Quantinsti-博客中文翻译-二-
Quantinsti 博客中文翻译(二)
资本资产定价模型
CAPM 或资本资产定价模型起源于 1964 年,是财务管理中极其重要的一部分,也是一个易于理解和应用的模型。该模型关注的是资产回报率对整个股票市场面临的风险的敏感性,这种风险被称为系统性风险。
它考虑了几个假设,并显示了投资特定资产的风险如何定义投资者从中获得的回报。这种风险与承担风险所获得的溢价之间的关系是 CAPM 的核心。然而,围绕本文所涉及的模型还有其他一些概念。
此外,在同一个模型中,风险的计算对于正确估计该风险的回报或溢价至关重要。除了这个模型,还有其他模型,我们将讨论资产定价。在本文中,我们将介绍:
- 资本资产定价模型及其运作
- 资本资产定价模型的用途和假设
- 你如何计算贝塔系数,什么是资本安全市场线?
- 该模式的两个主要优势和两个局限性
- 资产定价的其他因素模型
资本资产定价模型及其运作
资本资产定价模型是一个非常有用的模型,它可以帮助你公平地理解投资的估计回报与其风险或系统风险之间的关系。
现在,系统风险是指你在市场上的某项投资中可能承担的风险。这种多样化风险的一些例子是战争、衰退等。然而,这个模型假设有特定种类的金融资产可以获得零风险回报。
在这样的时候,这个模型给你在你的投资组合中分散资产的决策权。这种资产多样化有助于对冲特定金融资产的投资风险。
因此,系统性回报风险高于无风险投资回报。这个模型告诉你投资是否值得冒险。

在上图中,可以清楚地看到,您有两个选项,分别是:
- 没有风险的无风险投资回报,估计投资回报的 5%
或者
- 投资的系统风险,风险较高,但投资的估计回报也较高(与无风险回报相比),为 10%。
要在这两个选项中做出选择,CAPM 模型就派上了用场。
现在让我们来看看 CAPM 的公式,它给出了一个估计的投资回报,让你能够决定哪个选择更有利可图。公式是:
R =射频+ 𝝱 * (Rm -射频)
在上面的公式中,
Ra =估计投资回报
Rf =投资的无风险回报率
𝝱 =投资金融资产的贝塔值或风险值
Rm =资本市场的平均回报率
因此,上面的公式计算投资的估计回报率,目的是给你一个投资风险资产的回报率的估计。通过应用上面的公式,你将能够找到这个估计值。
在该公式中,投资于该资产的风险(𝝱)乘以市场风险溢价,即(Rm - Rf ),以获得高于投资于无风险金融资产的无风险回报的金额。
此外,将市场上任何其他金融资产的无风险投资回报率与产出相加,将会给你带来因承担该风险而获得的溢价(估计总回报)。
总之,这个估计是为了帮助你在投资高风险金融资产时获得更高的收益率。
举个例子,
假设资产 XYZ 为以下情况:
射频= 3%
Rm = 10%
= 0.75
通过使用 CAPM,资产 XYZ 的收益率为:
Ra = 0.03 + [0.75 * (0.10 - 0.03)]
0.0825 = 8.25%
如果一个投资者希望他/她的投资有 10%的回报,那么根据 CAPM 模型,他/她不应该在 XYZ 投资。但是,如果投资者寻求的回报率低于 8.25%,比如说 7%,那么投资 XYZ 会更好。
说到类型,这个模型涵盖了两种类型的风险,它们是:
- 系统风险
- 非系统性风险
创建资本资产模型的金融经济学家威廉·夏普(William Sharpe)提到了这两种风险。他认为任何投资都有两种类型的风险,并以此开始了这个模型。
系统风险
这意味着市场风险总是伴随着投资,并冲击整个股票市场。例如,在经济衰退的情况下,投资股票市场必然比其他时候风险更大。在这样的时候,这个模型帮助你决定哪些股票会更有利可图或风险更小。
非系统性风险
这种类型的风险被称为“特定风险”,因为它与单个股票相关。这种风险与整体市场走势无关。因此,这种风险与市场上某一特定股票有关,这种股票会因为任何商业失败而降临到投资者头上。
重要的是要明白,特定的或非系统的风险可以通过优化投资组合来处理。这是现代投资组合理论中提到的一个相关观察。
然而,在系统性风险的情况下,投资组合的优化有所帮助,但相对来说比在非系统性风险中的帮助要小。正如我们上面提到的,导致系统性风险的因素将整个市场纳入其范围。因此,对投资者影响最大的是系统风险。这就是这个模型如何专注于管理系统性风险。
现在,让我们看看 CAPM 的假设和用途。
资本资产定价模型的用途和假设
在这里,我们将看到 CAPM 存在的众所周知的假设,以及该模型在不同领域的应用。
由于假设对任何模型都很重要,资本资产模型也基于创建该模型的经济学家 William Sharpe 提到的一些假设:
- 投资者的多样化投资组合
- 单周期交易
- 无风险收益率
- 完美资本市场的存在
投资者的多样化投资组合
这意味着投资者只需要投资组合中系统风险的回报,因为非系统风险可以很容易地分散。因此,该模型忽略了非系统风险。
单周期交易
模型中假设了一个标准持有期,以使不同股票的回报具有可比性。因此,所有股票的持有期为一年。这样做是因为持有期为 5 个月的股票不能与持有期为 12 个月的股票相比较。
无风险收益率
这一假设表明,投资者可以在无风险回报率下借贷。这个假设是由现代投资组合理论做出的,这个模型也是从这个理论中衍生出来的。
完美资本市场的存在
根据这一假设,所有的股票都被正确地估价,它们的回报率也将被准确地估计出来。一个完美的资本市场意味着没有税收和成本;投资者很容易获得完美的信息,而且市场上有大量的交易者。
好了。让我们转到 CAPM 的实施/使用。
由于资本资产定价模型提供了对股票定价的洞察并确定了预期回报,因此它在以下方面有其实现/使用:
- 投资管理
- 企业融资
投资管理
CAPM 是许多投资者的重要工具,尤其是投资组合经理。这是可能的,因为 CAPM 通过考虑股票投资的 Beta 值或风险值来提供预期或估计的投资回报。这种估计有助于理解投资哪些股票,不投资哪些股票。因此,在市场上涨的情况下,投资者可以通过这种方式投资于高贝塔证券(贝塔系数大于 1)。然而,他们可以投资低贝塔证券(贝塔系数小于 1),以防市场预期下跌或正在下跌。
正如我们在第一节“ CAPM 和它的工作”中讨论的那样,它在投资管理方面的工作是简单明了的。
企业融资
在公司金融中,这个模型有很大的重要性,因为它建议将股权成本作为特定公司股票的最低预期回报。这种权益成本只不过是公司支付给股东的投资股票(风险较高的股票)的回报。这种股票的预期收益反过来就是股东投资公司股权基金的机会成本。
因此,简单地说,资本资产模型帮助公司或使用股票基金的企业获得估计的回报率。在此估计的基础上,公司向公司股东提供回报率。现在,由于该公司已经得到了一个估值,它必须至少赚取其资金中基于股权部分的成本,否则股票价格肯定会在市场上下跌。
相反,如果公司发现很难赚取股本成本,它就不能继续持有股份或股东的资金。这很重要,因为这样一来,股东就不用承担机会成本了。此外,股东可以投资于金融市场上的其他股票,他们希望在相同的风险水平下获得相同的预期回报。现在,一个重要的观察是,这个权益成本很难找到,除非我们在这里使用 CAPM。
让我们看看如何使用资本资产定价模型计算权益成本,也称为加权平均资本成本(WACC)。
权益成本或 WACC
现在,WACC 或权益成本的公式有助于确定,在特定的时间内,你到底能期望多少回报。让我们看一个例子。这里,为了帮助你理解 CAPM 是如何帮助计算权益成本的,我们将以 XYZ 公司为例,就像我们在解释 CAMP 时一样。权益成本的公式为:
权益成本=今天的现金流/(1+ra)t
所以,我们使用了下面的例子。
假设您的公司 XYZ 有以下变量:
ra =?
射频= 3%
rm = 10%
βa = 0.75
通过使用 CAPM,资产 XYZ 的收益率为:
ra = 0.03 + [0.75 * (0.10 - 0.03)]
0.0825 = ra
现在,向前看,8.25%是资产的预期回报率,你可以通过这个百分比来计算和决定股权成本。让我们假设一笔 1000 美元的现金流在 XYZ 完成。但是,由于现金今天更有价值,我们将在 2 年后计算其价值。
今天投资的现金-1000 美元
权益成本(考虑现金贴现值)-1000 美元/(1+ra)t = 1000 美元/(1+0.0825)t = 1000 美元/(1+0.0825)2
= $853.9
因此,853.9 美元是你当前时间段现金流的未来值。这给了你估计,以便你决定你的股权成本低于这个计算。
现在让我们来看看如何计算贝塔系数,资本安全市场线意味着什么。
你如何计算贝塔系数,什么是资本安全市场线?
正如资本资产定价模型所表明的,贝塔系数是衡量股票风险的唯一重要变量。这是通过找出股票在市场上的波动率来实现的。这意味着该模型将特定股票的向上或向下运动与整个股票市场的向上或向下运动进行比较。
因此,如果一只股票的价格以与市场相同的方式或围绕整个股票市场移动,那么这只股票的贝塔系数为 1。Beta 值大于 1 的股票将被视为风险较高的股票,小于 1 的股票将被视为风险较低的股票。这意味着风险较高的股票必须提供市场风险溢价,或者简单地说,与风险较低的股票或无风险资产相比,回报率更高。
因此,Beta 表明,比无风险投资风险更高的投资应该能够获得高于无风险投资回报的溢价(额外回报)。
在了解了 Beta 是投资市场中特定资产的计算风险量之后,现在让我们看看如何用 Python 计算 Beta。
职业发展-算法/HFT 交易方面的工作
原文:https://blog.quantinsti.com/career-development-webinar-25-jan-2017/
https://www.youtube.com/embed/UXGjeVQd_yU?rel=0
【iRage 技术总监 Sunith Reddy 先生的职业建议&Master Trust 董事 Puneet Singhania 先生
概述
- 在 Quant/Algo 交易领域中不同类型的角色和工作
- 成为算法交易者需要什么样的技能?
- 一个 quant 开发者是做什么的?
- 如何被 HFT 公司聘为开发人员?
- 量化分析师/交易员职位的面试中会问些什么问题?
- 为您的 Algo 交易平台组建团队时需要牢记的几点。
本次网上研讨会为与会者提供了一个独特的机会,让他们能够与 Quants & HFT 的开发团队进行一对一的互动,并提出与职业相关的问题。
分享您与职业相关的问题,我们将尽最大努力在网上研讨会中讨论这些问题!
扬声器小组
苏尼思·雷迪
孟买伊拉克资本经纪公司(亚洲领先的 HFT 公司)技术总监

Sunith 是进化算法和非常规计算模型领域的专家。在 IIT 马德拉斯大学攻读计算机科学学士学位期间,Sunith 参与了蛋白质计算和 dna 计算方面的一些开创性研究。他的工作已在“非常规计算模型研讨会”上发表。
然后他继续在雅虎 R&D 工作,在那里他设计了一些非常大的可扩展平台。他还有两项专利申请待批。
普内特·辛哈尼亚
董事——Master Trust,印度一家领先的经纪公司
 Pune et Singhania m . b . a .,C.F.A .先生是 Master Capital Services Limited 的全职董事。Singhania 先生参与集团的新举措,并协助其他董事制定公司战略..全职担任万事达资本服务有限公司董事。Singhania 先生参与集团的新举措,并协助其他董事制定公司战略。
Pune et Singhania m . b . a .,C.F.A .先生是 Master Capital Services Limited 的全职董事。Singhania 先生参与集团的新举措,并协助其他董事制定公司战略..全职担任万事达资本服务有限公司董事。Singhania 先生参与集团的新举措,并协助其他董事制定公司战略。
在加入 Master Trust Limited 之前,他在 ING Investment Management in India 的股票基金管理部门工作。
戈皮纳特·拉姆库马尔
市场风险量化——波兰领先银行

Gopinath Ramkumar 是一名数据分析师,在 IT 部门和算法交易等不同领域拥有丰富的经验。Gopinath 是一名训练有素的工程师,在加入曼彻斯特商学院获得计算金融学位之前,他是一名软件工程师。在英国时,他开始在 QuantInsti 攻读算法交易证书。EPAT 成功完成后,在 QuantInsti 的安置团队的帮助下,Gopinath 加入了在印度拥有算法交易平台的 Motilal Oswal。
一个 quant 分析师 Gopinath 一直在用他的量化知识和背景为不同的部门和领域做出贡献。
谁应该参加?
这个网上研讨会对高频交易工作、定量交易工作和算法交易工作的求职者非常有益。该会议非常适合:
- Algo/Quant/HFT 领域的求职者
- 为 Algo/HFT 办公桌组建团队的企业家
- 正在寻找专业成长量化分析师的现有算法/量化交易员和开发人员
关于伊拉克资本
iRageCapital 利用其在技术和量化金融方面的优势,设计尖端的高频交易系统和策略。2008 年 DMA 在印度市场的引入为印度算法交易领域带来了众多可能性。iRageCapital 由量化交易专业人士于 2009 年成立,旨在探索这一领域的可能性。
安吉拉与 EPAT 建立职业道路的故事
原文:https://blog.quantinsti.com/career-path-success-story-angela-zhao/
Angela Zhao 来自加拿大,是一名金融专业的毕业生,拥有数据分析硕士学位。她曾担任过分析师、研究员和数据科学家等多个角色,在科技和金融领域的多家公司任职。
安吉拉认为:应用你所学的概念非常重要,因为这是从你所学中获益的唯一途径。
她现在是一名 EPATian 人,持有 EPAT 优秀证书,并从 EPAT 社区中受益。安吉拉和我们分享了她的算法交易之旅。这是她的成功故事。
嗨,安吉拉,给我们介绍一下你自己吧

我叫安吉拉·赵,来自加拿大安大略省多伦多市。我本科学习的是金融,然后在一家共同基金从事了两年的投资管理工作。
我在一家科技公司做了几年机器学习,最近转到了一家养老基金的新职位。我从 EPAT 学到的所有知识真的帮助我实现了这种转变。
作为来自机器学习行业的人,我追求 ML 课程、会议、阅读论文,并且总是紧跟行业趋势。我在高中和大学的时候涉足过全权委托交易,但是在我开始朝九晚五的工作后,我再也不能在市场时间交易了。我可以管理长期投资,但不得不放弃短期交易。
那时候我就在想,
哦,要是我能自动化我的交易就好了!那样的话,我工作的时候就不用看了。
这是我进入算法交易的最初动机之一。
从商科学士到全面的数据科学家。那是一次相当有趣的旅行。那是怎么发生的?
量化金融是一个非常难进入的行业,尤其是在多伦多,因为这里没有纽约或芝加哥那么多的投资公司或对冲基金。我想变得更有竞争力,所以我决定攻读数据分析硕士学位。硕士毕业后,我花了三年时间在一家科技公司做 机器学习 。
当我开始从事金融工作时,我更倾向于基本面投资和自主投资。我根据公司的基本面选择股票和固定收益产品。我阅读了这些公司的年报,并进行了尽职调查,试图判断它们是否是良好的长期投资。我也考了两级我的 CFA 。
我注意到大量资金正流入量化基金,一切都越来越自动化。一段时间后,我的兴趣转向了算法交易和一些更量化的东西。
我更感兴趣的是建立一个可扩展的策略,可以很容易地在不同的资产类别中复制。这就是促使我学习更多量化金融和算法交易的原因。
这让我想到了 EPAT 项目。完成课程后,我想进一步提高我的技术技能,所以我获得了西方大学的数据分析硕士学位。从那以后,我一直从事机器学习方面的工作。
由于时间限制,我现在把独立交易作为一种爱好。我主要交易期货,有时交易股票。我未来的职业目标是成为一家投资公司的算法交易员。
成为一名养老基金的数据科学家,我在那里建立金融模型,帮助我更接近那个目标。
根据你的说法,统计在 Algo 交易中的重要性是什么?
我觉得如果你不理解统计数据,你甚至不会理解你得到的结果。回溯测试结果中可能包含许多偏见,缺乏统计学知识的人可能会忽略它们。
刚接触算法交易的人只看绝对收益,而忽略了其他方面。他们不衡量风险,而风险是交易的关键因素。
重要的是要考虑风险调整后的指标,如夏普比率(T0)或 T2 比率(T3),以及其他风险指标,如最大提取额。扎实的统计学基础可以帮助你更好地理解这些指标告诉你什么。
你在 EPAT 的学习有多重要?
我进入算法交易的最初动机是使我的策略自动化,这样它就不会干扰我朝九晚五的工作。全职工作,我可以投资,但我不能做短线交易。正是在这段时间里,我在网上寻找不同的资源来帮助我进入算法交易。
我找到了一些 YouTube 频道或博客,但它们太简单了。他们会教你如何制作一个基本的训练程序,比如 algo 交易的“Hello World ”,但不会涉及任何细节。它们甚至没有涵盖很多重要的主题,如协整和其他统计概念。
我想要更全面的东西。在做了大量研究后,我发现 EPAT 可能是最全面的项目之一。我相信 EPAT 会帮助我更深入算法交易的世界。
此外,我看了看董事会的教员,他们是有算法交易实际经验的人,而不是只懂理论的学者。这就是我选择 EPAT 的原因。
EPAT 的课程非常广泛,教会了我所有关于量化交易的知识。
你最喜欢 EPAT 的哪个特征?
我不认为 EPAT 是一个如此优秀的项目,而是所有因素的综合。课程、师资以及将你所学应用到项目中的机会——它们都增加了体验。
安置小组
安置小组给了我们极大的帮助。他们总是回答我关于潜在角色的任何问题,他们也始终如一地跟进我。
即使在我毕业后,EPAT 就业小组也会检查我,以确保我遵循职业道路。他们经常询问我对某个工作职位的兴趣。他们非常积极主动,不断分享各种工作机会。非常感谢!
我认为 QuantInsti 的教师是非凡的!如果你问他们一个问题,他们会很快回答。
支持
安置和支持团队也是如此。如果我有任何问题,或者我只是问他们任何问题,即使他们不知道答案,他们也会很快地问和回答。与这些优秀的人交谈非常有帮助。
我认为 EPAT 的主要好处是,它教会了我算法交易的最佳实践,这是我真正进入它之前不会知道的。
你会给那些想从事算法交易的人什么信息?
我能给人最大的提示是:
不要被 Algo 交易吓倒。
我想很多人看到这个行业被博士或者有很多学位的人所主导。他们觉得除非他们有同样的证书和知识,否则他们做不到。但是像 EPAT 这样的课程为每个人提供必要的知识,训练人们完全有能力独立创造和实施战略。
即使是有知识的人有时也害怕去实现任何事情,因为他们觉得自己做不到。当他们真正尝试的时候,他们意识到他们一直都有能力做到。
我鼓励每个人都走出去,亲自尝试,看看如何接近量化和算法交易。
非常感谢 QuantInsti 这些年来的支持!
感谢您抽出时间与我们分享您的旅程,Angela。我们确信我们的读者能够理解你的旅程,并被你的经历所引导。像你这样优秀的人说的友好的话,真的会有所不同,会让我们走得更远。祝你前程似锦。
算法交易(EPAT) 的高管课程是一门综合课程,涵盖从统计学&计量经济学到金融计算&技术,包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。点击这里查看。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
外汇套利交易策略
在这篇博客中,我们将通过各种例子了解外汇套息交易策略,并了解套息交易策略的各个方面。
我们将涵盖:
- 什么是套利交易?
- 为什么只有外汇市场?
- 我们在这项交易中赚了多少?
- 套利机会
- 未覆盖/覆盖利率平价
- 利率平价公式
- 利率平价的陷阱
- 外汇套利交易中的常见问题
我们开始吧!简单的外汇套利交易策略是将高收益货币利率的资金投资于低收益货币利率,以利用外汇利率之间的差异。
当我们阅读经典定义时,会有很多问题冒出来。
- 为什么这个词带着?
- 为什么只在外汇市场?
- 这一行我们赚了多少?
- 这不就是套利机会吗?
- 如果是套利,风险会更大吗?
我们退一步,一个一个来回答。
什么是套利交易?
Carry 这个词的意思是我们从持有资产中获得的回报。当我们长期“持有”商品时,我们最终会得到负回报,因为它们会产生存储成本。但外汇市场的情况并非如此。我们实际上并没有携带任何物理实体。
什么是外汇套利交易策略?为什么只有外汇市场?
套利交易策略并不局限于外汇市场。它在外汇市场上很受欢迎,因为市场上经常存在货币汇率的差异。直到全球金融危机之前,这些贸易策略产生了持续的正回报。
2008 年,这些贸易策略失败了,削弱了可预测外汇回报的理由。例如,美元兑日元汇率在 2008 年危机后花了近 5 年时间才恢复。

尽管有上述风险,只要你在投资前做了充分的市场调查,你就可以利用这个策略。
我们在套利交易策略中能赚多少?
在套利交易策略中,你赚取利息。当你持有一种货币的多头头寸时,你获得利息,当你持有空头头寸时,你支付利息。利率乘以买入名义利率的差额就是你的利润。例如,让我们以交易量最大的外汇货币之一欧元/美元为例。截至今日,美元和欧元的伦敦银行同业拆放利率如下。
- 美元- 2.379 %
- 欧元-0.476 %
假设我们持有名义金额为 100,000 美元的欧元/美元空头头寸。利息的计算方法如下:
(Interest Rate of the long currency – Interest Rate of the short currency) x notional
在我们的例子中,
(2.379 - (-0.476))*10000/365 = $78 a day
由于隔夜伦敦银行同业拆放利率的每日波动,这一数额可能会有所不同。如果你持有欧元/美元的多头头寸,你将会支付准确的金额。
这是一个套利机会吗?
关于外汇交易策略的担忧很少。这种策略违背了风险中性的有效市场假设,因为这显然是外汇市场的套利机会。此外,人们认为这是未覆盖利率平价的失败。在澄清这种误解之前,让我们先来简单了解一下什么是利率平价。
未覆盖/覆盖利率平价
- 该理论认为,两国之间的利率差等于两国的远期汇率和即期汇率之间的差。
- 与备兑利息不同,备兑利息不涉及使用远期或任何其他合同对冲外汇风险。
利率平价公式
(1 +本币利率)=(即期外汇汇率/远期外汇汇率) (1 +外币利率)*
但我们在这里忽略的是,利率平价(IIP)是基于预测结果,而不是基于实际结果。IIP 是一种事前条件,而不是事后条件。所以外汇交易策略不会辜负任何现有的理论。
利率平价的陷阱
虽然赚取利息和利润似乎很容易在外汇套利交易策略,有一些陷阱应该知道。
央行降低利率。
在上面的例子中,我们看到了利率的差异使你获利。但是利率一直在变。当央行降低利率,而你没有相应地改变你的头寸,你的盈利可能会变成亏损。
央行干预货币。
为了增加或减少一个国家的货币,中央银行会在外汇交易市场上买入或卖出。通过这样做,货币的价值可能会相对于替代货币相应地增加或减少。
使用的杠杆。
套利交易者使用的杠杆会使交易变得有风险。即使是一个货币对 10%的小幅下跌,再加上 10%的杠杆,也可能会抹去这笔交易的全部资本。
外汇套息交易策略常见问题解答
以下是一些关于外汇交易中套利交易策略的最常见问题:
1。外汇市场如何选择货币?T3】
答:如果你是套利交易策略的新手,我们建议你从风险较低的货币开始。G7 货币将是一个良好的开端。新兴市场的货币确实提供了更高的收益,但对金融体系的微小变化非常敏感,风险也更大。
2。影响货币价格的因素有哪些?T3】
答:影响货币价格的因素有很多。这些在我们的外汇市场交易因素博客中有更详细的讨论。这些因素如下:
- 政治格局
- 通货膨胀率
- 利率
- 政府债务
- 进出口交换比率
- 投机
- 资本市场
- 雇佣日期
- 经济规划
3。什么是外汇市场中常用的术语?。T3】
答:如果你在外汇交易策略市场工作,那么你会经常听到这个术语。PIP 是以百分比表示的“点”的简称。这是外汇市场上衡量货币对变化的最小尺度。外汇市场上的大多数货币都是按小数点后第四位来定价的。
例如,美元/澳元货币对的最小变化是 0.0001 美元。这等于 1/100 或 1%或一个基点。当您在投资组合中使用货币对进行对冲时,这很有帮助。外汇市场的套期保值吞噬了这两个头寸,价差的微小变化会使其显著增加。
如何在外汇套利交易策略中获得成功?
要想在外汇套利交易策略中取得成功,我们应该知道什么时候进场,什么时候出场。进入的最佳时机是当有一条来自央行的关于一个国家加息的信息时,一旦有关于这个消息的刺激,更多的人开始投资,你应该获得最佳回报,并退出特定的汇率。如果交易者看到一个巨大的机会,他们有时会改变仓位。
结论
根据上述获得的知识,在外汇套利交易策略,它应该是投资者最喜爱的策略,给予积极的回报永远。不幸的是,这不是我们在市场上观察到的情况。随着时间的推移,现有汇率差异的积极一面使其风险更大。
因为这些是存在于市场中的真实机会,而且对大多数人来说是显而易见的,所以每个人都去追逐它们,并使其风险更大。当越来越多的人购买一个国家的国债时,这个国家的利率就会上升。尤其是在危机期间,市场波动非常快,导致巨大的负回报。
一个例子是 2008 年全球金融危机期间,日元对英镑的汇率在 5 小时内上涨了 30%。因此,建议谨慎行事,采取预防措施,如实施止损策略。
您可以通过注册我们关于 Python 中的外汇交易策略的课程,了解更多关于外汇市场的信息,并在其中制定策略。交易愉快!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
学习外汇交易使用 Python 中的真实外汇市场数据创建动量交易策略,并在内置平台上进行回测并分析结果。
现金到期货套利
现金和衍生品(期货)之间的套利现在更加普遍。这个 EPAT 项目将帮助你理解和学习如何建立一个现金期货套利的模块。反过来,这将有助于你押注现金期货价差,以最大化当天利润。
本文是作者在 QuantInsti 提交的算法交易高管课程(【EPAT】)的最后一个项目。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Chandrashekhar Satoskar 是 Religare Securities Ltd .的套利交易员。他拥有孟买大学的商业学士学位,并在 Vinayaka Mission 的研究基金会完成了工商管理硕士学位(M.B.A .)。他目前是 Westbury Tradecom 有限公司的黄金、股票&衍生品交易员。
项目动机
作为一名 EPAT 校友,我对建立一个现金期货套利模块非常感兴趣,这将有助于交易者或批发商对现金期货价差进行押注,就像日内价差押注一样,以最大化日内利润。为了对上述策略进行回溯测试,我在 Excel 的帮助下做了同样的事情。
仲裁
套利有两种类型:
- 每当期货价格高于现货价格时,它被称为“期货溢价”或被称为期货交易@溢价
- 每当期货价格低于(贴水)现货价格时,它被称为“现货溢价”或被称为期货交易 @贴水。
还有两种套利者:
- 一种更像日内交易者或批发商,利用现金和期货的差价,尽可能捕捉差价。
- 另一类人更像中期投资者,他们对中期的固定收入流感兴趣,不承担任何信用风险或潜在观点。
数据挖掘
我们可以从许多 API 或交互式代理获得数据。对于数据挖掘,我使用 ZERODHA PI 软件,该软件提供每分钟的数据,有助于收集数据以对模块进行回测。
数据分析
以下是数据分析的步骤:
1.首先,按照时间框架得到现货和期货的利率——这里我用的是 1 分钟。时间范围
2.计算期货和现货之间的差额,称为价差。
3.计算价差的布林线,我们将确定价差的上限和下限,并获得相同的平均值。
4.计算价差的 CCI(商品通道指数)以确定价差的趋势
5.计算 CCI 的 MACD(移动平均转换转移),这将有助于识别来自 MACD 的扩展转换转移信号
6.在上述计算时间之后产生用于策略的信号,
- 每当价差大于大于或等于布林带上轨,且 MACD 值小于 MACD 信号值时,将买入现货并卖出期货,即刷新。
- 每当价差小于小于或等于布林带下轨,且 MACD 值大于 MACD 信号值时,将买入期货并卖出现货,即平仓。
- 如果上述条件与不匹配,那么我们将保留单元格空白。
7.计算 BPS(基点): BPS =价差/价格*100
8.现在,我们将定义状态列,以确定交易的当前状态,即平仓或平仓:
- 我们将一次进行一个交易——这意味着如果一个正在进行的交易忽略了所有的交易信号,直到 FA 结束(从新鲜的 P&L)或 UN 结束(从放松的 P&L)到来。
- 我们不会在下午 3 点 15 分后接受新的平仓信号,因为在印度市场,卖空是不允许的
- 如果之前的状态为空白(无交易),则将单元格保留为空白
- 如果之前的状态是新上涨,价差小于或等于布林带下轨,MACD 值大于 MACD 信号值,则 FA 结束(将 P&L 从新上涨中收回)。
- 如果之前的状态是平仓,价差大于或等于布林带上轨,MACD 值小于 MACD 信号值,则取消平仓(将解除 P&L 平仓)。
9.在我们了解了根据给定的资金规模执行交易数量的交易时间的状态后,我用了 1 cr 的资金对上述策略进行回溯测试。
所以我们用这个公式:
如果当前状态是新鲜出炉或平仓,则向下舍入(总资金/价格)/特定股票的手数*手数
10.现在我们定义买价或卖价,所以我们从现货价格或期货价格
- 如果当前状态是 Fresh up ,那么将把现货价格作为买入价,把卖出价作为期货价格
- 如果当前状态为平仓,则将期货价格作为买价,卖价作为现货价格)
11.现在定义买入价值和卖出价值所以公式是,
- 购买价值=价格*批量
- 销售价值=价格*批量
12.计算毛利:是最新价差与固定资产期末价差或展开价差与未期末价差的差额
13.计算净利润:净利润=毛利-交易费用
14.计算以 BPs 为单位的回报 NP:回报 NP =净利润/总资金*100
15.计算策略结果,例如:
- 积极的结果,
- 负面结果,
- 积极交易,
- 负面交易,
- 平均回报。
挑战
- 预测当天的上涨或平仓信号
- 缺点:不允许卖空
- 买方和卖方必须有一个唯一的 ID 来输入任何特定股票的交易,如果相同的交易将自动平仓并将被释放到交易费用中。
主要发现
- 为批发商和交易商开发日内交易,利用大资金创造回报
- 只要价差触及 MACD 的布林带上轨或下轨,或者越过 MACD 信号线,就交易
- 不要在下午 3 点 15 分后开始交易,因为获得好回报的机会很小
- 如果你正确地遵循上述步骤,有机会在一天内赚很多钱
- 每当进行新的交易时,看看 Nifty/Banknifty 现货和期货溢价/折价,这将是你交易的额外工具。
- 尝试搜索即将公布的业绩、公司行动、预算月份、RBI 政策等股票。这将创造更多的交易机会,有机会赚取额外的阿尔法。
结论
上述交易策略是一种低风险策略,旨在利用
- 布林线,
- 商品渠道指数,以及
- MACD。
不同的时间框架适用于不同的股票,因此在回溯测试和交易时,要选择正确的时间框架。
上述策略,整体性能比率将在 70%左右,但做回测根据你的结束。交易是艰难的,我希望这个策略能帮助所有交易者交易。从我的经验来看,没有交易策略是永恒的,我发现自己在重塑自己的交易风格,并尝试开发新的策略。
祝您好运,交易愉快!
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT) 的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐均由学生或 QuantInsti提供,不做任何保证。学生和 quantin STI否认对这些信息的使用负有任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。T15】**
中心极限定理介绍:例子,计算,Python 中的统计
由阿舒托什·戴夫
中心极限定理(CLT)经常被认为是最重要的定理之一,不仅在统计学中,而且在整个科学中。在这篇博客中,我们将尝试通过 Python 中的模拟来理解中心极限定理的本质。
内容
- 样本和采样分布
- 什么是中心极限定理?
- 中心极限定理-陈述&假设
- 使用 Python 模拟演示 CLT 的实际操作,并举例说明
- 例 1 -指数分布人口
- 示例 2 -二项分布人口
- CLT 在投资/交易中的应用
- 投资者面临的挑战
- 金融正态性的伟大假设
- 夏皮罗-维尔克测试
- 中心极限定理的作用
- 检验周收益和月收益的正态性
- 置信区间
样本和样本分布
在我们讨论定理本身之前,首先必须理解构建模块和上下文。推断统计学的主要目标是对给定的总体进行推断,仅使用其子集,称为样本。
We do so because generally, the parameters which define the distribution of the population, such as the population mean (\mu) and the population variance (\sigma^{2}), are not known.
在这种情况下,样本通常是以随机方式收集的,从样本中收集的信息随后被用于推导出整个总体的估计值。
对于进行分析的组织/公司/研究人员来说,上述方法既省时又省钱。为了以任何有意义的方式将从样本得出的推论推广到总体,样本很好地代表总体是很重要的。
挑战在于,作为一个子集,样本估计只是估计,因此容易出错!也就是说,它们可能没有准确反映人口。
For example, if we are trying to estimate the population mean ((\mu)) using a sample mean ((\bar x)), then depending on which observations land in the sample, we might get different estimates of the population with varying levels of errors.
什么是中心极限定理?
这里的核心点是样本均值本身是一个随机变量,依赖于样本观测值。
Like any other random variable in statistics, the sample mean ((\bar x)) also has a probability distribution, which shows the probability densities for different values of the sample mean.
这种分布通常被称为“抽样分布”。下图直观地总结了这一点:

中心极限定理本质上是关于在某些特定条件下样本均值的抽样分布性质的陈述,我们将在下一节讨论这一点。
中心极限定理-陈述和假设
Suppose (X) is a random variable(not necessarily normal) representing the population data. And, the distribution of (X), has a mean of (\mu) and standard deviation (\sigma). Suppose we are taking repeated samples of size 'n' from the above population.
然后,中心极限定理指出,给定足够高的样本量,以下性质成立:
- 抽样分布的均值=总体均值((\mu)),以及
- 抽样分布的标准偏差(标准误差)= (\sigma/√n),因此
- 对于 n ≥ 30,在实际应用中,抽样分布趋于正态分布。
换句话说,对于大 N,$ $ \ bar { x } \ long right arrow \ mathbb { N } \ left(\ mu,\ frac { \ sigma } { \ sqrt { N } } \ right)$ $
在下一节中,我们将借助 Python 中的模拟来尝试理解 CLT 的工作原理。
使用 Python 中的模拟和示例演示 CLT 的实际应用
本节要论证的要点是,对于服从任何分布的总体,对于足够大的样本量,抽样分布(样本均值分布)将趋于正态分布。
我们将考虑两个例子,并检验 CLT 是否成立。
- 示例 1 -指数分布的人口
- 示例 2 -二项式分布的人口
示例 1 -指数分布的人口
假设我们正在处理一个呈指数分布的人口。指数分布是一种连续分布,通常用于模拟事件发生前需要等待的预期时间。
The main parameter of exponential distribution is the 'rate' parameter (\lambda), such that both the mean and the standard deviation of the distribution are given by ((1/\lambda)).
以下代表我们指数分布的人口:

f(x)= (\ cases { \λe^{-\lambda x } & if x > 0 \ cr0 & \ text { otherwise } } )
e(x)= (1/\λ)= (\ mu )v(x)= (1/\lambda^2)= (\sigma^2),意思是 SD(x)= (1/\λ)= (\ sigma )
我们可以看到我们人口的分布远非正常!在下面的代码中,假设(\lambda)=0.25,我们计算总体的平均值和标准差:
实现和成长:从 CFA 特许持有人到算法交易员
原文:https://blog.quantinsti.com/cfa-charterholder-algorithmic-trader/
人们经常会因为一些狭隘的观念而阻碍他们的职业和专业发展。这阻止了他们去追求他们喜欢做的事情。
有许多非凡的故事展示了一个来自完全不同背景的人是如何做到的,但对某件事有兴趣却常常能做到。值得注意的是,如果他是 CFA 持有人,并且仍然追随他的愿望学习算法交易,特别是增长他的技能,迎合他成为其中一员的愿望。

我所指的人不是别人,正是 托德施耐德 。
CFA 特许持有人。作为特许金融分析师称号持有者(CFA 特许),Tod 被认为是全球投资管理知名职业的一部分。
Tod 是一名投资分析硕士,拥有相关行业经验的决策技能,他还在美国俄亥俄州哥伦布市建立了自己的公司 ' 施耐德咨询有限责任公司。目前,他是美国俄亥俄州俄亥俄州立大学费希尔商学院的高级讲师。
以下是他进入算法和量化交易世界的一瞥——这是一段激励你不断学习、不断成长、不断追求你一生中想做的事情的旅程。
我们与托德·施奈德的对话
嗨,托德!告诉我们你自己的情况
嗨,我是托德·施奈德。我一生都在投资并热衷于投资。我的父亲是一名兽医(已退休),但一直沉浸在市场研究和投资中。在他的带领下,我从 1994 年开始分享我对投资的热情。
你什么时候觉得有必要学习算法交易?
我读过关于量化交易和算法交易的书(Thorp,Simons,Woodriff ),但是我想自己去发现——通过实践。
在 EPAT 之前,你面临着哪些挑战?是什么促使你去解决它们?
作为一个拥有长期视野的自由投资者,我想知道量化领域将如何增加我的过程的价值。此外,我想提高我的情商,更好地理解我交易的另一面。解决这些问题的唯一方法是努力工作并付诸实践。
你能分享一下你考虑用来自学算法交易的可能选项吗?
我考虑了几个不同的项目(大学/在线课程)。
这里学到的知识对你有什么帮助?
我继续尝试,并在学习 Python 的过程中获得了新的乐趣。编程以难以表达的方式拓展了你的大脑,但如果我必须简洁地说,编程提高了你解决问题的能力。
你拥有一家咨询公司,并且是俄亥俄州立大学费舍尔商学院的高级讲师。EPAT 认证对你现在的工作有什么帮助?
作为一名教师,我觉得有责任调查商业前景,让我的学生为职业机会做好准备。EPAT 帮助我在 quant 和 Python/Pandas 和 context 方面打下了基础。
告诉我们你在 EPAT 的经历吧!
太棒了。鉴于我的金融/会计背景,准备工作和前几节课都很简单。我在 Excel 讲座中感到舒适和自信,但当谈到 Python 讲座时,我却像是在用消防水管喝水。我努力学习,尽我最大的努力完成工作和家庭责任(期末考试花了我 10 多个小时)。有时时差很难适应,但我非常兴奋地得知,有些晚上我无法入睡(直到我取得进展或弄明白)。
你会对那些在算法交易中面临类似挑战的人说些什么?
我读了一本很棒的书,名为《你是如何知道 T1 的》,它引发了我对我所知道的一切的不安。如果你想知道 quant 是如何工作的,交易的另一方在想什么,你必须自己去发现。
对 EPAT 的有志之士有什么建议吗?
正如我年幼的女儿教导我的那样:要冷酷无情。
对于一个拥有算法交易基础知识和统计学知识的人来说,托德获得了 EPAT 优秀证书,这帮助他探索创造交易算法、机器学习,并将在 EPAT 学到的技能应用到自己的交易中。
有了正确的技能、指导和支持,你就可以成为算法交易领域不断增长的一部分。算法交易高管课程 (EPAT)就是这么做的。它的综合课程包括培训模块,如统计学&计量经济学、金融计算&技术和算法&量化交易,让你成为一名成功的交易者。在这里了解更多。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,本案例研究是根据 quantin STI EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后取得的结果对所有人来说可能并不一致。
一个 CFA 和一个企业家——汉斯学习期货交易的经验
原文:https://blog.quantinsti.com/cfa-entrepreneur-futures-trading-success-story-hans-nordemann/
你多久会遇到一个将自己的职业生涯完全奉献给银行和金融领域的人?
汉斯·诺德曼来自美国,在银行业有着 35 年辉煌的职业生涯。另外,他是诺奎斯特资本的创始人。Hans 相信可以发展和提高他在该领域的知识以及他对金融市场的兴趣。
汉斯与我们分享他学习期货交易的旅程!
大家好,我是汉斯·诺德曼,我在美国工作。我本科毕业于宾利大学,主修经济学和会计学。我也是 CFA 持有者。
在 2000 年创办自己的公司 Norquest Capital 之前,我已经在金融行业工作了近 35 年,为纽约的大银行工作过。
多年来,我已经形成了一套投资方式、投资地点和投资内容的流程。我想尽可能地自动化这个过程。由于我识别投资机会的过程本质上是定量的,通过算法实现自动化符合这个目的。
我的编程经验主要是在 Python 和 Java 方面,这是我和我那些对机器人感兴趣的孩子一起学习的,当时他们正在追求工程。我对 Quantra 正在做的工作很感兴趣,因为它是用 Python 编写的,所以我决定继续使用 Quantra。
我也使用过其他在线学习平台,我注意到其他平台提供零碎的信息或学习材料,而 Quantra 有一个一揽子资源,有点像学习不同概念的一站式。教学方法很好,有视频和集成的 Jupyter 笔记本,课程设计得非常好。
我在 Quantra 关于期货交易的课程中学习期货交易的经历很不错,尽管我对期货是如何运作的很熟悉。我喜欢课程设置的方式,视频单元帮助我学习概念,PDF 非常有用,因为它们使我能够阅读更多关于概念的细节。
集成的 Jupyter 笔记本允许您在旅途中练习代码。练习设计得非常好。我喜欢这种形式,你可以同时学习和练习代码。
这个课程真的帮助我建立了信心,在不久的将来从事算法交易。
人们通过实践来学习,这部分内容在课程中有广泛的介绍。我也喜欢你为获得用户反馈和支持所做的努力。
向 Quantra 致以最美好的祝愿。继续努力吧!
谢谢你抽出时间,汉斯。我们很高兴 Quantra 能够在您的旅程中为您提供指导。你的话将激励许多人坚持学习。
Quantra 课程自定进度,规模小,提供了一种快速的方式,让有动力的学习者在几个小时内获得并完善在算法交易领域取得成功所需的技能。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
自动化交易中风险管理观念的改变
原文:https://blog.quantinsti.com/changing-trends-in-trading-risk-management/
如何才能跟上交易风险管理的变化趋势?一个人如何更好地管理风险?
交易中的风险管理可能是一个被低估的概念,但它是算法交易中非常重要的一部分。在创建投资组合时,交易中的风险管理不仅仅是投资组合优化、对冲、策略规划等。
随着算法交易的当代实践,风险管理现在也意味着确保其他方面没有风险,如数据质量、技术等等!
本博客涵盖:
- 围绕交易活动的风险管理
- 哪里需要风险管理?
- 与自动化交易相关的监管风险
- 如何确保良好的风险管理实践?
围绕交易活动的风险管理
在交易中,风险管理发生在创建带有策略的交易组合时,也围绕着交易活动。在这篇博客中,我们将讨论围绕交易活动的风险管理。
下面你可以看到算法交易架构的图解:

Architecture for Algorithmic Trading
从上图中可以看出,订单是通过应用程序以 R、MATLAB、Python 等计算机语言下达的。
然后,订单通过应用程序执行,并通过服务器进行所有必要的事件,如数据检索、根据输入的策略进行计算等。然后根据策略将数据发送到交换机。
在算法交易的整个过程中,存在着与系统网络、技术、人力资源正常工作等相关的风险。我们会进一步讨论。
现在让我们来详细看看这些风险管理的必要要点,以确保顺利的交易实践。
哪里需要风险管理?
正如我们在上面的图片中看到的,生成的订单信号是通过一个 API 执行的,然后该 API 将订单执行信息发送给交易所。
这是通过您的编程语言(R、Python 等)检索交易订单信息来完成的。).作为一个算法交易者,你必须确保遵循适当的风险管理实践,以使 API 准确工作。
传统上,交易操作通常关注以下风险:
市场风险或系统风险
市场风险是由于一些因素导致整个市场而不是一个行业或公司的失败而产生的。这些因素可以大致分为社会、政治和经济问题。
例如,公司面临的利率风险、通货膨胀风险或任何此类市场风险。这种风险降临到整个行业。解决这一风险的方法是通过 VIX 指标衡量波动性,当波动性高时退出高风险资产。
信用或交易对手风险
信用风险与个人、公司或主权政府的信誉有关。为了保持其信誉,一家公司需要一个良好的信用评级,由标准普尔、穆迪或惠誉等机构进行评估。当你作为交易者或组织需要为你的交易筹集资金时,信用评级会有所帮助。
流动性风险
与流动性有关的风险是指在不在很大程度上影响市场上当前资产价格的情况下,将资产转换为现金的能力和难易程度。
市场流动性是指市场允许股票、债券或衍生产品等资产在无需支付巨大买卖差价的情况下进行买卖的程度。拥有这样的流动资产有助于交易者管理流动性风险。
监管风险
监管风险是指法律和法规发生变化的风险,这些变化会对交易者的交易策略产生不利影响。在算法交易实践出现后,监管法律法规已经被修订,我们将进一步讨论。
然而,随着自动化交易的出现,除了上述内容之外,这一重点已经转移到以下内容:
- 操作风险
- 可扩展性风险
- 技术风险
- 人力资源风险
- 与自动交易相关的监管风险
操作风险
运营风险(OR)是交易机构因内部流程失败或系统/网络缺陷而面临的风险。
运营风险涉及广泛的“非财务问题”,例如:
- 计算机系统或网络架构未更新或人员不称职的技术风险。
- 缺乏结构化风险政策。
- 与过程相关的风险,如信息处理、数据传输、数据检索中出错的可能性以及结果或输出的不准确性。
- 其他风险包括缺乏对风险的适当监控、员工或管理层的非自愿错误、员工或管理层欺诈或犯罪活动。
- 最后,它可能包括自然灾害、恐怖主义等造成的损失。
可扩展性风险
由于可伸缩性,交易者面临最大的风险。可扩展性风险表明,一个特定的企业,无论是对冲基金、共同基金还是任何其他机构交易公司,都有在充满挑战的情况下无法扩展的风险。
例如,对冲基金可能无法增加其在市场上的资本配置,因为市场上持有其股票的人数减少了。除非股东人数增加,否则买卖股票和创造利润的机会是最少的。
技术风险
这是由技术结构故障和/或处理或操作技术/机器的人为错误引起的事件。例如,闪电崩盘(2010 年)的原因之一被认为是美国交易所价格报告中的技术故障。
人力资源风险
这是算法交易时代不可或缺的风险之一,给对冲基金、自营交易公司等交易公司带来风险。
为了成功的算法交易,雇佣在金融、计算机科学等方面有良好教育背景的人力资源。扮演着重要的角色。
除了教育背景调查之外,还必须有一个可靠的员工管理系统,用于:
- 定期监控生产力,检查员工使用的某些参数,如止损单、特定交易量、动量策略、刷单等。
- 确保员工遵守关于算法交易监管结构的法律法规。
与自动交易相关的监管风险
监管风险意味着如果您不遵守法律法规,您在交易中可能会受到特定国家政府的处罚。
通常,政府当局要求你的所有策略都要得到交易所的批准。监管机构、交易所和独立审计机构也要求进行半年度和年度审计。
一旦你有了自动交易策略,你需要在模拟交易环境中执行它。
向交易所提交策略以供批准时,需要进行以下风险管理检查:
- 自动交易系统禁用手动订单
- 订单应该在上次价格的 x%以内
- 对于每种工具,设定了订单规模冻结限额
- 订单不应违反工具的巡回限制(每日价格范围)
- 外国投资者不能交易精选的股票(RBI 指导的)
- 不能通过交易衍生产品来增加超过阈值的未平仓头寸
- 每股可出售的隔夜多头头寸
- 仅对选定的工具列表启用自动交易
- 如果指数上涨超过一个点,就不能发出买入指令。对于销售订单也是如此
- 客户对特定股票可以持有的最大头寸
- 如果达到可用保证金的阈值,则应用程序不应发送进一步增加头寸的指令
- 每个工具的净头寸价值
- 最大订单价值
仅仅知道积木是不够的;一个人应该知道其他人或竞争对手在使用什么策略。
为了让你了解这一点,我们在算法交易的执行课程中有一个名为“金融计算&技术的部分。这肯定会启发你设计你的交易策略;不同的概念可以用来设计你的策略。
如何确保良好的风险管理实践?
为确保良好的风险管理实践,以下帮助:
- 知识 -有了正确的知识,一个算法交易者可以建立上面讨论的所有要求。如果你知道你的策略需要什么才能不间断地工作,你也可以做同样的安排。
- 建立 -技术、硬件、软件等一应俱全的机构。到位会带来很大的不同。使用正确的设置将确保您对风险管理实践进行检查。
- 可靠的团队 对于那些在团队中工作的人来说——团队依靠算法交易者可以将责任分配给不同的团队。这样,交易者可以确保每个团队都执行了风险管理实践。
- 使用人工智能(AI) - 使用 AI,特别是机器学习(ML),可以确保良好的风险管理实践。通过输入带有如下任务的机器学习模型-
- 审查潜在员工的背景,确保良好的人力资源管理。该模型可用于管理人力资源管理领域的风险。
2.定期监控员工的生产力
3.确保员工遵守政府为算法交易实践制定的规章制度。
但是,最重要的是资本,以保持良好的风险管理实践遵循的所有必要条件。
结论
为了确保良好的风险管理实践,需要做出一些努力来找出防范风险所需要的东西。一旦弄清楚了,风险管理就变得更容易实施,你成功的交易策略可以不间断地给你带来你预见的回报。
为了获得如此成功的交易体验,交易者必须坚持遵循良好的风险管理实践,以获得愉快的交易之旅!
你也可以用你的算法交易策略来享受交易,在本课程中提供了正确的指导,指导你如何在交易中进行仓位调整。你可以学习所有关于资金管理的知识,找出金融市场的内在风险,并将所有的知识融入到课程中,以创建一个保守的头寸规模框架。一定要去看看!
注:原帖已于 2022 年 8 月 1 日在进行了更新,以确保准确性和及时性。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
一名特许会计师如何学习 Python 来实现交易自动化
从手工交易者,Yoginder 进入了一个新的先进的交易模式,即自动化交易。但是他想搞清楚他的基本情况。他来自一个非技术背景,他的研究导致了对 Python 交易的追求。
这是约金德,分享他的旅程。
嗨!我是约金德·辛格,来自印度。我的职业是特许会计师,目前自己开业。
我从 2018 年开始积极交易衍生品资产类别。我运用了很多基于印度波动率指数的期权策略。
在我的交易之旅中,我知道很多工作可以通过 python 自动化,看到了其中的潜力,我决定参加一些课程,学习更多关于 python 和算法交易的知识。
当我在寻找相同的在线学习资源时,我遇到了 Quantra。由于我过去没有编程经验,所以我报名参加了' Python for Trading: Basic '课程。我从这门课程中学到了很好的经验。我学会了导入数据、绘制图表等。但同时也意识到学习的旅程是漫长的,需要大量的练习。
这个课程有很多练习,帮助我更好地学习 python。我能够自己做这些练习中的大部分。朱庇特笔记本是课程中最有用的工具。笔记本包含预先编写的代码和解释,用户可以随时更改参数和结果。这是 Quantra 的独特之处。
总而言之,我期待在未来做更多的课程,同时同步学习和练习 python。
知道有人来自完全不同的背景,有你这样的交易经验,想在这个领域不断探索新的领域,真是太好了,约金德。我们确信您将从 Quantra 为您的学习提供的无数益处中受益。最美好的祝愿!
Quantra 拥有多门课程,深入研究如何在交易中利用不同的 Python 策略。 一定要把他们都检查出来。立即注册!
免责声明:为了帮助正在考虑从事算法和量化交易的个人,这个成功的故事是根据 Quantra 的一个学生的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。完成 Quantra 课程后获得的结果可能不会因人而异。T3】
化学到算法| Arushi 的算法交易之旅
原文:https://blog.quantinsti.com/chemical-engineering-algorithmic-trading-epat-success-story-arushi-roy/
一个对金融市场、数学、统计或编程一无所知的人能学会算法交易吗?你会惊讶地知道答案是肯定的!
这是阿鲁西·罗伊完成的壮举。如今,Arushi 是 EPAT 大学的校友,拥有化学工程的背景。她想在这个快速发展的算法交易世界中确立自己的地位。
她从未想过会成功,如今她是一名定量分析师。她与我们分享了她的旅程,并解释了她是如何实现她认为不可能的事情的。
嗨,Arushi,告诉我们关于你自己的情况吧!

嗨!我是 Arushi Roy,来自印度的德里。我是一名受过教育的化学工程师,目前在沸腾证券私人有限公司担任定量研究员。
目前沉浸在学习更多,探索算法的奇妙世界。我相信努力工作,并一直追求我的梦想和目标。这让我开始了算法和量化交易的职业生涯。
你是怎么从化学工程转到算法交易的?
在完成我的化学工程后,我收到了大学的校园安置,但它似乎并不正确,我仍然在寻找职业道路。
我追求各种前景,将我的热情发展成职业。我想在一家我对分配给我的角色或工作感兴趣的公司工作。我做了很多研究,查阅了我所知道的每一个领域,但是我的尝试都是徒劳的。
当我准备 UPSC 考试(为了进入政府服务部门)并必须学习经济和金融知识时,我的兴趣上升了。在此之前,我对这些科目一无所知。
我和我大学的学长讨论过这个问题,他来自计算机科学领域,他推荐了 EPAT。我上了 QuantInsti 网站,研究了一下,然后和我父母谈了这件事。我联系了来自 QuantInsti 的 Swapna 询问 EPAT 的情况。
这次经历让我受益匪浅,她帮了我很多忙,消除了我所有的疑惑和疑问。
我的父母并不是第一个同意这个想法的人,但是在与 QuantInsti 交谈时,他们同意并支持这个想法。我得到了家人和朋友的支持。
我从来没有想过我可以进入这个领域,但是你永远不知道,直到你尝试。我一生中冒了很多险,现在我确定了我想去的地方。我喜欢统计学,所以这也说服了我去做算法交易。这就是 EPAT 的故事。
在没有任何编程或交易知识或经验的情况下学习 algo 交易是一个挑战吗?
随着时间的推移,事情在变化,年轻人现在更清楚股票市场是什么,以及它如何成为一个可行的职业选择。
我选择这门课程是因为它们从最基础的开始。这不像给出代码然后打出来。他们教你什么是单元格,以及如何在 Excel 中以一种简单的方式从一个单元格移动到另一个单元格。稳步从最基础的水平向高级水平迈进。
这不像他们拿了你的钱然后继续。他们关心你,尽他们所能帮助你,这是我最喜欢 QuantInsti 和 EPAT 的地方。这些友好的姿态和温暖在他们与参加课程的每一个学生或个人的互动中都能感受到。
我对我的学习非常认真,所以在周末我会参加讲座,在一周的其余时间我会做很多练习——做作业,一周内重温课堂讲座 2-3 次,理解一切。
我意识到,如果你练习 Python 编程,对你来说甚至会变得很容易。我甚至创建了一个交易账户来观察市场是如何运作的。
课程结构和设计- 对我来说,EPAT 10/10 就是它的结构。我没有 algo 交易背景,懂 Excel。所以学习 excel 然后转行学习 python,然后机器学习等等的过程很神奇。课程设计的方式值得称赞。
QuantInsti 拥有最好的师资力量。他们的教学超棒!我一直很好奇,问了很多问题和疑问,提出了很多疑问,工作人员一直对我很有耐心,也很支持我。
我的许多朋友也喜欢上了 EPAT。我已经能够通过 LinkedIn 与其他 EPATians 人建立联系。我们经常联系和讨论各种讲座和话题。看到这么多人追求 EPAT 的兴奋,我很惊讶!
Subash 对我的学习有很大的帮助,无论是一天中的任何时候,甚至是周末和假期。当我加入 EPAT 的时候,甚至在结果出来的时候,我都很紧张——但是 Subash 非常支持我,在我在 EPAT 的时候,他一直是我的指导力量。
我珍惜 Swapna 给予她的所有动力、指导和支持,并在我感到无法前进时尽力帮助我。我也感谢她帮助我解答疑问,提供额外的学习资源等等。
从 EPAT 毕业后,我很高兴地知道我获得了“优秀证书”。我的家人为我感到骄傲和高兴。
你最喜欢 EPAT 的什么特征?
安置团队挺好的。作为一名大一新生,在去 EPAT 之前,我没有在这个领域接受过正规教育,也没有相关背景,是的,这对我来说是一个缓慢的过程。过了一段时间,工作机会才开始滚滚而来。
我建议大一新生去实习,而不是去任何公司的固定职位。获得实习机会,然后获得一份有经验的全职工作,这可能会帮助你获得更好的待遇。
对安置团队要有耐心,经常与他们联系,他们会给你提供最好的职业机会和工作选择。他们很有帮助,指导你制作简历,让你的个人资料曝光,并指导你通过面试过程。
多亏了安置团队,我在 FMI Technologies LLC 实习,成为一名定量分析师。我非常喜欢我的工作,喜欢和量化分析师一起工作的经历,学到了很多东西,有责任心,并努力做到最好。
今天,我在 Ebullient Securities Pvt. Ltd .担任量化研究员。
你会给那些希望学习算法交易的人什么信息?
我想从我的经历中分享以下几点,希望有所帮助:
- 如果你有一个分析的头脑,并且非常了解技术方面,你也应该知道你有能力做什么,不要浪费时间在你不能做的事情上。
- 如果你对自己的职业选择不满意,记住,你随时可以换。
- 在建立你的战略或设立办公桌之前,先去实习,积累经验,然后再去争取。
- 如果你坚持练习,你可以学到任何东西,实现任何你想要的。
工程师在从事算法交易领域会有优势。但是,如果我可以通过 EPAT,没有知识的领域,你也将能够。
如果你有追求某个职业的愿望,全身心投入,竭尽全力去实现,你一定能做到。如果是算法交易,那么我肯定会建议去 EPAT。EPAT 将为你提供直接的实践支持,帮助你实现你梦想的职业生涯。
谁可以学习算法交易
Arushi,谢谢你和我们联系并分享你的故事。我们希望你有最好的未来,并祝你在这个算法和量化交易的宏伟世界中有一个惊人的旅程。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
如何选择自动化交易平台?
原文:https://blog.quantinsti.com/choose-quantitative-trading-platform-2/
作者:阿波瓦·辛格
当选择一个自动交易平台时,在你决定你想要交易的自动交易平台之前,寻找一些重要的特征是非常重要的。不同的自动交易平台提供不同的服务,这些服务各有利弊,可能适合某些策略,也可能比其他的更好。
我们已经讨论了选择算法交易平台时应该考虑的重要特征。
选择合适的自动化交易平台
回溯测试
回溯测试是对算法交易策略的历史模拟,以观察它在过去对数据的表现。回溯测试结果通常以利润和损失以及一些流行的性能统计数据(如夏普比率或信息比率)来显示策略的性能,这些数据有助于量化策略的风险回报。因此,一个好的回溯测试软件对于自动化交易平台来说是一个很大的优势。回溯测试可以分为两类'研究型回溯测试人员'和'事件驱动型回溯测试。
编程语言
在决定使用哪个平台来自动化你的交易策略时,选择一种编程语言是非常重要的。不同的语言有不同的优缺点。算法交易最常用的编程语言有 C++,C#,Java,R, Python ,MATLAB。你可以参考我们最近在顶级回溯测试平台上的一篇帖子,在那里我们讨论了流行的编程语言。
数据
不同的自动化交易平台仅提供对某些证券的访问/支持交易/回溯测试;有些提供特定的访问途径,比如 T2 彭博和汤森路透 T3。例如,有专门从事外汇交易或特定市场股票交易的平台。你需要确定自动交易平台能提供什么,然后根据你的需求做出决定。您需要的数据的频率也应该考虑在内。有些策略需要每天的 EOD 数据,而有些策略可能需要当天的交易数据。
网络平台
一些自动交易平台还提供基于网络的在线交易和回溯测试平台,这使得在任何地方访问你的交易平台变得简单方便。与桌面交易平台相比,网络平台的功能可能较少。
复杂度
不同的自动股票交易平台在易用性上有所不同。一些平台可能需要实际的编程专业知识,而其他平台可能不需要。大多数平台都提供了一个演示版本,可以帮助你决定什么适合你的舒适度。对于不同的交易资产,平台的复杂性可能是不同的,人们应该检查可用于分析特定资产类别的不同工具&功能。
允许的策略数量
有时,在一个特定账户上加载的多头或空头策略的数量可能会有限制,你可能需要额外的账户来加载更多的策略。如果需要的话,你还应该检查你的电脑是否有足够的内存来运行多个账户,因为这可能会占用大量内存。一些平台还提供自己的交易策略作为附加服务,可以通过定期或一次性付费来订阅。
佣金/成本
交易佣金会在很大程度上影响你的利润。仔细选择适合你的交易要求的计划。此外,检查是否有初始和/或每月费用,以及针对它提供了什么,以确保您只为您实际需要的服务付费。
技术支持&客服
自动化交易平台预计会有非常高的“正常运行时间”,很少停止服务。在选择平台之前,您应该检查停机历史,如果过去有任何其他问题,这些问题多久得到解决,以及支持团队的知识和帮助有多大。
Bonus content
关于算法交易未来的常见问题
以下是我们在算法交易的提问环节中遇到的一些最常见的问题。
问题: 我们是一个 FPI,在一个券商没有子账户的情况下,如何处理一个券商账户中的多个策略?
回复:如果你是一个外国私人投资者,我需要知道你是第 2 类还是第 3 类,但你仍然可以在一个 CTCL ID 上运行多个账户。既然你提到了外国证券投资,我想你是在说印度市场。所以,是的,如果你的平台支持,这是可以做到的,你不需要一个子账户。另一种选择是,您可以使用多个帐户,并且可以在一台机器上映射多个帐户。有供应商可以帮助你,这取决于你使用什么样的交易平台。
问题: 次级经纪商如何从算法交易中获益? 有可能为我所有的客户自动执行算法交易策略吗? 还有,随机也覆盖吗?
回复:即使作为一个次级经纪人你也可以利用你的经纪人来获得你的算法交易策略的批准,所以是的,这是可能的。同样的事情也适用于你的客户,所以你的经纪人必须得到批准。我不确定我们是否在谈论技术分析随机指标&统计随机指标,但是无论哪种情况,两者都可以包含在任何策略中。
问题:在印度,什么样的券商都支持算法交易,在哪个平台上?
回复:支持程序化交易的不多,但也有少数(严格意义上可能不是纯粹的 algo)支持程序化交易,你可以利用一些程序,包括半 algo,和 algo。很少有支持 algo 的券商包括 Zerodha 、互动券商、主信托这样的。所有代理的编程基础可能不同。
问题:你建议交互经纪人用哪个 API 接口?
回复:我已经标记了几个,事实上,IB 已经提出了他们自己的API以及一些已经构建好的包装器,其中包括一个由刘辉博士创建的,他也是 EPAT 的一名讲师。所以你可以用这些在 Python 中直接发送命令。
问题:在撰写 LFT 在印度、南非、MCX 和疯牛病市场的战略时,有什么好的回测网站吗?
回复:不是很多。我们正在开发能够为市场提供所有这些服务的工具,敬请关注。我们在 QuantInsti 做了很多事情,所以你应该会看到一些填补空白的行动,以确保我们所有的参与者以及一般用户获得更好的曝光和访问。
建议阅读
- 自动交易:订单管理系统
- 什么是市场微观结构?
- 什么是交易策略的回溯测试?
- 自动交易:订单管理系统
如果你是想学习自动化交易的散户交易者或技术专家,今天就开始学习自动化交易吧!
QuantInsti 帮助人们获得适用于各种交易工具和平台的技能。算法交易(EPAT)的高管课程涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
量化交易策略的分类
原文:https://blog.quantinsti.com/classification-of-quantitative-trading-strategies/

拉多万·沃伊特科
每年发表数千篇金融学术研究论文。大学和研究中心的人们试图揭示全球金融体系的运作。他们中的一些人(出于好奇或者仅仅是因为钱)试图理解全球金融系统的一个子集——金融市场。
他们正在寻找战胜它的方法。
他们的探索成功了吗?他们是否发现了一些我们可以在现实交易世界中使用的东西?
这些是我们试图找到答案的问题。
我们在Quantpedia.com的使命是帮助交易者破解金融学术研究,为算法交易策略寻找新的思路。我们使用来自世界各地的大量金融研究资源。我们浏览这些资源,为的量化交易策略寻找新的有趣的文章和论文。每一篇文章都是基于策略的可实现性、回溯测试的时间长度和整体合理性进行评估的。如果该策略通过了选择标准,那么它将被分类并纳入我们的数据库。
但是,真的有可能在学术论文中找到有附加值的策略吗?
互联网上流传着许多关于金融学术研究的误解,比如:
- 一个流行的误解是,学术界脱离现实,只研究理论问题。
- 另一个流行的问题是,如果学者们如此聪明,那么他们为什么在学术界工作而不管理资金。
真相往往远离这些偏见。
学者通常是非常好奇和聪明的人。他们有时会纯粹出于好奇而检查问题。或者检查没有实际应用的问题。但是他们通常有很强的动机去研究实际问题。他们的动机可能很简单——职业自豪感、职业发展或者资产管理行业的大公司可能邀请他们根据自己发现的独特阿尔法/因子/策略开始管理外部资金。
也有很多对冲/共同基金行业之外的专业人士,他们以其学术工作而闻名。2008 年后,许多对冲基金变得更加透明,并开始展示它们如何管理客户的资金。这些公司发布的研究向外部世界展示了它们的能力,并有助于吸引新客户。我们可以从他们的工作中得到启发,并在我们的交易中使用。
公布的策略不再有效,因为...?!
对金融学术研究的一个常见批评是,发现并公布的因素/策略不再有效。随着其他玩家了解他们,他们在策略公布前套利所有可用的阿尔法。
研究表明,这也不完全正确。
在新的交易策略发布后,业绩确实会下降。然而,从统计上来说,异常阿尔法仍然存在,甚至在一个策略公开几年后。
这有多种原因:
- 套利的限度
- 金融市场中不情愿的参与者(资金注入新战略的速度比通常预期的要慢)
- 新策略/因素的时机不佳(大量新资金可能开始交易任何特定的策略,并可能导致该策略的盈利能力崩溃,以及之后对保持承诺的玩家的更高利差)。
盲点。
学术研究通常主要考察最受欢迎的资产类别和策略类型。因此,与选股策略相关的论文数量高于平均水平。对量化研究领域的了解有助于找到独特的阿尔法策略的来源,这些策略针对的资产类别不太为人所知,因此在未来可能不那么拥挤,更有利可图。
一个算法交易策略是一个非常模糊的术语。从历史上看,它涵盖了所有的策略——从快速的日内 HFT 策略到长期的系统投资策略,比如系统价值。在我们由 Quantpedia 和 QuantInsti 主办的网络研讨会中,我们探索了量化投资策略的宇宙。我们展示了 Quantpedia 如何对量化策略进行分类,并试图找到盲点——学术研究没有很好涵盖的策略类型,因此可以提供更好的性能。我们还强调了一些鲜为人知的来自学术论文的策略的例子。我们还研究了与实施这些策略相关的一些常见问题,并举例说明了避免这些问题的方法。
点击此处获取网上研讨会记录:量化交易策略分类
2019 年 CMT 协会印度峰会,孟买
原文:https://blog.quantinsti.com/cmt-association-india-summit-2019-mumbai/
关于活动
自从 18 世纪日本大阪大米市场出现交易以来,交易者已经认识到价格是市场参与者行为和个人证券需求的信息宝库。复杂的数据可视化、算法交易策略和量化方法都继续依赖于数百年前技术人员首先理解的市场基本原则。
在首届印度峰会上,您将花一整天的时间向世界领先的资产管理、研究和交易技术分析从业者学习和交流。了解如何观察、计算和捕捉持续的市场异常,如趋势、动量和均值回归,以在多资产投资组合中产生 alpha 并降低风险。
查看 Nitesh Khandelwal(quantin STI 联合创始人兼首席执行官)和 for ma ch heda(CMT)之间的对话,其中 Nitesh 讨论了他的技术分析背景,他是如何进入技术学科的,以及他即将在 2019 年 CMT 协会印度峰会上发表的演讲。
https://www.youtube.com/embed/Cl9N-YhLQzg?rel=0
概观
技术分析提供了其现代解释(如定量金融、算法交易和行为金融)所依据的首要原则。成功的数据科学家和定量方法的倡导者不断努力加深他们对统计方法和支撑市场行为的行为偏差的理解。现代学者认为技术分析是弥补内在价值和市场价格之间差距的手段。
此次峰会将金融界最著名的人物聚集在同一个平台上,作为量化金融的年轻明星,从而提升了围绕当代量化方法的对话。它为市场参与者创造了一个与行业中最优秀的人才交流的机会,并学习可操作的流程来增强他们的想法产生、投资管理和风险缓解流程。
为什么要参与
扬声器
可以说,在印度的技术分析中,从未出现过如此杰出的演讲者。像 Ralph Acampora 和 Martin Pring 这样的活着的传奇人物,衍生品交易亿万富翁和科技企业家 Anthony Saliba,JC Parets,社交媒体最受关注的分析印度 TA 图标,如 Atul Suri,Shiv Sehgal,以及年轻的明星,如 Piyush Chaudhry,Shubham Agarwal 和 QuantInsti 自己的 Nitesh Khandelwal 一起创造了一个独一无二的知识节日。完整的发言人名单和议程大纲见下表。
前所未有的访问
演讲者将全天出席峰会,让与会者在会议期间和会议结束后都能深入了解他们
网络机会
各种资产类别的机构基金经理、金融科技企业家、各银行的部门和机构负责人、经纪商、衍生品部门、共同基金、投资者、学者等等,为每一个认真的市场参与者提供了一些东西。
议程和议题

以下是此次活动的一些片段:
在由我们自己的首席执行官 @niteshkh 主持的小组讨论会上, @piyushchaudhry 、、【shubham_quant 、、【tejaskhoday】、 @Prashantshah267 分享的真知灼见让 CMT 印度峰会的观众欣喜若狂。# cmtindiasummit 19@ CMT association# goal gopic.twitter.com/1nDLR838Uh
— QuantInsti (@QuantInsti) November 25, 2019
卢森堡的成功故事——克里斯特尔的故事
原文:https://blog.quantinsti.com/cofounder-engineer-mba-epat-success-story-christelle-armenio/
专注和清晰非常重要——这两样东西可以很好地指引你前进的方向。
这是 EPAT 大学校友克里斯特尔·阿尔梅尼奥的话。克里斯特尔称自己是一名数字生产力应用集成、咨询和人工智能专家。她在法国完成了她的工程和 MBA,并且在一些大公司有超过 10 年的工作经验。
她作为联合创始人的新公司 Neo-Solution 位于卢森堡,提供工业创新和精益管理方面的咨询。
克里斯特尔与我们分享她的故事,她的人生旅程。
嗨,克里斯特尔,告诉我们关于你自己。
我是 Christelle Armenio,我来自法国,现在在卢森堡工作。我拥有工程双学位,并于 2010 年完成了 MBA 学业。
我曾在劳力士和通用电气等公司担任工程师,改进现有系统并实施新系统以适应数字化转型。
音乐一直是我生活中很重要的一部分。我唱歌,我弹吉他和钢琴。我甚至在音乐行业有过临时的职业生涯。在疫情之前,我喜欢音乐和旅游。随着时间的推移,我越来越倾向于工程和研究方面,因为我真的很喜欢数学。
我现在在卢森堡,新冠肺炎的情况变得越来越糟,因为新的变种从英国来到了欧洲。政府召开了一次会议,他们可能会关闭边境。
在卢森堡工作的法国人很难回到法国。这对我来说很难,因为我过去常常为了工作四处奔波,结识新朋友。卢森堡的病例不多,但未来几个月法国的情况可能会很糟糕。
在封锁期间的空闲时间,除了工作,我大部分时间都在作曲。我花了很多时间与我的合作伙伴一起推出我的新 Algo 交易平台。我现在能做的只有工作和照顾人。
工程、MBA 和现在的咨询——听起来是一段有趣的旅程!
我对人工智能很感兴趣,开始自学。最近,我从哥伦比亚大学获得了人工智能的 T2 硕士学位。我和我的合作伙伴真的专注于人工智能,开发主要用于医疗或工业应用的预测模型。我们在卢森堡成立了一个名为 Neo Solutions 的交易平台。这就是我进入金融行业的原因。
巴黎的一家金融机构找到了我们,他们让我开发一些金融时间序列的预测系统。我对将数据科学应用于金融很感兴趣,因为我以前从未做过这方面的工作。我真的需要积累我的金融知识,学习如何在金融环境中实现算法、机器学习和深度学习系统。
除了这些,我还必须学习经纪人、指标和交易策略。我基本上不得不学习如何做一名定量分析师。我开始开发应用于金融环境的人工智能模型,我做了很多培训来学习算法交易,但我并不真正满意。
我在谷歌上搜索了 algo 交易程序,我发现唯一一个全面的是 EPAT。据我所知,它确实是彻底的。
现在我已经完成了这个项目,我正与我的合作伙伴和一家对冲基金在卢森堡开发一个新的 algo 办公桌。我们正专注于加密领域。
EPAT 帮你成就了什么 ?
EPAT 是唯一一个完整的程序,除此之外,它还教会了我如何管理熊猫和所有其他图书馆的财务数据。我可以和老师们交流,这是一种真正专注的方法。
向在金融界工作并实际从事交易的人学习真的很好。
辅助人员帮了大忙。我和 Neeraj 谈过,他会跟进我需要的任何帮助。 LMS 平台非常全面。我可以接触到你所有的课程,课程表和所有的培训模块。它附带了帮助我练习和进步的评估。
我擅长统计分析,但对编码算法不够好,除了熟悉 Quantopian、 IBridgePy 和 Quantconnect。
与 EPAT,我希望获得知识:
- Algo 交易策略,
- HFT,
- 机器学习,
- 深度学习,
- 控制风险,
- 建筑,
- 信息技术法规,以及
- 对冲基金。
很高兴我能在 EPAT 报道这一切。
我在 EPAT 之前交易不多,但现在我正致力于建立一些策略,并在加密市场推出。EPAT 项目确实帮助我处理了所有这些问题。
据你说EPAT 最大的特点是什么?
EPAT 对我来说是一次很好的经历,因为我在疫情的时候有很多时间。这门课程充满了一些精彩的内容。我觉得整件事非常有趣。
我喜欢学习,再次成为学生对我来说很酷。讲座结束后,能和老师们交谈,练习作业,感觉真好。学以致用是很好的。
我也学到了很多关于实时交易的知识,这帮助我发展了量化分析师的技能。学习如何回溯测试是我现在经常使用的一项重要技能。我也创建了自己的回溯测试系统。
对我来说,从 EPAT 学到的关键是,任何人都可以创造一个好的策略,但重要的是学会如何优化并从有效的数据集中找到正确的参数。
我也从我的 EPAT 项目中学到了很多:
- 如何在流水线中建立和实现机器学习系统,
- 如何去直播,
- 如何改进适用于金融数据的机器学习系统,以及
- 如何利用阈值改进策略?
我认为对我来说更难的主题之一是微观结构和市场如何运作。关于订单簿的课程非常有用,学习如何实施止损和止盈非常有用——因为这是良好风险管理的关键。
你有什么话想和有抱负的量化分析师分享吗?T3】
这是一个需要努力的领域!你必须将你获得的所有知识应用于单一资产类别的真实数据。
举个例子,我关注的一项资产是加密,其他什么都没有。我从 EPAT 身上学到了一切,并对我的策略进行了回溯测试,看看它们是否赚钱。
我要给的一条建议是坚持练习,不要气馁。
每当你觉得你被 Python 或其他东西卡住了,记住,总有人和你有同样的问题。
我也想告诉以巴提人去寻求教师的指导,因为他们是最好的,也是非常有用的。
谢谢你的时间,克里斯特尔。你对清晰性的关注,对你前进方向的关注,以及你的计划已经步入正轨。我们相信你会实现所有这些目标。我们全体向你致以最美好的祝愿,克里斯特尔!
算法交易(EPAT) 的高管课程是一门综合课程,涵盖从统计学&计量经济学到金融计算&技术,包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。点击这里查看。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
在开源贸易项目中合作
原文:https://blog.quantinsti.com/collaborating-open-source-trading-project/
马里奥·比萨
任何个人程序员或开发团队的必备工具是版本控制软件。在这篇文章中,我们将向您介绍如何使用 Git/Github 来修改一个开源项目,比如 Pyfolio 库。
涵盖的主题:
范围
软件工程的一个基本原则是不要重新发明轮子。开发良好的软件可以在多个项目中反复使用。
Python 和它的生态系统开源库允许我们使用无数开发团队和个人程序员的工作来构建软件。
每个 Python 项目都以这样或那样的方式使用库。这些只不过是打包了具有特定功能的类和函数的软件,例如:
- 数学
- Numpy
- 轨道轨道
- Matplotlib 等。
这些库是通用的,足够灵活,可以适应我们正在构建的任何软件,并通过不必从头实现这些库提供的功能来节省我们的大量时间。
在我们的交易环境中,所有项目都需要对我们的策略进行绩效分析。一遍又一遍地对我们的统计数据进行编码是没有意义的,所以拥有一个性能分析库是必要的。
我们可以建立自己的库来计算:
- 返回
- 标准偏差
- 夏普比率
- Sortino 比率
- 斜交
- 性能图表
和无数的性能参数。或者我们可以使用现有的库,如果可能的话,用我们自己的性能指标来改进它。
在这篇文章中,我们将修改一个开源和自由软件库“pyfolio ”,以适应我们的需要,也许我们的改变会对社区有用。我们将发布我们的修改,以便其他开发者可以从中受益。在这个过程中,我们还将学习如何使用 Git/GitHub 工具来控制变更和软件版本。
“Pyfolio”是在 Apache 2.0 许可下发布的,该许可允许我们修改代码、发布代码甚至将其商业化。然而,值得一读的许可协议,至少在你的生活中有一次。
在这里,我们不会深入到开放和/或自由源码发布的许多许可证中,也不会深入到哲学中。
Pyfolio 简介
Pyfolio 是 Quantopian Inc .开发的用于金融投资组合的性能和风险分析 python 库。
注意:这家公司已经停止了在的运营,尽管他们的图书馆仍然在互联网上。
Pyfolio 是一个综合的库,可以生成性能报告,很好地满足了任何分析师的基本需求。
投资组合的突出特点:
-
简单撕页:
-
汇总性能统计表:
-
岁入
-
累积回报
-
年度波动性
-
夏普比率
-
最大水位下降
-
斜交
-
峭度
-
以及更多的关键性能指标。
-
情节:
-
累积回报
-
滚动贝塔
-
滚动锋利
-
在水下
-
更多
-
返回样张
-
汇总性能统计表
-
情节:
-
滚动退货
-
滚动贝塔
-
滚动锋利
-
滚动 Fama-法国风险因素
-
水位降低
-
水下地块
-
月度和年度回报图
-
每日相似性图和
-
返回分位数盒图
-
全撕裂片
-
汇总性能统计表
-
返回样张
-
交易撕页
-
往返撕页
-
有趣的时代撕页
-
容量撕页
-
绩效属性样张
所有这些特性使得 Pyfolio 库值得考虑。该库足够灵活,可以有效地涵盖策略或投资组合的性能分析。
Git 和 GitHub 简介
Git 是由 Linus Torvalds 开发的分布式版本和变更控制软件,目前归微软所有。它是一个允许控制软件随时间的变化和版本的工具,可以轻松地将代码恢复到以前的任何状态。
它允许分布式开发,不同的程序员团队可以进行修改并生成他们自己的版本,或者将他们的工作贡献给主版本。
基本上,Git 是一个与我们通过提交更新的每个项目相关联的代码库。
Git 的突出特点:
- 分支用于在不影响主版本的情况下处理和修改代码。它们还允许我们启动替代的开发,在那里分支变成一个新的库,由于变更的范围和新的功能,需要一个新的独立版本。
- 提交在某个时间点保存代码,提交保存工作并添加一个带有消息的标识,以便能够在将来恢复这个开发状态。
- 合并以融合不同的分支
- 回滚到通过提交保存的任何时间点的更改。
这个功能本身就足以引起任何一个开发人员的注意,对于从事同一个项目的开发团队来说更是如此。
GitHub 工具只不过是云中的 Git 服务器,它允许我们在互联网上发布我们的 Git 库,以便任何其他开发人员都可以使用代码或贡献自己的开发。
它也有一个非常有趣的工具,如票证管理器,用于管理软件中的错误或改进,以及其他有助于协作开发的工具。
获取 pyfolio 源代码
此时,我们已经决定使用 pyfolio 库作为我们的性能分析库。这样我们可以避免花费大量的时间来开发我们自己的库。然而,我们希望修改这个库来适应我们的目的。
我们还假设您已经将您的机器配置为像专业人员一样进行开发,如果没有,请在继续之前查看这篇文章。
然后第一步是在我们的开发机器上复制库的所有代码。为此,我们将从 GitHub 上的公共存储库中克隆这个库。
从您的项目所在的文件夹中,键入以下命令:

您将看到类似这样的内容:

此时,您已经在您的机器中克隆了 pyfolio 存储库。下图显示了一个图形表示。

让我们转到 pyfolio 文件夹,列出其中的文件,以检查代码文件和文件夹。

在根文件夹中,你可以看到这个包的文件,包括许可证,readme,whatsnew 等一些有趣的阅读文件。还有 setup.py 脚本来在我们的 python 环境中安装这个库。
如果我们键入命令 git log —oneline ,我们可以看到项目中所有开发人员执行的所有历史提交。更有趣的是,我们可以在历史开发时间线的任何点上移动,并检查开发人员留下的消息,以了解变更的原因。

要检查任何提交的变更细节,您可以键入 git show < commit Id >。您可以看到作者、日期、消息或更改原因以及一些红色和绿色的行。红线是旧代码,绿线是新代码。

为了安装位于我们机器中的 pyfolio 库,并且为了能够修改代码而不必在每次修改代码时反复安装库,我们将使用 develop 参数,以便 python 读取正在开发的项目的文件,而不是进行普通的安装。

让我们用命令 c onda list 检查一下我们确实已经在我们的机器上安装了库


因此,我们已经在我们的机器上安装了开发库,我们可以在我们最喜欢的 IDE 或编辑器中创建一个项目。

改进 pyfolio 图书馆
在修改代码之前,我们要做的第一件事是在 Git 中创建我们自己的分支,以避免在知道我们的更改是否会有预期的结果之前修改主分支。
让我们用 git status 命令检查 Git 中的当前情况。

输出显示我们在分支主机上,并且分支是最新的。
origin 分支是 GitHub 上的原始 pyfolio 存储库,我们可以使用 git remote -v 命令看到:

让我们用 git checkout -b mypyfolio 命令创建一个分支,以便在我们的 Git 存储库中有一个新的开发路径:

我们可以用 git status 命令检查它:

这告诉我们,我们正在分支 mypyfolio 上工作,还没有任何变化。
我们可以用图形表示如下:
删除滑索引用
为了使用 pyfolio 库,让我们创建一个新项目。
当我们导入 pyfolio 库时,我们会收到以下警告消息:
py folio/py folio/pos . py:27:user warning:找不到模块“zip line . assets”;乘数将不适用于头寸概念。找不到模块“zipline.assets ”;乘数将不适用'
该消息向我们表明 zipline.assets 库没有安装在我们的机器上,因为这是一个警告,所以不强制安装它。
zipline.assets 库附带了 zipline 库,这需要 python 3.5,我们使用的是 Python 3.6。
一种解决方法是忽略警告,如下所示:
warnings.filterwarnings('ignore')
但是,这会过滤任何警告消息,并可能隐藏其他重要消息。
因此,让我们修改源代码,删除任何对 zipline 的引用。警告消息说警告来自 pyfolio/pyfolio/pos.py 文件行 27。

第 21-22 行试图导入库 zipline.assets,如果不可行,那么它会触发我们在导入 pyfolio 库时看到的警告消息。
另一个有趣的事情是名为 ZIPLINE 的变量。在 python 中,当开发人员将变量名大写时,这意味着分配的值在整个代码运行时将保持不变。
因此,让我们在所有 pyfolio 库文件中查找 ZIPLINE 常量,看看它在哪里被使用。

在第 23、25 行中,我们看到了尝试导入 zipline.assets 库的 try-except 构造。每当 zipline.assets 库被导入时,在第 146 行使用常量 ZIPLINE,包括期货的乘数,因为股票的乘数是 1。

因此,对于这个简单的例子,我们假设我们没有一个乘数,并简单地避免导入 zipline.assets 库。为此,我们删除或注释掉整个 try-except,并将 ZIPLINE 变量初始化为 False。

现在,我们可以再次导入库来检查我们是否避免了警告消息。由于我们在导入 pyfolio 库时不再看到警告,这一更改是完美的,所以让我们检查一下 Git 中的更改。
使用 git status 命令,我们可以检查代码中发生了什么变化。

我们可以看到我们在分支 mypyfolio 中,修改后的文件是 pyfolio/pos.py. 它还告诉我们推荐的命令,以将文件添加到 Git tracker 和/或提交我们所做的更改。
在此之前,让我们检查一下在 Git 中注册的最后一个版本的文件和我们修改过的文件之间存在哪些差异。为此,我们使用命令 git diff pyfolio/pos.py

我们看到红色的行相对于 git 中注册的最新版本进行了修改,绿色的行相对于 Git 中注册的最新版本进行了添加。此外,这些正是我们刚刚做出的改变,因此我们对结果感到满意。
让我们用命令 git add pyfolio/pos.py 和 commit -m <在 git 中注册我们的更改,用 commit > 记录消息


如果我们再次键入 git status 命令,我们可以看到


再次检查 git 状态,我们可以看到 out 分支 mypyfolio 比分支起点提前一次提交。

更改夏普比率函数
目前,pyfolio 库严重依赖于同样由 Quantopian 开发的 empyrical 库来计算许多性能指标。我们将修改计算夏普比率的函数,使用我们自己的代码,而不是依赖经验库。
为此,打开负责编排时间序列分析的 pyfolio/timeseries.py 文件,并查找 Sharpe ratio 函数。

从第 651 行到第 665 行的代码块负责调用计算性能指标的函数,我们可以看到夏普比率是用empyric库计算的。

因此,我们将修改第 655 行来调用我们的函数来计算夏普比率。

在 timeseries.py 文件本身中,第 262 行有一个计算夏普比率的函数,但是正如函数的装饰所表明的,它已被弃用,事实上,它调用了empyric库的函数。
所以我们要修改这个函数来计算夏普比率

我们引入必要的更改来计算我们的夏普比率并保存文件。

有了这些变化,剩下的就是测试我们是否真的用我们的函数正确地计算了夏普比率。

一切似乎都工作正常,所以让我们检查一下 git 中的变化。我们键入命令 git status 来检查它

我们可以再次看到我们正在使用的是 mypyfolio 分支,并且我们已经修改了 pyfolio/timeseries.py 文件。
我们还可以使用git diff py folio/time series . py命令详细查看这些更改。


同样,我们可以看到红色表示更改前的情况,绿色表示更改后的当前情况。这与我们所做的修改完全一致。
让我们在 git 中注册变更,并使用命令git add pyfolio/time series . py和 git commit -m <变更原因> 将其与分支主机合并。

我们所做的改变是在 mypyfolio 分行,但是,我们将把我们的 mypyfolio 分行与 master 分行合并。

git merge mvypyfolio master 命令执行合并,并向我们总结了前面情况的变化。

如果我们再次检查 git 状态,我们可以看到我们的主分支比托管在 GitHub 上的原始存储库提前了两次提交。

在这一点上,我们有两个选择向世界发布我们的变更。
场景 1: 我们在由 Quantopian 维护的 GitHub 上的原始 pyfolio 存储库中发布我们的更改(记住,这家公司已经停产)。
- git push -u 原点主控
启动上面的命令并不意味着它会自动发布,因为需要手动管理存储库来批准和接受变更(如果适用的话)。
场景 2: 我们创建自己的 GitHub 库并发布,这样任何人都可以安装这个库,甚至参与开发。
在下一节中,我们将看看场景二。
发布新功能
此时,我们想要做的是在我们自己的 GitHub 库中发布我们的更改。
我们可以从 GitHub web 界面本身创建一个公共存储库:

然后,我们必须使用以下命令配置 GitHub 的新存储库:
git 远程添加分叉 https://github.com/mariope/mypyfolio.git

注意,forked 可以是任何名称。我们还可以看到,我们的 pyfolio 库现在有两个远程 GitHub。一个叫做 origin,是最初的 Quantopian 库,另一个是我们自己的 GitHub 库。
最后,为了发布我们对 GitHub 库的修改,我们输入命令 git push -u forked master 。

使用这个命令,我们将本地 git 存储库推送到 GitHub 存储库,它是公共的,任何想要使用、修改或修复它的人都可以使用。
不要忘记修改自述文件,以包括关于您的更改的注释,并提醒任何潜在的用户。
结论
在这篇文章中,我们已经看到了如何修改像 pyfolio 这样的开源库来引入我们自己的修改并在云中发布它们。
一路走来,我们已经了解了版本控制软件是如何工作的,以及如何处理基本的 git/github 命令。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
Python 中的领期权交易策略
原文:https://blog.quantinsti.com/collar-options-trading-strategy-python/

当前的市场环境非常具有挑战性,我们需要在投资和寻找其他机会的方式上更加明智。作为交易者,人们总是在寻找那些在市场上表现良好,同时又能获得丰厚利润的资产。
横盘策略为交易者提供了一个抓住的好机会。如果交易适度看涨,但对你的价格保持谨慎,这就是颈圈期权策略实施的时候。
这就带来了一个问题,
什么是衣领?
颈圈,也被称为对冲包装,是一种保护性的期权交易策略。它们防止了巨大的损失,但同时也防止了巨大的收益。
股票>多头头寸>可观收益>工具领
许多人经常想知道,
衣领的定义是什么?
或
衣领的意义是什么?
颈圈是一种期权交易策略。这是一个备兑看涨期权头寸,具有额外的保护性看跌期权,将安全头寸的价值限制在两个界限之间。颈圈期权交易策略可以通过同时持有标的股票并根据持有的股票买入看跌看涨期权和卖出看涨期权来构建。人们可以通过买入标的股票,同时以低于当前价格买入看跌期权并以高于当前价格卖出看涨期权来对冲股票的潜在下跌风险。
衣领交易策略有广泛的用途。保守的投资者发现,限制利润以换取有限的损失是一种很好的交易,投资组合经理利用它来保护他们在市场中的头寸,而一些投资者则利用它来降低保护性看跌期权的价格。
衣领交易策略结构的组成
- 买 1 个 OTM 看跌期权(看跌颈圈)-下限-用于保护
- 卖出 1 个 OTM 看涨期权(看涨期权)-上限
看涨期权和看跌期权都是场外期权,有相同的到期日,它们的数量必须相等
一般来说,价格会在两次罢工之间
该策略在理想情况下应该是这样的:

计算盈亏平衡点
- 买价-看涨期权费(你做空)+看跌期权费(你做多)
- 对于净信贷,BEP =当前股票价格-收到的净信贷
- 对于净借方,BEP =当前股票价格-支付的净借方
有限的利润潜力
- 最大值利润=看涨期权的执行价格-基础期权的购买价格
- 最大值亏损=买入价格(标的)-执行价格(长期看跌期权)
最佳回报:你希望标的价格以卖空期权的执行价格到期。
项圈期权策略如何运作
第一步:按现价

市场不稳定,波动完全出乎意料。当期权的价格上涨时,价格有可能下跌,你可能会损失利润。在这种情况下,资产需要得到保护。
第二步:练习衣领选项

领圈期权战略就是在这种情况下实施的。你卖出的看涨期权限制了上涨空间。
应用衣领策略的各种场景有哪些?
情景 1:当市场看涨时

颈圈期权提供有限的利润,用于从横向移动的市场中产生月收入。这个利润可以作为买入看跌期权的收益。由于交易者拥有期权,卖出的看涨期权被认为是“备兑的”。
情景二:大幅牛市

如果价格突然上涨并达到峰值,那么卖出看涨期权的价格就会上涨,导致很难在不影响市场的情况下快速卖出许多证券,从而无法实现利润。
情景 3:当市场看跌时

如果价格下跌,则执行看跌期权。价格随着基础资产的下跌而上涨。这里,卖出发生在使用期权的市场价值之上。因为你已经卖出了看涨期权,如果期权被转让,你就必须以执行价格卖出期权。
场景 4:侧向移动

如果价格在期权到期前保持不变,并且由于两个期权的到期日相同,因此两个期权都没有实施,因此它们都变得没有价值。在这种情况下,最大的损失只是为期权支付的溢价,因为它从看涨期权中抵消了为看跌期权支付的溢价,从而使损失最小化。
实施领盘交易策略
在这个例子中,我将使用 IDBI 银行有限公司(股票代号 IDBI)期权。
领策略示例
在此,我将以 IDBI 银行有限公司为例,因为该银行具备以下必备素质:
- 在横盘中表现
- 受到保护,不会向下移动
- 灵活并能适应变化
过去 1 个月的价格变动(来源——谷歌财经)

IDBI Bank Ltd .的价格有很大波动,最高为 194.65,最低为 117.05,这是根据谷歌金融的当前价值。
为了这个例子的目的;我会买 1 美元的看跌期权和 1 美元的看涨期权。
以下是 IDBI 银行有限公司截止日期为 2018 年 3 月 29 日的期权链,来源:nseindia.com



我将为行权价为 75 的看涨期权支付 3.25 印度卢比,为行权价为 65 的看跌期权支付 2.00 印度卢比。期权将于 2018 年 3 月 29 日到期,为了从中获利,IDBI Bank Ltd .的价格应在到期前大幅上涨。
发起这项交易支付的净保费将为 5.25 印度卢比。为了使这个策略达到盈亏平衡,在这个策略达到盈亏平衡之前,价格需要向下移动到 59.75 或者向上移动到 80.25。
Python 中如何计算策略收益?
现在,让我用 Python 编程代码带你看一下收益图。
Import libraries
import numpy as np
import matplotlib.pyplot as plt
import seaborn
定义参数
# IDBI Bank Ltd stock price
spot_price = 70.65
# Long put
strike_price_long_put = 65
premium_long_put = 2
# Short call
strike_price_short_call = 75
premium_short_call = 3.25
# Stock price range at expiration of the put
sT = np.arange(0,2*spot_price,1)
电话支付
我们定义一个函数来计算购买看涨期权的收益。该函数将 sT 作为输入,sT 是到期时股票价格、认购期权的执行价格和认购期权的溢价的可能值的范围。它返回看涨期权的收益。
+def call_payoff(sT, strike_price, premium):
return np.where(sT < strike_price, premium,+ premium -sT + strike_price)
payoff_short_call = call_payoff (sT, strike_price_short_call, premium_short_call)
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_short_call,label='Short Call',color='r')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()

放收益
我们定义一个函数来计算购买看跌期权的收益。该函数将 sT 作为输入,sT 是到期时股票价格、看跌期权的执行价格和看跌期权的溢价的可能值的范围。它返回看跌期权的收益。
def put_payoff(sT, strike_price, premium):
return np.where(sT < strike_price, strike_price - sT, 0) - premium
payoff_long_put = put_payoff(sT, strike_price_long_put, premium_long_put)
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_long_put,label='Long Put',color='g')
plt.xlabel('Stock Price')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()

衣领放线
payoff_collar = payoff_short_call + payoff_long_put
print ("Max Profit:", max(payoff_collar))
print ("Max Loss:", min(payoff_collar))
# Plot
fig, ax = plt.subplots()
ax.spines['top'].set_visible(False) # Top border removed
ax.spines['right'].set_visible(False) # Right border removed
ax.spines['bottom'].set_position('zero') # Sets the X-axis in the center
ax.plot(sT,payoff_short_call,'--',label='Short Call',color='r')
ax.plot(sT,payoff_long_put,'--',label='Long Put',color='g')
ax.plot(sT,payoff_collar+sT-spot_price,label='Collar')
plt.xlabel('Stock Price', ha='left')
plt.ylabel('Profit and loss')
plt.legend()
plt.show()

Max Profit: 66.25
Max Loss: -64.75
总结
可以实现的最大利润是无限的,可能发生的最大损失是 64.75 印度卢比。使用这种策略的好处是,人们从一开始就知道预期的损失和收益。随着时间的推移,买卖期权的价值都在下降。由于卖出看涨期权,回报可能会更少、更慢,但看跌期权保证了保护。
下一步
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)的高管课程。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。现在报名!
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载数据文件
- 衣领期权交易策略 Python 代码
从商品分析师到算法交易员
原文:https://blog.quantinsti.com/commodity-analyst-algorithmic-trader/

管理商品研究工作涉及对商品价格波动的日常理解和绘图。考虑到研究分析师每天获取和管理的数据,很有可能商品分析师要么已经是交易者,要么他很想开始交易。几年前,大宗商品交易并不多见。今天的情况完全不同;在印度总共有 19 个以商品为中心的交易所,我们看到商品交易的大幅增长。当考虑商品时,价格波动可能不剧烈,但是考虑能够将日内交易应用于同样的商品。如果你看一下代表黄金价格波动的图表,你会观察到每小时微小的价格变化和更长时间的大幅度变化。考虑一下,能够利用这些微小的波动并为自己赚钱。

来源:http://www.moneycontrol.com/commodity/gold-price.html
需要回答的问题是,你如何将这种价格变化货币化?你想过通过 Algos 进行交易吗?回答“是”意味着你知道技术要求。如果答案是否定的,让我们先带你了解算法交易的基础知识。
什么是 Algo 交易?
算法交易(自动化交易、黑箱交易或简单的算法交易)是使用计算机的过程,计算机被编程为遵循一组定义的指令进行交易,以便以人类交易者不可能的速度和频率产生利润。
【Algo 交易是如何运作的?
自动化或算法交易是利用计算机程序生成交易信号、发送订单和管理投资组合。算法使用复杂的电子市场/平台,以类似于电子交易的方式进行交易。不同之处在于,在算法交易中,关于成交量或规模、时机和价格的决策是由算法决定的。
高频交易(HFT)是一种特殊的算法交易,其特点是持仓时间异常短暂,响应时间低,一天内交易量大。写算法是为了利用出现在极短时间内的交易机会,短至毫秒或微秒。每笔交易的保证金很小,通过高速和大量交易来弥补。
为什么选择算法交易?
考虑能够通过自动化买卖过程将你的损失降到最低。交易的准确性和速度是增加的流形,反过来增加你的利润率。你的舒适度提高了,因为你不用担心睡觉时交易价格的下跌或暴涨。您可以根据历史数据对您的策略进行回溯测试,以提高安全性,从而坚持更好的风险管理。所有这些都有一个额外的优势,那就是在交易时,以最快的速度控制情绪。你所需要做的就是将它们自动化。
这里有一个例子,一个来自商品市场的人通过学习算法交易来利用技术。Vippinraj 先生目前担任 Reliance Commodities Limited 的南方区域负责人,此前他在 Motilal Oswal 的商品部门工作。
当他选择参加 QuantInsti 的算法交易管理课程时,他意识到了市场的功能,并获得了很强的交易能力。请继续阅读,了解更多关于他的经历。
我们与 Vippinraj 的对话
What is your educational/professional background? How long have you been engaged in trading?
我的职业生涯始于国际市场。我从 2001 年开始在全球市场交易。对金融市场的热情和激情让我接受了同一领域的一份 T2 工作,这进一步磨练了我的技术和基本面分析技能。
使用各种软件,如彭博、汤森路透、eSignal、Telequote、MT4 等。帮助我理解了国内和全球市场的细微差别。
我获得了金融 MBA 学位我得到了 motil al Oswal-Commodities 的一份工作,这给了我一个深入了解国内市场的机会。我在过去的 11 年里一直在 Reliance Commodities 工作,目前作为区域主管管理南印度(商品&货币部门)。凭借在金融市场 14 年的总体经验,我有机会在不同领域工作,如研究、业务管理和开发、客户管理、咨询服务、实物处置服务等。
How did you become interested in algorithm trading & Why Quantinsti ? What's your experience so far?
我在周围看到的当前趋势和革命性机器交易实践的发展和变化激励我参加算法交易的培训。贸易行业的朋友向我建议 QuantInsti ,我自发地联系他们以了解更多细节。
在与 QuantInsti 的人交谈后,我意识到这是学习算法交易的最好地方。我接受了尊敬的 QuantInsti 教师的讲课,他们反过来激励我完成这门课程。他们总是很乐意回答我的问题,并随时提供帮助。
对于一个有市场知识但不会编程的人来说,学习算法交易有点困难。然而,正如他们所说的,当你有热情和激情去实现你的目标时,没有什么是不可能的。因此,在 QuantInsti 杰出教师的帮助下,我克服了对编码的恐惧。在完成 QuantInsti 的 EPAT培训后,我现在已经获得了使用 Python、R 和 Matlab 编写策略的知识和信心。
到目前为止,这是一个伟大的旅程,我完全喜欢它。
How did EPAT change your trading practice?
手动交易有几个缺点,如情绪交易、基于技术指标的策略和偏见,所有这些都会导致不当的交易决策,并导致错误,进而影响交易业绩。
学习 algo 交易帮助我获得了信心,我可以用我的技能来准备策略,分析市场并获得最好的结果。使用 quants 对策略进行回溯测试有助于理解交易系统的有效性和准确性。
What do you think of EPAT's courses? How does it add value to your career?
由 QuantInsti 设计的 EPAT是最好的课程之一,它包括从交易基础到自动化技术的每个细节。该课程的课程设置很详细,来自全球各地的教师帮助我们获得了理论和实践方法的知识。这个在线门户网站用户友好,帮助我们与世界各地的其他爱好者互动。
有了 EPAT,我建立交易平台的梦想变得简单了。现在,我可以随时建立一个自动化交易平台,提高对客户的服务质量。这对我的职业生涯绝对是一个福音,它使我能够从整体上看待交易系统,并在使用自动化交易方法时做出公正的决定。
What do you have to say about the employment opportunities offered by Quantinsti ?
到目前为止,QuantInsti 的安置团队一直非常积极地为我提供各种资料。
Would you recommend QuantInsti to others who wish to engage in algorithm trading?
是的,当然,我会推荐 QuantInsti 给那些热衷于学习和成为 Quant 的人。事实上,我已经推荐了一些来自贸易行业的同事和朋友参加 EPAT,因为这将帮助他们更上一层楼。
下一步
你是否热衷于学习算法交易的各个方面来提高你现有的技能或者自己开始交易?查看算法交易(EPAT)中的执行程序。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。现在注册,开始你的算法交易生涯。
为了准确测量结果而进行回溯测试时要避免的常见错误
扎克·奥克斯
回溯测试是而不是本身就是一个开发工具,目标不是看你能做出多大的权益曲线。一个好的回测应该是指 它如何准确地反映实时交易 ,而不是系统看起来如何'好。
在这篇博客中,我们将讨论:
- 构建回溯测试* 佣金、复杂功能和细节* 战略逻辑* 对抗回测偏差* 回溯测试清单
所以,你刚刚写完你的自动交易算法,你正在接近关键时刻——最初的回溯测试。你已经花了几个小时来构建这个,所以你真的希望股票曲线至少是正斜率,并且希望没有任何大的下降。
这一时刻肯定会定义过去几个小时在这方面的工作,甚至可能用一条足够好的曲线改变你的未来——一条直的、绿色的、向上倾斜的线会带来纯粹的快乐,而一条起伏的黑/红线会降低你的自我价值。比方说这个例子,你的结果是一个巨大的、二次的、向上倾斜的曲线,它不会停止。
这条曲线将带你到应许之地,将粉碎你路上的任何人,并且对它的辉煌不做任何道歉。我们都见过其中的一个——但是我们怎么能确定这个回溯测试是有效的,并且我们可以在这些结果的范围内期待一些东西呢?
有一些技巧可以帮助我们确定回溯测试准确的概率。首先,我们从力学和假设开始。任何没有对佣金和滑点建模的回溯测试都不应该被认为是策略的代表。在一些系统中,这是一个无关紧要的差异,但在其他系统中,它可以彻底改变曲线——我见过它反转一些刷单系统的权益曲线。
那么多少才够呢——佣金通常是相当标准的费用表,所以简单地让他们是什么。这个东西并不复杂,但是不要忽略这些小细节是非常重要的。
滑点可能会更复杂一些,但在期货中,市场订单的常见估计是每边 12.50 美元,我想我对股票/ETF 使用每边 0.02-. 10 美元。我通常发现这是一个相当高的估计——但是重要的是根据你的执行历史来建模。
就我个人而言,我使用了其中的一半——但那只是因为我用我的执行对系统进行了广泛的测试,并且发现 6 美元更接近我实现的滑点。回顾一些你的实时交易与纸上交易的对比,看看它们相对于 sim 账户的填充情况。
这里不是所有的工具都相等,所以如果你发现 ES(埃米尼标准普尔 500 期货合约)有大约 12.50 的滑点,这并不意味着 KC(咖啡期货合约)也会有大约 10 美元——我见过 KC 交易在非流动性区间填补 40 美元。注意您测试的仪器,最简单的方法是比较现场报告和 sim 报告。这件事很值得你花时间去做。
所以一旦滑点和佣金被准确地或保守地包含在你的回溯测试中,让我们来看看实际的策略逻辑。有几个组件在现实生活中非常有效,但也会产生一些奇怪的回溯测试结果——其中之一就是百分比跟踪止损。
在许多回溯测试引擎(TradeStation、NT8、TradingView)中,默认设置是基于棒线而不是在棒线内进行回溯测试。这意味着一个长输入将简单地查看 OHLC 值来确定你的 trailstop 是否被执行——也就是说它将寻找一个大于你的% Trailing 的高收盘值。
在实时交易中,你会发现你的头寸可以在任何给定的棒线内被执行数百次,在任何收盘价之前——这可以显示大得多的平均获利交易,从而显示平均交易,以及总体表现。
在回溯测试中,引擎会假设绿色条是一个向上的运动,而不是许多小的向上运动的集合,并带有回溯。你所要做的就是将任何 30 分钟图与相同区间的 1 分钟图进行比较——中间有很多波动,很可能触发你的跟踪止损(很可能会生效)。
那么,我们如何对抗大多数测试引擎的这种回溯测试(事后诸葛亮)偏见呢?让我们看看。
在 TradeStation/Multicharts 中,您可以在属性中启用条内回溯测试(或 MC 中的条放大镜)(并将分辨率设置为分、秒或分笔成交点),这将使您对系统的性能有一个更好的了解。这将需要更长的时间,但它更准确。
如果没有任何设置可以做到这一点,比如在 Python 中,你可以运行 2 个数据集。一个作为信号间隔,例如,说 30M 条-以信号通知条目;另一个跟踪止损百分比,比如一个点,30 秒或 1 米棒线。
我将分享一个 IB 系统,在这个系统中,我用 5 秒钟的小节来测试我的测试站,而不是用 60 米的小节来测试入口——实现这样的东西是确保你自己的回溯测试尽可能准确的最可行的选择。
****
****
如果您无法实现更小的间隔棒线(可能没有任何 1 米或秒棒线或可用数据),那么您可以实现一个固定的目标值来代替您的跟踪止损,从而为您提供一个估计的最坏情况填充值。
我发现它的表现肯定比止损差,但不是对你的盈利交易完全不合理的估计。一个例子是用 90 - 120 美元的固定目标替换或简单地组合一个+100 美元的 PNL 止损点。
试着对自己诚实,你通常会在哪里被阻止。这也可以通过使用 100 美元的 pnl 跟踪止损点和来完成,也许是 150 美元的固定目标,限制你的上涨,计算机可以根据假设来创造。
假设你已经做到了这一步,你的回溯测试肯定会变得更加实际。通过回溯测试,我仍然发现一些事情会导致一些疯狂的结果,所以我将它们列出来进行最后的回顾。
- 同一酒吧内的入口和出口
- 周末/隔夜套利(+运气)
- 小样本量(包括至少 100 个交易和尽可能多的制度)
- 细价股票/流动性差的名字
- 宇宙包括杠杆 ETF/ETN
- 全域包括冗余符号(QQQ 和 TQQQ)
结论
如果你已经完成了这个基本的清单,你会对你看到的任何结果感觉更好。如果你从来没有考虑过这些,请不要气馁。请记住,大多数职业基金经理不会跑赢市场——也不会试图跑赢市场。他们专注于提高而不是达到特定的绩效水平。
为什么这么多都依赖于一个单独的折线图,我们怎么能确定一个漂亮的回溯测试不仅仅是我们的计算机在跟我们开一个残酷的玩笑呢?按照这个清单进行工作将会有很大的改进。
在我们复习的时候,让我们试着记住回溯测试的目的。我永远不会相信一个漂亮的回溯测试——即使是最好的假设也会有太多的假设。让我们重新定义一下什么是漂亮的回溯测试,同时,让我们记住它们只是一个验证工具,而不是开发工具。
你可以通过对历史数据进行回溯测试来提高交易成功的可能性。Quantra 的这个关于回溯测试交易策略的课程正是你从交易中获得最大收益所需要的。从基本步骤、数据、规则、风险管理等方面学习一切。立即注册!
-交易愉快!
编辑注:QuantInsti 尊重作者的选择和偏好,但我们绝不认可、支持或建议本文中的任何品牌。这些观点完全是作者的观点。我们更喜欢并提倡使用 Python 进行量化交易。T3】
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
算法交易的竞争优势|网络研讨会
原文:https://blog.quantinsti.com/competitive-edges-algorithmic-trading-21-june-2022/
https://www.youtube.com/embed/Z7KvqqqhwS0?rel=0
完成演示幻灯片
https://www.slideshare.net/slideshow/embed_code/key/4YmDvRE3O9x0pd?hostedIn=slideshare&page=upload
关于会议
你是作为个人/散户交易者还是作为机构交易?不管怎样,交易就像其他行业一样,你需要在某些方面做得更好,才能在竞争中保持领先。
同样,你的竞争对手也可能比你有某些竞争优势。了解这些竞争优势并准备好成功地与他人竞争是很重要的。
- 什么是优势,为什么你的交易系统需要它们?
- 不同类型的策略和交易系统。
- 如何在投资和交易领域识别和建立竞争优势?
- 个人/零售领域与机构领域的适用性。
关于演讲者

尼泰什·汉德尔瓦尔
(QuantInsti 联合创始人&首席执行官,iRage 联合创始人&合伙人)
Nitesh 在财政部的银行部门开始了他的职业生涯。在一家自营交易公司短暂担任领导后,他于 2009 年与人共同创立了 iRage。作为 iRage 的业务主管,iRage 成为了印度算法交易领域的领军人物之一。
2016 年,他将注意力转移到 QuantInsti,这是他在 2010 年作为 iRage 的一部分共同创立的一个研究所,并担任其首席执行官。在他的领导下,QuantInsti 已经发展到 100 多个团队和教师成员,通过其独特的基于学习和金融应用的生态系统,帮助来自 190 多个国家的受众在这一领域发展,并通过其 SaaS 平台产品帮助企业和机构发展。
Nitesh 拥有 IIT 坎普尔的电气工程学位和 IIM 勒克瑙的管理研究生学位。
本次活动于:
2022 年 6 月 21 日星期二
东部时间上午 9:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30
一个计算机科学毕业生从事算法交易的故事
原文:https://blog.quantinsti.com/computer-science-algo-trading-epat-success-story-srinivas-reddy/
“你可以做任何你下定决心要做的事情”——本杰明·富兰克林几十年前说过这句话,但它们仍然引起我们所有人的共鸣。有些人忘记了它们,有些人却在生活中吸收了它们。
Srinivas 是 CFA 二级候选人,在能源贸易风险管理(ETRM)领域有工作经验,对人工智能特别是 ML 在金融中的应用感兴趣。精通 Python、C++和 Excel,Srinivas 拥有很好的金融衍生品和统计知识。
作为一名计算机科学毕业生,他一直对市场感兴趣,并希望进入算法交易。他和我们分享了他跟随自己的愿望进入 Algo trading 的旅程,获得了算法交易(EPAT)高管课程的认证,并通过其就业单元找到了一份工作。
嗨,斯里尼瓦斯,告诉我们你自己的情况吧!
嗨!我是 Srinivas Reddy,住在印度的班加罗尔,是 Curl Capital 的 Jr 算法交易策略师。
我是一个相当不错的排球运动员。我在大学的时候经常玩,在我的第一份工作中偶尔会玩。现在减少了,因为由于封锁,没有太多的动力出去玩。我经常和我的朋友打扑克。我很喜欢这样。
我目前正在疫情期间出差,因为我住得很近。我的组织非常注意净化环境,保证每个人的安全。显然,如果病例增加,工作变得危险,我们将转向 WFH(在家工作)。
一个计算机专业的毕业生想进入算法交易有多现实?你是怎么做到的?
在 2000 年代,市场看涨并呈上升趋势。新闻中充斥着市场消息,人们在赚钱。我有兴趣了解如何投资和市场如何运作。
我从 Zerodha 的教育门户网站开始。我学习了期权、期货和股票的基本原理。作为一个计算机科学背景的人,我想探索如何自动化这个过程,因为我不想整天坐着看屏幕。这也是我开始学习 Algo 交易的原因。
鉴于我的技术背景和对金融的新兴趣,将两者结合起来似乎是一个显而易见的选择。我获得了一套计算机科学的工具,可以应用于无数的领域。大多数人将这些技能应用于科技行业,但同样的原则也可以应用于金融,这正是我所做的。
互联网上有数百门课程,但它们只教授该学科的一小部分,而没有更广泛的背景。网上学习的困难之处在于,你不知道如何对你所获得的知识进行分类,也不知道如何适当地进步。
经过几个月从不同渠道学习算法交易,EPAT 是我发现的唯一一个有结构化方法教授算法交易的课程。在 EPAT 之前,我习惯于学习一个概念,然后研究下一步该学什么。它提供了从基础到高级概念的完整包。
因为我有计算机科学背景,对数学和统计学有很好的理解。但是,有商业背景的人不会很好地理解这些话题。
学习金融绝对是一个挑战,但这正是它的有趣之处。我喜欢这个金融领域的一点是,我会不断学习和创新,即使是 10 年后。
EPAT 课程的结构适合各种背景的学习者。它从基本的统计数据和财务开始,技术方面引入了 excel,然后是 python。它为我提供了一个清晰而有条理的进程,让我擅长算法交易。
没有哪门课程只是给你现成的策略。你不能指望参加一个课程,第二天就开始交易,EPAT 也不例外。它为我提供了建立和测试策略的工具。
没有什么策略是突如其来的,这是一个从小处着手并不断完善的过程。EPAT 在教授这一过程方面做得很好。
我大部分时间都在自己的公司交易。我的工作包括开发策略、回溯测试,并让它们获得交易许可。如果它表现良好,我们将在现场市场推出它。我们还整合了人工智能和人工智能模型,以在适当的时候使我们的战略更好。
所以,回答你的问题- 对于一个计算机科学毕业生来说,成为算法和量化交易领域的一员是非常现实和非常可能的。
你是如何在算法交易中找到职业的?
此前,我曾在能源行业的贸易风险管理领域工作了 3 年,了解了企业的工作方式。我知道有一半的领域与后台相关的工作有关。
之后,我在中层办公室结束了工作,这主要是与技术相关的工作。当我在那里工作时,我意识到我想更多地参与市场。我想交易并产生影响。
实际上,我一直在积极寻找工作机会。我申请的很多公司都没有回复我,鉴于新冠肺炎的情况,这是可以理解的。我花了几个月的时间找工作,但只收到几份技术职位的邀请。我决心在金融行业找一份工作,所以尽管很沮丧,我还是继续寻找。我告诉自己,“如果不是今天,那么明天”。
我联系了 EPAT 安置小组。EPAT 最大的好处之一就是课程结束后收益不会停止。终身学习最新课程和持续的就业援助是皇冠上的宝石。
我对 EPAT 的安置过程特别满意,这使我有可能。
我全程都有人指导。它从优化我的简历开始,到更新与面试相关的重要概念。每当我要求时,他们总是让我了解最新情况,并向我提供进度反馈。
这与我在公司网站或招聘网站上申请时的情况形成了鲜明对比。大多数时候我都不知道我的应用程序发生了什么,但是 EPAT 的布局单元消除了这种模糊。
有各种各样的人在学习 EPAT 课程。一些人希望在 algo 交易领域找到工作,另一些人希望建立自己的交易平台。不管目标是什么,我认为大部分人都得到了就业安置小组的帮助,无论是工作机会还是社交机会。
我个人过去每周都会收到 2-3 个职位空缺,其中一些来自国际公司。
在疫情飓风来袭并给大多数求职者造成不利局面之前,我过去每周都能从 EPAT 获得一到两次机会。我还有几条有希望的线索。
一个是我错过的早期初创企业,另一个是与 Curl Capital 合作的机会,这是一家由行业领导者运营的非常好的公司,所以我抓住了这个机会。
我不知道我是否应该做出改变,因为我认为这可能是一个糟糕的时机,因为新冠肺炎。我只知道我真的想在这里交易或建立策略。故事结束!
所以,我现在是初级算法交易策略师。我的工作包括开发能够真正进入劳动力市场并赚钱的策略。这是一次很棒的经历,也正是我想要的职业生涯。
你给有抱负的定量分析师的建议!
很多人对待金融工作和科技工作的方式不同,因为他们认为自己没有足够的金融知识。但从我的经验来看,一旦你进入面试,金融知识就像一个奖金,但 algo 交易工作的主要焦点是数学和编码。
我的建议是开始申请工作并且相信你的技能,而不是基于你的金融知识来限制自己。
这真的很高兴知道你的努力和奉献精神,实现你的目标,进入算法交易领域。我们很高兴 EPAT 能成为你的向导和动力,斯里尼瓦斯。我们对你的未来致以最美好的祝愿。
如果你也想用终身技能武装自己,这些技能将永远帮助你提升你的交易策略。有了统计学&计量经济学、金融计算&技术、机器学习等主题,这个 algo 交易课程保证你精通在交易领域出类拔萃所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
EPAT 擅长算法交易|叶夫根尼的故事
原文:https://blog.quantinsti.com/computer-science-algorithmic-trading-epat-success-story-evgeny-tishkin/
作为 EPAT 大学的校友,Evgeny 在算法交易和 HFT 方面拥有超过 10 年的丰富经验,曾在多家自营交易公司和对冲基金担任量化开发人员、首席软件架构师、量化分析师和首席技术官。
在 2019 年 XTX 市场全球预测挑战赛中,叶夫根尼还在来自全球 100 个国家的 4000 多名定量研究人员中获得了第二名。
他希望提升自己的专业技能,为自己的职业、网络和其他方面发展算法优势。如今,他已经在该领域成功立足,并且仍在继续突飞猛进地发展。
这是他的故事,也是他如何让这一切成为可能的。
嗨,叶夫根尼!你能给我们介绍一下你自己吗?

嗨,我是叶夫根尼·蒂什金!本人量化分析师,算法交易整体经验 10 年,做软件开发,做高级软件开发,做各公司首席技术官,Quant,量化分析师,大概 10 年左右。
我在俄罗斯工作,拥有计算机科学学士学位、文凭和硕士学位。我喜欢极限运动,像滑水、滑雪板和风筝冲浪。我相信极限运动让你即使在交易时也能准备好应对风险。
在过去的五年里,我一直在远程工作,这就是为什么我的职业没有因为新冠肺炎疫情而受到影响。会议是在网上举行的,所以我没有去旅行。
教育和职业发展不成问题,因为疫情,我看不到任何障碍。我在教育上投入了更多的时间,大概是探索和研究新思想和新知识。
我认为,人们应该着眼于长远利益,培养他们的免疫力,而不是依赖疫苗和药片,从而保护他们免受所有类型的病毒,而不仅仅是冠状病毒。
你是如何以及为什么从软件开发转向算法交易的?
一旦我离开大学,我对算法交易产生了兴趣,我的计算机科学背景使我很容易进入这个领域。所以,对我来说,换成它,然后坚持下去,也并不难。
尽管我是一名 CTO,处理大量的职责、软件开发和分析,但我希望专注于战略而不是软件开发。我认为自己在这个领域更有效率。
我觉得一个人应该有概率论、统计学、数学的基础知识,以及正确的教育才能进入算法交易。这很复杂,因为没有太多关于它的信息。
由于我在这方面工作,我正在学习一些技术,如 C,C++,Linux 等。高频交易需要。如果你设法先发展这些技能,学习 Python 是很容易的。然而,举例来说,为了定量的目的,你也应该有数学背景。
我觉得编程+数学+统计,才是你进入算法交易所需要的。
交易是我的激情,我热爱我的工作,我觉得它像魔术一样。你预测未来,所以这很令人兴奋。
在 QuantInsti 和 EPAT 之前,我没有 algo 交易的经验。我只有软件教育、系统开发、一些数学和统计学以及机器学习方面的经验。
这就是为什么当我知道 EPAT 课程的存在时,我很感兴趣!我知道这件事是因为欧内斯特·陈博士是一名教员。我看了一下,看到其他讲师,觉得这是最好的!
你和 EPAT 的旅行怎么样?
对我来说,最重要的事情是 EPAT 引导我构建我的知识领域,给我的学习一个框架。
对于不熟悉 EPAT 的人来说,这是一门非常有效的课程,而且学习曲线非常短。根据你的目标,你可以开始应用你的知识或者直接开始交易。
我的期望是从教员那里挖掘出一些新的圣杯秘密。这些人有自己的生意,是成功的交易者,是业内知名人士。他们分享知识和经验,从现实世界的算法交易,而不仅仅是学术。
这部分让我感兴趣!我确实采纳了 EPAT 大学讲师们分享的宝贵建议,并付诸实践。这对我来说是无价的!因为我在这个领域有一些经验,他们的讲座对我来说可能比其他没有交易经验的人更有价值。
在 EPAT 期间,我对课程所涵盖的领域进行了一些反思,我获得了一些看法、见解、想法和新知识,这带来了一些新的体验。EPAT 现有的每一门课程都很有价值。
有缺陷的面板可能是 EPAT 最有价值的特征!你有机会与有实际交易经验的人交流,如 Ernest Chan 博士、Rajib Borah、Nitin Aggarwal、Nitesh Khandelwal 等,这些人你通常无法与之交流。
你想对有抱负的算法交易者说些什么?
当我从俄罗斯萨马拉州立航空航天大学毕业后,我开始在图像处理系统研究所工作,大概是在教育的第一年。我的教授给了我一些建议,我会永远记住:
你教育的 50%是实践教育。
最佳和最短的成功之路是进入算法交易。但是为了得到这样一份工作,你应该拥有有用的、有用的、足智多谋的知识以及合适的技能。
我建议发展对你的职业生涯有帮助的技能,试着找一份定量开发人员或定量分析师或仅仅是软件开发人员的工作。一家成功的做算法交易的公司。
关键是追随你的热情和兴趣。当你喜欢你正在做的事情时,就是这样!成长一点都不难。
非常感谢你抽出时间和我们谈话,Evgeny。祝贺你获得优秀证书,我们祝愿你在未来的旅途中一切顺利。祝你在职业生涯中实现所有的目标!
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
计算机科学到量化金融:图沙尔的算法交易之旅
对于对工程、数学、统计和金融感兴趣的人来说,算法交易是一个很好的职业选择。这是非常有启发性的,在经济上也是有益的。
Tushar 是一个定量开发人员。他建立了低延迟的量化交易系统。他精通 C++、Python、C、JavaScript 和 SQL。作为一名自豪的 EPATian 人,Tushar 正在利用他在 EPAT 中学到的一切来推进他在量化金融领域的职业生涯。
我们通过电话采访了图沙尔,以下是他的成功故事!
嗨,图沙尔,告诉我们你自己的情况吧!
嗨!我是图沙尔·舒拉。我在美国工作。我目前在迪拜工作,不久我将回美国攻读硕士学位。我在 iBloxx capital 做高级量化软件工程师。
我研究交易策略,对它们进行回溯测试,并建立系统在现实市场中运用它们。到目前为止,我们的团队主要使用 Python 来完成这项工作。
我于 2020 年从密歇根大学毕业,获得了计算机科学学士学位。
COVID 的情况在这里并不像现在世界上许多地方那样糟糕。这里的大多数人都接种了疫苗,COVID 病例的数量每天都在下降。我现在已经习惯了到哪里都带着口罩。
你是如何从计算机科学转向算法交易的?
我在大学开始是一名商科学生。我原本计划进入全权委托交易或投资银行。然而,在密歇根大学的第一年,我选了一门计算机科学课程,并对技术产生了兴趣。
我决定先专注于学习计算机科学。毕业后,我决定通过算法交易将我的两种激情结合起来。我毕业后成立了自己的基金,但由于缺乏经验和资金,没有成功。
大学毕业后,我在寻找学习定量/算法交易的方法,在谷歌上偶然发现了 EPAT。这似乎是互联网上关于这一主题的最佳课程,在我有机会为迪拜一家更大的基金工作之前,我花了四个月的时间在经营我的基金时上了这门课。
QuantInsti 对于算法交易者来说是一个很好的资源。即使在迪拜工作时,当我被要求将订单簿数据汇总到 OHLC 数据中时,我也使用 QuantInsti 博客文章作为参考。
你为什么选择 EPAT 而不是其他课程?
互联网上的大多数算法交易课程不够专业,其他课程都是关于量化金融的,没有深入讨论算法交易。
EPAT 是我在网上能找到的唯一一门对算法交易有适当技术关注的课程。我可以证实,它背后似乎也有一个强大的支持系统。EPAT 有一些伟大的成功故事,我通过联系 QuantInsti 网站上提到的一些人证实了它们的有效性。
通过 EPAT,我学到了很多关于市场微观结构、构建回溯测试程序以及套利和均值回归等交易策略的知识。我喜欢这个课程的授课内容和结构。
EPAT 最吸引你的地方是什么?
我非常喜欢 EPAT 的就业服务,通过它我找到了在迪拜的工作。我是通过一个直接申请链接得到这个机会的,这个链接是安置小组发给我的。
EPAT 就业中心会尽最大努力为你在不同的国家找到该领域的工作机会。我的一位同事也通过 QuantInsti 获得了同样的工作。他叫乔纳森·莫雷诺,也是 EPAT 大学的校友。
你对希望从事算法交易的个人的建议
首先,你应该根据你的经验和技能,决定你想在量化金融领域担任什么角色。尽管它是一个利基领域,但它有许多不同的角色,如风险管理、定价、定量研究、定量交易和定量发展。
你并不真的需要硕士学位才能进入这个领域,但这可能会有所帮助。如果你是这个领域的新手,学习更多的一个好方法就是通过像 EPAT 这样的课程学习量化金融或算法交易的基础知识,然后尝试在散户层面建立自己的交易记录。
对于对计算机科学、数学、统计和金融感兴趣的人来说,算法交易是一个很好的职业选择。如果你擅长的话,这是非常有智力刺激和经济回报的。
你专注于培养自己的技能,并运用它们来推进你的职业目标,这确实值得称赞。我们祝你在未来的事业中好运,我们期待着你对量化金融世界的贡献。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
金融进化-人工智能,ML 和情绪分析(香港)
原文:https://blog.quantinsti.com/conference-hongkong-ai-machine-learning-sentiment-analysis/

金融进化-人工智能、机器学习&情绪分析-2019 年 3 月 20 日
人工智能被认为是第四次工业革命的主要驱动力。金融行业预计将引领人工智能的采用,预计未来三年的支出将大幅增加。为了处理和理解大量数据,机器学习和情感分析等方法已经成为打开数据分析大门的必要手段。
这个会议将帮助你揭开人工智能的神秘面纱,并区分现实和炒作。了解如何从人工智能技术的空前进步中受益。参与者将获得如何为自己和公司利用这些技术进步的真知灼见。T3T5T7】
概述
人工智能和机器学习(AI & ML)以及情绪分析据说可以“通过分析过去来预测未来”——这是金融业的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,并对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。人工智能和人工智能在金融服务行业,尤其是在合规性、投资决策和风险管理方面越来越受欢迎。
这是一个复杂的会议,不仅质疑和探索人工智能和人工智能在金融服务行业的影响,而且还继续确定在金融领域分享知识和利用知识产权的投资机会。
为什么参与
- 演讲者——思想领袖、学科专家和初创企业家——分享他们对自己工作的知识和热情,以及他们在人工智能、机器学习和情感分析领域的愿景。
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解量子计算和替代数据的影响
- 受益于来自英国、美国、欧洲和印度/香港的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 课程包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
涵盖的主题
- 用人工智能+影响者分析+大数据寻找阿尔法信号
- 吹泡泡:量化新闻、社交媒体和传染效应如何推动投机狂热
- 替代数据
- 印度的金融科技前景
- 人工智能对金融的影响
金融发展-人工智能、人工智能和情绪分析(孟买)
原文:https://blog.quantinsti.com/conference-mumbai-ai-machine-learning-sentiment-analysis/

金融进化- AI,机器学习&情绪分析-2019 年 3 月 14 日,美国国家证券交易所, 孟买
人工智能被认为是第四次工业革命的主要驱动力。金融行业预计将引领人工智能的采用,预计未来三年的支出将大幅增加。为了处理和理解大量数据,机器学习和情感分析等方法已经成为打开数据分析大门的必要手段。
这个会议将帮助你揭开人工智能的神秘面纱,并区分现实和炒作。了解如何从人工智能技术的空前进步中受益。参与者将获得如何为自己和公司利用这些技术进步的真知灼见。T3T5T7】
概述
人工智能和机器学习(AI & ML)以及情绪分析据说可以“通过分析过去来预测未来”——这是金融业的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,并对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。人工智能和人工智能在金融服务行业,尤其是在合规性、投资决策和风险管理方面越来越受欢迎。
这是一个复杂的会议,不仅质疑和探索人工智能和人工智能在金融服务行业的影响,而且还继续确定在金融领域分享知识和利用知识产权的投资机会。
为什么参与
- 演讲者——思想领袖、学科专家和初创企业家——分享他们对自己工作的知识和热情,以及他们在人工智能、机器学习、情感分析和深度学习领域的愿景。
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解量子计算和替代数据的影响
- 受益于来自英国、美国、欧洲和印度/香港的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 课程包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
涵盖的主题
- 用人工智能+影响者分析+大数据寻找阿尔法信号
- 吹泡泡:量化新闻、社交媒体和传染效应如何推动投机狂热
- 替代数据
- 印度的金融科技前景
- 人工智能对金融的影响
金融革命——情绪分析、人工智能和机器学习
原文:https://blog.quantinsti.com/conference-zurich-sentiment-analysis-ai-ml/

金融革命——情绪分析、人工智能和机器学习—苏黎士,2018 年 10 月 30 日
概述
了解情感分析、 AI 和机器学习的创新如何影响和惠及金融领域;探索研究和实践交汇处最本质的问题,了解最新模型和方法,演示如何使用人工智能和机器学习方法成功生成投资决策。
演讲者包括阿伦·维尔马、彭博;马蒂亚斯 Uhl,瑞银;安德斯·巴利,森蒂菲;Gautam Mitra,OptiRisk &客座教授,UCL;项羽和克里斯蒂娜·埃尔文-塞耶斯,OptiRiskRonald Hochreiter,吴维也纳经贸大学&金融数据科学研究院。
除了会议之外,还有一个名为“日内交易技术和策略的研讨会,这是一次非常实用的实践体验,由iRage Capital(印度)首席执行官 Rajib Ranjan Borah 和【巴西】阿尔费纳斯联邦大学 Humberto Brandã主讲。这次会议在伦敦、新加坡、香港和班加罗尔取得了巨大成功;现在轮到瑞士了。
为什么要参加?
- 聆听来自英国、美国、欧洲和印度/香港的顶尖学科专家的演讲
- 该方案包括最新的最先进的研究,实际应用和案例研究
- 期待技术和深入的介绍和讨论;我们喜欢刺激你的脑细胞!
- 与所有参与者,包括主持人、投资者和参展商,全天都有极好的交流机会。
涵盖的主题
- 机器学习和深度学习的基础和应用
- 应用于数据、文本和多媒体的模式分类器、自然语言处理(NLP)和人工智能
- 情绪得分与新古典金融模型相结合
- 以定性和定量方法为基础的财务分析
- 应用于金融的预测和规范分析
- 行为和认知科学
- 人工智能的未来及其对工业的影响
参加本次活动,赢取 Earn 持续专业发展学分
联通已向 GARP 注册了该计划,以获得持续专业发展(CPD)学分。参加本课程可获得 7 个 GARP 持续专业发展学分。如果你是注册的金融风险经理 (FRM),请在你的信用追踪器中记录这一活动。
通过 FIX 连接 FXCM–详细教程
原文:https://blog.quantinsti.com/connecting-fxcm-fix-detailed-tutorial/

我们在上一篇关于 FIX 协议的文章中讨论了消息通信的事实标准。
“金融信息交换( FIX )协议是为了促进与证券交易相关的信息的电子交换而开发的消息标准。它旨在用于希望实现通信自动化的贸易伙伴之间。1
在本文中,我们将更进一步,讨论在 fix 上连接 FXCM】所涉及的一些操作。我们将使用 QuickFix 引擎对示例进行编码。Quickfix 是一个开源的修复引擎。
“quick FIX是一个开源的修复引擎。它与金融应用程序相集成,为他们提供了与全球数百个支持 FIX 的系统进行通信所需的连接。 QuickFIX 让您的应用程序能够使用简单的界面与所有这些系统进行电子交互。”
*你可以从这里了解更多关于 QuickFIX 的信息。
资格证书
就像我们拥有使用 IBridgePY 连接到交互式代理的凭证一样,我们在这里也拥有凭证。通过 fix 连接 FCMX 将需要一些凭据来标识 FXCM 的连接实体。全权证书由以下内容组成:
- 插座连接主机,端口–您要连接的地方
- 发送者公司 Id–识别信息的发送者。
- 目标公司 id–确定消息的预期接收人
- 目标子 id–完成接收方标识的子标识符。
对于 quickFix,这些凭证需要在配置文件中进行配置。配置文件将如下所示:
# Default settings. These settings are inherited by each
# individual session found below
[DEFAULT]
BeginString=FIX.4.4
ConnectionType=initiator
HeartBtInt=30
FileStorePath=.\Store
FileLogPath=.\Logs
# Start and End times for the FIX session (in UTC)
StartDay=Sunday
StartTime=21:15:00
EndDay=Friday
EndTime=20:00:00
UseDataDictionary=Y
DataDictionary=FIXFXCM10.xml
ValidateUserDefinedFields=N
ValidateFieldsHaveValues=N
ValidateFieldsOutOfOrder=N
ReconnectInterval=20
ResetOnDisconnect=Y
ResetSeqNumFlag=Y
SendResetSeqNumFlag=Y
ContinueInitializationOnError=Y
# Session specific settings along with FIX credentials
# supplied by FXCM
[SESSION]
SenderCompID=someID
TargetCompID=FXCM
SocketConnectHost=someHost
SocketConnectPort=somePort
TargetSubID=someTargetID
Username=someUsername
Password=somePassword
登录
都准备好了吗?很好,如果您的配置是正确的,那么 quickfix 引擎将启动连接。这包括连接到主机和端口,并发送登录请求。登录请求是任何会话的第一条消息。如果不是第一条消息,则在登录请求之前发送的所有消息都将被忽略。
"所有在登录请求之前发送的消息都被忽略."
示例登录消息如下所示:
#Send Username/Password on Logon (35=A)8=FIX.4.49=114 35=A 34=1 49=sendercompId 52=20120927-13:15:34.754 56=FXCM 57=someTargetSubId 553=someUsername 554=somePassword 98=0 108=30 141=Y 10=146
标签 553 和 554 意在传递用户名和密码。请注意,34=1 假定这是一天中的第一次尝试。在其他情况下,它只是消息的序列号。如果所有凭证都正确,那么来自 FXCM 的登录响应将如下所示
#FXCM Logon response 8=FIX.4.49=92 35=A 34=1 49=FXCM 50=someTargetSubId 52=20120927-13:15:34.810 56=somesenderCompId 98=0 108=30 141=Y 10=187
请注意,因为响应是由 fxcm 发送的,而预期接收方是我们的系统,所以 49 标签是 FXCM(发送方)和标签 56 = somesenderCompId(预期接收方)。
一旦验证了凭证并收到成功的响应,就可能需要一些初始化参数。例如,市场状态如何(开盘/收盘)、符号信息(批量大小、报价大小)等。为了做到这一点,我们使用了交易会话状态请求 (35=g)
下面的代码片段显示了如何发送交易会话状态请求
FIX44::TradingSessionStatusRequest request;request.setField(FIX::TradSesReqID(NextId())); request.setField(FIX::SubscriptionRequestType(FIX::SubscriptionRequestType_SNAPSHOT_PLUS_UPDATES)); FIX::Session::sendToTarget(request,session_id);
这将发送请求,对请求的响应是交易会话状态消息。会话状态消息如下所示
-- Core TradingSessionStatus Message -- 8=FIX.4.49=12384 35=h34=3 49=FXCM 50=U100D1 52=20120828-13:24:52.38756=fx1294946_client158=Market is closed. Any trading functionality is not available.60=20120828-13:24:52325=N 335=2336=FXCM339=2340=2625=U100D19019=09030=Coordinated Universal Time
#-- Embedded SecurityList --
#NoRelatedSym (This field shows the total number of securities. Below we only show the first 5 to save space)146=69 55=CAD/JPY15=CAD228=1231=1460=4561=19000=189001=39002=0.019003=0.159004=-0.339005=18009076=D9080=19090=09091=09092=09093=09094=500000009095=19096=O55=GBP/CHF15=GBP228=1231=1460=4561=19000=139001=59002=0.00019003=0.159004=-0.379005=13009076=D9080=19090=09091=09092=09093=09094=500000009095=19096=O55=JPN22515=JPY228=100231=1460=7561=19000=10079001=09002=19003=0.079004=-0.099005=1007009076=T9080=29090=259091=19092=259093=19094=10009095=19096=O55=EUR/SEK15=EUR228=1231=1460=4561=19000=329001=59002=0.00019003=-0.829004=0.269005=32009076=D9080=19090=09091=09092=09093=09094=500000009095=19096=O55=AUD/USD15=AUD228=1231=1460=4561=19000=69001=59002=0.00019003=0.639004=-1.319005=6009076=V9080=19090=09091=09092=09093=09094=500000009095=19096=O
-- FXCM System Parameters --
NoFXCMParam (This field shows the total number of system parameters)9016=17
9017=TP_949018=Y9017=BASE_CRNCY9018=USD9017=TRAILING_STOP_USED9018=Y9017=SERVER_TIME_UTC9018=UTC9017=BASE_TIME_ZONE9018=America/New_York9017=EXT_PRICE_TERMINAL9018=PDEMO1_PRICES9017=COND_DIST9018=0.19017=COND_DIST_ENTRY9018=0.19017=TP_1729018=Y9017=BASE_CRNCY_SYMBOL9018=$9017=REPORTS_URL9018=https://fxpa.fxcorporate.com/fxpa/getreport.app/9017=BASE_UNIT_SIZE9018=100009017=END_TRADING_DAY9018=21:00:009017=BASE_CRNCY_PRECISION9018=29017=FixSupport9018=FIXONLY9017=TRAILING_STOP_DYNAMIC9018=Y
9017=FORCE_PASSWORD_CHANGE9018=N10=058
然而,我们有兴趣从代码中读取这个消息。读取这些系统参数的方法如下:
int param_count = FIX::IntConvertor::convert(status.getField(9016));
cout << "TSS - FXCM System Parameters" << endl;
for(int i = 1; i =< param_count; i++)
{
FIX::FieldMap map = status.getGroupRef(1,9016);
string param_name = map.getField(9017);
string param_value = map.getField(9018);
cout << param_name << " - " << param_value << endl;
}
FXCM 在 tradingSessionStatus 消息中发送附加标签。这些可以在安全列表和系统参数中找到。该信息将在发送订单时使用。
安全列表中的自定义字段
- 9001-精度-安全的精度。前述,美元/日元值为 3 = >此符号的值字段引用到小数点后 3 位。
- 9002-点大小-这代表我们所说的证券的点。例如,欧元/美元将为该字段显示值 0.0001。
- 9003-syminterest buy–您的服务器默认批量的价格,以您的账户货币表示。例如,如果你的账户是美元,服务器默认的手数是 10000。那么 9003=0.64 = >你将得到 0.64 美元的 10K 大小。
- 9004—symInterestSell—同上。9004=-1.48 = >你要为每个 10K 尺码付 1.48 美元。您可以从标签 9017=BASE_UNIT_SIZE 9018=10000 中读取默认批量。
- 9080-product id–每种证券都属于一种产品类型。1 =外汇,2 =指数,3 =商品,4 =国库,5 =金条。例如,欧元/美元将为 1。
- 9090-条件止损单停止-止损单与当前市场价格的最小距离。如果你有买入头寸,那么你的止损单必须至少与当前出价有这个距离。
- 9091-conditionalDistanceLimit-限价单与当前市价的最小距离。如果您有买入头寸,那么您的限价订单必须至少与当前买价相差这个距离。
- 9092—conditionalDistanceEntryStop—新止损单(挂单)的最小距离。如果你想下止损单买入,那么这个订单的价格必须至少与当前的要价相差这个距离。
- 9093—conditionalDistanceEntryLimit—新限价挂单(挂单)的最小距离。如果你想下一个新的限价挂单买入,那么订单的价格必须至少与当前的要价相差这个距离。
- 9094-最大数量-单笔订单的最大数量。
- 9095-最小数量-单笔订单的最小数量。
- 9096—trading status—这表示目的地是开放(‘O’)还是关闭(‘C’)。
除了上述自定义字段,系统参数也在此消息中返回(9017,9018 标签的组合)
- BASE _ CRNCY—您账户的货币
- SERVER _ TIME _ UTC–如果此字段设置为 UTC,则服务器将以 UTC 表示所有时间字段。如果不是,那么它会用本地时区来表示
- BASE _ TIME _ ZONE–s如何显示服务器的本地时区,例如“亚洲/加尔各答”
- COND _ DIST–新止损单或限价单的价格与当前市场价格之间的最小距离。该值以点数表示,通常默认为 0.10
- COND _ DIST _ 进场–新止损进场单或限价进场单的价格与当前市场价格之间的最小距离。该值以点数表示,通常默认为 0.10
- BASE _ UNIT _ SIZE–外汇证券的最小订单量。对于 CFD 证券,我们需要检查 9095 标签
- END _ TRADING _ DAY–交易日收盘时间。它以 hh:mm:ss 格式表示。这个时间总是采用 UTC
请求市场数据
在与服务器建立连接后,我们准备请求市场数据。市场数据由快照消息和增量更新消息组成。marketdatasnapshotfullresh(W)消息包含市场数据的更新。它是作为对 marketdatarequest (v)消息的响应而获得的。
以下代码片段显示了如何发送 marketdatarequest 消息:
FIX44::MarketDataRequest mdr; mdr.set(FIX::MDReqID(NextId()));mdr.set(FIX::SubscriptionRequestType(FIX::SubscriptionRequestType_SNAPSHOT_PLUS_UPDATES));mdr.set(FIX::MarketDepth(0));mdr.set(FIX::NoMDEntryTypes(2)); FIX44::MarketDataRequest::NoMDEntryTypes types_group;types_group.set(FIX::MDEntryType(FIX::MDEntryType_BID));mdr.addGroup(types_group);types_group.set(FIX::MDEntryType(FIX::MDEntryType_OFFER));mdr.addGroup(types_group); int no_sym = FIX::IntConvertor::convert(security_list.getField(FIX::FIELD::NoRelatedSym));for(int i = 1; i <= no_sym; i++){ FIX44::SecurityList::NoRelatedSym sym_group; mdr.addGroup(security_list.getGroup(i,sym_group));} FIX::Session::sendToTarget(mdr,session_id);
示例marketDataSnapshotFullRefresh消息如下所示:
8=FIX.4.49=53335=W34=3649=FXCM50=U100D152=2012091313:07:51.38756=fx157369001_client155=AUD/USD228=1231=1262=4460=4 # Number of MDEntries268=4# High 269=7270=1.03902272=20120913273=13:07:49# Low269=8270=1.03843272=20120913273=13:07:49# Bid269=0270=1.04437271=0272=20120913273=13:07:49336=FXCM625=U100D1276=A299=FXCM-AUDUSD-12638558537=1 # Offer269=1270=1.04459271=0272=20120913273=13:07:49336=FXCM625=U100D1276=A299=FXCM-AUDUSD-12638558537=1# Custom FXCM Fields9000=69001=59002=0.00019005=6009011=09020=19080=19090=09091=09092=09093=09094=500000009095=19096=O10=030
MDEntryTypes
您可以接收的数据类型在 FIX 中称为 MDEntryTypes。FXCM 支持:
- 出价(0)
- 问(1)
- 高价(7)
- 低价(8)
其他 MDEntryTypes,如 MDEntryDate 、 MDEntryTime 等。在邮件的第一个重复组中只出现一次。
位置信息
在开始策略之前,总是检索位置信息是很重要的。这是使用位置报告(35=AP)消息来完成的。人们不仅可以请求位置报告,还可以订阅更新。发送订阅请求类型(263)设置为 1 的 RequestForPositions (AN)消息将订阅更新。
PosReqType(标签 724)用于确定接收的报告是开放(由 0 指示)还是关闭(由 1 指示)位置。
当收到开仓报告时,它还包含开仓的价格(标签 730)。在平仓报告的情况下,平仓时的价格,以及一些附加标签:
- 9052–头寸的总 P&L。
- 9040–适用于头寸的展期利息
- 9053–已申请佣金
- 9043–头寸的收盘价
职位报告示例
| 5 | 货币 | 美元 | 美元 |
| 37 | 订单 ID | 134757321 | 134757321 |
| 55 | 符号 | 美元/日元 | 美元/日元 |
| 58 | 正文 | 我 | 我 |
| 325 | 未冻结指示器 | Y | Y |
| 336 | 翻译 ID | 福汇 | 福汇 |
| 第 447 章 | 甲方来源 | D | D |
| 第 448 章 | 甲方 | FXCM ID | FXCMID |
| 第 452 章 | 甲方角色 | 3 | 3 |
| 第 453 章 | NoPartyIDs | 1 | 1 |
| 523 | PartySubID | 32 | 32 |
| 第 581 章 | 账户类型 | 6 | 6 |
| 625 | TradingSessionSubID | U100D1 | U100D1 |
| 702 | no position | 1 | 1 |
| 703 | PosType | TQ | TQ |
| 704 | 长脚 | 1000 | 1000 |
| 707 | PosAmtType | 现金 | 现金 |
| 708 | PosAmt | 0 | 0 |
| 第 715 章 | 清算业务日期 | 20121220 | 20121220 |
| 721 | 后期处理 | 2610968257 | 2610968446 |
| 724 | PosReqType | 0 | 1 |
| 727 | 总报告数 | 0 | 0 |
| 第 728 章 | PosReqResult | 0 | 0 |
| 730 | 设置价格 | 84.242 | 84.242 |
| 731 | 设置价格类型 | 1 | 1 |
| 第 734 章 | 优先价格 | 0 | 0 |
| 753 | NoPosAmt | 1 | 1 |
| 802 | NoPartySubIDs | 4 | 4 |
| 803 | 批量子类型 | 26 | 26 |
| 9000 | FXCMSymID | 2 | 2 |
| 9038 | FXCMUsedMargin | 5 | |
| 9040 | fxcmpostinterest | 0 | 0 |
| 9041 | FXCMPosID | 46961794 | 46961794 |
| 9042 | fxcmpospentime | 20121220-03:46:25 | 20121220-03:46:25 |
| 9043 | fxcmclossettlprice | | 84.231 |
| 9044 | FXCMCloseTime | | 20121220-03:46:37 |
| 9048 | FXCMCloseClOrdID | | 1_157 |
| 9052 | FXCMPosClosePNL | | -0.13 |
| 9053 | FXCMPosCommission | 0 | 0 |
| 9054 | FXCMCloseOrderID | | 134757323 |
基本订单类型概览
生效时间
生效时间表示订单在未执行的情况下保留在订单簿中的持续时间。可能的不同值有:
- GTC (取消前有效)——这意味着订单在明确执行或取消前一直有效。通常在您不希望订单被立即执行时使用。您希望订单保持活动状态,直到完成为止。
- Day -这意味着订单在执行前或当天到期前一直有效。通常,当您的订单意图随着时间的推移而过时时,会使用这种方法。
- IOC (立即或取消)–订单在进入订单簿时尽可能得到满足。剩下的被取消了。你想以特定的价格买进。
- FOK (填充或删除)——订单要么在进入订单簿时被完全填充,要么被立即取消。你有兴趣以特定价格购买全部产品。
订单类型
市场
不管价格如何,这个订单都会打到对方头上。只要订单簿不是空的,它将接受下一个可用价格的填充。通常用在填充订单比填充的价格更重要的时候。对于一个市场秩序来说,TIF 可以是 GTC、天、奥委会、霍英东。
FIX44::NewOrderSingle order;order.setField(FIX::ClOrdID(NextClOrdID())); order.setField(FIX::Account(account));order.setField(FIX::Symbol("EUR/USD")); order.setField(FIX::Side(FIX::Side_BUY)); order.setField(FIX::TransactTime(FIX::TransactTime())); order.setField(FIX::OrderQty(10000));order.setField(FIX::OrdType(FIX::OrdType_MARKET)); FIX::Session::sendToTarget(order,session_id);
停止极限
该订单是一个市价订单,有一个成交价格范围。这提供了防止填充价格滑动的保护。标签 40=4 表示这是一个停车限制命令,停车价格设置在标签 99 中。这代表了你愿意接受的最差价格。TIF 可以是国际奥委会或 FOK
FIX44::NewOrderSingle order;order.setField(FIX::ClOrdID(NextClOrdID())); order.setField(FIX::Account(account));order.setField(FIX::Symbol("EUR/USD")); order.setField(FIX::Side(FIX::Side_BUY)); order.setField(FIX::TransactTime(FIX::TransactTime())); order.setField(FIX::OrderQty(10000));order.setField(FIX::OrdType(FIX::OrdType_STOPLIMIT));order.setField(FIX::StopPx(stop)); FIX::Session::sendToTarget(order,session_id);
限制
订单将以等于或优于订单信息(标签 44)中提到的价格成交。当填料的价格比填料本身更重要时,使用这种订单类型。支持的 TIF 有 GTC、戴、国际奥委会、福克。
FIX44::NewOrderSingle order;order.setField(FIX::ClOrdID(NextClOrdID())); order.setField(FIX::Account(account));order.setField(FIX::Symbol("EUR/USD")); order.setField(FIX::Side(FIX::Side_BUY)); order.setField(FIX::TransactTime(FIX::TransactTime())); order.setField(FIX::OrderQty(10000));order.setField(FIX::OrdType(FIX::OrdType_LIMIT)); order.setField(FIX::Price(price)); FIX::Session::sendToTarget(order,session_id);
停止
这是一个市价单,当当前市价低于止损单消息中提到的止损价时,就会发出该市价单。填料的价格没有保证,因为这是市场订单。支持的 TIF 是 GTC 和戴。
FIX44::NewOrderSingle order;order.setField(FIX::ClOrdID(NextClOrdID())); order.setField(FIX::Account(account));order.setField(FIX::Symbol("EUR/USD")); order.setField(FIX::Side(FIX::Side_BUY)); order.setField(FIX::TransactTime(FIX::TransactTime())); order.setField(FIX::OrderQty(10000));order.setField(FIX::OrdType(FIX::OrdType_STOP)); order.setField(FIX::StopPx(price)); FIX::Session::sendToTarget(order,session_id);
密码
例子
这段代码假设安装了 quickfix 库。需要相应地编辑包含路径。这将使您对如何建立 FXCM 会话、订阅市场数据和发送订单有一个基本的了解。
Main.cpp
#include "fix_application.h"
// -- FIX Example --
//
// Upon starting this application, a FIX session will be created and the connection sequence will commence. This includes sending a Logon message, a request for TradingSessionStatus. After the responses to these requests are received, you can use the command prompt to test out the functionality seen below in the switch block.
int main()
{
FixApplication app;
// Start session and Logon
app.StartSession();
while(true){
int command = 0;
bool exit = false;
cin >> command;
switch(command){
case 0: // Exit example application
exit = true;
break;
case 1: // Get positions
app.GetPositions();
break;
case 2: // Subscribe to market data
app.SubscribeMarketData();
break;
case 3: // Unsubscribe to market data
app.UnsubscribeMarketData();
break;
case 4: // Send market order
app.MarketOrder();
break;
}
if(exit)
break;
}
// End session and logout
app.EndSession();
while(true){
} // Wait
return 0;
}
fix_application.h
#ifndef FIXAPPLICATION_H
#define FIXAPPLICATION_H
#include <iostream>
#include <vector>
#include "quickfix\Application.h"
#include "quickfix\FileLog.h"
#include "quickfix\FileStore.h"
#include "quickfix\fix44\CollateralInquiry.h"
#include "quickfix\fix44\CollateralInquiryAck.h"
#include "quickfix\fix44\CollateralReport.h"
#include "quickfix\fix44\ExecutionReport.h"
#include "quickfix\fix44\MarketDataRequest.h"
#include "quickfix\fix44\MarketDataRequestReject.h"
#include "quickfix\fix44\MarketDataSnapshotFullRefresh.h"
#include "quickfix\fix44\NewOrderList.h"
#include "quickfix\fix44\NewOrderSingle.h"
#include "quickfix\fix44\PositionReport.h"
#include "quickfix\fix44\RequestForPositions.h"
#include "quickfix\fix44\RequestForPositionsAck.h"
#include "quickfix\fix44\SecurityList.h"
#include "quickfix\fix44\TradingSessionStatus.h"
#include "quickfix\fix44\TradingSessionStatusRequest.h"
#include "quickfix\MessageCracker.h"
#include "quickfix\Session.h"
#include "quickfix\SessionID.h"
#include "quickfix\SessionSettings.h"
#include "quickfix\SocketInitiator.h"
using namespace std;
using namespace FIX;
class FixApplication : public MessageCracker, public Application
{
private:
SessionSettings *settings;
FileStoreFactory *store_factory;
FileLogFactory *log_factory;
SocketInitiator *initiator;
// Used as a counter for producing unique request identifiers
unsigned int requestID;
SessionID sessionID;
vector<string> list_accountID;
// Custom FXCM FIX fields
enum FXCM_FIX_FIELDS
{
FXCM_FIELD_PRODUCT_ID = 9080,
FXCM_POS_ID = 9041,
FXCM_POS_OPEN_TIME = 9042,
FXCM_ERROR_DETAILS = 9029,
FXCM_REQUEST_REJECT_REASON = 9025,
FXCM_USED_MARGIN = 9038,
FXCM_POS_CLOSE_TIME = 9044,
FXCM_MARGIN_CALL = 9045,
FXCM_ORD_TYPE = 9050,
FXCM_ORD_STATUS = 9051,
FXCM_CLOSE_PNL = 9052,
FXCM_SYM_POINT_SIZE = 9002,
FXCM_SYM_PRECISION = 9001,
FXCM_TRADING_STATUS = 9096,
FXCM_PEG_FLUCTUATE_PTS = 9061,
FXCM_NO_PARAMS = 9016,
FXCM_PARAM_NAME = 9017,
FXCM_PARAM_VALUE = 9018
};
public:
FixApplication();
// FIX Namespace. These are callbacks which indicate when the session is created,
// when we logon and logout, and when messages are exchanged
void onCreate(const SessionID& session_ID);
void onLogon(const SessionID& session_ID);
void onLogout(const SessionID& session_ID);
void toAdmin(Message& message, const SessionID& session_ID);
void toApp(Message& message, const SessionID& session_ID);
void fromAdmin(const Message& message, const SessionID& session_ID);
void fromApp(const Message& message, const SessionID& session_ID);
// Overloaded onMessage methods used in conjuction with MessageCracker class. FIX::MessageCracker
// receives a generic Message in the FIX fromApp and fromAdmin callbacks, constructs the
// message sub type and invokes the appropriate onMessage method below.
void onMessage(const FIX44::TradingSessionStatus& tss, const SessionID& session_ID);
void onMessage(const FIX44::CollateralInquiryAck& ack, const SessionID& session_ID);
void onMessage(const FIX44::CollateralReport& cr, const SessionID& session_ID);
void onMessage(const FIX44::RequestForPositionsAck& ack, const SessionID& session_ID);
void onMessage(const FIX44::PositionReport& pr, const SessionID& session_ID);
void onMessage(const FIX44::MarketDataRequestReject& mdr, const SessionID& session_ID);
void onMessage(const FIX44::MarketDataSnapshotFullRefresh& mds, const SessionID& session_ID);
void onMessage(const FIX44::ExecutionReport& er, const SessionID& session_ID);
// Starts the FIX session. Throws FIX::ConfigError exception if our configuration settings
// do not pass validation required to construct SessionSettings
void StartSession();
// Logout and end session
void EndSession();
// Sends TradingSessionStatusRequest message in order to receive as a response the
// TradingSessionStatus message
void GetTradingStatus();
// Sends the CollateralInquiry message in order to receive as a response the
// CollateralReport message.
void GetAccounts();
// Sends RequestForPositions which will return PositionReport messages if positions
// matching the requested criteria exist; otherwise, a RequestForPositionsAck will be
// sent with the acknowledgement that no positions exist. In our example, we request
// positions for all accounts under our login
void GetPositions();
// Subscribes to the EUR/USD trading security
void SubscribeMarketData();
// Unsubscribes from the EUR/USD trading security
void UnsubscribeMarketData();
// Sends a basic NewOrderSingle message to buy EUR/USD at the
// current market price
void MarketOrder();
// Generate string value used to populate the fields in each message
// which are used as a custom identifier
string NextRequestID();
// Adds string accountIDs to our vector<string> being used to
// account for the accountIDs under our login
void RecordAccount(string accountID);
};
#endif // FIXAPPLICATION_H
fix_application.cpp
#include "fix_application.h"
FixApplication::FixApplication()
{
// Initialize unsigned int requestID to 1\. We will use this as a
// counter for making request IDs
requestID = 1;
}
// Gets called when quickfix creates a new session. A session comes into and remains in existence
// for the life of the application.
void FixApplication::onCreate(const SessionID& session_ID)
{
// FIX Session created. We must now logon. QuickFIX will automatically send
// the Logon(A) message
cout << "Session -> created" << endl;
sessionID = session_ID;
}
// Notifies you when a valid logon has been established with FXCM.
void FixApplication::onLogon(const SessionID& session_ID)
{
// Session logon successful. Now we request TradingSessionStatus which is
// used to determine market status (open or closed), to get a list of securities,
// and to obtain important FXCM system parameters
cout << "Session -> logon" << endl;
GetTradingStatus();
}
// Notifies you when an FIX session is no longer online. This could happen during a normal logout
// exchange or because of a forced termination or a loss of network connection.
void FixApplication::onLogout(const SessionID& session_ID)
{
// Session logout
cout << "Session -> logout" << endl;
}
// Provides you with a peak at the administrative messages that are being sent from your FIX engine
// to FXCM.
void FixApplication::toAdmin(Message& message, const SessionID& session_ID)
{
// If the Admin message being sent to FXCM is of typle Logon (A), we want
// to set the Username and Password fields. We want to catch this message as it
// is going out.
string msg_type = message.getHeader().getField(FIELD::MsgType);
if(msg_type == "A"){
// Get both username and password from our settings file. Then set these
// respective fields
string user = settings->get().getString("Username");
string pass = settings->get().getString("Password");
message.setField(Username(user));
message.setField(Password(pass));
}
// All messages sent to FXCM must contain the TargetSubID field (both Administrative and
// Application messages). Here we set this.
string sub_ID = settings->get().getString("TargetSubID");
message.getHeader().setField(TargetSubID(sub_ID));
}
// A callback for application messages that you are being sent to a counterparty.
void FixApplication::toApp(Message& message, const SessionID& session_ID)
{
// All messages sent to FXCM must contain the TargetSubID field (both Administrative and
// Application messages). Here we set this.
string sub_ID = settings->get().getString("TargetSubID");
message.getHeader().setField(TargetSubID(sub_ID));
}
// Notifies you when an administrative message is sent from FXCM to your FIX engine.
void FixApplication::fromAdmin(const Message& message, const SessionID& session_ID)
{
// Call MessageCracker.crack method to handle the message by one of our
// overloaded onMessage methods below
crack(message, session_ID);
}
// One of the core entry points for your FIX application. Every application level request will come through here.
void FixApplication::fromApp(const Message& message, const SessionID& session_ID)
{
// Call MessageCracker.crack method to handle the message by one of our
// overloaded onMessage methods below
crack(message, session_ID);
}
// The TradingSessionStatus message is used to provide an update on the status of the market. Furthermore,
// this message contains useful system parameters as well as information about each trading security (embedded SecurityList).
// TradingSessionStatus should be requested upon successful Logon and subscribed to. The contents of the
// TradingSessionStatus message, specifically the SecurityList and system parameters, should dictate how fields
// are set when sending messages to FXCM.
void FixApplication::onMessage(const FIX44::TradingSessionStatus& tss, const SessionID& session_ID)
{
// Check TradSesStatus field to see if the trading desk is open or closed
// 2 = Open; 3 = Closed
string trad_status = tss.getField(FIELD::TradSesStatus);
cout << "TradingSessionStatus -> TradSesStatus -" << trad_status << endl;
// Within the TradingSessionStatus message is an embeded SecurityList. From SecurityList we can see
// the list of available trading securities and information relevant to each; e.g., point sizes,
// minimum and maximum order quantities by security, etc.
cout << " SecurityList via TradingSessionStatus -> " << endl;
int symbols_count = IntConvertor::convert(tss.getField(FIELD::NoRelatedSym));
for(int i = 1; i <= symbols_count; i++){
// Get the NoRelatedSym group and for each, print out the Symbol value
FIX44::SecurityList::NoRelatedSym symbols_group;
tss.getGroup(i,symbols_group);
string symbol = symbols_group.getField(FIELD::Symbol);
cout << " Symbol -> " << symbol << endl;
}
// Also within TradingSessionStatus are FXCM system parameters. This includes important information
// such as account base currency, server time zone, the time at which the trading day ends, and more.
cout << " System Parameters via TradingSessionStatus -> " << endl;
// Read field FXCMNoParam (9016) which shows us how many system parameters are
// in the message
int params_count = IntConvertor::convert(tss.getField(FXCM_NO_PARAMS)); // FXCMNoParam (9016)
for(int i = 1; i < params_count; i++){
// For each paramater, print out both the name of the paramater and the value of the
// paramater. FXCMParamName (9017) is the name of the paramater and FXCMParamValue(9018)
// is of course the paramater value
FIX::FieldMap field_map = tss.getGroupRef(i,FXCM_NO_PARAMS);
cout << " Param Name -> " << field_map.getField(FXCM_PARAM_NAME)
<< " - Param Value -> " << field_map.getField(FXCM_PARAM_VALUE) << endl;
}
// Request accounts under our login
GetAccounts();
// ** Note on Text(58) **
// You will notice that Text(58) field is always set to "Market is closed. Any trading
// functionality is not available." This field is always set to this value; therefore, do not
// use this field value to determine if the trading desk is open. As stated above, use TradSesStatus for this purpose
}
void FixApplication::onMessage(const FIX44::CollateralInquiryAck& ack, const SessionID& session_ID)
{
}
// CollateralReport is a message containing important information for each account under the login. It is returned
// as a response to CollateralInquiry. You will receive a CollateralReport for each account under your login.
// Notable fields include Account(1) which is the AccountID and CashOutstanding(901) which is the account balance
void FixApplication::onMessage(const FIX44::CollateralReport& cr, const SessionID& session_ID)
{
cout << "CollateralReport -> " << endl;
string accountID = cr.getField(FIELD::Account);
// Get account balance, which is the cash balance in the account, not including any profit
// or losses on open trades
string balance = cr.getField(FIELD::CashOutstanding);
cout << " AccountID -> " << accountID << endl;
cout << " Balance -> " << balance << endl;
// The CollateralReport NoPartyIDs group can be inspected for additional account information
// such as AccountName or HedgingStatus
FIX44::CollateralReport::NoPartyIDs group;
cr.getGroup(1,group); // CollateralReport will only have 1 NoPartyIDs group
cout << " Parties -> "<< endl;
// Get the number of NoPartySubIDs repeating groups
int number_subID = IntConvertor::convert(group.getField(FIELD::NoPartySubIDs));
// For each group, print out both the PartySubIDType and the PartySubID (the value)
for(int u = 1; u <= number_subID; u++){
FIX44::CollateralReport::NoPartyIDs::NoPartySubIDs sub_group;
group.getGroup(u,sub_group);
string sub_type = sub_group.getField(FIELD::PartySubIDType);
string sub_value = sub_group.getField(FIELD::PartySubID);
cout << " " << sub_type << " -> " << sub_value << endl;
}
// Add the accountID to our vector<string> being used to track all
// accounts under our login
RecordAccount(accountID);
}
void FixApplication::onMessage(const FIX44::RequestForPositionsAck& ack, const SessionID& session_ID)
{
string pos_reqID = ack.getField(FIELD::PosReqID);
cout << "RequestForPositionsAck -> PosReqID - " << pos_reqID << endl;
// If a PositionReport is requested and no positions exist for that request, the Text field will
// indicate that no positions mathced the requested criteria
if(ack.isSetField(FIELD::Text))
cout << "RequestForPositionsAck -> Text - " << ack.getField(FIELD::Text) << endl;
}
void FixApplication::onMessage(const FIX44::PositionReport& pr, const SessionID& session_ID)
{
// Print out important position related information such as accountID and symbol
string accountID = pr.getField(FIELD::Account);
string symbol = pr.getField(FIELD::Symbol);
string positionID = pr.getField(FXCM_POS_ID);
string pos_open_time = pr.getField(FXCM_POS_OPEN_TIME);
cout << "PositionReport -> " << endl;
cout << " Account -> " << accountID << endl;
cout << " Symbol -> " << symbol << endl;
cout << " PositionID -> " << positionID << endl;
cout << " Open Time -> " << pos_open_time << endl;
}
void FixApplication::onMessage(const FIX44::MarketDataRequestReject& mdr, const SessionID& session_ID)
{
// If MarketDataRequestReject is returned as the result of a MarketDataRequest message,
// print out the contents of the Text field but first check that it is set
cout << "MarketDataRequestReject -> " << endl;
if(mdr.isSetField(FIELD::Text)){
cout << " Text -> " << mdr.getField(FIELD::Text) << endl;
}
}
void FixApplication::onMessage(const FIX44::MarketDataSnapshotFullRefresh& mds, const SessionID& session_ID)
{
// Get symbol name of the snapshot; e.g., EUR/USD. Our example only subscribes to EUR/USD so
// this is the only possible value
string symbol = mds.getField(FIELD::Symbol);
// Declare variables for both the bid and ask prices. We will read the MarketDataSnapshotFullRefresh
// message for tthese values
double bid_price = 0;
double ask_price = 0;
// For each MDEntry in the message, inspect the NoMDEntries group for
// the presence of either the Bid or Ask (Offer) type
int entry_count = IntConvertor::convert(mds.getField(FIELD::NoMDEntries));
for(int i = 1; i < entry_count; i++){
FIX44::MarketDataSnapshotFullRefresh::NoMDEntries group;
mds.getGroup(i,group);
string entry_type = group.getField(FIELD::MDEntryType);
if(entry_type == "0"){ // Bid
bid_price = DoubleConvertor::convert(group.getField(FIELD::MDEntryPx));
}else if(entry_type == "1"){ // Ask (Offer)
ask_price = DoubleConvertor::convert(group.getField(FIELD::MDEntryPx));
}
}
cout << "MarketDataSnapshotFullRefresh -> Symbol - " << symbol
<< " Bid - " << bid_price << " Ask - " << ask_price << endl;
}
void FixApplication::onMessage(const FIX44::ExecutionReport& er, const SessionID& session_ID)
{
cout << "ExecutionReport -> " << endl;
cout << " ClOrdID -> " << er.getField(FIELD::ClOrdID) << endl;
cout << " Account -> " << er.getField(FIELD::Account) << endl;
cout << " OrderID -> " << er.getField(FIELD::OrderID) << endl;
cout << " LastQty -> " << er.getField(FIELD::LastQty) << endl;
cout << " CumQty -> " << er.getField(FIELD::CumQty) << endl;
cout << " ExecType -> " << er.getField(FIELD::ExecType) << endl;
cout << " OrdStatus -> " << er.getField(FIELD::OrdStatus) << endl;
// ** Note on order status. **
// In order to determine the status of an order, and also how much an order is filled, we must
// use the OrdStatus and CumQty fields. There are 3 possible final values for OrdStatus: Filled (2),
// Rejected (8), and Cancelled (4). When the OrdStatus field is set to one of these values, you know
// the execution is completed. At this time the CumQty (14) can be inspected to determine if and how
// much of an order was filled.
}
// Starts the FIX session. Throws FIX::ConfigError exception if our configuration settings
// do not pass validation required to construct SessionSettings
void FixApplication::StartSession()
{
try{
settings = new SessionSettings("settings.cfg");
store_factory = new FileStoreFactory(* settings);
log_factory = new FileLogFactory(* settings);
initiator = new SocketInitiator(* this, * store_factory, * settings, * log_factory/*Optional*/);
initiator->start();
}catch(ConfigError error){
cout << error.what() << endl;
}
}
// Logout and end session
void FixApplication::EndSession()
{
initiator->stop();
delete initiator;
delete settings;
delete store_factory;
delete log_factory;
}
// Sends TradingSessionStatusRequest message in order to receive as a response the
// TradingSessionStatus message
void FixApplication::GetTradingStatus()
{
// Request TradingSessionStatus message
FIX44::TradingSessionStatusRequest request;
request.setField(TradSesReqID(NextRequestID()));
request.setField(TradingSessionID("FXCM"));
request.setField(SubscriptionRequestType(SubscriptionRequestType_SNAPSHOT));
Session::sendToTarget(request, sessionID);
}
// Sends the CollateralInquiry message in order to receive as a response the
// CollateralReport message.
void FixApplication::GetAccounts()
{
// Request CollateralReport message. We will receive a CollateralReport for each
// account under our login
FIX44::CollateralInquiry request;
request.setField(CollInquiryID(NextRequestID()));
request.setField(TradingSessionID("FXCM"));
request.setField(SubscriptionRequestType(SubscriptionRequestType_SNAPSHOT));
Session::sendToTarget(request, sessionID);
}
// Sends RequestForPositions which will return PositionReport messages if positions
// matching the requested criteria exist; otherwise, a RequestForPositionsAck will be
// sent with the acknowledgement that no positions exist. In our example, we request
// positions for all accounts under our login
void FixApplication::GetPositions()
{
// Here we will get positions for each account under our login. To do this,
// we will send a RequestForPositions message that contains the accountID
// associated with our request. For each account in our list, we send
// RequestForPositions.
int total_accounts = (int)list_accountID.size();
for(int i = 0; i < total_accounts; i++){
string accountID = list_accountID.at(i);
// Set default fields
FIX44::RequestForPositions request;
request.setField(PosReqID(NextRequestID()));
request.setField(PosReqType(PosReqType_POSITIONS));
// AccountID for the request. This must be set for routing purposes. We must
// also set the Parties AccountID field in the NoPartySubIDs group
request.setField(Account(accountID));
request.setField(SubscriptionRequestType(SubscriptionRequestType_SNAPSHOT));
request.setField(AccountType(
AccountType_ACCOUNT_IS_CARRIED_ON_NON_CUSTOMER_SIDE_OF_BOOKS_AND_IS_CROSS_MARGINED));
request.setField(TransactTime());
request.setField(ClearingBusinessDate());
request.setField(TradingSessionID("FXCM"));
// Set NoPartyIDs group. These values are always as seen below
request.setField(NoPartyIDs(1));
FIX44::RequestForPositions::NoPartyIDs parties_group;
parties_group.setField(PartyID("FXCM ID"));
parties_group.setField(PartyIDSource('D'));
parties_group.setField(PartyRole(3));
parties_group.setField(NoPartySubIDs(1));
// Set NoPartySubIDs group
FIX44::RequestForPositions::NoPartyIDs::NoPartySubIDs sub_parties;
sub_parties.setField(PartySubIDType(PartySubIDType_SECURITIES_ACCOUNT_NUMBER));
// Set Parties AccountID
sub_parties.setField(PartySubID(accountID));
// Add NoPartySubIds group
parties_group.addGroup(sub_parties);
// Add NoPartyIDs group
request.addGroup(parties_group);
// Send request
Session::sendToTarget(request, sessionID);
}
}
// Subscribes to the EUR/USD trading security
void FixApplication::SubscribeMarketData()
{
// Subscribe to market data for EUR/USD
string request_ID = "EUR_USD_Request_";
FIX44::MarketDataRequest request;
request.setField(MDReqID(request_ID));
request.setField(SubscriptionRequestType(
SubscriptionRequestType_SNAPSHOT_PLUS_UPDATES));
request.setField(MarketDepth(0));
request.setField(NoRelatedSym(1));
// Add the NoRelatedSym group to the request with Symbol
// field set to EUR/USD
FIX44::MarketDataRequest::NoRelatedSym symbols_group;
symbols_group.setField(Symbol("EUR/USD"));
request.addGroup(symbols_group);
// Add the NoMDEntryTypes group to the request for each MDEntryType
// that we are subscribing to. This includes Bid, Offer, High, and Low
FIX44::MarketDataRequest::NoMDEntryTypes entry_types;
entry_types.setField(MDEntryType(MDEntryType_BID));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_OFFER));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_TRADING_SESSION_HIGH_PRICE));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_TRADING_SESSION_LOW_PRICE));
request.addGroup(entry_types);
Session::sendToTarget(request, sessionID);
}
// Unsubscribes from the EUR/USD trading security
void FixApplication::UnsubscribeMarketData()
{
// Unsubscribe from EUR/USD. Note that our request_ID is the exact same
// that was sent for our request to subscribe. This is necessary to
// unsubscribe. This request below is identical to our request to subscribe
// with the exception that SubscriptionRequestType is set to
// "SubscriptionRequestType_DISABLE_PREVIOUS_SNAPSHOT_PLUS_UPDATE_REQUEST"
string request_ID = "EUR_USD_Request_";
FIX44::MarketDataRequest request;
request.setField(MDReqID(request_ID));
request.setField(SubscriptionRequestType(
SubscriptionRequestType_DISABLE_PREVIOUS_SNAPSHOT_PLUS_UPDATE_REQUEST));
request.setField(MarketDepth(0));
request.setField(NoRelatedSym(1));
// Add the NoRelatedSym group to the request with Symbol
// field set to EUR/USD
FIX44::MarketDataRequest::NoRelatedSym symbols_group;
symbols_group.setField(Symbol("EUR/USD"));
request.addGroup(symbols_group);
// Add the NoMDEntryTypes group to the request for each MDEntryType
// that we are subscribing to. This includes Bid, Offer, High, and Low
FIX44::MarketDataRequest::NoMDEntryTypes entry_types;
entry_types.setField(MDEntryType(MDEntryType_BID));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_OFFER));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_TRADING_SESSION_HIGH_PRICE));
request.addGroup(entry_types);
entry_types.setField(MDEntryType(MDEntryType_TRADING_SESSION_LOW_PRICE));
request.addGroup(entry_types);
Session::sendToTarget(request, sessionID);
}
// Sends a basic NewOrderSingle message to buy EUR/USD at the
// current market price
void FixApplication::MarketOrder()
{
// For each account in our list, send a NewOrderSingle message
// to buy EUR/USD. What differentiates this message is the
// accountID
int total_accounts = (int)list_accountID.size();
for(int i = 0; i < total_accounts; i++){
string accountID = list_accountID.at(i);
FIX44::NewOrderSingle request;
request.setField(ClOrdID(NextRequestID()));
request.setField(Account(accountID));
request.setField(Symbol("EUR/USD"));
request.setField(TradingSessionID("FXCM"));
request.setField(TransactTime());
request.setField(OrderQty(10000));
request.setField(Side(FIX::Side_BUY));
request.setField(OrdType(OrdType_MARKET));
request.setField(TimeInForce(TimeInForce_GOODTILLCANCEL));
Session::sendToTarget(request, sessionID);
}
}
// Generate string value used to populate the fields in each message
// which are used as a custom identifier
string FixApplication::NextRequestID()
{
if(requestID == 65535)
requestID = 1;
requestID++;
string next_ID = IntConvertor::convert(requestID);
return next_ID;
}
// Adds string accountIDs to our vector<string> being used to
// account for the accountIDs under our login
void FixApplication::RecordAccount(string accountID)
{
int size = (int)list_accountID.size();
if(size == 0){
list_accountID.push_back(accountID);
}else{
for(int i = 0; i < size; i++){
if(list_accountID.at(i) == accountID)
break;
if(i == size - 1){
list_accountID.push_back(accountID);
}
}
}
}
下一步
福汇无疑是允许散户投资者进行外汇投机的领先在线交易平台之一。如果你是一名散户交易者或技术专业人士,希望开始自己的自动化交易平台,或者想了解更多关于外汇和算法交易的知识,那么从基本概念开始,如自动化交易架构、市场微观结构、策略回溯测试系统和订单管理系统。今天就开始学习 algo 交易!
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载代码
- FXCM over FIX 教程- C++代码*
期货延续:它是什么,挑战,方法和更多
通常,大多数交易活动都是在交易合同中进行的。期货延续合约是帮助期货合约延续到下个月的交易合约之一。如果你对期货延续还不熟悉,可以看一下之前关于期货交易的 。
这个博客将带你经历从基础到建立持续未来的所有事情。它包括:
什么是期货延续?
代表一系列连续到期的铅期货合约的合同,具有相关的间隔,在该间隔期间,铅期货在另一个接管之前结束。
例如,让我们看看一系列原油期货合约。使用以下合约,期货合约将如下所示:
公司 2022 年 1 月
公司 12 月
公司 11 月【202102】公司 10 月
公司 20210922
在上面的列表中,每个合同都以年/月/日的日期格式提及。例如,在合同“CO October' 20210922”中,2021 是年份,09 是九月,22 是日期。
上面的列表是一个连续合同的例子,每个合同显示了前一个合同的提前结束日期。在结束日期,前一个合同不再是主要合同,另一个合同将接管主要合同。
因此,该合约将于 2021 年 9 月 22 日到期,10 月合约将成为主力合约。那么下一个到期日是 2021 年 10 月 20 日。
接下来,合同在 2021 年 11 月 25 日到期,最后一份合同在 2022 年 1 月。这就是我们没有选择 2022 年合同最后到期日的原因。
期货延续合约的挑战
一种资产的期货合同有不同的到期日(在很短的时间内发生),这使得它们的技术分析和信号生成很困难。
例如,瘦肉型猪期货将于 10 月和 12 月到期。10 月份的瘦肉猪期货合约在到期日之后将不再存在。因此,数据将在很短的时间内可用。
这里的短时间,我们指的是大约三到六个月。计算瘦肉猪价格交叉的简单任务是 50 天移动平均线和 200 天移动平均线的交叉,这非常困难,因为我们没有太多的数据点。
但是有办法增加数据点吗?
我们需要将不同的到期期货缝合在一起,并创建一个连续的期货合约来增加数据点。
延续是通过将多个单独的序列拼接在一起而获得的时间序列。期货延续是通过拼接多个单独的期货合约获得的时间序列。
一个非常简单的解决方案是,当当月期货到期时,添加下一个到期日的数据。
例如,当 10 月瘦肉猪期货在 10 月 27 日到期时,我们可以追加 11 月瘦肉猪期货合约的数据。不幸的是,这可能导致错误的结果,因为这两个是不同的合同。
10 月 27 日的 10 月瘦肉猪期货价格将不同于 11 月瘦肉猪期货价格。通过简单地添加数据,你会在你的时间序列中引入人为的间隔。
让我们想象一下这个人为的缺口会是什么样子,因为这个缺口会让价格看起来像是在一个特定的方向上(下跌或上涨),而实际上却不是。
为了形象化,我们将使用 Python。首先,我们将导入必要的库。这里我们将阅读两份期货合约。这两份合约是 2020 年 10 月和 2020 年 12 月到期的瘦肉型猪的期货数据。
阿尔法生成-控制日内风险状况
原文:https://blog.quantinsti.com/controlling-intraday-risk-profile-10-jan-2017/
https://www.youtube.com/embed/ZUzBAHKRmiE?rel=0
网上研讨会日期和时间
2017 年 1 月 10 日星期二
上午 8:30 是|上午 9:00 在科技委
阿尔法生成
基于低频价格(如日末报价)的资产回报仍主导着现代投资组合分析。为了使投资组合指标在当天更相关,并提高估计的精确度,需要探索新的数据频率。
在本次演讲中,我们展示了如何使用高频市场数据进行投资组合风险管理和优化,从而改善传统的方差偏差权衡,并为策略回溯测试带来新的见解。
由于高频价格需要特殊处理,我们讨论微观结构噪声、价格跳跃、异常值、厚尾和长期记忆的自动模型管道的关键组成部分。
我们以基于日内投资组合指标的高频投资组合优化的介绍来结束我们的演讲。例子将在 Python 中显示。
斯蒂芬妮·托珀

- PortfolioEffect 投资组合分析总监
Stephanie 在 Karya Capital、UBS 和 Societe Generale 担任了 8 年的定量开发人员,并且是 MF Global 的高级风险分析师。她在利率衍生品和量化库开发方面拥有丰富的经验。
她拥有哥伦比亚大学的金融数学硕士学位和法国 ENSIMAG 大学的应用数学和计算机科学硕士学位。
谁应该参加?
对于那些需要任何频率的日内风险指标、投资组合优化、投资组合回溯测试和指标预测的人来说,本次网络研讨会非常有益。示例将在 Python 中显示。该会议非常适合:
- 研究人员
- 定量分析师
- 股票、交易所交易基金和指数交易员
- 那些寻找回溯测试策略的人
- 对金融市场感兴趣的 Python 程序员
关于 组合效应
PortfolioEffect 服务通过 4 个 API 提供投资组合优化、投资组合回溯测试、指标预测和日内风险指标:Python、R、Matlab 和 Java。我们服务的独特之处在于,所有的计算都是使用高频市场数据完成的,这有利于低频和高频交易者。我们涵盖 8000 多种美国股票(股票、指数、交易所交易基金)。客户也可以上传他们自己的市场数据。PortfolioEffect 服务采用高频市场微观结构理论的最新进展,以分笔成交点级别的分辨率提供经典的投资组合风险和优化结果。它使用自动模型管道以流式方式处理高频价格回报。
什么是校正人工智能以及它如何改善您的投资决策[研讨会]
原文:https://blog.quantinsti.com/corrective-ai-improve-investment-decisions-20-september-2022/
https://www.youtube.com/embed/nAOjbL5bsjA?rel=0
欧内斯特·陈博士向您介绍了人工智能的概念及其在金融市场中的应用。
扬声器
陈博士(创始人& CEO,PredictNow.ai Inc)

陈博士是 PredictNow.ai Inc .的创始人兼首席执行官,也是 QTS 资本管理有限公司的管理成员。自 1997 年以来,他曾在多家投资银行(摩根士丹利、瑞士瑞信银行、Maple)和对冲基金(Mapleridge、Millennium Partners、MANE)工作。
陈博士从康奈尔大学获得物理学博士学位,在加入金融业之前,他是 IBM 人类语言技术小组的成员。他是总部位于芝加哥的投资公司 EXP Capital Management,LLC 的联合创始人和负责人。
陈博士还是《量化交易:如何建立自己的算法交易业务》(Wiley)、《算法交易:制胜策略及其基本原理》(T2)(T3)的作者,他的第三本书也是最新的一本书是《机器交易:部署计算机算法征服市场》(T4)(T5)。
关于 Algo 交易大会 2022
QuantInsti 举办的 2022 年算法交易大会对有抱负的算法交易者来说是一个很好的学习机会。这是您联系您最喜爱的专家并免费获得所有问题答案的机会。
该活动于美国东部时间 2022 年 9 月 20 日上午 11:45(IST 时间晚上 9:15)举行。
协方差和相关性:简介、公式、计算等等
何塞·卡洛斯·冈萨雷斯·田中
让我们多了解你一点。你认为你需要在拳击场上看一场“协方差 vs 相关性”的比赛,这样你才能在它们之间做出正确的选择吗?
- 你是金融市场的初学者吗,想知道基本概念以便开始交易吗?
- 你知道原油是如何与美元、欧元或日元一起波动的吗?
- 你知道当世界陷入衰退时,黄金价格和利率是如何变化的吗?
无论你在行业中的地位如何,或者你有什么疑问,这篇简单易懂的文章将带你了解这两个概念:从定义和公式到交易应用,你也将准备好正确分析重要金融变量之间的关系。
所以,坐在舒适的座位上,喝杯咖啡,享受这种学习体验吧!
- 什么是协方差?
- 什么是相关性?
- 协方差和相关有什么区别?
- 如何计算协方差和相关性?
- 协方差和相关性的重要性
- 协方差和相关性的交易应用
- 协方差和相关性简单练习例题
- Python 中的协方差和相关性计算示例
什么是协方差?
协方差是一种统计测量,其定义如下:它测量两个变量之间线性关联的方向。
有了这个解释,你就开始想象我们是你的老师,你举手说:“老师,我不明白。
别担心!让我们简化一下:它测量两个变量之间的同步方向。换句话说,你有两个变量的数据,协方差衡量这两个变量是同向还是反向移动。
我们说正协方差,如果两个变量同向变动:如果一个股票价格上涨,那么另一个股票价格也会上涨。我们说负协方差,当一个股票价格上涨,另一个股票价格向相反的方向,意思是,下跌。
关于“线性联想”这几个字,后面你就明白重点了。所以,是的,协方差可以是正的,也可以是负的。
假设我们有四种股票价格的数据:
- 亚马逊,
- 苹果,
- 沃尔玛,还有
- 微软。
在顶部,你可以看到一个正的协方差图:当亚马逊的股价上涨时,苹果的股价也朝着同样的正方向上涨。在底部,你可以看到,当微软向下移动时,沃尔玛则相反,向上移动,这意味着它们之间存在负协方差。


问题: 如果变量 A 和 B 有一个正的协方差,那么我们是否应该解释为每当变量 A 的值变高时,B 也“总是”变高?”
不总是。这种直接或反向的同步也可能是强的或弱的。如果正负协方差的绝对值很大,那么我们说同步性很强,如果很小,我们说同步性很弱。
什么是强同步或弱同步?
我们能说的是,一个大的正协方差,或者说一个强的正同步性,意味着,大多数时候,两个变量会朝着同一个正方向运动。
负协方差也是如此:如果我们有两个变量的大的负协方差值,就绝对值而言,这意味着我们期望看到,大多数时候,两个变量的运动方向相反。
现在有了更清晰的定义,你有了一个推论和两个问题来测试你的知识:
- 协方差衡量的是两个变量之间的强关系还是弱关系?
- 两个变量之间能有完美的正向或反向同步吗?
对于这些问题,让我们带你去我们的另一个重要概念叫做相关性。
什么是相关性?
你可能会停下来,喝一口咖啡,然后对自己说:“【to】哦,这里有另一个定义,它包含了大量的信息!
嘿!完全不用担心!实际上,相关性也有类似的定义。先正式放一放。相关性衡量两个变量之间的线性关联程度。
我们知道,你很惊讶,又问:“我们还有‘线性联想’这几个字吗?
嘿!别急,我们以后再谈这个。现在,我们可以说:当协方差度量同步运动的方向时,相关性不仅度量同步运动的方向,还度量这种关系方向的程度,或“强度”。
我们稍后会看到这种“力量”是什么样子的。现在,让我们在下面表达这两个概念之间的区别:
协方差和相关有什么区别?
| 协方差 | 相关性 |
| 衡量一件事 | 衡量两件事 |
| 无限范围 | 有限范围 |
| 它有测量单位 | 无测量单位 |
| 可扩展值 | 不可伸缩值 |
区别#1:协方差衡量一件事,而相关性衡量两件事。
如上所述,协方差只测量两个变量的同步运动的方向。相关性不仅衡量关系的方向,还衡量这种关系的强度。
那么,亚马逊和苹果的股价同向或反向移动的效果如何呢?
你现在有两个技术工具来回答这个问题:
- 要找出两个变量是同向还是反向运动,可以使用协方差函数或相关函数。
- 关于这种正向或反向关系“有多好”,你需要用后者来回答这个问题。
区别#2:协方差和相关值范围不同。
协方差可以有一个无穷大的正值或无穷大的负值,取值范围是整个实数范围。然而,相关值范围仅在-1 和+1 之间。
所以你关于完美同步的问题可以在这里得到回答:因为协方差可以有任何实值,我们不能用这个统计量来评价两个变量之间完美的线性关联。
处理这个问题的最好方法是相关性。如果变量 A 和 B 的相关值为+1,你可以毫无疑问地说两个变量“总是”朝同一个方向运动。值为-1 的相关性也是如此:你可以毫无疑问地说,两个变量“总是”向相反的方向移动。
在这里你可以理解第一个区别。当相关性在-1 和 1 之间时,同步分别不是完全负的或正的。最后但并非最不重要的是,关于这种差异,我们必须说,几乎不可能看到现实世界中的变量具有恰好等于+1 或-1 的相关性。
区别#3:协方差和相关性有不同的度量单位。
你以后会从数学上理解它。现在,我们可以说协方差的度量单位是两个变量度量单位的乘积。
例如,如果你有亚马逊和苹果的两种股票价格,它们都以美元为度量单位,那么协方差的度量单位就是:美元乘以美元,也就是美元的平方。
然而,相关性根本没有任何度量单位。还不赶紧着急!啜饮你的咖啡,再等一会儿,就能完全理解这一点。
差异#4:如果变量的比例不同,协方差的值可能会改变,相关性不受此影响。
让我们举个例子来理解这种区别。你有两个股票价格,亚马逊和苹果,然后你计算它们的协方差和相关性,结果分别是“a”和“b”。
接下来,您决定将两个股票价格乘以 1000,并再次计算它们的协方差和相关性,结果得到值“c”和“d”。你会发现一件有趣的事情:
- 协方差“a”不同于协方差“c ”,
- 相关性“b”等于相关性“d”。
当您缩放一个或两个变量时,协方差的值会相应地改变。然而,相关性不受标度变化的影响。
如何计算协方差和相关性?
到目前为止,我们已经向你们解释了所有关于它们的概念和性质。但是从现在开始,你会对数学公式有更好的掌握。
首先,你必须区分什么是总体和样本数据。一旦您熟悉了这两个概念,让我们从公式的演示开始:
我们从协方差开始。
人口协方差:
你明白了吗?方差和协方差公式实际上是相同的;不同之处在于第二个括号,它由第二个变量的偏差代替。方差指的是单个变量,协方差指的是两个变量,这就是为什么它被称为“协”方差。
样本协方差与总体方差相同,但我们用被除数除以 N-1,而不是 N。这种差异的解释可以在本博客的“样本数据的标准偏差——贝塞尔的修正”部分找到。
如你所料,X 用 X 单位表示,Y 用 Y 单位表示。因为协方差公式是这两个变量的乘积,所以它将采用 XY 测量单位。
现在让我们来看看相关公式:
( \rho_{X,Y} = \frac{\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{\sqrt{\biggl(\sum_{i=1}\Bigl(X_{i}-\overline{X}\Bigr)2\biggr)\biggl(\sum_{i=1}\Bigl(Y_{i}-\overline{Y}\Bigr)^2\biggr)}} = \frac{\sum_{i=1}{N}\Bigl(X_{i}-\overline{X}\Bigr)\Bigl(Y_{i}-\overline{Y}\Bigr)}{\sqrt{\biggl(\sum_{i=1}\Bigl(X_{i}-\overline{X}\Bigr)2\biggr)}\sqrt{\biggl(\sum_{i=1}\Bigl(Y_{i}-\overline{Y}\Bigr)^2\biggr)}})$$ \rho_{X,Y} = \frac{Cov(X,Y)}{\sigma_X:\sigma_Y} $$Where:
( \rho_{X,Y} ): Correlation between variables (X) and (Y).
(Cov(X,Y)): Covariance between (X) and (Y).
(\sigma_X): Standard Deviation of variable (X).
(\sigma_Y): Standard Deviation of variable (Y).
那么,我们如何用简单的语言解释这个公式呢?你已经知道了被除数,关于除数,如果你能记住方差公式,你就能知道除数是两个变量 X 和 y 的标准差的乘积。
所以我们可以说相关性是协方差除以两个变量的标准差。你可能会认为协方差和标准差有除数“N”或“N-1”,所以你可能会认为我们写错了第一个公式。
别担心,让我们让你看看约数发生了什么:
( \rho_{X,y } =∞)
( \rho_{X,y } =∞)
( \rho_{X,y } = \frac{\sum_{i=1}{n}\bigl(x_{i}-\overline{x}\bigr)\bigl(y_{i}-\overline{y}\bigr)}{\sqrt{\biggl(\sum_{i=1}\bigl(x_{i}-\overline{x}\bigr)2\biggr)}\sqrt{\biggl(\sum_{i=1}\bigl(y_{i}-\overline{y}\bigr)^2\biggr)}} )
现在你明白了吗?协方差和标准偏差的除数相互抵消。此外,如前所述,被除数的度量单位是 X 和 y 两个度量单位的乘积。除数的度量单位也是 X 和 y 两个标准差的乘积。
因此,由于被除数和除数具有相同的 XY 测量单位,所以它们相互抵消,从而得到没有测量单位的相关值。现在你能理解之前解释的区别了吧?
此外,你现在可以理解区别#4 了。为什么?因为协方差以 XY 测量单位结束,所以无论何时改变两个变量中任何一个的比例,除数的测量单位也会随之改变。
同时,由于相关公式没有度量单位,所以您可以对这两个变量中的任何一个进行的标度更改都不会影响-1 和 1 之间的相关范围。
我们已经了解了所有这些解释,现在你可能会问:
协方差和相关性的重要性
好吧,你现在问这个重要的问题。答案在于经济学和金融学的本质。作为经济学的一个重要组成部分,金融是关于市场的,在这个市场中,经济主体从一个或多个市场中买卖资产。
在市场内部或市场之间,由于每天都有相同的代理人进行交易,资产可以与任何其他资产以相同或相反的方向移动。
资产价格根据代理人的行为、市场条件等而变化。如果有一个人买了 100 股苹果股票,或者有一群人因为银行挤兑而卖出他们的银行股票,那么每个人的交易不仅会对资产本身产生影响,还会对其他股票或其他市场产生影响。
市场是相互关联的,因此相关性和协方差是金融市场研究的重要组成部分。如果市场或金融资产不是相互关联的,我们就不需要考虑协同运动。
你现在不仅知道这两个概念的含义,而且知道它们为什么重要。我们达到了我们的主要目的。
所以,现在,你想交易,对吗?
你已经准备好检查苹果和亚马逊股票价格的相关性,现在你准备好按下你的经纪人平台上的买入和卖出按钮开始投资。你不是吗?
不要!等一下!在你做决定之前,让我们向你解释一下协方差和相关性在交易和投资中的实际应用。
协方差和相关性的交易应用
交易应用#1:投资组合波动性计算
当你开始投资多只股票时,你必须考虑你的投资组合的波动表现如何。只有当你完全理解了协方差和相关性是如何工作的,才可能计算出这个投资组合的波动性。
所以,请不要按购买键。你可以在 Quantra 上查看我们的投资组合管理课程,了解更多。再等一会儿,让我们向你解释更多。
交易应用#2:统计套利
每当你进入统计套利,你必须理解相关性和协整的定义。统计套利不利用相关性,但是理解这两个概念之间的区别非常重要。
我们关于统计套利交易的课程会解释这一切。我们可以猜测,你现在想要开始按下买入和卖出按钮进行套利,对吗?我们告诉过你,再等等!
交易应用#3:回归估计中的相关变量
在两个或多个变量之间进行回归的主要条件之一是拥有不相关的独立变量。所以,既然你已经知道了相关性的含义,现在你就能够在回归估计中出现违反这一条件的情况下纠正问题。你可以通过这门关于用机器学习进行交易:回归的课程来扩展你关于这个话题的知识。
交易应用#4:预测资产价格的相关性
你看,金融资产价格,与受控物理实验中的变量相反,往往会随着时间的推移而经历状态变化。因此,如果你使用 2021 年的数据计算美国 2 年期国债收益率与联邦基金利率的相关性,那么 2022 年的这个值不一定是相同的。
随着时间的推移,相关性可能会有很大变化,这通常发生在不利的经济冲击或经济或金融危机中。使用相关性来预测你的下一个交易信号时要小心!
交易应用#5:预测资产价格回报的 ARMA 模型
那么,你听说过自回归移动平均(ARMA)模型吗?该模型试图用通过回归模型计算的过去收益估计值来预测资产价格收益,其中回归误差的移动平均值也很重要。
在这里你会了解到什么是自协方差和自相关函数。所以为了理解这两个概念,你必须先理解这篇文章的两个概念。
自相关函数是什么样的?
请记住,相关函数是基于两个变量计算的,也请记住,ARMA 模型试图用以前的收益来预测资产价格收益。因此,如果你说这些回报可以称为 rt,那么,自相关函数可以表示为:
你想知道更多吗?在 Quantra 中获取关于时间序列分析的精彩课程。
交易应用#6:因果关系和相关性不是一回事
这是更多的交易知识,所以要注意这一点。因果关系意味着苹果股价的变动会导致亚马逊股价的变动。但是,我们这里所说的“原因”是什么意思呢?嗯,因果关系甚至在经济学中被哲学地讨论。哲学讨论到现在还没有结束。让我给你举个例子,这样你能更好地理解它。
想象一下,我们有纽约市每月的雨水量,也有纽约市每月的 GDP。你计算它们之间的相关性,得到的值是 0.95。
你可以说:“哦,真有趣!那么,我可以说,每当这个城市下大雨时,这将导致纽约的 GDP 增加。”没有!你不能说大量的雨水‘导致’了 GDP 的增长;或者相反,GDP 的增长会导致城市雨水的增加。
相关性只是意味着你可以找到这两个变量之间的同步模式,但这并不意味着雨水和 GDP 之间存在经济因果关系。
所以,当你作为交易者谈论相关性时,你必须记住这个概念不一定等同于因果关系。换句话说:
因果关系总是意味着相关,但相关并不总是意味着因果关系。
交易应用#7:相关性程式化事实
这也是融入你的背景知识的重要信息。当你想交易一些金融资产时,考虑一些全球相关性是很重要的。
在这里,我们向您呈现一些程式化的事实,当您想用这些资产进行交易时,请记住这些事实:
- 原油和货币:每当原油价格下跌,俄罗斯、加拿大、委内瑞拉或沙特阿拉伯等原油净出口国的货币就会下跌。然而,每当原油价格下跌时,像日本这样的原油净进口国往往会看到自己的货币升值。
- 逃向优质资产:每当世界某个重要国家或地区发生金融动荡时,比如 1997 年亚洲金融危机,投资者往往会将资金撤出这些高收益国家,购买美国国债。这一行动使得受影响国家的货币对美元大幅贬值,美国国债往往会大幅升值。因此,在亚洲危机中,亚洲国家的货币与美国债券价格之间存在负相关关系。
- 股票-债券负相关关系:例如,每当美国经济开始繁荣时,投资者就会重新配置他们的投资组合。他们大量投资风险更高的资产,减少对美国国债的投资。当经济进入衰退时,情况正好相反,固定收益投资增加,股票投资减少。股票和债券之间的这种负相关关系是世界各国的共同特征。
- 黄金时变相关性:当世界投资者更倾向于投资风险资产时,黄金与美国股市的正相关性增加。当他们变得更加厌恶风险时,由于全球经济衰退,黄金与美国股市成反比。
- 黄金和通货膨胀:当全球通货膨胀上升时,投资者倾向于增加黄金的投资组合配置,这意味着黄金和通货膨胀之间的相关性是正的。黄金具有对冲通货膨胀的作用。当通货膨胀超过预期时,贵金属会维持你的购买力。
- 黄金和美国利率:当美国看到其利率上升时,这意味着经济状况良好。这使得全球投资者将他们的资源分配给风险更高的资产。因此,黄金在这个时期开始贬值。我们可以说黄金和美国利率一直是负相关的。
- 地缘政治与黄金:每当出现影响全球的不利地缘政治冲击时,金价往往会上涨,因为这种贵金属充当了“避风港”的角色。
- 收益-波动率相关性:当股价下跌时,公司的负债权益比率会增加,进而使其股价收益波动率增加。股票价格收益与其波动性之间的这种负相关关系被称为“杠杆效应”。当你交易股票并想要模拟波动性时,你应该考虑这种对你的估计的影响,以便捕捉负相关。
协方差和相关性简单练习题
如何计算协方差?
你现在准备好了,对吗?好了,先说一个简单的例子。假设我们有两个资产价格,微软和特斯拉,我们有每只股票 5 天的数据。
下面我们将数据以表格的形式呈现如下:
| 日期\库存 | 微软 | 特斯拉 |
| 第一天 | Two hundred and forty | Eight hundred and fifty |
| 第二天 | Two hundred and sixty-five | eight hundred |
| 第三天 | Two hundred and fifty-five | Eight hundred and twenty |
| 第四天 | Two hundred and eighty | Eight hundred and seventy |
| 第五天 | Three hundred and one | Nine hundred |
由于我们有样本而不是总体数据,我们将使用样本协方差和相关函数。首先,我们知道我们有 5 个观测值,这就是为什么我们的 N 变量是 5。
然后,我们必须计算每只股票的平均值。我们会帮你的,这两个平均值分别是:微软 268.2,特斯拉 848。接下来,我们必须计算每个观察值与平均值的偏差,必须对每个股票进行计算:
| 日期\库存 | 微软 | 特斯拉 | 微软偏离平均值 | 特斯拉偏离平均值 |
| 第一天 | Two hundred and forty | Eight hundred and fifty | -28.2 | Two |
| 第二天 | Two hundred and sixty-five | eight hundred | -3.2 | -48 |
| 第三天 | Two hundred and fifty-five | Eight hundred and twenty | -13.2 | -28 |
| 第四天 | Two hundred and eighty | Eight hundred and seventy | Eleven point eight | Twenty-two |
| 第五天 | Three hundred and one | Nine hundred | Thirty-two point eight | fifty-two |
完成后,您可以将每个日期的两个偏差相乘,然后将所有乘法结果相加,得到协方差公式的被除数:
| 微软对平均值的偏离 | 特斯拉偏离均值 | 两个偏差的乘积 |
| -28.2 | Two | -56.2 |
| -3.2 | -48 | One hundred and fifty-three point six |
| -13.2 | -28 | Three hundred and sixty-nine point six |
| Eleven point eight | Twenty-two | Two hundred and fifty-nine point six |
| Thirty-two point eight | fifty-two | One thousand seven hundred and five point six |
| | 协方差红利 | Two thousand four hundred and thirty-two |
计算协方差缺少什么?
你差不多完成了。你有了被除数,却没有除数。除数就是观察总数减一。所以让我们用(N - 1)除协方差被除数:
( Cov(Microsoft,Tesla) = \frac{2432}{5-1} = \frac{2432}{4} )
( Cov(Microsoft,Tesla) = 608 )
还记得定义吗?协方差衡量的是微软和特斯拉之间的同步运动的方向。那么从这个值中我们可以得到什么样的解读呢?我们可以说,因为 608 是一个正数,我们得出结论,这两个股票价格之间存在正的同步性。
现在你问我,微软和特斯拉之间的这种同步有多“强”?这可以用相关系数来回答。
相关系数怎么算?
一旦我们有了协方差值,你可以从上面记住,我们只需要微软和特斯拉的标准差。我们会用这些价值观来帮助你。微软和特斯拉的标准差分别为 23.42 和 39.62。所以应用这个公式,我们得到:
( Cov(Microsoft,Tesla) = \frac{2432}{23.42*39.62} = \frac{2432}{928.15} )
( Cov(Microsoft,Tesla) = 0.66 )
如果我们选择 0.5 作为阈值来决定相关值是接近 1 还是接近 0,这取决于研究人员,因为 0.66 大于 0.5,我们可以说微软和特斯拉之间的同步是积极的,也是强有力的。
在相关性定义中,我们所说的“线性关联度”是什么意思?
之前,我们向你解释过,相关性衡量两个变量之间的线性关联程度。这个解释是统计学教科书中的正式定义。
你怎么能以一种简单的理解来面对这种解释?
现在就这么办。
我们知道相关性的取值范围在-1 到+1 之间。也可能是零,对吧?让我们将这两种极端情况和一种接近于零的情况绘制成散点图:



如您所见,当相关性完全为+1 或-1 时,散点图本身就像一条线。这意味着变量 A 和 B 都有线性关系或线性关联。
如果相关性接近 1,你可以说,如果你画一条贯穿这些值的线,你会得到这条斜率为正的线。如果相关性接近-1,并且如果您绘制一条贯穿这些值的直线,您将得到一条斜率为负的直线。随着该值从 1 减小到 0,这种线性关联变得不太明显,同样,该值从-1 增大到 0。
相关性等于零或非常接近零意味着两个变量之间完全没有相关性,您还会看到这个相关值几乎是一个随机散点图。
使用我们上面的相关性定义,正相关性的强度可以理解为公式值从零趋向于+1。负相关的强度可以理解为从零到-1 的公式值。
让我们用图表来看看弱相关性或强相关性是如何表现的:


你已经看到了完全负相关的样子。现在你可以从上面的图表中看到强相关和弱相关可能是什么样子。上图显示负相关为-0.83,下图显示相关等于-0.25。
正如你所看到的,当值接近-1 时,你可以说这种负相关性很强。但是当相关性趋近于零时,在图形中看不清楚线性关联,我们也说这种负相关性弱。


接下来,让我们看看正相关的例子。上图显示了 0.84 的正相关性,下图显示了等于 0.29 的相关性。正如你所看到的,当值接近 1 时,你可以说这种正相关性很强。
但是当相关性趋近于零时,在图形中看不清楚线性关联,我们也说这种正相关性弱。
我们在上面的图表中展示了零相关的情况。现在,你可能会问我们,难道没有其他形式的不相关吗?
让我们看看另一张图表:

正如你所看到的,X 和 Y 之间的相关性为零,它同时具有正负线性关联。因此,有两种类型的相关等于零的图形:
- 随机散点图,以及
- 非线性散点图。
什么是好的协方差和相关值?
看到上一张图或者之前的图,你可能会问自己这个问题。你一定知道答案,所以我们在这里解释一下。实际上,对于所有情况下的协方差和相关函数,没有“好的”或“完美的”值。
例如,对于投资组合管理,股票协方差为负是一个很好的值,因此你可以在资产之间进行更好的分散。对于回归估计中的独立变量,您认为它们的相关性接近零是一个好值。
对于 ARMA 模型,您会希望自相关函数不为零,以确认模型的构建适合股票价格回报。
正如你所看到的,我们的协方差或相关性公式的好值取决于你在寻找什么:它取决于交易者或研究人员,也取决于你谈论的话题。
Python 中的协方差和相关性计算示例
现在让我们利用真实世界的数据来计算我们的主要编程语言 Python 中的这两个重要概念:
Python 中如何计算协方差和相关性
让我们下载微软和特斯拉的股价,用它们来进行计算:
我们首先建立环境来完成工作。如果你没有“yfinance”库,不要忘记安装它:
使用机器学习的覆盖呼叫策略
原文:https://blog.quantinsti.com/covered-call-strategy-machine-learning/
投资者利用备兑买入期权在持有股票的同时赚取一些小利润。交易员想要创建备兑买入期权的主要原因是,交易员看好标的股票,并希望长期持有,但该股票不支付任何股息。该股预计将在未来 6 个月内上涨,与此同时,你可能希望将该股作为抵押品,卖出一些看涨期权,将溢价收入囊中。但这种策略有风险,即如果股票上涨,那么你的股票将在到期时被赎回。因此,你可以以较低的溢价买回期权,而不是等待期权到期。
利用机器学习进行交易的方法有很多种。在这篇博客中,我将尝试向你展示如何通过使用简单的决策树算法来预测期权溢价的短期变动,并在持有股票的同时赚取差价。
有关不同期权交易策略的更多详情,请访问 https://quantra.quantinsti.com/
让我给你看一个例子,用漂亮的期货。Nifty50 是一个印度指数,由来自不同行业的 50 只股票组成。
为了执行上面讨论的策略,我们假设我们持有期货合同,然后我们试图在相同的基础上卖出一个看涨期权。为了做到这一点,我们在由各种希腊文组成的过去数据上训练一个机器学习算法,比如选项的 IV、delta、gamma、vega、theta 作为输入。因变量或预测将在第二天的收益中进行。每当算法产生卖出信号时,我们就写调用。首先,让我们导入必要的库。
导入库
创建交易策略:实践在线研讨会
原文:https://blog.quantinsti.com/create-a-trading-strategy-hands-on-online-workshop/
以下是我们研讨会的摘要:
https://www.youtube.com/embed/B23sVOkzEjY?rel=0
2020 年 3 月 11 日星期三晚上 8:00-9:00 IST
概述
在这个实践研讨会中,学习创建和测试可用于交易外汇、股票、期权、商品、加密货币和其他工具的交易策略。除了实践培训,我们还将为您提供工具和知识,帮助您将这些知识应用到自己的交易经验中。
它将包括什么?
- 如何想出一个交易策略的点子?
- 如何使用数据分析来验证想法?
- 如何创建回测的交易系统?
- 如何分析结果?
- 如何为自己的交易做到这一点?
- 向专家提问
演讲者简介
伊山·沙阿(AVP,内容&在昆汀斯提研究)

伊桑·沙阿是 AVP,领导 QuantInsti 公司 Quantra 的内容和研究团队。在此之前,他曾在巴克莱全球市场团队和美国银行 Merill Lynch 工作。他在金融市场拥有丰富的经验,在不同的资产类别中担任不同的角色。
https://www.slideshare.net/slideshow/embed_code/key/72Qwt0tUgEN5xx
Create a Trading Strategy: Hands-on Online Workshop from QuantInsti
如何从头开始创建交易算法[网上研讨会]
原文:https://blog.quantinsti.com/create-trading-algorithm-webinar-22-july-2021/
网络研讨会录制
https://www.youtube.com/embed/tL5hpLIG3eo?rel=0
演示幻灯片
//www.slideshare.net/slideshow/embed_code/key/xfG2zGwjjPTJsW
How To Create A Trading Algorithm From Scratch from QuantInsti
关于会议
学习从零开始创建一个交易算法,并用真实的市场数据进行测试。了解创建交易算法的所有基本要素。本节将举例解释各种交易策略范例,如动量交易和均值回归。
会话大纲
- 一系列策略
- 基于动量的策略 vs 基于均值回复的策略
- 交易算法的组成部分
- 基于动量算法的一个例子
- 基于均值回复算法的一个例子
- 回溯测试和前瞻测试的重要性
- 互动问答
关于演讲者

Ashutosh Dave(高级助理,内容&在 QuantInsti 的研究)
Ashutosh 在金融衍生品交易和量化金融领域拥有十多年的经验。除了对 QuantInsti 的整体内容开发做出贡献之外,他还在我们的旗舰项目 EPAT 教授 Python。
在加入 QuantInsti 之前,他曾在伦敦的一家自营交易公司担任衍生品交易员,专门从事利率和大宗商品交易。他的主要兴趣领域包括将高级数据科学和机器学习技术应用于金融数据。
Ashutosh 拥有伦敦经济学院(LSE)的统计学硕士学位,并且是 GARP 的 FRM。他是《算法交易简易指南》(QuantInsti,2020)一书的合著者。
本次活动于: 2021 年 7 月 22 日星期四
美国东部时间上午 9:30 | IST 时间晚上 7:00 |新加坡时间晚上 9:30
对于那些正在寻找综合算法交易课程的人来说,QuantInsti 的 EPAT 课程是最好的选择。EPAT 提供业内最好的课程设置,在线课程由业内知名人士授课。您将获得专门的支持经理来解决您的所有疑问。完成认证课程后,你有资格获得终身职业援助。想知道更多关于 EPAT 的细节,今天就联系课程顾问吧。
使用 Python Seaborn 创建热图
原文:https://blog.quantinsti.com/creating-heatmap-using-python-seaborn/
在这篇博客中,我们将学习使用 Seaborn Python 包来创建热图,交易者可以用它来跟踪市场。
我们的博客路线图是:
- 面向 Python 数据可视化的 Seaborn】
- 什么是热图?
- 金融领域热图的使用案例
- 创建热图的逐步 Python 代码
-显示股票单日价格变化百分比-显示股票价格变化之间的相关性 - 用于绘制热图的其他 Python 库
在我们之前的博客中,我们讨论了使用散景的 Python 中的数据可视化。现在我们把目光转向 Python 中另一个很酷的数据可视化包。
用于 Python 数据可视化的 Seaborn
Seaborn 是基于 Matplotlib 的数据可视化库。它为绘制有吸引力的统计图提供了一个高级接口。
Seaborn 构建在 Matplotlib 之上,其图形可以使用 Matplotlib 工具进一步调整,并使用任何 Matplotlib 后端进行渲染,以生成出版物质量的图形。
可以使用 Seaborn 创建的地块类型包括:
- 分布图
- 回归图
- 分类图
- 矩阵图
- 时间序列图
- 热图
绘图函数对包含整个数据集的 Python 数据框和数组进行操作,并在内部执行必要的聚合和统计模型拟合以生成信息图。一些例子可以在这里找到。

Source: Seaborn.pydata.org
什么是热图?
热图是数据的二维图形表示,矩阵中包含的各个值用颜色表示。
Seaborn 包允许创建带注释的热图,可以根据创建者的要求使用 Matplotlib 工具进行调整。

Annotated Heatmap: Source
金融业热图的使用案例
如前所述,热图是变量的矩阵表示,根据值的强度进行着色。因此,它为比较各种实体提供了一个极好的可视化工具。
它易于创建和定制,解释起来也很直观。因此,在处理金融中的多种资产时,它被广泛使用。
热图提供强大可视化功能的一些重要使用案例包括:
- 比较价格变化、回报等。各种资产
- 检查多只股票之间的相关性
由于热图为我们提供了一种简单的工具来理解两个实体之间的相关性,因此它们可以用于可视化机器学习模型的特征之间的相关性。这可以通过消除高度相关的特征来帮助特征选择。
创建热图的分步 Python 代码
现在让我们看看其中的几个用例,看看我们如何为它们创建 Python 代码。
显示股票单日价格变化百分比
我们将为在印度国家证券交易所(NSE)上市的 30 家制药公司的股票创建一个 Seaborn 热图。Seaborn 热图将显示股票代码及其单日价格变化百分比。
我们整理了医药股所需的市场数据,并构建了一个逗号分隔值(CSV)文件,该文件由股票代码及其在 CSV 文件前两列中各自的价格变化百分比组成。
由于我们的列表中有 30 家制药公司,我们将创建一个 6 行 5 列的热图矩阵。此外,我们希望 Seaborn 热图以降序显示股票的价格变化百分比。
为此,我们在 CSV 文件中按降序排列股票,并添加两列来表示热图中每只股票在 X & Y 轴上的位置。
步骤 1 -导入所需的 Python 包
我们导入以下 Python 包:
财务中的交叉验证:清除、禁运、组合
原文:https://blog.quantinsti.com/cross-validation-embargo-purging-combinatorial/
亚历克斯·里贝罗·卡斯特罗
交叉验证(CV)并不是一个新颖的话题,但是根据我作为数据科学家和前台从业者的经验,它是一个经常被低估和误用的统计工具。我相信,如果用适当的统计方法来处理,无数糟糕的交易想法本可以被抛弃。因此,这篇博客既是一个警示故事,也是对金融领域现代 CV 方法的快速参考。
我们将讨论以下主题:
机器学习中的交叉验证之前已经讨论过了,我想在这里把重点放在作为回溯测试工具的交叉验证上。我还会提到金融领域交叉验证(CV)的一些陷阱,特别是在数据泄露和数据偷窥方面。
概括地说,CV 是一个重采样工具,旨在分配精确度的测量值(例如:偏差、方差、置信区间、预测误差等)。)到样本估计(例如:模型性能、夏普值等)。CV 是统计学中的一个老概念,随着现代计算机和机器学习的出现,它的时代似乎又回来了。
在金融领域,CV 在处理高噪声对信号的影响,以及减轻策略过度拟合导致的虚假结果方面变得尤为重要。我还应该说,CV 不仅仅限于 ML 交易模型,还可以应用于通过数据挖掘创建的基于规则的策略。
封(港)
我将在 CV 的上下文中交替使用这两个术语(数据泄漏和数据峰值)。这里指的是信息有意无意跨褶皱泄露的情况。当您的模型或策略包含需要大量回顾历史数据的指标时,这一点非常重要。
让我们用一个具体的例子来说明。为了具体起见,假设
- 你的模型或策略取决于一个指标,比如 63 天(或 3 个营业月)后的实际波动率
- 你的折叠是按时间顺序排列的,以 1 年为单位
- 您当前的测试或样本外折叠是第 4 年
示意性地,褶皱看起来像这样:| - 1 - || - 2 - || - 3 - |(| - 4 - |)| - 5 - |
在第 4 年和第 5 年之间,第 5 年早期计算的波动性需要的信息只能在 OOS 折叠中获得。(折叠 3 和折叠 4 之间没有问题,因为折叠 4 中所需的信息已经可用。)
处理这种意外数据泄露的一种常见方法是使用 De Prado 所说的清除和禁止。用专业术语来说,这包括去除受影响褶皱边界附近的一些数据点,但这两个过程之间有细微的区别。
还有比我在这里提到的更多的东西,因为在德普拉多的术语中,每个标记的数据点都有两个时间:交易时间和事件时间。我在上面的例子中建议的特定类型的数据删除是禁运的一个例子。(它发生在吹扫之前。)在我们的具体示例中,我将从 fold (5)中删除前 63 天左右的时间。
寓意:要意识到你的特征的时间依赖性。
清洗
在我们讨论清除之前,我们需要谈谈金融中的事件时间。本质上,这意味着在一个金融时间序列中的任何标记数据点都有一个交易时间和一个事件时间。事件时间通常表示资产的未来市值达到某一水平的时间,如止损或获利价格。在实践中,这意味着标签变得依赖于路径,并且需要小心,以便在计算标签时我们不会偷窥样本外折叠。
举一个具体的例子,假设我们试图建立一个 ML 模型,根据各种数据源预测 IBM 价格在未来 5 个工作日内是否会上涨或下跌至少 50 个基点。这些波动的规模是根据 IBM 股票最近的实际波动水平估算的。一个常见的标记方案是:如果股价波动超过 50 个基点,则为+1;如果股价绝对值波动小于 50 个基点,则为 0;如果股价下跌超过 50 个基点,则为-1。
接下来,让我们假设我们典型的交易期限是 1 周。你今天进入一个头寸,一周后平仓。然而在实践中,大多数人会在交易中设置止损或止盈水平,这样如果达到这两个水平,他们就可以提前退出交易。关键是,要按市值计价交易,你需要观察未来 5 天或未来 5 个基点的价格路径(你可以提前退出)。
在标记过程中,我们必须注意删除测试文件夹中事件时间与交易时间重叠的数据。这个过程称为净化。
在实践中,首先禁止数据集,然后清除它。可以通过在训练折叠之前增加测试折叠的事件时间来实现禁运。(详见德普拉多。)
寓意 : 注意交易和事件之间的价格路径(如交易期限结束、止损、止盈等。)
关于金融领域标签建设的更多深入信息,我推荐 Quantra 的金融数据科学&特征工程介绍视频。
通过交叉验证进行回溯测试
一旦你制定了一个策略,不管是基于规则还是基于 ML,是时候对它进行回溯测试了。第一次,你获得了 0.5 的夏普比率(SR),并且对你的结果不满意,你决定调整你的策略。也许,你告诉自己应该对第一个指标使用不同的阈值水平,看看会发生什么,或者对另一个 ML 超参数使用更高的值。
也许我也应该尝试不同的进出时间。最终,在多次反复调整这个或那个参数之后,您最终得到了一个“完美的”参数组合和一个夏普比率为 2.0 的策略。
不可思议!现在你可以交易了。
然而,在现场交易中,你的表现发生了变化:你基本上失败了,亏损了。哪里出了问题?
我用这个虚构的例子来说明过度适应策略的概念,并说明 CV 在什么地方可以派上用场,来帮助你评估你的结果的统计意义。
您可以使用相同的过程将数据分割成多个折叠,或许可以重复上述相同的过程来校准 IS 折叠中的参数,并对 OOS 折叠中的策略进行回溯测试。
您选择的参数在 Is 折叠中是否稳健?
你在 OOS 弯的表现强劲吗?
如果是这样,你就有更多的统计数据证明你的策略是正确的。(否则,你就是在瞎猜,作为量化投资者,我们不应该给事后批评留有余地。)
这个练习也能让你抛弃一些不可靠的交易参数,因为它们在后验测试中的突出表现可能是由于过度拟合。
我们在机器交易领域的大多数人都熟悉 ML 策略的 CV,但是如上所述,它也可以用于基于规则的策略。CV 启发的回溯测试的一个积极结果是,你可以获得你所研究的整个市场历史的真实表现评估——不管是 5 年的时间窗(对于日交易者),还是高频交易者 1 周的数据。
寓意:回溯测试不是一种研究工具。避免多重回溯测试中的选择偏差,因为你会错误地从随机的历史模式中获利。(相当多的金融研究仍然是由回溯测试驱动的。)
例如,De Prado 在[AFML]中就如何防止回测过度拟合提出了各种建议:
1.为整个资产类别或投资领域开发模型,而不是特定的证券
2.应用集成技术作为既防止过度拟合又减少预测误差方差的手段(参见 Quantra 关于交易树的课程)
3.在你的研究完成之前不要进行回溯测试
4.用各种“假设”情景对你的策略进行压力测试
5.如果回溯测试没有发现一个有利可图的策略,从头开始。
这需要更多的纪律和适当的技能,但它可能会让你免受许多挫折和浪费金钱。
组合清除交叉验证
金融学中标准 CV 方法的一个主要缺点是 CV 只测试单一路径。在没有市场模拟器的情况下,一种替代方法是使用一些组合技巧来生成多个回溯测试路径。

对于博客的这一部分,我将提供一些 Python 代码,说明如何使用所谓的组合清除交叉验证从 1 条历史路径中构建 5 条回溯测试路径。(见上图。)我这里用一个具体的例子。
Python 中组合清除交叉验证的示例
我们将首先下载所需的库
机器学习交易模型中的交叉验证
原文:https://blog.quantinsti.com/cross-validation-machine-learning-trading-models/
由伊山沙阿
什么是机器学习中的交叉验证?
机器学习中的交叉验证是一种提供机器学习模型性能的精确测量的技术。当模型用于未来未知的数据集时,这种性能将更接近您的预期。
The application of the machine learning models is to learn from the existing data and use that knowledge to predict future unseen events. The cross validation in machine learning model needs to be thoroughly done to profitably trade in live trading.After reading this, you will be able to:
- 确定机器学习模型在预测买入信号和/或卖出信号方面是否良好
- 展示你的机器学习交易模型在不同压力情景下的表现
- 全面做机器学习交易模型的交叉验证
But before I explain how to do cross validation in machine learning model, I will first create a sample machine learning decision tree classifier model using price data of the Apple stock. Then, I'll implement various cross validation measures on this model. To implement this in Python, I'll follow the below steps
If you are already well versed with these steps and Python coding then you can skim through this part.
导入库
In [1]:
import quantrautil as q
import numpy as np
from sklearn import tree
The libraries imported above will be used as follows:
- quantrautil -这将用于从雅虎财经获取 AAPL 股票的价格数据。
- numpy -对 AAPL 股票价格进行数据操作,计算输入特征和输出。如果你想了解更多关于 numpy 的信息,你可以在这里找到。
- sklearn 有很多工具和机器学习模型的实现。“树”将用于创建决策树分类器模型。
获取数据
The next step is to import the price data of AAPL stock from quantrautil. The get_data function from quantrautil is used to get the AAPL data for 19 years from 1 Jan 2000 to 31 Dec 2018 as shown below. The data is stored in the dataframe aapl.In [2]:
aapl = q.get_data('aapl','2000-1-1','2019-1-1')
print(aapl.tail())
[*********************100%***********************] 1 of 1 downloaded
Open High Low Close Adj Close \
Date
2018-12-24 148.149994 151.550003 146.589996 146.830002 146.830002
2018-12-26 148.300003 157.229996 146.720001 157.169998 157.169998
2018-12-27 155.839996 156.770004 150.070007 156.149994 156.149994
2018-12-28 157.500000 158.520004 154.550003 156.229996 156.229996
2018-12-31 158.529999 159.360001 156.479996 157.740005 157.740005
Date Volume
2018-12-24 37169200
2018-12-26 58582500
2018-12-27 53117100
2018-12-28 42291400
2018-12-31 35003500
创建输入和输出数据集
In this step, I will create the input and output variable.
- 输入变量:我使用了'(开盘价-收盘价)/开盘价','(高-低)/低',最近 5 天回报率的标准差(std_5),以及最近 5 天回报率的平均值(ret_5)
- 输出变量:如果明天的收盘价高于今天的收盘价,则输出变量设置为 1,否则设置为-1。1 表示买入股票,-1 表示卖出股票。
The choice of these features as input and output is completely random. If you are interested to learn more about feature selection, then you can read here.In [3]:
# Features construction
aapl['Open-Close'] = (aapl.Open - aapl.Close)/aapl.Open
aapl['High-Low'] = (aapl.High - aapl.Low)/aapl.Low
aapl['percent_change'] = aapl['Adj Close'].pct_change()
aapl['std_5'] = aapl['percent_change'].rolling(5).std()
aapl['ret_5'] = aapl['percent_change'].rolling(5).mean()
aapl.dropna(inplace=True)
# X is the input variable
X = aapl[['Open-Close', 'High-Low', 'std_5', 'ret_5']]
# Y is the target or output variable
y = np.where(aapl['Adj Close'].shift(-1) > aapl['Adj Close'], 1, -1)
训练机器学习模型
All set with the data! Let's train a decision tree classifier model. The DecisionTreeClassifier function from tree is stored in variable ‘clf’ and then a fit method is called on it with ‘X’ and ‘y’ dataset as the parameters so that the classifier model can learn the relationship between X and y.In [4]:
clf = tree.DecisionTreeClassifier(random_state=5)
model = clf.fit(X, y)
The model is ready. But how do we do cross validation of this model? Here's how.
机器学习模型的交叉验证
If the cross validation is done on the same data from which the model learned then it is a no brainer that the performance of the model is bound to be spectacular.In [5]:
from sklearn.metrics import accuracy_score
print('Correct Prediction: ', accuracy_score(y, model.predict(X), normalize=False))
print('Total Prediction: ', X.shape[0])
Correct Prediction: 4775
Total Prediction: 4775
As you can see above, all the predictions are correct. But there is a lot of Python code here. Yes! accuracy_score is a function from sklearn.metrics package which tells you how many predictions are correct. It takes as input the actual output (y) and predicted output (model.predict(X)), compares both the inputs and tells us how many of them were correct. If you want to see the output in percentage then set the normalized parameter to True as done below.In [6]:
print(accuracy_score(y, model.predict(X), normalize=True)*100)
100.0
您如何克服使用相同数据进行训练和测试的问题?
One of the easiest and most widely used ways is to partition the data into two parts where one part of the data (training dataset) is used to train the model and the other part of the data (testing dataset) is used to test the model.  In [7]:
In [7]:
# Total dataset length
dataset_length = aapl.shape[0]
# Training dataset length
split = int(dataset_length * 0.75)
split
Out[7]:
3581
In [8]:
# Splittiing the X and y into train and test datasets
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# Print the size of the train and test dataset
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
(3581, 4) (1194, 4)
(3581,) (1194,)
In the above code, the total dataset of 4775 points is divided into two parts; first 75% of dataset creates X_train and y_train which contains the dataset to train the model and the remaining 25% of dataset creates X_test and y_test which contains the dataset to test the model. The choice of 75% is random.In [9]:
# Create the model on train dataset
model = clf.fit(X_train, y_train)
In [10]:
# Calculate the accuracy
accuracy_score(y_test, model.predict(X_test), normalize=True)*100
Out[10]:
49.413735343383586
If you test the model on test dataset then a significant drop in accuracy is seen from 100% to 49.41%. The model performance in test dataset is closer to what you can expect if you take this model for live trading. However, there is still a major problem. The cross validation in the model is done on a single test dataset. In this example, on last 1194 data points. It could be by sheer luck that this model was able to predict with 49.41% in the test dataset. If I change the length of the train-test split from 75% to 80% or use different data points say first 1194 data points, then the accuracy of the model can vary a lot. Therefore, there is a need to test on multiple unseen datasets. But how do you achieve this?
K 重交叉验证技术
Don’t worry! K-fold cross validation technique, one of the most popular methods helps to overcome these problems. This method splits your dataset into K equal or close-to-equal parts. Each of these parts is called a "fold". For example, you can divide your dataset into 4 equal parts namely P1, P2, P3, P4. The first model M1 is trained on P2, P3, and P4 and tested on P1. The second model is trained on P1, P3, and P4 and tested on P2 and so on. In other words, the model i is trained on the union of all subsets except the ith. The performance of the model i is tested on the ith part. When this process is completed, you will end up with four accuracy values, one for each model. Then you can compute the mean and standard deviation of all the accuracy scores and use it to get an idea of how accurate you can expect the model to be.  Some questions that you might have.
Some questions that you might have.
你如何选择折叠的数量?
The choice of the number of folds must allow the size of each validation partition to be large enough to provide a fair estimate of the model’s performance on it and shouldn’t be too small, say 2, such that we don’t have enough trained models to perform cross validation.
为什么这比原来的单次训练和试拆分的方法要好?
Well, as discussed above that by choosing a different length for the train and the test data split, the model performance can vary quite a bit, depending on the specific data points that happen to end up in the training or testing dataset. This method gives a more stable estimate of how the model is likely to perform on average, instead of relying completely on a single model trained using a single training dataset.
如何在用于训练模型的数据集之前的数据集上执行模型的交叉验证?是不是历史不准确?
If you train the model on a data from January 2010 to December 2018 and test on data from January 2008 to December 2009. Rightly so, the performance which we will obtain from the model will not be historically accurate. One of the limitations of this method. However, from the other side, this method can help to perform cross validation of how the model would have performed in the stress scenarios such as 2008. For example, when investors ask how the model would perform if stress scenarios such as the dot com bubble, housing bubble, or qe tapering occur again. Then, you can show the out-of-sample results of the model when such scenarios occurred. That should be likely performance when such scenarios occur again.
用 Python 编写 K-fold 代码
To code, KFold function from sklearn.model_selection package is used. You need to pass the number of splits required and whether to shuffle (True) the data points or not (False) to shuffle it and store it in a variable say kf. Then, call split function on kf and X as the input. The split function splits the index of the X and returns an iterator object. The iterator object is iterated using for loop and the integer index of train and test is printed.In [11]:
from sklearn.model_selection import KFold
kf = KFold(n_splits=4,shuffle=False)
In [12]:
kf.split(X)
Out[12]:
<generator object _BaseKFold.split at 0x0000000009936F68>
In [13]:
print("Train: ", "TEST:")
for train_index, test_index in kf.split(X):
print(train_index, test_index)
Train: TEST:
[1194 1195 1196 ... 4772 4773 4774] [ 0 1 2 ... 1191 1192 1193]
[ 0 1 2 ... 4772 4773 4774] [1194 1195 1196 ... 2385 2386 2387]
[ 0 1 2 ... 4772 4773 4774] [2388 2389 2390 ... 3579 3580 3581]
[ 0 1 2 ... 3579 3580 3581] [3582 3583 3584 ... 4772 4773 4774]
The total dataset of 4775 points is divided into four different ways. For the first fold, points 0 to 1193 are used as test dataset and the points 1194 to 4774 are used as train dataset and so on. I'll create four different models for each of the fold shown above and determine the accuracy for each of the models. Again, this will be done through a for loop, by calling the fit method to train the model and by calling accuracy_score to determine the accuracy of the model.In [14]:
# Initialize the accuracy of the models to blank list. The accuracy of each model will be appended to this list
accuracy_model = []
# Iterate over each train-test split
for train_index, test_index in kf.split(X):
# Split train-test
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y[train_index], y[test_index] # Train the model
model = clf.fit(X_train, y_train)
# Append to accuracy_model the accuracy of the model
accuracy_model.append(accuracy_score(y_test, model.predict(X_test), normalize=True)*100)# Print the accuracy
print(accuracy_model)
[50.502512562814076, 49.413735343383586, 51.75879396984925, 49.79044425817267]
模型的稳定性
Let's determine the variation and average accuracy of the model by calling the standard deviation and mean function from the numpy package.In [15]:
np.std(accuracy_model)
Out[15]:
0.8939494614206329
In [16]:
np.mean(accuracy_model)
Out[16]:
50.3663715335549
The accuracy of the model is 50.36% +/- 0.89%. This is more likely to be the behaviour of the model in live trading.
混淆矩阵
With the above accuracy, you got an idea about the accuracy of the model. But what is the model's accuracy in predicting each label such as Buy and Sell? This can be determined by using the confusion matrix. In the above example, the confusion matrix will tell you the number of times the actual value was 'buy' and predicted was also 'buy', actual value was 'buy' but predicted was 'sell' and so on.In [18]:
# Import the pandas for creating a dataframe
import pandas as pd
# To calculate the confusion matrix
from sklearn.metrics import confusion_matrix
# To plot
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sn
# Initialize the array to zero which will store the confusion matrix
array = [[0,0],[0,0]]
# For each train-test split: train, predict and compute the confusion matrix
for train_index, test_index in kf.split(X):
# Train test split
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train the model
model = clf.fit(X_train, y_train)
# Calculate the confusion matrix
c = confusion_matrix(y_test, model.predict(X_test)) # Add the score to the previous confusion matrix of previous model
array = array + c
# Create a pandas dataframe that stores the output of confusion matrix
df = pd.DataFrame(array, index = ['Buy', 'Sell'], columns = ['Buy', 'Sell'])
# Plot the heatmap
sn.heatmap(df, annot=True, cmap='Greens', fmt='g')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
 From the above confusion matrix, if you focus on the darker green zone (1306), that is when actual value was sell and model also predicted sell. Then, out of 2509 (1306+1203) times, the model was right 1306 times when it predicted the sell signal. That is an accuracy of 52%. From this, we can infer that the model is better in predicting the sell signal compared to the buy signal. Time to say goodbye! I hope you enjoyed reading this blog. Do share your feedback, comments, and request for the blogs. Cross validation in machine learning is an important tool in the trader's handbook as it helps the trader to know the effectiveness of their strategies. Now that you know the methodology of cross validation, you should check the course on Artificial Intelligence and test the effectiveness of the models.Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis. **Suggested read: **Working Of Neural Networks For Stock Price Prediction
From the above confusion matrix, if you focus on the darker green zone (1306), that is when actual value was sell and model also predicted sell. Then, out of 2509 (1306+1203) times, the model was right 1306 times when it predicted the sell signal. That is an accuracy of 52%. From this, we can infer that the model is better in predicting the sell signal compared to the buy signal. Time to say goodbye! I hope you enjoyed reading this blog. Do share your feedback, comments, and request for the blogs. Cross validation in machine learning is an important tool in the trader's handbook as it helps the trader to know the effectiveness of their strategies. Now that you know the methodology of cross validation, you should check the course on Artificial Intelligence and test the effectiveness of the models.Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis. **Suggested read: **Working Of Neural Networks For Stock Price Prediction
众包情绪分析交易策略
原文:https://blog.quantinsti.com/crowdsourced-sentiment-analysis-strategy/

情绪分析交易策略在市场上并不新鲜。有许多资源可用于开发这种策略,捕捉市场情绪,并根据这些策略产生的信号进行交易。
我们也有一些金融新闻门户网站,它们使用情绪数据,建立情绪指标栏或进行民意调查,以衡量网站访问者的情绪。这个新闻网站可以测量各种话题和主题的情绪。
我遇到了一个这样的金融市场门户网站,它提供了所有股票的情绪指标栏,我想用情绪栏来创建一个策略。一般来说,基于情绪分析交易的策略涉及整理大量数据,并得出一个情绪分数,该分数可以给出有利可图的交易信号。在这种情况下,我直接使用情绪栏作为策略的输入。所以,这是我的简单策略。

我的第一步是找出我名单中每只股票的买入/卖出/持有值。我用 Python 写了一个简单的程序来帮助我实现这个目标。还需要 HTML 和 CSS 知识来找到情感栏的确切位置,并从 HTML 页面中获取相应的买入/卖出/持有值。我使用了相关的 Python 库,它们帮助我完成了所有繁重的工作。
下一步是以 Python 数据框或电子表格的形式存储这些值,以便进一步分析和验证这些值。

我能用这些值做什么?我如何知道网站上显示的情绪值是否公平地代表了股票的整体市场情绪?我做的一个实验是在开市前捕捉情绪得分,然后在市场交易结束时根据股票价格的变化进行验证。下表给出了股票样本的单日业绩。可以看出,结果并不令人鼓舞。然而,单日结果并不能告诉我们任何关于策略潜力的信息,因此,我们需要在一段时间内对其进行测试。

这是使用情感分数的一种方式。使用情感分数的其他方法有哪些?我在下面列出了一些可能的方法来处理情感分数和使用策略:
- 过滤分数,并在分数较高的股票中建仓。
- 将获得的情感分数与其他网站上显示的情感分数进行比较。
- 将这种策略与其他策略结合起来,产生强有力的交易信号。
我将继续致力于这个策略,观察一段时间后的结果,如果可能的话,尝试不同的方法来制定一个稳健的策略。我会在以后的博客里分享这个众包情绪策略的成果。所以,请关注我的下一篇关于情绪分析交易的博客。同时,你可以在我们的博客上阅读其他的情绪交易策略。
使用 R【工作模型】 进行交易情绪分析您可以报名参加 Quantra 上的情绪分析课程,该课程将帮助您利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
下一步
如果你想学习算法交易的各个方面,那就去看看我们的算法交易(EPAT)执行项目(T2)。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 旨在让你具备成为成功交易者的正确技能。现在报名!
加密套利:概述,交易策略,机会,等等
苏莱曼·埃姆雷·耶希尔
加密货币套利是一个有趣的概念,具有有利的结果,但对于加密市场中的套利机会,交易者必须知道更多。在这个博客中找到一切。
我们涵盖:
- 什么是套利?
- 加密货币是如何交易的?
- 什么是加密货币套利?
- 市场上为什么会出现加密货币套利机会?
- 如何识别加密货币套利机会
- 加密货币市场的套利机会类型
- 如何开始加密货币套利交易?
- 加密货币套利的优势
- 加密货币套利的弊端
什么是套利?
套利意味着捕捉一种资产在不同市场之间的价格差异带来的利润机会。
假设一个资产 X 在两个市场交易,市场 A 和市场 B。如果它在市场 A 以 100 交易,在市场 B 以 105 交易,一个人可以享受无风险的 5%的利润机会,不包括交易成本。
在潜入加密货币套利之前,我们先来了解一下加密货币是如何交易的。
加密货币是如何交易的?
加密货币大多在集中交易所交易。用户可以出价或要求他们想要交易的加密货币,一旦特定的买卖订单匹配,买方和卖方之间就可以实现资产交换。
基于这一逻辑,加密货币在全球范围内全天候交易。相同的加密货币在数千家不同的交易所交易。
例如,您可以在下面看到 BTC 的一些交易市场:

Source: Coinmarketcap
什么是加密货币套利?
加密货币套利是通过同时从一个交易所购买加密货币并以略高的价格在另一个交易所出售来获利。
如果你在上面的比特币市场列表中查看价格一栏,不同交易所的价格会略有差异。尽管这些微小的差异无法吸收交易成本,但在高度波动时期,你可以体验净套利机会。
为什么市场上会出现加密货币套利机会?
如前所述,加密货币在全球数千家交易所进行交易。它们以不同的法定货币交易,也以主要的加密货币交易。
有几个原因导致不同市场之间的套利机会。
当地对法定货币转移的限制
一些国家限制资本流出该国,导致当地加密货币投资者被禁止进入该国以外的加密货币市场。这导致了当地加密货币交易所的供需失衡。
这种情况最著名的例子就是泡菜溢价。在韩国,加密货币投资者受到严格的资本管制,外国加密货币投资者不得在当地的加密货币交易所交易。因此,该国的加密货币价格偏离了其他加密货币市场。
下图显示了这种偏差。正如你所看到的,大多数时候,比特币在韩国的价格比其他市场更贵,这种情况在加密货币投资者中被称为“泡菜溢价”。

Source: CryptoQuant. Green-Red Line: Korea Premium Index, Black Line: BTC Price in USD
价格的突然变化
历史证明,加密货币容易出现高价格波动。价格可以在同一天内上下浮动 20%。有时,手动下单的交易员可能无法取消订单。
此外,由于加密货币交易所之间的流动性差异,一些加密交易所对这些价格波动的反应可能会稍慢或稍快。
例如,当加密货币价格开始下降时,非流动性交易所的市场订单将导致价格下跌更严重,这可能会产生套利机会。
交易和转移成本
有时候虽然没有限制,没有高波动的环境,但是因为交易成本的原因,还是可以看到价格的差异。
你可能会认为,虽然价格之间存在差异,但这并不意味着存在套利机会。然而,加密货币交易所中的每个人的交易成本并不相同。
对于产生高交易量的投资者来说,加密货币交易所的交易成本通常要低得多。因此,这些价格差异对他们来说是微小的套利机会。
如何识别加密货币套利机会
从广义上讲,你可以通过两种方式识别套利机会,人工计算和自动筛选。
考虑到交易所和加密货币对的数量,手动计算在这里似乎不是一个选项。
识别加密货币套利机会的最佳方法是创建一个加密货币套利机器人,因为这些套利机会出现的时间非常短。
然而,这不足以捕捉套利机会。你需要在你运营的交易所同时拥有法定货币和加密货币,因为你不知道在套利机会出现的情况下,你将是哪个交易所的买方或卖方。
加密货币市场最大的好处之一是市场数据是免费的,每个人都可以通过 API 访问交易所的实时数据。你甚至不需要从头开始创建算法来连接交易所的服务器并获取实时数据。
大多数加密货币交易所都有现成的客户端软件包,使您可以通过调用软件包中的函数来获取实时数据、发送订单和检查账户余额。
例如,你可以在这里找到币安的 python 包。为了能够使用这个软件包,首先,您需要通过在计算机的终端或命令行中写入以下命令来安装它:
“pip 安装币安-连接器”
现在,您可以获得实时和历史数据,并使用 python 下订单。例如,使用“klines”函数获取烛台数据:
基于数据抽取技术的加密货币交易策略
原文:https://blog.quantinsti.com/cryptocurrencies-data-strategy/
有许多来源可以获取网络上各种加密货币的数据。Quandl、Coinmarketcap、Poloniex 等来源。大多数都有 API 或。他们提供 csv 功能。您可以使用它来获取数据。今天,我们将看到如何使用 python 以一分钟的分辨率获取这些数据。
在这篇博客中,我使用 python 库 coinmarketcap 从网站这里获取数据

我还将讨论如何将数据保存在 dataframe 和 csv 中。最后,我解释了一个简单的策略来交易硬币。
首先,让我们导入必要的库

您可以 pip 安装上述所有库:
pip 安装熊猫
pip 安装日期时间
pip 安装 coinmarketcap
接下来,我们将使用上面的市场函数获取数据。然后我们会把各种加密货币的名称列出来,保存在一个名为 coins_list 的列表中。

让我们把这个列表打印出来,看看里面所有的名字。

我们在这个列表上总共有 1121 种货币。

接下来,我们将获取开始时间并保存它。这是我们将运行该脚本的时间。

接下来,我们创建两个名为 usd price 和 usd vol 的字典,它们将用于存储所有 1121 枚硬币的数据。

假设我想获得接下来 3 分钟的数据,那么让我们将这个时间保存为变量‘t’。

此后,我将每分钟 ping coinmarketcap 站点以获取数据,然后将其保存为 dataframe。我将在接下来的 t 分钟内继续这样做。

在这之后,我们创建两个字典,将硬币名称作为它们的键,美元价格和交易量作为它们的值。我们将这些值添加到相应的字典 usd price 和 usd vol 中,并将获取数据的时间作为它们的键。

之后,我们将计算循环遍历所有货币所用的时间。这一点很重要,当运行时间超过 1 分钟时,下一次数据获取将在下一分钟发生。因此,如果我们的数据处理需要更多的时间,我们可能需要删除一些不重要或不被我们跟踪的货币,以使数据连续。

我现在将详细解释这一点。如果您一直运行该代码,输出将如下所示。

您可以打印两个字典 usd vol 和 usd price 来查看数据的样子。
如果我们将这些数据转换成数据帧以便更好地查看:

现在,打印数据帧“a”

现在,观察左边的时间戳,它有 2 分钟的时间增量,这是因为当我们编写代码时,我们指定每当一分钟结束时都应该获取数据。因为,我们观察到循环时间超过一分钟,所以数据是在这之后的一分钟开始时获取的。因此,我们需要减少交易的货币。
完成后,我们可以将这些数据保存在 excel 中,以便进一步进行回溯测试。

一旦有了初始数据,就可以简单地将每分钟获取的数据追加到这个数据中。
加密货币交易策略:
在像比特币这样波动性很大的市场,顺势交易是明智的。但这并不意味着一些经过深思熟虑和平衡的均值回归策略,如多空投资组合、IndexArb(创建自己的指数)等,不能应用于比特币。要了解这些策略,你可以查看我们的课程,由 E. P. Chan 博士撰写的均值回复策略。
在这里,我使用了一个简单的“从众”策略。这种策略的基本前提是,当市场高度波动时,通过观察交易发生的方向来跟踪市场的现有趋势是有利可图的。我们之前保存在数据框“b”中的成交量数据将有助于从假突破中筛选出真正的突破。我们将一根蜡烛线的交易量与过去 n 根蜡烛线的平均值进行比较,以检查价格的突然上涨是否与交易量的增加有关。如果是这样,那么我们假设这是一个真正的突破,沿着运动的方向交易。相反,如果交易量小于平均交易量,但回报大于过去“n”回报的标准差,那么我们认为这是假突破,逆着运动方向交易。
现在来谈谈策略。首先,让我们导入必要的库。

接下来,我们导入之前存储的数据。

让我们从所有货币中选择一个符号进行交易,并将其保存为变量' s'。(尝试一些流动性货币,如 BTC、瑞士法郎等,因为策略取决于交易量)

接下来,我们创建一个数据帧“data ”,它保存“s”的价格和数量信息。

接下来,我们决定时间段来计算回报和平均交易量的标准差。
在这种情况下,我假设这个窗口是 30。

为了应用这个策略,我们需要知道回报率,所以让我们先计算一下,然后计算回报率和平均交易量的标准差。

接下来,我们生成名为“Signal”的列,然后计算回报大于/小于观察到的标准偏差且成交量也高于观察到的平均成交量的信号。根据我们的基本假设,我们假设这是真实的信号。也就是说,市场是以成交量来支撑这一走势的。

接下来,我们创造反转信号,只要突破没有相应的交易量增加,我们就逆市场趋势而动。

在此之后,我们创建一个新的数据帧,只保存交替的信号,并丢弃其余的信号。我们这样做是为了减少交易噪音。本质上,我们持有一个位置,直到产生一个反信号。一旦我们准备好了新的信号,我们就可以计算策略的回报。

这里我们用不同于前面的方法计算回报,因为这个回报是我们根据过去的数据生成的信号执行头寸时得到的回报。这个回报会告诉你进场点之后的市场行为。
最后,我们将绘制策略回报的累计和,以直观显示策略的绩效。


这是一个简单的策略,不建议在没有适当的风险管理的情况下用于交易。在上图中,我们成功地捕捉到了一个突破。如果你想大幅减少交易次数,我们可以尝试增加时间周期或增加信号的标准差倍数。我在 ETH(以太坊)上尝试过同样的策略,结果很有希望。

这种策略只是为了向算法交易的新手演示,在没有适当的风险管理之前不应该交易。
下一步
在我们的后“9 大加密货币交易平台”中,详细介绍了国际市场交易商使用的一些最佳加密货币交易平台。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载 Python 代码
- 加密货币交易策略- Python 代码
印度的加密货币之旅
经历了十年的跌宕起伏、确定性和不确定性,印度最高法院似乎已经明确了加密货币在印度的前进方向。在这篇文章中,我们绘制了加密货币的完整旅程,谈论了它的兴衰以及与它相关的无数话题。
本文涵盖了事实知识,因此,我们将讨论以下内容:
什么是加密货币?
加密货币是一个创新的概念,作为在线购买商品和服务的交换媒介。加密货币的工作使用密码术。让我们简单了解一下加密货币的功能。对于每种加密货币,一个分布式账本技术(DLT) 用于保存所有交易的数据库。该数据库公开用于存储关于通过加密货币进行的金融交易的信息。此外,这个拥有完整交易记录列表(加密货币)的数据库被称为区块链。从技术上来说,这个列表或记录被称为块,它们在加密技术的帮助下连接在一起。
观看下面的视频,简单了解一些关于加密货币的有用信息:
https://www.youtube.com/embed/82LgksdhcvI?feature=oembed
那是在 2018 年,最高法院禁止在印度使用加密货币。但是,最近,最高法院解除了禁令。2019 年 4 月,印度储备银行发布了一份框架草案,用于监管沙箱。这将包括与金融技术相关的产品和服务,其中也包括区块链。
此外,这篇题为加密货币钱包-初学者指南的文章可能会帮助你,如果你希望更深入地研究加密货币的工作。另一篇名为9 大加密货币交易平台的文章将让你深入了解一些热门的加密货币交易平台。
接下来,我们将看看印度加密货币的现状。
印度加密货币的现状
最近,2020 年 3 月,印度央行实施的禁令被最高法院解除,自此加密货币交易变得合法。随着禁令的解除,你可以进行加密货币交易,但要有所有的预防措施。
提到取消禁令,NASSCOM 在推特上说,“我们欢迎最高法院取消 RBI 对加密货币交易的禁令。我们认为禁止技术不是解决办法,必须建立一个基于风险的框架来监管和监控加密货币和代币”。
根据 SEMrush 的通信主管 Fernando Angulo 发布的声明,“加密货币搜索在印度增长得太快了。因此,最近观察到该国的人们想要投资和购买加密货币。
可以看到,对加密货币的全面审查仍在进行。随着一切就绪和受监管的加密市场,毫无疑问,加密货币可以成为人们新的投资手段”。
尽管有些人反对加密货币,但在过去几年里,印度见证了比特币使用的增加。此外,根据研究论文非货币化对比特币的影响,政府也在考虑推出自己的加密货币,以使其成为印度卢比的替代货币。这样,任何价值下降都不会对经济造成太大影响。根据同一篇研究论文,印度中央政府已开始协商进程,以建立一个跨学科委员会,从而形成一个加密监管框架。
这些变化有望在资金的多样性方面对整个经济产生积极影响。
现在让我们来看看过去几年印度加密技术的兴衰。
印度加密技术的兴衰
自 2012 年至 2020 年,加密货币的价值经历了几次大起大落。从成为最受欢迎的支付方式,到随着禁令在 2018 年消失,我们将简要讨论这一切。
年份:2012 年
加密货币在 2012 年左右微妙地进入市场,当时小规模的比特币交易已经开始在全国范围内发生。
年份:2013 年
2013 年的某个时候,比特币开始在中国流行起来。
那是在 2013 年,当时名为 Kolonial(孟买沃利)的复古时代披萨店成为印度第一家接受比特币支付的餐厅服务。
2013 年后,这种平行货币的使用逐渐增多。
年份:2016 年
最后,当 2016 年实现去货币化时,更多的加密货币投资开始启动,以降低不确定性。人们开始大量购买比特币和其他加密货币,并在晚些时候出售。其他众所周知的加密货币类型有以太(ETH)、瑞波(XRP)和莱特币(LTC)。网上购物和股票投资的使用是从今年开始的。
年份:2017 年
自 2017 年比特币崩盘以来,围绕加密货币的使用一直存在一些担忧。2017 年的崩溃发生在政府发出警告反对使用相同的手段,并排除了被称为“庞氏骗局”的欺诈的可能性。政府仍然持有相同的观点,并可能继续下去,直到和除非密码市场得到监管。2017 年的加密崩溃还有另一个原因。由于中国警告不要投资加密货币的影响,加密市场受到了严重打击。中国人民银行反对虚拟货币投资,并提醒人们警惕洗钱、涉嫌操纵市场等负面影响。由于某些原因,这种情况在年底有所改善,例如:
- 日本于 2017 年 4 月宣布比特币为法定货币。
- 美国监管机构 CFTC(商品期货交易委员会)批准了加密货币交易。
- 在其他一些国家,人们对加密货币的使用越来越信任。
下图显示,比特币在 2017 年表现最低,但在年底有所上升:

来源:商业内幕
年份:2018 年
这一年,加密货币卷入了一场严肃的法律诉讼。此外,在 2018-19 年的预算讲话中,财政部长宣布政府不认为加密货币是法定货币。政府还提到,他们将采取一切必要措施,确保在所有活动中消除加密货币的使用。
然后,考虑到其不受监管的设置和风险,印度储备银行禁止使用相同的方法。
此外,根据 PRS 立法研究,法案草案于同年通过,该法案禁止在该国以任何形式开采(创造加密货币)、发行、购买、持有、出售或交易加密货币。然而,该法案允许将加密货币背后的技术或过程用于其他领域的任何实验、研究和教学。人们发现,crypto 使用的 DLT (分布式账本)可以用于支付、贸易融资、保险等等。
过去三年,加密货币经历了多次上下波动。
让我们来看看从 2014 年到 2020 年的过去七年中 BTC 价格变化的直观表示,以便对价格运动和 BTC 的表现有一个公平的想法。
以下 BTC 价格以美元为单位。

从上图中我们可以看到,从 2014 年到 2017 年,价格大致保持不变,或者在一个特定的价格范围内(在 0 美元到 2500 美元之间)。此外,可以分析出,在 2018 年的某个时候,BTC 接近 2 万美元,然后一直保持在 2 万美元以下,直到现在,即 2020 年。它显示了其间的许多上升和下降趋势,以及接近 2019 年的价格大幅下降。
还有,你可以看下面的视频,了解一下算法交易在加密货币热潮中的作用。
https://www.youtube.com/embed/UYilw_AvC7E?feature=oembed
让我们继续前进,了解印度的规章制度。
印度关于加密货币的法规
加密货币的规则和法规尚未建立,这种监管机构的缺乏剥夺了投资者对几种风险的安全。我们列出了以下风险:
- 散户投资者的潜在损失。
- 波动对发展中国家的经济可能是危险的。
- 滥用技术可能导致资助从事恐怖主义、贩运等的有害或危险组织。
这种不受监管的加密货币市场不同于金融机构和市场,如第三方审计、财务报告和披露等。
由于最高法院已经取消了对使用加密货币的禁令,因此这些货币的使用必须受到监管框架的约束。据 2020 年 3 月 20 日的彭博报道,印度已经在计划监管加密货币,并且正在等待最高法院的判决。
之后,印度将对监管市场做出最终决定。即使在加密货币的监管到位后,在支付系统中使用它们的许可仍然是一个疑问。这是因为人们不习惯这种虚拟货币。
接下来,让我们看看使用加密货币时的注意事项。
加密货币的注意事项
由于存在一些与加密货币和加密市场的使用相关的担忧,因此必须了解该做什么和不该做什么,以便我们能够从投资中获得最大收益。
| Do 的 | 不要 |
| 了解加密货币的详细功能。 | 不彻底了解就投资,碰碰运气。 |
| 分析和预测市场。 | 假设价格变动,并在此基础上进行投资。 |
| 安全保存公共地址或密钥。 | 只把它们保存在你的记忆中,因为你可能会忘记并失去平衡。 |
| 了解一些加密货币投资背后的算法。 | 认为算法或技术诀窍是浪费时间,不要在上面投资。 |
| 如果你是加密货币的新手投资者,请与杠杆(贷款)保持距离。 | 当你不是加密货币的经验丰富的投资者时,要抓住杠杆的机会。 |
让我们看看为什么你应该注意上面提到的该做什么和不该做什么。
所以,基本上,这些是你不能放弃要点的原因:
非管制系统
这意味着加密货币具有非集中式或分散式控制。与中央银行系统不同,加密货币交易不受中央银行或任何授权实体的监管。正如我们之前读到的,所有加密货币交易都保存在一个公开可见的账本中。这表明任何人都可以过滤最大余额的帐户,并尝试入侵相同的帐户。
理解其功能有所帮助
在使用加密货币进行交易之前,正确理解其功能非常重要,否则,你可能会损失大量财富。你需要很好地意识到你的公钥和私钥,并小心保存它们,因为它们是访问钱包余额的唯一来源。丢失您的密钥或公共地址可能会让您失去所有加密货币,以防其他人得到它们。此外,如果没有关于如何预测市场涨跌的良好知识,你可能无法在最有利可图的时候交易。
砍
由于地址或密钥可在公共分类账中获得,因此有人有可能侵入您的账户并获取您的余额。因为它不是正规的,所以没有安全措施来保证你的账户信息的安全。这意味着你需要对加密货币背后的技术有一个正确的理解。
波动性
这个市场有很大的波动,因为金融杠杆(贷款)可以导致许多上升和下降趋势。这导致对所拥有的加密货币的数量进行正确统计的障碍。
在继续之前,让我们看一个关于加密货币框架下的电子钱包的短片。
https://www.youtube.com/embed/sCxNO5Inetk?feature=oembed
现在让我们来看看加密货币在印度的未来。
印度加密货币的未来
由于最高法院最近下令解除禁令,加密货币得到了推动,加密市场似乎有一个光明的未来。这项裁决支持比特币和以太坊等加密货币的交易。尽管如此,加密交易的全面使用可能需要一段时间,因为印度央行的正式通知正在等待中。
据新印度快报报道,查看过去一年比特币价值的数据,它从卢比。2019 年 3 月 27 万卢比。2019 年 7 月 84.6 万。但是,在 2019 年 12 月,它再次下降到卢比。46.9 万卢比。随着最高法院最近做出解除印度储备银行禁令的判决,比特币的价值上升到了 100 万卢比。2020 年 3 月 67.4 万。
现在看来,未来是光明的
最高法院已经解除了 RBI 在 2018 年对加密货币实施的禁令,称禁令是不相称的。这意味着印度储备银行没有保持与加密公司行为的平衡。
最高法院的这一支持及其判决让亚洲第三大国印度重拾了对加密货币的信心。
由于 crypto 的回归,所有数字货币或金融技术公司都在努力恢复其在印度的扩张计划。据《经济时报》报道,总部位于新加坡的加密公司 ZPX 将考虑扩大业务。密码交易所 WazirX 的联合创始人尼斯查尔·谢蒂(Nischal Shetty)补充说,对印度市场的投资将从今年开始,也就是 2020 年。
既然未来似乎一片光明,那就让我们看看新闻报道说了些什么,并增强我们对加密货币和市场的了解。
关于加密货币的最新消息
现在,我们有一个与加密货币相关的新闻列表,最近所有这些文章都给了我们一个关于该国加密现状的最新消息。继续读下去,丰富你的知识。让我们按照新闻的日期和年份降序排列。
根据上面的消息,印度开始看好对衍生品的投资。尽管,不仅仅是衍生品,对衍生品加密的投资也是这个国家正在见证的。
《反密码法》建议对交易加密货币处以 10 年监禁(2019)
据《今日商业》报道,在加密货币交易禁令实施一年后,据称任何从事加密货币交易的人都将被判处 10 年监禁。法律加强了措施来抑制密码的传播。
由于第一台比特币 ATM 机是在印度央行禁止加密货币后出现的,安装在孟加拉鲁鲁的那台被立即查封。
自从首次公开募股(ICO)成为初创企业最受欢迎的融资方式以来,这种方式一直在起起落落,本文将对此进行详细讨论。
结论
在本文中,我们涵盖了加密货币在印度的表现和地位。我们从加密货币的简要概述开始,然后讨论了与印度加密市场相关的一大块信息。
这篇文章旨在给你一个关于印度加密货币市场的新视角。我们还讨论了与加密货币相关的各种问题,以便我们对此保持谨慎,避免陷入困境。
如果你想学习算法交易,用量化策略升级你的加密货币交易,探索印度最好的算法交易课程quantin STI 的“EPAT”。
免责声明:本文中关于加密货币的任何信息仅用于传达一般信息。本文不提供投资、法律、税务等。建议。您不应将本文中的任何信息视为就加密货币使用、法律事务、投资、税收、加密货币开采、交易所使用、钱包使用等做出任何特定决定的呼吁。我们强烈建议向您自己的财务、投资、税务或法律顾问寻求建议。QuantInsti 和本文作者均不对因依赖本文发布或链接的信息而导致的任何损失、损害或不便承担责任。
加密货币钱包-初学者指南
原文:https://blog.quantinsti.com/cryptocurrency-wallets-beginners-guide/
作者:沙古塔·塔西尔达
这篇博客解释了什么是加密货币钱包以及如何使用它们。它涵盖了从加密钱包的功能到使用它们的风险,还列出了最流行的加密钱包及其功能。 话题覆盖 :
从物物交换体系开始到黄金,再到纸币,现在我们已经到了加密货币时代。随着超过 1300 种加密货币的出现,探索这个领域是绝对必要的。但是为什么加密货币会如此受欢迎呢?为了理解这一点,让我们首先了解加密货币实际上是什么!
什么是加密货币?
让我们把这个词分解一下来理解它。“Crypto”通常指加密技术,它涉及使用加密技术来保护不同实体之间的交易,而 currency 则指货币。因此,加密货币是一种通过加密进行保护的货币,可以在实体之间基于区块链技术进行数字或虚拟交易。就像我们有在线钱包来存储我们的数字货币一样,我们需要特殊的钱包来存储、发送或交易加密货币。
什么是加密货币钱包?
如果一个人希望存储、使用、出售或购买加密货币,加密货币钱包是必要的。我们知道,加密货币使用加密机制来保护交易。由于这个原因,它涉及到使用私钥和公钥。但是这些是什么?公钥充当个人的账户标识符,而私钥充当使用加密货币所需的密码,类似于 ATM pin。发送者将需要接收者的公钥来向他发送加密货币,并且接收者将能够通过使用私钥来访问和使用这些加密货币。必须保护私钥,以避免诸如黑客攻击、窃取加密货币等欺诈行为。加密货币钱包用于存储这些密钥,使用这些密钥进行加密货币交易。加密钱包显示钱包中加密货币的数量,从而使人们能够监控余额。
加密货币钱包是如何工作的?
与允许用真实货币或美元和欧元等货币买卖加密货币的加密货币交易所不同,加密钱包用于存储、发送和接收加密货币(一些加密钱包可能内置了加密货币与真实货币之间的转换交易所)。一旦你从交易所购买了加密货币,它就会存储在你在交易所的账户中。但是,不建议将加密货币存储在交易所提供的钱包中,因为在这种情况下,交易所将拥有您的私钥,而不是您。因此,您可以将它转移到您自己的加密钱包中,以获得对您所拥有的加密货币的控制权。为此,您需要首先在您的钱包上生成一个公钥和一个私钥,然后您可以使用这个公钥地址将您的加密货币从交易所转移到您的钱包。完成后,您就可以轻松地执行交易,使用其他帐户的公钥向其发送加密货币,并通过与发送者共享您的公钥向您的帐户接收加密货币。公钥的作用类似于电子邮件地址,它是特定帐户的标识符。另一方面,私钥就像一个密码,你可以用它来访问你的个人电子邮件帐户。私钥用于访问您的加密货币,这就是为什么绝对有必要保持它的安全和秘密,以避免黑客攻击,盗窃和其他攻击。
加密货币钱包的种类
密码可以大致分为两种类型,热钱包和冷钱包。这两种类型的主要区别在于,热钱包是连接到互联网或在线的,而数据是以离线模式存储在冷钱包中的。这些钱包又可以分为以下几类:
- 桌面钱包(热门钱包)
就像我们安装任何其他软件一样,这些软件被安装并存储在计算机和笔记本电脑上。然而,桌面钱包有受到计算机病毒或恶意软件影响的风险,因此总是推荐使用防病毒软件和强大的防火墙。一些例子是出埃及记,Jaxx,Electrum 等。
- 手机钱包(热门钱包)
这些钱包基本上是移动应用程序,可以在任何移动设备上轻松下载。这些软件比桌面软件更容易使用,也更轻便。一些移动应用程序可能也有其桌面或网络版本。移动钱包的几个例子是菌丝体,Coinomi,绿色地址等。
- 网络钱包(热门钱包)
这些钱包是作为加密货币交易的在线平台提供的,可以通过谷歌 Chrome、Mozilla Firefox 等网络浏览器访问。这些钱包风险更大,因为它们连接到互联网,在线存储你的私人密钥,很容易受到黑客攻击和在线攻击。一些可用的网络钱包有比特币基地、BitGo、Copay 等。
- 纸质钱包(冷钱包)
纸钱包指的是你的公钥和私钥的物理拷贝,它可能只是一张纸。这也指通过软件生成的私有和公共密钥的任何打印副本。它被认为是最安全的钱包之一,因为它不容易在网上丢失你的私人钥匙。它也可以由 QR 码组成,可以在执行任何交易时使用。
- 硬件钱包(冷钱包)
像 USB 这样的设备符合硬件钱包的条件。由于私钥和公钥物理上存储在一些硬件设备中,它们提供了更高的安全性,因为它们不太容易受到在线攻击,因此是最安全的选择。这些可以通过电脑连接,并与在线软件一起使用。
选择加密货币钱包前需要考虑的参数
- 支持的硬币
您可以根据钱包支持的硬币或加密货币以及您可能有兴趣交易的硬币来选择钱包。每个钱包都支持或验证某些类型的加密货币的交易,如比特币、以太坊、Ripple 等。一些钱包也可能只针对一种加密货币,并允许只涉及该加密货币的交易。
- 交易成本
这是选择加密货币钱包的最重要的决定因素之一。交易费用因钱包而异,因此在开始使用钱包之前必须了解交易费用。交易成本可以是固定的、动态的或用户定义的。固定成本可以直接以特定金额给出(例如:0.0005 BTC),也可以指定为百分比,具体取决于您的交易金额(例如:交易金额的 5%),动态成本可能取决于网络拥塞、矿工可用性等因素。并且将相应地变化。用户自定义交易费用由用户根据交易的紧急程度决定;用户设定的交易成本越低,完成交易所需的时间就越长,反之亦然。
- 匿名
使用加密货币的最大优势之一是其底层技术;区块链,为加密货币用户提供匿名性。但实际上是不可能追踪任何身份的吗?即使您的身份与您在区块链上的公开地址没有直接联系,有人也可以跟踪到您的公开地址的交易,并使用该地址识别您的 IP 地址,最终追踪到您的身份。因此,钱包可以提供为不同的交易生成多个公共地址的能力,使得很难使用不同的公共地址来跟踪那个人的身份。
- 备份功能
如果您丢失了私钥,您将面临丢失全部数据和存储的加密货币的风险,因为如果没有私钥,您将无法访问它们。有些钱包具有备份功能,以防万一你丢失了私人钥匙等数据。某些钱包提供使用密码恢复数据等功能。
- 分层确定性钱包
我们已经讨论了与在区块链上获得匿名相关的问题,并且还提到了一种解决方案,即生成用于交易的多个公共地址。分级确定性加密钱包或 HD 加密钱包是能够使用一系列计算来创建多个私有和公共地址的钱包,从而在区块链上保护您的隐私。它们还提供了一种功能,通过使用种子短语(将您的私钥转换为一系列单词)来帮助找回丢失的加密钱包。
使用加密货币钱包的风险
- 欺骗
欺骗是指恶意软件试图在发送者不知情的情况下更改发送者的地址,从而使一个人在加密钱包中将加密货币交易到错误的地址。由于缺乏安全协议,加密钱包可能容易受到这种攻击,这使得绝对有必要检查加密钱包提供的安全程度。
- 遗失加密钱包
丢失钱包会导致个人公钥和私钥的丢失,这反过来意味着丢失您存储的加密货币。在你的私钥被加密或保护的情况下,任何人都不可能破解你的私钥,因为它有 2^256 的可能性。然而,如果你的私钥被其他人知道,那么就有可能访问和使用你存储的加密货币。
- 集中式结构
由于所有公共地址都存储在区块链上,黑客跟踪公共地址上的交易变得更加容易,这使得黑客能够识别大量的地址,从而使这些公共地址成为易受攻击的目标。
- 交易费用
如前所述,交易成本在选择加密钱包时发挥着巨大的作用,因为一些钱包收取高达 50%的交易费。忽视这些细节可能会导致不可逆转的巨大损失。
- 冲销付款
由于这些支付是不可逆的,因此输入正确的收款人公共地址至关重要,因为支付一旦完成就无法撤销,并且在加密钱包中输入错误地址的情况下可能会导致损失。
流行的加密货币钱包
支持的加密货币:BTC ETC,ETH,LTC 等更多在此列出。
功能:——可在 Windows、Linux、Chrome、Firefox、Mac OSX、Android、iOS 等多个平台上使用。-允许通过 Shapeshift 在比特币、以太和 DAO 之间转换。-不在中央服务器上存储用户钱包的详细信息,从而提供更高的安全性。
支持的加密货币: BTC、LTC、ETH、DASH、XRP、更多。
特点: -内置兑换将 altcoins 转换为比特币-直观易用的界面-加密私钥,安全性更高。-可在 Windows、Mac OS 和 Linux 上使用。
支持的加密货币: BTC,ETH,XRP,XMR 还有很多更多。
功能: -称为原子交换的内置交换功能-由于加密的私钥,安全性更高-目前可在 Windows,Mac OS,Ubuntu,Debian,Fedora 上使用,并很快推出 Android 和 iOS 的移动钱包。-能够通过 Changelly 和 ShapeShift 购买美元和欧元加密货币。
支持的加密货币: BTC
特点: -极大的安全性,因为硬币存储在本地钱包中,第三方无法访问。-可以与 Trezor 或 Ledger 等冷存储选项集成-提供五种不同类型的帐户,如 HD、Bit ID、单地址、“仅观看”帐户和硬件帐户。你可以在这里阅读更多关于他们的信息。-提供一个名为“菌丝体本地交易者”的分散式面对面交易平台,实现买卖双方之间的交易,并根据交易计算信誉等级。-这是一款可在 Android 和 iOS 上使用的移动加密钱包。
****支持的加密货币:BCH BTC
功能: -多签名钱包,具有共享钱包的功能。-允许安全的应用内钱包生成和备份,因为它是一个分层确定性(HD)加密钱包。-安全存放多个不同的钱包。-在 Windows、Linux、Mac OS、Android 和 iOS 上可用
支持的加密货币: BTC
功能: -加密私钥-可用冷存储-可在 Windows、Mac OS、Linux、Android 上使用-支持第三方插件、Multisig 服务等。
支持的加密货币: BTC
特点: -它是一个 HD(分级确定性钱包)从而提供良好的安全性。-可在 Windows、Mac OS、Linux、Android、iOS 和 F-Droid 上使用。-即时交易确认。-双重认证带来更高的安全性。-允许创建纸质钱包备份。
支持的加密货币: BTC、BCH、ETH、LTC 和更多。
特点: - HD multisig 硬件加密钱包。-紧凑型 USB 加密钱包。-支持第三方应用程序-兼容 Windows、Linux 和 Mac OS。-使用 24 字恢复短语轻松备份和恢复
支持的加密货币: BTC、瑞士联邦理工学院、XRP、BCH 和更多。
特点: -允许离线存储的硬件钱包。-由于有 12-24 个单词的恢复短语,因此很容易访问。-能够生成许多公共地址。-兼容 Windows、Linux 和 Mac OS。

我们已经在这个博客中介绍了与加密钱包相关的主要概念。然而,围绕加密货币的话题有很多误解。这门课程解释了一切,从加密货币的基础知识和加密钱包的工作原理到开发和回溯测试加密货币交易策略,如 Ichimoku 云策略。
免责声明:本文中关于加密货币的任何信息仅用于传达一般信息。本文不提供投资、法律、税务等。建议。您不应将本文中的任何信息视为就加密货币使用、法律事务、投资、税收、加密货币开采、交易所使用、钱包使用等做出任何特定决定的呼吁。我们强烈建议向您自己的财务、投资、税务或法律顾问寻求建议。QuantInsti 和本文作者均不对因依赖本文发布或链接的信息而导致的任何损失、损害或不便承担责任。
关于暗池的一切
这篇文章带你从暗池的含义,一直到它激动人心的历史和现状。如果你想探索这个话题或者了解暗池交易,这篇文章会给你一个很好的视角。
让我们继续前进,在本文中找到更多关于暗池的信息,因为它涵盖了:
- 什么是交易中的暗池?
- 简史:为什么会有暗池?
- 暗池现状
- 暗池列表或类型
- 有趣的事实
- 利与弊&暗池
什么是交易中的暗池?
“暗池”是一个非常有创意的名字,指的是银行等大型机构中的私人股票市场。它们是合法的私人证券市场,也被称为另类交易系统(ATS)。
基本上,这是纽约证券交易所和道琼斯等证券交易所的替代交易。因此,这些被称为场外交易行为。此外,通过暗池投资的交易者仍然远远领先于市场上的其他交易者。多年来,人们认为股票在暗池中的交易多于在证券交易所交易。
交易中暗池的实际目的是让投资者/交易者能够根据全国最佳买价和卖价(NBBO) 完成订单。NBBO 被美国证券交易委员会监管 (SEC) 。该规则为交易者提供了最佳(高)买入价(在出售证券的情况下)和最佳(低)卖出价(在购买证券的情况下)。
根据 NBBO 的说法,让他们的订单得到执行,对于在交易中投入大量资金的机构交易者来说尤其重要。
尽管这种交易降低了交易成本,但其对市场的影响(积极或消极的)(因为所有信息都是“私人的”)仍有待理解。
例如,如果一家投资银行购买一家公司价值 100 万美元的股票以分散其投资组合,这必然会对该公司的市场价格产生影响。然而,如果它私下交易,市场将不会有任何波动或影响。
渐渐地,暗池受到了美国当局的监管。监管是一个缓慢的过程,因为它们在 1979 年或 20 世纪 80 年代初首次出现,但 SEC 直到 1998 年才监管它们。
为了收集更多关于暗池的知识,让我们了解一下前方暗池的历史。我们将讨论暗池何时出现,以及它们这些年来的发展。
让我们向前看,回头看看为什么会有暗池存在?
简史:为什么会有暗池?
暗池的出现是因为机构投资者希望在没有交易所参与的情况下私下进行投资。之所以如此,是因为暗池提供了交易的机会,而不会让投资面临市场上潜在的不利价格波动风险。此外,所有交易都是匿名的,除非某些法律要求要求交易者分享任何细节。
这是一个关于它们如何形成的简介,我们现在将从头开始讨论暗池的历史,它是这样的:
- 暗池的起源可以追溯到 1979 年。1979 年 4 月 26 日之后,任何在特定交易所上市的证券都被允许私下交易。
- 上世纪 80 年代,他们加快了步伐,一些投资者开始投资暗池。一开始,暗池交易被称为“楼上交易”。在全部交易活动中,有一部分投资者在暗池中交易。
- 1986 年,暗池变得更加流行,投资者在白天输入订单。在美国东部标准时间 6:30 收盘时,一种交易算法会根据该证券的收盘价撮合买卖双方。这将意味着交易商的结算。
- 到 1998 年,SEC 对暗池进行了监管,而在此之前暗池一直不受监管。
- 2017 年,据彭博称,据观察,在美国所有执行的交易中,有 40%是在暗池中完成的
在探索了暗池的历史之后,简单来说,让我们了解一下暗池的现状是怎样的。
暗池的现状
目前,暗池比以往任何时候都更加普遍。暗池的出现是因为大型机构投资者或交易员的需要。这些年来,这成了一种管理个人资金或投资的好方法。尤其是经纪人和银行正在利用它们,在自己的暗池中匹配客户的订单。
这里需要注意的是,暗资金池不仅对投资者,而且对中间实体来说都是有利可图的业务。这些实体让他们的客户对使用他们的暗池足够乐观,因为同样的,他们可以进行交易,而无需向证券交易所支付任何费用。
此外,实体还可以进行自我交易(买卖证券),以便从交易中获得更多利润。因此,暗池现在遍布全球。
现在,2018 年 2 月,据华尔街大游行报道,当道指暴跌 1000 点时,像摩根大通这样的各种银行都在交易自己的股票。加上摩根大通的两笔暗池交易,摩根大通单周投资自己股票的次数是 2521 次。
此外,根据《华尔街日报》的一份报告,根据 SmartAsset 的数据,2019 年 4 月,暗池和其他场外交易工具执行的美国股票交易份额接近 39%。
如今,暗池更加普遍,在美国,暗池已经成为市场不可或缺的一部分。因此,似乎没有人能逃脱暗池,它们在美国比其他任何国家都要普遍。
接下来,我们将看一下暗池的列表或类型。
暗池列表或类型
暗池主要有三种类型,它们是:
- 自主的
- 基于经纪交易商
- 基于交换
独立
顾名思义,这些暗池提供商由独立或单一公司运营。这些供应商为客户提供了低交易费用,也降低了因流动性不足而产生的成本。例如,美国的独立提供商是 Instinet 和 ITG。
基于经纪交易商的
这些供应商基本上是投资银行,他们在 NBBO 的帮助下为客户提供价格改进。此外,这些供应商是与其他银行或“买方”参与者进行贸易的专家。例如,经纪自营商是摩根大通和巴克莱资本。
基于交换的
基于交易所的提供商为对场外交易感兴趣的散户交易者提供了机会。这些通常为市场参与者提供更高水平的流动性。例如,这些供应商是纽约泛欧交易所和国际证券交易所。
在下一部分,我们将了解一些与暗池交易相关的有趣事实。
有趣的事实
暗池本身是一个非常有趣的概念。它给参与者带来了不同的体验,因为暗池交易不是通过交易所完成的。暗池有几个方面,探索起来相当有趣。让我们一个一个来看看。
对于暗池,你可能不确定价格
这是事实,你可能不确定暗池的价格,因为有可能你最终支付太多或太少。然而,这可以通过密切关注市场上可用的数据来解决。这样,你就可以计算出你的交易价格。然而,投资于暗池的交易者,在市场之前交易。这使得你今天买卖的股票很快就会改变价格。
暗池不被认为是透明的
暗池,顾名思义,是黑暗的,不可见的。相反,当你通过证券交易所进行交易并发出一个待执行的指令时,该指令会显示在交易所的交易簿中。该订单(您希望交易的股票的价格和数量)可供公众查看。
暗池已经遍布全球
如今,暗池遍布全球,交易总量的很大一部分是在暗中或私下进行的。在美国,正如我们上面提到的,几乎一半的股票是在暗池中交易的。此外,它们在美国是最常见的,因为美国的市场主要是关于股票交易的,它们在任何股票交易增长的国家都会更常见。
暗池和股票市场
在暗池中,交易者通常根据股票市场中最佳买价和最佳卖价的平均价格进行操作。在这里,最佳出价是买方愿意支付的最高价格,而最佳报价是卖方愿意出售其股票的最低价格。交易者从市场的最佳买价和最佳卖价中取出一个平均价格,这样暗池帮助他们得到一个比市场价格更好的价格。
HFT 帮助暗池成长
值得注意的是,HFT 或高频交易已经帮助暗池发展到可以通过它进行几笔交易的程度。高频交易意味着交易发生的最高速度。由于它允许在尽可能短的时间内进行大量交易,更多的交易者希望私下利用大订单。
暗池不违法
这种私下交易是合法的,也受到美国当局的监管。自暗池开始增长以来,监管机构一直在密切关注这种情况。在有暗池交易的国家,国家金融当局一直在监控和监管他们开展业务的各个方面。
你可以在这里阅读研究论文中的规定。
前面提到了一些关于暗池的有趣事实。讨论它们旨在增强你对私人交易的了解。这种交易有它自己的优点和缺点,我们将在“暗池的优点和缺点”一节中讨论。
暗池的利弊
毫无疑问,暗池的存在,是因为它为通过这一渠道买卖证券的交易者提供了多种优势。但是,并不是所有的事情都是美好的。私人投资有好处,但肯定也有一些坏处或坏处。
意识到这两点有助于避免这种投资可能导致的损失或不利影响。
好了,现在让我们讨论一下暗池交易的双方。
优点
- 暗池的主要优势之一是,交易者或投资者在执行交易时占据上风。之所以如此,是因为通过私人渠道进行的交易领先于市场或在交易所进行的交易。
- 使用暗池,您还可以获得定价数据保持私密的优势。这意味着在私人交易的情况下,由于数据对公众不可见,与基于交易所的交易不同,交易量不会突然激增。这防止了波动性,因此,交易者的订单要么以这个价格成交,要么不成交。
- 交易者在暗池交易中保持匿名有助于他们,因为竞争的投资者或交易者无法针对他们制定策略。在这种情况下,由于未完成的市场订单对其他交易者来说是不可见的,他们不能计划任何不利于私人交易者的事情来从他们前面的交易中获取利益。
缺点
- 自从暗池出现以来,人们一直在争论它们对交易所交易行为的影响。人们认为,这种交易做法通过使这一领域的交易具有竞争性而对基于交易所的交易产生不利影响。
- 另一点是,私人交易正在导致参与交易所交易的公司的流动性流失。由于暗池不断增长,越来越多的交易者开始从事私人交易。
- 此外,由于流动性低,出现的另一个问题是买卖差价。它不可避免地增长,并导致交易所市场参与者的交易成本上升。因此,它导致市场效率下降。
- 私人交易最常见的缺点是交易活动中潜在的欺诈,因为所有的细节都是隐藏的。由于缺乏透明度,出现了不道德地使用高频交易的案例。正如我们上面讨论的 HFT,交易者可以在私下交易中不道德地利用 HFT。这就造成了一个“不均衡”的交易场。
好吧!我们已经到了文章的结尾,并且已经了解了暗池交易的几个重要方面。让我们看看我们都涵盖了什么。
结论
在本文中,我们讨论了暗池的基本方面,并涵盖了一些关于暗池的重要事实。有许多关于它给交易者带来的好处和投资是否安全的讨论和困惑。因此,我们简要地讨论了所有这些,以便使围绕它的各个方面更加清楚。虽然我们的一些读者发现历史和这个主题的清晰定义很有吸引力,但其他人希望更深入地研究同样的问题。本文介绍了暗池的相关主题,并简要概述了暗池投资。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
一名数据分析师,一名数据库系统专家,现在是一名算法交易员——阿克谢的旅程
原文:https://blog.quantinsti.com/data-analyst-database-system-expert-algo-trader-story-akshay/
站起来面对你的恐惧需要很大的勇气,我们有时会遇到一些有才华的人,他们的故事激发了我们潜在的能量。我们不是在传授一些圣经比例的神话故事,我们向你展示一个人的旅程,他勇敢地前进,学习和成长,以获得实现他的愿望的优势,并在算法交易领域建立自己。
这是阿克谢·派的故事。我们与阿克谢取得了联系,了解了他的全部情况。
对话是这样进行的:
嗨,阿克谢!你能给我们介绍一下你自己吗?
嗨,我是阿克谢·派。我是一名“自我激励”的数据分析师,拥有出色的组织能力、高效率和对细节的敏锐眼光。我学东西也很快。
我在协助开发和升级数据库系统和分析技术以及为有效的数据管理制作方法和文件方面有丰富的经验。我还管理过复杂的内部和外部数据分析职责。
我以前没有交易过,现在也没有。但我渴望尽快开始。我对研究、打卡、建模和编码更感兴趣。
我喜欢处理数据,我喜欢处理数字,我喜欢动物——这些也是我的爱好。我不是一个户外人士,但给我数据,我会真的很高兴致力于此!我和妻子照顾流浪动物。我仍然关心很多动物。现在我在家里照顾 9 只猫,在外面照顾超过 15 只流浪狗。
在你职业生涯的开始阶段,你有相当多的经验。你想谈谈吗?
在学生时代,我是一个非常聪明的学生。在我第 12 次性病期间。,CET 考试第一次推出——我为之出场,过关,考上了工科计算机专业。不幸的是,由于糟糕的公司,以及一些个人原因,我不得不在第二年辍学。我的职业生涯就这样开始了。
毕业后,我开始在一家制造公司工作,工作了 2 年后,我每月只有 3000 印度卢比的薪水。我当时很纠结。所以我加入了一个组织,成为一名支持工程师,理论上,这是我的第一份工作。我为之工作的客户来自马萨诸塞州,当我加入时,不到 4 个月,那个客户就离开了,因为马萨诸塞州有不外包工作的政策。
所以,我是这个大公司的一员,没有毕业就回到了街上。但是公司注意到了这一点,把我重新安排到了一个职能部门——一个我负责招聘、人力资源相关活动以及其他类似活动的职能部门。我是一个技术人员,来自技术背景,我也非常擅长校对,我的逻辑非常强。
当我为所有这些组织工作时,我了解到他们所做的工作没有一项是电子维护的。一切都是手动的。除了添加和删除数据,没有人知道如何正确使用 excel。没有人会使用 vlookup,给数据加边,提取信息,什么都不做。我不知道如何使用这些东西。手工任务对我来说也是压倒性的。
在那个特定的角色中,我是第一个开始自动化大部分数据相关工作的人。最终,我学会了如何大声说话,并开始做演讲。我是第一个在 8 个月内开始制作数据的人,也是在 PRM,在 CEO 面前的会议上。
这就是我喜欢数据的原因。我是生活和呼吸数据。我会处理数字,整理来自其他供应商的数据,混合和呈现数据,有时甚至会处理数据。
我在那里工作了 4 年半,没有得到任何形式的提升,甚至大一新生也得到了两次提升。原因是我还没有毕业。我从来没有试图完成我的毕业,被压倒性的工作所掩盖。
2014 年,我决定我需要下定决心,完成我的毕业——这是我需要做的事情。我无法安排两者兼顾,所以我辞职了。因为我想从经济学或统计学专业毕业,又因为我负担不起比我拥有的资本还要昂贵的统计学课程,我报名参加了一个经济学学士课程。
为了继续我的生计,我和我的父亲开了一家家族企业“SM consultants”——在浦那经营 CMC 机器、立式机器、卧式机器等特许经营业务。利用我的机械知识和行业背景。它失败了。为什么?我们没有计划。我从那次“如何不做生意”的经历中学到了很多。所以,我们关闭了这项业务。
这是一个糟糕的阶段,但我完成了毕业。
不过,你对数据科学有很好的体验。这对你的职业生涯有什么影响?
2017 年,我决定要进入数据科学领域。我想回到数据分析领域,但当我开始寻找与数据分析相关的工作时,我意识到数据分析的下一步是数据科学。
因为我擅长数学,所以我有两个选择——全日制金融工程课程或数据科学课程,然后先找份工作,看看进展如何。最终,我会拿到硕士和博士学位。
当我开始在数据科学市场找工作时,我意识到公司不愿意给没有功能知识的人提供工作。
如果你想成为一名工程领域的数据科学家,你需要在物理方面有很强的实力,并拥有理学学士和理学硕士等资格证书。对于销售数据,需要有非常强的统计学毕业。金融、CAs、经济学学士等。-我有后者。因此,我决定尝试一下金融市场。
在这之前,我不知道市场和交易。我知道市场如何运作,但不知道交易所,尽管我知道微观经济学和宏观经济学。在做数据科学的时候,偶然发现了算法交易,想给它一个机会。一旦我开始阅读书籍,浏览网站,学习一些课程。
我妻子在 Syntel 工作。我们是通过她的一个朋友了解到 QuantInsti 的。当我加入 QuantInsti 后,我学到了很多自己都没有意识到的术语。许多学生很容易理解,但我却很难理解大部分内容。
我记得先联系了 QuantInsti 的 Rashmi,他与我分享了阅读的小册子和计划书——这给我留下了非常深刻的印象。我注册了这门课程。我刚从第一家公司取出全部积蓄,支付了 QuantInsti 的费用。
我生命中的每一个决定对我来说都是重大的决定。我从来没有打过安全牌。
你需要从某个地方开始,我意识到这是我的机会。我的妻子非常支持我,在经济上、情感上、各方面都与我同甘共苦。只是因为她和她的经济支持,我才能自由地做出这样的决定。
我被录取了。这个介绍让我大吃一惊,并深深地激励我去尝试它。老实说,前三堂课的统计部分下降得很可怕。我在家里苦苦挣扎。毫无疑问,我有太多的时间学习和掩盖一切,我觉得我是幸运的。
有人不能 24 小时直上学习,你就努力学习。对我来说这是一场斗争,但最终,如果你真的想学这个,你需要付出很多努力。起初,由于课堂教育的心态,我犹豫着是否要寻求帮助或问问题,因为我认为老师会帮助你。
有一次我跟不上了,我从后援队里找来了拉克西米。她帮了很大的忙。不管是什么样的疑问,我总是能收到他们的回答;无论我去找什么样的老师,他们总是引导我,用恰当的答案回答我的问题,从来没有拒绝过我。
当你与 Nitesh Khandelwal 先生交谈时,动机是在不同的层面上。我真的很钦佩他,他是一个非常优秀的人。我只和他说过两次话,而且是在我上课期间。
我经历了一段艰难的日子,我被登革热感染,我爸爸得了心脏病,我妻子得了风湿性关节炎,我妈妈生病了,我的宠物狗和猫死了...太可怕了。
在学习方面,由于这一切,我错过了我的 EPAT 批次。所以,我联系了拉克西米。尽管参加了前一批,但我很高兴 QuantInsti 理解了我的情况,并为我参加了后一批。所以,我别无选择,只能重新开始我的课程。第二次对我来说容易多了。我做了调查,开始了解更多。
在我的课程重新开始的时候,我又一次和尼泰什先生交谈,是的,这对我来说是鼓舞人心的。我也仍然有一些家庭事务,但是我继续前进。
你不断前行的雄心,创业,意想不到的波折。继续前进,继续。
我来自浦那,那里有很多数据科学的研究所,我探索过,也去过很多,但我没有从 QuantInsti 得到的那种感觉。
当我第一次翻阅宣传册,与 Rashmi 和其他人交谈时,我非常确定这就是我想要做的。准确地说,我在任何其他学院支付的费用几乎是我在 QuantInsti 支付费用的一半。它得到了肯定——这就是我想在我的职业生涯中做的事情。
我开始知道与量化相关的工作可以在孟买找到,而不是在浦那,我想我不能在家附近找到任何地方,这让我有点失望。但就在那时,拉克西米再次拯救了我,他建议我们的定位单元也有远程选项可用——这就是我如何继续进行的。
我现在的角色是一份远程工作,整个公司都远程在线连接。
在你的简介中,你提到了很多关于数据分析和数据管理的内容。你如何在你的职业生涯中运用这一点?
在我目前的职位上,我几乎没有使用过任何与数据科学相关的活动,甚至没有制作图表。目前,我仍在学习我的工作场所 ie 的工具和工作模式。了解流程。我目前只研究技术指标。
在我之前的角色中,即使是数据科学的基本模型,例如,即使是帕累托图也可以帮助你了解和识别客户、员工、组织内的困难领域、收入流失等等。当你带着数据去见你的老板并提供见解时,他将无法了解他的公司中存在的批判性本质。
当时,我在关注全球流动性,根据他们的技能组合、他们为之工作的客户等,在全球的哪些地区分配了多少资源。在大多数公司,人们只是被雇来分析数据。在我的公司,没有人能做到这一点,所以自从我开始分析,他们开始依赖我的数据。
老实说,我想要成功,赚比我妻子更多的钱,让她嫉妒,好像我的远程工作还不够。她在我的旅程中给了我很多支持,有一天我想为她做同样的事情。
既然你有咨询背景,并且从事纯技术工作,与有交易背景的人打交道,你有什么想法:
数据科学
人们并没有完全意识到他们应该在数据科学中扮演的角色。他们有这样的感觉,他们有一个特定的软件,他们需要产生洞察力,就是这样。他们所说的被公司当作事实接受。
只有当你想出新的东西时,他们才意识到他们错过了某些东西,而这些东西可能非常有用。因此,除非你提出新的数据点,否则你将会陷入困境。
数据管理
数据管理的范围在印度非常少。我在国外有很多朋友,但即使是他们,使用的自动化程度也比我们想象的要低。人们在数据管理领域有很大的发展空间。复苏只是时间问题。
我所看到的是,数据科学领域的人非常擅长使用工具,但他们不太擅长处理数据——这就成了一个问题。最终发生的是,你感到厌倦,你放弃了。
获得和提高数据科学技能
学习。学习很容易。学习工具——Python,Excel,学习它不需要时间,但是练习它需要时间。当原始数据来到你面前,你需要体验它,理解它,呼吸它。只有到那时,你才能正确地使用这个工具来展现你的洞察力。
只有你一次又一次地坚持下去,它才会来到你身边。
数据在未来交易中的作用
我不是说它将是一个重要的角色,
我是说它将是唯一的角色。
公司正在尽可能地消除人为干预。即使是在金融领域,当你做决定时,情绪也是一个非常大的缺点,人类的偏见是一个“不不!”对于这个领域。未来,数据驱动的决策将成为行业中最准确的决策。它现在正在发生,并没有完全接管,但它可能发生在今天或明天
人工智能或人工智能等新兴技术在算法和量化交易中的作用
他们将发挥巨大的作用。印度的大多数小型零售交易商不使用这些技术。我父亲仍然不知道如何使用 iPhone,他不信任电子商务平台,认为他的凭据可能会被盗,他的帐户可能会被黑客攻击。
老一代人仍然不信任技术,原因是没有人能够说服他们正确使用这些技术,向他们展示它在市场上的真正潜力。到目前为止,它在市场上有很大的市场空间。所以,没有多少人在做。
你对自己的职业有什么计划?
在做 EPAT 的时候,我想在完成后,我会在家人和朋友的支持下成为一名独立的散户交易者,然后我会出去寻找投资者——这就是我的计划。在 EPAT 的结尾,我意识到这不会发生。为什么?只做这个课程就能为你指明道路。你还是要自己在上面走。
所以,目前,我的目标是学习任何关于市场的东西,试图教会自己像交易者一样思考,用金融语言“说话”。因此,将来如果我与我的客户交流,我应该能够立即理解他们。我之前的计划暂时搁置。但我希望有一天它会成功。
你有什么想对想成为算法交易员的人说的话吗?
努力!T3】
就是这样!全身心地投入。相信我,产出和回报将是惊人的。
阿克谢,我们感谢你与我们分享你的经验。还有很多事情要做,还有很多山要爬,我们祝你一切顺利。
任何希望进入算法交易和量化交易领域的人都可以用在这个领域出类拔萃的必要技能和知识来装备自己。EPAT 通过其全面的课程和实践培训,帮助您做到这一点。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti 的 EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT方案完成后取得的成果对所有个人而言可能不一致。T15】
为什么数据清理很重要,如何以正确的方式进行?
数据清理非常耗时,但却是数据分析过程中最重要、最有价值的部分。没有清理数据,数据分析的过程是不完整的。
但是如果我们跳过这一步会发生什么呢?
假设我们的价格数据中有一些错误的数据。不正确的数据在我们的数据集中形成了异常值。而我们的机器学习模型假设这部分数据集(也许特斯拉的价格确实在一天内从 50 美元跃升至 500 美元)。你现在知道分析的最终结果是什么了。
机器学习模型给出了错误的结果,没有人希望这样!由于预测相差甚远,您必须再次从头开始分析!因此,数据清理是分析的一个重要部分,不应该被忽略。
本博客将带您了解数据清理的整个过程,并为该过程中面临的一些挑战提供解决方案。
- 什么是数据?
- 各种数据来源
- 原始数据和经过处理的数据是什么样的?
- 数据清理的好处
- 高质量数据的特征
- 数据清理中使用的术语
- 清理数据的步骤
- 了解你的数据
- 清理数据时要解决的基本问题
- 交易数据清理
- 预先存在的软件
- 学习数据清洗的资源
- 常见问题解答
什么是数据?
数据科学是当今最受欢迎的职业之一。所以让我从回答这个古老的问题开始——什么是数据?嗯,根据维基百科,“数据是通过观察收集的一组关于一个或多个人或物体的定性或定量变量的值。”
考虑一个数据集,其中包含关于一批不同种类水果的信息。

数据集中的一些变量可能是定性的,如水果的名称、颜色、目的地和原产国、客户反馈(失望、满意、满意)或定量的,如水果的成本、运输成本、货物重量、运输成本和货物中的水果数量。
其中一些变量可能来自其他较低层次的变量。在这个例子中,运输成本来自水果成本和运输成本变量。

这些数量变量也可以分为两类,连续变量和离散变量。连续变量顾名思义在数轴上是连续的,可以取任何实值。离散变量可能只有特定的值,通常是整数。货物的重量将是一个连续变量,而如果我计算每批货物中水果的数量,它将是一个离散变量。
定性变量可以分为名义变量和序数变量。名义变量或无序变量是一种标签变量,这些标签没有量化值。例如,水果的颜色或货物的目的地可以是名义变量。序数或有序变量是那些标签有数量值的变量,也就是说,它们的顺序很重要。在水果的数据库中,顾客反馈将是一个有序变量。
大多数人认为数据科学是传达非常准确和精确信息的美丽图形和图表。然而,大多数人没有意识到的是产生这种数字的必要过程。
数据分析管道由 5 个步骤组成。
原始数据 - > 处理脚本->-整理数据->-数据分析 - > 数据通信
通常,管道的前三个步骤会被忽略。新手直接跳到数据分析这一步。任何企业或学术研究都将致力于获取他们的数据,并在内部对其进行预处理。所以你会想知道如何获取原始数据,并自己清理和预处理它。
这个博客将涵盖所有关于清理和获取数据进行分析的内容。
各种数据来源
首先,让我们谈谈你可以从哪里获得数据的各种来源。最常见的来源可能包括来自数据提供网站的表格和电子表格,如 Kaggle 或加州大学欧文分校机器学习库或从抓取网页或使用 API 获得的原始 JSON 和文本文件。的。xls 或者。来自 Kaggle 的 csv 文件可能经过预处理,但是原始的 JSON 和。txt 文件将需要工作,以获得一些可读格式的信息。详细的数据提取方法可以在这里找到。
原始数据和经过处理的数据是什么样的?
理想情况下,这是您希望干净数据的样子:

每列只有一个变量。在每一行中,您只有一个观察值。它被整齐地组织成一个矩阵形式,可以很容易地导入 Python 或 R 来执行复杂的分析。但通常情况下,原始数据并不是这样的。它看起来像这样-

让你头晕是吗?
这是使用 Twitter API 获得乔·拜登过去 20 条推文的查询结果。您还不能对这些数据进行任何形式的分析。
我们将在后面详细讨论原始和整洁数据的组成部分。
数据清理的好处

如上所述,要产生合理的结果,干净的数据集是必要的。即使您想要在数据集上构建模型,检查和清理数据也可以成倍地改善结果。向模型提供不必要的或错误的数据会降低模型的准确性。一个更干净的数据集会比任何花哨的模型给你更好的分数。一个干净的数据集也将使您组织中的其他人将来更容易处理它。
高质量数据的特征
在执行数据清理之后,您至少应该有以下这些东西-
- 你的原始数据
- 干净的数据集
- 描述数据集中所有变量的码本
- 包含对原始数据执行的产生干净数据的所有步骤的指令列表
当数据满足以下要求时,我们可以说它处于原始状态
- 自从交给它以来,没有任何软件应用于它
- 没有对数据执行任何操作。
- 没有执行任何汇总
- 没有从数据集中删除任何数据点
处理完数据后,它应该满足这些要求-
- 每行应该只有一个观察值
- 每列应该只有一个变量
- 如果数据存储在多个表中,请确保这些表之间至少有一列是公共的。如果需要,这将帮助您一次从多个表中提取信息。
- 在包含变量名称的每列顶部添加一行。
- 尽量使变量名易于阅读。例如,使用 Project_status 而不是 pro_stat
- 加工中使用的所有步骤都应记录下来,以便从头开始再现整个过程
对于第一次查看你的数据的人来说,密码本是必要的。这将帮助他们理解数据集的基本形式和结构。它应该包含-
- 关于变量及其单位的信息。例如,如果数据集包含一家公司的收入,一定要提到它是以百万还是以十亿美元为单位。
- 关于汇总方法的信息。例如,如果年收入是变量之一,说明你用什么方法得出这个数字,是收入的平均值还是中值。
- 提及你的数据来源,无论是你自己通过调查收集的还是从网上获得的。在这种情况下,也要提到网站。
- 常见的格式是. doc。txt 或降价文件(。md)。
说明列表是为了确保你的数据和研究是可重复的。使用指令列表,数据社区中的其他数据科学家可以验证您的结果。这增加了你研究的可信度。确保包括-
- 电脑脚本
- 这个脚本的输入应该是原始数据文件
- 输出应该是经过处理的数据
- 脚本中不应有用户控制的参数
数据清理中使用的术语
- 汇总 -使用多个观察值提供变量的某种形式的汇总。常用的聚合函数有。sum(),。均值()等。Python 提供了。aggregate() 可以同时执行多种功能的函数。
- Append - Append 意味着垂直连接或堆叠两个或多个数据帧、列表、序列等。使用。append() 函数追加数据帧。
- 估算 -一般来说,统计学家将估算定义为填补缺失值的过程。我们将在博客后面更详细地讨论插补。
- 删除重复数据 -删除重复数据是从数据集中删除重复观察值的过程。在本博客的后面会有更详细的讨论。
- 合并——合并和追加是数据清理中最容易混淆的术语。合并两个数据帧也包括将它们连接在一起。这里唯一的区别是我们将它们水平连接起来。例如,如果我们有两个数据集,一个包含用户的脸书数据,另一个包含用户的 Instagram 数据。我们可以根据用户使用的电子邮件 id(两个数据集中的公共列)合并这两个数据集,因为这对某个用户来说很可能是公共的。
- 缩放 -缩放或标准化是缩小特征范围并使其介于 0 和 1 之间的过程。这是用来为在上面建立机器学习模型准备数据的。ML 算法为高值分配较高的权重,为低值分配较低的权重。缩放将处理这种数值上的巨大变化。
- 解析 -解析是将数据从一种形式转换成另一种形式的过程。在博客的前面,我们查看了来自 Twitter API 的原始数据。原始形式的数据没有任何用处,因此我们需要对其进行解析。我们可以将每条推文作为观察,将推文的每个特征作为专栏。这将使数据以表格的形式呈现和可读。
清理数据的步骤
有几个步骤,如果遵循得当,将确保干净的数据集。
- 好好看看你的数据,了解数据中出现的基本问题
- 列出所有的基本问题,单独分析每个问题。试着估计问题的根源
- 清理数据集并再次执行探索性分析
- 检查清洗后的问题
了解您的数据
当你收到数据时,首先要做的一件事就是了解你收到了什么。了解数据集包含的内容——其中的变量、它们的类型、缺失值的数量等等。在这篇博客中,我们将使用一家银行的综合客户交易数据。数据集在这里可用。
首先,读取 excel 文件并使用。头()和。info()方法来获取数据帧的摘要。
数据工程及其在金融市场中的应用!
近年来,大数据的重要性迅速增长,随着时间的推移,数据工程师的任务变得更加重要。我们将在本文中讨论金融市场中数据工程师的一些事实和责任。
本文涵盖:
- 什么是数据工程?
- [数据工程领域的职责](#responsibilities-in-the-field-of-data- engineering)
- 金融市场中的数据工程
- 数据科学家 vs 数据工程师
- 数据工程的未来
什么是数据工程?
数据工程是一个为企业中的分析进行数据准备的领域。在这里,数据准备意味着构建和测试数据的个人。这个过程产生这样的数据,这些数据可以有效地用于实现特定企业所需的分析。这些现成的数据构建了数据架构。
数据工程师在开发和管理大量数据方面经验丰富。此外,数据工程师的主要职责之一是帮助数据科学家将原始数据转换为干净可用的数据。
这里的原始数据是指直接从源中提取的数据,可能包含多个问题,如重复、非平稳性等。干净和可用的数据是指准备好用于交易中各种目的的数据,例如回溯测试、分析和预测未来的交易。
接下来,我们将了解数据工程领域的职责。
数据工程领域的职责
数据工程通常是为了给企业提供准确的数据,需要精通 Python、Java 等编程语言。
同时,数据工程师具有以下特征:
- 支持数据科学家/分析师
- 管理数据
- 作为通才,以管道和数据库为中心
- 它们不断进化
支持数据科学家/分析师
数据工程师支持数据科学家/分析师根据优化的数据执行操作。数据工程师主要负责创建和维护数据基础设施。
管理数据
基本上也需要数据工程师来管理数据。他们的职责不仅仅是为专业用途创建优化的数据。他们还需要进一步管理数据,这意味着确保不会再出现错误、易于访问且可靠。
作为通才,以管道和数据库为中心
通常有三种类型的数据工程师,即:
- 通才
- 以管道为中心
- 以数据库为中心
多面手
有些数据工程师负责创建数据管道的所有工作,例如从数据源检索数据,对其进行处理并进行最终分析。这个过程也占用了数据科学家的全部技能。这是小公司或团队所需要的,他们没有足够的专业人员。
以管道为中心
中型公司需要他们,他们有复杂的数据需求,需要数据团队进行大量需要分布式系统和计算机科学背景的工作。
以数据库为中心
这些数据工程师通常在大公司工作,他们的数据分布在数据库中。这些公司中有各种数据分析师,数据工程师需要将信息从数据库的主应用程序中提取到分析数据库中。
它们不断进化
数据工程师随着技术进步和各种模型的引入而不断发展。在物联网(IOT)、人工智能和机器学习模型的推动下,数据工程领域正在快速发展。因此,数据工程师也需要不断发展和学习该领域的新实践。
展望未来,我们将了解金融市场中的数据工程。
金融市场中的数据工程
在金融市场中,数据工程师需要做收集数据、清理数据的常规工作,这意味着剔除重复数据等错误。最后一步是在清理数据的帮助下实现交易自动化。
- 风险管理
- 预测分析
- 欺诈检测
- 算法交易
风险管理
由于管理风险是任何金融机构的一个极其重要的方面,数据工程师扮演着重要的角色。在干净的数据集的帮助下,交易预测中的错误不会发生。这很重要,因为如果机器学习模型得到错误的数据,这将导致投资者持续亏损。
预测分析
在预测分析的帮助下,投资者可以预见数据模式,并采取正确的行动。数据工程师帮助公司/个人等以这种方式在金融市场投资时做出正确的决策。例如,如果机器学习模型被馈入具有重复或不规则的数据,它将导致错误的输入。这种错误的输入反过来会导致交易中的错误预测,从而减少收益。
欺诈检测
展望未来,数据工程还有助于欺诈检测。由于检测黑客是否已侵入系统以使数据恶意/不适合输入预测模型极其重要,因此必须由数据工程师检查和清理这些数据。
算法交易
在算法交易领域,数据工程师帮助清理数据,这些数据将被输入机器学习或深度学习模型,以预测交易。算法交易系统在预编程指令的帮助下执行指令。这样做时,历史回溯测试需要这些数据,这有助于了解所创建的策略对过去的数据是否有效。在这样做的时候,如果用于回溯测试的数据没有得到正确的研究,它可能会导致未来错误的交易决策。
现在让我们来看看数据科学家和数据工程师之间的区别。
数据科学家 Vs 数据工程师
数据科学家
- 与构建数据基础架构的数据工程师保持持续互动
- 通过使数据投入使用来对其采取行动
- 利用复杂的机器来处理数据或使数据投入使用
- 有一个数据管道,基本上是由数据工程师创建的优化数据
- 进行研究以确定他们提供数据的企业的趋势和需求
- 使用高级分析工具,如 R、Hadoop 和高级统计建模
数据工程师
- 提供可用于企业特定目的的数据基础设施。例如,用于交易、商业决策等。
- 需要构建高性能的数据,这些数据对于企业的特定目的而言是可靠的
- 使用 SQL、MySQL 等工具,这些工具支持数据科学家使用的工具
- 创建数据管道,为数据科学家提供优化的数据以便使用
- 通过维护数据科学家采取实际行动所需的数据基础设施来帮助他们。例如,将数据输入机器学习模型进行交易等。
这里的要点是,您将需要一名数据科学家和一名数据工程师来使数据集正常工作。对于任何使用数据集做出重要决策的企业来说,这两者都是至关重要的。
没有数据科学家,数据工程师不会有多大帮助,因为数据科学家使数据进入实际或实际使用。
同样,在数据工程师的帮助下,数据的建立不会出现诸如错误输入、重复数据等错误。
现在让我们进一步看看数据工程的未来。
数据工程的未来
随着技术的快速变化和进步,数据工程也在彻底转变。自从物联网(IOT)、人工智能、混合云计算等等。在进入金融市场等领域后,数据工程师也应该转型,并学会利用这些领域更好地发挥作用。
据 research 预计,到 2023 年,数据工程服务市场有望从 2017 年的 295.0 亿美元增长到 773.7 亿美元。
这是意料之中的,因为过去几年大数据被广泛采用。未来,随着技术的不断进步,大数据需求预计将会增长并主导市场。
结论
本文主要讨论了数据工程的基础知识。数据工程师在任何企业或交易中都起着至关重要的作用,因为数据集在决策时是最重要的。此外,随着更多的技术进步和对大数据使用的需求,数据工程的未来足够光明。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
使用 Python 将数据转化为见解并构建策略
原文:https://blog.quantinsti.com/data-insights-trading-strategy-python-project-lokesh-kumar/
这篇文章将帮助你学习如何分析数据,通过实时的股票市场数据和数据集获得洞察力。它还将帮助你学习如何使用 Python 编程创建自己的交易策略。
本项目中使用的完整数据文件和 python 代码也可以在本文末尾下载。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
Lokesh Kumar 是孟买一家最大的美国银行的风险经理。他在银行和金融领域拥有超过 6 年的经验,曾在监管模型、信贷决策模型、宏观经济研究和分析领域工作。

Lokesh 拥有德里大学经济学荣誉学士学位和马德拉斯经济学院金融经济学硕士学位。此外,他还持有风险管理证书(FRM-美国 GARP)。他也是 EPAT 大学的校友。
研究动机
我是一名经济学学生和风险经理。过去 6 年来,我一直在使用各种统计软件(R、SAS、STATA、EVIEWS)进行数据分析、统计、计量经济学、机器学习建模,但从未有机会处理印度股票数据。
这个项目被证明是一个踏脚石,跟随我的兴趣,并在印度股票市场的职业生涯。此外,我已经跟踪印度金融市场和全球新闻 5 年了。
数据
- 用于分析的数据包括这些变量。
- 每个部门 2 只(流动性强、波动性大、年回报率正)股票。
- 数据的频率是每天。
型号
动量、均值回归和配对交易:分析-超额回报、夏普比率、最大提取、提取持续时间、样本内和样本外测试、绝对回报、相对回报、盈利能力分析。
回溯测试模型
评估战略绩效
项目摘要
这个项目研究股票价格的行为和运动。我们分析了 2010 年 10 月至 2018 年 12 月期间 Nifty 行业指数的详尽股票列表中的 20 只股票;基于较高的年平均滚动回报率和波动性,考虑每个行业的 2 只股票。
我们研究了股票价格和交易量数据,建立了 3 个策略——基于交易量和价格、均值回归和趋势跟踪(RSI)。我们发现没有一种特定的策略对所有的股票都有效。
我们评估了策略的性能,发现了高回报率和命中率。我们还对 2019 年 1 月至 2019 年 3 月的小样本期间进行了样本外测试,以观察我们是否可以在实时市场中使用这些策略,然后我们可以产生多少利润。
简介
我们的目标是使用不同的建模方法来确定进场点和出场点,高信心地做多和做空交易。我们专注于构建能够产生高回报且易于实施的战略。
首先,我们探讨了量价关系,因为有许多基于量价的技术指标。如果交易量随着价格的上涨而增加,那么上升趋势就是强劲健康的,当市场进入反趋势时,上升趋势就会减弱。
第二,我们探索了横截面均值回归策略,该策略试图利用来自同一行业的两只证券之间的暂时错误定价。
第三,我们探索了趋势跟踪策略,即当价格上涨时做多,当价格下跌时做空。我们计算了相对强度指数(RSI ),该指数评估股票价格的超买和超卖情况。
数据挖掘
我们从印度股票市场的每一个板块中选择了两只股票。我们首先看了漂亮的行业指数和每个指数中包含的股票列表。这些指数由流动性最强、资本化程度最高的股票组成,反映了每个行业的行为和表现。
我们使用 20 天滚动窗口,根据平均年化滚动回报和滚动波动性分析了总共 126 只股票。
我们根据高波动性、高回报和正回报最终确定了每个行业的两只股票。
我们从雅虎财经中提取了 2010 年 1 月至 2018 年 12 月期间的股价和成交量数据。
最终数据集由 2010 年 10 月至 2018 年 12 月期间的 20 只股票组成。所有 20 只股票的数据都是从 2010 年 10 月开始的。
用于分析的股票列表:
| Sr 号 | 符号 | 公司名称 | 行业 |
| one | 阿波罗泰尔 | 阿波罗轮胎有限公司 | 汽车 |
| Two | 阿肖克利 | 阿肖克·利兰有限公司 | 汽车 |
| three | 声望 | 威望地产项目有限公司 | 建筑 |
| four | 上世界 | 奥贝罗伊房地产有限公司 | 建筑 |
| five | 朱布尔福德 | 喜洋洋食品厂有限公司 | 生活消费品 |
| six | UBL | 联合酿酒有限公司 | 生活消费品 |
| seven | 陆军一等兵(Private First Class) | 电力金融有限公司 | 金融服务 |
| eight | RECLTD | 雷克有限公司 | 金融服务 |
| nine | 尼泰克 | 尼伊特技术有限公司 | 信息技术 |
| Ten | 我的天 | 明德树有限公司 | 信息技术 |
| Eleven | 今天 | 今日电视网络有限公司 | 媒体和娱乐 |
| Twelve | INOXLEISUR | 伊诺克斯休闲有限公司 | 媒体和娱乐 |
| Thirteen | 威尔公司 | 韦尔斯普林有限公司 | 金属 |
| Fourteen | HINDALCO | 欣达尔科工业有限公司 | 金属 |
| Fifteen | 阿尔科法尔马 | 奥罗宾多制药有限公司 | 制药公司 |
| Sixteen | 百康 | 百康有限公司 | 制药公司 |
| Seventeen | 印度的 | 印度银行 | 公共银行 |
| Eighteen | 班克 boarda | 巴罗达银行 | 公共银行 |
| Nineteen | 联邦银行 | 联邦银行有限公司 | 私营银行 |
| Twenty | 轴心银行 | Axis 银行有限公司 | 私营银行 |
数据分析
我们计算了股票收益率、命中率和累计盈亏的描述性统计量。
以下是项目中使用的每个策略的技术说明:
在基于成交量和价格的交易策略中,如果当前成交量小于最近 3 天的移动平均成交量,且当前价格小于最近 3 天的移动平均价格,我们将生成做空信号。我们尝试了不同的短时间框架,如 3、4、5、14 天,但 3 天是最好的结果,也试图产生长信号,但这并没有给任何股票带来积极的结果,所以我们只进行了卖空交易。
在均值回复配对交易策略中,我们考虑了来自每个部门的 2 只类似股票,计算了价格比,并检查了价格比(价差或 P S1 /P S2 )是否是协整的,那么这些股票是均值回复的,可以应用配对交易策略。
我们发现许多价格比率不是协整的。我们使用扩展的 Dicky Fuller (ADF)检验来检验协整性。我们创造了信号——当价差低于低波段时在 S1 做多,当价差高于移动平均线时在 S1 做多,当价差高于高波段时在 S1 做空,当价差低于移动平均线时在 S1 做空,并在 S2 建立相反的头寸。
我们尝试了不同的时间框架,如 5 天、14 天、21 天来计算滚动回报和波动性,但 5 天给出了最佳结果,还尝试了+/- 1 或+/- 2 标准差来计算上下波动带,并根据结果最终确定了+/- 1 标准差。
在趋势跟踪 RSI 策略中,70 或以上的值表明证券超买,因此股票做空,30 或以下的值表明证券超卖,因此股票做多。我们用 21 天的时间来计算 RSI。然而,我们研究了不同的时间框架,如 5、14、21、30、60 天,但 21 天的结果最好。
主要发现
我们提供了 20 只股票的汇总统计数据。负偏度表示收益的分布是负偏的。
过度峰度(峰度大于 3)表明收益分布具有较厚的尾部(较高的极端结果)。
| 符号 | 表示 | Std。偏差 | 最小值 | 最大值 | 第 25 百分位 | 第 50 百分位 | 第 75 百分位 | 偏斜度 | 峰度 |
| 阿波罗泰尔 | Zero point zero six | Two point five one | -29.37 | Ten point one six | -1.34 | Zero point zero six | One point four three | -0.96 | Eleven point zero seven |
| 阿肖克利 | Zero point zero five | Two point three nine | -15.09 | Twelve point eight one | -1.30 | Zero | One point three four | Zero point zero two | Two point nine two |
| 声望 | Zero point zero one | Two point eight two | -13.35 | Sixteen point six two | -1.69 | -0.12 | One point five | Zero point four three | Two point one two |
| 上世界 | Zero point zero two | Two point three five | -11.70 | Sixteen point zero six | -1.32 | -0.10 | One point one three | Zero point seven two | Three point eight three |
| 朱布尔福德 | Zero point zero eight | Two point four nine | -11.91 | Fifteen point zero three | -1.25 | Zero | One point three four | Zero point one six | Three point one two |
| UBL | Zero point zero six | Two point five three | -12.67 | Seventeen point one eight | -1.16 | -0.02 | One point zero eight | Zero point seven eight | Six point six one |
| 陆军一等兵(Private First Class) | -0.03 | Two point seven two | -15.52 | Thirteen point four | -1.62 | -0.08 | One point five seven | Zero point zero seven | One point six six |
| RECLTD | -0.02 | Two point five nine | -13.55 | Twelve point nine nine | -1.47 | -0.07 | One point five | -0.04 | One point five seven |
| 尼泰克 | Zero point zero eight | Two point three six | -12.60 | Thirteen point nine one | -1.26 | -0.04 | One point two six | Zero point three five | Three point zero five |
| 我的天 | Zero point zero nine | Two point zero four | -18.36 | Nine point four two | -0.99 | Zero point zero three | One point zero nine | -0.13 | Six point one five |
| 今天 | Zero point zero eight | Three point zero four | -18.15 | Eighteen point two three | -1.44 | -0.19 | One point three | One point one six | Seven point four five |
| INOXLEISUR | Zero point zero six | Two point six four | -15.21 | Sixteen point nine | -1.38 | -0.09 | One point two six | Zero point seven four | Four point seven |
| 威尔公司 | -0.03 | Three point three one | -31.45 | Eighteen point two three | -1.76 | -0.19 | One point six four | -0.24 | Eight point one nine |
| HINDALCO | Zero | Two point five two | -10.17 | Twelve point six eight | -1.57 | -0.06 | One point five two | Zero point one three | One point two five |
| 阿尔科法尔马 | Zero point zero nine | Two point five one | -18.44 | Twelve point four four | -1.31 | Zero | One point four eight | -0.03 | Three point one three |
| 百康 | Zero point zero seven | Two point zero four | -12.46 | Fourteen point four seven | -1.02 | Zero point zero one | One point zero eight | Zero point five six | Five point one two |
| 印度的 | -0.01 | Two point seven four | -13.11 | Nineteen point one two | -1.56 | -0.11 | One point two seven | Zero point nine three | Five point six six |
| 班克 boarda | -0.02 | Two point five three | -17.89 | Twenty-seven point three three | -1.38 | -0.03 | One point two eight | Zero point eight five | Twelve point zero six |
| 联邦银行 | Zero point zero three | Two point one nine | -13.04 | Seventeen point four seven | -1.21 | -0.04 | One point one eight | Zero point three | Four point seven eight |
| 轴心银行 | Zero point zero four | Two point one three | -9.96 | Fourteen point six | -1.15 | -0.02 | One point one nine | Zero point two | Three point zero three |
基于数量/价格的卖空策略
我们对所有 20 只股票都采用了这种策略。数据显示,这种策略导致平均 55%的命中率和 9.7%的年化回报。累计 PnL 显示,2010 年 10 月的投资额(1 卢比)在 2018 年 12 月平均为 2.291 卢比。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 阿波罗泰尔 | Three hundred and twenty-four | Six hundred and five | 54% | Two point two nine four | 10.9% |
| 阿肖克利 | Three hundred and twenty-eight | Five hundred and seventy-six | 57% | Three point zero eight nine | 15.1% |
| 声望 | Four hundred and twenty-one | Six hundred and ninety-five | 61% | Four point seven zero three | 21.4% |
| 上世界 | Four hundred and five | Six hundred and eighty-three | 59% | Four point two five one | 19.8% |
| 朱布尔福德 | Three hundred and forty | Six hundred and one | 57% | Two point three two five | 11.1% |
| UBL | Three hundred and eighty-one | Six hundred and sixty-nine | 57% | Two point seven one two | 13.3% |
| 陆军一等兵(Private First Class) | Two hundred and ninety-two | Five hundred and sixty-two | 52% | One point four eight six | 5.1% |
| RECLTD | Three hundred and three | Six hundred and five | 50% | One point two two five | 2.6% |
| 尼泰克 | Three hundred and forty-six | Six hundred and sixty-nine | 52% | One point zero five two | 0.6% |
| 我的天 | Three hundred and forty-three | Six hundred and seventeen | 56% | Two point one zero five | 9.8% |
| 今天 | Four hundred and thirty-six | Seven hundred and fifty-one | 58% | Two point four four six | 11.8% |
| INOXLEISUR | Three hundred and eighty-four | Seven hundred and forty-nine | 51% | One point zero zero two | 0.0% |
| 威尔公司 | Four hundred and sixteen | Six hundred and ninety-one | 60% | Four point two seven one | 19.9% |
| HINDALCO | Two hundred and ninety-one | Five hundred and seventy-three | 51% | One point four zero two | 4.3% |
| 阿尔科法尔马 | Two hundred and ninety-five | Five hundred and sixty-three | 52% | Two point zero eight nine | 9.6% |
| 百康 | Three hundred and twenty-nine | Six hundred and twenty-two | 53% | One point eight eight six | 8.3% |
| 印度的 | Three hundred and seventy-two | Six hundred and thirty-nine | 58% | Two point seven five | 13.5% |
| 班克 boarda | Three hundred and thirteen | Six hundred and one | 52% | One point four five five | 4.8% |
| 联邦银行 | Three hundred and twenty-four | Five hundred and ninety-five | 54% | One point eight seven six | 8.2% |
| 轴心银行 | Two hundred and ninety-six | Five hundred and fifty-three | 54% | One point four zero two | 4.3% |
均值回归对交易策略
在我们的分析中,我们发现只有 2 对股票是协整的。PFC & RECLLTD 的 p 值小于 10%的显著性水平,TVTODAY & INOXLEISUR 的 p 值小于 1%的显著性水平。
数据显示,这种策略导致平均 52%的命中率和 13.7%的年化回报。累计 PnL 显示,2010 年 10 月的投资额(2 卢比)在 2018 年 12 月平均变成了(5.677 卢比)。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 陆军一等兵(Private First Class) | One thousand four hundred and seventy-five | Two thousand eight hundred and ninety-six | 51% | Four point six zero one | 11.0% |
| RECLTD |
| 今天 | One thousand five hundred and twenty-one | Two thousand eight hundred and seventy-nine | 53% | Six point seven five three | 16.4% |
| INOXLEISUR |
趋势跟随 RSI 策略
我们为 NIITTECH 开发了这种策略,因为基于数量和价格的卖空策略未能产生良好的回报,而且这对组合没有进行协整。
数据显示,这种策略导致平均 69%的命中率和 6.5%的年化回报。累计 PnL 显示,2010 年 10 月的投资额(1 卢比)在 2018 年 12 月平均为(1.652 卢比)。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 尼泰克 | Forty-six | Sixty-seven | 69% | One point six five two | 6.5% |
样本外回测
我们根据 2010 年 10 月至 2018 年 12 月期间的历史数据优化了策略。
我们运行一个样本外回溯测试,看看如果我们可以在市场上使用这些策略来产生利润,该策略的表现如何。分析中使用的样本外回测期为 2019 年 1 月至 2019 年 3 月。
基于数量/价格的卖空策略
根据历史数据结果,我们对过去产生超过 10%回报率的股票测试了这一策略,并观察了如果我们在 2019 年 1 月至 2019 年 3 月期间将资金投入市场,这一策略会如何表现。
数据显示,这种策略导致平均 55%的命中率和 25.3%的年化回报。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 阿波罗泰尔 | Twelve | Nineteen | 63% | One point zero zero two | 0.8% |
| 阿肖克利 | Ten | Seventeen | 59% | One point zero two five | 10.8% |
| 声望 | Sixteen | Twenty-four | 67% | One point one seven three | 93.1% |
| 上世界 | seven | Sixteen | 44% | Zero point nine six | -15.4% |
| 朱布尔福德 | six | Thirteen | 46% | Zero point nine nine six | -1.8% |
| UBL | six | Sixteen | 38% | Zero point nine four six | -20.5% |
| 今天 | Sixteen | Twenty-two | 73% | One point one five six | 82.3% |
| 威尔公司 | Seventeen | Twenty-seven | 63% | One point one six eight | 90.0% |
| 印度的 | seven | Fifteen | 47% | Zero point nine seven one | -11.3% |
均值回归对交易策略
数据显示,这种策略导致平均 45%的命中率和 5.4%的年化收益。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 陆军一等兵(Private First Class) | Forty | Eighty-three | 48% | Two point two zero two | 48.8% |
| RECLTD |
| 今天 | Forty | Ninety-five | 42% | One point seven eight one | -38.1% |
| INOXLEISUR |
趋势跟随 RSI 策略
数据显示,这种策略导致平均 50%的命中率和 4.5%的年化收益。
| 符号 | #积极交易 | #总交易量 | 命中率 | 累积 PnL | 平均。年化回报率 |
| 尼泰克 | Two | four | 50% | One point zero one one | 4.5% |
限制
为了计算回报,我们没有包括交易成本。
实施方法
这是一个完全活的项目,可以很容易地在交易系统中实现。
基于数量和价格的卖空策略
如果当天交易量低于过去 3 天的平均交易量,当天收盘价低于过去 3 天的平均收盘价,则在第二天以开盘价买入股票,以收盘价卖出股票。
均值回归对交易策略
如果当日价差(股票 1/股票 2 的价格比)低于下限(价差的 5 天移动平均值-价差的 5 天移动标准差),第二天在股票 1 中做多。
如果当日价差(股票 1/股票 2 的价格比)超过价差的 5 天移动平均线,第二天在股票 1 处做多。
如果当日价差(股票 1/股票 2 的价格比)高于上限(价差的 5 天移动平均线+价差的 5 天移动标准差),第二天在股票 1 中做一个短线。
如果当天的价差(股票 1/股票 2 的价格比)低于价差的 5 天移动平均线,在第二天做空股票 1。同时在 stock2 中取相反的位置。
如果多空信号是新的,以开盘价交易,否则以收盘价交易。
趋势跟随 RSI 策略
如果当天 RSI 低于 30,第二天做多股票。
如果当日 RSI 超过 70,第二天做空该股。
如果多空信号是新的,以开盘价交易,否则以收盘价交易。
结论
我们研究了股票价格和交易量数据,建立了 3 个策略——基于交易量和价格、均值回归和趋势跟踪(RSI)。
我们发现没有一个特定的策略对所有的股票都有效。我们评估了策略的性能,发现了较高的总体回报率和命中率。
然而,我们可以探索我们在课程中学到的许多其他策略,并产生比这些策略更高的回报。
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT) 的高管课程。该课程包括各种培训模块,让你具备在算法交易中建立一个有前途的职业生涯所需的技能。
参考书目
文件在下载
- Python 中的项目编码策略
- R 中的项目代码数据提取
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
Julia 中的数据操作和可视化技术
原文:https://blog.quantinsti.com/data-manipulation-visualization-using-julia/
安舒尔·塔亚尔
在本文中,我们将研究 Julia 中的数据操作和可视化技术。然而,我不会进入每个函数的每个参数的细节,因为这个系列的目标是使用 Julia 作为工具来实现我们的目标,即构建和回测交易策略T5。所以,我们会继续关注这一点。
如果你需要一个函数来解决你在编程时面临的任何特殊挑战,你可以参考它的详细文档。
本文分为以下几个部分:
在这个 Julia 编程系列的前几篇文章中,我介绍了语言,并从 Julia 编程的基本语法开始。你也可以去看看。
数据操作
无论何时使用任何编程语言,都需要理解处理大型异构数据集的数据结构。在 Julia 的世界里,它们被称为数据帧。
Julia 的 DataFrames.jl 包提供了一种结构化和操作数据的方法。
可以使用“Pkg”模块进行安装。
创建新的数据框架
这是一个创建新数据帧的示例。
**
Our cookie policyWe use cookies (necessary for website functioning) for analytics, to give you the best user experience, and to show you content tailored to your interests on our site and third-party sites. By closing this banner, scrolling this page, clicking a link or continuing to use our site, you consent to our use of cookies. Read more[Accept](javascript:😉****
数据预处理:Python,机器学习,例子等等
数据预处理是任何好的机器学习模型的基本要求。预处理数据意味着使用机器学习模型容易读取的数据。在本文中,我们将讨论数据预处理的基础知识,以及如何使数据适合机器学习模型。
本文涵盖:
- 什么是数据预处理?
- 为什么需要数据预处理?
- 使用 Python 对不同数据集类型进行数据预处理的示例
- 不同的日期格式
- 从哪里可以了解更多关于数据预处理的知识?
什么是数据预处理?
数据预处理是准备原始数据并使其适合机器学习模型的过程。数据预处理包括数据清洗,使数据准备好提供给机器学习模型。
我们关于数据清理的综合博客帮助您了解作为数据预处理一部分的数据清理,涵盖了从基础、性能等所有内容。
数据清洗后,数据预处理需要将数据转换成机器学习模型可以理解的格式。
为什么需要数据预处理?
数据预处理主要用于以下情况:
- 准确数据:为了使数据对机器学习模型可读,需要准确,没有缺失值、冗余值或重复值。
- 可信数据:更新后的数据应尽可能准确或可信。
- 可理解数据:更新的数据需要正确解读。
总而言之,数据预处理对于机器学习模型从这种数据中学习是重要的,这种数据是正确的,以便将模型引导到正确的预测/结果。
使用 Python 对不同数据集类型进行数据预处理的示例
由于数据有多种格式,让我们讨论如何将不同的数据类型转换成 ML 模型可以准确读取的格式。让我们看看如何通过以下方式从数据集中获取正确的要素:
- 缺少值
- 极端值
- 过度拟合
- 没有数值的数据
- 不同的日期格式
缺少值
缺失值是处理数据时常见的问题!由于各种原因,如人为错误、机械错误等,这些值可能会丢失。
在你开始算法交易过程之前,数据清理是一个重要的步骤,算法交易过程从历史数据分析开始,以使预测模型尽可能准确。
基于这个预测模型,你创建交易策略。因此,将遗漏的值留在数据集中可能会造成严重破坏,给出错误的预测结果,从而导致错误的策略创建,而且结果也不会很明显。
为了找出最准确的特征,有三种技术可以解决缺失值问题,它们是:
- 落下
- 数值插补
- 分类插补
掉落
删除是处理丢失值的最常见方法。丢弃数据集中具有缺失值的那些行或整个列,以避免在数据分析中出现错误。
有一些机器被编程为自动删除包含缺失值的行或列,从而减少训练规模。因此,这种下降会导致模型性能下降。
一个简单的解决方法是使用插补法来解决由于数值下降而导致的训练规模减小的问题。我们将进一步讨论有趣的插补方法。在跌落的情况下,您可以为机器定义一个阈值。
例如,阈值可以是任何值。可以是数据的 50%、60%、70%。让我们在我们的示例中取 60%,这意味着模型/算法将接受 60%的缺失值的数据作为训练数据集,但是缺失值超过 60%的特征将被丢弃。
为了删除这些值,使用了以下 Python 代码:
泽维尔是如何从日内交易转向算法交易的
Xavier 是一名来自澳大利亚的兼职交易员,他试图建立自己的算法交易平台。
他做过工程学和计算机科学硕士,有 8 年工作经验。通过尝试各种职业和工作,Xavier 最终决定成为一名 Algo 交易员。这是他的旅程。
嗨,Xavier,告诉我们你自己的情况
大家好,我是来自澳大利亚堪培拉的 Xavier Anthony。我攻读了工程学和计算机科学硕士学位。我尝试过很多工作,比如在大的咨询公司做程序员、建筑师,最后进入管理层。
我在神经网络领域做了一些研究,我喜欢玩技术和与技术互动。我目前是一名 IT 架构师。
你是如何超越算法交易的?
当我学习工程学的时候,我对金融市场产生了兴趣。所以,为了了解金融市场,我做了一些专业工作。我叔叔的市场故事总是让我感兴趣,这让我迷上了学习市场。
那些日子,数据分析和数据挖掘等等。还没有完全建立起来,我想我会进入这个领域,因为我能够发现市场的潜力。我打算做自己的老板,而不是为别人工作,而且这是我喜欢的事情。
我的思维方式也是以研究为导向的,因为我在硕士期间就一直在追求这种思维方式。通过研究和分析提取数据让我非常兴奋。
我发现金融市场是一个庞大的行业,有大量的数据。当我在澳大利亚攻读硕士学位时,我也对人工智能产生了兴趣。
我过去常常检查资产负债表,检查公司在做什么,他们的投资,股息等等。当我和我的朋友们热衷于投资时,我们经常创造模拟的交易场景来测试我们的技能。
由于工作的限制,我不能直接进入交易行业,因为当时我在一家著名的跨国公司担任重要职务。我也不知道如何在交易中追求自己的兴趣。然而,经过 4 年的经验,我开始进入日内交易。
进入金融市场,进入算法交易,对我来说是一件好事。我赚了一些钱,赔了一些钱,进入商品市场,有一次不太好的石油交易经历,这迫使我思考。这让我大开眼界。
我仍然缺乏适当的金融知识和如何进入这个领域的算法交易。我需要一些东西来到这个世界。幸运的是,在正确的时间,我找到了 EPAT。
我当时有很多疑惑和矛盾。
我的学历呢?
我应该把钱投到哪里?
我该怎么学?
我该去找谁?
在那里,当我探索更多的选择时,我遇到了 EPAT。毫无疑问,我会说我学到了很多,它教会了我很多东西。现在,我的处理方式完全不同了。
你和 EPAT 相处得怎么样?
EPAT 课程确实适合每个人,相信我,它非常有帮助。
EPAT 有一个很好的课程结构,而且很容易导航。这里的教职员工很棒,他们有经验丰富的专业人员在学习的每一步指导你。管理时间是一个挑战,但 EPAT &出色的支持团队非常有帮助。
我的支持经理 Dhiraj 非常支持我,并在我的 EPAT 之旅中全程指导我。由于我的个人情况,我在课程期间遇到了一些挑战,他帮助我克服了这些挑战。
出于某种原因,我从商品交易和股票交易中走出来,对期权交易产生了兴趣,这是一个很大的学习领域。
在 EPAT 之后,我更加自信了,自信是我以前没有的东西。这些天,我制定策略。现在,我知道了价值观,也知道了一些问题的答案,比如我为什么要选择这个策略,回溯测试报告是什么。
定位细胞是一个巨大的帮助。他们经常根据我的需要通过电子邮件和工作邀请给我发送工作机会。我想对一直帮助和支持我的支持经理和其他教职员工表示感谢。
当我开始用实时交易系统进行实时交易时,我肯定需要一些指导,告诉我犯了什么错误,哪里需要改进,我很确定 EPAT 会在这方面支持我。
你对那些有抱负的量化分析师有什么话要说?
- 永不放弃!
- 进入市场,做好遭受损失的准备。
- 花时间在你的教育上。
- 当专家给出建议时,试着理解他们为什么这么说。
我通过犯错误,然后从中吸取教训,学会了所有这些东西。当问题出现时,你可能想放弃,或者不想完成 EPAT 课程。不要放弃。
你可以在几个月后,或者甚至几年后再回来。EPAT 大学提供终身学习课程的机会,你以后可以在生活中的任何时候重新学习。
这一系列视频是 QuantInsti 专门为算法交易(EPAT)管理课程的学生进行的讨论表的记录。
https://www.youtube.com/embed/0ZWqH6l8v40?rel=0
非常感谢泽维尔与我们分享您的旅程。我们相信读者会被你的故事所感动。我们希望您能够实现自己的梦想,建立自己的算法交易平台,建立自己的业务。祝你一切顺利!
如果你也渴望用终身技能来武装自己,这些技能将永远帮助你提升你的交易策略,这个 algo 交易课程正是你所需要的。拥有统计学&计量经济学、金融计算&技术、机器学习等课题,确保你精通在交易领域出类拔萃所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
初学者指南:如何进行日内交易?
在这篇文章中,我们将详细讨论日内交易实践。虽然日内交易原则可能很简单,但要使你的策略更好确实需要时间和努力。
如果你是金融市场新手,我们建议你先了解金融市场的基础知识。
让我们在这篇 covers:的文章中找出作为日内交易者交易的必要方面
- 什么是日内交易?
- 新手日交易
- 什么都可以交易?
- 最佳日交易股票的特征
- 日内交易策略
什么是日内交易?
日间交易指的是在同一个交易日内买卖金融工具的证券投机行为。在日交易中,为了避免在非交易时间由于不可预见的事件而可能发生的损失风险,所有头寸都必须在当天市场关闭前平仓。例如,日交易者可以避免当天收盘价和第二天开盘价之间的价格差距,这可能会影响决策。
现在让我们来看看适合新手的日间交易练习。
作为初学者的日内交易
任何领域的初学者都需要尽可能多地收集该领域的知识。虽然可以从经验中获得很多,但我们将讨论这些信息,这可能有助于您作为初学者顺利完成您的旅程。该信息与以下几点有关:
- 先决条件
- 技能
- 需要考虑的事项
- 阅读蜡烛图
- 风险和资金管理
- 订单类型
先决条件
有一些先决条件,每天交易者在开始练习时必须检查,因为这些是帮助你有效操作的要素。这些是:
- 个人电脑
- 经纪人
- Demat 帐户
- 可靠的互联网连接
PC
PC 的技术规格应该是有利的,例如 RAM 和操作系统。此外,由于分析市场很重要,每天的金融市场分析屏幕应该看起来很舒服。
经纪人
你必须为你的日内交易选择正确的经纪人,在我们关于算法交易指南的博客文章中,我们有一份来自印度、美国、英国、欧盟和加拿大的可靠经纪人名单。您可以查看这里提到的代理和 API。
Demat 账户
如果您不是通过经纪人进行交易,您可以在您的银行合作伙伴处开立 Demat 账户。这是因为经纪人会为你提供这样的设施。
可靠的互联网连接
一个可靠的互联网连接是日内交易的最重要的先决条件之一,因为你不希望你的互联网服务器在你交易过程中出现故障。
技能
拥有一套技能不仅对日内交易者是非常重要的,对任何领域的专业人士也是如此。
进行交易通常需要一些技能,但要想成功地进行日间交易,你需要具备以下条件,才能顺利进行交易:
- 交易/金融市场知识
- 快速做出决策,以便抓住市场机会
- 执行交易策略的数学技巧
- 预测和分析市场趋势的知识
- 风险管理和资金管理的专业知识
- 资产管理技能
- 决定交易策略的计划技巧
需要考虑的事项
日内交易本身带来了很多作为初学者需要注意的事情。首先,让我们讨论一些简单但非常有用的事情,你可以在从事日内交易时注意:
- 只交易最适量的钱
- 被告知
- 保住你的日常工作
- 有足够的时间跟踪市场
只交易最佳金额的资金
你必须用那些不会让你失去财富或让你陷入债务的钱来交易,因为一旦亏损,你将无力偿还。
你不能在每笔交易中冒险投入太多资金。你需要知道你交易的仓位大小。
这里的仓位大小意味着你在交易中持有的股票数量。在决定股票数量之前,你必须考虑作为投资者的账户规模和风险承受能力。这样,你可以在进场时设置止损价格。
通常,风险资金/交易风险=最佳头寸规模
风险资金是你能够承担风险的金额,交易风险是市场交易的总体风险。
被通知
在你开始日内交易之前,你必须具备最大化收益所需的知识。你必须充分了解你计划交易的股票的走势,以及股市中任何可能影响股价的不太可能发生的事件的最新消息。
为了保持消息灵通,应该随时查看业绩公告,因为这样,投资者可以在分析上一季度或年度业绩后投资证券。通过这种方式,日间交易员可以在分析公司提供的财务补充/披露后,分析股票回报的可行性。可以评估回报率指标,如 RoE(股本回报率)、股息支付率、运营效率、P/E 比率等,以便做出明智的决策。
另一个重要的获得信息的方法是在交易中借助情绪分析。通过分析新闻和推文描绘的情绪,你可以创建这样的交易策略,这将有助于你获利。情感分析最好可以通过各种机器学习技术来完成,比如自然语言处理,分类和支持向量机。然后,可以使用 VADER 等技术计算情感得分。这在我们的交易情绪分析学习课程中有很好的解释。
保住你的日常工作
作为初学者,你可能不会很快熟悉股市的所有涨跌。开始的时候,你可能运气不错,可以在市场上维持下去。这种可能性更大,尤其是在有利的市场环境下。虽然,在市场形势不利的情况下,你的策略实际上会受到考验。看完了市场的所有涨跌,如果你觉得你可以全职交易下去,那就暴跌吧。
有足够的时间跟踪市场
在日内交易中,你需要投入的最重要的事情就是你的时间。这段时间用来跟踪市场,寻找合适的机会。因为这些机会在交易时间的任何时候都会出现,所以你需要保持警惕。
阅读蜡烛图
阅读蜡烛图是这里的另一个重要话题。当你日内交易时,你必须知道烛台上不同的点是什么意思。如你所见,在下图中,有两个烛台。一个看涨,一个看跌烛台。让我们找出方法。

每个点描述了:
- 高价意味着在此期间交易的最高价格。
- 低价意味着交易的最低价格。
- 开盘价描绘了蜡烛线形成后的第一个交易价格。如果价格与前一天的收盘价相比呈上升趋势,蜡烛将变成绿色/蓝色。另一方面,如果价格下跌,蜡烛会变红。
- 收盘价意味着蜡烛线形成期间的最后交易价格。如果收盘价低于开盘价,蜡烛就会变红。反之,如果收盘价高于开盘价,蜡烛线将变成蓝色/绿色。
左图显示了看涨的烛台,描绘了开盘价高于前一天的收盘价。然而,右边的图像显示了一个看跌的烛台,描绘了一天结束时的收盘价低于开盘价。
风险和资金管理
风险和资金管理是交易中最重要的两件事,日内交易者需要具备同样的知识。
在这里,我们将讨论一些重要的交易领域的事情,可能有助于获利日交易实践:
票据交易
由于纸交易是一种使用虚拟货币的交易行为,所以参与纸交易是最安全的。所谓虚拟货币,我们指的是不能在现实世界中交易,但可以用来进行纸面交易的货币。纸面交易平台要么是技术公司,要么是由在线经纪商提供的演示交易功能。它们或者以虚拟游戏的形式提供纸面交易,或者以一般的方式提供纸面交易账户,作为对真实交易账户的补充。
目标利润分析
你还必须做一个目标利润分析,而日间交易,这意味着找出估计的业务活动,以执行,以赚取目标金额的利润。
找出目标利润分析的公式:
SpQ = VeQ + Fe +Tp
这里,
Sp =单位销售价格
Q =在此期间生产或销售的数量
Ve =制造和销售每单位产品的可变费用
Fe =固定费用总额
Tp =目标利润
保证金杠杆
通常,日内交易者也可以利用保证金杠杆。
保证金是投资者要求存入交易对手(经纪人或交易所)的抵押品,用于覆盖交易对手在金融市场可能面临的风险。
另一方面,杠杆意味着投资者在经纪人或交易所的帮助下卖空或购买高于保证金的证券。在这里,卖空意味着投资者如果认为标的资产的价格在未来会下跌时所使用的策略。在美国,投资者可以以 2:1 的比例(最高)进行初始杠杆操作,这是法规 T 所允许的。要了解详细信息,你也可以看看我们关于算法交易规则-美国的博客文章。
但是,如果你使用保证金杠杆,就会有追加保证金的风险,我们接下来会讨论这一点。
追加保证金通知
在保证金杠杆的情况下,交易者可能有保证金通知的风险。经纪人在估计市场风险后,不断修正担保证券的价值。追缴保证金意味着,每当担保证券的市场价值低于修订后的保证金时,需要将投资者方的额外资金纳入保证金账户。
例如,如果投资者持有的投资组合贬值到低于经纪人的保证金要求,那么就要追加保证金。因此,投资者可以选择存入保证金或清算现有资产。
因此,你必须在一天结束时检查你能承受的损失后,再决定要杠杆的保证金数额。
订单类型
接下来,您必须了解订单类型,并根据您的偏好决定要选择的订单类型。
你不能冒险超出你当天的既定上限。一旦你达到上限,你需要停止交易。
例如,如果你输的钱超过了你赢的钱,那你就彻底输了。例如,如果你在盈利的一天赚了 200 美元,在亏损的一天,你的亏损不能超过 200 美元。
为了确保您最终不会损失超出您承受能力的资金,让我们来看看几种订单类型,它们是:
- 市场定购单
- 限价订单
- 止损单
- 限价止损单
- 括号顺序
市场订单
在市价单中,交易者或投资者指示经纪人或交易目的地立即以市场上的最佳时价买入或卖出股票。因此,当订单执行的确定性优先于执行价格时,使用市价订单。
例如,一个投资者下单购买 1000 股 XYZ 股票,而最佳报价是每股 3 美元。如果先执行其他订单,投资者的市价订单可能会以更高的价格执行。
限价单
限价订单是以特定或更好的价格买入或卖出股票的订单。买入限价单只能以限价或更低的价格执行,卖出限价单只能以限价或更高的价格执行。如果获得一个特定的价格比成交更重要,限价单是合适的。
例如,一个投资者想以不超过 70 美元的价格购买一只 ABC 股票,这只股票目前的交易价格是 75 美元。投资者发出限价单,以 70 美元的价格购买 ABC 的股票。如果 ABC 股票价格跌至 70 美元或以下,订单将被执行。如果价格从未降至 70 美元或以下,订单将不会执行。下限价单有风险;如果股票跌到 71 美元,之后又涨到 100 美元。投资者可能会错过从 71 美元涨到 29 美元的机会。
止损单
止损单是在股票价格达到指定价格(称为止损价)时买入或卖出股票的订单。止损价格不是止损单的保证执行价格。止损价格是导致止损单成为市价单的触发器。
例如,假设你以每股 50 美元的价格购买了 XYZ 的股票,你担心它会下跌,如果价格跌至每股 45 美元以下,你可以使用止损单卖出,以保护自己免受更大的损失。风险在于,如果价格下跌非常快,并且在你之前已经有其他订单,股票最终可能会以低于 45 美元的价格卖出。
限价止蚀单
投资者可以通过设置止损限价单来避免订单以意外价格执行的风险。止损限价单结合了止损和限价单的特点。一旦达到止损价格,止损限价单就会变成限价单,以指定的价格执行。
例如,假设你以每股 50 美元的价格购买了 XYZ 股票。你不想每股损失超过 5 美元,所以你设置了 45 美元的止损限价单。如果股价跌至 45 美元,止损价格就会触发限价单,在 45 美元卖出。如果价格迅速跌至 45 美元以下,限价将确保你不会以更低的价格出售。限价单只会在股价再次达到 45 美元时执行。
括号顺序
支架订单旨在投资者可以通过将一个订单与两个相反的订单“支架”在一起来限制他们的损失并锁定利润。
买入挂单:买入挂单由通常高于买入挂单价格的卖出限价挂单和通常低于买入挂单价格的卖出止损挂单组成。这使得投资者可以通过上涨锁定利润,限制下跌损失。
卖出委托单:卖出委托单由一个较高价格的买入止损委托单和一个较低价格的买入限价委托单组成。
例如,如果你以 50 美元的价格买入一只股票,以 55 美元的价格卖出限价单,以 45 美元的价格卖出止损单。如果价格上升到 55 美元或下降到 45 美元,头寸将被卖出。交易者要么通过限价单获得 5 美元的收益,要么通过止损单遭受 5 美元的损失。
接下来,让我们讨论一下在金融市场上可以交易什么。
什么都可以交易?
在我们之前关于金融市场简介的文章中,我们已经详细介绍了在交易所交易的内容。在这里,我们列出了一些你可以交易的市场,并简要解释了它们。
作为日内交易者,你可以探索如下市场:
- 外汇
- 股票
- 加密货币
- 商品
- 结合
外汇
外汇市场是世界上最受欢迎和最具流动性的市场。在这个市场上,你可以用印度卢比、英镑、美元和欧元等货币进行交易。
通过我们免费的外汇交易课程,学习创建和回溯测试您在外汇市场的交易策略。
此外,这里有一个简短的视频,解释如何使用 Python 进行外汇交易:
https://www.youtube.com/embed/mWA4a4Afezc?feature=oembed
股票
股票市场为你提供了投资属于同一行业或不同行业的不同公司股票的机会。你可以投资常规和杠杆 ETF、期货和股票期权。
如果你想了解更多关于如何选择股票进行日内交易的信息,你必须观看下面这段来自 Quantra 的视频:
https://www.youtube.com/embed/TJni2fxrEMY?feature=oembed
加密货币
第三个市场是加密货币市场。投资这个市场会给你带来大量交易比特币和以太坊等加密货币的机会。
为了更好地了解加密市场,您可以选择 Quantra 上的这三个课程:
您还可以从本博客中获得一些关于印度加密货币市场之旅的知识。
期货
投资期货合约是日间交易的另一个选择。
商品
最后但并非最不重要的是商品交易。在日内交易中,你可以投资石油和天然气、农产品、金属、矿产等商品。此外,你可以在商品市场投资从黄金到可可的任何东西。如果你想了解这个话题,你可以参考我们关于商品市场的详细博客。
结合
债券是固定收益证券,公司或政府(称为债券发行人)通过它向投资者(称为债券持有人)筹集债务。
有不同类型的债券,如不支付利息的债券(零息债券)、可在指定到期日之前赎回的债券(T2)、可赎回债券(T3)、可转换为公司股票的债券(T4 可转换债券(T5))等。大多数公司或政府债券在交易所公开交易,其他的在场外交易。
接下来,让我们看看最好的日交易股票具有哪些特征。
最佳日交易股票的特征
在寻找最好的日内交易股票时,你必须知道使它们适合日内交易的特征。这些特征是:
- 跟踪良好的股票
- 良好的音量
- 中等至高波动性
跟踪良好的股票
一只被你很好跟踪的股票,在各种因素的背景下,比如波动性、价格变化触发因素等,都会是你熟悉的股票。
良好的音量
高交易量的股票会带来流动性,而流动性是一个让你,作为一个交易者,在不影响价格的情况下买卖股票的因素。市场上的高交易量意味着一段时间内交易的股票数量。例如,10 笔 100 股的交易与 100 笔 10 股的交易相同。这是因为总共交易了 100 股。由于每天交易的股票数量可以在网上查到,人们可以很容易地跟踪交易量。
中等至高波动性
价格波动很大的股票被认为是波动性很大的股票,因此适合日内交易。
日内交易者必须分析股票,跟踪其走势。一旦你熟悉了股票市场的过程,你的知识将帮助你根据股票过去的表现来决定何时买入和卖出。
现在,我们将讨论日内交易策略。
日内交易策略
在选择了日内交易的内容后,你还必须选择正确的策略,以便从交易中获得最大收益。你可以专注于一个特定的策略,也可以选择不同策略的组合。在这里,你会发现简明的交易策略的解释。
在我们的一篇博客文章中,我们详细介绍了所有的交易策略。在我们的 algo 交易策略文章中,你可以随意探索和了解它们。
让我们在这里简单地找出流行的交易策略,你会在课程中找到细节。这些战略是:
- 动量交易策略
- 黄牛策略
- 滴答策略
这一系列视频是 QuantInsti 专门为算法交易(EPAT)管理课程的学生进行的讨论表的记录。
https://www.youtube.com/embed/0ZWqH6l8v40?rel=0
动量交易策略
动量原理表明,如果证券在向上移动,那么它将继续向同一方向移动。
同样,如果它在向下运动,那么它也会向同一个方向运动。您可以通过两种方式利用动量,即时间序列动量和截面动量。这两种方法在动量交易策略课程中都有详细解释。
黄牛策略
刷单是一种交易策略,交易者在很短的时间内持有一个头寸,以便能够获得少量利润。实施这种策略的交易者被称为黄牛党。他们希望在每笔交易中获得小利润,随着交易次数的增加,这些小利润会累积成一大笔钱。黄牛党就像做市商一样,希望以的买入价买入,以的要价卖出,以获取买卖差价。
滴答策略
分笔成交点是衡量证券价格最小上下波动的指标。分笔成交点也可以指一种证券在不同交易中的价格变化。
如果一笔交易的价格比上次交易的价格高出一个点或更多,这就叫做上涨。
类似地,如果一笔交易的价格比上次交易的价格低了一个点或更多,那么它被称为下跌点。
比如说;如果最小报价单位是 0.01 美元,股票从 10 美元涨到 10.01 美元,那么它将被视为上涨。相反,如果从 10 美元涨到 9.99 美元,那就是下跌。
此外,如果股票的报价单位大小为 0.1 美元,当前价格为 10 美元,则相关价格可以移动到 10.1 美元、10.2 美元或 9.9 美元、9.8 美元,但不能移动到 10.05 美元或 9.95 美元,因为它不符合 0.1 美元的报价单位大小。
现在,滴答作响的策略是从买卖价差中获利。这意味着你以高于最佳出价的价格买入,以低于最佳出价的价格卖出,以实现收益最大化。
另外,看看这段视频,了解日内交易策略的介绍:
https://www.youtube.com/embed/K3Q_tR30ZIc?feature=oembed
要深入研究,你可以报名参加 Quantra 上的日交易策略课程,这是专门为初学者提供的知识。
结论
在这篇文章中,我们介绍了日内交易的基础知识,以及新手需要了解的内容。作为初学者,你可以获得一些关于日内交易实践和日内交易者如何运作的知识。全面了解可以帮助新手在日内交易中承担计算好的风险。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
在 Python 中处理错误和异常
原文:https://blog.quantinsti.com/dealing-python-error-exceptions/

马里奥·比萨·培尼亚
所有程序员迟早都会发现自己花了大量时间处理代码中的错误。因此,有必要了解我们发现的错误类型以及如何处理它们。想了解更多关于 Python 进行交易的知识,也可以查看这篇文章
这篇文章将尝试用简单的语言回顾 Python 错误解释和 Python 错误解决的各个方面。
 T3】
T3】
理解 Python 中的错误和异常
有两种错误:Python 语法错误和 Python 异常。
Python 语法错误通常很容易检测和修复。除非我们在不包含 Python 解析器的文本编辑器中编写代码,否则编辑器通常会告诉我们何时出现了语法错误,也就是说,何时我们编写了 Python 无法理解的代码。
Python 异常则相反,是只有在代码执行时才能检测到的错误。在这里,代码在语法上是正确的,但是在执行时,它在某一行遇到了一些问题,导致代码无法继续执行。
Python 语法错误必须立即纠正,否则,我们无法对代码做任何事情。Python 异常是运行时可能发生的异常情况,我们能做的最好的事情是控制它们,以防止异常结束执行。
让我们看看如何处理这类错误。
Python 语法错误
用一个非常简单的例子,让我们看看 Python 语法错误是如何表现的。
我们将看到的第一件事是一个语法正确的代码,我们希望用 Python 3 在屏幕上打印一条消息:

由于没有 Python 语法错误,Python 给出了我们正在寻找的输出。
现在让我们试着做同样的事情,但是用 Python 2 的风格(记住,这里我们用的是 Python 3):

虽然对于 Python 2 来说,这个语句不成问题,但是 Python 3 解释器希望找到要打印的消息周围的括号。因此,这就是它让我们知道的方式,清楚地告诉我们有一个 Python 语法错误,并为我们提供了一个可能的解决方案。
现在让我们犯一些愚蠢的错误来观察 Python 的输出:

这里我们忘记了结束引号和括号,Python 解释器告诉我们在行尾(EOL)有问题,即行尾不是预期的。
我们将尝试通过犯另一个 Python 语法错误来纠正它:

这里我们关闭了 print 语句,但让字符串保持开放。Python 解释器再次给出一条错误消息,指出行尾仍然不正确。
好的,我们现在要关闭字符串文字,但是这次我们不关闭输出。

这里发生了什么? Python 没有给我们提供预期的输出,但也没有抛出错误。相反,它显示了一行二级提示(三个点…),即解释器正在等待更多信息。在这种情况下,我们可以关闭括号,甚至向 print 语句添加更多信息。


这里 Python 给了我们向 print 语句添加更多信息的机会,因为解释器仍然是打开的,并且在等待输入。直到我们结束句子,Python 解释器才知道我们已经完成了打印,因此期望我们输入更多的信息。
在迄今为止的例子中,我们已经在解释器中直接引入了语句,但是如果代码在文件中会发生什么呢?

在这里,它表示在文件结尾(EOF)有一个 Python 错误。然而这一次,它不允许我们输入任何信息,这是因为我们启动 Python 来运行文件。如果这个文件包含错误,Python 会返回到操作系统终端,指出文件和发现错误的行。
Python 异常
Python 异常是一种错误,只有在运行时发现异常时才会触发。
例如:
z = x + y
从语法上来说,这是正确的,但是指令结束的好坏取决于它从 x 和 y 得到的值,如果它们有值的话。
假设:
x = 1 & y = 4:

该指令将毫无问题地执行,并将给出以下结果:
5 for z.
如果 x 和/或 y 没有声明/初始化会发生什么?

我们得到一个异常,在这种情况下,称为 NameError ,它停止执行。这是因为它没有找到我们想要添加的变量(它们不存在,它们没有被声明或初始化)
如果 x 和/或 y 是字符,会发生什么?

我们得到一个 Python 异常,在这种情况下,称为 TypeError ,它停止执行。发生这种情况是因为我们试图添加一个有几个字母的数字,由于不可能完成这个操作,解释器抛出了一个异常。
到目前为止,我们只看到了两个异常: NameError 和 TypeError ,但是在 Python 中嵌入了更多的 Python 异常。此外,这是一个基本的优势,我们可以声明、捕捉和处理我们自己的 Python 异常。
处理 Python 异常的另一个最重要的方面是我们可以控制它们。也就是说,一旦出现异常情况,我们可以控制该异常并正确处理它,以允许代码继续执行,而不是停止执行。
在下一篇文章中,我们将看到如何处理异常,以及如何让我们的程序更加健壮。
接下来的步骤
对于那些渴望了解更多关于 Python,它在算法和量化交易领域的使用和应用,或者只是想开始用 Python 进行交易的人,他们可以选择 Quantra 的 Python For Trading 课程。它从头开始涵盖了重要的概念,也有助于发展和提高专门针对交易的 Python 技能。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
交易决策树分类器第一部分
原文:https://blog.quantinsti.com/decision-tree-classifier-trading-part-1/

这篇博客中的策略不会涉及正常的技术指标,而是一些我自己的创造。此外,我们将看到测试和训练数据上的策略性能之间的差异,以及训练数据大小和预测长度的变化。
与我以前的博客不同,在这里我将使用一个动态的时间框架来获取过去几天的数据。但是在我们开始之前,让我们导入必要的库。

我已经将要提取的数据的开始日期定义为过去 365 天/ 1 年的日期。您可以使用静态日期格式,但这将有助于您在运行这段代码时获取最新的数据。
接下来,我创建了几个指示器,并更改了一些列的名称,以便以后在代码中引用它们。

我将简要说明我使用的指标。我创建了一个名为“dif”的专栏。这衡量的是收盘价相对于昨天范围的变化。我们正试图检查今天的收盘与昨天的价格波动之间是否有任何关联。在这之后,我创建了一个名为“sec_dif”的列,这是收盘价变化的二阶差。这里我们衡量 dif 相对于昨天范围的变化。
我们还使用另一个称为 diff_v 的指标,该指标用于衡量今天与前一天相比的范围变化。
之后,我计算了市场回报。请注意,这些回报是前瞻性的。由于预测是在一天结束时或就在一天结束前生成的,我们可以简单地将预测的趋势与该回报相乘,并轻松地衡量策略绩效。

创建指标后,我们分别计算衡量策略绩效和训练算法所需的回报和信号列。我们将使用前一天的回报作为指标的一部分,看看明天的趋势和今天的市场表现之间是否有任何相关性。

在选择我们的指标后,我们使用最小最大缩放器来缩放数据。该缩放函数将特征值缩小到 0 到 1 的范围内。

接下来,我们决定测试数据的大小,在这种情况下,我选择了 20 天,代表最后一个月的数据。
在此之后,我使用了一个日益复杂的决策树分类器,通过添加更多的深度和特征,来看看该算法在这个决策树分类器的帮助下预测得有多好。
我将用递增的复杂度(1-9,9 是最复杂的)来绘制策略的性能,并测量这些算法的准确性。



没有明确的迹象表明任何趋势或算法的表现,总的来说,这个结果是非常复杂的。现在,让我们打印列车数据性能并可视化性能。


在这里,观察结果非常清楚。你可以清楚地看到,更复杂的算法在预测趋势方面做得非常好,而不太复杂的算法更像是扔硬币。给定这些训练数据,我们可以期望最复杂的算法在测试数据上表现得更好。但遗憾的是,事实并非如此。正如你所看到的,上图中最近 20 天的表现清楚地表明,所有的算法几乎一样糟糕。这样做的原因是,我们并没有使用截至当天该点的可用数据来进行预测。换句话说,我们不是通过使用在那天之前的整个数据上训练的算法来对最后的数据进行预测,而是我们假设过去(365 天- 20 天)的数据将具有与未来 20 天相似的趋势,但大多数情况下不是这样。让我们通过将预测的天数减少到仅仅 5 天来验证这一点,然后我们可以看到算法的测试数据性能的显著差异。

在这里,您可以看到,过度拟合或欠拟合训练数据的算法表现不佳,而具有最佳学习能力的算法具有一致的性能。请注意,您只能看到 9 个算法中的 4 个,因为它们大多数是重叠的。如果您想要验证策略的准确性,您可以使用新的测试数据再次打印包含准确性的代码。在这里,理想情况下,当我们使用时间序列数据时,我们需要使用 LSTM 类型的方法来进行预测。即使用过去“x”天的数据来训练算法,然后预测第二天的数据。这将大大提高你的准确性。我们将在我的下一篇博客中探讨这个问题。
下一步
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)中的 T2 高管课程。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。现在报名!
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
下载 Python 代码
- 决策树分类器 Python 代码
使用 Python 进行交易的决策树
马里奥·比萨·培尼亚
决策树是一种用于分类和回归问题的机器监督学习方法,也称为 CART。
请记住,分类问题试图将未知元素归类到一个类或类别中;输出总是分类变量(即是/否、上/下、红/蓝/黄等)。)
回归问题试图预测一个数字,例如第二天的收益。它不能与用于研究变量之间关系的线性回归混淆。虽然分类和回归问题有不同的目标,但树有相同的结构:
- 根节点位于顶部,没有传入路径。
- 内部节点或测试节点位于中间,可以位于不同的级别或子空间,并且具有传入和传出路径。
- 叶节点或决策节点在底部,有传入路径,但没有传出路径,在这里我们可以找到预期的输出。

多亏了 Python 的 Sklearn 库,树是自动为我们创建的,以我们假设认为负责我们正在寻找的输出的预测变量为起点。
在这篇决策树的介绍文章中,我们将用 Python 创建一个分类决策树,来预测我们将要分析的金融工具第二天是上涨还是下跌。
我们还将制作一个决策树来预测第二天指数的具体回报。
准备环境
确保您有以下可用的软件,以便遵循示例:
- Python 3.6
- 熊猫数据结构库。
- 带有科学数学函数的 Numpy 库。
- Quandl 图书馆检索市场数据。
- 计算技术指标的 Ta-lib 库。
- Sklearn ML 库来构建树并执行分析。(以及其他许多事情)
- Graphviz 库来绘制树。
构建决策树
构建分类决策树或回归决策树的方式与我们组织输入数据和预测变量的方式非常相似,然后,通过调用相应的函数,分类决策树或回归决策树将根据我们必须指定的一些标准自动为我们创建。
构建决策树的主要步骤是:
- 检索金融工具的市场数据。
- 引入预测变量(即技术指标,情绪指标,广度指标等)。)
- 设置目标变量或所需输出。
- 在训练和测试数据之间分割数据。
- 生成决策树训练模型。
- 测试和分析模型。
如果我们看一下前四个步骤,它们是数据处理的常见操作。如果你是决策树的新手,预测器和目标变量对你来说可能听起来很陌生。但是,它们只不过是数据框中包含某种类型指示器的附加列。这些指标或预测指标用于预测目标变量,即分类模型的金融工具将上涨或下跌,或回归模型的未来价格水平。同样,拆分数据在任何回测过程(ML 或 not)中都是一项强制性任务,其思想是用一组数据来训练模型,用另一组未在训练中使用的数据来测试模型。
步骤 5 和 6 与决策树的 ML 算法特别相关。正如我们将看到的,Python 中的实现非常简单。然而,很好地理解参数化和结果分析是非常重要的。这篇文章非常实用,如果想更深入地了解基础数学,我们建议阅读文章底部的参考资料。
获取数据
任何算法的原材料都是数据。在我们的例子中,它们是金融工具的时间序列,如指数、股票等。它通常包含开盘价、最高价、最低价、收盘价和成交量等细节。这些信息以一定的频率记录下来,如分钟、小时、天或周,形成时间序列。
有多个数据源可以下载数据,免费的和高级的。免费每日数据最常见的来源是 Quandl、雅虎或谷歌或我们信任的任何其他数据源。
在这里,我们将通过 Quandl 检索来自埃米尼标准普尔 500 二十年的每日数据。
import quandl
df = quandl.get("CHRIS/CME_ES2")
df.head()
df.tail()
df.shape

(5391, 8)
我们现在有超过 21 年的埃米尼·S&P500 的可用数据。我们将使用结算价作为收盘价参考。
创建预测器
预测变量是我们认为与市场行为相关的数据。这些数据可以是多种多样的,如技术指标、市场数据、情绪数据、广度数据、基本面数据、政府数据等。这将有助于我们对市场的未来行为做出预测。
这里我们将测试趋势跟踪和区间交易的经典指标,它们是:
- 导弹电子搜索系统
- (同 antitransmit-receive)反收发
- ADX
- RSI
- MACD
因此,决策树算法应该帮助我们选择指标及其参数的最佳组合,以最大化作为目标的预期输出。
我们将通过计算用作预测指标的指标来准备数据,为此,我们将使用 Ta-lib 库:
import talib as ta
df['EMA10'] = ta.EMA(df['Settle'].values, timeperiod=10)
df['EMA30'] = ta.EMA(df['Settle'].values, timeperiod=30)
df['ATR'] = ta.ATR(df['High'].values, df['Low'].values, df['Settle'].values, timeperiod=14)
df['ADX'] = ta.ADX(df['High'].values, df['Low'].values, df['Settle'].values, timeperiod=14)
df['RSI'] = ta.RSI(df['Settle'].values, timeperiod=14)
macd, macdsignal, macdhist = ta.MACD(df['Settle'].values, fastperiod=12, slowperiod=26, signalperiod=9)
df['MACD'] = macd
df['MACDsignal'] = macdsignal
df.tail()

我们已经计算了指标,但有必要强调的是,我们是用标准参数计算的,这些参数可以而且必须优化,因为决策树与预先计算的指标一起工作。
另一方面,EMAs 和 MACDs 并不是这样,因为信号来自相对于均线的价格,或者相对于另一个均线的价格。让我们计算作为平均值和 MACD 预测值的列。
import numpy as np
df['ClgtEMA10'] = np.where(df['Settle'] > df['EMA10'], 1, -1)
df['EMA10gtEMA30'] = np.where(df['EMA10'] > df['EMA30'], 1, -1)
df['MACDSIGgtMACD'] = np.where(df['MACDsignal'] > df['MACD'], 1, -1)
df.tail()

我们现在拥有的是可能的交易规则,我们将在决策树中引入这些规则,以帮助我们确定这些指标的最佳组合,从而使结果最大化。
- EMA,我们感兴趣的是什么时候价格高于平均线,什么时候最快的平均线高于最慢的平均线。
- ATR(14),我们对触发信号的阈值感兴趣。
- ADX(14),我们感兴趣的是触发信号的阈值。
- RSI(14),我们感兴趣的是触发信号的阈值。
- MACD,我们对 MACD 信号何时出现在 MACD 上空感兴趣。
在这个例子中,分类决策树和回归决策树的预测变量将是相同的,尽管目标变量是不同的,因为对于分类算法,输出将是分类的,而对于回归算法,输出将是连续的。
通过我们的 Quantra 课程,学习如何制作决策树利用人工智能技术预测市场和寻找交易机会。
创建目标变量
正如我们已经说过的,分类和回归决策树有不同的目标。分类决策树试图通过提供分类变量来表征未来,即市场上涨或下跌,而回归决策树试图预测未来值,即未来市场价格。
我们将在这里为这两类问题创建目标变量,尽管每一类都将使用自己的目标。
df['Return'] = df['Settle'].pct_change(1).shift(-1)
df['target_cls'] = np.where(df.Return > 0, 1, 0)
df['target_rgs'] = df['Return']
df.tail()

回归算法的目标变量( target_rgs )使用滞后回报,这是因为我们希望算法根据当前可用的信息了解第二天发生了什么。
分类算法的目标变量( target_cls )也使用滞后回报,但是因为输出是分类的,所以我们必须转换它。如果回报是正的,我们指定 1,如果是负的,我们指定 0。
获取决策树数据集
我们已经准备好了所有的数据!我们已经下载了市场数据,应用了一些技术指标作为预测变量,并为每种类型的问题定义了目标变量,为分类决策树定义了分类变量,为回归决策树定义了连续变量。
我们将执行一个小操作来净化数据,并准备每个算法将使用的数据集。我们必须清除丢弃 NA 数据的数据,这一步对于干净地计算树是至关重要的。
接下来,我们将创建预测变量的数据集,也就是说,我们已经计算的指标,该数据集是我们将要创建的两个决策树(分类决策树和回归决策树)所共有的。
predictors_list = ['ATR', 'ADX','RSI', 'ClgtEMA10', 'EMA10gtEMA30', 'MACDSIGgtMACD']
X = df[predictors_list]
X.tail()

然后,我们为分类决策树选择目标数据集:
y_cls = df.target_cls
y_cls.tail()

最后,我们为回归决策树选择目标数据集:
y_rgs = df.target_rgs
y_rgs.tail()

将数据分成训练和测试数据集
完成数据集准备的最后一步是将它们分成训练和测试数据集。这对于用一组数据(通常是 70%或 80%以及剩余部分)拟合模型来测试模型的良好性是必要的。如果我们不这样做,我们将冒过度拟合模型的风险。我们希望在模型拟合后,用未知数据测试模型,以评估模型的准确性。
我们将创建训练数据集,其中 70%的数据来自预测变量和目标变量数据集,其余 30%用于测试模型。
对于分类决策树,我们将使用 sklearn 模型选择库中的**训练测试*分割函数来分割数据集。由于输出是分类的,因此训练和测试数据集成比例很重要train***test _ split函数将预测器和目标数据集以及一些输入参数作为输入:
- test_size :测试数据集的大小,在本例中,30%的数据用于测试,因此 70%用于训练。
- random_state :由于采样是随机的,这个参数允许我们在每次执行中重现相同的随机性。
- 分层:为了确保训练和测试样本数据成比例,我们将参数设置为 yes。这意味着,例如,如果正回报的天数多于负回报的天数,则训练样本和测试样本将保持相同的比例。
from sklearn.model_selection import train_test_split
y=y_cls
X_cls_train, X_cls_test, y_cls_train, y_cls_test = train_test_split(X, y, test_size=0.3, random_state=432, stratify=y)
print (X_cls_train.shape, y_cls_train.shape)
print (X_cls_test.shape, y_cls_test.shape)
这里我们有:
- 训练预测变量数据集:X_cls_train
- 训练目标变量数据集:y_cls_train
- 测试预测变量数据集:X_cls_test
- 测试目标变量数据集:y_cls_test
对于回归决策树,我们只是以指定的速率分割数据,因为输出是连续的,所以我们不担心训练和测试数据集中输出的比例。
train_length = int(len(df)*0.70)
X_rgs_train = X[:train_length]
X_rgs_test = X[train_length:]
y_rgs_train = y_rgs[:train_length]
y_rgs_test = y_rgs[train_length:]
print (X_rgs_train.shape, y_rgs_train.shape)
print (X_rgs_test.shape, y_rgs_test.shape)
同样,这里我们有:
- 训练预测变量数据集:X_rgs_train
- 训练目标变量数据集:y_rgs_train
- 测试预测变量数据集:X_rgs_test
- 测试目标变量数据集:y_rgs_test
到目前为止,我们已经完成了:
- 下载市场数据。
- 计算我们将用作预测变量的指标。
- 定义目标变量。
- 将数据分为训练集和测试集。
除了在获取目标变量和分割数据集的程序上略有不同外,迄今所采取的步骤是相同的。
用于分类的决策树
现在让我们使用 sklearn.tree 库中的 DecisionTreeClassifier 函数创建分类决策树。
虽然 DecisionTreeClassifier 函数有许多参数,我邀请您了解并尝试一下(help(DecisionTreeClassifier)),但在这里我们将看到创建分类决策树的基础。

基本上是指算法必须用哪些参数来构建树,因为它遵循一种递归的方法来构建树,我们必须设置一些限制来创建它。
- 标准:对于分类决策树,我们可以选择基尼或熵和信息增益,这些标准指的是损失函数,以评估学习机算法的性能,并且最常用于分类算法,虽然这超出了本文的范围,但基本上可以帮助我们调整模型的准确性,并且构建树的算法停止评估根据损失函数没有获得改善的分支。
- max_depth :树的最大层数。
- min_samples_leaf :该参数是可优化的,表示我们希望在树叶中拥有的最小样本数。
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, min_samples_leaf=6)
clf
现在,我们将使用训练数据集来训练模型,我们拟合了模型,并且算法已经完全训练好了。
clf = clf.fit(X_cls_train, y_cls_train)
clf
现在,我们需要使用模型对未知数据进行预测,为此,我们将使用 30%的数据进行测试,最后评估模型的性能。但是首先,让我们用图形来看看 ML 算法为我们自动创建的分类决策树。
可视化分类决策树
我们有一个非常强大的工具,可以帮助我们图形化地分析 ML 算法自动生成的树。该图显示了最大化输出的最重要节点,如果适用,将帮助我们确定一些有用的交易规则。
graphviz 库允许我们用图形表示决策树分类器函数用训练数据自动创建的树。
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None,filled=True,feature_names=predictors_list)
graphviz.Source(dot_data)

请注意,该图像仅显示了最重要的节点。在此图中,我们可以看到每个节点中的所有相关信息:
- 用于分割数据集的预测变量。
- 基尼不纯值。
- 该节点上可用的数据点的数量
- 属于每个类别的目标变量数据点的数量,1 和 0。
我们可以观察一对纯节点,这使我们能够推导出一种可能的交易规则。例如:
- 在从左边开始的第三片叶子上,当收盘价低于 EMA10 且 ATR 高于 51.814 且 RSI 低于或等于 62.547 时,标记减少。
- 从左边开始的第五片叶子上,我们可以推导出以下规律:当 ADX 小于等于 19.243,RSI 小于等于 62.952,RSI 大于 62.547 时,行情上行。
进行预测
现在,让我们使用为测试保留的数据集进行预测,这部分将让我们知道该算法在训练中使用未知数据时是否可靠。
y_cls_pred = clf.predict(X_cls_test)
性能分析
最后,我们只能通过与训练过程中获得的结果进行比较来评估算法在未知数据上的性能。为此,我们将使用 sklearn.metrics 库的 classification_report 函数。
该报告显示了一些有助于我们评估算法优劣的参数:
- 精度:表明我们预测的质量。
- 回忆一下:表明我们预测的质量。
- F1-得分:显示精度和召回率的调和平均值。
- 支持:作为权重计算精度、召回率和 F-1 的平均值。
任何高于 0.5 的数字通常被认为是一个好数字。
from sklearn.metrics import classification_report
report = classification_report(y_cls_test, y_cls_pred)
print(report)

回归决策树
现在让我们使用 sklearn.tree 库中的 DecisionTreeRegressor 函数创建回归决策树。
虽然 DecisionTreeRegressor 函数有许多参数,我希望您了解并尝试一下(help(DecisionTreeRegressor)),但这里我们将看到创建回归决策树的基础。

基本上是指算法必须用哪些参数来构建树,因为它遵循一种递归的方法来构建树,我们必须设置一些限制来创建它。
- 标准:对于分类决策树,我们可以选择平均绝对误差(MAE)或均方误差(MSE),这些标准与损失函数相关,用于评估学习机算法的性能,并且最常用于回归算法,虽然这超出了本文的范围,但基本上可以帮助我们调整模型的准确性,以及构建树的算法,停止评估根据损失函数没有获得改善的分支。这里我们将默认参数设为均方误差(MSE)。
- max_depth :树将拥有的最大级别数,这里我们将默认参数设为 none。
- min_samples_leaf :这个参数是可优化的,表示我们希望树拥有的最少叶子数。
# Regression tree model
from sklearn.tree import DecisionTreeRegressor
dtr = DecisionTreeRegressor(min_samples_leaf = 200)
现在,我们将使用训练数据集来训练模型,我们调整模型,算法将已经得到充分训练。
dtr.fit(X_rgs_train, y_rgs_train)
现在,我们需要使用模型对未知数据进行预测,为此,我们将使用 30%的数据进行测试,最后评估模型的性能。但是首先,让我们用图形来看看 ML 算法自动为我们创建的回归决策树。
可视化模型
为了可视化该树,我们再次使用 graphviz 库,它为我们提供了用于分析的回归决策树的概述。
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(dtr,
out_file=None,
filled=True,
feature_names=predictors_list)
graphviz.Source(dot_data)

在此图中,我们可以看到每个节点中的所有相关信息:
- 用于分割数据集的预测变量。
- MSE 的值。
- 该节点上可用的数据点数
通过我们的 Quantra 课程,学习如何使用人工智能技术制作决策树来预测市场和寻找交易机会。
结论
这看起来像是我们发现了一个水晶球,但事实并非如此。掌握这些技术需要大量的学习和对背后的数学技术的整体理解。
显然,树很容易创建和提取一些有用的规则,但事实是,要创建决策树,它们需要参数化,这些参数可以而且必须优化。
为了继续加深我们对决策树的了解,并真正帮助我们提取可靠的交易规则,我们将在下一篇文章中使用集成机制来创建一个健壮的模型,该模型结合了一个算法创建的模型。
-
并行集成方法或平均方法:通过一种算法创建多个模型,预测是所有模型的平均值;
- 制袋材料
- 随机子空间
- 随机森林
-
序贯集成方法或 boosting 方法:该算法创建序贯模型,对每个新模型进行改进,以减少前一个模型的偏差;
- AdaBoosting
- 梯度推进
我们已经在这个博客中学习了如何使用 Python 创建分类和回归决策树,现在我们可以在 Ernest P. Chan 博士的课程中学习高级概念和策略。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
解读不断变化的交易格局
原文:https://blog.quantinsti.com/decode-the-changing-landscape-of-trading-webinar/
![Decode the Changing Landscape of Trading [WEBINAR]](https://github.com/OpenDocCN/geekdoc-quant-zh/raw/master/quantinsti/img/47489efe3ed9327dbf5739cd8ce11685.png)
如今,金融市场比以往任何时候都更加紧密相连。一个市场发生的任何事件都会影响其他地区的市场行为。甚至交易目的地的数量也在快速增加。
在这种不断变化的交易环境中,交易者利用来自多个来源的信息来设计他们的交易策略,以下问题确实会出现:
- 一个人如何跟上竞争的步伐?
- 如何从多个交易场所获取信息?
- 连接不同市场的技术复杂性是什么?
- 不同市场的监管挑战是什么?
- 各个地区的竞争格局是怎样的——交易量最大的资产类别是什么,在这些外国市场上,谁将是你的竞争对手?
- 国外市场的成熟和发展水平如何?
算法交易以技术而非交易员为中心,没有地理位置依赖性,因此能够在新的地理区域快速复制成功的策略。因此,对上述问题的回答可以帮助一个成功的交易者在算法上扩展他的操作。
所有这些问题都将在 2014 年 5 月 2 日由 QuantInsti 的联合创始人和教员 Rajib Ranjan Borah 在一个半小时的网络研讨会上回答。
网上研讨会将从以下几个方面比较和对比各个市场:
- 技术基础设施和协议
- 监管障碍
- 竞争格局-资产类别、竞争对手和复杂程度
本次网络研讨会可能有利于:
- 交易商在不同地区探索交易机会
- 量化求职者在不同地区评估算法交易的机会
访问我们博客中的所有独家网络研讨会内容:改变算法交易的格局
使用 Python 中的张量流的深度学习-人工神经网络
原文:https://blog.quantinsti.com/deep-learning-artificial-neural-network-tensorflow-python/
在这篇文章中,我们将通过使用张量流和用 python 预测股票价格来开发一种称为深度学习(人工神经网络)的机器学习技术。在本文的最后,你将学习如何使用张量流建立人工神经网络,以及如何使用神经网络的预测来编码策略。
系统需求:Python 3.6
如果你是神经网络的新手,想了解它们的工作原理,我建议你在建立神经网络之前浏览以下博客。
编码策略
导入库
我们将从导入所有库开始。请注意,如果下面的库还没有安装,您需要在导入之前先在 anaconda 提示符下安装。

TensorFlow 是一个开源软件库,用于跨一系列任务的数据流编程。它是一个符号数学库,用于机器学习应用,如深度学习神经网络。维基。
Numpy 是一个科学计算的基础包,我们将使用这个库来计算我们的数据集。使用别名 np 导入该库。
Pandas 将帮助我们使用强大的 dataframe 对象,它将在 Python 中构建人工神经网络的整个代码中使用。
Scikit-learn 是一个免费的 Python 编程语言的机器学习库。它具有各种分类、[回归](https://quantra.quantinsti.com/course/trading-with-machine-learning-regression target=)和聚类算法,包括支持向量机。维基百科
Matplotlib 是一个 Python 2D 绘图库,它以多种硬拷贝格式和跨平台的交互环境生成出版物质量数据
塔利布是一个技术分析库,将用于计算 RSI 和 Williams %R。这些将用作训练我们的人工神经网络的特征。我们可以使用这个库添加更多的特性。
导入数据集
我们将使用 2000 年 1 月 1 日至 2018 年 8 月 30 日期间在 NSE 交易的塔塔汽车股票的每日 OHLC 数据。我们首先导入数据集。CSV 文件命名为“塔塔汽车”。“NS.csv”保存在您计算机的个人驱动器中。这是使用 pandas 库完成的,数据存储在名为 dataset 的数据帧中。然后,我们使用 dropna()函数删除数据集中缺失的值。我们仅从该数据集中选择 OHLC 数据,该数据集中还包含日期、调整后收盘和成交量数据。我们将仅使用 OHLC 值构建输入要素。
请注意,您也可以从我的 github 下载这些数据。

准备数据集
然后,我们准备各种输入特征,人工神经网络将使用这些特征来训练自己进行预测。请注意,我只限于以下 8 个功能,但是你应该创建更多的,以获得更准确的结果。
- 高价减去低价
- 收盘减去开盘价
- 三天移动平均线
- 十天移动平均线
- 30 天移动平均线
- 5 天期间的标准偏差
- 相对强度指数
- 威廉姆斯%R

然后,我们将输出值定义为价格上涨,这是一个二进制变量,当明天的收盘价大于今天的收盘价时,存储 1。

接下来,我们使用 dropna()函数删除所有存储 NaN 值的行。

接下来,我们从“数据集”中移除所有 OHLC 数据,仅在名为“数据”的新数据框中保留“8 个输入要素”和“输出”。

接下来,我们将 data 中的所有数据设为 np.array。

分割数据集
接下来,我们将整个数据集分成训练数据和测试数据。从 2000 年 1 月 1 日开始,训练数据包含总数据集的前 80%,测试数据包含数据集的剩余 20%。数据没有被打乱,而是按顺序切片。

缩放数据&建筑 X,Y
数据预处理的另一个重要步骤是标准化数据集。此过程会使所有输入要素的平均值等于零,并将它们的方差转换为 1。这确保了在训练模型时不会因为所有输入要素的不同比例而产生偏差。如果不这样做,神经网络可能会混淆,并对那些平均值比其他特征高的特征给予较高的权重。此外,网络神经元(如 tanh 或 sigmoid)的最常见激活函数分别定义在[-1,1]或[0,1]区间上。如今,校正线性单位(ReLU)激活是普遍使用的激活,其在可能激活值的轴上是无界的。但是,我们将调整投入和目标。我们将使用 sklearn 的 MinMaxScaler 进行缩放。我们用 MinMaxScalerr()函数实例化变量 sc。之后,我们使用“先拟合后变换”函数训练和测试数据集。

然后,我们将训练和测试数据集分成 X 训练,y 训练& X 测试,y 测试。这从数据训练和数据测试中选择目标和预测值。价格上涨的目标(y train & y test)位于数据 train/test 的最后一列,从第 1 列到第 8 列数据 train/test 的 8 个特征(X train & X test)的预测值。整个数据集将如下所示。


这是任何机器学习算法的基本部分,模型使用训练数据来得出模型的权重。测试数据集用于查看模型如何处理将输入模型的新数据。测试数据集还有输出的实际值,这有助于我们理解模型的效率。既然数据集已经准备好了,我们可以继续使用 TensorFlow 库构建人工神经网络。
构建人工神经网络
输入,隐藏&输出图层
该模型由三个主要构件组成。输入层、隐藏层和输出层。输入层是 8 个要素。在输入层之后有 3 个隐藏层。第一个隐藏层包含 512 个神经元。后续隐藏层的大小总是前一层的一半,这意味着第二个隐藏层包含 256 个神经元,最后第三个隐藏层包含 128 个神经元。在 3 个隐藏层之后是输出层。Net 是由张量流交互分离产生的。

占位符&变量
人工神经网络从占位符开始。为了适应我们的模型,我们需要两个占位符:X 包含网络的输入(T = t 时股票的特征), Y 包含网络的输出(T+1 时股票的运动)。占位符的形状对应于 None,n_features,其中[None]表示输入是二维矩阵,输出是一维向量。理解神经网络需要哪些输入和输出维度以正确设计它是至关重要的。none 参数表示此时我们还不知道每批中流过神经网络图的观察值的数量,因此我们保持 if 灵活性。我们稍后将定义控制每个训练批次的观察数量的可变批次大小。

除了占位符,变量是张量流宇宙的另一个基石。占位符用于存储图形中的输入和目标数据,而变量用作图形中的灵活容器,允许在图形执行过程中改变。这里权重和偏差被表示为变量,以便在训练期间适应。在模型训练之前,需要初始化变量。
初始值设定项
初始化器用于在训练前初始化网络变量。由于使用数值优化技术来训练神经网络,因此优化问题的起点是找到潜在问题的良好解决方案的关键因素之一。张量流中有不同的初始化器,每一个都有不同的初始化方法。这里,我们将使用两个变量权重&偏差的 TF . variancescalinginitializer()作为默认初始化策略之一。

设计网络架构
在设计网络架构时,首先我们需要了解输入层、隐藏层和输出层之间所需的可变维度。在多层感知器(MLP)的情况下,我们在这里使用的网络类型,前一层的第二维是当前层的第一维的权重矩阵。这意味着每一层都将其输出作为输入传递给下一层。偏差维度等于当前层的权重矩阵的第二维度,其对应于该层中神经元的数量。

在定义了所需的权重和偏差变量之后,需要指定网络拓扑、网络架构。因此,占位符(数据)和变量(权重和偏差)需要组合成一个顺序矩阵乘法系统。此外,网络的隐藏层通过激活函数进行变换。激活函数是网络架构的重要元素,因为它们给系统引入了非线性。有许多可能的激活函数,其中最常见的是整流线性单元(ReLU ),它将在此模型中使用。

成本函数
我们使用成本函数来优化模型。成本函数用于生成网络预测和实际观察到的训练目标之间的偏差度量。对于回归问题,通常使用均方误差(MSE)函数。MSE 计算预测值和目标值之间的均方差。

优化器
优化器负责必要的计算,这些计算用于在训练期间调整网络的权重和偏差变量。这些计算调用梯度的计算,该梯度指示在训练期间权重和偏差必须改变的方向,以便最小化网络的成本函数。开发稳定和快速的优化器是神经网络和深度学习研究的一个主要领域。

在这个模型中,我们使用 Adam(自适应矩估计)优化器,它是随机梯度下降的扩展,是深度学习开发中的默认优化器之一。
拟合神经网络
现在,我们需要使我们创建的神经网络适合我们的训练数据集。在定义了网络的占位符、变量、初始化器、成本函数和优化器之后,需要训练模型。通常,这是通过小批量训练来完成的。在小批量训练期间,从训练数据中抽取 n = batch 大小的随机数据样本,并输入网络。训练数据集被分成 n / batch 大小的批次,这些批次被顺序输入到网络中。此时,占位符 X 和 Y 开始发挥作用。它们存储输入和目标数据,并将它们作为输入和目标呈现给网络。
X 的一个采样数据批次流经网络,直到它到达输出层。在那里,TensorFlow 将模型预测与当前批次中实际观察到的目标 Y 进行比较。之后,TensorFlow 执行优化步骤并更新网络参数,与所选的学习方案相对应。更新重量和偏差后,对下一批进行采样,重复该过程。该过程继续进行,直到所有批次都被呈现给网络。所有批次的一次完整扫描称为一个时期。一旦达到最大次数或者用户定义的另一个停止标准适用,网络的训练就停止。当 epoch 达到 10 时,我们停止训练网络。

有了这个,我们的人工神经网络就编译好了,可以做预测了。
预测股票的走势
既然已经编译了神经网络,我们可以使用 predict()方法进行预测。我们将 X test 作为参数传递,并将结果存储在一个名为 pred 的变量中。然后,我们将 pred 数据转换为 dataframe,并保存在另一个名为 y pred 的变量中。然后我们通过存储条件 y pred > 0.5,将 y pred 转换为存储二进制值。现在,变量 y_pred 根据预测值是大于还是小于 0.5 来存储 True 或 False。

接下来,我们在 dataframe 数据集中创建一个具有列标题“y pred”的新列,并将 NaN 值存储在该列中。然后,我们将 y pred 的值存储到这个新列中,从测试数据集的行开始。这是通过使用 iloc 方法对数据帧进行切片来实现的,如下面的代码所示。然后,我们从 dataset 中删除所有 NaN 值,并将它们存储在名为 trade_dataset 的新数据帧中。

计算策略返回
现在我们有了股票运动的预测值。我们可以计算这个策略的收益。当 y 的预测值为真时,我们将持有多头头寸,当预测信号为假时,我们将持有空头头寸。
我们首先计算如果在今天结束时做多,并在第二天结束时平仓,该策略将获得的回报。我们首先在 trade_dataset 中创建一个名为“Tomorrows Returns”的新列,并在其中存储一个值 0。我们使用十进制符号来表示浮点值将存储在这个新列中。接下来,我们在其中存储今天的对数回报,即今天收盘价除以昨天收盘价的对数。接下来,我们将这些值向上移动一个元素,以便根据今天的价格存储明天的回报。

接下来,我们将计算策略回报。我们在标题“Strategy Returns”下创建一个新列,并用值 0 初始化它。以指示存储浮点值。通过使用 np.where()函数,如果“y pred”列中的值存储为 True(长位置),则我们将存储“Tomorrows Returns”列中的值,否则我们将存储“Tomorrows Returns”列中的值的负值(短位置);“策略回报”一栏。

我们现在计算市场和策略的累积回报。这些值是使用 cumsum()函数计算的。

绘制收益图
现在,我们将绘制市场回报和我们的策略回报,以直观显示我们的策略在市场中的表现。然后,我们使用存储在 dataframe trade_dataset 中的累积值,使用 plot 函数绘制市场回报和策略回报的图表。然后,我们分别使用 legend()和 show()函数创建图例并显示绘图。下面显示的图是代码的输出。绿线代表使用该策略产生的回报,红线代表市场回报。


结论
这个项目的目标是让你了解如何使用 python 中的 tensorflow 建立一个人工神经网络并预测股票价格。目的不是让你得到好的回报。你可以通过各种方式优化这个模型,以获得良好的策略回报。
我的建议是,当你在建立人工神经网络或任何其他最有效的深度学习模型时,使用超过 100,000 个数据点。这个模型是根据每日价格开发的,目的是让您了解如何构建模型。建议使用分钟或分笔成交点数据来训练模型。
现在你可以用 Python 建立自己的人工神经网络,并开始利用机器的能力和智能进行交易。
您也可以从 my github a/c 下载 pyhon 代码和数据集
下一步
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载数据文件
- 使用 Python 中的张量流的深度学习-人工神经网络
金融领域的深度学习
深度学习在金融领域发挥着重要作用,这也是我们在本文中讨论它的原因。简单来说,深度学习是机器学习的一个子领域。由于他们处理的问题不同,他们的能力也各不相同。
让我们看看这篇文章将涵盖什么:
 T2】
T2】首先,我们将看到深度学习的概念在一个结构中得到解释,它是这个结构的一部分。
深度学习概述
深度学习是人工智能的一部分,它甚至可以为极其复杂的输入提供输出。
下面,我们以流程图的方式进行了可视化表示,以了解深度学习究竟在哪里发挥作用:

主要是,你可以在上图中看到,由机器学习、深度学习和神经网络组成的是人工智能(AI)。
那么我们先来了解一下人工智能的含义。用简单的话来解释,AI 是一个广泛的概念,它意味着所有由机器学习的最初是人类行为的概念。更简单地说,人工智能是任何显示人类思维特征的机器,如合理化、学习和解决问题。
然后是机器学习 的概念,涉及算法和统计模型的研究。基于这项研究,机器或系统执行特定的任务,不需要任何明确的指令。这是因为机器依赖于从过去学到的模式和推论。
第三,也是更深层次的概念是深度学习。这个概念被称为深度学习,因为它利用了大量的数据或可用信息的复杂性。有了这些信息,深度学习模型就足以识别错误,并在没有人工干预的情况下自行纠正它们。由于机器学习没有使用如此深入的信息,在没有人类参与的情况下,它无法识别和纠正错误。
另一个概念是 神经网络 ,它是机器学习的一部分,简单地说就是机器能够以与人类解决各种任务相同的方式处理信息的概念。因此,这是一个模仿生物神经网络的人工神经网络的概念。
现在,深度神经网络是人工神经网络的一个组织,它帮助对极其复杂的输入进行输出。深度神经网络起着重要的作用,因为它们处理极其复杂的输入以提供适当的输出。
在这里阅读更多关于深度神经网络的内容。
现在来看金融,人工智能作为一个整体在金融行业应用很多。例如,它有助于识别问题,如异常借记卡使用或账户中的巨额存款。这样,人工智能作为一个整体概念有助于将人们从欺诈活动中解救出来。此外,人工智能还用于根据市场中的各种因素,通过更有组织和更快的决策来使交易更容易和更好。
好吧!此外,让我们转向深度学习在金融领域的应用。
深度学习在金融领域的应用
正如我们上面提到的,深度学习是一个处理复杂输入并基于它们提供输出的概念。此外,它还有自我修正的潜力,因为它被设计得足够高效,不需要人工干预。因此,在数据被记录之后,该系统从它自己的成功和失败中学习。
在金融界,人工智能,或者更准确地说,深度学习,可以应用于几个重要领域。因此,让我们来看看深度学习的重要应用领域:
- 股票市场预测
- 过程自动化
- 分析交易策略
- 金融安全
- 机器人顾问
- 贷款申请评估
- 信用卡客户研究
股票市场预测
基于历史数据和当前市场状况的不同参数,深度学习中的神经网络预测股票价值。随着深度学习详细使用数据,并考虑隐藏层,预测的准确性会提高。因此,观察到利用深度学习,预测精度是最大的。
过程自动化
这项技术通过提供呼叫中心自动化、文书工作自动化和员工培训游戏化等来帮助处理流程。
分析交易策略
由于深度学习的算法可以同时分析成千上万的数据源,所以它比人类快得多。基于这样的分析,形成的交易策略,获利要多得多。
金融安全
在线交易的激增也增加了欺诈活动的发生率。随着深度学习算法在检测欺诈方面的出色表现,金融安全正在同时实现。
机器人咨询
机器人顾问只不过是为客户提供金融工具建议的算法。例如,推荐保险设施等金融产品,以及投资组合管理,即管理各种投资机会中的资产。
贷款申请评估
深度学习中的深度神经网络帮助银行根据学习到的批准和拒绝申请的模式来决定是否批准贷款申请。
信用卡客户研究
由于银行需要他们的客户利用他们的信用卡,深度学习系统有助于找到这样的客户。因此,为了识别正确的客户,该系统提供了更多有意义的问题,以放在信用卡申请上。
我们已经提到了具有深度学习的自动化已被证明是有益的大多数领域,但还有许多其他领域,如信贷审批、业务失败预测、银行盗窃等。
有几家顶级公司,如 CRISIL、Titan、JP 摩根大通、BNY 梅洛、Swiggy 等,都在使用深度学习来实现系统自动化。
此外,我们将看到深度学习的模型以及每个模型的意义。
深度学习的模型
将模型大致分类,有两种类型,即监督模型和非监督模型。这两个模型都经过不同的训练,并且具有各种不同的特征。

让我们首先取个监督模型,个监督模型,其中用特定数据集的例子进行训练。这些模型是:
- 经典神经网络
- 卷积神经网络
- 递归神经网络
经典神经网络
经典神经网络也称为多层感知器或感知器模型。这个模型是美国心理学家在 1958 年创造的。它也可以被称为一个简单的神经网络。这在本质上是奇异的,并且适应于具有一系列输入的基本二进制模式,以模拟人脑的学习模式。它的基本条件是由 2 层以上组成。

正如你所看到的,它只有一个带有几个隐藏层的输入层和一个输出层。
卷积神经网络
这是继经典神经网络之后的一个高级版本,因为它是为处理和计算数据输出方面的更高复杂性而设计的。
由于这些神经网络主要是为图像数据而构建的,它们应该最适合图像分类,但逐渐地,它们也能够处理非图像数据。
现在让我们讨论如何为图像建立卷积神经网络。因此,对于模型的构建,您首先将输入数据导入到模型中,这要经过五个步骤:

Steps for Building a CNN Image
- 输入图像——基本上,输入数据被视为一幅图像(以像素为单位)。
- 特征检测器和特征图-检测器基本上是图像特征的标识符。这些也被称为过滤器。特征地图由特征检测器或过滤器收集的信息组成。

Feature Detectors
- Max-Pooling -它使模型能够识别修改后的图像。因此,图像可以翻转、镜像、颠倒等。最大池有助于卷积网络通过获取不同区域的矩阵来识别图像的所有细节。这使得网络注意到它们都是同一图像的细节。

Max-Pooling
- 展平——在这一步中,数据被展平到一个数组中,以便模型能够读取它。现在,详细信息从矩阵转换或展平为垂直列。此后,输入通过人工神经网络进行进一步处理。

Flattening
- 完全连接——这是数据的隐藏层,然后将它考虑在内。这叫全连通数据层,和人工神经网络中的隐藏数据是一样的。在该步骤中,还进行误差函数的计算,该误差函数在人工神经网络中被称为损失函数。

Full Connection
递归神经网络
“递归神经网络”是六种神经网络中的一种,它以顺序的方式考虑数据。这种类型记住序列中的前一个信息,并有助于在序列的后面解释相同的元素。
例如,对文本的解释,它由单词或字符按顺序组成,以使读者理解它们的意图。
为了更好地理解递归神经网络,让我们看看视觉表示,并理解它支持的输入和输出类型:

Recurrent Neural Networks
好的,上面的图像显示:
- 一对一
这是从固定大小的输入到固定大小的输出处理信息的基本模式。例如,将图像分类到一个类别中。
- 一对多
这意味着处理一个信息并向显示器提供多于一个单词的输出。例如,将一幅图像作为输入,创建一个带有一句话的标题作为输出。
- 多对一
在这种情况下,输入作为一个单词的句子,被分类为积极或消极的情绪表达。随后输出需要预测下一个字符。例如,顺序输入(一个句子)和固定大小输出一个单词。
- 多对多
这意味着序列输入导致序列输出,但是输出被修改。例如,机器翻译,它导致机器将英语输入翻译成法语。
- 多对多
这是另一种类型的序列输入,它作为序列输出输出并被同步。例如,视频分类,其中视频的每一帧都被标记。
既然你现在已经清楚了深度学习的监督模型,让我们继续前进到非监督模型。这些模型只有给定的输入数据,没有任何可学习的设定输出。这些模型是:
- 自组织地图
- 玻尔兹曼机器
- 自动编码器
自组织地图
som 包含无监督的数据,通常会减少模型中随机变量的数量。在自组织映射中,输出维度通常是二维的。因此,如果我们有 2 个以上的输入特征,输出将下降到 2 维。在这种情况下,每个连接输入和输出节点的突触都有一个权重。现在,最近的节点被称为 BMU 或最佳匹配单元,SOM 将其权重移动到更接近 BMU 的位置。节点离 BMU 越近,其权重变化越大。
玻尔兹曼机器
现在,您一定已经注意到,在以前的模型中,所有的模型都朝着一个特定的方向,即从输入到隐藏层再到输出。即使是 SOM,作为一个无监督模型,也与监督模型中的所有其他模型走向相同的方向。
但是,波尔兹曼机器的情况就不一样了,因为它们不遵循特定的方向。正如您在下面模型的可视化表示中所看到的,所有节点都以圆形相互连接。
这里,
h ->隐藏层
v->视觉层

之所以如此,是因为玻尔兹曼机器可以生成模型的所有参数,而不是固定的输入。该模型被称为随机模型,而其他模型是确定性模型。
自动编码器
自动编码器基本上是简单的算法,用于显示与输入相同的输出。这种机制压缩输入数据,然后从中重构输出。
例如,作为输入的图像帮助系统学习特定的图形或结构。
因此,输入被压缩成几个类别。在自动编码中,数据在以下函数的帮助下被压缩:
- 数据特定,这意味着该系统一旦用人脸训练过,就不能很好地处理建筑物的图像。
- 自我表现者,即,如果有适当数量的数据用于训练,那么系统将在该特定类型的输入上保持良好表现。
在下面的视觉表示中,输入 X 是图像输入,在系统中编码器和解码器的帮助下,它呈现输出 X’。这里,输出与输入相同,因为系统存储了相同的特定特征。

在当今时代,用于数据可视化的自动编码的两个概念被称为数据去噪和降维,是已知的最佳实际应用。
好了,现在让我们来看看深度学习在金融领域的 python 代码应用。
深度学习在金融中的应用
在下面的代码中,我们试图使用一组特征来预测市场运动的方向。因为它可能是上升趋势,也可能是下降趋势,这是一个二元分类问题。
一个牙医和一个兼职交易员——Shubhrabaran 的故事
原文:https://blog.quantinsti.com/dentist-part-time-trader-story-shubhrabaran/
我们确信,并不是每天你都能了解到那些追求自己兴趣的真正杰出的人,他们已经有了 10 年以上的职业生涯,并且过得很好。一个牙科医生对交易产生了兴趣,倾向于算法交易——并且今天独立地创造和交易,他的旅程怎么样?
这就是 EPAT 大学校友 Shubhrabaran Das 博士的故事。他在不断增长的算法交易领域发现了潜力,不断追求,并实现了他的目标。他自豪地获得了 2018 年年度美容牙医的称号。
如果你觉得有趣的话,这就是从牙齿到虱子的旅程!
我们很高兴他选择与我们分享他的故事。我们的讨论是这样进行的。
嗨,Shubhrabaran,告诉我们你自己的情况
嗨!我是 Shubhrabaran Das ,我的职业是牙科医生。我来自特里普拉邦的阿加尔塔拉,业余时间喜欢看电影,对交易充满热情。我在特里普拉邦有 2 家诊所,我在做兼职交易。

在特里普拉邦完成学业后,我选择了牙医的职业,并在钦奈开始了我的学习。我在加尔各答的一位资深牙科医生手下工作了几个月。经过一段时间,我的工作经验已经超过 10 年,并且还在继续。
在新冠肺炎疫情的现状下,我的工作时间已经减少到平时的一半,同时我也在提高我的交易技巧。
牙科医生和算法交易员——这是一个有趣的组合。你能给我们讲讲吗?
在我知道交易之前,我是一名牙科医生。我对金融和交易的兴趣并不是一开始就有的。在我职业生涯的几年中,一个关于金融和投资的想法闪过我的脑海。我也尝试过投资不同的渠道,但结果并不令人满意。
我知道交易,但从未尝试过。吸引我的是回报——学习如何从市场中学习和赚钱是非常有利可图的。我以前从未想到过它。虽然我想交易,但我一直把它作为副业来做,而且我还在继续这样做。我用了一个交易软件来自动化我的策略,但是它把我限制在某些特定的策略上。结果并不好。
我经常参加各种网上研讨会和交易研讨会。在 Zerodha 的一次网络研讨会上,他们的嘉宾——一位“算法交易者”分享了他的交易经验。他谈到了“市场微观结构”、“做市”等短语。这激起了我的兴趣。这是我第一次接触算法交易。
我开始搜索大量的免费资源,观看无数的 YouTube 视频,并开始跟踪许多声称跟随他们的交易方法会获利的人。我记得尝试了很多他们的知识,但都失败了。但这是我所知道的大多数学习者的情况。
我很想知道如何让我的交易策略自动化。于是,我开始在网上搜索学习 Algo 交易的课程。不知不觉中,我被屏幕上一则关于算法交易(EPAT)高管课程的广告惊呆了。出于兴趣,我登陆了 QuantInsti 网站。
经过研究,并与那里的优秀人士交谈,我注册了。这个决定为我打开了一个全新的算法和交易世界。相信我,当我这么说的时候,我从来不知道我还学到了这么多。EPAT 向我介绍了很多细节。
我希望接触更广泛的交易领域,我也想学习如何将机器学习和人工智能应用到我的交易中。对于 EPAT,我做到了。
你能告诉我们你在 EPAT 的学习经历吗?
在 EPAT 的学习是非常有见地的,它打开了我的心灵和无数交易机会的大门。我喜欢周末授课的方式。我总是在一周内花更多的时间自学。
得知我可以编写自己的交易策略,进行自己的交易,这很令人兴奋。我知道统计学,但不知道它在交易中的应用。我从来不知道编程。
一个人可以学习和掌握所有的信息,但 EPAT 教它的实际应用。它测试你,确保你在完成 EPAT 的时候达到你的目标。
对于参加 EPAT 大学的期末考试,我有点激动,原因很简单,在经历了 10 年辉煌的职业生涯后,我终于可以参加了。但我很高兴我做到了。我很高兴也很自豪,我过得很好,获得了“EPAT 优秀证书”!
我也是 LinkedIn 上 EPAT 社区的一员,我很高兴在它开始的时候成为第一批人之一。我很高兴与过去和现在不同批次的人有过接触。
我在闲暇时间交易漂亮的期权,我喜欢这样。今天,当我的病人在我的笔记本电脑上浏览我的交易时,我觉得很有趣——在市场活跃的诊所里。接下来是关于市场、自动化和算法交易的有趣对话。有时候,他们会非常着迷地了解昆汀斯提和 EPAT 是如何帮助我实现这一目标的。
你认为 EPAT 最大的特点是什么?
虽然 EPAT 有许多我可以描述的特色,但最好的,我觉得对我,甚至对所有的以巴人来说最重要和最有益的,是他们提供的极好的支持。
EPAT 在我有限的知识范围内帮我理清头绪,填补空白。它引导我理解这一切是如何组合在一起的——就像一幅完整的图画。支持团队让我不断学习,让我坚持下去。
对我的支持经理 Dhiraj 特别大喊一声。他总是确保我所有的疑问都得到解答。我培养了这种信心,因为即使是我觉得很傻的最简单的疑问,迪拉吉和所有的教职员工都会非常专业地解答。
你对有抱负的算法交易者有什么建议吗?
永远不要停止学习。你学得越多,你就越渴望学到更多。跟上最新发生的事情,保持你的知识增长。
我们感谢你,Shubhrabaran 抽出时间与我们联系,分享你的 Algo 交易之旅。你对 EPAT 的赞誉也让我们受宠若惊。我们祝愿你在个人和职业生活中一切顺利。
在寻求学习算法交易的过程中,你需要正确的知识和必要的技能,算法交易(EPAT) 中的执行程序,帮助你实现你的学习目标。EPAT 是一门综合性课程,涵盖了广泛的主题。今天和我们连线了解更多关于 EPAT 的信息。
免责声明:为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。
是什么驱使人们走向衍生品市场?
无论您是否听说过金融市场中的衍生品,或者您对该术语是否陌生,本文都应服务于您的目的。为了了解衍生品市场以及围绕该市场的更多方面,让我们对本文的内容进行概述。
因此,本文涵盖了:
- 什么是衍生品市场?
- 衍生品市场的运作
- 股市中的衍生品是用来做什么的?
- 衍生品有危险吗?
什么是衍生品市场?
为了了解衍生品市场,我们必须首先知道什么是衍生品。衍生品不过是从资产、指数或利率中获取价值的合约。而且,这种资产或工具通常被称为“基础实体”。在某些股票的波动性比其他股票更大的情况下,衍生品主要用于保险,也用于农民保险他们未来农产品的价格。这就是为什么衍生品被称为市场起伏时期的减震器。
衍生产品市场这个术语意味着金融市场,在这个市场中人们可以得到衍生产品的期权以供选择。谈到市场规模,根据 BIS ,OTC(场外)衍生品名义金额于 2019 年 6 月底升至640 万亿美元。这高于 2018 年底的 544 万亿美元,也是 2014 年以来的最高水平。这标志着自 2016 年底以来明显上升的趋势仍在继续。
尽管如此,所有合同的总市值(实际)约为 12.7 万亿美元。重要的一点是,许多分析师认为名义价值(票面价值)和市场价值(实际价值)之间存在差异。
场外衍生品的总市值,加上正值和负值,也从 9.7 万亿美元上升到 12.1 万亿美元,主要是由于欧元利率衍生品合约的增加。
接下来,我们将讨论一些常见的衍生产品,如远期、期货、期权和掉期,人们通常投资这些产品是为了在不利的价格变动情况下为自己投保。
此外,我们将详细讨论我们提到的所有衍生合约,以及最流行的类型。一些常见的衍生合约有:
转发
众所周知,远期合同是双方(个人或实体)在未来某一特定时间买卖任何资产(以特定金额)的合同。对于远期衍生品,人们有两种立场,一种是做多,另一种是做空。例如,在双方中,决定在未来买入的一方持有多头头寸,而决定在未来卖出的一方持有空头头寸。
这意味着持有多头头寸的一方预测未来价格会进一步下跌,而持有空头头寸的一方则认为未来价格可能会上涨。此外,未来商定的价格被称为交货价格。
期货
在期货合同的情况下,购买和出售标准化数量和质量的特定资产的双方在同一天商定价格(期货价格)。但是,交货和付款都发生在未来确定的日期。与远期交易一样,在期货交易中,决定在未来买入的一方持有多头头寸,而决定在未来卖出的一方持有空头头寸。
在期货交易中,合同恰巧在被称为期货交易所的交易所进行谈判,以便在双方,即买方和卖方之间保持一个合法的中介。
选项
在期权的情况下,它是一个暗示所有者或买方拥有在特定日期或之前以特定的执行价格购买或出售基础资产的权利(但不是义务)的合同。在这种情况下,执行价格是固定价格或预定价格。如前所述,合约价值来源的资产、指数或利率被称为基础资产或工具(通常称为基础实体)。为此,买方必须向卖方支付溢价,有两种选择:
- 看涨期权——该合同意味着所有者有权以执行价格购买标的资产或工具。
- 看跌期权——这意味着所有者有权以执行价出售标的资产或工具。
互换
互换是另一种衍生品,是双方之间的合同,双方同意交换对方基础资产或工具(合同)的现金流。交换发生在未来的特定日期。在这种情况下,基础资产或工具的类型决定了各方的利润。例如,在涉及两种债券的情况下,利润是定期支付利息或息票。这些交易所被称为掉期交易的分支。最常见的互换类型是利率互换、商品互换、货币互换和信用违约互换,你可以在这里阅读。
要点:期权是最广泛使用的衍生品。看涨期权和看跌期权都起着重要的作用。
接下来,我们将看看衍生品市场是如何运作的?
衍生产品市场的运作
好的,正如我们所知,它在各种不同合约的帮助下进行风险管理,我们将简要回顾一下它的历史,以及它工作的其他方面。衍生品起源于 12 世纪欧洲的农民和交易商试图对冲他们的产品,以避免不利的价格波动。
衍生品市场是基于在一些不利的市场情况下转移风险的原则。
以下是衍生品市场运作中的一些"关键参与者":
- 有两种主要的市场参与者,一种是对冲基金(T1)或 T2 对冲者(T3),另一种是 T4 投机者/交易者。
套期保值者有助于转移未来不利价格变动的风险。
投机者根据历史数据帮助预测未来的价格变动。
- 第三类市场参与者是套利者,他们通过利用一种产品在两个不同市场的价格差异来防范风险。在这种情况下,买方可以在一个市场以较低的价格挑选一种产品,然后在另一个市场以较高的价格出售。
现在,我们刚刚讨论了在确保衍生品得到充分利用方面发挥关键作用的市场参与者,让我们进一步看看衍生品是如何交易的。因此,有两种主要的衍生品交易方式:
- 柜台交易
- 在交易所
场外交易的衍生品不受监管。尽管不受监管,场外交易是一种被各种交易者选择的方法。毫无疑问,这种方法风险更大,因为它不受控制。然而,在进入衍生品市场之前,交易者/投资者必须了解所有相关的风险,以便能够迅速采取行动。此类风险可能与交易对手相关(因为没有法律干预),与基础资产相关(如其价格变动)并涉及衍生产品的到期日。
然而,交易所的衍生品是受监管的,因此风险要小得多。然而,在投资衍生品时,我们总是建议要小心,因为它们无疑是一种常见的交易工具,但也一直被许多争议所包围。例如,导致 2008 年金融危机的因素之一据说是“过多的对冲”。
这里的结论是,一旦你很好地意识到并掌握了该做什么和不该做什么的知识,衍生品就会非常有用。我们将讨论一些预防措施和一个非常常见的问题“衍生品危险吗?”在文章的后面。
现在,让我们先来看看股票市场上的衍生品有什么用途?
股市中的衍生品是用来做什么的?
正如我们所知,衍生工具主要用于股票市场投资的风险管理。不同类型的衍生合约以不同的方式运作,因此,它们在不同的情况下是有帮助的。我们现在已经知道,最常用的衍生工具有四种,即远期、期货、掉期和期权。每一种都有自己的价值,取决于你在寻找什么样的风险管理措施。市场上存在一些不确定性,但多亏了衍生品,它们可以得到解决。
在波动股票的情况下,套期保值起着重要的作用。这是一个简单的术语,意思是借助衍生合约将你所有的投资放在不同的地方。对冲有助于消除与投资基础资产或工具相关的风险。在这种情况下,衍生品合约有助于投资者投资两只不同的股票,以抵消波动性更大的股票可能带来的潜在损失。在对冲中有用的衍生合约的一些例子是股票、远期、互换和期权。
让我们在这里举一个例子,假设你,作为股票交易员,觉得 X 公司的股票价格在下个月可能会上涨。这个预测会让你想投资 x 公司的股票。同时,你想保护自己免受任何不可预见的损失。
在这种情况下,你可以投资同等价值的 Y 公司的股票。比方说,你选择 Y 公司股票的期货衍生合约,并同意在未来某个特定日期以当前价格买入。如果股票价格在指定日期上涨,你将从合约中获利。而且,如果 X 公司的股票价格在未来下跌,你的损失将被投资 Y 公司股票的收益所抵消。
此外,你可以进入两个不同的市场,在衍生合约的帮助下,你可以设法抵消潜在的损失和收益。此外,如果两种或所有不同的投资在市场上获得动力,衍生品可以帮助你获利。
让我们来看一些现实世界中衍生合约有用的例子。我们将看看目前的情况。
衍生产品有助于冠状病毒爆发的真实例子(现状)
在目前的情况下,由于冠状病毒的爆发,我们看到 JP 摩根和花旗集团等银行对衍生品的投资激增,这些银行以“大吃大喝”而闻名。
根据彭博的说法,“全球股票市场的历史性恐慌为一些世界上最大的投资银行带来了财富。
知情人士称,摩根大通&公司和花旗集团今年迄今为止,与 2019 年同期相比,股票衍生品交易收入增加了约 5 亿美元。随着投资者争相押注股市走势并保护自己的持股,交易量大幅上升。"
在 MoneyControl 的另一篇新闻中,提到“自 2 月份以来,印度基准指数一直非常疲软,主要是因为担心冠状病毒爆发的影响。
报告补充称,2010 财年迄今,股票衍生品交易额增长了 43%。现金和衍生品市场的总成交量上升了 39%。
由于从 4 月 1 日起税收结构的变化,股息分配税(DDT)的征收增加了 2%。"
在阅读了 2020 年 3 月的当前情景后,应该会清楚衍生品如何以及何时被用于风险管理。
现在,让我们来谈谈衍生品的危险,并找出一些该做和不该做的事情。
衍生品有危险吗?
在这一节中,我们将讨论一些众所周知的与衍生产品有关的衍生产品合同的风险。签订此类合同时,有一些非常常见的“风险”可以避免。其他的仅仅依赖于你的评估、预测的准确性和其他相关方的有效性。
我们将提前讨论一些风险,以及知名投资者沃伦巴菲特和前印度央行行长拉古拉姆·拉扬对这些风险以及如何避免这些风险所做的陈述。
让我们来看看这些风险,因为它们与以下方面有关:
- 杠杆作用
- 第三方
- 巨额投资
- 虚幻的安全
杠杆作用
如果你,作为一个交易者,用借来的钱使用衍生品,你需要对用借来的钱投资的风险做好心理准备。有几个投资者从投资中赚了一大笔钱的例子,但也有他们损失惨重的例子。这是因为基础资产或工具的价格波动。正如维基百科所提到的,你可以看到一些实体在衍生品合约中因使用杠杆而损失巨大的例子:
- 美国国际集团(AIG)在前三个季度因 T2 信用违约互换(CDs)损失了超过 180 亿美元。
- 2008 年 1 月兴业银行因滥用期货合约损失 72 亿美元。
- 失败的基金 Amaranth Advisors 损失 64 亿美元,该基金在 2006 年 9 月价格暴跌时做多天然气。
- 1998 年失败的长期资本管理基金损失了 46 亿美元。
第三方
这意味着,如果您没有对交易中涉及的交易对手进行有效性检查,您可能会面临遭受损失的风险。私下或通过私下协议达成的衍生产品合同可能不像通过“在交易所”等法律干预达成的协议那样无风险。例如,带有法律干预(在交易所)的股票期权需要风险方在交易所存入一定金额,以确保其在遭受损失时的支付能力。此外,在互换的情况下,交易所对双方进行信用检查。但是,在私人协议的情况下,可能没有进行任何风险分析的基准。
巨额投资
每当涉及巨额资金时,总有损失大笔资金(即全部投资)的危险。如果你将收入的很大一部分用于投资,你所承担的风险可能是你无法补偿的。正如著名投资家沃伦·巴菲特在伯克希尔·哈撒韦的 2002 年年度报告中提到的,衍生品可以成为“金融大规模杀伤性武器”。因此,如果对衍生合约的投资不明智,它们可能会导致一个巨大的问题,而不是帮助规避风险。这是投资衍生合约时需要进行准确分析的主要原因
虚幻的安全
这意味着对冲概念提供的安全性可能会转向交易者,并可能成为一种虚幻的安全,以防整个市场在发生巨大危机时下跌。在这种情况下,整个市场跌至低点,没有股票仍然盈利足以弥补投资。
根据维基百科,国际货币基金组织(IMF) 前首席经济学家拉古拉姆·拉扬提到“这些公司(投资基金)的经理们很可能已经弄清楚他们持有的各种工具之间的相关性,并相信他们已经对冲了。然而,正如 Chan 等人(2005 年)指出的那样,俄罗斯政府债务违约后 1998 年夏季的教训是,正常时期为零或负的相关性可能在一夜之间变为 1,这种现象被他们称为“相位锁定”。对冲头寸“可能在最糟糕的时候变得不对冲,让那些误以为自己受到保护的人遭受重大损失”。
现在,真正的问题是,衍生品合约是否糟糕到可以对交易员的业务造成严重破坏,还是情况可以得到控制?
因此,要回答这个问题,我们先来看看华纳·巴菲特后来发表的自相矛盾的声明,他在声明中提到,如果交易者得到足够的信息并采取正确的措施,衍生品并没有那么糟糕。
根据 2011 年金融危机调查委员会的说法,沃伦·巴菲特说,“我不认为他们本身是邪恶的……拥有一份期货合同或类似的东西并没有错。”据《T2 时报》报道,巴菲特现在表示,衍生品的真正问题在于银行和“不知情的投资者”的过度投资他认为,衍生品可以为包括伯克希尔·哈撒韦公司在内的公司增值,只要这些公司的领导人保持克制,持有“有限的数量”
完美!在本文中,这些都是关于衍生合约的。让我们看看我们讨论的内容。
结论
在本文中,我们讨论了衍生合约的主要方面,它们的定义,规模和类型。然后,我们继续学习衍生品市场的运作,该市场的主要参与者以及投资衍生品的两个平台。
此外,我们还讨论了衍生合约的用途以及与之相关的风险。此外,我们还看到了一些当前的情景,作为帮助我们了解在危机时刻如何使用/帮助我们的例子。
最后但同样重要的是,我们看到了如何通过做出明智的决策来避免这些风险,并使它们只对我们有利。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
使用测辐射热计检测 twitter 上的机器人
原文:https://blog.quantinsti.com/detecting-bots-twitter-botometer/
在这篇博客中,我们将了解什么是机器人,以及它们如何扭曲你的交易策略中使用的情绪分析。我们将讨论以下主题:
- 为什么我们要识别一个机器人?
- 验光仪
- 在 Twitter 上识别机器人
当我们根据市场情绪进行交易时,我们需要从 Twitter、路透社、彭博和 Webhosie 等新闻来源获取数据。虽然阅读完整的文章并评估他们的情绪可能很困难,但估计一条推文的情绪并不复杂。
但在你评估一条推文的情绪之前,你需要知道这条推文是机器人的自动回复还是人类发出的。
你可能会问为什么这是相关的?
为什么我们要识别一个机器人?
这是相关的,因为你需要知道机器人在做什么,这反过来会告诉你 Twitter 上特定股票的情绪是如何被操纵的。当我们计算特定股票的 Twitter 情绪时,我们会识别并删除那些由 bot 用户发出的推文。这将给予真实的情感而不被操纵。当与其他技术指标一起使用时,这种真实情绪可以成为一个非常强大的指标,用来预测趋势的顶部和底部。
辐射热测定器
在 python 中,我们使用名为 botometer 的库来了解特定的 tweet 是否是由机器人发出的。botometer 库使用一种机器学习算法,该算法在数万个带标签的数据上进行训练。该算法的输出是 0 到 1 范围内的概率,其中 1 表示 twitter 帐户由机器人管理。
Botometer API 将用户 id 作为输入,然后提取与该用户相关的 1200 个特征来计算分数。Botometer 对以下类别给出单独的分数:
- 网络功能
- 用户功能
- 朋友功能
- 时间特征
- 内容特征
- 情感特征
让我们来讨论其中的一些特性。
网络功能
用户的网络特征包括用户过去发推的转发、提及和标签信息。
例如,如果用户只转发那些特定句柄的推文,那么该用户很可能是一个机器人。
用户功能
这包含特定于用户的信息,如用户名、语言、位置、帐户创建日期等。,一般来说,僵尸工具不包含这些信息。如果他们这样做,那将是一些胡言乱语。
时间特征
类别时间特征分析推文率、推文和转发的时间模式等。例如,如果该帐户在相同的时间间隔内发布推文,那么它很可能是一个机器人。
选举推特:识别机器人
目前,印度正在进行大选。而且推特上有很多机器人支持他们的政党。知道哪些推文是由机器人发出的很重要。但在此之前,让我们检查一下 botometer 是否正常工作。让我们以一个已知的 twitter 处理真正的政治领导人,并检查它是否预测正确。
首先,我们使用如下所示的 pip install 安装 botometer 库,然后实例化一个 botometer 对象。
!pip 安装 botometer

现在,让我们试试美国总统唐纳德·特朗普先生的已知手柄,看看 botometer 会说什么。

@realDonaldTrump 是美国总统的推特账号。获取该句柄的 bot 分数后,我们可以使用以下命令打印并检查它。

所有的机器人得分值在 0-1 的范围内都非常低,这表明用户很可能是人类。我们还可以使用下面的命令获得最终的分数或总数。

由于多安德·特朗普先生的大多数推文都是英文的,我们可以将英文 0.03 分(0-1 分)视为最终指标。一般来说,我们认为超过 0.6 的分数表明一个帐户被机器人控制。因此,如果你们中的任何人怀疑@realDonaldTrump 账户发出的推文是否真的是总统本人发出的,那么这些分数现在应该可以解决这个疑问了。
现在让我们回到印度大选,看看两位顶级候选人的推特账号表现如何。
首先,让我们来分析一下印度现任总理纳伦德·莫迪。他的推特账号是@纳伦德拉莫迪

他的机器人分数是

由于纳伦德拉·莫迪先生的一些推文是印地语,我们需要考虑这种情况下的普遍分数。其再次非常低,指示人类用户。
现在让我们对主要反对党总理候选人拉胡尔·甘地先生进行同样的测试。


同样,这里的分数很少表示人类用户。这个练习的目的是检查由 botometer 所做的预测的健全性,它们看起来显然是令人满意的和预期的。
但是我们还没有确定这些领导人的机器人追随者。我们可以通过使用 tweepy 库导入 Twitter IDs,然后在每个 Twitter IDs 上运行 botometer 检查来做到这一点。分离机器人和计算市场情绪的过程似乎是一项非常困难的任务,但通过适当的预处理,它可以很容易地完成。在我们关于交易中的情绪分析的新课程中,我们将向您展示如何使用条件语句获取与股票相关的推文,然后执行预处理以识别和删除不相关的推文。然后,我们产生市场情绪,并在此基础上制定交易策略。
结论
botometer 库是专门为分析 Twitter feed 而构建的。在 twitter 数据被用于创建交易策略之前,它是 Twitter 数据预处理中非常重要的库。衡量市场情绪是一项非常困难的任务,它需要各种来源的数据。所有的数据不能以同样的方式处理。所以,你需要开发新的技术来预处理来自博客和新闻文章的数据。
报名参加我们的新课程: 交易中的情绪分析 ,您可以学习如何预处理不同类型的数据以及情绪分析中涉及的其他重要步骤
建议读数
- 情绪分析在交易中的应用:它在哪里起作用?
- 建立趋势跟踪策略的五个指标
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
开发和回测你的交易策略-演示
原文:https://blog.quantinsti.com/develop-backtest-trading-strategy-webinar-28-august-2018/
https://www.youtube.com/embed/qLIgx0S8D0w?rel=0
IST 时间 2018 年 8 月 28 日星期二下午 6 点|格林威治时间下午 12 点 30 分|格林威治时间晚上 8 点 30 分
会议大纲
在本次网上技术交流讲座中,您将学习一步一步使用技术指标和投资组合管理技术的交易策略开发方法。我们将在 Blueshift 上展示整个策略开发和回溯测试过程,blue shift 是 QuantInsti 的一个免费回溯测试平台。
- 战略发展的系统方法
- 蓝移简介
- 带技术指标的阿尔法策略
- 管理战略组合
- 问答环节
演示文稿
您可以点击此处查看本次网络研讨会的 powerpoint 演示文稿:
//www.slideshare.net/slideshow/embed_code/key/mdbF4AppXhz6vR
Develop And Backtest Your Trading Strategy - Demo - Presentation from QuantInsti
演讲人![prodipta-ghosh]()

Prodipta Ghosh(QuantInsti 副总裁)
Prodipta 是一位经验丰富的 quant,目前作为副总裁领导 QuantInsti 的 Fin-tech 产品和平台开发。
他在银行业工作了十多年,在孟买和伦敦的德意志银行的交易和结构部门担任过各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
关于蓝移
Blueshift 是一个全面的交易和策略开发平台,让你更专注于策略,而不是编码和数据。其基于云的回溯测试引擎可以免费帮助你开发、测试和分析交易策略,并对其进行微调。它整合了涵盖股票、期货和外汇的高质量分钟级数据。用户完全拥有他们在这个平台上开发的所有策略的知识产权。
进入算法交易的网络开发者|克兰蒂的故事
原文:https://blog.quantinsti.com/developer-algorithmic-trading-epat-success-story-kranti-potluri/
对知识的渴望,对算法交易领域的专注和热情——这是克兰蒂·波特鲁里的描述。
他的旅程令人难以置信,从工程开始,到短暂的 IT 职业生涯,然后融入金融领域。克兰蒂今天已经成功地在算法交易领域建立了自己的地位,这个故事是关于他是如何做到的。
嗨,克兰提,告诉我们你自己的情况吧!
嗨!我叫 Kranti Potluri ,我是一名 IT 毕业生,在 IT 行业做了一年半的 Web 开发人员。
新冠肺炎疫情是一个不幸的事件,许多人失去了工作。在家工作让人们重新思考他们的职业道路,我的许多朋友都转行了。
我也是软件行业的前端开发人员,这给了我思考交易的时间。在家工作的条件让我明白了未来 5-10 年我更倾向于做什么。
我一直对交易和股票市场感兴趣,并辞去了工作,致力于发展全职 it 职业生涯。我完成了 EPAT,目前在算法交易领域站稳了脚跟。我也一直在交易 Nifty 和银行 Nifty 期权。
你是如何从软件领域转向金融领域的?
我是一名程序员,毕业于 CBIT,一直对自动化相关的东西感兴趣。以前做机器学习、数据科学等相关的课程。我以前做的工作类似于预测。
在学习中,我意识到 ML、编码、Python 是如何相互联系的。在我看来,虽然我们选择了这些工具,但我们必须了解我们应该在哪里使用这些工具,即它们的应用。我们可以在医学、军事、警察、政府等领域使用这些技术。
股票市场和复利的整个概念真的让我很感兴趣。结合股市,ML 和编程,algo 交易落入它们之间的甜蜜点。我就是这样想把我的职业生涯转向交易的。
我最近读到,25%的 STEM 相关课程的毕业生进入了金融行业,也许这就是为什么美国有强大的金融支柱。
我的第一个项目是自动化拉米纸牌游戏。那时我甚至不知道 algo 交易。
我朋友的父亲是卖期权的交易员。以我对 ML 和编程的背景和知识,我认为这是可以自动化的。
在研究中,我发现了算法交易领域。我渴望与这个行业中有经验的人一起工作,从而探索各种职业机会,而不仅仅是辞去工作,成为一名零售交易员,从事自己的交易。
站在定量分析师的角度,我意识到没有必要去读 MBA。只要有正确的知识和动力,任何人都可以进入。这让我来到了 EPAT。
你是怎么学会算法交易的?
当这个思想的种子进入我的脑海开始学习人工智能(AI)和机器学习(ML);我立刻开始研究寻找这方面的课程。
在线课程提供认证,帮助实现目标并进入公司。今天,知识不仅仅局限于印度理工学院或 MITs,在这个时代,任何人都可以教任何人。我真的很相信这种在线学习和在线培训的理念。
我没有从书本或网站上学到什么,它们只能让你学到这么多。但我开始了解股票市场——一级市场、二级市场,以及为什么所有这些在社会中如此重要,等等。
我希望以一种正式的方式学习这些概念以及更多。我看了教算法交易的课程,然后我发现了 EPAT。没有其他球场像 QuantInsti 一样——我找不到任何地方可以与之相比。
在加入之前,我对 EPAT 做了很多研究,和 QuantInsti 的团队谈过,我决定加入。有了这种认可,几乎每个金融公司都知道 QuantInsti 和他们提供的 EPAT 认证。
我离开了之前工作的公司,专注于 EPAT。这对其他人来说可能不是一个好的决定,可能会有所不同。这是我职业生涯中的一次彻底转变,我不想在周末或下班后半心半意地做这件事。我花了 6 个月的时间 24x7 全天候为 EPAT 服务。
如果你以职业为导向,那么深入了解你在做什么是很重要的。这有助于建立你的简历,展示你的个人资料,给招聘人员留下深刻印象。
由于我是 IT 出身,我也没有任何金融方面的经验可以展示。但是,在我的个人资料中有一个 EPAT 认证为我的职业生涯提供了急需的推动力。通过我在这里的项目,我有机会与 Vishal Mehta(创始人,市场扫描器)一起工作,然后我通过安置单元在 ARB 贸易集团找到了一份工作。
你最喜欢 EPAT 的哪个特色?
我真的很感激 EPAT。如果不是这样,我的职业生涯可能会走向完全不同的方向。我甚至把它推荐给我的朋友,他们已经加入了最新的一批。
在 EPAT,我真的很喜欢:
- 教员——我可以联系到专家人才库中的任何人,他们都是合格的导师和教员。我可以问他们问题并得到答案,作为一个 EPATian 人,我可以接触到他们。
- 录制的讲座-就我个人而言,我喜欢观看录制的讲座,因为我不必连续坐 3 个小时-我喜欢花自己的时间与他们在一起,暂停和学习,在互联网上搜索术语,做笔记等。
- 结构——一切都是预先安排在课程中的——从学习材料到位置,我只需要做课程中的事情。
- 上课的方式
- 作业和考试
- Python 和 ML——我在这方面有优势,因为我有这方面的知识
作为一名开发人员,你是如何在 Algo Trading 找到工作的?
我去 EPAT 的目的是建立我的投资组合和简历,然后进入一家好公司。因此,对我来说,理解 EPAT 的布局特征是如何工作的非常重要。
在加入 EPAT 之前,我与 EPAT 安置团队讨论了我的工作要求、公司类型、提供的个人资料,以及我在这个领域的位置,团队对此非常合作。尤其是对于我这样没有行业经验的人来说。他们给了我一次机会,告诉我应该期待什么,什么样的公司会提供不同的角色。
明白这一点后,为自己制定一个计划是很重要的。我的策略是在做这门课的同时做这个项目。我会参加每一次讲座,学习并同时在我的项目中实施它——在某种意义上,我变得更加以项目和工作为导向。
从加入 EPAT 的第一天起,在我在那里的 6 个月里,安置团队一直给我发电子邮件,内容是:
- 工作机会
- 什么样的公司提供工作机会
- 他们提供什么样的工作角色
- 他们的期望,以及
- 申请这些角色的先决条件
这有助于我了解招聘人员实际上在寻找什么,提供的各种待遇等等。
即使在完成课程后,EPAT 的每个人都非常支持我,给我 2-3 个月的时间来完成我的项目——让它变得更强大。完成项目后,我开始申请公司。
安置小组非常乐于助人!
- 他们给我介绍了适合我的公司和角色
- 他们帮我寻找适合我的角色
- 他们对面试中哪些进展顺利,哪些可以改进的反馈
所有这些帮助我反思自己,并在两个月内帮助我在算法交易领域找到了一个好的角色。
你对那些想进入算法交易的人有什么建议?
对你正在做的事情和你为什么要做这件事有一个清晰的目标是很重要的。你应该有问题的答案:
未来几年你打算去哪里?
你将如何着手实现你想要实现的目标?
金融现在正在蓬勃发展,许多公司都在这个领域积极招聘,金融科技也越来越多。
与 IT 相比,这一金融领域并不广为人知,例如,算法交易在印度正呈指数增长。对于任何想进入这个领域的人来说,这是一个好时机。
算法交易有很多机会,参加 EPAT 认证会让你的旅程更容易。我发现 EPAT 是众多课程中的一门,没有其他课程能提供 EPAT 所能提供的。它只需要你的时间和努力,安置小组会照顾你的工作前景。
谢谢你分享你的旅程,克兰提。你鼓舞了所有那些希望成为算法和量化交易这个快速增长和有利可图的领域的一部分的人。作为 EPAT 大学的校友,我们期待与你保持联系。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
博士,开发人员,经理,教授和算法交易员-路易斯博士的故事
原文:https://blog.quantinsti.com/developer-manager-professor-algo-trader-epat-success-story-luiz-guedes/
如果我们告诉你一个人,他不仅接受了科学教育,进入了软件行业,然后进入了金融行业,现在还学习了算法交易,你会相信我们吗?
如果我们说他也学会了三种武术呢?
难以置信?这正是路易斯博士的故事。
Luiz 博士拥有 PUC/里约 pontifíCIA Universidade católica do Rio de Rio de Janeiro/Rio 的计算机科学博士学位、IME 的计算机系统硕士学位和计算机工程师学位。此外,他拥有 FGV 瓦加斯基金会的工商管理硕士学位。
他总是在不断地寻求克服自己,成为一个更好的人——不仅在智力上,而且作为一个人。他说,学习让他变得更好,帮助他理解世界是如何运转的,并给他一个探索新机会的机会。
我们联系了路易斯博士,这是他与我们分享的他的生活故事。
嗨,路易斯博士,给我们介绍一下你自己

嗨!我的名字是路易斯·古德斯。我是一名计算机工程师,拥有计算机科学学位,是巴西里约热内卢军事学院的教授。
26 年前,我获得博士学位后,从事软件开发工作,后来,我获得了工商管理硕士学位,并为科技公司工作。我做了 30 年的软件开发人员,现在是 Occam Brasil gesto de Recursos 的资产经理和定量分析主管。
我喜欢武术,练过跆拳道,是合气道黑带,现在在练咏春。几年前,我的父亲心脏病发作,大约在那个时候,我意识到我需要努力保持健康。
那时,我喜欢让·克劳德·云顿的电影,这让我对学习武术产生了兴趣,从 1996 年开始学习跆拳道。
我热爱外语,我学过汉语、韩语和日语。总的来说,我知道超过 6 种语言。
从科学到金融,再到现在的算法交易——这是怎么发生的?
我妈妈说,
那些更优秀的人总会有一席之地。
所以,我总是努力变得更好。我不能做我不知道的事。所以,当我读 MBA 的时候,尽管我发现这些知识很有趣,但我不能应用它们。
在巴西,有一句谚语,
人们总是会成长到顶峰,然后就会跌倒。
我觉得这是真的,因此,尽管我很喜欢这个管理职位,但我还是决定不做了。我没有不愉快的感觉。
我对金融的兴趣是大约三年前通过我的哥哥产生的,他对比特币非常好奇。慢慢地,我也开始交易比特币。6 个月后,我意识到这不值得大肆宣传。所以,我去了股票市场,开始自学。
我总是通过各种量化网站和各种在线内容不断寻找学习算法交易。我仍然总是在网上寻找参考资料。
我开始学习技术分析,研究技术指标。那时我还不知道 Python,但是如果我使用 C 和 C++的话。我还为我的交易创造了一个 algo 交易机器人。
我注意到:
- 虽然技术分析很有趣,但有时它不起作用
- 有很多事情我不明白
- 有些我不知道为什么会发生
我意识到我需要很多知识:
- 关于市场
- 市场背后发生了什么
- 对图表的理解
我相信正规学习,因为尽管我自己学习过,自己研究过,但拥有结构化的知识对于避免信息差距非常重要。
这对你的知识和理解至关重要。这就是我当初开始修技术分析课程的原因,但都是徒劳。
因此,我一直在寻找有用的学习资源,就在那时,我发现了 QuantInsti 的白皮书和博客。此后不久,我浏览了 EPAT 的教学大纲,意识到这正是我要找的内容。
我可以回答我一直在问的所有问题。我终于有了一个可以问我问题的人,而不必再继续寻找答案了。
我心想,这看起来很有趣,我可以自己从中赚钱。我只用了一天时间就报名参加了 EPAT 项目!
我之前工作的软件开发公司被另一家公司收购了,公司的方向也变了。所以,我不得不搬家。我可能会跳槽到同一行业的另一家公司,或者干脆跳槽到一个新的行业。
我喜欢交易,写软件和做分析。所以,我和一个朋友谈了这件事。他的朋友在银行和市场工作,所以也许他可以把我介绍给他们。这正是我即将完成 EPAT 课程的时候。
就在那时,我被介绍给了三家公司!如果我没有参加 EPAT 的课程,我肯定能胜任这份工作。EPAT 让我的快速职业转变成为可能,并为我提供了新的机会。从 EPAT 毕业后,我现在在一家做投资基金的资产管理公司做量化分析师。
我一直认为交易是我退休后会做的事情,但我现在仍然在做。
EPAT 是如何为你的专业知识增值的?
EPAT 课程有三大支柱——计算机编程、金融和数学。这三个领域之间的平衡以及这种知识的混合方式使其更有意义和可操作性。我们可以在工作、交易或投资中使用这些知识。
我相信这才是真正打动我的地方!我觉得这是 EPAT 课程最大的好处和优势!
我以前的知识只和计算机科学有关,而且我有非常好的工科基础。但是我在金融方面有知识空白,我没有应用我所拥有的知识。这是我在 EPAT 期间做的事情。
在参加 EPAT 课程之前,我不知道交易中有一些东西。交易需要很多知识,尤其是当你投资股票的时候。
人们需要意识到:
- 事情应该如何发展
- 事情不应该怎样发展
- 风险管理
- 理解统计数据背后的数学
- 如何获得对你有利的概率等。
现场讲座:我以前参加过的所有课程都有预先录制的课程,而 EPAT 讲座提供了一种人情味,这是我所欣赏的。我发现现场课堂讲课非常有趣。
解决我的疑问:我提出的任何问题都很快得到了解答。我学到了很多我甚至不知道存在过的东西。在与我的 EPAT 团队联系时,我注意到 EPAT 有来自科学、数学、计算机科学和许多其他领域的参与者!
在 EPAT,我学到了很多现在对我有帮助的东西,特别是如何创造更好的交易算法。我学会了如何编写更好的 Algo 交易软件。我会在课堂上学习 Python,练习它,然后在我的系统上尝试。这帮助我找到了如何在交易中使用它的方法,我意识到这对我来说简单多了。这种实践学习是第一个直接的好处。
哦,我喜欢这些作业!他们对我来说是无价的。他们几乎是我所寻找的一切,来扩展我的边界。
项目工作:当我的 EPAT 项目工作被指派一名导师时,最初我有点担心导师是否知道我想做的事情,以及与之相关的话题。但是,令我惊讶的是,他们知道的比我做的多得多!所以,我的恐惧很快就消失了。
分享一个你最喜欢的 EPAT 特色!
师资力量、内容、平台——都非常好。
有像欧内斯特·陈博士、托马斯·斯塔克博士、尤安·辛克莱博士这样令人难以置信的教授上课,以及完整的师资基础是令人难以置信的。他们拥有的知识是杰出的,就好像他们是为此而生的。
即使在他们的讲座结束后,教员们也总是乐意回答你的问题和疑虑。我会和他们联系,给他们发问题,他们总是迅速回复我的问题,并给我的项目提供有用的建议。所以,对我来说,教师是 EPAT 最好的特色。
课程设置真的很好,平台完美无瑕,工作起来像新机器一样!
你给 Algo 交易爱好者的建议。
继续成长!
在攻读 MBA 期间,我发现学习管理比应用概念更有趣。今天,当我在团队项目中工作时,或者当我必须与人打交道或帮助他们时,这些知识对我很有帮助。
当我为支付行业开发技术时,我并不了解数据科学。所以,我做了一些数据科学方面的认证,我发现这真的很有趣。今天,它对我的背景帮助很大。学什么都没有浪费。
继续努力!
即使是在跳 EPAT 舞的时候,每周我都努力练习我所学的内容。如果我今天能或者不能练习我的编码,下周我会再试一次。我一直在努力。我发现做一点点事情比什么都不做要多得多。所以,继续努力。
人们为我会说 7 种语言而鼓掌,并对我是如何做到的感到震惊。但是这些年来,这对我来说是一种渐进的成长。你也可以的!
继续学习!
如果你知道一些东西,或者即使你对算法交易一无所知,EPAT 是一个很好的起点。当你成为全球 EPAT 校友社区的一员时,你可以终身学习。
您可以随时查看课程的最新进展,并通过最新的 EPAT 讲座获取最新的市场内容。
我只是一个金融初学者,因为我有计算机科学的背景。但是,我的金融和交易知识,以及技能,来自 EPAT 的课程,而且它们还在增长。
人们年轻时就开始在金融市场工作。50 多岁的我很难找到一份工作,相比之下,今天在这个领域刚刚起步的人。市场害怕雇佣老年人。
你可能有很多经验,很多技能和很多知识,但你可能会因为没有坚持学习而错过一个好的工作机会。所以,继续学习。首先,EPAT 是个好地方。
感谢您抽出时间与我们交谈,路易斯博士。得知你这些年来取得的成就和成功,我们感到很惊讶,我们希望你能有所成就。最美好的祝愿!
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
交易阿尔法:开发微阿尔法生成系统[网络研讨会]
原文:https://blog.quantinsti.com/developing-micro-alpha-generating-system-webinar-18-november-2022/
https://www.youtube.com/embed/xga-aObEd6g?rel=0
关于会议
这节课通过识别各种微阿尔法机会向你介绍阿尔法交易的技巧。它涵盖了各种微阿尔法策略,参数优化的过程,以及如何开发一个交易系统。
概观
- 阿尔法交易简介
- 微阿尔法的概念
- 参数置换过程
- 各种微阿尔法策略
- 阿尔法的类型
- 互动问答
扬声器简介
Thomas Starke 博士(AAAQuants 首席执行官)

Starke 博士拥有物理学博士学位,目前担任澳大利亚领先的自营交易公司 AAAQuants 的首席执行官,领导着该公司的量化交易团队。他还在牛津大学担任高级研究员。
rushda an sari(QuantInsti 技术内容经理)

Rushda 是 quantin STI Quantra 研究和内容团队的技术内容经理。她的教育背景包括金融管理研究生文凭。此外,在股票交易方面,她也有实践经验。
本次网络研讨会于:
2022 年 11 月 18 日星期五
东部时间上午 6:00 | IST 时间下午 4:30 |新加坡时间下午 7:00
Python 中的对角点差期权交易策略
原文:https://blog.quantinsti.com/diagonal-spreads-options-trading-strategy-python/
到了 Viraj Bhagat
市场发展迅速,交易在很短的时间内完成。无数的交易者和无数的策略在这个过程中扮演着他们的角色。在一天结束的时候,一些人漂浮着,而一些人向上航行,一些人绊倒,甚至跌倒,第二天再站起来。交易期权在这方面起着关键的作用,因为它们为交易者提供了创造多种策略的能力,但却耗费了时间。市场上有很多这样的策略,花时间去学习它们和研究它们的技术细节是很重要的。虽然股票可能只允许一个人交易看跌或看涨,但他们经常横向移动,但在特定的范围内。正是在这种情况下,你进入了一个对角线传播。
什么是价差?
证券的同时买入和卖出被称为价差或价差交易或相对价值交易,通常以期货合约和期权为支柱进行。除此之外,有时也使用证券。价差可以由买入或卖出构成,既可以是借方价差,也可以是贷方价差。基于月份和分支的关系,创建跨页结构并将其区分为垂直跨页、水平跨页和对角跨页。
什么是对角线传播?
对角传播策略是:
- 一个期权交易策略
- 两步战略
- 结合了长通话日历分布和短通话分布
垂直价差、水平价差和对角价差的比较
根据 Investopedia 的说法,对角线传播利用不同的月份和打击,它沿对角线移动,因此得名。

虽然据说这些在以前的报纸上被称为:【1】
- 期权价格>以表格方式列出
- 执行价格>按行列出,即垂直列出
- 过期时间>列中列出,即水平
因此,对角线分布意味着在不同行和列中存在具有不同执行价格和到期日的期权。
日历跨页和对角线跨页的差异
对角价差的近期前景可能是看跌或看涨。它类似于日历跨页,因为:
- 卖出近期期权
- 买入长期期权
- 利用即将到期选项中的快速时间衰减
什么是对角线呼叫传播?
当前景略微乐观时,人们会卖出较高的近月看涨期权,而卖出较低的远月看涨期权
什么是对角卖出价差?
当前景略微看跌时,人们卖出较低的近月看跌期权,而卖出较高的远月看跌期权
什么时候执行对角扩展?
- 你认为会上涨(如果买入)或再次下跌(如果卖出)的短期弱势或强势,然后利用它
- 该策略是在短期内控制风险,如果市场运行平稳,它就可以在长期内开放
- 当为了钱而执行时,它允许满足保证金要求
- 空头期权到期自动柜员机无价值> IV 扩大>增加剩余多头期权的价格>保留卖出期权的全部信用>降低我们拥有的多头期权的成本基础
- 对角线价差>短边到期无价值>金钱>买入>长边价差
改变是关键!
一个人必须时刻注意和警惕他/她的策略的表现。如果在任何情况下,传播需要一些调整,它将不得不小心,以防止任何损失。一个人可以在战略实施后,通过持续研究市场并暗示其战略的变化来获得最大利益,从而将它作为一种优势。
从对角价差交易策略中获利
对角线价差的最大利润可描述如下:
- 最大值利润=收到的净信贷* -为买入期权支付的溢价(买入期权 B)
- *净信贷是通过卖出买入期权 A)获得的
对角线价差交易策略的损失
对角线排列的最大损失可描述如下:
- 对于净信贷:最大损失=执行 A–执行 B–净信贷记录。
- 对于净借方:最大损失=执行 A–执行 B +已付净借方
对角扩展策略的设置
如果交易朝着我们的方向快速发展,你可能会赔钱。因此,与其他跨页相比,对角线跨页的设置非常重要。它涉及同时购买:
- 同等数量的选择
- 这两个选项应该属于同一类
- 两者应该具有相同的基础安全性
- 两种不同的执行价格
- 2 个不同的到期月
一个电话的对角线传播看起来像这样: 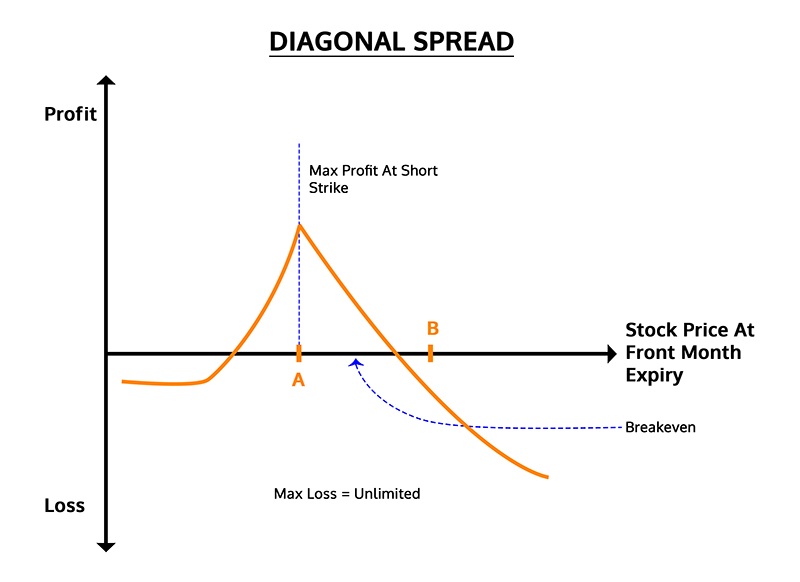
策略(在‘呼叫’的情况下)
- 卖出 1 个 OTM 看涨期权-较低的执行价格-交割月
- 购买 1 个 OTM 看涨期权–B–更高的执行价格–后一个月(长期)
- 股票通常会低于执行价 A
我们将借助一个例子来解释这个策略。
长呼对角传播
实施多头对角价差交易策略
我将解释使用长时间看涨期权的对角线传播的示例,为此,我将使用 NIFTY(Ticker-NIFTY)的示例。以下是 NIFTY  的期权链。我们现在将从 2018 年 4 月和 2018 年 5 月获取 2 个看涨期权价格2018 年 4 月:
的期权链。我们现在将从 2018 年 4 月和 2018 年 5 月获取 2 个看涨期权价格2018 年 4 月: 2018 年 5 月:
2018 年 5 月: 
策略
# Importing Libraries
# Data manipulation
import numpy as np
import pandas as pd
# To plot
import matplotlib.pyplot as plt
import seaborn
plt.style.use('ggplot')
# BS Model
import mibian
# Importing Libraries
# Data manipulation
import numpy as np
import pandas as pd
# To plot
import matplotlib.pyplot as plt
import seaborn
plt.style.use('ggplot')
# BS Model
import mibian
# Nifty futures price
nifty_april_fut = 10595.40
nifty_may_fut = 10625.50
april_strike_price = 10700
may_strike_price = 10800
april_call_price = 10
may_call_price = 82
setup_cost = may_call_price - april_call_price
# Today's date is 20 April 2018\. Therefore, days to April expiry is 7 days and days to May expiry is 41 days.
days_to_expiry_april_call = 6
days_to_expiry_may_call = 41
# Range of values for Nifty
sT = np.arange(0.97*nifty_april_fut,1.03*nifty_april_fut,1)
#interest rate for input to Black-Scholes model
interest_rate = 0.0
# Front-month IV
april_call_iv = mibian.BS([nifty_april_fut, april_strike_price, interest_rate, days_to_expiry_april_call],
callPrice=april_call_price).impliedVolatility
print "Front Month IV %.2f" % april_call_iv,"%"
# Back-month IV
may_call_iv = mibian.BS([nifty_may_fut, may_strike_price, interest_rate, days_to_expiry_may_call],
callPrice=may_call_price).impliedVolatility
print "Back Month IV %.2f" % may_call_iv,"%"
Front Month IV 8.53 %
Back Month IV 11.26 %
# Changing days to expiry to a day before the front-month expiry
days_to_expiry_april_call = 0.001
days_to_expiry_may_call = 35 - days_to_expiry_april_call
df = pd.DataFrame()
df['nifty_price'] = sT
df['april_call_price'] = np.nan
df['may_call_price'] = np.nan
# Calculating call price for different possible values of Nifty
for i in range(0,len(df)):
df.loc[i,'april_call_price'] = mibian.BS([df.iloc[i]['nifty_price'], april_strike_price, interest_rate, days_to_expiry_april_call],
volatility=april_call_iv).callPrice
# Since, interest rate is considered 0%, 35 is added to the nifty price to get the Nifty December futures price.
df.loc[i,'may_call_price'] = mibian.BS([df.iloc[i]['nifty_price']+35, may_strike_price, interest_rate, days_to_expiry_may_call],
volatility=may_call_iv).callPrice
df.head()
nifty_price april_call_price may_call_price
0 10277.538 0.0 27.305711
1 10278.538 0.0 27.455138
2 10279.538 0.0 27.605211
3 10280.538 0.0 27.755935
4 10281.538 0.0 27.907309
df['payoff'] = df.may_call_price - df.april_call_price - setup_cost
plt.figure(figsize=(10,5))
plt.ylabel("Payoff")
plt.xlabel("Nifty Price")
plt.plot(sT,df.payoff)
plt.show()
 T2】
T2】max_profit = max(df['payoff'])
min_profit = min(df['payoff'])
print "%.2f" %max_profit
print "%.2f" %min_profit
35.55
-88.94
最大利润:35.55 印度卢比 最大损失:88.94 印度卢比
结论
经验丰富的老手和更高级的人最常采用这种策略,因为它包括卖出 2 个期权,同时具有一定的波动性和可预测性;但股价稳定。因此,要实施这种策略,你需要对市场和他的选择相当透彻。
现代交易需要系统的方法,需要引导自己远离直觉交易。通过我们的系统期权交易课程,学习如何以系统的方式交易期权。此外,你可以探索期权交易策略,如蝴蝶,铁秃鹰和传播策略。立即注册!
下载数据文件
- 对角扩散期权策略——Python 代码
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
定量分析师和技术分析师的区别
原文:https://blog.quantinsti.com/difference-quants-technical-analysts/
定量分析师和技术分析师是一个硬币的两面。因为技术分析师和量化分析师都为算法交易实践工作,他们相互联系但又各自独立。通过找出每一个是如何单独工作的,您可以更好地了解每一个的重要性以及融合如何有用。
本博客涵盖:
定量分析师和技术分析师有什么相同点和不同点?
当我们在比较这两个角色时发现了相似之处,就更容易筛选出它们的不同之处。角色不同,责任也不同。
定量分析师和技术分析师的相似之处
| 定量分析师和技术分析师 |
| 用于算法交易领域 |
| 使用技术指标,如趋势线,移动平均线,均值回归 |
| 看看市场过去的表现 |
| 帮助创建交易策略,包括进场和出场信号,以及仓位大小算法 |
定量分析师和技术分析师的区别
| Quants | 技术分析师 |
| 定量分析师不仅预测市场未来的行为,还专注于创造交易策略 | 技术分析师专注于借助历史市场数据预测市场未来的行为 |
| 定量分析师使用数学、统计和金融学位 | 需要注册金融技术员、注册市场技术员或类似的金融学位 |
| 定量分析师给出夏普比率、预期风险、预期回报和其他特定算法或策略的统计数据 | 技术分析师根据过去类似的情况给出市场上的买入或卖出信号 |
| 以及技术指标/工具,如移动平均线、振荡指标、趋势线等。定量分析师还使用机器学习、神经网络和夏普比率等统计工具。 | 技术分析师利用技术指标和基于市场过去表现的先入之见 |
技术分析示例
我用图形表示了随机指标的值/结果,下面给出了一个简单的例子:

在上图中,从左到右显示了%K(随机指标值)线。这个%K 用蓝线表示,显示了在过去 14 个周期中收盘价和最低价之差占最高价和最低价之差的比例。当%K 高于 80 时,这是一个超买的情况,当%K 低于 20 时,这是一个超卖的情况。
类似地,%D 是平滑的随机指标值,它也产生买卖信号。要了解更多关于随机振荡器的知识,你可以注册我们的 Python 交易课程!
定量分析的例子
定量分析的一个例子是在使用技术指标后创建的交易策略的夏普比率。
在这种情况下,我们可以说,在使用随机振荡器并看到超买和超卖的情况后,定量分析师将在夏普比率的基础上制定交易策略。夏普比率衡量投资资产或交易策略中每单位标准差的超额回报。
- 高夏普比率——单位风险回报更高
- 夏普比率低——单位风险回报率更高
夏普比率方程:夏普比率= (Rp - Rf) / σ
其中,
Rp=平均投资组合收益
Rf= 无风险利率
σ=投资组合的标准差
假设你预期你的投资组合年化回报率为 12%。如果无风险利率是 7%,你的投资组合有 8%的标准差。您投资组合的夏普比率计算如下:
夏普比率= (12% - 7%)/ 8% = 0.625
定量分析师和技术分析师的组合以及他们在一起的好处
当一个定量分析师和一个技术分析师一起工作时,就会产生一个成功的算法交易团队。让我们看看如何。
技术分析师利用技术指标来预测市场情况,看市场是更有可能看跌还是看涨。在这些结果的帮助下,定量分析师可以利用统计工具来获得预期收益、风险、夏普比率等结果。
然后,结合两者,即基于历史市场表现和统计数字的市场预测,可以创建一个交易策略。
定量分析师和技术分析师一起工作的好处如下:
- 任务的专业化使工作更有效率
- 两者的结合有助于评估长期投资,因为一个根据历史表现预测市场情况,另一个进行统计测试以量化策略的表现
- 两者结合在一起可以帮助交易者意识到交易决策的潜在优势和风险
- 该策略被验证两次。一个借助于技术指标,另一个借助于统计工具
- 结合技术和数量分析会带来更多有利的交易
如何区分 Quants 和技术分析师的学历要求?
要成为一名定量分析师,你需要精通多门学科,比如金融、统计、数学、计算机科学等。
现在,既然一个定量分析师实际上需要在一个更广泛的框架中,那么他需要精通数学和统计学以及金融。
但是,要成为一名技术分析师,你主要需要拥有金融方面的教育资格,因为这个职位要求你研究历史市场数据或表现。根据历史市场数据,技术分析师预测市场未来的表现。
我们整理了一些最受欢迎的由专家撰写的关于技术分析的博客。
结论
我们在这篇博客中讨论了定量分析师和技术分析师,以及他们如何专注于自己的角色和职责。定量分析师和技术分析师在同一个算法交易领域工作。虽然他们在各自的岗位上表现出色,但结合起来,他们会在算法交易中取得成功。
如果你想学习如何将技术指标用于一种被称为摇摆交易的交易策略,你可以选择摇摆交易的这门课程。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
Dijkstra 算法
马里奥·比萨
开始学习寻找最短路径的 Dijkstra 算法。我们简要回顾了 Kruskal 算法、Prim 算法、Johnson 算法和 Bellman 算法。我们将涵盖:
- 什么是 Dijkstra 算法?
- Dijkstra 算法是如何工作的?
- Dijkstra 算法的伪代码
- Dijkstra 算法表
- Dijkstra 算法时间复杂度
- 什么时候使用 Dijkstra 算法?
- 迪杰斯特拉算法 vs 克鲁斯卡尔算法
- Dijkstra 算法 vs Prim 算法
- 普里姆算法 vs 克鲁斯卡尔算法
- 如何使用 Dijkstra 算法寻找最短路径?
- 为什么 Dijkstra 算法对于负权重会失败?
什么是 Dijkstra 算法?
Edsger W. Dijkstra (1930-2002) 是一位杰出的物理学家,他在分布式和并发计算以及其他数学领域取得了巨大的进步。
以他的名字命名的算法寻找最优解以获得图或网中的最短路径,尽管我们将在下面看到对算法的改进以提高效率。
Dijkstra 算法属于所谓的贪婪算法家族,因为它仅考虑当前时刻做出决策,而不考虑该决策可能如何影响未来,即,它在给定时刻做出最佳决策,而不考虑未来后果。
贪婪算法通常用于解决优化问题,例如选择最短路径或在计算机上执行任务的最佳顺序。
在这种情况下,贪婪算法在给定时刻选择最有希望的部分或任务,而不会在以后重新考虑这是否是最佳决策。因此,这是一个简单的算法实现,因为没有必要控制替代方案,也没有后续撤销以前的决定。
诸如 Dijkstra 算法、Kruskal 算法或 Prim 算法之类的贪婪算法的特征在于以下一般属性:
- 算法要求以最优的方式解决问题,在构建解决方案时,我们有一组或一列候选方案,如图的边、要计划的任务等。
- 随着算法的进行,两个集合被累积,一个包含已经被评估和选择的候选,另一个包含已经被评估但是被拒绝的候选。
- 有一个功能可以检查一组候选项是否形成了问题的解决方案,暂时忽略这是否是最佳解决方案。
- 还有第二个功能,测试给定的一组候选项是否可行,即是否有可能与其他候选项达成解决方案,以获得最终解决方案。同样,我们暂时忽略了解决方案是否是最优的。
- 还有第三个函数,用于选择既未被选中也未被拒绝的候选项,该候选项是在给定时间点最有希望的解决方案候选项。
- 最后,还有第四个函数叫做 objective,它返回我们已经找到的解,尽管严格来说它不是贪婪算法的一部分。
为了解决这个问题,我们寻找(第一)构成解的候选集,以及(第二)优化目标函数值的候选集。贪婪算法一步一步地进行。
最初,所选候选项的集合是空的,并且在每一步,最佳候选项被认为是通过选择函数添加到该集合中的。
- 如果所选候选的新扩展集对于一个解决方案是不可行的,无论最优与否,则该候选被拒绝。
- 如果候选的扩展集合仍然形成可能的解,无论最优与否,新的候选被添加到选择的候选集合中。
就这样,我们一步一步地继续前进,直到找到一个一定是最优的解决方案。
正如我们已经说过的,这些特征是贪婪算法所共有的,尽管我们将在后面看到,Dijkstra、Kruskal 和 Prim 贪婪算法具有独特的特征。
Dijkstra 算法是如何工作的?
Dijkstra 算法解决了给定图形的最小路径问题。
给定一个有向图 G = {N,E} 其中 N 是 G 的节点集,E 是有向边集,每条边都有非负的长度,我们也可以讨论重量或成本,其中一个节点作为原点节点。
问题是确定从原点到其他每个节点的最短路径的长度。
正如我们在贪婪算法的一般特征中所看到的,Dijkstra 算法使用两组节点 S 和 c。组 S 保存所选节点的集合以及在给定时间每个节点到原始节点的距离。集合 C 包含所有未被选择且距离未知的候选节点。
由此我们推导出一个不变性质 N = S U C 。
也就是说,节点集等于所选节点集和未选节点集的并集。
在算法的第一步中,集合 S 只有节点原点,当算法完成时,它包含所有图节点以及每条边的成本。
如果从原点到特殊节点的路径中涉及的所有节点都在所选节点的集合 s 内,则我们称之为特殊节点。Dijkstra 算法维护一个矩阵 D,该矩阵在每一步都用集合 s 中每个节点的最短特殊路径的长度或权重进行更新
当试图将一个新的“v”节点添加到 S 时,到“v”的最短特殊路径也是到所有其他节点的最短路径(参见参考书中的演示)。当算法完成时,所有的节点都在 S 中,矩阵 D 包含了从原点到图中任何其他节点的所有特殊路径,从而解决了我们的最小路径问题。
在查看 Python 实现之前,让我们先看看 Dijkstra 算法在伪代码中是如何工作的。
Dijkstra 算法的伪代码
Dijkstra 算法的伪代码是:
直接市场准入(DMA):简介、交易平台、经纪人等等
由查尼卡·塔卡和何塞·卡洛斯·冈萨雷斯·田中
直接市场准入是交易领域的一个有趣的部分,它在 20 世纪 80 年代开始被散户交易者使用,但在 20 世纪 90 年代逐渐在机构交易者中流行起来。投资银行、对冲基金等。主要在今天使用直接市场准入。
让我们通过这篇博客了解更多关于直接市场准入的信息,内容包括:
什么是直接市场准入?
直接市场访问 (DMA)是对金融市场交易所指令簿的直接访问,导致证券的日常交易。通常是投资银行(花旗集团、摩根大通)、对冲基金等公司。直接进入市场。
直接市场准入的运作
让我们假设一个交易者或公司想通过直接市场交易股票。首先,将需要一个平台,通过经纪人利用直接进入市场的设施。
之后,交易者会下订单,经纪人会做一个快速检查,找出在市场上开仓的保证金。在必要的检查之后,交易者将能够看到其他市场参与者的订单,并判断下达交易订单的市场情况。

Working of direct market access
直接市场准入交易平台
交易平台由经纪人提供,帮助交易者直接与交易所执行交易指令,无需任何中介。这些直接进入的经纪人必须为您提供一个高度专业化的交易平台,具有一些功能,例如:
- 可以用 Python、C 等语言编程的路由模块。
- 算法交易能力
- 用于进行技术分析、基本分析等分析的可编程扫描仪。
- 一个一次性进行大量交易的软件(在尽可能短的时间内)
下面您可以看到一些通过交易平台提供直接市场准入服务的经纪人:
| 经纪人 | 网站链接 | 量滴存款 | 交易平台 | 基础年 | 公开交易 |
| FP 市场 | 点击这里 | $100 | MT4、MT5、IRESS、WebTrader | Two thousand and five | 不 |
| 瑞士报价 | 点击这里 | $1000 | MT4、MT5、高级交易员 | One thousand nine hundred and ninety-six | 是 |
| 前沿(武器)系统 | 点击这里 | $1 | MT4、MT5,专有 | Two thousand and nine | 不 |
| VantageFX | 点击这里 | $200 | MT4,MT5,网上交易 | Two thousand and nine | 不 |
| 铁皮人 | 点击这里 | $100 | MT4 | Two thousand and ten | 不 |
| FXTM | 点击这里 | $10 | MT4, MT5 | Two thousand and eleven | 不 |
直接市场准入的成本
为了获得直接进入市场的好处,交易者要为上表中提到的每个经纪人支付最低保证金。因此,直接进入市场的所有者只需要支付执行费就可以将交易指令发送到市场。
直接市场准入与零售交易
说到直接进入市场和零售交易的区别,主要的区别是零售交易者通过中间人来执行他们的订单。然而,直接市场准入允许交易者直接与交易所执行交易指令。
让我们看看直接市场准入和零售交易之间的更多区别:
| 直接市场准入 | 非直接市场准入 |
| 直接进入市场是由经纪人提供的 | 在某些零售交易中,不提供直接进入市场的途径,而是由经纪人充当中介 |
| 下交易订单是一个快速的过程,因为交易者可以直接在交易所执行交易 | 交易指令的执行速度取决于经纪人的技术 |
| 支付执行费是为了将交易指令发送到市场 | 根据回报支付佣金 |
| 直接市场准入可以利用 ATS (替代交易系统)订单类型,这些订单类型向直接市场准入的所有者支付回扣,以向市场提供流动性 | 不支付回扣 |
超低延迟直接市场访问
直接市场访问的主要优势之一是,与一些经纪人拥有的路由器层相比,它提供了低延迟。一些技术供应商试图优化这一功能,将他们的服务称为超低延迟直接市场访问,这意味着与仅低延迟(LL)相比,他们在延迟方面有所改善。
低延迟和超低延迟直接市场访问有什么区别?
一旦你读了上面这段话,你可能会问自己这个问题。我们可以告诉你的是,业界对这两者没有明确的区分。
让我们给你解释一下为什么会这样。ULLDMA 是关于处理高资产量,只有 500 微秒的延迟,超过这个数字可以理解为 LLDMA。即使这个数字可以给你一个思路,也不要混淆!
如果你在 80 年代交易,ULL DMA 可能意味着一个更大的数字,可能是毫秒,现在 500 可能是区分两者的一个很好的代理数字,但在未来,随着技术的进步,你可以预期这个数字会减少到零!
什么样的交易者最能利用这种服务?
低频交易者投资的频率大于一分钟。高频交易者的交易频率不到一分钟。我们必须说,ULLDMA 服务在基础设施方面可能非常昂贵。
这也是因为如此高频率的交易只有在交易量非常大的情况下才能盈利。所以你可能会猜测,从成本效益的角度来看,高频交易者是可能从这种超低延迟中获利的人。
卖方如何提供 ULL DMA?
由于交易指令是以数字方式执行的,它们以光速从卖方传送到证券交易所。如果供应商的系统和证券交易所之间的距离更近,这一速度可能会有所提高。
您可能在寻找一些问题的答案,例如:
他们如何缩短这一距离?
他们与交易所的距离应该有多近?
嗯,这两个问题可以简单地回答:协同定位是一种实践,这意味着供应商在存放交易所计算机服务器的同一场所创建其基础架构。这样,它们就保证了信息传播速度方面的最近距离和最高效率。
外汇直接市场准入
在我们谈论外汇直接市场准入之前,让我们向您解释一下外汇间接市场准入。
没有外汇直接市场准入,外汇订单如何运作?
散户投资者进入外汇市场的常见服务是由所谓的经纪人交易台提供的。经纪人的交易台负责优化散户交易者的订单到达机构银行的最佳路径。
操作是这样的:经纪人接收银行机构的出价并要求报价,然后他们汇总报价为散户交易者“做市”。因此,交易台为散户交易者创建买入和卖出报价,这样,这些经纪人就允许市场的流动性和有效性。
此外,经纪人充当散户交易者的交易对手也很常见。当散户买入时,经纪人扮演卖家的角色,当散户卖出时,经纪人扮演买家的角色,即使投资者利用了杠杆。这类经纪人也被称为“做市”(MM)经纪人。
然而,由于越来越多的人在金融市场交易,越来越多的技术进步正在到来,越来越多的经纪人现在向散户交易者提供外汇直接市场准入。
外汇直接市场准入的运作
让我们了解外汇直接市场访问和股票直接市场访问的工作原理,在股票直接市场访问中,您可以在没有“智能路由器”的情况下从多个交易所访问订单簿。这款智能路由器可能会为您的特斯拉股票购买订单优化最佳路线。
在 forex direct market access 中,您可以访问相同银行机构的报价,而无需我们上面谈到的交易台的干预。因此,举例来说,每当你买入或卖出欧元美元时,你的订单会由经纪商直接发送到银行间市场执行。
那么交易会立即完成。为交易者直接进入市场的经纪人也称为无交易台经纪人(NDD 经纪人)。
所以你可能想知道:
与普通经纪人相比,我如何看待无交易台经纪人的买卖报价?
你能猜到吗? 很简单!
- 对于一个普通的经纪人,你只会看到一个买价和一个卖价,因为,正如我们前面讨论过的,经纪人的价格是其交易台提供的来自不同银行机构的“集合”。
- 在非交易台经纪人的情况下,你会看到来自这些银行机构的几个出价和要价,所以在这种情况下,你可以根据你的需要选择大量的出价和要价!
你能与直接市场准入经纪人交易外汇 CFD 衍生品吗?
差价合约(CFD)是一种使投资者能够按照货币对的方向进行交易,而不是按照现货报价进行交易的合约。一些外汇直接市场准入经纪人可以让你直接与银行机构交易这种类型的衍生品。
我们应该补充一点,通常情况下,最好的差价合约经纪商在行业内拥有最好的声誉,并且倾向于拥有专业或机构客户。所以,每当你对你的交易经验有疑问或问题时,所有这些经纪人都有正确的知识来帮助你,以防你需要它。
此外,我们可以说,如果你是一个交易量很大的交易员,那么你可能需要与提供差价合约的直接市场准入经纪商合作,这样你的大单就不会影响市场。这在大市场交易时很重要,就像在流动性差的市场一样。
佣金率呢?
一些做市商在交易外汇时只对每笔交易收取佣金,而其他人则按相同的差价收取费用。
但是,通常情况下,直接市场准入外汇经纪商会对买卖价差收取少量加价,并且不会对订单收取任何其他佣金。
直接市场准入的优势
以下是直接市场准入(DMA)的优势:
- 所有价格馈送都是可见的,并提供透明度,允许您评估出价和出价量
- 与经纪人设定报价的做市商模式不同,DMA 模式是订单驱动的,这使您成为价格制定者,而不是价格接受者
- 订单执行速度更快
- 经纪人不访问订单流,因此,没有重新报价,因此,DMA 意味着更快地执行交易订单
- 经纪人不作为你交易的对手,所以他们不会产生委托代理问题
- 收取小额差价加价
直接市场准入的缺点
直接市场准入的缺点可以列举如下:
- DMA 帮助您访问交易所中的订单簿,这意味着您只能交易有中央证券交易所的工具
- 除非你是一个有经验的交易者,否则很少有经纪人会为零售交易提供 DMA
- 如果用户不经常交易或者长时间不活动,经纪人费用可能会很高
- 价格并不总是比非 DMA 经纪人好
结论
在这篇博客中,我们讨论了交易领域中最相关的直接进入市场的概念。直接市场准入机制允许交易商/机构在金融市场进行交易,无需任何中介。
直接市场准入是一种更快的方法,使直接市场准入的所有者直接控制进出头寸。我们还讨论了不同类型的直接市场准入及其弊端。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就去看看吧!
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
基于股票相关性和指数波动性的分散策略[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-strategy-correlation-stocks-volatility-index/

尼廷·阿格沃尔和 T2·贾斯比尔·辛格
本文是贾斯比尔·辛格提交并由尼廷·阿加瓦尔指导的期末项目,是 QuantInsti 算法交易(EPAT) 高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
简介
本文基于股票相关性、指数波动性,使用分散策略检验交易利润。分散有助于交易者只考虑波动性(假设相关性均值回复),因此,确保通过购买或出售期货来对冲 delta 风险。在这种策略中,多头和空头都是建立在波动性的基础上的,现在有了更多的策略,最好使用利用相对价值而不是绝对价值的策略。这限制了风险资金的单向流动。
具体来说,当相关性很高时,分散交易利用指数期权相对于单个期权的过高定价。根据单个股票之间的相关值,可以通过卖出指数期权和买入指数成分期权或买入指数期权和卖出指数成分期权来交易离差。
最近几年,关于为什么离差交易有利可图,有很多假设。最广为接受的理论是市场无效理论,该理论认为期权市场的供给和需求驱动了偏离其理论价值的溢价。在 1996 年至 2005 年的研究中,这一点在 2000 年后离差交易不再盈利时得到了证明。
战略
为了区分分散交易,它只是一种对冲策略,利用指数和指数成份股之间隐含波动率的相对价值差异。它涉及一个指数的空头期权头寸和一个指数成分的多头期权头寸,反之亦然。在指数上建立空头头寸或接近资金扼杀的头寸,在构成该指数的 50-60 %的股票上建立多头头寸或资金扼杀的头寸。空头头寸减轻了多头带来的风险。此外,在资金多空和资金紧缩的情况下,delta 敞口接近于零。因此,分散策略针对较大的市场波动进行对冲,并构成较低的方向性风险。
对于指数 其中 W i 是指数中股票‘I’的权重。使用
其中 W i 是指数中股票‘I’的权重。使用 可以计算出指数的方差,其中σIT6】2 为指数方差,w i 为股票在指数中的权重。σ i 2 为个股方差,ρ ij 为股票 I 与股票 j 的相关性。
可以计算出指数的方差,其中σIT6】2 为指数方差,w i 为股票在指数中的权重。σ i 2 为个股方差,ρ ij 为股票 I 与股票 j 的相关性。
离差交易的利润来自于这样一个事实,即相关性均值回归,如果一个人购买了相关性,那么一只股票的已实现波动率将高于指数的已实现波动率。德里森认为,只有负相关风险溢价才有可能在分散策略中获利。但这可以通过指数期权相对于单个股票期权的过高定价来实现。因此,卖出指数期权,买入其成分的期权,并用期货合约进一步对冲,以始终保持 delta 中性,这也是一项有利可图的交易。
在整个交易过程中,买入或卖出的期权数量不变,期货头寸根据期权的 delta,通过买入或卖出期货合约进行调整。
对冲期权的利润可以通过以下方式计算:
P ≈ θ. (n<sup>2</sup>-1) + NV-dσ/σ
其中θ =时间-衰减,单位为美元;n =标准化移动;N=归一化织女星
数据
分散交易策略的重点是印度银行 Nifty 指数期权及其成份股银行股。我们将 15 分钟的数据用于这一策略。
实施战略
项目期间采取的步骤如下:
隐含波动率计算
为了实施这一策略,首先计算指数银行 Nifty 和银行 Nifty 股票的隐含波动率是很重要的。期权价格反映了一种工具的风险,无论是股票还是指数。期权价格传递的风险水平通常被称为隐含波动率。单一股票期权的隐含波动率只是反映了市场对该股票价格回报未来波动率的预期。然而,指数波动是由两个因素共同驱动的,即指数成分的单个 vol 和指数成分价格回报的相关性。通过计算隐含波动率,我们试图找出股票之间的相关性是高还是低。我们使用布莱克-斯科尔斯模型来计算 IV。我们需要时间来成熟,执行价格,无风险利率和当前的基础价格。由于我们使用的是当月期权,从当前价格我们确定了期权 ATM 罢工,我们有无风险利率。
隐含相关性计算
我们用隐含波动率来计算股票之间的隐含相关性。波动性之间的相关性是买入或卖出的标志。如果隐含相关性高,则有卖出指数期权和买入股票期权的迹象,反之亦然。
选择选项
对于这种策略,我们结合使用了看跌期权和看涨期权。当使用这种方法时,对冲期权是很重要的,这可以通过向银行 Nifty 指数和银行 Nifty 股票投资等量的资金来实现,以实现完美的对冲交易。时间衰减:交易在月初使用月度期权进行,并维持到到期。保持交易直到到期有助于获得卖出期权的时间衰减的好处。
对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。该策略的 Delta 每 15 分钟调整一次,当 delta 超过 1 时,卖出一份期货合约,当 delta 下降到-1 时,买入一份期货合约来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
损益计算
该策略的 PNL 来自两个因素,一个来自期权,另一个来自期货合约。增加期货合约以在到期时保持 delta 中性,所有头寸被平仓并计算最终利润。
结论
分散交易是一种非常有利可图的策略,它在低风险的情况下提供高回报,但正确地实施该策略以获得利润是至关重要的。如果策略是自动化的,套期保值是自动计算和执行的,那么使用这种策略会更容易。利用自动化系统,可以更容易地实现跟踪策略的自动化系统,套期保值计算可以根据期权价格的变化进行调整。
阅读我们的下一篇文章,它描述了开发一个完全基于云的自动交易系统,该系统将利用均值回复或趋势跟踪执行算法。本文是作者提交的最后一个项目,作为他们在 QuantInsti算法交易(EPAT) 高管课程的一部分。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。 本项目提供的所有内容仅供参考,我们不保证通过使用这些指导您将获得一定的利润。
NSE 股票的分散交易[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-trading-on-nse-stocks/

作者:普内特·金拉
什么是色散?
在离差或相关交易中,交易者关注波动性。波动性意味着回归,因此离差或相关性也意味着回归。
多头和空头都是基于波动性。为了应对方向性风险,通过买入或卖出期货来抵消头寸。所以方向性风险是有限的。
离差通过卖出指数期权和买入股票期权或买入指数期权和卖出股票期权进行交易。
分散策略详情
离差交易是一种对冲策略,利用指数和指数成分之间隐含波动率的相对价值差异。
跨股和扼制组合是通过在指数上建立空头期权头寸和在指数成分上建立多头期权头寸来实现的,反之亦然。
通过保持单个股票/指数期权投资组合的 delta 接近于零,每个股票和指数期权投资组合的方向风险得以保存。

- 离差交易的利润来自于这样一个事实,即相关性均值回归,如果一个人购买了相关性,那么一只股票的已实现波动率将高于指数的已实现波动率。
- 指数期权投资组合和每一个股票期权投资组合都是持续的 delta 中性,直到头寸被平仓。这里初始期权头寸不变,但我们在整个分散交易中买入或做空不同数量的期权指数或股票。
数据和时间框架
分散交易策略的重点是印度银行 Nifty 指数期权及其成份股银行股。我们将 15 分钟的数据用于这一策略。我们也可以使用 30 分钟的数据。这一切都取决于,哪个时间框架是最好的结果。
战略实践指南
项目期间采取的步骤如下:
隐含波动率计算
为了实施这一策略,首先计算指数银行 Nifty 和银行 Nifty 中股票的隐含波动率是很重要的。
我们使用布莱克-斯科尔斯模型来计算 IV。我们需要时间来成熟,执行价格,无风险利率,和当前的基础价格
举例:
成份股之一的银行 Nifty 和 SBIN 股票的隐含波动率计算。

隐含/脏相关计算
我们用隐含波动率来计算股票之间的隐含相关性。我们用指数 IV 除以加权平均股票 IV 来检查 IC 水平。如果隐含相关性高,则有卖出指数期权和买入股票期权的迹象,反之亦然。
举例:
银行 NIFTY 的隐含相关性计算

选项选择
我们结合运用了看跌期权和看涨期权的跨式和扼杀式策略。空头是指同一次买入和卖出的自动柜员机。扼杀意味着 OTM 打电话和放。最初的对冲是通过购买或出售相对股票期货来保持 delta 接近于零。
连续 Delta 中性/动态对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。这个策略的 Delta 每十五分钟调整一次。当 delta 超过 1 时,卖出一份期货合约,当 delta 下降到-1 时,买入一份期货合约来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
举例:
AXISBANK 股票的连续 delta 对冲

止损并退出
除了进场和持续的 Delta 中性,当交易对我们有利时和交易对我们不利时,也有必要制定一个退出分散交易的计划。这种风险管理可以防止意外损失或放弃已获得的利润。
损益计算
该策略的 PNL 来自两个因素,一个来自期权,另一个来自期货合约。增加期货合约以保持 delta 中性。到期时,结清所有头寸,并计算最终利润。
举例:
P&L 从个股(YESBANK)和总 P&L 的分散交易策略。

分散应用
分散交易是一种非常有利可图的低风险对冲策略,回报远远大于风险。如果这个策略在回溯测试后自动交易,那么可以产生更有效的结果。这种策略可用于任何交易指数,其中指数期货被交易且指数成分期权具有足够的流动性进行交易。在印度或全球市场,有许多指数适用于相关性/离差交易。
下一步
分散交易是一种非常有利可图的策略,它在低风险的情况下提供高回报,但正确地实施该策略以获得利润是至关重要的。我们的下一篇文章展示了一个基于离差交易的项目。这个项目是 QuantInsti 算法交易培训项目提供的 EPAT 课程的一部分。
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。 本项目提供的所有内容仅供参考,我们不保证通过使用这些指导您将获得一定的利润。
下载中的文件:
- NSE 股票的分散交易- Excel 表格
印度市场的分散交易策略
原文:https://blog.quantinsti.com/dispersion-trading-strategy-indian-markets-project-karthik-kaushal/
这个项目证明了统计套利交易中的机会。这种策略是建立在这样一种理念上的,即在指数及其成份股的波动性中存在一些可重复的模式。
我们对隐含波动率和一篮子股票的隐含波动率之间的价差进行建模,这些股票按其在指数中的实际权重进行加权。我们选择 BANKNIFTY 作为指数及其成份股来回测这种策略,也称为分散交易。
最后,我们证明了该策略的损益是正的。回溯测试基于一个月的日内数据,可以扩展到更长的时间。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Karthik Kaushal 是一名期权交易员,有 3 年的工作经验。他的职业生涯始于 EY 的一名数据工程师。后来,他追随自己的热情,从专业领域转向了金融市场。
这让他在孟买的一个自营交易部门获得了一份小工作,主要从事印度市场的期权交易。目前,他在 True beacon 的期权交易部门工作。他的职责包括在基于系统性波动的策略上部署大量机构资本。
除了传统市场,他还在自己的书中交易加密期权。他拥有迈索尔国家工程学院的电气和电子工程学士学位。
战略思想
我们以合适的日内频率计算指数及其成份股的波动率。
一旦我们有了每个股票成分和指数的波动性,我们将计算指数的波动性与成份股的加权(解释指数现货价格的权重)平均值之间的相关性。
现在,根据相关性,当相关性超过一个预定的阈值时,我们将采取立场。当它交叉时,我们进入一个买/卖第一 OTM 扼杀和跨在指数中,并采取指数成份股的反立场。只要我们在这个位置,我们就在选择的频率上对冲 delta。
在相关性回到退出阈值后,我们将退出所有头寸。当我们回测系统时,进入和退出阈值被确定/优化。
资料组
目前,作为 EPAT 项目的一部分,我们提供了指数和股票的期权和期货的 30 分钟内数据。我们必须进行预处理,并基于此计算 IV 和相关性。
动机
离差交易是基于高度量化的严格性和有前途的理论的策略。我确实浏览了一些学术论文,在这些论文中,该策略被应用于世界各地的多个市场,这表明了该策略在认真执行时的稳健性。
项目大纲
我对 BANKNIFTY 及其成份股的离差交易策略进行了回溯测试。
我在 2017 年 1 月以 15 分钟的频率进行了为期 1 个月的回溯测试。BANKNIFTY 指数主要有 AXISBANK、HDFCBANK、ICICIBANK、INDUSINDBANK、KOTAKBANK、SBIN 和 YESBANK,其他几只股票的权重可以忽略不计。
以下是股票在指数中的权重。
| 轴心银行 | 9.6% |
| hdfc 银行 | 30.1% |
| icici 银行 | 19% |
| 科塔银行 | 11.23% |
| SBIN | 9.82% |
| 工业银行 | 7.62% |
| YESBANK | 5.59% |
战略思想
我们使用第一个 OTM 执行价格合约计算股票和指数的平均隐含波动率,公式如下。
平均 IV = {(看跌期权的 IV *股价与第一次 OTM 看涨期权的执行价格的距离)+((看涨期权的 IV *股价与第一次 OTM 看跌期权的执行价格的距离)}/(两次执行之间的距离)。
然后我们通过股票在指数中的权重计算股票平均 IV 的加权平均值,并计算股票的 banknify/加权平均 IV 的比率- IV。
该比率也称为脏关联,每 15 分钟计算一次。在此基础上,我们计算出回望期为 30 的移动 Z 分数。
如果 Z 值大于 1,我们预计 BANKNIFTY IV 会下跌,或者股票的加权平均 IV 会上涨,因此,我们首先做空 banknify 的 OTM 扼杀,然后买入所有股票的 OTM 扼杀。相反,Z 值小于-1。
在我们按照上面的规则进场后,每隔 15 分钟我们对冲 delta——我们计算我们所有头寸的 delta 并使其接近零。
这可以通过计算我们投资组合中每只股票和指数的 delta 来完成,如果每只股票的单位数量 delta 大于 0.1 或小于-0.1,我们可以通过在期货中建仓来进行适当的对冲。
如果 Z 值达到小于 0.8 的数量级,我们对所有位置进行平方,并计算 PnL。
位置尺寸
后验测试考虑了 4 手 BANKNIFTY——4 手 PE 和 4 手 CE,关于这一点,成分股票的风险敞口是根据其在 bank nifty 上的各自权重计算的。
这种安排所需的保证金约为 150-200 万卢比(无杠杆),包括对冲和 MTM 处理的保证金。
例如,如果 Z>1,BANKNIFTY 当前价格为 18050。以下是回溯测试代码记录的交易(忽略数量中的小数,因为它可以四舍五入为整数)。

举例来说,对于 ce,AXISBANK 数量约为 380,因为 AXISBANK 的权重约为 9.6%。因此,合同价值为 380*460 = 174,800,是 100 数量 BANKNIFTY 18100 CE 价值的 9.6%(100 * 18100 = 1810000)。
回溯测试结果
Number of trades: 56
Total PnL: Rs. 7256

以上结果只是一个月的时间,所以周期太小,无法下结论。目的只是为了展示这种策略的潜力。
改进和建议
- 我们可以用不同的频率来测试这个策略。
- 我们可以优化对冲阈值及其频率。
- 对于我们测试策略的每个频率,我们可以优化/改变进入和退出的 z 分数阈值。
- 当然,后验期应该大大延长。
下面的 Python 代码中提供了完整的 Python 代码和相关信息。可以下载参考一下。
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
使用期权的分散交易[EPAT 项目]
原文:https://blog.quantinsti.com/dispersion-trading-using-options/
作者:杰耶什·库鲁普
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
简介
离差交易是一种利用隐含相关性和随后实现的相关性之间的差异的策略。离差交易利用了指数期权之间隐含波动率和实际波动率之间的差异大于单个股票期权之间的差异这一事实。因此,交易者可以基于这种波动性差异卖出指数上的期权并买入单个股票期权,反之亦然。分散交易是一种相关性交易,因为在个股相关性不强的时候,交易通常是盈利的,而在相关性上升的压力时期,这种策略会亏损。证券之间的相关性被用作确定交易进入的因素。根据单个股票之间的相关值,离差可以通过卖出指数期权和买入指数成分期权或买入指数期权和卖出指数成分期权进行交易。对于这种策略的盈利能力,最广为接受的理论是市场无效率,该理论认为期权市场的供给和需求驱动溢价偏离其理论价值。
策略
为了区分分散交易,它只是一种对冲策略,利用指数和指数成份股之间隐含波动率的相对价值差异。它涉及指数证券的空头期权头寸和指数成分的多头期权头寸,反之亦然。实际上,我们将根据进场信号做多/做空。我们必须注意,只有当 delta 敞口接近于零时,这种交易才会成功。因此,分散策略是针对大的市场波动。下面是成功的分散交易需要采取的一系列行动。
- 计算脏相关(ρ)
- 当脏相关超过阈值/达到极限时生成信号
- 根据逻辑买卖指数和个别证券
- 定期计算 delta,并通过购买/出售期货来抵消它,使交易 Delta 保持中性
- 当脏相关性超过平均值(ρ=0.5)时退出
为了理解波动性的差异是如何被捕捉的,我们需要理解一篮子股票的指数方差。它被给出为:

其中,σ I 2 是指数方差 wi 是股票在指数中的权重σIT6】2 是个股方差ρij 是股票 I 与股票 j 的相关性这一策略的好处在于相关性趋向于均值回复。因此,如果一个人在比率的极端情况下建仓,我们可以确信这将意味着在某一点的回复。
实施战略
要实施该策略,我们需要计算下面给出的指标。
计算最接近的隐含波动率
因为我们有溢价值,到期时间,利率,股息和最近的罢工,我们可以使用布莱克斯科尔斯模型计算最近罢工的隐含波动率。为了计算相关性,需要将单个证券和指数的最接近的加权平均隐含波动率相加。
在上面的函数 CalculateIV 中,我们可以看到,首先计算单个买入和卖出 IV,然后计算这些 IV 的加权平均值。权重更多地给予那些更接近未来价格的罢工。
脏关联
这是指数隐含波动率与股票加权平均值之比的平方。公式如下所示:


上面的代码片段显示了脏关联的计算。在这里,首先计算单个证券的交易量,然后在 Vol_IndSecurities 中求和。该比率是在指数和个股之间计算的,并且是平方。
定义阈值
这是根据风险偏好产生进/出信号的重要一步。在这个项目中,阈值是 z1=0.2,z2=0.8,z3=0.5,其中 z1 给出买入指数和做空单个证券的信号,z2 给出做空指数和做多单个证券的信号,z3 是所有头寸平仓的退出阈值
选择要交易的期权
一旦我们得到买入/卖出的信号,我们将会同时使用空头和空头。本项目考虑了最近的 3 个 OTM 走向。投资金额需要在指数和单个证券之间平均分配。录入时,需要记下批量、购买数量,以便每个阶段的增量便于使用。
对冲
这是进一步对冲使用期货合同,以保持整个过程 delta 中性。这个策略的 Delta 应该每十五分钟调整一次。当 delta 超过 1 时,卖出一份期货合同,当 delta 下降到-1 时,买入一份期货合同来抵消 delta。在交易过程中保持 delta 接近于零是很重要的。
上面的片段显示了如何根据进/出信号进行持仓。每当我们有进场信号时,我们就持续监控 delta,确保它是中性的。同样,总的 deltas 最初被加起来,然后用买入或卖出的期货合约来抵消。当前持仓的期货也便于计算每个点的 delta。买入或卖出的期货总额被确定,并乘以期货价格,以计算交易的额外投资。
损益计算
为了计算 PnL,需要考虑以下因素:
- 初始交易,进场时买入/卖出期权的成本
- 对冲成本,为使交易 delta 中性而投资的期货总量
- 期货结算,在退出信号时结算期货合约的金额
- 期权平仓,当所有头寸在退出信号时平仓的结果
 上面的片段展示了 PnL 的计算。这里我们可以看到,我们已经计算了初始交易的买入成本(买入/卖出看涨期权和看跌期权)。我们已经计算了看涨期权和看跌期权的平方价格。额外的投资或买卖的期货用 FutSet 表示,在交易结束时结算。对冲金额存储在对冲变量中。
上面的片段展示了 PnL 的计算。这里我们可以看到,我们已经计算了初始交易的买入成本(买入/卖出看涨期权和看跌期权)。我们已经计算了看涨期权和看跌期权的平方价格。额外的投资或买卖的期货用 FutSet 表示,在交易结束时结算。对冲金额存储在对冲变量中。  以上是执行的代码示例。可以看出,由于脚本中包含复杂的计算,执行需要相当长的时间。
以上是执行的代码示例。可以看出,由于脚本中包含复杂的计算,执行需要相当长的时间。
结论
分散交易是一个复杂的策略,然而,这是一个有利可图的策略,在低风险下提供高回报。为了使这种策略更好,有必要使策略自动化,套期保值应该根据价格变动而动态变化。在波动性高的时候交易(即季度业绩、个股新闻等。)当相关性不强时,可能会导致更多的利润。为了最大限度地提高策略的准确性,我们可以缩短捕捉波动的时间间隔,并相应地计算 deltas。了解期权交易中的未平仓合约一个可以在期货和期权交易中轻松使用的指标,未平仓合约表示什么,如何读取未平仓合约数据,并考虑如何使用 Python 建立未平仓合约交易的一些基本假设
为什么背离交易的经验是必须的?
在决定交易时,分歧是最重要的因素之一。但是,作为一个交易者,在做交易决定时,还有其他重要的因素需要考虑。我们将在本文前面非常简要地讨论这些因素。
虽然,有了背离交易的经验,你会理解它的实际作用,这是相当有利可图的。在这里,我们将通过所有重要的方面,如其意义,类型,指标,事实和实际证明其价值的用途。此外,还有一些订单类型可以帮助您根据自己的分析做出最佳决策。我们将讨论一切,从分析股票价格,预测它们,然后使用最相关的订单类型来执行订单。
现在,让我们深入探讨一下本文中涉及的一些基本主题,它们是:
- 交易中的背离:含义和类型
- 背离交易的指标/振荡指标
- 你知道吗?(关于背离交易的有用事实)
- 如何使用规则的和隐藏的发散?
交易中的分歧:意义和类型
交易中的背离意味着资产的实际价格和你所依赖的技术指标之间的不同步。技术指标意在帮助你估算一项资产的价格。如果价格下跌,技术指标上涨,这种不匹配被称为正背离。相反,如果价格上涨,技术指标下跌,这就是所谓的负背离。
准确地说,例如,如果一项资产的价格创出新高,而指标显示较低的低点,这就是背离。
发散的一个例子是下图。它表明市场(实际价格)创下新高,但不是指标。因此,指标显示背离。

来源:维基百科
在做交易决定时研究背离的主要理论是,指标/振荡指标表明实际价格可能很快发生反转。因此,背离有助于估计未来的市场价格,这样你就可以做出正确的交易决定。
但是,另一个重要的观点是,你不能把你的交易决定完全建立在背离的基础上。你还必须考虑其他重要的工具,比如趋势线(支撑位和阻力位)来确认反转。这尤其适用于指标/振荡器长期背离的情况。

来源:维基百科
在上图中,你可以看到支撑趋势线和反转趋势线。
- 支撑趋势线简单地暗示价格水平在一段时间内稳定,资产价格不会跌破该水平。例如,在该图中,在支撑趋势线上不同的时间间隔(年)有不同的价格水平,低于该水平价格不会下跌。
- 阻力趋势线,另一方面,是资产价格水平在一段时间内不会超过的趋势线。例如,在上面的图像中,显示了不同年份的不同价格水平,资产价格不会超过该价格水平。
现在,让我们前进到前方的分歧类型。
背离表明潜在的看涨(价格上涨)市场或潜在的看跌(股价下跌)市场,因此,主要是这两种类型。但是,两者(看涨和看跌)都有进一步的两种类型。
这就是为什么我们将它们分为两大类,即常规(看涨和看跌)和隐藏(看涨和看跌)背离。好了,事不宜迟,让我们来讨论一下。

常规发散有两种类型:
- 常规看涨背离
- 常规看跌背离
常规看涨背离
在常规看涨背离的情况下:
- 该指标显示更高的低点
- 实际市场价格显示更低的低点
常规看跌背离
在常规看跌背离的情况下:
- 指标显示较低的高点
- 实际市场价格显示更高的高点
隐藏的分歧有两种类型:
- 隐藏的看涨背离
- 隐藏的看跌背离
隐藏的看涨背离
在隐藏看涨背离的情况下:
- 指示器显示更低的低点
- 实际市场价格显示更高的低点
隐藏的看跌背离
在常规看跌背离的情况下:
- 指标显示更高的高点
- 实际市场价格显示较低的高点
我们试图通过下面描述趋势变化的图片来使理解变得清晰。有两行,即“价格”和“振荡指标”,每一列都有不同类型的背离,显示振荡指标与价格相反的运动或“振荡指标与价格的背离”。
每个背离都预示着潜在的价格反转。

资料来源:orbex
正如你在上面的图中看到的,一个振荡指标显示了与市场实际价格趋势的背离(反向运动)。这些背离表明趋势可能逆转。
在第一列中,当市场中的实际价格创出更高的高点,但指标创出更低的高点(下降趋势)时,注意到常规看跌背离。
第二列显示常规看涨背离,因为市场中的实际价格形成较低的低点,但指标形成较高的低点(上升趋势)。
第三列显示隐藏的看跌背离,当市场中的实际价格创造了一个较低的高点,但振荡器创造了一个较高的高点(下降趋势)时,就会出现这种背离。
第四列显示了隐藏的看涨背离,当市场中的实际价格出现更高的低点,但振荡器出现更低的低点(上升趋势)时,就会出现这种背离。
由于我们已经讨论了这些类型,我们将在本文的后面了解它们的用法。
现在让我们向前看,找出背离交易的指标/振荡指标。
背离交易的指标/振荡指标
背离交易需要指标/振荡指标来指示资产价格的特定运动。正如我们前面提到的,指标揭示了背离,因此,交易者能够根据指标的分析做出决定。因此,当任何指标显示背离时,实际市场中可能会有价格反转的警告。当实际价格显示一个更高的高点,而指标显示一个更低的高点时,它表明市场正走向一个常规的熊市。相反,如果实际价格显示一个更低的低点,指标显示一个更高的低点,这是一个常规的牛市。我们现在将讨论最受欢迎的指标/振荡指标,它们是:
- 相对强度指数
- 随机振荡器
- 移动平均收敛发散(MACD)
相对强度指数
相对强度指数(RSI)是 J. Welles Wilder (1978)提出的一个著名的背离指标/振荡指标。它帮助交易者获得当前价格相对于不同资产前一天收盘价的相对强度。RSI 也有助于验证市场的进入点和退出点,也像其他指标一样显示潜在的价格反转。另外,默认情况下,RSI 是在14 天的时间段内计算的。
这个指标让你知道什么时候买入资产,什么时候卖出。这通常通过查看 70 和 30 的阈值来完成。你可以在下图中看到 RSI 的工作原理。如果该指标高于 70,这意味着市场已经超买(这是卖出的好时机),可能会通过下跌来自我修正。另一方面,如果跌破 30,则资产处于超卖(这是买入的好时机),市场可以回撤至超过 30 的更高水平。

来源:维基百科
此外,据观察, RSI 和另一个振荡器 MACD 一起比单独更有力量。
随机振荡器
另一个非常流行的指标是由乔治·c·莱恩(1950 年)开发的随机振荡器。全世界的交易者都相信这一指标预示着潜在的价格反转。通过评估市场的势头,该指标通过比较收盘价和一段时间内的价格来提供帮助。在牛市中,人们认为价格通常会在高点附近收盘,而在熊市中则会发生相反的情况,因为价格会在低点附近收盘。这一指标基于上述假设。
该指标主要有两个阈值,即 80 和 20。高于上限 80,该指标表明价格超买,是卖出的好时机。反之,低于 20,表明价格超卖,是买入的好时机。
现在,我们将在这里了解一下慢速和快速随机指标的概念。慢速随机指标被称为%D,而快速随机指标被称为%K。在这里,重要的是要注意%D 比%K 更重要。

来源:维基百科
在上图中,您可以看到该指标是用从 0 到 100 的值绘制的。这意味着这个值既不能低于 0,也不能高于 100。另外,%K 显示快速随机线,也就是蓝线,%D 显示慢速随机线,也就是红线。80 以上是超买条件(卖出时机),20 以下是超卖条件(买入时机)。
这里要注意的是%K 线在%D 线之前改变方向。但是,如果慢速随机指标%D 在快速随机指标%K 之前改变方向,就有可能出现价格反转。尽管如此,价格反转将是一个渐进的过程。如果指标达到 0 或 100(极限),则表明出现了强烈的波动。这个指标对于抓住关键的反转点非常有用,因此被用于各种技术设置。
要点提示:当%K 穿过%D 上方时,产生买入信号(看涨),当%K 穿过%D 下方时,产生卖出信号(看跌)。
移动平均收敛发散(MACD)
在这里,重要的是要注意价格变动有助于使用 MACD 时的相关信息。
简而言之,趋同意味着趋势将会继续,而背离表明趋势逆转是可以预期的。
趋同和趋异分析要求你分析一段时间内的价格变化点。简单来说,它需要你关注一段时间内价格的转折点。两个主要观察结果是:
- 价格高点是上涨还是下跌?
- 价格的低点是上升还是下降?
因此,找出这些点的共同点和不同点有助于你成为获利者。在背离中,总是存在增加的波动性,这导致了频繁的盈利机会。
有了 MACD,你就能注意到实例,并通过观察和分析找出有利可图的机会。MACD 能让你理解市场行为,从而更准确地预测未来。在该振荡器的工作中,使用了指数移动平均和简单移动平均 e。让我们看看下图:

来源:维基百科
这张图显示了 MACD 的工作情况。因为经典设置将 EMA 保持为 12 和 26,而 SMA 设置为 9,所以您可以照原样使用它们。或者,您可以根据交易偏好选择任何其他值。
用这个振荡指标,当移动平均线彼此靠近时会发生收敛,反之,当移动平均线远离时会发生发散。此外,当 12 周期均线(较短周期)高于 26 周期均线(较长周期)时,指标高于 0。然而,当较短的 12 周期均线低于较长的 26 周期均线时,它低于 0。这意味着正值表示牛市,负值表示熊市。
现实世界的例子
接下来,你可以从道琼斯的真实例子中得到启示,如何根据我们刚刚讨论的预测振荡指标来推断市场的表现。
2020 年 3 月 25 日在当前冠状病毒爆发的场景中,根据livetradingnews.com,“DJ INDU AVERG 目前比其 200 期移动平均值低 23.3%,处于下降趋势。与过去 10 个周期的平均波动性相比,波动性非常高。波动性很有可能会降低,价格很有可能会在近期稳定下来。我们的交易量指标反映了 DJI 适度的交易量流出(轻度看跌)。我们的趋势预测振荡指标目前看跌 DJI,在过去的 21 个周期里一直如此。我们的动量振荡指标创下了 14 年来的新高,而证券价格却没有。这是一个看涨背离。”
接下来,让我们看看关于背离交易的有趣事实。
你知道吗?(关于背离交易的有用事实)
好吧!现在是时候找出一些有趣和有用的事实与分歧交易。这些事实是这种交易的独特之处,如果遵循这些事实,对你这个交易者来说是非常有益的。我们将逐一讨论它们。那么,你知道吗:
您可以通过特定的订单类型使您的交易更有利可图?
背离交易有一些“订单类型”,每种都有其重要性。总共有四种订单类型,我们将在这里了解一下,在特定情况下,特定的订单类型可能比其他订单类型更有利可图。订单类型包括:
市场订单
这种订单类型是当您进入市场时执行的基本类型,并且不指定相同的价格。但是,这可能对你不利,因为这意味着你将以当前的出价(例如,售价 11 美元)购买股票,即使它高于买入价(例如,买入价 10.50 美元)。
限价单
在这种情况下,为你购买股票设置了一个限价。例如,如果您以 10.50 美元的限价单进入市场,您的订单将不会在报价为 10.50 美元之前执行。
止损单
通过这种方式,你可以设定交易资金的上限。例如,如果你希望在一次交易中只交易 500 美元,那么你可以将你的止损(卖出股票)设置为 40 美分,一旦价格达到 499.40 美元,它就会变成市价单。这将最终限制我们的损失。
停止限价指令
这类似于止损单,但适用于购买股票。例如,如果你希望以 1.10 美元的价格买入股票,不超过 1.10 美元,那么你可以将其设定为你的触发价格。一旦股价达到 1.10 美元,你的限价单就会被触发。
现在,这里的要点是,如果你知道所有这些订单类型,那么在特定的买入或卖出情况下,你将能够从上述选项中选择一个来下单。
例如,限价单比市价单更有利可图。但是,只有在你不在乎速度或时间的情况下,你的首选价格才会被触发。而且,万一你想在某个价位卖出,止损会帮你做到。然而,如果你想在一个特定的价格买入,那么止损更有利于避免损失。因此,无论是帮助你获得更多的利润还是规避损失,了解订单类型是必不可少的。
连接正确的点是最重要的?
你必须重视这样一个事实,即在描绘实际价格的高点和低点的图表上连接正确的点是至关重要的。这里有四种情况--前高点、当前高点、前低点和当前低点。
如下图所示,仅将前一个电流与电流(高或低)相连非常重要。

另一件重要的事情是连接实际市场中所有的前期高点(更高的高点或更低的高点)和前期低点(更高的低点和更低的低点)以及下图所示的指标。

另一个要点是,你一定不能忘记连接垂直市场,这意味着实际市场价格(高或低)中的点应该在指标中连接。看看下面的图片。

较长的时间框架比较短的时间框架更相关?
人们已经正确地观察到,较长的时间框架比较短的时间框架更准确,因为其中的错误信号更少。这无疑意味着交易会更少,但有更准确的信号,如果你计划好交易,你可以在这种情况下获得更多。另一方面,较短的则不太可靠。例如,一小时图或者更长的时间图可以帮你搞定。
过早入市会导致亏损?
人们还看到,过早进入市场会导致亏损。而且,如果你太早太频繁地进入市场,可能会导致巨大的损失。但是,你在利用背离交易来获利,而不是亏损。在这种情况下,您必须记住以下几点:
你必须等待指标 交叉 ,因为它预示着势头的潜在转变。这意味着在交叉发生后,可能会有从买入到卖出或者从卖出到买入的转变。如下图所示。

来源:babypips
其次,你必须等待指标脱离超卖或超买的范畴,因为如果它长时间停留在其中一个范畴,它可能无法准确地指示反转。请参考下图了解相同的内容。

来源:babypips
好了。让我们向前看,找出如何使用规则的和隐藏的分歧。
如何使用规则的和隐藏的发散?
当我们在上面读到背离的类型和振荡因素时,我们正确理解了每一个的重要性。但是,现在剩下的是知道如何在交易中使用它们?
基本上,背离有助于交易者识别市场价格的潜在变化,也有助于在此基础上做出适当的交易决定。
让我们来看看如何利用常规和隐藏的背离(连同它们的振荡指标)来做交易决定。
正则散度
正如我们前面看到的,常规背离在发现趋势反转何时会发生方面起着非常重要的作用。看到 MACD 振荡指标的收敛-发散,我们知道收敛意味着趋势可能会继续,发散意味着趋势反转更有可能发生。
常规看涨背离是指当市场中的实际价格形成较低的低点,但指标形成较高的低点(上升趋势)。
常规看跌背离是指市场中的实际价格创出更高的高点,但指标创出更低的高点(下降趋势)。
在这两种情况下,我们预计趋势会逆转。
现在,正则散度可以用来进行如下观察:
- 背离意味着趋势反转是可以预期的。
- 如果货币出现二倍或三倍背离,趋势反转的可能性很大。因此,趋势延续(收敛)的可能性不大。
在常规背离中,振荡指标表明动量转移,因此表明趋势反转。这意味着观察背离有助于知道趋势的结束是预期的。但是,我们已经提到,但再次强调,利用其他因素,以及确认趋势反转或趋势结束是否真的会发生。
仅凭分歧就得出结论是不可取的。此外,获得一个趋势可能结束的额外确认总是有益的。
隐藏的分歧
隐藏背离另一方面,是趋势延续(收敛)的高明指标。
隐藏的看涨背离发生在市场的实际价格创出更高的低点,但振荡指标创出更低的低点(上升趋势)时。
隐藏的看跌背离发生在市场的实际价格创造了一个较低的高点,但振荡指标创造了一个较高的高点(下降趋势)。
你可以在下图中看到常规的背离和隐藏的背离。

来源:交易策略指南
在上图中,你可以看到常规背离导致趋势反转,因此,价格下跌+/-350 点。
同样,可以看到一个隐藏的背离导致趋势的延续,这使得价格上涨了 400 个点并持续下去。
结论
因为这篇文章的目的是讨论在交易中分歧的重要性,以及如何在交易中获得利润,我们把重点放在它的意义和用途上。除了基础知识之外,我们还讨论了一些重要的方面,这些方面的“事实”揭示了如何在每种情况下让分歧更有利可图。简要概述了所有重要的东西,这篇文章讲述了作为交易者,是什么让背离有利可图。因此,在发散方面的经验是必须的,因为它可以通过将应用程序放在正确的位置来获取利润。希望这篇文章能帮助你对背离交易有所了解!
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
多样化的 ETF 投资组合:从回溯测试到实时交易
原文:https://blog.quantinsti.com/diversified-etf-portfolio-project-chee-wai-wan/
这个项目解释了使用九个部门 ETF 的投资组合的交易策略的创建和回溯测试,以及使用 REST API 将该策略转化为交互式经纪人(IBKR)上的实时交易。这个项目完全编码在 Jupyter 笔记本上。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
CW Wan 是一名终身学习者,对商业、经济、金融和数据科学有着浓厚的兴趣。他认为算法交易是他所有兴趣汇聚的一个主题。他目前在新加坡的一家工程和技术集团工作。
他拥有 Quantic 商业和技术学院的高级工商管理硕士学位、新加坡国立大学商业分析理学硕士学位(MSBA)以及伦敦玛丽女王大学金融经济学理学硕士学位。
项目摘要
这个 EPAT 的期末专题包括两部分。
第一部分包括使用九只 SPDR 行业 ETF【1】的投资组合创建并回溯测试一个盈利策略。我创建了一个只做多的每日策略,基于短/长均线交叉的进场/出场信号,以及动态的资金分配(每个季度重新平衡)。
使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出的平均年回报率超过 30%,夏普比率为 1.4,最大下降幅度为-12%。
第二部分包括将上述策略转化为交互式经纪人(IBKR)上的实时交易。使用 IBKR 的客户端 Web API【2】(RESTful API),并在 Jupyter Notebook【3】上完全编码,我成功地创建了算法上执行上述策略的日常程序所需的所有函数。
项目的这一部分是最累人的,花了将近两个月才完成,但也是最令人满意的。
承认
我要感谢我的项目导师 Rekhit Pachanekar 和 Danish Khajuria 为项目提供的宝贵建议和指导,以及我的课程支持经理 Laxmi Rawat 在 EPAT 课程期间提供的无可挑剔的支持。
项目动机
在我参加 EPAT 课程之前,我问销售顾问,在最终项目中,是否有可能创建一个类似于以下内容的实时算法交易模型/投资组合:

Example Retail Investor Fund[4]
在我开始 EPAT 之前,我几乎没有现场交易市场的经验,但我有一些基本的数据科学和 Python 编程经验。我也有过一些关于量子乌托邦的经历。但是在我能学到很多算法交易之前,它就被关闭了。
因此,对我来说,如果没有别的事情,我希望从 EPAT 课程中学到建立和管理自己投资组合的能力,这种能力至少要与散户投资者的投资组合一样好。
介绍
本着这个目标,我的项目由两部分组成:
第一部分:回溯测试盈利策略——应用在 Python 交易上学到的经验教训——面向对象编程【6】、基于事件的回溯测试【7】和 ETF 交易【8】——我成功地利用 9 只 SPDR 行业 ETF 的投资组合创建了一个简单但盈利的策略。
使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出的平均年回报率超过 30%,夏普比率为 1.4,最大下降幅度为-12%。这一策略似乎有可能超越上述零售基金的业绩。
第 2 部分——实时交易盈利策略—应用在 REST API【9】和算法交易系统架构【10】上学到的经验,我设法编写了所有必要的函数,通过算法执行上述策略的日常程序,使用 IBKR 的客户端 Web API 连接到经纪人。我完全是在 Jupyter 笔记本上完成的。
本报告的其余部分结构如下:
- 第 2 节提供了关于回溯测试和结果的更多细节。
- 第 3 节解释了实时交易算法是如何设计的。
- 第 4 节总结。
第 1 部分:回溯测试
数据挖掘
为这一策略选择的主要工具是 9 只 SPDR 行业 ETF:
| 股票行情 | 描述 |
| XLY | 非必需消费品 |
| XLP | 消费品 |
| XLE | 活力 |
| XLF | 金融的 |
| XLV | 卫生保健 |
| x 连锁鳞癣 | 产业的 |
| XLB | 材料 |
| XLK | 技术 |
| XLU | 公用事业 |
选择这 9 只 ETF 的理由如下:
- 简单——跟踪 9 个行业的整体表现比跟踪 1500 家公司更容易。
- 交易成本–只交易 9 种工具比交易 1500 家公司更便宜。
- 多元化–每个 ETF 已经是每个领域中最好的公司的多元化投资组合。ETF 投资组合允许进一步分散投资。每季度进行一次的动态资本配置,允许投资组合买入表现更好的行业,“驾驭赢家”。
我们使用雅虎财经【11】(Python yfinance 库)下载了 10 年的每日价格数据,从 2012 年 1 月开始到 2021 年 12 月结束。
我们将 SPY 作为基准。这 9 只 ETF 和 SPY 的价格图表如下:

战略描述
进场/出场信号:我们采用了只做多的指数移动策略(EMA)交叉策略:如果空头 EMA 穿过 1.01 倍的多头 EMA,我们就进入多头。否则我们退出交易。
交易频率:我们使用每日收盘价来计算信号。因此,该策略将每天执行一次。在实时交易期间,该例行程序将在美国市场每个交易时段的最后 5 分钟内执行。
动态资本分配:我们每季度跟踪每个 ETF 的表现,并通过将其季度回报除以所有 ETF 的季度回报之和来计算每个 ETF 的新资本分配。这确保了 ETF 的构成越好,下一季度分配给它的资本就越多。
数据分析
使用面向对象编程,我们在 Jupyter Notebook 上使用 Python 执行了基于事件的回测。结果如下:

主要发现
该策略的 10 年累计对数回报率为 1.58(或简单回报率为 385%),略高于其 SPY 基准(对数回报率为 1.54,简单回报率为 366%)。
最大下降幅度为-0.13,相当于-12%。这发生在 2020 年 COVID19 疫情发作期间。可以看出,当时 SPY 经历的缩减幅度要大得多。
所达到的夏普比率为 1.39。
每个 ETF 的性能统计如下。
- 我们观察到,虽然所有的 ETF 都有正的平均利润,但只有非必需消费品和科技股的命中率超过 0.5。
- 对于其他人来说,积极交易的回报远远超过了消极交易的损失。

限制
上述策略的局限性在于它过于简单,尽管它提供了良好的性能。可以做更多的工作来改进战略或微调战略参数以取得更好的业绩。
然而,在第二部分,我必须将策略转化为现场交易,我认为这更重要。策略改进可以在项目提交后进行。
现场交易
实施方法
项目的第二部分是将策略转换成实时算法交易系统。
我已经有了一个交互式经纪人(IBKR)的账户,所以第一步是确定我将使用 EPAT 课程中教授的哪种方法来连接 IBKR。
- IBKR TWS API【12】——这是 IBKR 专有的开源 API。
- IBridgePy【13】——这是一个第三方应用程序,其外观和工作方式与 Quantopian 的平台相似。
- IBKR 的 REST API——这是 IBKR 的行业标准 RESTfulAPI。
下表总结了我对 EPAT 教授的三种方法的尝试:
| 考虑事项 | TWS API | 杂交 | REST API |
| 内置的交易方法 | 是 |
- be
- All-Trotskyist style
|
- not have
- You need to create your own methods/functions
|
| 要安装的文件 |
- Tw or IB gateway
- [TWS API installs 1016.01.msi file]
|
- Tw or IB gateway
- IBridgePy.zip file (only unzip, no need to install)
|
- [TWS] or IB gateway (optional)
- Client.gwzip file (only unzip, no need to install)
|
| 费用 | 自由的 |
- The free version needs to manually download a new IBridgePy.zip file every 1+ weeks.
- IBridgePy 高级版
需要 360 美元的年费 | 自由的 |
| 努力(排名) |
- medium-sized
- Need to learn how to use the built-in methods
|
- Low, if all goes well.
- Panoramic style
|
- tall
- You need to create your own methods/functions
|
| 易于故障排除 |
- It may be difficult to check what's wrong [under the hood]
|
- It's hard to check what's wrong [under the hood]
- Error messages are meaningless.
| 容易的 |
| Jupyter 笔记本友好? | 未确定的 |
- not have
- You need to run IBridgePy. Py file, and then run your own code, which must be in a separate. Py file
| 是 |
| 技能可转移给其他经纪人? | 不 | 仅限 IBKR、TD Ameritrade 和 Robinhood | 是的,许多经纪人提供 REST API |
归结为 IBridgePy(简单?)vs. REST API(灵活性)。
在与 IBridgePy 的故障排除困难(以及过于频繁地更新 zip 文件的恼人需求)斗争了几个星期后,我决定使用 REST API 方法。
虽然构建我自己的方法/函数来连接 IBKR 很费时间,但是使用 Jupyter Notebook 的能力(对初学程序员有用!),将它们设计成完全按照我想要的方式工作,并且立即排除错误是非常宝贵的。此外,在使用 RESTAPI 中学习的技能可以转移到其他经纪人(如羊驼【14】)和其他非交易目的。
交易系统设计
根据 EPAT 关于系统架构的教训,我按照自动交易系统的基本架构设计了我的系统:

Basic System Architecture [10]
我使用的交易者应用程序是 Jupyter Notebook,这是一个友好但强大的 Python GUI,适合初学者和高级用户。它的结构允许我将代码分解成独立的部分,分别进行测试和故障排除。
它包含标记语言的能力使我更容易记录每一步。我关于这个项目的笔记因此被包括在本报告的附件中。
其余的块由 Python 函数组成。有三种类型的函数:
- 交易序列函数–这些核心函数初始化交易环境,确保交易会话与经纪人连接并通过认证,并在交易日的预定时间调用适当的 ALGO 交易函数或 IB REST API 函数。
- ALGO 交易功能–这些功能旨在执行交易操作的特定部分。需要时,这些函数将调用 IB RESTAPI 函数与代理通信,以获取信息或下订单。
- IB REST API 函数–创建这些函数是为了向 IBRK 服务器发送 GET 或 POST 请求,并接收和处理响应。
下表列出并描述了为执行 algo 交易策略而编写的所有三种类型的函数,从交易序列函数开始。
- 第一个列出的是 algo_daily_schedule() ,它是主要的时间表控制功能,将在所示的交易日调用其他适当的交易序列功能。
- 其他交易序列函数将根据需要调用适当的 ALGO 交易函数或 IB REST API 函数。
- ALGO 交易函数将调用 IB REST API 函数来与经纪人通信。
为执行算法交易策略而编写的函数类型
为这个项目编写的各种类型的函数在下面的 pdf 中提到:
下载这个 PDF 的链接在这个博客的末尾。
挑战
使用 REST API 为交易系统编码是一件累人的事情。
- 事实上,许多时间都花在编写与代理连接的 IB REST API 函数上。
- 我首先必须得到正确的 get 或 POST 结构。
- 然后,我必须将响应解析成与我的系统兼容的格式。
- 花费了大量精力来处理错误响应或意外响应。
- 项目结束后,可以做更多的工作来改进错误处理。
局限性在于,季度再平衡和动态资本分配没有包括在内。遗漏的原因是我没有 3 个月的时间来测试它。
另一个主要限制是系统中没有内置风险管理模块。这两项限制将在项目结束后完成。
参考书目
- https://www.sectorspdr.com/sectorspdr/
- https://interactivebrokers.github.io/cpwebapi/
- https://jupyter.org/
- https://www.syfe.com/equity100
- https://en.wikipedia.org/wiki/Quantopian
- EPAT 课程:DMP 02 面向对象编程导论
- EPAT 课程:DMP-03/04 金融 Python
- EPAT 课程:EFS-06 理解交易所交易基金
- EPAT 课程:TBP-02 休息 API
- EPAT 课程:自动交易系统的 TIO-01 系统结构
- https://pypi.org/project/yfinance/
- https://interactivebrokers.github.io/tws-api/
- https://ibridgepy.com/
- https://alpaca.markets/
摘要
我已经完成了这个 EPAT 项目的两个部分。
在第一部分中,我创建并回测了一个盈利策略,使用了 9 只 SPDR 行业 ETF 的投资组合。使用 2012 年 1 月至 2021 年 12 月的每日数据进行的 10 年回溯测试得出:
- 年平均回报率超过 30%,
- 夏普比率为 1.4,以及
- 最大下降幅度为-12%。
这些结果令人鼓舞,它们似乎胜过了激励这个项目的散户基金。然而,该策略很简单,还可以做更多的工作来提高其性能。
在第二部分中,我使用 REST API 方法并在 Jupyter Notebook 上完全编码,将上述策略转化为交互式经纪人(IBKR)上的实时交易。
项目的这一部分是最累人的,花了将近 2 个月才完成,但也是最令人满意的。将做更多的工作来包括季度再平衡部分,并增加风险管理方面的考虑。
结论
参与这个项目是一次富有成效的经历,我从 EPAT 的许多课程中学到了很多东西。我能够想出一个有利可图的策略,使用 Python 进行回溯测试,并创建一个算法交易系统,在 IBKR 纸上交易账户上实时执行该策略。
从我开始课程前在这个领域的初学者到课程结束后能够完成这个(当然是在项目导师的帮助下!),我相信这证明了 EPAT 的课程是真正优秀的!
如果你想学习算法交易的各个方面,那就去看看这个算法交易课程,它涵盖了统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。EPAT 教你在算法交易中建立一个有前途的职业所需的技能。立即注册!
文件在下载
- 项目的完整 Python 代码
- PDF 文档-为执行算法交易策略而编写的函数类型
免责声明:就我们学生所知,本项目中的信息是真实和完整的。学生或 QuantInsti 不保证提供所有推荐。学生和 QuantInsti 否认与这些信息的使用有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
使用加密比较 API 下载 Python 中的加密货币数据
原文:https://blog.quantinsti.com/download-cryptocurrency-data-python-cryptocompare-api/
何塞·卡洛斯·冈萨雷斯·田中
Python 中如何使用 Cryptocompare API 下载加密货币数据?Cryptocompare 是一家加密货币市场数据提供商。这个博客解释了你如何用超级简单的步骤来做到这一点,并让你随时准备应用它!
如果你正在向算法交易或加密货币世界迈出第一步,那么这篇文章就是为你准备的!
我们涵盖:
为什么选择 CryptoCompare?
CryptoCompare 允许用户从大多数重要的加密交易所获得实时价格,绘制图表并进行市场研究分析。它还允许我们获得有限的免费数据进行下载。这就是我们在这篇文章中要做的。
导入库
首先,让我们在我们的 Jupyter 笔记本中安装 cryptocompare 库:
如何用 Python 下载外汇价格数据
原文:https://blog.quantinsti.com/download-forex-price-data-yfinance-library-python/
何塞·卡洛斯·冈萨雷斯·田中
在互联网上,你会找到许多下载外汇价格数据的来源,如 quandl,alpha vantage,brokers' APIs,yahoo finance 等。今天,我们将教你如何从雅虎财经获取外汇价格数据,从每天到每分钟的频率。
我知道你在想什么:“有很多网站解释如何用雅虎财经库下载股票价格数据,但几乎没有关于如何用它下载外汇价格数据的内容”。
我们都知道股票市场是一个投资的好地方。然而,当你有一个好的策略,外汇资产可以帮助你赚一大笔钱。作为一个探索这个神奇市场的 algo 交易者,yfinance 库将帮助我们轻松下载外汇价格数据。
雅虎财务库安装
太简单了!在我们进入下载部分之前,不要忘记在您的环境中安装这个库。您可以使用以下代码来实现这一点:
用 Python 的雅虎财经库下载期货数据
原文:https://blog.quantinsti.com/download-futures-data-yahoo-finance-library-python/
何塞·卡洛斯·冈萨雷斯·田中
你必须做的第一件事就是学会用 Python 下载期货数据。这个博客解释了完整的过程,并帮助您了解所需的各个步骤。
期货交易本来就是杠杆交易。在投资组合中使用杠杆时必须小心谨慎。管理杠杆的一个好方法是用算法进行交易,这就是这篇博客的重要性。
它包括:
雅虎!财务库安装
Python 是世界上最简单的编程语言之一。Python 使得新手更容易更快地掌握编程技能。建立自己的 Python 交易系统也很容易。
我们将使用一个 Jupyter 笔记本。我们来编码吧!如果你还没有在你的机器上安装这个著名的库,这里有代码:
使用神经网络的动态资产分配
原文:https://blog.quantinsti.com/dynamic-asset-allocation-neural-networks-project-mrinal-mahajan/
该项目旨在通过利用一组动态线性神经网络模型的每日回报预测,为包括 nifty 银行指数在内的股票建立资产配置策略。
神经网络模型是动态的,并且在每个交易日结束时每天更新,以对市场和股票趋势的变化做出反应。除此之外,模型的线性使得结果易于解释。
本项目中使用的完整数据文件和 python 代码也可以在本文末尾下载。
本文是作者提交的最后一个项目,作为他在 QuantInsti 的算法交易管理课程( EPAT )的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者

Mrinal Mahajan 毕业于 IIT 坎普尔大学机械工程专业。
交易和投资是他一直着迷的事情,为了在这一领域发展,他从全球风险专业人士协会(GARP)获得了金融风险管理(FRM)的许可。
过去 3 年,他一直在分析领域工作,曾为一些美国最大的银行工作。他目前在信用卡欺诈风险建模领域与一家领先的美国银行合作。
作为获得交易实践经验的下一步,他决定利用他的分析技能来开发一些有利可图且需要最少监控的东西。
就在那时,他萌生了这个项目的想法,在 Quantinsti 团队的指导下,他得以实施这个项目。
定义问题陈述
根据昨天的数据,预测股票价格从今天收盘到第二天收盘的百分比变化。
简而言之,如果我们可以获得每日频率的数据,那么基于昨天(d-1)数据中创建的变量,我们希望预测第二天(d+1)和今天(d)收盘时的价格变化百分比。
根据预测,我们可以知道,如果我们在今天收盘时买入股票,明天是否会盈利。
根据模型结果,我们希望制定一个资产分配策略,该策略可以利用 BTST(今天买明天卖)功能,与各种经纪人的当天交易相比,该功能的交易成本相对较低。
逼近解
第 1 部分-模型开发
我们创建了以下一组动态神经网络模型
- 概率预测器——确定正回报的概率
- 正回报预测器–仅针对正回报实例训练的模型,用于预测回报的正对数值
- 负回报预测器-仅在负回报实例上训练的模型,预测回报的负对数值
在这里,对数收益被用作因变量,而不是百分比收益或价格变化,以保持序列的平稳性。
- 发展数据–2010 年至 2015 年
- 验证数据–2016 年至 2018 年 4 月
- 过时数据–2018 年 5 月至 2020 年 12 月
股票的历史数据如下所示
| 银行/公司名称 | 符号 | 在漂亮银行的权重 | 数据来自 |
| HDFC 银行有限公司 | hdfc 银行 | 28.39% | 01-01-2010 |
| ICICI 银行有限公司 | ICICIBANK | 19.48% | 01-01-2010 |
| Kotak Mahindra 银行有限公司 | 科塔银行 | 16.31% | 01-01-2010 |
| Axis 银行有限公司 | 轴心银行 | 14.95% | 01-01-2010 |
| 印度国家银行 | SBIN | 9.56% | 01-01-2010 |
| 兴业银行股份有限公司。 | 工业银行 | 4.37% | 01-01-2010 |
| 班丹银行有限公司 | 班德汉银行 | 2.58% | 27-03-2018 |
| 联邦银行有限公司 | 联邦银行 | 1.33% | 01-01-2010 |
| RBL 银行有限公司 | rbl 银行 | 1.06% | 31-08-2016 |
| IDFC 第一银行有限公司 | IDFCFIRSTB | 0.85% | 06-11-2015 |
| 旁遮普国家银行 | PNB | 0.46% | 01-01-2010 |
| 巴罗达银行 | 班克 boarda | 0.66% | 01-10-2010 |
第二部分-战略
该策略的目的是每天在 12 只银行股之间分配现金流入和出售任何现有头寸产生的可用现金。
执行该策略的程序如下
- 从概率模型中获得第二天正回报(未来回报)的概率(p)。
- 从确定性回报模型中获得正的和负的对数回报,并将对数值转换为百分比。假设正百分比回报是 m ,负百分比回报是 n 。
- 将预期收益(e)计算为 p*m+(1-p)n .将预期收益转换为 log 并除以最近 5 天 log 收益的波动率(标准差)得到一个比值。让我们称这个比率为夏普。
- 将夏普修改为最小值(0,夏普)。对于夏普值为 0 的股票,如果持有预期损失(根据预期回报计算)/[到目前为止的利润]的比例,则卖出该股票,如果利润为正,则卖出该股票的所有股票。
- 对于夏普比率为正的股票,按其夏普比率分配出售股票获得的现金和实际现金。
第 3 部分-风险管理
对每只股票的投资应用 20%的止损,即如果一只股票现有头寸的市场价值低于投资价值的 80%,则卖出该股票的所有股票。
模型开发
作为模型输入而创建的变量如下
| 变量 | 尺寸 | 描述 |
| 返回 _1d | 过去的回报 | 前 1 天日志返回 |
| 返回 _2d | 过去的回报 | 最近 2 天日志返回 |
| 返回 _3d | 过去的回报 | 最近 3 天日志返回 |
| return_4d | 过去的回报 | 最近 4 天日志返回 |
| return_5d | 过去的回报 | 最近 5 天日志返回 |
| return_6d | 过去的回报 | 最近 6 天日志返回 |
| return_7d | 过去的回报 | 过去 7 天的日志返回 |
| 返回 _8d | 过去的回报 | 过去 8 天的日志返回 |
| return_9d | 过去的回报 | 最近 9 天日志返回 |
| return_10d | 过去的回报 | 最近 10 天日志返回 |
| 打开 _ 更改 | 变化 | 记录最后一天打开的更改 |
| 高 _ 变化 | 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 变化 | 记录最后一天的下限变化 |
| 范围 _ 变化 | 变化 | 记录前一天高低范围的变化 |
| 体积 _ 变化 | 变化 | 记录前一天的卷更改 |
| 挥发性 5 | 波动性 | 过去 5 天日志回报的标准偏差 |
| 挥发性 20 | 波动性 | 过去 20 天日志回报的标准偏差 |
| MA5 _ 比率 | 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 高 5 _ 比率 | 比率 | 最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 | 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 比率 | 最后一天接近最后 20 天高点的比率 |
| Low20_ratio | 比率 | 过去 20 天的最低价格与最后一天收盘价格的比率 |
| return_1d_nifty | 过去回报俏皮 | nifty bank 最近 1 天的日志回报 |
| return_2d_nifty | 过去回报俏皮 | nifty bank 最近两天的日志回报 |
| return_3d_nifty | 过去回报俏皮 | nifty bank 最近 3 天的日志回报 |
| return_4d_nifty | 过去回报俏皮 | nifty bank 最近 4 天的日志回报 |
| 返回 _5d_nifty | 过去回报俏皮 | nifty bank 最近 5 天的日志回报 |
| return_6d_nifty | 过去回报俏皮 | nifty bank 最近 6 天的日志回报 |
| return_7d_nifty | 过去回报俏皮 | nifty bank 最近 7 天的日志回报 |
| return_8d_nifty | 过去回报俏皮 | nifty bank 最近 8 天的日志回报 |
| return_9d_nifty | 过去回报俏皮 | nifty bank 最近 9 天的日志回报 |
| return_10d_nifty | 过去回报俏皮 | nifty bank 的最近 10 天日志回报 |
| MA5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 最后一天接近最后 20 天移动平均值的比率 |
| 高 5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 _ 俏皮 | 漂亮的比率 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | 漂亮的比率 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 挥发性 5_nifty | 波动俏皮 | nifty bank 过去 5 天日志回报的标准差 |
| 波动性 20_nifty | 波动俏皮 | nifty bank 过去 20 天日志回报的标准差 |
| 布林 5 _ 比率 | 布林格 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | 布林格 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| ADX5 | 动量指示器 | 5 天内的平均方向移动指数 |
| RSI5 | 动量指示器 | 5 天内的相对强度指数 |
| ADX20 | 动量指示器 | 20 天内的平均方向移动指数 |
| RSI20 | 动量指示器 | 20 天的相对强度指数 |
| 相互关系 | 巧妙的关联 | 最近 10 天的回报与最近 10 天的回报的相关性 |
首先创建一个公共输入数据集。然后,我们继续分析 3 个用例的可变趋势——概率、正回报和负回报模型。
例如,我们在下面展示了 3 个模型中相关变量的趋势。
模型 1 -概率模型趋势

模型 2 -正回报模型趋势

这一趋势表明了这样一种假设,即对于价格的上行,股票与市场的相关性越高,回报越高。
模型 3 -负回报模型趋势

趋势表明,总体而言,随着相关性的增加,对股价的负面影响也会增加。
在可视化趋势后,我们使用高级分析技术(如方差膨胀、变量聚类和反向选择)以及趋势的基本直观可视化,对每个模型进行了变量缩减。
注意:模型开发的代码和资源可以在博客的末尾找到。
在变量分析和简化之后,以下变量被用作模型的输入。
概率预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_5d | 最近 5 天日志返回 |
| return_10d | 最近 10 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 记录最后一天的下限变化 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| 布林 5 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| RSI5 | 5 天内的相对强度指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_8d_nifty | nifty 的最近 8 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
正回报预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _2d | 最近 2 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_4d | 最近 4 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| 电压 5 | 过去 5 天日志回报的标准偏差 |
| 电压 20 | 过去 20 天日志回报的标准偏差 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| 高 5 _ 比率 | 最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| ADX20 | 20 天内的平均方向移动指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_9d_nifty | nifty 的最近 9 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 |
负收益预测模型
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _2d | 最近 2 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 电压 5 | 过去 5 天日志回报的标准偏差 |
| 电压 20 | 过去 20 天日志回报的标准偏差 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| 返回 _5d_nifty | nifty 的最近 5 天日志返回 |
| return_9d_nifty | nifty 的最近 9 天日志返回 |
| 高 5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天高点的比率 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 |
使用给定的变量,开发具有收敛架构的线性神经网络模型。收敛架构是这样的,在下一个隐藏层,节点的数量是当前层的一半。
例如:在概率模型中有 26 个输入,即在输入层有 26 个节点,然后在第一隐藏层有 13 个节点,在第二隐藏层有 6 个节点,在第三隐藏层有 3 个节点,最后在输出层有一个节点。
在这种情况下,所有隐藏层节点都具有线性函数,只有输出层具有 sigmoid 函数。在正负收益模型中,包括输出在内的所有节点都是线性激活的。
用于训练模型的开发数据来自 2010-2015–5 年。
每个模型的静态方程系数如下
概率预测模型
比值对数(p/1-p)的线性方程
| 变量 | 描述 |
| 返回 _1d | 前 1 天日志返回 |
| 返回 _3d | 最近 3 天日志返回 |
| return_5d | 最近 5 天日志返回 |
| return_10d | 最近 10 天日志返回 |
| 打开 _ 更改 | 记录最后一天打开的更改 |
| 高 _ 变化 | 记录最后一天的高点变化 |
| 低 _ 变化 | 记录最后一天的下限变化 |
| 体积 _ 变化 | 记录前一天的卷更改 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 |
| 布林 5 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 5 天 |
| 布林 20 _ 比率 | (价格-布林下轨)/(布林上轨-布林下轨)在过去 20 天 |
| RSI5 | 5 天内的相对强度指数 |
| RSI20 | 20 天的相对强度指数 |
| return_1d_nifty | nifty 的最近 1 天日志返回 |
| return_2d_nifty | nifty 的最近 2 天日志返回 |
| return_3d_nifty | nifty 的最近 3 天日志返回 |
| return_4d_nifty | nifty 的最近 4 天日志返回 |
| return_8d_nifty | nifty 的最近 8 天日志返回 |
| return_10d_nifty | nifty 的最近 10 天日志返回 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 |
正回报模型
对数收益的线性方程
| 变量 | 描述 | 系数 |
| 返回 _1d | 前 1 天日志返回 | 0.112714604 |
| 返回 _2d | 最近 2 天日志返回 | 0.076917067 |
| 返回 _3d | 最近 3 天日志返回 | 0.137521163 |
| return_4d | 最近 4 天日志返回 | 0.139919728 |
| 打开 _ 更改 | 记录最后一天打开的更改 | 0.044385113 |
| 体积 _ 变化 | 记录前一天的卷更改 | 0.00109395 |
| 电压 5 | 过去 5 天日志回报的标准偏差 | -0.00038334 |
| 电压 20 | 过去 20 天日志回报的标准偏差 | 0.056020129 |
| MA5 _ 比率 | 最后一天接近最后 5 天移动平均值的比率 | 0.314374059 |
| 高 5 _ 比率 | 最后一天接近最后 5 天高点的比率 | 0.315460533 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 | 0.204366401 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 | 0.133332253 |
| ADX20 | 20 天内的平均方向移动指数 | 0.001150683 |
| RSI20 | 20 天的相对强度指数 | 0.01172027 |
| return_1d_nifty | nifty 的最近 1 天日志返回 | 0.267879993 |
| return_2d_nifty | nifty 的最近 2 天日志返回 | 0.193813279 |
| return_3d_nifty | nifty 的最近 3 天日志返回 | 0.161507115 |
| return_4d_nifty | nifty 的最近 4 天日志返回 | 0.104044914 |
| return_9d_nifty | nifty 的最近 9 天日志返回 | 0.039391026 |
| return_10d_nifty | nifty 的最近 10 天日志返回 | 0.029924326 |
| MA5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天移动平均值的比率 | 0.247091874 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 | 0.047915675 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 | 0.018904656 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 | 0.055917718 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 | 0.097226188 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 | 0.048495531 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 | 0.001289934 |
| 拦截 | | -0.232171148 |
负收益模型
对数收益的线性方程
| 变量 | 描述 | 系数 |
| 返回 _1d | 前 1 天日志返回 | 0.124469906 |
| 返回 _2d | 最近 2 天日志返回 | 0.094707593 |
| 返回 _3d | 最近 3 天日志返回 | 0.098002963 |
| 高 _ 变化 | 记录最后一天的高点变化 | 0.061372437 |
| 电压 5 | 过去 5 天日志回报的标准偏差 | 0.489989489 |
| 电压 20 | 过去 20 天日志回报的标准偏差 | 0.461109012 |
| MA20 _ 比率 | 最后一天接近最后 20 天移动平均值的比率 | 0.143796369 |
| 低 5 _ 比率 | 过去 5 天的最低价格与最后一天收盘价格的比率 | 0.245543823 |
| 高 20 _ 比率 | 最后一天接近最后 20 天高点的比率 | 0.214187935 |
| RSI20 | 20 天的相对强度指数 | 0.017691486 |
| return_1d_nifty | nifty 的最近 1 天日志返回 | 0.152266026 |
| return_2d_nifty | nifty 的最近 2 天日志返回 | 0.149913758 |
| return_3d_nifty | nifty 的最近 3 天日志返回 | 0.137844741 |
| return_4d_nifty | nifty 的最近 4 天日志返回 | 0.135978788 |
| 返回 _5d_nifty | nifty 的最近 5 天日志返回 | 0.005645283 |
| return_9d_nifty | nifty 的最近 9 天日志返回 | 0.035861455 |
| 高 5 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 5 天高点的比率 | 0.303022981 |
| 低 5 _ 比率 _ 俏皮 | nifty 银行的最近 5 天低点与最近一天收盘的比率 | 0.101814494 |
| 高 20 _ 比率 _ 俏皮 | nifty bank 的最后一天接近最后 20 天高点的比率 | 0.074914791 |
| 低 20 _ 比率 _ 俏皮 | nifty 银行的最近 20 天低点与最近一天收盘的比率 | 0.029958185 |
| 电压 5_nifty | nifty bank 过去 5 天日志回报的标准差 | 0.481154203 |
| 电压 20_nifty | nifty bank 过去 20 天日志回报的标准差 | 0.024172308 |
| 相互关系 | 最近 10 天的回报与最近 10 天的回报的相关性 | 0.000418738 |
| 拦截 | | -0.212120146 |
静态与动态模型
2010-2015 年(5 年)数据的模型开发为我们提供了所有模型的静态方程。然而,神经网络的好处是它不同节点的权重可以通过输入新数据来更新。
这在直觉上是有意义的,因为市场或股票并不总是遵循一个固定的静态方程,我们需要一个能够反映这些变化的动态解决方案。
作为相同概念的证明,我们通过每天输入 2016 年 1 月至 2018 年 4 月的数据并更新模型权重,创建了一个动态模型。所有 3 个模型的方程都显示了一段时间内的变化。
接下来,我们比较了 2018 年 1 月至 2018 年 4 月期间的结果,以了解差异。在这里,我们试图比较不同股票在这 4 个月中两个模型的准确度和精确度。
为了解释我们如何构建预测指标,假设概率模型返回价格上涨的概率 p,正负回报模型给出 x 和- y 作为回报,那么预期回报 e = px+(1-p)(-y) 。
如果 e 是正的,我们说正收益是预测的,我们的准确度和召回率都是基于此。
静态与动态——按月拆分
| 月 | 静态 | 动态 |
| 精度 | 精度 | 回忆 | 精度 | 精度 | 回忆 |
| 2018-01 | 43% | 42% | 41% | 46% | 46% | 53% |
| 2018-02 | 46% | 42% | 89% | 53% | 40% | 35% |
| 2018-03 | 50% | 44% | 46% | 54% | 46% | 27% |
| 2018-04 | 50% | 48% | 46% | 50% | 48% | 53% |
| 总计 | 47% | 44% | 54% | 51% | 46% | 43% |
从上面的统计数据可以看出,与静态模型相比,动态模型的预测更加准确和精确。此外,随着越来越多的数据输入到模型中,模型结果很有可能在未来得到改善。
静态与动态——股票分割
| 符号 | 静态 | 动态 |
| 精度 | 精度 | 回忆 | 精度 | 精度 | 回忆 |
| AXISBANK | 46% | 41% | 67% | 51% | 41% | 42% |
| 班克巴罗达 | 50% | 45% | 56% | 51% | 45% | 36% |
| 联邦银行 | 51% | 49% | 47% | 49% | 45% | 37% |
| HDFCBANK | 46% | 39% | 24% | 61% | 61% | 53% |
| ICICIBANK | 48% | 42% | 76% | 50% | 39% | 36% |
| 开始吧 | 48% | 48% | 37% | 49% | 50% | 43% |
| KOTAKBANK | 46% | 58% | 43% | 53% | 64% | 51% |
| PNB | 40% | 34% | 63% | 53% | 37% | 37% |
| SBIN | 45% | 40% | 75% | 49% | 36% | 38% |
| t0rb lbank t1 号 | 50% | 50% | 60% | 41% | 41% | 43% |
| bandhan 银行 | 69% | 40% | 67% | 54% | 29% | 67% |
| IDFCFIRSTB | 45% | 41% | 53% | 49% | 44% | 50% |
| 总计 | 47% | 44% | 54% | 51% | 46% | 43% |
可以看出,对于大多数股票来说,动态模型变得更加准确和精确。
战略
基于动态模型结果,我们实施了一些今天买明天卖(BTST)策略的变体。回溯测试期从 2018 年 5 月 1 日至 2020 年 12 月 10 日,为 2.61 年。
与之比较的基准策略是 nifty 银行指数上的买入并持有策略。最终成为最佳选择的变体是每月 SIP,每只股票投资的止损为 20%。我们案例中的 SIP 金额为每月 20,000 印度卢比。
以下是这方面的统计数字
| 统计数据 | 基准 | 月啜 |
| 最大投资回报率 | 26.89% | 131.87% |
| 米诺里 | -33.83% | -22.92% |
| 最大压降 | 47.86% | 55.39% |
| 最终国王 | 19.70% | 53.31% |
| 同比退货 | 7.14% | 17.80% |
可以看出,与买入并持有 bank nifty 的基准策略相比,这种策略产生的年回报率至少超过 10%。战略的加班表现可以在下图中看到:

从图表中可以看出,尽管该策略在最初几年比基准稍有滞后,但在最近一段时间却表现出色。
局限性
- 回溯测试不考虑任何交易成本,但是,对于这种策略,各种经纪人都可以获得最小的交易成本。然而,为了进一步微调,可以只出售已交付的股票,而不是未结头寸。
- 为了获得当天买卖股票的最佳价格,需要实施市场微观结构策略。
- 一个自动化的应用程序来执行每天的战略将是必需的。这是通过在 Zerodha 的 KITE 平台上创建一个应用程序来实现的。
结果
在 2011 年 2 月 11 日记录该项目时,该模型在一个月的时间内给出了大约 5%的投资回报。
详情见下表:-
| 符号 | 投入的资金 | 市值 | 损益表 | 股份持有量 | 德马特的股份 | LTP |
| HDFCBANK | 1387.15 | 1581.75 | 194.60 | 1 | 1 | 1581.75 |
| ICICIBANK | 6.20 | - | -6.20 | 0 | 0 | 632.15 |
| KOTAKBANK | 7066.20 | 7808.20 | 742.00 | 4 | 4 | 1952.05 |
| AXISBANK | - | - | - | 0 | 0 | 734.80 |
| SBIN | 16.55 | - | -16.55 | 0 | 0 | 392.25 |
| 开始吧 | 4256.60 | 5114.00 | 857.40 | 5 | 5 | 1022.80 |
| bandhan 银行 | 376.15 | - | -376.15 | 0 | 0 | 331.20 |
| 联邦银行 | 779.70 | 745.65 | -34.05 | 9 | 8 | 82.85 |
| t0rb lbank t1 号 | 2483.95 | 2673.55 | 189.60 | 11 | 11 | 243.05 |
| IDFCFIRSTB | 719.21 | 758.25 | 39.04 | 15 | 13 | 50.55 |
| 班克巴罗达 | 412.75 | 398.50 | -14.25 | 5 | 4 | 79.70 |
| PNB | 228.40 | 118.35 | -110.05 | 3 | 3 | 39.45 |
| 市场资金 | 17732.86 | 19198.25 | 1465.39 | | | |
| 库存现金 | 2267.14 | 1886.55 | -380.59 | | | |
| 总计 | 20000.00 | 21084.80 | 1084.80 | | | |
| ROI | 5.42% | | | | | |
编码
这个策略的代码和详细分析可以在这里找到。
结论
利用动态线性模型,为漂亮的银行股制定积极的每日投资组合再平衡资产配置策略,可以帮助在大约 3 年的时间内产生接近 20%的年回报率。
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT) 的高管课程。该课程包括各种培训模块,让你具备在算法交易中建立一个有前途的职业生涯所需的技能。
为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
动态资金管理
扎克·奥克斯
许多有抱负的交易者大多梦想上帝般的回报——从几笔好交易开始,他们拿出心理计算器,开始计算他们什么时候会成为亿万富翁,或者开下一家文艺复兴资本。
有经验的交易者会告诉你,好交易和坏交易在业余交易者和大师交易者之间没有太大的区别——真正的区别在于纪律,而这通常是以资金管理的形式实现的。
当我想到圣杯系统的时候,我主要梦到标准差、相关性和下降。我梦想有一个标准偏差的系统,需要科学的符号来衡量它的方差,平均相关度
在开发过程中,我只考虑一次回报,或者实际上是性能的任何上升指标——这是我第一次测试系统以确保它满足我的最低性能阈值。只要够用,直到投资组合层面我都不会再考虑回归。
对于好奇的人来说,我的系统门槛通常是:
- 同比增长 25%,
- 小于 2.5% DD,
- 夏普> 2.5,
- 平均交易> 75 美元,以及
- 胜率> 65%。
我们马上会回到胜率,因为我认为从数量上来说,胜率是系统实力的两个最重要的预测指标之一。系统通常会偏离到几对指标的平衡行为——赢率与平均交易(止损和目标平衡行为),最大损失/固定止损与提款——我发现低固定止损通常会增加提款(通过降低赢率——见平衡行为 1)。
对于那些不明白的人,让我们来定义胜率,然后我会告诉你它与这个版本的关系,因为有几种方法可以衡量它。我倾向于用盈利交易/总交易来衡量,但许多人更多地把它作为回忆统计来衡量,并把它作为盈利交易/亏损交易来对待,但我发现这个指标有太多的移动部分——当有选择时,我总是选择最简单的形式来表达任何问题。
回到资金管理——量化交易者的纪律化身。
如果你还没有注意到,我首先从风险的角度考虑策略——我总是考虑不利因素和最坏的情况,并从那里开始积累。我典型的资金管理倾向于遵循同样的逻辑,因为我更喜欢使用我能找到的最保守的资金管理算法。我认为交易中的“持久力”是有道理的——我的首要任务是确保当我的系统找到正确的事件组合来反弹时,我还活着。
你们中的一些人会说这太消极了——我应该把重点放在不需要恢复上——但是对于那些多年来系统交易的人来说,所有的系统都有亏损——系统越好,亏损在心理上就越困难。
我的 MM 解决方案一直使用固定比率,它使用一个 delta 值来保护你的利润,只有当你在每份合同中赚取了 Delta 量的利润时,才添加合同-因此,如果你的 Delta 是 50k,你有 1 份合同,你需要 50K 的利润增加到 2 份,然后达到 3 份,你需要 100k (2x50k)。
下面是公式,供参考。
*N = . 5 * SQRT(1+8 (ProfitPerContract/Delta))+1
或者用 Python:
数量= .5 * (np.sqrt(1 + 8*(P/D)) + 1)
虽然这是一个很好的基础解决方案,但我一直有兴趣找到一种方法,将这个难题的关键部分——胜率——运用到资金管理中。
也许有一种方法,我们可以增加每个方向的仓位大小,甚至是特定的进场,因为进场或出场以高胜率证明其实力?
这有点罗嗦——简单地说,假设你的短线是 9/10,长线是 4/10——也许我们应该把大部分资金放在短线上,直到它开始平衡?
(有人可能会说,我们应该权衡相反的情况,因为比率最终应该接近它们各自的均值——但这是一个效率 MM 系统,而不是均值回复 MM 系统!不过,自己试一试可能会很有趣。)
那么这在策略代码中需要什么呢?显然,我们需要一种方法来计算每个方向的交易,这可以简单地随着每个条目而增加—(注意范围,确保使用类变量或全局变量,否则它会随着方法的范围而清除)。
因此,让我们使用全局变量,因为这样更简单/更易读—我将添加 LONGS 和 SHORTS 变量,将它们初始化为 0(尽管将它们设置为 10 可能是个好主意,并将 WINS 初始化为 5 以开始偶数)。这些变量将计算方向性交易,但是如果你有 10 个不同的进场信号,你可以为每个信号加上全局计数。

对于每个计数(分母),我们将创建一个 LongWins(分子),以计算我们各自的 WinPct 变量—两者都应该是 globals 或 class vars。
对于位置,我通过导入将全局放在顶部,但是,我们应该如何增加 Wins?我选择这样做,只是在我的 trailStop 逻辑中增加“xWins”全局变量(就在它被调用之前——退出一个成功的交易),但是如果你有一个固定的目标也可以。
你也可以走相反的路线,只用固定止损跟踪亏损(然后确保计算 WinPct = (1-LongLosers)。

我也有两个基于逻辑的出场——它们在一系列的低点/高点之后出场,但是不清楚这是否有利可图。有几种方法可以处理这个问题——你可以打一个电话来确定成本基础,这样就可以在它之前打开 PnL,或者(为了简单起见)我只是将它们增加了 0.5,一般认为它们是中性的。
既然您已经设置了计数和所有需要的变量——是时候使用它们了!

我创建了一个方法,将这些值作为输入,并为您各自的条目确定适当的数量。我已经附上了代码,但为了澄清这是你要用 WinPctLongs = LongWins / Longs 分配 win pct 的地方。
另一个关键部分是为 MAXQTY 或完整数量设置一个全局值——我现在将它设置为 100。这是您的 win pct 将从中抽取的百分比,以确定固定数量,并确保您返回一个 int(或向下舍入一个 float — round(qty,0)),因为没有半股。
使用前面的例子,(9/10)空头现在将为下一个空头条目交易 90 股(. 9 x MAXQTY)空头。

虽然这个 MM 系统在基本示例上表现不佳——主要是因为它最初将其缩小到 1/100 的大小(我会将每个 WinPct 初始化为 50,并将测试 MAXQTY 的初始数量增加一倍,以获得可比的结果)——但我确实认为像这样的动态 MM 方法实际上可以与传统的 MM 算法结合使用,如 Fixed Ratio 目标是最终产品大于其各部分的总和。
纪律不能用 6 行代码来教。T3】
但希望通过一点探索,你可以利用这一点来培养市场所需的勇气。
交易愉快!
免责声明:本客座博文中提供的观点、意见和信息仅属作者个人观点,不代表 QuantInsti 的观点、意见和信息。本文中所做的任何陈述或共享的链接的准确性、完整性和有效性都不能得到保证。我们对任何错误、遗漏或陈述不承担任何责任。与侵犯知识产权相关的任何责任由他们承担。
下载中的文件:
- mod_beg - Python 代码
- Win_Rate_MM Jupyter 笔记本
(在示例代码中,我还包括了固定比率、代码和一种在一个系统中使用字典跟踪多种工具/策略的方法)
金融市场教育:结构化方法和新兴趋势[小组讨论]
原文:https://blog.quantinsti.com/education-financial-markets-emerging-trends-20-september-2022/
https://www.youtube.com/embed/x-t0QkIyJXI?rel=0
行业领袖小组讨论不断发展的交易领域及其挑战,以及新时代的学习平台如何为下一代交易者提供支持。
小组成员

安德烈亚斯·克莱诺(瑞士苏黎世)
阿塞斯资产管理公司首席投资官。经验丰富的对冲基金,企业家和小说家。

Binni Ong(新加坡)
SGX 学院教练。15 年外汇和股票交易和培训经验。

Karthik Rangappa(印度班加卢鲁)
Zerodha 教育服务副总裁。二十年的印度资本市场经验。

Vivek Bajaj(印度加尔各答)
StockEdge,elearnmarkets & QuantInsti 的联合创始人。连续企业家,投资者和导师。
关于 Algo 交易大会 2022
QuantInsti 举办的 2022 年算法交易大会对有抱负的算法交易者来说是一个很好的学习机会。这是您联系您最喜爱的专家并免费获得所有问题答案的机会。
该活动于美国东部时间 2022 年 9 月 20 日上午 10:30(IST 时间晚上 8:00)举行。
电子工程师到定量研究分析师| Pratik 的算法交易之旅
原文:https://blog.quantinsti.com/electronics-engineer-quant-analyst-epat-success-story-pratik-dokania/
我一直认为,对任何人来说,成功都与动力、奉献和渴望有关,但对我来说,它还与信心和信念有关。——斯蒂芬·库里
引用这句话,我们带来了我们的 EPATian Pratik Dokania 的故事,他有着正确的动力、奉献和信念,已经走上了成功的道路。他喜欢挑战他的东西,挑战前的东西现在变成了他的激情,那就是交易。
他目前在孟买 NeuralTechSoft 担任全职定量研究分析师。
Pratik 希望学习更多的交易知识,并希望有一天能用自己的资本投资市场。我们联系了他,了解他进入算法交易世界的旅程。
嗨,普拉蒂克,给我们介绍一下你自己吧!
嗨!我叫 Pratik Dokania,来自印度西孟加拉邦的加尔各答。我完成了马尼帕尔大学的电气和电子工程。我目前正在印度精算师学院攻读精算科学。
之前,我在 Axxela 咨询服务公司做过贸易市场分析师,在 LLP Dravyaniti 咨询公司做过 Python 开发人员,在印度石油有限公司做过工业实习生等等,通过这些工作,我积累了很多经验。
我喜欢玩战略游戏,比如在线纸牌游戏、扑克,尤其是国际象棋。我看过《女王的策略》系列,我个人认为这是描绘完美象棋游戏的最佳剧集之一。
在疫情期间,除了玩这些游戏,我还投资于市场。尽管市场波动很大,但市场从未关闭。所以这是一个小小的挫折,但是无论疫情如何,我们都应该为这样的事件做好准备。
作为一个工程出身的人,是什么让你对算法交易感兴趣?
交易在很长一段时间里从未进入我的视野,我也从未想过它会长大。在大学校园实习期间,我得到了一个在贸易公司工作的机会。我也做过一段时间的交易员。
为了快速起步,我开始寻找关于金融市场和交易相关的课程。在这样做的时候,我偶然发现了算法交易。
手工交易会在公司里教授,算法交易的知识会让人难以置信。我知道 Python、C++、Java,所以学习对我来说很容易。
最初,我对编程非常感兴趣,但我不知道如何以此为职业。所以这个职位给我提供了一个探索这个领域的机会,让我挑战自我。现在,交易绝对是我想从事的职业。
也许如果我被安排在其他地方,而不是交易公司,我就不会遇到交易。我非常感谢实习的经历和指导我的导师,他们帮助我到达了职业生涯的起点。因为这个,我觉得自己真的很幸运。
我在研究算法交易的过程中遇到了昆汀斯提和 EPAT。EPAT 是我一直在寻找的地方,也符合我的预算,而且非常可行。
我联系了我的一个大学毕业生,他是一名埃帕塔尼人,并收到了关于这门课程的积极反馈,以及它对我的益处。我想重新开始,这是一个完美的机会。
你学习算法交易的体验如何?
EPAT 大学的教职员工太棒了!在这里,专业交易者和行业专家讲授当前市场趋势、市场波动等。他们热衷于交易。
他们的见解、学识、故事和经历是书本上找不到的,是无价的。他们了解并分享最新的市场动态、不断变化的技术和他们的观点,这些东西可能不是每个人都知道的。
出版的和经历的有着巨大的差异。除了课程设置之外,教员的专业知识和经验也让我们对市场如何运作有了深入的了解。
向 EPAT 学习与阅读书籍和文章或观看视频非常不同,因为我们获得了实践学习的经验。
支持经理起着重要的作用,他们非常有帮助。你可以立即消除你的疑虑,它们会很好地引导你,帮助你能够专注于你的学习。终身学习该课程可以让您随时与支持经理和教职员工保持联系。
因为我有编码的知识,我不觉得那部分有挑战性。然而,也有不知道编码的人。即使在讲座结束后,支持团队也将学生与教师直接联系起来,他们解决了学生的疑问和疑问。
其他课程和机构有一个小的支持团队,为一大群被分开的学习者服务,你得不到单独的关注。但是,在 EPAT,每个学生都被分配了一个支持经理,在他们在 EPAT 的 6 个月里,指导他们的每一步。老实说,我发现这真的很有帮助。
当我感到困惑和担忧时,我的支持经理总是在那里指导和激励我。他们非常支持,积极响应,非常乐于助人。
几周前,我对机器学习有一些疑问。因此,尽管我几年前就已经完成了 EPAT 课程,我还是登录了 EPAT 大学的 LMS,获取了最新的更新内容,因为我可以终身访问该课程。我喜欢这个功能。
你在 EPAT 安置团队的经历是怎样的?
安置小组在他们的工作中非常有帮助和专业。来找工作的公司也非常专业,专门寻找那些拥有对他们的工作机会至关重要的知识和素质的人。而这些在 EPAT 都被彻底覆盖了。
我的电子邮件或电话从未无人回复。
我和朱玛娜有联系,她真的很棒。我得到的第一份工作中,有一份给了我基本的薪水,作为一名学生,我很高兴 Jumana 与公司协商给了我更好的待遇。我将永远感激她。
安置小组不仅考虑安置学生,还尽力帮助学生。
就业安置团队为我提供了符合我兴趣和技能的工作机会,他们今天也在这样做。他们会进行多次跟踪调查,了解你在公司的表现。
公司通常倾向于选择大学和研究所来招聘员工,EPAT 的就业安置小组会有所帮助。这与你自己去找一份 Algo trading 的工作相比,在工作描述、匹配技能、薪水、经常性工作机会等方面会有很大的不同。EPAT 的安置过程非常顺利。
你会对那些渴望学习算法交易的人说些什么?
算法交易是交易的一个分支。如果你有正确的驱动力和奉献精神,那么这可能是你的。有了努力和激情,你就能实现你下定决心要做的任何事情。
要自信,设定自己的最后期限,不断学习和成长——在这个快速发展的领域取得领先。
正如一位 EPAT 校友告诉我的那样,“如果你善于学习、把握和适应事物,那么 EPAT 将对你非常有帮助。”
你说得很对,如果一个人有必要的动力和毅力,他就能取得任何成就。谢谢你,Pratik,谢谢你充满抱负的话语,谢谢你与我们分享你的奇妙旅程。我们希望你也能实现你的目标。我们祝你未来一切顺利。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
能源工程到算法交易——雷纳托的旅程
原文:https://blog.quantinsti.com/energy-engineering-algorithmic-trading-epat-success-story-renato-votto/
一个工程学位可以让你掌握很多适用于算法交易的技能和知识。两者都要求有条不紊,善于分析,是一个好的计划者,但也要有创造力,跳出框框思考。
Renato 是一名能源工程师,是英国能源监管机构的能源批发市场分析师。他把交易作为一种爱好,并完成了 EPAT,把他自动化和标准化交易过程的技能和热情应用到交易中。
雷纳托分享了他完成 EPAT 的旅程,并将其工程背景转化为算法交易的世界。这是他的故事。
嗨,雷纳托,给我们介绍一下你自己
嗨!我叫雷纳托·沃托,我是意大利人,自 2016 年以来一直生活在英国伦敦。我是一名能源批发市场分析师,为英国能源监管机构工作。
我的角色是数据分析师/开发人员,我主要参与开发系统识别市场操纵的工具。我处理从交易所接收和操作交易数据的数据管道。
这些工具帮助我的团队开展调查,并使我们的组织能够实施积极的市场监控方法。我把交易作为一种爱好,我主要在加密空间交易。
在我的业余时间和旅行中,我喜欢用反光相机拍照。我也曾经弹吉他,在乐队唱歌。最近我也自己创作音乐。我也想开始画画。我会说我喜欢创造性的活动。
你是怎么从能源工程转到 Algo 交易的?
我的背景是能源工程。作为一名学生,在伦敦的头几年里,我在获得第一份工作之前在零售行业工作,在 Ofgem 担任可再生能源项目的审计助理经理。
我在工作中一直采用分析的方法,甚至在我之前在零售部门的工作中也是如此。例如,我开发了分析工具和方法,通过查看数据来增加销售额。我在以前作为审计员的工作中也做过同样的事情,当时我开发了工具和框架来改进流程或应用风险管理和数据分析/审查的量化方法。
我对自动化和标准化流程充满热情,并将这种热情应用于我生活中的每一件事。当我开始学习算法交易时,我想“这太酷了!”真的代表了我喜欢做什么,喜欢怎么做事。
我还意识到,我在这个领域有很好的知识和技能基础,可以在此基础上继续发展。这就是为什么我决定深入算法交易。算法交易要求你有条理,有分析能力,对每件事都有计划。
你需要跳出框框思考,这是它与工程的共同点,无论是软件工程还是经典工程。这就是 EPAT 出现的原因。在四处寻找并了解了那里的课程和道路之后,我最终决定参加这个项目。
学习更多关于机器学习和量化金融的知识感觉是我职业道路和个人兴趣的自然发展。对金融市场的好奇和热情支撑着我想把职业转变为交易的愿望。当我开始学习交易时,我自然而然地想到要寻找自动交易的方法。
这几年学的是数据工程和机器学习。机器学习可以应用于众多领域,然而,我对追求经典应用不感兴趣,如营销或机器人推荐。
疫情对你的生活和工作有什么影响?
在疫情之前,我渴望有空闲时间来专心学习。以前每天早上很早就进办公室,很早就离开赶回家学习 Python 等课程到深夜。
随着许多人失去工作,世界实际上正在关闭,经济正在崩溃。封闭和在家工作,不用通勤,让我有很多时间投资于个人发展。那段时间很忙,但我很享受。
所以,当我开始在 EPAT 上学和学习时,封锁帮助了我,因为它需要大量的时间、精力和注意力。我真的觉得我受益于疫情的限制。我感到幸运,但也为没有浪费时间,将这段不确定时期转化为我的优势而自豪。
我在学习 EPAT 课程的同时,也在学习 C++。所以我的一天被工作和学习塞满了。我通常在早上五六点钟醒来,学习几个小时的 C++,做我的全职工作,然后为 EPAT 学习到深夜。
当我回头看的时候,我觉得我在这方面比一年前有了更多的技能和信心。
你在 EPAT 的学习有多重要?
在决定入学前几个月,我了解了 EPAT。我正在完成几门关于机器学习和数据工程的在线课程,并在思考接下来会发生什么。
我想扩展我在交易方面的知识和技能,通过对量化金融和量化交易的在线研究,我遇到了 EPAT。
在仔细考虑了课程、课程结构和活动之后,我毫不怀疑这是值得投资和努力的。所以,我去了。
我喜欢一切需要智力努力和研究来完成的事情,否则很难实现。我真的很喜欢工程和解决问题。这就是我最终从事算法交易的原因。它满足了我对技术、解决问题、研究和自动化的热情。
算法交易是一个广阔的领域。对我来说,为 EPAT 学习最具挑战性的事情之一就是挑选出真正重要的东西。你需要有条不紊,了解自己的优势、劣势和学习方法。
关于以下方面的知识:
- 统计数据,
- 数学,
- 软件工程,
- 经济学,
- 市场基本面,
- 结构,以及
- 我们的社会和市场如何运作。
对我来说,把所有这些东西放在一起,并从中挑选出最相关的来继续进行,是 EPAT 课程中最具挑战性的部分之一。
另请阅读: Raj 的旅程:将工程技术与金融相结合
你最喜欢 EPAT 的哪个特征?
EPAT 的教师质量很高。有一些专家和交易者活跃在这个行业,把参与算法交易作为他们的日常工作。对我来说,他们直接参与真实的算法交易是 EPAT 的最大卖点之一。
我猜 QuantInsti 选择这些老师是因为他们的技能和教授这些科目的能力。我认为是这样的,因为他们都很聪明,可以回答学生可能有的所有问题。他们真的很关心在讲课时没有人被落下。
陈博士和辛克莱博士才华横溢,非常乐于听取学生的意见和想法。辛克莱博士讲课时非常有趣。所有的老师都是那么充满活力和热情,他们真的能够在讲课时转移到学生身上!这使得每次讲座都是一次很棒的经历。
总的来说,课程的质量和教师的质量是 EPAT 最大的卖点。你把最好的信息带回家,学习在这个行业取得成功的所有基础知识。
你会给那些想从事算法交易的人什么信息?
像算法交易这样复杂的主题需要你全神贯注,你必须对它充满热情才能继续下去。
首先,我认为尝试使用一些关于算法交易的资源是一个好的举措。玩编程和时间序列,探索金融市场,试着理解如果你决定从事这个职业,你每天可能会遇到什么。如果你喜欢,就去做吧。
现在你可以在网上获得所有你想要的信息,但是很容易迷失方向。这就是为什么我认为由专家制定的结构化路径是最好的方法。如果你有经验,只是想更深入地钻研某一特定学科,自学是有意义的。
如果你准备投入时间和精力来学习和完成 EPAT,我相信一旦完成,你会感激这门课程给你的知识量。
借此,祝你好运!
感谢你的时间,雷纳托。你将自己的技能转化到新领域并利用自己优势的能力令人振奋。我们祝你在算法交易的旅途中好运。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
学习工程学到在 Algo Trading - Deep 找工作的旅程
原文:https://blog.quantinsti.com/engineering-algo-trading-job-placement-epat-success-story-deep-lakhani/
“永远不要停止学习,因为生活永远不会停止教导。”这是迪普·拉哈尼的座右铭。
他报名参加了 EPAT 项目,在大学最后一年利用它的项目工作。通过 EPAT,他获得了探索和实施算法交易的指导,也是 EPAT 优秀证书的获得者。
我们联系了 Deep,以了解他进入 Algo Trading 的更多信息。
嗨,深度,告诉我们关于你自己!
嘿!我是深拉哈尼。我来自印度孟买。目前,我在一家专门研究密码的初创公司工作,我的工作需要开发一种算法,根据客户的要求在特定的交易所进行交易。
我喜欢打排球。我在大学的时候也玩过,也参加过锦标赛。我最近迷上了阅读。
疫情开始于我工程专业第三年快结束的时候。我努力学习,因为我不得不在资源有限的情况下完成我的项目。除此之外,生活还算不错,我很感激。
作为一名工程(IT)专业的学生,掌握算法交易的概念对你来说有挑战性吗?
当时,我只有股票和市场的基本知识,对我来说完全是另一回事。与此同时,我在研究它的不同领域。我进入了机器学习领域,但它并没有引起我太多的兴趣。
在大学期间,我听说了算法交易来到印度的整个过程。我参加了 Rishabh Sanghvi 的研讨会,他启发了我,让我的最终项目与 Algo 交易相关。
起初很难理解这些概念,但作为一名技术背景的人,我有优势去涵盖技术方面,我能够专注于并了解它的营销方面。由于我父亲是一名会计师,我对金融和印度市场有基本的了解和认识。
我已经精通了编程语言。但是,将策略降下来,这是一个挑战!
在 EPAT 有安置小组指导你,你学习算法交易的体验如何?
因为我不知道这个领域有什么样的工作,所以我与就业小组的第一次互动只是了解一下有哪些工作和职业。
对我来说,有几个配置文件看起来一样,它们帮助我区分了数据科学和分析部分。从那里,我被安排到一家我想要的公司,在那里有人可以指导我了解为客户制作端到端产品的流程图。
找到 QuantInsti 对我来说是一个福音,有这样一个庞大的团队让你在一个综合的水平上理解事情。这是一次很好的经历。
对我来说,一切都井井有条,拥有这些知识让我比其他人更有优势,尤其是在竞争激烈的世界里。
EPAT 的哪一个特征真正吸引了你?
EPAT 项目已被纳入课程。我们有充足的时间投入其中,被指派的导师都是各自领域的专家。他们帮助你理解并实际运用你的知识。他们还帮助安排项目工作。
讲座非常有趣,非常棒。他们在周末进行的工作对我有利。我发现理解理论部分有点困难,但讲师们都很精通,他们知道自己在做什么,也知道我们从何而来。
有什么给有抱负的定量分析师的消息吗?
总是问问题。他们有一个乐于助人的教师小组,随时准备解决你的疑问和疑虑。你可以依靠他们的专业知识来解决这些问题。
学习是一个不断进化的过程。
我没有太多的经验,但我想说的是——看待事物要有自己的视角,看自己喜欢什么,不要满足于别人给你的东西。强烈要求更多,通过努力你会成功的。
你说的完全正确,学习是一个不断发展的过程,努力工作会让你获得丰硕的成果。非常感谢你与我们分享你的故事。我们相信你一定努力工作,为你的项目取得最好的结果,祝贺你的工作!我们祝你未来一切顺利。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
将工程技术与金融相结合:Raj 的旅程
原文:https://blog.quantinsti.com/engineering-algorithmic-trading-epat-success-story-raj-mahajan/
对很多事情都知道一点。——罗伯特·t·清崎,《富爸爸,穷爸爸》的作者
这句话解释了 Raj 对学习和发展他的知识和技能的热情。他是一名对金融世界着迷的工程师。他在银行、技术和金融领域的职业生涯充满活力。
在攻读工程学位期间,他曾做过兼职交易员,后来他将自己的学习与激情结合起来,为自己创造了独一无二的机会。这是他进入算法交易世界的旅程。
嗨,Raj,跟我们谈谈你自己吧!
嗨,我是 Raj Mahajan,住在美国特拉华州的威尔明顿市。我在贝莱德担任客户发票服务流程经理。我是一名主管,负责北美客户的计费、主要计费、生产和监督。

我是一名倾向于金融的工程师。我也在攻读 CFA,因为我想提高自己的技能,学习更多的金融知识。在我的业余时间,我阅读书籍和报纸。我喜欢让自己跟上各种潮流和成长中的文化。
你是如何从银行、教育技术、科技发展到现在的金融的?
我想在技术领域建立自己的事业,并继续攻读电子和电信工程学士学位。
在我的学士学位期间,我意识到我对金融感兴趣。我开始阅读像《富爸爸,穷爸爸》这样的书,并被沃伦·巴菲特迷住,并开始跟随他了解他的旅程,同时雕刻我的。
我身边都是会投资股市的朋友和导师。这有助于为我创造一个环境,让我更多地了解金融市场和经纪公司。我也通过投资股票市场开始交易。
在获得工程学位后,我完成了金融 MBA 课程,并发现了自己对理解金融技术层面的迷恋。
我在天普大学攻读金融工程硕士学位,在那里我了解了金融市场中衍生市场等新的分支。金融科技公司正在快速发展,我渴望从事金融工程方面的职业,所以我开始深入研究这些公司、各种交易策略和多种交易技术。
在探索的时候,我偶然发现了 EPAT 的课程,它是算法交易的专属课程,我发现它的模块和课程非常全面。因此,我联系了该团队,并在 EPAT 注册。
您对技术在金融中的作用的看法!
我已经交易了将近十年,我知道像投资、做比率分析、研究和阅读金融书籍和报纸这样的过程。今天,我可以说技术在金融中的作用是巨大的。现在投资衍生品市场更容易了。
编程语言被用来建立交易策略。以前我们用 C++,现在 Python 接手了,大部分行业都在用 Python 工作。很多创业公司已经开始在交易中采用机器学习和深度学习。
我目前正在研究机器学习和几个项目,探索机器学习在信用卡行业的实施以及使用 Python 进行欺诈检测。
你为什么选择 EPAT 学习算法交易?
在寻找专注于算法交易的课程时,我遇到了 EPAT。
虽然这是一个为期六个月的课程,但以下是使 EPAT 课程独一无二且值得学习的一些特点:
- Python 编程进行交易
- 在交易中学习和实现机器学习和 NLP 的机会
- 经验丰富的交易者和行业专家作为导师-提供指导,课程评估和一流的教学
- 精心设计的课程
- 就业机会——提供实习或工作机会,不管你在哪个国家
- 全球存在
- 他们与 GARP 的联系——一个进行金融风险管理的机构
- 实时在线课程
- 支持团队-快速解决任何类型的查询
- 一节课结束后,会进行一个解疑会来解答学生的疑问。这是教职员工自己的事。
总的来说,这是在 EPAT 的一次很好的学习经历,我肯定会推荐它。
你的下一步是什么?
目前,我在贝莱德工作,在学习 CFA 课程的同时,还在学习机器人过程自动化课程。此外,贝莱德赞助了该课程,因为我们正在与我在美国地区的团队合作,实现不同流程的自动化。
我的计划包括未来三四年在美国工作,可能会回到印度。我期待着建立我的交易平台,在算法交易领域建立我的创业公司。
你对所有有抱负的算法交易者有什么话要说?
多年来,我意识到人们想进入算法交易领域,他们正在积极寻找机会,比如工作或创业。但更多的时候,他们认为课程很难或者某些领域太专业。
我相信一旦你获得了一些关于课程的知识,并建立了完成课程的愿望,这个旅程会变得更容易。你也可以在 Quantra 上学习免费课程,并与导师交流。
这正是我所做的,这些年来我一直在学习新的课程。我发展了我的技能,这帮助我在算法交易中追求职业生涯。
感谢您分享这些关于您的旅程和您在广泛职业生涯中的学习的内在细节。你对学习和成长的热情会帮助你实现目标。我们祝愿你在未来的努力中一切顺利。
在我们看来,技术对交易世界有很大的影响。对任何有抱负的交易者来说,学习和发展技术是至关重要的。算法交易课程是为那些希望发展技能以追求交易世界中不断增长的机会的个人而建立的。
如果你也希望开始你的职业生涯,发展技能成为一名算法交易员,这个算法交易课程是你成功的关键。这门课程涵盖了统计学&计量经济学、金融计算&技术和机器学习等主题。通过 EPAT 项目,它可以帮助你在难以置信的指导下为职业生涯做准备。
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
从工程到算法交易——Sanjot 雄心勃勃的追求
原文:https://blog.quantinsti.com/engineering-algorithmic-trading-sanjot-ambition/
“知道是不够的;我们必须申请。愿意是不够的;我们必须这样做。”
——约翰·沃尔夫冈·冯·歌德
知识是一种强大的工具,只有当你运用它时,你才会真正理解它的真正力量。同样,无论是个人还是职业,都需要不断成长和前进。提升自己的学习技能就是这样一种媒介。
当开始从事算法交易时,一个工程师可能会疑惑,可能经常充满疑惑和无数的问题。但是那些被他们的野心驱使的人已经为自己赢得了名声。这些例外的少数之一是 Sanjot。
我们和 EPAT 大学的校友 Sanjot 进行了一次非正式的交谈,了解了他的故事,并揭示了一系列有趣的事实和故事,帮助我们理解成为一名 Algo 交易者需要什么。
以下是我们与 Sanjot 的对话:
你好,Sanjot,能介绍一下你自己吗?
大家好,我是桑乔特·雷巴格。交易是我的激情,我真的很喜欢它,我已经做了 10 年了。目前,我是一家知名国际金融服务公司的执行董事,在软件、投资和交易领域有 20 年的工作经验。我也是 Moksh Tech and Investment 的联合创始人。
关于我的教育,我已经完成了我的机械工程从阿姆拉瓦蒂大学,我还持有硕士文凭从 CDAC,孟买。我是一个主要在技术方面的狂热学习者。我也喜欢打板球,曾代表我的大学和公司打过。
你的工作简介令人印象深刻。你会如何叙述你的职业旅程?
我的职业生涯始于加入孟买的科技行业。我开始在 Netdecisions 从技术角度工作,主要是从开发角度。我先后在 Syntel 和 Cognizant 工作了 11 年。那段时间,我为多家客户工作——银行、投资银行、理财客户。我会为他们开发多个项目,从客户经纪业务到算法交易,再到后台和中台运营,等等。
正是在这段时间里,我接触到了算法交易。
你的交易经历是怎样的?
我的“交易生涯”始于 2007 年。除了我的职业生涯,我还使用图表技术进行平行交易。我对股票交易也很感兴趣。慢慢地,我开始用图表交易,并且稳步地从技术中获得成功。我只是从低频交易的角度来看算法交易。
从现在开始,我不打算从事高频交易。目前,我只做期权交易,这是我的强项。我只在俏皮银行工作,没有其他工作。一般来说,我不在股票上交易,我只在指数上工作,在这种情况下我得到了我的主要理解。
对于分析,我使用我的数据科学和软件背景来分析期权和股票。我用图表再次确认分析,然后手动检查交易。
到目前为止,我还没有把交易完全交给系统。现在我的算法交易风格只用于分析,不用于下单。
这些年来,你已经获得了很多技能,而且还会继续下去。你如何在算法交易中运用这些技巧?
2017 年 9 月,我创办了自己的算法交易公司——Moksh Tech and Investment。Moksh 还不是注册公司。只是朋友之间的公司。我们在管理一些密友的钱。我们开始使用机器学习、深度学习和人工智能来构建我们自己的股票软件,主要是期权软件。
我还开发了一个软件,传授我在算法交易、数据科学和软件开发方面的知识,受到了全球一些最大投资银行的关注。目前,我在一家最好的投资公司工作,帮助投资者做出正确的投资决定。
在 Moksh 期间,我向包括媒体公司在内的企业教授数据科学,也向金融领域的多批企业教授数据科学。
根据你的说法,技术在算法交易中的作用有多重要?
没有技术,世界上的大部分地区可能都离不开它。作为一名技术人员,我觉得仅仅了解领域是不行的,技术知识也很重要。但是独立地,两者都不会帮助你生存。你需要两者的结合。
Algo 交易现在正在接管全球,它被誉为交易的下一个阶段。是什么激起了你对算法交易的兴趣?
认识之后,我加入了德意志银行。那时我开始寻找一个学习算法交易的好机构,因为我已经有了编程背景和金融背景,我也对金融感兴趣。
因为我是用图表交易的,我花了很多时间在分析上,并且有技术背景,我意识到,因为我们已经有了很多数据,可能有无数的模式可以从这些数据中解读出来。我想,如果我能利用计算机以某种方式建立一个模式来理解幕后,使用数据。
手动交易也容易出现一些可能导致灾难的错误,与其花费大量时间或容易犯人为错误,不如完全避免这些错误。
当我开始学习更多关于数据科学的知识时,我意识到与其花太多时间手动分析,还不如研究算法交易,尤其是从自动化的角度。那是我第一次开始想到算法交易。
经过研究,我意识到我需要学习算法交易,从背景开始,因此我开始寻找一个可以帮助我的机构。进入 EPAT。这就是我遇到 QuantInsti 并加入 EPAT 的时候。由于我的工作和积极的工作,这个项目占用了我更多的时间。
你认为你的算法交易过程中的里程碑是什么?
我会把它们列为:
- 语言和技术:我总是使用 Python,因为很多金融库很容易获得;互联网上也有大量的文章和指南。
- 学习数据科学——我了解了数据的重要性。金融市场上有海量的数据,你只需要解读和分析它们。
- 学习——我很自豪也很高兴能从像 QuantInsti 这样著名的量化研究所学到东西。
你会对想从事算法交易的人说些什么?
这是一个全新的世界。你以前的经历在这个世界上并不重要。一个人需要提高技能才能成长。
一般来说,算法交易的关键,甚至是交易的关键,是耐心。
它总是需要大量的时间。它不是一个能立即产生影响的银弹——你写一个代码,它就会出现。
您的代码不必总是工作。需要进行大量的实验,而且这种实验不一定总是有效的。这就是人工智能和人工智能可以发挥作用的地方,因为它也可以从市场中学习。
理解数据、清理数据、从数据中学习、获取知识需要大量的时间,而且大多数时候可能会失败。耐心是成功的唯一关键。
谁激励或激励你继续前进?
以下是一直让我坚持下去的动力:
- 从技术的角度来看,我的一位来自 Cognizant 的老板(Aan S Chauhan 先生)一直是我不断学习的巨大灵感来源,他给我的生活带来了很大的变化。
- 第二,所有利用自己的知识进行交易的大交易者,他们的故事和旅程,比如尼古拉斯·塔勒布。
- 杰西·利弗莫尔关于交易的观点——更多的是从情感交易的角度。
Sanjot,我们理解您是一个大忙人,我们非常感谢您抽出时间与我们互动并分享您的故事-这有助于我们了解真实的您!我们希望你的故事也能成为其他人的灵感源泉。我们祝你一切顺利。
成功的旅程从来都不容易。这需要时间,就像桑乔特说的,耐心。你可以了解他作为个人、交易者和整个人是如何成长的。不断学习算法交易,不断成长。如果您需要任何指导,请联系我们,我们很乐意为您提供在该领域取得成功所需的必要技能和知识。让我们做你的向导。点击与我们联系。
免责声明:为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。
从工程到自动化交易——金梅的故事
Chinmay 相信,他将能够开发一个有利可图的系统,并能够自动执行基于价格的策略。作为一名 CFA 候选人和工程系学生,他在 EPAT 的就业小组的帮助下,在一家算法交易公司实习,从而实现了这一壮举。
通过 EPAT,Chinmay 能够学习算法交易的其他先进技术,并对 Python 有很好的掌握。他能够利用历史数据实施策略,并找到交易水平。
他期待在算法交易中设立自己的办公桌。我们联系了他,了解他进入 Algo 交易的历程。
嗨,Chinmay,告诉我们关于你自己的情况!
大家好,我是 Chinmay Patil 。我在孟买工作,今年 21 岁,是工程学的最后一年。目前在准备考 CFA。
我的兴趣是股票市场,我喜欢音乐,我喜欢弹吉他。我喜欢运动,尤其是足球,我也是一个健身爱好者。
你为什么选择学习算法交易?
我对这个领域感兴趣是因为我叔叔了解这个领域。疫情让我发现了算法交易。当封锁发生时,我回到了我的家乡,我有相当多的空闲时间。
在封锁期间,我叔叔使用了一种特殊的日间交易策略。他有了一个想法,让一切自动化。
他说服我研究它,我经常被他的问题困扰,帮助我更好地理解。
我们如何做到这一点?
你能做到吗?
你能做到吗?
能不能让这个过程自动化?
发布我的研究后,我开始了解回测、自动化、回测所需的数据等等。
这让我开始探索算法交易领域,最终,我找到了 QuantInsti。我了解到他们提供了一个很好的课程,EPAT,在这个课程中,他们教授技术和金融知识。
另请阅读: Raj 的旅程:将工程技术与金融相结合
你在 EPAT 的经历是怎样的?
EPAT 满足了我的期望。最初,由于是技术背景,有些主题对我来说似乎很难,然而,后来我逐渐熟练了。回溯测试教得很好,也很容易理解。
这是一次很棒的经历。因为 EPAT,我不仅了解了夏普比率等概念,还熟悉了回测等重要过程。我意识到,人工智能(AI)和机器学习(ML)在交易中有广阔的应用前景。我很好奇。
在 EPAT 之前,我曾上过另一门课,但它非常基础、入门,更多的是关于编码。
但当我浏览 EPAT 的课程时,它非常深入,非常广泛。各个模块的流程描绘了一个结构化的方法,对像我这样的学习者很有帮助。它涵盖了一切,从机器学习、期权、统计,甚至市场如何运作。这激起了我的兴趣,我选择了 EPAT。
我已经具备了技术知识,在 EPAT 的帮助下,我能够深入发展金融知识和技术技能。
EPAT 最好的部分是它在周末!
你最喜欢 EPAT 的什么特色?
我最喜欢 EPAT 的这些特色:
终身访问球场- 一旦成为 EPAT 的一部分,我们可以在未来的任何时间访问其内容。我经常用它来重温讲座、修改主题和学习更新的概念。几天前,我访问了这个网站,了解了统计学知识,并进行了简单的修改。如果教学大纲有变化,它也会在我的帐户中更新。
全球量化分析师社区- 有了 EPAT,我们成为全球量化分析师、交易员和算法交易专家社区的一员。
终身就业服务- 我很期待实习结束后的就业团队,以及 CFA。就业小组总是给我发电子邮件,询问各种工作机会。我会检查工作的标准和要求,然后努力提升自己的技能,发展自己不具备的技能。就业小组给了我指导,并给我提供了合适的寻找实习生的公司。到目前为止,这是一次非常好的经历。
你对想学习算法交易的学生有什么话要说?
我给算法交易爱好者的建议是——如果你想学习算法和量化交易,就去学吧。因为当我开始的时候,我这样做是因为我想帮助我叔叔完成他的项目。
但当我进入这个领域时,我发现它足够吸引人,足以让我把它作为自己的职业。
你永远不知道,除非你去探索。你可能会发现算法交易更有趣。
非常感谢你与我们分享你的经验,Chinmay。我们很高兴知道你在 EPAT 身上找到了你想要的东西。我们希望你实现完成 CFA 的梦想,我们期待着帮助你实现你的职业目标。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
挑战算法交易的现状| Gaurav 的成功故事
原文:https://blog.quantinsti.com/engineering-dairy-algorithmic-trading-epat-success-story-gaurav-thakur/
学习,追求,失败,重复,爬起来,再尝试,永不放弃,成功,超越,然后继续前进。这些也许是交易者应该具备的最好的品质。
然而,EPAT 大学的校友 Gaurav Thakur 在很小的时候就展示了这些照片。在他的工程教育和帮助他的家庭经营乳品生意之间摇摆不定,他经历了这一切。无论是成为企业家,不得不放弃,还是重新开始,实现他进入算法交易的愿望。
高拉夫的是一个值得一读的故事!我们与他联系,了解他的旅程,这是它是如何进行的。
嗨,Gaurav,你能给我们介绍一下你自己吗?

嗨!我是 Gaurav Thakur,来自马哈拉施特拉邦的 Vardha 区。我是一名量化交易者,最近注册了自己的 Algo 交易平台。大多数时候,我在做量化交易的同时也做零售交易,做研究,阅读和分析数据。
我喜欢健身,我是一名冥想和灵气治疗师。我也喜欢在空闲时间阅读和观看纪录片。疫情是一段艰难的时期。我利用大部分时间,追求 EPAT 和学习。
你会如何描述你进入算法交易世界的旅程?
我一直对汽车感兴趣,所以出于兴趣我选修了机械工程。但是,在两年的时间里,我意识到我想去的地方和方向在课程和教学大纲的覆盖下是不可能的。因为我没有学到任何东西,我对这个失去了兴趣。我在机械工程的最后一年退学了。
我的家人拥有一家乳制品企业,我经营了一段时间,然后我设计了自己的企业,构建了它,开始运营,并推出了 10 种新产品。
为了提高农民使用技术的意识,我设计了一个试点项目——一个高效的、全自动化的、同类中的第一个,跨功能的,我们地区的奶牛场。马哈拉施特拉邦的前农业部长是我的合作伙伴,他资助了 4 Cr。INR,并运行了一年,但由于管理问题不得不停止。
由于金融和交易总是让我着迷,我从乳品转向金融,我选择了交易作为我的全职工作。但由于我没有完成我的毕业和日记,我很少有信心和更多的金融背景,我的家人在不同类型的企业,但没有人在金融。
2019 年 3 月我进入了交易,我从零开始,开始学习写作,练习一切,花数周和数小时学习最基础的课程。
我完成了 NCFM 和 NISM 的课程,之后我接触了 algo 交易。我追求 EPAT。然后,成功地完成了那个。现在,我进入了量化交易的领域。
网上有很多免费资源。你为什么选择 EPAT?
我一直在网上阅读各种资源——免费的或付费的——我意识到了算法交易的力量。
EPAT 是印度唯一的课程,我完成了课程。我和一些已经是 CFA 并进入这个领域的朋友重新核对了一下。他们说,这是一个非常强大的课程,算法交易是未来,课程非常相关,非常面向应用。
我比较了 EPAT 的一些课程,但没有一个是如此全面的。QuantInsti 团队有交易员、行业从业者,他们有自己的交易公司,或者他们有自己的专有形式,所以知识是非常更新的,从当前的情况来看。
这是学习的最好方法。EPAT 最有说服力。我甚至检查了 CQF,但即使对初学者来说,这似乎也很复杂。所以,EPAT 是我的选择。
概念也更新了。为了在这个竞争激烈的世界生存,我需要更好的工具,更好的技能。因为我进入了我的学习曲线,我没有停止它。我坚持学习了 2.5 年,只为了进入交易行业。完成基础课程后,我直接搬到了 EPAT。
EPAT 是一个游戏改变者,它相当全面,它打开了许多大门,给了我最终坚持下去的信心。EPAT 是唯一全面而多样的课程。基础工作完成后,我必须专注于新技术,如编码、统计、ML、AI 等。
你对算法交易的概念完全陌生。EPAT 是如何帮助你的?
我想以这种方式来解决这个问题:
方法
- 在 EPAT 之前,我有一个常规的方法。
- EPAT 之后:我发展了一种科学的方法,变得注重逻辑和精确。
信心
- 在 EPAT 之前:我的自信程度很低,在学校面前感觉自己很渺小。
- 在 EPAT 之后:我更有信心,我能生存下来。我还不能像专业人士那样竞争,但是我有这些技能,我可以成为一个更好的交易者,并且比现在处于一个更好的位置。
精确
- 在 EPAT 之前:我的方法很随意,犯了很多错误。
- EPAT 事件后:我的方法训练有素,非常严格,所以我的损失得到了控制,生存也更有保障。
见解和信息
- 在 EPAT 之前:散户的大部分信息都是隐藏的,你无法接触到。
——订阅和获取数据需要巨大的成本,所以你负担不起。
-由于缺乏经验,你无法从极少的信息中发展出你伟大的哲学。所以,这就是竞争,可以超越你的地方。 - EPAT 之后:我可以在更短的时间内获得更多的见解!老实说,因为数据说明了很多问题,但我从来不知道如何解码它。
——技术分析,我曾经用过很多——我做过高级技术分析——它曾经帮过我很多。
-但当我学习这种数据分析时,它变得像是双重验证,是的,当我接近它时,逻辑在支持它。这个可以量化。这给了我更多的信心。
——因此,我的研究质量和搜索速度都提高了很多。在那之前。就像图表一样。
-所以,我有两种方法来优化和设计我的交易,这对我帮助很大。
弱点
- 在 EPAT 之前:作为一名普通交易者,我非常容易受到日常交易市场的影响。
——当市场上涨 1%或 1.5%时,我不知道为什么会这样。交易世界发生了什么新的变化?所以即使我习惯了理论上的概念,我也不习惯这样。
-我的感觉,我的情绪还没有准备好接受大蜡烛。这会让我紧张。我会停下来。交易后有很多反省自己概念不清晰。我能做些什么来更好地交易? - EPAT 之后: EPAT 向我介绍了回溯测试。
——这帮助我把我的概念和逻辑扔在我见过许多大大小小蜡烛的多个场景中。
-我现在可以看到数据了,所以我做了充分的准备。这让我更擅长风险管理。随着我的风险管理的改善,我的损失在 1 至 1.5 年内恢复,我的提款不超过 20%。
——那时我终于想到“是的!现在,我可以生存,现在我可以维持。”第一件事是不要赔钱,我成功地做到了。
这是 EPAT 学习时开始数数的地方。
对于交易来说,选股的过程,就像我以前做的图表一样,分析,摆动和止损,但是每个止损都有特定的性质。这更有助于我解码,我可以和股票对话。
因为它是时间序列数据,我会确定主要的股票组合,并相应地设置我的交易组合。
你最喜欢的 EPAT 特色之一!
EPAT 大学的教员非常好,我的支持经理 Siddhesh Kulkarni 也很棒!如果不是他,我可能会中途放弃,因为课程越来越难了。
EPAT 支持团队非常好。师资力量很优秀!
Rajib Borah,Vivek Krishnamoorthy(他写的关于 Python 的书),Ishan Shah,Nitesh Khandelwal——每个教员都非常非常好。他们让复杂的概念变得非常简单,便于我们从机器学习的人工智能中理解。我不敢相信这是我的第一年,我可以如此清晰地理解这个概念。
以前我在网上上过课程。从设计、解释和完成后的支持来看,这要好得多,甚至直到今天,校友支持的形式就像在帮助我们一样,安置团队已经连续给我邮寄了 4 到 45 个安置机会。
你所说的,承诺的,交付的,一切都太棒了!而且你的内容也不错,不断更新。
EPAT 的荣誉属于全体教员、核心结构、基础支持团队、作业、持续评估过程等等。
我会给 EPAT 打五分之五的分数,因为它什么都不缺!
你对那些想成为量化分析师的人有什么话要说?
如果你希望持续下去,那就去适应。
如果你希望适应,那么你应该和 EPAT 一起去。
这个领域完全是关于适应和改变。我在两年半的学习中明白了这一点,市场中唯一永恒的东西就是变化和波动。而如果你想不断更新自己,你需要一个高技能集,更好的技能集,更好的工具,适应生存是强制性的,尤其是在这个部门。
通过像 EPAT 这样的课程来适应和学习——强烈推荐!也可以参考 Quantra 的课程。现在,任何人,任何初学者,只要愿意花上几个小时,用这样的课程和工具进入这个领域并坚持下去,都是可能的。
万事如意!
非常感谢你分享你的话,高拉夫。知道你的成功故事真的很鼓舞人心。理解你对目标的坚持和追求给了我们快乐。我希望你继续做这项了不起的工作。不断学习,不断成长越来越多。
如果你也想用终生的技能来武装自己,这将永远帮助你提升你的交易策略。这门 algo 交易课程的主题包括统计学和计量经济学、金融计算和技术、机器学习,确保你精通在交易领域取得成功所需的每一项技能。现在就报名 EPAT 吧!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
工程、金融,现在是算法交易——这位首席财务官无所不为
原文:https://blog.quantinsti.com/engineering-finance-algo-trading-cfo-story-ruben/
像 EPAT 校友鲁文·马丁内斯·范纳斯这样的算法交易爱好者并不多。他是一名工程师,硕士持有人和中美洲可再生能源投资组合的首席财务官,拥有十多年的经验。Rubén 从销售和客户管理开始,然后在可再生能源领域站稳了脚跟。
学习是让他坚持下去的东西,你可以从他的许多执照和证书中找到这一点。在新冠肺炎封锁期间,我们联系了鲁本,分享了他的旅程。我们的讨论是这样进行的。
嗨,鲁本,给我们介绍一下你自己
嗨!我是鲁文·马丁内斯的粉丝。我是一名西班牙人,在一家私募股权基金担任首席财务官,住在巴拿马的巴拿马城。我现在和我的家人在一起,但最重要的是,我现在很健康。在目前冠状病毒的情况下是可持续的。

我是一个充满好奇和热情的人,每天都在挤出时间学习新技能,努力变得更好。我喜欢阅读,喜欢和儿子在一起。
我拥有工程学硕士学位,还额外学习了金融学,以及算法交易管理课程(EPAT)等等。我的可再生能源硕士学位让我在能源领域的职业生涯得以发展。
销售、产品营销、财务——你一直在专业上不断成长,直到现在担任首席财务官&投资经理。
你的职业生涯是怎样的?
在可再生能源领域拥有超过 12 年的丰富经验,这是一段令人惊叹的旅程。我曾在 4 个不同的国家担任过 3 个主要职位:财务和投资管理、产品管理和营销,以及销售和客户管理。
2006 年,我从西班牙来到德国,开始为一家机械工程公司工作。我开始阅读关于外汇、技术分析和交易方面的书籍,但没有什么帮助。当时,我不知道有任何与量化金融或算法交易相关的机构。我也做了一些投资,但显然出了问题,所以我暂时搁置了那块地。
2008 年,我回到西班牙,开始在一家风力涡轮机制造商做销售工程师。市场崩盘刚刚发生;那是一段相当坎坷的时期。
2010 -我从销售岗位转到了风力涡轮机部门的产品营销岗位。这是我接触 it 财务方面的时候,即商业案例、财务模型、投资、股权、股权回报等。我有点喜欢这样。
2012 年 -我看到一些网页,上面建议人们如何成为量化交易者。我意识到,没有支持、毅力和自律,这是不可持续的。
2013——我发现了 MOOCs 我开始在业余时间学习金融方面的课程。
2015 年——我和家人从西班牙搬到纽约,开始为一家私募股权基金工作,该基金在拉丁美洲投资可再生能源。我从高级助理做起,责任稳步增长。我开始更加关注太阳能。
几年过去了,现在我负责对中美洲的投资组合进行富有挑战性但又令人兴奋的财务管理。
我的交易经验并不丰富。我开始像其他数百万人一样进行技术分析,盯着图表看,但这对我不起作用,所以我开始了算法交易。
我仍在进步,我很高兴由于冠状病毒的情况,我没有认真地开始。现在,市场在拖我的后腿。我会一步一步慢慢来,先建立我的基础,然后再在基础上发展。
你为什么选择和 EPAT 一起学习算法交易?
不久前,在彭博,我读到一个使用编程语言应用算法交易技术的算法基金,这引起了我的注意。
在我看来,Python 是开始这段旅程的第一件事。我明白 Python 是算法交易的基石,所以我开始学习 Python。我在密歇根大学上了一些关于 Python 的在线课程。
经过几门课程和几个小时的学习,我对自己的学习不满意了。一天,在调查时,我看到了 QuantInsti 的广告,引起了我的注意。我开始了解它,并下载了小册子。我联系了一位 EPAT 大学的校友,了解他对 EPAT 的看法。贴出那个,我决定报名。我会说那是我算法交易之旅的开始。
对我来说,EPAT 就像是打开了这个广阔领域的一扇门。在注册之前,我认为经过 6 个月的培训和学习,我将准备好开始我的 Algo 交易台。我会开始应用我的算法,但在我的情况下,这不是真的。
我觉得这 6 个月是开始浏览这个世界的浩瀚。这是很好的准备,让你知道在你希望追求的方向下一步是什么。
我意识到,我必须将学到的东西分段,才能迈出第一步。由于下班后我没有太多的时间,我决定一次只采取很少的步骤。所以,现在我不认为自己已经准备好每天或短期交易了。更不用说高频交易了,这已经超出了我的范围。
我决定慢慢来,以避免沮丧并获得好的结果。我为自己设定的目标是从投资组合中的基本被动投资开始。
我正在建立一个 ETF 投资组合,试图尽可能降低波动性。然后我会把它们结合起来,创造出完美的前沿投资组合。最大可能的回报和最小可能的波动。由于它不需要太多的监督,我在业余时间建造它,我希望很快开始投资。一旦我对此感到满意,我将继续下一步的工作——比如增加频率,开发算法等等。
在未来,我将不得不进化,变得更加老练。但就目前而言,我在练习被动投资组合,因为这最适合我。建立一个稳定的投资组合不需要太多的关注,但它们会随着时间的推移缓慢而稳定地增长。
你最喜欢 EPAT 的哪个特色?
我很高兴我决定去 EPAT 注册。在 EPAT 的学习是非常全面的,它建立得非常好,非常全面。
我很欣赏实际的课程,在这些课程中,我们应用了我们所学的一些策略,例如,擅长策略以获得一个好的画面;还有 Python 的课程。课程学习材料、获得的知识和技能肯定会在不久的将来得到应用。如果你对 EPAT 感兴趣,就去吧。
这是打开这个世界大门的旅程的开始。你必须花更多的时间做研究,练习,磨练你的技能。强烈推荐给有动力有时间的人。
你对有抱负的算法交易者有什么话要说吗?
这个旅程需要动力和激情。如果你这么做只是为了钱,或者如果你在看这个世界上的财富,不要去追求它,因为那样你会失望的。
这很耗时,而且你必须充满激情。你一定喜欢创造算法、做研究、监管市场等等。你必须在这个旅程中找到快乐。
感谢您与我们分享您的完整旅程,Rubén。我们很高兴得知您的进步,并祝您在职业生涯和交易能力方面一切顺利。
你对 EPAT 的溢美之词让我们受宠若惊,这鼓励我们更加努力地为有志于交易 Algo 的人服务。
EPAT 确保你精通在交易领域取得成功所需的每一项技能。它涵盖了统计学和计量经济学,金融计算和技术,机器学习等主题。用终身技能武装自己,这将永远帮助你提升你的交易策略。在此查询。
免责声明:为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。
工程学、MBA、CFA 以及现在的 EPAT -巴拉穆鲁甘之旅
原文:https://blog.quantinsti.com/engineering-mba-cfa-epat-balamurugan/
在算法交易中,我们说不要让情绪战胜你。EPATian Balamurugan G .实际上在专业上实现了这一点,并试图在他的个人生活中也实现这一点。当涉及到工作而不仅仅是交易的时候,这确实很重要,因为所有这些纪律最终会对你的生活产生连锁反应。
巴拉已经完成了 CFA 考试,获得了 MBA 学位,并完成了 EPAT 课程。他迅速成长为一名交易员,并在多家公司担任过不同的角色——这是人们梦寐以求的工作之旅。
他曾与美国银行、法国巴黎银行、CRISIL 和威瑞森等知名公司合作,如今他已在量化金融领域站稳了脚跟。我们向你展示他的成功故事。
我们的对话是这样进行的:
向我们介绍一下你自己吧!
你好,我是巴拉穆鲁甘·加内桑。我是一名产品专业人士,拥有 9 年左右的业务分析师/产品经理经验,在金融科技和 CRM 领域的产品建设方面有着良好的记录。我也有 2 年的开发经验。

我非常热爱这个领域。我认为这更多的是关于主题。我真的很有兴趣学习算法交易,这也是我进入这个行业的原因。我对 Python、交易和机器学习概念有浓厚的兴趣。
当我开始交易时,我读了很多书。我读过很多书,比如《股票操作者回忆录》、《市场奇才》、亚历山大·埃尔德的《以交易为生》,还有马克·道格拉斯的《区域交易》等心理学书籍。
我在 NIT Calicut 完成了我的工程设计。之后我加入了威瑞森,做了几年的软件开发员。有了几年工作经验后,我参加了 CAT 考试,考上了 SP Jain,攻读 MBA。
由于我非常擅长数学,熟悉 Excel,并且有编程背景,我对数字运算和学习一些有挑战性的东西很有信心。因此,我选择了投资银行专业,这被认为是最难的分支。这就是我对股票市场感兴趣的地方,我发现它真的很迷人。
为了提高自己的知识,我决定攻读这个领域最渴望的认证——CFA(特许金融分析师),并在 2014 年成功完成了所有 3 个级别。
读完 MBA 后,我在不同的公司担任过不同的角色,比如产品经理/业务分析师,我们为金融科技行业开发产品。在法国巴黎银行,我负责 APAC 地区上市衍生产品的开发。
在 CRISIL,我是组织内部培养的产品管理团队的一员,努力将 CRISIL 在金融研究领域的深厚专业知识具体化。我们作为客户与全球研究公司和研究分析师合作,并推出产品来解决他们的潜在需求和棘手问题。该产品致力于提高研究分析师在构建金融模型、发布研究报告、新闻分析和数据分析方面的效率和生产力。
你学习成为职业交易者的过程是怎样的?
在我的第一份工作中,我是一名软件开发人员,没有接触过股票市场。今天,我已经在股票、期货和期权市场交易了大约 7 年。
大约在 2012 年,我做了很多自主交易,根据新闻和人们谈论的话题来买卖股票。同时我也开始投资期权,并因此损失了很多钱。我还记得在收益日的前一天卖出了一份印孚瑟斯的裸看涨期权。
第二天,当市场开盘公布结果时,我看到了 3 万多英镑的损失。一开始我运气不错,后来损失惨重,过了一段时间就停止了自由交易。
2017 年,我再次开始交易,但这一次我更系统地进行交易,采用适当的头寸规模,定义明确的风险参数,并且只使用经过回溯测试的系统。
最初,有几个例子,每当回测系统出现亏损,不遵守规则并犯一些错误时,我会想在回测系统上即兴发挥。然后,一旦我理解了大数定律,我变得更加系统化,这帮助我消除了情感因素。
当我看到 EPAT 的课程时,我认为算法交易需要多方面的技能,完全符合我的要求。在 EPAT 期间,我遇到了一些令人惊奇的老师。它帮助我对定量金融和高频交易中的各种现实实施技术有了深入的了解。
我还为我在 EPAT 的项目工作开发了一个深度学习神经网络模型,用来预测银行漂亮的日内价格,并自动完成了我的一些日内交易策略。这确实节省了时间,避免了大量的屏幕时间。
那么你主要交易什么?
早些时候,我经常在不同的交易策略之间切换,从来没有坚持某个特定风格的信念。经过多次尝试和失败,我终于找到了自己的优势,并坚持了一些策略。
我只在 NSE 看成交量不错的 F&O 股票。
- 在一个系统中,我寻找当天最活跃的股票,根据其他标准,我建立了一些头寸。
- 在另一个系统中,我根据过去几天的交易范围来检查波动性是否扩大。
- 我有一个反转预测系统,在这个系统中,我持有期权头寸,这有助于根据我的观点定义风险。
- 我还有一个系统,我只在周四交易到期的银行漂亮期权。
我之前也尝试过大宗商品和外汇,但实际上很难持续赚钱,最终我失去了兴趣。现在我只交易股票和期权。我已经找到了我的最佳点,并开始坚持下去。
我还发现很难进行头皮交易,你可以在几分钟左右的时间内进出。我有点担心,因为在头皮交易中,你实际上必须增加仓位,才能在更短的时间内获得丰厚的利润。但这对我没用。这种交易需要很多谨慎,不适合我的情况
为了克服我们在生活和交易中面临的心理障碍,我定期冥想以保持冷静。这在交易中对我帮助很大,让我更加坚持遵守规则。
你已经完成了很多个人资料。在目前的职位上,你做哪些事情,这些事情与交易有关吗?
实际上一点也不。我做过这么多角色的原因是我一直在寻找和寻找真正适合我的角色。
我觉得不知何故有一个差距,我没有满足感。因此,一旦你进入业务分析师的角色,你就不用做任何编程,更多的是关于业务理解,与客户利益相关者交谈,确保正确收集需求,按时交付产品,以及更多的面向客户的角色。我没有运用我的数学或编程技能。
我目前在美国银行的财务控制团队工作,开发全球监管产品。作为世界上最大的金融机构之一,我们在不同的地区与许多监管机构打交道,应该遵守这些机构的规定。
为此,我们的团队负责构建和维护全球应用程序。
你说过你喜欢数学和编程等。当你为了交易而做的时候有多刺激?
数学和编程在系统交易中帮助很大。
我们可以使用统计模型来识别均值回归和趋势股票,这有助于制定您的交易策略假设。
编程有助于我们自动化大部分手工任务。我们可以运行一段代码,在几秒钟内自动给出相同的结果集,而不是手动查看 150 只股票的图表,这可能需要几个小时。
随着机器学习的出现,我们甚至可以识别数据集中的非线性关系,这对于人眼来说不是很明显。这是我目前正在探索的。所有这些技术对交易来说都很方便,节省了我们很多时间。
每个程序员都有自己喜欢的语言。哪个是你的?
我的是 Python 。我使用 Python 已经有两年了,这是一次非常好的经历。
- 它在自动化我的许多日常任务方面帮助了我很多
- 它非常容易学习,并且有很好的在线支持
- 它有一套很好的与机器/深度学习相关的库,可以减少您的编程工作量
- 大多数经纪人提供 Python API 来自动化你的交易
所以在你现有的支持下,我发现 Python 非常有用。
你对 CFA 和 EPAT 有什么看法?
如果你在交易方面有实际的专业知识,想让你的策略自动化,并有一些 Python 的基础知识,那么最好选择 EPAT。EPAT 的另一个优势是,你可以在 6 个月内完成课程,并理解算法交易中的大多数实际细微差别。
如果你想成为一名金融分析师,并喜欢对股票进行更多的研究,创建金融模型和发布股票研究报告,CFA 将是一个更好的选择。它有三个层次,你必须花几乎三年的时间来完成它们。最快你可以在 18 个月内完成,但那会非常忙乱。
如果有人已经考过 CFA,他们想进入算法交易,他们应该走什么样的道路?
如果他们已经考过 CFA,并且有 1 到 2 年的交易经验,那么参加 EPAT 是最理想的,它涵盖了交易的实际方面,并有助于自动化他们的策略。特别是 EPAT 的可选项目工作将会给算法交易的世界带来很多实际的见解。
你在 EPAT 的学习经历是怎样的?
课程内容很好,也很实用。尤其是像欧内斯特·P·陈博士、伊夫·希尔皮施博士、尤安·辛克莱博士和刘辉博士这样的教师的课程非常出色。
此外,我得到的支持真的很棒,非常专业和友好,我不需要犹豫,认为这太天真了..在我所学的其他课程中,我从未见过这样的支持。每当我有一个与主题或项目工作相关的问题,我总是在一天内得到答复。
你对未来有什么计划?
我想花更多的时间学习人工智能和机器学习及其在金融中的应用。我只是想做一年的兼职项目,这样我就可以在这个领域建立自己。
目前,我正在探索其他深度学习技术,如 fastai 和强化学习,并试图将它们应用于金融数据。
你对想从事算法交易的人有什么要说的吗?
花几年时间交易,这样你就能真正理解实际的细微差别和与交易相关的心理学方面。这里的目标应该是首先关注风险,将损失最小化,而不要过于担心利润。
如果一个人真的对编程感兴趣,对交易充满热情,那么做 EPAT 是有意义的。最重要的是把情感部分完全从交易中剔除。
因此,EPAT 实际上有助于自动化执行部分,你不会看着你的屏幕,不时检查你的 P&L。这可能会导致一些随意的判断和情绪化的行动。
非常感谢你的时间,巴拉。和你谈话是一次愉快的经历。你对算法交易有热情,你学会了,这就是你如何遵循它。很高兴知道你在兼职交易中运用了在 EPAT 学到的所有知识。
EPAT 是一门综合课程,涵盖的主题从统计学和计量经济学到金融计算和技术,包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti 的 EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT方案完成后取得的成果对所有个人而言可能不一致。T15】
整体方法——装袋和增压
原文:https://blog.quantinsti.com/ensemble-methods-bagging-boosting/
由马里奥·皮萨·培尼亚和 T2 主持
在这篇 帖子 中,我们已经简单地看到了什么是决策树,以及如何为分类和回归问题构建决策树。我们还看到,它们对于进行定性或定量预测非常有用,而且构建它们并没有太大的困难。
但是,有必要了解决策树通常存在的问题,因为算法构建决策树的贪婪方法并不总是提供最佳输出,预测的精度和稳健性也不像我们希望的那样稳定。
通常,决策树有以下已知问题:
- 噪音
- 欠拟合(偏差)
- 过度拟合(方差)
在本帖中,我们将重点关注 Bagging 和 Boosting,以分别并行和顺序地构建决策树,并集成输出以提高预测精度和减少方差。
什么是装袋?
Bagging ,也称为 bootstrapping,是一种减少预测方差的集成方法。
Bagging 算法与 N 个随机生成的数据集并行构建 N 棵树,并替换以训练模型,最终结果是在树上获得的所有结果的平均值(对于回归树)或最高评级(对于分类树)。
因此,打包或自举算法执行的步骤很简单:
- 用训练数据集的替换生成 N 个随机数据集。
- 并行拟合每个随机训练数据集的 N 个预测值,每棵树一组。
- 对回归树的结果进行平均,或者对分类树进行最多投票。
我们必须考虑到,这种方法并不总是改进我们的决策树的最佳算法,因为它只适用于当我们有一个复杂的树,它的预测显示出很大的差异。
我们使用 sklearn.ensemble 库中的函数 BaggingRegressor 和 BaggingClassifier 来实现 bagging 算法。
用 Python 构建决策树
让我们记住用 Python 构建决策树的主要步骤:
- 检索和整理金融工具的市场数据。
- 引入预测变量(即技术指标、情绪指标、广度指标等)。)
- 设置目标变量或所需输出。
- 在训练数据和测试数据之间拆分数据。
- 生成训练模型的决策树。
- 测试和分析模型。
你可以参考这篇博客来了解更多关于如何构建决策树、决策树分类器等等。
用 Bagging 增强决策树
我们几乎可以重用上面提到的关于决策树的所有步骤。虽然当我们到达第五步时,我们必须用 Bagging 算法替换它。
增压
与并行集成技术 bagging 不同,boosting 按顺序工作。它的目的是通过顺序改进先前的分类,将弱学习者转换为强学习者,从而随着我们的前进将偏差误差最小化。
增压是如何工作的?
最初,通过从训练数据集中随机选择数据集,Boosting 开始类似于 bagging。它使用这些特征创建分类模型,并在现有的“训练数据集”上测试该模型。
训练数据集中的一些数据点被正确分类。现在,为了构建下一个随机数据集,在前一个数据集中被错误分类的实例或数据点将被给予更高的优先级,这仅仅意味着这些实例或数据点将具有在下一个数据集中被选择的更高可能性。
通过这种方式,boosting 使用从先前选择的实例中获得的数据来顺序构建 N 个随机数据集。
升压算法的类型
-
AdaBoost
自适应增强技术迭代地工作,以改进在某一阶段发生的分类。它使用决策树桩。
什么是决策树桩?
决策树桩基本上是基于单个特征做出决策的一级决策树。
决策树桩用于对数据点进行分类,并通过增加误分类数据点的优先级来迭代改进。不同的决策树桩也可以组合起来,以创建一个更好的决策树桩,这将确保数据没有任何错误。
我们可以使用 sklearn.ensemble 库中的 AdaBoostRegressor 和 AdaBoostClassifier 来实现 AdaBoost 算法。
-
Gradient propulsion
就像 AdaBoost 专注于最小化错误分类的点一样,梯度提升专注于最小化模型内的损失函数。
一旦为特定模型定义了损失函数,就使用梯度提升来最小化该函数的值,从而通过修改与数据点相关联的权重来最小化构建另一棵树时的误差。
通过使用库 sklearn.ensemble,GradientBoostingRegressor 和 GradientBoostingClassifier 可用于在 Python 中实现此方法。
-
XGBoostT3】
XGBoost 或极端梯度增强模型是梯度增强的一种实现。这是一个可用于实现梯度推进算法的库。
你可以在 R 这里详细阅读并学习如何实现。
结论
In the fabulous world of ML, this enhancement method for our decision trees helps us to reduce the variance and increase the accuracy but it is necessary to know when to apply it because if our decision trees have other problems it will be more convenient to know and apply other serial or parallel enhancement methods.
在本课程中,您可以了解更多关于决策树和集成方法在 Python 中的实现。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。T3】
一个企业家的算法交易之旅
原文:https://blog.quantinsti.com/entrepreneur-algo-trader-narciso/
如果我们告诉你,我们将要分享一个企业家的故事,他只是想学习如何更好地交易,但最终在 EPAT 考试中名列前茅?难以置信?嗯,是真的。
他是一个走在消耗知识的道路上的人,以满足他越来越强烈的求知欲。我们联系了这位成功的创新者、企业家和自豪的算法交易者——EPAT 大学的校友,纳西索·佩雷兹。
下面是我们与他的讨论:
你好纳西索。你能给我们介绍一下你自己吗?
嗨!我是纳西索·佩雷斯,住在阿根廷。我对人类整体发展、创新和技术充满热情。我有一家小公司“TrioIngenieria ”,专门为汽车行业制作软件,所以我编写 PLC、PC 和 S.c.a.d.a .系统的程序。
- 我已经自动化了几台重要的机器和装配线,有些甚至已经自动化了。全在汽车行业。
- 我在另一个市场的另一个项目是逆向设计一个电子医疗机器,通过电刺激进行淋巴引流。
- 我还发明并出售了一台自动洗啤酒桶的机器。
尽管如此,我在经济和职业上并没有像我希望的那样发展。这促使我进入并学习交易。
我是一名系统工程师。中学毕业后,我成了一名电子技师,后来从事工程设计。当我完成工程学时,我专攻人工智能。
2007 年-我在航空大学学院学习了系统嵌入式硕士课程
2011 年,我在萨拉曼卡大学攻读创新与发展企业家硕士学位。它对我评估新的创业机会、个人特征、专业技能、环境以及一个创业者的所有谬误都有很大帮助。它只是缺少提出我的论文。
2011 年末——我签约成为一名自由职业者,开始为需要大量努力的汽车行业工作,主要处理坏账、高税收和巨大的经济贬值。
我是一名中等技术学校和技术学院的教师,在那里我教计算机网络,统计学,编程语言和数据库。
我婚姻幸福,有两个孩子,弗朗西斯科 16 岁,瓦伦蒂娜 13 岁。
我的狗是一个重要的家庭成员。我喜欢定期锻炼,也喜欢学习。我想帮助其他人实现他们的目标和幸福。
我有一份很好的工作,是在电力公司,我自愿退休,但这不是理想的工作,我想学习工程。今天,考虑到我国的经济形势不好,我出于需要成为了一名企业家。为此,我认为算法交易是一个很好的选择。
你能和我们分享一下你的算法交易之旅吗?
算法交易——这是一个我不知道的职业。我用 MetaTrader 模拟账户开始交易,从那以后我一直在交易。我觉得我的风格是黄牛。
我从来不知道我可以利用我喜欢的主题的知识,比如编程、机器学习、金融、经济等等。培养分析和解决问题的能力和技巧。我在谷歌上搜索关于企业家精神的交易信息时,偶然发现了 EPAT 的课程。
现在很多题目我都懂了,也在学。在 EPAT 之后,我现在有了一个真正的账户,里面有 30 美元的礼物。怎么会?我从 1 月 20 日开始,做了 39 次阳性手术,夏普指数为 2.07,零阴性。我知道有些人可能会觉得这很好笑,但我过去和现在都非常投入。
我希望学习更多,理解更多。我很想教算法和量化交易!
我非常自豪能成为 QuantInsti 会员,并下定决心成为推荐人,追随自己的激情生活。我在 EPAT 的时光是一段美好的经历,现在依然如此。其实我还在学习更多,学习机器学习。我想通过 QuantInsti 的职业介绍所找到一份工作。
你的下一步是什么?
我现在正朝着用真实账户交易的方向前进,用更多的资本和投资,我希望能赚到一些利润。我希望成为一名优秀的算法交易者,并把它作为我的生活方式。
你最喜欢 EPAT 的哪个特色?
卓越,对卓越的热爱。
但我也相信,QuantInsti 对你所做的事情非常诚实,因此 QuantInsti 做得非常好。
课程刚开始的时候,我觉得自己学不完,QuantInsti 的 Afrin 和 Dionne 激励了我,对我帮助很大。然后我放松下来,穿上我最好的衣服。我在 EPAT 考试中获得了第二名!
我想向获得第一名的 Balamurugan Ganesan 和获得第三名的 Krunal Vyas 致以问候和祝贺。整个过程中我们都和他们在一起守护着冰山。
你有什么想对有抱负的量化分析师说的吗?
“如果你认为你能做一件事,或者你认为你不能做一件事,你是对的。”
——亨利·福特
努力实现你的愿望。投入你的努力,全心全意。如果你认为你不能实现你想要的,你将永远不会实现它。这都是你的想法。
谢谢你抽出时间接受采访,纳西索。我们真的很感激。感谢你对 QuantInsti 和 EPAT 的赞誉。我们祝愿你在算法交易中取得最好的成长。
在追求提升算法交易知识的过程中,你需要具备必要的知识和技能。我们的算法交易(EPAT) 高管课程是一门综合性课程,帮助您实现学习目标。它涵盖的主题从统计学&计量经济学到金融计算&技术,包括机器学习等等。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti 的 EPAT 项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT方案完成后取得的成果对所有个人而言可能不一致。T15】
平衡企业家精神、学习和算法交易——奥古斯丁的旅程
原文:https://blog.quantinsti.com/entrepreneur-algo-trading-journey-agustin/
学习是一个持续的过程,让你保持警觉,帮助你实现和成长。如果你建立了自己的金融科技组织,这种情况会停止吗?
当你有了 12 年的交易经验后,它会停止吗?
奥古斯汀的故事反映了这些情况,并优雅地回答了它们。奥古斯汀是 EPAT 大学的校友,是一名企业家,也是一名连续学习者。我们通过一次聊天采访了他,了解了他的故事和他进入算法交易的历程。
讨论是这样进行的。
嗨,奥古斯汀,给我们介绍一下你自己
我是奥古斯汀·拉梅洛·德拉维加,目前住在阿根廷的科尔多瓦。我是 Invera 的首席执行官和联合创始人,Invera 是一家金融科技公司,为金融机构提供机器人咨询,以实现投资自动化。

作为一名企业家,我热爱我的工作,但除了工作,我也喜欢学习新技能(现在我正在学习数据科学)。我于 2013 年获得了国立科尔多瓦大学的经济学学士学位,并于 2015 年获得了 Torcuato Di Tella 大学的金融学硕士学位。
我在 2019 年创立 Invera 后加入 QuantInsti,因为我意识到有必要获得一种围绕算法交易获取编码技能的系统方法。2020 年,我参加了为期一年的数据科学课程。
你在不同领域担任过无数角色,拥有 12 年的丰富经验,并且拥有自己的公司。算法交易是如何走进你的生活的?
作为一名经济学家和金融硕士,我对投资有着丰富的理论知识,但要把这些知识应用到算法中,还有很长的路要走。与开发人员一起工作时,我喜欢对系统核心所发生的一切有第一手的了解。这就是为什么要设置适当的标准,我决定得到所需的技能。
我个人从 19 岁开始投资。我来自一个没有金融包容性的前沿市场。因此,我一直认为这是一项个人使命,以简单的方式帮助人们投资于资本市场。这就是因维拉诞生的原因。
Invera 将大部分投资过程自动化,允许机构在向客户提供投资服务时创造规模经济。这反过来又大大降低了初始投资的资本要求。
我想改进来自现代投资组合理论的订单的执行,特别是在像阿根廷这样交易量很低的市场。那时我遇到了算法交易。EPAT 是我的朋友马可·迪博推荐给我的。
你把你的成功归因于学习。为什么?
为了应对每天可能出现的新挑战,学习能力至关重要。当谈到编码时,有很多信息,但如果你需要一个系统,以一种逻辑和可伸缩的方式把它们放在一起,这就是 EPAT 为我做的。
EPAT 是一个开发编码、交易和策略技能的很好的实践项目。从欧内斯特·陈博士、伊夫·希尔皮希和其他杰出人士那里了解到这一点,我感到非常激动。
我也钦佩分享他们观点和知识的以巴提人团体。它为课程增添了巨大的价值。
你最喜欢 EPAT 的什么特征?
我认为 EPAT 最好的部分是当你开始测试你的第一个策略的时候。就在那时,你意识到你在理论上所做的一切,也许还有 Excel,都可以通过几行巧妙的代码实现,并且可以根据需要进行扩展。
你会给那些有抱负的算法交易者什么信息?
在金融机构的金融科技部门工作让我意识到,科技正以前所未有的方式增强人力资本。因此,在技术方面跟不上行业发展会降低你的收益,直到你投资一个指数会更好。
感谢你抽出时间和我们分享你的故事,奥古斯汀。看到你对学习和建立技能的接受程度是非常令人鼓舞的。这是一种罕见的品质。
恭喜因维拉!我们祝你在未来的旅途中一切顺利。
在寻求学习算法交易的过程中,你需要正确的知识和必要的技能,算法交易(EPAT ) 中的执行程序,帮助你实现你的学习目标。EPAT 是一门综合性课程,涵盖了广泛的主题。
免责声明:为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。
成为算法交易员的企业家——Rohit 的旅程
原文:https://blog.quantinsti.com/entrepreneur-algorithmic-trader-rohit/
“他们总是说时间会改变事物,但实际上你必须自己去改变它们。”T3】
安迪·沃霍尔的这些话反映了这样一个事实:你独自拥有成为命运创造者的力量。对 Rohit Chugh 来说,这绝对不容易,因为他的生活另有安排。Rohit 的故事是关于坚持,永不放弃,提高技能和成长。他努力工作,成为一名企业家,实现了建立自己的制造公司的愿景,但情况发生了变化,他很快适应了未来。
以下是我们与 Rohit 的对话:
嗨,Rohit,你能给我们介绍一下你自己吗?
嗨,我是 Rohit Chugh 。我在孟买获得了会计和金融学士学位。我在孟买的一家安全印刷公司实习,因为我一直想进入印刷领域。我也在考虑攻读硕士学位。2010 年,在我获得学位 6 个月后,我去了英国攻读我的研究生 MBA。2011 年,我回到孟买,开始着手开发一项新业务。
你能和我们分享一下你的职业生涯吗?
我最初是通过获得客户、建立成熟的制造部门、认证等方式开始创业的。但是,像去货币化这样的事件影响了扑克牌行业,Reliance Jio 的推出影响了我们的印刷预付费充值卡业务 pan India。我们失去了客户,不得不裁员,失去了生意。到 2017 年底,我们一直在亏损,并最终在 2018 年 2 月停止运营。
你是何时开始交易的,又是如何开始交易的?
正是在这 6 个月的艰难时期,我开始寻找新的赚钱机会。我对任何领域都持开放态度,也在找工作,但没有找到满意的工作角色。那时我意识到交易是一种收入来源,而不是财富。
资本市场真的很吸引我。我用 10 万卢比的有限资金开始日内交易,试图产生百分比利润,看看我是否真的能赚钱,看看我的表现如何。
这段时间我只是想按百分比产生利润。几个月后,我的股票曲线为负,我意识到我没有正确的交易技能,因为我选择了错误的交易或者停留太久。
谈谈你在交易中的学习经历。
我在网上搜索,开始学习和发展技能。我开始参加每一个免费研讨会,并在 YouTube 上观看大量视频,这些视频可以帮助我发展技能,赚取可观的利润。但是它仍然没有帮助我。就在那时,我决定只专注于寻找一份有保障的工作,即拥有 MBA 学位的业务开发人员。在我寻找工作的时候,我碰巧搜索了最高和最新的职位,在那里我遇到了数据分析师,那时我在资本市场上看到了一些数据分析师的职位空缺。那时我已经决定了我想在哪个领域工作。
你是什么时候决定学习算法交易的,是什么促使你这样做的?
我没有这方面的技能,我知道我必须学习一些专业课程,这些课程也会帮助我在毕业后找到一份工作。这是我偶然发现 QuantInsti,并了解到它是印度唯一一所开设算法交易课程并提供终身工作支持的学院。我开始研究学院,并决定报名参加 EPAT。我在 QuantInsti 发现了自己,我成为了难忘的经历和独一无二的机会的一部分,我认为我在其他任何地方都找不到这些机会。我感谢 QuantInsti 将我塑造成今天的我,感谢他给了我真正关心我的成功、不把我当成数字的教授,感谢他给了我一生的导师,我知道在我职业生涯的任何时候,我都可以去找他们。
认证对您的交易产出和利润有何影响?你能分享一些百分比方面的数据吗?
通过 QuantInsti,我得以在一家金融科技公司获得一份战略开发人员的实习工作,现在继续全职工作。在这里,我编码和回测不同的策略,我还没有通过算法交易部署任何资金,因为我还在开发阶段。感谢你为我打开这么多机会的大门,感谢你为我的成功奠定基础。
我们为你的成功感到骄傲,Rohit。我们钦佩你的勇气,并祝你继续成功。
释放你学习算法交易的渴望,不断前进,学习,成长,永不放弃。用必要的技能和知识武装自己,在这个领域取得成功。让我们的算法交易管理课程(EPAT)成为你的向导。点击 了解更多 [**。
免责声明:为了帮助正在考虑从事算法和量化交易的个人,本案例研究是根据 QuantInsti EPAT项目的学生或校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。**](https://www.quantinsti.com/)
EPAT 如何迎合算法交易所需的基本技能?
原文:https://blog.quantinsti.com/epat-cater-need-essential-skill-sets-required-algorithmic-trading/

“交易一直处于采用尖端技术的最前沿,尤其是在短期交易领域。昔日的交易大厅不断被由少数掌握关键技能的人管理的复杂交易模型所取代。在过去的几年里,交易技术的前景发生了巨大的变化,随着机器学习的出现,机器做出关键决策的可靠性有了显著的飞跃。从大型对冲基金所需的关键技能来看,这一点非常明显。我们需要提升我们的技能,迎接机器交易的新时代。”iRage 技术副总裁 Sameer Kumar 说。
考虑到上面的陈述,很容易推断出算法交易领域对拥有高级技术技能的人有很高的需求。为了迎合量化组织不断变化的要求,候选人需要了解和意识到当代的工具和实践。针对这一需求, QuantInsti 提供了一个全面的算法交易执行程序(EPAT)。该项目为期六个月,为有志成为量化交易者的人提供深入的实地培训。在这个案例研究中,我们详细讲述了一个叫 Jayalaxmi Ganihar 的 EPATian 人的故事。Jayalaxmi 在加入 EPAT 之前是一名金融分析师。成功完成课程后,Jayalaxmi 加入了总部位于康涅狄格州老格林威治的 WorldQuant LLC。详细介绍了她在 QuantInsti 的课程、安置程序和机会。
我们与 Jayalaxmi 的对话
What is your background?
我是果阿管理学院金融 MBA 毕业生,在此之前,我在果阿工程学院学习过电子和电信工程。
How do you know about QuantInsti & Why did you choose QuantInsti? What's your experience so far?
我在找量化金融的好课程,偶然发现了 Quantinsti 。我发现这里的教员很优秀,课程在深度和广度上都很广泛,并且在不断更新,此外,我们还定期举办客座讲座、世界级交易员的精彩演讲以及我们可以直接提问的互动会议。我们在作业和项目工作中也得到了很好的反馈和帮助。
一旦你成为 Quantinsti 的一员,你就永远是它的一部分。全体教职员工很容易交谈和互动,即使作为校友,如果我们在量子金融方面有任何问题或需要任何帮助,人们可以随时问 Quantinsti 。同样作为校友,我经常被邀请参加他们的网络研讨会和讲座。
What do you have to say about the employment opportunities offered by QuantInsti?
我们经常收到关于印度、新加坡和阿联酋的贸易公司的各种工作和角色的电子邮件。我们还会定期了解领先的量化公司提供的实习机会。
Would you recommend QuantInsti to others who wish to pursue a career in in Algo trading?
我强烈推荐 QuantInsti 给任何想进入 Algo 交易世界的人。除了学习丰富的信息,关系和网络机会也很好。一个人也可以从 Quantinsti 蝙蝠身上学到很多东西。与 MFE 或 CQF 相比,行政课程也非常经济,可以帮助你在这个领域快速起步。
Jayalaxmi 出身于技术和金融背景,具备完美掌握课程的基本条件。她与 QuantInsti 的成功故事激励了许多具有相似教育背景的人。虽然这只是一种情况,但 EPAT 为来自不同背景的参与者提供了良好的就业机会。
注册 EPAT 的参与者来自各行各业,包括交易员、程序员、数据分析师和全日制学生。大多数恰好是交易者;第二大类是程序员和数据分析师,其次是学者。在过去的十年中,金融领域的技术进步使其运作方式发生了彻底的转变。以下是全球知名的期权、衍生品和基于新闻的交易研究演讲者 Rajib Ranjan Borah 对这个问题的看法:“当我回到印度并与市场参与者交谈时,我意识到虽然大多数公司都非常热衷于大规模采用算法交易,但他们中的大多数人对如何进行算法交易一无所知。最大的挑战源于这样一个事实,即现有的劳动力要么是金融专业人员,要么是技术专业人员。为了在算法交易中表现出色,他们需要专业人士能够同时理解技术和金融,以及如何在两者之间发挥杠杆作用。
问题是,我们如何迎合这种需求,并带来变革,让人们知道如何在新的场景中发挥作用。EPAT 为您提供了一个优化现有知识的选项,让您享受知识带给您的最大益处。这对 Jayalaxmi 的职业生涯有什么影响?她告诉了我们更多。
What do you think of EPAT and how does it add value to your career?
我目前是 WorldQuant 印度公司的兼职研究顾问。我在 EPAT 项目中学到的东西极大地帮助了我理解交易的细微差别。它帮助我在 Alphathon 竞赛中获得了一个好位置,并在 WorldQuant 获得了一个研究职位。在 QuantInsti 的推荐下,我也进入了世界量子大学 MSFE 项目。
下一步
希望了解更多关于算法交易的各个方面,请查看算法交易(EPAT)中的执行程序。课程涵盖统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。点击这里了解更多关于最全面的算法交易程序!
利用机器学习开发基于云的自动交易系统[EPAT 项目]
原文:https://blog.quantinsti.com/epat-project-automated-trading-maxime-fages-derek-wong/

本文是作者提交的最后一个项目,作为他们在 QuantInsti 的算法交易(EPAT)执行程序课程的一部分。
作者
 Maxime Fages Maxime 的职业生涯跨越了价值和风险的战略层面,过去几年特别关注交易行为和市场微观结构。他在并购、基金管理或当前的公司战略中采用了量化的角度,并且一直是一个狂热的开源软件用户。Maxime 拥有欧洲工商管理学院的 MBA 学位和法国国立高等艺术学院的工程硕士学位;他目前是芝加哥商品交易所集团的战略总监 APAC。
Maxime Fages Maxime 的职业生涯跨越了价值和风险的战略层面,过去几年特别关注交易行为和市场微观结构。他在并购、基金管理或当前的公司战略中采用了量化的角度,并且一直是一个狂热的开源软件用户。Maxime 拥有欧洲工商管理学院的 MBA 学位和法国国立高等艺术学院的工程硕士学位;他目前是芝加哥商品交易所集团的战略总监 APAC。
 Derek Wong
Derek WongDerek 在 CBOT 开始了他的职业生涯,然后上楼专注于自营交易和策略开发。他管理全球多策略投资组合,专注于期货和期权领域。他目前是福瑞贸易投资有限公司系统交易副总监。
构思
在算法交易(EPAT)高管课程(T1)讲座结束时,德里克和我花了大量时间通过各种媒体交换意见。我们讨论了一个项目的想法,同样的主题让我们兴奋不已。首先,我们对处理期货而不是现金工具感兴趣。第二,我们都有使用 R 进行定量研究的丰富经验,并且都有兴趣在执行方面动手,尤其是在 Python 中实现事件驱动的策略(在 EPAT 项目之前我们都不知道这一点)。第三,我们花了几个小时讨论和评估用于交易的应用程序的机器学习的性能,并且非常渴望尝试我们的想法。最后,我们对实际的架构设计非常感兴趣,特别是管理任何机器学习框架的可变资源需求的最佳方式(训练与评估)。
因此,我们项目的范围自然而然地产生了:开发一个完全基于云的自动化交易系统,该系统将利用简单、快速的均值回复或趋势跟踪执行算法,并调用机器学习技术在这些算法之间切换。
项目描述
EPAT 项目的机器学习课程使用了支持向量机,并证明了它在预测波动性方面的表现略好于 GARCH 模型。文献表明,递归神经网络模型在正确的情况下甚至可以表现得更好[1],并且组合模型(“厚建模”)可能会减轻过度拟合问题[2]。这确实是一个吸引人的前景,但是我们对使用 ML 框架(主要是 e1071、caret 和用于 R 的 nnet,以及优秀的 scikit-learn 或 Python 中更简单的 pybrain)的涉猎揭示了一个关键问题:资源管理。在中档台式计算机上,大多数模型的学习阶段可能会非常漫长,而且大多数数据集的庞大规模会占用大量 RAM。例如,一台相对高端的 PC 使用 GPU 优化可能会做得相当好。然而,这将带来成本之外的进一步挑战:管理这样一个系统本身就是一门艺术,而且我们没有这方面的经验。此外,上面提到的大多数库可能很难正确设置;这对于机器学习研究来说尤其成问题,因为例如神经元系数没有可以容易地进行健全检查的显著值。表现不佳的模型有足够多的潜在根本原因,不需要增加一层业余管理,尤其是在我们的规模上。
结构

图 1:技术堆栈
我们的架构相对简单,并且被设计成驻留在远程服务器中。在提取历史市场数据的启动序列之后,计时器流程触发均值和标准差的更新[3]以及增量分钟数据条的更新。每 5 分钟,它将触发一次机器学习堆栈的调用,以获得接下来 5 分钟的评估。从代理流出的数据由处理程序排队并处理,以更新所有关键的交易参数。一个非常简单的策略是持续评估信号:如果机器学习堆栈显示趋势状态,它会将 Z 分数阈值作为开始趋势,否则它会进行均值回归交易。信号被排队,订单执行将获取它们并“天真地”处理订单。实际上,执行在出价(长)或要价(短)时执行限价单,并等待 ack(当从代理的 API 捕捉到 ack 消息时,ack 消息被推入第三个队列中)。如果在超时参数内未检测到确认,订单将被视为过期,如果是初始头寸订单,订单将被取消;如果是获利回吐订单或止损订单,订单将被更改为市价订单。从 ack 推断的填充被添加到 plot.ly 监视器(第三方流图表)。

图 2:实时监控,交易执行和指标
我们不会公布机器学习模型的全部细节,但总的原则是,我们有两个分别训练的“半球”来预测测距或趋势条件。每个半球都有三个不同的模型,每个模型都有特定的参数,每一方都会对模型进行投票,以决定即将到来的情况。如果双方意见不一致(例如检测到“范围”和“趋势”条件),堆栈将评估模型的置信参数以做出决定。

图 3:机器学习栈概述

图 4:样本外结果分布
Azure Machine Learning Studio 的一个非常好的特性是它支持定制功能的开发。在我们的案例中,我们开发了一个简单的投票方法来投票给两个“半球”,如果出现不一致的情况,就选择总体信心最高的一方。
# Map 1-based optional input ports to variables
dataset1 <- maml.mapInputPort(1) # class: data.frame
#simple polling
dataset1$trend_poll <- ifelse((dataset1$trend_NN == "trend") +(dataset1$trend_TCdeep == "trend") + (dataset1$trend_boostDT == "trend") >
(dataset1$trend_NN == "notrend") +(dataset1$trend_TCdeep == "notrend") + (dataset1$trend_boostDT == "notrend"), "trend", "notrend")
#poll trend confindence (as in "sum of confidence if youwere right")
dataset1$trend_poll_conf <- (dataset1$trend_NN == dataset1$trend_poll)*dataset1$trend_NNprob+
(dataset1$trend_TCdeep == dataset1$trend_poll)*dataset1$trend_TCdeepprob+
(dataset1$trend_boostDT == dataset1$trend_poll)*dataset1$trend_boostDTprob
#simple polling as the threshold is not really helping
dataset1$range_poll <- ifelse((dataset1$range_NN == "range") +(dataset1$range_TCdeep == "range") + (dataset1$range_boostDT == "range") >
(dataset1$range_NN == "norange") +(dataset1$range_TCdeep == "norange") + (dataset1$range_boostDT == "norange"), "range", "norange")
#poll trend confindence (as in "sum of confidence if youwere right")
dataset1$range_poll_conf <- (dataset1$range_NN == dataset1$range_poll)*dataset1$range_NNprob+
(dataset1$range_TCdeep == dataset1$range_poll)*dataset1$range_TCdeepprob+
(dataset1$range_boostDT == dataset1$range_poll)*dataset1$range_boostDTprob
dataset1$final <- ifelse(dataset1$trend_poll == "trend" & dataset1$range_poll == "norange", "trend",
ifelse(dataset1$trend_poll == "notrend" & dataset1$range_poll == "range", "range",
ifelse(dataset1$trend_poll == "trend" & dataset1$range_poll == "range",
ifelse(dataset1$trend_poll_conf>dataset1$range_poll_conf,"trend","range"),"nothing")))
data.set <- as.data.frame(dataset1$final)
# Select data.frame to be sent to the output Dataset port
maml.mapOutputPort("data.set")
R 片段 1:简单的轮询设备,连接到 Azure Stack 网络
在一些罕见的情况下,双方都没有信号,在这种情况下,我们在 5 mn 内不做任何事情。这个 5 mn 的选择并不完全是任意的,而是我们对“稳定的”(即使是暂时的)交易环境的看法和 WTI 的实际确定周期之间的一种有根据的妥协4。](https://cran.r-project.org/web/packages/wavelets/wavelets.pdf)

图 5:WTI 价格的小波(频谱)视图
样本外性能达到了令人印象深刻的 74%,非常重要的是,我们的样本仅限于 6 个月的 1 分钟棒线。处理数据的 R 代码是 github 库的一部分,本质上转换了一系列“标准”指标(SMA、LMA、RSI、ATR 等)。)为前 5 mn 进单个 50 个数据点(输入)+ 1 输出。Azure 框架上的培训速度很快,出色的界面使得用 python 或 r 添加自定义代码变得很容易。从培训到一个实时的 RESTful API 非常简单,响应时间明显低于 100 毫秒。

| 图 6:用于训练的“范围”条件输入 | 图 7:用于训练的“趋势”条件输入 |
#eyeball using quantmod
eyeb<-function(x){
i=x
start <- index(df)[1]+i*60*5
mid <-start+5*60
end <- start+10*60
tmp <- df[index(df) >=start & index(df) < mid]
tmp2 <- df[index(df) >=mid & index(df) < end]
tmp3 <- df[index(df) >=start & index(df) < end]
mychartTheme <- chart_theme()
mychartTheme$rylab = T
chart_Series(tmp3[,c("open","high","low","close")], theme=mychartTheme)
slp_av <- mean(tail(tmp2$trend,3))
ln_slp <- function(x){xts(coredata(first(x)+slp_av*as.numeric((index(x)-first(index(x))))),order.by=index(x))}
dummy <- (tmp2$high+tmp2$low)/2
add_TA(ln_slp(dummy),on=1, col=3)
ta_up <- xts(rep(mean(tmp$close)+z_thresh*last(tmp$atr),length(index(tmp2))),order.by = index(tmp2))
add_TA(ta_up, on=1, col=4)
ta_dn <- xts(rep(mean(tmp$close)-z_thresh*last(tmp$atr),length(index(tmp2))),order.by = index(tmp2))
add_TA(ta_dn, on=1, col=4)
}
R 片段 2:眼球函数生成图 6 & 7
交易策略开发
我们确定了三个指导原则,并在战略制定过程中坚持这些原则。首先,我们需要一种策略,这种策略将极大地依赖和利用机器学习架构。其次,我们需要策略以这样一种方式执行,即来自不同制度状态的绩效的实证分析将允许我们判断交易策略本身,但也可以查看机器学习是否实时执行良好。最后,当然,对于所有的交易策略,我们都希望它有利可图。
我们的机器学习架构的内在复杂性导致我们在交易策略上保持相对简单。这是必要的,有几个原因,简化的交易逻辑让我们避免了经典的策略发展陷阱。例如:过度拟合、限制自由度、混淆逻辑错误和数据污染。当运行几种不同类型的训练和回溯测试时,首先是机器学习架构,然后是开发交易逻辑本身,这使陷入经典策略开发陷阱的机会增加了一倍。
交易系统是基于我们计算的频率统计推断。我们决定使用一个简单的统计方法,Z 分数作为我们策略的基础。这是一个极其简单的标准统计公式。这样做的原因是因为我们不希望 ML 结构和我们的交易逻辑模型的结合带来额外的复杂性。
zscore = (self.last_trade - self.cur_mean)/self.cur_sd
Python 片段 1: z-score 公式片段
录入触发流程
我们的参赛条件简单地基于两个因素,主要是机器学习市场机制状态和 Z 分数生成的触发条件。
| 进入条件 | 高于 Z 分数阈值 | 低于 Z 分数阈值 |
| 测距机制状态 | 卖空 | 买空 |
| 趋势政权状态 | 买空 | 卖空 |
表 1:进入条件逻辑矩阵
if abs(zscore) >= self.zscore_thresh and \
abs(zscore) <= settings.Z_THRESH + settings.Z_THRESH_UP and \
self.trading.is_set() and \
(self.fill_dict == [] or self.fill_dict[-1]["type"] != "main") and \
self.flag != "nothing":
self.exec_logger.info("signal for main detected - strategy")
try:
if zscore >= self.zscore_thresh:
if self.flag == "trend":
action = "BUY"
if self.flag == "range":
action = "SELL"
if zscore <= -self.zscore_thresh:
if self.flag == "trend":
action = "SELL"
if self.flag == "range":
action = "BUY"
Python 片段 2:交易逻辑触发条件
我们使用简单对称触发逻辑的理由如下。通过保持绝对最简单的触发方法,我们可以最大限度地依赖机器学习。如果市场机制由于触发器的简单性质而不正确,如果包括市场摩擦,产生的独立 alpha 值应该接近于 0 或负值。这是假设短期高频数据的市场是一个几何布朗运动(GBM)过程,如随机游走。
如果机器学习可以检测到什么时候不是这种情况,并且有一些分布的尾部偏离了对数正态分布,那么我们可以生成 alpha。例如,我们有三种状态:趋势、范围和无。如果 GBM 为真,那么时间序列要么不存在,要么在范围内。图 4 清楚地表明了这一点,但是,我们确实显示了统计意义上的大部分时间花在趋势区域。这表明时间序列在峰度上存在方差,并且具有随机波动性。由于过度的峰度,这导致我们可以从趋势策略中产生 alpha。然而,一个标准的 Z 值不能辨别这些不同的时间序列状态,它假设了一个正态分布。因此,当且仅当机器学习架构能够准确地辨别市场制度状态时,交易触发器才能够变得有利可图。
这种策略还包括我们的机器学习两个半球中存在的相同类型的假设,即在不同的制度下,我们应该有两种类型的市场价格分布。一种是更薄的,导致更厚的尾巴,标志着一种趋势。另一种可能是更正常的,甚至是尾部相对较薄的扁 kurtic,导致一个范围制度。
Z 分数将假设正态分布,这意味着我们希望利用的所有目标活动都在尾部。因此,通过使用 Z 分数触发器,我们可以简单地做到这一点,并且只在我们判断为极端值的地方有触发点,希望利用不同的尾部条件。我们的参数触发点是 2 到 2.5 之间的任何 Z 值(Z THRESH 和 Z THRESH + Z THRESH UP)
退出
鉴于我们的主要目标,我们的退出也非常简单。我们使用两种退出条件。对于“区间”制度均值回复交易,多头使用高于我们的 Z_TARGET 的 Z 值,空头使用低于我们的 Z _ TARGET 的 Z 值。我们预计平均恢复活动将是 Z 分数为 0,但我们有一个稍大的范围来关闭我们参数中的+/-0.2 的位置。我们还有一个额外的 4 点跟踪止损,这是用于两个系统。然而,趋势交易是唯一的退出条件。
参数
我们的参数集直接取自正态分布假设。在我们的架构中,这些由一个单独的配置文件控制,这使得修改变得容易。我们使用的 Z 得分阈值(Z THRESH)为 2,并限制为 2.5(ZTHRESH+ZTHRESHUP)。这就是为什么我们不试图进入已经背离很远的交易。跟踪止损的止损点偏移量是以点为单位的,Z 目标是 0.2 的 Z 值,我们在均值附近关闭均值回复位置。
# trading parameters
Z_THRESH = 2
Z_THRESH_UP = 0.5
STOP_OFFSET = 0.04
Z_TARGET = 0.2
Python 片段 3:交易逻辑参数
项目进展如何?
我们一直使用的参数导致每小时 14x-16x 的旋转(7-8 次旋转)。这一数字意义重大,尤其是从名义价值的角度来看:每天的名义交易额约为 1650 万美元,利润率约为 5000 万美元(然而,从净资产收益率的角度来看,后者是唯一有趣的参数)
该策略表现相当好:45%在每份合约 1.8 个基点左右获利,29%在每份合约 1.7 个基点左右亏损,26%亏损。然而,平均利润,在 ca。每笔往返交易的 0.32 点必须与 IB 每笔交易向我们收取的 1.42 美元相比较[5];散户交易者的经济状况很艰难。2.84 美元的经纪费和交易费带来的 3.2 美元的净利润,理论上会产生 20%-30%的月利润率。这可能看起来令人印象深刻,但考虑到所涉及的杠杆远不能补偿不可预见的、奇怪的市场条件(与公告相关的峰值、流动性下降)可能产生的潜在损失,更不用说运营风险(漏洞或系统崩溃)了。此外,还不清楚我们是否能在不出现重大下滑的情况下,将策略扩展到足以让一些“真正的”投资获得回报。
另一方面,资源成本低得离谱:AWS 微实例免费一年,鉴于 azure 完成了繁重的工作(ML ),这对我们来说是足够的处理能力,Azure 堆栈的价格不到 10 美元/米(“seat ”,然后是 1000 个 API 调用的 50 美分)
结论
关于交易,我们的三个主要结论是:
- 只要有可能,软件作为机器学习的服务是绝对有意义的。50 毫秒-100 毫秒的响应时间是一个明确的限制,但低于这个标准的增量投资和运营风险非常大。对于任何更长的 horizon 应用程序来说,这项技术,尤其是微软的 Azure ML Studio,都是值得探索的。
- 即使是在 outrights 上,用有限的资源进行自动交易仍然有可能赚钱。然而,交易所/经纪费可以迅速侵蚀甚至取消利润。激励/分级计划对于这些策略的盈利至关重要。是的,这是显而易见的,但我们现在有了第一手的经验。
- 在显而易见的研究和编码部分之间,将抽象概念设计成可操作的对象和代码可能更像是艺术而不是科学。在那个领域拥有实际经验(和失败)显然是有好处的。
对未来学生/程序员的建议:
- 探索图书馆,并彻底了解它们可以/将要做什么。例如,IBPY 具有简单存在的优点。文档几乎不存在,但是它有大量调用所有 API 功能的包装器。有可能我们最终会重写一些已经存在的功能(当我们这样做时,我们的实现很可能是最差的)
- “棋如斗剑,先想后动”——吴唐门。这种古老的智慧肯定也适用于开发,尤其是当涉及到类和并发性时。由于我们没有这种开发或设计软件架构的经验,我们从黑进 James Ma“高频”项目开始。可以肯定地说,詹姆斯在我们的项目中的出色工作几乎没有留下任何东西;解决由范围差异引起的限制最终总是以块和重构告终。最终,我们将节省大量时间,花更多时间思考概念模块,然后从头开始朝它们努力(注意,当时我们不知道如何做,Jame 的工作是一个很好的引导)。讽刺的是,我们最终的架构看起来非常像 Quantinsti 的系统架构 101 中的那个。
- 我们工作中的大部分 R/Python 都涉及顺序工作流,迭代开发。交易系统涉及从交易所流出的数据、基于信号、确认或订单等的订单推送。事后看来,这当然是“线程”和“并发”的叫法,但是 James 已经(非常好地)成功地保持了他的工作顺序,并且只依赖于类。这对我们来说并不奏效,并且与前面提到的问题结合起来导致了第一次重构(不成功,因为我们押错了任务库: threading )。如果同时使用 python 3.5 或 的话,我们非常鼓励任何研究 python 交易的人去钻研**** asyncio 。期货 也是 2.7 的后移植(我们用的是后者)。现在,多重处理有它自己令人沮丧的挑战:线程在沉默中死去,(不是)线程安全的对象,等等。并且通常是非常不同的设计范例。从积极的一面来看,当它起作用时,令人难以置信的满足
- 质量保证可能是开发中最不性感的方面。这也是我们已经并将投入大量学习/阅读时间的领域。这种技能在笔记本型环境中并不重要,因为大多数情况下,调试可以一步一步地进行。当然,当多个线程与不同来源的数据交互时,这是一种非常不同的情况。到处编写打印语句是不够的,无论是****还是trace back都是非常值得投入时间的库。公平地说,没有一个是特别直观的(顺便说一下,异常类的使用也是如此),但是系统化的 try/except 和日志记录确实是救命稻草
*** “现在感受痛苦或以后感受痛苦”这个老掉牙的说法在发展问题上尤为贴切。使用类和其他不太直观的对象和进程分类法是一把双刃剑。大多数类和函数不会直接进行测试,试图在集成测试中测试基本功能(例如,输出的正确类型)会导致灾难。我们最终使用非常好的 main python 语义来“搭建”运行所需的基础的单个类,作为一个穷人的 unitest (另一个非常关键的不性感的库)。最后,开发测试特性所需的时间并不是微不足道的(我们假设可能是 20%左右),但是这是一个非常好的资源利用。一个很好的例子是,我们没有建立一个市场模拟器。这是我们做出的决定,基于我们实际上与 IB 交易的有限利益(很大程度上是由于合同限制),以及坦率地说,基于我们在开始时拥有的技能。仅从时间角度来看,这是一个非常糟糕的决定:在 IB 上注册的引导序列大约有 20 秒长。考虑到信号的发生,这可能最少需要 30 秒,而在 4 小时的开发序列中,可能需要 20 到 30 次重启。保守估计,10-20 分钟的时间浪费或 5%-10%的生产力损失。这甚至是在能够测试具体情况而不是等待情况发生之前,并且在我们看来,毫无疑问,即使中途咬紧牙关也会有很大的好处(包括参数调整)。**
**概括地说,这是关键的收获:完成一个项目的 80%是容易和有趣的部分。艰难而乏味的是最后的 20%,这也是实际技能重要的地方(尤其是在质量保证方面)。
在这个过程中,我们收获了很多,感谢老师们的帮助和指导。鉴于我们各自的合同限制,我们不打算继续公开发布该程序,但计划在近期再次合作。
Github 库:https://github.com/FaGuoMa/Azure-IB/.
参考文献
[1]实证金融学中的非线性时间序列模型——Philip Hans Franses,Dick van Dijk 使用基于波动率的递归神经网络进行变化方向预测——Stelio be kiros 和 Dimitris Georgoutsos
[2]组合分类器比选择最好的一个更好吗——Saso Dzeroski 和 Bernard Zenko 流行的集成方法:一项实证研究
[3]对于标准差,我们使用了无偏估计量(R . ALM gren–时间序列分析和统计套利,NUY)
[4]金融时间序列的小波多分辨率分析
[5]零售佣金是 0.85 美元的经纪费加上 1.45 美元的纽约商品交易所交易费。然而,根据 NYMEX/CME 和 IB 的分级交易量计划,费率可能分别为每笔交易 0.65 美元和 0.77 美元
后续步骤
对于更多这样的学生项目,如果你是一名程序员或科技专业人士,想创建自己的自动化交易平台,请查看使用 R. 的统计套利策略。从日常从业者的实时互动讲座中学习自动交易。算法交易高管课程涵盖统计学&计量经济学、金融计算&技术和算法&量化交易等培训模块。现在报名!**
雅克·儒贝尔的 R -中的统计套利策略[EPAT 项目]
原文:https://blog.quantinsti.com/epat-project-jacques-statistical-arbitrage/

由雅克·儒贝尔
本文是作者提交的最后一个项目,作为他在 QuantInsti算法交易(EPAT) 高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
背景
过去 6 个月一直关注我博客的人会知道,我参加了 QuantInsti 提供的算法交易的管理课程。
这是一个旅程,这篇文章是我关于统计套利的期末项目的报告,用 r 语言编写。这篇文章是我的课堂笔记和源代码的结合。
为了欢迎读者贡献、改进、使用或参与这个项目,我把所有东西都上传到了 GitHub。它也将成为我在博客 QuantsPortal 上的开源对冲基金项目的一部分
我要特别感谢 QuantInsti 的团队。谢谢你为我的期末项目所做的所有修改,谢谢你不厌其烦地帮助我学习,谢谢你高水平的客户服务。
统计套利的历史
由摩根许仁杰的农齐奥·塔尔塔利亚的量化小组在 20 世纪 80 年代中期首次开发和使用。
- 配对交易是一种“反向策略”,旨在利用配对比率的均值回复行为
- 大卫·肖,D.E .肖公司的创始人,离开摩根士丹利,在 20 世纪 80 年代后期创立了自己的“量化”交易公司,主要从事配对交易
什么是配对交易?
众所周知,统计套利交易或配对交易被定义为交易一种金融工具或一篮子金融工具,在大多数情况下是为了创造一个价值中立的篮子。
它的想法是,协整合对在本质上是平均回复。这些工具之间存在价差,偏离均值越远,反转的可能性就越大。
然而请注意,统计套利并不是一种无风险的策略。比方说,你已经为一对投资者建立了头寸,然后价差出现了趋势,而不是均值回归。
概念
第一步:找到 2 只相关证券
找到两种属于同一行业的证券,它们应该有相似的市值和平均交易量。
这方面的一个例子是盎格鲁黄金和和谐黄金。
第二步:计算价差
在接下来的代码中,我使用了线对比率来表示分布。就是简单的资产 A 的价格/资产 b 的价格。
步骤 3 :计算配对比率/扩散的平均值、标准偏差和 z 值。
步骤 4 :协整测试
在接下来的代码中,我使用扩展的 Dicky Fuller 检验(ADF 检验)来检验协整性。我设置了三个测试,每个测试都有不同数量的观察值(120,90,60),所有三个测试都必须拒绝两者不协整的无效假设。
第五步:生成交易信号
交易信号是基于 z 值的,假设它们通过了协整测试。在我的项目中,我使用的 z 值为 1,因为我注意到与我竞争的其他算法使用的参数非常低。(我更希望 z 值为 2,因为它更符合文献,但是它的利润更低)
第六步:根据信号处理交易
第 7 步:汇报
我的项目的 R 降价
**#### 导入包并设置目录
第一步总是导入所需的包。
#Imports
require(tseries)
require(urca) #Used for the ADF Test
require(PerformanceAnalytics)
这一战略将适用于在约翰内斯堡证券交易所(JSE)上市的股票;因此,我不会使用 quantmod 包从 yahoo finance 中提取数据,相反,我已经获取并清理了存储在 SQL 数据库中的数据,并将其移动到桌面上的 CSV 文件中。
我将策略中使用的所有对添加到一个文件夹中,现在我将该文件夹设置为工作目录。
##Change this to match where you stored the csv files folder name FullList
setwd("~/R/QuantInsti-Final-Project-Statistical-Arbitrage/database/FullList")
将从其他函数中调用的函数(无用户交互)
下一步:创建所有需要的函数。下面的函数将从其他函数中调用,所以您不需要担心参数。
添加列
AddColumns 函数用于将存储变量所需的列添加到数据框中。
#Add Columns to csvDataframe
AddColumns
准备数据
PrepareData 函数计算对比率和对的 log10 价格。它还调用其中的 AddColumns 函数。
PrepareData
GenerateRowValue
GenerateRowValue 函数计算数据框中给定行的平均值、标准差和 z 得分。
#Calculate mean, stdDev, and z-score for the given Row [end]
GenerateRowValue
生成信号
GenerateSignal 函数基于 z 得分创建一个多头、空头或收盘信号。您可以手动更改 z 值。对于进场信号,我将它设置为 1 和-1,任何介于 0.5 和-0.5 之间的 z 值都会产生一个收盘/出场信号。
GenerateSignal trigger)
csvData$signal[counter] -close)
csvData$signal[counter]
生成交易
GenerateTransactions 函数负责为创建一对所需的多头和空头头寸分别设置进场和出场价格。
注意:QuantInsti 教了我们一个非常具体的交易策略回溯测试方法。他们使用 excel 来教授策略,当我编写这个策略时,我使用了很大一部分 excel 方法。
然而,展望未来,我将探索存储变量的其他方法。这种方法的一大好处是,你可以提取整个数据框架,分析交易的原因和所有相关细节。
#Transactions based on trade signal
#Following the framework set out initially by QuantInsti (Note: this can be coded better)
GenerateTransactions
get returns day
GetReturnsDaily 计算每个头寸的日收益,然后计算总收益并加上滑点。
#Calculate daily returns generated
#Add implementation shortfall / slippage at close of trade
GetReturnsDaily 0){csvData$LongReturn[end] 0){csvData$ShortReturn[end]
生成报告
接下来的两个参数用于生成报告。报告包括以下内容:制图:1 .权益曲线 2。下降曲线 3。每日回报条形图
统计:1。年度回报 2。年度夏普比率 3。最大水位下降
表:1。前 5 名提款及其持续时间
注意:如果你有一些额外的时间,那么你可以进一步将这个函数分解成更小的函数,以减少代码行,提高可用性。更少的代码=更少的错误
#Returns an equity curve, annualized return, annualized sharpe ratio, and max drawdown
GenerateReport 0){
positiveTrades
用户将参数传递给的函数
接下来的两个函数是用户应该摆弄的唯一函数。
回溯测试对
当您想要对交易对(通过 CSV 文件传递的交易对)运行回溯测试时,使用回溯测试对
函数参数:
- pair data = CSV 文件日期
- 平均值=用于计算分布平均值的观察次数。
- 滑点=充当经纪和滑点的基点数量
- adfTest =布尔值—如果回溯测试应该测试协整
- Critical Value = ADF 测试中用于测试协整的临界值
- generateReport =布尔值-如果必须生成报告
#The function that will be called by the user to backtest a pair
BacktestPair 130){
begin = mean){
#Generate Row values
pairData
回溯测试组合
BacktestPortfolio 接受一个 CSV 文件向量,然后生成一个权重相等的投资组合。
函数参数:
- names = CSV 文件名的原子向量,例如:c('DsyLib.csv ',' OldSanlam.csv ')
- 平均值=用于计算分布平均值的观察次数。
- 杠杆=你想在投资组合中应用多少杠杆
#An equally weighted portfolio of shares
BacktestPortfolio
运行回溯测试
现在我们可以开始使用我们的代码测试策略了。
JSE 的纯套利
当开始这个项目时,主要关注的是使用统计套利来寻找共同整合的股票对,然后进行交易,但是,我很快意识到,可以使用相同的代码来交易在同一交易所既有其主要上市又有其次要上市的股票。
如果两个上市都是在同一个交易所发现的,这就为纯粹的套利策略打开了大门,因为两个上市都是指同一种资产。因此,你不需要测试协整。
JSE 有两个非常明显的例子。
第一个例子 Investec
主要= Investec 有限公司:次要= Investec 有限公司
Investec 样品内测试(2005-01-01 - 2012-11-23)
测试以下参数
- Investec 有限公司/ plc 对
- 平均值= 35
- 设置 adfTest = F(不测试协整)
- x3 的杠杆作用
#Investec
leverage

## [1] "Annual Returns: 0.619853087807437"
## [1] "Annualized Sharpe: 3.29778431709924"
## [1] "Max Drawdown: 0.105016628973292"
## From Trough To Depth Length To Trough Recovery
## 1 2009-03-19 2009-03-25 2009-05-04 -0.1050 28 5 23
## 2 2006-06-08 2006-07-13 2006-08-14 -0.0955 46 25 21
## 3 2008-10-03 2008-10-17 2008-10-24 -0.0887 16 11 5
## 4 2009-03-02 2009-03-02 2009-03-06 -0.0733 5 1 4
## 5 2008-10-27 2008-10-27 2008-11-05 -0.0697 8 1 7
Investec 样本外测试(2012-11-23 - 2015-11-23)
注意:如果你增加滑点,你很快就会和利润吻别。
GenerateReport.xts(investec.returns, startDate = '2012-11-23', endDate = '2015-11-23')

## [1] "Annual Returns: 0.1754103210963"
## [1] "Annualized Sharpe: 2.20385429706265"
## [1] "Max Drawdown: 0.0335642102186873"
## From Trough To Depth Length To Trough Recovery
## 1 2015-07-10 2015-11-13 -0.0336 96 89 NA
## 2 2013-06-18 2013-06-21 2013-07-01 -0.0267 10 4 6
## 3 2014-04-16 2014-08-13 2014-09-19 -0.0262 107 80 27
## 4 2015-01-20 2015-05-25 2015-06-01 -0.0258 91 86 5
## 5 2013-01-18 2013-01-24 2013-01-25 -0.0249 6 5 1
第二个例子蒙迪
主要= Mondi 有限公司:次要= Mondi 有限公司
蒙迪样品内测试(2008-01-01 - 2012-11-23)
测试以下参数
- Mondi 有限公司/ plc 对
- 平均值= 35
- 设置 adfTest = F(不测试协整)
- x3 的杠杆作用
世界日期
mondi.returns

## [1] "Annual Returns: 0.973552250431717"
## [1] "Annualized Sharpe: 2.88672185296756"
## [1] "Max Drawdown: 0.254688711989788"
## From Trough To Depth Length To Trough Recovery
## 1 2008-07-01 2008-08-01 2008-09-01 -0.2547 45 24 21
## 2 2009-03-11 2009-03-18 2009-04-08 -0.1906 21 6 15
## 3 2008-04-16 2008-06-03 2008-06-23 -0.1040 45 32 13
## 4 2008-09-02 2008-09-17 2008-09-18 -0.0926 13 12 1
## 5 2009-03-09 2009-03-09 2009-03-10 -0.0864 2 1 1
蒙迪样本外检验(2012-11-23 - 2015-11-23)
注意:在我所有的测试中,我发现我的数据越靠后,就越难从当天的数据中获利。我用当天的数据测试了同样的策略,它有更高的回报。
GenerateReport.xts(mondi.returns, startDate = '2012-11-23', endDate = '2015-11-23')

## [1] "Annual Returns: 0.0809094579019469"
## [1] "Annualized Sharpe: 1.25785312960412"
## [1] "Max Drawdown: 0.0385234269750542"
## From Trough To Depth Length To Trough Recovery
## 1 2013-12-19 2014-10-13 2015-01-26 -0.0385 273 202 71
## 2 2015-06-05 2015-08-14 -0.0313 120 49 NA
## 3 2015-01-27 2015-04-22 2015-04-28 -0.0245 63 60 3
## 4 2013-05-29 2013-05-30 2013-06-14 -0.0179 13 2 11
## 5 2013-11-08 2013-11-18 2013-12-18 -0.0175 28 7 21
JSE 的统计套利
接下来,我们将看一看配对交易策略。
通常,一对包含 2 个部分,它们是:
- 分享一个市场领域
- 有相似的市值
- 相似的商业模式和客户
- 是相互整合的
在下面的所有投资组合中,我使用 3 倍杠杆
建筑组合
入样测试(2005-01-01 - 2012-11-01)
names

[1] "Annual Returns: 0.0848959306632411"
## [1] "Annualized Sharpe: 0.733688101181479"
## [1] "Max Drawdown: 0.193914686702112"
## From Trough To Depth Length To Trough Recovery
## 1 2008-05-19 2008-07-08 2008-11-03 -0.1939 119 36 83
## 2 2008-11-04 2008-12-03 2009-06-29 -0.1345 160 22 138
## 3 2006-08-25 2007-12-19 2008-02-19 -0.1272 372 331 41
## 4 2009-08-04 2009-10-01 2009-11-10 -0.0701 69 41 28
## 5 2009-11-25 2010-03-10 2010-09-29 -0.0486 211 73 138
样本外检验(2012-11-23 - 2015-11-23)
GenerateReport.xts(ReturnSeries, startDate = '2012-11-23', endDate = '2015-11-23')

## [1] "Annual Returns: 0.0159094762396512"
## [1] "Annualized Sharpe: 0.268766025866724"
## [1] "Max Drawdown: 0.0741426720423424"
## From Trough To Depth Length To Trough Recovery
## 1 2013-08-05 2013-09-06 2014-11-17 -0.0741 322 24 298
## 2 2014-11-20 2015-01-29 -0.0737 253 47 NA
## 3 2012-11-30 2013-04-23 2013-05-02 -0.0129 102 96 6
## 4 2013-06-10 2013-06-13 2013-06-24 -0.0100 10 4 6
## 5 2013-05-03 2013-05-03 2013-06-04 -0.0050 23 1 22
保险组合
入样测试(2005-01-01 - 2012-11-01)
names

## [1] "Annual Returns: 0.110600985165525"
## [1] "Annualized Sharpe: 0.791920916349154"
## [1] "Max Drawdown: 0.233251846760865"
## From Trough To Depth Length To Trough Recovery
## 1 2005-05-26 2005-10-14 2006-08-31 -0.2333 318 100 218
## 2 2008-10-15 2008-12-05 2009-04-30 -0.1513 134 38 96
## 3 2009-06-10 2009-12-10 2010-01-29 -0.1223 162 129 33
## 4 2011-10-04 2012-10-09 -0.0991 267 249 NA
## 5 2006-11-08 2007-12-11 2007-12-14 -0.0894 277 274 3
样本外检验(2012-11-23 - 2015-11-23)
GenerateReport.xts(ReturnSeries, startDate = '2012-11-23', endDate = '2015-11-23')

## [1] "Annual Returns: -0.0265926093350092"
## [1] "Annualized Sharpe: -0.319582293135835"
## [1] "Max Drawdown: 0.128061204573991"
## From Trough To Depth Length To Trough Recovery
## 1 2014-08-08 2015-11-20 -0.1281 326 324 NA
## 2 2012-11-28 2013-05-13 2013-07-31 -0.0393 167 111 56
## 3 2014-06-10 2014-06-26 2014-07-23 -0.0284 31 12 19
## 4 2013-08-01 2013-08-30 2013-09-03 -0.0255 23 21 2
## 5 2013-09-11 2013-10-22 2013-12-04 -0.0209 60 29 31
一般零售组合
入样测试(2005-01-01 - 2012-11-01)
names

## [1] "Annual Returns: 0.120956981644048"
## [1] "Annualized Sharpe: 1.4694780839876"
## [1] "Max Drawdown: 0.125406256082082"
## From Trough To Depth Length To Trough Recovery
## 1 2010-01-05 2012-01-17 -0.1254 705 504 NA
## 2 2008-09-29 2008-10-29 2009-02-20 -0.0690 101 23 78
## 3 2006-03-06 2006-05-15 2006-05-23 -0.0568 52 46 6
## 4 2005-07-18 2005-11-01 2005-12-06 -0.0538 101 76 25
## 5 2008-04-11 2008-04-29 2008-06-26 -0.0512 51 12 39
样本外检验(2012-11-23 - 2015-11-23)
GenerateReport.xts(ReturnSeries, startDate = '2012-11-23', endDate = '2015-11-23')

[1] "Annual Returns: -0.0171898953593881"
## [1] "Annualized Sharpe: -0.336265418351652"
## [1] "Max Drawdown: 0.0884145115767888"
## From Trough To Depth Length To Trough Recovery
## 1 2013-10-15 2015-11-11 -0.0884 528 519 NA
## 2 2013-03-18 2013-06-24 2013-08-12 -0.0279 100 66 34
## 3 2013-09-05 2013-09-06 2013-09-20 -0.0088 12 2 10
## 4 2013-09-23 2013-10-02 2013-10-08 -0.0049 11 7 4
## 5 2013-02-20 2013-02-20 2013-03-15 -0.0037 18 1 17
结论
在我所有的测试结束时,相信我——我做的测试比这份报告中的多得多,我得出的结论是,纯套利策略很有希望被用作使用真实资金的策略,但对特定行业股票组合的配对交易策略很紧张,不太可能以目前的形式用于生产。
我认为可以添加许多东西来提高性能。接下来,我将使用卡尔曼滤波器进行研究。
更上一层楼纯套利交易策略
我只发现两只股票在同一个交易所同时上市;这意味着我们不能为该战略分配大量资金,因为它会产生很大的市场影响,但是,我们可以使用多个交易所,并增加使用的股票数量。
关于配对交易策略的更多信息
- ADF 测试中使用的观测值数量很大。问题是,必须进行协整检验,才能提出统计套利的要求,然而,通过使用 120、90 和 60 作为三个检验的参数,很难找到符合标准的配对,并且在不久的将来会以这种形式继续下去。(卡尔曼滤波在这里可能有用)
- 我没有花太多时间去改变不同的参数,比如平均值计算中的观察次数。(这需要进一步探索)
- 从上述行业投资组合中,我们可以看到,最初几年是非常有利可图的,但随着时间的推移,回报越来越低。我和业内的一些人以及我在开普敦大学做 stat arb 项目的朋友聊过,当地的传说是,2009 年高盛打开了他们的 stat arb 包,关于 JSE 上市的证券。
- 同样的情况也出现在其他投资组合中,我没有把它们包括在这个报告中,但是它们在 R 代码文件中。
- 我认为,这是由于大型机构使用相同的面包和黄油策略。你会注意到(如果你花足够的时间测试所有的策略),在 2009 年,数据似乎突然转向低回报。
- 我觉得我使用的日末数据限制了我,如果我用日内数据测试策略,利润会更高。(我对 Mondi 的日内数据进行了一次测试,结果要高得多,但我仍要对行业投资组合进行测试)
- 这是一种更简单的统计套利策略,我相信,如果我们改进计算价差的方法,并改变一些进场和出场规则,这种策略将变得更有利可图。
如果你看到了这篇文章的结尾,我感谢你,并希望它能增加一些价值。这是我第一次使用 Github,所以我很期待看到这个项目是否有新的贡献者。
Github 资源库:https://github . com/jackal 08/quantin STI-Final-Project-Statistical-Arbitrage
在这篇关于算法交易策略范例的文章中阅读其他策略。如果你想学习算法交易,那么点击这里。
更新 - 我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。**
EPAT,匡特拉或两者兼而有之!你应该学什么,为什么?
QuantInsti 提供广泛的课程,它明白你需要知道 EPAT 和 Quantra 课程到底提供什么,以及它们之间的区别。
在为自己寻找最佳课程时,可能会有几个问题,如参加特定课程的好处、与位置相关的查询、学习平台的类型等等。
在这篇文章中,我们旨在消除所有的困惑,并提供几乎所有必要的答案,使您的决定更容易。
本文涵盖:
- 什么是 EPAT?
- 什么是 Quantra?
- 课程表
- 什么是独特?
- 什么最适合你?
- 对比表——EPAT 和 Quantra
什么是 EPAT?
EPAT 是一个为期 6 个月的综合虚拟课堂项目,涵盖算法交易的基本模块,例如:
- 市场微观结构
- 金融工具
- 统计数字
- 数据分析
- 证券管理
- Python/Matlab/Excel 编码基础
- 机器学习的使用
- 交易、技术、基础设施和运营
- 实时交易策略构建
市场微观结构
它是对金融市场的研究,主要是关于它们是如何运作和发挥作用的。在本模块中,你将学习所有关于金融市场的知识。
金融工具
金融工具,如期权、期货、远期等。都包括在 EPAT 方案中。你可以学习所有关于这些金融工具的交易。
统计数据
通过这个模块,你将能够学习在算法交易中使用统计信息建立量化策略。
Python 中的数据分析和建模
这个模块将有助于在实时交易环境中使用 Python 实现面向对象编程等概念。
投资组合管理和风险优化
本模块研究风险管理和投资组合优化。因此,它有助于识别和管理不同策略中涉及的风险。
Python/Matlab/Excel 编码基础
算法交易的关键之一是回溯测试你的策略,你需要一定的编程技能。本模块将帮助你理解编写和回溯测试交易策略所需的 Python 概念的应用。
使用机器学习
本模块帮助您在实时交易环境中实施交易策略。机器学习模型,如逻辑回归、支持向量机等。包含在本模块中。
交易技术、基础设施和运营
这个模块帮助你了解算法交易的需求、要求、优势和应用。此外,您还需要了解基础设施的要求,如硬件、网络等。以及在启动 algo 交易台时的业务环境。
实时交易策略构建
本模块旨在帮助您了解在实时交易环境中如何实施您的策略,并将向您介绍使用 Python 编程语言的互动经纪人等平台。
在 EPAT 项目工作中,你在指定导师的指导下从零开始建立自己的战略。您总共将获得 300 多个小时的学习材料、100 多个小时的现场讲座、41 场讲座、来自 7 个国家的 19 名教师和来自 70 多个国家的参与者,最后还将获得 Prometric 的认证。你可以和老师互动,并获得所有疑问所需的帮助。此外,EPAT 还提供实习、职位安排和开设交易平台方面的支持。
QuantInsti 算法交易的高管课程是为希望在该领域发展或计划在算法和量化交易领域开始职业生涯的专业人士设计的。本课程以监考考试结束,完成本课程后,您将获得终身访问和支持,在整个过程中随时为您提供帮助。
它通过专注于衍生品、量化交易、电子做市或交易相关技术和风险管理,激励传统交易者走向成功的算法交易生涯。
接下来,我们将了解什么是 Quantra。
什么是 Quantra?
Quantra 是 QuantInsti 的一个电子学习门户网站,专门提供算法&量化交易的短期课程。Quantra 提供小型自定进度和自学课程,包括视频、音频、文档、演示、python 笔记本、多项选择问题和高度互动的练习。Quantra 平台上有 30 多门课程,10 位作者,200 小时的培训材料,包括 30 小时的视频和 pdf 形式的免费培训材料。每一项都可以在一两天内完成。此外,Quantra 有专业知识,即 NLP(自然语言处理)和强化学习。此外,还教授了不同主题的 Python 语言编码,并提供了一些提示和解决方案来帮助您练习这些代码。学习交易策略有一些特别之处,从一行代码开始,一步一步来!
你可以通过实时交易帮助来体验教学技巧,让你掌握重要的概念。
https://www.youtube.com/embed/0dcrrB6Ivmc
此外,它为您提供了无与伦比的实际动手学习体验,使您能够轻松地学习和实施复杂的概念。
Quantra 上最好的学习途径是:
- 面向所有人的算法交易
- 金融市场中的机器学习和深度学习
- 使用 Python 进行自动交易
- 高级算法交易策略
- 股票市场:自动化交易
- 期权交易:定量方法
- 交易中的情绪分析
本学习课程有助于学习不同的交易策略,包括日交易、机器学习、ARIMA、GARCH,以及在交易中使用期权定价模型。这些课程对于想要学习和使用 Python 进行交易的交易者和量化分析师来说是完美的。
对于那些对机器学习及其在交易中的应用感兴趣的人来说,这是一个强烈推荐的途径。从简单的逻辑回归模型到复杂的 LSTM 模型,这些课程非常适合初学者和专家。通过这些课程,您将学习调整超参数、梯度推进、集成方法和高级技术,从而构建稳健的预测模型。
该学习课程是一个完整的端到端学习计划,旨在在实时市场中实施流行的算法交易技术,用于日交易和低频交易。如果你想增加你的投资组合,并在你的交易中包括历史数据回溯测试和纪律,这个学习路线是强烈推荐给你的。
对于想通过统计分析改善交易结果的交易者来说,这条路线是最好的。它包括一系列课程,在这些课程中,你将学习 30 多种新策略,如动量、均值回归、指数套利、多空、突破、季节性交易策略和投资组合管理。此外,您还可以通过本专题的课程获得 Python 和实时交易可部署模型的实践培训。
如果你是一名交易者,希望运用量化技术来改善和自动化你在股票市场的交易,那么这是一条适合你的学习路线。学习使用 25 种以上的交易策略,包括日交易策略、机器学习、量化技术、卖空、投资组合管理以及本课程中的更多内容。
通过本学习路线中的课程,您将学会创建期权定价模型、期权希腊模型和各种策略,如离差交易、情绪交易、箱式策略和日历价差。使用 ARIMA 和 GARCH 模型,机器学习技术和动量交易策略。
通过本学习课程,学习使用机器学习技术量化新闻和推文中表达的人类情感。完成本学习课程后,您将能够使用情绪指标和情绪得分来制定交易策略。此外,您将学习在现场交易中实现同样的功能。这是强烈推荐给想利用其他数据来源的交易者的。
让我们向前看,找出每个方案的课程。
课程
每个项目的结构都因其向学生提供的学习类型而异。虽然你可以选择两者中的任何一个,即 EPAT 或任何 Quantra 的课程(或学习课程),如果你是算法交易领域的新手,你可以先从 Quantra 选择初学者课程,然后再转移到 EPAT。
好吧!让我们看看这个结构,它将帮助你更好地理解这些概念。
EPAT
算法交易执行程序(EPAT)以循序渐进的方式帮助学生,如下所示:
- 学问
- (使)自动化
- 贸易
此外,这是一个为期六个月的在线部分时间制课程,在课程中,您可以接触到以下概念:

上述模块提供了对统计、Python、市场微观结构等概念的全面了解。此外,最后,你将利用动手项目,在指定导师的帮助下,你将能够从零开始建立自己的交易策略。之后,举行一次考试,这是为了帮助你确定你对这些概念的理解程度。
Quantra
Quantra 提供学习课程,每个课程下都有各种课程。一旦你进入这个页面,你就可以选择你的学习目标,根据这个目标,你将会被推荐相关的课程。
下面你可以看到如何根据你的学习目标找到最适合你的学习路线:

现在让我们来看看是什么让我们与其他在线课程区分开来。
什么是独特?
EPAT 和 Quantra 课程都是互补的课程,为您提供显著的好处。作为一名初学者,你可以选择 Quantra 上 learning tracks 下的初学者课程,如面向所有人的算法交易,然后搬到 EPAT。
有了 Quantra,你可能以前从未编写过代码,或者从未创建过任何交易策略,你可以从基础课程开始,然后继续学习高级课程。由于存在学习曲线,我们建议您致力于学习,并定期练习本课程中提供的实践学习练习。Quantra 与 Ernest P. Chan 博士、Laurent Bernut、NSE Academy、FXCM、Thomas Starke 博士和其他作者合作,确保从专家那里获得知识。
由于 EPAT 和 Quantra 都有自己独特的方式,我们在这里提出了这些要点,帮助您了解这两个项目提供的内容。接下来,这里列出了每种方式的独特之处:
EPAT
在 QuantInsti,我们意识到需要为个人提供动力,以利用这种大规模的算法交易。这催生了算法交易的高管课程(EPAT)。
行业专家、中坚分子、学者、交易员和市场从业者都加入了我们的教师队伍。我们与 Ernest Chan 博士、Gautam Mitra 博士、Rajib R. Borah 博士、Yves Hilpisch 博士、Euan Sinclair 博士和其他知名人士的联系为所有与会者提供了一个全球性的机会,并要求他们参加专门的客座讲座和活动。
我们的 EPAT 课程是专门设计的,以确保在短短的 6 个月内,为学生们讲述成为算法交易员的最重要的话题。EPAT 课程的每一个主题都一步一步地为你提供必要的知识,帮助你实现交易策略的自动化。
现在,为了讨论 EPAT 的独特之处,我们为您准备了一份列表,内容如下:
- 专职支持经理和终身支持/学习
- 职业细胞
- 现场讲座
- 校友社区
- 独家客座演讲
- 行业认知概念
- 向从业者学习经验的平台
专职支持经理和终身支持/学习
有了 EPAT,你将得到一个专门的支持经理,他将指导你完成整个学习过程,并帮助你解决你对编程、策略、平台以及最终对量化和算法交易的理论和实践的所有疑问。
职业单元格
Career cell 为来自世界各地的 EPATians 人带来最好的 Algo 和 Quant 交易工作机会。他们还协助面试准备和简历建设。下面你可以看到 EPAT-伊恩的逐步旅程:

我们为您提供校友支持,并帮助您快速安置,因为安置从批次开始就可用,而不仅仅是在完成您的 EPAT 课程之后。
现场讲座和讲座录音
有了我们的现场讲座,你会感到与在教室里由讲师面对面授课时类似的舒适。此外,对于您的所有疑问,我们有一个专门的积极支持团队,以便您的所有疑问都能在社区支持中得到解答。此外,我们还提供讲座录音设备,以便您可以录制讲座,并在有时间时观看。
如果您需要关于某个概念的进一步帮助,我们的主题专家也会与您通话,以确保您对答案感到满意,并尽快获得您的支持。
校友社区
EPAT 的校友社区将帮助您在任何与职业援助和培训相关的课程后获得联系,或获得最新 EPAT 内容的提示。作为校友网络特权的一部分,我们还为校友提供 Quantra 和 Blueshift 门户网站的特别折扣。
嘉宾讲座独家
通过遍布 155 个以上国家的 quants 和 algo 交易者全球网络,我们为您提供独家客座讲座。这些客座演讲由行业中坚分子主讲,为你未来的努力提供最好的知识。
行业认可
一旦你参加了 EPAT 课程,你在未来的日子里,你在这个行业的所有经历和进步都会得到行业的认可。因为你熟悉了算法交易的核心知识,这是一个巨大的进步。
学习从业者经验的平台
EPAT 是一个平台,在这里你将从许多从业者和他们的经验中获得知识。我们来自全球各地的从业者可以帮助你接触到算法交易方面的世界最佳实践。再者,学习算法交易策略和技术后,可以练习现场交易。
此外,我们很自豪能够满足具有不同要求和偏好的学生的不同需求,以下是对其中一个 EPATians 的引用:

Quantra
Quantra 课程是专为满足您的需求而设计的学习课程。每条学习路线都包含从基础到高级的课程。这样,你就可以在每个宽泛的概念下获得一套课程。
例如,大家都知道的算法交易的学习路线由以下课程组成,这些课程需要一步一步地完成,以结合概念方面的知识。建议的课程从基础水平开始,到初级水平,最后到中级水平。
以下是其中一个学习项目的简介:

Quantra 课程的一些独特之处如下:
- 可用的专业
- 实时市场中的实施
- 按照您自己的进度完成
可用专业
提供专业的学习轨道和课程,如高级算法交易策略、自然语言处理和机器学习和金融市场深度学习。
有了这些特殊的平台,你可以利用统计分析和机器学习在交易中的重要性。
在实时市场中实施
完成选定的 Quantra 课程后,您可以开始实时交易实施。当你学习实施实时交易的策略时,你可以应用你喜欢的实时交易方法。
按照自己的节奏完成
有了 Quantra 课程,您将不再受讲座或培训的束缚,并且可以随时重新开始学习。此外,没有时间限制,因此,它允许您按照自己的进度完成课程。
在此视频中了解更多关于 Quantra 课程的信息和学习体验:
https://www.youtube.com/embed/E6waVks18s0?feature=oembed
此外,让我们找出什么是最适合你的,取决于各种因素。
什么对你最好?
由于 EPAT 和 Quantra 都为您提供涵盖所有重要概念的“全面知识传授”课程,我们愿意帮助您决定最适合您的课程。根据各种因素,我们列出了以下几点:
选择 EPAT 如果:
- 你需要 6 个月的全面培训
- 你想获得最大的接触和知识
- 您需要在完成课程后获得支持,以便在自己的实践中实施
- 您希望与我们的专家保持联系,以获得讲座后任何问题的答案,以及在课程期间您是否需要通过专门的支持经理获得持续支持
- 你觉得与教员交流有助于你更好地获取知识
- 您想要探索广泛的安置合作伙伴,因为我们有 150 多个安置合作伙伴为您提供最佳安置
- 你是一个坚定的学习者,想要从学习中获得最大的收获
选择 Quantra,如果:
- 您正在寻找一个贸易领域的专业化,如金融市场中的机器学习实现和自然语言处理及其实现
- 你不想受时间的限制,希望按照自己的进度完成课程
- 你希望练习 Python 及其在交易中的应用
- 你希望你的交易策略在交易平台上实现自动化
- 你至少对金融市场有基本的了解
- 你更喜欢自学
观看这个来自纽约的 EPATian 人和 Quantra 课程的热心学生 Kevin Gaughan 先生的锁定故事,了解他的经历:
https://www.youtube.com/embed/aTqXuvjP5A0?feature=oembed
此外,你可以浏览 EPAT 和 Quantra 课程的快速对比分析。
对比表- EPAT 和 Quantra
| 课程特色 | EPAT | Quantra |
| 课程设置 | 40 多场现场讲座 | 30 多门课程 |
| 课程持续时间 | 6 个月 | 每个课程都有自己的持续时间 |
| 按照自己的进度学习 | 不 | 是 |
| 学习类型 | 混合或混合学习实践 | 自学习 |
| 综合性 | 为期 6 个月的结构化课程 | 选修课程的学习路线 |
| 选择特定的主题 | 不 | 是 |
| 能力 | 15 名以上的教员 | 10 位作者 |
| 兼职 | 是 | 取决于你自己的步伐 |
| 现场讲座 | 是 | 不 |
| 演讲录音 | 是 | 不 |
| 验证认证 | 是 | 是 |
| 教员互动 | 是 | 不 |
| 职业援助 | 是 | 不 |
| 终身社区支持 | 是 | 是 |
| 指导项目工作 | 是 | 不 |
结论
在 QuantInsti 提供的所有课程中,我们旨在为您提供 EPAT 和 Quantra 课程的简要概述,以及它们如何为您带来益处。根据他们自己的背景和专业,这两个项目都是专门为帮助学生学习自动交易而设计的。
由于我们的学生从初学者到专业交易者都有,我们把课程分开了,也就是说,EPAT 是为寻找定量观点和自动交易策略的经验丰富的交易者准备的。
另一方面,Quantra 的课程设计有最适合所有人的学习路线,这取决于您想要选择的速度。对于初学者来说,有一些课程会给出这个主题的详细知识,如果你是专业人士,你可以跳过初学者的课程,甚至在相同的学习轨道上学习高级课程。Quantra 的课程将通过互动功能让您按照自己的节奏学习。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
EPAT 先睹为快讲座-如何优化交易策略?
原文:https://blog.quantinsti.com/epat-sneak-peek-lecture-27-february-2020/
2020 年 2 月 27 日星期四
东部时间上午 8:00 | IST 时间下午 6:30 |新加坡时间晚上 9:00
https://www.youtube.com/embed/sme-4-VsD04?rel=0
我们已经收到了许多感兴趣的个人的请求,他们想要一个简短的想法或者一个演示讲座,来感受一下典型的 EPAT 讲座。虽然一堂课可能不会给你整个综合课程和 6 个月的时间的确切指示,但它肯定为探索一个有代表性的会议打开了一扇窗。
本次会议将满足的问题
- 战略之旅是怎样的?
- 如何优化策略以获得更好的回报?
- 如何创建更安全的策略?
- EPAT 的内容提示
会议大纲
- 将战略概念化
- 创建战略模型
- 把它带到一个平台上进行回溯测试
- 策略优化
- 在模拟环境中执行
关于演讲者

Prodipta Ghosh(QuantInsti 副总裁)
Prodipta 领导 QuantInsti 的 Fin-tech 产品和平台开发。
他在银行业工作了十多年,在孟买和伦敦的德意志银行的交易和结构部门担任过各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
他毕业于 Jadavpur 大学,获得机械工程学士学位,并拥有 IIM 勒克瑙大学的管理学研究生学位。
简报
您可以点击此处查看本次网络研讨会的 powerpoint 演示文稿:
https://www.slideshare.net/slideshow/embed_code/key/kTbpXYrigwkhZm
EPAT Sneak Peek Lecture - How to Optimize a Trading Strategy with Prodipta Ghosh from QuantInsti
在 QuantInsti GitHub 上可用的代码文件:
- opening_range_base.py
- opening_range_optimized.py
- 2020 02 27 _ 深 _ 潜。稀有
- 2020 02 27 _ EPAT _ 交易 _ 策略. pdf
EPAT 如何帮助德布杜塔成为一名量化分析师
现在,交易者知识的一个关键部分是他的交易软件,这是千真万确的。尤其是在毫秒到微秒的算法交易中。
它需要市场知识、股票意识、外汇、策略、期货、图表、数据分析、指标等。全面了解整个行业。然而,程序、算法和策略等的创建。是算法交易的核心。
然而,问题依然存在:怎么做?
最好的方法是学习、教育和训练自己算法交易。从 Debdutta,一个认证的 EPATian 和一个经验丰富的专业人士那里学习真的很棒。
让我们看看他对自己的旅程有什么看法,这段旅程让他在算法交易领域与量化分析师齐名。
告诉我们你自己的情况
大家好,我是 Debdutta Bhattacharya,摩根大通信贷风险和金融副总裁。在学术上,我有电气工程学士学位。Kolkata Jadavpur 大学毕业,美国 Clemson 大学电子和计算机工程硕士,专攻神经网络。
在参加算法交易(EPAT)高管课程之前,你有什么工作经验?
以前,我忙于设计与贷款资格预审、信贷风险分析、信贷和决策、分布式信息和财务报告相关的软件系统。我有交易股票、期权和指数期货的经验。
是什么促使你改变你的领域?
从事定向交易多年后,我明白了交易的成功不在于工具方向正确,而在于识别和交易具有统计优势的机会。QuantInsti 教会了我寻找这些机会的工具和利用这些机会的策略。
要成为量化分析师,你必须面对哪些障碍?
最大的挑战是学会从概率的角度思考市场及其交易。接下来是通过持续验证对方法的信任。EPAT 的课程提供了理论和实践的良好结合,为学生建立黄金时间市场行动所必需的基础知识和技能。
EPAT 是如何帮助你的?
EPAT 教了我分析工具、交易策略和测试策略表现的回溯测试方法。EPAT 还提倡独立思考,并提供咨询来评估我自己的策略。所有这些学习和鼓励让我今年战胜了市场。教育是有回报的,我希望通过对我的交易理念进行勤奋的回溯测试来保持我的盈利能力。
到目前为止,你成为 Algo Trading 一员的经历如何?
EPAT 的课程与众不同。理论和实践的独特融合培养了必要的敏锐度,让我们能够满怀信心地与市场展开辩论。最重要的是,学生们从这个项目中得到了一些合理的策略,他们可以马上采用。
你的新技能对你的职业生涯有什么贡献?
当一个人开始从概率的角度看世界,并意识到虽然他能控制的很少,但他的成功取决于他找到具有统计优势的高概率机会的能力。他思维过程中的这种范式转变打开了一个机会的彩虹,他可以评估这些机会,并在尽职调查后,最终满怀信心地聘用这些机会。这是 EPAT 方案的无价之宝。
那么,下一步是什么?
我的目标是建立一个成功的全职交易业务。为此,我正在构建内置风险管理的算法,这种算法允许我进行规模化交易,并扩大仓位。另一方面,我想帮助建立一个交易教育课程,直接从市场上最好的交易者的实时经验中吸取经验。
有什么给有抱负的量化分析师的信息吗?
交易的成功取决于一个人用统计优势发现机会的能力。学习定量分析的工具和技术。EPAT 项目提供了优秀的课程,EPAT 校友的支持会给你必要的鼓励,让你一路走下去。最重要的是要记住,没有什么比创造自己的自动化策略更令人高兴的了,看着你的创造成功地在市场中导航。
结论
最近报道称,像花旗银行这样的公司发现雇佣程序员和编码员并对他们进行交易领域的培训变得更加容易。他们的经验和技能让他们对交易有了全面的了解。对于所有希望成为算法和量化交易一员的有抱负的量化分析师来说,Debutta 是一个灵感和理想。你也能做到。
下一步
如果有任何学习可以指导你在这方面走上正确的道路,请随时查看算法交易 (EPAT)的高管课程。你也可以在这里联系我们。帮助我们帮助你。
EPAT 教你成为成功交易者所需的技能。它涵盖了统计与计量经济学、金融计算与技术、算法与量化交易等培训模块。立即注册开始你的算法交易生涯。
免责声明:为了帮助那些考虑从事算法和量化交易的人,这个案例研究是根据一个学生或 QuantInsti 的 EPAT 项目的校友的个人经历整理的。案例研究仅用于说明目的,并不意味着用于投资目的。EPAT 项目完成后所取得的成果对所有人来说可能并不一致。
EPAT 如何帮助你!
https://www.youtube.com/embed/mxwYzflPmZw?rel=0
2018 年 6 月 28 日星期四 IST 时间下午 6:00 |美国东部时间上午 8:30 |新加坡时间晚上 8:30
会议大纲
如果你一直在寻找进入定量和算法交易领域的职业生涯,你很可能听说过 EPAT 项目。但是它能帮助你在这个领域实现你的职业和学习目标吗?关于 EPAT 的这次信息通报会讨论了这一问题,同时涵盖了 EPAT 方案的各个实际方面。除了每个 EPAT 模块的详细概述,它还涵盖了 EPAT 如何填补现有的技能差距,并解决行业和个人的学习要求。
在这个关于 EPAT 的简短而有效的信息会议中,您将了解所有这些以及更多信息:
- 为什么 EPAT 一直为来自 60 多个国家的专业人士工作?
- 了解 EPAT 的实际情况。
- EPAT 能帮你解决定量和算法交易领域的痛点吗?
- 终身学习和其他 EPAT 特色如何让你保持领先?
演讲者

nitesh Khan delwal(QuantInsti 首席执行官)
Nitesh Khandelwal 毕业于 IIT 坎普尔大学电气工程专业,并获得了 IIM 勒克瑙大学的管理学研究生学位,他的职业生涯始于财政部的银行部门。在一家自营交易公司短暂担任领导后,他在孟买共同创立了 iRage。如今,iRage 是印度算法交易领域的领先企业。后来,当 Nitesh 搬到新加坡时,他成立了一家贸易公司,在全球交易所进行交易。
2016 年,他将重心转移到 QuantInsti 担任其 CEO。QuantInsti 继续致力于将面向科学&技术的贸易知识和途径带给全球大众,并且已经帮助来自 130 多个国家的用户实现了同样的目标。
EPATians 的份额|构建 Algo 基础设施,作者 BNS·库马尔
原文:https://blog.quantinsti.com/epatians-share-building-algo-infrastructure-bns-kumar/
https://open.spotify.com/embed-podcast/episode/4X2udaGK4eI7uglj7jdaAN
描述
BNS·库马尔是一个有 10 年交易经验的量化交易者,他在一家知名公司做量化交易。在建模、分析、设置交易台和自动化等许多关键因素方面拥有丰富的经验,在本课程中,BNS 将带您了解构建 Algo 基础设施的整个过程。BNS·库马尔是 EPAT 大学的校友。
关于 EPATians 的股份
在这些考验时期,“EPATians ' Share”是一项倡议,来自不同领域的 EPATian 人通过一系列 25 - 40 分钟的简短会议,在他们的专业领域与 epat Ian 社区分享他们丰富的知识。
关键要点
- 对从 exchange 到本地系统的数据包流有基本的了解。
- 对相关部件有基本的了解。
- 算法交易涉及的风险。
关于演讲者
BNS·库马尔是一名定量交易员,在金融市场建模和风险与投资组合分析方面有 10 年的经验。目前,他是 TIAA Nuveen 的一名 Quant。
在此之前,他为一家印度贸易公司设立了 algo 交易平台,并管理 algo 基金。后来,他为一家机构投资者担任顾问,让自己的外汇交易实现自动化。
点击访问我们的 Spotify 频道。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
EPATians ' s Share | Rohit Gupta 的私募股权二级市场
原文:https://blog.quantinsti.com/epatians-share-private-equity-secondary-markets-rohit-gupta/
https://open.spotify.com/embed-podcast/episode/0QPymwi5mY4yXTyo8fEvhZ
描述
rohit Gupta(ARC Capital Singapore-Investment Bank 的副总裁)在本次会议中解释了二级市场,涵盖了从介绍、卖方、案例研究到买方、因素以及所有您需要了解的入门知识。Rohit 是 EPAT 大学的校友。
关于 EPATians 的股份
在这些考验时期,“EPATians ' Share”是一项倡议,来自不同领域的 EPATian 人通过一系列 25 - 40 分钟的简短会议,在他们的专业领域与 epat Ian 社区分享他们丰富的知识。
关键要点
- 二级市场介绍
- 什么是次要的
- 市场中卖方的概述(天使投资人、私募股权投资人、家族理财室、风险投资人的案例)
- 销售者的动机
- 新加坡一家风险投资公司的真实案例研究
- 市场中买方的概况
- 购买者的动机
- 风险投资/私募股权投资的视角:与主要投资相比,吸引次要投资的因素
- 独角兽(Grab- Singapore、Paytm- India、Face++/Touitiao(中国))和风投/家族理财室通过次级途径进行投资的真实案例研究
- 二级基金的成长与一级基金和二级基金的收益比较分析
关于演讲者
Rohit Gupta 目前在 ARC Capital Singapore-Investment Bank 担任副总裁,总部设在上海,专注于公共和私人市场。在他目前的职位上,他与来自 APAC 的顶级风投和私募股权公司合作,为他们提供关于使用替代融资方式进行融资的建议,并帮助他们的投资组合公司/现有有限合伙人在二级市场上寻找潜在的退出机会。
此前,Rohit 曾在香港一家对冲基金工作,管理一个中国/香港股票投资组合。在印度担任自营交易员期间,他还拥有投资美国固定收益市场的经验。
Rohit 于 2015-16 年完成了 CUHK 大学的 MBA 学位,在 CUHK 任职期间,他还因改善了同行学习环境而获得了圣加仑大学 50 强商学院的全球领导力奖。
点击访问我们的 Spotify 频道。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
吉甘·甘地的《交易是一次孤独的旅程》
原文:https://blog.quantinsti.com/epatians-share-trading-lonely-journey-jigam-gandhi/
https://open.spotify.com/embed-podcast/episode/5AioAng84QxHgd8sgllOBA?si=aU-vleDtQYyQYfEHv2fYlg
描述
在这个播客中,EPAT 大学的校友 Jigam Gandhi 分享了他的交易经验和心得。他关注交易者的个性、前提条件、思维过程和各种场景。
关于 EPATians 的股份
在这些考验时期,“EPATians ' Share”是一项倡议,来自不同领域的 EPATian 人通过一系列 25 - 40 分钟的简短会议,在他们的专业领域与 epat Ian 社区分享他们丰富的知识。
关键要点
- 个人交易者的优势
- 交易者的先决条件/流程
- 个人交易者可以执行的思维过程/策略
- 个人交易者可以过滤掉的情景/策略。
关于演讲者
Jigam Gandhi 已从 NMIMS 大学获得金融 MBA 学位。自 2009 年以来,他目前在 Arcadia Share and stock brokers PVT . ltd .工作,担任高级交易员,在股票市场拥有 25 年的丰富经验,其中 16 年从事自营交易。
他的专长包括处理账户、股票经纪人的结算、处理 NSE 经纪业务,包括合规。
点击访问我们的 Spotify 频道。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
以 ETF 作为领先指标的交易
原文:https://blog.quantinsti.com/etf-msci-futures-excel-model/

指数跟踪交易模式
指数跟踪交易是一种策略,你观察前 n 个烛台上的价格,并据此下注。直觉是 MSCI 期货跟随 ETF。因此,如果 ETF 表现良好,我们假设 MSCI 期货也表现良好,从而做出相应的买卖决定。
谁可以使用?
对算法交易感兴趣的人和想了解 ETF 作为领先指标的人。
如何发挥作用?
该 excel 模型将帮助您:
- 建立一个以 ETF 为主要指标的策略
- 理解策略执行的交易逻辑
- 优化交易参数
为什么要下载交易模型?
由于交易逻辑编码在表格的单元格中,你可以在方便的时候下载并分析这些文件来加深理解。不仅如此,你还可以通过玩弄数字来获得更好的结果。您可能会找到比文章中指定的利润更高的合适参数。
模型说明
在这个例子中,我们考虑摩根士丹利资本国际期货数据。我们跟踪一只 ETF,并假设摩根士丹利资本国际指数对该 ETF 有很强的正贝塔。我们观察 ETF 和 MSCI 的 5 分钟间隔价格,并根据 ETF 回报买入/卖出 MSCI。如果 ETF 回报为正,我们就买入一手 MSCI 期货。如果 ETF 回报为负,我们卖出一手 MSCI 期货。我们跟踪的 ETF 是印度 SP 股票。本质上,如果 ETF 看涨,我们就做多(买入)MSCI 期货;如果 ETF 看跌,我们就做空(卖出)MSCI 期货。
**用于 MSCI 期货合约的数据是从 2015 年 2 月 2 日日到 2015 年 3 月 4 日日间隔 5 分钟的数据。
假设
- 出于简化目的,我们忽略买卖价差。
- 价格以 5 分钟为间隔,我们只以 5 分钟收盘价交易。
- 由于这是离散数据,平仓发生在蜡烛线结束时,即在 5 分钟结束时的可用价格。
- 仅交易常规时段(T)
- MSCI 期货的交易成本为 1.10 美元。
- 每笔交易的保证金是 1500 美元。
- 交易数量为 1 手(MSCI 订单规模为 50),交易时间为新加坡时间上午 11:30 至下午 5:55
输入参数
请注意,下面提到的所有输入参数值都是可配置的。
- 考虑 5 分钟间隔结束时的价格。
- 我们使用 ETF 作为领先指标
从第 12 行开始,市场数据和交易模型包含在电子表格中。因此,当参考 D 列时,显然应该从 D12 开始参考。
Excel 模型中列的说明
C 列代表 ETF 的价格。
列 D 代表 MSCI 期货的价格。
E 列表示 ETF 数据的对数收益。
列 F 表示 MSCI 数据的对数回报。
G 列代表 ETF 数据的平均收益。
H 列代表 MSCI 数据的平均回报率。
栏 I 计算交易信号。公式 =IF(G13= ""," ",IF(G13 > H13,"买入",IF(G13 < H13,"卖出"," I12 "))表示如果单元格 G13 中的条目为空,则保持 I13 为空,否则,如果 G13 (MSCI 期货数据)大于 H13,则生成 MSCI 期货合约的买入信号,否则,如果 G13 小于 H13,则生成 MSCI 期货合约的卖出信号。
J 列代表交易价格。这是产生交易信号的价格。公式 =IF(I13= ""," ",IF(I13=I12,J12,D13)) 表示如果单元格 I13 中的条目为空,则该条目为空。否则,如果 I13=I12,则交易价格由 J12 中的条目给出。如果 I13 既不为空也不等于 I12,则交易价格由 D13 给出。
列 K 代表标记上市。公式 =IF(OR(I13= ",I12= " "),0,IF(I13=I12,K12,IF(I13="Buy ",K12+J12-J13,IF(I13="Sell ",K12+J13-J12,0)))表示如果单元格 I12 或 I13 为空,则 MTM 为零。否则,如果 I13=I12,则 MTM 是 K12,否则,如果 I13 不等于 I12,并且如果 I13=“购买”,则 MTM 由 K12+J12-J13 给出,如果 I13 不等于 I12,并且如果 I13 =“出售”,则 MTM 由 K12+J13-J12 给出。
列 L 代表交易的损益状态。公式 =IF(OR(I13= ",I12= " " "),IF(K13 < K12,"亏损",IF(K13 > K12,"盈利",IF(I13<T9】I12," NPNL "," "))表示如果 I13 或 I12 中有一个为空,则盈利分录也为空。否则,如果 K13 小于 K12,则进场是亏损,如果 K13 大于 K12,则进场是盈利。下一部分 I13 < > I12 表示如果 I13 不等于 I12 那么就没有利润没有损失(NPNL)。这是有意义的,因为我们已经计算了以前平仓的利润。
列 M 计算交易的盈亏。公式 =IF(L22= ",0,K22-K21 ) 表示如果 L23 为空,表示无盈利无亏损,则交易盈亏为零。如果 L23 不为空,则利润计算为 MTM 值的差值。
输出
输出表列出了一些性能指标。
盈利交易数量为 118 笔,亏损交易数量为 77 笔。
总交易量为 277 笔,总利润为 1970 美元。每笔交易的平均利润是 7.24 美元。每笔交易的净利润为 5.04 美元。计算方法是每笔交易的平均利润减去两倍的交易成本。交易区间数为 23。月收益的计算方法是总交易量和每笔交易的净利润的乘积除以每笔交易的保证金和插值天数的乘积
现在轮到你了!
- 首先,下载模型
- 修改参数并研究回测结果
- 对其他历史价格运行模型
- 修改公式和策略,添加新的参数和指标!玩逻辑!探索研究!
- 请在下面评论您的结果和建议
点击下载 excel ( )如果您还没有登录,请先登录/注册 !)**
探索以太坊和以太交易
以太坊和以太交易已经获得了广泛的吸引力,尽管时间跨度很短。你有没有想过它们是什么,以太坊交易是如何发生的?在哪里可以获得关于以太坊和以太的完整理解?
在这篇博客中,我们将一窥以太坊以及它给这个被比特币冲昏了头脑的世界带来的所有变化。
我们涵盖以下内容:
让我们开始吧!
以太坊是什么?
在我们早期的博客中,我们探索了区块链技术和比特币——第一种使区块链技术诞生的加密货币。比特币是一种去中心化的金融交易方式。尽管这是一个巨大的突破,但这种分布式分类账仅限于存储交易。
但是,
- 如果我们也能在区块链上存储和执行代码,那会怎么样?
- 如果我们可以根据一些预先约定的条件进行交易,会怎么样?
- 或者使用区块链来运行我们的程序?
- 进入以太坊!
用 Solidity(它的原生编程语言)和 Ether(它的货币)编写的智能合约武装起来——随着以太坊的进入,我们所知道的世界永远改变了!
以太坊简史

2011 年,17 岁的俄裔加拿大少年维塔利克·布特林(Vitalik Buterin)发现自己对比特币非常感兴趣。他对比特币如此着迷,以至于创办了《比特币杂志》,并积极开始为其写作。
他认为比特币可以通过一种允许它运行代码的脚本语言变得更加强大。然而,由于未能获得比特币社区的同意,布特林在 2013 年 11 月 27 日的白皮书中提出了一个名为以太坊的新平台。
以太坊在其白皮书中被介绍为‘下一代智能合约和分散应用平台’。相比之下,比特币被简单地称为“,一种点对点电子现金系统。
2014 年 4 月 1 日,当时以太坊项目的 CTO Gavin Wood 发布了以太坊黄皮书。创始人在 2014 年 7 月 22 日至 9 月 2 日期间发起了一场众筹活动,他们出售以太(以太币)以换取比特币,并筹集了超过 1800 万美元。

以太坊于 2015 年 7 月上线,这是其第一个名为 Frontier 的现场发布。
以太坊的联合创始人名单很长。你可以在这里阅读更多关于以太坊的历史。
以太坊的特点
以太是什么?
以太(ETH)是区块链以太坊的本地货币。给它提供动力的是燃料。像比特币一样,以太是一种点对点货币,你可以用它来交易或购买“汽油”。气体是以太坊宇宙中用于交易费用的术语。你需要天然气来支付以太坊区块链上任何智能合约或交易的计算费用。
什么是智能合约?
合同是双方之间的协议。智能合同只是以计算机程序的形式编写的合同。因此,智能合约用编程语言概述了转移任何资产(不一定是货币)的条款和条件。这里的资产可以是任何东西——股票、金钱、财产或任何数字资产。
以太坊区块链的任何人都可以创建智能合约。智能合约的一个重要特征是,一旦它们进入区块链,就不能以任何方式改变。它们是不可改变的。
但是,您可以在以后上传修改了条款和条件的另一个版本的合同。接下来,交易将根据修订后的条款和条件进行。
与由中央机构验证合同的传统合同相比,智能合同由区块链验证。契约以简单的 if-then-else 语句的格式编码,并在满足预定义的条件时自动执行。
在以太坊上,Solidity 通常用于智能合约的编码。支持智能合约编码的其他流行语言有 Vyper 、 Yul 和 DAML 。

以太坊虚拟机
虚拟机是一种模拟计算机的程序。它有一个中央处理器,内存等。,就像一台物理计算机。以太坊虚拟机(EVM)就像一个分散在区块链的计算机网络,只是每台计算机都是一个虚拟机。
区块链上的每个节点运行这个 EVM。智能合同被上传并部署在 EVM 上,节点使用 EVM 来维护整个区块链的共识。
EVM 是智能合约的沙盒隔离运行时环境。EVM 理解智能合约的语言。我们可以在这个独立的环境中编码和测试我们的代码,当我们准备好部署它时,我们可以在区块链上这样做。
固态
Solidity 是一种面向对象的高级编程语言,类似于 C++、Python、Javascript。它被设计用来开发以太坊上的智能合约。如上所述,这些智能合约在 EVM 上运行。
Solidity 编译器将代码编译成 EVM 字节码和 ABI(应用二进制接口)。字节码是用低级编程语言编写的可执行代码,可以被 EVM 理解,而 ABI 是智能合约和字节码之间的接口。
除了以太坊,Solidity 在其他平台也有以太坊经典、币安连锁、雪崩、 Tron 等。

气体
煤气是在以太坊区块链上处理交易所支付的费用。所需的汽油量取决于交易的复杂程度——简单的交易需要较少的汽油,复杂的交易需要较多的汽油。
还需要更多的汽油来确定交易的优先顺序。由于区块大小有限,更高的天然气量会激励矿商更快地进行交易。天然气价格也是动态的,并且根据网络中的流量而变化。
天然气价格以 gwei 表示。在这里,g 代表“气体”,而“微”指的是引入 b 货币概念的。1 ETH 等于 1,000,000,000 gwei。

以太坊因其高昂的燃气费而面临批评。不符合矿工门槛的交易可能会被延迟或干脆拒绝。有时费用会涨到 100 美元!用户可能需要利用来自各个站点的数据,在汽油费较低的时候为他们的交易计时。这对于寻找更便宜和更有效的选择的用户来说是令人沮丧的。
虽然以太坊 2.0 试图解决这一问题,但高昂的燃气费和低廉的缓慢交易时间将继续成为用户的祸根,直到以太坊完全转向 PoS。高额的燃气费使得以太坊无法用于微支付,而微支付是其必不可少的用例之一。
与此同时,区块链的许多竞争对手,如索拉纳、T2、卡尔达诺、T4 和雪崩,正在开发更高效、更实惠的系统,并越来越受欢迎。
以太坊用例
分散应用
分散式网络带来了分散式应用(dapps)!
让我们看看我们传统上使用的应用程序的结构。通常,有一个前端,一个用户界面,和一个后端,一个位于单台计算机或服务器上的数据库。
但是如果数据库现在位于一个区块链——一个分散的节点网络——上呢?
这些年来,web 的面貌从前端使用静态脚本的 Web 1.0 转变为前端使用动态脚本的 Web 2.0,从而带来了更好的用户交互。现在我们在区块链上有了后端的 Web 3.0 ,真正革新了应用程序的结构。

当您登录到一个常规应用程序时,数据是通过一个 API 从数据库中获取的。类似地,当您登录到 dapp 时,将通过智能合约接口从区块链获取数据。一些著名的 dapps 例子有:
- Steemit(一个博客和社交媒体网站)
- Uniswap(一个分散的加密货币交易所)
- 占卜(一个投注平台)
- Cryptokitties (一款游戏)
- Ethlance (首个完全在以太坊区块链运营的就业市场平台)

分散的自治组织
什么是组织?它是一群有特定目的的有组织的人。
目的是由组织的指导方针定义的,通常有一个适当的层次结构。
现在,以我们对区块链的了解为背景,想象一个分散的组织,由其成员控制,它是透明的,具有以计算机程序形式明确定义的指导方针。其账目和记录保存在区块链。这是一个分散的自治组织(DAO)。
智能合同可以被编码为包括组织的所有过程和功能,以便它变得自我可持续,并且可以在没有任何人类参与的情况下运行。这意味着它们不能被一个集中的权力机构关闭——它们将继续运行。如果规则有任何变更,区块链将达成共识,并在《守则》中实施变更。
一个简单的 DAO 例子可以是无人驾驶出租车服务,它可以接送客户,产生付款,在加油站加油,并将其账户上传到区块链-所有这些都基于智能合同。
分散金融
去中心化金融(DeFi)是一个基于区块链的去中心化金融生态系统,它使用智能合约而不是集中的权力机构或中介。所以没有交易所,银行,券商等。!
一个不眠的市场。
有了 DeFi,市场永远向所有人开放。使用它的服务不需要很长的应用程序进程。由于没有人工操作,这些 DeFi 市场全天候运行。
所有用户都使用假名,它提供了一个基础设施,以一种不可信的方式与陌生人交易。交易在几分钟而不是几天内完成,并且数据在区块链上透明地维护。
DeFi 提供了几乎所有金融交易的替代方案,如全球汇款、借款、购买保险、交易等。
MakerDAO 是 DeFi 应用的主要例子之一。
DEFI的利弊如下:
| DEFI |
| 优点 | 缺点 |
| 访问所有 | 早期阶段 |
| 透明度 | 缺乏可扩展性 |
| 省时 | 诈骗风险 |
| 减少人为错误的可能性 | 缺乏用户友好性 |
| 无中介 | 高需求-高利率 |
不可替换的令牌
不可替换令牌(NFT)是代表唯一且不可互换的项目的令牌。这里的项目可以是一首歌曲,艺术,收藏品,甚至是房地产。这种独特的物品只能有一个认证的所有者,并且这种所有权证明由区块链保护。因此,NFT 代表了这些独特物品的所有权。
不可替代的物品有独特的属性,比如一件家具或一首歌。可替代的物品都是一样的,比如苹果、纸币等。他们可以很容易地交换,因为每个项目是相同的,与其他相同的价值。NFTs 也可以用来表示游戏中的资产。
NFT 可以在数字市场上交易或出售。但与可以自由兑换的加密货币不同,NFT 代表的是基础资产。因此,内容创作者可以转让 NFT 的所有权(例如,在艺术作品的情况下),也可以保留所有权并使用 NFT 来赚取转售版税(例如,在音乐作品的情况下)。
在线艺术画廊古玩卡是以太坊 NFT 最早的实现之一。NFT 的一些例子是艺术品、豪华运动鞋、散文,以及其他数字资产。
NFT 音乐产业正在迅速发展。2021 年 3 月,莱昂国王乐队成为第一个以 NFT 的身份发布新专辑的乐队,2021 年 12 月在,NFT 音乐初创公司 sound.xyz 筹集了 500 万美元的种子资金。
工作证明的缺点
比特币使用的工作证明算法,目前以太坊也在使用,非常有效和流行。在这里,一群矿工竞争解决一个重型密码难题。获胜的节点将该块添加到链中,从而从所挖掘的块中的所有交易中赢得奖励和交易费。
PoW 是高度安全的,激励采矿节点,并分散网络。
然而,它有两个主要缺点:
高能耗
随着比特币网络规模的扩大,加密难题的难度也在增加,这是由区块链自动调整的。随着难度的增加,人们设计了专门的硬件来开采这些区块。
目前,比特币只能使用 ASICs(专用集成电路)进行挖掘,挖掘过程消耗大量能量。
明确地说,我非常相信加密,但是它不能推动化石燃料使用的大规模增长,尤其是煤
— Elon Musk (@elonmusk) May 13, 2021
这几天大家都在学习算法交易的 5 个原因!
原文:https://blog.quantinsti.com/everyone-learning-algorithmic-trading/
算法交易是当今最受欢迎的交易形式,比人工交易更有利,因为它能实现更快更准确的交易实践。
全球算法交易市场预计在预测期内(2021-2026 年)以 10%左右的 CAGR 增长。
因此,无论是数据分析师、散户交易员还是 T4 工程师,几乎每个人都在努力学习算法交易。让我们讨论一下学习算法交易的 5 个原因,它们是:
在不断增长的金融科技领域获得理想的工作
由于快速、准确和安全的方法,金融科技领域是世界上增长最快的领域。算法交易是金融科技领域的一部分,它吸引了那些希望赚取丰厚薪水和奖金的个人。
由于这个众所周知的事实,许多人渴望学习算法交易,但他们必须记住,有各种各样的工作角色,如量化分析师、量化开发员等。
不管你选择什么角色,在算法交易中你都需要学习不同的方面,这些方面是:
- 程序设计语言
- 金融市场经验
- 数据管理
- 定量分析
开发一个更加数据驱动的交易方法
数据驱动的交易更准确,遭受损失的机会更少。借助数据,您可以:
数据是算法交易过程中最重要的部分。分析数据可以揭示金融市场的趋势,为所有的交易想法和策略创造奠定基础。因此,数据是金融市场交易的燃料。
此外,它通常是关于“一个能快速获取交易数据的人”。不仅快速访问有效,您还需要了解关于数据管理的知识,因为这两者都是不可或缺的。
因此,通过快速访问数据、良好的数据管理以及正确的数据实施,一个人可以在金融市场中先于他人进行交易并获得优势。
在人工智能或机器学习的帮助下,可以更快地提取数据,并将其转化为有用的信息。
5 种不同类型的数据产品是:
- 实时数据(1 级、2 级、3 级和逐节拍数据)
- 快照数据
- 一天结束(EOD)的数据
- 公司数据
- 史料
建立自己的交易平台或咨询公司
为了建立自己的交易平台或咨询公司,你需要掌握算法交易的必要知识,没有这些知识就不可能前进。
一旦你很好地理解了算法交易,你将能够以最有效的方式遵循这个过程。交易台有助于给你一个优势,因为它是一种有着美好未来的业务。
随着算法交易在全球范围内的快速增长,拥有一个交易平台或一家咨询公司可能会非常有益和成功。就像任何其他业务一样,建立自己的交易平台或咨询公司需要资金、奉献精神和丰富的知识。
此外,由于交易员的专业知识和表现,他们依赖于交易台。
减少交易中与人工相关的障碍
谈到算法交易优于传统交易,已经证明通过算法进行交易更快更准确,没有可能导致错误的人类情绪。此外,交易成本降低,因为算法只按指示的方式执行。
让我们看看算法交易扫除了什么障碍:
恐惧、贪婪或过度兴奋等情绪不会占上风
在算法交易中,人们可以确信不会被情绪所驱使,这种情绪会导致在制定交易策略或执行交易时做出错误的决策。算法交易完全建立在逻辑的基础上,以最佳回报为目标。

No human emotions
降低交易中的交易成本
在算法交易的帮助下,交易成本被降至最低,因为算法不会因受情绪影响而在短时间内跳到不同的交易。因此,算法按照指示的方式工作。

Less transaction costs
交易时的时间效率
说到节省时间,算法交易效果最好,因为它在不同的金融市场同时监控和交易。算法基于不断变化的市场条件、趋势和止损、止损限制等指令来执行交易。

Time efficient
帮助为未来做好准备
算法交易是一个为未来做好准备的强大工具,因为我们已经在开始讨论了算法交易者是如何随着时间变得越来越强大的。

Future ready
更好、更方便地管理风险
交易中的风险管理对于避免承担因股市交易而产生的损失风险至关重要。风险管理涉及风险的识别、评估和缓解,这些风险通常在市场走势与预期相反时出现。
因此,在对市场进行彻底分析的基础上,在预测所有风险之后,设定你的预期是非常重要的。
借助算法交易,以下是风险管理的措施:
投资组合优化
投资组合优化意味着分析不同投资比例的投资组合。通过计算每个投资组合的风险和回报,可以实现投资的最优化。
例如,可以使用[夏普比率]( https://quantra.quantinsti.com/glossary/Sharpe-Ratio#:~:text=The Sharpe ratio measures the ,taking%20to%20earn%20additional%20returns.)来分析一个投资组合,利用该比率可以找到投资组合中每项投资的超额收益与额外风险的比率。
因此,可以优化投资组合,使夏普比率较高的股票多于夏普比率较低的股票。
对冲
对冲是一种投资策略,旨在抵消潜在的损失,或者换句话说,未来预期的价格波动。对于套期保值,金融工具如保险、期货合约、掉期、期权等。可以用来对冲。
例如,A 级大米的期货在商品交易所交易,每份合约的价格是 100 公斤。Mani 希望在该月的最后一周购买 5000 公斤 A 级大米,而 Russell 希望在该月的最后一周出售 5000 公斤 A 级大米。
现在,期货合约对双方都合适,因为双方可以在交易所执行 50 份合约的交易。
1%法则和 2%投资法则
交易中的 1%和 2%原则意味着每笔交易中可行的最大风险应该是 1%或 2%。这有助于你避免否则可能发生的过度损失。
例如,通过使用衡量波动性的 Beta ,如果投资一只股票的风险超过 2%,就可以避免交易。
利用先进技术监控金融市场
应该使用机器学习等人工智能来监控交易,以便找到最佳的交易机会。例如,通过利用机器学习技术,算法监控不同的金融市场以及金融资产,以找到最有利的交易机会。
避免不明确的交易设置
如果你使用均线、均线等移动指标。其中一个指标显示了清晰的交易设置,但与其他指标的交易设置不一致,这就造成了混乱。
在这种情况下,最好等待合适的交易,不要在不确定的时候做任何决定。例如,如果均线不符合均线,在沉迷交易之前,必须耐心等待合适的交易场景。
止损
止损是当股票价格达到被称为止损价格的特定价格时触发的买入或卖出指令。这有助于交易者避免持续监控市场。
例如,如果你以每股 50 美元的价格买入 XYZ 股票,而你担心它会下跌,你可以使用止损单。止损单可以指示在价格跌破某个价位时卖出。比方说,你决定把价格定为每股 45 美元,如果低于这个价格,算法就会卖出股票,以避免更大的损失。
结论
这篇文章旨在简要提及算法交易成为趋势的 5 个最重要的原因。此外,这篇文章旨在帮助你了解这种先进的交易技术与传统的手工交易的区别。
如果你想开始学习算法交易,你可以报名参加算法交易入门课程!从头开始。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
交易的演变:从物物交换系统到算法交易
原文:https://blog.quantinsti.com/evolution-trading-barter-system-algo-trading/

由尼廷·塔帕尔
贸易史
交易的发展是人类旅程中最重要的因素之一。人类已经进化了几个世纪,如果他们被限制在地理范围内,这是不可能的。
贸易是一种为了共同利益将人们聚集在一起的系统,尽管原始社会只在宗教和文化活动中看到人们的聚集,这受到习俗或亲属关系的限制。
今天,贸易给各国带来了静态和动态的收益。贸易激发了技术的创新,导致了国家间更快更好的交流,创造了一个统一的贸易世界。让我带你经历“贸易之旅”,它在塑造现代经济中发挥了至关重要的作用,并让你了解简单的商品和服务交换是如何发展成为更加复杂的股票交易实践的。
贸易的起源
文明之前的贸易:交易石头

石器时代大约开始于 260 万年前;在这个时代,石器被用来打猎,人们自给自足。他们四处寻找食物和住所,贸易是在相对较小的范围内进行的,在较小的社区内,在较短的距离内。石器时代早期(石器时代旧石器阶段)没有农耕和商人的概念。贸易是史前人类的主要工具,他们交换货物和服务,包括狩猎设备和被认为有巨大价值的石头。
使用货币:易货系统
公元前 17000 年至公元前 9000 年
第一次长途贸易:黑曜石&农业

黑曜石

《收获》展示了梅内那墓中的一幅壁画
黑曜石是公元前 17000 年后广泛使用的贸易物品,因为这种材料在金属使用之前非常受欢迎。黑曜石被用来制作切割工具,比其他可用材料更受青睐,因为它也象征着部落的更高地位。
在地中海地区,黑曜石的交易距离为 900 公里。
随着新石器时代(新石器时代)的引入,即从公元前 9000 年开始,农业开始发展,人们开始驯养动物和种植作物,这导致社区在一个地方定居。
随着农业和新农具的出现,有了更多的剩余食物,这些食物被用来交换其他有用的商品(易货贸易制度)。不同社区之间开始进行贸易,不仅交换剩余的食物,还交换农具(石头制成的工具)和手工艺品。由此,一个新的商人社会阶层产生了;他们会步行数千英里与其他社区进行贸易。
使用的货币:牲畜、盐、金属、稀有宝石等商品
公元前 8000 年至公元前 6000 年
成熟的贸易体系:正在崛起的文明
现在是公元前 8000 年,世界人口在 500 万左右。人们现在已经学会了耕作和驯养动物的艺术,农业正在蓬勃发展,一个生产粮食的经济已经出现。
陶器传统在现在被称为亚洲、日本、韩国、中国、墨西哥和更多的地方兴起。黑曜石仍然是贸易习惯的重要组成部分,但是现在有了更多的贸易(物物交换),包括牲畜、剩余产品、盐、铜、贝壳、陶器、兽皮、农具、种子等。

在釜山发现的韩国新石器时代的壶
在接下来的几个世纪里,人们开始居住在世界的其他地方,包括印度河流域、约旦、爱尔兰、安纳托利亚、苏格兰、北美、尼日利亚、土耳其、挪威、意大利、欧洲、埃及等。饰品(金和铜)出现了,并在世界各地有巨大的需求。
基于居住区域,这些文化群体开始适应基于邻近地区自然资源可用性的必需品。现在的物品不仅仅限于功能,还具有美学价值。
新定居下来的人现在开始从几百英里以外的地方进口异国商品。
使用的货币:武器、金属制品、陶器、铜、植物产品等形式的货币。
公元前 5000 年至公元前 4000 年
重要发明:fast &编年史
“轮子”的发明和发展是贸易史的重要组成部分。这个见证了轮子使用的文明比他们的祖先有更好的优势,因为他们有更大的能力生产食物,制造商品,并在更远的距离运输人和货物。

最早的轮子是由一块实心木头制成的。
社区开始扩大,因为他们在短时间内走更远的距离变得更加容易,而且没有必要靠近粮食生产区。轮子也用于制作陶器;这是早期文明的重要组成部分。
5000 年到 4000 年(T2)这段时间也很重要,因为这是原始文字或第一种书写形式被发现的时候。人们现在能够更好地通勤和交流。

粘土护身符,一块托特利亚石板,可追溯到公元 200 年。公元前 4500 年
使用的货币:易货,陶罐或工具,种子,谷物,工具等
公元前 3000 年至公元前 1000 年
崛起中的国际贸易:印度的商队
Ebla(叙利亚)在第三个千年成为一个突出的贸易中心。属于不同王国的社区之间的贸易繁荣发展。随着越来越多的发明成为贸易相关活动的催化剂,商品的流动增加了,新的职业也出现了。
到公元前 2000 年,前死水岛塞浦路斯通过将其丰富的铜矿资源运往近东和埃及,成为地中海的主要参与者,这些地区因其自身的自然资源如纸莎草纸和羊毛而富裕。以航海技术闻名的腓尼基,在整个地中海兜售其珍贵的雪松木和亚麻染料。中国通过交易玉石、香料以及后来的丝绸而繁荣起来。英国分享其丰富的锡。
随着骆驼的驯化,陆上贸易路线变得流行起来,被称为商队的商队利用这些贸易路线与印度和地中海进行贸易。城镇开始以前所未有的方式涌现,中转站或商队到船只的港口随处可见。

一队骆驼穿越星光灿烂的沙漠之夜
资料来源:sahapedia.org
正是在这个时候,熏香路线被用来运输乳香和没药,它们被用作油、香水、熏香和药物,这些只在阿拉伯半岛的南端(今天的也门和阿曼)被发现。
使用的货币:金、银、铜、牛、贝壳、盐、商品交换等
公元前 700 年至公元 1500 年
贸易路线:主年和更多

武尔奇城成为贸易和制造中心的枢纽。
希腊殖民者在萨罗纳建立了贸易中心。殖民地的建立允许奢侈品的进出口,如陶器、酒、石油、金属制品和纺织品。
汉朝开辟了中国和中亚之间的“丝绸之路”贸易路线。许多不同种类的商品沿着丝绸之路运输,它是世界上最古老的国际贸易路线之一。
从埃及到印度的第一次不间断航行开始于共同时代。印度的香料闻名世界,是向西方世界出口的主要商品。香料贸易促进了东西方之间新的外交关系,克里斯托弗在 1492 年出发并最终发现了美洲,部分原因是考虑到了香料贸易
从公元 7 世纪开始,“茶马古道”被用来交易中国茶叶和西藏战马。这条路线长达 6000 多英里,主要用于从中国向西藏和印度出口茶叶。
由于从北非到西非的跨撒哈拉贸易路线,黄金、盐和布料的贸易在非洲也蓬勃发展。这些贸易路线最早出现在公元 4 世纪,到公元 11 世纪,由一千多只骆驼组成的商队将带着货物穿越撒哈拉沙漠。
使用的货币:从青铜制成的小刀和铲子形状的金属开始,到印度和中国首先制造硬币,铸造硬币到汇票。
证券交易所的演变
1531 年:比利时在安特卫普有一个证券交易所。经纪人和放债人将在那里会面,处理商业、政府甚至个人债务问题。没有期票、债券或真正的股票。

17 世纪:东印度公司的成立改变了做生意的方式。这些公司的股票将为公司所有航行的收益支付股息。这些是第一批现代股份公司。这使得公司可以要求更多的股份,并建立更大的车队。投资者的利润基于公司的规模,结合禁止竞争的皇家特许。

伦敦利登霍尔街的东印度大厦
1773 年:伦敦第一个证券交易所正式成立
18 世纪 80 年代:一名日本商人发明了烛台模式来预测大米市场的价格变动。 1790 年:美国投资市场的诞生以联邦政府发行 8000 万美元债券偿还独立战争债务为标志。两年后,“梧桐树协议”由 24 名股票经纪人签署,后来转移到 Tontine 咖啡屋进行交易。
1792 年:纽约证券交易所收购首次交易的证券
1817 年:纽约证券交易所的章程被采纳
19 世纪 30 年代:孟买首次出现了公司股票、银行股票和棉纺厂股票的交易。
19 世纪 40 年代:在加州淘金热期间,路边石经纪人为矿业公司创造了市场机会,促进了一个快速发展的新兴行业的发展。
1856 年:从 19 世纪 50 年代中期开始,一个由 22 名股票经纪人组成的非正式团体,带着当时可观的 1 卢比,开始在孟买市政厅对面的一棵榕树下投资。同样的榕树仍然矗立在孟买的霍尼曼圆形公园里。
1859 年:宾夕法尼亚西部发现石油后,石油股票在场外市场交易。
1860 年:交易所蓬勃发展,有 60 名经纪人。事实上,印度的“股票热”始于美国内战爆发,美国对欧洲的棉花供应停止。此外,经纪人增加到 250 人。一个非正式的股票经纪人团体成立了“本地股票和股票经纪人协会”,该协会于 1875 年正式成立为孟买证券交易所(BSE)。

现今位于印度孟买的孟买证券交易所大楼
1864 年:由以前的路边石经纪人建立的股票经纪人公开委员会开始运作。它于 1869 年与纽约证券交易所合并。
另一方面,伦敦证交所成立于 1875 年,是亚洲最古老的证券交易所。它已经发展成为目前最重要的股票交易所。
19 世纪 90 年代:路边市场转移到交易所附近的宽街。
1904 年:伊曼纽尔·s·门德尔斯开始组织场外交易市场,鼓励合理和道德的交易。纽约场外市场机构成立于 1908 年,旨在规范交易行为。
1921 年:纽约路边市场在曼哈顿下城格林威治街的一栋新建筑里找到了一个新家。
1944 年:纽约场外交易市场成立时,制定了更高的经纪和上市标准。
1956 年:印度政府承认孟买证券交易所为该国第一家依据《证券合同(监管)法》成立的证券交易所。
1960 年:20 世纪 60 年代,网上股票交易账户还不存在。订单预订流程是通过致电您的经纪人并要求他代表您在自己的系统中输入订单来启动的。如果所订购的股票在纽约证券交易所交易,它将被调用到纽约证券交易所的交易大厅,例如,在经纪人的系统中,购买 100 股的订单与出售 100 股的订单相匹配。
如果是场外交易(OTC)股票,即没有在纽约证券交易所或美国证券交易所上市但仍在交易的股票,经纪人会通过电话打电话给做市商,他们会报出不同的价格来买卖股票。
1969 年:为了让经纪人在正常交易时间后发布买卖股票的报价,Instinet 作为第一个电子通信网络(ECN)成立
20 世纪 70 年代:纳斯达克成立。
1971: 全美证券交易商协会(National Association of Securities Dealers)是一个由场外交易(OTC)做市商组成的协会,成立于 1939 年,创建了第一个电子股票市场:全美证券交易商协会自动报价(NASDAQ)市场。
1975 年:证券交易委员会废除了固定佣金。这使得折扣佣金上升,促进了查尔斯·施瓦布和其他公司的发展。美国证券交易所推出期权市场。
1976 年:纽约证券交易所推出了指定订单周转(DOT)系统,允许经纪人将 100 股订单直接发送给场内的专家。这些不是真正的电子执行,因为专家仍然匹配订单,但它确实绕过了场内经纪人。
80 年代:电子交易的兴起。
1984 年:纽约证券交易所采用了更复杂的 SuperDOT 系统,允许高达 100,000 股的订单直接发送到交易大厅。更多的场内经纪人出局了。
1987 年:1987 年的崩盘被部分归咎于“投资组合保险”(做空股票组合的股指期货)。随着纳斯达克扩展小订单执行系统(SOES ),电子交易又向前迈进了一步,该系统允许小额交易的交易商以电子方式而不是通过电话输入订单。这样做是因为在 1987 年崩盘期间,许多经纪自营商干脆不接电话了。

80 年代的股票经纪人
1990-95: 网上交易的兴起。
1994 年:NSE 于 1994 年 11 月 4 日开始交易。不到一年,NSE 的营业额就超过了 BSE。
1996-1999 年:随着互联网流量的急剧增加,在线交易开始爆炸式增长。小交易者突然可以像专业经纪人一样获得实时定价。“日内交易者”这个词进入了词汇表。
2000 年代: 十进制化,算法交易,高频交易。
2000 年:NASD 从纳斯达克分离出来,成为一家上市公司。
2001 年:以便士为单位的股票交易开始了。纽约证券交易所推出了 Direct+,这有助于立即自动执行高达 1099 股的限价单。这是真正的电子交易(买卖订单的自动匹配),是旧的场内专家系统结束的开始。
2005 年: Reg-NMS 改变一切- HFT 进入黄金时段。美国证券交易委员会将全国市场系统的所有规则合并为 NMS 规则,这迫使纽约证券交易所走向电子化,并促进了竞争性电子交易系统和交易所的发展。
纽约证交所于 12 月推出 NYSE Hybrid,试图将纽约证交所场内业务与场外电子交易结合起来。Direct+系统上的 1,099 个份额限制已被取消。专业人士在市场中的参与度开始大幅下降。
2006 年:纽约证券交易所股份化,成为一家营利性上市公司。这给了交易所开始盈利管理的动力,也给经纪人带来了更多基于竞争的动力。
2007 年:纽约证券交易所与泛欧交易所合并,泛欧交易所成立于 2000 年,由阿姆斯特丹、布鲁塞尔和巴黎交易所合并而成。
2008 年:纽约证券交易所取消了专家,将他们重新命名为指定做市商,尽管他们仍然负责维持股票市场的公平有序。 Algo 交易在印度开始。

算法交易-市场交易量的百分比
2009 年:瑞士瑞信银行的高级执行服务(AES)部门推出了印度股票的算法交易。AES 算法套件包括传统算法策略和策略,前者寻求将交易量按时间划分,后者寻求以股票的交易量加权平均价格进行交易。
同年,软件开发商中本聪提出了比特币,这是一种基于数学证明的电子支付系统。
2010 年: Direct Edge,以前是一个 ECN,现在变成了一个交易所。在印度,印度国家证券交易所(NSE)从 2010 年 6 月开始向经纪公司提供额外的 54 个协同定位服务器“机架”,以提高交易速度。此外,采用固定协议。亚洲 algo 交易教育的先驱 Multiple QuantInsti 在印度推出并开始了第一个 Algo 交易教育项目。
2012 年:纽约证券交易所创造了一种叫做单一股票熔断机制的东西。如果道琼斯指数在特定时间内下跌特定点数,那么断路器将自动停止交易。该系统旨在降低股票市场崩溃的可能性,并在崩溃发生时,限制崩溃的损害。
截至 2012 年底,全球股票市场规模(总市值)约为 55 万亿美元。按国家划分,最大的市场是美国(约占 34%),其次是日本(约占 6%)和英国(约占 6%)
单幅 GIF 中的美国股市 40 年演变
 T2】
T2】来源:https://qz . com/230196/the-40-years-of-the-the-u-s-one-stock market-gif/
2013 年:2013 年,约 70%的美国股票是通过自动化交易实现的。算法交易占印度现金股票总交易量的三分之一,几乎是衍生品交易量的一半。
2015: 社交媒体整合;彭博终端公司将实时推文整合到其经济数据服务中。彭博社交速度追踪关于特定公司的异常聊天记录。
2017: 纳斯达克破 6000,世界股市再创新高。
纳斯达克指数收盘上涨 41.7 点,收于 6025.5 点,此前曾创下 6031.91 点的历史新高。这一里程碑事件发生在该指数触及 5000 点关口逾 17 年之后。
正如伊莎贝尔·霍文正确引用的那样,“贸易的积极方面是世界被搅在一起”,几个世纪以来,我们人类通过相互帮助使世界走到一起而繁荣发展。交易的发展只是这个旅程的一部分,但我们还没有看到在不久的将来会有什么样的创新方法来塑造未来几代人的经济。
下一步
如果你想学习算法交易的各个方面,那就去看看算法交易(EPAT)中的 T2 高管课程。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 让你具备成为成功交易者所需的技能。现在报名!
如何成功投资交易所交易基金?
交易所交易基金是投资者众所周知的投资工具/渠道之一,如果合理利用,可以实现收益最大化。接下来,我们将更多地讨论“ETF 的明智投资”。
简而言之,投资交易所交易基金提供了投资一批金融证券的机会。这个资金池是作为一个单一实体建立的,但持有不同投资者的不同类型的投资。此外,这些股票在主要的证券交易所交易,而不是在 T2 的场外交易。
就其运作而言,ETF 的每个投资者都会获得与其在全部证券中所占份额成比例的股份。此外,还有一些创新的 ETF 相关计划,让投资者做空市场。这有助于他们从杠杆中获益,而无需承担短期资本利得税。
好吧!我们已经讨论了 ETF 的含义和工作原理,让我们继续看一看这篇文章的内容。本文涵盖:
- ETF 的起源和种类
- 为什么你应该选择 ETF?
- 波动时期的 ETFs】
- 什么是 VIX,它有什么帮助?
- 构建全 ETF 投资组合时需要考虑什么?
起源&ETF 的种类
ETF 起源于 1993 年,它们最初的产品通常被称为“蜘蛛”或“间谍”(股票代码)。SPY 就是这样一种产品,被公认为历史上交易量最高的 ETF。
但是,ETF 的起步并不顺利。在“真正的”或“实际的”ETF 出现之前,有过几次尝试。根据“交易所交易基金手册”的作者所说,第一次尝试交易所交易基金是在 1989 年,主要针对标准普尔 500 指数的被称为指数参与股的产品。但是,芝加哥的一家联邦法院提到,该基金并不是独一无二的,其运作方式与 T4 期货合约非常相似。因此,有人提到,如果要进行交易,必须在期货交易所进行。这一观察推迟了“实际”ETF 的出现。
接下来是多伦多证券交易所在 1990 年的一次尝试,该产品以跟踪 TSE-35 指数的名称多伦多 35 指数参与单位 (TIPs 35)推出。
终于在三年后,1993 年 1 月 22 日,道富环球投资公司推出了 S & P500 信托 ETF 也就是我们上面提到的蜘蛛或间谍。这仍然是一个众所周知的 ETF,并继续保持其受欢迎程度。
好吧!让我们继续讨论交易所交易基金的类型,找出你可以投资的不同选择。我们将快速浏览投资者用来成功获利的最受欢迎和最常见的 ETF 类型。这 7 种交易所交易基金是:
- 市场交易所交易基金
- 部门和行业交易所交易基金
- 红利 ETF
- 基于风格的 ETF
- 商品交易所交易基金
- 货币交易所交易基金
- 债券交易所交易基金
交易所交易基金带来了投资实践的演变,并使投资者更容易获得多种投资机会。既然市场上有这么多 ETF,找到一个最适合自己的是一件相当艰巨的任务。在这里,我们将讨论最常见和最受欢迎的,以便您能够找到最适合您的投资组合非常容易。让我们来看看上面提到的每一只 ETF。
市场 ETF
这些是专为跟踪特定指数而设计的,是最常见和最著名的指数。例如, SPDR S & P 500 跟踪美国股票的 S & P 500 或“间谍”,是最著名的市场 ETF。这种类型跟踪涵盖整个或大部分股票市场的指数,也包括各种指数。有趣的是,最便宜的 ETF 是市场上最便宜的投资渠道之一。此外,它们还为您的资产配置提供一站式解决方案。
部门或行业 ETF
这些交易所交易基金提供了对特定行业或部门的投资,如制药、快速消费品等。这些交易所交易基金的运作包括将整个市场分成十个不同的部分。通过这种方式,你可以清楚地了解对你最有利的特定行业或领域。虽然市场交易所交易基金为你提供了整个市场的覆盖范围,但行业交易所交易基金让你受益于选择特定的行业。这意味着,当你选择一个特定的部门,它表现良好,你得到全部利润,而不必担心利润下降,因为其他一些部门或股票可能表现不佳。
红利 ETF
这些交易所交易基金包括那些支付股息的股票,以帮助投资者获得可观的收入。有各种各样的红利 ETF 是基于当前收益或收入最大化或基于过去红利增长的表现。这两种类型的股息 ETF 的回报率彼此相差很大。由于每种类型的应用背后都有不同的策略,因此选择最适合您的投资组合的策略非常重要。此外,您的投资风格在决定哪种红利 ETF 将服务于您的目的方面发挥着重要作用,因为您熟悉的投资类型可能是您更有信心的投资类型。
基于风格的 ETF
投资交易所交易基金有两种众所周知的方式,投资者根据成长股或基于价值投资的股票做出决策。这是因为这两只股票的表现非常相似。投资哪一种股票取决于投资者的风格。基于他们不时的表现,投资者决定选择哪一个。这些交易所交易基金适用于国内外各种规模(大盘股、小盘股和中型公司)的各种股票。
商品 ETF
这些交易所交易基金在商品市场上提供了多种多样的选择。这个主要用于跟踪商品的价格,如黄金、玉米等。这些基金的回报可能与股市同步,也可能不同步。这符合那些寻求多元化投资组合(跨资产类别)的投资者的目的。最大 ETF 利用期货、远期等衍生品来获取不同市场的敞口。然而,一些投资者购买实物商品时,每只股票都显示相同的数量。
货币 ETF
这些交易所交易基金通过帮助你从外币相对于美元的价值变动中获利而使你受益。ETF 与货币价值有两种对应方式。一,通过直接对应一定数量的特定货币的价值。其次,通过跟踪美元指数等基准货币的走势。
这些交易所交易基金有助于对冲投资或分散投资,例如度假或保护自己免受不利价格波动的影响。货币 ETF 的主要重要性在于,它们可以作为外币的现金投资。此外,正因为如此,它们可以在资产配置策略中用作现金等价物(对于外币敞口也是如此)。
债券 ETF
基本上,这些交易所交易基金为投资者提供了巨大的风险敞口。债券 ETF 有两类,投资者可以购买的债券都包括在其中。
- 覆盖整个市场的广义市场债券 ETF。
- 债券类 ETF专注于特定的债券,如国债、公司债等。
主要是,债券 ETF 背后的想法是为投资者提供市场上所有类型的债券。在这种类型中,你应该意识到基金的重点可能是到期,也可能是将到期的债券展期并重点购买新的债券。这取决于你的投资组合的要求,因为每种类型的利率风险不同。
太好了!有了 ETF 的起源和类型的良好知识,我们可以进一步讨论你应该选择其中一个 ETF 的原因。这将带我们了解投资 ETF 的优势,以及过去使用 Python 投资 ETF 的前 5 名表现。
为什么你应该选择 ETF?
如果你知道在哪里利用 ETF,你也能同样成功。有几个原因使投资这些基金非常有益,其中之一是投资这些基金不需要很多钱 。这是因为,在股票池中,每股很少超过 100 美元。通常是 100 美元或更少。即使是这么多的投资,由于总额相当于一大笔资金,你的每一份股票都可以让你对几十家甚至几百家不同的公司产生兴趣。相反,如果涉及的资金很少,而你决定投资一两只股票,那么如果这些公司表现不佳,你就有可能损失全部资金。然而,如果这些公司继续表现良好,你会看到你的利润大幅上升。这种因投资少数股票而导致的上涨或下跌在多元化投资组合中不太可能发生。值得注意的是,交易所交易基金有潜力提供稳定的利润,让投资者感到放心。
其次,有 ETF 的存取方便。 这只是暗示有 ETF 考虑了金融市场上的大部分投资资产。由于其覆盖面广,ETF 允许你投资股票、债券、大宗商品、外汇,以及被称为混合型 ETF 的资产组合。正如我们所看到的,这种多样化有助于轻松获得各种资产类别。一般来说,这些交易所交易基金在一只基金中为你提供整个市场。此外,由于投资持有量每天公布,因此透明度很高,即使在建立全 ETF 投资组合时,投资者也可以放心。
第三,ETF 提供特定资产类别的子行业。 这种分类让你可以投资一些公司,而不是属于不同行业的不同公司。当这些交易所交易基金挖掘为你提供特定的资产时,你可能会从投资你预期表现良好的公司的股票中受益。如果你意识到某个特定行业或某些公司相对于竞争对手(其他行业或某些公司)的优势趋势(特定场景),这种情况就会发生。例如,在冠状病毒爆发中表现良好的药品。
第四,ETF 性价比高。 这意味着 ETF 不收取很高的管理费。这尤其是因为基金经理的责任有限。跟踪 ETF 的基金经理需要跟踪 ETF 选择作为其基准的特定指数(股票指数或债券指数)的表现。这有助于节省投资专业人士的开支,他们帮助你决定超越市场的特定投资选项。将交易所交易基金的费用与共同基金和指数基金等类似的选择进行比较,你会发现交易所交易基金是最具成本效益或成本最低的选择。此外,你从 ETF 获得的税收优惠也很好,因为 ETF 的纳税义务不会因为市场波动而受到影响。
投资于一个适合你的投资组合和投资风格的交易所交易基金,同时选择最好的,你肯定能从中获益。ETF 可以通过各种方式帮助投资者获利,现在看来我们已经掌握了许多必要的信息。
关键要点:
ETF 类似于共同基金,因为它们都来自于相同的集合基金投资概念。集合基金将所有证券集合在一起,为投资者提供多样化投资组合的好处。
ETF 和共同基金的区别在于:
- 费用相关-ETF 比共同基金更划算
- 税收-与 ETF 相比,共同基金征收更多的税收
- 管理-ETF 管理起来更简单,因为与共同基金相比,它们更加结构化
让我们更多地了解 ETF 及其表现。
去年,交易所交易基金获得了一些丰厚的回报。您可以查看下表,了解 2019 年表现最佳的 ETF(不包括杠杆/反向)及其报价器和 YTD 回报率(%) 。
根据雅虎财经的数据,去年排名前 20 的 ETF 的涨幅都在 50%以上。这还不包括那里的杠杆产品,如迪瑞克森每日半导体牛 3X 股(SOXL) 、迪瑞克森每日科技牛 3X 股(TECL) 或迪瑞克森每日住宅建筑商&供应牛 3X 股(NAIL) ,每股上涨超过 185%。

来源:雅虎财经
此外,2019 年有 4 只表现最佳的杠杆 ETF,它们是:

来源:雅虎财经
让我们看看如何用 Python 取出数据来分析市场中的股票情况。
要了解 2019 年的表现,我们可以选择任何股票,并获取第一个月和上个月的数据。这样我们就可以比较股票在年初和年末的表现。让我们看看“SOXL”股票行情系统,看看该股票在第一个月(1 月)和最后一个月(12 月)的表现。
异国情调的选择!
传统的期权交易可以追溯到古代,当时第一个著名的期权购买者是古希腊数学家米利都的泰勒斯。当泰勒斯预测某个特定季节的橄榄收成会比平时多时,期权的使用就出现了。当春天到来时,橄榄的收获实际上比平时多得多,他行使了他的选择权,以比他支付的价格高得多的价格租用了橄榄压榨机。
为了让你对传统期权(也称为普通期权)合同有一个总体的了解,它赋予持有者以预先确定的价格或在到期日购买或出售基础资产(资产投资可能有所不同)的权利。
买入权被称为看涨期权,而卖出权是看跌期权。虽然买或卖(交易)的权利存在,但义务不存在!这些是普通期权的投资风格。未来我们还将看到普通期权的类型与奇异期权的类型。
好吧!让我们从奇异的选择开始吧!
众所周知,奇异期权是“非传统的、实验性的,也是相当奇怪的”。与此同时,它们也很有趣,可以带来超越传统选择的收益。
然而,我们稍后将讨论投资这一有趣工具的利弊。奇异期权(如普通期权)也从基础资产中获得价值。这些基础资产可以是债券、股票、期货、指数、商品或货币。
此外,让我们了解更多关于奇异期权的信息,本文将介绍:
- 什么是奇异的选择?
- 普通期权与特殊期权
- 如何用 Python 给奇异期权定价?
- 是什么让奇异期权交易如此有趣?
- 赞成&反对奇异期权
什么是奇异的选择?
奇异期权属于期权交易或期权合同的范畴,与传统的普通期权有点不同。这些差异与支付结构、到期日和履约价格有关。
此外,奇异期权提供了各种投资选择。这为投资者带来了更广泛的投资组合。
有一些特征可以很好地解释奇异期权,它们是:
- 一个奇异期权有一个“收益结构,这不同于传统期权的收益结构。期权收益就是期权的买方和卖方的净盈利/亏损。
在奇异期权的情况下,到期时的回报不仅基于标的指数在到期时的价值,还基于其在合同有效期内的几次价值。
- 此外,奇异期权的另一个有趣特征是,它们可能还包括专门为特定客户或特定市场开发的非标准基础资产/工具。
- 基础资产或工具的价值可以基于多个指数。
- 它们通常在场外交易。一般来说,投资者选择异国情调的选择,以获得多元化的投资组合,这是相当广泛的。
- 可能有看涨期权和看跌期权。
- 此外,它可能以各种方式涉及外汇汇率。我们将在前面讨论奇异的外汇期权。
因为他们是先进的,他们肯定也有一些不寻常的优势。奇异期权通过以下方式超越了传统的普通期权:
- 定制投资者的风险管理需求。
- 为投资者提供广泛的投资组合,以满足他们的投资组合需求。
- 与传统期权相比,提供更低的保费。
这就是奇异期权的含义。现在让我们继续前进,找出不同类型的香草和异国情调的选择,然后进行比较。
普通期权与奇异期权
到目前为止,我们已经了解了什么是普通期权和高级奇异期权。更进一步说,这些选项中的每一个在功能方面都有很大的不同,通过研究每个选项的类型可以更好地理解它们。
普通期权和特殊期权的划分如下。

普通选项
香草或传统的选择分为两大类,即美国和欧洲的风格或类型。
美式期权允许期权持有者在到期日前或到期日的任何时候行使相关权利。
然而,欧式期权则相反,灵活性较低,不允许持有者在到期日之前行使其权利。只有在合约到期日,持有者才有权根据其权利进行交易。
奇异的选择
奇异期权不过是美式期权和欧式期权的混合或高级版本,并一直介于两者之间。让我们逐一讨论最常见的奇异期权类型。
这些期权在本质上与传统的看涨和看跌期权非常相似。唯一的区别是,当基础资产或工具达到预定价格时,它们就会被触发。这些通常在外汇和股票市场交易。
例如,让我们假设一个障碍期权的取消价格为 110 美元,执行价格为 100 美元,目前股票在市场上的交易价格为 90 美元。这是为了防止你行使卖出看跌期权的权利。除非标的资产或股票的价格保持在 109.99 美元以下,否则期权将像标准期权一样。但是,一旦标的股票价格达到 110 美元,期权就会被取消。取消期权仅仅意味着它变得毫无价值。
相反,买进是在你行使购买权(看涨)的时候。在这种情况下,如果基础股票价格低于 109.99 美元,期权将变得一文不值,它将不复存在。因此,只有当股价达到 110 美元时,它才会存在。
敲入和敲出的风险听起来可能不太妙,但你可以以比传统期权更低的溢价(投资期权的成本)行使一种奇异的期权。屏障选项的类型有:
- 上涨-标的资产或股票的价格上涨并取消期权。
- 下跌-价格下跌,取消了期权。
- 涨价到达特定级别,期权开始生效。
- 跌价下跌到要求的水平,期权被敲入。
这些期权合约为投资者提供了固定的支付金额,以防价格变动。这些遵循“全有或全无”的支付结构。
在传统的普通期权的情况下,最终支付随着标的资产价格超过执行价格而上升。
然而,在二元期权中,二元看涨期权的持有者在标的资产高于执行价格的情况下可以获得一笔有限的总额。此外,二元看跌期权的持有者将获得有限的一次性付款,以防资产价格收于执行价以下。
例如,如果交易者持有二元看涨期权,并在执行价格为 70 美元时预先支付 20 美元,那么当股票价格在到期日高于执行价格时,持有人将获得 20 美元的一次性付款。不管股价会涨到多高,都是如此。相反,如果到期时股价低于执行价,持有者将一无所获,损失将是溢价。
利用二元期权,投资者还可以交易外汇或原油等大宗商品。
这些期权考虑了标的资产价格的平均值,以确定是否存在与执行价格相当的利润。在这种情况下,例如,如果亚式看涨期权的平均价格为 35 天,并且在到期日平均价格低于执行价格,期权将毫无价值地到期。
这不同于简单的普通期权,如欧式和美式期权,在这些期权中,期权收益取决于行权时基础工具的价格。
亚式期权的收益可以用两种方法计算:
平均价格期权:到期收益等于标的资产在特定时间段内的平均价格减去期权的固定执行价格。
平均行权期权:收益等于标的资产到期时的价格减去可变行权,等于标的资产在特定时间段内的平均价格。
这些期权赋予期权持有者行使权利(而非义务)的权力,并在特定日期以特定价格购买任何其他期权。由于传统的看涨或看跌期权以标的资产作为权益证券,因此复合期权有所不同。复合期权将标的资产作为另一种期权。
四种类型的复合选项是:
- 随叫随到-提供购买看涨期权的权利。
- 看涨看跌期权-提供购买看跌期权的权利。
- 看跌期权-提供卖出看涨期权的权利。
- 卖出看涨期权-提供卖出看跌期权的权利。
这些期权在外汇和固定收益市场上被广泛使用。
让我们向前看,看看如何用 Python 为奇异的期权定价。
如何用 Python 给奇异期权定价?
现在,我们将看到如何使用 Python 来为奇异期权定价。我们将利用蒙特卡洛模拟进行同样的操作。
蒙特卡洛模拟在这里很有帮助,因为它是一种众所周知的期权定价方法。根据这个模型,期权的价值取决于到期日标的资产价格的预期值。然而,价格是一个随机变量,寻找价格期望值的最有效方法之一是模拟。
你可以在这里阅读更多蒙特卡洛模拟。
要用 Python 应用这个模型,首先让我们根据到期日、模拟运行次数、现货价格、执行价格、障碍期权和波动性等信息找出回报。我们将每天创造 N 条收益路径。
Python 中的探索性数据分析
原文:https://blog.quantinsti.com/exploratory-data-analysis-python/
以重香重香
探索性数据分析(EDA)是指使用可用的数据,并尝试以不同的形式将其可视化,并使用各种排列和组合来熟悉数据并得出有意义的观察结果。这是在我们清理和准备数据之后,开始数据建模之前的一步。但是为什么我们不能直接转移到数据建模部分呢?
好吧,当你想到它的时候,你实际上可以跳过探索性的数据分析部分。但是如果你不熟悉数据,你就不会知道哪个变量会产生最大的影响,从而使问题陈述变得容易解决。就这么简单。
“对正确问题的近似回答(通常是模糊的)远胜于对错误问题的准确回答(通常是精确的)。”约翰·图基
是的,探索性数据分析确实有助于我们更快地得到答案。让我们更进一步,看看我们将在这个博客中涉及的主题。
什么是探索性数据分析?
据说是 John Tukey 引入了探索性数据分析,并使其成为数据科学过程中的关键步骤。当被问及这意味着什么时,他只是说,“探索性数据分析”是一种态度,一种灵活的状态,一种寻找那些我们认为不存在的东西以及我们认为存在的东西的意愿。"
探索性数据分析的主要目的是:
- 深入了解可用数据
- 找出不同变量之间的任何关系
- 发现任何不寻常的东西
- 测试任何假设或直觉
- 找到任何有助于我们更快解决问题陈述的最佳参数或变量
是的,大概就是这样。您可以在下面的
中看到 EDA 流程在整个数据科学流程中的位置

探索性数据分析的主要组成部分是数据的可视化。让我们在下一节看看如何执行探索性数据分析。
EDA 方法有哪些类型?
现有文献告诉我们,探索性数据分析有四种类型。下面我们来看看:
单变量非图形方法
分解名称,单变量意味着只有一个变量,非图形的也很好,在这个方法中没有视觉元素。
这种方法有大量的例子,可以是一支球队中 NBA 球员的身高,也可以只是特斯拉公司 2019 年的开盘价。单变量非图形方法之一可以是变量的 5 个数字汇总。
以特斯拉 11 天的收盘价为例,我们将只取收盘价,并将其列表如下。因此,它看起来像这样:

五位数汇总由最小值、第一个四分位数、中值、第三个四分位数和最大数组成。
让我们用 Python 来计算一下:
要素投资:它是什么,类型,利弊,等等
影响投资决策的因素就像营养对于食物一样。根据营养成分,你决定吃哪种食物,吃多少。对于了解特定投资方法的风险和回报来说,因素是不可或缺的。
因此,每个个体交易者将根据交易者对每个产生的回报的风险承受能力,寻求投资于具有相似风险和回报因素的股票。在本文的后面,我们将详细了解要素投资。
本文涵盖:
什么是要素投资?
因素投资意味着利用“因素”或使各种股票回报互不相同的特殊“特征”的投资方法。这些因素包括波动性、动量、股票规模等。
在创建基于因素的投资策略时,调整投资组合(包括或删除因素)的方式是投资组合资产的因素产生有利的长期投资回报。
要素投资经过一段时间已经从仅仅针对市场和公司发展到各种要素。下面是描绘相同的图像:

Factor investing evolved gradually
要素投资的类型
投资组合的两种因素或特征是:
宏观经济因素或特征
这些是捕捉各种资产类别回报的广泛风险的工具。此外,宏观经济因素的一些简单例子是:

Examples of macroeconomic factors
经济增长
经济增长是股票回报的一个非常好的因素,经济增长预测导致投资决策的最佳分配。随着积极的经济增长,国内生产总值(GDP)上升,因此,更多的投资发生在金融市场。
例如,当新冠肺炎在 2020 年爆发时,经济大幅下滑,导致股市下跌。
实际利率或利率变动
实际利率或利率变动也是做出投资决策的关键因素之一。当中央银行的利率提高时,贷款成本就会增加。因此,企业或商人的消费能力会受到影响。
消费能力下降导致投资减少。同样,随着利率的降低,消费能力增加,因为商人或企业可以借更多的钱,从而增加投资。例如,道琼斯指数在 2020 年 3 月大幅下跌,因为美联储在全球冠状病毒疫情期间将利率降至接近零。
通货膨胀或价格变化
通货膨胀或价格变化会对经济产生重大影响,因为高通货膨胀会降低每单位货币的购买能力。此外,这意味着公众可获得的资本更少,利率更高。因此,借贷成本上升,导致投资减少。
虽然,金融资产的价值随着通货膨胀的上升而增加。一些投资者将“高通胀”作为投资的积极因素,因为他们认为基础资产的价格未来可能会上涨。这种积极的投机导致市场波动性增加。
例如,与 2019 年相比,2020 年印度的通货膨胀率增长了 2.9%。2019 年,股市的繁荣发生在通胀率较低的情况下,因为苹果上涨了 85%,微软上涨了 15% 。
风格因素或特征
风格因素或特征有助于解释资产类别中的回报和风险。以下是一些风格因素的例子:

Examples of style factors
值
价值是一种股票,旨在从价格低于其基本价值的股票中获取超额回报。价值股票最常用市盈率、股息和自由现金流的数量来跟踪。
例如,花旗集团的市盈率为 9.67 倍,而标准普尔&500 指数公司的平均市盈率为 19.12 倍。
最小波动率
最小波动性意味着波动性较小的股票比波动性较大的股票获得更高的风险调整回报率。因此,波动性最小的资产被认为是投资的好资产。
例如,印度斯坦联合利华、高露洁、景顺是目前低波动股票中的一些。
气势T5】
动量是另一个重要因素,它意味着过去表现优异的股票或金融资产在未来会继续表现良好。动量交易策略通常执行几个月到一年。
例如,通过使用 Python 代码和蓝移应用多空策略,策略回报如下:

Momentum as a style factor
上图显示了多空策略如何超越基准。你可以在我们关于动量交易策略的博客中看到用 Python 编码的策略和详细解释。
要素投资与智能测试有何不同?
Smart beta 是要素投资的子集。这些策略最常用于一只 ETF ,仅做多,并且基于指数。
Smart beta 与要素投资一样,是被动和主动投资策略的结合,下面你可以看到是什么让 smart beta 成为被动和主动的结合:
| 特性 | 被动 | 智能测试版 | 激活 |
| 基于规则 | 是 | 是 | 不 |
| 资产流动性 | 高的 | 中到高 | 从低到高 |
| 投资能力 | 高的 | 高的 | 从低到高 |
| 投资组合周转 | 低的 | 低的 | 中到高 |
| 因素暴露 | 低的 | 中等 | 中等 |
| 微距曝光 | 高的 | 高的 | 高的 |
此外,smart beta 包括通常指单一资产类别(债券、商品、现金和现金等价物等)中风格因素的策略。).
让我们从下表中清楚地看到要素投资和 smart beta 在风格要素方面的相似之处和不同之处:
| 要素投资 | 智能测试版 |
| 多头/多头空头策略 | 通常,它被认为是一个只做多,简单和基于规则的策略 |
| 宏观和风格因素 | 仅风格因素 |
| 不管有没有杠杆 | 没有杠杆 |
要素投资的优点
由于要素投资是根据决定收益和风险的因素进行投资,这种投资有几个优点。这些优点是:
- 改善投资组合的结果
- 降低波动性和
- 增加投资的多样化
因素投资找出交易时每个因素的回报风险。基于因素的分析有助于改善投资组合结果,降低波动风险,增加投资组合投资的多样化。
要素投资的缺点
因素不是完全没有风险的,不知道这些风险会导致在交易过程中准备不足。首先,我们必须考虑到,有时一个因素可能只是从回报的角度来看,而不是从与之相关的错误的角度来看。
例如,在势头强劲的情况下,一支股票在过去两年的表现可能很好。但是,也有可能该股早在 6-7 年前就已经开始下跌。
在决定投资方式之前,你必须权衡利弊。在权衡两者之后,你可以在这个因素的基础上得到一个接近准确的投资风险和回报的估计。
或许最危险的是,要素投资带来了数据挖掘的风险。仅显示显示良好回测结果的因子。这种偏差被称为选择偏差。一个因素的历史记录随机良好/准确会导致错误的决策。
结论
我们在本文中讨论了要素投资对于金融市场交易者来说是一个简单而有益的概念。它有助于获得评估投资策略风险回报所需的必要知识。
要素投资和聪明贝塔之间有一个微小但重要的区别。最后,我们还讨论了各种因素的优缺点。
你想量化构建你的投资组合,创造回报并有效管理风险吗?
您是否希望学习不同的投资组合管理技术,如要素投资、风险平价和凯利投资组合,以及现代投资组合理论?
Quantra 关于量化投资组合管理的课程正是你需要的。立即注册!
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
Fama French 五因素模型及其应用
原文:https://blog.quantinsti.com/fama-french-five-factor-asset-pricing-model/
**本文原载于 Quants 门户网站。T3】
由鲁杰科·穆萨鲁尔瓦
风险和收益之间的关系一直是讨论和研究的话题。投资者和投资经理寻求量化风险的金融模型,并将风险转化为对预期股本回报率的估计(穆林斯,1982)。这篇文章将关注并讨论 Fama French 5 因素模型及其应用。
本文将从讨论理论和模型的起源开始。随后将讨论何时以及如何实施和应用该模型。
最终可以看出,Fama-French 五因素模型比以前的模型有所改进,但仍有一些缺点和可以改进的地方。
背景和历史
证券定价的不同方法和模型以及由此确定资本投资的预期回报的方法和模型多年来已经得到了改进和发展。
最初,在 1964 年,单因素模型也被称为资本资产定价模型被开发出来。这个单一因素就是贝塔,据说贝塔说明了一只股票相对于市场的波动程度。比市场波动更大的股票具有更高的贝塔系数,因此风险和回报也更高(DeMuth,2014)。
1993 年,Fama 和 French 提出了三因素模型,其中两个额外因素是规模和价值(如账面市值比)。三因素模型是对 CAPM 的重大改进,因为它调整了优于大盘的趋势。
但是,它没有解释一些异常现象,也没有解释与盈利能力和投资特别相关的预期回报的横截面变化(ValueWalk,2015)。
Fama-French 五因素模型增加了两个因素,即盈利能力和投资,这是因为有证据表明三因素模型是一个不适合预期回报的模型,因为它的三个因素忽略了与盈利能力和投资相关的平均回报的大量变化(Fama 和 French,2015)。
法玛法 5 因子模型T5】的应用
Fama-French 五因素模型的理论起点是股息贴现模型,因为该模型表明股票今天的价值取决于未来的股息。Fama 和 French 利用股利贴现模型从中得到两个新的因素,投资和盈利能力(Fama 和 French,2014)。
Fama French 模型的实证测试旨在解释在规模、B/M、盈利能力和投资方面产生巨大利差的投资组合的平均回报。
- 首先,该模型适用于根据规模、B/M、盈利能力和投资形成的投资组合。要解释的投资组合收益来自产生该因子的各种改进版本。
- 其次,在解释与模型未针对的主要异常相关的平均回报方面,将五因素模型的表现与三因素模型的表现进行了比较(Fama and French,2014)。
随着盈利能力和投资因素的增加,五因素模型时间序列回归具有以下等式:
Rit—RFt= aI+bI(RMt—RFt+sISMBt+hIHMLt+RIRMWt+c
**其中:
- R ft 是其中一个投资组合在 t 月的回报率
- R Ft 是无风险利率
- Rm - Rf 是资本加权股票市场和现金之间的收益差
- SMB 是小股票减去大股票的收益差(即规模效应)
- HML 是廉价股票减去昂贵股票的收益差(即价值效应)
- RMW 是利润最高的公司减去利润最低的公司的收益差
- CMA 是保守投资减去激进投资的公司的收益差(AQR,2014)
回归测试的目的是观察五因素模型是否捕捉到变量的平均回报,并查看哪些变量彼此正相关或负相关,此外还确定回归斜率的大小以及所有这些因素如何与股票价值的平均回报相关并影响股票价值的平均回报。
Fama 和 French (2014)所做的测试表明,当盈利能力和投资因素被添加到等式中时,价值因素 HML 对于描述平均回报是多余的,对于唯一感兴趣的是异常回报的应用,可以使用四或五因素模型,但是如果除了异常回报之外,投资组合倾斜也是感兴趣的,那么最好使用五因素模型。
结果还表明,Fama-French 五因素模型解释了规模、价值、盈利能力和投资组合的预期回报的 71%至 94%的横截面方差。
事实证明,旨在捕捉平均股票回报的规模、价值、盈利能力和投资模式的五因素模型比三因素模型表现更好,因为它减少了无法解释的异常平均回报。
新的模型表明,最高的预期回报是由规模小、盈利和价值公司获得的,没有重大的增长前景(Fama 和 French,2014)。
然而,Fama-French 五因素模型的主要挫折是,它未能捕捉到小型股票的低平均回报,这些股票的回报表现类似于那些尽管利润率低但投资很多的公司,并且该模型的表现与其因素的定义方式无关(Fama 和 French,2015)。
结论
与以前的模型相比,Fama French 5 因子模型仍有待证明是一种改进,但它为将来进一步开发更好的模型留下了空间。
大多数投资者仍然使用著名的三因素模型,但是人们开始使用这种方法似乎需要几年时间,因为行业人员总是心存疑虑。
从 Fama 和 French 所做的实际工作来看,在这种方法在经验证据中证明自己之前,使用其他因素模型似乎对投资者最有利。
如果你也对发展终身技能感兴趣,这些技能会帮助你提高交易策略。在这个 algo 交易课程中,你将接受统计学&计量经济学、编程、机器学习和量化交易方法的培训,因此你精通每一项在量化&算法交易中出类拔萃所必需的技能。现在就了解更多关于 EPAT 的课程吧!
参考文献
- AQR,2014 年。我们的模型达到了六个,并通过冗余节省了价值。[在线]见:https://www . aqr . com/cliffs-perspective/our-model-goes-to-six-saves-value from-the-redundancy-by-way[2015 年 6 月 5 日访问]
- DeMuth,p .,2014 年。Fama & French 的新 5 因素模型是怎么回事?神秘的新因素诉福布斯,[在线]可在以下网址查阅:http://www . Forbes . com/sites/phildemuth/2014/01/20/whats-up-with-Fama-frenchs-new-5-factor-model-the-mystery-new-factor-v/[2015 年 6 月 6 日查阅]
- 法玛,E 和法国,k,2015。用五因素模型剖析异常。社会科学研究网络。[在线]可在:http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2503174[2015 年 6 月 5 日访问]
- Fama,E 和 French,k,2014 年。五因素资产定价模型。社会科学研究网络。[在线]可在:http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2287202[2015 年 6 月 5 日访问]
- 穆林斯特区,1982 年。资本资产定价模型有效吗?哈佛商业评论。[在线]见:https://HBR . org/1982/01/does-the-capital-asset-pricing-model-work[2015 年 6 月 6 日访问]
- 2015 年价值行走。五因素 Fama-French 模型:国际证据。[在线]见:http://www . value walk . com/2015/05/the-five-factor-Fama-French-model-international-evidence/[2015 年 6 月 7 日查阅]
免责声明:本客座博文中提供的观点、意见和信息仅属于作者个人,不代表 QuantInsti 的观点、意见和信息。本文中所做的任何陈述或共享的链接的准确性、完整性和有效性都不能得到保证。我们对任何错误、遗漏或陈述不承担任何责任。与侵犯知识产权相关的任何责任由他们承担。T3】**
斐波那契数-调和模式
原文:https://blog.quantinsti.com/fibonacci-numbers-harmonic-patterns/
作者:桑吉·库马尔
在这篇博客中,我们学习了斐波那契数,调和模式,以及如何找到不同长度和大小的模式。然后,交易者可以将斐波纳契比率应用于这些模式,并尝试预测未来的走势。
本文是作者提交的最后一个项目,作为他在 QuantInsti算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
Sanjeet Kumar 是一名 EPATian 人,现居印度德里,拥有锡金马尼帕尔大学的金融 MBA 学位。
他是 ThoughtFocus 的高级分析师,拥有 EPAT 优秀证书。
项目摘要
调和交易将模式和数学结合成一种精确的交易方法,它基于模式重复的前提。基本比率存在于几乎所有的自然和环境结构和事件中;它也存在于人造建筑中。由于这种模式在自然界和社会中重复出现,这种比率在金融市场中也能看到,金融市场受到交易环境和社会的影响。
通过发现不同长度和大小的模式,交易者可以应用斐波纳契比率来预测未来的走势。这种交易方法很大程度上归功于斯科特·卡尼,尽管其他人也做出了贡献或发现了提高业绩的模式和水平。
什么是“斐波那契数/线”?
斐波那契数列和线是使用意大利数学家列奥纳多·斐波那契开发的数学序列的技术指标。斐波那契数列是一个数字序列,从 0 和 1 开始,由前面两个数字相加而成。例如,序列的前一部分是 0、1、1、2、3、5、8、13、21、34、55、89 和 144。
谐波模式
调和价格模式通过使用斐波那契数来定义精确的转折点,将几何价格模式提升到一个新的水平。不同于其他常见的交易方法,谐波交易试图预测未来的运动。让我们来看一些例子,看看调和价格模式是如何在外汇市场交易货币的。
结合几何和斐波那契数列
调和交易将模式和数学结合成一种精确的交易方法,它基于模式重复的前提。这种方法的基础是基本比率,或它的一些衍生物(0.618 或 1.618)。互补比包括:0.382,0.50,1.41,2.0,2.24,2.618,3.14,3.618。
基本比率存在于几乎所有的自然和环境结构和事件中;它也存在于人造建筑中。由于这种模式在自然界和社会中重复出现,这种比率在金融市场中也能看到,金融市场受到交易环境和社会的影响。
通过发现不同长度和大小的模式,交易者可以应用斐波纳契比率来预测未来的走势。调和交易法主要归功于斯科特·卡尼,尽管其他人也贡献或发现了提高业绩的模式和水平。
谐波问题
调和价格模式是精确的,要求该模式显示特定幅度的变动,以便该模式的展开提供准确的反转点。交易者可能经常看到一个看起来像调和模式的模式,但是斐波纳契水平不会在模式中对齐,因此从调和方法的角度来看,该模式是不可靠的。这可能是一个优势,因为它要求交易者耐心等待理想的设置。
谐波模式可以衡量电流移动将持续多长时间,但它们也可以用来隔离反转点。当一个交易者在反转区域建仓,并且形态失败时,危险就发生了。当这种情况发生时,交易者可能会在趋势对他不利的情况下被抓住。因此,和所有的交易策略一样,必须控制风险。
值得注意的是,模式可能存在于其他模式中,非调和模式也可能存在于调和模式的上下文中。这些可以用来帮助谐波模式的有效性,并增强进入和退出性能。
几个价格波也可能存在于单个谐波中(例如,CD 波或 AB 波)。价格不断波动;因此,重要的是要着眼于交易时间框架的大局。市场的分形性质允许该理论从最小到最大的时间范围应用。
使用这种方法,交易者将受益于一个图表平台,这个平台允许他绘制多个斐波纳契回撤来衡量每一波。
视觉模式以及如何交易它们
有相当多的谐波模式可以用于谐波交易,虽然有四种模式似乎是最受欢迎的。这些是 Gartley,蝴蝶,蝙蝠和螃蟹模式。
The Gartley
Gartley 最初是由 H.M. Gartley 在他的书《股票市场的利润》中发表的,后来 Scott Carney 在他的书《调和交易者》中加入了斐波那契水平。下面讨论的级别来自那本书。多年来,其他交易者提出了一些其他的常见比率。相关时,也会提及这些内容。

看涨形态通常出现在趋势的早期,这是一个信号,表明修正波正在结束,在 d 点之后将出现向上移动。所有形态都可能出现在更广泛的趋势或范围内,交易者必须意识到这一点。(相关见解见《艾略特波浪理论》)。
这需要吸收很多信息,但这就是如何阅读图表。我们将使用看涨的例子。
价格上升到 A,然后修正,B 是 A 波的 0.618 回撤。
价格通过 BC 向上移动,是 AB 的 0.382 到 0.886 的回撤。
下一步棋是通过 CD 向下,是 AB 的 1.13 到 1.618 的延伸。
D 点是 XA 的 0.786 回撤。很多交易者找 CD 把 AB 的 1.27 延伸到 1.618。
D 处的区域称为潜在反转区。这是多头可以进入的地方,尽管等待一些价格开始上涨的确认是被鼓励的。止损就放在进场下方不远的地方,尽管其他止损策略将在后面的章节中讨论。
对于看跌模式,在 D 附近做空,止损在上方不远。
蝴蝶
蝴蝶图案不同于 Gartley 图案,因为蝴蝶的 D 点延伸到 x 点之外。

这里我们将看看跌的例子来分解数字。
价格降到了 1 英镑。
AB 的上行波是 XA 的 0.786 回撤。
BC 是 AB 的 0.382 到 0.886 回撤。
CD 是 AB 的 1.618 到 2.24 的扩展。
d 在 XA 波的 1.27 延伸处。
d 是一个考虑短期交易的区域,尽管等待价格开始走低的一些确认是被鼓励的。在上方不远处设置止损。
有了所有这些模式,一些交易者寻找提到的数字之间的任何比率,而其他人寻找其中的一个。例如,上面提到 CD 是 AB 的 1.618 到 2.24 扩展。一些交易者只会寻找 1.618 或 2.24,忽略中间的数字,除非他们非常接近这些特定的数字。
蝙蝠
蝙蝠图案在外观上与 Gartley 相似,但在尺寸上不同。

让我们看看看涨的例子。
通过 XA 有一个上升。
b 回撤 XA 的 0.382 到 0.5。
BC 回撤 AB 的 0.382 到 0.886。
CD 是 AB 的 1.618 到 2.618 扩展。
d 位于 XA 的 0.886 回撤位。
d 是可以做多的区域,尽管要等价格开始上涨后再做。止损可以放在下方不远处。
对于看跌形态,在 D 附近做空,止损在上方不远处。
螃蟹
卡尼认为螃蟹是最精确的模式之一,它提供了非常接近斐波那契数列的反转。

这种模式类似于蝴蝶,但尺寸不同。
在看涨形态中,B 点将拉回 0.382 至 0.618 的 XA。
BC 会回撤 AB 的 0.382 到 0.886。
CD 延伸 AB 的 2.618 到 3.618。
D 点是 XA 的 1.618 扩展。
在 D 附近做多,止损在下方不远。
对于看跌形态,在 D 附近进场做空,止损在上方不远处。
微调入口和止损
每个形态都提供了一个潜在的反转区(PRZ),但不一定是一个确切的价格。这是因为两个不同的投影形成了点 d。如果所有的投影水平都很接近,交易者可以在该区域建仓。如果预测区域是分散的,例如在长期图上,水平可能相差 50 点或更多,寻找价格朝着预期方向移动的其他确认。这可能来自一个指标,或者仅仅是观察价格的变化。
止损也可以放在最远投影的外面。这意味着止损不太可能达到,除非这个模式因为走得太远而失效。
底线
调和交易是一种精确和数学的交易方式,但是它需要耐心,练习和大量的研究来掌握模式。基本的测量只是开始。与正确的模式测量不一致的波动会使模式无效,并使交易者误入歧途。
Gartley,Butterfly,Bat 和 Crab 是交易者比较关注的模式。当价格确认显示反转时,在潜在反转区进行交易,止损位于多头交易的下方或空头交易的上方,或者在形态的最远投影之外。
如果你想学习算法交易的各个方面,那就去看看我们的算法交易(EPAT)执行项目(T2)。该课程涵盖了统计学&计量经济学、金融计算&技术和算法&定量交易等培训模块。EPAT 旨在让你具备成为成功交易者的正确技能。现在报名!
推荐阅读:Python 中的斐波那契回撤交易策略
免责声明:就我们学生所知,本项目中的信息是真实和完整的。所有推荐都不代表学生或 QuantInsti 的保证。学生和 QuantInsti 否认与使用这些信息有关的任何责任。本项目中提供的所有内容仅供参考,我们不保证通过使用该指南您将获得一定的利润。
zip 存档中的文件列表:
- 包含 OHLC 数据的 Excel 文件
- 提取新闻网址的 Python 代码
Python 中的斐波那契回撤交易策略
原文:https://blog.quantinsti.com/fibonacci-retracement-trading-strategy-python/
由伊山沙阿
斐波纳契交易工具用于确定支撑位/阻力位或确定价格目标。正是斐波那契数列在自然界的存在吸引了技术分析师的注意力,让他们使用斐波那契数列进行交易。斐波那契数列在寻找任何广泛交易的证券的关键水平方面有着神奇的作用。在这篇文章中,我将解释著名的斐波那契交易策略之一:回撤,以确定支撑位。
斐波那契数列
斐波那契数列是一系列数字,从 0 和 1 开始,其中每个数字都是前两个数字的和。

斐波纳契数列是 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610……它延伸到无穷大,可以用下面的公式来概括:
Xn= Xn-1+Xn-2T7】
关于斐波那契数列,有哪些有趣的事实?
斐波那契数列有一些有趣的性质。将序列中的任意数字除以前一个数字;比率始终约为 1.618 。
Xn/Xn-1 = 1.618
55/34 = 1.618
89/55 = 1.618
144/89 = 1.618
1.618 被称为黄金比例。我建议在谷歌图片上搜索黄金比例的例子,你会惊喜地发现这个比例与自然的相关性。
同样,将序列中的任意一个数除以下一个数;该比率始终约为 0.618。
Xn/Xn+1 = 0.618
34/55 = 0.618
55/89 = 0.618
89/144 = 0.618
0.618 用百分比表示为 61.8%。0.618 的平方根是 0.786 (78.6%)。
当序列中的任何一个数被它右边两位的数整除时,也会发现类似的一致性。
Xn/Xn+2 = 0.382
13/34 = 0.382
21/55 = 0.382
34/89 = 0.382
0.382 以百分比表示为 38.2%
同样,当序列中的任何一个数被它右边三位的数整除时,也存在一致性。
Xn/Xn+3 = 0.236
21/89 = 0.236
34/144 = 0.236
55/233 = 0.236
0.236 以百分比表示为 23.6%。
23.6%、38.2%、61.8%和 78.6%的比率被称为斐波那契比率。
斐波那契回撤交易策略
斐波纳契比率 23.6%、38.2%和 61.8%可用于时间序列分析以找到支撑位。每当价格大幅上涨或下跌时,它通常会在继续向原来的方向移动之前回撤。例如,如果股票价格从 200 美元涨到 250 美元,那么在继续上涨之前,它很可能会回调到 230 美元。使用斐波纳契比率预测 230 美元的回撤水平。

我们可以通过一个简单的数学计算得出 230 美元总上涨= $250 - $200 = $50 上涨的 38.2% = 38.2% * 50 = $ 19.1 回撤预测= $250 - $19.1 = $230.9
任何低于 230 美元的价格水平都为交易者提供了一个很好的机会,在趋势的方向上建立新的头寸。同样,我们可以计算 23.6%,61.8%和其他斐波纳契比率。
如何找到斐波那契回撤水平?
正如我们现在所知,回撤是与最初趋势相反的价格运动。为了预测斐波纳契回撤水平,我们应该首先确定总的向上移动或总的向下移动。为了标记这个移动,我们需要选择图表上最近的最高点和最低点。
让我们以埃克森美孚为例来理解斐波纳契回撤构造
# To import stock prices
from pandas_datareader import data as pdr
# To plot
import matplotlib.pyplot as plt
df = pdr.get_data_google('XOM','2017-08-01', '2017-12-31')
fig, ax = plt.subplots()
ax.plot(df.Close, color='black')

从图表中可以看出,从 2017 年 9 月到 2017 年 10 月底,价格有大幅上涨。在这种情况下,最低价格是 76 美元,最高价格是 84 美元。8 美元是总的上升趋势。
price_min = 76 #df.Close.min()
price_max = 84 #df.Close.max()
斐波纳契比率 23.6%、38.2%和 61.8%的回撤水平计算如下:
# Fibonacci Levels considering original trend as upward move
diff = price_max - price_min
level1 = price_max - 0.236 * diff
level2 = price_max - 0.382 * diff
level3 = price_max - 0.618 * diff
print "Level", "Price"
print "0 ", price_max
print "0.236", level1
print "0.382", level2
print "0.618", level3
print "1 ", price_min
ax.axhspan(level1, price_min, alpha=0.4, color='lightsalmon')
ax.axhspan(level2, level1, alpha=0.5, color='palegoldenrod')
ax.axhspan(level3, level2, alpha=0.5, color='palegreen')
ax.axhspan(price_max, level3, alpha=0.5, color='powderblue')
plt.ylabel("Price")
plt.xlabel("Date")
plt.legend(loc=2)
plt.show()
输出: 

23.6%的第一回撤位 82.10 美元,38.6%的第二回撤位 80.90 美元,61.8%的下一回撤位 79.05 美元。在 11 月中旬,埃克森美孚股价下跌至 80.40 美元,(跌破 38.6%的回撤水平),然后继续上行。
如何使用斐波那契回撤交易策略?
当你想买一只特定的股票,但由于股价大幅上涨而未能如愿时,可以使用回撤水平。在这种情况下,等待价格修正到斐波纳契回撤水平,如 23.6%、38.2%和 61.8%,然后买入股票。比率 38.2%和 61.8%是最重要的支撑位。
这种斐波纳契回撤交易策略在更长的时间间隔内更有效,像任何指标一样,将该策略与其他技术指标一起使用,如 RSI、【MACD】和蜡烛图可以提高成功的概率。
祝 Fibonacci trading:)好运
下一步
从网上可用的各种加密货币中获取数据的来源有很多。在我们的文章“使用数据提取技术的加密货币交易策略中,学习使用 python 库 coinmarketcap 来提取数据。要了解更多的量化交易策略,你可以通过
.
免责声明: 股票市场的一切投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
下载 Python 代码
- 斐波那契回撤交易策略 Python 代码
填充或杀死订单
填充或删除订单是一个有趣的概念,它来自于订单类型,如买入订单和卖出订单。在同样的买卖实践中,根据交易者的偏好,有几种类型的订单可供选择。此类订单为市价订单、限价订单、止损订单、止损订单、支架订单和日订单。
转到填充或压井订单,本文包括:
什么是填单?
履行订单是指订单的执行或完成。这是所有金融市场的惯例。
为了完成订单,需要满足一些条件。这些是:
- 有足够的交易量或交易者进行买卖
- 确保交易的股票没有过期
- 在市场运作时或交易时间内进行交易
满足这些条件极其重要,因为只有当市场全面运转时,订单才更有可能得到满足。
尽管如此,并不是每个订单都能得到满足,这也是为什么我们将在前面学习更多关于这个主题的内容。
让我们来看看什么是补货单或杀价单?
什么是补货单或杀价单?
“成交”或“取消”订单是指那种需要经纪人立即全部(不是部分)或完全不执行(取消订单)的限价市场订单。简而言之,这种类型的订单将完全和自发地以特定的价格执行,否则如果不执行就取消订单。
填充或删除命令的使用
除了是一种取决于个人偏好的类型之外,填充或删除订单的一个很好的用途是它可以用于测试市场。我们将借助一个例子来看看这一点。让我们假设同一市场中的两种情况:
场景 1
在这种情况下,让我们假设 5 月 S&P 期货在 406.50 和 406.90 之间交易。你在 406.50 点发出买入信号。还有,我们是假设交易量少。现在,随着买入信号,价格上升到 406.90。但是,由于您担心市场会跌回 406.50 的原价,您正在犹豫是否购买。
在这种情况下,您可以在 406.45 点下单买入或杀跌,这远低于当前的交易范围。最初,你下单时看到价格是 406.55。然后,逐渐价格如下… 406.50… 406.55…..406.50...… 406.45.一旦你的出价出现,也就是 406.45,你的交易就成交了。
上述情景表明市场疲软,因为有卖方愿意以如此低的价格出售。这样,它有助于描述一个疲软的市场。
场景二
现在,让我们假设另一个结果不同的场景。我们将假设相同的市场。同样在这种情况下,让我们在 406.45 接受你的成交或杀价指令。现在,以同样的方式,你观察到价格如下……406.65..406.55....406.55...406.60...406.65...406.65...406.60...406.65....406.60...406.75..406.70...406.65...406.70...406.75.在这种情况下,市场更接近你的出价 406.45,但永远不会等于它。因为它从未达到出价,所以订单被返回并被取消。这种情况表明市场需求旺盛,这就是为什么永远不要打出很低的价格。在这里,你最好快点上船。
现在让我们来看看填充或删除订单是如何工作的?
补货单或杀价单是如何运作的?
“执行或取消订单”的工作逻辑很简单,要么执行订单,要么完全取消订单。让我们假设你,作为一个交易者,希望以每股 20 美元的价格购买 100,000 股股票,而且必须是立即购买。
因此,它满足三个条件:
- 购买一定数量的股票,
- 以特定的价格,
- 而且,马上
然后,你可以向你的经纪人提出请求,为这笔交易下一个买入或卖出的订单。现在,经纪人只能:
- 完成订单或
- 取消订单
如果你的限价和市价相同,订单会立即成交。在填充或删除订单中,没有部分填充,只有订单的完全填充。这意味着订单要么按照您希望的方式执行,要么根本不执行。此外,如果订单被取消,订单将被完全取消,根本无法进入股票市场。
这个工具在一次性交易机会中派上了用场。通过这种方式,您可以在所有条件都具备的情况下,根据您的要求发挥作用。
接下来,我们将看看“填充订单”或“杀死订单”与其他订单类型的异同。
与其他订单类型的异同
上表清楚地表明,所提到的每种订单类型之间都有一些差异和一些相似之处。
| 命令 | 立即填补 | 可以部分填充 | 如果没有立即完成,可以在日订单或取消前有效的订单之外使用 | 当供应不足以满足需求数量时,订单将在交易日结束时取消 |
| 立即或取消 | 真实的 | 真实的 | 错误的 | 错误的 |
| 填充或杀死 | 真实的 | 错误的 | 错误的 | 错误的 |
| 全部或没有 | 真实的 | 错误的 | 真实的 | 真实的 |
太好了!我们学习了有关填充或杀死顺序的重要主题,现在让我们看看结论。
结论
在本文中,我们首先介绍了填充或删除顺序的基础知识以及填充顺序的含义。然后,我们讨论了填充或杀死订单的含义。如果你不想交易超过一个特定的价格,你可以根据自己的喜好来选择下单。此外,履行或取消订单用于测试市场,其工作包括履行订单的条件。条件是以特定的价格立即购买特定数量的股票。然后,我们简要讨论了填充订单或删除订单与其他订单类型的相似之处和不同之处。希望这篇文章对你的目的有所帮助,让你对填充或杀死订单有一个全面的了解。
免责声明:本文中提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害承担任何责任。所有信息均按原样提供。
金融、算法交易和南非-约翰的故事
原文:https://blog.quantinsti.com/finance-algo-trading-south-africa-success-story-john-moss/
远见卓识、远见卓识、对未来时代的信念、持续的学习和对自己技能的信心——无论你来自哪个领域,这些品质都会让你为自己职业的未来做好准备。
约翰·莫斯来自南非。他喜欢与人共事,热爱金融和技术,希望通过创新影响人类的未来。
拥有硕士和领导力和人员管理认证,他也获得了国际软件测试资格。约翰毕业于项目管理、数学和计算机科学专业,还持有 EPAT 优秀证书。
约翰在金融和交易领域的经历揭示了一段旅程,在算法和量化交易的世界里,他对学习和准备明天的努力、奉献和同情。
约翰和我们分享了他的成功故事。
嗨,约翰,给我们介绍一下你自己吧!
我是来自南非的约翰·莫斯。我目前在一家投资银行领导一个团队,负责交易系统。我喜欢阅读,最近开始锻炼,这很有趣。我喜欢科技和金融,当我不管理和领导别人时,我大部分时间都呆在这。
今年是新冠肺炎年,这相当具有挑战性。从我作为管理者的角度来看,除了我们与人交往的方式,没有什么特别的变化。
不幸的是,对我来说,我已经去工作了,所有关键员工都得去。所以,我不允许在家工作。在管理投资银行的交易系统时,人们需要站在更高的地方。
你与金融和技术世界的关系非常密切。Algo 交易是怎么进来的?
我的第一个学位是计算机科学和数学。我喜欢解决问题,如今技术解决了大多数问题。也是计算数字,我现在的工作基本就是这么做的。
我已经获得了领导力和项目管理的认证。进入投资银行界,我最初实际上是在保险领域,在那里我是一名精算。
大多数和我一起学习的人,以及我不得不教的人,最后都去了投资银行。他们告诉我,我来到了投资银行业,我会成功的。
一开始我并不相信,但后来我加入了中台团队。
在投资银行,你有明显的隔离:
- 前台是主要的交易环节,
- 中间办公室-进行定量计算,以及
- 后勤办公室-管理会计。
我和交易员一起工作,做了很多归因工作,解释 P&L 全天的走势,并确保项目与前台办公空间保持一致。我被要求领导一个前沿办公室技术领域的团队,在这种情况下,这实际上是从技术的角度照顾前沿办公室。
这很容易,因为我喜欢交易业务和量化空间的编码方面。我就是这样走到了现在的位置。
尽管总是有挑战。我最初接受这份工作是因为我对技术、金融和金融市场的热爱。
当我在中层办公室工作时,我对后来成为算法交易的不同方面有所了解
- 在我以前的工作中,对交易的计算和量化理解。
- 在我接管我的银行的技术团队之前。
在算法交易成为现实之前,我从来没有把所有的东西放在一起。
algo trading 中的 AI 集成其实就是编程 ie 的组合。计算机科学、数学原理、微积分和统计模型。基本上,结合所有这些使算法交易特别。
在过去,所有这些学科从未在一个保护伞下被考虑过。
- 如果你是做计算机科学的,你应该编程。
- 如果你在做统计,你应该理解一些基于统计原理的算法。
- 如果你在做数学,你需要理解计算和一大堆其他的数学原理。
当你结合所有这些方面,以及全球市场交易的金融,P&L 的计算,你会真正理解市场如何运动,以及一个人如何赚钱或赔钱。
为什么选择学习算法而不是软件交易?
最终,我成长为一名领导者随着越来越多的成员加入我的团队,我花在领导上的时间比实际执行或构建任何代码的时间都多。
我选择了算法交易,因为这是我职业生涯的下一步。我想要么利用这些技能来实现我目前的目标,要么在同一个机构里占据一个更好的交易位置。
我在当前组织中的 Algo 交易平台尚未完全开发。现在我们正在小规模的应用上努力,但是希望在不久的将来,我们可以在更大的规模上追求它。还有很多未定义的结构。
我正在帮助我的一个交易者执行他的算法,回测它们,当他说他已经在 QuantInsti 学习了算法交易。这非常令人着迷,我想这就是我发现它并最终选择追求它的原因。
EPAT 课程的财务结构也是我的一个卖点。 QuantInsti 给人的印象不像是那些以赚钱为目的的节目。
南非面临的挑战之一是贫富差距巨大。整体而言,教育并不便宜。这里提供的算法交易课程非常昂贵。这对于 EPAT 来说不是问题。
我的公司也非常支持我的个人发展,尤其是对公司有益的发展。我鼓励我的大多数同事抓住机会,培养他们未来需要的技能。我的信念一直是尝试和研究一些我今天可能不需要,但在未来 10 年可能会用到的东西。
我可以预见,在未来十年,算法交易将会和人工智能、人工智能一样成为一项非常有用的技能。
你认为 EPAT 最大的特点是什么?
我认为 EPAT 的所有特色都是至关重要的,它们会给你一个有益健康的学习体验。我想提一些我非常喜欢的。
终身访问内容:EPAT 最大的卖点之一就是终身访问内容。这很重要,因为算法交易领域在未来将会有很大的进步,这门课程将会适应这一点。很高兴知道我可以从课程材料的持续改进中受益。
实践学习:通过多种媒介学习,我注意到大部分材料直到你开始应用它们才变得有意义。有时候我想回去重温一下基本原则。终身访问在这方面对我很有帮助。
实际应用:我真的很喜欢这门课程的结构。EPAT 是以一种非常实用的方式被教授的,教员们知道他们在谈论什么。当只从理论上教授高级概念时,它们有时会变得令人厌烦。这对于 EPAT 来说从来都不是问题,因为讲座中充满了实践练习。
现实生活中的经历:对我个人来说有所不同的一次经历是,我学会了如何用数学方法以及从系统管理的角度来评估期权及其交易。当讲师给我他们经历的例子时,我学得更好。
录讲座:录讲座的能力也是蛮酷的。作为一个有家室的男人,有时候我没有时间在周末参加会议。如果有录音的话,我就能进去体验这个过程——就像所有参加过的人一样。
你能和我们分享你的密码交易经验吗?
我尝试未来 10 年相关的事物。当它们在未来成熟时,它不再是一项新技术,而是我已经在做的事情。
我已经以个人身份在密码领域进行了试验。我正在实施算法,寻找加密货币市场中的套利机会,并寻找跨交易交易所的模式,这些模式非常非常酷,非常有用。我的大部分算法纯粹是基于多头头寸的假设,即不管市场是否调整,它都会继续上涨。
区块链有可能以前所未有的方式改变金融市场。
南非的监管者在区块链和加密货币上下了大赌注。在我看来,政府法规承认密码是未来的一部分。如果一切顺利,我们至少可以在此基础上建立一个合法的企业。希望有一天,我能开一个基于密码的算法交易平台。
我在 2017 年开始交易密码,我们在 2020 年来到这里,这个领域真的很有趣。今年对加密来说是个好年头。
我的信念一直是——不管方向如何,优秀的交易者都会赚钱。
对你的同学们有什么智慧的话语吗?
对我来说,一切都始于对某事的热情。当我在一家保险公司工作的时候,我在精算领域,它本质上更加数学化。然后我去了中层办公室,这让我了解了市场,并把我推向了技术领域。
我最坚定的信念是,如果你不把手弄脏,你可能学不到任何有用的东西。即使你从书上读到的,如果不付诸实践,你也会忘记的。
我的建议是从某个地方开始,要么在投资银行找份工作,要么进入资本市场。现在工作很少,所以在这种情况下,人们总是可以阅读,开始小规模交易,只是为了理解买卖金融工具的基本原理。祝你好运!
约翰,谢谢你与我们联系并分享你的故事。这是一场艰苦的战斗,但你从未被机会打败。你的努力、毅力和学习意愿一定会引起很多人的共鸣。
算法交易(EPAT) 的高管课程是一门综合课程,涵盖从统计学&计量经济学到金融计算&技术,包括机器学习等等。开始你的探索,与 EPAT 一起提升你的算法交易知识。点击这里查看。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
在贸易和商业中融合情感:雨果如何探索机遇
原文:https://blog.quantinsti.com/finance-director-csaf-success-story-hugo-valdivia-carrillo/
眼睛盯着星星,脚踏实地。西奥多·罗斯福
引用分享了很多关于我们的 EPATian 和 CSAF 认证毕业生 Hugo Valdivia Carrillo 和他的 Algo 交易之旅。他是一个冲浪者,喜欢观星,同时他很实际,有责任心,已经取得了很大的成就,并希望学习更多。
他周游过世界,在多个国家生活过,并在这些国家的文化中度过了美好的时光。他将同样的热情和多样性带到了学习中,并成功地为自己创造了巨大的机会。
凭借近 20 年的工作经验,Hugo 已经成为一名财务总监/经理、定量和数据分析师、数据科学家以及算法和系统交易员。这是他的算法交易之旅。
嗨,雨果,告诉我们关于你自己的事情吧!
大家好,我是雨果·巴尔迪维娅·卡里略。我出生在墨西哥,但在我很小的时候,我们全家搬到了美国,我在加利福尼亚州的洛杉矶长大。我于 2002 年开始了我的金融职业生涯,在该行业的各个领域工作过,包括投资合规分析、财务分析、投资分析、广义的交易和一些基金管理。
我之前在香港的一家公司担任财务总监。他们是一家经纪公司,我帮助他们从马来西亚获得了在亚洲经营的金融许可证。我目前驻扎在墨西哥。
作为一个孩子,我一直热衷于天文学和天体,我收集望远镜来满足我的好奇心。我喜欢冲浪,在洛杉矶我喜欢那里的海滩。我还喜欢阅读,获取知识以发展技能,了解动态趋势。
你从财务经理到财务总监的 17 年历程是怎样的?
信不信由你,我的第一个职业选择是当医生,但这是一个广泛而昂贵的轨迹,也有我自己的一套责任。
一天,我在浏览新闻时,看到了美国消费者新闻与商业频道。我看着屏幕上显示的字母和数字,这成了我对金融世界的介绍。我被这些数字迷住了,我开始了我的研究,也就是在那时,我决定研究它们。我在洛杉矶注册了一门课程,毕业时主修金融。
我的第一份工作是在一家经纪公司担任合规官,在那里我将为期货和外汇市场做出更多贡献。由于一个同事,我对交易产生了兴趣,并报名参加了一个项目来学习更多。我了解了技术分析中开发的系统,这让我很想知道更多关于日内交易的知识。我在同一家公司获得了职业发展,成为了一名金融分析师。
后来,我去了墨西哥,在一家风险管理私人银行工作,涉足期权交易、期货交易、大宗商品等。我站在交易的风险一边,但我并不积极交易。我学到了情绪是交易的重要组成部分,以及它是如何影响交易者的。
我想知道如何才能成为一名成功的交易者。我积极与金融市场打交道,了解到 90%的市场是感性的,10%是技术性的。一个人可以很容易地学习技术方面,这是容易的部分,更难的部分是控制情绪。
在交易过程中掌握情绪,不向偏见屈服,需要很多时间。仅仅几个月的交易是不够的,交易者必须学习,研究,获得知识来理解和解决问题。
然后我搬到中国上海,在一家金融公司担任总经理。该公司在中国和其他亚洲国家都设有办事处,这给了我一个出差的机会。在这里,我有机会在关注发展的同时,更深入地研究投资和金融分析。
我想了解更多关于算法交易的概念,在做研究的时候,我发现了 QuantInsti。我发现了 EPAT 项目,但是时差和工作日程限制了我。
当我换了工作,加入了香港的一家公司后,我获得了更多的学习机会。这个项目帮助我对算法交易有了更深的理解。
最初,我只想成为一名交易员,创办自己的交易公司,这就是我报名参加 EPAT 项目的原因。我做了彻底的研究,阅读了关于算法交易的资料,这个课程是一个重大的启示,向我展示了算法交易的可能性和机会。我在 EPAT 的职业生涯和旅程教会了我技术是如何发展和改变行业范围的。
我第一次在 QuantInsti 网站上看到 CSAF 计划,我很好奇,因为我想了解更多关于 NLP 的信息。我看了网站上的信息,QuantInsti 的教员把课程内容发给了我。这让我对这个项目更加好奇,因为我对 NLP 做了更多的研究,这让我对交易大开眼界。
你对金融界的情绪分析和 NLP 有什么看法?
在了解情绪分析和 NLP 之前,我发现每当我交易时,市场的动态都很有趣。我发现某些消息会对市场产生影响。那时我意识到这个消息在推动金融市场方面发挥了重要作用。
我明白,情感分析和 NLP 是认识到创造理解这些变化的指标的机会的未来。这无疑给了交易者在金融市场上比其他公司和交易者更大的优势,而他们并没有意识到这一点。这也是我对 CSAF 项目越来越感兴趣的原因,因为它教导我们根据某些情绪和情感来构建策略。
我记得当我开始交易的时候,有关于花旗银行和花旗集团的新闻流传。我后来意识到,市场受到了这一消息及其周围情绪的影响。那是我想通过新闻渠道获取所有信息的时候。当我得知 CSAF 项目时,我立即报名参加了。
CSAF 对你丰富的金融知识和经验有何帮助?
当我报名参加 CSAF 项目时,我对这门课程抱有很高的期望。同时,因为这是一个新概念,我很想知道它对我的交易有什么帮助。这个项目完全改变了游戏规则,让我大开眼界。
我学会了如何量化情绪和情感,以及它与市场的关系。此外,我还通过联通在项目之外举办的网络研讨会,从其他活跃的从业者那里学到了很多东西。这是一次独特的经历,因为我可以从那些每天都在实践这些知识和策略的人那里学到东西。
我看到了他们在 CSAF 项目中学到的东西和在交易中成功运用它们之间的关系。在我的经历中,没有任何一个项目有如此活跃的交易者群体,他们愿意分享和帮助交易者成长。
CSAF 是一个历史悠久、结构完善的项目,我从中学到了很多东西。这里的教师很棒,他们在现场会议中实时回答了所有的问题。作为教员,他们是专家,知识渊博。这让我很好奇,我开始热衷于了解更多。因为我有一个要实现的目标,所以我管理我的工作和计划以及我的个人生活。
EPAT 和 CSAF 的课程都是一次不可思议的旅程,在我看来,是业内最好的,包括客户服务。一个伟大的团队和一个伟大的公司,帮助我通过大量的科目发展和学习。
您可以方便地接触到专家和专业人员,与知识渊博的从业者建立联系,并参加更多的网络研讨会,联通还组织了一些您可以参加的国际活动。
我非常感谢在您完成课程后继续举办的网络研讨会、活动和会议提供的额外学习机会。你可以从社区和实时从业者那里学到很多东西,这意味着很多,超过了我的预期。
你的下一步是什么?
疫情迫使许多公司停止业务和运营。这也对我的生活产生了影响,因为我之前的公司停止了运营并关闭了。
我目前正在找工作,并积极寻找更多的机会。与此同时,我正在尝试运用我在交易项目和构建策略中学到的东西。
我对交易的看法已经改变,我正在积极地寻找积极交易的机会。不仅仅是在交易领域,我在项目、社区和专家那里学到的东西也可以应用到商业领域。
对那些希望改进交易的人有什么信息吗?
你将从 EPAT 和 CSAF 的课程中受益匪浅,因此我建议你同时参加这两个项目。这些课程教给你如此多的概念,至于你如何运用它们来创造各种策略,那是你的想象。
这些程序帮助你交易的方式令人难以置信,我会把它推荐给所有的交易者,不管是新的还是现有的。它为我所不知道的新事物和影响市场的各个方面开辟了道路,以及如何量化情绪。这些课程很棒,相互补充,教你一些全新的东西。
谢谢你分享你不可思议的旅程,雨果。你表现出了难以置信的激情和热情来学习和发展你在交易世界中的技能,很高兴看到你仍然希望学习更多。我们祝你在事业中一切顺利。
情感和技术的结合在交易领域是非常新颖和独特的。情绪在金融市场中发挥着关键作用,可以改变趋势。量化和实施交易中的情绪指标是发展策略的关键。
你希望学习和发展你的技能,获得更多的知识,成为一名成功的交易者吗?通过这个关于交易情绪分析的讲师指导课程,发展你在现代金融方法方面的职业生涯。它涵盖了交易、投资决策的各个方面&使用新闻分析、情绪分析和替代数据的应用。现在就去看看吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti CSAF 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。CSAF 方案完成后取得的成果对所有人来说可能不尽相同。T3】
新冠肺炎联通面临的金融业挑战
原文:https://blog.quantinsti.com/finance-industry-challenge-covid-19-unicom/
此活动已经结束
主题: 新冠肺炎金融业面临的挑战:用数据、统计、分析和可视化进行防御
日期:2020 年 7 月 2 日
时间:英国夏令时 15:30/美国东部时间 10:30/IST 时间 20:00
关于会议
为了应对新冠肺炎事件造成的中断,联通已经计划了一系列在线小组会议,届时领先的学科专家/权威人士将出席并举行小组讨论。
会议持续时间约为 60-75 分钟,并有额外的问答时间
这些会议以互动的形式进行,为所有远程与会者提供了物理会议的数字体验。在这里,代表们积极参与,通过问答交流,在会议期间和休息时间分别与同行和小组成员交流。
讨论主题
- 全球社会经历了前所未有的攻击
- 敌人不是人类,而是摧残身体和灵魂的病毒
- 疾病传播的流行病学模型
- 数据驱动模型和基于证据的方法
- 投资者正面临金融市场的传染
- 流行病学家和行为金融专家:守军
主讲人

小组主持人

发言人和小组成员


印度金融工程课程的演变
原文:https://blog.quantinsti.com/financial-engineering-courses-india/
不断变化的市场结构-和金融工程的出现
随着全球形势的快速变化和竞争的加剧,大型金融银行和经纪公司面临着开发定制解决方案和复杂模型的需求,以解决利基和困难的客户问题。这些导致了一门新学科的诞生——金融工程;因此需要一批新的专业人士。作为一个新兴的高薪领域,越来越多的人试图获得必要的知识和技能,并转移到这个行业。
金融工程课程在所有领域的增长
随着上述事件的发生,在印度出现了由不同层次的大学和 T2 机构提供的金融工程课程。这些金融课程面向不同阶段的学生/专业人士:中级、毕业、甚至毕业后,并提供金融工程学位/证书。此外,它们中的一些也作为职业人士的技能发展项目提供。
金融工程课程的传统结构
传统上,这些课程中的大多数都是长期金融学位,在这里人们可以获得该领域所有主题的基础知识,例如量化技术、股票和衍生品的估价和定价、风险管理、计量经济学、金融建模、对信用风险的理解、投资组合分析等。这类课程通常由大型大学提供。
金融工程课程结构的新变化
然而,最近,市场参与者对在利基领域具有专长的金融专业人员的需求不断增长。其中一个领域是定量交易和算法交易。在 SEBI 批准后,印度于 2008 年批准并引入了算法交易,这是一种由计算机系统完成的全自动交易。算法交易不需要人工干预。这些算法基于数学模型,这些模型做出交易决定并生成订单。然后,该技术帮助执行这些订单。这是一个即将到来的非常令人兴奋的领域,专业人士不仅需要交易和金融知识,还需要编写和编码量化策略策略,在高级交易平台上实施这些策略的知识以及量化金融的基础知识。这个领域的职业主要有三种:交易员(利用交易平台在真实市场中交易,并提出新策略)、量化专家(开发数学模型,并据此开发策略)或开发人员(围绕新策略编写程序)。
提供算法交易金融工程课程的机构
作为一个新兴领域,在印度很少有机构和大学可以学习算法交易。其中,Quantinsti 是亚洲提供专门算法交易培训项目的先驱机构。Quantinsti 的旗舰课程 EPAT (算法交易的执行课程)旨在让人们学习算法交易所需的所有技能。它使学生和专业人士能够编写量化策略,并在先进的交易平台上实施。
前进的道路
因此,人们可以得出结论,虽然传统上的动力是学习金融工程中所有主题的基础知识,但未来肯定在于深入探索利基市场。
下一步
如果你从事业务开发、战略或技术方面的工作,这篇文章将告诉你如何转向盈利方面。请继续阅读,了解马克西姆·法吉斯是如何加入 QuantInsti 的,她来自一个强大的并购和公司战略背景。获得认证后,马克西姆创办了自己的量子研究公司。
金融进化:人工智能、机器学习和情感分析|联通|伦敦
原文:https://blog.quantinsti.com/financial-evolution-ai-machine-learning-sentiment-analysis-london/
于 2019 年 6 月 25 日至 26 日在伦敦肯辛顿希尔顿酒店举行
人工智能被认为是第四次工业革命的主要推动力。金融业预计将引领人工智能的采用,预计未来三年的支出将大幅增加。为了处理和理解那里的大量数据,机器学习和情绪分析交易等方法已经成为打开数据分析大门的必要手段。
这个会议将帮助你揭开人工智能的神秘面纱,区分现实和炒作。了解如何从人工智能技术的空前进步中受益。参与者将获得如何为自己和公司利用这些技术进步的真知灼见。
概述
人工智能和机器学习(AI & ML)以及情绪分析交易据说是“通过分析过去来预测未来”——这是金融界的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。AI & ML 正在被金融服务行业采用,尤其是在合规、投资决策和风险管理方面。
这是一个复杂的会议,不仅质疑和探索人工智能& ML 在金融服务行业的意义,而且还继续确定在金融领域分享知识和开发知识产权的投资机会。
参加本次活动,赢取 earn 持续专业发展学分。
联通已向 GARP 注册了该计划,以获得持续专业发展(CPD)学分。参加本课程可获得 14 个学分。如果您是经过认证的 ERP 或 FRM,请将此活动记录在您的信用跟踪系统中。
为什么参与
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解量子计算和替代数据的影响
- 受益于来自英国、美国、欧洲和印度/香港的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 该方案包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
你可以报名参加 Quantra 上的情绪分析课程,这将帮助你利用 Twitter、新闻情绪数据设计新的交易策略。在本课程中,你将学习通过量化市场情绪来预测市场趋势。
专属量词
- 有机会获得两张伦敦联通研讨会“金融发展:人工智能、机器学习和情感分析”会议的嘉宾门票。
- 为了获得优惠,请在 2019 年 7 月 12 日之前向 info@unicom.co.uk 发送电子邮件,附上您的姓名、职务、组织名称、电子邮件和电话号码。
- 还提供团体预订(4 对 3),您可以联系阿尼班:+44 (0)1895 819475
来源:https://conference . Unicom . co . uk/情操分析/2019/伦敦/
金融进化人工智能、机器学习和情感分析|联通|孟买
原文:https://blog.quantinsti.com/financial-evolution-ai-machine-learning-sentiment-analysis-mumbai-2020/
此活动已经结束。
日期:2020 年 9 月 3 日
联通研讨会举办的“金融发展人工智能、机器学习和情感分析”会议质疑并探讨了人工智能和人工智能在金融服务行业中的意义。
概观
人工智能和机器学习(AI & ML)以及情绪分析据说可以“通过分析过去来预测未来”——这是金融业的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,并对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。人工智能和人工智能在金融服务行业,尤其是在合规性、投资决策和风险管理方面越来越受欢迎。
这是一个复杂的会议,不仅质疑和探索人工智能和人工智能在金融服务行业的影响,而且还继续确定在金融领域分享知识和利用知识产权的投资机会。
为什么要参与?
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解量子计算和替代数据的影响
- 受益于来自英国、美国、欧洲和印度/香港的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 课程包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
****参加本次活动,赢取 earn 持续专业发展学分。T3】
联通已向 GARP 注册了该计划,以获得持续专业发展(CPD)学分。参加本课程可获得 7 个学分。如果您是经过认证的 ERP 或 FRM,请将此活动记录在您的信用追踪器中。
金融进化:人工智能、机器学习和情感分析|联通|孟买
此活动已经结束。
概述
人工智能和机器学习(AI & ML)以及情绪分析据说可以“通过分析过去来预测未来”——这是金融业的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,并对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。人工智能和人工智能在金融服务行业,尤其是在合规性、投资决策和风险管理方面越来越受欢迎。
这是一个复杂的会议,不仅质疑和探索人工智能和人工智能在金融服务行业的影响,而且还继续确定在金融领域分享知识和利用知识产权的投资机会。
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解来自多个来源的替代数据的影响。
- 受益于来自英国、美国和印度的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 课程包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
事件时间
此次活动主要针对来自东南亚和印度的参与者。因此,我们设定了活动时间,以便印度和中国的参与者可以在前三天(周三、周四、周五)下午 14:30(IST 时间)或 17:00(美国中部时间)参加活动。
活动时间定在 9 月 26 日星期六,以便来自印度和中国的参与者可以在 IST 时间上午 09:30 或美国中部时间中午 12:00 参加活动。
扬声器

参加本次活动,赢取 earn 持续专业发展学分
联通已向 GARP 注册了该计划,以获得持续专业发展(CPD)学分。参加该计划可获得 28 个 GARP 持续专业发展学分小时。如果你是注册的金融风险经理(T1)(FRM)或能源风险专家(ERP),请将此活动记录在你的信用跟踪系统(T2)中。
打折考勤优惠
如果你是 GARP 校友,也就是说,ERP 或 FRM 证书持有人,然后利用活动注册费 20%的优惠。欲了解更多优惠信息,请联系[email:info @ Unicom . uk; ankita.talit@unicom.uk
金融进化人工智能、机器学习和情感分析|联通|上海
原文:https://blog.quantinsti.com/financial-evolution-ai-machine-learning-sentiment-analysis-shanghai/
此活动已经结束。
日期:2020 年 9 月 12 日
联通研讨会举办的“金融发展人工智能、机器学习和情感分析”会议质疑并探讨了人工智能和人工智能在金融服务行业中的意义。
概述
人工智能和机器学习(AI & ML)以及情绪分析据说可以“通过分析过去来预测未来”——这是金融业的圣杯。它们可以复制人类做出的认知决策,同时避免人类固有的行为偏差。
处理新闻数据和社交媒体数据,并对(市场)情绪进行分类,以及它如何影响金融市场,是一个不断发展的研究领域。该领域最近取得了进一步进展,出现了许多新的“替代”数据源,如电子邮件收据、信用卡/借记卡交易、天气、地理位置、卫星数据、Twitter、微博和搜索引擎结果。人工智能和人工智能在金融服务行业,尤其是在合规性、投资决策和风险管理方面越来越受欢迎。
这是一个复杂的会议,不仅质疑和探索人工智能和人工智能在金融服务行业的影响,而且还继续确定在金融领域分享知识和利用知识产权的投资机会。
为什么要参加?
- 了解如何从前所未有的技术进步中为自己和公司获益
- 了解量子计算和替代数据的影响
- 受益于来自英国、美国、欧洲和印度/香港的世界级主持人的经验
- 获得对人工智能、机器学习和金融情感分析领域开创性项目的独家见解
- 课程包括最新的最先进的研究,实际应用和案例研究
- 享受与所有参与者(包括演示者、投资者和参展商)交流的绝佳机会。
参加本次活动,赢取 earn 持续专业发展学分。
联通已向 GARP 注册了该计划,以获得持续专业发展(CPD)学分。参加本课程可获得 7 个学分。如果您是经过认证的 ERP 或 FRM,请将此活动记录在您的信用追踪器中。
金融市场导论
原文:https://blog.quantinsti.com/financial-markets-introduction/
由杰伊·帕尔马和 T2 合作
这篇文章非常适合没有金融背景的读者。如果您是这个领域的新手,这篇文章将作为学习它的第一步。如果你已经有了一些投资/交易的工作知识,你可以在进入交易世界的更高级的话题之前,用这个作为复习。让我们开始吧。
假设你已经决定投资/交易金融市场,但不确定如何开始。一个有用的起点是问自己一些相关的问题,然后寻求这些问题的答案。让我们征募他们。
- 什么是市场?* 我如何进入市场?* 在交易所交易的是什么?* 如何跟踪市场?* 有哪些不同类型的市场?* 谁是参与者?* 谁监管市场?* 市场参与者进行哪些类型的分析?* 什么是策略回溯测试?* 有哪些不同的企业行为及其对价格的影响?* 常用术语
什么是市场?
通俗地说,市场是交易物品的地方,通常是为了获利。
在我们的日常生活中,我们无时无刻不在处理各种事情。我们处理公共汽车票、杂货、电话、公寓、租赁协议、雇佣合同等等。注意“transact”这个词的用法。因为我们有时是买家,有时是卖家。
在金融市场中,我们比喻性地聚集在一起进行金融工具交易。在我们的金融世界中,市场可以是一个在线市场(类似于现实世界中的亚马逊),也可以是一个实际的实体场所。
金融市场的一些例子有股票市场、商品市场、货币市场、衍生市场等。
我们交易一家公司的股份或股票的市场被称为证券交易所或证券市场或简称为市场。
所有这些术语都可以互换使用,在金融领域的使用相当宽松。
下面是世界上一些主要股票交易所的列表。
- 美国纽约证券交易所-纽约市
- ——美国纽约纳斯达克
- 日本交流团——日本东京T3】
- 香港证券交易所-香港,香港
- 伦敦证券交易所——英国伦敦
- 孟买证券交易所——印度孟买
- 印度孟买国家证券交易所
- 德国法兰克福证券交易所
- 韩国交易所——首尔&韩国釜山T3】
现在你对市场有了一些了解,也对不同地区的各种股票交易所有了一些了解,你可能会问的下一个问题是我如何访问它们?
我们继续前进。
我如何进入市场?
有多种方式可以连接到股票交易所,但是,我们将讨论两种最常见的方法:第一,通过经纪人,第二,通过直接进入市场。
通过经纪人访问
经纪人是一个独立于交易所的机构,它允许你连接到交易所进行交易。
为了提供这种服务来连接并在交易所进行交易,它以经纪费或佣金的形式向你收取费用。
在世界大部分地区,交易者(包括像你我这样的个人,以及中小型银行这样的机构)通常使用这一渠道与市场联系。这样既方便又划算。
当你为自己的交易账户选择经纪人时,要记住以下几点。
经纪或佣金
不同的经纪人根据他们提供的服务收取不同的佣金或佣金。
经纪人联系或提供进入的交易所(市场)的数量。
你可能有一个需要在多个交易所执行的投资/交易策略,因此有必要检查你考虑的经纪人是否提供所有交易所的访问权限。
交易工具
大多数现代经纪人提供基于网络的交易平台,以及移动应用程序和特定于平台的编程 API。
除此之外,大多数经纪人还经常提供桌面应用程序和交易调用工具。经纪人为促进交易而提供的工具和服务是特定于账户的。可以有一个经纪人提供所有这些设施,或者有选择地提供其中的一些设施。
全方位服务或折扣经纪人
同样,经纪人之间的区别之一是基于服务。顾名思义,全方位服务的经纪人还提供交易或投资建议,并承担交易员的大部分工作。
然而,这些服务是有代价的。因此,提供全方位服务的经纪人收取更高的费用。相比之下,折扣经纪商将大部分投资/交易决策留给交易者自己。他们的服务因此更便宜。他们的收入是由高交易量驱动的。
经纪人示例
经纪人的例子包括互动经纪人、罗宾汉、美林、查尔斯·施瓦布等。对你来说,搜索和探索你所在地区的各种经纪人将是一个有趣的练习。
注: QuantInsti 与上述任何一家经纪公司均无关联,也不支持其中任何一家。
直接市场准入(DMA)
DMA 是交易者(不仅仅是高净值个人(HNIs)、大型金融机构或对冲基金,甚至是散户)进入股票市场的另一种方式。这通常包括获得交易所会员资格,以便开展交易活动。
虽然任何人都可以走这条路,但它通常成本很高,并且需要满足各种先决条件。不同交易所的先决条件不同,会员费用也相应不同。对冲基金、自营交易柜台和其他此类机构通常选择这条路。
好吧!我们已经完成了多部分流程中的两部分。这里的目标是让你以尽可能平稳的方式开始。
在这个阶段,一个好奇的人可能会问,现在我知道了什么是市场,如何进入市场,我在 T4 交易什么?我们去看看。
在交易所交易的是什么?
简短的回答:金融工具
工具可以是公司的股票、衍生合约、债券、ETF 等。每种工具在交易的每个交易所都有独特的符号。
例如,在纳斯达克交易所,微软股票的代码是 MSFT。一家公司的股票也有可能在多个交易所进行交易。
在任何一个主要的股票交易所,都有成千上万的交易工具。像纳斯达克和印度国家证券交易所这样的交易所在任何给定的时间点都有成千上万的工具可供交易。
讨论在交易所交易的每一种工具超出了本文的范围。
然而,我们将讨论一些常见类型的工具。
股票
在交易所交易的主要投资工具是公司的股票。当一家公司决定上市时,它通过提供一定数量的股票供公众认购而在交易所上市。
例如,快乐餐,一家位于印度孟买的(虚构的)公司决定上市以扩大业务。为此总共需要投资 1000 万印度卢比。因此,它决定向公众中的潜在投资者提供 10,000 股,每股价格为 1000 印度卢比。这个过程被称为首次公开发行(IPO)。
公司首次发行股票的市场被称为一级市场。一旦一家公司在交易所上市,它的正常交易活动就开始了。
- 交易活动发生的市场被称为二级市场。
- 所有上述交易几乎都是通过交易所进行的(我们前面已经看到了)。
如果你仔细观察,你会发现我交替使用了股票和股份这两个词。股份也被称为股权股份或仅股权。这就是股票市场的各种参与者对它们的称呼。
这里解释的首次公开募股过程被故意简化了。具体流程因地域而异。这可能是一个有趣的自学练习,让你去详细了解这个过程。
衍生品
衍生工具(合约)是一种金融证券,其价值来自其他证券。这种其他证券通常被称为基础证券或基础资产。基础资产可以是任何东西:股票、商品、货币等。
衍生品在衍生品交易所交易(这些交易所也被称为 T2 衍生品市场)。
一些交易所只提供衍生品交易,而其他交易所允许交易多种类型的工具,如股票和衍生品。下面我列举了一些全球范围内交易的常见衍生品。
转发
远期是衍生品最简单的形式。远期合约的买方和卖方签订合约,将标的资产换成现金。
交易在特定的未来日期以特定的价格发生。交易发生的价格是在他们签订合同的当天决定的。
其他参数,如待交换的基础资产数量(又名批量)、交易发生的日期(又名到期日)也是固定的。
这些参数由买方和卖方共同决定,没有任何第三方的干预。这被称为“场外交易”或 OTC 交易。
远期合约只有在个人/机构基于交易双方的私下合约协议进行交易的情况下,才在场外市场进行交易。
在远期交易中,买方有义务购买标的资产,卖方有义务在达成交易时确定的日期出售标的资产。
转发者的例子 :
比如开心乐园餐(THM)公司想尝试减少开支。所以它决定直接从农民那里购买蔬菜。为此,THM 选择新鲜蔬菜(TFV)作为其蔬菜供应商。
2020 年 1 月 5 日,TFV 与 THM 签订合同,在两个月内(2020 年 3 月 5 日)供应一公吨(1000 公斤)胡萝卜。他们将胡萝卜的价格固定在当前的市场价格上,恰好是每公斤 12 个货币单位。
因此,根据该协议,在 2020 年 3 月 5 日,THM 预计向 TFV 支付 12000 英镑,以换取一公吨胡萝卜。本协议于 2020 年 1 月 5 日执行,因此,无论 2020 年 3 月 5 日的胡萝卜价格如何,THM 和 TFV 都有义务按照 2018 年 10 月 5 日的预定价格履行本协议。
与远期合约相关的潜在风险是交易对手风险。签订合同后,买卖双方都必须履行各自的义务,才能达成交易。
在我们的例子中,如果 TFV 不能在 2020 年 3 月 5 日向 THM 提供一公吨的胡萝卜,根据胡萝卜的当前价格,THM 可能不得不承担损失。
期货
期货是标准化的远期合约。所谓标准化,我们指的是有第三方(即交易所)参与其中,监管合约的各个方面。
期货合约中的数量(手数)、交易日期(到期日)、交易地点等。是由交易所决定的。另外,你可能不会惊讶于期货是交易所交易的。
期货合约的买卖双方只参与交易活动,而不决定其其他方面。
期货可以根据资产的基础类型进行分类。例如,股票期货被称为股票期货。
其他常见的期货有商品期货、指数期货、货币期货,其标的资产分别是商品、指数、货币。
选项
期权是一种合同,根据合同类型,买方有权在未来的特定日期或之前购买或出售基础资产。卖方有义务购买或出售标的。
买方向卖方支付额外费用以获得这一选择权。如果期权合约的买方不行使期权,卖方可以保留期权费。与期货类似,期权也是根据标的资产进行分类的。比如指数期权、股票期权、货币期权、商品期权等。
除了我们上面讨论的,其他衍生产品包括
-大部分是在柜台交易。
交易所交易基金
一只交易所交易基金(ETF) 是一个跟踪指数的证券集合(接下来将讨论)。它们是一种替代投资工具,可以像试图复制市场指数的股票一样进行交易。
ETF 的例子有跟踪 NIFTY50 指数的 Nifty50 ETF ,跟踪 S & P 500 指数的 SPDR S & P 500 ETF (SPY) 。
唷!那是很多仪器。好吧,那很好,但是我们怎么跟踪他们呢?让我们找出答案。
如何跟踪市场?
假设你的朋友问你市场表现如何。它是上升还是下降??对你来说,查看交易所交易的每一种工具并评估形势几乎是不可能的。
一个更好的方法是查看一些主要公司的股票,对它们进行评估,并报告你的发现。根据这个概述,你的朋友将能够判断市场的表现。这正是市场指数所做的。
指数是衡量股票市场相对变化的统计指标。它是根据在交易所交易的一些主要股票的价格计算出来的。每个交易所都有自己的指数。它是投资者和财务经理用来总结市场运动的工具。
例如,印度国家证券交易所(NSE)交易约 1700 只股票。其旗舰指数 NIFTY50 股票指数由 50 只股票组成,根据每只股票的市值(股票数量*股票价格)分配权重。
股票选择标准可以是行业类型、公司规模、公司过去的业绩等因素。基于 50 只股票的每日交易活动,指数值会发生变化,这种相对变化反映了投资者的情绪。
这些股票价格的任何变化都会影响指数的价值。此外,一个交易所可以有多个基于不同标准计算的指数。
以下是一些世界主要股票指数的列表:
- T3】IXIC =纳斯达克综合指数-纳斯达克
- SPX = S &普 500 指数-纽交所/纳斯达克
- FTSE =金融时报证券交易所 100 指数-伦敦证券交易所
- 【DAX =德国股票指数-法兰克福股票交易所
- 日经=日经 225 指数-东京证券交易所(TSE)
- 恒指=恒生指数-香港交易所
- KOSPI =韩国综合股价指数-韩国交易所(KRX)
- 【NIFTY = NIFTY 50 指数-印度国家证券交易所(NSE)
指数显示了市场的表现,通常是不可交易的。然而,有一些指数衍生品合约可以在各种交易所交易。例如,NIFTY 指数的指数期货和指数期权。
股票市场指数就像一个反映市场整体状况的晴雨表。它有助于投资者识别市场的一般模式。它也可以用作基准测试工具。投资者可以使用该指数来衡量他们投资的表现。
大多数指数要么遵循价格加权法,要么遵循市值加权法。价格加权指数赋予价格较高的股票更多的权重,例如道琼斯工业平均指数。
相比之下,市值加权指数根据每只股票的市值为其分配权重。其中一个例子是标准普尔 500,苹果和微软等大公司在该指数中占很大比重,而市值较小的股票在该指数中所占比重较小。
现在你知道了如何跟踪市场,让我们讨论一下你可以跟踪的不同类型的市场。
市场有哪些不同类型?
可以基于各种因素对市场进行分类,如交易地点、在其中交易的工具类型等等。
传统的分类标准之一是交易地点。类似地,另一个标准是在市场上交易的工具的类型。
这两个标准讨论如下:
交易地点
- 交易地点决定一个市场是场外交易还是受监管。
- 场外交易或简称为场外交易市场是分散的、不受监管的市场,交易直接发生在直接的两个实体之间,没有任何中间方。这种交易可以在任何地方进行。它没有中心物理位置。外汇市场是这类市场的完美例子。
- 基于交易所的金融市场是受监管的集中市场,各种实体之间的交易通过物理交易大厅或电子系统在一个集中的物理场所进行。任何证券交易所都可以是这种市场的一个例子。
仪器贸易
市场也可以根据在其中交易的工具来分类。
例如,它可以是:
- 股票/股票市场公司股票进行交易的地方。比如纽约证券交易所(NYSE)、上海证券交易所(SSE)等。
- 衍生品市场是衍生品合约进行交易的地方。其中一些市场只交易期货合约,而其他市场可能交易一种或多种衍生品合约。这类市场的例子有芝加哥期权交易所(CBOE)和印度国家证券交易所(NSE)。
- 商品市场是黄金、白银、玉米等商品的交易场所。被交易。通常,这类商品的衍生品在这些市场交易,例如芝加哥商品交易所(CME)、马来西亚证券交易所(MDEX)等。
- 货币市场是货币及其衍生品交易的场所。这类市场通常是场外交易。
大多数交易所在一个屋檐下经营着上述多个市场。
例如,印度国家证券交易所(NSE)是一个股票交易场所;因此,这是一个股票市场。它还促进股票衍生品合约的交易,因此,它也是一个衍生品市场。此外,货币和商品衍生品也可以交易;因此,它也可以分别被称为货币市场和商品市场。
参与者是谁?
交易员和投资者。他们是金融市场中从事买卖的主要参与者。我们用交易者这个术语来描述那些经常在市场上交易来赚取利润的人。
相比之下,我们将投资者定义为那些将资金投资于金融工具以随着时间的推移创造财富的人。根据从事的活动,一个人可以是交易者、投资者或两者兼而有之。
根据他们从事的活动类型,他们也可以分类如下:
投机者
投机者在市场上投机。他们是交易者,交易是为了从他们掌握的未来价格信息中获利。一些分析通常支持这样的信息。
他们相信市场会朝着特定的方向发展,并以此为基础进行交易。消息灵通的投机者比其他交易者更能预测期货价格。
然后,他们根据预期哪一方有利可图来选择买入或卖出。
仲裁员
套利者是试图从类似金融工具的低效率价格中获利的交易者。根据定义,套利利润是无风险的,这使得它成为一种特殊的交易类型。
在金融市场上发现套利机会是很困难的,需要很高的交易速度和准确性来实现利润。由于这个原因,套利者通常是非常有经验的投资者。他们通常买入较便宜的工具,卖出较贵的工具,从而获取较便宜和较贵工具之间的差价。
例如,如果人们知道,两个类似的工具或两个不同的期货合约之间的价格差异平均为 X,如果两者之间的当前价差大于 X,则可能存在套利机会。
对冲者
对冲者是指通过进行对冲投资来采取措施降低投资风险的投资者。他们试图通过持有与现有头寸相反的头寸来规避市场风险,并使自己对市场波动保持中立。-
到目前为止,我们已经讨论了各种类型的市场及其参与者,以及它们各自的角色。我们还讨论了基于交易所的市场是受监管的市场。
现在,让我们了解更多关于市场监管者的信息。
谁监管市场?
不同的参与者在交易生态系统中扮演着重要的角色。作为这一生态系统中的关键组成部分,交易所提供了一系列设施,从交易各种工具到在买方和卖方之间进行清算,并确保整个过程顺利进行。
但是谁来监督或管理各种交易所呢?答案是监管委员会或机构。
管理机构对经济中的各种活动行使管理或监督权力。
与证券市场相关的监管机构包括
- 美国证券交易委员会(SEC)、
- 印度证券交易委员会(SEBI)
这里值得注意的是,这些董事会是特定于他们经营的地理位置。在上面的例子中,SEBI 只监管印度的股票市场,而不监管任何其他国家的股票市场。
好吧。我们已经走了很长一段路。
既然你已经掌握了一些基础知识,让我们试着好好利用这些知识。考虑到你几乎万事俱备,想要战胜市场。你想比其他交易者有优势。为此,你决定你的交易决策应该是数据驱动的,并基于一些分析。
你可能想知道是什么样的分析?让我们开始吧。
市场参与者进行哪些类型的分析?
几乎所有金融领域的交易者和投资者都遵循一些分析方法来做出交易决定。那些没有的人只是在赌丨博和碰运气。
一个方便的分类分析的方法是分成三种类型,即基本面分析、技术分析和定量分析。
让我们简单讨论一下:
基本面分析(FA)
顾名思义,这种方法包括从基础层面研究公司。它包括对公司经营中各种金融和经济因素的研究。
现金流、盈利能力、资产负债表规模、公司管理的有效性等因素。都是在 FA 学的。任何一种分析的目标都是确定某一种证券的价值是否正确。
FA 通常从宏观到微观的角度进行,以确定证券的定价是否正确。基本面分析师试图通过与行业或经济的整体状况相比较来确定证券的公允价值。
如果公司的公允价值高于股票的当前市场价格,则认为其被低估,并给出买入建议。\
否则,如果公司的公允价值低于当前市场价格,则认为其被高估,并给出卖出建议。
技术分析(TA)
一个工具的价格是技术分析的关键组成部分。它大量涉及对变量的研究,如历史价格模式、一段时间内的交易量。
TA 的从业者使用图表软件来可视化价格模式和运动。
它基于以下三个假设:
- 市场贴现一切:TA 的一切都围绕价格。它还假设工具的当前价格反映了市场上所有可用的信息。
- 价格在趋势中运动 : TA 告诉我们,基于关于一个工具价格的信息流,它遵循一些模式,因此,它随着时间的推移在趋势中运动。
- 历史往往会重演 : TA 也假设过去发生的事情,将来也会发生。交易者和投资者在过去做的事情,在未来也会继续做,这是基于人类的心理。因此,为了从这种重复行为中获利,它试图研究过去的价格模式,寻找未来的价格模式,并据此做出交易决定。
定量分析
这一分析领域包括通过数学和统计建模对金融事件的研究。使用统计技术识别交易机会。
量化交易者利用现代技术、数学和大量历史数据来做交易决策。这些技术非常强大,包括密切监控市场动向、交易模式和新闻。
基于 QA 的交易策略经常在几分之一秒内处理大量订单。
以上是交易者和投资者用来产生新的交易想法的一些常用技巧。他们倾向于使用多种技术结合战略思想。
值得一提的是,策略想法可以有多种来源,可以来自研究论文、交易杂志、观察其他交易者的交易等等。考虑你从最近的分析中得到一个交易的想法。
你如何验证你手头的交易想法是否会成功?
回答:回溯测试策略,看看它在过去的历史数据上表现如何。如果这种策略在过去有效,那么它很有可能在未来继续有效。
这是我们接下来要学习的内容。
什么是策略回测?
策略想法的确认是交易生命周期中的重要步骤之一。可以通过对历史数据进行回溯测试来验证策略思想。
回溯测试
回溯测试是使用历史数据测试交易策略的过程,以确定该策略的有效性。
回溯测试结果通常以一些流行的性能统计数据来显示策略的性能,如夏普比率或索蒂诺比率,这些数据有助于量化策略的风险回报。
如果结果满足必要的标准,就可以在一定程度上放心地实施策略。如果结果没有达到预期,可以修改和优化策略,以达到理想的结果。
回溯测试系统主要有两种形式:
- 研究回溯测试
- 事件驱动回溯测试
回溯测试不仅为您提供关于策略的见解,还允许您微调策略中的各种参数(如果有的话)。基于回溯测试性能,您可以更改策略使用的各种参数,并再次回溯测试和检查性能。
重复这个过程,直到你得到想要的结果。这个过程被称为优化。
比如手头的策略思路是:如果一只股票的现价高于最近五天的高价就买入,如果现价低于最近五天的低价就卖出。这是一个简单的战略思想。
回测结果表明,该策略的性能并不理想。因此,你想调整策略,看看你是否能让它有利可图。在这种情况下,策略的参数可以是用于比较的天数,即最近五天。您将该参数更改为 6,并用新参数对策略进行回溯测试,并查看其性能。
另一个参数可以代替最低价格;你可以用最近五天的收盘价。
接下来,我们将讨论企业在一段时间内采取的不同企业行动。
有哪些不同的企业行为及其对价格的影响?
公司行为是指上市公司采取的可能导致其发行的股票价格发生变化的事件。公司行为由公司董事会达成一致,并由股东授权。例子包括股息、股票分割、红利、权利等。
这些事件由公司自行决定。没有必要每个公司都采取上述行动。
让我们简单地讨论一下它们。
股息
股息是公司向股东分配的收益或利润。支付给股东的金额取决于股东持有的股份数量和每股支付的金额。
公司通常在盈利良好时支付股息;然而,这不是必须的。如果一家公司发生了亏损,它也可能会支付股息,但它们持有大量现金。
公司没有义务支付它。通常,早期阶段的公司不会支付这笔费用,因为他们更愿意将大部分利润再投资于企业,以刺激更高的增长。另一方面,成熟的公司经常向股东支付定期股息。
分红是公司足够稳定,可以分享超额利润,未来前景良好的信号。此外,有些投资者更喜欢投资定期支付股息的公司。
另一方面,我们必须注意到,公司支付股息会减少其留存收益,限制其增长能力。
例如,一家公司的股票交易价格为 101 美元。它决定向股东支付每股 5.40 美元的股息。持有公司 10 股股份的股东在公司支付股息时将获得 54 美元= 5.4 美元 x 10。
股票分割
股票分割是增加公司股票数量的事件。调整价格,使得事件前后的市场资本总额保持不变。
例如,当每只股票的价格变得如此之高,以至于其交易量显著下降,流动性增加时,一家公司可能会拆分其股票。
例如,一家公司有 2000 股已发行股票,每股交易价格为 100 美元,其市值为 2000 x 100 美元= 200000 美元。如果公司决定以 2:1(2:1)的比例分割其股票,分割后将有 4000 股。拆分后,每个股东将拥有两倍的股份。每股的价格将调整为 50 美元= 200000 美元/ 4000 美元。市值将保持不变,即 4000 x 50 美元= 200000,与拆分前相同。
红股(又名红股)
红股是公司免费分配给现有股东的股票。红股通常在公司现金短缺时发行,股东期望获得固定收入。
股东可以出售红股,满足他们的流动性需求。红股是根据股东在公司的股份发行的。
例如,一家公司可能决定为股东已经拥有的每 x 股提供 n 股红股。因为奖金发放并不代表经济事件——没有财富易手。目前的股东可以免费获得新的股份,并且与他们以前在公司的股份成比例。
除了上面提到的公司行为之外,该列表还可以包括分拆、配股、流通股变更、合并/拆分/合并等等,这些都不在本文的讨论范围之内。
我们已经回答了几乎所有关于金融市场的问题。
但是在我们结束之前,让我们看一下交易领域中一些常用的术语。
常用术语
牛市/看涨
如果你期待股票价格上涨,据说你看好这些股票。从更广泛的角度来看,如果股票市场在特定的时间段内上涨,就说是牛市。
熊市/熊市
与看涨相反,如果你预计股票价格会下跌,就说你看跌这些股票。从更广泛的角度来看,如果股市在特定时间段下跌,就被称为熊市。
多头头寸
多头头寸或简单的多头指的是你交易的方向。例如,如果你正在购买一家公司的股票,据说你正在做多这家公司。如果你已经持有该公司的股票,据说你是该公司的多头。
空头头寸
类似于多头,空头,或者简单的空头也是指你交易的方向。例如,如果你在没有持有股票的情况下卖出股票,这就是说你在做空股票。或者你在卖空股票。如果你已经卖出了股票,这被认为是你做空股票。
开方
平仓是指退出现有头寸,无论是买入还是卖出。如果你做多一只股票,平仓意味着你卖出已买入的股票,取消你的头寸。如果你做空一只股票,平仓需要你买入这只股票,以抵消你的头寸。
体积
交易量是指特定时间段内的交易总数(买和卖的总和)。如果股票 THM 的日交易量为 150 万股,则意味着当天交易了 150 万股。
OHLC
开盘、盘高、盘低和收盘(OHLC)的缩写,指的是股票价格数据集,其中每个数据点都有四种价格。例如,如果您有一个特定股票从 2013 年到 2018 年的每日价格数据集,每个数据点(每天)将有四个价格,分别指开盘价、最高价、最低价和收盘价。
通常情况下,这些数据也可能包含数量。在这种情况下,它也可以被称为 OHLCV 数据。
趋势
趋势是指证券价格的特定方向。如果价格在一段时间内呈上升趋势,可以说证券处于上升趋势。如果价格呈下降趋势,这种证券就被认为处于下降趋势。
仲裁
套利是同时交易多种金融证券以从价格差异中获利的过程。这可以通过多种方式实现,例如:
- 相同证券在不同市场的买卖(空间套利)或
- 同时买卖证券的现货价格和期货合约,或者在卖出收购公司股票的同时买入被收购公司的股票(合并套利
套利是一种无风险的策略,尽管情况并非总是如此。始终存在执行风险的可能性,即由于市场的高波动性和价格的突然变化导致无法以有利可图的价格成交的风险。涉及的其他风险包括交易对手风险和流动性风险。
订单
指令是投资者或交易者向经纪人或经纪公司或直接向交易场所(交易所)发出的购买或出售股票、债券或衍生品等证券的指令。可以通过电话或在线手动/通过算法下订单。最常见的订单类型是限价订单和市价订单。
投资组合
投资组合是由个人、投资公司或金融机构持有的金融工具的集合,如股票、债券、现金等价物、基金。
一个投资组合可以被看作是一个被分成不同部分的馅饼,每个部分代表一种金融工具,其目标是实现特定水平的风险和回报。投资者应该根据投资目标、风险承受能力和时间框架来构建投资组合。
传播
在金融学中,价差可以定义为任意两个价格之间的差异。它也被定义为给定证券的当前买价和当前卖价之间的差额(买卖差价)。
在期权的情况下,它是相同资产类别、相同基础证券、但具有不同执行价格或到期日(期权差价)的等量期权合约的买卖。
流动性
流动性是指资产转换为现金而不会在很大程度上影响市场上当前资产价格的能力和难易程度。市场流动性是指市场允许股票、债券或衍生产品等资产在无需支付巨大买卖差价的情况下进行买卖的程度。算法交易在提供市场中高达 70 %的流动性方面也发挥了重要作用。
基点
一个基点等于 1%的 1/100,或 0.01%,或 0.0001,用于表示金融工具的百分比变化。
行业领袖小组讨论不断发展的交易领域及其挑战,以及新时代的学习平台如何为下一代交易者提供支持。
https://www.youtube.com/embed/x-t0QkIyJXI?rel=0
结论
我们从市场的定义开始,接着学习市场的参与者、类型、监管者以及市场中使用的不同类型的分析。
我们只是触及了一个深入发展的领域的表面。我们希望你喜欢阅读它,并敦促你检查我们的课程,作品和其他内容。
要开始学习 Python 并编写不同类型的交易策略,您可以在 Quantra 上选择“人人算法交易”学习课程。
进一步阅读
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
Finbridge 2015 -印度首届金融服务和技术展览会
原文:https://blog.quantinsti.com/finbridge-2015-indias-first-financial-services-technologies-exhibition/
金融服务和技术展览会 FINBRIDGE 于 2015 年 3 月 14-15 日在孟买的孟买展览中心举行。
FINBRIDGE,为期两天的大型活动由 Ashishkumar Chauhan 先生(医学博士&首席执行官,BSE) 揭幕。它汇集了成千上万的零售金融市场参与者、分销商、投资者、供应商、服务专家以及顶级共同基金、保险公司、领先的经纪商、银行或金融机构、基金经理、负责业务管理、数据管理、基础设施、交易技术、风险管理、支付、合规性和运营的决策者。
许多金融和科技行业的领先市场参与者,如Reliance Securities&Mutual Fund、sharekan、 Angel Broking 、 Kotak Mutual Fund 、 Birla Sun Insurance 、 Nirmal Bang 、 SMC Global 、 Atom Technologies 、 Financial Technologies 参加了此次活动。所有人都聚集在一起,体验印度有史以来第一次综合金融服务提供商展览会。
QuantInsti 出席 Finbridge 2015
QuantInsti 受邀成为其知识合伙人。QuantInsti 的专家应邀在自动化交易大会上分享经验和知识。QuantInsti 针对算法和高频交易下的各种主题举办了研讨会,听众包括散户投资者、交易员、经纪人、次级经纪人、金融企业家和传道者。这些行业专业人士能够收集专家对“算法交易”这一新兴交易趋势的评论。
在展览中,我们与来自金融和技术部门的参观者进行了丰富的面对面互动。QuantInsti 的展位展示了一个虚拟交易台,并向相关观众解释了交易的技术创新。我们展示了一个使用高级算法交易平台执行的配对交易策略的演示。展台的专家还就算法交易系统架构进行了简短的讲座,从应用程序、服务器和交易所等多个层面解释了整个系统(如下图)。在这次活动中,很高兴能与我们的校友见面并交谈,他们在各自的专业领域都享有盛名!

关于尖端交易技术的会议和研讨会
1 本次活动的第一次会议是关于“股票市场的交易技术”,来自金融科技、迪昂全球解决方案等领先公司的专家小组参加了会议,并就当前股票交易的市场技术场景提出了他们的想法,并阐明了交易的未来趋势和技术。
2 本次活动的第二次会议是关于“自动化交易”的,来自领先的 Algo 交易公司如 QuantInsti 、 BP Wealth 、 Symphony Fintech 的一组雄辩的演讲者参加了会议,并向观众发表了演讲,回答了诸如“如何改进执行、风险控制程序和合规性”等问题“如何使用自动化策略来利用期货、期权、外汇和股票市场?”以及“印度自动化交易的未来”。
 gaur av rai zada 先生(右一)在自动交易会议的小组中
gaur av rai zada 先生(右一)在自动交易会议的小组中
gaur av raiz ada 先生(董事&联合创始人- QuantInsti)向听众讲述了散户和投资者如何利用自动化交易增加利润。
事件概述
在这两天的交易技术研讨会上,许多散户投资者、交易员、经纪人和次级经纪人提出了问题,并与领先市场参与者的发言人讨论了他们的问题和经验,如 Birla Sunlife 、 Atom Technologies 。

对于散户投资者、交易员和经纪商而言,关于“算法交易”的研讨会证明是神话终结者。QuantInsti 研讨会由专家教员主持,【Rajib Ranjan Borah 先生和shau rya Chandra 先生,他们讨论了行业内的最新创新,如基于新闻的自动化交易、基于情绪的分析、盈利能力分析、量化交易中的资金管理等主题。我们的定量分析和技术大师same er Kumar先生和Anil Yadav先生向观众展示了提高交易利润的工具和策略。他们实际演示了如何利用开源工具利用大数据设计交易策略。
Finbridge Expo 2015 是一个很好的平台,让所有参观者和参展商获得关于金融和技术行业其他细分市场的宝贵行业知识和见解。
了解更多关于我们的旗舰 EPAT 项目,欢迎联系我们或致电 1800-266-5401。
金融信息交换(FIX)交易协议

FIX(金融信息交换)协议是近二十年来电子交易中信息交流的事实标准。1992 年,Salamon brothers 和 Fidelity Investments 发起了用于股票交易的 FIX 协议。今天,它被各种市场参与者、公司和供应商所使用。随着电子交易的出现,各种交易所和公司设计了他们自己的报文格式,因此 FIX 被看作是一种中间报文格式,一种标准化通信的通用基础手段。
好处
几十年来,交易前、交易中和交易后的过程发生了显著的变化,对于不同的市场参与者和公司来说,变化更大。流程的自动化要求总体上的通信自动化,以及消息的标准化格式。
连接成本
标准消息传递协议的广泛使用降低了集成各种内部流程的成本和复杂性,因此对所有利益相关者都有利。与使用专有协议的应用程序相比,在 FIX 上维护应用程序的容易程度有了很大的提高。FIX 的使用降低了建立交易平台、自动化执行工具等的成本。只需允许从现有实现中复制即可。
降低了涉及多个合作伙伴的复杂性
如果三个人在交谈,他们使用三个人通用的语言是有意义的,同样的类比可以应用于不同市场参与者和利益相关者之间的信息交互。有了 FIX 作为标准,就更容易让多个合作伙伴参与进来,因为一个合作伙伴可以避免使用专有协议与多个公司/交易所打交道所增加的复杂性。

资料来源:Oxera
来源:Oxera
可靠、降低风险、持续发展
FIX 是一个经过充分测试、广泛使用的协议。因此保证了固定可靠性。FIX 协议有限公司是拥有权利并研究 FIX 标准发布的组织。
提高服务质量
由于通用标准协议的存在,投资管理公司将能够更容易地在经纪人之间转换。因此,增加了经纪人之间对交易服务的竞争;从而提高服务质量。
不用说,当更多的公司使用相同的消息传递协议时,好处会更大。
一些数字……
- 为了客观地看待 FIX 支持的影响,目前受益于该议定书的市场规模包括美国、欧洲和亚太股票市场,2008 年的年交易额为 113 万亿美元,此外还有大量新兴股票市场;政府和公司债券市场,2009 年 6 月全球流通价值为 83.9 万亿美元;交易所交易衍生品市场,2009 年 6 月在美国、欧洲和亚太地区的名义金额为 63.4 万亿美元,全球场外(OTC)衍生品市场,2008 年 12 月的名义金额为 591 万亿美元。
- 在 2000 年实施 FIX 后的六个月内,GIM 将其 OMS 升级到了 FIX 兼容版本,建立了服务器并安装了 FIX 网关,完成了测试并通过 FIX 发送订单。最初,只有一家经纪商使用 FIX,但在三年内,GIM 与 50 家或更多经纪商进行了电子通信,以处理 FIX 订单和执行,其中 13 家还处理 FIX 分配。
- 就 ACI 而言,1996 年引入了 FIX。在引入 FIX 执行能力的三年内,超过 97%的美国执行和 93%的国际执行都是使用 FIX 执行的。与此同时,在引入 FIX 兼容分配的三年内,超过 88%的美国分配和 43%的国际分配是使用 FIX 进行的。
- NBIM 在 2002 年末采用了 FIX,并在一年内通过 FIX 从 100%的人工执行提高到 80–90%。它目前对 FIX 的使用率几乎是 100%。
最近的发展
***新开放技术资源(github.com)
2015 年 11 月 23 日,FIX Trading community 向金融行业的开发者开放了其技术标准流程。该接口托管在 Github 上。几个 FIX 项目已经发布到 Github,更多项目正在进行中。
***传输独立性框架(FIXT)
随着“传输独立性”的出现,多个应用程序消息可以通过一个信号传送。这允许通过任何合适的传输技术从消息队列、总线等使用 FIX 消息。
***快速(适用于流的修复)协议
FAST 框架是作为低延迟解决方案开发的,它在网络上提供了优化的数据表示,从而提高了吞吐量,并使金融机构之间的通信更加高效。
***修复简单二进制编码(修复 SBE)
FIX SBE 再次致力于更快的通信,其消息设计致力于无需复杂转换和条件逻辑的直接数据访问。它使用本机二进制数据类型,并且更喜欢支持直接访问的固定位置、固定宽度的字段。
消息结构
修复是在 TCP 连接之上分层的。固定消息具有标签值对;每一对用 ASCII 字符代码 SOH (0x001)分隔,该标记用等号(=)与值分隔。每条消息都有头、体和尾。尾部是带有标签 10 的校验和。消息的 fix 版本和正文长度在头部分(分别是 8 和 9 个标签)。消息类型由标签 35 的值表示。
例子
8=FIX.4.19=11235=049=BRKR56=INVMGR34=23552=19980604-07:58:28112=19980604-07:58:2810=157
8=FIX.4.19=15435=649=BRKR56=INVMGR34=23652=19980604-07:58:4823=11568528=N55=SPMI.MI54=227=20000044=10100.00000025=H10=159
下一步
如果你是一名散户交易者或专业技术人员,想要建立自己的自动化交易平台,今天就开始学习算法交易吧!从基本概念开始,如自动交易架构、市场微观结构、策略回溯测试系统和订单管理系统。
使用极端梯度推进(XGBoost)预测市场
原文:https://blog.quantinsti.com/forecasting-markets-using-extreme-gradient-boosting-xgboost/
近年来,用于交易的机器学习因其在交易中的有利可图的应用而引起了很多好奇。许多机器学习模型,如线性/逻辑回归、支持向量机、神经网络、基于树的模型等。正在被尝试和应用于分析和预测市场。研究人员发现,与其他机器学习模型相比,一些模型的成功率更高。极端梯度推进也称为 XGBoost 就是这样一种机器学习模型,吸引了机器学习从业者的大量关注。
在本帖中,我们将介绍 XGBoost 的基础知识,它是许多 kaggle 竞赛的获胜模型。然后,我们尝试使用 R 编程中的“xgboost”包开发一个 XGBoost 股票预测模型。
XGBoost 及相关概念的基础知识
极端梯度推进(XGBoost)模型由陈天琦开发,是梯度推进框架的一种实现。梯度推进算法是一种用于构建基于树的预测模型的机器学习技术。(机器学习:决策树介绍)。
Boosting 是一种集成技术,其中添加了新的模型来纠正现有模型产生的错误。模型按顺序添加,直到不能再进一步改进。
集成技术使用树集成模型,它是一组分类和回归树(CART)。使用集成方法是因为单个 CART 通常没有很强的预测能力。通过使用一组 CART(即,树集合模型),考虑多棵树的预测的总和。
梯度推进是一种方法,在这种方法中,创建新模型来预测先前模型的残差或误差,然后将它们相加在一起以做出最终预测。
XGBoost 模型的目标如下:
Obj = L+****ω
其中,L 是控制预测能力的损失函数,ω是控制简单性和过拟合的正则化分量
需要优化的损失函数(L)可以是回归的均方根误差、二元分类的对数损失或多类分类的对数损失。
正则化分量(ω)取决于树叶的数量和在树集合模型中分配给树叶的预测分数。
它被称为梯度提升,因为它使用了一种梯度下降算法来最小化添加新模型时的损失。梯度推进算法支持回归和分类预测建模问题。
 T2】
T2】样本 XGBoost 模型:
我们将使用“xgboost”R 包来创建一个样本 XGBoost 模型。这里可以参考“xgboost”包的文档。
安装并加载 xgboost 库—
我们使用 install.packages 函数在 R 中安装 xgboost 库。为了加载这个包,我们使用库函数。我们还加载运行代码所需的其他相关包。
install.packages("xgboost")
# Load the relevant libraries
library(quantmod); library(TTR); library(xgboost);
创建输入特征和目标变量—我们获取一只股票的 5 年 OHLC 和成交量数据,并使用该数据集计算技术指标(输入特征)。计算的指标包括相对强度指数(RSI)、平均方向指数(ADX)和抛物线 SAR (SAR)。我们在计算指标中创建一个滞后,以避免前瞻偏差。这为我们提供了在 r 中构建 XGBoost 模型的输入特性,因为这是一个示例模型,所以我们只包含了几个指标来构建我们的输入特性集。
# Read the stock data
symbol = "ACC"
fileName = paste(getwd(),"/",symbol,".csv",sep="") ;
df = as.data.frame(read.csv(fileName))
colnames(df) = c("Date","Time","Close","High", "Low", "Open","Volume")
# Define the technical indicators to build the model
rsi = RSI(df$Close, n=14, maType="WMA")
adx = data.frame(ADX(df[,c("High","Low","Close")]))
sar = SAR(df[,c("High","Low")], accel = c(0.02, 0.2))
trend = df$Close - sar
# create a lag in the technical indicators to avoid look-ahead bias
rsi = c(NA,head(rsi,-1))
adx$ADX = c(NA,head(adx$ADX,-1))
trend = c(NA,head(trend,-1))
我们的目标是使用这些输入特征预测每日股票价格变化的方向(上涨/下跌)。这使得它成为一个二元分类问题。我们计算每日价格变化,如果每日价格变化为正,则分配正 1。如果价格变化是负的,我们指定一个零值。
# Create the target variable
price = df$Close-df$Open
class = ifelse(price > 0,1,0)
将输入特征组合成一个矩阵-将输入特征和上述步骤中创建的目标变量组合成一个矩阵。我们在 xgboost 模型中使用矩阵结构,因为 XGBoost 库允许矩阵格式的数据。
# Create a Matrix
model_df = data.frame(class,rsi,adx$ADX,trend)
model = matrix(c(class,rsi,adx$ADX,trend), nrow=length(class))
model = na.omit(model)
colnames(model) = c("class","rsi","adx","trend")
将数据集分为训练数据和测试数据—在下一步中,我们将数据集分为训练数据和测试数据。使用这个训练和测试数据集,我们创建各自的输入特征集和目标变量。
# Split data into train and test sets
train_size = 2/3
breakpoint = nrow(model) * train_size
training_data = model[1:breakpoint,]
test_data = model[(breakpoint+1):nrow(model),]
# Split data training and test data into X and Y
X_train = training_data[,2:4] ; Y_train = training_data[,1]
class(X_train)[1]; class(Y_train)
X_test = test_data[,2:4] ; Y_test = test_data[,1]
class(X_test)[1]; class(Y_test)
在训练数据集上训练 XGBoost 模型—
我们使用 xgboost R 函数来训练模型。xgboost R 函数的参数如下图所示。

xgboost R 函数中的数据参数用于输入要素数据集。它接受矩阵、dgCMatrix 或本地数据文件。nrounds 参数指的是最大迭代次数(即添加到模型中的树的数量)。obj 参数指的是定制的目标函数。它返回给定预测和数据的梯度和二阶梯度。
# Train the xgboost model using the "xgboost" function
dtrain = xgb.DMatrix(data = X_train, label = Y_train)
xgModel = xgboost(data = dtrain, nround = 5, objective = "binary:logistic")
输出—输出是训练数据集上的分类误差。

交叉验证
我们还可以使用 xgboost R 的交叉验证功能,即 xgb.cv。在这种情况下,原始样本被随机划分为 n 个相同大小的子样本。在 nfold 子样本中,保留一个子样本作为测试模型的验证数据,其余(nfold - 1)子样本用作训练数据。然后,交叉验证过程重复 n 次,每个 nfold 子样本仅用一次作为验证数据。
# Using cross validation
dtrain = xgb.DMatrix(data = X_train, label = Y_train)
cv = xgb.cv(data = dtrain, nround = 10, nfold = 5, objective = "binary:logistic")
Output-xgb . cv 返回包含交叉验证结果的 data.table 对象。

对测试数据进行预测
为了对看不见的数据集(即测试数据)进行预测,我们对其应用了经过训练的 XGBoost 模型,该模型给出了一系列数字。
# Make the predictions on the test data
preds = predict(xgModel, X_test)
# Determine the size of the prediction vector
print(length(preds))
# Limit display of predictions to the first 6
print(head(preds))
输出—

这些数字看起来不像二元分类{0,1}。因此,在我们能够使用这些结果之前,我们必须执行一个简单的转换。在下面显示的示例代码中,我们将预测的数字与阈值 0.5 进行比较。阈值可以根据建模者的目标、建模者想要跟踪和优化的度量(例如 F1 分数、精确度、召回率)来改变。
prediction = as.numeric(preds > 0.5)
print(head(prediction))
输出-

测量模型性能
可以使用不同的评估指标来衡量模型性能。在我们的例子中,我们将计算一个简单的指标,平均误差。它将预测得分与阈值 0.50 进行比较。
例如:如果预测得分小于 0.50,则(preds > 0.5)表达式给出的值为 0。如果这个值不等于测试数据集中的实际结果,那么它被认为是错误的结果。
我们将所有预测值与 Y_test 中的相应数据点进行比较,并计算平均误差。下面给出了测量性能的代码。或者,我们可以使用命中率或创建混淆矩阵来衡量模型性能。
# Measuring model performance
error_value = mean(as.numeric(preds > 0.5) != Y_test)
print(paste("test-error=", error_value))
输出-

绘制特征重要性集合- 我们可以通过使用 xgb.importance 函数来找到模型中最重要的特征。
# View feature importance from the learnt model
importance_matrix = xgb.importance(model = xgModel)
print(importance_matrix)

绘制 XGBoost 树
最后,我们可以使用 xgb.plot.tree 函数绘制 XGBoost 树。为了将绘图限制在特定数量的树上,我们可以使用 n first tree 参数。如果为空,则绘制模型的所有树。
# View the trees from a model
xgb.plot.tree(model = xgModel)
# View only the first tree in the XGBoost model
xgb.plot.tree(model = xgModel, n_first_tree = 1)

结论
这篇文章介绍了流行的 XGBoost 模型,以及用 R 编程预测股票价格每日变化方向的示例代码。读者可以看到我们以前的一些机器学习博客(下面给出了链接)。我们将在未来的帖子中涵盖更多的机器学习概念和技术。
下一步
阅读我们的帖子“使用 ARIMA 模型预测股票回报”,该帖子涵盖了流行的 ARIMA 预测模型来预测股票回报,并演示了使用 R 编程进行 ARIMA 建模的一步一步的过程。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
下载数据文件
- ACC.csv
用 ARIMA 模型预测股票收益
原文:https://blog.quantinsti.com/forecasting-stock-returns-using-arima-model/
“股价预测很难,尤其是关于未来”。你们中的许多人一定听过丹麦物理学家尼尔·玻尔的这句名言。股价预测是这篇博文的主题。在本帖中,我们将介绍流行的 ARIMA 预测模型来预测股票回报,并演示使用 R 编程的 ARIMA 建模的一步一步的过程。
什么是时间序列中的预测模型?
预测包括使用变量的历史数据点预测变量的值,也可以包括在给定一个变量的值的变化的情况下预测另一个变量的变化。预测方法主要分为定性预测和定量预测。时间序列预测属于定量预测的范畴,其中将统计原理和概念应用于变量的给定历史数据,以预测同一变量的未来值。使用的一些时间序列预测技术包括:
- 自回归模型
- 移动平均模型(MA)
- 季节性回归模型
- 分布式滞后模型
什么是自回归综合移动平均(ARIMA)模型?
ARIMA 代表自回归综合移动平均线。ARIMA 也被称为博克斯-詹金斯方法。Box 和 Jenkins 声称,非平稳数据可以通过对序列进行差分而变得平稳,Yt .Yt的一般模型写为:
和和-
其中 Y t 是差分时间序列值,ϕ和θ是未知参数,ϵ是具有零均值的独立同分布误差项。这里,T3】Yt用它的过去值和误差项的当前和过去值来表示。
ARIMA 模型结合了三种基本方法:
- 自回归(AR)-在自回归中,给定时间序列数据的值根据其自身的滞后值进行回归,这在 ARIMA 模型中由“p”值表示。
- 差分(I-代表综合)-这涉及差分时间序列数据,以消除趋势,并将非平稳时间序列转换为平稳时间序列。这由 ARIMA 模型中的“d”值表示。如果 d =1,它查看两个时间序列条目之间的差异,如果 d = 2,它查看 d = 1 时获得的差异的差异,依此类推。
- 移动平均(MA)–ARIMA 模型的移动平均性质由“q”值表示,它是误差项的滞后值的数量。
这个模型叫做 Y t 的自回归综合移动平均或 ARIMA(p,d,q)。我们将按照下面列举的步骤来构建我们的模型。
步骤 1:测试并确保稳定性
要用 Box-Jenkins 方法对时间序列建模,该序列必须是平稳的。平稳时间序列是指没有趋势的时间序列,具有恒定的均值和方差,这使得预测值变得容易。
平稳性测试- 我们使用扩展的 Dickey-Fuller 单位根测试来测试平稳性。ADF 测试得出的 p 值必须小于 0.05 或 5%,时间序列才能稳定。如果 p 值大于 0.05 或 5%,您可以得出时间序列有单位根的结论,这意味着它是非平稳过程。
差分–为了将非平稳过程转换为平稳过程,我们应用差分方法。差分时间序列是指找出时间序列数据的连续值之间的差异。差值形成新的时间序列数据集,可以对其进行测试以揭示新的相关性或其他有趣的统计特性。
我们可以不止一次地连续应用差分方法,产生“一阶差分”、“二阶差分”等。
在进行下一步之前,我们应用适当的差分顺序(d)使时间序列平稳。
步骤 2:p 和 q 的识别
在这一步中,我们通过使用自相关函数(ACF)和偏自相关函数(PACF)来识别自回归(AR)和移动平均(MA)过程的适当顺序。关于 ACF 和 PACF 函数的解释,请参考我们的博客“从时间序列开始”。
识别 AR 模型的 p 阶
对于 AR 模型,ACF 将指数衰减,PACF 将用于识别 AR 模型的阶(p)。如果我们在 PACF 的滞后 1 处有一个显著的尖峰,那么我们有一个 1 阶的 AR 模型,即 AR(1)。如果我们在 PACF 上的滞后 1、2 和 3 处有显著的尖峰,那么我们有 3 阶的 AR 模型,即 AR(3)。
识别 MA 模型的 q 阶
对于 MA 模型,PACF 将呈指数衰减,ACF 图将用于确定 MA 过程的顺序。如果我们在 ACF 上的滞后 1 处有一个显著的尖峰,那么我们有一个 1 阶的 MA 模型,即 MA(1)。如果我们在 ACF 上的滞后 1、2 和 3 处有显著的尖峰,那么我们有一个 3 阶 MA 模型,即 MA(3)。
第三步:估算和预测
一旦我们确定了参数(p,d,q ),我们就估计训练数据集上的 ARIMA 模型的准确性,然后使用拟合的模型,通过使用预测函数来预测测试数据集的值。最后,我们反复检查我们的预测值是否与实际值相符。
用 R 编程建立 ARIMA 模型
现在,让我们按照解释的步骤在 r 中建立一个 ARIMA 模型。有许多软件包可用于时间序列分析和预测。我们为时间序列分析加载相关的 R 包,并从雅虎财经获取股票数据。
library(quantmod);library(tseries);
library(timeSeries);library(forecast);library(xts);
# Pull data from Yahoo finance
TECHM = getSymbols('TECHM.NS', from='2012-01-01', to='2015-01-01',auto.assign = FALSE)
TECHM = na.omit(TECHM)
# Select the relevant close price series
stock_prices = TECHM[,4]
在下一步中,我们计算股票的对数回报,因为我们希望 ARIMA 模型预测的是对数回报,而不是股票价格。我们还使用绘图函数绘制了对数收益序列。
# Compute the log returns for the stock
stock = diff(log(stock_prices),lag=1)
stock = stock[!is.na(stock)]
# Plot log returns
plot(stock,type='l', main='log returns plot')

接下来,我们对收益率序列数据调用 ADF 测试来检查平稳性。ADF 测试的 p 值 0.01 告诉我们该序列是平稳的。如果序列是不稳定的,我们将首先对收益序列进行差分,使其稳定。
# Conduct ADF test on log returns series
print(adf.test(stock))

在下一步中,我们修复了一个断点,该断点将用于将 returns 数据集在代码中进一步分成两部分。
# Split the dataset in two parts - training and testing
breakpoint = floor(nrow(stock)*(2.9/3))
我们截断原始的返回序列直到断点,并在这个截断的序列上调用 ACF 和 PACF 函数。
# Apply the ACF and PACF functions
par(mfrow = c(1,1))
acf.stock = acf(stock[c(1:breakpoint),], main='ACF Plot', lag.max=100)
pacf.stock = pacf(stock[c(1:breakpoint),], main='PACF Plot', lag.max=100)


我们可以观察这些图,并得出自回归(AR)阶和移动平均(MA)阶。
我们知道,对于 AR 模型,ACF 将呈指数衰减,PACF 图将用于确定 AR 模型的阶数(p)。对于 MA 模型,PACF 将指数衰减,ACF 图将用于确定 MA 模型的阶数(q)。从这些图中,我们选择 AR 阶数= 2,MA 阶数= 2。因此,我们的 ARIMA 参数将是(2,0,2)。
我们的目标是预测从断点开始的整个收益序列。我们将利用 R 中的 For 循环语句,在这个循环中,我们将预测测试数据集中每个数据点的返回。
在下面给出的代码中,我们首先初始化一个存储实际回报的序列和另一个存储预测回报的序列。在 For 循环中,我们首先基于动态断点形成训练数据集和测试数据集。
我们在训练数据集上调用 ARIMA 函数,为其指定的顺序是(2,0,2)。我们使用该拟合模型通过使用预测来预测下一个数据点。Arima 函数。该函数被设置为 99%的置信水平。可以使用置信度参数来增强模型。我们将使用模型中的预测点估计。forecast 函数中的“h”参数表示我们要预测的值的数量,在本例中,第二天返回。
我们可以使用汇总功能来确认 ARIMA 模型的结果在可接受的范围内。在最后一部分,我们将每个预测收益和实际收益分别附加到预测收益序列和实际收益序列中。
# Initialzing an xts object for Actual log returns
Actual_series = xts(0,as.Date("2014-11-25","%Y-%m-%d"))
# Initialzing a dataframe for the forecasted return series
forecasted_series = data.frame(Forecasted = numeric())
for (b in breakpoint:(nrow(stock)-1)) {
stock_train = stock[1:b, ]
stock_test = stock[(b+1):nrow(stock), ]
# Summary of the ARIMA model using the determined (p,d,q) parameters
fit = arima(stock_train, order = c(2, 0, 2),include.mean=FALSE)
summary(fit)
# plotting a acf plot of the residuals
acf(fit$residuals,main="Residuals plot")
# Forecasting the log returns
arima.forecast = forecast.Arima(fit, h = 1,level=99)
summary(arima.forecast)
# plotting the forecast
par(mfrow=c(1,1))
plot(arima.forecast, main = "ARIMA Forecast")
# Creating a series of forecasted returns for the forecasted period
forecasted_series = rbind(forecasted_series,arima.forecast$mean[1])
colnames(forecasted_series) = c("Forecasted")
# Creating a series of actual returns for the forecasted period
Actual_return = stock[(b+1),]
Actual_series = c(Actual_series,xts(Actual_return))
rm(Actual_return)
print(stock_prices[(b+1),])
print(stock_prices[(b+2),])
}
在我们进入代码的最后一部分之前,让我们检查来自测试数据集中的样本数据点的 ARIMA 模型的结果。

根据获得的系数,回归方程可以写成:
和= 0.6072和-0.8818和【t-1】
给出了系数的标准误差,这需要在可接受的限度内。阿凯克信息标准(AIC)评分是 ARIMA 模型准确性的一个很好的指标。AIC 分数越低,模型越好。我们还可以查看残差的 ACF 图;一个好的 ARIMA 模型的自相关低于阈值极限。预测的点回报是-0.001326978,在输出的最后一行给出。

让我们通过比较预测回报和实际回报来检验 ARIMA 模型的准确性。代码的最后一部分计算这些准确的信息。
# Adjust the length of the Actual return series
Actual_series = Actual_series[-1]
# Create a time series object of the forecasted series
forecasted_series = xts(forecasted_series,index(Actual_series))
# Create a plot of the two return series - Actual versus Forecasted
plot(Actual_series,type='l',main='Actual Returns Vs Forecasted Returns')
lines(forecasted_series,lwd=1.5,col='red')
legend('bottomright',c("Actual","Forecasted"),lty=c(1,1),lwd=c(1.5,1.5),col=c('black','red'))
# Create a table for the accuracy of the forecast
comparsion = merge(Actual_series,forecasted_series)
comparsion$Accuracy = sign(comparsion$Actual_series)==sign(comparsion$Forecasted)
print(comparsion)
# Compute the accuracy percentage metric
Accuracy_percentage = sum(comparsion$Accuracy == 1)*100/length(comparsion$Accuracy)
print(Accuracy_percentage)


如果预测回报的符号等于实际回报的符号,我们就给它一个正的准确度分数。ARIMA 模型的准确率达到 55%左右,这看起来是一个不错的数字。可以尝试运行(p,d,q)的其他可能组合的模型,或者改为使用 auto.arima 函数,该函数选择最佳参数来运行 arima 模型。
结论
总之,在这篇文章中,我们介绍了 ARIMA 模型,并使用 R 编程语言将其应用于预测股票价格回报。我们还交叉检查了我们的预测结果和实际回报。在我们即将发布的帖子中,我们将介绍其他时间序列预测技术,并在 Python/R 编程语言中尝试它们。
下一步
这里有一个循序渐进的教程,让你在 R 中实现自动交易的预测建模。你可以使用预测模型浏览算法交易的历史数据。
更新
我们注意到一些用户在从雅虎和谷歌金融平台下载市场数据时面临挑战。如果你正在寻找市场数据的替代来源,你可以使用 Quandl 来获得同样的信息。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
影响外汇市场交易的 9 个因素
原文:https://blog.quantinsti.com/forex-market-trading-factors/
以重香重香
外汇市场交易并不困难,如果你有一个基本的想法,当一个国家的外汇将发生变化。
但是你是怎么知道的?
经过一段时间后,人们意识到外汇市场会受到某些宏观经济因素的影响。在这篇文章中,我会带你通过一些影响外汇市场交易的因素。
要阅读外汇市场交易的基础和要点,可以访问这篇文章。
我们现在来看一下清单。以下是影响外汇市场交易的 9 个因素
政治格局
当政府愿意采取措施提高人民的生活水平时,经济就会增长。因此,一个稳定的政府可能是一个投资者友好国家的第一个标志。这意味着经济增长的障碍更少,机会更大。

与外汇市场交易的关系:交易者可能会购买政治局势稳定的国家的货币。
外汇交易领域的例子:
英国退出欧盟的消息导致英镑对美元的汇率下跌。 1
通货膨胀率
没什么好惊讶的。如果一个国家的通货膨胀率与另一个国家相比相对较低,那么与通货膨胀率较高的货币相比,该国的货币预计会升值。

与外汇市场交易的关系:投资者会寻求购买通货膨胀率较低的货币。
外汇交易领域的例子:
正如你在图表中看到的,随着津巴布韦通货膨胀率的上升,其货币价值急剧贬值。因此,津巴布韦元对外汇交易者来说并不是一个有吸引力的目的地。
利率
我想用一个店主向五个孩子出售钢笔的例子来解释这个问题。
假设你是卖 10 卢比钢笔的店主。现在,五个孩子拿着 10 卢比的钞票来找你要一支笔,但问题是你只有三支笔。一种情况是,你发起了一场竞价战,最需要它的人会出价这支笔的两倍或三倍。但是等等!还有一个办法。
假设你意识到其中两个孩子现在并不真的需要这支笔。所以你告诉他们把 10 卢比存到你这里,当你有新的股票时,你会把它给他们。为了增加交易的甜头,你说你会给他们 1 卢比和笔。两个孩子同意了,你的问题就解决了。
诚然,这是一种过于简化的说法,但这就是每当央行决定通胀率失控时,它就会通过提高利率来控制通胀率,从而控制市场上的货币量的逻辑。
利率上升对投资者来说是一个好兆头,因为货币利率上升会导致货币利率上升。
它与外汇市场交易的关系:随着收益率的提高,投资者会被利率较高的经济体所吸引。这增加了对货币的需求,反过来也增加了汇率。
外汇交易领域的例子:
印度央行提高了利率,以遏制卢比的下跌。 3
政府债务
你会把钱给一个已经负债的人吗?你不会的。
这里是同样的概念,一个国家的债务越高,它吸引外资的机会就越低,这反过来降低了该国的汇率。
它与外汇市场交易的关系:投资者可能会看到多年来政府债务的趋势,以确定投资该国货币是否是一个明智的决定
外汇交易领域的例子:
印度卢比疲软的原因之一是政府债务并未因油价上涨而减少。
贸易条件(出口价格对进口价格的比率)
贸易条件可以解释为出口价格与进口价格的比率。如果该国的贸易条件很大,即他们的出口大于进口,货币总是会升值,会有需求。这意味着它的货币价值将大于另一个贸易条件相对较低的国家。
与外汇市场交易的关系:投资者可能希望投资于一个出口大于进口的国家。
外汇交易领域的例子:
由于中国的贸易条件大多是积极的,这是一个有吸引力的外汇交易来源。 4
猜测
这不完全是一个可衡量的因素。如果有人猜测货币汇率将会上升,其他投资者将会要求更多的货币,其货币汇率将会进一步上升。另一方也是如此。
它与外汇市场交易的关系:这里的诀窍是识别跟风效应,并确保在效应消失前退出。
外汇交易领域的例子:
在 2005 年至 2006 年期间,由于美国房地产市场的贷款利率较低,有人猜测房地产价格将会上涨,而这反过来会提高美元的价值。
资本市场
通过观察资本市场的趋势,你可以大致了解经济状况。股票市场的长期下跌通常表明投资者信心不足,因此,可以用来预测与其他国家相比的汇率。
与外汇市场交易的关系:如果资本市场呈现上升趋势,这意味着汇率将上升。
外汇交易领域的例子:
自 2005 年以来,随着中国资本市场的飙升,美元/CNY 货币对下降,这意味着人民币走强。5T5】6
就业数据
每个国家都会定期发布就业率。这是经济运行良好的另一个标志。如果经济停滞不前,高失业率意味着经济增长与人口增长不同步。
与外汇市场交易的关系:高失业率可能导致货币贬值,从而降低该货币的汇率。
外汇交易领域的例子:
9 月份美国非农就业报告以乐观的基调发布后,美元指数(DXY)即美元相对于一篮子外币的表现从 94.95 上升至 95.35。 7
经济规划
一个国家的货币和财政政策会给你一个好主意,它是否对投资者友好。因此,如果政府有吸引外国资本的计划和激励措施,投资者可能会涌向这个国家,增加对特定货币的需求。
与外汇市场交易的关系:由于海外的大量投资,该国的货币汇率将会上升。
外汇交易领域的例子:
在提交 2018 年预算后,在国内市场,BSE 和 NSE 呈下降趋势,据估计,印度股票总共损失了 460 万卢比。
谈到外汇市场交易,卢比兑美元汇率下跌了 44 便士。
这些是每个投资者在开始外汇交易前应该知道的几个因素。
在阅读了这篇关于影响外汇交易的各种因素的文章后,你不仅知道了外汇交易策略的基础,还了解了某些因素是如何影响外汇市场交易的。
但是,为什么就此打住呢?我们来试着理解一下,如何评价一个国家的汇率相对于其他一篮子国家的汇率。提示:它叫 REER。让我们现在就去看那篇文章。
您可以报名参加 Quantra 上的外汇交易策略课程,学习根据实际有效汇率(REER)等基本面创建价值策略。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
外汇交易策略和回溯测试技术
原文:https://blog.quantinsti.com/forex-trading-strategies-backtesting-webinar-14-august-2018/
https://www.youtube.com/embed/3xQW7Rm91hA
IST 时间 2018 年 8 月 14 日星期二下午 6:00 |格林威治时间下午 12:30 |格林威治时间晚上 8:30
会议大纲
在这场由FXCM&quantin STI联合举办的网络研讨会中,您将了解外汇市场数据、交易策略、回溯测试&优化技术以及新的 nextgen 工具&平台。
- 即期货币市场概述
- 相关市场、宏观驱动因素(融资回购+xccy 互换、远期和短期利率风险)
- 访问外汇数据和概述外汇交易策略
- 优化和回溯测试
- 外汇风格:进位,动量,价值和防御
- 阿尔法策略
演示文稿
您可以点击此处查看本次网络研讨会的 powerpoint 演示文稿:
//www.slideshare.net/slideshow/embed_code/key/QqULjw6ehO9sm
Forex Trading Strategies and Backtesting Techniques using Blueshift - Presentation from QuantInsti
演讲人![prodipta-ghosh]()
Prodipta Ghosh(QuantInsti 副总裁)
Prodipta 是一位经验丰富的 quant,目前作为副总裁领导 QuantInsti 的 Fin-tech 产品和平台开发。
他在银行业工作了十多年——在孟买和伦敦的德意志银行的交易和结构部门担任各种职务,并在渣打银行担任企业银行家。在此之前,Prodipta 作为科学家在印度国防 R&D 组织(DRDO)工作。
关于蓝移
Blueshift 是一个全面的交易和策略开发平台,让你更专注于策略,而不是编码和数据。其基于云的回溯测试引擎可以免费帮助你开发、测试和分析交易策略,并对其进行微调。它整合了涵盖股票、期货和外汇的高质量分钟级数据。用户完全拥有他们在这个平台上开发的所有策略的知识产权。
关于福汇
FXCM 是一家领先的在线外汇(FX)交易、CFD 交易、点差交易及相关服务提供商。该公司成立于 1999 年,其使命是通过提供创新的交易工具、聘用优秀的交易教育者、满足严格的财务标准以及努力获得市场上最佳的在线交易体验,为全球交易者提供进入全球最大和最具流动性市场的机会。
神经网络中的前向传播:组件和应用
原文:https://blog.quantinsti.com/forward-propagation-neural-networks/
让我们直接进入主题。到底什么是神经网络中的前向传播?如果你把这些词分开,forward 意味着向前移动,propagation 是一个表示任何事物传播的术语。前向传播意味着我们在神经网络中只向一个方向移动,从输入到输出。把它想象成穿越时间,在那里我们别无选择,只能勇往直前,只希望我们的错误不会回来困扰我们。
现在,如果你认为神经网络在交易中用处很小,那么我们必须告诉你,几乎所有的量化对冲基金都从神经网络转向了深度学习和人工智能,以某种方式保持对其他人的优势。从文艺复兴理工到两个适马,神经网络正以前所未有的方式被利用。
现在,在我们开始一个前向传播的例子之前,让我们看看这个博客中涉及的主题。
神经网络简史
我们试图理解自古以来人类是如何工作的。事实上,甚至哲学也在试图理解人类的思维过程。但是,直到最近几年,我们才开始在理解我们的大脑如何运作方面取得进展。这也是传统计算机不同于人类的地方。
你看,虽然我们可以开发一个算法来解决一个问题,但我们必须确保我们已经考虑到了各种可能性。然而,当涉及到人类时,我们可能会从有限或不完整的信息开始,但我们会更快、更准确地“学习”和解决问题。嗯,至少大家都是这么说的!
于是,我们开始研究开发人工大脑,其实现在叫神经网络。
神经网络的基本结构是感知器,它模仿我们细胞中的神经元。

Basic structure in the Neural Network
用黄色圆圈标记的是神经元的输入,经过一些计算后,神经元发出输出信号。
输入层类似于神经元的树突,输出信号是轴突。每个输入信号被分配一个权重 wi。这个权重乘以输入值,神经元存储所有输入变量的加权和。
然后将激活函数应用于加权和,这产生神经元的输出信号。
神经网络的一个流行的例子是图像识别软件,它可以识别人脸,并且能够在不同的照明条件下标记同一个人。话虽如此,现在让我们更详细地理解正向传播。
什么是神经网络中的前向传播?
第一个神经网络使用了前向传播的概念。我将借助一个简单的直线方程来解释正向传播。
我们都知道,一条线可以借助于方程来表示:y = mx + b
其中 y 是该点的 y 坐标,m 是斜率,x 是 x 坐标,b 是 y 截距,即直线与 y 轴相交的点。
但是为什么我们要在这里写直线方程呢?这将有助于我们稍后详细了解神经网络的组件。
还记得我们说过神经网络应该模仿人类的思维过程吗?好吧,让我们假设我们不知道直线的方程,但是我们有一张图纸,在上面随机画一条直线。
在这个例子中,你画了一条穿过原点的线,当你看到 x 和 y 坐标时,它们看起来像这样:

x and y coordinates
这看起来很眼熟。如果我让你找出 x 和 y 之间的关系,你会直接说是 y = 3x。但是让我们来看看正向传播是如何工作的。
这里我们假设 x 是输入,y 是输出。
这里的第一步是参数的初始化。我们会猜测 y 一定是 x 的乘法因子,所以我们假设 y = 5x,然后看结果。让我们把这个加到表上,看看我们离答案还有多远。

请注意,取数字 5 只是一个随机的猜测,别无其他。我们可以在这里取任何一个数字。我应该指出,这里我们可以将 5 项作为模型的权重。
好了,这是我们的第一次尝试,现在我们将看看我们离实际输出有多近(或多远)。
一种方法是使用实际输出和我们计算的输出之差。我们称之为错误。这里,我们不关心正负符号,因此我们取误差的绝对差值。因此,我们现在将使用错误更新表格。

如果我们对这个误差求和,我们得到值 30。但是我们为什么要合计误差呢?因为我们要尝试多次猜测以得出最接近的答案,所以我们需要知道我们离前面的答案有多近或多远。这有助于我们完善我们的猜测并计算出正确的答案。
等等。但是如果我们只是把所有的误差值相加,感觉就像我们给了所有的答案同等的权重。我们不应该惩罚那些远远偏离目标的价值观吗?例如,这里的 10 比 2 高得多。正是在这里,我们引入了有点著名的“误差平方和”或简称 SSE。在 SSE 中,我们将所有的误差值平方,然后相加。因此,非常高的误差值被夸大了,这有助于我们了解如何进一步处理。
让我们把这些值放在下表中。

权重为 5 的上证综指(记得我们假设 y = 5x)是 145。我们称之为损失函数。损失函数对于理解神经网络的效率是重要的,并且当我们将反向传播结合到神经网络中时,也有助于我们。
好了,到目前为止,我们了解了神经网络如何试图学习的原理。我们也看到了神经元的基本原理。现在让我们来理解神经网络本身的前向传播。
正向传播模型的组件

在上图中,我们看到一个由三层组成的神经网络。第一和第三层是简单的输入和输出层。但是这个中间层是什么,为什么叫隐藏层呢?
现在,在我们的例子中,我们只有一个方程,因此每层只有一个神经元。
然而,隐藏层包含两个功能:
预激活功能 :该功能计算输入的加权和。激活函数 :这里,基于加权和,应用激活函数来使网络非线性化,并使其随着计算的进行而学习。激活函数使用偏置使其非线性。
这就是关于神经网络中的前向传播的所有知识。但是等等!如何在交易中应用这个模型?下面就来了解一下。
正向传播的应用
在本例中,我们将使用 3 层网络(2 个输入单元、2 个隐藏层单元和 2 个输出单元)。网络和参数(或权重)可以表示如下。
假设我们想训练这个神经网络来预测市场是上涨还是下跌。为此,我们将两个类指定为类 0 和类 1。
这里,类 0 表示市场收盘时的数据点,相反,类 1 表示市场收盘时的数据点。为了进行这种预测,训练数据(X)包括两个特征 x1 和 x2。
这里 x1 代表收盘价和收盘价的 10 天简单移动平均线(SMA)之间的相关性,x2 指收盘价和 10 天 SMA 之间的差异。
在下面的例子中,数据点属于类 1。输入数据的数学表示如下:
X = [x1,x2] = [0.85,. 25] y= [1]
具有两个数据点的示例:
模型的输出是分类的或离散的数字。我们还需要将这个输出数据转换成矩阵形式。这使得模型能够预测数据点属于不同类别的概率。当我们进行这种矩阵转换时,列表示该示例所属的类,行表示每个输入示例。
在矩阵 y 中,第一列表示类别 0,第二列表示类别 1。因为我们的例子属于类 1,我们在第二列中有 1,在第一列中有 0。

这种将离散/分类类别转换为逻辑向量/矩阵的过程称为一键编码。这有点像转换十进制系统(1,2,3,4....9)到二进制(0,1,01,10,11)。我们使用一次性编码,因为神经网络不能直接对标签数据进行操作。它们要求所有输入变量和输出变量都是数字。
在一个神经网络学习中,除了输入变量之外,我们给除输出层之外的每一层增加一个偏置项。这个偏置项是一个常数,通常初始化为 1。该偏置使得能够沿着 x 轴移动激活阈值。


当偏差为负时,向右侧移动,当偏差为正时,向左侧移动。因此,一个有偏见的神经元应该能够学习,甚至是一个无偏见的神经元无法学习的输入向量。在数据集 X 中,为了引入这种偏差,我们添加了一个由 1 表示的新列,如下所示。
让我们随机初始化第一层中每个神经元的权重或参数。正如你在图中看到的,我们有一条线连接第一层的每个细胞和第二层的两个神经元。这给了我们总共 6 个要初始化的权重,隐藏层中的每个神经元 3 个。我们将这些权重表示如下。
这里,θ1是对应于第一层的权重矩阵。

以上表示中的第一行示出了对应于第二层中的第一神经元的权重,第二行表示对应于第二层中的第二神经元的权重。现在,让我们进行前向传播的第一步,将每个示例的输入值乘以它们相应的权重,数学上如下所示。
θ1* X
在我们继续乘法之前,我们必须记住,当你做矩阵乘法时,乘积 X *θ的每个元素是第一个矩阵 X 的行与第二个矩阵θ1 的每个列的点积和。
当我们将两个矩阵 X 和θ1 相乘时,我们需要将权重与相应的输入示例值相乘。这意味着我们需要转置示例输入数据 X 的矩阵,以便矩阵将每个权重与相应的输入正确相乘。
z2=θ1* Xt
这里 z 2 是矩阵相乘后的输出,X t 是 X的转置
矩阵乘法过程:
假设我们在输入层之后应用了 sigmoid 激活。然后,我们必须对上面 z 矩阵中的元素应用 sigmoid 函数。sigmoid 函数由以下等式给出:
应用激活函数后,我们剩下一个 2×1 的矩阵,如下所示。
这里 a (2) 表示激活层的输出。
激活层的这些输出充当下一层或最后一层(即输出层)的输入。让我们为隐藏层初始化另一个随机权重/参数,称为θ2。θ2中的每一行代表对应于输出层中两个神经元的权重。
在初始化权重(Theta 2 之后,我们将重复输入层的相同过程。我们将为前一层的输入增加一个偏置项。添加偏置向量后,a (2) 矩阵如下所示:
让我们看看添加偏置单元后神经网络的样子:

在我们运行矩阵乘法来计算最终输出 z 之前,请记住,在 z 计算之前,我们必须转置输入数据 a,使其正确“排列”,以便矩阵乘法产生我们想要的计算结果。在这里,我们的矩阵已经按照我们想要的方式排列好了,所以不需要对 a (2) 矩阵进行转置。为了清楚地理解这一点,问自己这样一个问题:“哪些权重与哪些输入相乘?”。现在,让我们执行矩阵乘法:
z3=θ2* a(2)其中 z 3 是应用激活函数之前的输出矩阵。
对于最后一层,我们将把一个 2x3 乘以一个 3x1 矩阵,得到一个输出假设的 2x1 矩阵。数学计算如下所示:
在此乘法之后,在获得最终层的输出之前,我们使用 z 矩阵上的 sigmoid 函数进行元素转换。
a3= s 形(z 3
其中 a 3 表示最终输出矩阵。$ $ a^3 = \ begin { b matrix } 0.7333 \ \ 0.6548 \ \ \ end { b matrix } $ $
sigmoid 函数的输出是给定示例属于特定类别的概率。在上面的表示中,第一行表示该示例属于类 0 的概率,第二行表示类 1 的概率。
结论
如您所见,该示例属于 1 类的概率小于 0 类,这是不正确的,需要改进。因此,我们不仅理解了神经元的基本结构,也理解了神经网络。此外,我们借助于一个例子来研究神经网络中的前向传播。
在下一篇博客中,我们将讨论如何实现反向传播来减少预测中的误差。如果你想学习如何在交易中应用神经网络,那么请查看我们的新课程神经网络&陈博士的《交易中的深度学习》。
免责声明:股票市场的所有投资和交易都有风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。
Rajib 在 2018 年 FOW 印度国际衍生品大会上的讨论
原文:https://blog.quantinsti.com/fow-india-international-derivatives-conference-2018/

简介
FOW 发起了印度国际衍生品会议,该会议将当地市场的关键人物与国际代表聚集在一起,进行为期一天的知识分享和辩论。
Gift City 可能代表着近年来全球衍生品市场最重大的发展之一,它使国际投资者能够进入印度庞大的流动性池。该小组将研究该倡议迄今为止的进展,并询问还需要做些什么来吸引国际贸易流动。
- 礼品城给全球市场带来哪些机遇?
- 礼品城第一年的交易进展如何?
- 国际公司如何通过 Gift City 获得印度的流动性?
- 从国际交易所到礼品城的连接计划前景如何?
会议亮点
由 Hemal Randerwala(Arjun Global ltd .总裁)主持,小组成员包括 Ravindranath Thota (RBL)、Nagendra Kumar(NSE 首席商务官)、shala ban Rakyan(Estee Advisors 副总裁)和 Rajib ran Jan Borah(irage capital 和 QuantInsti 联合创始人)
Rajib 受邀于 2018 年 9 月 25 日在印度孟买举行的 2018 年印度国际衍生品大会上发表演讲,他在会上 讨论了 GIFT city 的 INX & NSE-IFSC 交易所交易机会的潜力和增长。他分享了他是如何成为一名礼品城转换者的:从犹豫不决到充满热情,并谈到了礼品城的其他愿望清单-作为一家贸易公司。
关于 Rajib Ranjan Borah
iRage 首席执行官 Rajib Ranjan Borah 先生是 iRage 的联合创始人,iRage 是一家高频交易公司,管理着印度最广泛的交易所交易期权投资组合。他还是 QuantInsti 的联合创始人和董事,quantin STI 是一家“算法和量化交易”培训和研究机构,培训了来自 130 多个国家的数千名专业人士。他之前的经验包括在所有主要的美国和欧洲交易所(Optiver,Amsterdam)进行高频交易;数据分析技术(甲骨文公司);商业战略咨询(普华永道)和股票衍生品研究(纽约州彭博市)。Rajib 拥有 IIM 加尔各答的 MBA 学位,是一名来自卡纳塔克邦 NIT 的计算机工程师。
QuantInsti is one of the leading quantitative and algorithmic trading education providers across the globe. QuantInsti' EPAT is most popular algo trading course in India, Singapore and across the globe. It offers endless list of benefits, get in touch with a course counsellor to know more.
学习机器学习交易的免费资源
原文:https://blog.quantinsti.com/free-resources-learn-machine-learning-trading/
如今,几乎每个行业都需要机器学习。医药、交通、医疗保健、广告和金融技术等行业都非常依赖机器学习。谈到金融技术领域,使用机器学习算法,算法交易实践非常有效。有各种各样的资源可以用来学习机器学习交易,但是这篇文章的目的是让你可以使用免费的资源来学习机器学习交易。这些免费资源分为以下几类,以便于导航:
课程
这个免费课程非常适合使用机器学习进行交易的初学者。该课程帮助您了解机器学习算法如何在金融市场数据上实现。通过本课程,学习为算法交易实践建立稳健的预测模型。完成本课程后,您将对交易机器学习的概念有深入的了解。
本课程向学生介绍了实施基于机器学习的交易策略的现实挑战,包括从信息收集到市场订单的算法步骤。重点是如何将机器学习概念应用于交易决策。
这门课程帮助学生学习使用基于机器学习技术的回归来制定投资策略。通过涵盖卡尔曼滤波器、套索和山脊等高级主题,本课程旨在提供深入的学习。
电子书
如何利用机器学习进行交易? ,由匡特拉
这本电子书包含了所有的信息,从解释人工神经网络的基础和工作,到演示用 Python 实现股票价格预测的代码。
可解释的机器学习 ,作者克里斯托夫·莫尔纳尔
这本书主要帮助读者学习表格数据的机器学习模型。为了学习用于交易的机器学习,这本书将帮助获得关系或结构化数据的知识,这是使用机器学习进行交易时的重要概念之一。
这本书是为数据分析师和数据科学家写的,他们是算法交易不可或缺的一部分。这本书的第 9 章介绍了回溯测试的概念,这在算法交易中很有用。此外,它还涵盖了 XGBoost 机器学习模型和交叉验证技术。
【从数据中学习】 ,作者亚塞尔·s·阿布-穆斯塔法、马利克·马格东-伊斯梅尔、林宣天
这本书为读者提供了机器学习的完整介绍,这种技术使计算系统能够利用从观察到的数据中积累的经验来自适应地提高它们的性能。这种技术广泛应用于工程、科学、金融和商业。这本书的第五章谈到了机器学习在交易中的应用。
此外,还有 ipython 笔记本,它们不断更新,包括关于热门机器学习主题的最新资源,对初学者和有经验的数据科学家都非常有帮助。
博客
Quantinsti 为您提供了一系列机器学习的交易博客,如使用 Python 中的机器学习进行交易,人工智能和人工智能中的机器学习以及股票市场。你可以根据你在机器学习方面的专业水平来找出哪个博客适合你。
在这里,你会发现一些博客,例如使用 PyTorch 为时间序列构建 RNN、LSTM 和 GRU,为自动股票交易构建深度强化学习,以及一位作者的提示,他的机器学习交易算法超过 SP500 10 年。
Quantocracy 是一个你可以找到许多来自不同来源的关于机器学习的博客的地方。他们在自己的网站上为用户提供了最丰富的博客混搭,如 Metalabeling 和横截面与时间序列因素之间的二元性[E.P. Chan]以及减轻对神经网络过度拟合的不同方法。
Quantstart 有统计机器学习初学者指南和每日 OHLC 棒线数据的 K-Means 聚类等文章,可以帮助你在交易中应用机器学习。
诸如算法交易中的大数据和各种回归分析的博客文章为你提供了关于数据、回归等概念的信息。用于交易。在网站上找到更多这样的博客。
毕马威(一个跨国组织)通过他们的博客文章迎合了被告知和教育的需求。网站上的博客页面包含了大量关于使用机器学习进行算法交易的信息。
研究论文
这篇研究论文的目的是创造和分析交易的机器学习方法。这里的方法有助于解决最重要的问题,例如策略性能对微小参数变化的敏感性。例如,市场趋势的突然转变就是这种变化,策略表现会对其敏感。但是,使用这里的机器学习方法,对策略质量的影响应该不会很大。因此,你得到了计算时间的缩短,而没有战略质量的实质性损失。
ResearchGate 的这篇文章研究了在交易中实现神经网络(机器学习的一部分)的理论和实践方面。这项研究表明,高精度的预测和参数的正确选择有助于建立有利的交易策略。
本文提出了一些先进的算法。分布式最近邻框架在这里意味着对大型数据集的重要帮助,否则这些数据集将无法容纳在机器的内存中。这对于使用机器学习进行算法交易的回溯测试非常有用。
最近,研究人员专注于采用机器学习(ML)算法来预测股票价格趋势。本文对各种最大似然算法进行了评估,观察了有交易成本和无交易成本下股票的日交易绩效。此外,本研究论文还考虑了大型数据集,以帮助从更长的回溯测试时间段(历史)进行分析。
本文研究了如何在使用机器学习设计交易算法的过程中管理模型的复杂性。这项研究有助于对人-模型相互作用的金融研究的社会研究,并将其用于创建机器学习模型。
这篇科学研究论文提出了一种基于深度强化学习 (DRL)的创新方法,以解决在股票市场的交易活动中确定任意时间点的最佳交易位置的算法交易问题。它提出了一种新颖的 DRL 交易策略,以便在广泛的股票市场上最大化由此产生的夏普比率表现(一个指标)。
研究论文建议在训练期间从神经网络中随机丢弃单元(以及它们的连接)。这种删除单元的过程大大减少了过度拟合。这可以帮助你防止交易数据的过度拟合,从而导致建立一个低效的策略。此外,在交易中使用数据进行历史分析时,主要改进发生在其他正规化方法上。
录像
这个视频讲到了交易者机器学习入门的要点。它解释了从机器学习的基础到机器学习在交易中的实现。观看此视频,深入了解交易机器学习:
本视频为您带来了一个时长一小时的网络研讨会,会上, Inovance 的首席执行官 Tad Slaff 先生讲述了策略开发应用以及构建实时交易策略。请看这里的视频:
- 算法交易的机器学习
这个视频有两个部分。Quant News 的视频在机器学习的帮助下为算法交易提供了信息。在这些视频中,您将看到实现机器学习的逐步介绍过程,以及如何使用 Python 将机器学习算法用于交易。
此外,在这些视频中,您将学习调整参数的过程,以提高交易系统的性能。在第 2 部分中,您将学习如何选择最重要的特性来提取和清理数据。
算法交易的机器学习|第一部分:机器学习&第一步
除了在交易中应用机器学习的注意事项,这个视频还描述了一个应用机器学习技术解决交易问题的系统方法。这不是一个关于机器学习的教程,而是关于如何采用常见的 ML 技术来开发盈利策略的教程。
在这个视频中,Jenia(算法交易员)使用机器学习工具编写了他的交易算法,现在交易的初始投资为 100 万美元。他正在谈论他的方法和他的主要收获。杰尼亚的算法目前的夏普比率为 2.66
这个播客为你提供了使用机器学习预测交易盈利能力的全面知识。这个播客视频涵盖了在交易中使用机器学习的许多方面。
结论
有很多关于在线交易机器学习的信息来源。最好的被研究并且在这个博客中被公开。此外,很有可能免费找到信息来源!
如果你对学习机器学习及其在交易中的应用感兴趣,这里有一个来自 Quantra - 学习轨道的强烈推荐轨道:机器学习&金融市场深度学习。
非常适合初学者和专家,如果你认为机器学习是金融市场未来的重要组成部分,你不能错过这个专业。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
学习算法交易的免费资源
原文:https://blog.quantinsti.com/free-resources-list-compilation-learn-algorithmic-trading/
这是一个非常全面和强大的资源汇编列表,在算法交易和量化交易领域,人们可能需要或需要这些资源。
我们在此讨论以下主题:
在过去的几十年里,交易行业和几乎所有其他行业一样,经历了巨大的技术变革。现在进入市场的人比以往任何时候都多。然而,在金融领域持续取得成功是另一回事。
随着量化交易的出现,无论是新手还是经验丰富的交易者,无论是机构还是散户,都必须对现代金融市场有一个广泛的了解。为了做到这一点,使用现代工具并在我们的交易风格中加入量化因素是必不可少的。
这里提到的所有资源都是完全免费的!
- 免费电子书
- 免费教程
- 网络研讨会记录
- 免费 Python 教程
还有更多...
我们把知识和工具带给任何想了解算法和量化交易行业并成为其中一员的人。这次是以这篇文章的形式。
算法交易
算法交易书-一个粗略的现成指南|免费书籍

这本书介绍了算法交易的原理、实践和组成部分。它还讨论了成为这个行业的一部分的职业道路
我们希望这本书将作为这类好奇的读者的入门指南,并激励他们向它迈出第一步。
金融市场介绍|免费博客
- 什么是市场?
- 我如何进入市场?
- 什么在交易所交易?
- 一个人如何跟踪市场?
- 有哪些不同类型的市场?
- 参与者是谁?
- 谁监管市场?
- 市场参与者进行哪些类型的分析?
- 什么是策略回溯测试?
- 有哪些不同的企业行为及其对价格的影响?
- 常用术语
交易介绍|免费博客
- 介绍
- 新量化交易者的基本能力
- 宏观经济学
- 交易理论
- 观察
- 编码的最优化
- 机器学习
- Python/R/C++
算法交易|免费博客
- 算法交易是什么,为什么?
- 从人工交易到算法交易的转变
- 算法交易是什么时候开始的?
- 交易频率:HFT,MFT,LFT
- 算法交易策略
- 算法交易工资
- 印度有什么规章制度?
- 如何学习算法交易
- 算法交易的工作流程
- 如何建立自己的算法交易业务?
印度的算法交易|免费博客
- 印度的算法交易:过去、现在和未来
- 印度股票市场的监管
- 算法交易平台
- 如何开始你的算法交易之旅
- 关于算法交易未来的常见问题
问我任何关于算法交易的问题
75%的全球交易是通过算法执行的。有没有想过,如何从算法中获益?我们为您带来我们的最高老板在 AMA 的独家采访。
https://www.youtube.com/embed/ZjZ_qWTGFB4?rel=0
算法交易的增长和未来|免费博客
- 为什么要选择算法交易?
- 谁在赶时髦?
- 算法交易的法规
- 机器学习和算法交易
- 人工智能和算法交易
- 未来的交易系统
- 额外内容
- 下一步是什么?
学习算法交易:一步一步指南|免费教程
- 以下是你应该知道的
- 算法交易、量化交易、自动交易和高频交易的区别
- 成为算法交易专家的步骤
- 关于如何学习算法交易的常见问题
以算法交易为职业|免费博客
- 算法交易中的工作
- Quants 的类型
- 谁雇佣定量分析师?
- 招聘人员在简历中寻找什么?
- 定量分析师的工资
- 算法交易所需的技能和成为量化分析师的资格
- 机器学习、人工智能和你的职业
- 不断学习。不断升级。
- 重要链接
- 额外内容
散户交易者的算法交易指南|免费博客
- 什么是算法交易?
- 散户为什么要做算法交易?
- 散户如何开始算法交易?
- Algo 交易规则
- 建立算法交易平台的要求
- 算法交易经纪人
- 学习算法交易的课程
算法交易——为什么要这么做?免费录制
如果你是金融市场的交易者或投资者,你可能会意识到在过去的 10-15 年里,投资领域发生了翻天覆地的变化。在这个网上研讨会的录像中,我们讨论了交易的演变、它的含义以及如何为交易的未来做好准备。
https://www.youtube.com/embed/73gr7qkQedo?rel=0
开始算法交易前要知道的 5 件事|免费博客
这篇文章特别针对那些想学习算法交易并希望建立自己的交易系统的人。作为算法交易者,你的成功不仅取决于你的量化技能,还很大程度上取决于你选择的分析、设计和执行策略的过程和工具。
基本算法交易书籍|免费资源
- 市场微观结构
- 统计学和计量经济学
- 技术分析
- 股票预购买卖
- 高级统计学
- 机器学习
- 计算机编程语言
交易爱好者的阅读清单|免费资源
- 关于 Python 的最佳书籍
- 日内交易的最佳书籍
- 量化交易中的机器学习
- 新手最佳日交易书籍
- 算法交易书籍
- 算法交易的最佳非 Python 书籍
深入挖掘:什么是算法交易,你如何进入算法交易?|播客
本播客基于 Shishir Asthana (Moneycontrol)和 Nitesh Khan delwal(QuantInsti 首席执行官)之间关于算法交易的互动。它深入探讨了如何进入算法交易,你需要具备什么资格,以及你需要注意哪些熊市陷阱。
https://embeds.audioboom.com/posts/7139212/embed/v4
EPAT |免费博客提供的 Algo 交易职业机会
- 在交易中拥抱和融入技术
- 工作和机会来了——我不骗你!
- 如果有工作,合适的人选在哪里?
- 工作、职业和缺失因素“X”
- 让学习成为一种体验
- 赋予思想力量
- 优秀是关键
- 珍惜利益
关于算法交易你不知道的 7 件事|免费博客
有一些信仰,不信仰和谣言阻止人们充分利用算法交易,现在是每个人都意识到它的真正潜力的时候了。因此,我们带给你 7 件事,我们相信每个人都应该知道算法交易。
巨蟒进行交易
Python for Trading:基础|免费课程
时长:9 小时
你将学到什么:导入股票数据,操作和可视化
总结:学习 Python 并使用其分析金融数据集的入门课程。它包括数据结构、表达式、函数的核心主题,并解释了金融市场中使用的各种库。这是一门详细而全面的课程,旨在为 Python 打下坚实的基础。
Python 基础手册|免费书籍

这本书对任何想要简要介绍 Python 及其数据科学堆栈的关键组件的人,以及想要快速复习使用 Python 进行数据分析的 Python 程序员都很有用。最好对编程有所了解。这里的概念和想法包括几个例子,以帮助理论联系实际。
Python For Trading |免费博客
- 为什么是 Python?
- Python 在算法交易中的利与弊
- Python vs. C++ vs. R
- Python 在金融中的应用
- Python 入门和设置
- Python 中流行的库/包
- 在 Python 中使用数据
- 创建样本交易策略和回溯测试
- 评估样本交易策略
Python 数据结构|免费教程
- 索引和切片
- 排列
- 元组
- 列表
- 堆栈和队列
- 字典
- 设置
Python 数据类型和变量|免费教程
- Python 变量
- Python 数据类型
- Python 数据类型转换
Python 函数|免费教程
- 内置 python 函数
- 用户定义的 python 函数
- 变量命名空间和范围
- Lambda python 函数
Scikit |免费教程
- 装置
- 使用数据的要求
- 虹膜数据集
- 拆分数据
- 构建分类模型
Jupyter 笔记本|免费教程
- 介绍
- 装置
- 奔跑
- 成分
- 细胞
- 如何用 markdown 语言写作
- 魔法命令
- 如何下载和分享
Matplotlib |免费教程
- 如何导入
- 基本术语和概念
- 绘图数据
- 情节定制
- 多重情节
Numpy |免费教程
- 装置
- NumPy 数组
- 使用内置函数创建数组
- 随意采样
- 数组属性和方法
- 数组操作
- 数组索引和迭代
熊猫|免费教程
- 装置
- 它解决什么问题?
- 系列
- 数据帧-过滤、迭代、合并、追加、连接
- 导入数据
- 索引和子集
- 操作数据帧
- 统计探索性数据分析
Plotly Python |免费教程
- 介绍
- 如何在 Python 中安装 Plotly
- 在线与离线使用
- 呈现为 HTML 文件或在笔记本中呈现
- OHLC 海图
- 散点图
- 使用 Plotly Express 的折线图
- 柱状图
- 等高线图
- 三维散点图
机器学习
交易机器学习介绍|免费课程
时长:2 小时
你将学到什么:基本术语,研究论文,工作模型
总结:一个免费的课程,让你开始使用机器学习进行交易。了解不同的机器学习算法是如何在金融市场数据上实现的。浏览并理解该领域的不同研究。获得这个利基领域的全面概述。
如何使用机器学习进行交易|免费书籍

机器学习技术已经提升了金融、医学等主要领域的工作方式。一种广泛的机器学习技术涉及人工神经网络。
它们是什么,如何在金融市场中实施?这本电子书包含了关于它的所有信息,从解释人工神经网络的基础和工作到演示用 Python 实现股票价格预测的代码。
机器学习基础|免费教程
- 什么是机器学习
- 机器学习、深度学习、人工智能的区别
- 机器学习的组件
- 用于机器学习基础的 Python 库
- 流行的机器学习算法分类
- 机器学习基础知识中需要了解的常见术语
- 机器学习和深度学习的区别
- 深度神经网络的工作原理
- 机器学习的应用
- 机器学习的发展和未来
交易中的机器学习 Q & A 陈博士|免费录音
与欧内斯特·陈博士(QTS 资本管理有限公司的管理成员)的问答环节获得了观众的巨大反响。
陈博士是“算法期权交易”的行业专家,并在许多国际论坛上举办过研讨会和讲座。除了在 QuantInsti 任教,他的学术论文也可以在 Quantra 和主要门户网站上看到。
他将自己在统计模式识别方面的专业知识应用于多个项目,从 IBM Research 的文本检索、Morgan Stanley 的客户关系数据挖掘,到瑞士瑞信银行、Mapleridge Capital Management 和其他对冲基金的统计套利交易策略研究。
他因写了这些书而出名:量化交易;算法交易:获胜策略及其原理;机器交易:运用计算机算法征服市场。
https://www.youtube.com/embed/m4BFOSaos7M?rel=0
在此阅读所有问答。
使用 Python 中的机器学习进行交易|免费博客
- Python 中的机器学习如何流行起来
- Python 机器学习算法的先决条件
- 获取数据并使其可用
- 创建超参数
- 将数据分为测试集和训练集
- 获取最佳参数以创建新函数
- 进行预测并检查性能
- 额外收获:与 Python 机器学习算法相关的常见问题
免费资源学习机器学习交易|免费资源
- 课程
- 资源
- 推荐书籍
- 机器学习的应用
现场交易中的机器学习|免费视频播放列表
一个简短的视频播放列表,为你提供交易中机器学习的各种主题的摘要
https://www.youtube.com/embed/playlist?list=PLvoal9WEcFgLtHyyEHP4B0yLLHvTKYd6T
交易中的自然语言处理(NLP)分步指南|免费教程
- 使用 NLP 进行交易
- 新闻和 NLP
- 交易中使用 NLP 的步骤
交易中的大师级自然语言处理 |特里·本茨沙维尔 |免费录音
特里·本茨沙维尔(本茨沙维尔科学有限责任公司的创始人和负责人)和伊山·沙阿(AVP,QuantInsti 的内容和研究)主持了这个关于交易中的自然语言处理的大师班。
在本节课中,Terry 和 Ishan 讨论了:
- 自然语言处理在金融市场中是如何应用的?
- 在 Quantra 学习门户网站上计算每日情绪得分
- 比较不同的单词嵌入方法及其优缺点
- Quantra 学习门户如何提供独特的学习体验?
https://www.youtube.com/embed/LBGr1lm3Jqs?rel=0
金融深度学习|免费教程
- 深度学习概述
- 深度学习在金融中的应用
- 深度学习的模型
- 深度学习在金融中的应用
- 深度学习在金融领域的前景如何?
深度学习和神经网络介绍|免费教程
- 什么是深度学习?
- 深度学习的历史
- 深度学习和机器学习的区别
- 深度神经网络的工作原理
- 深度学习的应用
人工智能和股市,这里有你没想到的!免费博客
人工智能(或 AI)已经在发挥作用,它正在许多方面改变市场。在这篇博文中,作者分享了他对这种转变的影响的看法。
期权交易
Python 中的期权交易策略:基础|免费课程
时长:3 小时
你将学到什么:看涨期权、保护性看跌期权、铁鹰期权、看涨期权、看跌期权
总结:期权交易初学者的必备课程。它从你必须知道的能够交易期权的基本术语和概念开始。它涵盖了货币的概念,看跌期权平价,波动性及其类型,期权对冲,以及各种期权交易策略。
期权交易基础讲解|免费教程
- 什么是期权交易?
- 期权交易与股票交易
- 选项术语
- 选项的类型
- 期权交易示例
- Python 中什么是看跌期权奇偶性?
- 希腊期权
- 布莱克-斯科尔斯期权定价模型
- 开立期权交易账户
- 期权交易策略
期权交易|免费博客
一系列关于期权交易的教程,包括定义、期权定价模型、期权希腊人、不同的交易策略以及免费下载的代码和数据,如离差交易、指数套利等。
期权交易策略|免费博客
数据科学
数据科学介绍|免费课程
时长:3 小时
你要做的:做一个体育获胜团队预测的项目
总结:通过做一个有趣的项目来学习数据分析。预测英格兰超级联赛的获胜球队。强烈推荐给那些想要获得数据科学实用知识的人。了解所有重要步骤,如数据补救、探索性数据分析、数据建模和结果交流。
数据科学- 3 分钟视频|免费播放列表
开始学习当今最受欢迎的领域和技能——数据科学——我们的 3 分钟视频将为您提供对它的概述。
https://www.youtube.com/embed/playlist?list=PLvoal9WEcFgK_V7d0zyC4SazJ5hV2msK3
数据科学入门:食品配送应用案例研究|免费博客
这篇关于“数据科学的步骤”的博客将带领你通过一个有用的框架来理解数据科学的过程。通过对一个食品配送应用程序的案例研究,我们将尝试分解步骤,以帮助您了解任何数据科学项目的生命周期。
Quants
Quant 面试问题准备|免费课程
时长:5 小时
你将学到什么:面试准备和简历制作
总结:本课程的主要目的是通过为您提供正确的面试问题组合来练习和提高您的知识和技能,从而帮助您破解量化面试。涵盖的主题包括逻辑推理、谜题、统计学、概率、时间序列分析、投资组合管理、期权、机器学习和 Python,以及关于非技术轮次的讨论和撰写简历。
针对量化交易新手|免费播放列表
免费开始你的量化和算法交易生涯!学会在现实市场中创造和实施你的策略!
https://www.youtube.com/embed/playlist?list=PLvoal9WEcFgIJXRLQrszAnSXDdiC5Sh9W
统计和概率分布初学者指南|免费教程
- 历史数据分析-数据集、平均值、众数、中位数
- 概率分布-标准差、直方图、正态分布
- 相互关系
量化金融入门|免费教程
- 什么是量化金融?
- 量化金融有多重要?
- 成为量化分析师需要什么资格?
- 定量金融领域的工作
一个 Quant 挣多少工资?免费博客
- 什么是 Quant?
- 定量工资
- 定量分析师的工作职责
- 量化基金
- 与算法交易员的坦诚对话
量化时代的技能提升|免费博客
像 Python 编程、金融计算、统计分析、定量能力等技能都需要成为其中的一部分。个人正在迅速学习这些技能。企业也没有落在后面。
成为更好的量化分析师的 5 种方法|免费博客
总有一些品质、技巧、重要的事实和令人惊讶的故事会派上用场,但不是每个人都能一次获得所有这些。我们给你列出了成功交易者最常用的技巧和品质。
Quants 最佳网站的非传统指南|免费资源
- 博客和量化交易策略
- 研究论文
- 自定进度的学习门户
- 市场数据来源
- 编程资源
外汇
外汇动量交易|免费课程
时长:1.5 小时
你将学到什么:动量交易,历史价格的表现
总结:本课程推荐给外汇交易新手和专家。使用 Python 中的真实外汇市场数据创建动量交易策略。在内置平台上做回测,分析结果。了解日内交易的风险管理。
新手外汇交易基础|免费教程
- 外汇史
- 为什么需要不同的货币?
- 什么是外汇市场?
- 什么是外汇交易或外汇买卖?
- 外汇交易中使用的术语
- 外汇交易是如何运作的?
- 外汇交易中如何计算盈亏?
- 外汇交易示例
Alexis Stenfors 博士的外汇市场算法交易|免费录音
全球外汇市场的交易额几乎是所有股票市场总和的十倍。然而,令人惊讶的是,人们对这个领域的 HFT 和算法交易知之甚少。本次网络研讨会将深入探讨这一快速增长市场的一些独特方面。
https://www.youtube.com/embed/WExt8o0s0hY
自动交易
使用交互式经纪人平台的 IBridgePy 自动交易|免费课程
时长:3.5 小时
你将学到什么: IBridgePy API,安装,订单&投资组合管理
摘要:由交互式经纪人提供,用 Python 迈出自动化和执行交易策略的第一步。它涵盖了从获取数据到使用交互式经纪人交易平台上的免费模拟账户发送订单的所有基本步骤。立即开始自动交易!
自动交易系统|免费教程
- 传统建筑
- 传统建筑的局限性
- 自动交易系统的新体系结构
- 自动交易系统协议的出现
- 低延迟架构的出现
- 复杂程度
- 建立你自己的自动交易系统
什么是交易策略的回溯测试?|免费教程
- 自动回溯测试和手动回溯测试
- 回溯测试交易策略的关键决策
- 评估交易系统的典型回溯测试参数
- 回溯测试过程
- 用于回溯测试的平台
- 意识到偏见
蓝移|免费回测平台
蓝移帮助你把你的想法变成交易策略。你可以研究你的想法。对它们进行回溯测试,并和你选择的经纪人一起实践你的策略。
这是一个快速,灵活和可靠的平台,研究和交易系统的投资策略。它是资产级的。工具和风格不可知-我们支持多种资产类别和工具,如外汇、股票、期货。
https://www.youtube.com/embed/DegANUaZwOE?rel=0
Laurent Bernut 的卖空|免费录音
如果市场失灵,你能从中获利吗?学习什么时候卖出你的股票,什么时候在市场下跌或调整时退出。向拥有数十年市场经验的交易者学习,使用卖空方法创建各种交易策略。
https://www.youtube.com/embed/NKp8YsTn9UA?rel=0
附加资源
所有关于算法和量化交易的免费课程
获得我们提供的所有免费课程。
网络研讨会录像和自学视频
https://www.youtube.com/embed/playlist?list=PLD7IrLyN7uvKmhJQFJ4I6Rg6PDyKI4_9q
在这里观看它们!
幻灯片和演示文稿
免费访问我们迄今为止举办的 50 多个网络研讨会、会议和研讨会的所有幻灯片和演示文稿
成功案例
获得灵感。阅读来自全球各地的企业家、交易者、开发者和分析师,他们来自不同的生活领域,有着不同的经历。了解他们如何通过获得必备的技能改变了他们的生活,今天他们已经在算法交易和量化交易领域站稳了脚跟。这是他们的一系列故事。
所有与算法交易相关的博客
以绝对零成本查看我们所有的普通博客和量化博客,开始你的学习目标。我们的博客深受全球读者的追捧和分享。
涵盖的类别:
职业成长
教程T5】
- 自动交易
- Excel & R 进行交易
- 外汇&加密交易
- 机器学习
- 数学和计量经济学
- 均值回归&统计套利
- 动量交易
- 更多交易策略
- 期权交易
- 投资组合&风险管理
- 用于交易的 Python
- 情绪交易
- 技术指标
- 网络研讨会
您也可以在这里访问所有的 !T3】
我们希望你喜欢阅读这篇文章,就像我们制作它一样。我们非常感谢您的意见和建议。
如果你喜欢,别忘了在你的社交媒体手柄上分享这个博客。可能真的对某个人有帮助。
如果你真的想以结构化的方式学习量化交易,QuantInsti 还提供 EPAT,这是世界上第一个经过验证的算法交易课程。联系课程顾问,了解更多通过 EPAT 学习算法交易的好处。
免责声明:本文提供的所有数据和信息仅供参考。QuantInsti 对本文中任何信息的准确性、完整性、现时性、适用性或有效性不做任何陈述,也不对这些信息中的任何错误、遗漏或延迟或因其显示或使用而导致的任何损失、伤害或损害负责。所有信息均按原样提供。
基金管理和算法交易|穆罕默德如何让两者成为可能
位列全球前三的全球基金经理,拥有多项 IBM 关于数据科学、人工智能、ML 和 ACCA、CFA 和 FDP 的认证,今天我们为您带来 EPAT 校友 Muhammad Tariq 的旅程。
正是他学习进步的速度让他的教育转向了对资本市场的热情和对投资的热爱。他是瑞典商业委员会驻巴基斯坦的副总裁,同时也是瑞典 Tundra Fonder AB 公司的首席信息官/合伙人。
他的每一项成就都掩盖了他以前的非凡成就。带着永不满足的学习和成长的欲望,从生活和市场中获得更多,甚至更有生产力——这就是穆罕默德的旅程。
嗨,穆罕默德,给我们介绍一下你自己吧!

嗨!我是默罕默德·沙蒙·塔里克,我是巴基斯坦人,曾在瑞典&生活和工作。在过去的 12 年里,我一直与资本市场联系在一起,我的职业生涯始于分析师,这让我对金融建模有了相当的了解。
当我搬到瑞典时,我开始从事金融建模工作,当时我是一名驻瑞典的资产经理,负责在新兴市场进行全球投资。
我纯粹是一个资本市场的人,遵循传统,比如 Excel 建模。在 Citywire 和晨星的新兴市场领域,我们被评为全球前三大全球基金管理公司。
我去了很多地方旅行,见识了很多文化,这是我热爱我的工作的最大好处之一。为了工作,我去过大约 20 个国家,尤其是欧洲、美国、南亚和东南亚,这些都是世界上增长最快的市场。
疫情使旅行变得不太可能,这种情况需要几年时间才能改变。谢天谢地,有了现在的技术,网上会议和聚会已经开始了。
对我来说,就工作而言,这是一个优势,因为这样你就有更多的时间来沟通、主持会议、管理时间表,还可以培养一些技能。
我现在正在研究巴基斯坦的第一台机器人顾问,为这个拥有 2 . 2 亿人口的国家提供储蓄产品。
我的爱好当然包括旅游,但我也喜欢钓鱼、跳伞和潜水。我也是有执照的跳伞运动员!
你能描述一下你的旅程以及 Algo Trading 是如何进入这个画面的吗?
我实际上是一名工科学生,擅长数学和物理。所以,我在暑假,我的朋友有一个经纪公司,我们花了大约一个月的时间。这让我意识到这是我想做的。
然后我改变了我的教育,转向金融,并在 2008 年完成了我的 ACCA 和 CFA。当时我在伊斯兰堡,但没有太多的金融机会,所以我搬到了卡拉奇,开始做金融分析师,并在那里工作了两年。在那里,我自己从零开始创建了这个行业的金融模型,并且热爱金融建模。
几年来,我创建了各种金融模型,并进行了大量的编码工作,这感觉就像是这个领域的重复例行工作,我想尝试一些新的东西。当我开始与国际客户交谈时,机会出现了。我为客户提供建议,为高净值人士提供指导,但此外,在这里工作对我来说很有成就感。
我的一个客户是一家瑞典公司,它雇佣我做研究。几个月后,我成了基金经理,六个月后我成了合伙人,一年后我成了公司的正式股东。
我喜欢自动化。这不仅仅是因为计算机科学,更像是当你在做一个金融模型的时候——你在创造它并使它自动化。你改变了变量,你改变了逻辑,模型本身给了你结果。
我热爱资本市场。我喜欢投资。我喜欢尝试新事物,经常全神贯注于深入研究金融模型。目前,我参加了伦敦经济学院的数据科学和商业分析项目。
所以,我已经习惯了,习惯了 Excel 或其他我们过去一直在使用的常规工具,但不是用 Python 或任何计算机语言。随着时间的推移,我看到了技术的进步,并在 2015 年帮助我哥哥的技术创业公司建立后端基础设施时体验到了这一点。
我开始思考——为什么不把模型自动化呢?我手头有数据,我想为什么不为这些公司创建研究模型来预测它们的收益呢?这就是它开始的地方。
我从能给我的工作带来效率的东西开始。带着这个想法,我开始寻找某些特定的课程,我注册并完成了一些热门课程提供商提供的许多与数据科学和机器学习相关的在线课程。然而,我对方向并不满意。
课程没有结构化,无论是 Python 课程还是数据科学课程,等等。他们中没有一个人知道具体的步骤,接下来是什么,等等。例如,如果我学习了 ML 和 AI,然后继续学习 Python,这将是一场灾难。
所以,我在这里,寻找一个更结构化的方法,因为这是我想做的。尽管我正在自动化,尽管我已经给我的工作带来了效率,但我需要那种指导。
编程知识的匮乏是否阻止了你学习 Algo 交易?
我擅长逻辑,但我不擅长技术,因为我从未接触过技术。
所以,我想知道,在交易中使用技术能做些什么?
需要什么样的架构?
需要什么编程语言?
哪种语言对编程有好有坏?
这就是我如何经过大量的搜索,发现了 EPAT。
在新冠肺炎疫情期间,有一些在线课程已经开始,数据科学吸引了我,它是非常基础的。我必须理解这些非常基本的东西,因为这需要数据科学和机器学习。
但是,那不是我想要的!他们在教一些过时的编程语言。虽然我支付了费用,但我并不开心,所以我停止了那些课程。
那是我遇到 EPAT 的时候,我和 QuantInsti 团队通过多次电话进行了讨论,由于我以前的经历,我有点担心课程的成本。但我天生喜欢冒险,想试一试。
最糟糕的结果可能是时间和金钱的损失,但这根本没有发生。但是当我和 EPAT 开始交往时,我所有的疑虑都烟消云散了。
要创建一个算法,一种方法是导入已经实现的库,另一种方法是尝试一下。对于像我这样对逻辑和算法有所了解的人来说;如果我想创建自己的算法,我不知道如何着手。我不得不付出很大的努力才达到基础。
然而,对于拥有不同技能和不同知识和经验的人来说,学习经历可能是不同的。
我最喜欢 EPAT 的一点是:
- 该结构
- 从基础到高级领域的牵手
- 专门支持
在过去的 6 个月里,我有了很好的学习经历,并获得了 EPAT 优秀证书,EPAT 给了我一个坚实的基础。
作为高层管理者,你是个大忙人——你是如何为 EPAT 安排时间的?
我是一个有工作的人,但我的热情让我抽出时间去 EPAT 和学习。尽管身处不同的时区,而且被疫情环绕,我还是习惯早起工作,之后还可以参加现场讲座。
参加现场讲座时,您有一些问题可以立即得到解答。如果你正在听录音讲座,支持系统真的很好——说实话,确实如此。
每当你在学习过程中遇到问题,或者遇到概念问题时,你可以找人询问,支持团队会很快为你安排电话,他们会尽力解决你的疑问。我真的很欣赏并认为课程和支持是 EPAT 最好的特点。
例如,当你在一个新的国家,有一个向导在那里,你会立刻感觉舒服很多,这就是我对 EPAT 支持团队的感觉。舒服。
我过去是,现在仍然是编程新手,要真正精通它并能够编写代码还需要一些时间。当我开始做这个的时候,我真的需要帮助,为此,支持系统总是在那里帮助和指导我。
你对有抱负的算法交易者有什么建议?
QuantInsti 通过 EPAT 提供的不仅仅是算法交易。不仅仅是这样!
这是一个投资领域,交易是其中的一部分。有完整的选股、研究和分析、建议,然后转化为交易——这使整个过程成为一次旅行。
EPAT 已经在做的是覆盖整个旅程,而不仅仅是创建算法交易的基石。人们可以利用这些知识来提高工作效率,或者预测价格变动,提出经济模型等等。
EPAT 不仅提供算法交易的知识,还提供算法投资,因为它涵盖了整个投资过程。EPAT 不仅仅局限于贸易领域。它吸引了研究分析师、基金经理、技术交易员和销售人员。
现在看起来可能不太必要,但 5 年后,算法交易将成为一种必然。任何拥有这种知识的人都将在竞争中获得优势,无论是在 it 公司还是在工作中,并且能够获得和利用这种知识。
即使 Algo 不是你的激情所在,也要去投资,但这样做只是为了你能在那里生存下去。这是一场生存游戏。大家都在砍掉人力资源,用技术和自动化,不如今天就做好未来的准备。如果你没有学习算法投资或在交易中采用技术,现在是时候了。
穆罕默德,感谢你在百忙之中抽出时间与我们交谈。和你交谈很愉快。你的旅程非常鼓舞人心,我们希望它继续变得更好。给你最好的祝愿。
如果你也渴望用终身技能武装自己,这些技能将永远帮助你提升你的交易策略,这个 algo 交易课程正是你所需要的。拥有统计学&计量经济学、金融计算&技术、机器学习等课题,确保你精通在交易领域出类拔萃所需的每一项技能。现在就来看看 EPAT 吧!
免责声明:为了帮助那些正在考虑从事算法和量化交易的人,这个成功的故事是根据 QuantInsti EPAT 项目的学生或校友的个人经历整理的。成功案例仅用于说明目的,不用于投资目的。EPAT 方案完成后取得的成果对所有人来说可能不尽相同。T3】
算法交易的基本分析
原文:https://blog.quantinsti.com/fundamental-analysis-performed-algorithmic-trading/
根据基本面制定策略的投资者与基于定量分析的交易者有很大不同。将策略建立在技术分析基础上的量化交易者能够每分钟扫描数千张图表,这些图表配有一系列指标、比率和数据点,找到适合他们的算法交易策略的合适工具。另一方面,基本面分析是不同的。基本面不会像价格变化那样每分钟都在变化。资产负债表、损益表、存货清单、现金流量表这些东西每个季度最多提供一次。考虑到这一点,有没有一种方法可以像定量分析师分析价格-交易量运动那样分析基本面?你能自动完成这个过程并从中创造出一个算法交易策略吗?这个博客会帮你做到这一点。
积木!
 什么是算法交易策略?很简单,当然,有数据、策略(算法)和经纪人的 API,可以让你按照策略执行交易。现在让我们深入研究每一部分。
什么是算法交易策略?很简单,当然,有数据、策略(算法)和经纪人的 API,可以让你按照策略执行交易。现在让我们深入研究每一部分。
数据
这是等式中最关键的部分。你从哪里获得一家公司的统一、结构化、准确的基本面数据,最重要的是以一种机器(算法)可以理解的格式?这里列出了一些著名的基本面数据来源,它们以数据的准确性、多样性和大量交易工具的可用性而闻名。
| 数据源 | 覆盖的市场 | 提供的数据点 | 定价 | 数据格式 | 更多信息 |
| Quandl | 主要是美国和加拿大证券。并且可以从全球(~67 个国家)市场选择证券 | 90–200 个数据点可用美国&加拿大证券。59 为全球指标 | 起价 49 美元/用户 pm,最高可达 1000 美元/用户 pm | CSV,JSON,XML | 点击这里 |
| 彭博 | 访问所有资产类别的 3500 万种工具,这些工具来自 330 多个交易所 | 关键基础数据、见解、研究报告等。 | $ 1500-$ 3000 一个月 | CSV,JSON,XML | 点击这里 |
| SEC.gov(埃德加) | 美国证券包括 12000 多家公司 | 各种公司形式(10Q、10K、8K、S1、F6 等。) | 自由存取,用于手动数据存取。已付(大约。1200 美元/年)用于通过第三方 API 进行算法交易 | XML,HTML,JSON | 点击这里 |
| 晨星 | 全球 26000 多家公司 | 关键基础数据、见解、研究报告等。 | 定制价格,你得和他们联系 | 通过 API 和 XML | 点击这里 |
此外,为了以防万一,您还可以查看以下数据源:
- 本辛加
- 资产宏观
- Airex 市场
- S & P 全球网络优势
- EventVestor
- 事实集
需要采取的预防措施:
因为基本面数据的本质不同于你通常的价格数据。你的算法交易策略可能会因为不太正确的数据而做出错误的决定。例如,一些公司可能会在他们的报告中撒谎,关于他们为什么会这样做有多种原因,但最主要的是为了让他们看起来更好。这里有一些这样的例子,
- 如果公司在报告的收益中包括应收账款。这笔钱还没有进入他们的账户,但公司认为这笔钱肯定会在某个时候到来。但对于基本面交易员来说,这可能是一个巨大的错误
- 有时,公司会展示通过向自己的相关公司销售产品而获得的销售数字
- 报告可能不会显示前三个季度的任何税收成分,但在最后一个季度有一个大的税收成分
这种事情在审计中出现,审计师让公司解决这些问题,但问题是重要的审计是每年进行的,你可能已经根据预审计的数据做出了交易决定。那么我们如何避免这些事情呢?你可以遵守一些基本规则:
- 只考虑那些有准确披露数据历史的公司
- 包括针对少量或不可靠股票的定性过滤器
- 确保回溯测试的时间足够长
- 在进行回溯测试时要注意远期风险,这意味着未来可能发生的影响股票表现的事情通常不会出现在资产负债表上
基于基本面的交易策略示例
现在让我们深入到一个实际的基于基本面数据的算法交易策略。我们在这方面得到了 Quantopian 的帮助。Quantopian 已经与晨星合作开发基本面数据,在你的算法交易策略中,有超过 600 个指标可以利用。Quantopian 的专职分析师 Peter Poon 开发了一种基本面策略算法,他称之为“一种利用基本面数据的量化价值投资策略”。这就是这个策略的全部内容。
- 选择不超过 15 只符合以下规则的股票:市盈率< 12, P/B < 2, ROE > 15%,市值> 1 亿美元
- 保持选择一年,并在下一年重新进行选择
You can sign up for our ‘Python for Trading’ course that will teach (actually hand-hold you) to code your own algorithmic trading strategy. Here’s how the strategy performed during the backtest:  Performance in numbers:
Performance in numbers:  Peter thinks the strategy results are in good agreement with the traditional value investing. The selected stocks in this algorithmic trading strategy outperformed the market by almost twice. However, backtesting results are on paper, there are multiple factors (more in number than quantitative trading) that affect fundamentals of a company and its performance. Developing a strategy that includes all of them is a mammoth task. Having said that, the markets are already moving towards algorithmic trading and slowly all sorts of data are being made available in machine-readable format. For example, news, social media and economic events based feeds are prevalent today.
Peter thinks the strategy results are in good agreement with the traditional value investing. The selected stocks in this algorithmic trading strategy outperformed the market by almost twice. However, backtesting results are on paper, there are multiple factors (more in number than quantitative trading) that affect fundamentals of a company and its performance. Developing a strategy that includes all of them is a mammoth task. Having said that, the markets are already moving towards algorithmic trading and slowly all sorts of data are being made available in machine-readable format. For example, news, social media and economic events based feeds are prevalent today.
结论
将基本面纳入算法交易策略,并让它来承担重任,这是前进的方向。这种方法提供了传统基本面交易者无法获得的新的可能性。通过我们的自学门户 Quantra 和我们的综合虚拟课堂课程算法交易高管课程(EPAT) ,迈出学习算法交易的第一步。
使用不同数据源的基本面和情绪分析
原文:https://blog.quantinsti.com/fundamental-sentiment-analysis-data/
由克里斯托夫·勒鲁和雷希特·帕查内卡和
制作
价格和成交量历史的技术分析在当今不会单独削减它。当我们想要进行价值投资和/或衡量证券的内在价值时,我们需要对证券进行基本面分析。
为了进行基本面分析,我们需要数据,大量的数据。我们需要比率、财务报表、收益等形式的基本数据。除此之外,我们还可以使用宏观经济数据,如国内生产总值、失业率、消费者价格指数。
最近,金融新闻和推文被用于情绪分析来帮助交易者做决定。
我们将研究每一种不同类型的数据,为它们找到合适的数据提供者,并用 Python 代码给出一个如何使用这些数据的例子。
所有代码示例都是在 Google Colab 中制作的,但是当然可以在任何 jupyter notebook 服务器或任何 python 环境中执行。
这篇文章的结构如下:
基本数据
基本面数据包括用于初步筛选公司财务状况的财务比率,例如,市盈率(PE)、市净率(PBV)、净资产收益率(ROE)、复合年增长率(CAGR)、流动比率、股息率等。
它还包括用于评估企业的核心财务报表,如资产负债表、损益表和现金流量表。这些有价值的数据可以很容易地从 Yahoo!当然,有一个 Python 包用于此,我们将使用 yahoofinancials。
其他著名的基础数据提供者(带有 python 包)是 Quandl 和 Intrinio。现在让我们看看如何检索这些信息。
财务比率
期货交易讲解
你一定听说过金融市场中的衍生品,也许在某个时候,你可能也交易过/想过交易它们。在本文中,你将了解期货市场,它是衍生品市场的重要组成部分之一。你将学习期货合约的特征和参数。您还将了解期货数据和期货市场的趋势跟踪策略。
在这篇博客中,我们将讨论以下主题:
衍生品市场在维持市场平衡方面发挥着非常关键的作用。衍生品是从其他金融资产中获取价值的合约。这些资产被称为基础资产。基础资产可以是任何东西,如股票、货币、利率或农业和非农业商品。
期货市场是衍生品市场不可分割的一部分。在了解期货市场之前,了解远期市场的概念是非常重要的。
远期和期货
远期合同是衍生产品的最简单形式。在远期合同中,有双方(称为买方和卖方)同意在固定(未来)日期以固定价格购买和出售固定数量的特定资产。
他们根据 ISDA 主协议签订了一份合同,规定了双方的义务。价格由双方在协议之日决定。远期合同的主要目的是保护买卖双方免受未来风险。
让我们借助一个例子来理解远期和期货。
彼得有一个大农场,再过三个月就要收割小麦了。收获的成本是每公吨 150 美元。因为将来会收获,所以价格没有保证。它可以上升,也可以由于一些不可预见的事件而下跌。如果小麦价格跌破每公吨 150 美元,彼得将不得不承担损失。
同样,像 Mondelez 这样的食品制造巨头需要数吨小麦来生产产品。如果它以每公吨 300 多美元的价格购买小麦,它就会亏损。和彼得一样,蒙德勒兹也不确定三个月后小麦的价格会是多少。
因此,为了维护他们的利益,他们可以签订合同。根据这份合同,彼得将在三个月后向蒙德勒兹出售 100 公吨小麦,每公吨 200 美元。
这样,彼得(卖方)和蒙德勒兹(买方)都将保护自己免受任何未来风险。这是最简单的合同形式,被称为远期合同。
根据这份合同,卖方必须在固定的日期以预定的价格向买方出售固定数量的货物。远期合约涉及的最大风险是交易对手风险。只有双方同意,合同才能继续执行。
远期合约不能进一步交易,必须在买卖双方之间结算。然而,类似的合同可以与另一方交易。虽然远期合同的结构相当简单,但并不固定。这些合同的条款因情况而异。
期货合同类似于远期合同,但它们是标准化的。
现在让我们来看看期货合约的特点。
期货合约的特征
- 标准化:期货合约的所有参数都是标准化的。例如,在上述情况下,在远期合同中,根据买方和卖方的决定,小麦的数量可以是 90 公吨或 110 公吨。但是期货合约中的数量不能改变,其他任何参数也不能改变。
- 期货合约的价格:由于期货市场是衍生品市场不可分割的一部分,期货合约的价格是以标的资产的价格为基础的。相反,期货合约的价格是基于标的资产的未来价格。它考虑了现货价格、无风险收益率、到期时间等。来决定最终价格。
- 有时间限制:每份期货合约都是有时间限制的。这个时间被称为期货合约的到期日。期货合约在当月的最后一个星期四到期。如果上周四是节假日,合同将在前一个工作日到期。期货合约有三种不同的时间期限。这意味着你可以交易在三个不同时间到期的期货合约。我们用一个例子来理解这个。让我们假设你在一月份做交易。
- 近月- 即将在当月到期的合约为近月合约。一月份,一份近一个月的合同将于一月份到期。
- 下个月- 即将在下个月到期的合约是下个月合约。1 月份,下个月的合同 2 月份到期。
- 远月- 即将在次月到期的合约是远月合约。一月份,下个月的合同三月份到期。
- 与期货市场不同,期货市场受到监管机构的高度监管。在美国,期货市场由商品期货交易委员会(CFTC)监管。这个机构的作用是监督所有的期货合同,并确保它们顺利运行。因此,期货合约违约的可能性被消除,每份合约都被集中清算。
- 可交易:每个期货合约都是可交易的。这意味着你不需要等到合同到期才兑现。如果中途改变主意,可以在期货市场进一步买入/卖出合约(将合约转让给别人)。因此,你可以随时退出期货合约。
- 结算:期货合约大多以现金结算。这意味着只需支付结算时的差额。这种解决受到管理机构的监督。您不一定要制造或接受交易的货物。
这些特征使得期货合约独一无二。这段视频解释了这一点:
https://www.youtube.com/embed/7n3fSFZo_Ng?rel=0
期货合约的参数
- 批量大小:期货合约的批量大小规定了您必须交易的资产的最小数量(或该数量的倍数)。这是一个预定的数字。例如,假设你想交易苹果股票的期货。苹果未来的批量是 100。这意味着你可以购买最少 125 股。或者可以 100 的倍数购买。如 2 手是 200 股,以此类推。每份合约的批量都不同。
- 合约价值:我们继续上面的例子。你想买 1 手苹果股票,而苹果股票的交易价格是每股 125 美元。因此,苹果期货的合约价值将等于 12500 美元(125 * 100 美元),即批量和价格的乘积。
- 保证金:你不需要全部合约价值就可以进行交易。取而代之的是,你需要向经纪人交存一部分合同价值才能签订合同。这部分被称为保证金。当你进入期货合约时,保证金被冻结,当你退出期货合约时,保证金被解冻。
- 到期日:众所周知,期货合约是有期限的,每份期货合约都有到期日。这是合同终止的日期。您需要在到期日当天或之前平仓,否则监管机构会为您平仓。在合同到期日,引入新的合同。你可能需要在这里注意,对于商品期货,你需要在第一个通知日期(通常在到期日之前一个月)之前出场。
期货合约的报价器
像你在金融市场交易的其他资产/商品一样,每份期货合约也有一个报价器。期货合约的代号是基础资产的根符号、到期月份和到期年份的组合。
- 根符号- 每种资产都有一个根符号,通常是两三个字母,代表市场。例如,GC 是 Comex 黄金市场的根符号,SI 是 Comex 白银市场的根符号。
- 月- 现在当你购买黄金合约时,你不是简单地购买黄金合约,而是购买特定月份的合约。比如,你到 2021 年 1 月的黄金合约。在合同中用一个字母来表示月份。这在不同的期货市场都很常见。例如,一月由字母 f 表示。下表显示了与不同月份相关的字母。
| 月 | 密码 | 月 | 密码 |
|---|---|---|---|
| 一月 | F | 七月 | 普通 |
| 二月 | G | 八月 | Q |
| 三月 | H | 九月 | U |
| 四月 | J | 十月 | V |
| 五月 | K | 十一月 | X |
| 六月 | M | 十二月 | Z |
- 年份- 这是用一位数或两位数来表示的。当使用单个数字时,它表示当前十年中的年份。
因此,2021 年 1 月 黄金 合约的股票代码将为 GCF1 。
期货交易的损益
正如你已经看到的,为了进入期货合约,你只需要在你的账户上有一定的保证金,这意味着期货市场使用高杠杆。杠杆越高,风险越高,潜在利润越高。
例如,让我们考虑你以 1000 美元的保证金购买一批苹果股票。请记住,对于苹果的未来,我们已经看到了这样的例子:
- 批量: 100
- 价格: $125
- 合同价值:$ 125 * 100 = $ 12500
现在可以有三种情况。
- 价格上涨:苹果公司的股价超过 125 美元,达到 140 美元。在这种情况下,100 股股票在合同到期时的价值为 14,000 美元。因此,在合同结束时,支付给你的差额是 1500 美元(14000-12500 美元)。因此,通过冻结 1000 美元,你获利 1500 美元。
- 价格下跌:苹果公司的股价跌至 110 美元,低于 125 美元。在这种情况下,100 股股票在合同到期时的价值为 11,000 美元。尽管如此,你仍有义务以 12,500 美元的价格购买 100 股苹果股票。因此,这将导致 1500 美元的损失。
- 价格不变:在这种情况下,你既不会获利,也不会亏损。在这种情况下,买方或卖方的投资组合都不会受到影响。
因此,你可以说期货市场是一个零和游戏。这意味着未来市场的锅永远长不大。金钱只是从输家转移到赢家。买方的利润相当于卖方的损失,反之亦然。
这段视频解释了期货交易中如何计算盈亏:
https://www.youtube.com/embed/BpznbF8lM_0?rel=0
获取期货数据
您可以从多个 web 源和 Python APIs 访问期货合约的历史数据。参考下面的文章,探索如何获取期货数据的 Python 代码。
期货延续
正如你在本文前面看到的,一份期货合同在到期日之后将不再存在。因此,任何合约的可用数据都是很短时间内的(由于期货合约的寿命有限),大多是一个月左右。这导致了处理期货数据时最棘手的问题之一。
问题是缺乏一个长期的时间序列来分析市场。像分析资产的一年移动平均线这样非常简单的任务不再那么简单了。你需要首先操纵数据,以实现更长时期的连续时间序列。这是通过延续实现的。
延续是通过将多个单独的序列拼接在一起而获得的时间序列。
期货延续是通过拼接多个单独的期货合约获得的时间序列。
您可能想到的一个非常简单的解决方案是,在前一个月的月底追加月度数据。然而,这可能导致灾难性的结果。如果你分析这些数据,你会发现一种资产/商品在本月的交易价格与上个月的交易价格大相径庭。
比如看下图。你可以看到这个系列中突然出现的峰值。这是因为连续两个月之间的价格差异。这并不意味着实际价格已经见顶。

Fig. 1: Appending monthly data
因此,为了缝合单个合同,您需要小心避免这样的错误。你可以用不同的方法来装订合同。让我们来看看其中的几个。
- 附加调整- 在这种方法下,您及时调整以前的合同,使以前合同的最后一个值与当前合同的第一个值相匹配。这是通过简单地增加或减少一个价值的整个系列的前一个合同。该值等于先前合约的最后一个值与当前合约的第一个值之间的差值。
$ $ \ text {调整系数=第二个合同的第一个价格-第一个合同的最后价格}$$
这种方法的主要缺点是,经过一定的调整后,它会给我们留下负值。
- 比例调整- 在这种方法下,调整系数不是差额,而是百分比。这里整个系列按百分比移动。
$ $ \ text {调整系数=第二个合同的第一个价格/第一个合同的最后价格}$$
整个时间序列不是加上或减去该因子,而是乘以该因子。缺点是绝对价格水平不再反映调整后的真实市场价格。
通过应用上述调整获得期货延续序列后,您可以对时间序列进行分析,并创建您的交易策略。我们来看一个在期货市场已经使用了几十年的简单策略,趋势跟随策略。
期货交易策略
趋势跟踪期货策略的出现可以追溯到 20 世纪 80 年代,今天通过这种策略管理的资金估计有 50000 亿美元。趋势跟踪策略是基于这样一个原则,即价格在一段持续的时间内通常会继续向同一个方向移动。
趋势跟踪策略的目的不是在底部买入,在顶部卖出。但它试图捕捉趋势的变化。当趋势发生变化时,它就会进场。这并不意味着一有变化就产生进场信号,而是模型等待一段时间,让变化成为趋势。
只要趋势持续,模型就保持在这个位置。同样的逻辑也适用于退出交易。退出信号不是在改变后立即产生,而是在等待一段时间后产生。如果趋势是看涨的,你做多,如果趋势是看跌的,你做空。
这里要注意的重要一点是,大多数趋势跟踪交易都以亏损告终。即使是一个成功的趋势跟踪模型,成功的交易也只有 30%到 40%。然而,如果处理得当,失败的交易会有小的损失,很少有大的收益可以弥补,甚至远远超过损失。
为了保持高利润的机会,有必要确保参与所有的交易,不要错过任何一笔交易。既然赢的交易次数少了,大赢的就更少了,为了不错过这个会弥补其他损失的巨大的赢,参与所有的交易是非常重要的。
这个视频解释了趋势跟踪策略的原则。
https://www.youtube.com/embed/cctiEodJZJw?rel=0
期货市场有多种多样的资产可供你折价交易。期货合约的基础资产可以是任何东西,如股票、货币、利率或农业和非农业商品。
期货市场上一些最具流动性的资产是原油、天然气、玉米、大豆和小麦。下表显示了可以在期货市场交易的资产。
| 货币 | 农业 | 非农 | 股票 | 息 |
| 澳元 | 饲料小麦 | 原油 | 标准普尔 500 指数 | 欧洲美元 |
| 增益带宽乘积(Gain-Bandwidth Product 的缩写) | 玉米 | 金色的 | 纳斯达克 | 2y 国库 |
| 计算机辅助设计 | 棉花 | 铜 | 日经 225 指数 | 5y 国库 |
| 欧元 | 育肥用牛 | 民用燃料油 | 道琼斯 | 10y 国库 |
| 美元指数 | 阿拉比卡咖啡 | 柴油 | 维克斯 | 30y 债券 |
| 日元(JapaneseYen) | 罗布斯塔咖啡 | 钯 | | |
| 新西兰元 | #5 糖 | 铂 | | |
| 充血性心力衰竭(congestive heart failure) | #11 糖 | 汽油 | | |
| | 燕麦 | 银 | | |
| | 黄豆 | 比特币 | | |
| | 大豆粉 | | | |
| | 木材 | | | |
| | 稻谷 | | | |
| | 可可粉 | | | |
让我们看看这一策略在非农业大宗商品钯上的表现。该策略通过 Palladium 从 1977 年到 2020 年的历史数据进行回溯测试。
步骤是定义趋势过滤器。为此,我们考虑了 40 天和 80 天的指数移动平均线。
趋势定义如下:
- 如果 40 天指数移动平均线越过 80 天平均线,趋势被认为是看涨的。
- 如果 40 天指数移动平均线穿过 80 天平均线,趋势被认为是熊市。
下图显示了价格趋势。

Fig. 2: Price trend of Palladium
趋势定义后,开仓规则定义如下:
- 如果趋势过滤器显示看涨趋势,价格突破 50 天高点,则建立新的多头头寸。
- 相反,如果趋势过滤器看跌,价格突破 50 天低点,则建立新的空头头寸。

Fig. 3: Long and shorty entry signal
接下来,让我们定义退出头寸的规则。为了定义退出规则,我们需要计算回调值。拉回值计算如下:
- 对于多头头寸,我们按照以下公式计算回调。
$ $回调= \ frac { Close ~ price-Rolling 最高 price } { Volatility ~ of ~ the ~ asset } $ $
如果回调小于-3,则生成多头退出信号。 - 对于空头头寸,我们按照以下公式计算回调。
$ $ pull back = \ frac { Close ~ price-Rolling ~最低价} { Volatility ~ of ~ asset } $ $
如果回调幅度大于 3,则产生空头退出信号。
下图显示了多头和空头头寸。

Fig. 4: Long and short positions
在上图中,绿色阴影区域是持有多头头寸的时期。类似地,红色阴影区域是持有空头头寸的时期。
观察到的策略回报如下:

Fig. 5: Cumulative returns
指数期货
期货合约不仅可以用来交易上述的商品,而且你也可以用一种特殊的期货合约来交易股票指数。这就是所谓的指数期货。
根据指数期货合约,你有义务在未来的某个固定日期以预定的价格交易特定的股票指数。浏览关于指数期货的博客,深入了解概念。
期货市场交易的优势
现在让我们来看看在期货市场交易的一些好处。
- 高杠杆:T5】期货市场的交易是高杠杆的。正如你之前读到的,你不需要全部合约价值就可以进行期货交易。你所需要的只是保证金金额,这只是合同价值的一小部分。这意味着,与实际资产相比,在期货市场交易时,你会面临更大的潜在资产价值。反过来,这可以让你更快地赚钱。
- 高流动性: 市场上总是有大量的买方和卖方,确保你几乎可以在任何时候签订期货合约。期货市场流动性很高。
- 佣金和执行成本低: 期货市场的佣金低至 0.5%,平仓时收取。
- 没有内幕交易: 很难利用任何内幕信息在期货市场进行交易。因此,期货市场为所有人提供了平等的机会。
- 风险管理工具: 签订期货合约可以保护你免受未来价格波动的影响。
期货市场交易的局限性
除了优点,在期货市场交易也有一些缺点。让我们看看其中的一些。
- 高波动:T5】高杠杆在期货交易中是一把双刃剑。在提供巨大风险的同时,它也导致了未来价格的大幅波动。如果你不能预测价格变化的正确方向,你可能会失去所有的利润。
- 到期日: 期货合约带有到期日。随着合同接近到期日,它变得不那么受欢迎了。这可能导致合同失效。
- 对一个新交易者来说很复杂: 一份期货合约对不同的资产有不同的规格和参数。从而使新交易者难以理解。
其他参考文献
结论
期货市场是衍生金融市场的一个组成部分。这是一个零和游戏,维持着市场的平衡。如果你能推测资产的未来价格,你可以进入期货合约。
期货合约由中央机构标准化、监管和清算,从而避免了远期市场的风险。期货市场允许你交易任何商品,而不用担心货物的收取或实际交付。
在这篇博客中,我们讨论了期货市场的特征和参数。我们也看到了趋势跟随策略。探索我们的期货交易:概念&策略课程,深入了解概念并获得如何在期货市场系统交易的知识。
免责声明:股票市场的所有投资和交易都涉及风险。在金融市场进行交易的任何决定,包括股票或期权或其他金融工具的交易,都是个人决定,只能在彻底研究后做出,包括个人风险和财务评估以及在您认为必要的范围内寻求专业帮助。本文提到的交易策略或相关信息仅供参考。T3】
在外汇市场实施配对交易/统计套利策略[EPAT 项目]
原文:https://blog.quantinsti.com/fx-market-pairs-trading-strategy/

本文是作者提交的最后一个项目,作为他在 QuantInsti算法交易(EPAT)高管课程的一部分。请务必查看我们的项目页面,看看我们的学生正在构建什么。
关于作者
 T2】
T2】哈里什·马拉纳尼是一名 EPATian 人。他的学历包括:
- Acharya Nagarjuna 大学电子和通信工程技术学士学位,
- 英国斯塔福德郡大学 MBA 金融专业,
- 数量金融学证书(CQF),以及
- 美国纽瓦克新泽西理工学院数学和计算金融理学硕士。
哈里什参加了第 27 批EPAT,这份报告是他最后项目工作的一部分。
目的:实施货币的配对交易/统计套利策略。
对事物:欧律林、usdinr、GBPINR、AUDINR、CADINR、JPYINR
频率:每日
时间段: 2011 年 4 月 21 日至 2013 年 5 月 22 日
使用: Python 实现。
外汇市场的配对选择标准:
- 上面选择的货币对的时间序列数据是从 quandl 导入的。
- 对所有可能的配对组合进行协整检验,即欧元兑美元、欧元兑英镑等。
- 选择 t-static 值小于-2.8 的 5%临界值的协整对。
- 对满足协整条件的配对进行切片,以便进一步分析。
- 为了进一步测试共整合的确认,对来自库的切片对进行 CADF 测试。
- 为每个选定的配对组合计算 z 得分,并应用该策略。
- 计算/列表/绘制利润/损失、权益曲线、最大提取额。
- 考虑两种货币对欧元/印度卢比和美元/印度卢比。这里的基础货币分别是欧元和美元,对应货币是印度卢比。
初步测试:
- 为了找到共同整合的货币对,通过来自 statsmodels.tsa.stattools 的 coint(x,y)进行初步测试,并在下面绘制它们各自的 pvalues,tstatic。
- 下面显示的 t-static 值是通过了协整测试的值。即 t 静态值小于-2.86 的 5%临界值。
 T2】
T2】
以下是 T-static 值小于-2.86 的 5%临界值的配对列表:
- ['欧洲卢比/美元卢比:-3.892142826 ',
- 欧元兑英镑汇率:-3.04457063111 ',
- 欧元兑加元:-3.16044058632 ',
- 美元兑人民币:-3.14784526027 ',
- 美元兑加元:-3.19434173492 ',
- 英镑兑人民币汇率:-3.86588509209 ',
- AUDINR/CADINR: -3.10827352646']
下面是协整对的 p 值图: 
在拒绝零假设以确认价格是均值回复之前,我们将进行协整的增广迪基-富勒(CADF)检验,以确认从整个货币组中分离出的上述切片对也是如此。下面是结果和图。
我们将考虑基于 CADF 测试的 T 静态值的 4 个协整对。
以下是 4 个共整合对:
欧洲卢比/美元卢比:-3。38660 . 63868686861
GBP INR/CADINR:-3.864863868686
美元/加拿大元:-3.192538363686
欧洲卢比/加拿大卢比:-3.163676363686
欧元/美元
欧元/美元的时间序列图

从上图可以明显看出,价格是协整的,但是,为了从统计上证实这一点,我们实施了以下一组测试/程序。

创建一个价格散点图,看看这种关系大体上是线性的。

给定上面的残差图,它是相对稳定的。
协整增强 Dickey-Fuller 测试结果
协整增广迪基-富勒 (CADF)测试通过对两个时间序列进行线性回归,然后测试线性组合下的平稳性,从而确定最佳套期保值比率。
在 python 中实现会产生以下结果:
(-3.0420602182962395,
0.03114885626164075,
1L,
652L,
{'1%': -3.440419374623044,
'10%': -2.5691361169972526,
'5%': -2.8659830798370352},
852.99818965061797)
鉴于上述结果,t-static 为-3.04,小于-2.8 的 5%临界值,我们可以拒绝零假设,并可以确认价格是均值回复的。
GBPINR/CADINR
下面是 GBPINR/CADINR 的时间序列、散点图和残差图



CADF 测试结果:
(-3.3637522231183872,
0.012258395060108089,
2L,
651L,
{'1%': -3.440434903803665,
'10%': -2.569139761751388,
'5%': -2.865989920612213},
-179.04749802146216)
鉴于上述结果,t-static 为-3.36,小于-2.8 的 5%临界值,我们可以拒绝零假设,并可以确认价格是均值回复的。
美元兑人民币

 T2】
T2】
CADF 测试结果
鉴于上述结果,t-static 为-2.93,小于-2.8 的 5%临界值,我们可以拒绝零假设,并可以确认价格是均值回复的。
(-2.9344605252608607,
0.041484961304201866,
1L,
652L,
{'1%': -3.440419374623044,
'10%': -2.5691361169972526,
'5%': -2.8659830798370352},
-99.577663481220952)
美元印度卢比/奥地利卢比

 T2】
T2】
以下是 CADF 测试的结果:
(-3.2595055880757768,
0.016788501512565262,
4L,
649L,
{'1%': -3.440466106307706,
'10%': -2.5691470850496558,
'5%': -2.8660036655537744},
381.77145926378489)
随着 t 静态值-3.25 小于 5%临界值-2.86,我们可以拒绝零假设,并可以确认该对是协整的。
现在我们已经找到了具有 t-static 值的以下配对形式的协整配对:
- 欧元兑美元:3.04 卢比
- 英镑兑人民币汇率:-3.363
- 美元兑加元:-2.934
- 美元兑人民币:3.259 元
下一步是计算 30 天移动平均线和 30 天标准差的价格比率的 Z 值:
- 分别在上述货币对的数据框架(df,df1,df2,df4)中计算价格比率并创建新的列比率。
以下是数据框的快照:
df:

Df1:

计算 30 天移动平均线和标准差窗口的价格比率的 Z 值:
- 以下是上述协整对的 z 得分图及其各自的价格比率:




从上述选定对的 Z 得分图来看,Z 得分在 2 个标准偏差内表现出均值回复行为。
建立交易策略:
- 当 z-score 触及+2 时,做空该对,当它回复到+1 时平仓
- 当 z-score 触及-2 long 对,当它回复到-1 时平仓。
- 在一个时刻只有一个位置。
权益曲线:
绘制股本曲线,起始资本为 100 印度卢比,平均分配给 4 对。

初始资本为 100 印度卢比,股本最终为 114.05 印度卢比。
在没有任何杠杆作用的情况下,累计利润为 14%。10 倍的杠杆(对于外汇交易来说是理想的),利润可以达到 140%。以下是该战略的重要绩效指标。
| 无杠杆利润百分比 | 14.0514144897 % |
| 10 倍杠杆的利润百分比 | 140.514144897 % |
| 正交易的数量 | Fifty-nine |
| 负交易数量 | Twenty-three |
| 命中率 | 71.9512195122 % |
| 平均正贸易 | 0.46886657456220338 |
| 平均负交易 | -0.59181362649660851 |
| 平均利润/平均损失 | 0.792253766338 |
| 最大水位下降 | -5.1832506579 % |

上图显示了用红点标记的最大下降点,该值添加到上表中。
实施说明
- 请运行名为 harish_stat_arb.ipynb 的 IPython 笔记本,以确认结果和图。
- 另一种方法是在任何 python IDE 上运行 python 脚本 harish _ quantin STI _ final _ project _ code . py 来确认结果和图形。
- 使用以下代码将最终数据帧导出到 excel 文件。
writer = pd.ExcelWriter('pairs_final.xlsx',engine = 'xlsxwriter')
pairs.to_excel(writer,'Sheet5')
writer.save()
结论
尽管该策略在 2 年的回溯测试期内产生了 140%的回报,但为了更准确地评估该策略的绩效,应考虑以下因素。
- 该模型忽略了滑点和佣金
- 该模型忽略了买卖订单时的买卖价差
在这篇关于算法交易策略范例的文章中阅读其他策略。如果你也想了解更多的算法交易,那么点击这里。
参考书目
- 统计套利讲座 Quantinsti, Nitesh Khandelwal
- Pairs Trading,Ganapathy Vidyamurthy,Wiley Finance
- 成功的算法交易,迈克尔·霍尔斯-摩尔

 浙公网安备 33010602011771号
浙公网安备 33010602011771号