Quantinsti-博客中文翻译-六-
Quantinsti 博客中文翻译(六)
与孟买一家主要交易所举办研讨会
原文:https://blog.quantinsti.com/seminar-held-with-a-leading-exchange-in-mumbai/
https://www.youtube.com/embed/56Wv-O7urEE
作为我们持续知识共享计划的一部分, QuantInsti 与一家领先的交易所一起,为交易所会员举办了一场关于算法交易的教育研讨会,帮助他们通过使用 量化技术 丰富自己的交易策略,以及使用算法扩大交易范围。这是一次与买方交易者的互动会议。
相关帖子:
来自加州的高级数据分析师的算法交易之旅
原文:https://blog.quantinsti.com/senior-analytics-consultant-automation-success-story-thomas-orgler/
几年前,只有少数人会想到自己做算法交易。然而,今天,有更多的途径和机会来学习和实现算法交易。
Thomas Orgler 来自美国圣地亚哥,是一名经验丰富、充满激情的高级数据分析师,曾在金融科技、公共部门、金融服务和制造业工作。
托马斯已经有 10 年的工作经验,他还兼职投资,并渴望在未来创办自己的资本管理公司。托马斯学了很多编程语言像 Visual Basic、Python、R、C++ 和Matlab;有一个敏捷、Alteryx 和 Tableau 认证,并且从很多其他课程中学习来补充他的专业。
现在,他是一个骄傲的 EPATian 人,正在将他的知识应用于算法交易。我们通过电话采访了托马斯,这是他的故事。
嗨,托马斯,给我们介绍一下你自己吧!

我是托马斯·奥格勒,住在加利福尼亚州圣地亚哥的美丽城市 T2。我已经搬了很多地方,可以很容易地把圣地亚哥称为我真正的家,因为那里的自然美景、悠闲的氛围和做无数户外活动的能力让我很开心。
从徒步旅行到山地车,从划桨板到滑雪板,所有这些都可以在很短的车程内完成。我曾经是一名工业和系统工程师,在学校的时候还主修经济学。计量经济学课让我真正迷上了统计学。
我最终以工程师的身份开始了我的职业生涯,并转向了它。我目前在一家金融科技公司 Intuit 工作,做大数据 ETL、dashboarding、Python 脚本和 A/B 测试。
我总是在学习新的话题,并试图应用我所学到的东西来增加我产生的被动收入。
我在房地产建立了一个小型精品企业,提供长期和短期租赁,algo trading 似乎是创造被动收入的一个很好的补充。
10 年内从流程工程到商业和金融分析——你的旅程是如何倾向于算法交易的?
尽管我总是擅长数学和科学,工程似乎是最合适的,但我真的这么做了,因为我想进入投资银行业,这听起来可能违反直觉。
原因是我来自巴西,在巴西获得的工程学学位为我打开了不同领域的大门。理由是,如果你能在巴西成为一名工程师,你就证明了你很聪明,非常适合任何领域的高技能职位,他们就会聘用你。
17 岁那年,我获得了一份准全额奖学金,来到美国纽约伦斯勒理工学院学习 T2 工业系统工程。
我毕业了,最终进入了制造业,因为我得到了一个很好的工作机会,为一家伟大的公司工作,宝洁公司。作为一名工程师,这是阻力最小的道路,我想看看它会把我带到哪里。
不过,回到这个问题,我在大学辅修金融时学到了一些有趣的概念,比如 CAPM 和统计套利,我一直想把我学到的东西结合起来:
- 来自工程的自动化和分析,
- 经济学的统计数据,以及
- 金融市场理解。
我不得不专注于我的工程生涯,但我从未有过这样的机会。
然后,我读了罗伯特·清崎写的《富爸爸,穷爸爸》,这本书让我大开眼界。
被动收入的整个想法非常吸引我。我开始投资房地产,并且非常成功。很快,资本开始流入,那是我真正开始交易的时候。
当我真正进入算法交易时,我是一名数据/金融分析师。该公司从事大宗商品交易,我认为自己有可能在未来接管对冲责任,其中也包括期货交易。
我与该公司的首席财务官非常接近,我告诉他我们如何通过基于算法的方法,通过量和数据密集型分析来降低风险,而不是让人类做出这些决定。当我在公司自动化了几个功能后,我开始学习 Python。我通过 Coursera 自学了很多,并开始玩 Quantopian(最近关闭了)来试水,我知道我想了解更多。
就在那时,我看到了 EPAT 的广告,决定打几个电话了解更多。我和一些教授和其他校友聊了聊,问了很多问题,看起来非常适合。
我很快注意到还有一个我不熟悉的层次。这似乎是一个从头开始学习的好机会。
EPAT 是一个非常坚实有力的项目。我付出了很多努力。当我有问题的时候,我会和教授以及我的支持经理保持联系。他们对建立一个坚实的基础很有帮助。
现在我正在做兼职交易,因为我喜欢继续工作。我正在研究基于宏观新闻情绪分析的手动全权委托交易,到目前为止,它已经获得了丰厚的回报。
我最终想进入统计套利领域。配对交易、均值回归策略和识别平稳性是我想深入研究的概念。然而,现在我真正看到了自然语言处理的力量所在,我渴望在接下来的几个月里参加 QuantInsti 的 T4 情感分析课程。
你在 EPAT 的经历是怎样的?
我一直相信我的直觉和我的决策能力。我已经向自己证明,无论是在房地产还是交易领域,我都有能力创造回报。
2/3 的共同基金没有跑赢市场,我亲眼看到一些基金经理并不真正知道他们在做什么。
这就是为什么我真诚地相信,只要有合适的工具,任何参加 EPAT 项目的人都可以运用知识,并通过自己的能力创造回报。特别是在我们现在所处的零美元佣金环境中,使用 TD Ameritrade 这样的典型经纪人和他们的 Think or Swim 平台(以及 API)进行更高频率的交易,打开了许多大门。
你可以利用大量的数据。你可以利用 Python 和它的库来构建 ML 算法,只需要 10-20 行代码。它不像以前那么复杂了。你不需要写太多的代码来构建这样的东西。
我一直对编程充满热情。对我来说,这从来都不是用户体验或用户界面的问题。它总是关于自动化。
你可以让计算机在更短的时间内为他们做出决定,并利用更多的数据获得更快、更精确的解决方案,而不是让某人做出决定并使用他们自己的人类洞察力。
疫情如何影响了你的日常生活?
因为 COVID19,我还没有机会真正建立我的 algo 交易业务。对于疫情,很难训练模型并对其进行回溯测试,因为我们发现自己所处的这种新情况使得未来的价格走势难以预测。
但是我在我的房地产投资中利用了很多知识。EPAT 教我基础设施部署和利用 API。
我个人使用 TD Ameritrade,如果你必须构建算法,你显然需要学习如何获取数据,操作数据,并通过 API 发送回数据。我用这种技能研究了 Airbnb 和多房源服务 MLS data 的 API,以便分析美国短期租赁投资的最佳邮政编码。
我开始在房地产领域建立和发展我的业务,甚至在新冠肺炎,它已经产生了超过 60%的投资回报率。一旦新冠肺炎·疫情事件平息下来,我将更加重视建立我的基金——尤其是关注 NLP。
我现在终于把职业生涯转向了数据科学和软件开发。我不一定想去贸易公司工作。
我有我需要的资本,我喜欢创造被动收入的想法。
你最喜欢 EPAT 的哪个特征?
EPAT 确实专注于严肃的数据科学,并教授了很多关于金融市场的知识。老实说,这是一个非常好的旅程,对我来说是一个非常平稳的过渡。
我已经知道 Python 了,所以那部分并不难。学习金融交易以及滚动回报和期货的概念对我来说是全新的。
实际上,有几个功能我非常喜欢:
基础设施课程太棒了!
它真的教会了我如何为高频交易基金建立合适的基础设施。也教会了我如何将这些运用到低频和中频交易中。您所需要的只是一个云基础架构,一切就完成了。EPAT 做了一件伟大的工作,他在这头巨象的每一部分都加入了非常深刻的见解。金融和算法交易。
支持经理系统
我不得不说,EPAT 的支持经理系统非常出色。我发信息的时候没关系,我的支持经理拉克西米总是在我身边,她真的很棒。我要说的是,你可以问问题的那种人情味非常有帮助。她会很快把我和教授联系上,并帮助回答这个问题。
时差
如果你迷路了,总会有人来帮你。因为我在美国,我不能看比赛,因为他们在 IST,现在是凌晨 3 点。所以我总是要看录像,然后再问问题。支持系统无疑是帮助我在课程中取得成功的支柱。
实践课程
在技术方面,我真的很喜欢整个课程的实践。这真的迫使我去挖掘和弄脏我的手。我必须编码和建立一个海龟算法,布尔带或一些自定义的移动平均算法,并让它工作。老实说,我真的很喜欢这样,因为它让你在实践中学习。这是一个巨大的优势。
你有什么话想和有抱负的量化分析师分享吗?
我会非常真诚地提出我的建议。它同时具有警示性和激励性。现在交易中有很多炒作,作为一个人交易是非常困难的。
就像自主交易或手动交易一样,算法交易也有得有失。在某些方面,风险几乎更高,因为代码中的一行可能会提取你在一项资产上的所有资本——例如——因为你没有设定一个良好的风险配置。这是有风险的,可能会让你很难失败。
避免陷阱
有很多警告,但如果你知道你在做什么,这是一个很大的假设,你可以减轻很多风险。你需要知道你在做什么,这也是 EPAT 项目真正能帮助你的地方。从这个意义上来说, EPAT 可以被视为一张保险单。你知道你需要做什么,这样你就不会掉进大多数人刚开始时会掉进的洞里。避免陷阱将加速你创造回报的能力。
摆脱情绪
老实说,我最大的挑战是控制自己的情绪。自己手动交易是一项情绪压力很大的工作。你正在亏损,接下来你知道的事情是,“哦,我的上帝,我现在需要摆脱这个职位。“当你离开那个位置的时候,就是市场转向并达到历史新高的时候——你知道它是怎么回事...如果你做的正好相反,你就会获利。我愿意承认,这种情况发生得更频繁,在情绪交易中,你通常会亏钱,除非运气站在你这边。
这就是我喜欢算法交易的原因。你制定规则,你有交易计划,你应该像机器人一样遵守交易计划。我们做不到,但建立在相同交易规则上的算法可以,因为它是机器人。这个算法会不带感情地跟随交易计划,你真的可以衡量这个成功。
想象你自己通过机器人方法建立 20、30 种不同的策略,不带感情。现在,你在所有的策略中分散你的资本。不带感情的交易,对我来说,是算法交易最大的力量。
长话短说,总有风险。EPAT 将帮助你了解这些风险,而不是落入这些陷阱和陷阱。交易中最大的挑战是控制情绪,算法交易将从本质上消除情绪陷阱。
很高兴和你聊天,托马斯。请在疫情期间保重身体,继续学习,我们希望你会升得更高。祝你前程似锦。
算法交易(EPAT) 的高管课程是一门综合课程,涵盖从统计学&计量经济学到金融计算&技术,包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。点击这里查看。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
新加坡金融会议中的情绪分析
原文:https://blog.quantinsti.com/sentiment-analysis-in-finance-conference-singapore/

关于会议
这次会议是由联通和印度管理学院加尔各答。情感分析应用机器学习,对新闻发布中表达的情感进行快速评估。本次会议讨论并解释了多种信息来源,如:
- 新闻专线
- 宏观经济公告
- 社会化媒体
- 微博/推特
- 在线(搜索)信息,如谷歌趋势
来构建市场情绪。
高塔姆·米特拉教授

Gautam Mitra 是 OptiRisk Systems 的创始人和总经理。他在运筹学领域,尤其是计算优化和建模领域,是一位国际知名的研究科学家。他与来自欧洲、英国、美国和印度的研究人员在其专业领域建立了一个世界级的研究小组。他已经出版了五本书和一百五十多篇研究文章。他是 UCL 的校友,目前是 UCL 的客座教授。2004 年,他被布鲁内尔大学授予“杰出教授”称号,以表彰他在计算优化、风险分析和建模领域的贡献。
研讨会&会议日程
2016 年 3 月 9 日
- 会前晚餐
2016 年 3 月 10 日至 11 日
- “金融中的情绪分析:对交易和市场的情报和见解”会议
2016 年 3 月 11 日会后研讨会
基于 R - Working 模型的交易情感分析
原文:https://blog.quantinsti.com/sentiment-analysis-in-trading/
在这篇文章中,我们简要讨论了情绪分析,然后在 R. 中介绍了情绪分析的基本模型。情绪分析 是对新闻报道/博客帖子/twitter 消息等中表达的感觉(即态度、情绪和观点)的分析。,使用自然语言处理工具。
自然语言处理 (NLP)简单来说就是指使用计算机处理英语等自然语言的句子/文本。这里的目标是从这些推文/博客/文章中发现的非结构化或半结构化数据中提取信息。为了实现这一点,NLP 利用了人工智能、计算语言学和计算机科学。
使用 NLP 模型,可以处理数百个文本文档,在几秒钟内确定情绪。如今,情感分析交易
是一个热门话题,在商业智能、政治、金融、决策等领域有着广泛的应用。
交易中的情绪分析- 情绪通常可以驱动市场的走向。因此,金融市场中的交易员和其他参与者试图衡量新闻报道/推文/博客帖子中表达的情绪。交易者建立自动交易系统,从自然语言中提取情感。这些交易系统根据产生的交易信号在市场上建立多头/空头头寸。交易系统也可以与其他交易系统相结合。最终的目标是从提取的信息中获得更高的回报。
情感分析有各种方法和模型。让我们来看一个非常基本的 R 模型,用于情感分析。
模型:R 中的情感分析
在这个模型中,我们在 r 中实现了用于情感分析的“单词包”方法。该过程识别文章中的正面和负面单词(或一串单词)。为此,它使用了一个包含有情感词汇的大字典。这本词典中的每个单词都可以被赋予一个权重。正面词和负面词之和就是模型生成的最终情感得分。
我们将在 Eicher Motors Ltd .最新收益电话会议记录中的管理层评论文本上测试我们的模型。Eicher Motors 是一家领先的印度汽车制造公司,拥有 Royal Enfield Motors。我们模型的目标是评估他们在 2015 年第四季度收益电话会议中表达的观点。
为了构建我们的情绪分析交易模型,我们使用 r 中的“tm”和“Rweka”包。我们加载库,然后读取包含正面和负面术语的两个文档。为了准备这些文件,我们查阅了 2015 年第四季度之前的四份电话会议记录。我们从这些抄本中挑选出积极/消极的词来填充我们的词典。除了这些词,我们还添加了一些与摩托车行业相关的一般肯定/否定词。

我们将只考虑 R 中用于情绪分析的管理层评论。我们使用语料库功能在 R 中加载包含 CEO 准备的文本评论的文本文档(2015 年第四季度)。为此,我们将评论文档存储在 R 的工作目录下的 TextMining 文件夹中。

下一步是清理文本。我们将所有单词转换成小写,去掉标点符号,去掉数字,去掉空格。writeLines 函数使我们能够看到清理后的文本。
在下面的代码中,我们对上面清理过的文本进行了标记。标记化是将文本流分解成单词或一串单词的过程。我们在这里使用 NGramTokenizer 函数。这就产生了 N 个字母的文本。
n 元语法基本上是给定文本中一组共现的单词。比如考虑这句话“菜很好吃”。如果 n= 2,则 n 元语法将为:
- 食物
- 食物是
- 很好吃
此后,我们创建一个术语-文档矩阵(代码中称为“terms”),该矩阵列出了语料库中所有出现的单词。

下面我们检查字典中的肯定/否定单词是否出现在文本文档中。

现在,我们从文本文档中提取所有与字典中的单词相匹配的正面/负面单词。

下面的代码行计算正面/负面分数,最后是情感分数。

R 中的情感分析:最终情感得分

情感分析模型发现了 14 个正面词和 4 个负面词,最终情感得分为 10。这告诉我们,从管理层的角度来看,2015 年第四季度的季度业绩不错。下面的单词云显示了从我们运行模型的文本文档中选取的一些正面/负面单词。

R 中的情绪分析:验证我们的模型—让我们检查季度业绩数字,以确认我们的模型生成的积极情绪得分。可以看出,艾希尔汽车公司公布了一个强劲的季度。凭借 125,690 辆摩托车的强劲销量,EBIT 的年增长率约为 72%。尽管该季度其生产设施遭遇洪水,导致生产停工数日,但业绩依然强劲。
下图显示了 Eicher Motors 公布财报当天,股票市场对其强劲业绩的反应。该股开盘在 17100 点左右,大幅波动,触及 18500 卢比左右的盘中高点,最终收于 18500 卢比。18,175.
 T2】
T2】

结论
这是对 r 中情感分析的基本介绍。上面的模型可以做得更健壮,并进一步微调。在以后的文章中,我们将尝试涵盖其他情感分析方法,并尝试围绕它们建立一个模型。
你可以报名参加 Quantra 上的情绪分析课程,这将帮助你利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
QuantInsti 一直积极参与情绪分析会议,并且是最近于 2016 年在新加坡举行的“金融情绪分析”会议的主要营销和教育合作伙伴之一。 Rajib Ranjan Borah ,iRageCapital Advisory Pvt. Ltd .的联合创始人&董事& QuantInsti 是会议上“情绪分析应用于金融的新范例”的受尊敬的小组成员之一。
如果你希望在现代金融方法方面发展你的职业生涯,一定要参加这个关于金融情绪分析的课程。它涵盖了交易的各个方面,投资决策&应用使用新闻分析,情绪分析和替代数据。
下载数据文件
- Files.rar 交易中的情绪分析
- Eicher Motors 情绪分析- R Code.txt
- 负面条款. csv
- 积极条款. csv
- Q4.txt
使用情绪分析进行股票交易[EPAT 项目]
原文:https://blog.quantinsti.com/sentiment-analysis-trade-equities/
本文是作者提交的最后一个项目,作为他们在 QuantInsti 的算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。

关于作者
Siddhant R Vaidya 是一名 EPATian 人,现居印度浦那,拥有浦那大学的工程学学士学位。
作为一名在 Capstone Securities Analysis PVT . Ltd .工作的交易员,他拥有 EPAT 优秀证书。
平台:Python
项目摘要
市场是由人驱动的,人是由情绪驱动的。我们遇到过许多事件,在这些事件中,情绪比任何其他与股票基本面或技术面相关的因素更能影响股票的涨跌。此类事件的几个例子:新 iPhone 的发布、加密货币热潮、特斯拉推出新车、高管辞职或被解雇等。
我相信,在任何时候,如果我们能够衡量市场上一项资产的情绪,我们就能够成功地交易这项资产并获利。评估市场情绪的最好方法是分析人们使用的主要信息来源;新闻。
所需数据:
过去 6 个月的历史新闻数据来自 newsapi.org。我的项目选择的资产是英伟达公司( NVDA ),我从雅虎财经下载了相同 6 个月期间的历史数据。
程序:
该项目分为三个主要部分。新闻提取、情感得分生成和策略执行。
1.新闻摘录
为了获得所有与 Nvidia 相关的新闻文章,我们在查询 URL 中使用了多个过滤器。我们得到的输出是新闻文章的 URL。我们将这些 URL 保存在一个 excel 文件中。
2.情感得分生成
一旦我们有了所需新闻文章的 URL,我们就使用 python 的请求和新闻包从每篇文章中提取文本。一旦我们获得了文本,我们需要在消费它之前处理数据。我们删除所有符号和特殊字符以及停用词。完成后,我们分析每篇文章,以获得该文章的情感分数。
a.Textblob 包为我们提供了极性和主观性得分 b. Vader 情感情感强度分析器包中的分析器,为我们提供了-1 到+1 之间的得分
对于最终策略,我们将只使用 Vader 情绪评分,因为它更简单,结果也更好。
3.战略执行
我们有几天的多个分数,因为那天我们可能有多篇新闻文章。但是我们只对最有影响力的新闻文章感兴趣。因此,使用 groupby,我们找到每天的最大和最小情感分数。然后,我们将两者相加,创建一个名为“极端得分”的指标。这背后的逻辑是,比如说,在某一天,我们得到 2 篇相互矛盾的新闻文章,一篇非常正面,一篇非常负面,我们应该远离这些事件,不要交易。我们的指示器会处理这个问题。
然后,我们为我们的多头和空头头寸设置阈值,然后将我们的策略结果与买入并持有策略进行比较。
结果:
测试期(2018 年 3 月-2018 年 8 月)
- 买入并持有回报(绝对): 17.76%
- 策略回报(绝对): 24.72%
- 买入并持有夏普比率: 0.906
- 策略夏普比率: 1.34 (假设无风险利率为 4%)
收益图

项目的限制
Vader 情绪分析器是社交媒体分析的首选。在我们的例子中,它很好地告诉我们一篇新闻文章是正面还是负面地谈论英伟达,但它不能理解商业方面。新闻提供者在他们的文章中相当有礼貌,即使事情在现实中是灾难性的。因此,在这种情况下,衡量真实情绪变得很困难。解决方案是创建一个包含业务方面的词典。
项目的进一步范围
- 可以进一步改进该指标,并且可以优化阈值
- 使用机器学习来生成更有效的情感分数
- 对于任何其他策略,情绪分析可以用于风险管理
- 利用情感分析识别黑天鹅事件
下一步
如果你想学习算法交易的各个方面,那就去看看我们的算法交易(EPAT)执行项目(T2)。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 旨在让你具备成为成功交易者的正确技能。现在报名!
你可以报名参加 Quantra 上的情绪分析课程,这将帮助你利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
推荐阅读:
- 众包情绪分析交易策略
- 情绪分析在交易中的应用:它在哪里起作用?
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
zip 存档中的文件列表:
- 包含日期范围的 Excel 文件
- 提取新闻网址的 Python 代码
- 情感得分生成策略
情绪交易策略和指标——第一部分
原文:https://blog.quantinsti.com/sentiment-trading-indicators-1/
情绪交易指标和策略-第一部分
【市场决定价格】
一个情绪交易策略由市场情绪驱动。在我们探讨这个话题之前,让我们从证券的估价开始。
俗话说得好,你对一种证券的估值是否符合其基本面,以及你的估值模型对其所有敏感输入是否正确,都不重要,重要的是市场是否对你的估值达成共识,这将决定该证券的价格。因此,重要的是由市场决定的价格。这些价格由内在定价和市场情绪决定,因为证券的价格是其内在价值和投资者行为因素的函数。
证券的价格会偏离其内在价值,这是一种常见的规范,分析师会将证券评估为定价过低、平价或过高,但随后只需回顾一下文章开头引用的说法。说到这里,我们到了讨论的主题:市场情绪。
市场情绪
市场情绪是投资者对证券、指数或其他市场工具的当前价格和预测价格的总体态度和感觉。这种态度可以是积极的、中立的或消极的。这种态度形成的基础与宏观经济报告、世界大事、基本面分析、技术分析、历史价格模式、行业报告和非经济因素(新闻、天气等)有关。).
看涨情绪
当有积极的态度时,情绪被认为是乐观的。在牛市中,价格预计会向上移动。当市场被牛市拉动时,市场中存在贪婪。
悲观情绪
当有消极的态度时,这种情绪被认为是悲观的。在熊市中,价格预计会下降。当被熊市拖累/打压时,市场会有恐惧。
情绪交易策略
一个情绪交易策略包括在这样的多头或空头驱动的市场中建立头寸。情绪交易策略可以是基于动量的,即跟随一致意见或市场情绪,如果是牛市,我们就高投资高卖出,反之亦然。
情绪交易策略甚至可以是逆势或均值回复,即与市场情绪相反。反向投资者从这一理论中获利,即当某一证券存在某种群体行为时,它会导致某种可利用的错误定价(对已经普遍上涨的证券定价过高),而在大牛市之后,该证券的价格会因回调而下跌,反之亦然。我们已经在关于算法交易策略&范例的文章中谈到了基于动量的交易策略。
“大牛市之后,证券价格会因回调而下跌,反之亦然”
情绪指标
一个情绪交易策略使用不同的指标。这些情绪指标试图在牛市或熊市占据市场之前,估计或衡量投资者的活动,寻找任何看涨或看跌的迹象。这些情绪交易指标在价格反映之前,给你一个特定证券的乐观或悲观迹象。这些指标有助于我们在市场情绪反映到市场价格之前抢先一步。
情绪交易指标可以像民意调查一样定性。有许多公司提供这些服务的调查市场专业人士和投资者进行定期民意调查并公布他们。一些民意调查是投资者情报顾问情绪报告,市场风向标看涨共识,共识看涨情绪指数。所有这些调查投资专业人士和报告都来自美国个人投资者协会(AAII)对个人投资者的调查。这些民意调查是定期的,数据被汇编成图表和可视化的形式,以了解特定的情绪。最广泛使用的民意调查是基于美国的民意调查。
情绪交易指标甚至可以是定量的,从市场数据如证券价格、交易量、未平仓合约等计算得出。其中一些指标如下:
- 卖出/买入比率
- Arms 指数或短期交易指数(TRIN)
- 维克斯
- 保证金债务
- 共同基金现金头寸
- 短期利率比率
在这篇文章中,我们将向您概述看跌看涨期权比率和 TRIN。
卖出/买入比率
卖出/买入比率是一个非常重要的情绪交易指标。投资者在进行情绪交易时使用这一点,其中最受欢迎的市场之一是期权市场,因为期权为交易机会、灵活性和不对称回报提供了杠杆,这被一些人(通常是买入/做多者)视为彩票,被一些人(通常是卖出/做空者)视为溢价/稳定收入工具。然而,当有人购买看涨期权或看跌期权时,买方预期市场将分别向上或向下移动。由于交易活跃(成交量)。
看跌/看涨比率是最可靠的市场情绪指标之一。

卖出/买入比率=卖出量/买入量
卖出量是市场上买入的看跌期权的数量。每当投资者买入看跌期权时,投资者都预期证券价格会下跌。而看涨期权量是市场上买入的看涨期权的数量。每当投资者买入看涨期权时,投资者都预期证券价格会上涨。
因此,大于 1 的比率表明卖出期权比买入期权买得多,这反过来意味着情绪是看跌的,投资者预计市场在不久的将来会下跌。小于 1 的比率表明,由于看涨期权在市场上被买得更多,总体情绪是看涨的,市场将在不久的将来上行。交易者根据情绪交易指标进行交易。
基于看跌期权比率的情绪交易策略
这一比率通常被视为反向指标,策略如下:
- 当这个比率远大于 1 时,就有极端的看跌情绪,市场可能超卖,有可能出现回调。因此购买。这些修正将使市场上涨,在这样的底部做多将为我们的反向策略带来丰厚的回报。
- 当这一比率大大小于 1 时,就有一种极度看涨的情绪,市场可能超买,很可能出现回调。因此出售。
虽然没有标准的数字来说明在比率的哪个点上应该买入或卖出,但是交易者应该观察比率在更高或更低的值上移动的一般趋势。一旦出现高峰或低谷,比率偏离了这些交易范围,这就是你应该行动和建仓的时候了。
所有数据提供商都提供世界领先交易所的期权交易量数据,这一指标可以很容易地在电子表格中创建。
在处理反向策略时,检查甚至是潜在的基本面也是很重要的。如果基本面非常弱,价格下跌是合理的,那么反向策略可能不起作用。
军火指数或短期交易指数(TRIN)
这一指数是由 Richard Arms 于 1967 年开发的,也称为交易指数(TRIN),是一种常见的“资金流动”指标。我们所说的资金流是指该指标表明投资于指数/交易所证券的资金量,并帮助我们解读情绪。要了解 TRIN,我们首先需要了解一些常用术语:
- 上涨的股票:在一个指数或交易所中,从前一天收盘开始上涨或以绿色收盘的股票数量。
- 下跌的股票:在一个指数或交易所中,以红色收盘或在前几天收盘后下跌的股票数量。
- 上涨成交量:这些上涨股票的总成交量。
- 下跌量:这些下跌股票的总量。
![TRIN = [(No. of advancing stocks/ No. of declining stocks) / (Advancing volume/Declining volume)]](https://github.com/OpenDocCN/geekdoc-quant-zh/raw/master/quantinsti/img/e79b1b711446b3f7b00cdf0f8965c756.png)
TRIN = [(上涨股数量/下跌股数量)/(上涨量/下跌量)]
当 ARMS 指数高于 1 时,表明市场情绪看跌。发生这种情况是因为当收盘时红色股票的数量多于绿色股票的数量时,就会产生一个小于 1 的 AD 股票比率,合理地说,这表明红色股票的交易量比绿色股票大得多。结果,广告量比率将甚至小于广告存量比率,并且整个比率变得大于 1。
同样,当 ARMS 指数低于 1 时,它表明看涨情绪。接近 1 的比率表明市场平衡。因此,当 TRIN 出现上涨时,它们与市场的日均大幅下跌相吻合,而 TRIN 出现下跌时,它们与市场的日均大幅上涨相吻合。
基于看跌期权比率的情绪交易策略
在图表上缩放该指标时,我们将观察该指标的一个范围,在该范围内,出于交易目的,我们将持有反向投资头寸的时间是:
- 当这个比率远大于 1(接近 3)时,有一个极端的看跌情绪和一个可能的超卖市场,一个修正是可能的。因此购买。这些修正将使市场上涨,在这样的底部做多将为我们的反向策略带来丰厚的回报。
- 当这一比率大大小于 1(接近 0.5)时,市场人气极度看涨,市场可能超买,很可能出现回调。因此出售。
虽然这些不是标准数字,但你总能找到一个交易区间,从这条均线的任何一边偏离都可以帮助我们在交易时逆势建仓。
每个情绪交易指标和与之相关的策略都有自己的缺点;为了了解市场中的真实情绪,我们可以做的是查看一个以上的情绪指标来衡量市场情绪。如果有确凿的证据表明这是一个牛市或熊市,更重要的是(因为我们正在处理反向策略),这是一个超买的牛市或超卖的熊市,我们可以在市场上建立适当的头寸,使我们的回报最大化。
结论
在上面的文章中,我们只讨论了两个用于市场分析的情绪交易指标。然而,有许多这样的指标从广度、波动性、成交量、资金流动、空头或市场保证金来衡量人气,每个指标都可以用一个人自己的投资风格来解读。我们专注于反向投资风格,利用市场普遍的乐观或悲观情绪,观察特定趋势,在趋势反转时建仓,一旦反转获利就退出交易。
永远记住,当你使用情绪交易策略时,不要孤立地使用这些指标。使用一个以上情绪指标的指示,试图理解这种模式背后的基本面和合理性,但要足够勇敢,采取逆向立场,利用其他投资者的恐惧或贪婪。
如果你希望在现代金融方法方面发展你的职业生涯,一定要参加这个关于金融情绪分析的课程。它涵盖了交易的各个方面,投资决策&应用使用新闻分析,情绪分析和替代数据。
情绪交易指标和策略——第二部分
原文:https://blog.quantinsti.com/sentiment-trading-indicators-strategy-part-2/
由杰伊·马尼尔
在我们关于情绪指标的上一篇文章中,我们看到了如何使用看跌/看涨比率、Arms 指数或短期交易指数(TRIN)等情绪指标进行交易,并围绕这些情绪指标制定策略。在本帖中,我们将探索更多这样的情绪指标,并举例说明使用这些指标可以设计出不同的策略。
波动指数
VIX 是芝加哥期权交易所(CBOE)波动率指数的注册股票代码。这是对标准普尔 500 指数期权在未来 30 天的隐含波动率的测量。
VIX 作为一个指标
- CBOE 波动率指数(VIX)是标准普尔 500 指数隐含波动率的最新市场估计,通过采用实时标准普尔 500 指数期权的买价/卖价(期权价格)的中点来计算。
- 在 VIX 波动率指数的每一个基点,它提供了一个从最后一个基点开始的 30 天内市场波动的即时指标。
- 因此,波动指数是前瞻性的,预测未来市场的波动。
- VIX 以百分点引用,即 VIX 为 20 表示在 68%的置信水平下或在正态概率分布的一个标准偏差内,标准普尔 500 指数任一方向的预期年变化为 20%。
- VIX 的通用计算公式为

VIX 解读
- 实际上,高 VIX 对应于指数水平的价格下降。
- 在理解其中的原因之前,理解期权定价的基础是很重要的。期权价格=内在价值+外在价值;其中外在价值是时间价值和波动性的总和。因此,波动性在期权定价中起着重要的作用。
- 由于波动性,市场下跌通常会导致看跌期权溢价上升。此外,投资者对看跌期权的需求很高,因为持有股票的投资者希望通过购买这些看跌期权来确保他们的股票投资。这种需求是由于进一步预期市场将在实现下跌后下跌,因为波动性导致风险较高。市场波动是由于价格下跌和投资者担心失去投资或获得的资本。因此,他们可能决定通过出售标的资产来获取收益或实现亏损。这增加了期权的溢价,导致 VIX 急剧上升。
- 一般来说,VIX 值超过 30 表明市场存在高度不确定性和恐惧。
- 较低的 VIX 值表明,由于市场中出现的反弹,预计市场将保持平静。
- 上涨增加了投资者的贪婪,他们预计市场会继续上涨。因此,期权卖方以不同的执行价格为他们的看涨期权定价,使得投资者购买期权有足够的利润,但期权在到期前兑现的概率不会太高。在反弹中,买入更多的看涨期权,降低(看跌/看涨比率)PCR 比率——表明市场看涨。投资者可能不希望在某一特定价格水平上一次性实现所有收益,因为他们预计市场会进一步上涨,只会将投资组合中的一小部分系统性地出售给希望进入这轮涨势并持有投资组合中另一部分的新买家。定价过高的股票可能会出现稳步反弹和小幅修正,从而降低整体波动性。
- 这反过来又降低了 VIX 值。VIX 低于 20 通常表明市场平静。
策略
我们将采取基于 VIX 的反向头寸。采取逆势头寸是指在市场大幅下跌时‘买入’,在市场非理性上涨时‘卖出’。反向投资者受益于这样一个理论,即当有某种证券出现积极或消极的群体行为时;由于普遍的看涨或看跌情绪,它会导致证券的错误定价。
- 当 VIX 指数高时(通常高于 30),我们买入标的指数。由于这表明市场是熊市,隐含波动率很高,我们买入,因为我们预计熊市将从这一水平进行修正,并预计隐含波动率将从这一点回到其均值,表明牛市。
另一个策略是“做空”,即 delta 为正,vega 为负。Delta 为正意味着,随着股价上涨,期权价格也上涨,vega 为负意味着可以从隐含波动率下降中受益。
- 当 VIX 很低(通常低于 15)时,这表明市场看涨,可能会出现回调。我们做“多头”,即 delta 为负,vega 为正,或者我们可以卖出指数。
图片:VIX 水平和相应的标准普尔 500 指数水平

保证金债务指标
一个普通的现金账户允许你购买与账户中可用现金金额等值的证券。例如,如果你的账户上有 5000 美元,你想投资在交易所以 100 美元交易的 ABC 公司的股票,那么你可以购买(5000/$100) 50 股 ABC 公司的股票。但是,如果根据你的分析,ABC 公司被低估了,而你预计该股票的价值在短期内会上涨,你可以利用这个机会,要求你的经纪人借钱给你,以便购买你账户上的证券。为此,经纪人会要求你开立一个保证金账户。保证金账户是你和你的经纪人之间的协议,经纪人同意借给你一定比例的钱,用于购买金融证券(股票、债券和其他金融工具)。这笔贷款的抵押品将是所购买的金融证券(例如我们的 ABC 公司股票)。然而,在您贷款购买这些证券并签署保证金账户协议之前,有几个先决条件。
- 在用保证金购买证券时,投资者支付的部分称为保证金,经纪人借给你的部分称为保证金债务。
- 这些由各种投资者承担的债务由交易所汇总并公布,因为经纪人需要向交易所报告这些数据。
解读
- 随着时间的推移,未偿还保证金债务总额的增加将与市场的上涨相一致,这表明了积极的购买和看涨的情绪。
- 投资者用保证金购买股票的一个理性原因是,自由现金已经耗尽,投资者仍然看到了买入的机会,因此,投资者用保证金买入股票。
- 但每个保证金账户都有自己的信用额度,即经纪商借给投资者的比例。当这些保证金投资者达到他们的保证金信用限额时,他们继续购买的能力下降,因为市场需求减少,价格可能会停滞不前,甚至可能因为需求减弱而下降。
- 这种疲软的需求是投资者达到其购买自有资产(或投资者的现金)和保证金债务(购买贷款证券的能力)能力极限的结果。
- 这可能导致股票价格或整个指数下跌,从而导致追加保证金。
- 无法获得自由现金和价格下降,并可能迫使投资者或经纪人出售这些保证金账户中的证券,进一步增加抛售压力,进一步将价格降至新低。
- 因此,保证金债务的增加往往与市场价格的上升相一致,而保证金债务的减少往往与市场价格的下降相一致。
策略
- 在历史最低水平的保证金债务,我们将购买指数期货,因为有额外的空间来购买保证金证券,这可能是一个超卖市场的迹象。
- 在历史最高水平的保证金债务,我们将出售指数期货,因为没有更多的空间来购买保证金证券和触发保证金通知的可能性。
图片:保证金债务图表和相应的标准普尔 500 指数水平

共同基金现金头寸指标
共同基金持有市场上所有可投资资产的很大一部分。
- 共同基金现金头寸是共同基金的现金与总资产的比率。
共同基金现金头寸=(共同基金的现金/共同基金的总资产)。
- 这些现金可以是手头的现金,也可以是投资于高流动性货币市场证券的现金,赚取名义回报率。
- 一般来说,这种现金头寸最高可达 5%,这些基金需要随时保持可用,以处理股票赎回、日常运营费用等。
- 现金也每天从客户(投资者)的存款、获得的利息和收到的股息中进入共同基金。
- 在基金经理卖出头寸并持有资金进行再投资后,现金也会增加。
解读
- 在市场上涨期间,基金经理会希望迅速将现金投入市场,因为现金(理想或货币市场工具)只能获得接近无风险的回报率。把钱留在现金中会降低回报,因为用这些现金投资上涨趋势可以获得高于无风险利率的收益,并提高基金的业绩或整体回报。
- 因此,一般来说,当市场出现中长期上涨趋势时,共同基金的现金头寸低于 4.5 - 5%,因为最大的现金投资于市场,并期望最大限度地利用这些现金。
- 同样,在下跌趋势中,现金投资将获得接近无风险的利率,这将高于市场中可能获得的负回报。因此,基金的现金投资余额增加,期望改善基金的业绩或整体回报。
- 一般来说,在这种短期和中期下跌趋势中,共同基金的现金头寸可能会增加到 11%以上。
- 分析师通常将此解读为逆向投资
- 这是因为当共同基金积累现金时;基金经理看跌,这表明这些基金未来在市场上的购买力。
- 较高的共同基金现金比率表明,市场价格在不久的将来可能会上涨。
- 另一方面,当共同基金的现金很少时,这意味着它们已经被投资,市场价格反映了它们的购买。这使得市场价格上涨的空间变小,因为基金经理预计价格会上涨。
策略
- 当共同基金的现金比率比最近几年前的现金头寸大幅上升时,我们会买入指数期货。

共同基金现金头寸水平和相应的标准普尔 500 指数&水平;图片来源:caps.fool.com
结论
永远记住,当你交易时,不要孤立地使用这些情绪指标。使用不止一个情绪指标的指示,试着理解这种模式背后的基本面和合理性,但要有足够的勇气进行反向操作,利用其他投资者的恐惧或贪婪。在我们关于使用期权情绪指标进行交易的课程中,我们更深入地研究了这些概念,其中也包括可下载的代码。
下一步
详细学习期权交易策略。参加我们的 3 门课程包,Python 中的期权交易策略:初级、中级和高级。与 NSE 学院联合开发。该套餐提供 30%的折扣,单击此处了解更多信息。
关于情绪交易的 7 大博客| 2022
聪明的投资者是现实主义者,他们卖给乐观者,从悲观者手中买入——本杰明·格拉哈姆
情绪交易策略对市场情绪及其趋势起作用。这些策略通常由可能波动的资产价格和价值决定。
市场情绪会影响特定资产或金融市场的投资者行为。它是通过某些活动和定价动态表现出来的情绪和心理偏见。
这些专家精心研究的文章简要概述了情绪如何在交易中发挥关键作用。我们列出了涵盖主题、概念、方法等的各种顶级文章。以下是在 2022 年对我们的读者有所帮助的关于情绪交易的顶级博客。
VADER 情绪分析完全指南
这个博客是一个 VADER 情绪分析的演练指南,以及你如何在 Python 的帮助下在算法交易模型中利用它。
这个博客使你能够使用 SMA 作为一个主要的技术指标作为一个实际的例子。您还将学习 VADER 如何评估输入文本和句子的配价分数。近年来,情绪正在推动金融市场。学习如何使用这种方法通过算法交易获得结果。
情绪交易策略和指标-第一部分
本文是讨论情绪交易策略和指标的第一部分。有多个指标可用于市场分析,如波动性、成交量、资金流等。在这里,您可以阅读看跌/看涨期权比率和 Arms 指数或短期交易指数(TRIN)。它概述了两种反向投资方法如何利用市场上普遍的乐观或悲观情绪。
不同数据来源的基本面和情绪分析
许多量化分析师依赖多种数据源来增强策略,从而为交易活动创造价值。这篇文章对各种数据源提供了很好的指导,有助于开发风险最小的强大交易策略。你将学习如何利用各种来源的数据,并在交易活动中优化使用数据。
文章讨论了:
- 基本数据
- 宏观经济数据
- 收入日历
- 财经新闻数据
- 推特数据
- 情感数据
实际运用情绪分析进行股票交易
这篇文章是我们的 EPATian Siddhant R Vaidya 提交的期末项目,作为他在 QuantInsti 的课程工作的一部分。该项目的范围包括:
- 可以进一步改进该指标,并且可以优化阈值
- 使用机器学习来生成更有效的情感分数
- 对于任何其他策略,情绪分析可以用于风险管理
- 利用情感分析识别黑天鹅事件
Tweepy -使用 Python 中的 Twitter API 生成情绪交易指标
社交媒体和 Twitter 是分析市场情绪的替代数据来源。博客评论 Tweepy 库,以从 Twitter 获取实时和历史数据。通读这篇文章,深入了解:
- Twitter 和情感分析
- 社交网络对市场趋势的影响
- 一个 Python Twitter API,Tweepy
- 如何安装设置 Tweepy?
- Twitter API 上的认证
- 如何使用 Tweepy 获取推文
- Tweets 用光标分页
- 构建一个简单的情绪指标
包话:方法、Python 代码、局限性
该博客详细讨论了开发文本数据的矢量化表示的单词包方法。这些表示支持 NLP 任务的执行,如情感分析。您也可以学习相关的术语、限制和该方法的关键优势。
使用价格和情绪指标开发外汇交易的森林回归模型
这篇文章讲述了如何建立一个机器学习模型来使用历史数据预测资产价值的见解。它使用历史定价数据和 Twitter 情绪指标来构建模型。了解实际实施的潜力以及如何创新您的模型。
可敬的提到了
利用 R - Working 模型进行交易中的情绪分析
该博客概述了情感分析,并展示了 r 中情感分析的基本模型。了解如何使用情感方法开发一个健壮的模型。
众包情绪分析交易策略
通常,情绪分析交易获取大量数据,并建立情绪得分,以在交易活动中提供信号。本文展示了如何直接利用情绪栏作为策略的输入。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
新加坡南洋理工大学的算法交易课程
原文:https://blog.quantinsti.com/session-algorithmic-trading-ntu/

简介
新加坡南洋理工大学邀请 QuantInsti 为他们的 MFE 学生进行算法交易的会议。
nitesh Khandelwal(QuantInsti 首席执行官)和 Prodipta Ghosh(QuantInsti 副总裁)与这些聪明的学生进行了互动,并与他们分享了他们的行业经验!
会议亮点
一些重点会议包括:
- 概观
- 系统结构
- 市场数据类型
- 系统策略
- 技术指标
- 管理战略组合
关于 NTU
新加坡南洋理工大学(NTU 新加坡)是一所国际化的研究密集型公立大学。2018 年,NTU 在 Quacquarelli Symonds (QS)世界大学排名中名列全球第 12 位,也是许多世界级机构的所在地。
活动照片


在 IIT 德里举行的“算法交易系统的系统架构”会议
原文:https://blog.quantinsti.com/session-iit-delhi-october-2018/

概述
QuantInsti 于 2018 年 10 月 28 日为 IIT 德里举办了一场关于“算法交易系统的系统架构”的会议。nitesh Khandelwal(quantin STI 的联合创始人和主管)在这个会议上介绍了算法交易系统的内部知识。
关于演讲者

Nitesh Khan delwal(QuantInsti 联合创始人兼首席执行官)
Nitesh Khandelwal 毕业于 IIT 坎普尔大学电气工程专业,并获得了 IIM 勒克瑙大学的管理学研究生学位,他的职业生涯始于财政部的银行部门。在一家自营交易公司短暂担任领导后,他在孟买共同创立了 iRage。如今,iRage 是印度算法交易领域的领先企业。后来,当 Nitesh 搬到新加坡时,他成立了一家贸易公司,在全球交易所进行交易。
2016 年,他将重心转移到 QuantInsti 担任其 CEO。QuantInsti 继续致力于将面向科学&技术的贸易知识和途径带给全球大众,并且已经帮助来自 130 多个国家的用户实现了同样的目标。
活动照片


在 IIT 马德拉斯举行的“系统交易策略和因素建模”会议
原文:https://blog.quantinsti.com/session-iit-madras-november-2018/

概述
IIT·马德拉斯于 2018 年 11 月 1 日主持了一场关于“系统交易策略和因素建模”的会议。prodipta Ghosh(QuantInsti 副总裁)解释了如何利用像 T2 Quantra blue shift T3 这样的平台构思、转换和测试自己的交易策略。

![prodipta-ghosh]() T2】
T2】
 T2】
T2】Prodipta Ghosh(QuantInsti 副总裁)
Prodipta 是一位经验丰富的 quant,目前作为副总裁领导 QuantInsti 的 Fin-tech 产品和平台开发。
他在银行业工作了十多年,在孟买和伦敦的德意志银行的交易和结构部门担任过各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
新加坡国立大学商学院“建立你的算法交易平台”课程

概述
作为新加坡国立大学投资学会量化金融系列“量化金融 101”的一部分,QuantInsti 于 2018 年 10 月 20 日在新加坡国立大学商学院举办了一场关于“设置你的算法交易平台”的会议。
nitesh Khandelwal(QuantInsti 联合创始人兼首席执行官)介绍了算法交易领域的知识,并解释了如何在其他关键主题中建立算法交易平台,随后是互动问答环节。
关于事件
QF101 是新加坡国立大学投资学会举办的年度活动,旨在向观众介绍量化金融的基础知识。此外,我们邀请了算法和量化交易的先驱培训机构 QuantInsti 来谈谈建立算法交易台的过程。每个人,不管之前的背景知识,都将受益于这个为期一天的速成班!
关于演讲者
Nitesh Khan delwal(QuantInsti 联合创始人兼首席执行官)
Nitesh Khandelwal 毕业于 IIT 坎普尔大学电气工程专业,并获得了 IIM 勒克瑙大学的管理学研究生学位,他的职业生涯始于财政部的银行部门。在一家自营交易公司短暂担任领导后,他在孟买共同创立了 iRage。如今,iRage 是印度算法交易领域的领先企业。后来,当 Nitesh 搬到新加坡时,他成立了一家贸易公司,在全球交易所进行交易。
2016 年,他将重心转移到 QuantInsti 担任其 CEO。QuantInsti 继续致力于将面向科学&技术的贸易知识和途径带给全球大众,并且已经帮助来自 130 多个国家的用户实现了同样的目标。
关于 新加坡国立大学
新加坡国立大学(NUS)是一所自主研究型大学,也是新加坡历史最悠久的高等学府(IHL)。就学生注册人数和课程设置而言,它是美国最大的大学。它在全球研究和教育领域的成就和影响力使其成为世界上最负盛名的大学之一。该大学的校友中有四位新加坡总理或总统和两位马来西亚总理。
活动照片




在您的系统上设置 Python
以重香重香
Python 是一种通用的编程语言,相对来说更容易学习和编程。Python 的优势之一是用户可以在他们的系统上安装大量的库,这样他们就不必从头开始编写代码。
这些库被一次又一次地更新,以确保一切顺利运行。但是有时由于一个库中的更新,一些库可能变得彼此不兼容。
您可以使用本文来设置您的本地 Python 环境,它类似于 Quantra 门户。Quantra 门户包含所有推荐的 quant 分析和算法交易软件包。
这个博客包括以下几个部分。如果您已经熟悉了蟒蛇的安装或者已经安装了蟒蛇,那么您可以直接进入“设置 Python 版本并安装软件包”部分。
如果您想探讨某个特定问题,可以直接访问下面的链接:
Python 安装步骤
安装并运行 Anaconda
- 在 Windows 上安装 Anaconda
- 在 Mac 上安装 Anaconda
- 解决 Anaconda 安装问题
设置 Python 环境
对于 Quantra 用户
- 如何运行 Quantra 课程下载部分包含的文件
- data _ module 中有哪些不同的文件类型?
- 故障排除笔记本
- 您如何访问存储在 data_modules 中的 CSV 文件?
- 如何访问存储在 data_modules 文件夹中的函数?
Anaconda 帮助你组织你的代码,在 markdown 单元格中编写简单的代码解释,以及控制程序应该如何运行。
您还可以使用 Anaconda 提示符轻松安装 Python 包。
在 Windows 上安装 Anaconda
(跳过这个
如果您已经安装了 Anaconda,那么您可以跳过这一节,直接进入关于设置 python 版本的章节。
请记住,您创建的每个环境都有一个特定的名称。现在是“基地”。
现在,您可以前往“设置 Python 版本并安装包”部分。如果 Anaconda 没有正确安装,请转到这个部分。
在 Mac 上安装 Anaconda
(跳过这个
请记住,您创建的每个环境都有一个特定的名称。现在是“基地”。
现在,您可以直接进入“设置 Python 版本并安装包”部分。如果 Anaconda 没有正确安装,请转到这个部分。
Anaconda 安装问题疑难解答
我们在安装 Anaconda 时遇到的一个常见问题是文件位置问题。通常建议在安装 Python 的地方安装 Anaconda。
有时,由于系统要求,您的系统可能无法安装 Anaconda。那样的话,你可以从这个 链接 中挑选一个较早的版本。
现在已经安装了 Python 和 Anaconda,我们将把 Python 环境修改为 Quantra 使用的相同环境。让我们在下一节看看这个过程。
设置 Python 版本并安装包
我们现在不要使用 Anaconda 提示符在 Python 中创建环境。
下面列出了您必须键入的命令:
- a)使用机器学习库创建新环境:
conda env create-f https://quantra . quantin STI . com/downloads/machine learning/environment . yml
- b)用于创建没有机器学习库的新环境:
conda env create-f https://quantra . quantin STI . com/downloads/general/environment . yml
2.用于激活新环境:康达激活 quantra_py
3.用于在新环境中打开 jupyter 笔记本:Jupyter 笔记本
现在,您可以打开任何笔记本,并立即开始工作。
设置环境的故障排除提示
安装软件包时,您可能会收到一条错误消息,提示“需要 Windows C++或更高版本才能安装软件包。你可以简单地复制粘贴 链接 并下载构建工具。

点击安装文件,确保您已经选择了“C++构建工具”复选框,并进一步选择了 5 个“可选”工具,如下图所示。

按照安装过程中的说明进行操作,将会安装所需的软件包。然后,您可以再次尝试安装 Python 包,这一次设置将会完成。
为了获得最佳的用户体验,您应该将所有文件提取到安装 Python 的根目录下。例如,如果 Python 安装在文件夹“C:\Users\rekhi”中,那么将文件提取到这个文件夹中。
如果您想要删除现有环境,可以通过以下方式完成。
- 停用环境
- 运行以下命令:conda remove - name quantra_py - all

注意:这里,环境名为“quantra_py”。您可以写下要删除的环境的名称。
设置好环境后,您可以运行课程中下载的 zip 文件中的所有笔记本。
现在让我们看看 Quantra 课程的 zip 文件夹中的不同文件。
仅 Quantra 学员专用的部分
如何运行 Quantra 课程下载部分包含的文件
data_module 中有哪些不同的文件类型?
数据文件:这些是包含字母数字数据的文本文件。Quantra 以 CSV、bz2 或 pick 文件的形式提供某些财务数据,因此用户不必每次都从 web 资源下载数据。
例如,“infy_dv.csv”文件可以包含 2018 年的 OHLC 数据。
这些文件可以是 csv、bz2 或 pick 格式。但是使用它们的方法是一样的,用熊猫的方法。
扩展名为的模块或文件。py : Quantra 在一个函数中整理所有重复使用的代码,比如计算策略回报,这个函数存储在模块中。这样,不用在每一个笔记本上都写相同的代码行,你可以简单地调用模块文件中定义的函数。
这样,你就收到了所有的数据文件以及用于分析的策略笔记本。因此,您不必花费时间来确保一切正常运行。相反,你可以花时间优化和调整你的策略,以便开始系统交易。
笔记本故障排除
1.在设置环境之前,请确保您安装的 Python 版本是正确的。您可以通过在命令提示符下键入“python”来检查版本。
2.如果您遇到“ModuleNotFound”错误,那么您可以通过安装所需的软件包来解决这个问题。
3.如果您遇到“FileNotFound”错误,您可能没有写正确的文件路径。
如果在运行 Quantra 课程中提供的代码时仍然遇到错误,该怎么办?
您可以随时将您的问题发布到社区页面上,在那里像您一样志同道合的人正在学习 Python,并回答彼此的问题。
如何访问存储在 data_modules 中的 CSV 文件?
你可以去任何文件夹,打开 Jupyter 笔记本。因为您需要编写以下代码来访问该文件
1.导入熊猫库
import pandas as pd
2.正确陈述数据文件的路径。
比如“infy_dv.csv”存储在文件位置“C:\ Downloads \ Python-for-Trading-Basic-Resources \ Data _ modules”,笔记本“Data Visualization.ipynb”在文件夹“C:\ Downloads \ Python-for-Trading-Basic-Resources \ Importing Data and Data Visualization”中。
您需要转到笔记本位置上方的一个文件夹,然后进入“data_modules”文件夹。这里”..“表示我们将转到笔记本位置上方的一个文件夹。
'..\数据模块'
然后,你会写“..\ data _ modules \您要访问的文件的名称。
代码如下所示:
infy = pd.read_csv('../data_modules/infy_dv.csv')
这里,infy 是我们存储内容的数据帧,以便我们可以在以后分析它。
如何访问 data_modules 文件夹中存储的函数?
这些函数的访问方式与导入库的方式相同。但是还有一些额外的步骤。现在让我们来看一看:
1.假设函数“分析性能”存储在“ST_functions_quantra.py”文件中。如前所述,该模块位于 data_modules 文件夹中。位置给定为。“C:\ Downloads \ Python-for-Trading-Basic-Resources \ Data _ modules”,笔记本“Data Visualization.ipynb”在文件夹“C:\ Downloads \ Python-for-Trading-Basic-Resources \ Importing Data and Data Visualization”中。
2.你应该先写下这一行
“导入系统”将帮助您导入模块中的函数。
3.然后,您应该编写“sys.path.append(”..”)以便我们可以添加特定的路径供解释器搜索。
4.最后,我们指定想要导入的文件和函数的名称。此处文件名为“quantra_functions ”,函数名为“分析性能”。
因此,代码将如下所示
from data_modules.quantra_functions import analyse performance
通过这种方式,函数将被导入。
总结
你已经开始了算法交易的旅程。首先,您安装了 Python 和 Anaconda Navigator。你已经安装了所有必要的库,当你进行回溯测试和分析自己的交易策略时,这些库会对你有所帮助。您还看到了 Quantra 课程中使用的不同数据文件,这样您就可以最大限度地减少回溯测试时检索数据所需的时间。最后,您设置的环境与 Quantra 相同,因此,在使用任何课程策略笔记本时,您都会遇到最小的错误。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
建立 Algo 交易平台
原文:https://blog.quantinsti.com/setting-up-an-algo-trading-desk/
作者:阿波瓦·辛格
你需要领域知识、技术资源、硬件和软件形式的技术和基础设施来建立任何业务或启动。这些要求,尤其是在法规、基础设施和成本估算方面的要求,可能会因您计划设立办公桌的国家而异,但总体而言,一切都会在这个大框架下进行。
这个博客会给你一个建立一个算法交易柜台或公司的要求的概述。
Requirements for setting algorithm trading desk
-
注册你的公司:第一步是注册你的公司。你可以将你的贸易公司注册为公司、合伙企业、LLP 甚至个人。然而,如果你想与投资者建立对冲基金,还需要获得监管机构的其他批准(例如印度的 SEBI 和新加坡的新加坡金融管理局),合规规则和法规通常要严格得多。
-
交易和操作所需的资金:一般来说,高频交易所需的交易资金通常相对多于低频交易所需的交易资金。LFT 是可扩展的,可以吸收更多的交易资本。但是,考虑到 HFT 的基础设施和技术要求,HFT 的交易运作所需的资本通常比 LFT 高得多。
-
交易模式 :你需要决定你要适应的交易哲学。最常见的交易哲学包括基于执行的策略,其重点是获得执行的最佳价格,而不是关注 Alpha。然后是高频策略,对延迟非常敏感,主要包括做市、刷单和套利。然后是基于市场情绪、基于机器学习和基于新闻的交易算法,与 HFT 相比,它们对延迟相对不太敏感。
-
市场准入:交易所提供不同种类的会员资格——结算会员、交易会员、交易暨结算会员、专业结算会员等。如果你不想直接成为交易所的会员,你也可以通过经纪人。这涉及较少的合规规则和监管要求。然而,另一方面是你必须支付佣金,而且大多数 HFT 策略对交易成本高度敏感。
-
基础设施要求:该标题下的主要重点领域是主机托管、硬件和网络设备以及网络线路。
a)主机托管:主机托管是指您的服务器与交换机位于同一场所和同一局域网内。现在大多数交易所都提供主机托管设施。在某些情况下,当交易所不提供主机托管设施时,会有供应商提供主机托管或邻近托管设施。现在,交易所收到的订单中有很大一部分是由算法生成的,其中大多数订单是由协同定位空间生成的。
硬件:许多领先的公司生产算法交易设置所需的服务器。还提供用于高频交易的可定制硬件,可以根据需要进行修改以提高性能。鉴于技术的快速变化,目前的情况要求服务器几乎每年或最多两年更换和更新一次。
c)网络设备:这主要包括路由器/调制解调器、交换机和网络接口控制器(NIC)和 FPGAs。对于路由器和调制解调器,您需要检查与交换机的版本兼容性。网卡基本上是以太网卡,帮助你的计算机连接到网络。FPGA 代表现场可编程门阵列。它基本上是包含可编程逻辑块阵列的集成电路,并且被配置为执行复杂的操作。
d)网络线路:网络线路大致可分为以下四类-
一、交易租赁线——用于向交易所发出指令。不同的线路为要发送的消息提供不同的带宽,并相应地定价。
二。市场数据租赁线路 -这条线路用于从交易所或您的数据提供商接收市场数据。交易所发送市场数据的方式主要有两种,即逐笔交易或快照数据(例如 NSE)。
->-分笔成交点 (TBT)-分笔成交点数据是连续“分笔成交点”的集合,是最新的报价、交易、价格和交易量信息。您还可以订阅 bucket feed,它可以过滤特定仪器请求的数据。
->-快照数据 -快照数据馈送包含与证券交易所交易报价相关的数据以及与定期生成的不同工具的交易相关的其他相关信息。
三世。交换机之间的线路:这些是交换机之间的点对点线路,可以帮助 SOR。智能订单路由(SOR)允许您将订单发送到不同的交易所,实际上帮助您以最有效的价格在不同的交易所挑选可用的流动性。
四。在场所和交换机之间:在印度,您无法在主机托管区域使用互联网,因此在主机托管场所和您的设施之间有一条专用线路。这条线路的费用取决于距离。
测试连通性:交易所提供测试市场,你可以在那里测试你的交易算法。例如,在印度,NSE 提供两个测试市场;正常测试市场和专用测试市场。一些全球交易所,如 CME,也提供测试连接的互联网 VPN。
- 算法交易平台:算法交易平台有三个主要部分-
a)市场数据适配器 - MDA 用于从交易所接收数据,并将其转换为我们的交易系统能够理解的格式。
b)复杂事件处理引擎 - CEP 是系统的大脑,主要的策略逻辑就在这里。
c)订单路由系统 - CEP 向 ORS 发送指令,后者将订单转换为交易所可理解的格式。FIX 是大多数交换中使用最广泛的格式,一些交换可能也有自己的本地格式。当交换同时使用本机和 FIX 格式时,由于更快的连接性,有时本机可能是优选的,因为 FIX 转换器可能应用于下一层,但是使用交换的本机格式也可能涉及维护方面的专门工作。
各种平台的延迟因系统而异,价格也是如此。
-
回测:回测是对算法交易策略的历史模拟,看其在过去数据中的表现。大多数 ATP 都配有回溯测试平台,可用于在回溯测试数据期间获得模拟结果,如利润&损失、风险和绩效统计数据,这有助于量化策略的风险回报。接下来,我们在“测试市场”中测试这个策略,我们已经在上一节简要讨论过了。市场测试确保在通过策略连接到市场时没有可能发生的技术故障。
-
风险管理:风险管理通常涉及更多关注市场风险监控。但在高频交易中,操作风险要重要得多。技术、网络、数据流的故障可能是灾难性的。您需要对数据进行多级检查,从套接字级开始捕捉任何异常,如果有问题就立即停止策略。几秒钟的事情可能导致巨大的损失,这使得非常快速地做出反应并在几毫秒或更短的时间内断开连接变得非常重要。
-
在印度,你需要得到交易所的批准,然后才能实施一项策略。这个过程包括参与一个模拟,向交易所演示你的策略。如果所有要求的条件都得到满足,那么就可以实施该策略。像 CME 这样的一些交易所并不要求每种策略单独测试;他们只是测试交易系统并授予访问权限。
-
审计&合规 :所有在印的 HFT 公司都要接受半年一次的审计。审计只能由交易所网站上列出的注册审计师进行。对于审计,您需要维护订单日志、交易日志、控制参数等。在过去的几年里。CME 等其它全球交易所要求保存过去几年的类似数据,以供审计之用。
-
最后但同样重要的是,你需要一个专业团队来管理你的办公桌。一般来说,交易员/策略师、IT 专业人员、网络经理、风险经理、人力资源和法律团队需要合作。但是从 IT 专业人员和交易员/策略师开始就足够了。一个由 3-5 名交易员和 IT 专业人员以及支持人员组成的小团队,即总共约 7-10 人,可以组成一个算法交易公司。在创业的情况下,一个人可以身兼数职,负责几项任务,一个 4-5 人的团队就可以开始创业。
Bonus content
关于建立 Algo 交易平台的常见问题
以下是我们在算法交易的提问环节中遇到的一些最常见的问题。
问题:算法交易对硬件有什么要求?
回复:这取决于你说的是哪种交易,如果是 LFT,那么你不需要太多,你需要的是一台像样的笔记本电脑/台式机,你可以在上面打开浏览器,编写策略并运行它,或者安装一个经纪人平台,编写策略并运行它。
如果我们讨论的是低频交易和定量分析,在这种情况下,您还需要进行大量的数据分析和数据分块,那么您有两种选择,要么选择一台价格不高的机器,价格大约在 1000-2000 美元左右(取决于您所处的地理位置),另一种选择是您可以在云上进行大量分析。 云服务的成本正在快速下降,尤其是在亚马逊和谷歌提供真正有竞争力的价格和随增长付费模式的地方。 这使得个人和散户交易者更容易获得金融计算能力,而这在几年前可能是不存在的,他们无需在这种硬件上花费大量金钱就可以获得这种能力。
如果你在谈论中频交易策略,在这种情况下,你需要使用一些算法交易平台,这意味着你需要几千美元左右的像样的服务器。如果你说的是 HFT,那么这将是一个专门的服务器,通常应该在 10-25000 美元的范围内。
推荐阅读: 印度算法交易:历史、法规、平台与未来
问题:开办 algo 交易业务需要多少投资?HFT 的增量投资是什么?
****回复:对于 algo 交易业务,如果它的低频或中频不多,所以你可以使用谷歌平台或供应商平台,这些平台并不昂贵,每年几千美元到每月几千美元不等,这取决于你要找的供应商或平台。
对于 HFT 来说,你将花费几十万美元来获得所需的基础设施和平台。所以成本肯定会更高。我一般不建议人们开始算法交易,如果他们还没有建立业务的话。因此,如果你没有做过自动化,启动 HFT 可能不是一个好主意,因为自动化本身就伴随着许多循环。
Next
我们向您介绍了我们的一位员工劳伦斯·特劳德·K·拉吉,他在技术领域已经工作了二十多年,领导过不同的业务部门。了解算法交易执行项目(EPAT) 如何帮助他掌握算法交易的概念,并在这一领域脱颖而出。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
夏普比率:计算、应用、限制
原文:https://blog.quantinsti.com/sharpe-ratio-applications-algorithmic-trading/
夏普比率有助于比较不同的投资组合,找到最可行的。这个博客解释了它的机制和你需要知道的一切。
我们涵盖:
我们都知道你不应该把所有的鸡蛋放在一个篮子里。因此,我们试图建立一个由不同金融工具组成的投资组合。与此同时,你可能会制定不同的策略来平衡各种措施,如风险、波动性、预期收益等。
但是你怎么说一个策略比另一个更好呢?
通常的答案,即它的返回,在范围上有些狭窄,并且无助于抓住全局。
有些策略可能是方向性的,有些是市场中性的,有些可能是杠杆化的,这使得年化回报率本身成为一种无效的业绩衡量指标。此外,即使两种策略的年回报率相当,风险仍然是需要衡量的一个重要方面。
一个年回报率高的策略,如果有高风险的成分,不一定很有吸引力;我们通常更喜欢更好的风险调整回报,而不仅仅是“更好的回报”。
考虑到这一点,William Sharpe 引入了一个简单的公式来帮助比较不同的投资组合,并帮助我们找到其中最可行的——夏普比率。
****什么是夏普比率?T3】
夏普比率是一种计算风险调整回报率的方法。它是投资的每单位波动率
或投资收益标准差的
超额预期收益(超过无风险利率)的比率。
让我们看看夏普比率的公式,这将使事情更清楚。
夏普比率公式
夏普比率公式为:
Sharpe Ratio = ((R_x – R_f ) / StdDev_x)
在哪里,
- R x 是 x 的平均收益率
- R f 为无风险利率
- StdDev x 是投资回报的标准差
夏普比率的计算
一旦你看到公式,你就会明白我们扣除了无风险收益率,这有助于我们弄清楚策略是否有意义。
如果分子结果是负数,投资保证你无风险回报率的政府债券不是更好吗?你们中的一些人会认为这是风险调整后的回报。
在分母中,我们有投资回报的标准差。它帮助我们识别与投资相关的波动性和风险。因此,夏普比率有助于我们识别哪种策略与波动性相比回报更高。这就是夏普比率计算的全部内容。
夏普比率示例
现在让我们举一个例子,看看夏普比率计算如何帮助我们。
你设计了一个策略,创建了一个不同股票的投资组合。经过回溯测试,你观察到这个投资组合,姑且称之为投资组合 A,会给出 11%的回报率。然而,你关心的是 8%的波动率。
现在,你改变某些参数,选择不同的金融工具来创建另一个投资组合,投资组合 b。这个投资组合的预期回报率为 8%,但波动率现在下降到 4%。
考虑到无风险收益率为 3%,两个投资组合的夏普比率计算。如下所示
| | 投资组合 A | 投资组合 B |
| 收益率 | Eleven | eight |
| 无风险收益率 | three | three |
| 波动性 | eight | four |
| 夏普比率 | (11-3)/8 = 1 | (8-3)/4 = 1.25 |
因此,根据夏普比率计算,我们应该考虑投资组合 B,因为即使预期回报低于投资组合 B,投资组合 B 的波动性也低于投资组合 A,因此风险更低。
目前,大多数交易所交易基金也在其网站上提供其投资的夏普比率。
夏普比率可用于许多不同的情况,如业绩衡量,风险管理和测试市场效率。谈到战略绩效衡量,作为一个行业标准,夏普比率通常被称为“年度夏普”。
年度夏普是根据衡量回报的交易期计算的。如果一年中有 N 个交易周期,则年度夏普比率的计算方法如下:
夏普比率=√N(E(Rx–Rf)/StdDev(x))
交易水平夏普比率为日内策略
对于日内交易策略,我们可以计算交易级别夏普,而不是使用传统的夏普计算,以更好地了解策略的表现。
在这种情况下,无风险利率可以被认为是 0,因为我们没有滚动头寸,没有利息费用。夏普比率可以通过以下简单步骤计算:
假设这个策略一天做了“N”笔交易;计算:
- 每笔交易的 P&L(本质上是你支付的佣金之外的收入)
- 所有交易损益的平均值
- 所有交易损益的标准差
现在,根据定义,当你考虑所有的交易时,分子,也就是 PnL 的平均值乘以 N。此外,在分母中,标准偏差乘以“N”的平方根。所以实际上,夏普比率是 sqrt(N) *(平均值/标准差)。
对于高频策略,特定数量的大量小规模成功交易使 PnL 曲线变得平滑,标准偏差接近于零,这大大增加了夏普比率,因此它可能在两位数的范围内。
就其本身而言,任何“年化夏普比率”小于 1(包括执行成本后)的策略通常都会被忽略。大多数量化对冲基金忽略年化夏普比率小于 2 的策略。
- 对于散户算法交易者来说,年化夏普比率大于 2 就很不错了。
- 如前所述,对于高频交易,这一比例也可能达到两位数,尤其是对于机会驱动但不具备高度可扩展性的策略。
当个人在现有投资组合中增加新的金融工具时,他们会使用该比率,并希望检查它对投资组合的影响。
****夏普Ratio in PythonT5】
如果您想自己找到夏普比率,可以尝试以下 Python 代码:
当前市场中的卖空行为
原文:https://blog.quantinsti.com/short-selling-current-markets-webinar-laurent-bernut-25-june-2020/
https://www.youtube.com/embed/6g1DNeHJCf4?rel=0
2020 年 6 月 25 日星期四
IST 时间下午 05:30-08:00 |美国东部时间上午 08:00-10:30 |格林威治时间下午 12:00-02:30
概述
这是一次实践会议,使用全功能筛选工具,无法让参与者更好地理解这些概念。与会者有机会让 Laurent 直接回答他们的问题。
涵盖的主题
在本次网络研讨会中,Laurent 谈到了:
地板/天花板:导航所有市场的简单框架:
- 它是如何工作的
- 秋千和制度
- S&P 的相对与绝对序列示例,TPX500
- 时间框架一致性
年初至今的世界状况:
- 哪些市场陷入了熊市
- 熊市反弹为何不可避免:如何玩,为何出乎意料
“新常态”:刺激后的世界:
- “不要对抗美联储”:道德风险已经从投资银行家转移到央行行长身上
- 各市场的世界状况:谁看涨/看跌?
- 如何平静地驾驭市场机制向前发展?
演讲者简介
【Laurent Bernut 先生(阿尔法安全资本首席执行官)
Bernut 先生在 Fidelity Investments、Rockhampton 和 Ward Ferry 拥有超过 18 年的另类投资经验。在富达的 8 年多时间里,他一直在现代史上持续时间最长的熊市之一——日本股市——中担任专职卖空者。
洛朗·伯努特卖空的原因、内容和方式
原文:https://blog.quantinsti.com/short-selling-webinar-10-october-2019/
https://www.youtube.com/embed/NKp8YsTn9UA?rel=0
为什么您应该参加本次网络研讨会?
如果你想做多头/空头生意,你需要学会卖空。喜欢做多的人供应充足,但真正能做空的人少之又少,而且在对冲基金界需求非常大。低波动性、不相关的多空投资组合是从空头开始构建的。本次网络研讨会将带您了解卖空的原因、内容和方式。两大症结是创意和风险。在这次网上研讨会中,你将学习一种方法,这种方法能在书的两边持续产生高概率的想法,并确切知道你能承担多少风险资本。
扬声器配置文件
Alpha Secure Capital 首席执行官 Laurent Bernut 先生
Bernut 先生在 Fidelity Investments、Rockhampton 和 Ward Ferry 拥有超过 18 年的另类投资经验。在富达的 8 年多时间里,他一直是现代史上最长熊市之一——日本股市——的专职卖空者。
卖空:例子、策略、神话
以重香重香
特斯拉 1 月 13 日跨过 500 美元!特斯拉的市场估值实际上超过了 1000 亿美元,并击败了大众汽车和通用汽车,成为第二大估值最高的汽车制造商。然而,如果我们看看生产的汽车数量,特斯拉和其他顶级汽车制造商之间有巨大的差距。因此,我们必然会想,这种价格水平是会持续下去,还是会变成一个泡沫?你准备好了吗?
如果你觉得这个价格不可持续,迟早会崩盘怎么办?假设你在过去分析了相当多的公司,像其他公司一样,特斯拉会减去几个点,回到正常水平。你能在股票市场上使用这些信息吗?
如果你有这样的想法,那么恭喜你,你已经在考虑卖空了。
我们将在这篇博客中讨论以下几点:
什么是卖空?
让我们以黄金为例来理解卖空。作为参考,让我们看看最近一个月的金价。

你只是在分析过去一个月的黄金价格,觉得自己已经认识到了一种模式。你放大并看到现在的几周预测,即 2020 年 1 月 23 日至 1 月 29 日。

假设,截至 2020 年 1 月 24 日,黄金价格为 50514 美元。但是你感觉过几天就能达到 50400 美元以内。现在你的熟人今天想买黄金。所以,你向一个店主借黄金,然后卖给你的熟人。现在你有 50,400 美元,但你仍然要给店主一部全新的手机。幸运的是,黄金价格在 2020 年 1 月 29 日降至 50,304 美元,你急切地购买黄金(从公开市场)并将其归还给你借的店主。
让我们看看这里发生了什么。
- 你的熟人想买黄金,以 50,514 美元成交。熟人满意。
- 店主借出了黄金,然后从你那里拿了回来(同样的东西可能得到了 10 美元)。店老板,满意。
- 你以 50,514 美元卖出黄金,但以 50,304 美元买入。减去你给店主的 10 美元,你会得到 200 美元的利润。你非常满意!
这是理解卖空的一个非常简单的方法。取决于你是谁,每个人都对这笔交易感到满意,他们将继续他们的生活。
Quantra 的这段视频用不到两分钟的时间解释了卖空行为,请看:
https://www.youtube.com/embed/kQP9YY18RHk?rel=0
让我们在下一部分进入问题的核心。
卖空是如何运作的?
在与前面比较相同的格式中,我们用以下步骤来说明该过程:
- 借入股票——通常,交易者会从经纪人那里借入股票,并保证他们将在未来交付所述股票。在这种情况下,交易者必须查看不同的收费标准,这样你才可以卖空股票
- 卖出借来的股票——交易者将把借来的股票以当前市场价格卖给买家
- 以较低的价格买入股票——根据协议,交易者会等到股票价格下跌,这样他们就可以买入借来的股票,赚取差价。我们称之为“平仓”
在美国市场,你的经纪人将负责借贷部分。你只要按一下按钮就可以卖空股票。我们知道用例子来解释一个概念是最好的方法。因此,我们现在将举一个例子来解释卖空。
卖空示例

正如我们在开始时所说,特斯拉在 1 月 13 日达到了 500 美元。它创下新高有几个原因,包括特斯拉在中国的前景看好,以及中国政府对中国本土制造的电动汽车的补贴。但你相信这波牛市不会持续太久,股票会恢复正常。
我们来看看 1 月 13 日的数据。特斯拉收于 524 美元。你决定第二天卖空特斯拉股票。1 月 14 日到了,你看到了什么?
特斯拉公司(TSLA)的开盘价为 543.76 美元。你决定这是做空 100 只股票的最佳时机,也就是说,你可以通过向你的经纪人收取费用来卖出 100 只特斯拉股票。你找个买家觉得特斯拉会明显涨价。
因此,你以 543.76 美元的价格卖出了 100 只股票,得到 54376 美元。
这是一个很大的数字!但这只是你计划的第一部分。现在你要确定你买了 100 股特斯拉,还给经纪人。
现在让我们看看允许卖空的成本。通常,你需要有一个保证金账户,账户中有一定比例的交易金额作为抵押。根据你所在地区的监管机构,这个比例可能在 20% - 50%之间。
举个例子,假设你有一个 25%的约定。因此,当你以 54376 美元做空 100 只股票时,你必须在保证金账户中保留 13594 美元。此外,由于你实际上是在“借”股票,你必须为此支付利息。想想看,如果他们什么也得不到,为什么经纪人会允许你借股票。除此之外,还有交易费和经纪费。
简单来说,你看到卖空特斯拉股票将被收取 100 美元。
现在我们等着!
你现在会看到股价,如果你的分析是正确的,股价应该会下跌。
1 月 14 日中午 12 点,您看到 Tesla 股价下跌到 531.74 美元,您下单购买 100 股,订单立即得到履行。耶!但是你赚了多少?
简单,531.74 美元* 100 = 53174 美元。从售价中减去这一数额,即 54376 美元,得到 1202 美元。你支付所有的费用和利息,总共 100 美元,你净赚 1102 美元。
还不错吧。
当然,我们看到了光明的一面,你的预测是正确的,你也因此得到了回报。有时股票价格也会上涨,这会导致你的交易亏损。
顺便说一下,既然我们在谈论特斯拉,你必须知道它是美国最被做空的股票之一。根据时代的不同,卖空者在做空特斯拉时会大赢或大输。因此,你也应该知道什么时候退出交易。
我希望这个例子有助于消除你对卖空的所有疑虑。如果没有,你可以随时评论你想让我多说哪方面。现在让我们进入下一部分,看看卖空的全貌。
卖空时要记住的事情
假设你已经分析了几只股票并锁定了一只感兴趣的股票进行做空。现在怎么办?
嗯,首先要检查的是股票的需求量有多大。想想看,如果没有人想买这只股票,你为什么要做空它?
第二件事,就像我前面说的,你应该知道什么时候退出。无论是股票的高低。
以我们的例子为例,如果你在特斯拉股票定价为 543.76 美元时卖空,你应该记住一个数字,如果股价上涨,你将在何时退出交易。对于像特斯拉这样波动的股票,价格可能会在几个小时内迅速上涨,如果不是几分钟的话。大多数情况下,如果你的保证金账户不能满足最低要求,你的经纪人就会终止交易,因此,也要注意账户余额。
这被称为卖空挤压,由于股票价格的快速上涨,卖空者不得不平仓。这导致股票价格上涨更高,因为卖空者不得不从市场上购买。
对于第三点,确保你知道所有与卖空股票相关的费用。根据地区的不同,你的经纪人和监管机构可能对卖空有不同的限制和规定。
另一点要提到的是,在你做空股票和平仓之间的时间里,如果公司发放股息,那么你有责任将上述股息转移给相关人员。原因是经纪人只借出股票,因此任何股息都是卖空者的责任。
当然,我们没有涵盖所有这些因素,但这些是你卖空时应该注意的一些因素。
很好,现在你已经有了基本的想法,有些人实际上想继续下去,开始卖空。但也许你还在对股票借贷感到困惑。
你如何借一只股票来卖空?
在转到真正的答案之前,我们先举个小例子。假设你因为某种原因需要一笔 10,000 美元的小额贷款。你去银行申请贷款。现在,银行本身并没有钱。因此,它从其他个人的存款账户中取钱,然后借给你相应的金额。
由于银行向你提供资金,它对贷款金额收取利息。你同意支付 5%的利息,因此,在一段时间后,你归还这笔钱和利息。银行保留利息,并将钱存回储户的账户。
以类似的方式,当你卖空一只股票时,你向你的经纪人提出你想要的股票数量的请求。通常,经纪人会与他们的客户达成协议,或者从其他账户中取出一些股票,并以一定的利息借给你。通常是从个人的保证金账户中取出。
一旦你收到股票,你就可以在任何时候收到购买请求时将它们卖给买家。当然,根据你所在地区的不同,允许你借入股票的时间范围可能会有很大的不同。例如,在印度,你应该在一天结束前结清账户,也就是说,如果你上午卖空了股票,你应该在一天结束前把股票还给经纪人,不管股票的价格如何。相比之下,美国没有限制,只要卖空者的保证金账户有足够的余额。
当然,并不是所有的股票每次都可以做空。有时,经纪人不允许某些股票,因为它们要么被大量卖空,要么在公开市场上没有股票。
太好了!我们现在越来越倾向于做空。到目前为止,我们已经了解了这个过程是如何运作的,以及卖空游戏中的不同参与者是谁。但是这个游戏怎么玩呢?
好吧,如果你是一个知道买股票但从未尝试过卖空的人,你可能会认为卖空是做多的一面镜子。洛朗·伯努特(Laurent Bernut)说,事实并非如此,他已经做了 18 年的卖空交易。他认为,如果你抱着与做多相同的心态,那将是灾难性的,因为做空有不同的方式。
一个常见的误区是,有时你会看到股票看起来被高估了,但仍会飙升相当长一段时间。在没有合理分析的情况下做空这些股票可能是灾难性的,一个主要的例子就是特斯拉。
好了,这是足够的理论,让我们来看看其中的一个策略
多空策略
这是一个著名的策略,你应该买入表现好的股票,卖出表现差的股票。听起来很简单,对吧?事实上是的。既然我们在这里学习了卖空,现在让我们把注意力集中在表现不佳的股票上。
如何识别表现不佳者?
表现不佳者是那些价格下跌速度似乎超过重力的人,这一概念有些误导。在关于卖空的课程中,提到当表现不佳时,你需要注意一些因素。
首先,表现不佳者相对于竞争对手开始下降。那么就会跌破其经营所在的行业/部门。如果我们更进一步,你会看到它将开始跑输指数,最后,它的绝对值开始下降。
因此,在卖空方面,你并不确切地寻找“高”和“低”的正确时间,而是专注于为你的股票领域定义行业、竞争对手等。
当然,我上面说的是过于简单化了。实际上,卖空是由经验丰富的老手执行的,相对于做多风险更大。
首先,我们从制度定义开始,即试图理解股票是买还是卖,是在牛市还是熊市。通常,技术分析包括但不限于突破、移动平均线或更高的高点/更低的低点。
对于高点/低点模型,概念很简单,如果股票公布了更高的高点,那么它可能是一个跑赢大盘的股票。然而,如果它持续发布更低的低点,那么这意味着它跑输市场。
一旦我们确定了表现不佳的股票,我们将继续做空这些股票。正如我们以前说过的,一旦你开始交易,你需要很大的耐心来度过难关,即在交易对你有利之前的一段时间内,交易会暂时对你不利。
这是一个非常简短的解释,关于卖空和做多的区别。我们在这篇文章中讨论了很多东西,但是我们没有触及一个问题,这个问题是人们在提到卖空这个话题时经常会问的。让我们在下一节讨论这个问题。
https://www.youtube.com/embed/mbzCD8ZBnyc?rel=0
卖空符合道德吗?
是的,它是。事实上,世界各地的监管机构都同意,卖空是交易领域不可或缺的一部分,因为它有助于约束公司。索伦·安达尔就是其中之一。在格劳库斯研究集团担任研究总监和首席信息官期间,他报告了 28 份观点报告,陈述了他做空所选公司的理由。市场总是对报告做出反应,一些公司也因虚假陈述而被起诉。不仅市场意识到了这些公司的真实性质,而且据报道,他的投资回报率为 51%,相比之下,空头群体的回报率为负 4%。
事实上,如果我们以印度的卖空交易为例,SEBI(印度证券交易委员会)曾在 2003 年禁止卖空交易,但后来又取消了禁令。最初只向散户投资者开放,2007 年也向共同基金公司和机构投资者开放了卖空交易。在讨论文件中,SEBI 坚持认为卖空是一种增加价值的合法活动,而不是操纵市场。
这些只是世界各地的市场已经接受卖空,并认为卖空是对试图抬高估值的公司的反击的一些例子。我想我们已经基本上涵盖了卖空交易的所有内容。如果你对卖空的世界非常感兴趣,你可以看看 Quantra 的卖空课程,它涵盖了许多概念以及可以用来卖空股票的策略。
让我们在文章的下一部分列出几个误区。
其他神话
卖空者被归咎于很多事情,从摧毁公司、市场到个人投资者。事实是,卖空和买进是投资者硬币的两面,两者都很重要。
据说卖空者通过压低股票价格来破坏价值。实际上,以我们做空特斯拉为例,你赚取的 1102 美元利润类似于投资者以 440 美元买入 11 股,一个月后以 540 美元卖出,赚取 1100 美元利润。两种情况都发生在同一个月,因此我们可以说特斯拉保持了其生产汽车的时间表。
关于单个公司的另一点是,当涉及到受监管的市场时,只有一定比例的股票被允许卖空,通常在可用流通股的 10 -30%之间。如果被卖空的股票数量超过这一水平,经纪人将自动将其从可卖空股票池中删除。因此,卖空者可以拖垮整个公司的事实是错误的。
从公司的角度缩小到整个市场,我们都听说过大型投资者宣布他们的投资以及预测。有时候,这可以被用来作为抛售自己股票的一种方式。虽然这是一个常见的地方,但没有多少投资者出来发表关于他们正在做空的股票的声明。这是因为卖空者受到严格审核。相对而言,坐在桌边看空的一方,很难让市场下跌。
当谈到经济时,你会发现围绕卖空的严格规定使得操纵市场进而操纵经济变得极其困难。
另一个误区是,我们应该只在熊市期间做空。这可能是有害的,因为一旦大量投资者试图做空股票,你将面临很多竞争。因此,在牛市中练习卖空技巧会让你在熊市到来时相对容易胜过竞争对手。
这些只是我们在本文中提到的几个误区。如果这没有吊起你的胃口,你可以随时查看下面的链接了解更多这样的神话。
结论
卖空交易已经从被认为是邪恶的行为,演变成一种如果操作得当就可能获利丰厚的投资方式。我们还看到了卖空在现实世界中是如何发生的,以及识别可能被卖空的股票的简单策略。最后,我们还讨论了卖空如何帮助市场,而不是负面影响市场。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
MBA 毕业后做什么——MBA 金融毕业后的顶级课程
原文:https://blog.quantinsti.com/short-term-courses-mba-finance/
商业世界是一个激烈竞争的领域。MBA 金融学位有助于培养在许多情况下都可以使用的技能。与 10 年前相比,这是一个巨大的转变,金融职位与科技行业或其他领域的职位一样吃香。金融领域的 MBA 毕业生正在证明,作为许多不同行业的领导者,他们可以有所作为。然而,许多人仍对 MBA 毕业后做什么来提升职业生涯存有疑问。这就是为什么这篇文章列出了 MBA 金融之后学生可以选修的顶级课程。
任何列表都包含一定程度的主观性,因此永远不会完美。尽管如此,我们必须尝试创建一个列表。毕竟,一份清单以最简单的方式帮助我们知道为什么我们决定采取某个行动。
这份清单是一系列的技术技能和实际专业知识,它们在 MBA 课程中没有完全涵盖。MBA 金融课程之后的这些课程肯定会增加你的学习
- 公司秘书:参与制定公司政策、维护法律记录、处理公共事务、管理并购相关活动。主要是管理层和董事会之间的调解人。如果你在印度,你可以做兼职,并且可以在一年中的任何时间注册。点击这里开始做公司秘书。
- 精算师:作为一名精算师,你的工作是评估风险和不确定性的财务影响。精算师评估金融安全系统,密切关注它们的复杂性、其中涉及的数学以及它们的机制。点击这里了解如何开始。
- 算法交易中的执行程序 :尖端工具已经成为交易行业的趋势。想在金融机构有一份利润丰厚的职业,并且比其他知道算法交易的申请者更有优势,这是必须的。你可以成为算法风险分析师、量化分析师、量化算法开发者或市场风险分析师。来自孟买的 QuantInsti 提供了一个关于算法交易的综合在线课程,你可以点击这里查看。此外,QuantInsti 还通过其学习门户Quantra提供短期自定进度在线课程。课程充满了许多互动练习,轻松涵盖复杂的概念,查看课程此处
- 特许金融分析师:在金融服务领域,CFA 特许持有人是为数不多的让 MBA 金融课程物有所值的课程之一。CFA 特许持有人是任何组织中最有价值的人之一。你因为有分析输入支持的见解而受人尊敬。点击此处了解更多信息。
- 量化金融 证书:一个严谨而实用的认证承诺培训人们,帮助他们在衍生品、量化 IT、量化交易、风险管理或保险领域找到工作。我们已经写了一整篇博文,讲述如何成为一名量化分析师,即使你认为现在开始为时已晚。看看我们的博客,我能在 40 多岁的时候成为一名定量分析师吗?’。如果你好奇的话,这里有一篇关于的博客文章,“定量分析师的实际工资是多少?”?看了这篇博客,你会感到困惑。
- 国际金融理财师:要想从事财富管理工作,本课程将为你提供个人理财各方面的深入培训,如税务规划、保险规划、遗产规划等。在印度这样一个金融教育正在兴起的国家,对 CFP 的需求也会更高。
- 特许另类投资分析师:CAIA 特许认证是另类投资教育的最高成就标准,提供广泛的知识、专业技能和另类投资的全球信誉。虽然 CFA 和 CAIA 听起来非常相似,但事实上它们确实有一些相似之处,比如需要努力学习和高昂的考试费用。然而,这两者也有一些不同之处,你可以查看这个链接了解更多关于不同之处的信息。
- 金融风险经理:这一称号是全球最受尊敬和最广泛认可的金融风险管理认证。该考试是全球公认的衡量金融风险管理人员技能和知识的标准。如果你选择成为一名金融风险经理,那么你将被期望管理伴随着任何投资的风险,并希望拓宽他们的知识。点击这里开始。
以下是 MBA 课程中没有教授的其他内容的简要列表
- 现实是不同的:再多关于有效定价的学术理论也不会让你为这份工作做好充分准备,找到“最优”价格真的很难。与此同时,记住次优价格要好得多。
- 总有比看上去更多的东西:在营销上花钱的方式是无限的。广泛试验,廉价吸取教训。与此相关的一点是,再多的 MBA 市场营销课程也不会让你为有一天你不得不为完成销售而制造线索做好准备。事实证明,市场营销不仅仅是产品特征矩阵和你的标志的蓝色色调。
- 招聘的关键?:招到最好的人,公平的薪酬,还有股权?没错,但他们没有告诉你的是,公司文化和对你的愿景表现出的热情同样重要。(哦,你的眼光应该放在通往真理、正义和整体善的更大道路上)。你的视野不应该包括伤害小猫。他们很可爱。当你开始创业时,这变得更加重要。
- 把大学的理论留在大学里:先进的博弈论格外有用。基本的博弈论是危险的——因为它假设你在和一群理性的“玩家”打交道。这就像试图设计一辆真正的汽车,它将在理论上无摩擦的表面上行驶,没有空气阻力,路上也没有白痴。
![And It's Gone]()
- 工商管理硕士? : 做生意应该是 MBA 最重要的课程,这是它教不了你的。如果你想成为一名企业家,MBA 绝对不是必须的。几年的实践经验会教会你比书呆子气多得多的东西。
- 沟通!大学里确实会教你这些,但那只是企业沟通,但日常沟通和自信行为是不同的,在你的工作中同样需要,如果掌握了,也会带你走向巅峰,但这在商学院里是学不到的。
- 编程和技术技能:MBA 不教技术技能。有很多理论和模型,还有更多理论。但是从技术上讲,没有教授如何实现理论知识。曾经有一段时间,金融领域的专业人士不需要具备编程技能,但现在许多公司要求分析师等职位必须具备编程技能。不要担心,我们已经为你准备好了,你可以报名参加我们的“Python for Trading”课程,该课程会教你 Python(一种开源的、广泛使用的编程语言),专门针对金融应用。下面是课程环节。


尽管你可能在技术上是健全的,并且在 MBA 期间学到了不少原则,但如果你不得不进入定量分析或定量策略师等技能领域,你肯定需要比 MBA 更多的东西。量化策略已经从后台办公箱演变成主流的复杂工具。为了利用商业中最好的头脑和最快的计算机,利用低效率,利用杠杆进行市场押注。为了实现这一目标,你必须用实际的技术经验和指导来武装自己。
下一步
了解一个有抱负的金融背景的算法交易者是如何在算法交易领域保住自己的职业生涯的。案例研究算法交易如何为金融&科技毕业生增加价值?带你了解 Rohit Gupta 的旅程,以及算法交易(EPAT)高管课程如何帮助他塑造职业生涯。
高位做空:EPAT 项目中的 Algo 交易策略
原文:https://blog.quantinsti.com/shorting-high-algo-trading-strategy-r/

Milind 的职业生涯始于 Gridstone Research,为纽约证券交易所上市公司构建收益模型和撰写收益报告,涵盖科技和房地产投资信托基金行业。Milind 还曾在 CRISIL 和德意志银行工作,在那里他参与了美国和 EMEA 地区涵盖资产支持证券(ABS)和债务抵押债券(CDO)的结构化融资交易的建模。
Milind 拥有孟买大学的金融 MBA 学位和孟买圣泽维尔学院的物理学学士学位。
构思
算法交易(EPAT)高管课程(T1)让我接触到了学习算法交易所需的所有必要科目。作为 EPAT 项目工作的一部分,我尝试编码许多策略。因为我是算法交易的新手,所以我想编写最简单、最基本的策略。虽然简单和基本的,人们不应该低估这种策略的力量,因为它们可以产生良好的回报。
“高位做空”是我为项目工作制定的策略之一。这篇文章简要解释了这个策略和编码部分。我欢迎读者给建议,随机应变或使用策略。
战略简介
策略是在日内交易中做空超过设定上涨百分比阈值(比如 8%-9%)的最佳股票。卖空股票的预期下跌量与执行代码时生成的指标表中预测的一样。
该代码分为两部分:
首先,我们在代码中设置一个高百分比阈值限制。在执行代码时,它扫描股票列表中的所有股票,并确定哪些股票超过了设定的阈值限制。
其次,对于每一只这样的股票,它会计算某些指标,如股票在过去一年中越过设定阈值的次数、这些时间内的平均上涨百分比、未来三天价格的平均绝对下跌、RSI、相关性等。这些指标可以用来确定哪只股票是做空的最佳选择。收盘时或根据个人的利润目标平仓。
R 中的策略代码
步骤 1:加载包,读取股票符号,初始化数据框
首先,加载必要的 R 包。以百分比形式设置高阈值水平。代码中的下一行读取包含股票列表的 csv 文件。使用这个文件,我们创建一个包含符号的向量,以及另一个包含经纪人提供的每只股票的杠杆比率的向量。
在执行代码的第一部分后,我们还初始化了一个包含每只股票基本信息的数据框。只有那些超过给定阈值的股票将被包括在该数据框中。
# Upload the required packages
library(xlsx);library(zoo);library(quantmod);library(rowr);library(TTR);
# Set the parameters here
pc_up_level = 6 # Set the high percentage threshold level
noDays = 2 # No of lookback days
# Read the csv file that contains the Stock tickers to be scanned
test_tickers = read.csv("F&O Stock List.csv")
symbol = as.character(test_tickers[,4])
leverage = as.character(test_tickers[,5])
sig_finds = data.frame(0,0,0,0,0,0)
colnames(sig_finds) = c("Ticker","Leverage","Previous Price","Current Price","Abs Change","% Change")
第二步:生成数据帧
在下一步中,我们从 google finance 获取每只股票当天和前一天的 1 分钟盘中价格数据。我有相同的定制脚本。您可以使用自己的脚本从 Google finance 或任何其他来源下载数据。然后读取下载的文件,我们计算前一天收盘价的绝对价格变化和百分比价格变化。所使用的当前价格是在当天交易时间内运行代码时对应的最新价格。
如果计算出的价格变化百分比大于设定的阈值,我们将该股票添加到数据框中。对于这样的股票,数据框架增加了杠杆、前一天的收盘价、当前价格、价格的绝对变化和价格的百分比变化等信息。
对所有股票执行代码后得到的数据帧被写入一个 excel 文件,命名为“在 High.xlsx 做空”。从 google finance 下载的 R 目录下的所有股票文件都使用 unlink 命令删除。
for(s in 1:length(symbol)){
print(s)
# Custom function to download stock data from Google finance
source("Stock price data.R")
intraday_price_data(symbol[s],noDays)
dirPath = paste(getwd(),"/",sep="") # Specify the R directory
fileName = paste(dirPath,symbol[s],".csv",sep="") # Specify the filename
data = as.data.frame(read.csv(fileName)) # Read the downloaded file
data_close =subset(data, select=(CLOSE), subset=(TIME == 1530))
pdp = tail(data_close,1)[,1]
lp = tail(data,1)[,3]
# Compute absolute and the percentage change
apc = round((lp - pdp),2)
pc = round(((lp - pdp) / pdp) * 100,2)
if (pc > pc_up_level ){
# Create a temporary empty data frame, only if the Percentage change is significant
sig_finds_temp = data.frame(0,0,0,0,0,0)
colnames(sig_finds_temp) = c("Ticker","Leverage","Previous Price","Current Price","Abs Change","% Change")
sig_finds_temp = c(symbol[s],leverage[s],pdp,lp,apc,pc)
sig_finds = rbind(sig_finds, sig_finds_temp) # combines the previous and current data frame
rm(sig_finds_temp) # deletes the temporary data frame
print(sig_finds)
}
# Deletes the downloaded stock price files for each ticker from the directory
unlink(fileName)
}
# Write the results in an excel sheet
write.xlsx(sig_finds,"Shorting at High.xlsx")
示例:
我们把门槛定在 4%吧。我们的股票列表中有 146 个股票代码。当我们执行代码时,在 146 个股票代码中,代码列出了 6 只股票,它们在当天市场交易时间内超过了 4%的阈值。下表说明了执行代码后保存在“Shorting at High.xlsx”工作簿中的初始输出。

第三步:计算指标,确定做空的最佳股票
这部分代码使用“在高位做空. xlsx”表中的股票代码。基于 1 年的回顾期,本节中的代码计算以下指标:
- RSI -相对强度指数
- 计数——在给定的回顾期内,股票越过阈值的次数
- 平均高点% -股票高于阈值时的平均高点百分比
- Abs 平均下降-卢比从平均最高百分比的绝对平均下降
- 下一个三维价格移动-这给出了未来三天的绝对价格变化
- 过去 15 天为负-过去 15 天股票为负的次数
- 股票的 1 年高点和 1 年低点
- 股票与 NIFTY 的相关性
# Compute the different metrics which will be used in evaluating the best stock to short
# Pull NIFTY data for the last 1 year
source("Stock price data.R")
daily_price_data("NIFTY",1)
dirPath = paste(getwd(),"/",sep="")
fileName = paste(dirPath,"NIFTY",".csv",sep="")
nifty_data = as.data.frame(read.csv(file = fileName))
# Read the stock symbols from "Shorting at High.xlsx" workbook
test_tickers = read.xlsx("Shorting at High.xlsx",header=TRUE, 1, startRow=1, as.data.frame=TRUE)
t = nrow(test_tickers)
test_tickers$Count = 0; test_tickers$Avg_high = 0;
test_tickers$Avg_decline = 0; test_tickers$Next_3d_Change = 0;
test_tickers$Low_1Yr = 0; test_tickers$High_1Yr = 0;
test_tickers$Neg_Last15_days = 0 ; test_tickers$RSI = 0;
test_tickers$NIFTY_Correlation = 0
symbol = as.character(test_tickers[2:t,2])
noDays = 1
# Compute the metrics for each stock
for (s in 1:length(symbol)){
print(s)
table_sig = data.frame(0,0,0,0,0,0,0)
colnames(table_sig) = c("Date","Days High in %","Days Close in %","RSI","Entry Price","Exit Price","Profit/Loss")
source("Stock price data.R")
daily_price_data(symbol[s],noDays)
dirPath = paste(getwd(),"/",sep="")
fileName = paste(dirPath,symbol[s],".csv",sep="")
data = as.data.frame(read.csv(file = fileName))
N = nrow(data)
# Initializing variables to zero
nc = 0 ; Cum_hc_diff = 0;
Cum_threshold_per = 0;Cum_next_3d_change = 0;
diff = data$HIGH - data$CLOSE
rsi_data = RSI(data$CLOSE, n = 14, maType="WMA", wts=data[,"VOLUME"])
for (i in 2:N) {
days_close = (data$CLOSE[i] - data$CLOSE[i-1])*100/data$CLOSE[i-1]
days_high = (data$HIGH[i] - data$CLOSE[i-1])*100/data$CLOSE[i-1]
condition = ((days_high > pc_up_level) == TRUE)
if (condition)
{
nc = nc + 1
date_table = data$DATE[i]
high_per_table = round(days_high,2)
close_price_per_table = format(round(days_close,2),nsmall = 2)
rsi_table = format(round(rsi_data[i],2),nsmall = 2)
entry_price = format(round(data$CLOSE[i-1]*(1+(pc_up_level/100)),2),nsmall = 2)
exit_price = format(round(data$CLOSE[i],2),nsmall = 2)
pl_trade = format(round(((data$CLOSE[i-1]*(1+(pc_up_level/100))) - data$CLOSE[i]),2),nsmall = 2)
hc_diff = diff[i] # difference between day's high and day's close whenever the price crossed the threshold level.
Cum_hc_diff = Cum_hc_diff + hc_diff # Cumulative of the difference for all trades
Average_hc_diff = round(Cum_hc_diff / nc , 2) # Computing the average for difference between high and low.
# Computes the total of Day's high's whenever price crossed the threshold.
Cum_threshold_per = Cum_threshold_per + days_high
# Average of High's
Average_threshold_per = round(Cum_threshold_per / nc , 2)
if ( i < (N - 5)){ # Captures the average next 3-day price movement
next_3d_change = data$CLOSE[i+3] - data$CLOSE[i]
Cum_next_3d_change = Cum_next_3d_change + (data$CLOSE[i+3] - data$CLOSE[i])
Average_next_3d_change = round(Cum_next_3d_change / nc,2)
}
# Create a temporary dataframe to add values and then later merge with the final table
table_temp = data.frame(0,0,0,0,0,0,0)
colnames(table_temp) = c("Date","Days High in %","Days Close in %","RSI","Entry Price","Exit Price","Profit/Loss")
table_temp = c(date_table,high_per_table,close_price_per_table,rsi_table,entry_price,exit_price,pl_trade)
table_sig = rbind(table_sig, table_temp)
rm(table_temp)
}
}
table_sig = table_sig[order(table_sig$Date),]
# Write the individual results in an excel sheet
name = paste(symbol[s]," past performance",".xlsx",sep="")
write.xlsx(table_sig,name)
# load it back to format the excel sheet for column width
wb = loadWorkbook(name)
sheets = getSheets(wb)
autoSizeColumn(sheets[[1]], colIndex=1:16)
saveWorkbook(wb,name)
# Price performance in the last 15 days, checks for many days the price change was negative.
nc_last_15 = 0
for ( p in (N-15):N){
condition_1 = (((data$CLOSE[p] - data$CLOSE[p-1])< 0 ) == TRUE )
if (condition_1)
{
nc_last_15 = nc_last_15 + 1
}
}
# Correlation between the ticker and NIFTY
Cor_coeff = round(cor(data$CLOSE , nifty_data$CLOSE),2)
# Filling the “Shorting at High.xlsx” with the computed metrics
e = s + 1
test_tickers$Count[e] = nc
test_tickers$Avg_high[e] = format(Average_threshold_per,nsmall = 2) # Indicates the Avg. percentage above the threshold in the past
test_tickers$Avg_decline[e] = format(Average_hc_diff,nsmall = 2) # Indicates the Avg. decline in Absolute rupee terms from the Avg. high to the closing price in the past test_tickers$Next_3d_Change[e] = round(Average_next_3d_change,2) # Indicates the next 3 day price movement.
test_tickers$Next_3d_Change[e] = format(Average_next_3d_change,nsmall = 2)
test_tickers$Low_1Yr[e] = format(min(data$CLOSE),nsmall = 2) # 1 year low price
test_tickers$High_1Yr[e] = format(max(data$CLOSE),nsmall = 2) # 1 year high price
test_tickers$Neg_Last15_days[e] = nc_last_15 # Indicates how many times in the last 15 days has the price been negative.
test_tickers$RSI[e] = round(tail(rsi_data,1),2)
test_tickers$NIFTY_Correlation[e] = Cor_coeff # Computes the correlation between the Stock and NIFTY.
unlink(fileName) # Deletes the downloaded stock price files for each ticker after processing the data
rm("data","table_sig")
} # This closes the for loop
test_tickers = test_tickers[-1,-1]
colnames(test_tickers) = c("Ticker", "Leverage","Previous Price","Current Price","Abs. Change","% Change","Count","Avg.High %","Abs Avg.Decline","Next 3-d price move","1-yr low","1-yr high","-Ve last 15-days","RSI","Nifty correlation")
# Write and format the final output file
write.xlsx(test_tickers,"Shorting at High.xlsx")
wb = loadWorkbook("Shorting at High.xlsx")
sheets = getSheets(wb)
autoSizeColumn(sheets[[1]], colIndex=1:19)
saveWorkbook(wb,"Shorting at High.xlsx")
步骤 4:将指标添加到 excel 表中
上一节中计算的指标将添加到“在高位做空. xlsx”工作簿中。上一节中显示的代码也为每个股票代码生成一个交易摘要。交易摘要提供了在回顾期内,每当股票超过阈值百分比时,所有历史交易的详细信息。交易摘要自动保存在 R 工作目录下,名称为“symbol past performance.xlsx”(如 BEL past performance.xlsx)。
第五步:分析汇总表
下表显示了添加到初始输出中的各种指标。我们设定了 4%的门槛。从表中我们可以看出,在过去 1 年中,BEL 仅 16 次超过 4%,平均下降了卢比。从平均高点 5.66%升至 25.48。此外,在此期间,BEL 的下一个 3 日价格变动为负值。贝尔似乎是做空的好对象。

人们可以使用这些指标制定进一步的规则,以确定卖空的最佳股票。在确定最佳股票后,可以通过任何提供算法交易平台的经纪人自动下单和执行。可以根据个人的风险收益目标添加止损和盈利目标。
结论
该策略试图从价格越过高门槛后的下跌中获利。代码可以进一步优化,以提高执行速度。你也可以制定一个类似的策略,当股票下跌超过某个阈值时,你可以做多。我已经在 GitHub 上发布了策略代码(高位做空。R )也欢迎读者提出建议和意见。
后续步骤
如果你是一名程序员或技术专业人士,想开始自己的自动交易平台,从日常从业者的实时互动讲座中学习自动交易。算法交易高管课程涵盖统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。现在报名!
更新- 我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
下载中的文件:
- 股票价格数据文件
斯米兰非凡的故事——从工程、CQF 到 Algo 交易
原文:https://blog.quantinsti.com/similo-remarkable-story-engineering-cqf-algo-trading/
激情、不断学习和不断成长的愿望都是推动成功的因素。有许多人渴望成为算法交易领域的一员,但由于教育资格的想法,或来自其他人的道听途说,他们可能会降低实现这一目标的信心,所以没有这样做。
另一方面,也有杰出的个人和他们的故事——就像 Similo Ntshuntshe 写的这个故事。
一个工程师毕业的人进入了 ICT/电信行业,但利用他在那里获得的经验,通过获得硕士学位、完成 CQF 并最终从事算法交易和量化交易来追求他对金融的热情。你必须读他的故事才会相信。
我们与你分享斯米兰的旅程。
-
Hello, Smilan, tell us something about yourself.
你好。我是 Similo Ntshuntshe 。从专业角度来说,我是 ICT 部门/电信行业的解决方案架构师,在南非开普敦工作,在该领域拥有 15 年以上的经验。
我获得了 CQF 定量金融和 IFID 的认证。在学术上,我是一名电气工程师,拥有工商管理硕士和理学硕士学位。
我喜欢学习新事物,对金融领域充满热情。
-
How did you get into the field of algorithmic trading?
记不清了,但我想我的 1 级 CFA 学习和我想有一个替代收入来源和开始自己的事业的愿望。
-
What prompted you to explore it further?
在我考虑选择哪家企业时,我寻找的是进入和退出壁垒较低的企业,不需要在实体建筑上进行巨额投资,也不需要巨额资本支出。一个我可以在做日常工作的同时做的生意。
-
You are very experienced in the field of science and technology. How does it help you learn algorithmic trading?
我为零售公司销售 ICT 解决方案,这让我获得了所需的技术工具和在线学习。它为我提供了获得经济高效的解决方案的方法。编程也是我喜欢做的事情。
-
How did EPAT help you achieve your goals?
EPAT 是一门实用的课程,它将为你指明一个很好的方向,让你可以独立完成进一步的训练。EPAT 教授了一个很好的方法来发展和测试交易策略。我们学到了很多风险管理的知识。你还会接触到 Algo 交易的真实环境,最终,你会掌握开办 Algo 交易公司所需的知识。
-
What are your future plans? How do you want to apply this knowledge to your professional life?
我已经开始在入门级做现场交易,基本策略是从 EPAT 学来的。算法交易是基于规则的交易,这是令人兴奋的!
我也知道了当你因为兴奋而打破自己的规则,没有在盈利交易或止损交易中设置止损点时会发生什么。这些在 EPAT 都有报道。
尽管我在现实环境中有头寸,但我仍在研究和测试我在 EPAT 项目中学到的其他环境中的其他交易策略,一旦我有了成功的公式,我就会加大资金投入并付诸实施。
-
What information do you want to share with aspiring algorithmic traders and quantitative traders?
尽快开始实时交易,尤其是在 EPAT 项目期间,不要像我一样等到项目结束后。甚至在你加入这个项目之前,就建立一个真实的交易环境。
谢谢你的时间,斯米兰。我们确信,有抱负的算法交易者会从中学到很多。有如此惊人的成功故事激励着。帮助我们帮助您构建您的故事。EPAT 通过其全面的课程和实践培训,帮助任何希望进入算法交易和量化交易领域的人,让他们具备在这一领域取得成功所需的技能和知识。在这里报名EPAT。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的成果可能对所有人都不一样。T13】
Algo 交易的软件开发 Efrin 如何使之成为可能
Efrin 是一名软件开发工程师,在大型北欧企业(如 Postnord Stralfors 和 Nordea Bank Denmark)以及危地马拉银行监管局拥有超过 15 年的工作经验。
他毕业于 KEA(kobenhavns Erhvervsakademi)网站开发专业,并完成了哥本哈根 IT 大学的软件开发和技术研究生课程。他还通过了 Java 编程的专业认证,专攻普及计算和分布式系统。
我们联系了 Efrin,想知道是什么激发了他对算法交易的兴趣。这是他的旅程。
嗨,Efrin,告诉我们关于你自己的情况!
嗨,我是埃夫林·冈萨雷斯。我住在丹麦。我来自中美洲拉丁美洲的危地马拉。我目前是丹麦一家经纪公司的软件工程师,从事各种金融工具和交易项目。
我喜欢练武术,因为它能帮助我集中注意力,致力于目标。在我投身于学习之前,我曾经是跆拳道的半职业拳击手。我参加过世界锦标赛,赢得过许多国家级的奖牌。
除此之外,我还喜欢文学和哲学。
15 年以上的软件开发经验,是什么激励你学习算法交易?
从高中开始,我就对技术感兴趣。于是,我开始为各种小企业打工,或者做自由职业者。
此外,在与银行合作并接触了金融概念和环境之后,我有理由相信我也拥有必要的天赋来创建可能让我受益的算法。算法交易对我来说似乎是一个新的挑战,我开始在这个领域寻找任何选择。
如果你积累了所有必需的和额外的技能,你无疑会在职业生涯中处于更有利的地位。从这个意义上来说,我认为这很有挑战性。
由于自动化,一旦你进入算法交易,你可以选择不同的路线,还有一些高度尖端的技术,如机器学习,以及有利的金融环境。
自动化是目前最突出的技术之一,所以我选择参加 EPAT 的课程。
我想更好地了解算法交易领域正在发生的事情。我浏览了一下材料,发现它们很有趣。所以这是我的决定因素。
课程内容和质量都不错,效果立竿见影。我获得了在贸易环境中有效工作的信心。
这也是我在 EPAT 拿到算法交易证书后换工作的原因。
EPAT 是一个非常高质量的课程——就材料而言,就你从支持经理和整个团队获得的支持而言。
你得到反馈,你的问题得到回答,你得到练习的帮助,等等。总的来说,这是一次有趣又刺激的经历。
你最喜欢 EPAT 的一个特征
EPAT 组织得非常好,学习平台(LMS)非常容易使用。这些材料组织得很好。当你需要什么的时候,你知道去哪里。专业讲师和支持经理会关注您的每一个需求。
课程组织得非常好。录像是一个人可以长期欣赏的东西,你可以在你一生中的任何时候随时回到课程材料中来。
你有什么话想和有抱负的量化分析师分享吗?
学习如何分解问题是非常重要的,这样你才能理解目标。但是你不需要掌握所有的知识来达到目标,但是你可以通过积累来达到目标。你学习,再学习,每一天都在不断提高自己。
所以,要有目标。一步一步来,不要犹豫问问题。
非常感谢 Efrin 与我们分享您的旅程,我们祝您未来一切顺利。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
Jose Ferrer |美国|软件工程到量化金融入门
我们带给你一个有趣的旅程,何塞·费勒想实现他的目标,学习所有快速增长的算法交易领域。
Jose 解释了他是如何让自学成为可能的,同时管理他的职业生涯,从软件工程走向量化金融。
你好,
我叫何塞·费勒,来自美国。我获得了金融学士学位,主要是投资组合和资产管理。我在本科期间还辅修了计算机科学。
目前,我是一名软件工程师,在一家为世界上最重要的公司、政府和机构提供解决方案的金融服务全球领先公司分析信用贷款。我的最终目标是在量化金融领域工作。
我在网上寻找算法交易课程,在那里我看到了 Quora 上的一篇评论,这篇评论向我介绍了 Quantra。
我从开始学习算法交易的课程开始,这被证明是对算法交易的一个很好的介绍。我一直在寻找开始我的 Algo 交易之旅,但我总是被外面的大量信息所打击,不知道从哪里开始。这门课有助于澄清这个问题。
它指导你完成整个过程,并让你更好地理解你的下一步旅程。我强烈推荐这个课程给那些真正想开始学习算法交易,但不知道如何去做的人。
我真的很喜欢 Quantra 有一个很好的算法交易的基本方法。这些人做了很好的工作,为从哪里开始学习铺平了道路,因为互联网上有很多信息,非常丰富。
- 我真的很喜欢 jupyter 笔记本,它允许我调整代码并获得输出。没有多少课程能做到这一点。代码解释得很好,真的很有帮助。
- 这些视频非常精确,切中要害。
- 里面的图表进一步帮助我理解概念。
总的来说,这个平台很棒,课程结构也很好。在这个平台上导航非常容易。我真的很兴奋,期待着完成我在 Quantra 注册的所有课程。
干得好,伙计们,继续努力!
谢谢何塞!你的故事非常鼓舞人心,我们希望你接下来的步骤将充满成功和价值,以指导你的量化金融之旅。我们很高兴您对我们的评价如此之高,我们也很高兴您对 Quantra 的赞誉。谢谢你。
像 Jose 一样,如果你也想赶上算法交易的潮流,建立一个基础,然后开始学习算法交易 -看看我们的课程,它非常适合那些想了解这个领域全貌的人。立即注册!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
使用 spaCy 的 Python 自然语言处理
人类的思维是一个神奇的地方。无数的想法在一瞬间产生,掺杂着各种情绪。许多这样的想法和情绪散布在越来越受欢迎的社交媒体平台的“墙”和“订阅”上。
为了寻找难以捉摸的阿尔法,数据科学家和量化分析师现在已经将注意力转移到处理互联网用户产生的大量“大数据”上。使用程序来理解和分析人类语言被称为自然语言处理。
在这篇文章中,我们将看看 Python 中自然语言处理的流行库之一- spaCy 。
我们将讨论的主题有:
- 什么是 spaCy?
- 如何安装 spaCy?
- NLTK vs spaCy
- 空间训练管道
- 使用空间的标记化
- 使用空间的词汇化
- 使用空格将文本分割成句子
- 使用空格删除标点符号
- 使用空格删除停用词
- 使用空间的位置标记
- 使用空间的命名实体识别
- 使用 displaCy 的依赖性可视化
- 使用空间获取语言注释
- Github 上的空间示例
spaCy 是什么?
spaCy 是一个免费的开源 Python 自然语言处理库。它是 NLP 最受欢迎的两个库之一,另一个是 NLTK 。我们将在后面的章节中讨论这两者之间的重要区别。
spaCy 网站将其描述为“工业实力自然语言处理的首选工具。spaCy 提供的丰富特性使其成为 NLP、信息提取和自然语言理解的绝佳选择。
spaCy 的主要优势在于,它被设计为以一种最优且健壮的方式处理大量数据。
如何安装 spaCy?
安装 spaCy 的最简单方法是遵循以下步骤:
- 在您的浏览器上打开 spaCy 网站的这个页面。
- 为操作系统、平台、软件包管理器等选择适当的选项。
- 相应的命令将显示在选项下的黑色面板中。单击黑色面板右下角的“复制”图标,复制安装命令,并将其粘贴到您的终端/命令提示符下。
注意:如果您从 Jupyter 笔记本电脑上安装,不要忘记在命令前加上前缀“!”签名。
NLTK vs spaCy
自然语言工具包 (NLTK)是最大的自然语言处理库,支持多种语言。让我们比较一下 NLTK 和 spaCy。
| 序列号 | NLTK | 空间 |
| 1. | NLTK 主要是为研究而设计的。 | spaCy 是为生产使用而设计的。 |
| 2. | NLTK 提供了对许多语言的支持。 | 目前,spaCy 为 23 种语言提供训练有素的管道,并支持 66 种以上的语言。 |
| 3. | NLTK 遵循一种字符串处理方法,并且具有模块化的体系结构。 | spaCy 遵循面向对象的方法。 |
| 4. | NLTK 提供了大量不同的 NLP 算法,因此是研究和构建创新解决方案的首选。用户可以从特定任务的可用选项中选择特定算法。 | spaCy 为特定任务使用最佳算法。用户不必选择算法。 |
| 5. | NLTK 可以慢一点。 | 空间针对速度进行了优化。 |
| 6. | 它是使用 Python 构建的。 | 它是使用 Cython 构建的。 |

空间训练管道
spaCy 引入了管道的概念。当您通过管道传递文本时,它会经过不同的处理步骤(或管道)。一个步骤(或管道)的输出被送入下一个步骤(或管道)。
spaCy 为不同的语言提供了许多训练有素的管道。通常,经过训练的管道包括标记器、语法分析器、解析器和实体识别器。
我们也可以在 spaCy 中设计自己的定制管道。

spaCy 入门
现在让我们做一些自然语言处理,并在接下来的几节中看看这些组件是如何工作的。
我们需要安装空间和我们想要使用的训练模型。在这篇博客中,我们将使用英语语言的模型 en_core_web_sm。
聚焦 EPAT 算法交易
原文:https://blog.quantinsti.com/spotlight-on-algorithmic-trading-with-epat/
这篇文章分享了我们在全球举办的“聚焦 EPAT 算法交易”系列活动。
算法交易是更聪明的交易方式。
2019 年 5 月 18 日,印度班加卢鲁
EPAT 校友 Aman Saxena 也与与会者分享了他的学习经验。




【2019 年 6 月 29 日,印度浦那




印度孟买,2019 年 7 月 27 日


2019 年 9 月 26 日,澳大利亚悉尼

西班牙马德里,2019 年 9 月 28 日

美国纽约 2019 年 11 月 5 日


感谢所有与会者和参与者的参与,并使这些活动取得成功。我们希望您学习愉快!
标准差及其在交易中的应用
由阿苏托什·戴夫和乌迪莎·阿洛克
测量金融数据集中的离差是量化金融中最重要的任务之一。无论是交易策略中的信号生成还是风险管理,标准差都是金融市场中最常用的波动性度量。在这篇博客中,我们揭示了这一指标,并讨论了它在 Python 中处理真实金融数据的各种用例。
我们将讨论以下内容:
标准差的定义
在统计学中,
【σ】标准差是用于量化数据相对于其均值的变化量或离差的度量。
换句话说,标准差给了我们关于数据平均值的平均偏差大小的信息。因此,如果数据集中的值靠得很近,标准偏差就会很小。
另一方面,如果数值分散,标准偏差会更大。
什么是标准差?
让我们回到最基本的问题。
偏离均值是什么意思?
Simply put, the deviation is the distance of a data point from the mean. Consider a random variable X which consists of n different observations (x_1, x_2, ..., x_n) Below, we show the deviations of two observations (x_1) and (x_2) from the mean of X.

Deviations of two observations
这里的偏差告诉我们一个观察值离平均值有多远。它可以是正的,也可以是负的,取决于观察值是大于还是小于平均值。
What if we measure the total deviation by summing all such values i.e., (x_{1}-\overline{x}, x_{2}-\overline{x}, ..., x_{n}-\overline{x}?)
我们最终会得到零,因为正值和负值会相互抵消!如果我们取绝对值并求和呢?我们可以。或者我们可以求差的平方,然后把它们加起来。后者是优选的,因为它具有吸引人的数学特性。
所以,重复一遍,我们对差值求平方,去掉正负符号,然后计算它们的平均值。这个结果量被称为方差,它捕获了数据中的离差。
标准差是方差的标准化版本,通过取方差的正平方根获得,因此得名标准差。在下一节中,我们将讨论计算标准差的公式。
标准差公式
计算标准偏差(用 σ 表示)的公式如下:
(\西格玛= \sqrt\frac{{\sum_{i=1}{n}(x_{i}-\mu)2}}{n})
在哪里,
(x_i) = value of the (i^{th}) point in the data set
(\mu) = mean of the data points, calculated as (\frac{1}{N}\sum_{i=1}^{N}x_i)
N = total number of data points
现实生活中标准偏差的例子
标准差这个术语听起来像是你在统计学课上听到的,但是不要把它当成一个过于专业的术语。它可以用在我们生活的不同方面。
教师可以使用考试中学生分数的标准差作为衡量标准来评估学生对该科目的整体理解水平。如果平均值和标准差都很高,则表明平均而言,学生对主题有很好的理解。
然而,会有许多学生的分数远高于平均分数,也远低于平均分数。如果平均值较高而标准差较低,则表明平均分数与前一种情况相似。
低标准差告诉她,大多数学生的分数接近(即略高于和略低于)平均值。在天气预报中,它可以用来比较两个或更多地区的天气模式。
如果我们比较杰萨尔默(极端天气)和孟买(温和天气)的温度标准偏差,我们会发现前者在平均温度附近有更多的可变性。
为什么要用标准差?
标准偏差单位
标准差的单位将与我们数据的单位相同。与方差相比,这更容易解释。在下一节中,我们将对这两种离差度量进行详细比较。
标准差与方差
The variance ((σ^2)) of a random variable X is given by the formula below:
(方差= \frac{\sum_{i=1}{n}(x_i-\mu)2}{n})
正如我们所看到的,根据它的结构,方差是原始单位的平方。这意味着,如果我们用公里来表示距离,那么方差的单位就是平方公里。
Now, square kilometres may be easy to visualize as a unit, but what about (year^2) or (IQ^2), if we are working with ages or IQs of a group? They are harder to interpret.
因此,使用可以与相同规模/单位的数据进行比较的测量是有意义的,例如标准差。
标准差计算为方差的平方根。它与我们的数据具有相同的单位,这使得它易于使用和解释。
例如,考虑这样一个场景,我们正在查看一个街区居民的身高数据集。假设身高呈正态分布,平均值为 165 厘米,标准偏差为 5 厘米。
我们知道对于正态分布,
- 68%的数据点落在一个标准偏差内,
- 两个标准偏差内的 95%,以及
- 99.7%落在平均值的三个标准偏差内。

Standard Normal Distribution (Image Source: Standard Normal Distribution)
因此,我们可以得出结论,几乎 68%的居民的身高将位于平均值的一个标准偏差之间,即在 160 cm(平均值-标准差)和 170 cm(平均值+标准差)之间。你可以在这里阅读更多关于正态分布。
样本数据的标准偏差-贝塞尔校正
当计算总体的标准差时,我们使用上面讨论的公式。然而,我们在处理样本时会稍微修改一下。
这是因为与总体相比,样本要小得多。为了说明随机选择的样本和整个总体中的差异,我们通过在等式 1 的分母中使用“ ( n-1 ) ”而不是“ n ”来“无偏”计算。这被称为贝塞尔校正。
因此,我们使用下面的公式来计算样本的标准差。
(s = \sqrt\frac{{\sum_{i=1}{n}(x_{i}-\overline{x})2}}{n-1})
在哪里,
(x_i) = value of the (i^{th}) point in the sample
(\overline{x}) = sample mean
n = total number of data points in the sample
请注意,随着样本量 n 变大,除以“ ( n-1 ) ”或“ n ”的影响会变小。
金融和交易中的标准差
标准差作为波动性的度量
在交易和金融中,量化资产的波动性很重要。与收益或价格不同,资产的波动性是一个不可观察的变量。
标准差在风险管理和绩效分析中具有特殊的意义,因为它通常被用作证券波动性的代表。例如,与小盘股相比,成熟的蓝筹股证券的回报率标准差较低。
另一方面,像加密货币这样的资产具有更高的标准差,因为它们的回报与其均值相差很大。
在下一节中,我们将学习用 Python 计算股票的年波动率。
使用 Python 计算股票的年波动率
现在让我们计算并比较两只印度股票的年波动率,即 ITC 和 Reliance。我们首先使用 yfinance 库获取最近 5 年的收盘价格数据:
用 Python 解释时间序列分析中的平稳性
在处理时间序列数据时,你会经常遇到两个术语——平稳时间序列和非平稳时间序列。平稳性是时间序列分析的关键要素之一。
在这个博客中,你会读到以下主题。
让我们从理解什么是平稳过程开始。
平稳性的定义
在维基百科中定义,平稳过程是“其无条件联合概率分布不随时间推移而改变的过程。”
这意味着一个平稳过程的分布在不同的时间点看起来是一样的。因此,平稳过程的参数,如均值和方差,在一段时间内保持不变。
如果你有一个过程,假设有一百个值。您从 1 到 30 或 30 到 50 或 50 到 100 的数值中取样。为了使这个过程稳定,不同样本的平均值和其他统计特性应该大致相同。
平稳性是时间序列分析中的关键组成部分之一。停下来想想为什么?我们将在观察平稳和非平稳时间序列后回到这个问题上。
平稳时间序列和非平稳时间序列
一种时间序列,其统计特性,如均值、方差等。在一段时间内保持不变,称为平稳时间序列。
换句话说,平稳时间序列是其统计特性独立于观察时间点的序列。一个平稳的时间序列有一个恒定的方差,它总是返回到长期均值。

Fig.1: Stationary Time Series
统计特性随时间变化的时间序列称为非平稳时间序列。因此,具有趋势或季节性的时间序列本质上是非平稳的。这是因为趋势或季节性的存在会影响任何给定时间点的均值、方差和其他属性。

Fig. 2: Non-Stationary Time Series
让我们总结一下平稳时间序列和非平稳时间序列的区别。
| 平稳时间序列 | 非平稳时间序列 |
| 平稳时间序列的统计特性与被观察的时间点无关。 | 非平稳时间序列的统计特性是观测时间的函数。 |
| 平稳时间序列的均值、方差和其他统计量保持不变。因此,平稳序列分析的结论是可靠的。 | 非平稳时间序列的均值、方差等统计量随时间而变化。因此,从非平稳序列分析中得出的结论可能会产生误导。 |
| 固定时间序列总是恢复到长期平均值。 | 非平稳时间序列不会回复到长期均值。 |
| 平稳的时间序列不会有趋势、季节性等。 | 趋势和季节性的存在使得一个序列是非平稳的。 |
平稳性的重要性
记得我们留了一个问题,“为什么平稳性是时间序列分析的关键成分之一?
在你回答这个问题之前,如果一个过程不是静态的,会发生什么?
是的,从非平稳过程中得出的推论是不可靠的,因为它的统计特性会随着时间不断变化。在执行分析时,您通常会对平均值、方差等的期望值感兴趣。
但是,如果这些参数是不断变化的,通过在一段时间内求平均值来估计它们将是不准确的。因此,平稳数据更容易分析,使用非平稳数据做出的任何预测都是错误和误导的。
正因为如此,许多应用于时间序列分析的统计程序都假设基本的时间序列数据是平稳的。
这种假设是必要的,因为大多数时间序列预测方法预测时间序列的统计特性在未来将保持与过去相同。
让我们转到平稳性的类型。
平稳性的类型
不同类型的平稳性如下。
- 严格平稳性 -这意味着任何矩(如期望值、方差、三阶和更高阶矩)的无条件联合分布在一段时间内保持不变。这种类型的系列在现实生活实践中很少见到。
- 一阶平稳性 -这些序列在一段时间内有一个平均常数。任何其他统计数据(如方差)都可能在不同的时间点发生变化。
- 二阶平稳性(也叫弱平稳性) -这些时间序列在一段时间内具有恒定的均值和方差。系统中的其他统计数据可以随时间自由变化。这是现实生活中最常见的系列之一。
- 趋势平稳性 -这些数列是有趋势的数列。当从系列中去除这种趋势时,会留下一个固定的系列。
- 差分平稳性 -这些序列是需要一次或多次差分才能变得平稳的序列。我们将在本文的后面详细研究这个问题。
检测平稳性
由于许多分析工具和统计测试假设时间序列是平稳的,因此确定给定的序列是否由平稳过程生成是非常重要的。下面是一些同样的方法。
可视化
检查给定数据是否来自平稳序列的最常用方法是简单地绘制数据或其函数。现在让我们看看这些技术如何帮助我们识别平稳性。
- 看数据- 平稳和非平稳序列都有一些性质,可以很容易地从数据的绘图中检测出来。例如,在一个平稳序列中,数据点将总是以恒定的方差返回到长期均值。在非平稳序列中,数据点可能显示某种趋势或季节性。让我们参考一下网站上的一系列情节,预测:Hyndman & Athanasopoulos 著,2018 。

Fig. 3: Examples of Time Series Data
图:时间序列数据的九个示例
从上图的九个图中,你认为哪些是平稳序列?
系列(b)是固定的。你可以在这里查看解释。这种方法仅用于初步了解数据,并不完全可靠。
- 看自相关函数图- 让我们从上面看序列(a)和序列(b)的 ACF 图。在这里你将了解什么是自协方差和自相关函数。

Fig. 4: ACF Plots
图:
来源:hynd man 著《预测:原理与实践》& Athanasopoulos,2018 。
你已经知道数列(a)是非平稳的,数列(b)是平稳的。
从上面两个图中你观察到了什么?
在第一个图中,滞后 1 的 ACF 值非常高,接近 1,并且下降非常缓慢。这是非平稳序列的情况。然而,在第二个图中,对于平稳序列,滞后 1 的 ACF 值非常小,并且很快下降到零。
因此,对于平稳序列,滞后 1 的 ACF 值较大且为正。而对于非平稳序列,则接近于零。对于非平稳序列,ACF 的值相对较快地下降到零。
让我们看另一个例子。我们将读取 2019 年 1 月至 2020 年 4 月 yfinance.com 的谷歌股价数据,并可视化该系列。


Fig. 5: Google Stock Price Series
你对以上系列有什么看法?它是静止的吗?
没有。该系列的数据在不同层面显示出不同的趋势。因此,它似乎不是静止的。
您了解了如何直观地检查数据的平稳性。让我们转到另一种技术来分析数据是否是稳定的。
汇总统计
你已经知道一个平稳的时间序列有一个恒定的均值、方差等。久而久之。因此,像均值和方差这样的汇总统计数据有助于估计时间序列是否是平稳的。
您可以将数据划分为随机的时间段,并分析不同时间段的汇总统计数据。如果不同分区的均值和方差非常接近,则该序列是平稳的。
如果不同分区的均值和方差之间存在显著差异,则该序列不是平稳的。
让我们把上面看到的谷歌价格数据分成两半,分析统计数据。
上述代码的输出是

你可以看到两个均值和两个方差的值有很大的不同。这再次表明该序列不是平稳的。
您比较了不同数据分区的汇总统计数据的平稳性。检查序列平稳性的一种更可靠、更方便的方法是对数据进行不同的统计检验,以检查它们是否来自平稳过程。
统计测试
许多参数和非参数检验可用于检查序列的平稳性。让我们看看几个参数测试及其 Python 实现。
- 增强的迪基-富勒测试-增强的迪基-富勒测试是最流行的检验平稳性的测试之一。它测试了下面的假设。
- 零假设,H0:时间序列不是平稳的。
- 另一个假设,H1:时间序列是平稳的。
您可以使用 statsmodels 库中的 adfuller 方法在 Python 中执行这个测试,并比较测试统计值或 p 值。
- 如果 p 值小于或等于 0.05,或者检验统计量的绝对值大于临界值,则拒绝 H0,得出时间序列是平稳的结论。
- 如果 p 值大于 0.05 或者检验统计量的绝对值小于临界值,你就不能拒绝 H0,并得出时间序列不是平稳的结论。
让我们看看如何用 Python 实现这一点。
结果以元组的形式返回。你可以在下面的格式中看到结果。

代码的输出如下所示。

可以看到,p 值大于 0.05。你未能拒绝零假设并得出时间序列不是平稳的结论。
或者,您可以将 ADF 测试统计数据与临界值进行比较。由于 ADF 检验统计量的绝对值小于临界值的绝对值,你无法拒绝零假设并得出时间序列不是平稳的结论。
- 科维亚特科夫斯基-菲利普斯-施密特-申检验- 另一个非常常用的平稳性检验是 KPSS 检验。这里要注意的非常重要的一点是,KPSS 的解释与 ADF 测试完全相反,因此这些测试不能互换使用。在解释这些测试时需要非常小心。KPSS 测试测试以下假设。
- 零假设,H0:时间序列是平稳的。
- 另一个假设,H1:时间序列不是平稳的。
您可以使用 statsmodels 库中的 kpss 方法在 Python 中执行这个测试,并比较测试统计值或 p 值。由于假设与 ADF 测试中看到的相反,对 p 值的解释也是相反的。
- 如果 p 值小于或等于 0.05,或者检验统计量的绝对值大于临界值,则拒绝 H0,得出时间序列不是平稳的结论。
- 如果 p 值大于 0.05,或者检验统计量的绝对值小于临界值,则不能拒绝 H0,不能得出时间序列是平稳的结论。
让我们看看如何用 Python 实现这一点。
结果以元组的形式返回。你可以在下面的格式中看到结果。

代码的输出如下所示。

可以看到,p 值小于 0.05。你拒绝零假设,并得出结论,时间序列不是平稳的。这与 ADF 测试获得的结果一致。
除了这些参数检验,还有其他半参数和非参数检验也可用于检查序列的平稳性。这些测试超出了本文的范围。
将非平稳序列转化为平稳序列
由于平稳序列易于分析,可以通过差分的方法将非平稳序列转化为平稳序列。实际上,为了使用时间序列预测模型,需要将非平稳序列转换为平稳序列。
在这种方法中,数列中连续项的差计算如下。

让我们计算谷歌价格系列的差异,并绘制结果。

Fig. 6: First Order Differenced Series
让我们对差分序列进行 ADF 检验,检查序列是否平稳。
上述代码的输出是

可以看到,p 值小于 0.05。你拒绝零假设,并得出结论,时间序列是平稳的。
因此,谷歌价格系列是一个差异平稳系列。Google 价格系列的一阶差导致了平稳系列。
建议读数
可以看下面关于平稳性的视频了解更多。
https://www.youtube.com/embed/bXr1LmBY8yo
结论
平稳性是时间序列分析的关键要素之一。平稳的时间序列独立于被观察的时间点。时间序列中的大多数预测模型都假设基础时间序列是平稳的。因此,为了使预测可靠,时间序列必须是平稳的。
您可以使用不同的技术来检查给定的时间序列是否是平稳的。金融市场中的大多数时间序列数据远非平稳,因此在进行预测之前必须将其转换为平稳序列。
要了解更多关于平稳和非平稳时间序列数据,以及各种时间序列分析模型,请查看我们的课程交易的金融时间序列分析。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
巴西股票市场的统计套利配对交易
这个项目为巴西的 B3(前 Bovespa)证券交易所建立了一个统计套利对交易策略模型。我们在两个不同的时间间隔运行我们的策略。2009 年 1 月 1 日至 2014 年 12 月 31 日以及 2018 年 1 月 1 日至 2021 年 4 月 30 日。由于我们只有当前的部门分布可用,前一时期的结果明显遭受生存偏差。
股票部门分类是直接从巴西 B3 证券交易所下载的。
在所有行业中,我们只考虑了拥有五只或更多股票的行业,即:
石油、金属、钢铁、纸张、运输材料、机械、铁路、公路、仓储、服务、农业、肉类、食品、建筑、纺织品、服装、鞋类、教育、汽车租赁、零售、医院、药店、it、电信、电力、水、银行、金融服务、保险、房地产。
结果非常令人鼓舞,尽管它没有考虑交易费或滑点成本。所有计算都基于每日收盘价。
这个项目的完整 python 代码也可以在文章末尾以可下载的格式获得。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

【Luiz Guedes 博士在其软件开发职业生涯中拥有超过 30 年的经验,尤其是在支付卡行业。此外,他还是 IME 军事学院的教员,教授编译器和编程语言。
作为一名软件开发人员和创新者,Guedes 博士广泛使用创新的问题解决方法为受限系统和安全电子交易编写软件,尤其是在编程和执行环境、加密算法和安全通信协议的开发方面。
最近,他将注意力集中在将数据科学方法应用于量化交易上。他还拥有 6 门外语的优秀表达能力。
Guedes 博士拥有 PUC/里约热内卢天主教大学计算机科学博士学位、IME 计算机系统硕士学位和计算机工程师学位。此外,他还获得了 FGV getu lio Vargas 基金会的工商管理硕士学位。
介绍
这个项目旨在为巴西 B3(前圣保罗证交所)股票市场建立一个统计套利对交易策略模型。我们在两个不同的时间间隔运行我们的策略。
- 从 2009 年 1 月 1 日至 2014 年 12 月 31 日,以及
- 从 2018 年 1 月 1 日至 2021 年 4 月 30 日。
由于我们只有当前的部门分布可用,前一时期的结果明显遭受生存偏差。
股票板块分类从【B32021】下载。在所有行业中,我们只考虑了拥有五只或更多股票的行业,即:
石油、金属、钢铁、纸张、运输材料、机器、铁路、高速公路、仓储、服务、农业、肉类、食品、建筑、纺织品、服装、鞋子、教育、汽车租赁、零售、医院、药店、it、电信、电力、水、银行、金融服务、保险、房地产
这些板块上市的所有股票的历史数据都来自雅虎财经。
使用的数据
在每个行业中,我们使用 Johansen 测试选择显著性水平大于 90%的股票对,以获得它们的套期保值关系[Chan,2013]。
从协整对中,我们只保留那些利差没有转换符号并且半衰期不超过 60 天的。这些过滤器减少了我们可用的股票市场数据,如表 1 所示。
| #扇区 x #对 | 2009 年 1 月 1 日至 2014 年 12 月 31 日
| 2018 年 1 月 1 日至
2021 年 4 月 30 日 |
| 所有(大于 5 的扇区) | 10 x 750 | 15 x 1098 |
| 协整(显著大于 90%) | 10 x 393 | 15 x 442 |
| 常数符号 | 10 x 333 | 14 x 361 |
| 半衰期< = 60 年 | 4 x 89 | 12 x 140 |
表 1:扇区数量 x 可用对数
另一个我们只能应用最近数据的考虑因素是可以卖空的股票。巴西股票市场的流动性不如我们所需要的那样高,我们需要确保总是有可能购买一对股票(做多一只股票,做空另一只)。
因此,我们也运行我们对当前前 100 只股票的策略。这些股票按名为 IBrX100 [B32021a]的指数上市。表 2 示出了在应用上述过滤器之后属于当前前 100 个的扇区和对的数量。
| #扇区 x #对 | 全部 | 前 100 名 |
| 所有(大于 5 的扇区) | 15 x 1098 | 5 x 81 |
| 协整(显著大于 90%) | 15 x 442 | 5 x 21 |
| 常数符号 | 14 x 361 | 4 x 18 |
| 半衰期< = 60 年 | 12 x 140 | 3 x 5 |
表 2:2017 年 1 月 1 日至 2021 年 4 月 30 日期间的#部门 x #对可用性
交易策略
由于生成的成对价差应该是均值回复,我们建立了一个布林线指标策略,其长度对应于每对半衰期和一个标准差宽度。
当价差穿过上波段时,我们建立一个空头头寸,当价差穿过下波段时,我们建立一个多头头寸。当价差穿过移动平均线时,我们平仓任何未平仓的头寸,如果有的话。
我们还定期运行扩展的 Dickey-Fuller (ADF)测试,以检查利差是否仍在均值回复。由于 ADF 测试是一项长期测试,因此每天运行它是没有意义的。
因此,我们进行了网格搜索,以便找到运行测试的最佳频率和最佳长度。网格检查每月运行测试一次、两次或三次,时间长度为 6、12、18 和 24 个月。
表 3 总结了网格搜索找到的最佳超参数。
| 周期 | 每月次 | 以月为单位的长度 |
| 2009 年 1 月 1 日至 2014 年 12 月 31 日 | one | Twenty-four |
| 2018 年 1 月 1 日至 2021 年 4 月 30 日(全部) | one | Twelve |
| 2018 年 1 月 1 日至 2021 年 4 月 30 日(前 100 名) | Two | Twelve |
表 3:最佳 ADF 检查频率和长度
结果
对于每种情况,最后一年的数据作为测试集,用剩余的数据训练策略。在各自的测试集上测试每个训练集上的前 10 名表演者。
考虑杠杆系数 1、2 和 3 收集的结果分别显示在表 4、5 和 6 中。表 4 只显示了五对,因为正如我们在表 2 中看到的,在那个场景中只剩下五对。
2020-05-01 to 2021-05-01 - Top 100:
leverage = 1
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('ARZZ3.SA', 'HGTX3.SA') 1.23 2.60 2.33 0.37 -11.07%
('JHSF3.SA', 'MRVE3.SA') 0.72 4.33 0.80 0.19 -19.31%
('CMIG4.SA', 'CPFE3.SA') 0.58 3.00 1.46 0.20 -4.43%
('CPFE3.SA', 'ENBR3.SA') 0.36 2.00 1.44 0.13 -5.43%
('ENBR3.SA', 'TRPL4.SA') 0.10 1.00 1.35 0.08 -22.27%
leverage = 2
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('ARZZ3.SA', 'HGTX3.SA') 3.52 2.60 2.33 1.05 -21.49%
('JHSF3.SA', 'MRVE3.SA') 1.63 4.33 0.80 0.45 -38.62%
('CMIG4.SA', 'CPFE3.SA') 1.39 3.00 1.46 0.51 -8.86%
('CPFE3.SA', 'ENBR3.SA') 0.80 2.00 1.44 0.29 -10.86%
('ENBR3.SA', 'TRPL4.SA') 0.12 1.00 1.35 0.17 -40.94%
leverage = 3
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('ARZZ3.SA', 'HGTX3.SA') 7.44 2.60 2.33 2.22 -31.26%
('CMIG4.SA', 'CPFE3.SA') 2.49 3.00 1.46 0.93 -13.29%
('JHSF3.SA', 'MRVE3.SA') 2.43 4.33 0.80 0.78 -57.93%
('CPFE3.SA', 'ENBR3.SA') 1.31 2.00 1.44 0.46 -16.35%
('ENBR3.SA', 'TRPL4.SA') 0.06 1.00 1.35 0.27 -56.35%
表 4: 2020 年 5 月 1 日至 2021 年 5 月 1 日-前 100 个结果
2020-05-01 to 2021-05-01 - Top All:
leverage = 1
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('AFLT3.SA', 'CPLE3.SA') 10.13 6.60 1.11 3.00 -17.51%
('MRVE3.SA', 'RDNI3.SA') 3.42 8.50 0.87 1.36 -17.39%
('IGTA3.SA', 'SCAR3.SA') 2.44 4.00 1.18 0.86 -17.97%
('BRSR3.SA', 'ITSA4.SA') 2.38 2.57 1.16 0.89 -46.01%
('GEPA4.SA', 'TRPL4.SA') 1.61 3.33 1.18 0.42 -15.79%
('CRDE3.SA', 'RDNI3.SA') 1.39 5.33 0.79 0.40 -25.13%
('BRIV4.SA', 'PINE4.SA') 1.09 4.00 0.83 0.21 -14.84%
('ARZZ3.SA', 'HGTX3.SA') 1.03 2.75 1.99 0.31 -11.07%
('ARZZ3.SA', 'CGRA4.SA') 0.94 3.00 2.85 0.25 -5.75%
('ARZZ3.SA', 'GUAR3.SA') 0.87 3.25 2.18 0.26 -3.99%
leverage = 2
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('AFLT3.SA', 'CPLE3.SA') 64.45 5.67 1.27 21.62 -35.03%
('IGTA3.SA', 'SCAR3.SA') 7.17 3.00 1.49 2.78 -35.94%
('BRSR3.SA', 'ITSA4.SA') 6.72 2.57 1.17 2.23 -75.99%
('BMIN4.SA', 'PINE4.SA') 6.03 6.00 1.82 2.28 -22.28%
('GEPA4.SA', 'TRPL4.SA') 4.95 3.33 1.18 1.35 -30.35%
('BMIN4.SA', 'BRSR3.SA') 4.64 5.00 1.97 1.82 -22.34%
('BRIV4.SA', 'PINE4.SA') 2.87 6.00 0.57 0.54 -29.68%
('ARZZ3.SA', 'HGTX3.SA') 2.77 2.75 1.99 0.82 -21.49%
('ARZZ3.SA', 'CGRA4.SA') 2.54 3.00 2.85 0.62 -11.39%
('ARZZ3.SA', 'GUAR3.SA') 2.29 3.25 2.18 0.66 -7.99%
leverage = 3
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('AFLT3.SA', 'CPLE3.SA') 237.23 5.67 1.27 87.74 -52.54%
('BMIN4.SA', 'PINE4.SA') 18.06 4.33 3.47 6.77 -24.71%
('IGTA3.SA', 'SCAR3.SA') 13.80 3.00 1.49 5.87 -53.91%
('BMIN4.SA', 'BRSR3.SA') 12.91 3.67 3.70 4.94 -24.63%
('BRSR3.SA', 'ITSA4.SA') 11.49 2.57 1.32 3.52 -90.64%
('ARZZ3.SA', 'HGTX3.SA') 5.50 2.75 1.99 1.58 -31.26%
('ARZZ3.SA', 'CGRA4.SA') 5.10 3.00 2.85 1.16 -16.91%
('ARZZ3.SA', 'GUAR3.SA') 4.47 3.25 2.18 1.25 -11.98%
('BRIV4.SA', 'PINE4.SA') 4.06 4.60 0.63 0.76 -44.52%
('CPFE3.SA', 'ENBR3.SA') 1.53 4.50 0.84 0.56 -19.35%
表 5: 2020 年 5 月 1 日至 2021 年 5 月 1 日-所有结果排名
2014-01-01 to 2015-01-01
leverage = 1
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('CBEE3.SA', 'EKTR4.SA') 5.18 15.00 4.50 1.36 -2.94%
('BAZA3.SA', 'BNBR3.SA') 4.62 6.00 1.58 1.62 -12.25%
('BAZA3.SA', 'BMIN4.SA') 4.11 8.50 1.09 0.99 -17.30%
('CTSA4.SA', 'TXRX4.SA') 2.39 2.50 1.54 0.69 -45.70%
('BRSR3.SA', 'ITSA4.SA') 1.13 5.00 5.19 0.37 -1.61%
('CPFE3.SA', 'CSRN3.SA') 0.90 5.50 8.44 0.26 -1.15%
('BMEB4.SA', 'ITSA4.SA') 0.46 1.40 2.10 0.17 -12.08%
('BAZA3.SA', 'BGIP4.SA') 0.40 3.14 0.83 0.19 -10.02%
('BMIN4.SA', 'SANB4.SA') 0.36 6.00 0.58 0.14 -13.62%
('BMIN4.SA', 'RPAD3.SA') 0.32 5.00 0.69 0.13 -12.59%
leverage = 2
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('CBEE3.SA', 'EKTR4.SA') 26.89 15.00 4.50 6.53 -5.88%
('BAZA3.SA', 'BNBR3.SA') 22.42 6.00 1.58 8.77 -24.50%
('BAZA3.SA', 'BMIN4.SA') 18.14 8.50 1.09 4.46 -34.60%
('BRSR3.SA', 'ITSA4.SA') 3.19 5.00 5.19 0.96 -3.22%
('CPFE3.SA', 'CSRN3.SA') 2.41 5.50 8.44 0.69 -2.30%
('BMEB4.SA', 'ITSA4.SA') 0.96 1.40 2.10 0.35 -23.63%
('BAZA3.SA', 'BGIP4.SA') 0.88 3.14 0.83 0.41 -20.04%
('BMIN4.SA', 'SANB4.SA') 0.73 6.00 0.58 0.27 -27.25%
('BMIN4.SA', 'RPAD3.SA') 0.65 5.00 0.69 0.26 -25.18%
('CEPE3.SA', 'LIPR3.SA') 0.04 inf inf 0.00 0.00%
leverage = 3
Pair CAGR Hit Ratio Avg Profit/Loss Rets StdDev Max Draw-down
('CBEE3.SA', 'EKTR4.SA') 101.08 15.00 4.50 23.10 -8.82%
('BAZA3.SA', 'BNBR3.SA') 76.64 6.00 1.58 34.36 -36.75%
('BAZA3.SA', 'BMIN4.SA') 63.20 8.50 1.70 15.45 -26.56%
('BRSR3.SA', 'ITSA4.SA') 6.94 3.00 6.94 1.50 -4.83%
('BMEB4.SA', 'ITSA4.SA') 1.44 1.40 2.10 0.54 -34.64%
('BAZA3.SA', 'BGIP4.SA') 1.42 3.14 0.83 0.65 -30.06%
('BMIN4.SA', 'SANB4.SA') 0.54 4.00 0.72 0.18 -33.68%
('BMIN4.SA', 'RPAD3.SA') 0.52 3.00 1.03 0.18 -27.88%
('BMEB4.SA', 'BRSR3.SA') 0.48 2.50 0.92 0.17 -27.01%
('CEPE3.SA', 'LIPR3.SA') 0.08 inf inf 0.01 0.00%
表 6: 2014 年 1 月 1 日至 2015 年 1 月 1 日的结果
考虑到属于前 100 名名单的股票的最近情况,整个投资组合的结果总结在表 7 中
| 杠杆 | 返回 | CAGR | 标准发展 | 最大压降 |
| 1 | 58% | 60% | 2% | -9% |
| 2 | 142% | 149% | 22% | -71% |
| 3 | 259% | 272% | 41% | -87% |
表 7: 2020 年 5 月 1 日至 2021 年 5 月 1 日 100 大投资组合结果
对于每一个杠杆水平,我们可以在图 1、2 和 3 中看到每一对的单位金额的 MTM 权益曲线。对于所有三个杠杆,投资组合初始金额为 5.0,因为有五对。
投资组合收益率:0.58 CAGR: 0.60 标准差:0.02 最大下降:-0.09

Figure 1: 2020-05-01 to 2021-05-01 - Top 100 Portfolio Equity Curve – Leverage 1
投资组合收益率:1.42 CAGR: 1.49 标准差:0.22 最大下降:-0.7

Figure 2: 2020-05-01 to 2021-05-01 - Top 100 Portfolio Equity Curve – Leverage 2
投资组合收益率:2.59 CAGR: 2.72 标准偏差:0.41 最大下降:-0.87

Figure 3: 2020-05-01 to 2021-05-01 - Top 100 Portfolio Equity Curve – Leverage 3
参考
- Chan 2013–Chan,Ernie。“算法交易”,威利贸易,威利,2013 年
- b 32021-B3,∞部门,源自〔t0〕http://www . B3 . com . br/pt _ br/products-e-services/negotiatao/revenue-variable/acos/consultation/classifo-sectorial/2021 年 5 月 27 日
- b 32021 a–B3,“巴西指数 100 (IBrX 100 B3)”,摘自2021 年 5 月 27 日 http://www . B3 . com . br/pt _ br/market-data-e-indexes/indexes/indexes-amplos/indice-Brasil-100-IBrX-100-composicao-da-carte IRA . htm。
结论
在这个项目中,我们模拟了一个对交易策略,特别是巴西 B3(前 Bovespa)股票市场交易所的统计套利对交易策略。我们在两个不同的时间间隔运行我们的策略。2009 年 1 月 1 日至 2014 年 12 月 31 日以及 2018 年 1 月 1 日至 2021 年 4 月 30 日。
为了运行我们的策略,我们考虑了拥有 5 只或更多股票的所有部门。由于我们现在只有行业股票分类,前一个时期固有地遭受生存偏差。
对于最近一段时间,我们还考虑了卖空股票可能缺乏流动性,因此只对属于前 100 名股票指数 IBrX100 的股票进行了单独测试。
在所有场景中,我们使用去年的数据作为测试集,剩余的数据作为训练集。
结果非常好,从杠杆率为 3 的 272% CAGR 到杠杆率为 1 的更现实的 60% CAGR。
获得的结果没有考虑交易费用或滑点成本。所有计算都基于每日收盘价。
这个项目表明量化交易策略在巴西股票市场可以非常多产和有利可图,主要是因为潜在的统计套利目标市场低效似乎还没有被大多数交易者解决。
下载中的文件:
- 统计套利-巴西股票市场的配对交易-最终 Python 笔记本
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
统计套利:墨西哥股票市场的配对交易[EPAT 项目]
原文:https://blog.quantinsti.com/statistical-arbitrage-pair-trading-mexican-stock-market/
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易(EPAT)高级管理课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

哈维尔塞万提斯,CFA
Javier Cervantes 目前是 BCP 证券公司的公司债券交易员,专门从事 MXN 债券。他也是 CFA 特许持有人,于 2017 年 8 月获得特许证书。Javier 拥有 ITAM 墨西哥自治技术学院的经济学学士学位。
项目
在墨西哥证券交易所运营的 algo 交易公司/策略非常少。我相信这将提供很好的机会,因为竞争很少。与更发达的市场相反,套利机会并不容易实现,这表明那些寻找并能够利用它们的人可能有机会。
这是这个策略的主要动机,也是我联系 Quantinsti 的主要原因。由于参与交易的玩家很少,学习算法交易可能会给我未来带来很好的机会。
事实上,墨西哥市场并不发达,也会造成一定的复杂性。墨西哥证券交易所大约有 200 家上市公司。其中,我过滤了那些信息不完整的股票(使用谷歌金融),得到了 117 只股票(见附件 Excel“emis oras bmv . xlsx”),这些股票将被进一步过滤和清理,以满足某些条件。
本项目实施的交易策略称为“统计套利交易”,也称为“Pairs Trading”,是一种反向策略,旨在从某一对比率的均值回复行为中获利。这种策略背后的假设是,显示协整特性的货币对的价差本质上是均值回复的,因此如果价差显著偏离均值,将提供套利机会。
交易策略将在 2012 年 1 月 1 日至 2017 年 6 月 30 日期间进行回溯测试。这一期间将分为样本内回测(2012 年 1 月 1 日至 2015 年 12 月 31 日)和样本外回测。
在确定策略之前,我必须确定哪些股票可以交易。为此,我将建立每日交易量,协整和相关性限制。一旦股票领域被清理干净,回溯测试就可以开始了。
给定所选的股票,我将首先对那些在给定时间范围内没有完整每日价格的股票应用一个过滤器。一旦这些股票被剔除,我设定的最低日均交易量为 1500 万比索(MXN)才有资格交易。
现在,股票已经根据其数据和每日流动性进行了筛选,每个行业的每个可能的股票对都将进行协整测试。进行 ADF 测试时,另一个假设是要测试的货币对是稳定的。对于 p 值< 0.025,将拒绝零假设。
要使用的最后一个滤波器是相关性。相关系数低于 0.60 的那些对将被消除。以下几对是成功晋级的:

以下是将在交易策略中使用的其余每一对的价格散点图:

现在,将为剩下的每个价格比率创建 zscores。在移动平均和标准偏差计算中用于构建 zscores 的时间范围是 60 天。这是带有+2/-2 标准偏差线的 zscore 图的外观:
 交易策略将包括创建一个一级卖出信号,如果一对股票的交易高于平均值 2 到 2.25 个标准差,则做空相对昂贵的股票,同时买入相对便宜的股票,此时,该比率的 75%的可用风险资本将被卖出。如果该对的 zscore 跨越 2.25 个标准差,则剩余 25%的风险资本会出现一个二级卖出信号。当一对交易分别低于平均值 2 和 2.25 个标准差时,会产生类似的初级买入和次级买入信号。一旦回溯测试完成,两步进场信号的有用性将使用集合结果的夏普比率进行评估。一旦这对组合的 zscore 越过 0,每笔交易的退出信号就会被触发。
交易策略将包括创建一个一级卖出信号,如果一对股票的交易高于平均值 2 到 2.25 个标准差,则做空相对昂贵的股票,同时买入相对便宜的股票,此时,该比率的 75%的可用风险资本将被卖出。如果该对的 zscore 跨越 2.25 个标准差,则剩余 25%的风险资本会出现一个二级卖出信号。当一对交易分别低于平均值 2 和 2.25 个标准差时,会产生类似的初级买入和次级买入信号。一旦回溯测试完成,两步进场信号的有用性将使用集合结果的夏普比率进行评估。一旦这对组合的 zscore 越过 0,每笔交易的退出信号就会被触发。
如果把每一对都当作一个单独的交易,下面是会得到的结果:

可以看出,不同对之间的结果差异很大。最大提取率从 2%到 32%不等。CAGR 从 12%到 31%不等。如果每一对的回报相关性很低,这种策略可以从多样化中获益。让我们来看看相关矩阵:

这是为之前分析的每一对股票生成的权益曲线:

将一个人的全部风险资本分配给一对可能风险太大。鉴于观察到的配对之间的相关性相对较低,让我们分析以下策略:我们现在假设每个剩余的配对都接受相同的初始风险资本分配。
首先,我们分别分析一级和二级交易,并测试我们是否从执行单独的(一级和二级)进场信号中获益。如果满足以下条件,投资组合的夏普比率将因增加新工具而提高:

评估 2.41>2.12 中的先前表达式结果;因为这个条件是真的,使用两个进场信号运行策略将导致这个交易策略的更高的夏普比率。
以下是完整交易策略的最终结果:

首先要注意的是,样本内夏普比率(2.79)高于之前仅使用初级信号交易计算的夏普比率(2.41)。第二,这种策略的最大提款相当低,这使得杠杆的使用具有很大的灵活性。第三,我们可以观察到样本外的结果较低,但仍然提供了异常的风险调整后的回报。
这是这一策略产生的权益曲线:

上述结果无法直接比较,但我们可以估计这一策略与墨西哥股市指数 IPC(谷歌股票代码“INDEXBMV:ME”)的相关性。对于样本内数据,相关系数为 0.62,这可以为“市场投资组合”提供多样化的好处。另一种可以实现这种模式的策略是“股票化市场中性的多空投资组合”。该策略包括使用市场指数期货(名义上相当于卖空股票所需的储备现金头寸)的被动投资策略,并寻求通过我们的统计套利策略产生一些 alpha。
结论:
有重大的机会,可以抓住在墨西哥股票市场的战略适合许多类型的投资者。
你还必须意识到,在实施这个交易策略之前,还有一些事情需要考虑;许多将取决于投资者类型:
- 鉴于该策略中观察到的低最大提款,谨慎使用杠杆可以进一步增强之前的结果
- 先前的结果没有考虑隐性和显性交易成本
- 建议进行进一步的回溯测试,尤其是在不同的时间段,以便更好地掌握这种交易策略在不同市场条件下的表现。人们也可以在 ADF 测试中使用不同的变量值来测试策略,如进入水平、风险资本分配、时间范围、相关性和置信度
- 和两步进场信号一样,我们可以用多步出场策略来检验结果。特别重要的是实施止损,止损可以基于不同水平的 zscore、相关性、波动性等
- 假设策略中使用的所有股票都可以卖空。该战略的实际执行可能会出现复杂情况。
参考书目:
欧内斯特·陈。算法交易,获胜策略,以及它们的基本原理。
蔡,瑞伊。金融时间序列分析
QUANTINSTI。统计套利(配对交易和指数套利)讲座
下一步
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 为你提供了在算法交易中建立一个有前途的职业生涯所需的技能。现在报名!
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
下载中的文件:
- BMV.csv 发行者
- 巴黎交易 BMV 墨西哥。稀有
套利策略:理解统计套利的运作
统计套利起源于 20 世纪 80 年代左右,由摩根士丹利和其他银行牵头。统计套利策略,也被称为 StatArb,在金融市场中得到了广泛的应用。这一策略的流行持续了 20 多年,围绕这一策略产生了不同的模式,以获取高额利润。
简单来说,统计套利包括一套量化驱动的算法交易策略。这些策略旨在通过分析价格模式和金融工具之间的价格差异,利用数千种金融工具的相对价格变动。
这里需要注意的一点是,统计套利不是一种高频交易(HFT)策略。它可以被归类为中频策略,交易周期在几个小时到几天内。
让我们了解更多关于统计套利的信息,因为本博客涵盖:
什么是套利?
套利是同时交易多种金融证券以从价格差异中获利的过程。
这可以通过多种方式实现,例如:
套利可应用于金融工具,如
套利是一种无风险的策略,尽管情况并非总是如此。始终存在执行风险的可能性,即由于市场的高波动性和价格的突然变化导致无法以有利可图的价格完成交易的风险。涉及的其他风险是交易对手风险和流动性风险。
现在让我们看看这个例子。假设一家公司 ABC 的股票在伦敦证券交易所的交易价格为每股 10 美元,而同样的股票在纽约证券交易所的交易价格为 10.5 美元,那么套利策略将是在伦敦证券交易所(LSE)以 10 美元购买股票,在纽约证券交易所(NYSE)以 10.5 美元出售,每股获利 0.5 美元。
什么是统计套利?
在金融界,统计套利(或 stat arb)指的是一组交易策略,它们利用均值回归分析在非常短的时间内投资于多达数千种证券的不同投资组合,通常只有几秒钟,但也可能长达几天。
统计套利(Stat Arb)是一种交易策略,基于一项或多项资产相对于该资产预期未来价值的统计错误定价。
此外,StatArb 的策略之一是对算法进行编码,以监控历史上已知具有统计相关性或协整性的金融工具或资产,关系中的任何偏差都表明存在交易机会。
统计套利涉及统计学、定量方法和数据挖掘的计算方法,可以通过算法高频交易。
因此,统计套利包括不同类型的策略,如对交易、指数套利、篮子交易或delta-中性策略。这些策略因投资组合中工具的数量、类型和权重及其风险承受能力而异。
成对交易中最受欢迎的例子之一是百事可乐对可口可乐的股票。两只股票属于同一个行业,或者同一个业务类型,并且随着同样的市场事件影响它们的价格而同步波动。
例如,如果百事可乐的股票与可口可乐相比上涨了很多,那么人们可能会做空百事可乐,做多可口可乐,以期待有利的回报。
统计套利是如何运作的?
当股票等证券倾向于在上升和下降周期中交易时,Stat arb 起作用,量化方法寻求利用这些趋势。
定量交易的趋势行为使用软件程序来跟踪模式或趋势。揭示的趋势是基于交易的数量、频率和证券价格。
在下图中,您可以看到两只股票之间的统计套利,即汽车行业的 LAD (Lithia Motors Inc .)和 TTM (Tata Motors Limited ADR)。

Close prices for statistical arbitrage
在上图中,拉德和 TTM 的股票价格。你可以看到两只股票在整个时间跨度内都非常接近,只有几次分开。
正是在这些分离期,基于股价将再次靠拢的假设,出现了套利机会。
识别这种机会的关键在于两个主要因素:
- 确定需要高级时间序列分析和统计测试的配对
- 为利用市场地位的战略指定进入点和退出点
热门平台上有大量内置的 pairs trading 指标,用来识别和进行配对交易。然而,很多时候,交易成本是从策略中获利的一个关键因素,但在计算预期回报时通常不考虑交易成本。
因此,建议交易者在回测时考虑所有影响交易最终盈利能力的因素,制定自己的统计套利策略。
统计套利的类型
不同的统计套利策略包括:
- 市场中性套利
- 交叉资产套利
- 跨市场套利
- ETF 套利
市场中性套利
市场中性意味着利用一个或多个市场的价格上涨和下跌,同时试图避免特定的市场风险。此外,市场中性套利意味着使用对冲等策略,这有助于利用基于历史数据的股票价格差异。
跨市场套利
它寻求利用同一资产在不同市场的价格差异。该策略是在估值较低的市场买入资产,然后在估值较高的市场卖出。
交叉资产套利
该模型押注于金融资产与其基础资产之间的价格差异。例如,在股票指数期货和构成该指数的股票之间。
ETF 套利
ETF 套利可以被定义为一种跨资产套利的形式,它识别 ETF 的价值和其基础资产之间的差异。
使用统计套利策略的风险
统计套利并非完全无风险,因为它依赖于从以下原因留下的缺口中寻找机会:
平均值回复
在市场价格最终回到平均值之前,价格与平均值的偏离。回归均值的做法通常被称为均值回归。在 Quantra 课程中详细学习均值回归策略。
无能
价格差距是在高频交易中造成的,以便利用任何持续毫秒左右的低效率。这样,在交易过程中可以捕捉到大量的低效率,因为高估的股票可以卖空,低估的股票可以买入。
价格差异
在成对交易策略的情况下,成对股票的价格差异也是统计套利最常用的方法之一,因为当成对股票的价格彼此不同时,就会出现低效率。
但是,当有外部干预,如货币贬值等时,问题就出现了。此外,当套利策略的假设受到干扰时,例如,如果配对股票之间的关系发生变化,该策略就会失败。
统计套利和配对交易
StatArb 是配对交易策略的进化版本,其中股票根据基本面或基于市场的相似性进行配对。
当一对股票中的一只表现优于另一只时,表现较差的股票被买入,同时预期它会超越表现更好的股票。通过做空其他表现突出的股票,多头头寸可以免受市场变化/运动的影响。
在统计套利策略中,大量的股票参与其中。此外,还有很高的投资组合周转率和大量的交易。这增加了交易和滑点成本。
因此,该战略通常以自动化的方式实施,并非常重视降低交易成本。统计套利策略已经成为对冲基金和投资银行的主要力量。

Steps of statistical arbitrage strategy
在上图中,你可以看到一个统计套利策略的实施步骤。
StatArb 考虑的不是成对的股票,而是一百只或更多股票的投资组合——一些做多,一些做空——这些股票按照行业和地区仔细匹配,以消除对 beta 和其他风险因素的暴露。
如何在 pairs 交易中使用统计套利?
为了使统计套利在成对交易策略中发挥作用:
- 首先,你要选择配对的股票。
- 在你选择了股票之后,第二,你将找出这两只股票的收盘价,并将它们可视化。
- 现在,您将计算并可视化该对的分布和分布的 z 值
- 然后,您将通过运行增强的 Dickey-Fuller 来检查传播的平稳性。
- 最后,如果根据 ADF 测试,货币对是稳定的,则可以产生交易信号。一段时间后,配对的股票总是回到他们的平均水平。
用 Python 实现成对交易中的统计套利
第一步是选择配对的股票。我们买入了 Blink Charging Co(股票代码:BLNK)和 NIO(股票代码:NIO)这两只股票。
让我们先来看看这两只股票的收盘价。
统计思维导论
由维维克·克里什纳·摩尔蒂和安舒尔·塔亚尔
统计思维是一种通过概率和统计的视角处理信息的方法,以便做出明智的决策。
这一系列博客将带您开始一段旅程,我们从介绍统计思想开始,做一个短暂的停留来理解贝叶斯统计,然后使用 Python 详述其在金融市场中的应用。
总有一天,统计思维会像读写能力一样成为高效公民的必要条件
赫伯特·乔治·威尔斯(1866-1946),科幻小说之父
做出选择是我们日常生活的一部分,无论是个人生活还是职业生活。如果你尽可能地应用统计思维,你可以做出更好的选择。
在本文中,我们将一步一步地解构有限信息下的决策过程。我们将看一些例子,术语和统计在这个过程中的重要性。
什么是统计学?
有两种方法来定义统计数据。统计学的正式定义是:统计学处理数据的收集、分析、解释和表达。
直观地说,统计学被定义为统计学是在不确定性下做出决策的科学。
也就是说,统计学是一个在你没有完整信息的情况下,帮助你做决策的工具。
什么是统计问题?

看着上面的图片,让我们来解决一些问题!
上图有几只猫?
4,对吗?
我们有回答这个问题的所有信息吗?
是的。
所有健康的猫都有四条腿吗?
是的。
我们有回答这个问题的所有信息吗?
不是,因为这是世界上现存的所有猫中仅有的 4 只的照片!
但是我们还能确定的回答吗?
是的。
那么,这是一个统计问题吗?
号
为什么?
因为如果你有所有的信息来回答这个问题,或者如果你能肯定地回答这个问题,这就不是一个统计问题。
对于一个统计学问题来说,
- 这个问题必须超越现有的信息,而且
- 这个问题不应该有确定的答案。
这一概念将在本文中反复强调,即统计学是在不确定性下做出决策的科学。
我们为什么需要统计数据?
我们现在通过这篇文章用一个玩具例子来回答上面的问题。
假设我们决定设计一门关于 Julia 编程的 Quantra 课程。
- 我们如何决定是否应该投入时间和精力来建设这个球场?
- 如果我们设计的课程失败了,没有得到很多感兴趣的用户怎么办?
这些都是需要大量资源的重要商业决策。因此,我们决定调查这样的课程是否有销路。
现在,这提出了以下问题:
- 谁会是我们的潜在付费用户?
- 我们应该找谁?程序员?数据科学家?研究人员?大学毕业生?量化分析师?
- 理想情况下,他们都是,对吗?
然而,
- 我们能接触到所有这些人吗?不太可能。
- 那么,我们该怎么办呢?
- 我们应该放弃设计新课程的想法吗?
那听起来不太对劲。
如果我们能接触到所有的人,这个过程会很简单。如果大多数人说他们会购买这样的课程,你就创建它。如果没有,那就放弃吧。
然而,既然我们做不到,我们就退而求其次,也就是说,我们询问我们能接触到的最多人数,根据他们的回答,我们估计这个课程成功的可能性。
为了计算这个估计值,我们需要统计数据。
概括地说,在现实世界中,我们很少拥有与我们想要做出的决定相关的完整信息,无论是对个人还是对企业。
因此,我们需要一个工具来帮助我们在有限的信息下做出决定。统计学就是这样一种工具,在统计框架内做出这些决定被称为统计思维。
统计思维不仅仅是用公式计算 p 值和 z 值;这是一种思考世界的方式。一旦你内化了这个想法,它会改变你对世界的看法。你将开始考虑可能性而不是确定性,这将帮助你在职业和个人生活中做出更好的决定。
描述统计学与推断统计学
描述性统计是采用集中趋势(均值、中值和众数)、离差(标准差、四分位距)等方法获取数据并描述其特征的过程。
然而,推断统计学是关于处理有限的数据,并使用它来推断我们先验地向自己提出的一个更大的问题。这个问题不能肯定地回答。
我们的文章着重于后者,即推断统计学。
我们应该使用描述性统计还是推断性统计?
这取决于你问的问题和可用的数据。在决定使用哪一种时,可以问自己一个简单的问题:
- 我们要描述现有的数据吗?运筹学
- 我们是否希望从现有数据(样本)中进行推论,从而推断出总体情况?
我们对前者采用描述性统计,对后者采用推断性统计。
统计学术语
让我们看看统计学中使用的一些关键术语,这将有助于你更好地理解这些概念。
人口
我们感兴趣的物品的世界。回到我们的 Quantra 课程的例子,人群是世界上所有对 Julia 课程感兴趣的人。
样品
它是总体的一个子集,也就是我们能够得到的信息量。这可能是我们拥有的 Quantra 或 EPAT 用户群。我们可以把问题框定为:你购买茱莉亚课程的可能性有多大(从 1 到 10 分)?
统计的
可用数据的汇总衡量,即来自样本的数据。在这里,它可以是从 Quantra 和 EPAT 用户那里获得的上述问题的平均分数,比如说 7 分。
参数
一个参数是总体的一个汇总度量。这里,它可以是从人群中获得的平均分数,比如说 6 分(如上所述)。
一个统计量是对现有数据(样本)的汇总测量,而一个参数对于总体来说是相同的。
假设
对我们如何看待世界的描述。我们假设 EPAT 和 Quantra 用户不太可能购买 Julia 的课程(评分为 1)。这是我们开始的假设,我们称之为零假设。
虚假设
在开始任何统计分析之前,有一个零假设是至关重要的。无效假设主要是现状。另一种假设是你认为可能是真的,并且正在寻找证据来验证它的理论。
为了澄清,我们的零假设({H_0})和替代假设({H_1})是({H_0}): EPAT 和 Quantra 用户不太可能购买关于 Julia 的课程(平均评分= 5)
({ h1 } ):EPAT 和 Quantra 用户可能会购买该课程(平均评分> =5)
假设检验
假设检验是一种从样本中得出数据结论的方法,即检验假设是否正确。
估计
并且估计可以被定义为是参数实际值的最佳猜测的变量。
为什么要花时间在统计推断上?
让我们考虑两种情况:
- 场景 1 -我们只有一个用户,她对购买课程的可能性评分为 6。
- 场景 2 -我们访问了 10 名用户,他们对购买课程的平均评分为 8 分。
这些是我们最好的估计。然而,
哪个是更好的估计?
有 10 个用户的那个因为数据多。
对场景 2 的估计是否足够好,可以采取行动?
因为 10 个人购买课程的可能性很大,我们应该创建课程吗?
也许不是。
为什么? 因为 10 个用户的响应可能不够,所以可能会导致一个糟糕的决策。
这就是统计推断的用武之地。
正如我们之前提到的,如果你想要正确的答案,你将需要所有的数据。没有什么灵丹妙药能在有限的数据下给你正确的答案。但是请记住,正如我们所讨论的,统计学是在不确定性下做出决策的科学。
我们没有兴趣用统计推断来知道正确的答案,因为我们不能!
使用推断统计学,你要回答的问题是:
最佳猜测足以改变我们的想法吗?
这构成了我们在统计推断中所做的一切的基础。注意,问题提到了“改变我们的想法”。这意味着我们首先需要在头脑中有一些想法,一个决定,一个观点。
我们只有默认已经决定要做的事情,才能改变主意。还记得我们提到过零假设的重要性吗?
假设可能是人们极不可能购买 Julia 编程的 Quantra 课程,所以如果最好的猜测是还不足以改变我们的想法,我们将不创建新课程。
这就是需要有一个预先定义的假设的地方。这是推断统计学中的另一个基本概念。假设我们要进行统计推断。
在这种情况下,我们需要有一个预定义的决策或意见,因为,以重复为代价,我们使用统计学提出的问题是:
最佳猜测足以改变我们的想法吗?
如果你有一个默认的动作,整个统计推断的练习是有意义的。如果您没有默认的操作,只需根据样本数据做出最佳猜测。
我们再举一个例子来理解这一点。想象一下,如果百事可乐公司决定将它的标志颜色改为黑色或绿色。记录 100 万人的回答作为样本。
现在,这里总结了我们可以根据默认操作和数据做出的决定:
| 未决定 | 数据支持绿色。 | 遵循最佳猜测。绿色。 |
| 不要改变 | 数据略微偏向黑色 | 标志保持不变 |
| 不要改变 | 数据压倒性地支持绿色 | 将标志改为绿色。 |
上表由 3 个场景组成,用于解释上述概念。
- 在第一个场景中,没有默认动作,数据支持绿色。因此,我们继续将徽标更改为绿色。
- 在第二个场景中,默认操作是“不要改变颜色”,数据支持黑色,但不够强烈。所以 logo 颜色保持不变。
- 在第三个场景中,默认操作是“不要改变颜色”,但是数据强烈支持绿色。所以 logo 改成了绿色。
学习统计思维的资源
以下是一些资源,您可以参考这些资源来详细了解该主题:
结论
我们希望这篇文章激起了你在面临选择时应用统计方法的兴趣。请在下面分享你对博客的想法和评论。下次见!
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
统计、数据分析到算法交易| Kalpesh 的旅程
无畏是成功的关键!作为一名成功的数据分析师,Kalpesh 在印度最大的 IT 公司之一 TCS 工作了 7 年多,成功地超越了 EPAT 的算法交易领域。
Kalpesh 拥有数学专业的毕业学位和应用统计学硕士学位。有了克服一切的意志和技能,他开始了和 EPAT 一起成为成功的算法交易者的旅程。我们联系了 Kalpesh,以下是讨论的过程。
你好,Kalpesh,跟我们介绍一下你自己吧!
你好,我是卡尔佩什·拉莫莉娅。我在一家总部位于瑞士的公司工作,是一名定量开发人员,之前在 TCS 担任数据分析师。
然而,我想做一份我热爱的职业,一份涉及数学和统计学的职业。后来我把领域换成了算法交易。
从小,我一直对数学感兴趣,这导致我追求数学毕业。在此之后,我攻读了应用统计学硕士学位,在那里我学到了大量基于现实世界的统计技术。
除了工作,我真的很喜欢徒步旅行,尤其是在季风季节。我也喜欢探索山区车站的美丽。
你的故事是如何从应用统计学硕士变成算法交易的?
硕士毕业后,我开始在 TCS 工作,担任数据分析师。我的工作职责包括使用许多统计技术、编程,以及为电视收视率和点击率建立预测模型。我在那里工作了 7 年多。
我是在网上几篇股市相关文章的帮助下开始手动交易的。然而,这导致了我的一些损失。
我在 TCS 的一个同事建议让交易自动化。但是,我完全不知道这个概念,因为在手动交易中,一个人必须做出买入或卖出的决定。我也不知道你可以用来交易的技术和方法。
现在,这对我来说是一个全新的探索领域。这引起了我的注意,我做了人生中另一个最好的决定,改变我的领域,尝试算法交易。
这让我开始寻找这方面的指导,从而开始了我的新旅程。就在那时,我的朋友向我介绍了 QuantInsti & EPAT,提到了良好的评论和经验。
适应金融和交易领域对你来说有挑战吗?
我研究并发现课程、教学大纲和特色非常有趣。因此,我在 EPAT 注册了。在 EPAT,我获得了股票市场的高级知识的基础,它是如何工作的,以及应用。
我于 2019 年报名参加了 EPAT 大学。数学和统计概念很容易掌握,因为我有这方面的教育背景。金融和股票市场的基本原理和深层概念也很容易理解。
每当我在编码或理解任何概念时遇到困难,我都可以自由地联系我的老师,并访问 QuantInsti 的校友社区和资源。我花了大约 6 -7 个月的时间熟悉 Python,但是现在我可以很容易地用 Python 编写我的策略。
但这并不是作为一个 EPATian 人最好的部分。
最棒的是,即使在今天,我也能接触到所有的学习材料、资源和社区。我仍然使用这些自由。我所要做的就是问我的问题,我会很快得到回复。
我发现 EPAT 在很多方面都很独特。只是分享几个我最喜欢的:
- 多样性 -世界各地的学生。我可以看到 EPAT 有来自世界各地的学生,而不仅仅是来自印度。所以我可以和他们联系,分享我的想法,获得意见,和来自不同大陆的人讨论话题。
- 内容 -从初学者到专家的各种课程,结构化的内容,终身访问课程内容,以及他们的校友社区
- 工作机会——你可以获得与行业领袖共事的机会。我给自己争取到了一个与欧洲对冲基金公司合作的绝佳机会。以巴提人有很大的发展空间。
今天,我非常自信和自豪地说,我是一家欧洲对冲基金的量化开发人员。
我管理着价值数百万美元的投资组合。我的工作围绕着编程、统计技术的应用和数据分析。
你给所有有抱负的算法交易者的信息
我会向所有想学习量化交易和算法交易的有志学生推荐 EPAT。如果你有奉献精神,并准备投入 100%,那么你一定要考虑 EPAT。
这真的很鼓舞人心,谢谢你和我们分享你不可思议的旅程,Kalpesh。就像你说的,如果一个人有必要的动力和毅力,他可以取得任何成就。我们祝愿你在未来的努力中一切顺利。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术以及机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
统计学和概率分布初学者指南
原文:https://blog.quantinsti.com/statistics-probability-distribution/
我们都意识到,当谈到算法交易时,统计学的实用知识对于建立不同策略的模型是必不可少的。事实上,数据科学是这十年来最受欢迎的技能之一,它利用统计数据对数据进行建模,并得出有意义的结论。带着这个目的,我们将学习一些基本的术语以及在算法交易领域使用的概率分布的类型。
我们将讨论以下主题:
历史数据分析
在这一部分,我们将尝试回答一个基本问题,“你如何分析一只股票的历史数据,并将其用于策略构建?”当然,为了分析,我们首先需要一个数据集!
资料组
为了保持其通用性,我们采用了苹果公司从 2018 年 12 月 26 日到 2019 年 12 月 26 日的每日股价数据。可以从雅虎财经下载历史数据。如果你有兴趣用 python 下载数据,可以访问下面的链接。
暂且用下面的 python 代码从雅虎财经下载;
import yfinance as yf
aapl = yf.download('AAPL','2018-12-26', '2019-12-26')
这是一个时间序列数据集合,包含苹果的每日收盘价和交易量。我们将根据这只股票的收盘价进行分析。在这篇文章中,我们将仅仅触及每日股票价格的基本统计属性,然后是简单的相关性。
意思是?Mode?中位数?有什么区别!!!
我们就以 5 个数字为例:12,13,6,7,19,21,理解这三个术语。
平均
简单来说,mean 就是我们最习惯的一个,即平均值。因此,在上面的例子中,平均值= (12 + 13 + 6 + 7 + 19 + 21)/6 = 13。
在 AAPL 数据集中,收盘价的平均值是 204.84。滚动平均是技术交易策略中广泛使用的方法。交易者非常重视 50 天和 200 天滚动平均线的交叉。并以此为基础发起贸易。
对于 AAPL 数据集,我们将使用以下 python 代码:
mean = np.mean(aapl['Adj Close'])
mean
输出结果是:204。56864 . 68686868667
方式
在给定的数据集中,众数将是出现次数最多的数字。在上面的例子中,因为没有重复的值,所以没有模式。你可以说每个元素都是一种模式。但这对汇总数据集没有帮助。
在 AAPL 数据集中,收盘价模式不存在,因为没有重复值。
当我们尝试运行以下代码来查找 python 中的模式时,它会抛出以下错误
import statistics
mode = statistics.mode(aapl['Adj Close'])
mode

另外,如果你的数据集如下,你会选择哪个模式值?

很难回答这个问题,应该使用一些其他方法。此外,该模式对收盘价或其他连续数据没有太大意义。当您想要绘制直方图并可视化频率分布时,模式特别有用。
中位数
有时,数据集值可能有一些处于极端的值,这可能会导致数据集的平均值描绘出不正确的画面。因此,我们使用中位数,它给出了排序数据集的中间值。
要求中位数,你得把数字按升序排列,然后求中间值。如果数据集包含偶数个值,则取中间两个值的平均值。在我们的例子中,中位数是(12 + 13)/2 = 12.5
在我们的数据集中,收盘价的中位数是 201.05
用于查找中值的 python 代码如下:
median = np.median(aapl['Adj Close'])
太好了!当我们开始学习统计学时,我们现在转到一个非常重要的术语,即概率分布。
概率分布
我们都经历过寻找掷骰子概率的例子。现在,我们知道掷骰子只有六种结果,即{1,2,3,4,5,6}。掷出 1 的概率是 1/6。这种概率称为离散的,其中有固定数量的结果。
顾名思义,概率分布就是一个给定事件所有结果的列表。因此,掷骰子事件的概率如下:
| 骰子点数 | 概率分布 |
| one | 1/6 |
| Two | 1/6 |
| three | 1/6 |
| four | 1/6 |
| five | 1/6 |
| six | 1/6 |
在这里列出所有的值是可行的,因为我们有一组有限的结果,但是如果结果很大,我们就使用函数。
如果概率是离散的,我们称这个函数为概率质量函数。在掷骰子的情况下,P(x) = 1/6,其中 x = {1,2,3,4,5,6}。
对于离散概率,有一些案例被广泛研究,以至于它们的概率分布已经标准化。让我们以伯努利分布为例,它考虑了当我们掷硬币时得到正面或反面的概率。我们把它的概率函数写成 px(1–p)(1–x)。这里 x 是结果,可以写成正面= 0,反面= 1。
现在,有些情况下,结果并不明确。比如一个年级所有高中生的身高。虽然实际原因不同,但我们可以说,列出所有的身高数据和概率会太麻烦。在这种情况下,功能是必不可少的。
前面我们说过,对于离散值,概率函数就是概率质量函数。相比之下,对于连续值,概率函数称为概率密度函数。
让我们退一步,理解一些与概率分布有关的术语。
范围
范围只是给出了数据集的最小值和最大值之间的差值。
在所取的数据集中,收盘价的最小值是 140.08,而最大值是 284.26。因此,范围= 284.26 - 140.08 = 144.18。现在,我们将走向标准差。
在 python 中,我们可以通过一行简单的代码找到这些值:
aapl['Adj Close'].describe()
输出如下所示:

标准偏差
简单来说,标准差告诉我们这个值偏离均值有多远。让我们使用完整的数据集,试着理解标准差如何在交易中帮助我们。
我们在计算时考虑了收盘价。如前所述,我们数据集的平均值是 204.84。用收盘价和平均值绘制图表的 python 代码应该给出下图。
import matplotlib.pyplot as plt
aapl['Adj Close'].plot(figsize=(10,7))
plt.axhline(y=mean, color='r', linestyle='-')
plt.legend()
plt.grid()
plt.show()

标准差计算如下:
- 计算这些数字的简单平均值
- 从每个数字中减去平均值
- 计算结果的平方
- 计算结果的平均值
- 取第 4 步答案的平方根

对于给定的数据集,代码如下:
std = np.std(aapl['Adj Close'])
收盘价的标准差是 34.05。
现在我们将绘制上图,在平均值的两边各有一个标准差。我们将它写成(+标准差)= 204.84 + 34.05 = 238.89,而(-标准差)= 204.84 - 34.05 = 170.79。
代码如下:
aapl['Adj Close'].plot(figsize=(10,7))
plt.axhline(y=mean, color='r', linestyle='-')
plt.axhline(y=mean+std, color='r', linestyle='-')
plt.axhline(y=mean-std, color='r', linestyle='-')
plt.legend()
plt.grid()
plt.show()

在图中,中间的红线表示平均值,而+标准差和-标准差是其他红线。
那么告诉我们,通过观察上面的图表,你能观察到什么?
嗯,快速浏览一下,我们会发现大多数收盘价值都在两个标准差之间。因此,这给了我们一个关于大多数价格行为的粗略概念。
但是你可能仍然想知道,知道一定范围的价格值有什么用呢?首先,标准差在布林线中扮演着重要的角色,这是一个非常受欢迎的指标。你可以用标准偏差上限作为突破的标志。当价格高于上限时开始买入交易。
股票的波动性可以用标准差来计算。股票波动性是许多机器学习算法中使用的一个重要特征。它也用于正态概率分布,我们一会儿会讲到。
等等!正态分布?
正态分布在统计世界中是一个非常简单却又非常深奥的概念,实际上在日常生活中也是如此。基本前提是,给定一系列观察值,发现大多数值都集中在平均值附近,并在平均值的一个标准偏差内。其实据说 68%的数值都在这个范围内。如果我们继续,那么我们看到 95%的值在平均值的两个标准偏差之内。
等等,我们现在要超越自我了。让我们首先借助直方图来理解这一点。
柱状图
我们以一批学生的身高为例。现在可能有些学生的身高是 60.1 英寸、60.2 英寸等等,直到 60.9 英寸。有时候,我们并不需要那么详细,我们只想知道有多少学生的身高在 60 - 61 英寸之间。那不是会让我们的工作变得更容易更简单吗?这正是直方图的作用。它给出了观察值的频率分布。
谈到交易,我们通常使用每日百分比变化,而不是收盘价。
对于我们的数据集,我们将使用以下代码:
aapl['daily_percent_change'] = aapl['Adj Close'].pct_change()
aapl.daily_percent_change.hist(figsize=(10,7))
plt.ylabel('Frequency')
plt.xlabel('Daily Percentage Change')
plt.show()
输出如下所示:

回想一下,我们说过大多数值都接近平均值。你可以在上面绘制的柱状图中清楚地看到这一点。
事实上,如果我们在这些值周围画一条曲线,它看起来就像一个钟。
我们称之为钟形曲线,这是正态概率分布的另一个名称,或简称为正态分布。您可以看到大多数值位于标准偏差之间,即(+S.D.) = 239.6 和(-S.D.) = 172.64。
您可能需要记住,在正态分布中,68%的值位于一个标准差之间,95%的值位于两个标准差之间。进一步说,我们会说 99.7%的值位于平均值的 3 个标准偏差之间。
正态分布
当你的数据的分布满足一定的要求,比如围绕均值和钟形曲线对称,我们就说你的数据是正态分布。
从统计学上讲,如果 x 是均值和标准差为σ的正态分布,我们写 x∞n(,σ^2),其中和σ是分布的参数。
为什么知道数据集的分布函数很有用?
如果你知道你的数据样本是正态分布的,你就可以很有把握地对你的人口进行预测。
例如,假设您的数据样本 X 表示在一个学生样本的入学测试中获得的满分 100 分。数据是正态分布的,比如 X∞N(50,102)。绘制时,该数据如下所示:

如果将样本数据集中的观察次数从 100 次增加到 1000 次,结果如下:

看起来更像钟形!
现在我们知道,X 具有均值为 50、标准差为 10 的正态分布数据,我们可以有把握地预测整个学生群体或未来学生(来自同一群体)的分数。在几乎 99.7%的信心下,我们可以说学生不会得到低于 20 或高于 80 的分数。在 95%的置信度下,我们可以说学生的分数在 30 到 70 分之间。

从统计学的角度来说,分布函数给出了两点之间给定观测值的期望值的概率。因此,使用分布函数,也称为概率密度函数,我们可以“预测”一定的“信心”。
收盘价正态分布吗?
在我们试图回答这个问题之前,让我们看另一个数据集,看看它的直方图是什么样的。
我们绘制了同一时期特斯拉公司的直方图,如下所示:

在这里,平均值(收盘价)是 270.9,+标准差和-标准差分别是 319.14 和 222.66。那么从上面的直方图可以得出什么结论呢?
综上所述,概率分布函数应用于技术分析的每一步,是定量分析的核心。这些分析构成了任何战略制定过程的核心部分。
到目前为止,我们已经了解了统计领域的一些基本概念。现在,我们将试着在这个迷人的世界里走得更远一点,看看它在交易中的应用。我们将首先从相关性开始。
相关性
我和你到底有没有关系?
在某种程度上,相关性告诉我们两组值之间的关系。到目前为止,我们已经获取了苹果公司从 2018 年 12 月 26 日到 2019 年 12 月 26 日的数据集。现在,我们应该指出苹果是标准普尔 500 指数的一部分。因此,苹果股票的任何变化都会在某种程度上反映在 S&P 指数上。
让我们获取同一时间段的 S&P500 数据集,并找出相关性。
代码如下:
import yfinance as yf
spx = yf.download('^GSPC','2018-12-26', '2019-12-26')
spx['daily_percent_change'] = spx['Adj Close'].pct_change()
plt.figure(figsize=(10,7))
plt.scatter(aapl.daily_percent_change,spx.daily_percent_change)
plt.xlabel('AAPL Daily Returns')
plt.ylabel('SPY Daily Returns')
plt.grid()
plt.show()

from scipy.stats import spearmanr
correlation, _ = spearmanr(aapl.daily_percent_change.dropna(),spx.daily_percent_change.dropna())
print('Spearmans correlation is %.2f' % correlation)

理解相关性
相关性是一个介于-1 和 1 之间的单位自由数,它给出了变量之间关系的度量。介于 0.7 和 1.0 之间的高度正相关值意味着一个变量的变化与另一个变量的变化正相关。这意味着,如果一个变量增加,另一个变量也很可能增加。在其他值减少或不变的情况下,该行为也是一致的。
另一方面,位于-0.7 到-1.0 之间的高度负相关值告诉我们,一个变量的变化与另一个变量的变化负相关。这意味着,如果一个变量增加,另一个变量很可能会减少。
在-0.2 和 0.2 附近的低相关值告诉我们,这两个变量之间没有很强的关系。
需要注意的一点是,相关性并没有告诉我们任何关于因果关系的事情。我们都听说过这样一句话,“相关性并不意味着因果关系”。例如,在一个人群中,肺癌的例数可能与一生中吸烟的数量相关,但这并不能确定吸烟与肺癌的因果关系。人们需要做一个控制组研究,保持所有其他影响因素不变,以建立这种因果关系。基于机器学习的交易模型非常擅长提取不同指标之间的因果关系。
相关性是线性关系的量度。例如,x 和 x2 之间的相关性可能接近于 0。即使这两个变量之间有很强的关系,它也不会在相关值中被捕获。
太好了!我们已经学习了很多与统计相关的概念。你可以进一步回归;事实上,关于线性回归的博客是你探索掌握算法交易艺术的完美下一步。
结论
我们已经学习了均值、中值和众数的基本概念,然后理解了离散变量和连续变量的概率分布。我们详细研究了正态分布,并触及了相关性主题,以确定两个数据集是否相关。
如果你想学习算法交易和自动交易系统的各个方面,那就去看看算法交易(EPAT ) 的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。现在报名!
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
数据科学入门:食品配送应用案例研究
作者:普拉奇·乔希
"我们的目标是将数据转化为信息,将信息转化为洞察力."卡莉·菲奥莉娜。
你有没有想过 Spotify 是如何根据你的喜好连夜准备你的每日播放列表的?或者在你输入完整的句子之前,谷歌是如何完成你的搜索的?网飞或亚马逊 Prime 如何预测你偏好的所有节目?他们是怎么做到的?这背后的过程可能是什么?这些都是我们时常思考的问题。这不是魔术,这是数据科学!

给你一个关于数据科学的简单介绍,它只不过是对数据的研究。数据科学是一个探索的领域。它结合了领域知识、编程、统计、沟通和解决问题的技能,从数据中提取有价值的见解。数据科学正在改变我们周围的世界,它正在影响我们的日常决策,从您向购物车添加什么到您为谁投票。随着数据的疯狂爆炸,将数据科学与任何行业相结合的可能性确实对我们有利。在这个数据驱动的世界中,机会和应用正在增长,并将继续扩大。
“从文明诞生到 2003 年,总共有 5eb 的信息,但现在每两天就有这么多信息产生。”
谷歌首席执行官埃里克·施密特。

我们今天拥有的超过 90%的数据是在过去两年中生成的。数据呈指数级增长,每天都有大约 2.5 万亿字节的数据被创建出来。数据的急剧增长为数据科学创造了无尽的机会,为意想不到的事情铺平了道路。
这篇关于“数据科学的步骤”的博客将带领你通过一个有用的框架来理解数据科学的过程。通过对一个食品配送应用程序的案例研究,我们将尝试分解步骤,以帮助您了解任何数据科学项目的生命周期。
在这篇博客中,我们将讨论以下主题:
了解数据科学
在我们进入案例研究之前,让我们先看一下“数据科学的步骤”视频,以便更好地理解数据科学。

食品配送市场的兴起

今天,食品配送市场的格局正在改变世界各地人们的饮食习惯。只需在你的 Iphone 或 Android 上下载一次,你就可以轻松地从各种美食、折扣优惠、订单大小中进行选择,并节省时间,所有这一切都可以在你家方便地完成。目前,食品配送行业处于最佳状态。这些服务不一定能在你当地的餐馆里找到。
据研究公司 Cohen and Company 称,未来 4 年,食品配送应用程序将增长 12%。在过去的 3 年里,这些应用的下载量已经增长了 380%。这种影响是如此之大,以至于一些新餐厅开始选择“云厨房”,一种没有厨房和服务员的餐厅,100%在线运营。
你会问,这个行业可能会面临什么问题?管理及时交付、保持食品质量、应对滔滔不绝的请求、回应客户询问和留住客户是一些挑战。
让我们以“Zomato”在线送餐应用程序为例,尝试理解数据科学的 6 个步骤。
定义问题陈述
数据科学的第一步是定义问题陈述。如果你有一个业务问题需要解决,那么问很多问题就变得很重要。识别有助于解决问题的适当问题。理解和定义需要解决的问题的目标是很重要的。当你提出相关问题时,你就建立了一个更强有力的问题陈述。好奇心是任何数据科学家的关键技能。他或她必须有认识相关问题的好奇心和从数据中发现真知灼见的好奇心。
所需技能:批判性思维、好奇心、领域知识和解决问题的技能。

一家被评为五星级的中国餐馆“汤姆的晚餐”希望继续成为其竞争对手中的佼佼者。在送餐应用 Zomato 上,Tom's Diner 被列为最佳餐厅之一。为 Tom's Diner 工作的数据科学分析师需要特定的信息来帮助理解餐厅的结构以及如何改进。
分析师提出相关问题来构建问题陈述。
像这样的问题:
- 交货的平均时间是多少?
- 哪个地区的订单率最高?
- 买得最多和最少的食物是什么?
- 顾客对食物的质量和数量满意吗?
- 我们在解决应用程序上的负面评论吗?
- 是否有必要更新食物菜单,如果有,我们添加什么?
可以问类似的问题,形成强有力的问题陈述。本案例研究的问题陈述可以是:“汤姆的晚餐”应该采取什么措施来增加和改善其客户服务和评级?
想象一下,你工作了一整天。你回到家却发现没有晚餐,因为你的厨师今天没来。你决定从 Zomato 点中餐。
有这么多选择,你选择从汤姆餐馆点辣椒大蒜面和软饮料。你选择 Tom's Diner 餐厅是因为它是五星级的,而且在你的预算之内。您选择数量,添加烹饪说明,并添加您的地址供餐厅参考。然后你付款,等待送货。

数据收集
数据科学的第二步是数据收集。在定义了问题陈述之后,获取正确的数据变得很重要。数据可以从各种开放的数据源平台上搜集和收集。开源网站上也有许多数据科学项目,如 Github 、 Kaggle 和 Gapminder 。
这可以通过主要方法和次要方法来收集。第一种方法是原始数据收集。初级方法非常适合于实证研究。当没有针对某个特定主题的预先研究时,就必须收集新的数据。第二种方法使用现成的数据进行任何类型的研究。此类数据已经被其他人使用或收集。你可以在互联网、杂志、文章和几乎任何地方找到这样的数据。这种方法被称为二次数据收集。
所需技能:网页抓取,注意细节,数据处理等。
与您类似,有许多人在同一家餐厅下了订单。这就产生了大量的订单。这就是所谓的数据收集。
以下是过去 5 分钟内收集的 10 个最新订单的数据快照:

数据质量和补救
数据科学的第三步是数据质量和补救。由于数据的爆炸,互联网上有大量的数据。但是这些数据集大多不完善。您可以找到丢失的值、不一致的数据类型和拼错的属性。因此,采集的数据需要清理,因为这将提高信息的准确性和质量。如果数据没有得到适当的清理,那么分析或得出的见解将是不准确的。
所需技能:关注细节等
餐馆接受你的订单。一名员工开始处理您的订单。他检查您的订单,并检查食品项目、食品数量、烹饪说明(如果有)和送货地址。如果他发现任何异常或任何缺失信息,他会联系相关人员并确认信息。这个人可以是客户或送货代理。然后,他在系统中更新这些信息。然后,清理后的数据可用于执行分析。这一步有助于您熟悉数据。这是数据质量和补救。
 T2】
T2】
 T2】
T2】
数据分析和解释
数据科学的第四步是数据分析和解释。清理完这个数据集后,我们执行数据分析。这是至关重要的一步,因为它有助于您熟悉数据并获得有用的见解。如果您跳过这一步,那么您可能会最终生成不准确的模型,并在您的模型中选择无关紧要的变量。您在此步骤中执行的所有分析都属于探索性数据分析。选择有助于理解数据集结构的所有变量和参数。理解你可以用这些数据做什么是非常重要的。在这里,你可以玩数据,创建自己的图表,并学习推导推论。
所需技能:编程,统计,绘图技能等。
您的订单被分配了所需的准备和交付时间。送货人员会立即将您的订单送到。但是永远记住你的评论是有价值的。干净的数据集现在被分成不同的类别,以便更好地进行分析。被任命的分析师创建了一些他认为对提高餐厅生产率很重要的参数。
绘制分类数据是为了理解所选参数之间的关系。面条、馍馍和汤的“当年销售额”与“上年销售额”等参数。这将有助于我们了解销售是否有所改善。这是探索性的数据分析。这一步被称为数据分析和解释。
下面是一个非常小规模的分析,使用了过去 5 分钟内生成的 10 个订单数据。类似地,您可以对大型数据集进行自己的数据分析。你可以比较去年的销售额和今年的销售额。您还可以分析平均交货时间是否比前一年的交货时间有所改善。

最近 10 个订单的平均交货时间:38.1
数据建模
数据科学的第五步是数据建模。数据建模关注于如何组织数据。它使用流程图来表示数据流动的方式。建模改善了分析的结构,使任何人都容易理解。数据建模有助于识别计算流程。您可以根据需求使用统计或机器学习来获得期望的结果。数据模型有三种基本样式:
- 概念数据模型:用于与项目涉众一起探索领域概念。这种类型的数据模型是其他两种数据模型的前身。
- 逻辑数据模型:用于探索和理解领域概念和问题领域之间的关系。
- 物理数据模型:用于设计和理解列和表之间的数据库内部模式。
必备技能:统计学、机器学习、领域知识、绘制流程图的能力、分析技能等。
在逻辑方法和分析技术的基础上,分析员创建并添加一些列和表。他比较了前一年的销售额,并提出了一个模型,以制定更好的策略来营销潜在客户。分析师检查销售额上升或下降的幅度。对于这种分析,我们将使用统计学,也可以使用机器学习。这就是数据建模,它有助于建立商业战略。

传达结果
数据科学的第六步是交流结果。所有这些见解和数字都需要好好沟通。您可以创建易于理解的报告和仪表盘,使用图形和图表来传达您的发现。这使得任何观众都能够轻松地交流商业发现,并为他们的决策提供意义。仪表板和报告提供了对重要指标的访问,并为进一步对话奠定了有效的基础。
所需技能:Matplotlib,Tableau,R,Shiny 等。

你成功地完成了你的分析。这是数据科学的最后一步。分析师使用图形来形象化他的发现。他使用图表来解释参数,如购买最多和购买最少的食品,食品交付时间,食品的质量和数量。最后,分析师提出并传达他的发现,让餐馆老板理解。根据这一解释,餐馆现在决定增加新的食品,提高食品质量,缩短食品配送时间,并修改一些食品的价格。这是传达结果。
结论
因此,我们已经涵盖了数据科学中的六个步骤,以及每个步骤所需的技能,以及如何为任何数据科学项目执行这些步骤。现在,使用这些步骤,你可以自愿地在你选择的领域中从事项目,并开始实践。你练习得越多,你在数据科学方面就会越好。提高你的技能。改进您的编程和统计。
要进一步了解这些步骤,您可以报名参加 Quantra 上的数据科学简介课程,学习者将了解如何对英格兰超级联赛进行探索性数据分析,这是一个由 20 家世界著名俱乐部组成的职业足球联赛。想象一下,学习数据科学并对最吸引人和最受欢迎的运动之一进行深入了解会有多有趣。你们不想知道 2019 年 EPL 奖的得主吗?
快乐学习!
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
随机振子:类型、计算和应用
以重香重香
随机振荡器是一种动量指标,它将资产的最近收盘价与特定时期的价格范围进行比较。虽然随机指标应该和另一个技术指标 RSI 相似,但我们会在文章后面看到这两个指标的不同之处。
我们将试图理解和计算不同类型的随机振荡器。我们也将看到它们如何被用来加强你的交易技巧,帮助你创造一个强大的策略。此外,我们将看看随机 RSI 振荡器如何帮助克服随机振荡器的某些限制
我们将在本文中讨论以下主题:
为什么要用随机振荡器?
用帮助创建随机振荡器的乔治·莱恩博士的话说,它是一个不跟随价格或交易量的指标,而是表示价格的速度或动量。通过这种方式,它帮助我们预测价格方向的变化。
因此,随机振荡指标已经成为交易者识别市场看涨或看跌趋势的一个众所周知的指标。
现在我们将借助一个例子来理解如何绘制随机振荡器。
理解随机振荡器的例子
随机振荡器由两条线组成,%K 和% D。
故事发生在 20 世纪 50 年代,当乔治·莱恩和他的同事们试图手工绘制不同的振荡器时,由于数值的范围,他们会用完图表纸。因此,他们试图用百分比来表示它们。
经过反复试验,每个公式都用一个字母表示,他们最终设法创建了一个稳定的%K 指标。
我们现在将更详细地研究%K。
计算%K 的公式
%K 可以表示为,

计算随机振荡器-实时市场示例
可接受的范围通常是 14 天。我们将使用 17 年 4 月至 5 月的 Apple 股票信息来计算%K。
因此,该表如下所示,

解释市场实例
为了解释这一点,让我们以日期为 2017 年 5 月 4 日的行的%K 为例。
- 为了选择所选价格(1)的最高价,我们检查从 4 月 17 日到 5 月 4 日的“高”列,即 148.089996
- 对于所选价格(2)的最低下限,值为 140.449997
- 要计算%K,公式为:
[(当前收盘价)-(选定范围内的最低最低价)]* 100
[选定范围内的最高价]-(选定范围内的最低最低价)]
=[146.529999-140.449997]/[148.089996-140.449997]* 100
=(6.080002/7.639999)* 100
= 0.7958118 * 100
= 79.58118%
类似地,我们也填写其余的字段。
4.%D 只是%K 的三天简单移动平均线(SMA)。
因此,该表将被更新如下,

使用随机振荡器的结果图
随机振荡器相对于收盘价的图形如下所示:

随机振荡器指标策略
随机振荡指标的使用方式如下:
超买和超卖信号
随机振荡指标通常用于生成超买或超卖信号。在这方面%K 和%D 都起着至关重要的作用。

你可以在上面的图像中看到%K 和%D 线触及超买水平,在 6 月 9 日,它们开始向下,价格紧随其后。
背离指标(多头和空头)
我们在之前的指标系列中已经看到了这种策略,随机振荡器也可以用来检测市场的波动,或者更确切地说,是市场趋势的变化。

在上图中,你可以看到在 8 月的最后一周,随机振荡指标开始下降,随后,价格从 9 月 1 日开始下降,除非出现短暂的上升趋势,否则一直下降到 9 月底。
交叉策略
该策略中有两种类型的信号:
- 在超买区,k 线在%D 线下方交叉,表示卖出信号
- 在超卖区域,k 线在 D 线上方交叉,表示买入信号

下跌趋势:你可以看到,在上图中,5 月 15 日%K 线开始下跌,并在超买区域穿越%D 线,构成卖出信号。后面可以明显看到下跌趋势。
价格上涨:另外,6 月 19 日%K 线开始上涨,并在超卖区穿过%D 线,构成买入信号。后面可以明显看到涨价。
这是一些可以在随机指标的帮助下使用的策略。虽然随机振荡器是识别超买或超卖水平的良好指标,但市场发现让读数更有意义是偶然的或草率的。于是,另一种类型的随机振荡器诞生了。我们将在下一节讨论这个问题。
什么是快速随机振荡器?什么是慢随机振荡器?
我们之所以用两条线,是因为我们可以用两条线的交叉作为信号,更确切的说%D 线可以称为信号线。
为了强调%D 线的重要性,随机振荡器被修改成两种类型:
- 快速随机振荡器,以及
- 慢速随机振荡器
计算快速随机振荡器
我们计算的指标被认为是快速随机振荡器。
计算慢随机振荡器
为了计算慢速随机指标,我们找到了%K 的 3 天均线(本质上和之前的%D 一样)。
%D 变成了新的慢速随机振荡指标的 3 日均线。
这在另一种形式上帮助了我们,因为最初的随机振荡指标被认为是非常不稳定的,因此慢速随机振荡指标起到了平滑波动的作用。
计算全随机振荡器
另一个版本,称为完全随机,是当我们在计算完全随机振荡器时修改%K 的周期以及要考虑的天数时的类型。让我们考虑计算完全随机振荡器的%K 的时间周期为 10,而%D 是完全%K 的 5 天 SMA。
比较快速、慢速和完全随机振荡器
因此,三种类型的随机振荡器如下:

 T2】
T2】
随机振荡指标和 RSI 指标的区别
相对强弱指数(RSI)指标和随机振荡指标都是动量振荡指标,都是用来衡量价格运动的动量,但它们有本质的不同。
当 RSI 被用来检测市场趋势的速度时,随机振荡器是建立在收盘价应该与总趋势的方向一致的前提下的。
有趣的是,尽管存在差异,但人们发现将它们结合在一起实际上是有意义的,因此,随机 RSI (stochRSI)指标诞生了。我们将在下一节讨论这一点。
随机振子的极限
和其他指标一样,随机振荡指标也有假信号的问题。
随机振荡器通常用于价格有规律波动的市场,因此,如果价格处于长期趋势位置,它会给出错误的信号。
在随机震荡器教程的前一部分,我们介绍了不同类型的随机震荡器,并基于它们学习了一些基本策略。但是,我们没有涵盖一个可以称为两个指标组合的指标,这就是随机 RSI 指标。除此之外,我们还将介绍另一个指标,ATR 指标,并学习如何将它与其他一些流行的指标一起使用。
随机 RSI
随机 RSI 的创造者 Chande 和 Kroll 表示,就其本身而言, RSI 指标通常会停留在 80 和 20 的“超买”和“超卖”水平之间,因此不会产生很多买入或卖出信号。
因此,他们建议通过首先计算 RSI 值,然后对其应用随机振荡器公式来创建一个指标的指标。
随机 RSI 是如何工作的?
- 计算 14 天期间的 RSI 值。
- 然后找出最高 RSI 值和最低低 RSI 值
- 使用修改的随机振荡器公式 ie

为了使用与随机指标相同的数据,表格如下:

假设在 14 天的时间内(5 月 24 日-6 月 13 日),随机 RSI 值的计算如下:
= (39 - 35)/(66 -35) * 100 = (4/31)* 100 = 12.
如果你画出相对强弱指数和随机相对强弱指数的图表,结果如下:

正如你所看到的,随机 RSI 指标比普通 RSI 指标给出更多的信号。由于随机 RSI 的敏感性,它可以用来识别短期趋势,因此,短期交易者可以从这个指标中受益。
随机 RSI 的局限性
虽然随机 RSI 是为了提高指标的灵敏度而开发的,但它使指标很快从超买跳到超卖,反之亦然,从而在交易者中产生混乱。
随机 RSI 的另一个缺点是,作为一个指标的指标,它离价格只有两步之遥,因此,它可能与当前市场价格不同步。
随机 RSI 相对于收盘价的曲线如下所示,以供参考。

如果你能根据上面给出的图表对价格走向形成看法,请在评论中告诉我们。
我们在这个随机振荡器教程中已经重申过,虽然一个指标是衡量市场的好方法,但有时几个指标一起使用是个好主意。在这方面,我们现在将涵盖平均真实指标,这有助于我们做出更明智的交易,通常会提高我们的信心水平。
平均真实范围(ATR)指标定义
本文包含 ATR 的原因有两个:ATR 不是一个可以单独使用的指标,更多的是作为一种验证你的观察的手段。因此,它会给你的交易策略注入信心。第二个原因是,它与其他指标配合得很好。
应该注意的是,ATR 捕捉的只是波动,而不是市场的方向。让我们在下一节看看如何找到一项资产的 ATR。
TR 计算
在我们计算平均真实范围之前,我们首先推导出资产的真实范围。
根据以下三个分量的最大值进行计算:
- 当天的(最高价-最低价)
- (今日高点-昨日收盘价)和
- (昨日收盘价-今日低点)
请注意,对于(2)和(3),我们使用绝对值。
给你举个例子:真实范围会按以下方式计算。

我们从三个值中选择最大值的原因是,它有助于我们捕捉缺失的波动率,如果我们只采用当天的最高值和最低值来计算 ATR,就会忽略这一点。
一旦我们计算出资产的真实范围,我们就用 14 天的时间来计算资产的平均真实范围。
计算 ATR 的公式
ATR 的当前值=[(ATR 的前值* 13) +真实范围的当前值)] / 14。
因此,资产的 ATR 如下:

ATR 相对于收盘价的曲线是这样的

你可以看到 ATR 在以下时间达到峰值:
- 收盘价格开始大幅下跌
- 收盘价格开始上涨。
因此,ATR 被视为趋势反转即将发生的确认。
ATR 和随机振荡器

你可以看到上图中,2019 年 1 月第一周,%K 穿越%D 线表示一个趋势的反转。为了支持这一趋势,ATR 在同一时期也很高。因此,收盘价格随后回升。
ATR 的局限性
我们必须明白,ATR 不是用来预测价格方向的,相反,它向我们展示了特定资产的波动性。在这方面,当仅基于 ATR 值形成观点时,必须小心谨慎。一种常见的方法是将 ATR 与之前的值进行比较,以了解市场的趋势,当然,结合其他指标使用,如随机指标、RSI 或 MACD。
结论
总之,我们已经学习了随机振荡指标和 ATR 指标的定义和计算。我们还看到了一些可以在这些指标的帮助下使用的策略。技术指标确实帮助我们更好地理解市场,做出明智的交易。您可以在下面的学习轨道中了解更多关于指标及其应用的知识:人人算法交易
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
[算法交易网上研讨会]股票数据分析:Excel 与 Python
原文:https://blog.quantinsti.com/stock-data-analysis-excel-python-23-february-2021/
https://www.youtube.com/embed/I2jxs-1UWHk?rel=0
本次网络研讨会于美国东部时间 2021 年 2 月 23 日星期二上午 8:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30举行
会议大纲
学习使用 Excel 和 Python 分析和回溯测试金融市场数据。了解这两种工具的区别及其各自的优缺点。知道哪个最适合自己。
关键要点
https://www.slideshare.net/slideshow/embed_code/key/wxi9wauKi4qBpz
Stock Data Analysis Excel Vs Python [Algo Trading Webinar] from QuantInsti
扬声器配置文件

杰伊·帕尔马
助理,内容&在 QuantInsti 的研究
Jay Parmar 在 QI 担任内容与研究助理,在行业拥有数年的工作经验。他积极参与 quant finance 课程的内容开发,并指导全球的 EPAT 参与者。
他热衷于 algo 交易和编程,喜欢开发自动化交易系统。他拥有计算机科学学士学位和 EPAT 证书。他的研究兴趣是将机器学习模型应用于交易的各个方面。
文件在下载
- aapl_daily_data CSV
- aapl_daily_data Excel 工作表
- 对单一股票的移动平均交叉策略进行回溯测试- Python 代码
股票市场数据:用 Python 获取数据、可视化和分析
原文:https://blog.quantinsti.com/stock-market-data-analysis-python/
由伊山沙阿
您是否希望获得股票市场数据并使用 Python 分析历史数据?你来对地方了。
读完这篇文章,你将能够:
- 获取股票的历史数据
- 绘制股票市场数据并分析其表现
- 获取基本面、期货和期权数据
为便于导航,本文分为如下:
- 如何用 Python 获取股市数据?
- 如何获取不同地区的股市数据?
- 标准普尔 500 指数成份股公司
- 日内或分钟频率股票数据
- 重新采样股票数据
- 基础数据
- 期货和期权数据
- 股市数据可视化与分析
如何用 Python 获取股市数据?
雅虎财经
Yahoo finance 是获得历史日价量股票市场数据的第一个来源。您可以使用pandas_datareader或yfinance模块获取数据,然后可以使用 pandas.to_csv 方法下载或存储在 csv 文件中。
如果你的电脑上没有安装 yfinance,那么从你的 Jupyter 笔记本上运行下面一行代码来安装 yfinance。


要可视化调整后的收盘价数据,可以使用 matplotlib 库和 plot 方法,如下所示。

让我们通过调整大小、给出适当的标签和添加网格线来提高可读性。

优势
- 调整后的收盘价股票市场数据可用
- 最近的股票市场数据可用
- 不需要 API 键来获取股票市场数据
这是 Nitesh Khandelwal(QuantInsti 联合创始人兼首席执行官)的一个有趣的视频,它回答了你所有关于获取 Algo 交易数据的问题。
https://www.youtube.com/embed/f_noS2Tu7jI?rel=0
如何获取不同地域的股市数据?
要获得不同地区的股市数据,请在雅虎财经上搜索股票代码,并将其用作股票代码。
获取多个报价机的股票市场数据
要获得多个股票报价机的股票市场数据,您可以创建一个报价机列表,并为每个股票报价机调用 yfinance 下载方法。
为了简单起见,我创建了一个数据框架data来存储股票调整后的收盘价。


标准普尔 500 证券交易所
如果你想分析组成标准普尔 500 的所有股票的市场数据,下面的代码将会帮助你。它从维基百科页面获取股票列表,然后从 yahoo finance 获取股票市场数据。


日内或分钟频率股票数据
yfinance 模块可用于获取分钟级别的股票市场数据。它返回过去 7 天的股票市场数据。
如果你的电脑上没有安装 yfinance,那么从你的 Jupyter 笔记本上运行下面一行代码来安装 yfinance。
yfinance 模块有下载方法,可以用来下载股市数据。
它采用以下参数:
ticker:您想要股票市场数据的报价机的名称。如果你想得到多个报价机的股票市场数据,那就用空格把它们分开period:需要多少天/月的股市数据。有效频率为 1d、5d、1mo、3mo、6mo、1y、2y、5y、10y、ytd、maxinterval:股市数据的频率。有效间隔为 1 米、2 米、5 米、15 米、30 米、60 米、90 米、1 小时、1 天、5 天、1 周、1 天、3 天
下面的代码以 1 分钟的频率获取 MSFT 过去 5 天的股票市场数据。

重新采样股票数据
将 1 分钟数据转换为 1 小时数据或对股票数据进行重新采样
在策略建模过程中,您可能需要使用自定义频率的股票市场数据,例如 15 分钟、1 小时甚至 1 个月。
如果您有分钟级别的数据,那么您可以通过重新采样轻松构建 15 分钟、1 小时或每日蜡烛线。因此,您不必单独购买它们。
在这种情况下,您可以使用熊猫重采样方法将股市数据转换为您选择的频率。这些的实现如下所示,其中 1 分钟的频率数据被转换为 10 分钟的频率数据。
第一步是用转换逻辑定义字典。例如,要获得开放值,将使用第一个值,要获得高值,将使用最大值,依此类推。
开盘、盘高、盘低、收盘和成交量的名称应该与数据框架中的列名相匹配。
将索引转换为日期时间时间戳,因为默认情况下会返回字符串。然后调用重采样方法,频率如下:
- 10T 10 分钟,
- d 持续 1 天,并且
- m 为 1 个月

雅虎财经拥有有限的分钟级数据集。如果你需要更高范围的股票市场数据,那么你可以从 Quandl、AlgoSeek 或你的经纪人那里获得数据。
使用 Quandl 获取股票市场数据(可选)
Quandl 有很多数据源可以得到不同类型的股市数据。但是,有些是免费的,有些是付费的。 Wiki 是 Quandl 的免费数据源,用于获取 3000+美股的收盘价格数据。它是由 Quandl 社区策划的,也提供关于分红和分割的信息。
Quandl 还提供分钟和更低频率的付费数据源。
要获取股票市场数据,如果尚未安装 quandl 模块,您需要使用如下所示的 pip 命令首先安装该模块。
您需要从 quandl 获得自己的 API 密钥,以使用下面的代码获得股票市场数据。如果您在获取 API 密钥时遇到问题,那么您可以参考此链接。
获得密钥后,将变量 QUANDL_API_KEY 赋给该密钥。然后设置开始日期、结束日期和您想要获取其股票市场数据的资产的股票代号。
quandlget方法以这个股市数据作为输入,返回开盘价、最高价、最低价、收盘价、成交量、调整值等信息。
| 日期 | 打开 | 高的 | 低的 | 关闭 | 卷 | 除息 | 分流比 | 开放的 | Adj .高的 | 低的 | 接近的 | 可调音量 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1997-05-16 | Twenty-two point three eight | Twenty-three point seven five | Twenty point five | Twenty point seven five | One million two hundred and twenty-five thousand | Zero | One | 1.865000 | 1.979167 | 1.708333 | 1.729167 | Fourteen million seven hundred thousand |
| 1997-05-19 | Twenty point five | Twenty-one point two five | Nineteen point five | Twenty point five | Five hundred and eight thousand nine hundred | Zero | One | 1.708333 | 1.770833 | 1.625000 | 1.708333 | Six million one hundred and six thousand eight hundred |
| 1997-05-20 | Twenty point seven five | Twenty-one | Nineteen point six three | Nineteen point six three | Four hundred and fifty-five thousand six hundred | Zero | One | 1.729167 | 1.750000 | 1.635833 | 1.635833 | Five million four hundred and sixty-seven thousand two hundred |
| 1997-05-21 | Nineteen point two five | Nineteen point seven five | Sixteen point five | Seventeen point one three | One million five hundred and seventy-one thousand one hundred | Zero | One | 1.604167 | 1.645833 | 1.375000 | 1.427500 | Eighteen million eight hundred and fifty-three thousand two hundred |
| 1997-05-22 | Seventeen point two five | Seventeen point three eight | Fifteen point seven five | Sixteen point seven five | Nine hundred and eighty-one thousand four hundred | Zero | One | 1.437500 | 1.448333 | 1.312500 | 1.395833 | Eleven million seven hundred and seventy-six thousand eight hundred |
要了解更多关于如何使用 Quandl 的信息,请查看这篇文章:
基本数据
我们已经使用了 yfinance 来获得基本数据。
第一步是设置股票代码,然后调用适当的属性来获取正确的股票市场数据。
如果你的电脑上没有安装 yfinance,那么从你的 Jupyter 笔记本上运行下面一行代码来安装 yfinance。
关键比率
您可以获取最新的市净率和市盈率,如下所示。
收入

息税前收益(EBIT)

资产负债表、现金流等信息
在本次网络研讨会录音中,Deepak Shenoy(capital mind 创始人兼首席执行官)解释了如何使用金融市场数据进行基本面分析。
https://www.youtube.com/embed/yfAVYce7Xhk?rel=0
建议改为
要了解更多关于 Jupyter notebook 的信息,这里有一个关于 Jupyter Notebook 的教程。它不需要任何先决知识,也不假定您熟悉该框架。
期货和期权数据
如果你正在寻找期权链数据,那么你可以参考 Quantra 上关于获取市场数据的免费课程。
NSEpy
nsepy 包用于获取期货和印度股票和指数期权的股市数据。
期货数据
| 日期 | 标志 | 满期 | 打开 | 高的 | 低的 | 关闭 | 最后的 | 结算价格 | 合同数量 | 营业额 | 未平仓利息 | OI 的变化 | 底层 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019-01-15 | HDFC | 2019-02-28 | One thousand nine hundred and eighty-six point seven | Two thousand and eleven | One thousand nine hundred and eighty-two point nine five | Two thousand and eight point two five | Two thousand and six point two | Two thousand and eight point two five | Four thousand eight hundred and ten | 4.796817e+09 | Two million five hundred and thirty-seven thousand five hundred | Two million two hundred and ninety-nine thousand five hundred | One thousand nine hundred and ninety-two point one five |
| 2019-01-16 | HDFC | 2019-02-28 | Two thousand and two point one | Two thousand and ten point one five | One thousand nine hundred and eighty-five point two | One thousand nine hundred and ninety-two point one five | One thousand nine hundred and ninety-one point three | One thousand nine hundred and ninety-two point one five | Two thousand six hundred and fifty-six | 2.655748e+09 | Three million seven hundred and eighty-three thousand five hundred | One million two hundred and forty-six thousand | One thousand nine hundred and seventy-five |
| 2019-01-17 | HDFC | 2019-02-28 | Two thousand and three point six | Two thousand and nineteen point zero five | One thousand nine hundred and ninety-one point six | Two thousand and seventeen point one five | Two thousand and thirteen | Two thousand and seventeen point one five | Three thousand nine hundred and ninety-three | 4.008667e+09 | Five million five hundred and forty-five thousand | One million seven hundred and sixty-one thousand five hundred | 圆盘烤饼 |
| 2019-01-18 | HDFC | 2019-02-28 | Two thousand and eighteen point five five | Two thousand and twenty-five point seven five | Two thousand and five | Two thousand and eighteen point four | Two thousand and seventeen point two five | Two thousand and eighteen point four | Four hundred and eighty-one | 4.845300e+08 | Five million six hundred and thirty-seven thousand | Ninety-two thousand | Two thousand and six point eight five |
| 2019-01-21 | HDFC | 2019-02-28 | Two thousand and eleven point two five | Two thousand and thirty-one point one | One thousand nine hundred and ninety-eight | Two thousand and sixteen point five five | Two thousand and sixteen point six | Two thousand and sixteen point five five | One thousand four hundred and eighty-nine | 1.505249e+09 | Six million two hundred and fifty-eight thousand | Six hundred and twenty-one thousand | Two thousand and four point four five |

选项数据
| 日期 | 标志 | 满期 | 选项类型 | 执行价格 | 打开 | 高的 | 低的 | 关闭 | 最后的 | 结算价格 | 合同数量 | 营业额 | 溢价周转率 | 未平仓利息 | OI 的变化 | 底层 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019-01-15 | HDFC | 2019-02-28 | 这一个 | Two thousand | Fifty-two point seven | Fifty-six | Fifty-two point seven | Fifty-six | Fifty-six | Fifty-six | three | Three million and eighty-one thousand | Eighty-one thousand | ten thousand | One thousand | One thousand nine hundred and ninety-two point one five |
| 2019-01-16 | HDFC | 2019-02-28 | 这一个 | Two thousand | Fifty-five | Fifty-five | Forty-nine | Forty-nine | Forty-nine | Forty-nine | Fourteen | Fourteen million three hundred and fifty-eight thousand | Three hundred and fifty-eight thousand | Eleven thousand | One thousand | One thousand nine hundred and seventy-five |
| 2019-01-17 | HDFC | 2019-02-28 | 这一个 | Two thousand | Fifty-nine point one five | Sixty-four point six five | Fifty-one | Sixty-one point nine | Sixty-one point nine | Sixty-one point nine | Twenty-seven | Twenty-seven million seven hundred and fifty thousand | Seven hundred and fifty thousand | Eighteen thousand five hundred | Seven thousand five hundred | 圆盘烤饼 |
| 2019-01-18 | HDFC | 2019-02-28 | 这一个 | Two thousand | Sixty-three | Sixty-three | Sixty | Sixty | Sixty | Sixty | seven | Seven million two hundred and twelve thousand | Two hundred and twelve thousand | Eighteen thousand five hundred | Zero | Two thousand and six point eight five |
| 2019-01-21 | HDFC | 2019-02-28 | 这一个 | Two thousand | Sixty-two point zero five | Sixty-nine | Sixty-two point zero five | Sixty-two point nine | Sixty-two point nine | Sixty-two point nine | six | Six million one hundred and ninety-eight thousand | One hundred and ninety-eight thousand | Twenty thousand | One thousand five hundred | Two thousand and four point four five |

建议读数
股市数据可视化与分析
有了股市数据之后,下一步就是制定交易策略并分析表现。分析性能的简易性是 Python 的主要优势。
我们将分析累积回报、提款图、不同比率,例如
- 夏普比率,
- Sortino 比率,以及
- 卡尔马尔比率。
这里有一篇描述上述比率的文章:使用 Python 的投资组合分配和配对交易策略
为了便于说明,我创建了一个简单的买入并持有策略,其中包括四只股票:
- 苹果
- 亚马逊
- 微软
- 沃尔玛
要分析性能,您可以使用如下所示的 pyfolio 撕页。
如果尚未安装 pyfolio,请安装,如下所示:

建议使用 Python 进行数据可视化读取
你会发现阅读这些精选的顶级博客很有用,也很有见识:
Python 进行交易
机器学习
情绪交易
算法交易
期权交易
技术分析
结论
我希望这篇文章将使你能够使用 Python 代码来获取你最喜欢的股票的股市数据,使用这些股市数据建立策略并分析这些数据。如果您能在下面分享您的想法和评论,我将不胜感激。
Python 对于理解数据结构、数据分析、处理金融数据,以及生成交易信号是相当必要的。
如果你也想学习如何获取各种数据,如股票的定价数据、基本面数据、按关键字发布的推文和最新的新闻标题数据,请查看 Quantra 的这个完全免费的课程获取市场数据:股票、加密、新闻&基本面。
您也可以查看我们关于加密交易策略的课程,这对于希望探索加密货币交易机会的程序员和定量分析师来说是完美的。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
使用 Python 的跨期权交易策略
原文:https://blog.quantinsti.com/straddle-options-trading-strategy-python/

简介
期权是金融市场中一种易于理解但用途广泛的工具,在过去十年中其受欢迎程度突飞猛进。它们可以通过利用你的市场地位来提高回报。期权非常灵活,也就是说,人们可以通过对冲来管理风险,并从市场的方向运动中获利。
这篇文章的目的是提供一个在交易中的跨期权的介绍性理解,可以用来创建你自己的交易策略。
什么是多空期权策略?
多头是一种期权交易策略,其中交易者通过支付两种期权费,持有具有相同执行价格、相同到期日和相同标的资产的看涨期权和看跌期权。
如何练习多空期权策略?
有两种方法来实践跨期权策略。
- 方向性策略:在这样一个动态的市场中,一只股票很有可能会随时间而上涨或下跌,这为这只股票描绘了一个不确定的未来。在这种情况下,股票的价格可能会向两个方向发展。它的未来不确定。这通常被称为“隐含波动率”。
- 波动玩法:这是一种不同的多空期权策略玩法。这可能是即将到来的收益报告,也可能是年度预算报告等等。人们怀疑,在收益公布之前,波动性会增加。按照一般的观念,人们会蜂拥购买这些股票。正是在这种时候,交易者过早地购买跨期权策略。必须理解的是,市场会意识到这一事实,这将导致自动柜员机调用和自动柜员机看跌期权的明显增加,使它们相当昂贵。这里的关键是在事件发生前退出。
在已知或可以预测种群命运的情况下,这种情况可被视为例外。
跨期权策略的类型
跨期权策略有两种类型:
- 多头买卖:当买入具有相同执行价格的看涨期权和看跌期权时,它被认为是多头买卖
- 空头:与多头正好相反
多头多空
它们通常以基础资产的价格或接近基础资产的价格交易,但也可以以其他方式交易。
跨期权策略在低 IV 状态下运行良好,设置成本低,但股票预计会大幅波动。它将看涨期权和看跌期权置于相同的价格,并且它们对相同的资产有相同的到期日。这不同于扼杀期权交易策略中期权价格的变化。
该策略在理想情况下应该是这样的:

多空期权策略集锦
要购买的期权的金额
这可以通过以下两种方法之一实现:
- 在货币买入期权中
- 在看跌期权中
最大损失:买入溢价+卖出溢价
盈亏平衡
到期时,如果执行价格高于或低于支付的溢价,那么该策略将实现盈亏平衡。
在执行价格高于或低于任何一种情况下,
- 一份期权的价值将等于为该期权支付的溢价,并且
- 另一个期权的价值将变得一文不值。
可以描述如下:
- 上行盈亏平衡=成交+支付的保费
- 下行盈亏平衡=支付的履约溢价
如何从多空期权策略中获利?
如果工具(在这种情况下,股票)在任何一个方向剧烈波动,或者 IV 突然大幅上升,这就是多头可以获利的时候。波动幅度越大,收益越好。这意味着很有可能获得可观的利润,而最大的损失将是保险费。
现在,如果市场波动小于 10%,那么就很难在这个策略上获利。如果股价以执行价到期,最大风险就会出现。
实施跨期权策略
在这个例子中,我将使用 PNB (Pujab 国家银行)(股票代码:PNB)期权。
如果标的资产大幅波动,无论其走势如何,交易者都会从多头策略中受益。如果你看看下面的图表,你会发现 PNB 的股价也是如此:

过去 1 个月的股价变动(来源——谷歌财经)
PNB 的股票价格有很大的波动,最高为 194.65,最低为过去 1 个月的 117.05,这是根据谷歌金融和 18.25%的 IV 的现值
为了这个例子的目的;我会买入 1 份看跌期权和 1 份看涨期权。
以下是截止日期为 2018 年 3 月 29 日的 PNB 期权链来源:nseindia.com



我将为行权价为 110 的看涨期权支付 16.05 印度卢比,为行权价为 110 的看跌期权支付 8.30 印度卢比。这些期权将于 2018 年 3 月 29 日到期,为了从中获利,PNB 股票在到期前应该会出现大幅波动。
启动该交易所支付的净溢价将为 24.35 印度卢比,因此在该策略实现盈亏平衡之前,股票需要向下移动到 85.65 或 134.35。
考虑到各种因素导致的市场大幅波动,并考虑到市场从最近的下跌中复苏的过程,我们可以假设这里有机会获利。
Python 中如何计算跨期权策略收益?
现在,让我用 Python 编程代码带你浏览一下收益图。
导入库
import numpy as np
import matplotlib.pyplot as plt
import seaborn
Define parameters
# PNB stock price
spot_price = 117.05
# Long put
strike_price_long_put = 110
premium_long_put = 8.3
# Long call
strike_price_long_call = 110
premium_long_call = 16.05
# Stock price range at expiration of the put
sT = np.arange(0,2*spot_price,1)
电话支付
我们定义一个函数来计算购买看涨期权的收益。该函数将 sT 作为输入,sT 是到期时股票价格、认购期权的执行价格和认购期权的溢价的可能值的范围。它返回看涨期权的收益。
理想的回报应该是这样的:

def call_payoff(sT, strike_price, premium):
return np.where(sT > strike_price, sT - strike_price, 0) - premium
payoff_long_call = call_payoff (sT, strike_price_long_call, premium_long_call)
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_long_call,label='Long Call',color='r')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()

放收益
我们定义一个函数来计算购买看跌期权的收益。该函数将 sT 作为输入,sT 是到期时股票价格、看跌期权的执行价格和看跌期权的溢价的可能值的范围。它返回看跌期权的收益。
def put_payoff(sT, strike_price, premium):
return np.where(sT < strike_price, strike_price - sT, 0) - premium
payoff_long_put = put_payoff(sT, strike_price_long_put, premium_long_put)
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_long_put,label='Long Put',color='g')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()

跨期支付
payoff_straddle = payoff_long_call + payoff_long_put
print ("Max Profit: Unlimited")
print ("Max Loss:", min(payoff_straddle))
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_long_call,'--',label='Long Call',color='r')
ax.plot(sT,payoff_long_put,'--',label='Long Put',color='g')
ax.plot(sT,payoff_straddle,label='Straddle')
plt.xlabel('Stock Price', ha='left')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()
Max Profit: Unlimited
Max Loss: -24.35
最终输出如下所示:

空头多空期权策略
这与多头期权策略正好相反。然而,多头比空头更常用。
结论
从上图可以看出,对于跨式期权策略,最大利润是无限的,最大损失限制在 24.35 印度卢比。因此,当你的前景是适度看跌股票时,这种策略是合适的。
在本文中,我们通过一个真实的市场例子以及理解如何用 Python 计算策略,涵盖了跨期权策略的所有要素。
下一步
铁蝴蝶期权交易策略是一种期权交易策略。这是蝶式价差期权的一部分。同样,这种策略也是多头价差和空头价差的组合。铁蝴蝶策略限制了交易者的输赢。这是一种有限风险和有限利润的交易策略,包括使用四种不同的选项。点击这里阅读完整的帖子。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载数据文件
- 跨期权策略 Python Code.txt
使用趋势跟踪指标的策略:MACD、ST 和 ADX [EPAT 项目]
原文:https://blog.quantinsti.com/strategy-using-trend-following-indicators-macd-st-adx/
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Gopal 是一名管理专业人士,在 IT 行业拥有超过 20 年的经验,拥有强大的全球交付背景,对量化金融和小工具充满热情。他高度重视流程,专注于通过自动化来实现质量。他在 PreludeSys India Ltd. 负责交付,Gopal 拥有远程教育共生中心的 MBA 学位。他已于 2016 年 11 月成功完成了算法交易(EPAT)高管项目的课程工作。
有句名言说得好:“趋势是朋友”。根据权威人士的说法,股票市场的成功率是 5%。当然,每个人都想成为那 5%的人!要进入那 5%的范围,即使不是不可能,也是很困难的。我们所需要的只是一个适当的策略。即使制定了战略,了解市场状况是否有助于该战略也很重要。成为一个成功的交易者的决定性因素是及时了解市场。
我的策略是基于几年前我从一位受人尊敬的著名技术分析师那里得到的培训。我使用了这一策略,并根据我从导师 Abhishek Kulkarni 先生那里得到的反馈对其进行了改进。
使用该策略的动机
我跟踪图表已经有几年了。作为我学习的一部分,我使用了一些技术和趋势指标。我对技术分析师如何使用这些指标来应对市场很感兴趣。
由于我的强项是编程,所以我用了一个策略,不太重概念。在作业阶段,我用 R 实现了对交易策略。
战略详情
我的策略适用于趋势市场——包括熊市和牛市。它使用几个技术指标来识别市场的动能,并在市场的多头和空头进行交易。
我用过的趋势跟踪指标是移动平均线收敛发散 (MACD)指标,一个趋势跟踪动量指标和超级趋势(ST)指标,一个趋势跟踪指标。
关于使用 MACD 和 ST 作为趋势指标的简要说明
移动平均收敛发散(MACD)
MACD 是使用两个指数移动平均线(EMA)计算的——短期和长期。MACD 的指数移动平均线被用作信号线,表示上涨或下跌的动力。
使用 MACD 时,需要考虑两个入口点。一,当 MACD 线穿过信号线时。第二,当 MACD 在正数区域时,这意味着较小的移动平均线在较大的移动平均线之上。
超级趋势(ST)
超级趋势指标是一种趋势指标,用于确定价格是处于上升趋势还是下降趋势。如果价格高于指标线,那么价格点就是一个支撑点。如果价格低于指标线,那么它就是一个阻力点。
我已经通过管理仓位大小优化了策略,为 MACD 设定 1 个单位的权重,为超级趋势设定 2 个单位的权重。我希望 MACD 能提供快速的出入境通道。当与 SuperTrend 一起使用时,它将提供更清晰的趋势运行。
选择股票
使用这种策略没有特定的股票标准。然而,任何有效的策略,流动股票是首选。因此,这个策略的重点是漂亮的 50 只股票。
数据用途
我在每天的时间框架内对这个策略进行了回溯测试,从雅虎下载了每天的数据。
我从 2012 年开始测试我的策略。显然,我用过的一些股票没有 2012 年的数据。这是一个众所周知的警告,我用它来测试我的趋势跟踪指标策略。
我用 Python 实现了我的策略,还有像 Numpy、Panda、Matplotlib、TA-Lib 这样的包。TA-Lib 通过必要的参数帮助计算 MACD。
由于没有现成的方法来计算超级趋势价格点,我已经编码了该方法,并在程序中使用。
当我把这个话题介绍给我的导师 Abhishek 时,他建议我使用平均方向指数(ADX)指标来即兴制定策略。ADX 是 TA-LIB 包中另一个可用的方法,用于确定价格趋势。
基于 MACD 和 ST 的买卖策略只有在股票有趋势时才执行。股票走势将根据 ADX 决定。只有当 ADX 数据高于预定阈值时,才会做出任何买入/卖出决定。ADX 跌破阈值的那一刻,所有未平仓头寸将在第二天开市时平仓。
战略的实施
我在这个策略中使用的 Python 包包括:

我创造了一种方法来计算超级趋势指标。可以通过在数组中传递数据来进一步优化。然而,为了简单起见,我传递每条记录来标识高频带、低频带和超级趋势。

如果决定进行回溯测试的时期是在很久以前,有可能一些股票在这段时间内没有在市场上交易。这是一个众所周知的警告。
以下 Python 代码从 nseindia.com 获取最新的 Nifty50 列表,并将输出转换为数据框。

要设置数据检索的日期并从 yahoo finance 中检索历史数据:

在浏览和分析这些数据后,我发现雅虎提供的“调整后收盘”数据在公司对该股采取行动时是有偏差的。为此,我在程序上做了一点小小的调整。如果每日回报有巨大的差异,比如说差异小于 0.75 或大于 1.50,那么我用“收盘”数据更新“调整后的收盘”数据。

以下 Python 代码将技术指标数据放入数据框中进行进一步处理。

虽然平均真实范围(ATR)指标没有直接用于策略中,但它是计算超级趋势所需要的。我使用下面的代码将它放入数据框中。

现在计算 SuperTrend 并将其添加到数据框中。

为了识别交叉,我已经为每天的交易数据准备了包含前期数据的数据框架-需要 2 期数据趋势指标,MACD 和 ST 以避免回测偏差。对于 ADX 来说,前一天的数据就足够了。

生成 MACD 和 ST 交易信号,并将信号添加到数据帧中。(我已经张贴了详细的内联注释,后面是 for 循环代码。)

ADX 指标为策略提供了重要的数据点,以确定股票是否是趋势性的。只有当 ADX 高于阈值时,买入或卖出才会发生。ADX 下降到阈值以下时,所有未平仓头寸将被平仓。
当出现 MACD 交叉或 ST 交叉时,ADX 用于决定股票交易。该战略使用了两个指标。一个是信号(macdsig/supersig),一个是策略(macdstr/superstr)。
当 MACD / ST 出现正交叉且 ADX 呈趋势时,信号和策略设置为“1”。当 MACD / ST 出现负交叉,ADX 出现趋势时,信号和策略设置为“-1”。
当没有交叉时,信号设置为‘0’,但使用策略变量来决定是继续交易还是结束交易(无论买入还是卖出)。当 ADX 高于阈值(趋势)时,此策略变量设置为延续前一天的相同值。如果不是趋势,策略值设置为 0,从而给出一个完整的信号来关闭所有未平仓交易。


为了根据分析分别计算 MACD 交叉和 ST 交叉的日回报率,为了得到接近准确的回报,我根据每日活动交替使用了“调整收盘”和“收盘”数据。

所有数据准备工作完成后,将实施策略和信号的实际处理。
我在数据框中包含了一个带佣金的输出列,以帮助找到佣金后的利润。第一笔交易我考虑了 1%,有反向交易时考虑了 2%。

这里实现了信号和策略的处理。趋势指标, MACD 和 ST 分别处理,但使用相同的逻辑。处理时,数据框中的单独列用于计算准确的利润/损失。
使用的逻辑是
- 当信号和策略相同且积极时,买入。
- 如果跑路交易卖出了,那就补仓买入。
- 如果没有,就买。


还有,
- 当信号和策略相同且为负值时,卖出。
- 如果连续交易被买入,那么卖出并做空。
- 如果没有,就做空。


当信号和策略相同(0)且没有信号时,平仓。如果买入了正在运行的交易,那么卖出,如果卖出了,那么回补。


所有其他计算都在每行级别完成,并存储在数据框的附加列中——累积回报、年化回报、年化标准差、年化夏普比率。以上数据用于计算趋势指标,分别为 MACD 和 ST。

综合计算:

根据路由的位置,在控制台或文件上打印相同的内容。

此外,还计算了交易成功的详细信息,用于进一步分析策略——CAGR、交易成功率和平均盈亏。

要打印出数据:

要使用 Matplotlib 绘制图表:

我花了很多时间来完成这个策略,因为(1)我工作非常忙(2)我必须接受角膜移植手术。
我经常和我的导师 Abhishek 联系,分享工作进展中的代码。他一直很友好,定期给予反馈。QuantInsti 团队令人鼓舞,并为各种示例项目提供了指导。
我不认为这种不展示结果的博客体验是完整的。




经历这个项目和编码这个策略是一次很好的学习经历。Stackoverflow,Pandas 文档是我访问技术诀窍时最喜欢的网站。我试图保持代码简单明了。我已经优化了代码,并通过将数据帧的循环减少到最少来临时凑合。我保持了代码的动态性,这样在数据帧中包含新列的任何代码都不会影响程序的其他部分。

我确信 Python 专家可以进一步润色代码。我很感谢你花时间阅读这个策略。如果你们中的任何人找到了更简单的方法来做我所做的事情,请随时给我写信。
EPATian 的另一个项目是利用简单的均值回归策略对 ETF 进行配对交易。这个项目的目标是观察大型和中型金融交易所交易基金之间是否存在套利机会。点击这里阅读更多。
更新: 我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。 本项目提供的所有内容仅供参考,我们不保证通过使用这些指导您将获得一定的利润。
下载中的文件:
支持向量机简介
原文:https://blog.quantinsti.com/support-vector-machines-introduction/
支持向量机十年前曾被广泛使用,但现在已经失宠了。以下来自谷歌趋势的数据可以更清楚地证明这一点。

(来源:谷歌趋势)
为什么会这样?
随着越来越多的高级模型被开发出来,支持向量机失宠了。训练支持向量机的非线性核,例如 RBF(径向基函数),需要花费大量时间。但是已经发现它们在文本分类问题中非常有效。支持向量机(SVM)也擅长解决小数据集的非线性问题。这正是我在交易中更喜欢支持向量机的原因。
交易中的支持向量机
说到交易,如果你用的是日频数据,那么很有可能你的数据集极其有限,大概只有几千个数据点。假设你已经创建了一个交易策略,使用决策树从过去的数据中提取一个大概率规则。现在您想了解这条规则在看不见的或测试数据上的表现。创建一个 SVC 来预测规则何时成功或失败,这将帮助你消除不好的交易。在您尝试 SVM 之前,首先让我们了解它们是如何工作的。
因此,在本文中,我们将讨论以下主题:
支持向量机
支持向量机是一种通常用于执行分类任务的方法,它使用多维空间中的分离超平面来执行给定的任务。从技术上讲,在 p 维空间中,超平面是 p-1 维的平坦子空间。例如,在二维中,超平面是平坦的一维子空间或直线。在三维中,超平面是平坦的二维子空间,即平面。
如果维度大于 3,可能很难将超平面可视化,但是 p-1 维空间的概念仍然适用。
用一个例子理解支持向量机
现在你对超平面有了基本的了解,让我们来了解一下支持向量机背后的直觉。考虑两个不同类的数据集,用蓝色和红色显示。

数据是线性可分的,存在多条分隔线,以黑色显示。所有这些行都提供了一个解决方案,但是只有一行是最佳的,并且可以准确地将类分开。

例如,如果线非常靠近数据点,即使很小的噪声也会导致错误分类。这是另一条分隔类的线,但看起来不太自然。所以,问题是哪条线最好?
支持向量机选择一条最优线,该线最大化到任一类中最近点的距离。这个距离叫做边缘。如图所示,边距是从实线到任一虚线的距离。

我们的目标是最大限度地提高利润,以获得最佳生产线。因此,支持向量机有时被称为最大间隔分类器。在图中,虚线上有一些蓝色和红色的数据点。这些点被称为支持向量。值得注意的是,最大边缘线或决策边界仅取决于支持向量,而不取决于其他数据点。

如图所示,移动支持向量也会移动最大边缘线,而移动其他点则没有影响。最大边距线仅在数据可线性分离时有用,换句话说,数据可以用直线分离。在该图中,数据点属于两个类别,并且不一定由最大边缘线分开。事实上,如果分隔线确实存在,它也不是最佳的,因为它会错误分类,而且误差很小。那么,当数据是非线性的时候,我们应该采用什么方法呢?
在这种情况下,我们考虑扩大特征空间,例如二次、三次甚至更高阶的多项式,以解决这种非线性。我们可以用一种特殊的方式扩大特征空间,使用一种叫做“核”的函数。让我们了解一下核函数和支持向量机背后的一些数学知识。
支持向量机的数学
关于支持向量机,您需要理解的要点是:
- 支持向量机通过最大化平面和最近的输入数据点(称为支持向量)之间的距离来找到超平面(对数据进行分类)。
- 这通过最小化用于定义超平面的权重向量“w”来完成。
- 步骤 2 依赖于最优化理论和某些假设(下面将详细说明)。
最大化超平面和支持向量之间的距离
为简单起见,考虑属于 C 类 1 或 C 类 2 的线性可分数据点,没有任何数据点的错误分类。

对于未知的输入数据 x,我们定义一个线性判别函数。
y = f(x) = w. x + b
其中 w 是垂直于超平面的权重向量。
b 是偏差项
 ...(1)
...(1)
设所有输入点用 x 1 ,…,x p 表示,它们对应的类用 y 1 ,…,y p 表示。所以,如果 x i 属于 c 类 1 ,那么对应的 y i 等于+1,如果 x i i 属于 c 类 2 ,那么对应的 y i 等于-1。
 ...(2)
...(2)
之前,我们假设属于两个类的数据点是线性可分的。那么有可能以在它们之间没有点的方式选择两个超平面,然后尝试最大化两个超平面之间的距离。这种类型的支持向量机被称为硬边界 SVM。

这两个超平面可以用下面的等式来最好地表示
H1 : w.x i + b = -1...(3)
H2 : w.x i + b = 1...(4)
假设 x 1 和 x 2 是超平面每一边最近的两个点。然后,超平面 H1 和 H2 的方程变成:
w.x 1 + b = -1...(5)
w.x 2 + b = +1...(6)
通过对等式(5)和等式(6)进行差分,我们得到,
w(x1x2)= 2...(7)
用等式(7)的两边除以我们得到的“w”的大小,
w(x1-x2)/| | w | | = 2/| | w | |...(8)
我们知道,当我们把一个矢量除以它的大小,我们得到一个单位矢量。单位向量的大小是 1。所以,我们的等式变成了:
(x 1 - x 2 ) = 2 / ||w||...(9)
(x 1 - x 2 )是两个超平面之间的距离。所以,我们要最大化的距离是 2 / ||w||。最大化 2 / ||w||就是最小化||w||为了防止数据点落入页边距,我们添加了以下约束。
最小化 2 / ||w||...(10)

将两个方程乘以它们对应的 yI,它们就转化为一个方程
yI(w . xI+b)≤1&∞1、…,N}
上面的优化问题很难解决,但是可以在不改变解的情况下,将等式 2/ ||w||替换为||w||2。这个问题现在属于二次规划(QP)优化,更容易计算。
最小化||w|| 2 ...(11)
使得 y i (w. x i + b)≥1,& nbsp ∀i ∈ {1,…,N}
这是二次优化问题或原始形式。借助拉格朗日乘子,这个原问题可以转化为另一个优化问题,即对偶问题。
具有拉格朗日乘数的对偶优化方程如下所示:

服从αIT2】= 0 ∀i∈{ 1,…,N}
其中αi 是拉格朗日乘数
通过将等式(12)的括号中的分量相乘:

将 L w.r.t w 和 b 的导数分别设置为 0:
∂L/∂b = - Σ αi y i = 0
⇒ Σαi y i = 0 ... (13)
∂L/∂w = w - Σ αi y i x i = 0
⇒ w = Σ αi y i x i i ... (14)
将等式(13)和(14)的值代入 L,我们得到:
l =≤σδj y〖t0〗I〖t1〗y〖T2〗j〖T3〗(x〖T4〗I〖t5〗x〖T6〗j〖T7〗-φⅰδj y〖t8〗I〗

在这里,我们的目标是最大化不同拉格朗日乘子值(即α)的对偶优化问题。

需要注意的一件重要事情是,如果拉格朗日乘数,即αi = 0,那么数据点不是支持向量。所以,只有对于αi > 0,x i 才是支持向量(SV)。
软边界分类器
上述优化问题仅在数据点被正确分类时有用,这意味着页边空白之间没有点。有时,数据中的高噪声会导致类别重叠,如图所示。

在这种情况下,我们可以通过使用软间隔 SVM 来完成分类任务。
软边界 SVM 通过最大限度地减少样本数量,为模型错误分类某些数据点提供了自由。软边际 SVM 允许违反约束的可能性
yI(w . xI+b)≤1≤1、…,N}
通过引入松弛变量ξi
yI(w . xI+b)≥1-ξIξI≥0 ∀i∈{ 1,…,N}
现在,我们的目标是通过保持ξi 尽可能小来最大化裕量。
引入松弛变量后,我们的原始或二次优化问题:

这里,C 是正则化参数(分类和误差之间的折衷)。转换到拉格朗日对偶问题,我们得到:

这里,μ i 是新的拉格朗日乘数。
分别对 L w.r.t w 和 b 取偏导数后为 0。我们的对偶优化问题变成了:

除了α i 的值位于 0 和 c 之间之外,这与硬边界情况非常相似。
非线性模型
到目前为止,我们所学的知识只适用于数据是线性可分的情况。当数据不可分时,这些优化问题是不可行的。这样的问题可以通过一个被称为核的函数来扩大特征空间来解决。
数学上,核是对应于某个扩展特征空间中的内积的某个函数。如果每个数据点通过某种变换φ:x→φ(x)被映射到高维空间,那么核函数被定义为:
K(x i ,xj )= φ(x i )。φ(xj)
我们可以通过引入如下核函数来修改我们的优化问题:

(来源:维基百科)
因此,我们已经看到了支持向量机的复杂性及其作为非线性模型的应用。我们还理解了软间隔分类器的含义,以及它如何克服支持向量机模型中的优化问题。
在下一节中,我将向你展示如何使用在早期的博客中做出的制度预测来实现基于机器学习的交易策略。
在你阅读这部分之前,有一件事你应该记住:这个算法只是为了演示,不应该在没有适当优化的情况下用于实际交易。
使用 Python 中的支持向量机进行交易
让我先解释一下这里的议程:
- 创建一个无监督的 ML(机器学习)算法来预测制度。
- 画出这些政权来形象化它们。
- 训练一个支持向量分类器算法,将政权作为特征之一。
- 使用此支持向量分类器算法来预测开市当天的趋势。
- 在测试数据上可视化这个策略的性能。
- 为您的利益可下载的代码
导入库和数据:
首先,我导入了必要的库。请注意,我已经导入了 fix yahoo finance 包,所以我可以从 yahoo 中提取数据。如果你没有这个包,我建议你先安装或者把你的数据源换成谷歌。

接下来,我提取了我们在上一篇博客中使用的相同引文“SPY”的数据,并将其保存为 dataframe df。我选择了 2000 年这个数据的时间段。

在这之后,我创建了可以用作训练算法的特征的指标。
但是,在此之前,我决定了这些指标的回望时间段。我选择了 10 天的回顾期。你可以试试其他适合你的号码。我选择 10 来检查过去 2 周的交易数据,以避免较小的回顾期所固有的噪音。
除了回望期之外,让我们也决定数据的测试序列分割。我更愿意给出 80%的数据用于训练,剩下的 20%用于测试。您可以根据自己的需要进行更改。

接下来,我将高、低和收盘列移动 1,以便只访问过去的数据。在此之后,我创建了各种技术指标,如 RSI,SMA,ADX,相关性,抛物线 SAR,以及过去 1 天的回报。

接下来,我打印了数据框。

它看起来像这样:

如你所见,有许多 NaN 值。我们需要估算它们或者放弃它们。如果你是机器学习的新手,想要了解估算器功能,请阅读这个。我在这个算法中去掉了 NaN 值。

在代码的下一部分,我实例化了一个 StandardScaler 函数,并创建了一个无监督学习算法来进行状态预测。我在以前的博客中讨论过这个问题,所以我不会再赘述。

在最后一篇博客的结尾,我打印了所有区域的平均值和协方差值,并绘制了区域图。将指示器作为功能集的新输出如下所示:

接下来,我缩放了 Regimes 数据框,不包括在前面的代码中创建的 Date 和 Regimes 列,并将其保存回相同的列中。通过这样做,我不会丢失任何特征,但数据将被缩放,并为训练支持向量分类器算法做好准备。接下来,我创建了一个信号列作为预测值。该算法将在特征集上训练以预测该信号。

接下来,我实例化了一个支持向量分类器。为此,我使用了与 sklearn 在示例中使用的相同的 SVC 模型。我没有优化这个支持向量分类器的最佳超参数。在 Quantra 上的机器学习课程中,我们广泛讨论了如何使用超参数和优化算法来预测每日高点和低点,进而预测一天的波动性。
回到博客,支持向量分类器的代码如下:

接下来,我将无监督制度算法的测试数据分为训练和测试数据。我们使用这个新的训练数据来训练我们的支持向量分类器算法。为了创建训练数据,我删除了不属于特性集的列:
信号','返回','市场 cu 返回','日期'
然后,我将 X 和 y 数据集拟合到算法中,对其进行训练。

接下来,我计算了测试集的大小,并根据数据帧 df 对预测进行了索引。
这样做的原因是,“SPY”的原始返回值存储在 df 中,而 Regimes 中的那些值是按比例缩放的,因此对于获取累积和来检查性能是没有用的。

接下来,我将 SVC 做出的预测保存在一个名为 Pred 信号的专栏中。
然后,基于这些信号,我通过将当天开始时的信号乘以第二天开盘时的回报(因为我们的回报是从开盘到开盘)来计算策略的回报。

最后,我计算了累积策略回报和累积市场回报,并将其保存在 df 中。然后,我计算夏普比率来衡量性能。为了清楚地理解这个指标,我绘制了性能图来衡量它。

最后的结果看起来是这样的。

经过这么多代码和努力,如果最终结果看起来像这样,那么没有机器学习背景的人会说这不值得。我现在同意。但是,看看这行代码:

我只是把数据从 SPY 改成了 IBM。那么结果看起来是这样的:

我知道你在想什么:我只是在拟合数据以得到结果。这并不是完全错误的。我会给你看另一个股票,然后你决定。

我把股票换成了 Freeport-McMoRan Inc,结果是这样的:

可以进一步改成 ge 或者别的,自己查。这种策略对一些股票有效,但对其他股票无效,大多数量化策略都是如此。有几个原因可以解释为什么这个算法能够稳定的工作,我将在这里列出其中的一些。
- 没有回报的自相关
- 无支持向量超参数优化
- 无误差传播
- 无特征选择
我们没有检查回报的自相关性,这将增加算法的可预测性。通过将 returns 列移动 1 并将其作为 feature set 传递,自己尝试一下。结果将如下所示:

虽然从 3.4 到 3.49 的提升不多,但这仍然是一个很好的特性。
请注意,代码最好在 Python 2.7 中运行
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
结论
因此,我们不仅看到了支持向量机背后的数学,而且还理解了如何使用 Python 中的 SVM 构建交易策略。
如果您想学习如何在金融市场数据上使用支持向量机并创建自己的预测算法,您可以报名参加机器学习交易:分类和 SVM 课程,该课程涵盖分类算法、机器学习中的性能测量、超参数和监督分类器的构建。
如果你想学习算法交易的各个方面,那么看看我们在算法交易 (EPAT)的执行项目。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 旨在让你具备成为成功交易者的正确技能。立即注册!
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
下载数据文件
- Python_3
生存偏差:例子,影响,回避!
这篇文章帮助你探索围绕生存偏差的一切,以及它的一般意义和它如何影响金融市场。我们还将讨论你应该在多大程度上让生存偏差来指导你的交易决策,以及它是哪种偏差的一部分。
本文涵盖:
- 什么是生存偏差?
- 生存偏差的例子
- 生存偏差的工作
- 生存偏差对交易的影响
- 生存偏差的重要性
- 如何避免生存偏差?
什么是生存偏差?
幸存者偏差,也称为幸存者偏差,基本上是在相同的历史表现的基础上看待市场上现有股票的方式。也可以有一些股票的一般特征,它们可以干预对股票表现或市场指数的估计。因此,投资者或交易者的决定变得有偏见。
此外,当投资者做出一个由于偏差而被误导的决策时,这就是投资者所承担的生存偏差风险。
现在,让我们看一个生存偏差的例子。
存活偏差的例子
为了使对生存偏差的理解更有趣,我们可以看一个军队中偏差的例子。

来源:维基百科
第二次世界大战期间,军队看着完成任务返回的飞机。他们看到飞机在某些地方受到了敌人炮火的伤害。这些位置在图像中显示为红点。
首先,有人建议这些地方应该用重型装甲来加固,这样飞机受到的损伤就会最小。
然而,有人指出,这项研究只在那些幸免于撞击的飞机上进行。
那些没有返回的飞机呢?
红点似乎是飞机被击中后仍能返回的地方。因此,建议对没有红点标记的地方,例如发动机,进行加固。
好的,让我们进一步了解生存偏差的工作原理。
生存偏差的工作
谈到生存偏差的工作,这是一个相当简单的过程。现在让我们假设在 2018 年,一个交易者有一个由股票、债券和共同基金组成的投资组合。明年,也就是 2019 年,这些债券因当年表现不佳而被从投资组合中移除。
现在,投资组合只包括股票和共同基金。
如果你只根据股票和共同基金来计算这两年的投资组合表现,而不考虑债券的糟糕表现,那么在 2018 年,结果肯定会受到生存偏差的影响。之后,股票和共同基金也有可能表现不佳。
生存偏差的另一个例子可以在下面看到。当你跟踪一个人却不知道损失是否会大于收益时,你最终会成为生存偏差的受害者。

来源:培养基
最后明确提到,像这样的励志演讲必须附带免责声明或警告,可能会出现生存偏差。因此,你需要相应地权衡你所承担的风险和潜在收益。
好了,现在我们将进入下一个讨论,生存偏差如何影响投资者。
生存偏差对交易的影响
生存偏差的影响来自于对股票或市场指数的看法,这种看法可能看起来过于乐观或过于悲观。这两种情况都会影响投资者的交易决策,因为相反的实际情况会导致损失。
在交易的情况下,市场可能会变得不稳定,一些股票可能表现不佳。
投资共同基金是投资金融市场的一个例子,其中可能存在生存偏差。在经济衰退时期,投资共同基金可能会帮助你的基金度过市场危机。
帮助这些基金生存下来的因素可能是它们的综合崩溃,甚至是基金管理公司对市场做出有效反应的能力。
另一方面,其他一些共同基金可能表现不佳,可能已经被迫关闭。总之,净效应只会是一个正面扭曲的结果,无法描绘实际结果。
因此,为了得到实际的结果,重要的是要考虑到市场上所有的共同基金。如果你希望只研究顶级共同基金,那么你必须考虑所有顶级共同基金在衰退期间的表现,然后再做决定。
让我们再举一个例子,假设你投资了 5 只共同基金,你的投资组合在 2020 年的 3 年回报率如下:

来源:清税
当你取出所有基金的平均值,你发现你的净收益是 1.94%。另一方面,如果你查看表现最好的前三只基金的平均值,结果是平均值为 3.58%,远远高于 1.94%。
现在,如果你把未来投资的决策建立在表现最好的共同基金的基础上,这将带来生存偏差风险。然而,1.94%回报的实际结果表明,你应该投资于共同基金,同时考虑到实际损失。
接下来让我们讨论生存偏差的重要性。
生存偏差的重要性
在生存偏差中,有一种可能性是,在对投资组合进行估值时,有些投资可能因为表现不佳而没有被考虑在内。
让我们用上述投资共同基金的例子来理解这一点。因此,根据投资组合的历史估值,对同一投资组合的投资可能看起来有利,但实际上可能并非如此。
因此,重要的是要保持你正在进行回溯测试的数据库不受生存偏差的影响,然后在考虑了我们刚刚讨论过的变量之后做出交易决定。
这里有一个视频可以帮助你更好地了解生存偏差的重要性:
https://www.youtube.com/embed/GyEbt9zUhAM?feature=oembed
展望未来,让我们找出如何避免生存偏差。
如何避免生存偏差?
为了防止生存偏差,在开始工作或研究数据库之前,您可以做一些简单的事情。首先,你必须对数据来源进行真正的选择,因为你不应该挑选已经有偏差的数据。
我们在上面的视频中提到了一些数据库源,如 Tick data 和 Kibot ,您可以使用它们来选择数据库。提到的来源并没有删除不再存在的观察。它仅仅意味着投资组合或数据库的估价应该包括所有的变量,而不管它们的性能状态如何。
这就是你的决定将如何基于实际观察或估价。
结论
我们讨论了如果我们不查看包含所有变量(表现最好和表现不好的)的数据库,不管是债券、股票还是共同基金,生存偏差是多么容易发生。即使一个表现不佳的变量在评估时被从数据库中跳过,也会导致不可靠的信息。这些信息会导致你在交易时做出错误的决定。生存偏差的有趣方面也让我们意识到,虽然它可能在一些领域如军事上成功,但在交易中会导致糟糕的评估。我们可以通过追踪您研究的数据库的正确来源来降低生存偏差风险。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
交换选项-简介
生活中有一个选择总是一种享受,给我们一些不同的期待。“互换期权”或术语互换期权为您提供了互换金融工具、现金流的选项,但通常是双方之间的利率。此外,还有不同类型的互换期权。此外,您可以更深入地研究我们在本文中提到的关于交换选项的工作和其他方面,并找到它们。我们将从互换的含义开始,以便首先讨论互换的基础。
因此,本文涵盖了:
互换
互换只是双方之间的契约性协议。在这种协议中,一方可以交换利率、货币(同值),甚至为违约方偿还贷款的责任(信用违约互换)。
借助下面的流程图,你可以看到互换合约在双方之间是如何运作的。

来源:维基百科
现在让我们向前看一看互换期权合约。
掉期期权合约
现在,掉期期权或掉期期权合同意味着一种期权类型,给予买方在未来某个特定日期签订 T2 掉期合同的权利,但没有义务。互换期权合约通常以溢价购买。互换期权是场外交易的合约,即不在交易所交易。互换期权有两种类型,分别是:
- 付款人互换期权
- 接收器交换选项
付款人掉期期权
购买赋予你支付固定利率并在未来获得浮动利率 (LIBOR) 的权利的合约被称为支付者互换期权。
伦敦银行同业拆放利率是标准的浮动利率,前面有简要的解释。
接收器交换选项
相反,互换期权合约为你提供了支付浮动利率(LIBOR)并在未来获得固定利率的权利,这种合约被称为接收者互换期权。
此外,付款人互换期权和收款人互换期权在下图中也有明确区分:

来源: CFI
最重要的是,当不确定未来利率是上升还是下降时,可以使用互换期权。利率有两种类型,即:
- 固定利率(不变)
- 浮动汇率(可变)
固定利率(不变)
固定利率是不随市场变化而波动的利率。这种利率是对债务收取的,如贷款。固定利息在整个预定期限内保持不变,直到偿还本金为止。
浮动利率(可变)
浮动利率是指在预先确定的一段时间内,利率不会保持不变,直到偿还本金为止。浮动利率的变化取决于参考利率。在这里,最常见的参考利率是 LIBOR。伦敦银行同业拆放利率是根据汇丰银行、巴克莱银行等伦敦主要银行提交的估价计算得出的平均利率。
此外,掉期合约的双方需要就以下两个方面达成一致,即:
- 溢价(价格)
- 期权合约的期限(到期日)
现在让我们来看一个互换期权合同的例子。
互换期权合同示例
让我们假设你有一家 XWZ 公司,该公司提供借贷便利,并规定 6 个月后到期,无需再融资。现在,作为经理,您预计利率可能会在到期日之前超过约定的利率。因此,你将采取互换期权来降低风险。在未来,在到期日,如果利率上升超过掉期利率,您将不会行使掉期期权来享受利率(LIBOR)上升带来的利润。另一方面,如果市场利率没有上升,你将行使掉期期权,并获得高于掉期利率的利率,因为利率下降将是你的损失。
好吧!让我们来看看如何使用图形表示。
在下图中,
- 期权的行权日是到期日
- 互换利率是决定互换的利率
- 市场利率是伦敦银行同业拆借利率浮动利率
- 期权期限截止到行权日

现在,我们可以看到 y 轴上显示的是利率,x 轴上显示的是时间。举个和上面一样的例子,如果你有一家便利借贷的公司,那么在到期日,我们可以看到市场利率或 LIBOR 高于掉期利率。在这种情况下,你将不会行使互换期权,而将获得更高的 LIBOR。
现在,我们将进一步讨论为什么应该选择互换期权。
为什么选择互换期权?
掉期期权主要用于对冲固定或浮动利率。
对冲
一般来说,套期保值仅仅是减轻市场波动风险的行为。如果你不希望在未来交换你的固定或浮动利率,你可以选择退出。掉期期权有助于你对冲购买合约(付款人的掉期期权或收款人的掉期期权)的未来风险。如果你选择退出互换,唯一的损失将是你购买合约所支付的溢价。
例如,一个有三笔贷款将于 2021 年到期的借款人希望对冲利率的任何剧烈波动,他将购买掉期期权,以减轻未来的任何风险。
进一步看这个例子,如果你目前支付浮动利率,你将选择付款人的掉期期权。而且,如果你预见到未来浮动利率会上升,那么你会希望支付固定利率而不是浮动利率。
因此,在浮动利率上升的情况下,付款人的掉期期权将给予你支付固定利率的权利,而不是义务。
相反,如果你已经支付了固定利率,并且你预见到浮动利率在未来可能会下降,你会希望支付浮动利率。在这种持有未来支付浮动利率而不是固定利率的权利的情况下,你将购买一个接受者的互换期权。
现在让我们进一步了解互换期权合同的类型。
互换期权的类型
有趣的是,有三种类型可供支付者或接受者选择(如我们所讨论的),它们是:
- 百慕大互换期权
- 欧洲互换期权
- 美国互换期权
百慕大互换期权
这种类型的互换期权本身可以在几个预定的日期行使,这使得它足够灵活。此外,互换期权的实际执行日期并不重要,因为基础互换将有相同的到期日。
例如,百慕大互换期权持有者可能有权在最初四个季度的任何一天行使合同,而到期日最初是 4 年或 5 年。
欧洲互换期权
这种掉期期权合约要求持有者只能在行权日或到期日行使掉期合约。因此,与百慕大互换期权合同相比,这种合同的灵活性较低。
例如,这份合约的持有者只能在合约到期后,比如说 4 年或 5 年内,行使其持有的互换权。
美国互换期权
在美国互换期权合约中,互换权可以在起始日和到期日之间的任何一天行使。同样,它也可以在到期日行使。
例如,如果你持有美国互换期权合约,到期日是 4 年或 5 年后的某个特定日期,那么你可以在该日期以及两者之间的任何日期行使互换期权。
此外,还有两种可能的解决方案。一种是现金结算,支付的金额是掉期的价值;另一种是实物结算,在到期日进行掉期交易。
展望未来,掉期期权的定价也很重要。现在让我们讨论一下互换期权的定价问题。
互换期权定价的推导
在互换期权的情况下,对于定价,使用黑色模型。互换期权是互换期权,这意味着它们允许在未来以预定的价格互换利率。让我们来看看支付者互换期权的定价公式,它是:
$ $ n = the \;数字\;的\;年\;交换选项\;合同\;will \;last \;对于$$
$ $ m =付款\;per \;年份$$
$ $ s _ k = strike \;利率$$
$ $ N = the \;累积\;标准\;正常\;分发\;函数$$
此外,因为它是按价掉期期权定价,这就是为什么$$s_0= s_k$$让我们假设这是欧式掉期期权合同,因此,利率掉期从到期日 t 开始。这里的利率基准是 LIBOR。
现在,我们假设每年有 m 笔付款。但是,为了去掉所有的计数,我们取了$ $ s _ k \ frac { L } { m } = every \固定\;付款\;on \;的\;互换$美元
现在,
$ \(自\;\frac{1}{m}\sum_{i=1}^{mn} P(0,t _ I)\;是\;的\;折扣\;因子,我们\;will \;take \;a = \ frac { 1 } { m } \sum_{i=1}^{mn} p(0,T_i)\)$
因此,
$ $ s _ { payer } = la[s _ 0n(d _ 1)-s _ kn(d _ 2)]$。
类似地,我们将评估接受者互换期权,即我们接受固定利率并支付浮动利率,即 LIBOR。那么,接收器交换选项将是,
$ $ S _ { receiver } = LA[S _ 0N(d _ 2)-S _ kN(d _ 1)]$ $
要了解更多关于掉期期权定价的信息,你可以参考研究论文这里。
让我们向前看,看看互换期权是如何交易的。
你如何交易掉期期权?
互换期权合同是场外交易,这意味着互换期权不是在纽约证券交易所(NYSE)这样的正式交易所进行交易。场外交易是在经纪人-交易商网络的帮助下进行的。这种交易是通过计算机网络或电话使用在线报价和交易服务完成的,这有助于信息共享,如 OTCBB 。
但是,场外期权不适用于个人交易者。然而,一些私人银行向他们的客户提供访问权限。此外,一些银行向小企业提供场外对冲。因此,如果你成立了一家小公司,你也许可以进入。但是,他们的产品不是很有吸引力。
好吧!我们现在将看到互换期权市场的运作。
互换期权市场是如何运作的?
互换期权市场意味着参与者建立互换期权合约的平台。掉期期权市场通常由大型公司组成,因为后者涉及大量的技术和人力资本。
此外,掉期期权市场适用于大多数主要的世界货币,如美元、欧元和英镑。
更进一步,让我们也讨论一下当你决定持有互换期权合约时所遵循的步骤:
- 互换期权市场通常涉及两方,即收款人和付款人、到期日、各种类型的互换期权和预定价格。
- 在开始时,掉期合约的买方支付卖方一笔溢价。
- 现在,买方有权利但没有义务在预定的未来日期(到期日)交换利率。互换利率的决定取决于利率是否对合同持有人有利。
- 到期日取决于互换期权合同的类型。例如,在百慕大合同中,有一些预先确定的日期,可以在到期日之前行使互换。另一方面,美国合约允许在到期日之前的任何时候行使期权。
这里互换期权的一个很好的例子是 risk-free 的最新新闻,提到高盛在与 SOFR(美国无风险利率)相关的互换期权中处于领先地位。
现在,让我们来看看交易掉期合约的利与弊。
互换期权的利弊
在预测更好的利率(如果你贷款了)或更好的利率(如果你贷款了)时,互换期权非常有用。然而,为了不被积极的一面所驱使,你应该意识到一些不利的一面。
优点
- 当你预期你的固定利率将高于伦敦银行同业拆放利率或反之亦然时,掉期期权被用来规避风险。
- 与其他类型的期权相比,互换期权可以持续更长的时间。
缺点
- 如果你没有在合约终止前行使权利,你将最终失去购买掉期合约所支付的溢价金额。
- 互换可能还有其他风险,比如与另一方的违约者打交道。
结论
本文旨在涵盖交换选项的基本方面。由于它为交易方提供了降低成本或实现收益最大化的机会,因此它是最受青睐的选择之一。期权合约为你提供了大量预测和交易掉期的机会。同时,你必须与一个值得信赖的实体进行交易,并应谨慎对待其他风险。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
摆动交易:概述,设置,技术分析和策略
你是百米短跑运动员还是马拉松运动员?还是介于两者之间?还是两者都有?说到交易,摇摆交易介于短跑和马拉松之间。
所以如果你不喜欢跑得太快或跑得更远,你想在交易中应用同样的哲学,那么摆动交易适合你。
在这篇博客中,我们将关注摇摆交易的概念,并创建一个摇摆交易策略。
我们将讨论以下主题:
什么是摇摆交易?

Apple close price

看到这些股价,你首先想到的是什么?是的,苹果公司的股价在上涨,是的,银行的股价在下跌。但如果你仔细观察,价格会以之字形上下波动。这些模式被称为摆动。
当价格达到一个高水平,然后开始下降,这被称为摆动高。同样,当价格到达低位,然后开始向上移动,这被称为摆动低点。
波动交易是一门艺术,它能识别波动的高点和低点,并建立交易头寸。目标是确定总体趋势并从中获取更大收益。例如,在苹果股票价格中,当价格在 2020 年 4 月左右创下新低时,你可以做多并获得收益。
摇摆交易 vs 日内交易
大部分人都搞不清摆动交易和日内交易。我们先来了解一下这两者的区别以及摆动交易的一些属性。
摆动交易和日交易的主要区别是持有期。日内交易是在一个交易日内买卖证券。例如,您在市场开盘时建立买入头寸,并在交易日结束时平仓。
然而,在摇摆交易中,你持有的头寸从几天到几周不等。这意味着你今天开仓,几周后平仓。
根据时间框架,我们可以将交易风格分为两种类型。
- 持仓交易:这是一种长期交易风格,持有期从几个月到几年不等。
- 刷单交易:刷单交易被认为是一种短线交易,你在几秒到几分钟内开仓并平仓。
| 交易风格 | 保持时间 |
| 缩放比例 | 几秒到几分钟 |
| 日间交易 | 仅限白天 |
| 摇摆交易 | 几天到几周 |
| 头寸交易 | 几个月到几年 |
| 日间交易 | 摇摆交易 |
| 交易头寸持续几个小时或更少。所有交易头寸应在交易日结束时平仓。 | 交易头寸持续几天到几周。 |
| 没有隔夜风险。 | 隔夜持有风险 |
| 高度杠杆化 | 与日间交易相比杠杆更低 |
| 利用微小的价格变动 | 捕捉更大的价格波动 |
摇摆交易系统
你知道你需要找到波动的高点和低点,并抓住收益。
但是你如何找到波动的高点和低点呢?
会目测秋千或使用烛台图案或一些技术指标吗?
目视检查可能会出错,所以我们不会这样做。使用烛台模式也不是一个合适的方法,因为它是一种自主交易。
例如,不同交易者的支撑位和阻力位可能不同。因为这可能导致难以确定成功与否的主观分析,所以我们也不会走这条路。
我们将采用一些有数学依据的方法。我们将使用技术指标来识别波动的低点和高点。一旦我们确定了切入点,我们还需要计划退出。我们可以用止损和止盈来退出策略。
您还需要选择要实施摇摆交易策略的资产。
在摇摆交易中交易哪种资产?
您可以从以下选项中选择资产:
- 股票,
- 商品,
- 期货,
- 债券,和
- 货币和加密货币。
作为摇摆交易者,你必须创建一个多样化的投资组合。你至少应该有十个不同的职位,而且应该在不同的部门。如果可以的话,在你的波段交易中加入其他资产类别。
例如,包括以下内容(假设这些证券符合您策略的基本和技术标准):
- 科技股,
- 发达市场股票,
- 新兴市场股票,
- 交易所交易基金,以及
- 实物黄金。
但是太多的好事会伤害你。分散投资太多是可能的——比如持有 30 个或更多的头寸。摇摆交易者需要专注才能获得大利润。你持有的头寸越多,投资组合的回报就越接近市场。
所有这些头寸代表了投资组合多样化的不同方式。持有多个头寸可以降低特质风险(这是一种将风险归因于单个头寸的奇特说法)。多样化可以让你的投资组合抵御市场波动——一些头寸的收益可以抵消其他头寸的损失。
在摇摆交易中哪个市场交易?
只要资产价格图中有可识别的波动,波动交易可以在任何市场使用。但是可以看出,当市场趋势时,摇摆交易是最有益的。
想想吧。你可能有一个只做多的摇摆交易策略。你发现低点太晚了,当你开始交易时,价格已经上涨了。但是因为你知道市场的趋势,亏损的风险被最小化了。
技术分析在摇摆交易中的作用
在前面的章节中,我们简要地讨论了如何识别波动低点和高点。你如何识别这些波动?答案是技术指标。
但是任何技术指标都可以使用吗?
不正是吗?
因为我们想在趋势市场中交易波动,我们将使用趋势指标来识别这些波动低点。最简单的技术指标之一是均线。
您也可以使用:
- 移动平均收敛-发散(MACD)指标,
- 威廉姆斯的分形,
- 随机指标,
- 相对强度指标(RSI),
- 论天平卷(OBV)等。
现在你一定在想,你应该只用一个技术指标吗?
实际上,如果你想确定产生的交易信号,你可以使用两个或三个指标的组合。如果你使用两个指标,两个都给你买入信号,你会比只用一个更有信心做多。
然而,如果你使用更多的指标,你的交易信号可能会减少。这就是为什么我们试图限制用于摇摆交易的技术指标的数量。
你如何交易波动?
让我们试着列出你需要创建一个摇摆交易策略的步骤。
如何创建摇摆交易策略?
在你创建摇摆交易策略之前,你应该决定你要交易哪些资产。最好,你可以选择趋势股,如苹果,特斯拉。不限于股票,也可以看看大宗商品。
一旦你选择了股票,你就可以决定你将使用的技术指标。在我们的波段交易课程中,我们选择了 MACD 和威廉姆斯分形。
在您计划投入使用之前,策略应该总是经过彻底的回溯测试。确保你有计划交易的资产的历史数据。比如你想交易苹果,可以下载过去 10 -15 年的每日历史数据。如果你想更仔细地了解资产价格,你甚至可以查看分钟时间框架数据。
一旦有了所需的历史数据,就可以设置策略的规则。你要做的第一件事是计划你的进场规则。
如果你使用 MACD 指标,你的进场原则是当 MACD 线穿过信号线并在信号线上方时买入。
除了进入规则,退出规则同样重要。一个退出规则将取决于你对指标的选择。如果你使用 MACD 指标,当 MACD 线低于信号线时,你可以退出。
你还应该有基于获利和止损水平的退出规则。摇摆交易者寻求小利润,从长远来看,小利润会越积越多。因此,如果你的资产回报率为 4%,摇摆交易者就会退出交易。
此外,如果你的资产价格下跌并超过 2%的损失,摇摆交易者将退出交易。止盈和止损水平取决于你的风险回报比。在这个例子中,风险回报比为 1:2。这个比例是主观的,取决于个人的风险偏好。
除了上面的退出标准,摇摆交易者通常会在一个月后退出交易,不管盈利还是亏损。回想一下,波段交易者不会在交易中停留很长时间。
因此,通过这种方式,您可以为自己的摆动交易策略定义进场和出场规则。
然而,摇摆交易也有一些风险。让我们在下一节找出优缺点。
摇摆交易的优势
摇摆交易的优势如下:
- 如果你在趋势市场交易,摇摆交易的风险较小
- 这是初学者使用的简单策略
- 不像日内交易者,你不必在一天结束前平仓
- 你不必整天坐在电脑前跟踪市场
摇摆交易的缺点
摇摆交易的缺点如下:
- 存在缺口风险。例如,如果关于公司的负面消息在盘后时间被披露,第二天可能会出现大幅下跌,并导致相当大的损失
- 应详细研究所使用的技术指标,以检查其固有的缺点
结论
新手和有经验的交易者都使用摆动交易策略。底层逻辑相对更容易理解和实现。
但是像任何其他交易策略一样,摇摆交易策略不是没有风险的,你必须小心选择技术指标以及进入和退出交易的参数。
首先,你可以随时查看 Quantra 上的摇摆交易策略课程,了解并学习如何在真实市场中实施。要了解更多关于摇摆交易策略的信息,请探索我们的摇摆交易策略课程。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
Python 中的综合多头期权交易策略
原文:https://blog.quantinsti.com/synthetic-long-put-strategy-python/
有无数的交易者在练习无数的交易策略。比较熟悉的有铁蝴蝶、长勒死、熊出没等。期权交易策略在这种快速的交易生活中开辟了自己的空间,并通过改善交易策略极大地帮助了交易者。在这样做的时候,我们经常会遇到合成期权,这就给我们带来了今天的交易策略,合成长期看跌期权交易策略。在交易时,最重要的是要知道仅仅依靠旧的传统的交易方法和实践是不可能生存的。世界正在向算法交易转变,交易者有必要改进他们的交易实践和方法。这也导致了模型、策略甚至实践的快速复制和相同的进化,结果,今天,我们看到许多修改的期权交易策略。交易者进行合成交易是为了利用他们的看涨期权和看跌期权,而不是原来的东西,作为另一种交易工具,以确保它是市场独有的,可定制的,有助于利用市场优势,并且易于操作。其中之一就是我们今天要学习的。
什么是合成看跌期权?
可以形象地表示为:  这个组合正好类似于一个看跌期权,具有相似的性质。在看跌期权中,一个人只从标的股票的价格变动中获利,而股票中没有标的头寸。这将模拟一个长期看跌头寸,其回报将等同于长期看跌。因此,它经常被用来代替长时间投掷。在这里,人们可以通过持有看涨期权和卖空股票来节省交易成本。这两个因素结合在一起,就形成了一个直线看涨期权的确切风险/回报曲线。
这个组合正好类似于一个看跌期权,具有相似的性质。在看跌期权中,一个人只从标的股票的价格变动中获利,而股票中没有标的头寸。这将模拟一个长期看跌头寸,其回报将等同于长期看跌。因此,它经常被用来代替长时间投掷。在这里,人们可以通过持有看涨期权和卖空股票来节省交易成本。这两个因素结合在一起,就形成了一个直线看涨期权的确切风险/回报曲线。
在我们继续之前,让我们快速回顾一下交易中合成头寸的一些基础知识。
什么是交易中的综合头寸?
合成头寸通常用于模拟市场头寸,因为它们能够表现得与原始头寸相似,并且具有相似的风险和回报。它们可以通过以下两种方式创建:
1 通过组合不同的期权合约来模拟股票的多头或空头头寸。
2 通过结合期权合约和股票来模仿基本策略
合成头寸的类型
有六种不同类型的综合头寸存在并被交易者用于交易。这些措施如下:

多头买入价差=空头卖出价差
做空买入价差=做空卖出价差
就合成看跌期权而言,它是卖空股票和看涨期权的组合,提供流动性和灵活性。这是一种让它看起来像看跌期权的策略,但它是合成看跌期权。
为什么要合成仓位?
人们经常质疑创建一个类似于原始策略的策略的目的,以及从长远来看它将如何给他们带来好处。不像普通的交易策略,它最有效的利用了资金。我们将详细讨论所有这些内容。在这篇文章中,我将特别关注综合长期看跌期权交易策略。
何时进入合成看跌期权?
一个交易者建立了一个空头期货头寸,感觉股票正在超卖,并预见到了危险,他担心证券的长期疲软。如果当股价下跌时,他不太确定这是否真的会发生,于是买入一个看涨期权来对冲短期的下跌。如果这一战略尽可能快地螺旋式下降,它将被证明更有成效。交易者在期货中有一个空头头寸,如果股票上涨,它将受到多头买入期权的保护。这也经常被认为是对空头头寸的一种改善。
合成多头看跌交易策略集锦
构建综合多头策略
- 做空 100 股
- 长 1 自动柜员机呼叫(批量= 100)
最大收益/利润 =卖空价格/股票价格-溢价支付最大亏损 =执行价格-卖空价格溢价支付标的价格> /=看涨期权的执行价格盈亏平衡点 =执行价格+盈亏平衡点时支付的溢价,执行价格与利润成反比
实施综合多头交易策略
在这个例子中,我将使用 SBI。 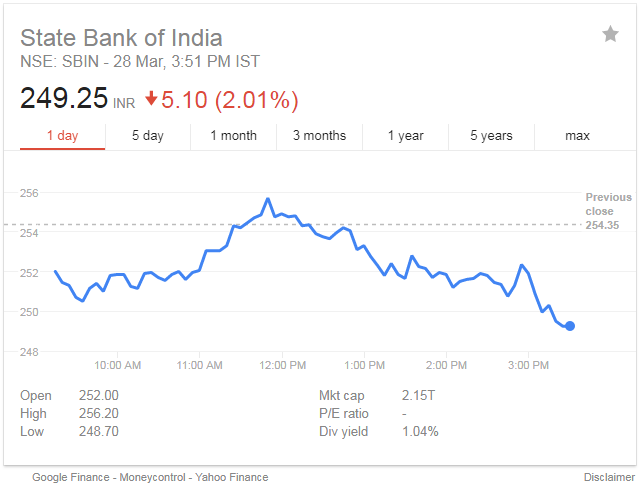 最近 1 个月的股价走势(来源——谷歌财经)。SBI 的股价一直在波动,最高为 255.70,最低为过去 1 个月(截至 2018 年 3 月 28 日)的 249.25,这是根据谷歌金融的当前价值。为了这个例子的目的;我将买入 1 个 ATM 看涨期权(执行价:250,升水:9.80),卖出 1 个期货(最后价格:250.70)。这是从 nseindia.com
最近 1 个月的股价走势(来源——谷歌财经)。SBI 的股价一直在波动,最高为 255.70,最低为过去 1 个月(截至 2018 年 3 月 28 日)的 249.25,这是根据谷歌金融的当前价值。为了这个例子的目的;我将买入 1 个 ATM 看涨期权(执行价:250,升水:9.80),卖出 1 个期货(最后价格:250.70)。这是从 nseindia.com 到 2018 年 4 月 26 日到期日的 SBIN 期权链,这是 SBIN 期货
到 2018 年 4 月 26 日到期日的 SBIN 期权链,这是 SBIN 期货  的期权链
的期权链
Python 中如何计算合成多头策略收益?
现在,让我用 Python 编程代码带你看一下收益图。
导入库
Import Libraries
import numpy as np
import matplotlib.pyplot as plt
Define Parameters
# SBIN stock price
spot_price = 249.25
# Long call
strike_price_long_call = 250
premium_long_call = 9.80
# Stock price range at expiration of the put
sT = np.arange(150,350,1)
电话支付
我们定义一个函数来计算看涨期权的收益。该函数将 sT 作为输入,sT 是到期时股票价格、认购期权的执行价格和认购期权的溢价的可能值的范围。它返回看涨期权的收益。
def call_payoff(sT, strike_price, premium):
return np.where(sT > strike_price, sT - strike_price, 0) - premium
payoff_long_call = call_payoff (sT, strike_price_long_call, premium_long_call)
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_long_call,label='Long Call',color='g')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()
 T2】
T2】股票收益
stock_payoff = (sT - spot_price)*-1.0
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,stock_payoff,label='Stock Payoff',color='b')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()
 T2】
T2】合成长期看跌回报
payoff_synthetic_long_put = payoff_long_call + stock_payoff
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_synthetic_long_put,label='Synthetic Long Put')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()
 T2】
T2】print ("Max Profit:", max(payoff_synthetic_long_put))
print ("Max Loss:", min(payoff_synthetic_long_put))
89.45
-10.55
最大盈利: 89.45 印度卢比最大亏损: -10.55 印度卢比由于上面的收益图代表了一个看跌期权的收益图,所以称为合成多头看跌。
结论
就相似的风险和回报而言,这种策略与看跌策略非常相似。那些对卖出期货合约或构建激进期权价差没有把握,但希望获利的交易者可以采用这种策略。如果你想创造一个合成的长期看跌期权,你必须记住期权和股票不同,它是有期限的。
现代交易需要系统的方法,需要引导自己远离直觉交易。通过我们的系统期权交易课程,学习如何以系统的方式交易期权。此外,你可以探索期权交易策略,如蝴蝶,铁秃鹰和传播策略。立即注册!
下载数据文件
- 合成多头交易策略- Python 代码
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
系统期权交易介绍|网上研讨会
原文:https://blog.quantinsti.com/system-options-trading-webinar/
网络研讨会录制
https://www.youtube.com/embed/OliTS9tq81E?rel=0
介绍会;展示会
https://www.slideshare.net/slideshow/embed_code/key/mPZzQp6hg9v1Rr?hostedIn=slideshare&page=upload
关于会议
你是不是想开始你的期权交易之旅,但不确定该怎么做?这是一个必须参加的网上研讨会,您可以从中获得所有问题的答案。无论你对系统性期权交易过程的某个特定部分还是整个过程感到好奇,本次网络研讨会都会让你对其有一个全面的了解。
会话大纲
- 需要系统的期权交易
- 流程的简要概述
- 交易期权时常见的注意事项
- 互动问答
关于演讲者
阿克谢·乔杜里(量化分析师,QuantInsti)

阿克谢拥有 IIT 坎普尔大学的学士学位。他在 QuantInsti 的 Quantra 研究和内容团队担任定量分析师。在此之前,他在 Jio 担任数据科学家。他喜欢交易期权,阅读市场心理学。
本次活动于:
2022 年 8 月 18 日星期四
东部时间上午 9:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30
Nitesh Khandelwal 在 Better System Trader - Backtesting 平台、统计套利和 HFT
原文:https://blog.quantinsti.com/system-trader-backtesting-platforms-statistical-arbitrage-and-hft/
我们的联合创始人兼董事 Nitesh Khandelwal 应 Better System Trader 的 Andrew Swanscott 的邀请接受了采访,他分享了对各种回溯测试平台、统计套利和高频交易的见解。
讨论的话题
- 算法交易平台的 3 个关键组成部分,以及在选择交易平台之前你需要回答的基本问题
- 为什么回溯测试和执行平台应该分开
- 选择编程语言以及为什么 python 成为交易中的热门选择
- 在交易中使用 python 的利与弊
- 统计套利,它是如何产生的,以及这种方法的好处
- 统计套利的主要风险,尤其是在市场紧张时期,以及如何降低这些风险
- 统计套利交易中最重要的因素
- 交易者在建立统计套利模型时常犯的错误
关于更好的系统交易员
Better System Trader 由安德鲁·斯旺斯科特(Andrew Swanscott)创立,以两个主要功能而闻名,即博客和播客。BST 联系领先的行业专家,与所有级别的交易者分享他们行之有效的战术和策略,帮助他们提高交易水平。
系统交易:介绍,策略,等等
有了这篇文章,你将能够用系统交易的要领充实自己。找出系统交易者的角色需要什么样的技能和资格。此外,要做好这份工作,你必须知道我们将要讨论的系统交易者的责任。
本文涵盖:
什么是系统交易?
系统交易(Systematic trading),也称为方法交易(methodical trading),通过算法交易程序的帮助来交易宏观经济市场,主要由对冲基金使用。此外,系统交易者利用市场数据的技术分析,如价格或交易量,来检测市场趋势。然后,他们持有头寸,根据信号获利。通过这门关于量化投资组合管理的课程,你可以学习如何构建自己的投资组合,从而获得最大收益并管理风险。
系统交易意味着在计算模型的帮助下设计交易策略,以使交易自动化。深入研究这个概念,除了根据有利可图的交易信号进行交易,系统交易者还要注意:
- 定义贸易目标
- 交易时的风险控制措施和规则
- 在处理新的数据源时进行数据清理,因为也可能存在一些错误条目
此外,这并不是说系统交易仅仅意味着完全自动化的实践。系统交易既包括手工交易,也包括使用计算机的全部或部分自动化交易。但是,您可以参考 Quantra 上专门为学习自动化交易而设计的学习课程。
好了,继续,让我们也找出为什么选择系统交易。
为什么要系统交易?
系统交易带来很多好处,因此,作为一个系统交易者,你将在对冲基金中解决很多问题。我们列出了系统交易带来的好处,如下所示:
- 系统交易有助于避免人类情绪带来的风险
- 完全或部分自动化交易系统有助于利用市场中有利可图的情况,因为自动化系统以更快的速度识别有利可图的情况并执行交易
- 回溯测试交易策略的能力
- 有助于有效管理复杂投资组合的风险
系统交易有助于避免与人类情绪相关的风险
作为一个手工交易者,有几种情绪可能会妨碍交易决策。例如,在市场波动期间,一种恐惧的情绪使交易者不知所措。因此,交易者最终基于恐惧而不是理性的方法做出决定。但是,一旦交易策略到位,这种风险可以减轻。交易策略是自动化的,因此,决策都是理性的,而不是情绪化的。
自动交易系统有助于利用市场中有利可图的情况
还有一个优点是,自动交易系统可以找出最有利可图的情况,即使它们发生的时间间隔很短。该系统可以在整个实时交易过程中通过交易平台自动买卖订单。更快地执行交易指令减少了因猜测而错过交易的机会。例如,交易系统可以在股票的一分钟棒线上运行,这对自动化交易系统来说是一件容易的事情。
回测交易策略的能力
有了系统交易,就有可能根据历史数据测试策略。这就是所谓的回溯测试交易策略,它告诉你该策略在过去的表现。因此,它给出了一个关于策略在当前情况或实际市场中的表现的想法。虽然它不能保证将来的结果,但是对策略进行回溯测试可以为您提供对潜在策略的评估。这样,那些在市场上表现不佳的策略就可以被淘汰。
现在,接下来让我们找出系统交易策略的类型。
系统交易策略的类型
系统交易者使用交易策略,特别是为了克服市场的波动。在动荡时期,恐惧或恐慌会突然爆发,在这种情况下,系统的交易策略可以在非情绪化决策的帮助下拯救投资者。这些策略与一般策略没有太大的不同。唯一的好处是,这些策略是通过算法自动化的,以做出最理性的决定,并保护投资者免受动荡市场的影响。
对冲基金的系统交易员可以采用的一些常见的类型的交易策略有:
- 动量交易
- 配对交易
- 隐马尔可夫模型
- 现金期货套利
- 基于新闻的自动交易
动量交易
动量交易策略的主要目标是在有短期上涨趋势时买入,每当股票开始失去动量(开始显示下跌趋势或已经达到峰值)时卖出或做空。
使用系统交易方法,算法被创建来决定进入市场的最有利时间,持有期和退出时间。
因此,算法会完成所有工作,并确保波动性不会对投资者产生负面影响。在自动化流程的帮助下,过早建仓、过晚退出或错过投资有利时机的风险得到了缓解。
而且,你可以从这门课中学到关于动量交易策略的一切。
配对交易
在配对交易的情况下,两个高度相关的股票的多头和空头是匹配的。高相关性的存在是策略有益的必要条件。当相关性存在差异时,这种策略是有益的。
Pairs 交易又被称为统计套利交易。你可以参考这门课学习同样的内容,使用 Python 创建交易模型,并对商品市场数据的策略进行回溯测试。
系统交易中的算法确保他们发现相关性何时开始变弱。因此,如果表现不佳的资产恢复价值,做多将是有益的。另一方面,表现突出的资产价格可能开始下跌,在这种情况下,投资者必须做空该资产。系统交易通过自动化这个过程来帮助你。
隐马尔可夫模型
隐马尔可夫模型,也称政权机器模型,可以部署进行有利交易。
马尔可夫分析是一种用于预测变量值的模型,其预测值基于当前位置而不是任何历史表现。因此,如果一只股票今天上涨,投资者可以预测它明天上涨的概率。
在系统交易的帮助下,股票价值的可预测性可以在特定天数内自动进行有益的交易。
现货期货套利
这种策略利用了股票的现货价格和期货价格之间的差异。这意味着投资者可以卖出目前报价较高的期货,并以较低的价格买入等量的股票。这样,两者之间的差额就是利润。
系统交易有助于这一策略,因为自动算法可以预测当前和未来的最佳买入或卖出时间。
基于新闻的自动交易
这是一种先进的自动交易策略,它基于金融市场的新闻。在基于新闻的交易中,新闻的情绪被用来估计股票价格的变动。
此外,你可以在这里的课程中通过新闻和推文了解交易策略。
因此,一旦投资者了解了股票的可能回报,他/她就可以交易了。
您还可以在下面的视频中根据交易风格和系统交易策略的类别找到更深入的观点:
https://www.youtube.com/embed/EnQDHtifjVo?feature=oembed
此外,你应该通读关于量化策略的初级读本,以便更好地理解。好的,我们将继续前进,找出系统交易和自主交易的区别。
系统交易与全权委托交易
虽然我们这里有一篇全面的文章让你详细了解系统交易和全权委托交易的区别,但在这里你可以找到简单的要点:
系统交易
- 市场中的交易决策取决于各种事情,如编程、历史数据研究、回溯测试、风险管理和预测市场表现。然后形成进入和退出市场的算法。
- 在系统交易中,交易决策没有受情绪影响的风险,因为算法是基于一套逻辑指令的。
- 系统交易不需要监控市场图表。信息被输入系统,根据可能的最佳结果自动做出决定。
- 这些规则是预先定义的,并通过创建的算法提供给系统。这些规则还依赖于回溯测试历史数据,这增加了成功的结果。
- 交易的成功取决于对历史数据的回溯测试。交易被置于预先定义的水平,并由算法导航。
- 情绪分析和这样的方法帮助交易者在交易时保持有利地位。算法被设计用来解读市场的波动,并做出合乎逻辑的决定。
全权委托交易
- 策略和交易决策来源于学习图表、市场条件、指示信号和此类相关因素。然后进入和退出市场。
- 交易员有时可能会变得容易受情绪因素影响,尤其是在市场波动期间。交易者可能会被恐惧、贪婪等抓住把柄。这导致重大损失。
- 交易者不根据机器来做决定,下一个最好的决定是人工决定的。
- 没有预先定义的规则作为交易决策的基础。这些决定是基于交易者的经验,基于多年的研究和多次执行。
- 随着市场的突然波动,交易者可能会做出冲动的决定,导致亏损。这些损失是由于恐惧而无法评估形势造成的。
接下来,我们将讨论成为系统交易者的技巧和首选资格。
成为系统交易者的技能和优先资格
在一些对冲基金中,对系统交易者的要求包括一系列资格和技能。让我们讨论一下所需的资格和技能。
资格
以下专业的学士学位:
- 科学,
- 技术,
- 工程或
- 数学
技能
- 定量研究感知
- 处理不确定性并相应调整行动的能力
- 运营领导力
- 对交易和交易算法有浓厚的兴趣
- 解决问题的态度和战略决策
此外,让我们通过一些简单的步骤来了解如何成为系统交易者。
如何成为系统交易者?
要成为系统交易者,你应该在以下方面投入时间和精力:
- 培养
- 书
- 交易知识
- 了解工作流程
训练
培训,你可以作为实习生或实习生加入一个组织,以便熟悉工作流程和道德规范。
你也可以选择在线课程。这里有一些你可以选择的在线课程。
书籍
书籍扮演着重要的角色,因为它们是你开始算法交易的最佳指南。在这里阅读你的精彩事业中可能需要的所有基本书籍。
交易知识
还有,一定要有交易知识。从算法交易开始,你必须了解:
- 交易工具的类型(股票、期权、货币等。),
- 策略类型(趋势跟踪、均值反转等。),
- 套利机会,
- 期权定价模型,以及
- 风险管理
想了解更多从算法交易入手的知识,可以参考博客这里。
了解工作流程
系统交易的实际工作流程包括以下内容:
- 战略制定
- 用 Python 等计算机语言编写策略代码
- 回溯测试策略
- 实施战略
要详细了解工作流程,请参考此处的博客。为了成为系统交易者,你也可以从我们的 EPAT 项目中学习系统交易策略。对于系统交易的入门,你可以试试蓝移。
现在,让我们来讨论系统交易者的角色和责任。
角色和职责
为了有效的结果和最好的交易实践,系统交易者每天需要扮演几个角色和责任。这些角色和职责包括:
- 定期检查当前新闻,以确定潜在风险和战略利润或损失。
- 使用新的数据源来保持准确性。
- 数据清理实践,以便从新数据中删除错误条目。
- 用诸如 Python、C++等计算机编程语言创建代码。来制定新的策略。
- 开发有利于投资者的新交易策略。为了确保策略的成功,系统交易者需要对策略进行彻底的回溯测试。
- 研究新想法,以便将其发展为战略。
系统交易者平常的一天
此外,许多交易者喜欢住在离工作场所近的地方(通勤时间在 30-40 分钟之内),因为他们必须早点到办公室。例如,一个在伦敦进行欧洲市场交易的交易员,至少需要在英国时间早上 8 点欧洲开盘前的早上 7- 7:30 到达交易台。
这给了你足够的时间来为一天的剩余时间做准备,我们接下来会讨论这一点。
为即将到来的一天所做的准备包括对一夜之间世界上发生的事情的所有研究和分析,以及当天是否会有任何关键数据发布。
例如,如果你是一名利率交易员,那么你需要关注央行的任何发展或声明,以及前一天的任何关键数据发布,如非农就业数据(美国就业数据)。除此之外,你还需要考虑你的隔夜头寸,以及你打算如何增持、减持或对冲它们。量化交易员可能不得不考虑如何调整模型的参数。
然后是开盘时段,这是一个相当繁忙的时段,可能会持续两到三个小时(比如从上午 8 点到 12 点),这取决于市场。有一些很好的机会来建立一些新的职位或削减一些现有的职位。
再次,市场在收盘时变得繁忙,你和/或你的算法在上面!在所有的会议中,你要关注 PnL/风险,确保你的交易在你的限额和公司/交易台的授权范围内。在一天结束时,你再次考虑你的立场,并对冲你的风险,如果需要的话。
好吧!既然我们已经到了文章的结尾,让我们也看看结论。
结论
这篇文章旨在带你了解与系统交易相关的重要话题。我们讨论了系统交易的几个方面,从什么和为什么开始。系统交易是一种专业,旨在使交易自动化,以方便投资者。在 Quantra 的课程中有一些简单的步骤来开始系统交易,一旦你准备好开始系统交易,Blueshift 会帮助你。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
纳税日交易-季节性优势?
原文:https://blog.quantinsti.com/tax-day-trade-seasonal-advantage/

JB 玛沃德的客座博文
尽管有效市场假说可能会有所暗示,但金融市场中仍存在许多季节性边缘和市场异常。
通常,棘手的部分是发现这些异常,并能够在它们被发现和套利之前从中获利。
斯蒂芬·莫菲特(Stephen Moffitt)调查的纳税日交易是另一个至今仍然存在的优势。
纳税日策略
纳税日交易是一种基于美国联邦所得税到期日的交易策略。这是一个单日交易,你在纳税日收盘时进入标准普尔 500,然后在第二天收盘时卖出。
因此,这是一个非常容易执行的交易,它依赖于简单的行为偏差。
交易结果
自 1980 年以来,纳税日交易每年的回报率约为 0.5%。你可以看到自 1980 年以来的回报率相当稳定:

来源:莫菲特、史蒂文,《纳税日交易:一个有效的市场异常》(2017 年 2 月 2 日)。可在 SSRN 买到。
这个策略最有趣的部分是为什么在 1980 年后有优势,而在此之前没有。自 1980 年以来,回报率一直非常稳定。但是在 1980 年之前,结果远没有吸引力…
为什么会有边缘?
为了理解这一点,我们必须看一看实际的税法和当时发生的变化,以了解优势的基础。
在那段时间里,美国的税收和退休状况发生了两大变化。
1974 年
- 1974 年雇员退休收入保障法案(ERISA) -建立有限制的个人退休帐户。
1981 年
- 1981 年经济复苏税法(肯普-罗斯法案)-允许所有在职纳税人创建个人退休账户(IRA)。
爱尔兰共和军的力量
1974 年制定的法律允许一些纳税人在纳税截止日当天或之前向免税个人退休账户(IRA)缴款。
1981 年的变化意味着爱尔兰共和军扩大到包括所有工人。
个人退休帐户是一个强有力的工具,因为他们允许免税捐款。
从 2017 年开始,你可以选择在取款时不缴税,也可以选择缴纳捐款税。或者不缴纳任何供款,在提取时缴纳税款。
这种账户非常受公众欢迎,因为它们可以大幅减少通常用于资本收益的税收。
股市异常
因此,市场优势是存在的,因为许多人不到最后一刻都不想交税。
这可能是出于行为原因(比如想要推迟令人不快的报税任务)或理性原因(比如直到最后一天才获得正确报税所需的所有信息)。
不管是哪种情况,大量的投资者都坚持到最后一刻,然后他们会争先恐后地把钱投资到个人退休帐户,以节省税收。
其结果是,正当纳税人试图避税、应该缴税的时候,资金源源不断地流入美国股市。
分析显示,自 1980 年以来,在纳税日收盘时买入标准普尔 500 期货,一天后收盘时退出,平均收益为 0.5%。
结论
这种策略似乎是金融市场中存在的另一种季节性优势,表明市场并非完全有效。
像所有市场异常现象一样,没有人能保证它会继续有效,但在过去 30 年左右的时间里,它一直表现稳定。
今年(2018 年)美国的纳税日是 4 月 17 日星期二。
免责声明:这篇客座博文中提供的观点、意见和信息仅属于作者个人,并不代表 QuantInsti 的观点、意见和信息。本文中所做的任何陈述或共享的链接的准确性、完整性和有效性都不能得到保证。我们对任何错误、遗漏或陈述不承担任何责任。与侵犯知识产权相关的任何责任由他们承担。
一个技术专家如何为进入量子金融领域铺平道路
原文:https://blog.quantinsti.com/tech-expert-quant-finance-domain/
技术在交易中的作用越来越大,这促使人们用更先进的技术取代旧的手工交易技术。算法交易的指数增长就是证明!
这使得许多技术专业人士能够通过开发和优化交易算法,在交易领域应用他们的技术专长。Sunil Guglani 先生就是这样一个人,他决定扩展自己的技术知识,进入算法交易领域。
Sunil Guglani 先生是一位拥有 19 年经验的技术爱好者,他还开发了多个用于回溯测试和技术分析的库,他决定分享他进入算法和量化交易领域的惊人旅程的经验!
我们与 Sunil Guglani 先生的对话
你好!给我们介绍一下你自己。
我是一名拥有 19 年经验的 IT 专业人员,在我的任期内,我扮演过不同的角色。我 6 个月前开始交易。老实说,股票市场吸引了每个人,因为它感觉你可以从这里赚快钱。我也不例外。
是什么激起了你对算法交易的兴趣?
作为一名 IT 专业人员,我们必须掌握最新的技术。我学习数据科学已经有一段时间了。然后我开始了解算法交易,我意识到数据科学的概念可以很容易地应用在这个领域。
是什么促使你将职业生涯转向量化金融领域?
作为一名数据科学爱好者和对股票的兴趣让我将职业生涯转向了量子金融领域。
是什么让你认为 EPAT 是你的最佳选择?
我在网上搜索了一下,发现这个领域的课程并不多。在我看来,EPAT 很有希望首发。
你和 EPAT 相处得怎么样?
在 EPAT 的经历令人满意。该课程结构良好,几乎触及了算法交易的所有方面。许多老师是真正的交易者,这有助于对交易有更多的了解。
离开 EPAT 后,你的旅程如何?它给你的职业生涯/技能组合增加了什么价值?
我辞去了目前的送货经理的工作。并开始为自己做 Algo 交易。我有一个推特账号,可以在上面发布我的分析。从那以后,许多人开始对我的工作感兴趣,并想通过使用我的服务来投资他们的钱。
既然你已经完成了这个里程碑。你未来的职业生涯有什么计划?
到目前为止,我在交易方面做得相当不错。我的逻辑和交易者使用的常规逻辑有点不同,这让我比其他人有优势,他们不会失败。我正计划启动我的 Algo 交易聚合平台,这个平台可以被大众所接触到。
你想给正在算法交易领域开始旅程的人什么信息?
不要认为交易是一个不同的领域,把它想象成一个谜题,你必须在低位买入,在高位卖出,然后退出。像这样制定你的战略,你的战略越独特,它就越具有可持续性。
Sunil 的经历和他决定培养自己对算法交易的兴趣的方式,证明了你需要的只是热情和坚持下去、不断学习的渴望!EPAT 有助于培养你对算法交易的兴趣!
凭借全面的课程结构,EPAT 不仅让学生熟悉金融知识,还传授在算法交易领域取得成功所需的必要技能。EPAT 涵盖的主题给你一个关于算法交易的整体知识,以及它如何应用于金融市场。你可以在这里了解更多所涉及的话题。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 quantin STI EPAT 项目的一名学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的结果对所有人来说可能并不一致。T3】
技术分析十大博客| 2022
原文:https://blog.quantinsti.com/technical-analysis-top-blogs/
听说过技术分析吗?
技术分析是一种通过分析过去的交易活动和历史数据(如价格和交易量)来预测证券未来价格变动的方法。
技术分析着眼于历史数据,主要是价格和交易量,来预测价格波动。利用统计分析和行为经济学等策略帮助交易者和投资者弥合内在价值和市场价格之间的差距。
从无数可用的学习辅助工具中,我们编辑了一些最好的列表。下面列出了 10 大技术分析博客。
如何利用技术指标进行交易?
交易者广泛使用各种技术指标来产生交易信号,包括移动平均线和相对强弱指数。广泛的技术指标被用来预测证券日交易者的价格变动。
通过这个博客,学习技术指标的基础知识,以及技术分析和基本面分析的区别。使用 RSI 和 Ichimoku cloud 这样的流行指标开始你的交易策略。
定量分析师和技术分析师的区别
定量分析师和技术分析师是一个硬币的两面。因为技术分析师和量化分析师都为算法交易实践工作,他们相互联系但又各自独立。通过找出每一个是如何单独工作的,您可以更好地了解每一个的重要性以及融合如何有用。
这是你的量化分析师和技术分析师的信息指南,他们的区别和相似之处,以及量化分析师和技术分析师的联合力量。
用 Python 构建技术指标
你知道吗?
技术指标本质上是基于数据集的数学表示,如价格(高、低、开、闭等)。)或证券交易量来预测价格趋势。
Python 中的技术指标已经成为每个算法交易者的核心概念。分析和确定价格的运动方向使用各种技术指标。学会开发技术分析师用来分析价格变动的最好的技术指标。
头肩底图案
头肩底模式广为人知。技术分析模式需要考虑的一个信息来源是 Bulkowski 的模式库,他对模式进行了严格的定义,并从统计上描述了它们的特征。
在本帖中,你将回顾著名的技术分析模式“头肩底”,我们将分析允许我们利用这种价格配置在市场中建仓的交易规则。
RSI 指标:股票、公式、计算和策略
RSI 是交易者工具箱中的重要工具,因为它有助于在选择市场时机时做出更好的决定。它被认为是一个可靠的技术信号,可以应用于市场分析。RSI 告诉我们股票本身的表现如何。
本文将解释 RSI 指标,演示如何计算它,并研究一些可以使用它的交易技术。必读文章!
市云与交易策略
市云指标是一种技术指标,包括计算证券价格的高、低和收盘的五条短期至中期持续时间线,并在这五条线中的两条线之间绘制一个区域,通常称为市云。为了改善决策并提供更精确的图,生成买卖交易信号的 Ichimoku 云指标通常绘制在烛台旁。
完整的交易技巧和可下载的代码,这本书将教你一切关于一片云的知识。
交易指数(TRIN):公式、计算&策略用 Python 举例
你知道吗?
1967 年,Richard W. Arms,Jr .发明了 TRIN 指数来评估市场的力量,衡量市场供求关系。
今天,TRIN 指数被成功地用来了解市场情绪。此外,未来的价格运动由 TRIN 指示,因为它生成超买和超卖水平,以发现价格指数何时可能改变方向。借助 TRIN 及其应用探索交易。这篇文章将为您提供关于这个振荡器的详细信息。
VWAP 战略:计算、使用和限制
什么是 VWAP?为什么对冲公司、散户和日内交易者会用这个来指导他们的决策?
在这篇博客中,我们将了解 VWAP,如何通过一个例子来计算它,以及如何使用它。在此过程中,我们还将评估它与另一个指标(如移动平均线)相比的优缺点。
价格行为交易概念
价格行动交易方法在不断增长的交易社区中非常流行。个人和机构交易者经常使用价格行为交易策略来预测和研究金融资产的价格变动。
这篇文章将为你提供价格行为交易概念的全面介绍,并教你如何在真实的图表中发现关键的价格行为模式。
低 ADX 交易&其他动量指标
当放缓的势头开始显示出一些力量时,你会怎么做?
EPATian Vijayabhasker Iyer 在他的 EPAT 项目中解释了如何在低 ADX 和其他动量指标下交易。他分享了一个捕捉短期潜在价格波动的技术策略。
本项目中使用的完整数据文件和 python 代码也可以在本文末尾下载。
荣誉奖
建立趋势跟踪策略的五个指标
想学习一种策略来帮助你关注市场的任何新趋势吗?
当你使用趋势跟踪策略时,你只是顺应趋势——也就是说,你在价格上涨时买入,在价格开始下跌时卖出——帮助你保持对市场趋势的关注。在这个博客中,你可以使用最流行的趋势跟踪指标来建立趋势跟踪策略,比如布林线、均线、MACD、RSI 和 OBV。
如何使用布林线?
布林线是一种技术指标,用于以更好的方式分析市场,并帮助我们对资产价格做出更好的假设,即资产是超买还是超卖。一个单一的技术指标可能不会给你带来预期的利润,但是一个组合可以做到。
在这篇文章中,你将了解布林线指标,如何绘制图表,布林线为基础的交易策略,及其局限性。
使用技术分析和随机森林预测股票趋势
这是一个由 EPATian 人 Desigan Reddy 研究、实践和创作的真实案例项目。这篇博客讨论了如何通过使用随机森林、机器学习和技术分析来使用技术指标预测市场走势和股票趋势
技术和金融专家如何成为量化分析师?
股票市场提供了广泛的职业机会。如果你从事业务开发、战略或技术方面的工作,这篇文章将告诉你如何转向盈利方面。良好的行业工作知识会给你巨大的推动。
结论
除了免费的 python 代码,还有许多其他博客和教程可以帮助您探索和理解技术分析的各种概念。你可以在我们的博客这里查看它们。
我们真诚地希望你喜欢这个快速浏览的关于技术分析的 10 大博客,我们的读者发现这些博客在 2022 年是最受欢迎的。请发表评论,让我们知道您希望我们在 2023 年的博客中涉及的主题。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
如何利用技术指标进行交易?
原文:https://blog.quantinsti.com/technical-indicators-trading/
如果你是交易新手,你可能听说过技术指标。移动平均线、相对强弱指数等技术指标是交易员每天用来预测证券价格变动的最常见和最流行的技术指标。在本文中,我们将使用这些技术指标在 Blueshift 平台上创建并回测一个交易策略。
但在此之前,我们将涵盖以下主题,以更好地理解技术指标。
- 什么是技术分析?
- 技术分析和基本面分析的区别
- 什么是技术指标?
- 为什么我们需要技术指标?
- 技术指标的最佳组合是什么?
- 技术分析库(ta-lib)
- 使用 Ichimoku 云和 RSI 的交易策略
- 技术指标的限制
- 关于技术指标的热门书籍
什么是技术分析?
技术分析是一种通过分析过去的交易活动和历史数据(如价格和交易量)来预测证券未来价格变动的方法。
它基于这样一个假设,即关于一种证券的所有相关信息都已经存在于其价格中。基于这些假设,技术分析师使用各种技术指标和图表模式来衡量证券运动背后的趋势、势头和总体情绪。
另一方面,基本面分析是一种通过分析各种微观和宏观经济因素来评估证券内在价值的方法。然后将证券的内在价值与证券的当前市场价格进行比较。这有助于确定证券是否被高估、低估或公平估价。
例如,为了分析一只股票的表现,基本面分析师关注各种因素,如公司的收益、市盈率、利润率和其他财务指标。为了分析一个经济体的整体健康状况,基本面分析师依赖于宏观经济因素,如 GDP、利率、通货膨胀。
技术分析和基本面分析的区别
| 技术分析 | 基本面分析 |
| 技术分析使用图表模式、历史价格、交易量和未平仓合约(仅限衍生品)来预测证券的未来价格变动。 | 基本面分析使用微观和宏观经济因素来发现证券的内在价值。 |
| 技术分析通常用于短期交易 | 用于长期投资 |
| 交易决策基于技术指标,如均线,振荡指标,和基于动量的指标。它也使用烛台模式:多奇,晨星。 | 收入、收益、市盈率、利润率等因素被用来做出投资决策。 |
你也可以看看这个视频,它彻底解释了技术分析和基本面分析的区别。T3】
什么是技术指标?
在本文的前面部分,我们已经多次使用了技术指标。
但是到底什么是技术指标呢?
技术指标是价格和交易量的数学表达式,用来检测证券的价格变动。技术指标的一个例子是用于识别证券趋势的移动平均线。
移动平均是指定数据字段的平均值,例如给定的一组连续期间的价格。当有新数据可用时,通过丢弃最早的值并添加最新的值来计算数据的平均值。
假设你有一个证券的每日价格数据,你需要计算周期为 5 的移动平均线。

5-Day Moving Average
前四个值是 NaN,因为您正在计算 5 天移动周期的移动平均值。第一个移动平均线是为“2021-05-14”计算的,这是从“2021-05-10”到“2021-05-13”的最后五天价格的平均值。同样,“2021-05-17”的移动平均线是从“2021-05-11”到“2021-05-14”的平均价格。
演示移动平均线计算的目的是我们已经使用了一种证券的价格,并做了一些简单的数学计算。同样,所有的技术指标都是用简单到复杂的数学公式,利用证券的价格和成交量计算出来的。
为什么我们需要技术指标?
技术指标有各种各样的好处,让交易者的生活更轻松。
价格的平稳
股票价格波动很快,很难跟踪。简单或指数移动平均线等技术分析指标使数据变得平滑。您可以绘制价格的移动平均线,这有助于更好地理解价格的变动。
价格的走向
技术指标提供了关于证券价格方向和强度的想法。它告诉价格的运动,上升或下降趋势,并确定趋势是强还是弱。这对交易者很重要,因为它有助于确定证券的未来价格。
支撑和阻力位
技术分析指标有助于确定支撑位和阻力位。支撑位和阻力位是价格图表中的特定水平,在这个水平上,价格会停止并反转。
预测波动性
平均真实波动幅度(ATR)等技术指标有助于识别市场的波动性。
你可以阅读更多关于五个指标来建立趋势跟踪策略。
不同类型的技术指标
技术指标大致分为领先指标和滞后指标。
前导指数
领先指标试图通过在趋势即将开始时发出信号来预测证券的价格。这些指标在计算中使用较短的时间周期,因此引导价格运动。一些流行的领先指标是 RSI 和随机振荡指标。
后续指标
滞后指标跟随证券价格,在趋势反转开始后给出信号。均线是最常见的滞后指标。
进一步来说,技术指标可以根据趋势、、动量、成交量、波动率来划分。这些可以分为领先或落后。
趋势指标
- 抛物线止跌反转(抛物线 SAR) : 抛物线 SAR 是一种滞后指标,用于确定趋势的方向和反转。
- 一片云 : 一片云指标同时作为动量和趋势指标,帮助确定方向、动量和支撑位-阻力位。
势头指标
动量指标用于确定价格运动的方向和速度。大多数动量指标使用某种基线或平均值来确定趋势的方向。
例如,低于平均线或基线的价格可以被认为是看跌或看涨,这取决于指标的类型和计算方法。
- 【MACD】:【MACD】显示了证券价格的两条移动平均线之间的关系,主要用于识别趋势。
- 随机振荡器 : 它是一个领先指标,用于识别超卖和超买的情况。
- 相对强弱指数(RSI): RSI 是用来衡量价格运动速度和变化的领先指标。它用于识别超卖和超买的情况。
波动指标
这些技术指标衡量价格运动的速度,不考虑方向。
- 布林线 : 布林线是价格的简单移动平均线,绘制在移动平均线的某些标准偏差之上或之下。它用于识别一种证券的趋势和波动性。
- 平均真实范围:显示价格波动的程度。
音量指示器
这些技术指标根据交易量来衡量趋势的强度。
- 柴金振荡器:监控资金进出市场的情况,可以帮助确定顶部和底部。
- 平衡交易量(OBV): 试图通过比较交易量与价格来衡量积累或分配的水平。
技术指标的最佳组合是什么?
知道哪个指标属于哪个类别是不够的,你必须知道如何以有意义的方式组合指标,以做出更好的交易决策。以错误的方式组合各种指标会导致误导信号。
例如,组合属于同一类别的指标,如 MACD,RSI 导致冗余,不会增加任何价格预测的价值。本质上,这两个指标提供了相同的信号,因为它们考察的是价格行为的动力。
因此,谨慎地组合技术指标以产生良好的交易信号是很重要的。比如 RSI 指标和 Ichimoku 云的组合是更好的选择。
RSI 测量和识别动量交易,Ichimoku 云帮助识别趋势的方向。
我们将使用这些指标,通过 TA-Lib 库创建交易策略。
技术分析库
Ta-Lib 是 Mario Fortier 库开发的最著名的技术分析 Python 库之一。它包括 150+指标,如 MACD,RSI,布林线和烛台模式识别。
在 Python 中安装 TA-Lib 有点棘手。但是在这篇文章中有一步一步的解释。
使用 talib 库计算技术指标非常简单。您只需要调用一个函数并传递所需的参数。让我们使用一行代码来计算 talib 中的相对强度指数。
股票代号“AAPL”的价格数据存储在 aapl_stock_data 数据帧中,如下所示。
泰国期货交易所期权交易技术会议
原文:https://blog.quantinsti.com/thailand-futures-exchange-conference-options-trading-techniques/
 Nitesh Khandelwal addressing the conference
Nitesh Khandelwal addressing the conference
日期:【2014 年 10 月
泰国证券交易所(SET)、泰国期货交易所(TFEX)、FlexTrade & QuantInsti 于 2014 年 10 月在泰国曼谷进行了期权交易技术会议。会议由 QI 联合创始人 Nitesh Khandelwal 和 Rajib Ranjan Borah 主持,出席会议的有 150 多名交易员和一些 HNI 散户投资者。
关于事件
为了让交易者熟悉泰国新兴的期权市场,会议讨论了期权市场、期权交易的风险管理以及通过期权可以实施的各种交易策略。
自动化和算法交易——在泰国交易所期权衍生品交易领域越来越受欢迎——是泰国一个新的但发展迅速的领域。
Nitesh Khandelwal 在泰国期货交易所会议上
 泰国期货交易所会议与会者
泰国期货交易所会议与会者
 泰国期货交易所期权交易技术会议
泰国期货交易所期权交易技术会议
熊猫 OHLC:将分笔成交点数据转换为 OHLC 数据
原文:https://blog.quantinsti.com/tick-tick-ohlc-data-pandas-tutorial/
丹麦 Khajuria
原始形式的交易数据是逐笔成交点数据,其中每笔成交点代表一笔交易。它很有用,但是噪音太大。在这篇博客中,我们使用 Pandas 库的重采样功能将这些点对点(TBT)数据转换成 OHLC(开盘价、最高价、最低价和收盘价)格式。
我们涵盖:
什么是分笔成交点数据?
在我们继续之前,让我们先了解一下什么是分笔成交点数据。买方和卖方之间的单笔交易由一个分笔成交点表示。
换句话说,当一个买方和一个卖方在一个商定的价格上做股票数量的横切时,它用一个分笔成交点来表示。这种类型的多个事务可以在一秒钟内发生,每个事务都用一个分笔成交点来表示。
逐笔数据如下所示。

This data was downloaded from First Rate Data
数据的第一列是交易发生的日期和时间。第二列是最后交易价格(LTP ),第三列是在该特定交易中交易的比特币数量,即最后交易数量(LTQ)。
最后一栏是交易代码。对于本教程,我们将使用 2021 年 2 月 4 日的比特币数据。这个数据是从一级数据下载的。
我们可以添加一些关于数据、预处理等现有博客的推荐读物。
我们也可以在这里添加一段关于熊猫的文字,并链接到我们的博客。
什么是 OHLC 数据?
正如我们现在所知道的,分笔成交点数据是非常高频的数据。如果我们想快速查看 1 分钟、10 分钟或 1 天内的价格时刻,该怎么办?
我们将不得不手动检查每一个点,以检查价格时刻。这听起来很麻烦,但如果我们将数据总结为开盘价、最高价、最低价和收盘价,这实际上可以很快完成。
现在,我们将使用 pandas 库中的重采样功能,完成将分笔成交点数据转换为 OHLC 格式的整个过程。
将分笔成交点数据转换为 OHLC 数据
可以使用以下步骤将分笔成交点数据转换为 OHLC 数据:
步骤 1 -导入熊猫包
Pandas 是一个流行的 Python 包,最广泛地用于处理表格数据。Pandas 用于重要的功能,如数据争论、数据操作、数据分析等。
Rajib Ranjan Borah 通过 Ticker 邀请参加 AIM 2018

简介
由 Ticker 主办的 AIM 2018 旨在解决任何盲点,并探索孵化一些成果的可能性,以及弥合行业需求和主题专家之间的差距。
rajib ran Jan Borah(iRage 和 QuantInsti 首席执行官)应邀参加了 Ticker 于 2018 年 7 月 7 日(周六)在孟买 Leela Palaces 举办的“市场分析(AIM 2018)”的“金融数据科学”讨论小组。
小组讨论由 Diganta Mukerjee 博士(印度统计研究所)主持,参加讨论的有 K . R.C Murty 先生(德意志银行印度分行集团首席信息官副总裁)、Pallab Bhattacharya 先生(雪绒花金融服务部副主任)、Rajib Ranjan Borah 先生(iRage 和 QuantInsti 首席执行官)、Ujjyaini Mitra 女士(Viacom 18 Media PVT . ltd . AVP 战略分析主管)
会议亮点
人工智能/机器学习是当今任何行业的最新热门话题。尽管对其进行了深入研究,但至少在印度的金融服务领域,其潜力仍未得到充分发掘。
金融数据的速度、种类和数量都出现了爆炸式增长。社交媒体活动、移动交互、服务器日志、实时市场反馈、客户服务记录、交易细节、来自现有数据库的信息——洪水永无止境。为了理解这些庞大的数据集,公司越来越多地向数据科学家寻求答案。这些活动包括:
- 捕捉和分析新的数据源,建立预测模型和市场事件模拟
- 使用 Hadoop、NoSQL 和 Storm 等技术挖掘非传统数据集(如地理位置、情感数据),并将其与更传统的数据(如贸易数据)相结合
活动照片
以下是此次活动的更多图片:


关于 Rajib Ranjan Borah
iRage 首席执行官 Rajib Ranjan Borah 先生是 iRage 的联合创始人,iRage 是一家高频交易公司,管理着印度最广泛的交易所交易期权投资组合。他还是 QuantInsti 的联合创始人和董事,QuantInsti 是一家“算法和量化交易”培训和研究机构,培训了来自 130 多个国家的数千名专业人士。他之前的经验包括在所有主要的美国和欧洲交易所(Optiver,Amsterdam)进行高频交易;数据分析技术(甲骨文公司);商业战略咨询(普华永道)和股票衍生品研究(纽约州彭博市)。Rajib 拥有 IIM 加尔各答的 MBA 学位,是一名来自卡纳塔克邦 NIT 的计算机工程师。
关于股票行情
TickerPlant Limited 是金融信息服务行业领先的全球内容提供商之一,整合并传播超低延迟数据馈送、新闻和信息。
时间序列:分析和预测
由于预测股票市场的未来股价对投资者来说至关重要,时间序列及其相关概念在组织数据以进行准确预测方面具有特殊的优势。在这篇文章中,让我们通读时间序列的重要性,它的分析和预测。
这里涉及的一些基本副主题是:
- 什么是时间序列和时间序列分析?
- 时间序列的类型
- 时间序列分析有哪些组成部分?
- 分解构件的结构
- 什么是时间序列预测?
- [如何在 Python 中导入、计算&图、验证时间序列进行预测?](#Import-Calculate & Plot-Validate-Time-Series)
- 时间序列分析:在 Python 中处理日期时间数据
- [时间序列分析中的均值回归](#Mean Reversion-Time-Series)
什么是时间序列和时间序列分析
简单来说,时间序列是一段时间内的一系列观测值,这些观测值通常以固定的间隔排列。为了支持这种说法,下面是一些时间序列的例子:
- 过去 5 年的每日股票价格
- 过去 90 天的 1 分钟股价数据
- 公司过去 10 年的季度收入
- 汽车制造商过去 3 年的月汽车销量
- 过去 50 年中一个州的年失业率
说到时间序列分析,它仅仅意味着识别那些有助于时间序列数据分析的方法。
时间序列分析的主要目的是开发能够最好地捕捉或描述时间序列或数据集的模型。此外,这有助于了解数据集的潜在原因,从而帮助您创建有意义且准确的预测。
此外,我们还会看到一些时间序列的类型。
时间序列的类型
现在让我们看看数据集可能属于的时间序列类型:
- 单变量和多变量
- 静止和非静止
单变量&多变量
单变量时间序列是指单个变量在一段时间内的一组观察值。这里需要注意的一点是,这种类型总是将时间作为隐式变量。并且,如果数据点是等间距的,则不需要明确给出时间变量。这种类型有助于您决定因变量(价格值)如何随时间变化,因变量是自变量。
例如,A 公司过去两年的股票价格数据被取出,每年每个月的股票价格被提及。这里,让我们假设十二月和一月的股票价格在一个特定的范围内。
现在,每当我们需要预测未来的股票价格时,我们都会查看过去的数据。这将告诉我们,在接下来的一年中,股票价格可能会在 12 月和 1 月的特定范围内。在此基础上,你也许可以做出交易决定。
这样,你可以从过去的许多年中提取数据,并找出一个依赖于时间的变量在这些年中是如何表现的,以便正确地预测未来。
在这个例子中,我们只使用了一个变量,即“股票价格”,它依赖于时间。
太好了!更进一步,还有另一种被称为多元的类型。现在让我们看看什么是多元时间序列。
多变量时间序列是指一段时间内几个变量而不是一个变量的一组观察值。在这种类型中,每个变量不仅依赖于一种等间距数据,还依赖于除此之外的其他变量。
例如,同一家公司 A 的股票价格不仅取决于每年每个月的时间,还取决于其他变量,如时尚趋势、场合等。
现在,这样一个变量(股票价格)依赖于如此多的其他变量,如何帮助你预测未来的股票价格?
为此,你必须考虑你观察到的变量所依赖的每一个变量,并且基于这项研究,你也要预测未来的股票价格。
让我们向前看一看平稳和非平稳时间序列。
平稳&非平稳时间序列
平稳时间序列
定义一个平稳的时间序列,它是一个均值和方差都是常数的时间序列。换句话说,它的性质不依赖于观测时间。因此,时间序列是没有趋势的平坦序列,具有随时间的恒定方差、恒定均值、恒定自相关和无季节性。这使得平稳的时间序列易于预测。
非平稳的
非平稳时间序列是指均值或方差或两者都不随时间恒定的时间序列。
有不同的测试可用于检查给定的时间序列是否是平稳的:
- 自相关函数(ACF)测试
- 偏自相关函数(PACF)检验
自相关函数(ACF)测试–自相关函数检查由滞后“h”分隔的时间序列的两个不同数据点之间的相关性。例如,ACF 将检查点#1 和#2、#2 和#3 等之间的相关性。类似地,对于滞后 3,ACF 功能将在点#1 和#4、#2 和#5、#3 和#6 等之间进行检查。
自相关函数检验主要用于两个原因:
- 用于检测数据中的非随机性
- 用于识别特定数据集的适当时间序列模型。
因此,自相关函数测试对于提供准确的结果非常重要。
用于 ACF 的 Python 代码
在算法交易中开创自己的事业
原文:https://blog.quantinsti.com/tips-start-business-algorithmic-trading/

你在工作中做得很好,但总是觉得需要迎合做更多事情的愿望,建立自己的东西?你对所选择的工作领域充满热情。您已经广泛探索了不同的组织及其工作流程。
创业似乎是唯一合乎逻辑的前进步骤。唯一关心的是怎么做?你需要回答的基本问题是还有谁,他们是如何做到的。形势分析有助于你展现最好的一面。来自两个不同国家的金融专家德里克和马克西姆在 QuantInsti 的算法交易的高管项目中进行了交流。
相似的工作经历和人生目标引发了一段友谊,这段友谊导致了一次商业冒险。德里克的量化研究公司 Golden Compass 表现出色,是我们的招聘伙伴之一。请继续阅读,详细了解这个关于职业卓越和企业家精神的故事。
下面是我们与德里克互动的记录
Tell us a little about yourself?
我和妻子在中国生活了 3 年多。有了机械工程的学术背景,我开始了我的期货交易生涯,在芝加哥期货交易所做跑腿和文员。在娱乐方面,我喜欢航海、游戏、滑雪和射击。在前世,我是一个国际二十一点队的成员,职业玩扑克。
When did you discover your passion for the financial market? (especially quantization and algorithmic transactions)
我一直在我的家族企业工作,觉得这不适合我的心态。在玩了大量的扑克和 21 点后,很明显这不是一个很受社会欢迎的职业道路。所以我开始和一些老同事谈论交易,因为我正在考虑回到过去。一旦我能够将我的赌丨博背景与我的工程、交易背景和科学方法结合起来。要打败的新“游戏”是市场,从那以后我就迷上了它。
How did you come into contact with QuantInsti's EPAT project?
我总是在寻找新的地方来获得想法或继续获得技能和专业知识。我想我只是碰巧点击了链接。在那个时候,没有很多评论或博客谈论这种体验。但是看了一下课程,我想我应该试一试。那最终是正确的决定。
How was your study experience?
我觉得程序挺严谨的。然而,这确实需要一些认真的时间投入。从内容的角度来看,它是优秀的。我认为,在我们毕业后,校友小组的建立保持了一种支持的感觉。与你在美国或欧洲看到的相比,来自亚洲的视角非常与众不同。此外,能够与像 Max 这样聪明的同学交流也很重要。这让我们能够分享经验和新奇的材料,让我们有机会请求教授允许我们作为一个团队来完成我们的最终项目。
When and how did you come up with the idea of starting your own quantitative research company?
现在,通过使用 Skype 或微信等通讯技术,世界变得小了很多,马克斯和我能够继续进行 6 个月的研发工作。然后,我们决定在曼谷见面,因为我们在衍生品领域的背景非常契合。我们俩都有丰富的期货和期权工作经验,而大部分内容都是关于股票的。我们在游泳,在一个轻松的灵光乍现的时刻,我们决定“让我们做点什么吧”。让我们的合作更上一层楼。
So far, how is your golden compass plan going?
对我来说,这是一次发现创业世界的全新而激动人心的旅程。作为一个项目经理和交易员出身的人,加入这样一个能充分利用我们团队力量的团队确实是一个巨大的激励。此外,我们在技术堆栈和基础设施方面的发展也是我们成功的重要因素。我们也很喜欢 QuantInsti 的就业计划给予我们的支持,帮助我们接触到合格的 EPAT 校友。
What does the future look like? (for entrepreneurship and the whole industry)
以前阿尔法的商品化已经并将继续蚕食基金经理的业绩。这影响了所有类型的交易员,从 HFT、商品化速度到大型股票基金,智能贝塔 ETF 的廉价复制给费用和 AUM 带来了压力。
对我们公司来说,我们认为这是一个好处,因为大多数公司需要了解他们在这个新世界中的实际位置。我们公司可以提供具有成本效益的研究、开发和服务,让那些可能面临压力的公司在这个新世界中实现业绩。同时也提高了中小型客户的门槛,这些客户无力开设整个部门,但仍需要这种类型的工作来保持竞争力或变得过时。
How does EPAT help you? Would you recommend it to others?
EPAT 帮助了我,不仅把我介绍给了马克斯,还让我与越来越多来自不同背景的校友进行了互动。如果您正在寻找该领域的专业概述,或者已经是研究一些新主题的专家,EPAT 可以帮助您学习一些新知识。我期待着看到 QuantInsti 的持续发展,以及来自该计划的聪明人的网络。
向所有未来的领导者和算法商业的渴望者欢呼
向所有对市场、企业家精神有浓厚兴趣的人大声疾呼。与像德里克和马克西姆这样志同道合的人交流,报名参加算法交易(EPAT)高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。
下一步
我们将向您介绍我们的一位员工劳伦斯·特劳德·K·拉吉,他已经在技术领域工作了二十多年,领导过不同的业务部门。在我们的帖子中了解他如何在算法交易领域出类拔萃如何成为一名独立的算法交易员?’。
对阅读马克西姆的故事也感兴趣,点击这里。
面向初学者的 10 大机器学习算法
原文:https://blog.quantinsti.com/top-10-machine-learning-algorithms-beginners/
以重香重香
英国数学家、计算机科学家、逻辑学家和密码分析学家艾伦·图灵推测,
“这就像一个学生从他的老师那里学到了很多,但通过自己的工作又增加了更多。当这种情况发生时,我觉得一个人不得不认为机器显示了智能。”
为了给你一个机器学习影响的例子,Man group 的 AHL 维度计划是一个 51 亿美元的对冲基金,部分由 AI 管理。在它开始运作后,到 2015 年,它的机器学习算法贡献了该基金一半以上的利润,尽管它管理的资产要少得多。
读完这篇博客后,你将能够理解一些流行的和不可思议的足智多谋的机器学习算法背后的基本逻辑,这些算法已经被交易界使用,并作为你创建最好的机器学习算法的基石。它们是:
线性回归
最初在统计学中开发用于研究输入和输出数值变量之间的关系,它被机器学习社区采用来基于线性回归方程进行预测。
线性回归的数学表示是一个线性方程,它结合一组特定的输入数据(x)来预测该组输入值的输出值(y)。线性方程为每组输入值分配一个系数,这些值称为用希腊字母 Beta (β)表示的系数。
下面提到的方程代表一个线性回归模型,有两组输入值,x 1 和 x 2 。y 代表模型的输出,β 0 ,β 1 ,β 2 为线性方程的系数。
y =β+β【1】x【1】+β【2】【2】
当只有一个输入变量时,线性方程代表一条直线。为简单起见,考虑β 2 等于零,这意味着变量 x 2 不会影响线性回归模型的输出。在这种情况下,线性回归将表示一条直线,其方程如下所示。
y =β0+β1x1
线性回归方程模型的图表如下所示

线性回归可以用来找出股票在一段时间内的总体价格趋势。这有助于我们了解价格变动是积极的还是消极的。
逻辑回归
在逻辑回归中,我们的目标是产生一个离散值,1 或 0。这有助于我们为我们的场景找到一个明确的答案。
逻辑回归在数学上可以表示为,

与线性回归类似,逻辑回归模型计算输入变量的加权和,但它通过特殊的非线性函数(逻辑函数或 sigmoid 函数)运行结果,以生成输出 y。
sigmoid/logistic 函数由下式给出。
y = 1 / (1+ e -x

简单来说,逻辑回归可以用来预测市场的走向。
KNN 分类
K 近邻(KNN)分类的目的是将数据点分成不同的类,以便我们可以基于相似性度量(例如距离函数)对它们进行分类。
KNN 边走边学,在这种意义上,它不需要明确的训练阶段,并开始对由邻居的多数投票决定的数据点进行分类。
该对象被分配到其 k 个最近邻居中最常见的类别。
让我们考虑将一个绿色圆圈分类为 1 类和 2 类的任务。考虑基于 1-最近邻的 KNN 的情况。在这种情况下,KNN 会将绿色圆圈归入 1 类。现在让我们将最近邻居的数量增加到 3,即 3-最近邻居。如图所示,圆圈内有“两个”类别 2 对象和“一个”类别 1 对象。KNN 将绿色圆圈归类为 2 类物体,因为它占大多数。

支持向量机(SVM)
支持向量机最初用于数据分析。最初,一组训练样本被输入到 SVM 算法中,属于一个或另一个类别。然后,该算法建立一个模型,开始将新数据分配给它在训练阶段学习的类别之一。
在 SVM 算法中,创建一个超平面作为类别之间的分界。当 SVM 算法处理一个新的数据点时,根据它出现的一侧,它将被分类到其中一个类别中。

当与交易相关时,可以建立一个 SVM 算法,将股票数据分类为有利的买入、卖出或中性类别,然后根据规则对测试数据进行分类。
决策树
决策树基本上是一种树状的支持工具,可以用来表示原因及其结果。因为一个原因可能有多种影响,我们把它们列出来(就像一棵树有它的分支)。

我们可以通过组织输入数据和预测变量,并根据我们将指定的一些标准来构建决策树。
构建决策树的主要步骤是:
- 检索金融工具的市场数据。
- 引入预测变量(即技术指标、情绪指标、广度指标等)。)
- 设置目标变量或所需输出。
- 在训练数据和测试数据之间拆分数据。
- 生成训练模型的决策树。
- 测试和分析模型。
决策树的缺点是,由于其固有的设计结构,它们容易过拟合。
随机森林
一个随机森林算法被设计用来解决决策树的一些限制。
随机森林由决策树组成,决策树是表示其行动过程或统计概率的决策图。这些多棵树被映射到称为分类和回归 (CART)模型的单棵树。
为了根据对象的属性对其进行分类,每棵树都给出一个分类,据说是为该类“投票”。然后,森林选择票数最多的分类。对于回归,它考虑不同树的输出的平均值。

随机森林的工作方式如下:
- 假设案例数为 N,将这 N 个案例的样本作为训练集。
- 考虑 M 是输入变量的数目,选择一个数 M,使得 m < M 和 M 之间的最佳分裂用于分裂节点。随着树的生长,m 的值保持不变。
- 每棵树都长得尽可能大。
- 通过聚合 n 棵树的预测(即分类的多数票,回归的平均值),预测新数据。
人工神经网络
在我们扮演上帝的探索中,人工神经网络是我们最高的成就之一。我们已经创建了多个相互连接的节点,如图所示,这模仿了我们大脑中的神经元。简单来说,每个神经元通过另一个神经元接收信息,对其执行工作,并将其作为输出传输到另一个神经元。

每个圆形节点代表一个人工神经元,一个箭头代表从一个神经元的输出到另一个神经元的输入的连接。
如果我们用神经网络来寻找各种资产类别之间的相互依赖性,而不是试图预测买入或卖出的选择,那么神经网络会更有用。
k 均值聚类
在这个机器学习算法中,目标是根据数据点的相似性来标记它们。因此,我们没有在算法之前定义聚类,而是算法在前进的过程中找到这些聚类。
一个简单的例子是,给定足球运动员的数据,我们将使用 K-means 聚类并根据他们的相似性标记他们。因此,这些聚类可以基于前锋对任意球或成功铲球得分的偏好,即使算法一开始没有给出预定义的标签。
k-均值聚类对那些认为不同资产之间可能存在表面上看不到的相似性的交易者是有益的。
朴素贝叶斯定理
现在,如果你还记得基本概率,你会知道贝叶斯定理是以这样一种方式表述的,即我们假设我们有与前一事件相关的任何事件的先验知识。
例如,为了检查你上班迟到的概率,人们想知道你在路上是否遇到交通堵塞。
然而,朴素贝叶斯分类器算法假设两个事件相互独立,因此,这在很大程度上简化了计算。最初,朴素贝叶斯仅仅被认为是一种学术练习,但它已经证明了它在现实世界中也能非常好地工作。
朴素贝叶斯算法可用于在没有完整数据的情况下找到不同参数之间的简单关系。
递归神经网络(RNN)
你知道 Siri 和谷歌助手在编程中使用了 RNN 吗?rnn 本质上是一种神经网络,其具有连接到每个节点的存储器,这使得处理顺序数据变得容易,即一个数据单元依赖于前一个数据单元。
解释 RNN 优于普通神经网络的一种方式是,我们应该一个字符一个字符地处理一个单词。如果单词是“trading ”,正常的神经网络节点在移动到“d”时会忘记字符“t ”,而递归神经网络会记住该字符,因为它有自己的记忆。

结论
根据 Preqin 的一项研究,已知有 1,360 只量化基金在其交易过程中使用计算机模型,占所有基金的 9%。如果个人的机器学习策略在测试阶段赚钱,公司会为其组织现金奖励,事实上,公司会投入自己的资金,并在实时交易阶段获利。因此,在竞争中领先一步,每个人,无论是数十亿美元的对冲基金还是个人交易,都试图理解并在其交易策略中实现机器学习。
你可以通过 Quantra 上的 AI in Trading 课程详细学习这些算法,并成功有效地将它们应用到实际市场中。
您可以在 Quantra 上注册在线机器学习课程,该课程涵盖分类算法、机器学习中的性能测量、超参数以及监督分类器的构建。
建议阅读:
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
9 大加密货币交易平台
原文:https://blog.quantinsti.com/top-9-cryptocurrency-trading-platforms/
作者希普拉·特里帕蒂
在我们进入中心主题之前,详细阐述一下加密货币的概念和区块链效应。正如 Daniel Gasteiger 在 TEDxLausanne 的“区块链去神秘化”主题中所说,“区块链只不过是一个数据库,一个公共的数据库,因此不属于任何人。分布式,因此不是集中存储在一台计算机上,而是存储在世界各地的许多计算机上。不断同步以保持交易最新,并通过加密技术进行整体保护,以防止篡改和黑客攻击。这四个特点使这项技术与众不同。丹尼尔对加密货币概念的团结的强烈信念促使他离开他在金融服务领域 20 年的全面职业生涯,专注于区块链概念。想了解更多关于如何制定加密货币策略的信息?阅读我们关于使用数据提取技术的加密货币交易策略的博客。
加密货币交易为什么受欢迎?
- 可以在全球范围内交易的通用货币的概念,其价值和价格每天都在飙升,这是交易者最赚钱的方面。在最初阶段,1 比特币的交易价格是 0.003 美元,比 1 美分还便宜!这种货币迅速升值,价值数百美元。截至今日,1 比特币等于 9881 美元。

来源:https://www . technology review . com/s/607947/the-cryptocurrency-market-is-growing-exponentially/
- 加密货币基于分布式平台上的知识共享。所有人都可以看到整个交易历史。一个区块链是一个事务线程。一个单元或一个块存储许多事务。块的大小是 1MB,通常存储大约 1000 到 2000 个事务。输入的数据不能被更改,也不能被删除,从而使系统完全透明和可信。工作模型的整个资金流动超出了控制税率、信贷使用和市场货币供应的传统做法。
- 那些相信加密货币的人声称它是人类历史上的下一件大事。加密货币不受任何政府机构的控制,这一事实吸引了大量眼球。想象一种不受流动性、通胀和政府补贴控制的通用货币。这将意味着从事加密货币的经济体的商业活动将被完全私有化。
- 严格来说,在这个领域有太多的东西需要测试和验证,然而加密货币是迄今为止被认为最有利可图的货币形式。大多数国家都没有禁止它,但是大多数国家都坚持严格的不管制和不介入的立场。同理,加密货币交易者总是在寻找最可靠的经纪和 加密货币交易平台。
9 最好的 加密货币 交易所
eToro
eToro 是一个社交交易和多资产经纪平台,在塞浦路斯、以色列和英国设有办事处。该平台允许用户观看他人的交易策略并复制它们。该公司的产品 OpenBook 和 WebTraders 允许交易者相互学习。这些功能对用户友好,使用简单,而费用取决于市场动态。

北海巨妖
北海巨妖的创新功能声称是为了迎合快速执行、出色支持和高安全性的需求。该组织总部设在美国旧金山。北海巨妖在全球范围内运行,对于不符合条件的国家进行了预验证。该平台接受加密货币和法定货币,交易通过电汇完成,应在银行完成。平台不接受借记卡、信用卡和现金。

费用低至 0%,取决于你的交易量。计算费用时考虑过去 30 天的交易量。
普罗尼克斯T3】
Poloniex 是一家总部位于美国的资产交易所。在 Poloniex 上交易是安全的,交易者可以探索新的和流行的硬币进行投机。它为主要加密资产提供大量保证金交易和贷款服务。据报道,该网站交易的最大用户群来自俄罗斯(6.06%)和美国(24.84%)。该网站的一个与众不同的因素是它不支持法定货币。
Poloniex 作为加密货币交易平台很受欢迎,用户寻求转换加密货币、保证金交易和贷款。服务遍及全球。费用取决于制造商和接受者,制造商的名字已经列在清单上,接受者是下订单的人。做市商之所以如此命名,是因为他们维持着市场的流动性。每隔 24 小时,该平台根据过去 30 天市场和接受者之间的交易量计算费用,并动态更新费用。

BitFinex
Bitfinex,一个流行的加密货币交易平台,非常适合交易大多数加密货币,如比特币、Bcash、以太坊、Iota、NEO、莱特币、EOS、Dash、Ripple、比特币黄金、Monero、Zcash、以太坊经典、OmiseGO、ETP、Santiment、Qtum、Eidoo、Streamr 和 Aventus。
BitFinex 既允许限价、市价、止损等传统订单,也允许 Iceberg、OCO 和 Post Only 等算法交易。
BitFinex 有三个不同用途的钱包,即。交易所、保证金和融资。费用与北海巨妖相同,交易是零费用还是少量费用取决于交易者在过去 30 天的交易活动。交易费分为“庄家”费和“庄家”费。

hit BTCT3】
HitBTC 是一个全球交易平台,自 2013 年开始运营,支持多种货币形式。交易平台拥有交易数字资产、代币和 ico 的市场。
HitBTC 为每笔市场交易收取费用,同时允许您交易各种加密货币和法定货币,包括比特币、Dogecoin、莱特币、欧元、美元和一系列鲜为人知的加密货币。你可以点击查看费用详情。
该平台在想要测试代码的开发人员中很受欢迎,因为该平台也允许演示交易。

Bittrex
Bitrex 提供对新加密货币令牌的全面审查,并非常重视用户安全。因此被誉为具有良好安全模块的安全钱包。这个加密货币交易平台大量交易 Altcoin。这里列出了平台的交易费用。区块链的最低交易费规定了存款和取款的费用。

位 X 位
BitMEX 是一家衍生品交易所,提供用比特币买卖的杠杆合约。这是一个加密货币交易平台,提供比特币衍生品交易。交易的衍生品是永续掉期合约,这是一种类似于传统期货合约的衍生产品。掉期合约像现货一样交易,跟踪基础资产。

比特币基地
比特币基地总部位于三藩市,是一个在线比特币交易平台,服务于美国、加拿大、欧洲、英国、澳大利亚和新加坡。每天在比特币基地上最多可以买到 150 美元和 150 英镑。比特币基地提供了非常高的限制。限额取决于您的帐户级别,这取决于您验证了多少信息。

本地比特币
Localbitcoins 是一个人与人之间交易的门户,你可以在这里直接与卖家互动。在这个平台上,不同国家的人可以将本国货币兑换成比特币。该网站是为寻求更多隐私的临时交易者建议的。该网站使用托管系统,在卖家账户收到资金后进行比特币转账。在本地比特币上注册、购买和销售是完全免费的,而创建广告的本地比特币用户是收费的,如这里提到的。
所有受欢迎的比特币交易所及其特点的简明表格对比:
 T2】
T2】
寻找更多关于如何开始的指导?阅读我们的博客,了解一位 EPAT 参与者是如何开始加密货币交易的。
下一步
如果你想学习一个简单的策略来从各种加密货币平台获取数据,你可以查看我们关于“加密货币交易策略与数据提取技术”的帖子。该策略将帮助您使用 python 库以分钟的分辨率获取数据。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
2018 年交易策略热门博客
原文:https://blog.quantinsti.com/top-blogs-on-trading-strategies-of-2018/
作者:沙古塔·塔西尔达
一个交易者总是在头脑中保持一个特定的框架,想法或过程,他通过最大化利润或最小化损失或两者兼而有之来实现交易的利益。一个好的战略可以增加获得目标收益和回报最大化的机会。某些参数有助于衡量交易策略的效率。
选择一个交易策略或者自己设计一个,需要你知道这些策略的工作原理,以及它们是如何帮助交易的。我们为初学者和高级学习者列出了一些 QuantInsti 关于交易策略的最好的博客,你绝对需要查看这些博客来增长和提高你的交易策略知识。
以下是我们关于交易策略的一些顶级博客:
如果你想了解所有算法交易策略,这是必去的博客。对算法交易策略的全面描述,如基于动量的策略、套利、统计套利、做市和交易中的机器学习。讨论了它们的工作原理、类型和建模思想。博客继续给你一步一步的建立算法交易策略的方法。
斐波纳契比率用于时间序列分析,以找到支撑位。这篇博客解释了这些比率是什么,以及如何用它们来追溯股票价格。它首先定义了什么是斐波纳契数列,并陈述了一些有趣的事实。这篇博客解释了斐波纳契回撤策略,并展示了实现该策略的 Python 代码。它包括像斐波纳契比率和斐波纳契回撤水平的概念。
铁秃鹰交易策略,这是一个结合了牛看跌价差和熊看涨价差期权交易策略,交易者甚至可以使用一个小账户。该博客首先用简单的例子解释了这种策略及其工作原理,然后继续演示如何使用 Python 实现这种策略。它使用 Yes Bank Limited 的期权数据来执行该策略。除了 Python 代码,人们还可以学习如何计算最大利润和最大损失,这可以帮助我们确定策略将如何工作。
交易者持有看涨和看跌期权的头寸,具有相同的执行价格、相同的到期日和相同的资产,以执行跨期权交易策略。如何实践这个策略,它有哪些类型,你如何从这个策略中获利,都在这个博客中有所解释。使用 Python 代码演示了这种策略的实现,以及买入和卖出收益的计算。
蜡烛图描绘了一种证券在特定时间内的 OHLC 价格。蜡烛图被广泛用于表示价格和技术分析。博客解释了如何使用 Python 绘制图表。它还向我们介绍了一个被称为“三根每日蜡烛”的烛台交易策略,并给出了实现该策略的 Python 代码。
什么是对角点差,如何用它们来设计交易策略?这篇博客回答了这个问题,并比较了不同类型的跨页,如垂直跨页、水平跨页、日历跨页和对角线跨页。它还告诉我们如何计算最大的利润和损失使用对角线传播交易策略。这个策略在 Python 中的实现和它的收益图的演示也包含在这个博客中。
博客从简单讨论蝴蝶差价期权交易策略开始,这是牛市差价和熊市差价的结合,然后列出蝴蝶策略的组成部分。此外,我们了解蝶式价差策略参数的计算,如最大损益、有限损益和盈亏平衡点。最后,博客向我们提供了这种策略在 Python 中的实现,以及收益的计算,如看涨期权收益、看涨期权收益、较高的看涨期权收益、看跌期权收益和蝴蝶差价收益。
这篇博客讨论了如何使用立体投资组合框架来改进量化交易策略。该博客包含高斯混合模型、K 均值聚类和随机森林等概念的详细数学描述。它包含了逐步构建投资组合的 Python 代码。
铁蝴蝶期权交易策略与蝴蝶差价期权交易策略类似,是牛市差价和熊市差价策略的结合。博客展示了这种策略的收益图的构建,以及诸如最大损益和盈亏平衡点等参数的计算。我们从使用 HDFC 期权数据的给定 Python 代码中学习了这种策略的实现。
时间序列数据的方向、动量和支撑位可以用一分云指标来确定。除了解释 Ichimoku 云指标及其计算,该博客还为我们提供了使用 OHLC 数据实现加密货币交易策略的 Python 代码。
颈圈是一种保护性的期权交易策略,可以防止巨大的损失,但也限制了巨大的收益。博客讨论了衣领期权交易策略的组成部分,工作和实施。它还列出了可以应用该策略的各种场景。使用 IDBI Bank Ltd .的数据,用 Python 演示了这种策略及其收益图的一个例子。
这些博客让你熟悉有效交易的不同策略。如果你希望获得更多的实践知识,并想了解更多的各种交易策略及其实现,你可以查看以下课程,其中涵盖了 19+交易策略及其在 Python 中的执行。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
建议阅读:
2018 年顶级加密货币交易博客
原文:https://blog.quantinsti.com/top-cryptocurrency-trading-blogs-2018/
作者:沙古塔·塔西尔达
加密货币对世界和金融市场产生了巨大影响。他们不仅带来了一种新的货币形式,还引进了一种叫做区块链的技术。使它吸引人的是它的特点,如它的分散结构和它提供的安全性。所有这些都让探索加密货币这个话题变得有趣起来。
为了让你了解这个加密货币的世界以及它是如何工作的,以下是关于加密货币的顶级博客的汇编,这将有助于澄清围绕它的许多疑问,并将提供高级主题,以帮助你了解更多关于加密货币交易的信息。
2018 年顶级加密货币交易博客
加密货币交易基础博客
比特币在传播加密货币方面发挥了巨大作用,并创造了对加密货币的大肆宣传。这是因为比特币的价格正处于上升轨道,并达到新高。很快,其他加密货币被开发出来,加密市场充斥着新的加密货币。这篇关于“比特币替代品”的博客提供了你需要了解的除比特币之外的所有其他加密货币的信息。了解主要新兴加密货币,如 Ripple、Monero、Ethereum、Litecoin 等。
随着围绕加密货币交易的所有讨论,越来越多的人正在进入这个领域。但为什么它会如此受欢迎,人们可以使用哪些平台开始加密货币交易?这个博客讨论了这一切!它列出了广泛使用的顶级加密货币交易平台或交易所,并解释了每个平台的特点,以便人们可以根据自己的喜好选择最佳平台。
区块链——为加密货币提供动力的技术!它是什么,如何工作,有什么特点?这篇博客简要介绍了这一切,并解释了区块链是如何与各种福利联系在一起的。如果你有兴趣了解加密货币,那么了解区块链是必须的!很快,由于其广泛的特性,区块链将被用于加密货币以外的其他应用。
就像我们用钱包储钱一样,我们有加密货币钱包来存储加密货币。这个博客讨论了这一切!如果你是加密货币交易的新手,并想了解加密货币钱包的工作原理,那么这是一个非常适合你的博客!它涵盖了加密货币钱包的所有方面,从其基础到选择加密钱包时要考虑的风险和参数。除此之外,它还列出了普遍使用的加密货币钱包,以及它们的功能!
关于加密货币交易的高级博客
这篇博客解释了 Aroon 指标以及它如何用于加密货币交易,并演示了如何计算它。用适当的例子详细说明了它的工作和实现。AroonUp 和 AroonDown 等概念以及它们如何用于加密货币交易将在本博客中讨论。
加密货币数据可以从各种来源获取,如 Quandl、Coinmarketcap、Poloniex 等。这篇博客解释了如何使用 Python 获取数据,包括代码,加密货币交易策略如何工作,以及如何用 Python 编写加密货币交易策略。而且还不止于此!它甚至展示了一种称为“随大流”的策略,这种策略可用于加密货币交易。
市云指标有助于确定时间序列数据的方向、动量和支撑位。这不仅解释了什么是 Ichimoku 云指标,而且还提供了实现这种交易策略的 Python 代码。它展示了如何使用其 OHLC 数据和 Python 代码在加密货币交易中使用它。它还解释了 Ichimoku 云指标所需的计算。
这些博客让人们深入了解加密货币交易的世界。然而,加密货币交易是一个广阔的领域,还有很多东西需要学习。高级策略、机器学习在加密货币交易中的应用、使用的技术指标是一些有趣的主题,人们可以通过学习来发展自己的加密货币交易技能。所有这些主题都包含在下面的课程中!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
2018 年顶级机器学习博客
原文:https://blog.quantinsti.com/top-machine-learning-blogs-2018/
作者:沙古塔·塔西尔达
有了大量关于机器学习的可用信息,很难分离出学习机器学习的最佳来源。因此,我们在一个地方汇编了一份 QuantInsti 2018 年最佳机器学习博客的列表,以便轻松获取有关机器学习的信息。这些机器学习博客包括基础和高级主题。
顶级机器学习博客
对任何希望了解机器学习基础的人的初学者指南。它试图解释机器学习到底是什么,以及它与人工智能和深度学习等最常见的混淆术语的区别。它简要介绍了机器学习的历史、发展和应用,并附有图表。这篇博客的主题是机器学习算法,如无监督和有监督的机器学习算法,并有相同的例子。
类似于人脑中神经元的功能,人工神经网络是帮助解决复杂问题的互连处理单元。这个博客从数学上演示了一个神经网络如何向前传播。它包括一步一步地解释神经网络隐藏层内的整个过程,包括激活函数、偏差等概念,并辅以示例。
反向传播通过允许我们调整权重和偏差以最小化损失函数来帮助克服正向传播的缺点。这个博客帮助你理解神经网络如何与反向传播一起工作,包括一个详细的例子。它解释了如何通过使用反向传播调整权重和偏差来减少损失函数。
- 深度学习——使用 Python 中 TensorFlow 的人工神经网络(包含可下载文件)
深度学习是一种机器学习技术,涉及通过神经网络的许多层进行复杂处理。深度学习中的‘深度’指的是网络内的层数。这是一篇高级博客文章,你可以通过开发一个人工神经网络来学习预测股票价格。它由开发给定技术并实现它的全部 Python 代码组成。
- Python 中的机器学习逻辑回归:从理论到交易(包含可下载文件)
股票价格的预测可以通过各种方法来完成,这篇博客介绍了一种叫做“逻辑回归”的方法。逻辑回归属于监督学习的范畴,它通过使用 sigmoid 函数给出概率来测量一个或多个变量之间的关系。本博客给出了这个主题的详细解释以及数学函数,后面是 Python 代码,演示了如何实现这个算法来预测股票价格。
深度学习和神经网络的概念通常被视为复杂。这个博客在一个简单和基本的层面上解释了这些概念,让你开始了解它们。它涵盖了深度学习的演变、神经网络的工作、机器学习和深度学习的区别以及深度学习的应用等主题。对于希望开始学习深度学习和神经网络的初学者来说,这是一个完美的博客。
机器学习博客系列:用于股票价格预测的神经网络
本主题分为三个机器学习博客,第一个解释神经网络的基础知识,第二个解释训练模型如何帮助进行预测,第三个指定 Python 代码来实现神经网络模型以预测股票价格。
- 第一部分:用于股票价格预测的神经网络的工作
这是博客系列的第一部分,简要介绍了什么是神经网络,它们与人脑中的神经元有何相似之处,以及这些网络如何解决复杂的问题。它还概述了如何使用神经网络通过 OHLCV(开盘-盘高-盘低-收盘-成交量)数据来预测股票价格。
- 第二部分:训练用于股票价格预测的神经网络
一旦你理解了上一篇博客的工作,这篇博客将继续解释训练神经网络进行预测以获得准确结果的过程。训练网络将有助于降低成本函数和最小化误差。您可以了解梯度下降如何通过最小化误差函数来帮助优化模型。这个博客还列出了实现随机梯度下降来训练神经网络的步骤。
在从前一篇博客中了解了神经网络的主要方面之后,我们最终继续了解如何实际编码神经网络模型,并使用机器学习库 Keras 将其用于股票价格预测。这篇博客作为一步一步的指南来理解用 Python 编码模型的过程。它还演示了如何计算策略回报,并以图形表示形式绘制出来。
机器学习博客系列:用于配对选择的 K-Means 聚类
顾名思义,这个全面的机器学习博客系列提供了对用于对选择和统计套利策略的 K-Means 聚类算法的详细理解和实现。
- 第一部分:
它给出了一个有趣的见解,即在没有 K-Means 帮助的情况下,如何使用蛮力进行配对选择。它演示了使用暴力实现配对选择的整个过程及其 Python 代码。最终,我们明白用蛮力来实现这个策略是多么困难和复杂。
- 第二部分:
作为前一篇博客的延续,这篇博客现在介绍 K-Means 算法,并展示它的优势如何帮助克服我们在使用暴力的系列的第一篇博客中所面临的问题。您可以了解 K-Means 如何将数据点分配给聚类,它是如何工作的,以及如何用图形表示它。
- 第三部分:
在这篇博客中,我们将学习如何使用 Python 代码使用 K-Means 算法构建统计套利策略。这个博客列出了实现机器学习算法的步骤。确定我们应该用什么样的 K 值是很重要的,这解释了如何准确地使用它。最后,我们还学习了一种可视化 K-Means 肘图的方法。
- 第四部分:
在之前关于 K-Means 的机器学习博客中奠定了基础之后,我们最终转向用 Python 编码和实现统计套利策略。我们学习创建一个类,允许我们清理数据,测试协整性,并运行策略。我们终于理解了这个分析,它显示了 K-Means 在寻找非传统统计套利交易对方面的优势。
在通过机器学习博客获得理论知识之后,现在是时候开始使用 Python 实践和实现自己的机器学习策略了。下面的课程让你熟悉交易中使用的主要机器学习算法,并让你用 Python 中的 Jupyter Notebook 练习编码技能。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
您可以报名参加 Quantra 上的在线机器学习课程,该课程涵盖分类算法、机器学习中的性能测量、超参数以及监督分类器的构建。
建议阅读:
获得量化分析师或交易者面试的顶级技巧
原文:https://blog.quantinsti.com/top-skills-nailing-quant-trader-interview/
想保住一份量化分析师或交易员的工作吗?为了得到理想的工作,你应该关注以下几个方面。

1)股票衍生品/期权
衍生品是高度交易的工具。必须了解期权定价模型、希腊人、波动性、对冲和各种期权策略。
2)编程
回测、编写低延迟和超高效代码需要良好的编程技能。
3)统计&概率
概率和统计是交易的关键部分。基本统计学、时间序列、多元分析等。用于制定战略和风险管理。
4)市场和经济
对市场和经济如何运作有很好的了解。
5)数字&脑筋急转弯
数字和思维问题测试用合理的推理得出答案的能力。
关于你的问题
问这些是为了确定你是否适合这份工作。
7)工作意识问题
工作认知问题评估你对工作简介的理解。
使用量化方法交易:要素投资| PyData
原文:https://blog.quantinsti.com/trade-using-quant-methods-factor-investing/
此活动已经结束
2019 年 6 月 22 日星期六
格林威治时间下午 2:30 至 7:30+5:30
由 Sukanya M 主持。
细节
PyData Mumbai 很高兴能与 QuantInsti 联合举办此次 Algo 交易活动。QuantInsti 是一家领先的培训和教育提供商,在 165 多个国家提供算法和量化交易方面的培训和教育,并拥有世界上第一个认证项目。QuantInsti 与许多知名的行业合作伙伴密切合作,并为这些协会为彼此和整个社区增加的价值感到自豪。
举几个例子,QuantInsti 为证券交易所、国际知名券商开设了课程;与领先的行业参与者一起举办研讨会,并受邀参加全球顶级行业活动。
除此之外,QuantInsti 的课程中还包含一些工具&功能,为我们的用户&课程参与者提供更多信息。
议程
参加研讨会的先决条件:
a .外汇动量交易
b .使用 Python 中的真实外汇市场数据创建动量交易策略。在内置平台上做回测,分析结果。
资源:https://quantra.quantinsti.com/courses?
filter = Momentum % 20 trading % 20 in % 20 forex
会议 A -下午 2:30 至 4:15-由伊山·沙阿
主持 A .资产定价
b .要素投资
会议 B - 4:30 至 6:30 -由 Prodipta Ghosh 主持:基于动量的策略的实际演示(本会议需要一台笔记本电脑)
a .回溯测试工具介绍
b .基于动量的投资
c .动量的类型:时间序列和横截面【T11
学习成果
a.计算投资一项资产的预期回报 b .解释要素投资
c .计算超过市场投资组合的表现
演讲者简介
伊山沙阿
向他学习如何建立数据模型、交易规则、自相关函数等统计参数以及如何使用统计学和机器学习来自动化您的交易策略。
行业经验
配对交易策略是伊山的另一个专业领域,他在课程中详细介绍了配对交易策略建模。他在金融市场拥有丰富的经验,在不同的资产类别中担任不同的角色。他曾在巴克莱银行的全球市场团队&和美国银行 Merill Lynch 共事。
Prodipta Ghosh
IIM PGDM 勒克瑙
Prodipta 是 R、Python 和量化交易技术方面的专家。他对 quant &能够将复杂的理论与实践相结合的一切都有诀窍。他就金融计算与金融市场相关的编程概念&发表演讲。
行业经验
Prodipta 是一位经验丰富的 quant,目前在 QuantInsti 担任副总裁,领导 Fin-tech 产品和平台开发。
他在银行业工作了十多年,在孟买和伦敦的德意志银行的交易和结构部门担任过各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
全球曝光
他曾为东南亚的多个机构/企业举办讲座/研讨会,包括马来西亚的肯南加、IIM 的艾哈迈达巴德、IIT 的钦奈和新加坡的 NTU。
活动照片




trade tech FX Europe 2017:quantin STI 作为官方知识合作伙伴
原文:https://blog.quantinsti.com/tradetech-fx-europe-2017-quantinsti/

QuantInsti 作为知识合作伙伴
QuantInsti 是欧洲领先的外汇交易和投资组合管理买方负责人唯一聚会场所——trade tech FX 2017 的官方知识合作伙伴!
我们支持为贸易技术行业创建一个统一平台的想法,并认为我们必须团结起来,提高标准,并借此机会为那些需要支持的人提供支持;我们所有人。
关于 TradeTech FX
TradeTech FX Europe 是必去之地:只有在这里,你才能与 250 名来自领先买方公司的外汇交易和投资组合管理主管一起,对你的人员、流程和技术进行基准测试。
来自欧洲领先买方公司的 250 名外汇交易和投资组合管理主管齐聚巴塞罗那。来自价值链其余部分的 200 名外汇领导者——监管者、卖方、交易平台和技术合作伙伴——加入其中。很简单,这是一个必须参加的会议场所,你所在行业的未来就在这里形成。
如果你真的想建立一个成功的外汇交易平台,那么不要错过这个机会,用那些领先的公司来衡量你的人员、流程和技术。
日期和地点
2017 年 9 月 11 日至 13 日
费尔蒙特雷伊胡安卡洛斯一世,Av。巴塞罗那对角线 661-671 号,邮编 08028
更多关于 https://tradetechfx.wbresearch.com/about-us的细节
基于 Python 社交媒体数据分析的中国 a 股交易
原文:https://blog.quantinsti.com/trading-china-share-stocks-based-social-media-data-analysis-python/
In this article, we will understand how natural language processing, sentiment analysis and social media play a role in the share markets with the help of Python. This would be explained with respect to the trading in China markets A-share stocks.
This article is the final project submitted by the authors as a part of their coursework in the Executive Programme in Algorithmic Trading (EPAT®) at QuantInsti®. Do check our Projects page and have a look at what our students are building.
关于作者
The author of this blog is Fan Zhang, an Assistant Analyst at Fitch (Bohua) Rating located in Beijing, China. Fan is an Engineer, completing his Master of Financial Engineering from Cornell University.

动机
I have been working as a day trader in China A-shares for 2.5 years and frequently check insights from experts on Weibo (Chinese version of Twitter). Based on my experience, the general consensus from social media is predictive of China A-share stock performance in 2-3 days.
By attending the EPAT programme, I learned a comprehensive understanding of quantifying various trading strategies through intensive projects on real market data. Therefore, I am eager to utilize this final project to research my own trading strategy: **the forecasting power of social media for the stock market. **So, let’s proceed with the project.
数据集
i) Stock data for China A-share equitiesDaily equity data includes the date, high, low, open, close, adjusted close and volume. This historical equity data ranges from January 2014 to July 2017.ii) Social media dataWeibo (the Chinese twitter) can be accessed through API, but the Weibo content retrieved and requesting frequency are limited for free accounts. For example, if one account requests more than ~5000 times in 30 minutes through API, the corresponding Weibo account will be blocked for further access.
入围 id
Because of the API requesting limitation and the noise in thousands of not-so-informative public accounts, for this project, twenty Weibo financial IDs were selected based on trading experience.
A strong assumption is that these selected IDs are insightful market players and that the consensus inferred from their tweets will be predictive of future market movements.
The retrieved tweets starting date varies among different IDs. The backtest period is determined as 2016-10-01 to 2017-07-14.
策略
- 在每个交易日上午 00:00-09:30 期间,从认可的微博理财 id 获取社交媒体数据。
- 选择四个有代表性的、被广泛交易或讨论的行业作为潜在的投资组合构成。
- 如果某个板块被至少 3 个专家看好(微博理财 id),就买这个板块的龙头股。股票在投资组合中的资本权重相等。
- 开盘价买入,持有一天,第二天开盘价卖出。
扇区
Sectors in consideration: Artificial Intelligence (AI), Banking, Lithium and Securities. These sectors were chosen because they are frequently discussed sectors and their corresponding keywords are easy to parse using Natural Language Processing techniques, thus avoiding ambiguities in analyzed tweets.
In each sector, only the most five representative and actively-traded equities are bought if the related sector is favoured by Weibo expert consensus.
中文自然语言解析器
Although several Chinese natural language parsers are available, there is no one package is designed for the Chinese financial market. So many financial keywords are not correctly parsed.
For example, the equity “Bank of China (****中国银行)” will be parsed into “China (中国)” and “Bank (银行)”, instead of being recognized as a whole. Such wrong-parsings due to the lack of a financial keyword database create confusion for trading decisions.
Therefore, modifications were made to one public Chinese language parser (HanLP). Chinese financial dictionary was constructed for this project with 4952 financial keywords, including all traded A-share equities and most slangs/jargons used in Weibo tweets.
The modified Chinese financial parser significantly improved parsing performance for trading.
情感分析
The sentiment analysis trading is performed through a commercial package: BosonNLP. For each tweet, the sentiments will consist of two scores for positive tendency and negative tendency, respectively; the sum of the two scores will be 1.
For example, the sentiment scores for “This meal is good” are 0.98 and 0.02, which signifies that this statement is strongly positive and the two scores sum to 1.
战略绩效
The criterion for a buy consensus is set as at least three Weibo IDs favour one sector on one particular day during 00:00-09:30 am.
There are 188 trading days between 2016-10-01 and 2017-07-14 in the Chinese A-share market. Four trading opportunities were traded: two for AI and two for Securities. Three out of these four trades yields positive PnL.
你可以报名参加 Quantra 上的情绪分析课程,这将帮助你利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
结论
This strategy achieved a 3.74% return (annualized return 5.14%) and a Sharpe ratio of 0.86. You can check out the complete project along with related files, python codes and examples in the download section below.
If you want to learn various aspects of Algorithmic trading then check out the Executive Programme in Algorithmic Trading (EPAT®). The course covers training modules like Statistics & Econometrics, Financial Computing & Technology, and Algorithmic & Quantitative Trading. EPAT equips you with the required skill sets to build a promising career in algorithmic trading. Enroll now!
Disclaimer: The information in this project is true and complete to the best of our Student’s knowledge. All recommendations are made without guarantee on the part of the student or QuantInsti®. The student and QuantInsti® disclaim any liability in connection with the use of this information. All content provided in this project is for informational purposes only and we do not guarantee that by using the guidance you will derive a certain profit./overseas
下载中的文件列表:
- 最终项目 PDF 文件
- 项目的 3 个 Python 代码文件
结合交易和编码技巧:毗湿奴如何开始算法交易
原文:https://blog.quantinsti.com/trading-coding-skills-algorithmic-trading/
每个人都有一定的技能,但很少有人知道如何利用这些技能并将其应用到日常活动中。同时,正确的技能组合可以帮助一个人探索新的领域和领域。
算法交易就是这样一个领域,一个人的交易技能结合编码知识可以帮助他成功地实现交易算法。
雅典娜投资公司(Athena Investments)的期权交易员 Vishnu Bharath 就是这样一个人,他将交易和编码技能结合在一起,帮助他在算法交易领域取得成功,找到了一份期权交易员的工作。
下面是我们与毗湿奴的对话。
-
Hi Vishnu, tell us about yourself.
我来自喀拉拉邦一个叫帕拉卡德的地方。这是一个非常宁静的慢节奏环境。然而,我离开家的大部分时间都是为了教育和工作。当我假期回家探亲时,我清楚地了解到生活方式的不同。我必须从这两种环境中吸取最佳实践。我是一个非常守时的注重过程的人。我是一个热情的社交者和跑步爱好者。我喜欢听励志演讲,并给出几个。我总是渴望在一顿美味的晚餐上进行一次精彩的谈话。我拿到了电子和通信工程学位,在爱立信工作了 2 年,然后接受挑战,在 6 个月内转换了职业领域,7 个月内就完成了。谁不喜欢好的挑战呢?
-
你是何时开始交易的,又是如何开始交易的?
2016 年前几个月做了第一笔交易。我记得我买的第一只股票是 HDFC 的,我只买了两只。这有点令人兴奋。对于一个即将上大学的孩子来说,你第一次把这么多钱投入到一个摸不着的东西上是一种体验。我没有做太多的分析,但是我到处听说过 HDFC,我的父亲经常谈到它,这就是我如何结束了我的第一笔交易。
-
来自工程背景的你,是什么促使你探索算法交易领域的?
从大学二年级开始,我就对股票市场非常感兴趣,因为我经常和我爸爸讨论股票市场。我当时的处境是,尽管我在学业上表现得很好,但我认为工程学真的不适合我。作为一个注重过程的人,我必须完成我开始的事情。然而,我的父亲一直在和我讨论,因为他是一名全职期权卖方。即使我不得不加入他,我也需要一些自己的技能,这就是算法交易的由来。问题,“如果我能结合我爸爸的技能和我的编码技能,产生更好的结果,会怎么样?”是游戏规则的改变者。
-
是什么让你认为 EPAT 是学习算法交易的理想选择?
在决定我需要掌握成为算法交易者的技能后,我开始做研究,记住我只有 6 个月到一年的时间来做转换。EPAT 似乎是完美的选择。完成了超过 39 批,得到了各地的好评,并且是唯一一个提供算法交易认证的知名机构,这让我除了 EPAT 别无选择。
-
告诉我们你在 EPAT 的经历。
我想我的经历会非常个人化,因为周末我搬到孟买只是为了做 EPAT 的节目。我参加了每一堂课,按时完成了所有的作业。我喜欢的是服务。我会给它最高的评价。从澄清疑问到采纳反馈,再到在被要求时为我做额外的定制作业,这让我感到非常满意。总而言之,考虑到我付出的努力,这对我来说是一次相当顺利的经历。我要特别感谢我的支持经理和安置团队,他们一丝不苟地做了许多事情来帮助我得到安置。
-
你是如何将学到的知识融入职业生活的?
我在雅典娜投资顾问公司的角色是期权交易员。我在期权交易方面有很好的技能。我得到这份工作也仅仅是因为这个。薪资谈判的最后推动力是我在 Quantinsti 的 EPAT 项目中学到的编程技能。我现在使用 Python 对各种复杂的策略进行回溯测试,从而得到一种更加量化的方法。
-
你有什么建议想和有抱负的量化交易者和算法交易者分享吗?
最重要的是课后你投入的工作量。尝试阅读更多面向行业的文章,并充分利用 QuantInsti 团队的支持,因为他们在自己的领域是最棒的。每天做一点编码。这不是目的地,而是一次旅行。你做得越多,你就做得越好。祝你好运,祝你即将选择的职业一切顺利。
毗湿奴的编码技能和通过 EPAT 获得的知识帮助他进入了算法交易领域。
EPAT 为每个人提供了在算法交易领域取得成功所需的完美技能。通过其全面的课程,包括统计学&计量经济学、金融计算&技术和算法&量化交易等主题,以及作为讲师的行业专家,EPAT 确保人们接触到算法交易的所有重要概念。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,本案例研究是根据 quantin STI EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的结果对所有人来说可能并不一致。
危机时期如何交易:类型、计划和策略
对于金融市场上的任何交易者来说,危机时刻都是艰难的。因为有不同类型的危机,如自然灾害、人为灾害等。在每一种类型中,某一特定行业或一组行业比其他行业受影响更大。
这一点在新冠肺炎时期很明显,因为一些行业,如酒店、航空等。受到了严重的影响。相反,由于对消费品的需求增加,快速消费品做得很好。
让我们通过这篇博客了解更多关于危机时期的交易,因为它涵盖了:
- 什么是危机?
- 影响金融市场的危机类型
- 过去危机的时间表及其对贸易的影响
- 如何为潜在的市场崩盘做准备?
- 在金融危机期间,你如何从交易中获得良好的回报?
- 哪些股票在金融危机中表现出色?
- 为什么黄金能抵御衰退或危机?
- 金融危机期间,大宗商品价格会发生什么变化?
什么是危机?
从全球的角度来看,危机听起来就像是一种严重的情况,影响到很多人、部分、社区、行业等。
地震、海啸等自然灾害。往往会导致危机。然而,过去也有一些人为危机的例子,如大衰退严重打击了世界经济。
影响金融市场的危机类型
让我们看看以下各种类型的危机:
天灾
顾名思义,它们是地球自然过程的结果。例如,在卡特里娜飓风(2005 年)期间,股票市场崩盘。
技术危机
这是由技术结构故障和/或处理或操作技术/机器的人为错误引起的事件。例如,闪电崩盘(2010 年)的原因之一被认为是美国交易所价格报告中的技术故障。
谣言
这些是由个人或团体在社区、国家或全球范围内编造或伪造的事件。这种谣言会对行业产生影响。例如,2013 年 4 月有一个关于美国总统奥巴马先生在白宫爆炸中受伤的谣言。
人为的灾难
恐怖袭击等人为灾难也在很大程度上冲击着金融市场。例如,在 9/11 恐怖分子的自杀活动中,恐怖分子撞上了美国的世界贸易中心,造成了如此大的影响,以至于股票市场关闭了一周。
危机时间表及其对过去市场的影响
当任何危机发生时,市场都害怕最坏的情况,股票也随之暴跌。
但历史证明,过一段时间后,乐观情绪会回归,价格会反弹回原来的水平。一旦市场最终开始对基本面因素做出反应,而不是感知到的暂时动荡,危机对市场的影响就开始消退。事后看来,市场似乎经常反应过度,跌幅过大,但随后很快就恢复了。
证明这一点的一些众所周知的事件如下:
- 1929 年华尔街崩盘
- 【1989 年 13 日星期五(小车祸)
- 1987 年黑色星期一
- 20 世纪 90 年代初的经济衰退
- 网络泡沫 2000 年
- 2007-08 年的金融危机
- 2010 年的闪电崩盘
- 【2020 年新冠肺炎崩盘
如何为潜在的市场崩盘做准备?
在危机中为有利回报让路的一个方法是,分析波动期是否在意料之中,并提前做好准备。衡量崩盘是否即将来临的一个极其可靠的方法是通过 VIX 波动率指数。
让我们看看下面的例子,VIX 在过去是如何成为波动指标的:

VIX indicator during crisis
正如你在上面的图像中所看到的,VIX 图表显示了中美贸易战情景下的峰值。与此同时,S&P500 股价图显示其股票价格大幅下跌。
如果市场崩盘即将来临,该怎么办?
金融市场是由基于新闻、推特等的情绪等因素驱动的。当预期市场崩盘时,会给交易者带来恐惧和不确定性。此时,新闻和社交媒体的更新会对交易策略的决策产生巨大的影响。
在为市场崩盘做准备时,一些常用的策略是:
卖空
卖空股票或卖空股票指数期货是在预期的熊市中获得有利回报的一个好方法。卖空者借入他们并不拥有的股票以便卖出,希望以后以更低的价格买回。
选项策略
使用期权策略是为熊市做准备的另一种方式,例如当市场下跌时,买入价值上升的看跌期权,或者卖出价格为零的 T2 看涨期权,以防到期时没有钱。
债券和商品市场
债券和商品市场也可以在预期的熊市场景中使用,因为这两个市场的价格通常会在市场崩溃时上涨。
对冲
对冲是一种旨在抵消潜在损失的投资策略。对冲市场价格风险意味着通过锁定价格来保护自己免受价格不利变动的影响。这是通过在对冲信贷风险的同时,利用对冲合约来对冲你所持有的自然头寸来实现的。
可以使用衍生产品进行套期保值,因为在大多数情况下,衍生产品与其相应基础产品之间的关系是明确定义的。其他金融工具如保险、期货合约、掉期、期权以及多种类型的场外产品被用于对冲。
注意:QuantInsti 不建议遵循任何特定的策略。这些信息完全是为了教育目的。
然而,许多投资者被限制卖空,或者无法进入衍生品市场。即使他们这样做了,他们也可能在情绪上或认知上对卖空有偏见。
此外,如果市场不跌反涨,并发出追加保证金通知,卖空者可能会被迫弥补头寸损失。此外,交易所交易基金的股东也对市场进行多空投资。
谣言的影响
这里需要注意的是,在危机或动荡时期,最大的风险是谣言。谣言会使你的投资走向错误的方向,因此,损失是不可避免的。
例如,如果媒体描绘了一个错误的场景,你的交易就会被误导。这可能会导致市场崩溃。通过相信消息仅来自可靠来源来减轻此类欺诈或风险是极其重要的。
在金融危机期间,你如何从交易中获得良好的回报?
有几个步骤可以将金融危机对你投资组合的影响降到最低。
投资组合多样化
最重要的一步是确保你的投资组合多元化(即分散投资于多个领域,包括股票、债券、现金、房地产、衍生品、贵金属等)。).
你也可以将一小部分储蓄用于更安全的投资,如定期存单和国债。
及时分析
据观察,每一次,市场反应过度,下跌太多,然后很快恢复。例如,随着新冠肺炎的影响开始消退,股票(包括酒店、航空等行业。)开始看到复苏。
作为投资者,你不应该因为害怕失去财富而考虑恐慌性抛售。及时的分析可以帮助你做出明智的决定,避免以后以更高的价格回购投资组合。
价值投资
同样,价值投资有助于这种情况。价值投资策略主要集中于投资那些交易价格远低于其真实价值的股票。
简而言之,价值投资有助于降低风险,因为我们只在价值股的当前价格远低于其真实价值时投资价值股。这种真实价值和购买价格的差异也被称为“安全边际”。
推荐阅读:投资组合&风险管理
哪些股票在金融危机中表现出色?
没有人知道最好的股票是什么,但是一些商品如黄金在危机中表现更好。但是,如果你看到我们讨论过的例子,每一次危机都有不同的表现,在每一种情况下哪些股票表现强劲。
例如,在新冠肺炎期间,快速消费品部门表现良好。因此,这完全取决于金融危机的类型。
让我们看一个印度斯坦联合利华的例子。观察 HINDUNILVR 的价格是如何在新冠肺炎情景中大幅下跌的。以下是 2020 年 3 月至 2020 年 4 月的图表:

Trading in crisis - Hindustan Unilever prices
上图显示了 HINDUNILVR 最初是如何受到新冠肺炎危机的影响,但随后,其股价加速上涨。
建议观察:危机时期应该买股票
注意-上面的视频描述了内容所有者的观点。QuantInsti 不建议交易任何特定的股票。
为什么黄金被认为是抗衰退或抗危机的?
黄金是一种通常被认为不受经济衰退影响的商品。这是因为:
- 黄金是一种在危机情况下可以从一个国家转移到另一个国家的商品。因此,黄金的价值可以从一种货币转换成另一种货币。
- 据观察,在经济衰退期间,当股市崩盘时,黄金价格通常会上涨。由于黄金的价值增加,这表明黄金具有负贝塔值,这意味着黄金价值与股票指数相反。
金融危机期间,大宗商品价格会发生什么变化?
对商品价格的影响的结果是不确定的,但取决于形势或危机类型。例如,在原油和白银价格上涨的战争场景中,油价会全面上涨。
让我们借助乌克兰-俄罗斯战争场景中的一个例子来找出同样的答案。以下是原油、白银和黄金这三种商品的价格状况:

Commodities' prices during Ukraine-Russia war
上图显示了三种商品的价格都处于历史最高水平。相比之下,原油价格正处于顶峰,而黄金和白银的价格趋势却没有那么高。因此,可以看出,商品价格上涨,但崩溃最初发生。
让我们看看另一个时间线,即新冠肺炎疫情。在这种情况下,价格也是先降后升。在这个时间线上,与黄金和原油相比,白银的价格更高。让我们看看当时的图表是什么样的:

Commodities' prices during COVID-19
结论
危机时刻可能充满情绪,比如对交易者的恐惧。这种情绪会影响交易策略,但是,如果危机从一开始就被预测和计划好,情况会好得多。
在这篇博客中,我们讨论了危机对金融市场的影响,以及如何提前做好准备。在危机期间,交易最重要的一步是始终检查可靠的来源,以了解金融市场的实际情况。
如果你想为危机时刻做好准备,建议你也开始学习算法交易。与金融市场中的手工交易相比,这种当代实践可以让你保持领先。你可以利用算法在危机中保持你的决定不带任何情绪。此外,与人工交易相比,算法为你提供了更快速、更可靠的行动。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
从交易到建立定量研究公司——索拉博不可思议的故事
你有没有想过,一个人可以开始他们的旅程,建立一个交易台,然后更进一步,将开始自己的量化研究公司?这可能对你来说难以置信,但是相信我们,这是可能的。Sourabh 完成了两级 CFA 考试,并拥有工程技术背景,他从一名零售交易员发展到建立了自己的 algo 交易基础设施。
我们带给你,他不可思议的故事。
-
Hi, Solabo, tell us about yourself.
大家好,我是 Quantify Capital 的联合创始人,Quantify Capital 是一家量化研究公司,主要致力于建立量化投资&交易模型,以产生稳定一致的阿尔法值。我之前从事过股票研究、衍生品交易和金融分析。
我的学历包括工商管理硕士和信息技术工程学士。我是印度国家证券交易所有限公司的 NSE 认证市场专家。我也完成了 CFA 项目的 1 级和 2 级。
-
When did you become interested in algorithm trading?
早些时候,我用简单的技术分析&烛台模式交易。但是这涉及到很多主观性,我不确定这个系统的优势。我意识到,要在市场上获得长期成功,需要遵循一个经过回溯测试的系统,这让我对算法交易产生了兴趣。作为一名工程出身的人,我一直对数据和数学感兴趣,并且知道算法交易是我前进的方向。
-
What makes you think EPAT is an ideal choice for learning algorithm trading?
EPAT 是唯一一个拥有来自世界各地校友的算法交易综合课程。这门课程是由曾在像 Optiver 这样的大公司工作过的前交易员开设的。在与几位校友交谈后,我确信 EPAT 会帮助我在算法和量化交易方面成长。
-
What skills do you hope to improve? Tell me about your experience.
我希望了解交易策略的回溯测试和扩展,以及如何正确管理衍生品的风险。那时我遇到了 EPAT。我玩得很开心,也学到了很多关于建立可扩展交易系统的知识。
EPAT 的哲学一直是:
想法- >规则- >回溯测试- >丢弃或部署- >优化- >规模
-
How did you apply what you learned to your professional life?
完成《EPAT》并工作一段时间后,我开始量化资本,在这里我们主要交易 3 种策略:
- 均值回归策略
- 趋势跟踪策略和
- 捕捉θ衰减的期权写入
所有这些策略都是不相关的,这使得系统压降保持在最低水平。我在 EPAT 期间所学到的一切一直是激励我的因素。
-
What information do you want to share with aspiring quantitative traders and algorithm traders?
正如《如何在股票中赚钱》的作者威廉·奥尼尔所说,
“在股票市场上大获全胜的全部秘密不在于永远正确,而在于当你错了的时候损失最小。”
一个有利可图的交易系统只需要大赢小输。
永远记住,胜率不是最重要的因素。
说得对,说得好,索拉博。我们对你未来的努力致以最良好的祝愿。
通过算法交易(EPAT ) 中的[执行程序,开始你升级算法交易知识的探索,这将确保你具备必要的知识,并增强你的算法交易技能。EPAT 是一门综合性课程,涵盖的主题从统计学&计量经济学到金融计算&技术,包括机器学习等等。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti EPAT项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。](https://www.quantinsti.com/)
动荡市场中的交易和对冲策略
原文:https://blog.quantinsti.com/trading-hedging-strategies-turbulent-market-unicom/
此活动已经结束
【2020 年 5 月 28 日 15:30 英国夏令时| 10:30 美国东部时间| 20:00 IST
关于在线小组讨论
为了应对新冠肺炎事件造成的中断,联通已经计划了一系列在线小组会议,届时领先的学科专家/权威人士将出席并举行小组讨论。
会议持续时间约为 60 分钟,还有额外的问答时间。
这些会议以互动的形式进行,为所有远程与会者提供了物理会议的数字体验。在这里,代表们积极参与,通过问答交流,在会议期间和休息时间分别与同行和小组成员交流。
讨论主题
- 我们从新冠肺炎危机对交易策略的影响中学到了什么?
- 在这场危机中有哪些胜败策略?
- 会对市场产生长期影响吗?
- 市场参与者:(做市商、全权委托交易者、Algo 交易者、投资者、基金经理);赢家和输家
发言人和小组成员

基于指数动量的交易指数期权[EPAT 项目]
原文:https://blog.quantinsti.com/trading-index-options-index-momentum/

本文是作者提交的最后一个项目,作为他们在 QuantInsti 的算法交易 (EPAT)的高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
Naveen Edamana在 IT 行业拥有超过 10 年的经验,在技术领域享有盛誉,目前在 Oracle India Pvt. Ltd .担任首席顾问。Naveen 以优异的物理成绩毕业,之前曾在 NIIT、新达和安联工作过。
项目摘要
项目目标是建立和研究基于指数动量的指数期权交易模型。交易指数期权模型的设计考虑了以下标准:
- 信号生成的最少参数
- 限制意外事件导致的财务风险
- 保证金要求低或为零
本项目研究的交易指数期权模型使用 NIFTY 及其期权的每日 OHLC 数据。进场和出场信号是用漂亮的 OHLC 蜡烛线的简单移动平均线(SMA)得出的。这些信号是为看涨期权或看跌期权中的多头头寸生成的
简介/项目动机
期权的使用有很多原因,包括投机、对冲、扩散和创建合成头寸。大量的期权交易模型被广泛使用,并有据可查。然而,大多数模型要求两个或两个以上的看涨/看跌期权组合头寸,具有相同或多重执行价格,有/无日历价差。手动跟踪和交易这些组合可能会变得复杂。因此,需要定制/自动化的软件来跟踪投资组合的表现,并几乎同时或在很短的时间内执行仓位的进/出。时间范围内的快速价格变化可能会极大地影响模型的回报。
在这个项目中,试图使用基于指数的期权作为工具来跟踪指数动量并以最小的风险产生可接受的回报。该项目的目标如下:
- 建立一个简单的“进入和退出”的交易模式
- 信号很快产生,不需要复杂的计算——使用简单的 OHLC 图表和一些简单的分析工具就可以得出结论
- 该模型应该只有有限的金融风险,保护投资者免受意外市场波动的影响。
- 在交易窗口开始的 10-20 分钟和结束的 10-20 分钟内进行交易,应该足够模型运行
交易模式-策略
为了满足项目设定的目标和标准,设计了以下交易指数期权模型。交易模式:
- 使用 Nifty-50 的 OHLC 数据,NIFTY-50 期货和期权的当前和近月 OHLC 数据
- 使用 NIFTY-50 每日 OHLC 数据的高值和低值的 15 天 SMAs 生成进场/出场信号
- 还为现有信号生成使用预设目标/止损限制
- 信号仅用于进入多头头寸,在当天收盘前的最后 5-10 分钟执行
- 在任何时间点只维持一个未平仓头寸
人们还可以了解情绪指标,如何解读它们,并根据这些解读设计交易策略。
参赛规则
买入/卖出期权进入多头头寸的交易模型规则如下:
- 如果当天的 OHLC 烛台为绿色,在下列情况下输入多头仓位:
当天的 OHLC 烛台(包括主体和尾部)位于 HIGH-SMAs 上方,前一天的 OHLC 烛台为绿色(以下任何一种) 前一天的 OHLC 烛台的主体穿过两个 SMA 或前一天的 OHLC 烛台的主体穿过两个 SMA 或前一天的 OHLC 烛台的主体在低 SMA 下方但具有上部尾部穿过低 SMA 或前一天的 OHLC 烛台的主体在两个 SMA 之间,尾部(上部或下部或两者)穿过一个或两个 SMA 或前一天的 OHLC 烛台(主体和尾部)在两个 SMA 之间
- 如果当天的 OHLC 烛台为红色,在下列情况下输入多头头寸:
当天的 OHLC 烛台(包括主体和尾部)位于 LOW-SMAs 下方,前一天的 OHLC 烛台是红色的(以下任何一种) 前一天的 OHLC 烛台主体穿过两个 SMA 或前一天的 OHLC 烛台主体穿过两个 SMA 或前一天的 OHLC 烛台主体在高 SMA 之上但具有较低的尾部穿过高 SMA 或前一天的 OHLC 烛台主体在两个 SMA 之间,尾部(上部或下部或两者)穿过一个或两个 SMA 或前一天的 OHLC 烛台(主体和尾部)在两个 SMA 之间
退出规则
买入/卖出期权的多头头寸退出交易模型规则如下:
如果头寸的价值已经达到或超过目标值,退出头寸并记录利润或
如果头寸的价值已经达到或低于止损限额,退出头寸并记录损失或
在多头头寸的情况下,退出头寸,如果:当天的 OHLC 烛台低于低 SMA 或当天的 OHLC 烛台的身体或尾巴(或两者)穿过任何或两个 SMA
如果是长期看跌头寸,在以下情况下退出头寸:当天的 OHLC 烛台高于高 SMA 或当天的 OHLC 烛台的主体或尾部(或两者)穿过任何或两个 SMA,或者如果头寸在到期日或到期日之前未能达到目标/止损,则标记头寸到期
目标/止损规则
交易模型有预定义的目标值和止损限额。这些值是在输入时计算的。使用的公式是:
Profit booking TARGET price = Buy Rate * (1 + pre-fixed target percentage)
and
Stoploss limit = Buy Rate * (1 - pre-fixed target percentage)
仓位大小规则
头寸规模(即在多头交易的情况下要购买的手数或单位数)由当前账户余额决定。帐户余额的预定义百分比值用于购买最大可能的手数(一手= 75 个期权单位)。使用的公式是:
lot count = floor ((account balance * pre-fixed percentage / 100) / option price / lot size)
and
number of units to purchased = lot count * lot size
执行价格&到期选择规则
交易模型使用自动柜员机/OTM 执行价格创建头寸。到期时间可以是当月或近月,根据预定义的到期天数限制值进行选择。
交易费用规则
交易模型将经纪费用和税收视为买卖双方交易成本的一部分。
预定义值
交易模型基于一些预定义的参数。它们是:
- 考虑当月或近月期权行权的到期期限的天数
- 用于购买期权手数/单位的账户余额限额的百分比
- 获利(目标)限额
- 止损限额
- 经纪费
- 税收百分比
回测&交易指数期权评估
为了评估交易指数期权模型,使用 PYTHON 语言将交易策略转换成算法。使用 Python 代码,对交易模型进行回测,评估模型的有效性。
数据收集
为了进行回溯测试,从 2007 年 1 月 1 日到 2017 年 11 月 30 日的数据从 NSE 的网站上收集。以下数据可从 NSE 网站以 bhav / excel 文件的形式获得:
- NIFTY 50 的每日 OHLC 数据
- 漂亮期货的每日 OHLC 数据
- 漂亮期权(看涨和看跌期权)的每日 OHLC 数据
这些下载的数据被上传到 Oracle 数据库表中,然后由 Python 代码使用 Oracle 数据库连接器模块(cx_Oracle)读入这些表,用于测试周期。
以下是 w.r.t NIFTY-50 指数可用的各种字段

以下是各种可用的期货和期权领域

数据准备
数据准备和过滤在 Python 代码中执行。执行以下步骤:
- 每日 OHLC 数据从 NIFTY、当月期货和近月期货的数据库中提取,用于测试周期的执行。
- 使用 NIFTY 的高和低 OHLC 值计算数据集的 15 天简单移动平均值
- 烛台(OHLC)属性-颜色和位置 w . r . t . SMAs-是派生的
- 烛台属性被扫描,以识别基于进入规则的交易信号
交易指数模型测试&优化参数
整个数据集被分成四个测试块:
- 第一组:从 2007 年 1 月 1 日至 2010 年 12 月 31 日
- 第二组:从 2011 年 1 月 1 日至 2015 年 12 月 31 日
- 第三套:2016 年 1 月 1 日至 2017 年 11 月 30 日
- 全套:从 2007 年 1 月 1 日至 2017 年 11 月 30 日
使用集合 1 和 2 优化交易模型规则和参数,并在其他集合上运行相同的规则和参数进行验证。根据多项测试,运行以下确定的优化规则/参数:
- 据观察,ATM 执行价格能产生最好的结果
- 投资部分(账户余额的百分比)= 15%
- 获利目标限额= 100%
- 止损限额= 75%
- 距离到期限制的天数= 20
设置 1 -测试结果
以下是具有优化参数的组 1 的测试结果:

下图显示了策略回报与漂亮回报的对比以及本期的账户余额。


设置 2 -测试结果
以下是具有优化参数的组 2 的测试结果:

下图显示了策略回报与漂亮回报的对比以及本期的账户余额。


设置 3 -测试结果
以下是具有优化参数的组 3 的测试结果:

下图显示了策略回报与漂亮回报的对比以及本期的账户余额。


全套测试结果
以下是优化参数的全套测试结果:

下图显示了策略回报与漂亮回报的对比以及本期的账户余额。


交易模式的主要发现、挑战/限制
交易指数期权模型被观察到提供合理的回报,同时最小化金融风险。交易指数期权模型在 10 年的时间框架内仅用 119 笔交易就提供了 600%的回报。尽管模型的成功率并不吸引人,但由于负回报的平均值的绝对值小于正回报的平均值,且标准差较小,因此提供了净值生成。
交易指数期权模型也能够在 2008 年市场崩盘期间保护投资者,如从集合 1 /全套测试结果的图表中观察到的。在 2011 年、2015 年和 2016 年 11 月/12 月期间也观察到同样的情况。
然而,交易指数期权模型未能利用 2009 年市场的大幅复苏。此外,它未能防止 2012 年下半年和 2013 年市场波动时的提款。
尽管从图表来看,与做多交易相比,交易指数期权模型在做多交易方面表现良好,但是,做多交易产生的回报是做多交易的 3 倍。多头交易产生的净利润为 457,651 印度卢比,而多头交易产生的净利润为 167,372 印度卢比。
面临的主要挑战之一是过早退出,导致无法充分利用动力驱动。下图显示了 2017 年的第一个交易信号是在 2017 年 1 月 24 日生成的,目标是 100%的买入价。目标于 2017 年 2 月 2 日实现。
然而,交易指数期权模型在 2017 年 3 月 6 日生成了下一个交易信号,错过了 2017 年 2 月期间获得的整个 NIFTY 的势头,因为该配置文件没有任何未平仓头寸。

试图解决这个问题没有多大帮助,任何后续的长期买入都以止损告终,因为在 2 月 12 日至 17 日的日期范围内,Theta 衰减和 NIFTY 下跌。
类似地,观察到的另一个问题是在止损退出的情况下,导致错过跟随它的势头。
结论
在这个项目中使用的交易指数期权模型需要相当大的未来改进,以及处理由于目标/止损触发的提前退出。使用额外的分析工具有助于改进模型。
阅读更多
您可能还会发现我们之前的以下文章很有意思:
下一步
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 为你提供了在算法交易中建立一个有前途的职业生涯所需的技能。立即注册!
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
下载中的文件:
- 使用基于指数动量的指数期权进行交易- Python 文件
用低 ADX 和其他动量指标进行交易
原文:https://blog.quantinsti.com/trading-low-adx-momentum-indicators-project-vijayabhasker-iyer/
当放缓的势头开始显示出一些力量时,你会怎么做?EPATian Vijayabhasker Iyer 在他的 EPAT 项目中解释了如何在低 ADX 和其他动量指标下交易。他分享了一个捕捉短期潜在价格上涨的技术策略。
本项目中使用的完整数据文件和 python 代码也可以在本文末尾下载。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Vijayabhasker Iyer 是一名学习型&发展专家,在 BFSI 拥有超过 15 年的工作经验。他曾与跨国金融机构、再保险经纪人、国内 kpo/BPO 合作,并持有英国特许保险协会颁发的保险证书。他目前在一家全球银行担任能力开发的现场主管。
Vijay 不断努力学习和获得新的技能,吸引他进入交易世界。在完成了加尔各答 Kredent 学院的技术分析入门课程后,他在 2018 年通过了特许市场技术员(CMT)一级考试。
为了继续追求他的激情并进一步加强他的技能,他注册了 2020 年 EPAT,这是 QuantInsti 在量子/算法交易领域提供的一个包罗万象的课程。Vijay 通过课程讲座和作业获得的知识在 Ishan Shah 的指导下在这个项目中付诸实践。
战略简介
这是一种技术策略,用于在放缓的势头开始显示出一些力量时,捕捉短期潜在的价格上涨。
要求
技术指标
- 指数移动平均线–21、42 和 63 周期
- 平均方向指数–14 期
- MACD——12、26、9 岁
可选指示器
- 随机的
- 相对强度指数
- n 拷贝& get_history
- 日期时间
- 熊猫和熊猫
- matplotlib.pyplot
- 塔利卜
策略参数
- EMA 21 必须在 EMA 42 之上,EMA 42 必须在 EMA 63 之上
- ADX 小于或等于 25 &大于前一天的值
- 当前 MACD 柱状图必须高于前一天的柱状图
- 可以添加像随机指标和相对强弱指标这样的可选过滤器,但是,这可能会大大减少交易的数量
策略解释
ADX 是一个技术指标,帮助我们确定趋势的强弱。一般来说,在盘整阶段,ADX 下跌,而在趋势市场中,ADX 上涨。较低的 ADX 也可能预示着整体上升趋势或下降趋势的暂时疲软或巩固。
我们的策略是寻找这样的机会,在这个动量指标显示的任何强势迹象下一笔短线交易,同时考虑几个其他的确认。
图 1 展示了 ADX 的工作原理:从左图看,随着价格的上涨,ADX 上升,表示强劲的上升趋势。当它下跌时,你可以看到趋势失去了势头,或者价格在中间盘整。在右边,随着价格下跌,ADX 指数再次上升,预示着潜在的下跌趋势。

在这个策略中,我们只希望执行多头交易。因此,指数移动平均线被选择为 21、42 和 63,以识别最有可能上升的市场。当 ADX 开始从 25 或以下的水平向上倾斜时,我们预计上升趋势将开始/继续。
为了增加一个额外的确认,我们寻找 MACD 直方图,MACD 家族的另一个动量指标,也从之前的值增加。
基于这一点,我们在一天结束时进行买入交易,然后在 T+3 日进行交易。换句话说,在交易日的第 4 天结束时,我们平仓。
回测数据
来自 NSEPy 的 2012 年 1 月 1 日至 2020 年 12 月 31 日期间的每日数据
Python 代码
步骤 1 -导入库,从 nsepy 中提取数据并创建技术指标
建立自己的交易机器,像专业人士一样发展
马里奥·比萨
在本帖中,我们将回顾每个量化开发者工具箱中应该有的基本工具。为此,我们将创建一个小项目来修改自由软件库并发布我们的更改。
本文涵盖:
为什么建造自己的交易机器是个好主意!T3】
有许多工具可以让 quant 程序员在与机器交互时更加轻松。选择合适的工具往往是个人喜好的问题,所以每个程序员都有自己的偏好。
然而,无论我们使用什么样的软件应用,我们都必须考虑能够促进算法和应用开发任务的工具箱,因为我们使用的具体应用并不重要,重要的是它提供的功能。
操作系统(Windows/Mac/Linux)对部署专业开发系统漠不关心。尽管有数不清的付费工具,这里我们将把重点放在所有操作系统都可用的免费软件工具上,或者在必要时特别提及。
这里提到的开发工具是所有编程语言通用的。然而,我想提一下,有些语言有非常特殊的 ide,这可能是最方便的。
无论如何,这里我们将 Python 作为一种示例语言,但坚持认为我们阐述的思想对任何编程语言都是有效的。
最后,这不是这里提到的任何工具的安装或说明手册,因此建议感兴趣的读者访问感兴趣的应用程序的页面。
代码编辑
代码编辑器只不过是一个简单的文本编辑器。为此,我们可以使用 Windows 的记事本、Mac 的 TextEdit 或 Linux 的 Vi。然而,这些工具在功能上非常有限,因为它们缺乏编程帮助。编程辅助工具让我们在工作时变得更有效率。
一个好的代码编辑器必须允许集成小的编程工具、解释器和编译器来帮助我们完成对机器编程的任务。
Emacs 代码编辑器
Emacs 是卓越的编辑。它是一个拥有 35 年历史的应用程序,来自 Unix/Linux 世界,最新版本可用于 Windows 和 Mac。
它无疑是最灵活的,可以与任何编程语言一起工作,但在处理上有一定的复杂性。尽管最新版本提供了 GUI,但是编辑器的真正威力来自 Emacs 本身的命令行。
Atom 代码编辑器
另一个为任何编程语言提供巨大通用性的优秀文本编辑器是 Atom 。它是多平台的(Windows/Mac/Linux ),并允许我们集成许多工具来简化编程任务。Atom 有数以千计的附加包,可以将它变成一个完全为我们的目的定制的完整 IDE。
由于我们将使用 Python 作为编程语言,我们必须做的第一件事是安装一些可用的软件包,以增强我们在 Atom 中使用 Python 的开发体验。
例如,软件包 hydrogen 、 python-ide 和 python-tools 将允许我们在 Atom 中运行 python 代码,并将帮助我们自动完成代码、函数定义等等。
Atom 有许多其他的包可以帮助我们,例如,根据 WBS 风格指南编写代码、重构代码、生成测试代码等等。

正如我在介绍中所说,选择代码编辑器和/或 IDE 是个人喜好的问题,因此任何其他让您感到舒适并有帮助和编程的编辑器都完全有效。
命令行终端
“最初……是命令行”是尼尔·斯蒂芬森的《T1》一书的标题,该书精彩地讲述了机器与人类界面的演变。一本值得一读,了解人机关系如何演变的书。
毫无疑问,当前的操作系统及其 GUI 已经显著改善了我们与机器的交互。我们只要想一想,在穿孔卡片中实现一个简单的均值交叉算法,或者用汇编语言(ASM)开发它,就会感到幸运。
从用鼠标操作机器到用头脑操作机器的设备都是值得称赞的界面,但仅限于开发人员已经实现的独特功能。
为了通过操作系统充分发挥机器的能力,我们需要一个命令行终端。终端,也称为控制台或外壳,打开机器管道的门,并允许我们通过命令进行交互。
Linux 的命令行终端
对于 Linux 来说,它是经典的界面,尽管下载量最大的发行版是像 Windows 一样的,比如 Ubuntu。有些“纯”发行版是简单的终端,比如 Slackware 发行版。如果你正在使用 GUI,你可以打开项应用程序或者按 Alt+Ctrl+F1 。
对于 Mac 来说,有一个终端应用程序,命令和 Linux 中的一样,因为 Mac 是建立在 AT & T Unix 上的。
对于 Windows,我们可以打开 MS-DOScmd.exe应用程序,尽管它在我们可以启动的命令集方面非常有限。为了升级我们在 Windows 中的命令行,我们需要安装 Powershell ,它扩展了命令目录,你也可以在 Windows 中获得 Linux shell,或者为旧版本 Windows 的用户简单地安装 Cygwin 。
当我们轻松处理命令行时,我们会发现自己有多个打开的终端和繁琐的窗口或应用程序更改,为了方便使用多个终端并为每个终端配置自己的配置文件,我们可以使用 Mac 的 iTerm 或 Windows 的 ConEmu 。
这些应用程序不会取代终端,只是允许我们在应用程序本身中管理多个窗口,并管理每个窗口中的配置文件。

学会很好地使用命令行不是一件容易的事情,但是它只需要耐心、毅力和一本手边的好手册。
最后指出,Atom 允许我们在编辑器本身中集成一个终端,因此我们不必更改窗口来启动命令,我们可以在 Atom 中运行脚本,您可以尝试使用 terminal-tab 包,尽管还有其他不同用途的包。

开发环境
当我们处理几个项目时,隔离我们正在使用的库的版本是很方便的,这样一个项目中的变化就不会对另一个项目产生负面影响。
如果一个项目需要 Python 3.5 和 Pandas 0.21,而另一个项目需要 Python 3.7 和 Pandas 1.0.2,则必须使用开发环境管理器。
换句话说,一个开发环境管理人员需要使用我们正在使用的编程语言的不同版本的解释器或编译器,以及项目需要的额外的库。
通过隔离开发环境,我们避免了在安装一个新版本的库时发生的悲剧,这样其他的项目就停止工作了。
大多数编程语言都有这些管理器。一些比较有名的是 ruby 版本管理器 rvm 、R 内核的 RSwitch 和 R 包的 renv 。
为了使用不同版本的 Python 和不同版本的库,我们将使用 Conda 。Conda 是 Anaconda 提供的开发环境管理器,尽管高级用户更喜欢安装 miniconda ,以避免安装完整的 Anaconda 套件。
用 conda 管理开发环境非常简单,因为只需要很少的指令或命令,我们就可以管理所有的开发环境。
为了在 Python 3.5 中创建开发环境,我们在终端中启动以下命令:
conda create -n py35 python=3.5
这个命令将在 Python 3.5 中创建一个开发环境。要查看并激活新环境,我们可以启动以下命令:
康达环境列表 列出了我们已经创建的环境的集合,名称越有描述性,就越容易记住它包含的内容。
康达激活 py35 用 Python 版本激活我们之前创建的名为 py35 的开发环境。一旦环境被激活,我们就可以使用‘pip’为该开发环境安装特定的库。
安装在一个环境中的库只能在该环境中使用,因此,每个环境都需要自己的库集合。
开发环境的另一个非常有趣的用途是,我们可以导出一组库(环境),将它们导入到另一个项目或另一台机器中。开发环境管理器是一个非常强大的工具,任何开发人员的工具箱中都不应该缺少它。
conda env export py35.yml
软件变更和版本控制
我们可以在任何开发人员的工具箱中找到的另一个最强大的工具是软件变更和版本控制。尽管有不同的工具可以实现这一目的,但这里我们将关注最广泛使用的一种,它被认为是一种标准,即 Git 工具。
Git 在 Linux 上默认是嵌入式的,对于 Mac,你需要用xcode-select-install命令安装开发者工具,对于 Windows,你需要安装。
Git 是一个命令行软件,可以让你保存开发的快照,标记它们,并生成代码版本。这对于恢复到代码的先前版本、开始并行开发、恢复文件、参与自由软件项目以及提出改进和/或修复等非常有用。
这可能看起来有点抽象,所以让我们假设我们正在开发一个项目,当我们完成小的功能包时,我们保存代码的快照,当我们完成项目时,我们可以保存另一个快照并用版本号标记它。
虽然这已经很有趣了,但是当项目需要修正、修改、功能扩展或者团队开发的时候,这个工具就成为了我们将在任何项目中使用的工具的基石。
另一方面,使用 Git,你可以访问开源库,或者在 Github 或 T2 bit bucket 上创建你自己的开源或私有库。
我们需要一个特定的帖子来查看 Git 提供给我们的所有命令,所以我们把它留给感兴趣的读者在官方文档中查看。
最后,我们可以在 Atom 代码编辑器中集成一个 Git 客户端,使其更容易与 git-plus 包一起使用。
尽管图形界面很常见,但它的功能仅限于最基本的命令,我们必须使用命令行来获得 Git 的全部功能。

数据仓库
任何开发人员工具箱中的另一个基本实用工具是管理数据存储库的能力。csv 文件和数据库。这是非常通用的,因为我们可以在 csv 、 excel 、 hdf5 文件和关系数据库(如 MySQL 或 PostgreSQL 或非 SQL(如 MongoDB )中找到数据。
作为开发人员,我们只关心通过编程语言连接到这些数据存储库的接口。然而,当我们在开发时,我们通常需要可视化原始状态的数据,以了解我们必须进行的转换,并知道如何攻击我们感兴趣的数据。
通常,我们可以使用窗口应用程序来可视化数据文件或连接到数据库,尽管我们的代码编辑器应该足够灵活,允许我们直接从编辑器本身可视化和修改数据。
在 Atom 中,我们可以找到有助于连接、可视化以及在某些情况下修改数据存储库(无论是文件还是数据库格式)的包。
rainbow-csv 为我们提供了可视化 csv 文件的功能,通过将每一列涂上不同的颜色,可以更快地查看数据。寻找其他 Atom 包,甚至可以像查询数据库一样对 csv 文件进行查询。

对于数据库,Atom 中有特定的客户端,您还可以使用通用的快速查询在 MySQL 或 PostgreSQL 上启动 SQL 查询。
【ide(集成开发环境)
ide 拥有最好的代码编辑器和一组工具,理论上,它们可以防止我们在整个开发工作流程中改变应用程序,一般来说,它们都集成了以前见过的工具。
虽然大多数 ide 能够处理几种编程语言,但它们通常面向特定的语言,如 R 的 RStudio、Python 的 Spyder、Java 的 Eclipse、C#的 VisualStudio 和 long 等。
在许多情况下,最好的选择可能是使用 IDE,比如 R、Java 或 C#,但是即使我们最终在 IDE 中使用它们,了解本文中提到的工具仍然是必要的。
在这位作者看来,很多时候 IDE 把你禁锢在一个框架里,限制了通用性。毫无疑问,Atom 是这篇文章订阅者的选择。
但正如我在开始时所说的,没有开发工具这样的东西,最好的工具是使您的工作更容易,使您的生活更舒适的工具,所以最好的事情是不要太关注我,做一个尝试不同工具的人,以决定哪一个是您的最好工具。
云中的机器
开发者目录中不能缺少的最后一个工具是云机器。目前,我们可以以合理的价格获得配置简单的 Windows/Linux 机器或超级计算机配置。
不管我们使用哪种机器进行开发,在生产中部署系统都需要考虑架构、可用性、安全性等方面。
两个最受欢迎的云机器服务提供商是 Google Cloud 和 AWS ,你可以开始免费使用云机器一年,使用简单但足够的配置来学习甚至部署应用程序或简单的算法。没有理由不去尝试!
开发库
让我们以一个简单的例子来结束如何管理一个开发项目。让我们假设我们想要创建一个神话般的买入并持有策略,并且我们想要生成一个性能报告来展示给我们的客户。
对于报告,我们将使用开源库,我们将修改并发布我们的更改,以便其他开发人员可以使用我们的修改。
用 Conda 创建一个 Python 环境
在我们终端的命令行中,我们键入以下命令,用 Conda 创建一个 Python 环境版本 3.6。
conda create -n EPAT36 python=3.6
我们将创建一个项目名为 devlikeapro 的文件夹,
- 通过在终端 中键入以下命令 mkdir devlikeapro ,
- 用命令 移动到项目文件夹
- 用 激活终端中的环境,conda 激活 EPAT36 。
这里我们可以执行 python - version 命令,看看我们确实在使用 Python 3.6。
现在我们可以用‘pip’以通常的方式安装我们将在项目中使用的库。
pip install pandas pandas_datareader pyfolio
最后,我们用 atom 命令打开 Atom,并在刚刚创建的文件夹中创建一个新项目。

我们假设已经安装了帖子中提到的所有 Atom 包。请看图片,我们已经在 Atom 中打开了终端,但是我们使用的 python 开发环境是 Conda 的“基础”。
因此,我们必须使用 conda 激活 EPAT36 来更改我们创建的名为“EPAT36”的环境

我们将在 Atom 代码编辑器中使用我们出色的策略创建一个新的 Python 脚本:

为了在 Atom 中运行报告,我们使用了 Atom hydrogen 包,它允许我们逐行运行 Python 脚本。输出为我们提供了一个简单的 pyfolio 报告,其中包含一个统计表和一些有趣的图形。

假设我们想要修改 pyfolio 库,以改进、扩展或纠正库中的任何内容。当我们想要在一个自由软件项目中合作,或者只是想要修改库中的一些小细节时,这是非常有用的。在这个简单的例子中,我们将修改'累积回报'图表的一些细节。
在开始之前,我们将回顾一下我们在系统中安装 pyfolio 库的情况。为此,我们执行命令 conda list ,它提供了我们已经安装在名为“ EPAT36 的 conda 环境中的库的列表。
找 pyfolio 我们可以发现我们已经从 pypi 库安装了 0.9.2 版本,也就是说带' pip '的标准安装。

为了修改库,我们需要将库源代码下载到我们的机器上,进行我们需要的更改并重新安装修改后的库的新版本。
用 Git 创建变更和版本控制库
我们将找到对 pyfolio 库公开可用的代码库,并在绿色的“代码”按钮中复制 URL 地址以克隆该库。

将 URL 复制到剪贴板后,我们在终端中键入 git 克隆 https://github.com/quantopian/pyfolio。这个命令将项目从 Github 克隆(复制)到我们的机器上。现在我们可以用 Atom 打开一个新项目并修改库。
当我们想要修改由create _ simple _ tear _ sheet函数创建的报告时,我们将打开py folio/py folio/tears . py文件并查找create _ simple _ tear _ sheet函数,该函数将位于我们正在处理的版本的第 231 行。
在这个函数中,我们定位我们想要修改的图形,例如“累积回报”,在这种情况下从第 349-354 行开始,我们修改标题使其更具描述性。

最后,我们需要再次安装库,但这一次我们将安装我们机器中的 pyfolio 项目,我们已经修改了它。
为此,我们运行以下命令python setup . py develop在我们的机器上安装开发版本。
如果一切顺利,我们没有得到任何错误,我们应该看到我们已经安装了一个带有命令 conda list 的开发版本。

如果我们返回执行我们的代码来生成报告,我们应该看到我们所做的更改。
为了完成这项工作,我们需要将更改保存在 Git 中,以便进行更改控制。让我们通过运行 git 状态命令 来看看 git 告诉我们对 pyfolio 所做的更改。

我们看到 tears.py 文件被标记为已修改,我们需要使用命令git add py folio/tears . py将该更改添加到 git 存储库中,然后我们提交一条消息,说明更改的原因 git commit -m '改善累积回报图表标题 。
在您将代码修改推送到原始服务器之前,您应该确保您已经做了正确的事情,并且只上传了必要的文件,并且这些更改是有足够的动机的。
另一个选择是用 github 上的 fork 创建自己的资源库,并向全世界发布自己的版本。但这是读者应该了解的另一个故事。
结论
我们已经回顾了一些基本工具,任何有自尊的量化程序员都应该很好地掌握这些工具,以便自己使用和在团队中工作。我们已经回顾了一些基本工具,这些工具经过适当的配置,可以达到任何专业 IDE 的高度。
在任何情况下,我想强调的是,工具本身的名称并不太重要,但正是它提供的功能和舒适性应该引导我们使用这样或那样的工具。
最后,我们通过一个例子来了解职业发展的工作流程。
本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
交易 API:它是什么,类型,用途,用于交易的 API,等等!
不断增长的市场,监管机构的批准,以及越来越多的算法交易 API,都使得使用 API 的交易市场成为一种趋势。此外,经纪人在很大程度上为散户和公司提供算法交易发挥了关键作用。
交易市场有不同的方式。一种方法是使用经纪人提供的交易 API。这个博客简要介绍了 API,它们的类型和一些提供交易 API 的经纪人。
让我们通过包含以下内容的索引进一步了解这一切:
- 什么是 API?
- API 示例
- API 的类型
- 为什么要用 API 进行交易?
- 获得实时和历史市场数据的流行 API
- 经纪人自动化交易的 API
- 使用 API 开始交易的步骤
- 使用 API 进行交易的示例
- 如何安装 Python-币安库?
- 如何保护 API 密钥?
- 如何用币安 API 获取比特币的最新价格?
- 获取 API 的资源
什么是 API?
API 是应用编程接口的缩写。API 是一种软件中介,能够让两个软件应用程序相互对话。让我们深入了解 API 是如何工作的。
正如您在下图中看到的,当您向应用程序发送执行某项操作的请求时,API 的角色位于应用程序和服务器之间。
因此,在交易时,当您向应用程序发出获取数据的请求时,应用程序会通过交易 API 将请求发送到服务器。到达服务器后,请求得到处理,并显示出期望的结果。
API 的示例
API 为交易者提供以下服务:
- 市场反馈(用于分析的历史数据、流或实时数据)
- 订单相关设施(修改以及下订单、状态更新、交易信息等。)
- 关于订单簿(收到订单的地方)和交易簿(显示执行的订单)等的报告。
- 交易信息和更多!
API 的类型
现在让我们来看看不同的 API 类型。我发现这个图表很好地划分了 API 类型。我们将介绍一些在交易中使用的 API。
API 是这样分类的:

REST API
REST 或表述性状态转移是一个 API,它使用 HTTP 来发出请求。它用于需要根据用户操作传输某些信息的应用程序中。
对于实时传输或数据流,REST 不是最好的协议,可以使用 WebSockets 来代替。我们将在下一部分讨论 WebSockets。
当交易者的需求是:
- 灵活性- 因为他们可以同时处理不同订单执行的大量请求
- 可扩展性- 因为它们是为两个软件应用程序之间的通信而设计的,不管它们的大小或能力如何
- 易于适应 web 技术- 这使得它们易于构建和使用
WebSocket API
WebSocket 是一种允许与服务器之间传输数据的协议。连接到服务器的套接字保持打开以进行通信。因此,可以实时按需推送或请求数据。
当交易者的要求是:
- 实时传输或流数据,这是交易时 WebSocket API 的一大优势。它有助于实时市场时段的数据传输,尤其是高频交易。
- 获取数据后定制交易策略
基于库的 API
基于库的 API 使得开发者很方便,因为库是由代码或二进制函数组成的。可以直接引用这些库来使应用程序与 API 进行交互。因此,开发人员不必花时间写代码。
基于库的 API 的主要用途是可以拉取市场报价,可以发送或修改订单,可以提取历史数据等。在图书馆的帮助下。例如,Zerodha 的 Kite Connect API 有自己的 kiteconnect 库,其中包含交易订单、执行等代码。都能找到。
为什么要用 API 做交易?
现在让我们看看为什么 API 是交易的首选。以下是一些好处:
安全
交易 API 网站与您之间的通信是通过小数据包进行的,这些数据包只包含它被告知要获取的信息。例如,只有交易订单通过交易 API,而没有来自系统的其他信息。
根据需要定制 API
有了交易 API,最有用的一点是用户界面可以根据交易者的需求定制。因此,可以根据您的喜好使用交易 API。
获取实时数据
有了交易 API,你可以获得交易的流数据或实时数据。对于任何交易者来说,获取实时数据是主要的,也是第一步。通过快速访问实时数据,您可以使您的交易之旅取得成功。
灵活的 REST API
交易 API 为您提供了灵活的 RESTful API,它与多种计算机语言兼容,最适合您的需求。
获得实时和历史市场数据的流行 API
有两种类型的数据提供程序用于访问实时数据:
- 外部提供商
- 经纪人
外部提供商
以下是已知的印度外部实时数据提供商,其优势包括通过直接交换连接实现低延迟馈送。:
现在,让我们看看实时数据的全球外部提供商,即 Finnhub 。Finnhub 利用最先进的机器学习算法来收集、清理和标准化全球市场的数据。
经纪人
通过 API 提供数据的最著名的经纪人有:
- Zerodha - Kite Connect - 印度经纪人
- 互动经纪人 - 全球经纪人
经纪人自动化交易的 API
更进一步,下面是使用 API 来自动化交易过程的流行经纪人:
用 API 开始交易的步骤
交易者使用交易 API 的一个常见做法是为 Python 安装 Anaconda。由于 Python 是最首选的语言,所有步骤都用 Python 本身解释。
让我们来了解一下如何用 API 开始交易。以下是常见步骤:
步骤 1 -注册和密钥
向 API 提供者注册并获得 API 密钥(API 密钥和 API 秘密密钥)
步骤 2 -构建 API
选择构建 API 的语言或应用程序。你可以使用任何最适合你的语言。比如 C,C++,Python,Java 等等。另外,如果你喜欢高频交易,那么通常会选择 C++,而在低频交易中,通常会选择 Python。
步骤 3 -登录
现在,使用 API 密钥登录交易 API
第 4 步-访问
登录后,您现在可以访问所有功能,如获取数据(历史数据和当前数据)、下订单、修改订单、获取您帐户的详细信息,如可用保证金、您持有的股票以及所下订单的状态等。
建议阅读:
- 使用 IBrokers 包在交互式代理 API 中实现 R
- 使用 IBridgePy 在交互式代理 API 中实现 Python
- 在印度市场使用 Zerodha Kite Connect API 与 Python 进行交易
使用 API 进行交易的示例
让我们以加密交易者的币安为例,看看其中一个交易 API 是如何工作的。
以币安为例,让我们看看如何开始使用 API 进行交易。以下是步骤:
第一步-注册
在本页注册:

步骤 2 -创建 API
登录后,从控制面板转到 API 管理,然后单击“创建 API ”,之后您将看到一个安全验证弹出窗口,如下所示:

步骤 3 -验证
完成一级验证后,您需要填写安全验证详细信息并继续。这里有一个例子:

认证代码将在谷歌认证中随机生成。
步骤 4 -创建 API 密钥
现在,创建一个带有名称的 API 键。这里,我们使用的名称是“齐博客”

步骤 5 - API 创建
然后,您需要创建一个 API 密钥和一个秘密密钥。这是您创建的 API 的外观:

您必须确保记下 API 密钥和安全密钥,否则下次登录时会被屏蔽。
此外,作为交易 API 的新手,你必须阅读币安的教程章节。
如何安装 Python-币安库?
安装 python-币安库的最简单和最好的方法是:
pip install python-binance
此外,还有几个可用的第三方库,最受欢迎的有:
如何保护 API 密钥?
API 密钥必须存储为环境变量,这将防止您在将代码上传到 GitHub 时暴露您的凭证。
以下是语法:
set binance_api=your_api_key_here
set binance_secret=your_api_secret_here
此外,您可以使用如下命令提示符来确保正确保存密钥:

如何用币安 API 获取比特币的最新价格?
目前最好的方法是使用这个函数:
get_symbol_ticker
如果您在寻找另一个资产,您可以通过这里的任何 ticker,而不是 BTCUSDT。
交易选项:多头组合交易策略
原文:https://blog.quantinsti.com/trading-options-long-combo-trading-strategy/
由尼廷·塔帕尔
简介
在我最近关于一些最流行的期权交易策略的博客中,我谈到了包含有限风险和回报的策略。我以前的文章中解释的策略包括期权多头扼杀、看涨期权价差和铁鹰有一个共同点,那就是它是为谨慎的交易者准备的,他们希望以低到中等水平的风险进行最小的投资,但回报较低。基于反馈和需求,这一次我将带你经历一个包含无限风险和回报的策略。
我们今天将学习“长组合策略”,它很容易理解和实施。
[点击至tweet tweet = " Trading Options:Long Combo Trading Strategy by @ quantin STI " quote = " Trading Options:Long Combo Trading Strategy "]
什么是多头连击交易策略?
作为期权交易者,如果你看好市场,也就是说,你预计股价会上涨,你可以考虑使用多头组合策略。它包括卖出看跌期权和买入看涨期权。
策略特征
期权的价格-
- 卖出 1 份 OTM 看跌期权(下限)
- 购买 1 个 OTM 电话(更高的罢工)
最大利润:无限制
最大损失:无限制(下限+净保费)
盈亏平衡:更高的履约价+净溢价
如何实施这一战略?
为了简单起见,我将在一个真实的市场场景中执行这个策略。
让我在巴罗达银行有限公司股票期权(代码:BANKBARODA)上实施这个策略。考虑到我看好这只股票的事实,我假设由于股价处于历史低点(考虑到过去 3 个月),我预计它会由于一些外部因素而上涨。
银行巴罗达过去 3 个月的股价变动(来源——谷歌财经)

截至 2018 年 3 月 5 日,巴罗达银行的股价为 138.95 印度卢比。
以下是巴罗达银行有限公司 2018 年 3 月 5 日日到期日的期权链。

我将采取以下立场:
- 以 1.45 印度卢比的价格卖出 120 份看跌期权
- 以 2.60 印度卢比买入 150 份看涨期权


来源:nseindia.com
下面是一系列基础价格的收益情况:

现在,让我们用 Python 代码向您展示收益汇总:
长期买入回报
def long_call(sT, strike_price, premium_paid):
return np.where(sT > strike_price, sT - strike_price, 0)-premium_paid
# Stock price
spot_price = 138.95
# Long call
strike_price = 150
premium_paid = 2.60
# Stock price range of call at expiration
sT = np.arange(40,240,1)
long_call_payoff = long_call(sT, strike_price, premium_paid)
fig, ax = plt.subplots()
ax.spines['bottom'].set_position('zero')
ax.plot(sT,long_call_payoff,color='g')
ax.set_title('Long 150 Strike Call')
plt.xlabel('Stock Price (sT)')
plt.ylabel('Profit and loss')
plt.legend()
plt.grid()
plt.show()

看跌回报
def short_put(sT, strike_price, premium_recived):
return np.where(sT > strike_price, 0, sT- strike_price) + premium_received
# Stock price
spot_price = 138.95
# Short Put
strike_price = 120
premium_received = 1.45
# Stock price range of put at expiration
sT = np.arange(40,240,1)
short_put_payoff = short_put(sT, strike_price, premium_received)
fig, ax = plt.subplots()
ax.spines['bottom'].set_position('zero')
ax.plot(sT,short_put_payoff,color='r')
ax.set_title('Short 120 Strike Put')
plt.xlabel('Stock Price (sT)')
plt.ylabel('Profit and loss')
plt.legend()
plt.grid()
plt.show()

长连击收益
long_combo_payoff = long_call_payoff + short_put_payoff
fix , ax = plt.subplots()
ax.spines['bottom'].set_position('zero')
ax.plot(sT,long_combo_payoff,color='b')
ax.set_title('Long Combo Payoff')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.grid()
plt.show()

print max(long_combo_payoff)
print min(long_combo_payoff)
87.85000000000001
-81.14999999999999
long_combo_payoff = long_call_payoff + short_put_payoff
fix , ax = plt.subplots()
ax.spines['bottom'].set_position('zero')
ax.plot(sT,long_combo_payoff,color='b')
ax.plot(sT,short_put_payoff,'--',color='r')
ax.plot(sT,long_call_payoff,'--',color='g')
ax.set_title('Long Combo Payoff')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.grid()
plt.show()

下一步
如果你是第一次接触期权交易并且想学习基础知识,你可以阅读我们在上的帖子《期权交易基础知识解读,了解期权的特性。
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)中的 T2 高管课程。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。现在报名!
您可以报名参加 Quantra 上的期权交易课程,在您的交易中创建成功的策略和应用知识。它涵盖了零售和机构交易策略。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载数据文件
- Long+Combo.ipynb
交易中的风险管理介绍
风险管理是交易最重要的方面之一,交易者需要对风险识别、评估和管理有很好的了解。本文涵盖了风险管理的以下方面:
- 什么是交易中的风险管理?
- 风险识别
- 交易风险评估
- 流行的风险管理策略和要素
什么是交易中的风险管理?
交易中的风险管理对于避免承担股票市场交易损失的风险至关重要。风险管理涉及风险的识别、评估和缓解,这些风险通常在市场走势与预期相反时出现。
因此,在对市场进行彻底分析的基础上,在预测所有风险之后,设定你的预期是非常重要的。
趋势是这里最重要的因素。趋势意味着市场的大方向或势头,资产价格或其他类似的措施。
趋势是由投资者的风险偏好形成的,这意味着在某些事件中的预期风险,如选举(政治事件)、利率决策(经济事件)和新技术进步(商业事件)。
因此,在预见到这些风险后,你可以投资于股市,权衡你的预期风险和预期收益。
在这段视频中,我们的专家 Rajib Ranjan Borah 详细介绍了当前市场中风险管理理念的变化:
https://www.youtube.com/embed/uzAhV94UiF8?feature=oembed
接下来,我们将了解交易风险的识别和评估。
风险识别
在识别交易风险时,你需要知道市场中起作用的不同变量。
这些变量可以是经济因素,如中央银行的利率决定或贸易战。
在做出交易决策时,我们必须确保我们考虑了那些可能影响我们资产的经济因素。
在这里,我们提到了这些因素造成这些资产价格波动的能力,如果它们确实对价格有很大影响,那么我们必须知道这些因素的频率。
找出这些要点将有助于我们识别这些因素对投资组合的潜在威胁。通过这种方式,我们可以借助对冲、投资于期权、将资产分散为低风险和高风险等做法,为应对市场中的风险情景做好准备。
建议阅读:关于投资组合的文章&风险管理
现在让我们开始评估交易风险。
交易风险评估
交易风险评估意味着找出投资组合在市场中的表现。
评估市场风险有两种方法。一个是α,另一个是β。
Alpha 是衡量一项投资相对于某个基准的表现。投资组合超过基准指数的超额回报是投资组合的 alpha。如果阿尔法是积极的投资超过了基准。同样,如果是负数,则投资组合表现不佳。alpha 值为 0 表示投资组合完全符合基准。
例如,阿尔法值为 1 意味着基金比基准指数的回报率高出 1%,阿尔法值为-1 意味着基金表现差 1%。
建议阅读:阿尔法生成-控制日内风险概况
是一种证券或投资组合相对于整个市场的波动性的度量。一般来说,贝塔系数大于 1 表明投资组合或证券比市场波动更大,而贝塔系数小于 1 表明投资波动相对较小。低贝塔股票也被称为防御性股票,因为投资者喜欢在市场波动特别大的时候持有它们。当市场稳步上升,投资者乐于承担更大风险以实现利润最大化时,高贝塔股票往往会受到青睐。
例如,如果一只股票的贝塔系数是 1.5,理论上它比市场波动大 50%。相反,如果一只股票的贝塔系数是 0.60,理论上它比市场波动小 40%。
接下来,我们将找出有助于良好资金管理的风险管理方法。
建议阅读:动态资金管理
流行的风险管理策略和要素
最受欢迎的风险管理策略和元素,使您的交易成功,同时规避风险如下:
- 投资组合优化
- 对冲
- 1%法则和 2%投资法则
- 利用先进技术监测贸易
- 避免不明确的交易设置
- 止损
投资组合优化
投资组合优化是构建投资组合以最大化预期回报同时最小化风险的过程。它包括通过计算每个投资组合的风险和回报来分析具有不同投资比例的投资组合,并选择实现期望的风险回报平衡的投资组合。
现代投资组合理论是由 Harry Markowitz 于 1952 年提出的一个假设,假设投资者希望在给定的风险下最大化投资组合的预期回报,风险由投资组合回报率的标准差来衡量。一个投资组合的风险和回报可以绘制成图表:

最佳风险投资组合通常被确定在曲线中间的某个位置,因为当你走得越高,你承担的风险就越大,回报就越低,当你走得越低,投资组合的回报就越低,所以投资这样的投资组合是没有意义的,因为你可以通过投资无风险资产来获得类似的回报。
讨论桌录制了 QuantInsti 专门为算法交易(EPAT)高管课程的学生制作的视频。
https://www.youtube.com/embed/bqAZHvG89DQ?rel=0
对冲
对冲是一种投资策略,旨在抵消潜在的损失。换句话说,对冲就是投资以降低风险。对冲市场价格风险意味着通过锁定价格来保护自己免受价格不利变动的影响。这是通过在对冲信贷风险的同时,利用对冲合约来对冲你所持有的自然头寸来实现的。
可以使用衍生产品进行套期保值,因为在大多数情况下,衍生产品与其相应基础产品之间的关系是明确定义的。其他金融工具如保险、期货合约、掉期、期权以及多种类型的场外产品被用于对冲。
例子
让我们假设 ABC 公司生产玉米片作为其消费者的早餐产品。那么对于 ABC 公司来说,商品市场上玉米价格的波动就是一种风险。由于 ABC 公司处于天然的空头头寸(因为它是以玉米片的形式出售玉米),它必须确保玉米价格在玉米采购过程中不会一成不变地上涨。
该公司将在玉米期货市场以 400 美元/蒲式耳的价格签订对冲多头合约。明天,如果玉米的现货价格为 425 美元/蒲式耳,ABC 公司通过签订玉米采购的期货多头合同成功对冲了这一价格波动。如果现货价格低于 400 美元,比如 375 美元/蒲式耳,ABC 公司仍然会以 400 美元/蒲式耳的价格购买玉米,因为它已经签订了期货合同。因此,ABC 公司获得了 400 美元/蒲式耳的价格锁定。
1%法则的意义和重要性& 2%投资法则
交易中的 1%和 2%原则意味着每笔交易中可行的最大风险应该是 1%或 2%。
这有助于你避免否则可能发生的过度损失。因此,单笔交易的风险不应超过资本的 1%或 2%。这通常可以通过日交易实现。
例如,持有 10,000 美元资金的交易者不会在单笔交易中冒险超过 100 美元。
利用先进技术监控交易
监控你的交易是非常重要的。可以通过以下方式监控交易:
- 利用算法交易——股票的趋势不断变化,为了最大限度地利用你的交易,密切关注市场的变化是极其重要/关键的。在今天的高级交易中,自动化交易使得找到最有利可图的位置并自动投资变得更加容易,因为交易是由算法驱动的。这被称为算法交易。像神经网络、机器学习和深度学习模型这样的技术有助于监控的自动化以及在几秒钟内决定交易头寸。
- 回溯测试策略- 回溯测试是使用历史数据测试交易策略的过程,以确定该策略的有效性。回溯测试结果通常以一些流行的性能统计数据来显示策略的性能,如夏普比率和索蒂诺比率,这有助于量化策略的风险回报。如果结果满足必要的标准,就可以在一定程度上合理地确信该策略可以实现。如果结果不太理想,可以修改、调整和优化战略,以达到理想的结果。
避免不明确的交易设置
当你的一个指标同意某个交易头寸,而其他指标不同意时,不清楚的交易设置就发生了。例如,如果你使用均线、均线等移动指标。其中一个指标显示了清晰的交易设置,但与其他指标的交易设置不一致,这就造成了混乱。
在这种情况下,最好等待合适的交易,不要在不确定的时候做任何决定。一套混合交易系统不应该成为你决策的基础。
止损
止损是当股票价格达到被称为止损价格的特定价格时触发的买入或卖出指令。止损对于不想持续监控证券的投资者来说非常有用。使用止损的另一个好处是防止过多的损失,并能更好地控制你的账户。止损的一个缺点是,它主要是一个市场订单,因此,它夸大了损失。
例如,假设你以每股 50 美元的价格购买了 XYZ 的股票,你担心它会下跌,如果价格跌至每股 45 美元以下,你可以使用止损单卖出,以保护自己免受更大的损失。
此外,您可以观看这段精心制作的视频,了解我们的专家 Marco Nicolas Dibo 关于风险管理实践的更多信息:
https://www.youtube.com/embed/kt1jSw9BDt0?feature=oembed
结论
在交易实践中,确保你的交易是安全的,有正确的风险管理是非常重要的。对风险管理实践和策略有很好的了解对任何交易者都有好处,因为它能帮助你最小化损失,最大化收益。通过对风险的正确识别和评估,你可以成功地管理风险。
风险管理也有必要了解与日交易、日内交易以及现代加密货币交易相关的风险。您可以查看我们关于加密交易策略的课程,以了解加密货币及其所涉及的风险。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
使用逻辑和线性回归的 Nifty 50 指数的交易策略
该项目涉及使用逻辑和线性回归模型,以预测 Nifty 50 指数下一个交易时段的收盘价,使用一组来自该指数 OHLC 数据的输入变量。
使用一组输入变量,例如(C-L) > (H-C),(H > Ht-1)&(L>Lt-1)我们拟合上一个日历年的模型,并使用当前年份运行模型并回溯测试交易策略。
基于由逻辑模型和线性回归模型创建的策略的性能,我们通过在它们之间以及与基准进行比较来评估性能。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Vatsin Thaker 将自己描述为一个期待整合金融知识和技术的人。Vatsin 目前在 Vista Intelligence 担任研究主管,在那里他将技术&人工智能与金融界&商业融合在一起。
他拥有金融硕士学位和金融市场学士学位,并在衍生品、研究和证券等领域获得认证。瓦辛也是 EPAT 大学的校友。
项目摘要
复杂的机器学习和深度学习技术、人工神经网络和计算密集型数学模型正在金融领域得到广泛应用。特别是在全球证券和股票市场指数的预测方面。
这个项目的最终目标是使用简化的机器学习模型,使用合理的逻辑创建交易策略。这样做是为了根据基准评估这些模型的预测能力。
这有助于评估这些模型是否可以用来生成 alpha,作为高度复杂的模型和技术的替代。
简介
随着技术的出现,多种机器学习技术已经发展用于证券价格的预测。
- 线性回归是机器学习技术的最简单形式之一,用于根据自变量集合估计因变量的值。
- 逻辑回归是另一种类型的机器学习技术,它基于一组二元独立变量来估计事件发生(或不发生)的概率。
该项目是一项研究,涉及线性和逻辑回归技术,以创建交易策略,以确定两个模型的预测能力,并与基准 Nifty 50 指数进行比较。
数据挖掘
出于本研究的目的,我们从 NSE 网站收集了 4 个日历年(2018-2021)期间该指数的每日收盘价数据。我们将数据分为训练期和测试期。
2018 年的数据用于训练模型,2019 年是测试期,之后根据各种指标等对战略进行评估。该过程在所有年份重复,其中当年的数据用于训练模型,下一年的数据用于测试模型。
4 年的数据将捕捉市场的多个阶段,即 COVID 前阶段、COVID 下降阶段和 COVID 后恢复阶段。这些策略在不同阶段的表现可以让我们深入了解这些模型在较长时间框架和不同市场阶段的能力和可靠性。
数据分析
逻辑回归模型
逻辑回归模型也称为预测模型,它以二元结果的形式给出输出。
- 线性回归以基于自变量的贝塔值和自变量的值的形式给出输出值
- 逻辑回归模型给出的输出可以解释为事件发生的概率。
当数据是二分的或二进制的(1 或 0)时,使用这样的模型。对于这个模型,独立变量被转换成二进制的基础上,从原始数据提供的 Nifty 50 指数。
我们希望计算的概率是 Nifty 50 指数第二天的收盘价是否高于当天的收盘价。
如果该事件发生的概率大于提供的阈值(50%),
- 我们以当天的收盘价建仓
- 以第二天的收盘价平仓
- 前提是第二天的交易时段的开盘价不低于我们的进场价。
在这种情况下,我们在开盘价本身的基础上平方,并基于市场开盘疲软可能导致进一步走软的假设来限制损失。
为了计算这个概率,我们使用我们的训练数据集通过创建编码为 1 和 0 的 3 个独立变量来创建逻辑模型。我们根据提供的数据拟合模型,并通过最大化可能性的自然对数来计算贝塔系数。
用于逻辑模型的独立变量为:
1。(C-L) > (H-C): 当日收盘与当日低点之差大于当日高点与当日收盘之差。这个变量表示当天的收盘价是接近高价位还是低价位。
如果它更接近高价,那么高价和收盘价之间的差异将小于收盘价和低价之间的差异,这是看涨的标志。
如果满足该条件,则当天变量的值为 1,否则为 0。
2。(H > H t-1 ): 当日高点高于前一日高点。这是一个看涨的迹象,因为前一天的高点被打破,标志着购买势头,可以推动价格进一步上涨。
如果条件满足,变量被赋 1,否则赋 0。
3。(L > L t-1 ): 当日低点高于前一日低点。这是一个看涨的信号,因为前一天的低点没有被打破,这表明有强大的支撑,可以推动价格进一步上涨。
如果条件满足,变量被赋 1,否则赋 0。
因变量是与当天收盘价相比的下一天的收盘价。
(C t+1
基于 Nifty 50 指数历史价格数据编码为 1 和 0 的上述变量,我们对 2018 年 1 月 1 日至 2018 年 12 月 31 日期间的数据拟合了一个逻辑模型,以计算自变量的贝塔系数。
给定比值比,我们以线性方程的形式表示 Z,由下式给出:
zI= c+β1 xI1+β2 xI2+?。+ βkX 我 k
z 也称为比值比,由下式给出:
ZI= log[pI/(1-pI)]
在我们的研究中,我们将 Z 表示为:
zI= c+β1[(c-l)>(h-c)]+β2[h>【t-1】【t-4】+β3[l>【t-1】【t-6】]。
对于表示为 1 和 0 的上述独立变量的值,β乘以相同的值,并且基于该等式,计算 Z 的值。
在逻辑回归中,该模型依赖于比值比,该比值比使用 sigmoid 函数转换成概率,该函数由下式给出:
pI= 1/(1+e-z)
在我们的研究中,优势比是成功概率除以失败概率的比值。这里,成功的概率是第二天收盘价高于当天收盘价。
然后通过使用 sigmoid 函数(也称为逻辑转换)将优势比转换为成功的概率。通过最大化自然对数似然的总和来计算贝塔系数后,使用 sigmoid 函数对 Z 值进行变换并进行预测。
为了评估模型的准确性,我们创建了一个称为混淆矩阵的矩阵,用于计算模型预测与实际事件相比的准确性。
线性回归模型
线性回归,顾名思义,就是在因变量和自变量之间建立线性关系的线性模型,也就是说是两者的线性组合。
线性回归中最常用的符号是用 Y 表示的独立变量(或多个变量),它们被用作输入,通过使用由方程的截距和斜率表示的线性方程来确定因变量 X 的值,该方程也被称为独立变量的β。
在线性回归中,因变量是用 Y 表示的单一特征,它是用自变量预测的。根据用于预测因变量数值的变量数量,回归模型可分为:
- 简单线性回归模型 -在单一自变量的情况下,或
- 多元线性回归模型 -在多个自变量的情况下。
从给定数据集创建线性回归模型最常用的技术是使用普通最小二乘(OLS) 或最小二乘回归。
为了这项研究的目的,我们使用逻辑回归模型创建了一个交易策略,并与基准 Nifty 50 指数进行了比较。
我们使用由(C-L) > (H-C)、H>H t-1 和 L > L t-1 给出的三个独立变量来预测第二天的收盘价是否会高于当天的收盘价。
我们使用多元线性回归建立了一个类似的交易策略,使用相同的独立变量,但创建了一个与逻辑模型中使用的逻辑密切相关的进入逻辑。
多元线性回归模型表示如下
yI= c+β1 xI1+β2 xI2+?。+ βkX 我 k
上面给定,我们用 x 表示的自变量来预测 Y(因变量)的值。
独立变量的系数(也称为斜率或β)由 OLS 方法给出的迭代方法确定,该方法计算来自给定线的每个数据点的平方和,并使用迭代过程最小化该和。
在迭代过程的最后,我们得到一条具有最小平方和的直线,这是模型的回归方程。对于我们的研究,要形成的回归方程由下式给出
和我= c+β1(h-c)+β2(c-l)+β3[h>ht-1]+β4【l>lt-1
主要发现

上表总结了使用逻辑回归模型和线性回归模型构建的策略的各种指标。
这些模型与基准 Nifty 50 指数在给定年份产生的回报方面进行了比较,我们看到这两个模型在 6 种情况中的 5 种情况下都表现出色。
如果我们要比较这两个模型,就所有阶段的回报而言,逻辑回归模型比线性回归模型表现得更好。
就衡量交易准确性的命中率而言,这两种模型之间没有太大区别。
限制
尽管这些策略优于其基准,但在研究中还是有一些限制
- 对交易成本和下滑的无知
- 考虑到漂亮的 50 指数作为基础,而不是它的期货合约
- 假设执行发生在准确的开盘价和收盘价
- 无法实施职位调整
结论
这些模型表现出显著优于 Nifty50 基准的能力。它强调了这样一个事实,即使用这些变量创建的简单策略可以被证明是有利可图的。
在交易策略的形成过程中,必须注意合理的逻辑,包括进场、出场和止损逻辑,在此之前要创建和计算相应的模型。
下面的 Python 代码中提供了完整的 Python 代码和相关信息。可以下载参考一下。
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
- excel 格式的 2018 年至 2021 年的数据文件
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
如何产生交易想法并进行评估?
对于一个交易者来说,交易理念的知识是一种恩惠,因为它会让你的交易成功。我们将在这篇关于交易思想的文章中讨论这些重要的方面。
本文涵盖:
- 什么是交易理念?
- 产生交易想法的来源
- 评估和回测交易想法或策略
交易想法是什么意思?
交易想法只是你为实际交易或在股票市场执行交易前建立的蓝图。例如,当你看到一只股票在某种情况下朝某个特定方向移动时,你会预测它的涨跌和时间框架。
因此,重复发生的事情让你对股票的走势有点确定。虽然你不能完全确定预期的方向,但你至少可以在交易理念的帮助下增加获得更多的可能性。
让我们继续前进,找出产生交易想法的方法。
产生交易想法的来源
产生交易想法的主要来源应该是你的经验和学习,而不是明确指出的规则。最重要的是,你要在交易中开拓自己的成功之路,为此,你需要产生交易想法。
下面,我们列出了可以帮助你采取正确步骤的最重要的事情,它们是:
自由资源
- 博客和论坛
- 研究论文
优质资源
- 通过课程向专家及其经验学习
- 书
博客&论坛
博客和论坛有助于增加你的交易知识和交易策略。
你可以浏览这个非常规指南中的完整列表,找到适合 Quants 的最佳网站。
这些网站和论坛包括:
- 量化交易(欧内斯特·陈)
- 量子百科
- ETF 总部
- 精英交易者论坛
- 财富实验室
- 量子统治
- 机器学习掌握
- 黑人
- 量子连接
- KDnuggets
研究论文
研究论文起着至关重要的作用,因为你可以深入学习,理解一段时间内观察到的不同交易因素的稳健性。
例如,Jegadeesh 和 Titman 对动量交易进行了研究,发现在 3 到 12 个月期间表现最好的股票往往在随后的 3 到 12 个月期间表现良好。虽然这项研究主要是在美国市场甚至其他发展中国家进行的,但你可以尝试创建一个类似的交易策略,并在其他市场或资产中进行回溯测试,看看它在那里是否有效。
查找研究论文的一些著名网站有:
此外,你可以在事件驱动交易策略的课程中学习使用研究论文。通过掌握这种技能,你可以研究研究论文以获得丰富的知识。
通过课程向专家及其经验学习
为了理解和学习交易,一个非常成功的方法是和成功的交易者接触。为了创建一个职业网络,你可以使用 LinkedIn,活跃在各种平台和论坛上,这有助于了解市场的动向以及这些交易者采取的行动。因为有很多策略存在,你可以不断研究什么对每个交易者最有效,在什么情况下最有效。
找出在什么情况下哪个策略适合谁,然后创建你自己的交易策略。
学习有助于获得对自己知识的信心,并帮助你学习和利用各种交易机会的策略。Quantra 的课程是一个很好的来源。对于学习,有以下几类多门课程:
- 数据科学
- 情绪交易
- 外汇和加密货币交易
- 量化交易
- 机器学习
- 期权交易
- 用于交易的 Python
- 工作准备
根据专业知识和内置理论、实践知识、基础设施、数据、社区支持等进行设计。它们有助于快速掌握各种交易理念。此外,这些课程是数百个小时的研究和学习的精华,以易于理解的语言和设置呈现。
为上述课程和学习路线做出贡献的机构/合著者/专家:
- MCX
- NSE 学院
- 福汇
- 交互式经纪人
- 多种商品交易所
- 托马斯·斯塔克
- terry benzschawel 医生
- 欧内斯特·陈博士
- 劳伦特·伯纳特
书籍
交易方面的书对获得大量知识极其有帮助,需要时间和精力去学习。如果你喜欢读书,你不会后悔阅读这些关于算法交易的必备书籍或者这个交易爱好者阅读清单。
在这里你可以找到所有关于当代和自动化交易的书籍。
这里有一个有趣的列表,对获得最好的交易有很大的帮助:
- 量化交易:如何建立自己的算法交易业务
- 算法交易和 DMA:直接交易策略介绍
- 期权波动和定价:高级交易策略和技术
- 波动交易——尤安·辛克莱
- 金融 python-Yves Chan
- Python 衍生产品分析- Yves Chan
- 上市波动率和方差衍生品- Yves Chan
让我们向前看,看看回测和评估交易想法/策略是多么重要。
评估和回测交易想法或策略
评估交易策略通过使用统计分析帮助你改善交易结果,并衡量你的交易表现(优势和劣势)。
学习高级算法交易策略将帮助你运用正确的交易策略。
有一些指标可以找出你投资组合中的潜在风险,在此基础上你可以决定你的交易策略。这些已知指标是:
- 年化波动率- 这意味着一个模型在一年中每日收益的标准差。由于波动性是衡量风险的标准,波动性越高,策略的风险就越大。
年波动率的公式是$ $σ_ { P } =σ_ { DAILY } $ $
以上,P=交易日数量
$ \(σ_ { DAILY } = Standard \;偏差\;的\;每\;第\)$
或者每日百分比变化=(当前收盘价-昨天收盘价)/100
通过应用该公式,您可以在 Excel 上找出一年中的每日百分比变化。然后,你可以找出每日百分比变化总数的标准差,并乘以 252 的平方根,即交易天数。
这个计算将会给你一个股票或指数的移动百分比。这个百分比可以帮助你预测市场,在这个预测的基础上,可以评估你的交易策略的表现。虽然,这可能不会给你提供准确的股票或指数的运动,但它仍然被认为是一个可靠的计算。
- 夏普比率 -这是年化回报率/年化波动率的比率,意味着特定策略的回报/风险比率或风险调整后的回报。
夏普比率由以下等式给出:
夏普比率= (Rp - Rf) / σ
在哪里,
Rp=平均投资组合回报
Rf= 无风险利率
σ=投资组合的标准差
例如,假设您预期您的投资组合的年化回报率为 12%。如果无风险利率是 7%,你的投资组合有 8%的标准差。您投资组合的夏普比率计算如下:
夏普比率= (12% - 7%)/ 8% = 0.625
这个比率有助于你发现你的策略是否考虑了你的回报和市场上的风险。
- 最大下跌- 最大下跌是指在股票趋势达到新高之前,从最大高点到后续低点的量度。
在您的交易或投资期间,您的投资组合会多次贬值。这些价值的减少被称为提取。这些提款值的最大值给了我们一个投资组合可能遭受的最大损失的估计。从技术上讲,它被定义为一个投资组合从高峰到低谷的最大损失。
它可以用公式表示为:

在哪里,
P =最大下降前的最大值
L =新高之前的最低值
假设你的投资组合的初始值是 10,000 美元。在一段时间内,它增加到 50,000 美元,然后下降到 7500 美元。然后反弹到 55,000 美元,然后再次下跌到 48,000 美元。在这种情况下,最大下降值为
(7500 – 50000) / 50000 = -85%.
首选较低的最大提款值,因为它表明投资组合中的投资损失较少。换句话说,你的资本不会有任何重大损失。这是大型机构投资者所追求的特征。
此外,在交易领域的经历会给你带来大量的知识,这些知识是你无法从理论来源获得的。当你是一个有经验的交易者时,你会意识到情绪在市场中是没有用的。因此,你的交易理念和策略应该完全基于逻辑。这里的逻辑是找出市场的优势,通过了解股票的表现,有可能预测未来的表现。虽然,通过分析市场过去的表现,不能保证表现会如预期的那样。
最后,一旦你获得了经验,对你所做的决定有了信心,你就可以开始不同类型的交易,比如刷单等等。
回溯测试
回溯测试是使用历史数据测试交易策略的过程,以确定该策略的有效性。回溯测试结果通常以一些流行的性能统计数据来显示策略的性能,如夏普比率、索蒂诺比率,这些数据有助于量化策略的风险回报。如果结果满足必要的标准,就可以在一定程度上合理地确信该策略可以实现。
你可以在这里了解关于回溯测试交易策略的所有信息。
你可以使用像 Blueshift 这样的回溯测试平台进行回溯测试和性能分析,找出你的策略/交易想法的可行性。
你可以从纸上交易开始,这种交易可以买卖证券,而不需要冒任何风险。使用虚拟货币进行票据交易的整个机制被称为“票据交易”
一旦你对自己的交易策略或技术有了信心,你就可以开始实时交易了。现场交易涉及真实的钱,因此,进入现场交易意味着真实的利润和真实的损失。
这段视频让我们对实时交易有了更深入的了解:
https://www.youtube.com/embed/wfeS2QLWRuI?feature=oembed
此外,你可以沉浸在刘辉博士和阿迪蒂亚·古普塔的大师级实践录音中,他们解释了如何创建算法交易策略,并在真实市场中实施。他们探索了交易策略的领域,创建了一个样本策略,对其进行了回溯测试,并分析了以下结果:
https://www.youtube.com/embed/VFhSKz4hyTA?feature=oembed
结论
在交易领域,对产生、评估和回测交易想法有很好的理解和知识是非常重要的,因为在特定情况下应用正确的策略有助于改善你的交易体验。
成为一个成功的交易者的主要方面是每笔交易背后适合特定市场情况的策略。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
交易策略:股票 52 周高点效应
原文:https://blog.quantinsti.com/trading-strategy-52-weeks-high-effect-in-stocks/

在今天的算法交易中,拥有交易优势是最关键的因素之一。这很简单。如果你没有优势,就不要交易!因此,作为一个量化分析师,你总是在寻找好的交易思路。Quantpedia 网站是广受欢迎的量化交易策略的良好资源之一。Quantpedia 有数以千计的金融研究论文,可以用来创建有利可图的交易策略。

Quantpedia 上的“筛选”页面根据不同的参数,如周期、工具、市场、复杂性、性能、亏损、波动性、夏普等,对数百种交易策略进行了分类。

Quantpedia 已经向用户免费提供了一些交易策略。在这篇文章中,我们将探讨一个这样的交易策略,列在他们的网站上,名为“52 周股票高点效应”。
股市 52 周高点效应
Quantpedia 页面【1】为该交易策略提供了详细的描述,其中包括 52 周高效解释、源研究论文、其他相关论文、策略表现的可视化以及其他相关交易策略。
什么是 52 周高效?
让我们把量子百科上提供的清晰解释写在这里-
“52 周高点效应”指出,价格接近 52 周高点的股票比价格远离 52 周 - 高点的股票有更好的后续回报。投资者将 52 周高点作为他们评估股票价值的“锚”。当股价接近 52 周高点时,投资者不愿意把价格一直标到基本面价值。因此,当股价接近 52 周高点时,投资者反应不足,这就产生了 52 周高点效应。
源文件
源论文【2】“行业信息与 52 周高效效应”由、Bradford D. Jordan 和 Mark H. Liu 撰写。
金融论文称,交易员将 52 周高点作为一个参考点,以此评估消息的潜在影响。当好消息推动股票价格接近或达到 52 周新高时,交易者不愿意抬高股票价格,即使该消息是合理的。信息最终占据上风,价格上涨,导致延续。它同样适用于 52 周低点。
作者开发的交易策略是在股价接近 52 周高点的行业买入股票,在股价远离 52 周高点的行业做空股票。他们发现行业 52 周高点交易策略比 George 和 Hwang (2004)提出的个人 52 周高点交易策略更有利可图。
使用 R 编程制定我们的 52 周高效战略
理解了 52 周高点效应后,我们将尝试使用 R 编程回测一个简单的交易策略。请注意,我们并不是要复制作者在他们的研究论文中提出的交易策略。
我们使用在印度国家证券交易所(NSE)上市的约 140 只股票的每日数据,对我们的交易策略进行了为期 3 年的回溯测试。
战略简介
交易策略读取列表中每只股票的每日历史数据,并在每个月初检查股票价格是否接近其 52 周高点。我们已经在下面的交易策略制定过程的第 4 步中展示了如何检查这种情况。对于所有通过这个条件的股票,我们在那个月形成一个等权重的投资组合。我们在月初持有这些股票的多头头寸,并在下个月初平仓。我们在回溯测试期间的每个月都遵循这个过程。最后,我们计算并绘制交易策略的绩效指标。
现在,让我们一步步了解交易策略制定的过程。为了便于参考,我们在交易策略的各个步骤下发布了相关部分的 R 代码片段。
交易策略制定的过程
步骤 1
首先,我们设置回溯测试周期,以及用于确定股票是否接近其 52 周高点的上限和下限。
# Setting the lower and upper threshold limits
lower_threshold_limit = 0.90 # (eg.0.90 = 90%)
upper_threshold_limit = 0.95 # (eg.0.95 = 95%)
# Backtesting period (Eg. 1 = 1 year) minimum period selected should be 2 years.
noDays = 4
第二步
在这一步中,我们使用来自 r 的 read.csv 函数读取历史股票数据。我们使用来自 Google finance 的数据,它由开盘价/最高价/最低价/收盘价(OHLC)和成交量值组成。
# Run the program for each stock in the list
for(s in 1:length(symbol)){
print(s)
dirPath = paste(getwd(),"/4 Year Historical Data/",sep="")
fileName = paste(dirPath,symbol[s],".csv",sep="")
data = as.data.frame(read.csv(fileName))
data$TICKER = symbol[s]}
# Merge NIFTY prices with Stock data and select the Close Price
data = merge(data,data_nifty, by = "DATE")
data = data[, c("DATE", "TICKER","CLOSE.x","CLOSE.y")]
colnames(data) = c("DATE","TICKER","CLOSE","NIFTY")
N = nrow(data)
第三步:
由于我们使用每日数据,我们需要确定每个月的开始日期。开始日期不一定是每个月的 1 号1 号,因为 1 号1 号可以是周末或证券交易所的假日。因此,我们写一个 R 代码,它将决定每个月的第一天。
# Determine the date on which each month of the backtest period starts
data$First_Day = ""
day = format(ymd(data$DATE),format="%d")
monthYr = format(ymd(data$DATE),format="%Y-%m")
yt = tapply(day,monthYr, min)
first_day = as.Date(paste(row.names(yt),yt,sep="-"))
frows = match(first_day, ymd(data$DATE))
for (f in frows) {data$First_Day[f] = "First Day of the Month"}
data = data[, c("TICKER","DATE", "CLOSE","NIFTY","First_Day")]
第四步:
检查股票是否在 52 周高点附近。在这一部分,我们首先计算每只股票的 52 周最高价。然后,我们使用 52 周的最高价格计算上限和下限。
举例:
如果下限阈值= 0.90,上限阈值= 0.95,52 周上限= 1200,则阈值范围由下式给出:
阈值范围=(0.90 * 1200)–(0.95 * 1200)
阈值范围= 1080 到 1140
如果本月初的股价在这个范围内下跌,我们就认为该股接近 52 周高点。我们还在该步骤中加入了一个附加条件。该条件检查过去 30 天的股票价格是否达到了当前 52 周的最高价格,以及它现在是否在阈值范围内。这样的股票将不包括在我们的投资组合中,因为我们假设股价在达到今天的 52 周高点后正在下跌。
# Check if the stock is near its 52-week high at the start of the each month
data$Near_52_Week_High = "" ; data$Max_52 = numeric(nrow(data));
data$Max_Not = numeric(nrow(data));
frows_tp = frows[frows >= 260]
for (fr in frows_tp){
# This will determine the max price in the last 1 year (252 trading days)
data$Max_52[fr] = max(data$CLOSE[(fr-252):(fr-1)])
# This will check whether the max price has occurred in the last "x" days.
data$Max_Not[fr] = max(data$CLOSE[(fr-no_max):(fr-1)])
if ((data$CLOSE[fr] >= lower_threshold_limit * data$Max_52[fr])
& (data$CLOSE[fr] <= upper_threshold_limit * data$Max_52[fr])
& (data$Max_Not[fr] != data$Max_52[fr]) == TRUE ){
data$Near_52_Week_High[fr] = "Near 52-Week High"
} else {
data$Near_52_Week_High[fr] = "Not Near 52-Week High"
}
}
第五步:
对于所有符合上述标准的股票,我们创建一个只做多的投资组合。进场价格等于月初的价格。我们在下个月初结清我们的多头头寸。我们考虑股票的收盘价作为我们的进场和出场交易。
# Enter into a long position for stocks at each start of month
data = subset(data,select=c(TICKER,DATE,CLOSE,NIFTY,First_Day,Max_52,Near_52_Week_High)
,subset=(First_Day=="First Day of the Month"))
data$NEXT_CLOSE = lagpad(data$CLOSE, 1)
colnames(data) = c("TICKER","DATE","CLOSE","NIFTY","First_Day","Max_52","Near_52_Week_High",
"NEXT_CLOSE")
data$Profit_Loss = numeric(nrow(data)); data$Nifty_change = numeric(nrow(data));
for (i in 1:length(data$CLOSE)) {
if ((data$Near_52_Week_High[i] == "Near 52-Week High") == TRUE){
data$Profit_Loss[i] = round(data$CLOSE[i+1] - data$CLOSE[i],2)
data$Nifty_change[i] = round(Delt(data$NIFTY[i],data$NIFTY[i+1])*100,2)
}
}
for (i in 1:length(data$CLOSE)) {
if ((data$Near_52_Week_High[i] == "Not Near 52-Week High") == TRUE){
data$Profit_Loss[i] = 0
data$Nifty_change[i] = round(Delt(data$NIFTY[i],data$NIFTY[i+1])*100,2)
}
}
第六步:
在这一步中,我们编写了一个 R 代码,它创建了回溯测试期间每个月所有交易的汇总表。下面显示了一个样本汇总表。它还包括当月每笔交易的盈利/亏损。
# Create a Summary worksheet for all the trades during a particular month
final_data = final_data[-1,]
final_data = subset(final_data,select=c(TICKER,DATE,CLOSE,NEXT_CLOSE,Max_52,
Near_52_Week_High,Profit_Loss,Nifty_change),
subset=(Near_52_Week_High == "Near 52-Week High"))
colnames(final_data) = c("Ticker","Date","Close_Price","Next_Close_Price",
"Max. 52-Week price","Is Stock near 52-Week high",
"Profit_Loss","Nifty_Change")
merged_file = paste(date_values[a],"- Summary.csv")
write.csv(final_data,merged_file)

第七步:
最后一步,我们计算整个回溯测试期间的投资组合绩效,并使用 r 中的 PerformanceAnalytics 包绘制权益曲线。投资组合绩效保存在 CSV 文件中。
cum_returns = Return.cumulative(eq_ts, geometric = TRUE)
print(cum_returns)
charts.PerformanceSummary(eq_ts,geometric=TRUE, wealth.index = FALSE)
print(SharpeRatio.annualized(eq_ts, Rf = 0, scale = 12, geometric = TRUE))
投资组合表现的样本摘要如下所示。在这种情况下,我们交易策略的输入参数如下:

![]() 绘制股权曲线
绘制股权曲线
 绘制股权曲线
绘制股权曲线
从权益曲线可以看出,我们的交易策略在初始阶段表现良好,但在后验阶段的中期出现了下滑。交易策略的夏普比率为 0.4098。
Cumulative Return 1.172446
Annualized Sharpe Ratio (Rf=0%) 0.4098261
这是一个简单的交易策略,我们用 52 周高效解释开发的。人们可以进一步调整这种交易策略,以提高其性能,使其更加稳健,或者在不同的市场进行尝试。
下一步
访问 Gopal 提交的最终项目,作为他在 QuantInsti 的算法交易(EPAT) 高管课程的一部分。该项目涵盖了基于 MACD、超级趋势和用 Python 编码的 ADX 等指标的趋势跟踪策略。
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
Python 中用于算法交易的机器学习
原文:https://blog.quantinsti.com/trading-using-machine-learning-python/
你有没有好奇过如何利用 Python 中的机器学习进行算法交易?
近年来,机器学习,更具体地说是 Python 中的机器学习,已经成为许多 quant 公司的热门词汇。为了寻找难以捉摸的阿尔法,许多基金和交易公司已经采用了机器学习算法进行 T2 算法交易。
虽然量化对冲基金部署的算法从未公开,但我们知道顶级基金在很大程度上使用机器学习算法进行交易。
举个例子,曼集团的 AHL 维度计划是一个 51 亿美元的对冲基金,部分由 AI 管理。还有 Taaffeite Capital 表示,它使用专有的机器学习系统以完全系统化和自动化的方式进行交易。
在这篇 Python 机器学习教程中,我们试图理解机器学习是如何改变交易世界的。然后,我们创建一个简单的 Python 机器学习算法来预测股票的第二天收盘价。
因此,在本 Python 机器学习教程中,我们将涵盖以下主题:
- Python 中的机器学习如何流行起来
- 为什么在 Python 中使用机器学习进行交易?
- 使用 Python 为交易创建机器学习算法的先决条件
- 获取数据并使其可用于机器学习算法
- 创建超参数
- 将数据分成测试和训练集
- 获得最佳拟合参数以创建新函数
- 进行预测并检查性能
- 奖金内容
如何MachineL在 Python 中赚得了人气****
机器学习包/库由公司内部开发,供其专有使用,或者由第三方免费提供给用户社区。
近年来,机器学习软件包的数量大幅增加,这有助于开发者社区获得各种机器学习技术,并将其应用于他们的交易需求。
有数百种最大似然算法,根据它们的工作原理可以分为不同的类型。
比如用机器学习回归算法对变量之间的关系进行建模;决策树算法构建决策模型,用于分类或回归问题。其中,一些算法已经在 quants 中流行起来。
其中包括:
这些交易机器学习算法被交易公司用于各种目的,包括:
- 使用大型数据集分析历史市场行为
- 确定策略的最佳输入(预测)
- 确定最佳策略参数集
- 进行贸易预测等。
Python 中为什么要用机器学习进行交易?
多年来,我们已经意识到 Python 正成为程序员的流行语言,这是一个普遍活跃和热情的社区,他们总是在那里相互支持。
根据 Stack Overflow 的 2020 年开发者调查,开发者报告说他们想学习 Python,这是连续第四年占据榜首。

Python ranking #1 on StackOverflow
Python trading 已经在 quant finance 社区获得了关注,因为它可以轻松地构建复杂的统计模型,因为有足够的科学库可用,如:
- 熊猫
- NumPy
- PyAlgoTrade
- Pybacktest 等等。
对 Python 交易库的首次更新在开发者社区中是经常发生的。事实上, Scikit-learn 是一个专门为机器学习开发的 Python 包,它具有各种分类、回归和聚类算法。因此,对于一个初学者(或者更确切地说,一个经验丰富的交易者)来说,开始学习 python 中的机器学习是有意义的。
近年来,技术和电子交易的兴起只是加快了自动化交易的速度。对于交易员或基金经理来说,相关的问题是“我如何应用这个新工具来产生更多的阿尔法值?”。我现在将探索一个回答这个问题的模型。
****创造机器学习算法进行交易使用 Python
您可以添加一行来安装软件包“pip install numpy pandas …”您可以在 Anaconda 提示符下使用以下代码来安装必要的软件包。想了解更多关于 Python numpy 的知识,点击这里。
- pip 安装熊猫
- pip 安装熊猫-datareader
- pip 安装数量
- pip 安装硬化
- pip 安装 matplotlib
在我们继续之前,让我声明这段代码是用 Python 2.7 编写的。所以让我们开始吧。
问题陈述
让我们首先了解我们的目标是什么。在本 Python 机器学习教程的最后,我将向您展示如何创建一个算法,该算法可以根据以前的 OHLC(开盘、盘高、盘低、收盘)数据预测一天的收盘价。
我还想监控预测误差以及输入数据的大小。
让我们导入构建这个机器学习算法所需的所有库和包。
获取数据并使其可用于机器学习算法
要创建任何算法,我们都需要数据来训练算法,然后对新的未知数据进行预测。在这个 Python 机器学习教程中,我们将从 Yahoo 获取数据。
为此,我们将使用熊猫图书馆的数据阅读器功能。该函数被广泛使用,它使您能够从许多在线数据源获取数据。
我们正在获取与标准普尔 500 挂钩的 SPDR ETF 的数据。这只股票可以作为标准普尔 500 指数表现的代表。我们指定从哪一年开始提取数据。
数据输入后,我们将丢弃除 OHLC 之外的任何数据,如成交量和调整后收盘价,以创建我们的数据框架“df”。
现在我们需要从过去的数据中做出我们的预测,这些过去的特征将有助于机器学习模型交易。因此,让我们在数据框中创建新列,其中包含有一天延迟的数据。
请注意,在新列的名称中,小写字母被去掉了。
创建超参数
虽然超参数的概念本身就值得写一篇博客,但现在我只想说几句。这些是机器学习算法无法学习但需要迭代的参数。我们使用它们来查看哪些预定义函数或参数产生最佳拟合函数。
在这个例子中,我使用了套索回归,它使用了 L1 类型的正则化。这是一种基于回归分析的机器学习模型,用于预测连续数据。
使用要素选择时,这种正则化非常有用。它能够将系数值减小到零。SimpleImputer 函数将任何可能影响我们预测的 NaN 值替换为平均值,如代码中所指定的。
“步骤”是作为管道功能的一部分并入的一组功能。管道是对数据集执行多重操作的非常有效的工具。这里,我们还传递了 Lasso 函数参数以及一个可以迭代的值列表。
虽然我不打算详细说明这些参数到底是做什么的,但它们是值得深入研究的。最后,我调用了随机搜索函数来执行交叉验证。
在本例中,我们使用了 5 重交叉验证。在 k 重交叉验证中,原始样本被随机分成 k 个大小相等的子样本。在 k 个子样本中,保留一个子样本作为测试模型的验证数据,其余 k-1 个子样本用作训练数据。
然后,交叉验证过程重复 k 次(折叠),k 个子样本中的每一个正好用作验证数据一次。交叉验证合并(平均)拟合(预测误差)度量值,以获得更准确的模型预测性能估计值。
基于拟合参数,我们决定最佳特征。在 Python 机器学习教程的下一部分,我们将研究 int 测试和训练集。
将数据拆分成测试和训练集
首先,让我们将数据分为输入值和预测值。在这里,我们将滞后一天的 OHLC 数据作为数据帧 X 传递,当天的收盘值作为 y 传递。请注意下面小写的列名。
在本例中,为了保持 Python 机器学习教程的简短和相关性,我选择不创建任何多项式要素,而是仅使用原始数据。如果您对输入参数的各种组合和高次多项式特征感兴趣,您可以使用 scikit learn 预处理包中的 PolynomialFeature()函数随意变换数据。
现在,让我们也创建一个保存训练数据集的大小及其对应的平均预测误差的字典。
拟合参数创建新函数
我想测量回归函数相对于输入数据集大小的性能。换句话说,我想看看通过增加输入数据,我们是否能够减少误差。为此,我使用 For 循环来迭代相同的数据集,但长度不同。
在这一点上,我想补充的是,对于那些感兴趣的人,请探索“重置”功能,以及它将如何帮助我们做出更可靠的预测。
(提示:它是 Python 魔术命令的一部分)
我来分几步解释一下我是怎么做的。
首先,我创建了一组周期数“t ”,从 50 到 97,步长为 3。这些数字的目的是选择将用作训练数据集的数据集的百分比大小。
第二,对于给定的‘t’值,我将数据集的长度分割成与这个百分比相对应的最接近的整数。然后,我将全部数据分为训练数据和测试数据,前者包括从开始到分割的数据,后者包括从分割到结束的数据。采用这种方法而不使用随机分割的原因是为了保持时间序列的连续性。
在此之后,我们提取产生最低交叉验证误差的最佳参数,然后使用这些参数创建新的 reg1 函数,该函数将是具有最佳参数的简单套索回归拟合。
进行预测并检查业绩
现在让我们预测一下未来的收盘价。为此,我们使用 predict()函数将包含从 split 到 end 的数据的 test X 传递给回归函数。我们还想看看函数执行得如何,所以让我们将这些值保存在一个新列中。
您可能已经注意到,我创建了一个新的错误列来保存绝对错误值。然后,我取绝对误差值的平均值,保存在我们之前创建的字典中。
现在是时候策划一下,看看我们得到了什么。
我创建了一个新的范围值来保存数据的平均每日交易范围。这是一个我在做预测时想要比较的指标。这种比较背后的逻辑是,如果我的预测误差超过一天的范围,那么很可能就没有用了。
我还不如用前一天的高点或低点作为预测,结果会更准确。请注意,我在循环外使用了分割值。这意味着您在这里看到的一天的平均范围与最后一次迭代相关。
让我们执行代码,看看会得到什么。

一些值得思考的问题。
这个散点图告诉你什么?让我问你几个问题。
- 方程是否过度拟合?
- 随着训练数据集大小的增加,数据的性能显著提高。这是否意味着如果我们给出更多的数据,误差会进一步减小?
- 市场中是否存在一种内在趋势,允许我们随着数据集大小的增加做出更好的预测?
- 最后,也是最重要的一个问题,我们如何利用这些预测来制定交易策略?
****奖金内容
关于使用 Python 进行交易的机器学习算法的常见问题
在交易的机器学习算法教程的最后一节,我问了几个问题。现在,我将同时回答它们。我还将讨论一种无需训练趋势算法就能检测市场状态/趋势的方法。
但是在我们继续之前,请使用一个补丁从 Google 获取数据来运行下面的代码。
如果您在从雅虎和谷歌金融平台下载市场数据时遇到挑战,并且正在寻找市场数据的替代来源,您可以使用 Quandl 来完成同样的任务。
我们现在开始提问,好吗?
问:方程是否过拟合?
答:这是我问的第一个问题。要知道您的数据是否过度拟合,最好的测试方法是检查算法在训练和测试数据中产生的预测误差。
要做到这一点,我们必须向已经编写好的代码中添加一小段代码。
首先,让我开始我的解释,为打破常规道歉:超过 80 列标记。
第二,如果我们运行这段代码,那么输出看起来会像这样。

与训练数据相比,我们的算法在测试数据中表现更好。这一观察本身就是一个危险信号。我们的测试数据误差可能优于列车数据误差的原因有几个:
- 如果与测试集相比,训练数据具有更大的波动性(每日范围),那么预测也会表现出更大的波动性。
- 如果市场中有一种内在的趋势可以帮助算法做出更好的预测。
现在,让我们检查一下这些情况中哪一个是真的。如果测试数据的范围小于训练数据,那么在将超过 80%的数据作为训练集传递之后,误差应该已经减小,但是它增加了。
接下来,为了检查是否有趋势,让我们传递不同时间段的更多数据。
如果我们运行代码,结果将如下所示:

因此,给出更多的数据并没有让你的算法更好地工作,而是让它变得更糟。在时间序列数据中,内在趋势对算法在测试数据上的表现起着非常重要的作用。
正如我们在上面看到的,它有时会产生比预期更好的结果。我们的算法做得如此好的主要原因是测试数据坚持在训练数据中观察到的主要模式。
因此,如果我们的算法可以检测潜在的趋势,并针对该趋势使用策略,那么它应该会给出更好的结果。我将在下面更详细地解释这一点。
问:机器学习算法能否检测出内在趋势或市场阶段(牛市/熊市/横盘/突破/恐慌)?
问:是否可以对数据库进行调整,以便针对不同的情况训练不同的算法
答:两个问题的答案都是肯定的!
我们可以将市场划分为不同的区域,然后使用这些信号来整理数据,并为这些数据集训练不同的算法。为了实现这一点,我选择使用一种无监督机器学习算法。
从这里开始,这个 Python 机器学习教程将致力于创建一个可以检测市场内在趋势的算法,而无需对其进行显式训练。
首先,让我们导入必要的库。
然后,我们从谷歌获取 OHLC 数据,并将其移动一天,只根据过去的数据训练算法。
然后放下所有的 NaN。
接下来,我们将使用 sklearn 的“高斯混合”模型实例化一个无监督的机器学习算法。
在上面的代码中,我创建了一个无人监管的算法,它会根据自己选择的标准将市场分成 4 个区域。我们没有像 Python 机器学习教程的前一部分那样提供任何带有标签的训练数据集。
接下来,我们将拟合数据并预测政权。然后我们会把这些状态预测存储在一个新的变量里,叫做状态。
现在让我们来计算一天的收益。
然后,创建一个名为 Regimes 的数据框架,该数据框架将包含 OHLC 和返回值以及相应的 regime 分类。
在此之后,让我们创建一个名为“order”的列表,其中包含与制度分类相对应的值,然后绘制这些值,以查看算法的分类效果。
最终的政权区分如下所示:

这张图表对我来说很不错。不用实际查看分类所基于的因素,我们只需查看图表就可以得出一些结论。
- 红色区域是低波动或横向区域
- 紫色区域是高波动区域或恐慌区域。
- 绿色区域是突破区域。
- 蓝区:不完全确定,但让我们找出答案。
使用下面的代码打印每个制度的相关数据。
输出如下所示:

数据可以推断如下:
- 体制 0:低均值和高协方差。
- 制度 1:高均值和高协方差。
- 制度 2:高平均值和低协方差。
- 制度 3:低均值和低协方差。
到目前为止,我们已经看到了如何将市场分成不同的区域。
但是实施成功战略的问题仍然没有答案。如果你想学习如何编写机器学习交易策略,那么你的选择很简单:
套用《黑客帝国》电影三部曲中的墨菲斯,
这是你最后的机会。在这之后,就没有回头路了。你吃了蓝色药丸——故事结束,你在床上醒来,相信你可以手动交易。
你服用红色药丸——你待在阿尔果兰,我让你看看兔子洞有多深。记住:我提供的都是事实。仅此而已。
向交易的机器学习算法世界迈进了一步
在当今世界,保持自我更新是最重要的。拥有一个学习者的心态总是有助于提升你的职业生涯,并在为自己或自己的公司制定交易策略时获得技能和额外的工具。
这里有几本书可能会很有趣:
- Gareth James,Daniela Witten,Trevor Hastie 和 Robert Tibshirani 统计学习简介
- 安德烈·布尔科夫的《百页机器学习书》
- Hastie、Tibshirani 和 Friedman 的统计学习的要素
机器学习竞赛
有许多举办职业棒球大赛的网站。这些竞赛虽然不是专门针对 Python 机器学习在交易中的应用。
他们可以通过参加竞赛和论坛,让定量分析师和交易者很好地接触不同的 ML 问题,并帮助扩展他们的 ML 知识。一些受欢迎的 ML 竞赛主办网站包括:
你会发现阅读这些精选的顶级博客很有用,也很有见识:
机器学习
T3】Python 进行交易
情绪交易
算法交易
期权交易
技术分析
结论
总的来说,我们已经通过各种例子,经历了你如何学习在 python 中为算法交易创建和使用你自己的机器学习的整个旅程。整个过程借助 Python 代码进行了解释,这对你的练习也有帮助。
如果您对本文有任何意见或建议,请在下面的评论中与我们分享。
如果你也想创建交易策略,并了解你的模型的局限性,看看欧内斯特·p·陈博士撰写的关于“交易中的决策树”的课程,它揭示了分类树中的黑箱。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
使用 Zerodha Kite Connect API 在印度市场与 Python 进行交易
原文:https://blog.quantinsti.com/trading-with-python-indian-markets/

我们已经在本文的中告诉你为什么 Python 是进行算法交易的首选语言之一。我们也告诉过你在印度的程序化 T2 交易。我们还成功举办了一场关于使用 python 在印度市场进行交易的网上研讨会(点击此处观看网上研讨会),我们应该向您介绍一下这个交易平台,它将使您能够使用 Python 实现您的算法交易策略。
为了使用 Python 在印度市场进行交易,我们将利用 Zerodha Kite Connect API,这是印度第一个面向零售客户的市场 API。我们将在网络研讨会中详细讨论这一点。我们涵盖了EPAT的大多数交易平台,这是我们广受欢迎的算法交易和量化金融课程。在之前的一篇文章中,我们还介绍了 python 中可用于编程交易的各种库,在这篇文章中,我们还将讨论用于与 Zerodha Kite Connect API 通信的官方 Python 客户端。
什么是 Zerodha Kite Connect?
Kite Connect 是类似 REST 的基于超文本传输协议的 API 的汇编,这些 API 缓解了构建投资和交易平台所需的众多能力。它建立在 Zerodha 的在线交易平台之上。用户只能是 Zerodha 的客户,他们可以通过编程方式访问有关经纪业务的所有信息。您还可以将 Kite Connect API 用于:
- 实时执行订单
- 管理投资组合
- 流式实时市场数据
- 异地订单执行
- 获得订单的可靠更新
- 当然,获取历史数据
现在,如果你还记得,在我们关于交互式经纪人交易的文章中,我们提到了使用 IB API 进行算法交易的一些优势。对于印度市场来说,Zerodha Kite Connect 是使用 Python 实现算法交易策略的绝佳选择,这在我们的网络研讨会中有进一步解释。
Zerodha 风筝会的目标
散户投资者远离资本市场的日子已经一去不复返了,因为他们没有任何务实地进入交易账户的选择。Zerodha Kite Connect 致力于为印度的交易方式带来革命性的变化,承诺:
- 降低在印度进行交易的成本
- 将来完全没有经纪业务
- 使过程更加透明
- 提供一个更好的交易平台
- 保持客户至上的态度。
- 支持多种编程语言,包括 Python、Java、C#、Excel VBA 等。你也可以在 Kite Connect 上使用命令行控制台。
除了下订单和管理订单,Kite Connect 还承诺让用户建立:
- 多资产风险建模系统
- 股票筛选员
- 量化策略
- 股票选择模型
- 期权希腊计算器
- 回溯测试,机器学习
- 个人风筝或 Pi。
Zerodha Kite Connect 的一个关键优势是,您将拥有并控制您的交易账户和与之相关的数据,并且您将不会被限制在您的经纪人提供的平台上。
用于 Kite Connect 中程序化交易的 Python
我们已经在标题为为什么 Python 程序化交易是交易者的首选的文章中告诉了你为什么 Python 足以成为程序化交易的最佳选择?
Zerodha 的 Kite Connect 拥有多种编程语言的客户端库,包括 PHP、JS,当然还有 Python。Python 的官方库可从以下网址获得:
https://github.com/rainmattertech/pykiteconnect
要求
Zerodha 是印度第一家折扣经纪商,Kite Connect 的所有交易都通过 Zerodha 执行。所以,你需要做的第一件事是在 Zerodha 上创建一个交易账户,这样你就可以访问 API 了。一旦你有了这些,接下来要做的就是注册一个开发者账户。就是这样!你可以马上开始。在我们的网络研讨会中,Zerodha 的创始人&兼首席执行官 Nithin Kamat、&zero DHA 的软件开发人员 Satyajit Sarangi 将以循序渐进的方式解释这一切。
因为 Zerodha 已经为 Kite Connect API 的用户获得了所有必要的批准,所以作为 Kite Connect 的用户,你不需要获得任何其他的批准。
Python 客户端的安装
从 github 资源库下载资源后,您必须安装这些文件。要安装客户端,您必须使用以下命令:
pip install kiteconnect
API 用法
您也可以在 github 存储库中找到以下代码。然而,为了方便起见,我们在这里给出它:
from kiteconnect import KiteConnect
kite = KiteConnect(api_key="your_api_key")
# Redirect the user to the login url obtained
# from kite.login_url(), and receive the request_token
# from the registered redirect url after the login flow.
# Once you have the request_token, obtain the access_token
# as follows.
data = kite.request_access_token("request_token_here", secret="your_secret")
kite.set_access_token(data["access_token"])
# Place an order
try:
order_id = kite.order_place(tradingsymbol="INFY",
exchange="NSE",
transaction_type="BUY",
quantity=1,
order_type="MARKET",
product="NRML")
print("Order placed. ID is", order_id)
except Exception as e:
print("Order placement failed", e.message)
# Fetch all orders
print(kite.orders())
WebSocket 用法
from kiteconnect import WebSocket
# Initialise.
kws = WebSocket("your_api_key", "your_public_token", "logged_in_user_id")
# Callback for tick reception.
def on_tick(tick, ws):
print tick
# Callback for successful connection.
def on_connect(ws):
# Subscribe to a list of instrument_tokens (RELIANCE and ACC here).
ws.subscribe([738561, 5633])
# Set RELIANCE to tick in `full` mode.
ws.set_mode(ws.MODE_FULL, [738561])
# Assign the callbacks.
kws.on_tick = on_tick
kws.on_connect = on_connect
# Infinite loop on the main thread. Nothing after this will run.
# You have to use the pre-defined callbacks to manage subscriptions.
kws.connect()
你可以在这里进一步阅读所有支持方法的列表。Zerodha 的精英们将在我们关于使用 Python 在印度市场进行交易的网络研讨会上详细介绍这一点。如果你没有参加,那么请点击这里观看的录音。
最后
得益于 Zerodha 的 Kite Connect API,使用 Python 在印度市场进行算法交易变得更加有趣和简单。你现在要做的就是:
- 向 Zerodha 注册一个交易账户
- 注册一个 Kite Connect 帐户
- 登录你的 kite connect 开发者账户
- 开始创造你的策略
就是这样!享受 Kite Connect 提供的程序化交易
下一步
Python 算法交易在 quant finance 社区中获得了牵引力,因为它可以轻松地建立复杂的统计模型,这是因为有足够的科学库可用,如 Pandas、NumPy、PyAlgoTrade、Pybacktest 等。
如果您希望掌握使用 Python 生成交易策略、回溯测试、处理时间序列、生成交易信号、预测分析等艺术,您可以注册我们的 Python for Trading 课程!
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
印度国家证券交易所算法交易培训

QuantInsti 的联合创始人 Rajib Ranjan Borah 和 Gaurav Raizada 为印度国家证券交易所(NSE India)监督和合规部门的高级管理人员举办了一次特别培训活动。
该活动旨在为印度最大交易所的监管和合规团队提供自动化、算法和高频交易领域的最新知识。
随着贸易公司认识到自动化可以大幅提升贸易利润,市场结构发生了巨大而迅速的变化。因此,监管机构和合规专业人员需要跟上这些最新发展,以便能够在这一新的复杂环境中检查市场参与者。
此次活动旨在为最新发展搭建桥梁——特别关注与算法交易相关的风险管理失败、应适用于自动化交易的额外风险管理程序和流程、交易中的技术干预等。有一个自动交易策略的各种类别的详细分析,以及每一个的特点。讨论了设计算法交易策略的整个生命周期,还讨论了算法交易策略的技术复杂性和创新。
NSE 风险、监督和合规部门的高级和中级经理参加了这一整天的活动,并得到了参与者的积极响应。QuanInsti 很荣幸能与 NSE 合规团队合作,共同追求卓越。
如果你是一名散户交易者或专业技术人员,想要建立自己的自动化交易平台,今天就开始学习算法交易吧!从基本概念开始,如自动交易架构、市场微观结构、策略回溯测试系统和订单管理系统。你也可以报名参加 EPAT,这是业内最广泛的算法交易课程之一。
旅游教授如何学习期权交易
“一个好老师可以激发希望,点燃想象力,并灌输对学习的热爱”布莱德·亨利说。
Jyotish 的职业是教授,兴趣是期权交易者。在印度市场手动交易期权后,他想尝试使用 Python 进行期权交易。
他是来分享经验的。
大家好,
我是来自印度的乔蒂什·塞巴斯蒂安。我是钦奈的一名旅游和旅行管理教授。在过去的一年里,我开始对股票市场感兴趣,并打算了解更多。我就是在那里发现了 Quantra。
由于我已经在印度市场交易期权,我觉得 Quantra 的“使用 Python 的期权交易策略:基础”课程最适合我。该课程是基础性的,讨论了许多我已经熟悉的话题,因此我很容易就能轻松浏览内容。
因为底部有字幕,所以很容易理解内容。没有使用高级语言或行话,内容用简单的通俗语言解释。这与印度的背景非常相关,帮助我理解了课程中给出的大部分类比。
因为我自己是一名教授,我理解测验的价值,因为它可以帮助你在学习时规划自己的进步。测验很有趣,并且与正在处理的单元相关。
整个课程的结构方式引起了我的兴趣,一个真正观察过课堂上的指示的人将能够正确地回答小测验。
另一件事是,即使你犯了错误,也没有惩罚,所以对于一个正在学习的人来说,这是一种积极的强化形式,只要提到正确的答案,你就可以继续前进。
Jupyter 笔记本可能有助于更好地理解概念,而不仅仅是看视频。引起我注意的另一件有趣的事情是,课程的最后一部分是关于 python 安装的。通常,很多用户在安装 python 时会发现很多问题,本单元有一些截图,以非常清晰的方式解释了这些问题。
任何发现安装软件有困难的人都会感谢编写这部分课程的人。因为所有的单元都非常好,不知道的人会真正从最后一部分中受益。
课程中提到了很多交易策略,也提到了很多学术参考,我很确定,对于一个可能会在网上和 Youtube 上寻找这种东西的人来说,他不可能以一种对他们有益的方式来消费知识,练习,消化和使用它。
想法是有效地使用 python 来理解期权交易。本课程的关键收获是将这些技术用于我自己的利益。我期待着在 Quantra 上做更多的课程,从一些 python 基础课程开始,进一步加强我的 python 知识。
谢谢你,你的话让我们受宠若惊,周谛士。我们希望你继续致力于学习和成长。我们祝你未来一切顺利。
使用 Python 的期权交易策略:基础是一门详细而全面的课程,面向希望在期权及其各种策略方面打下坚实基础的初学者。对于那些有志开始,现在注册!
免责声明:为了帮助正在考虑从事算法和量化交易的个人,这个成功的故事是根据 Quantra 的一个学生的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。完成 Quantra 课程后获得的结果可能不会因人而异。T3】
旅行和徒步旅行如何让 Kurt 走向自动化和系统化的算法交易
原文:https://blog.quantinsti.com/travelling-hiking-algorithmic-trading-epat-success-story-kurt-selander/
在过去的几年里,由于可进入性的提高和摩擦性经纪人费用的降低,散户投资者正以惊人的速度进入全球交易市场。
与此同时,以前价格昂贵的数据也在激增。价格数据、基本面数据和另类数据现在对对冲基金和散户来说都唾手可得。原始信号速度不再是关键的制胜因素,而是什么系统能够解释各种数据信号并在最重要的时候保持正确。
Kurtis Selander (Kurt),是一名来自加利福尼亚的计算机工程师。从加州大学圣地亚哥分校毕业后,Kurt 合伙创建了一家航空工程咨询公司,专门从事一次性定制航空平台。这给他在系统、代理、数据和自动化方面打下了坚实的基础,然后他在完成 EPAT 交易后开始系统化的算法交易。
他目前专注于数据的结构几何和机器学习方法的结合。Kurt 认为,通过结合无监督学习技术来识别隐藏结构,然后使用强化学习过程来训练神经网络可以实现很多目标,这对许多应用来说都有巨大的潜力。他相信“数据优先”的决策模式。
Kurt 分享了他从加州大学圣地亚哥分校到算法交易的最新经历。
嗨,库尔特,给我们介绍一下你自己
我叫库蒂斯·塞兰德,来自美国加利福尼亚州的圣地亚哥。我拥有加州大学圣地亚哥分校的金融算法交易硕士学位和计算机工程学士学位。我大部分空闲时间都在爬山和热带岛屿冲浪。
我爸爸是一名化学工程师,我哥哥是计算机科学专业的,所以我上大学时基本上选择了这两个学科的结合。我从小就对技术感兴趣。我的父亲总是在他的办公室里到处散落着电脑零件,因为他在进行一些不同的电脑组装或改造。他喜欢摆弄零件——组装和拆卸。
随着我对世界历史和我们在时间线上所处位置的进一步了解,我看着科技,听着父亲讲述电脑如何占据整个房间的故事。
- 我记得我的父亲使用软盘,移动到写在光盘上,然后使用 USB。
- 我记得美国在线互联网有一个可怕的声音连接,并完全占领了电话线。
- 我记得 56k 的网速很快,在 myspace 上与朋友即时通讯或社交是多么酷。
一晃 20 年过去了,现在地球上几乎每个人的口袋里都有一个小盒子。它能够随时随地访问世界上的数据。电话、移动计算和我们的数据网络使得个人在山顶或热带岛屿上进行交易和参与市场成为可能。
我最终意识到,通过创建一个自动化系统,当我外出徒步旅行而没有互联网时,或者当我在没有互联网的海滩上时,系统会自动为我执行我的规则。这正是我想要的,比任何人自己处理和反应的速度都要快。
在旅途中,如果我能在同一天爬山和听一本书,我认为这是一种成功。这就是我几个月来日复一日所做的事情。我听了各种类型的书,找到了一些我想向其学习的金融英雄,比如沃伦巴菲特、彼得·林奇、查理芒格、大卫多德、本杰明·格拉哈姆。我还搜索了埃隆·马斯克、菲利普·奈特、史蒂夫·乔布斯和比尔·盖茨的传记,寻找这些远见卓识者眼中的未来走向的线索。
现在,在 QuantInsti 课程的另一边,我具备了一套技能和一个由一些有史以来最伟大的投资者传承下来的投资规则的坚实基础。
你是怎么进入算法交易的世界的?
失去了几个亲密的人,让我的价值观发生了转变,让我萌生了用单程票去南美旅行的想法。
两年后,在经历了一千次不同的经历后,我接受了挑战,接触了不同的文化,接触了各行各业,打了不同的零工。这真的帮助我提高了对世界和现实的视角和理解。
因为我有了更多的空闲时间,所以我在寻找另一种方式来赚更多的旅行钱。我偶然发现了区块链、加密和智能合同/自动化的想法。
智能合同的想法真的触动了我的机器人背景,我从小就渴望制造一个智能自动家庭。但我在自动化和金融之间建立了另一种联系,直到我在没有电脑或互联网的情况下在山里徒步旅行时,这种联系才会影响到我。
我现在正在买卖比特币,了解这个生态系统,而那时我将有 1-2 周无法访问。对于密码界的人来说,数字资产上下移动的速度令人吃惊。我永远也忘不了那种感觉,在经历了两个星期的大幅下跌后,我再次回到这里,对自己说‘下次我该如何更好地保护自己?’?
在 YouTube 上呆了几个小时后,我开始熟悉 MACD、随机统计、RSI 和订单结构。我意识到我真正在做的是寻找一堆模式或模式的一个“T0”状态“T1”,它给我一个上升、下降或中性的概率置信度。
这些模式是我反复寻找的,在我下一次上山时,我想也许有一种方法可以系统地、有计划地将它们结合起来,在买入信号时买入,在卖出信号时卖出。这是我 python 算法生涯中金融算法和自动化的开始。
我试着进入谷歌搜索“如何程序化地交易股票”,以此迅速进入状态。我的发现并没有吸引我。
有许多要么极其复杂,要么极其昂贵的系统。我希望能够对一个想法进行回溯测试,看看它的能力,然后在同一个领域推出它。
- 有一个金本位的量子乌托邦,很适合分享想法,但你不能从那里开始,然后最终被一个亿万富翁收购并关闭。即使你能让 Quantopian 工作,那也是在虚拟环境中,对 python 包的访问是有限的。
- 有黄金标准、交互式代理,但使用成熟的 pythonic API 似乎过于复杂。
- 当你可能与不同的经纪人交易时,一些服务提供了你想要处理的数据。
python 的世界看起来过于复杂,因为有数百个重要的包和细微差别需要加入,没有任何结构来接近大的学习曲线。
我意识到我需要的是一所学校,在那里我可以发展更强的数学基础来帮助解释代码。我需要知道从哪里开始的方向,这样我就不会学习无效的材料。这让我在网上搜索,我找到了 EPAT。
在那里,我学会了如何从互联网上获取付费数据和搜集数据(价格、基本面、另类),处理这些数据,创建阿尔法信号,对策略进行回溯测试,分析策略,确定下注规模,以及投资组合/头寸风险管理。
在你的职业生涯中,你身兼数职——创始人、工程师、销售、教师。那是怎么发生的?
在大学里,我发现那门课不能很好地吸引我的注意力,所以我开始探索朋友们在校园的研究实验室里做的项目。
我的一个朋友正在为“国家地理勘探工程师”开发无人机,以便在蒙古找到成吉思汗墓。不用说,我认为那是自切片面包以来最酷的东西。我们感觉就像莱特兄弟在创造新的飞行发明。
我们开始熟悉系统、系统控制器、环路、来自加速度计/陀螺仪/气压计/摄像机的信号输入、所需的电机和 GPS 输出、高通滤波器、低通滤波器、信号干扰、系统噪声等。我的“书呆子”背景从这里延伸。
我们的空中机器人公司积累了一份令人印象深刻的客户名单,包括 Twitter、谷歌、通用电气、卡特彼勒、布鲁明戴尔和 DJI。大学刚毕业,我们必须快速成长。无人机过去和现在都是一个快速发展的行业,所以它要么沉要么游。
白天,我们不得不忙于创造更多的交易、业务销售、市场营销和外联,而晚上,我们会在办公室呆到很晚,研究我们的产品交付。
除了那次经历,我一直有一种强烈的渴望去体验和探索这个世界。
在一个最好的朋友因抑郁症去世后,我意识到生命太短暂了。于是,我收拾好行李,开始了一场单程旅行,这让我在这条路上走了两年多。反思,这是真正允许我去测试和失败,去学习我感兴趣的东西,而不是学校想让我学的东西的时候。
这段时间给了我基本的信心,让我相信我可以处理任何遇到的事情,并且很可能让我相信我可以理解制作一个成功算法的所有复杂性。
一路走来…是的,我甚至在哥伦比亚的阿卡迪亚当了几个月的英语老师!
但我现在努力的主要目标是围绕机器学习的思想和原则发展自己。我真的认为,通过使用无监督学习来发现数据中的隐藏结构,你可以做很多事情。然后你可以像一个游戏一样反复模拟,使用强化学习来寻找通向最高奖励函数的最佳路径。
你是如何克服困难学会算法交易的?
我脑子里有想实施的想法,但由于缺乏可编程的技能组合而受阻。编程对我来说从来都不是天生的。数学是。但是编程似乎总是有点难,而且每种语言都有太多的记忆。
我没有很强的编程能力。开始学习 Java,Javascript,Ruby,Rails,Django。但是我觉得我的语言知识总是有点笨拙。
其实直到我偶然发现了《禅与摩托车保养艺术》这本书。这本书给了我一个视角去欣赏美丽的代码对我意味着什么,以及一门编程语言的美丽之处,而不仅仅是把它看作达到目的的一种手段。
阻止我进行算法编程的是:
- 我的 Python 语言知识库。
- 不知道如何回测我的策略。
直到我对语言有了更多的经验,并且个人坚持流利地使用另一种语言,当我回去的时候,我才最终开始更深入地理解这种语言。
我开始将 Python 视为一门美丽的语言。一看这种语言,我就会说,“哦,我的天哪!我能做到!“这需要做很多工作,但现在我相信我能做到。我认为这种信念同样重要。
在我学习 python 和自动化交易的过程中,我偶然发现了 Quantopian、Interactive Brokers 和 EPAT。一些例子让我意识到我不具备理解和执行交易的技能。我可以去 YouTube 上自学。
但是我真的认为每个人都需要导师。虽然我们可以独自走这条路,但如果我们认识一个导师或向导,本质上来说,他们已经到达山顶并分享他们的一些知识,那就容易得多。
这真的把我推向了 EPAT。很快,我意识到这里有很多我从未想过的好信息。例如,有许多细微差别来确保我们的逻辑在回溯测试时不是“展望未来”。
在使用 python 系统化我的交易之前,我花了很多时间在 Microsoft Excel 和 Google Sheets 上尝试手动建立模型。所以,我对 excel 中的数据结构有了扎实的基础。看到 EPAT 大学教授在 excel 中对时间序列的逐格分解,对理解这个话题的细微差别非常有帮助。
现在我已经知道了 EPAT 教授的算法结构,我可以把看似巨大的任务分解成易于管理的块和步骤。
你最喜欢 EPAT 的哪个特征?
EPAT 非常有用。我感觉到一点力量。感觉像魔术一样。
这很酷,如果我有一个想法,我就能实现它。通过 EPAT,我学到了一些非常非常有用的技能。
- 我可以在脑子里操纵和组合数据结构。
- 在编程时,我可以使用基本工具和 python 包进行构建。
- 知道了我们想要创建的数据对象的最终结构,我就能够对它进行剪切、排序、准备、规范化、选择,并将其与其他数据组合成一个信息丰富的数据结构。
- 我可以从任何 API 引入数据。我可以从雅虎财经、IE 或 Polygon 以及所有不同的数据交换平台获取数据。
- 我可以搜集互联网上任何结构化的信息。
- 我可以把新闻数据、股票、价格、基本面和技术面的数据都放在一个区域来创造阿尔法信号。
- 我知道如何把数据放在一起,输入机器学习算法。
我非常高兴,并为我在未来用这个基础算法库创造的东西感到兴奋。
你会给那些想从事算法交易的人什么信息?
我想和大家分享以下几点,它们一直指引着我,我希望也能指引你!
- 坚持不懈!
- 培养对数据的深刻理解 -最后,我们正在做的是我们有面板数据,我们只是试图找到结构并操纵它。
- 你投入的努力呈指数增长 -想象一下,如果你想出某种交易算法,可以让你获得 2%或 3%的阿尔法值,并且你用了 10 年。那你现在会怎么样?
- 计划——写下你一个月甚至一年需要多少钱才能活下去。并把它写在纸上。那么问题就变成了“我如何让它发生”而不是“我能让它发生。
- 提出富有成效的问题,解决手头的问题 -我认为这个小小的思想转变为,“我怎样才能找到处理我的风险管理的工具,”或者“我怎样才能找到一个工具来发展知识和我的 Python 编程?”。这将真正帮助你实现你的目标。
- 活出生命!——最后,去外面。因为健康快乐和合理饮食有助于你的大脑更有效地解决问题。如果你没有这种权利,那么无论你在做什么都会进展缓慢。
万事如意!
谢谢你,Kurt,和我们连线并分享你的旅程。看到一个背景如此多样化的人从事算法交易真是太好了。我们很高兴成为你旅程的一部分。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
使用 Python 中的未平仓权益、展期交割和 FII/DII 活动进行趋势分析
原文:https://blog.quantinsti.com/trend-analysis-open-interest-rollover-fii-dii-python/
由阿舒托什·戴夫
2020 年第一季度是二战后最具挑战性的时期之一。地缘政治原因导致的油价暴跌和新冠肺炎全球疫情是主导主题。
金融市场充当着风向标的角色,为我们提供了对全球经济整体情绪的反映。这些情绪不仅反映在价格上,也反映在其他指标上,如未平仓利息、展期百分比、FII/DII 交易。
这篇博客旨在分析 Nifty 50 的上述三个重要指标,Nifty 50 是印度领先的广泛市场指数。我们将使用 Python 来进行这一分析。
内容:
T3】
在用 Python 开始任何分析之前,我们需要导入所需的库。我们将使用 pandas、NumPy 和 Matplotlib 等流行的库(用于可视化)。
让我们现在导入它们。
使用时间序列动量和连续预测的期货趋势跟踪策略
黄继荣的这个 EPAT 项目解释了如何使用时间序列动量(TSMOM)和连续预测(CF)来创建一个趋势跟踪期货交易策略。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

黄继荣目前是一名独立的量化交易员,通过系统性策略管理其投资组合(> 50 万英镑),投资工具(股票、期货、期权)的风险回报率较高。他在过去的 3 年里保持着大于 1 的夏普比率。
作为一名经济学家和数据科学家,吉荣拥有多学科的学术和专业背景。他拥有统计学硕士学位、经济学和金融学学士学位以及计算机科学研究生文凭。
为了加深他在机器学习领域的理解,他目前正在佐治亚理工学院攻读计算机科学的兼职硕士学位。目前,他住在新加坡。
概述
在 2010 年 6 月之前,在不同的配置中,趋势跟踪策略表现良好,Sharpe > 1,Calmar 比率高,提取合理。
2010 年 6 月后,风险调整后的回报率、夏普比率显著下降,两种策略的业绩都降至 0.7 以下。
尽管趋势跟踪策略的表现有所恶化,但它仍可能在投资者的投资组合中占有一席之地。
根据凯瑟琳·卡明斯基的说法:
"趋势跟随表现出危机阿尔法特征"
凯瑟琳是 AlphaSimplex group 的首席投资策略师,也是麻省理工学院斯隆管理学院的金融学客座讲师。她研究了 800 年来的危机,发现所有的危机都会创造趋势,并且存在采取不同策略的机会。
项目动机
正如 19 世纪英国经济学家大卫·李嘉图所说:
"缩短你的损失,让你的利润趋势"
这暗示了一点,趋势跟踪作为一种有利可图的策略甚至可以追溯到那个时候。
在阅读了 AQR 关于时间序列动量 (TSMOM)的论文后,我热衷于在期货领域探索这个话题(莫斯科维茨、T. J .、Ooi、Y. H .、&彼得森、L. H. (2012) )。
除了 AQR 的论文,我还密切关注罗伯特·卡弗的工作,他以前是 AHL 的定量分析师,专门研究中长期趋势跟踪期货策略。
在这项研究中,我将探索两种方法:
- AQR 开发的 TSMOM 方法
- 持续预测方法(大致基于罗伯特·卡弗在他的书《杠杆交易和系统交易》中的框架)
注意:由于我将使用的数据集的限制,我无法在罗伯特·卡弗的书中加入“结转回报预测”。我认为这将对该战略的有效性产生影响。
战略的绩效将分两个阶段进行评估,
- 样本期:1984 年至 2010 年 6 月
- 样本期外:2010 年 6 月至 2016 年
数据集
在这项研究中,我将使用 Quantopian 提供的截至 2016 年的 4 个资产类别的期货数据集:指数、债券、货币、大宗商品。
连续数据集可能是通过向后、向前或按比例调整的方法缝合的(在 Quantopian 的 github 知识库中没有明确提到)。
下面是本研究中使用的 50 种仪器的描述性统计。

时间序列动量(TSMOM)方法
在 AQR 的论文中,作者试验了 1 年的固定回顾期,这决定了下个月的交易信号,即如果资产价格在 1 年内上涨,下个月的交易信号将会很长。
当资产价格下跌时,情况正好相反。每项资产的头寸基于每日回报的回顾指数标准差,年波动率为 40%。
以下是作者的解释,

资本分布在具有可用数据的工具中。例如,如果在 1987 年之前只有 X 种工具,投资组合收益将是 X 种工具的平均收益。
连续预测(CF)方法
在传统的技术分析中,交易的进场和出场通常是二元的,当前的头寸大小取决于之前定义的进场和出场条件。
当前仓位大小~进场、出场条件(取决于当前状态)t 期前定义
但是在金融世界中,资产回报结果在本质上是连续的,具有分布性。因此,根据当前预测、风险资本分配、工具的当前波动性、整体投资组合波动性、相关矩阵、再平衡成本,当前头寸规模最好与预期回报成正比。
这与贝叶斯学派产生了共鸣,在贝叶斯学派中,假设的概率应该随着更多证据的出现而更新。
当前头寸规模~ E(收益|当前预测、风险资本、工具的当前波动率、整体投资组合波动率、相关矩阵、再平衡成本)
连续预测方法的优势在于,您只需将当前条件下的最佳头寸规模与当前头寸进行比较。如果它偏离了 x%,那么你重新平衡。
风险管理层和头寸规模固有地构建在框架中。并且它不依赖于当前位置的状态。这不同于依赖于国家的二元交易系统。
原始连续预报的计算
出于我的研究目的,我将考虑两个常用的技术指标,
- 指数移动平均线
- 唐奇安海峡
1.1 指数移动平均线
1)选择成对的快速移动平均线和慢速移动平均线以反映不同的时间范围:8-32、16-64、32-128、64-254
2)原始预测:首先,我取一对移动平均线的差值
3)风险调整后的预测:接下来,我将原始预测除以工具风险(工具在价格单位中的波动性),得到风险调整后的预测。

1.2 唐奇安频道
1)选择回顾以反映不同的时间范围:40、80、160、320
- 预测:通过将当前价格与中间价格之间的差值(N 次回顾中最高价和最低价的一半)除以 N 次回顾中最高价和最低价的差值得出。公式如下,其中乘数 40 适用于将预测范围扩大到(-20,20)
(Forecast )= (40 )* (P _ t )–((R _ { middleN }))/((R _ { maxN }))–((R _ { minN }))

1.3 预测标量
(a)为了跨工具和时间的一致性,将预测重新调整到平均值 10
1)每天提取预测类型(例如 8-32 指数移动平均预测)内跨工具的绝对中值预测。
2)接下来,使用扩展窗口来计算点中值预测的平均值
3)然后,我通过将点 2 中的平均值除以 10 来计算预测标量,即我们将预测调整为平均绝对值 10。10 代表每个工具的平均预测强度。在下图中,您会注意到随着时间的推移,预测标量会达到一个水平(即,由于较大数据点的平均效应)。
(b)预测标量,即原始预测的乘数,以将平均预测缩放至 10 的平均绝对值
EWMAC 预测标量

突破预测标量

4)最后,预测标量被映射到工具的单个预测时间序列。调整后的预测上限在[-20,20]之间。这是为了避免过度乐观或悲观的预测导致投资组合中任何特定工具的过大头寸。


1.4 将调整后的预测合并为每个工具的加权预测
从之前的第 1.3(a)节,我将获得每个工具的调整预测。下一步是通过权重合并预测。在这项研究中,我将使用两种加权方案,
1)重量相等
在第一个加权方案中,我给规则分配相等的权重。在我的研究中,我有 8 个不同的预测,4 个指数移动平均线,4 个唐奇安通道。这些预测各占 12.5%的权重。
2)通过块自举进行加权
在下一个加权方案中,我执行了以下步骤,
在样本期内,我抽取了 25 个连续的日周期。每个周期占可用天数的 25%。
ii. For each instrument, I compute the returns stream, (AR_{it}) associated with each forecast. First, similar to TSMOM, I find the leverage, (L_{it}) required to bring up the realized volatility, (Vol_{it-1}) to a reference level of 40%. Next, I scale the leverage up/down according to the strength of the forecasts.
(AR _ { it } )= (40% )/(Vol _ { it-1 } )* (F _ { it } )* (R _ { it } )= (L _ { it } )* (F _ { it } )* (R _ { it } )
三。每笔交易还收取 0.1%的佣金,以惩罚频繁的再平衡。仅当当前预测与上次预测相差 X 点(在优化中,发现总体水平相差 6 点)时,才会发生重新平衡。
iv. With the derived returns stream, I proceed to find optimal weights, (W_{rbi}) amongst rules, r for the highest Sharpe associated for each bootstrapped block, b per instrument, i.
动词 (verb 的缩写)最后,我将权重汇总在一起,找出样本期内所有工具的平均最优权重,
(W _ r )= (Average _ { bi } )((W _ { RBI }))

注意:由于自举模块的数量相对较少,因此避免了对每个仪器应用优化的权重。根据罗伯特·卡弗的建议,乐器在它们的动量特性上更可能是相似的而不是不同的。也就是说,在我的下一次迭代中,我可以测试这个假设。
根据允许的最大整体投资组合风险,在投资组合层面扩大或缩小规模
随着工具和预测的多样化,投资组合的已实现波动率将大大低于每个工具 40%的参考年化波动率。在 AQR 的研究中,年化波动率平均在 12%左右。
出于本研究的目的,我将使用 15%的最大已实现波动率上限。步骤如下:
i. Assume forecasts, (F_{t-1}) are at both extreme of -20 and +20 depending on the polarity of the forecasts. And find the maximum realized volatility, (Mv_{t-1})

二。接下来,在投资组合层面找到杠杆调整系数,
(A_t) = (最大已实现波动率上限 15%) / (Mv_{t-1})

注:在 2008-2009 年危机期间,投资组合的调整系数下降到 0.50,表明各种工具之间的相关性可能已经增加。
iii. Last but not the least, I will map the leverage adjustment factor, At to the leverage factor in section 1.4,2,ii. The final leverage, (FL_{it}) for the instrument will be as follows:
(FL_{it}) = (A_t) * (L_{it})
四。就头寸规模而言,假设该工具的风险资本为 20,000 美元。
The notional capital, (NC_{it}) to be deployed for this instrument would be
(NC _ { it } )= (FL _ { it } )* 20,000 美元
注:另一种方法是考虑仪器之间的相关矩阵,并找出调整系数。
策略评估
我在样本期内(2010-06-07 之前)和样本期外(2010-06-06 之后)测试了以下策略。下面是不同的配置,
一、样本内不含成本的 ts mom:AQR ts mom 策略在样本内不含成本期间进行检验。
二。包含样本成本的 ts mom:AQR ts mom 策略在包含成本的样本期内进行测试。
三。样本中的预优化:为不同的预测分配相同的权重。并在样本期内对该策略进行了测试。
四。在样本中优化:基于块引导的优化权重被分配给不同的预测。并在样本期内对该策略进行了检验。
动词 (verb 的缩写)样本外预优化:为不同的预测分配相等的权重。并且在“样本外”期间测试该策略。
不及物动词样本外优化:基于块引导的优化权重被分配给不同的预测。并在样本期内对该策略进行了检验。
月度回报汇总统计
采样期间的性能
总的来说,在样本期内,我注意到两种类型的策略都表现良好,Sharpe > 1,Calmar 比率高,TSMOM 和连续预测方法的提取合理。
令人惊讶的是,尽管在投资组合层面上信号和风险管理多样化,TSMOM 1 年回顾方法的表现优于连续预测。
样本期外的性能
在样本外期间,风险调整回报、夏普比率显著下降,两种策略的绩效都下降到 0.7 以下。TSMOM 策略的表现仍然优于连续预测。
根据温顿集团的创始人和量化趋势跟踪的先驱大卫·哈丁在一篇文章中提到的,回报恶化的一个原因可能是策略的过度拥挤和商品化。
两种方法的权益曲线



针对 Fama French 3 因子、动量因子、债券和商品回报的因子分析
t 样本数据中的 mom
因子分析表明,只有债券和市场(股票)因素是显著的。TSMOM 显示了市场(股票)因子的负 beta 和债券因子的巨大 beta。这似乎预示着一个基于危机阿尔法的策略,因为股票往往在危机期间跳水。

在样本中优化的引导程序
与 TSMOM 类似,该策略显示了市场(权益)因子的负 beta。这对于基于危机阿尔法的策略来说也是个好兆头,因为在危机期间,股票往往会跳水。

t 样本中的 mom
结果反映在样本数据中。

从样本中优化的助推器
结果不会反映在样本数据中。样本外数据中不存在负的市场贝塔关系。
此外,它与债券表现出显著的正相关关系,与商品表现出显著的负相关关系。

结论
尽管趋势跟踪策略的表现有所恶化,但它仍然在投资者的投资组合中占有一席之地。根据凯瑟琳·卡明斯基的说法,“趋势跟踪表现出危机阿尔法特征”。
战略的未来发展
在下一次迭代中,我热衷于探索超越 2016 年数据的策略的可行性
目前,这项研究中使用的数据是由 Quantopian(摘自彭博)拼凑的。在下一次迭代中,我热衷于通过向前或向后调整的方法将合同缝合在一起。
对于单个合约,我还能够将套利期限结构(期货溢价或现货溢价)信号纳入连续预测系统
块引导优化可能没有很好地工作,因为我只从数据集中提取了 25 个连续周期。理想情况下,我更愿意提取更多的数据块(~1000)。
但是,我受限于计算能力。在下一次迭代中,我将探索使用云平台(例如 Google Collaboratory 或 AWS)进行引导优化
在具有更多计算能力的下一次迭代中,我将执行引导优化和向前分析。也就是说,我从 t-x 到 t 推导优化权重,并在 t+1 测试结果。这将在每个时间步中随着窗口的扩大而重复。
免责声明:作者对这项研究的策略没有立场,但对开发和投资跨资产类别的可行趋势跟踪策略有浓厚的兴趣。
参考文献
- 赫斯特,布赖恩,华钥 Ooi,和 Lasse Heje 彼得森。“趋势跟踪投资的一个世纪的证据。”《投资组合管理杂志》44 期,第 1 期(2017): 15-29。
- 莫斯科维茨,托拜厄斯 j .,华钥 Ooi,和 Lasse Heje 彼得森。“时间序列动量。”《金融经济学报》104 期,第 2 期(2012): 228-250。
- 罗伯特·卡弗。系统交易:设计交易和投资系统的独特新方法。哈里曼建筑有限公司,2015 年
- 罗伯特·卡弗。杠杆交易。哈里曼房屋有限公司,2019。
- 温顿公司的大卫·哈丁在谈到背离潮流时说道
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT) 的高管课程。该课程包括各种培训模块,让你具备在算法交易中建立一个有前途的职业生涯所需的技能。
黄继荣的这个策略可以在他的 Github 页面上看到。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
算法交易中的趋势测试
原文:https://blog.quantinsti.com/trend-testing-algorithmic-trading/
这是一个项目,将指导你了解如何通过使用某些技术和工具来执行你的战略。简而言之,如何测试一个趋势。
本文是作者提交的最后一个项目,作为他们在 QuantInsti 的算法交易 (EPAT)的管理课程的一部分;。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
Gunraj Mehta 是来自孟买 VJTI 的一名华人华侨;拥有孟买大学的计算机科学学士学位。他目前在加拿大多伦多工作,担任加拿大丰业银行流动性风险技术高级软件程序员。
目的
我想开发一个简单的工具,我们可以输入股票代码,添加一些技术指标和一些基本规则,以便在进行实际实施和花费额外的时间优化它之前,了解策略将如何执行。
结果是一个网络工具,能够绘制 OLHC 数据的收盘价,增加了基本的统计指标,如 SMA 和布林线;然后应用定制的交易策略来获得性能。
趋势跟踪策略
趋势跟踪策略使用简单的统计系统,它们是对变化做出反应,而不是预测市场走向。它们的简单性质使人们很容易想象何时买卖和评估利润。市场趋势如何并不重要,它总是趋势向上或向下,这些策略遵循更科学的交易方法。一些用于趋势跟踪策略的指标有 SMAs,布林线,MACD 和 RSI。
工具详情
该工具是用 Python 编写的。它对 web 服务使用 Flask,对 UI 使用 JQuery 和 Bootstrap。Numpy,熊猫和雅虎负责数据和运营。Gunicorn 部署在 Heroku。
逻辑
executeRule 函数构成了执行逻辑的核心。它将输入作为规则,检查指令,并相应地选择要比较的列。然后,基于逻辑输入翻转买/卖标志。在同一函数下,我们计算损益值、提款期和买入/卖出次数。
特性
多滚动条搜索可用于配对策略(目前仅交叉)

添加均线,布林线

添加规则并执行它们,以获得关于性能的基本细节

限制
- 只能与交叉配合使用
- 考虑 1 次股票买入/卖出
- 使用交叉时不能理解日志、ln 等
- 每个规则中只允许一个条件
- 未添加 MACD 和 RSI
未来范围/可能的改进
- 掩盖局限性
- 能够获取实时提要并设置规则执行警报
- 添加复杂的规则评估,可能是一个基本的 excel 公式,如脚本
项目文件可以在 Github 上获得。
如果你想学习算法交易的各个方面,那就去看看算法交易的高管课程( EPAT )。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。现在报名!
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都是学生或 QuantInsti 不做任何保证的。学生和 QuantInsti 否认与使用这些信息有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
交易指数(TRIN):Python 中的公式、计算和策略
摘要
为了评估市场的力量,Richard W. Arms,Jr .于 1967 年发明了 TRIN 指数,并用于衡量市场供求关系。TRIN 指数被成功地用于了解市场情绪。此外,未来的价格运动由 TRIN 指示,因为它生成超买和超卖水平,以发现价格指数何时可能改变方向。
基于 TRIN 的价值,交易者可以发现市场是上升还是下降的趋势,并据此做出交易决定。在 Python 中可以高效地计算 TRIN。我们将使用 TRIN 和布林线来创建一个交易策略,根据这些指标的交叉产生买卖信号。我们在这一策略中使用了 S&P500、DJI 和纳斯达克 100 指数的价格数据,发现它以较低的最大提现产生了可观的回报。这将有利于喜欢低风险的交易者。
关键词
交易指数,TRIN,TRIN Python,交易指数 Python
引文
https://github.com/PyPatel/Options-Trading-Strategies-in-Python/blob/master/TRIN_strategy.py
目录:
- 什么是 TRIN 的军备指数?
- TRIN 公式
- 如何从 arms index 或 TRIN 读取数据?
- TRIN 的例子
- 用 Python 计算 TRIN
- 描述 TRIN 布林线策略
- 投资领域规格
- 战略绩效
- TRIN 的风险
- 结论
- 参考文献
TRIN 的军备指数是多少?
武器指数或交易指数(TRIN)是一个技术指标(T1),通过对其的透彻了解,你可以减少一些不必要的事件。
该技术指标有助于衡量内部市场的强弱。TRIN 将上涨和下跌的股票数量与上涨和下跌的交易量进行比较。我们将在文章的后面适当地讨论 TRIN 的比率。Richard W. Arms,Jr .于 1967 年发明了 TRIN 指数,用于衡量市场供求关系。因此,TRIN 指数被成功地用来发现市场情绪。此外,未来的价格变动由 TRIN 指示,因为它生成超买和超卖水平,以发现价格指数何时可能改变方向。
在这段信息丰富的视频中了解更多关于 TRIN 的信息:
https://www.youtube.com/embed/iM9mqsO5XjM?feature=oembed
现在让我们找出 TRIN 的公式。
TRIN 公式
TRIN 或 arms 指数是一种短期工具,用于指示股票市场的交易情况。基于 TRIN 的价值,交易者可以发现市场是上升还是下降的趋势,然后交易者可以根据预测的方向做出决定。
我们将看看公式,并讨论如何做到这一点。
TRIN =上涨股/下跌股除以上涨量/下跌量
这里:
上涨的股票=当天交易价格上涨的股票数量
下跌股票=当天交易价格较低的股票数量
上涨成交量=所有上涨股票的总成交量
下跌量=所有下跌股票的总成交量
该公式表明,TRIN 通过测量数量和体积来讨论上涨和下跌股票之间的关系。
上涨的 TRIN 值简单地表明市场疲软,趋势看跌,而下跌的 TRIN 表明市场强劲或趋势看涨。
接下来,我们将找到从 arms index 或 TRIN 中读取数据的方法,以便将其投入实际使用。
如何从 Arms Index 或 TRIN 读取数据?
要阅读 arms 指数或 TRIN 的数据,你只需要找出 TRIN 指数是高于 1.0 还是低于 1.0。因此,有两种情况:
- 如果市场出现强劲的上升趋势,或者出现牛市,TRIN 将低于 1.0。
- 相反,在强烈下跌趋势或熊市的情况下,TRIN 将出现在 1.0 以上。
除了上面提到的两个级别,还有一些情况下,指数的读数很高。这些高读数是极端水平,通常是即将发生逆转的指标。
例如,如果 TRIN 显示读数 2.0 或 3.0,这是一个极值,这是一个市场已经形成短期底部的指标。类似地,如果该值变为 0.5,则表明市场仅在短期内呈上升趋势。
所以建议交易者等待价格确认。一旦价格被确认,交易者可以据此行动,这样就不会有意外的损失。
这些都是关于阅读 TRIN 的数据,这样你就知道如何根据这些数据采取行动。现在让我们看看 TRIN 的例子。
TRIN 的例子

Fig1: $TRIN (Daily)
根据上面的例子,上涨的 TRIN 表示熊市,而下跌的 TRIN 表示牛市。上面的例子表明,当 TRIN 值高于 3.00 时买入的交易者表现良好,因为这是一个超卖的情况。处于超卖状态的交易者在买进时,肯定从股票供应的增加中获益。此外,基于 0.50 以下的超买值在市场上卖出的交易者,一定没有获利的时间。
SMA 或移动平均线平滑数据系列,并使其进入在市场中产生超买或超卖信号或价值所需的范围。
我们现在将借助 Python 代码来了解 TRIN 值的计算。要学习和运用其他类似的情绪指标,例如 VIX、看跌看涨期权比率,请查看 Quantra 的“使用期权情绪指标进行交易”课程。这是一个 5 小时的课程,帮助你一步一步地学习 Python,并在真实的市场数据上实现你的交易想法。
Python 中 TRIN 的计算
让我们看看如何用 Python 计算 TRIN 值来分析市场状况。尽管如果你愿意,你可以通过我们关于用 Python 构建技术指标的博客文章了解更多。
在计算 TRIN 值时,我们将首先获取股票的价格和成交量数据。我们用 python 代码计算了 S&P500 股票。
Python 中的海龟交易
由伊山沙阿
海龟交易系统是理查德·丹尼斯发明的,在 20 世纪 80 年代对交易者来说非常有效。但是事实证明,这个系统需要一些调整来反映新的市场情况,并且现在有效。也就是说,趋势仍在发生,这意味着有过多的交易机会。
海龟交易策略的核心是在 55 天突破时建仓。55 天突破是指价格超过过去 55 天的最高价或最低价。完整的策略更加复杂,但是在本文中,我用 Python 编写了策略的关键部分,并交易了苹果公司、Kinder Morgan 公司和福特汽车公司的股票。
Python 代码
步骤 1:导入必要的库
# To get closing price data
from pandas_datareader import data as pdr
import yfinance as yf
yf.pdr_override()
# Plotting graphs
import matplotlib.pyplot as plt
import seaborn
# Data manipulation
import numpy as np
import pandas as pd
第二步:定义一个函数来计算股票的策略表现
- 我们将把 Apple、Kinder Morgan 和 Ford Motor 的股票代码传递给这个函数。
def strategy_performance(stock_ticker):
- 从 yahoo finance 获取 stock_ticker 的数据
stock = pdr.get_data_yahoo(stock_ticker, start="2009-01-01", end="2017-10-01")
- 计算 5 天突破和平均值
计算过去 5 天的最高值、最低值和平均值,并存储在数据框架库存中。5 是要在回溯测试中优化的自由参数。熊猫滚动函数用于计算突破和平均值。
# 5-days high
stock['high'] = stock.Close.shift(1).rolling(window=5).max()
# 5-days low
stock['low'] = stock.Close.shift(1).rolling(window=5).min()
# 5-days mean
stock['avg'] = stock.Close.shift(1).rolling(window=5).mean()
- 进入规则
当股票的收盘价高于过去 55 天的高点时,我们做多股票,当股票的收盘价低于过去 55 天的低点时,我们做空股票。
stock['long_entry'] = stock.Close > stock.high
stock['short_entry'] = stock.Close < stock.low
- 退出规则
如果股价超过过去 55 天的平均值,我们将退出头寸。
stock['long_exit'] = stock.Close < stock.avg
stock['short_exit'] = stock.Close > stock.avg
- 位置
我们现在将在一列中存储进入和退出信号。多头头寸由 1 表示,空头头寸由-1 表示,退出或无头寸由 0 表示。如果在一段时间内没有头寸,我们将使用 fillna 方法结转以前的头寸。
stock['positions_long'] = np.nan
stock.loc[stock.long_entry,'positions_long']= 1
stock.loc[stock.long_exit,'positions_long']= 0
stock['positions_short'] = np.nan
stock.loc[stock.short_entry,'positions_short']= -1
stock.loc[stock.short_exit,'positions_short']= 0
stock['Signal'] = stock.positions_long + stock.positions_short
stock = stock.fillna(method='ffill')
- 战略回报
我们已经计算了股票的对数回报,并乘以信号(1,-1 或 0)得到策略回报。
daily_log_returns = np.log(stock.Close/stock.Close.shift(1))
daily_log_returns = daily_log_returns * stock.Signal.shift(1)
# Plot the distribution of 'daily_log_returns'
print(stock_ticker)
daily_log_returns.hist(bins=50)
plt.show()
return daily_log_returns.cumsum()
每日日志回报直方图
苹果公司。

金德·摩根

福特汽车公司

第三步:创建一个股票投资组合,计算每只股票的策略表现
portfolio = ['AAPL','KMI','F']
cum_daily_return = pd.DataFrame()
for stock in portfolio:
cum_daily_return[stock] = strategy_performance(stock)
# Plot the cumulative daily returns
print("Cumulative Daily Returns")
cum_daily_return.plot()
# Show the plot
plt.show()

结论
如果你想修改策略,那么你可以复制这段代码,这应该很简单。你可以在投资组合中增加更多的股票,并评估这些股票的策略表现。
结果的局限性之一是它不包括交易成本。理解上述策略包含大量风险也很重要。你根据其他市场参与者最近的买卖来买卖股票。
这篇关于 Python 中的量化价值投资策略的文章结合了价值和量化投资的最佳方面,并将它们应用于一种完全独特的方法来筛选投资股票。
更新——我们注意到,一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果您正在寻找市场数据的替代来源,您可以使用 Quandl 来获得相同的数据。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
文件下载中:海龟交易- Python 代码
时间加权平均价格(TWAP):介绍、一些例子和计算
本文详细讨论了时间加权平均价格,因为这种执行策略对大宗交易订单非常有帮助。如果你想知道 TWAP 是什么,为什么和如何,以及它与 VWAP 的不同,那么这篇文章将很好地为你服务。
让我们看看这篇文章涵盖了什么。它包括:
- 什么是 TWAP?
- TWAP 的例子
- TWAP 是如何计算出来的?
- 为什么选择 TWAP?
- TWAP vs VWAP
- TWAP 的优点
- TWAP 的缺点
什么是 TWAP?
时间加权平均价格(TWAP)是一种著名的交易算法,它以加权平均价格为基础,由时间准则定义。TWAP 是为执行大宗交易订单而设计的。有了 TWAP 价值,交易者可以将一个大订单分散成几个小订单,以 TWAP 价格计价,因为这是最有利的价值。
这基本上是为了不让巨额订单突然增加金融市场中特定金融资产的价值。
现在让我们看一个 TWAP 的例子。
TWAP 的例子
让我们假设有人想制定一个购买 10,000 股资产的策略。在制定战略的过程中,人们可以从两种可能的战略中进行选择。一个交易者可以在 5 小时内每 15 分钟发出购买 500 股的指令。
第二,交易者可以执行这样的策略,即在 2.5 小时内,每 15 分钟发出购买 1,000 股的指令。
但是,随着金融市场上策略的实施,跟踪其他交易者的交易模式并猜测下一个策略变得更加简单,直到并且除非其订单通过调整参数而被修改。此外,这种修改意味着订单的大小可以随机化,或者每个订单之间的时间可以延迟。
现在,让我们看看如何计算更长时间内的 TWAP 值。
TWAP 是如何计算出来的?
在时间加权平均价格的情况下,TWAP 是通过对全天的价格棒线(即当天的开盘价、最高价、最低价和收盘价)进行平均来计算的。然后,在决定执行订单的时间的基础上,每天的平均价格被用于计算整个持续时间价格的平均值。这就是所谓的 TWAP。
TWAP 策略是最好的执行策略,可以将交易分散在一个特定的时间段,减少交易对市场的影响。
像所有交易一样,TWAP 也在所有条件都满足时执行,在此之前,价格从订单输入开始计算,直到收盘。
计算 TWAP 的公式
TWAP 的计算如下:
每日平均价格 =(开盘+高+低+收盘)/4
28 天平均值 =(第一天价格平均值+第二天价格平均值+)........+第二十八天的平均价格)/28
在 Excel 中计算 TWAP
在 excel 表格中,您可以计算每天的平均值。你可以从纳斯达克(NASDAQ)获取历史数据,只需输入你想要的股票代码。这里,我们采用了苹果公司的数据,在 excel 表格中,每天的平均值是按照以下方式计算的:

上面的计算是使用公式=平均值(B2:E2)完成的,如单元格中所示。我们从苹果公司获取了两个月的数据。
要计算每一行的平均值,您只需复制并粘贴 TWAP 下单元格中每一行的公式。
此外,要计算整个周期的平均值,只需输入公式=AVERAGE(G2:G23 ),如下所示:

在 Av_row 项下取出的平均值为 328.15 美元。
计算 TWAP 后,你的订单价格在低于 TWAP 时会被认为低估,在高于 TWAP 时会被认为高估。
使用 Python 计算 TWAP
我们也可以用 Python 计算 TWAP。首先,我们将获取我们希望计算 TWAP 的股票的数据。
Tweepy -使用 Python 中的 Twitter API 生成情绪交易指标
马里奥·比萨
尤其是社交媒体和 Twitter 是替代数据来源,被广泛用于把握市场情绪的脉搏。
在本帖中,我们将回顾 Tweepy 库从 Twitter 获取实时和历史数据。我们将讨论以下主题:
- 推特和情感分析
- 社交网络对市场趋势的影响
- 什么是推特?
- 一个 Python Twitter API,tweepy
- 如何安装设置 Tweepy?
- Twitter API 上的认证
- 如何使用 Tweepy 获取推文
- Tweets 用光标分页
- 建立一个天真的情绪指标
Twitter 和情感分析
尤其是社交网络和 Twitter 是替代数据来源,被广泛用作市场情绪指标。
新闻和社交网络的情感分析是一个综合性的研究领域,其中自然语言处理对于从非结构化信息源中提取定量信息至关重要。
我们需要一本书,如果不是一本百科全书,来描述情绪分析的整个过程,并将其整合到我们的交易系统中。
因此,在这篇文章中,我们将从第一步开始,从 Twitter 中提取信息,以供我们的自然语言处理算法使用。
建议阅读:
社交网络对市场趋势的影响
社交网络已经成为主流通信媒体,用户可以既是消费者也是信息的创造者。
用户不断地产生数据,或者被动地仅仅作为信息的接收者,我们的兴趣、阅读时间等等。或者通过创造内容,表达我们对另一个内容的兴趣,甚至分享它。
此外,足够有趣或令人震惊的新闻可以传遍世界,成为一种全球趋势。拥有数百万追随者的用户也可以创造特定主题的趋势或影响。
对这类数据的分析是多年来的研究课题,已经产生了大量的学术材料来模拟信息流、其解释以及情绪、趋势和预测的提取。
Twitter 是什么?
Twitter 是一个微博社交网络,用户可以通过发布信息、转发分享或通过将信息标记为收藏来表达自己的兴趣。
它还有一个 hashtags (#)机制来标记内容,能够将消息传达给更多的人,而不仅仅是追随者。
根据互联网实时统计数据,Twitter 拥有超过 3.72 亿活跃用户,并且这个数字还在持续增加,每天发布超过 7 亿条推文。
有些拥有数百万粉丝的用户,他们的推文可以对市场产生巨大影响。众所周知,唐纳德·川普和埃隆·马斯克的例子,一条推特就能引起震惊或繁荣。
另一方面,数百名用户可以就一家公司展开激烈的辩论,从而形成投资者情绪的趋势。与数以千计(如果不是数百万的话)被动和主动观众进行辩论。
因此,对于那些认为社交媒体情绪可以增加他们在市场中的优势的分析师来说,Twitter 已经成为替代信息的相关来源。
一个 Python Twitter API,Tweepy
Tweepy 是一个简单易用的 Python 库,用于访问 Twitter API,正如其网站所宣称的。它不是一个连接 Twitter API 的独特库,但它是最著名的库之一,并且在 GitHub 上有非常活跃的开发。
从上一段可以很容易地推断出,Tweepy 允许我们连接到 Twitter 信息来提取历史和实时数据。这意味着我们有大量的信息可以通过这个库进行分析。
来自社交网络,尤其是 Twitter 的信息是非结构化数据,使用了大量的行话、俚语、表情符号等。,这使得分析起来特别复杂。
自然语言处理或 NLP 是一个专门从所有这些非结构化信息中提取定量和定性信息的领域。当它与经典统计工具或机器学习结合使用时,我们能够对社交网络和一般非结构化数据进行情感分析。
在一篇帖子中,没有足够的空间来完整地覆盖社交网络中的情感分析,所以这里我们将专注于情感分析的第一步,但也是最重要的一步,即提取、转换 Twitter 信息并将其加载到分析算法中。
如何安装设置 Tweepy?
通过 pip 安装程序照常安装 Tweepy Python 库:
pip install tweepy
或者从 GitHub 克隆源代码,并作为开发人员安装在您的机器上,如果您计划修改代码并对社区做出自己的贡献。
git clone https://github.com/tweepy/tweepy.git
cd tweepy
python setup.py develop
除了在 Python 中安装 Tweepy 库之外,还需要在 Twitter 上创建一个开发人员帐户,以便获得允许我们连接 Twitter 服务器以提取数据的密钥。
一旦安装了库并获得了开发人员密钥,我们就可以开始处理来自 Twitter 的信息了。
Twitter API 上的认证
启动一个终端(如果需要,可以使用 Anaconda 提示符)并使用 ipython 命令启动一个交互式 python 会话,导入 tweepy 库并为键分配变量。
接下来,我们必须创建一个身份验证处理程序对象,最后,用身份验证处理程序对象创建一个 tweepy 对象。


现在我们有了一个名为 api 的对象,它是一个与 Twitter 机器相连的套接字,使我们能够提取特定用户的推文,提取与某个单词或一组单词相关的推文,甚至管理我们自己的 Twitter 帐户。
如何使用 Tweepy 获取推文
我们创建的对象 api 允许我们使用 Twitter API 中的 105 个 RESTful 方法,其中一些只适用于高级 API。
我们可以列出所有可用的方法:


这个列表并不完整,尽管我们已经看到有 105 种方法可用。如果我们看一看,我们会发现我们可以执行比应用程序本身更多的功能,我们可以自动化我们自己的 Twitter 帐户和管理我们的出版物,甚至创建一个完全自主的机器人来管理帐户。
下面是一些最常用的获取数据的方法:
- 搜索搜索包含特定单词的推文
- user_timeline 搜索特定用户的推文
搜索
让我们通过查找一个词来获得一些推文。我们使用输入参数 q 调用 api 对象的 search 方法进行查询。

检查结果,我们得到一个模型(另一个对象),其中包含请求查询的推文,我们得到 15 条推文,寻找强生$JNJ 的股票

虽然这是默认的数字,但是我们可以使用 count 输入参数将它增加到 100,这是免费 Twitter API 开发人员的最大请求数。

令人难以置信的是,一条 140 个字符的简单推文中包含了大量的元信息,我只包括了结果的第一部分,因为要完整地显示它需要几页。

所以让我们来看看更具体的信息,如推文的日期和时间,用户和发布的内容。



同样,对于用户,它返回大量与用户相关的元数据,如姓名、别名、关注者数量等。
为了查看更多的细节,我们需要再次使用 search 对象中可用的方法。

请记住,Twitter 返回给我们的是一个对象模型,因此,我们有无数的方法来处理这些对象。
每条 tweet 都是 Status 类的一个对象,我们可以在这里看到它的方法。

对于用户模型,我们有 52 种方法可用于处理用户。

请查看文档以了解可用于搜索的大量参数。
用户时间线
Twitter API 的另一个最常用的方法是 user_timeline,它允许我们分析特定用户的所有发布。
埃隆·马斯克的账户炙手可热,他拥有数百万粉丝,他的一些帖子引起了地震般的运动。我们来看看他的一些微博。

我们可以再次看到,我们得到的是一个类 ResultSet 的对象,或者确切地说,是一个对象模型,它为我们提供了处理信息的多种方法。


注意,默认情况下返回的 tweets 的最大数量是 20,尽管我们可以用 count 参数将它扩展到 200。

这里不可能描述 user_timeline 函数的每个参数,所以我们强烈建议您访问 Tweepy 文档。
Tweets 用光标分页
当我们需要大量数据时,我们将不断需要使用游标。游标是一种 API 方法,用于创建可迭代对象和处理信息块。
cursor 对象有两个主要方法,处理信息块或 tweet 的页面和处理单个 tweet 的项目。

游标用一个模型初始化,例如 search 或 user_timeline,它返回一个 iterable 对象。


正如我们所看到的,我们得到了比使用 user_timeline 更多的 tweets,在这种情况下,它被限制为 200 条。在这个例子中,我们使用光标获取了多达 950 条推文,如下所示:

通过日期范围、用户、单词、标签等过滤光标是非常有趣的。
到目前为止,我们所看到的使我们能够处理来自 Twitter 的历史信息。我们现在将了解如何处理实时信息。
实时推文
为了实时检索 Twitter 消息,或者换句话说,或多或少地检索连续的 tweets 流(取决于使用的过滤器),我们需要创建一个侦听器。
与我们一直在讨论的对象不同,这些对象通过 RESTful 接口为我们提供了一系列发送请求的方法,监听器打开一个套接字,并通过推送技术接收消息。
这听起来可能有点奇怪,但实际上所有困难的工作都是由 Tweepy 库完成的,我们只需要创建适当的对象。
我们唯一要做的就是创建一个从 StreamListener 类继承的类,在这里我们可以覆盖我们感兴趣的方法。再次建议查看官方文档以了解可用的方法。

过一会儿,我们将开始看到基于我们定义的过滤器到达的推文流。

图像被截断。除非我们停止执行,否则每当一条新的 tweet 满足过滤标准时, on_data 方法就会神奇地执行。
注意,有几种以 on_*开头的方法会根据不同的标准自动执行,例如 on_status、on_error 等。
构建情绪指标
为了利用 Twitter 上的信息流建立一个情绪指标,有必要理解 tweets 中包含的信息。我们可以通过$AMZN 这样的代码进行搜索,但我们需要通过解释积极或消极的单词和句子来找出发布它的人的情绪。
为了帮助我们解释文本,还有其他的自然语言处理库可以帮助我们量化和定性我们正在接收的文本,比如 T2 NLTK T3 或 T4 VADER T5。
事实上,我们需要一系列模型来获得信息内容的量化解释,以便解释推文的情绪。
建议写着
结论
我们已经看到 Tweepy 库如何轻松地与 Twitter 建立连接,以便从用户或推文中提取信息。
可以使用 Twitter 提供的 RESTful 方法访问历史信息,从包含特定单词的推文中获取数据,从特定用户、标签等获取推文。
为了从 Twitter 收集实时信息,从 StreamListener 类继承的方法被覆盖,以便可以基于我们拥有的过滤器通过推送技术发送推文。
有了 Tweepy,我们可以从 Twitter 上获得很多信息,但正如我们所看到的,这只是情感分析的第一步。下一步是学习如何处理自然语言处理库。
想要利用替代数据源,使用机器学习技术量化新闻和推文中表达的人类情感吗?查看本课程关于交易策略的新闻和推文。您可以使用情绪指标和情绪得分来创建交易策略,并在实时交易中实施。
参考文献
- https://dev.twitter.com/docs
- https://docs.tweepy.org/en/latest/index.html
- https://quantra . quantin STI . com/course/trading-Twitter-情操-分析
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
如何使用 Python 和 Twitter API v2 获取推文
在这篇博客中,我们继续使用 Tweepy 的 API 接口探索 Twitter API 的高级搜索功能,了解费率限制以及如何处理它们,并了解 Twitter 上的本地趋势。
我们还将了解 Tweepy 库为 Twitter API v2 提供的客户端接口,以及如何使用它从 Twitter 获取不同类型的数据。
在这个小系列的前一篇博客中,我们介绍了使用 Twitter API v1 接口从 Twitter 获取不同类型数据的方法。我们还研究了 Twitter API 的访问级别类型。
在这里,我们将讨论以下主题:
- 高级搜索
搜索最近 30 天
搜索完整存档 - 速率限制
如何查看速率限制状态?
如何设置 app 等待直到速率限制被补足? - 获取一个位置的趋势
- 【Twitter API v2 的 Tweepy 客户端
- 客户端认证
- 使用客户端获取特定用户 ID 的用户名
- 使用客户端获取特定用户名的用户 ID
- 使用客户端获取多个用户 id 的用户名
- 使用客户端获取带有推文 Id 的推文
- 使用客户端获取用户的关注者
- 使用客户端获取用户关注的用户
- 使用客户端获取用户的推文
- 使用客户端获取用户喜欢的推文
- 获取使用客户端转发推文的用户
- 使用客户端搜索最近的推文
- 使用客户端获取搜索查询的 tweet 计数
- 客户端分页
- 使用扩展获取用户和媒体信息
- 将搜索结果写入文本文件
- 将搜索结果放入数据帧
- Twitter API v2 GitHub
高级搜索
Premium search 是 Twitter 提供的订阅 API。该 API 提供了两种产品:
- 搜索推文:30 天终点
- 搜索 Tweets:完整存档端点
要开始使用任何订阅 API,您需要为端点设置一个开发环境 ⁽ ⁾ 。
搜索最近 30 天
Twitter 提供高级搜索 Tweets: 30 天 API,让你可以访问过去 30 天内发布的 Tweets。你可以搜索这个数据库,其中的推文与你的查询相匹配并被返回。
可以使用 API 类的 search_30_day ()方法来访问这个特性。
交易策略的类型:组成部分,方法,等等
有各种类型的交易策略,正如我们所知,交易策略是现场交易的重要组成部分。如果研究和执行得当,交易策略可以帮助交易者在执行交易指令时达到预期的结果。
当策略执行完全自动化时,这种类型的交易策略称为算法交易策略。通过运用正确的交易策略,交易者可以更加准确和自信地执行交易。在这篇文章中,你将学习不同类型的交易策略
更进一步,本文解释道:
什么是交易策略?
交易策略是分析市场状况和做出交易决定的详细计划。策略由估计价格变动的最佳实践和进出交易的规则组成。
交易策略的组成部分
以下是交易策略的组成部分:
- 创建交易策略的方法
- 贸易领域
- 进入和退出逻辑
- 风险管理
创造交易策略的方法
设计交易策略有三种主要方法:
- 技术分析
- 基本面分析
- 定量分析
除此之外,还有:
4.用于设计交易策略的机器学习
机器学习是当代的实践,是一种人工智能。现在,让我们讨论每种方法的介绍:
技术分析T3】
技术分析是一种通过研究价格图表中的趋势和模式来识别交易机会的方法。技术分析假设所有与股票相关的信息,如新闻、基本面因素、情绪等。,已经包含在其当前价格中。因此,它关注价格和交易量的当前趋势,并估计价格的未来走势。
基本面分析
基本面分析是一种估计股票内在价值的方法。是通过研究股票所属行业、经济、公司基本面因素来完成的。内在价值被认为是股票的真实价值。通过比较资产的内在价值和当前价格,可以认为资产被低估或高估。被低估的股票将被买入,被高估的股票将被卖出。
定量分析
在交易中,定量分析是一种借助数学模型和统计技术预测股票价格的方法。定量分析师评估股票的价格和方向,寻找交易机会。
设计交易策略的机器学习
机器学习,顾名思义,就是机器学习的能力,即使没有明确的编程。机器学习基于算法来检测数据中的模式,并相应地调整程序的动作。机器学习系统检测一个交易模式,学习它,每次都自动执行交易。
贸易领域
交易领域包括你应用交易策略的产品和市场。交易的产品范围很广,比如期货、期权、股票。这些产品促进了货币、商品、股票、加密货币等市场的交易。每个交易产品和市场都有自己的风险和交易动态。
出入境逻辑
进场和出场逻辑是买入/卖出股票应该满足的一组条件。进场和出场价格水平由交易策略的分析方法定义。
风险管理T5】
风险管理是交易策略的重要组成部分。资本配置和止损是风险管理的主要内容。资本分配表示分配给每笔交易的资本数量。止损用来限制交易的风险。一旦交易策略被设计出来,就要进行回溯测试以了解它的表现。
交易策略的类型
交易策略可以大致分为五种类型:
- 趋势交易策略
- 均值回复策略
- 突破交易策略
- 套利交易策略
- 基于事件的交易策略
趋势交易策略
趋势交易策略根据股票的趋势产生进场和出场条件。根据趋势交易策略,一项资产在其上升趋势期间买入,在下降趋势期间做空,假设价格继续朝着趋势方向发展。并且,一旦趋势逆转,交易就被终止。
使用技术分析,趋势交易策略是根据移动平均线交叉、相对强弱指标(RSI)和平均方向指标(ADX)等指标设计的。
下面是一个用技术分析创建的趋势交易策略的例子。
策略名称:均线交叉
当股票趋势上升时,价格的移动平均线向上倾斜,并随着价格的上升而上升。根据均线交叉策略,当较短周期均线从下方穿过较长周期均线时,就会买入一只股票。
要生成短线交易信号,一般认为 21 日均线是更短周期的均线,50 日均线是更长周期的均线。对于长期交易,50 天移动平均线、200 天移动平均线被认为是更短和更长周期的移动平均线。
在下面给出的 AAPL 日线图中,长期移动平均线交叉策略用于生成交易信号。2016 年 9 月 2 日,当 50 日均线穿越 200 日均线上方时,产生买入信号。卖出信号产生于 2018 年 12 月 20 日,当时 50 天移动平均线交叉低于 200 天移动平均线。

Moving average crossover strategy
在定量分析中,横截面和时间序列动量策略属于趋势交易策略。
在横截面动量策略中,通过研究证券在一段选定时间内的相对表现来创建多空投资组合。
例如,考虑一下标准普尔 500 指数。为了创建横截面动量策略,我们将计算 500 只股票最近 3 个月的表现。多空组合是通过在最高的 20%建立多头头寸,在最低的 20%建立空头头寸。投资组合将每 3 个月重新平衡一次。
同样,为了创建时间序列动量策略,我们将通过考虑一段时间内证券的绝对表现来创建多空投资组合。将定义一个截止日期,并根据证券在选定时期的表现,创建一个多空投资组合。
例如,对于标准普尔 500 指数中的股票,在过去 3 个月中回报率超过 5%的股票中持有多头头寸,在过去 3 个月中回报率低于-5%的股票中持有空头头寸。
在基本面分析中,基于因素的投资是趋势交易方法的一个例子。基于因素的投资通过考虑解释股票回报的因素来选择投资的股票。
这些因素包括价值、规模、波动性、动力、增长。除此之外,还要考虑通货膨胀、利率、国内生产总值(GDP)等宏观经济因素。
基于这些因素选择的股票有望长期跑赢市场。这些因素的趋势决定了是买还是卖一只股票。
均值回复策略
均值回归策略是基于这样的假设而设计的,即随着时间的推移,价格和经济指标会回到均值。股票的组成部分,如价格、波动性等。预期表现出均值回复特性。
在突然跌破均值后买入股票是均值回复交易策略的一个基本例子。使用技术分析设计了几种均值回复交易策略。一些主要的例子是:
- 回调和回撤交易策略
- 超卖和超买交易策略
- 区间交易系统
均值回归交易策略在区间市场表现良好。
让我们考虑一个最常用的均值回归策略的例子,它是利用布林线设计的。
当布林线是非趋势线时,上下带分别代表价格的超买和超卖水平。
- 当价格在低波段附近交易时,就会产生买入信号
- 当价格在上限附近交易时,就会产生卖出信号。
考虑以下 TSLA 的例子。如前所述,均值回归策略在市场无趋势(即区间波动)时效果最佳。平坦的布林线代表区间市场,在超卖和超买水平产生买入和卖出信号。

Mean reverting strategy
在定量分析中,配对交易和统计套利策略被归类为均值回复交易策略。
- 统计套利策略是为了利用价格的均值回复特性以及市场微观结构异常而创建的。
- Pairs trading 是一种市场中性的交易策略,在这种策略中,多空头寸都是在具有高度正相关性的股票中进行的。
在基本面分析中,价值投资策略是均值回复策略的典型例子。
使用基本面分析,计算证券的内在价值。如果证券的交易价格低于其内在价值,则被认为被低估。价值投资包括购买被低估的证券。
突破交易策略
突破交易策略包括在突破股票的长期支撑位和阻力位等重要价格水平后买入或卖出资产。在技术分析中,突破阻力位后买入或突破支撑位后卖出属于突破交易策略。
技术分析策略,如开盘区间策略、双推力策略和基于楔形、旗形、头肩顶和三角形等形态突破的策略都属于突破策略。
下面是一个楔形下跌突破策略的例子。楔形下跌是一种形态,价格在两条向下倾斜的线之间移动,这两条线相互靠近。当价格高于楔形形态的上线时,买入。
在下面的图表中,在 2 月和 3 月的每日时间框架中,安全性 GOOGL 呈楔形下降。在 2021 年 4 月 1 日,观察到楔形上线的突破,这是买入信号的触发点。

Breakout trading strategy
在定量分析中,使用了先进的定量模型,如时序机制转换和隐马尔可夫模型来设计突围策略。
在基本面分析中,相对价值策略被认为是突破策略。将证券的基本比率与行业的基本比率进行比较,并据此确定多头/空头头寸。例如,微软(MSFT)的市盈率(P/E 比率)与信息安全部门的市盈率相比较。
如果 MSFT 的 P/E 比它的部门小,那么 MSFT 被认为是被低估的,并采取了一个长期立场。同样,如果 MSFT 的市盈率大于该行业的市盈率,那么它就被认为是高估的,并持有空头头寸。
套利交易策略
套利交易旨在从支付的利息和赚取的利息之间的差额中获利。这在货币市场上被广泛使用。
在外汇市场,套息交易策略是通过卖出低收益货币和买入高收益货币来执行的。套利策略通过购买基础货币利率高于报价货币的货币对来执行。
例如,考虑货币对 A/B 的情况,其中货币 A 的利率为 6%,货币 B 的利率为 4%。通过购买货币对 A/B 来执行套息交易,这被称为正套息交易。
一旦交易被执行,只要差价为正,你就会从经纪人那里收到利率的差价。然而,如果利息差变成负数,也就是说,如果货币 B 的利率上升并与货币 a 的利率交叉,你就会遭受损失。
在定量分析中,做市和现金-期货套利都是套息交易策略的例子。在技术分析中,波动性卖出策略,即做空伽马就是套利交易的一个例子。
基于事件的交易策略
基于事件的交易策略用于利用经济和公司事件发布后形成的价格低效率。
在定量分析中,基于新闻的股票交易被认为是基于事件的交易策略。阅读文章量化新闻分析:盈利能力与陷阱以深入了解基于新闻的股票交易。
在基本面分析中,通过研究新闻事件和经济事件后的价格变化来买卖股票属于基于事件的交易策略。
基于 ML 的交易策略
基本上,基于 ML 的交易策略是当代的实践。它们是上面提到的每种交易策略的定量、技术和基本方法的混合,即趋势、均值回复、突破、套利和基于事件。
基于 ML 的战略的三个垂直领域是:
- 监督学习交易策略
- 无监督学习交易策略
- 强化学习交易策略

监督学习交易策略
机器学习模型的监督学习方法包括两种主要技术,即:
- 回归(用于预测任何变量(如股票、商品等)的实数。)
- 分类(用于对变量的类别进行分类,如 TSLA、谷歌等。库存)
回归
回归是确定变量之间关系的统计过程。它有助于理解当任何一个自变量变化时,因变量的值是如何变化的。
它还允许比较不同尺度上测量的变量的影响,例如价格变化的影响。在交易中,回归被广泛使用,尤其是在成对交易策略中,以及在需要评估股票与市场回报相比的表现时。
线性回归
线性回归是最广为人知的建模技术之一。线性回归使用最佳拟合直线在因变量(Y)和一个或多个自变量(X)之间建立关系。
如果只有一个独立变量,那么它被称为简单线性回归,但如果有多个独立变量,那么它被称为多元线性回归。
让我们通过下图来理解这一点:

Linear regression
上图在 x 轴上显示了“标准普尔 500 回报率”的给定数据,在 y 轴上显示了“股票回报率 ABC”的预测数据。要计算回归线斜率,可以使用 Python 中的 Scikit-learn 库。
Scikit-learn library 提供监督和非监督模型的算法,包括回归技术、分类、聚类、随机森林等。
要计算因变量/预测变量 y 截距,公式如下:

Formula for y intercept of linear regression
例如,如果您计算的斜率为 1.5,截距为 20,则股票的最终线性回归公式为:
y= 20 + 1.5x
监督学习方法中的下一个是逻辑回归。
逻辑回归
逻辑回归类似于线性回归,但只有一个区别。逻辑回归模型通过特殊的非线性函数运行结果,逻辑函数产生输出“y”。这里,输出是二进制或 0/1 或-1/1 的形式。
逻辑回归通过使用逻辑函数估计概率来测量因变量和一个或多个自变量之间的关系。
因此,逻辑回归的公式如下:
y = 1 / 1+ e-x
分类
分类是使用支持向量分类器(SVC)技术应用的方法之一,并且是机器学习中无监督学习方法的一部分。分类技术将输入映射到一个离散的类或类别,如下图所示:

Classification
例如,交易域中的类别可以被分类为以下任何市场中的进入位置和退出位置-股票、商品、债券、衍生品。
推荐阅读:Python 中的机器学习分类策略
随机森林
随机森林,也称为随机决策森林,是机器学习中的一种方法,能够执行回归和分类任务。这是一种使用多种学习算法进行预测的集成学习。
随机森林由决策树组成,这些决策树是表示其行动过程或统计概率的决策图。这些多重树被绘制成称为分类和回归(CART)模型的单一树。
为了根据对象的属性对其进行分类,每棵树都给出一个分类,据说是为该类投票。然后,森林选择票数最多的分类。对于回归,它考虑不同树的输出的平均值。
工作
- 让我们假设情况的数量为“N”。然后,随机但有替换地取出这 N 个案例的样本,这将是训练集。
- 考虑将 M 作为输入变量,选择一个数 M,使得 m < M 和 M 之间的最佳分裂用于分裂节点。随着树的生长,m 的值保持不变。
- 每棵树都长得尽可能大。
- 通过聚合 n 棵树的预测(即分类的多数票,回归的平均值),随机森林预测新数据。
例如,在股票市场中,随机森林用于根据预期回报来识别股票的行为(取股票在“n”年中的过去表现)。
无监督学习交易策略
无监督学习是一种机器学习,其中只提供输入数据,不提供输出数据(标记)。在无监督学习中的算法没有任何帮助来找到结果,并且在这种学习方法中,没有正确或错误的答案。
k 均值聚类
K-Means 聚类是一种无监督的机器学习,它根据相似性对数据进行分组。K-Means 是一种在数据集中寻找子组的技术。K-Means 与其他聚类方法的一个区别是,在 K-Means 中,我们有预定数量的聚类,而其他技术不要求我们预先定义聚类的数量。
该算法首先将每个数据点随机分配到一个特定的聚类中,任何两个聚类中都没有一个数据点。然后,它计算这些点的质心或平均值。
该算法的目的是减少总的组内变化。换句话说,我们希望将每个点放入一个特定的聚类中,测量距该聚类质心的距离,然后取这些距离的平方和,以获得总的聚类内变化。我们的目标是降低这个值。
分配数据点和计算平方距离的过程继续进行,直到聚类的组成不再有变化,或者换句话说,我们已经最佳地减少了聚类内的变化。
推荐阅读:Python 中用于对选择的 K-Means 聚类算法
强化学习交易策略
强化学习是一种通过系统来鼓励或改变特定的不想要的行为的方式。每当系统因为给出了期望的结果而得到奖励时(如反馈给系统的那样),它就会得到积极的强化,而当系统做了与期望结果相反的事情时,它就会得到消极的强化。机器学习系统就是这样学习的。
这与人类的学习方式非常相似。当他们在某个领域获得了想要的结果,比如说,在一次考试中得了高分,他们就会得到一份好工作的奖励。以下是机器学习模型如何与强化学习一起工作的图示:

Reinforcement learning
推荐课程:交易机器学习入门
机器学习交易策略最好借助流行的计算机语言 Python 来应用。有一个 Python 包叫做 Scikit-learn ,它是专门为机器学习开发的,具有各种分类、回归和聚类算法。
策略组合
本文中解释的策略可以组合起来创建一个投资组合。比如你可以把基本面分析和技术面分析下的策略结合起来。基本面分析将用于选择交易的资产,技术分析将用于确定进场时间。
现在,市场以不同的方式运行。因此,当市场没有趋势时,动量策略可能无法正常工作。同时,当市场是趋势时,均值回归策略可能不会表现得最好。因此,你可以结合动量策略和均值回归策略来获得一致的回报。
在这里,你可以将一部分资金分配给动量策略,一部分分配给均值回复策略(基于预期的市场情况)。同样,您可以根据市场波动(当前和预期)等情况,将资金分配给不同的策略。
此外,你可以交易各种可交易的项目,如外汇(货币),股票,商品等。创建一个投资组合并应用上述不同的策略。
此外,这些策略,即趋势交易策略、均值回复策略、突破、进位和基于事件的策略,可以在如上所述的机器学习模型/方法/策略的帮助下建模。
在这里,组合策略将:
- 降低整体最大提取额
- 增加回报的稳定性,以及
- 多样性是我们交易的资产
结论
交易策略创建是自动执行交易过程中的一个重要步骤。交易策略有助于系统地执行交易,使交易结果对交易者有利。
有几种交易策略,每一种都可以根据特定的市场情况来实施。我们讨论了不同的交易策略及其应用类型,即技术、数量、基本面和机器学习方法。
报名参加算法交易入门课程,了解更多关于算法交易的实践。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
金融回归的异国风味——一瞥
由 Vivek Krishnamoorthy 和 Udisha Alok
回归是一种挖掘因变量和自变量之间关系的技术。它通常出现在机器学习中,主要用于预测建模。在本系列的最后一部分,我们将扩展我们的范围,以涵盖其他类型的回归分析及其在金融中的应用。
我们探索:
- 线性回归
- 简单线性回归
- 多元线性回归
- 多项式回归
- 逻辑回归
- 分位数回归
- 岭回归
- 套索回归
- 岭回归和套索回归的比较
- 弹性网回归
- 最小角度回归
- 多元线性回归和主成分分析的比较
- 岭回归和主成分分析的比较
- 主成分回归
- 决策树回归
- 随机森林回归
- 支持向量回归
之前我们已经非常详细地介绍了线性回归。我们探索了如何将线性回归分析用于金融,将其应用于金融数据,并查看其假设和限制。一定要给他们读一读。
线性回归
我们已经在本系列前面的博客中详细介绍了线性回归。在进入更新的内容之前,我们在这里展示它的一个胶囊版本。如果您之前已经花了足够的时间来学习,可以跳过这一部分。
简单线性回归
简单的线性回归允许我们研究两个连续变量之间的关系——一个自变量和一个因变量。

Linear regression: Source
简单线性回归方程的一般形式如下:
(y_{i} = β_{0} + β_{1}X_{i} + ϵ_{i}) - (1)
其中(β_{0})是截距,(β_{1})是斜率,(ϵ_{i})是误差项。在这个等式中,y 是因变量,X 是自变量。误差项包含除回归变量之外影响因变量的所有其他因素。
多元线性回归
我们研究多元线性回归中两个以上变量之间的线性关系。这里不止一个自变量被用来预测因变量。
多元线性回归的方程可以写成:
(y_{i} = β_{0} + β_{1}X_{i1} + β_{2}X_{i2} + β_{3}X_{i3} + ϵ_{i}) -(2)
其中,(β{ 0 } )、(β{ 1 } )、(β{ 2 } )和(β{ 3 } )是模型参数,(ϵ_{i}\是误差项。
多项式回归
线性回归适用于建立因变量和自变量之间的线性关系模型。但是如果这种关系是非线性的呢?
在这种情况下,我们可以将多项式项添加到线性回归方程中,使其更好地模拟数据。这被称为多项式回归。由于模型的参数是线性的,严格来说,它仍然是线性回归。

Linear vs Polynomial regression: Source
使用多项式回归,我们可以用多项式方程的形式模拟自变量和因变量之间的关系。
(k 次)阶多项式的方程可以写成:
我是说,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是,我的意思是-我不知道(三)
选择多项式阶是至关重要的,因为高阶多项式可能会使数据过拟合。因此,我们尽量保持多项式模型的阶数尽可能低。
有两种方法可以选择模型的阶数:
- 正向选择程序,我们以递增顺序连续拟合模型,并在每次迭代中测试系数的显著性,直到最高阶项的 t 检验不显著。
- 反向消除程序,从最高阶多项式开始,在每次迭代中连续降低阶数,直到最高阶项具有显著的 t 统计量。
最常用的多项式回归模型是一阶和二阶多项式。
当我们有大量的观察值时,多项式回归更适合。然而,它对异常值的存在很敏感。
多项式回归模型可用于预测股票价格等非线性数据。你可以在这里阅读更多关于多项式回归及其在预测股票价格中的应用。
逻辑回归
这也称为 logit 回归。逻辑回归是一种分析方法,根据过去的数据预测某一事件的二元结果。
当因变量是定性的且取二进制值时,称为二分变量。
如果我们使用线性回归来预测这样一个变量,它将产生 0 到 1 范围之外的值。此外,由于二分变量只能取两个值,因此残差不会正态分布在预测线周围。
逻辑回归是一种非线性模型,它生成的逻辑曲线的值限于 0 和 1。
将该概率与阈值 0.5 进行比较,以决定数据的最终分类。因此,如果一个类别的概率大于 0.5,则标记为 1,否则为 0。
逻辑回归在金融学中的一个用例就是可以用来预测股票的表现。
你可以在这个博客上阅读更多关于逻辑回归和 Python 代码如何使用它来预测股票走势的信息。

Logistic regression: Source
分位数回归
正如我们在上一篇博客中看到的,线性回归模型在处理金融时间序列数据时有几个局限性,比如在处理偏斜度和异常值时。
1978 年,Koenker 和 Bassett 提出分位数回归作为一种工具,允许我们探索整个数据分布。因此,我们可以在分布的不同部分检查自变量和因变量之间的关系,比如说,第 10 百分位、中间值、第 99 百分位等。
分位数回归估计给定自变量的因变量的条件中位数或条件四分位数。

Quantile regression: Source
经典的线性回归试图根据自变量的不同值来预测因变量的平均值。独立变量的 OLS 回归系数表示相关预测变量单位变化的变化。类似地,独立变量的分位数回归系数表示相关预测变量单位变化的指定分位数的变化。
分位数和百分位数用于将数据样本分成不同的组。线性回归模型基于误差呈正态分布的假设。
然而,这种方法可能会失败的情况下,我们有重大的离群值,也就是说,如果分布有一个厚尾。分位数回归在本质上比线性回归更稳健,能够有效地捕捉异常值。在这里你会了解到什么是自协方差和自相关函数。
在分位数回归中,条件中位数函数由中位数估计量估计,这减少了绝对误差的总和。
分位数回归可以帮助风险管理者更好地管理尾部风险。因此,它被用于风险管理,尤其是在风险值( VaR )的上下文中,根据定义,风险值是一个条件分位数。
VaR 可以解释为一个投资组合在一段时间内以给定的概率损失的金额。我们还可以根据分位数回归来确定高风险暴露期。
分位数回归可以用来预测回报,也可以用来构建投资组合。
里脊回归
正如我们之前在中讨论的,线性回归假设数据中没有多重共线性。因此,当预测变量相关时,这是不合适的。多重共线性会导致回归模型系数大幅波动。
岭回归适合在这种情况下使用。当预测变量的数量大于观测值的数量时,以及当每个预测变量都有助于预测因变量时,这种方法特别有用。
岭回归旨在通过限制系数的大小来减少标准误差。
它通过引入一个等价于系数幅度之和的罚项λ(𝜆)来做到这一点。Lambda 惩罚大的回归系数,并且随着 lambda 值的增加,惩罚也增加。因为它正则化系数,它也被称为 L2 正则化。
需要注意的重要一点是,虽然 OLS 估计量是尺度不变的,但岭回归却不是。因此,在应用岭回归之前,我们需要调整变量。
岭回归降低了模型的复杂性,但没有减少变量的数量,因为它可以将系数缩小到接近零,但不会使它们完全为零。因此,它不能用于特征选择。
你可以在这里阅读更多关于岭回归。
套索回归
Lasso 代表最小绝对收缩和选择运算符。
它是岭回归的近亲,也用于正则化回归模型中的系数。当我们有大量使模型更复杂的预测变量时,进行正则化是为了避免过度拟合。
套索回归的惩罚项等于系数大小的绝对值。
套索回归也称为 L1 正则化。
顾名思义,套索回归可以将一些系数缩小到绝对零。因此,它可用于特征选择。

Ridge vs Lasso regression: Source
岭回归和套索回归的比较
岭回归和套索回归可以比较如下:
- 套索回归可用于特征选择,而岭回归则不能。
- 虽然岭回归和套索回归都能很好地处理数据中的多重共线性,但它们处理多重共线性的方式不同。岭回归缩小了所有相关变量的系数,使它们相似,而拉索回归保留了一个系数较大的相关变量,而其余的趋于零。
- 岭回归适用于有大量重要预测变量的情况。Lasso 回归在有许多预测变量,但只有少数显著变量的情况下是有效的。
- 这两个模型都可以用于股票预测。但是,由于 Lasso 回归执行要素选择,并且只选择非零系数来训练模型,因此在某些情况下它可能是更好的选择。你可以阅读这篇论文了解更多关于使用套索回归进行股市分析的知识。
弹性净回归
Lasso 回归的要素选择可能不可靠,因为它依赖于数据。弹性网回归是岭回归和套索回归模型的组合。它结合了这两个模型中的惩罚项,通常表现得更好。
我们首先计算弹性网回归中的岭回归系数,然后使用套索回归缩小这些系数。
弹性网络回归可用于正则化以及特征选择。
阅读这个博客了解更多关于山脊、套索和弹性网回归以及它们在 Python 中的实现。

Penalty terms for Ridge, Lasso, and Elastic net regression: Source
最小角度回归
正如我们前面看到的,套索回归通过应用偏差来约束模型的系数,从而避免过度拟合。然而,我们需要为模型提供一个超参数λ(𝛌),它控制函数的惩罚的权重。
最小角度回归( LARS )是解决线性回归模型中过度拟合问题的一种替代方法,它可以在不提供超参数的情况下进行调整以执行套索回归。
当我们有高维数据,即具有大量特征的数据时,就使用 LARS。类似于正向逐步回归。
在 LARS 中,我们从所有系数都等于零开始,找到与响应变量最相关的解释变量。然后,我们在这个解释变量的方向上尽可能迈出最大的一步,直到另一个解释变量与残差具有相似的相关性。
现在,LARS 在这两个解释变量之间以等角方向前进,直到出现第三个解释变量,其与残差具有相同的相关值。
如前所述,我们在这三个解释变量的方向上等角度(角度最小)前进。这样做,直到所有的解释变量都在模型中。
然而,必须指出,LARS 模型对噪声很敏感。

Geometric representation of LARS: Source
主成分回归
主成分分析用于以最少的信息损失简洁地表示数据。PCA 的目的是找到主成分,这些主成分是相互正交且具有最大方差的估计量的线性组合。如果两个主分量的向量的标量积等于零,则称这两个主分量是正交的。
主成分回归包括使用 PCA 对原始数据进行降维,然后对顶部的主成分进行回归并丢弃剩余的主成分。

Image representing principal component analysis: Source
多元线性回归与主成分分析的比较
主成分回归是多元线性回归的替代方法,多元线性回归有一些主要缺点。
MLR 不能处理估计量之间的多重共线性,并且假设估计量被精确测量并且没有噪声。它不能处理丢失的值。
此外,如果我们有大量的估计,这是超过观察的数量,最大似然法不能使用。
PCA 用较少数量的主成分代替大量的估计量,这些主成分捕获估计量所代表的最大方差。它简化了模型的复杂性,同时保留了大部分信息。它还能够处理任何丢失的数据。
岭回归与主成分分析的比较
岭回归和主成分回归是类似的。从概念上讲,岭回归可以想象为将估计量投影到主成分的方向上,然后按照方差的比例缩小估计量。
这将缩小所有的主要组成部分,但不会完全缩小到零。然而,主成分分析有效地将一些主成分收缩到零(其被排除),并且根本不收缩一些主成分。
决策树回归
决策树在节点处将数据集分割成越来越小的子集,从而创建一个树状结构。根据标准拆分数据的每个节点称为内部/拆分节点,最后的子集称为终端/叶节点。
决策树可用于解决分类问题,如预测金融工具的价格会上涨还是下跌。它也可以用来预测金融工具的价格。
决策树回归是指使用决策树模型来执行回归任务,该任务用于预测连续值而不是离散值。
决策树遵循一种自上而下的贪婪方法,称为递归二进制分裂。这是一种贪婪的方法,因为在每一步,最好的分裂是在特定的节点上进行的,而不是向前看,选择一个可能导致未来更好的树的分裂。
每个节点被分裂以最大化信息增益。信息增益被定义为父节点的杂质和子节点的杂质之和的差。
对于回归树,杂质的两种流行度量是:
- 最小二乘法:选择每个分裂,使每个节点的观测值和平均值之间的残差平方和(RSS)最小。
- 最小绝对偏差:该方法最小化每个节点内与中位数的平均绝对偏差。这种方法对异常值更稳健,但在处理具有大量零值的数据集时可能不敏感。
如果解释变量和响应变量之间存在高度非线性和复杂的关系,决策树可能优于经典方法。
决策树更容易解释,有一个很好的可视化表示,可以很容易地处理定性预测,而不需要创建虚拟变量。
然而,与其他一些回归模型相比,它们不够稳健,预测精度也较差。此外,对于具有许多估计变量的数据集,它们容易过度拟合。
通过使用集成方法,如 bagging、boosting 和随机森林,我们可以提高决策树的预测性能。
随机森林回归
随机森林回归是一种集合回归方法,其性能明显优于单个决策树。这符合运用“群众智慧”的简单逻辑。它采用许多不同的决策树,以“随机”方式构建,然后让它们投票。
多重回归树建立在自举训练样本上,并且每次在树中考虑分裂时,从预测器的总数中选择预测器的随机样本。
这意味着当在随机森林中构建树时,算法甚至不允许考虑整个可用的预测器集。因此,如果我们有一个强预测器和一些中等强度的预测器,随机森林中的一些树将在不考虑强预测器的情况下构建,从而给其他预测器更好的机会。
这实质上就像在树之间引入一些去相关性,从而使结果更加可靠。
如果你想了解更多关于随机森林以及如何在交易中使用它们的信息,请阅读这篇帖子。

Image representation of a Random forest regressor: Source
支持向量回归
支持向量回归(SVR)应用支持向量机 (SVM)的原理来预测离散数字。它试图找到包含最大数量数据点的超平面。你可以在这里了解更多关于支持向量机在交易中的应用。
与试图最小化响应变量的预测值和实际值之间的误差的其他回归算法不同,SVR 试图在用于创建一对边界线的容限(ε)内拟合超平面。
SVR 使用不同的数学函数(核)来转换输入数据,这些数据用于在高维空间中寻找超平面。一些核是线性的、非线性的、多项式的等等。要使用的内核类型基于数据集。
SVR 使用对称损失函数来惩罚较高和较低的错误估计。SVR 模型的复杂性使得它很难在大型数据集上使用。因此,如果我们正在处理一个大的数据集,就使用线性核函数。
SVR 对异常值具有鲁棒性,并且具有高预测精度。你可以在这里阅读更多关于使用 SVR、线性和多项式回归模型进行股市预测的信息。

Image representation of Support vector regression: Source
参考
- 计量经济学举例-达摩达尔古吉拉特语
- 金融计量经济学基础——Frank j . fabo zzi,Sergio M. Focardi,Svetlozar T. Rachev,Bala G. Arshanapalli
- 计量经济学数据科学-弗朗西斯·x·迪堡
- 统计学习导论
结论
在这篇博客中,我们已经讨论了金融领域中使用的一些重要的回归类型。每一种都有自己的优势,也许还会有一些挑战。
我们希望您喜欢阅读这些内容,并继续尝试其中的一些来实现您的想法。
在行业专家的正确培训和指导下,你可以学习它以及统计学和计量经济学、金融计算和技术、算法和量化交易。这些以及算法交易的各个方面都包含在这个算法交易课程中。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。一定要去看看。
下次见!
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
最佳量化博客的非传统指南|交易博客|金融博客
原文:https://blog.quantinsti.com/unconventional-guide-best-websites-quants/
一般来说,quant 是金融科技行业的专业人士,在定量分析的帮助下设计复杂的算法。定量分析师精通数学、金融和计算机技能——这是一种罕见的混合技能。在交易领域,定量分析师设计并实现预测价格的算法。
找到有质量的信息在这里是最重要的,因为这是有助于增加我们知识价值的信息。而这些知识可以通过 quant 博客、文章等找到。这就是为什么我们做了一个彻底的研究,并编制了一个网站清单,在这些网站上,量化分析师愿意投入他们的时间和精力。网站分为四个类别,以便于导航。这些类别如下:
博客
首先也是最重要的,我们有一个网站列表,其中包含了对定量分析师来说信息量最大的博客文章。因此,我们下面要看到的网站之所以存在,是因为它们的博客有一群忠实的粉丝。
我怎么知道他们的粉丝群?在这个行业中,我和一些定量分析师交谈过,他们帮我找到了他们最喜欢的阅读博客文章的网站。它们是:
Quantocracy
Quantocracy 是一个算法和量化交易博客的策划混搭,聚集了互联网上一些最好的文章。他们在定量交易领域发表了许多发人深省和有见地的文章。Quantocracy 被一个庞大的交易者群体所追随,被认为是商业界的佼佼者之一。
在“Quant Mashup”部分,你可以看到一些排名靠前的读者博客,这将帮助你缩小搜索范围,找到一些免费的量化交易策略。
陈博士的博客
著名的从业者和作家,陈博士是 QTS 资本管理有限公司的管理成员。他还是 QuantInsti EPAT 项目的教员,也是一位受欢迎的金融博客作者。
交易界尊敬他,他是大多数有抱负的算法交易者的榜样。有什么比他自己的网站更好的方式向他学习呢?这个网站涵盖了关于算法交易平台、书评、因子模型和交易策略的信息。
Quantinsti
我们是一家研究和培训机构,旨在为量化和算法交易领域培养金融市场专业人才。
我们的博客页面以其高质量的内容、由市场专家起草的精选交易策略的详细摘要和庞大的追随者群而闻名。
我们博客页面上的文章基于广泛的类别,包括职业建议、可下载的交易策略、算法交易入门、新闻、编程和交易工具、Python 交易平台、项目工作、网络研讨会等等。
此外,对于定量分析师来说,有超过 141 篇博客文章与交易策略相关,以帮助不同市场(外汇、股票等)的策略创建。).您还可以查看我们的项目作品 EPAT 类别,以获取 EPAT 项目的学生和校友发布的项目作品集。
量化度
为了创建你的量化交易策略,这个网站给你提供了一些可以利用的策略想法的博客。该网站汇集了所有经过充分研究的博客文章,为您带来了最好的量化交易策略理念。
那么,你能用量化交易策略思想做什么呢?你可以制定和回测这些交易策略。此外,您可以执行自己的优化程序。
Quantstart
QuantStart 由迈克尔·霍尔斯-摩尔(Michael Halls-Moore)于 2012 年创立,为潜在的和在职的量化分析师提供教育资源。
有超过 200 个教程和三个非常受欢迎的教科书,很少有人不关注这个门户网站。
这是 QuantStart 擅长的领域之一。一些最受欢迎的文章类别包括算法交易、quant 阅读列表、机器学习、时间序列和 python 实现。
投资媒体
Investopedia 由 IAC(纳斯达克代码:IAC)全资拥有,是全球最大的金融教育网站。顾名思义,它是金融行业的百科全书。Investopedia 有大量与金融和股票交易相关的文章,是想要做出更明智金融决策的投资者的首选。Investopedia 身边有一个由数据科学家和金融专家组成的团队,为每月 3000 多万的访问者提供可靠的金融信息。
Geeksforgeeks
geeksforgeeks 是由 JIIT 诺伊达的一位名叫 Sandeep Jain 的教授创办的,是一个著名的计算机科学门户网站。在这里,您可以找到与编程、算法、数据结构和面试准备材料相关的问题的答案。网站被分成不同的类别来传递信息,而博客很好地服务于这个目的。
堆栈溢出
Stack overflow 由 Jeff Atwood 和 Joel Spolsky 于 2008 年创建,是一个面向程序员的问答社区,但也有一些非常有用和有趣的博客文章。他们有一系列博客文章,涉及不同的主题,包括计算机语言、技术专家、编程语言在医学中的应用等。
程序员问答社区
堆叠交换
Stack Exchange 是一个由 177 个社区组成的网络,这些社区由对某个特定主题充满热情的专家和爱好者创建和运营。此外,他们还建立了高质量的问答库,专注于每个社区的专业领域。
需要注意的最重要的一点是,他们不是一个“闲聊”的社区,或者简单地说,他们不是用来讨论的。相反,他们相信直截了当的提问方式和一群人对答案的回复。最佳答案会显示在顶部,提问者可以将一个适合他/她的答案标记为“被接受”的答案。
Quora
Quora 是一个美国问答网站,互联网用户在这里提问、回答、关注和编辑问题。虽然互联网用户可以访问 Quora 的话题很多,但编程是其中之一。
研究论文
现在,我们转到一些网站,这些网站提供一些基于算法和量化交易相关主题的高质量研究论文。一些来源可靠的原创作品是量化分析师的真正财富。
[Quantpedia]( https://quantpedia.com/#::text=Quantpedia%20database%20has%2070%20free ,sample%20implementation%20in%20python%20code.)
Quantpedia 被称为量化交易策略的百科全书。他们的网站上列出了数千篇金融研究论文。
他们的使命是将金融学术研究转化为更加用户友好的形式,以帮助任何寻求新的量化交易策略想法的人,他们有 70 种免费提供的策略。
SSRN
SSRN 于 1994 年由两位金融经济学家迈克尔·詹森和韦恩·马尔创立。他们有许多专门的研究网络,根据 PDF 文件、反向链接和谷歌学术结果的数量,2013 年 1 月,SSRN 通过知识库网站排名被评为世界上最大的开放存取知识库(由网络计量学实验室发起)。
Arxiv
Arxiv 是电子版预印本和后印本(被称为电子版)的开放存取储存库,在审核后被批准发布,但不是同行评审。由数学、电气工程、计算机科学、统计学、数理金融、经济学等领域的科学论文组成。所有的研究论文都可以在线获取,因为它们是开放获取的。
研究之门
ResearchGate 是一个欧洲商业社交网站,供科学家和研究人员分享论文、提问和回答问题以及寻找合作者。虽然阅读文章不需要注册,但希望成为网站成员的人需要在一个公认的机构拥有一个电子邮件地址,或者被手动确认为已发表的研究人员,以便注册一个帐户。
自定进度的学习门户
到目前为止,你的知识库中已经有了大量的网站。让我们在网上找到一些免费的课程,其中一些给你算法交易技术的实践经验。
Quantra
Quantra 是一个专门从事算法和量化交易的电子学习门户网站。Quantra 提供自定进度的课程,包括视频、音频、演示、选择题和高度互动的练习。
Quantra 因所有好的理由而受到高度赞赏,包括他们发布的高质量课程,这些课程将支持你成为一名成功的 Algo 交易者。不要忘记由 E. P. Chan 博士撰写的“Python 中的均值回归策略”
Quantra 上的一些免费课程包括:
Coursera
由斯坦福大学教授吴恩达和达芙妮·柯勒创建的 Coursera 是一家风险投资支持的、专注于教育的技术公司,提供各种领域的在线课程。
他们有一些令人惊叹的课程,也可以帮助你获得在线认证。我最近发现,您可以注册并享受 7 天免费试用帐户,其中大部分课程将为您解锁。
以下是您可以在 7 天免费试用帐户中访问的一些相关课程的列表:
该课程是为投资者和资金管理者设计的,他们希望获得设计自己的交易策略所需的技能。
本课程将为你提供八个现成的交易策略,这些策略都是基于严谨的学术研究。本课程也将帮助你设计自己的交易策略,回溯测试和衡量表现。学习者还将学会科学的回溯测试方法,而不会屈服于前瞻(或)生存偏见。
如果你是一名投资者或基金经理,并且正在寻找能够帮助你发展和测试自己在新兴市场的交易策略的技能,那么这就是适合你的课程。
麻省理工学院开放课件
也被称为开放式课程,它是麻省理工学院大部分课程内容的网络出版物。任何人都可以自由访问内容。
他们的网站上有两门免费课程:
本课程将帮助你通过深入了解分析思维、数学推导和金融市场来学习如何做出良好的投资决策。
这门课程帮助本科生和研究生学习金融行业中使用的数学概念和技术。
结论
有很多网站可以在网上找到定量分析师,但很少有网站能进入最佳评级类别。不同的网站以量化博客、文章、研究论文、课程、问答社区和市场数据来源的形式迎合量化者的知识。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
理解链式法则
在这篇关于“理解链式法则”的博客中,我们将借助一个例子来学习链式法则背后的数学原理。
目录
对于那些对神经网络和深度学习感兴趣的人来说,反向传播的过程是一个非常重要的概念,在创建这些高级模型时被广泛使用。在执行反向传播时,我们使用链式法则的概念反向传播预测中的误差值来调整权重。
为了能够理解这个单位,你应该知道什么是导数。
 什么是导数?
什么是导数?
不要多心,万一不知道或者不记得一样,可以去 Quantra 网站的词汇表版块了解一下。
 什么是链式法则?
什么是链式法则?
链式法则基本上是一个计算两个或多个函数合成的导数的公式。
 理解链式法则
理解链式法则
假设 f 和 g 是函数,那么链式法则将它们合成的导数表示为 f ∘ g (将 x 映射到 f(g(x)) 的函数)。如下所述计算该组成的导数。

这里 f 是 g 的函数 g 是变量 x 的函数。
上述规则的另一种写法是:

其中函数 F 代表复合函数 f(g(x))
假设我们有三个变量 x,y 和 z ,这样,变量 z 取决于变量 y ,而变量y又取决于变量 x 。所以 y 和 z 是因变量, z 通过中间变量 y 依赖于 x 。那么用于微分变量 z 的链式法则可以以下面的方式书写。

这是我们在反向传播中使用的最后一个公式。
这里 z 是 y 的函数,
z = f(y)
并且 y 是 x 的函数,
y= g(x)
使用前面的公式,我们可以将微分方程改写如下:

让我们借助一个例子来更好地理解这一点。
 链式法则的例子
链式法则的例子
让我们借助维基百科的一个众所周知的例子来理解链式法则。假设你是从天上掉下来的,在下落的过程中,大气压一直在变化。查看下图,了解这一变化。

在你坠落的时候,海拔 4000 米,初速度为零,重力是 9.8 米每秒平方。现在将这种情况与之前的链式法则方程进行比较。假设方程中的变量 x 是变量 t ,或者时间。
那么变量 y 或 g(t) ,也就是你从下落开始所走的距离,由下式给出
g(t)= 0.5 * 9.8t2T5】
因此,平均海平面的高度可由变量 h 给出,即
h = 4000g(t)
假设我们也知道,基于模型,高度 h 处的大气压力为:
f(h)= 101325 e—0.0001h
这两个方程可以通过它们各自的变量来区分,以获得以下信息:
g′(t)= 9.8t,
其中,g′(t)是你在时间 t 的速度
f′(h)=-10.1325e-0.0001h
其中,f′(h)是大气压相对于高度的变化率 h
现在让我们来理解如何把这两个方程结合起来,得出
在跳伞者跳伞后的 t 秒,大气压力相对于时间的变化率,使用链式法则:


这个方程给出了自秋季以来大气压力随时间的变化率。在神经网络中,我们需要计算每个神经元的权重相对于预测误差的变化。现在你可能已经想到了,链式法则有助于相应地调整这些权重。
结论
如果我们想应用链式法则来反向传播神经网络中的误差,那么我们将使用这样一个方程。

在与 E. P. Chan 博士合作的 Quantra 关于 交易中的深度学习的课程中,我们不仅会帮助您理解深度学习等先进概念,还会将它们应用到交易的背景中。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
建议阅读:
交易的无监督学习介绍
由阿舒托什·戴夫
在之前的博客中,我们详细研究了线性回归等监督学习算法。在这篇博客中,我们来看看什么是无监督学习,以及它与有监督学习有何不同。
然后,我们继续讨论投资和交易中无监督学习的一些用例。我们特别探索了两种无监督的技术——k-means 聚类和 PCA,并给出了 Python 中的例子。
内容
什么是无监督学习?

顾名思义,“无人监督”的学习发生在没有监督者或老师,学习者自己学习的时候。
例如,想象一个孩子第一次看到并品尝一个苹果。她记录水果的颜色、质地、味道和气味。下一次她看到一个苹果时,她知道这个和前一个苹果是相似的物体,因为它们具有非常相似的特征。
她知道这和橘子很不一样。但是,她仍然不知道它在人类语言中被称为什么,即“苹果”,因为没有标签的知识。
这种学习中标签不存在(在没有老师的情况下),但学习者仍然可以自己学习模式,这种学习被称为无监督学习。
在机器学习算法的背景下,当算法从没有任何相关响应的简单示例中学习并自行确定数据模式时,就会发生无监督学习。
在下一节中,我们将讨论这种类型的学习与机器学习中另一种类型的流行学习算法(即监督学习算法)有何不同。
监督与非监督学习
顾名思义,监督学习中的学习是在监督下进行的,即当算法从训练数据中预测样本值时,它会被告知该预测是否正确。
这是可能的,因为我们将正确的值存储为“标签”/“目标变量”,这些值将与输入数据一起传递给算法。常见的监督学习任务是分类和回归的任务。
在分类任务中,标签是样本所属的正确类别,而在回归中,因变量(Y)的实际值用作比较预测的基准。然后,该算法可以调整其参数,以实现更高的预测精度。
因此,监督学习的主要目标是建立一个稳健的预测模型。
另一方面,在无监督学习中,我们只传递输入数据,没有标签。无监督模型寻求发现数据中潜在的或隐藏的结构或分布,以便了解更多关于数据的信息。
换句话说,无监督学习是指我们只有输入数据,没有相应的输出变量,主要目标是从输入数据本身学习更多或发现新的见解。
无监督算法的一个常见示例是聚类算法,它根据机器检测到的模式对数据进行分组。
例如,让我们考虑这样一种情况,其中我们有一些基于两个输入特征 X1 和 X2 的数据点。
- 如果我们希望我们的算法将数据分类/归类到两个已知的类别,我们将使用监督的分类算法。
- 另一方面,如果我们希望算法告诉我们数据是如何构造的,我们将使用无监督聚类算法。

我们什么时候使用无监督算法?
无监督学习在以下条件下使用:
- 我们没有产出/目标数据。
- 我们并不确切知道我们在寻找什么,而是希望机器在数据中发现模式/见解。机器发现的见解可以用来解决各种挑战。
- 我们希望从数据中只过滤出必要的信息(与原始数据相比,它的维度更低),并使用它来训练监督学习模型。
在接下来的两节中,我们将看看两种流行的无监督算法,即聚类和维数约简,它们在这些情况下对我们有所帮助。
聚类算法
聚类的概念
聚类是无监督学习领域中最流行的任务之一。这里,基本的假设是相似的数据点倾向于属于相似的组(称为聚类),这由它们与局部质心的距离来确定。
因此,聚类使我们能够找到并分析有机形成的组,即基于数据本身,而不是在查看数据之前定义组。
有不同的聚类算法,如 K-means 聚类、层次聚类、DBSCAN、OPTICS 等。,它根据自己对数据点之间相似性的定义对数据进行分组。
在下一小节中,我们将看一个 K-means 聚类的例子,这是一种广泛使用的聚类算法。它创建了“K”个相似的数据点聚类。
k-均值聚类算法
当我们有未标记的数据(即,没有定义的类别或组的数据)时,使用 K-means 聚类。该算法在数据中查找组/聚类,组的数量由变量“k”表示(因此得名)。
该算法迭代地工作,以基于所提供特征的相似性将每个观察值分配给 k 个组中的一个。
K-means 算法的输入是数据/特征(Xis)和“K”值(要形成的聚类数)。
的步骤可以概括为:
- 该算法从随机选择“K”个数据点作为“质心”开始,其中每个质心定义一个聚类。
- 在该步骤中,每个数据点被分配给由质心定义的聚类,使得该数据点和该聚类的质心之间的距离最小。
- 在这一步中,通过取上一步中分配给该聚类的所有数据点的平均值来重新计算质心。
该算法在步骤(ii)和(iii)之间迭代,直到满足停止标准,例如达到预定义的最大迭代次数或者数据点停止改变聚类。
使用 Python 代码进行交易或投资的 K 均值聚类示例
通常,交易者和投资者希望根据某些特征的相似性对股票进行分组。
例如,希望进行配对交易策略交易的交易者,在该策略中,她同时持有两只相似股票的多头和空头头寸,理想情况下,她希望浏览所有股票,并找到在行业、部门、市值、波动性或任何其他特征方面彼此相似的股票。
现在考虑一个场景,一个交易者基于两个特征对 12 家美国公司的股票进行分组/聚类:
- 股本回报率(ROE) =净收入/股东权益总额,以及
- 股票的贝塔系数
投资者和交易者使用净资产收益率来衡量公司相对于股东权益的盈利能力。高净资产收益率当然是投资一家公司的首选。另一方面,贝塔系数代表股票相对于整个市场(由标准普尔 500 或 DJIA 等指数代表)的波动性。
手动检查每一只股票,然后进行分组是一个繁琐而耗时的过程。相反,可以使用聚类算法,如 k-means 聚类算法,根据一组给定的特征对股票进行分组/聚类。
下面我们用 Python 实现一个 K-means 算法对这些股票进行聚类。我们首先使用以下命令导入必要的库并获取所需的数据:
非系统风险:类型,计算,避免和更多!
围绕非系统风险管理有几个概念。这篇文章是你的指南,它以一种非常全面的方式解释了你需要知道的关于非系统风险的所有知识。
本文涵盖:
什么是非系统风险?
就像这个问题一样,答案也很简单,因为非系统风险与公司的内部风险因素有关。非系统风险也称为特定风险、可分散风险、特质风险或剩余风险。
非系统性风险来自企业没有准备好的任何此类事件,它会扰乱企业的正常运作。
例如,在股票价格上涨的情况下,一个公司可能产生高利润。另一方面,一些其他公司可能产生低利润,使其股票价格下跌。
什么导致了非系统风险?
导致非系统性风险的一些因素包括:
- 管理层的低效率
- 商业模式的缺陷
- 企业中的流动性紧缩
- 资本结构的变化
- 生产不需要的产品
- 劳工罢工
非系统风险本质上是可以分散的,因此是可以避免的。事实上,你可以通过购买不同地理位置的不同公司的股票来分散你的投资组合。
这样,即使你投资的一些企业因为非系统风险而面临逆境,也不是所有的企业都会。因此,一只或几只股票特有的非系统风险得以避免。
下面,你可以看到解释非系统性风险的图表。

Source: CFI
在图表中,我们在 y 轴上表示总投资组合风险,在 x 轴上表示股票数量。
从图中可以清楚地看到,如果你没有多样化的投资组合,非系统风险更大。但是,当你开始投资一只以上的股票时,你的非系统风险就会下降,接近于零。
然而,系统性风险取决于各种宏观经济因素,如加息和通货膨胀,这是不可避免的。
最近,我们可以以疫情冠状病毒的爆发为例。它影响了整个金融生态系统,金融市场遭受了巨大损失。
我们现在将讨论非系统风险的定义,以简单明了地说明这种类型的风险意味着什么。
接下来,让我们看一个例子。
非系统风险示例
让我们假设,在 2019 年 1 月 1 日,你在你的投资组合中投资了 100,000 美元,这是一个多元化的投资组合,投资情况如下:
- 思科系统- 15%
- 花旗银行- 30%
- 苹果公司- 5%
- 福特- 35%
- 亚马逊- 10%
- 伯克希尔·哈撒韦公司
现在,在 2019 年 12 月 31 日,你发现投资组合的总价值现在是 114,531 美元,因为总投资年增长率为 14.5%。
在下面你可以看到一个详细的计算方法,在你的投资组合中分解投资和回报:

当你试图找出哪些股票表现良好时,你就会知道,如果你只投资于花旗银行(Citibank)和伯克希尔哈撒韦(Berkshire Hathaway)这样的金融服务行业,回报率会低得多。
但是像思科系统、苹果和亚马逊这样的公司表现很好,因此你的 10 万美元总投资上涨了 14.5%。因此,你从投资组合多样化中受益。
非系统风险的最大好处在于它与市场风险无关,因此可以借助投资组合的多样化来消除。
通过这种方式,你减轻了像花旗银行、福特和伯克希尔·哈撒韦这样的少数公司由于内部问题而面临的非系统性风险。
接下来,我们将看看如何计算系统和非系统风险。
系统风险公式
系统风险由公司的贝塔系数表示。贝塔系数就是金融市场中股票的波动水平。
现在,你可以很容易地在雅虎财经等在线网站上找到你的股票的贝塔系数。例如,苹果公司在雅虎财经上的贝塔系数是 1.17,而微软的贝塔系数是 0.93。
由于微软的贝塔系数较小,这表明它是一只波动性较小的股票,因此可以对微软进行更多的投资,而对苹果公司进行更少的投资。
计算总体贝塔系数
我们将使用以下公式计算您的投资组合的总体 beta 或潜在风险:
总贝塔=总投资的百分比 1 x(投资 1 的贝塔)+总投资的百分比 2 x(投资 2 的贝塔)
计算每项投资的贝塔系数
在上面的公式中,你可以借助下面的公式求出每项投资的 beta,即投资 1 和投资 2:
贝塔=协方差/方差
在哪里,
- 协方差 暗示了两只股票如何一起运动的度量。当股票价格上涨或下跌时,如果股票一起运动,这就是正协方差。另一方面,如果它们彼此远离,这是一个负协方差。
- 方差 暗指股票价格在一段时间内波动性的度量。此外,这是股票相对于其均值的度量。
太好了!接下来,我们还将了解如何计算非系统风险,以便能够减轻同样的风险。
如何计算非系统风险?
计算非系统风险很简单,可以通过系统风险的减轻来衡量,这种减轻发生在你分散投资组合的时候。
如上所述,系统性风险是一种依赖于宏观经济因素的风险,而宏观经济因素是市场因素。这些因素是不可避免的,因为它们不是内在的。
我们假设投资 1 可以是苹果公司的股票,投资 2 可以是微软的股票。
假设我们在苹果公司投资 40%,在微软投资 60%。这样,我们将按如下方式计算总β值:
总β= 0.40 x(1.17)+. 60 x(0.93)= 0.468+0.558 = 1.026
从上面的计算中我们可以看出,在整个投资组合中,我们的总 beta 或潜在风险为 1.026。
让我们来看看这两种类型的风险,即系统风险和非系统风险有什么不同。
系统风险与非系统风险
系统性风险
系统风险也称为不可分散风险或因市场中的宏观经济因素而上升的市场风险。例如,这些因素可以大致分为社会、政治和经济因素。系统风险可以是公司面临的利率风险、通货膨胀风险或任何市场风险。这种风险降临到整个行业。
系统风险与非系统风险在本质上有很大不同。
非系统性风险
某些微观经济因素会影响特定企业的经营,因此,这些因素会导致企业回报的波动。由于这些风险因素是内部的,如果在组织内部采取了必要的措施,它们是可以避免的。
例如,罢工和经营管理不善是一家公司可能以非系统性风险的形式面临困境的两个原因。
非系统风险的类型有业务风险、财务风险和运营风险,我们将在下一个分主题中讨论这些风险。
非系统风险的类型
非系统风险本身是一种可由组织控制的风险。
然而,如果组织不能照顾任何部分,如管理,流动性等。,非系统风险会干扰正常运营。
主要有三种类型的非系统风险:
- 业务风险/流动性风险
- 金融风险/信用风险
- 操作风险
业务风险/流动性风险
商业风险,基本上,意味着非系统风险的类型,质疑公司是否能够赚取可观的利润。
每个企业都有一些日常开支,为了支付这些开支,至少应该有足够的收入来支付这些日常开支。例如,工资、营销成本等等。
金融风险/信用风险
一家公司的财务风险意味着使用财务杠杆或贷款,该公司可能使用这些杠杆或贷款为其业务或部分业务提供资金。财务风险是公司支付贷款利息的责任。
还可能有其他债务相关的义务,如在贷款到期日支付本金。如果公司不能产生足够的收入来支付贷款和相关费用,它就会成为金融风险的牺牲品。
一家公司背负的贷款相关债务越多,风险就越高。不履行与杠杆或贷款相关的承诺会让任何公司陷入困境,这也可能导致破产。
有一些因素会使公司容易受到财务风险的影响,例如:
- 与收入相比,市场利率的提高会突然增加支出
- 与杠杆融资相比,股权融资较少
- 关于费用和收入投机的管理问题
通常,分析师和投资者会考虑财务风险比率,即负债/权益比率。
负债/权益比率=负债总额/股东权益
债务与权益比率是确定运营融资杠杆数量(债务)的恰当方法,因为该比率有助于保持负债或债务低于权益。因此,你最终不会增加你的负债。
此外,如果您的业务扩展到国外,外币兑换风险也是金融风险的一部分。外币价值的下降可能会导致突然的损失,因为您将收到以该国货币支付的款项。
操作风险
运营风险意味着每个组织都准备承担的损失,因为它包括所有那些自然的错误。
错误可能是:
- 员工相关,如人为错误
- 涉及硬件系统(计算机、机器)等技术问题
- 与需要高级过程的任务的旧过程有关的
然而,需要建立运营风险管理,以避免损害组织的财务。应该清楚地确定一家公司准备承受的操作失误或损失的数量。此外,有些错误也是可以纠正的,但是公司也必须准备好承担纠正这些错误的费用。
因此,总运营风险是以下因素的组合:
- 公司愿意承担的损失
- 纠正某些错误的成本
导致操作风险的操作错误在确定有助于避免这种风险的程序中起着关键作用。这种程序的例子有风险管理程序、灾难恢复程序等等。此类计划有助于评估潜在的风险因素,传达这些因素,然后最终确定减轻风险的步骤。
现在,我们知道计划和有效的措施可以帮助降低运营风险。
但是商业风险和财务风险呢?
在降低业务风险和财务风险时,业务风险和财务风险都比运营风险稍微复杂一些。此外,对于经营风险,管理层准备承担。但是,商业风险和财务风险就不一样了,因为承担这些风险会给组织带来巨大的损失。
如何防范商业风险?
商业风险可以通过减少不必要的成本来减轻,例如,实体营销的营销成本(在不需要的情况下),而不是转移到在线营销。
减轻业务风险的措施 -现在让我们详细了解一下减轻每种风险的措施。
- 识别风险
- 分析每个风险的影响,并根据影响对其进行排序
- 从需要立即关注的风险开始处理风险
- 定期监控和审查已识别的风险
识别风险
这仅仅意味着识别和揭示与你的业务相关的风险。这些可以是营销、维修、欺诈等方面的过度支出。
分析每种风险的影响,并对其进行排序
在您确定了您的企业更容易遭受的风险之后,您可以找出影响的严重程度,然后根据严重程度对每个风险进行排序。
企业可以接受这样的风险,因为它们可能不会对企业造成损害。另一方面,一些足够严重的风险需要尽早解决。
例如,如果业务的一个关键部分发生故障,需要立即修复。然而,如果一个不重要的部分因为维护而停机,它可以等到重要的事情被处理好之后。
从需要立即关注的风险开始处理风险
在上面的步骤中,根据严重性对风险进行分级将有助于您尽早处理最严重的风险(对利润有相当大的影响)。一旦你处理完最严重的问题,你可以移到列表中不太严重的地方。
定期监控和审查已识别的风险
应定期跟踪和审查所有已识别和解决的风险,以防将来出现任何不便。可以为同样的事情成立一个员工团队,领导或经理可以实施所需的解决方案。
如何防范金融风险?
企业还可以通过管理财务来降低财务风险,例如,计算负债/权益比率,并明智地在负债和权益之间分配资金。
减轻财务风险的措施 -财务风险可以通过以下一些简单的步骤来避免。
- 从收入中节省足够的钱
- 为企业投保
- 建立收益最大化的业务结构
- 涉及股东
从收入中节省足够的钱
弄清楚你的企业是否可以在没有你正在承担的某些费用的情况下生存下去。例如,你发现外包一些临时工作(如研究统计数据)比雇佣全职员工更好。
为企业投保
你的企业应该为某些不可预见的事件投保,如网络攻击、自然灾害等。这种保险可以帮助你节省大量的收入,并作为一种保障。
建立收益最大化的业务结构
有了正确的业务结构,你将只在正确的地方消费。例如,你必须在培养人才上花些钱,这能让你的员工坚持在公司工作。
从长远来看,一批优秀的员工可以帮助你,但如果你不需要全职员工,那么在他们身上的支出会以额外支出的名义增加你的财务风险。
根据度量标准做出决策
除非你能衡量其后果,否则你不能做任何决定。例如,在举办活动之前,你知道你想从中获得什么,这可以通过营销你的公司获得更多的客户,更好的认可等等。
同样,在采取任何关键步骤之前,如雇佣员工、签署协议等。你必须确保它给你带来长期的利益。
结论
通过计算非系统风险,可以了解金融市场中股票的波动水平。任何企业都可以通过采取必要的措施来降低任何类型的风险。
这篇博客已经深入讨论了非系统风险的所有要点。如果你想了解它,请随时查看关于量化投资组合管理课程的免费预览,在其中你将学习不同的投资组合管理技术,如因素投资、风险平价和凯利投资组合,以及现代投资组合理论。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
升级以在 Quant 领域保持领先

什么让你与众不同?T3】
为什么要有人雇佣你?T3】
你可能拥有的哪些技能会让任何组织受益?T3】
如果你不能回答这些问题,尤其是那些关于你职业生涯的问题,你会很沮丧。当你想成为一名量化分析师,一名算法交易员时,更是如此。然而,当一个人准备好并能回答这些问题时,情况就完全不同了。
但是如果你在市场上有多年的实际经验呢?你知道你可以利用这些知识成为专业的算法交易者吗?好吧,那你就在正确的轨道上。
Karthick Jonagadla 的情况就是如此。
Karthick 是一个定量研究分析师,但在内心深处,他总是渴望成长,学习,并在算法交易领域保持领先。他有需求,有目标,这时他找到了一个能满足他所有愿望的项目。我们来看看他的旅程是如何形成的。
告诉我们你自己的情况
我的职业是定量研究分析师,在股票和衍生品资本市场有 5 年的经验。我是一名 MBA 和工程学毕业生,过去 5 年在孟买工作。
我想跟上量化金融的最新趋势。因此,我选择做 EPAT 计划。当我在寻找能够满足我需求的程序时,我遇到了 Quantinsti。因为它是一个虚拟程序,考虑到我的工作量,它运行得很好。大多数课程都是在周末进行的,这意味着我目前的工作时间表没有受到影响。
你和 EPAT 一起旅行时最珍贵的记忆或经历是什么?
我喜欢厄尼·陈的讲座。太棒了。我和 EPAT 的旅程很愉快。我远程参加了。我喜欢这个入口。它设计得很好,有每堂课的录音和笔记。这有助于我参考。
课程结束后,你的职业发展如何?
我认为,量化金融是一个秘密领域,人们不会分享想法。但是,通过 EPAT 项目,我学到了一些好的概念和策略。
你有什么想对有抱负的以巴提人说的话吗?
EPAT 是数量金融学的基础课程。任何对这个领域感兴趣的人都可以通过学习这门课程来加强他们的领域知识。学生有责任在课程之外进一步探索,积累知识。
下一步
你想开始自己的交易,提高你现有的技能,并通过算法交易 (EPAT)的管理课程学习算法交易的各个方面吗?EPAT 让你具备成为成功交易者所需的技能。它涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。现在报名开始你的算法交易生涯。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,本案例研究是根据 quantin STI EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的结果对所有人来说可能并不一致。
量化时代的技能提升
查理·卓别林的巨著《现代生活》完美地展示了工业化是如何改变世界的,以及一个普通理发师是如何陷入其中的。尽管卓别林就是卓别林,但当他的角色努力学习这个行业的方式并适应生存时,滑稽随之而来。这部作品今天被认为是杰作。然而,它的叙述完美地总结了几代人的工作演变。
商业崛起,全球经济增长。随着技术的发展,各行各业也需要适应。算法交易占全球交易量的 70%,展示了其光明的前景。它已经成为一个控制全球经济、大公司、多种业务、无数交易交易所和个人交易者如何在市场上交易的领域。像 Python 编程、金融计算、统计分析、定量能力等技能一直是 it 行业的需求。个人正在迅速学习这些技能。企业也没有落在后面。
更多内容: 一个 Quant 挣多少工资?
提高技能越来越重要
为了关注经济增长,任何国家都必须关注劳动力,帮助他们培养自己的天赋和创新能力。全球的公司和政府都注意到了这一点。考虑到这一点,许多国家制定了各种教育计划来鼓励大众学习。
据海市蜃楼新闻报道,2018-19 年,国际教育出口对澳大利亚经济的价值为 377 亿美元。
澳洲全球人才计划,是一项建立在全球人才雇主赞助计划(GTES)基础上的计划,将招募 5000 名移民,包括院士、高技能研究人员,并提供高薪工作。在众多排名和指数中,新加坡学生在数学、阅读和科学测试中成绩最佳。
技能未来信贷是政府的一项计划。指新加坡,个人通过学习和获得技能获得学分。这些积分可以进一步兑换成任何培训计划。政府。为每个新加坡人提供最高 500 美元的信贷限额。
IBF 认证是新加坡金融专业人士的行业认可质量标志。成功完成合格的IBF-标准培训计划(“IBF-STS”)认证培训和评估计划并满足相关标准的个人可申请 IBF 认证。更多关于 IBF 认证的信息可以在这里找到。
根据调查雇主的Hays Asia Salary Guide 2019,

这些数字不仅限于新加坡。同样的因素在全球许多国家普遍存在。世界各地的专业人士都想提高技能,在工作中帮助他们……但培训就是不存在。
关于 STS 计划& IBF Singapore
IBF-STS 为直接培训费用提供高达 70%的资助,每个项目每位候选人的最高资助额为 7,000 新元,前提是符合所有资格标准。这适用于居住在新加坡的新加坡公民或新加坡永久居民。了解更多关于 www.ibf.org.sg 的信息。
关于 CPD 英国
CPD 代表持续专业发展 (CPD),是用于描述专业人士为发展和提高自身能力而参与的学习活动的术语。
EPAT 获得 CPD(英国)认证,这是一家跨行业运营的领先机构,旨在补充专业机构和学术团体的持续专业发展政策。
经认证的持续专业发展培训是指学习活动已达到所需的持续专业发展标准和基准。学习价值已经过审查,以确保完整性和质量。
CPD 认证培训课程、研讨会和活动允许专业人员利用学习时间达到个人 CPD 要求。
在 QuantInsti,我们在做什么?
在 QuantInsti ,我们专注于通过算法交易 (EPAT )的执行计划、各种拓展计划、我们的自学门户 Quantra 、大学拓展计划,以及通过各种事件和活动(如举办会议、举办免费网络研讨会和会议)为金融行业做贡献。我们的课程已经使来自 160 多个国家的注册用户受益。QuantInsti 的旗舰项目 EPAT 也得到全球企业和机构的认可。根据新加坡银行金融协会(IBF)的标准,EPAT 获得了 IBF 的认证。这适用于新加坡公民或新加坡永久居民,实际上是在新加坡,也认可了英国的 CPD。
为什么是 EPAT?

In addition to the above point, EPAT also offers:
- 通过 Prometric 全球考试中心监考的中心内考试,EPATians 拥有实际经验、专家教师(如 Ernest P. Chan 博士、Euan Sinclair 博士)、专门的支持经理、每周 7 天支持、CPD 认证,以及世界上第一个“量化和算法交易领域认证”,为 EPATians 提供了增强其各自领域增长可能性的优势。
- 人脉:我们强大的校友&注册用户网络遍布 160 多个国家,为您提供与他们互动和联系的完美平台。社区互动和聚会提供了面对面交流的机会。
- 职业服务:我们的职业管理&职业发展资源专门为寻求新机会的学生和职场人士提供支持,并帮助他们创办企业。一旦你加入该计划,你就可以利用我们的就业服务,你将有资格获得终身职业援助。
EPAT 提供交互式在线学习,24 小时访问所有录制的讲座和课程材料,可通过您的笔记本电脑、平板电脑和手机访问。课程是实时的,录音会上传到我们的门户网站上,参与者会获得一个个人帐户,允许他们全天候访问实时讲座、练习、示例代码和电子表格。
除了访问专门设计的学习管理系统,我们还提供开源工具和软件,并为 EPATians 提供一系列服务的独家折扣。
接下来是什么?
我们需要生活在未来。随着对技能和有技能的个人的需求上升,一个人在考虑未来的同时磨砺自己的技能是很自然的。像 STS 计划这样的学习计划是其他国家效仿的典范。通过我们的各种举措,我们已经并正在为算法交易和量化交易做出贡献。希望你能从这场世界范围内的大规模技术运动中受益。
所以,今年的单词是:技能提升
你知道你的国家正在提供什么机构或支持吗?请评论并与我们的读者分享。
如果您有任何疑问或需要更多信息,或者需要任何关于 QuantInsti 和 STS 的信息,您也可以联系我们。
快乐学习!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T19】
从美国到阿联酋,从会计到投资组合管理——史蒂文的旅程
今天,我们向您讲述来自美国的 EPATian Steven Downey 的故事,他住在 T2 的阿联酋,在 T4 从事金融和投资已经超过十年。
Steven 热衷于投资,渴望达到最高的道德和财务水平。特许金融分析师( CFA )特许持有人和特许市场技术员( CMT )持有人,是自学量化分析师。他还在攻读伦敦商学院的工商管理硕士学位。
我们通过电话采访了史蒂文,了解他的旅程和成长,以及他是如何在如此短的职业生涯中取得如此大的成就的。电话是这样的。
嗨,史蒂文,给我们介绍一下你自己吧!

嗨!我是史蒂文·唐尼。我在阿联酋呆了 7 年,我来自美国。我有三个小孩,一个 5 岁,一对 2 岁的双胞胎。我经常和他们一起玩。我有一个伟大的妻子,作为一名家长,她在职业、智力和道德上挑战我。
我喜欢学习不同的观点,甚至是矛盾的观点——不是关于投资,也是关于生活。我阅读不同的哲学,从孙子的《孙子兵法》或孔子到《拿撒勒的耶稣》以及现代怀疑论,此外还有经济学、小说和非小说类的东西。
从小就想从事投资行业。我关心看到财富增长的想法,我对复利的概念很着迷。我想帮助人们管理金钱,做出合理的财务选择。
你已经完成了 CFA、CMT、MBA 课程,并成为一名投资组合经理。你是怎么进入算法交易的?
进入大学后,我意识到我想成为一名投资组合经理或投资分析师。毕业后我开始了 CFA 和后来的 CMT 项目。我在一家名为查尔斯·施瓦布的美国公司的账户和证券交易部门工作。后来我去了阿联酋,在公司财务部、工作,最终回到资产管理部。
四五年前,我开始跟踪投资者,比如科里·霍夫斯坦(新发现研究公司的首席执行官)和 T2·马科斯·洛佩兹·德·普拉多(T3),从他们的经历中学到了很多。
我见过很多次,在投资中,人们会相信一个想法,只是因为他们从某人那里听到了一些原则。通常没有数据支持。我和我的朋友谈论黄金作为通货膨胀的对冲,他说,“也许它有效,但我从未见过数据来支持它。”
这次谈话让我开始挑战自己的想法,并开始查看数据。我想亲自测试一个想法,看看投资策略是否有效,投资关系是否有统计学意义。
我询问了一些量化分析师和业内的朋友。我根据他们的建议开始学习 R,但是我意识到 Python 是金融的首要语言。
我想从不同的角度理解投资和交易,从基本面到技术再到量化交易。作为一名投资者,如果有一种技能或工具可以帮助我,我想得到它。我在互联网上寻找一种经济高效的学习 Python 的方法,就在那时我发现了 QuantInsti。
考虑到内容、价值和成本,我认为 EPAT 是个不错的选择。我需要正式的培训,因为我觉得如果我自己学习的话,我无法到达我想要的地方。我最初是自己开始学习 Python 的,用 EPAT 来规范和组织我的学习。
目前,我在马达资本公司担任投资组合经理。我们是一家年轻的公司,管理着大约 1.4 亿美元的资产,我们正努力在明年将其增长到 5 亿美元。我们的客户来自阿拉伯湾和埃及,我负责构建多资产投资组合。
我还在攻读伦敦商学院的高级工商管理硕士学位。
我想在智力上不断成长,达到自己的极限,知道是我逼自己的,而不是以后有遗憾。
EPAT 给你的职业生涯带来了什么变化?
我喜欢算法交易的一点是,它让我能够系统地测试一个想法,并验证它的功效。例如,当我做我的 EPAT 项目时,我很好奇我们是否可以使用 ML 和基本面数据来建立一个产生 alpha 的价值投资组合。
我喜欢构建一些东西并立即进行测试的想法。
我觉得 EPAT 值得我花费时间和金钱,我是一个满意的顾客。当我八月份面试我现在的职位时,我现在的老板注意到的一件事是我的研究出版物——基本上是我的 EPAT 项目。
我改进了一下,得到了一些外界的反馈。我尊敬的一个组织决定在他们的网站上发布我的作品。我也在 Medium 上写了一些博客类型的帖子,获得了很多关注。我把这些放在我的简历上,这增加了我的职业机会。
我们还对黄金和不同的公司进行了自主研究,并利用系统的思维过程和 python 代码来测试石油和埃克森美孚之间的关系,或者例如将黄金作为一种资产类别的趋势跟踪策略。
通常,一家投资银行或一家研究公司可能会使用图表叠加来寻找相关性,但我们更进一步来寻找统计意义,并实际找出在交易成本等因素后是否可以赚钱。
最近市场上对通货膨胀有很多担忧。我很好奇是否可以使用梯度推进或随机森林 python 库生成一个通胀预测模型。
我并不认为我的任意通胀预测优于市场,但也许我可以利用从 QuantInsti 学到的编程技巧,建立一个 90%置信区间的通胀模型。这些是我为工作而做的事情。
EPAT 有什么你真正看重的特色吗?
真正有帮助的一个特点是 EPAT 大学的教学大纲。
它的结构是从在 excel 中构建系统策略并将其移植到 python 中发展而来的。首先,在 excel 上构建一个策略,理解其中的机制、胜率和止损,并将其转化为 Python 代码。
对我来说,最重要的事情之一是学习如何建立系统的策略。
还有许多其他特点,但 QuantInsti 设法教授系统战略构建的方式非常有帮助。我费了很大的劲才弄明白这一点,因为没有很多免费的资源可以提供代码并一步一步地指导我完成这个过程。在那之后,我了解到我可以采取一个想法,比如如何在随机的标准普尔&股票上建立突破模型,并在大型数据集上运行这个程序。这非常令人满意。
EPAT 的课程帮助我了解了不同类型的波动策略和短期均值回归策略。我个人还没有制定任何内部策略来执行这一点。不过,这有助于我了解应该把资金分配给什么样的基金经理,并意识到我应该参与竞争的领域。
现在,我工作的公司没有能力实现任何系统性波动或均值回归算法交易,但我们将来可能会。
一天结束时,如果你在 55-60 岁的年龄组,并且你已经选择了传统的金融路线,你可以完成你的 CFA 和 CMT,不用担心其他任何事情。
但是当你在我的职业生涯中期的时候,花 6 到 12 个月学习编程技能将会在我的职业生涯中帮助我。
所有从大学毕业的年轻人都开始学习 Python,然后去对冲基金工作。我要么适应,要么变成恐龙。
现在,你需要不断提高技能,发展更平衡的技能组合。如果你真的擅长自主基本面分析,这很好,但如果你看看回报率排名靠前的公司,你会看到像文艺复兴科技这样的大型量化公司。
如果你有一个考过 CFA 的人可以做基本面分析,而他旁边的人也可以做同样的事情,而且他们会编码和编程,谁更有价值?
是技能多的人。
我的看法是,你花一点时间和金钱在自己身上投资,这将为你的职业生涯带来回报。
- 如果你真的雄心勃勃,去读计算金融硕士吧。
- 如果你有工程学位,去读计算金融硕士
- 还有传统的金融人士。
但是,很少有人能两者兼得。
我希望能够在 excel 中或手工对一家公司进行基本面估值,并能够形成系统的战略。我想知道如何做到这两点,因为当我管理一个团队时,我希望能够说两种语言。
你对有抱负的量化分析师有什么话要说?
有些人的动机是职业和适者生存的心态,但对我来说,一个额外的动机是好奇和渴望了解更多。
对我来说,如果我学会一项技能,我会更强大。我能理解更多,做更多的事情。我没有这样做,主要是因为我想在 5 年或 10 年后有一份工作。
我学过 CFA 和 CMT,但有一个投资领域叫做量化投资,我不太了解。我想学习,因为我认为我在这个领域有价值。好奇是必不可少的。
有很多人做了 EPAT,但在他们的职业生涯中从未使用过 Python,但是如果你很好奇,你可以说,“我想以一种新的方式应用这个概念。
这是一种永远不想停留在原地,而是不断发展和成长的想法。
我的职业生涯中有很多低谷,当我在 QuantInsti 和 Algo Trading 进入 EPAT 时,我的部分想法是:
我不能控制环境和发生在我身上的事情,但是我可以控制我做什么,我学什么,我获得什么技能。
我总是想,“作为一名工人,我怎样才能掌握更多技能,变得更有价值、更有效率?“我是从角色扮演游戏的角度来看待技能的;当一个玩家得到一把新的剑或一把新的枪,他们会变得更强大,达到更高的水平。
你把更多的技能添加到你的工具库中,总有一天你会探索 10-20 个策略,坚持严格的科学和系统的方法,你没有找到任何有用的东西,但你会继续前进。很大一部分是毅力。
我认为这是双重的:你必须学会坚持下去,即使在令人沮丧的时候也不要放弃,或者你觉得你的事业不行了,或者你陷入了困境。
但是,与此同时,你必须继续前进,学习和提高技能。你必须在自己的技能中加入令你满意的技能,不管这些技能是否有助于你的职业生涯,但也要在简历上看起来不错,为你打开大门。保持好奇心的毅力和动力至关重要。
持续的学习和技能提升是你学习的优势,帮助你在职业上进步,同时为未来做好准备。你的学习经历和对职业的态度很有感染力,史蒂文。我们确信我们的许多读者会从你的经历中学到很多东西。谢谢你的时间。
算法交易(EPAT)高管课程(T1)是一门综合课程,涵盖的主题从统计学(T4)、计量经济学到金融计算技术(T5),还包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。点击这里查看。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
如何使用 R 检查数据质量

您使用干净的数据吗?
永远追求干净的数据!为什么有经验的交易者/作者经常在他们的交易文章/书中强调这一点?作为一名交易新手,你可能会使用来自谷歌或雅虎财经的免费数据。这些来源提供准确、高质量的数据吗?
我们决定做一个快速检查,并对在印度国家证券交易所上市的 143 只股票进行了抽样调查。对于这些股票,我们下载了 2016 年 1 月 8 日至 2016 年 8 月 19 日期间的 1 分钟盘中数据。目的是检查谷歌金融是否捕捉到了 143 只股票在此期间的每一根 1 分钟棒线。
NSE 的交易时段从 IST 时间上午 9:15 开始,到下午 15:30 结束,总共 375 分钟。对于 14 个交易时段,我们应该有每只股票的 5250 个数据点。我们用 R 编写了一个简单的代码来执行检查。
这是我们的发现。在扫描的 143 只股票中,89 只股票的数据点少于 5250 点,这超过了我们样本集的 60%!!下表列出了这 89 只股票中的 10 只。

让我们以 PAGEIND 为例。谷歌金融只捕捉到了这只股票的 4348 个 1 分钟数据点,因此错过了 902 个点!!
示例-缺少 20160801 上的 1306 分钟条形图:

示例-缺少 20160802 上的 1032 分钟条形图:

如果一个交易者运行一个日内策略,根据 1 分钟棒线产生买入/卖出信号,这个策略必然会给出一些错误的信号。
从上面的快速检查可以看出,来自免费来源或廉价数据供应商的数据质量并不总是有保证的。许多廉价的数据供应商从雅虎财经获得数据,并提供给他们的客户。糟糕的数据反馈是许多交易者面临的一个大问题,你会发现许多交易者在各种交易论坛上抱怨同样的问题。
回测 excel 使用此类数据的交易策略会给出错误的结果。如果你在实时交易中使用这些数据,万一谷歌或雅虎财经的服务器出现问题,就会导致数据传输延迟。作为一个交易者,你不想处于一个你有未平仓交易的位置,数据输入停止或延迟。当用真钱交易时,总是建议使用可靠的数据供应商提供的高质量数据。毕竟数据就是一切!
下一步
如果你是一个对学习算法交易的各个方面感兴趣的散户交易者,可以看看算法交易(EPAT) 的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。这门课程让你具备成为成功交易者所需的技能。
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
下载数据文件
- 你用干净的 Data.rar 吗
- 15 天内历史数据. zip
- F&O 股票列表. csv
- r 码- Google_Data_Quality_Check.txt
- r 码-股价数据. txt
在机器学习中使用决策树来预测股票走势
原文:https://blog.quantinsti.com/use-decision-trees-machine-learning-predict-stock-movements/
用于交易的机器学习是今天的新流行语,一些科技公司正在用它做一些不可思议的事情。今天,我们将向您展示如何借助“决策树”来预测股票走势(上涨或下跌),决策树是最常用的 ML 算法之一。
 T8】
T8】
机器学习中的决策树用于建立分类和回归模型,用于数据挖掘和交易。决策树算法在到达最终结果之前执行一组递归操作,当您在屏幕上绘制这些操作时,视觉效果看起来像一棵大树,因此得名“决策树”。
这里有一个机器学习中简单决策树的例子。 
基本上,决策树是帮助你做决定的流程图。机器学习使用相同的技术来做出更好的决策,让我们来看看如何实现。
可视化样本数据集和决策树结构
现在让我们进入正题,我们想使用机器学习中的决策树来预测你的股票将走向何方。为此我们需要股票过去的数据。考虑一个样本股票数据集,如下表所示。数据集包括开盘价、盘高、盘低、收盘价和成交量指标(OHLCV)。你可以使用雅虎财经或谷歌财经下载任何股票的历史数据。
我们将用 R 编程语言做这个练习,你必须在你的 mac/pc 上安装支持软件。这里有一个 链接 帮你搞定。下面是将这些数据导入到的代码(包含代码的数据文件将在博客的结尾提供)- 
这是数据的可视化表示。

让我们给这个数据集添加一些技术指标(RSI,SMA,LMA,ADX)。在我们的例子中,技术指标是使用基本股票价值(OHLC)计算的,它们帮助我们预测股票走势。我们的机器学习算法将利用技术指标的值来做出更准确的股价预测。我们滞后于技术指标值,以避免前瞻偏差。
我们还添加了“Class”列,它表示基于股票收盘价的每日收益。在“类别”栏中,“向上”表示正回报,而“向下”表示负回报。这是相同的代码


现在有趣的部分来了,我们想用这些技术指标来预测每日的变化(涨/跌)。我们将通过在这个数据集上应用机器学习决策树算法来做到这一点。首先,我们必须将数据集分成两部分;训练数据集和测试数据集。该算法使用训练数据来了解股票的走势,并做出某些假设,这也称为“信息增益”。训练完成后,我们将其应用于测试数据集,以进行股票价格预测。这种类型的机器学习被称为监督学习。下面是应用这些步骤的代码

训练数据集的结果输出可以以树形结构的形式查看,如下所示。

决策树示例图
在了解机器学习的决策树算法是如何工作的之前,我们先来了解一下树的结构。
决策树的组成部分
决策树结构由根节点、测试节点和决策节点(叶子)组成。根节点是决策树中的主节点。在上面的决策树中,我们从 RSI>50 开始,因此 RSI 指标被用作根节点。你可能会问为什么 RSI 指标的值在 50,为什么不说 34?这就是训练发挥作用的地方,机器学习决策树算法能够理解 50 的 RSI 比任何其他值都有助于做出更准确的决策。
在根节点之后,每个测试节点根据一些设定的标准将数据分割成更多的部分。在上面的决策树中,我们有 SMA> 80,LMA>55,ADX>25(这些值也是训练的结果)。基于这些充当测试节点的指示器,数据被进一步分割。
最后一个节点是叶节点。在决策树图中,包含 Up/Down 类以及指示目标属性概率的概率值的节点是叶节点。任何节点的左侧都被认为是“是”,意味着在该节点询问的问题(例如 RSI >50,如果回答是,则算法导航到树的左侧,如果不是,则导航到右侧)
因此,根据设定的标准,通过从决策树的根节点向下导航到叶子,整个数据集得到分类。

决策树的组成部分
例如,这支股票在某一天的 RSI 为 39,所以到树的右边检查 SMA 是否大于 80,如果是,那么到叶子上,它说,“这只股票有 0.52 的下跌概率”。
决策树算法是如何工作的?
现在我们已经理解了决策树的结构,让我们来理解决策树是如何构造的。
决策树诱导器
决策树由决策树诱导器(也称为分类器)构成。有各种决策树诱导器,如 ID3、C4.5、CART、CHAID、QUEST、CRUISE 等。等等。(你可以找到关于这些诱导器的更多信息这里和这里)决策树诱导器基本上是一种算法,它从给定的(训练)数据集自动构建决策树。典型地,决策树诱导器的目标是基于指定的目标函数构建最优决策树。目标函数的一个例子可以是最小化决策树的节点数量,以便降低复杂性。另一个例子可以是最小化泛化误差(或者获得更精确的结果)。
虽然我们说了诱导器自动构造决策树,但实际上决策树诱导器遵循一定的方法。决策树归纳器通常使用两种流行的方法。其中包括广泛使用的自顶向下方法和不太流行的自底向上方法。
自上而下方法解释
在自顶向下的方法中,诱导器以自顶向下、递归的方式创建决策树。让我们使用之前创建的技术指标来理解这种自上而下的递归方法。
我们创建的技术指标是 RSI、SMA、LMA 和 ADX 指标。我们的决策树算法将这些指标视为属性。
从这些指标(属性)中,诱导者会使用哪个指标(属性)作为根节点开始?剩下的属性将如何拆分?
所有这些都由使用离散分裂函数的诱导器决定。离散分裂函数使用某些标准(例如,信息增益、基尼指数)来确定开始时的最佳属性,并分裂训练数据集。这里有一些链接可以了解更多关于信息增益、基尼指数的信息。
在每次迭代中,诱导算法使用输入属性的离散函数的结果来划分训练数据集。在选择了适当的分裂之后,每个节点进一步将训练集细分成更小的子集,直到不可能进一步分裂或者当满足停止标准时。在完成树的创建之后,使用特定的修剪规则对其进行修剪,以减少分类错误。
这就是决策树是如何构建的,它可以用于在机器学习中进行股票价格预测。在我们未来的帖子中,我们将演示如何用 python 构建决策树,还将探索一些基于决策树的机器学习模型。
下一步
报名参加我们在 Quantra 上的最新课程“交易中的决策树”。本课程由 Ernest P. Chan 博士撰写,揭示了分类树中的黑盒,帮助您创建交易策略,并教会您理解模型的局限性。本课程由 7 个部分组成,从基础到高级。
阅读我们的下一篇文章“Python 中的机器学习分类策略”,这是一个使用支持向量分类器(SVC)在 S & P 500 上逐步实现机器学习分类算法的指南。分类算法基于训练数据建立模型,然后将测试数据分类到其中一个类别中。
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
下载数据文件
- 决策树 R 代码第一部分。稀有
- 决策树 R 代码第二部分。稀有
使用 R: Ibrokers 交易 API 的交互式代理
原文:https://blog.quantinsti.com/using-ibrokers-package-implement-r-interactive-brokers-api/

Interactive Brokers(IB)是一家领先的美国电子经纪公司。Interactive Brokers 提供不同编程语言的 API 解决方案,如 Java。NET (C#)、C++、ActiveX 或 DDE 来构建自己的交易应用程序。除了这些编程语言,交易者还可以用 R 或 Python 在交互式代理上交易。
在我们之前的文章中,我们介绍了刘辉博士写的 IBridgePy。 IBridgePy 是一个交互式经纪人 C++ API 的包装器,允许人们使用 Python 进行交互式经纪人(IB)交易。这篇文章涵盖了网上研讨会“使用 Python 与交互式经纪人进行交易”的关键主题,该研讨会由刘辉博士主持,QuantInsti 主办。你可以点击这里观看刘辉博士网络研讨会的录像。
另一种被算法开发人员广泛用于数据分析、编码策略和回溯测试的流行编程语言是 R 编程。Interactive Brokers 与 QuantInsti TM 合作主办了一场网络研讨会,“在 Interactive Brokers 上使用 R 进行交易”,该研讨会于 2017 年 3 月 2 日美国东部时间上午 10:00 举行。网上研讨会由 QuantInsti 总监 Anil Yadav 主持。Anil 还是 iRageCapital 的算法策略顾问,irage capital 是印度领先的 HFT 公司之一,他管理着一个使用 R 的交互式经纪人的股票期货投资组合。网上研讨会受到了观众的好评,它涵盖了所有相关主题,让您可以在实时市场上使用 R!您可以点击下面的下载按钮,获取网上研讨会中使用的相关 R 文件。
网上研讨会涵盖了以下主题:
- 安装 R-studio IDE
- I brokers 包的参考表
- TWS 构型
- 理解结构-回调、eWrapper、ProcessMessage
- 在 R 中查看帐户信息详细信息
- 下载 R 中的历史数据
- 在 R 控制台上打印实时数据
- 使用 R 脚本发送预定义订单
- 使用 R 脚本发送基于事件的订单
网上研讨会包括策略示例,还提到了开发人员在与 r。
这篇文章为所有的 R 程序员/爱好者、交互式经纪人的客户和想要成为交易者的人简要介绍了 IBrokers 包。
关于互动经纪人的 API
在我们介绍 IBrokers 包之前,先简要介绍一下交互式代理(IB)为程序化交易提供的应用程序编程接口(API)。IB 是一家国际经纪公司,专门从事从股票到债券、期权到期货、外汇等产品的电子执行,所有这些都来自一个帐户。交易员工作站(TWS)是交互式经纪人广泛使用的桌面交易平台。Interactive Brokers 提供了几种 API 编程语言(Java、.Net,C++,ActiveX,DDE。)可用于链接到您的系统,并在您的 IB 帐户上进行交易。API 允许您通过 TWS 或 IB 网关进行连接。
- 通过 TWS 连接要求您运行应用程序,但也允许您测试和确认您的 API 订单是否正常工作。
- 通过 IB 网关连接允许您在没有运行大型图形用户界面(GUI)应用程序的情况下使用 API,但是不提供用于测试和确认 API 活动的界面。
API 的一些主要用途包括:
- 从 TWS 检索实时数据
- 以编程方式执行订单(查看、修改和提交要执行的订单)
- 访问帐户信息、连接状态。
- 从 TWS 获得合同细节和新闻公告。
探索 IBrokers 包
Jeffery Ryan 编写的 IBrokers 包是 TWS API 的纯 R 实现,它让您可以与 R 进行交互式代理交易。在本文中,我们将介绍该包中的一些重要函数。
要安装 IBrokers 包,请遵循 R 中的标准安装函数,即 install.packages()。
install.packages("IBrokers ")
【IBrokers 包中的一些重要函数:
tws 连接功能
此功能用于建立、检查或终止与 TWS 的连接。该函数返回一个 twsConnection 对象,供后续 TWS API 调用使用。
举例:
# To establish a connection to TWS
tws = twsConnect()
# To check the connection to TWS
isConnected(tws)
# To disconnect
twsDisconnect(tws)
twsConnectionTime 函数
此功能提供了连接到 TWS 的时间。
举例:
library(IBrokers)
tws = twsConnect()
twsConnectionTime(tws)
[1] “20170227 10:10:38 IST”
reqAccountUpdates 函数
此功能用于从交互式经纪人处请求和查看账户详情。
举例:
library(IBrokers)
tws = twsConnect()
accountInfo = reqAccountUpdates(tws)
head(accountInfo)
# [[1]]
# value currency
# AccountCode DU15157
# AccountOrGroup DU15157 USD
# AccountReady true
# AccountType UNIVERSAL
# AccruedCash 0 USD
tws 收缩功能
此函数创建、测试或强制在 API 调用中使用的 twsContract。该函数返回的值是 twsContract 对象。
举例:
contract = twsContract(0,"AAPL","STK","SMART","ISLAND", "","0.0","USD","","","",NULL,NULL,"0")

类似地,有一个 twsCurrency 函数,它是 twsContract 的包装器,使“货币/外汇”合约更容易指定。
reqMktData 函数
这个函数允许在 r 中处理流式市场数据。
举例:
library(IBrokers)
tws = twsConnect()
symbol = twsSTK("AAPL")
reqMktData(tws,symbol)

请求历史数据功能
该函数用于从 TWS 请求历史数据。
举例:
library(IBrokers)
tws = twsConnect(port=7497)
symbol = twsSTK("AAPL")
data_AAPL = reqHistoricalData(tws, symbol)
print (data_AAPL)

下单功能
此功能用于向 TWS 下订单或取消订单。
举例:
library(IBrokers)
tws = twsConnect()
id = as.numeric(reqIds(tws))
myorder = twsOrder(id, orderType="STP LMT", lmtPrice="108.01",
auxPrice="108.10",action="SELL",totalQuantity="10"
transmit=FALSE)
placeOrder(tws, twsSTK("AAPL"), myorder))

这些是 IBrokers 包的一些关键功能。可以使用 R 中的其他统计包制定策略,然后使用 IBrokers 包中的函数通过 R 检索市场数据、查看账户信息和执行/修改订单。
免责声明: 互动经纪公司或其任何关联公司不以任何方式附属、认可或批准本软件。它没有任何保证,除非用户能够阅读并理解源代码,否则不应该在实际交易中使用。IBrokers 是 TWS API 的纯 R 实现。
下一步
接下来是一个项目工作,解释配对交易策略和使用 Quantstrat 库的回溯测试。这个项目是由一名学生提交的,作为 QuantInsti 的算法交易培训计划(算法交易中的执行计划)的一部分。
下载数据文件
- 网络研讨会文件
在交易中使用 Python Lambda 函数
原文:https://blog.quantinsti.com/using-python-lambda-function-in-trading/
如果你是一个使用 Python 为交易头寸编码的交易者,lambda 是你想要探索的函数。Lambda 帮助你只使用一次函数,因此避免了函数定义使代码混乱。
简而言之,Python 的 lambda 关键字允许您在一行代码中定义一个函数,并立即使用它。
让我们通过这篇博客进一步了解有趣的 lambda 函数,它涵盖了:
- Python 中的 lambda 函数是什么?
- 为什么叫 lambda 函数?
- λ参数和语法
- 常规功能和λ功能的区别
- 什么时候使用 lambda 函数?
- lambda 函数是如何工作的?
- Python lambda 在交易
- λ函数在交易中的好处
Python 中的 lambda 函数是什么?
首先进入我们的主题,让我们讨论一下简短的匿名 lambda 函数。
lambda 函数也称为匿名函数或内联函数,是计算表达式的一行 Python 代码。此外,lambda 函数可以接受任意数量的参数,并且总是返回值。
为什么叫 lambda 函数?
在 Python 中,lambda 是一个匿名函数,因此没有名字。在 Python 中,普通函数是使用“def”关键字定义的,而匿名函数是使用“lambda”关键字定义的。
Lambda 参数和语法
让我们看看下面的 lambda 语法。
舔着 num: num * num * num
当插入实数值时,上述语法返回给定数字的立方。lambda 函数没有名字,这就是为什么你可能会看到它被称为匿名函数。
常规功能和 lambda 功能之间的差异
Lambda 用于构造 python 函数;它是一个内联函数,不像传统的 def 函数允许分块构造。让我们比较一下传统函数构造的语法和 lambda 函数的语法,以便弄清楚。

Conventional function vs lambda function
在传统的 def 函数中可以有任意数量的语句,它从给函数命名开始。另一方面,lambda 是一个匿名函数。您不需要为 lambda 构造提供任何名称。
让我们举一些简单的例子来说明它们的用法。

Conventional vs lambda function
lambda 构造更多地是为了方便使用,而不是使用 lambda 可以执行的操作范围。当您需要构造 lambda 函数时,请记住以下几点。
- Lambda 是一个表达式,而不是一个语句。它不支持表达式块。
- Lambda 是在我们需要使用它的地方定义的,不需要命名
- Lambda 不需要 return 语句。它总是在求值之后返回一些东西。
什么时候使用 lambda 函数?
嗯,使用 lambda 函数的最大好处是,它可以用来代替任何计算单个表达式并返回值的常规函数。
但是,如果你想让你的函数改变一个全局变量,从一个文件中读取,或者计算一个以上的表达式,它就不能作为一个 lambda 函数。然而,在 Python 编程中,lambda 函数在大多数情况下都很简单。
lambda 函数是如何工作的?
使用带有映射、过滤和减少功能的 Lambda
地图功能
Lambda 函数通常与 map()、filter()和 reduce()等函数一起使用。让我们举例说明它们的用法。
map 函数用于将函数传递给 iterable 对象中的每一项。map 函数返回包含所有结果的列表,而不修改原始对象。
示例:
score = [
(10, 5),
(20, 2),
(30, 4),
(40, 7)
]
result = map(lambda x: x[0] / x[1], score)
for item in result:
print(f"Lambda returned the answer: {item}")
在上面的代码中,我们定义了一个名为 score 的元组列表。然后,调用 map 函数,将 lambda 函数作为第一个参数,将 list 作为第二个参数。
Lambda 函数在代码中被编写为将元组作为参数。它返回存储在元组的元素 0 中的值除以存储在元素 1 中的值。
在 map 运行之后,我们将把结果存储在变量 result 中。然后,遍历结果列表并打印它们。在所有情况下,除法的结果都应该是 10。
滤波函数
filter 函数用于提取 iterable 对象中该函数返回 True 的每个元素。在这种情况下,我们将使用 lambda 构造来定义函数,并应用 filter 函数。
让我们看看如何使用 filter 来查找偶数编号的列表项。为此,我们需要写一个 lambda 函数,只有当我们传递给它的数满足我们的条件时,它才为真。
示例:
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result = filter(lambda x: x % 2 == 0, data)
print(f"Lambda returned the answer: {list(result)}")
在上面的代码中,每个列表项被一分为二,并检查余数。如果余数为零,我们知道这个数是偶数。
减少功能
reduce 函数是一个独特的函数,它通过调用作为参数的一部分提供的函数,将输入列表缩减为单个值。默认情况下,reduce 函数从列表的第一个值开始,并将当前输出传递给列表中的下一个项目。
示例:
from functools import reduce
score = [20, 30, 40, 50]
result = reduce(lambda x, y: x + y, score)
print(f"Lambda returned the answer: {result}")
在上面的例子中,我们在 lambda 表达式中一起添加了列表项。Reduce 从一个空累加器开始,并添加第一项。然后,它将累加器设置为第一次操作的结果,并重复该操作。
这些是我们使用 lambda 结构的一些方法。
交易中的 Python lambda
使用 Python 的 lambda 函数,我们可以为不同的贸易相关输入编写几个代码。让我们看看下面的交易例子。
VADER 情绪分析:完全指南,算法交易和更多
由纳曼·斯旺卡
在金融和交易中,每天都会产生大量的数据。这些数据以新闻、预定的经济发布、就业数字等形式出现。很明显,这个消息对股票价格有很大的影响。
每个交易者都尽最大努力跟踪最新消息,并相应更新交易电话。这项任务的自动化提供了更好的交易机会。
在这篇博客中,我们将研究什么是 VADER 情绪分析,以及如何在我们使用 Python 的算法交易模型中使用它。
涵盖的主题:
- 什么是 VADER?
- VADER 的精确度是多少?
- 什么是化合价分值?
- VADER 如何计算输入文本的配价分数?
- VADER 如何计算输入句子的配价分数?
- 用于分析情绪的复合 VADER 分数
- VADER 的 Python 实现
- 使用解释 5 种启发法的句子进行演示
- 如何在交易中使用 VADER?
- 使用 VADER 和简单移动平均线生成交易需求
什么是 VADER?
VADER 是一种消耗资源较少的情感分析模型,它使用一组规则来指定数学模型,而无需显式编码。与机器学习模型相比,VADER 消耗的资源更少,因为它不需要大量的训练数据。
VADER 的资源高效方法帮助我们解码和量化文本、音频或视频等流媒体中包含的情感。VADER 并没有因为速度和性能的权衡而严重受损。
代表ValenceAwareDictionary 代表 sEntimentReasing
如果这些话现在对你没有任何意义,不要担心。在这篇博客结束的时候,你会对这些词的意思有很深的理解。

继续下一节,讨论 VADER 模型的分类精度以及 VADER 是如何实现的。
VADER 的精确度是多少?
研究表明,在匹配基本事实方面,VADER 的表现与个人评分者一样好。
进一步检查 F1 分数(分类准确度),我们看到 VADER (0.96)在正确地将推文的情绪分为积极、中立或消极类别方面优于个人评分者(0.84)。
这背后的原因是,对情绪的**(情绪是积极还是消极)和 强度 (情绪是积极还是消极)都很敏感。****
VADER 通过给单词提供一个的化合价来考虑这个问题。这就把我们带到了下一节。
什么是化合价分数?
它是通过观察和经验而不是纯粹的逻辑来给所考虑的单词打分。
- 想想“可怕”、“无望”、“悲惨”这些词。任何有自知之明的人都会很容易判断出这些话的负面情绪。
- 而另一方面,像“不可思议的”、“值得的”、“足够的”这样的词表示积极的情绪。
根据关于 VADER 的学术论文(T0 ),效价分数是从-4 到+4 来衡量的,其中-4 代表最“消极”的情绪,+4 代表最“积极”的情绪。人们可以直观地猜测,中点 0 代表“中性”情绪,这也是它实际上的定义。
VADER 如何计算输入文本的配价分数?
VADER 依靠一本字典来映射微博中情感表达常见的词汇和其他众多词汇特征。
这些功能包括:
- 西式表情符号的完整列表(例如- 😄 和:P)
- 与情感相关的首字母缩写词(例如- LOL 和 ROFL)
- 具有情感价值的常用俚语(例如- Nah 和 meh)
手动创建一个完整的情感词典是一个劳动密集型的过程,有时还容易出错。因此,难怪许多自然语言处理研究人员如此依赖现有的字典作为主要资源。
无需深入技术细节,这里有一个创建这样一个字典的两步过程分解。

研究 VADER 的研究人员使用Crowd’(WotC)方法确认了这些负责情感的词汇特征的普遍适用性。****
【WotC】依赖于这样一种思想,即一组人通过他们的聚集意见所表达的集体知识可以作为专家知识的替代而被信任。这有助于他们获得每个上下文无关文本的情感效价分数的有效点估计。
亚马逊土耳其机器人就是这样一个著名的众包市场,分散的专家评分员在这里执行远程评分等任务。
一些上下文无关文本的价分值是:
- 正价:“还好”是 0.9,“好”是 1.9,“很棒”是 3.1
- 负价:“恐怖”是–2.5,表情' 😦 '是–2.2,而“糟透了”及其俚语派生词“sux”都是–1.5
VADER 如何计算输入句子的配价分数?
VADER 利用某些规则来将每个子文本对句子级文本中情感感知强度的影响结合起来。这些规则被称为启发式规则。他们有 5 个人。**
- 高级读者注意:这些启发超出了通常在典型的单词袋模型中捕获的内容。它们合并了术语之间的词序敏感关系。
VADER 的五种启发式:
- 标点 ,即感叹号(!),在不修改语义方向的情况下增加强度的大小。比如:“天气热!!!"比“天气很热”更强烈
- 大写 ,具体是在其他非大写单词存在的情况下,使用全大写来强调一个与情感相关的单词,在不影响语义指向的情况下,增加情感强度的大小。比如:“天气热。”传达比“天气很热”更强烈的信息
- (也称为加强词、助词或程度副词)程度修饰语通过增加或减少强度来影响情绪强度。比如:“天气酷热难耐。”比“天气很热”更强烈,而“天气略热。”降低强度。
- 因连词 极性转移,对比连词“but”发出情感极性转移的信号,连词后的文本情感占主导地位。例如:“天气很热,但还可以忍受。”喜忧参半,后半部分决定了总体评分。
- 捕捉极性否定,通过检查充满情感的词汇特征之前的 3 个项目的连续序列,我们捕捉到了近 90%的否定翻转文本极性的情况。例如,一个否定的句子会是“天气并不真的那么热。”。
用于分析情感的复合 VADER 分数
通过将词典中每个单词的化合价分数相加来计算复合分数,根据规则进行调整,然后归一化为-1(最极端的负面)和+1(最极端的正面)之间的值。如果你想对一个给定的句子进行单一的一维情感测量,这是最有用的度量。
正如论文中所解释的,研究人员使用了下面的归一化。
*****$$x = \frac{x}{\sqrt {x^2 + \alpha}} $$
其中 x =组成单词的价分数之和,α =归一化常数(默认值为 15)
VADER 的 Python 实现
VADER 也被移植到其他编程语言上。标准的 Python 发行版没有捆绑 VADER 模块。我们将使用流行的 Python 包安装程序、 pip 来完成这项工作。
一个包包含一个模块所需的所有文件。模块是可以包含在项目中的 Python 代码库。我们在 Anaconda 终端中使用以下代码来安装 VADER。*****
价值投资:意义,例子,重要性和更多
价值投资是交易领域中最有趣的投资方法之一,它不仅仅基于股票的合理价格。一只股票可能以较低的价格交易,但同时价值却高得多。与真实价值相比,这种股票折价出售,对交易者来说肯定是有利的。
让我们通过这篇博客了解更多关于价值投资的内容,内容包括:
- 什么是价值投资?
- 价值投资的例子
- 价值投资的重要性
- 本杰明·格拉哈姆公式
- 如何识别价值投资机会?
- [价值投资者的特质](#traits-of-a-value investor)
- 新手价值投资
- 价值投资 vs 成长型投资
- 价值投资的优势
- 价值投资的弊端
什么是价值投资?
价值投资策略主要集中于投资那些交易价格远低于其真实价值的股票。
简而言之,价值投资有助于降低风险,因为我们只在价值股的当前价格远低于其真实价值时投资价值股。
这种真实价值和购买价格的差异也被称为“安全边际”。价值投资的概念首先由本杰明·格拉哈姆提出,他也是 T2 的导师。
对本杰明·格拉哈姆来说,价值投资意味着找到被低估的公司,等待市场将它们抬高到真正的价值。
价值投资者的主要动机是寻找这类被低估的公司。通过投资这种被低估的股票,已经有了安全边际,因为支付的价格更低。
这里的策略是当股票的价格反映了它的真实价值或者当它超过了它的真实价值时卖出股票。

Value investing
- 内在价值 -反映公司实际价值或价值的价格水平
- 安全边际 -购买价值与真实价值之间的差异
价值投资的例子
由于 2020 年 3 月的疫情,全球金融市场出现下跌。市场参与者受到惊吓,导致大幅抛售。
但即使在如此动荡的时期,价值投资者也看到了机会。几乎每个部门都有多种机会。这些股票是根据它们的估价确定的。
被低估且盈利的公司吸引了价值投资者的目光,并在他们的投资组合中获得了优先地位。此外,一年后他们在这些股票上获得的回报几乎令人难以置信!
让我们来看看几只股票以及它们在 1 年内获得的回报:
| 名字 | 2020 年 3 月至 2021 年 3 月期间返回 |
| 现代公司 | 343% |
| 德文能源公司 | 261% |
| 马拉松石油公司 | 215% |
Source: Yahoo Finance
但是价值投资并不全是购买由于最近事件的发生而大幅下跌的股票。以元股票(脸书)的价格下跌为例。
2022 年 2 月的脸书崩盘
2022 年 2 月 2 日,脸书的股价暴跌近 26% 。这有三个原因:
用户
首先,该公司报告称,自 2004 年推出以来,用户数量首次出现下降。用户数量是预测这家公司未来增长的一个关键指标。
根据价值投资理论,这种你可能开始质疑公司未来存在的情况是一个主要的危险信号。
元宇宙
dull earning 报告的第二个原因是用于“Meta-Verse”项目的费用增加。这些费用预计在不久的将来还会增加,这意味着收入预计也将保持低迷。
对于那些从短期角度重新平衡投资组合的交易者来说,这是退出的信号。但另一方面,价值投资者可能会尝试更深入地研究,并可能会发现这对未来的增长前景是一个很好的贡献。
苹果
第三个原因是苹果的隐私更新,这迫使脸书在跟踪用户的活动之前征得用户的同意。众所周知,脸书收入的很大一部分来自于运营广告。
广告是在跟踪用户活动后有策略地投放的。苹果最近的更新直接影响了脸书的收入。这将再次对该公司未来的收益增长提出质疑。
作为一个价值投资者,如果你怀疑 Meta 的价值可能会因为某些项目而增加,比如元宇宙,那么你可以购买这只股票。但是,如果根据你的真实价值低于现在的价格,那就不要打扰了。
成为一个成功的价值投资者的一个重要特征是正确估计公司的真实价值,并在市场对特定股票的定价明显偏低时利用机会。
价值投资的重要性
你有没有仅仅因为一只股票正在经历上涨趋势或者因为其他人都在买而买了它?
那么,就像大多数散户投资者一样,你也会受到市场情绪的影响。对于短线交易者来说,能够跟踪市场趋势是一个重要的特质。
但对于具有长期眼光的投资者来说,这可能不是正确的选择。价值投资与基于市场情绪的交易相反。价值投资的概念很简单——当高质量股票的估值较低时买入。
价值投资对于确保你的钱花得值很重要。你可以在一定程度上预测未来的增长和业绩,但你无法控制未来的事件。即使公司未来有望做得很好,但任何事情都有可能发生!
例如,疫情病毒可能会爆发。或者发展中国家可以开始暗示冷战。或者你自己的国家可以经历一些边境骚乱。
所有这些都会影响整体经济,而且这些事件不在任何人的控制范围之内。你唯一能控制的是你的进场和出场价格。
那么,难道你不想确保你做得对吗?
你不能确定一项投资是好是坏,但你可以肯定它的真正价值。
你是否见过因与业务无关的事件而引起购买/出售兴趣的股票? 基于不相关事件的发生投资股票可能导致不利后果。这类股票非常不稳定,其走势很难预测。
但作为一个价值投资者,如果你看到一只股票价格因无关事件而大幅下跌,那么这就是买入的机会。
我们以特斯拉为例。特斯拉创始人埃隆·马斯克(Elon Musk)发布的推文导致股价突然波动,这已经成为新闻。
这里有一个例子:
最近有很多人认为未实现收益是避税的一种手段,因此我提议卖掉我 10%的特斯拉股票。
你支持这个吗?
— Elon Musk (@elonmusk) November 6, 2021
具有尾部保护的方差风险溢价捕获
原文:https://blog.quantinsti.com/variance-risk-premium-capture-tail-protection-project-siddharth-bhatia/
卖出指数波动性已被证明是一种有利可图的策略。但是,回报曲线是倾斜的,带有脂肪损失尾部。新冠肺炎危机加剧了市场的波动性,导致这种流行策略的缩减。
这是每周机械地卖出 SPY ETF 上的交叉头寸并持有至到期的回溯测试。没有 delta 对冲或损失管理。DTE 在 45-60 之间。
我们的目标是看看这段时间的情况有多糟糕,以及恢复期(如果有的话)。用 python 编写代码很简单,但是需要创建正确的数据帧,这是项目中的主要挑战。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

西达尔特·巴蒂亚自 2006 年以来一直在孟买工作,目前在迪拜工作,自 2011 年以来拥有特定的交易经验。他最初是一家活跃在美国和欧盟债券期货市场的阿联酋本地自营公司的交易员,拥有交易期货的经验。
然后,他转到一家著名的家族办公室从事交易,管理着一个活跃于全球指数和期货期权的波动性交易账户。然后,他在一家财富管理公司工作,为公司的客户监督结构化产品的定价和交易以及各种保护性/尾部风险策略。在这里,他还负责一本包含结构化产品和基金的复杂书籍的投资组合管理。
从 2018 年开始,他创立了一家名为 Third Group 的自营交易和投资研究公司。第三组活跃于波动性交易,应用先进的定量分析来开发和部署交易策略。
西达尔特是 CFA 特许持有者,于 2012 年获得特许资格。他是 2021 年第 50 批毕业的 QuantInsti 校友。他对算法交易有浓厚的兴趣,主要是探索所有类型的机器学习和人工智能(AI),以在市场中获得优势。
战略思想
- 选择美国股票和期货市场最具流动性的 8 大期权链
- 选择 DTE:35–25
- 在 16-20 delta,空头 ATM 空头加上多头 OTM 空头
- 多头 OTM 扼杀的数量应该使 ATM 织女星在交易开始时保持中性。
- Delta 中性将通过 delta 套期保值在开盘时和收盘时各维持一次。
- 让头寸到期。
可能的优化参数
可能的优化参数如下:
- 入口 DTE
- OTM 之翼三角洲
- Delta 对冲频率
- 织女星中立每周调整与否?
- 退出 DTE(到期前退出?)
- 扩展到全球期货、股票、指数等更多市场?
要使用的数据集
就每日交易量而言,这些大致是流动性最强的美国期权市场
- ES1 -埃米尼 S&P 期货公司
- AAPL 苹果公司
- TSLA -特斯拉
- 九-九 ADR
- CL1 - WTI 原油期货
- GC1 -黄金期货
- ZC1 -美国玉米
- AMD -高级微型设备
我需要过去 3 年的每日现货和期权价格。我有一个 IBKR 基金账户,可以付费订阅这些市场数据。我将尝试使用 API 进行检索。
选择的动机
我已经用正 PNL 交易了 2 年了。我想检查这是否是一个有效的战略,以扩大规模并长期持续下去,同时优化以获得最佳的风险调整结果。
项目大纲
有许多研究和各种商业网站谈论一个著名的策略,涉及机械销售股票指数主要是 SPX 的跨和扼杀。由于持续的市场风险溢价称为方差风险溢价,它被认为是长期有利可图的。
严格来说,这是隐含波动率高于指数实际实现波动率的过高定价。由于恐惧/需求,市场参与者超额支付期权,因此期权,尤其是稍微长期的期权定价过高(在以向下倾斜的期限结构为标志的正常市场机制期间)。
我想测试一个非常简单的策略,每周在 SPY ETF 上机械地卖出交叉盘。为避免疑问,多头是一种期权头寸,在这种情况下,一个人在货币买入时卖出,然后将期权放在一起,将净贷方记入账户。
当基础资产在启动时没有移动到离选择的 ATM 攻击太远时,它起作用。到期时,如果标的处于原始 ATM 执行价格,那么多空产生最大利润。
因此,可以看出,这种头寸是利用标的波动性的直接方式,因为如果标的的移动距离(表现出更大的波动性)超过了多空合约的定价,这就是我们亏损的时候。
实际上,由于基础资产的变动可能远远超过正常衡量的标准差,这种策略有很大的风险。它的优势仅限于启动时收到的信贷,但下行风险是无限的,尤其是在优势方面。
战略
周一卖出 60 DTE(到期日)的多头头寸。我们使用了或的期权数据。这些价格基本上是美国市场的收盘价(收盘前 5 分钟捕捉的)。数据源使用 endpoint REST URLs 来检索所有需要的数据。
我们选择了 60 天左右的到期日,因为这正好在期货溢价最高的期限结构点上。每笔多空交易将一直持有到到期,同时进场的交易每周都会发生。
因为所选的 DTE 大约是 8 周,所以最多可以有 8 次跨骑,每次间隔一周。12.5%的资本将专门用于每只基金。
用 Python 编写策略代码
python 中的实际编码非常简单。
- 创建一个每周输入日期的数据框架。
- 使用这些输入日期作为 REST URL 的输入,我们检索对应于每个输入日期的到期日期。通常是 45-60 天。
- 然后,我们创建一个例程来检索进场日的执行价格。然后将这些执行价格输入到其他 REST URL 中,以便在输入日期之后的任何需要的日期检索期权价格。
- 在我们的例子中,我们持有到到期日,因此我们检索进入日期和到期日本身的跨期价格。
- 使用上述例程逐个单元格地创建两列,以填充对应于同一行的进场日期和到期日期的跨仓进场价格和出场价格。
注:
- 这里的每个单元格必须单独填充,因为 API 不产生时间序列数据,而只产生单独的数据点。
- 这确实需要一些时间,因此使用该数据源进行回溯测试是一件耗时的事情。
- 我们已经提交了代码,导出的数据帧作为一个 CSV 文件,所以人们可以直接导入它,而不是从 API 中重新检索所有的期权价格。
结果
最后,简单的百分比回报是用出场价格和出场价格计算的。计算累积回报,最后计算提款。

结果这个策略表现很差。该数据集涵盖了冠状病毒崩盘期间,SPX 在一个月内下跌 30%,并以同样快的速度反弹。由于指数表现出严重的波动性,所有进入这一机制的基金都遭受了损失,这是理所当然的。

结论
机械地卖出空头头寸风险很大,下跌的风险比上涨的收益更大。可以根据隐含波动率水平或期限结构的形状对时间条目进行进一步研究。
下面的 Python 代码中提供了完整的 Python 代码和相关信息。可以下载参考一下。
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
- 作为 csv 文件的数据帧
- excel 文件
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
Excel 中的长短移动平均交叉策略回测
原文:https://blog.quantinsti.com/vectorized-backtesting-in-excel/
雅克·儒贝尔
现在,对于那些知道我是一个博客作者的人来说,这篇文章可能会觉得有点偏离我传统的写作风格,但是本着进化的精神,受我的一个朋友 Stuart Reid (TuringFinance.com)的启发,我将遵循下面的博客文章中建议的一些技巧。
作为 EPAT 项目的一名学生,我很高兴了解到其他人在进行回溯测试时使用的方法。像往常一样,我们从开始回溯测试 Excel,然后迁移到 r
我之前写过一个关于 Excel 回溯测试的博客系列,然后转到 R ,我非常有兴趣看到 QuantInsti 团队使用的一个稍微不同的方法。
请下载 Excel 电子表格,以便您可以在我们进行的过程中遵循示例。
“通过计算交易价格,它为实施 MAE 分析打开了一些非常有趣的大门”
该方法的一个主要区别在于,它为以下性能指标打开了大门:
- 总正回报
- 负回报
- 积极交易
- 负面交易
- 命中率
- 平均收入
- 最大反向偏移
但苦于不能像我最初的方法(我喜欢把我们看作一个矢量化的回溯测试)那样绘制股票曲线,然而,你可以很容易地合并股票曲线,就像我在这篇文章中所做的那样。
构建交易策略的“Hello World”:“多空均线交叉策略”。

第一步:获取数据
您可以从几个地方获取数据,但是在这个例子中,我们将从 Yahoo Finance 获取数据。我将建立这个例子使用谷歌作为一个共享。

CSV 文件格式的雅虎价格数据
第二步:创建一个长短期简单移动平均线(SMA)的列
在这个例子中,我希望你利用 5 日和 25 日的均线。对于那些刚接触交易策略的人来说,均线就是收盘价除以观察次数的总和。
2.1)创建短期 SMA (5 天)
在 Excel 中使用以下公式:=AVERAGE(G2:G6)

2.2)创建长期 SMA (25 天)
在 Excel 中使用以下公式:=AVERAGE(E2:E26)

第三步:生成交易信号
在这一步,读者将会发现与我之前关于构建矢量化回溯测试器的博文的一个主要区别。为了绘制股票曲线,我将在这篇文章中加入我最初的方法。
我们需要做的下一件事是产生买入和卖出信号
第三步的逻辑:
如果:
在前一天,( 5)SMA 在(25)SMA 的下方,而在当天,( 5)SMA 现在在(25)SMA 的上方,
然后:
在当前字段中写入字符串“BUY”
否则如果:
在前一天,( 5)SMA 在(25)SMA 之上,而在当天,( 5)SMA 现在在(25)SMA 之下,
然后:
在当前字段中写入字符串“SELL”
其他:
将空字符串""添加到当前字段。
这在 Excel 中用以下公式表示:
= IF(AND(H26>I26,H25
 T2】
T2】
注:
SMAs 是根据收盘价计算的,不进行收盘调整,因为我们希望交易信号是根据价格数据生成的,不受支付的股息的影响。

第四步:获取交易的买入/卖出价格
在下一列中添加以下 Excel 公式:=IF(J26 <>" ",G27,K26)
逻辑如下:
如果前一天的交易信号列(对于滞后指标以消除前瞻偏差非常重要)不是空字符串,则使用当前字段上方的前一价格,否则将当前字段设置为当天的收盘价。

注:
有些人可能会说,你实际上无法获得当天的收盘,但如果你在收盘时下单,你就可以,即使在拍卖结束后,还有一些剩余订单可以填补,我之前工作的一只基金就是这样做的。
第五步:计算回报
添加一个名为 returns 的列,该列使用以下 Excel 公式:=IF(J26="SELL ",K27/K26-1,IF(J26="BUY ",1-K27/K26,"")
逻辑:
如果 前一天产生了卖出信号 那么 取今天的收盘价除以买入价再减 1。
否则如果 前一天产生买入信号 那么 加 1 减(今天的收盘价除以买入价)。

这个公式计算给定交易的回报。
第六步:计算一些性能指标
- 正回报:=SUMIF(L:L," > 0 ")
- 负回报:=SUMIF(L:L," < 0 ")
- 正向交易:=COUNTIF(L:L," > 0 ")
- 负交易:=COUNTIF(L:L," < 0 ")
- 命中率=O4/(O4+O5)
- 平均回报率=平均值(L:L)

这些不是传统的投资组合业绩指标,但通过计算购买和销售价格,它为实施最大不利偏移分析打开了一些非常有趣的大门,这些分析可用于优化止损。
“注意:由于没有记录交易的购买和销售价格,我无法在之前的方法中计算这些指标。”

添加权益曲线
第一步:添加两个新列,分别用于股票的日收益和自然对数日收益
为此,我将利用调整后的收盘价,因为我希望支付的股息能够反映在我们的战略权益曲线和总回报曲线中。
每日回报的公式是:(今天的价格/昨天的价格)- 1
Excel 公式:=G3/G2-1
用于自然对数每日收益的公式是:LN(今天的价格/昨天的价格)
Excel 公式:= LN(G3/G2)

第二步:计算多头或空头持有信号
在本专栏中,我们想知道我们目前是持有多头还是空头头寸。这用 1 表示长,用-1 表示短。
这建立在均线交叉策略的基础上,如果短期 SMA 高于长期 SMA,则做多,反之则做空。
注意:你必须将信号延迟一天,以消除前瞻偏差
在本例中,Excel 公式如下:=IF(H26>I26,1,-1)

第三步:计算策略 ln 日收益
这是容易的部分,简单地将自然日志日收益乘以当前头寸。
Excel 公式:=R27*S27

第四步:计算策略和股票的累计回报,就像你买入并持有一样。(这样做是为了做比较)
累积回报的公式很简单,对于 LN 回报,您只需使用=T27+U26 将它们相加。

接下来,您需要使用以下公式来反转自然对数:=EXP(U27)-1

然后你需要计算股票的累积收益:
Excel 公式=(1+Q27)*(1+Q26)-1

第五步:绘制回报图

从上面的图表可以看出,在这个特定的时间框架和份额上,这种策略并不有利可图。我鼓励读者探索其他交易策略,尝试将 RSI 指标作为如何确定头寸的指南。

在 Excel 中进行回溯测试后,学习使用来自谷歌的数据和 CSV 格式的 OHLC 数据在 Zipline 上导入和回溯测试。计算回测结果,如 PnL、交易数量等。
你可以通过对历史数据进行回溯测试来提高交易成功的可能性。Quantra 的这个关于回溯测试交易策略的课程正是你从交易中获得最大收益所需要的。从基本步骤、数据、规则、风险管理等方面学习一切。立即注册!
更新: 我们注意到一些用户在从雅虎和谷歌财经平台下载市场数据时面临挑战。如果您正在寻找市场数据的替代来源,您可以使用 Quandl 进行同样的操作。
基于 Python 的风险调整收益率的波动性和度量
原文:https://blog.quantinsti.com/volatility-and-measures-of-risk-adjusted-return-based-on-volatility/
在这篇文章中,我们将看到如何在 python 中计算历史波动率,以及基于它的不同的风险调整回报率度量。我们还提供了这些措施的 python 代码,可能对读者有所帮助。
简介
波动性衡量给定证券回报的离差。在期权交易中起到关键作用。
波动性可以用一段时间内证券回报的标准差来衡量。
历史波动率来自于过去价格数据的时间序列,而隐含波动率来自于期权合约等交易衍生工具的市场价格。
示例:计算 NIFTY 的风险调整回报的历史波动率
首先,我们使用 numpy 的 log 函数来计算使用 NIFTY 收盘价的对数回报,然后使用 pandas 的 rolling_std 函数加上 numpy 的平方根函数来计算年波动率。
滚动函数使用 252 个交易日的窗口。所选回顾期内的每一天都分配有相等的权重。用户可以根据自己的需要选择更长或更短的时间。
## Computing Volatility
# Load the required modules and packages
import numpy as np
import pandas as pd
import pandas_datareader.data as web
import yfinance as yf
# Pull NIFTY data from Yahoo finance
NIFTY = yf.download('^NSEI',start='2012-6-1', end='2016-6-1')
# Compute the logarithmic returns using the Closing price
NIFTY['Log_Ret'] = np.log(NIFTY['Close'] / NIFTY['Close'].shift(1))
# Compute Volatility using the pandas rolling standard deviation function
NIFTY['Volatility'] = NIFTY['Log_Ret'].rolling(window=252).std() * np.sqrt(252)
print(NIFTY.tail(15))
# Plot the NIFTY Price series and the Volatility
NIFTY[['Close', 'Volatility']].plot(subplots=True, color='blue',figsize=(8, 6))

基于波动性的风险调整回报率的衡量
夏普比率
诺贝尔奖获得者威廉·夏普于 1966 年引入的夏普比率是一种计算风险调整后回报的方法。夏普比率是每单位波动率超过无风险利率的平均回报率。
Sharpe ratio = (Mean return − Risk-free rate) / Standard deviation of return
以下是 python 中计算夏普比率的代码。所需的投入是投资的回报。
# Sharpe Ratio function
def sharpe(returns, daily_risk_free_rate, days=252):
volatility = returns.std()
sharpe_ratio = (returns.mean() - daily_risk_free_rate) / volatility * np.sqrt(days)
return sharpe_ratio
信息比率(IR)
信息比率是夏普比率的延伸,夏普比率将基准投资组合的回报与投入相加。它衡量交易者创造相对于基准的超额回报的能力。
下面是用 python 计算信息比率的代码。所需的投入是投资回报和基准回报。
import numpy as np
def information_ratio(returns, benchmark_returns, days=252):
return_difference = returns - benchmark_returns
volatility = return_difference.std()
information_ratio = return_difference.mean() / volatility * np.sqrt(days)
return information_ratio
莫迪利阿尼比率(M2 比率)
莫迪利亚尼比率衡量投资组合的回报,根据投资组合相对于某个基准的风险进行调整。
为了计算 M2 比率,我们首先计算夏普比率,然后乘以所选基准的年化标准差。然后,我们将无风险利率加到衍生价值上,得到 M2 比率。
以下是 python 中计算莫迪利亚尼比率的代码。所需的输入是投资回报、基准回报和无风险利率。
# Modigliani Ratio
import numpy as np
def modigliani_ratio(returns, benchmark_returns, rf, days=252):
volatility = returns.std()
sharpe_ratio = (returns.mean() - rf) / volatility * np.sqrt(days)
benchmark_volatility = benchmark_returns.std() * np.sqrt(days)
m2_ratio = (sharpe_ratio * benchmark_volatility) + rf
return m2_ratio
因此,这就是我们在 python 中计算历史波动率的方式,我们还基于它研究了不同的风险调整回报率衡量标准。
学习使用蒙特卡洛模拟在 Python 中优化你的投资组合。
本文解释了如何给你的股票分配随机权重,并计算你的投资组合的年回报率和标准差,这将允许你选择一个具有最大夏普比率的投资组合。
更新——我们注意到,一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果您正在寻找市场数据的替代来源,您可以使用 Quandl 来获得相同的数据。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
文件在下载
- 风险调整回报的波动性和度量- Python 代码
如何在 Python 中对波动微笑建模
原文:https://blog.quantinsti.com/volatility-smile-origin-implications/
在本文中,你将了解易变性微笑的起源和含义。您还将看到如何用 Python 绘制波动率微笑曲线。首先,我们将通过分析 Black Scholes 模型(BSM)中的假设来理解波动率微笑的概念,该假设认为标的的每日收益是对数正态分布的。
布莱克-斯科尔斯模型-对数正态假设
Black Scholes 模型假设标的收益服从对数正态分布。然而在现实世界中,回报的分布要比这复杂得多。为了更好地理解这一点,让我们通过分析下表中所示的基础资产的每日回报来看一个例子。

第一列表示给定一天的每日回报的偏差量,即每日回报的偏差大于一个标准偏差、两个标准偏差等等,直到六个标准偏差。第二列和第三列存储日收益率偏离超过一个、两个等等直到六个标准差的百分比或概率。第二列存储真实资产的值,而第三列存储人工创建的对数正态模型的值。
现在,在比较百分比值时,可以观察到,在现实世界中,与对数正态模型相比,回报率值偏离超过 4、5 和 6 个标准差的天数百分比要高得多。可以看出,对于真实世界的资产,超出 4 个标准差的值的百分比是对数正态模型的 29 倍。因此,我们希望做得比假设收益是对数正态更好。
波动的微笑
深度价外期权需要更高的偏差来结束。这意味着,在现实世界中,与具有对数正态分布的标的相比,远高于货币的期权更有可能以货币结束。BSM 模型计算期权溢价时考虑了标的的不变波动性和对数正态分布。因此,考虑到基础资产不遵循对数正态分布且不具有恒定的波动性,使用 BSM 计算的溢价相对于公允价值会更便宜。因此,当将看涨期权和看跌期权溢价的值放入 BSM 公式以得出隐含波动率的值时,可以观察到隐含波动率呈微笑状,货币期权的最小值和波动率随着您向任一侧移动而上升,如下图所示。
用 Python 绘制波动微笑
现在让我们了解如何在 Python 中绘制波动微笑。首先,您需要了解数据的结构。看看下面的数据帧,观察数据的结构,从 NSE 的 Nifty50 选项的网站下载后,数据的结构略有修改。

1。导入库
现在让我们看看如何使用这些数据来绘制波动微笑。我们将从导入相关的库开始。

我们将导入 pandas 库以使用其强大的数据框架的特性。接下来,我们将导入 matplotlib.pyplot 库来绘制微笑。最后,我们将导入 Mibian 库,它用于计算隐含波动率。我们从这个库中导入了函数 BS,它有助于实现 BSM 公式。要了解更多关于这个库以及它是如何被用来进行各种计算的,你可以看看下面这篇博文的后半部分:期权定价模型——布莱克·斯科尔斯、德曼·卡尼&赫斯顿模型
2。提取选项数据
接下来,我们将获取以上述格式存储在 CSV 文件中的选项数据。

我们使用 pandas 库将 csv 文件中的数据转换成名为 nifty_data 的数据帧。然后,我们在列标题“IV”下创建一个新列来存储隐含波动率,并初始化该列来存储零。
3。计算隐含波动率

我们现在将计算 dataframe nifty 数据中所有期权在不同日期的隐含波动率。我们通过运行 for 循环,遍历 dataframe nifty 数据的所有行来实现这一点。然后,我们定义不同的变量,这些变量将用于调用 BS 函数来计算隐含波动率。利率设为 0 是因为我们的数据框架中的基础价值是期货合约价格 50,而不是现货价格 50。隐含波动率的值使用所示的 BS 函数计算,并存储在列标题“IV”下的数据框架 nifty_data 中。
4。定义 Plot_smile()函数

接下来,我们定义 Plot smile()函数,该函数将日期作为输入,并绘制特定日期的微笑。这是通过定义一个名为 option data 的新数据帧来实现的,该数据帧存储该特定日期的数据行。然后,我们通过将期权数据的“执行价格”和“IV”列作为 x 轴和 y 轴作为 plot()函数的参数来绘制微笑。然后,我们为该图定义图例和标签,最后在函数的末尾显示该图。
5。定义接受输入的函数

6。调用 Take_input()函数

最后,我们调用 Take_input()函数从用户那里获取输入。下面显示了 2017 年 11 月 17 日代码的输出图。

结论
我们观察到隐含波动率曲线是一个微笑的形状,而不是像 BSM 模型假设的那样平坦。因此,基础并不遵循对数正态分布,而是遵循修正的随机游走。德曼卡尼模型和赫斯顿模型是为了纠正 BSM 模型中的错误假设而开发的。
如果你有兴趣学习基于波动性的编码交易策略,你应该报名参加 Quantra 的以下课程:
下载数据文件
- Option_data_NIFTY.csv
- VOL SMILE.py
波动性交易:交易 VIX 恐惧指数[网络研讨会]
原文:https://blog.quantinsti.com/volatility-trading-vix-10-may-2022/
https://www.youtube.com/embed/-w6V3QlH14E?rel=0
演示幻灯片
https://www.slideshare.net/slideshow/embed_code/key/iFizKmgnUMszTR?hostedIn=slideshare&page=upload
关于会议
市场波动很大!恐惧指数正在攀升,交易者们被吓到了!
你以前一定见过这样的陈述。但是恐惧指数到底是什么呢?你能量化恐惧吗?
恐惧指数是 VIX 的名字。它让我们看到了预期的市场波动。是的,就像我们试图衡量资产的波动性一样,VIX 帮助我们理解市场的波动性。但是像指数一样,VIX 不能交易。
因此,基于 VIX 的不同产品可以帮助你根据你对市场波动的预期进行交易。VIX 不仅适用于股票,不同的资产类别也有相应的 VIX。和地理。
请加入我们,了解更多关于 VIX 及其产品的信息。
会话大纲
会议大纲如下:
- 波动性简介
- 为什么 VIX 被称为恐惧指数
- 不同类型的 VIX
- VIX 衍生产品
- 交易 VIX 的简单策略
- 问与答(Question and Answer)
关于演讲者

雷希特·帕查内卡尔(Quant 分析师,QuantInsti)
瑞基特·帕查内卡首先完成了他的计算机工程,然后在 IIM·印多尔完成了他的 PGDM。他是 Quantra 内容团队的一员,研究股票和固定收益证券。工作之余,他喜欢阅读市场中的异常数据,并怀着浓厚的兴趣关注特斯拉公司(Tesla Inc .)。
本次活动于:
2022 年 5 月 10 日星期二
东部时间上午 9:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30
波动率加权投资组合
原文:https://blog.quantinsti.com/volatility-weighted-portfolio/
马里奥·比萨
可以使用多种方法来确定位置大小。在这篇博客中,我们关注并解释波动率加权投资组合。波动加权投资组合确保投资组合的所有组成部分对风险/回报比率的贡献相等。
涵盖的主题:
范围
交易时仓位大小很重要。一个受过教育的高效交易者应该关心他/她的投资组合的仓位大小,因为这是他/她控制自己承担的风险的方法。
无论我们使用何种策略进入或退出市场,也无论我们使用何种金融工具,都有必要控制我们在市场中的名义敞口,因为这决定了我们所承担的风险。
确定头寸规模有多种方法,这里我们将重点关注波动率加权投资组合,以确保投资组合的所有组成部分对风险/回报比率的贡献比例相同。
基本上,该方法包括根据投资组合要求的波动性以及工具和/或策略提供的波动性来调整风险敞口。
名义风险敞口
现金型经纪人账户中的股票的名义风险很容易理解。
如果一只股票的价格是 100 美元,我们想买 100 股,我们需要在经纪人的账户上有 10,000 美元。
让我们假设一个保证金账户,允许我们 4:1 杠杆。
这意味着购买 100 股价格为 100 美元的股票,我们只需要 2500 美元,假设风险是现金账户的四倍,如果我们完全暴露。或者,对于一个 10,000 美元的账户,我们可以以 1:1 的杠杆比率购买 100 股,以 2:1 的杠杆比率购买 200 股,以此类推,直到 4:1。
在保证金产品的情况下,杠杆可以高得多,因此会增加投资组合的风险。
以 3 月迷你标准普尔 500 期货合约 ESH21 为例,其价格为 3,935.00 美元,乘数为 50,这意味着一份合约在市场上的名义敞口为 196,750 美元,这意味着我们应该拥有至少 200,000 美元的账户,以便能够管理合理的杠杆。
对于外汇,经纪人通常会提供疯狂的杠杆,尽管这并不意味着我们应该承担尽可能多的风险,仅仅因为经纪人允许这样做。
在上述任何一种情况下,关键是如何管理市场的名义风险。
因此,想法是要知道一种方法,在构成投资组合的不同工具之间分配资本。
杠杆投资组合分配
杠杆金融产品允许在市场中持有大大超过经纪人账户中实际可用资本的头寸。这是因为相对于名义风险,只需要很少的保证金。
通常保证金在 5%到 20%之间,尽管这取决于市场的波动性和/或工具本身的波动性。
让我们创建一个期货的投资组合,并查看每个工具中单一合约的名义风险。
ESH21: Emini 标准普尔 500 2021 年 3 月
HGH21:铜 2021 年 3 月
GGH21:欧元债券 2021 年 3 月
GCJ21:黄金 2021 年 4 月
名义敞口=价格 x 乘数 x 货币
|
| ESH21 | HGH21 | GGH21 | GCJ21 |
| 价格 2021-02-21 | 3922.25 | 38105 | 174.79 | 1784.7 |
| 乘数 | 50 | 25000 | 1000 | 100 |
| 货币美元 | 1 | 1 | 1206430 | 1 |
| 1 合同未生效。exp。 | 196112.50 | 95,262.50 | 210,871.90 | 178,470.00 |
注意:我包括了工具的货币,因为在这种情况下,德国国债以欧元报价,而我们的投资组合以美元计价。因此,我们必须将名义敞口转换为我们投资组合的货币。
总名义风险敞口:680,716.90
加上总的名义风险敞口,我们通过购买每种工具的单一合约获得 680,716.90 美元,收益或损失将与名义风险敞口相反。
为了获得 1:1 的杠杆比率,我们需要用 700,000 美元资本化账户,以购买这些工具中每一种的一份合同,问题是对投资组合的风险/回报的贡献非常不平衡,使投资组合非常暴露于波动性更大的工具,而对波动性较小的工具的影响非常小。
为了平衡每种工具对整个投资组合波动性的贡献,我们将采用每种工具的 ATR 测量的波动性来获得我们需要的合约数量。
Perry Kauffman 在《交易系统和方法》一书中提出的以下公式,简单来说就是将资金除以 ATR 得到合约数量,波动率越高仓位越低,反之亦然。
*【头寸规模=(分配/货币)/ (ATR 乘数)
| 70 万 | ESH21 | HGH21 | GGH21 | GCJ21 |
| 17.5 万 | 3922.25 | 3.8105 | 174,79 | 1784.7 |
| ATR(20) | 51.95 | 0.0665 | 0.62 | 28.0 |
| 乘数 | 50 | 25000 | 1000 | 100 |
| 货币 | 1 | 1 | 1206430 | 1 |
| 1 合同未生效。exp。 | 196112.5 | 95262.5 | 210.871,8997 | 178470 |
| 合同 | 67 | 105 | 234 | 63 |
| 名义风险敞口 | 13,139,537.50 | 10,002,562.50 | 40.900.860,00 | 11,243,610.00 |
总名义风险敞口:75,286,570.00
该公式的结果建议购买/出售非常多的合同,这将给我们 75,286,570.00 美元的名义风险,并将给我们 75,286,570.00 美元的致命杠杆:700,000.00 美元或 107:1,以烧掉你的帐户,并在一次打击中让你出局。
因此,我们将调整头寸,以找到 2:1、3:1 或 4:1 的合理杠杆。
主要的关键是找到比例来衡量名义风险,这是通过将总资本除以总名义风险的总和而获得的。
| 700000 | ESH21 | HGH21 | GGH21 | GCJ21 |
| 175.000 | 3922.25 | 3.8105 | 174.79 | 1784.7 |
| ATR(20) | 51.95 | 0.0665 | 0.62 | 28.0 |
| 乘数 | 50 | 25000 | 1000 | 100 |
| 货币 | 1 | 1 | 1.206430 | 1 |
| 1 合同未生效。exp。 | 196112.5 | 95262.5 | 210,871.8997 | 178470 |
|
|
|
|
|
|
| 合同 | 67 | 105 | 234 | 63 |
| 名义风险敞口 | 13,139,537.50 | 10,002,562.50 | 40,900,860.00 | 11,243,610.00 |
|
|
|
|
|
|
| 比例 | 0.009298 |
|
|
|
| 曝光比例 | 122168.88 | 93001.90 | 380,288.30 | 104540.92 |
| 杠杆 1:1 | 0.62 | 0.98 | 1.80 | 0.59 |
| 杠杆 2:1 | 1.25 | 1.95 | 3.61 | 1.17 |
| 杠杆 3:1 | 1.87 | 2.93 | 5.41 | 1.76 |
| 杠杆 4:1 | 2.49 | 3.91 | 7.21 | 2.34 |
请注意,相对于波动性较低但合约数量较多的工具,波动性较高的工具获得的合约数量较少。
有趣的是,对于 1:1 的杠杆比率,我们只能购买没有杠杆的德国债券。我留下小数只是为了看到我们只能购买合同的一部分。这是不可能的。
另一个关键方面是,我们需要至少 2:1 的杠杆比率才能在所有工具中建立未结头寸。在这种情况下,有 1 份标准普尔 500 和黄金合约,2 份铜合约和 4 份德国国债合约。
股票投资组合配置
对于不可能使用杠杆的现金账户,我们可以用同样的方法通过波动性来平衡投资组合。
假设以下交易所交易基金:
SPY:标准普尔 500 SPDR ETF
GLTR:实物贵金属篮子 ETF
TLT: 20 年以上 Treas 债券 Ishares ETF
GSG: S & P GSCI 商品指数 Ishares ETF (GSG)
*【头寸规模=(分配/货币)/ (ATR 乘数)
股票的乘数是 1。
| 400.000 | 间谍 | GLTR | TLT | 脑电图 |
| 100.000 | 392.3 | 97.11 | 144.87 | 14.07 |
| ATR(20) | 4.2 | 1.58 | 1.23 | 0.19 |
| 乘数 | 1 | 1 | 1 | 1 |
| 货币 | 1 | 1 | 1 | 1 |
|
|
|
|
|
|
| 股 | 23810 | 63291 | 81301 | 526316 |
| 名义风险敞口 | 9,340,663.00 | 6146189.01 | 11,778,075.87 | 7405266.12 |
|
|
|
|
|
|
| 比例 | 0.0115 |
|
|
|
| 曝光比例 | 107765.92 | 70,910.35 | 135,887.05 | 85436.69 |
| 股 | 274.70 | 730.21 | 937,99 | 6072.26 |
通过这种方式,我们可以将每种工具的当前波动性考虑在内,确定每种工具的股份数量。如果我们把总风险加起来,我们就得到最大的可用资本。
分配总额:400,000.00
结论
这里我们只看到了基于波动性平衡投资组合的众多方法中的一种。这是一个有用的工具,因此投资组合的风险/回报比率不会因波动性更大的工具而失衡。
在这个关于量化投资组合管理的课程中,你可以学习如何构建投资组合和使用各种量化技术管理风险。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
VWAP 教程:计算、使用和限制
通常如果一个交易者必须比较两个看起来不错的证券,一个有经验的交易者会检查股票的价格和交易量。
现在,你会问,“价格是显而易见的,但为什么是数量呢?”
成交量和价格一样重要,因为我们不想被一只只有少数人买的股票套牢,即使价格太有吸引力。因此,VWAP 的建立是为了同时考虑数量和价格。
用 VWAP 作为交易的衡量标准,潜在的交易者会比仅仅考虑价格更准确地决定多头和空头头寸。
让我们通过这篇博客了解更多关于 VWAP 的信息,因为它包括:
什么是 VWAP?
成交量加权平均价格,也称为 VWAP,是衡量金融工具根据交易量调整后的平均价格的方法。
简单来说,成交量加权平均价格就是相对于成交量的累计平均价格。
数量加权平均价格(VWAP)计算简单,用途广泛。当对冲基金或共同基金使用 VWAP 来指导其购买大量股票的决定时,散户投资者会使用它来检查价格是否足够好来做多。
VWAP 公式
计算 VWAP 的公式是累计典型价格乘以总交易量,再除以累计交易量。内容如下:
VWAP =(累计(价格*成交量))(累计成交量)
虽然公式很简单,但让我们通过一个例子来了解 VWAP 在 Excel 中的应用。
VWAP 在 Excel 中的应用
为了计算 VWAP,我们将采用亚马逊的分钟级数据。你可以从阿尔法华帝 ⁽ ⁾ 获得样本历史数据。你也可以阅读更多关于股票 API 提供商如 Alpha Vantage 如何根据分割和股息调整历史价格的 ⁽ ⁾ 。我们使用了 2022 年 4 月 1 日的数据。数据示例如下:
| 日期 | 打开 | 高 | 低 | 关闭 | 体积 |
| 2022-04-01 08:00:00 | 3281.0000 | 283.7374 | 3281.0000 | 3281.0000 | Three hundred |
| 2022-04-01 08:01:00 | 3284.9000 | 3284.9000 | 3284.9000 | 3284.9000 | Two hundred and fifty |
| 2022-04-01 08:02:00 | 3284.9000 | 3284.9000 | 3284.9000 | 3284.9000 | One hundred |
第一步:求平均值
为了获得给定期间证券交易价格的可靠估计,我们取价格数据的平均值,在这种情况下,是最高价、最低价和收盘价的平均值。
因此,8:00 时的平均价格=(283.7374+3281.000+3281.000)/3 = 2281.91
同样,对于 8:01,平均价格=(3284.9000+3284.9000+3284.9000)/3 = 3284.90
第二步:将平均价格乘以该时期的交易量,并加上前一时期的累计总额
因为我们要寻找的时间段是 8:00,所以交易量是 300。
因此,8:00 时的价格累计总额=(价格成交量)= 2,281.91300 = 684573。
因为是一天的第一节,所以是简单的乘法。从第二列开始,我们取累计总数,即将前一期的值加到当前值上。
因此,对于 8:01,交易量为 250,累计平均价格=((8:01 的平均价格)* 8:01 的交易量)+8:00 的累计总额
= [ 3284.90 * 250] + 684573 = 15,05,798.
第三步:求累计总量
因为我们找到了累计平均价格*交易量,所以我们必须保存证券交易量的累计总数。
因此,对于 8:00,刚好是 300,因为这是一天的第一个时段。
对于 8:01,则为(8:01 的成交量)+前期累计成交量,即
(250+ 300) = 550.
第四步:找到 VWAP
我们简单的用累计价格*成交量除以累计成交量。
因此,对于 8:00,VWAP = 684573 / 300 = 2281.91
对于 8:01,VWAP = 15,05,798 / 550 = 2737.8145
在 Excel 中,它看起来像这样:
| 日期 | 打开 | 高 | 低 | 关闭 | 体积 | 平均价格 | 均价*成交量 | 累计量 | VWAP |
| 2022-04-01 08:00:00 | 3281.0000 | 283.7374 | 3281.0000 | 3281.0000 | Three hundred | Two thousand two hundred and eighty-one point nine one | Six hundred and eighty-four thousand five hundred and seventy-three | Three hundred | Two thousand two hundred and eighty-one point nine one |
| 2022-04-01 08:01:00 | 3284.9000 | 3284.9000 | 3284.9000 | 3284.9000 | Two hundred and fifty | Three thousand two hundred and eighty-four point nine | 15,05,798 | Five hundred | 2737.8145 |
| 2022-04-01 08:02:00 | 3284.9000 | 3284.9000 | 3284.9000 | 3284.9000 | One hundred | Three thousand two hundred and eighty-four point nine | 18,34,198 | Three hundred and fifty | Five thousand two hundred and forty point five six five |
与 VWAP 的交易——解读
有了 VWAP,交易者可以获得关于股票价格变动的完整信息,帮助他们确定最佳进场点。
例如,一个交易者等待特定股票的价格线超过 VWAP 线。如果市场上有大量卖出(空头头寸)该股票,该股票可能无法突破 VWAP 线。
这是因为 VWAP 线以上的股票被认为是昂贵的,因此价值很高。当股价上涨到 VWAP 线以上时,这意味着很多交易者在买入股票。这是当交易者在价格达到最高点之前就离开的时候。
另一方面,低于 VWAP 线的股票被认为是被低估的,并呈下降趋势,这使得交易者做空这些股票。
借助趋势线(支撑线和阻力线)和烛台模式(代表价格运动),交易者可以发现股票何时高于或低于 VWAP 线。
如何使用 VWAP
至此,我们在 Excel 的帮助下学习了 VWAP 的计算和应用。让我们看看交易者是如何利用 VWAP 的,原因有很多,如下所示:
- VWAP 是趋势的印证
- VWAP 作为交易者的执行策略
- VWAP 作为一个指标
- VWAP 作为盈利能力的检验
VWAP 是趋势的印证
我们以前提到过 VWAP 如何给我们提供与数量和价格相关的信息。它还帮助我们确认可能正在出现的趋势的存在。
让我们用下面的一个图表例子来理解这一点(显示 VWAP 和股票的收盘价),计算完成后可以在 Excel 中绘制出来。

VWAP vs. Closing price
如果你看到 VWAP 的图表,尽管收盘价频繁波动,我们可以清楚地看到 VWAP 在上升。上升的 VWAP 表明买方比卖方多。
它也表明一个看涨阶段,反之,下降的 VWAP 表明一个看跌阶段。
作为交易执行策略的 VWAP
机构买家也使用 VWAP,他们需要购买或出售大量股票,但不想引起交易量飙升,因为它会吸引注意力并影响价格。
为了进一步解释这一点,我们假设一家机构有兴趣购买 10,000 股亚马逊股票。如果他们下了 10,000 份订单,当交易所执行订单时,立即采取的行动将是价格飙升。
现在,如果其他交易员知道对该股票的需求很大,他们会要求更高的股票价格,从而使该机构的股票价格更高。
为了避免这种情况,这些机构开发了一种自动交易策略,将股票数量分成更小的数量,并以这样的方式出价,即他们的交易不会让收盘价远离 VWAP。
由于 VWAP 是某些交易者交易决策的依据,它有助于使收盘价尽可能接近 VWAP。
VWAP 作为一个指标
在日内交易者中,VWAP 指标也可以用于交易策略。关于如何准确地使用 VWAP 作为一个指标,存在着相互矛盾的理论,因此我们将试图更详细地了解这一方面。
我们通常会考虑收盘价穿过 VWAP 作为信号的情况,因此,VWAP 交叉可以根据你的风险状况用来进场或出场。
在我们看不同的场景之前,让我们退后一步,理解 VWAP 在交易者身上实际上是自我实现的。如前所述,某些机构交易者试图以收盘价不超过 VWAP 的方式执行交易。
这可能会影响其他交易者,他们会查看收盘价并做出交易决定,认为收盘价最终会接近 VWAP。
因此,当收盘价开始上涨并远离 VWAP 时,交易者之间会有卖出的压力,因为逻辑是其他人会在任何时候卖出。
这就造成了一种普遍认为股票被高估的情况。类似地,当收盘价开始下跌并远离 VWAP 时,人们认为股票被低估,交易者有购买股票的压力。
这样,我们可以称 VWAP 为自我实现。当然,根据市场的心态,可能会有不同的情况,因此,人们不能只依靠 VWAP 来做出交易决定。
现在让我们看看其他几个场景。
一些交易者更喜欢将 VWAP 交叉作为一个指标,当收盘价从下方穿过 VWAP 并攀升时,买入该股,这表明了看涨趋势。
然后,要么等待收盘价达到当天的高点,然后卖出并退出交易。一旦收盘价出现反转迹象,其他交易者就会退出。
相反,当收盘价从上方穿过 VWAP 并持续下跌时,一些交易者会做空股票。一旦收盘价达到当天的低点,他们就会结束交易。
现在,一些交易者更喜欢低于 VWAP 的价格,因为这是买入的好价格,高于 VWAP 的价格可能表明这是卖出的好时机。以前面的 VWAP 图为例,你可以看到当价格高于 VWAP 时,有一个小的时期,价格持续上涨,然后价格下跌。
然而,对于交易策略来说,交易者认为收盘价与 VWAP 的交叉是一个信号。然而,人们应该注意到,VWAP 是一个滞后指标,这意味着它是完全基于历史数据计算的。因此,它不应该是交易策略中的唯一指标。
VWAP 作为盈利能力的检验
一旦交易者结束了交易,他们就会查看 VWAP 来检查他们的交易是否盈利。例如,如果一个交易者以 248 美元的价格购买了一股亚马逊股票,当天的 VWAP 是 250 美元,那么这个交易者实际上是以一个好价格购买了这只股票,并可以在这笔交易中获利。
到目前为止,我们已经看到了 VWAP 的一些用途。然而,通读这篇文章时,你是否有某种似曾相识的感觉,或者说,你是否意识到你曾读到过不同指标的类似特征?
你认为 VWAP 只是均线的另一种变化吗?为了回答这个问题,让我们看看 VWAP 和移动 VWAP (MWAP)之间的区别。
VWAP vs MVWAP
以下是 VWAP 和 MVWAP 的区别:
| MVWAP | VWAP |
| 移动 VWAP 是一条移动平均线,直观地表示股价运动。它在一段时间内跟踪一天结束时的 VWAP。 | VWAP 代表通常在特定一天内根据交易量调整的平均价格。 |
| MVWAP 给出了要分析的 VWAP 计算的平均数量。这意味着 MVWAP 可以从一天运行到下一天,给出一段时间内 VWAP 值的平均值。这使得 MVWAP 更加可定制,因为它是为满足特定需求而定制的。它还可以对短期交易的市场波动做出更灵敏的反应,如果选择更长的周期,它还可以消除市场噪音。 | VWAP 将提供全天的运行总数。因此,当天的最终价值就是当天的成交量加权平均价格。
例如,如果对某只股票使用一分钟图表,当天将进行 390 次(6.5 小时 X 60 分钟)计算,最后一次计算提供当天的 VWAP。 |
| MVWAP 看起来与 VWAP 相似,但不如 VWAP 流畅。这意味着 MVWAP 中有更多的突然变化,因为它处理的数据周期更长。 | VWAP 是一条平滑得多的线,它所建立的数据中的突然变化要少得多。 |
因此,虽然 MVWAP 和 VWAP 之间只有一线之隔,但这一线之隔也代表了显著的差异。
使用 VWAP 的优点
说到优点,我必须提到,成交量加权调整价格是股票的真正平均价格,并不影响其收盘价。
让我们看看 VWAP 如此受欢迎的原因:
VWAP 可以指示市场是看跌还是看涨:
当价格低于 VWAP 时,市场是看跌的,如果价格高于 VWAP,则市场是看涨的。牛市表明有买入压力,图表上的趋势线向上移动。熊市表明抛售压力,导致股价图呈下降趋势。
在 VWAP,买卖的指标很突出:
以 VWAP 线为指标的交易者,将可以低价买入,从而在卖出股票时获得更有利的回报。因此,VWAP 帮助投资者做出明智的决定。
VWAP 可以和移动平均线以及其他交易策略和指标一起使用:
在选择购买什么股票时,VWAP 是一个很好的指标,但在和其他交易策略一起使用时,它能提供更大的价值。VWAP 可以告诉你很多关于股票的当前和未来状态,包括多头和空头。
此外,VWAP 可以与另一个技术指标相结合来确认趋势,使用这种多指标策略可以大大减少错误信号的数量。
使用 VWAP 的缺点
VWAP 是一个滞后指标,因此,如果你试图用它超过一天,它将无法描绘正确的趋势。因此,它应该只被日内交易者使用。
此外,在某些情况下,某些股票(或市场本身)处于强劲的牛市阶段,因此全天不会有交叉,这反过来向交易者和机构描绘了非常少的信息。
在某种程度上,VWAP 的主要缺点是它不能被使用超过一天,因此,从历史的角度来看,它不能提供太多的信息。
结论
VWAP 是价格和交易量的结合,因此与均线相比,它为交易者提供了一组有价值的信息。计算 VWAP 听起来很复杂,但非常简单,这就是我们在博客前面讨论过的。
此外,当 VWAP 和收盘价一起使用时,解释起来也很简单。记住 VWAP 是做多或做空决策的工具,你可以成功运用 VWAP 方法。
通过 Python 中的技术指标策略课程,你可以了解更多关于技术指标的知识,并使用 Python 建立自己的交易策略。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
你的交易策略失败的 10 种方式
由苏尼尔·古格拉尼
算法交易试图消除我们交易时的情绪。我们提出交易策略,设定买卖资产的规则,并在部署前进行彻底测试。然而,在这个过程中我们会犯一些常见的错误。忽视它们会导致我们的策略悲惨地失败。
通过一系列的例子/测验,这篇文章涵盖了十种我们经常会犯的错误。这些例子基于算法交易的各个方面,如前瞻偏差、过度拟合、性能参数的误算等。
在本文中,我们将介绍以下内容:
完整博客的链接以 Google Colab 格式出现在博客的末尾,以防你想亲自尝试。
竞猜 1-2
下面是一个经过历史数据检验的交易策略。这里面有什么逻辑/技术错误吗?
如果有,是什么?
(时间段:2019 年 1 月 1 日至 2019 年 6 月 28 日,间隔:1 分钟,脚本:BANKNIFTY)
战略背后的理念
- 如果(sma_short/sma_long)>long_ratio,则在开盘时买入,在下一分钟收盘时卖出
- 如果(SMA _ short/SMA _ long)< short _ ratio,则在开盘时做空,在下一分钟收盘时买入
- 注:出于演示目的,回报仅按百分比计算,不考虑该工具的最小可交易单位。
利用人工智能构建算法交易策略
原文:https://blog.quantinsti.com/webinar-artificial-intelligence-algorithmic-trading-strategies/
https://www.youtube.com/embed/V7UGqi83iJw?rel=0
关于网上研讨会
制定稳健的量化交易策略是一个密集、严格、耗时的过程,不能保证成功。在本次网络研讨会中,您将学习如何应用人工智能和机器学习领域的技术来改进定量策略开发流程,并最大限度地提高每项策略的成功几率。
本次网络研讨会将涵盖:
- 人工智能和机器学习概述以及在交易中的实际应用
- 最佳实践和常见陷阱
- 模式识别算法
- 关联规则学习
- 在 TRAIDE 建立一个活的策略
与会者将学习实际应用,他们可以应用到自己的交易中,并将带着他们可以实际交易的策略离开。参加者应该对数量交易和算法交易有一个基本的了解。不需要编程经验。
关于演讲者
Tad Slaff,Inovance 首席执行官/联合创始人
Tad 拥有 6 年多将机器学习和数据科学技术应用于金融市场的经验。作为 Inovance 的首席执行官和联合创始人,他的使命是让更多的人了解这些技术。他拥有科罗拉多大学博尔德分校的数学学位,是一名注册外汇、期货和商品专业人士。
关于提前
Inovance Financial Technologies 是量化交易软件的领先开发商,专注于让交易者更容易获得人工智能和机器学习。迄今为止,Inovance 已经帮助数百名交易者创造了成功的策略。
Inovance 的财务分析平台 TRAIDE 是一个开发强大算法策略的创新工具。TRAIDE 帮助交易者从测试想法到实时交易的每一步。交易者选择他们想要分析的数据,TRAIDE 的算法揭示数据中的信息,并将信息呈现在交互式仪表板上,交易者可以为他们的策略建立简单直观的规则。Inovance 还管理着自己的量化基金。
如果你是一个散户交易者或专业技术人员,想建立自己的自动化交易平台,今天就开始学习 algo 交易吧!从自动化交易架构、市场微观结构、策略回溯测试系统和订单管理系统等基本概念开始。也可以看看这个 algo 交易课程。
本次活动于 2016 年 3 月 22 日星期二格林威治时间下午 05:00 |美国东部时间下午 01:00 | IST 时间晚上 10:30 举行。
陈博士的均值回归策略基础
原文:https://blog.quantinsti.com/webinar-basics-of-mean-reversion-strategies-by-dr-ernest-p-chan/
https://www.youtube.com/embed/5G7YdjnRvVI?rel=0
11 月 2 日星期四,IST 时间晚上 8:30 |美国东部时间上午 11:00 |美国标准时间晚上 11:00
均值回归策略是交易技术敏锐度的主要组成部分。价格和回报最终会回到他们的平均水平,这个概念是许多成功的反转策略的基础。我们 Quantra 很荣幸与 Ernest Chan 博士联合举办第一次关于“均值回归策略基础”的网络研讨会。
“均值回归策略基础”是与欧内斯特·陈博士的现场互动,他是全球知名的计算机化交易演讲者。陈博士在世界各地举办了多次教育会议,迄今已撰写了三本书。他在量化、算法和机器交易方面的著作是交易者和有抱负的量化分析师的主要文献。在本次网络研讨会中,陈博士将向观众概述交易的均值回复。
会议大纲
- 介绍
- 时间序列的平稳性
- 平稳性测试:ADF 测试
- 协整与相关性
- 均值回归策略
- 问题
扬声器
欧内斯特·陈博士
QTS 资本管理有限责任公司管理成员

欧内斯特·陈博士是 QTS 资本管理有限公司的管理成员。自 1997 年以来,他曾在多家投资银行(摩根士丹利、瑞士瑞信银行、Maple)和对冲基金(Mapleridge、Millennium Partners、MANE)工作。陈博士从康奈尔大学获得了物理学博士学位,在加入金融业之前,他是 IBM 人类语言技术小组的成员。他是总部位于芝加哥的投资公司 EXP Capital Management,LLC 的联合创始人和负责人。陈也是《量化交易:如何建立自己的算法交易业务》(Wiley)、《算法交易:获胜策略及其基本原理》的作者,他的第三本也是最新的一本书是关于机器交易:部署计算机算法征服市场。他是 http://epchan.blogspot.com 一位受欢迎的财经博客作者。
通过交易技术用 ADL 建立你自己的算法
原文:https://blog.quantinsti.com/webinar-build-your-own-algos-with-adl-r--by-trading-technologies/
https://www.youtube.com/embed/3tPMHBc_EN8?rel=0
2017 年 10 月 26 日星期四,IST 时间晚上 7:30 |美国东部时间上午 10:00 |新加坡时间晚上 10:00
构建您的算法
了解如何使用 ADL 构建、部署和启动基本算法
会议大纲
- 介绍
- 谁在交易技术
- 什么是 ADL,为什么贸易技术(TT)建立它
- ADL 的用例(做市、订单开发、整轮算法开发)
- Andrew 将介绍 ADL 中基本算法的构建(构建、部署、启动)
- 问题
//www.slideshare.net/slideshow/embed_code/key/ajKBWZkiE6cg69
Build your own algos with ADL® by Trading Technologies from QuantInsti
关于演讲者
安德鲁·雷纳尔德
产品经理-自动交易工具

Andrew Renalds 已经在 TT 贸易技术公司工作了 15 年。他目前是产品经理,负责 ADL 和 TT 交易 API 的产品战略。在加入 TT 之前,Andrew 在 ABN AMRO 银行担任了七年的财资系统副总裁,负责利率衍生品交易系统开发的设计工作。他还曾在芝加哥第一国民银行和自营交易公司 O'Connor & Associates 担任开发人员。Andrew 拥有罗切斯特大学的物理学学士学位、东北伊利诺伊大学的计算机科学学士学位以及佐治亚理工学院的核科学硕士学位。
我们能用混合模型预测市场底部吗?
原文:https://blog.quantinsti.com/webinar-can-we-use-mixture-models-to-predict-market-bottoms/
https://www.youtube.com/embed/o5BFAQK_Acw?rel=0
4 月 25 日星期二,MST 上午 8:30 | IST 时间晚上 8:00
预测市场底部的混合模型
网上技术交流讲座将解释混合模型,并探索其应用,以预测资产的回报分布,并确定可能意味着恢复的异常回报。
网上研讨会将涵盖
- 何必呢?用混合模型激发实验
- 混合模型是如何工作的?(直观的解释)
- 设计研究实验(我们如何回答原问题?)
- 定义策略
- 评估策略
- 结论
- 进一步探索的领域
- 资源
//www.slideshare.net/slideshow/embed_code/key/1wus9Iqi3Cg91I
Can we use Mixture Models to Predict Market Bottoms? by Brian Christopher - 25th April 2017 from QuantInsti
扬声器
布莱恩·克里斯托弗
量化研究员,Python 开发者,CFA 特许持有人,量化研究公司 Blackarbs LLC 创始人。

6 年前,他学会了用 Python 编写代码,目的是创建算法交易策略。四年前,他决定自行发表他的研究,重点是实际的、可重复的应用。
现在,他继续为越来越多的交易者、研究人员、开发人员、工程师、建筑师和各行各业的从业者开展他的开放式研究计划。他获得了马萨诸塞州波士顿东北大学的经济学学士学位,并于 2016 年获得了特许金融分析师(CFA)称号。
谁应该参加?
- 对算法交易研究感兴趣的交易员/定量分析师/分析师
- python/软件/策略开发人员
- 算法/系统交易者
- 投资组合经理和顾问
- 学生和学者
量化交易策略的分类
原文:https://blog.quantinsti.com/webinar-classification-of-quantitative-trading-strategies/
https://www.youtube.com/embed/4Byp_JHZftE?rel=0
7 月 11 日星期二,IST 时间晚上 7:00 |美国东部时间上午 9:30 |新加坡时间晚上 9:30
量化交易策略
有成千上万的关于交易策略的学术研究论文。了解这些学者发现了什么,以及我们如何在交易世界中使用他们的知识。
会议大纲
- “Quantpedia & QuantInsti”简介
- 数量交易领域的研究综述
- 量化交易策略的分类
- 去哪里寻找独一无二的阿尔法
- 鲜为人知的交易策略的例子
- 定量研究中的常见问题
- 问题和答案
//www.slideshare.net/slideshow/embed_code/key/BEHlVxgUwWglkx
Classification of quantitative trading strategies webinar ppt from QuantInsti
扬声器
Radovan 的贴身男仆
Quantpedia.com 首席执行官兼研究主管

Radovan Vojtko 获得了斯洛伐克技术大学的电信硕士学位。不久之后,他发现了自己对金融的真正热情,并开始为斯洛伐克共和国最大的资产管理公司(Tatra 资产管理公司)工作。他在公司晋升为投资组合经理,花了 5 年时间在几个量化基金中管理超过 3 亿欧元的资产(专注于多资产 CTA/趋势跟踪策略、市场时机和波动性交易)。2015 年,他迈出了下一大步,成为了 Quantpedia.com 的首席执行官。这是一家定量研究公司,其使命是将金融学术研究转变为更加用户友好的形式,以帮助任何寻求新的量化交易策略想法的人。
谁应该参加?
- 从业者(交易员/量化分析师/分析师和基金经理)。
- 理论家(学生和学者)对量化交易的研究理念感兴趣。
如何通过订单流序列分析获得实时交易优势

日期:2016 年 8 月 9 日星期二
时间:美国东部时间中午 12:00 |太平洋标准时间上午 9:00 | IST 时间晚上 9:30
为什么你不能错过这次培训
你是否在对 200 多个静态参数进行回溯测试,希望创造出一个适用于所有市场条件的“圣杯”式自动化公式?即使你创造了一个能在几个月内赚 20,000 美元以上的公式,请放心:一旦机构和高频交易算法明白了你在做什么,它就不再起作用了。
如果你想获得真正的交易优势,你必须了解机构——它们创造并控制了你市场中高达 90%的交易量——是如何影响你每笔交易的价值和市场结构的。
本次网络研讨会将向您展示
- 如何像机构交易者那样退后一步理解市场的实时结构和估值
- 为期货、股票甚至外汇制定实时订单流序列博弈计划和策略的最佳方式
- 哪些交易理念现在有效(哪些永远不会有效)
- 如何避免让你事后诸葛亮的“分析麻痹”
- 如果你想从你的分析中赚很多钱,为什么你不能“编码市场”
- 为什么你的分析必须包括实时的机构买家/卖家攻击行为
- 实时订单流序列分析如何始终如一地找到低风险/高回报的交易思路,给你一直想要的优势
演讲者简历
 特洛伊·埃珀森,NOFT-Traders.com
特洛伊·埃珀森,NOFT-Traders.com
Troy Epperson 介绍如何通过订单流序列分析获得实时交易优势。Troy 在华尔街工作了 15 年,是美国一家著名对冲基金和自营公司的首席交易员。他全职交易,使用他在 NOFT-Traders.com 教学生的相同的机构订单流序列跟踪分析和工具
关于NOFT-Traders.comT3 】
NOFT-Traders.com 是期货、股票和外汇交易者可以获得机构级培训和实时工具以停止亏损并开始与机构进行持续盈利交易的唯一在线场所。
我们广受欢迎的机构优势系统已经帮助 600 多名学生一劳永逸地解决了他们最大的交易位置、进场、止损、风险管理、出场和利润纪律问题。
我们的最新加入是我们的外汇阿尔法计划。这是唯一的在线机构级货币分析套件,帮助外汇交易者看到任何一对积极的机构买家和卖家——在你图表上的每根蜡烛线里面!
关于NinjaTraderT3】
NinjaTrader Group,LLC 及其子公司为活跃的交易者提供屡获殊荣的交易软件和经纪服务。
NinjaTrader 成立于 2003 年,现已发展成为行业领导者,凭借一流的技术、高额折扣佣金和世界一流的支持,为全球 40,000 多名交易员提供支持。
如何使用金融市场数据进行基本面和定量分析
https://www.youtube.com/embed/yfAVYce7Xhk?rel=0
QuantInsti 将与来自全球的三位顶尖专家举办独一无二的网络研讨会。注册参加网上技术交流讲座,了解有利可图的交易基本面,了解高频数据分析面临的挑战,发现期货交易中的机会和陷阱,并观看关于最受欢迎的交易策略之一“配对交易策略”的分步教程的现场演示!
不要错过这个向市场从业者本身学习的机会
|
Topic
|
Speaker
|
|
- Sources of fundamental data
- Different things (profits, sales data, etc.) that may affect the stock price. )
- When it comes to price correlation, what should you pay attention to in the posterior test?
| 迪帕克·谢诺伊 |
|
- High-frequency data for quantitative analysis
- Challenges of vectorization analysis and out-of-core processing
- Futures Trading-Opportunities and Traps
- Value at Risk (VaR) and Expected Shortage (ES)
| 马克西姆法哥斯 |
|
- Download the price from Quandl
- Pair trading strategy
| 马可·迪波 |
扬声器
迪帕克·谢诺伊
capital mind 创始人兼首席执行官

Deepak Shenoy 是一位在技术和金融市场拥有超过 16 年经验的企业家,他是印度最好的货币、市场和交易网站 Capitalmind 的创始人兼首席执行官。Deepak 专注于金融市场、大数据、分析、可视化、软件编程、架构和设计、商业分析、战略。
过去,Deepak 曾为 iCreate Software 提供咨询,帮助他们进行监管报告。Deepak 曾与 Estee Advisors 在量化策略领域合作。迪帕克也是专注于股票市场投资者的创业公司 Moneyoga.com 的创始人。在此之前,他是 Flovate Technologies 印度公司的首席执行官(后来被卖给了 WNS),也是 Agni Software 的首席执行官和联合创始人。Deepak 拥有卡纳塔克邦国家理工学院的计算机科学工程学位。
最大噬菌体
创始人,黄金罗盘量化研究

Maxime 的职业生涯跨越了价值和风险的战略层面,过去几年特别关注交易行为和市场微观结构。他在 M&A、基金管理以及目前的公司战略中采用了量化的角度。Maxime 拥有 INSEAD 大学的 MBA 学位和法国国立高等艺术学院的工程硕士学位。Maxime 是一名成功的 EPAT 校友,并与人合作开发了一个基于云的自动交易系统项目,将机器学习作为课程的一部分。
马尔科·尼古拉斯·迪博
quanti cko Trading 首席执行官

Marco 的职业生涯是作为交易员和投资组合经理度过的,他特别关注股票和衍生品市场。他专门研究量化金融和算法交易,目前担任阿根廷 Valores S.A .的量化交易部门主管和副总裁。Marco 还是 Quanticko Trading S.A .的联合创始人兼首席执行官,quanti cko Trading s . a .是一家致力于开发高频交易策略和交易软件的公司。Marco 拥有圣安德烈斯大学的经济学学士学位和金融学硕士学位。Marco 是 EPAT 的成功校友,并在课程中撰写了一个关于配对交易策略和使用 Quantstrat 进行回溯测试的项目。
谁应该参加?
- 股票分析师和研究人员
- 高频量化交易者
- 定量开发人员
- 期货交易员
- 技术分析师
- 学生和学者
最近的市场事件对算法交易的影响
原文:https://blog.quantinsti.com/webinar-impact-of-recent-market-events-on-algorithmic-trading/
https://www.youtube.com/embed/IZ2EEswfW2g?rel=0
日期:2016 年 7 月 19 日星期二
时间:IST 时间下午 06:00 |新加坡时间下午 08:30 |格林威治时间下午 12:30
简介
最近的全球事件,如英国退出欧盟和随后的外汇市场波动,吓坏了许多投资者。在这种事件之后,风险厌恶情绪的增加是一个自然的结果,因为市场参与者在交易时会保持谨慎。
然而,即使在如此动荡的时期,自动化交易者也有一个好日子。据媒体报道,使用算法交易的对冲基金经常胜过人工交易者,尤其是在如此紧张的市场条件下。
信息会议内容
- 本季迄今为止最大的交易事件
- 英国退出欧盟及其对当天全球不同市场参与者的影响
- 交易成本上涨的影响。例证:SEBI 在印度 STT 徒步旅行
- 算法交易公司对此类事件的反应如何?
- 成为量化/算法交易者需要什么?
- 行业要求
- 所需的技能和知识
- Quantinsti 的算法交易执行程序有什么帮助?
- 问与答——询问算法和量化交易专家
在英国退出欧盟时期,阿尔戈斯智胜了人类吗?

发言人简介
Nitesh Khan delwal 先生,iRageCapital 咨询有限公司联合创始人
Nitesh 在金融市场拥有丰富的经验,在不同的资产类别中扮演不同的角色。他共同创立了 irage capital Advisory Private Limited 和 QuantInsti,前者是在印度提供算法交易技术和策略服务领域值得信赖的公司,后者是算法交易研究和培训机构。他领导了 iRageCapital 和 QuantInsti 的业务部门。在 QuantInsti,他还是衍生品培训部门的负责人&跨市场研究。他目前是印度 iRage 全球咨询服务私人有限公司的主管。
他曾在银行资金部(外汇和利率领域)和自营交易部门工作过。他在 IIT 坎普尔获得电子工程技术学士学位,之后在 IIM 勒克瑙获得管理学研究生学位。
关于算法交易的信息会议
原文:https://blog.quantinsti.com/webinar-informative-session-aabout-algorithmic-trading/
https://www.youtube.com/embed/6TgMx6dKk64?rel=0
日期和时间
2016 年 5 月 24 日星期二
IST 时间下午 06:00 |格林威治时间下午 08:30 |格林威治时间下午 12:30
会话内容
- 算法交易行业概述
- 目前的市场份额和数量
- 全球算法交易的增长和未来
- 风险措施和技术进步
- 如何开始——免费且便宜的试水方法
- EPAT——算法交易管理课程
- 这是什么?
- 这和你有什么关系?
- 为什么你需要参与进来?
- 问与答——询问算法和量化交易专家
发言人简介

先生 Nitesh Khandelwal ,iRageCapital 咨询有限公司的联合创始人
Nitesh 在金融市场拥有丰富的经验,在不同的资产类别中扮演不同的角色。他共同创立了 irage capital Advisory Private Limited,这是一家在印度提供算法交易技术和策略服务领域值得信赖的公司。他领导了 iRageCapital 和 QuantInsti 的业务部门。在 QuantInsti,他还是衍生品和跨市场研究培训部门的负责人。他目前是位于新加坡的 iRage 全球咨询服务私人有限公司的董事。
他曾在银行资金部(外汇和利率领域)和自营交易部门工作过。他在 IIT 坎普尔获得电子工程技术学士学位,之后在 IIM 勒克瑙获得管理学研究生学位。
下一步
如果你是一名散户交易者或专业技术人员,想要建立自己的自动化交易平台,今天就开始学习算法交易吧!从基本概念开始,如自动交易架构、市场微观结构、策略回溯测试系统和订单管理系统。你也可以报名参加 EPAT,这是业内最广泛的量化交易课程之一。
一瞥基于人工智能的 HFT 交易策略
原文:https://blog.quantinsti.com/webinar-machine-learning-artificial-intelligence/
https://www.youtube.com/embed/nzPX_NQZuKg?rel=0
高频交易使用复杂的算法来分析市场,尖端技术工具实现最快的执行速度。
关于网上研讨会
在本次网络研讨会中,我们了解了机器学习技术如何帮助我们设计更好的交易策略。我们学习了交易中的阿尔法,以及如何应用市场结构和订单流的知识提取阿尔法。我们也理解了如何使用机器学习来预测资产路径。网上研讨会对所有有兴趣了解高频交易和使用人工智能进行交易的人开放。
关于演讲者
萨米尔·库马尔

Sameer 是 QuantInsti 的董事和教员。在算法交易的高管课程中,他教授学生构建低延迟系统以及涉及人工智能的策略。Sameer 已经在 iRageCapital Advisory Private Ltd 领导基础设施开发团队和低延迟编程部门超过 5 年。
要了解如何为交易实现机器学习,请加入我们即将举行的关于机器学习的网络研讨会。
如果你是一名散户交易者或专业技术人员,正在寻找自己的自动化交易平台,今天就开始学习高频交易吧!从自动化交易架构、市场微观结构、策略回溯测试系统和订单管理系统等基本概念开始。您还可以报名参加我们的 algo 交易课程,这是业内最广泛的认证课程之一。
本次网络研讨会于 2015 年 2 月 27 日下午 6:00 在 IST 举行
股票交易策略建模
原文:https://blog.quantinsti.com/webinar-modelling-trading-strategies-in-equities/
https://www.youtube.com/embed/RRWvQzX6upA?rel=0
美国东部时间 2018 年 3 月 8 日星期四下午 7:00 | IST 时间下午 4:30 |美国东部时间早上 6:00
会议大纲
本次网络研讨会将简要概述 SGX 的现金市场,这为全球投资者提供了一个独特的市场机会。我们还将讨论每日杠杆凭证(DLC),这是一种创新的金融产品,最近在亚洲市场首次在 SGX 推出。我们将讨论上述主题的要点,并强调有效的短期和中期系统交易策略,以从这些产品中受益。本次网络研讨会将由 QuantInsti 与 SGX 和互动经纪人合作举办。
扬声器

Lionel Lin,SGX 证券研究主管
Lionel is part of the Research and Products team and is responsible for writing research content on current developments in SGX stock market. Lionel spent several years as an equity analyst on the sell-side in both Hong Kong and Singapore, focusing on the Asian Technology sector. He is a graduate with a Business Management degree (Finance major) from the Singapore Management University. 
QuantInsti 副总裁 Prodipta Ghosh
Before joining QuantInsti as Vice President, Prodipta spent more than a decade in the banking industry - in various roles across trading and structuring desks for Deutsche Bank in Mumbai & London, and as a corporate banker with Standard Chartered Bank. Prior to that, Prodipta worked as a scientist in India's Defence R&D Organization (DRDO). He is a graduate with a B.E. in Mechanical Engineering from the Jadavpur University and has a postgraduate degree in management from the IIM Lucknow.
[网上研讨会]选项-真正的游戏
原文:https://blog.quantinsti.com/webinar-options-the-real-game-30-september-2020/
https://www.youtube.com/embed/CAs1vPfuMro?rel=0
加入 EPATian Vishnu Bharath 这个一小时的盛会,他解释了所有关于期权,期权交易和相关主题。毗湿奴已经交易了很多年,并获得了大量的经验,知识和对期权的见解——他在这段视频中分享了这些。毗湿奴也分享了一些有用的提示、建议和指导,告诉你如何学习和更好地交易。
观看完整视频了解更多信息。别忘了看,赞,分享,评论,订阅!
关键要点
- 希腊期权的简单理解
- 期权希腊人的相互依赖
- 利用现有的算法系统
- 管理直接反应策略。
建议读数
- 期权交易基础讲解
- 学习轨迹|期权交易中的量化方法
- 期权交易系列教程包括定义、期权定价模型、期权希腊人、不同的交易策略以及可免费下载的代码和数据,如离差交易、指数套利等。
- 视频|选项简介
- 播放列表|交易期权和衍生品,如 Quants
- 讲座|高级选项
关于演讲者

Vishnu Bharath(印度期权交易员)
Vishnu 是一名工程师出身的交易员,之前曾为爱立信设计电信网络。为了成为一名可信的交易者,他选择了 EPAT,在获得 QuantInsti 认证后;他交易了 Quants Capital,这是一家位于浦那的自营交易机构。
现在,他致力于自己的自营交易业务,也为一些交易社区提供咨询。他专门研究期权交易中的头寸调整。他还开发了交易 API,使用图像识别来自动执行基于价格行为的策略。
关于 EPATians 的股份
在新冠肺炎疫情的这些考验时期,“EPATians' Share”是一项倡议,来自不同领域的 EPATians 通过一系列 25 - 40 分钟的简短会议,与 EPATian 社区分享他们在专业领域的知识财富。会议的主题是涵盖 EPAT 课程以外的主题,涵盖各个领域,甚至包括非金融和非贸易背景。
本次会议于:
2020 年 9 月 30 日星期三【This 时间下午 07:00 |美国东部时间上午 09:30 |美国标准时间下午 09:30
如何在对冲基金找到工作?
原文:https://blog.quantinsti.com/what-do-hedge-funds-look-for-when-employing/
对于几个极度倾向于金融市场的人来说,在对冲基金找到一份工作一直是他们的梦想。这些人每天都在关注金融市场。在本文中,我们将从求职者的角度讨论对冲基金的这一角色。
本文涵盖:
- 什么是对冲基金?
- 对冲基金的工作类型
- 教育要求和所需技能
- 在对冲基金开始职业生涯的更多技巧/方法
- 利弊
- 顶级对冲基金名单
什么是对冲基金?
对冲基金是一种投资基金,它利用投资者汇集或积累的财富。对冲基金的主要目标是实施这样的交易策略,帮助所有投资者尽快获得最大收益。因此,他们关注短期收益。此外,他们利用借来的或杠杆资金来达到最大化投资者回报的目的。虽然,由于杠杆基金涉及的风险,美国和欧洲的对冲基金在 2007-08 年的金融危机后受到监管,危机的主要原因是银行和金融机构的债务增加。
接下来,我们将看到对冲基金的工作类型。
对冲基金的工作类型
作为对冲基金专业人士,你有各种各样的工作机会可供选择。让我们简单了解一下对冲基金的工作类型。
这些是:
- 执行交易员
- 投资分析
- 投资组合经理
执行交易员
执行交易者是那些提出新想法并执行新想法的人。同样,一些交易者执行想法,但不产生想法。
投资分析师
这些人投入大量精力进行研究,产生新的想法,并帮助经理们做出有关投资的关键决策。投资分析师也被称为研究分析师。
投资组合经理
投资组合经理是做出关于买/卖什么和在哪里投资的关键决定的人。他们还负责确认投资分析师的研究和发现的真实性和正确性。如果研究中有任何差异或问题,他们会要求投资分析师审查报告并加以纠正。此后,投资组合经理为投资者做出买入/卖出的最终决定。
展望未来,我们将了解进入对冲基金所需的教育要求和技能。
教育要求和所需技能
要想成为对冲基金的员工,你需要拥有以下专业之一的学士学位:
- 金融
- 会计
- 统计数字
- 经济学
- 工程/数学
除了学士学位,其他首选资格包括:
- 工商管理硕士
- 金融硕士(金融硕士)
- 特许金融分析师
- CFP(国际金融理财师)
- CTFA(注册信托和财务顾问)
- CAIA(特许另类投资分析师)
- FRM(金融风险经理)
基本上,你最好有一些证书和研究金融市场的热情。此外,在其中一个领域拥有专长,将对你作为对冲基金员工的职业生涯大有帮助。这是因为每个领域都提供了特定角色所独有的知识。例如,对金融和会计有透彻的了解可以帮助你进行投资分析。
此外,比任何资格证书更重要的是,在该领域丰富的经验将帮助你在你所选择的角色中获得最大的专业知识。
此外,在对冲基金中,有些技能可以帮到你,它们是:
- 定量分析——在定量相关的工作中,你会发现自己获得了最好的技能发展时间。你可以选择经济学家或金融分析师的职位,甚至可以写一篇论文来获得这项技能。
- 管理投资——这是对冲基金最重要的技能之一。有了管理自己投资的经验,你也可以准备好管理对冲基金的投资。
- 善于讨论技术细节——你应该善于用通俗的语言讨论复杂的分析或技术信息,以便能够用一些术语帮助投资者。
- 强大的数学和统计技能——这些技能在对冲基金中可能是也可能不是必须的。在工作中应用机器学习模型可能需要一些数学知识,如线性代数。
- 风险管理-你必须了解管理风险,因为对冲基金有时是高风险投资,同时也获得高回报。你也可以成为对冲基金的初级风险分析师。
接下来,我们将讨论更多的技能/方法,让你在对冲基金开始职业生涯。
在对冲基金开始职业生涯的更多技巧/方法
因此,主要问题是,对冲基金在招聘时还会寻找什么?
当然,一系列的面试问题以及努力准备一些真正重要的话题,如逻辑推理、Python 等。预先投资将极大地帮助量化分析师进入对冲基金。
此外,我们上面讨论的技能并不是进入对冲基金并开始职业生涯的唯一途径。要想在对冲基金谋得一份工作,你还必须投资其它一些东西,它们是:
- 阅读
- 实习
- 持续学习
- 专业/贸易经验
- 保持专注
- 建立工作关系网
阅读
想要在对冲基金工作,还需要尽可能多地获取相关知识。并且,没有什么比阅读大量投资导向的书籍更好的了。你可以在网上找到一些非常有知识的书籍,你可以参考。只有从百忙之中抽出多达 20 分钟的专门阅读,才能帮助你获得足够的知识。
实习
为了学习交易的秘密和事先获得专业知识,你必须早点开始,成为一名实习生。在彻底阅读并获得一些良好的理论知识后,下一步是获得一些实践经验。通过实习,你将获得一个极好的机会去了解对冲基金的工作。
持续学习
理解好的和坏的投资是最重要的。你必须反思那些表现良好的投资,并从那些表现不佳的投资中吸取教训。在对冲基金开始职业生涯时,持续学习也非常重要。
专业/贸易经验
在对冲基金的良好职业经历是开启你职业生涯的最佳方式。学习如何牢牢把握估值和擅长 excel 可以在许多方面帮助你。此外,你需要相信自己的决策,找出市场中的最佳位置。这样,你的技能将被视为一种资产。
保持专注
一旦你开始一个角色,最好在你的职业生涯中坚持下去,而不是试图跳到另一个角色。这样,任何新的招聘在任何时候都不会成为你的麻烦。除了你对两个角色感到困惑,你的雇主也会怀疑你对一个团队的承诺和奉献。
建立工作关系网
人脉是在对冲基金找到工作的另一个重要方面。当你希望第一次做某件事时,除了阅读、获得经验或实习,你还必须与那些已经熟悉角色并能帮助你进入角色的人建立联系。通过这种方式,你可以从他们进入这个行业的步骤中学到很多。
既然你已经了解了在对冲基金工作所需的工作类型、教育要求和技能,让我们进一步看看顶级对冲基金的名单。
展望未来,让我们找出在对冲基金工作的利弊。
利弊
在对冲基金工作给你带来了很多选择,同时也带来了一些好处,但也有一些不好的方面。
让我们先来看看在对冲基金工作的好处:
- 对冲基金规模较小,给员工提供了更大的控制权
- 它提供了一个非常有回报的职业,因为有些人还被发现年薪 500 万美元
- 在对冲基金中,你通常会有机会快速晋升,因为对冲基金会对你的努力给予很好的补偿
现在,我们将找出对冲基金的缺点,它们是:
- 大量的竞争会让你不知所措
- 责任相当多,因为对冲基金要对所有投资者的钱负责
展望未来,你现在可以在下一个副题中探索顶级对冲基金的名单。
值得工作的顶级对冲基金列表
世界上有几家对冲基金,在其中的顶级公司工作可以为任何员工提供突破。提供最佳员工满意度的公司是行业中最大的公司。
让我们看看我从和购买的对冲基金列表,并找出为什么它们被认为是最好的:
德·肖
这家公司获得了最高的排名,因为员工给它的评分是 90 分(满分 100 分),这使它成为所有竞争对手中最好的公司。德肖以纯量化基金起家,利用计算机驱动的分析结合基本面策略。这就是该公司也被称为“quantamental”的原因。
两项适马投资
Two 适马投资公司的员工评分为 80 分(满分为 100 分),排名第二,仅次于德肖公司。由于其工作文化、对员工的高额报酬和设施,这家公司被评为第二大最佳对冲基金。
城堡
Citadel 的工作文化评分为 4.3 分(满分为 5 分),员工薪酬也相当不错,在员工总体满意度中排名第三。它为所有员工提供了成长和赚钱的机会。
另外,从 Glassdoor 的评论来看,有两家对冲基金被员工认为是最好的,它们是:
布里奇沃特
Bridgewater Associates 的员工评价为 4.1 分(满分 5 分),首席执行官 100%认可,在工作文化和薪酬方面享有良好声誉。
文艺复兴首都
在 Renaissance,员工的满意度为 3.6 分(满分为 5 分),该公司不仅被视为一个体面的工作场所,还被视为一家定期支付高薪的公司。
结论
由于进入对冲基金是许多人的梦想,因此获得该领域的全面知识并按照要求行事非常重要。要在对冲基金开始你的职业生涯,你必须尽早开始,尽可能多地获得实践领域的知识。除了知识之外,在你涉足对冲基金并开始职业生涯之前,获得该领域的经验也至关重要。
本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
是什么让 Python 成为算法交易者最喜欢的语言
原文:https://blog.quantinsti.com/what-makes-python-most-preferred-language-for-algorithmic-traders/
生存!知识!技能!
对于那些希望在竞争激烈的量化交易市场中茁壮成长的人来说,Python、C++或 Java 编程技能是必须的。使用这些编程语言进行算法交易的核心概念是一样的。
我们在 QuantInsti 收到的最常见的问题之一是:“对于算法交易,我应该学习哪种编程语言?”这个问题的答案是:没有什么比算法交易更好的语言了。但是你可以看看 Python,当谈到算法交易时,它是一个完全不同的游戏改变者。
Python 是什么?
Python 是一种免费的开源和跨平台语言,它有一个丰富的库,可以用于几乎所有可以想象的任务和专门的研究环境。
在低/中交易频率的情况下,即对于持续时间不少于几秒钟的交易,这是自动交易的绝佳选择。它有多个 APIs 库,可以链接起来,使它更优化,更便宜,并允许多种贸易想法的更大探索性发展。

是什么让 Python 成为算法交易者最喜欢的语言?
开源:
帮助他们建立自己的:
- 数据连接器,
- 执行机制,
- 回溯测试,
- 风险和订单管理,
- 向前走,然后
- 优化测试模块。
功能编程:
- 更容易编写和评估算法交易结构
- 该代码可以很容易地扩展到动态交易算法
- 与 C/C++相比,创建交易平台需要更少的时间
- 与其他语言(如 R)相比,易于使用
较短的代码:
- 使用 Python 进行交易需要更少的代码行,因为有大量的库可用
- 量化交易者可以跳过其他语言如 C 或 C++可能需要的各种步骤
- 这降低了维护交易系统的总成本
更少的回溯测试担忧:
更容易使用:
- 相对更容易将新模块固定到 Python 语言中,并使其具有可扩展性
- 现有的模块也使算法交易者更容易在不同程序之间共享功能,方法是将它们分解成可应用于各种交易架构的独立模块
下一步
如果你正在寻找更多关于算法交易的 Python 库的信息,请查看我们的博客文章。如果你是一名程序员或技术专家,希望向 Yves Hilpisch 博士这样的专家学习自动化交易,看看我们的课程算法交易(EPAT) 高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 教你成为成功交易者所需的技能。立即注册!
您还可以查看我们的互动课程' Python for Trading ',通过对自己的策略进行编码和回溯测试,以及 QuantInsti 和 MCX 的联合认证,您将获得 Python 编码的实践经验。
算法交易——为什么要采取行动?
原文:https://blog.quantinsti.com/why-algo-trading-webinar-12-december-2019/
https://www.youtube.com/embed/73gr7qkQedo?rel=0
【2019 年 12 月 12 日星期四
美国东部时间上午 9:00 | IST 时间下午 7:30 |新加坡时间晚上 10:00
会议大纲
如果你是金融市场的交易者或投资者,你可能会意识到在过去的 10-15 年里,投资领域发生了翻天覆地的变化。
它的核心是在市场中使用定量技术来做买卖决策。我们经常从我们的社区听到,他们希望了解更多关于这些新时代工具的知识,并利用它们来提高投资回报。
- 当前的交易和投资格局:过去二十年交易者的处境如何
- 手动/全权交易者面临的问题
- 传统分析方法(技术分析和基本面分析)的局限性
- 给你现有的交易风格增加一个定量分析的维度
- 问与答
谁应该参加?
- 全权委托/手工交易者(例如专业交易者,兼职交易者),他们希望提高技能并获得更好的回报
- 技术专业人士,他们希望利用自己的技术技能明智地投资于金融市场
- 希望从事定量金融的学生和其他爱好者
演讲者简介

Vivek Krishnamoorthy
内容负责人&QuantInsti
的研究 Vivek 教授 Python 数据分析,为我们在世界各地的学生构建量化策略和时间序列分析。他在印度、新加坡和加拿大的工业、学术和研究领域拥有十多年的经验。他拥有 VESIT(孟买大学)的电子&电信工程学士学位、NTU 的 MBA 学位和 Takshashila Institution 的公共政策研究生证书。

Ashutosh Dave
QuantInsti 内容研究高级助理&
除了参与我们的旗舰项目 EPAT 的整体内容开发,Ashutosh 还负责 quantin STI 的推广活动。在加入 QuantInsti 之前,他曾在伦敦的一家 prop 公司担任衍生品交易员,专门从事利率和大宗商品交易。他以优异的成绩获得了伦敦经济学院(LSE)的统计学硕士学位,并获得了 FRM (GARP)的认证。
简报
您可以点击此处查看本次网络研讨会的 powerpoint 演示文稿:
https://www.slideshare.net/slideshow/embed_code/key/Itc3zZFSAPh8YA
Webinar on Algorithmic Trading - Why make the move? with Vivek Krishnamoorthy and Ashutosh Dave from QuantInsti
在 Slideshare 上查看我们所有的 40 多个之前的网络研讨会 powerpoint 演示文稿。
为什么你应该做算法交易?
原文:https://blog.quantinsti.com/why-you-should-be-doing-algorithmic-trading/

“机器人!啊?他们对交易了解多少?当我问他对算法交易的看法时,我的朋友说:“股票市场需要只有人类才能拥有的洞察力、时机把握和天才水平。”。这可能是真的吗?算法交易是噱头吗?不完全是这样,事实上正相反。
纽约证交所 84%的交易、伦敦证交所 60%的交易和纽约证交所 40%的交易都是通过算法交易完成的。从表面上看,似乎每笔交易迟早都会使用算法来完成。但这是为什么呢?
什么是算法交易?
假设你有一个基于定量分析的策略,这个策略是你开发(或窃取)的,并且对你很有效。让我们假设你的策略告诉你什么时候买/卖股票,什么时候记录利润或减少损失。这是一项战略应该具备的最低要求。如果你的没有,孩子,你就有麻烦了!因此,当你坐在办公桌前啜饮伯爵茶时,你在任何时候都在做以下事情之一
- 根据你的策略,看图表、报价或新闻,试图找到交易信号
- 当你发现交易信号时,填写订单细节(赚钱时间!耶!)
- 监控你的交易,看看它们是否达到了你的目标或者相反的方向(就像他们经常做的那样)
- 平仓,要么记录利润,要么减少损失
- 冲洗并重复
这是你工作时的样子(平均而言):

现在记住,你的策略,无论在理论上多么成功,只要你坚持,它就是好的。虔诚地遵循你的策略是长期获利的重要前提。这意味着你不会屈服于你的情绪,你不会进行近似计算,你不会过早地预定利润或取消止损,因为你认为股票最终会朝着你的方向发展。让我们假设你没有做所有这些事情,假设你像一个虔诚的天主教徒一样遵循你的系统,你是一个像佛教僧侣一样控制自己情绪的超人(我知道你甚至没有接近,但让我们假设你是)。

即使做了所有这些(达到超人/僧侣的水平),你还没有完成。在你开始从你的策略中获得实际利润之前,还有许多因素你需要弄清楚。例如,你需要不断地回溯测试和调整你的策略,以确保它与这些不断变化的市场相关。只有一种策略会让你面临各种风险,为了减轻这种风险,你必须分散投资,使用至少两种不同的策略。为此,你需要不断扫描市场,寻找适合你策略的新交易资产,等等。
简而言之,要想在交易中成功(特别是量化交易),你应该表现得像个超人。但我们都知道真相是不同的。我们经常犯错误,我们经常做我们不应该做的事情,我们最终会变得悲伤、痛苦和净资产减少。
但是,如果有一种方法可以外包大部分这种沉重和令人沮丧的工作,如果其他人揪着自己的头发尖叫着亏损,如果你只是站在旁边(啜饮马提尼)知道你的战略被正确地遵循,你最终会赚钱,你唯一要做的工作是专注于战略,会怎么样?
让我为你调制马提尼,欢迎你来到算法交易的世界。算法交易正在把控制权交给计算机。你只需要用计算机能理解的语言写下你的策略,然后让计算机来帮你完成繁重的工作。作为交易者,你在一天中所做的所有工作(如上所述)本质上都是机械的,可以由机器以更好的方式来完成。计算机可以扫描数百只股票,并在几秒钟内执行尽可能多的订单(这用于高频交易或 HFT),自动化交易台的设置成本也在下降。让机器做平凡的工作,而我们专注于更高智能的事情,这一概念不仅在交易领域,而且在其他任何地方都是一种趋势。阅读:自动驾驶汽车、智能家居、siri 等。
算法交易的好处
人类情感= 0
机器没有情感(至少现在没有,祝你好运谷歌!)我们可以利用这一点。在手动交易中,这是一个巨大的损失。恐惧和贪婪阻止我们做正确的事情。机器不会因为任何外部因素而影响它们的决策,因为它们只是遵循程序中写的东西。当你意识到市场上的大多数交易都不是由情绪驱动的,它会自动让你陷入被动,让算法交易成为一种必要。当你把情绪排除在等式之外时,你的策略真正获得了一个公平的机会。
 T2】
T2】

准确度+速度= 100
机器在处理交易中的操作问题时,每次都很准确。例如,填写正确的订单明细,我发现自己在这个部门犯了很多次愚蠢的错误。我很确定每个人在他们的交易生涯中至少这样做过一次。我们在速度和准确性方面的低效率会让我们失去很多机会。即使是熟练的交易者也至少需要 10-15 秒才能下单,在机器交易的时代,10-15 秒是永恒的,价格可以大幅波动。这是真的,尤其是在 HFT 交易方面。在这段时间内,计算机将会发出和关闭 100 多个订单。

舒适度= 1000%
想象一下,不用每天都经历那种紧张的过山车。仅此一点就足够让你开始学习算法交易了。毕竟,当他们把交易作为一种职业卖给你时,压力部分并没有提到,所以为什么现在要处理它呢?相信我,这种感觉棒极了。

可扩展性= 100 级
考虑到当今巨大的计算能力,我们可以同时运行多种策略来扫描成千上万的交易机会信号。这对于人类来说无论如何都是不可能的。见鬼,我们人类甚至不能长时间专注于一项任务,我们怎么能呢?去你的,9gag!

说到这里,让我告诉你一些与算法交易相关的次要但重要的细节。
更多详情
算法交易是一种使用计算机编程的过程,遵循一套定义好的指令进行交易,以便以人类交易员无法实现的速度和频率产生利润。有多种编程语言可用于此目的,其中一些是 R、Python、C++等(点击这里阅读为什么 Python 是算法交易者最喜欢的语言)。无论你选择哪种语言,你都需要确保你的算法能正确地与计算机沟通,并涵盖市场可能发生的所有事件。否则,你的电脑将像一个松散的大炮。这种情况下的损害可能是巨大的。
如果你对建立自己的 algo 交易平台感兴趣,这篇文章将指导你完成一整套的要求。简而言之,你需要一个有效的策略,允许自动程序运行的交易软件,为你的策略编码的编程技能,以及测试用的历史数据,这是除了经纪人、许可证等通常的交易之外的东西。
下一步
算法交易是未来,唯一的问题是你什么时候上船?
通过查看 Quantra 上的自定进度认证课程,现在就开始学习交易策略范例、可用于交易的不同编程语言以及算法交易相对于传统交易技术的优势!
如果你想学习算法交易的各个方面,那就去看看《算法交易》( EPAT)的高管课程。这个算法交易课程涵盖了统计学&计量经济学、金融计算&技术、算法&量化交易等培训模块。EPAT 为你提供了在算法交易中建立一个有前途的职业生涯所需的技能。
区块链将如何改变股市?
原文:https://blog.quantinsti.com/will-blockchain-change-stock-markets/

Sushant Ratnaparkhi
不,我们不是在谈论比特币。比特币和区块链是两回事,人们经常会误解。区块链是一个比比特币大得多的概念,你可以说比特币是区块链的一个应用。
那么,什么是区块链呢?
区块链的快速而简单的定义——一个分布式在线账本系统,它有多个节点,每个节点(一台计算机)维护账本的更新副本。可以有任意数量的节点,任何人或组织都可以成为节点。分类帐中有交易条目块,这些块是公共的,任何节点都可以添加新的块(假设节点遵循规则)。
块在网络中一个接一个地被正式化,并且分类帐(具有新块)由整个网络更新。尽管这些块是公开的,但它的内容受密码保护,不允许修改过去的块。由于分类帐有多个副本,任何人都不能删除或修改现有的块,这提供了内在的安全性,而不需要中央机构。

由于区块链的性质,它有许多优势,可以在各种领域实施,如智能合同、资产注册和其他金融和法律用途。
让我们关注一下,如果区块链技术在股票市场实施,会发生什么。
没有中间人
目前,有许多实体参与股票市场,如经纪人,监管机构和证券交易所本身。区块链可以让证券交易所去中心化。该技术可以强制执行规则和条例,并确保 100%的合规性。这不仅会降低客户在佣金方面的巨额成本,还会加快交易过程,从而大大加快交易结算。
区块链还可以在很大程度上消除对第三方监管机构的需求,因为规则和法规将被建立并要求每次都遵循,以使你的交易成为官方的(作为区块链的一部分),所以在这种情况下,网络充当每一笔交易的监管机构。
转向区块链的行动已经开始,日本金融服务厅已经允许东京证券交易所的运营商日本交易所集团使用区块链作为其核心交易基础设施【1】
2015 年,纳斯达克公开了使用其纳斯达克 Linq 区块链总账技术成功完成并记录私人证券交易【2】
降低交易成本
目前,区块链交易比任何其他跨境交易都要快得多。交易确认是由同行而不是任何第三方完成的,几乎可以是即时的。
例如,从一个国家向另一个国家汇款需要大约 2-3 天,而设计用于此目的的区块链应用程序可以在几分钟内完成。不难想象这种效率对全球经济发展的影响。
此外,由于系统中的中介数量减少,与它们相关的成本,如交易记录保存、审计和交易验证也将减少。例如,在当前的系统中,1%的处理费可能看起来不多,但增加了许多中介,成本会显著增加,从长远来看会产生影响。这也限制了很多小玩家的进入。区块链扫除了这个障碍。任何有助于小企业与大企业竞争的变革都会产生重大的全球影响。
更高的安全性和透明度
基于区块链的交易所可以具有内置功能,可以自动阻止和报告网络中任何人的恶意尝试。这使得市场监管机构的监管更加透明。由于制度的缺陷给政策制定者带来的限制可以消除,他们可以在不降低标准的情况下实现政策目标。这可以极大地加速世界经济的增长。
由于区块链分类账的设计方式是所有参与者都有交易的完整记录,因此投资者的持股情况也是如此,这为市场带来了完全的透明度和信任。
更高的流动性
区块链削减了低效率,从而降低了准入门槛和成本。这意味着许多由于这些障碍而无法进入市场的人现在可以参与进来。这意味着流动性增加,谁不喜欢流动性呢?更高的流动性意味着更多的投资。
结论
当然,在部署区块链方面存在挑战,首先是重新思考定义当前基于旧纸张(伪装成数字)系统的可能性和政策。该系统的性质也带来了新的挑战,例如,比特币区块链的运作方式,首先解决数学问题的矿工可以决定他/她的区块为官方区块,这将对股票市场的时机产生巨大影响。如果投资者能够使用高端基础设施首先记录他们的交易,这将造成一个实体比其他实体更有优势的局面。然而,这些挑战是可以克服的,我们将有一个真正彻底改变金融世界的系统,为每个人造福。从我们的博客了解更多关于加密货币交易平台的信息。
QuantInsti 的 Quantra 专门提供算法和量化交易的自定进度在线课程。凭借最先进的人工智能学习技术,Quantra 提供了高度互动的练习,有助于促进对交易中复杂概念的理解。请点击查看课程。
智慧和勇气——维贾亚库玛鼓舞人心的光荣之旅
原文:https://blog.quantinsti.com/wit-grit-vijay-journey-glory/
失败,成功,失败,成功……这就是循环的方式,不管是你的生活还是交易。尽管你可能会跌倒,但评估、改进、创新和前进是必要的。
今天,一个只有 4 年交易经验的成功的专业人士,Vijayakumar 通过实践学习和利用他的知识。他的故事讲述了永不放弃,勇往直前的态度。他是一个独立的人,克服了生活带给他的所有挑战,甚至当他分享他的故事时,他都带着自豪和微笑。
我们向你呈现他的故事!
嗨,Vijay,你能跟我们介绍一下你自己吗?
大家好!我是 Vijayakumar Mylsami。我对股市和数字很感兴趣,每天都有很强的阅读习惯。我和市场分分合合已经有一段时间了,我很高兴有机会和你分享我的经验。我在马杜赖完成了生物技术工程。我来自一个中产阶级家庭,父亲在印度泰米尔纳德邦的 Shakti Sugars 工作,挣着普通的薪水来养家糊口。
提问是我的一种隐藏天赋,没有多少人知道。我在大学期间参加过商业问答比赛,参加了 Tata Crucible,这是一次用我们的智慧和知识对抗时间的惊人经历。
你能描述一下你的交易历程吗?
我最初渴望成为一名医生,但由于一些情况,我选择了我想进入的下一个最好的蓬勃发展的方向,那就是生物技术。我也对研究感兴趣。但是,当我继续我的职业生涯时,我的生活见证了一个不可思议的转折。
你瞧!几年后,我从一名 IT 专业人员转向了金融领域。我努力向前,想在银行和金融公司工作。尽管没有成功,我还是积极地对待它,意识到我应该继续前进。
不要把消极的事情放在心里——这是我对待生活的方式,也是我的人生理论。T3】
市场提供了大量的知识——令人惊讶的是市场也可能是这样。这是我投资生涯之初的学习。
这些年来,我一直在学习和寻找自己真正的使命,但我并不认为这是一种损失。我认为这是为学习支付的费用,就像你向学校或大学支付的费用一样。我不后悔。
今天,我能够获得持续的利润,而且,我很高兴。
我现在明白了风险管理、交易策略、市场能做什么和不能做什么。
今天,我喜欢在金融行业工作。即使你拿我过去 10 年的软件职业生涯来说,我也一直与银行或金融服务公司有联系。我不涉及任何其他行业。我喜欢在银行业工作,能够理解并真正欣赏事物。
2009 年,当我在追求宝洁的时候,展望商业杂志《孟买-浦那》上有一篇文章,说的是一位来自先锋的女士和另一位来自美国的男士,他们已经开始了 algo 交易。那是我开始了解算法交易的时候。
我原以为如果我在接下来的一年里努力学习 Python 的话,我会适应的,而且我可以进入 QuantInsti 的 EPAT 课程。
你什么时候意识到需要提高和培养自己的市场交易技能?
在我 2007-2008 年的交易间隙,我看到了沃伦巴菲特的自传,这让我在文章、报纸和杂志上读到了更多关于他的内容。一个人能在市场上赚这么多,这很有趣。
就在那时,我决定我想进入金融领域,做一名研究生。然后我考上了 PSGIM。
受此启发,我在没有任何知识的情况下开始交易(这不是一个明智的举动),并几次烧掉了我的投资,但这对我来说是一个巨大的学习曲线。
我的第一次交易是在 2008 年:当我开始交易时,一开始并不是一次好的经历——我经历了几次下跌,账户资金不足,导致我停止交易 8 个月。
但是我没有放弃。相反,我下定决心要赢,并在接下来的 8 个月里开始阅读大量的书籍。我开始阅读更多关于衍生品和基本面分析的书籍,因为我认为交易不适合我。
在这之后,我修改了我的方法,在市场上实践,并开始投资像 Britannia,Treehouse Education,MT Educare 这样的公司,经历了一系列的起起落落,面临了一些失败,但也获得了一些相当不错的回报。
我真正的旅程可以说是从 2009 年开始的,当时我在印度哥印拜陀的 PSG 管理学院读研究生。
在我从 2010 年开始的第二次运行中:如果表现良好,我会持有股票两年,然后决定何时退出市场。
在 2013 年的第三次投资中:我从 Priya Cement、Godrej Properties 这样的房地产公司和 Heritage Foods 这样的消费品公司获得了不错的回报。这是我认为我已经准备好再次交易的时候,但是唉!我又输了。
我第四次跑:投资 60 万,亏了 7 万。就在那时,我阻止了它。
经验很重要,这些都是非常宝贵的经验。我不想面对同样的命运。我想改进和发展我的交易。
但由于我缺少指导或辅导,即使这样也没有产生一致的表现或结果,所以我继续努力。这让我意识到,要想进入算法交易并理解其中的细微差别,我需要向那些对这个领域了如指掌的人学习。因此,我的探索让我来到了 QuantInsti。
你能分享一下期权交易的经验吗?
我一直对期权很感兴趣。从去年开始我只做期权交易。
在我第五次跑步期间-从 2018 年 8 月。:我只有两个月的提款时间——2018 年 3 月和 2019 年 8 月,这对我很好。这些缺点对我来说并不算什么,累积起来只有 0.5%到 1%。虽然我的回报也不太好。从 8 月份开始,我使用期权,到目前为止每个月赚 3%到 5%。
在 QuantInsti 讲座的帮助下,尤其是 Nitin 和 Rajib 的讲座给了我们关于如何进行交易的深刻见解。与他们的几次通话帮助我了解了可以部署哪些策略,以便我可以持续受益,等等。
从那时起,我在 IIFL 专门创建了一个期权交易账户,并一直在交易。
QuantInsti 对我帮助很大。它给了我信心,现在我甚至可以离开工作,开始以交易为生。
你对 Python 的体验如何?
尽管我不精通 Python,也不擅长技术,但我对衍生品等产品有很好的了解。
我在 Python 中尝试做的是——使用 Upstox API,其中我们获得实时市场数据,我们尝试将所有期权连接到一个 web 应用程序中,在那里我可以查看期权敏感度、波动率微笑——有点像仪表板——我自己的应用程序。我一直在研究这个。并将很快完成。
我以前没有任何关于 Python 的知识,并且在没有 Python 的情况下开始学习。
但今天,我能够模拟某些统计模型,如 ADF 测试、Z 值,以及一些 ML 算法,如训练回归数据,我正在并行工作。
现在,我已经根据历史数据设计了两个策略,我将在今年 11 月或 12 月部署。在过去的两个月里,自从我懂了 Python,我甚至在周末也一直在做这个。
我希望在接下来的一年里,我自己能创造更多——这是我加入 QuantInsti 后获得的信心。不知道其他机构是如何帮助我的,但是 QuantInsti 一直在毫不犹豫地帮助我。我早上发一个问题,晚上就有答案了。这就是他们如何在我的交易生涯中帮助我的。
我特别想提一下 Rajib 和 Nitin(关于价值观的建议帮助了我的交易生涯)和 Vivek(Python 的导师),Jay(帮助我实施策略),以及来自 aluminum Cell 的 Deepa(及时回复和解决我的问题)。
是什么让你坚持下去?
首先-我对域名的热爱!我喜欢从事金融行业。
其次,书籍!
我仍然阅读商业杂志,我对金融领域即将到来的技术感兴趣。目前,我正在读本华·B·曼德博的《市场的(错误)行为:风险、破产和回报的分形观》,作者是理查德·l·哈德森。
艾德·索普给了我很多启发。他的采访令人惊讶,他对凯利公式、概率和更多的知识启发了我——他如何每年持续增长 20%非常有趣。
这些都是我喜欢的事情——交易和投资。它每天激励着我,每天醒来,阅读很多东西,甚至尝试新事物。
即使是现在,我也不想浪费时间。我一直在 QuantInsti 看视频。我看得越多,学到的就越多。
你认为这些年来市场发生了什么变化?
波动性和技术在市场中的运用。T3】
像技术一样飞速发展的算法交易。
当我开始交易时,大约有 5% - 10%的算法交易量,但现在每个人都在练习。在我看来,这是一个非常大、非常受欢迎的变化。
如果机器可以预测,在市场上有交易经验和专业知识的人
最初,当我在 2008-2009 年开始交易时,我会练习系统交易,我会担心我的交易,不管是醒着还是睡着——这是一种精神压力。但是今天,一旦系统显示波动性很高,你就需要卖出期权,因为期权费飙升。
因为我现在知道了基于每周每天的标准差的范围,一旦超过了这个范围,我意识到我的风险水平增加了,我的交易状态不好。我意识到我的错误,这是退出交易的正确时机。所以,是的,我能睡得安稳是因为有一个安全的风险管理系统。
我在交易和运用风险管理方面更有信心了。我很高兴自 2018 年 8 月以来我没有失去我的资本。
我不看利润,我看保护我的资本——这是我的口头禅。T3】
即使我不赚钱,我也很开心。但我不会失去我的资本。T3】
你对 NLP 和情感分析有什么想法?
目前,我在我的交易实践中没有使用 NLP,但我一直在为我们的客户澳大利亚联邦银行增加价值,我提供银行在全球使用的 NPS(净推介值),所以基于文本、博客、Scrappy 和 Python 的其他库,我使用它向他们提供价值建议。
下一个是 NLP,我计划在市场上使用。我正在一步一步地走,因为我还没有达到那个水平。首先,我想学习项目和其他一切,然后我计划继续向 NLP 方面发展。
有抱负的交易者的注意事项。有什么建议吗?
我不认为我已经达到了我可以建议的水平,但建议我会推荐:
- 遵循良好的风险管理-非常非常重要。这是一个人需要观察和学习的最重要的东西
- 具备期权、期货等产品知识
- 如何在到期日分配产品。
对于第三点,这个信息是非常重要的,因为现在很多人都喜欢销售,它像任何东西一样被销售。如果你关注媒体,你会发现人们在推销期权。期权销售需要更多的对期权的了解,期权和结算的知识,以及完善的风险管理体系。
风险管理在交易中非常重要。T3】
非常感谢你与我们分享你的故事,Vijay,我们希望你的故事能激励无数的人。我们祝愿你在未来的旅程中取得巨大成功!
释放你学习算法交易的渴望,继续前进,学习,成长,永不放弃。用必要的技能和知识武装自己,在这个领域取得成功。让我们的算法交易管理课程(EPAT)成为你的向导。点击了解更多信息。
Disclaimer: In order to assist individuals who are considering pursuing a career in algorithmic and quantitative trading, this case study has been collated based on the personal experiences of a student or alumni from QuantInsti’s EPAT® programme. Case studies are for illustrative purposes only and are not meant to be used for investment purposes. The results achieved post completion of the EPAT® programme may not be uniform for all individuals.
为 Kenanga 集团举办的算法交易研讨会-马来西亚吉隆坡

简介
吉隆坡的 Kenanga 集团采取了这个惊人的举措,让客户和员工熟悉算法和量化交易领域。
Nitesh Khandelwal 和 Prodipta Ghosh 代表 QuantInsti 举办了为期一天的“了解算法交易的概念和实际实施”研讨会,并与他们分享了经验!
会议亮点
一些重点会议包括:
- 算法和量化交易,历史和自动化
- 网络基础设施和连接
- 算法交易策略&策略演示
- 算法交易的风险管理
- 行业预测和增长预测
演讲者
Nitesh Khandelwal (CEO, QuantInsti)
Nitesh Khandelwal 毕业于 IIT 坎普尔大学电气工程专业,并获得了 IIM 勒克瑙大学的管理学研究生学位,他的职业生涯始于财政部的银行部门。在一家自营交易公司短暂担任领导后,他在孟买共同创立了 iRage。如今,iRage 是印度算法交易领域的领先企业。后来,当 Nitesh 搬到新加坡时,他成立了一家贸易公司,在全球交易所进行交易。
2016 年,他将重心转移到 QuantInsti,担任其首席执行官。QuantInsti 将继续致力于为全球大众带来科技导向型贸易的知识和途径,并已帮助来自 130 多个国家的用户实现这一目标。
![prodipta-ghosh]() T2】
T2】
Prodipta Ghosh(QuantInsti 副总裁)
Prodipta 是一位经验丰富的 quant,目前作为副总裁领导 QuantInsti 的 Fin-tech 产品和平台开发。
他在银行业工作了十多年,在孟买和伦敦的德意志银行的交易和结构部门担任过各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
关于 Kenanga 集团
Kenanga 是马来西亚一家拥有 40 年历史的金融集团,在股票经纪、投资银行、上市衍生品、资金、企业咨询、伊斯兰银行、财富管理和投资管理方面拥有丰富的经验。
活动照片





量化交易策略工作坊
原文:https://blog.quantinsti.com/workshop-quantitative-trading-strategy/
2013 年 6 月 1 日, Nitesh Khandelwal 先生参加了一个关于量化交易策略的研讨会。会议向参与者展示了包括 R 在内的各种金融计算工具,同时他们学习了量化交易策略的建模。在会议期间,演讲者使用了各种回溯测试和优化技术,并在开源交易平台上部署了该策略。
https://www.youtube.com/embed/vau7GwumxRo?rel=0
研讨会取得了巨大成功,来自全球各地的 50 多名与会者参加了研讨会。参与者主要来自贸易、银行、经纪和技术领域。
汤森路透关于算法和高频交易的研讨会
原文:https://blog.quantinsti.com/workshop-with-thomson-reuters/

QuantInsti 和 Thomson Reuters 南亚成功举办了为期一天的研讨会,主题为 “算法和高频交易” 面向印度资本市场的领先国际和国内金融机构和卖方券商。
由算法交易进行;该课程非常成功地向观众介绍了高频交易中的先进概念。 iRageCapital advisors 就系统架构&延迟、标准化协议、HFT 的交易策略设计方法、HFT 的风险管理以及该领域的新发展/工具等方面提供了实用见解。
该活动得到了参与者的积极响应,参与者包括来自国际和国内交易和经纪公司以及交易所(汇丰银行、野村证券、瑞士瑞信银行、ICICI、Kotak、IDBI、Religare、大和资本、Prabhudas Leeladhar、Edelweiss、Karvy、古董经纪等)的交易和技术专业人士。
赢得世界交易冠军- Nikolas 分享他的学习经验
原文:https://blog.quantinsti.com/world-trading-champion-trader-experience/

交易一直是一个有利可图的领域,人们不断被它吸引。虽然情况并不总是这样,但时代变了,交易的方式也变了。
没有人生来就有成为任何职业一部分的本能,是他们的兴趣、动力和渴望驱使他们选择自己喜欢的工作。为了实现这一目标,全球无数人自学成才。算法交易的追求者没有落后。有了像 Quantra 这样的程序指导,他们正在快速进入这个领域。
令人惊讶的是,有像尼古拉这样的人让这一切看起来简直不可思议!他的故事是一个不屈不挠的坚持,渴望了解更多,渴望实现的故事。这难道不像是直接出自电影剧本吗?嗯,是真的!
加入我们的旅程,尼古拉与我们分享他的故事。
我们与 Nikolas Pareschi 的对话

你好,Nikolas,给我们介绍一下你自己吧!
嗨!我是来自巴西的 Nikolas Pareschi。我毕业于应用数学专业,并获得了金融工程硕士学位。除了独立交易,我还是巴西教育网站 Investidor de Sucesso 的讲师。
是什么让你成为交易者的?
我一直对碰运气的游戏感兴趣,在大学期间和几年后,我玩过专业水平的扑克。金融界自然而然地成为从扑克和其他来源赚取资本的途径。我在 2007 年开始交易,对新手来说这一年并不好,至少从财务角度来看是这样。然而,最初几年是艰难的。这并没有让我放弃,我读了我能找到的每一本书(超过 200 本),并不断进步。
你能解释一下你的交易之旅吗?
2011 年,我开始从事算法交易,那一刻是一个顿悟。现实情况是,大多数指标和方法都经受不住统计稳健性测试。即使是那些通过交叉验证或向前走的人,他们也可能突然停止工作!我的道路逐渐变得越来越量化。
我不认为我是一个有创造力的人,我自己在我的生活中没有发现很多阿尔法甚至贝塔,但是我能认出宝石在哪里。我开始阅读关于 SSRN 的金融论文,这是我第二次顿悟的时刻。金融论文是交易思想的一个很好的来源,大多数论文写得很好,后验测试通常以一种形式完成,这样它们可以有统计学意义。
顺便说一下,我开始阅读学术论文是由于欧内斯特·陈博士在他的一本书中提出的建议。
赢得外汇锦标赛世界杯——这是怎么回事?
在 2015 年获得巨大回报后,2016 年我决定参加 2017 外汇世界杯。这是因为一个朋友的坚持,过了一会儿我说,为什么不呢,如果我参加了,2016 年的成绩会是第二名。如果真的发生了,那就太好了。要赢得世界交易冠军,你必须持续交易阿尔法(理想情况下)和贝塔,达到高夏普比率,当然,还需要一些运气。2017 年是美妙的一年,我对交易员的承诺和特朗普/墨西哥局势进行了计时,并利用购买力平价、回归均值和动量在东欧货币中进行了一些操作。这些都是伟大的比赛,我也犯了一些错误,但很高兴这些错误被最小化了。
在算法、回溯测试等方面有着丰富的经验,是什么让你加入了 Quantra?
我非常尊重欧内斯特·陈博士的工作,当我知道 Quantra 时,我立即报名参加了一些课程。我最喜欢 Quantra 的是交易经验和学术水平的完美结合。
我在交易中融入的一些想法来自于我在 Quantra 课程中的学习。
对交易者有什么提示或建议吗?
我建议新手在每个市场交易,并且要全面。一切都是相互关联的,有些外汇失衡来自股市,有些时候则来自大宗商品,有些时候则来自国债。此外,如果你在每个市场都交易,你可以开始更有选择性地玩游戏,你也不会有分散投资的问题。有时更好的投资是房地产投资信托基金,有时是期权。
例如,在 2014 年和 2015 年美元走强和布伦特原油价格暴跌之后,我在 2016 年早些时候发现,一家巴西石油公司的现金超过了其市值,同时还考虑到了债务(PRIO3)。从那时起,它的价值已经超过了 700%(不幸的是,我在 700%之前卖出了股票,但获得了一些不错的利润)。
我们永远不知道机会会在哪里。但是以整体的方式思考,我们会有线索去寻找。由于美元走强,当时的新兴市场遭受了疯狂的打击,石油公司遭受的打击更大。为什么不在新兴市场寻找石油公司呢?
去贝叶斯,永远坚持科学的方法。
在 QuantInsti 学习解决方案
学习交易策略有一些特别之处,从一行代码开始,一步一步来!如果你正在寻找量化和算法交易的短期自学课程,我们推荐你 Quantra 。它提供实用的实践培训来创建你自己的交易策略。对于那些正在寻找算法交易认证,并在算法交易中开始自己的事业的人,请了解更多关于 EPAT 的信息。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的EPAT项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的结果对所有人来说可能并不一致。
用 Python 编写覆盖呼叫策略
原文:https://blog.quantinsti.com/write-covered-call-strategy-in-python/
简介
衍生品市场的交易者经常行使以下权利之一:看涨期权或看跌期权。
【买入期权】是买卖双方之间的金融合同,据此买方有权但无义务在某一时间以某一价格(履约价格)从期权卖方处购买约定数量的金融工具。“看跌期权的作用正好相反。
在“备兑买入中,买入期权的卖方拥有相应数量的基础工具。
备兑买入是一种创收期权策略,包括两个部分:
- 购买股票
- 卖出价外(OTM)看涨期权
如果买进股票的同时卖出看涨期权,这种策略称为"买入-卖出"策略。
在备兑看涨期权中,交易者持有中性至看涨的观点。备兑买入是一种净借记交易,因为你支付股票,并从卖出的买入期权中获得少量溢价。
这篇博文的想法是通过一个例子来详细说明有担保的买入策略,并使用 Python 绘制其收益图。这篇文章还强调了“日历电话”,因为它是对覆盖电话策略的修改。
让我们直接举一个例子来理解备兑买入的运作、其回报以及策略中涉及的风险。
备兑通话策略示例
SBI 股票的交易价格是 50 卢比。2015 年 4 月 29 日 189。第一步:用卢比购买 100 股股票。189 Leg 2:在 2015 年 5 月 26 日卖出 195 次罢工认购价 6.30 卢比,每手 100 股
买入这两个头寸所支付的金额等于支付的股票价格减去收到的认购溢价,即卢比。18,900 卢比(股票购买)630(收到的溢价)=卢比。18,270
如果股价上涨超过 195 的看涨期权,它将被执行,股票将被出售。但是,该策略会获利,因为你被你所拥有的股票覆盖。
比方说,到期时的股票价格是卢比。200.利润由下式给出:
Profit = Call premium received + ((Call strike - stock price paid) x Shares)
Profit = Rs. 630 + ((195 – 189) x 100) = Rs. 1,230
如果股票跌破最初的股票买入价,你的多头头寸就处于亏损状态,但你可以从卖出看涨期权获得的看涨期权溢价中获得一些缓冲。
比方说,股票下跌,在卢比。到期时 180。发生的损失由下式给出
Loss = Call premium received + ((stock price at expiration - stock price paid) x Shares)
Loss = Rs. 630 + ((180 – 189) x 100) = - Rs. 270
人们可以采用备兑买入策略,按月卖出买入期权,从而通过溢价的方式产生月收入。
涵盖电话的风险回报概况如下所示:
- 最大风险-(支付的股票价格-收到的认购溢价)
- 最高奖励-(看涨期权-支付的股票价格)+收到的看涨期权费
- 盈亏平衡-(股票价格支付-收到的认购溢价)
备兑买入回报图的 Python 代码
下面是 Python 中多头股票、空头看涨期权和备兑看涨期权收益图的代码。
# Covered Call
import numpy as np
import matplotlib.pyplot as plt
s0=189 # Initial stock price
k=195;c=6.30; # Strike price and Premium of the option
shares = 100 # Shares per lot
sT = np.arange(0,2*s0,5) # Stock Price at expiration of the Call
# Profit/loss from long stock position
y1= (sT-s0) * shares
# Payoff from a Short Call Option
y2 = np.where(sT > k,((k - sT) + c) * shares, c * shares)
# Payoff from a Covered Call
y3 = np.where(sT > k,((k - s0) + c) * shares,((sT- s0) + c) * shares )
# Create a plot using matplotlib
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.tick_params(top=False, right=False) # Removes the tick-marks on the RHS
plt.plot(sT,y1,lw=1.5,label='Long Stock')
plt.plot(sT,y2,lw=1.5,label='Short Call')
plt.plot(sT,y3,lw=1.5,label='Covered Call')
plt.title('Covered Call')
plt.xlabel('Stock Prices')
plt.ylabel('Profit/loss')
plt.grid(True)
plt.axis('tight')
plt.legend(loc=0)
plt.show()
我们使用 matplotlib 库来绘制图表。我们首先创建一个空的图形,并添加一个支线剧情。然后,我们删除顶部和右边框,并在中心移动 X 轴。使用 plt.plot 函数,我们绘制了多头股票、空头看涨期权和备兑看涨期权的收益。最后,我们在图表中添加标题、标签和图例。

日历通话策略
日历买入是备兑买入策略的一种变体,在这种策略中,多头股票头寸被长期多头买入期权所替代。
日历拜访策略包括两个部分:
- 以接近货币执行价的价格买入长期到期看涨期权
- 卖出具有相同执行价格的短期看涨期权
有了日历看涨期权,交易者的前景从中性到看涨。这是一项净借记交易,因为买入的看涨期权比卖出的看涨期权更贵,卖出的看涨期权没有时间价值。日历看涨期权(如保险看涨期权)可以是一种创收策略,通过每月销售短期看涨期权来实现。
让我们举一个日历呼叫的例子来理解它的回报,以及策略中包含的风险。
举例:
XYZ 股票的交易价格为卢比。2015 年 5 月 2 日为 187,历史波动性为 40%,无风险利率为 8%。
第 1 阶段:购买 2015 年 7 月 28 日的 190 罢工认购权,每手 20.70 卢比,每手 100 股
第二阶段:在 2015 年 5 月 26 日卖出 190 次罢工认购价 7.50 卢比,每手 100 股
1 st 场景:
5 月到期时,股价跌至 180 卢比
长途电话价值约 8.80 卢比;损失 11.90 卢比
短期看涨期权毫无价值地到期,我们获得了 7.5 卢比的利润
总头寸–损失 4.40 卢比
2 和场景:
在 5 月到期时,股票上涨到 205 卢比
在这种情况下,股票已经上涨到执行价以上。短期看涨期权将得到行使。长通话价格约为 23.60 卢比;利润 2.90。
卖出看涨期权,获利 2.90 卢比
保持 7.50 卢比的短期溢价
短期电话在 Rs.15 卢比到期。以 205 卢比购买股票;以 190 卢比的价格出售股票——损失 15 卢比
因此,总头寸损失 4.60 卢比
日历呼叫的风险回报情况如下:
- 最大风险-限于支付的净借方
- 最大回报–(当股票价格处于执行价格时,卖空期权到期时看涨期权的价值)减去(净借方)
日历呼叫回报图的 Python 代码
下面是短期买入、长期买入溢价和日历买入回报的代码。
# Calendar Call Strategy
import p4f
import numpy as np
from datetime import datetime
import matplotlib.pyplot as plt
s0 = 187 # Initial stock price on May 2nd, 2015
k = 190 # Strike price of the May 26th 2015 and July 28th 2015 Call Option
cs = 7.50; # Premium of the Short call on May 2nd, 2015
cl = 20.70; # Premium of the Long call on May 2nd, 2015
shares = 100 # Shares per lot
sT = np.arange(0,2*s0,5) # Stock Price at expiration of the Call
sigma = 0.4 # Historical Volatility
r = 0.08 # Risk-free interest rate
t = datetime(2015,7,28) - datetime(2015,5,26) ; T = t.days / 365;
# Payoff from the May 26th 2015 Short Call Option at Expiration
y1 = np.where(sT > k,((k - sT) + cs) * shares, cs * shares)
# Value of the July 28th 2015 long Call Option on May 26th 2015
lc_value = p4f.bs_call(sT,k,T,r,sigma) * shares
# Payoff from the Calendar Call
y2 = y1 + (lc_value - cl)
# Create a plot using matplotlib
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.tick_params(top=False, right=False) # Removes the tick-marks on the RHS
plt.plot(sT,y1,lw=1.5,label='Short Call')
plt.plot(sT,lc_value,lw=1.5,label='Long Call')
plt.plot(sT,y2,lw=1.5,label='Calendar Call')
plt.title('Calendar Call')
plt.xlabel('Stock Prices')
plt.ylabel('Profit/loss')
plt.grid(True)
plt.axis('tight')
plt.legend(loc=0)
plt.show()

我们使用 matplotlib 库来绘制图表。我们首先创建一个空的图形,并添加一个支线剧情。然后,我们移除顶部和右边界,并使用 plt.plot 函数将 X 轴移动到中心,我们绘制短期看涨期权、长期看涨期权溢价和日历看涨期权的收益。最后,我们在图表中添加标题、标签和图例。
如果你喜欢你所读的,请在下面的评论区给我们反馈。更多这样的策略和 python 代码,请浏览我们的博客部分。如果您正在寻找 python 代码来构建像移动平均线或移动难易程度这样的技术指标,您会在这里找到。如果你想知道是什么让 Python 成为算法交易者最喜欢的语言,我们有一个关于它的很酷的信息图。
下一步
如果你是一名程序员或科技专业人士,想开始自己的自动化交易平台。从日常从业者的实时互动讲座中学习自动交易。算法交易高管课程涵盖统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。现在报名!
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载 Python 代码
- 备兑买入回报- Python 代码
Python 中的 XGBoost 简介
作者:伊桑·沙阿,编译:雷希特·帕查内卡
啊!XGBoost!这是机器学习爱好者和竞赛获胜者的首选武器。据说开发 XGBoost 是为了提高计算速度,优化模型性能。
当我们修补 XGBoost 的特性和参数时,我们决定建立一个由五家公司组成的投资组合,并在其上应用 XGBoost 模型来创建交易策略。这是我们得到的。这五家公司是苹果、亚马逊、网飞、英伟达和微软。

那真的很体面。想想看,我们甚至没有尝试优化它。
让我们看看如何在本文中实现 XGBoost 模型。我们将涵盖以下内容:
XGBoost 是什么?
Xgboost 代表极限梯度增强,是在梯度增强的框架上发展起来的。我喜欢这个声音,极端!实际上,听起来更像超级跑车而不是 ML 车型。
但这正是它所做的,提高常规梯度推进模型的性能。
XGBoost 使用了一种更有规律的模型形式化来控制过拟合,这给了它更好的性能。
- XGBoost 的作者陈天琦
让我们分解一下名字来了解 XGBoost 是做什么的。
什么是助推?
顺序集成方法,也称为“增强”,创建一系列模型,试图纠正序列中在它们之前的模型的错误。第一个模型建立在训练数据上,第二个模型改进第一个模型,第三个模型改进第二个模型,依此类推。

在上面的图像示例中,训练数据集被传递到分类器 1。黄色背景表示分类器预测了连字符,蓝色背景表示它预测了加号。分类器 1 模型错误地预测了两个连字符和一个加号。这些用圆圈突出显示。这些不正确预测的数据点的权重增加并被发送到下一个分类器。也就是分类器 2。分类器 2 正确地预测了分类器 1 不能预测的两个连字符。但是分类器 2 也犯了一些其他的错误。这个过程继续,我们有一个组合的最终分类器,它正确地预测所有的数据点。
可以添加分类器模型,直到正确预测了训练数据集中的所有项目,或者添加了最大数量的分类器模型。要训练的分类器模型的最佳最大数量可以使用超参数调整来确定。
在这里停一下。也许你不知道什么是序列模型。让我们一步一步来。
简而言之,机器学习
早些时候,我们习惯于编码某种逻辑,然后将输入给计算机程序。该计划将使用逻辑,即算法,并提供一个输出。所有这些都很棒,但是随着我们理解的增加,我们的程序也在增加,直到我们意识到对于某些问题语句,有太多的参数需要编程。
然后一些聪明的人说,我们应该给计算机(机器)一个样本集的问题和解决方案,然后让机器学习。
在开发机器学习的算法时,我们意识到我们可以将机器学习问题粗略地分为两个数据集,分类和回归。简单来说,分类问题可以是给定一张动物的照片,我们试图将它归类为狗或猫(或其他一些动物)。相比之下,如果我们要预测一个城市的温度,这将是一个回归问题,因为温度可以说是连续的值,如 40 度、40.1 度等。
太好了!然后我们转向决策树模型,贝叶斯,聚类模型等等。所有这些都很好,直到我们遇到另一个障碍,当我们只使用一个模型时,某些问题陈述的预测率令人沮丧。除此之外,对于决策树,我们意识到我们必须忍受模型中的偏差、方差和噪声。这引出了另一个好主意,我们把模型结合起来怎么样,我的意思是,两个脑袋比一个好,对吗?这被称为整体学习。但是在这里,我们可以使用一个以上的模型来创建一个合奏。梯度推进就是集成学习的一种方法。。
什么是梯度增强?
在结合模型时的梯度增强中,使用梯度下降来最小化损失函数。从技术上讲,损失函数可以说是一个误差,即预测值与实际值之间的差异。当然,误差越小,机器学习模型越好。
梯度推进是一种方法,在这种方法中,创建新模型来预测先前模型的残差或误差,然后将它们相加在一起以做出最终预测。
XGBoost 模型的目标如下:
obj = L+ω
其中 L 是控制预测能力的损失函数,ω是控制简单性和过拟合的正则化分量
需要优化的损失函数(L)可以是回归的均方根误差、二元分类的对数损失或多类分类的对数损失。
正则化分量(ω)取决于树叶的数量和在树集合模型中分配给树叶的预测分数。
它被称为梯度提升,因为它使用梯度下降算法来最小化添加新模型时的损失。梯度推进算法支持回归和分类预测建模问题。
如果你想了解梯度下降,那么你可以在这里阅读。
好了,我们已经了解了机器学习是如何从简单模型进化到模型组合的。不知何故,人类无法长时间满足,随着问题陈述变得越来越复杂,数据集越来越大,我们意识到我们应该更进一步。这就引出了 XGBoost。
XGBoost 为什么这么好?
XGBoost 是用 C++编写的,考虑到计算时间,它真的很快。XGBoost 的伟大之处在于它可以很容易地导入 python 中,并且由于 sklearn 包装器,我们也可以使用 python 包中使用的相同参数名。
虽然实际的逻辑解释起来有些冗长,但是 xgboost 的一个主要特点是它能够并行化 boosting 算法的树构建组件。这导致处理时间大幅增加,因为我们可以使用更多的 CPU 内核,甚至还可以利用云计算。
虽然机器学习算法支持调整,并可以与外部程序一起工作,但 XGBoost 具有内置的正则化和交叉验证参数,以确保偏差和方差保持在最低水平。内置参数的优点是它导致更快的实现。
让我们在下一节讨论一个这样的实例。
Xgboost 特性重要性
简而言之,特征就是我们用来预测目标变量的变量。有时候,我们不满足于仅仅知道我们的机器学习模型有多好。我想知道哪个特征更有预测能力。。了解特性的重要性可以帮助我们,原因有很多。下面让我们列举几个:
- 如果我知道某个特性比其他特性更重要,我会更加关注它,并尝试看看是否可以进一步改进我的模型。
- 运行模型后,我会看看删除一些特征是否会改进我的模型。
- 最初,如果数据集很小,那么在我们设计系统时,运行模型所花费的时间不是一个重要的因素。但是,如果策略很复杂,并且需要运行大型数据集,那么运行模型所需的计算资源和时间就成为一个重要因素。
XGBoost 的好处是它包含了一个计算特性重要性的内置函数,我们不必担心在模型中对它进行编码。
下面给出了稍后在 XGBoost python 代码部分使用的示例代码:
from xgboost import plot_importance
# Plot feature importance
plot_importance(model)

好了,在我们继续写代码之前,让我们确保我们的系统上都有 XGBoost。
如何在 anaconda 中安装 XGBoost?
Anaconda 是一个 python 环境,它使我们编写 python 代码变得非常简单,并处理与代码相关的任何细节。因此,我指定了在 Anaconda 中安装 XGBoost 的步骤。它实际上只是一行代码。
您可以简单地打开 Anaconda 提示符并输入以下内容
Anaconda 环境将下载所需的安装文件并为您安装。它看起来会像下面这样。

这就是全部了。厉害!现在我们来看真实的东西,即 XGBoost python 代码。
Python 中的 Xgboost
在我们深入研究 XGBoost 机器学习模型之前,让我先总结一下。我们正在使用过去 16 年来美国科技股(如苹果、亚马逊、网飞、英伟达和微软)的股票数据,并训练 XGBoost 模型来预测第二天的回报是正还是负。
我们以可下载的 python 笔记本的形式包含了代码,供您以后使用。附在博客最后。
为了更好地理解该模型,我们将 XGBoost python 代码分成以下几个部分
- 导入库
- 定义参数
- 创建预测值和目标变量
- 将数据分为训练和测试
- 初始化 xgboost 机器学习模型
- 训练数据集中的交叉验证
- 训练模型
- 特征重要性
- 预测报告
导入库
我们在评论里写了库的用途。例如,由于我们使用 XGBoost python 库,我们将导入相同的库,并将# Import XGBoost 编写为注释。
# Import warnings and add a filter to ignore them
import warnings
warnings.simplefilter('ignore')
# Import XGBoost
import xgboost
# XGBoost Classifier
from xgboost import XGBClassifier
# Classification report and confusion matrix
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
# Cross validation
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# Pandas datareader to get the data
from pandas_datareader import data
# To plot the graphs
import matplotlib.pyplot as plt
import seaborn as sn
# For data manipulation
import pandas as pd
import numpy as np
太好了!所有库都已导入。现在我们进入下一部分。
定义参数
我们已经定义了我们将在这个博客中使用的股票列表、开始日期和结束日期。
# Set the stock list
stock_list = ['AAPL', 'AMZN', 'NFLX', 'NVDA','MSFT']
# Set the start date and the end date
start_date = '2004-1-1'
end_date = '2020-1-28'
为了让事情变得有趣,我们将在苹果、亚马逊、网飞、英伟达和微软等公司上使用 XGBoost python 模型。创建预测值和目标变量
我们定义了一个预测值列表,模型将从中挑选出最佳预测值。这里,我们将不同时间段的百分比变化和标准偏差作为预测变量。
目标变量是第二天的收益。如果第二天的收益是正的,我们把它标为 1,如果是负的,我们把它标为-1。你也可以尝试用三个标签来创建目标变量,比如 1,0 和-1,分别代表 long,no position 和 short。
现在让我们看看代码。
# Create a placeholder to store the stock data
stock_data_dictionary = {}
for stock_name in stock_list:
# Get the data
df = data.get_data_yahoo(stock_name, start_date, end_date)
# Calculate the daily percent change
df['daily_pct_change'] = df['Adj Close'].pct_change()
# create the predictors
predictor_list = []
for r in range(10, 60, 5):
df['pct_change_'+str(r)] = df.daily_pct_change.rolling(r).sum()
df['std_'+str(r)] = df.daily_pct_change.rolling(r).std()
predictor_list.append('pct_change_'+str(r))
predictor_list.append('std_'+str(r))
# Target Variable
df['return_next_day'] = df.daily_pct_change.shift(-1)
df['actual_signal'] = np.where(df.return_next_day > 0, 1, -1)
df = df.dropna()
# Add the data to dictionary
stock_data_dictionary.update({stock_name: df})
在我们继续讨论 XGBoost python 模型的实现之前,让我们先画出存储在字典中的 Apple 的每日收益,看看是否一切正常。
# Set the figure size
plt.figure(figsize=(10, 7))
# Access the dataframe of AAPL from the dictionary
# and then compute and plot the returns
(stock_data_dictionary['AAPL'].daily_pct_change+1).cumprod().plot()
# Set the title and axis labels and plot grid
plt.title('AAPL Returns')
plt.ylabel('Cumulative Returns')
plt.grid()
plt.show()
您将获得如下输出:

看起来很准确。
将数据分为训练和测试
由于 XGBoost 毕竟是一个机器学习模型,我们将把数据集分成测试集和训练集。
# Create a placeholder for the train and test split data
X_train = pd.DataFrame()
X_test = pd.DataFrame()
y_train = pd.Series()
y_test = pd.Series()
for stock_name in stock_list:
# Get predictor variables
X = stock_data_dictionary[stock_name][predictor_list]
# Get the target variable
y = stock_data_dictionary[stock_name].actual_signal
# Divide the dataset into train and test
train_length = int(len(X)*0.80)
X_train = X_train.append(X[:train_length])
X_test = X_test.append(X[train_length:])
y_train = y_train.append(y[:train_length])
y_test = y_test.append(y[train_length:])
初始化 xgboost 机器学习模型
我们将初始化分类器模型。我们将设置两个超参数,即 max_depth 和 n _ estimators。这些设置在较低的一侧,以减少过度拟合。
# Initialize the model and set the hyperparameter values
model = XGBClassifier(max_depth=2, n_estimators=30)
model
输出如下所示:

好了,我们现在将在列车组上执行交叉验证以检查准确性。
训练数据集中的交叉验证
# Initialize the KFold parameters
kfold = KFold(n_splits=5, random_state=7)
# Perform K-Fold Cross Validation
results = cross_val_score(model, X_train, y_train, cv=kfold)
# Print the average results
print("Accuracy: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))
输出如下所示:

精度略高于半分。这可以通过超参数调整和将相似的股票组合在一起来进一步改善。我会把优化的部分留给你。如果您有任何疑问,请随时发表评论。
训练模型
我们将使用 fit 方法来训练 XGBoost 分类器。
符合模型
model.fit(X_train, y_train)
您会发现输出如下:

特征重要性
我们绘制了 7 大特征,并根据其重要性进行了分类。
# Plot the top 7 features
xgboost.plot_importance(model, max_num_features=7)
# Show the plot
plt.show()
那很有趣。XGBoost python 模型告诉我们,pct_change_40 是其他特性中最重要的特性。因为我们提到我们只需要 7 个特性,所以我们收到了这个列表。这里有一个有趣的想法,你为什么不增加数字,看看其他功能如何叠加,当涉及到他们的 f 分数。也可以删除不重要的特征,然后重新训练模型。这会增加模型的准确性吗?我让你来验证。
不管怎样,我们继续前进!
预测和分类报告
# Predict the trading signal on test dataset
y_pred = model.predict(X_test)
# Get the classification report
print(classification_report(y_test, y_pred))

坚持住!我们快到了。让我们看看 XGBoost 现在告诉我们什么:
那很有趣。与短边相比,长边的 f1 分数更强大。我们可以修改模型,使之成为只做多策略。
让我们尝试另一种方式来描述 XGBoost 的性能。
混淆矩阵
array = confusion_matrix(y_test, y_pred)
df = pd.DataFrame(array, index=['Short', 'Long'], columns=[
'Short', 'Long'])
plt.figure(figsize=(5, 4))
sn.heatmap(df, annot=True, cmap='Greens', fmt='g')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
输出如下所示:

但是这告诉我们什么呢?这是一个简单的矩阵,显示了 XGBoost 准确与否地预测了多少次“买入”或“卖出”。例如,在预测“Long”时,XGBoost 预测正确 1926 次,而错误 1608 次。
另一种解释是 XGBoost 倾向于预测“长”而不是“短”。
个股表现
让我们看看基于 XGBoost 的策略回报如何与正常的每日回报相比较,即买入并持有策略。我们将绘制一张我们之前提到的所有公司的策略回报和每日回报的对比图。代码如下:
# Create an empty dataframe to store the strategy returns of individual stocks
portfolio = pd.DataFrame(columns=stock_list)
# For each stock in the stock list, plot the strategy returns and buy and hold returns
for stock_name in stock_list:
# Get the data
df = stock_data_dictionary[stock_name]
# Store the predictor variables in X
X = df[predictor_list]
# Define the train and test dataset
train_length = int(len(X)*0.80)
# Predict the signal and store in predicted signal column
df['predicted_signal'] = model.predict(X)
# Calculate the strategy returns
df['strategy_returns'] = df.return_next_day * df.predicted_signal
# Add the strategy returns to the portfolio dataframe
portfolio[stock_name] = df.strategy_returns[train_length:]
# Plot the stock strategy and buy and hold returns
print(stock_name)
# Set the figure size
plt.figure(figsize=(10, 7))
# Calculate the cumulative strategy returns and plot
(df.strategy_returns[train_length:]+1).cumprod().plot()
# Calculate the cumulative buy and hold strategy returns
(stock_data_dictionary[stock_name][train_length:].daily_pct_change+1).cumprod().plot()
# Set the title, label and grid
plt.title(stock_name + ' Returns')
plt.ylabel('Cumulative Returns')
plt.legend(labels=['Strategy Returns', 'Buy and Hold Returns'])
plt.grid()
plt.show()





这很有趣,不是吗?你怎么看待这种比较?请在评论中告诉我们你的观察或想法,我们会很乐意阅读。
投资组合的绩效
我们非常享受这一切,以至于我们不能停留在个人层面。因此,我们想,如果我们平等地投资所有公司,并按照 XGBoost python 模型行事,会发生什么。让我们看看会发生什么。
# Drop missing values
portfolio.dropna(inplace=True)
# Set the figure size
plt.figure(figsize=(10, 7))
# Calculate the cumulative portfolio returns by assuming equal allocation to the stocks
(portfolio.mean(axis=1)+1).cumprod().plot()
# Set the title and label of the chart
plt.title('Portfolio Strategy Returns')
plt.ylabel('Cumulative Returns')
plt.grid()
plt.show()

请记住,这些是累积收益,因此它应该会让你对 XGBoost 模型的性能有所了解。
如果您想要关于测试集的更详细的反馈,请尝试下面的代码。
import pyfolio as pf
pf.create_full_tear_sheet(portfolio.mean(axis=1))
虽然生成的输出有些冗长,但我们还是附加了一个快照


唷!那是一个长的。但是我们希望你能理解像 XGBoost 这样的增强模型是如何帮助我们产生信号和创建交易策略的。
结论
我们从基础开始,即机器学习算法的出现及其下一个层次,即集成学习。我们学习了提升树以及它们如何帮助我们做出更好的预测。我们最终来到 XGBoost 机器学习模型,以及它如何优于常规的 boosted 算法。然后,我们浏览了一个简单的 XGBoost python 代码,并根据代码创建的交易信号创建了一个投资组合。在这之间,我们还列出了特性的重要性以及 XGBoost 中包含的某些参数。
如果你想对机器学习交易策略的完整生命周期进行循序渐进的培训计划,那么你可以参加机器学习策略开发和实时交易学习课程,并接受 Ernest P. Chan 博士、Terry Benzschawel 和 QuantInsti 等专家的指导。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
点击下载按钮获取我们在博客中使用的代码。
为 Yahoo CSV 文件构建 zip 包
马里奥·比萨
Zipline 是一个非常棒的回溯测试工具,数据是进行这种分析的主要原材料。在这篇文章中,我们将关注如何加载我们自己的数据文件。通过一个例子,我们将创建一个包来加载从 Yahoo finance 下载的 csv 文件中的数据。
我们涵盖:
滑索摘要
正如我们在上一篇文章中看到的,Zipline 库是一个强大的回溯测试工具,它让我们专注于策略,而不是首先尽一切努力让系统做好准备。
虽然 Quantopian 已经停止运营,但我们仍然可以享受他们对 Zipline 库所做的伟大工作。
在这篇博客中,我们将会看到如何在 Zipline 中加载来自雅虎等多个来源的数据。数据将来自未注明日期的工具的 csv 文件,例如:
- 股票,
- 交易所交易基金,
- 儿童发展基金会,
- 外汇等。
在继续阅读之前,必须记住,如果你想简化你的生活,你可以使用 Blueshift 提供回溯测试的历史数据和连接到几个经纪人的实时数据,毫不费力地将你的算法投入使用。否则,继续读。
Zipline 称之为 摄取 过程。让我们能够读取数据源并加载到 Zipline 的连接器是 bundle 脚本。
默认情况下,Zipline 库附带了几个包来连接 Quandl Wiki DB 和 csv 文件。然而,通常我们需要连接到具有不同格式、列名等的其他数据源。
因此,我们需要创建一个包,以便能够接收数据并对其进行回溯测试。这就是我们在这里讨论的话题。
建议阅读:Python 中的 Zipline 介绍T3】
捆绑包概述
bundle 是一个 ETL 工具。提取、转换和加载(ETL)是数据科学中众所周知的过程。这意味着捆绑 Python 脚本需要连接到数据源(web、文件或数据库)。
- 提取数据,并以数据帧的形式以方便的数据结构加载到内存中。
- 通过清理和转换NA、列名、日期和时间等来标准化数据。
- 最后,将规范化的数据加载到 Zipline 数据存储库中。默认情况下是一个 SQLite,虽然可以是任何其他数据库。
虽然这看起来是一项艰巨的任务,但是我们可以使用可用的 csvdir 包作为模板。所以捆绑包的开发会更容易一些。
为雅虎 csv 每日数据创建捆绑包
假设我们有一个文件夹,里面有从 Yahoo 下载的每日数据。注意,默认情况下, csvdir.py 脚本在名为 daily 和 minute 的文件夹中查找数据,因此我们需要将雅虎的 csv 文件包含在 daily 文件夹中。
整个过程在一条线上:
我们需要读取数据,将它们转换成 Zipline 格式,并加载到 Zipline 存储库中。这就是 ETL 过程。
我们将使用库附带的 csvdir 包作为模板。 csvdir.py 脚本位于以下文件夹中:
~/opt/miniconda3/envs/zipline35/lib/python3.5/site-packages/zipline/data/bundles
路径的标记部分取决于您的机器和您使用的 Conda 环境名称。我们定制的包文件也必须在那个文件夹中。
首先,让我们创建一个 csvdir.py 的副本,为我们将要做的事情起一个可识别的名字。例如,在这里,我们将对在纽约证券交易所上市的雅虎数据进行捆绑。比如 yahoo_NYSE.py
在你最喜欢的编辑器中打开新的 yahoo_NYSE.py 包。我们将开始编辑它,使雅虎数据适应 Zipline 数据格式,并能够在摄取过程中使用它。
如果我们看看文件内部,我们有在 ETL 过程中需要承担的函数、类和方法。在这篇文章中,我们不会解释所有的代码,你有相关的 API 文档。在这里,我们将看看理解和改变所需的部分。
改变主函数的名字,我喜欢用和文件名一样的名字。所以名字将会是雅虎纽约证券交易所。

该函数接受两个输入参数。第一个是数据频率的列表。分钟、每天或两者。第二个,是我们有雅虎每日数据的文件夹。我们在这一点上不使用这些参数,但是知道它们是有用的。
这个函数的输出是一个名为 CSVDIRBundle 的类,例如,将这个名称修改为 Yahoo_NYSEBundle。

在第 92、97 和 98 行,需要更改包名,这是我们用摄取 zipline 命令调用的函数名。第 97 行表示我们将在 Zipline 中注册为一个包的名称。

在第 98 行声明的函数中,我们可以看到 Zipline 所期望的数据格式,有一些处理输入参数和元数据、分割等的代码。
我们需要修改市场日历 CSVDIR,以便在第 161 行使用 NYSE 的通用市场日历。

为了使我们的数据适应 Zipline 格式,需要修改的函数在第 171 行被命名为 _pricing_iter 。这个函数读取 csv 文件并将它们加载到 Zipline DB 中。

这里我们可以看到代码的关键部分:

它读取 csv 文件,然后我们可以检查内容、修改列名、删除 NA 或数据中所需的任何其他更改。例如,在第 188 行,我们删除了可能的重复日期。
我们可以根据需要包含尽可能多的 print 句子来跟踪代码执行。

这里的关键是使 csv 数据指数与纽约证券交易所市场日历保持一致。第 207 行需要 sessions 变量来完成。
我们从数据的第一个日期到最后一个日期创建会话日期。包括在第 154 行中。

将变量名包含在调用函数的的参数中,第 156 行。

并在 _pricing_iter 函数的输入参数中接受。

最后,注释或删除最后一行代码,因为我们希望将 NYSE 日历用于这些数据文件。

注册包
最后一步是注册我们的 yahoo_nyse 捆绑包。打开(如果存在)或创建(如果不存在)这个扩展名. py 文件并包含这个新的包。
~/.zipline/extension.py

看输入的参数, tframes 是一个列表,可以是分钟,每日或者两者兼而有之, csvdir 是从雅虎下载的数据文件所在的文件夹。尽管在 csvdir 路径中没有指定这个端点,但是数据在每日文件夹中。
将数据接收到 Zipline 中
好了,我们到了,让我们测试一下新的包,从雅虎获取一些存储在
~/DATA/Yahoo_NYSE/daily

如果一切正常,您将看到我们在代码中包含的所有打印句子。如果这个过程没有错误地结束,我们的数据就在 Zipline DB 中了。
使用新的包运行回溯测试
让我们用我们的数据来检验一下这个简单的算法。
用现有符号初始化算法:

完整的算法代码可以在这篇文章的结尾和/或关于安装滑索的第一篇文章中下载。
在结果部分,确保您使用的是新的捆绑包 yahoo_NYSE

希望事情进展顺利,你会得到一个好的图表。
建议阅读:
结论
在这里,我们可以修改 csvdir.py 文件,以获得针对 Yahoo NYSE 每日数据的优化包。我们不太关心代码。但是,为了获得干净的代码,可以删除许多行。
加载分钟数据或从其他提供者加载数据是非常相似的。只需在 _pricing_iter 函数中将 Pandas 数据帧调整为 Zipline 格式。
在未来的帖子中,我们将尝试摄取在线数据,以避免 csv 文件。
记住,为了用 Zipline 简化你的生活,把你的时间花在思考策略而不是架构上,你可以使用 Blueshift 来回溯测试策略并随时上线。
文件在下载
- 第一个 Zipline 回溯测试 python 代码
- Yahoo_NSE python 代码
- 扩展 python 代码
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
Zipline 库-在 Windows 10 上安装
原文:https://blog.quantinsti.com/zipline-library-installation-windows/
马里奥·比萨
在这篇文章中,我们将一步一步地描述 Python Zipline 库在 Windows 机器上的安装过程。
这是我们在这篇文章中将要做的事情的概述:
- 滑索-简介* 在 AWS 上设置 Windows 机器* 安装蟒蛇* 为 Zipline 创建 Conda 环境* 设置 Zipline Conda 环境* 从 Quandl(摄取过程)中检索数据* 执行简单的回溯测试* 生成绩效报告
滑索——一个简介
Zipline 是 Python 中最完整的库之一,它与 Pyfolio 库一起为我们的机器提供了一个完整的回溯测试平台,可以处理多种金融工具和时间框架。
推荐阅读:Python 中的 Zipline 介绍T3】
回溯测试是我们用历史数据或随机序列测试交易策略的过程,目的是了解它们过去的表现,并对预期的未来行为做出推断。
作为程序员,除了时间,没有什么能阻止从零开始开发一个回溯测试平台,但是根据复杂性,它可以成为一个持续数年的项目。因此,有了正确的工具,我们几乎可以专注于交易策略的实施,并加快回溯测试过程。
推荐阅读:在 Zipline 中导入 CSV 数据进行回溯测试T3】
在开始安装过程之前,请记住,您可以直接在 Blueshift 中试验该库,它可以连接到不同市场和时间频率的数据,随时可以使用。
如果你想让你的生活变得复杂一点,那就继续读下去。
在 AWS 上设置 Windows 机器
我们首先需要一台能够运行 Python 的机器,几乎任何或多或少现代的机器都可以,从简单的 RaspberryPi 到 Linux、Mac 或 Windows PC。
对于这篇文章,我们将使用亚马逊网络服务(AWS)的 Windows 服务器,所以首先要启动这台机器。如果您打算在本地机器上安装 Zipline,可以跳到下一步。
如果这是您第一次使用 AWS,您必须在设置 EC2 机器之前创建一个帐户。
步骤 01 -连接到您的 AWS EC2:https://console.aws.amazon.com/ec2
步骤 02 -单击正在运行的实例。

步骤 03 -单击“启动实例”按钮。

步骤 04 -选择一个 Windows 实例。即微软 Windows Server 2019 基础:

AWS 有各种各样的机器配置,从简单和免费的机器到超级计算机,选择一个最适合您的项目和预算。对于这个简单的例子,他们称之为“符合自由层条件”的机器就足够了。
步骤 05 -选择一个实例类型,如带有 8Gb RAM 的 t2.large 或任何其他适合您需要的类型。

步骤 06 -点击查看和启动按钮。
步骤 07 -查看实例的详细信息,然后单击启动按钮。(这里我们接受默认配置)。

步骤 08 -现在,我们已经运行了一个随时可用的 Windows 2019 服务器实例:

步骤 09 -单击 Connect 按钮获取实例的 DNS、用户名和密码。

步骤 10 -启动远程管理员工具,并使用上一步中的凭证连接到远程机器。

这里我们有一台远程 Windows 机器可以使用。
安装蟒蛇
在这一步中,我们将安装 Anaconda,这是一个包含多种工具的数据科学套件。真的不需要安装这么多工具,有了 Miniconda 就足够了。
步骤 01 -让我们用 Python 3.7 为 Windows 安装 Anaconda 2019.10
https://www.anaconda.com/distribution/

步骤 02 -下载过程完成后,我们就可以开始安装了。








现在我们已经在机器上安装了 Anaconda 套装。
步骤 03 -启动 Anaconda 导航器:


步骤 04 -点击环境按钮:

步骤 05 -在 base root 环境中,单击 play 按钮启动 Conda 终端。

为 Zipline 创造康达环境
一个 Conda 环境是一个容器,让我们处理不同版本的 Python 及其库。例如,我们可以在一个环境中使用 Python 3.5 和 Pandas 0.24,在另一个环境中使用 Python 3.7 和 Pandas 1.0.3。这对于隔离项目的特定版本非常有用。
步骤 01 -让我们使用以下命令检查 conda 环境:
>康达环境列表

此时,我们只能看到默认安装的基础环境。
步骤 02 -现在让我们用 Python 3.5 安装一个名为“z35”的新环境:
>康达 create -n z35 python=3.5

步骤 03 -让我们再次检查 conda 环境,看看我们的新 z35 环境:
>康达环境列表

步骤 04 -现在,我们开始激活 z35 环境:
>康达激活 z35

星号表示活动环境。
步骤 05 -让我们尝试检查 Python 版本:
> python -版

步骤 06 -安装 ipykernel:
>康达安装 ipykernel

> python -m ipykernel 安装-用户

步骤 07 -安装 Jupyter:
>康达安装 jupyter

步骤 08 -启动 Jupyter 笔记本:
> jupyter notebook

默认的 web 导航器打开 Jupyter 应用程序。

步骤 09 -创建一个新的笔记本并选择 z35 内核。

如果笔记本显示消息:内核错误!这意味着新环境不存在!
我们的 z35 环境发生了什么变化?
我们已经在 Conda 上安装了 ipykernel,但是我们还需要在 Python3 上安装它。
步骤 10 -尝试修复错误:
> python3 -m pip 安装 ipykernel

> python3 -m ipykernel 安装-名称 z35 -用户

步骤 11 -再次启动 Jupyter 笔记本:

步骤 12 -再次启动 Jupyter 笔记本:

现在我们已经在 z35 环境中的 Python 3.5 上安装了 Jupyter notebook。
设置 Zipline Conda 环境
到目前为止,我们已经有了一台运行 Python 3.7 的 Anaconda 套件的 Windows 机器,我们已经安装了一个名为 z35 的新 Python 3.5 环境,我们还安装了 Jupyter notebook 的内核,并检查了我们是否可以访问 z35 环境。
现在我们必须安装所需的 Python 库来运行 Zipline。虽然我们可以一次安装所有的东西,但是我们将安装通用库,然后专注于以特定的方式安装 Zipline 库。
步骤 01 -让我们安装 Numpy、Pandas 和 matplotlib 库:
>伯爵安装 numpy 熊猫 matplotlib

步骤 02 -和 zipline 库,只获取该库的安装消息:
> 康达安装-康达-锻造滑索

步骤 03 -现在,我们再次启动笔记本电脑,检查 zipline 库是否安装成功:
> jupyter notebook

太好了!zipline 库已成功导入。
从 Quandl(摄取过程)中检索数据
我们现在已经安装了 zipline 库。为了测试一些代码,我们需要用摄取过程检索数据。为此,我们需要在 Quandl 中注册并获得个人密钥:https://www.quandl.com
之后,需要将 Quandl API key 包含到一个名为 QUANDL_API_KEY 的系统变量中,命令如下:
>设置 QUANDL _ API _ KEY = "
步骤 01 -设置 QUANDL_API_KEY 环境变量:

如果您想将环境变量配置为永久性的,您可以在系统属性窗口中包含它,单击环境变量按钮。

现在,我们已经安装了 Zipline 库,创建了一个 Quandl 帐户,获得了从 Quandl Wiki DB 检索数据的令牌,并使用该令牌配置了我们的 Windows 机器。是时候检索 Wiki DB 数据集了,以便在 Zipline 回溯测试中使用它们。
步骤 02 -从 Quandl 获取数据:
> zipline 摄取-b quandl


现在我们有一些来自 Quandl 的数据来测试一些策略。是时候测试一个基本策略了。
Zipline 实际上存在 2000 年之前的日期问题,因此需要对 zipline 安装文件夹中的 benchmark.py 脚本应用一个解决方法。找到它,并通过对内容进行评论来修改它,然后在上面放上这段文字。
使用命令 conda env list 在之前创建的 zipline z35 环境中查找 benchmark.py 脚本。
步骤 03 -在 benchmark.py 上应用变通方法

执行简单的回溯测试
启动 Jupyter 并创建一个新笔记本。
下面的代码改编自 Andreas Clenow 的书“交易进化”,是一个简单的算法,当价格穿过移动平均线时买入股票,当价格穿过移动平均线时平仓。

生成绩效报告
如果一切顺利,回溯测试以一个统计表和一些简单的性能图表结束。
在“分析”功能中,我们可以编写任何代码来分析回测,这里我们使用 Pyfolio 库来创建一个简单的退货单。值得研究该图书馆,以发挥其全部力量。



结论
虽然在本文中,我们已经在本地机器上安装了 Zipline 库进行回溯测试,但这场战斗才刚刚开始,因为数据接收过程必须适应每个数据提供商和市场时间表。
另一方面,Zipline 库无疑是一个强大的回测工具,但它不允许我们轻松地切换到实时,所以有一个具有这种能力的库的并行开发 ie。http://www.zipline-live.io/
最后,我们可以利用这个库的功能,而不需要将它安装在我们的机器上,这个平台有几个市场可以实时使用。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
参考文献
- 量子乌托邦
- 蓝移
- Zipline.io
- 文件夹
- 书:交易由安德烈亚斯·克莱诺发展
左正|毕业于 NYU 大学经济学专业|投资分析师
原文:https://blog.quantinsti.com/zuo-zheng-graduate-economics-nyu-investment-analyst/

金融市场的交易和它为你带来利润的潜力对许多人来说一直很有吸引力。然而,很少有人意识到需要数字化,以便在更短的时间内完成更多的工作。
郑(音译)就是这样一个故事,他从学生时代就被交易世界所吸引,想开始用数据交易,玩数字游戏,以求正确。找出他是如何做到的。
以下是我们与郑的对话。
告诉我们一些关于你自己的情况:你目前的工作概况,你的教育背景。
你好,我是郑,我毕业于纽约大学,获得经济学学士学位。目前,我在森马集团担任投资分析师。我希望扩展我的自动化交易知识,进入量化领域,有可能进入对冲基金行业。
是什么激励你学习量化交易?
从学生时代起,我就对金融市场感兴趣。我曾经是一个手工交易者,后来我意识到有一个合适的策略可以让我获利。但是要做到这一点,速度,准确性和纪律性,我不得不使用电脑,这就是我决定学习量化交易的原因。
你能在工作中应用你学到的东西吗?怎么会?
是的,事实上,我目前正在根据我在 QuantInsti 学到的东西,创建自己的交易策略。
我从 QuantInsti 的老师那里得到了巨大的支持,尤其是我和卖空课程的作者 Laurant Bernut 先生
我会向有抱负的交易者和交易者推荐 QuantInsti,因为他们提供了实用有用的学习材料和解决问题的强大支持。
你对劳伦特·伯努特的《交易中的卖空》这门课有什么体验?
劳伦特·伯努特的课程棒极了,在我看来,这是业内最好的课程,不仅仅是对卖空,而是对一般交易。课程中提供的源代码非常有见地,策略的变化令人振奋。我正在利用从课程中学到的知识来编写自己的代码。
您将从本课程中学到的三件事可能在其他地方都得不到:
- 根据重计基数系列而不是绝对系列来计算体制,将使你在竞争中脱颖而出。
- 能够选择顶部和底部是一项必须学习的技能。
- 多时间框架组合在零售交易领域是一个古老的童话,专业交易者通过扩大和缩小来获取利润。
你有什么想和有抱负的算法交易者和量化交易者分享的信息吗?
- 关注风险管理和订单执行。能够对论文中的策略进行回溯测试固然很好,但是实际部署它需要更多的技能,并且需要对风险管理和实际执行进行更严格的测试。
- 我建议不要在课程中使用给定的模板,而是使用这些模板作为基础,根据您的要求创建新的策略或修改现有的策略。
- 特别是对于算法交易者或有抱负的算法交易者:能够以稳健的方式发现政权是成为成功的算法交易者的关键。
Quantra 课程使积极的学习者获得在算法交易领域取得成功所需的完美技能。Quantra 课程是自定进度的小型课程,是获得使用 Python 或 excel 创建自己的交易策略所需技能的快速方法。所以你可以在几个小时内获得有用的技能。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个案例研究是根据 QuantInsti 学习者的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。完成任何 QuantInsti 课程后获得的结果对所有人来说都不尽相同。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号