠的结果,您让`timeit`执行每个函数 100 次,并为每个函数收集 30 个这样的时间样本。基于这些样本,你创建两个`NormalDist`对象。注意,如果您自己运行代码,可能需要一分钟来收集不同的时间样本。
`NormalDist`有很多方便的属性和方法。完整列表见[文档](https://docs.python.org/3.8/library/statistics.html#normaldist-objects)。考察`.mean`和`.stdev`,你看到老款`statistics.mean()`跑 0.826±0.078 秒,新款`statistics.fmean()`花 0.0105±0.0009 秒。换句话说,`fmean()`对于这些数据来说大约快了 80 倍。
如果您需要 Python 中比标准库提供的更高级的统计,请查看 [`statsmodels`](https://www.statsmodels.org/) 和 [`scipy.stats`](https://docs.scipy.org/doc/scipy/reference/tutorial/stats.html) 。
[*Remove ads*](/account/join/)
### 关于危险语法的警告
Python 有一个 [`SyntaxWarning`](https://docs.python.org/3/library/exceptions.html#SyntaxWarning) ,它可以警告可疑的语法,这通常不是一个 [`SyntaxError`](https://realpython.com/invalid-syntax-python/) 。Python 3.8 增加了一些新功能,可以在编码和调试过程中帮助你。
`is`和`==`的区别可能会让人混淆。后者检查值是否相等,而只有当对象相同时,`is`才是`True`。Python 3.8 将试图警告你应该使用`==`而不是`is`的情况:
>>>
Python 3.7
version = "3.7"
version is "3.7"
False
Python 3.8
version = "3.8"
version is "3.8"
:1: SyntaxWarning: "is" with a literal. Did you mean "=="? False
version == "3.8"
True
当你写一个很长的列表时,很容易漏掉一个逗号,尤其是当它是垂直格式的时候。忘记元组列表中的逗号会给出一个混乱的错误消息,说明元组不可调用。Python 3.8 还发出了一个警告,指出了真正的问题:
>>>
[
... (1, 3)
... (2, 4)
... ]
:2: SyntaxWarning: 'tuple' object is not callable; perhaps
you missed a comma? Traceback (most recent call last):
File "", line 2, in
TypeError: 'tuple' object is not callable
该警告正确地将丢失的逗号识别为真正的原因。
### 优化
Python 3.8 进行了多项优化。一些能让代码运行得更快。其他的可以减少内存占用。例如,与 Python 3.7 相比,Python 3.8 在 [`namedtuple`](https://realpython.com/python-namedtuple/) 中查找字段要快得多:
>>>
import collections
from timeit import timeit
Person = collections.namedtuple("Person", "name twitter")
raymond = Person("Raymond", "@raymondh")
Python 3.7
timeit("raymond.twitter", globals=globals())
0.05876131607996285
Python 3.8
timeit("raymond.twitter", globals=globals())
0.0377705999400132
你可以看到在 Python 3.8 中,在`namedtuple`上查找`.twitter`要快 30-40%。当列表从已知长度的 iterables 初始化时,可以节省一些空间。这可以节省内存:
>>>
import sys
Python 3.7
sys.getsizeof(list(range(20191014)))
181719232
Python 3.8
sys.getsizeof(list(range(20191014)))
161528168
在这种情况下,Python 3.8 中的列表使用的内存比 Python 3.7 少 11%。
其他优化包括 [`subprocess`](https://docs.python.org/library/subprocess.html) 更好的性能、 [`shutil`](https://docs.python.org/library/shutil.html) 更快的文件复制、 [`pickle`](https://realpython.com/python-pickle-module/) 更好的默认性能、更快的 [`operator.itemgetter`](https://docs.python.org/library/operator.html#operator.itemgetter) 操作。有关优化的完整列表,请参见[官方文档](https://docs.python.org/3.8/whatsnew/3.8.html#optimizations)。
## 那么,应该升级到 Python 3.8 吗?
先说简单的答案。如果您想尝试这里看到的任何新特性,那么您确实需要能够使用 Python 3.8。像 [`pyenv`](https://realpython.com/intro-to-pyenv/) 和 [Anaconda](https://realpython.com/python-windows-machine-learning-setup/#introducing-anaconda-and-conda) 这样的工具使得并排安装几个版本的 Python 变得很容易。或者,可以运行[官方 Python 3.8 Docker 容器](https://hub.docker.com/_/python/)。亲自尝试 Python 3.8 没有任何坏处。
现在,对于更复杂的问题。您是否应该将生产环境升级到 Python 3.8?您是否应该让自己的项目依赖于 Python 3.8 来利用这些新特性?
在 Python 3.8 中运行 Python 3.7 代码应该没什么问题。因此,升级您的环境以运行 Python 3.8 是非常安全的,并且您将能够利用新版本中的[优化](#optimizations)。Python 3.8 的不同测试版本已经发布了好几个月了,所以希望大多数错误已经被解决了。然而,如果你想保守一点,你可以坚持到第一个维护版本(Python 3.8.1)发布。
一旦您升级了您的环境,您就可以开始尝试 Python 3.8 中才有的特性,比如[赋值表达式](#the-walrus-in-the-room-assignment-expressions)和[仅位置参数](#positional-only-arguments)。但是,您应该注意其他人是否依赖您的代码,因为这将迫使他们也升级他们的环境。流行的库可能会在相当长的一段时间内至少支持 Python 3.6。
有关为 Python 3.8 准备代码的更多信息,请参见[移植到 Python 3.8](https://docs.python.org/3.8/whatsnew/3.8.html#porting-to-python-3-8) 。
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:[**Python 3.8 中很酷的新特性**](/courses/cool-new-features-python-38/)*********
# Python 3.9:很酷的新特性供您尝试
> 原文:<https://realpython.com/python39-new-features/>
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:[**Python 3.9 中很酷的新特性**](/courses/cool-new-features-python-39/)
[Python 3.9 来了!](https://www.python.org/downloads/release/python-390/)在过去的一年里,来自世界各地的志愿者一直致力于 Python 的改进。虽然测试版已经发布了一段时间,但 Python 3.9 的第一个正式版本于 2020 年 10 月 5 日在[发布。](https://www.python.org/dev/peps/pep-0596/)
Python 的每个版本都包括新的、改进的和废弃的特性,Python 3.9 也不例外。[文档](https://docs.python.org/3.9/whatsnew/3.9.html)给出了变更的完整列表。下面,您将深入了解最新版本的 Python 带来的最酷的特性。
在本教程中,您将了解到:
* 使用**时区**访问和计算
* 有效合并和更新**字典**
* 基于**表达式**使用**装饰器**
* 结合**类型提示**和**其他注释**
要自己尝试新功能,您需要安装 Python 3.9。可以从 [Python 主页](https://www.python.org/download/pre-releases/)下载安装。或者,你可以使用[官方 Docker 图片](https://hub.docker.com/_/python/)来尝试一下。参见 Docker 中的[运行 Python 版本:如何尝试最新的 Python 版本](https://realpython.com/python-versions-docker/)了解更多详情。
**免费下载:** [从 Python 技巧中获取一个示例章节:这本书](https://realpython.com/bonus/python-tricks-sample-pdf/)用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
**额外学习材料:**查看[真实 Python 播客第 30 集](https://realpython.com/podcasts/rpp/30/)和[这段办公时间记录](https://realpython.com/lessons/office-hours-2020-10-21/)Python 3.9 技巧和与*真实 Python* 团队成员的小组讨论。
## 正确的时区支持
Python 通过标准库中的 [`datetime`](https://realpython.com/python-datetime/) 模块广泛支持处理日期和时间。然而,对使用时区的支持却有所欠缺。到目前为止,[推荐的处理时区的方式](https://realpython.com/python-datetime/#working-with-time-zones)一直是使用第三方库,比如 [`dateutil`](https://dateutil.readthedocs.io/en/stable/) 。
在普通 Python 中处理时区的最大挑战是您必须自己实现时区规则。一个`datetime`支持设置时区,但是只有 [UTC](https://en.wikipedia.org/wiki/Coordinated_Universal_Time) 立即可用。其他时区需要在抽象的 [`tzinfo`](https://docs.python.org/3/library/datetime.html#tzinfo-objects) 基类之上实现。
[*Remove ads*](/account/join/)
### 访问时区
你可以像这样从`datetime`库中得到一个 [UTC 时间戳](https://blog.ganssle.io/articles/2019/11/utcnow.html):
>>>
```py
>>> from datetime import datetime, timezone
>>> datetime.now(tz=timezone.utc)
datetime.datetime(2020, 9, 8, 15, 4, 15, 361413, tzinfo=datetime.timezone.utc)
注意,产生的时间戳是时区感知的。它有一个由tzinfo指定的附加时区。没有任何时区信息的时间戳被称为幼稚。
保罗·甘索多年来一直是dateutil的维护者。他在 2019 年加入了 Python 核心开发人员,并帮助添加了一个新的 zoneinfo 标准库,使时区工作更加方便。
zoneinfo提供对互联网号码分配机构(IANA) 时区数据库的访问。IANA 每年都会几次更新它的数据库,它是时区信息最权威的来源。
使用zoneinfo,您可以获得一个描述数据库中任何时区的对象:
>>> from zoneinfo import ZoneInfo >>> ZoneInfo("America/Vancouver") zoneinfo.ZoneInfo(key='America/Vancouver')您可以使用几个键中的一个来访问时区。在这种情况下,您使用
"America/Vancouver"。注意:
zoneinfo使用驻留在您本地计算机上的 IANA 时区数据库。有可能——特别是在 Windows 上——你没有这样的数据库或者zoneinfo找不到它。如果您得到如下错误,那么zoneinfo无法定位时区数据库:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZoneInfoNotFoundError: 'No time zone found with key America/Vancouver'
IANA 时区数据库的 Python 实现可以在 PyPI 上作为 tzdata 获得。可以用 pip 安装:
$ python -m pip install tzdata
一旦安装了tzdata,zoneinfo应该能够读取所有支持的时区的信息。tzdata由 Python 核心团队维护。请注意,为了访问 IANA 时区数据库中的最新更改,您需要保持软件包更新。
您可以使用datetime函数的tz或tzinfo参数制作时区感知时间戳:
>>> from datetime import datetime >>> from zoneinfo import ZoneInfo >>> datetime.now(tz=ZoneInfo("Europe/Oslo")) datetime.datetime(2020, 9, 8, 17, 12, 0, 939001, tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo')) >>> datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver")) datetime.datetime(2020, 10, 5, 3, 9, tzinfo=zoneinfo.ZoneInfo(key='America/Vancouver'))用时间戳记录时区对于记录非常有用。它还方便了时区之间的转换:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
>>> release.astimezone(ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 10, 5, 12, 9,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
请注意,奥斯陆时间比温哥华时间晚九个小时。
调查时区
IANA 时区数据库非常庞大。您可以使用zoneinfo.available_timezones()列出所有可用的时区:
>>> import zoneinfo >>> zoneinfo.available_timezones() {'America/St_Lucia', 'SystemV/MST7', 'Asia/Aqtau', 'EST', ... 'Asia/Beirut'} >>> len(zoneinfo.available_timezones()) 609数据库中时区的数量可能因您的安装而异。在本例中,您可以看到列出了
609时区名称。每个时区都记录了已经发生的历史变化,您可以更仔细地观察每个时区。Kiritimati ,又名圣诞岛,目前位于世界最西部时区,UTC+14。情况并非总是如此。1995 年以前,该岛位于协调世界时 10 时国际日期变更线的另一侧。为了跨越日期线,Kiritimati 完全跳过了 1994 年 12 月 31 日。
通过仔细观察
"Pacific/Kiritimati"时区对象,您可以看到这是如何发生的:
>>> from datetime import datetime, timedelta
>>> from zoneinfo import ZoneInfo
>>> hour = timedelta(hours=1)
>>> tz_kiritimati = ZoneInfo("Pacific/Kiritimati")
>>> ts = datetime(1994, 12, 31, 9, 0, tzinfo=ZoneInfo("UTC"))
>>> ts.astimezone(tz_kiritimati)
datetime.datetime(1994, 12, 30, 23, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
>>> (ts + 1 * hour).astimezone(tz_kiritimati)
datetime.datetime(1995, 1, 1, 0, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
1994 年 12 月 30 日,Kiritimati 岛上的时钟显示 23:00 时,新年开始了一个小时。1994 年 12 月 31 日,从来没有发生过!
您还可以看到相对于 UTC 的偏移量发生了变化:
>>> tz_kiritimati.utcoffset(datetime(1994, 12, 30)) / hour -10.0 >>> tz_kiritimati.utcoffset(datetime(1995, 1, 1)) / hour 14.0
.utcoffset()返回一个timedelta。计算一个给定的timedelta代表多少小时的最有效的方法是用它除以一个代表一小时的timedelta。关于时区还有很多其他奇怪的故事。Paul Ganssle 在他的 PyCon 2019 演讲中谈到了其中的一些问题,处理时区:你希望不需要知道的一切。看看能不能在时区数据库里找到其他人的踪迹。
使用最佳实践
与时区打交道可能会很棘手。然而,随着标准库中
zoneinfo的出现,事情变得简单了一些。这里有一些建议在处理日期和时间时要记住:
民用时间像开会、火车离站或音乐会的时间,最好存储在他们的本地时区。您通常可以通过存储一个简单的时间戳和时区的 IANA 键来实现这一点。以字符串形式存储的民用时间的一个例子是
"2020-10-05T14:00:00,Europe/Oslo"。拥有关于时区的信息可以确保您总是能够恢复信息,即使时区本身发生了变化。时间戳代表特定的时刻,通常记录事件的顺序。计算机日志就是一个例子。您不希望您的日志因为您的时区从夏令时变为标准时间而变得混乱。通常,您会将这些类型的时间戳存储为 UTC 中的原始日期时间。
因为 IANA 时区数据库一直在更新,所以您应该注意保持本地时区数据库的同步。如果您正在运行任何对时区敏感的应用程序,这一点尤其重要。
在 Mac 和 Linux 上,您通常可以信任您的系统来保持本地数据库的更新。如果你依赖于
tzdata包,那么你应该记得不时地更新它。特别是,你不应该把它固定在一个特定的版本上好几年。像
"America/Vancouver"这样的名字可以让你明确地访问给定的时区。但是,当与用户交流时区相关的日期时间时,最好使用常规的时区名称。这些在时区对象上作为.tzname()可用:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> tz = ZoneInfo("America/Vancouver")
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=tz)
>>> f"Release date: {release:%b %d, %Y at %H:%M} {tz.tzname(release)}"
'Release date: Oct 05, 2020 at 03:09 PDT'
您需要向.tzname()提供一个时间戳。这是必要的,因为时区的名称可能会随时间而改变,例如夏令时:
>>> tz.tzname(datetime(2021, 1, 28)) 'PST'冬天,温哥华处于太平洋标准时间(PST) ,而夏天,温哥华处于太平洋夏令时(PDT) 。
zoneinfo仅在 Python 3.9 及更高版本的标准库中可用。然而,如果您正在使用 Python 的早期版本,那么您仍然可以利用zoneinfo。PyPI 上有后端口,可以安装pip:$ python -m pip install backports.zoneinfo当导入
zoneinfo时,您可以使用下面的习语:try: import zoneinfo except ImportError: from backports import zoneinfo这使得您的程序与 3.6 及更高版本的所有 Python 兼容。关于
zoneinfo的更多细节见 PEP 615 。字典更新更简单
字典是 Python 中最基本的数据结构之一。它们在语言中随处可见,并且随着时间的推移得到了极大的优化。
有几种方法可以合并两本词典。然而,该语法要么有点晦涩,要么很麻烦:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> {**pycon, **europython}
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> merged = pycon.copy()
>>> for key, value in europython.items():
... merged[key] = value
...
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
这两种方法都是在不改变原始数据的情况下合并字典。注意"Cleveland"已经被merged中的"Edinburgh"覆盖。您也可以就地更新字典:
>>> pycon.update(europython) >>> pycon {2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}不过,这改变了你原来的字典。请记住,
.update()不会返回更新后的字典,所以在不改变原始数据的情况下使用.update()的巧妙尝试并不奏效:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> merged = pycon.copy().update(europython) # Does NOT work
>>> print(merged)
None
注意merged是 None ,当两个字典合并时,结果已经被丢弃。你可以使用 Python 3.8 中引入的海象操作符 ( :=)来完成这项工作:
>>> (merged := pycon.copy()).update(europython) >>> merged {2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}尽管如此,这不是一个特别可读或令人满意的解决方案。
在 PEP 584 的基础上,新版 Python 引入了两个新的字典操作符: union (
|)和 in-place union (|=)。您可以使用|来合并两个字典,而|=将就地更新一个字典:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> pycon | europython
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> pycon |= europython
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
如果d1和d2是两本字典,那么d1 | d2和{**d1, **d2}做的一样。|运算符用于计算集合的并集,因此您可能已经熟悉这个符号了。
使用|的一个优点是,它可以处理不同的类似字典的类型,并在合并过程中保持这种类型:
>>> from collections import defaultdict >>> europe = defaultdict(lambda: "", {"Norway": "Oslo", "Spain": "Madrid"}) >>> africa = defaultdict(lambda: "", {"Egypt": "Cairo", "Zimbabwe": "Harare"}) >>> europe | africa defaultdict(<function <lambda> at 0x7f0cb42a6700>, {'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}) >>> {**europe, **africa} {'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}当您想要有效地处理丢失的按键时,可以使用
defaultdict。注意|保留了defaultdict,而{**europe, **africa}没有。在
|如何为字典工作和+如何为列表工作之间有一些相似之处。事实上,+操作符是最初提出的来合并字典。当你观察就地操作者时,这种对应变得更加明显。
|=的基本用途是就地更新字典,类似于.update():
>>> libraries = {
... "collections": "Container datatypes",
... "math": "Mathematical functions",
... }
>>> libraries |= {"zoneinfo": "IANA time zone support"}
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support'}
当您用|合并字典时,两个字典都需要是正确的字典类型。另一方面,就地操作符(|=)乐于使用任何类似字典的数据结构:
>>> libraries |= [("graphlib", "Functionality for graph-like structures")] >>> libraries {'collections': 'Container datatypes', 'math': 'Mathematical functions', 'zoneinfo': 'IANA time zone support', 'graphlib': 'Functionality for graph-like structures'}在这个例子中,您从一个 2 元组列表中更新
libraries。当您想要合并的两个字典中有重叠的关键字时,会保留最后一个值:
>>> asia = {"Georgia": "Tbilisi", "Japan": "Tokyo"}
>>> usa = {"Missouri": "Jefferson City", "Georgia": "Atlanta"}
>>> asia | usa
{'Georgia': 'Atlanta', 'Japan': 'Tokyo', 'Missouri': 'Jefferson City'}
>>> usa | asia
{'Missouri': 'Jefferson City', 'Georgia': 'Tbilisi', 'Japan': 'Tokyo'}
在第一个例子中,"Georgia"指向"Atlanta",因为usa是合并中的最后一个字典。来自asia的值"Tbilisi"已被覆盖。注意,键"Georgia"仍然是结果字典中的第一个,因为它是asia中的第一个元素。颠倒合并的顺序会改变"Georgia"的位置和值。
运算符|和|=不仅被添加到常规字典中,还被添加到许多类似字典的类中,包括UserDictChainMapOrderedDictdefaultdictWeakKeyDictionaryWeakValueDictionary_EnvironMappingProxyType。它们已经而不是被添加到抽象基类 Mapping 或 MutableMapping 中。 Counter 容器已经使用|寻找最大计数。这一点没有改变。
您可以通过分别实现 .__or__() 和 .__ior__() 来改变|和|=的行为。详见 PEP 584 。
更灵活的装饰者
传统上,装饰器必须是一个命名的、可调用的对象,通常是一个函数或类。 PEP 614 允许装饰者是任何可调用的表达式。
大多数人不认为旧的修饰语法是限制性的。事实上,为装饰者放宽语法主要有助于一些特殊的用例。根据 PEP,激励用例与 GUI 框架中的回调相关。
PyQT 使用信号和插槽来连接小部件和回调。从概念上讲,你可以像下面这样把button的clicked信号连接到插槽say_hello():
button = QPushButton("Say hello")
@button.clicked.connect
def say_hello():
message.setText("Hello, World!")
当你点击按钮向问好时,将会显示文本Hello, World!。
注意:这不是一个完整的例子,如果您试图运行它,它会引发一个错误。它故意保持简短,以保持对装饰者的关注,而不是陷入 PyQT 如何工作的细节中。
有关 PyQt 入门和设置完整应用程序的更多信息,请参见 Python 和 PyQT:构建 GUI 桌面计算器。
现在假设您有几个按钮,为了跟踪它们,您将它们存储在一个字典中:
buttons = {
"hello": QPushButton("Say hello"),
"leave": QPushButton("Goodbye"),
"calculate": QPushButton("3 + 9 = 12"),
}
这一切都很好。然而,如果您想使用装饰器将一个按钮连接到一个插槽,这就给你带来了挑战。在 Python 的早期版本中,当使用装饰器时,不能使用方括号来访问项目。您需要执行如下操作:
hello_button = buttons["hello"]
@hello_button.clicked.connect
def say_hello():
message.setText("Hello, World!")
在 Python 3.9 中,这些限制被取消,现在您可以使用任何表达式,包括访问字典中的项的表达式:
@buttons["hello"].clicked.connect
def say_hello():
message.setText("Hello, World!")
虽然这不是一个大的变化,但在某些情况下,它允许您编写更干净的代码。扩展的语法也使得在运行时动态选择装饰器变得更加容易。假设您有以下可用的装饰者:
# story.py
import functools
def normal(func):
return func
def shout(func):
@functools.wraps(func)
def shout_decorator(*args, **kwargs):
return func(*args, **kwargs).upper()
return shout_decorator
def whisper(func):
@functools.wraps(func)
def whisper_decorator(*args, **kwargs):
return func(*args, **kwargs).lower()
return whisper_decorator
@normal装饰器根本不改变原始函数,而@shout和@whisper使函数返回的任何文本大写或小写。然后,您可以将对这些装饰器的引用存储在一个字典中,并让用户可以使用它们:
# story.py (continued)
DECORATORS = {"normal": normal, "shout": shout, "whisper": whisper}
voice = input(f"Choose your voice ({', '.join(DECORATORS)}): ")
@DECORATORS[voice]
def get_story():
return """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into
the book her sister was reading, but it had no pictures or
conversations in it, "and what is the use of a book," thought Alice
"without pictures or conversations?"
"""
print(get_story())
当您运行这个脚本时,会询问您将哪个装饰器应用于故事。然后,生成的文本被打印到屏幕上:
$ python3.9 story.py
Choose your voice (normal, shout, whisper): shout
ALICE WAS BEGINNING TO GET VERY TIRED OF SITTING BY HER SISTER ON THE
BANK, AND OF HAVING NOTHING TO DO: ONCE OR TWICE SHE HAD PEEPED INTO
THE BOOK HER SISTER WAS READING, BUT IT HAD NO PICTURES OR
CONVERSATIONS IN IT, "AND WHAT IS THE USE OF A BOOK," THOUGHT ALICE
"WITHOUT PICTURES OR CONVERSATIONS?"
这个例子就好像@shout已经应用于get_story()一样。然而,在这里,它是在运行时根据您的输入应用的。与按钮示例一样,通过使用临时变量,您可以在早期版本的 Python 中实现相同的效果。
关于 decorator 的更多信息,请查看 Python Decorators 的初级读本。关于轻松语法的更多细节,请参见 PEP 614 。
带注释的类型提示
在 Python 3.0 中,函数注释被引入。该语法支持向 Python 函数添加任意元数据。下面是一个向公式添加单位的示例:
# calculator.py
def speed(distance: "feet", time: "seconds") -> "miles per hour":
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
在本例中,注释仅用作读者的文档。稍后您将看到如何在运行时访问注释。
PEP 484 建议对类型提示使用注释。随着类型提示越来越受欢迎,它们在 Python 中已经挤掉了注释的其他用途。
由于除了静态类型之外还有几个注释的用例, PEP 593 引入了 typing.Annotated ,你可以用它将类型提示与其他信息结合起来。您可以像这样重做上面的calculator.py示例:
# calculator.py
from typing import Annotated
def speed(
distance: Annotated[float, "feet"], time: Annotated[float, "seconds"] ) -> Annotated[float, "miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Annotated至少需要两个参数。第一个参数是常规类型提示,其余参数是任意元数据。类型检查器只关心第一个参数,将元数据的解释留给您和您的应用程序。类型检查器会将类似于Annotated[float, "feet"]的类型提示与float同等对待。
您可以像往常一样通过.__annotations__访问注释。从calculator.py进口speed():
>>> from calculator import speed >>> speed.__annotations__ {'distance': typing.Annotated[float, 'feet'], 'time': typing.Annotated[float, 'seconds'], 'return': typing.Annotated[float, 'miles per hour']}每个注释都可以在字典中找到。您用
Annotated定义的元数据存储在.__metadata__中:
>>> speed.__annotations__["distance"].__metadata__
('feet',)
>>> {var: th.__metadata__[0] for var, th in speed.__annotations__.items()}
{'distance': 'feet', 'time': 'seconds', 'return': 'miles per hour'}
最后一个示例通过读取每个变量的第一个元数据项来挑选出所有的单元。另一种在运行时访问类型提示的方法是使用来自typing模块的get_type_hints()。get_type_hints()默认情况下会忽略元数据:
>>> from typing import get_type_hints >>> from calculator import speed >>> get_type_hints(speed) {'distance': <class 'float'>, 'time': <class 'float'>, 'return': <class 'float'>}这应该允许大多数在运行时访问类型提示的程序继续工作,而无需更改。您可以使用新的可选参数
include_extras来请求包含元数据:
>>> get_type_hints(speed, include_extras=True)
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
使用Annotated可能会导致非常冗长的代码。保持代码简短易读的一个方法是使用类型别名。您可以定义表示注释类型的新变量:
# calculator.py
from typing import Annotated
Feet = Annotated[float, "feet"] Seconds = Annotated[float, "seconds"] MilesPerHour = Annotated[float, "miles per hour"]
def speed(distance: Feet, time: Seconds) -> MilesPerHour:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
类型别名可能需要一些工作来设置,但是它们可以使您的代码非常清晰易读。
如果您有一个广泛使用注释的应用程序,您也可以考虑实现一个注释工厂。将以下内容添加到calculator.py的顶部:
# calculator.py
from typing import Annotated
class AnnotationFactory:
def __init__(self, type_hint):
self.type_hint = type_hint
def __getitem__(self, key):
if isinstance(key, tuple):
return Annotated[(self.type_hint, ) + key]
else:
return Annotated[self.type_hint, key]
def __repr__(self):
return f"{self.__class__.__name__}({self.type_hint})"
AnnotationFactory可以用不同的元数据创建Annotated对象。您可以使用注释工厂来创建更多的动态别名。更新calculator.py以使用AnnotationFactory:
# calculator.py (continued)
Float = AnnotationFactory(float)
def speed(
distance: Float["feet"], time: Float["seconds"] ) -> Float["miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Float[<metadata>]代表Annotated[float, <metadata>],所以这个例子的工作方式和前面两个例子完全一样。
更强大的 Python 解析器
Python 3.9 最酷的特性之一是你在日常编码生活中不会注意到的。Python 解释器的一个基本组件是解析器。在最新版本中,解析器被重新实现。
从一开始,Python 就使用一个基本的 LL(1)解析器将源代码解析成解析树。您可以将 LL(1)解析器想象成一次读取一个字符,并计算出如何在不回溯的情况下解释源代码的解析器。
使用简单解析器的一个优点是它的实现和推理相当简单。一个缺点是有个难题需要你用特殊的技巧来规避。
在一系列博客文章中,Python 的创始人吉多·范·罗苏姆调查了 PEG(解析表达式语法)解析器。PEG 解析器比 LL(1)解析器更强大,并且不需要特殊的修改。由于 Guido 的研究,在 Python 3.9 中实现了一个 PEG 解析器。详见 PEP 617 。
目标是让新的 PEG 解析器产生与旧的 LL(1)解析器相同的抽象语法树(AST) 。最新版本实际上附带了这两种解析器。虽然 PEG 解析器是默认的,但是您可以通过使用 -X oldparser 命令行标志来使用旧的解析器运行您的程序:
$ python -X oldparser script_name.py
或者,您可以设置 PYTHONOLDPARSER 环境变量。
旧的解析器将在 Python 3.10 中被移除。这将允许没有 LL(1)语法限制的新特性。目前正在考虑包含在 Python 3.10 中的一个这样的特性是结构模式匹配,如 PEP 622 中所述。
让两个解析器都可用对于验证新的 PEG 解析器来说是非常好的。您可以在两个解析器上运行任何代码,并在 AST 级别进行比较。在测试过程中,对整个标准库以及许多流行的第三方包进行了编译和比较。
您还可以比较这两种解析器的性能。一般来说,PEG 解析器和 LL(1)的性能相似。在整个标准库中,PEG 解析器稍微快一点,但是它也使用稍微多一点的内存。实际上,当使用新的解析器时,您不会注意到任何性能上的变化,无论是好是坏。
其他非常酷的功能
到目前为止,您已经看到了 Python 3.9 中最大的新特性。然而,Python 的每个新版本也包括许多小的变化。官方文件包括了所有这些变化的列表。在本节中,您将了解一些其他非常酷的新特性,您可以开始使用它们。
字符串前缀和后缀
如果您需要删除一个字符串的开头或结尾,那么.strip()似乎可以完成这项工作:
>>> "three cool features in Python".strip(" Python") 'ree cool features i'后缀
" Python"已经被删除,但是字符串开头的"th"也被删除。.strip()的实际行为有时令人惊讶——并引发了许多 bug 报告。人们很自然地认为.strip(" Python")会删除子串" Python",但它删除的是单个字符" "、"P"、"y"、"t"、"h"、"o"和"n"。要真正删除字符串后缀,您可以这样做:
>>> def remove_suffix(text, suffix):
... if text.endswith(suffix):
... return text[:-len(suffix)]
... else:
... return text
...
>>> remove_suffix("three cool features in Python", suffix=" Python")
'three cool features in'
这样效果更好,但是有点麻烦。这段代码还有一个微妙的错误:
>>> remove_suffix("three cool features in Python", suffix="") ''如果后缀碰巧是空字符串,不知何故整个字符串都被删除了。这是因为空字符串的长度是 0,所以
text[:0]最终被返回。您可以通过将测试改为在suffix and text.endswith(suffix)上来解决这个问题。在 Python 3.9 中,有两个新的字符串方法可以解决这个用例。您可以使用
.removeprefix()和.removesuffix()分别删除字符串的开头或结尾:
>>> "three cool features in Python".removesuffix(" Python")
'three cool features in'
>>> "three cool features in Python".removeprefix("three ")
'cool features in Python'
>>> "three cool features in Python".removeprefix("Something else")
'three cool features in Python'
注意,如果给定的前缀或后缀与字符串不匹配,那么字符串将原封不动地返回。
.removeprefix()和.removesuffix()最多去掉一个词缀。如果你想确保将它们全部移除,那么你可以使用 while循环:
>>> text = "Waikiki" >>> text.removesuffix("ki") 'Waiki' >>> while text.endswith("ki"): ... text = text.removesuffix("ki") ... >>> text 'Wai'关于
.removeprefix()和.removesuffix()的更多信息,请参见 PEP 616 。直接输入提示列表和字典
为基本类型添加类型提示通常很简单,比如
str、int和bool。您可以直接用类型进行注释。这种情况与您自己创建的自定义类型类似:radius: float = 3.9 class NothingType: pass nothing: NothingType = NothingType()仿制药是一个不同的故事。泛型通常是一个可以参数化的容器,比如一列数字。出于技术原因,在以前的 Python 版本中,您不能使用
list[float]或list(float)作为类型提示。相反,您需要从typing模块导入一个不同的列表对象:from typing import List numbers: List[float]在 Python 3.9 中,不再需要这种并行层次结构。现在,您终于可以使用
list进行适当的类型提示了:numbers: list[float]这将使您的代码更容易编写,并消除同时拥有
list和List的困惑。在未来,使用typing.List和类似的泛型如typing.Dict和typing.Type将被弃用,这些泛型最终将从typing中移除。如果您需要编写与旧版本 Python 兼容的代码,那么您仍然可以通过使用
__future__导入来利用新语法,这在 Python 3.7 中是可用的。在 Python 3.7 中,您通常会看到类似这样的内容:
>>> numbers: list[float]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
然而,使用__future__导入可以让这个例子工作:
>>> from __future__ import annotations >>> numbers: list[float] >>> __annotations__ {'numbers': 'list[float]'}这是因为注释在运行时不会被计算。如果您尝试评估注释,那么您仍然会体验到
TypeError。有关这种新语法的更多信息,请参见 PEP 585 。拓扑排序
由节点和边组成的图对于表示不同种类的数据很有用。例如,当您使用
pip安装来自 PyPI 的一个包时,该包可能依赖于其他包,而其他包又可能有更多的依赖项。这种结构可以用一个图来表示,其中每个包是一个节点,每个依赖项用一条边来表示:
A graph showing the dependencies of realpython-reader 此图显示了
realpython-reader包的依赖关系。直接取决于feedparser和html2text,而feedparser反过来又取决于sgmllib3k。假设您希望按顺序安装这些软件包,以便始终满足所有依赖关系。然后你可以做所谓的拓扑排序来找到你的依赖关系的总顺序。
Python 3.9 在标准库中引入了一个新的模块
graphlib,做拓扑排序。您可以使用它来查找集合的总顺序,或者考虑到可以并行化的任务来进行更高级的调度。要查看示例,您可以在字典中表示早期的依赖关系:
>>> dependencies = {
... "realpython-reader": {"feedparser", "html2text"},
... "feedparser": {"sgmllib3k"},
... }
...
这表达了您在上图中看到的依赖关系。例如,realpython-reader依赖于feedparser和html2text。在这种情况下,realpython-reader的具体依赖关系写成一个集合:{"feedparser", "html2text"}。您可以使用任何 iterable 来指定这些,包括一个列表。
注意:记住一个字符串在其字符上是可迭代的。因此,您通常希望将单个字符串包装在某种容器中:
>>> dependencies = {"feedparser": "sgmllib3k"} # Will NOT work这个不不是说
feedparser依赖sgmllib3k。而是说feedparser要靠s、g、m、l、l、i、b、3、k每一个。要计算图表的总顺序,可以使用
graphlib中的TopologicalSorter:
>>> from graphlib import TopologicalSorter
>>> ts = TopologicalSorter(dependencies)
>>> list(ts.static_order())
['html2text', 'sgmllib3k', 'feedparser', 'realpython-reader']
给定的顺序建议你先安装html2text,再安装sgmllib3k,再安装feedparser,最后安装realpython-reader。
注:一个图的全序不一定唯一。在本例中,其他有效的排序是:
sgmllib3k、html2text、feedparser、realpython-readersgmllib3k、feedparser、html2text、realpython-reader
TopologicalSorter有一个扩展的 API,允许你使用.add()增加节点和边。您还可以迭代地使用该图,这在调度可以并行完成的任务时特别有用。完整示例见文档。
最大公约数(GCD)和最小公倍数(LCM)
数的除数是一个重要的性质,在密码学和其他领域都有应用。Python 很早就有了计算两个数的最大公约数(GCD) 的函数:
>>> import math >>> math.gcd(49, 14) 749 和 14 的 GCD 是 7,因为 7 是 49 和 14 的最大数。
最小公倍数(LCM) 与 GCD 有关。两个数的 LCM 是能被两个数相除的最小数。可以根据 GCD 来定义 LCM:
>>> def lcm(num1, num2):
... if num1 == num2 == 0:
... return 0
... return num1 * num2 // math.gcd(num1, num2)
...
>>> lcm(49, 14)
98
49 和 14 的最小公倍数是 98,因为 98 是能被 49 和 14 整除的最小数。在 Python 3.9 中,您不再需要定义自己的 LCM 函数:
>>> import math >>> math.lcm(49, 14) 98
math.gcd()和math.lcm()现在都支持两个以上的数字。例如,你可以这样计算273、1729、6048的最大公约数:
>>> import math
>>> math.gcd(273, 1729, 6048)
7
注意math.gcd()和math.lcm()不能基于列表进行计算。然而,您可以将列表解包成逗号分隔的参数:
>>> import math >>> numbers = [273, 1729, 6048] >>> math.gcd(numbers) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'list' object cannot be interpreted as an integer >>> math.gcd(*numbers) 7在 Python 的早期版本中,您需要嵌套几个对
gcd()的调用或者使用functools.reduce():
>>> import math
>>> math.gcd(math.gcd(273, 1729), 6048)
7
>>> import functools
>>> functools.reduce(math.gcd, [273, 1729, 6048])
7
在 Python 的最新版本中,这些计算变得更加简单易懂。
新的 HTTP 状态代码
IANA T2 协调几个关键的互联网基础设施资源,包括你之前看到的时区数据库。另一个这样的资源是 HTTP 状态代码注册表。HTTP 状态代码可在 http标准库中获得:
>>> from http import HTTPStatus >>> HTTPStatus.OK <HTTPStatus.OK: 200> >>> HTTPStatus.OK.description 'Request fulfilled, document follows' >>> HTTPStatus(404) <HTTPStatus.NOT_FOUND: 404> >>> HTTPStatus(404).phrase 'Not Found'
>>> from http import HTTPStatus
>>> HTTPStatus.EARLY_HINTS.value
103
>>> HTTPStatus(425).phrase
'Too Early'
如您所见,您可以根据号码和名称访问新代码。
超文本咖啡壶控制协议(HTCPCP) 于 1998 年 4 月 1 日引入,用于控制、监控和诊断咖啡壶。它引入了像BREW这样的新方法,同时主要重用现有的 HTTP 状态代码。一个例外是新的 418(我是一把茶壶)状态码,意在防止因在茶壶里煮咖啡而毁坏一把好茶壶的灾难。
用于茶流出设备的超文本咖啡壶控制协议(HTCPCP-茶)也包括 418(我是茶壶)并且该代码也找到了进入许多主流 HTTP 库的方法,包括 requests 。
2017 年发起的从主要图书馆移除 418(我是茶壶)的倡议遭到了的迅速抵制。最终,辩论以 418 被提议为保留的 HTTP 状态码而结束。418(我是茶壶)也加入了http:
>>> from http import HTTPStatus >>> HTTPStatus(418).phrase "I'm a Teapot" >>> HTTPStatus.IM_A_TEAPOT.description 'Server refuses to brew coffee because it is a teapot.'你可以在一些地方看到 418 错误,包括在谷歌上。
删除不赞成使用的兼容性代码
Python 去年的一个重要里程碑是 Python 2 的日落。Python 2.7 是在 2010 年首次发布的。2020 年 1 月 1 日,官方对 Python 2 的支持结束。
Python 2 已经为社区服务了近 20 年,并且被许多人亲切地怀念。同时,不用担心 Python 3 与 Python 2 的兼容性,核心开发人员可以专注于 Python 3 的持续改进,并在此过程中做一些清理工作。
Python 3.9 中移除了许多不推荐使用但为了向后兼容 Python 2 而保留下来的函数。Python 3.10 中还会移除一些。如果您想知道您的代码是否使用了这些旧特性,那么尝试在开发模式下运行它:
$ python -X dev script_name.py使用开发模式会向您显示更多的警告,帮助您的代码经得起未来的考验。参见Python 3.9 新特性了解更多关于被移除特性的信息。
Python 的下一个版本是什么时候?
Python 3.9 中与代码无关的最后一个变化由 PEP 602 描述——Python 的年度发布周期。传统上,Python 的新版本大约每十八个月发布一次。
从 Python 的当前版本开始,大约每隔 12 个月,即每年的 10 月,就会发布新的版本。这带来了几个好处,最明显的是更可预测和一致的发布时间表。对于年度发布,更容易计划和同步其他重要的开发者活动,如PyCon USsprint 和年度核心 sprint。
虽然发布会越来越频繁,但 Python 不会更快变得不兼容,也不会更快获得新特性。所有版本将在最初发布后的五年内得到支持,因此 Python 3.9 将在 2025 年前获得安全修复。
随着发布周期的缩短,新特性的发布会更快。同时,新版本将带来更少的变化,使更新变得不那么重要。
Python 的指导委员会的选举在每次 Python 发布后举行。今后,这意味着指导委员会的五个职位将每年选举一次。
尽管 Python 的新版本将每 12 个月发布一次,但新版本的开发在发布前大约 17 个月就开始了。这是因为在 beta 测试阶段,没有新的特性被添加到一个版本中,这个阶段持续了大约五个月。
换句话说,Python 的下一个版本 Python 3.10 的开发已经在进行中。你已经可以通过运行最新的核心开发者 Docker 镜像来测试 Python 3.10 的第一个 alpha 版本。
Python 3.10 的最终特性仍有待确定。然而,版本号有些特殊,因为它是第一个带有两位数次要版本的 Python 版本。这可能会导致一些问题,例如,如果您的代码将版本作为字符串进行比较,因为
"3.9" > "3.10"。更好的解决方案是将版本作为元组进行比较:(3, 9) < (3, 10)。包flake8-2020测试代码中的这些和类似的问题。那么,应该升级到 Python 3.9 吗?
首先,如果您想尝试本教程中展示的任何很酷的新特性,那么您需要使用 Python 3.9。可以将最新版本与当前版本的 Python 并行安装。最简单的方法就是使用类似
pyenv或者conda这样的环境管理器。通过 Docker 运行新版本会更少干扰。当您考虑升级到 Python 3.9 时,您应该问自己两个不同的问题:
- 您应该将开发人员或生产环境升级到 Python 3.9 吗?
- 您是否应该让您的项目依赖于 Python 3.9,以便能够利用新特性?
如果您的代码在 Python 3.8 中运行流畅,那么在 Python 3.9 中运行相同的代码应该不会遇到什么问题。主要的绊脚石是,如果你依赖的函数在 Python 的早期版本中已经被否决,现在被移除。
新的 PEG 解析器自然没有像旧的那样经过广泛的测试。如果你运气不好,你可能会遇到一些奇怪的棘手问题。但是,请记住,您可以使用命令行标志切换回旧的解析器。
总之,在方便的时候尽早将自己的环境升级到 Python 的最新版本应该是相当安全的。如果你想保守一点,那么你可以等待第一个维护版本,Python 3.9.1。
您是否能够开始真正利用自己代码中的新特性,很大程度上取决于您的用户群。如果您的代码只在您可以控制和升级到 Python 3.9 的环境中运行,那么使用
zoneinfo或新的字典合并操作符没有任何害处。然而,如果你正在分发一个被许多人使用的库,那么最好保守一点。上一个版本的 Python 3.5 发布于 9 月,现在已经不支持了。如果可能的话,你应该仍然致力于让你的库与 Python 3.6 和更高版本兼容,这样尽可能多的人可以享受你的成果。
有关为 Python 3.9 准备代码的详细信息,请参见官方文档中的移植到 Python 3.9 。
结论
新 Python 版本的发布是社区的一个重要里程碑。您可能无法立即开始使用这些很酷的新特性,但是几年后 Python 3.9 将会像现在的 Python 3.6 一样普及。
在本教程中,您已经看到了像这样的新功能:
zoneinfo模块用于处理时区- Union 运算符可以更新字典
- 更具表现力的装饰语法
- 除了类型提示之外,还可以用于其他事情的注释
要了解更多 Python 3.9 技巧以及与真正的 Python 团队成员的小组讨论,请查看以下附加资源:
留出几分钟时间来尝试最让你兴奋的功能,然后在下面的评论中分享你的体验!
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解:Python 3.9 中很酷的新特性********
PyTorch vs TensorFlow,用于您的 Python 深度学习项目
PyTorch vs TensorFlow:有什么区别?两者都是开源 Python 库,使用图形对数据进行数值计算。两者都在学术研究和商业代码中广泛使用。两者都被各种 API、云计算平台和模型库所扩展。
如果它们如此相似,那么哪个最适合你的项目呢?
在本教程中,您将学习:
- PyTorch 和 TensorFlow 有什么区别
- 每个人都有哪些工具和资源
- 如何为您的特定用例选择最佳选项
您将从仔细研究这两个平台开始,从稍旧的 TensorFlow 开始,然后探索一些可以帮助您确定哪个选择最适合您的项目的考虑因素。我们开始吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
什么是张量流?
TensorFlow 由谷歌开发,于 2015 年开源发布。它源于谷歌自主开发的机器学习软件,该软件经过重构和优化,可用于生产。
“TensorFlow”这个名称描述了如何组织和执行数据操作。TensorFlow 和 PyTorch 的基本数据结构是一个张量。当你使用 TensorFlow 时,你通过构建一个有状态数据流图,对这些张量中的数据执行操作,有点像记忆过去事件的流程图。
谁用 TensorFlow?
TensorFlow 有着生产级深度学习库的美誉。它拥有大量活跃的用户,以及大量用于培训、部署和服务模型的官方和第三方工具和平台。
2016 年 PyTorch 发布后,TensorFlow 人气下滑。但在 2019 年末,谷歌发布了 TensorFlow 2.0 ,这是一次重大更新,简化了库,使其更加用户友好,引发了机器学习社区的新兴趣。
代码样式和功能
在 TensorFlow 2.0 之前,TensorFlow 需要你通过调用
tf.*API 来手动拼接一个抽象语法树——图形。然后,它要求您通过向一个session.run()调用传递一组输出张量和输入张量来手动编译模型。一个
Session对象是一个用于运行 TensorFlow 操作的类。它包含了评估Tensor对象和执行Operation对象的环境,它可以像tf.Variable对象一样拥有资源。使用Session最常见的方式是作为上下文管理器。在 TensorFlow 2.0 中,您仍然可以用这种方式构建模型,但是使用急切执行更容易,这是 Python 通常的工作方式。急切执行会立即评估操作,因此您可以使用 Python 控制流而不是图形控制流来编写代码。
为了看出区别,让我们看看如何用每种方法将两个张量相乘。下面是一个使用旧 TensorFlow 1.0 方法的示例:
>>> import tensorflow as tf
>>> tf.compat.v1.disable_eager_execution()
>>> x = tf.compat.v1.placeholder(tf.float32, name = "x")
>>> y = tf.compat.v1.placeholder(tf.float32, name = "y")
>>> multiply = tf.multiply(x, y)
>>> with tf.compat.v1.Session() as session:
... m = session.run(
... multiply, feed_dict={x: [[2., 4., 6.]], y: [[1.], [3.], [5.]]}
... )
... print(m)
[[ 2\. 4\. 6.]
[ 6\. 12\. 18.]
[10\. 20\. 30.]]
这段代码使用 TensorFlow 2.x 的tf.compat API 来访问 TensorFlow 1.x 方法,并禁用急切执行。
首先使用 tf.compat.v1.placeholder 张量对象声明输入张量x和y。然后定义要对它们执行的操作。接下来,使用tf.Session对象作为上下文管理器,创建一个容器来封装运行时环境,并通过用feed_dict将实值输入占位符来执行乘法。最后,还是在会话里面,你 print() 的结果。
借助 TensorFlow 2.0 中的热切执行,您只需 tf.multiply() 即可实现相同的结果:
>>> import tensorflow as tf >>> x = [[2., 4., 6.]] >>> y = [[1.], [3.], [5.]] >>> m = tf.multiply(x, y) >>> m <tf.Tensor: shape=(3, 3), dtype=float32, numpy= array([[ 2., 4., 6.], [ 6., 12., 18.], [10., 20., 30.]], dtype=float32)>在这段代码中,您使用 Python 列表表示法声明您的张量,当您调用时,
tf.multiply()立即执行元素级乘法。如果你不想或者不需要构建底层组件,那么推荐使用 TensorFlow 的方式是 Keras 。它具有更简单的 API,将常见用例转化为预制组件,并提供比 base TensorFlow 更好的错误消息。
特殊功能
TensorFlow 拥有庞大而成熟的用户群,以及大量帮助生产机器学习的工具。对于移动开发,它有用于 JavaScript 和 Swift 的 API,而 TensorFlow Lite 可以让你压缩和优化物联网设备的模型。
您可以快速开始使用 TensorFlow,因为谷歌和第三方都提供了丰富的数据、预训练模型和谷歌 Colab 笔记本。
TensorFlow 内置了很多流行的机器学习算法和数据集,随时可以使用。除了内置的数据集,你可以访问谷歌研究数据集或使用谷歌的数据集搜索来找到更多。
Keras 使模型的建立和运行变得更加容易,因此您可以在更短的时间内尝试新的技术。事实上,Keras 是 Kaggle 上五个获胜团队中使用最多的深度学习框架。
一个缺点是,从 TensorFlow 1.x 到 TensorFlow 2.0 的更新改变了太多的功能,你可能会发现自己很困惑。升级代码繁琐且容易出错。许多资源,如教程,可能包含过时的建议。
PyTorch 没有同样大的向后兼容性问题,这可能是选择它而不是 TensorFlow 的一个原因。
Tensorflow Ecosystem
TensorFlow 扩展生态系统的 API、扩展和有用工具的一些亮点包括:
- TensorFlow Hub ,一个可重用机器学习模块的库
- 模型花园,使用 TensorFlow 高级 API 的官方模型集合
- 用 Scikit-Learn、Keras 和 TensorFlow 进行动手机器学习,全面介绍使用 TensorFlow 进行机器学习
PyTorch 是什么?
PyTorch 由脸书开发,于 2016 年首次公开发布。创建它是为了提供类似 TensorFlow 的生产优化,同时使模型更容易编写。
因为 Python 程序员发现它使用起来如此自然,PyTorch 迅速获得了用户,激励 TensorFlow 团队在 TensorFlow 2.0 中采用了 PyTorch 的许多最受欢迎的功能。
谁用 PyTorch?
PyTorch 以在研究中比在生产中应用更广泛而闻名。然而,自从在 TensorFlow 发布一年后,PyTorch 被专业开发人员大量使用。
2020 Stack Overflow 开发者调查最受欢迎的“其他框架、库和工具”列表显示,10.4%的专业开发者选择 TensorFlow,4.1%选择 PyTorch。在 2018 中,TensorFlow 的比例为 7.6%,PyTorch 仅为 1.6%。
至于研究,PyTorch 是一个受欢迎的选择,像斯坦福大学的计算机科学项目现在用它来教授深度学习。
代码样式和功能
PyTorch 基于 Torch ,这是一个用 c 语言编写的快速计算框架。Torch 有一个用于构建模型的 Lua 包装器。
PyTorch 将相同的 C 后端包装在 Python 接口中。但它不仅仅是一个包装纸。开发人员从头开始构建它是为了让 Python 程序员更容易编写模型。底层的低级 C 和 C++代码针对运行 Python 代码进行了优化。由于这种紧密集成,您可以:
- 更好的内存和优化
- 更合理的错误消息
- 模型结构的细粒度控制
- 更透明的模型行为
- 与 NumPy 的兼容性更好
这意味着你可以直接用 Python 编写高度定制的神经网络组件,而不必使用大量的底层函数。
PyTorch 的 eager execution ,可以立即动态地计算张量运算,启发了 TensorFlow 2.0,所以两者的 API 看起来非常相似。
将 NumPy 对象转换成张量是 PyTorch 的核心数据结构。这意味着您可以轻松地在
torch.Tensor对象和numpy.array对象之间来回切换。例如,您可以使用 PyTorch 将 NumPy 数组转换为张量的本机支持来创建两个
numpy.array对象,使用torch.from_numpy()将每个对象转换为torch.Tensor对象,然后获取它们的元素级乘积:
>>> import torch
>>> import numpy as np
>>> x = np.array([[2., 4., 6.]])
>>> y = np.array([[1.], [3.], [5.]])
>>> m = torch.mul(torch.from_numpy(x), torch.from_numpy(y))
>>> m.numpy()
array([[ 2., 4., 6.],
[ 6., 12., 18.],
[10., 20., 30.]])
使用torch.Tensor.numpy()可以将矩阵乘法的结果——它是一个torch.Tensor对象——作为一个numpy.array对象打印出来。
一个torch.Tensor对象和一个numpy.array对象最重要的区别就是torch.Tensor 类有不同的方法和属性,比如 backward() ,它计算渐变, CUDA 兼容性。
特殊功能
PyTorch 为 Torch 后端添加了一个用于自动分化的 C++模块。自动微分在反向传播期间自动计算torch.nn中定义的函数的梯度。
默认情况下,PyTorch 使用急切模式计算。您可以在构建神经网络时一行一行地运行它,这样更容易调试。这也使得构造具有条件执行的神经网络成为可能。对于大多数 Python 程序员来说,这种动态执行更加直观。
PyTorch 生态系统
PyTorch 扩展生态系统的 API、扩展和有用工具的一些亮点包括:
- fast . ai API,这使得快速构建模型变得非常容易
- TorchServe ,AWS 和脸书合作开发的开源模型服务器
- TorchElastic 使用 Kubernetes 大规模训练深度神经网络
- PyTorch Hub ,一个分享和推广前沿模型的活跃社区
PyTorch vs TensorFlow 决策指南
使用哪个库取决于您自己的风格和偏好、您的数据和模型以及您的项目目标。当您开始您的项目时,稍微研究一下哪个库最好地支持这三个因素,您将为自己的成功做好准备!
风格
如果你是一个 Python 程序员,那么 PyTorch 会感觉很容易上手。开箱即可按照您的预期方式运行。
另一方面,TensorFlow 比 PyTorch 支持更多的编码语言,py torch 有一个 C++ API。在 JavaScript 和 Swift 中都可以使用 TensorFlow。如果你不想写太多的底层代码,那么 Keras 抽象出了很多常见用例的细节,这样你就可以构建 TensorFlow 模型,而不用担心细节。
数据和模型
你用的是什么型号?如果你想使用一个特定的预训练模型,像伯特或深梦,那么你应该研究它与什么兼容。一些预训练的模型只在一个库中可用,而一些在两个库中都可用。模型花园、PyTorch 和 TensorFlow 中心也是很好的资源。
需要什么数据?如果您想要使用预处理数据,那么它可能已经被构建到一个或另一个库中。查看文档,这将使你的开发更快!
项目目标
你的模特会住在哪里?如果您想在移动设备上部署模型,那么 TensorFlow 是一个不错的选择,因为 TensorFlow Lite 及其 Swift API。对于服务模型,TensorFlow 与 Google Cloud 紧密集成,但 PyTorch 集成到 AWS 上的 TorchServe 中。如果你想参加 Kaggle 比赛,那么 Keras 会让你快速迭代实验。
在项目开始时考虑这些问题和例子。确定两三个最重要的组件,TensorFlow 或 PyTorch 将成为正确的选择。
结论
在本教程中,您已经了解了 PyTorch 和 TensorFlow,了解了谁使用它们以及它们支持哪些 API,并了解了如何为您的项目选择 PyTorch 和 TensorFlow。您已经看到了每种语言支持的不同编程语言、工具、数据集和模型,并了解了如何选择最适合您独特风格和项目的语言。
在本教程中,您学习了:
- PyTorch 和 TensorFlow 有什么区别
- 如何使用张量在每个中进行计算
- 对于不同类型的项目,哪个平台最适合
- 各自支持哪些工具和数据
既然已经决定了使用哪个库,就可以开始用它们构建神经网络了。查看进一步阅读中的链接以获取想法。
延伸阅读
以下教程是实践 PyTorch 和 TensorFlow 的好方法:
-
用 Python 和 Keras 进行实用的文本分类教你用 PyTorch 构建一个自然语言处理应用。
-
在 Windows 上设置 Python 进行机器学习有关于在 Windows 上安装 PyTorch 和 Keras 的信息。
-
纯 Python vs NumPy vs TensorFlow 性能对比教你如何使用 TensorFlow 和 NumPy 做梯度下降,以及如何对你的代码进行基准测试。
-
Python 上下文管理器和“with”语句将帮助您理解为什么需要在 TensorFlow 1.0 中使用
with tf.compat.v1.Session() as session。 -
生成对抗网络:构建您的第一个模型将带您使用 PyTorch 构建一个生成对抗网络来生成手写数字!
-
Python 系列中的机器学习是更多项目想法的伟大来源,比如构建语音识别引擎或执行人脸识别。****
Qt Designer 和 Python:更快地构建您的 GUI 应用程序
要在 PyQt 中为你的窗口和对话框创建一个 GUI,你可以采取两个主要的途径:你可以使用 Qt Designer ,或者你可以用普通的 Python 代码手工编写GUI。第一种方法可以极大地提高您的工作效率,而第二种方法可以让您完全控制应用程序的代码。
GUI 应用程序通常由一个主窗口和几个 T2 对话框组成。如果你想以一种高效和用户友好的方式创建这些图形组件,那么 Qt Designer 就是你的工具。在本教程中,您将学习如何使用 Qt Designer 高效地创建 GUI。
在本教程中,您将学习:
- 什么是 Qt Designer 以及如何在您的系统上安装它
- 什么时候使用 Qt Designer 和手工编码来构建你的 GUI
- 如何使用 Qt Designer 构建和布局应用程序主窗口的 GUI
- 如何用 Qt Designer 创建和布局你的对话框的 GUI
- 如何在你的 GUI 应用中使用 Qt Designer 的
.ui文件
为了更好地理解本教程中的主题,您可以查看以下资源:
- Python 和 PyQt:构建 GUI 桌面计算器
- Python 和 PyQt:创建菜单、工具栏和状态栏
- PyQt 布局:创建专业外观的 GUI 应用程序
您将通过在一个示例文本编辑器应用程序中使用 Qt Designer 构建的 GUI 将所有这些知识结合在一起。您可以通过单击下面的链接获得构建该应用程序所需的代码和所有资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
Qt Designer 入门
Qt Designer 是一个 Qt 工具,它为你提供了一个所见即所得(WYSIWYG) 用户界面,为你的 PyQt 应用程序高效地创建 GUI。使用这个工具,你可以通过在一个空表单上拖拽 QWidget 对象来创建图形用户界面。之后,您可以使用不同的布局管理器将它们排列到一个连贯的 GUI 中。
Qt Designer 还允许你使用不同的风格和分辨率预览图形用户界面,连接信号和插槽,创建菜单和工具栏,等等。
Qt Designer 独立于平台和编程语言。它不产生任何特定编程语言的代码,但是它创建 .ui文件。这些文件是XML文件,详细描述了如何生成基于 Qt 的 GUI。
可以用 PyQt 自带的命令行工具 pyuic5 将.ui文件的内容翻译成 Python 代码。然后,您可以在 GUI 应用程序中使用这些 Python 代码。你也可以直接读取.ui文件并加载它们的内容来生成相关的 GUI。
安装和运行 Qt Designer
根据您当前的平台,有几种方法可以获得和安装 Qt Designer。如果您使用 Windows 或 Linux,则可以从终端或命令行运行以下命令:
$ python3 -m venv ./venv
$ source venv/bin/activate
(venv) $ pip install pyqt5 pyqt5-tools
在这里,你创建一个 Python 虚拟环境,激活它,安装pyqt5和pyqt5-tools。pyqt5安装 PyQt 和所需的 Qt 库的副本,而pyqt5-tools安装一套包括 Qt Designer 的 Qt 工具。
安装会根据您的平台将 Qt Designer 可执行文件放在不同的目录中:
- Linux:T0】
- 视窗:
...Lib\site-packages\pyqt5_tools\designer.exe
在 Linux 系统上,比如 Debian 和 Ubuntu,您也可以通过使用系统包管理器和以下命令来安装 Qt Designer:
$ sudo apt install qttools5-dev-tools
这个命令在您的系统上下载并安装 Qt Designer 和其他 Qt 工具。换句话说,你将有一个系统范围的安装,你可以通过点击文件管理器或系统菜单中的图标来运行 Qt Designer。
在 macOS 上,如果你已经使用brew install qt命令安装了来自家酿的 Qt,那么你的系统上应该已经安装了 Qt Designer。
最后,您可以从官方下载网站下载适用于您当前平台的 Qt 安装程序,然后按照屏幕上的说明进行操作。在这种情况下,要完成安装过程,你需要注册一个 Qt 账号。
如果您已经安装了 Qt Designer,并使用了到目前为止讨论过的选项之一,那么继续运行并启动应用程序。您应该会在屏幕上看到以下两个窗口:
前台的窗口是 Qt Designer 的新表单对话框。背景中的窗口是 Qt Designer 的主窗口。在接下来的两节中,您将学习如何使用 Qt Designer 界面的这些组件的基础知识。
使用 Qt Designer 的新表单对话框
当您运行 Qt Designer 时,您会看到应用程序的主窗口和新表单对话框。在此对话框中,您可以从五个可用的 GUI 模板中进行选择。这些模板包括创建对话框、主窗口和自定义小部件的选项:
| 模板 | 表单类型 | 小工具 | 基础类 |
|---|---|---|---|
| 底部有按钮的对话框 | 对话 | 确定和取消按钮水平布置在右下角 | T2QDialog |
| 右边有按钮的对话框 | 对话 | 确定和取消右上角垂直排列的按钮 | QDialog |
| 没有按钮的对话框 | 对话 | 不 | QDialog |
| 主窗口 | 主窗口 | 顶部的菜单栏和底部的状态栏 | T2QMainWindow |
| 小部件 | 小部件 | 不 | T2QWidget |
默认情况下,当运行 Qt Designer 时,新表单对话框出现在前台。如果没有,那么你可以点击 Qt Designer 工具栏上的新建。也可以点击主菜单中的文件→新建或者按键盘上的 Ctrl + N 。
在新建表单对话框中,您可以选择想要启动的表单模板,然后点击创建生成一个新表单:
https://player.vimeo.com/video/500145925?background=1
要使用 Qt Designer 模板创建一个新的空表单,您只需从新表单对话框中选择所需的模板,然后单击创建或按键盘上的 Alt + R 。
注意,前两个对话框模板有自己的默认按钮。这些是 QDialogButtonBox 中包含的标准按钮。这个类自动处理不同平台上按钮的位置或顺序。
例如,如果你使用一个取消按钮和一个确定按钮,那么 Linux 和 macOS 上的标准是以同样的顺序显示这些按钮。但在 Windows 上,按钮的顺序会对调,先出现 OK ,再出现 Cancel 。QDialogButtonBox自动为您处理此问题。
使用 Qt Designer 的主窗口
Qt Designer 的主窗口提供了一个菜单栏选项,用于保存和管理表单、编辑表单和更改编辑模式、布局和预览表单,以及调整应用程序的设置和访问其帮助文档:
主窗口还提供了一个显示常用选项的工具栏。在编辑和布局表单时,您会用到这些选项中的大部分。这些选项在主菜单中也是可用的,特别是在文件、编辑和表单菜单中:

Qt Designer 的主窗口还包括几个 dock 窗口,它们提供了一组丰富的特性和工具:
- 部件盒
- 对象检查器
- 属性编辑器
- 资源浏览器
- 动作编辑器
- 信号/插槽编辑器
小部件框提供了一系列布局管理器、间隔器、标准小部件和其他对象,您可以用它们来为您的对话框和窗口创建 GUI:
https://player.vimeo.com/video/500146161?background=1
微件框在窗口顶部提供了一个过滤器选项。您可以键入给定对象或 widget 的名称并快速访问它。这些对象被分组到反映其特定用途的类别中。通过单击类别标签旁边的手柄,可以显示或隐藏类别中的所有可用对象。
当您创建表单时,您可以用鼠标指针从小部件框中取出对象,然后将它们拖放到表单上以构建 GUI。
小部件框还在窗口底部提供了一个便签本部分。在此部分中,您可以将常用对象分组到单独的类别中。通过将当前放在表单上的任何小部件拖放回小部件框中,可以用这些小部件填充便签簿类别。您可以通过右键单击小部件并在上下文菜单中选择移除来移除小部件。
对象检查器提供了当前表单上所有对象的树视图。对象检查器的顶部还有一个过滤框,允许您在树中查找对象。您可以使用对象检查器来设置表单及其小部件的名称和其他属性。您也可以右键单击任何小部件来访问带有附加选项的上下文菜单:
https://player.vimeo.com/video/500145888?background=1
使用对象检查器,您可以管理表单上的小部件。您可以重命名它们,更新它们的一些属性,从表单中删除它们,等等。对象检查器中的树形视图反映了当前表单上小部件和对象的父子关系。
属性编辑器是出现在 Qt Designer 主窗口中的另一个 dock 窗口。该窗口包含一个两列表格,其中包含活动对象的属性及其值。顾名思义,您可以使用属性编辑器来编辑对象的属性值:
https://player.vimeo.com/video/500146210?background=1
属性编辑器提供了一种用户友好的方式来访问和编辑活动对象的属性值,如名称、大小、字体、图标等。编辑器上列出的属性将根据您在表单上选择的对象而变化。
这些属性根据类的层次结构从上到下列出。例如,如果您在表单上选择了一个 QPushButton ,那么属性编辑器会显示QWidget的属性,然后是 QAbstractButton 的属性,最后是QPushButton本身的属性。请注意,编辑器上的行显示不同的颜色,以便直观地区分基础类。
最后,您有三个 dock 窗口,它们通常以标签的形式出现在右下角:
- 资源浏览器提供了一种快速向应用程序添加资源的方式,例如图标、翻译文件、图像和其他二进制文件。
- 动作编辑器提供了一种创建动作并将它们添加到表单中的方法。
- 信号/插槽编辑器提供了一种在表单中连接信号和插槽的方法。
以下是这些工具提供的一些选项:
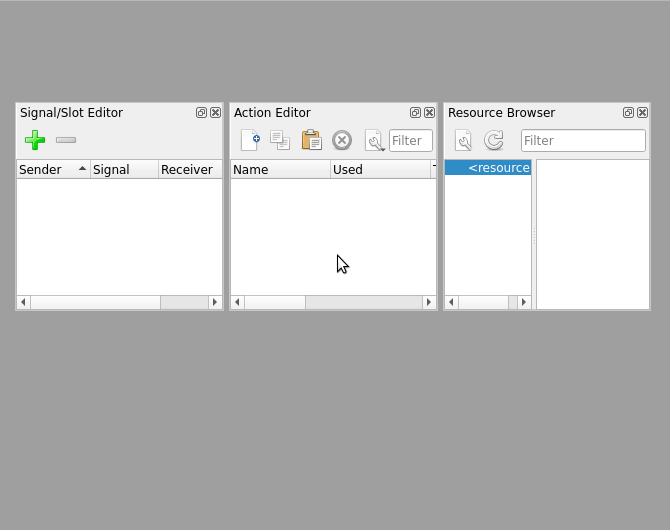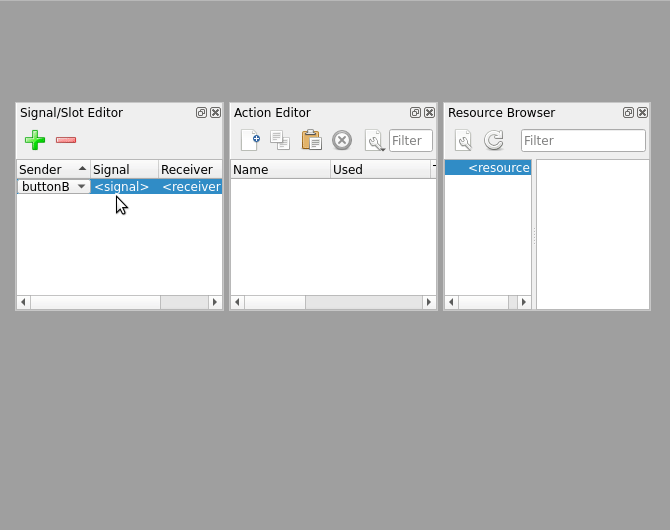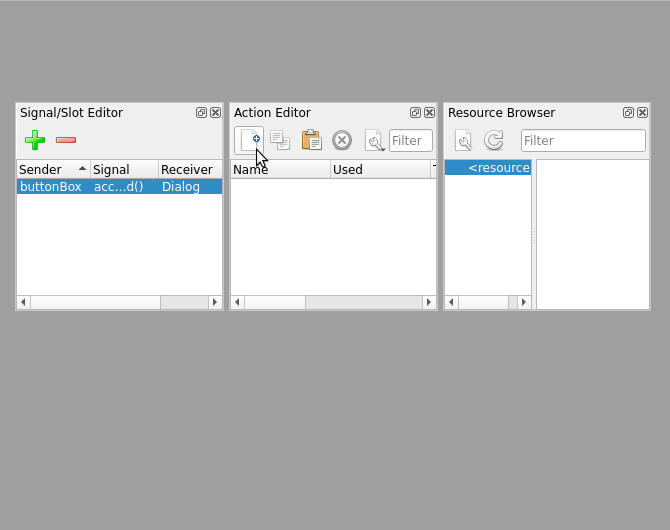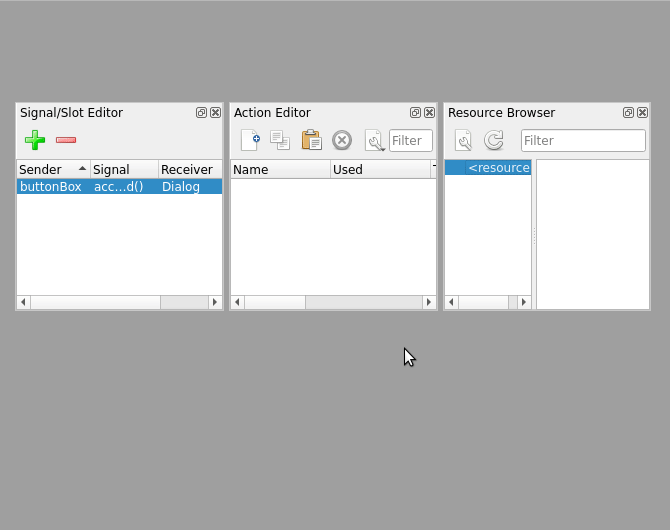
就是这样!这三个 dock 窗口完善了 Qt Designer 为您创建和定制对话框和窗口的 GUI 提供的工具和选项。
使用 Qt Designer 与手工编写图形用户界面
使用 PyQt,您至少有两种选择来创建窗口或对话框的 GUI:您可以使用 Qt Designer,或者您可以用普通的 Python 代码手工编写 GUI。两种选择各有利弊。有时很难决定何时使用其中之一。
Qt Designer 提供了一个用户友好的图形界面,允许您快速创建 GUI。这可以提高开发人员的工作效率,缩短开发周期。
另一方面,手工编写图形用户界面可以给你更多的控制权。使用这种方法,添加新的组件和特性不需要除了您的代码编辑器或 IDE 之外的任何额外工具,这在一些开发环境中非常方便。
你是使用 Qt 设计器还是手工编码你的 GUI 是一个个人决定。以下是这两种方法的一些一般注意事项:
| 特征 | Qt 设计器 | 手工编码 |
|---|---|---|
| 开发人员的生产力 | 高的 | 如果您熟悉 PyQt,则为高,否则为低 |
| GUI 逻辑与业务逻辑的分离 | 高的 | 低的 |
| 对 GUI 组件的控制 | 低的 | 高的 |
| 动态添加和删除小部件的能力 | 低的 | 高的 |
| 探索、学习、原型制作和草图绘制的灵活性 | 高的 | 低的 |
| 使用定制小部件的灵活性 | 低的 | 高的 |
| 样板代码的数量 | 高的 | 低的 |
除了这些问题,如果您刚刚开始使用 PyQt,那么 Qt Designer 可以帮助您发现可用的小部件、布局管理器、基类、属性及其典型值,等等。
使用 Qt Designer 和手工编写 GUI 之间的最后一个区别是,在使用 Qt Designer 时,您需要运行一个额外的步骤:将.ui文件翻译成 Python 代码。
用 Qt Designer 和 Python 构建主窗口
使用 PyQt,您可以构建主窗口风格的和对话框风格的应用程序。主窗口风格的应用程序通常由一个带有菜单栏、一个或多个工具栏、中央小部件和状态栏的主窗口组成。它们也可以包括几个对话框,但是这些对话框独立于主窗口。
Qt Designer 使您能够使用预定义的主窗口模板快速构建主窗口的 GUI。一旦基于该模板创建了表单,您将拥有执行以下操作的工具:
- 创建主菜单
- 添加和填充工具栏
- 布局小部件
Qt Designer 的主窗口模板还提供了一个默认的中央小部件和一个位于窗口底部的状态栏:
https://player.vimeo.com/video/500145960?background=1
Qt Designer 将其表单保存在.ui文件中。这些是XML文件,包含您稍后在应用程序中重新创建 GUI 所需的所有信息。
要保存表格,进入文件→保存,在将表格另存为对话框中输入main_window.ui,选择保存文件的目录,点击保存。您也可以通过按键盘上的 Ctrl + S 进入保存表单为对话框。
不要关闭 Qt Designer 会话——待在那里继续向刚刚创建的主窗口添加菜单和工具栏。
创建主菜单
Qt Designer 的主窗口模板在表单顶部提供了一个空的菜单栏。您可以使用菜单编辑器将菜单添加到菜单栏。菜单是选项的下拉列表,提供对应用程序选项的快速访问。回到 Qt Designer 和你新创建的主窗口。在表单的顶部,您会看到一个菜单栏,带有占位符文本在此输入。
如果您在这个占位符文本上双击或按下 Enter ,那么您可以键入您的第一个菜单的名称。要确认菜单名称,只需按下 Enter 。
假设您想要创建自己的文本编辑器。通常,这种应用程序有一个文件菜单,其中至少有以下一些选项:
- 新建 用于新建一个文档
- 打开 打开已有文档
- 打开最近的 打开最近查看的文档
- 保存 用于保存文档
- 退出 退出应用程序
以下是如何使用 Qt Designer 创建此菜单:
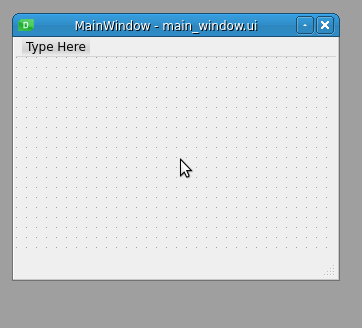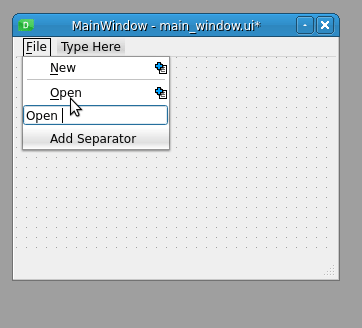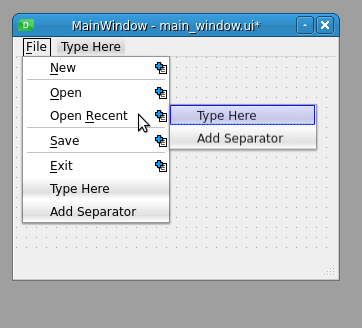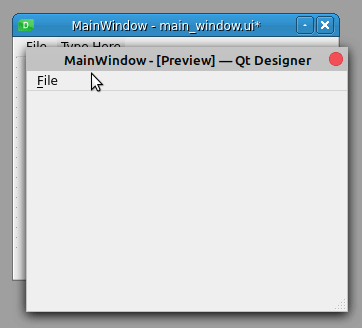
Qt Designer 的菜单编辑器允许您以用户友好的方式向菜单栏添加菜单。当您输入菜单或菜单选项的名称时,您可以在给定的字母前使用一个&符号(&)来提供一个键盘快捷键。
例如,如果您在文件菜单中的 F 前添加了一个&符号,那么您可以通过按 Alt + F 来访问该菜单。同样,如果您在新建中的 N 前添加了一个&符号,那么一旦您启动了文件菜单,您就可以通过按 N 来访问新建选项。
使用菜单编辑器,您还可以将分隔符添加到菜单中。这是在视觉上分离菜单选项并按逻辑分组的好方法。要添加分隔符,双击菜单编辑器中活动菜单末端的添加分隔符选项。右键点击现有分隔符,然后在上下文菜单中选择移除分隔符,即可移除该分隔符。此菜单还允许您添加新的分隔符。
如果您需要将分隔符移动到给定菜单中的另一个位置,那么您可以将分隔符拖动到所需的位置并将其放在那里。一条红线将指示分离器的放置位置。
您也可以将子菜单添加到给定的菜单选项中。为此,点击你想要附加子菜单的菜单选项右侧的图标,就像你在上面的例子中使用打开最近的选项一样。
要运行表单的预览,请转到表单→预览,或者点击键盘上的组合键 Ctrl + R 。
当您在示例文本编辑器中创建类似于文件菜单的菜单时,一个新的QMenu对象会自动添加到您的菜单栏中。当您向给定菜单添加菜单选项时,您创建了一个动作。Qt Designer 提供了一个动作编辑器,用于创建、定制和管理动作。该工具提供了一些方便的选项,您可以使用它们来微调您的操作:
https://player.vimeo.com/video/500146019?background=1
使用动作编辑器,您可以微调、更新或设置以下选项:
- 动作的文本,将显示在菜单选项和工具栏按钮上
- 对象名,您将在代码中使用它来引用 action 对象
- 将显示在菜单选项和工具栏按钮上的图标
- 动作的可检查的属性
- 键盘快捷键,它将为用户提供一种快速访问该操作的方式
菜单选项文本中的最后一个省略号(...)是一种广泛使用的命名约定,它不执行立即操作,而是启动一个弹出对话框来执行进一步的操作。
对于图标,你需要将这些图标作为独立的文件打包到你的应用程序中,或者你可以创建一个资源文件,也称为.qrc文件。对于此示例,您可以通过单击下面的链接下载所需的图标和其他资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
下载完图标后,在main_window.ui文件旁边创建一个resources目录,并将图标复制到那里。然后回到动作编辑器,像这样给你的动作添加图标:
https://player.vimeo.com/video/500145992?background=1
请注意,您的菜单选项现在会在左边显示一个图标。这为您的用户提供了额外的视觉信息,并帮助他们找到所需的选项。现在继续添加一个带有以下选项的编辑菜单:
- 复制 用于复制一些文字
- 粘贴 用于粘贴一些文字
- 剪切 用于剪切一些文字
- 查找和替换 用于查找和替换文本
接下来,添加一个帮助菜单,带有一个关于选项,用于启动一个对话框,提供关于你的文本编辑器的一般信息。最后,转到属性编辑器,将窗口的标题设置为Sample Editor。添加这些内容后,您的主窗口应该如下所示:
有了这些补充,您的示例文本编辑器的主菜单开始看起来像真正的文本编辑器的菜单了!
创建工具栏
您可以使用 Qt Designer 在主窗口的 GUI 中添加任意数量的工具栏。为此,右键单击表单并从上下文菜单中选择添加工具栏。这将在窗口顶部添加一个空工具栏。或者,您可以通过选择将工具栏添加到其他区域来预定义您想要放置给定工具栏的工具栏区域:
一旦你的工具栏就位,你就可以用按钮来填充它们。为此,您使用动作而不是小部件框中的特定工具栏按钮。要将动作添加到工具栏,可以使用动作编辑器:
https://player.vimeo.com/video/500146235?background=1
操作可以在菜单选项和工具栏按钮之间共享,因此在这种情况下,您可以重用在上一节填充菜单时创建的操作。要填充工具栏,单击动作编辑器上的动作,然后将其拖放到工具栏上。请注意,通过右键单击工具栏,您可以添加分隔符来直观地分隔工具按钮。
布局单个中央部件
Qt Designer 使用QMainWindow构建它的主窗口模板。这个类提供了一个默认布局,允许您创建一个菜单栏、一个或多个工具栏、一个或多个 dock 小部件、一个状态栏和一个中央小部件。默认情况下,Qt Designer 使用一个QWidget对象作为主窗口模板上的中心小部件。
使用一个基本的QWidget对象作为主窗口 GUI 的中心部件是一个很好的选择,因为在这个部件之上,你可以在一个连贯的布局中放置一个单个部件或者多个部件。
例如,在您的示例文本编辑器中,您可能希望使用一个小部件为您的用户提供一个工作区来键入、复制、粘贴和编辑他们的文本。为此,您可以使用一个QTextEdit对象,然后添加一个垂直(或水平)布局作为中心小部件的布局:
https://player.vimeo.com/video/500146185?background=1
在本例中,首先将一个QTextEdit拖到表单上。然后你点击表单来选择你的中心部件。最后,通过点击 Qt Designer 工具栏上的垂直布局,将垂直布局应用到您的中心小部件。
由于QTextEdit周围的间距看起来不合适,您使用对象检查器将布局的边距从9像素更改为1像素。
使用 Qt Designer,您可以使用不同的布局管理器来快速排列您的小部件。可以说,用 Qt Designer 布局 GUI 最容易的方法是使用主工具栏上与布局相关的部分:

从左到右,您会发现以下选项用于创建不同类型的布局:
| [计]选项 | 小部件排列 | 布局类 | 键盘快捷键 |
|---|---|---|---|
| 水平布局 | 水平地排成一行和几列 | T2QHBoxLayout |
Ctrl + 1 |
| 垂直布局 | 垂直排列成一列和几行 | T2QVBoxLayout |
Ctrl + 2 |
| 在分离器中水平布置 | 在可调整大小的拆分器中水平显示 | T2QSplitter |
Ctrl + 3 |
| 在分离器中垂直布置 | 在可调整大小的拆分器中垂直显示 | QSplitter |
Ctrl + 4 |
| 布置成网格 | 有几行和几列的表格 | T2QGridLayout |
Ctrl + 5 |
| 以表格形式布局 | 在两列表格中 | T2QFormLayout |
Ctrl + 6 |
工具栏中的最后两个选项与布局相关,但不创建布局:
-
打破布局 允许你打破一个已有的布局。一旦在布局中排列了小部件,您就不能单独移动它们或调整它们的大小,因为它们的几何图形是由布局控制的。要修改单个部件,您可能需要中断布局并在以后重做。要访问此选项,您可以按键盘上的
Ctrl+0。 -
调整大小 调整布局的大小,以容纳所包含的小工具,并确保每个小工具都有足够的空间可见。要访问此选项,您可以按键盘上的
Ctrl+J。
您也可以通过 Qt Designer 的主菜单栏,在表单菜单下访问所有这些布局相关的选项:
在表单菜单中,您可以访问所有与布局相关的选项,以及访问这些选项的完整键盘快捷键参考。您也可以通过表单的上下文菜单,在布局选项下访问这些选项。
布局一个复合中心部件
当你创建你的主窗口时,你可能会遇到这样的情况,你需要在给定的布局中使用多个窗口部件作为你的中心窗口部件。由于 Qt Designer 的主窗口模板附带了一个QWidget对象作为其中心小部件,因此您可以利用它来创建您自己的定制小部件排列,然后将其设置为中心小部件的顶层布局。
通过 Qt Designer,您可以使用布局管理器来布局您的小部件,正如您在上一节中已经看到的那样。如果您需要主窗口 GUI 的复合小部件布局,那么您可以通过运行以下步骤来构建它:
- 将小部件拖放到您的表单上,并尝试将它们放置在所需的位置附近。
- 选择应该由给定布局一起管理的小部件。
- 使用 Qt Designer 的工具栏或主菜单,或者使用表单的上下文菜单应用适当的布局。
虽然您可以将布局拖到表单上,然后将小部件拖到布局上,但最佳做法是首先拖动所有小部件和间隔器,然后重复选择相关的小部件和间隔器,以将布局应用于它们。
例如,假设你正在构建一个计算器应用程序。你需要一个 QLineEdit 对象在你的窗体顶部显示操作和它们的结果。在线编辑下,您需要一些用于数字和操作的QPushButton对象。这给了你一个这样的窗口:
这看起来有点像一个计算器,但是 GUI 是杂乱的。要将它安排到一个更加完美的计算器 GUI 中,您可以为按钮使用网格布局,并使用垂直框布局作为计算器的顶层布局:
https://player.vimeo.com/video/492155782?background=1
你的计算器还需要一些额外的润色,但它现在看起来好多了。要获得更完美的版本,您可以使用属性编辑器来调整按钮上某些属性的值,例如它们的最大和最小大小。您还可以为计算器的主窗口设置固定的大小,等等。来吧,试一试!
拥有状态栏
Qt Designer 的主窗口模板默认提供了一个状态栏。状态栏是一个水平面板,通常位于 GUI 应用程序主窗口的底部。它的主要目的是显示关于应用程序当前状态的信息。
您可以将状态栏分成几个部分,并在每个部分显示不同的信息。状态栏上的信息可以是临时的或者永久的,大部分时间都是以短信的形式出现。状态栏上显示的信息的目的是让你的用户了解应用程序当前正在做什么,以及它在给定时间的一般状态。
您还可以使用状态栏来显示帮助提示,这是描述给定按钮或菜单选项功能的简短帮助消息。当用户将鼠标指针悬停在工具栏按钮或菜单选项上时,这种消息会出现在状态栏上。
用 Qt Designer 和 Python 创建对话框
对话框是小尺寸窗口,通常用于提供辅助功能,如首选项对话框,或通过显示错误消息或给定操作的一般信息与用户交流。您还可以使用对话框向用户询问一些必需的信息,或者确认即将发生的操作。
PyQt 提供了一组丰富的内置对话框,可以直接在应用程序中使用。你只需要从 PyQt5.QtWidgets 中导入即可。这里有一个总结:
| 对话类 | 目的 |
|---|---|
T2QFontDialog |
选择和设置给定文本的字体 |
T2QPrintDialog |
指定打印机的设置 |
T2QProgressDialog |
显示长期运行操作的进度 |
T2QColorDialog |
选择和设置颜色 |
T2QInputDialog |
从用户处获取单个值 |
T2QFileDialog |
选择文件和目录 |
T2QMessageBox |
显示错误、一般信息、警告和问题等消息 |
T2QErrorMessage |
显示错误消息 |
所有这些内置对话框都可以直接在代码中使用。它们中的大多数都提供了类方法来根据您的需要构建特定类型的对话框。除了这些对话框,PyQt 还提供了 QDialog 类。您可以使用这个类在代码中创建您自己的对话框,但是您也可以使用 Qt Designer 快速创建您的对话框。
在接下来的几节中,您将学习如何使用 Qt Designer 及其对话框模板来创建、布局和定制您的对话框。
创建对话框图形用户界面
要用 Qt Designer 创建自定义对话框,从新表单对话框中选择合适的对话框模板。将所需的小部件拖放到表单上,正确地布置它们,并将表单保存在一个.ui文件中,供以后在应用程序中使用。
回到您的示例文本编辑器,假设您想要添加一个查找和替换对话框,如下所示:
要创建这个对话框,从没有按钮的对话框模板开始,向表单添加所需的小部件:
https://player.vimeo.com/video/500146098?background=1
这里,首先使用无按钮对话框模板创建一个空对话框,并在对象检查器中将窗口标题设置为查找并替换。然后使用小部件框将两个 QLabel 对象拖放到表单上。这些标签向用户询问他们需要查找和替换的单词。这些单词将被输入到标签附近相应的QLineEdit对象中。
接下来,将三个QPushButton对象拖放到表单上。这些按钮将允许您的用户在当前文档中查找和替换单词。最后,您添加两个 QCheckBox 对象来提供匹配大小写和匹配全字选项。
一旦表单上有了所有的小部件,请确保将它们放置在与您希望在最终对话框中实现的目标相似的位置。现在是时候布置小部件了。
布局对话框 GUI
正如您之前看到的,要在一个表单中排列小部件,您可以使用几个布局管理器。要布置您的查找和替换对话框,请为标签、线条编辑和复选框使用网格布局。对于按钮,使用垂直布局。最后,使用水平布局作为对话框的顶层布局管理器:
https://player.vimeo.com/video/500146036?background=1
在这里,您用鼠标指针选择标签、线条编辑和复选框,并对它们应用网格布局。之后,在替换和取消按钮之间添加一个垂直间隔,使它们在视觉上保持分离。
最后一步是设置对话框的顶层布局。在这种情况下,使用水平布局管理器。就是这样!您已经用 Qt Designer 构建了查找和替换对话框的 GUI。用文件名find_replace.ui保存。
使用 Qt Designer,您可以在对话框中调整许多其他属性和特性。例如,您可以设置输入小部件的 tab 键顺序,以改善用户使用键盘导航对话框的体验。还可以提供键盘快捷键,连接信号和插槽等等。
连接信号和插槽
到目前为止,您已经在 Edit Widgets 模式下使用了 Qt Designer,这是它的默认模式。在这种模式下,您可以向表单添加小部件,编辑小部件的属性,在表单上布置小部件,等等。但是,Qt Designer 有多达四种不同的模式,允许您处理表单的不同功能:
| 方式 | 目的 | 菜单选项 | 键盘快捷键 |
|---|---|---|---|
| 编辑小部件 | 编辑小部件 | 编辑→编辑小工具 | T2F3 |
| 编辑信号/插槽 | 连接内置信号和插槽 | 编辑→编辑信号/插槽 | T2F4 |
| 编辑好友 | 设置键盘快捷键 | 编辑→编辑好友 | 不 |
| 编辑 Tab 键顺序 | 设置小部件的 tab 键顺序 | 编辑→编辑标签顺序 | 不 |
您也可以通过单击 Qt Designer 工具栏中与模式相关部分的相应按钮来访问这些模式,如下所示:

为了能够编辑部件和表单的内置信号和插槽,首先需要切换到编辑信号/插槽模式。
注意:在 Qt 中,术语好友指的是标签和小部件之间的特殊关系,其中标签提供了键盘快捷键或快捷方式,允许您使用键盘访问好友小部件。
用户在小部件和表单上的动作,比如点击或按键,在 PyQt 中被称为事件。当事件发生时,手边的小工具发出一个信号。这种机制允许您运行操作来响应事件。这些动作被称为槽,它们是方法或函数。
要执行一个插槽来响应一个事件,您需要选择一个由小部件发出的信号来响应一个事件,并将其连接到所需的插槽。
大多数小部件,包括对话框和窗口,都实现了内置的信号,当给定的事件在小部件上发生时,就会发出这些信号。小部件还提供了内置的插槽,允许您执行某些标准化的操作。
要使用 Qt Designer 在两个小部件之间建立信号和插槽连接,您需要用鼠标选择信号提供器小部件,然后将它拖放到插槽提供器小部件上。这将启动 Qt Designer 的配置连接对话框。现在回到查找和替换对话框,切换到 Qt Designer 的编辑信号/插槽模式。然后将取消按钮拖放到表单上:
配置连接对话框有两个面板。在左侧面板上,您可以从信号提供商小部件中选择一个信号,在右侧面板上,您可以从插槽提供商小部件中选择一个插槽。要创建连接,按下 OK :
连接显示为从信号提供者小部件到插槽提供者小部件的箭头,表示连接已经建立。您还会看到信号的名称和您刚刚连接的插槽。
在这种情况下,您将取消按钮的 clicked() 信号与对话框的 reject() 槽相连。现在,当您点击取消时,您的操作将被忽略,对话框将关闭。
要修改连接,请双击箭头或其中一个标签。这将显示配置连接对话框,在该对话框中,您可以根据需要更改信号或连接所涉及的插槽。
要删除连接,选择代表连接的箭头或识别信号和插槽的标签之一,然后按 Del 。
设置微件的标签顺序
为了提高你的对话框的可用性,你可以为你的输入部件设置一致的标签顺序。tab 键顺序是当您在键盘上按下 Tab 或 Shift + Tab 时,表单上的小部件成为焦点的顺序。
如果您使用 Qt Designer 创建表单,那么小部件的默认 tab 键顺序是基于您在表单上放置每个小部件的顺序。有时这个顺序不对,当你点击 Tab 或 Shift + Tab 时,焦点会跳到一个意想不到的小部件上。查看一下查找和替换对话框中的 tab 键顺序行为:
焦点从查找行编辑开始,然后经过替换行编辑,然后通过复选框,最后通过按钮。如果您希望焦点从查找行编辑跳到替换行编辑,然后跳到查找按钮,该怎么办?在这种情况下,您可以更改对话框中输入小部件的 tab 键顺序。在 Qt Designer 中切换到编辑 Tab 键顺序模式。您会看到类似这样的内容:
在编辑 tab 键顺序模式下,表单中的每个输入小部件都显示一个数字,标识它在 Tab 键顺序链中的位置。您可以通过点击所需顺序的数字来更改顺序:
您可以通过按所需顺序单击数字来更改输入小部件的 tab 键顺序。请注意,当您选择一个数字时,它会变为红色,表示这是 tab 键顺序链中当前编辑的位置。未设置的号码显示为蓝色,已设置的号码显示为绿色。如果你犯了一个错误,那么你可以通过从表单的上下文菜单中选择 Restart 来重新开始排序。
提供键盘快捷键
一个键盘快捷键是一个组合键,你可以在键盘上按下它来快速移动焦点到一个对话框或窗口的给定部件上。通常,键盘快捷键由 Alt 键和一个字母组成,该字母标识您想要访问的小工具或选项。这可以帮助您提高应用程序的可用性。
要在包含标签(如按钮或复选框)的小部件上定义键盘快捷键,只需在要在快捷键中使用的标签文本中的字母前放置一个&符号(&)。例如,在查找和替换对话框的取消按钮上的 C 前放置一个&符号,运行预览,然后按下 Alt + C ,如下例所示:
通过在取消按钮文本中的字母 C 前放置一个&符号,您就创建了一个键盘快捷键。如果按下键盘上的 Alt + C ,则取消按钮被选中,对话框关闭。
要在不包含标签的小部件上定义键盘快捷键,例如行编辑,您需要使该小部件成为标签对象的伙伴。如果您想要创建好友连接,需要采取四个步骤:
- 在标签文本中选择一个字母来标识好友连接,并提供键盘快捷键。
- 在标签文本中的选定字母前放置一个&符号(
&)。 - 在 Qt Designer 中切换到编辑好友模式。
- 将标签拖放到好友小部件上。
以下是如何在 Find 标签及其相关的行编辑之间创建伙伴关系:
要在标签和小部件之间创建伙伴关系,请用鼠标选择标签,并将其拖到要设置为伙伴的输入小部件上。标签和输入部件将成为伙伴。从这一点开始,您可以按下 Alt 加上标签文本中选定的字母,将焦点移动到相关的小部件。
需要注意的是,在给定的表单中,不应该有两个带有相同键盘快捷键的小部件。这意味着您需要为每个键盘快捷键选择一个唯一的字母。
继续使用 Qt Designer 为您的查找和替换对话框上的小部件设置键盘快捷键。最终的结果应该像你在创建对话框 GUI 一节开始时看到的对话框。
在应用程序中集成窗口和对话框
至此,您已经学习了如何使用 Qt Designer 为您的主窗口和对话框创建 GUI。在本节中,您将学习如何将这些 GUI 集成到您的 Python 代码中,并构建一个真正的应用程序。在 PyQt 中有两种主要的方法:
- 使用
pyuic5将.ui文件的内容转化为 Python 代码 - 加载
.ui文件的内容动态使用uic.loadUi()
第一种方法使用pyuic5,它是 PyQt 安装中包含的一个工具,允许您将.ui文件的内容翻译成 Python 代码。这种方法因其高效而被广泛使用。但是,它有一个缺点:每次用 Qt Designer 修改 GUI 时,都需要重新生成代码。
第二种方法利用uic.loadUi()将.ui文件的内容动态加载到您的应用程序中。当您使用不涉及大量加载时间的小型 GUI 时,这种方法是合适的。
设置使用的窗口和对话框
现在是时候设置您的窗口和对话框了,以便在实际应用程序中使用(在本例中,是一个示例文本编辑器)。如果你一直遵循这个教程,那么你应该至少有两个.ui文件:
main_window.ui带有文本编辑器的 GUI 示例应用程序find_replace.ui用一个的 GUI 找到并替换对话框
继续创建一个名为sample_editor/的新目录。在这个目录中,创建另一个名为ui/的目录,并将您的.ui文件复制到其中。另外,将包含菜单选项和工具栏按钮图标的resources/目录复制到sample_editor/ui/目录。到目前为止,您的应用程序的结构应该如下所示:
sample_editor/
│
└── ui/
├── resources/
│ ├── edit-copy.png
│ ├── edit-cut.png
│ ├── edit-paste.png
│ ├── file-exit.png
│ ├── file-new.png
│ ├── file-open.png
│ ├── file-save.png
│ └── help-content.png
│
├── find_replace.ui
└── main_window.ui
由于主窗口 GUI 相对复杂,您可以使用pyuic5将main_window.ui的内容翻译成 Python 代码。
您可以通过单击下面的链接下载构建示例文本编辑器所需的所有代码和资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。
现在打开一个终端,导航到sample_editor/目录。一旦到达那里,运行以下命令:
$ pyuic5 -o main_window_ui.py ui/main_window.ui
这个命令从ui/main_window.ui文件生成一个名为main_window_ui.py的 Python 模块,并将其放在您的sample_editor/目录中。这个模块包含了主窗口 GUI 的 Python 代码。下面是代码的一个小样本:
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'ui/main_window.ui'
#
# Created by: PyQt5 UI code generator 5.15.1
#
# WARNING: Any manual changes made to this file will be lost when pyuic5 is
# run again. Do not edit this file unless you know what you are doing.
from PyQt5 import QtCore, QtGui, QtWidgets
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(413, 299)
self.centralwidget = QtWidgets.QWidget(MainWindow)
# Snip...
def retranslateUi(self, MainWindow):
_translate = QtCore.QCoreApplication.translate
MainWindow.setWindowTitle(_translate("MainWindow", "Sample Editor"))
self.menu_File.setTitle(_translate("MainWindow", "&File"))
# Snip...
Ui_MainWindow拥有生成样本编辑器主窗口 GUI 的所有代码。注意.setupUi()包含了创建所有需要的小部件并在 GUI 上展示它们的代码。.retranslateUi()包含了国际化和本地化的代码,但是这个主题超出了本教程的范围。
注意:如果pyuic5对您不起作用,那么您需要检查您当前的 PyQt 安装。如果您在 Python 虚拟环境中安装了 PyQt,那么您可能需要激活该环境。您还可以移动到您的虚拟环境目录,并从那里运行pyuic5。通常,你会在bin/目录下找到这个应用程序。
如果您在系统范围内安装了 PyQt,那么您应该能够直接从命令行运行pyuic5,而不需要激活虚拟环境。
现在,您的工作目录应该如下所示:
sample_editor/
│
├── ui/
│ ├── resources/
│ │ ├── edit-copy.png
│ │ ├── edit-cut.png
│ │ ├── edit-paste.png
│ │ ├── file-exit.png
│ │ ├── file-new.png
│ │ ├── file-open.png
│ │ ├── file-save.png
│ │ └── help-content.png
│ │
│ ├── find_replace.ui
│ └── main_window.ui
│
└── main_window_ui.py
由于您的查找和替换对话框非常小,您可以使用uic.loadUi()直接从您的.ui文件加载它的 GUI。这个函数将一个带有.ui文件路径的字符串作为参数,并返回一个实现 GUI 的QWidget子类。
这种动态加载.ui文件的方式在实践中很少使用。你可以用它来加载不需要太多努力的小对话框。使用这种方法,您不需要在每次使用 Qt Designer 修改.ui文件时都为对话框的 GUI 生成 Python 代码,这在某些情况下可以提高生产率和可维护性。
既然您已经选择了构建每个 GUI 的策略,那么是时候将所有东西放在一个真正的应用程序中了。
将所有东西放在一个应用程序中
示例文本编辑器的所有部分就绪后,您可以创建应用程序并编写所需的代码来使用主窗口和查找和替换对话框。在您的sample_editor/目录中启动您最喜欢的代码编辑器或 IDE,并创建一个名为app.py的新文件。向其中添加以下代码:
1import sys
2
3from PyQt5.QtWidgets import (
4 QApplication, QDialog, QMainWindow, QMessageBox
5)
6from PyQt5.uic import loadUi
7
8from main_window_ui import Ui_MainWindow
9
10class Window(QMainWindow, Ui_MainWindow):
11 def __init__(self, parent=None):
12 super().__init__(parent)
13 self.setupUi(self)
14 self.connectSignalsSlots()
15
16 def connectSignalsSlots(self):
17 self.action_Exit.triggered.connect(self.close)
18 self.action_Find_Replace.triggered.connect(self.findAndReplace)
19 self.action_About.triggered.connect(self.about)
20
21 def findAndReplace(self):
22 dialog = FindReplaceDialog(self)
23 dialog.exec()
24
25 def about(self):
26 QMessageBox.about(
27 self,
28 "About Sample Editor",
29 "<p>A sample text editor app built with:</p>"
30 "<p>- PyQt</p>"
31 "<p>- Qt Designer</p>"
32 "<p>- Python</p>",
33 )
34
35class FindReplaceDialog(QDialog):
36 def __init__(self, parent=None):
37 super().__init__(parent)
38 loadUi("ui/find_replace.ui", self)
39
40if __name__ == "__main__":
41 app = QApplication(sys.argv)
42 win = Window()
43 win.show()
44 sys.exit(app.exec())
下面是这段代码的作用:
- 第 3 行 导入构建应用程序和 GUI 所需的 PyQt 类。
- 6 号线从
uic模块导入loadUi()。这个函数提供了一种动态加载.ui文件内容的方法。 - 第 8 行导入了
Ui_MainWindow,它包含了主窗口的 GUI。 - 第 10 行定义了
Window,它将提供你的应用程序的主窗口。在这种情况下,该类使用多重继承。它继承了QMainWindow的主窗口功能和Ui_MainWindow的 GUI 功能。 - 第 13 行调用
.setupUi(),为你的主窗口创建整个 GUI。 - 第 16 行定义
.connectSignalsSlots(),连接所需的信号和插槽。 - 第 21 行定义
.findAndReplace()。这个方法创建了一个查找和替换对话框的实例并执行它。 - 第 25 行定义了
.about(),它创建并启动一个小对话框来提供关于应用程序的信息。在这种情况下,您使用基于QMessageBox的内置对话框。 - 第 35 行定义了
FindReplaceDialog,提供了查找和替换对话框。 - 第 38 行调用
loadUi()从文件ui/find_replace.ui中加载对话框的 GUI。
最后,在第 41 到 44 行,您创建应用程序,创建并显示主窗口,并通过调用 application 对象上的.exec()运行应用程序的主循环。
值得注意的是,Qt Designer 可以用与上面代码中不同的方式来命名您的操作。例如,您可能会发现名字.actionE_xit而不是.action_Exit是指退出动作。因此,为了让这个例子正常工作,您需要确保您使用了正确的名称。
如果您想使用自己的名字而不是 Qt Designer 生成的名字,那么您可以进入属性编辑器,将.objectName属性更改为适合您的名字。
注意:你也可以用合成而不是多重继承来创建Window。
例如,您可以这样定义Window及其初始化器:
class Window(QMainWindow):
def __init__(self, parent=None):
super().__init__(parent)
self.ui = Ui_MainWindow() self.ui.setupUi(self) self.connectSignalsSlots()
def connectSignalsSlots(self):
self.ui.action_Exit.triggered.connect(self.close) self.ui.action_Find_Replace.triggered.connect( self.findAndReplace
)
self.ui.action_About.triggered.connect(self.about) # Snip...
在这种情况下,您创建了.ui,它是Ui_MainWindow的一个实例。从现在开始,您需要使用.ui来访问主窗口 GUI 上的小部件和对象。
如果您运行此应用程序,您将在屏幕上看到以下窗口:
https://player.vimeo.com/video/500233090?background=1
就是这样!您已经使用 Qt Designer 创建了一个简单的文本编辑器。请注意,要编写这个应用程序,您只需编写 44 行 Python 代码,这远远少于您从头开始编写等效应用程序的 GUI 所需的代码。
结论
在 PyQt 中创建应用程序时,通常会构建一个主窗口和几个对话框。如果您手工编写代码,构建这些窗口和对话框的 GUI 会花费很多时间。幸运的是, Qt 提供了 Qt Designer ,这是一个强大的工具,旨在使用用户友好的图形界面快速高效地创建 GUI。
有了 Qt Designer,您可以将所有需要的小部件拖放到一个空的表单上,对它们进行布局,然后马上创建您的 GUI。这些图形用户界面保存在.ui文件中,您可以将其翻译成 Python 代码并在您的应用程序中使用。
在本教程中,您学习了如何:
- 在你的系统上安装 Qt Designer
- 决定什么时候使用 Qt Designer vs 手动编码你的 GUI
- 使用 Qt Designer 构建应用程序主窗口的 GUI
- 使用 Qt Designer 创建和布局您的对话框的 GUI
- 在你的 GUI 应用程序中使用 Qt Designer 的
.ui文件
最后,通过使用 Qt Designer 创建构建示例文本编辑器应用程序所需的窗口和对话框的 GUI,将所有这些知识付诸实践。您可以通过单击下面的链接获得构建此应用程序所需的所有代码和资源:
获取源代码: 点击此处获取源代码,您将在本教程中使用了解如何使用 Qt Designer 创建 Python GUI 应用程序。*********
实践中的 Python 堆栈、队列和优先级队列
队列是游戏、人工智能、卫星导航和任务调度中众多算法的支柱。它们是计算机科学学生在早期教育中学习的顶级抽象数据类型。同时,软件工程师经常利用更高级的消息队列来实现微服务架构更好的可扩展性。另外,在 Python 中使用队列非常有趣!
Python 提供了一些内置的队列风格,您将在本教程中看到它们的作用。您还将快速入门关于队列及其类型的理论。最后,您将看到一些外部库,用于连接主要云平台提供商上可用的流行消息代理。
在本教程中,您将学习如何:
- 区分各种类型的队列
- 在 Python 中实现队列数据类型
- 通过应用正确的队列解决实际问题
- 使用 Python 的线程安全、异步和进程间队列
- 通过库将 Python 与分布式消息队列代理集成在一起
为了充分利用本教程,您应该熟悉 Python 的序列类型,例如列表和元组,以及标准库中更高级别的集合。
您可以通过单击下面框中的链接下载本教程的完整源代码以及相关的示例数据:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。
了解队列的类型
队列是一种抽象数据类型,表示根据一组规则排列的元素的序列。在本节中,您将了解最常见的队列类型及其相应的元素排列规则。至少,每个队列都提供了使用大 O 符号在常数时间或 O(1)中添加和删除元素的操作。这意味着无论队列大小如何,这两个操作都应该是即时的。
一些队列可能支持其他更具体的操作。是时候多了解他们了!
队列:先进先出
单词 queue 根据上下文可以有不同的含义。然而,当人们在没有使用任何限定词的情况下提到队列时,他们通常指的是 FIFO 队列,这类似于你可能在杂货店收银台或旅游景点看到的队列:

请注意,与照片中人们并排聚集的队伍不同,严格意义上的队列是一列纵队,一次只允许一个人进入。
FIFO 是先进先出的缩写,它描述了元素通过队列的流动。这种队列中的元素将按照先到先服务的原则进行处理,这是大多数真实队列的工作方式。为了更好地观察 FIFO 队列中元素的移动,请看下面的动画:
https://player.vimeo.com/video/723390369?background=1
请注意,在任何给定的时间,新元素只允许在称为尾的一端加入队列,在本例中是在右边,而最旧的元素必须从另一端离开队列。当一个元素离开队列时,它的所有跟随者向队列的头移动一个位置。这几条规则确保了元素按照到达的顺序进行处理。
注意:你可以把 FIFO 队列中的元素想象成停在交通灯前的汽车。
向 FIFO 队列中添加一个元素通常被称为入队操作,而从其中检索一个元素被称为出列操作。不要将出列操作与dequee(双端队列)数据类型混淆,稍后您将了解到这一点!
入队和出队是两个独立的操作,可能以不同的速度进行。这一事实使得 FIFO 队列成为完美的工具,用于在流场景中缓冲数据以及调度需要等待直到某些共享资源可用的任务。例如,被 HTTP 请求淹没的 web 服务器可能会将它们放入队列中,而不是立即错误地拒绝它们。
注意:在利用并发的程序中,一个 FIFO 队列通常成为共享资源本身,以促进异步工作者之间的双向通信。通过临时锁定对其元素的读或写访问,阻塞队列可以优雅地协调生产者池和消费者池。在后面关于多线程和多处理中队列的章节中,你会找到更多关于这个用例的信息。
关于上面描述的队列,值得注意的另一点是,随着新元素的到来,它可以无限制地增长。想象一下,在繁忙的购物季节,结账队伍一直排到了商店的后面!然而,在某些情况下,您可能更喜欢使用一个预先知道固定容量的有界队列。有界队列有助于以两种方式控制稀缺资源:
- 通过不可逆地拒绝不适合的元素
- 通过重写队列中最老的元素
在第一种策略下,一旦一个 FIFO 队列饱和,它就不会再占用更多的元素,直到其他人离开队列来腾出一些空间。您可以在下面的动画示例中看到这种工作方式:
https://player.vimeo.com/video/723396777?background=1
这个队列的容量为三,这意味着它最多可以容纳三个元素。如果你试图往里面塞更多的元素,那么它们会弹开消失,不留任何痕迹。同时,一旦占据队列的元素数量减少,队列将再次开始接受新元素。
在野外哪里可以找到这样一个有界的 FIFO 队列?
大多数数码相机都支持连拍模式,以尽可能快的速度连续拍摄一系列照片,希望能捕捉到至少一张运动物体的清晰照片。因为将数据保存到存储卡上是瓶颈,通常有一个内部缓冲使相机能够在压缩和保存早期照片的同时继续拍摄新照片。
在老式静态相机中,缓冲区通常很小,几秒钟内就会填满。当这种情况发生时,按住快门按钮将不再有任何效果,或者拍摄新照片的速度将明显降低。只有在清空数据缓冲区后,摄像机的最大速度才能完全恢复。
处理有界 FIFO 队列中的传入元素的第二个策略是让您实现一个基本的缓存,它会忘记最老的元素,而不考虑您访问它的次数或频率。当新的元素比旧的元素更有可能被重用时,FIFO 缓存工作得最好。例如,您可以使用 FIFO 缓存回收策略强制注销很久以前登录的用户,而不管他们是否仍然活跃。
注意:为了简单比较其他缓存回收策略,请阅读使用 LRU 缓存策略的 Python 中的缓存。
下面是一个有界 FIFO 队列的可视化描述,它最多可以容纳三个元素,但与以前不同的是,它不会阻止您添加更多元素:
https://player.vimeo.com/video/723397721?background=1
当该队列达到其最大容量时,添加新元素将首先将所有现有元素向头部移动一个位置,丢弃最旧的元素并为新元素腾出空间。请注意,被丢弃的元素会被它的近邻覆盖。
虽然无界 FIFO 队列及其两个有界对应队列涵盖了广泛的用例,但它们都有一个共同的特征,即具有独立的入口点和出口点。在下一节中,您将了解另一种流行的队列类型,它的布局略有不同。
堆栈:后进先出(LIFO)
堆栈是一种更特殊的队列,也称为 LIFO 或后进先出队列。它的工作方式几乎和普通队列完全一样,除了元素现在必须通过称为栈顶的一端加入和离开。名称 top 反映了现实世界的书库往往是垂直的这一事实。厨房水槽中的一堆盘子就是一堆的例子:

当洗碗机装满时,员工们会在吃完饭后把他们的脏盘子推到最上面。一旦橱柜里没有更多的干净盘子,饥饿的员工将不得不从堆叠的顶部弹出最后一个脏盘子,并用海绵擦干净,然后用微波炉加热他们的午餐。
如果在盘子堆的底部有一把非常需要的叉子,那么一些可怜的人将不得不一个接一个地翻遍上面所有的盘子,才能找到想要的餐具。类似地,当清洁人员在一天工作结束后来到办公室时,他们必须以相反的顺序检查盘子,然后才能检查最后一个盘子。
您将在以下动画堆栈中看到此元素移动:
https://player.vimeo.com/video/723398613?background=1
尽管上面的 LIFO 队列是水平方向的,但它保留了堆栈的一般概念。新元素通过仅在右端连接来增加堆栈,如前面的示例所示。然而,这一次,只有最后一个推入堆栈的元素可以离开它。其余的必须等待,直到没有更多的元素后来加入堆栈。
堆栈广泛用于各种目的的计算中。也许程序员最熟悉的上下文是调用栈,其中包含了按调用顺序排列的函数。在出现未处理的异常的情况下,Python 会通过回溯向你揭示这个堆栈。它通常是一个容量有限的有界堆栈,你会在过多的递归调用导致的堆栈溢出错误中发现。
在具有静态类型检查的编译语言中,局部变量被分配在堆栈上,这是一个快速内存区域。堆栈可以帮助检测代码块中不匹配的括号,或者评估用反向波兰符号(RPN) 表示的算术表达式。您还可以使用堆栈来解决河内的塔难题,或者跟踪使用深度优先搜索(DFS) 算法遍历的图或树中访问过的节点。
注意:当你在 DFS 算法中用一个 FIFO 队列替换堆栈,或者 LIFO 队列,并做一些小的调整,那么你将几乎免费得到广度优先搜索(BFS) 算法!在本教程的后面,您将更详细地研究这两种算法。
虽然堆栈是队列的一种特化,但是双端队列是一种一般化的队列,可以用来作为实现 FIFO 和 LIFO 队列的基础。在下一节中,您将看到 deques 是如何工作的,以及在什么地方可以使用它们。
队列:双端队列
双端队列或双端队列(发音为 deck )是一种更通用的数据类型,它结合并扩展了堆栈和队列背后的思想。它允许您在任何给定的时刻,在恒定的时间内将元素从两端入队或出队。因此,一个 deque 可以作为 FIFO 或 LIFO 队列工作,也可以作为介于两者之间的任何队列工作。
使用与前面相同的一行人的例子,您可以利用 deque 来建模更复杂的极限情况。在现实生活中,队列中的最后一个人可能会不耐烦,决定提前离开队列,或者在刚刚开放的新收银台加入另一个队列。相反,提前在网上预定了某个特定日期和时间的人可能会被允许在前面排队,而无需等待。
下面是一个动画,展示了一个无界队列的运行:
https://player.vimeo.com/video/723399870?background=1
在这个特殊的例子中,大多数元素通常遵循一个方向,加入右边的队列,离开左边的队列,就像普通的 FIFO 队列一样。但是,一些特权元素被允许从左端加入队列,而最后一个元素可以通过相对端离开队列。****
将一个元素添加到已经达到其最大容量的有界队列中将会覆盖当前位于另一端的元素。这个特性对于从序列中分离出前几个或后几个元素可能很方便。您可能还想在该序列中的任何位置停止,然后以较小的步长向左或向右移动:
https://player.vimeo.com/video/723401029?background=1
假设您正在计算光栅图像的扫描线中像素强度的移动平均值。向左或向右移动可以预览几个连续的像素值,并动态计算它们的平均值。这或多或少就是卷积核在高级图像处理中应用过滤器的工作方式。
大多数 deques 支持两个额外的操作,称为向左旋转和向右旋转,它们以循环的方式在一个或另一个方向上移动元素指定的位置。因为 deque 的大小保持不变,突出的元素会在末端缠绕,就像在模拟汽车里程表中一样:
https://player.vimeo.com/video/723405800?background=1
向右旋转时,队列中的最后一个元素成为第一个。另一方面,向左旋转时,第一个元素成为最后一个元素。也许你可以更容易地想象这个过程,把德克的元素排成一个圆圈,使两端相交。那么,向右和向左旋转将分别对应于顺时针和逆时针旋转。
旋转与 deque 的核心功能相结合,开启了有趣的可能性。例如,您可以使用一个队列来实现一个负载平衡器或者一个以循环方式工作的任务调度器。在一个 GUI 应用中,你可以使用一个队列来存储最近打开的文件,允许用户撤销和重做他们的操作,或者让用户在他们的网页浏览历史中来回导航。
正如您所看到的,deques 有许多实际用途,尤其是在跟踪最近的活动方面。然而,有些问题需要您利用另一种类型的队列,您将在接下来读到这一点。
优先级队列:从高到低排序
一个优先级队列与你目前看到的不同,因为它不能存储普通元素。相反,每个元素现在必须有一个关联的优先级,以便与其他元素进行比较。队列将保持一个排序的顺序,让新元素在需要的地方加入,同时根据需要调整现有元素。当两个元素具有相同的优先级时,它们将遵循它们的插入顺序。
注意:确保通过比较运算符为您的优先级选择一个值为可比的数据类型,例如小于(<)。例如,整数和时间戳可以,而复数不能用来表示优先级,因为它们没有实现任何相关的比较操作符。
这种排队方式类似于飞机上的优先登机:

普通乘客会排在队伍的最后,除非他们有小孩陪伴,有残疾,或者有积分,在这种情况下,他们会被快速排到队伍的前面。商务舱乘客通常享受单独的、小得多的队列,但即使是他们有时也不得不让头等舱乘客通过。
下面的动画演示了通过无限优先级队列的具有三个不同优先级的元素的示例流:
https://player.vimeo.com/video/723407699?background=1
蓝色方块代表最低优先级,黄色三角形在层级中较高,红色圆圈最重要。一个新元素被插入到一个具有更高或相等优先级的元素和另一个具有较低优先级的元素之间。这个规则类似于插入排序算法,它恰好是稳定的,因为具有相同优先级的元素从不交换它们的初始位置。
您可以使用优先级队列来按照给定的键对一系列元素进行排序,或者获取前几个元素。然而,这可能有些矫枉过正,因为有更有效的排序算法可用。优先级队列更适合元素可以动态进出的情况。其中一种情况是使用 Dijkstra 算法在加权图中搜索最短路径,稍后您将会读到这一点。
注意:尽管优先级队列在概念上是一个序列,但它最有效的实现是建立在堆数据结构之上的,这是一种二叉树。因此,术语堆和优先级队列有时可以互换使用。
这是对队列理论和分类的一个比较长的介绍。在此过程中,您了解了 FIFO 队列、堆栈(LIFO 队列)、deques 和优先级队列。您还看到了有界队列和无界队列之间的区别,并且对它们的潜在应用有了一定的了解。现在,是时候尝试自己实现一些队列了。
用 Python 实现队列
首先,是否应该用 Python 自己实现一个队列?在大多数情况下,这个问题的答案将是决定性的否。语言自带电池,队列也不例外。事实上,您会发现 Python 有大量适合解决各种问题的队列实现。
也就是说,尝试从零开始构建东西是一种非常宝贵的学习经历。在技术面试中,你可能还会被要求提供一个队列实现。所以,如果你觉得这个话题有趣,那么请继续读下去。否则,如果您只是想在实践中使用队列,那么完全可以跳过这一部分。
用队列表示 FIFO 和 LIFO 队列
为了表示计算机内存中的 FIFO 队列,您需要一个具有 O(1)或常数时间的序列,一端用于入队操作,另一端用于类似的高效出列操作。正如您现在已经知道的,双端队列可以满足这些要求。另外,它的通用性足以适应 LIFO 队列。
然而,因为编写代码超出了本教程的范围,所以您将利用 Python 标准库中的 deque 集合。
注意:dequee 是一种抽象数据类型,你可以用几种方式实现它。使用双向链表作为底层实现将确保从两端访问和移除元素将具有期望的 O(1)时间复杂度。如果你的 deque 有一个固定的大小,那么你可以使用一个循环缓冲区,让你在固定的时间内访问任何元素。与链表不同,循环缓冲区是一种随机存取的数据结构。
为什么不用 Python list代替collections.deque作为 FIFO 队列的构建模块呢?
这两个序列都允许用它们的.append()方法以相当低的代价将元素入队,并为列表保留一点空间,当元素数量超过某个阈值时,偶尔需要将所有元素复制到一个新的内存位置。
不幸的是,用list.pop(0)将一个元素从列表的前面退出,或者用list.insert(0, element)插入一个元素,效率要低得多。这种操作总是移动剩余的元素,导致线性或 O(n)时间复杂度。相比之下,deque.popleft()和deque.appendleft()完全避免了这一步。
这样,您就可以基于 Python 的deque集合来定义您的自定义Queue类。
构建队列数据类型
既然您已经选择了合适的队列表示,那么您可以启动您最喜欢的代码编辑器,例如 Visual Studio 代码或 PyCharm ,并为不同的队列实现创建一个新的 Python 模块。您可以调用文件queues.py(复数形式)以避免与 Python 标准库中已经可用的类似命名的queue(单数形式)模块冲突。
注意:在后面专门讨论 Python 中的线程安全队列的章节中,您将更仔细地了解内置的queue模块。
因为您希望您的自定义 FIFO 队列至少支持入队和出队操作,所以继续编写一个基本的Queue类,将这两个操作分别委托给deque.append()和deque.popleft()方法:
# queues.py
from collections import deque
class Queue:
def __init__(self):
self._elements = deque()
def enqueue(self, element):
self._elements.append(element)
def dequeue(self):
return self._elements.popleft()
这个类仅仅包装了一个collections.deque实例,并将其称为._elements。属性名中的前导下划线表示实现的一个内部位,只有该类可以访问和修改。这种字段有时被称为 private,因为它们不应该在类体之外可见。
您可以通过在一个交互式 Python 解释器会话中从本地模块导入来测试您的 FIFO 队列:
>>> from queues import Queue >>> fifo = Queue() >>> fifo.enqueue("1st") >>> fifo.enqueue("2nd") >>> fifo.enqueue("3rd") >>> fifo.dequeue() '1st' >>> fifo.dequeue() '2nd' >>> fifo.dequeue() '3rd'正如预期的那样,入队的元素会以它们原来的顺序返回给您。如果你愿意,你可以改进你的类,使它成为可迭代的,并且能够报告它的长度和可选地接受初始元素:
# queues.py from collections import deque class Queue: def __init__(self, *elements): self._elements = deque(elements) def __len__(self): return len(self._elements) def __iter__(self): while len(self) > 0: yield self.dequeue() def enqueue(self, element): self._elements.append(element) def dequeue(self): return self._elements.popleft()一个
deque接受一个可选的 iterable,您可以在初始化器方法中通过不同数量的位置参数*elements来提供它。通过实现特殊的.__iter__()方法,您将使您的类实例在for循环中可用,而实现.__len__()将使它们与len()函数兼容。上面的.__iter__()方法是一个生成器迭代器的例子,它产生元素和。注意:
.__iter__()的实现通过在迭代时将元素从队列中取出来,减少了自定义队列的大小。重新启动 Python 解释器并再次导入您的类,以查看运行中的更新代码:
>>> from queues import Queue
>>> fifo = Queue("1st", "2nd", "3rd")
>>> len(fifo)
3
>>> for element in fifo:
... print(element)
...
1st
2nd
3rd
>>> len(fifo)
0
该队列最初有三个元素,但是在一个循环中消耗完所有元素后,它的长度下降为零。接下来,您将实现一个 stack 数据类型,它将以相反的顺序将元素出队。
构建堆栈数据类型
构建一个栈数据类型要简单得多,因为您已经完成了大部分艰苦的工作。由于大部分实现保持不变,您可以使用继承来扩展您的Queue类,并覆盖.dequeue()方法以从堆栈顶部移除元素:
# queues.py
# ...
class Stack(Queue):
def dequeue(self):
return self._elements.pop()
就是这样!现在,元素从您之前推送它们的队列的同一端弹出。您可以在交互式 Python 会话中快速验证这一点:
>>> from queues import Stack >>> lifo = Stack("1st", "2nd", "3rd") >>> for element in lifo: ... print(element) ... 3rd 2nd 1st使用与前面相同的设置和测试数据,元素以相反的顺序返回给您,这是 LIFO 队列的预期行为。
注意:在本教程中,您将继承作为一种方便的重用代码的机制。然而,当前的类关系在语义上是不正确的,因为堆栈不是队列的子类型。您也可以先定义堆栈,然后让队列扩展它。在现实世界中,你可能应该让两个类都从一个抽象基类继承,因为它们共享相同的接口。
在一次性脚本中,如果您不介意不时复制值的额外开销,那么您可能可以使用普通的旧 Python
list作为基本堆栈:
>>> lifo = []
>>> lifo.append("1st")
>>> lifo.append("2nd")
>>> lifo.append("3rd")
>>> lifo.pop()
'3rd'
>>> lifo.pop()
'2nd'
>>> lifo.pop()
'1st'
Python 列表是开箱即用的。他们可以报告自己的长度,并有一个合理的文本表示。在下一节中,您将选择它们作为优先级队列的基础。
用堆表示优先级队列
您将在本教程中实现的最后一个队列是优先级队列。与堆栈不同,优先级队列不能扩展前面定义的Queue类,因为它不属于同一个类型层次结构。FIFO 或 LIFO 队列中元素的顺序完全由元素的到达时间决定。在优先级队列中,元素的优先级和插入顺序共同决定了它在队列中的最终位置。
有许多方法可以实现优先级队列,例如:
- 一个由元素及其优先级组成的无序列表,每次在将优先级最高的元素出队之前都要搜索这个列表
- 元素及其优先级的有序列表,每次新元素入队时都会对其进行排序
- 一个元素及其优先级的有序列表,通过使用二分搜索法为新元素找到合适的位置来保持排序
- 一棵二叉树,它在入队和出列操作后保持堆不变
您可以将优先级队列想象成一个列表,每次新元素到达时都需要对其进行排序,以便在执行出列操作时能够删除最后一个优先级最高的元素。或者,您可以忽略元素顺序,直到删除优先级最高的元素,这可以使用线性搜索算法找到。
在无序列表中查找元素的时间复杂度为 O(n)。对整个队列进行排序会更加昂贵,尤其是在经常使用的情况下。Python 的list.sort()方法采用了一种叫做 Timsort 的算法,该算法具有 O(n log(n))的最坏情况时间复杂度。用 bisect.insort() 插入元素稍微好一点,因为它可以利用已经排序的列表,但是这种好处被后面缓慢的插入抵消了。
幸运的是,您可以聪明地通过使用一个堆数据结构来保持元素在优先级队列中排序。它提供了比前面列出的那些更有效的实现。下表快速比较了这些不同实现提供的入队和出队操作的时间复杂度:
| 履行 | 使…入队 | 出列 |
|---|---|---|
| 在出列时查找最大值 | O(1) | O(n) |
| 排队时排序 | O(n log(n)) | O(1) |
| 入队时对分和插入 | O(n) | O(1) |
| 排队时推到堆上 | O(log(n)) | O(log(n)) |
对于大型数据卷,堆具有最佳的整体性能。虽然使用二分法为新元素找到合适的位置是 O(log(n)),但是该元素的实际插入是 O(n),这使得它不如堆理想。
Python 有heapq模块,它方便地提供了一些函数,可以将一个常规列表变成一个堆,并有效地操纵它。帮助您构建优先级队列的两个函数是:
heapq.heappush()heapq.heappop()
当你把一个新元素放到一个非空的堆上时,它会在正确的位置结束,保持堆不变。请注意,这并不一定意味着结果元素将被排序:
>>> from heapq import heappush >>> fruits = [] >>> heappush(fruits, "orange") >>> heappush(fruits, "apple") >>> heappush(fruits, "banana") >>> fruits ['apple', 'orange', 'banana']上例中结果堆中的水果名称没有按照字母顺序排列。但是,如果你以不同的顺序推动它们,它们可以!
堆的意义不在于对元素进行排序,而是让它们保持某种关系,以便快速查找。真正重要的是,堆中的第一个元素总是具有最小(最小堆)或最大(最大堆)的值,这取决于您如何定义上述关系的条件。Python 的堆是最小堆,这意味着第一个元素具有最小的值。
当你从一个堆中取出一个元素时,你总是得到第一个,而其余的元素可能会有一点混乱:
>>> from heapq import heappop
>>> heappop(fruits)
'apple'
>>> fruits
['banana', 'orange']
请注意香蕉和橙子如何交换位置,以确保第一个元素仍然是最小的。当您告诉 Python 按值比较两个字符串对象时,它开始从左到右成对地查看它们的字符,并逐个检查每一对。具有较低的 Unicode 码位的字符被认为较小,这决定了单词顺序。
现在,你如何将优先级放入混合中?毕竟,堆通过值而不是优先级来比较元素。要解决这个问题,您可以利用 Python 的元组比较,它考虑了元组的组成部分,从左向右查看,直到结果已知:
>>> person1 = ("John", "Brown", 42) >>> person2 = ("John", "Doe", 42) >>> person3 = ("John", "Doe", 24) >>> person1 < person2 True >>> person2 < person3 False在这里,你有三个元组代表不同的人。每个人都有名字、姓氏和年龄。Python 根据他们的姓氏决定
person1应该在person2之前,因为他们有相同的名字,但是 Python 不考虑他们的年龄,因为顺序已经知道了。在第二次比较person2和person3时,年龄变得很重要,他们碰巧有相同的姓和名。通过存储第一个元素是优先级的元组,可以在堆上强制执行优先顺序。然而,有一些细节你需要小心。在下一节中,您将了解更多关于它们的内容。
构建优先级队列数据类型
假设您正在为一家汽车公司开发软件。现代车辆实际上是车轮上的计算机,它利用控制器局域网(CAN)总线来广播关于汽车中正在发生的各种事件的信息,例如解锁车门或给安全气囊充气。显然,其中一些事件比其他事件更重要,应该相应地排列优先次序。
有趣的事实:你可以为你的智能手机下载一个移动应用程序,例如 Torque ,它可以让你通过蓝牙或特设的 WiFi 网络连接到你汽车的 can 总线,通过一个小的扫描设备连接到你汽车的车载诊断(OBD) 端口。
这种设置将允许您实时监控您的车辆参数,即使它们没有显示在仪表板上!这包括冷却液温度、电池电压、每加仑行驶英里数和排放量。此外,你还可以检查汽车的ECU是否报告了任何故障代码。
错过一个有故障的大灯信息或者多等一会儿音量降低也没关系。然而,当您踩下制动踏板时,您会期望它立即产生效果,因为它是一个安全关键子系统。在 CAN 总线协议中,每条消息都有一个优先级,它告诉中间单元是应该进一步转发该消息还是完全忽略该消息。
尽管这是一个过于简单化的问题,但是你可以把 can 总线看作是一个优先级队列,它根据消息的重要性对消息进行排序。现在,返回到代码编辑器,在之前创建的 Python 模块中定义以下类:
# queues.py from collections import deque from heapq import heappop, heappush # ... class PriorityQueue: def __init__(self): self._elements = [] def enqueue_with_priority(self, priority, value): heappush(self._elements, (priority, value)) def dequeue(self): return heappop(self._elements)这是一个基本的优先级队列实现,它使用一个 Python 列表和两个操作它的方法定义了一堆元素。
.enqueue_with_priority()方法接受两个参数,一个优先级和一个对应的值,然后它将这些参数封装在一个元组中,并使用heapq模块推送到堆上。注意,优先级在值之前,以利用 Python 比较元组的方式。不幸的是,上面的实现有一些问题,当您尝试使用它时,这些问题变得很明显:
>>> from queues import PriorityQueue
>>> CRITICAL = 3
>>> IMPORTANT = 2
>>> NEUTRAL = 1
>>> messages = PriorityQueue()
>>> messages.enqueue_with_priority(IMPORTANT, "Windshield wipers turned on")
>>> messages.enqueue_with_priority(NEUTRAL, "Radio station tuned in")
>>> messages.enqueue_with_priority(CRITICAL, "Brake pedal depressed")
>>> messages.enqueue_with_priority(IMPORTANT, "Hazard lights turned on")
>>> messages.dequeue()
(1, 'Radio station tuned in')
您定义了三个优先级:关键、重要和中立。接下来,您实例化了一个优先级队列,并使用它将一些具有这些优先级的消息入队。但是,您没有将具有最高优先级的消息出队,而是获得了与具有最低优先级的消息相对应的元组。
注意:最终,你要如何定义你的优先顺序取决于你自己。在本教程中,较低的优先级对应于较低的数值,而较高的优先级具有较大的值。
也就是说,在某些情况下,颠倒这个顺序会更方便。例如,在 Dijkstra 的最短路径算法中,您会希望将总成本较小的路径优先于总成本较高的路径。为了处理这种情况,稍后您将实现另一个类。
因为 Python 的堆是最小堆,所以它的第一个元素总是有最低的值。要解决这个问题,您可以在将一个元组推到堆上时翻转优先级的符号,使优先级成为一个负数,这样最高的优先级就变成了最低的:
# queues.py
# ...
class PriorityQueue:
def __init__(self):
self._elements = []
def enqueue_with_priority(self, priority, value):
heappush(self._elements, (-priority, value))
def dequeue(self):
return heappop(self._elements)[1]
有了这个小小的改变,你将会把关键信息放在重要和中立的信息之前。此外,在执行出列操作时,您将通过使用方括号([])语法访问元组的第二个组件(位于第一个索引处)来解包该值。
现在,如果您回到交互式 Python 解释器,导入更新的代码,并再次将相同的消息排队,那么它们会以更合理的顺序返回给您:
>>> messages.dequeue() 'Brake pedal depressed' >>> messages.dequeue() 'Hazard lights turned on' >>> messages.dequeue() 'Windshield wipers turned on' >>> messages.dequeue() 'Radio station tuned in'你首先得到关键的信息,然后是两个重要的信息,然后是中性的信息。到目前为止,一切顺利,对吧?但是,您的实现有两个问题。其中一个您已经可以在输出中看到,而另一个只会在特定的情况下出现。你能发现这些问题吗?
处理优先队列中的疑难案例
您的队列可以正确地按优先级对元素进行排序,但同时,在比较具有相同优先级的元素时,它违反了排序稳定性。这意味着在上面的例子中,闪烁危险灯优先于启动挡风玻璃雨刷器,即使这种顺序并不遵循事件的时间顺序。两条消息具有相同的优先级,重要,因此队列应该按照它们的插入顺序对它们进行排序。
明确地说,这是 Python 中元组比较的直接结果,如果前面的元组没有解决比较问题,就移动到元组中的下一个组件。因此,如果两条消息具有相同的优先级,那么 Python 将通过值来比较它们,在您的示例中,值是一个字符串。字符串遵循的字典顺序,其中单词 Hazard 在单词挡风玻璃之前,因此顺序不一致。
与此相关的还有另一个问题,这在极少数情况下会完全破坏元组比较。具体来说,如果您试图将一个不支持任何比较操作符的元素入队,比如一个自定义类的实例,并且队列中已经包含了至少一个您想要使用的具有相同优先级的元素,那么它将会失败。考虑下面的数据类来表示队列中的消息:
>>> from dataclasses import dataclass
>>> @dataclass
... class Message:
... event: str
...
>>> wipers = Message("Windshield wipers turned on")
>>> hazard_lights = Message("Hazard lights turned on")
>>> wipers < hazard_lights
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Message' and 'Message'
对象可能比普通的字符串更方便,但是与字符串不同,它们是不可比较的,除非你告诉 Python 如何执行比较。如您所见,默认情况下,自定义类实例不提供小于(<)操作符的实现。
只要使用不同的优先级对消息进行排队,Python 就不会按值对它们进行比较:
>>> messages = PriorityQueue() >>> messages.enqueue_with_priority(CRITICAL, wipers) >>> messages.enqueue_with_priority(IMPORTANT, hazard_lights)例如,当您对关键消息和重要消息进行排队时,Python 会通过查看相应的优先级来明确确定它们的顺序。但是,一旦您尝试将另一个关键消息排入队列,您将会得到一个熟悉的错误:
>>> messages.enqueue_with_priority(CRITICAL, Message("ABS engaged"))
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'Message' and 'Message'
这一次,比较失败了,因为两条消息具有相同的优先级,Python 退回到通过值来比较它们,而您还没有为您的自定义Message类实例定义值。
您可以通过向堆中存储的元素引入另一个组件来解决这两个问题,即排序不稳定性和坏元组比较。这个额外的分量应该是可比较的,并且代表到达时间。当放置在元组中元素的优先级和值之间时,如果两个元素具有相同的优先级,它将解析顺序,而不管它们的值。
表示优先级队列中的到达时间的最直接的方式可能是一个单调递增的计数器。换句话说,您希望计算执行的入队操作的数量,而不考虑可能发生的潜在出队操作。然后,您将在每个入队的元素中存储计数器的当前值,以反映当时队列的状态。
可以使用 itertools 模块中的count()迭代器,以简洁的方式从零计数到无穷大:
# queues.py
from collections import deque
from heapq import heappop, heappush
from itertools import count
# ...
class PriorityQueue:
def __init__(self):
self._elements = []
self._counter = count()
def enqueue_with_priority(self, priority, value):
element = (-priority, next(self._counter), value) heappush(self._elements, element)
def dequeue(self):
return heappop(self._elements)[-1]
当您创建一个新的PriorityQueue实例时,计数器被初始化。每当您将一个值排入队列时,计数器都会递增,并在推送到堆上的元组中保留其当前状态。因此,如果您稍后将另一个具有相同优先级的值排入队列,则较早的值将优先,因为您用较小的计数器将其排入队列。
在元组中引入这个额外的计数器组件后,需要记住的最后一个细节是在出列操作期间更新弹出的值索引。因为现在元素是由三个部分组成的元组,所以应该返回位于索引二而不是索引一的值。然而,更安全的做法是使用负数作为索引来指示元组的最后一个组件,而不考虑它的长度。
您的优先级队列几乎准备好了,但是它缺少两个特殊的方法,.__len__()和.__iter__(),您在其他两个队列类中实现了这两个方法。虽然您不能通过继承重用他们的代码,因为优先级队列是而不是FIFO 队列的一个子类型,Python 提供了一个强大的机制让您解决这个问题。
使用 Mixin 类重构代码
为了跨不相关的类重用代码,您可以识别它们的最小公分母,然后将代码提取到一个 mixin 类中。mixin 类就像一种调味品。它不能独立存在,所以你通常不会实例化它,但是一旦你把它混合到另一个类中,它可以增加额外的味道。下面是它在实践中的工作方式:
# queues.py
# ...
class IterableMixin:
def __len__(self): return len(self._elements) def __iter__(self): while len(self) > 0: yield self.dequeue()
class Queue(IterableMixin):
# ...
class Stack(Queue):
# ...
class PriorityQueue(IterableMixin):
# ...
您将.__len__()和.__iter__()方法从Queue类移到了一个单独的IterableMixin类,并让前者扩展了 mixin。你也让PriorityQueue继承了同一个 mixin 类。这与标准继承有何不同?
不像像 Scala 这样的编程语言用特征直接支持混合,Python 使用多重继承来实现相同的概念。然而,扩展 mixin 类在语义上不同于扩展常规类,后者不再是类型专门化的一种形式。为了强调这个区别,有人称之为 mixin 类的包含而不是纯粹的继承。
注意你的 mixin 类引用了一个._elements属性,你还没有定义它!它是由具体的类提供的,比如Queue和PriorityQueue,这些类是在很久以后才加入进来的。Mixins 非常适合封装行为而不是状态,很像 Java 接口中的默认方法。通过用一个或多个 mixins 组成一个类,您可以改变或增加它的原始行为。
展开下面的可折叠部分以显示完整的源代码:
# queues.py
from collections import deque
from heapq import heappop, heappush
from itertools import count
class IterableMixin:
def __len__(self):
return len(self._elements)
def __iter__(self):
while len(self) > 0:
yield self.dequeue()
class Queue(IterableMixin):
def __init__(self, *elements):
self._elements = deque(elements)
def enqueue(self, element):
self._elements.append(element)
def dequeue(self):
return self._elements.popleft()
class Stack(Queue):
def dequeue(self):
return self._elements.pop()
class PriorityQueue(IterableMixin):
def __init__(self):
self._elements = []
self._counter = count()
def enqueue_with_priority(self, priority, value):
element = (-priority, next(self._counter), value)
heappush(self._elements, element)
def dequeue(self):
return heappop(self._elements)[-1]
有了这三个队列类,您终于可以应用它们来解决一个实际问题了!
在实践中使用队列
正如本教程介绍中提到的,队列是许多重要算法的支柱。一个特别有趣的应用领域是访问图中的节点,例如,它可能代表城市之间的道路地图。在寻找两个地方之间的最短或最佳路径时,队列非常有用。
在本节中,您将使用刚刚构建的队列来实现经典的图遍历算法。用代码表示图形的方法有很多,同样数量的 Python 库已经做得很好了。为了简单起见,您将利用 networkx 和 pygraphviz 库,以及广泛使用的 DOT 图形描述语言。
您可以使用pip将这些库安装到您的虚拟环境中:
(venv) $ python -m pip install networkx pygraphviz
或者,您可以按照补充资料中的README文件中的说明,一步安装本教程剩余部分所需的所有依赖项。注意,安装 pygraphviz 可能有点困难,因为它需要一个 C 编译器工具链。查看官方安装指南了解更多详情。
样本数据:英国路线图
一旦您安装了所需的库,您将从一个 DOT 文件中读取英国城市的加权和无向图,您可以在随附的资料中找到:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。
该图有 70 个节点代表英国城市,137 条边按连接城市之间的估计英里距离加权:

请注意,上面描述的图表是英国道路网络的简化模型,因为它没有考虑道路类型、通行能力、速度限制、交通或旁路。它还忽略了一个事实,那就是连接两个城市的道路通常不止一条。因此,由卫星导航或谷歌地图确定的最短路径很可能与你在本教程中找到的排队路径不同。
也就是说,上面的图表代表了城市之间的实际道路连接,而不是直线。即使这些边缘在视觉上看起来像直线,但在现实生活中它们肯定不是。在图形上,您可以用多种方式来表示同一个图形。
接下来,您将使用 networkx 库将这个图读入 Python。
城市和道路的对象表示
虽然 networkx 本身不能读取点文件,但是该库提供了一些帮助函数,将这项任务委托给其他第三方库。在本教程中,您将使用 pygraphviz 来读取示例点文件:
>>> import networkx as nx >>> print(nx.nx_agraph.read_dot("roadmap.dot")) MultiGraph named 'Cities in the United Kingdom' with 70 nodes and 137 edges虽然在某些操作系统上安装 pygraphviz 可能有点困难,但它是迄今为止最快的,并且最符合点格式的高级特性。默认情况下,networkx 使用文本标识符表示图节点,这些文本标识符可以选择具有关联的属性字典:
>>> import networkx as nx
>>> graph = nx.nx_agraph.read_dot("roadmap.dot")
>>> graph.nodes["london"]
{'country': 'England',
'latitude': '51.507222',
'longitude': '-0.1275',
'pos': '80,21!',
'xlabel': 'City of London',
'year': 0}
例如,"london"字符串映射到一个相应的键值对字典。 pos 属性包含将墨卡托投影应用于纬度和经度后的归一化坐标,该属性由 Graphviz 用于在图形可视化中放置节点。year属性表示一个城市何时获得它的地位。当等于零时,表示自古以来。
因为这不是考虑图表的最方便的方式,所以您将定义一个自定义数据类型来表示您的道路地图中的一个城市。继续,创建一个名为graph.py的新文件,并在其中实现以下类:
# graph.py
from typing import NamedTuple
class City(NamedTuple):
name: str
country: str
year: int | None
latitude: float
longitude: float
@classmethod
def from_dict(cls, attrs):
return cls(
name=attrs["xlabel"],
country=attrs["country"],
year=int(attrs["year"]) or None,
latitude=float(attrs["latitude"]),
longitude=float(attrs["longitude"]),
)
您扩展了一个名为 tuple 的,以确保您的节点对象是可散列的,这是 networkx 所需要的。您可以使用正确配置的数据类来代替,但是一个命名的元组是现成的。它也是可比较的,稍后您可能需要它来确定图的遍历顺序。.from_dict()类方法从一个点文件中提取一个属性字典,并返回一个City类的新实例。
为了利用您的新类,您需要创建一个新的 graph 实例,并注意节点标识符到 city 实例的映射。将以下助手函数添加到您的graph模块中:
# graph.py
import networkx as nx
# ...
def load_graph(filename, node_factory):
graph = nx.nx_agraph.read_dot(filename)
nodes = {
name: node_factory(attributes)
for name, attributes in graph.nodes(data=True)
}
return nodes, nx.Graph(
(nodes[name1], nodes[name2], weights)
for name1, name2, weights in graph.edges(data=True)
)
该函数为节点对象接受一个文件名和一个可调用工厂,比如你的City.from_dict()类方法。它首先读取一个点文件,并构建节点标识符到图节点的面向对象的 T4 表示的映射。最后,它返回该映射和一个包含节点和加权边的新图。
现在,您可以在交互式 Python 解释器会话中再次开始使用英国路线图:
>>> from graph import City, load_graph >>> nodes, graph = load_graph("roadmap.dot", City.from_dict) >>> nodes["london"] City( name='City of London', country='England', year=None, latitude=51.507222, longitude=-0.1275 ) >>> print(graph) Graph with 70 nodes and 137 edges从模块中导入 helper 函数和
City类后,从一个示例点文件中加载图形,并将结果存储在两个变量中。nodes变量让您通过指定的名称获得对City类实例的引用,而graph变量保存整个 networkxGraph对象。当寻找两个城市之间的最短路径时,您会想要识别给定城市的紧邻邻居,以找到可用的路径。使用 networkx 图形,您可以通过几种方式做到这一点。在最简单的情况下,您将使用指定的节点作为参数在图上调用
.neighbors()方法:
>>> for neighbor in graph.neighbors(nodes["london"]):
... print(neighbor.name)
...
Bath
Brighton & Hove
Bristol
Cambridge
Canterbury
Chelmsford
Coventry
Oxford
Peterborough
Portsmouth
Southampton
Southend-on-Sea
St Albans
Westminster
Winchester
这仅显示相邻结点,而不显示连接边的可能权重,例如距离或估计行驶时间,您可能需要了解这些信息来选择最佳路径。如果您想包括权重,那么使用方括号语法访问一个节点:
>>> for neighbor, weights in graph[nodes["london"]].items(): ... print(weights["distance"], neighbor.name) ... 115 Bath 53 Brighton & Hove 118 Bristol 61 Cambridge 62 Canterbury 40 Chelmsford 100 Coventry 58 Oxford 85 Peterborough 75 Portsmouth 79 Southampton 42 Southend-on-Sea 25 St Albans 1 Westminster 68 Winchester邻居总是以您在点文件中定义它们的相同顺序列出。要按一个或多个权重对它们进行排序,可以使用下面的代码片段:
>>> def sort_by(neighbors, strategy):
... return sorted(neighbors.items(), key=lambda item: strategy(item[1]))
...
>>> def by_distance(weights):
... return float(weights["distance"])
...
>>> for neighbor, weights in sort_by(graph[nodes["london"]], by_distance):
... print(f"{weights['distance']:>3} miles, {neighbor.name}")
...
1 miles, Westminster
25 miles, St Albans
40 miles, Chelmsford
42 miles, Southend-on-Sea
53 miles, Brighton & Hove
58 miles, Oxford
61 miles, Cambridge
62 miles, Canterbury
68 miles, Winchester
75 miles, Portsmouth
79 miles, Southampton
85 miles, Peterborough
100 miles, Coventry
115 miles, Bath
118 miles, Bristol
首先,定义一个 helper 函数,该函数返回一个邻居列表以及按照指定策略排序的邻居权重。该策略采用与边相关联的所有权重的字典,并返回排序关键字。接下来,定义一个具体的策略,该策略根据输入字典生成浮点距离。最后,迭代伦敦的邻居,按距离升序排序。
有了这些关于 networkx 库的基本知识,现在就可以根据前面构建的定制队列数据类型来实现图遍历算法了。
使用 FIFO 队列的广度优先搜索
在广度优先搜索算法中,通过在同心层或级别中探索图来寻找满足特定条件的节点。您从任意选择的源节点开始遍历该图,除非该图是树数据结构,在这种情况下,您通常从该树的根节点开始。在每一步,你都要在深入之前访问当前节点的所有近邻。
注意:当图中包含循环时,为了避免陷入循环,请跟踪您访问过的邻居,并在下次遇到它们时跳过它们。例如,您可以将访问过的节点添加到 Python 集合中,然后使用in操作符检查该集合是否包含给定的节点。
例如,假设您想在英国找到一个在二十世纪被授予城市地位的地方,从爱丁堡开始搜索。networkx 库已经实现了许多算法,包括广度优先搜索,它可以帮助交叉检查您未来的实现。调用图中的nx.bfs_tree()函数来揭示广度优先的遍历顺序:
>>> import networkx as nx >>> from graph import City, load_graph >>> def is_twentieth_century(year): ... return year and 1901 <= year <= 2000 ... >>> nodes, graph = load_graph("roadmap.dot", City.from_dict) >>> for node in nx.bfs_tree(graph, nodes["edinburgh"]): ... print("📍", node.name) ... if is_twentieth_century(node.year): ... print("Found:", node.name, node.year) ... break ... else: ... print("Not found") ... 📍 Edinburgh 📍 Dundee 📍 Glasgow 📍 Perth 📍 Stirling 📍 Carlisle 📍 Newcastle upon Tyne 📍 Aberdeen 📍 Inverness 📍 Lancaster Found: Lancaster 1937 ```py 突出显示的线条表示爱丁堡的所有六个近邻,这是您的源节点。请注意,在移动到图形的下一层之前,它们会被连续不间断地访问。后续层由从源节点开始的第二级邻居组成。 你探索突出显示的城市的未访问的邻居。第一个是邓迪,它的邻居包括阿伯丁和珀斯,但你已经去过珀斯了,所以你跳过它,只去阿伯丁。格拉斯哥没有任何未到访的邻居,而珀斯只有因弗内斯。同样,你去了斯特灵的邻居,却没有去卡莱尔的,卡莱尔与兰开斯特相连。你停止搜索,因为兰开斯特就是你的答案。 搜索结果有时可能会有所不同,这取决于您对起始点的选择,以及相邻结点的顺序(如果有多个结点满足某个条件)。为了确保结果一致,您可以根据某些标准对邻域进行排序。例如,您可以先访问纬度较高的城市:
>>> def order(neighbors):
... def by_latitude(city):
... return city.latitude
... return iter(sorted(neighbors, key=by_latitude, reverse=True))
>>> for node in nx.bfs_tree(graph, nodes["edinburgh"], sort_neighbors=order):
... print("📍", node.name)
... if is_twentieth_century(node.year):
... print("Found:", node.name, node.year)
... break
... else:
... print("Not found")
...
📍 Edinburgh
📍 Dundee 📍 Perth 📍 Stirling 📍 Glasgow 📍 Newcastle upon Tyne 📍 Carlisle 📍 Aberdeen
📍 Inverness
📍 Sunderland
Found: Sunderland 1992
```py
现在,答案不同了,因为纽卡斯尔比卡莱尔先被访问,因为它的纬度略高。反过来,这使得广度优先搜索算法在兰卡斯特之前找到桑德兰,这是一个符合你条件的备选节点。
**注意:**如果你想知道为什么`order()`在对`iter()`的调用中包装一个排序邻居列表,那是因为 [`nx.bfs_tree()`](https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.traversal.breadth_first_search.bfs_tree.html) 期望一个迭代器对象作为其`sort_neighbors`参数的输入。
现在您已经对广度优先搜索算法有了大致的了解,是时候自己实现它了。因为广度优先遍历是其他有趣算法的基础,所以您将把它的逻辑提取到一个单独的函数中,您可以将它委托给:
graph.py
from queues import Queue
...
def breadth_first_traverse(graph, source):
queue = Queue(source)
visited = {source}
while queue:
yield (node := queue.dequeue())
for neighbor in graph.neighbors(node):
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
def breadth_first_search(graph, source, predicate):
for node in breadth_first_traverse(graph, source):
if predicate(node):
return node
第一个函数将 networkx 图和源节点作为参数,同时产生用广度优先遍历访问的节点。请注意,它使用来自`queues`模块的 **FIFO 队列**来跟踪节点邻居,确保您将在每一层上依次探索它们。该函数还通过将被访问的节点添加到一个 [Python 集合](https://realpython.com/python-sets/)中来标记它们,这样每个邻居最多被访问一次。
**注意:**不要使用`while`循环和 [walrus 操作符(`:=` )](https://realpython.com/python-walrus-operator/) 在一个表达式中产生一个出列节点,您可以利用这样一个事实,即您的定制队列是可迭代的,通过使用`for`循环使元素出列:
def breadth_first_traverse(graph, source):
queue = Queue(source)
visited = {source}
for node in queue:
yield node
for neighbor in graph.neighbors(node):
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
然而,这依赖于您的`Queue`类中一个不明显的实现细节,所以在本教程的剩余部分,您将坚持使用更传统的`while`循环。
第二个函数建立在第一个函数的基础上,循环遍历生成的节点,一旦当前节点满足预期标准,就停止。如果没有节点使谓词为真,那么函数隐式返回 [`None`](https://realpython.com/null-in-python/) 。
为了测试广度优先搜索和遍历实现,可以用自己的函数替换 networkx 内置的便利函数:
>>>
from graph import (
... City,
... load_graph,
... breadth_first_traverse,
... breadth_first_search as bfs,
... )
def is_twentieth_century(city):
... return city.year and 1901 <= city.year <= 2000
nodes, graph = load_graph("roadmap.dot", City.from_dict)
city = bfs(graph, nodes["edinburgh"], is_twentieth_century)
city.name
'Lancaster'
for city in breadth_first_traverse(graph, nodes["edinburgh"]):
... print(city.name)
...
Edinburgh
Dundee
Glasgow
Perth
Stirling
Carlisle
Newcastle upon Tyne
Aberdeen
Inverness
Lancaster
⋮
正如您所看到的,遍历顺序与您第一次尝试使用 networkx 时是一样的,这证实了您的算法对于这个数据集是正确的。但是,您的函数不允许以特定的顺序对邻居进行排序。尝试修改代码,使其接受可选的排序策略。您可以单击下面的可折叠部分查看一个可能的解决方案:
graph.py
...
def breadth_first_traverse(graph, source, order_by=None):
queue = Queue(source)
visited = {source}
while queue:
yield (node := queue.dequeue())
neighbors = list(graph.neighbors(node)) if order_by: neighbors.sort(key=order_by) for neighbor in neighbors: if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
def breadth_first_search(graph, source, predicate, order_by=None):
for node in breadth_first_traverse(graph, source, order_by): if predicate(node):
return node
广度优先搜索算法确保在搜索满足所需条件的节点时,您最终会探索图中所有连接的节点。例如,你可以用它来解决一个迷宫。广度优先遍历也是在无向图和无权重图中寻找两个节点之间的最短路径的基础。在下一节中,您将修改您的代码来做到这一点。
[*Remove ads*](/account/join/)
### 使用广度优先遍历的最短路径
在许多情况下,从源到目的地的路径上的节点越少,距离就越短。如果您的城市之间的连接没有权重,您可以利用这一观察来估计最短距离。这相当于每条边的权重相等。
使用广度优先方法遍历图将产生保证具有最少*个*节点的路径。有时两个节点之间可能有不止一条最短路径。例如,当您忽略道路距离时,在阿伯丁和珀斯之间有两条这样的最短路径。和以前一样,这种情况下的实际结果将取决于如何对相邻节点进行排序。
您可以使用 networkx 显示两个城市之间的所有最短路径,这两个城市具有相同的最小长度:
>>>
import networkx as nx
from graph import City, load_graph
nodes, graph = load_graph("roadmap.dot", City.from_dict)
city1 = nodes["aberdeen"]
city2 = nodes["perth"]
for i, path in enumerate(nx.all_shortest_paths(graph, city1, city2), 1):
... print(f"{i}.", " → ".join(city.name for city in path))
...
1. Aberdeen → Dundee → Perth
2. Aberdeen → Inverness → Perth
加载图表后,你[列举出](https://realpython.com/python-enumerate/)两个城市之间的最短路径,并将它们打印到屏幕上。你可以看到在阿伯丁和珀斯之间只有两条最短的路径。相比之下,伦敦和爱丁堡有四条不同的最短路径,每条路径有九个节点,但它们之间存在许多更长的路径。
广度优先遍历是如何帮助你准确找到最短路径的?
无论何时访问一个节点,都必须通过将该信息作为一个键-值对保存在字典中来跟踪引导您到该节点的前一个节点。稍后,您将能够通过跟随前面的节点从目的地追溯到源。回到您的代码编辑器,通过复制和改编您之前的`breadth_first_traverse()`函数的代码来创建另一个函数:
graph.py
...
def shortest_path(graph, source, destination, order_by=None):
queue = Queue(source)
visited = {source}
previous = {} while queue:
node = queue.dequeue() neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in neighbors:
if neighbor not in visited:
visited.add(neighbor)
queue.enqueue(neighbor)
previous[neighbor] = node if neighbor == destination: return retrace(previous, source, destination)
这个新函数将另一个节点作为参数,并允许您使用自定义策略对邻居进行排序。它还定义了一个空字典,在访问邻居时,通过将它与路径上的前一个节点相关联来填充该字典。该字典中的所有键值对都是直接邻居,它们之间没有任何节点。
如果在您的源和目的地之间存在一条路径,那么该函数返回一个用另一个帮助函数构建的节点列表,而不是像`breadth_first_traverse()`那样产生单个节点。
**注意:**如果你愿意,你可以通过将`shortest_path()`和`breadth_first_traverse()`组合成一个函数来尝试重构这段代码。然而,有经验的程序员普遍认为,只要能让你的代码更容易理解并专注于一项职责,有一点重复有时是没问题的。
要重新创建源和目的地之间的最短路径,您可以迭代地查找之前使用广度优先方法遍历图时构建的字典:
graph.py
from collections import deque
...
def retrace(previous, source, destination):
path = deque()
current = destination
while current != source:
path.appendleft(current)
current = previous.get(current)
if current is None:
return None
path.appendleft(source)
return list(path)
因为您从目的地开始,然后往回走,所以在左侧使用 Python `deque`集合和快速追加操作会很有帮助。在每次迭代中,将当前节点添加到路径中,并移动到前一个节点。重复这些步骤,直到到达源节点或者没有前一个节点。
当您调用最短路径的基于队列的实现时,您会得到与 networkx:
>>>
from graph import shortest_path
" → ".join(city.name for city in shortest_path(graph, city1, city2))
'Aberdeen → Dundee → Perth'
def by_latitude(city):
... return -city.latitude
...
" → ".join(
... city.name
... for city in shortest_path(graph, city1, city2, by_latitude)
... )
'Aberdeen → Inverness → Perth'
第一条路径遵循点文件中相邻点的自然顺序,而第二条路径更喜欢纬度较高的相邻点,这是通过自定义排序策略指定的。要强制执行降序,您需要在`.latitude`属性前添加减号(`-`)。
请注意,对于某些节点,路径可能根本不存在。例如,贝尔法斯特和格拉斯哥没有陆地连接,因为它们位于两个独立的岛屿上。你需要乘渡船从一个城市到另一个城市。广度优先遍历可以告诉你两个节点是否保持**连接**。下面是实现这种检查的方法:
graph.py
...
def connected(graph, source, destination):
return shortest_path(graph, source, destination) is not None
从源节点开始,遍历连接节点的整个子图,比如北爱尔兰,之前节点的字典不会包括你的目的节点。因此,回溯将立即停止并返回`None`,让您知道在源和目的地之间没有路径。
您可以在交互式 Python 解释器会话中验证这一点:
>>>
from graph import connected
connected(graph, nodes["belfast"], nodes["glasgow"])
False
connected(graph, nodes["belfast"], nodes["derry"])
True
厉害!使用自定义的 FIFO 队列,您可以遍历图形,找到两个节点之间的最短路径,甚至确定它们是否相连。通过在代码中添加一个小的调整,您将能够将遍历从广度优先改为深度优先,这就是您现在要做的。
### 使用 LIFO 队列的深度优先搜索
顾名思义,深度优先遍历沿着从源节点开始的路径,在**回溯**到最后一个边交叉并尝试另一个分支之前,尽可能深地陷入图中。注意当您通过用`nx.dfs_tree()`替换`nx.bfs_tree()`来修改前面的示例时,遍历顺序的不同:
>>>
import networkx as nx
from graph import City, load_graph
def is_twentieth_century(year):
... return year and 1901 <= year <= 2000
...
nodes, graph = load_graph("roadmap.dot", City.from_dict)
for node in nx.dfs_tree(graph, nodes["edinburgh"]): ... print("📍", node.name)
... if is_twentieth_century(node.year):
... print("Found:", node.name, node.year)
... break
... else:
... print("Not found")
...
📍 Edinburgh
📍 Dundee 📍 Aberdeen
📍 Inverness
📍 Perth 📍 Stirling 📍 Glasgow 📍 Carlisle 📍 Lancaster
Found: Lancaster 1937
现在,不再按顺序浏览源节点的突出显示的邻居。到达邓迪后,算法继续沿着相同的路径前进,而不是访问第一个图层上爱丁堡的下一个邻居。
为了便于回溯,您可以在广度优先遍历函数中用一个 **LIFO 队列**来替换 FIFO 队列,您将非常接近深度优先遍历。然而,它只有在遍历树数据结构时才会正确运行。有圈的图有细微的差别,这需要在代码中做额外的修改。否则,您将实现一个基于[堆栈的图遍历](https://11011110.github.io/blog/2013/12/17/stack-based-graph-traversal.html),它的工作方式完全不同。
**注意:**在[二叉树](https://en.wikipedia.org/wiki/Binary_tree)遍历中,深度优先搜索算法定义了几个众所周知的[排序](https://en.wikipedia.org/wiki/Tree_traversal#Depth-first_search)供子节点访问——例如,前序、按序、后序。
在经典的深度优先遍历中,除了用堆栈替换队列之外,最初不会将源节点标记为已访问:
graph.py
from queues import Queue, Stack
...
def depth_first_traverse(graph, source, order_by=None):
stack = Stack(source)
visited = set()
while stack:
if (node := stack.dequeue()) not in visited:
yield node
visited.add(node)
neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in reversed(neighbors):
stack.enqueue(neighbor)
请注意,在开始从堆栈中弹出元素之前,您访问过的节点被初始化为一个空集。您还要检查该节点是否比广度优先遍历中更早就被访问过。当迭代邻居时,您颠倒它们的顺序以考虑 LIFO 队列的颠倒。最后,在将邻居推入堆栈后,不要立即将其标记为已访问。
因为深度优先遍历依赖于堆栈数据结构,所以您可以利用内置的**调用堆栈**来保存当前的搜索路径,以便稍后进行回溯,并递归地重写您的函数:
graph.py
...
def recursive_depth_first_traverse(graph, source, order_by=None):
visited = set()
def visit(node):
yield node
visited.add(node)
neighbors = list(graph.neighbors(node))
if order_by:
neighbors.sort(key=order_by)
for neighbor in neighbors:
if neighbor not in visited:
yield from visit(neighbor)
return visit(source)
通过这样做,您可以避免维护自己的堆栈,因为 Python 会在后台为您将每个函数调用推到一个堆栈上。当相应的函数返回时,它弹出一个。您只需要跟踪被访问的节点。递归实现的另一个优点是,迭代时不必反转邻居,也不必将已经访问过的邻居推到堆栈上。
有了遍历函数,现在可以实现深度优先搜索算法了。因为广度优先和深度优先搜索算法看起来几乎相同,只是遍历顺序不同,所以可以通过将两种算法的公共部分委托给模板函数来重构代码:
graph.py
...
def breadth_first_search(graph, source, predicate, order_by=None):
return search(breadth_first_traverse, graph, source, predicate, order_by)
...
def depth_first_search(graph, source, predicate, order_by=None):
return search(depth_first_traverse, graph, source, predicate, order_by)
def search(traverse, graph, source, predicate, order_by=None):
for node in traverse(graph, source, order_by):
if predicate(node):
return node
现在,你的`breadth_first_search()`和`depth_first_search()`函数用相应的遍历策略调用`search()`。继续在交互式 Python 解释器会话中测试它们:
>>>
from graph import (
... City,
... load_graph,
... depth_first_traverse,
... depth_first_search as dfs,
... )
def is_twentieth_century(city):
... return city.year and 1901 <= city.year <= 2000
...
nodes, graph = load_graph("roadmap.dot", City.from_dict)
city = dfs(graph, nodes["edinburgh"], is_twentieth_century)
city.name
'Lancaster'
for city in depth_first_traverse(graph, nodes["edinburgh"]):
... print(city.name)
...
Edinburgh
Dundee
Aberdeen
Inverness
Perth
Stirling
Glasgow
Carlisle
Lancaster
⋮
即使搜索结果恰好与广度优先搜索算法相同,您也可以清楚地看到,遍历的顺序现在不同了,而是遵循一条线性路径。
您已经看到了在 FIFO 和 LIFO 队列之间进行选择会如何影响底层的图遍历算法。到目前为止,在寻找两个城市之间的最短路径时,您只考虑了中间节点的数量。在下一节中,您将更进一步,利用优先级队列来查找最佳路径,该路径有时可能包含更多的节点。
### 使用优先级队列的 Dijkstra 算法
根据样本点文件中的图表,伦敦和爱丁堡之间节点数最少的路径有 9 个站点,总距离从 451 英里到 574 英里不等。有四条这样的路径:
| 451 英里 | 460 英里 | 465 英里 | 574 英里 |
| --- | --- | --- | --- |
| 伦敦城 | 伦敦城 | 伦敦城 | 伦敦城 |
| 考文垂 | 彼得伯勒 | 彼得伯勒 | 布里斯托尔 |
| 伯明翰 | 林肯 | 诺丁汉 | 纽波特 |
| 斯托克 | 设菲尔德 | 设菲尔德 | St Asaph |
| 利物浦 | 韦克菲尔德 | 韦克菲尔德 | 利物浦 |
| 普雷斯顿 | 约克 | 约克 | 普雷斯顿 |
| 兰克斯特 | 达勒姆 | 达勒姆 | 兰克斯特 |
| 卡莱尔 | 泰恩河畔的纽卡斯尔 | 泰恩河畔的纽卡斯尔 | 卡莱尔 |
| 爱丁堡 | 爱丁堡 | 爱丁堡 | 爱丁堡 |
这些路径之间有很大的重叠,因为它们在到达目的地之前会在几个十字路口迅速汇合。在某种程度上,它们也与伦敦和爱丁堡之间距离**最短的路径**重叠,相当于 436 英里,尽管还有两个停靠站:
1. 伦敦城
2. 圣奥尔本斯
3. 考文垂
4. 伯明翰
5. 斯托克
6. 曼彻斯特
7. 索尔福德
8. 普雷斯顿
9. 兰克斯特
10. 卡莱尔
11. 爱丁堡
有时,为了节省时间、燃料或里程,绕道而行是值得的,即使这意味着沿途要经过更多的地方。
当你在组合中加入边缘砝码时,有趣的可能性就会出现在你面前。例如,您可以在视频游戏中实现基本的人工智能,方法是将导致虚拟敌人的负权重分配给边缘,将指向某种奖励的正权重分配给边缘。你也可以把像[魔方](https://rubiks.com/)这样的游戏中的移动表示为[决策树](https://en.wikipedia.org/wiki/Game_tree)来寻找最优解。
也许遍历加权图最常见的用途是当[计划路线](https://en.wikipedia.org/wiki/Journey_planner)时。在加权图或有许多并行连接的[多重图](https://en.wikipedia.org/wiki/Multigraph)中寻找最短路径的一个方法是 [Dijkstra 的算法](https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm),它建立在广度优先搜索算法的基础上。然而,Dijkstra 的算法使用了一个特殊的**优先级队列**,而不是常规的 FIFO 队列。
解释 [Dijkstra 的最短路径算法](https://www.youtube.com/watch?v=pVfj6mxhdMw)超出了本教程的范围。然而,简而言之,你可以把它分解成以下两个步骤:
1. 构建从一个固定源节点到图中所有其他节点的三条最短路径。
2. 使用与之前使用普通最短路径算法相同的方式,追溯从目的节点到源节点的路径。
第一部分是关于以贪婪的方式扫描每个未访问节点的加权边,检查它们是否提供了从源到当前邻居之一的更便宜的连接。从源到邻居的路径的总成本是边的权重和从源到当前访问的节点的累积成本之和。有时,包含更多节点的路径总开销会更小。
以下是 Dijkstra 算法第一步对源自贝尔法斯特的路径的示例结果:
| 城市 | 以前的 | 总成本 |
| --- | --- | --- |
| 阿马 | 利斯本 | Forty-one |
| 贝尔法斯特 | - | Zero |
| 存有偏见 | 贝尔法斯特 | Seventy-one |
| 利斯本 | 贝尔法斯特 | nine |
| 纽里 | 利斯本 | Forty |
上表中的第一列表示从出发地到目的地的最短路径上的城市。第二列显示了从源头到目的地的最短路径上的前一个城市。最后一列包含从源到城市的总距离信息。
贝尔法斯特是源城市,因此它没有前一个节点通向它,距离为零。源与 Derry 和 Lisburn 相邻,可以从贝尔法斯特直接到达,代价是相应的边。要去阿马或纽瑞,穿过利斯本会给你从贝尔法斯特最短的总距离。
现在,如果你想找到贝尔法斯特和阿玛之间的最短路径,那么从你的目的地开始,跟随前一篇专栏文章。要到达阿玛,你必须经过利斯本,而要到达利斯本,你必须从贝尔法斯特出发。那是你逆序的最短路径。
您只需要实现 Dijkstra 算法的第一部分,因为您已经有了第二部分,第二部分负责根据之前的节点重新寻找最短路径。然而,为了将未访问的节点排队,您必须使用 min-heap 的**可变版本,这样您就可以在发现更便宜的连接时更新元素优先级。展开下面的可折叠部分以实现这个新队列:**
在内部,这个专门的优先级队列存储数据类元素,而不是元组,因为元素必须是可变的。注意附加的`order`标志,它使元素具有可比性,就像元组一样:
queues.py
from collections import deque
from dataclasses import dataclass
from heapq import heapify, heappop, heappush
from itertools import count
from typing import Any
...
@dataclass(order=True)
class Element:
priority: float
count: int
value: Any
class MutableMinHeap(IterableMixin):
def init(self):
super().init()
self._elements_by_value = {}
self._elements = []
self._counter = count()
def setitem(self, unique_value, priority):
if unique_value in self._elements_by_value:
self._elements_by_value[unique_value].priority = priority
heapify(self._elements)
else:
element = Element(priority, next(self._counter), unique_value)
self._elements_by_value[unique_value] = element
heappush(self._elements, element)
def getitem(self, unique_value):
return self._elements_by_value[unique_value].priority
def dequeue(self):
return heappop(self._elements).value
这个可变的最小堆的行为与您之前编写的常规优先级队列基本相同,但是它还允许您使用方括号语法查看或修改元素的优先级。
一旦所有元素都就位,您就可以最终将它们连接在一起了:
graph.py
from math import inf as infinity
from queues import MutableMinHeap, Queue, Stack
...
def dijkstra_shortest_path(graph, source, destination, weight_factory):
previous = {}
visited = set()
unvisited = MutableMinHeap()
for node in graph.nodes:
unvisited[node] = infinity
unvisited[source] = 0
while unvisited:
visited.add(node := unvisited.dequeue())
for neighbor, weights in graph[node].items():
if neighbor not in visited:
weight = weight_factory(weights)
new_distance = unvisited[node] + weight
if new_distance < unvisited[neighbor]:
unvisited[neighbor] = new_distance
previous[neighbor] = node
return retrace(previous, source, destination)
最初,到所有目的地城市的距离都是未知的,因此您为每个未访问的城市分配一个无限的成本,但源城市除外,其距离等于零。稍后,当您找到一条到邻居的更便宜的路径时,您将更新它与优先级队列中的源的总距离,这将重新平衡自身,以便下次具有最短距离的未访问节点将首先弹出。
您可以交互式地测试您的 Dijkstra 算法,并将其与 networkx 实现进行比较:
>>>
import networkx as nx
from graph import City, load_graph, dijkstra_shortest_path
nodes, graph = load_graph("roadmap.dot", City.from_dict)
city1 = nodes["london"]
city2 = nodes["edinburgh"]
def distance(weights):
... return float(weights["distance"])
...
for city in dijkstra_shortest_path(graph, city1, city2, distance):
... print(city.name)
...
City of London
St Albans
Coventry
Birmingham
Stoke-on-Trent
Manchester
Salford
Preston
Lancaster
Carlisle
Edinburgh
def weight(node1, node2, weights):
... return distance(weights)
...
for city in nx.dijkstra_path(graph, city1, city2, weight):
... print(city.name)
...
City of London
St Albans
Coventry
Birmingham
Stoke-on-Trent
Manchester
Salford
Preston
Lancaster
Carlisle
Edinburgh
成功!这两个函数在伦敦和爱丁堡之间产生完全相同的最短路径。
这就结束了本教程的理论部分,这是相当激烈的。至此,您已经对不同种类的队列有了相当扎实的理解,您可以从头开始高效地实现它们,并且您知道在给定的算法中选择哪一种。然而,在实践中,您更可能依赖 Python 提供的高级抽象。
## 使用线程安全队列
现在假设你已经写了一个有不止一个执行流的程序。除了作为一个有价值的算法工具,队列还可以帮助抽象出[多线程](https://realpython.com/intro-to-python-threading/)环境中对共享资源的[并发](https://realpython.com/python-concurrency/)访问,而不需要显式锁定。Python 提供了一些**同步队列**类型,您可以安全地在多线程上使用它们来促进它们之间的通信。
在本节中,您将使用 Python 的[线程安全](https://en.wikipedia.org/wiki/Thread_safety)队列来实现经典的[多生产者、多消费者问题](https://en.wikipedia.org/wiki/Producer%E2%80%93consumer_problem)。更具体地说,您将创建一个命令行脚本,让您决定生产者和消费者的数量、它们的相对速度以及队列的类型:
$ python thread_safe_queues.py --producers 3
--consumers 2
--producer-speed 1
--consumer-speed 1
--queue fifo
所有参数都是可选的,并且有合理的默认值。运行该脚本时,您将看到生产者和消费者线程通过同步队列进行通信的动画模拟:
[](https://files.realpython.com/media/queue_fifo.4bfb28b845b0.png)
<figcaption class="figure-caption text-center">Visualization of the Producers, Consumers, and the Thread-Safe Queue</figcaption>
该脚本使用丰富的库,您需要首先将它安装到您的虚拟环境中:
(venv) $ python -m pip install rich
这将允许你添加颜色、[表情符号](https://en.wikipedia.org/wiki/Emoji)和可视组件到你的终端。请注意,有些终端可能不支持这种富文本格式。请记住,如果您还没有下载本教程中提到的脚本的完整源代码,可以随时通过下面的链接下载:
**获取源代码:** [单击此处获取源代码和示例数据](https://realpython.com/bonus/queue-code/),您将使用它们来探索 Python 中的队列。
在开始使用队列之前,您必须做一些搭建工作。创建一个名为`thread_safe_queues.py`的新文件,并定义脚本的入口点,脚本将使用 [`argparse`](https://realpython.com/command-line-interfaces-python-argparse/) 模块解析参数:
thread_safe_queues.py
import argparse
from queue import LifoQueue, PriorityQueue, Queue
QUEUE_TYPES = {
"fifo": Queue,
"lifo": LifoQueue,
"heap": PriorityQueue
}
def main(args):
buffer = QUEUE_TYPESargs.queue
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("-q", "--queue", choices=QUEUE_TYPES, default="fifo")
parser.add_argument("-p", "--producers", type=int, default=3)
parser.add_argument("-c", "--consumers", type=int, default=2)
parser.add_argument("-ps", "--producer-speed", type=int, default=1)
parser.add_argument("-cs", "--consumer-speed", type=int, default=1)
return parser.parse_args()
if name == "main":
try:
main(parse_args())
except KeyboardInterrupt:
pass
首先,将必要的模块和队列类导入到全局名称空间中。`main()`函数是您的入口点,它接收由`parse_args()`提供的解析后的参数,定义如下。`QUEUE_TYPES`字典将队列名称映射到它们各自的类,您可以调用它来基于命令行参数的值创建一个新的队列实例。
接下来,您定义您的生产商将随机挑选并假装正在生产的产品:
thread_safe_queues.py
...
PRODUCTS = (
"🎈",
"🍪",
"🔮",
"🤿",
"🔦",
"💎",
"🎁",
"🪁",
":party_popper:",
"📯",
"🎀",
"🚀",
"🧸",
"🧵",
":yo-yo:",
)
...
这些是文本代码,里奇最终会用相应的表情符号[符号](https://en.wikipedia.org/wiki/Glyph)来替换它们。例如,`:balloon:`将呈现为🎈。您可以在您的终端中运行`python -m rich.emoji`来查找 Rich 中所有可用的表情代码。
您的生产者线程和消费者线程将共享大量属性和行为,您可以将它们封装在一个公共基类中:
```py
# thread_safe_queues.py
import threading
# ...
class Worker(threading.Thread):
def __init__(self, speed, buffer):
super().__init__(daemon=True)
self.speed = speed
self.buffer = buffer
self.product = None
self.working = False
self.progress = 0
worker 类扩展了threading.Thread类,并将自己配置为守护进程线程,这样当主线程结束时,它的实例不会阻止你的程序退出,例如,由于键盘中断信号。一个 worker 对象需要一个速度和一个缓冲队列来存放或取出成品。
除此之外,您还可以检查工作线程的状态,并请求它模拟一些工作或空闲时间:
# thread_safe_queues.py
from random import randint
from time import sleep
# ...
class Worker(threading.Thread):
# ...
@property
def state(self):
if self.working:
return f"{self.product} ({self.progress}%)"
return ":zzz: Idle"
def simulate_idle(self):
self.product = None
self.working = False
self.progress = 0
sleep(randint(1, 3))
def simulate_work(self):
self.working = True
self.progress = 0
delay = randint(1, 1 + 15 // self.speed)
for _ in range(100):
sleep(delay / 100)
self.progress += 1
.state 属性返回一个字符串,该字符串包含产品名称和工作进度,或者是一条通用消息,表明工作人员当前处于空闲状态。.simulate_idle()方法重置工作线程的状态,并随机选择几秒钟进入睡眠状态。类似地,.simulate_work()根据工人的速度随机选择延迟时间,并在工作中不断进步。
研究基于 Rich library 的表示层对于理解这个例子并不重要,但是可以随意展开下面的可折叠部分以获得更多细节:
下面的代码定义了一个视图,该视图以每秒十次的速度呈现生产者、消费者和队列的当前状态:
# thread_safe_queues.py
from itertools import zip_longest
from rich.align import Align
from rich.columns import Columns
from rich.console import Group
from rich.live import Live
from rich.panel import Panel
# ...
class View:
def __init__(self, buffer, producers, consumers):
self.buffer = buffer
self.producers = producers
self.consumers = consumers
def animate(self):
with Live(
self.render(), screen=True, refresh_per_second=10
) as live:
while True:
live.update(self.render())
def render(self):
match self.buffer:
case PriorityQueue():
title = "Priority Queue"
products = map(str, reversed(list(self.buffer.queue)))
case LifoQueue():
title = "Stack"
products = list(self.buffer.queue)
case Queue():
title = "Queue"
products = reversed(list(self.buffer.queue))
case _:
title = products = ""
rows = [
Panel(f"[bold]{title}:[/] {', '.join(products)}", width=82)
]
pairs = zip_longest(self.producers, self.consumers)
for i, (producer, consumer) in enumerate(pairs, 1):
left_panel = self.panel(producer, f"Producer {i}")
right_panel = self.panel(consumer, f"Consumer {i}")
rows.append(Columns([left_panel, right_panel], width=40))
return Group(*rows)
def panel(self, worker, title):
if worker is None:
return ""
padding = " " * int(29 / 100 * worker.progress)
align = Align(
padding + worker.state, align="left", vertical="middle"
)
return Panel(align, height=5, title=title)
# ...
注意使用结构模式匹配来基于队列类型设置标题和产品。一旦生产者和消费者就位,您将创建一个视图实例并调用它的.animate()方法。
接下来,您将定义生产者和消费者类,并将这些部分连接在一起。
排队。队列
您将尝试的第一个同步队列是一个无界 FIFO 队列,或者简单地说,是一个队列。你需要把它传递给你的生产者和消费者,所以现在就去定义他们吧。producer 线程将扩展一个 worker 类,并获取额外的产品集合以供选择:
# thread_safe_queues.py
from random import choice, randint
# ...
class Producer(Worker):
def __init__(self, speed, buffer, products):
super().__init__(speed, buffer)
self.products = products
def run(self):
while True:
self.product = choice(self.products)
self.simulate_work()
self.buffer.put(self.product)
self.simulate_idle()
# ...
方法是所有魔法发生的地方。生产者在一个无限循环中工作,选择一个随机的产品并在将该产品放入队列之前模拟一些工作,称为buffer。然后它会随机休眠一段时间,当它再次醒来时,这个过程会重复。
消费者非常相似,但比生产者更直接:
# thread_safe_queues.py
# ...
class Consumer(Worker):
def run(self):
while True:
self.product = self.buffer.get() self.simulate_work()
self.buffer.task_done() self.simulate_idle()
# ...
它还在无限循环中工作,等待一个产品出现在队列中。默认情况下,.get()方法是阻塞,这将使消费者线程停止并等待,直到队列中至少有一个产品。这样,当操作系统将宝贵的资源分配给其他线程做有用的工作时,等待的消费者不会浪费任何 CPU 周期。
注意:为了避免死锁,您可以通过传递一个带有放弃前等待秒数的timeout关键字参数,在.get()方法上设置一个超时。
每次从同步队列中获取数据时,它的内部计数器都会增加,让其他线程知道队列还没有被清空。因此,当您完成处理一个出列任务时,将它标记为 done 是很重要的,除非您没有任何线程加入队列。这样做会减少队列的内部计数器。
现在,回到您的main()函数,创建生产者和消费者线程,并启动它们:
# thread_safe_queues.py
# ...
def main(args):
buffer = QUEUE_TYPES[args.queue]()
producers = [
Producer(args.producer_speed, buffer, PRODUCTS)
for _ in range(args.producers)
]
consumers = [
Consumer(args.consumer_speed, buffer) for _ in range(args.consumers)
]
for producer in producers:
producer.start()
for consumer in consumers:
consumer.start()
view = View(buffer, producers, consumers)
view.animate()
生产者和消费者的数量由传递给函数的命令行参数决定。一旦您启动它们,它们就会开始工作并使用队列进行线程间通信。底部的View实例不断地重新呈现屏幕,以反映应用程序的当前状态:
https://player.vimeo.com/video/723346276?background=1
生产商总是会把他们的成品通过这个队列推向消费者。尽管有时看起来好像消费者直接从生产者那里获取元素,但这只是因为事情发生得太快,以至于没有注意到入队和出队操作。
注意:值得注意的是,每当生产者将某个元素放入同步队列时,至多一个消费者会将该元素出队并处理它,而其他消费者不会知道。如果您希望将程序中的某个特定事件通知给多个用户,那么看看 threading 模块中的其他线程协调原语。
您可以增加生成器的数量,提高它们的速度,或者两者都提高,以查看这些变化如何影响系统的整体容量。因为队列是无限的,它永远不会减慢生产者的速度。但是,如果您指定了队列的maxsize参数,那么它将开始阻塞它们,直到队列中再次有足够的空间。
使用 FIFO 队列使得生产者将元素放在上面可视化的队列的左端。同时,消费者相互竞争队列中最右边的产品。在下一节中,您将看到当您使用--queue lifo选项调用脚本时,这种行为是如何变化的。
尾巴!尾巴!LIFO queue〔t0〕
从员工的角度来看,完全没有必要为了修改他们的交流方式而对代码做任何修改。仅仅通过向它们注入不同类型的同步队列,您就可以修改工人通信的规则。现在使用 LIFO 队列运行您的脚本:
$ python thread_safe_queues.py --queue lifo
使用 LIFO 队列或堆栈时,刚创建的每个新产品都将优先于队列中的旧产品:
https://player.vimeo.com/video/723358546?background=1
在极少数情况下,当新产品的开发速度快于消费者的应对速度时,旧产品可能会遭遇饥饿,因为它们被困在堆栈的底部,永远不会被消费掉。另一方面,当你有足够大的消费者群体或者当你没有获得同样多的新产品时,这可能不是一个问题。饥饿还可能涉及到优先级队列中的元素,您将在接下来读到这一点。
排队。优先级队列
要使用同步优先级队列或堆,您需要在代码中做一些调整。首先,您将需要一种具有相关优先级的新产品,因此定义两种新的数据类型:
# thread_safe_queues.py
from dataclasses import dataclass, field
from enum import IntEnum
# ...
@dataclass(order=True)
class Product:
priority: int
label: str = field(compare=False)
def __str__(self):
return self.label
class Priority(IntEnum):
HIGH = 1
MEDIUM = 2
LOW = 3
PRIORITIZED_PRODUCTS = (
Product(Priority.HIGH, ":1st_place_medal:"),
Product(Priority.MEDIUM, ":2nd_place_medal:"),
Product(Priority.LOW, ":3rd_place_medal:"),
)
为了表示产品,您使用了一个数据类,并启用了定制的字符串表示和排序,但是您要注意不要通过标签来比较产品。在这种情况下,您希望标签是一个字符串,但通常,它可以是任何可能根本不可比的对象。您还定义了一个具有已知优先级值的 enum 类和三个优先级从高到低递减的产品。
注意:与之前的优先级队列实现相反,Python 的线程安全队列首先对优先级数值最低的元素进行排序。
此外,当用户在命令行中提供--queue heap选项时,您必须向您的生产者线程提供正确的产品集合:
# thread_safe_queues.py
# ...
def main(args):
buffer = QUEUE_TYPES[args.queue]()
products = PRIORITIZED_PRODUCTS if args.queue == "heap" else PRODUCTS producers = [
Producer(args.producer_speed, buffer, products) for _ in range(args.producers)
]
# ...
您可以根据使用条件表达式的命令行参数来提供普通产品或优先产品。
只要生产者和消费者知道如何处理新的产品类型,您的代码的其余部分就可以对这种变化保持不可知。因为这只是一个模拟,工作线程并不真正对产品做任何有用的事情,所以您可以用--queue heap标志运行您的脚本,看看效果:
https://player.vimeo.com/video/723371195?background=1
请记住,堆数据结构是一棵二叉树,它的元素之间保持着特定的关系。因此,尽管优先级队列中的产品看起来排列不太正确,但它们实际上是按照正确的顺序被消费的。此外,由于多线程编程的不确定性,Python 队列并不总是报告它们最新的大小。
好了,您已经看到了使用三种类型的同步队列来协调工作线程的传统方式。Python 线程非常适合于受 I/O 约束的任务,这些任务大部分时间都在等待网络、文件系统或数据库上的数据。然而,最近出现了同步队列的单线程替代方案,利用了 Python 的异步特性。这就是你现在要看的。
使用异步队列
如果您想在异步上下文中使用队列,那么 Python 可以满足您。 asyncio 模块提供了来自threading模块的队列的异步副本,您可以在单线程上的协程函数中使用。因为两个队列族共享一个相似的接口,所以从一个队列族切换到另一个队列族应该相对容易。
在本节中,您将编写一个基本的网络爬虫,它递归地跟踪指定网站上的链接,直到给定的深度级别,并计算每个链接的访问量。要异步获取数据,您将使用流行的 aiohttp 库,而要解析 HTML 超链接,您将依赖 beautifulsoup4 。在继续之前,请确保将这两个库都安装到您的虚拟环境中:
(venv) $ python -m pip install aiohttp beautifulsoup4
现在,您可以异步发出 HTTP 请求,并从从服务器接收的所谓的标记汤中选择 HTML 元素。
注:你可以用美汤和 Python搭建一个网页刮刀,在访问网页的同时收集有价值的数据。
为了给你的网络爬虫打基础,你首先要做几个构件。创建一个名为async_queues.py的新文件,并在其中定义以下结构:
# async_queues.py
import argparse
import asyncio
from collections import Counter
import aiohttp
async def main(args):
session = aiohttp.ClientSession()
try:
links = Counter()
display(links)
finally:
await session.close()
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("url")
parser.add_argument("-d", "--max-depth", type=int, default=2)
parser.add_argument("-w", "--num-workers", type=int, default=3)
return parser.parse_args()
def display(links):
for url, count in links.most_common():
print(f"{count:>3} {url}")
if __name__ == "__main__":
asyncio.run(main(parse_args()))
与大多数异步程序一样,您将您的main()协程传递给asyncio.run(),以便它可以在默认的事件循环上执行它。协程接受一些用下面定义的 helper 函数解析的命令行参数,启动一个新的aiohttp.ClientSession,并定义一个已访问链接的计数器。稍后,协程会显示按访问次数降序排列的链接列表。
要运行脚本,您需要指定一个根 URL,还可以选择最大深度和工作线程数。这里有一个例子:
$ python async_queues.py https://www.python.org/ --max-depth 2 \
--num-workers 3
仍然缺少一些部分,如获取内容和解析 HTML 链接,所以将它们添加到您的文件中:
# async_queues.py
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# ...
async def fetch_html(session, url):
async with session.get(url) as response:
if response.ok and response.content_type == "text/html":
return await response.text()
def parse_links(url, html):
soup = BeautifulSoup(html, features="html.parser")
for anchor in soup.select("a[href]"):
href = anchor.get("href").lower()
if not href.startswith("javascript:"):
yield urljoin(url, href)
只要接收的内容是 HTML,你就只返回它,这可以通过查看Content-Type HTTP 头来判断。当从 HTML 内容中提取链接时,您将跳过href属性中的内联 JavaScript ,并可选地加入一个带有当前 URL 的相对路径。
接下来,您将定义一个新的数据类型,表示您将放入队列的作业,以及执行该作业的异步工作器:
# async_queues.py
import sys
from typing import NamedTuple
# ...
class Job(NamedTuple):
url: str
depth: int = 1
# ...
async def worker(worker_id, session, queue, links, max_depth):
print(f"[{worker_id} starting]", file=sys.stderr)
while True:
url, depth = await queue.get() links[url] += 1
try:
if depth <= max_depth:
print(f"[{worker_id} {depth=} {url=}]", file=sys.stderr)
if html := await fetch_html(session, url):
for link_url in parse_links(url, html):
await queue.put(Job(link_url, depth + 1))
except aiohttp.ClientError:
print(f"[{worker_id} failed at {url=}]", file=sys.stderr)
finally:
queue.task_done()
作业由要访问的 URL 地址和当前深度组成,工作人员将使用该深度停止递归爬行。由于将一个作业指定为一个命名元组,所以在将它出队之后,您可以在突出显示的行上解包它的各个组件。如果不指定作业的深度,则默认为 1。
该工人坐在无限循环中,等待队列中的作业到达。消耗完一个作业后,工人可以将一个或多个深度提升的新作业放入队列中,由自己或其他工人消耗。
因为你的工人既是的生产者又是的消费者,所以在try … finally条款中无条件地将一项工作标记为已完成以避免僵局是至关重要的。您还应该处理您的 worker 中的错误,因为未处理的异常将使您的 worker 停止接受新的任务。
注意:你可以在异步代码中使用 print() 函数——例如,记录诊断消息——因为一切都运行在一个线程上。另一方面,你必须在多线程代码中用 logging 模块替换它,因为print()函数不是线程安全的。
另外,请注意,您将诊断消息打印到标准错误(stderr) ,而您的程序的输出打印到标准输出(stdout) ,这是两个完全独立的流。例如,这允许您将一个或两个重定向到一个文件。
您的员工在访问 URL 时会增加点击次数。此外,如果当前 URL 的深度没有超过允许的最大深度,那么 worker 将获取 URL 指向的 HTML 内容,并遍历其链接。walrus 操作符(:=)允许您等待 HTTP 响应,检查内容是否返回,并在单个表达式中将结果赋给html变量。
剩下的最后一步是创建异步队列的实例,并将其传递给工作线程。
阿辛西奥。队列
在本节中,您将通过创建队列和运行工作线程的异步任务来更新您的main()协程。每个 worker 将收到一个唯一的标识符,以便在日志消息、aiohttp会话、队列实例、访问特定链接的计数器和最大深度中区分它。因为您使用的是单线程,所以不需要确保互斥访问共享资源:
1# async_queues.py
2
3# ...
4
5async def main(args):
6 session = aiohttp.ClientSession()
7 try:
8 links = Counter()
9 queue = asyncio.Queue()
10 tasks = [
11 asyncio.create_task(
12 worker(
13 f"Worker-{i + 1}",
14 session,
15 queue,
16 links,
17 args.max_depth,
18 )
19 )
20 for i in range(args.num_workers)
21 ]
22
23 await queue.put(Job(args.url))
24 await queue.join()
25
26 for task in tasks:
27 task.cancel()
28
29 await asyncio.gather(*tasks, return_exceptions=True)
30
31 display(links)
32 finally:
33 await session.close()
34
35# ...
下面是更新代码的逐行分解:
- 第 9 行实例化一个异步 FIFO 队列。
- 第 10 行到第 21 行创建了许多包装在异步任务中的工作协程,这些任务在事件循环的后台尽快开始运行。
- 第 23 行将第一个作业放入队列,开始爬行。
- 第 24 行使主协程等待,直到队列被清空,并且不再有作业要执行。
- 第 26 到 29 行在不再需要后台任务时进行优雅的清理。
请不要对一个实际的在线网站运行网络爬虫。它会导致网络流量出现不必要的峰值,给你带来麻烦。为了测试您的爬虫,您最好启动 Python 内置的 HTTP 服务器,它会将文件系统中的本地文件夹转换为可导航的网站。例如,以下命令将使用 Python 虚拟环境启动本地文件夹中的服务器:
$ cd venv/
$ python -m http.server
Serving HTTP on 0.0.0.0 port 8000 (http://0.0.0.0:8000/) ...
不过,这与现实世界的网站不太相似,因为文件和文件夹构成了树状层次结构,而网站通常由带有反向链接的密集多图表示。无论如何,当您在另一个终端窗口中针对一个选定的 URL 地址运行网络爬虫时,您会注意到爬虫会按照链接出现的自然顺序进行搜索:
$ python async_queues.py http://localhost:8000 --max-depth=4
[Worker-1 starting]
[Worker-1 depth=1 url='http://localhost:8000']
[Worker-2 starting]
[Worker-3 starting]
[Worker-1 depth=2 url='http://localhost:8000/bin/']
[Worker-2 depth=2 url='http://localhost:8000/include/']
[Worker-3 depth=2 url='http://localhost:8000/lib/']
[Worker-2 depth=2 url='http://localhost:8000/lib64/']
[Worker-1 depth=2 url='http://localhost:8000/pyvenv.cfg']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.csh']
[Worker-1 depth=3 url='http://localhost:8000/bin/activate.fish']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate.ps1']
[Worker-2 depth=3 url='http://localhost:8000/bin/pip']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip3']
[Worker-1 depth=3 url='http://localhost:8000/bin/pip3.10']
[Worker-2 depth=3 url='http://localhost:8000/bin/python']
[Worker-3 depth=3 url='http://localhost:8000/bin/python3']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3.10']
[Worker-2 depth=3 url='http://localhost:8000/lib/python3.10/']
[Worker-3 depth=3 url='http://localhost:8000/lib64/python3.10/']
[Worker-2 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/']
[Worker-3 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/']
⋮
它访问第一层上深度等于 1 的唯一 URL。然后,在访问了第二层上的所有链接之后,爬虫前进到第三层,等等,直到到达所请求的最大深度层。一旦浏览了给定级别上的所有链接,爬行器就不会返回到更早的级别。这是使用 FIFO 队列的直接结果,它不同于使用堆栈或 LIFO 队列。
阿辛西奥。LifoQueue
与同步队列一样,它们的异步伙伴让您可以在不修改代码的情况下更改工作线程的行为。回到您的async_queues模块,用 LIFO 队列替换现有的 FIFO 队列:
# async_queues.py
# ...
async def main(args):
session = aiohttp.ClientSession()
try:
links = Counter()
queue = asyncio.LifoQueue() tasks = [
asyncio.create_task(
worker(
f"Worker-{i + 1}",
session,
queue,
links,
args.max_depth,
)
)
for i in range(args.num_workers)
]
await queue.put(Job(args.url))
await queue.join()
for task in tasks:
task.cancel()
await asyncio.gather(*tasks, return_exceptions=True)
display(links)
finally:
await session.close()
# ...
在不停止 HTTP 服务器的情况下,再次使用相同的选项运行 web crawler:
$ python async_queues.py http://localhost:8000 --max-depth=4
[Worker-1 starting]
[Worker-1 depth=1 url='http://localhost:8000']
[Worker-2 starting]
[Worker-3 starting]
[Worker-1 depth=2 url='http://localhost:8000/pyvenv.cfg']
[Worker-2 depth=2 url='http://localhost:8000/lib64/']
[Worker-3 depth=2 url='http://localhost:8000/lib/']
[Worker-1 depth=2 url='http://localhost:8000/include/']
[Worker-2 depth=3 url='http://localhost:8000/lib64/python3.10/']
[Worker-3 depth=3 url='http://localhost:8000/lib/python3.10/']
[Worker-1 depth=2 url='http://localhost:8000/bin/'] [Worker-2 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/']
[Worker-1 depth=3 url='http://localhost:8000/bin/python3.10'] [Worker-2 depth=3 url='http://localhost:8000/bin/python3']
[Worker-3 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/']
[Worker-1 depth=3 url='http://localhost:8000/bin/python'] [Worker-2 depth=3 url='http://localhost:8000/bin/pip3.10']
[Worker-1 depth=3 url='http://localhost:8000/bin/pip3']
[Worker-3 depth=3 url='http://localhost:8000/bin/pip']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate.ps1']
[Worker-1 depth=3 url='http://localhost:8000/bin/activate.fish']
[Worker-3 depth=3 url='http://localhost:8000/bin/activate.csh']
[Worker-2 depth=3 url='http://localhost:8000/bin/activate']
⋮
假设自上次运行以来内容没有改变,爬虫访问相同的链接,但是顺序不同。突出显示的行表示访问了先前探索的深度级别上的链接。
注意:如果您跟踪已经访问过的链接,并在随后的遭遇中跳过它们,那么这可能会导致不同的输出,具体取决于所使用的队列类型。这是因为许多不同的路径可能起源于不同的深度水平,但却通向同一个目的地。
接下来,您将看到一个异步优先级队列在运行。
异步的。优先权队列〔t0〕
要在优先级队列中使用您的作业,您必须指定在决定它们的优先级时如何比较它们。例如,您可能想先访问较短的 URL。继续将.__lt__()特殊方法添加到您的Job类中,当比较两个作业实例时,小于(<)操作符将委托给该类:
# async_queues.py
# ...
class Job(NamedTuple):
url: str
depth: int = 1
def __lt__(self, other): if isinstance(other, Job): return len(self.url) < len(other.url)
如果你把一个作业和一个完全不同的数据类型做比较,那么你不能说哪个更小,所以你隐式地返回None。另一方面,当比较Job类的两个实例时,通过检查它们对应的.url字段的长度来解析它们的优先级:
>>> from async_queues import Job >>> job1 = Job("http://localhost/") >>> job2 = Job("https://localhost:8080/") >>> job1 < job2 TrueURL 越短,优先级越高,因为较小的值在最小堆中优先。
脚本中的最后一个变化是使用异步优先级队列,而不是另外两个队列:
# async_queues.py # ... async def main(args): session = aiohttp.ClientSession() try: links = Counter() queue = asyncio.PriorityQueue() tasks = [ asyncio.create_task( worker( f"Worker-{i + 1}", session, queue, links, args.max_depth, ) ) for i in range(args.num_workers) ] await queue.put(Job(args.url)) await queue.join() for task in tasks: task.cancel() await asyncio.gather(*tasks, return_exceptions=True) display(links) finally: await session.close() # ...尝试使用更大的最大深度值运行网络爬虫——比方说,5:
$ python async_queues.py http://localhost:8000 --max-depth 5 [Worker-1 starting] [Worker-1 depth=1 url='http://localhost:8000'] [Worker-2 starting] [Worker-3 starting] [Worker-1 depth=2 url='http://localhost:8000/bin/'] [Worker-2 depth=2 url='http://localhost:8000/lib/'] [Worker-3 depth=2 url='http://localhost:8000/lib64/'] [Worker-3 depth=2 url='http://localhost:8000/include/'] [Worker-2 depth=2 url='http://localhost:8000/pyvenv.cfg'] [Worker-1 depth=3 url='http://localhost:8000/bin/pip'] [Worker-3 depth=3 url='http://localhost:8000/bin/pip3'] [Worker-2 depth=3 url='http://localhost:8000/bin/python'] [Worker-1 depth=3 url='http://localhost:8000/bin/python3'] [Worker-3 depth=3 url='http://localhost:8000/bin/pip3.10'] [Worker-2 depth=3 url='http://localhost:8000/bin/activate'] [Worker-1 depth=3 url='http://localhost:8000/bin/python3.10'] [Worker-3 depth=3 url='http://localhost:8000/lib/python3.10/'] [Worker-2 depth=3 url='http://localhost:8000/bin/activate.ps1'] [Worker-3 depth=3 url='http://localhost:8000/bin/activate.csh'] [Worker-1 depth=3 url='http://localhost:8000/lib64/python3.10/'] [Worker-2 depth=3 url='http://localhost:8000/bin/activate.fish'] [Worker-3 depth=4 url='http://localhost:8000/lib/python3.10/site-packages/'] [Worker-1 depth=4 url='http://localhost:8000/lib64/python3.10/site-packages/'] ⋮您会立即注意到,链接通常是按照 URL 长度决定的顺序浏览的。当然,由于服务器回复时间的不确定性,每次运行的确切顺序会略有不同。
异步队列是 Python 标准库的一个相当新的补充。它们故意模仿相应线程安全队列的接口,这应该让任何经验丰富的 python 爱好者有宾至如归的感觉。您可以使用异步队列在协程之间交换数据。
在下一节中,您将熟悉 Python 标准库中可用的最后一类队列,它允许您跨两个或更多操作系统级进程进行通信。
使用
multiprocessing.Queue进行进程间通信(IPC)到目前为止,您已经研究了只能在严格 I/O 受限的任务场景中有所帮助的队列,这些任务的进度不依赖于可用的计算能力。另一方面,使用 Python 在多个 CPU 内核上并行运行受 CPU 限制的任务的传统方法利用了对解释器进程的克隆。您的操作系统提供了用于在这些进程间共享数据的进程间通信(IPC) 层。
例如,您可以使用
multiprocessing启动一个新的 Python 进程,或者从concurrent.futures模块中使用一个这样的进程池。这两个模块都经过精心设计,以尽可能平稳地从线程切换到进程,这使得并行化现有代码变得相当简单。在某些情况下,只需要替换一个 import 语句,因为代码的其余部分遵循标准接口。你只能在
multiprocessing模块中找到 FIFO 队列,它有三种变体:
multiprocessing.Queuemultiprocessing.SimpleQueuemultiprocessing.JoinableQueue它们都是模仿基于线程的
queue.Queue的,但是在完整性级别上有所不同。JoinableQueue通过添加.task_done()和.join()方法扩展了multiprocessing.Queue类,允许您等待直到所有排队的任务都被处理完。如果不需要这个功能,那就用multiprocessing.Queue代替。SimpleQueue是一个独立的、显著简化的类,只有.get()、.put()和.empty()方法。注意:在操作系统进程之间共享一个资源,比如一个队列,比在线程之间共享要昂贵得多,而且受到限制。与线程不同,进程不共享公共内存区域,所以每次从一个进程向另一个进程传递消息时,数据必须在两端进行编组和解组。
而且 Python 使用
pickle模块进行数据序列化,不处理每种数据类型,相对较慢且不安全。因此,只有当并行运行代码带来的性能提升可以抵消额外的数据序列化和引导开销时,才应该考虑多个进程。为了看到一个关于
multiprocessing.Queue的实际例子,您将通过尝试使用蛮力方法反转一个短文本的 MD5 哈希值来模拟一个计算密集型任务。虽然有更好的方法来解决这个问题,无论是算法上的还是程序上的和,并行运行多个进程将会让你显著减少处理时间。在单线程上反转 MD5 哈希
在并行化您的计算之前,您将关注于实现算法的单线程版本,并根据一些测试输入来测量执行时间。创建一个名为
multiprocess_queue的新 Python 模块,并将以下代码放入其中:1# multiprocess_queue.py 2 3import time 4from hashlib import md5 5from itertools import product 6from string import ascii_lowercase 7 8def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6): 9 for length in range(1, max_length + 1): 10 for combination in product(alphabet, repeat=length): 11 text_bytes = "".join(combination).encode("utf-8") 12 hashed = md5(text_bytes).hexdigest() 13 if hashed == hash_value: 14 return text_bytes.decode("utf-8") 15 16def main(): 17 t1 = time.perf_counter() 18 text = reverse_md5("a9d1cbf71942327e98b40cf5ef38a960") 19 print(f"{text} (found in {time.perf_counter() - t1:.1f}s)") 20 21if __name__ == "__main__": 22 main()第 8 行到第 14 行定义了一个函数,该函数试图反转作为第一个参数提供的 MD5 哈希值。默认情况下,该函数只考虑最多包含六个小写 ASCII 字母的文本。您可以通过提供另外两个可选参数来更改要猜测的字母表和文本的最大长度。
对于字母表中给定长度的每个可能的字母组合,
reverse_md5()计算一个哈希值,并将其与输入进行比较。如果有匹配,那么它停止并返回猜测的文本。注意:现在,MD5 被认为是密码不安全的,因为你可以快速计算这样的摘要。然而,从 26 个 ASCII 字母中抽取的 6 个字符给出了总共 308,915,776 种不同的组合,这对 Python 程序来说已经足够了。
第 16 行到第 19 行调用函数,将样本 MD5 哈希值作为参数传递,并使用 Python 定时器测量其执行时间。在一台经验丰富的台式计算机上,可能需要几秒钟才能找到指定输入的散列组合:
$ python multiprocess_queue.py queue (found in 6.9s)如您所见,单词 queue 就是答案,因为它有一个 MD5 摘要,与您在第 18 行上的硬编码哈希值相匹配。七秒钟并不可怕,但是通过利用空闲的 CPU 内核,您可能会做得更好,这些内核渴望为您做一些工作。为了利用它们的潜力,您必须将数据分块并将其分发给您的工作进程。
分块平均分配工作负载
您希望通过将整个字母组合集分成几个更小的不相交的子集来缩小每个 worker 中的搜索空间。为了确保工作人员不会浪费时间去做已经由另一个工作人员完成的工作,这些集合不能有任何重叠。虽然您不知道单个块的大小,但是您可以提供与 CPU 核心数量相等的块。
要计算后续块的索引,请使用下面的帮助函数:
# multiprocess_queue.py # ... def chunk_indices(length, num_chunks): start = 0 while num_chunks > 0: num_chunks = min(num_chunks, length) chunk_size = round(length / num_chunks) yield start, (start := start + chunk_size) length -= chunk_size num_chunks -= 1它产生由当前块的第一个索引和它的最后一个索引加 1 组成的元组,这使得元组可以方便地用作内置
range()函数的输入。由于对后续数据块长度的取整,那些不同长度的数据块最终很好地交错在一起:
>>> from multiprocess_queue import chunk_indices
>>> for start, stop in chunk_indices(20, 6):
... print(len(r := range(start, stop)), r)
...
3 range(0, 3)
3 range(3, 6)
4 range(6, 10) 3 range(10, 13)
4 range(13, 17) 3 range(17, 20)
例如,分成六个块的总长度 20 产生在三个和四个元素之间交替的索引。
为了最大限度地降低进程间数据序列化的成本,每个 worker 将根据出列作业对象中指定的索引范围生成自己的字母组合块。您需要为特定的索引找到一个字母组合或 m-set 的一个 n 元组。为了让您的生活更轻松,您可以将公式封装到一个新的类中:
# multiprocess_queue.py
# ...
class Combinations:
def __init__(self, alphabet, length):
self.alphabet = alphabet
self.length = length
def __len__(self):
return len(self.alphabet) ** self.length
def __getitem__(self, index):
if index >= len(self):
raise IndexError
return "".join(
self.alphabet[
(index // len(self.alphabet) ** i) % len(self.alphabet)
]
for i in reversed(range(self.length))
)
该自定义数据类型表示给定长度的字母组合的集合。多亏了这两个特殊的方法和当所有组合都用尽时抛出的IndexError异常,您可以使用一个循环迭代Combinations类的实例。
上面的公式确定了由索引指定的组合中给定位置的字符,就像汽车中的里程表或数学中的定位系统一样。最右边的字母变化最频繁,而越靠左的字母变化越少。
现在,您可以更新您的 MD5-reversing 函数,以使用新的类并删除itertools.product import 语句:
# multiprocess_queue.py
# ...
def reverse_md5(hash_value, alphabet=ascii_lowercase, max_length=6):
for length in range(1, max_length + 1):
for combination in Combinations(alphabet, length): text_bytes = "".join(combination).encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
# ...
不幸的是,用纯 Python 函数替换用 C 实现的内置函数并在 Python 中进行一些计算会使代码慢一个数量级:
$ python multiprocess_queue.py
queue (found in 38.8s)
你可以做一些优化来获得几秒钟的时间。例如,你可以在你的Combinations类中实现.__iter__(),以避免产生if语句或引发异常。您还可以将字母表的长度存储为实例属性。然而,对于这个例子来说,这些优化并不重要。
接下来,您将创建工作进程、作业数据类型和两个单独的队列,以便在主进程及其子进程之间进行通信。
以全双工模式通信
每个工作进程都将有一个对包含要消费的作业的输入队列的引用,以及一个对预期解决方案的输出队列的引用。这些引用支持工人和主进程之间的同步双向通信,称为全双工通信。要定义一个工作进程,您需要扩展Process类,它提供了我们熟悉的.run()方法,就像一个线程:
# multiprocess_queue.py
import multiprocessing
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
稍后,主进程将定期检查是否有一个工人在输出队列中放置了一个反转的 MD5 文本,并在这种情况下提前终止程序。工人是守护进程,所以他们不会耽误主进程。另请注意,workers 存储输入哈希值以进行反转。
添加一个Job类,Python 将序列化该类并将其放在输入队列中供工作进程使用:
# multiprocess_queue.py
from dataclasses import dataclass
# ...
@dataclass(frozen=True)
class Job:
combinations: Combinations
start_index: int
stop_index: int
def __call__(self, hash_value):
for index in range(self.start_index, self.stop_index):
text_bytes = self.combinations[index].encode("utf-8")
hashed = md5(text_bytes).hexdigest()
if hashed == hash_value:
return text_bytes.decode("utf-8")
通过在作业中实现特殊的方法.__call__(),你可以调用你的类的对象。由于这个原因,当工人收到这些任务时,他们可以像调用常规函数一样调用这些任务。该方法的主体与reverse_md5()相似,但略有不同,您现在可以移除它,因为您不再需要它了。
最后,在启动工作进程之前,创建两个队列并用作业填充输入队列:
# multiprocess_queue.py
import argparse
# ...
def main(args):
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("hash_value")
parser.add_argument("-m", "--max-length", type=int, default=6)
parser.add_argument(
"-w",
"--num-workers",
type=int,
default=multiprocessing.cpu_count(),
)
return parser.parse_args()
# ...
if __name__ == "__main__":
main(parse_args())
和前面的例子一样,您使用argparse模块解析命令行参数。脚本的唯一强制参数是要反转的哈希值,例如:
(venv) $ python multiprocess_queue.py a9d1cbf71942327e98b40cf5ef38a960
您可以使用--num-workers命令行参数指定工作进程的数量,该参数默认为您的 CPU 内核的数量。由于上下文切换的额外成本,将工作者的数量增加到超过硬件中的物理或逻辑处理单元的数量通常没有好处,这种成本开始增加。
另一方面,在 I/O 绑定的任务中,上下文切换变得几乎可以忽略不计,在这种情况下,您可能最终拥有数千个工作线程或协程。流程是一个不同的故事,因为它们的创建成本要高得多。即使您使用一个进程池预先加载这个成本,也有一定的限制。
此时,您的工作人员通过输入和输出队列与主流程进行双向通信。然而,程序在启动后突然退出,因为主进程没有等待它的守护进程子进程处理完它们的作业就结束了。现在是时候定期轮询输出队列,寻找潜在的解决方案,当您找到一个解决方案时,就可以跳出循环了:
1# multiprocess_queue.py
2
3import queue
4import time
5
6# ...
7
8def main(args):
9 t1 = time.perf_counter() 10
11 queue_in = multiprocessing.Queue()
12 queue_out = multiprocessing.Queue()
13
14 workers = [
15 Worker(queue_in, queue_out, args.hash_value)
16 for _ in range(args.num_workers)
17 ]
18
19 for worker in workers:
20 worker.start()
21
22 for text_length in range(1, args.max_length + 1):
23 combinations = Combinations(ascii_lowercase, text_length)
24 for indices in chunk_indices(len(combinations), len(workers)):
25 queue_in.put(Job(combinations, *indices))
26
27 while any(worker.is_alive() for worker in workers): 28 try: 29 solution = queue_out.get(timeout=0.1) 30 if solution: 31 t2 = time.perf_counter() 32 print(f"{solution} (found in {t2 - t1:.1f}s)") 33 break 34 except queue.Empty: 35 pass 36 else: 37 print("Unable to find a solution") 38
39# ...
您在队列的.get()方法上设置可选的timeout参数,以避免阻塞并允许 while 循环运行其条件。找到解决方案后,将它从输出队列中取出,在标准输出中打印匹配的文本以及估计的执行时间,然后退出循环。注意,multiprocessing.Queue引发了在queue模块中定义的异常,您可能需要导入这些异常。
然而,当没有匹配的解决方案时,循环将永远不会停止,因为您的工人仍然活着,等待更多的作业来处理,即使已经消耗了所有的作业。他们被困在queue_in.get()通话中,这是阻塞。您将在接下来的部分中解决这个问题。
用毒丸杀死一名工人
因为要消耗的作业数量是预先知道的,所以您可以告诉工人在清空队列后优雅地关闭。请求线程或进程停止工作的典型模式是将一个特殊的标记值放在队列的末尾。每当一个工人发现哨兵,它会做必要的清理,并逃离无限循环。这种哨兵被称为毒丸,因为它会杀死工人。
为 sentinel 选择值可能很棘手,尤其是对于multiprocessing模块,因为它处理全局名称空间的方式。查看官方文档中的编程指南了解更多细节。最安全的方法可能是坚持使用预定义的值,比如None,它在任何地方都有一个已知的身份:
# multiprocess_queue.py
POISON_PILL = None
# ...
如果您使用一个定义为全局变量的自定义object()实例,那么您的每个工作进程都将拥有该对象的自己的副本,并具有惟一的标识。一个 worker 入队的 sentinel 对象将被反序列化为另一个 worker 中的一个全新实例,该实例具有与其全局变量不同的标识。因此,您无法在队列中检测出毒丸。
另一个需要注意的细微差别是,在使用完毒丸之后,要小心地将它放回源队列中:
# multiprocess_queue.py
# ...
class Worker(multiprocessing.Process):
def __init__(self, queue_in, queue_out, hash_value):
super().__init__(daemon=True)
self.queue_in = queue_in
self.queue_out = queue_out
self.hash_value = hash_value
def run(self):
while True:
job = self.queue_in.get()
if job is POISON_PILL: self.queue_in.put(POISON_PILL) break if plaintext := job(self.hash_value):
self.queue_out.put(plaintext)
break
# ...
这将会给其他工人一个吞下毒丸的机会。或者,如果您知道您的员工的确切人数,那么您可以让那么多的毒丸入队,每个人一粒。在消耗完哨兵并将其放回队列后,一个工人跳出了无限循环,结束了它的生命。
最后,不要忘记将毒丸作为最后一个元素添加到输入队列中:
# multiprocess_queue.py
# ...
def main(args):
t1 = time.perf_counter()
queue_in = multiprocessing.Queue()
queue_out = multiprocessing.Queue()
workers = [
Worker(queue_in, queue_out, args.hash_value)
for _ in range(args.num_workers)
]
for worker in workers:
worker.start()
for text_length in range(1, args.max_length + 1):
combinations = Combinations(ascii_lowercase, text_length)
for indices in chunk_indices(len(combinations), len(workers)):
queue_in.put(Job(combinations, *indices))
queue_in.put(POISON_PILL)
while any(worker.is_alive() for worker in workers):
try:
solution = queue_out.get(timeout=0.1)
t2 = time.perf_counter()
if solution:
print(f"{solution} (found in {t2 - t1:.1f}s)")
break
except queue.Empty:
pass
else:
print("Unable to find a solution")
# ...
现在,您的脚本已经完成,可以处理查找匹配文本以及面对 MD5 哈希值不可逆转的情况。在下一节中,您将运行几个基准测试,看看整个练习是否值得。
分析并行执行的性能
当您比较原始单线程版本和多处理版本的执行速度时,您可能会感到失望。虽然您注意最小化数据序列化成本,但是将代码重写为纯 Python 才是真正的瓶颈。
更令人惊讶的是,速度似乎随着输入哈希值以及工作进程数量的变化而变化:
您可能会认为增加工作线程的数量会减少总的计算时间,在一定程度上确实如此。从单个工人到多个工人的比例大幅下降。然而,随着您添加更多的工作线程,执行时间会周期性地来回跳动。这里有几个因素在起作用。
首先,如果匹配的组合位于包含您的解决方案的块的末尾附近,那么被分配到该块的幸运工人将运行更长时间。根据搜索空间中的分割点(来源于工人的数量),您将在一个块中获得不同的解决方案距离。其次,即使距离保持不变,你创造的工人越多,环境切换的影响就越大。
另一方面,如果你的所有员工总是有同样多的工作要做,那么你会观察到一个大致的线性趋势,没有突然的跳跃。如您所见,并行化 Python 代码的执行并不总是一个简单的过程。也就是说,只要有一点点耐心和坚持,你肯定可以优化这几个瓶颈。例如,您可以:
- 想出一个更聪明的公式
- 通过缓存和预先计算中间结果来换取速度
- 内联函数调用和其他昂贵的构造
- 查找带有 Python 绑定的第三方 C 库
- 编写一个 Python C 扩展模块或者使用 ctypes 或者 Cython
- 为 Python 带来实时(JIT) 编译工具
- 切换到另一个 Python 解释器,比如 PyPy
至此,您已经了解了 Python 标准库中所有可用的队列类型,包括同步线程安全队列、异步队列和基于进程的并行性的 FIFO 队列。在下一节中,您将简要了解几个第三方库,它们将允许您与独立的消息队列代理集成。
将 Python 与分布式消息队列集成
在有许多移动部件的分布式系统中,通常希望使用中间的消息代理来分离应用程序组件,它承担生产者和消费者服务之间弹性消息传递的负担。它通常需要自己的基础架构,这既是优势也是劣势。
一方面,它是另一个增加复杂性和需要维护的抽象层,但是如果配置正确,它可以提供以下好处:
- 松耦合:您可以修改一个组件或用另一个组件替换它,而不会影响系统的其余部分。
- 灵活性:您可以通过更改代理配置和消息传递规则来改变系统的业务规则,而无需编写代码。
- 可伸缩性:您可以动态添加更多给定种类的组件,以处理特定功能领域中增加的工作量。
- 可靠性:消费者可能需要在代理从队列中删除消息之前确认消息,以确保安全交付。在集群中运行代理可以提供额外的容错能力。
- 持久性:当消费者由于故障而离线时,代理可以在队列中保留一些消息。
- 性能:为消息代理使用专用的基础设施可以减轻应用程序服务的负担。
有许多不同类型的消息代理和您可以使用它们的场景。在这一节中,您将领略其中的一些。
RabbitMQ: pika
RabbitMQ 可能是最受欢迎的开源消息代理之一,它允许您以多种方式将消息从生产者发送到消费者。通过运行一个临时的 Docker 容器,您可以方便地启动一个新的 RabbitMQ 代理,而无需在您的计算机上安装它:
$ docker run -it --rm --name rabbitmq -p 5672:5672 rabbitmq
一旦启动,您就可以在本地主机和默认端口 5672 上连接到它。官方文档推荐使用 Pika 库来连接 Python 中的 RabbitMQ 实例。这是一个初级制作人的样子:
# producer.py
import pika
QUEUE_NAME = "mailbox"
with pika.BlockingConnection() as connection:
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME)
while True:
message = input("Message: ")
channel.basic_publish(
exchange="",
routing_key=QUEUE_NAME,
body=message.encode("utf-8")
)
您使用默认参数打开一个连接,这假设 RabbitMQ 已经在您的本地机器上运行。然后,创建一个新的通道,它是 TCP 连接之上的轻量级抽象。您可以拥有多个独立的频道进行单独的传输。在进入循环之前,确保代理中存在一个名为mailbox的队列。最后,您继续发布从用户那里读取的消息。
消费者只是稍微长一点,因为它需要定义一个回调函数来处理消息:
# consumer.py
import pika
QUEUE_NAME = "mailbox"
def callback(channel, method, properties, body):
message = body.decode("utf-8")
print(f"Got message: {message}")
with pika.BlockingConnection() as connection:
channel = connection.channel()
channel.queue_declare(queue=QUEUE_NAME)
channel.basic_consume(
queue=QUEUE_NAME,
auto_ack=True,
on_message_callback=callback
)
channel.start_consuming()
大多数样板代码看起来与您的生产者相似。但是,您不需要编写显式循环,因为使用者将无限期地监听消息。
继续,在单独的终端选项卡中启动一些生产者和消费者。请注意,在队列已经有一些未使用的消息之后,或者如果有多个消费者连接到代理,当第一个消费者连接到 RabbitMQ 时会发生什么情况。
再说一遍:redis
Redis 是远程词典服务器的简称,其实真的是很多东西在伪装。它是一个内存中的键值数据存储,通常作为传统的 SQL 数据库和服务器之间的超高速缓存。同时,它可以作为一个持久化的 NoSQL 数据库,也可以作为发布-订阅模型中的消息代理。您可以使用 Docker 启动本地 Redis 服务器:
$ docker run -it --rm --name redis -p 6379:6379 redis
这样,您将能够使用 Redis 命令行界面连接到正在运行的容器:
$ docker exec -it redis redis-cli
127.0.0.1:6379>
看一下官方文档中的命令列表,并在连接到 Redis 服务器时试用它们。或者,您可以直接跳到 Python 中。Redis 官方页面上列出的第一个库是 redis ,但值得注意的是,您可以从许多备选库中进行选择,包括异步库。
编写一个基本的发布者只需要几行 Python 代码:
# publisher.py
import redis
with redis.Redis() as client:
while True:
message = input("Message: ")
client.publish("chatroom", message)
您连接到一个本地 Redis 服务器实例,并立即开始在chatroom通道上发布消息。您不必创建通道,因为 Redis 会为您创建。订阅频道需要一个额外的步骤,创建PubSub对象来调用.subscribe()方法:
# subscriber.py
import redis
with redis.Redis() as client:
pubsub = client.pubsub()
pubsub.subscribe("chatroom")
for message in pubsub.listen():
if message["type"] == "message":
body = message["data"].decode("utf-8")
print(f"Got message: {body}")
订阅者收到的消息是带有一些元数据的 Python 字典,这让您可以决定如何处理它们。如果有多个活动订阅者在一个频道上收听,那么所有订阅者都会收到相同的消息。另一方面,默认情况下,消息不会被持久化。
查看如何使用 Redis 和 Python 来了解更多信息。
Apache Kaka:kafka-python3
到目前为止,Kafka 是你在本教程中遇到的三个消息代理中最高级、最复杂的一个。这是一个用于实时事件驱动应用的分布式流媒体平台。它的主要卖点是处理大量数据而几乎没有性能延迟的能力。
要运行 Kafka,您需要设置一个分布式集群。您可以使用 Docker Compose 一次性启动一个多容器 Docker 应用程序。比如可以抢比特纳米打包的阿帕奇卡夫卡:
# docker-compose.yml version: "3" services: zookeeper: image: 'bitnami/zookeeper:latest' ports: - '2181:2181' environment: - ALLOW_ANONYMOUS_LOGIN=yes kafka: image: 'bitnami/kafka:latest' ports: - '9092:9092' environment: - KAFKA_BROKER_ID=1 - KAFKA_CFG_LISTENERS=PLAINTEXT://:9092 - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 - ALLOW_PLAINTEXT_LISTENER=yes depends_on: - zookeeper
当您将此配置保存在名为docker-compose.yml的文件中时,您可以通过运行以下命令来启动这两个服务:
$ docker-compose up
有时,当 Kafka 版本与您的客户端库版本不匹配时,您可能会遇到问题。似乎支持最近的 Kafka 的 Python 库是 kafka-python3 ,模仿 Java 客户端。
您的制作人可以就给定主题发送消息,如下所示:
# producer.py
from kafka3 import KafkaProducer
producer = KafkaProducer(bootstrap_servers="localhost:9092")
while True:
message = input("Message: ")
producer.send(
topic="datascience",
value=message.encode("utf-8"),
)
.send()方法是异步的,因为它返回一个未来对象,你可以通过调用它的阻塞.get()方法来等待它。在消费者端,您将能够通过迭代消费者来读取发送的消息:
# consumer.py
from kafka3 import KafkaConsumer
consumer = KafkaConsumer("datascience")
for record in consumer:
message = record.value.decode("utf-8")
print(f"Got message: {message}")
消费者的构造函数接受一个或多个它可能感兴趣的主题。
自然,对于这些强大的消息代理,您仅仅触及了皮毛。您在这一部分的目标是获得一个快速概览和一个起点,以防您想自己探索它们。
结论
现在,您已经对计算机科学中的队列理论有了很好的理解,并且知道了它们的 T2 实际应用,从寻找图中的最短路径到同步并发工作者和分离分布式系统。你能够认识到队列可以优雅地解决的问题。
你可以在 Python 中使用不同的数据结构从头开始实现 FIFO 、 LIFO 和优先级队列,理解它们的权衡。同时,您知道构建到标准库中的每个队列,包括线程安全队列、异步队列和一个用于基于进程的并行的队列。您还知道这些库允许 Python 与云中流行的消息代理队列集成。
在本教程中,您学习了如何:
- 区分各种类型的队列
- 在 Python 中实现队列数据类型
- 通过应用正确的队列解决实际问题
- 使用 Python 的线程安全、异步和进程间队列
- 通过库将 Python 与分布式消息队列代理集成在一起
一路走来,你已经实现了广度优先搜索 (BFS) 、深度优先搜索 (DFS) 和 Dijkstra 的最短路径算法。您已经构建了一个多生产者、多消费者问题的可视化模拟,一个异步的网络爬虫和一个并行的 MD5 散列反转程序。要获得这些实践示例的源代码,请访问以下链接:
获取源代码: 单击此处获取源代码和示例数据,您将使用它们来探索 Python 中的队列。**********
在 Python 中读写文件(指南)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 读写文件
使用 Python 可以完成的最常见的任务之一是读写文件。无论是写入简单的文本文件,还是读取复杂的服务器日志,甚至是分析原始字节数据,所有这些情况都需要读取或写入文件。
在本教程中,您将学习:
- 文件是由什么组成的,为什么这对 Python 很重要
- Python 中读写文件的基础
- 读写文件的一些基本场景
本教程主要面向初级到中级 Pythonistas,但是这里有一些提示,更高级的程序员也可能会喜欢。
免费奖励: ,它向您展示 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
参加测验:通过我们的交互式“用 Python 读写文件”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
什么是文件?
在我们进入如何在 Python 中处理文件之前,理解文件到底是什么以及现代操作系统如何处理它们的某些方面是很重要的。
文件的核心是一组连续的字节,用于存储数据。这些数据以特定的格式组织,可以是简单的文本文件,也可以是复杂的可执行程序。最终,这些字节文件会被翻译成二进制的1和0,以便于计算机处理。
大多数现代文件系统上的文件由三个主要部分组成:
- Header: 关于文件内容的元数据(文件名、大小、类型等)
- 数据:创建者或编辑者所写的文件内容
- 文件结束(EOF): 表示文件结束的特殊字符

这些数据表示什么取决于所使用的格式规范,通常由扩展名表示。例如,扩展名为.gif的文件很可能符合图形交换格式规范。即使没有上千个文件扩展名,也有数百个。对于本教程,您将只处理.txt或.csv文件扩展名。
文件路径
当您在操作系统上访问文件时,需要文件路径。文件路径是表示文件位置的字符串。它分为三个主要部分:
- 文件夹路径:文件系统上的文件夹位置,后续文件夹由正斜杠
/(Unix)或反斜杠\(Windows)分隔 - 文件名:文件的实际名称
- 扩展名:文件路径的结尾,前面加一个句点(
.),用来表示文件类型
这里有一个简单的例子。假设您有一个位于如下文件结构中的文件:
/
│
├── path/
| │
│ ├── to/
│ │ └── cats.gif
│ │
│ └── dog_breeds.txt
|
└── animals.csv
假设您想要访问cats.gif文件,而您当前的位置与path在同一个文件夹中。为了访问这个文件,你需要通过path文件夹,然后是to文件夹,最后到达cats.gif文件。文件夹路径为path/to/。文件名是cats。文件扩展名为.gif。所以完整路径是path/to/cats.gif。
现在让我们假设您的当前位置或当前工作目录(cwd)在我们的示例文件夹结构的to文件夹中。不用通过path/to/cats.gif的完整路径来引用cats.gif,可以简单地通过文件名和扩展名cats.gif来引用文件。
/
│
├── path/
| │
| ├── to/ ← Your current working directory (cwd) is here
| │ └── cats.gif ← Accessing this file
| │
| └── dog_breeds.txt
|
└── animals.csv
但是dog_breeds.txt呢?如果不使用完整路径,如何访问它呢?您可以使用特殊字符双点(..)向上移动一个目录。这意味着../dog_breeds.txt将从to的目录中引用dog_breeds.txt文件:
/
│
├── path/ ← Referencing this parent folder
| │
| ├── to/ ← Current working directory (cwd)
| │ └── cats.gif
| │
| └── dog_breeds.txt ← Accessing this file
|
└── animals.csv
双点(..)可以链接在一起,遍历当前目录以上的多个目录。例如,要从to文件夹中访问animals.csv,可以使用../../animals.csv。
行尾
当处理文件数据时经常遇到的一个问题是新行或行尾的表示。行尾可以追溯到摩尔斯电码时代,当时一个特定的手势被用来表示传输结束或行尾。
后来,这个被国际标准化组织(ISO)和美国标准协会(ASA)标准化为电传打字机。ASA 标准规定行尾应该使用回车(CR或\r ) 和换行符(LF或\n)CR+LF或\r\n)的顺序。然而,ISO 标准允许使用CR+LF字符或仅允许使用LF字符。
Windows 使用CR+LF字符来表示新的一行,而 Unix 和较新的 Mac 版本只使用LF字符。当您在不同于文件来源的操作系统上处理文件时,这会导致一些复杂情况。这里有一个简单的例子。假设我们检查在 Windows 系统上创建的文件dog_breeds.txt:
Pug\r\n
Jack Russell Terrier\r\n
English Springer Spaniel\r\n
German Shepherd\r\n
Staffordshire Bull Terrier\r\n
Cavalier King Charles Spaniel\r\n
Golden Retriever\r\n
West Highland White Terrier\r\n
Boxer\r\n
Border Terrier\r\n
相同的输出在 Unix 设备上会有不同的解释:
Pug\r
\n
Jack Russell Terrier\r
\n
English Springer Spaniel\r
\n
German Shepherd\r
\n
Staffordshire Bull Terrier\r
\n
Cavalier King Charles Spaniel\r
\n
Golden Retriever\r
\n
West Highland White Terrier\r
\n
Boxer\r
\n
Border Terrier\r
\n
这可能会使每一行的迭代出现问题,您可能需要考虑这样的情况。
字符编码
您可能面临的另一个常见问题是字节数据的编码。编码是从字节数据到人类可读字符的转换。这通常是通过分配一个数值来表示一个字符来实现的。两种最常见的编码是 ASCII 和 UNICODE 格式。 ASCII 只能存储 128 个字符,而 Unicode 最多可以包含 1114112 个字符。
ASCII 实际上是 Unicode (UTF-8)的子集,这意味着 ASCII 和 Unicode 共享相同的数字到字符值。需要注意的是,用不正确的字符编码解析文件可能会导致失败或错误的字符表达。例如,如果一个文件是使用 UTF-8 编码创建的,而您试图使用 ASCII 编码解析它,如果有一个字符不在这 128 个值之内,那么将会抛出一个错误。
在 Python 中打开和关闭文件
当你想处理一个文件时,首先要做的就是打开它。这是通过调用 open()内置函数来完成的。open()有一个必需的参数,它是文件的路径。open()有一个返回单,文件对象:
file = open('dog_breeds.txt')
打开一个文件后,接下来要学习的是如何关闭它。
警告:你应该始终确保一个打开的文件被正确关闭。要了解原因,请查看为什么关闭 Python 中的文件很重要?教程。
重要的是要记住关闭文件是你的责任。在大多数情况下,当应用程序或脚本终止时,文件最终会被关闭。然而,没有人能保证具体什么时候会发生。这可能会导致不必要的行为,包括资源泄漏。这也是 Python (Pythonic)中的一个最佳实践,以确保您的代码以一种良好定义的方式运行,并减少任何不必要的行为。
当你操作一个文件时,有两种方法可以确保一个文件被正确关闭,即使是在遇到错误的时候。关闭文件的第一种方法是使用try-finally块:
reader = open('dog_breeds.txt')
try:
# Further file processing goes here
finally:
reader.close()
如果你不熟悉什么是try-finally块,看看 Python 异常:介绍。
关闭文件的第二种方法是使用 with语句:
with open('dog_breeds.txt') as reader:
# Further file processing goes here
一旦文件离开with块,with语句会自动关闭文件,即使出现错误。我强烈推荐你尽可能多地使用with语句,因为它可以让代码更简洁,并让你更容易处理任何意外的错误。
最有可能的是,您还会想要使用第二个位置参数,mode。这个参数是一个字符串,它包含多个字符来表示您希望如何打开文件。默认的也是最常见的是'r',它表示以只读模式将文件作为文本文件打开:
with open('dog_breeds.txt', 'r') as reader:
# Further file processing goes here
其他模式选项在中有完整的在线文档,但最常用的选项如下:
| 性格;角色;字母 | 意义 |
|---|---|
'r' |
打开以供阅读(默认) |
'w' |
打开进行写入,首先截断(覆盖)文件 |
'rb'或'wb' |
以二进制模式打开(使用字节数据读/写) |
让我们回过头来谈一谈文件对象。文件对象是:
"向底层资源公开面向文件的 API(使用诸如
read()或write()的方法)的对象。"(来源
有三种不同类别的文件对象:
- 文本文件
- 缓冲二进制文件
- 原始二进制文件
这些文件类型都在io模块中定义。这里有一个所有事情如何排列的快速纲要。
文本文件类型
文本文件是你会遇到的最常见的文件。以下是如何打开这些文件的一些示例:
open('abc.txt')
open('abc.txt', 'r')
open('abc.txt', 'w')
对于这些类型的文件,open()将返回一个TextIOWrapper文件对象:
>>> file = open('dog_breeds.txt') >>> type(file) <class '_io.TextIOWrapper'>这是由
open()返回的默认文件对象。缓冲二进制文件类型
缓冲二进制文件类型用于读写二进制文件。以下是如何打开这些文件的一些示例:
open('abc.txt', 'rb') open('abc.txt', 'wb')对于这些类型的文件,
open()将返回一个BufferedReader或BufferedWriter文件对象:
>>> file = open('dog_breeds.txt', 'rb')
>>> type(file)
<class '_io.BufferedReader'>
>>> file = open('dog_breeds.txt', 'wb')
>>> type(file)
<class '_io.BufferedWriter'>
原始文件类型
原始文件类型是:
"通常用作二进制和文本流的底层构件."(来源)
因此通常不使用它。
以下是如何打开这些文件的示例:
open('abc.txt', 'rb', buffering=0)
对于这些类型的文件,open()将返回一个FileIO文件对象:
>>> file = open('dog_breeds.txt', 'rb', buffering=0) >>> type(file) <class '_io.FileIO'>读写打开的文件
一旦你打开了一个文件,你会想读或写这个文件。首先,让我们来读一个文件。可以对 file 对象调用多种方法来帮助您:
方法 它的作用 T2 .read(size=-1)这是根据 size字节数从文件中读取的。如果没有参数被传递或者None或-1被传递,那么整个文件被读取。T2 .readline(size=-1)这最多从该行读取 size个字符。这一直延续到行尾,然后绕回。如果没有参数被传递或者None或-1被传递,那么整行(或整行的剩余部分)被读取。T2 .readlines()这将从 file 对象中读取剩余的行,并将它们作为一个列表返回。 使用上面使用的同一个
dog_breeds.txt文件,让我们看一些如何使用这些方法的例子。下面是一个如何使用.read()打开和读取整个文件的例子:
>>> with open('dog_breeds.txt', 'r') as reader:
>>> # Read & print the entire file
>>> print(reader.read())
Pug
Jack Russell Terrier
English Springer Spaniel
German Shepherd
Staffordshire Bull Terrier
Cavalier King Charles Spaniel
Golden Retriever
West Highland White Terrier
Boxer
Border Terrier
下面是一个使用 Python .readline()方法每次读取一行中 5 个字节的例子:
>>> with open('dog_breeds.txt', 'r') as reader: >>> # Read & print the first 5 characters of the line 5 times >>> print(reader.readline(5)) >>> # Notice that line is greater than the 5 chars and continues >>> # down the line, reading 5 chars each time until the end of the >>> # line and then "wraps" around >>> print(reader.readline(5)) >>> print(reader.readline(5)) >>> print(reader.readline(5)) >>> print(reader.readline(5)) Pug Jack Russe ll Te rrier下面是一个如何使用 Python
.readlines()方法将整个文件作为一个列表读取的示例:
>>> f = open('dog_breeds.txt')
>>> f.readlines() # Returns a list object
['Pug\n', 'Jack Russell Terrier\n', 'English Springer Spaniel\n', 'German Shepherd\n', 'Staffordshire Bull Terrier\n', 'Cavalier King Charles Spaniel\n', 'Golden Retriever\n', 'West Highland White Terrier\n', 'Boxer\n', 'Border Terrier\n']
上面的例子也可以通过使用list()从文件对象中创建一个列表:
>>> f = open('dog_breeds.txt') >>> list(f) ['Pug\n', 'Jack Russell Terrier\n', 'English Springer Spaniel\n', 'German Shepherd\n', 'Staffordshire Bull Terrier\n', 'Cavalier King Charles Spaniel\n', 'Golden Retriever\n', 'West Highland White Terrier\n', 'Boxer\n', 'Border Terrier\n']遍历文件中的每一行
读取文件时通常要做的一件事是遍历每一行。下面是一个如何使用 Python
.readline()方法执行迭代的例子:
>>> with open('dog_breeds.txt', 'r') as reader:
>>> # Read and print the entire file line by line
>>> line = reader.readline()
>>> while line != '': # The EOF char is an empty string
>>> print(line, end='')
>>> line = reader.readline()
Pug
Jack Russell Terrier
English Springer Spaniel
German Shepherd
Staffordshire Bull Terrier
Cavalier King Charles Spaniel
Golden Retriever
West Highland White Terrier
Boxer
Border Terrier
迭代文件中每一行的另一种方法是使用 file 对象的 Python .readlines()方法。记住,.readlines()返回一个列表,其中列表中的每个元素代表文件中的一行:
>>> with open('dog_breeds.txt', 'r') as reader: >>> for line in reader.readlines(): >>> print(line, end='') Pug Jack Russell Terrier English Springer Spaniel German Shepherd Staffordshire Bull Terrier Cavalier King Charles Spaniel Golden Retriever West Highland White Terrier Boxer Border Terrier然而,上面的例子可以通过迭代文件对象本身来进一步简化:
>>> with open('dog_breeds.txt', 'r') as reader:
>>> # Read and print the entire file line by line
>>> for line in reader:
>>> print(line, end='')
Pug
Jack Russell Terrier
English Springer Spaniel
German Shepherd
Staffordshire Bull Terrier
Cavalier King Charles Spaniel
Golden Retriever
West Highland White Terrier
Boxer
Border Terrier
最后一种方法更加 Pythonic 化,速度更快,内存效率更高。因此,建议您改用这个。
注:以上部分例子包含print('some text', end='')。end=''是为了防止 Python 向正在打印的文本添加额外的换行符,并且只有打印从文件中读取的内容。
现在让我们开始编写文件。与读取文件一样,文件对象有多种方法可用于写入文件:
| 方法 | 它的作用 |
|---|---|
.write(string) |
这会将字符串写入文件。 |
.writelines(seq) |
这会将序列写入文件。每个序列项都不会附加行尾。由您决定添加适当的行尾。 |
这里有一个使用.write()和.writelines()的简单例子:
with open('dog_breeds.txt', 'r') as reader:
# Note: readlines doesn't trim the line endings
dog_breeds = reader.readlines()
with open('dog_breeds_reversed.txt', 'w') as writer:
# Alternatively you could use
# writer.writelines(reversed(dog_breeds))
# Write the dog breeds to the file in reversed order
for breed in reversed(dog_breeds):
writer.write(breed)
使用字节
有时候,你可能需要使用字节串来处理文件。这是通过将'b'字符添加到mode参数中实现的。适用于 file 对象的所有相同方法。然而,每个方法都期望并返回一个bytes对象:
>>> with open('dog_breeds.txt', 'rb') as reader: >>> print(reader.readline()) b'Pug\n'使用
b标志打开一个文本文件并不有趣。假设我们有一张可爱的杰克罗素梗(jack_russell.png)的照片:
Image: [CC BY 3.0 (https://creativecommons.org/licenses/by/3.0)], from Wikimedia Commons](https://commons.wikimedia.org/wiki/File:Jack_Russell_Terrier_1.jpg) 您实际上可以用 Python 打开该文件并检查其内容!由于
.png文件格式被很好地定义,文件的头是 8 个字节,分解如下:
价值 解释 0x89一个“神奇”的数字,表示这是一个 PNG的开始0x50 0x4E 0x47PNG在 ASCII 码中0x0D 0x0ADOS 风格的行尾 \r\n0x1A一种 DOS 风格的字符 0x0AUnix 风格的行尾 \n果不其然,当你打开文件,逐个读取这些字节时,你可以看到这确实是一个
.png头文件:

>>> with open('jack_russell.png', 'rb') as byte_reader:
>>> print(byte_reader.read(1))
>>> print(byte_reader.read(3))
>>> print(byte_reader.read(2))
>>> print(byte_reader.read(1))
>>> print(byte_reader.read(1))
b'\x89'
b'PNG'
b'\r\n'
b'\x1a'
b'\n'
完整示例:dos2unix.py
让我们把这整个事情带回家,看看如何读写文件的完整示例。下面是一个类似于 dos2unix 的工具,可以将包含行尾\r\n的文件转换为\n。
该工具分为三个主要部分。第一个是str2unix(),它将一个字符串从\r\n行尾转换成\n。第二个是dos2unix(),将包含\r\n字符的字符串转换成\n。dos2unix()内部调用str2unix()。最后,还有 __main__ 块,只有当文件作为脚本执行时才调用它。可以把它想象成其他编程语言中的main函数。
"""
A simple script and library to convert files or strings from dos like
line endings with Unix like line endings.
"""
import argparse
import os
def str2unix(input_str: str) -> str:
r"""
Converts the string from \r\n line endings to \n
Parameters
----------
input_str
The string whose line endings will be converted
Returns
-------
The converted string
"""
r_str = input_str.replace('\r\n', '\n')
return r_str
def dos2unix(source_file: str, dest_file: str):
"""
Converts a file that contains Dos like line endings into Unix like
Parameters
----------
source_file
The path to the source file to be converted
dest_file
The path to the converted file for output
"""
# NOTE: Could add file existence checking and file overwriting
# protection
with open(source_file, 'r') as reader:
dos_content = reader.read()
unix_content = str2unix(dos_content)
with open(dest_file, 'w') as writer:
writer.write(unix_content)
if __name__ == "__main__":
# Create our Argument parser and set its description
parser = argparse.ArgumentParser(
description="Script that converts a DOS like file to an Unix like file",
)
# Add the arguments:
# - source_file: the source file we want to convert
# - dest_file: the destination where the output should go
# Note: the use of the argument type of argparse.FileType could
# streamline some things
parser.add_argument(
'source_file',
help='The location of the source '
)
parser.add_argument(
'--dest_file',
help='Location of dest file (default: source_file appended with `_unix`',
default=None
)
# Parse the args (argparse automatically grabs the values from
# sys.argv)
args = parser.parse_args()
s_file = args.source_file
d_file = args.dest_file
# If the destination file wasn't passed, then assume we want to
# create a new file based on the old one
if d_file is None:
file_path, file_extension = os.path.splitext(s_file)
d_file = f'{file_path}_unix{file_extension}'
dos2unix(s_file, d_file)
提示和技巧
现在您已经掌握了读写文件的基本知识,这里有一些提示和技巧可以帮助您提高技能。
__file__
__file__属性是模块的一个特殊属性,类似于__name__。它是:
如果从文件中加载模块,则为从中加载模块的文件的路径名(来源
注意:为了进行迭代,__file__返回路径相对于调用初始 Python 脚本的位置。如果您需要完整的系统路径,您可以使用os.getcwd()来获取正在执行的代码的当前工作目录。
这里有一个真实的例子。在我过去的一份工作中,我为一个硬件设备做了多项测试。每个测试都是使用 Python 脚本编写的,测试脚本文件名用作标题。然后这些脚本将被执行,并可以使用__file__特殊属性打印它们的状态。下面是一个文件夹结构示例:
project/
|
├── tests/
| ├── test_commanding.py
| ├── test_power.py
| ├── test_wireHousing.py
| └── test_leds.py
|
└── main.py
运行main.py会产生以下结果:
>>> python main.py
tests/test_commanding.py Started:
tests/test_commanding.py Passed!
tests/test_power.py Started:
tests/test_power.py Passed!
tests/test_wireHousing.py Started:
tests/test_wireHousing.py Failed!
tests/test_leds.py Started:
tests/test_leds.py Passed!
通过使用__file__特殊属性,我能够动态地运行并获得所有测试的状态。
附加到文件
有时,您可能希望追加到文件中,或者从已经填充的文件的末尾开始写。这很容易通过使用'a'字符作为mode参数来实现:
with open('dog_breeds.txt', 'a') as a_writer:
a_writer.write('\nBeagle')
当您再次检查dog_breeds.txt时,您会看到文件的开头没有改变,而Beagle现在被添加到了文件的末尾:
>>> with open('dog_breeds.txt', 'r') as reader: >>> print(reader.read()) Pug Jack Russell Terrier English Springer Spaniel German Shepherd Staffordshire Bull Terrier Cavalier King Charles Spaniel Golden Retriever West Highland White Terrier Boxer Border Terrier Beagle同时处理两个文件
有时候,您可能希望同时读取一个文件和写入另一个文件。如果您使用学习如何写入文件时显示的示例,它实际上可以合并为以下内容:
d_path = 'dog_breeds.txt' d_r_path = 'dog_breeds_reversed.txt' with open(d_path, 'r') as reader, open(d_r_path, 'w') as writer: dog_breeds = reader.readlines() writer.writelines(reversed(dog_breeds))创建自己的上下文管理器
有时,您可能需要通过将 file 对象放在自定义类中来更好地控制它。当你这样做的时候,使用
with语句就不能再用了,除非你增加几个神奇的方法:__enter__和__exit__。通过添加这些,你就创建了所谓的上下文管理器。当调用
with语句时,调用__enter__()。从with语句块退出时,调用__exit__()。这里有一个模板,您可以使用它来制作您的自定义类:
class my_file_reader(): def __init__(self, file_path): self.__path = file_path self.__file_object = None def __enter__(self): self.__file_object = open(self.__path) return self def __exit__(self, type, val, tb): self.__file_object.close() # Additional methods implemented below既然您已经有了自己的自定义类,它现在是一个上下文管理器,您可以像使用内置的
open()一样使用它:with my_file_reader('dog_breeds.txt') as reader: # Perform custom class operations pass这里有一个很好的例子。还记得我们可爱的杰克·罗素形象吗?也许你想打开其他的
.png文件,但不想每次都解析头文件。这里有一个如何做到这一点的例子。这个例子也使用了自定义迭代器。如果你不熟悉它们,看看 Python 迭代器:class PngReader(): # Every .png file contains this in the header. Use it to verify # the file is indeed a .png. _expected_magic = b'\x89PNG\r\n\x1a\n' def __init__(self, file_path): # Ensure the file has the right extension if not file_path.endswith('.png'): raise NameError("File must be a '.png' extension") self.__path = file_path self.__file_object = None def __enter__(self): self.__file_object = open(self.__path, 'rb') magic = self.__file_object.read(8) if magic != self._expected_magic: raise TypeError("The File is not a properly formatted .png file!") return self def __exit__(self, type, val, tb): self.__file_object.close() def __iter__(self): # This and __next__() are used to create a custom iterator # See https://dbader.org/blog/python-iterators return self def __next__(self): # Read the file in "Chunks" # See https://en.wikipedia.org/wiki/Portable_Network_Graphics#%22Chunks%22_within_the_file initial_data = self.__file_object.read(4) # The file hasn't been opened or reached EOF. This means we # can't go any further so stop the iteration by raising the # StopIteration. if self.__file_object is None or initial_data == b'': raise StopIteration else: # Each chunk has a len, type, data (based on len) and crc # Grab these values and return them as a tuple chunk_len = int.from_bytes(initial_data, byteorder='big') chunk_type = self.__file_object.read(4) chunk_data = self.__file_object.read(chunk_len) chunk_crc = self.__file_object.read(4) return chunk_len, chunk_type, chunk_data, chunk_crc您现在可以打开
.png文件,并使用您的自定义上下文管理器正确解析它们:
>>> with PngReader('jack_russell.png') as reader:
>>> for l, t, d, c in reader:
>>> print(f"{l:05}, {t}, {c}")
00013, b'IHDR', b'v\x121k'
00001, b'sRGB', b'\xae\xce\x1c\xe9'
00009, b'pHYs', b'(<]\x19'
00345, b'iTXt', b"L\xc2'Y"
16384, b'IDAT', b'i\x99\x0c('
16384, b'IDAT', b'\xb3\xfa\x9a$'
16384, b'IDAT', b'\xff\xbf\xd1\n'
16384, b'IDAT', b'\xc3\x9c\xb1}'
16384, b'IDAT', b'\xe3\x02\xba\x91'
16384, b'IDAT', b'\xa0\xa99='
16384, b'IDAT', b'\xf4\x8b.\x92'
16384, b'IDAT', b'\x17i\xfc\xde'
16384, b'IDAT', b'\x8fb\x0e\xe4'
16384, b'IDAT', b')3={'
01040, b'IDAT', b'\xd6\xb8\xc1\x9f'
00000, b'IEND', b'\xaeB`\x82'
不要重新发明蛇
在处理文件时,您可能会遇到一些常见的情况。这些情况中的大多数可以使用其他模块来处理。您可能需要处理的两种常见文件类型是.csv和.json。 Real Python 已经就如何处理这些问题整理了一些很棒的文章:
此外,还有一些内置的库可以帮助您:
wave:读写 WAV 文件(音频)aifc:读写 AIFF 和 AIFC 文件(音频)sunau:读写孙盟文件tarfile:读写 tar 存档文件zipfile:处理 ZIP 档案configparser:轻松创建和解析配置文件xml.etree.ElementTree:创建或读取基于 XML 的文件msilib:读写微软安装程序文件plistlib:生成并解析 Mac OS X.plist文件
外面还有很多。此外,PyPI 上还有更多第三方工具。下面是一些流行的方法:
你是文件巫师哈利!
你做到了!您现在已经知道如何使用 Python 处理文件,包括一些高级技术。在 Python 中处理文件应该比以往任何时候都容易,并且当你开始这样做时会有一种值得的感觉。
在本教程中,您已经学习了:
- 什么是文件
- 如何正确打开和关闭文件
- 如何读写文件
- 使用文件时的一些高级技巧
- 一些库可以处理常见的文件类型
如果你有任何问题,请在评论中联系我们。
参加测验:通过我们的交互式“用 Python 读写文件”测验来测试您的知识。完成后,您将收到一个分数,以便您可以跟踪一段时间内的学习进度:
*参加测验
立即观看本教程有真实 Python 团队创建的相关视频课程。和文字教程一起看,加深理解: 用 Python 读写文件********
真正的 Python 播客:已经一年了!
本周,真正的 Python 播客即将到达其第五十集!
这是不平凡的一年,充满了在 Python 社区的分享、学习和联系。我们期待为您带来更多有趣的嘉宾、对专家 Pythonistas 的采访,以及与真 Python 团队的大量幕后。
让我们快速回顾一下播客在过去一年中发生的一些事情,并先睹为快吧!
免费奖励: 并学习 Python 3 的基础知识,如使用数据类型、字典、列表和 Python 函数。
PyCon 演讲者分享了他们的专业知识
PyCon 是 Python 社区的一个重要中心,所以我们绝对要邀请专家来参加这次会议,分享他们的专业知识。以下是您在过去一年中听到的一些演讲者:
-
金伯利·费塞尔 在网上讨论了她为 PyCon 2020 创作的优秀教程,它是正式合法的,所以让我们刮网。我们讨论了如何开始使用 web 抓取,并介绍了工具和技术。Kimberly 给出了如何在 HTML 中找到元素的建议,并分享了清理数据的技巧。她还参与了网络抓取法律领域的最新变化。要了解更多,请查看第 12 集:Python 中的 Web 抓取:工具、技术和合法性。
-
茹卡斯兰加 在线讨论他为 PyCon 2020、 AsyncIO + Music 的演讲。在演讲中,他展示了关于协程、聚集、事件循环以及被触发以创建一段音乐的事件的实例。我们还谈到了他作为 Python 3.8 和 3.9 发布经理的角色。ukasz 介绍了他非常受欢迎的、不妥协的代码格式化程序 Black 的起源,以及它可以在组织中解决的问题类型。要了解更多,请查看第 7 集:AsyncIO +音乐、黑色起源和管理 Python 版本。
-
汉娜·斯捷潘内克 讨论了她在 2019 年 PyCon US 上的演讲,像熊猫一样思考:正确使用熊猫所需的一切。她分享了在 pandas 中处理数据时获得更高性能的技巧。我们还谈到了她最近的 PyCon US 2020 在线演示,让我们谈谈 Python 中的数据库:SQLAlchemy 和 Alembic 。要了解更多信息,请查看第 16 集:熊猫思维:正确的 Python 数据分析。
Python 项目负责人让你深入了解了
开源 Python 项目的领导者来到节目中给我们带来了内幕消息。以下是我们邀请的一些客人:
-
阿明·罗纳彻 谈到了第一个十年的烧瓶。阿明讲述了 Flask 的起源以及构成框架的组件。他还讨论了记录框架或 API 的内容,并谈到了正在开发 Flask 的社区。要了解更多,请查看第 18 集:烧瓶十年:与创作者阿明·罗纳彻的对话。
-
乔治亚布伦 和Sumana Harihareswara讲过
pip。Sumana 是pip的项目经理,Georgia 一直致力于软件包安装程序的用户体验。我们讨论了如何提供帮助,从更新到最新版本,到用您的项目测试新的解析器,以及回答关于您的体验的调查。要了解更多信息,请查看第 29 集:使用新版 Pip 解决包依赖性。 -
罗素凯斯-麦咭 是蜂产品项目的创始人和维护者。Russell 谈到了公文包,这是一个将 Python 应用程序转换成 macOS、Windows、Linux 和移动设备上的原生安装程序的工具。他还研究了在多个计算平台之间转换图形用户界面组件的一些复杂性。要了解更多,请查看第 22 集:用 BeeWare 创建跨平台 Python GUI 应用程序。
你找到了学习旅程的下一步
真正的 Python 作者热爱教学和写作,所以他们出版一些全面可靠的书籍来帮助你克服学习过程中的障碍是很自然的。以下是去年参加播客的一些作者:
-
大卫·阿莫斯 是播客的常客,但他也花时间讨论他的书 Python 基础知识:Python 3 实用介绍。这本书把你真正需要知道的核心概念分成了小块。一步一步地,你将掌握基本的 Python 概念,这将帮助你开始学习 Python 的旅程,并从初级提升到中级。要了解更多,请查看第 32 集:我们新的“Python 基础”书&填补了你学习道路上的空白。
-
安东尼肖 讨论了他的书 CPython Internals:你的 Python 3 解释器指南。在 CPython Internals 中,您将解开 Python 语言的内部工作原理,学习如何从源代码编译 Python 解释器,并涵盖您需要知道的内容,以便自信地开始为 CPython 做贡献!要了解更多信息,请查看第 11 集:Python 测试入门建议。
-
戴恩·希拉德 讨论了他的书中的 Python Pro 的做法。他探讨了从一个业余 Python 程序员成为一个真正的专业人员需要做些什么,以及当你开始为他人编写代码时需要做些什么改变。要了解更多,请查看第 49 集:成为 Python 专业人士的挑战。
您参加了学习资源的导览
每两周, Chris Bailey 和 David Amos 会带你深入探究在 Real Python 和其他地方发布的 Python 教程,这样你就能跟上 Python 世界的发展。
由于一位听众提出了一个问题,我们也开始展示 Python 项目,这些项目是供您研究和学习的很好的模型,因此您可以在自己的项目中使用最佳实践。现在,在第 15 集:Python 正则表达式、Pandas 中的视图与副本以及更多之后的每第二集的结尾,我们分享一些项目供你研究和学习。
以下是我们重点介绍的一些项目:
- ERP next:SAP 的免费开源替代品
- Colorpedia :一个用于查找颜色、阴影和调色板的命令行工具
- Django
Unicorn:Django 的神奇全栈框架 - Jupylet :一个用于编程 2D 和 3D 游戏、图形、音乐和声音合成器的 Python 库
- 尼古拉:一个静态网站和博客生成器
toolz:Python 的功能标准库- Evennia:一个基于文本的在线多人游戏框架
- 排序-算法-可视化器:一个用 Pygame 制作的程序,展示了排序算法是如何工作的
- Python-Adventure :最初的巨型洞穴探险游戏,但是在 Python 3 中
- Clifford:Python 的一个数值几何代数包
- 皮皮:Python 的计算机音乐模块库
- SDV :表格、关系和时间序列数据的综合数据生成器
- SkyAR :视频中动态天空替换和协调的工具
- Google Research Football :代理学习踢足球的强化学习环境
- zxcvbn-python : Dropbox 的现实密码强度估算器
- Manim :解释性数学视频的动画引擎
下一步是什么?
会议季节即将来临!我们将参加一些(虚拟)会议,并将为您带来来自 PyCon US 、 PyCascades 和 Python Web Conference 的最新消息。如果你不能亲自参加这些会议,那么请继续收听播客来了解下一个好消息。
我们将继续为您带来:
- 采访 Python 专家
- 实用技巧帮助你高效学习
- 深入了解 Python 社区发生的事情
如果你想让我们在播客上报道什么,那么让我们知道!当听众告诉我们他们想学习更多关于安全性的知识,从 Python 老师那里听到更多,或者任何有助于你不断提高 Python 水平的事情时,我们很高兴。
快乐的蟒蛇!*
真正的 Python 播客来了!
真正的 Python 播客终于上线了!收听有趣的嘉宾、对专家 Pythonistas 的采访以及真实 Python 团队的许多幕后活动。
今天我们正式推出真正的 Python 播客,这是一个面向像你这样的 Python 爱好者的新的(免费的)播客。
这已经酝酿了一段时间,克里斯托弗和我都非常自豪终于在本周向你们发布了第一集。
我们将为您准备一份有趣嘉宾的花名册,对专家 Pythonistas 的采访,以及许多真实 Python 团队的幕后故事。
以下是关于该节目的更多信息以及如何收听:
什么是真正的 Python 播客?
这是一个免费的每周节目,有采访、编码技巧和与来自 Python 社区的嘉宾的对话,由真正 Python 的克里斯托弗·贝利主持。
我们将涵盖广泛的主题,包括 Python 编程最佳实践、职业技巧和相关的软件开发主题。看看真实 Python 的幕后。
因此,请加入我们,了解 Python 编程领域的最新动态,成为一名更有效的 Python 爱好者。
你怎么能听这个节目?
该节目现在可以在所有常见的播客目录中看到,如苹果播客、谷歌播客、Spotify、Stitcher 等。只需启动你最喜欢的播客听应用程序,搜索“真正的 Python”。
或者,你可以在realpython.com/podcast在线收听
表演什么时候开始?
从 2020 年 3 月 20 日星期五起,真正的 Python 播客可以在所有常见的播客目录中找到。所以,预热你的播客应用程序🙂

我们想听听你的意见!
这是一个社区的播客,面向社区。我们希望你参与进来,我们希望听到你的反馈,我们希望随着时间的推移,播客会越来越好。
你对一集有什么想法吗?你想和我们分享你的故事或者问克里斯托弗一个问题吗?在 @realpython 或发推文,给我们留下语音邮件,有机会在节目中亮相。
你怎么能支持这个节目?
使用你最喜欢的播客应用程序订阅,在苹果播客或其他目录上留下对该播客的评论,并在脸书、LinkedIn 和 Twitter 上告诉全世界关于该节目的信息。
这是播客和节目笔记的链接:
快乐的蟒蛇!
—丹·巴德*
PyCon US 2022 上的真蟒蛇
PyCon US 作为面对面的会议又回来了。 PyCon US 2022 将于 4 月 29 日至 5 月 1 日在盐湖城举行,真正的蟒蛇也在那里。周六在我们的展位和开放空间加入我们。
在本文中,您将了解在盐湖城的 PyCon 上哪里可以找到真正的 Python,并了解我们的一些团队成员在会议上对什么感到兴奋。
在 PyCon US 2022 上认识真正的 Python
自 2003 年以来,PyCon US 大会一直是 Python 社区的年会。因为科维德·疫情,会议在 2020 年和 2021 年变成了虚拟的。在 Real Python,我们很高兴今年能够亲自见面。如果你在盐湖城,来打个招呼吧!
参观真正的 Python 展台
在任何 PyCon 会议上,展厅都是一个热闹的地方。在这里,您可以四处逛逛,与其他与会者聊天,同时探索赞助商和参展商带来了什么。这是一个闲逛和交新朋友的好地方!
Real Python 在今年的大会上有一个展位。我们很高兴有自己的地方闲逛,并向每个人展示我们的内容。你可以在微软和 AWS 正对面的228 号展位找到我们。寻找我们的标志和友好的面孔——我们会用眼睛微笑!

在展台前停下来听听我们提供的所有内容,或者聊聊您最喜欢的软件包、平方根或 Python 的最新发展。
加入我们的开放空间
空地是 PyCon 的独特特色。这些是自组织的一小时聚会式的活动,在整个会议期间不断发生。查看开放空间版块,看看有没有你想加入的东西!

Real Python 将在周六下午 2 点在250 f房间举办一个开放空间。欢迎加入我们,了解更多关于我们新内容的计划以及我们正在为网站做些什么。我们也很想听听你对真正的 Python 的体验,以及对改进和未来教程的建议。
认识团队
我们很高兴终于能参加会议,并再次与社区成员交流。
您可以在我们的展位和整个会议期间与我们见面。但也许在那之前你想了解一下我们。这是一些参加 PyCon 的团队成员。
丹·巴德

作为 Real Python 的所有者和主编,我非常高兴今年我们能在 PyCon 上有一个展位。这是我的第五次 PyCon,今年第一次拥有我们自己的 PyCon 小角落来展示真正的 Python,这感觉像是一个巨大的里程碑!
周五或周六的任何时候都可以来我们的展位打个招呼,与团队见面,或者了解更多关于我们为 Python 开发人员提供的学习资源和为企业提供的培训选项。我很期待见到你!
巴尔托什初学者

我的名字叫 Bartosz Zaczyński ,我是 Real Python 的内容创建者之一,帮助为您提供精彩的 Python 教程和课程。当我不制作或审查内容时,我经常在我们的 Slack 社区平台上参与对话,或者在每周办公时间为真正的 Python 订户举办的网络研讨会期间参与现场讨论。我还积极参与了 Python 的教学,并在一个编码训练营担任学生的导师。
在我进入教育行业之前,我是一名全职软件工程师,为几家不同领域的公司工作。奇怪的是,在我的职业生涯中,Python 从来不是主要的编程语言,但不知何故,它成了我的最爱,并一直伴随着我。尽管 Python 并不完美,但我还没有发现比它更通用或更令人愉快的代码。
这将是我第二次参加 PyCon US,尽管这是我第一次亲自参加,对此我感到非常兴奋。我已经期待这个特别的活动很久了,因为这将是我三年前加入以来第一次有机会与真正的 Python 团队面对面。除此之外,我希望与一些长期办公时间的参与者握手,与我们的读者和订户聊天,并与其他 Python 爱好者结交新朋友。
今年,我们将在展厅拥有自己的展位,这应该会让我们更容易找到。如果你在附近,想要与真正的 Python 团队成员互动,成为真正的 Python 播客的客人,挑选一本我们的书籍,或者只是拿一些酷礼品,那么一定要来看看。我们很想听听我们的读者、观众和听众的意见,了解他们喜欢和不喜欢 Real Python 的什么,以及我们未来的教程和课程应该涵盖哪些主题。
我们还可以为一群人预订一个开放空间的房间,一起做一个项目,解决一个问题,或者谈论一些你觉得有趣的事情。如果你已经有了一些想法,请在下面的评论中告诉我们。我们在那里见!
Geir Arne Hjelle

我是 Geir Arne Hjelle ,真实 Python 团队的内容创建者之一。我住在挪威的奥斯陆,在那里我试图将户外活动和编写 Python 教程结合起来。
我在 2018 年以自由职业者的身份加入了 Real Python。但是从去年 12 月份开始,我就开始全职工作了。除了创建教程,我还参与了我们的评审过程,在这个过程中,我评审了其他作者和团队成员写的一些内容。
我有幸参加了在克里夫兰举行的 2019 年PyCon US,在那里我做了一个关于插件和模块化代码的演讲。这是一个很好的机会来认识我的一些真正的 Python 同事和令人惊叹的 Python 社区的其他人。
我确实参加了 2020 年和 2021 年的远程 PyCon 会议,并有幸在这两个场合讲授了一堂关于装饰师的教程。尽管如此,我对终于能够再次亲自参加会议感到非常兴奋。
在会议前几天,我飞到盐湖城,这样我可以克服时差,参加一些辅导课,并通过 T2 志愿者帮助组织者。
随着会议的进行,我很高兴能再次和整个社区的人在一起。我期待着看到有趣的谈话,对所有事情进行有趣的聊天,不管是不是 Python。
马丁·布鲁斯*
*
嗨,我是马丁!我在 2019 年初开始为 Real Python 制作视频课程,从那以后,我不断地与团队进行更多的接触。我从 2021 年初开始做全职内容创作者。
这是我第一次亲自参加 PyCon US,但我去年有机会参加在线 PyCon US。通过一些幸运的地理巧合,我还参加了我的第一次现实生活中的 Python 会议, Kiwi PyCon X ,2019 年在 [Wellington,NZ]( https://www.google.com/maps/place/Wellington ,+New+Zealand/) 。
我目前与妻子和三个月大的女儿住在奥地利,我们在 PyCon 开始前飞到盐湖城,这意味着你会通过我眼睛下面的阴影认出我,因为不可避免的时区转换和夜间的婴儿醒来。
像盖尔·阿恩一样,我决定在会议上做志愿者。我最近完成了我在登记处的工作,这很有趣!本周晚些时候,我也会在绿色房间做志愿者,但大多数时候,你会在展厅的真正 Python 展台看到我。
在会议的第一天,能够在现实生活中见到办公时间的参与者和其他真正的 Python 读者和订阅者,已经很令人惊讶了。
顺道去电话亭打个招呼!我很乐意谈论任何事情,听取您对我们可以开发的新教程和视频课程的建议和想法,并谈论我们在 Real Python 提供的所有产品。
结论
终于!我们很高兴能再次见面。如果您在盐湖城参加 PyCon 2022,请到真正的 Python 展台前打个招呼。**
PyCon US 2019 上的真蟒蛇
每年世界各地都有许多 PyCon,但其中最大的是美国 PyCon。今年,3000 多名 Pythonistas 来到俄亥俄州的克利夫兰,学习、合作、贡献,并会见新老朋友。我相信你们中的许多人已经知道 PyCon US 是什么,但如果不知道,那么我建议阅读我们的PyCon 指南以了解更多信息。
我们第一次聚在一起
今年, Real Python 有机会在 PyCharm 内容创作者展台加入其他内容创作者,在那里我们花了一些时间与 Real Python 社区的读者和成员见面。哦,我们还分发了一吨真蟒蛇贴纸,而且我们的货已经卖完了!你拿到你的了吗?

团队也为我们的作者盖尔·阿恩·哈杰尔和 T2·安东尼·肖感到兴奋,他们也作为演讲者出席了会议。你可以在 PyCon YouTube 频道上听到他们关于插件:为你的应用增加灵活性和狡猾的 Python:编写更简单更易维护的 Python 的谈话录音。
我们也很幸运能够在 PyCon 为我们的读者安排一个真正的 Python 开放空间。我们的出席人数非常多,有 30 人出席。
这是一个很好的机会,我们不仅可以和您握手,感谢您对我们的鼓励和反馈,还可以确保我们能够继续推动和制作越来越好的内容。听取与会者的反馈是一次奇妙的经历,我们将采纳一些产生的想法,帮助我们为您提供更好的阅读和学习体验。
尽管成员和员工 Slack 小组每天都有对话,但大多数真正的 Python 团队成员从未见过面。对我个人来说,面对面地与我的同事见面,并与他们一起用餐或喝啤酒绝对是整个会议的亮点之一。
但我决定询问团队中其他人的经验,希望我们能为你提供一些有用的建议或可行的技巧,以防你第一次参加 PyCon。
我向一些参加 PyCon 的团队成员提出了同样的三个问题,并整理了他们的答案。这些问题是:
- 你能简单地告诉我们你是谁,你做什么,进出真正的 Python 吗?这是你第一次参加皮肯节吗?如果是,是什么让 2019 年成为你第一次决定去的一年?
- 你的 PyCon 有哪些亮点?PyCon 2019 你会有哪些回忆?
- PyCon 有太多的事情要做,不可能面面俱到。有什么事情是你没有机会去做,但又希望自己有机会去做的?

团队面试
事不宜迟,让我们看看他们有什么要说的。
吉姆·安德森

我是吉姆·安德森,白天是嵌入式固件开发人员,主要用 C++做视频安防摄像头。我在工作中也接触了一些 Python。在 Real Python ,我是一名作者和一名技术评论者,通常倾向于低级、工具相关或一般 CS 主题的文章。
这是我第一次参加 PyCon。我最终决定去,只是因为我在真正的 Python 社区中看到的兴奋。我认识的人之前都在谈论这个话题。他们是对的。
有这么多亮点!当然,能够最终见到我的一些真正的 Python 同事非常酷,就像在 PyCharm 展台的内容创作者区闲逛一样。(谢谢 JetBrains!)
我想说,我最美好的记忆,也是真正在我脑海中凝固气氛的记忆,是看到一个来自 PythonistaCafe 和 PyCon 的朋友与一个正在打扫场地的人交谈。她被会议的友好气氛深深吸引,以至于她开始询问会议的情况,并考虑明年如何成为会议的一员。也许我们能在匹兹堡见到她。
我本来计划去听一个报告,但是错过了时间,错过了。那是建造一个开源的人工胰腺,我仍然对我没能成功感到失望。这是一个很棒的话题,也是一次很棒的演讲。
Geir Arne Hjelle

我的名字是盖尔·阿恩·哈杰尔,我在挪威北部的一个小村庄长大。目前,我住在奥斯陆,从事不同的数据科学和机器学习项目。大多数时候,我会使用 Python 和构建在 numpy 之上的优秀数据科学堆栈。
我从 2018 年春天开始为真正的 Python 写作,大部分是关于一般的 Python 包和概念。我的第一篇文章是关于 pathlib包,目前我正在写一篇关于导入如何工作的文章。此外,我通过对其他作者的文章进行评论来支持他们,包括大纲评论和技术评论。
今年是我第一次参加 PyCon US。我住在挪威,所以我主要在欧洲参加会议。今年秋天,我将第五次参加 EuroSciPy 。然而,在加入真正的 Python 团队后,我真的被在野外结识一些新朋友和同事的机会所诱惑。
去年夏天,詹姆斯和我设法见了面,但除此之外,我主要是通过他们松弛的头像来了解这个团队。与真正的 Python 团队的其他成员见面和闲逛,以及对我们为彼此做的一些评论感到厌烦,这些都是我将珍藏很久的美好回忆。
皮肯发生了这么多事。我全力以赴,参加了辅导课、主会议和部分冲刺赛。我真的很喜欢这一切。
教程很棒,包括大卫·比兹利的深入探究λ微积分。(耶,数学!)我很幸运地在会议期间去了做了一个演讲,非常有趣。在我演讲之前,我被照顾得很好:我想这是我第一次有自己的准备室,有人陪我去演讲室。
后来,我得到了一些非常好和有趣的问题。在冲刺阶段,我对 Jason Coombs 和 Barry Warsaw 为 Python 3.8 开发的新 importlib.metadata 库提供了一点帮助。能够亲眼看到一些核心开发人员是如何工作的,真是太棒了。
我在克利夫兰有很多美好的经历,很难想象我没有机会做的事情。虽然,我承认在这次 PyCon 上,我非常关注我自己(特别是我的演讲是在会议的最后一部分)。
下一次,我会留出一些时间来做志愿者,并确保比这次更多地支持会议的运行。很高兴看到每个人都参与进来:我受到了欧内斯特·w·德宾三世的欢迎和接待,他也是整个会议的主席。
詹姆斯·默茨*
*
我是詹姆斯·默茨,是美国宇航局喷气推进实验室(JPL)的软件保障工程师。我目前正在进行欧罗巴快船项目,这是一颗将围绕木星轨道运行并在欧罗巴卫星附近进行近距离旅行的卫星。我已经为真正的 Python 写了大约一年了,主题从记录 Python 到如何最大限度地利用 PyCon 。
这是我在 PyCon 的第四年,所以我开始了解我在大会上的方式,尽管每年都有不同,足以让我继续回来。到目前为止,今年对我来说是最好的一年,原因有两个:做志愿者和会见真正的 Python 帮(作者和读者)。
在我关于如何充分利用 PyCon 的指南中,我真的把重点放在了在 PyCon 做志愿者上。我意识到,虽然我在过去几年里做了一些事情,但我并没有真正实践我所宣扬的东西。我决定完全接受这一点,并尽我所能提供帮助。
会议结束时,我已经:
- 成为大卫·比兹利深入研究λ微积分的辅导“保镖”
- 帮助登记入住,甚至从 Python Bytes 和跟我说说 Python帮迈克尔·肯尼迪登记入住
- 完成了拉里·黑斯廷斯主持的行舞
- 成为一名会议工作人员跑者(确保演讲者准时出现在房间里的人)
- 担任会议工作人员主席(介绍演讲者的人)
通过这一切,我建立了一些非常惊人的联系,能够为我如此热爱的社区做一点贡献,我感到很棒。
说到社区,与真正的 Python 社区见面是另一大亮点。作为作者,我们真的没有太多面对面的机会。因此,最终在现实世界中见到一些我在数字上非常熟悉的人,是一种超现实的体验。更好的是,尽管我们来自世界不同的地方,有着不同的生活经历,但我们能够很快建立起团队精神。
也许比见到我的其他真正的 Python 团队成员更好的是见到你们,读者们。我们举行了我们的第一次真正的蟒蛇 开放空间,在那里你们许多人停下来聊天。作为一名数字出版商的作者,有时很难与你为之写作的人联系,但对我来说,这变得更容易了。

今年的 PyCon 体验总体来说相当平衡,因为我进行了大量的网络交流,观看了演讲和教程,甚至参加了志愿者活动。我能想到的唯一一件我希望我能做的事就是做一个某种形式的展示。这就是明年的目的。
丹·巴德

嘿,我是丹·巴德,我是真正的 Python 的所有者和主编。我还为基于 Django 的 CMS 和其他运行于其上的基础设施做所有的后端和前端开发。
我是一个长期的 Python 爱好者,并且非常热衷于教授 Python。出版我自己的 Python 编程书籍是我一生的梦想,现在能够和一个令人敬畏的团队一起运行真正的 Python 是锦上添花!
今年是我第五次参加 PyCon,这肯定不会是最后一次…
我个人的亮点是和真正的 Python 教程团队在一起,第一次见到他们中的许多人。那简直让我心跳加速!有几天晚上我们出去吃东西喝饮料,我可能永远不会忘记的一个随机记忆是发现洛根有多喜欢黄金女郎电视节目 : - D
白天, JetBrains 的好心人在他们的 PyCharm 展位给了我们一些空间,所以我们都穿上了我们的真蟒蛇饰品,与读者聊天,并分发贴纸和别针。太有趣了!
另一个美好的回忆是我们组织的 Real Python 开放空间,几十名读者和成员前来打招呼这让我大吃一惊,是迄今为止我最喜欢的 PyCon 体验之一!
在为推出我们的视频订阅功能连续工作了几个月之后,当我第一次到达 PyCon 时,我感到非常疲惫,看到如此巨大的参与人数感觉令人惊讶。一开始我真的不知道该说什么!感谢大家的光临:)
今年也是我们第二次为 PythonistaCafe 论坛举办露天聚会,看到这个古怪的小项目现在如何引发如此紧密团结和令人敬畏的社区真是太酷了。

另一个亮点是与 Mike Kennedy 一起录制了一集现场直播的 Talk Python 播客。和这家伙在一起总是一种享受:)
我希望我有更多的时间去参加会谈。来自真正的 Python 辅导团队的盖尔·阿恩和安东尼给我留下了非常深刻的印象。有机会一定要去看看录音。
小蟒快乐,明年见!
总结*
*
不管在什么地方,PyCon 都是一种快乐的体验。无论你是会见同事、网上朋友,还是与 Python 以外的人有共同爱好的陌生人,都是这些人让你的经历变得特别。“为语言而来,为社区而留”这句老话在 PyCon US 听起来再正确不过了。
没有两个毕达哥尼亚是相同的,在发生的事件、谈话和教程的多样性中,每个人都有一些东西。就个人而言,我已经开始期待明年的 PyCon 了。如果时间允许,我会尽全力参加 2020 年的短跑比赛。但是即使我没有把它从我的清单上划掉,我已经知道明年我会很兴奋地见到你和许多其他人,尽管我很内向。
如果你参加了 PyCon US 并前来打招呼,或者加入了我们的真正的 Python 或Python stacafe开放空间,那么请在下面留下评论,让我们知道你最喜欢 PyCon 的哪一部分。对于明年第一次参加 PyCon 的人,你有什么建议要给他们吗?编码快乐!***
正则表达式:Python 中的正则表达式(第 2 部分)
在本系列的之前的教程中,你已经涉及了很多内容。您了解了如何使用re.search()通过 Python 中的正则表达式执行模式匹配,并了解了许多正则表达式元字符和解析标志,您可以使用它们来微调您的模式匹配功能。
尽管如此,模块还能提供更多。
在本教程中,您将:
- 探索
re模块提供的re.search()之外的更多功能 - 了解何时以及如何将 Python 中的正则表达式预编译成一个正则表达式对象
- 发现您可以用由
re模块中的函数返回的匹配对象做的有用的事情
准备好了吗?让我们开始吧!
免费奖励: 从 Python 基础:Python 3 实用入门中获取一个示例章节,看看如何通过完整的课程(最新的 Python 3.9)从 Python 初学者过渡到中级。
re模块功能
除了re.search()之外,re模块还包含其他几个函数来帮助您执行与 regex 相关的任务。
注意:您在之前的教程中已经看到了re.search()可以带一个可选的<flags>参数,它指定了修改解析行为的标志。除了re.escape()之外,下面显示的所有函数都以同样的方式支持<flags>参数。
您可以将<flags>指定为位置参数或关键字参数:
re.search(<regex>, <string>, <flags>)
re.search(<regex>, <string>, flags=<flags>)
<flags>的缺省值总是0,这表示匹配行为没有特殊修改。记得在之前的教程中关于标志的讨论中,re.UNICODE标志总是默认设置的。
Python re模块中可用的正则表达式函数分为以下三类:
- 搜索功能
- 替代函数
- 效用函数
以下部分将更详细地解释这些功能。
搜索功能
搜索函数在搜索字符串中扫描指定正则表达式的一个或多个匹配项:
| 功能 | 描述 |
|---|---|
re.search() |
扫描字符串以查找正则表达式匹配 |
re.match() |
在字符串的开头查找正则表达式匹配 |
re.fullmatch() |
在整个字符串中查找正则表达式匹配 |
re.findall() |
返回一个字符串中所有正则表达式匹配的列表 |
re.finditer() |
返回一个迭代器,它从字符串中产生正则表达式匹配 |
从表中可以看出,这些功能彼此相似。但是每一个都以自己的方式调整搜索功能。
re.search(<regex>, <string>, flags=0)
扫描字符串中的正则表达式匹配。
如果你已经完成了本系列的前一篇教程,那么现在你应该已经很熟悉这个函数了。re.search(<regex>, <string>)在<string>中寻找<regex>匹配的任何位置:
>>> re.search(r'(\d+)', 'foo123bar') <_sre.SRE_Match object; span=(3, 6), match='123'> >>> re.search(r'[a-z]+', '123FOO456', flags=re.IGNORECASE) <_sre.SRE_Match object; span=(3, 6), match='FOO'> >>> print(re.search(r'\d+', 'foo.bar')) None如果找到匹配,函数返回一个匹配对象,否则返回
None。
re.match(<regex>, <string>, flags=0)在字符串的开头查找正则表达式匹配。
这与
re.search()相同,除了如果<regex>在<string>中的任何地方匹配则re.search()返回一个匹配,而re.match()只有在<regex>在<string>的开始处匹配时才返回一个匹配:
>>> re.search(r'\d+', '123foobar')
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> re.search(r'\d+', 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.match(r'\d+', '123foobar')
<_sre.SRE_Match object; span=(0, 3), match='123'>
>>> print(re.match(r'\d+', 'foo123bar'))
None
在上面的例子中,当数字在字符串的开头和中间时,re.search()匹配,但是只有当数字在开头时,re.match()才匹配。
请记住,在本系列的上一篇教程中,如果<string>包含嵌入的换行符,那么 MULTILINE标志会导致re.search()匹配位于<string>开头或<string>中包含的任何一行开头的脱字符(^)定位元字符:
1>>> s = 'foo\nbar\nbaz' 2 3>>> re.search('^foo', s) 4<_sre.SRE_Match object; span=(0, 3), match='foo'> 5>>> re.search('^bar', s, re.MULTILINE) 6<_sre.SRE_Match object; span=(4, 7), match='bar'>
MULTILINE标志不会以这种方式影响re.match():
1>>> s = 'foo\nbar\nbaz'
2
3>>> re.match('^foo', s)
4<_sre.SRE_Match object; span=(0, 3), match='foo'>
5>>> print(re.match('^bar', s, re.MULTILINE)) 6None
即使设置了MULTILINE标志,re.match()也只会在<string>的开头匹配脱字符(^)锚,而不是在<string>中包含的行的开头。
请注意,虽然它说明了这一点,但上面例子中第 3 行的符号(^)是多余的。使用re.match(),匹配基本上总是锚定在字符串的开头。
re.fullmatch(<regex>, <string>, flags=0)
在整个字符串中查找正则表达式匹配。
这类似于re.search()和re.match(),但是只有当<regex>完全匹配<string>时,re.fullmatch()才返回一个匹配:
1>>> print(re.fullmatch(r'\d+', '123foo')) 2None 3>>> print(re.fullmatch(r'\d+', 'foo123')) 4None 5>>> print(re.fullmatch(r'\d+', 'foo123bar')) 6None 7>>> re.fullmatch(r'\d+', '123') 8<_sre.SRE_Match object; span=(0, 3), match='123'> 9 10>>> re.search(r'^\d+$', '123') 11<_sre.SRE_Match object; span=(0, 3), match='123'>在第 7 行的调用中,搜索字符串
'123'从头到尾全部由数字组成。所以这是唯一一种re.fullmatch()返回匹配的情况。第 10 行上的
re.search()调用,其中\d+正则表达式被显式定位在搜索字符串的开头和结尾,在功能上是等效的。
re.findall(<regex>, <string>, flags=0)返回字符串中正则表达式的所有匹配项的列表。
re.findall(<regex>, <string>)返回<string>中<regex>所有非重叠匹配的列表。它从左到右扫描搜索字符串,并按找到的顺序返回所有匹配项:
>>> re.findall(r'\w+', '...foo,,,,bar:%$baz//|')
['foo', 'bar', 'baz']
如果<regex>包含一个捕获组,那么返回列表只包含该组的内容,而不是整个匹配:
>>> re.findall(r'#(\w+)#', '#foo#.#bar#.#baz#') ['foo', 'bar', 'baz']在这种情况下,指定的正则表达式是
#(\w+)#。匹配的字符串是'#foo#'、'#bar#'和'#baz#'。但是散列字符(#)不会出现在返回列表中,因为它们在分组括号之外。如果
<regex>包含不止一个捕获组,那么re.findall()返回包含捕获组的元组列表。每个元组的长度等于指定的组数:
1>>> re.findall(r'(\w+),(\w+)', 'foo,bar,baz,qux,quux,corge') 2[('foo', 'bar'), ('baz', 'qux'), ('quux', 'corge')]
3
4>>> re.findall(r'(\w+),(\w+),(\w+)', 'foo,bar,baz,qux,quux,corge') 5[('foo', 'bar', 'baz'), ('qux', 'quux', 'corge')]
在上面的例子中,行 1 上的正则表达式包含两个捕获组,所以re.findall()返回一个包含三个二元组的列表,每个二元组包含两个捕获的匹配。第 4 行包含三个组,所以返回值是两个三元组的列表。
re.finditer(<regex>, <string>, flags=0)
返回产生正则表达式匹配的迭代器。
re.finditer(<regex>, <string>)扫描<string>寻找<regex>的非重叠匹配,并返回一个迭代器,从它找到的任何匹配对象中产生匹配对象。它从左到右扫描搜索字符串,并按照找到匹配项的顺序返回匹配项:
>>> it = re.finditer(r'\w+', '...foo,,,,bar:%$baz//|') >>> next(it) <_sre.SRE_Match object; span=(3, 6), match='foo'> >>> next(it) <_sre.SRE_Match object; span=(10, 13), match='bar'> >>> next(it) <_sre.SRE_Match object; span=(16, 19), match='baz'> >>> next(it) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>> for i in re.finditer(r'\w+', '...foo,,,,bar:%$baz//|'): ... print(i) ... <_sre.SRE_Match object; span=(3, 6), match='foo'> <_sre.SRE_Match object; span=(10, 13), match='bar'> <_sre.SRE_Match object; span=(16, 19), match='baz'>
re.findall()和re.finditer()非常相似,但它们在两个方面有所不同:
re.findall()返回一个列表,而re.finditer()返回一个迭代器。列表中
re.findall()返回的条目是实际的匹配字符串,而re.finditer()返回的迭代器产生的条目是匹配对象。任何你可以用一个完成的任务,你也可以用另一个来完成。你选择哪一个将视情况而定。正如您将在本教程后面看到的,可以从 match 对象中获得许多有用的信息。如果你需要这些信息,那么
re.finditer()可能是更好的选择。替代功能
替换函数替换搜索字符串中与指定正则表达式匹配的部分:
功能 描述 re.sub()扫描字符串中的正则表达式匹配项,用指定的替换字符串替换字符串中的匹配部分,并返回结果 re.subn()行为就像 re.sub()一样,但也返回关于替换次数的信息
re.sub()和re.subn()用指定的替换创建一个新的字符串并返回它。原始字符串保持不变。(记住字符串在 Python 中是不可变的,所以这些函数不可能修改原始字符串。)
re.sub(<regex>, <repl>, <string>, count=0, flags=0)返回对搜索字符串执行替换后得到的新字符串。
re.sub(<regex>, <repl>, <string>)在<string>中找到<regex>最左边不重叠的出现,按照<repl>的指示替换每个匹配,并返回结果。<string>保持不变。
<repl>可以是字符串,也可以是函数,如下所述。字符串替换
如果
<repl>是一个字符串,那么re.sub()将它插入到<string>中,代替任何匹配<regex>的序列:
1>>> s = 'foo.123.bar.789.baz'
2
3>>> re.sub(r'\d+', '#', s)
4'foo.#.bar.#.baz'
5>>> re.sub('[a-z]+', '(*)', s)
6'(*).123.(*).789.(*)'
在第 3 行上,字符串'#'替换了s中的数字序列。在第 5 行的上,字符串'(*)'替换了小写字母序列。在这两种情况下,re.sub()都会像往常一样返回修改后的字符串。
re.sub()将<repl>中带编号的反向引用(\<n>)替换为相应捕获组的文本:
>>> re.sub(r'(\w+),bar,baz,(\w+)', ... r'\2,bar,baz,\1', ... 'foo,bar,baz,qux') 'qux,bar,baz,foo'这里,捕获的组 1 和 2 包含
'foo'和'qux'。在替换串'\2,bar,baz,\1'中,'foo'替换\1,'qux'替换\2。还可以使用元字符序列
\g<name>在替换字符串中引用用(?P<name><regex>)创建的命名反向引用:
>>> re.sub(r'foo,(?P<w1>\w+),(?P<w2>\w+),qux',
... r'foo,\g<w2>,\g<w1>,qux',
... 'foo,bar,baz,qux')
'foo,baz,bar,qux'
事实上,您也可以通过在尖括号内指定组号来引用编号为的反向引用:
>>> re.sub(r'foo,(\w+),(\w+),qux', ... r'foo,\g<2>,\g<1>,qux', ... 'foo,bar,baz,qux') 'foo,baz,bar,qux'如果一个带编号的反向引用后面紧跟着一个文字数字字符,您可能需要使用这种技术来避免歧义。例如,假设您有一个类似于
'foo 123 bar'的字符串,并且想要在数字序列的末尾添加一个'0'。你可以试试这个:
>>> re.sub(r'(\d+)', r'\10', 'foo 123 bar') Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.6/re.py", line 191, in sub
return _compile(pattern, flags).sub(repl, string, count)
File "/usr/lib/python3.6/re.py", line 326, in _subx
template = _compile_repl(template, pattern)
File "/usr/lib/python3.6/re.py", line 317, in _compile_repl
return sre_parse.parse_template(repl, pattern)
File "/usr/lib/python3.6/sre_parse.py", line 943, in parse_template
addgroup(int(this[1:]), len(this) - 1)
File "/usr/lib/python3.6/sre_parse.py", line 887, in addgroup
raise s.error("invalid group reference %d" % index, pos)
sre_constants.error: invalid group reference 10 at position 1
唉,Python 中的 regex 解析器将\10解释为对第十个捕获组的反向引用,这在本例中并不存在。相反,您可以使用\g<1>来指代该组:
>>> re.sub(r'(\d+)', r'\g<1>0', 'foo 123 bar') 'foo 1230 bar'反向引用
\g<0>是指整个匹配的文本。即使在<regex>中没有分组括号,这也是有效的:
>>> re.sub(r'\d+', '/\g<0>/', 'foo 123 bar')
'foo /123/ bar'
如果<regex>指定零长度匹配,那么re.sub()将把<repl>替换到字符串中的每个字符位置:
>>> re.sub('x*', '-', 'foo') '-f-o-o-'在上面的例子中,正则表达式
x*匹配任何零长度序列,所以re.sub()在字符串中的每个字符位置插入替换字符串——在第一个字符之前,在每对字符之间,在最后一个字符之后。如果
re.sub()没有找到任何匹配,那么它总是不变地返回<string>。函数替换
如果您将
<repl>指定为一个函数,那么re.sub()会为每个找到的匹配调用那个函数。它将每个相应的匹配对象作为参数传递给函数,以提供关于匹配的信息。然后,函数返回值变成替换字符串:
>>> def f(match_obj):
... s = match_obj.group(0) # The matching string
...
... # s.isdigit() returns True if all characters in s are digits
... if s.isdigit():
... return str(int(s) * 10)
... else:
... return s.upper()
...
>>> re.sub(r'\w+', f, 'foo.10.bar.20.baz.30')
'FOO.100.BAR.200.BAZ.300'
在这个例子中,f()在每个匹配中都被调用。结果,re.sub()将<string>的每个字母数字部分全部转换为大写,并将每个数字部分乘以10。
限制替换数量
如果您为可选的count参数指定了一个正整数,那么re.sub()最多执行那么多的替换:
>>> re.sub(r'\w+', 'xxx', 'foo.bar.baz.qux') 'xxx.xxx.xxx.xxx' >>> re.sub(r'\w+', 'xxx', 'foo.bar.baz.qux', count=2) 'xxx.xxx.baz.qux'和大多数
re模块函数一样,re.sub()也接受可选的<flags>参数。
re.subn(<regex>, <repl>, <string>, count=0, flags=0)返回对搜索字符串执行替换后得到的新字符串,并返回替换次数。
re.subn()与re.sub()相同,除了re.subn()返回一个由修改后的字符串和替换次数组成的二元组:
>>> re.subn(r'\w+', 'xxx', 'foo.bar.baz.qux')
('xxx.xxx.xxx.xxx', 4)
>>> re.subn(r'\w+', 'xxx', 'foo.bar.baz.qux', count=2)
('xxx.xxx.baz.qux', 2)
>>> def f(match_obj):
... m = match_obj.group(0)
... if m.isdigit():
... return str(int(m) * 10)
... else:
... return m.upper()
...
>>> re.subn(r'\w+', f, 'foo.10.bar.20.baz.30')
('FOO.100.BAR.200.BAZ.300', 6)
在所有其他方面,re.subn()的行为就像re.sub()一样。
实用功能
Python re模块中还有两个 regex 函数需要介绍:
| 功能 | 描述 |
|---|---|
re.split() |
使用正则表达式作为分隔符将字符串分割成子字符串 |
re.escape() |
转义正则表达式中的字符 |
这些函数涉及正则表达式匹配,但不属于上述任何一个类别。
re.split(<regex>, <string>, maxsplit=0, flags=0)
将一个字符串拆分成子字符串。
re.split(<regex>, <string>)使用<regex>作为分隔符将<string>分割成子字符串,并将子字符串作为列表返回。
以下示例将指定字符串拆分为由逗号(,)、分号(;)或斜线(/)字符分隔的子字符串,并由任意数量的空格包围:
>>> re.split('\s*[,;/]\s*', 'foo,bar ; baz / qux') ['foo', 'bar', 'baz', 'qux']如果
<regex>包含捕获组,那么返回列表也包含匹配的分隔符字符串:
>>> re.split('(\s*[,;/]\s*)', 'foo,bar ; baz / qux')
['foo', ',', 'bar', ' ; ', 'baz', ' / ', 'qux']
这一次,返回列表不仅包含子字符串'foo'、'bar'、'baz'和'qux',还包含几个分隔符字符串:
','' ; '' / '
如果您想将<string>分割成带分隔符的标记,以某种方式处理这些标记,然后使用最初分隔它们的相同分隔符将字符串拼凑在一起,这将非常有用:
>>> string = 'foo,bar ; baz / qux' >>> regex = r'(\s*[,;/]\s*)' >>> a = re.split(regex, string) >>> # List of tokens and delimiters >>> a ['foo', ',', 'bar', ' ; ', 'baz', ' / ', 'qux'] >>> # Enclose each token in <>'s >>> for i, s in enumerate(a): ... ... # This will be True for the tokens but not the delimiters ... if not re.fullmatch(regex, s): ... a[i] = f'<{s}>' ... >>> # Put the tokens back together using the same delimiters >>> ''.join(a) '<foo>,<bar> ; <baz> / <qux>'如果需要使用组,但不希望在返回列表中包含分隔符,则可以使用非捕获组:
>>> string = 'foo,bar ; baz / qux'
>>> regex = r'(?:\s*[,;/]\s*)'
>>> re.split(regex, string)
['foo', 'bar', 'baz', 'qux']
如果可选的maxsplit参数存在并且大于零,那么re.split()最多执行那么多分割。返回列表中的最后一个元素是所有拆分发生后的剩余部分<string>:
>>> s = 'foo, bar, baz, qux, quux, corge' >>> re.split(r',\s*', s) ['foo', 'bar', 'baz', 'qux', 'quux', 'corge'] >>> re.split(r',\s*', s, maxsplit=3) ['foo', 'bar', 'baz', 'qux, quux, corge']显式指定
maxsplit=0相当于完全省略它。如果maxsplit是负的,那么re.split()不变地返回<string>(以防你在寻找一种什么都不做的复杂方法)。如果
<regex>包含捕获组,因此返回列表包含分隔符,并且<regex>匹配<string>的开始,那么re.split()将一个空字符串作为返回列表的第一个元素。类似地,如果<regex>匹配<string>的结尾,则返回列表中的最后一项是空字符串:
>>> re.split('(/)', '/foo/bar/baz/')
['', '/', 'foo', '/', 'bar', '/', 'baz', '/', '']
在这种情况下,<regex>分隔符是一个单斜杠(/)字符。在某种意义上,在第一个分隔符的左边和最后一个分隔符的右边有一个空字符串。因此,re.split()将空字符串作为返回列表的第一个和最后一个元素是有意义的。
re.escape(<regex>)
转义正则表达式中的字符。
re.escape(<regex>)返回<regex>的副本,每个非单词字符(除字母、数字或下划线以外的任何字符)前面都有一个反斜杠。
如果您正在调用一个re模块函数,并且您传入的<regex>有许多特殊字符,您希望解析器照字面意思而不是作为元字符,这是很有用的。它可以省去手动输入所有反斜杠字符的麻烦:
1>>> print(re.match('foo^bar(baz)|qux', 'foo^bar(baz)|qux')) 2None 3>>> re.match('foo\^bar\(baz\)\|qux', 'foo^bar(baz)|qux') 4<_sre.SRE_Match object; span=(0, 16), match='foo^bar(baz)|qux'> 5 6>>> re.escape('foo^bar(baz)|qux') == 'foo\^bar\(baz\)\|qux' 7True 8>>> re.match(re.escape('foo^bar(baz)|qux'), 'foo^bar(baz)|qux') 9<_sre.SRE_Match object; span=(0, 16), match='foo^bar(baz)|qux'>在这个例子中,行 1 上没有匹配,因为正则表达式
'foo^bar(baz)|qux'包含表现为元字符的特殊字符。在的第 3 行,它们被用反斜杠显式转义,所以出现了匹配。第 6 行和第 8 行展示了您可以使用re.escape()获得相同的效果。Python 中编译的正则表达式对象
re模块支持将 Python 中的一个正则表达式预编译成一个正则表达式对象,这个对象可以在以后重复使用。
re.compile(<regex>, flags=0)将正则表达式编译成正则表达式对象。
re.compile(<regex>)编译<regex>,返回对应的正则表达式对象。如果包含一个<flags>值,那么相应的标志将应用于对该对象执行的任何搜索。有两种方法可以使用编译后的正则表达式对象。您可以将它指定为
re模块函数的第一个参数来代替<regex>:re_obj = re.compile(<regex>, <flags>) result = re.search(re_obj, <string>)您也可以直接从正则表达式对象调用方法:
re_obj = re.compile(<regex>, <flags>) result = re_obj.search(<string>)上面的两个例子都与此等价:
result = re.search(<regex>, <string>, <flags>)下面是您之前看到的一个示例,使用编译后的正则表达式对象进行了重新转换:
>>> re.search(r'(\d+)', 'foo123bar')
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re_obj = re.compile(r'(\d+)')
>>> re.search(re_obj, 'foo123bar') <_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re_obj.search('foo123bar') <_sre.SRE_Match object; span=(3, 6), match='123'>
下面是另一个,它也使用了IGNORECASE标志:
1>>> r1 = re.search('ba[rz]', 'FOOBARBAZ', flags=re.I) 2 3>>> re_obj = re.compile('ba[rz]', flags=re.I) 4>>> r2 = re.search(re_obj, 'FOOBARBAZ') 5>>> r3 = re_obj.search('FOOBARBAZ') 6 7>>> r1 8<_sre.SRE_Match object; span=(3, 6), match='BAR'> 9>>> r2 10<_sre.SRE_Match object; span=(3, 6), match='BAR'> 11>>> r3 12<_sre.SRE_Match object; span=(3, 6), match='BAR'>在这个例子中,行 1 上的语句将 regex
ba[rz]直接指定给re.search()作为第一个参数。在第 4 行上,re.search()的第一个参数是编译后的正则表达式对象re_obj。在线 5 上,在re_obj上直接调用search()。所有三种情况都产生相同的匹配。为什么要编译正则表达式呢?
预编译有什么好处?有几个可能的优势。
如果您经常在 Python 代码中使用特定的正则表达式,那么预编译允许您将正则表达式的定义与其用法分开。这增强了模块性。考虑这个例子:
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault'
>>> import re
>>> re.search('\d+', s1)
>>> re.search('\d+', s2)
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search('\d+', s3)
<_sre.SRE_Match object; span=(3, 5), match='99'>
>>> re.search('\d+', s4)
在这里,正则表达式\d+出现了几次。如果在维护这段代码的过程中,您决定需要一个不同的正则表达式,那么您需要在每个位置对它进行更改。在这个小例子中,这并不坏,因为它们的用途彼此接近。但是在一个更大的应用程序中,它们可能非常分散,很难跟踪。
以下内容更加模块化,更易于维护:
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault' >>> re_obj = re.compile('\d+') >>> re_obj.search(s1) >>> re_obj.search(s2) <_sre.SRE_Match object; span=(3, 6), match='123'> >>> re_obj.search(s3) <_sre.SRE_Match object; span=(3, 5), match='99'> >>> re_obj.search(s4)同样,通过使用变量赋值,无需预编译也可以实现类似的模块化:
>>> s1, s2, s3, s4 = 'foo.bar', 'foo123bar', 'baz99', 'qux & grault'
>>> regex = '\d+'
>>> re.search(regex, s1)
>>> re.search(regex, s2)
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> re.search(regex, s3)
<_sre.SRE_Match object; span=(3, 5), match='99'>
>>> re.search(regex, s4)
理论上,您可能期望预编译也会导致更快的执行时间。假设您在同一个正则表达式上调用re.search()成千上万次。看起来,提前编译一次正则表达式要比在数千次使用中每次都重新编译更有效。
然而实际上,情况并非如此。事实是,re模块编译并且缓存一个在函数调用中使用的正则表达式。如果随后在同一个 Python 代码中使用了同一个正则表达式,那么它不会被重新编译。而是从缓存中提取编译后的值。所以性能优势微乎其微。
总而言之,没有任何令人信服的理由用 Python 来编译正则表达式。像 Python 的大部分内容一样,它只是您工具箱中的一个工具,如果您觉得它可以提高代码的可读性或结构,您可以使用它。
正则表达式对象方法
编译后的正则表达式对象re_obj支持以下方法:
re_obj.search(<string>[, <pos>[, <endpos>]])re_obj.match(<string>[, <pos>[, <endpos>]])re_obj.fullmatch(<string>[, <pos>[, <endpos>]])re_obj.findall(<string>[, <pos>[, <endpos>]])re_obj.finditer(<string>[, <pos>[, <endpos>]])
除了它们也支持可选的<pos>和<endpos>参数之外,这些函数的行为方式都与您已经遇到的相应的re函数相同。如果这些都存在,那么搜索只适用于由<pos>和<endpos>指示的<string>部分,其作用与切片标记中的索引相同:
1>>> re_obj = re.compile(r'\d+') 2>>> s = 'foo123barbaz' 3 4>>> re_obj.search(s) 5<_sre.SRE_Match object; span=(3, 6), match='123'> 6 7>>> s[6:9] 8'bar' 9>>> print(re_obj.search(s, 6, 9)) 10None在上面的例子中,正则表达式是
\d+,一个数字字符序列。第 4 行上的.search()调用搜索所有的s,所以有一个匹配。在第 9 行上,<pos>和<endpos>参数有效地将搜索限制在从字符 6 开始一直到但不包括字符 9 的子串(子串'bar'),该子串不包含任何数字。如果指定了
<pos>但省略了<endpos>,那么搜索将应用于从<pos>到字符串末尾的子字符串。注意,插入符号(
^)和美元符号($)等锚点仍然指整个字符串的开头和结尾,而不是由<pos>和<endpos>确定的子串:
>>> re_obj = re.compile('^bar')
>>> s = 'foobarbaz'
>>> s[3:]
'barbaz'
>>> print(re_obj.search(s, 3))
None
这里,尽管'bar'出现在从字符 3 开始的子字符串的开头,但它不在整个字符串的开头,所以脱字符(^)定位符无法匹配。
以下方法也适用于编译后的正则表达式对象re_obj:
re_obj.split(<string>, maxsplit=0)re_obj.sub(<repl>, <string>, count=0)re_obj.subn(<repl>, <string>, count=0)
这些函数的行为类似于相应的re函数,但是它们不支持<pos>和<endpos>参数。
正则表达式对象属性
re模块为编译后的正则表达式对象定义了几个有用的属性:
| 属性 | 意义 |
|---|---|
re_obj.flags |
任何对正则表达式有效的<flags> |
re_obj.groups |
正则表达式中捕获组的数量 |
re_obj.groupindex |
将由(?P<name>)结构定义的每个符号组名(如果有的话)映射到相应组号的字典 |
re_obj.pattern |
产生该对象的<regex>模式 |
下面的代码演示了这些属性的一些用法:
1>>> re_obj = re.compile(r'(?m)(\w+),(\w+)', re.I) 2>>> re_obj.flags 342 4>>> re.I|re.M|re.UNICODE 5<RegexFlag.UNICODE|MULTILINE|IGNORECASE: 42> 6>>> re_obj.groups 72 8>>> re_obj.pattern 9'(?m)(\\w+),(\\w+)' 10 11>>> re_obj = re.compile(r'(?P<w1>),(?P<w2>)') 12>>> re_obj.groupindex 13mappingproxy({'w1': 1, 'w2': 2}) 14>>> re_obj.groupindex['w1'] 151 16>>> re_obj.groupindex['w2'] 172注意,
.flags包括任何指定为re.compile()参数的标志,任何在正则表达式中用(?flags)元字符序列指定的标志,以及任何默认有效的标志。在行 1 上定义的正则表达式对象中,定义了三个标志:
re.I: 指定为re.compile()调用中的<flags>值re.M: 在正则表达式内指定为(?m)re.UNICODE: 默认启用在第 4 行可以看到,
re_obj.flags的值是这三个值的逻辑或,等于42。在第 11 行定义的正则表达式对象的
.groupindex属性的值在技术上是一个类型为mappingproxy的对象。实际上,它的功能就像一本字典。匹配对象方法和属性
如您所见,当匹配成功时,
re模块中的大多数函数和方法都返回一个匹配对象。因为匹配对象是真的 T4,所以你可以在条件中使用它:
>>> m = re.search('bar', 'foo.bar.baz')
>>> m
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> bool(m)
True
>>> if re.search('bar', 'foo.bar.baz'): ... print('Found a match')
...
Found a match
但是 match 对象也包含相当多的关于匹配的有用信息。您已经看到了其中的一些——解释器在显示匹配对象时显示的span=和match=数据。使用 match 对象的方法和属性,您可以从 match 对象中获得更多信息。
匹配对象方法
下表总结了匹配对象match可用的方法:
| 方法 | 返回 |
|---|---|
match.group() |
从match中指定的一个或多个捕获组 |
match.__getitem__() |
来自match的一个捕获组 |
match.groups() |
从match捕获的所有组 |
match.groupdict() |
来自match的命名捕获组的字典 |
match.expand() |
从match执行反向引用替换的结果 |
match.start() |
match的起始索引 |
match.end() |
match的结束索引 |
match.span() |
作为元组的match的起始和结束索引 |
以下部分更详细地描述了这些方法。
match.group([<group1>, ...])
从匹配中返回指定的捕获组。
对于编号组,match.group(n)返回n th 组:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz') >>> m.group(1) 'foo' >>> m.group(3) 'baz'记住:编号的捕获组是从 1 开始的,不是从 0 开始的。
如果使用
(?P<name><regex>)捕获组,那么match.group(<name>)返回相应的命名组:
>>> m = re.match(r'(?P<w1>\w+),(?P<w2>\w+),(?P<w3>\w+)', 'quux,corge,grault')
>>> m.group('w1')
'quux'
>>> m.group('w3')
'grault'
如果有多个参数,.group()将返回所有指定组的元组。给定的组可以出现多次,您可以按任何顺序指定任何捕获的组:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz') >>> m.group(1, 3) ('foo', 'baz') >>> m.group(3, 3, 1, 1, 2, 2) ('baz', 'baz', 'foo', 'foo', 'bar', 'bar') >>> m = re.match(r'(?P<w1>\w+),(?P<w2>\w+),(?P<w3>\w+)', 'quux,corge,grault') >>> m.group('w3', 'w1', 'w1', 'w2') ('grault', 'quux', 'quux', 'corge')如果您指定了一个超出范围或不存在的组,那么
.group()会引发一个IndexError异常:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
>>> m.group(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
>>> m = re.match(r'(?P<w1>\w+),(?P<w2>\w+),(?P<w3>\w+)', 'quux,corge,grault')
>>> m.group('foo')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
Python 中的正则表达式可能作为一个整体匹配,但包含一个不参与匹配的组。在这种情况下,.group()返回未参与组的None。考虑这个例子:
>>> m = re.search(r'(\w+),(\w+),(\w+)?', 'foo,bar,') >>> m <_sre.SRE_Match object; span=(0, 8), match='foo,bar,'> >>> m.group(1, 2) ('foo', 'bar')从 match 对象可以看出,这个正则表达式是匹配的。前两个捕获的组分别包含
'foo'和'bar'。不过,第三组后面有一个问号(
?)量词元字符,所以该组是可选的。如果在第二个逗号(,)后面有第三个单词字符序列,那么就会匹配,如果没有,那么也会匹配。在这种情况下,没有。所以总的来说有匹配,但是第三组不参与其中。因此,
m.group(3)仍然被定义并且是一个有效的引用,但是它返回None:
>>> print(m.group(3))
None
也可能发生一个组多次参与整个比赛的情况。如果您为那个组号调用.group(),那么它只返回搜索字符串中最后一次匹配的部分。无法访问更早的匹配项:
>>> m = re.match(r'(\w{3},)+', 'foo,bar,baz,qux') >>> m <_sre.SRE_Match object; span=(0, 12), match='foo,bar,baz,'> >>> m.group(1) 'baz,'在这个例子中,完全匹配是
'foo,bar,baz,',如所显示的匹配对象所示。'foo,'、'bar,'和'baz,'中的每一个都匹配组内的内容,但是m.group(1)只返回最后一个匹配项'baz,'。如果您使用一个参数
0或根本没有参数来调用.group(),那么它将返回整个匹配:
1>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
2>>> m
3<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'> 4
5>>> m.group(0)
6'foo,bar,baz' 7>>> m.group()
8'foo,bar,baz'
这是解释器在显示匹配对象时在match=之后显示的相同数据,正如你在上面的行 3 中看到的。
match.__getitem__(<grp>)
从匹配中返回捕获的组。
match.__getitem__(<grp>)与match.group(<grp>)相同,返回<grp>指定的单组:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz') >>> m.group(2) 'bar' >>> m.__getitem__(2) 'bar'如果
.__getitem__()只是简单地复制了.group()的功能,那么你为什么要使用它呢?你可能不会直接,但你可能会间接。请继续阅读,了解原因。魔法方法简介
.__getitem__()是 Python 中称为魔法方法的方法集合之一。当 Python 语句包含特定的对应语法元素时,解释器会调用这些特殊的方法。注:魔法方法因为方法名的开头和结尾的分值下的ddouble也被称为 dunder 方法。
在本系列的后面,有几个关于面向对象编程的教程。在那里你会学到更多关于魔法的方法。
.__getitem__()对应的特定语法是用方括号索引。对于任何对象obj,无论何时使用表达式obj[n],Python 都会在幕后悄悄地将其翻译成对.__getitem__()的调用。以下表达式实际上是等效的:obj[n] obj.__getitem__(n)语法
obj[n]只有在obj所属的类或类型存在.__getitem()__方法时才有意义。Python 如何解释obj[n]将取决于该类的.__getitem__()的实现。返回匹配对象
从 Python 版本开始,
re模块为匹配对象实现了.__getitem__()。实现是这样的,即match.__getitem__(n)与match.group(n)相同。所有这些的结果是,您可以使用方括号索引语法从 match 对象访问捕获的组,而不是直接调用
.group():
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
>>> m.group(2)
'bar'
>>> m.__getitem__(2)
'bar'
>>> m[2] 'bar'
这也适用于命名的捕获组:
>>> m = re.match( ... r'foo,(?P<w1>\w+),(?P<w2>\w+),qux', ... 'foo,bar,baz,qux') >>> m.group('w2') 'baz' >>> m['w2'] 'baz'这可以通过显式调用
.group()来实现,但这仍然是一个非常快捷的符号。当一种编程语言提供了并非绝对必要的替代语法,但允许以更清晰、更易读的方式表达某种东西时,它被称为 句法糖 。对于匹配对象,
match[n]是match.group(n)的语法糖。注意:Python 中的许多对象都定义了一个
.__getitem()__方法,允许使用方括号索引语法。但是,此功能仅适用于 Python 版或更高版本中的正则表达式匹配对象。
match.groups(default=None)从匹配中返回所有捕获的组。
match.groups()返回所有捕获组的元组:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
>>> m.groups()
('foo', 'bar', 'baz')
正如您之前看到的,当 Python 中正则表达式中的一个组不参与整体匹配时,.group()会为该组返回None。默认情况下,.groups()也是如此。
在这种情况下,如果您希望.groups()返回其他内容,那么您可以使用default关键字参数:
1>>> m = re.search(r'(\w+),(\w+),(\w+)?', 'foo,bar,') 2>>> m 3<_sre.SRE_Match object; span=(0, 8), match='foo,bar,'> 4>>> print(m.group(3)) 5None 6 7>>> m.groups() 8('foo', 'bar', None) 9>>> m.groups(default='---') 10('foo', 'bar', '---')这里,第三个
(\w+)组不参与匹配,因为问号(?)元字符使其可选,并且字符串'foo,bar,'不包含第三个单词字符序列。默认情况下,m.groups()返回第三组的None,如第 8 行所示。在第 10 行上,您可以看到指定default='---'会导致它返回字符串'---'。
.group()没有对应的default关键字。对于不参与的组,它总是返回None。
match.groupdict(default=None)返回命名捕获组的字典。
match.groupdict()返回用(?P<name><regex>)元字符序列捕获的所有命名组的字典。字典关键字是组名,字典值是相应的组值:
>>> m = re.match(
... r'foo,(?P<w1>\w+),(?P<w2>\w+),qux',
... 'foo,bar,baz,qux')
>>> m.groupdict()
{'w1': 'bar', 'w2': 'baz'}
>>> m.groupdict()['w2']
'baz'
与.groups()一样,对于.groupdict(),default参数决定了不参与组的返回值:
>>> m = re.match( ... r'foo,(?P<w1>\w+),(?P<w2>\w+)?,qux', ... 'foo,bar,,qux') >>> m.groupdict() {'w1': 'bar', 'w2': None} >>> m.groupdict(default='---') {'w1': 'bar', 'w2': '---'}同样,由于问号(
?)元字符,最后一组(?P<w2>\w+)不参与整体匹配。默认情况下,m.groupdict()为这个组返回None,但是您可以使用default参数来更改它。
match.expand(<template>)从匹配中执行反向引用替换。
match.expand(<template>)返回通过对<template>执行反向引用替换得到的字符串,就像re.sub()会做的那样:
1>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
2>>> m
3<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'>
4>>> m.groups()
5('foo', 'bar', 'baz')
6
7>>> m.expand(r'\2') 8'bar'
9>>> m.expand(r'[\3] -> [\1]') 10'[baz] -> [foo]'
11
12>>> m = re.search(r'(?P<num>\d+)', 'foo123qux')
13>>> m
14<_sre.SRE_Match object; span=(3, 6), match='123'>
15>>> m.group(1)
16'123'
17
18>>> m.expand(r'--- \g<num> ---') 19'--- 123 ---'
这适用于数字反向引用,如上面的第 7行和第 9 行,也适用于命名反向引用,如第 18 行的。
match.start([<grp>])
match.end([<grp>])
返回匹配的开始和结束索引。
match.start()返回搜索字符串中匹配开始处的索引,而match.end()返回匹配结束后紧接着的索引:
1>>> s = 'foo123bar456baz' 2>>> m = re.search('\d+', s) 3>>> m 4<_sre.SRE_Match object; span=(3, 6), match='123'> 5>>> m.start() 63 7>>> m.end() 86当 Python 显示一个匹配对象时,这些是用关键字
span=列出的值,如上面的行 4 所示。它们的行为类似于字符串切片值,所以如果您使用它们来切片原始搜索字符串,那么您应该得到匹配的子字符串:
>>> m
<_sre.SRE_Match object; span=(3, 6), match='123'>
>>> s[m.start():m.end()]
'123'
match.start(<grp>)和match.end(<grp>)返回<grp>匹配的子串的起始和结束索引,可以是编号或命名的组:
>>> s = 'foo123bar456baz' >>> m = re.search(r'(\d+)\D*(?P<num>\d+)', s) >>> m.group(1) '123' >>> m.start(1), m.end(1) (3, 6) >>> s[m.start(1):m.end(1)] '123' >>> m.group('num') '456' >>> m.start('num'), m.end('num') (9, 12) >>> s[m.start('num'):m.end('num')] '456'如果指定的组匹配一个空字符串,那么
.start()和.end()相等:
>>> m = re.search('foo(\d*)bar', 'foobar')
>>> m[1]
''
>>> m.start(1), m.end(1)
(3, 3)
如果你记得.start()和.end()的行为类似于切片索引,这是有意义的。任何开始和结束索引相等的字符串切片都将始终是空字符串。
当正则表达式包含不参与匹配的组时,会出现一种特殊情况:
>>> m = re.search(r'(\w+),(\w+),(\w+)?', 'foo,bar,') >>> print(m.group(3)) None >>> m.start(3), m.end(3) (-1, -1)正如您之前看到的,在这种情况下,第三组不参与。
m.start(3)和m.end(3)在这里没有实际意义,所以它们返回-1。
match.span([<grp>])返回匹配的开始和结束索引。
match.span()以元组的形式返回匹配的起始和结束索引。如果您指定了<grp>,那么返回元组应用于给定的组:
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(\d+)\D*(?P<num>\d+)', s)
>>> m
<_sre.SRE_Match object; span=(3, 12), match='123bar456'>
>>> m[0]
'123bar456'
>>> m.span() (3, 12)
>>> m[1]
'123'
>>> m.span(1) (3, 6)
>>> m['num']
'456'
>>> m.span('num') (9, 12)
以下内容实际上是等效的:
match.span(<grp>)(match.start(<grp>), match.end(<grp>))
match.span()只是提供了一种在一次方法调用中同时获得match.start()和match.end()的便捷方式。
匹配对象属性
像编译的正则表达式对象一样,match 对象也有几个有用的属性:
| 属性 | 意义 |
|---|---|
match.pos |
|
| T1】 | 匹配的参数<pos>和<endpos>的有效值 |
match.lastindex |
最后捕获的组的索引 |
match.lastgroup |
最后捕获的组的名称 |
match.re |
匹配项的已编译正则表达式对象 |
match.string |
匹配的搜索字符串 |
以下部分提供了关于这些匹配对象属性的更多详细信息。
match.pos
match.endpos
包含用于搜索的
<pos>和<endpos>的有效值。
请记住,一些方法在编译后的正则表达式上调用时,接受可选的<pos>和<endpos>参数,将搜索限制在指定搜索字符串的一部分。这些值可以从带有.pos和.endpos属性的匹配对象中访问:
>>> re_obj = re.compile(r'\d+') >>> m = re_obj.search('foo123bar', 2, 7) >>> m <_sre.SRE_Match object; span=(3, 6), match='123'> >>> m.pos, m.endpos (2, 7)如果调用中没有包含
<pos>和<endpos>参数,要么是因为它们被省略了,要么是因为正在讨论的函数不接受它们,那么.pos和.endpos属性实际上指示了字符串的开始和结束:
1>>> re_obj = re.compile(r'\d+')
2>>> m = re_obj.search('foo123bar') 3>>> m
4<_sre.SRE_Match object; span=(3, 6), match='123'>
5>>> m.pos, m.endpos
6(0, 9)
7
8>>> m = re.search(r'\d+', 'foo123bar') 9>>> m
10<_sre.SRE_Match object; span=(3, 6), match='123'>
11>>> m.pos, m.endpos
12(0, 9)
上面第 2 行的调用可以接受<pos>和<endpos>参数,但是它们没有被指定。8 号线上的re.search()呼叫根本带不走他们。无论哪种情况,m.pos和m.endpos都是0和9,搜索字符串'foo123bar'的起始和结束索引。****
match.lastindex
包含最后捕获的组的索引。
match.lastindex等于最后一个捕获组的整数索引:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz') >>> m.lastindex 3 >>> m[m.lastindex] 'baz'如果正则表达式包含潜在的未参与组,这允许您确定有多少组实际参与了匹配:
>>> m = re.search(r'(\w+),(\w+),(\w+)?', 'foo,bar,baz') >>> m.groups()
('foo', 'bar', 'baz')
>>> m.lastindex, m[m.lastindex]
(3, 'baz')
>>> m = re.search(r'(\w+),(\w+),(\w+)?', 'foo,bar,') >>> m.groups()
('foo', 'bar', None)
>>> m.lastindex, m[m.lastindex]
(2, 'bar')
在第一个示例中,第三个组是可选的,因为问号(?)元字符,它确实参与了匹配。但是在第二个例子中没有。你能看出来,因为第一种情况下m.lastindex是3,第二种情况下2。
关于.lastindex,有一个微妙的问题需要注意。最后一个匹配的组并不总是语法上遇到的最后一个组。Python 文档给出了这个例子:
>>> m = re.match('((a)(b))', 'ab') >>> m.groups() ('ab', 'a', 'b') >>> m.lastindex 1 >>> m[m.lastindex] 'ab'最外面一组是
((a)(b)),匹配'ab'。这是解析器遇到的第一个组,因此它成为组 1。但它也是最后一组匹配的,这就是为什么m.lastindex是1。解析器识别的第二组和第三组是
(a)和(b)。这是组2和3,但是他们在组1之前匹配。
match.lastgroup包含最后捕获的组的名称。
如果最后捕获的组来自于
(?P<name><regex>)元字符序列,那么match.lastgroup返回该组的名称:
>>> s = 'foo123bar456baz'
>>> m = re.search(r'(?P<n1>\d+)\D*(?P<n2>\d+)', s)
>>> m.lastgroup
'n2'
如果最后捕获的组不是命名组,则match.lastgroup返回None:
>>> s = 'foo123bar456baz' >>> m = re.search(r'(\d+)\D*(\d+)', s) >>> m.groups() ('123', '456') >>> print(m.lastgroup) None >>> m = re.search(r'\d+\D*\d+', s) >>> m.groups() () >>> print(m.lastgroup) None如上所示,这可能是因为最后捕获的组不是命名组,也可能是因为根本没有捕获的组。
match.re包含匹配的正则表达式对象。
match.re包含产生匹配的正则表达式对象。如果您将正则表达式传递给re.compile(),您将得到相同的对象:
1>>> regex = r'(\w+),(\w+),(\w+)'
2
3>>> m1 = re.search(regex, 'foo,bar,baz')
4>>> m1
5<_sre.SRE_Match object; span=(0, 11), match='foo,bar,baz'>
6>>> m1.re
7re.compile('(\\w+),(\\w+),(\\w+)')
8
9>>> re_obj = re.compile(regex)
10>>> re_obj
11re.compile('(\\w+),(\\w+),(\\w+)')
12>>> re_obj is m1.re 13True
14
15>>> m2 = re_obj.search('qux,quux,corge')
16>>> m2
17<_sre.SRE_Match object; span=(0, 14), match='qux,quux,corge'>
18>>> m2.re
19re.compile('(\\w+),(\\w+),(\\w+)')
20>>> m2.re is re_obj is m1.re 21True
记住前面的内容,re模块在编译正则表达式后缓存它们,所以如果再次使用它们,不需要重新编译。出于这个原因,正如第 12 行和第 20 行的同一性比较所示,上面例子中所有不同的正则表达式对象都是完全相同的对象。
一旦您可以访问匹配的正则表达式对象,该对象的所有属性也是可用的:
>>> m1.re.groups 3 >>> m1.re.pattern '(\\w+),(\\w+),(\\w+)' >>> m1.re.pattern == regex True >>> m1.re.flags 32您还可以调用为编译后的正则表达式对象定义的任何方法:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz')
>>> m.re
re.compile('(\\w+),(\\w+),(\\w+)')
>>> m.re.match('quux,corge,grault')
<_sre.SRE_Match object; span=(0, 17), match='quux,corge,grault'>
这里,.match()在m.re上被调用,使用相同的正则表达式在不同的搜索字符串上执行另一个搜索。
match.string
包含匹配的搜索字符串。
match.string包含作为匹配目标的搜索字符串:
>>> m = re.search(r'(\w+),(\w+),(\w+)', 'foo,bar,baz') >>> m.string 'foo,bar,baz' >>> re_obj = re.compile(r'(\w+),(\w+),(\w+)') >>> m = re_obj.search('foo,bar,baz') >>> m.string 'foo,bar,baz'从示例中可以看出,当 match 对象也是从一个编译过的正则表达式对象派生出来时,
.string属性是可用的。结论
您对 Python 的
re模块的游览到此结束!这个介绍性系列包含两篇关于 Python 中正则表达式处理的教程。如果你已经学完了之前的教程和本教程,那么你现在应该知道如何:
- 充分利用
re模块提供的所有功能- 用 Python 预编译正则表达式
- 从匹配对象中提取信息
正则表达式非常通用和强大——实际上是一种独立的语言。您会发现它们在您的 Python 编码中是无价的。
注意:
re模块很棒,它可能在大多数情况下都能很好地为你服务。然而,有一个替代的第三方 Python 模块叫做regex,它提供了更好的正则表达式匹配能力。你可以在regex项目页面了解更多。在本系列的下一篇文章中,您将探索 Python 如何避免不同代码区域中标识符之间的冲突。正如您已经看到的,Python 中的每个函数都有自己的名称空间,与其他函数截然不同。在下一篇教程中,您将学习如何在 Python 中实现名称空间,以及它们如何定义变量范围。
« Regular Expressions: Regexes in Python (Part 1)Regular Expressions: Regexes in Python (Part 2)Namespaces and Scope in Python »********
正则表达式:Python 中的正则表达式(第 1 部分)
*立即观看**本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 正则表达式和用 Python 构建正则表达式
在本教程中,您将探索 Python 中的正则表达式,也称为正则表达式。正则表达式是一种特殊的字符序列,它为复杂的字符串匹配功能定义了一种模式。
在本系列的前面,在教程Python 中的字符串和字符数据中,您学习了如何定义和操作字符串对象。从那时起,您已经看到了一些确定两个字符串是否匹配的方法:
您可以使用相等(
==) 运算符来测试两个字符串是否相等。你可以用
in操作符或者内置的字符串方法.find()和.index()来测试是否是另一个字符串的子串。像这样的字符串匹配是编程中的常见任务,使用字符串操作符和内置方法可以完成很多工作。但是,有时您可能需要更复杂的模式匹配功能。
在本教程中,您将学习:
- 如何访问 Python 中实现正则表达式匹配的
re模块- 如何使用
re.search()来匹配字符串的模式- 如何用正则表达式元字符创建复杂的匹配模式
系好安全带!正则表达式语法需要一点时间来适应。但是一旦你熟悉了它,你会发现正则表达式在你的 Python 编程中几乎是不可或缺的。
免费下载: 从 Python 技巧中获取一个示例章节:这本书用简单的例子向您展示了 Python 的最佳实践,您可以立即应用它来编写更漂亮的+Python 代码。
Python 中的正则表达式及其用途
假设你有一个字符串对象
s。现在假设您需要编写 Python 代码来找出s是否包含子串'123'。至少有几种方法可以做到这一点。您可以使用in操作符:
>>> s = 'foo123bar'
>>> '123' in s
True
如果你不仅想知道'123'是否存在于s中,还想知道存在于哪里,那么你可以使用.find()或者.index()。每个函数都返回子字符串所在的字符在s中的位置:**
**>>>
>>> s = 'foo123bar'
>>> s.find('123')
3
>>> s.index('123')
3
在这些例子中,匹配是通过简单的逐字符比较来完成的。在许多情况下,这将完成工作。但有时候,问题比这更复杂。
例如,与其搜索像'123'这样的固定子串,不如假设您想确定一个字符串是否包含任何三个连续的十进制数字字符,如字符串'foo123bar'、'foo456bar'、'234baz'和'qux678'。
严格的字符比较在这里是行不通的。这就是 Python 中正则表达式的用武之地。
正则表达式的(非常简短的)历史
1951 年,数学家斯蒂芬·科尔·克莱尼描述了正则语言的概念,这是一种可被有限自动机识别并可使用正则表达式进行正式表达的语言。20 世纪 60 年代中期,计算机科学先驱肯·汤普森,Unix 的最初设计者之一,使用克莱尼符号在 QED 文本编辑器中实现了模式匹配。
从那以后,正则表达式出现在许多编程语言、编辑器和其他工具中,作为确定字符串是否匹配指定模式的一种手段。Python、 Java 和 Perl 都支持 regex 功能,大多数 Unix 工具和许多文本编辑器也是如此。
re模块
Python 中的正则表达式功能驻留在一个名为re的模块中。re模块包含许多有用的函数和方法,其中大部分将在本系列的下一篇教程中学习。
现在,您将主要关注一个功能,re.search()。
re.search(<regex>, <string>)
扫描字符串中的正则表达式匹配。
re.search(<regex>, <string>)扫描<string>寻找模式<regex>匹配的第一个位置。如果找到匹配,那么re.search()返回一个匹配对象。否则,返回 None 。
re.search()接受可选的第三个<flags>参数,您将在本教程结束时了解到。
如何导入re.search()
因为search()驻留在re模块中,你需要导入才能使用它。一种方法是导入整个模块,然后在调用函数时使用模块名作为前缀:
import re
re.search(...)
或者,您可以通过名称从模块中导入函数,然后在没有模块名称前缀的情况下引用它:
from re import search
search(...)
在你能够使用它之前,你总是需要以某种方式导入re.search()。
本教程剩余部分中的例子将假设所示的第一种方法——导入re模块,然后引用带有模块名前缀的函数:re.search()。为了简洁起见,import re语句通常会被省略,但是记住它总是必要的。
有关从模块和包导入的更多信息,请查看 Python 模块和包——简介。
第一个模式匹配示例
现在您已经知道如何访问re.search(),您可以试一试:
1>>> s = 'foo123bar' 2 3>>> # One last reminder to import! 4>>> import re 5 6>>> re.search('123', s) 7<_sre.SRE_Match object; span=(3, 6), match='123'>这里,搜索模式
<regex>是123,<string>是s。返回的匹配对象出现在第 7 行。Match 对象包含大量有用的信息,您将很快了解这些信息。目前,重要的一点是
re.search()实际上返回了一个匹配对象,而不是None。告诉你它找到了一个匹配。换句话说,指定的<regex>图案123存在于s中。
>>> if re.search('123', s):
... print('Found a match.')
... else:
... print('No match.')
...
Found a match.
解释器将匹配对象显示为<_sre.SRE_Match object; span=(3, 6), match='123'>。这包含了一些有用的信息。
span=(3, 6)表示在<string>中找到匹配的部分。这与在切片符号中的意思相同:
>>> s[3:6] '123'在这个例子中,匹配从字符位置
3开始,延伸到但不包括位置6。
match='123'表示来自<string>的哪些字符匹配。这是一个好的开始。但是在这种情况下,
<regex>模式只是普通的字符串'123'。这里的模式匹配仍然只是逐字符的比较,与前面显示的in操作符和.find()示例非常相似。match 对象告诉您匹配的字符是'123',这很有帮助,但是这并不能说明什么,因为这些正是您要搜索的字符。你才刚开始热身。
Python 正则表达式元字符
当
<regex>包含称为元字符的特殊字符时,Python 中正则表达式匹配的真正威力就显现出来了。这些对于正则表达式匹配引擎有着独特的意义,并极大地增强了搜索能力。再次考虑如何确定一个字符串是否包含任何三个连续的十进制数字字符的问题。
在正则表达式中,方括号(
[])中指定的一组字符组成了一个字符类。此元字符序列匹配类中的任何单个字符,如以下示例所示:
>>> s = 'foo123bar'
>>> re.search('[0-9][0-9][0-9]', s)
<_sre.SRE_Match object; span=(3, 6), match='123'>
[0-9]匹配任何单个十进制数字字符——包括'0'和'9'之间的任何字符。完整表达式[0-9][0-9][0-9]匹配三个十进制数字字符的任意序列。在这种情况下,s匹配,因为它包含三个连续的十进制数字字符,'123'。
这些字符串也匹配:
>>> re.search('[0-9][0-9][0-9]', 'foo456bar') <_sre.SRE_Match object; span=(3, 6), match='456'> >>> re.search('[0-9][0-9][0-9]', '234baz') <_sre.SRE_Match object; span=(0, 3), match='234'> >>> re.search('[0-9][0-9][0-9]', 'qux678') <_sre.SRE_Match object; span=(3, 6), match='678'>另一方面,不包含三个连续数字的字符串不匹配:
>>> print(re.search('[0-9][0-9][0-9]', '12foo34'))
None
使用 Python 中的正则表达式,您可以识别字符串中使用in操作符或字符串方法无法找到的模式。
看看另一个正则表达式元字符。点(.)元字符匹配除换行符之外的任何字符,因此它的功能类似于通配符:
>>> s = 'foo123bar' >>> re.search('1.3', s) <_sre.SRE_Match object; span=(3, 6), match='123'> >>> s = 'foo13bar' >>> print(re.search('1.3', s)) None在第一个例子中,正则表达式
1.3匹配'123',因为'1'和'3'完全匹配,而.匹配'2'。在这里,您实际上是在问,“s是否包含一个'1',然后是任何字符(除了换行符),然后是一个'3'?”对于'foo123bar'答案是肯定的,对于'foo13bar'答案是否定的。这些例子快速展示了正则表达式元字符的强大功能。字符类和点只是
re模块支持的两个元字符。还有很多。接下来,您将全面探索它们。
re模块支持的元字符下表简要总结了
re模块支持的所有元字符。有些角色有多种用途:
字符 意义 .匹配除换行符以外的任何单个字符 ^在一个字符串的开头锚定一个匹配 √补充一个字符类 $在字符串末尾锚定一个匹配 *匹配零次或多次重复 +匹配一个或多个重复 ?匹配零个或一个重复 ∏指定 *、+和?、的非贪婪版本∏引入前视或后视断言 ∏创建命名组 {}匹配明确指定的重复次数 \转义具有特殊含义的元字符 √引入特殊字符类 √引入分组反向引用 []指定了字符类 |指定变更 ()创建一个组 :#=指定一个专门小组 <>创建命名组 这似乎是一个巨大的信息量,但是不要惊慌!接下来的章节将详细介绍其中的每一项。
regex 解析器将上面没有列出的任何字符视为只匹配自身的普通字符。例如,在上面显示的第一个模式匹配示例中,您会看到:
>>> s = 'foo123bar'
>>> re.search('123', s)
<_sre.SRE_Match object; span=(3, 6), match='123'>
在这种情况下,123从技术上来说是一个正则表达式,但它并不是一个非常有趣的正则表达式,因为它不包含任何元字符。它只是匹配字符串'123'。
当您将元字符融入其中时,事情会变得更加令人兴奋。以下部分详细解释了如何使用每个元字符或元字符序列来增强模式匹配功能。
匹配单个字符的元字符
本节中的元字符序列尝试匹配搜索字符串中的单个字符。当正则表达式解析器遇到这些元字符序列中的一个时,如果当前解析位置的字符符合该序列描述的描述,就会发生匹配。
[]
指定要匹配的特定字符集。
方括号([])中包含的字符代表一个字符类——一组要匹配的枚举字符。字符类元字符序列将匹配该类中包含的任何单个字符。
您可以像这样逐个列举字符:
>>> re.search('ba[artz]', 'foobarqux') <_sre.SRE_Match object; span=(3, 6), match='bar'> >>> re.search('ba[artz]', 'foobazqux') <_sre.SRE_Match object; span=(3, 6), match='baz'>元字符序列
[artz]匹配任何单个'a'、'r'、't'或'z'字符。在这个例子中,正则表达式ba[artz]匹配'bar'和'baz'(也将匹配'baa'和'bat')。字符类还可以包含由连字符(
-)分隔的字符范围,在这种情况下,它匹配范围内的任何单个字符。例如,[a-z]匹配'a'和'z'之间的任何小写字母字符,包括:
>>> re.search('[a-z]', 'FOObar')
<_sre.SRE_Match object; span=(3, 4), match='b'>
[0-9]匹配任何数字字符:
>>> re.search('[0-9][0-9]', 'foo123bar') <_sre.SRE_Match object; span=(3, 5), match='12'>在这种情况下,
[0-9][0-9]匹配两位数的序列。匹配的字符串'foo123bar'的第一部分是'12'。
[0-9a-fA-F]匹配任意十六进制数字字符:
>>> re.search('[0-9a-fA-f]', '--- a0 ---')
<_sre.SRE_Match object; span=(4, 5), match='a'>
这里,[0-9a-fA-F]匹配搜索字符串中的第一个十六进制数字字符,'a'。
注意:在上面的例子中,返回值总是最左边的可能匹配。re.search()从左到右扫描搜索字符串,一旦找到与<regex>匹配的内容,它就停止扫描并返回匹配内容。
您可以通过将^指定为第一个字符来补充字符类,在这种情况下,它匹配集合中不属于的任何字符。在以下示例中,[^0-9]匹配任何不是数字的字符:
>>> re.search('[^0-9]', '12345foo') <_sre.SRE_Match object; span=(5, 6), match='f'>这里,match 对象表示字符串中第一个不是数字的字符是
'f'。如果一个
^字符出现在一个字符类中,但不是第一个字符,那么它没有特殊的含义,并且匹配一个文字'^'字符:
>>> re.search('[#:^]', 'foo^bar:baz#qux')
<_sre.SRE_Match object; span=(3, 4), match='^'>
如您所见,您可以通过用连字符分隔字符来指定字符类中的字符范围。如果您希望字符类包含文字连字符,该怎么办?您可以将其作为第一个或最后一个字符,或者用反斜杠(\)将其转义:
>>> re.search('[-abc]', '123-456') <_sre.SRE_Match object; span=(3, 4), match='-'> >>> re.search('[abc-]', '123-456') <_sre.SRE_Match object; span=(3, 4), match='-'> >>> re.search('[ab\-c]', '123-456') <_sre.SRE_Match object; span=(3, 4), match='-'>如果你想在一个字符类中包含一个文字
']',那么你可以把它作为第一个字符或者用反斜杠对它进行转义:
>>> re.search('[]]', 'foo[1]')
<_sre.SRE_Match object; span=(5, 6), match=']'>
>>> re.search('[ab\]cd]', 'foo[1]')
<_sre.SRE_Match object; span=(5, 6), match=']'>
其他正则表达式元字符在字符类中失去了它们的特殊意义:
>>> re.search('[)*+|]', '123*456') <_sre.SRE_Match object; span=(3, 4), match='*'> >>> re.search('[)*+|]', '123+456') <_sre.SRE_Match object; span=(3, 4), match='+'>如上表所示,
*和+在 Python 的正则表达式中有特殊的含义。它们表示重复,稍后你会学到更多。但是在这个例子中,它们在一个字符类中,所以它们在字面上匹配它们自己。点(
.)指定通配符。
.元字符匹配除换行符之外的任何单个字符:
>>> re.search('foo.bar', 'fooxbar')
<_sre.SRE_Match object; span=(0, 7), match='fooxbar'>
>>> print(re.search('foo.bar', 'foobar'))
None
>>> print(re.search('foo.bar', 'foo\nbar'))
None
作为一个正则表达式,foo.bar本质上意味着字符'foo',然后是除换行符之外的任何字符,然后是字符'bar'。上面显示的第一个字符串'fooxbar'符合要求,因为.元字符与'x'匹配。
第二个和第三个字符串不匹配。在最后一种情况下,尽管在'foo'和'bar'之间有一个字符,但它是一个换行符,默认情况下,.元字符不匹配换行符。然而,有一种方法可以强制.匹配一个换行符,您将在本教程的末尾了解到这一点。
\w
T1】
基于字符是否是单词字符进行匹配。
\w匹配任何字母数字单词字符。单词字符是大小写字母、数字和下划线(_)字符,所以\w实际上是[a-zA-Z0-9_]的简写:
>>> re.search('\w', '#(.a$@&') <_sre.SRE_Match object; span=(3, 4), match='a'> >>> re.search('[a-zA-Z0-9_]', '#(.a$@&') <_sre.SRE_Match object; span=(3, 4), match='a'>在这种情况下,字符串
'#(.a$@&'中的第一个单词字符是'a'。
\W正相反。它匹配任何非单词字符,相当于[^a-zA-Z0-9_]:
>>> re.search('\W', 'a_1*3Qb')
<_sre.SRE_Match object; span=(3, 4), match='*'>
>>> re.search('[^a-zA-Z0-9_]', 'a_1*3Qb')
<_sre.SRE_Match object; span=(3, 4), match='*'>
这里,'a_1*3!b'中的第一个非文字字符是'*'。
\d
T1】
基于字符是否为十进制数字进行匹配。
\d匹配任何十进制数字字符。\D则相反。它匹配不是十进制数字的任何字符:
>>> re.search('\d', 'abc4def') <_sre.SRE_Match object; span=(3, 4), match='4'> >>> re.search('\D', '234Q678') <_sre.SRE_Match object; span=(3, 4), match='Q'>
\d本质上相当于[0-9],\D相当于[^0-9]。
\s
T1】基于字符是否代表空白进行匹配。
\s匹配任何空白字符:
>>> re.search('\s', 'foo\nbar baz')
<_sre.SRE_Match object; span=(3, 4), match='\n'>
注意,与点通配符元字符不同,\s匹配换行符。
\S是\s的反义词。它匹配不是空格的任何字符:
>>> re.search('\S', ' \n foo \n ') <_sre.SRE_Match object; span=(4, 5), match='f'>同样,
\s和\S认为换行符是空白。在上面的例子中,第一个非空白字符是'f'。字符类序列
\w、\W、\d、\D、\s和\S也可以出现在方括号字符类中:
>>> re.search('[\d\w\s]', '---3---')
<_sre.SRE_Match object; span=(3, 4), match='3'>
>>> re.search('[\d\w\s]', '---a---')
<_sre.SRE_Match object; span=(3, 4), match='a'>
>>> re.search('[\d\w\s]', '--- ---')
<_sre.SRE_Match object; span=(3, 4), match=' '>
在这种情况下,[\d\w\s]匹配任何数字、单词或空白字符。并且由于\w包括\d,相同的字符类也可以表示为略短的[\w\s]。
转义元字符
偶尔,你会想在你的正则表达式中包含一个元字符,除非你不想让它有特殊的含义。相反,您会希望它将自己表示为一个文字字符。
反斜杠(\)
删除元字符的特殊含义。
正如您刚才看到的,反斜杠字符可以引入特殊的字符类,如单词、数字和空格。还有一些特殊的元字符序列,称为以反斜杠开头的锚,您将在下面了解到。
当反斜杠不满足这两个目的时,它会对元字符进行转义。以反斜杠开头的元字符失去了它的特殊含义,而是匹配原义字符。考虑下面的例子:
1>>> re.search('.', 'foo.bar') 2<_sre.SRE_Match object; span=(0, 1), match='f'> 3 4>>> re.search('\.', 'foo.bar') 5<_sre.SRE_Match object; span=(3, 4), match='.'>在第 1 行的
<regex>中,点(.)作为通配符元字符,匹配字符串中的第一个字符('f')。第 4 行的<regex>中的.字符由反斜杠转义,所以它不是通配符。它被逐字解释并匹配搜索字符串索引3处的'.'。使用反斜杠进行转义会变得混乱。假设您有一个包含单个反斜杠的字符串:
>>> s = r'foo\bar'
>>> print(s)
foo\bar
现在假设您想要创建一个<regex>,它将匹配'foo'和'bar'之间的反斜杠。反斜杠本身是正则表达式中的特殊字符,所以要指定字面反斜杠,需要用另一个反斜杠对其进行转义。如果是这种情况,那么应该执行以下操作:
>>> re.search('\\', s)不完全是。这是你尝试的结果:
>>> re.search('\\', s)
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
re.search('\\', s)
File "C:\Python36\lib\re.py", line 182, in search
return _compile(pattern, flags).search(string)
File "C:\Python36\lib\re.py", line 301, in _compile
p = sre_compile.compile(pattern, flags)
File "C:\Python36\lib\sre_compile.py", line 562, in compile
p = sre_parse.parse(p, flags)
File "C:\Python36\lib\sre_parse.py", line 848, in parse
source = Tokenizer(str)
File "C:\Python36\lib\sre_parse.py", line 231, in __init__
self.__next()
File "C:\Python36\lib\sre_parse.py", line 245, in __next
self.string, len(self.string) - 1) from None
sre_constants.error: bad escape (end of pattern) at position 0
哎呀。发生了什么事?
这里的问题是反斜杠转义发生了两次,第一次是由 Python 解释器对字符串进行转义,第二次是由 regex 解析器对收到的 regex 进行转义。
事情的顺序是这样的:
- Python 解释器首先处理字符串文字
'\\'。它将其解释为转义反斜杠,并且只将一个反斜杠传递给re.search()。 - 正则表达式解析器只接收一个反斜杠,这不是一个有意义的正则表达式,所以混乱的错误随之而来。
有两种方法可以解决这个问题。首先,您可以对原始字符串中的两个反斜杠进行转义:
>>> re.search('\\\\', s) <_sre.SRE_Match object; span=(3, 4), match='\\'>这样做会导致以下情况发生:
- 解释器将
'\\\\'视为一对转义反斜杠。它将每一对简化为一个反斜杠,并将'\\'传递给 regex 解析器。- 然后,正则表达式解析器将
\\视为一个转义反斜杠。作为一个<regex>,它匹配一个反斜杠字符。您可以从 match 对象中看到,它按照预期匹配了s中索引3处的反斜杠。很繁琐,但是很管用。第二种,也可能是更干净的处理方式是使用一个原始字符串来指定
<regex>:
>>> re.search(r'\\', s)
<_sre.SRE_Match object; span=(3, 4), match='\\'>
这抑制了解释器级别的转义。字符串'\\'被原封不动地传递给 regex 解析器,解析器再次根据需要看到一个转义反斜杠。
在 Python 中,每当包含反斜杠时,使用原始字符串来指定正则表达式是一个好习惯。
锚
锚点是零宽度匹配。它们不匹配搜索字符串中的任何实际字符,并且在解析过程中不消耗任何搜索字符串。相反,锚点指示搜索字符串中必须出现匹配的特定位置。
^
T1】
将一场比赛锚定到
<string>的开始。
当正则表达式解析器遇到^或\A时,解析器的当前位置必须在搜索字符串的开头,以便找到匹配。
换句话说,regex ^foo规定'foo'不仅要出现在搜索字符串中的任何旧位置,还要出现在开头:
>>> re.search('^foo', 'foobar') <_sre.SRE_Match object; span=(0, 3), match='foo'> >>> print(re.search('^foo', 'barfoo')) None
\A功能相似:
>>> re.search('\Afoo', 'foobar')
<_sre.SRE_Match object; span=(0, 3), match='foo'>
>>> print(re.search('\Afoo', 'barfoo'))
None
^和\A在MULTILINE模式下的表现略有不同。在下面关于标志的章节中,你会了解到更多关于MULTILINE模式的信息。
$
T1】
将一场比赛锚定到
<string>的结尾。
当正则表达式解析器遇到$或\Z时,解析器的当前位置必须在搜索字符串的末尾,这样它才能找到匹配。位于$或\Z之前的内容必须构成搜索字符串的结尾:
>>> re.search('bar$', 'foobar') <_sre.SRE_Match object; span=(3, 6), match='bar'> >>> print(re.search('bar$', 'barfoo')) None >>> re.search('bar\Z', 'foobar') <_sre.SRE_Match object; span=(3, 6), match='bar'> >>> print(re.search('bar\Z', 'barfoo')) None作为一个特例,
$(而不是\Z)也匹配搜索字符串末尾的一个换行符之前的内容:
>>> re.search('bar$', 'foobar\n')
<_sre.SRE_Match object; span=(3, 6), match='bar'>
在这个例子中,'bar'在技术上并不在搜索字符串的末尾,因为它后面跟了一个额外的换行符。但是 regex 解析器让它滑动,不管怎样都称它为匹配。这个例外不适用于\Z。
$和\Z在MULTILINE模式下的表现略有不同。关于MULTILINE模式的更多信息,参见下面关于标志的部分。
\b
将匹配锚定到单词边界。
断言正则表达式解析器的当前位置必须在单词的开头或结尾。一个单词由一系列字母数字字符或下划线([a-zA-Z0-9_])组成,与\w字符类相同:
1>>> re.search(r'\bbar', 'foo bar') 2<_sre.SRE_Match object; span=(4, 7), match='bar'> 3>>> re.search(r'\bbar', 'foo.bar') 4<_sre.SRE_Match object; span=(4, 7), match='bar'> 5 6>>> print(re.search(r'\bbar', 'foobar')) 7None 8 9>>> re.search(r'foo\b', 'foo bar') 10<_sre.SRE_Match object; span=(0, 3), match='foo'> 11>>> re.search(r'foo\b', 'foo.bar') 12<_sre.SRE_Match object; span=(0, 3), match='foo'> 13 14>>> print(re.search(r'foo\b', 'foobar')) 15None在上面的例子中,匹配发生在的第 1 行和第 3 行,因为在
'bar'的开头有一个单词边界。在第 6 的线上情况并非如此,所以匹配在那里失败。同样的,在第 9 行和第 11 行也有匹配,因为在
'foo'结尾有一个字边界,而在第 14 行没有。在
<regex>的两端使用\b锚将使它作为一个完整的单词出现在搜索字符串中时匹配:
>>> re.search(r'\bbar\b', 'foo bar baz')
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> re.search(r'\bbar\b', 'foo(bar)baz')
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> print(re.search(r'\bbar\b', 'foobarbaz'))
None
这是另一个将<regex>指定为原始字符串的例子,就像上面的例子一样。
因为'\b'是 Python 中字符串文字和正则表达式的转义序列,所以如果不使用原始字符串,上面的每次使用都需要双转义为'\\b'。这不会是世界末日,但原始字符串更整齐。
\B
将匹配锚定到非单词边界的位置。
\B做与\b相反的事。它断言正则表达式解析器的当前位置必须而不是在单词的开头或结尾:
1>>> print(re.search(r'\Bfoo\B', 'foo')) 2None 3>>> print(re.search(r'\Bfoo\B', '.foo.')) 4None 5 6>>> re.search(r'\Bfoo\B', 'barfoobaz') 7<_sre.SRE_Match object; span=(3, 6), match='foo'>在这种情况下,匹配发生在第 7 行,因为在搜索字符串
'barfoobaz'中的'foo'的开头或结尾不存在单词边界。量词
一个量词元字符紧跟在一个
<regex>的一部分之后,并指示该部分必须出现多少次才能成功匹配。
*匹配前面正则表达式的零次或多次重复。
例如,
a*匹配零个或多个'a'字符。这意味着它将匹配一个空字符串,'a','aa','aaa',等等。考虑这些例子:
1>>> re.search('foo-*bar', 'foobar') # Zero dashes 2<_sre.SRE_Match object; span=(0, 6), match='foobar'>
3>>> re.search('foo-*bar', 'foo-bar') # One dash 4<_sre.SRE_Match object; span=(0, 7), match='foo-bar'>
5>>> re.search('foo-*bar', 'foo--bar') # Two dashes 6<_sre.SRE_Match object; span=(0, 8), match='foo--bar'>
在第 1 行,在'foo'和'bar'之间有零个'-'字符。在线 3 上有一个,在线 5 上有两个。元字符序列-*在所有三种情况下都匹配。
你可能会在 Python 程序中遇到正则表达式.*。这匹配任何字符的零次或多次出现。换句话说,它基本上匹配任何字符序列,直到一个换行符。(记住.通配符元字符不匹配换行符。)
在本例中,.*匹配'foo'和'bar'之间的所有内容:
>>> re.search('foo.*bar', '# foo $qux@grault % bar #') <_sre.SRE_Match object; span=(2, 23), match='foo $qux@grault % bar'>注意到 match 对象中包含的
span=和match=信息了吗?到目前为止,示例中的正则表达式已经指定了可预测长度的匹配。一旦你开始使用像
*这样的量词,匹配的字符数量可能会有很大的变化,match 对象中的信息变得更加有用。在本系列的下一篇教程中,您将了解更多关于如何访问存储在 match 对象中的信息。
+匹配前面正则表达式的一次或多次重复。
这类似于
*,但是量化的正则表达式必须至少出现一次:
1>>> print(re.search('foo-+bar', 'foobar')) # Zero dashes 2None
3>>> re.search('foo-+bar', 'foo-bar') # One dash 4<_sre.SRE_Match object; span=(0, 7), match='foo-bar'>
5>>> re.search('foo-+bar', 'foo--bar') # Two dashes 6<_sre.SRE_Match object; span=(0, 8), match='foo--bar'>
记住上面的内容,因为*元字符允许'-'不出现,所以foo-*bar匹配字符串'foobar'。另一方面,+元字符要求至少出现一次'-'。这意味着在这种情况下行 1 上没有匹配。
?
匹配前面正则表达式的零次或一次重复。
同样,这类似于*和+,但是在这种情况下,只有前面的正则表达式出现一次或者根本没有出现,才匹配:
1>>> re.search('foo-?bar', 'foobar') # Zero dashes 2<_sre.SRE_Match object; span=(0, 6), match='foobar'> 3>>> re.search('foo-?bar', 'foo-bar') # One dash 4<_sre.SRE_Match object; span=(0, 7), match='foo-bar'> 5>>> print(re.search('foo-?bar', 'foo--bar')) # Two dashes 6None在这个例子中,在线 1 和 3 上有匹配。但是在第 5 的行,有两个
'-'字符,匹配失败。以下是展示所有三个量词元字符用法的更多示例:
>>> re.match('foo[1-9]*bar', 'foobar')
<_sre.SRE_Match object; span=(0, 6), match='foobar'>
>>> re.match('foo[1-9]*bar', 'foo42bar')
<_sre.SRE_Match object; span=(0, 8), match='foo42bar'>
>>> print(re.match('foo[1-9]+bar', 'foobar'))
None
>>> re.match('foo[1-9]+bar', 'foo42bar')
<_sre.SRE_Match object; span=(0, 8), match='foo42bar'>
>>> re.match('foo[1-9]?bar', 'foobar')
<_sre.SRE_Match object; span=(0, 6), match='foobar'>
>>> print(re.match('foo[1-9]?bar', 'foo42bar'))
None
这次量化的正则表达式是字符类[1-9]而不是简单字符'-'。
*?
+?
T2】
*、+和?量词的非贪婪(或懒惰)版本。
单独使用时,量词元字符*、+和?都是贪婪,这意味着它们产生最长的可能匹配。考虑这个例子:
>>> re.search('<.*>', '%<foo> <bar> <baz>%') <_sre.SRE_Match object; span=(1, 18), match='<foo> <bar> <baz>'>正则表达式
<.*>实际上意味着:
- 一个
'<'人物- 那么任何字符序列
- 然后是一个
'>'字符但是哪个
'>'人物呢?有三种可能性:
- 就在
'foo'之后的那个- 就在
'bar'之后的那个- 就在
'baz'之后的那个由于
*元字符是贪婪的,它规定了可能的最长匹配,这包括了从'>'字符到'baz'之后的所有内容。从 match 对象可以看出,这是产生的匹配。如果您想要最短的可能匹配,那么使用非贪婪元字符序列
*?:
>>> re.search('<.*?>', '%<foo> <bar> <baz>%')
<_sre.SRE_Match object; span=(1, 6), match='<foo>'>
在这种情况下,匹配以跟在'foo'后面的'>'字符结束。
注意:您可以用正则表达式<[^>]*>完成同样的事情,这意味着:
- 一个
'<'人物 - 然后是除
'>'以外的任何字符序列 - 然后是一个
'>'字符
这是一些不支持惰性量词的旧解析器的唯一选项。令人高兴的是,Python 的re模块中的正则表达式解析器却不是这样。
还有懒惰版本的+和?量词:
1>>> re.search('<.+>', '%<foo> <bar> <baz>%') 2<_sre.SRE_Match object; span=(1, 18), match='<foo> <bar> <baz>'> 3>>> re.search('<.+?>', '%<foo> <bar> <baz>%') 4<_sre.SRE_Match object; span=(1, 6), match='<foo>'> 5 6>>> re.search('ba?', 'baaaa') 7<_sre.SRE_Match object; span=(0, 2), match='ba'> 8>>> re.search('ba??', 'baaaa') 9<_sre.SRE_Match object; span=(0, 1), match='b'>1 号线和 3 号线的前两个例子与上面所示的例子类似,只是使用了
+和+?而不是*和*?。第 6 行和第 8 行的最后一个例子略有不同。一般来说,
?元字符匹配零个或一个前面的正则表达式。贪婪的版本?匹配一个事件,所以ba?匹配'b',后跟一个'a'。非贪婪版本??匹配零个出现,所以ba??只匹配'b'。
{m}精确匹配前面正则表达式的
m次重复。这类似于
*或+,但是它精确地指定了前面的正则表达式必须出现多少次才能成功匹配:
>>> print(re.search('x-{3}x', 'x--x')) # Two dashes
None
>>> re.search('x-{3}x', 'x---x') # Three dashes
<_sre.SRE_Match object; span=(0, 5), match='x---x'>
>>> print(re.search('x-{3}x', 'x----x')) # Four dashes
None
在这里,x-{3}x与'x'匹配,紧接着是'-'角色的三个实例,接着是另一个'x'。当'x'字符之间的破折号少于或多于三个时,匹配失败。
{m,n}
匹配前面正则表达式从
m到n的任意重复次数,包括 T0 和 T1。
在下面的例子中,量化的<regex>是-{2,4}。当'x'字符之间有两个、三个或四个破折号时,匹配成功,否则匹配失败:
>>> for i in range(1, 6): ... s = f"x{'-' * i}x" ... print(f'{i} {s:10}', re.search('x-{2,4}x', s)) ... 1 x-x None 2 x--x <_sre.SRE_Match object; span=(0, 4), match='x--x'> 3 x---x <_sre.SRE_Match object; span=(0, 5), match='x---x'> 4 x----x <_sre.SRE_Match object; span=(0, 6), match='x----x'> 5 x-----x None省略
m意味着一个0的下界,省略n意味着一个无限的上界:
正则表达式 比赛 相同 <regex>{,n}小于或等于 n的<regex>的任何重复次数<regex>{0,n}<regex>{m,}大于或等于 m的<regex>的任意重复次数----<regex>{,}重复任意次数的 <regex><regex>{0,}T1】 如果您省略了所有的
m、n和逗号,那么花括号不再作为元字符。{}仅匹配文字字符串'{}':
>>> re.search('x{}y', 'x{}y')
<_sre.SRE_Match object; span=(0, 4), match='x{}y'>
事实上,要有任何特殊意义,带花括号的序列必须符合以下模式之一,其中m和n为非负整数:
{m,n}{m,}{,n}{,}
否则,它匹配字面意思:
>>> re.search('x{foo}y', 'x{foo}y') <_sre.SRE_Match object; span=(0, 7), match='x{foo}y'> >>> re.search('x{a:b}y', 'x{a:b}y') <_sre.SRE_Match object; span=(0, 7), match='x{a:b}y'> >>> re.search('x{1,3,5}y', 'x{1,3,5}y') <_sre.SRE_Match object; span=(0, 9), match='x{1,3,5}y'> >>> re.search('x{foo,bar}y', 'x{foo,bar}y') <_sre.SRE_Match object; span=(0, 11), match='x{foo,bar}y'>在本教程的后面,当您了解到
DEBUG标志时,您将看到如何确认这一点。
{m,n}?
{m,n}的非贪(懒)版本。
{m,n}将匹配尽可能多的字符,{m,n}?将匹配尽可能少的字符:
>>> re.search('a{3,5}', 'aaaaaaaa')
<_sre.SRE_Match object; span=(0, 5), match='aaaaa'>
>>> re.search('a{3,5}?', 'aaaaaaaa')
<_sre.SRE_Match object; span=(0, 3), match='aaa'>
在这种情况下,a{3,5}产生最长的可能匹配,因此它匹配五个'a'字符。a{3,5}?产生最短的匹配,所以它匹配三个。
分组构造和反向引用
分组构造将 Python 中的正则表达式分解成子表达式或组。这有两个目的:
- 分组:一个组代表一个单一的句法实体。附加元字符作为一个单元应用于整个组。
- 捕获:一些分组结构也捕获搜索字符串中匹配组中子表达式的部分。您可以稍后通过几种不同的机制检索捕获的匹配。
下面来看看分组和采集是如何工作的。
(<regex>)
定义子表达式或组。
这是最基本的分组结构。括号中的正则表达式只匹配括号中的内容:
>>> re.search('(bar)', 'foo bar baz') <_sre.SRE_Match object; span=(4, 7), match='bar'> >>> re.search('bar', 'foo bar baz') <_sre.SRE_Match object; span=(4, 7), match='bar'>作为一个正则表达式,
(bar)匹配字符串'bar',与不带括号的正则表达式bar一样。将一个组视为一个单元
组后面的量词元字符将组中指定的整个子表达式作为一个单元进行操作。
例如,以下示例匹配一个或多个字符串
'bar':
>>> re.search('(bar)+', 'foo bar baz')
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> re.search('(bar)+', 'foo barbar baz')
<_sre.SRE_Match object; span=(4, 10), match='barbar'>
>>> re.search('(bar)+', 'foo barbarbarbar baz')
<_sre.SRE_Match object; span=(4, 16), match='barbarbarbar'>
下面是有分组括号和没有分组括号的两种正则表达式之间的区别:
| 正则表达式 | 解释 | 比赛 | 例子 |
|---|---|---|---|
bar+ |
+元字符仅适用于字符'r'。 |
'ba'之后是一次或多次出现的'r' |
'bar' |
'barr' |
|||
| T2】 | |||
(bar)+ |
+元字符适用于整个字符串'bar'。 |
一次或多次出现'bar' |
'bar' |
'barbar' |
|||
| T2】 |
现在看一个更复杂的例子。正则表达式(ba[rz]){2,4}(qux)?将2与'bar'或'baz'的4匹配,可选地后跟'qux':
>>> re.search('(ba[rz]){2,4}(qux)?', 'bazbarbazqux') <_sre.SRE_Match object; span=(0, 12), match='bazbarbazqux'> >>> re.search('(ba[rz]){2,4}(qux)?', 'barbar') <_sre.SRE_Match object; span=(0, 6), match='barbar'>以下示例显示您可以嵌套分组括号:
>>> re.search('(foo(bar)?)+(\d\d\d)?', 'foofoobar')
<_sre.SRE_Match object; span=(0, 9), match='foofoobar'>
>>> re.search('(foo(bar)?)+(\d\d\d)?', 'foofoobar123')
<_sre.SRE_Match object; span=(0, 12), match='foofoobar123'>
>>> re.search('(foo(bar)?)+(\d\d\d)?', 'foofoo123')
<_sre.SRE_Match object; span=(0, 9), match='foofoo123'>
正则表达式(foo(bar)?)+(\d\d\d)?相当复杂,所以让我们把它分成更小的部分:
| 正则表达式 | 比赛 |
|---|---|
foo(bar)? |
'foo'可选后接'bar' |
(foo(bar)?)+ |
上述一个或多个事件 |
\d\d\d |
三个十进制数字字符 |
(\d\d\d)? |
上述情况出现零次或一次 |
把它们串在一起,你会得到:至少出现一次'foo',后面可选地跟着'bar',后面可选地跟着三个十进制数字字符。
如您所见,您可以使用分组括号在 Python 中构造非常复杂的正则表达式。
捕捉组
分组并不是分组构造服务的唯一有用的目的。大多数(但不是全部)分组结构也捕获搜索字符串中与组匹配的部分。您可以检索捕获的部分,或者以后以几种不同的方式引用它。
还记得re.search()返回的 match 对象吗?为 match 对象定义了两个方法来提供对捕获组的访问:.groups()和.group()。
m.groups()
返回一个元组,其中包含从正则表达式匹配中捕获的所有组。
考虑这个例子:
>>> m = re.search('(\w+),(\w+),(\w+)', 'foo,quux,baz') >>> m <_sre.SRE_Match object; span=(0, 12), match='foo:quux:baz'>三个
(\w+)表达式中的每一个都匹配一个单词字符序列。完整的正则表达式(\w+),(\w+),(\w+)将搜索字符串分成三个逗号分隔的标记。因为
(\w+)表达式使用分组括号,所以对应的匹配标记是捕获的。要访问捕获的匹配,您可以使用.groups(),它返回一个元组,其中按顺序包含所有捕获的匹配:
>>> m.groups()
('foo', 'quux', 'baz')
请注意,元组包含标记,但不包含搜索字符串中出现的逗号。这是因为组成标记的单词字符在分组括号内,但逗号不在。您在返回的标记之间看到的逗号是用于分隔元组中的值的标准分隔符。
m.group(<n>)
返回一个包含
<n>th捕获匹配的字符串。
对于一个参数,.group()返回一个捕获的匹配。请注意,参数是从 1 开始的,而不是从 0 开始的。所以,m.group(1)指第一个被捕获的匹配,m.group(2)指第二个,依此类推:
>>> m = re.search('(\w+),(\w+),(\w+)', 'foo,quux,baz') >>> m.groups() ('foo', 'quux', 'baz') >>> m.group(1) 'foo' >>> m.group(2) 'quux' >>> m.group(3) 'baz'由于捕获的匹配项的编号是从 1 开始的,并且没有任何编号为 0 的组,
m.group(0)具有特殊的含义:
>>> m.group(0)
'foo,quux,baz'
>>> m.group()
'foo,quux,baz'
m.group(0)返回整个匹配,m.group()也做同样的事情。
m.group(<n1>, <n2>, ...)
返回包含指定的捕获匹配项的元组。
使用多个参数,.group()返回一个元组,该元组包含按给定顺序捕获的指定匹配项:
>>> m.groups() ('foo', 'quux', 'baz') >>> m.group(2, 3) ('quux', 'baz') >>> m.group(3, 2, 1) ('baz', 'quux', 'foo')这只是方便的速记。您可以自己创建匹配元组:
>>> m.group(3, 2, 1)
('baz', 'qux', 'foo')
>>> (m.group(3), m.group(2), m.group(1))
('baz', 'qux', 'foo')
所示的两条语句在功能上是等效的。
反向引用
您可以稍后在同一个正则表达式中使用一个称为反向引用的特殊元字符序列来匹配先前捕获的组。
\<n>
匹配以前捕获的组的内容。
在 Python 的正则表达式中,序列\<n>,其中<n>是从1到99的整数,匹配<n> th 捕获组的内容。
下面是一个正则表达式,它匹配一个单词,后跟一个逗号,再跟同一个单词:
1>>> regex = r'(\w+),\1' 2 3>>> m = re.search(regex, 'foo,foo') 4>>> m 5<_sre.SRE_Match object; span=(0, 7), match='foo,foo'> 6>>> m.group(1) 7'foo' 8 9>>> m = re.search(regex, 'qux,qux') 10>>> m 11<_sre.SRE_Match object; span=(0, 7), match='qux,qux'> 12>>> m.group(1) 13'qux' 14 15>>> m = re.search(regex, 'foo,qux') 16>>> print(m) 17None在第一个示例中,在第 3 行,
(\w+)匹配字符串'foo'的第一个实例,并将其保存为第一个捕获的组。逗号完全匹配。那么\1是对第一个捕获组的反向引用,并再次匹配'foo'。第二个例子,在第 9 行的上,除了(\w+)匹配'qux'之外是相同的。最后一个例子,在第 15 行的上,没有匹配,因为逗号前面的和后面的不一样,所以
\1反向引用不匹配。注意:任何时候在 Python 中使用带有编号反向引用的正则表达式时,最好将其指定为原始字符串。否则,解释器可能会将反向引用与八进制值的混淆。
考虑这个例子:
>>> print(re.search('([a-z])#\1', 'd#d'))
None
正则表达式([a-z])#\1匹配一个小写字母,后面是'#',后面是相同的小写字母。本例中的字符串是'd#d',应该匹配。但是匹配失败了,因为 Python 将反向引用\1误解为八进制值为 1 的字符:
>>> oct(ord('\1')) '0o1'如果将正则表达式指定为原始字符串,您将获得正确的匹配:
>>> re.search(r'([a-z])#\1', 'd#d')
<_sre.SRE_Match object; span=(0, 3), match='d#d'>
请记住,只要您的正则表达式包含包含反斜杠的元字符序列,就要考虑使用原始字符串。
编号的反向引用是从 1 开始的,就像.group()的参数一样。通过反向引用只能访问前九十九个捕获的组。解释器会将\100视为'@'字符,其八进制值为 100。
其他分组结构
上面显示的(<regex>)元字符序列是在 Python 的正则表达式中执行分组的最直接的方式。下一节将向您介绍一些增强的分组构造,这些构造允许您调整分组发生的时间和方式。
(?P<name><regex>)
创建命名的捕获组。
这个元字符序列类似于分组括号,因为它创建了一个组匹配<regex>,可通过 match 对象或后续反向引用访问。这种情况下的不同之处在于,您通过给定的符号<name>而不是它的编号来引用匹配的组。
之前,您看到了这个示例,其中有三个被捕获的组,编号分别为1、2和3:
>>> m = re.search('(\w+),(\w+),(\w+)', 'foo,quux,baz') >>> m.groups() ('foo', 'quux', 'baz') >>> m.group(1, 2, 3) ('foo', 'quux', 'baz')除了这些组具有符号名称
w1、w2和w3之外,下面的代码实际上做了同样的事情:
>>> m = re.search('(?P<w1>\w+),(?P<w2>\w+),(?P<w3>\w+)', 'foo,quux,baz')
>>> m.groups()
('foo', 'quux', 'baz')
您可以通过符号名称来引用这些捕获的组:
>>> m.group('w1') 'foo' >>> m.group('w3') 'baz' >>> m.group('w1', 'w2', 'w3') ('foo', 'quux', 'baz')如果您愿意,仍然可以通过数字访问带有符号名称的组:
>>> m = re.search('(?P<w1>\w+),(?P<w2>\w+),(?P<w3>\w+)', 'foo,quux,baz')
>>> m.group('w1')
'foo'
>>> m.group(1)
'foo'
>>> m.group('w1', 'w2', 'w3')
('foo', 'quux', 'baz')
>>> m.group(1, 2, 3)
('foo', 'quux', 'baz')
用这个构造指定的任何<name>必须符合一个 Python 标识符的规则,并且每个<name>在每个正则表达式中只能出现一次。
(?P=<name>)
匹配以前捕获的命名组的内容。
(?P=<name>)元字符序列是一个反向引用,类似于\<n>,除了它引用一个命名的组而不是一个编号的组。
这又是上面的例子,它使用一个带编号的反向引用来匹配一个单词,后跟一个逗号,再跟同一个单词:
>>> m = re.search(r'(\w+),\1', 'foo,foo') >>> m <_sre.SRE_Match object; span=(0, 7), match='foo,foo'> >>> m.group(1) 'foo'下面的代码使用命名组和反向引用来做同样的事情:
>>> m = re.search(r'(?P<word>\w+),(?P=word)', 'foo,foo')
>>> m
<_sre.SRE_Match object; span=(0, 7), match='foo,foo'>
>>> m.group('word')
'foo'
(?P=<word>\w+)匹配'foo'并保存为一个名为word的捕获组。同样,逗号字面上匹配。那么(?P=word)是对已命名捕获的反向引用,并再次匹配'foo'。
注意:当创建一个命名的组时,在name周围需要尖括号(<和>),但当以后引用它时,无论是通过反向引用还是通过.group():
>>> m = re.match(r'(?P<num>\d+)\.(?P=num)', '135.135') >>> m <_sre.SRE_Match object; span=(0, 7), match='135.135'> >>> m.group('num') '135'在这里,
(?P<num>\d+)创建了被捕获的组。但是对应的反向引用是(?P=num)不带尖括号。
(?:<regex>)创建非捕获组。
(?:<regex>)就像(<regex>)一样,它匹配指定的<regex>。但是(?:<regex>)没有捕获匹配供以后检索:
>>> m = re.search('(\w+),(?:\w+),(\w+)', 'foo,quux,baz')
>>> m.groups()
('foo', 'baz')
>>> m.group(1)
'foo'
>>> m.group(2)
'baz'
在这个例子中,中间的单词'quux'位于非捕获括号内,所以它在捕获组的元组中是缺失的。它不能从 match 对象中检索,也不能通过反向引用进行引用。
为什么要定义一个组,而不是捕获它?
记住,正则表达式解析器将把分组括号内的<regex>视为一个单元。您可能会遇到这样的情况,您需要这个分组特性,但是您不需要在以后对该值做任何事情,所以您不需要捕获它。如果您使用非捕获分组,那么捕获组的元组不会被您实际上不需要保留的值弄得乱七八糟。
此外,捕获一个组需要一些时间和内存。如果执行匹配的代码执行了多次,并且您没有捕获以后不打算使用的组,那么您可能会看到一点性能优势。
(?(<n>)<yes-regex>|<no-regex>)
T1】
指定条件匹配。
条件匹配根据给定组是否存在来匹配两个指定正则表达式之一:
-
如果编号为
<n>的组存在,则(?(<n>)<yes-regex>|<no-regex>)与<yes-regex>匹配。否则匹配<no-regex>。 -
如果名为
<name>的组存在,(?(<name>)<yes-regex>|<no-regex>)与<yes-regex>匹配。否则匹配<no-regex>。
通过一个例子可以更好地说明条件匹配。考虑这个正则表达式:
regex = r'^(###)?foo(?(1)bar|baz)'
以下是这个正则表达式的各个部分,并附有一些解释:
^(###)?表示搜索字符串可选地以'###'开头。如果是,那么###周围的分组括号将创建一个编号为1的组。否则,这样的团体将不复存在。- 下一部分
foo,字面上匹配字符串'foo'。 - 最后,如果组
1存在,(?(1)bar|baz)与'bar'匹配,如果不存在,'baz'与组'bar'匹配。
以下代码块演示了上述正则表达式在几个不同的 Python 代码片段中的用法:
示例 1:
>>> re.search(regex, '###foobar') <_sre.SRE_Match object; span=(0, 9), match='###foobar'>搜索字符串
'###foobar'确实以'###'开头,所以解析器创建了一个编号为1的组。条件匹配然后与匹配的'bar'相对。示例 2:
>>> print(re.search(regex, '###foobaz'))
None
搜索字符串'###foobaz'确实以'###'开头,所以解析器创建了一个编号为1的组。条件匹配然后对'bar',不匹配。
示例 3:
>>> print(re.search(regex, 'foobar')) None搜索字符串
'foobar'不是以'###'开头,所以没有编号为1的组。条件匹配然后对'baz',不匹配。示例 4:
>>> re.search(regex, 'foobaz')
<_sre.SRE_Match object; span=(0, 6), match='foobaz'>
搜索字符串'foobaz'不是以'###'开头,所以没有编号为1的组。条件匹配然后与匹配的'baz'相对。
下面是另一个条件匹配,它使用命名组而不是编号组:
>>> regex = r'^(?P<ch>\W)?foo(?(ch)(?P=ch)|)$'这个正则表达式匹配字符串
'foo',前面是一个非单词字符,后面是相同的非单词字符,或者字符串'foo'本身。同样,让我们把它分成几个部分:
正则表达式 比赛 ^字符串的开头 (?P<ch>\W)在名为 ch的组中捕获的单个非单词字符(?P<ch>\W)?上述情况出现零次或一次 foo文字字符串 'foo'(?(ch)(?P=ch)|)名为 ch的组的内容,如果存在,则为空字符串` 正则表达式 --- --- ^字符串的开头 (?P<ch>\W)在名为 ch的组中捕获的单个非单词字符(?P<ch>\W)?上述情况出现零次或一次 foo文字字符串 'foo'(?(ch)(?P=ch)|)名为 ch的组的内容,如果存在,则为空字符串字符串的结尾 如果一个非单词字符在
'foo'之前,那么解析器会创建一个包含该字符的名为ch的组。条件匹配然后与<yes-regex>匹配,也就是(?P=ch),同样的角色。这意味着同一个角色也必须跟随'foo'才能赢得整个比赛。如果
'foo'前面没有非单词字符,那么解析器不会创建组ch。<no-regex>是空字符串,这意味着为了整个匹配成功,在'foo'之后不能有任何东西。因为^和$锚定了整个正则表达式,所以字符串必须正好等于'foo'。以下是在 Python 代码中使用此正则表达式进行搜索的一些示例:
1>>> re.search(regex, 'foo')
2<_sre.SRE_Match object; span=(0, 3), match='foo'>
3>>> re.search(regex, '#foo#')
4<_sre.SRE_Match object; span=(0, 5), match='#foo#'>
5>>> re.search(regex, '@foo@')
6<_sre.SRE_Match object; span=(0, 5), match='@foo@'>
7
8>>> print(re.search(regex, '#foo'))
9None
10>>> print(re.search(regex, 'foo@'))
11None
12>>> print(re.search(regex, '#foo@'))
13None
14>>> print(re.search(regex, '@foo#'))
15None
在1 号线,'foo'是单独的。在第 3 行和第 5 行上,相同的非文字字符在'foo'之前和之后。正如广告所说,这些比赛成功了。
在其余情况下,匹配失败。
Python 中的条件正则表达式非常深奥,很难理解。如果你找到了使用它的理由,那么你可以通过多次单独的re.search()调用来完成同样的目标,并且你的代码阅读和理解起来也不会那么复杂。
前视和后视断言
Lookahead 和look ahead断言根据搜索字符串中解析器当前位置的正后方(左侧)或正前方(右侧)来确定 Python 中正则表达式匹配的成功或失败。
像锚一样,前视和后视断言是零宽度断言,所以它们不消耗任何搜索字符串。此外,即使它们包含括号并执行分组,它们也不会捕获它们匹配的内容。
(?=<lookahead_regex>)
创建一个正向前瞻断言。
(?=<lookahead_regex>)断言正则表达式解析器当前位置之后的内容必须与<lookahead_regex>匹配:
>>> re.search('foo(?=[a-z])', 'foobar') <_sre.SRE_Match object; span=(0, 3), match='foo'>前瞻断言
(?=[a-z])指定跟随'foo'的必须是小写字母字符。在本例中,是人物'b',所以找到了匹配。另一方面,在下一个示例中,前瞻失败。
'foo'之后的下一个字符是'1',所以没有匹配:
>>> print(re.search('foo(?=[a-z])', 'foo123'))
None
lookahead 的独特之处在于,搜索字符串中匹配<lookahead_regex>的部分不会被消耗,它也不是返回的 match 对象的一部分。
再看一下第一个例子:
>>> re.search('foo(?=[a-z])', 'foobar') <_sre.SRE_Match object; span=(0, 3), match='foo'>正则表达式解析器只向前看跟在
'foo'后面的'b',但是还没有跳过它。您可以看出'b'不被认为是匹配的一部分,因为匹配对象显示的是match='foo'。与之相比,一个类似的例子使用分组括号,但没有前瞻:
>>> re.search('foo([a-z])', 'foobar')
<_sre.SRE_Match object; span=(0, 4), match='foob'>
这一次,正则表达式使用了'b',它成为最终匹配的一部分。
下面是另一个例子,说明了 Python 中的前瞻与传统正则表达式的区别:
1>>> m = re.search('foo(?=[a-z])(?P<ch>.)', 'foobar') 2>>> m.group('ch') 3'b' 4 5>>> m = re.search('foo([a-z])(?P<ch>.)', 'foobar') 6>>> m.group('ch') 7'a'在第一次搜索中,在行 1 上,解析器如下进行:
- 正则表达式的第一部分
foo,匹配并使用搜索字符串'foobar'中的'foo'。- 下一部分
(?=[a-z]),是一个匹配'b'的前瞻,但是解析器不会前进超过'b'。- 最后,
(?P<ch>.)匹配下一个可用的单个字符,即'b',并将其捕获到一个名为ch的组中。
m.group('ch')呼叫确认名为ch的群组包含'b'。将其与第 5 行上的搜索进行比较,后者不包含前瞻:
- 和第一个例子一样,正则表达式的第一部分
foo,匹配并使用搜索字符串'foobar'中的'foo'。- 下一部分
([a-z]),匹配并消耗'b',解析器前进通过'b'。- 最后,
(?P<ch>.)匹配下一个可用的单个字符,现在是'a'。
m.group('ch')确认,在这种情况下,名为ch的组包含'a'。
(?!<lookahead_regex>)创建一个负的前瞻断言。
(?!<lookahead_regex>)断言正则表达式解析器当前位置后面的内容必须不匹配<lookahead_regex>。以下是您之前看到的正面前瞻示例,以及它们的负面前瞻对应示例:
1>>> re.search('foo(?=[a-z])', 'foobar')
2<_sre.SRE_Match object; span=(0, 3), match='foo'>
3>>> print(re.search('foo(?![a-z])', 'foobar')) 4None
5
6>>> print(re.search('foo(?=[a-z])', 'foo123'))
7None
8>>> re.search('foo(?![a-z])', 'foo123') 9<_sre.SRE_Match object; span=(0, 3), match='foo'>
第 3 行和第 8 行上的否定前瞻断言规定'foo'后面的不应该是小写字母字符。这在线 3 上失败,但在线 8 上成功。这与相应的正向前瞻断言的情况相反。
与正向前瞻一样,与负向前瞻匹配的内容不是返回的 match 对象的一部分,也不会被使用。
(?<=<lookbehind_regex>)
创建正的后视断言。
(?<=<lookbehind_regex>)断言正则表达式解析器当前位置之前的内容必须匹配<lookbehind_regex>。
在下面的例子中,lookbehind 断言指定'foo'必须在'bar'之前:
>>> re.search('(?<=foo)bar', 'foobar') <_sre.SRE_Match object; span=(3, 6), match='bar'>这里就是这种情况,所以匹配成功。与 lookahead 断言一样,搜索字符串中与 look ahead 匹配的部分不会成为最终匹配的一部分。
下一个示例无法匹配,因为 lookbehind 要求
'qux'在'bar'之前:
>>> print(re.search('(?<=qux)bar', 'foobar'))
None
对后视断言有一个限制,不适用于前视断言。lookbehind 断言中的<lookbehind_regex>必须指定固定长度的匹配。
例如,下面是不允许的,因为由a+匹配的字符串的长度是不确定的:
>>> re.search('(?<=a+)def', 'aaadef') Traceback (most recent call last): File "<pyshell#72>", line 1, in <module> re.search('(?<=a+)def', 'aaadef') File "C:\Python36\lib\re.py", line 182, in search return _compile(pattern, flags).search(string) File "C:\Python36\lib\re.py", line 301, in _compile p = sre_compile.compile(pattern, flags) File "C:\Python36\lib\sre_compile.py", line 566, in compile code = _code(p, flags) File "C:\Python36\lib\sre_compile.py", line 551, in _code _compile(code, p.data, flags) File "C:\Python36\lib\sre_compile.py", line 160, in _compile raise error("look-behind requires fixed-width pattern") sre_constants.error: look-behind requires fixed-width pattern然而,这是可以的:
>>> re.search('(?<=a{3})def', 'aaadef') <_sre.SRE_Match object; span=(3, 6), match='def'>
任何与a{3}匹配的都有固定的长度 3,所以a{3}在后视断言中是有效的。
(?<!<lookbehind_regex>)
创建负的后视断言。
(?<!<lookbehind_regex>)断言正则表达式解析器当前位置之前的内容必须不匹配<lookbehind_regex>:
>>> print(re.search('(?<!foo)bar', 'foobar')) None >>> re.search('(?<!qux)bar', 'foobar') <_sre.SRE_Match object; span=(3, 6), match='bar'>与肯定的后视断言一样,
<lookbehind_regex>必须指定固定长度的匹配。其他元字符
还需要介绍几个元字符序列。这些是分散的元字符,显然不属于已经讨论过的任何类别。
(?#...)指定注释。
正则表达式解析器忽略序列
(?#...)中包含的任何内容:
>>> re.search('bar(?#This is a comment) *baz', 'foo bar baz qux')
<_sre.SRE_Match object; span=(4, 11), match='bar baz'>
这允许您在 Python 中的正则表达式内指定文档,如果正则表达式特别长,这可能特别有用。
竖条或竖线(|)
指定要匹配的一组备选项。
一个表达式的形式<regex1>|<regex2>|...|<regexn>最多匹配一个指定的<regex i >表达式:
>>> re.search('foo|bar|baz', 'bar') <_sre.SRE_Match object; span=(0, 3), match='bar'> >>> re.search('foo|bar|baz', 'baz') <_sre.SRE_Match object; span=(0, 3), match='baz'> >>> print(re.search('foo|bar|baz', 'quux')) None这里,
foo|bar|baz将匹配'foo'、'bar'或'baz'中的任何一个。您可以使用|分隔任意数量的正则表达式。交替是非贪婪的。正则表达式解析器从左到右查看由
|分隔的表达式,并返回找到的第一个匹配。剩余的表达式不会被测试,即使其中一个会产生更长的匹配:
1>>> re.search('foo', 'foograult')
2<_sre.SRE_Match object; span=(0, 3), match='foo'>
3>>> re.search('grault', 'foograult')
4<_sre.SRE_Match object; span=(3, 9), match='grault'>
5
6>>> re.search('foo|grault', 'foograult')
7<_sre.SRE_Match object; span=(0, 3), match='foo'>
在这种情况下,在线 6 、'foo|grault'上指定的模式将在'foo'或'grault'上匹配。返回的匹配是'foo',因为当从左到右扫描时,它首先出现,即使'grault'是一个更长的匹配。
您可以组合交替、分组和任何其他元字符来实现您需要的任何级别的复杂性。在下面的例子中,(foo|bar|baz)+表示一个或多个字符串'foo'、'bar'或'baz'的序列:
>>> re.search('(foo|bar|baz)+', 'foofoofoo') <_sre.SRE_Match object; span=(0, 9), match='foofoofoo'> >>> re.search('(foo|bar|baz)+', 'bazbazbazbaz') <_sre.SRE_Match object; span=(0, 12), match='bazbazbazbaz'> >>> re.search('(foo|bar|baz)+', 'barbazfoo') <_sre.SRE_Match object; span=(0, 9), match='barbazfoo'>在下一个例子中,
([0-9]+|[a-f]+)表示一个或多个十进制数字字符的序列,或者一个或多个字符的序列'a-f':
>>> re.search('([0-9]+|[a-f]+)', '456')
<_sre.SRE_Match object; span=(0, 3), match='456'>
>>> re.search('([0-9]+|[a-f]+)', 'ffda')
<_sre.SRE_Match object; span=(0, 4), match='ffda'>
有了re模块支持的所有元字符,实际上就没有限制了。
就这些了,伙计们!
这就完成了我们对 Python 的re模块所支持的正则表达式元字符的浏览。(实际上,并不完全是这样——在下面关于标志的讨论中,您将了解到更多的落伍者。)
有很多东西需要消化,但是一旦您熟悉了 Python 中的正则表达式语法,您可以执行的模式匹配的复杂性几乎是无限的。当您编写代码来处理文本数据时,这些工具非常方便。
如果你是正则表达式的新手,想要更多地练习使用它们,或者如果你正在开发一个使用正则表达式的应用程序,并且想要交互地测试它,那么请访问正则表达式 101 网站。真的很酷!
修改了与标志匹配的正则表达式
re模块中的大多数函数都有一个可选的<flags>参数。这包括你现在非常熟悉的功能,re.search()。
re.search(<regex>, <string>, <flags>)
应用指定的修饰符
<flags>,扫描字符串中的正则表达式匹配。
标志修改正则表达式解析行为,允许您进一步优化模式匹配。
支持的正则表达式标志
下表简要总结了可用的标志。除了re.DEBUG之外的所有标志都有一个简短的单字母名称和一个较长的完整单词名称:
| 简称 | 长名字 | 影响 |
|---|---|---|
re.I |
re.IGNORECASE |
使字母字符的匹配不区分大小写 |
re.M |
re.MULTILINE |
使字符串开头和字符串结尾的锚点与嵌入的换行符匹配 |
re.S |
re.DOTALL |
使点元字符匹配换行符 |
re.X |
re.VERBOSE |
允许在正则表达式中包含空白和注释 |
---- |
re.DEBUG |
使正则表达式分析器向控制台显示调试信息 |
re.A |
re.ASCII |
用于字符分类的指定 ascii 编码 |
re.U |
re.UNICODE |
字符分类的指定 unicode 编码 |
re.L |
re.LOCALE |
基于当前区域设置指定字符分类的编码 |
以下部分更详细地描述了这些标志如何影响匹配行为。
re.I
T1】
使匹配不区分大小写。
当IGNORECASE生效时,字符匹配不区分大小写:
1>>> re.search('a+', 'aaaAAA') 2<_sre.SRE_Match object; span=(0, 3), match='aaa'> 3>>> re.search('A+', 'aaaAAA') 4<_sre.SRE_Match object; span=(3, 6), match='AAA'> 5 6>>> re.search('a+', 'aaaAAA', re.I) 7<_sre.SRE_Match object; span=(0, 6), match='aaaAAA'> 8>>> re.search('A+', 'aaaAAA', re.IGNORECASE) 9<_sre.SRE_Match object; span=(0, 6), match='aaaAAA'>在第 1 行的搜索中,
a+只匹配'aaaAAA'的前三个字符。同样,在第 3 行的上,A+只匹配最后三个字符。但是在随后的搜索中,解析器忽略大小写,所以a+和A+匹配整个字符串。
IGNORECASE影响包括字符类别的字母匹配:
>>> re.search('[a-z]+', 'aBcDeF')
<_sre.SRE_Match object; span=(0, 1), match='a'>
>>> re.search('[a-z]+', 'aBcDeF', re.I)
<_sre.SRE_Match object; span=(0, 6), match='aBcDeF'>
当情况重要时,[a-z]+匹配的'aBcDeF'的最长部分就是最初的'a'。指定re.I使得搜索不区分大小写,所以[a-z]+匹配整个字符串。
re.M
T1】
使字符串开头和字符串结尾的锚点在嵌入的换行符处匹配。
默认情况下,^(字符串开头)和$(字符串结尾)锚点仅在搜索字符串的开头和结尾匹配:
>>> s = 'foo\nbar\nbaz' >>> re.search('^foo', s) <_sre.SRE_Match object; span=(0, 3), match='foo'> >>> print(re.search('^bar', s)) None >>> print(re.search('^baz', s)) None >>> print(re.search('foo$', s)) None >>> print(re.search('bar$', s)) None >>> re.search('baz$', s) <_sre.SRE_Match object; span=(8, 11), match='baz'>在这种情况下,即使搜索字符串
'foo\nbar\nbaz'包含嵌入的换行符,当锚定在字符串的开头时,只有'foo'匹配,当锚定在字符串的结尾时,只有'baz'匹配。然而,如果一个字符串嵌入了换行符,你可以认为它是由多个内部行组成的。在这种情况下,如果设置了
MULTILINE标志,^和$锚元字符也匹配内部行:
^匹配字符串的开头或字符串中任何一行的开头(即紧跟在换行符之后)。$匹配字符串末尾或字符串中任何一行的末尾(紧接在换行符之前)。以下是如上所示的相同搜索:
>>> s = 'foo\nbar\nbaz'
>>> print(s)
foo
bar
baz
>>> re.search('^foo', s, re.MULTILINE)
<_sre.SRE_Match object; span=(0, 3), match='foo'>
>>> re.search('^bar', s, re.MULTILINE)
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> re.search('^baz', s, re.MULTILINE)
<_sre.SRE_Match object; span=(8, 11), match='baz'>
>>> re.search('foo$', s, re.M)
<_sre.SRE_Match object; span=(0, 3), match='foo'>
>>> re.search('bar$', s, re.M)
<_sre.SRE_Match object; span=(4, 7), match='bar'>
>>> re.search('baz$', s, re.M)
<_sre.SRE_Match object; span=(8, 11), match='baz'>
在字符串'foo\nbar\nbaz'中,'foo'、'bar'和'baz'这三个都出现在字符串的开头或结尾,或者出现在字符串中一行的开头或结尾。随着MULTILINE标志的设置,当锚定^或$时,所有三个匹配。
注意:MULTILINE标志只以这种方式修改^和$锚。对\A和\Z主播没有任何影响:
1>>> s = 'foo\nbar\nbaz' 2 3>>> re.search('^bar', s, re.MULTILINE) 4<_sre.SRE_Match object; span=(4, 7), match='bar'> 5>>> re.search('bar$', s, re.MULTILINE) 6<_sre.SRE_Match object; span=(4, 7), match='bar'> 7 8>>> print(re.search('\Abar', s, re.MULTILINE)) 9None 10>>> print(re.search('bar\Z', s, re.MULTILINE)) 11None在第 3 行和第 5 行上,
^和$锚点指示必须在一行的开始和结束处找到'bar'。指定MULTILINE标志使这些匹配成功。第 8 行和第 10 行上的例子使用了
\A和\Z标志。您可以看到,即使MULTILINE标志有效,这些匹配也会失败。
re.S
T1】使点(
.)元字符匹配换行符。请记住,默认情况下,点元字符匹配除换行符以外的任何字符。
DOTALL旗解除了这一限制:
1>>> print(re.search('foo.bar', 'foo\nbar'))
2None
3>>> re.search('foo.bar', 'foo\nbar', re.DOTALL)
4<_sre.SRE_Match object; span=(0, 7), match='foo\nbar'>
5>>> re.search('foo.bar', 'foo\nbar', re.S)
6<_sre.SRE_Match object; span=(0, 7), match='foo\nbar'>
在这个例子中,在行 1 上,点元字符与'foo\nbar'中的换行符不匹配。在第 3 行和第 5 行,DOTALL是有效的,所以点确实匹配换行符。注意,DOTALL国旗的简称是re.S,而不是你所想的re.D。
re.X
T1】
允许在正则表达式中包含空格和注释。
VERBOSE标志指定了一些特殊的行为:
-
regex 解析器忽略所有空格,除非它在字符类中或者用反斜杠转义。
-
如果正则表达式包含一个字符类中没有的或者用反斜杠转义的
#字符,那么解析器会忽略它和它右边的所有字符。
这有什么用?它允许你用 Python 格式化一个正则表达式,使它更具可读性和自我文档化。
这里有一个例子,展示了如何使用它。假设您想要解析具有以下格式的电话号码:
- 可选的三位数区号,在括号中
- 可选空白
- 三位数前缀
- 分离器
'-'或'.' - 四位数行号
下面的正则表达式完成了这个任务:
>>> regex = r'^(\(\d{3}\))?\s*\d{3}[-.]\d{4}$' >>> re.search(regex, '414.9229') <_sre.SRE_Match object; span=(0, 8), match='414.9229'> >>> re.search(regex, '414-9229') <_sre.SRE_Match object; span=(0, 8), match='414-9229'> >>> re.search(regex, '(712)414-9229') <_sre.SRE_Match object; span=(0, 13), match='(712)414-9229'> >>> re.search(regex, '(712) 414-9229') <_sre.SRE_Match object; span=(0, 14), match='(712) 414-9229'>但是
r'^(\(\d{3}\))?\s*\d{3}[-.]\d{4}$'是满眼不是吗?使用VERBOSE标志,您可以用 Python 编写相同的正则表达式,如下所示:
>>> regex = r'''^ # Start of string
... (\(\d{3}\))? # Optional area code
... \s* # Optional whitespace
... \d{3} # Three-digit prefix
... [-.] # Separator character
... \d{4} # Four-digit line number
... $ # Anchor at end of string
... '''
>>> re.search(regex, '414.9229', re.VERBOSE)
<_sre.SRE_Match object; span=(0, 8), match='414.9229'>
>>> re.search(regex, '414-9229', re.VERBOSE)
<_sre.SRE_Match object; span=(0, 8), match='414-9229'>
>>> re.search(regex, '(712)414-9229', re.X)
<_sre.SRE_Match object; span=(0, 13), match='(712)414-9229'>
>>> re.search(regex, '(712) 414-9229', re.X)
<_sre.SRE_Match object; span=(0, 14), match='(712) 414-9229'>
re.search()调用与上面显示的相同,所以您可以看到这个正则表达式的工作方式与前面指定的相同。但是一看就没那么难懂了。
注意,三重引号使得包含嵌入的换行符变得特别方便,这些换行符在VERBOSE模式中被视为被忽略的空白。
当使用VERBOSE标志时,要注意那些你希望有意义的空白。考虑这些例子:
1>>> re.search('foo bar', 'foo bar') 2<_sre.SRE_Match object; span=(0, 7), match='foo bar'> 3 4>>> print(re.search('foo bar', 'foo bar', re.VERBOSE)) 5None 6 7>>> re.search('foo\ bar', 'foo bar', re.VERBOSE) 8<_sre.SRE_Match object; span=(0, 7), match='foo bar'> 9>>> re.search('foo[ ]bar', 'foo bar', re.VERBOSE) 10<_sre.SRE_Match object; span=(0, 7), match='foo bar'>至此您已经看到了一切,您可能想知道为什么第 4 行的正则表达式
foo bar与字符串'foo bar'不匹配。这是因为VERBOSE标志会导致解析器忽略空格字符。为了按照预期进行匹配,用反斜杠对空格字符进行转义,或者将其包含在一个字符类中,如第行第 7 行和第 9 行所示。
与
DOTALL标志一样,注意VERBOSE标志有一个不直观的简称:re.X,而不是re.V。
re.DEBUG显示调试信息。
DEBUG标志使 Python 中的 regex 解析器向控制台显示关于解析过程的调试信息:
>>> re.search('foo.bar', 'fooxbar', re.DEBUG)
LITERAL 102
LITERAL 111
LITERAL 111
ANY None
LITERAL 98
LITERAL 97
LITERAL 114
<_sre.SRE_Match object; span=(0, 7), match='fooxbar'>
当解析器在调试输出中显示LITERAL nnn时,它显示的是正则表达式中文字字符的 ASCII 代码。在这种情况下,字面字符是'f'、'o'、'o'和'b'、'a'、'r'。
这里有一个更复杂的例子。这是前面关于VERBOSE标志的讨论中显示的电话号码正则表达式:
>>> regex = r'^(\(\d{3}\))?\s*\d{3}[-.]\d{4}$' >>> re.search(regex, '414.9229', re.DEBUG) AT AT_BEGINNING MAX_REPEAT 0 1 SUBPATTERN 1 0 0 LITERAL 40 MAX_REPEAT 3 3 IN CATEGORY CATEGORY_DIGIT LITERAL 41 MAX_REPEAT 0 MAXREPEAT IN CATEGORY CATEGORY_SPACE MAX_REPEAT 3 3 IN CATEGORY CATEGORY_DIGIT IN LITERAL 45 LITERAL 46 MAX_REPEAT 4 4 IN CATEGORY CATEGORY_DIGIT AT AT_END <_sre.SRE_Match object; span=(0, 8), match='414.9229'>这看起来像是很多你永远不需要的深奥信息,但它可能是有用的。参见下面的实际应用。
深潜:调试正则表达式解析
正如您从上面所知道的,元字符序列
{m,n}表示特定的重复次数。它匹配从m到n之前的任何重复:`>>> re.search('x[123]{2,4}y', 'x222y') <_sre.SRE_Match object; span=(0, 5), match='x222y'>`您可以用
DEBUG标志来验证这一点:`>>> re.search('x[123]{2,4}y', 'x222y', re.DEBUG) LITERAL 120 MAX_REPEAT 2 4 IN LITERAL 49 LITERAL 50 LITERAL 51 LITERAL 121 <_sre.SRE_Match object; span=(0, 5), match='x222y'>`
MAX_REPEAT 2 4确认正则表达式解析器识别元字符序列{2,4}并将其解释为范围限定符。但是,如前所述,如果 Python 中正则表达式中的一对花括号包含除有效数字或数值范围之外的任何内容,那么它就失去了特殊的意义。
您也可以验证这一点:
`>>> re.search('x[123]{foo}y', 'x222y', re.DEBUG) LITERAL 120 IN LITERAL 49 LITERAL 50 LITERAL 51 LITERAL 123 LITERAL 102 LITERAL 111 LITERAL 111 LITERAL 125 LITERAL 121`您可以看到在调试输出中没有
MAX_REPEAT标记。LITERAL标记表明解析器按字面意思处理{foo},而不是作为量词元字符序列。123、102、111、111和125是字符串'{foo}'中字符的 ASCII 码。通过向您展示解析器如何解释您的正则表达式,
DEBUG标志显示的信息可以帮助您排除故障。奇怪的是,
re模块没有定义单字母版本的DEBUG标志。如果您愿意,您可以定义自己的:
>>> import re
>>> re.D
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 're' has no attribute 'D'
>>> re.D = re.DEBUG >>> re.search('foo', 'foo', re.D)
LITERAL 102
LITERAL 111
LITERAL 111
<_sre.SRE_Match object; span=(0, 3), match='foo'>
但是这可能更令人困惑,而不是更有帮助,因为您的代码的读者可能会将其误解为DOTALL标志的缩写。如果你真的做了这个作业,最好把它完整地记录下来。
re.A
re.ASCII
re.U
re.UNICODE
re.L
指定用于分析特殊正则表达式字符类的字符编码。
几个 regex 元字符序列(\w、\W、\b、\B、\d、\D、\s和\S)要求您将字符分配给某些类别,如单词、数字或空格。该组中的标志决定了用于将字符分配给这些类的编码方案。可能的编码是 ASCII、Unicode 或根据当前的区域设置。
在关于 Python 中的字符串和字符数据的教程中,在对 ord()内置函数的讨论中,您已经简要介绍了字符编码和 Unicode。有关更深入的信息,请查看以下资源:
为什么字符编码在 Python 的正则表达式环境中如此重要?这里有一个简单的例子。
您之前已经了解到\d指定了一个数字字符。对\d元字符序列的描述表明它等同于字符类[0-9]。对于英语和西欧语言来说,情况确实如此,但对于世界上大多数语言来说,字符'0'到'9'并不代表所有甚至任何一个数字。
例如,这里有一个由三个梵文数字字符组成的字符串:
>>> s = '\u0967\u096a\u096c' >>> s '१४६'对于 regex 解析器来说,要正确处理 Devanagari 脚本,数字元字符序列
\d也必须匹配这些字符中的每一个。Unicode 协会创建了 Unicode 来处理这个问题。Unicode 是一种字符编码标准,旨在代表世界上所有的书写系统。Python 3 中的所有字符串,包括正则表达式,默认都是 Unicode 的。
那么,回到上面列出的标志。这些标志通过指定使用的编码是 ASCII、Unicode 还是当前区域设置来帮助确定字符是否属于给定的类别:
re.U和re.UNICODE指定 Unicode 编码。Unicode 是默认值,所以这些标志是多余的。支持它们主要是为了向后兼容。re.A和re.ASCII基于 ASCII 编码强制判定。如果你碰巧用英语操作,那么无论如何都会发生这种情况,所以这个标志不会影响是否找到匹配。re.L****re.LOCALE根据当前地区确定。区域设置是一个过时的概念,不被认为是可靠的。除非在极少数情况下,你不太可能需要它。使用默认的 Unicode 编码,regex 解析器应该能够处理任何语言。在下面的示例中,它正确地将字符串
'१४६'中的每个字符识别为数字:
>>> s = '\u0967\u096a\u096c'
>>> s
'१४६'
>>> re.search('\d+', s)
<_sre.SRE_Match object; span=(0, 3), match='१४६'>
下面是另一个例子,说明了字符编码如何影响 Python 中的正则表达式匹配。考虑这个字符串:
>>> s = 'sch\u00f6n' >>> s 'schön'
'schön'(德语中表示漂亮的或漂亮的)包含了'ö'字符,该字符具有 16 位十六进制 Unicode 值00f6。这个字符不能用传统的 7 位 ASCII 码表示。如果您使用德语,那么您应该合理地期望正则表达式解析器将
'schön'中的所有字符都视为单词字符。但是看看如果您使用\w字符类在s中搜索单词字符并强制使用 ASCII 编码会发生什么:
>>> re.search('\w+', s, re.ASCII)
<_sre.SRE_Match object; span=(0, 3), match='sch'>
当您将编码限制为 ASCII 时,regex 解析器只将前三个字符识别为单词字符。比赛在'ö'停止。
另一方面,如果您指定了re.UNICODE或者允许编码默认为 Unicode,那么'schön'中的所有字符都符合单词字符的条件:
>>> re.search('\w+', s, re.UNICODE) <_sre.SRE_Match object; span=(0, 5), match='schön'> >>> re.search('\w+', s) <_sre.SRE_Match object; span=(0, 5), match='schön'>
ASCII和LOCALE标志可以在特殊情况下使用。但是一般来说,最好的策略是使用默认的 Unicode 编码。这应该可以正确处理任何世界语言。在函数调用中组合
<flags>个参数定义了标志值,以便您可以使用按位 OR (
|)运算符将它们组合起来。这允许您在单个函数调用中指定几个标志:
>>> re.search('^bar', 'FOO\nBAR\nBAZ', re.I|re.M)
<_sre.SRE_Match object; span=(4, 7), match='BAR'>
这个re.search()调用使用按位 OR 同时指定IGNORECASE和MULTILINE标志。
设置和清除正则表达式中的标志
除了能够向大多数re模块函数调用传递一个<flags>参数之外,您还可以在 Python 中修改 regex 中的标志值。有两个正则表达式元字符序列提供了这种能力。
(?<flags>)
为正则表达式的持续时间设置标志值。
在正则表达式中,元字符序列(?<flags>)为整个表达式设置指定的标志。
<flags>的值是集合a、i、L、m、s、u和x中的一个或多个字母。以下是它们与re模块标志的对应关系:
| 信 | 旗帜 |
|---|---|
a |
re.A re.ASCII |
i |
re.I re.IGNORECASE |
L |
re.L re.LOCALE |
m |
re.M re.MULTILINE |
s |
re.S re.DOTALL |
u |
re.U re.UNICODE |
x |
re.X re.VERBOSE |
(?<flags>)元字符序列作为一个整体匹配空字符串。它总是匹配成功,不消耗任何搜索字符串。
以下示例是设置IGNORECASE和MULTILINE标志的等效方式:
>>> re.search('^bar', 'FOO\nBAR\nBAZ\n', re.I|re.M) <_sre.SRE_Match object; span=(4, 7), match='BAR'> >>> re.search('(?im)^bar', 'FOO\nBAR\nBAZ\n') <_sre.SRE_Match object; span=(4, 7), match='BAR'>请注意,
(?<flags>)元字符序列为整个正则表达式设置了给定的标志,不管它放在表达式中的什么位置:
>>> re.search('foo.bar(?s).baz', 'foo\nbar\nbaz')
<_sre.SRE_Match object; span=(0, 11), match='foo\nbar\nbaz'>
>>> re.search('foo.bar.baz(?s)', 'foo\nbar\nbaz')
<_sre.SRE_Match object; span=(0, 11), match='foo\nbar\nbaz'>
在上面的例子中,两个点元字符都匹配换行符,因为DOTALL标志是有效的。即使(?s)出现在表达式的中间或末尾,也是如此。
从 Python 3.7 开始,不赞成在正则表达式中除开头以外的任何地方指定(?<flags>):
>>> import sys >>> sys.version '3.8.0 (default, Oct 14 2019, 21:29:03) \n[GCC 7.4.0]' >>> re.search('foo.bar.baz(?s)', 'foo\nbar\nbaz') <stdin>:1: DeprecationWarning: Flags not at the start of the expression 'foo.bar.baz(?s)' <re.Match object; span=(0, 11), match='foo\nbar\nbaz'>它仍然产生适当的匹配,但是您将得到一个警告消息。
(?<set_flags>-<remove_flags>:<regex>)设置或删除组持续时间的标志值。
(?<set_flags>-<remove_flags>:<regex>)定义与<regex>匹配的非捕获组。对于组中包含的<regex>,正则表达式解析器设置<set_flags>中指定的任何标志,并清除<remove_flags>中指定的任何标志。
<set_flags>和<remove_flags>的值通常是i、m、s或x。在以下示例中,为指定的组设置了
IGNORECASE标志:
>>> re.search('(?i:foo)bar', 'FOObar')
<re.Match object; span=(0, 6), match='FOObar'>
这产生了一个匹配,因为(?i:foo)规定与'FOO'的匹配是不区分大小写的。
现在对比一下这个例子:
>>> print(re.search('(?i:foo)bar', 'FOOBAR')) None和前面的例子一样,与
'FOO'的匹配会成功,因为它不区分大小写。但是一旦在组之外,IGNORECASE就不再有效,所以与'BAR'的匹配是区分大小写的,并且会失败。以下示例演示了如何关闭组的标志:
>>> print(re.search('(?-i:foo)bar', 'FOOBAR', re.IGNORECASE))
None
同样,没有匹配。尽管re.IGNORECASE为整个调用启用了不区分大小写的匹配,但是元字符序列(?-i:foo)在该组的持续时间内关闭了IGNORECASE,因此与'FOO'的匹配失败。
从 Python 3.7 开始,您可以将u、a或L指定为<set_flags>,以覆盖指定组的默认编码:
>>> s = 'sch\u00f6n' >>> s 'schön' >>> # Requires Python 3.7 or later >>> re.search('(?a:\w+)', s) <re.Match object; span=(0, 3), match='sch'> >>> re.search('(?u:\w+)', s) <re.Match object; span=(0, 5), match='schön'>但是,您只能以这种方式设置编码。您不能删除它:
>>> re.search('(?-a:\w+)', s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.8/re.py", line 199, in search
return _compile(pattern, flags).search(string)
File "/usr/lib/python3.8/re.py", line 302, in _compile
p = sre_compile.compile(pattern, flags)
File "/usr/lib/python3.8/sre_compile.py", line 764, in compile
p = sre_parse.parse(p, flags)
File "/usr/lib/python3.8/sre_parse.py", line 948, in parse
p = _parse_sub(source, state, flags & SRE_FLAG_VERBOSE, 0)
File "/usr/lib/python3.8/sre_parse.py", line 443, in _parse_sub
itemsappend(_parse(source, state, verbose, nested + 1,
File "/usr/lib/python3.8/sre_parse.py", line 805, in _parse
flags = _parse_flags(source, state, char)
File "/usr/lib/python3.8/sre_parse.py", line 904, in _parse_flags
raise source.error(msg)
re.error: bad inline flags: cannot turn off flags 'a', 'u' and 'L' at
position 4
u、a和L是互斥的。每组只能出现一个。
结论
这就结束了你对正则表达式匹配和 Python 的re模块的介绍。恭喜你!你已经掌握了大量的材料。
你现在知道如何:
- 使用
re.search()在 Python 中执行正则表达式匹配 - 使用正则表达式元字符创建复杂的模式匹配搜索
- 用标志调整正则表达式解析行为
但是你仍然只看到了模块中的一个函数:re.search()!re模块有更多有用的函数和对象可以添加到您的模式匹配工具包中。本系列的下一篇教程将向您介绍 Python 中的 regex 模块还能提供什么。
« Functions in PythonRegular Expressions: Regexes in Python (Part 1)Regular Expressions: Regexes in Python (Part 2) »
立即观看本教程有真实 Python 团队创建的相关视频课程。和书面教程一起看,加深理解: 正则表达式和用 Python 构建正则表达式***********

 浙公网安备 33010602011771号
浙公网安备 33010602011771号