PythonCentral-博客中文翻译-一-
PythonCentral 博客中文翻译(一)
2022 年 10 大最佳 Python IDE 和代码编辑器[更新]
原文:https://www.pythoncentral.io/10-best-python-ide-code-editors-in-2022-updated/
集成开发环境的核心是一个编译器文本编辑器,旨在为编码人员和程序员提供一站式工具,满足他们所有的编写、编译和调试需求。
今天市场上有几种 ide,它们都提供了一些独特的功能和优势。
在本帖中,我们将回顾 Python 编程的 10 个最佳 ide,比较它们的特性,权衡它们的优缺点,以帮助您找到满足您需求的 ide。
【2022 年十大最佳 Python IDE &代码编辑器
#1 Visual Studio 代码
Visual Studio Code 是微软开发的开源、健壮的 IDE,可用于 Linux、Mac OS 和所有 Windows 平台。
VS 代码是轻量级和高度可定制的,允许用你自己的库编辑和扩展源代码,使得切换到 VS 代码非常容易,只需要两分钟。
这种易访问性,加上对初学者友好的界面,使得 VS Code 成为当今最好的、没有争议的 ide 之一,并且非常受许多开发人员的欢迎。
VS 代码也支持其他语言。事实上,它是使用“电子”创建的,这是一个用于编写 C++或 Java 应用程序的应用程序,只有在安装了 Python 扩展后才能用于 Python。
这些扩展是 VS 代码的一大优势,因为它的市场上总是有大量可用的扩展。最重要的是,这些扩展大部分是社区生成的,可以免费试用。
许多 Windows 系统的初学者最初将 VS 代码视为唯一可用的 IDE,这一事实进一步促进了这个围绕 VS 代码构建的用户生成社区的发展。换句话说,VS 代码背后的社区是巨大的,并且在不断增长。
这款看似轻巧的应用程序的另一个显著特点是“禅”模式。它会隐藏您的桌面和其他窗口,但您当前正在处理的文件除外。对于许多开发人员来说,杂乱的桌面通常会导致生产力下降,并妨碍手动调试。
VS 代码有 Intellisense,这是微软的代码完成算法。在许多需要编码重复循环的情况下,您可以可靠地使用 Intellisense。它不是完美的,但是这个系统确实有助于提高你的生产力。
微软也是世界上最大的公司之一,拥有非常优秀的支持团队,因此在很多情况下都是可靠的。
优点
- 可在所有平台上使用
- 开源
- 轻量级
- 可定制
- ‘禅’模式
- 良好的界面
缺点
- 它不是 Python 特有的
- 没有市场访问,它几乎就像任何其他基本代码文本编辑器一样
- 如果市场无法访问,它就无法离线工作。
#2、 原子在这里

Atom 是另一个高度可修改的代码文本编辑器,拥有众多功能。它连接到 GitHub,GitHub 是最大的在线代码社区之一,根据您的设置,它提供了许多扩展,使 Atom 具有高度的通用性。它 有一个极简的界面,这是很多开发者的首选。
它并不仅仅意味着 Python,因为它可以处理许多开发者涉足的其他语言。您需要在 IDE 中安装一个扩展和一个库来启用 Python 支持。它不会开箱即用地运行 Python 代码。
这也意味着该应用程序不会在本地运行代码,而是使用 javascript 环境来运行。对于一些用户来说,这有时会导致膨胀和较慢的执行。
但是也不全是坏事。Atom 还拥有其他几个特性,可以提高工作效率,实现快速的跨应用处理。Atom 有一个简洁的界面,易于导航,可以轻松跟踪多个项目。这也有助于提高你的工作效率。
Atom 最大的优势在于下载插件或根据需要编辑源代码的便利。唯一的缺点是,要创建一个可下载的插件,开发者必须精通 Java 和 C++,因为 Atom 不是用 Python 编写的。
不过,这并不是什么大问题,因为程序员和开发人员面临的大多数常见问题都可以通过安装 GitHub 的插件来轻松解决。
最棒的是,如果你有一个特定的问题,但没有特定的插件可以解决,你可以加入社区,在论坛上解释你的问题。精通 javascript 的人可能能够与 Atom 的源代码进行交互,并为您的解决方案创建一个插件。论坛社区的成员也可能会告诉您某些解决方法。
此时此刻,有几十万个插件正在被生成和下载,它们中的大多数都有不同的用途。
它支持同时运行不同代码的多个并行窗口,如果您的项目通常需要同时运行多个程序,这可以真正改善您的工作流程。
它拥有一些最好的代码自动完成算法,语法高亮和格式识别提高了你浏览代码的速度。虽然基础应用程序没有好的调试器或编译器,但源代码编辑的提供允许有进取心的开发人员为 Atom 创建免费甚至付费版本的调试器和编译器。换句话说,无限的可定制性只受您的独创性的限制。
最后,GitHub 社区的支持使 Atom 成为许多开发人员和程序员最可行和首选的 ide 之一。
优点
- 非常强大的自动完成算法
- 大社区
- 开源
- 强大的文件保存和云保存选项
- 可以一次运行多个代码
- 无尽定制
缺点
- 基于浏览器导致膨胀
- 非原生应用可能导致内存问题
- 只能在 javascript 中编辑源代码
- 需要下载大量庞大的插件来实现全部功能
#3 皮查姆 IDE
PyCharm 已经成为当今领先的 ide 之一,部分原因是它惊人的打包功能,还因为它是语法高亮和自动完成算法的先驱,这已经成为当今开发人员的一种规范。
PyCharm 有两个版本:一个是面向专业开发人员的基于订阅的专业模块,另一个是面向初学者和业余时间编写代码的人的基于社区的开源模块。专业版拥有几个在大多数 ide 中不容易获得的特性。
由 JetBrains 开发的这款 IDE 拥有时尚的设计和令人惊叹的功能,如导航快捷方式、智能编辑器和一些最好的自动完成算法(也是首批自动完成算法之一)。PyCharm 是真正的 IDE,因为它开箱即用,可以突出显示语法和格式代码,运行和调试它,而无需安装任何插件或扩展。
它的界面看起来真的很不错,因为一大串复杂的文本和代码变成了颜色协调的超链接,可以轻松地自动导航。最引人注目的时刻是将 python 库从旧的文本编辑器加载到 PyCharm 中。
这使得手动调试成为可能,但是 PyCharm 也拥有最强的调试器之一。突出显示和整洁的排列得益于它的代码编辑器,该编辑器可以格式化代码,在开发人员需要或忘记的地方添加缩进和标点符号,并有几个更方便的功能。
编辑软件确保恼人的吹毛求疵的错误从你的程序中平滑掉。因此,在调试代码时,您只需要关注严重的语法错误和编译错误。
PyCharm 的功劳在于,专业版和开源版在功能上的差异并不大。尽管订阅的价格相对较高,但许多开发者选择支持 PyCharm 背后的公司。开发人员发现它物有所值,因为它给你提供了一个巨大的库和扩展市场,订阅是免费的。
PyCharm 还支持编辑 javascript、HTML、CSS 和 Live,对于项目中需要的人来说,这是一个方便的跨平台编辑器。PyCharm 可以将 web 开发的不同方面结合在一起,并允许编辑源代码,包括开源版本。
优点
- 卓越的界面,易于导航
- 第一个自动完成算法
- 强大健壮的调试器
- 跨平台支持
- 各种各样的工具和功能
- 可编辑界面
- 它也有一个开源版本
缺点
- 你必须为 PyCharm 付费才能解锁全部功能。
- 由于预装了扩展,IDE 的尺寸相对较大。
- PyCharm 初始化有点复杂
# 4Spyder IDE
Spyder IDE 是目前市场上功能最强大的编译器之一。这是另一个具有多功能的 IDE,可以根据个人用途进行定制。
对于科学家来说,Spyder 是一个完美的 IDE,因为它有一套引人注目的科学工具插件,可以免费获得。开发人员和编码人员也使用它来开发基于 Python 的程序。然而,需要注意的是 Spyder 的学习曲线很陡,不适合初学者。
也就是说,经验丰富的程序员会发现导航和快捷方式相当直观,他们很快就会习惯 Spyder 的 GUI。
这个级别的 IDE 非常适合那些对所用语言稍有经验的人,因为它不像其他入门者 Atom、PyCharm 甚至 Thonny 那样提供极端的可操作性。
开发人员已经利用这种方式来利用调试、编译和控制台信息中的细微差别。导航调试菜单所需的专业水平比其他 ide 要高得多。
Spyder 提供输入许多不同的非常规类型的输入和设备,并配有科学工具包,您可以免费下载。它还有其他几个扩展和库,使 Spyder 成为科学家、物理学家和数据工程师的宝贵工具。它可以帮助自动化许多过程,并通过复杂的算法减轻手动计算的负担。
Spyder IDE 是开源的,允许源代码交互。它也不是很占用内存,即使在旧设备上运行也相当流畅。在大型多文件程序中,执行代码可能需要时间,但 Spyder 编译器相当健壮,也是最常用的编译器之一。
因此,开发人员遇到的任何问题都会被快速修补,并且社区会建立永久的解决方案。
正是因为这个社区,许多算法和软件(比如探测器)被上传到在线插件市场,而且大部分是免费的。这极大地帮助了那些想写这样的程序却发现程序已经存在的科学家。
Spyder 的库非常广泛,对于应用程序开发人员来说也是非传统的,这意味着 Spyder 的使用非常广泛,而且与它的同类产品和其他多功能开源 ide 相比也是多种多样的。
优点
- 活跃社区
- 非常适合科学家、工程师、分析人员等
- 开源
- 轻量级、内存密集型防护
- 多样化的插件市场
- 非常适合开发应用或程序
缺点
- 不适合初学者
- 对于习惯了超链接 ide 的人来说,导航可能会很困难
- 控制台实时运行代码,新手很难。
# 5Thonny IDE
**
Thonny 是一个主要面向学习 Python 的 IDE,最适合初学者和教授 Python 的学校。它奖励探索,适合以前没有编写 Python 经验的人。
虚拟环境很容易操作,会让你想起经典的微软界面。Thonny 是用 Python 编写的,是一个本机应用程序,这意味着它不是内存密集型的。
Thonny 有一个特殊的功能,可以让你跟踪编译器的活动,并查看不同的 shell 命令如何影响变量。调试器是我们遇到的最简单的工具之一,它被整齐方便地放置在不同的功能按钮上,以便于访问。
即使在运行代码之前,它也会自动突出显示常见错误。Thonny IDE 可以识别和格式化变量,告诉您它所做的更改,以便您了解您的编码并获得对您的程序的实时反馈。
自动突出显示和完成算法工作良好,但需要一点修补才能使其正确。幸运的是,源代码允许在 javascript 中进行编辑和交互,这意味着您可以为自己创建扩展和应用程序。
调试器也非常高效,这意味着大多数代码都很容易调试,因为 Thonny 会一行一行地检查你的错误。调试器运行的图形用户界面是光滑的,没有任何额外的修饰。它不是内存密集型的,并且整个 IDE 在 ROM 上只占用最小的空间。
对于不太了解如何与 PATH 或其他 Python 解释器交互的用户来说,它非常受欢迎。用户还可以根据自己的喜好添加不同的模块和插件来定制自己的 Thonny IDE。
但是这种对图形用户界面和虚拟环境的严重依赖经常导致资深开发人员和程序员觉得浏览起来太麻烦了。一些开发人员可能会发现缺乏简单的个性化是他们工作中的一个障碍,并影响他们的生产力。
文本编辑器有点笨拙和过时,但是自动编辑算法是健壮和有效的。
优点
- 初学者的最佳 IDE
- 掌握和学习 Python 的最佳 IDE
- 相当可定制
- 开源
- 有用的 GUI
- 好用的调试器
- 自动编辑、完成和高亮显示算法是高效的
缺点
- GUI 使用率高
- 对于老兵来说可能有些繁琐
- 不适合官方使用或核心开发
#6 崇高文字 IDE![]()
Sublime Text 是另一个面向跨平台开发的高级 IDE,支持多种编程语言。它有一个很棒的文本编辑器,拥有所有最先进的自动完成、高亮显示和格式化算法,成功率高得惊人。
它最适合编写 C++,但是它有一个优秀的 Python 基础和一个 Python API。它还支持最新版本的 HTML,使其成为网站开发以及其他标记相关应用程序的一站式 IDE。您可以使用 Sublime Text IDE 轻松创建网站、应用程序和其他可执行文件。
市场上有大量的免费插件可供选择,这些插件扩展了 Sublime Text IDE 的多功能性和潜在用途。
Sublime Text IDE 缺乏一个有意义的、有贡献的在线社区,但它用自己巧妙的、设计良好的插件弥补了这一点。使用扩展,您可以让 Sublime Text IDE 在您的浏览器上运行,增加它在 web 开发中的实力。
Sublime Text IDE 有一个多级撤销选项,这意味着您可以在几个级别上调试和撤销错误代码,这取决于您在哪里排队和在哪里循环。它的调试功能非常强大,并且在出现任何意外错误时,它会提供持续的帮助热线服务。Sublime Text 支持多种语言,也提供了对它所支持的所有语言的支持。
Sublime Text 的界面极具吸引力,有不同的主题和多种个性化选项。它还支持一个可执行控制台中的多窗口和多个工作区。
对于同时使用 Python 的当代 web 开发人员来说,它是首选的 IDE,因为它可以翻译成 C++和 javascript,是最方便的选择。
一些人对 Sublime 的唯一疑虑是它有点太贵了,而且除此之外还对某些基本插件收费。
优点
- 良好的多选工具,GUI
- 美丽的主题和美学
- 转到步进特征
- 调试能力
- 高性能和出色的 API
- 可定制界面
- 个性化选项
- 最适合跨平台项目
缺点
- 价格昂贵,仅面向专业人士
- 它可能令人生畏,因为它是为专业人士打造的
- 依赖于 GUI,不支持快捷方式
# 7Vim
Vim 是一个开源的文本编辑器,可以用多种语言编写程序,并且在使用上是可调整的和通用的。它有一个 Python 扩展和几个 Python 库,现在被认为是最好的轻量级 ide 之一,具有跨平台能力和几个有用的特性。
Vim IDE 并不面向新手,而是基于一个非常活跃的程序员社区,他们维护开源社区并明确发布更新和补丁。有数百个免费插件可供选择,这使得 VIM 成为最具可定制性的文本编辑 ide 之一。
Vim 可以作为命令行控制台单独使用,但它在独立的应用程序中也有自己的虚拟环境。
Vim 唯一的缺点是配置起来很费力——不管你是用 Python 还是其他语言来编码。也就是说,有了正确的指南,初学者可以没有太多麻烦地设置它。
优点
- Vim 非常健壮和持久
- 一个优秀的插件和库市场
- 强大的搜索工具
- 好的高亮算法
缺点
- 没有超链接和调试
- 主要是一个文本编辑器,IDE 后来的
- 初学者甚至老手都难以掌握
#8 闲 IDE
IDLE 是 Python 自己定制的 IDE,是用 Python 创建的。因为它是一个本地应用程序,所以它最适合 Python,但也包含编辑其他语言的功能。
你可能想知道为什么 Python 的官方 IDE 在列表中如此靠后,那是因为这个列表没有任何特定的顺序。虽然 IDLE 缺少很多未来主义的特性,但它凭借其令人惊叹的编译器和强大的调试功能弥补了这些不足。
GUI 非常简单,需要相当多的 Python 知识才能轻松导航。也就是说,你可以很容易地学习虚拟环境,因为它并不太复杂。
由于是用 Python 写的,所以运行 Python 最好,而且极其轻量。GUI 和应用程序在 ROM 上占用最小的空间,打开应用程序会打开一个 shell 命令控制台。
较新的更新和追溯插件为 IDLE 增加了自动高亮和格式化功能,使它成为一个可行的竞争选择。
优点
- 最小、重量轻
- 原生于 Python
- 自动缩进和格式化
- 强大的调试器
- 强大的编译器
CONS
- 缺乏普通应用程序的特性
- 大型项目文件不能很好地编译或存储
- 不适合职业发展
【pydev ide】
****
Eclipse 开源代码编辑器多年来一直是许多编码人员和程序员的主食,随着 PyDev 的不断流行,似乎该编辑器将在未来几年继续使用。
PyDev 是使用 Eclipse 编写的,它像 Electron 一样用于编写 ATOM 和 VS 代码。它是一个用于设计其他 javascript、HTML、C++以及现在的 Python 应用程序的应用程序。
PyDev 提供了巨大的灵活性和可定制性,是目前最流行的 ide 之一。事实上,高级功能是免费提供的,并且是由专门的计算机科学家团队开发的,这应该是您尝试将 PyDev 作为应用程序开发的一站式解决方案的充分理由。
优点
- 开源
- 坚固、轻便
- 非原发性,可能导致腹胀
缺点
- 缺少某些特征
- UI 笨拙
#10 翼 IDE
Wing IDE 是由一群计算机工程毕业生编写的,他们想要一个模块化和可调整的 IDE 来编写代码。其结果是一个高度健壮的 IDE,拥有市场上最好的调试器之一和其他价格不菲的特性。
Wing IDE 是会员制的,提供 30 天的免费试用期,没有任何问题要求退款。开发人员对他们的产品非常有信心,因为 Wing 的导航、突出显示和编辑非常流畅。虚拟环境具有惊人的可访问性,直观的 GUI 设计是一个额外的优势。
如果您使用 pytest、nose 和 doctest 等框架进行测试驱动开发,这是一个不错的 IDE 选择。可以免费试用 Wing Pro。但是,试用结束后,您需要支付 Wing 的费用。它与所有操作系统兼容。
优点
- 优秀的调试器
- 令人印象深刻的测试能力
- 兼容所有操作系统
缺点
- 对学生或爱好者来说价格昂贵
- 缺乏过度定制,因为它不是开源的
结论
以上列表包含了对当今市场上各种 ide 的不同特性的综合评估。
没有所谓的“最佳 IDE ”,因为每个开发人员都有不同的技能、偏好和需求。权衡了每种 IDE 的优缺点后,找到合适的 IDE 应该很容易。
我们的结论是,最适合你的 IDE 取决于你打算用它做什么。希望这篇帖子对你有所帮助,编码愉快!******
Python 基础:什么是模块?
原文:https://www.pythoncentral.io/python-basics-what-are-modules/
Python 的 help()函数
原文:https://www.pythoncentral.io/pythons-help-function/
使用 Python 包索引
原文:https://www.pythoncentral.io/using-the-python-package-index/
快速提示:在哪里报告您的 Python 错误
原文:https://www.pythoncentral.io/quick-tip-where-to-report-your-python-bugs/
调试您的 Python 代码:PyChecker
原文:https://www.pythoncentral.io/debug-your-python-code-pychecker/
互动资源:免费学习和练习 Python
原文:https://www.pythoncentral.io/interactive-resources-learn-and-practice-python-for-free/
Python 的枕头图像处理
原文:https://www.pythoncentral.io/image-processing-with-pillow-for-python/
美丽的汤:Python 的网络刮刀
原文:https://www.pythoncentral.io/beautiful-soup-a-web-scraper-for-python/
理解 Python 的数值类型
原文:https://www.pythoncentral.io/understanding-pythons-numeric-types/
Python 比较运算符
原文:https://www.pythoncentral.io/python-comparison-operators/
4 种最常见的网络攻击类型以及公司如何避免它们
原文:https://www.pythoncentral.io/4-most-common-types-of-cyber-attacks-and-how-companies-can-avoid-them/

近年来,网络攻击呈上升趋势。根据 Ponemon Institute 的数据,66%的 T2 中小企业在过去的 12 个月中至少经历过一次网络攻击。
黑客瞄准此类企业,因为它们往往没有足够的安全措施。
本文将向您展示最常见的网络攻击类型以及如何避免它们。
什么是网络攻击?
网络攻击是指对计算机系统进行未经授权的访问,目的是改变、
破坏或窃取数据。随着网络攻击的增加,一些行业比其他行业更容易成为攻击目标。
拥有大量敏感数据的公司是黑客的完美目标。这些公司通常是:
- 银行和金融机构;
- 医疗保健机构;
- 高等教育机构;
- 公司。
常见的网络攻击类型以及公司如何防范这些攻击
1。网络钓鱼攻击
网络钓鱼是发送看似来自可信来源的电子邮件以获取敏感信息或影响用户做某事的过程。它既涉及社会
工程,也涉及技术。为了实施攻击,黑客可能会给你发送一个
的下载链接,这是一个实际上是病毒的文件。
为了避免网络钓鱼攻击,不要点击陌生人发送的电子邮件中的链接。还有,不要在没有先分析的情况下打开陌生人的
邮件。一些电子邮件可能有有说服力的标题
和电子邮件副本,引导您下载有害的附件。
2。中间人攻击
中间人(MITM)攻击是指攻击者窃听两个来源之间发送的数据。假设您正通过
公共 wifi 登录您的在线账户。黑客可以通过充当 wifi
网络和你的设备之间的中间人来拦截你的连接。这样,黑客就可以监视你的活动。
MITM 攻击的危险在于,黑客可能会窃取你的凭证,在你不知情的情况下访问你的私人信息。或者,在社交媒体账户的情况下,他们可能会将你锁在门外,并开始发布可能会损害你形象的信息。
避免 MITM 攻击的一个方法是停止使用公共 wifi 访问您的在线帐户。对许多用户开放的网络很容易被黑客攻击和操纵。但是,如果你还是选择使用
公共 wifi,至少要使用虚拟专用网(VPN)。虚拟专用网将阻止来自
的黑客进行中间人攻击。像 NordVPN 这样增加了威胁保护的 VPN 将会在保护你的设备方面走得更远
。
3。密码攻击
密码是网上最常用的验证工具。这也是为什么黑客经常锁定密码。
密码攻击包括通过暴力攻击猜测密码或欺骗
密码持有者泄露密码。黑客也可能使用字典攻击,他们尝试字典中的每个单词来匹配密码。
创建超过八个字符的密码,以减少密码攻击的机会。如果你有太多的密码,试试密码管理器。它允许您创建强密码。
您只需记住密码管理器的密码。
4。DDoS 攻击
拒绝服务攻击旨在压倒系统,使其无法响应合法的
请求。目标站点收到来自攻击者的大量请求。因为它必须
响应每个请求,所以它会到达一个耗尽所有资源的点。所以
合法的请求最终没有通过。结果是站点
完全关闭,因为它无法再正常运行。
DDoS 攻击不同于其他类型的网络攻击,因为黑客不会试图进入你的系统。相反,他们试图让你慢下来,给你的
客户带来不便。你的竞争对手可以利用这种攻击来获得对你的优势。
使用防火墙防止 DDoS 攻击。防火墙决定对你网站的请求是否合法。冒名顶替者的请求将被丢弃,以确保您网站的正常流量不会受到任何
干扰。
结论
为了给你的计算机系统建立良好的防御,你必须了解常见的网络攻击类型。它们包括网络钓鱼攻击、DDoS 攻击、密码攻击和 MITM
攻击。减轻这些攻击的措施包括使用 VPN 和密码管理器,以及避免打开陌生人的电子邮件的
。
Python 在网络安全中有用的 5 个不可否认的理由
原文:https://www.pythoncentral.io/5-undeniable-reasons-python-is-useful-in-cybersecurity/

简单的服务器安全解决方案足以维护相对安全的系统的日子已经一去不复返了。随着网络攻击越来越复杂,我们抵御网络攻击的能力也必须提高。网络罪犯的目标不是单个的计算机,而是整个网络和组织——他们利用的不是中央服务器,而是框架中的漏洞。这就是 Python 发挥作用的地方。
Python 已经成为一种强大的编程语言,可以用于从 web 开发和机器学习到网络安全应用的所有事情。它的流行源于比其他语言更好的可理解性和显著的性能提升。
包括 Django 或 Flask 等 Python 衍生工具在内,Python 越来越多地用于各种应用中,在这些应用中,安全性和业务连续性是重中之重——无论是您最喜欢的电影流媒体网站还是政府网络。以下是 Python 在网络安全中有用的一些不可否认的原因。
Python 是开源的
关于编程语言是否可以开源的争论已经持续了一段时间。但是答案是一个响亮的“是”——特别是当谈到那些带有嵌入式解释器或编译器的应用时,比如 Python。
开源软件的主要好处是,它是免费的,任何想使用它的人都可以轻松获得。这使得它成为网络安全应用程序的理想语言,因为开源的特性允许专家轻松地整合风险管理策略和解决安全漏洞。
Python 是一种高级语言
Python 作为一种高级编程语言,提供了比其他编程语言更具可读性和可理解性的优势。这使得开发人员可以更容易地获取任何代码并对其进行处理,而无需任何大量的文档。
然而,更重要的是,它允许对您正在使用的数据和硬件层进行更细粒度的控制。一个充分部署的应用程序不应该允许直接访问底层硬件或系统,Python 可以帮助您实现这一点。
Python 有广泛的库
Python 库是预先编写的代码包,可以在用该语言编写的任何程序中使用。这意味着开发人员不必在每次想要反复使用相同的功能或流程时从头开始编写自己的代码,他们只需将库导入到他们的应用程序中,然后快速高效地构建新功能。
从加密算法到恶意软件分析工具,仅出于安全目的就有大量开源库可用;其中许多模块已经过世界各地专家的同行评审,因此您知道使用这些模块构建您的应用程序是非常安全的。
最重要的是,使用已经制作好的库(通常)会让你的代码不那么脆弱——这正是你在网络安全方面所需要的。
Python 与许多平台兼容
很可能你的应用程序并不支持所有的操作系统,然而,拥有这样的能力是非常宝贵的。平台独立性给你带来的好处是,不管设备、操作系统或应用程序处理程序如何,你的所有应用程序都有一个单一的代码库。
这允许更简化的基础设施更新和维修。每当发现重大安全漏洞时,可以在您的所有应用程序中部署该修补程序,而不必单独对每个平台进行更改和调试。
python 管理器自动记忆
与低级语言不同,Python 自动分配和释放内存。一方面,它让程序员更加方便,让他们专注于实际的代码,而不是内存管理。另一方面,这使得更难犯诸如缓冲区溢出和其他源于糟糕的内存管理的安全漏洞之类的错误。
此外,Python 的垃圾收集器提供了额外的性能和可靠性。这使您可以快速构建应用程序,而不必担心由于糟糕的编码实践而导致计算机资源被过度使用或泄露。不需要解释为什么这在网络安全领域会带来巨大的好处。
网络安全使用 Python 案例
鉴于上述优点,Python 被广泛用于网络安全应用。它可以用于开发入侵检测和预防系统、恶意软件分析工具、防火墙或 VPN 等网络安全解决方案,甚至加密算法。
Python 还提供了对 Scapy 等包的访问,这些包允许开发人员快速制作自定义协议,例如发送欺骗包,帮助测试应用程序对网络攻击的鲁棒性。此外,由于其大量与该领域明确相关的库,它使组织有可能参与数据挖掘,从而帮助他们在威胁成为活跃问题之前检测到威胁。
其他网络安全 Python 应用包括:
- 渗透测试
- 恶意软件分析和逆向工程
- 网络安全审计
- Web 应用程序安全测试
- 网络取证和事件响应
最后的想法
Python 是网络安全应用中使用的最高效、最强大的编程语言之一。它提供了开源兼容性、具有出色可读性的高级语言、大量用于引导开发的库以及自动内存管理,同时与众多平台兼容。
出于这些原因以及更多原因,难怪 Python 会成为想要开发可靠解决方案来保护网络免受网络罪犯攻击的安全专业人员的热门选择。只要这种语言随着现代技术趋势继续发展,我们预计随着时间的推移,它在网络安全中的使用只会继续增长。
初创公司拥有 Python 程序员的 8 大好处
原文:https://www.pythoncentral.io/8-benefits-of-having-python-programmers-for-startups/

建立一个内部团队是一个漫长的过程,需要寻找最佳候选人,进行招聘,并为员工提供必要的工作资源。对于许多创业公司来说,这个过程会占用大量本可以花在其他地方的时间和金钱。这就是为什么许多创业公司最初会外包一个专门的团队。
为启动项目雇佣程序员使你能够专注于你的业务,避免花费宝贵的时间在建立开发团队或创建项目基础设施上。它还可以避免您不得不花钱为团队寻找工作空间。
创业公司雇佣海外网站开发者的好处
纵观初创公司的发展趋势,许多企业选择将他们的开发团队外包给外部个人或公司。这有几个原因,包括:
- 接触更有技能的专业人士
你所在的地区可能没有具备合适经验和技能的候选人。外包意味着你可以接触到更大的人才库。
- 节省内部资源的成本
为内部团队建立一个工作空间并投入资源可能会很昂贵。而且再加上高昂的招聘成本,外包就划算多了。
- 节省时间
当你雇佣一家外部公司或海外初创公司的开发人员时,你和你的员工就可以腾出时间专注于其他优先事项。
- 获得最先进的工具和技术
在海外雇佣软件网络开发人员的另一个主要好处是,它能让你接触到国内没有的技术和平台。这意味着您不需要投资新工具或新员工来让您的团队跟上速度。
- 风险降低
考虑到初创公司处于发展的初始阶段,最初几年的失败是一个主要问题。因此,扩展通常会带来各种挑战和风险,包括金钱和精力的损失。通过为创业项目外包一个专门的团队,创业公司可以避免这些风险,并充满信心地成长。
为什么 Python 对初创公司来说是完美的

来源:https://Mobil unity . com/blog/cost-of-python-developer-in-Ukraine/
每种规模和类型的企业都与众不同。初创企业是一个统称,用于指处于可行产品和服务开发第一阶段的企业。此外,它们还处于早期融资阶段。
初创公司经常在预算紧张的情况下工作,他们必须仔细考虑他们需要的开发速度、编程语言的易用性、开发成本、对库的访问、可伸缩性和稳定性。正是由于这些原因,作为一家初创公司,你最好的选择是使用 Python 等成熟的编程语言。
Python 程序员给创业公司带来的 8 大好处
研究表明,多达 70%的初创企业会在头五年内失败。因此,对于新企业来说,在发展决策时做出正确的选择是非常重要的。要考虑的最重要的因素之一是使用正确的编程语言。让我们来看看成功的初创公司选择使用 Python 编程语言并雇佣 Python 程序员的八个原因:
- 很人性化
Python 开发者最喜欢这种语言的简单性。对于负担不起培训时间的初创公司来说,Python 是快速有效开发的理想选择。
- 多功能性
向 Python 代码添加特性所需的最少工作就是通用的。当开发人员需要跨平台(如 mac-OS 和 Windows)工作的代码时,Python 是语言的最佳选择之一。
- 平滑整合
与许多编程语言不同,Python 很容易与 C、Java 等其他语言集成。
- 强化创新
虽然许多新来者更喜欢 Python 而不是其他语言,但许多大型知名公司如 Instagram 和 Google 也依赖于用 Python 编写的代码。问题来了,为什么?原因是 Python 是创新的,它允许企业将其服务提升到新的高度,并在竞争对手中脱颖而出。
- 它很健壮
初创公司通常基于网络,而网络是由大数据驱动的。这个因素是处理的复杂性和错综复杂的同义词。幸运的是,Python 能够很好地应对这些挑战,非常适合初学者。
- 便于顺利测试
Python 的测试驱动开发是使用 python 最吸引人的原因之一。这一特点使得它既省时又划算。它的即时测试工具可以大大简化开发过程。
- 可扩展性
可伸缩性是任何初创公司都必须考虑的一个不可避免的因素。这就是为什么 Python 是一个很好的解决方案。借助 Django 框架(一系列现成的组件),Python 可以提供高度可伸缩的应用程序。
- 大型社区
Python 由一个庞大而活跃的支持者社区组成。这意味着在开发过程中,您将很容易找到对任何类型复杂性的支持。
简而言之,让我们看看使用 Python 的利与弊:

来源:https://mobilunity.com/blog/hire-python-developers/
底线
如今,市场上有许多编程语言,每一种都有自己的优势和发展潜力。对于创业公司来说,Python 是一种通用的语言,因其易用性、流畅的集成能力和庞大的支持社区而受到青睐。考虑到创业公司必须从一开始就做出最佳决策以避免失败,为创业网站开发项目雇佣熟练的 Python 开发人员是一个极好的选择。
关于如何用 Pytest 测试 Python 应用程序的完整指南
原文:https://www.pythoncentral.io/a-complete-guide-on-how-to-test-python-applications-with-pytest/
编写测试是 Python 开发的关键部分,因为测试使程序员能够检查他们代码的有效性。它们被认为是最有效的方法之一,可以证明编写的代码正在按需要运行,并减少将来的更改破坏功能的可能性。
这就是 Pytest 的用武之地。尽管 Pytest 主要用于为 API 编写测试,但测试框架使得程序员可以轻松地为 UI 和数据库编写可伸缩的测试用例。
在这本全面的指南中,我们将带您了解如何安装 Pytest,它的强大优势,以及如何使用它在您的机器上编写测试。
安装 Pytest
与大多数 Python 包一样,您可以从 PyPI 安装 Pytest,并使用 pip 将其安装在虚拟环境中。如果你用的是 Windows 电脑,在 Windows PowerShell 上运行以下命令:
PS> python -m venv venv
PS> .\venv\Scripts\activate
(venv) PS> python -m pip install Pytest
另一方面,如果你运行的是 macOS 或者 Linux 机器,在终端上运行这个:
$ python -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install Pytest
Pytest 的优势
如果你熟悉用 Python 编写单元测试,你可能使用过 Python 内置的 unittest Python 模块。该模块为程序员构建测试套件提供了良好的基础;但是,它也不是没有缺点。
许多第三方测试框架试图克服 unittest 的缺点,但 Pytest 是最有效的,因此也是最受欢迎的解决方案。Pytest 有几个特性,可以与各种各样的插件结合使用,使测试更加容易。
更具体地说,使用 Pytest,您可以执行普通任务而无需编写太多代码,并使用内置的省时命令更快地完成高级任务。
此外,Pytest 可以运行您现有的测试,而不需要额外的插件。再来详细讨论一下优势:
#1 少重码
大部分功能测试使用排列-动作-断言模型,其中:
- 安排测试的条件,
- 一个函数或方法执行一些动作,
- 代码断言特定的结束条件是否为真
测试框架通常在断言上工作,允许它们在断言失败时提供一些信息。例如,unittest 模块提供了几个断言工具,但是即使是最小的测试也需要大量重复的代码。
如果您要编写一个测试套件来检查 unittest 是否正常工作,理想情况下,套件应该有一个总是通过的测试和一个总是失败的测试。然而,要编写这个测试套件,您需要做以下事情:
- 从 unittest 导入 TestCase 类。
- 写一个 TestCase 的子类,姑且称之为“TryTest”
- 为每个测试编写一个 TryTest 方法。
- 使用 unittest 中的 self.assert*方法。断言的测试用例。
这四项任务是创建任何测试所需的最低要求。以这种方式编写测试是低效的,因为它涉及到多次编写相同的代码。
有了 Pytest,工作流程就简单多了,因为你可以自由地使用普通函数和内置的 assert 关键字。当使用 Pytest: 编写相同的测试时,它看起来像这样
# test_with_Pytest.py
def test_always_passes():
assert True
def test_always_fails():
assert False
就这么简单——不需要导入任何模块或使用任何类。只需编写一个带有前缀“text_”的函数。因为 Pytest 使您能够使用 assert 关键字,所以没有必要阅读 unittest 中出现的所有 self.assert*方法。
Pytest 将测试您期望评估为真的任何表达式。除了你的测试套件有更少的重复代码,它也变得更加详细和易读。
#2 吸引输出
Pytest 的一个优点是,您可以从项目的顶层文件夹中运行它的命令。现在您可能已经发现,Pytest 模块产生的测试结果与 unittest 不同。该报告将向您显示:
- 系统状态,包括 Python 版本、Pytest 和其他插件的详细信息;
- 您可以在其中搜索测试和配置的目录;和
- 跑步者发现的测试数量。
报告的第一部分介绍了这些内容,在下一部分,它在测试名称旁边显示了每个测试的状态。如果出现圆点,则表示测试通过。如果出现 F,测试失败,如果出现 E,测试抛出意外异常。
失败的测试总是伴随着详细的分解,这种额外的输出使得调试更加易于管理。在报告的最后部分,有一个测试套件的总体状态。
#3 简单易学
如果您熟悉 assert 关键字的使用,那么学习使用 Pytest 并不新鲜。这里有一些断言的例子来帮助你理解用 Pytest 测试的不同方法:
# test_examples_of_assertion.py
def test_uppercase():
assert "example text".upper() == "EXAMPLE TEST"
def test_reverseList():
assert list(reverseList([5, 6, 7, 8])) == [8, 7, 6, 5]
def test_some_primes():
assert 37 in {
num
for num in range(2, 50)
if not any(num % div == 0 for div in range(2, num))
}
上面套件中的测试看起来像常规的 Python 函数,这使得 Pytest 易于学习,并且消除了程序员学习任何新构造的需要。
注意测试是如何简短和独立的——这是 Pytest 测试的趋势。您可能会看到很长的函数名,但函数名中几乎没有什么内容。通过这种方式,Pytest 保持了测试的独立性;如果出了问题,程序员知道去哪里找问题。
#4 更易管理的状态和依赖关系
使用 Pytest 编写的大多数测试将依赖于数据类型或模拟代码可能遇到的对象的测试类型,比如 JSON 文件和字典。
另一方面,当使用 unittest 时,程序员倾向于将依赖项提取到。设置()和。tearDown()方法。这样,类中的每个测试都可以使用依赖项。
虽然使用这些方法没有错,但是随着测试类变得越来越庞大,程序员可能最终会使测试的依赖性完全隐含。换句话说,当您查看孤立的测试时,您可能看不到该测试依赖于其他东西。
这些隐含的依赖会使测试变得混乱,并使理解它们变得困难。使用测试背后的想法是让代码更容易理解,从长远来看,使用这些方法会适得其反。
在使用 Pytest 时,你不必担心这一点,因为 fixtures 会将你引向可重用的显式依赖声明。
Pytest 中的 Fixtures 是使您能够为测试套件创建数据、测试 doubles 和初始化系统状态的函数。如果您决定使用一个 fixture,您必须显式地使用下面的 fixture 函数作为测试函数的参数:
# fixture_example.py
import Pytest
@Pytest.fixture
def example_fixture():
return 1
def testing_using_fixture(example_fixture):
assert example_fixture == 1
以这种方式使用 fixture 函数可以保持依赖性。当你浏览测试函数时,很明显它依赖于 fixture。您不需要检查夹具定义的文件。
注意: 将你的测试放在一个单独的文件夹中,这个文件夹叫做 tests,位于你的项目文件夹的根目录下,这被认为是最佳实践。
Pytest 提供了很多灵活性,因为 fixture 可以通过简单、明确的依赖声明来使用其他 fixture。但是由于这个原因,当你继续使用它们的时候,固定装置可以变得模块化。换句话说,随着测试套件变得越来越大,您将需要小心地管理您的依赖项。
我们将在本帖的后面更详细地讨论夹具。
#5 过滤测试很简单
测试套件的规模肯定会增长,程序员发现自己想要对一个特性运行少量的测试,并保存完整的套件以备后用。使用 Pytest,有几种方法可以做到这一点:
- 目录范围: Python 默认只运行当前目录下的测试。使用这个特性只运行所需的测试被称为目录范围。
- 基于名字的过滤: Pytest 允许程序员只运行那些完全限定名与特定表达式相同的测试。使用-k 参数很容易实现基于名称的过滤。
- 测试分类: 使用-m 参数可以很容易地从定义的类别中包含或排除测试。这是一个有效的方法,因为 Pytest 使程序员能够为测试创建称为“标记”的定制标签。单个测试可能有几个标签,允许程序员对将要运行的测试进行粒度控制。
#6 测试参数化
程序员用 Pytest 测试处理数据的函数是很常见的;所以程序员经常会写很多类似的测试。这些测试可能只是在被测试代码的输入或输出上有所不同。
由于这个原因,程序员最终会重复测试代码,这有时会掩盖他们试图测试的代码的行为。
如果您熟悉 unittest,您可能知道有一种方法可以将许多测试收集为一个测试。但是这些测试的结果不会作为单独的测试出现在结果报告中。这意味着,如果除了一个测试之外的所有测试都通过了,那么整个测试组将返回一个失败的结果。
但是 Pytest 不是这种情况,因为它具有内置的参数化特性,允许每个测试独立地通过或失败。
#7 基于插件的架构
Pytest 的可定制性使其成为想要测试代码的程序员的首选框架。添加新功能很容易,因为程序的几乎每个部分都可以改变。难怪 Pytest 有一个巨大的有用插件生态系统。
虽然有些插件只适用于 Django 这样的框架,但大多数可用的插件可以用于几乎所有的测试套件。
使用夹具管理状态和依赖关系
如前所述,Pytest fixtures 允许你为测试提供数据,测试 doubles,或者描述测试的设置。fixture 函数能够返回大范围的值。每一个依赖于 fixture 的测试都需要将 fixture 作为一个参数显式地传递给它。
何时使用夹具
理解何时使用夹具的最好方法之一是模拟测试驱动的开发工作流程。
假设您需要编写一个函数来处理从 API 端点接收的数据。该数据包括一个人员列表,每个条目都有姓名和工作职位。
这个函数需要输出一个带有全名的字符串列表,后跟一个冒号和它们的标题。你可以这样做:
# format_data.py
def reformat_data(people):
... # Instructions to implement
由于我们正在模拟一个测试驱动的开发工作流程,首要任务是为它编写一个测试。有一种方法可以做到这一点:
# test_format_data.py
def test_reformat_data ():
people = [
{
"given_name": "Mia",
"family_name": "Alice",
"title": "Software Developer",
},
{
"given_name": "Arun",
"family_name": "Niketa",
"title": "HR Head",
},
]
assert reformat_data(people) == [
"Mia Alice: Software Developer",
"Arun Niketa: HR Head",
]
让我们更进一步,假设您需要编写另一个函数来处理数据,并以逗号分隔值的形式输出,以便在电子表格中使用:
# format_data.py
def reformat_data(people):
... # Instructions to implement
def format_data_for_excel(people):
... # Instructions to implement
您的待办事项列表正在增长,通过测试驱动的开发,您可以轻松地提前计划事情。这个新函数看起来类似于 format_data()函数:
# test_format_data.py
def test_reformat_data():
# ...
def test_format_data_for_excel():
people = [
{
"given_name": "Mia",
"family_name": "Alice",
"title": "Software Developer",
},
{
"given_name": "Arun",
"family_name": "Niketa",
"title": "HR Head",
},
]
assert format_data_for_excel(people) == """given,family,title
Mia,Alice, Software Developer
Arun,Niketa,HR Head
"""
如您所见,两个测试都必须再次定义 people 变量,并且将这些代码行放在一起需要时间和精力。
如果几个测试使用相同的测试数据,夹具会有所帮助。使用 fixture,您可以将重复的数据放在一个函数中,并使用@Pytest.fixture 来表明该函数就是 fixture,就像这样:
# test_format_data.py
import Pytest
@Pytest.fixture
def example_people_data():
return [
{
"given_name": "Mia",
"family_name": "Alice",
"title": "Software Developer",
},
{
"given_name": "Arun",
"family_name": "Niketa",
"title": "HR Head",
},
]
# More code
使用 fixture 并不复杂——你只需要添加函数引用作为参数。请记住,程序员不是调用 fixture 函数的人,Pytest 会处理这些。fixture 函数的返回值可以作为 fixture 的名称:
# test_format_data.py
# ...
def test_reformat_data(example_people_data):
assert reformat_data(example_people_data) == [
"Mia Alice: Software Developer",
"Arun Niketa: HR Head",
]
def test_format_data_for_excel(example_people_data):
assert format_data_for_excel(example_people_data) == """given,family,title
Mia,Alice, Software Developer
Arun,Niketa,HR Head
"""
现在,测试变得更小了,同时有了一条清晰的返回测试数据的路径。为您的 fixture 起一个突出的名字是在您以后添加更多测试时识别和使用它的最快方法。
何时不使用夹具
夹具使得提取跨多个测试使用的对象和数据变得很方便。但是当测试要求数据发生变化时,使用 fixtures 并不总是正确的解决方案。
在测试套件中放置固定装置就像在其中放置对象和数据一样容易。使用 fixture 的结果有时会更糟,因为 fixture 引入了测试套件的一个额外的间接层。
学习使用任何抽象都需要练习,虽然使用 fixtures 很容易,但你需要一些时间来找到正确的数字。
不管怎样,你可以期待夹具成为你的测试套件的重要部分。随着项目变得越来越大,你会遇到扩展的挑战。幸运的是,Pytest 有一些特性可以帮助您克服这种伴随增长而来的复杂性挑战。
按比例使用夹具
随着测试中夹具提取数量的增加,您可能会注意到一些夹具可能会因为更多的抽象而变得更加有效。
Pytest 框架夹具是模块化的,这意味着您可以导入它们和其他模块。此外,设备可以依赖于其他设备,也可以导入其他设备。
这种巨大的灵活性允许你根据用例创建合适的夹具抽象。
例如,不同模块中的设备可能有一个共同的依赖关系。在这种情况下,您可以将夹具从测试模块移动到通用模块。这将允许您将它们导入到需要它们的测试模块中。
程序员可能想在整个项目中使用一个夹具,而不需要导入它,这可以通过 conftest.py 配置模块来实现。
Pytest 自动在每个目录中寻找这个模块。如果您将通用夹具添加到这个模块中,那么您可以在整个父目录和子目录中使用这些夹具。
您还可以使用 conftest.py 和 fixtures 来保护对资源的访问。例如,如果您为处理 API 调用的代码编写一个测试套件,您将需要确保该套件不会进行任何调用,即使程序员无意中编写了一个测试来实现这一点。
Pytest 附带了一个 monkeypatch fixture,使您能够替换行为和值,就像这样:
# conftest.py
import Pytest
import requests
@Pytest.fixture(autouse=True)
def disable_network_calls(monkeypatch):
def stunted_get():
raise RuntimeError("Network access unavailable in testing")
monkeypatch.setattr(requests, "get", lambda *args, **kwargs: stunted_get())
将 disable_network_calls()方法放入上述模块的配置中,并将 autouse 选项设置为 true,可以确保在整个套件中禁用网络调用。
当你的测试套件增长时,你会变得更有信心做出改变,因为你不会意外地破坏代码。然而,随着测试套件的增长,做出改变可能需要更长的时间。
如果做出改变不需要很长时间,一个核心行为可能会慢慢渗透并破坏许多测试。在这种情况下,最好将测试运行程序限制为只运行特定类别的测试。这是我们接下来要讨论的。
分类测试
当你需要快速迭代特性时,大型测试套件可能是有害的,阻止所有测试运行可以节省时间。如前所述,Pytest 默认在当前工作目录下运行测试,但是使用标记也是一个很好的解决方案。
在 Pytest 中,您可以为您的测试定义类别,并在套件运行时提供包含或排除类别的选项。一个单独的测试可以分为几个类别。
标记测试是根据依赖关系和子系统对测试进行分类的一个很好的方法。例如,如果一些测试需要访问数据库,您可以做一个@Pytest.mark.database_access 标记并使用它。
此外,在 Pytest 命令中添加- strict-markers 标志可以确保在 Pytest.ini 配置文件中注册测试中的标记。这个文件将在你显式注册未知标记之前避免运行所有的测试。
如果您只想运行需要数据库访问的测试,您可以使用 Pytest -m database_access 命令。但是,如果您想要运行除了需要数据库访问的测试之外的所有测试,您所要做的就是运行命令 Pytest-m“not database _ access”。
您可以将其与 autouse fixture 配对,以限制对标记为可访问数据库的测试的访问。一些插件通过添加自定义防护为标记功能增加了更多功能。例如,Pytest-django 插件有一个 django_db 标记,没有该标记的测试无法访问数据库。
当一个测试试图访问数据库时,Django 将创建一个测试数据库。您在 django_db 标记中指定的需求导致您显式地陈述依赖关系。
您也可以运行不需要数据库的测试,因为您运行的命令会首先阻止数据库的创建。虽然在较小的测试套件中节省的时间可能不明显,但是在较大的测试套件中,它可以节省您几分钟的时间。
Pytest 默认包含的一些标记有 skip、skipif、xfail 和 parametrize。如果您想查看 Pytest 默认附带的所有标记,可以运行 Pytest - markers。
结论
Pytest 拥有生产力特性,允许程序员优化编写和运行测试所需的时间和精力。此外,灵活的插件系统允许程序员扩展 Pytest 的基本功能之外的功能。
无论程序员是在处理一个庞大的遗留单元测试套件还是开始一个新的项目,Pytest 都能派上用场。有了这个指南,你就可以使用它了。
使用 Python 创建 VPN 的指南
原文:https://www.pythoncentral.io/a-guide-to-creating-a-vpn-with-python/

随着 VPN 在英国和美国的使用不断增加(约有 [44%的英国人使用虚拟专用网]( https://cybercrew.uk/blog/vpn-usage-statistics-uk/#:~:text=44%25 of UK internet users have used a VPN at some point ,-As%20you%20can&text=This%20percentage%20is%20higher%20than,knew%20why%20VPNs%20were%20used.)),这项技术的范围和功能也在不断扩大。
我们也看到不同的编程语言被用来支持 VPN 和增加功能。包括高级和动态迭代,例如 Python。
在这篇文章中,我们将仔细看看如何创建一个 Python 驱动的 VPN,包括你需要什么来成功地实现这个目标。
什么是 VPN?
VPN 描述了虚拟专用网络,它是在您的设备和由专用客户端操作的远程服务器之间创建的加密隧道或连接。
作为一个加密的隧道,所有传输的数据和网络流量对黑客和第三方来说都是无法破译的代码串,因此几乎不可能被恶意访问和利用。
同样,使用远程服务器位置有助于掩盖您设备的 IP 地址和物理位置,这反过来消除了 doxxing 和恶意软件攻击的风险,同时帮助您通过网飞等流媒体平台访问地理位置受限的内容。
Python 是什么?
正如我们已经提到的,Python 是一种复杂的通用编程语言,是一种专门为强调代码可读性而设计的语言。
它还通过使用重要的缩进来强调这一点,而 Python 被认为是一种动态类型语言。
后者意味着在使用 Python 时,解释器会根据相关变量的实时值,在运行时给变量分配一个类型。这使得 Python 类似于广泛使用的替代方案,如 JavaScript,同时两者都支持多种编程范例,如结构化和函数式系统。
由于这些因素,Python 在创建基于软件的 VPN 时是理想的,而硬件替代方案依赖于 OpenVPN 等开源平台的部署。
*用 Python 创建 VPN 需要什么?
Python 也是一种相对容易学习和部署的编程语言,因此无论您是初学者还是经验丰富的开发人员,它都是创建 VPN 的理想选择。
但是用 Python 创建虚拟专用网需要什么呢?以下是一些基本组件:
- 可以上网的正常工作的电脑
- 有效的 VPN 客户端帐户
- VPN 库(如 VPNSocket)
- 创建加密连接的 SSH 隧道模块(比如 sshtunnel)
- 对 Python 及其工作原理的知识和理解
- 网络概念的基本知识
如何使用 Python 创建 VPN
如果你仍然想为英国创建一个 VPN,你还需要遵循一些按时间顺序排列的步骤。 这些包括:
** #1。选择一个可行的 Python 库:从优化隐私到对高级网络保护的需求,您可能有许多理由想要创建自己的 VPN。不管怎样,你需要选择一个相关的库或协议来适应你想要的应用,OpenVPN 提供了一个可行的通用选项。这提供了创建一个正常工作的 VPN 所需的所有特性,同时它也非常容易使用。
-
#2。安装库:下一步是安装库,首先创建一个 VPN 项目并建立 VPN 类的“实例”。该类需要两个参数;即您希望 VPN 客户端激活的服务器(或 IP)地址和端口号。这应该是一个很容易完成的快速简单的步骤!
-
#3。建立设置:接下来是设置过程,要求您首先建立一个 VPN 对象,并使用正确的设置进行配置。这可以通过打开一个 VPN 对象并用以下参数构造它来实现:
-
您的 VPN 的名称
-
您选择的服务器的 IP 地址
-
您的服务器端口
-
您要使用的加密类型
-
与 VPN 连接的用户帐户的密码
-
#4。连接到服务器并测试您的连接:倒数第二步是连接到 VPN 服务器,方法是打开一个终端窗口并键入‘python-m VPN . Server-port 443’。这将打开到 VPN 服务器的连接,通过该连接,您可以输入相关的 VPN 凭据并点击“enter”。最后,只需连接到 VPN 服务器进行测试,以保证安全性和功能性。
最后一个字
如果你要创建一个定制的 VPN,那么 Python 可以说是最好的和最容易使用的编程语言之一。
这当然很容易学习和部署, 同时,只要您具备 Python 的基础知识和基本的网络原理,它就能支持出色的功能!**
Python 运算符指南
原文:https://www.pythoncentral.io/a-guide-to-pythons-operator/
当用 Python 写程序时,很有可能你需要添加两个值,并在某个时候将结果值保存在变量中。
即使你没有太多编程经验,这样做也很简单。但是好的一面是 Python 提供了一个操作符来快速完成这个任务。
在这个简短的教程中,我们将讨论这个运算符是什么,并举例说明如何使用它来添加值和分配结果。
操作员的简短复习
操作符是 Python 中的符号,代表语言中预定义的操作。你首先想到的可能是加号,它代表加法。当然,Python 中有几个运算符。
假设你想保存几个数字的累计总数。你可以写一个简单的程序:
runningTotal = 10 # Assigning initial value
runningTotal = runningTotal + 7.5
print(runningTotal)
在第一行,我们给 runningTotal 变量赋值 10。
然后,我们将 runningTotal 中的值加上 7.5,并将该总和保存在 runningTotal 中。
最后,我们打印了 runningTotal 的值。
如你所料,这个程序将打印 17.5。
现在,让我们看看+=操作符如何使这个程序更容易编写。
Python+=操作符:解释和示例
运算符+=是一个预定义的运算符,它将两个值相加,并将总和赋给一个变量。因此,它被称为“加法赋值”运算符。
运算符通常用于存储计数器变量中数字的和,以跟踪特定运算的重复频率。
和其他操作符一样,这个操作符也有相关的语法。以下是您需要如何使用它,以便它正确工作:
exampleVariable += someValue
需要注意的是,您设置的变量必须是数字或字符串。该数字可以是整数或浮点数。
假设你最初给变量赋了一个字符串值。然后,您在等号后面写的值将被追加到字符串的末尾。
另一方面,如果一个数字被初始分配给一个变量,等号后面的数字将被加到初始分配的数字上。
让我们来看看这两种情况的一个例子:
数值例子
让我们重写我们在这篇文章开始时讨论过的程序。下面是如何在程序中使用加法赋值操作符:
runningTotal = 10 # Assigning initial value
runningTotal += 7.5
print(runningTotal)
运行这段代码会得到和我们之前写的程序一样的结果。
首先,将值 10 赋给 runningTotal。然后,第二条语句将 runningTotal 加上 7.5。
最后,runningTotal 值会被打印出来,你会看到 17.5 出现在控制台中。
使用这个操作符,而不是将代码建立在前面程序中使用的基本逻辑之上,会使代码更加“Pythonic 化”此外,该程序更容易阅读和更快地编写。
字符串示例
假设我们定义了一个存储用户名字的变量。这个变量的值是 Chloe。
然后,我们定义第二个变量来保存用户的姓氏。这个变量的值是 Reid。
代码应该是这样的:
forename = "Chloe"
surname = " Reid"
我们现在想要添加这些名称,或者更确切地说,追加它们并将其存储为一个值。我们可以使用加法运算符来实现这一点。
如你所见,姓氏的开头有一个空格。我们这样做是因为加法运算符不会向存储的字符串添加空格。
为了合并这两个名字,我们使用代码:
forename += surname
代码将返回值“克洛伊·里德”
+=运算符的结合律
让我们用一个例子来确定加法赋值运算符的结合律。
A = 5
B = 10
A += B>>1
print(A)
如你所见,变量 A 和 B 被赋值为 5 和 10。然后,B 的值向右移动一位。然后将移位后的结果加到 A 中,并存储在 A 中。
最后一条语句打印出 A 值,显示它等于 10。因此,加法赋值运算符的结合律是从左到右的。
你应该知道的其他赋值运算符
除了加法赋值运算符,Python 还提供了各种其他赋值运算符。一些最有趣的操作符包括比较操作符、成员操作符和标识操作符。
赋值运算符允许你执行数学函数并将结果赋给一个变量。下面是 Python 中“主”赋值操作符的列表:
| 操作员 | 类型 | 例子 | 当量 |
| += | 加法 | val += 2 | val = val + 2 |
| /= | 分部 | val /= 2 | val = val / 2 |
| = | 等于 | val = 2 | val = 2 |
| *= | 乘法运算 | val *= 2 | val = val * 2 |
| ** | 功率 | val ** 2 | val = val ** 2 |
| -= | 减法 | val -= 2 | val = val–2 |
结论
有了这个指南,你就可以充分发挥加法赋值运算符的潜力了。您还可以尝试上表中提到的其他操作符。
你现在离掌握 Python 又近了一步。你可能还有很长的路要走,但是只要你继续学习、实验和重复,你就会不断进步,成为一名更好的程序员。
Python 程序员:关于这个职业你需要知道的一切
原文:https://www.pythoncentral.io/a-python-programmer-everything-you-need-to-know-about-this-profession/
你知道什么是 Python 程序员吗?他们的工作包括什么?成为 Python 程序员需要学习什么?能赚多少?如果你有兴趣学习更多关于这个职业的知识,你会找到一个完整的指南,里面有作为 Python 程序员工作的所有细节。
在我们生活的时代,编程是推动世界的力量。工作世界在不同的国家和所有的公司提供了极好的工作机会。然而,如果有一种编程语言是我们应该关注的,那无疑是 Python。

Python 编程语言是近年来使用率增长最快的语言之一。
如果你想过上数字游牧生活或为国外大公司工作,掌握 Python 的你可以从事的职业提供了巨大的经济利益和从家里或世界任何地方远程发展的机会。
目录
谁是 Python 程序员?
作为 Python 程序员所需的技能
软技能
技术
Python 程序员的专业领域
成为 Python 程序员的培训
职业发展
Python 程序员的工资
谁是 Python 程序员?
它是 Python 编程的专家 Python 是一种具有各种用途的语言,从数字科学、数据学习、机器学习、web、脚本到可扩展软件等等。Python 程序员通常能够编写任何程序,从 Windows 应用程序到网络服务器甚至网页。
成为 Python 程序员所需的技能
精通 Python 的程序员必须具备的几项软技能和更多的技术方面,以确保最佳的工作表现。
请记住,这些总是主要取决于所选择的重点领域;然而,下面,我们将审查公司最需要的个人和技术技能。
软技能:
分析和解决问题的思维:作为一名 Python 程序员,你的日常工作将包括解决所有需要面对的问题,以最终实现自动化流程的目标,并使工作在各方面都更加有效。
团队合作:团队工作是程序员日常工作中必不可少的一部分。你很可能不是一个人,但你必须与其他领域的专业程序员合作,补充你的功能并与他们合作。
自学: Python 和其他编程语言都在不断发展,正如环境和它可以应用的领域一样。
技术技能:
Django、Flask 和 Pylons 等框架的使用:如果你对使用 Python 进行 web 开发感兴趣,Django、Flask 和 Pylons 等框架应该在你的技能列表中,这样你就可以依赖一个更快、更干净、更实用的完整开发模式。
面向对象编程的用途: Python 是一种面向对象的语言。它在收集数据和控制结构时更有效地安排代码,允许程序员通过创建新的类来解决问题,这些类对解决问题所需的数据进行建模。掌握 Python 的一个基本要素是了解面向对象编程。
数据库的使用:Python 程序员详细了解什么是关系数据库,以及在操作中与它们一起工作意味着什么,以便能够根据适当的规范使用库从 Python 中完成操作,并提高他们构建系统的能力,确保所创建的数据库中的数据的持久性。
Python 程序员的专业领域
一旦你学会了 Python,或者甚至在你开始训练之前,决定你想用这种编程语言去哪里是很重要的。我们会给你一个提示,选项不仅限于一个路径。下面,我们将看看您可以运用 Python 技能的四个主要领域。
数据科学
对 Python 程序员需求的指数级增长主要是由于数据科学的兴起,数据科学使用这种语言来处理海量数据集,从中提取高价值的信息并进行分类。
深度学习和机器学习
这两种技术都指能够通过人工智能“自行”学习的系统,要求 Python 执行与分类、回归、聚类、预处理或生成算法模型相关的任务。
DevOps
当涉及到与软件开发和操作相关的所有流程与实用的 DevOps 方法的统一和集成时,Python 也可以满足需求,因为它允许为流程的自动化和编排编写相关的脚本。
网页开发
如果你对建立网站和网络应用感兴趣,就像 Instagram 和 Pinterest 等社交网络的最佳程序员一样,Python 将在这方面帮助你。
成为 Python 程序员的培训
假设您已经决定接受 Python 程序员的培训。在这种情况下,你应该知道有很多免费和低价的课程,可以让你在舒适的电脑前促进学术和职业发展。
此外,如果您在培训过程中的任何时候需要支持,Python 有一个最活跃和最愿意的开发人员(和见习开发人员)社区,鼓励围绕这种语言的使用进行讨论,并分享有助于提高您作为程序员的技能的相关信息。
职业发展
正如我们最初提到的,Python 程序员的就业模式是多种多样的,可以根据不同的偏好进行调整。下面我们将回顾在这种情况下你可以发展你的职业的主要方法,这样你就可以选择你觉得更舒服的方法:
传统模式
它指的是员工与公司关系的经典模式,在这种情况下,你根据合同协议为技术公司或不同部门服务,特别是在他们的 It 部门,通常是亲自服务。然而,现在有些人愿意提供远程工作的可能性作为一种福利。
自由职业者和自主模态
在这种模式下,你将有机会成为一名自由程序员,提供你的专业服务来完成公司或各种客户要求的特定任务或项目。
如果您对在家或在任何地方工作的更大灵活性和自由度感兴趣,工作模式最适合您,就像优秀的数字流浪者一样。
企业家模式
编程和创业的世界是携手并进的。掌握 Python 和其他语言是开发你的技术项目和赚钱的一个很有前途的跳板。你可以用 Python 创建许多项目,从心理帮助应用程序到论文作者服务或有声读物应用程序——随你挑!
一个 Python 程序员的工资
你能得到的薪水数字与你处理 Python 的技能和能力相关——你决定锻炼你的活动的领域、培训程度、经验水平(初级、中级或高级)、招聘公司的类型和规模、条件、额外福利等。
既然您已经清楚了作为一名 Python 程序员的基本工作,那么您已经掌握了开始学习编程中最流行的专业概要之一的一切。毫无疑问,这为近年来的持续增长开了绿灯。
激活 Python Django 网站的管理应用程序
原文:https://www.pythoncentral.io/activate-admin-application-for-your-python-django-website/
在上一篇文章中,我们学习了如何为 Django 应用程序myblog编写两个模型Post和Comment。在这篇文章中,我们将学习如何激活 Django 的自动管理站点,该站点为您网站的用户或管理员myblog创建、阅读、更新和删除( CRUD )您网站的内容提供了一个方便的界面。CRUD 操作是持久存储的四个基本功能。缩写词 CRUD 描述了一组在任何基于数据库的计算机应用程序中几乎都很常见的操作。由于这些操作是常识,从现在开始,我们将在本系列中使用 CRUD 。
什么是 Django 管理站点,如何激活它
Django 管理站点是一个应用程序,它是由命令django-admin.py startproject创建的任何新 Django 项目的默认应用程序。几乎可以肯定的是,任何基于数据库的网站都应该允许用户对其内容进行 CRUD ,Django 提供了一个现成的管理站点,它是任何新的 Django 项目的一部分。
默认情况下,Django 管理站点是不激活的,因为不是所有的程序员都想启用它。为了实现它,您需要做三件事:
-
取消对
myblog/settings.py
【python】
中INSTALLED_APPS中django.contrib.admin和django.contrib.admindocs的注释= (
'django.contrib.auth ',
' django . contrib . content types ',
'django.contrib.sessions ',
'django.contrib.sites ',
'django.contrib.messages ',
' django . contrib . static files ',取消对下一行的注释
-
Uncomment the following lines in
myblog/urls.py:
[python]
from django.contrib import admin
admin.autodiscover()url(r'^admin/doc/', include('django.contrib.admindocs.urls')),url(r'^admin/',包括(admin.site.urls)),
现在,您应该有一个类似这样的
myblog/urls.py:from django.conf.urls import patterns, include, url #取消对下面两行的注释,以启用 django.contrib 中的 admin: import admin admin . auto discover() urlpatterns = patterns(', #示例: # url(r'^$',' myblog.views.home ',name='home '), # url(r'^myblog/',include('myblog.foo.urls '), #取消对下面的管理/文档行的注释以启用管理文档: url(r'^admin/doc/',包括(' django.contrib.admindocs.urls '), #取消注释下一行以启用 admin: url(r'^admin/',include(admin.site.urls)), ) -
在您的 shell 中运行以下命令:
【shell】
% python manage . py syncdb
创建表...
创建表 django_admin_log
安装定制 SQL...
安装索引...
已从 0 个设备
[/shell]安装 0 个对象由于管理应用程序django.contrib.admin已在myblog/settings.py中取消注释,您应该重新运行syncdb命令为其创建数据库表。注意,这个命令已经创建了一个新表django_admin_log。
享受管理网站的乐趣
现在,您可以通过访问管理网站
- 运行网站:
【shell】
% python manage . py runserver
验证模型...发现 0 个错误
2013 年 04 月 05 日- 12:08:17
Django 版本 1.5,使用设置‘my blog . settings’
开发服务器运行在 http://127.0.0.1:8000/
用 CONTROL-C 退出服务器
[/shell】 - 打开 web 浏览器,导航到 http://127.0.0.1:8000/admin 。你应该可以看到 admin 的登录界面:
![Django Admin Login Page]()

现在,您可以使用您在文章中创建的超级用户的凭证登录。如果您忘记了超级用户的密码,可以通过以下方式修改其密码:
>>> from django.contrib.auth import models as m
>>> m.User.objects.all()
[]
>>> superuser = m.User.objects.all()[0]
>>> superuser.set_password('12345')
>>> superuser.save()
登录后,您应该能够看到以下通用管理主页:

请注意,型号Post和Comment未在此页面列出。因此,我们应该通过在目录myblog/中创建一个新文件admin.py来添加它们,如下所示:
from django.contrib import admin
from myblog import models as m
管理员网站注册(m.Post)
管理员网站注册(m.Comment)
现在,通过终止命令python manage.py runserver重启 Django 开发服务器,并重新运行它。尽管 Django 开发服务器监听目录myblog/中的文件变化,并在每次有文件变化时自动重启,但如果有文件创建,它不会自动重启。
现在您可以访问页面http://127 . 0 . 0 . 1:8000/admin并看到模型Post和Comment已经被添加到 myblog 应用程序中。
使用管理站点修改模型
现在您可以点击“评论”来查看数据库中存储的评论列表:

点击第一个“评论对象”将显示一个基于 HTML 表单的页面,允许您修改message 文本字段、created 日期时间字段和post 外键字段:

现在你可以把任何一个字段改成你喜欢的值:

完成修改后,可以点击“保存”将修改保存到数据库:

有几点值得注意:
Post、Comment等机型变更表格由myblog/models.py中定义并在myblog/admin.py中注册的机型自动生成- 不同的模型字段类型,例如用于
Comment.created_at的类型DateTimeField和用于Comment.message的类型TextField,对应于不同种类的 HTMLinput元素。
总结和见解
我们已经用几行代码激活了 Django 的管理站点,由此产生的 URL“/Admin”为网站管理员提供了一个全功能的 web 界面,以便通过admin.site.register()函数注册 CRUD 任何模型。虽然这看起来像魔术,但它是不要重复自己 ( 干)原则的体现。我们编写的激活管理站点的代码保持在绝对最小的程度,你当然可以想象如果 Django 不提供管理站点,我们要编写多少代码。
在本系列接下来的文章中,我们将反复拜访和考察干原理。由于 DRY 促进了代码的可重用性和面向可维护性的设计,Django 的开发者将它作为实现 Django 框架的指导方针,我们在编写软件时也应该记住这一点。
将 python 添加到 PATH 环境变量中(“Python”不被识别为内部或外部命令)
编程已经成为最重要的技术课程。除了良好的逻辑思维能力,你还需要成功安装软件才能在这个领域脱颖而出。Python 是需要学习的最基础的编程语言,但是在安装 Python 设置时,您可能会遇到一些错误。对于 Windows 用户来说,你的电脑屏幕上显示的最常见的错误可能是“Python 不被识别为内部或外部命令。”
这篇文章将指导你找出这个错误的原因,以及如何修复它。
在电脑上访问 Python 的步骤
在你的电脑上访问 Python 的第一种方法是按照安装软件的路径,直接访问可执行文件。
截图展示了如何定位下载的可执行文件并打开 Python。
执行此任务将打开 Python 的 IDE,您可以在其中轻松编写代码。
访问 Python 的第二种方法是通过 命令提示符 。该方法的步骤如下:
1)通过 Windows 的搜索选项卡打开命令提示符。
2)键入 Python 并按回车键
在这一步之后,Python IDE 将在同一窗口中打开。但是在某些情况下,可能会出现如下错误。

错误原因
每当我们访问任何文件或已安装的程序时,我们的计算机都需要知道文件存储的整个位置。计算机将该位置读取为文件的 【路径】 。当我们通过直接访问 Python 可执行文件的位置来访问它时,我们遵循文件的路径,这消除了出错的可能性。但是,当我们使用命令提示符来访问文件时,计算机可能知道也可能不知道该路径。如果计算机不知道该路径,Windows 将不会运行该程序并显示一条错误消息。
路径变量
计算机通过 path 环境变量知道文件的路径。你可以把一个路径 环境变量 想象成一组包含已安装程序的可执行文件地址的目录。path 变量使计算机更容易搜索程序。但是,如果这个 path 变量加载了许多不必要的路径,就会降低计算机的速度。因此,请确保您正确并有选择性地提及路径。
当我们在命令提示符下键入一个程序名,而没有指定目录(或者更具体地说,路径)时,计算机系统会搜索 path 环境变量中提到的所有路径。假设环境变量中提到了(特定程序的)路径。在这种情况下,计算机系统将能够找到并运行该可执行文件。然而,假设计算机系统没有找到任何通向可执行文件的路径。在这种情况下,它将显示错误消息。
因此,我们需要确保在 path 环境变量中添加 Python 可执行文件的路径。
修复错误
解决方案 1
修复此错误的第一种方法是在命令提示符中提及可执行文件的路径,这样系统就不必在 path 环境变量中进行搜索。
我们可以找到可执行变量的路径如下:
第一步:打开 Windows 的搜索选项卡,输入 Python。
第二步:点击“打开文件位置”
步骤 3:电脑浏览器窗口打开。
第四步:右键点击【Python 3.9(64 位)】 ,选择“打开文件位置”
第五步:查找文件【python . exe。”右键单击该文件,然后选择“属性”
第六步:你可以看到 python 可执行文件的‘位置’和完整路径。
第七步:复制路径,粘贴到命令提示符下。
第八步:加一个反斜杠' \ ',写' python.exe ',回车。

现在你可以在命令提示符下成功运行 Python 了。
在这种方法中,每次打开 Python 时,你都必须在命令提示符下复制路径。这一过程可能是乏味和耗时的。为了将您从所有这些麻烦中解救出来,让我们看看第二种方法提供了什么。
解决方案 2
这种方法的概念是将 python 可执行文件的路径添加到 path 环境变量中,这样计算机就可以自己搜索整个目录。有两种不同的方法可以将路径添加到环境变量:
使用 Python 设置更新路径变量
当您安装 Python 时,安装程序最初会为您提供将可执行文件的路径添加到 path 环境变量的选项。您可以选中该框,路径将会自动添加。
假设你第一次安装 Python 的时候漏选了这个选项;不用担心!您仍然可以通过以下步骤修改安装设置并更新 path 变量:
第一步:在你的文件浏览器中,搜索【python-3 . 9 . 6-amd64】并打开。
安装程序现在看起来像这样:
第二步:点击修改。窗口现在将显示如下:
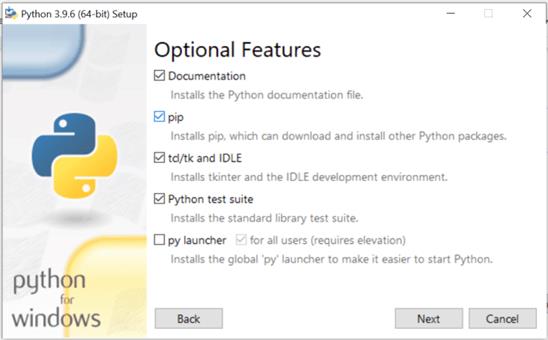
第三步:点击“下一步”,直到出现“高级选项”窗口。
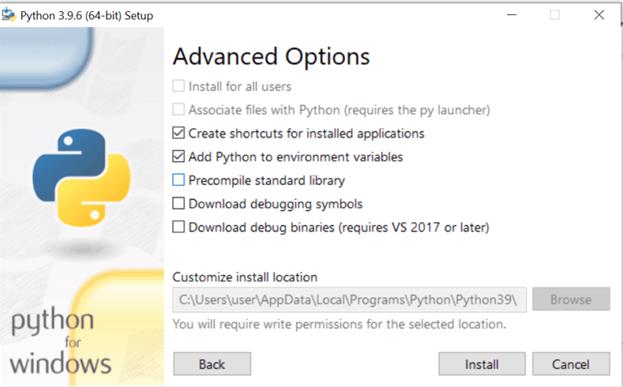
步骤 4:选中“将 Python 添加到环境变量”选项,然后点击安装。
现在您系统的 path 变量已经更新,您可以通过命令提示符访问 Python,不会出现任何错误。
手动更新路径变量
手动更新 path 变量的最关键要求是,您应该有 python 可执行文件的位置(或者更恰当地说,路径)。您可以按照 【解决方案 1】中给出的步骤获得所需的路径。
获得路径后,可以按照以下步骤操作:
第一步:打开电脑上的“设置”。
步骤 2:点击设置窗口中的“系统”,然后点击左侧可用选项中的“关于”。
步骤 3:点击“关于”窗口右侧的“高级系统设置”。
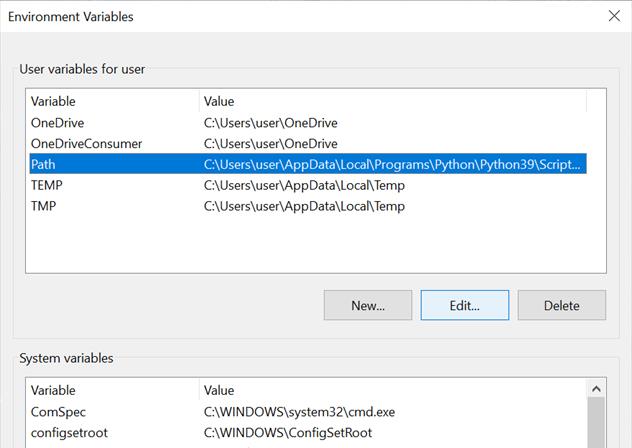
第四步:点击窗口右下角的“环境变量”。
第五步:在环境变量窗口中,点击路径选项(它将使文本背景变成蓝色),然后点击“编辑”
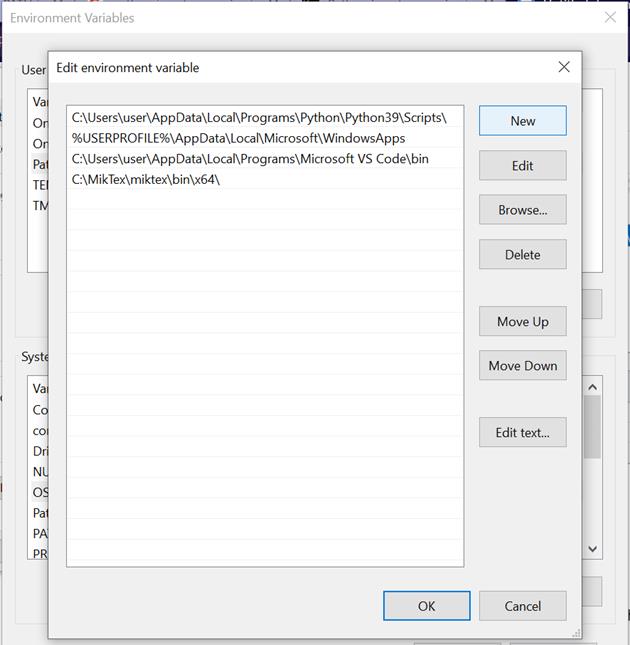
步骤 6:在编辑环境变量窗口中,点击“新建”(窗口右侧)。
步骤 7:点击“新建”,光标将开始闪烁,您可以在此粘贴 Python 可执行文件路径。
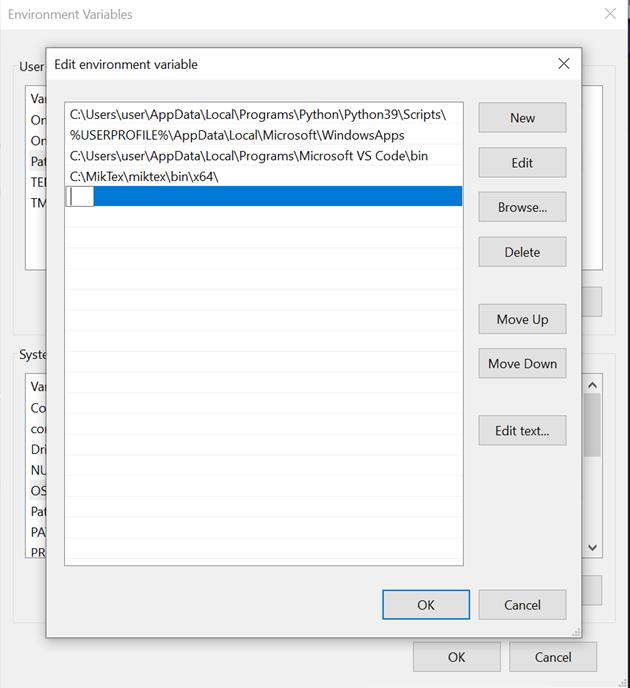
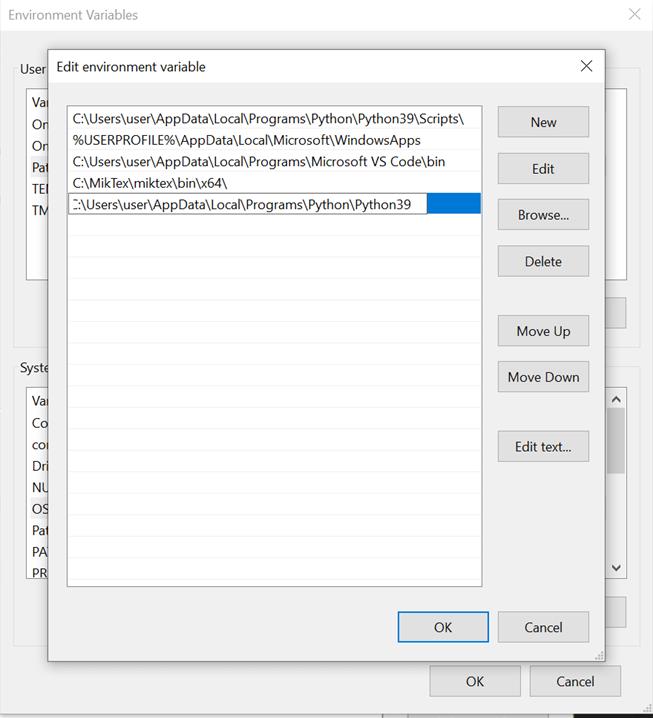
第八步:点击“确定”,你的工作就完成了!
完成所有这些步骤后,您将能够通过命令提示符无误地运行 Python。
结论
程序员应该了解操作系统的几个不同方面,以便在安装或编码时处理错误。“Python 不被识别为内部或外部命令 ”是一个程序员最初可能遇到的一个很基本的问题。我们希望这篇文章能帮助你修复这个错误。您可以应用任何解决方法,并有效地纠正您的系统代码。既然您已经安装了 Python,并且可以无误地运行它,那么您就可以用您独特的代码征服逻辑世界了。编码快乐!
使用 pip 在 Python 中添加、删除和搜索包
原文:https://www.pythoncentral.io/add-remove-and-search-packages-installed-with-pythons-pip/
使用 pip 管理 Python 包
像许多有用的编程生态系统一样,Python 提供了一个强大且易于使用的包管理系统,称为 pip。它是用来取代一个叫做 easy_install 的旧工具的。从高层次的角度来看,pip 比 easy_install 具有以下优势:
- 所有的软件包在安装前都被下载,以防止部分安装。
- 输出信息是经过预处理的,因此比古怪的消息更有用。
- 它记录了执行操作的原因。例如,需要一个包的原因被记录下来以备将来参考。
- 包可以作为平面模块安装,这使得库代码调试比 egg 档案容易得多。
- 对其他版本控制系统的本机支持。例如,如果设置正确,您可以直接从 GitHub 库安装 Python 包。
- 软件包可以卸载。这是 easy_install 的一个巨大优势,easy _ install 需要程序员手动卸载软件包。
- 定义需求集很简单,因此跨不同环境复制一组包也很容易。
设置 virtualenv 和 pip 以执行简单操作
virtualenv 是一个用于沙盒 Python 环境的工具。virtualenv 允许程序员设置类似于独立沙箱的独立 Python 上下文,而不是修改全局 Python 环境。将您的 Python 环境沙箱化的一个优点是,您可以在不同的 Python 版本和包依赖项下毫不费力地测试您的代码,而无需在虚拟机之间切换。
要安装和设置 pip 和 virtualenv,请运行以下命令:
# easy_install is the default package manager in CPython
% easy_install pip
# Install virtualenv using pip
% pip install virtualenv
% virtualenv python-workspace # create a virtual environment under the folder 'python-workspace'
如果您当前的 Python 环境不包含任何包管理器,您可以从这里的下载一个 Python 文件并运行它:
# Create a virtual environment under the folder 'python-workspace'
% python virtualenv.py python-workspace
一旦在“python-workspace”下设置了新的 virtualenv,您需要激活它,以便当前 shell 中的 python 环境将过渡到 virtualenv:
% cd python-workspace
% source ./bin/activate # activate the virtualenv 'python-workspace'
% python # enter an interpreter shell by executing the current virtual python program under 'python-workspace/bin/python'
如果你看一下文件夹“python-workspace/bin”的内容,你会看到一个可执行程序的列表,如“python”、“pip”和“easy_install”等。不是在系统默认的 Python 环境下执行程序,而是执行 virtualenv 的 Python 程序。
使用 pip 添加/安装软件包
要安装软件包,请使用“install”命令。
% pip install sqlalchemy # install the package 'sqlalchemy' and its dependencies
有时,您可能希望在安装软件包之前检查它的源代码。例如,您可能希望在安装软件包之前检查其新版本的源代码,以确保它能与您当前的代码一起工作。
% pip install --download sqlalchemy_download sqlalchemy # download the package 'sqlalchemy' archives into 'sqlalchemy_download' instead of installing it
% pip install --no-install sqlalchemy # unpack the downloaded package archives into 'python-workspace/build' for inspection
% pip install --no-download sqlalchemy # install the unpacked package archives
如果您想要安装软件包的最新版本,您可以直接从它的 Git 或 Subversion 存储库中安装它:
% pip install git+https://github.com/simplejson/simplejson.git
% pip install svn+svn://svn.zope.org/repos/main/zope.interface/trunk
使用 pip 升级软件包
对于已安装的软件包,您可以通过以下方式升级它们:
% pip install --upgrade sqlalchemy # upgrade sqlalchemy if there’s a newer version available. Notice that --upgrade will recursively upgrade sqlalchemy and all of its dependencies.
如果不希望升级软件包及其依赖项(有时您可能希望测试软件包的向后兼容性),您可以通过以下方式执行非递归升级:
% pip install --upgrade --no-deps sqlalchemy # only upgrade sqlalchemy but leave its dependencies alone
保存您的 pip 包列表
到目前为止,您应该已经使用 pip 安装了一堆包。为了在不同的环境下测试已安装的软件包,您可以将已安装的软件包列表保存或“冻结”到一个需求文件中,并在另一个环境中使用该需求文件重新安装所有的软件包:
% pip freeze > my-awesome-env-req.txt # create a requirement file that contains a list of all installed packages in the current virtualenv 'python-workspace'
% virtualenv ../another-python-workspace # create a new virtualenv 'another-python-workspace'
% cd ../another-python-workspace
% source ./bin/activate # activate the new empty virtualenv 'another-python-workspace'
% pip install -r ../python-workspace/my-awesome-env-req.txt # install all packages specified in 'my-awesome-env-req.txt'
移除/卸载 pip 软件包
如果不知何故,你决定某些包对你的项目不再有用,你想删除它们来清理 virtualenv。您只需输入以下命令即可删除软件包:
% pip uninstall sqlalchemy # uninstall the package 'sqlalchemy'
或者通过以下方式删除软件包列表:
% pip uninstall -r my-awesome-env-req.txt # uninstall all packages specified in 'my-awesome-env-req.txt'
请注意,pip 不知道如何卸载两种类型的软件包:
- 用纯发行版安装的软件包:'【T0]'
- 使用脚本包装安装的包:'【T0]'
因为这两种类型的已安装软件包不包含任何元数据,所以 pip 不知道应该删除哪些文件来卸载它们。
搜索 pip 包
如果要搜索解决特定类型问题的软件包,可以通过以下方式执行搜索:
% pip search database # search package titles and descriptions that contain the word 'database'
搜索包对于检索问题域中所有包的概述非常有用,这样您就可以比较和选择最适合您需要做的事情的包。
使用 pip 的提示
1.为了防止意外运行 pip 将不需要的软件包安装到全局环境中,您可以通过设置 shell 环境变量来告诉 pip 仅在 virtualenv 当前处于活动状态时运行:
% export PIP_REQUIRE_VIRTUALENV=true
2.通常,软件包将安装在“站点软件包”目录下。但是,如果您想要对包进行修改和调试,那么直接从包的源代码树中运行包是有意义的。您可以通过告诉 pip 使用“-e”选项/参数来安装软件包,使其进入“编辑模式”,如下所示:
# create a .pth file for sqlalchemy in 'site-packages' instead of installing it into 'site-packages'
# so that you can make changes to the package and debug the changes immediately
% pip install -e path/to/sqlalchemy
软件包索引,以及关于 pip 的更多信息
Python 有一个网站,包含许多您可能想要查看的有用包,称为“ Python 包索引”,或“ PyPI ”。这是许多常用 Python 库/模块的一个很好的存储库,它们都是预打包的,很容易安装。
关于 Python 的 pip - checkout 的更多信息,请访问本网站。
Python 中的高级 SQLite 用法
原文:https://www.pythoncentral.io/advanced-sqlite-usage-in-python/
继 SQLite3 系列之后,这篇文章是关于我们使用 SQLite3 模块时的一些高级主题。如果你错过了第一部分,你可以在这里找到它。
使用 SQLite 的日期和日期时间类型
有时我们需要在 SQLite3 数据库中插入和检索一些date和datetime类型。当使用日期或日期时间对象执行插入查询时,sqlite3模块调用默认适配器并将它们转换成 ISO 格式。当您执行查询来检索这些值时,sqlite3模块将返回一个字符串对象:
>>> import sqlite3
>>> from datetime import date, datetime
>>>
>>> db = sqlite3.connect(':memory:')
>>> c = db.cursor()
>>> c.execute('''CREATE TABLE example(id INTEGER PRIMARY KEY, created_at DATE)''')
>>>
>>> # Insert a date object into the database
>>> today = date.today()
>>> c.execute('''INSERT INTO example(created_at) VALUES(?)''', (today,))
>>> db.commit()
>>>
>>> # Retrieve the inserted object
>>> c.execute('''SELECT created_at FROM example''')
>>> row = c.fetchone()
>>> print('The date is {0} and the datatype is {1}'.format(row[0], type(row[0])))
# The date is 2013-04-14 and the datatype is <class 'str'>
>>> db.close()
问题是,如果您在数据库中插入了一个日期对象,大多数情况下,当您检索它时,您期望的是一个日期对象,而不是一个字符串对象。将PARSE_DECLTYPES和PARSE_COLNAMES传递给connect方法可以解决这个问题:
>>> import sqlite3
>>> from datetime import date, datetime
>>>
>>> db = sqlite3.connect(':memory:', detect_types=sqlite3.PARSE_DECLTYPES|sqlite3.PARSE_COLNAMES)
>>> c = db.cursor()
>>> c.execute('''CREATE TABLE example(id INTEGER PRIMARY KEY, created_at DATE)''')
>>> # Insert a date object into the database
>>> today = date.today()
>>> c.execute('''INSERT INTO example(created_at) VALUES(?)''', (today,))
>>> db.commit()
>>>
>>> # Retrieve the inserted object
>>> c.execute('''SELECT created_at FROM example''')
>>> row = c.fetchone()
>>> print('The date is {0} and the datatype is {1}'.format(row[0], type(row[0])))
# The date is 2013-04-14 and the datatype is <class 'datetime.date'>
>>> db.close()
更改连接方法后,数据库现在返回一个日期对象。sqlite3模块使用列的类型返回正确的对象类型。因此,如果我们需要使用一个datetime对象,我们必须将表中的列声明为一个timestamp类型:
>>> c.execute('''CREATE TABLE example(id INTEGER PRIMARY KEY, created_at timestamp)''')
>>> # Insert a datetime object
>>> now = datetime.now()
>>> c.execute('''INSERT INTO example(created_at) VALUES(?)''', (now,))
>>> db.commit()
>>>
>>> # Retrieve the inserted object
>>> c.execute('''SELECT created_at FROM example''')
>>> row = c.fetchone()
>>> print('The date is {0} and the datatype is {1}'.format(row[0], type(row[0])))
# The date is 2013-04-14 16:29:11.666274 and the datatype is <class 'datetime.datetime'>
如果您已经声明了一个列类型为DATE,但是您需要使用一个datetime对象,那么有必要修改您的查询以便正确解析该对象:
c.execute('''CREATE TABLE example(id INTEGER PRIMARY KEY, created_at DATE)''')
# We are going to insert a datetime object into a DATE column
now = datetime.now()
c.execute('''INSERT INTO example(created_at) VALUES(?)''', (now,))
db.commit()
#检索插入的对象
c . execute(' ' ' SELECT created _ at as " created _ at[timestamp]" FROM example ' ')
在 SQL 查询中使用as "created_at [timestamp]"将使适配器正确解析对象。
用 SQLite 的 executemany 插入多行
有时我们需要在数据库中插入一个对象序列,sqlite3模块提供了executemany方法来对序列执行 SQL 查询。
# Import the SQLite3 module
import sqlite3
db = sqlite3.connect(':memory:')
c = db.cursor()
c.execute('''CREATE TABLE users(id INTEGER PRIMARY KEY, name TEXT, phone TEXT)''')
users = [
('John', '5557241'),
('Adam', '5547874'),
('Jack', '5484522'),
('Monthy',' 6656565')
]
c.executemany(' ' '插入用户(姓名,电话)值(?,?)' ' ' ',用户)
db.commit()
#打印用户
c . execute(' ' ' SELECT * FROM users ' ')
用于 c:
打印(row)
db.close()
请注意,序列的每个元素必须是一个元组。
用 SQLite 的 executescript 执行 SQL 文件
execute方法只允许您执行一个 SQL 语句。如果您需要执行几个不同的 SQL 语句,您应该使用executescript方法:
# Import the SQLite3 module
import sqlite3
db = sqlite3.connect(':memory:')
c = db.cursor()
script = '''CREATE TABLE users(id INTEGER PRIMARY KEY, name TEXT, phone TEXT);
CREATE TABLE accounts(id INTEGER PRIMARY KEY, description TEXT);
插入到用户(姓名,电话)值(' John ',' 5557241 '),
('Adam ',' 5547874 '),(' Jack ',' 5484522 ');' '
c.executescript(脚本)
#打印结果
c . execute(' ' ' SELECT * FROM users ' ')
用于 c:
中的行打印(行)
db.close()
如果需要从文件中读取脚本:
【python】
FD = open(' myscript . SQL ',' r ')
script = FD . read()
c . execute script(script)
FD . close()
请记住,为了捕捉异常,用一个try/except/else子句包围代码是一个好主意。要了解更多关于try/except/else关键字的信息,请查看捕捉 Python 异常——try/except/else 关键字一文。
定义 SQLite SQL 函数
有时我们需要在语句中使用自己的函数,特别是当我们为了完成某个特定的任务而插入数据时。一个很好的例子是,当我们在数据库中存储密码时,我们需要加密这些密码:
import sqlite3 #Import the SQLite3 module
import hashlib
def encrypt _ password(password):
#不要在真实环境中使用此算法
encrypted _ pass = hashlib . sha1(password . encode(' utf-8 '))。hexdigest()
返回加密 _ 通行证
db = sqlite3 . connect(':memory:')
#注册函数
db.create_function('encrypt ',1,encrypt _ password)
c = db . cursor()
c . execute(' ' '创建表用户(id 整数主键,电子邮件文本,密码文本)' ')
user = ('johndoe@example.com ',' 12345678')
c.execute(' ' '插入用户(电子邮件,密码)值(?,加密(?))''',用户)
create_function接受 3 个参数:name(用于在语句中调用函数的名称)、函数期望的参数数量(本例中为 1 个参数)和一个可调用对象(函数本身)。为了使用我们注册的函数,我们在语句中使用encrypt()来调用它。
最后,当您存储密码时,请使用真正的加密算法!
Python 相对于其他语言的优势
原文:https://www.pythoncentral.io/advantages-of-python-over-other-languages/
 Python 是一种流行语言,吸引了各国大量的追随者。程序员在 1989 年开始开发它,但它在 1991 年正式出版。那些认为 Python 这个名字是关于一条蛇的人错了。开发者给这种语言起了个名字,这要归功于 70 年代的一个流行节目“巨蟒剧团的飞行马戏团”创造这种语言的人之一是它的爱好者。这个名字引出了一个哲学观点,即开发必须是有趣的。培训项目也是根据这一原则创建的。Python 开发人员在创建和更新它的时候使用了其他的哲学陈述,也许正是由于这个位置,Python 的受欢迎程度和社区每年都在增长。所以让我们来发现它相对于其他语言的优势。
Python 是一种流行语言,吸引了各国大量的追随者。程序员在 1989 年开始开发它,但它在 1991 年正式出版。那些认为 Python 这个名字是关于一条蛇的人错了。开发者给这种语言起了个名字,这要归功于 70 年代的一个流行节目“巨蟒剧团的飞行马戏团”创造这种语言的人之一是它的爱好者。这个名字引出了一个哲学观点,即开发必须是有趣的。培训项目也是根据这一原则创建的。Python 开发人员在创建和更新它的时候使用了其他的哲学陈述,也许正是由于这个位置,Python 的受欢迎程度和社区每年都在增长。所以让我们来发现它相对于其他语言的优势。
学习和使用 Python 的好处
这些好处并不详尽,但我们认为它们是最有价值的。其他一些语言可能会分享 Python 的一些好处,但这并不意味着它们可以同时拥有所有这些好处。只有使用 Python 才能获得如此丰富的优势。
自由语言和公开可用的库
它不需要任何额外的平台或预付费服务。一切都可以免费下载。各种企业都对降低成本感兴趣。这就是为什么 Python 是他们很好的解决方案。这个特性表明 Python 是一种稳定而自信的语言,它对新成员开放,并准备好与他们协同工作。
简单直观的语言
如果你对编码有所了解,你会很容易理解 Python 的逻辑。这就是为什么它简化了对错误的搜索。你不需要深究语法,花更少的时间找麻烦,因为你毫无疑问地阅读和解密它。
多用途语言
几乎不可能在编码中找到 Python 无能为力的区域。它占据了编程的所有方式,并依此发展。人工智能程序员使用 Python 来完成他们的许多任务,将来也会这样做。空间领域、各种应用程序、机器人技术、硬件编程只是 Python 有用之处的一部分。
兼容编程语言
这种面向对象的语言可能是许多其他语言中最兼容的。你能记住的任何平台对 Python 开发者来说都不是问题,所以他们从一开始就处于胜利的位置。
简单优化编码
例如,比较 Python 和 C++(一种非常重要、流行和广泛使用的语言),我们会看到相同的请求在 Python 上包含三行,而在 C++上包含七行。这意味着编码变得更快更容易,你可以在一个屏幕上看到更多的过程和逻辑循环。
受雇主欢迎
你知道有哪些大公司使用 Python 作为编程语言吗?谷歌、NASA、迪士尼都在其中。如果你打算在一家著名的公司谋得一个职位,那么 Python 就是你的入场券。它同时适用于中小型公司,所以如果你努力工作,你总能在任何你想去的地方找到工作。
庞大的开发者社区
Python 够老了。这就是为什么 python 程序员的社区足够大的原因。很难想象以前没有解决的问题,所以你总会找到建议和解释。无论如何,如果你发现这样一个以前没有人面对过的问题,很多人会试图帮助你并讨论解决它的方法。
高薪和大量空缺职位
Python 的流行和国际认可简化了双方的雇佣过程。如果你是一个 Python 程序员,那么你会在所有你只能想象的领域被要求。工资的问题根本不是问题。在 IT 领域,从初级职位到中级职位再到高级职位的转换比任何地方都要简单。这里只有资格是指,而不是指工作年限或大学文凭。 这个列表并不详尽——你可以问任何用 Python 编程的人,特别是如果他们有其他语言的经验,他们会和你分享更多优势的例子。尽管如此,我们认为这个列表足以做出正确的决定,选择 Python 作为您的主要编程语言。
如何精通 Python
本文致力于 Python 相对于其他语言的优势,也就是说我们现在不会详细教你如何开始用 Python 编程。我们要说的是,这是一项值得投资的技能。如果你觉得卡住了,需要一些 Python 作业在线帮助,一个简单的“ 做我的 Python 作业 ”请求就可以了。如果你不知道什么,不要放弃,向专业程序员寻求帮助,继续你的 Python 编程任务。你可以说这些优势中的一些也是其他语言所固有的,你是对的。然而,它们的组合是独一无二的,确保了 Python 在 IT 世界中的长寿。用它来开始你的职业生涯是一个完美的选择,在现代世界中开启一个美好的未来。世界上有数百种(或数千种)编程语言。它们每天都在出现,改变着我们的生活。有些是专门为特定任务创建的,有些是为需要额外安全性的公司创建的。开发并使用它们的程序员是独特的专家,对宇宙有着独特的见解。同时,他们深深地依赖于他们的雇主,而雇主又深深地依赖于开发商。更安全还是更不安全还是个问题。Python 不是这种类型的语言。恰恰相反。如果你最终想进入稀有语言的世界,甚至想创造自己的语言,最好的例子就是 Python。
把人们带到你的网站需要 Python 编程技能吗
原文:https://www.pythoncentral.io/are-python-programming-skills-required-to-bring-people-to-your-website/
将用户吸引到自己的网站并不一定需要 Python。完全有可能实现 web 构建平台的使用,甚至雇佣一个 web 开发人员为您的网站工作,这意味着您不需要 Python 知识。也就是说,如果你想要一个非常高质量、完全独一无二的网站,那么 Python 会非常有用。Python 是 web 开发的一个非常流行的选择,因为它是免费的、开源的,并且广泛可用。如果你已经掌握了 Python,那么用它创建一个网站将会非常简单。
本文将介绍如何利用 Python 编程技能来提高网站的曝光率和受欢迎程度:
数据可视化
为了给你网站的访问者带来积极的体验,数据可视化是必不可少的。数据可视化指的是图表、图解和图片,作为与你的网站相关的数据的可视化表示。Python 是一种灵活的编程语言,提供了广泛的图形库。您可以使用这些库来创建有意义的数据洞察。图形图像对网站的成功至关重要,因为它们引人入胜。不要用枯燥和难以阅读的图表来表达你的网站数据,使用数据可视化技术,这是 Python 的优势。
数据收集
数据收集对大多数网站的成功至关重要。如果数据没有被恰当地编辑,那么网站给出的建议或指导将是不准确的。质量数据收集的一个很好的例子是 InCityLife 在线商业目录 ,它汇集了成千上万家企业的信息。如果他们的数据不正确,那么他们就无法为用户提供可靠和值得信赖的体验。Python 的工具使得数据收集变得极其容易。一些最常用的数据收集(和一般在线营销)工具包括 SciBy、Pandas、NumPy 和 StatsModel。还有其他库可用于分析收集的数据。

数字营销
如果你想让你的网站成功, 那么你需要营销它 。Python 可以帮助营销过程。Python 可以帮助你营销网站的一些主要方式包括 API 文档、网页抓取、技术 SEO 和内部工具的构建。Python 还允许营销人员自动化复杂和重复的任务。它还可以用来分析大型数据集,这有助于更广泛的数据分析和市场研究。
开发
正如本文介绍中提到的,Python 可以用来创建高质量的、吸引人的网站。如果你希望你的生意成功,那么这正是你需要的那种网站。Python 是构建网站的流行选择,因为它有众多的 web 开发框架。目前最流行的是 Pyramid、Flask 和 Django。一些最大的网站都是由于 Python 而创建的,包括 Mozilla、Spotify,甚至互联网最大的论坛 Reddit。Python 的无数模块和库很容易访问,而且 有一个简单的语法 ,即使对初学者来说也很容易使用。
Python 是网络上最流行的编程语言是有原因的。如果你想创建自己的网站,那么用 Python 来做绝对是个好主意。这是因为这种语言有无数的好处和应用。学起来也很直白。
Prisma 对象关系映射的优势
原文:https://www.pythoncentral.io/benefits-of-object-relational-mapping-with-prisma/

在使用数据库时,经常会出现是使用结构化查询语言(SQL)还是对象关系映射(ORM)的问题。因为开发人员需要维护各种系统和服务之间的信任链,所以 ORM 通常是最佳选择,较少依赖开发人员的 SQL 知识。
在构建 web 应用程序时,开发人员可以从利用对他们需要的平台、库和工具提供本机支持的开发环境中获得巨大的好处。这些环境中的应用程序开发通常通过自动代码完成来简化,从而加速开发并提高代码的语法正确性。在行业中,开发人员经常被本地支持 Nestjs 和 Prisma 的开发环境所吸引,因为它提供了更高级别的兼容性,并减少了由开发人员的简单错误导致的错误。
引入对象关系映射的概念。
ORM 是开发人员使用的技术,允许他们使用面向对象的编程范例从数据存储中检索和修改数据。ORM 与处理对象有着密切的关系,可用于开发人员可能使用的任何编程语言,例如 Python 。
映射器生成可引用的编程对象,这些对象虚拟地映射数据存储中的所有数据表。然后,开发人员将利用这些编程对象与数据进行交互。主要方法是尝试减轻开发人员设计和开发复杂 SQL 查询和存储过程的任务,以访问数据。
虽然使用较小对象集合的项目可能不会从已安装的 ORM 库中受益,但是更大更复杂的项目将会从这些库的可用性中受益匪浅。
在开发人员构建一个小项目的场景中,安装 ORM 库不会比创建专门的 SQL 查询提供更多的好处。在这种情况下,使用 SQL 语句驱动您的应用程序就足够了。然而,对于需要访问来自数百个数据存储的源数据的大中型项目来说,ORM 变得非常有用。这里,需要一个允许开发人员一致地利用和维护应用程序数据层的框架。
那么,利用 ORM 有什么好处呢?
ORM 能够创建语法正确的 SQL 查询,并针对高效的数据检索和修改进行了优化。消除了开发人员构建、部署和调试其应用程序所使用的任何 SQL 的需要。
这反过来又为开发人员改进了 CI/CD 过程,使得代码更容易维护和重用。给予开发人员改进的创造性自由来操作数据,而没有技术和时间开销。
样板代码是指需要重复使用的代码片段,很少或没有变化。这意味着开发人员必须编写许多行代码来执行甚至是最简单的任务。利用 ORM 为开发人员提供了标准化的接口,有效地减少了样板文件和代码,极大地缩短了应用程序上市的时间。
ORMs 提供了数据库抽象,方便了数据库切换。最后,它可以通过自主过滤传入请求来防范 SQL 注入攻击。
是什么让 Prisma 有别于其他 ORM?
Prisma 是下一代 ORM,用于访问 Nest.js 应用程序上的数据。无论开发团队是构建 REST 还是 GraphQL APIs,Prisma 都与 NestJS 的模块化架构无缝集成。然而,Prisma 的独特之处在于它不需要复杂的对象模型,而是通过模式文件映射应用程序的数据结构,如表和列。
Prisma 提供的工具之一叫做 Prisma Migrate 。Migrate 利用模式文件为 SQL 生成迁移文件,从而生成类型定义。保持 Prisma 模式文件与源数据库模式一致。
Prisma 可以在普通 JavaScript 中使用,但包括 TypeScript,提供了超过 TypeScript 生态系统中其他 ORM 的类型安全级别。
总之
不同的开发人员可能在不同的时间使用 SQL 和 ORM。两种选择都是正确的。然而,这并不是每种情况下的最佳选择。记住这一点,开发人员在决定方法之前应该考虑项目范围、组织需求和能力。
Prisma 开源 ORM 提供了业内其他 ORM 无法比拟的优势,因此是业内领先的选择之一。
Python 开发的最佳文本编辑器
原文:https://www.pythoncentral.io/best-text-editors-for-python-development/
Python 是一种如此流行的语言,以至于大多数“程序员的文本编辑器”至少有基本的支持,包括语法高亮。但是有几个编辑得到了特别好的支持。我测试了以下编辑器,按字母顺序排列,因为大多数都是不错的选择:
Emacs
Emacs 并不是一个真正的文本编辑器;它是一个有近 40 年历史的文本编辑器家族,从 TECO·EMACS 开始,这是一套由理查德·斯托尔曼使用 TECO 编辑器/编程语言实现的文本编辑宏,今天继续用 GNU Emacs 开发,也是由斯托曼创建的。还有其他的 Emacsen,包括 Gosling Emacs 和最著名的 XEmacs,但是它们大部分都被 GNU Emacs 取代了。它在 Windows 上运行。Mac OS X、Linux、BSD、俳句、Minix、Android——或多或少无处不在。
Emacs 的名声在于它的可扩展性,它允许用户为几乎所有东西创建编辑模式。Emacs 拥有每一种主要编程语言和大多数次要语言的模式;它可以作为新闻阅读器、电子邮件客户端、网络浏览器、终端模拟器、图像浏览器和博客客户端;它有一个包管理器,圣经学习工具,一个网络服务器——你开始明白这一点了。Emacs 对于文本编辑器来说是巨大的,但是它被称为操作系统是有原因的。
Emacs 扩展器并没有忽视 Pythonpython-mode包含在基础发行版中,允许用语法高亮显示编辑 Python 代码;自动缩进;对关键字、模块、类等的描述;片段插入;一个交互式 Python REPL,在一个分割窗口中,能够进行部分重新编译;代码折叠;还有更多。通过使用包管理器添加的
anything-ipython,强大的语法补全很容易实现,包括您导入的任何模块。还有几个用于集成单元测试、virtualenv、pylint、实时错误指示等的包。有了
pymacs包,你甚至可以用 Python 来扩展 Emacs 本身,尽管如果你认为你的扩展可能对其他人有用,我不推荐你这么做。
Emacs 的缺点是它疯狂的学习曲线。它的文本模式不同于你所习惯的任何东西,它的键盘快捷键完全不像今天的事实上的标准,它的外观和感觉完全是 1985 年的。然而,它有一个内置的教程——仔细阅读开始屏幕,看看如何打开它——一旦你学会了使用它,还有更多的文档可以随时访问。一旦你学会了使用它,你就可以用它来做
任何事情。
简而言之,要想有效,Emacs 必须是一种生活方式——但如果你坚持下去,这是一种很好的生活。这篇文章是用 Emacs 写的;我完成的所有东西都是用 Emacs 写的。
Geany
Geany 是一个跨平台的程序员文本编辑器,它提供了 IDE 最基本的功能。它有 Python 语法高亮;粗略的自动缩进,尽管在return和break语句后没有自动取消缩进;合理的代码导航;代码折叠;堆栈跟踪分析以定位错误;并且,通过一个额外的插件,一些不错的片段——就这些了。
Geany 做它擅长的事情,但是它做不好的事情,它根本不做。它的主要优点是它满足了一个严肃的 Python 程序员的编辑器的最低要求,同时有一个平缓的学习曲线。如果你没有附属的编辑器,也不想花时间学习 Emacs 或 Vim,Geany 是个不错的选择。
Komodo Edit
Komodo Edit 是一个编辑器/轻量级 IDE,由 ActiveState 的 Komodo IDE 的免费子集组成。优点:
- 自动缩进效果很好
- 项目和代码导航是有效的
- 代码折叠工作良好
- 自动完成在项目中运行良好
- 片段非常出色,处理得当
然而,也有一些严重的缺点:
- 自动完成不适用于非标准模块
- 没有 Python 控制台
- 没有调试,甚至没有运行脚本的内置支持
- 项目处理效率低下且不透明
可用的功能与类似 IDE 的接口开销不相称。
记事本++
Notepad++基本上是一个不错的文本编辑器,但至少对于 Python 来说,它几乎不是程序员的编辑器。它有可接受的语法突出显示,但这是它所能提供的全部。它有基于当前文件的单词级和函数级自动补全,这几乎没有帮助;名义上的自动缩进对 Python 来说根本不起作用;坦白说,仅此而已。它唯一的建议是,它很容易学习,比同名的更好。
除非你因为某种原因和 Notepad++绑在一起,否则 Geany 或者这里推荐的其他编辑器可能是更好的选择。
赛特
SciTE 最初是一个用于
Scintilla 源代码编辑组件的演示应用程序,但是它失去了控制,变成了一个可以用 Lua 编写脚本的真正的文本编辑器。尽管它历史悠久,但它实际上相当不错,并且完成了上面 Geany 所做的大部分文本编辑工作;它缺少的是项目和文件导航功能。如果对你有用的话,它可以使用令牌文件进行粗略的自动补全;对我来说不是。
SciTE 有两个优点:轻便快捷,简单易学。像 Geany 一样,它是严肃的 Python 程序员的最小编辑器,如果这就是你想要的,它可能是一个不错的选择。
SPE (Stani 的 Python 编辑器)
SPE 介于专用 Python 文本编辑器和 Python IDE 之间,看起来很有前途,但最终无法提供令人满意的编辑体验。基本编辑器足够有效,可以立即使用,它提供了许多好的工具,包括集成良好的 Python 控制台、有效的搜索面板和文件浏览器。
SPE 的网站承诺了语法突出显示、自动完成、自动缩进、语法检查、wxPython GUI 设计器和集成调试器,但有些功能比其他功能更成功。我测试了最新的稳定版本 0.8.4.h,虽然语法突出显示、自动缩进、语法检查和 GUI 设计器的功能都可以接受,但自动完成功能却非常糟糕;除了标准库中最常见的部分之外,建议似乎只是从文件中每个标记的列表中提取出来的。集成调试器完全无法工作;每次我试图调用编辑器时,它都会崩溃。
虽然 SPE 看起来是 Python 编辑器或 proto-IDE 的良好开端,但上一个稳定版本是在 2008 年,所以它最初的承诺实现的可能性越来越小。
崇高的文字
Sublime Text 是一个非常好的程序员编辑器,它的优点是吸引人——就像 Mac 级别的漂亮。它有一系列强大的功能,包括多个光标(允许在多个地方同时进行相同的编辑),一个灵活的“转到任何地方”界面,一个命令面板,允许基于键盘轻松访问 Sublime Text 的所有功能,分屏编辑,无干扰模式,以及两种定制:一种相对简单的使用 JSON,一种更高级的使用 Python 的插件 API。
这些能力都很吸引人,几乎足够自己推荐编辑器了。然而,也有一些缺陷。自动缩进是存在的,但是除了在每个冒号后添加一级缩进之外,它不能处理太多。自动补全可以通过 SublimeCodeIntel 或 SublimeRope 插件来实现,但是这两种插件都不太先进。最棒的是,由于编辑器是如此的可扩展,如果你愿意,你可以修复这些问题。
我不能完全推荐 Sublime Text,因为在我的测试中插件的性能很差,但编辑器非常优秀,如果你不是自动完成的经常用户,你可以考虑一下。如果我没有其他爱好,我可以把它作为 Python 的主要编辑器。
Vim
Vi 是反 Emacs 的,也是一个优秀的文本编辑器。它创建于 1976 年,从软件的角度来说已经很老了,几乎和 Emacs 一样老了。它轻便、快速,并且几乎总是默认安装在 Linux 和其他 Unixes 中。vim——vi 改进版——是当今最常见的 VI 实现,尽管还有其他实现。Vim 或 elvis 是另一个克隆版本,可用于 Windows、Mac OS X、BSDs、Minix、Haiku 和大多数其他操作系统。Vim 有扩展,允许它编辑几乎任何编程语言,无论多么晦涩难懂。
Vim 内置了语法高亮显示、代码折叠和自动缩进,通过在每个源文件中添加一些 modeline 注释或对其设置文件.vimrc进行一些添加,它可以确保您不会混淆空格和制表符。通过rope-vim、python-mode或jedi-vim,它可以自动完成,包括非系统模块,并且有许多模块可以让它用上面为 Emacs 列出的 Python 代码做几乎任何事情。Vim 还可以使用内置的脚本语言 VimScript 进行扩展,尽管通常 Vim 用户不会使用 Emacs 丰富的扩展特性。(我不是 vim 专家,但约翰·安德松是;关于为 Python 设置 vi 的高级技巧,请参阅他的文章
将 Vim 变成现代 Python IDE 。
Vim 和 Emacs 一样,有一个学习曲线——可能比 Emacs 更陡峭,因为它是一个模态编辑器,其中不同类别的操作,如导航和编辑,在不同的时间处于活动状态。Vim 内置了优秀的帮助,输入:help即可访问;它包括参考指南和教程。
Vim,确切地说是另一种文本编辑器的生活方式。大多数忠实的 vim 用户使用 vim 进行几乎所有的编辑工作。
编辑:总结
Python 有很多不错的编辑器,但是有几个很突出:有生活方式编辑器,Emacs 和 Vim,这两个都很强大,但是学习曲线很糟糕。有 SciTE 和 Geany,像许多类似的编辑器一样,对于那些想在编辑器中不投入太多精力就能进入 Python 编程的人来说,它们是很好的基本选择。最后,还有 Sublime Text,虽然有缺陷,但它有许多独特的功能,看起来将成为这一代人的 Emacs 和 Vim 对前一代人的贡献:他们自己的编辑器。
接下来,我们将讨论ide:Python 开发的最佳 ide。
冒泡排序:快速教程和实施指南
原文:https://www.pythoncentral.io/bubble-sort-implementation-guide/
先决条件
要了解冒泡排序,您必须知道:
- Python 3
- Python 数据结构-列表
什么是冒泡排序?
在上一个教程中,我们看到了如何在未排序和排序的列表中搜索元素。我们发现对列表进行排序后,搜索效率会更高。那么我们如何对列表进行排序呢?在本教程和接下来的教程中,我们将研究一些常用的列表排序算法。每种算法都有其优点和缺点,我们将在后面讨论。
注意:所有这些算法都侧重于按升序对列表进行排序(降序被认为是未排序的)。
首先,我们来看看最基本最简单的算法之一——冒泡排序。它可能不是最高效的,但是非常容易实现。冒泡排序接受一个未排序的列表,并不断将每个元素与其右侧的邻居进行比较,以便对数据进行排序。较小的元素会向左移动。一轮结束后,最大的数字会回到正确的位置。换句话说,在这种情况下,最大数量的气泡位于顶部或右侧。然后,一次又一次地重复这个过程,直到所有的数据都被排序。让我们看一个例子来更好地理解这一点。
a = [6,8,1,3,0,5]
第一轮:
0 - 6 < 8(无互换)-【6,8,1,3,0,5】
1 - 8 > 1(互换)-【6,1,8,3,0,5】
2 - 8 > 3(互换)-【6,1,3,8,0,5】
3 - 8 > 0(互换)-【6,1,3,0,8,5】
4 - 8 > 5(互换)-【6,1,3,0,5,8】
注意: 8 在其正确的位置
第二轮:
0 - 6 > 1(互换)-【1,6,3,0,5,8】
1 - 6 > 3(互换)-【1,3,6,0,5,8】
2 - 6 > 0(互换)-【1,3,0,6,8】
3 - 6 < 8(无交换)- [1,3,0,6,8] -不需要
注意: 6 在其正确的位置
第三轮:
0 - 1 < 3(无互换)-【1,3,0,6,8】
1 - 3 > 0(互换)-【1,0,3,6,8】
2 - 3 < 6(无互换)-【1,0,3,6,8】
3 - 6 < 8(无交换)- [1,0,3,6,8] -不需要
注意: 3 在其正确的位置
第四轮:
0 - 1 > 0(互换)-【0,1,3,6,8】
1 - 1 < 3(无互换)-【0,1,3,6,8】
2 - 3 < 6(无交换)- [0,1,3,6,8] -不需要
3 - 6 < 8(无交换)- [0,1,3,6,8] -不需要
注意: 1 在其正确的位置
第五轮:
0 - 0 < 1(无互换)-【0,1,3,6,8】
1 - 1 < 3(无交换)- [0,1,3,6,8] -不需要
2 - 3 < 6(无交换)- [0,1,3,6,8] -不需要
3 - 6 < 8(无交换)- [0,1,3,6,8] -不需要
注意:0 位于正确的位置。即使 0 在第 4 轮中处于正确的位置,我们的算法也不理解这一点,直到该过程完成。
上面的未排序列表不是最坏的情况,最坏的情况是未排序列表是降序列表。对于这样一个包含了 n 元素的列表,我们需要执行(n-1)次交换来对其进行升序排序。你自己试试这个。观察如何在第一轮中对所有的 n 元素进行排序,而在第二轮中对(n-1)元素进行排序,以此类推。
尝试这个动画来获得算法的可视化。
如何实现冒泡排序?
在我们进入算法和代码之前,理解交换是如何工作的是很重要的。为了交换两个元素 a = 10 和 b = 5 的值,我们需要一个 temp 变量。该变量暂时存储 a 的值,该值后来被赋给b。
a = 10
b = 5
温度= a #a = 10,温度= 10,b = 5
a = b #a = 5,温度= 10,b = 5
b =温度#a = 5,温度= 10,b = 10
打印(a)#打印 5 张
打印(b)#打印 10 张
算法
现在,让我们看看如何实现优化版本的冒泡排序:
- 对于第一次迭代,比较所有元素(n)。对于后续运行,比较(n-1) (n-2)等。
- 将每个元素与其右侧的邻居进行比较。
- 将最小的元素交换到左边。
- 继续重复步骤 1-3,直到覆盖整个列表。
代码
def bubbleSort(alist):
#Setting the range for comparison (first round: n, second round: n-1 and so on)
for i in range(len(alist)-1,0,-1):
#Comparing within set range
for j in range(i):
#Comparing element with its right side neighbor
if alist[j] > alist[j+1]:
#swapping
temp = alist[j]
alist[j] = alist[j+1]
alist[j+1] = temp
return alist
print(bubbleSort([5,1,2,3,9,8,0]))
这个算法是 0(n^2 的(n 的 2 次方)
结论
你可以进一步优化上面的代码,检查输入列表是否已经排序。这可以通过检查给定回合中发生的交换次数来完成。如果没有交换,则列表被排序。这种算法适用于小列表,但总的来说,它显然不是一个有效的算法。本教程到此为止。请务必尝试自己编写这段代码,并了解它的应用。快乐的蟒蛇!
使用 Pygame 为 Python 构建游戏
原文:https://www.pythoncentral.io/build-games-python-using-pygame/
Pygame 是一组模块,通过提供额外的功能和库来帮助你编写 Python 游戏。它是免费的,支持 Python 3.2 和更高版本,可以在几乎所有的操作系统和平台上运行,并且有超过一百万的下载量,所以它的应用非常广泛。

Pygame 速度超快,因为它对核心函数使用了优化的 C(C 可以比 Python 快 10 到 20 倍)。该库还提供了快速而周到的支持——如果您发现了一个 bug 或者遇到了代码的任何问题,他们会非常积极地响应。成千上万的游戏都是用 Pygame 制作的,包括这款街机风格的游戏,目标是尽可能多地射击小行星,并接回被困的宇航员返回空间站。
不仅用 Pygame 制作游戏很有趣(创建者说“包含了愚蠢”),而且玩用这个库创建的游戏也很有趣。如果你是一个游戏制作者,一直在寻找能使 Python 游戏的制作过程更快更有效的模块和库,Pygame 可能是适合你的工具。如果你需要帮助,请务必查看教程页面。
捕捉 Python 异常——try/except/else 关键字
原文:https://www.pythoncentral.io/catching-python-exceptions-the-try-except-else-keywords/
通常,在编写 python 杰作时,在执行您精心设计的代码时,会出现某些问题。诸如丢失的文件或目录、空字符串、应该是字符串但在运行时实际上是数组的变量。
这些东西在 Python 中被称为异常。这就是try关键字的用途。
它允许执行嵌套在一个合适的块中的潜在中断代码。这个块将试图捕捉任何那些讨厌的异常,然后执行代码或者从错误中恢复,或者通知用户这个错误。
例如,此函数希望运行:
def succeed(yn):
if yn:
return True
else:
raise Exception("I can't succeed!")
但是,据我们所知,它有可能引发一个异常。当一个异常被引发,并且它不在一个有适当异常处理的try块中时,它将停止代码的执行。
如果此代码以下列身份运行:
>>> succeed(True)
True
会没事的,没人会知道有什么不同。
但是,如果它运行为
>>> succeed(False)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in succeed
Exception: I can't succeed!
我们得到这个可爱的消息,代码不能成功。只是没那么可爱。其实挺丑的。
那么我们能做什么呢?
这就是try块的用武之地!
因此,为了使上面的代码运行时友好,我们可以这样做:
from random import randint
def handle _ exception(e):
print(e)
print('但是我可以安全!')
try:
success(randint(False,True))
Exception as e:
handle _ Exception(e)
我们刚刚做了什么?嗯,randint会在两个给定的输入之间选择一个随机整数。在这种情况下,False为 0,True为 1。所以succeed函数会随机引发一个异常。
现在除了例外。如果succeed函数引发异常,我们告诉 Python 只执行handle_exception。
*因此,如果我们运行这段代码,如果成功,输出将是空的,如果失败:
I can't succeed!
But I can be safe!
但是如果你想在成功后执行一段代码呢?你可以这样做
def another_method_that_could_fail():
fail = randint(False, True)
如果失败:
抛出 runtime error(‘我肯定失败了。’)
else:
print("耶!我没有失败!")
try:
success(randint(False,True))
another _ method _ that _ could _ fail()
Exception as e:
handle _ Exception(e)
现在,我们看到如果succeed没有引发异常,那么another_method_that_could_fail就会运行!太神奇了!我们做到了!
但是等等!如果another_method_that_could_fail运行,它将再次运行handle_exception,我们希望打印不同的消息。可恶。
那我们该怎么办?嗯,我们可以向我们的try块添加另一个块,如下所示:
def handle_runtime(re):
pass
try:
success(randint(False,True))
another _ method _ that _ could _ fail()
Exception runtime error as re:
handle _ runtime(re)
Exception as e:
handle _ Exception(e)
好吧,那很好。但是现在,我们如何成功运行一段代码,没有例外?嗯,try区块还有一部分不太为人所知。这是关键字else。观察:
如果我们将之前的代码稍加修改:
try:
succeed(randint(False, True))
another_method_that_could_fail()
except RuntimeError as re:
handle_runtime(re)
except Exception as e:
handle_exception(e)
else:
print('Yes! No exceptions this time!')
然后,只有当我们成功时,才会打印出一条漂亮的消息。好吧,但是如果我们无论如何都需要一段代码来运行呢?对于关闭一个已经在try块中打开的文件有用吗?是啊!
从舞台左侧,输入finally关键字。它会如我们所愿。
在光荣的行动中观察它:
try:
succeed(randint(False, True))
another_method_that_could_fail()
except RuntimeError as re:
handle_runtime(re)
except Exception as e:
handle_exception(e)
else:
print('Unknown error occurred. Exiting.')
exit(2)
finally:
print("Finally! I'm done. I don't care if I failed or not. I'm DONE.")
瞧!我们找到了。现在我们将总是在finally部分打印消息。
这就是 try/except/else/finally 块。我希望我在你成为一名 Python 大师的过程中很好地教育了你。
Sayō nara,暂时的。*
用 Python 检查目录中是否存在文件
原文:https://www.pythoncentral.io/check-file-exists-in-directory-python/
在 Python 中,有几种方法可以用来检查某个目录中的文件是否存在。当检查文件是否存在时,通常在访问(读取和/或写入)文件之前执行。下面我们将介绍检查文件是否存在(以及是否可访问)的每种方法,并讨论每种方法的一些潜在问题。
1. os.path.isfile(路径)
如果给定的路径是现有的常规文件,此函数返回 true。它遵循符号链接,因此有可能os.path.islink(path)为真,而os.path.isfile(path)也为真。这是一个检查文件是否存在的方便函数,因为它是一个简单的命令行程序。不幸的是,该函数只检查指定的路径是否是一个文件,但不保证用户可以访问它。它也只告诉你在你调用这个函数的时候这个文件已经存在了。有可能(尽管可能性极小),在调用这个函数和访问这个文件之间,它已经被删除或移动/重命名了。
例如,它可能在以下场景中失败:
【python】
OS . path . is File(' foo . txt ')
True
f = open(' foo . txt ',' r')
Traceback(最近一次调用 last):
File " ",第 1 行,in
IOError: [Errno 13]权限被拒绝:' foo.txt'
2.os.access(路径,模式)
这个函数测试当前用户(拥有真实的 uid/gid)是否有访问给定路径的权限(读和/或写权限)。要测试文件是否可读,可以使用os.R_OK,使用os.W_OK来确定文件是否可写。比如如下。
>>> # Check for read access to foo.txt
>>> os.access('foo.txt', os.R_OK)
True # This means the file exists AND you can read it.
>>>
>>> # Check for write access to foo.txt
>>> os.access('foo.txt', os.W_OK)
False # You cannot write to the file. It may or may not exist.
如果您计划访问一个文件,使用这个函数会更安全一些(尽管不完全推荐),因为它还会检查您是否可以访问(读或写)该文件。但是,如果您计划访问该文件,则在您检查该文件是否可访问和您访问该文件之间,该文件可能已经被删除或移动/重命名。这就是所谓的竞争条件,应该避免。下面是一个如何发生的例子。
>>> # The file 'foo.txt' currently exists and is readable.
>>> if os.access('foo.txt', os.R_OK):
>>> # After executing os.access() and before open(),
>>> # another program deletes the file.
>>> f = open('foo.txt', 'r')
Traceback (most recent call last):
File "", line 1, in
IOError: [Errno 2] No such file or directory: 'foo.txt'
3.试图访问(打开)文件。
为了绝对保证文件不仅存在,而且在当前时间是可访问的,最简单的方法实际上是尝试打开文件。
try:
f = open('foo.txt')
f.close()
except IOError as e:
print('Uh oh!')
这可以转换成一个易于使用的函数,如下所示。
def file_accessible(filepath, mode):
''' Check if a file exists and is accessible. '''
try:
f = open(filepath, mode)
f.close()
except IOError as e:
return False
返回真值
例如,您可以按如下方式使用它:
>>> # Say the file 'foo.txt' exists and is readable,
>>> # whereas the file 'bar.txt' doesn't exist.
>>> foo_accessible = file_accessible('foo.txt', 'r')
True
>>>
>>> bar_accessible = file_accessible('bar.txt', 'r')
False
因此...哪个最好?
无论您决定使用哪种方法,都取决于您为什么需要检查文件是否存在,速度是否重要,以及在任何给定时间您经常尝试打开多少个文件。在许多情况下,os.path.isfile应该足够了。但是请记住,在使用任何一种方法时,每种方法都有自己的优点和潜在问题。
如何在 Python 中检查对象类型
这篇 Python 初学者教程将教你如何在 Python 中检查对象类型的基础知识。你可能已经知道了,Python 中不同类型的对象。对象可以是列表、字符串、整数等。在您作为开发人员的职业生涯中,有时您需要知道一种类型或另一种类型之间的区别,因为肉眼并不总是显而易见的。如果您发现自己需要找出正在处理的对象的类型,Python 有一个内置的功能来确定这一点。type()函数,顾名思义,使用起来非常简单,它将帮助您快速确定您正在处理的 Python 对象的类型。
要使用它,你只需要把对象作为参数传递给函数,你很快就会得到答案。例如,如果您正在寻找一个如下所示的对象类型:
one = ['purple', 'yellow', 'green']
您只需要使用 type()函数,就像这样:
type(one)
根据对象的格式,您可能已经知道了答案(两个[]括号之间的任何对象都是列表),但是您的输出将是这样的:
<type 'list'>
您也可以使用以下语法,以稍微不同的方式使用 type()。
type(one) is a list
>>>True
在上面的例子中,第一行是如何使用 type()函数,第二行是告诉您对象是否是您所认为的类型的输出(在本例中,它实际上是一个列表)。在 Python 中使用 type()函数是一种简单且相对容易的方法,可以确定您正在处理的对象的类型,所以可以尝试使用它,直到您可以在任何编码环境中轻松使用它。
循环队列:实现教程
先决条件
要了解循环队列,您首先应该很好地理解以下内容:
- Python 3
- 线性队列(你可以在这里了解更多)
- 基本 Python 数据结构概念-列表
- 基本数学运算-模数(%)
什么是循环队列?
在你继续阅读本教程之前,我强烈推荐你阅读我们之前的关于队列的教程,因为我们将建立在这些概念之上。循环队列被广泛使用,并且经常在工作面试中被测试。循环队列可以看作是对线性队列的改进,因为:
- 由于头尾指针会自行复位,因此无需复位。这意味着一旦头部或尾部到达队列的末尾,它会将自己重置为 0。
- 尾部和头部可以指向同一个位置——这意味着队列是空的
- 头可以比尾大,反之亦然。这是可能的,因为头指针和尾指针允许相互交叉。
看看 这个 的动画可以更好地理解环形队列。
基于上述动画的观察:
- 头指针——指向队列的最前面。或者换句话说,如果调用出列操作,它指向要删除的元素。
- 尾指针指向下一个可以插入新元素的空白点。在上面的动画中,如果您试图完全填满队列,您将无法在第 13 个位置之后排队。这是因为在第 14 个位置插入一个元素后,尾部没有空的点可以指向。即使还有一个空位,也认为队列已满。您还应该尝试执行三次或四次出列操作,然后将一个元素入队。在这里,您将看到元素从第 14 个位置插入,然后从 0 重新开始。正是由于这个原因,它被称为循环队列。
- 元素数量:
- 尾>=头:元素个数=尾-头。例如,如果 Head = 2,Tail = 5,那么元素的数量将是 5 - 2 = 3
- 头>尾:元素个数=(队列大小)-(头尾)=(队列大小)-头+尾。例如,头= 14,尾= 5,队列大小= 15,那么元素数= 15 - (14 - 5) = 6
如何实现循环队列?
我希望你现在有信心知道什么是循环队列。让我们 看看如何使用语言不可知的方法来实现它。为此,我们需要像对待数组一样对待列表,因此我们将限制它的大小。
注意: 在出队操作期间,头指针将增加 1,但实际上不会从队列中移除任何元素。这是因为一旦删除了一个元素,列表会自动将所有其他元素向左移动一个位置。这意味着位置 0 将总是包含一个元素,该元素不是实际队列/循环队列的工作方式。
算法
以下步骤可以看作是循环队列操作的流程图:
- 初始化队列、队列大小(maxSize)、头指针和尾指针
- 排队:
- 检查元素的数量(size)是否等于队列的大小(maxSize):
- 如果是,抛出错误消息“队列已满!”
- 如果没有,则追加新元素并递增尾指针
- 检查元素的数量(size)是否等于队列的大小(maxSize):
- 出列:
- 检查元素数量(大小)是否等于 0:
- 如果是,抛出错误消息“队列为空!”
- 如果没有,则增加头指针
- 检查元素数量(大小)是否等于 0:
- 尺寸:
- 如果尾部> =头部,则大小=尾部-头部
- 如果 head>tail,size = maxSize -(头尾)
注意:头和尾指针的范围应该在 0 和 maxSize - 1 之间,因此我们使用的逻辑是,如果我们将 x 除以 5,那么余数永远不会大于 5。换句话说,应该在 0 到 4 之间。因此,将此逻辑应用于公式 tail = (tail+1)%maxSize 和 head = (head+1)%maxSize。请注意,这有助于我们避免在队列变满时将 tail 和 head 重新初始化为 0。
程序
class CircularQueue:
#Constructor
def __init__(self):
self.queue = list()
self.head = 0
self.tail = 0
self.maxSize = 8
#Adding elements to the queue
def enqueue(self,data):
if self.size() == self.maxSize-1:
return ("Queue Full!")
self.queue.append(data)
self.tail = (self.tail + 1) % self.maxSize
return True
#Removing elements from the queue
def dequeue(self):
if self.size()==0:
return ("Queue Empty!")
data = self.queue[self.head]
self.head = (self.head + 1) % self.maxSize
return data
#Calculating the size of the queue
def size(self):
if self.tail>=self.head:
return (self.tail-self.head)
return (self.maxSize - (self.head-self.tail))
q = CircularQueue()
print(q.enqueue(1))
print(q.enqueue(2))
print(q.enqueue(3))
print(q.enqueue(4))
print(q.enqueue(5))
print(q.enqueue(6))
print(q.enqueue(7))
print(q.enqueue(8))
print(q.enqueue(9))
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
print(q.dequeue())
应用
循环队列有多种用途,例如:
- 计算机架构(调度器)
- 磁盘驱动器
- 视频缓冲
- 打印机作业调度
结论
开始时,循环队列可能看起来有点混乱,但掌握它的唯一方法就是不断练习。在上面提供的动画链接中尝试不同的入队和出队操作,看看它是如何工作的。本教程到此为止。快乐的蟒蛇!
代码片段:使用 Python 求解二次方程
原文:https://www.pythoncentral.io/code-snippets-using-python-to-solve-the-quadratic-equation/
Python 是一种通用且强大的编码语言,可用于执行各种功能和流程。感受 Python 如何工作的最好方法之一是用它来创建算法和求解方程。在这个例子中,我们将向您展示如何使用 Python 来求解一个更广为人知的数学方程:二次方程(ax ² + bx + c = 0)。
import cmath
print('Solve the quadratic equation: ax**2 + bx + c = 0')
a = float(input('Please enter a : '))
b = float(input('Please enter b : '))
c = float(input('Please enter c : '))
delta = (b**2) - (4*a*c)
solution1 = (-b-cmath.sqrt(delta))/(2*a)
solution2 = (-b+cmath.sqrt(delta))/(2*a)
print('The solutions are {0} and {1}'.format(solution1,solution2))
正如您所看到的,为了求解方程,必须导入 cmath 模块,并且通过使用乘法、除法和 cmath.sqrt 方法(可用于求一个数的平方根)来求解方程。打印出来的文字可以定制成你喜欢说的任何话。
Python 开发 ide 的比较
原文:https://www.pythoncentral.io/comparison-of-python-ides-development/
This article was written by Jason Fruit. For another opinion on Python IDES by Sergio Tapia Gutierrez, checkout our article Best IDEs for Python Development. We also have a Review of Python's Best Text Editors.Edit: Mike has pointed out in the comments that PyCharm now comes with a free version (community edition). We've updated the article to reflect this.
直到最近,我已经好几年没有研究 Python IDEs 了;我通常不是一个 IDE 用户——我通常使用 Emacs 。当我最后一次检查它们时,Python IDEs 是令人沮丧的;为动态语言编写工具并不容易,因为他们必须分析代码,并且它的许多行为在运行前很难预测。然而,现在有一点对我来说变得特别明显:Python IDEs 已经有了很大的改进。如果我现在开始成为一名 Python 程序员,我很可能会选择 IDE——其中一些确实令人印象深刻。我已经测试并回顾了其中的许多,所以下面你会发现 Python IDEs 的比较,按字母顺序排列:
PyDev 的月食
完全公开:在编程环境(或者文学环境,就此而言)中,“Eclipse”这个词让我充满恐惧;在我心目中,月食就是一头被绑在鲸鱼身上的猪和一只被绑在鲸鱼身上的狗。我不愿意安装 Eclipse,因为它是一个非常大的应用程序;有人会说臃肿。鉴于此,我对 PyDev 有些偏见——但我试图公平地评价它,它给我留下的印象比我预期的要多得多。
PyDev 的安装比这里讨论的许多 ide 要复杂一些,因为 Eclipse 必须单独安装。然后,Eclipse 必须关闭并作为管理员运行,您必须添加 PyDev 的软件源,接受它的证书,并等待插件安装。那么您必须以普通用户的身份重启 Eclipse。(优秀的说明可从pydev.org处获得。)

PyDev 的 Eclipse
我最初的反应是,它很好,但有些笨重。代码导航做得很好,也很有效,自动缩进和去缩进工作得很漂亮。自动补全功能运行良好,并给出了很好的建议,但是用户交互实现有些笨拙;在某些情况下,例如,如果您有一个缩小到单个建议的列表,并且您想键入其他内容,您必须按 Escape 键来退出自动完成列表,将您的手从它们的键入位置移开。出于某种原因,在项目中创建一个新的 Python 文件有时需要几秒钟。对于类和函数来说,代码折叠是可用的,但是由于某种原因,对于任何其他类型的块来说都是不可用的。调试器工作正常,但它的用户界面——它打开了一个不同的调试视图,而不是将调试集成到常规的 PyDev 视图中——只是比它需要的更加分散,到处都是额外的 chrome,使得可用空间如此之小,以至于你必须滚动才能看到一切。
PyDev 确实有一些其他 ide 没有的东西,那就是远程调试;如果这对您很重要,您必须使用 Emacs 或 PyDev,这是我发现的唯一可行的选择。
总的来说,Eclipse 和 PyDev 是一个非常好的 IDE。如果您是一个已经习惯了 Eclipse 的 IDE 用户,并且您喜欢它,我会让 PyDev 试试,这样您就可以使用您已经熟悉的工具了。如果 Eclipse 对您不重要,但是您想要一个 IDE,我会尝试 PyCharm,它以一个更干净、更快、更好的软件包提供了所有相同的特性;尽管如此,PyDev 还是一个不错的选择。
埃里克
Eric 是用 Python 写的 IDE,带 PyQt 。它集成了一些熟悉的 Qt 工具,比如 Designer 和 languages,使用了无处不在的 Scintilla 编辑组件,并且拥有一些看起来非常有用的工具。
这就是我对 Eric 的总结,因为它有一个非常严重的缺点:它有一个非常复杂的界面,可发现性很低,文档很少。感觉就像它被设计成让用户感到愚蠢和无能。我可以直接进入并使用这个列表中的其他编辑器和 ide,并查阅文档中不明显的部分,Eric 每次都阻止我,尽管它的插件 API 是有文档记录的(我想是通过一个工具),但没有包括用户文档。没有。零文档。
毫无疑问,你会原谅这篇评论中沮丧的语气。

Eric 4 Python IDE 截图
自动完成起初似乎没有打开,所以我翻遍了首选项,在两个地方启用了它,我认为这是必要的。这太糟糕了——事实上糟糕得可笑,所以我搜索并找到了自动补全替代插件的参考资料。我安装了其中的一个,基于 Rope,检查了偏好设置以启用和,发现有变化但没有改进——然后厌恶地放弃了。
自动缩进是勉强可以接受的。Qt 的 GUI 设计器已经足够好了,但是祝你好运找到它。提示:它不在菜单上。调试工作,并声称可以远程调试,虽然我没有测试。哦,偏好设置里禁用了。
重构?不知道行不行;我从未见过菜单被启用。也许它在首选项中也被禁用了,但是我找不到它的设置。对于完全无用的帮助查看器,有广泛的定制选项,如果有帮助的话。
我见过比 Eric 用户体验更好的狗屎。
无所事事
大多数 Python 发行版都有 IDLE,它将自己描述为“用 tkinter GUI 工具包构建的 Python IDE”。它宣传以下功能:
- 用 100%纯 Python 编码,使用 Tkinter GUI 工具包。
- 跨平台:适用于 Windows、Mac 和 Linux/Unix。
- 多窗口文本编辑器,具有多重撤销、Python 着色和许多其他功能,例如智能缩进和呼叫提示。
- Python shell 窗口(也称为交互式解释器)。
- 调试器(不完整,但可以设置断点、视图和步骤)。

Python IDE 空闲截图
所有这些特性实际上都存在,但它们并不能真正构成一个 IDE。事实上,虽然 IDLE 提供了一些你期望从 IDE 中得到的特性,但它并不是一个令人满意的文本编辑器。该界面存在缺陷,未能考虑 Python 的工作方式,特别是在交互式 shell 中,自动完成在标准库之外没有用,编辑功能如此有限,以至于没有一个认真的 Python 程序员——见鬼,没有一个认真的
打字员——可以全职使用它。
如果你使用 IDE,它不应该是空闲的。
Komodo IDE
ActiveState 提供了“额外电池”的 Python 优秀发行版,他们的 Perl 和 Tcl 发行版也不错,但是他们应该把 Python IDE 的业务留给别人。为科莫多巨蜥支付 295 美元是令人难以容忍的;PyDev 不免费或者 PyCharm 花更少的钱做的事情很少,而且它做的很多事情只是名义上有效,至少在 Ubuntu 上是现成的。
公平地说,他们从事的工作比本文所讨论的大多数 IDE 的开发人员更困难:Komodo IDE 还为 CSS、HTML、JavaScript、PHP、Perl、Ruby、Tcl、XML、XSLT、XUL 和各种模板语言提供了编辑和代码完成功能。我没有测试其中任何一个,尽管我了解到它们的 JavaScript 支持非常出色。尽管如此,这对你写 Python 还是没什么帮助。
PyCharm
PyCharm 是由 IntelliJ IDEA、WebStorm、RubyMine 和其他强大的单一语言 ide 背后的人 JetBrains 创建的。他们当然知道 IDEs,他们的经验用 PyCharm 表现出来。这是一个完美的、强大的、多功能的 IDE,运行良好、快速,并且提供了很多功能。
PyCharm 实际上拥有 IDE 的所有功能:代码突出显示、真正有效的自动缩进、可定制的代码格式、我见过的最好的 Python 自动完成功能(尽管在第一次创建项目时构建索引花费了大量时间)、实时错误检测(加上拼写检查,我觉得这很有价值)、代码片段、代码折叠、智能引号、括号、冒号,甚至参数:它真的非常强大。它拥有强大的项目导航工具、自动纠错建议、优秀的重构工具、文档浏览器、Python 调试器、单元测试工具等等。太棒了。

PyCharm Python IDE 截图
它还提供了使用和调试 Django 和 Google App Engine 应用程序的特殊功能,强大的 JavaScript、CoffeeScript、HTML 和 CSS 编辑器,各种模板工具,JavaScript 调试器——你相信了吗?我唯一想从一个 IDE 中得到的是一个 GUI 设计器;也许 JetBrains 的人不希望他们优秀的 IDE 被称为“PyGTK 的 RAD IDE”,或者他们选择的任何工具包。无论如何,有很多独立的 GUI 设计器可用于各种 GUI 工具包,而且我也不使用它们,所以我觉得这并不是一个不足。
PyCharm 有两个版本——社区版和专业版。社区版是免费的(就像 freedom 一样),而专业版是部分专有的,价格不等。他们向开源项目和教育机构免费提供专业版,而价格从 29 美元到 199 美元不等。你可以点击查看全部定价。
如果我是一个几乎完全依赖 Python 的开发人员,并且我还没有投入太多时间来学习如何用 Emacs 做 PyCharm 做的所有事情,我会强烈考虑转向 PyCharm。你绝对应该把它放在你的候选名单上。
机翼 IDE
Wing IDE 专业版(我评测的版本)和 Komodo IDE 价格差不多,但相似之处也就到此为止了。它速度快,功能全,而且有效。自动完成和自动缩进与这里最好的评论一样好,集成测试和调试工作良好,具有直观的界面,尽管重构选项非常有限,但是一旦您在运行工具之前确定了应该选择什么,它们就工作得很好。
片段是存在的,但不像 PyCharm 中那样干净地实现,或者更严重的是,Sublime Text;尽管如此,它们仍然是合理的默认值,您可以编辑它们并添加更多。

Wing Python IDE 截图
几个杂项:Wing 可以做 Django 项目,集成了 diff 和 merge,一个很好的 Python shell,一个操作系统命令接口,我发现它令人困惑,不如一个简单的控制台,并且通常可以做你期望从 IDE 中得到的所有事情。
我发现 UI 比 Eclipse/PyDev 好,但比 PyCharm 稍差一些,而且比这两者都不落后。机翼是一个非常好的选择,但价格昂贵;如果我掏钱,我会注意到两件事:个人版只省略了一些我认为有用的功能,而且价格低得多;而 PyCharm,一般来说也一样好但是速度慢,价格和 Personal 差不多。
Python ide 对比总结
ide 中有一些非常好的选择:如果你想要一个运行良好的免费的,安装 Eclipse 和 PyDev 如果你愿意出钱,PyCharm 和 Wing IDE 的能力差不多,都是优秀的 IDE。也有一些灾难,包括免费的和不免费的,但是很明显 Python 的 ide 在过去的十年里有了很大的进步,可以和不太动态的语言的工具相比较。
要了解关于 Python IDEs 的另一个观点,请查看塞尔吉奥的文章。
互联 CMMS

什么是连通 CMMS?
互联 CMMS 是一种连接您的系统、人员和流程的新型维护和物业运营方法。它将 CMMS 的范围扩展到维护和工作单之外,以简化流程,促进利益相关方的参与,并在一个位置提高效率和连接性。
联网 CMMS 是为大型物业运营和维护团队提供单一平台的最有效方式。
联网 CMMS 不再要求运营专业人员依赖各种单点解决方案来处理超出维护、电子邮件沟通、电子表格报告等范围的工作,而是将所有运营工作流程(包括客户参与和物业维护、工作场所管理、供应商管理、资产绩效和物联网信息)整合到一个单一的综合平台中。
T2 的大部分工作不是在 CMMS 进行的,而是在境外进行的。
CMMS/CaFM 系统的构建方式存在问题,即使是作为一个记录保存系统。它们不再与房地产业务的投资组合兼容。
投资组合不断发展,需要关注客户参与、合同管理、支出可见性、基于条件的投资组合规模维护优化....不胜枚举。
然而,在目前的 CMMS 模式中,通过电子表格和电子邮件完成的工作比 CMMS 还要多。这还没有提到登录几个系统来满足不同需求的困难。每个工作流程都必须通过各种工具,数字的和模拟的,每一步都变得低效、无效和缓慢。
您的 CMMS 必须超越资产&维护管理的范畴。
《连线 CMMS》如何将 CMMS 重新思考成一个现代的“行动系统”
在我们生活的这个时代,使用企业软件就像发短信一样简单——它速度快、界面友好、使用简单,并且采用了尖端技术。相比之下,56%的 O & M 利益相关者面临着维护和运营技术以及数字化转型的挑战。当前的 CMMS 只关注技术人员,很少或没有自动化或与 O & M 技术堆栈的其余部分集成。
互联 CMMS API 通过整合流程、人员和系统,提高效率并转变用户体验的提供方式。
【ConnectedCMMS(实际上)应该是什么样的,我们如何应对?
互联 CMMS 是一种灵活的方法。互联 CMMS 方法不需要您完全更换当前的技术堆栈并从头开始。它旨在与您当前的企业运营和业务软件协同工作,并开发基础设施(传感器和监控基础设施)。它必须使用 API 优先的设计来构建,这种设计将数据民主化和规范化,以允许访问第三方应用程序。它应该被设计为通过移动、网络和信息亭应用服务于 O & M 利益相关者(所有者、经营者、租户和居住者)。使用零代码 SaaS 平台而不是单点解决方案方法来解决与投资组合运营和维护相关的最常见的自动化、定制和集成问题是至关重要的。
《连线 CMMS》将其归结为三个支柱/步骤:
- 自动化
- 订婚
- 效率
第一步:在 CMMS 实现流程自动化,以简化操作并缩短时间
通常,今天的运营团队使用多个记录系统。这意味着各种工具在团队中存储和传递信息。此外,他们还投资软件或开发仪表板和分析工具。最终,你的日常工作流程缓慢而混乱。他们也挤满了不断变化的工具,很难跟踪。例如,团队使用电子邮件进行相互间的沟通,使用电话或聊天发出警告,使用企业工具进行会计和供应商 CRM,使用电子表格进行报告,以及所有其他事情。
为了解决这一问题,互联 CMMS 通过利用工作流自动化,帮助企业从记录系统“转向行动系统”。
在整个生命周期中,它通过各种流程的自动化来连接流程。这包括创建工作订单、发送通知、提醒技术人员、通信和批准、创建仪表板、报告、报表等。当所有的日常任务都由自动化工作流处理时,您的团队将有时间和精力专注于收入优化和向客户交付价值。
第二步:与 CMMS 的 O & M 参与者接触,提高各个层面的知名度和价值
从一开始,你的 CMMS 就必须设计成确保全面参与,而不是作为一种课外活动。它应向用户提供对物业单位的运营至关重要的用户界面,包括但不限于物业经理、现场技术人员、主管、物业经理和管理人员,他们可以在需要时访问所需的数据。所有来自外部的关键利益相关方(住户和工作中的员工以及租户/客户和承包商)都需要在他们的位置通过移动、网络或信息亭应用程序获得服务。
互联 CMMS 通过让多个利益相关方参与进来,帮助企业实现信息访问民主化,促进内部协作,并增强用户体验。
从财务和资产洞察、组织范围的进度监控到服务请求的反馈和互动响应,互联 CMMS 可以满足所有利益相关方的需求。
第三步:通过以有意义的方式整合 OT,在 CMMS 实现完全互联运营
运行 ppm 并不是唯一的业务运营要求。建筑物在能源管理、居住者健康和效率/预测性维护方面有更多的需求。连接到建筑系统并收集实时信息对于优化与之相关的流程至关重要。此外,CMMS 作为一个独立的解决方案是不够的。连接到第三方应用程序和软件以实现最大的企业 T2 价值是必不可少的。
互联 CMMS 通过一种 API 优先的方法,集成了 BMS 传感器、BIM 或任何第三方商业软件,使您能够更快地创建无缝的数字体验。
它支持互操作性,解决了企业应用程序最常见的集成问题。通过将来自第三方访问的数据大众化,您能够加快组合规模的物联网部署过程,而无需重复的站点级集成,并在更大范围内创造新的效率。
如何在 Python 中将字典值转换为列表
原文:https://www.pythoncentral.io/convert-dictionary-values-list-python/
在 Python 中,字典是一种内置的数据类型,可用于以不同于列表或数组的方式存储数据。字典不是序列,所以它们不能由一系列数字索引,而是由一系列关键字索引。在学习字典时,将字典数据看作无序的键:值对是有帮助的,在单个字典中,键需要是唯一的。您可以在一对花括号内轻松创建字典。用 key: value 格式的数据填充括号,用逗号分隔 key: value 对,这样就有了一个字典。
请参见下面的代码,了解字典的样子以及应该如何格式化的示例:
example = {'key1': value1, 'key2': value2, 'key3': value3}
如果你的键是字符串,记住把它们放在引号中是很重要的。
字典的有趣之处在于它们可以用来映射数据的不同方式。一个常见的字典操作是从键:值对中提取值,并将它们转换成一个列表,其代码实际上非常简单。要了解这是如何做到的,请查看下面的代码片段。
首先,我们需要一本字典:
food = {'pizza': 324, 'sandwich': 78, 'hot dog': 90}
接下来,我们需要可以用来执行从字典到列表的值转换的代码,如下所示:
food_list=list(data.values())
print(food_list)
就是这样。上面代码的输出应该是字典中键:值对的数据值,与它们在字典中出现的顺序完全一致。因此,您的输出应该如下所示:
324, 78, 90
您可以使用这个代码片段将任何字典的键:值对的值打印为一个列表。
在 Python 中剪切和切片字符串
原文:https://www.pythoncentral.io/cutting-and-slicing-strings-in-python/
作为字符序列的 Python 字符串
Python 字符串是单个字符的序列,与其他 Python 序列共享它们的基本访问方法——列表和元组。从字符串中提取单个字符(以及任何序列中的单个成员)的最简单方法是将它们解包到相应的变量中。
>>> s = 'Don'
>>> s
'Don'
>>> a, b, c = s # Unpack into variables
>>> a
'D'
>>> b
'o'
>>> c
'n'
不幸的是,为了存储字符串中的每一个字符,我们很难事先知道需要多少个变量。如果我们提供的变量数量与字符串中的字符数量不匹配,Python 会给我们一个错误。
s = 'Don Quijote'
a, b, c = s
Traceback (most recent call last):
File "", line 1, in
ValueError: too many values to unpack
在 Python 中通过索引访问字符串中的字符
通常,使用 Python 的类似数组的索引语法来访问字符串的单个字符更有用。这里,和所有序列一样,重要的是要记住索引是从零开始的;也就是说,序列中的第一项是数字 0。
>>> s = 'Don Quijote'
>>> s[4] # Get the 5th character
'Q'
如果您想从字符串的末尾开始计数,而不是从开头,请使用负索引。例如,索引-1 表示字符串最右边的字符。
>>> s[-1]
'e'
>>> s[-7]
'Q'
Python 字符串是不可变的,这只是一种奇特的说法,一旦它们被创建,你就不能改变它们。尝试这样做会触发错误。
>>> s[7]
'j'
>>> s[7] = 'x'
Traceback (most recent call last):
File "", line 1, in
TypeError: 'str' object does not support item assignment
如果你想修改一个字符串,你必须创建一个全新的字符串。在实践中,这很容易。我们一会儿就来看看。
切片 Python 字符串
在此之前,如果你想提取一个以上的字符,位置和大小已知的块呢?这相当简单和直观。我们稍微扩展了方括号语法,这样我们不仅可以指定我们想要的片段的起始位置,还可以指定它的结束位置。
>>> s[4:8]
'Quij'
让我们看看这里发生了什么。和以前一样,我们指定要从字符串中的位置 4(从零开始)开始。但是现在,我们不再满足于字符串中的单个字符,而是说我们想要更多的字符,直到,但不包括位于第 8 位的字符。
你可能会认为你也会得到 8 号位的字符。但事情不是这样的。别担心,你会习惯的。如果有帮助的话,可以把第二个索引(冒号后面的那个)想象成指定你不想要的第一个字符。顺便说一句,这种机制的一个好处是,您可以通过简单地从第二个索引中减去第一个索引来快速判断您将得到多少个字符。
使用这种语法,您可以省略一个或两个索引。第一个索引,如果省略,默认为 0,这样您的块从原始字符串的开头开始;第二个默认为字符串中的最高位置,因此您的块在原始字符串的末尾结束。省略这两个指标不太可能有多大的实际用途;正如您可能猜到的,它只是返回整个原始字符串。
>>> s[4:]
'Quijote' # Returns from pos 4 to the end of the string
>>> s[:4]
'Don ' # Returns from the beginning to pos 3
>>> s[:]
'Don Quijote'
如果你还在纠结于这样一个事实,例如,s[0:8]返回到为止的所有内容,但不包括第 8 位的字符,这可能会有所帮助:对于你选择的任何 index、n值,s[:n] + s[n:]的值将始终与原始目标字符串相同。如果索引机制是包含的,则位置 n 处的字符将出现两次。
>>> s[6]
'i'
>>> s[:6] + s[6:]
'Don Quijote'
就像以前一样,您可以使用负数作为索引,在这种情况下,计数从字符串的结尾(索引为-1)开始,而不是从开头开始。
>>> s[-7:-3]
'Quij'
分割 Python 字符串时跳过字符
方括号语法的最后一个变化是添加了第三个参数,该参数指定了“步幅”,即在从原始字符串中检索每个字符后要向前移动多少个字符。第一个检索到的字符总是对应于冒号之前的索引;但此后,无论您指定多少个字符作为步幅,指针都会向前移动,并在该位置检索字符。依此类推,直到达到或超过结束索引。就像我们目前遇到的情况一样,如果参数被省略,它默认为 1,这样就可以检索指定段中的每个字符。一个例子更清楚地说明了这一点。
>>> s[4:8]
'Quij'
>>> s[4:8:1] # 1 is the default value anyway, so same result
'Quij'
>>> s[4:8:2] # Return a character, then move forward 2 positions, etc.
'Qi' # Quite interesting!
您也可以指定负步幅。正如您所料,这表明您希望 Python 在检索字符时后退。
>>> s[8:4:-1]
'ojiu'
正如你所看到的,因为我们是在后退,所以起始索引比结束索引高是有意义的(否则什么都不会返回)。
>>> s[4:8:-1]
''
因此,如果您指定了一个负的步幅,但是忽略了第一个或第二个索引,Python 会将缺少的值默认为在这种情况下有意义的值:开始索引到字符串的末尾,结束索引到字符串的开头。我知道,它会让你一想到它就头疼,但是 Python 知道它在做什么。
>>> s[4::-1] # End index defaults to the beginning of the string
'Q noD'
>>> s[:4:-1] # Beginning index defaults to the end of the string
'etojiu'
这就是方括号语法,如果你知道你需要的字符块在字符串中的确切位置,它允许你检索字符块。
但是,如果您想基于字符串的内容检索一个块,而我们可能事先并不知道,该怎么办呢?
检查内容
Python 提供了字符串方法,允许我们根据指定的分隔符将字符串分割。换句话说,我们可以告诉 Python 在我们的目标字符串中寻找某个子字符串,并围绕该子字符串分割目标字符串。它通过返回结果子字符串的列表(减去分隔符)来实现这一点。顺便说一下,我们可以选择不显式指定分隔符,在这种情况下,它默认为空白字符(空格,' \t ',' \n ',' \r ',' \f ')或此类字符的序列。
请记住,这些方法对调用它们的字符串没有影响;它们只是返回一个新的字符串。
>>> s.split()
['Don', 'Quijote']
>>> s
'Don Quijote' # s has not been changed
更有用的是,我们可以将返回的列表直接存储到适当的变量中。
>>> title, handle = s.split()
>>> title
'Don'
>>> handle
'Quijote'
让我们的西班牙英雄暂时离开他的风车,让我们想象一下,我们有一个字符串,其中包含以小时、分钟和秒表示的时钟时间,用冒号分隔。在这种情况下,我们可以合理地将单独的部分收集到变量中,以便进一步操作。
>>> tim = '16:30:10'
>>> hrs, mins, secs = tim.split(':')
>>> hrs
'16'
>>> mins
'30'
>>> secs
'10'
我们可能只想分割目标字符串一次,不管分隔符出现多少次。split()方法将接受第二个参数,该参数指定要执行的最大分割数。
>>> tim.split(':', 1) # split() only once
['16', '30:10']
这里,字符串在第一个冒号处被拆分,其余部分保持不变。如果我们想让 Python 从字符串的另一端开始寻找分隔符呢?嗯,有一个叫做rsplit()的变体方法,它就是这么做的。
>>> tim.rsplit(':', 1)
['16:30', '10']
建造隔墙
类似的字符串方法是partition()。这也基于内容分割一个字符串,不同之处在于结果是一个tuple,它保留了分隔符,以及它两边的目标字符串的两个部分。与split()不同,partition()总是只做一次拆分操作,不管分隔符在目标字符串中出现多少次。
>>> tim = '16:30:10'
>>> tim.partition(':')
('16', ':', '30:10')
与split()方法一样,partition()、rpartition()也有一个变体,它从目标字符串的另一端开始搜索分隔符。
>>> tim.rpartition(':')
('16:30', ':', '10')
使用 Python 的 string.replace()
现在,回到我们的堂吉诃德。早些时候,当我们试图通过将“x”直接赋给s[7]来将“j”改为“x”从而使他的名字英语化时,我们发现我们做不到,因为你不能改变现有的 Python 字符串。但是我们可以通过在旧字符串的基础上创建一个我们更喜欢的新字符串来解决这个问题。允许我们这样做的字符串方法是replace()。
>>> s.replace('j', 'x')
'Don Quixote'
>>> s
'Don Quijote' # s has not been changed
再说一次,我们的字符串没有被改变。所发生的是 Python 只是根据我们给出的指令返回了一个新的字符串,然后立即丢弃它,留下我们的原始字符串不变。为了保存我们的新字符串,我们需要将它赋给一个变量。
>>> new_s = s.replace('j', 'x')
>>> s
'Don Quijote'
>>> new_s
'Don Quixote'
当然,我们可以重用现有的变量,而不是引入新的变量。
>>> s = s.replace('j', 'x')
>>> s
'Don Quixote'
这里,虽然看起来我们改变了原来的字符串,但实际上我们只是丢弃了它,并在它的位置存储了一个新的字符串。
注意,默认情况下,replace()将用新的子字符串替换搜索子字符串的每一次出现。
>>> s = 'Don Quijote'
>>> s.replace('o', 'a')
'Dan Quijate'
我们可以通过添加一个额外的参数来指定搜索子串应该被替换的最大次数,从而控制这种浪费。
>>> s.replace('o', 'a', 1)
'Dan Quijote'
最后,replace()方法不限于作用于单个字符。我们可以用某个指定的值替换整个目标字符串。
>>> s.replace(' Qui', 'key ')
'Donkey jote'
有关所用字符串方法的参考,请参见以下内容:
- str.replace(old,new[,count])
- 字符串分区(sep)
- str.rsplit(sep=None,maxsplit=-1)
- str.split(sep=None,maxsplit=-1)
Python 中@staticmethod 和@classmethod 的区别
原文:https://www.pythoncentral.io/difference-between-staticmethod-and-classmethod-in-python/
Python 中的类与静态方法
在本文中,我将尝试解释什么是staticmethod和classmethod,以及它们之间的区别。staticmethod和classmethod都使用装饰器将方法定义为staticmethod或classmethod。请阅读文章 Python Decorators Overview ,对 Decorators 如何在 Python 中工作有一个基本的了解。
简单、静态和类方法
类中最常用的方法是实例方法,即实例作为第一个参数传递给方法。
例如,基本的实例方法如下:
class Kls(object):
def __init__(self, data):
self.data = data
def printd(self):
打印(self.data)
ik1 = Kls(' arun ')
ik2 = Kls(' Seema ')
ik1 . printtd()
ik2 . printtd()
这为我们提供了以下输出:
arun
seema
查看代码示例和图表后:
- 在 1 和 2 中,参数被传递给方法。
- 在 3 上,
self参数指的是实例。 - 在 4 中,我们不需要向方法提供实例,因为它由解释器本身处理。
现在,如果我们要编写的方法只与类交互,而不与实例交互,该怎么办呢?我们可以在类之外编写一个简单的函数来实现这一点,但是这会将与类相关的代码分散到类之外。这可能会导致未来的代码维护问题,如下所示:
def get_no_of_instances(cls_obj):
return cls_obj.no_inst
Kls 类(对象):
no_inst = 0
def __init__(self):
Kls.no_inst = Kls.no_inst + 1
ik1 = Kls()
ik2 = Kls()
print(get _ no _ of _ instances(Kls))
为我们提供了以下输出:
2
Python @ class method
我们现在要做的是在类中创建一个函数,它让类对象而不是实例工作。如果我们想得到实例的数量,我们所要做的就是下面这样的事情:
def iget_no_of_instance(ins_obj):
return ins_obj.__class__.no_inst
Kls 类(对象):
no_inst = 0
def __init__(self):
Kls.no_inst = Kls.no_inst + 1
ik1 = Kls()
ik2 = Kls()【打印 IGES _ no _ of _ instance(ik1)】
2
使用 Python 2.2 之后引入的特性,我们可以使用`@classmethod`在类中创建一个方法。
class Kls(object):
no_inst = 0
def init(self):
Kls.no_inst = Kls.no_inst + 1
@ class method
def get _ no _ of _ instance(cls _ obj):
return cls _ obj . no _ inst
ik1 = Kls()
ik2 = Kls()
print ik1 . get _ no _ of _ instance()
print kls . get _ no _ of _ instance()
我们得到以下输出:
2
2
这样做的好处是:无论我们从实例还是从类中调用方法,它都将类作为第一个参数传递。
**Python @ static method**
通常有些功能与类相关,但不需要类或任何实例来完成某些工作。比如设置环境变量,改变另一个类的属性等等。在这些情况下,我们也可以使用一个函数,但是这样做也会传播相关的代码,这会导致以后的维护问题。
这是一个示例案例:
IND = 'ON'
def checkind():
return(IND = = ' ON ')
Kls 类(object):
def init(self,data):
self.data = data
def do _ Reset(self):
if checkind():
print(' Reset done for:',self.data)
def set _ DB(self):
if checkind():
self . DB = '新数据库连接'
print('数据库连接为:',self.data)
ik1 = kls(12)
1 到 _reset()
ik1.set_db()
的缩写形式
这为我们提供了以下输出:
Reset done for: 12
DB connection made for: 12
这里如果我们使用一个`@staticmethod`,我们可以把所有的代码放在相关的地方。
IND = 'ON'
Kls 类(object):
def init(self,data):
self.data = data
@ static method
def checkind():
return(IND = = ' ON ')
def do _ Reset(self):
if self . checkind():
print(' Reset done for:',self.data)
def set _ DB(self):
if self . checkind():
self . DB = '新数据库连接'
print('数据库连接为: ',self.data)
ik1 = kls(12)
1 到 _reset()
ik1.set_db()
的缩写形式
这为我们提供了以下输出:
Reset done for: 12
DB connection made for: 12
下面是一个更全面的代码示例,用图表向您展示
@staticmethod 和@classmethod 有何不同。
class Kls(object):
def init(self, data):
self.data = data
def printd(self):
打印(self.data)
@ Static method
def s method(* arg):
print(' Static:',arg)
@ Class method
def cmethod(* arg):
print(' Class:',arg)
[/python]
【python】
ik = Kls(23)
ik . printd()
23
ik . smethod()
Static:()
ik . cmethod()【t】Kls' >,)
Kls . printd()
type error:必须以 Kls 实例作为第一个参数调用未绑定方法 printd()(改为 get nothing)
Kls . s method()
Static:()
Kls . cmethod()
Class:(<Class ' _ _ main _ _。Kls' >,)
这里有一个图表来解释这是怎么回事:
[](https://www.pythoncentral.io/wp-content/uploads/2013/02/comparison.png)
CCNA/CCNP 要求学习 Python 编程吗?
原文:https://www.pythoncentral.io/does-ccna-ccnp-require-one-to-learn-programming-in-python/

Python 是一种面向对象的、交互式的解释语言。它包括最高级别的动态数据类型、动态类型、模块和类。也支持其他类型的编程,如过程和函数编程。除了面向对象编程,Python 还支持各种编程系统。它支持多种 Windows 系统以及 C 和 C++。它在与语法一起使用时执行。
Python 也在许多应用程序中被用作扩展语言。它是可移植的,可以适应各种 Unix 变种,包括 Linux、macOS 和 Windows。这在 CCNA 训练中至关重要。Python 是软件开发中最常用的编程语言。对于网络工程师来说,这是一门至关重要的语言。你可以在这里找到思科考试的完整指南。
CCNA 需要编码吗?
一个网络工程师不一定要精通一门编程语言才能有效率。通过完成 CCNA、CCNP 和 CCIE 的课程,你可能会获得所有这些能力并由于你的教育而在 IT 组织中找到网络职位。
为什么网络工程师理解 Python 至关重要?
与其他语言相比,这种语言容易学习和阅读。
像大多数网络提供商一样,Cisco 喜欢这种语言,并在其所有组织中实施。
许多网络自动化技术已经用 Python 编写,这对网络工程师来说很有价值。
因为它是最流行的编程语言之一,所以它有一个相当大的社区。
想要使用这种语言的工程师应该确保它安装在 Linux 和 macOS 上。
目前在大量的 Cisco 交换机上都可以访问它。由于其受欢迎程度,这种情况下的职业机会非常好。
它已经被证明是许多软件应用程序的理想脚本语言。
Python 的优势:
以下是 Python 对于网络工程师和 IT 组织的一些主要优势:
- 网络管理得到简化。
- 改进的性能
- 为价值更高的工作保留 IT 人员
- 复兴网络
- 更少的错误
网络行业的科技巨头思科公司公布了 DevNet(开发网络)作为助理级和专业级认证的新途径。你会在我们的官方网站上看到完整的 CCNP 350-401 文章。网络自动化工程师需求量很大。然而,在网络架构中引入自动化需要专家的专业知识。他们可以使用网络可编程性更有效地操作网络。
不幸的是,网络工程师缺乏编程能力,这阻碍了他们适应招聘经理的雇佣标准。Python 简单且对代码友好的语法,以及其动态而强大的库,使得许多程序员和大型技术组织可以轻松地过渡到 Python,Python 已经取代了许多古老而著名的编程语言。
结论:
如果你在一家网络设备很少的小公司工作,并且不想成为一名程序员或者学习网络自动化,那就坚持你擅长的。你应该学习 Python 和网络自动化。最后,许多网络工程师担心自动化和 Python 会让他们失业。这意味着如果你建立了一系列的脚本来完成你的工作,你的雇主将不再需要你。
如何嵌入交互式 Python 解释器控制台
原文:https://www.pythoncentral.io/embed-interactive-python-interpreter-console/
你可以在应用程序中使用解释器做一些事情。其中最有趣的是让你的用户能够在运行时编写你的应用程序,就像 GIMP 和 Scribus 所做的那样,但它也可以用来构建增强的 Python shells,像 IPython 。
首先:首先从标准库的code模块导入InteractiveConsole类,然后子类化它,这样你就可以添加一些钩子。Python 2 和 3 之间的code模块没有真正的变化,所以本文对两者都有效。
from code import InteractiveConsole
类控制台(InteractiveConsole):
def _ _ init _ _(* args):interactive console。__init__(*args)
到目前为止,代码只是样板文件;它创建了一个名为Console的类,它只是InteractiveConsole的子类。
下面的代码演示了该类的工作方式。第 4 行调用了从InteractiveConsole继承而来的runcode方法。runcode方法获取一串源代码并在控制台内部执行,在本例中,将1分配给a,然后打印出来。
a = 0
code = 'a = 1; print(a)'
console = Console()
console.runcode(code) # prints 1
print(a) # prints 0
第 5 行打印了0,因为控制台有自己的名称空间。注意,console对象是一个常规的运行时对象;它在与初始化它的代码相同的线程和进程中运行代码,所以对runcode的调用通常会被阻塞。
Python 的code模块还提供了一个InteractiveInterpreter类,它会自动对表达式求值,就像 Python 的交互模式一样,但是使用多行输入会更复杂。InteractiveConsole.runcode接受任意有效的 Python 块。通常,当您需要使用终端时,您应该使用InteractiveInterpreter类,当您的输入将是完整的 Python 块时,通常作为文件或来自图形用户界面的输入字符串,您应该使用InteractiveConsole。
处理用户输入
你经常想要处理用户的输入,可能需要转换编译一个语法扩展,比如 IPython Magic,或者执行更复杂的宏。
向名为preprocess的Console添加一个新的静态方法,该方法只接受一个字符串并返回它。添加另一个名为enter的新方法,它接受用户的输入,通过preprocess运行,然后传递给runcode。这样做可以很容易地重新定义处理器,要么通过子类化Console,要么在运行时简单地给实例的preprocess属性分配一个新的 callable。
class Console(InteractiveConsole):
def _ _ init _ _(* args):interactive console。__init__(*args)
def enter(self,source):
source = self . preprocess(source)
self . runcode(source)
@staticmethod
def 预处理(源):返回源
Console = Console()
Console . preprocess = lambda source:source[4:]
Console . enter(>>>print(1)’)
灌注命名空间
InteractiveConsole类构造函数接受一个可选参数,这是一个字典,用于在创建控制台的名称空间时填充它。
names = {'a': 1, 'b': 2}
console = Console(names) # prime the console
console.runcode('print(a+b)') # prints 3
当你创建一个新的Console实例时,传入对象允许你将任何对象放入用户编写应用程序可能需要的名称空间中。重要的是,这些可以是对对象的特定运行时实例的引用,而不仅仅是来自库导入的类和函数定义。
现在,您已经有了充实控制台所需的钩子。添加一个在新线程中调用enter的spawn方法,可以让输入阻塞或并行运行。添加一个允许编写阻塞和非阻塞输入的预处理器的额外好处。
访问名称空间
要在控制台的名称空间创建后访问它,可以引用它的locals属性。
console.locals['a'] = 1
console.runcode('print(a)') # prints 1
console.runcode('a = 2')
print(console.locals['a']) # prints 2
因为这有点难看,您可以将一个空的模块对象传入控制台,在外层空间保存对它的引用,然后使用该模块共享对象。
标准库的imp模块提供了一个new_module函数,让我们在不影响sys.modules(或者不需要实际文件)的情况下创建一个新的模块对象。您需要将新模块的名称传递给函数,并取回空模块。
from imp import new_module
superspace = new_module('superspace')
现在您可以在控制台创建时将superspace模块传递到控制台的名称空间中。在控制台内部也称它为superspace,这使得它们是同一个对象变得更加明显,但是您可以使用不同的名称。
console = Console({'superspace': superspace})
现在superspace是一个单独的空模块对象,在两个名称空间中都被这个名称引用。
superspace.a = 1
console.enter('print(superspace.a)') # prints 1
console.enter('superspace.a = 2')
print(superspace.a) # prints 2
舍入
将共享模块绑定到控制台实例是有意义的,因此每个控制台实例都有自己的共享模块。__init__方法需要扩展来更直接地处理它的参数,所以它仍然能够接受可选的名称空间字典。
最好将预处理器的钩子传递到控制台的名称空间,这样用户就可以将自己的处理器绑定到这个名称空间。为了简单起见,下面的例子只是将对self的引用作为console传递到它自己的名称空间中,不是因为它是元的,只是因为它更容易阅读代码。
from code import InteractiveConsole
from imp import new_module
类控制台(InteractiveConsole):
def __init__(self,names=None):
names = names 或者{}
names['控制台'] = self
InteractiveConsole。__init__(self,names)
self . super space = new _ module(' super space ')
def enter(self,source):
source = self . preprocess(source)
self . runcode(source)
@staticmethod
def 预处理(源):
返回源
console = Console()
如果你运行这段代码,现在在外部空间和控制台内部都有一个名为console的全局变量引用相同的东西,所以console.superspace在两者中都是相同的空模块。
在实践中,如果你允许用户编写你的应用程序,你会想要写一个你想要公开的运行时对象的包装器,这样用户就有一个干净的 API,他们可以在不崩溃的情况下入侵。然后将这些包装对象传递到控制台。
编码和解码字符串(在 Python 3.x 中)
原文:https://www.pythoncentral.io/encoding-and-decoding-strings-in-python-3-x/
在我们的另一篇文章编码和解码字符串(在 Python 2.x 中)中,我们研究了 Python 2.x 如何处理字符串编码。在这里,我们将看看 Python 3.x 中的字符串编码和解码,以及有何不同。
Python 3 . x 与 Python 2.x 中的字符串编码/解码
当 Python 2.x 发展到最新的 Python 3.x 版本时,该语言的许多方面并没有发生很大的变化。Python 字符串是而不是其中之一,事实上它可能是变化最大的。与 Python 2.x 相比,它所经历的变化在 Python 3.x 的编码/解码中处理字符串的方式上最为明显。在 Python 2.x 中编码和解码字符串有点麻烦,您可能在另一篇文章中读到过。令人欣慰的是,将 8 位字符串转换为 unicode 字符串,反之亦然,在 Python 3.x 中,两者之间的所有方法都被遗忘了。让我们直接通过一些示例来检查这意味着什么。
我们将从一个包含非 ASCII 字符(即“ü”或“umlaut-u”)的示例字符串开始:
s = 'Flügel'
现在,如果我们引用并打印该字符串,它会给出基本相同的结果:
>>> s
'Flügel'
>>> print(s)
Flügel
与 Python 2.x 中的相同字符串s相比,在这种情况下s已经是 Unicode 字符串,而在 Python 3.x 中所有的字符串都是自动 Unicode 的。明显的区别是的在我们实例化后没有改变。
虽然我们的字符串值包含一个非 ASCII 字符,但它离 ASCII 字符集不远,也就是基本拉丁字符集(实际上它是基本拉丁字符集的一部分)。如果我们有一个字符,不仅是非 ASCII 字符,而且是非拉丁字符,会发生什么?让我们来试试:
>>> nonlat = '字'
>>> nonlat
'字'
>>> print(nonlat)
字
正如我们所看到的,它是否包含所有拉丁字符并不重要,因为 Python 3.x 中的字符串都是这样的(与 Python 2.x 不同,您可以在空闲窗口中键入任何字符!).
如果你在 Python 2.x 中处理过编码和解码字符串,那么你会知道处理起来会麻烦得多,而 Python 3.x 让这变得不那么痛苦了。然而,如果我们不需要使用unicode、encode或decode方法,或者在我们的字符串变量中包含多个反斜杠转义来立即使用它们,那么我们还有什么必要编码或解码我们的 Python 3.x 字符串呢?在回答这个问题之前,我们先来看一下 Python 3.x 中的b'...'(字节)对象,与 Python 2.x 中的对象形成对比。
Python 3 . x Bytes 对象
在 Python 2.x 中,在字符串前面加上“B”(或“B”)是合法的语法,但它没有什么特别之处:
>>> b'prefix in Python 2.x'
'prefix in Python 2.x'
然而,在 Python 3.x 中,这个前缀表示字符串是一个不同于普通字符串的bytes对象(我们知道普通字符串默认为 Unicode 字符串),甚至“b”前缀也被保留:
>>> b'prefix in Python 3.x'
b'prefix in Python 3.x'
关于字节对象的事情是,它们实际上是整数的数组,尽管我们把它们看作 ASCII 字符。在这一点上,它们如何或者为什么是整数数组对我们来说并不重要,但是重要的是我们将只把它们看作一串 ASCII 文字字符,并且它们可以只有包含 ASCII 文字字符。这就是为什么下面的代码(或任何非 ASCII 字符)不起作用的原因:
>>> b'字'
SyntaxError: bytes can only contain ASCII literal characters.
现在,为了了解字节对象与字符串的关系,我们先来看看如何将字符串转换成字节对象,反之亦然。
将 Python 字符串转换为字节,并将字节转换为字符串
如果我们想把之前的nonlat字符串转换成 bytes 对象,我们可以使用bytes构造函数方法;然而,如果我们只使用字符串作为唯一的参数,我们会得到这个错误:
>>> bytes(nonlat)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: string argument without an encoding
正如我们所看到的,我们需要在字符串中包含一个编码。让我们用一个常见的,UTF 8 编码:
>>> bytes(nonlat, 'utf-8')
b'\xe5\xad\x97'
现在我们有了我们的bytes物体,用 UTF 8 编码...但是这到底是什么意思呢?这意味着包含在我们的nonlat变量中的单个字符被有效地翻译成一串代码,这意味着“字“在 UTF-8 中——换句话说,它是用编码的。这是否意味着如果我们在nonlat上使用encode方法调用,我们会得到相同的结果?让我们看看:
>>> nonlat.encode()
b'\xe5\xad\x97'
事实上,我们得到了相同的结果,但在这种情况下我们不必给出编码,因为 Python 3.x 中的 encode 方法默认使用 UTF-8 编码。如果我们将其更改为 UTF-16,我们会得到不同的结果:
>>> nonlat.encode('utf-16')
b'\xff\xfeW['
尽管这两个调用执行相同的功能,但它们根据编码或编解码器的不同,以稍微不同的方式执行。
既然我们可以对字符串进行编码以生成字节,我们也可以对字节进行解码以生成字符串——但是当解码一个字节对象时,我们必须知道使用正确的编解码器来获得正确的结果。例如,如果我们尝试使用 UTF-8 来解码上面 nonlat 的 UTF-16 编码版本:
# We can use the method directly on the bytes
>>> b'\xff\xfeW['.decode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
我们得到一个错误!现在,如果我们使用正确的编解码器,结果会很好:
>>> b'\xff\xfeW['.decode('utf-16')
'字'
在这种情况下,由于解码操作失败,Python 向我们发出了警告,但警告是,当编解码器不正确时,错误不会总是发生!这是因为编解码器通常使用相同的代码短语(组成 bytes 对象的“\xXXX”转义)来表示不同的内容!如果我们在人类语言的背景下考虑这一点,使用不同的编解码器编码和解码相同的信息就像试图用意大利语-英语词典将一个或多个单词从西班牙语翻译成英语一样——意大利语和西班牙语的一些音素可能相似,但你仍然会得到错误的翻译!
在 Python 3.x 中向文件写入非 ASCII 数据
关于 Python 3.x 和 Python 2.x 中的字符串,最后一点要注意的是,我们必须记住,使用open方法写入两个分支中的文件不允许将 Unicode 字符串(包含非 ASCII 字符)写入文件。为了做到这一点,字符串必须经过编码。
这在 Python 2.x 中没什么大不了的,因为只有当你这样做时(通过使用unicode方法或str.decode),字符串才会是 Unicode 的,但是在 Python 3.x 中,默认情况下所有字符串都是 Unicode 的,所以如果我们想将这样的字符串(例如nonlat)写入文件,我们需要使用str.encode和open的wb(二进制)模式将字符串写入文件,而不会导致错误,如下所示:
>>> with open('nonlat.txt', 'wb') as f:
f.write(nonlat.encode())
同样,当读取非 ASCII 数据的文件时,使用rb模式并用正确的编解码器对数据进行解码也很重要——当然,除非你不介意用“意大利语”翻译你的“西班牙语”
如何通过文件或外壳运行 Python 脚本
原文:https://www.pythoncentral.io/execute-python-script-file-shell/
如果你不能执行或运行 Python 脚本,那么编程就毫无意义。当您运行 Python 脚本时,解释器会将 Python 程序转换成计算机可以理解的东西。执行 Python 程序有两种方式:用 shebang 行调用 Python 解释器,以及使用交互式 Python shell。
将 Python 脚本作为文件运行
通常程序员编写独立的脚本,独立于真实环境。然后他们用一个。py”扩展名,它向操作系统和程序员表明该文件实际上是一个 Python 程序。在解释器被调用后,它读取并解释文件。Python 脚本在基于 Windows 和 Unix 的操作系统上运行的方式非常不同。我们将向您展示不同之处,以及如何在 Windows 和 Unix 平台上运行 Python 脚本。
使用命令提示符在 Windows 下运行 Python 脚本
Windows 用户必须将程序的路径作为参数传递给 Python 解释器。比如如下:
C:\Python27\python.exe C:\Users\Username\Desktop\my_python_script.py
注意,您必须使用 Python 解释器的完整路径。如果你想简单地输入python.exe C:\Users\Username\Desktop\my_python_script.py,你必须将python.exe添加到你的PATH环境变量中。要做到这一点,请查看将 Python 添加到路径环境的文章..
窗口的 python.exe 对 pythonw.exe
注意,Windows 附带了两个 Python 可执行文件- python.exe和pythonw.exe。如果你想在运行脚本时弹出一个终端,使用python.exe,但是如果你不想弹出任何终端,使用pythonw.exe。pythonw.exe通常用于 GUI 程序,在这里你只想显示你的程序,而不是终端。
在 Mac、Linux、BSD、Unix 等下运行 Python 脚本
在像 Mac、BSD 或 Linux (Unix)这样的平台上,你可以在程序的第一行加上一个“shebang ”,表示 Python 解释器在硬盘上的位置。它的格式如下:
#!/path/to/interpreter
用于 Python 解释器的常见 shebang 行如下:
#!/usr/bin/env python
然后,您必须使用以下命令使脚本可执行:
chmod +x my_python_script.py
与 Windows 不同,Python 解释器通常已经存在于$PATH环境变量中,因此没有必要添加它。
然后,您可以通过手动调用 Python 解释器来运行程序,如下所示:
python firstprogram.py
用外壳执行 Python(实时解释器)
假设你已经安装了 Python 并且运行良好(如果你得到一个错误,见这篇文章),打开终端或控制台,输入‘Python’并按下‘Enter’键。然后,您将立即被定向到 Python live 解释器。您的屏幕将显示如下信息:
user@hostname:~ python
Python 3.3.0 (default, Nov 23 2012, 10:26:01)
[GCC 4.2.1 Compatible Apple Clang 4.1 ((tags/Apple/clang-421.11.66))] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
Python 程序员应该记住一件事:在使用实时解释器时,一切都是实时读取和解释的。例如,循环会立即迭代,除非它们是函数的一部分。所以需要一些心理规划。使用 Python shell 通常用于交互式执行代码。如果你想从解释器运行一个 Python 脚本,你必须import它或者调用 Python 可执行文件。
在 Python 中使用 API 的专家提示
原文:https://www.pythoncentral.io/expert-tips-for-using-apis-in-python/
Python 是一种通用的编程语言,你可以在 web 应用程序的后端、前端或整个堆栈上使用。在本文中,我们将回顾一些在 Python 中使用 API 的专家提示。首先,理解什么是 API 以及它是如何工作的很重要。API 或应用程序编程接口规则控制一个软件如何与另一个软件交互。当您使用 API 时,您向服务器请求可以在应用程序中使用的数据。例如,当您使用 Google Maps API 获取路线时,您正在向 Google Maps 服务器发送一个请求,以获取您需要的信息。然后,服务器用请求的数据进行响应。

进行 API 调用
API(应用编程接口)是一组允许软件程序相互通信的定义规则。当需要从远程数据源(如基于 web 的数据库)访问数据时,会使用 API。软件程序将向 API 发送访问数据的请求,返回所需的信息。
Python 使得使用 API 变得相对容易,并且可以使用几个不同的库来进行 API 调用。对于简单的 API 操作,可以考虑将 API 文件上传到云中。https://upload.io/cloudinary-alternative背后的团队建议上传你的 API 文件应该简单安全。在 Python 中进行 API 调用时,首先需要导入相关的库,并指定希望访问的 API 端点的 URL。根据您使用的 API,您可能还需要提供身份验证凭证。一旦进行了 API 调用,返回的数据将是 JSON 格式的,然后可以根据需要对其进行解析和处理。
在 Python 中进行 API 调用是一个相对简单的过程,但是你需要记住一些事情以确保一切顺利进行。首先,确保你已经安装了最新版本的 Python 解释器。其次,花一些时间熟悉您正在使用的 API,因为这将使您更容易理解返回的数据。最后,在部署代码之前一定要测试它,因为这将有助于避免任何潜在的问题。
使用 API 认证
在 Python 中使用 API 时,确保正确地验证请求是很重要的。毕竟,如果您没有正确的身份验证,您将无法访问您试图获取的数据。幸运的是,Python 中有几种不同的 API 认证方式。
使用 API 进行认证的一种常见方式是使用 HTTP 基本认证。使用这种方法,您可以在每次请求时提供您的用户名和密码。虽然这相对容易设置,但不是最安全的选择。如果您担心安全性,您可能会考虑使用 OAuth 令牌。
使用 OAuth,首先需要在服务器端生成一个令牌。一旦有了令牌,就可以在每个请求中包含它。它增加了一层额外的安全,因为如果需要的话,令牌可以很容易地被撤销。如果您想获得更高的安全性,还可以在 API 调用中使用双因素身份验证。除了用户名和密码之外,您还需要输入一个发送到您手机或电子邮件的代码。
无论您选择哪种身份验证方法,确保您安全地处理您的凭据都很重要。这意味着将它们存储在一个安全的地方,不与任何不需要访问的人共享。
错误处理
使用 API 的一个常见任务是处理错误。毕竟,即使是设计最好的 API 有时也会返回意想不到的结果。幸运的是,Python 的异常处理能力可以使处理错误变得更加容易。以下是在 Python 中使用 API 时使用异常的一些准则。
首先,清楚地理解什么是异常是很重要的。在 Python 中,异常是程序执行过程中出现的错误。当出现异常时,程序将停止运行,并显示一条错误消息。异常处理就是处理这些错误,使程序能够继续顺利运行。
Python 中有两种处理异常的方法:try/except 块和 Try/Except/Finally 块。Try/except 块用于捕获可能发生的特定错误,而 Try/Except/Finally 块用于捕获所有错误。确保根据您的需要使用合适的块。
使用异常处理有助于使你的代码更加健壮。但是,一定要明智地使用它,因为过多的异常处理会使您的代码更难阅读和理解。
了解 API 比率限值

我们通常使用 API 的宝贵资源之一来调用 API。这就是为什么大多数原料药都有比率限制,以防止过度使用和滥用。如果你是第一次使用 API的 ,了解这些速率限制是如何工作的以避免超过它们是很重要的。大多数 API 会限制在某个时间段内的请求数量。例如,GitHub API 的速率限制是每小时 60 个请求。如果您试图在一个小时内发出超过 60 个请求,您将会收到一条错误消息。一些 API 还使用“突发”,这允许您发出一定数量的超出限制的请求,只要它们随时间间隔开。例如,Twitter API 将允许您在 15 分钟内发出 100 个请求。因此,如果您在此期间尝试发出超过 100 个请求,您将会收到一条错误消息。理解这些速率限制是如何工作的对于有效地使用 API 是至关重要的。
要使用 API 进行认证,您需要知道它的基本 URL、用户名和密码。通过身份验证后,您可以使用适当的端点进行 API 调用,并传入必要的参数。如果您的请求导致错误,Python 将引发一个异常。一定要适当地处理这些异常,这样你的程序才不会崩溃。最后,注意 API 比率限制,确保不要超过它们。
FastAPI 初学者教程:您需要的资源
原文:https://www.pythoncentral.io/fastapi-tutorial-for-beginners-the-resources-you-need/
虽然 Flask 是 2004 年愚人节的一个玩笑,而 Django 是同一时期《劳伦斯世界日报》的一个内部项目,但这两个 Python web 框架都获得了巨大的声望和流行。
然而,构建这些框架时的 Python 不同于今天的 Python。该语言的当代元素,如 ASGI 标准和异步执行,要么不流行,要么不存在。
这就是 FastAPI 的用武之地。
它是一个较新的 Python web 框架,建于 2018 年,融入了 Python 的现代特性。除了能够使用 ASGI 标准与客户机进行异步连接之外,它还可以使用 WSGI。
此外,FastAPI web 应用程序是用带有类型提示的干净代码编写的,异步函数可用于路由和端点。
顾名思义,FastAPI 的主要用途之一是构建 API 端点。有了这个框架,构建端点就像以 JSON 的形式返回 Python 字典的数据一样简单。或者,您可以使用 OpenAPI 标准,它包括一个交互式的 Swagger UI。
但是 FastAPI 并不局限于 API,它可以用来完成 web 框架可以完成的任何任务——从交付网页到服务应用程序。
在本帖中,我们将讨论如何安装 FastAPI 以及使用它的基本原则。
什么是快速 API?是什么让它从其他框架中脱颖而出?
FastAPI 是一个高性能的 web 框架,它使用标准的类型提示来帮助构建 Python APIs。其主要特点包括:
- 易于学习: 框架的简单本质使得阅读文档的时间最小化。
- 直观: FastAPI 提供优秀的编辑器支持,完善你的代码,减少你需要投入调试的时间。
- 减少 bug:由于使用起来相当直截了当,所以开发者犯错的几率较低。
- 健壮: 它有助于生产就绪代码和自动交互文档。
- 速度: 号称极致性能,框架堪比 NodeJS 和 Go。此外,它支持快速开发。
- 基于标准: 基于 JSON Schema、open API 等开放 API 标准。
除此之外,它最大限度地减少了代码重复。总的来说,该框架优化了开发人员的体验,并通过在默认情况下实施最佳实践,使他们能够有效地编码。
如何安装 FastAPI
建议在新的虚拟环境中启动 FastAPI 项目,因为框架会在没有提示的情况下安装许多组件。要安装框架的核心组件,可以运行下面的命令:
pip install fastapi
除此之外,你需要安装一个 ASGI 服务器来执行本地测试。该框架与 Uvicorn 无缝协作。因此,我们将在示例中使用该服务器。
要安装 Uvicorn,您可以运行命令:
pip install uvicorn[standard]
上面的命令安装一组最佳的组件,包括 C 库。如果想安装一个只使用 Python 的最小版本,可以运行:
pip install uvicorn
FastAPI 应用程序的基本示例
下面是一个基本的 FastAPI 应用程序的样子:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def root():
return {"greeting":"Hello coders"}
要运行这个应用程序,您可以将代码保存在一个文本文件中,并将其命名为 main.py,然后使用以下命令在您的虚拟环境中运行它:
uvicorn main:app
虽然上述命令中的“uvicorn”部分是不言自明的,但是“app”是一个可以用于 ASGI 服务器的对象。如果您想使用 WSGI,您可以使用 ASGI-to-WSGI 适配器。但是,最好使用 ASGI。
当应用程序开始运行时,进入 localhost:8000,默认的 Uvicorn 测试服务器。您将看到浏览器上显示的(" greeting":" Hello coders "),这是字典生成的有效 JSON 响应。
现在您可以看出使用 FastAPI 从一个端点交付 JSON 是多么容易。想法很清楚——您必须创建一个路由并返回一个 Python 字典,它将被序列化为 JSON,而不需要您的干预。
也就是说,序列化复杂的数据类型需要一些工作,我们将在后面的文章中详细讨论。
如果你以前使用过 Flask 这样的系统,你会很容易认出 FastAPI 应用的大致轮廓:
- ASGI/WSGI 服务器导入应用程序对象并使用它来运行应用程序。
- 你可以使用装饰器给应用程序添加路线。例如,@ app . get(“/”)decorator 在网站的根位置生成一个 GET 方法路由,包装后的函数返回结果。
但是对于熟悉框架工作的人来说,一些不同之处会很明显。首先,路由函数是异步的,这意味着任何部署的异步组件——比如异步数据库中间件连接——都可以在函数中运行。
需要注意的是,如果你愿意,你可以使用常规的同步功能。如果您有一个使用大量计算能力的操作,而不是一个等待 I/O 的操作(这是 async 的最佳用例),那么最好使用 sync 函数,让 FastAPI 为您做一些工作。
在其他情况下,使用异步函数是正确的方法。
FastAPI 中的路线类型
使用@app decorator,您可以设置路线的方法。您可以使用@app.get 或@app.post 来完成此操作。post、get、DELETE 和 PUT 方法就是这样使用的。不太为人所知的函数 HEAD、TRACE、PATCH 和 OPTIONS 也是这样使用的。
通过在一个函数上使用@app.get("/")和在另一个函数上使用@app.post("/")将路由函数包装在一起,也可以在一个路由上使用多种方法。
FastAPI 中的主要参数
从 route 的路径中提取变量就像在将它们传递给 route 函数之前在 route 声明中定义它们一样简单,就像这样:
@app.get("/users/{user_id}")
async def user(user_id: str):
return {"user_id":user_id}
接下来,您可以使用 route 函数中的类型化声明从 URL 中提取查询参数。框架将自动检测这些声明:
userlist = ["Spike","Jet","Ed","Faye","Ein"]
@app.get("/userlist")
async def userlist_(start: int = 0, limit: int = 10):
return userlist[start:start+limit]
使用表单数据相对来说更复杂。您需要手动安装 Python 多部分库来解析表单数据。当您安装了这个库时,您可以使用一个类似于查询参数语法的语法:
from fastapi import Form
@app.post("/lookup")
async def userlookup(username: str = Form(...), user_id: str = Form("")):
return {"username": username, "user_id":user_id}
上面代码中的表单对象从表单中取出指定的参数并向前传递。您必须记住,在声明中使用格式(…)意味着必须输入相应的参数,例如本例中的用户名。
另一方面,如果有一个可选的表单元素,比如上面例子中的 user_id,您可以将元素的默认值传递给表单。
FastAPI 响应类型
JSON 是 FastAPI 中的默认响应类型,本文中的所有例子都会自动将数据序列化为 JSON。但是,您也可以返回其他响应。比如:
from fastapi.responses import HTMLResponse
@app.get("/")
def root():
return HTMLResponse("<b>Hello world</b>")
fastapi . responses 模块是 FastAPI 最有用的模块之一,它支持大量的响应,包括:
- FileResponse: 从特定路径返回一个文件,异步流。
- PlainTextResponse 或 HTMLResponse: 文本以纯文本或 HTML 的形式返回。
- RedirectResponse: 重定向到特定的 URL。
- StreamingResponse: 接受一个生成器作为输入,并将结果传送给客户机。
除了使用上面列出的响应,您还可以使用通用的响应对象,并提供自定义的标题、媒体类型、状态代码和内容。
FastAPI 的响应对象
无论是设置 cookies 还是头来处理响应,都需要接受一个响应对象作为路由函数的参数:
from fastapi import Response
@app.get("/")
def modify_header(response:Response):
response.headers["X-New-Header"] = "Hi, I'm a new header!
return {"msg":"Headers modified in response"}
FastAPI 中的 Cookies】
从客户端检索 cookies 的工作方式类似于处理表单参数或查询的工作方式:
from fastapi import Cookie
@app.get("/")
async def main(user_X: Optional[str]=Cookie(none)):
return {"user_X": user_X}
您可以用。响应对象上的 set_cookie()方法:
from fastapi import Response
@app.post("/")
async def main(response: Response):
response.set_cookie(key="user_X", value="")
return {"msg":"User X cookie cleared"}
Pydantic 模型和 FastAPI
虽然 Python 类型是可选的,但与大多数其他 Python 框架不同,FastAPI 坚持使用类型。这个框架利用 Pydantic 库来验证提交的数据,不需要您编写逻辑来完成验证。
让我们仔细看看 Pydantic 库,其中包含一些验证传入 JSON 的代码:
from typing import List, Optional
from fastapi import FastAPI
from pydantic import BaseModel, EmailStr
app = FastAPI()
class Movie(BaseModel):
name: str
year: int
rating: Optional[int] = None
tags: List[str] = []
@app.post("/movies/", response_model=Movie
async def create_movie(movie: Movie):
return movie
上面的代码通过 name、year、rating 和 tags 字段接受 POST 上的 JSON 数据,而不是 HTML。接下来,验证字段的类型。
OpenAPI in FastAPI
OpenAPI 是一种 JSON 格式的标准,用于创建 API 端点。客户端可以读取端点的 OpenAPI 定义,并自动识别站点 API 传输的数据的模式。
如果使用 FastAPI,它会自动为端点生成所需的 OpenAPI 定义。例如,如果您在 openapi 站点的根目录访问/openapi.json,您将收到一个 json 文件,它描述了每个端点以及它可以接收和返回的数据。
FastAPI 的另一个好处是它自动为你的 API 创建文档接口。你可以通过网络界面与他们互动。此外,框架附带了钩子,允许您扩展或修改自动生成的模式。它还允许您有条件地生成模式或完全禁用它。
单链表:如何查找和删除一个节点
原文:https://www.pythoncentral.io/find-remove-node-linked-lists/
先决条件
要了解单链表,你应该知道:
- Python 3
- OOP 概念
- 单链表——插入节点并打印节点
我们会学到什么?
在上一个教程中,我们讨论了什么是单链表,如何添加一个节点以及如何打印所有的节点。如果您还没有阅读,我们强烈建议您先阅读,因为我们将基于这些概念进行构建。
本教程是关于如何删除一个节点,以及如何知道一个特定的元素是否存在于链表中。这两种方法都属于linked list类。让我们一个一个来看这些。
如何找到一个元素?
像大多数数据结构一样,找到一个元素是否存在的唯一方法是遍历整个链表。注意,如果链表是排序的,我们可以使用二分搜索法。但是这里我们要考虑一个未排序的链表。其工作方式是,用户给我们一个元素,我们返回 真 如果我们找到其他元素,我们返回 假 。您也可以使用计数器并返回元素的索引(如果它存在的话)。
算法
- 设置指针到 头
- 比较curr . data与输入值:
- 如果相等,返回 真
- 否则,移动到下一个指针
- 重复步骤 1-2,直到找到元素或到达链表的末尾
代码
def findNode(self,value):
curr = self.head
while curr:
if curr.getData() == value:
return True
curr = curr.getNextNode()
return False
如何从单链表中移除节点?
现在你知道如何找到一个节点,我们可以用它来删除一个节点。同样,有几种方法可以做到这一点。您可以删除第一个节点,也可以通过维护一个指向链表最后一个节点的尾指针来删除最后一个节点。我们在这里讨论的方法是,我们从用户那里获得一个值,在链表中找到这个元素,如果它存在,就删除它。让用户知道元素是否被成功移除是非常重要的。为此,我们返回 真 为成功,返回 假 否则。记得将 大小 属性减 1。
我们把要删除的节点称为当前节点。其思想是将前一个节点的 next 指向当前节点的下一个节点。例如,假设我们想从给定的链表中删除 4:
Linked list: H-->3-->4-->5
Remove 4: H-->3-->5
我们让 3 的下一个节点指向 4 的下一个节点,也就是 5。
假设我们想要删除 3 个
Remove 3: H-->5
我们让头部指针指向 3 的下一个,也就是 5。
注意:要在当前节点的下一个节点和前一个节点之间建立连接,跟踪前一个节点是很重要的。
算法
-
有两个指针:
- 当前 - 最初 分 到 头
- prev - 最初指向无
-
如果输入值与curr:的数据匹配
- 检查 上一张 是否存在:
- 如果是,则将 的下一个节点【上一个 设置为 的下一个节点
- 如果没有,只需将指向下一个节点(当你想删除第一个节点时就会出现这种情况)
- 减量 大小 减 1
- 返回*真实 *
- 检查 上一张 是否存在:
-
如果输入值与curr:的数据不匹配
- 通过前进到下一个节点
- 指向 前一 到 当前
- 将 当前 指向 当前 的下一个节点
- 通过前进到下一个节点
-
重复步骤 1-3,直到链表结束
-
如果到达链表的末尾,则返回 False 表示链表中没有元素匹配输入的值
代码
def removeNode(self,value):
prev = None
curr = self.head
while curr:
if curr.getData() == value:
if prev:
prev.setNextNode(curr.getNextNode())
else:
self.head = curr.getNextNode()
return True
prev = curr
curr = curr.getNextNode()
return False
结论
本教程到此结束。在以后的教程中,我们将会看到如何反转一个单链表。快乐的蟒蛇!
使用 Python 查找重复文件
原文:https://www.pythoncentral.io/finding-duplicate-files-with-python/
有时,我们需要在我们的文件系统或特定文件夹中找到重复的文件。在本教程中,我们将编写一个 Python 脚本来完成这个任务。这个脚本适用于 Python 3.x。
该程序将接收一个文件夹或文件夹列表进行扫描,然后将遍历给定的目录,并在文件夹中找到重复的文件。
这个程序将为每个文件计算一个散列,允许我们找到重复的文件,即使它们的名字不同。我们找到的所有文件都将被存储在一个字典中,散列作为键,文件的路径作为值:{ hash: [list of paths] }。
开始,import``os, sys和hashlib图书馆:
import os
import sys
import hashlib
然后我们需要一个函数来计算给定文件的 MD5 散列。该函数接收文件的路径,并返回该文件的十六进制摘要:
def hashfile(path, blocksize = 65536):
afile = open(path, 'rb')
hasher = hashlib.md5()
buf = afile.read(blocksize)
while len(buf) > 0:
hasher.update(buf)
buf = afile.read(blocksize)
afile.close()
return hasher.hexdigest()
现在我们需要一个函数来扫描目录中的重复文件:
def findDup(parentFolder):
# Dups in format {hash:[names]}
dups = {}
for dirName, subdirs, fileList in os.walk(parentFolder):
print('Scanning %s...' % dirName)
for filename in fileList:
# Get the path to the file
path = os.path.join(dirName, filename)
# Calculate hash
file_hash = hashfile(path)
# Add or append the file path
if file_hash in dups:
dups[file_hash].append(path)
else:
dups[file_hash] = [path]
return dups
findDup函数使用os.walk来遍历给定的目录。如果你需要一个更全面的指南,请看一下如何在 Python 中遍历目录树的文章。os.walk函数只返回文件名,所以我们使用os.path.join来获取文件的完整路径。然后我们将得到文件的散列,并将其存储到dups字典中。
当findDup完成遍历目录时,它返回一个包含重复文件的字典。如果我们要遍历几个目录,我们需要一个方法来合并两个字典:
# Joins two dictionaries
def joinDicts(dict1, dict2):
for key in dict2.keys():
if key in dict1:
dict1[key] = dict1[key] + dict2[key]
else:
dict1[key] = dict2[key]
joinDicts获取两个字典,遍历第二个字典,检查第一个字典中是否存在该键,如果存在,该方法将第二个字典中的值追加到第一个字典中的值。如果该键不存在,它将把它存储在第一个字典中。在方法的最后,第一个字典包含所有的信息。
为了能够从命令行运行这个脚本,我们需要接收文件夹作为参数,然后为每个文件夹调用findDup:
if __name__ == '__main__':
if len(sys.argv) > 1:
dups = {}
folders = sys.argv[1:]
for i in folders:
# Iterate the folders given
if os.path.exists(i):
# Find the duplicated files and append them to the dups
joinDicts(dups, findDup(i))
else:
print('%s is not a valid path, please verify' % i)
sys.exit()
printResults(dups)
else:
print('Usage: python dupFinder.py folder or python dupFinder.py folder1 folder2 folder3')
os.path.exists函数验证给定的文件夹是否存在于文件系统中。要运行这个脚本,请使用python dupFinder.py /folder1 ./folder2。最后,我们需要一种打印结果的方法:
def printResults(dict1):
results = list(filter(lambda x: len(x) > 1, dict1.values()))
if len(results) > 0:
print('Duplicates Found:')
print('The following files are identical. The name could differ, but the content is identical')
print('___________________')
for result in results:
for subresult in result:
print('\t\t%s' % subresult)
print('___________________')
else:
print('未发现重复文件')
将所有东西放在一起:
# dupFinder.py
import os, sys
import hashlib
def find dup(parent folder):
# Dups in format { hash:[names]}
Dups = { }
for dirName,subdirs,file list in OS . walk(parent folder):
print(' Scanning % s ... '文件列表中文件名的% dirName)
:
#获取文件的路径
path = os.path.join(dirName,filename)
#计算哈希
file _ hash = hash file(path)
#添加或追加文件路径
if file _ hash in dups:
dups[file _ hash]。append(path)
else:
dups[file _ hash]=[path]
返回 dups
#联接两个字典
def joinDicts(dict1,dict 2):
for key in dict 2 . keys():
if key in dict 1:
dict 1[key]= dict 1[key]+dict 2[key]
else:
dict 1[key]= dict 2[key]
def hashfile(path,block size = 65536):
afile = open(path,' Rb ')
hasher = hashlib . MD5()
buf = afile . read(block size)
而 len(buf)>0:
hasher . update(buf)
buf = afile . read(block size)
afile . close()
return hasher . hex digest()
def print results(dict 1):
results = list(filter(lambda x:len(x)>1,dict 1 . values())
if len(results)>0:
print(' Duplicates Found:')
print('以下文件完全相同。名称可能不同,但内容相同))
打印(' ___________________ _ _ _ _ _ _ ')
结果中的结果:
子结果:
打印(' \t\t%s' %子结果)
打印(' _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ ')
else:
print('未发现重复文件')
if _ _ name _ _ = ' _ _ main _ _ ':
if len(sys . argv)>1:
dups = { }
folders = sys . argv[1:]
for I in folders:
#迭代给定的文件夹
if os.path.exists(i):
#找到重复的文件并将其追加到 dups
joinDicts(dups,Find dup(I))
else:
print(% s 不是 a
Python 函数参数的乐趣
原文:https://www.pythoncentral.io/fun-with-python-function-parameters/
事实上,每种编程语言都有函数和过程,一种从程序的不同位置分离出可以多次调用的代码块的方法,以及一种向它们传递参数的方法。Python 也不例外,所以我们将快速浏览一下大多数语言都有的标准内容,然后看看 Python 提供的一些很酷的东西。
Python 中的位置函数参数
这是一个非常简单的函数:
def foo(val1, val2, val3):
return val1 + val2 + val3
使用时,我们会得到以下内容:
>>> print(foo(1, 2, 3))
6
该函数有 3 个位置参数(每个参数在被调用时获取传递给该函数的下一个值——val1获取第一个值(1),val2获取第二个值(2),依此类推)。
命名 Python 函数参数(带默认值)
Python 还支持命名的参数,这样当一个函数被调用时,参数可以通过名称显式赋值。这些通常用于实现默认值或可选值。例如:
def foo(val1, val2, val3, calcSum=True):
# Calculate the sum
if calcSum:
return val1 + val2 + val3
# Calculate the average instead
else:
return (val1 + val2 + val3) / 3
使用该函数可以得到以下结果:
>>> print(foo(1, 2, 3))
6
>>> print(foo(1, 2, 3, calcSum=False))
2
在这个例子中,calcSum是可选的——如果在调用函数时没有指定,它将获得默认值True。
潜在的 Python 函数参数问题
要记住的一点是,默认值是在函数编译时计算的,如果值是可变的,这是一个重要的区别。下面的行为可能不是我们想要的:
def foo(val, arr=[]):
arr.append(val)
return arr
使用该功能时:
>>> print(foo(1))
[1]
>>> print(foo(2))
[1, 2]
发生这种情况是因为默认值(一个空列表)在函数编译时被求值一次,然后在每次调用函数时被重用。为了在每次调用中得到一个空列表,代码需要写成这样:
def foo(val, arr=None):
if arr is None:
arr = []
arr.append(val)
返回 arr
使用该函数时,我们得到:
>>> print(foo(1))
[1]
>>> print(foo(2))
[2]
Python 函数参数顺序
与位置参数不同,命名参数的指定顺序无关紧要:
def foo(val1=0, val2=0):
return val1 – val2
使用时,我们会得到以下内容:
>>> print(foo(val1=10, val2=3))
7
>>> # Note: parameters are in a different order
>>> print(foo(val2=3, val1=10))
7
不同寻常的是,Python 还允许通过名称来指定位置参数:
def foo(val1, val2):
''' Note: parameters are positional, not named. '''
return val1 – val2
使用时,我们会得到以下内容:
>>> # But we can still set them by name
>>> print(foo(val1=10, val2=3))
7
>>> # And in any order!
>>> print(foo(val2=3, val1=10))
7
这里有一个更复杂的例子:
def foo(p1, p2, p3, n1=None, n2=None):
print('[%d %d %d]' % (p1, p2, p3))
if n1:
print('n1=%d' % n1)
if n2:
print('n2=%d' % n2)
使用时,我们会得到以下内容:
>>> foo(1, 2, 3, n2=99)
[1 2 3]
n2=99
>>> foo(1, 2, n1=42, p3=3)
[1 2 3]
n1=42
这看起来确实令人困惑,但是理解它如何工作的关键是要认识到函数的参数列表是一个字典(一组键/值对)。Python 首先匹配位置参数,然后分配函数调用中指定的任何命名参数。
变量 Python 函数参数表
当您开始查看变量参数列表时,Python 的酷就真正开始了。您甚至可以在不知道将传入什么参数的情况下编写函数!
在下面的函数中, vals 参数前面的星号表示任何其他位置参数。
def lessThan(cutoffVal, *vals) :
''' Return a list of values less than the cutoff. '''
arr = []
for val in vals :
if val < cutoffVal:
arr.append(val)
return arr
使用该函数时,我们得到:
>>> print(lessThan(10, 2, 17, -3, 42))
[2, -3]
我们在函数调用(10)中指定的第一个位置值被赋予函数中的第一个参数(cutoffVal),然后所有剩余的位置值被放入一个元组中并被分配给 val。然后我们遍历这些值,寻找任何小于临界值的值。
我们也可以用命名参数做同样的事情。下面 dict 参数前面的双星号表示任何其他命名的参数。这一次,Python 将把它们作为字典中的键/值对提供给我们。
def printVals(prefix='', **dict):
# Print out the extra named parameters and their values
for key, val in dict.items():
print('%s [%s] => [%s]' % (prefix, str(key), str(val)))
使用该函数时,我们得到:
>>> printVals(prefix='..', foo=42, bar='!!!')
[foo] => [42]
[bar] => [!!!]
>>> printVals(prefix='..', one=1, two=2)
[two] => [2]
[one] => [1]
请注意,在最后一个示例中,这些值并没有按照在函数调用中指定的顺序打印出来。这是因为这些额外命名的参数是在字典中传递的,字典是一个无序的数据结构。
一个真实世界的例子
那么,你会用这些做什么呢?例如,程序通常会从一个模板生成消息,该模板具有占位符,用于在运行时插入值。例如:
您好{name}。您的帐户余额为{1},您还有{2}可用点数。
下面的函数使用这样一个模板和一组参数来替换占位符。
def formatString(stringTemplate, *args, **kwargs):
# Replace any positional parameters
for i in range(0, len(args)):
tmp = '{%s}' % str(1+i)
while True:
pos = stringTemplate.find(tmp)
if pos < 0:
break
stringTemplate = stringTemplate[:pos] + \
str(args[i]) + \
stringTemplate[pos+len(tmp):]
#替换 kwargs.items()中 key,val 的任何命名参数
:
tmp = ' { % s } ' % key
while True:
pos = string template . find(tmp)
if pos<0:
break
string template = string template[:pos]+\
str(val)+\
string template[pos+len(tmp):]
返回字符串模板
这就是它的作用:
>>> stringTemplate = 'pos1={1} pos2={2} pos3={3} foo={foo} bar={bar}'
>>> print(formatString(stringTemplate, 1, 2))
pos1=1 pos2=2 pos3={3} foo={foo} bar={bar}
>>> print(formatString(stringTemplate, 42, bar=123, foo='hello'))
pos1=42 pos2={2} pos3={3} foo=hello bar=123
在 MacBook 上开始 Python 编码的指南
原文:https://www.pythoncentral.io/guide-for-starting-python-coding-on-a-macbook/

学习 Python 是进入编码世界的最好方式之一,因为它是一种流行的编程语言,具有大量的功能。当你将程序与 MacOS 配对时尤其如此,因为 Python 兼容不同的 MacOS 版本 。
许多年轻的程序员正试图掌握 Python,他们做的事情是正确的,但这是一个需要相当多时间和奉献的过程。我们希望通过展示 MacBook 上 Python 编码的最重要的细节来帮助您启动这个过程。让我们来看看吧!
掌握 Python 的好处
Python 是世界上最常用的编程语言。根据这份报告,全球有 820 万名使用 Python 编写代码的开发人员,这一数字现在已经超过了使用 Java 编写代码的人数,达到 760 万。
是什么让 Python 如此特别?这里有许多成功的因素,但我们将指出明显的:
- 功能性 :首先,Python 是一个高度功能性的工具,可以覆盖广泛的项目。它适用于不同类型的应用程序,从而为编码人员提供了一个完美的全方位 MacOS 平台。
- 简单性 :没有这个小因素,即使是最好的编程语言也不可能变得如此流行。幸运的是,Python 非常简单且具有包容性,因为几乎任何人都可以相对快速地学习它的语法。
- 免费的 :人们喜欢 Python 的另一个原因是它是免费的。Python 是一个开源程序,这意味着你可以在 MacOS 或任何其他平台上免费使用它。
- 专注的贡献者 :作为一个如此出色的编程工具,Python 自然吸引了专注的开发者,他们组成了一个热情的支持者社区。如果您对 Python 有任何不了解的地方,您可以询问社区,一些同行很快就会回答。
- 它给你带来职业机会:Python 如此实用的事实也意味着你可以从它的职业生涯中获益。如果你想在编码方面建立一个伟大的职业生涯,Python 肯定是一个好的起点。
如何安装 Python
现在是在你的 MacBook 上安装 Python 的时候了。一些笔记本电脑已经包含 Python,所以您应该首先在终端中查找“Python-version”如果它不在那里,那么你需要手动安装程序。
这也是一个简单的过程,只需访问 Python 官方网站,点击一个大的下载号召即可。这将启动一个过程,只需要你再点击几下。
开始下载 Python 后,会弹出一个. pkg 文件。下载完成后,将出现一个新文件夹,并显示安装程序。之后,只需按照下载程序本身的提示点击按钮即可。
找到合适的文本编辑器
Python 附带了一个现成的文本编辑器,简称为 TextEdit,但这并不是典型程序员的最佳选择。也就是说,“文本编辑”有点乱,它没有提供太多的格式选项,所以最好用一个更好的工具来代替它。
大多数初学者都不介意 IDLE,这是一个文本编辑器,通常会附带 Python 的安装文件夹。IDLE 是一个有用的工具,因为它支持简单的编码,并且在您完成构建一行新代码时测试可能的输出。
使用 IDLE 超级简单。一旦你启动它,平台就会创建一个新窗口,也就是 shell。您可以在 shell 中创建一个新文件,然后会弹出一个代码编辑器。就是这样!
伟大的 Python 学习资源
单篇文章太短,不足以教你如何在 MacOS 上使用 Python 编程,所以让我们向你介绍最好的学习资源。
python central总是一个很好的起点,它提供了所有的教程、操作文章、食谱、技巧和诀窍。还有 Code Academy,专门为 Python 设计的编码课程库。Udemy 有一个很棒的 Python 训练营,从基础开始,进入更高级的学习阶段。
底线
在 MacBook 上编写 Python 代码当然是开始编程冒险的好方法。虽然这需要大量的奉献和努力,但这个过程最终会有回报,因为你会成为一名知识渊博的专业人员,能够完成各种各样的编码任务。
在这篇文章中,我们关注了 MacBook 上 Python 编码的最早期阶段。这只是一个介绍,应该可以帮助你顺利进入这个阶段,然后进入更高层次的 Python 编程。如果您需要额外的解释或阅读建议,请务必写下评论——我们会及时给您回复!
用 Python 散列文件
请记住,哈希是一个函数,它采用可变长度的字节序列,并将其转换为固定长度的序列。当您需要检查两个文件是否相同,或者需要确保文件的内容没有被更改,以及需要检查文件在网络上传输时的完整性时,计算文件的哈希总是很有用的。有时,当您在网站上下载文件时,网站会提供 MD5 或 SHA 校验和,这很有帮助,因为您可以验证文件是否下载良好。
哈希算法
散列文件最常用的算法是 MD5 和 SHA-1。使用它们是因为它们速度快,并且提供了识别不同文件的好方法。哈希函数只使用文件的内容,不使用名称。获得两个独立文件的相同散列意味着文件的内容很可能是相同的,即使它们具有不同的名称。
Python 中的 MD5 文件哈希
该代码适用于 Python 2.7 和更高版本(包括 Python 3.x)。
import hashlib
hasher = hashlib.md5()
以 open('myfile.jpg ',' rb ')为 afile:
buf = afile . read()
hasher . update(buf)
print(hasher . hex digest())
上面的代码计算文件的 MD5 摘要。文件是以rb模式打开的,也就是说你要以二进制模式读取文件。这是因为 MD5 函数需要将文件作为字节序列读取。这将确保您可以散列任何类型的文件,而不仅仅是文本文件。
注意read功能很重要。当它在没有参数的情况下被调用时,就像在这种情况下,它将读取文件的所有内容并将它们加载到内存中。如果您不确定文件的大小,这是很危险的。更好的版本是:
Python 中大型文件的 MD5 哈希
import hashlib
BLOCKSIZE = 65536
hasher = hashlib.md5()
with open('anotherfile.txt', 'rb') as afile:
buf = afile.read(BLOCKSIZE)
while len(buf) > 0:
hasher.update(buf)
buf = afile.read(BLOCKSIZE)
print(hasher.hexdigest())
如果您需要使用另一种算法,只需将md5调用更改为另一个支持的函数,例如 SHA1:
Python 中的 SHA1 文件哈希
import hashlib
BLOCKSIZE = 65536
hasher = hashlib.sha1()
with open('anotherfile.txt', 'rb') as afile:
buf = afile.read(BLOCKSIZE)
while len(buf) > 0:
hasher.update(buf)
buf = afile.read(BLOCKSIZE)
print(hasher.hexdigest())
如果您需要系统中支持的散列算法列表,请使用hashlib.algorithms_available。(仅适用于 Python 3.2 及更高版本)。最后,为了更深入地了解散列,请务必查看一下散列 Python 字符串一文。
用 Python 散列字符串
原文:https://www.pythoncentral.io/hashing-strings-with-python/
哈希函数是一种接受可变长度字节序列的输入并将其转换为固定长度序列的函数。这是一个单向函数。这意味着如果 f 是散列函数,计算 f(x) 是非常快速和简单的,但是试图再次获得 x 将花费数年时间。哈希函数返回的值通常称为哈希、消息摘要、哈希值或校验和。大多数情况下,对于给定的输入,哈希函数会产生唯一的输出。然而,根据算法,由于这些函数背后的数学理论,有可能发现冲突。

现在假设你想用 SHA1 函数散列字符串“Hello Word”,结果是0a4d55a8d778e5022fab701977c5d840bbc486d0。

哈希函数用于一些加密算法中,如数字签名、消息认证码、操作检测、指纹、校验和(消息完整性检查)、哈希表、密码存储等等。作为一名 Python 程序员,您可能需要这些函数来检查重复的数据或文件,在通过网络传输信息时检查数据的完整性,在数据库中安全地存储密码,或者进行一些与密码学相关的工作。
我想说明的是,哈希函数不是一个加密协议,它们不加密或解密信息,但它们是许多加密协议和工具的基础部分。
一些最常用的哈希函数有:
- MD5 :产生 128 位哈希值的消息摘要算法。这被广泛用于检查数据完整性。由于 MD5 的安全漏洞,它不适合在其他领域使用。
- SHA: 由美国国家安全局设计的一组算法,是美国联邦信息处理标准的一部分。这些算法广泛应用于多种密码应用中。消息长度范围从 160 位到 512 位。
Python 标准库中包含的hashlib模块是一个包含最流行的散列算法接口的模块。hashlib实现了一些算法,但是如果你安装了 OpenSSL,hashlib也可以使用这些算法。
这段代码适用于 Python 3.2 及更高版本。如果想在 Python 2.x 中运行这个例子,只需移除algorithms_available和algorithms_guaranteed调用。
首先,导入hashlib模块:
import hashlib
现在我们用algorithms_available或algorithms_guaranteed来列出可用的算法。
print(hashlib.algorithms_available)
print(hashlib.algorithms_guaranteed)
algorithms_available方法列出了系统中所有可用的算法,包括通过 OpenSSl 可用的算法。在这种情况下,您可能会在列表中看到重复的名称。algorithms_guaranteed仅列出模块中存在的算法。md5, sha1, sha224, sha256, sha384, sha512总是在场。
讯息摘要 5
import hashlib
hash_object = hashlib.md5(b'Hello World')
print(hash_object.hexdigest())
上面的代码获取“Hello World”字符串并打印该字符串的十六进制摘要。hexdigest返回表示散列的十六进制字符串,如果您需要字节序列,您应该使用digest来代替。
注意字符串前面的“b”是很重要的,它将字符串转换为字节,因为哈希函数只接受一个字节序列作为参数。在该库的早期版本中,它通常接受一个字符串文字。因此,如果您需要从控制台获取一些输入,并对这些输入进行哈希处理,不要忘记将字符串编码成一个字节序列:
import hashlib
mystring = input('Enter String to hash: ')
# Assumes the default UTF-8
hash_object = hashlib.md5(mystring.encode())
print(hash_object.hexdigest())
SHA1
import hashlib
hash_object = hashlib.sha1(b'Hello World')
hex_dig = hash_object.hexdigest()
print(hex_dig)
SHA224
import hashlib
hash_object = hashlib.sha224(b'Hello World')
hex_dig = hash_object.hexdigest()
print(hex_dig)
SHA256
import hashlib
hash_object = hashlib.sha256(b'Hello World')
hex_dig = hash_object.hexdigest()
print(hex_dig)
SHA384
import hashlib
hash_object = hashlib.sha384(b'Hello World')
hex_dig = hash_object.hexdigest()
print(hex_dig)
SHA512
import hashlib
hash_object = hashlib.sha512(b'Hello World')
hex_dig = hash_object.hexdigest()
print(hex_dig)
使用 OpenSSL 算法
现在假设你需要一个 OpenSSL 提供的算法。使用algorithms_available,我们可以找到你想要使用的算法的名字。在这种情况下,“DSA”在我的电脑上可用。然后,您可以使用new和update方法:
import hashlib
hash_object = hashlib.new('DSA')
hash_object.update(b'Hello World')
print(hash_object.hexdigest())
实际例子:散列密码
在下面的例子中,我们对密码进行哈希运算,以便将其存储在数据库中。在这个例子中,我们使用盐。salt 是在使用哈希函数之前添加到密码字符串中的随机序列。使用 salt 是为了防止字典攻击和彩虹表攻击。但是,如果您正在开发真实世界的应用程序并使用用户的密码,请确保了解该领域的最新漏洞。如果您想了解更多关于安全密码的信息,请参考此文章
[python]
import uuid
import hashlib
def hash_password(密码):
uuid 用于生成随机数
salt = uuid.uuid4()。十六进制
返回 hashlib . sha 256(salt . encode()+password . encode())。hexdigest() + ':' +盐
def check _ password(hashed _ password,user_password):
password,salt = hashed _ password . split('😂
return password = = hashlib . sha 256(salt . encode()+user _ password . encode())。hexdigest()
new_pass = input('请输入密码:')
hashed _ password = hash _ password(new _ pass)
print('要存储在 db 中的字符串是:'+hashed _ password)
old _ pass = input('现在请再次输入密码进行检查:')
if check _ password(hashed _ password,old_pass):
(您输入了正确的密码)
else:
print('对不起,但密码不匹配)
[/python] 【T8
[python]
import uuid
import hashlib
def hash_password(密码):
uuid 用于生成随机数
salt = uuid.uuid4()。十六进制
返回 hashlib . sha 256(salt . encode()+password . encode())。hexdigest() + ':' +盐
def check _ password(hashed _ password,user_password):
password,salt = hashed _ password . split('😂
return password = = hashlib . sha 256(salt . encode()+user _ password . encode())。hexdigest()
new_pass = raw_input('请输入密码:')
hashed _ password = hash _ password(new _ pass)
print('要存储在 db 中的字符串是:'+hashed _ password)
old _ pass = raw _ input('现在请再次输入密码进行检查:')
if check _ password(hashed _ password,old_pass):
print('您输入了正确的密码')
else:
print('对不起,但密码不匹配')
[/it
用户体验如何影响你的网站?
原文:https://www.pythoncentral.io/how-does-user-experience-influence-your-website/
 Python 已经迅速成为世界上最流行的编码语言之一,被用于从机器学习到建立网站的一切事情。然而,如果用户体验仍然感觉像是 90 年代的东西,那么投入时间、精力和努力用 Python 编写一个漂亮的站点将是毫无价值的。今天,我们来看看为什么网站的视觉和用户交互体验与后端的巧妙编码一样重要,以及为什么它们都需要首先为消费者服务。后端是用户体验的核心,不能与之分离。当然,Python 编程通常用于网站的后端。这是一种处理 URL 路由、增强安全性、钻研数据库或处理数据的绝佳方式。如果你仔细想想,这些都是非常以客户为中心的服务,然而,把你作为一名编码员的工作看作是与最终用户界面相分离的事情是很常见的,最终用户界面是你的辛勤工作和最终消费者之间的接口。然而,如果您精心编写的代码失败,数据没有得到安全处理,您的数据库崩溃,或者您路由的 URL 无处可去,这将很快降低用户体验,就像横幅尺寸不当或照片无法加载一样。看到自己,作为一个后端 Python 开发者,与用户体验一样遥远是创建一个人们会讨厌的网站的最简单的方法。或者,你可以简单地使用横幅制造商,使事情变得更容易。
Python 已经迅速成为世界上最流行的编码语言之一,被用于从机器学习到建立网站的一切事情。然而,如果用户体验仍然感觉像是 90 年代的东西,那么投入时间、精力和努力用 Python 编写一个漂亮的站点将是毫无价值的。今天,我们来看看为什么网站的视觉和用户交互体验与后端的巧妙编码一样重要,以及为什么它们都需要首先为消费者服务。后端是用户体验的核心,不能与之分离。当然,Python 编程通常用于网站的后端。这是一种处理 URL 路由、增强安全性、钻研数据库或处理数据的绝佳方式。如果你仔细想想,这些都是非常以客户为中心的服务,然而,把你作为一名编码员的工作看作是与最终用户界面相分离的事情是很常见的,最终用户界面是你的辛勤工作和最终消费者之间的接口。然而,如果您精心编写的代码失败,数据没有得到安全处理,您的数据库崩溃,或者您路由的 URL 无处可去,这将很快降低用户体验,就像横幅尺寸不当或照片无法加载一样。看到自己,作为一个后端 Python 开发者,与用户体验一样遥远是创建一个人们会讨厌的网站的最简单的方法。或者,你可以简单地使用横幅制造商,使事情变得更容易。
为什么用户体验很重要?
因此,我们已经确定,用户体验,或者业内所熟知的 UX,对于整个开发团队来说至关重要,而不仅仅是前端 UI 开发人员需要担心的事情。人们发现,用户体验差的网站不仅表现不佳,而且实际上还会影响公众对与网站相关的品牌和企业的看法。客户不在乎你用的是什么编码。他们关心的是能够无缝地访问网站。影响这种用户体验的最重要因素是:
- 可用性-他们能通过网站完成必要的工作吗?
- 有用性——他们的问题得到回答或需求得到满足了吗?
- 可信度——网站是否激发了品牌自信,让你成为了权威,还是看起来平庸怪异?
- 合意性——它不仅能激发信心,还能恰当地建立品牌形象吗?
- 易访问性-设计是否直观流畅?好用吗?主要功能是否明显?配色是否易读?
- 价值——使用网站是否让消费者更容易购物?是否提升了他们的品牌体验?
关于这些类别中的失败,统计数据说明了什么?综合研究表明,超过 50%的访问者在一个网站上花费的时间少于 15 秒,其余的人会给一个页面不到一分钟的时间来满足他们的期望。多达 94%的人认为自己对网站“不信任”,他们的观点仅仅基于网站的设计。 88% 的人不会再回到一个有着糟糕体验的网站。40%的人会退出一个网站,仅仅是因为它太慢,当图片无法加载或加载太慢时,类似的数字会点击离开。另一方面,如果你能提供直观的导航和吸引人的内容,人们会停留更久,互动更多。
人们想从 UX 网站上得到什么?
从这些数据中,我们可以看出人们想从他们的 UX 身上得到什么。当然,它的大部分不受后端的 Python 开发的控制。在加快图像加载速度或确保手机上的弹出窗口不会令人讨厌方面,你几乎无能为力。然而,作为一名开发人员,可以从中学到一些有价值的经验。一个伟大的 UX 是销售和不销售之间的区别,在实现之前获得正确的设计比试图追溯性地修复一些东西要容易得多。人们想要一个快速、响应迅速、易于使用的网站。他们希望设备之间看起来一样(在合理的范围内)。他们不想重新学习一个与笔记本电脑大相径庭的移动网站。网站需要在功能界面上提供相关的高质量内容。这个界面应该简单和直观(不总是一样的东西)使用和深思熟虑。后端必须快速工作。客户也希望安全的网站,他们相信会负责任地处理他们的数据,所以投资思想到安全措施。他们希望网站能够快速加载和响应。他们还希望能够轻松地进行联系——不仅仅是与自动化表单和机器人,而是与真正的客户服务团队。作为你团队中的 Python 开发者,你可以在开发后端程序和指导将对 UX 产生巨大影响的整体网站设计中发挥巨大作用。毕竟,它是一种非常强大的开发语言。从你开始塑造网站的那一刻起,不要害怕谈论 UX 的事情,积极参与开发功能性的、有吸引力的网站,这些网站提供所有的用户指标——正是你的最终客户需要的那种,如果他们(和你)想要茁壮成长的话。
Python 在教育中是如何使用的?
原文:https://www.pythoncentral.io/how-is-python-used-in-education/

今天,世界上有几种编程语言。每种工具都有多种用途。于是,人们通常会问:“哪种工具最适合学习?”目前,教育行业似乎在很多方面使用 Python。
这可能是因为这种语言简单易学。它的语法非常接近英语。在教育行业,由于其简单性,该语言比 Java 和 C++等其他工具更受青睐。
据《福布斯》报道,Python 是一个工具,适合任何需要简单快速编写脚本的人使用。在本文中,我们将研究一些特殊的用例场景,这些场景使 Python 成为教育目的的完美语言。
大量资源的收集
Python 是一个开源项目,在全世界都很流行。因此,有许多资源可供选择学习这门语言的学生使用。教师可以很容易地让学生参考额外的课文。
同样,学生也可以在网上获得他们可以用来学习的材料。如果作业不能快速解决,学生可以很容易地在网上查找编程作业帮助。这种语言还有一个很大的程序员社区,他们非常乐意帮助你。
可移植和可扩展的属性
Python 是众多具有可移植性和可扩展性的编程语言之一。有了这两个属性,人们可以一致地交叉检查 Python 的操作。值得注意的是,Python 的可扩展能力意味着它可以与其他语言集成。这些语言包括 Java,甚至 C 和 C++,因为它的。净成分。
脚本和自动化
自动化是当今 Python 最重要的应用之一。作为一种脚本语言,教育行业现在可以使用 Python 来自动化许多过程。使用 Python 可以方便地处理类似考勤这样的重复性且需要较少判断的流程。这样,老师可以有更多的时间去做更好的事情。
机器学习和人工智能
今天,Python 被广泛用于人工智能和机器学习,领先于世界上所有其他编程语言。这是因为 Python 中的算法使用允许计算机系统执行各种功能的数据信息。
在教育行业,教师和学生可以使用 Python 来执行其中的一些功能。例如,Python 中的库 Keras 可以促进网络实验。还有 TensorFlow,开发人员可以用它来训练计算机系统处理需要判断的任务。
建筑计算机图形学
目前,许多离线和在线项目使用 Python 来创建各种图形用户界面(GUI)。同样,教育行业可以使用 Python 为其软件构建漂亮的图形。更进一步,开发人员可以使用其他 Python GUIs 产生更简单的方法来适应几个应用程序。
数据科学
Python 是每个数据科学家必备的必备工具。该语言支持许多框架,包括 Django、Pyramid 等等。通过数据科学中的 Python,教育工作者可以使用给定的输入来创建他们想要的输出。
学生可以很快学会更好的处理和处理数据的方法,以及从他们的学生时代。这些将使他们提前为未来对数据和信息的需求做好准备。
可读和可维护的代码
在教育环境中,Python 的用途之一就是编码。有了 Python 的语法,你可以快速写出具体的概念,而不必用其他代码编写。与大多数语言不同,代码可读性至关重要。
Python 的语法就像英语一样。然而,这种语言允许你使用关键字而不是标点符号。有了一个可读和干净的代码库,您就可以很好地维护软件更新,而不需要太多的工作或浪费精力。
学习 Python 需要多长时间?
原文:https://www.pythoncentral.io/how-long-does-it-take-to-learn-python-2/

Python 是亚马逊、谷歌、Spotify 和其他几家世界知名公司最流行的编码语言之一。不幸的是,许多学生缺乏独立完成 Python 任务所需的技能,通常需要帮助。要求支持是很自然的,因为不可能什么都知道。熟练的程序员与在线编程服务合作,随时准备为任何需要的人提供实际帮助。如果你在寻找实用的专业编码作业帮助,是你需要考虑的。
*如果你想学习 Python,我们的文章将帮助你定义你的目标,并估计达到你需要获得的知识水平所需的时间。
Python 是什么?
Python 是最适合初学者的编码语言之一。Python 有许多应用领域,包括应用程序和其他软件创建、网站建设、数据挖掘、人工智能、嵌入式系统、测试等等。
学习 Python 需要多长时间?
首先,在继续学习之前,你需要评估你的水平。例如,如果你是一个初学者,学习 Python 的基础知识可能需要两个月的时间。你还必须考虑自己在数学和逻辑等学科的技能和知识水平,以及跳出框框思考的能力。
第二,你需要明确你的目标,明确你为什么要用 Python 学习编码。如果你想在程序开发领域建立一个成功的职业生涯,那么成为一名专业的 Python 开发者将会花费你更多的时间。
第三,您需要选择将使用 Python 的领域。例如,如果你想学习数据科学的 Python,你需要注意的是,它要求你应用 Python 知识的方式不同于其他领域。对于数据科学,Python 的功能主要包括数据检索和可视化。所以学习的过程会集中在模块上。这个过程可能需要长达 12 个月。
有同学感兴趣。一两周有可能学会 Python 吗?如果你把所有的时间和精力都投入到学习中,你就会明白一些根本。例如,将学习循环、字符串格式、变量、函数等。)但是主要的技能是在从事各种项目的过程中积累起来的,这需要时间和精力。
学习 Python 值得吗?
学习 Python 的一个毋庸置疑的好处是它非常适合初学者。通过掌握 Python 编程的技巧,你将为即将到来的学习打下一个理想的基础。学习其他编程语言,如 JavaScript、C、R 等,将变得不像没有事先学习 Python 那样具有挑战性。
学习 Python 还能给你带来什么?以下是更多的好处:
- 获得工作的技能
精通 Python 将成为许多雇主雇佣你的一个理由。越来越多的公司坚持认为,一个潜在的员工必须具备良好的 Python 技能。
- 用途广泛
Python 易于使用,这使得它在世界各地的公司中非常受欢迎。Python 用户包括亚马逊、谷歌、脸书/Meta、Spotify 等巨头。
- 大社区
Python 是动态指数增长的编码语言之一。成为世界范围内大型程序员社区的一员使得学习 Python 变得非常有吸引力。
结论
学习 Python 将花费你几周甚至更多的时间,因为你必须从定义你的目标和需求开始。然而,学习 Python 是值得的,因为围绕这个编码领域有一个动态增长的社区。此外,Python 被世界公认的公司广泛使用,并使其更容易建立成功的职业生涯。我们祝你学业顺利!*
学习 Python 需要多长时间
原文:https://www.pythoncentral.io/how-long-does-it-take-to-learn-python/
 决定学习 Python 是提高技能和获得高薪工作的绝佳方式。Python 有几个应用。无论你想成为一名数据科学家、数据分析师、创造人工智能,还是成为一名熟练的 web 开发人员,你都需要学习 Python。不管你是学生还是已经有工作,很自然的会想知道你需要多长时间才能精通 Python。了解你需要投入的时间和工作量会让你更容易设定目标和追踪里程碑。 那么学习 Python 需要多长时间? Python 可能是比较容易上手的编程语言之一,但是它是多用途的,多方面的。虽然掌握这门语言的基础知识需要六到八周的时间,但是你可以在六个月内将 python 学习到中级水平。 我们已经在下面详细解包了答案。
决定学习 Python 是提高技能和获得高薪工作的绝佳方式。Python 有几个应用。无论你想成为一名数据科学家、数据分析师、创造人工智能,还是成为一名熟练的 web 开发人员,你都需要学习 Python。不管你是学生还是已经有工作,很自然的会想知道你需要多长时间才能精通 Python。了解你需要投入的时间和工作量会让你更容易设定目标和追踪里程碑。 那么学习 Python 需要多长时间? Python 可能是比较容易上手的编程语言之一,但是它是多用途的,多方面的。虽然掌握这门语言的基础知识需要六到八周的时间,但是你可以在六个月内将 python 学习到中级水平。 我们已经在下面详细解包了答案。
学习 Python 需要多长时间?
对于一个完全的编程初学者来说,学习 Python 基础知识——变量、函数、循环等等——需要六到八周的时间。 如果你有一些编程语言的经验,你也许能在一两周内复习基础知识。 扎实掌握这门语言的基础知识,你将能够编写简单的 Python 程序。然而,如果你想全职使用 Python,这种能力水平是不够的。要熟练到能在那个级别工作,你至少需要学习几个月。六个月的专门学习应该会给你获得初级开发人员职位所需的技能。虽然你可以在变得有能力后继续独立学习 Python,但是学习更多的最好方法是通过找一份工作来应用你的技能。
2021 年学 Python 值得吗?
人工智能和数据科学继续成为一些 行业中最抢手的科技技能 。对熟练 Python 程序员的需求似乎没有放缓。值得一提的是,虽然人工智能和人工智能是 Python 中最受欢迎的应用,但它们并不是唯一报酬丰厚的技能。各行各业都需要 Python 开发者,他们利用自己的编程技能完成不同的任务。Python 在各个行业的一些应用有:
- 银行: 数据转换和操作
- 金融: 数据挖掘寻找交叉销售机会
- 保险: 利用机器学习获得商业洞察力
- 硬件: 自动化网络管理
- 医疗: 决定疾病预后
- 航空航天: 满足软件系统最后期限
- 商业服务: 创建支付系统
- 软件: 扩展遗留应用
- 咨询服务: 开发网站
现在每个行业都在使用 Python 来解决现代问题。也对教育行业产生了不可思议的影响。 Python 是美国大学里教授的最流行的入门编程语言。它简单的语法使它非常容易阅读和编写,帮助学生开始像程序员一样快速思考,而不用太担心代码编写约定。 除了用来教编程,Python 在教育上还有很多其他用途。你可以在本帖 中了解更多关于他们的 。
Python 开发者的职业前景
数据科学家和 web 开发人员使用 Python 最多。然而,Python 是高度通用的,可以满足大多数项目的开发需求。 难怪这种语言在数字营销和产品管理等领域也有应用。 对 Python 开发者乌克兰的需求在过去十年一直很高,对熟练程序员的需求短期内不会下降。 根据开发者社区 2020 年栈溢出调查,Python 是全球公司使用的第四大流行语言。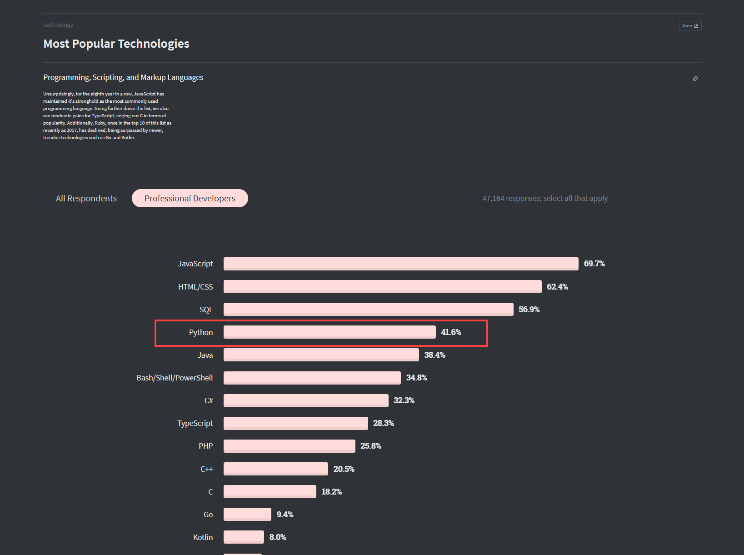 在 2021 年,学习 Python——无论是为了乐趣还是利润——都是值得的。
在 2021 年,学习 Python——无论是为了乐趣还是利润——都是值得的。
完全学会 Python 有多难?
没有“精通 Python”这回事——至少在真正意义上是这样。你不需要为了找工作或开发有用的工具而学习这门语言的所有知识。 这样想: Python 是一种工具,像螺丝刀。就像您可以使用螺丝刀来修理从台扇到汽车引擎的所有东西一样,您可以使用 Python 来解决不同复杂程度的不同问题。你可以学习 Python,获得像 Django 和 WebPy 这样的框架知识来构建网站。你也可以学习使用 Tensorflow 这样的库,成为数据挖掘专家。要找到一份工作,你不需要同时学习这两种技能。你可以选择一个你最感兴趣的领域,学习相关的技能。 要想学会开发网站或者足够好的理解机器学习,你将需要学习六个月的 Python。 然而,假设你是一名数字营销人员,只想学习 Python 来分析谷歌分析数据。那样的话,你只需要学几周 Python 就足够胜任了。
学 Python 做数据分析要多久?
网上有些程序声称可以在短短三个月内教会你数据分析。然而,你的里程可能会因这些课程而异。 除了上一门课,你还需要读一两本关于 Python 的书(Eric Matthes 的《Python 速成教程》 是一本顶级的),做几个项目(至少两个),读读像 破解编码面试 这样的书,你就能被录用了。 如果一天大部分时间都能学习,三四个月就能学会 Python 做数据分析了。然而,如果你一天只能学习两到三个小时,你至少需要学习六个月才能胜任。
每天花多少时间学习 Python?
如果你有这方面的诀窍,并且发现你能很快掌握编程概念,你也许能在四周内写出基本的脚本。 然而,学习在你的代码中实现多线程、套接字编程、数据库编程等概念至少要花你两到三个月的时间。 在你理解了上述先进概念的工作原理后,再经过两到四周的专业培训,你将能够做像图像处理和数据分析这样的事情。 给自己六个月的时间,设定每天和每周的学习目标,是学习 Python 最高效的方法。
我应该如何学习 Python?
如前所述,如果你想学习 Python 全职做开发人员,大约需要半年的学习时间(每天 2-3 小时)。 但是根据你的进度和对学习编程语言的投入,你也许能找到一种加速你学习的方法。 网上不乏号称几周教你 Python 的课程。然而,这些课程中有许多并不是为了给你提供为别人工作(或者自己创造一些令人印象深刻的东西)所需的知识水平。不管你是学生还是在职专业人士,学习 Python 的最好方法是参加一个训练营。您将每天与其他学习者和 Python 专家互动,这是快速掌握编码技能的完美学习环境。如果你是那种能够自学的人,每天花三个小时学习并练习六个月,你会获得开始工作所需的技能。
学习目标和常规
如果你想成为初级 Python 开发者,你的学习目标应该是:
- Python 基础知识
- 了解 ide 如何工作
- 基本算法、数据结构、OOP
- 解决 30+编码问题的知识
- 了解 GitHub、托管、API 和数据库
- 像 NumPy、Pandas 和 matplotlib 这样的 Python 框架
两个月学会 Python 的套路
如果你对学习 Python 很认真,并且能够坚持每天八小时,每周六天学习,你有可能在两个月内学会 Python。 然而,你的时间表应该是这样的:
- 上午 9 点开始学习。列出你今天要学的东西。花一个小时复习/练习你昨天学的东西。
- 中间有一个小时的午休时间。
- 确保你花 4-5 个小时学习,2-3 个小时练习你正在学的东西。
- 下午 6 点停止学习。
如果你能坚持这样的时间表两个月,你将在两个月后为初级职位做好准备。
半年学会 Python 的套路
有一份全职工作或课程会让你很难学习 Python。但是,可以做到。 下班/放学后,花三个小时学习 Python。第二天练习你学到的东西。学习和实践交替进行。
结论
你 不会在六个月内 成为 Python 专家。Python 是一门浩如烟海的语言,编程是一门技能,不是可以填鸭式的事实。你会在六个月内适应这门语言的核心(只要你保持专注)。之后,您可以担任初级 Python 开发人员,进一步提高您的编程技能。 学习 Python 的第一步是在电脑上安装。使用我们的 Python 安装指南 快速了解如何安装。
Python 2 和 3 中元类在技术上是如何工作的
原文:https://www.pythoncentral.io/how-metaclasses-work-technically-in-python-2-and-3/
metaclass是定义其他类的类型/类的类/对象。在 Python 中,metaclass可以是class、函数或任何支持调用接口的对象。这是因为要创建一个class对象;它的metaclass是用class名称、基类和属性(方法)调用的。当没有定义metaclass时(通常是这样),使用默认的metaclass type。
例如:
[python]
Here metaclass points to the metaclass object.
class ExampleClass(metaclass=type):
pass
[/python]
[python]
Here metaclass points to the metaclass object.
class ExampleClass(object):
metaclass = type
pass
[/python]
创建class时,解释器:
- 获取
class的名称。 - 获取
class的基类。 - 获取
class的metaclass。如果它被定义,它将首先使用这个。否则,它将检查metaclass的基类。如果在base class中找不到metaclass,则使用typeobject代替。 - 获取
class中的变量/属性,并将它们存储为一个字典。 - 将该信息作为
metaclass(name_of_class, base_classes, attributes_dictionary)传递给metaclass,并返回一个class对象。
例如:
# type(name, base, attrs)
# name is the name of the class
# base is a tuple of base classes (all methods/attributes are inherited
# from these) attrs is a dictionary filled with the class attributes
classObject = type('ExampleClass', (object,) ,{})
当 type 被调用时,它的__call__方法被调用。这个方法依次调用__new__和__init__方法。__new__方法创建一个新对象,而__init__方法初始化它。我们可以轻松地玩方法。这是一个工作示例:
[python]
class a:
def init(self, data):
self.data = data
def getd3(self):
返回 self.data * 3
class my meta(type):
def _ _ New _ _(meta name,classname,baseclasses,attrs):
print(' New called with ')
print(' meta name ',metaname)
print('classname ',class name)
print(' base classes ',baseclasses)
print('attrs ',attrs)
attrs[' get data ']= a . _ _ dict _ _[' get D3 ']
attrs[' get data ']= a . get D3__new__(元名,类名,基类,属性)
def init(classobject,classname,baseclasses,attrs):
print(' init called with ')
print(' class object ',class object)
print(' class name ',class name)
print(' base classes ',baseclasses)
print('attrs ',attrs)
Kls 类(元类=MyMeta):
def init(self,data):
self.data = data
def printd(self):
打印(self.data)
我= kls(‘arun’)【t0 I . printtd()【print(我. getdata())
运行代码时,我们得到:
New called with
metaname <class '__main__.MyMeta'>
classname Kls
baseclasses ()
attrs {'__module__': '__main__', 'printd': <function printd at 0x7f3ebca86958>, '__init__': <function __init__ at 0x7f3ebca868d0>}
init called with
classobject <class '__main__.Kls'>
classname Kls
baseclasses ()
attrs {'__module__': '__main__', 'getdata': <function getd3 at 0x7f3ebca86408>, 'printd': <function printd at 0x7f3ebca86958>, '__init__': <function __init__ at 0x7f3ebca868d0>}
arun
arunarunarun
[/shell]
[python]
class a(object):
def init(self, data):
self.data = data
def getd3(self):
返回 self.data * 3
class my meta(type):
def _ _ New _ _(meta name,classname,baseclasses,attrs):
print ' New called with '
print ' meta name ',metaname
print 'classname ',classname
print 'baseclasses ',baseclasses
print 'attrs ',attrs
attrs[' get data ']= a . _ _ dict _ _[' get D3 ']
attrs[' get data ']= a . get D3
返回类型。new(元名,类名,基类,属性)
def init(classobject,classname,baseclasses,attrs):
print ' init called with '
print ' class object ',classobject
print 'classname ',classname
print 'baseclasses ',baseclasses
print 'attrs ',attrs
Kls 类(object):
_ _ 元类 __ = MyMeta
def init(self,data):
self.data = data
def printd(self):
打印自我数据
我= kls(‘arun’)【t0 我. printtd()
我. getdata()
运行代码时,我们得到:
New called with
metaname <class '__main__.MyMeta'>
classname Kls
baseclasses (<type 'object'>,)
attrs {'__module__': '__main__', '__metaclass__': <class '__main__.MyMeta'>, 'printd': <function printd at 0x7fbdab0176e0>, '__init__': <function __init__ at 0x7fbdab017668>}
init called with
classobject <class '__main__.Kls'>
classname Kls
baseclasses (<type 'object'>,)
attrs {'__module__': '__main__', 'getdata': <function getd3 at 0x7fbdab017500>, '__metaclass__': <class '__main__.MyMeta'>, 'printd': <function printd at 0x7fbdab0176e0>, '__init__': <function __init__ at 0x7fbdab017668>}
arun
arunarunarun
[/shell]
通常我们只需要覆盖一个方法__new__或__init__。我们也可以用function来代替class。这里有一个例子:
[python]
def meta_func(name, bases, attrs):
print('meta function called with', name, bases, attrs)
nattrs = {'mod' + key:attrs[key] for key in attrs}
return type(name, bases, nattrs)
MyMeta = meta_func
Kls 类(元类=MyMeta):
def setd(self,data):
self.data = data
def getd(self):
返回 self.data
k = Kls()
k . modsetd(' arun ')
print(k . modgetd())
为我们提供了以下输出:
meta function called with Kls () {'setd': <function setd at 0x7f3bafe7cd10>, '__module__': '__main__', 'getd': <function getd at 0x7f3bafe7cd98>}
arun
[/shell]
[python]
def meta_func(name, bases, attrs):
print 'meta function called with', name, bases, attrs
nattrs = {'mod' + key:attrs[key] for key in attrs}
return type(name, bases, nattrs)
MyMeta = meta_func
Kls 类(object):
_ _ 元类 __ = MyMeta
def setd(self,data):
self.data = data
def getd(self):
返回 self.data
k = Kls()
k . modsetd(' arun ')
打印 k.modgetd()
为我们提供了以下输出:
meta function called with Kls (<type 'object'>,) {'setd': <function setd at 0x88b21ec>, 'getd': <function getd at 0x88b22cc>, '__module__': '__main__', '__metaclass__': <function meta_func at 0xb72341b4>}
arun
[/shell]
除了修改基类和要创建的类的方法,元类还可以修改实例创建过程。这是因为当我们创建一个实例(ik = Kls())时,这就像调用class Kls。需要注意的一点是,无论何时我们调用一个对象,它的类型的__call__方法都会被调用。所以在这种情况下,class类型是metaclass,因此它的__call__方法将被调用。我们可以这样检查:
[python]
class MyMeta(type):
def call(clsname, args):
print('MyMeta called with')
print('clsname:', clsname)
print('args:', args)
instance = object.new(clsname)
instance.init(args)
return instance
Kls 类(元类=MyMeta):
def init(self,data):
self.data = data
def printd(self):
打印(self.data)
ik = Kls(' arun ')
ik . printd()
[/python]
[python]
class MyMeta(type):
def call(clsname, args):
print 'MyMeta called with'
print 'clsname:', clsname
print 'args:' ,args
instance = object.new(clsname)
instance.init(args)
return instance
Kls 类(object):
_ _ 元类 __ = MyMeta
def init(self,data):
self.data = data
def printd(self):
打印自我数据
ik = Kls(' arun ')
ik . printd()
[/python]
输出如下所示:
MyMeta called with
clsname: <class '__main__.Kls'>
args: ('arun',)
arun
有了这些信息,如果我们开始讨论class的创建过程,它以调用metaclass对象结束,该对象提供了一个class对象。事情是这样的:
Kls = MetaClass(name, bases, attrs)
因此这个调用应该调用metaclass的类型。metaclass型是metaclass的metaclass!我们可以这样检查:
[python]
class SuperMeta(type):
def call(metaname, clsname, baseclasses, attrs):
print('SuperMeta Called')
clsob = type.new(metaname, clsname, baseclasses, attrs)
type.init(clsob, clsname, baseclasses, attrs)
return clsob
class MyMeta(type,metaclass = super meta):
def _ _ call _ _(cls,args, * kwargs):
print(' MyMeta called ',cls,args,kwargs)
ob = object。new(cls,args)
ob。init(args)
返回 ob
打印(“创建类”)
Kls 类(元类=MyMeta):
def init(self,data):
self.data = data
def printd(self):
打印(self.data)
print(' class created ')
ik = Kls(' arun ')
ik . printd()
ik2 = Kls(' avni ')
ik2 . printd()
[/python]
[python]
class SuperMeta(type):
def call(metaname, clsname, baseclasses, attrs):
print 'SuperMeta Called'
clsob = type.new(metaname, clsname, baseclasses, attrs)
type.init(clsob, clsname, baseclasses, attrs)
return clsob
class MyMeta(type):
_ _ metaclass _ _ = super meta
def _ _ call _ _(cls,args, * kwargs):
print ' MyMeta called ',cls,args,kwargs
ob = object。new(cls,args)
ob。init(args)
返回 ob
打印“创建类”
Kls 类(object):
_ _ 元类 __ = MyMeta
def init(self,data):
self.data = data
def printd(self):
打印自我数据
打印“类别已创建”
我= kls(‘arun’)【t0 I . printd()
ik2 = kls(名称)
ik2 . print TD()
[/python]
为我们提供了以下输出:
create class
SuperMeta Called
class created
MyMeta called class '__main__.Kls' ('arun',) {}
arun
MyMeta called <class '__main__.Kls' ('avni',) {}
avni
Python 如何解决您的移动安全问题
原文:https://www.pythoncentral.io/how-python-may-be-the-answer-to-your-mobile-security-issues/

作为数据科学家最喜欢和最易于使用的语言之一,Python 是构建许多应用程序最常用的编程语言之一。从脸书到 DropBox,几家领先的科技公司都使用这种语言来推广他们的产品。网飞也不例外。
2019 年 5 月在美国俄亥俄州克利夫兰举行的 Pycon 上。网飞的工程师还参加了使用和开发这种开源编程语言的社区的最大的年度聚会。在离开之前,网飞的高级软件工程师 Amjith Ramanujam 花时间描述了 Python 在网飞的使用是如何成为网飞发展背后的驱动力的。
除了用于优化网飞之外,由于其特性和功能,Phyton 还可以解决大多数移动安全问题。阅读以下内容:
python 和数据安全
理解编程有利于检查软件和发现安全漏洞,检测恶意代码,以及执行涉及分析网络安全技能的任务。
甚至为了网络安全选择自己想学的编程语言也不容易。要学的语言取决于你的专注力。一些语言是计算机取证、web 应用程序安全、信息安全、恶意软件分析或应用程序安全。
无论您以后使用哪种语言,角色都会有很大的不同;编程经验为网络安全专家提供了比其他人更高的竞争优势。
虽然不是所有的网络安全职位都需要编程背景,但精通编程语言是中级和高级网络安全的一项基本技能。
对编程语言的深刻理解有助于世界上的数字安全专家能够处理网络犯罪的各种问题,并且对系统架构的良好理解意味着维护它更容易。
Python 作为一种高级编程语言,越来越受到网络专家的欢迎。Python 特别吸引人是因为它坚持代码可读性、清晰简单的语法以及大量库的可用性。
基本上所有的事情都可以用 Phyton 来完成。Phyton 可用于发送 TCP 数据包、分析恶意软件等。
然而,与 C/C++不同,Python 可能无法提供足够的硬件资源可见性。学习编程 Phyton 的安全性可能对你很有价值。使用 Python,您将具备编程技能,可以帮助您识别数字安全中的漏洞,并找到修复它们的方法。
Phyton 还可以用来增强移动应用的安全性。但是,由于需要高级编程,该方法有时会非常复杂。然而,你可以用几种方法保护你的手机免受黑客攻击,包括使用 VPN 之类的工具。安装 VPN 更容易,也更有益,但只适用于那些有价值的知名服务。
然而,尽管复杂,我们强烈建议学习这种编程语言,因为大多数应用程序和网站都使用它。
Phyton 在网飞数据保护中的应用
完整多样的 Python 库对于产品开发来说非常方便,这使得学习和使用 Python 变得更加有趣。我们不知道网飞是什么时候选择 Python 作为其旗舰编程语言的,这肯定是用 Python 编写的大量创新。
这是 Phyton 在网飞开发中的可用性:
打开连接
你听说过 Open Connect 吗?它是负责将网飞内容(电视节目和电影)带给全球成员的全球网络的名称。网飞在 2011 年推出了 Open Connect,作为提高网飞流媒体质量的一种形式。
这种类型的网络通常被称为内容交付网络(CDN)或内容交付网络,其工作是向全球的网飞观众高效地交付基于互联网的内容。一旦推荐系统完成工作,流媒体视频的 CDN 功能就会启动。
Open Connect 需要各种软件系统来设计、构建和运行这个 CDN,其中很多都是用 Python 编写的。不仅如此,底层网络设备也使用 Python。
技术故障
2012 年,由于美国亚马逊网络服务(AWS)出现问题,网飞经历了长达 7 个小时的崩溃。当时,网飞还没有自己的数据中心。除了视频流,所有观众与网飞的互动都由 AWS 提供,因为视频(电影或电视节目)都在他们自己的 CDN 上。
为了防止同样的问题发生,网飞决定建立一个区域故障转移系统,该系统能够抵御网飞基础服务提供商的技术故障。
故障转移保护计算机系统免受技术故障的影响,当主系统出现故障时,设备将自动处于待机状态以接管工作。现在,网飞可以在 7 分钟内完成区域故障切换。
统计分析
网飞的团队主要使用 Python 来分析统计数据,通常使用 Python 库,如 NumPy、SciPy 和 Pandas,这将有助于在出现问题时分析大量信号。
Python 还用于配置关联系统,以便可以在工作人员之间分配分析工作,从而实现更均衡的工作量和更快的结果。
此外,Python 还常用于数据清理和自动化任务。
信息安全
网飞团队主要使用 Phyton 来获得几个重要信息,包括
- 汽车修理
- 安全自动化
- 风险分类
- 汽车修理
- 漏洞识别
- SSH 资源保护(安全外壳)
- 身份权限设置和访问管理
- TLS(传输层安全性)证书创建
- 敏感数据检测
网飞使用的框架网络 Prism 可能有助于帮助安全工程师测量风险因素。
如何在 Python 代码中添加时间延迟
原文:https://www.pythoncentral.io/how-to-add-time-delay-in-your-python-code/
假设你正在开发一个用户界面,你用你的代码来支持它。您的用户正在上传文档,您的代码需要等待文件上传的时间。同样,当你参观一个有自动门的建筑群时,你一定注意到当你进入建筑群时,门是静止的。只有当你进入建筑群时,门才会自动关闭。是什么导致了这两种情况下的延迟?
代码支持上述两种系统。正是编程语言的 延时函数 导致了所需的延时。我们还可以在 Python 代码中添加时间延迟。Python 的 time 模块允许我们在两个语句之间建立延迟命令。添加时间延迟的方法有很多种,在本文中,我们将逐步讨论每种方法。
Python 的 time . Sleep()–暂停、停止、等待或休眠您的 Python 代码
Python 的 时间 模块有一个很好用的函数叫做 sleep() 。本质上,顾名思义,它暂停您的 Python 程序。 time.sleep() 命令相当于 Bash shell 的 sleep 命令。几乎所有的编程语言都有这个特性。
功能
****使用该函数时,我们可以指定延时,编译器将执行固定的延时。 该函数的语法如下:

当程序员需要在许多不同的情况下暂停代码的执行时,他们可以使用这个功能。例如,当需要在 API 调用之间暂停执行时,开发人员可以使用该函数。当开发人员希望通过在屏幕上出现的文字和图形之间添加停顿来增强用户体验时,该功能是非常宝贵的。
sleep()函数通过停止调用线程的执行来工作。它会在参数中指定的持续时间内这样做。时间值是 sleep 函数接受的唯一参数。让我们仔细看看。
time.sleep()参数
- secs-Python 程序应该暂停执行的秒数。这个参数应该是一个 int 或者 float 。
使用 Python 的 time.sleep()
这里有一个快速简单的语法示例:
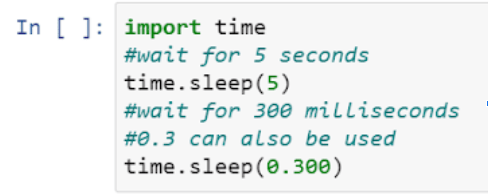
Python 中的时间模块有几个函数可以帮助开发者在代码中处理时间。sleep()方法只是这些方法中的一种。因此,不能直接使用 sleep()函数,必须首先在程序中导入时间模块。
在上面的代码中, 我们通过第一个命令指示系统等待五秒,然后等待 三百毫秒,等于 0.3 秒。 你可以在这里注意到,我们已经根据语法把时间延迟的值写在括号里面了。
现在让我们考虑另一个执行时间延迟的例子。

这里我们取了一个变量“a ”,它的值存储为 5。现在我们打印值“a ”,然后再次打印增加的值“a”。但是,两个语句的执行之间存在时间延迟。并且,我们已经指定使用 time.sleep() 函数。你一定观察到了,我们在代码的开头也导入了 time 模块。
现在我们来看看输出是什么:
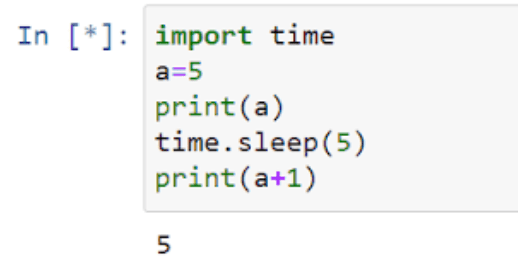
在这里,我们可以看到只有第一个命令被执行。现在五秒钟后的输出:
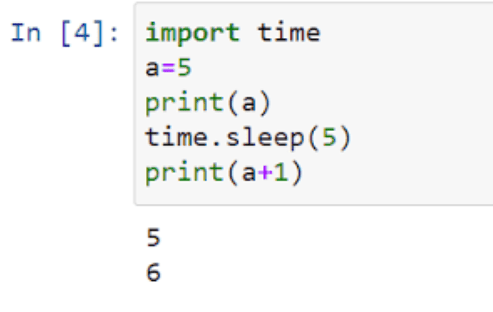
现在,经过五秒钟的延迟后,第二条语句也被执行。
需要注意的是,sleep()函数只能对您输入的任何整数值进行近似暂停。换句话说,如果您输入参数“5 ”,就像我们在上面的例子中那样,函数将暂停大约 5 秒钟,但不会暂停 5 秒到 1 毫秒。
有一种方法可以让程序员在使用该功能时更精确地确定他们需要的时间延迟。这就像将浮点作为参数传递给 sleep()一样简单。
输入参数“0.5”将使代码停止大约半秒钟。该函数提供了很大的灵活性,可以让代码暂停多长时间。然而,sleep()函数可以提供的暂停时间有一些限制。我们将在后面的部分讨论这一点。
睡眠的高级语法() 功能
**这里有一个更高级的例子。它接受用户输入,并询问您想要()睡眠多长时间。它还通过打印出 time.sleep() 调用前后的时间戳来证明它是如何工作的。注意 Python 2.x 使用 raw_input() 函数获取用户输入,而 Python 3.x 使用 input() 函数。现在让我们看看输入语法:

上面给出的代码询问用户要等待多长时间。我们已经在 sleeper() 函数中提到了这个输出的命令。然后,代码在代码执行开始时和代码实现后打印计算机时间。通过这种方式,我们可以看到延迟功能的实际功能。现在让我们看看输出:
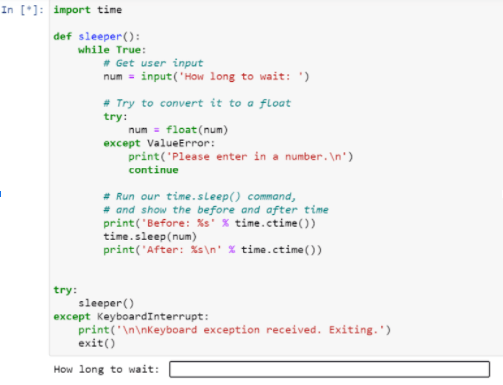
系统要求我们输入,即我们希望系统等待多长时间。让我们输入 5 秒,观察最终的输出。
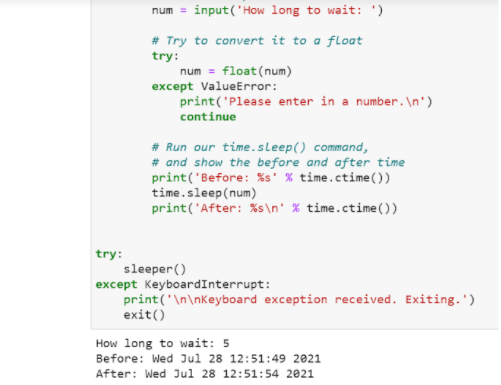
我们可以看到起始计算机时间(“之前”)和结束计算机时间(“之后”)有五秒钟的时间差。
time . sleep()的准确性
time . sleep()函数使用底层操作系统的 sleep() 函数。最终,这一功能有其局限性。例如,在标准的 Windows 安装中,您可以延迟的最小时间间隔是 10 - 13 毫秒。Linux 内核倾向于具有更高的滴答率,其时间间隔通常接近 1 毫秒。注意,在 Linux 中,你可以安装 RT_PREEMPT 补丁集,它允许你拥有一个半实时内核。使用实时内核将进一步增加 time.sleep() 函数的准确性。但是,除非你想让 睡眠 一小段时间,你一般可以忽略这个信息。
使用装饰人员添加 time.sleep() 命令
装饰器 用于创建调用高阶函数的简单语法。什么时候可以用装修工?假设我们不得不再次测试一个功能,或者用户不得不再次下载一个文件,或者你不得不在特定的时间间隔后检查一个接口的状态。您需要在第一次尝试和第二次尝试之间有一段时间延迟。因此,您可以在需要重复检查和需要时间延迟的情况下使用 decorators。
让我们考虑一个使用装饰者的例子。在这个程序中,我们将计算执行函数所花费的时间。

这里的 time_calc() 是装饰函数,它扩展并包含了其他函数,从而提供了简单的语法。让我们看看输出是什么。
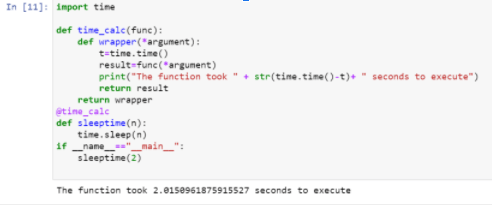
使用线程添加 time.sleep() 命令
Python 中的多线程 相当于同时运行几个程序。当多线程与 时间 模块相结合时,我们可以快速解决复杂的问题。多线程功能可从 线程 模块中获得。
让我们使用多线程和时间延迟来打印字母表歌曲。

这里一个线程被用来打印单个的字母。也有 0.5 秒的时间延迟。当你运行这个程序时,你会看到字母表歌曲的每一行都在 0.5 秒的延迟后被打印出来。我们来看看输出是什么:
Python wait()函数
Python wait()方法的工作方式就像它的名字所暗示的那样:它暂停一个进程,这样另一个进程(比如子进程)就可以在恢复之前完成执行。
该方法是 Python 中 os 模块的一部分,通常用于同步父进程与子进程。wait()也在 Python 线程模块的 event 类中定义。
它的功能与操作系统模块中的方法略有不同。方法挂起内部标志设置为 false 的事件的执行。这反过来会挂起当前事件或块以供执行,直到内部标志设置为 true。
函数的语法是 os.wait()。它以元组的形式返回子进程的 ID,还返回元组中的一个 16 位整数,表示退出状态。返回 16 位整数的方法也有一个高位字节和一个低位字节,低位字节的信号数为零,这会终止进程。另一方面,高位字节保存退出状态通知。
延时练习题
*** ### Print two delayed reports:
在这个问题中,我们将打印两条语句,第一条是“大家好!”
第二个问题是“这是一个关于时间延迟的练习题。”我们将在这两个语句之间引入 5 秒的时间延迟。我们来看看这个问题的代码语法:

如你所见,基本步骤很简单。我们首先导入时间模块。接下来,我们给出第一条语句的打印命令。然后我们通过 t ime.sleep() 函数引入时间延迟,然后我们给出打印以下语句的命令。我们来看看输出是什么:

此图显示了第一个输出。

现在,这个输出比前一个输出晚五秒钟获得。
-
Program for displaying date and time:
让我们创建一个程序,在这个程序中,我们制作一个也能显示日期的数字钟。
该任务的代码如下:
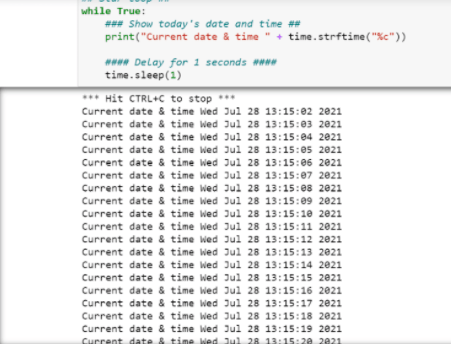
这里我们给出了显示日期和时间的命令。然后,我们添加了一秒钟的时间延迟,以便更新时间。该程序的输出如下:
结论
时间延迟在用户界面中有着巨大的应用。对于程序员来说,知道如何在程序中增加时间延迟是很重要的。我们希望这篇文章能帮助你了解 Python 的时间模块。现在,您可以有效地在代码中添加时间延迟,并提高代码的生产率!********
如何成为一名 Python 开发者
原文:https://www.pythoncentral.io/how-to-become-a-python-developer/

在编程界,Python 正迅速流行起来,他在学生中就像 paper help 可靠的 service 一样受欢迎。事实上,根据 TIOBE 编程社区的十大最受欢迎的编程语言指数,Python 是第三大最受欢迎的语言。它落后于编程界的两个玩家,C 和 Java。
如果你一直在考虑 Python 软件开发人员的职业生涯,你可能会想到很多问题。你所有迫切的问题都在下面得到了回答。
但是在我们成为 Python 软件开发人员之前,让我们看看为什么学习 Python 对于几乎所有开发人员都是至关重要的,即使是很少使用它的人。
为什么要学 Python?
Python 是一种广泛应用于不同领域和行业的语言,加上其对简单和清晰的强调,使其成为初学者的最佳语言之一。
然而,使这种语言更好的是机器学习、数据科学和人工智能的首选,因为它具有分析能力和为这些领域量身定制的各种库。
Python 如此强大,以至于像 Google、Spotify、Dropbox 和网飞这样的公司都在使用它,这为这些创新公司打开了一个优秀 Python 开发者的专业潜力。
Dropbox 的桌面客户端,以及它的服务器端代码,都是完全用 Python 编写的。另一方面,Google 混合使用多种语言,但是对于需要快速交付和维护的部分使用 Python。
一个 Python 软件开发人员是做什么的?
简而言之,Python 软件开发者使用 Python 作为编程语言或代码来创建计算机程序。
Python 开发人员的日常工作是通过分析和数据收集为关键决策者提供信息。作为一名 Python 程序员,您可以使用 Python 来执行 web 开发、web 抓取、自动化、脚本编写和数据分析。
脚本包括创建执行重复任务的小程序,以帮助数据分析师消除繁琐的工作。然而,Python 的用途并不局限于自动化任务。开发者也可以用它来设计新代码的框架、创建新工具、发布新服务和创建网站。
如何成为一名 Python 软件开发人员?
Python 编程可以通过多种方法学习。最常见的方法是获得计算机科学学位。在计算机科学学位课程中,你将学习 JavaScript、Python 和 Ruby 等 web 开发语言。
如果你已经在另一个领域获得了学士或硕士学位,并且想从事 Python 软件开发人员的职业,可以考虑一个编码训练营。
让我们仔细看看 CS 学位和编码训练营需要什么。
CS 学位
CS 学位为有抱负的 Python 软件开发人员提供了全面的教育,但是您也可以选择软件工程或数据科学学位。在这些专业中,你将获得数学和计算机科学的基础,这将帮助你对软件架构、编程和测试有更广泛的理解。
然而,获得两年或四年的编程学位需要相当多的时间和金钱。根据 CollegeData 的数据,州内居民在公立大学毕业的年学杂费约为 9970 美元,私立大学为 34740 美元,州外居民在公立大学为 25620 美元。
反过来,一个编码学位证明你已经努力学习编码了。一些公司要求你有学位才能被考虑申请 Python 软件开发人员的职位,但是其他公司只需要证书和经验就可以了。
编码训练营
通常,招聘经理并不寻求相似的学位。相反,他们需要你的编程技能和 Python 编码的证明。根据调查,89%的雇主认为编码训练营的毕业生和在职者一样准备充分,甚至准备得更好。
编码训练营是一个技术培训项目,它向编码能力较弱的学生传授入门的必要技能。学生们学习编码的基础知识,以及如何应用这些技能来解决现实世界中的问题。
编码训练营旨在通过教学生如何创建专业级的应用程序来帮助他们走向编码或软件开发的职业生涯。
出于这个原因,编码创业训练营对于建立一个强大的投资组合和学习雇主编码测试所需的技能是非常好的。
与 CS 资格不同,编码训练营往往不贵,而且可以帮助你获得个人指导和额外的资源。编码训练营的平均费用从 10,000 美元到 15,000 美元不等。新兵训练营也比获得 CS 学位要短得多,因为他们通常只持续 12 到 26 周。
除了为工作面试做准备之外,加入编码训练营还可以帮助你创建一个包含你曾经参与过的项目的文件夹。完成课程后,你可以向潜在雇主展示这个作品集。
虽然编码训练营不会授予你学位,但它表明你有编码经验的教育基础。
获得 Python 认证
虽然文凭授予你在学校几年后的学术学位,但认证课程为你提供了一份文件,证明你已经为某项工作完成了一定的准备。因此,Python 认证证明了你对 Python 的承诺,并极大地提升了你的简历。
文凭项目和认证项目的主要区别在于时间和费用。
要获得证书,你必须首先获得 Python 经验,这可能需要几个月到两年的时间利用自己的时间编写代码或参加新兵训练营。一旦你获得了这些经验,你就准备好参加考试了。一个学位需要两到四年的时间,但是你可以通过课程获得 Python 经验。
然而,文凭的额外费用带来了一些成本效益。文凭给人比证书更深入的知识,并通过其非编码类教授特定的专业技能。
如何获得一份 Python 软件开发人员的工作?
如果你已经在寻找一份 Python 软件开发人员的工作,或者即将完成一个编码训练营,这些提示将帮助你加快求职的速度。
如果你是新手,先熟悉一下 Linux / Unix 命令行。不管你想找哪种语言,大多数雇主都希望你熟悉这种语言。
- 从事开源 Python 项目。“开放”意味着每个人都可以自由地使用、研究、修改和贡献项目。这样的项目可以让你磨练自己的才能,为以后的就业获得宝贵的经验。
- 维护网站或 LinkedIn 个人资料。如果你觉得创建一个网站太昂贵和耗时,选择 LinkedIn 个人资料。它可以提供人际关系网的可能性,并可能帮助你获得一份工作,而不必去其他地方寻找。
- 学一点其他语言。雇主在开发者身上寻找的最重要的东西之一是你对不断扩展你的知识的兴趣。Java 和 C++是不错的选择,即使 Python 是你的目标。
- 尽可能参加行业会议和活动。这些都是极好的社交机会。你可能会有机会与你将来要面试的经理和高管交谈。
准备与 Python 软件开发人员的面试
由于缺乏 Python 软件开发人员,你可能会认为找工作只是介绍和回答一些基本的 Python 问题。情况不太可能是这样。如果您想进入 Python 开发领域,下面是您应该做的准备工作:
证明你会编码。创建一个文件夹,在公共论坛上添加你所做的一切来描述你的经历。大多数开发人员更喜欢 Github 创建概要文件来展示他们的项目示例。
掌握常用的 Python 算法和数据结构。这些包括字典、列表、元组和类创建。您还应该能够比较和对比基本的 Python 数据结构,以及解释如何利用现有的数据结构来构建堆栈功能。堆栈是用于创建和运行单个应用程序的所有技术服务的列表)。
成为一名高效的 Python 开发者不仅仅是记忆。它不仅仅是记住语言语法或经常使用的算法和数据结构。帮助你脱颖而出的是你通过良好的技能理解和解决问题的能力。投入大量练习,让自己接触各种解题问题。
Python 软件开发人员工资
根据 Indeed 的数据,美国 Python 软件开发人员的工资中位数是每年 111,080 美元或每小时 52.96 美元。请注意,这些环境包括工资较高的地区和有多年工作经验的员工。祝你找到第一份工作!
如何使用?格式()
原文:https://www.pythoncentral.io/how-to-build-strings-using-format/
开发人员经常试图在 Python 中构建字符串,方法是将一串字符串连接在一起,形成一个长字符串,这肯定可行,但并不完全理想。Python 的。format()方法允许您执行与连接字符串(将一串字符串加在一起)基本相同的效果,但是以一种更加高效和轻量级的方式执行。
假设您想要将以下字符串相加来创建一个句子:
name = "Jon"
age = 28
fave_food = "burritos" fave_color = "green"
要打印上面的字符串,您总是可以选择将它们连接起来,就像这样:
string = "Hey, I'm " + name + "and I'm " + str(age) + " years old. I love " + fave_food +
" and my favorite color is " + fave_color "."
print(string)
也可以使用。format()方法,像这样:
string = "Hey, I'm {0} and I'm {1} years old. I love {2} and my favorite color is {3}.".format(name,
age, fave_food, fave_color)
print(string)
以上两个示例的输出是相同的:
Hey, I'm Jon and I'm 28 years old. I love burritos and my favorite color is green.
虽然上面的两个例子都产生了一个长字符串的相同结果,但是使用。format()方法比连接字符串的其他解决方案要快得多,也轻得多。
如何在 Python 指南中调用函数
原文:https://www.pythoncentral.io/how-to-call-a-function-in-python-guide/
在本文中,我们将了解如何在 Python 中调用函数。你应该在你的机器上安装 Python。你应该知道 Python 语法的基础。如果您没有查看我们的安装指南和入门指南。
内容
- 如何在 Python 中创建函数
- Python 中的作用域是什么
- 如何在 python 中调用函数
在上一篇文章中,我们更多地讨论了 Python 以及它如何支持许多范例。其中一个范例是函数。函数式编程范式是最流行的范式之一。许多语言都支持这种范式。简而言之,函数范式就是将逻辑分离成函数。你可以在任何地方调用这些函数。这种模式的好处是什么?
这有助于代码易于阅读和维护。每个功能执行一项工作。这使得在代码的不同位置重用不同的函数变得很容易。它有助于轻松维护和更改业务逻辑,而无需重构整个代码。
如何在 Python 中创建函数
在 Python 中定义函数可以通过添加def关键字来完成。Python 会知道这个逻辑会在这个函数里面。变量只能在函数内部访问。这叫做范围。我们将在下一节详细讨论它。让我们定义一个函数。
def func_name():
"""
Here is a docstring for the fucntion.
"""
return True
上面的代码描述了如何在 Python 中定义函数。它有def关键字来告诉 Python 下一个名字是一个函数名。下一部分是func_name()函数的名字。它有括号来接受你需要传递给这个函数的参数。docstring 部分是一个自由文本区域,它解释了这个函数的作用。最后一部分是返回关键字。它有你需要从函数中返回的值。
上面是一个非常简单的函数例子。让我们试着从更复杂的例子开始。
def sum_static():
return 1 + 2
def sum_dynamic(x, y):
return x + y
def welcome_msg(name):
welcome_text = "Dear {name} welcome to our guide to python functions".format(name=name)
return welcome_text
def check_type(number):
"""
Function that detrimine the type of integer
"""
if not isinstance(number, int):
return "Invalid number"
if number % 2 == 0:
return "Even"
else:
return "Odd"
def dictify(key, value):
"""
Return a dict {key: value}
"""
data = dict()
data[str(key)] = value
return data
在上面的例子中,我们有几个不同用途和复杂程度的函数。让我们解释一下。
在第一个 sun_static 函数中,它是一个不带任何参数的静态函数。它总是返回 1 和 2 的和。Python 函数可以接受参数。这些参数的目标是使 Python 函数动态化。在第二个 sum_dynamic 中,接受两个参数 x 和 y。如果你将它们传递给函数,它会将它们相加并返回结果。第三个函数有更复杂的逻辑,它将返回一个带有 name 参数的欢迎消息。在这个函数中,我们定义了一个变量 welcome_text。这个变量只在这个函数的范围内。我们需要更多地了解 Python 中的作用域。
Python 中的作用域是什么?
作用域或者在 Python 中可以称为名称空间,就是这个变量效果的区域。用更简单的方式。如果你调用这个变量,它就是有效的。这意味着函数内部定义的变量只能在函数内部访问。如果你试图在函数之外调用它,它会引发一个异常。下图解释了 Python 中名称空间的类型。

这意味着在我们的 welcome_msg 函数中,welcome_text 变量不能在函数外部调用。让我们看一个例子。
language = "python"
def welcome_msg(name):
welcome_text = "Dear {name} welcome to our guide to {language} functions"
welcome_text.format(name=name, language=language)
return welcome_text
语言变量可以在函数内部调用。
继续其他函数的例子。在以前的函数中,我们没有添加逻辑。它在回复一条短信。在 check_type 函数中,我们添加了检查数字类型的条件。
该功能应该有一个单一的目标,这需要验证功能输入。避免不必要的行为是任何功能的必要组成部分。如果没有检查类型的输入,用户可以传递一个字符串或一个字典。代码会尝试将它除以 2,这会引发一个异常。添加实例类型验证将有助于使该函数可用。
Python 函数中的 return 语句可以返回任何类型的数据。这是我们在 dictify 函数中添加的内容。该函数返回一个 Python 字典。这使得将函数的返回结果赋给变量并使用它变得很容易。现在让我们调用我们创建的函数,并查看它的输出。
如何在 Python 中调用函数
要在 python 中调用函数,只需提及函数。这将调用函数逻辑并返回结果。我们来调用上面的函数。
# print the falue of sum_static
print(sum_static())
# output:
3
x = 2
y = 2
# Passing arguments to the function
result = sum_dynamic(x, y)
print(result)
# output:
4
# print the welcome message by passing name directly
result = welcome_msg("John")
print(result)
# output:
Dear John welcome to our guide to Python functions
# Apply the function logic multiple time inside a for loop
numbers = [5, 8, 9, 87, 12, 67]
for number in numbers:
result = check_type(number)
print(result)
# output:
Odd
Even
Odd
Odd
Even
Odd
key = "name"
value = "John"
# assign a function to a variable and use it.
data = dictify(key, value)
print(data)
print(data[key])
# output:
{'name': 'John'}
'John'
我们调用自己创建的函数,并在不同的情况下使用它们。
结论
Python 函数在不同的 Python 应用程序中非常有用。您可以使用它来避免多次编写相同的逻辑。一般规则是,如果你两次写同样的代码,把它添加到一个函数中并调用它。为了在 python 中定义一个函数,我们使用了def。每个功能都有它的范围。这将使函数内部定义的变量在函数外部不可访问。要调用这个函数,你只需要写下它的名字,如果需要的话,加上适当的参数。您可以将返回结果赋给一个变量并使用它。检查我们在 dictify 函数中做了什么。
如何在 Python 中检查字谜
原文:https://www.pythoncentral.io/how-to-check-for-anagrams-in-python/
在 Python 中,有一种相当简单的方法来创建一个方法,该方法可用于检查字符串是否是变位词。看看下面的函数,看看这个方法是如何工作的——本质上,它是通过使用“==”比较操作符来查看操作符两边的字符串在通过计数器时是否相等,这将确定两个字符串之间是否有任何共享字符。如果字符串是字谜,函数将返回 true,如果不是,将返回 false。
from collections import Counter
def is_anagram(str1, str2):
return Counter(str1) == Counter(str2)
>>> is_anagram('cram','carm')
True
>>> is_anagram('card','cart')
False
正如你在上面的例子中所看到的,这个方法是通过传递两个参数来使用的,在那里它们被相互比较。当试图查看特定字符串是否只是重复相同的内容或保存相同的值时,这种方法特别有用——尤其是当这些字符串很长并且很难跟踪自己时。
如何在 Python 中检查列表、元组或字典是否为空
原文:https://www.pythoncentral.io/how-to-check-if-a-list-tuple-or-dictionary-is-empty-in-python/
在 Python 中检查任何列表、字典、集合、字符串或元组是否为空的首选方法是简单地使用一个if语句来检查它。
例如,如果我们这样定义一个函数:
def is_empty(any_structure):
if any_structure:
print('Structure is not empty.')
return False
else:
print('Structure is empty.')
return True
它会神奇地检测任何内置结构是否是空的。所以如果我们运行这个:
>>> d = {} # Empty dictionary
>>> l = [] # Empty list
>>> ms = set() # Empty set
>>> s = '' # Empty string
>>> t = () # Empty tuple
>>> is_empty(d)
Structure is empty.
True
>>> is_empty(l)
Structure is empty.
True
>>> is_empty(ms)
Structure is empty.
True
>>> is_empty(d)
Structure is empty.
True
>>> is_empty(s)
Structure is empty.
True
>>> is_empty(t)
Structure is empty.
True
那么,如果我们给每一个加一些东西:
>>> d['element'] = 42
>>> l.append('element')
>>> ms.add('element')
>>> s = 'string'
>>> t = ('element')
我们再次检查每一个,这将是结果:
>>>is_empty(d)
Structure is not empty.
False
如您所见,所有默认的数据结构都被检测为空,方法是在if语句中将该结构视为布尔值。
如果数据结构为空,当在布尔上下文中使用时,它“返回”False。如果数据结构有元素,当在布尔上下文中使用时,它“返回”True。
需要注意的一点是,在字典中有值的“空”键仍然会被算作“非空”。例如:
>>> d = {None:'value'}
>>> is_empty(d)
Structure is not empty.
False
这是因为即使键是“空”的,它仍然被算作字典中的一个条目,这意味着它不是空的。
“真的这么简单吗?我还需要做什么吗?”,我听到你说。
是的,就是这么简单。Python 很神奇。处理好它。🙂
如何不检查列表、元组或字典是否为空
"如果我想用不同的方法来检查这些结构是否为空呢?",你说。
好吧,大多数其他方式都不是“错误的”,它们只是不是 Python 做事的方式。例如,如果你想通过使用 Python 的len函数来检查一个结构是否为空,那就不会被认为是Python 的。
例如,你可以用这种方法来检查一个列表是否为空:
if len(l) == 0:
print('Empty!')
现在,这肯定没有错,但是为什么要输入所有额外的代码呢?当某个东西被标记为“Python”时,它通常指的是 Python 非常简洁的特性。因此,如果你可以通过缩短代码来节省空间,这通常是更 Pythonic 化的做事方式。
上面的方法可能会被称为“C”做事方法,因为它看起来很像 C 代码。
本文到此为止!
直到我们再次相遇。
在 Python 中用 str.isdigit()检查字符串是否为数字
原文:https://www.pythoncentral.io/how-to-check-if-a-string-is-a-number-in-python-including-unicode/
编辑 1:本文已经过修改,以显示str.isdigit()和所提供的定制解决方案之间的差异。
编辑 2:样本也支持 Unicode!
通常你会想检查 Python 中的字符串是否是一个数字。这种情况经常发生,例如用户输入、从数据库获取数据(可能返回一个字符串)或读取包含数字的文件。根据您期望的数字类型,您可以使用几种方法。比如解析字符串、使用正则表达式或者只是尝试将它转换成一个数字,看看会发生什么。您还会经常遇到用 Unicode 编码的非 ASCII 数字。这些可能是也可能不是数字。例如๒,在泰语中是 2。不过仅仅是版权符号,而显然不是一个数字。
请注意,如果您在 Python 2.x 中执行以下代码,您必须将编码声明为 UTF-8/Unicode -如下:
【Python】
--编码:utf-8 --
下面的函数可以说是检查一个字符串是否为数字的最快最简单的方法之一。它支持 str 和 Unicode,并将在 Python 3 和 Python 2 中工作。
检查 Python 字符串是否为数字
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
try:
导入 unicode data
unicode data . numeric(s)
返回 True
except (TypeError,ValueError):
通过
返回 False
当我们测试这个函数时,我们得到如下结果:
[python]
Testing as a str
print(is_number('foo'))
False
print(is_number('1'))
True
print(is_number('1.3'))
True
print(is_number('-1.37'))
True
print(is_number('1e3'))
TrueTesting Unicode
5 in Arabic
print(is_number('٥'))
True2 in Thai
print(is_number('๒'))
True4 in Japanese
print(is_number('四'))
TrueCopyright Symbol
print(is_number('©'))
False
[/python]
[python]
Testing as a str
print(is_number('foo'))
False
print(is_number('1'))
True
print(is_number('1.3'))
True
print(is_number('-1.37'))
True
print(is_number('1e3'))
TrueTesting Unicode
5 in Arabic
print(is_number(u'٥'))
True2 in Thai
print(is_number(u'๒'))
True4 in Japanese
print(is_number(u'四'))
TrueCopyright Symbol
print(is_number(u'©'))
False
[/python]
我们首先尝试简单地将它转换/转换为浮点型,看看会发生什么。当字符串不是严格的 Unicode 时,这将适用于str和 Unicode 数据类型。然而,我们也尝试使用unicodedata模块来转换字符串。unicodedata.numeric功能是做什么的?一些 Unicode 字符被赋予了数字属性,如果它们是数字的话。unicodedata.numeric将简单地返回字符的数值,如果它存在的话。如果没有数值属性,你可以给unicodedata.numeric分配一个默认值,否则默认情况下会产生一个ValueError。
检查 Python 字符串是否是 Python 中的数字(str.isdigit)
Python 有一个方便的内置函数str.isdigit,可以让你检查一个字符串是否是一个数字。
数字对数字
确保当您使用str.isdigit函数时,您真正检查的是一个数字,而不是一个任意的数字。根据 Python 文档,数字的定义如下:
如果字符串中的所有字符都是数字并且至少有一个字符,则返回 true,否则返回 false。数字包括十进制字符和需要特殊处理的数字,如兼容性上标数字。
https://docs.python.org/3/library/stdtypes.html#str.isdigit
这里有一个例子:
>>> print('foo'.isdigit())
False
>>> print('baz'.isdigit())
False
>>> print('1'.isdigit())
True
>>> print('36'.isdigit())
True
>>> print('1.3'.isdigit())
False
>>> print('-1.37'.isdigit())
False
>>> print('-45'.isdigit())
False
>>> print('1e3'.isdigit())
False
如何在 Python 中检查对象是否有属性
原文:https://www.pythoncentral.io/how-to-check-if-an-object-has-an-attribute-in-python/
因为 Python 中的一切都是对象,而对象都有属性(字段和方法),所以编写程序来检查对象有什么样的属性是很自然的。例如,一个 Python 程序可以在服务器上打开一个套接字,它接受从客户机通过网络发送的 Python 脚本。在接收到新脚本时,服务器端 Python 程序可以检查或更精确地内省新脚本中的对象、模块和函数,以决定如何执行函数、记录结果和各种有用的任务。
hasattr vs. try-except
有两种方法可以检查 Python 对象是否有属性。第一种方法是调用内置函数hasattr(object, name),如果字符串name是object的一个属性的名称,则返回True,否则返回False。第二种方式是通过try来访问object中的属性,并在AttributeError被触发时执行一些其他功能。
>>> hasattr('abc', 'upper')
True
>>> hasattr('abc', 'lower')
True
>>> hasattr('abc', 'convert')
False
并且:
>>> try:
... 'abc'.upper()
... except AttributeError:
... print("abc does not have attribute 'upper'")
...
'ABC'
>>> try:
... 'abc'.convert()
... except AttributeError:
... print("abc does not have attribute 'convert'")
...
abc does not have attribute 'convert'
这两种风格有什么区别?hasattr通常被称为“三思而后行”(LBYL)的 Python 编程风格,因为在访问一个对象之前,你会检查它是否有属性。而try-except被称为“请求原谅比请求允许容易”(EAFP),因为你try属性先访问,在except块请求原谅,而不是像hasattr那样请求允许。
那么,哪种方式更好呢?嗯,这两种学说都有忠实的支持者,而且这两种风格似乎都精通于处理任何现实世界的编程挑战。有时,如果您希望确保某个属性确实存在,并在不存在时停止执行,那么使用 LBYL 是有意义的。例如,在程序的某一点上,您肯定知道传入的object应该有一个有效的文件指针属性,下面的代码可以在这个属性上工作。另一方面,如果您知道某个属性在程序执行的某个时候可能不存在,那么使用 EAFP 也是有意义的。例如,音乐播放器不能保证 MP3 文件总是在磁盘上的同一位置,因为它可能会被用户随时删除、修改或移动。在这种情况下,音乐播放器可以先try访问 MP3 文件,并通知用户该文件不存在于except块中。
hasattr vs dict
虽然hasattr是一个内置函数,它被设计用来检查一个属性是否存在于一个对象中,但有时检查一个对象的__dict__来检查一个属性的存在可能更准确,因为hasattr并不关心一个属性为什么被附加到一个对象上,而你可能想知道一个属性为什么被附加到一个对象上。例如,属性可能由于其父类而不是对象本身而被附加到对象。
>>> class A(object):
... foo = 1
...
>>> class B(A):
... pass
...
>>> b = B()
>>> hasattr(b, 'foo')
True
>>> 'foo' in b.__dict__
False
在前面的代码中,由于类B是类A的子类,类B也有属性“foo”。但是,因为“foo”是从A继承而来的,B.__dict__并不包含它。有时,知道一个属性是来自对象本身的类还是来自对象的超类可能是至关重要的。
提示和建议
-
hasattrfollows the duck-typing principle in Python:当我看到一只像鸭子一样走路、像鸭子一样游泳、像鸭子一样嘎嘎叫的鸟时,我就把那只鸟叫做鸭子。
所以,大多数时候你要用
hasattr来检查一个属性是否存在于一个对象中。 -
try-except和__dict__有它们自己的用例,与hasattr相比,这些用例实际上非常狭窄。因此,将这些特殊的用例记在脑子里是有益的,这样你就可以在编码时识别它们,并相应地使用正确的习惯用法。
一旦你学会了如何在 Python 中检查一个对象是否有属性,看看如何从一个对象中获取属性。
如何检查 Python 版本
原文:https://www.pythoncentral.io/how-to-check-python-versions/
2019 年,Python 软件基金会 宣布了一个发布日历的变化,使得它每 12 个月发布一个新版本的语言。
该组织还宣布,每一个 Python 版本都将接受一年半的错误修复更新和三年半的安全更新,然后在五年结束时终止该版本。
使用最新版本的 Python 是确保您获得安全无漏洞体验的最佳方式。
但是如何检查 python 版本呢?
这比你想象的要容易得多——但你必须首先确保你的电脑上安装了 Python。如果你还没有安装 Python,我们的 简易安装指南 分分钟帮你安装好。
如果你的电脑上安装了 Python,以下是如何快速找到版本的方法。
如何在 Linux,Mac,& Windows 中查看 Python 版本
Python 在 Stack Overflow 2020 开发者调查中人气排名第四 。这项调查是由全球 65,000 名开发人员进行的,这使得它成为开发人员和企业对编程语言使用偏好的可靠描述。
在你可以查看你的电脑加载了什么版本的 Python 之前,你必须了解 Python 的版本方案。每个 Python 版本都有三个数字。
第一个数字代表主要版本,第二个数字代表次要版本,第三个数字代表微型版本或“修订级别”
你还必须注意到,主要版本之间通常并不完全兼容。换句话说,用 Python 2 . x . x 版编写的软件可能无法在 Python 3.x.x 上正确运行
然而,次要版本通常与以前的版本兼容。例如,用 Python 3.1.x 编写的代码将在 Python 3.9.x(这是当前的 Python 版本)上运行。
检查 Linux 中的 Python 版本
大多数现代 Linux 发行版都预装了 Python。你不需要输入任何代码来自己安装它——除非你用的是一个相对不太流行的 Linux 发行版。
在 Linux 机器上检查 Python 版本很简单。第一步是打开终端。如果你使用的是 Ubuntu 这样的发行版,你可以进入菜单搜索它。
然而,打开终端最简单的方法是按 Ctrl+Alt+T。或者,您可以同时按 Ctrl、Alt 和 F2 键。
屏幕上会出现一个终端窗口。然后,您可以输入以下命令:
python——版本
或者:
python -V
您的机器可以安装多个版本的 Python。如果您的机器安装了 Python 3,在终端中输入以下命令也可以实现这个目的:
python 3–版本
或
python3 -V
在终端中输入命令后,按回车键。Python 版本会出现在下一行,像这样:

你可以在任何运行 Linux 操作系统的硬件上运行这个命令——包括 Raspberry Pi。
在 Mac 中检查 Python 版本
macOS 上没有 PowerShell 或命令提示符。但是,操作系统有一个像 Linux 和 Unix 系统一样的终端。您需要访问终端来检查 Mac 上的 Python 版本。
要打开终端,请打开 Finder。然后导航到应用程序,并选择实用程序。从这里找到并发射终端。
此处的说明类似于 Windows 系统的说明。要找到 Python 版本,您必须输入以下命令:
python 版本
如果您的计算机上也安装了 Python 3,您可以通过输入以下命令找到您正在使用的 Python 3 的确切版本:
python 3–版本
Python 版本的细节会出现在下一行,像这样:

在 Windows 中检查 Python 版本
如果你用的是 Windows 10,你可以用 Windows PowerShell 找到 Python 版本。启动 powershell 最简单的方法是按 Windows 键,然后输入“PowerShell”然后,您可以从出现的选项列表中选择它。
接下来你要做的就是键入以下内容:
python 版本
细节将出现在下一行。

用程序检查 Python 版本
你可以在你的终端上打开 Python 解释器,写几行代码来确定 Python 的版本。
在电脑上运行 Python 解释器:
- 在 Windows 上: 启动 PowerShell,在终端中输入“python”。
- 在 macOS 上: 导航到应用>实用程序>终端,键入“python”如果您安装了 python3,请键入“Python 3”
- 在 Linux 上: 打开终端,输入“python”或“python3”,这取决于你在机器上安装了什么。
如果你看到“> > >”出现在终端上,Python 处于交互模式。接下来,您必须将下面几行代码复制粘贴到解释器中:
导入系统
print("用户当前版本:-",sys.version)
输出中将显示已安装 Python 版本的详细信息。
要退出解释器,可以输入“quit()”或“exit()”,这两个都是内置的 Python 函数。
或者,如果你在 Windows 上,你可以按 Shift+Ctrl+Z 并输入。在类 Unix 系统上,按 Shift+Ctrl+D 应该可以停止解释器。
结论
Python 的每一个版本——甚至最新发布的——都有自己的局限性。然而,保持 Python 更新将提高安全性,并使体验更少出错。
更新到最新版本还可以确保您可以使用 Python 提供的最新特性、语法和库模块。
现在你知道了如何找到安装在你电脑上的 Python 版本,你可以即时了解你是否是最新的。
如何选择最好的 Django 公司?10 大 Django 发展公司名单

Django 是一个 Python 框架,它简化了基于 web 的应用程序的创建。它附带了一个预定义的工具箱,提供了创建 web 应用程序所需的所有功能。这个框架允许你创建安全可靠的网络应用。web 开发人员广泛使用它来创建 web 应用程序。
找到最好的 Python 和 Django 开发公司可能很困难,尽管全世界有超过 2200 万家。有许多自由职业者的市场可以帮助你找到最好的 Django 或 Python 开发公司。
我们是顶级的 Python 开发公司,我们知道 Python/Django 开发者的需求。我们也知道如何找到最好的 Python 开发公司。雇佣最好的远程开发者来创建完美的应用程序是至关重要的。本文将讨论一些 Python Django 开发公司。
找到最好的 Python Django 开发人员和全栈团队成员,他们可以使用 Django 的高级 Python web 框架创建各种 web 应用程序。下面,我们为您的 Django/Python 开发任务列出了一些最好的 Django 公司。
1。 Webisoft
Webisoft 是一家 Python/Django 开发公司,在数字化转型咨询和产品开发方面拥有多年的经验。它的核心专长在 SaaS、软件开发和区块链。
专长
- 解决 IT 问题
- MVP 开发
- 长期项目开发
- 企业软件开发
- 支持和维护
- 区块链
您是否希望加快软件程序的开发?也许你正在寻找具有特定技能的专家。webisoft 是一家 Python 和 Django 开发公司,可以在一周内迅速找到最好的专家。 Webisoft 可以帮助您满足所有基础设施需求。
2。 Dev。亲
结果导向。质量至上。戴夫。Pro 创建了可以交付定制软件开发体验的团队,以适应任何技能集、复杂性或规模。戴夫。Pro 拥有一支由 900 多名专家组成的高素质员工队伍。
专长
- 软件开发
- 云和开发运维
戴夫。Pro 在五大洲的 50 多个国家设有办事处。
3. ELEKS
ELEKS 通过提供软件工程和咨询服务来帮助客户进行数字化转型。ELEKS 为财富 500 强公司和大型企业提供高科技创新,改善他们的工作流程,增加他们给现代世界带来的价值。
4。T2【根带】
Rootstrap 的使命不仅仅包括创建漂亮的界面,还包括迭代地创建软件解决方案。最终的结果是什么?结果如何?
- Rootstrap 教会了谷歌设计冲刺的基本知识。
- Rootstrap 帮助 MasterClass 实现了收入翻番。
- Rootstrap 为全球化合作伙伴节省了 500 万美元。
- 帮助 Ownable 在黑色星期五一天之内赚了 250 万美元。
- 25 家初创公司获得了平均 25 万美元的风险投资。
- Rootstrap 以 2500 万美元收购了最大的探索明矾。
5。 滨米科技
Binmile Technologies 为初创公司和中小型企业以及企业提供端到端的数字产品开发服务。这包括专门从事定制软件和应用开发的财富 500 强公司。
专长
- 定制软件开发
- 移动应用程序开发
- 产品开发
- Web 开发
- 体验设计
- 品质保证
6。****radix EB
Radixweb 是一家已有 22 年历史的科技公司,提供无与伦比的 IT 咨询和定制软件开发能力。Radixweb 是全球外包的首选合作伙伴,并基于传统的专业知识和技术建议提供卓越的技术解决方案。
专长
- 定制软件开发
- 软件产品开发
- 软件开发外包
- 移动应用程序开发
- Web 和桌面应用程序开发
- 云咨询和计算
- 应用现代化
- 企业移动性
- DevOps
7 号。外形相似****
Simform 是一家技术公司,旨在帮助成功的公司提高其技术能力。我们成立于 2010 年 10 月,帮助过从上市的初创公司到财富 500 强企业和世卫组织支持的非政府组织。
专长
- 定制软件开发
- 企业应用程序开发
- 移动应用程序开发
- 云咨询和管理
- 软件测试
- DevOps 的咨询和实施
- 专门的开发团队
- API 集成
8。****brocoder
七年来,Brocoders 一直在提供高质量的移动和网络应用程序。众所周知,Brocoders 能够有效、透明地交流和开发产品。从与我们的技术专家的第一次通话到产品发布,Brocoders 时刻关注您的业务。您可以相信,无论您是要开发新产品,还是要扩大现有开发团队的规模。
专长
- 交通和移动软件
- 金融科技软件
- 农业技术软件
- 教育科技软件
- 数字化转型
9。 EvaCodes
每个项目都被认真对待。每个商业想法都被视为自己的想法。EvaCodes 带来了企业家精神、专业知识和技术诀窍,帮助客户的想法数字化。EvaCodes 致力于为客户提供最好的解决方案,并引进顶尖的 IT 人才来解决不可避免的问题。
专长
- 区块链解决方案
- 移动应用开发
- 定制软件开发
- 电子商务
- 软件质量保证和测试
- 物联网解决方案
- 数字化转型
10。 E2Developers
这是一家成立于 2013 年的网络机构。它利用自己的专业知识为各种预算的企业提供网络解决方案。
E2Developers 为 web、移动和电子商务网站创建了丰富的 UI 和 UX 数字品牌标识。客户从他们传播商业价值和分析用户行为以确定可衡量的参与度和其他策略的工作中受益。为了创造直观和优质的体验,E2Developers 使用迭代设计流程。
结论
你的 Python 开发公司必须是你的组织的价值观和文化的延伸。在无数可能为你提供服务的公司中选择合适的公司是很困难的。
您需要 Django/Python 专家来理解和适应开发的不断变化的本质。当在几个 Python 开发公司中选择合作伙伴时,要确保寻找正确的组合。这包括经验、可承受的价格、轻松的协作、技术知识、文化理解和技术敏锐度。
如何选择最好的网页开发公司?
原文:https://www.pythoncentral.io/how-to-choose-the-best-web-development-company/
您的企业需要一个强大而专业的网站。如果你自己不是开发者,你最好聘请专业的网站开发机构。如你所知,在美国有很多公司提供他们的服务,所以选择最好的可能不是那么简单。让我们告诉你更多关于如何选择完美的机构,以及它的评级可以帮助你。
如何获得一个专业的网站?
嗯,你有三种方式:
- 找到贵公司的开发人员 。如果你是一个年轻的 IT 机构或公司,在这个领域工作,你的一些员工可能知道什么是网站开发。请他们为您创建一个网站,或者请其他工作人员找到他们认识的可以处理这项任务的人。
- 借助自由职业者的帮助 。你可以通过自由职业者服务找到对网站开发了如指掌的专家。有时,他们提供的质量可以与拥有良好体验的大公司相媲美。
- 联系专业机构 。这里的家伙知道如何创建一个坚实的质量网站的一切。他们是真正的专业人士,拥有丰富的 IT 和网站开发经验和知识,许多成功完成的项目和大量积极的反馈证明了这一点。
是的,专业机构可能比一般的自由职业者拿更多的钱。但是你应该明白的一件事是,自由职业者可能没有必要的工具来创建一个网站来解决你客户的所有问题。如果短时间内需要一个有实力的项目,就要聘请专业的代理公司。
如果你遵循下面的建议,你完全有机会雇佣到一家完美的网站开发公司。
最佳选择:使用可信平台
有了可靠的平台,可以快速找到专业的代理机构。你所要做的就是在特定领域工作的最佳公司目录中查找它们,看到它们的优缺点,并决定哪家上市公司最适合你。让我们来看看美国最受欢迎的平台,它可以帮助你做出决定。
好公司
GoodFirms 是最值得信赖的排名服务,它允许你比较不同的公司和软件产品,以便你选择最合适的。在 GoodFirms 的帮助下,你可以看到最可靠的 web 开发公司,看到他们的投资组合、案例、弱势和强势方面,并决定哪个代理机构提供的服务最赚钱。GoodFirms 拥有经过验证的投资组合、诚实的评论和有用的评级。
离合器
Clutch 是最受欢迎的 B2B 网站,对许多公司进行了排名。在 Clutch 上,你可以看到在 web 开发领域提供最佳服务的公司名单,阅读他们的评论,并找到你应该与他们合作的理由。许多商人和代理商都信任离合器,因为它可以让他们选择最可靠的公司。
前进
Awwwards 的目标是为网页开发者、设计师和其他专家提供一个被关注的机会,并找到一个客户来完成任何难度的项目。Awwards 是最值得信赖的平台,允许您阅读经过验证的评论并查看代理机构的成就。有了这个网站,你可能会找到一个完美的代理机构,随时准备帮助你的网站开发。
IT 评级
与上面提到的平台相比,IT 评级不仅仅是一个给公司排名的网站。IT 评级是一个完整的数字生态系统,美国第一。使用这个平台,你不仅可以找到创建网站的承包商,还可以使用其他服务。IT Rating 提供基于云的解决方案,帮助您根据个人偏好选择公司。该平台使用一种独特的公式,根据公司的可靠性自动对其进行排序。
只有可靠的机构才能获得评级,因此您无需担心——为了获得 IT 评级,公司必须通过严格的检查。IT Rating 还提供诸如 IT 界新闻信息等服务,以便随时了解网站的最新动态。It Rating 将通知您即将举行的有趣的活动和会议,并提供如何选择优质网站开发公司的建议。
你应该遵循的标准
让我们简单地解释一下,如果你想选择最完美的网络开发公司并在众多公司中进行比较,你需要遵循什么标准。
反馈和建议
选择公司时,评论是你首先要注意的。他们可以立即看出一个高质量的公司是如何工作的。区分真实评论和定制评论很重要。为此,反馈中应该有建设性的批评;不应该有平庸的赞美;一切都应该画得准确而中肯。向你的同事和熟人征求意见是有道理的;也许他们会推荐一个他们测试过的优秀公司。
你的想法实现的成本
价格有时会立刻说明公司的情况。如果价格太低,那么要么是公司还年轻,要么是它提供的服务质量差。如果价格太高,那么代理可能有问题。最好的选择是联系那些为他们的服务提供最优惠价格的公司,这些价格等于市场平均价格。然而,值得记住的是,你想得到的质量越好,你付出的就越多这是一种适用于任何商业领域的潜规则。
便捷支付
适用于 IT 行业的主要规则是,你永远不需要为尚未完成的项目全额付款。是的,你需要支付预付款——这是项目总成本的一定比例。收到订单后,公司将立即开始履行订单。由于 IT 行业没有固定的条件,因此在起草合同时,应与公司亲自讨论接受预付款的条件、成本和回报条件。你还需要商定一个便捷的支付模式:在哪些部分,以及以何种具体方式,支付公司的工作。这和其他步骤一样,是迈向合作的重要一步。
公司船员资质
在任何一家可靠的公司,网站开发团队都由出色完成工作的高级员工组成。通常,他们可以做任何项目,即使太难实现。他们有所有的专业工具和大量的知识。与合格的专家合作不仅节省时间,而且更有成效和洞察力。为了确保您的项目由合格的工作人员负责,只需访问该机构的网站,或通过电子邮件或电话直接与他们联系。查看他们链接的个人资料,他们完成的项目,以及任何其他证明他们是网站开发领域真正专家的成就。
投资组合
这个投资组合很能说明这家公司的情况。如果他们真的有很酷的项目,他们不会隐藏它们——通常,你可以在代理公司的网站上看到这些作品。如果你决定与这家公司合作,这个投资组合还能让你想象结果。通过观察他们的工作,你可以看到一个专业公司是如何工作的,以及它有什么工具来达到最佳效果。如果你看到一个坚实的投资组合,这可能是你应该与这家机构合作的原因。但是如果没有工作,或者他们质量很低,对你来说最好的决定就是忽略这个机构。
总之
多亏了这篇文章,现在你知道了更多关于如何选择最好的网络开发公司,以及它的评级如何对你有所帮助。使用上面提到的建议,你会找到最好的代理,它将创建一个强大的网站,解决你的所有业务问题。但不要忘记 IT Rating,这家公司随时准备在您的商务之旅中为您提供帮助,并为您提供高质量的数字服务。
如何选择正确的 ML 基础设施
原文:https://www.pythoncentral.io/how-to-choose-the-right-ml-infrastructure/

当开始一个新项目时,选择正确的机器学习基础设施是这个过程的重要部分。无论是研究、开发还是生产应用,拥有一个可靠的工具管道来获取和管理数据就是一切。确保你的最终模型强大的最好方法不是使用最新的研究工具,而是拥有一个为你和你的团队服务的管道。
当你开始为你的企业建立机器学习模型时,你可能会对运行这些模型所需的基础设施有一些疑问,特别是在培训方面。在哪里部署机器学习模型?架构应该是什么样的?或者您将使用集中式方法还是分布式模型?
当您选择正确的基础设施时,其他一切都会水到渠成。下面是如何做的详细指南:
- 考虑运行要求
在考虑满足机器学习(ML)需求的合适基础设施时,了解您希望运行什么操作非常重要。如果您不明白它如何满足您的运营需求,您可以咨询像 cnvrg.io 这样的公司以及其他专门在任何基础设施上构建和部署 ML 模型的公司。最常见的 ML 工作负载是训练、推理和数据处理。
- 训练 :训练是机器学习模型通过在数据中寻找模式从数据集“学习”的过程。然后,模型使用这些模式对未知数据进行预测或提出建议。一旦模型被训练,它就可以用于推理。
- 推理 :推理是将经过训练的模型应用到新数据中,做出预测或建议。
- 数据处理 :数据处理是将原始数据转换成可用于训练和推理的格式。
一旦您了解了您的 ML 模型所需的操作要求以及模型需要提供什么,您就可以轻松选择支持它的基础设施。
- 考虑编程语言
机器学习中最流行的编程语言是 Python、R 和 Scala。关于用例,它们有各自的优点和缺点。例如,如果您构建一个图像识别模型,Python 可能是您的最佳选择,因为它有几个库【比如 sci-kit-learn】,可以轻松地在大型数据集上构建复杂的模型。这些库可以帮助您处理、存储和操作非结构化数据。
但是,如果你想为自然语言处理(NLP)建立一个模型,R 将是一个更好的选择,因为它支持正则表达式,正则表达式可用于 NLP 任务,如词性标记或将句子解析为单词。Scala 对于 NLP 任务来说也是一个很好的选择,但是它不像 R 那样内置了现成的正则表达式支持,所以在开始使用它们之前,您可能需要做一些额外的设置工作。
- 看看你的数据
为你的机器学习项目选择合适的基础设施的另一个步骤是查看你的数据。盘点一下你拥有的东西,它们来自哪里,有多少,最重要的是,它们是如何构成的。
从看看你拥有什么开始。看看你收集的所有数据的来源。你可能从不同的来源获得数据。这些来源需要特殊考虑吗?它们是实时传输的,还是更新频率较低的?他们多久更新一次,他们提供了多少数据?它们是什么格式的?这些来源的内容是否比其他来源更重要?这种情况会随着时间而改变吗?想想这些东西会如何影响你最终产品的质量。
接下来,考虑你的数据类型。它主要是文本、图像、音频、视频、数字测量,还是其他完全不同的东西?你的模型需要产生什么样的输出?这些输出可能会随着时间的推移而改变吗?您使用的数据源类型、您希望回答的问题类型以及数据集的大小将影响您需要使用的工具。
- 成本估算
在选择一个 ML 基础设施时, 估算你将招致的成本 总是很重要的。这一点很重要,因为当开发和部署 ML 模型时,资金耗尽可能会阻碍一切。以下是你需要考虑的:
- 电脑资源 :你需要多少内存和 CPU?这与数据集的规模直接相关。例如,如果你在数百万张图像上训练一个图像分类器,你将需要比在几千条记录上训练一个简单的线性回归模型更多的资源。
- 训练时间 :训练你们的模特需要多长时间?这也与数据集大小有关,取决于模型的复杂性。如果你的模型很小,你也许可以使用不太强大的机器,并等待他们训练更长的时间。
结论
机器学习是一项非常强大且广泛适用的技术,有着大量的应用。正确的模型将提高您企业的效率和生产力。因此,您需要首先使用本文中讨论的技巧来选择合适的基础设施。这将为构建和部署您的模型奠定适当的基础。
如何用这个 Python 格式化程序清理您的代码
原文:https://www.pythoncentral.io/how-to-clean-up-your-code-with-this-python-formatter/
没有人喜欢看到杂乱无章的代码。如果您遇到过这样的代码(或者,即使您编写了这样的代码...这里没有判断),您可以尝试自己重新格式化代码,这取决于文件有多大,可能需要几个小时甚至几天,或者您可以使用 Python 格式化程序,如 Python 美化来为您完成。
这个 Python 格式化程序是由负责一个伟大的 CSS 格式化程序和许多其他有用的开发工具的同一批人带给我们的,它非常适合清理任何杂乱的代码。它让你完全定制你想要的代码组织方式和你想要遵守的格式规则。

你可以指定你想要缩进多少个空格,你是否想要换行,你想要大括号和方括号如何显示,等等。下一次,当你发现自己处于一些格式不良的 Python 中时,记住你有这个工具,将你的代码复制并粘贴到文本输入框中,几秒钟内你就可以使用你的新的和改进的干净代码了。
如何在 Pandas 中连接数据帧(快速简单)
原文:https://www.pythoncentral.io/how-to-concatenate-data-frames-in-pandas-fast-and-easy/
使用熊猫合并()和。join()为您提供了一个混合了初始数据集行的数据集。这些行通常基于公共属性进行排列。
但是,如果父数据集的所有行之间没有任何匹配,那么结果数据集也有可能不包含这些行。
Pandas 提供了第三种处理数据集的方法:concat()函数。它沿着行或列轴将数据框缝合在一起。在本指南中,我们将带您了解如何使用函数来连接数据帧。
如何在 Pandas 中连接数据帧
连接数据帧就是在第一个数据帧之后添加第二个数据帧。使用 concatenate 函数对两个数据帧执行此操作就像向它传递数据帧列表一样简单,就像这样:
concatenation = pandas.concat([df1, df2])
请记住,上面的代码假设两个数据框中的列名相同。它沿着行连接数据框。
如果名称不同,并且代码被设置为沿行连接(被认为是轴 0),则默认情况下也将添加列。另外,Python 会根据需要填充“NaN”值。
但是如果你想沿着列执行连接呢?concat()函数可以让您轻松实现这一点。
你可以像上面的例子一样调用这个函数——唯一的区别是你必须传递一个值为 1 或“列”的“轴”参数
下面是代码的样子:
concatenation = pandas.concat([df1, df2], axis="columns")
在这个例子中,Python 假设数据帧之间的行是相同的。
但是,当您沿列进行连接并且行不同时,默认情况下,额外的行将被添加到结果数据框中。当然,如您所料,Python 会根据需要填充“NaN”值。
在下一节中,我们将看看 concat()可用的各种参数。
优化 concat()
学习 concat()函数的基础知识可能已经向您展示了它是组合数据帧的最简单的方法之一。它通常用于创建一个大型集合,以便可以进行其他操作。
重要的是要记住,当 concat()被调用时,它会复制被连接的数据。因此,您必须仔细考虑是否需要多次 concat()调用。使用太多会降低程序速度。
如果打几个电话无法避免,可以考虑将复制参数设置为 False。
concat()中轴的作用
您现在知道可以指定想要连接数据帧的轴。那么,当一个轴是首选时,另一个轴会发生什么呢?
由于串联函数总是默认产生一个集合并集——所有数据都被保留——另一个轴不会发生任何变化。
如果你用过。join()作为外部连接和 merge()之前,您可能已经注意到了这一点。您可以使用 join 参数强制实现这一点。
当使用 join 参数时,缺省为 outer。但是,内部选项也是可用的,允许您执行集合相交或内部联接。
但是请记住,在 concat()函数中以这种方式使用内部连接可能会导致少量的数据丢失,原因与常规内部连接发生数据丢失的原因相同。
只有轴标签匹配的行和列才会被保留。再次注意,join 参数只指示 pandas 处理你 没有 连接的轴。
concat()值得注意的参数
下面快速浏览一下 concat()可以使用的一些最有用的参数:
- 轴: 该参数代表函数将连接的轴。默认情况下,它的值为 0,表示行数。但是您可以将该值设置为 1,以便沿着列进行连接。您还可以使用字符串“index”来表示行,使用“columns”来表示列。
- objs: 它接受一个列表或你想要连接的数据帧或系列对象的任何序列。使用字典也是允许的,但是如果使用字典,Python 将使用键创建一个层次索引。
- ignore_index: 它接受一个布尔值,默认为 False。设置为 True 时,创建的新数据框不会保留轴中的原始索引值,如轴参数所指定。因此,使用该参数可以提供新的索引值。
- 键: 它使你能够创建一个层次索引。最常见的使用方法是创建一个新的索引,同时保留原来的索引。这样,您就可以知道哪些行来自哪个数据框。
- 复制: 此参数说明是否要复制源数据。默认情况下,它的值为 True,但是如果设置为 False,Python 将不会复制数据。
- join: 该参数的工作方式类似于 how 参数的工作方式,只是它只能接受值 inner 和 outer。默认情况下,它的值是 outer,它保存数据。但是,将其设置为 inner 会删除在其他数据集中没有匹配项的数据。
如果你想查看 concat()参数的详细列表,你可以在 熊猫官方文档 中找到。
正确使用 concat()的技巧
下面是使用 concat()时需要记住的四件事,以及一些例子:
#1 小心使用索引和轴
假设两个数据框保存着考试的结果,就像这样:
firstDataFrame = pd.DataFrame({
'name': ['I', 'J', 'K', 'L'],
'science': [72,56,91, 83],
'accounts': [67,95,80,77],
'psychology': [81,71,87,86]
})secondDataFrame = pd.DataFrame({
'name': ['M', 'N', 'O', 'P'],
'science': [73,85,81,90],
'accounts': [88,93,72,89],
'psychology': [75,83,74,87]
})
现在,用 concat()方法连接的最简单的方法是向它传递一个数据帧列表。如您所知,默认情况下,该方法沿 0 轴垂直连接,并保留所有索引。
因此,使用简单连接的方法看起来应该是这样的:
pd.concat([firstDataFrame, secondDataFrame])
您可能想要忽略预先存在的索引。在这种情况下,可以将 ignore_index 参数设置为 True。这样,得到的数据帧索引将被标记为从 0 到 n-1。
因此,对于这种情况,concat()方法应该这样调用:
pd.concat([firstDataFrame, secondDataFrame], ignore_index=True)
您也可以选择水平连接数据帧。这就像将轴参数设置为 1 一样简单,就像这样:
pd.concat([firstDataFrame, secondDataFrame], axis=1)
#2 避免重复索引
如前所述,concat()函数按原样保存索引。但是您可能希望验证由 pd.concat()产生的索引没有重叠。
谢天谢地,这很容易做到。您必须将 verify_integrity 参数设置为 True 这样,如果有重复的索引,pandas 将引发异常。
我们来看一个相关的例子:
try:
pd.concat([firstDataFrame, secondDataFrame], verify_integrity=True)
except ValueError as e:
print('ValueError', e)ValueError: Overlapping indices: Int64Index([0, 1, 2, 3], dtype='int64')
#3 使用分层索引简化数据分析
将多级索引添加到连接的数据框中可使数据分析更加容易。继续考试结果数据框架示例,我们可以分别在 firstDataFrame 和 secondDataFrame 中添加学期 1 和学期 2 的指数。
实现这一点就像使用 keys 参数一样简单:
res = pd.concat([firstDataFrame, secondDataFrame], keys=['Semester 1','Semester 2'])
res
要访问一组特定的值,您可以使用:
res.loc['Semester 1']
您也可以使用 names 参数向分层索引中添加名称。让我们看看如何将名称“Class”添加到我们上面创建的索引中:
pd.concat(
[firstDataFrame, secondDataFrame],
keys=['Semester 1', 'Semester 2'],
names=['Class', None],
)
也可以重置索引,然后将其转换为数据列。为此,您可以像这样使用 reset_index()方法:
pd.concat(
[firstDataFrame, secondDataFrame],
keys=['Semester 1', 'Semester 2'],
names=['Class', None],
) .reset_index(level=0)
#4 考虑匹配和排序列
concat()函数的一个优点是它可以对数据帧的列进行重新排序。默认情况下,该函数保持排序顺序与第一个数据框相同。
要按字母顺序对数据框进行排序,您可以将 sort 参数设置为 True,如下所示:
pd.concat([firstDataFrame, secondDataFrame], sort=True)
你也可以像这样自定义排序参数:
custom_sort = ['science', 'accounts', 'psychology', 'name']
res = pd.concat([firstDataFrame, secondDataFrame])
res[custom_sort]
如何用 Python 把 Mp3 转换成文本?
原文:https://www.pythoncentral.io/how-to-convert-mp3-to-text-in-python/
将 Mp3 等音频文件转换为文本对于许多任务来说都是一个有用且省时的工具。在 Python 中,有几个库允许您将音频文件从 Mp3 格式转换为纯文本。这个过程包括使用语音识别和自然语言处理(NLP)算法来识别音频文件中的单词和短语,并将它们转换为文本。
在本文中,我们将讨论如何使用 Python 将 Mp3 文件转换成文本。我们还将查看可以帮助我们完成这项任务的各种可用库。
什么是 Mp3 到文本的转换?
Mp3 到文本的转换是获取音频文件(Mp3 格式)并使用语音识别和 NLP 技术将其转换为文本的过程。将 mp3 转换成文本可以让你轻松阅读音频文件的内容,并以一种易于搜索的形式存储。
你为什么想把 Mp3 转换成文本?
将音频文件从 Mp3 转换为文本对于各种任务都非常有用。最重要的是,它让有听力障碍的人有机会访问他们难以或不可能理解的内容。此外,如果您有一个会议或讲座的音频记录,您可以轻松地将其转换为文本并存储为可搜索的文档。
这使得将来访问这些内容变得更加容易,也使得其他人更容易阅读和理解。此外,如果您想创建一个语音到文本的应用程序,Mp3 到文本的转换会很有用。此外,将 mp3 转换为文本可以创建对市场营销有用的文本,如博客文章或广告内容。
如何用 Python 把 Mp3 转换成文本?
本质上,语音只是一种声波。更具体地说,它具有组成音频信号的特征,如振幅、峰值和谷值、波长、周期和频率。
因为音频信号是连续的,所以它们包含无限数量的数据点。为了将模拟音频信号转换为可由计算机处理的数字信号,网络使用离散的样本分布,非常类似于音频信号的连续性。
在我们确定一个合理的采样频率后(一个好的起点是 8000 Hz,考虑到大多数语音频率都在这个范围内),我们可以使用 Python 包来分析音频信号,如 SQLite 和 PySide/PyQt 。有了这些输入,我们就可以将数据集分成两部分:一部分用于训练模型,另一部分用于验证结果。
Conv1d 模型架构是一种具有单维运算的卷积神经网络,可在此阶段使用。然后,我们可以构建一个模型,并使用神经网络建立其损失函数,以便将有声文本(语音)转换为书面文本。
为了实现更广泛的接受和适用性,我们可以使用深度学习和 NLP(自然语言处理)将语句转换为文本。
安装支持语音识别的库
第一步是安装一个支持语音识别的库,如 CMU 斯芬克斯或谷歌语音识别。一旦你安装了这个库,你就可以用它把 Mp3 文件转换成文本。您可以通过使用以下代码来实现这一点:
将语音识别作为 sr 导入
r =高级识别器()
audio _ file = Sr . audio file(' example . MP3 ')
使用音频文件作为源:
音频= r.record(信号源)
text = r.recognize_google(音频)
打印(文本)
这段代码将识别并打印出 Mp3 文件中的文本。一旦您成功地将 Mp3 文件转换为文本,您就可以使用自然语言处理(NLP)算法来分析它并提取有价值的见解。
流行的 Python 库
NLTK、TextBlob 和 SpaCy 是一些流行的 Python 库,可以用于自然语言处理任务。NLTK 提供了对单词和句子进行标记的功能,以及对它们进行词干和词目化的功能。TextBlob 是一个易于使用的库,它提供了将文本分解成其组成部分的功能,并识别与每个单词相关联的情感。SpaCy 是一个高级的 NLP 库,提供深度学习、实体识别等功能。
一旦您使用这些库分析了 Mp3 文件中的文本,您就可以使用这些见解来创建功能强大的应用程序,如聊天机器人、语音识别系统或自动化客户服务系统。使用 python 转录音频是一种有效的方法,可以加速许多过程,并为您的项目增加价值。
把 Mp3 转换成文本有更多的选择吗?
是的,有几种方法可以将 Mp3 文件转换成文本。你可以使用基于人工智能和机器学习的自动转录服务,或者你可以使用专业服务人员转录服务,这比第一个选项更耗时和昂贵。
结论
总之,将 Mp3 文件转换成文本是存储音频内容并使其易于访问的好方法。通过使用 Python 库,如 CMU Sphinx 或谷歌语音识别,您可以快速将音频文件转换成文本。此外,还有各种其他的转录 Mp3 文件的选择,如自动转录服务或专业人员转录。无论您选择哪种方法,将 Mp3 转换为文本都是一种释放宝贵见解和创建强大应用程序的好方法。
如何用 Shutil 在 Python 中复制文件
原文:https://www.pythoncentral.io/how-to-copy-a-file-in-python-with-shutil/
所以你想知道如何用 Python 复制一个文件?很好!这是非常有用的学习和最复杂的应用程序,你可能会设计至少需要某种形式的复制文件。
用 Python 复制单个文件
好吧,我们开始吧。第一部分将描述如何将单个文件(不是目录)复制到硬盘上的另一个位置。
Python 有一个名为shutil的特殊模块,用于简单的高级文件操作,在复制单个文件时非常有用。
下面是一个将单个文件复制到目标文件或文件夹的函数示例(带有错误处理/报告):
import shutil
def copyFile(src,dest):
try:
shutil . copy(src,dest)
# eg. src 和 dest 是同一个文件
除了 shutil。错误为 e:
打印('错误:%s' % e)
#例如,源或目标不存在
除了 io 错误为 e:
打印('错误:%s' % e.strerror)
就是这样!我们只要调用那个方法,文件就被复制了。如果源文件或目标文件不存在,我们打印一个错误通知用户操作失败。如果源文件和目标文件相同,我们不会复制它们,也不会通知用户操作失败。
Python shutil 的不同复制方法
除了我们上面看到的简单的copy方法之外,模块shutil还有几个复制文件的方法。
我将在这里详细介绍它们,解释它们之间的区别以及我们可能需要它们的情况。
shutil.copyfileobj(fsrc, fdst[, buffer_length])
该功能允许复制带有实际文件对象本身的文件。如果您已经使用内置的open函数打开了一个要读取的文件和一个要写入的文件,那么您应该使用shutil.copyfileobj。当需要指定复制操作的缓冲区长度时,使用这个函数也很有意义。在复制大文件时,增加缓冲区长度(默认值为 16 KB)可能有助于加快复制操作。
下面提到的所有其他复制函数都会在某个时候调用这个函数。它是“基本”复制方法。
让我们来看一个使用 50 KB、100 KB、500 KB、1 MB、10 MB 和 100 MB 缓冲区大小与普通复制操作进行文件复制的基准测试。我们将测试一个 iso 格式的 3.2 GB 存档文件。
我们将使用这个函数来指定缓冲区的大小:
def copyLargeFile(src, dest, buffer_size=16000):
with open(src, 'rb') as fsrc:
with open(dest, 'wb') as fdest:
shutil.copyfileobj(fsrc, fdest, buffer_size)
并且 Ubuntu 内置了time bash 命令来为操作计时。
结果如下:
50kb:29.539s
100 KB:27.423s
500 KB:25.245s
1mb:26.261s
10mb:25.521s
100 MB:24.886s
正如您所看到的,缓冲区大小之间有很大的差异。使用 50 KB 的缓冲区比使用 100 MB 的缓冲区花费的时间减少了近 16%。
最佳的缓冲区大小最终取决于可用的 RAM 容量和文件大小。
shutil.copyfile(src, dst)
此方法将文件从源位置src复制到目标位置dst。这与copy的不同之处在于,您必须确保目标路径存在,并且还包含文件名。例如,'/home/'可能是无效的,因为它是一个目录的名称。'/home/test.txt'将是有效的,因为它包含一个文件名。
shutil.copy(src, dst)
我们上面使用的copy检测目标路径是否包含文件名。如果路径不包含文件名,copy在复制操作中使用原始文件名。它还将权限位复制到目标文件。
如果您不确定目标路径的格式,或者想要复制源文件的权限位,您可以使用这个函数。
shutil.copy2(src, dst)
这与我们使用的 copy 函数相同,只是它将文件元数据与文件一起复制。元数据包括许可位、最后访问时间、最后修改时间和标志。
如果你想要一个几乎完全相同的文件副本,你可以在copy上使用这个函数。
Python 文件复制功能对比
下面我们可以看到shutil的文件复制功能的对比,以及它们的不同之处。
| 功能 | 复制元数据 | 拷贝权限 | 可以指定缓冲区 |
| shutil.copy | 不 | 是 | 不 |
| shutil.copyfile | 不 | 不 | 不 |
| shutil.copy2 | 是 | 是 | 不 |
| shutil.copyfileobj | 不 | 不 | 是 |
复制文件到此就差不多结束了。我希望您能从这篇文章中受益,也希望花时间学习一点 Python 中的文件操作是值得的。
直到下一次!
再见。
如何用 Python 计数器对 Python 3 中的对象计数
原文:https://www.pythoncentral.io/how-to-count-objects-in-python-3-with-a-python-counter/
Python 被认为是最容易使用的编程语言之一,这是有充分理由的。有一些库和内置功能可以让你做任何你想做的事情。
对多个重复的对象进行计数是一个编程问题,几十年来开发人员不得不寻找复杂的解决方案。但是在 Python 中,作为集合模块一部分的 Counter 子类为这个问题提供了一个简单有效的解决方案。
它是 dict 类的子类,学习使用它可以让你在程序中快速计算对象。在本指南中,我们将带您了解如何使用 counter 子类对 Python 3 中的对象进行计数。
在 Python 中使用计数器的基础知识
有很多原因可以解释为什么你想要计算一个对象在给定数据源中出现的次数。也许您想确定某个特定项目在列表中出现的次数。
如果清单很短,你或许可以数一数手上的物品数量。但是如果列表很大,你能做什么呢?
这个问题的典型解决方案是使用计数器变量。该变量的起始值为 0,并且每当对象出现在数据源中时,该变量就递增 1。
当你想计算一个物体出现的次数时,使用计数器变量是最合适的。你要做的就是做一个单独的计数器。
然而,如果你需要对多个不同的对象进行计数,你将需要写和对象一样多的计数器。
使用 Python 字典是避免编写多个计数器的一个好方法。字典的键将存储您想要计数的对象,值将保存每个对象出现的频率。
要用 Python 字典对序列中的对象进行计数,只需循环遍历序列,检查每个对象是否在字典中,如果是,递增计数器。
让我们看一个简单的例子。下面,我们试图找出字母在单词“簿记员”中出现的次数
word = "bookkeeper"
counter = {}
for letter in word:
if letter not in counter:
counter[letter] = 0
counter[letter] += 1
print(counter)
运行代码给我们输出:
{'b': 1, 'o': 2, 'k': 2, 'e': 3, 'p': 1, 'r': 1}
在示例中,for 循环遍历变量 word 中的字母。循环中的条件语句检查被检查的字母是否在字典中,在本例中,字典被称为 counter。
如果没有,它会创建一个保存该字母的新键,并将其值设置为零。最后,计数器变量加 1。
最后一条语句打印出计数器变量。因此,在输出中,您可以看到字母起到了键的作用,而值就是计数。
需要注意的是,当你用字典计算几个对象时,它们需要是可散列的,因为它们将作为字典的键。换句话说,对象在其整个生命周期中必须有一个常量哈希值。
还有第二种用字典计数对象的方法——使用 dict.get()并将零设置为默认值:
word = "bookkeeper"
counter = {}
for letter in word:
counter[letter] = counter.get(letter, 0) + 1
print(counter)
代码的输出将是:
{'b': 1, 'o': 2, 'k': 2, 'e': 3, 'p': 1, 'r': 1}
使用时。get()与 dict,它要么给出零(缺省值)如果字母丢失或字母的当前计数。在代码中,该值随后递增 1,并作为字典中相应字母的值存储。
Python 还支持使用集合中的 defaultdict 来计算循环中的对象:
from collections import defaultdict
word = "bookkeeper"
counter = defaultdict(int)
for letter in word:
counter[letter] += 1
print(counter)
运行代码,我们得到输出:
defaultdict(<class 'int'>, {'b': 1, 'o': 2, 'k': 2, 'e': 3, 'p': 1, 'r': 1})
用这种方式解决问题更具可读性,也更简洁。首先用 defaultdict 初始化计数器,使用 int()作为工厂函数。这样做允许您访问一个在 defaultdict 中不存在的键。
正如你使用 int()所预料的,缺省值将是零,这发生在你调用不带参数的函数时。
字典会自动创建一个键,并用工厂函数返回的值初始化它。
上面的解决方案是有效的,但是就像 Python 中的其他东西一样,还有更好的方法来解决这个问题。collections 模块创建了一个类来帮助同时计数不同的对象。这是计数器类。
Python 的计数器类入门
Counter 类是 dict 的一个子类,用来计算可散列对象。如您所料,这是一个保存对象的字典,您将这些对象计数为键,计数为值。
要使用这个类,你必须向类的构造函数提供一个可迭代的或可散列的对象序列作为参数。
这个类在内部遍历序列,计算一个对象出现的频率。让我们看看构造计数器的不同方法。
构造计数器
要同时计数多个对象,必须使用 iterable 或 sequence 来初始化计数器。
让我们看看如何用这种方法编写一个程序来计算“簿记员”中的字母数:
from collections import Counter
print(Counter("bookkeeper")) # Passing a string argument
print(Counter(list("bookkeeper"))) # Passing a list as an argument
这段代码的输出将是:
Counter({'e': 3, 'o': 2, 'k': 2, 'b': 1, 'p': 1, 'r': 1})
Counter({'e': 3, 'o': 2, 'k': 2, 'b': 1, 'p': 1, 'r': 1})
Counter 类遍历“bookkeeper”,生成一个字典,将字母存储为键,将计数存储为值。在这个例子中,我们首先导入计数器类,然后传递一个字符串作为参数。然后,我们传递一个列表,得到相同的输出。
除了列表,你还可以传递元组或者任何其他包含重复对象的可重复对象。
如前所述,有许多方法可以创建 Counter 类的实例。但是这些方法严格来说并不意味着计数。你可以做的一件事就是使用字典:
from collections import Counter
print(Counter({"e": 3, "o": 2, "k": 2, "b": 1, "p": 1, "r": 1}))
运行该命令会得到输出:
Counter({'e': 3, 'o': 2, 'k': 2, 'b': 1, 'p': 1, 'r': 1})
以这种方式使用字典给出键计数对的计数器初始值。还有另一种方法可以通过调用类的构造函数来做同样的事情,就像这样:
from collections import Counter
print(Counter(e=3, o=2, k=2, b=1, p=1, r=1))
你也可以通过调用 set()函数来使用 Counter 类,就像这样:
from collections import Counter
print(Counter(set("bookkeeper")))
其输出为:
Counter({'e': 1, 'o': 1, 'p': 1, 'r': 1, 'b': 1, 'k': 1})
你可能知道,Python 中的集合存储唯一的对象。因此,以这种方式调用 set()会输出重复的字母。但是这样一来,原始 iterable 中的每个字母都有了一个实例。
由于 Counter 是 dict 的子类,所以它继承了常规字典的接口。但是没有实现。fromkeys()来防止歧义。
记住你可以在键中存储任何类型的可散列对象,而值可以存储任何类型的对象。但是作为一个计数器,值必须是整数。
让我们来看一个保存零和负计数的计数器实例的例子:
from collections import Counter
collection = Counter(
stamps=10,
coins=-15,
buttons=0,
seeds=15
)
在这个例子中,你可能会问为什么有-15 个硬币。它可能用来表示你已经把它们借给朋友了。底线是 Counter 类允许以这种方式存储负数,并且您可能能够找到它的一些用例。
更新对象计数
现在,您已经了解了如何获得一个计数器实例。用新的计数更新它并引入新的对象就像使用。更新()。
它是 Counter 类的一个实现,能够将现有的计数相加。它还使得创建新的键计数对成为可能。
。update()处理计数的映射和可重复项。当使用 iterable 作为参数时,该方法对项目进行计数,并根据需要更新计数器:
from collections import Counter
letters = Counter({"e": 3, "o": 2, "k": 2, "b": 1, "p": 1, "r": 1})
letters.update("toad")
print(letters)
运行代码给出输出:
Counter({'e': 3, 'o': 3, 'k': 2, 'b': 1, 'p': 1, 'r': 1, 't': 1, 'a': 1, 'd': 1})
我们将前面讨论的“簿记员”示例中的字母和相应的计数放在本示例的开头。然后,我们用了。更新以将单词“toad”中的字母添加到组合中。这引入了一些新的键计数对,如输出所示。
请记住,iterable 需要是一个元素序列,而不是键计数对,这样才能工作。但有趣的是:
使用整数以外的值作为计数会破坏计数器。我们来看看:
from collections import Counter
letters = Counter({"e": "3", "o": "2", "k": "2", "b": "1", "p": "1", "r": "1"})
letters.update("toad")
print(letters)
运行代码给出输出:
Traceback (most recent call last):
File "<string>", line 5, in <module>
File "/usr/lib/python3.8/collections/__init__.py", line 637, in update
_count_elements(self, iterable)
TypeError: can only concatenate str (not "int") to str
由于示例中定义的字母计数是字符串。update()不起作用,引发了 TypeError。
。还可以通过提供第二个计数器或计数映射作为参数来以另一种方式使用 update。下面是方法:
from collections import Counter
sales = Counter(cheese=19, cake=20, foil=5)
# Using a counter
monday_sales = Counter(cheese=5, cake=4, foil=3)
sales.update(monday_sales)
print(sales)
# Using a dictionary of counts
tuesday_sales = {"cheese ": 4, "cake": 3, "foil": 1}
sales.update(tuesday_sales)
print(sales)
在程序开始时,用另一个名为“monday_sales”的计数器更新现有的计数器在程序的后半部分,使用一个包含项目和计数的字典来更新计数器。如你所见。update()适用于两个计数器
访问计数器的内容
由于 Counter 类具有与 dict 相同的接口,它可以执行与标准字典相同的操作。通过扩展,您可以像在字典中一样使用键访问来访问计数器中的值。
用典型的方法迭代键、项和值也很容易。我们来看看:
from collections import Counter
letters = Counter("bookkeeper")
print(letters["e"])
# Output: 3
print(letters["k"])
# Output:2
for letter in letters:
print(letter, letters[letter])
# Output:
b 1
o 2
k 2
e 3
p 1
r 1
for letter in letters.keys():
print(letter, letters[letter])
# Output:
b 1
o 2
k 2
e 3
p 1
r 1
for letter, count in letters.items():
print(letter, count)
# Output:
b 1
o 2
k 2
e 3
p 1
r 1
for count in letters.values():
print(count)
# Output:
1
2
2
3
1
1
关于 Counter 值得注意的一件有趣的事情是,访问一个丢失的键会导致一个零错误而不是一个键错误。看一看:
from collections import Counter
letters = Counter("bookkeeper")
print(letters["z"])
# Output: 0
寻找最常出现的物体
使用 Counter 类的另一个方便之处是您可以使用。most_common()方法根据对象出现的频率列出对象。如果两个对象具有相同的计数,则它们以第一次出现的顺序显示。
如果一个数字“n”作为一个参数传递给该方法,它将输出“n”个最常见的对象。这里有一个探索该方法如何工作的例子:
from collections import Counter
sales = Counter(cheese=19, cake=20, foil=5)
print(sales.most_common(1))
# Outputs the most common object.
print(sales.most_common(2))
# Outputs the two most common objects.
print(sales.most_common())
# Outputs all objects in order of frequency.
print(sales.most_common(None))
# Outputs all objects in order of frequency.
print(sales.most_common(20))
# Outputs all objects in order of frequency since the argument passed is greater than the total number of distinct objects.
当没有参数或“无”作为参数传递时。most_common()返回所有对象。当参数超过计数器的当前长度时,该方法还返回所有对象。
有趣的是,你也可以有。most_common()按照频率从低到高的顺序返回对象。用切片很容易就能完成。你可以这样做:
from collections import Counter
sales = Counter(cheese=19, cake=20, foil=5)
print(sales.most_common()[::-1])
# Returns objects in reverse order of commonality.
Print(sales.most_common()[:-3:-1])
# Returns the two least-common objects.
如你所见,第一次切片从最不常见到最常见返回变量中的对象。第二个切片从方法输出的结果中返回最后两个对象。
当然,您可以通过改变切片操作符中的第二个值来改变输出中最不常用对象的数量。为了得到三个最不常用的对象,运算符中的-3 将变成-4,依此类推。
要记住的重要一点是,计数器中的值必须是可排序的,这样方法才能正确工作。因为任何类型的数据都可以存储在计数器中,所以排序会变得复杂。
结论
在本指南中,您已经了解了如何使用 collections 模块中的 Counter 类对对象进行计数。它消除了使用循环或嵌套数据结构的需要,简化了考验。将您在本指南中所学的知识整合到您的代码中,可以使代码更干净 和 更快。
如何用 Python 创建移动应用程序:行业中的 3 个例子
使用 Python 创建移动应用的方法
智能手机的销售正以闪电般的速度增长,制造公司正以前所未有的规模投资于移动技术及其开发和市场推广。移动开发是一个快速增长的编程领域,因为移动设备的数量远远超过了个人计算机,而且这种趋势只会继续增长。
许多开发者在安装一个或另一个软件后,用一系列开放的可能性来展示他们的产品以取悦用户。然而,值得花时间考虑各个方面,其中包括加密、跨站点跟踪和执行多种任务。
用 Python 开发应用程序的细节
移动设备的技术开发和项目实施有两种方式,包括网站和应用。起初,这两种方法看起来非常相似。但实际上,它们各有利弊。与通过浏览器运行的网站不同,原生应用需要从特定的门户网站下载,如 Google Play Market、App Store 等。
这些产品是为每个操作系统单独开发的,需要安装,并提供更快的内容访问。在可能提供的多样性中,有语言应用程序、信使、词汇或 花卉和植物标识符 ,它们将在某些情况下成为解决方案。使用百合植物鉴定将通过提供如何护理它们的信息来帮助你学习花和各种植物珍品的名称。每个人都会找到有价值的东西。
方便。 在选择移动应用而非网络资源的优势列表中,It 占据最高位置。分析显示,由于便利的条件,应用程序比跨站点跟踪更受欢迎。它们提供了更好的用户交互,加载内容更快,也更容易使用。此外,它们有推送通知和灵活兼容不同屏幕尺寸的设计。
个性化。 对于需要经常使用的服务,移动应用将是最佳解决方案。它们允许用户创建个人账户,并将必要的信息保存在手边。
语言中过多的亮点
Python 是最著名的通用解释编程语言之一。这个系统包括严格的动态类型和自动内存管理。它支持许多编程范例,包括以下:
- 面向对象;
- 祈使;
- 功能性;
- 程序性;
- 还有其他的。
越来越多的开发人员选择 Python mobile space,因为它高效且具有许多使用这种语言的优势。
简单。 你可以在网页开发和其他专家没有深入知识的领域使用这种语言。Python 语法开发的本质类似于普通的数学运算,没有任何特别的困难。
实现的多样性。 最著名最典型的是 CPython ,C 实现。这意味着用它编写的代码与 C 完全交互,使用这种语言的库来实现。这样的例子很多,上至与 Android、iOS 的交互。
用途广泛。 甚至迪士尼的代表也诉诸使用这种语言。这一事实的结果是,关于他的许多情况已经为人所知。只要你在用 Python 编程时遇到问题,你就可以立即在网上寻求帮助。也许有人已经为我们每个人提出了一个解决方案。
无需编译。 Python 是一种解释型语言。后者意味着您可以在更改程序文件后立即运行该程序。导致各种说法。后者之一是程序的完成、处理和调试比许多其他语言要快得多。
应用程序开发示例
专用语言是开源的,可以自由发布。您可以免费下载并在您的应用程序中使用它。也可以读取和修改源代码。任何代码都容易出错。Python 中的开发抛出了可以处理的异常,从而避免了程序崩溃。自动内存管理包括一个包含所有对象和数据结构的私有堆。内存管理器为对象和其他内部缓冲区分配空间。
网页开发
使用 Python 作为服务器端编程语言,有机会从一系列 web 框架中进行选择。Django 是一个用于开发复杂大型 web 应用程序的全栈 web 框架。同时,还有一个名为 Flask 的可扩展 web 框架。这对于构建简单的 web 应用程序是必要的,因为它简单易学。
Youtube、Spotify、Mozilla、Dropbox 和 Instagram 等应用巨头都使用 Django 框架。与此同时,Airbnb、网飞、优步和三星都在使用 Flask。
机器学习
因为它是一种非常容易理解的语言,我们有大量的库来简化任何活动。许多现有的 Python 库将帮助您专注于比重新发明轮子更有趣的事情。它也是最好的包装语言,用于更有效地实现 C/C++和 CUDA/cuDNN 算法,因此现有的机器学习和深度学习库在 Python 移动领域中有效地工作。它对机器学习和人工智能的工作也很重要。
数据分析
高亮语言的发展为科学计算的几乎每个方面提供了工具。它对处理金融数据很有用。此外,脸书使用熊猫 Python 库进行数据分析。
- SciPy 使用 NumPy 数组,并提供高效的数值积分和优化例程。
- 建立在 NumPy 之上的 Pandas 提供了几种数据结构和操作来处理数字表和时间序列。
- Matplotlib 是一个 2D 绘图库,只需几行代码就能以直方图、功率谱、直方图和散点图的形式创建可视化数据。
游戏
Python 和 Pygame 是快速制作游戏原型的最佳语言和框架,也是任何想要制作简单游戏的初学者的最佳语言和框架。一些军事第一人称射击模拟视频游戏使用这种语言作为附加组件和功能。
- Frets on Fire 是一款用 Python 编写的免费开源芬兰音乐视频游戏。
- Pygame 是一个免费的开源编程语言库,用于创建游戏等多媒体应用。
遗言
高科技时代给了我们每个人很多在特定领域工作的机会。Python 中的移动应用程序开发是各种产品的宝库,为数百万用户浏览网站提供最佳体验。考虑用所选语言编程的各种优势和特性是很重要的。
详细的复习会告诉你新的东西,让你找到最适合你的领域。后者是影响力规模的结果,它为创建任何软件提供了许多功能。
Python 的发展并没有停滞不前,它继续为我们带来许多发现,并继续为开发人员提供创作和磨练技能的功能。
如何创建 Python 包
原文:https://www.pythoncentral.io/how-to-create-a-python-package/
使用包是 Python 编程的基本部分。如果包不存在,程序员将需要花费大量时间重写以前编写过的代码。想象一下这样一个场景,每当你想使用一个解析器时,你都必须编写一个解析器——这将浪费大量的时间和精力,程序员也不会做任何其他事情。
当您拥有大量 Python 类(或“模块”)时,您会希望将它们组织成包。当任何项目中的模块数量(简单地说,一个模块可能只是包含一些类的文件)显著增长时,将它们组织成包是更明智的——也就是说,将功能相似的模块/类放在同一个目录中。这篇文章将向你展示如何创建一个 Python 包。
Python 中的包是什么?
在你理解什么是 Python 包之前,你必须对什么是脚本和模块有一个概念。脚本由您在 shell 中运行以完成特定任务的代码组成。程序员可以在自己选择的文本编辑器中编写脚本,并将其保存在。py 扩展名。运行脚本就像在终端中使用 Python 命令一样简单。
相比之下,模块是一个 Python 程序,程序员可以将其导入到其他程序中,或者直接在 Python shell 的交互模式下导入。术语“模块”在 Python 中没有严格的定义;它是可重用代码的总称。
Python 包通常包含几个模块。实际上,一个包是一个模块文件夹,它可能包含更多的文件夹,这些文件夹包含更多的文件夹和模块。
从概念上讲,Python 包是一个名称空间,这意味着包中的模块被包的名称所绑定,并且可以被该名称所引用。
由于模块被定义为可重用、可导入的代码,每个包都可以被定义为一个模块。但是,不能将每个模块都定义为一个包。
包文件夹通常包含一个“init”。py”文件,它向 Python 表明该目录是一个包。该文件可能为空,或者包含需要在包初始化时执行的代码。
如果你有一些 Python 编程的经验,你可能对术语“库”很熟悉在 Python 语言中,“库”并不像包或模块那样明确定义。然而,当一个包被发布时,它可以被称为一个库。
创建 Python 包的步骤
使用 Python 包非常简单。你需要做的就是:
- 创建一个目录,并以您的包名命名。
- 把你的班级放进去。
- 创建一个 init。目录中的 py 文件
仅此而已!为了创建一个 Python 包,这是非常容易的。__init__.py文件是必需的,因为有了这个文件,Python 将知道这个目录是一个 Python 包目录,而不是一个普通的目录(或文件夹——无论你想叫它什么)。无论如何,就是在这个文件中,我们将从我们全新的包中为 import 类编写一些导入语句。
如何创建 Python 包的示例
在本教程中,我们将创建一个Animals包——它只包含两个名为Mammals和Birds的模块文件,分别包含Mammals和Birds类。
步骤 1:创建包目录
因此,首先我们创建一个名为Animals的目录。
步骤 2:添加类
现在,我们为我们的包创建两个类。首先,在Animals目录中创建一个名为Mammals.py的文件,并将以下代码放入其中:
[python]
class Mammals:
def __init__(self):
''' Constructor for this class. '''
# Create some member animals
self.members = ['Tiger', 'Elephant', 'Wild Cat']
def printMembers(self):
print('Printing members of the Mammals class')
for member in self.members:
print('\t%s ' % member)
[/python]
代码几乎是不言自明的!该类有一个名为members的属性——这是我们可能感兴趣的一些哺乳动物的列表。它还有一个名为printMembers的方法,简单地打印这个类的哺乳动物列表!记住,当你创建一个 Python 包时,所有的类都必须能够被导入,并且不会被直接执行。
接下来我们创建另一个名为Birds的类。在Animals目录下创建一个名为Birds.py的文件,并将以下代码放入其中:
[python]
class Birds:
def __init__(self):
''' Constructor for this class. '''
# Create some member animals
self.members = ['Sparrow', 'Robin', 'Duck']
def printMembers(self):
print('Printing members of the Birds class')
for member in self.members:
print('\t%s ' % member)
[/python]
这段代码类似于我们为Mammals类提供的代码。
第三步:添加 init。py 文件
最后,我们在Animals目录中创建一个名为__init__.py的文件,并将以下代码放入其中:
[python]
from Mammals import Mammals
from Birds import Birds
[/python]
就是这样!这就是创建 Python 包的全部内容。为了测试,我们在Animals目录所在的同一个目录中创建一个名为test.py的简单文件。我们将下面的代码放在test.py文件中:
[python]
# Import classes from your brand new package
from Animals import Mammals
from Animals import Birds
# Create an object of Mammals class & call a method of it
myMammal = Mammals()
myMammal.printMembers()
# Create an object of Birds class & call a method of it
myBird = Birds()
myBird.printMembers()
[/python]
如何使用 Python 包
如果你以前没有使用过 Python 包,我们已经涵盖了你需要知道的所有东西,以理解在你的脚本中使用 Python 包的过程:
导入 Python 包
您可以使用 import 关键字将包导入到您的 Python 程序中。假设您没有安装任何包,Python 在标准安装中包含了大量的包。预安装软件包的集合被称为 Python 标准库。
标准库装载了各种用例的工具,包括文本处理和数学。您可以通过运行语句:来导入一个用于计算的库
import math
你可以把 import 语句想象成 Python 查找模块的搜索触发器。搜索器是严格组织的,Python 从在缓存中查找指定的模块开始。接下来,Python 在标准库中查找模块,最后,它搜索路径列表。
将 sys 模块(标准库中的另一个模块)导入程序后,可以访问路径列表。
import sys
sys.path
前面提到的代码中的 sys.path 行返回 Python 试图在其中找到一个包的所有目录。有时,当程序员下载一个包并试图导入它时,他们会遇到导入错误。这里有一个例子:
>>> import gensim
Traceback (most recent call last)
File "<stdin>", line 1, in <module>
ImportError: No module named genism
如果发生这种情况,您必须检查您导入的包是否位于 Python 的搜索路径之一。如果包不在这些路径中,您将需要扩展搜索路径列表以包含包的位置:
>>> sys.path.append('/home/monty/gensim-package')
运行上面那行代码将为解释器提供一个额外的位置来查找您导入的包。
名称空间和别名的相关性
例如,当您将数学模块导入 Python 时,您实际上是在初始化数学名称空间。换句话说,您可以使用点符号引用 math 模块中的函数和类。这里有一个例子:
>>> import math
>>> math.factorial(3)
6
如果程序员只对模块的特定函数感兴趣,比如说数学模块的阶乘函数,他们可以使用 import 语句只导入相关的函数,就像这样:
>>> from math import factorial
也可以从同一个包中导入多个资源,用逗号分隔:
>>> from math import factorial, log
需要注意的是,每当你导入一个包时,总会有一些变量冲突的小风险。例如,如果脚本中的一个变量名为 log,并且您从 math 包中导入了 log 函数,Python 将使用您的变量覆盖该函数。这样会产生 bug。
如前所述,通过导入整个包可以避免这些错误。如果您想节省每次使用模块时键入包名的时间,您可以通过以下方式导入包:
>>> import math as m
>>> m.factorial(3)
这被称为混叠。一些常用的包有众所周知的别名。例如,NumPy 库通常作为“np”导入。
从一个包中导入所有的资源到你的名字空间也可以避免变量冲突的错误,就像这样:
>>> from math import *
但是需要注意的是,上述方法带来了严重的风险,因为你不知道包中使用的所有名字,因此你的变量被覆盖的可能性很高。
如何在 Python 中创建线程
原文:https://www.pythoncentral.io/how-to-create-a-thread-in-python/
Python 线程简介
什么是线程?简单地说,试着把它们想象成在一个进程中同时运行几个程序。当您在程序中创建一个或多个线程时,它们会同时执行,彼此独立,最重要的是,它们可以毫无困难地共享信息。
这些特性使线程在网络编程等情况下变得轻量和方便,当您试图 ping(发送网络数据包或请求)数百个工作站,而您不想一个接一个地 ping 它们时!由于网络回复可能会延迟很长时间,如果不同时 ping 许多工作站,程序将会非常慢。本文将向您展示如何在 Python 中创建线程,以及如何在一般情况下使用它们。
在 Python 中创建线程
Python 中的线程很容易。你需要做的第一件事是使用下面的代码import Thread:
from threading import Thread
要在 Python 中创建一个线程,你需要让你的类像线程一样工作。为此,您应该从Thread类中继承您的类:
class MyThread(Thread):
def __init__(self):
pass
现在,我们的MyThread类是Thread类的子类。然后我们在类中定义一个run方法。当我们调用我们的MyThread类中任何对象的start方法时,这个函数将被执行。
完整类的代码如下所示。我们使用sleep函数让线程“休眠”(防止它在一段随机的时间内执行)。如果我们不这样做,代码会执行得如此之快,以至于我们无法注意到任何有价值的变化。
class MyThread(Thread):
def __init__(self, val):
''' Constructor. '''
线程。__init__(self)
self.val = val
def run(self):
for i in range(1,self . val):
print(' Value % d in thread % s ' %(I,self.getName()))
#在 1 ~ 3 秒之间随机休眠一段时间
seconds stosleep = randint(1,5)
print(' % s sleeping for % d seconds ... '% (self.getName()、secondsToSleep))
time . sleep(secondsToSleep)
为了创建线程,下一步是创建我们的线程支持类的一些对象(在这个例子中是两个)。我们调用每个对象的start方法——这反过来执行每个对象的run方法。
# Run following code when the program starts
if __name__ == '__main__':
# Declare objects of MyThread class
myThreadOb1 = MyThread(4)
myThreadOb1.setName('Thread 1')
mythtreadob 2 = mythtread(4)
mythtreadob 2.set name(' thread 2 ')”
#开始运行线程!
myth readob 1 . start()
myth readob 2 . start()
#等待线程完成...
myth readob 1 . join()
myth readob 2 . join()
打印('主终端...')
就是这样!注意,我们需要调用每个对象的join方法——否则,程序将在线程完成执行之前终止。
该程序的完整版本如下所示:
from threading import Thread
from random import randint
import time
类 MyThread(线程):
def __init__(self,val):
' ' '构造函数‘
线程。__init__(self)
self.val = val
def run(self):
for i in range(1,self . val):
print(' Value % d in thread % s ' %(I,self.getName()))
#在 1 ~ 3 秒之间随机休眠一段时间
seconds stosleep = randint(1,5)
print(' % s sleeping for % d seconds ... '% (self.getName()、secondsToSleep)
time . sleep(secondsToSleep)
#程序启动时运行以下代码
if _ _ name _ _ = = ' _ _ main _ _ ':
#声明 MyThread 类的对象
myth readob 1 = myth read(4)
myth readob 1 . setname(' Thread 1 ')
mythtreadob 2 = mythtread(4)
mythtreadob 2.set name(' thread 2 ')”
#开始运行线程!
myth readob 1 . start()
myth readob 2 . start()
#等待线程完成...
myth readob 1 . join()
myth readob 2 . join()
打印('主终端...')
如何用 python 创建字典
原文:https://www.pythoncentral.io/how-to-create-dictionary-in-python/
内容
今天我们将深入探讨如何用 Python 创建字典。它要求您已经具备 Python 语法的基础知识。去查看我们的python 用法介绍来了解更多关于 Python 的知识。你需要在你的机器上安装 Python。要知道如何在你的系统上安装 python,请查看我们的安装指南。
- 什么是字典数据结构
- 用 Python 创建字典
- Python 字典用法
什么是字典数据结构
Python 字典是一种键值对数据结构。每个键都有一个值。密钥必须是唯一的,以避免冲突。python 应用程序中大量使用字典。如果你有学生和班级,每个学生有一个班级。Python dictionary 将帮助您将学生姓名定义为键,将班级定义为值。会帮助你从他的名字值了解学生课程。
字典是 Python 中的哈希表实现。哈希表使用哈希函数将键映射到它的值。每个槽可以存储一个条目。和 python 字典做的一样。下图解释了它的工作原理。
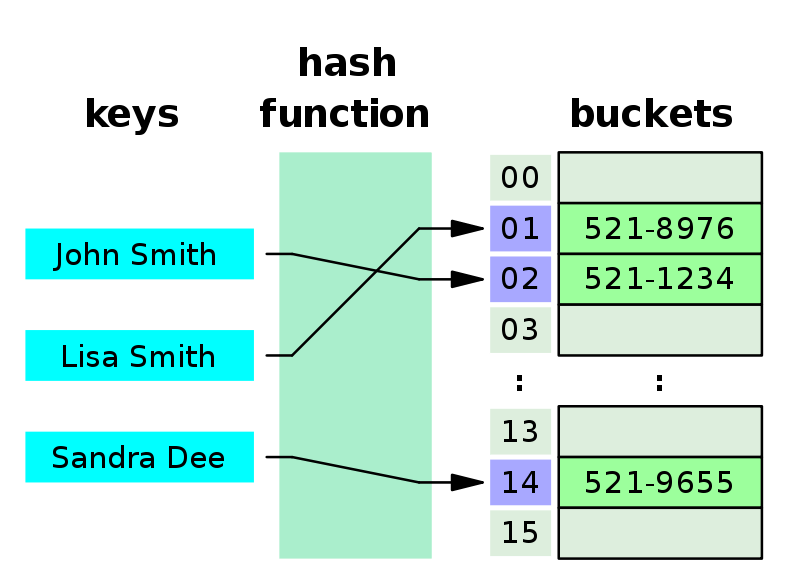
如果我们知道这个值是关键的,我们就使用 Python 字典来检索它。和我们在上面学生的例子中做的一样。在幕后,python 所做的是用一个键保留一个内存位置,并指向它的值。它有助于内存优化和效率。现在让我们创建一个 python 字典。
用 Python 创建字典
要定义一个 Python 字典,你应该在花括号中定义它,例如:{}。要将值分配给它的键,应该添加列。
data = {"key": "value"}
继续以学生的课程为例,让我们看看如何实现这一点:
class_data = {
"sam": "Intro to Python",
"Jack": "Intro to data science",
"Emma": "Machine Learning course",
"Wattson": "Web development."
}
班级词典有学生的名字。每个名字都有他注册的课程。这是一个非常基本和简单的创建 python 字典的例子。我们需要知道如何使用 python 字典来插入、删除和检索值。
我们提到过这是一个键值存储。这意味着要获得项目值,您需要知道它的关键。要从类别字典中获取 Jack 课程,您需要:
print(class_data['Jack'])
# output
"Intro to data science"
如果钥匙不在字典里怎么办。在这种情况下,Python 将引发一个关键错误异常。
class_data['holo']
# ourtput
KeyError Traceback (most recent call last)
<ipython-input-4-73376fec291d> in <module>()
----> 1 class_data['holo']
KeyError: 'holo'
您需要使用 try/catch 块来处理这个异常。还有另一种更安全的方法来访问字典数据,如果不存在异常,也不会引发异常。
print(class_data.get('hoho', None))
# output
None
get()方法提供了一种简单的方法来检查字典中是否存在这个键。它将返回它,否则它将提供一个默认值。这种方法允许您在缺少键的情况下始终提供默认值。现在让我们将数据插入字典。
# add new key and value to dictionary.
class_data['new_student'] = 'Ronaldo'
print(class_data)
# output
{
'Emma': 'Machine Learning course',
'Jack': 'Intro to data science',
'Wattson': 'Web development.',
'sam': 'Intro to Python',
'new_student' : 'Ronaldo'
}
您可以通过如上所述更新任意键的值来将其设置为 none。您可以使用 pop()函数从字典中删除项目键和值。
class_data.pop('new_student')
# output
'Ronaldo'
print(class_data)
# output
{
'Emma': 'Machine Learning course',
'Jack': 'Intro to data science',
'Wattson': 'Web development.',
'sam': 'Intro to Python'
}
Python 提供了一个删除所有字典条目的函数。使用 clear()函数,你可以对所有的字典项。
class_data.clear()
print(class_data)
# output
{}
在下一节中,我们将更多地讨论 Python 字典的用法和一些技巧。
Python 字典用法
字典键和值可以是任何值类型。您可以创建一个键,并使其值成为一个字典或数组。现实世界示例中的一些字典用法是嵌套字典。检查下面的例子。
school = {
"students":[
{
"id": "1",
"name": "Sam",
"classes" : ["Web development"]
},
{
"id": "2",
"name": "Clark",
"classes" : ["Machine learning", "Data science"]
},
{
"id": "3",
"name": "Watson",
"classes" : ["Game development"]
}
],
"teachers":[
{
"id": "1",
"name": "Emma",
"Courses" : ["Data science", "Machine learning"]
},
{
"id": "2",
"name": "Jack",
"Courses" : ["Game development", "Web development"]
}
],
"staff": [
{
"id": "1",
"name": "Jo",
"Profission" : "Office admin"
},
{
"id": "2",
"name": "Raj",
"Profission" : "Cleaning"
},
{
"id": "3",
"name": "Ronald",
"Profission" : "sales"
}
]
}
我们来解释一下上面的代码。我们有一所学校,有老师、学生和教职员工。每个人都有名字和身份证。学生将有一个他注册的班级。学生可以注册多门课程。老师有他教给学生的课程。学校教职员工有名字和职业。这是一个单一的职业。
这是一个在 Python 字典中排列学校数据的简单设计。如果你是系统管理员,你需要得到每个学生的名字和班级。使用 for 循环 Python 语句。您可以这样做:
# get all students
students = school['students']
for student in students:
print("Studnet name: {0} is enrolled in classes: {1}".format(student['name'], student['classes']))
# output
Studnet name: Sam is enrolled in classes: ['Web development']
Studnet name: Clark is enrolled in classes: ['Machine learning', 'Data Science']
Studnet name: Watson is enrolled in classes: ['Game development']
这将得到所有学生的数据。如果你想更新学生的数据来添加一个新的学生,你需要做的就是添加一个新的键和它的值。
students = school['students']
# add student dictionary to students list.
students.append({
"id": "4",
"name": "Holmes",
"classes" : ["Web development"]
})
print(students)
# output
[
{
"id": "1",
"name": "Sam",
"classes" : ["Web development"]
},
{
"id": "2",
"name": "Clark",
"classes" : ["Machine learning", "Data science"]
},
{
"id": "3",
"name": "Watson",
"classes" : ["Game development"]
},
{
"id": "4",
"name": "Holmes",
"classes" : ["Web development"]
}
]
你在学生名单上增加了一本新的学生词典。你也可以对老师和员工做同样的逻辑。
结论
Python 字典是一个非常强大的数据结构。它有很多用法。添加任何键和值类型的灵活性使其在不同的应用程序中易于使用。您可以使用 Python 字典的函数轻松地更新和删除其中的数据。在 python 中使用字典是你需要掌握的一项非常重要的技能。它会帮你解决很多问题。如果你有兴趣了解更多关于它的实现,你可以查看官方文档。
如何使用 Python 显示日期和时间
原文:https://www.pythoncentral.io/how-to-display-the-date-and-time-using-python/
如果您需要在任何 Python 项目中打印和显示日期和时间,那么执行这些操作的代码非常简单。要开始,您需要导入时间模块。从那以后,只有几行简短的代码妨碍了显示准确的当前日期和时间。看看下面的代码片段:
导入时间
24 小时格式#
print(time . strftime(" % H:% M:% S "))
12 小时格式#
print(time . strftime(" % I:% M:% S "))
dd/mm/yyyy 格式
打印(time.strftime("%d/%m/%Y "))
mm/dd/yyyy 格式
打印(time.strftime("%m/%d/%Y "))
dd/mm/yyyy hh:mm:ss 格式
print(time . strftime(' % d/% M/% Y % H:% M:% S '))
mm/dd/yyyy hh:mm:ss 格式
print(time . strftime(' % M/% d/% Y % H:% M:% S '))
在上面的例子中,你会看到 4 种不同的显示日期和时间的格式选项。对于时间,有 24 小时格式,这是指包括所有 24 小时的时钟,而不是一天重复两次的 12 小时时钟,也有 12 小时格式的选项。有一个示例演示了如何以 dd/mm/yyyy 格式显示日期,还有一个示例演示了如何以 mm/dd/yyyy 格式显示日期,这是美国最流行的日期格式。
最后,有一个例子以日/月/年,小时:分钟:秒的格式组合了日期和时间(还有一个例子是一天之前的月份,适用于美国的程序员)。您可以随意将这些添加到您想要轻松快速显示日期和时间的任何 Python 项目中。
如何在 Python 中生成随机数
原文:https://www.pythoncentral.io/how-to-generate-a-random-number-in-python/
程序员创建程序的目的是确保程序经得起任何随机输入的考验。程序应该正确地处理输入,并精确地计算任意数据的输出。程序员必须对程序进行广泛的信息测试,并相应地修改代码以实现这一目标。
但是你如何从无限的可能性中选择一个随机数呢?即使你已经得到了一组数字,你如何把它变成一个高效的程序?有没有内置的函数来实现这个?嗯,答案是肯定的!
Python 提供了大量的模块和函数来使用随机数据。本文将指导您在代码中包含这些函数,并为您提供代码片段。我们将我们的范围限制在{1,10}内,但是请记住,您可以将这些方法和编程语法用于您喜欢的任何范围。我们开始吧!
使用的 Python 库:Anaconda 发行版(Jupyter 笔记本)
可用于生成随机数的函数列表:
- random . randint()功能
- random . rand range()功能
- 功能
- 功能
- numpy . random . randint()功能
- numpy . random . uniform()功能
- numpy . random . choice()功能
- 功能
使用'T5【random . randint()'****函数 :
random . randint()函数是 随机 模块的一部分。randint()函数返回一个整数值(当然是 random!)在函数中输入的起点和终点之间。该函数包括输入的两个端点。
我们可以这样写代码:
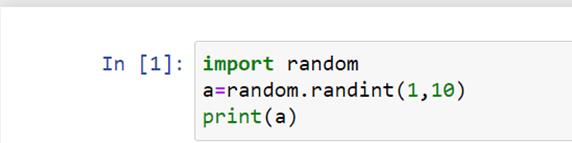
该程序的输出如下:
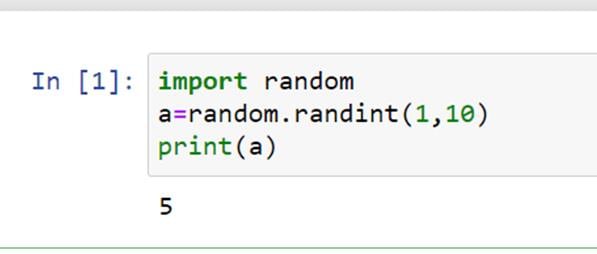
该函数将数字 5 作为随机输出返回。请注意,这里我们只生成了一个随机数。您也可以创建一个随机数列表。生成随机数列表的代码如下所示:
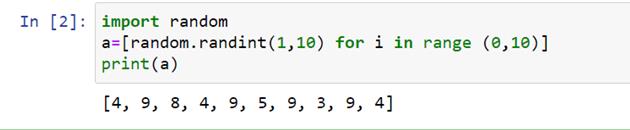
输出也显示在上面给出的代码片段中。For 循环可以用来生成一个列表。
使用'T5【random . rand range()'****函数 :
该函数类似于函数。该功能包括 步长参数 ,不包括在该功能中输入的上限。step 参数是可选的,用于排除给定范围内的特定值。该参数的默认值为 1。
使用函数的语法如下:
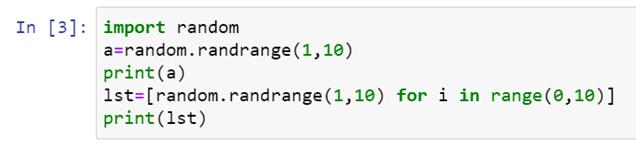
这里给出的代码打印单个随机值以及随机值列表。
输出如下所示:

正如我们在这里看到的,第一行给出了一个位数的输出,而下面一行给出了一个值列表。
使用''函数 :
我们使用 sample() 函数创建一个具有我们选择的长度的列表。此外,它返回一个没有重复值的列表。
我们可以这样写代码:

注意,该函数的语法使用range()参数来获得所需的起始值和结束值。此外,要生成一位数的输出,我们必须在range()参数旁边输入‘1’作为列表长度。
我们得到的输出如下:

使用、、、、、功能:
我们用函数来寻找给定范围内的浮点数。该函数包括给定范围的两个端点。
**此代码的语法与前面提到的函数的语法相同。

这个代码的输出是一个浮点数。
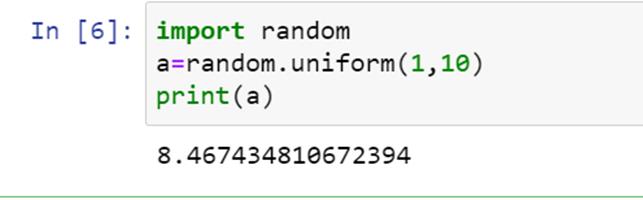
为了获得整数形式的输出,我们可以专门对 【统一()】 函数进行类型化。
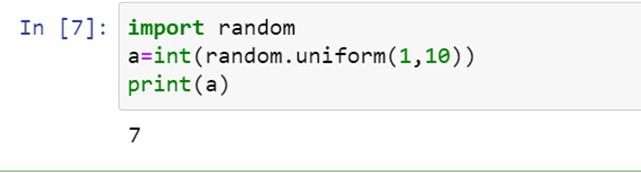
该函数输出整数。
使用‘numpy . random . randint()‘函数:
numpy模块还有子模块。 当我们想要生成大量的数字时,可以使用 numpy 模块。该模块将输出存储在所需大小的 数组 中。
randint()方法的使用与 random 模块类似。
该模块的语法如下:

在这段代码的输出中,我们将获得一个随机数数组。
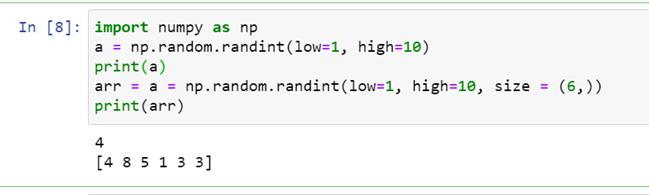
如你所见,生成了一个大小为 6 的数组。
使用'numpy . random . uniform()'函数:
numpy模块还具有uniform()函数来生成一个数组的浮点数。
**
输出:
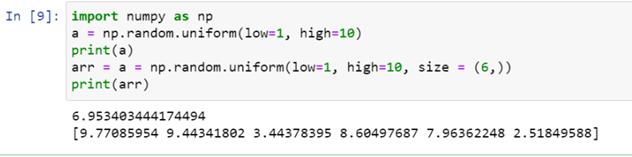
使用'numpy . random . choice()'功能:
当我们已经有一个数字列表,并且我们必须从那个特定的列表中选择一个随机数时,这个函数用于获得随机数。这个函数还将输出存储在一个数组中。
我们可以这样写这个函数的输入:
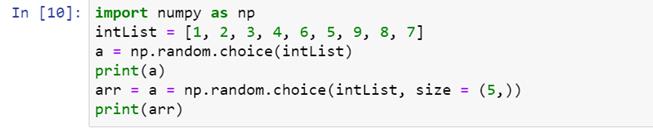
注意用户输入列表中数字的任意顺序。
让我们看看给定代码的输出是什么:
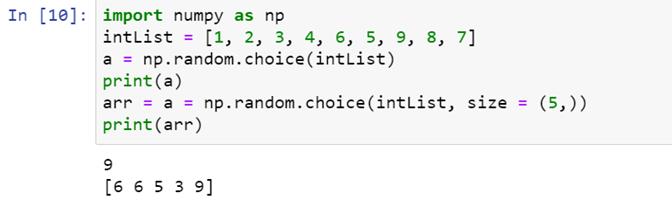
使用'secrets . rand below()'功能:
秘密 模块是生成随机数最安全的方法,在密码学中有很好的用途。这个模块的一个应用是创建强大、安全的随机密码、令牌等。
rand below()函数包含了函数中输入的两个限值。
该模块的语法如下:

输出如下所示:
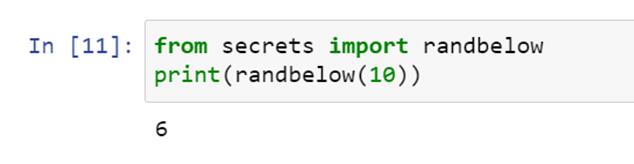
结论
在编程中,随机测试用例的使用非常广泛。几种编程语言的内置功能使我们——程序员更容易执行数百万个任意测试用例,并开发出高效而准确的程序。正如我们在上面看到的,Python 还提供了一个应用于密码学的模块。如果我们想要创建用户安全的平台,这个模块是有益的。我们希望这篇文章能帮助你学习 随机数生成的基础知识。****
如何在 Python 中从字符串中获取子字符串——切片字符串
原文:https://www.pythoncentral.io/how-to-get-a-substring-from-a-string-in-python-slicing-strings/
那么如何在 Python 中获得子字符串呢?Python 有一个非常方便的特性,叫做“切片”,可以用来从字符串中获取子字符串。
但是首先,我们必须回顾一些事情来理解它是如何工作的。
切片 Python 对象
在 Python 中,字符串是字符的数组,只是它们的行为与数组稍有不同。但是,在大多数情况下,您可以将它们视为数组。
利用这些信息,我们可以在字符串上使用 Python 的数组功能,称为“切片”!切片是一种通用的功能,可以应用于 Python 中的任何数组类型的对象。
这是一个具体的例子,用一个简单的数组开始。
>>> a = [1,2,3,4,5]
>>> # This is slicing!
>>> a[:3]
[1, 2, 3]
正如你所看到的,这给了我们一个直到第三个元素的数组子集。切片接受两个“参数”,指定您希望在数组中的起始和结束位置。
语法:array[start:end]
因此,在上面的例子中,如果我们只需要元素 2 和 3,我们将执行以下操作:
>>> a[1:3]
[2, 3]
好吧,好吧。这与子弦有什么关系?问得好!
获取子字符串:切片 Python 字符串!
上面,我提到我们可以像对待数组一样对待字符串。这意味着我们可以将相同的逻辑应用到我们的字符串中!
这里有一个例子:
>>> s = 'Hello, everybody!'
>>> s[0]
'H'
>>> s[:3]
'Hel'
>>> s[2:5]
'llo'
哇!我们访问这个字符就像它是数组中的一个元素一样!厉害!
所以我们在这里看到的是一个“子串”。要从一个字符串中得到一个子字符串,只需输入字符串的起始位置和结束位置。
当然,我们也可以省略开始位置或结束位置,这将告诉 Python 我们希望分别从开始处开始我们的子字符串,或者在结尾结束它。
这是另一个使用我们上面的字符串的例子。
>>> # Start from the beginning and go to character 5
>>> s[:5]
'Hello'
>>> # Start from character 5 and go to the end
>>> s[5:]
', everybody!'
>>> s[:]
'Hello, everybody!'
好吧,这很好,但是我在最后一行做了什么?我没有指定开始或结束,那么它怎么还能工作呢?
我们所做的是告诉 Python 从开始元素一直到结束元素。完全有效。它还创建字符串或数组的新副本。如果你需要原件的副本来修改,你可以用这个!
Python 中的反向子串切片
另一个例子,使用扩展切片,可以逆序得到子串。这只是一个“好玩”的例子,但是如果你需要在 Python 中反转一个字符串,或者得到一个字符串的反转子字符串,这肯定会有帮助。
开始:
【python】
s[::-1]
'!ydobyreve,olleH '
s【4::-1】
【olleH '
厉害!
解释扩展切片超出了本文的范围,所以我不会说太多。唯一不同的是结尾多了一个冒号和后面的数字。额外的冒号告诉 Python 这是一个扩展片,而“-1”是遍历字符串时使用的索引。如果我们在“-1”的位置放一个“1”,我们会得到和以前一样的结果。
你有它!Python 中获取子串真的很容易,希望我用 Python-fu 多教育了你一些。
再见了!
如何在 Python 中获得对象的属性
原文:https://www.pythoncentral.io/how-to-get-an-attribute-from-an-object-in-python/
一旦我们知道如何在 Python 中检查一个对象是否有属性,下一步就是获取那个属性。在 Python 中,除了普通的点样式属性访问之外,还有一个内置函数getattr,它对于访问属性也非常有用。
Python 的 Getattr
内置函数getattr(object, name[, default])返回object的一个name d 属性的值,其中name必须是一个字符串。如果object有一个带name的属性,那么返回该属性的值。另一方面,如果object不具有带name的属性,则返回default的值,或者如果不提供default则提高AttributeError的值。
>>> t = ('This', 'is', 'a', 'tuple')
>>> t.index('is')
1
>>> getattr(t, 'index')
<built-in method index of tuple object at 0x10c15e680>
>>> getattr(t, 'index')('is')
1
在前面的代码片段中,我们创建了一个 tuple t并以普通方式调用了它的方法index,然后以getattr方式调用。注意getattr(t, 'index')返回一个绑定到对象t的函数。
如果一个object没有带name的属性会怎么样?回想一下getattr的定义,它声明要么返回default的值,要么引发AttributeError。
>>> getattr(t, 'len')
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'tuple' object has no attribute 'len'
>>> getattr(t, 'len', t.count)
<built-in method count of tuple object at 0x10c15e680>
除了像元组、列表和类实例这样的“普通”对象,getattr也接受模块作为参数。因为模块也是 Python 中的对象,所以模块的属性可以像对象中的任何属性一样被检索。
>>> import uuid
>>> getattr(uuid, 'UUID')
<class 'uuid.UUID'>
>>> type(getattr(uuid, 'UUID'))
<type 'type'>
>>> isinstance(getattr(uuid, 'UUID'), type)
True
>>> callable(getattr(uuid, 'UUID'))
True
>>> getattr(uuid, 'UUID')('12345678123456781234567812345678')
UUID('12345678-1234-5678-1234-567812345678')
getattr 和 Dispatcher 模式
与访问属性的常用方法相比,getattr更不稳定,因为它接受一个标识属性名称的字符串,而不是在源代码中硬编码名称。所以用getattr做调度就很自然了。例如,如果您想编写一个程序,根据文件扩展名以不同方式转换不同类型的文件,您可以将转换逻辑编写为类中的独立函数,并根据当前文件扩展名调用它们。
>>> from collections import namedtuple
>>> import os
>>> Transformer = namedtuple('Transformer', ['transform_png', 'transform_txt'])
>>> transformer = Transformer('transform .png files', 'transform .txt files')
>>> # Suppose the current directory has two files 'tmp.png' and 'tmp.txt'
>>> current_directory = os.path.dirname(os.path.abspath(__file__))
>>> for dirname, dirnames, filenames in os.walk(current_directory):
... for filename in filenames:
... path = os.path.join(dirname, filename)
... filename_prefix, ext = filename.rsplit('.', 1)
... if ext == 'png' or ext == 'txt':
... print(getattr(transformer, 'transform_{0}'.format(ext)))
...
transform .png files
transform .txt files
使用 getattr 的提示和建议
- 尽管
getattr在处理自省和元编程时非常方便,但它确实使代码更难阅读。所以,当你跃跃欲试要用getattr的时候,先静下心来想想是否真的有必要。通常情况下,您的用例可能不需要getattr。 - 当你确实想使用
getattr时,写代码要比平时慢,并确保你有单元测试来支持它,因为几乎所有涉及getatrr的错误都是运行时错误,很难修复。通过一次正确地编写代码来节省时间比以后再调试要有效得多。
如何在 Python 中获取和格式化当前时间
原文:https://www.pythoncentral.io/how-to-get-and-format-the-current-time-in-python/
时间回顾
我们知道时间由几个部分表示,其中一些是数字,如秒、分和小时,而其他的是字符串,如时区、上午和下午。Python 在处理时间对象和字符串时提供了大量的实用工具。因此,在 Python 中获取和格式化当前时间相对容易。
用 Python 获取当前时间
有两个函数可用于检索系统的当前时间。time.gmtime([secs])将自纪元以来以秒表示的时间(参见本文以了解纪元概述)转换为 UTC 中的struct_time。如果没有提供参数secs或None,则使用time.time返回的当前时间。
类似地,time.localtime([secs])将从纪元开始以秒表示的时间转换为本地时区的struct_time。如果没有提供参数secs或None,则使用time.time返回的当前时间。
>>> import time
>>> time.gmtime()
time.struct_time(tm_year=2013, tm_mon=2, tm_mday=21, tm_hour=5, tm_min=27,
tm_sec=32, tm_wday=3, tm_yday=52, tm_isdst=0)
>>> time.localtime()
time.struct_time(tm_year=2013, tm_mon=2, tm_mday=20, tm_hour=23, tm_min=27,
tm_sec=36, tm_wday=2, tm_yday=51, tm_isdst=0)
那么,什么是time.struct_time对象呢?一个time.struct_time对象封装了一个特定时间点的所有信息。它充当一个包装器,将某个时间点的所有相关信息包装在一起,这样就可以将它们作为一个单元进行访问。
用 Python 格式化当前时间
一旦我们有了一个time.struct_time对象,我们可以把它格式化成一个字符串,这样它就可以被另一个程序进一步处理。我们可以通过使用当前时间对象作为参数t来调用time.strftime(format[, t])来实现。如果没有提供 t 参数或None,则使用time.localtime返回的time_struct对象。
这里有一个例子:
>>> current_time = time.localtime()
>>> time.strftime('%Y-%m-%d %A', current_time)
'2013-02-20 Wednesday'
>>> time.strftime('%Y Week %U Day %w', current_time)
'2013 Week 07 Day 3'
>>> time.strftime('%a, %d %b %Y %H:%M:%S GMT', current_time)
'Wed, 20 Feb 2013 23:52:14 GMT'
format参数接受一系列指令,这些指令在 Python 关于时间的文档中有详细说明。请注意,前面代码中的最后一个例子演示了一种将time_struct对象转换成可以在 HTTP 头中使用的字符串表示的方法。
从字符串中获取 Python 中的时间对象
到目前为止,我们已经介绍了如何获取当前的time_struct对象并将其转换成字符串对象。反过来怎么样?幸运的是,Python 提供了一个函数time.strptime,将一个string对象转换成一个time_struct对象。
>>> time_str = 'Wed, 20 Feb 2013 23:52:14 GMT'
>>> time.strptime(time_str, '%a, %d %b %Y %H:%M:%S GMT')
time.struct_time(tm_year=2013, tm_mon=2, tm_mday=20, tm_hour=23,
tm_min=52, tm_sec=14, tm_wday=2, tm_yday=51, tm_isdst=-1)
当然,在strings和time_struct对象之间来回转换很容易。
>>> time.strftime('%Y-%m-%dT%H:%M:%S', current_time)
# ISO 8601
'2013-02-20T23:52:14'
>>> iso8601 = '2013-02-20T23:52:14'
>>> time.strptime(iso8601, '%Y-%m-%dT%H:%M:%S')
time.struct_time(tm_year=2013, tm_mon=2, tm_mday=20, tm_hour=23,
tm_min=52, tm_sec=14, tm_wday=2, tm_yday=51, tm_isdst=-1)
使用 Python 的时间模块的技巧和建议
- 虽然 Python 的
time_struct对象非常有用,但是它们在 Python 的解释器之外是不可用的。很多时候,您希望将 Python 中的时间对象传递给另一种语言。例如,基于 Python 的服务器端 JSON 响应包括以 ISO 8601 格式表示的time_struct对象,可以由客户端 Javascript 应用程序处理,以一种很好的方式向最终用户呈现时间对象。 - 在
time_struct和string对象之间转换的两个函数很容易记住。time.strftime可以记为“从时间格式化的字符串”,而time.strptime可以记为“从字符串表示的时间”。
专业编程如何入门?
原文:https://www.pythoncentral.io/how-to-get-started-in-professional-programming/

当我们想要开始专业编程时,我们首先必须清楚我们想要学习什么,因为有许多编程语言可供选择。在本帖中,我们将讨论在开始专业编程之前你必须考虑的一些方面。
专业编程中需要考虑的方面
重要的是一开始就要明确自己要发展什么。来自 essaywritercheap.org 的网络开发团队建议记住你将能够以不同的方式编程。但是,您应该从特定的技术开始。下面,我们和大家分享一下专业编程中你必须要学习的几个方面。
编程基础:如何声明变量,赋值,使用循环执行重复任务,利用条件,以及更一般的概念。
伪代码和算法:这些练习可以让你发展你的编程逻辑。这个阶段对接下来的阶段是决定性的,因为一切的基础是练习和完全理解你在做什么。
桌面程序(在控制台中):您可以从在控制台中创建程序开始,无需用户界面。然后你可以学习更多桌面级别的语言:Java,C#,Visual Basic,Python。
数据结构:它不是必不可少的,但了解计算机的内存是如何工作的很重要。练习数组和矩阵的运算,学习面向对象的范例。
桌面程序(带图形界面):理解更高级的概念,比如事件和线程,用窗口和按钮开发你的程序是很有趣的。
网页:重要的是,你接近 HTML、CSS 和 JavaScript。如今,JavaScript 有许多框架。
数据库:理解与数据库相关的概念很重要,因为它们将出现在我们所有的应用程序中。此外,还要学习 SQL 语法和关系数据库引擎,如 MySQL、PostgreSQL、SQLite、SQL Server 和 Oracle。另一方面,了解非关系数据库也很重要,例如,MongoDB 或 Firebase 数据库。
web 应用:你可以学习如何使用 PHP,以及如何将 Web 应用与 MySQL 数据库连接起来。这是最常见的选择之一。
学习专业编程
当我们决定独立学习专业编程时,会有许多危险,例如,在我们推进和开发项目时,忽略了未来可能需要的理论、基础知识和基本工具等重要方面。
学习编程的基础知识
首先,知道如何选择我们要学习的编程语言是至关重要的。我们的推荐是从 Python 开始,因为它简单如英语,易于使用。此外,它还广泛应用于 Web 开发和大数据等不同专业。
然而,你可以去学习其他语言,这取决于你将来想要开发的项目类型。如果你想开发一个移动应用程序,最好坚持使用 Java 或 Kotlin 的 Android 和 Swift 的 iOS,如果你决定专注于 web 开发,JavaScript 是最好的选择。如果是针对数据科学方面的职业,Python & R 是你最感兴趣的语言。
学习专业编程有两种方法。一方面,通过编程学校,这是最好的选择,因为现场会议和个性化的关注可以解决你在这个最困难的阶段的所有疑问,在这些地方你也可以找到专业的帮助,找到你作为程序员的第一份工作。
另一方面,视频教程更多地与喜欢以循序渐进的指导方式自学但没有帮助解决疑问的支持的人有关。
每天练习
要成为一名职业程序员,基础一定要加强。建议您创建自己的问题,并用代码解决它们。有必要关注大多数编程语言中常见的主题,如变量、函数、数组、映射和条件循环等。
构建您的第一个项目
构建你的项目是分析和巩固你所学知识的最好方法之一。花时间决定什么类型的项目适合你是很重要的。用 Python 创建一个网页、应用程序或程序将有助于你巩固你所学的知识,也有助于你开发一个作品集,这将是选择过程的关键。
最流行的编程语言
计算机编程语言
Python 是世界上最流行和使用最广泛的语言之一,它和 j JavaScript 一起领先所有排名。
一方面,Python 非常简单,但这并不意味着它是一种非常基础的语言。你可以做非常高级的事情,但是学习很简单,它省略了大括号、分号和其他语言中的各种东西。
你读 Python 的时候就像读基础英语一样,另外它的行动领域,它的工作机会,现在和将来都是非常大的,既然你可以做后端的 web 开发,比如计算机安全,你也可以做数据科学,一切都是大数据或者进入机器学习或者人工智能(AI)。
Java Script 语言
JavaScript 有一个特点,那就是你不需要安装任何东西来使用它,因为只要有一个浏览器,你就可以用它来学习如何编程。如果你右击并点击“inspect”(control+shift+I),一个名为 console 的选项会在你的浏览器中打开,在那里你可以开始写和做你的编程练习。
JavaScript 的语法很简单,并且已经被逐步简化。像句号和逗号这样复杂的元素已经被删除了。现在它几乎是所有浏览器的标准。
此外,JavaScript 还有许多应用领域,它的主要用途是 web,尽管它也广泛应用于移动开发和某些技术领域,如机器学习或虚拟现实。
结构化查询语言
SQL 或结构化查询语言与其他编程语言非常不同,因为它不能单独用于网站或应用程序开发。
在当今世界,数据至关重要,有效的数据分析可以影响业务决策和战略。SQL 是存储和分析这些数据的最流行的方法。
这意味着,如果你想在消费者数据分析领域建立职业生涯,SQL 无疑是最好的编程语言。如果你已经是一名前端工程师,SQL 可以成为一项补充技能。
我们列出了一些指导方针和建议,让你开始专业编程,这样你就可以促进你的职业生涯。
如何为你的最新项目雇佣 Python 专家
原文:https://www.pythoncentral.io/how-to-hire-python-experts-for-your-latest-project/

当谈到需要一个开发者来增强,重新开发或着手从零开始制作一个网站,你不会发现有特别的短缺。然而,你会发现一个巨大的诱惑,那就是选择便宜的,为了得到一笔“好交易”而忽略那些有丰富经验的人。对于 Python 开发来说尤其如此。
用 Python 开发有一种特殊的艺术。在编程语言之外,还有大量的帮助。用更传统的方式开发,你会发现许多爱好者、业余爱好者甚至可能的 DIY 方法,而这个真正有用的博客只是开始的一种方式。但是,Python 不一样。如果你想做好工作,你需要找到最好的交易。这需要找到一个专家…但是怎么做呢?
嗯,这不容易。雇佣一名 Python 开发人员可能是一项棘手的任务,但这是可能的,尤其是如果你确实考虑了所有正确的因素。为了助你一臂之力,我们决定整理一份清单,列出你在招聘过程中应该考虑的因素…
考虑项目规模
首先,你需要考虑项目的规模。如果只是一个较小的项目,你也许可以从一个最小的可行产品开始,让项目向前发展。另一方面,更大规模的产品将要求您扩大项目范围,并雇佣一个 Python 开发团队。
一旦你明确了你需要多少人,你就可以开始招聘了…
确保你间接雇佣
雇佣 Python 开发人员不同于你在企业内部招聘的任何其他角色。这是不一样的。你不能像其他人一样调查该领域的技能,最终如果你直接招聘,那么当涉及到他们的技能时,你就要相信开发人员的话。这可能会导致你与简历上的一些修饰相冲突,让你的项目陷入困境。
雇佣 Python 开发人员的最佳方式通常是通过已经完成招聘和解雇工作的 Python 开发公司或代理机构,最终意味着您将得到一组经验丰富的开发人员为您工作,满足您为任务指定的所有要求。
不要忽视沟通和报告技巧
开发人员,尤其是 Python 开发人员,在报告、沟通和日常任务等软技能方面通常会有回旋余地。因为他们在技术上很有天赋,这几乎就像他们的那部分技能是不需要的。然而,这与事实相去甚远。
他们将需要报告进展情况,你应该能够沟通任何问题,发展和更多的日常工作..有人能做到这一点,这将使整个过程更加天衣无缝。
设置技术任务
在你雇佣任何人之前,你应该为开发人员列出技术任务,以绝对确保你的 Python 开发在合适的人手里。许多 Python 开发公司会在这方面提供帮助,这将允许你组建一个合适的团队,一个拥有所有相关技能的团队。
在你看到他们在一项技术任务中所能做的最终结果之前,不要承诺雇佣某人。
如何在 Python 中实现“枚举”
原文:https://www.pythoncentral.io/how-to-implement-an-enum-in-python/
什么是 enum,我们为什么需要它?
枚举类型(也称为枚举)是一种数据类型,由一组命名值组成,这些命名值称为该类型的元素、成员或枚举器。这些枚举的命名值在计算语言中充当常数。例如,COLOR枚举可以包括命名值,如RED、GREEN和BLUE。请注意,所有命名的值都以大写形式书写,以区别它们是常量,这与变量有很大的不同。
那么,为什么我们需要使用枚举呢?想象一下这样一个场景,您可能希望将网站中用户的性别类型限制为MALE、FEMALE和N/A。当然,字符串列表也能很好地完成这项工作,比如user.gender = 'MALE'或user.gender = 'FEMALE'。然而,使用字符串作为性别属性的值对于程序员错误和恶意攻击来说并不健壮。程序员可以很容易地将“男性”错打成“麦芽酒”,或者将“女性”错打成“电子邮件”,代码仍然会运行,并产生有趣但可怕的结果。攻击者可能会向系统提供精心构建的垃圾字符串值,试图导致系统崩溃或获得根用户访问权限。如果我们使用 enum 将user.gender属性限制在有限的值列表中,上述问题都不会发生。
Python enum 简单易行
在 Python 中,内置函数type接受一个或三个参数。根据 Python 文档,当你传递一个参数给type时,它返回一个对象的类型。当你向type传递三个参数时,比如type(name, bases, dict):
它返回一个新的类型对象。这本质上是一种动态形式的
class语句。第一个参数name字符串是类名。第二个参数basestuple 指定了新类型的基类。第三个参数dict是包含类体定义的名称空间。
使用type,我们可以通过以下方式构建一个enum:
>>> def enum(**named_values):
... return type('Enum', (), named_values)
...
>>> Color = enum(RED='red', GREEN='green', BLUE='blue')
>>> Color.RED
'red'
>>> Color.GREEN
'green'
>>> Gender = enum(MALE='male', FEMALE='female', N_A='n/a')
>>> Gender.N_A
'n/a'
>>> Gender.MALE
'male'
现在Color和Gender是行为类似于enum的类,你可以以如下方式使用它们:
>>> class User(object):
... def __init__(self, gender):
... if gender not in (Gender.MALE, Gender.FEMALE, Gender.N_A):
... raise ValueError('gender not valid')
... self.gender = gender
...
>>> u = User('malicious string')
Traceback (most recent call last):
File "", line 1, in
File "", line 4, in __init__
ValueError: gender not valid
注意传入的无效字符串被User的构造函数拒绝。
Python enum 的奇特方式
尽管前面实现enum的方法很简单,但它确实需要您为每个named value显式指定一个值。例如,在enum(MALE='male', FEMALE='female', N_A='n/a')中,MALE是一个名称,'male'是该名称的值。由于大部分时间我们只通过名称使用enum,我们可以通过以下方式实现自动赋值的enum:
>>> def enum(*args):
... enums = dict(zip(args, range(len(args))))
... return type('Enum', (), enums)
...
>>> Gender = enum('MALE', 'FEMALE', 'N_A')
>>> Gender.N_A
2
>>> Gender.MALE
0
使用zip和range,代码自动为args中的每个name分配一个整数值。
Python 枚举的技巧和建议
enum有助于限制属性值的公开选择,这在现实编程中非常有用。当处理数据库时,在 Python 和数据库管理系统中相同的enum可以防止许多难以发现的错误。- 使用一个
enum来保护你的系统免受恶意输入。在系统接受输入值之前,一定要检查它们。
如何在 Python 中初始化 2D 列表?
原文:https://www.pythoncentral.io/how-to-initialize-a-2d-list-in-python/

列表是一种用于线性存储多个值的数据结构。然而,存在二维数据。需要一个多维数据结构来保存这类数据。
在 Python 中,二维列表是一种重要的数据结构。要有效地使用 Python 2D 列表,学习 Python 1D 列表的工作原理是非常重要的。我们称 Python 2D 列表为嵌套列表和列表列表。
在下面的文章中,我们将学习如何使用 Python 2D 列表。会有更好学习的例子。
可以访问 Codeleaks.io 获取 Python 详细教程及示例。
Python 1D 榜 vs 2D 榜
Python 列表的一维列表如下所示:
List= [ 2,4,8,6 ]
另一方面,Python 2D 列表如下所示:
List= [ [ 2,4,6,8 ],[ 12,14,16,18 ],[ 20,40,60,80 ] ]
如何初始化 Python 2D 列表?
Python 提供了多种在 Python 中初始化 2D 列表的技术。列表理解用于返回一个列表。Python 2D 列表由嵌套列表作为其元素组成。
让我们逐一讨论每种技术。
01 号技术
该技术使用列表理解来创建 Python 2D 列表。这里我们使用嵌套列表理解来初始化一个二维列表。
行数= 3
列= 4
Python_2D_list = [[范围(列)中的 j 为 5]
对于范围内的 I(行)]
打印(Python _ 2D _ 列表)
输出:
[[5, 5, 5, 5], [5, 5, 5, 5], [5, 5, 5, 5]]
02 号技术
行数= 2
列= 3
python _ 2D _ list =[[7]列]行
打印(Python _ 2D _ 列表)
输出:
[[7, 7, 7], [7, 7, 7]]
03 号技术
行数= 6
列= 6
Python_2D=[]
对于范围内的 I(行):
列= []
对于范围内的 j(列):
column.append(3)
Python_2D.append(列)
打印(Python_2D)
输出:
[[3, 3, 3, 3, 3, 3], [3, 3, 3, 3, 3, 3], [3, 3, 3, 3, 3, 3], [3, 3, 3, 3, 3, 3], [3, 3, 3, 3, 3, 3], [3, 3, 3, 3, 3, 3]]
Python 2D 列表的应用
现在我们将列出 Python 2D 列表的应用。
- 游戏板
- 表列数据
- 数学中的矩阵
- 网格
- web 开发中的 DOM 元素
- 科学实验数据
还有很多。
结论
Python 2D 列表有其局限性和优点。Python 2D 列表的使用取决于 Python 程序的要求。我希望这篇文章能帮助你学习 Python 2D 列表的概念。
如何在 Python 中安装熊猫?一个简单的循序渐进的多媒体指南
原文:https://www.pythoncentral.io/how-to-install-pandas-in-python/
Pandas 是 Python 可用的 最流行的开源框架 之一。它是用于数据分析和操作的最快和最易于使用的库之一。
熊猫数据帧是任何图书馆中最有用的数据结构。它在每个数据密集型领域都有用途,包括但不限于科学计算、数据科学和机器学习。
该库不包含在 Python 的常规安装中。要使用它,您必须单独安装 Pandas 框架。
在本教程中,我们已经介绍了在 Windows 和 Linux 机器上安装 Pandas 的最简单的方法。
如何在 Windows 和 Linux 上安装 Python 熊猫?
在你安装 Pandas 之前,你必须记住它只支持 Python、3.8 和 3.9 版本。因此,如果您的计算机上没有安装 Python 或安装了旧版本的 Python,则必须在您的计算机上安装支持 Pandas 的版本。
要轻松安装 Python,请务必遵循我们的 Python 安装指南 。
在 Windows 上安装熊猫
在 Windows 上安装熊猫有两种方式。
方法#1:用 pip 安装
它是一个包安装管理器,使得安装 Python 库和框架变得简单。
只要你安装了较新版本的 Python(>Python 3.4),默认情况下 pip 会和 Python 一起安装在你的电脑上。
然而,如果你使用的是旧版本的 Python,你需要在安装 Pandas 之前在电脑上安装 pip。最简单的方法就是升级到 Python 的最新版本,可在上获得。
步骤#1:启动命令提示符
按键盘上的 Windows 键或单击开始按钮打开开始菜单。键入“cmd”,命令提示符应用程序应该会出现在开始菜单中。
打开命令提示符,这样你就可以安装 Pandas 了。
步骤#2:输入所需的命令
启动命令提示符后,下一步是键入所需的命令来初始化 pip 安装。
在终端上输入命令“pip install pandas”。这将启动 pip 安装程序。所需的文件将被下载,熊猫将准备好在您的计算机上运行。
安装完成后,您将能够在您的 Python 程序中使用 Pandas。
方法 2:用 Anaconda 安装
如果你没有太多使用终端和编程的经验,用 Anaconda 安装 Pandas 是最好的选择。Anaconda 是一个强大的 Python 发行版,除了熊猫之外,它还提供了各种工具。随着您对 Python 了解的越来越多,您会发现 Anaconda 越来越有用。
第一步:下载 Anaconda
要安装 Anaconda,必须先访问 https://www.anaconda.com/products/individual,点击右边的“下载”按钮。
将开始下载适用于您的 Windows 系统上安装的 Python 版本的文件。
第二步:安装 Anaconda
启动您从网站下载的安装程序,然后单击“下一步”按钮。
接下来,要同意许可协议,请按“我同意”按钮。
然后,您必须选择您想要安装 Pandas 的用户帐户。出于教程的考虑,我们选择了推荐的“只有我”选项。
在向导的倒数第二步,您必须选择您想要安装发行版的位置。
最后,您必须选中“高级安装选项”部分中的“将 Anaconda 添加到我的 PATH 环境变量”和“将 Anaconda3 注册为我的默认 Python 3.8”选项。
点击“安装”按钮将开始 Anaconda 的安装过程。几分钟后,当安装完成时,您将看到“安装完成”屏幕。看起来是这样的:
你现在可以在你的电脑上访问所有的熊猫图书馆。这是因为 Anaconda 会在安装过程中自动为您安装所有主要的库。
第三步:使用 Jupyter 笔记本(可选)
如果你要用熊猫,很有可能你正在从事机器学习项目。Jupyter 笔记本是一个漂亮的 IDE,使机器学习项目的工作更加简单。
要在安装 Anaconda 后使用 Jupyter 笔记本,请按 Windows 键并搜索“Anaconda Navigator”将出现一个屏幕,列出几个应用程序。

从列表中,您必须找到并启动 Jupyter 笔记本。您的默认浏览器将打开一个类似下图的本地主机页面。你会发现在屏幕的右边有一个下拉菜单,就像指示的那样。
您必须打开下拉菜单并选择“Python 3”选项。然后,一个新的标签会打开,你可以开始编码。
在 Linux 上安装熊猫
有三种方法可以在 Linux 发行版上安装 pandas。您可以(1)从发行版的存储库中安装它,(2)使用 pip 安装它,或者(3)使用 Anaconda 或 Miniconda 安装它。
从发行版的仓库安装 pandas 是一种不可靠的安装方法,因为仓库通常有一个旧版本的 pandas。用 Anaconda 或 Miniconda 安装 pandas 将需要您进行设置,这会延长这个过程。
使用 pip 安装 Pandas 是最好的方法,因为它安装的是最新版本,不需要经过几个步骤来设置另一个必备工具。
方法#1:用 pip 安装
所有技能水平的 Python 用户都使用两个 Python 包管理器中的一个。一个叫 pip,是官方的 Python 包管理器。另一个包管理器被称为 conda。Conda 可能代表 Anaconda 或 Miniconda,这取决于用户在计算机上安装了什么。
用 pip 安装 Pandas:
步骤#1:安装 pip
在您的 Linux 机器上安装 pip3 就像在您的终端上运行以下命令一样简单:
| sudo 安装 python3-pip |
你必须记住,由于 pip 需要 Python 3 来运行,Python 3 将被安装在你的 Linux 机器上。当您运行该命令时,您应该会看到类似如下的输出:
如你所见,该命令还会安装 python-pip-whl 和 python3-wheel。“Wheel”是一种内置的 Python 包格式。
您需要按下“Y”按钮来启动安装。然后,当该过程完成时,您可以继续下一步。
第二步:安装熊猫
现在你的机器已经安装了 pip,你可以用它来安装 Pandas。你所要做的就是运行下面的命令:
| pip3 安装熊猫 |
当命令运行完毕,Pandas 将被安装到你的机器上。
方法 2:用 Anaconda 安装
如果您的机器上已经安装了 Anaconda,您可以直接跳到第 2 步。
步骤#1:安装 Anaconda
要安装 Anaconda,您必须首先下载所需的安装程序。为此,请访问 https://www.anaconda.com/products/individual 的,并向下滚动一点。你会在页面右侧看到“获取附加安装程序”部分。单击 Linux 图标。
页面会将你向下滚动到“Anaconda 安装程序”部分。找到适合您的 Linux 机器的安装程序,然后右键单击它。接下来,选择“复制链接地址”选项。
现在您已经有了 bash 安装程序的链接。sh 扩展名复制到您的剪贴板上,您必须使用 wget 来下载脚本。
打开您的终端,使用 cd 命令浏览您的主目录。接下来,创建一个名为“tmp”的目录导航到 tmp 文件夹,使用 wget 命令下载其中的安装程序。
这个脚本很大,你需要等待一段时间来完成下载。
下载完脚本后,您必须运行该脚本以在您的机器上安装 Anaconda3。在运行任何命令之前,请确保您在 tmp 目录中。然后,运行以下命令:
| $ bash anaconda 3-5 . 2 . 0-Linux-x86 _ 64 . sh |
许可协议会出现,你必须接受它才能安装 Anaconda。您必须允许 Anaconda 包含在您机器的 PATH 变量中。当 Anaconda 被添加到机器的路径中时,只要在终端中键入$ python,就会调用 Anaconda。
安装 Anaconda 后,PATH 变量不会自动加载到您的终端中。为此,您必须获取。bashrc 文件。请记住,该文件将位于主目录中。
| $来源。巴沙尔 |
如果在终端上运行 python 命令显示出 Anaconda 安装的详细信息,则安装已经成功。然后,您可以使用 exit()命令退出 Python REPL。
第二步:安装熊猫
当您在 Linux 机器上安装了 Anaconda 或 Miniconda 之后,您所要做的就是运行下面的命令来安装 pandas:
| 康达安装熊猫 |
电脑会提示您确认安装。接下来,您应该会看到终端上弹出一条“继续(y/n)”消息。当你按下“y”,熊猫的安装过程将开始。
要验证 Pandas 是否正确安装在您的系统上,请在终端上运行 python3,并在交互式 shell 中输入以下代码:
import pandas as pd
s = pd.Series([1, 6, 8, 10])
s
您应该看到 Pandas 安装的详细信息出现在终端中。
结论
Pandas 是全球 Python 开发者广泛使用的许多漂亮的库之一。要了解其他库并理解如何使用它们,请访问我们的 Python 库教程 页面。
在电脑上安装熊猫有几种方法。这篇文章中列出的方法相当简单,在你的机器上设置 Pandas 应该不会花费你超过五分钟的时间。
如何在 Windows、Mac 和 Linux 上安装 Django
原文:https://www.pythoncentral.io/how-to-install-python-django-windows-mac-linux/
在本文中,我们将学习如何在 Windows、Mac 和 Linux 上安装 Django。由于 Mac 和 Linux 都源自 Unix 平台,所以关于在 Mac 和 Linux 上安装 Django 的说明几乎是相同的,我们将在同一节中介绍它们。然而,Windows 与其他两个操作系统是如此的不同,以至于我们需要用一个章节来介绍如何在 Windows 上安装 Django。
Python 虚拟环境设置
如果你使用的是主流操作系统,如 Windows、Mac OS X 或 Linux,Python 通常已经安装在你的系统上了。然而,如果不是,你可以在官方 Python 网站上下载并安装适合你的操作系统的 Python 版本。假设您的操作系统上安装了 Python 2.7.x,在接下来的章节中,我们将带您完成在 Window、Mac OS X 和 Linux 上创建 Django 开发环境的步骤。
在我们深入创建 Django 开发环境的步骤之前,我们想回顾一下一个叫做virtualenv的有用工具。virtualenv是一个创建隔离 Python 环境的工具。virtualenv不是在一个全局 Python 环境上编写代码,而是允许你创建 Python 环境的孤立“岛”或目录,每个“岛”或目录都是一个独立的 Python 环境,拥有自己的“系统级”包和库。
既然我们可以编写运行在全球 Python 环境之上的代码,为什么我们还需要virtualenv?
好吧,让我们想象一种情况,其中my_library依赖于另一个版本必须是 1.0.0 的包dependent_library。当您将全球 Python 环境从 2.7.3 升级到 2.3.3 时,dependent_library也将升级到 1.2.0。现在my_library不再工作了,因为它调用了dependent_library1 . 0 . 0 中的方法和类。如果你能写my_library对抗一个独立的 1.0.0 dependent_library以及另一个upgraded_my_library对抗 1.2.0 不是很好吗?
或者想象一下,您正在一个共享的托管环境中编程,其中您的用户不能访问根级目录,比如/usr/lib,这意味着您不能将全局 Python 环境修改成您喜欢的版本。如果能在自己的主目录下创建一个 Python 环境岂不是很好?
幸运的是,virtualenv通过创建一个拥有自己的安装目录的环境解决了上述所有问题,该环境不与其他环境共享任何库。
在 Windows 中设置 virtualenv 和 Django
首先,打开浏览器,导航到 virtualenv 。点击下载按钮获取最新 virtualenv 的源代码。
其次,打开一个 Powershell 实例,导航到下载了virtualenv源代码的目录,并将 tar 文件解压到一个目录中。然后您可以切换到该目录,为您当前的 Python 解释器安装virtualenv,该解释器可以从命令行调用。
...> $env:Path = $env:Path + ";C:\Python27"
...> cd virtualenv-x.xx.x
...> python.exe .\setup.py install
Note: without Setuptools installed you will have to use "python -m virtualenv ENV"
running install
running build
......
现在您可以在您的主目录中创建一个virtualenv实例。
...> python.exe -m virtualenv python2-workspace
New python executable in ...
Installing Setuptools...
Installing Pip...
现在我们可以使用activate脚本激活新环境。请注意,Windows 的执行策略在默认情况下是受限制的,这意味着不能执行像activate这样的脚本。因此,我们需要将执行策略更改为 AllSigned ,以便能够激活 virtualenv。
...> Set-ExecutionPolicy AllSigned
执行策略改变
执行策略...
...:Y
...> cd python2-workspace
...>。\脚本\激活
(python-workspace)...>
注意,一旦 virtualenv 被激活,您将看到一个字符串“(python2-workspace)”被添加到命令行的 shell 提示符前。现在您可以在新的虚拟环境中安装 Django 了。
...> pip install django
Downloading/unpacking django
......
在 Mac OS X 和 Linux 中设置 virtualenv 和 Django
在 Mac OS X 和 Linux 上安装 virtualenv 和 Django 类似于 Windows。首先,下载virtualenv源代码,解包并使用全局 Python 解释器安装它。
$ curl -O https://pypi.python.org/packages/source/v/virtualenv/virtualenv-1.10.1.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1294k 100 1294k 0 0 498k 0 0:00:02 0:00:02 --:--:-- 508k
$ tar xvf virtualenv-1.10.1.tar.gz
$ cd virtualenv-1.10.1/
$ sudo python setup.py install
Password:
running install
running bdist_egg
running egg_info
writing virtualenv.egg-info/PKG-INFO
writing top-level names to virtualenv.egg-info/top_level.txt
writing dependency_links to virtualenv.egg-info/dependency_links.txt
writing entry points to virtualenv.egg-info/entry_points.txt
reading manifest file 'virtualenv.egg-info/SOURCES.txt'
...
Installed /Library/Python/2.7/site-packages/virtualenv-1.10.1-py2.7.egg
Processing dependencies for virtualenv==1.10.1
Finished processing dependencies for virtualenv==1.10.1
然后返回到主目录,并在该目录中创建新的 virtualenv。
$ virtualenv python2-workspace
New python executable in python2-workspace/bin/python
Installing Setuptools..............................................................................................................................................................................................................................done.
Installing Pip.....................................................................................................................................................................................................................................................................................................................................done.
一旦创建了环境,就可以激活环境并在其中安装 Django。
$ cd python2-workspace/
$ pip install django
Downloading/unpacking django
Downloading Django-1.5.4.tar.gz (8.1MB): 8.1MB downloaded
Running setup.py egg_info for package django
警告:在目录“*
下没有找到匹配“__pycache__”的先前包含的文件警告:没有匹配“*”的先前包含的文件。在目录' *'
下找到的 py[co]'正在安装收集的包:django
正在运行 setup.py install for django
将 build/scripts-2.7/django-admin . py 的模式从 644 更改为 755
警告:在目录“*
下没有找到匹配“__pycache__”的先前包含的文件警告:没有匹配“*”的先前包含的文件。将/private/tmp/python 2-workspace/bin/django-admin . py 的模式更改为 755
成功安装 django
清理...
总结和提示
在这篇文章中,我们学习了如何在 Windows、Mac OS X 和 Linux 上安装virtualenv,并使用它的pip命令来安装 Django。因为虚拟环境与系统的其余部分是分离的,所以安装的 Django 库只影响在特定环境中执行的文件。与 Mac OS X 和 Linux 相比,在 Windows 中设置virtualenv需要一个额外的步骤来改变脚本的执行策略。否则,建立 Django 虚拟环境的步骤在所有平台上几乎是相同的。
如何在 windows 上安装 python 安装指南
原文:https://www.pythoncentral.io/how-to-install-python-on-windows-installation-guide/
先决条件
在本文中,我们将更多地讨论如何在 windows 上安装 python。如果你是 python 的新手。你可以查看我们的 python 初学者指南来了解更多关于它的用法。在本文中,我们将讨论:
- 下载 Python
- 如何安装
- 在 windows 操作系统中安装 Python
- 如何卸载 python
首先,让我们从
下载 Python
这取决于你使用的操作系统。下载 Python 是一个简单的过程。这是 Python 的主要目标之一。要易于运行,易于安装。你可以从不同的资源下载 python。python 官方网站是下载 Python 的必经之路。它有所有操作系统的下载链接。它有详细的版本差异说明。如果你要升级你的 python 版本,你需要看一下发行说明。它会帮助你确切地知道变化。
要下载 python,您需要
您的下载将自动开始。现在是时候安装 Python 了。
在 windows 上安装 Python
下载 Python 后。现在我们将安装它。在本文中,我们将重点介绍在 windows 上安装 python。在 windows 上安装 python 有两种方法。如果你安装了 Bash ubuntu,第一个选项。Bash ubuntu 是 windows 操作系统中的一个 ubuntu 终端。它允许你在 windows 中运行 ubuntu 命令。如果您需要使用 bash shell,这将非常有帮助。请记住,它不是完全的 ubuntu 终端。它有一些 windows 限制。
在 bash ubuntu 中安装 Python。你首先需要下载 ubuntu 终端。您可以从 Windows 应用商店下载。下载后,你需要打开终端。开始时,下载和安装终端必需的软件包可能需要一些时间。完成后,你会发现正常的 ubuntu 终端。你可以在里面运行所有你想运行的命令。
-
安装依赖项。
$ sudo apt install software-properties-common $ sudo add-apt-repository ppa:deadsnakes/ppa -
更新操作系统软件包管理器
sudo apt update -
安装最新版本
$ sudo apt install python3.8
检查 python 是否已安装。您应该键入下面的命令。
python --version
输出:
Python 3.8.2
现在您已经成功安装了 python。注意,您在这个 shell 中安装了 Python。这意味着它不是全局安装在系统上。这意味着如果你有一个 python 脚本并试图在终端之外运行这个脚本。您需要从 shell 中运行它。它不会跑。我们来解释一下原因。
你的 python 只安装在 Ubuntu 子系统上。Ubuntu 终端是一个运行在 windows 中的容器。它有助于将您的命令转换成 Windows 的二进制系统调用。通过安装 python。您只能在子系统上安装它。
在 windows 操作系统中安装 Python
如果想在 windows 上全局安装 python。你应该遵循这些步骤。下载 Python 后。在你的下载中,你会有一个. exe 文件。打开它将打开这个屏幕。
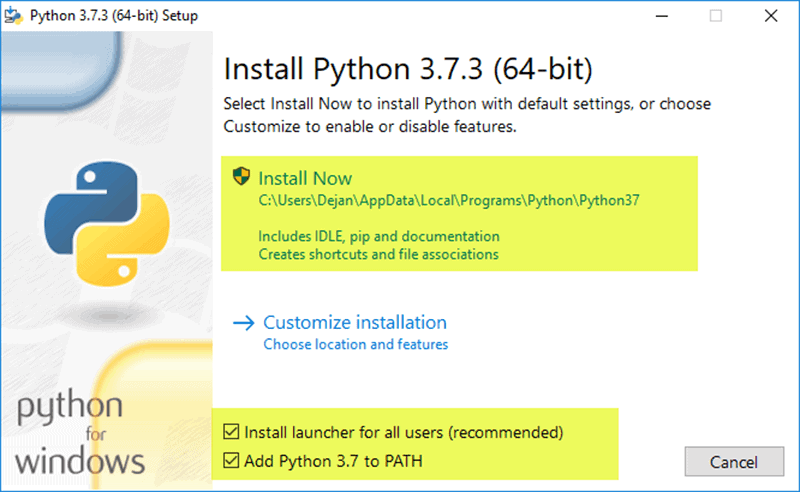
为 windows 设置 python
您可以选择现在安装。它将在您的系统分区中添加 python 路径。您可以自定义安装路径和用户访问。
windows 安装的最后一步。
安装完成后。您将看到安装成功屏幕。它将链接到文档和入门指南。关闭此屏幕后,您将在桌面或 windows 菜单上找到 python 快捷方式。现在,您可以运行任何 python 脚本。
如何卸载 python
如你所见,安装 Python 很容易。移除它怎么样。如果您使用的是 Windows,要从您的设备中移除 Python,您有两种选择。最简单的方法是:
- 转到控制面板
- 搜索 python
- 右键单击并选择卸载
这将从您的系统中完全删除 python。
如果你通过 ubuntu 子系统安装 python。这意味着它不是全球安装的。现在你应该打开一个新的终端窗口。运行下面的命令。
$ sudo apt remove python3.8
这将从子系统中卸载 python。将安装依赖包。这个命令不会删除你系统中仍然存在的 python 数据文件。如果您想从系统中完全删除它。你应该跑:
$ sudo apt autoremove python3.8
这也将从您的系统中移除 python 依赖项。
结论
安装或卸载 python 是一个简单的过程。Python 从一开始就被设计成这样。你可以用一个简单的 GUI 在 windows 中安装它。或者你可以使用 Ubuntu 子系统来安装它。移除 python 就像安装它一样简单。您可以通过 GUI 或终端卸载它。
如何安装 SQLAlchemy
在 Python 的 SQLAlchemy 的系列介绍教程的上一篇文章中,我们学习了如何使用 SQLAlchemy 的声明编写数据库代码。在本文中,我们将学习如何在 Linux、Mac OS X 和 Windows 上安装 SQLAlchemy。
在 Windows 上安装 SQLAlchemy
在 Windows 上安装 SQLAlchemy 之前,您需要使用 Python 的 Windows 安装程序来安装 Python。你可以在 Python 的发布页面下载一个 Python 的 Windows MSI 安装程序。双击.msi文件即可安装。
在您的 Windows 系统上安装 Python 之后,您可以从 SQLAlchemy 下载页面下载 SQLAlchemy 的源代码,并使用其 setup.py 脚本进行安装。
C:\> C:\Python27\python.exe .\setup.py install
running install
running build
running build_py
......
Plain-Python build succeeded.
*********************************
在 Linux 上安装 SQLAlchemy
建议我们在安装 SQLAlchemy 之前创建一个 virtualenv。所以,让我们开始吧:
$ virtualenv sqlalchemy-workspace
New python executable in sqlalchemy-workspace/bin/python
Installing distribute....................done.
Installing pip...............done
$ cd sqlalchemy-workspace
$ source bin/activate
那么,安装 SQLAlchemy 最简单的方法就是使用 Python 的包管理器pip:
$ pip install sqlalchemy
Downloading/unpacking sqlalchemy
Downloading SQLAlchemy-0.8.1.tar.gz (3.8Mb): 3.8Mb downloaded
Running setup.py egg_info for package sqlalchemy
......
没有找到与' doc/build/output'
匹配的以前包含的目录成功安装 sqlalchemy
清理...
在 Mac OS X 上安装 SQLAlchemy
在 Mac OS X 上安装 SQLAlchemy 相对来说与 Linux 相同。按照与 Linux 相同的步骤创建 Python virtualenv 后,可以使用以下命令安装 SQLAlchemy:
$ virtualenv sqlalchemy-workspace
New python executable in sqlalchemy-workspace/bin/python
Installing setuptools............done.
Installing pip...............done.
$ cd sqlalchemy-workspace
$ source bin/activate
$ pip install sqlalchemy
Downloading/unpacking sqlalchemy
Downloading SQLAlchemy-0.8.2.tar.gz (3.8MB): 3.8MB downloaded
Running setup.py egg_info for package sqlalchemy
......
没有找到与' doc/build/output'
匹配的以前包含的目录成功安装 sqlalchemy
清理...
就是这样。您已经成功地安装了 SQLAlchemy,现在您可以开始使用新的 SQLAlchemy 驱动的 virtualenv 编写声明性模型。
摘要
在 Linux 或 Mac OS X 下,建议使用 pip 在 virtualenv 中安装 SQLAlchemy,因为这比从源代码安装更方便。而在 Windows 下,您必须使用系统范围的 Python 安装从源代码安装它。
如何安装 Virtualenv (Python)
原文:https://www.pythoncentral.io/how-to-install-virtualenv-python/
注:编辑了关于--no-site-packages参数现在被默认为的评论,感谢 Twitter 上的@dideler。
Python 是一种非常强大的脚本语言。这种语言有许多 Python 包,您可以在项目中安装和使用。有时,您可能有不同的项目需要相同包/模块的不同版本。例如,假设您正在为一个客户开发一个带有最新版本的 Django 的 web 应用程序。同时,你支持一些需要 Django 版本的老项目。在这种情况下,您必须在每次切换项目时更改指向 Django 的路径。如果有一些工具可以让你从一个环境切换到另一个环境而互不影响,那就非常方便了。那个工具叫做虚拟人。在这篇文章中,我们将向您展示如何安装 Virtualenv,并开始。
Virtualenv 允许您创建虚拟 Python 环境。您在该环境中安装或删除的所有内容都保持不变,其他环境不受影响。最重要的是,你没有污染你的系统的全局包目录。例如,如果你想测试一个不稳定的包,virtualenv 是最好的选择。如果您测试的不稳定模块在安装/卸载过程中出现错误,您的系统不会受到影响。当你准备移除新的不稳定模块时,你需要做的只是移除你创建的 virtualenv 环境。
使用 pip 安装 Virtualenv
在本文中,我们将使用pip作为 Python 包管理器。喜欢的话也可以用easy_install。首先,让我们设置 pip (你可能需要成为 root 或者在 Unix 机器上使用sudo):
$ easy_install pip
下一步是安装 virtualenv 软件包:
$ pip install virtualenv
就是这样!要安装 virtualenv,非常简单。
用 virtualenv 创建一个环境
下一步是使用 virtualenv 创建环境:
virtualenv my_blog_environment
使用前面的命令,我们在目录my_blog_environment下创建了一个独立的 Python 环境。注意,在 virtualenv 的当前版本中,默认情况下它使用--no-site-packages选项。这告诉 virtualenv 为我们创建一个空的 Python 环境。
另一个选择是让我们的虚拟环境包含全局 Python 目录中的所有包(例如 C:\Python27 或/usr/lib/python2.7)。如果需要这样做,可以使用--use-site-package参数。
探索虚拟环境
下一步是激活您的虚拟环境:
$ cd my_blog_environment/
$ source bin/activate
现在,您应该会看到您的提示发生了一点变化(请参考开头的括号):
user@hostname:~/my_blog_environment
现在你在你的虚拟环境中。如果您列出当前目录(virtualenv)的内容,您将看到 3 个目录:
user@hostname:~/my_blog_environment$ ls
bin include lib
“bin”目录包括我们的 virtualenv 环境的可执行文件。那就是 Python 解释器所在的地方。此外,一些软件包安装的可执行文件也将包含在该目录中。“include”目录包含环境的头文件。最后,“lib”目录包括我们的 virtualenv 系统的已安装模块的 Python 文件。
安装 Virtualenv 软件包
下一步是安装一些包并使用我们的环境。正如我们在例子中提到的,让我们安装一个旧版本的 Django,版本 1.0。
pip install Django==1.0
现在,我们可以通过检查 Python shell 来检查 Django 是否安装在我们的虚拟环境中。
>>> import django
>>> print django.VERSION
(1, 0, 'final')
>>> exit()
$ deactivate
虚拟沙盒
virtualenv 的另一个有趣的特性是能够为不同版本的 Python 解释器创建沙箱。使用-p标志,您可以创建使用不同版本 Python 解释器的环境。举个例子,你想用 Python 的最新版本 3 创建一个项目。要做到这一点,您首先需要在您的系统上安装想要尝试的 Python 版本。之后,你需要找到解释器的可执行文件的路径。你通常可以在 Linux 的/usr/bin(例如/usr/bin/python3)下找到它,在 Windows 的C:\(例如C:\Python31)下找到它。
$ virtualenv --no-site-packages -p /usr/bin/python3 p3_test
$ cd p3_test
$ source bin/activate
$ python
Python 3.2 (r32:88445, Dec 8 2011, 15:26:51)
[GCC 4.5.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> print('Hello There')
Hello There
现在,您已经准备好试验新的 Python 3 环境了。
如何保护您的数据安全
原文:https://www.pythoncentral.io/how-to-keep-your-data-secure/

我们都知道数据安全是一个大问题。每天都有如此多的网络攻击发生,确保您的数据安全比以往任何时候都更加重要。在这篇博文中,我们将讨论一些保护数据安全的最佳方法。我们将涵盖从密码保护到数据加密的所有内容。遵循这些提示,您可以放心,您的数据是安全和健全的!
1。安全访问服务
保护数据安全的第一步是确保只有授权人员才能访问。这意味着建立一个安全访问控制系统,根据用户权限限制对敏感数据的访问。有许多不同的方法可以做到这一点,但最重要的是要确保只有那些需要访问数据的人才拥有它。还有, 根据禅悟 的说法,你应该定期检查和更新你的门禁系统,确保它仍然有效。在主系统出现任何问题的情况下,准备一个备份系统也是一个好主意。
2。数据加密
数据加密是保护数据安全的另一个重要步骤。这是一个将数据转换成只能由授权用户解密的代码的过程。这个确保了即使有人获得了你的数据,他们也无法读取或以任何方式使用它。有许多不同类型的数据加密,所以请务必选择最适合您需求的一种。此外,确保加密所有敏感数据,而不仅仅是其中的一部分。
3。密码保护
保护数据安全的一个最基本也是最重要的方法是用密码保护它。这样可以保证只有那些 知道密码的人才能访问 的数据。确保选择不易被猜到的强密码。定期更改密码也是一个好主意,千万不要为多个帐户使用同一个密码。有许多密码管理工具可以帮助您跟踪您的密码,并确保它们是强有力的。
4。备份您的数据
数据安全的另一个重要步骤是定期备份数据。这样,如果原始数据发生任何变化,您将有一个副本可以用来恢复它。有许多不同的方法来备份数据,所以选择一个最适合你的需要。您可以将数据备份到外部硬盘、云或本地服务器。只要确保你选择的备份方法是可靠和安全的。
5。让您的软件保持最新
在数据安全方面,最重要但经常被忽视的一个步骤是保持你的软件最新。这包括您的操作系统和您安装在计算机上的任何应用程序。过时的软件是黑客获取数据的最常见方式之一。通过使您的软件保持最新,您可以修补任何可能存在的安全漏洞。有许多不同的方法可以让您的软件保持最新,因此请选择最适合您需求的方法。
6。使用 VPN
保护数据安全的另一个好方法是使用 VPN。VPN 对您的计算机和 VPN 服务器之间的所有流量进行加密,使任何人都无法窃听您的连接。如果您使用公共 Wi-Fi,这一点尤其重要,因为如果您不使用 VPN,黑客很容易获得您的数据。有许多不同的 VPN 提供商可供选择,因此一定要做好调查,选择最适合您需求的提供商。
如何对员工进行数据安全教育
对员工进行数据安全教育的第一步是制定数据安全政策。该政策应概述哪些类型的数据被视为敏感数据,以及违反该政策的后果。请务必定期与您的员工一起审查该政策,并确保他们理解该政策。您还应该让员工能够轻松举报任何违反政策的行为。另一个重要的步骤是对你的员工进行数据安全培训。此培训应涵盖诸如如何识别敏感数据、如何保护敏感数据以及如果他们怀疑自己的数据遭到破坏时该怎么办等主题。
你可以采取许多措施来保护你的数据安全。最重要的是确保只有经过授权的人员才能访问它,并且它是加密的。此外,您还应该用密码保护您的数据,并定期备份。最后,确保你的软件是最新的,并使用 VPN 来增加安全性。通过遵循这些步骤,您可以确保您的数据是安全的。
如何学习用 Python 编程?
原文:https://www.pythoncentral.io/how-to-learn-to-program-with-python/
Python 的流行使其成为 GitHub 上第二受欢迎的编程语言。这主要是因为它在新兴技术中的使用,如数据科学、机器学习和人工智能。由于它的高效性、多功能性和易学性,它在软件开发中也有很强的影响力。在这篇文章中,我们将讨论如何学习用 Python 编程。
Python 是一种编程语言,具有易于编写和阅读的特性。在这种情况下,一些学习者需要获得 Python 作业帮助,因此他们为此使用特殊服务。然而,程序员必须有一系列的技能和知识来使用它。
诸如自学能力、团队合作能力、分析和解决问题的思维等软技能尤为突出。这些是你可以拥有或者可以发展的技能,重要的是要有一系列具体的知识来理解这种编程语言。其中一些如下:
- 了解其他编程语言,如 CSS、JAVA 和 TypeSCript 等。
- 对关系数据库有所了解。使用 Python,您将能够构建确保所创建的数据库的持久性的系统。
- 想要从头开始学习 Python 的开发人员必须了解一些框架,如 Flask、DJango 或 Pyramid。
- 具备面向对象编程的知识。这将允许您将代码组织成单元,并创建彼此相关的对象。
如何学习如何用 Python 编程?
有很多关于如何学习 Python 编程的视频教程,但是它们可能会让你偏离目标。下面,我们将回顾开始学习这种编程语言的步骤。
定义学习 Python 的原因
你需要找到一个令人信服的理由来学习 Python,因为它必须让你在整个过程中保持专注,否则,到最后可能会非常痛苦。
所以每个学生都应该自己去找。例如,专家挑出以下原因:成为专业的 Python 开发人员,无论是在数据科学、机器学习、数据分析、人工智能还是任何其他学科。
学习基础知识
学习语法,以及编程语言的要点,比如变量、数据类型、函数等等。除了理论,还需要大量的实践。自己或者通过看到的 Python 教程写简单代码。一旦你掌握了基础知识,你就可以进入高级话题了。
是时候把你学到的东西用在你从头开始创建的项目中了。这些类型的练习将释放你的潜力,并帮助你在这个过程中学习。此外,这些项目可以放入你的文件夹中,供你找工作时使用。
你可以在数据科学、机器学习、网站、移动应用、游戏和自动化脚本等领域创建结构化项目。此外,您还会找到许多结构化项目的资源,例如 Dataquest、Scikit-learn documentation、使用 Python 学习机器人技术,以及使用 Python 自动完成枯燥的工作,这是您可以访问的几个网站。
在这一过程中,您需要学习如何找到错误并寻找它们的解决方案。此外,您可以扩展以前的项目,找到开源平台进行贡献,为非营利组织做志愿者,为 GitHub 做贡献...
如何学习如何用 Python 编程?
与更多人合作
与其他学生和专家合作将有助于你扩大知识面,讨论问题,获得在工作中应用的技巧和诀窍。有不同的 Python 社区、论坛、聚会和活动。我们可以提到一些像堆栈溢出,Python.org,Reddit 和 Sololearn。
继续练习
学习编程是一个永无止境的过程。所以,在你完成了所有的步骤之后,要一直坚持练习你所学到的东西。以全职 Python 开发人员或业余爱好者的身份进入这个世界,在各种行业垂直领域创建 Python 项目。
在提到如何学习如何使用 Python 编程以及您事先需要什么之后,现在是冒险开始使用这种编程语言的理想时机。
你想学 Python 编程吗?通过我们的 Full Stack Jr. Bootcamp 从零开始学习编程,您将掌握计算思维,同时开始使用 Python 编写有用、快速和优雅的代码的方法和关键。
如何使用 Python 制作自定义软件应用程序
原文:https://www.pythoncentral.io/how-to-make-a-custom-software-application-using-python/

使用 Python 制作定制软件应用程序有几个关键步骤。根据最近的研究,Python 是全世界发展最快的编码语言之一。而且,预计在未来几年,它还会以更快的速度增长。这就是为什么许多软件工程师选择使用这个前瞻性的框架来设计、开发、部署和分发他们的产品。作为一名开发人员,用 Python 编程语言 构建软件有很多好处。毕竟,这种语言特别容易学习、阅读、解释和书写。此外,它非常经济实惠,便于携带,而且充满活力。为了帮助您立即开始,请继续阅读,了解如何使用 Python 制作定制软件应用程序。
学习语言
在开始构建之前,您需要熟练掌握 Python 编程语言。首先确定什么会激励你学习 Python。这可能需要你选择一个合适的重点领域,如定制软件、嵌入式应用程序或数据处理工具。一些 Python 开发者严格地为工作流自动化构建脚本。一旦你有了足够的动力,你就可以开始学习基本语法了。在这个阶段花尽可能少的时间,因为它往往会变得相当耗时和无动力。一旦你完成了,你就可以开始自己制作结构化的 Pyton 项目了。当然,学习 Python 对于使用 Python 制作一个定制的软件应用程序是至关重要的。
配置您的技术平台
现在,您已经准备好为 Python 软件开发配置技术栈了。每个开发团队都需要一些强大的编程工具、资源和技术。例如,您可以使用一个由 JFrog 创建的 Helm 存储库来实现隐私保护、简化访问控制并提升高可用性。同时,您可以利用可大规模扩展的企业级存储功能。借助这一功能,您将能够标准化配置模板、优化测试并加速软件发布。当然,在使用 Python 制作定制软件应用程序时,技术栈配置是至关重要的。
构建图形用户界面(GUI)
一旦后端准备就绪,就该开始为 python 软件应用程序构建 GUI 了。简单地说,你的图形用户界面作为一个高级系统来存储你所有的交互式可视组件。这里,用户可以使用他们的指示器表示与电子设备进行交互。对于相对简单的软件应用程序,在你的界面中只需要一些必要的项目。首先,您需要一个设计良好的标题,在这里您可以显示您的软件应用程序的标题。此外,还包括一些文本区域小部件、按钮和表单。当然,在用 Python 制作定制软件解决方案时,您需要构建一个 GUI。
测试软件应用
至此,正式到了测试 Python 构建的软件产品的时候了。从一些基本功能开始。这将帮助您确保每个按钮、功能、界面和屏幕都正常工作。如果所有这些都通过检查,您就可以进入代码审查了。这只是意味着让另一双眼睛来检查你的项目的源代码。一旦这些通过,运行静态代码分析。基本上,这有助于您彻底分析系统的代码库,而无需执行它。另一个主要步骤是单元测试。最终,这些检查过程促进了敏捷过程、代码质量和简单的调试。它们还简化了设计,促进了有效的变更,并促进了软件缺陷的发现。事实上,系统测试对于使用 Python 开发定制软件应用程序至关重要。
发布您的软件解决方案
当您的 Python 软件应用程序通过了所有必需的应用程序后,您就可以正式发布了。你需要从仔细计划你的释放开始。这可能是整个发布管理过程(RMP)中最耗时、最复杂、最密集的阶段。在这个阶段,你的目标是提出一个结构良好、有组织的、健壮的发布计划。这需要确保在您的解决方案上线之前,所有的质量和性能标准都得到适当的满足。之后,您可以进入构建发布、用户验收测试(UAT)和部署。毫无疑问,在使用 Python 构建定制软件应用程序时,发布是最能改变游戏规则的阶段之一。
在构建基于 Python 的定制软件应用程序时,需要记住几个关键步骤。首先也是最重要的,花一些时间来熟练掌握这门语言。然后,包括您的技术堆栈所需的所有必要的开发工具、技术和资源。之后,您可以专注于构建一个安全的 GUI 环境。如果你从来没有这样做过,从了解 GUI 的 网页历史开始。此时,是时候彻底测试您的软件应用程序了。一旦采取了所有这些步骤,你就可以正式发布你的新软件产品了。遵循上面强调的要点,学习如何使用 Python 制作自定义软件应用程序。
如何在 Python 中合并列表
原文:https://www.pythoncentral.io/how-to-merge-lists-in-python/
如果您曾经想要将 Python 中的多个列表合并到一个列表中,不要惊慌。Python 实际上使得执行这样的功能变得非常容易。您可以通过使用加号(+)来合并和连接列表——说真的,没有比这更简单的了。如果你想更好地了解合并列表是如何工作的,看看下面的例子。
假设我们有两个列表,它们是这样定义的:
listone = [9, 13, 16]
listtwo = [21, 36, 54]
现在让我们假设我们想合并列表来创建一个列表。这是如何做到的:
newlist = listone + listtwo
print newlist
上面代码的输出将是:9,13,16,21,36,54。当然,新列表的定义是这样的:newlist = [9,13,16,21,36,54]。合并两个列表来创建一个新列表就是这么简单。
如何在 Python 中使用进度条移动或复制文件
在上一篇名为如何在 Python 中递归复制文件夹(目录)的文章中,我介绍了如何将文件夹从一个地方递归复制到另一个地方。
虽然这很有用,但我们还可以添加一些东西,让复制目录变得更加用户友好!
从舞台左侧进入进度条。这是一个有用的工具,所有知名软件都使用它来告诉用户正在发生的事情,以及它正在执行的任务的位置。
那么,我们如何将它合并到复制目录中呢?很高兴你问了,我的问题充满了朋友!
进度条
首先,我们将创建一个简单的类,使打印过程简单 100 倍,同时给我们一个很好的可重用类,用于其他可能需要它的项目。
开始了。首先我们将添加__init__方法:
# -*- coding: utf-8 -*-
import sys
class progress bar(object):
def _ _ init _ _(self,message,width=20,progressSymbol=u'▣',empty symbol = u '□'):
self . width = width
如果 self.width < 0:
self.width = 0
self . message = message
self . progress symbol = progress symbol
self . empty symbol = empty symbol
这并不难!我们传入我们想要打印的消息、进度条的宽度以及表示进度完成和空进度的两个符号。我们检查宽度是否总是大于或等于零,因为我们不能有负的长度!🙂
简单的东西。
好了,接下来是最难的部分。我们必须弄清楚如何在输出窗口中更新和显示进度条,而不是每次都打印一行。
这就是回车(\r)的用武之地。回车符是一个特殊字符,它允许打印的消息在打印时从一行的开头开始。每次我们打印一些东西,我们只是在我们的行的开始使用它,它应该照顾我们的需要就好了。唯一的限制是,如果进度条碰巧在终端换行,回车将不会像预期的那样工作,只会输出一个新行。
下面是我们的update函数,它将打印更新的进度:
def update(self, progress):
totalBlocks = self.width
filledBlocks = int(round(progress / (100 / float(totalBlocks)) ))
emptyBlocks = totalBlocks - filledBlocks
progress bar = self . progress symbol * filled blocks+\
self . empty symbol * empty blocks
如果不是 self . message:
self . message = u ' '
progress message = u“\ r { 0 } { 1 } { 2 } %”。格式(自我信息,
进度条,
进度)
sys . stdout . write(progress message)
sys . stdout . flush()
def calculated and update(self,done,total):
progress = int(round((done/float(total))* 100))
self . update(progress)
我们刚刚做的是使用所需的总块数来计算填充块数。看起来有点复杂,我来分解一下。我们希望填充的块数等于progress除以 100%除以总块数。calculateAndUpdate功能只是为了让我们的生活更轻松一点。它所做的只是计算并打印给定当前项目数和项目总数的完成百分比。
filledBlocks = int(round(progress / (100 / float(totalBlocks)) ))
对float的调用是为了确保计算以浮点精度完成,然后我们用round将浮点数四舍五入,用int将它变成整数。
emptyBlocks = totalBlocks - filledBlocks
那么空块就是totalBlocks减去filledBlocks。
progressBar = self.progressSymbol * filledBlocks + \
self.emptySymbol * emptyBlocks
我们将填充块的数量乘以progressSymbol并将其加到乘以空块数量的emptySymbol上。
progressMessage = u'\r{0} {1} {2}%'.format(self.message,
progressBar,
progress)
我们在消息的开头使用回车来将打印位置设置为行首,并使消息的格式如下:“message!▣ ▣ ▣ □ □ □ 50%".
sys.stdout.write(progressMessage)
sys.stdout.flush()
最后,我们将信息打印到屏幕上。我们为什么不用print函数呢?因为print函数在我们的消息末尾添加了一个新行,这不是我们想要的。我们希望它按照我们设定的那样打印出来。
继续表演!到复制一个目录功能!
使用 Python 复制目录(文件夹)
为了知道我们的进展,我们将不得不牺牲一些速度。我们需要计算我们正在复制的所有文件,以获得剩余的总进度,这需要我们递归地搜索目录并计算所有文件。
让我们写一个函数来做这件事。
import os
def countFiles(目录):
files = []
if os.path.isdir(目录):
对于 os.walk(目录)中的路径、目录、文件名:
files.extend(文件名)
返回 len(文件)
相当直接。我们刚刚检查了传入的目录是否是一个目录,如果是,那么递归地遍历目录并将目录中的文件添加到文件列表中。然后我们只返回列表的长度。简单。
接下来是复制目录功能。如果你看了本文开头提到的那篇文章,你会注意到我使用了shutil.copytree函数。这里我们不能这样做,因为shutil不支持进度更新,所以我们必须编写自己的复制函数。
我们开始吧!
首先,我们创建一个ProgressBar类的实例。
【python】
p = progress bar('复制文件...')
接下来,我们定义一个函数来创建尚不存在的目录。这将允许我们创建源目录的目录结构。
【python】
def make dirs(dest):
如果不是 OS . path . exists(dest):
OS . make dirs(dest)
如果目录不存在,我们创建它。
现在是复制功能。这是一个有点花哨的东西,所以我会把它们都放在一个地方,然后再把它们分开。
import shutil
def copyfilewithprogress(src,dest):
numFiles = count files(src)
如果 numFiles > 0:
makedirs(dest)
numCopied = 0
对于 os.walk(src)中的路径、目录、文件名:
对于目录中的目录:
destDir = path.replace(src,dest)
make dirs(OS . path . join(destDir,directory))
对于文件名中的 sfile:
src file = OS . path . join(path,sfile)
dest file = OS . path . join(path . replace(src,dest),sfile)
shutil.copy(srcFile,destFile)
numCopied += 1
p . calculated and update(numCopied,numFiles)
print
首先,我们计算文件的数量。
def copyFilesWithProgress(src, dest):
numFiles = countFiles(src)
这没什么难的。
接下来,如果确实有要复制的文件,我们将创建目标文件夹(如果它不存在),并初始化一个变量来计算当前复制的文件数。
if numFiles > 0:
makedirs(dest)
num copied = 0
然后,我们遍历目录树并创建所有需要的目录。
for path, dirs, filenames in os.walk(src):
for directory in dirs:
destDir = path.replace(src, dest)
makedirs(os.path.join(destDir, directory))
这里唯一棘手的部分是,我用目标文件夹路径替换了 path 中的源目录字符串,它是根路径。
接下来,我们复制文件和更新进度!
for path, dirs, filenames in os.walk(src):
(...)
for sfile in filenames:
srcFile = os.path.join(path, sfile)
dest file = OS . path . join(path . replace(src,dest),sfile)
shutil.copy(srcFile,destFile)
numCopied += 1
p . calculated and update(num copied,numFiles)
在这里,我们遍历所有文件,复制它们,更新到目前为止复制的文件数量,然后绘制我们的进度条。
就是这样!我们完了!现在你有了一个不错的复制功能,它会在复制文件时提醒你进度。
在 Python 中移动目录(文件夹)
注意,你也可以将copyFilesWithProgress中的shutil.copy函数调用改为shutil.move,并有一个移动进度条。所有其他代码都是一样的,所以我不打算在这里重写。我会让你决定的!🙂
下次再见,我向你道别。
如何在 Python 中打开文件
原文:https://www.pythoncentral.io/how-to-open-a-file-in-python/
Python 是 最流行的编程语言 之一,与其他一些语言不同,它不需要你导入一个库来处理文件。
文件是在 Python 中原生处理的;然而,处理文件的方法与其他语言不同。
在这个 Python 教程中,你将学习如何打开、读取、写入和关闭文件。在这篇文章中,我们还将介绍如何使用“with”语句。
如何在 Python 中打开文件?
Python 内置了创建、打开、关闭、读取和写入文件的功能。在 Python 中打开一个文件就像使用 open()函数一样简单,该函数在每个 Python 版本中都可用。该函数返回一个“文件对象”
文件对象由方法和属性组成,这些方法和属性可以用来收集关于你打开的文件的信息。此外,当您想要操作您打开的文件时,这些细节也会派上用场。
例如,“模式”是每个文件对象都关联的少数属性之一。它描述了文件打开的模式。
同样,file 对象的“name”属性揭示了打开的文件的名称。
你必须记住,虽然文件和文件对象在根本上是相互关联的,但它们是分开的。
什么是文件?
当您使用像 Windows 这样的操作系统时,“文件”意味着图像、文档、视频、音频剪辑、可执行文件等等。在技术层面上,文件只是磁盘驱动器上存储相关数据的命名位置。
磁盘驱动器用于永久存储数据,因为 RAM 是易失性的,当计算机关机时会丢失数据。
在操作系统中,你可以操作这些文件,并把它们组织在文件夹中,形成复杂的目录。本质上,Windows 中的文件是您可以创建、操作和删除的任何项目。
然而,Python 处理文件的方式不同于 Windows 或任何其他操作系统。
Python 中的文件类型
Python 将文件分为两类:文本或二进制。在学习如何使用 Python 文件之前,理解它们之间的差异是至关重要的。
文本文件是具有数据序列的文件,数据是字母数字字符。在这些文件中,每一行信息都以称为 EOL 或行尾字符的特殊字符结束。
一个文本文件可以使用许多不同的 EOL 字符。然而,新行字符(" \n ")是 Python 的默认 EOL 字符,因此是最常用的字符。
新行字符中的反斜杠向 Python 解释器表明当前行已经结束。反斜杠后面的“n”向解释器表明后面的数据必须被视为新的一行。
二进制文件与文本文件截然不同。顾名思义,二进制文件包含二进制数据 0 和 1,只能由理解二进制的应用程序处理。
这些文件不使用 EOL 字符或任何终止符。数据在转换成二进制后被存储。
注: Python 字符串不同于文件,但学习如何使用字符串可以帮助更好地理解 Python 文件的工作原理。要了解更多关于在 Python 中使用字符串的知识,请查看我们的 关于字符串 的综合指南。
打开文本文件
在写入或读取文件之前,必须先打开文件。为此,您可以使用 Python 内置的 open()函数。
这个函数有两个参数:一个接受文件名,另一个保存访问模式。它返回一个文件对象,语法如下:
file_object = open("File_Name", "Access_Mode")
你必须注意,你要打开的文件必须和 Python 脚本在同一个文件夹/目录中。如果文件不在同一个目录中,在写入文件名参数时,必须提到文件的完整路径。
例如,要打开与脚本在同一个目录中的“example.txt”文件,您需要编写以下代码:
f = open("example.txt")
另一方面,要在桌面上打开“example.txt”文件,您需要编写以下代码:
f = open("C:\Users\Krish\Desktop\example.txt")
访问模式
Python 有几种访问模式,这些模式控制着你可以对一个打开的文件执行的操作。换句话说,每种访问模式都是指当文件以不同方式打开时如何使用它。
Python 中的访问模式也指定了文件句柄的位置。您可以将文件句柄想象成一个光标,指示必须从哪里读取或写入数据。
也就是说,使用访问模式参数是可选的,如前面的示例所示。
Python 中有六种访问模式:
- 只读(' r'): 这是默认的访问模式。它打开文本文件进行读取,并将文件句柄定位在文件的开头。如果 Python 发现该文件不存在,它会抛出 I/O 错误,并且不会创建具有指定名称的文件。
- 只写(' w'): 用于写文件。如果文件不在文件夹中,则会创建一个具有指定名称的文件。如果文件存在,数据将被截断,然后被覆盖。文件句柄位于文件的开头。
- 读写(' r+'): 你可以读写用这种访问模式打开的文件。它将句柄定位在文件的开头。如果文件不在目录中,就会引发 I/O 错误。
- 读写(' w+'): 与前一种模式一样,你可以读写用这种访问模式打开的文件。它将句柄定位在文件的开头。如果文件不在文件夹中,它会创建一个新文件。此外,如果指定的文件存在,其中的数据将被截断和覆盖。
- 仅追加(' a'): 此模式打开文件进行写入。如果特定文件不在目录中,则会创建一个同名的新文件。但是,与其他模式不同,句柄位于文件的末尾。因此,输入的数据会附加在所有现有数据之后。
- 追加和读取(' a+'): 在 Python 中用来读写文件。它的工作方式与前面的模式类似。如果目录中没有该文件,则会创建一个同名的文件。或者,如果文件可用,则输入的数据会附加在现有数据之后。
访问模式参数中的“+”实质上表示文件正在被打开以进行更新。
还有另外两个参数可以用来指定文件的打开模式。
Python 默认以文本模式读取文件,文本模式由参数“t”指定,open()函数在读取文件时返回字符串。相反,在使用 open()函数时使用二进制模式(“b”)会返回字节。二进制模式通常用于处理非文本文件,如图像和可执行文件。
这里有几个在 Python 中使用这些访问模式的例子:
f = open("example.txt") # Uses default access mode 'r'
f = open("example.txt",'w') # Opens the file for writing in text mode
f = open("img.bmp",'r+b') # Opens the file for reading and writing in binary mode
With 语句
除了有更清晰的语法之外,“with”语句还使得处理文件对象时的异常处理更加容易。在处理文件时,只要适用,最好使用 with 语句。
使用 with 语句的一个显著优点是,它会在操作完成后自动关闭你打开的所有文件。因此,您不必担心在对文件执行任何操作后关闭文件并进行清理。
with 语句的语法是:
with open("File_Name") as file:
要使用 with 语句读取文件,您需要编写以下代码行:
with open("example.txt") as f:
data = f.readlines()
当第二行代码运行时,存储在“example.txt”中的所有数据都将存储在一个名为“data”的字符串中
如果你想将数据写入同一个文件,你可以运行下面的代码:
with open("example.txt", "w") as f:
f.write("Hello World")
阅读内容
在 Python 中读取一个文件很简单——你必须使用“r”参数或者根本不提及参数,因为这是默认的访问模式。
也就是说,在 Python 中还有其他从文件中读取数据的方法。例如,您可以使用 Python 内置的 read(size)方法来读取指定大小的数据。如果不指定 size 参数,该方法将读取文件,直到文件结束。
我们假设“example.txt”有以下文字: Hello world. This file has two lines.
要使用 read()方法读取文件,可以使用下面的代码:
f = open("example.txt",'r',encoding = 'utf-8')
f.read(5) # reads the first five characters of data 'Hello'
f.read(7) # reads the next seven characters in the file ' world.'
f.read() # reads the rest till EOF '\nThis file has two lines.'
f.read() # returns empty string
在上面的例子中,read()方法在行结束时返回新的行字符。此外,一旦到达文件末尾,它将返回一个空字符串。
在 seek()方法的帮助下,无论使用何种访问模式,都可以改变光标位置。要检查光标的当前位置,可以使用 tell()函数。
你也可以使用 for 循环逐行读取文件,就像这样:
for line in f:
print(line, end = '')
...
Hello world.
This file has two lines.
readline()和 readlines()方法是另外两种从文件中读取数据的可靠技术。readline()方法在读取一个新的行字符后停止读取该行。
f.readline() # reads the first line 'Hello world.'
另一方面,readlines()读取文件,直到到达 EOF。
f.readlines() # reads the first line 'Hello world.'
追加新文本
要写入 Python 文件,必须以写(w)、追加(a)或独占创建(x)模式打开。
使用写模式时必须小心,因为它会覆盖文件中已经存在的数据。
无论是文本文件还是二进制文件,你都可以使用 Python 的 write()方法。
with open("example.txt",'w',encoding = 'utf-8') as f:
f.write("Hello world.\n\n")
f.write("This file has two lines.")
如果目录中不存在“example.txt ”,将使用写入的指定文本创建它。另一方面,如果文件与脚本存在于同一个目录中,则文件先前保存的数据将被删除并用新文本覆盖。
关闭文件
在读取或写入文件后,您必须关闭文件。这是释放文件占用资源的唯一方法。
在 Python 中关闭一个文件很容易——你所要做的就是使用 close()方法。运行方法可以释放文件占用的内存。语法是:
File_object.close()
要在读写后关闭“example.txt ”,只需运行以下代码即可:
f.close()
close()方法有时会抛出异常,导致代码在文件没有关闭的情况下退出。
操作后关闭文件的更好方法是使用 try…finally 块。
try:
f = open("example.txt", encoding = 'utf-8')
# perform operations
finally:
f.close()
使用 try… finally 块可以确保打开的文件被正确关闭,而不管是否出现异常。
结论
学习文件处理和复制/移动文件和目录将帮助你掌握 Python 中的文件操作。
接下来,看看我们关于使用 Python 使用进度条 复制/移动文件的简单教程 。
如何腌制:腌制和拆洗教程
原文:https://www.pythoncentral.io/how-to-pickle-unpickle-tutorial/
先决条件
需要了解以下内容:
- Python 3
- 字典等基本 Python 数据结构
- Python 中的文件操作
简介
字面意思, 泡菜 的意思是 在盐溶液中储存东西。只是在这里,它的对象不是蔬菜。并不是生活中的一切都可以看成 0 和 1(天哪!哲学),但 pickling 帮助我们实现了这一点,因为它将任何类型的复杂数据转换为 0 和 1(字节流)。这个过程可以被称为酸洗、序列化、展平或编组。产生的字节流也可以通过一个称为拆包的过程转换回 Python 对象。
为什么是泡菜?
由于我们处理的是二进制,数据不是被写入而是被转储,同样,数据不是被读取,而是被加载。例如,当你玩一个像“戴夫”这样的游戏,并且你达到了一定的级别,你会想要保存它,对吗?如你所知,这个游戏有各种属性,比如健康,收集的宝石等等。所以当你保存你的游戏时,比方说在第 7 级,当你有一颗健康的心和 300 点时,一个对象是从一个具有这些值的 Dave 类创建的。 当你点击“保存”按钮时,该对象被序列化并保存,或者换句话说被腌制。不用说,当你恢复一个已保存的游戏时,你将会从它的 pickled 状态中加载数据,从而对它进行解包。
酸洗和拆洗在现实世界中应用广泛,因为它们可以让你轻松地将数据从一台服务器发送到另一台服务器,并将其存储在文件或数据库中。
警告: 不要从不可信的来源提取数据,因为这可能会带来严重的安全风险。Pickle 模块无法在 Pickle 恶意数据时知道或引发错误。
只有导入相应的模块酸洗,才能进行酸洗和拆洗。您可以使用下面的命令来完成这个任务:
import pickle
工作中的泡菜
现在让我们看一个简单的例子来说明如何编写字典。
import pickle
emp = {1:"A",2:"B",3:"C",4:"D",5:"E"}
pickling_on = open("Emp.pickle","wb")
pickle.dump(emp, pickling_on)
pickling_on.close()
请注意使用“wb”而不是“w ”,因为所有操作都是使用字节完成的。此时,您可以使用记事本打开当前工作目录中的 Emp.pickle 文件,并查看 pickle 数据的外观。
那么,既然数据已经被剔除,让我们来研究一下如何拆开这本字典。
pickle_off = open("Emp.pickle","rb")
emp = pickle.load(pickle_off)
print(emp)
现在您将获得我们之前初始化的 employees 字典。当我们读取字节时,注意使用“rb”而不是“r”。这是一个很基础的例子,一定要自己多尝试。
如果您想获得一个包含酸洗数据的字节字符串,而不是 obj 的酸洗表示,那么您需要使用转储。类似地,要从字节流中读取对象的 pickled 表示,应该使用 loads。
数据流格式
数据流格式被称为协议,它规定了酸洗数据的输出格式。有几种可用的协议版本。您必须了解协议版本,以避免兼容性问题。
- 协议版本 0——原始的基于文本的格式,向后兼容早期版本的 Python。
- 协议版本 1——一种旧的二进制格式,也兼容早期版本的 Python。
- 协议第 2 版——在 Python 2.3 中引入,提供高效的类和实例选择,
- 协议版本 3——在 Python 3.0 中引入,但它不是向后兼容的。
- 协议版本 4 -在 Python 3.4 中添加。它增加了对非常大的对象的支持,支持更多种类的对象,以及一些数据格式优化。
注意,协议版本保存为 pickle 数据格式的一部分。但是,要在特定协议中解包数据,需要在使用 dump() 命令时指定数据。
要了解所使用的协议,在导入 pickle 库后使用以下命令。这将返回正在使用的最高协议。
pickle.HIGHEST_PROTOCOL
异常情况
需要注意的一些常见例外:
- 咸菜。PicklingError :当你试图 pickle 一个不支持 pickle 的对象时,这个异常被抛出。
- 咸菜。UnpicklingError :当文件包含损坏的数据时引发该异常。
- EOFError :当检测到文件结束时引发该异常。
优势
- 帮助保存复杂的数据。
- 相当容易使用,不需要几行代码,因此不庞大。
- 保存的数据不可读,因此提供了一些数据安全性。
缺点
- 非 Python 程序可能无法重建腌制的 Python 对象。
- 从恶意来源中提取数据的安全风险。
腌制被认为是一个高级话题,所以继续练习和学习掌握它。一定要去看看这些与腌制相关的有趣话题- 挑拣者、去挑拣者、去挑拣者。快乐的蟒蛇!
如何在 Python 中读取“CSV”文件
原文:https://www.pythoncentral.io/how-to-read-csv-file-in-python/
我们日常遇到的计算机系统需要大量的数据和信息交换。为了确保这种交换顺畅而容易,用户更喜欢文本文件,而这些文本文件最常见的格式之一就是’。csv
但是什么是 CSV 文件呢?我们如何使用它来提取和修改数据?什么是 python 库?有其他可用的库来处理这种格式吗?每个库中的命令和程序是什么?
不要担心!所有这些问题都在本文中得到解答。您将学习如何使用 csv 文件,并使用代码正确处理它们,以最大限度地提取数据。让我们开始吧。
什么是 CSV 文件?
逗号分隔值(CSV)文件是一种纯文本文件,使用 ASCII 或 Unicode(UTF-8)等字符集来存储数据。它主要用于存储最初以表格形式存储的数据,每行代表一条记录。特定记录的不同字段用逗号分隔,因此这种格式就有了它的名字。分隔符被称为“分隔符”
该图显示了 CSV 文件的外观。文件的每一行代表表格数据的一行。您可以观察到逗号分隔字段。
为什么要创建 CSV 文件?
处理大量数据的程序创建 CSV 文件,以便从电子表格或数据库中方便地导出数据,并将其导入不同的程序。从程序员的角度来看,CSV 文件很容易处理。任何接受文本文件输入并支持字符串数据操作的编程语言都可以直接处理 CSV 文件。
用 Python 内置的 CSV 库读取 CSV 文件
Python 内置的 CSV 库包含读取和写入 CSV 文件的函数。该库支持各种 csv 格式,并包括用于处理 CSV 文件的对象和代码函数。
读取文件用 csv
用于从 CSV 文件中读取的对象: reader 对象
用于打开 CSV 文件的函数:【open()】
Python 内置的 open() 函数将 CSV 文件作为文本文件打开。该函数提供了一个文件对象,然后该文件对象被传递给 阅读器对象 ,后者进一步处理该文件。
让我们以一个 CSV 文件为例,它存储学生的详细信息作为数据。
文件名: 学生. txt
Python 代码读取此文件: 
输出如下:
阅读器对象 返回的每一行都是一个字符串元素的数组,其中包含删除分隔符后的数据。
将文件读入字典用 csv
我们使用与上面相同的文件。
把它当字典读的代码如下:
注意这里代码的不同。当我们使用字典时,行名写在 行{} 语句中而不是行号中(就像前面的方法一样)。
结果与之前的输出相同:

CSV 文件的第一行包含构建字典的关键字。例如,如果您的 csv 文件中没有这些密钥,那么您可以指定自己的密钥。
阅读器对象可选参数:
阅读器 对象可以在附加参数的帮助下处理不同风格的 CSV 文件。这里讨论其中的一些参数:
- 分隔符 参数指定用于分隔记录中每个字段的字符。默认为逗号(',')。
- quotechar 定义用于表示包含分隔符的字段的字符。此参数的默认值是一个双引号(“”)。
- escapechar 描述在用户不使用引号的情况下,用于转义分隔符的字符。默认情况下没有转义字符。
例如,在上面讨论的【students . txt】文件中,我们要添加另一个字段作为‘日期’
日期的格式本身包含“逗号”,在这种情况下使用“逗号”作为分隔符会造成很多混乱,使处理变得繁琐。为了使用更方便,我们可以指定另一个字符作为分隔符。或者,您可以使用quote char参数将您的数据放在引号中,因为放在引号中的任何数据都会忽略分隔符的功能。如果你想完全取消分隔符的解释,那么你可以使用 escapechar 参数。
用 csv 编写 CSV 文件
所用对象: 作家对象。
使用方法: 。write_row()
quote char可选参数用于定义在书写时哪个字符用于引用字段。 引用 参数可以取以下值:
- 如果 引用 参数的值等于 csv。QUOTE_MINIMAL ,然后是方法 。writerow() 仅在字段包含分隔符或 quotechar 时才会引用字段。此设置是默认情况。
- 如果报价 参数的值等于 csv。【QUOTE _ ALL,然后是方法 。writerow() 引用数据中出现的所有字段 。
- 如果 引用 参数的值等于 csv。QUOTE_NONNUMERIC ,然后是方法 。writerow() 将引用所有包含文本数据的字段,并将所有数值字段转换为浮点数据类型。
- 如果 引用 参数的值等于 csv。QUOTE_NONE ,那么方法 。writerow() 将转义分隔符,而不是引用它们。
用 csv 从字典中编写文件
注意,在 writerow() 字段中,我们还必须提到字段名。
用熊猫库处理 CSV 文件
熊猫 是另一个可用于处理 CSV 文件的库。如果用户有大量数据要分析,建议使用这个库。它是一个开源 python 库,可用于所有 Python 安装。对于使用 熊猫 库来说,最受欢迎的 python 安装之一是配备了 Jupyter notebook 的 Anaconda 发行版。它可以在许多可用工具和数据结构的帮助下处理、共享和分析数据。
在 Anaconda 中安装 熊猫 及其依赖,如下图:

如果您使用 pip/pipenv 进行 python 安装,那么命令如下:

随着 熊猫 库的安装完成,现在让我们学习如何在这个库中读写 csv 文件。
和熊猫一起读 CSV 文件。
与其他库相比,在 熊猫 库中读取 csv 文件非常容易,因为它的代码结构非常紧凑。
文件名: 学生. csv 
df 这里是‘data frame’的简称****pandas . read _ csv()方法打开并分析提供的 CSV 文件,并将数据保存在 DataFrame 中。 打印 数据帧 给出期望的输出。
当我们使用前面提到的方法时,我们可以看到输出的不同。同样,使用 熊猫 库获得的结果具有从‘0’而不是‘1’开始的索引。
用熊猫写 CSV 文件
将数据写入 CSV 文件的代码如下:
文件名: 学生. csv

此处,文件的“名称”列已成为索引列。此外,在写入模式下, 打印(df) 命令更改为 df.to_csv() 。
结论
在当前的数据和信息交换场景中,CSV 文件有着巨大的用途。因此,如果您理解了它们的结构、组成和用法,那么您就准备好统治编程世界了。
应用 CSV 文件评估数据使操作效率日益提高。当与 Python 等编程语言结合时,这些文件的效率增加了数据操作、评估和应用的多样性。Python 中还有其他库可用于处理 CSV 文件。尽管如此,为了让程序员拥有最高效的程序,本文还是讨论了最高效和最紧凑的方法。
如何在 Python 中递归复制文件夹(目录)
原文:https://www.pythoncentral.io/how-to-recursively-copy-a-directory-folder-in-python/
尝试过用 Python 复制目录/文件夹吗?失败过吗?没关系。再试一次!
如果你还没有读过,看看文章如何用 shutil 在 Python 中复制一个文件,获得如何用shutil复制文件的解释。
用 Python 递归复制文件的目录/文件夹
在上面提到的文章中,我们看到了如何用 Python 复制单个文件。我想你会同意,更有用的是将整个目录复制到其他目录的能力。
Python 的shutil模块又一次拯救了我们,它有一个名为copytree的函数来做我们想做的事情。
我们不需要如此大的改变,所以我将稍微修改上面的代码,以便能够复制目录,如下所示:
import shutil
def copyDirectory(src,dest):
try:
shutil . copy tree(src,dest)
#目录相同
除了 shutil。错误为 e:
打印('目录未复制。错误:%s' % e)
#任何表示目录不存在的错误
除了 OSError as e:
print('未复制目录。错误:%s' % e)
好的,很好!几乎和我们复制单个文件的函数一样,但是它只允许复制目录而不是文件,抛出的异常有点不同。太棒了。
用 Python 复制文件和目录
但是如果我们想要一个可靠的函数来复制文件和目录呢?没问题!我们可以写一个简单的,稍微复杂一点的函数。
观察:
import errno
def copy(src,dest):
try:
shutil . copy tree(src,dest)
除 OSError as e:
#如果错误是因为源不是目录引起的
如果 e.errno == errno。ENOTDIR:
shutil.copy(src,dest)
else:
print('目录未复制。错误:%s' % e)
这个函数将复制文件和目录。首先,我们将我们的copytree函数放在一个try块中,以捕捉任何讨厌的异常。如果我们的异常是由于源目录/文件夹实际上是一个文件引起的,那么我们就复制这个文件。简单的东西。
需要注意的是,实际上不可能复制一个目录。您需要递归地遍历目录并基于旧目录创建目录结构,然后将每个子目录中的文件复制到目的地的正确目录中。如果你想自己实现,请看本文中关于如何用 Python 递归遍历目录的例子。
忽略文件和目录
函数shutil.copytree接受一个参数,该参数允许您指定一个函数来返回应该被忽略的目录或文件的列表。
这样做的一个简单示例函数如下:
【python】
def ignore _ function(ignore):
def _ ignore _(path,names):
ignored _ names =[]
if ignore in names:
ignored _ names . append(ignore)
return set(ignored _ names)
return _ ignore _
好的,这个函数是做什么的?嗯,我们指定某种文件或目录名作为参数ignore,它充当names的过滤器。如果ignore在names中,那么我们将它添加到一个ignored_names列表中,该列表向copytree指定跳过哪些文件或目录。
我们将如何使用这个函数?请参见下面我们修改后的复制功能:
def copy(src, dest):
try:
shutil.copytree(src, dest, ignore=ignore_function('specificfile.file'))
except OSError as e:
# If the error was caused because the source wasn't a directory
if e.errno == errno.ENOTDIR:
shutil.copy(src, dest)
else:
print('Directory not copied. Error: %s' % e)
但是如果我们想过滤掉不止一个文件呢?幸运的是,shutil再次为我们提供了掩护!它有一个名为shutil.ignore_patterns的功能,允许我们指定 glob 模式来过滤掉文件和目录。请看下面我们再次修改的复制功能:
def copy(src, dest):
try:
shutil.copytree(src, dest, ignore=ignore_patterns('*.py', '*.sh', 'specificfile.file'))
except OSError as e:
# If the error was caused because the source wasn't a directory
if e.errno == errno.ENOTDIR:
shutil.copy(src, dest)
else:
print('Directory not copied. Error: %s' % e)
这将忽略所有 Python 文件、shell 文件和我们自己的特定文件。ignore_patterns接受指定要忽略的模式的参数,并返回一个copytree可以理解的函数,很像我们的自定义函数ignore_function所做的,但更健壮。
这就是我要和你分享的全部!
和平。
如何在 Python 中重命名(移动)文件
原文:https://www.pythoncentral.io/how-to-rename-move-a-file-in-python/
重命名(在 Python 中称为移动)Python 中的文件非常简单,由于有一个方便的模块叫做shutil,只需几行代码就可以完成。
shutil有一个名为move的函数,它准确地执行函数名所暗示的功能。它将文件或目录从一个位置移动到另一个位置。
这是一个非常简单但完整的例子:
import shutil
def move(src, dest):
shutil.move(src, dest)
简单的东西。该函数接收源文件或目录,并将其移动到目标文件或目录。
shutil.copy vs os.rename
如果文件或目录在当前的本地文件系统上,shutil.move使用os.rename来移动文件或目录。否则,它使用shutil.copy2将文件或目录复制到目的地,然后删除源。
我们之所以用shutil.move而不用os.rename是因为上面的原因。函数shutil.move已经处理了一个文件不在当前文件系统上的情况,它还处理将目录复制到目的地的操作。任何os.rename抛出的异常在shutil.move中也会得到妥善处理,因此无需担心。
shutil.move确实以shutil.Error的形式抛出自己的异常。当目标文件或目录已经存在时,或者当您试图将源文件或目录复制到自身时,它会这样做。
不幸的是,shutil.move中没有选项提供用于测量进度的回调函数。你必须为此编写自己的复制函数,由于需要计算文件数量和测量它们的大小,这可能会慢一点。
真的就这么简单。另一件需要注意的事情是,如果在当前的文件系统上,我们调用move函数的时间将是瞬时的,而当用于移动到一个单独的驱动器时,例如,调用将花费与典型的复制操作相同的时间。
如果你有兴趣了解shutil.move函数是如何实现的,请点击链接获取源代码。
超级短,超级简洁,超级牛逼。
后来的 Pythonistas!
如何在熊猫数据框架中重置索引(快速简单)
原文:https://www.pythoncentral.io/how-to-reset-index-in-a-pandas-dataframe-fast-and-easy/
Python pandas 库中的表格结构也称为数据帧。
这些结构用标签表示行和列。行标签称为索引,列标签称为列索引/标题。
通过过滤和操作大型数据集来创建数据帧。但是这些经过处理的数据帧与它们的原始数据集具有相同的索引。这需要重置数据帧的索引。
重置索引也很有帮助:
- 在预处理阶段,当丢弃缺失值或过滤数据时。除了使数据帧变小之外,它还使索引变得混乱。
- 当索引标签不能提供太多关于数据的信息时。
- 当索引需要被当作一个普通的 DataFrame 列时。
您可以在 pandas 中使用 reset_index()方法来重置数据帧中的索引。这样做可以将数据帧的原始索引转换为列。
在这篇文章中,我们将带你了解如何重置熊猫数据帧。
熊猫基础知识. reset_index
除了将数据帧的索引重置为默认索引之外,reset_index()方法还有助于删除具有多索引的数据帧的一个或多个级别。
该方法的语法为:
pandas.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill= ”)
其中参数具有以下含义:
| 参数 | 可接受的数据类型 | 默认值 | 描述 |
| 级别 | int,str,tuple,list | 无 | 默认删除所有级别。如果提到级别,它会删除这些级别。 |
| 下降 | bool | 假 | 默认情况下将旧索引添加到数据帧中。如果值更改为 True,则不会添加它。 |
| 原地 | 布尔 | 假 | 对当前数据帧对象进行修改 |
| col_level | int,str | 0 | 确定标签需要插入的层级(如果涉及多个层级)。默认情况下,标签插入到第一层(0)中。 |
| col_fill | 物体 | | 如果列有多个级别,它确定如何命名级别。如果值为 None,则重复索引名称。 |
The。如果 inplace = True,reset_index()方法返回 None。否则,返回具有新索引的数据帧。
用重设索引。reset_index()
使用。重置索引的 reset_index()方法与将该方法链接到 DataFrame 对象一样简单。
你必须从创建一个数据帧开始,就像这样:
import pandas as pd
import numpy as np
import random
# We're making a DataFrame with an initial index. It represents marks out of 50.
df = pd.DataFrame({
'Global Finance': [44, 29, 50, 17, 36],
'Politics': [31, 43, 21, 42, 17],
'Family Enterprise': [30, 30, 16, 46, 41]
}, index=['Leonard', 'Brayan', 'Wendy', 'Nathaniel', 'Edwin']
)
df
在表格形式中,数据帧看起来像这样:
| | 全球金融 | 政治 | 家族企业 |
| 伦纳德 | 44 | 31 | 30 |
| 布雷安 | 29 | 43 | 30 |
| 温迪 | 50 | 21 | 16 |
| 纳撒尼尔 | 71 | 42 | 46 |
| 埃德温 | 36 | 17 | 41 |
重置指数现在只需打个电话就行了。reset_index(),像这样:
df.reset_index()
索引将作为名为“index”的新列应用于数据帧它从零开始,沿着数据帧的长度继续。它看起来像这样:
| | 索引 | 全球金融 | 政治 | 家族企业 |
| 0 | 伦纳德 | 44 | 31 | 30 |
| 1 | 布雷安 | 29 | 43 | 30 |
| 2 | 温迪 | 50 | 21 | 16 |
| 3 | 纳撒尼尔 | 71 | 42 | 46 |
| 4 | 埃德温 | 36 | 17 | 41 |
保持对数据帧的改变
您在上面看到的输出表明数据帧的索引已经被更改。但是,如果您运行“df”,您将会看到更改没有持久化,并且输出没有索引。
如果您希望更改持续,您必须使用“inplace”参数,将其值设置为“True”下面是它运行的样子:
df.reset_index(inplace=True)
df
这段代码的输出将是:
| | 索引 | 全球金融 | 政治 | 家族企业 |
| 0 | 伦纳德 | 44 | 31 | 30 |
| 1 | 布雷安 | 29 | 43 | 30 |
| 2 | 温迪 | 50 | 21 | 16 |
| 3 | 纳撒尼尔 | 71 | 42 | 46 |
| 4 | 埃德温 | 36 | 17 | 41 |
用命名索引重置数据帧中的索引
如果数据帧具有命名索引,即具有名称的索引,则重置索引将导致所讨论的命名索引成为数据帧中的列名。
让我们看看这是如何工作的,首先创建一个带有命名索引的数据帧:
namedIndex = pd.Series(['Leonard', 'Brayan', 'Wendy', 'Nathaniel', 'Edwin'], name='initial_index') # Creating a series and giving it a name
df = pd.DataFrame({
'Global Finance': [44, 29, 50, 17, 36],
'Politics': [31, 43, 21, 42, 17],
'Family Enterprise': [30, 30, 16, 46, 41]
}, index=['Leonard', 'Brayan', 'Wendy', 'Nathaniel', 'Edwin']
) # Creating the DataFrame, then passing the named series as the index
df
这个数据帧应该是这样的:
| | 全球金融 | 政治 | 家族企业 |
| 初始 _ 索引 | | | |
| 伦纳德 | 44 | 31 | 30 |
| 布雷安 | 29 | 43 | 30 |
| 温迪 | 50 | 21 | 16 |
| 纳撒尼尔 | 71 | 42 | 46 |
| 埃德温 | 36 | 17 | 41 |
执行 df.reset_index 会将表中的“initial_index”条目作为数据帧中的列名,如下:
| | 初始 _ 索引 | 全球金融 | 政治 | 家族企业 |
| 0 | 伦纳德 | 44 | 31 | 30 |
| 1 | 布雷安 | 29 | 43 | 30 |
| 2 | 温迪 | 50 | 21 | 16 |
| 3 | 纳撒尼尔 | 71 | 42 | 46 |
| 4 | 埃德温 | 36 | 17 | 41 |
重置数据帧中的多级索引
让我们来看看数据帧中的多级索引:
# Creating a multi-level index
newIndex = pd.MultiIndex.from_tuples(
[('BBA', 'Leonard'),
('BBA', 'Brayan'),
('MBA', 'Wendy'),
('MBA', 'Nathaniel'),
('BSC', 'Edwin')
],
names= ['Branch', 'Name'])
# Creating multi-level columns
columns = pd.MultiIndex.from_tuples(
[('subject1', 'Global Finance'),
('subject2', 'Politics'),
('subject3', 'Family Enterprise')
])
df = pd.DataFrame([
(45, 31, 30),
(29, 21, 30),
(50, 21, 16),
(17, 42, 46),
(36, 17, 41)
], index=newIndex,
columns=columns)
df
其输出为:
| | | 主题 1 | 主题 2 | 主题 3 |
| | | 全球金融 | 政治 | 家族企业 |
| 分支 | 名称 | | | |
| BBA | 伦纳德 | 44 | 31 | 30 |
| 布雷安 | 29 | 43 | 30 |
| MBA | 温迪 | 50 | 21 | 16 |
| 纳撒尼尔 | 71 | 42 | 46 |
| BSC | 埃德温 | 36 | 17 | 41 |
分支级别映射到多行,使其成为多级索引。应用。reset_index()函数将级别合并为数据帧中的列。
所以,运行“df.reset_index()”会这样:
| | | | 主题 1 | 主题 2 | 主题 3 |
| | | | 全球金融 | 政治 | 家族企业 |
| | 分支 | 名称 | | | |
| 0 | BBA | 伦纳德 | 44 | 31 | 30 |
| 1 | BBA | 布雷安 | 29 | 43 | 30 |
| 2 | MBA | 温迪 | 50 | 21 | 16 |
| 3 | MBA | 纳撒尼尔 | 71 | 42 | 46 |
| 4 | BSC | 埃德温 | 36 | 17 | 41 |
您也可以使用级别参数重置分支级别的索引,如下:
df.reset_index(level='Branch')
产生输出:
| | | 主题 1 | 主题 2 | 主题 3 |
| | | 全球金融 | 政治 | 家族企业 |
| 名称 | 分支 | | | |
| 伦纳德 | BBA | 44 | 31 | 30 |
| 布雷安 | BBA | 29 | 43 | 30 |
| 温迪 | MBA | 50 | 21 | 16 |
| 纳撒尼尔 | MBA | 71 | 42 | 46 |
| 埃德温 | BSC | 36 | 17 | 41 |
如何在 Python 中舍入数字:简单步骤
原文:https://www.pythoncentral.io/how-to-round-numbers-in-python-easy-steps/
Python 被认为是最容易学习的编程语言之一,拥有庞大的标准库。更不用说,它提供了以不同方式处理问题的灵活性。
典型的例子:四舍五入一个数字。
在 Python 中,有几种不同的方法可以舍入一个数字。在本文中,我们将从内置的 round()函数开始,探讨四种方法。
用 round()函数对数字进行舍入
在 Python 中,使用 round()函数是舍入数字的最直接的方法之一。它接受两个数字参数,“n”和“ndigits”
它处理这些输入,将保存在“n”中的数字舍入到“ndigits”默认情况下,“ndigits”参数的值为零。所以,如果你不给它任何值,“n”中的数字就会变成一个整数。
如果你以前处理过数字舍入,很有可能你会这样处理:
- 通过将 n 的小数点移动 p 位,将数字“n”四舍五入到“p”位。n 中的值乘以 10 p 得到值“m”
- 然后你看 m 的第一位小数。假设这个数是“d”,如果“d”小于 5,你把 m 向下取整;否则,你就围捕我。
- 最后,你将 m 除以 10 p ,将小数点后的 p 位移回。
这个算法非常简单。即使你通常不这样处理舍入,你也应该能够理解它。
它所做的只是取小数点后的最后一位数字,如果该数字小于 5,则向下取整。如果大于 5,算法将其向上取整。
这意味着如果你试图用这个算法来舍入 2.5,它会舍入到 3。但是如果你试图用它来舍入 1.64,它会被舍入到 1.6。
但是 round()函数不是这样工作的。
下面是当你试图用函数舍入 2.5 时会发生的情况。
>>> round(2.5)
2
令人惊讶,对吧?但是当你试图用同样的函数舍入 1.5 会发生什么呢?
>>> round(1.5)
2
这不是你所期望的。但是这些输出不会引起恐慌——您不必在 Python bug tracker 上提出问题。这是因为该方法被设计成以这种方式工作。
这是因为 Python 使用 IEEE 754 标准进行舍入。这种方法被称为“银行家舍入”,其背后的思想是将数字舍入到最接近的值,甚至是最不重要的数字。
如果你认为这种舍入策略不符合你的需要,在 Python 中还有其他三种方法可以舍入一个数字。
通过截断舍入数字
截断是舍入数字最简单的方法,但也是最原始的方法。截断背后的思想是给定位置之后的所有数字都被替换为零。
| 值 | 截断为 | 结果 |
| 14。568 | 十位数 | 10 |
| 14。568 | 一锅端 | 14 |
| 14。568 | 十分之一位 | 14.5 |
| 14。568 | 第百名 | 14.56 |
截断算法的作用如下:
- 你提供的数字乘以 1000。这将小数点向右移动三位。
- 新数的整数部分用 int()取。
- 这个数字除以 1000,将小数位向后移三位。
这个过程很容易概括——你要做的就是用 10 p 代替“1000”,用“p”表示要截断的小数位数。
下面是这个函数的样子:
def truncate(n, decimals=0):
multiplier = 10 ** decimals
return int(n * multiplier) / multiplier
这个 truncate()函数中的第二个参数默认为 0。如果没有传递第二个参数,函数将返回传递给它的数字的整数部分。
您可以使用正数和负数来使用此功能:
>>> truncate(12.5)
12.0
>>> truncate(-5.963, 1)
-5.9
>>> truncate(1.625, 2)
1.62
>>> truncate(125.6, -1)
120.0
>>> truncate(-1374.25, -3)
-1000.0
你可能已经注意到截断一个正数会导致四舍五入。另一方面,截断负数会导致四舍五入。
如果你正在编写的程序需要你特别地向上或向下舍入数字,你可以为这两种应用程序编写程序。
让我们来看看这些舍入方法是什么样子的。
四舍五入数字
将一个数向上舍入的想法是将它向上舍入到下一个更高的数,直到一个特定的位数。下面的表格总结了这一点:
| 值 | 截断为 | 结果 |
| 14。568 | 十位数 | 20 |
| 14。568 | 一锅端 | 15 |
| 14。568 | 十分之一位 | 14.6 |
| 14。568 | 第百名 | 14.57 |
在 Python 中,可以使用 math 模块中的 ceil()函数对数字进行四舍五入。您可能已经猜到,ceil()方法的名称来源于单词“ceiling”
数学术语上限描述的是大于或等于给定数字的最接近的整数。同理,小于或等于给定数字的最接近的整数就是它的底数。
你必须注意,位于两个整数之间的数本身并不是整数。更重要的是,两个区间的上限是两个区间中较大的一个。让我们用一个例子来回顾一下这个概念。
数字 2.2 位于 2 和 3 之间,所以它的地板是 2,天花板是 3。您可能知道 ceiling 函数的概念,它将每个数字映射到它的上限。
该函数也接受整数,将它们的上限映射到整数本身。Python 还提供了上限函数 math.ceil(),该函数返回大于或等于输入的最接近的整数。
>>> import math
>>> math.ceil(3.2)
4
>>> math.ceil(4)
4
>>> math.ceil(-0.7)
0
因此,这是一个优秀的内置 Python 函数,您可以使用它来舍入数字。但是你也可以选择编写自己的函数,比如:
def round_up(n, decimals=0):
multiplier = 10 ** decimals
return math.ceil(n * multiplier) / multiplier
这个 round_up()函数看起来很像 truncate()函数。这是因为它们的算法相当相似。
它将 n 中的小数点向右移动适当的位数。这是通过将 n 乘以 10 **小数来实现的。
使用 math.ceil()函数将导出的值向上舍入到最接近的整数。然后,程序通过将该值除以 10 **小数来将小数点向左移动。
大多数舍入数字的技术都有相似的步骤——小数点被移动,一些舍入方法被应用,然后小数点被移回。
这种舍入数字的模式非常流行,因为这是人类想出的舍入数字的最明显的心算方法。
这里有几个上舍入函数的实例:
>>> round_up(2.1)
3.0
>>> round_up(4.23, 1)
4.3
>>> round_up(7.543, 2)
7.55
同样值得注意的是,您可以向算法的“小数”部分传递一个负值,就像在 truncate()中一样。这是如何工作的:
>>> round_up(32.45, -1)
40.0
>>> round_up(1452, -2)
1500
当一个负数以这种方式传递给函数时,函数中写的第一个参数将其四舍五入到小数点左边适当的位数。
了解了这一点,您是否会好奇向 round_up()传递一个负值会做什么?
我们来看看:
>>> round_up(-1.5)
-1.0
在对数字进行舍入时,你可能会期望围绕零对称。这可能会让你认为就像 1.5 被舍入到 2 一样,-1.5 必须被舍入到-2.0。
你需要记住 math.ceil()函数是如何工作的,以便理解真实的结果。
这有助于记住向上取整和向下取整的区别。
想象一个从-5 到 5 的数字范围。向上舍入意味着值从左向右跳跃。相反,向下舍入意味着值从右向左跳跃。
向下舍入数字
向下舍入是向上舍入的反义词。
向下舍入一个数字的想法是将它舍入到下一个更小的数字,直到一个特定的位数。
下面的表格总结了这一点:
| 值 | 截断为 | 结果 |
| 14。568 | 十位数 | 10 |
| 14。568 | 一锅端 | 14 |
| 14。568 | 十分之一位 | 14.5 |
| 14。568 | 第百名 | 14.56 |
在 Python 中向下舍入数字或多或少涉及 round_up()和 truncate()使用的相同算法。你移动小数点,四舍五入到整数,然后移回小数点。
Python 的好处在于标准库附带了 math.floor()方法,它的作用与 ceil()方法相反。在移动小数点后,它舍入到有问题的数字的下限。
>>> math.floor(2.2)
2
>>> math.floor(-1.5)
-2
现在让我们看看如何编写 round_down()函数:
def round_down(n, decimals=0):
multiplier = 10 ** decimals
return math.floor(n * multiplier) / multiplier
所以,你可以看到,这个程序和 round_up()程序是一样的,只是 math.ceil()被 math.floor()代替了。
让我们试着在 round_down()中放几个不同的值:
>>> round_down(2.5)
2
>>> round_down(3.37, 1)
3.3
>>> round_down(-0.7)
-1
编写一个 round_up()或 round_down()函数是快速舍入数字的一个很好的方法。但是请记住,对数据的影响是极端的。
如果在大型数据集中使用这些函数,数据集可能会变得非常不精确。精度的降低会极大地改变使用数据进行的计算。
如何运行 Python 脚本
范围
在本文中,我们将了解更多关于如何运行 Python 脚本的信息。您应该熟悉 Python 语法。如果你对 Python 了解不多,查看我们的指南这里。你需要在你的机器上安装 Python。要知道如何在你的系统上安装 python,请查看我们的安装指南。
我们将讨论:
- 如何更新 python
- 运行 Python 脚本
- 在终端中运行 python
- Python 中的注释
如何更新 Python:
我们在上一篇文章中讨论了如何安装 Python。总是建议使用最新版本的 Python。这会让你避免很多问题。在每次更新中,Python 都添加了新的修复和增强。更新 python 将使利用新的修复。要更新 Python 版本,您需要首先检查您的操作系统。
在 windows 中更新 python
- 访问 Python 官方页面
- 下载最新的 Python 版本
- 它会下载一个. exe 文件。
- 打开它,然后像安装一样继续。
- 它将更新你机器上安装的 Python 版本。
为 windows 设置 python
在 Ubuntu 中更新 Python
在 Ubuntu 中更新 Python 是一个简单的命令。
-
更新 apt 包管理器
sudo apt update && sudo apt-get upgrade -
安装最新版本的 Python。
sudo apt install python3.8.2
这将把 Python 版本更新到 3.8.2。
在 Mac 中更新 Python
- 访问 Python 官方页面
- 下载最新的 Python 版本
- 它会下载一个文件。
- 打开它,然后像安装一样继续。
- 它会更新你 macOS 上安装的 Python 版本。
全局更新 Python 可能不是一个好主意。我们在上一篇文章中了解到,在 Python 项目中最好使用虚拟环境。在大多数情况下,您只需要在虚拟环境中更新 python 版本。
python -m venv --upgrade <env_directory>
这只会更新虚拟环境中的 python 版本。
确保安装了 Python 之后。而且是最新版本。现在您可以运行 Python 脚本了。
运行 Python 脚本
通常,python 脚本看起来像这样
import os
def main():
path = input("Enter folder path: ")
folder = os.chdir(path)
for count, filename in enumerate(os.listdir()):
dst ="NewYork" + str(count) + ".jpeg"
os.rename(src, dst)
if __name__ == '__main__':
main()
它的主要功能是脚本逻辑。这段代码是脚本的主要功能。它实际上定义了你需要做什么。调用主函数的另一部分是
if __name__ == '__main__':
main()
首先,定义包含你的代码的函数。Python 将输入 if name == 'main ':条件并调用 main()函数。我们需要知道幕后发生了什么。
- 解释器读取 python 源文件。解释器设置 name 特殊变量,并将其赋给“main”字符串。
- 这将告诉解释器运行它内部调用的函数。在我们的例子中,它是 main()函数。
脚本是 Python 最大的特性之一。为了实现这一点,Python 需要使它的代码在不同的地方可执行。
在终端中运行 python 脚本
您可以从终端运行 Python 代码。可以写 python <file_name.py>。这将告诉 Python 解释器运行这个文件中的代码。</file_name.py>
python my_script.py
这将调用脚本中的 main 函数并执行逻辑。如果您需要从终端自动完成一些工作,像这样的功能非常有用。假设您是 DevOps,每次启动机器时,您都需要记录时间和用户。您可以编写 Python 代码来检查登录用户的时间和用户名。它会在每次有人登录并运行机器时用这些数据更新日志文件。在这种情况下,您不能手动打开文件。您将在系统启动命令中添加运行该脚本的命令。
您可以在终端中打开 Python shell。它会帮助你直接执行你的代码。有了这个,你就不需要每次想测试新的变化时都要重新运行脚本了。您可以编写您的脚本,并在同一个地方进行测试。这会帮助你更快地开发脚本。
Python 脚本中的注释
Python 因其可读性而大放异彩。注释可以帮助你解释更多从代码中难以理解的逻辑。添加注释有助于您的同事理解复杂的逻辑。评论在团队中很有帮助。它帮助团队成员了解代码每一部分的原因。这使得工作变得容易,并使开发过程更快。在 python 中添加注释只是通过添加 hash。
# the below code will print items from 1 to 5
for x in range(1, 5):
print(x)
请注意,#符号后面的代码将不会运行。Python 将这段代码视为注释。它不会执行它
结论
您可以从系统 GUI 或终端运行 Python 脚本。看你想怎么用了。Python 中的注释用于在代码中添加人类可读的文本。Python 注释以散列符号开始。Python 解释器跳过散列文本。更新 python 很重要。它让您了解最新的修补程序。您可以在整个系统中全局更新 Python。最有效的是在你的虚拟环境中更新 Python 版本。在大型项目中,它有助于保持事物的安全,而不是破坏它。
如何在 Python 中查看一个字符串是否包含另一个字符串
原文:https://www.pythoncentral.io/how-to-see-if-a-string-contains-another-string-in-python/
曾经想看看一个字符串是否包含 Python 中的一个字符串?以为会像 C 一样复杂?再想想!
Python 以一种非常易读和易于实现的方式实现了这个特性。有两种方法,有些人会更喜欢其中一种,所以我会让你决定你更喜欢哪一种。
第一种方式:使用 Python 的 in 关键字
检查一个字符串是否包含另一个字符串的第一种方法是使用in语法。in接受两个“参数”,一个在左边,一个在右边,如果左边的参数包含在右边的参数中,则返回True。
这里有一个例子:
>>> s = "It's not safe to go alone. Take this."
>>> 'safe' in s
True
>>> 'blah' in s
False
>>> if 'safe' in s:
... print('The message is safe.')
The message is safe.
你明白了。这就是全部了。关键字in在后台为你完成所有神奇的工作,所以不用担心for循环或任何类似的事情。
第二种方式:使用 Python 的 str.find
这种方式是不太 Pythonic 化的方式,但是仍然被接受。它更长,也更令人困惑,但它仍然完成了任务。
这种方式要求我们在字符串上调用find方法,并检查它的返回代码。
下面是我们的例子,使用上面定义的字符串:
>>> if s.find('safe') != -1:
... print('This message is safe.')
This message is safe.
就像我上面说的,这种方式不太清晰,但它仍然完成了工作。find方法返回字符串在字符串中的位置,如果没有找到则返回-1。所以我们简单地检查位置是否不是-1,然后继续我们的快乐之路。
本文的长度表明了用 Python 检查字符串中的字符串是多么容易,我希望它能让您相信,就编写更多 Python 代码而言,第一种方法远远好于第二种方法。
暂时先这样。
如何在 Python 中切片定制对象/类
原文:https://www.pythoncentral.io/how-to-slice-custom-objects-classes-in-python/
关于切片的介绍,请查看文章如何在 Python 中对列表/数组和元组进行切片。
分割你自己的 Python 对象
好了,这一切都很酷,现在我们知道如何切片。但是我们如何分割我们自己的物体呢?如果我实现了一个有列表或者自定义数据结构的对象,我如何使它可切片?
首先,我们定义我们的自定义数据结构类。
from collections import Sequence
class my structure(Sequence):
def _ _ init _ _(self):
self . data =[]
def __len__(self):
返回 len(self.data)
def append(自身,项目):
自身.数据. append(项目)
定义移除(self,item):
self . data . remove(item)
def __repr__(self):
返回 str(self.data)
def __getitem__(self,sliced):
返回 self.data[sliced]
这里,我们声明一个带有列表的类作为我们结构的后端。并没有做那么多,但是你可以添加、删除和获取项目,所以从某种意义上来说它还是有用的。这里我们唯一需要特别注意的方法是__getitem__方法。每当我们试图从我们的结构中获取一个项目时,就会调用这个方法。当我们调用structure[0]时,这实际上是在后台调用__getitem__方法,并返回该方法返回的任何内容。这在实现列表样式对象时非常有用。
让我们创建自定义对象,向其添加一个项目,并尝试获取它。
>>> m = MyStructure()
>>> m.append('First element')
>>> print(m[0])
First element
是啊!我们做到了!我们分配了我们的元素,并正确地取回了它。很好。现在是切片的部分!
>>> m.append('Second element')
>>> m.append('Third element')
>>> m
['First element', 'Second element', 'Third element']
>>> m[1:3]
['Second element', 'Third element']
厉害!因为使用了list的功能,我们基本上可以免费获得所有切片。
这真是太神奇了。Python 很神奇。来点更复杂的怎么样?使用字典作为我们的主要数据结构怎么样?
好吧。让我们定义另一个使用字典的类。
class MyDictStructure(Sequence):
def __init__(self):
# New dictionary this time
self.data = {}
def __len__(self):
返回 len(self.data)
def append(self,item):
self . data[len(self)]= item
def remove(self,item):
if item in self . data . values():
del self . data[item]
def __repr__(self):
返回 str(self.data)
def __getitem__(self,sliced):
sliced keys = self . data . keys()【sliced】
data = { k:self . data[k]for key in sliced keys }
返回数据
好吧,那我们在这里做什么?基本上和我们在MyStructure中做的一样,但是这一次我们使用字典作为我们的主要结构,并且__getitem__方法定义已经改变。让我解释一下__getitem__发生了什么变化。
首先,我们获得传递给__getitem__的slice对象,并使用它来分割字典的键值。然后,使用字典理解,我们使用我们的分片键将所有的分片键和值放入一个新字典中。这给了我们一个很好的切片字典,我们可以用它来做任何我们喜欢的事情。
这就是它的作用:
>>> m = MyDictStructure()
>>> m.append('First element')
>>> m.append('Second element')
>>> m.append('Third element')
>>> m
{0: 'First element', 1: 'Second element', 2: 'Third element'}
>>> # slicing
>>> m[1:3]
{1: 'Second element', 2: 'Third element'}
仅此而已。简单、优雅、强大。
如果你想知道如何分割字符串,在另一篇名为如何在 Python 中从字符串中获取子字符串——分割字符串的文章中有所涉及。
目前就这些。希望你喜欢学习切片,我希望它会帮助你的追求。
再见。
如何在 Python 中切片列表/数组和元组
原文:https://www.pythoncentral.io/how-to-slice-listsarrays-and-tuples-in-python/
所以你已经有了一个列表、元组或数组,你想从中获得特定的子元素集合,而不需要任何冗长的循环?
Python 有一个惊人的特性,叫做切片。切片不仅可以用于列表、元组或数组,还可以用于定制数据结构,使用切片对象,这将在本文后面使用。
理解 Python 切片语法
为了理解 Python 中 slice 函数的工作原理,你有必要理解什么是索引。
在 Python 中,可以将 slice 函数用于几种不同的数据类型,包括列表、元组和字符串。这是因为 Python 在它们中使用了索引的概念。
类似列表的数据类型中的字符或元素的“索引”是字符或元素在数据类型中的位置。不管数据类型包含什么数据,索引值总是从零开始,以列表中的项数减一结束。
Python 还使用了负索引的概念,使数据更容易访问。使用负索引,Python 用户可以从容器的末尾而不是开头访问数据类型中的数据。
切片的语法为:
[python]
slice(start, end, step)
[/python]
切片功能同时接受多达三个参数。start 参数是可选的,它指示要开始对数据类型进行切片的容器的索引。如果没有提供值,则 start 的值默认为 【无】 。
另一方面,输入 stop 参数是强制性的,因为它向 Python 指示切片应该发生的索引。默认情况下,Python 将在值“stop - 1”处停止切片
换句话说,如果使用 slice 函数时停止值为 5,Python 将只返回值,直到索引值为 4。
Python 接受的最后一个参数叫做 step,可以根据需要随意输入。它是一个整数值,向 Python 表明当对列表进行切片时,用户希望在索引之间增加多少。默认的增量是 1,但是用户可以在 step 中放入任何适用的正整数。
切片 Python 列表/数组和元组语法
让我们从一个正常的日常清单开始。
[python]
>>> a = [1, 2, 3, 4, 5, 6, 7, 8]
[/python]
没什么疯狂的,只是一个从 1 到 8 的普通列表。现在假设我们真的希望子元素 2、3 和 4 在一个新的列表中返回。我们如何做到这一点?
不是用一个for循环,就是这样。这是 Pythonic 式的做事方式:
[python]
>>> a[1:4]
[2, 3, 4]
[/python]
这正是我们想要的结果。那个语法到底是什么意思?好问题。
我来解释一下。1表示从列表中的第二个元素开始(注意切片索引从0开始)。4表示在列表的第五个元素处结束,但不包括它。中间的冒号是 Python 的列表识别我们想要使用切片来获取列表中的对象的方式。
高级 Python 切片(列表、元组和数组)增量
我们还可以添加一个可选的第二子句,它允许我们设置列表的索引在我们设置的索引之间如何递增。
在上面的例子中,假设我们不希望返回难看的3,我们只希望列表中有好的偶数。很简单。
[python]
>>> a[1:4:2]
[2, 4]
[/python]
看,就这么简单。最后一个冒号告诉 Python 我们想要选择切片增量。默认情况下,Python 将这个增量设置为1,但是数字末尾的额外冒号允许我们指定它是什么。
Python 逆向切片(列表、元组和数组)
好吧,如果我们想让我们的列表倒过来,只是为了好玩呢?让我们尝试一些疯狂的事情。
[python]
>>> a[::-1]
[8, 7, 6, 5, 4, 3, 2, 1]
[/python]
什么?!那是什么鬼东西?
列表在切片时有一个默认的功能。如果第一个冒号前没有值,则意味着从列表的起始索引开始。如果第一个冒号后没有值,就意味着一直到列表的末尾。这为我们节省了时间,这样我们就不必手动指定len(a)作为结束索引。
好吧。我最后偷偷溜了进去?这意味着每次增加索引-1,意味着它将通过向后遍历列表。如果想让偶数索引倒退,可以跳过每隔一个元素,将迭代设置为-2。简单。
切片 Python 元组
上面的一切也适用于元组。完全相同的语法和完全相同的做事方式。我举个例子只是为了说明确实是一样的。
[python]
>>> t = (2, 5, 7, 9, 10, 11, 12)
>>> t[2:4]
(7, 9)
[/python]
仅此而已。简单、优雅、强大。
使用 Python 切片对象
还有一种更容易理解的语法形式可以使用。Python 中有称为slice对象的对象,可以用来代替上面的冒号语法。
这里有一个例子:
[python]
>>> a = [1, 2, 3, 4, 5]
>>> sliceObj = slice(1, 3)
>>> a[sliceObj]
[2, 3]
[/python]
slice对象初始化接受 3 个参数,最后一个是可选的索引增量。一般的方法格式是:slice(start, stop, increment),应用于列表或元组时类似于start:stop:increment。
就是这样!
Python 切片示例
为了帮助你理解如何使用 slice,这里有一些例子:
#1 基本切片示例
让我们假设你有一个字符串列表,如下:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
[/python]
下面的代码使用 slice 函数从条目列表中导出一个子列表:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
sub_items = items[1:4]
print(sub_items)
[/python]
代码的输出是:
[python]
['bike', 'house', 'bank']
[/python]
由于起始索引是 1,Python 以‘bike’开始切片另一方面,结束索引是 4,所以切片在“bank”处停止列表
由于这个原因,代码的最终结果是一个包含三项的列表:自行车、房子和银行。因为这段代码没有使用 step,所以 slice 函数接受该范围内的所有值,并且不跳过任何元素。
#2 用 Python Slice 切片列表中的前“N”个元素
使用 slice 从列表中获取前“N”个元素就像使用下面的语法一样简单:
[python]
list[:n]
[/python]
我们以之前的例子同一个列表为例,通过切片输出列表的前三个元素:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
sub_items = items[:3]
print(sub_items)
[/python]
代码将输出以下结果:
[python]
['car', 'bike', 'house']
[/python]
注意项目[:3]如何与项目[0:3] 相同
#3 用 Python Slice 从列表中获取最后“N”个元素
这个和上一个例子差不多,只是我们可以要求后三个要素,而不是要求前三个要素。
下面是我们如何处理上一个例子中的列表:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
sub_items = items[-3:]
print(sub_items)
[/python]
该代码将为我们提供以下结果:
[python]
['purse', 'photo', 'box']
[/python]
#4 使用 Python 对列表中的每“n”个元素进行切片
为此,我们必须使用 step 参数并返回我们想要的子列表。使用与之前相同的列表,并假设我们希望代码每隔一个元素返回一次:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
sub_items = items[::2]
print(sub_items)
[/python]
该代码将显示以下结果:
[python]
['car', 'house', 'purse', 'box']
[/python]
#5 使用 Python 切片反转列表
slice 函数使得反转列表变得异常简单。你只需要给 slice 函数一个负的步长,函数就会从列表的末尾到开头列出元素——反过来。
继续我们之前使用的示例列表:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
reversed_items = items[::-1]
print(reversed_items)
[/python]
这将为我们提供输出:
[python]
['box', 'photo', 'purse', 'bank', 'house', 'bike', 'car']
[/python]
#6 使用 Python 切片替换列表的一部分
除了可以提取列表的一部分,slice 函数还可以让你很容易地改变列表中的元素。
在下面的代码中,我们将列表的前两个元素更改为两个新值:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
items[0:2] = ['new car', 'new bike']
print(items)
[/python]
代码的输出是:
[python]
['new car', 'new bike', 'house', 'bank', 'purse', 'photo', 'box']
[/python]
#7 用切片部分替换列表并调整其大小
使用 slice 函数改变元素和向列表中添加新元素非常容易:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
print("The list has {len{items)} elements")
items[0:2] = ['new car', 'new bike', 'new watch']
print(items)
print ("The list now has {len(items)} elements")
[/python]
该代码给出以下输出:
[python]
The list has 7 elements
['new car', 'new bike', 'new watch', 'house', 'bank', 'purse', 'photo', 'box']
The list has 8 elements
[/python]
#8 使用切片从列表中删除元素
使用我们一直在使用的示例列表,下面是如何使用 slice 函数从列表中删除元素:
[python]
items = ['car', 'bike', 'house', 'bank', 'purse', 'photo', 'box']
del items[2:4]
print(items)
[/python]
代码的输出是:
[python]
['car', 'bike', 'purse', 'photo', 'box']
[/python]
如果你想知道如何分割字符串,在另一篇名为如何在 Python 中从字符串中获取子字符串——分割字符串的文章中有所涉及。
目前就这些。希望你喜欢学习切片,我希望它会帮助你的追求。
再见。
如何为 Python 新手解决 Python Bugs
原文:https://www.pythoncentral.io/how-to-solve-python-bugs-for-python-novices/
不管一个人如何学习编写 Python,除非他们花很长时间学习编码,否则修复 bug 的过程不会变得直观。
许多 Python 新手在他们编写的代码不起作用时往往会感到停滞不前和沮丧,他们也不知道哪里出了问题。
我们列出了十个关于修复 bug 的建议,来帮助你改进代码故障排除的方法。
这些技巧将教会你在整个编码生涯中能够使用的基础知识。
如何为 Python 新手解决 Python Bugs】
这里为 Python 新手提供十个关于解决 Python bugs 的初学者小技巧。
#1 在已经工作的代码上构建
即使是最好的程序员有时也会怀疑他们编写 Python 程序的方法是否正确。
因此,当有疑问时,看看别人已经运行的代码是个好主意。编码有一个陡峭的学习曲线;最初,最好依赖现有的结构,并根据需要进行调整。
如果你正在从一本书或一个在线课程中学习编写 Python,你将有机会使用许多参考程序。
然而,如果你在独立完成一个项目,你必须试着用谷歌搜索一个脚本来完成你想做的事情。在对代码进行任何更改之前,运行代码并验证它是否正常工作。
总是做一些小的改动,并在每一步进行测试,看看你的代码是否引入了任何错误。
#2 经常使用打印功能
要理解代码,你应该知道每一行执行时变量的值。如果不确定,使用 print 函数是了解变量值的一个很好的方法。
运行程序,并查看控制台,看看这些值是如何变化的。您可能会发现变量被设置为 null 或其他意外值。
最好在打印变量之前打印一个固定的字符串。这样,您的打印语句就不会一起运行,并且您可以知道哪个变量在哪里被打印。
在一些程序中,你可能很难判断一段代码是否正在运行。像“running”或“got here”这样简单的打印语句就足以确定程序的控制流中是否有错误。检查 if 语句和 for 循环是否不一致。
#3 注释掉代码
像大多数编程语言一样,Python 允许你发表评论。注释是开发人员在代码中做笔记的一种方法。然而,当 Python 试图执行代码时,注释中的文本会被忽略。
你可以使用这个特性来暂时阻止一些代码被语言运行时检测到,而不用从文件中删除它们。这被称为“注释掉”代码。
这样做很简单,只需将注释字符“#”放在不想让运行时检测的代码行的开头。
如果你正在处理一个很长的脚本,你可以注释掉与你正在实现的改变无关的代码块。这样,程序可以运行得更快,并允许您在程序的剩余部分查找错误。
小心使用这个特性是很重要的,因为很容易注释掉设置程序后面要使用的变量的代码。注释中的所有文本都会被完全跳过,因此程序中后面的语句将无法访问被注释掉的行中的变量集。
此外,在测试完代码的其余部分后,你还必须记得删除注释字符。
#4 每当你做出改变时运行代码
无论你是否从一个空白文件开始,不停地修改代码一个小时然后才运行它都不是一个好策略。
你很可能会被几个相互叠加的小错误搞糊涂——如果你慢慢来的话,大部分错误都是可以避免的。
这种情况下最糟糕的事情是,你可能需要更长的时间来剥离你所做的事情,并找出你错在哪里。
你花在编码而不是测试上的时间越长,可能出错的代码就越多。
由于不可能在每次更新时都编码和测试程序并保持高效,所以每隔几分钟运行一次脚本是最好的。
最优秀的程序员记得每次他们运行代码时,都会收到关于他们工作的反馈。他们能够确定他们是否正在把项目引向正确的方向,或者它开始失败了。
#5 休息一下,走开
一般来说,Python 新手和新程序员容易被手头的实现细节所困扰。陷入细节而看不到大局是许多程序员学习处理的常见经历。
如果你发现自己在 20 或 30 分钟内没有取得太大进展,最好离开代码一段时间。选择另一项活动,然后花几分钟时间完全忘记代码,这样当你回来的时候,你就有足够的时间去搞清楚它。
喝杯水或一杯咖啡,散散步,或者吃点零食,都是重新调整心态和放松的好方法。休息过后,你可以探索其他方法。
对于没有尝试过的人来说,这个建议似乎并不令人满意,因为大多数人认为,“如果我现在离开,我会忘记细节。”从头开始和让代码处于中断状态都让人感觉像是后退了一步,而不是前进了一步。
但是使用这个技巧会有意想不到的帮助,大量的研究表明它有很多好处,例如 提高表现降低压力提高创造力 。
#6 读取错误信息
当你花了很多心血编写的代码出现错误时,你很容易想放弃。新的 Python 程序员看到栈迹也会感到失落。
但是重要的是要记住大多数错误信息都是准确的和描述性的。
阅读错误信息可以让你知道是缺少了什么还是代码中有拼写错误。你也可能漏掉了一行,让程序无法完成它需要做的事情。
错误信息指出哪里出错了,但是如果你不能理解错误,至少你会知道问题在哪一行。您可以使用这些信息开始查找 bug。
#7 在线搜索错误
了解错误信息含义的最好方法之一是将其复制并粘贴到 Google 中。你可以在 Google 上搜索一个栈跟踪的最后一行。
你可能会在社区中找到一些 stackoverflow.com 页面,其他人会询问关于错误的问题,并给出答案和解释。
虽然这种方法经常奏效,但根据错误是特定的还是一般的,它也可能是偶然的。始终阅读问题中的代码,并与您自己的代码进行比较。这是了解答案是否与你的问题相关的唯一方法。
接下来,阅读一些评论和一些答案,看看这些解决方案是否适合你。
#8 猜测和检查
在你编程生涯的早期阶段,你经常会发现许多潜在的解决方案,但并不 100%确定如何修复一个 bug。
在这种情况下,你必须尝试两三种不同的解决方案,看看会发生什么。正如提示 4 所指出的,经常运行你的代码,这样你就能很快得到反馈,如果你的方法看起来不起作用,你就可以改变它。
当你试图修改代码时,很可能会在程序中引入一些其他的错误。这可能会让人很难理解你是离一个固定的计划更近了还是后退了一步。
为了避免完全破坏代码并重新开始,尽量不要太深入你在网上或其他地方找到的解决方案的兔子洞。
在你决定向别人寻求帮助之前,保持尝试几种解决方案的开放态度是很重要的。当你向程序员寻求帮助时,他们首先会问你的一件事就是列出一些你尝试过的解决方案。
尝试了几种解决方案,并向你寻求帮助的人解释它们,这不仅会给他们一个下一步该做什么的线索,还会显示出你解决问题的决心。
#9 如果你不能确定问题,运行二分搜索法
你运行的程序越大,你需要检查错误的地方就越多。
当一个项目超过 50 行时,找出代码中的错误是一项挑战。虽然堆栈跟踪和错误消息可以为您提供在哪里查找 bug 的线索,但有时这些根本没有帮助。
如果你发现自己处于这种情况,最好跑一趟二分搜索法。它将允许你在你的程序中不按预期运行的部分进行区域划分。
下面是二分搜索法工作原理的简要分析:
从高层次来看,二分搜索法包括将数据分成两半,并在这两半中搜索您想要的任何内容。
一旦搜索确定了数据在哪一半,这一半的数据就被一分为二,两者都被搜索以找到感兴趣的对象(在这种情况下,是一个错误)在哪里。
二分搜索法是发现代码错误的最快方法之一,因为它将程序分成两半,让你可以找出问题所在。
当在程序中寻找 bug 时,只运行前半部分,把后半部分注释掉。打印中途运行程序的结果。
如果结果看起来像预期的那样,您可以断定程序的前半部分运行良好。你要找的问题可能在程序的后半部分。
但是,如果结果有问题,错误是在程序的前半部分。
一遍又一遍地重复运行部分代码的过程,直到找到问题的根源。
这个技巧结合了本文前面提到的许多技巧。
#10 求助
如果你已经尝试了所有的方法,但还是找不出程序中的问题所在,你可以向别人寻求帮助。
无论你是向朋友、老师还是同事寻求帮助,都要确保你具备以下所有条件来提出一个好问题:
- 解释目标。
- 显示有错误的代码。
- 显示堆栈跟踪和错误信息。
- 解释你已经尝试了什么,以及为什么这些解决方案不起作用。
有时候,当你记下这些细节或者在脑海中仔细思考时,一个新的解决方案可能会浮现在脑海中。为什么会发生这种情况背后的想法是,问一个好问题会使解决方案变得显而易见。
由于这个原因,许多程序员在向某人寻求帮助之前收集了上面列出的所有事实。这个建议也许能解决你的问题。
如何在 Python 中对列表进行排序
原文:https://www.pythoncentral.io/how-to-sort-a-list-in-python/
每个程序员都必须编写在某些时候涉及到数据排序的代码。随着 Python 技能的进步,您可能会发现自己正在处理一个排序问题,这个问题对于应用程序中的用户体验至关重要。
您可能需要编写代码来通过时间戳跟踪用户活动。您可能还需要编写一个脚本,按照字母顺序排列电子邮件收件人。
Python 拥有内置的排序功能,这使得程序员可以很容易地对不同类型的数据进行排序。该语言还包括一些特性,使程序员能够在粒度级别定制排序操作。
这里有一个如何在 Python 中对列表排序的快速指南。
如何在 Python 中对列表进行排序
Python 有两个内置函数可以帮助你对列表进行排序:sort()和 sorted()。这两个函数使用相同的参数。但是,这两个函数具有不同的语法,并且与 iterables 的交互方式也不同。
也就是说,学会使用这两个功能会让列表排序变得轻而易举。如果你不熟悉用 Python 创建一个列表,在阅读之前先浏览一下我们的 简易指南 是个不错的主意。
下面是如何使用这两种排序方法的详细分析。
分类方法
Python list sort()方法允许程序员按照升序和降序对数据进行排序。默认情况下,该方法将按升序对列表进行排序。
程序员也可以编写一个函数来定制排序标准。
排序方法的语法是:
*list*.sort(reverse=True|False, key=myFunc)
其中“列表”必须替换为存储数据的变量名。sort()函数不返回任何值。它直接对列表中的值进行排序,而不创建新的变量来存储排序后的列表。
下面是一个如何使用 sort()函数对数据进行升序排序的例子:
names = ['Liam', 'Noah', 'Emma']
names.sort()
print(names)
输出将是:
['Emma','Liam','Noah']
因素
sort()函数不需要任何参数就能工作。但是,如果您想改变数据的排序方式,可以使用以下参数:
- 键: 该参数作为排序操作的键。
- 反转: 如果参数设置为“真”,列表将按降序排序。
下面是一个使用 reverse 参数对列表进行降序排序的例子:
names = ['Liam', 'Noah', 'Emma']
names.sort(reverse=True)
print(names)
代码的输出是:
['Noah', 'Liam', 'Emma']
您可以使用 key 参数根据长度对列表进行排序。下面是一个执行此操作的脚本示例:
def myFunc(e):
return len(e)
names = ['Emily', 'Fred', 'Robert']
names.sort(key=myFunc)
print(names)
脚本的输出是:
['Fred', 'Emily', 'Robert']
排序方法
另一种在 Python 中对列表进行升序或降序排序的方法是使用 sorted()方法。像 sort()一样,它不需要定义,因为它是一个内置函数。Python 的每个标准版本都带有内置的方法。
此外,它可以不带任何参数使用,类似于 sort()。默认情况下,该函数按升序排列数据。
然而,与 sort()不同的是,sorted()函数将排列后的值存储在一个新的列表中。应用该函数后,原始列表保持不变。相反,sort()函数返回“无”
因此,由函数返回的数据的有序列表可以在函数执行后被分配给变量。
Python 中可以迭代的对象称为 iterables。sorted()方法适用于所有的。换句话说,除了列表,sorted()还可以处理字符串、元组和集合。
该方法的语法为:
sorted(iterable, key, reverse)
使用 sorted()的另一个优点是,您可以将值传递给它,而不必先创建一个变量并在其中存储值。
例如:
sorted([10, 9, 8, 7, 6])
#result = [6,7,8,9,10]
这并不是说 sorted()函数不能处理变量:
>>> exampleList = [7, 9, 2, 4]
>>> sorted(exampleList)
[2, 4, 7, 9]
>>> exampleList
[7, 9, 2, 4]
# Values of exampleList did not change. New list was returned.
参数
sorted()方法与 sort()共享参数。使用“reverse”参数将按降序输出一个列表,您可以使用“key”参数定义排序顺序。
下面是一个使用 sorted()方法进行降序排序的例子:
>>> names = ['Liam', 'Noah', 'Emma']
>>> sorted(names)
['Emma', 'Liam', 'Noah']
>>> sorted(names, reverse=True)
['Noah', 'Liam', 'Emma']
排序逻辑没有改变——名字仍然按照第一个字母排序。但是,由于参数设置为“真”,输出已经反转如果参数设置为“False”,结果将保持不变。
“key”参数是 sorted()方法中最强大的组件。它期望传递一个函数,然后对列表中的每个值使用该函数来导出数据的顺序。
例如,您可以使用关键字参数根据单词的长度对单词列表进行排序
>>> exampleWords = ['cat', 'mouse', 'chicken', 'bird']
>>> sorted(exampleWords, key=len)
['cat', 'bird', 'mouse', 'chicken']
要按长度降序排列上面的列表,可以将 key 参数与 reverse 参数结合使用。
>>> exampleWords = ['cat', 'mouse', 'chicken', 'bird']
>>> sorted(exampleWords, key=len, reverse=True)
['chicken', 'mouse', 'bird', 'cat']
有时,您可以使用 lambda 函数,这是一个内置函数,而不是编写一个独立的函数来使用 key 参数。
匿名功能有四个特点:
- 必须内联定义;
- 它不能包含语句;
- 它没有名字;和
- 它就像一个函数一样执行。
假设一个程序员想写一个程序,根据数字的绝对值对它们进行排序。
这个脚本看起来应该是这样的:
num_list = [1,-5,3,-9,25,10]
def absolute_value(num):
return abs(num)
num_list.sort(key = absolute_value)
print(num_list)
但是,我们可以使用下面的代码行,而不是编写 absolute_value 函数并将其分配给 key 参数:
num_list.sort(key = lambda num: abs(num))
结论
选择使用哪种方法对列表进行排序可能会令人困惑。这里有一个选择方法的好方法:
如果你不需要原始列表,使用 sort()是正确的方法。它不创建新的列表,因此使用更少的内存并提高代码的效率。
然而,如果你认为你以后需要访问原始列表,你必须使用 sorted()函数。
Python 能帮你做的不仅仅是排序数据。阅读 我们的使用指南 是了解 Python 所有功能的好方法。
如何在 Python 中对列表、元组或对象(已排序)进行排序
原文:https://www.pythoncentral.io/how-to-sort-a-list-tuple-or-object-with-sorted-in-python/
在 Python 中对列表或元组排序很容易!因为一个元组基本上就像一个不可修改的数组,所以我们将它视为一个列表。
对 Python 列表排序的简单方法
好的,如果你只想对一系列数字进行排序,Python 有一个内置的函数可以帮你完成所有的困难工作。
假设我们有一个数字列表:
>>> a = [3, 6, 8, 2, 78, 1, 23, 45, 9]
我们想把它们按升序排列。我们所做的就是在列表上调用sort进行就地排序,或者调用内置函数sorted不修改原始列表并返回一个新的排序列表。除了上面的原因之外,这两个函数接受相同的参数,可以被视为“相同的”。
我们开始吧:
>>> sorted(a)
[1, 2, 3, 6, 8, 9, 23, 45, 78]
>>>
>>> a.sort()
>>> a
[1, 2, 3, 6, 8, 9, 23, 45, 78]
降序呢?
给你:
>>> sorted(a, reverse=True)
[78, 45, 23, 9, 8, 6, 3, 2, 1]
>>> a.sort(reverse=True)
>>> l
[78, 45, 23, 9, 8, 6, 3, 2, 1]
Python 在幕后做什么?它在列表上调用一个版本的 mergesort。它在比较值时对每个对象调用函数__cmp__,并根据从__cmp__返回的值决定将哪个放在另一个的前面。返回值为0表示等于比较值,1表示大于比较值,-1表示小于比较值。我们稍后将使用这些信息来使我们自己的对象可排序。
你说元组呢?我正要说到这一点。
用简单的方法排序 Python 元组
因为元组是不能修改的数组,所以它们没有可以直接调用的就地sort函数。他们必须总是使用sorted函数来返回一个排序后的列表。记住这一点,下面是如何做到这一点:
>>> tup = (3, 6, 8, 2, 78, 1, 23, 45, 9)
>>> sorted(tup)
[1, 2, 3, 6, 8, 9, 23, 45, 78]
注意sorted是如何返回一个数组的。
好了,现在让我们来看看如何解决一些更复杂的问题。
对列表或元组列表进行排序
这有点复杂,但仍然很简单,所以不要担心!sorted函数和sort函数都接受一个名为key的关键字参数。
key所做的是它提供了一种方法来指定一个函数,该函数返回你想要的排序依据。该函数获得一个传递给它的“不可见”参数,该参数表示列表中的一个项目,并返回一个值,您希望该值作为该项目的“键”进行排序。
让我来举例说明一下key关键字的论点,仅供你高超的眼光参考!
因此,我们来看一个新列表,通过对每个子列表中的第一项进行排序来测试它:
>>> def getKey(item):
... return item[0]
>>> l = [[2, 3], [6, 7], [3, 34], [24, 64], [1, 43]]
>>> sorted(l, key=getKey)
[[1, 43], [2, 3], [3, 34], [6, 7], [24, 64]]
在这里我们可以看到,列表现在是按照子列表中的第一个条目以升序排序的。注意,您也可以使用sort函数,但是我个人更喜欢sorted函数,所以我将在以后的例子中使用它。
发生了什么事?还记得我说过的那个“看不见的”论点吗?这就是每次sorted需要一个值时传递给getKey函数的内容。刁钻,刁钻的 python).
根据每个子列表中的第二个项目进行排序就像将getKey函数改为这样一样简单:
def getKey(item):
return item[1]
好吧。一切都好。那么,元组列表呢?很高兴你问了!
它实际上与我们上面的例子完全相同,但是列表是这样定义的:
>>> a = [(2, 3), (6, 7), (3, 34), (24, 64), (1, 43)]
>>> sorted(l, key=getKey)
[(1, 43), (2, 3), (3, 34), (6, 7), (24, 64)]
唯一改变的是,我们现在得到的是一个由个元组构成的列表,而不是返回给我们的一个由个列表构成的列表。
完全相同的解决方案可以应用于一个元组,所以我不打算去那里,因为这只是多余的。这也将浪费更多制造这种漂亮的数字纸的数字树。
对定制 Python 对象的列表(或元组)进行排序
这是我创建的一个自定义对象:
class Custom(object):
def __init__(self, name, number):
self.name = name
self.number = number
为了便于分类,我们将它们列出来:
customlist = [
Custom('object', 99),
Custom('michael', 1),
Custom('theodore the great', 59),
Custom('life', 42)
]
好了,我们已经在一个列表中获得了所有新的定制对象,我们希望能够对它们进行排序。我们如何做到这一点?
好吧,我们可以定义一个函数,就像我们上面做的那样,接收条目并返回一个列表。让我们开始吧。
def getKey(custom):
return custom.number
这个有点不同,因为我们的对象不再是列表了。这允许我们在自定义对象中按照number属性进行排序。
因此,如果我们对我们的定制对象列表运行sorted函数,我们会得到这样的结果:
>>> sorted(customlist, key=getKey)
[<__main__.Custom object at 0x7f64660cdfd0>,
<__main__.Custom object at 0x7f64660d5050>,
<__main__.Custom object at 0x7f64660d5090>,
<__main__.Custom object at 0x7f64660d50d0>]
一大堆我们无法理解的丑陋。完美。但是不要担心,亲爱的观众,有一个简单的修复,我们可以应用到我们的自定义对象,使它变得更好!
让我们像这样重新定义我们的对象类:
class Custom(object):
def __init__(self, name, number):
self.name = name
self.number = number
def _ _ repr _ _(self):
return ' { }:{ } { } '。格式(自我。__class__。__ 姓名 _ _,
自我名,
自我号)
好吧,我们刚才到底做了什么?首先,__repr__函数告诉 Python 我们希望对象如何表示为。用更复杂的术语来说,它告诉解释器当对象被打印到屏幕上时如何显示它。
因此,我们告诉 Python 用类名、名称和编号来表示对象。
现在让我们再次尝试排序:
>>> sorted(customlist, key=getKey)
[Custom: michael 1, Custom: life 42,
Custom: theodore the great 59, Custom: object 99]
那就好多了!现在,我们实际上可以说,它排序正确!
但是有一点小问题。这只是吹毛求疵,但我不想每次调用 sorted 时都必须键入那个key关键字。
那么,我该怎么做呢?嗯,还记得我跟你说过的那个__cmp__函数吗?让我们付诸行动吧!
让我们像这样再一次重新定义我们的对象:
class Custom(object):
def __init__(self, name, number):
self.name = name
self.number = number
def _ _ repr _ _(self):
return ' { }:{ } { } '。格式(自我。__class__。__ 姓名 _ _,
自我名,
自我号)
def __cmp__(self,other):
if hasattr(other,' number'):
返回 self . number . _ _ CMP _ _(other . number)
看起来不错。这样做的目的是告诉 Python 将当前对象的值与列表中的另一个对象进行比较,看看比较的结果如何。就像我上面说的,sorted函数将对它正在排序的对象调用__cmp__函数,以确定它们相对于其他对象的位置。
现在我们可以直接调用sorted而不用担心包含key关键字,就像这样:
>>> sorted(customlist)
[Custom: michael 1, Custom: life 42, Custom: theodore the great 59, Custom: object 99]
瞧!它工作得很好。请注意,以上所有内容也适用于自定义对象的元组。但是你知道,我喜欢保存我的数码树。
对定制 Python 对象的异构列表进行排序
好吧。因为 Python 是一种动态语言,所以它不太关心我们将什么对象放入列表中。它们可以都是同一类型,也可以都是不同类型。
所以让我们定义另一个不同的对象来使用我们的Custom对象。
class AnotherObject(object):
def __init__(self, tag, age, rate):
self.tag = tag
self.age = age
self.rate = rate
def _ _ repr _ _(self):
return ' { }:{ } { } { } '。格式(自我。__class__。__name__,
self.tag,
self.age,self.rate)
def __cmp__(self,other):
if hasattr(other,' age '):
return self . age . _ _ CMP _ _(other . age)
这是一个类似的物体,但仍然不同于我们的Custom物体。
让我们列出这些物品和我们的Custom物品:
customlist = [
Custom('object', 99),
Custom('michael', 1),
Custom('theodore the great', 59),
Custom('life', 42),
AnotherObject('bananas', 37, 2.2),
AnotherObject('pants', 73, 5.6),
AnotherObject('lemur', 44, 9.2)
]
现在,如果我们尝试在这个列表上运行sorted:
>>> sorted(customlist)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: an integer is required
我们得到一个可爱的错误。为什么?因为Custom没有名为age的属性,AnotherObject也没有名为number的属性。
我们该怎么办?慌!
开玩笑的。我们知道该怎么做。让我们再次重新定义那些对象!
class Custom(object):
def __init__(self,name,number):
self.name = name
self.number = number
def _ _ repr _ _(self):
return ' { }:{ } { } '。格式(自我。__class__。__ 姓名 _ _,
自我名,
自我号)
def __cmp__(self,other):
if hasattr(other,' getKey'):
返回 self.getKey()。__cmp__(other.getKey())
def getKey(self):
返回自身编号
class another object(object):
def _ _ init _ _(self,tag,age,rate):
self . tag = tag
self . age = age
self . rate = rate
def _ _ repr _ _(self):
return ' { }:{ } { } { } '。格式(自我。__class__。__name__,
self.tag,
self.age,self.rate)
def __cmp__(self,other):
if hasattr(other,' getKey'):
返回 self.getKey()。__cmp__(other.getKey())
def getKey(self):
return self . age
厉害!我们刚刚做了什么?我们定义了一个两个对象共有的函数getKey,这样我们就可以很容易地对它们进行比较。
所以现在如果我们再次运行sorted函数,我们会得到:
>>> sorted(customlist)
[Custom: michael 1, AnotherObject: bananas 37 2.2,
Custom: life 42, AnotherObject: lemur 44 9.2,
Custom: theodore the great 59, AnotherObject: pants 73 5.6,
Custom: object 99]
不错!现在,我们的对象可以进行比较和排序,以满足他们的需求。
你说你还是喜欢使用key关键字?
你也可以这样做。如果您在每个对象中省略掉__cmp__函数,并像这样定义一个外部函数:
def getKey(customobj):
return customobj.getKey()
然后像这样调用排序:
>>> sorted(customlist, key=getKey)
[Custom: michael 1, AnotherObject: bananas 37 2.2,
Custom: life 42, AnotherObject: lemur 44 9.2,
Custom: theodore the great 59, AnotherObject: pants 73 5.6,
Custom: object 99]
现在你知道了!相当直截了当,但不像有些人猜测的那样直截了当。尽管如此,Python 通过其内置的sorted函数使其变得非常简单。
要了解更多的排序方法,请阅读如何通过键或值对 Python 字典进行排序。你也可以查看 Python 中的 Lambda 函数语法(内联函数),了解如何使用 Lambda 函数进行排序。
这就是你。离成为世界巨蟒大师又近了一步。
再见,暂时的。
如何按键或值对 Python 字典进行排序
原文:https://www.pythoncentral.io/how-to-sort-python-dictionaries-by-key-or-value/
注意:如果你想在 Python 中对列表、元组或对象进行排序,请查看本文:如何在 Python 中对列表或元组进行排序
Python 中的dict (dictionary)类对象是一个非常通用和有用的容器类型,能够存储一组值并通过键检索它们。值可以是任何类型的对象(字典甚至可以与其他字典嵌套),键可以是任何对象,只要它是可散列的,基本上意味着它是不可变的(因此字符串不是唯一有效的键,但是像列表这样可变的对象永远不能用作键)。与 Python 列表或元组不同,dict对象中的键和值对没有任何特定的顺序,这意味着我们可以有一个像这样的dict:
numbers = {'first': 1, 'second': 2, 'third': 3, 'Fourth': 4}
虽然键-值对在实例化语句中是按照一定的顺序排列的,但是通过调用它的 list 方法(这将从它的键中创建一个列表),我们可以很容易地看到它们没有按照那个顺序存储:
>>> list(numbers)
['second', 'Fourth', 'third', 'first']
按关键字排序 Python 字典
如果我们想按关键字对字典对象进行排序,最简单的方法是使用 Python 内置的 sorted 方法,该方法接受任何 iterable 并返回一个已排序的值列表(默认情况下按升序)。没有像列表那样对字典进行排序的类方法,但是sorted方法的工作方式完全相同。下面是它对我们的字典的作用:
# This is the same as calling sorted(numbers.keys())
>>> sorted(numbers)
['Fourth', 'first', 'second', 'third']
我们可以看到这个方法给出了一个按升序排列的键列表,几乎是按字母顺序排列的,这取决于我们定义的“字母顺序”还要注意,我们按照键对键列表进行了排序——如果我们想按照键对键列表值进行排序,或者按照值对键列表进行排序,我们必须改变使用sorted方法的方式。我们一会儿将看看sorted的这些不同方面。**
按值排序 Python 字典
与我们使用键的方式相同,我们可以使用 sorted 按照值对 Python 字典进行排序:
# We have to call numbers.values() here
>>> sorted(numbers.values())
[1, 2, 3, 4]
这是默认顺序的值列表,按升序排列。这些都是非常简单的例子,所以现在让我们检查一些稍微复杂一点的情况,在这些情况下我们对我们的dict对象进行排序。
使用 Python 字典定制排序算法
如果我们简单地给sorted方法字典的键/值作为一个参数,它将执行一个简单的排序,但是通过利用它的其他参数(即key和reverse),我们可以让它执行更复杂的排序。
sorted的key参数(不要与字典的键混淆)允许我们定义在排序项目时使用的特定函数,作为迭代器(在我们的dict对象中)。在上面的两个例子中,键和值都是要排序的项和用于比较的项,但是如果我们想要使用我们的dict 值对我们的dict 键进行排序,那么我们将通过它的key参数告诉sorted这样做。比如如下:
# Use the __getitem__ method as the key function
>>> sorted(numbers, key=numbers.__getitem__)
# In order of sorted values: [1, 2, 3, 4]
['first', 'second', 'third', 'Fourth']
通过这个语句,我们告诉sorted对数字dict(它的键)进行排序,并通过使用 numbers 的类方法来检索值来对它们进行排序——本质上我们告诉它“对于数字中的每个键,使用数字中的相应值进行比较来对其进行排序。”。
我们还可以通过关键字对数字中的值进行排序,但是使用key参数会更复杂(没有字典方法可以像使用list.index方法那样通过使用某个值来返回关键字)。相反,我们可以使用列表理解来保持简单:
# Uses the first element of each tuple to compare
>>> [value for (key, value) in sorted(numbers.items())]
[4, 1, 2, 3]
# In order of sorted keys: ['Fourth', 'first', 'second', 'third']
现在要考虑的另一个参数是reverse参数。如果这是True,顺序将被反转(降序),否则如果是False,它将处于默认(升序)顺序,就这么简单。例如,与前两种排序一样:
>>> sorted(numbers, key=numbers.__getitem__, reverse=True)
['Fourth', 'third', 'second', 'first']
>>> [value for (key, value) in sorted(numbers.items(), reverse=True)]
[3, 2, 1, 4]
这些排序仍然相当简单,但让我们看看一些特殊的算法,我们可能会使用字符串或数字来排序我们的字典。
用字符串和数字算法排序 Python 字典
按照字母顺序对字符串进行排序是很常见的,但是使用sorted可能不会按照“正确的”字母顺序对我们的dict的键/值进行排序,即忽略大小写。为了忽略大小写,我们可以再次利用key参数和str.lower(或str.upper)方法,这样在比较时所有的字符串都是相同的大小写:
# Won't change the items to be returned, only while sorting
>>> sorted(numbers, key=str.lower)
['first', 'Fourth', 'second', 'third']
为了将字符串与数字相关联,我们需要一个额外的上下文元素来正确地关联它们。让我们先创建一个新的dict对象:
>>> month = dict(one='January',
two='February',
three='March',
four='April',
five='May')
它只包含字符串键和值,所以如果没有额外的上下文,就没有办法将月份按正确的顺序排列。为此,我们可以简单地创建另一个字典来将字符串映射到它们的数值,并使用该字典的__getitem__方法来比较我们的month字典中的值:
>>> numbermap = {'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5}
>>> sorted(month, key=numbermap.__getitem__)
['one', 'two', 'three', 'four', 'five']
正如我们所看到的,它仍然返回了第一个参数(month)的排序列表。为了按顺序返回月份,我们将再次使用列表理解:
# Assuming the keys in both dictionaries are EXACTLY the same:
>>> [month[i] for i in sorted(month, key=numbermap.__getitem__)]
['January', 'February', 'March', 'April', 'May']
如果我们想根据每个字符串中重复字母的数量对键/值字符串进行排序,我们可以定义自己的自定义方法,在sorted 键参数中使用:
def repeats(string):
# Lower the case in the string
string = string.lower()
#获取一组唯一的字母
uniques = set(string)
# Count 每个唯一字母的最大出现次数
counts =[string . Count(letter)for letter in uniques]
返回最大值(计数)
使用该功能可按如下方式进行:
# From greatest to least repeats
>>> sorted(month.values(), key=repeats, reverse=True)
['February', 'January', 'March', 'April', 'May']
更高级的分类功能
现在,假设我们有一个字典,记录每个月一个班级的学生人数,如下所示:
>>> trans = dict(January=33, February=30, March=24, April=0, May=7)
如果我们想首先用偶数和奇数来组织班级规模,我们可以这样定义:
def evens1st(num):
# Test with modulus (%) two
if num == 0:
return -2
# It's an even number, return the value
elif num % 2 == 0:
return num
# It's odd, return the negated inverse
else:
return -1 * (num ** -1)
使用evens1st排序函数,我们得到以下输出:
# Max class size first
>>> sorted(trans.values(), key=evens1st, reverse=True)
[30, 24, 33, 7, 0]
同样,我们可以首先列出奇数个类的大小,然后执行许多其他算法来得到我们想要的排序。还有许多其他复杂的排序方法和技巧可以用于字典(或任何可迭代的对象),但是现在希望这些例子已经提供了一个很好的起点。
如何开始使用 Python 进行日志记录
原文:https://www.pythoncentral.io/how-to-start-logging-in-python/
Python 提供了对日志记录的内置支持,为程序员提供了对其应用程序的关键可见性,而没有太多麻烦。
要理解 Python 日志模块,需要了解语言中相应的日志 API 以及使用它们的步骤。在使用这些 API 进行无故障日志记录时,学习最佳实践也同样重要。
本指南向您介绍了许多与 Python 日志相关的概念。虽然 Python 从 2.3 版起就提供了内置的日志支持,但本文是基于 Python 3.8 版的。它假设读者了解与通用和面向对象编程相关的概念和结构。
什么是 Python 日志记录?
标准 Python 库有一个内置的日志模块,允许用户轻松地记录来自库和应用程序的事件。配置好记录器后,只要代码运行,它就作为 Python 解释器的一部分运行。简单来说;它是全球性的。
Python 还允许用户使用外部配置文件来配置日志子系统。您可以在 Python 库中找到日志配置格式的规范。
内置日志库遵循模块化方法,具有以下组件:
- 记录器: 这些暴露了应用程序使用的接口
- 处理程序: 这些处理程序将记录器生成的日志记录发送到正确的目的地
- 过滤器: 他们过滤记录并决定输出哪一个
- 格式化程序: 这些定义了最终日志条目的布局。
几个 logger 对象被组织成一棵树,代表系统的许多部分和安装在其上的各种第三方库。当用户向这些记录器中的一个发送消息时,消息由它们的格式化程序输出到所有的处理程序。
消息沿记录器树向上移动,直到到达配置了 propagate=False 的记录器或根记录器。
Python 日志记录是如何工作的?
下面是 Python 用户使用日志库时触发的所有任务的分类:
客户端运行日志记录语句并发出日志请求。这些语句通常调用日志库 API 中的方法,提供日志级别和日志数据作为参数。
日志级别参数定义了请求的重要性。日志数据通常是日志消息字符串,但也记录一些其他数据。logger 对象通常公开日志 API。
然后,日志记录库创建一个代表日志请求的日志记录,并捕获相关数据,以便在请求穿过该库时能够对其进行处理。
按照程序库的指示过滤日志请求/记录。在过滤期间,将日志记录级别请求与阈值日志记录级别进行比较。然后记录通过用户提供的过滤器。
最后,处理程序检查过滤后的记录,通常通过将数据写入文件来存储数据。但是,可以设置处理程序将日志数据通过电子邮件发送到特定的地址。
某些日志库中的处理程序可能会根据日志级别和用户指定的处理程序过滤器对日志记录进行第二次过滤。需要时,处理程序还依赖用户提供的格式化程序将日志数据格式化为日志条目。
Python 中的日志模块
Python 标准库有以下模块为日志提供支持:
- 日志模块: 具有主要的面向客户端的 API。
- logging . config 模块: 它有允许客户端配置的 API。
- logging . handlers 模块: 它提供了以不同方式处理和存储日志记录的各种处理程序。
这些模块统称为 Python 日志库,它们将前面章节中讨论的概念具体化为类、模块级方法或常量。
Python 中的日志记录级别
Python 中的日志库支持五个日志级别:关键、错误、警告、信息和调试。
它们由同名的常量表示,比如:logging。临界,记录。错误,记录。警告,记录中。这些常量的值分别为 50、40、30、20 和 10。
运行期间,日志级别的值表示该级别的含义。通过使用大于零且不等于预定义的日志记录级别值的值,客户端还可以使用其他日志记录级别。
当日志记录级别的名称可用时,它们在日志条目中按其名称显示。每个预先存在的日志记录级别都与相应的常数同名。例如,伐木。警告和 30 个级别在日志条目中显示为“警告”。
另一方面,默认情况下,自定义日志记录级别没有任何名称。因此,Python 在条目中打印一个值为 n 的自定义级别(作为“级别 n”)。
但是,当涉及多个自定义日志记录级别时,日志条目可能会变得混乱,因为条目之间使用了相同的默认名称。
为了防止这个问题,客户端可以使用 logging.addLevelName 函数通过传递 level 和 LevelName 参数来命名它们的自定义日志记录级别。
换句话说,运行 logging.addLevelName(43,' CUSTOM1 ')会将级别 43 记录为日志条目中的' CUSTOM1 '。
官方文档概述了 Python 日志库中内置的五个日志级别的 社区范围的适用性规则 。这些准则表明:
- 使用调试级别记录诊断问题的详细信息。
- 使用信息级别确认应用程序是否按预期运行。
- 使用警告级别来报告意外行为,这些行为可能预示着未来的问题,但目前不会影响应用程序的正常运行。
- 使用错误等级报告应用程序运行中的严重问题。
- 使用临界级别报告错误,表明程序可能无法继续运行。
Python 记录器的功能
伐木。记录器对象(简称为“记录器”)充当用户和库之间的接口。这些对象便于发出日志请求,还提供了查询和修改方法状态的方法。
通常,程序员使用 logging.getLogger(name)工厂函数来创建记录器。使用函数,客户端可以按名称访问和管理记录器。不需要存储和传递对记录器的引用!
函数中传递的参数一般是用点分隔的层次名称(如 a.b.c)。以这种方式传递值允许库维护记录器层次结构。
当记录器被创建时,库确保在每个层级都有一个记录器。它还确保所有记录器都链接到它们的父记录器和子记录器。
这也是阈值日志记录级别的概念出现的地方。每个日志记录器都有一个阈值级别来帮助确定是否需要处理请求。
如果请求的日志记录级别的值等于或高于阈值级别,则记录器处理日志请求。
客户端可以使用 Logger.getEffectiveLevel()和 Logger.setLevel(level)函数来检索和更改记录器的阈值日志记录级别。
工厂功能将记录器的阈值水平设置为与相同的值
父。Python 日志记录方法
每个日志记录器都有以下方法来方便发出日志请求:
- Logger.critical(msg,*args,**kwargs)
- Logger.error(msg,*args,**kwargs)
- 记录器. debug(msg、*args、**kwargs)
- 记录器. info(msg、*args、**kwargs)
- Logger.warn(msg,*args,**kwargs)
用户可以使用这些方法发出具有预定义日志记录级别的请求。除了这些方法,记录器还提供了另外两种方法:
- Logger.log(level,msg,*args,kwargs)😗* 它以明确指定的日志记录级别发出日志请求。在使用自定义日志记录级别时,这很有帮助。
- Logger.exception(msg,*args,kwargs)😗* 它发出带有错误级别的请求,并在日志条目中捕获当前异常。因此,客户端应该只从异常处理程序中使用此方法。
这些方法中的“msg”和“args”参数一起在日志条目中创建日志消息。
此外,上述所有方法都支持“exc_info”参数,允许客户端将异常信息添加到日志条目中。还支持“stack_info”和“stacklevel”参数,允许用户向日志条目添加调用堆栈详细信息。
关键字参数“extra”使客户端能够传递相关的过滤器、处理程序和格式化程序值。
当这些方法运行时,它们执行上一节提到的所有任务,然后执行以下任务:
- 在比较了阈值和日志记录级别之后,记录器决定处理日志请求,它创建一个 LogRecord 对象。对象表示请求的下游处理中的请求。设置 LogRecord 对象是为了捕获方法的参数、调用堆栈细节和异常。它还可以将额外参数中的值和键捕获为字段。
- 每个处理程序处理一个日志请求,它的前身记录器的处理程序在记录器层次结构中适当地处理请求。记录器控制 handlers.propagate 字段的这一方面,默认情况下是这样的。
过滤器不仅仅是一种与日志记录级别交互的手段。它们允许对请求进行细粒度过滤,并忽略特定类中的请求。用户可以使用 Logger.addFilter(filter)和 Logger.removeFilter(filter)方法分别在记录器中添加和删除筛选器。
Python 中的日志过滤器
任何接受日志作为参数并返回零(拒绝)或非零值(接受)以接受记录的可调用函数都是过滤器。具有签名过滤器方法的对象(记录:日志记录)- > int 也可以是一个过滤器。
日志记录的子类。可以覆盖日志记录的 Filter(name)方法。Filter.filter(record)方法也可以成为筛选器。
但是,这种类型的过滤器会将记录器生成的记录设置为与子过滤器同名,而不会覆盖过滤器方法。
如果过滤器名称为空,则过滤器接纳所有记录。另一方面,当方法被重写时,它返回零以拒绝记录,或者返回非零以接受记录。
Python 中的日志处理程序
伐木。处理程序对象负责处理 Python 中的日志记录。这些组件负责记录日志请求。处理程序的最终处理通常包括通过将记录写入系统日志或其他文件来存储记录。
然而,最终处理也可能涉及将其发送给其他实体或通过电子邮件将记录数据发送到特定的电子邮件地址。
与记录器一样,处理程序也有一个阈值日志记录级别。客户端可以使用 Handler.setLevel(level)方法设置它,使用 Handler.addFilter(filter)和 Hander.removeFilter(filter)方法支持过滤器。
处理程序使用过滤器和阈值日志记录级别来过滤要处理的记录。额外的过滤允许对记录进行上下文控制,这意味着通知处理程序将只处理来自损坏或关键模块的请求。
当处理程序处理日志记录时,记录被格式化器格式化成日志条目。客户端可以使用 Handler.setFormatter(formatter)方法来设置格式化程序。不带格式化程序的处理程序可以与 Python 标准库中的默认格式化程序一起使用。
logging.handler 模块有十几个不同的处理程序,可以在几种情况下使用。因此,在大多数情况下,客户端可以快速配置这些处理程序。
然而,有些情况下需要使用自定义处理程序。在这些情况下,开发人员可以使用 Handler.emit(record)方法扩展处理程序类或他们选择的预定义处理程序类。
Python 中的日志格式化程序
伐木。格式化程序对象对于处理程序来说是无价的,因为它们将日志记录格式化为基于字符串的日志条目。然而,重要的是要记住格式化程序不能控制日志消息的创建。
格式化程序将日志记录中的数据或字段与用户指定的格式字符串相结合。但是与处理程序不同,Python 日志库只有一个基本的格式化程序来记录级别、日志记录者的名字和消息。
因此,如果客户需要一个超越简单用例的应用格式化程序,他们将需要构建新的日志记录。具有所需格式字符串的格式化程序对象。
格式化程序支持格式字符串的 printf、str.format()和 str.template 样式。此外,格式字符串可以是 LogRecord 对象的任何字段,包括基于额外参数的键的字段。
在格式化日志记录之前,格式化程序使用 LogRecord.getMessage()结合日志记录方法的 msg 和 args 参数,使用%运算符来构造日志消息。
格式化程序最终使用指定的格式字符串将日志消息与日志记录数据结合起来,以创建条目。
Python 中的日志模块
当客户端起诉日志库时,该库建立一个根日志记录器来维护日志记录器的层次结构。所有记录器的根记录器的默认阈值记录级别是 logging.WARNING.
该模块提供 Logger 类的所有日志记录方法,作为具有相同名称和签名的模块级方法。客户端可以使用这些方法发出日志请求,而无需创建日志记录器,最终由根日志记录器处理所有请求。
也就是说,如果根日志记录器在服务方法中的日志请求时没有任何处理程序,那么日志记录库会添加一个日志记录。使用 sys.stderr 流作为根记录器的处理程序的 StreamHandler 实例。这个实例被称为最后的处理程序。
给没有处理程序的记录器的日志请求被日志库定向到最后一个处理程序。客户端可以使用 logging.lastResort 属性访问处理程序。
Python 日志记录的良好实践
下面我们为您重点介绍了登录 Python 的最佳实践。然而,需要注意的是,没有灵丹妙药。在使用任何这些实践之前,最好考虑它们在您的程序中的适用性,并考虑它们的适当性。
#1 使用 getlogger 函数
logging.getLogger()函数使库能够管理记录器名称到记录器实例的映射,并维护记录器的层次结构。映射和层次因此提供了以下好处:
- 通过按名称检索记录器,客户可以使用该功能从程序的不同部分访问记录器。
- 运行时创建有限的记录器。
- 日志请求可以在日志记录器层次结构中传播。
- 未指定时,阈值日志记录级别可以从以前的日志记录程序中推断出来。
- 库的配置可在运行时使用记录器名称进行更新。
#2 使用预定义的日志记录级别
库中预定义的日志记录级别涵盖了几乎所有的日志记录场景。此外,大多数开发人员都熟悉预定义的日志记录级别,因为跨编程语言的日志记录库具有相似的级别。
使用预定义的级别可以简化配置、部署和维护。除非必要,否则最好使用预定义的级别。
#3 创建模块级记录器
客户端可以为每个类和每个模块创建日志程序。为每个类创建记录器允许详细的配置;然而,它加载了几个记录器的程序。
另一方面,为每个模块创建记录器可以使记录器的总数保持较小。因此,只有当细粒度配置是必须的时候,使用类级记录器才是理想的。
#4 命名模块级记录器与模块相同
记录器的名称是字符串值,不包含在 Python 名称空间中。因此,它们不会与模块名冲突。
使用相应模块级记录器的模块名使得在代码中识别它们变得轻而易举。以这种方式命名日志程序使用了点符号,使得引用日志程序变得容易。
#5 使用日志记录注入本地上下文信息。记录器适配器方法
将上下文信息插入日志记录就像使用日志记录一样简单。LoggerAdapter 方法客户端也可以使用它来修改日志请求中的消息和数据。
日志库不管理这些适配器,这意味着不能使用通用名称访问它们。因此,开发人员根据需要使用它们将上下文信息插入到类或模块中。
#6 避免使用过滤器插入全局上下文信息
将全局上下文信息插入日志记录就像使用过滤器修改提供给过滤器的记录参数一样简单。
您可以编写这样一个过滤器,将详细信息插入到传入的日志记录中:
def version_injecting_filter(logRecord):
logRecord.version = '3'
return True
然而,这种方法有两个缺点。首先,如果过滤器从日志记录中获取数据,那么将数据注入到记录中的过滤器必须在使用注入数据的过滤器之前运行。过滤器添加到记录器的顺序变得至关重要。
其次,过滤器扩展了日志记录,滥用支持来过滤它们。
还有另一种方法将上下文信息注入到日志记录器中——您可以使用 logging.setLogRecordFactory()函数初始化日志库。假设注入的信息是全局的,当工厂函数创建日志记录时,客户端可以将它注入到日志记录中。
使用 logging.setLogRecordFactory()函数是确保数据在程序中的每个日志组件中都可用的一个很好的方法。然而,这种方法也有缺点:
客户必须确保程序不同部分的工厂功能能够很好地相互配合。而客户端可以链接日志记录工厂函数,使程序变得不必要的复杂。
#7 将通用处理程序放在记录器的高层
如果两个记录器有相同的处理程序,并且其中一个是另一个的后代,那么最好将处理程序附加到上级记录器。客户端可以依靠日志库将请求从下层日志记录器传播到上层日志记录器的处理程序。
此外,如果 propagate 属性没有被修改,将处理程序放在上层记录器中可以防止重复消息的出现。
#8 使用 logging.disable()函数调节记录输出
如果请求的记录级别等于或高于记录器的有效记录级别,它将处理该请求。但是有效的日志记录级别由阈值日志记录级别和库范围的日志记录级别之间的较高者来确定。
客户端可以使用 logging.disable(level)方法来设置库范围的日志记录级别。默认情况下,此级别为 0;因此,它处理每个日志记录级别的请求。
使用该函数是提高整个程序的日志记录级别和抑制程序的日志记录输出的一个很好的方法。
#9 缓存对记录器的引用考虑周到
缓存对记录器的引用并使用缓存的引用来访问它们有助于避免重复调用 logging.getLogger()函数来获取相同的记录器,从而提高程序的效率。
也就是说,如果检索不是冗余的,这些调用函数的消除会导致丢失日志请求。更新对记录器的引用会有所帮助,但是使用 logging.getLogger()函数是避免这个问题的最好方法。
如何判断你的电脑是否可以运行 Python
原文:https://www.pythoncentral.io/how-to-tell-if-your-computer-can-run-python/
Python 是一种非常通用的脚本语言,可以用在网站后端、数据科学或自动化任务中。如果你不是程序员,并且你想知道你的计算机是否能运行 Python,有一些东西你可以寻找。在这篇文章结束时,你会更好地理解这种语言,它固有的多功能性,以及你的电脑或笔记本电脑是否能有效地运行它。

Python 是什么?
Python 编程语言是一种通用语言,可以应用于许多不同的领域。它有一个简单、易学的语法,而且足够灵活,可以在各种环境中表达概念。Python 自 1991 年由吉多·范·罗苏姆创建以来就一直存在。它还具有极高的内存效率,这意味着您无需担心使用高度先进的计算机或寻找更多存储空间来启动和运行它。该语言是开源的,包括一个广泛的标准库,带有内置的数据结构和算法,用于处理文本、数字、列表等。,以及许多 OS 系统调用和 Python 包索引中的其他库的接口。它用于各种结果,包括:
- 建设高级网站
- 创建复杂的软件
- 解析数据集
- 用于数据科学的多个方面
- 开发高级自动化脚本
- 机器学习
这些只是使用这种语言可以实现的一些奇妙的事情,可以说,如果你可以想象一些事情,你很可能使用 Python 来实现它!
Python 相对于其他语言有哪些优势?
Python 是一种强大的语言,虽然与其他语言相比它有一些限制,但由于它的灵活性、简洁的语法和广泛的应用,它是一种很好的学习语言。与其他更复杂的编程语言相比,它的主要优势包括:
- 简单: 大多数新手在尝试阅读特定的编程语言(看你,C++)时会变得不知所措。然而,Python 是为了消除其他语言中的复杂性而创建的,因此具有非常易于读写的语法。例如, 打印(‘你好,世界!’) 将创建一个带有消息“Hello World”的输出。当你把它和 C++比较时,你就能看到区别了!:
#包括< iostream >
int main() {
STD::cout<“你好世界!”;
返回 0;
}
- 力量: 由于 Python 的简单,初学者常常会惊讶于它的强大。然而,它的简单性使程序员能够 编写强大的应用程序 而不用担心记住大量的语法。此外,它可以通过各种扩展来实现高度复杂的结果。
- 费用: 由于其开源性质,可以免费使用。此外,它还会被大量专门用户不断更新和扩展。
- 它有一个很棒的社区:Python 社区被公认为编程中最友好和最有帮助的社区之一。你不仅可以在 Stack Exchange 这样的网站上找到几乎所有的解决方案,还可以在很多论坛上寻求帮助。
- 对推进你的事业大有裨益: 与 Java 和 JavaScript 一起,Python 已经成为最受欢迎的语言之一。
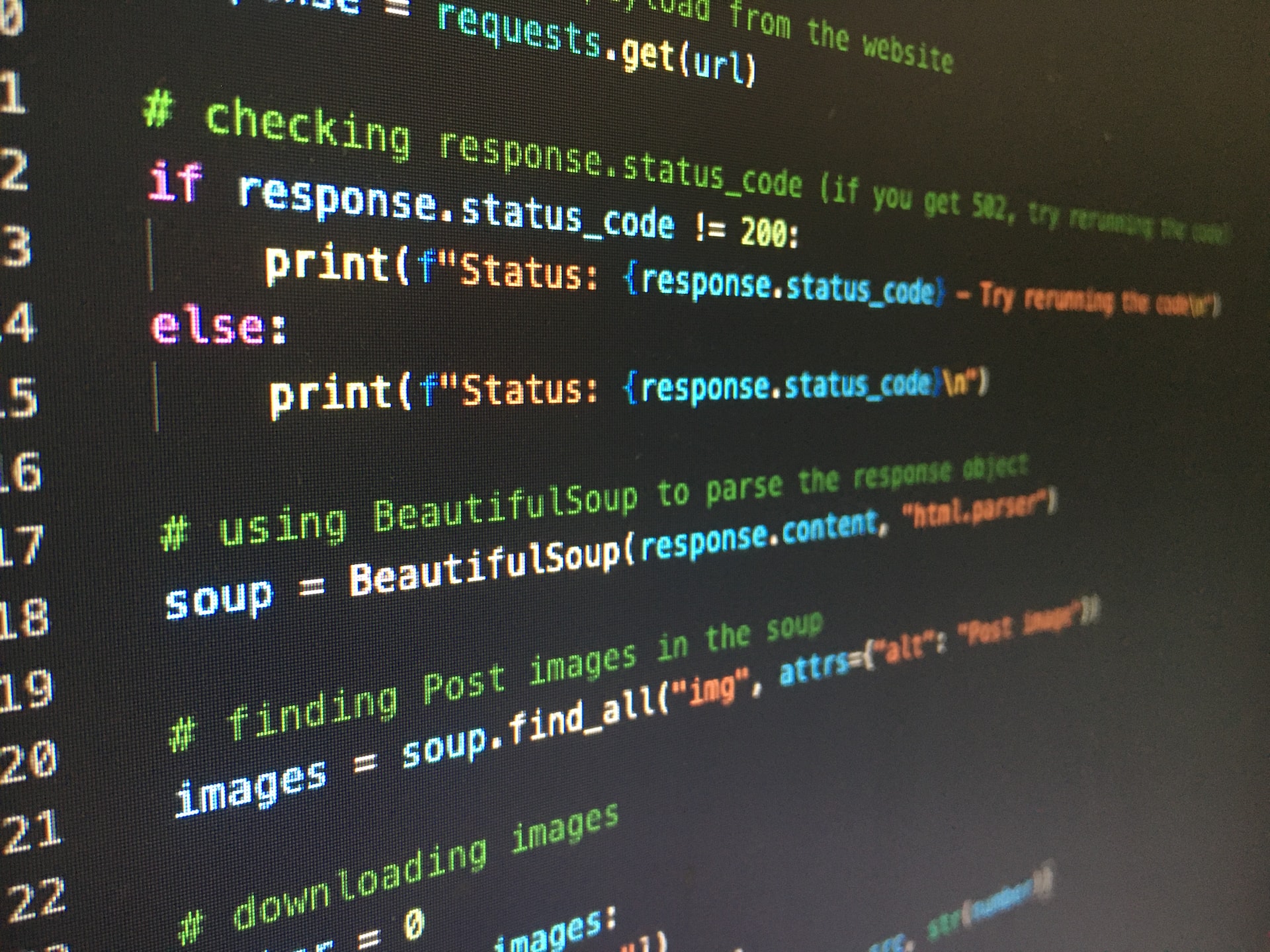
你怎么知道你的电脑能不能运行它?
这个问题的答案并不简单。您需要做的第一件事是检查 Python 的硬件要求。幸运的是,由于其轻量级的特性,几乎任何现代设备都可以运行开始编写和测试代码所需的软件。但是,如果你的电脑是老式的,你可能会考虑升级,如果你是认真的。虽然 Python 可以在大多数机器上运行,但是旧的模型会使一切都变得更慢、更令人沮丧,从而导致购买新机器的需求。尽管如此,只要它有足够的内存来防止你拔头发,一个像样的 CPU 和一个 SSD(出于同样的原因,你需要足够的内存!).
入门需要什么?
一旦你确定你的硬件符合标准,你就可以进入软件方面了。虽然苹果 Macbooks 等一些品牌往往已经安装了 Python,但其他品牌不会,你需要通过他们的网站 直接安装 。然而,对于初学者来说,最好的方法之一是使用像 Anaconda 这样的程序,它包含了入门所需的一切。您还可以使用 Anaconda 安装一个笔记本,比如 Jupyter Notebook,它允许您动态地编写和测试代码。
Python 是一门很棒的语言,简单易学,而且可以免费使用,由于它有无数的应用,所以是一门很好的入门语言。此外,由于它的轻量级,您可以将它安装在过去十年的几乎任何计算机上。
如何在 Python 中测试正数
原文:https://www.pythoncentral.io/how-to-test-for-positive-numbers-in-python/
以下 Python 片段演示了如何测试输入的数字是正数、负数还是零。代码简单明了,适用于任何数字或整数。该代码使用 if... 否则如果...else 语句确定如果一个数大于 0(在这种情况下它必须是正数),则 elif 一个数等于 0(在这种情况下它既不是正数也不是负数...简直是零),或者 else 小于零(负)。
num = 3
if num > 0:
print("Positive number")
elif num == 0:
print("Zero")
else:
print("Negative number")
在上面的例子中,数字等于 3,所以输出将是“正数”,因为它大于零。如果 num 等于-19,那么输出将是“负数”代码非常简单明了。
使用这段代码的一种方法是让用户输入一个数字,并向他们显示输出。您还可以使用该代码根据所讨论的数字是正数还是负数来执行函数。为此,您需要调整代码以插入函数来代替打印命令。
如何在 Python 中测试质数
原文:https://www.pythoncentral.io/how-to-test-for-prime-numbers-in-python/
与任何 OOP 语言一样,您可以使用 Python 进行计算并收集关于数字的信息。用 Python 可以做的一件很酷的事情是测试一个数是否是质数。你可能记得很久以前数学课上讲过,质数是任何整数(它必须大于 1),它的唯一因子是 1 和它自己,这意味着它不能被任何数整除(当然,除了 1 和它自己)。质数包括 2、3、5、7、11、13 等等,直到无穷大。
在 Python 中,我们可以使用下面的代码片段很容易地测试素数。
if num > 1:
for i in range(2,num):
if (num % i) == 0:
print(num,"is not a prime number")
print(i,"times",num//i,"is",num)
break
else:
print(num,"is a prime number")
else:
print(num,"is not a prime number")
首先,代码检查以确保数字大于 1(任何小于 1 的数字都不可能是质数,因为它不是整数)。然后它检查这个数字是否能被 2 和你要检查的数字之间的任何数字整除。如果它是可分的,那么你会从输出中看到这个数不是质数。如果它不能被这些数字中的任何一个整除,那么输出的消息将会是“[num]不是一个质数。”
如何在 Python 中遍历目录树 os.walk 指南
原文:https://www.pythoncentral.io/how-to-traverse-a-directory-tree-in-python-guide-to-os-walk/
当您使用像 Python 这样的脚本语言时,您会发现自己反复做的一件事就是遍历目录树和处理文件。虽然有许多方法可以做到这一点,但 Python 提供了一个内置函数,使这一过程变得轻而易举。
什么是 os.walk()函数?
walk 函数类似于 os.path 函数,但可以在任何操作系统上运行。Python 用户可以利用该函数在目录树中生成文件名。该函数在两个方向上导航树,自上而下和自下而上。
任何操作系统的任何树中的每个目录都有一个作为子目录的基目录。os.walk()函数以三元组的形式生成结果:路径、目录和任何子目录中的文件。
生成的元组有:
- 目录路径: 该字符串将文件或文件夹导向目录路径。
- 目录名: 包含所有不包含“.”的子目录还有“..”。
- 文件名: 这是系统或用户创建的文件或文件夹列表。它是包含目录文件之外的文件的目录路径。
需要注意的是,列表中的名字不包含路径的任何部分。如果用户想要获取从路径中的目录或文件顶部开始的完整路径,他们必须使用 os.walk.join(),它有 dirpath 和目录名的参数。
如前所述,os.walk()函数可以以自顶向下和自底向上的方式遍历树。top-down 和 bottom-up 是两个可选参数,如果用户想要生成一个目录序列,函数中必须使用其中的一个。
在某些情况下,如果用户没有提及任何与序列相关的参数,则默认使用自顶向下遍历选项。如果 top-down 参数为真,该函数首先为主目录生成三元组,然后是子目录。
另一方面,如果 top-down 参数为 false,函数将为子目录之后的目录生成三元组。简而言之,序列是以自下而上的方式生成的。
此外,当 top-down 参数为真时,用户可以更新目录名列表,os.walk()函数将仅适用于子目录。当 top-down 为 false 时,不可能更新目录名,因为在自下而上模式中,目录名显示在路径之前。
使用 listdir()函数可以消除默认错误。
Python OS . walk()函数的工作原理
在 Python 中,文件系统以特定的方式被遍历。文件系统就像一棵树,只有一个根,这个根将自己分成多个分支,而这些分支又会扩展成子分支,以此类推。
os.walk()函数通过从底部或顶部遍历目录树来生成目录树中文件的名称。
OS . walk()的语法
OS . walk 函数的语法是:
os.walk(top[, topdown=True[ onerror=None[ followlinks=False]]])
其中:
- Top: 表示子目录遍历的起点或“头”。如前所述,它会生成三元组。
- Topdown: 当该属性为真时,从上到下扫描目录,为假时,从下到上扫描目录。
- Onerror: 这是一个帮助监控错误的特殊属性。它要么显示一个错误以继续运行该函数,要么引发一个异常以关闭该函数。
- 跟随链接: 当设置为 true 时,如果任何链接指向它自己的基目录,该属性将导致无法停止的递归。需要注意的是,os.walk()函数从不记录它以前遍历过的目录。
如何使用 os.walk()
由于 os.walk()与操作系统的文件结构一起工作,用户必须首先将 os 模块导入到 Python 环境中。该模块是标准 Python 安装的一部分,将解决文件列表脚本其余部分中的任何依赖性。
接下来,用户必须定义文件列表功能。用户可以给它起任何名字,但是使用一个能清楚表达其目的的名字是最佳实践。该函数必须给出两个参数: filetype 和filepath。
文件路径 参数将指示函数必须从哪里开始寻找文件。它将使用操作系统格式的文件路径字符串。
-
注意: 对字符进行适当的转义或编码是必须的。
-
当文件列表功能运行时,该参数假定基本目录包含用户需要检查的所有文件和子文件夹。
另一方面, 文件类型 参数将向函数指示用户正在寻找什么类型的文件。该参数接受字符串格式的文件扩展名,例如,“. txt .”
接下来,用户需要存储脚本在文件列表函数中找到的所有相关文件路径。因此,用户必须创建一个空列表。
使用该函数时,将查找 文件路径 中的每个文件,并验证扩展名是否与所需的 文件类型 匹配。然后,它会将相关结果添加到空列表中。
因此,要开始迭代过程,我们必须使用 for 循环来检查每个文件。然后 os.walk()函数会在 filepath 中找到所有的文件和路径,并生成一个三元组。让我们假设我们将这些组件命名为 【根】**dirs和files。
由于 文件 组件会列出路径内的所有文件名,该函数必须遍历每个文件名。为此,我们必须编写一个 For 循环。
现在,在这个文件级循环下,文件列表函数必须检查每个文件的所有方面。如果您正在编写的应用程序有其他需求,这就是您必须修改脚本的地方。但是,为了便于解释,我们将重点检查所有文件的所需文件扩展名。
在 Python 中,比较字符串是区分大小写的。但是,文件扩展名的写法不同。因此,我们必须使用 lower()方法将 文件 和 文件类型 转换成小写字符串。这样,我们可以避免由于大小写不匹配而丢失任何文件。
接下来,我们必须使用 endswith()方法将存储文件扩展名的小写 文件 属性的末尾与小写 文件类型 属性进行比较。该方法将根据是否匹配返回 True 或 False。
布尔结果必须包含在 if 语句中,因此只有当存在匹配的文件类型时,脚本中的下一行才会被触发。
如果文件扩展名符合要求,那么 文件 属性及其位置的信息必须添加到 路径 组件中,这就是我们的相关文件路径列表。
使用 os.path.join()函数将根文件路径和文件名结合起来,形成一个操作系统可以使用的完整地址。可以使用 append()方法组合数据。
最后,Python 将遍历循环,遍历所有文件夹和文件,毫不费力地构建一个 路径 列表。为了使这个列表在文件列表函数之外可用,我们必须在脚本的末尾写 return(paths)。
总的来说,代码应该是这样的:
import os
def list_files(filepath, filetype):
paths = []
for root, dirs, files in os.walk(filepath):
for file in files:
if file.lower().endswith(filetype.lower()):
paths.append(os.path.join(root, file))
return(paths)
在这个脚本之后,您必须编写另一个函数,将结果位置保存到您选择的文件中。代码可能是这样的:
my_files_list = list_files(' C:\\Users\\Public\\Downloads', '.csv')
现在你的脚本已经准备好找到你需要的文件,你可以专注于分析文本,合并数据,或者任何你需要做的事情。
基本 Python 目录遍历
下面是一个非常简单的例子,它遍历一个目录树,打印出每个目录的名称和包含的文件:
[python]
# Import the os module, for the os.walk function
import os
# Set the directory you want to start from
rootDir = '.'
for dirName, subdirList, fileList in os.walk(rootDir):
print('Found directory: %s' % dirName)
for fname in fileList:
print('\t%s' % fname)
[/python]
os.walk关注细节,在每一次循环中,它给我们三样东西:
dirName:找到的下一个目录。subdirList:当前目录下的子目录列表。fileList:当前目录下的文件列表。
假设我们有一个如下所示的目录树:
+--- test.py
|
+--- [subdir1]
| |
| +--- file1a.txt
| +--- file1b.png
|
+--- [subdir2]
|
+--- file2a.jpeg
+--- file2b.html
上面的代码将产生以下输出:
[shell]
Found directory: .
file2a.jpeg
file2b.html
test.py
Found directory: ./subdir1
file1a.txt
file1b.png
Found directory: ./subdir2
[/shell]
改变遍历目录树的方式
默认情况下,Python 将按照自顶向下的顺序遍历目录树(一个目录将被传递给您进行处理),然后 Python 将进入任何子目录。我们可以在上面的输出中看到这种行为;父目录(。)首先被打印,然后是它的 2 个子目录。
有时我们希望自底向上遍历目录树(首先处理目录树最底层的文件),然后我们沿着目录向上遍历。我们可以通过 topdown 参数告诉os.walk这样做:
[python]
import os
rootDir = '.'
for dirName, subdirList, fileList in os.walk(rootDir, topdown=False):
print('Found directory: %s' % dirName)
for fname in fileList:
print('\t%s' % fname)
[/python]
这给了我们这样的输出:
[shell]
Found directory: ./subdir1
file1a.txt
file1b.png
Found directory: ./subdir2
Found directory: .
file2a.jpeg
file2b.html
test.py
[/shell]
现在,我们首先获取子目录中的文件,然后沿着目录树向上。
选择性递归进入子目录
到目前为止,示例只是遍历了整个目录树,但是os.walk允许我们有选择地跳过树的某些部分。
对于os.walk给我们的每个目录,它也提供了一个子目录列表(在subdirList中)。如果我们修改这个列表,我们可以控制os.walk将进入哪个子目录。让我们调整一下上面的例子,跳过第一个子目录。
[python]
import os
rootDir = '.'
for dirName, subdirList, fileList in os.walk(rootDir):
print('Found directory: %s' % dirName)
for fname in fileList:
print('\t%s' % fname)
# Remove the first entry in the list of sub-directories
# if there are any sub-directories present
if len(subdirList) > 0:
del subdirList[0]
[/python]
这为我们提供了以下输出:
[shell]Found directory: .
file2a.jpeg
file2b.html
test.py
Found directory: ./subdir2
[/shell]
我们可以看到第一个子目录( subdir1 )确实被跳过了。
这只在自顶向下遍历目录时有效,因为对于自底向上遍历,子目录在它们的父目录之前被处理,所以试图修改subdirList是没有意义的,因为到那时,子目录已经被处理了!
就地修改subdirList也很重要,这样调用我们的代码就会看到这些变化。如果我们这样做:
[python]
subdirList = subdirList[1:]
[/python]
...我们将创建一个新的子目录列表,一个调用代码不知道的列表。
列出目录中文件的四种其他方式
除了 os.walk()方法之外,还有四种方法可以列出目录中的文件:
#1 用 listdir()和 isfile()函数列出一个目录下的所有文件
串联使用 listdir()和 isfile()函数可以很容易地以目录方式获得文件列表。这两个函数是操作系统模块的一部分。下面是你如何使用它们:
第一步:导入操作系统模块
操作系统模块是一个标准的 Python 模块,使用户能够使用依赖于操作系统的功能。它包含许多使用户能够与操作系统交互的方法,包括文件系统。
第二步:使用 os.listdir()函数
使用 os.listdir()函数并向其传递 路径 属性将返回由 路径 属性提供的文件和目录的名称列表。
第三步:迭代结果
写一个 for 循环,迭代函数返回的文件。
第四步:使用 isfile()函数
循环的每次迭代都必须有 os.path.isfile('path ')函数来验证当前路径是文件还是目录。
如果该函数发现它是一个文件,它返回 True,并且该文件被添加到列表中。否则该函数返回 False。
下面是一个 listdir()函数的例子,它只列出了一个目录中的文件:
import os
# setting the folder path
dir_path = r'E:\\example\\'
# making a list to store files
res = []
# Iterating the directory
for path in os.listdir(dir_path):
# check whether the current path is a file
if os.path.isfile(os.path.join(dir_path, path)):
res.append(path)
print(res)
需要注意的是,listdir()函数只列出当前目录中的文件。
如果您熟悉生成器表达式,您可以缩短脚本并使其更简单,就像这样:
import os
def get_files(path):
for file in os.listdir(path):
if os.path.isfile(os.path.join(path, file)):
yield file
# Now, you can plainly call it whatever you want
for file in get_files(r'E:\\example\\'):
print(file)
函数也可以用来列出文件和目录。这里有一个例子:
|
import os
# folder path
dir_path = r'E:\\account\\'
# list file and directories; Directly call the listdir() function to get the content of the directory.
res = os.listdir(dir_path)
print(res)
|
#2 使用 os.scandir()函数获取一个目录下的文件
众所周知,scandir()函数比 os.walk()函数更快,而且它迭代控制器的效率也更高。它是一个类似于 listdir()的目录迭代函数;唯一的区别是它产生了包含文件类型数据和名称的 DirEntry 对象,而不是返回一个普通文件名的列表。
利用 scandir()函数可以将 os.walk()函数的速度提高 2 到 20 倍,具体取决于操作系统和文件系统的配置。它通过避免对 os.stat()函数的不必要调用来提高速度。
需要注意的是 scandir()函数返回 os 的迭代器。DirEntry 对象,包含文件名。
早在 2015 年 9 月,scandir()函数就包含在 Python 3.5 的标准 Python 库中。
下面是一个使用函数检索目录文件的例子:
import os
# retrieve all the files from inside the specified folder
dir_path = r'E:\\example\\'
for path in os.scandir(dir_path):
if path.is_file():
print(path.name)
#3 使用 Glob 模块
glob 模块也是标准 Python 库的一部分。用户可以利用该模块来查找其名称遵循特定模式的文件和文件夹。
例如,如果你想获得一个目录下的所有文件,你可以使用 dire_path/。模式,其中" 。 "表示具有任何扩展名的文件。
下面是一个使用该模块获取目录中文件列表的例子:
import glob
# search all the files inside a directory
# The *.* indicates that the file name may have any extension
dir_path = r'E:\example\*.*'
res = glob.glob(dir_path)
print(res)
您也可以使用该模块,通过将递归属性设置为 true 来列出子目录中的文件:
import glob
# search all the files inside a directory
# The *.* indicates that the file name may have any extension
dir_path = r'E:\demos\files_demos\example\**\*.*'
for file in glob.glob(dir_path, recursive=True):
print(file)
#4 使用 Pathlib 模块
在 Python 3.4 中,pathlib 模块被引入到 Python 标准库中。它为大多数操作系统功能提供了包装器。它包括一些类和方法,使用户能够处理文件系统路径,并为各种操作系统检索与文件相关的数据。
下面是如何使用该模块来检索目录中的文件列表:
- 导入 pathlib 模块。
- 写一个 pathlib。Path('path ')行来构造目录路径。
- 使用 iterdir()函数迭代一个目录中的所有条目。
- 最后,使用 path.isfile()函数检查当前条目是否是一个文件。
这里有一个利用 pathlib 模块实现这一目的的示例脚本:
import pathlib
# Declaring the folder path
dir_path = r'E:\\example\\'
# making a list to store file names
res = []
# constructing the path object
d = pathlib.Path(dir_path)
# iterating the directory
for entry in d.iterdir():
# check if it a file
if entry.is_file():
res.append(entry)
print(res)
什么时候使用 os.listdir()函数代替 os.walk()函数比较合适?
这是程序员在了解 os.walk()之后最常问的问题之一。答案很简单:
函数将返回一个文件树中所有文件的列表,而函数将返回一个目录中所有文件和文件夹的列表。
通过一个例子可以更清楚地理解 os.listdir()函数的工作原理:
假设我们有一个目录“Example”,有三个文件夹 A、B 和 C,以及两个文本文件 1.txt 和 2 . txt。A 文件夹有另一个文件夹 Y,其中包含两个文件。B 和 C 文件夹各有一个文本文件。
将“Example”文件夹的目录路径传递给 os.listdir()方法:
import os
example_directory_path = './Example'
print(os.listdir(example_directory_path))
上面的脚本将给你一个输出:
['1.txt', '2.txt', 'A', 'B', 'C']
换句话说,os.listdir()函数只会生成目录的第一个“层”。这使得它与 os.walk()方法非常不同,后者搜索整个目录树。
简单地说,如果你需要一个根目录下所有文件和目录名的列表,你可以使用 os.listdir()函数。但是,如果您想查看整个目录树,使用 os.walk()方法是正确的方法。
结论
使用 Python 中的 os walk 函数是以自顶向下和自底向上的方式遍历目录中所有路径的简便方法之一。在这篇文章中,我们还介绍了在目录中列出文件的其他四种方法。
现在您已经了解了不同的方法,您可以编写一个脚本来轻松地遍历目录,并将精力集中在分析文本或合并数据上。
要获得关于 Python 的os.walk方法的更全面的教程,请查看 Python 中递归文件和目录操作的方法。或者看看用另一种方式遍历目录(使用递归),看看 Python 中的递归目录遍历:列出你的电影!。*
如何卸载 Python
Python 的每个版本都有错误修复和安全补丁。为了确保您不会受到已修复的错误和安全问题的影响,删除旧版本是必要的。
虽然你可以在同一台电脑上使用多个 Python 版本,但是在卸载旧版本之前安装新版本的 Python 有时会破坏电脑上的 Python。
谢天谢地,在安装新版本之前卸载 Python 可以解决这个问题,而且做起来并不困难。在这篇文章中,我们已经分解了如何在每个操作系统上移除 Python。
如何从 Windows、Mac、Linux 卸载 Python
没有在操作系统上卸载 Python 的标准方法。您需要遵循特定于您计算机上操作系统的卸载步骤。
| 注意: 如果你想从你的电脑中移除 Python 包,你不需要从你的电脑中卸载 Python。您可以使用 pip 工具添加、移除和搜索特定的 Python 包。如果你不知道如何使用 pip, 我们的详细指南 将在几分钟内教你需要知道的东西。 |
如何从 Windows 中卸载 Python
Windows 轻松卸载 Python。您可以通过三个简单的步骤移除计算机上安装的任何 Python 版本。
步骤#1:导航至控制面板
按键盘上的 Windows 键或屏幕左下角的 Windows 按钮打开开始菜单。
输入“控制面板”,从选项列表中找到并启动控制面板。
步骤#2:导航到卸载菜单
控制面板打开后,您必须点击左下方“程序”部分下的“卸载程序”按钮。
将会打开一个菜单,其中包含计算机上安装的所有程序。
第三步:卸载 Python
您必须向下滚动程序列表,找到您计算机上安装的 Python 版本。接下来,通过左键单击选择程序,然后单击“卸载”按钮。
卸载向导将启动,在您确认卸载 Python 的决定后,它将从您的计算机中删除。
要从您的电脑中完全删除 Python,您需要从 Path 中删除 Python。
步骤#4:从路径中移除 Python
Python 卸载程序在运行时会自动从 Path 中删除 Python。也就是说,最好检查 Python 是否已经从 Path 中移除。这很容易做到,不需要很长时间:
- 按下 Windows 键,输入“环境变量”启动控制面板中的设置菜单。
![Windows Search Environment Variables]()
- 将出现一个“系统属性”菜单。找到并单击“环境变量”按钮。
![Windows System Properties Menu]()
- 左键点击系统变量部分的“Path”变量,将其高亮显示。然后按“编辑”按钮。
![Windows Environment Variables Menu]()
- 如果您在菜单中看到 Python bin 文件夹的路径,选择该路径并按下菜单右侧的“删除”按钮将其删除。
![Windows Edit Environment Variable]()
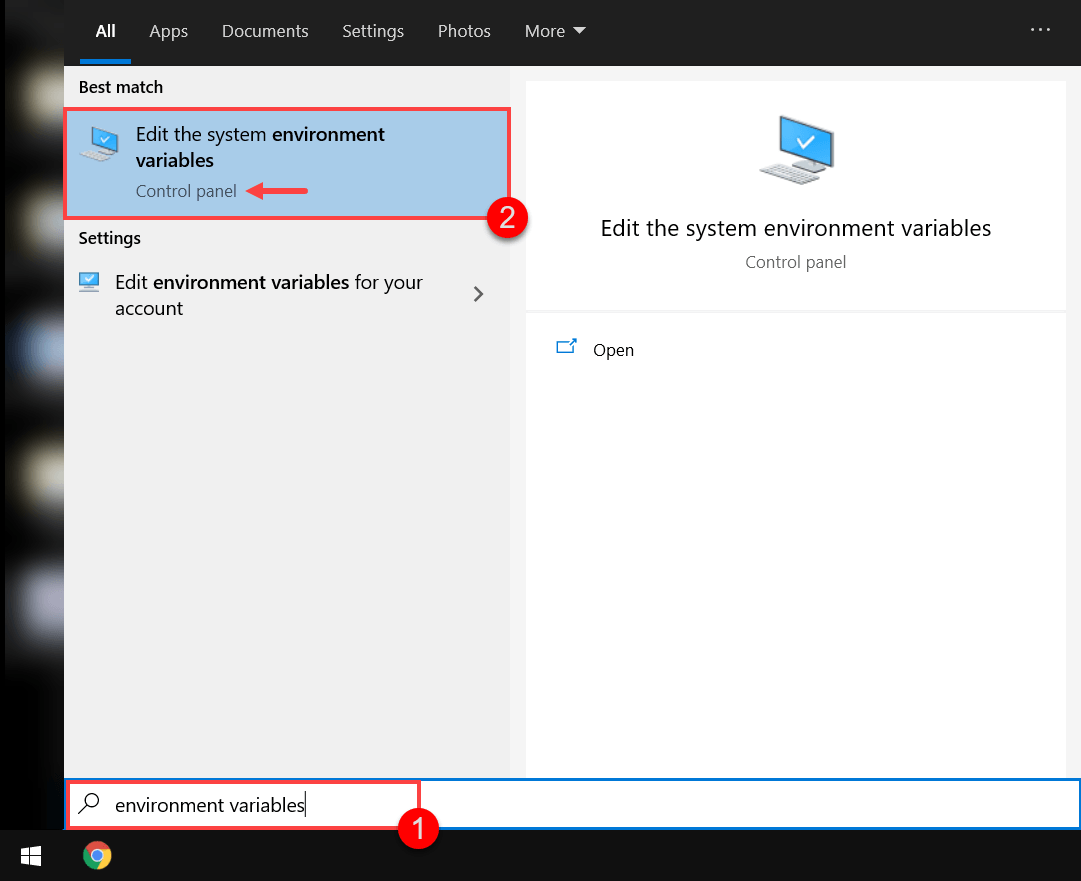

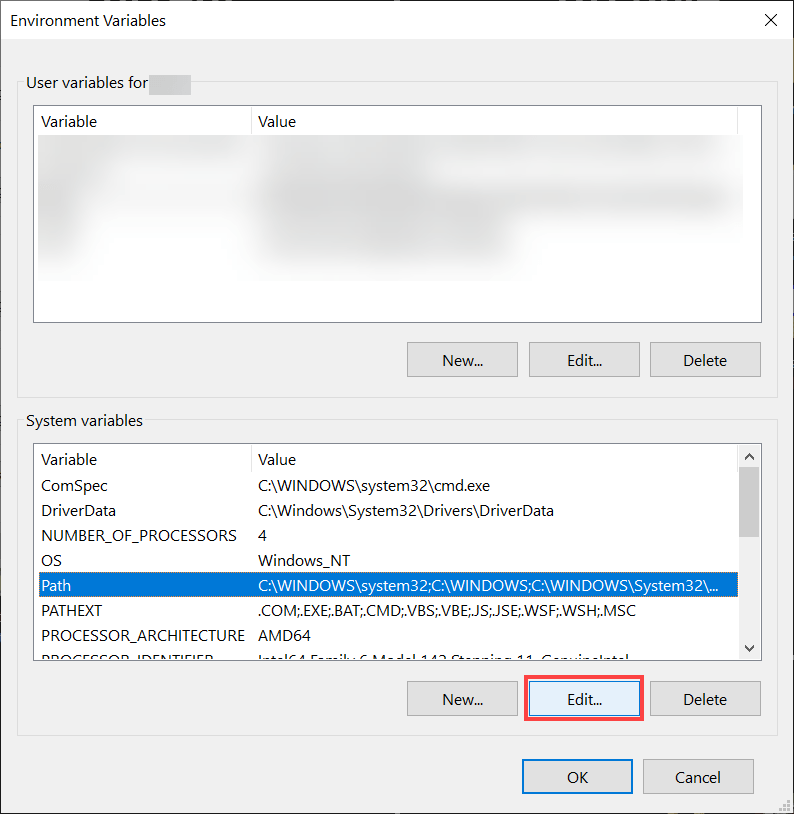
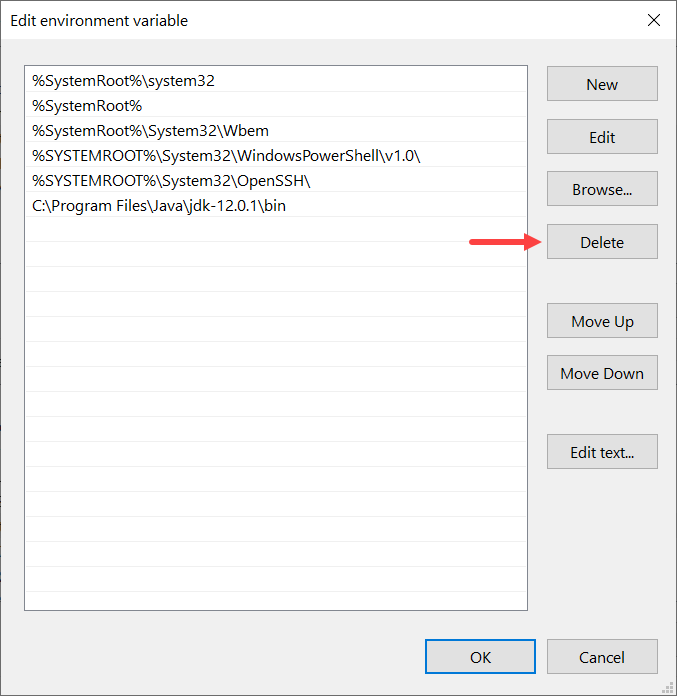
这样,你就可以将 Python 从你的 Windows 电脑上完全移除了。
如何从 Mac 卸载 Python
在运行 macOS 的电脑上卸载 Python 并不总是一个好主意。这是因为 macOS 预装了 Python,操作系统的内部工作依赖于 Python。
预装的 Python 框架出现在/System/Library/Frameworks/Python . framework 中,在 usr/bin/python 中可以找到几个符号链接。
移除此版本的 Python 将会破坏 macOS,并可能导致 OS 故障。你可以在 Stack Exchange 的面向程序员的 Q & A 站点、Stack Overflow了解更多信息。
也就是说,如果你已经在 Mac 上安装了第三方 Python 框架,你可以安全地卸载它。你可以这样做:
步骤#1:从应用程序中移除 Python
打开 Finder,并导航至应用程序文件夹。在这里,您将找到您已安装的 Python 版本的文件夹。你必须把它们扔到垃圾桶里。
如果您只想从 Mac 上移除特定版本的 Python,请确保您只将相关的 Python 文件夹移到废纸篓中。
如果出现一个对话框,要求您输入电脑密码,请输入密码并点击“确定”
这些文件夹将被移至垃圾箱。接下来,您必须导航到回收站,高亮显示 Python 版本,然后右键单击。从出现的选项中,选择“立即删除”选项。
删除文件夹不会将 Python 从电脑中完全删除。您必须将其从库目录中删除,并删除符号链接。
步骤#2:从/Library 中移除 Python
您需要使用终端从库目录中移除 Python。要打开终端,按 Cmd ⌘ + Space 并搜索,然后启动。
要从目录中删除第三方框架,请在终端中输入以下命令:
| sudo RM-RF/Library/Frameworks/python . framework |
可能会要求您输入系统密码。如果出现提示,请输入。
如果您只想从您的计算机中删除特定版本的 Python,请通过修改命令来指定版本,如下所示:
| sudo RM-RF/Library/Frameworks/python . framework/Versions/3.8 |
步骤#3:移除符号链接
第 1 步和第 2 步将从您的 Mac 上移除 Python 目录和文件。但是,引用已被删除的 Python 文件夹的链接可能会保留在您的计算机上。这些链接被称为符号链接(或符号链接)。
有两种方法可以从您的电脑中删除这些链接:
#1 手动删除
引用 Python 文件夹的链接在/usr/local/bin 中。由于链接中引用的文件夹不再存在,这些链接将会断开。
您可以通过在终端中输入以下命令来查看所有断开的符号链接:
| ' ls -l /usr/local/bin | grep '../Library/Frameworks/python . framework ' |
如果您只删除了 Python 的一个特定版本,请确保将上述命令中的路径替换为您在步骤#2 中使用的路径。
看到所有断开的链接后,使用这些命令删除它们:
进入目录:
| cd /usr/local/bin |
删除断开的链接:
| ' ls -l /usr/local/bin | grep '../Library/Frameworks/python . framework“| awk“{ print $ 9 }”| tr-d @ | xargs RM * |
如果上述命令中的路径不同于您在步骤#2 中使用的路径,请用您使用的路径替换上述命令中的路径。
运行这些命令后,已安装的 Python 版本将从 Mac 中移除。
#2 使用自制软件
你也可以用自制软件从你的电脑中删除断开的符号链接。如果您还没有安装它,运行下面的命令来安装它:
| /bin/bash-c " $(curl-fsSLhttps://raw . githubusercontent . com/home brew/install/master/install . sh)" |
用自制软件找到断开的链接要容易得多。要找到它们,运行以下命令:
| 酿造医生 |
将出现一个断开的符号链接列表。然后,您可以使用以下命令来删除它们:
| 酿造清洗 |
如何从 Linux 卸载 Python
Linux 与 macOS 相似,Python 预装在操作系统中。此外,删除软件的预安装版本会导致操作系统出现故障。
通常,从 Linux 卸载 Python 时,图形显示管理器会失败。
因此,您只能卸载手动安装的 Python 版本。
要删除您安装的 Python 版本,请在终端上使用以下命令:
| sudo apt purge-y python 2 . x-minimal |
您可以使用这个命令从 Linux 发行版中删除 Python 3:
| sudo ln-s/usr/bin/python 3/usr/bin/python |
从系统中移除 pip:
| sudo apt install -y python3-pipsudo ln-s/usr/bin/pip 3/usr/bin/pip |
如果您发现这些命令不起作用,您可能需要使用 sudo 来更新您的回购列表,以获得更新 。
结论
至此,你知道如何从你的电脑上完全卸载 Python 了。
现在你可以在电脑上安装最新版本的 Python,而不用担心它会崩溃或处理已经修复的错误。
为确保您在电脑上安全安装新的 Python 版本,请务必阅读我们的 Python 安装指南 。如果这篇文章有所帮助,或者你认为我们可以改进这个答案,请在评论中告诉我们。
如何更新 Python
Python 每 12 个月接受一次重大更新,每隔几个月发布一次 bug 修复更新和安全补丁。Python 的最新版本——Python 3.9——引入了像 dict 中的联合操作符、灵活函数和类型提示泛型这样的特性。无论你运行的是哪种操作系统,更新 Python 都会令人困惑。 是否先去掉旧版本?或者可以直接更新包吗?这里有一个关于如何更新 Python 的简单教程。
如何在 Linux、Mac 或 Windows 中更新 Python
在一台计算机上安装两个主要版本的 Python——比如 Python 2.x 和 Python 3 . x——并同时使用是可能的。如果想从 Python 2.x 迁移到 3.x,除非不想再用了,否则不必卸载之前的版本。 此外,Python 3 现在默认集成了“py.exe”启动器。启动器以两种方式帮助用户:
- 用户可以使用命令“py”在任何 shell 中运行 Python 不再需要输入“python”。
- 允许你同时使用两个不同版本的 Python 3。您可以通过命令中的简单开关(如“py -3.6”)来指定想要使用哪个版本的 Python 来运行代码。
换句话说,当你想使用另一个版本的 Python 时,你不需要每次都改变 PATH 变量。 但是启动器只安装在 Python 3 的 Windows 版本上。在装有 Linux 或 macOS 的电脑中更新 Python 可能会更复杂。
注意: 如果你的电脑上还没有安装 Python,你就无法更新到更新的版本。如果你在电脑上安装 Python 有困难,阅读我们的 Python 安装指南 会有帮助。
在 Linux 中更新 Python
在运行任何命令之前,您可以通过检查 Linux 安装是否安装了最新版本的 Python 来节省大量精力。 要检查您的机器上的 Python 3 是什么版本,请按 Ctrl+Alt +T 打开终端,并键入以下命令:Python 3–version或者: python3 -V 输出应该是这样的: 如果您发现您的机器没有 Python 3.9,您必须运行以下命令现在可以通过两种方式安装最新版本的 Python:使用 Apt 和使用源代码。 使用 Apt 更新 Python 更快更简单。你可以这样做:
如果您发现您的机器没有 Python 3.9,您必须运行以下命令现在可以通过两种方式安装最新版本的 Python:使用 Apt 和使用源代码。 使用 Apt 更新 Python 更快更简单。你可以这样做:
使用 Apt-Get 更新 Python
使用 Apt 包管理器是在 Linux 上安装 Python 3.9 最简单的方法。 首先,您必须通过运行以下命令将 deadsnakes PPA 配置到您的机器:sudo add-apt-repository PPA:dead snakes/PPA您现在可以更新 apt 缓存并安装 Python 3.9 包: sudo apt 更新 sudo apt 安装 Python 3.9Python 更新将会安装。但是,默认情况下,Python 将指向以前安装的 Python 3 版本。 安装完成后,必须更新 Python 3 指向 Python 3.9。输入这个命令来配置 Python 3:sudo update-alternatives-config Python 3会出现一个选项列表,提示你选择你希望 Python 3 指向哪个版本的 Python。提示应该是这样的: 你所要做的就是输入正确的选择号,这样你就将 Python 更新到了你的 Linux 机器上的最新版本。 要验证正在使用的 Python 版本,可以运行: python3 - V
你所要做的就是输入正确的选择号,这样你就将 Python 更新到了你的 Linux 机器上的最新版本。 要验证正在使用的 Python 版本,可以运行: python3 - V
在 Mac 中更新 Python
在装有 macOS 的机器上更新 Python 比在 Linux 机器上更新要容易得多。 一台 Mac 可以安装多个版本的 Python。因此,你可以通过访问【 https://www.python.org/downloads/mac-osx/ 】,下载安装程序,并运行它来更新 Python。 如果你的 Mac 上安装了 Homebrew,你可以在终端上运行以下命令: brew 安装 python 这个过程完成后,你的电脑上就有了最新版本的 Python 3。您可以通过运行命令来验证这一点:python 3-version如果您想要升级 pip 并向其添加新的库,您可以输入以下命令: pip3 install <项目名称>
在 Windows 中更新 Python
在运行 Windows 的计算机上,更新到新的 Python 版本很容易。你所要做的就是访问 Python 下载页面 下载最新版本。 如果你正在更新到 Python 的新补丁(3.x.a 到 3.x.b),当你运行安装程序时,它会提示你“立即升级”安装程序会是这样的: 点击按钮会用新版本替换现有版本的 Python。旧版本将从您的计算机中删除。重新启动计算机后,新的修补程序将安装在您的计算机上。 相比之下,如果你正在将 Python 更新到一个新的次要版本(3.x 到 3.y),你会在安装程序上看到“立即安装”的提示,而不是“立即升级”的提示。点击按钮将安装 Python 的新版本。但是,旧版本不会被删除。您的计算机可以安装多个 Python 版本。不管您使用的是哪个版本的 Python,py 启动器都会自动安装。它将允许您选择想要使用的 Python 版本。 运行一个特定版本的程序,就像使用“py”命令,输入你想要使用的版本一样简单,就像这样: py -3.8 或者 py -3.9 假设你的机器上有很多项目使用的是之前版本的 Python,你都是在一个虚拟环境中使用的。在这种情况下,您可以使用以下命令在该环境中更新 Python:Python-m venv-upgrade<虚拟环境路径此处为>
点击按钮会用新版本替换现有版本的 Python。旧版本将从您的计算机中删除。重新启动计算机后,新的修补程序将安装在您的计算机上。 相比之下,如果你正在将 Python 更新到一个新的次要版本(3.x 到 3.y),你会在安装程序上看到“立即安装”的提示,而不是“立即升级”的提示。点击按钮将安装 Python 的新版本。但是,旧版本不会被删除。您的计算机可以安装多个 Python 版本。不管您使用的是哪个版本的 Python,py 启动器都会自动安装。它将允许您选择想要使用的 Python 版本。 运行一个特定版本的程序,就像使用“py”命令,输入你想要使用的版本一样简单,就像这样: py -3.8 或者 py -3.9 假设你的机器上有很多项目使用的是之前版本的 Python,你都是在一个虚拟环境中使用的。在这种情况下,您可以使用以下命令在该环境中更新 Python:Python-m venv-upgrade<虚拟环境路径此处为>
结论
Python 的每个版本,包括最新发布的都有一定的局限性。然而,更新到 Python 的最新版本允许您使用所有新功能。此外,更新版本还提供了错误修复和改进的安全措施。有了这本指南,您应该能够在几分钟内获得最新的 Python 版本。 通读我们的 Python 使用指南 接下来会帮你快速拿起你能用 Python 做的一切。
如何使用 Argparse 编写命令行程序:示例和提示
原文:https://www.pythoncentral.io/how-to-use-argparse-to-write-command-line-programs-examples-and-tips/
命令行界面是最简单的界面,它的使用可以追溯到几十年前第一台现代计算机诞生的时候。
虽然图形用户界面已经变得很普通,但 CLI 今天仍在继续使用。它们促进了一些 Python 操作,例如系统管理、开发和数据科学。
如果你正在构建一个命令行应用程序,你还需要一个用户友好的命令行界面来促进与应用程序的交互。Python 的好处在于,其标准库中的 argparse 模块使开发人员能够构建全功能的 CLI。
在本指南中,我们将带领您使用 argparse 构建 CLI。
需要注意的是,除了理解 OOP、包和模块等概念之外,你还需要了解终端或命令行界面的基本工作原理。
如何使用 Argparse 编写命令行程序
最早出现在Python 3.2中,argparse 可以接受可变数量的参数,解析命令行参数和选项。
使用该模块非常简单,只需导入它,制作一个参数解析器,将参数和选项放入图片中,然后调用。parse_args()从解析器获取参数的名称空间。
让我们看一个例子来理解 argparse 是如何工作的。
这里有一个程序列出了目录中的文件,就像 Linux 上的 ls 命令一样:
# ls.py v1
import argparse
from pathlib import Path
parser = argparse.ArgumentParser()
parser.add_argument("path")
args = parser.parse_args()
target_dir = Path(args.path)
if not target_dir.exists():
print("Target directory doesn't exist")
raise SystemExit(1)
for entry in target_dir.iterdir():
print(entry.name)
如您所见,导入模块后,我们用 ArgumentParser 类创建了一个解析器。然后,定义“path”参数,获取目标目录。
接下来,程序调用。parse_args(),解析输入参数并获取带有所有用户参数的名称空间对象。
在我们深入剖析 argparse 模块之前,您必须注意到它可以识别两种命令行参数。
第一种是位置论元,或简称为论点。之所以这样称呼它,是因为它的用途是由它在命令结构中的相对位置定义的。上例中的“path”参数是一个位置参数。
第二种是可选参数。它也被称为选项、开关或标志。这种类型的参数使您能够修改命令的工作方式。顾名思义,不需要使用它来运行命令。
编写一个参数解析器
参数解析器是用 argparse 构建的任何 CLI 的基本组件,因为它处理传递的每个参数和选项。
您必须通过实例化 ArgumentParser 类来编写一个:
>>> from argparse import ArgumentParser
>>> parser = ArgumentParser()
>>> parser
ArgumentParser(
prog='',
usage=None,
description=None,
formatter_class=<class 'argparse.HelpFormatter'>,
conflict_handler='error',
add_help=True
)
ArgumentParser 构造函数接受几个参数,您可以用它们来调整 CLI 的功能集。
它接受的参数是可选的,所以如果实例化不带任何参数的 ArgumentParser 类,您将得到一个简洁的解析器。
添加参数和选项
向您的 CLI 添加参数和选项就像使用。您创建的 ArgumentParser 实例上的 add_argument()方法。
你添加到。add_argument()方法对比了选项和参数的区别。第一个参数称为“名称”或“标志”,这取决于您是在定义参数还是选项。
让我们给上面创建的 CLI 添加一个“-l”选项:
# ls.py version2
import argparse
import datetime
from pathlib import Path
parser = argparse.ArgumentParser()
parser.add_argument("path")
parser.add_argument("-l", "--long", action="store_true") #Creating an option with flags -l and --long
args = parser.parse_args()
target_dir = Path(args.path)
if not target_dir.exists():
print("The target directory doesn't exist")
raise SystemExit(1)
def build_output(entry, long=False):
if long:
size = entry.stat().st_size
date = datetime.datetime.fromtimestamp(
entry.stat().st_mtime).strftime(
"%b %d %H:%M:%S"
)
return f"{size:>6d} {date} {entry.name}"
return entry.name
for entry in target_dir.iterdir():
print(build_output(entry, long=args.long))
在第 11 行创建选项时(突出显示为黄色),我们还将“action”参数设置为“store_true”这指示 Python 在命令行中提供选项时存储布尔值“True”。
如您所料,如果没有提供选项,该值将保持“False”
在程序的后面,我们使用 Path.stat()和 datetime.datetime 对象等工具来定义 build_output()函数。
当“long”为“True”时,它会产生一个详细的输出该输出包括目录中每个项目的名称、修改日期和大小。
当该值为“假”时,它生成一个基本输出。
解析参数和选项
需要对提供的参数进行解析,以便您的 CLI 可以相应地使用这些操作。在前面的程序中,这发生在第一次定义“args”变量的那一行。
该语句调用. parse.args()方法。然后,它的返回值被赋给 args 变量,这是一个包含命令行提供的所有参数和选项的名称空间对象。该对象还通过点符号存储其相应的值。
这个名称空间对象在你的应用程序的主要代码中很方便——就像前面提到的程序中的 for 循环一样。
使用 Argparse 设置描述、Epilog 消息和分组帮助消息
定义描述和结尾消息
对您的 CLI 应用程序进行描述是一种很好的方式,可以让应用程序的功能更容易理解。结尾信息或结束语通常用来感谢用户。
你可以使用“描述”和“结尾”参数来完成这些事情。让我们继续我们的定制 ls 命令示例,看看参数是如何工作的:
# ls.py version3
import argparse
import datetime
from pathlib import Path
parser = argparse.ArgumentParser(
prog="ls", # This argument sets the program's name
description=" This program lists a directory's content",
epilog="Thank you for using %(prog)s",
)
# ...
for entry in target_dir.iterdir():
print(build_output(entry, long=args.long))
我们设置的描述将出现在帮助信息的开头。
仔细看看 epilog 参数,您会看到使用了“%”格式说明符。这可能会让您感到惊讶,但是帮助消息确实支持这种格式说明符。
由于 f 字符串说明符在运行时用值替换名称,所以它们不受支持。因此,如果你尝试将 prog 放入 epilog 并在调用 ArgumentParser 时使用 f 字符串,应用程序将抛出一个 NameError。
执行该应用程序将得到以下输出:
| $ python ls.py -h用法:ls [-h] [-l] path这个程序列出了一个目录的内容立场论点:路径选项:-h,- help 显示该帮助信息并退出-l,- long感谢您使用 ls |
显示分组帮助信息
argparse 模块拥有帮助组功能,允许您将相关命令和参数组织成组,并使帮助消息更容易阅读。
创建帮助组需要使用 ArgumentParser 的. add_argument_group()方法,如下:
# ls.py version4
# ...
parser = argparse.ArgumentParser(
prog="ls", # This argument sets the program's name
description=" This program lists a directory's content",
epilog="Thank you for using %(prog)s",
)
general = arg_parser.add_argument_group("general output")
general.add_argument("path")
detailed = arg_parser.add_argument_group("detailed output")
detailed.add_argument("-l", "--long", action="store_true")
args = arg_parser.parse_args()
# ...
for entry in target_dir.iterdir():
print(build_output(entry, long=args.long))
虽然在这样一个简单的例子中,对参数进行分组似乎是不必要的,但这样做的目的是让你改善应用程序的用户体验。
如果你的应用程序有几个参数和选项,这种帮助信息的分组方式对 UX 来说尤其有效。
使用-h 选项执行应用程序将提供以下结果:
| python ls.py -h用法:ls [-h] [-l] path这个程序列出了一个目录的内容选项:-h,- help 显示该帮助信息并退出一般输出:路径详细输出:-l,- long感谢您使用 ls |
改进您的命令行参数和选项
设置选项后的动作
向 CLI 添加标志或选项时,在大多数情况下,您必须定义选项的值必须如何存储在其对应的名称空间对象中。
要做到这一点,需要使用。add_argument()方法。有问题的参数存储为选项提供的值,就像它在命名空间中一样。这是因为默认情况下,参数的值为“store”。
然而,自变量可以有其他值。让我们看看 action 参数可以存储的所有值及其含义。
| 允许值 | 描述 |
| 追加 | 当提供选项时,将当前值追加到列表中。 |
| 追加常量 | 当提供选项时,将常数值追加到列表中。 |
| 计数 | 统计当前选项被提供的次数,并存储该值。 |
| 商店 | 将输入放入命名空间对象。 |
| store_const | 如果指定了选项,存储一个常数值。 |
| store_false | 默认值为“真”如果指定了选项,它将存储“False”。 |
| store_true | 默认值为“假”如果指定了选项,它将存储“True”。 |
| 版本 | 显示应用程序的版本,然后应用程序终止。 |
如果您提供任何带有“_const”后缀的值,您将需要提供常数值。这样做很简单,只需在调用。add_argument()。
出于同样的原因,您需要在对的调用中使用 version 参数向“version”操作提供应用程序的版本。add_argument()
这里有一个例子,让我们更深入地了解这些动作是如何工作的:
# Toy app
# actions.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
"--name", action="store"
)
# This option will store the passed value without any considerations
parser.add_argument("--pi", action="store_const", const=3.14) # When the option is supplied, this option will automatically store the target constant
parser.add_argument("--is-valid", action="store_true")
# This option will store True when supplied and False otherwise
parser.add_argument("--is-invalid", action="store_false")
# This option will store False when supplied and True otherwise
parser.add_argument("--item", action="append")
# This option will help you create a list of all values, but you will need to repeat the option for every value. The argparse method will append the supplied items to a list with the same name as the option.
parser.add_argument("--repeated", action="append_const", const=42)
# This option works similarly to the "--item" option. The only difference being it'll append the same constant value you provide with the const argument.
parser.add_argument("--add-one", action="count")
# It will count the frequency of the option's total usage in the command line.
parser.add_argument(
"--version", action="version", version="%(prog)s 0.1.0"
)
# It'll show the app's version before terminating it. For this option to work, you will need to supply the version number beforehand.
args = parser.parse_args()
print(args)
如你所见,我们已经在上面的程序中使用了 action 参数的所有可能值。我们还评论了每个已定义选项的功能。
当你运行它时,它将打印所有使用的动作参数的名称空间对象。
尽管 argparse 提供的一组默认动作没有缺陷,但值得注意的是,您可以通过对 argparse 进行子类化来创建自定义动作。动作类。
为你的命令行应用定制输入值
有时,你的应用程序可能会要求所提供的参数接受一个字符串、值列表或其他类型的值。默认情况下,命令行将提供的参数视为字符串。
但是 argparse 模块具有允许它检查参数是否是有效的列表、字符串、整数等的机制。让我们来看看定制输入值的不同方式。
定义输入值的类型
您可以使用。add_argument()方法来定义要存储在 Namespace 对象中的输入。
假设你正在开发一个将两个数相除的 CLI 应用程序。为了让它像预期的那样工作,它将接受两个选项:-被除数和-除数。
为了使这些选项正确工作,它们必须在命令行中只接受整数。你可以这样做:
# divide.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--dividend", type=int)# Setting "int" as the acceptable input type
parser.add_argument("--divisor", type=int) # Setting "int" as the acceptable input type
args = parser.parse_args()
print(args.dividend / args.divisor)
当使用选项时,此 CLI 现在将只接受整数。它将尝试将提供的值转换为整数,但如果提供了文本字符串和浮点值,将会失败。
接受多个输入值
argparse 模块假设您接受每个选项和参数的单个值。要改变这种行为,可以使用“nargs”参数。
该参数向模块表明,所讨论的参数(或选项)可以接受零个或几个输入值,这取决于您分配给 nargs 的具体值。
nargs 参数可以接受以下值:
| 允许值 | 意为 |
| * | 接受零个或多个值,并将它们存储在一个列表中 |
| ? | 接受零或一个值 |
| + | 接受一个或多个值,并将它们存储在一个列表中 |
| argparse。余数 | 收集命令行中剩余的所有值 |
让我们通过一个例子来看看允许的值是如何工作的。假设您创建了一个命令行选项“- coordinates”的 CLI,它接受两个值。如你所想,这个想法是接受笛卡尔平面的 x 和 y 坐标。
下面是代码的样子:
# point.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--coordinates", nargs=2) # The option will only accept two arguments
args = parser.parse_args()
print(args)
程序中的最后一条语句指示 Python 打印名称空间对象。如果您为它提供两个值,您将看到如下预期结果:
| $ python point . py-coordinates 2 3名称空间(坐标=['2 ',' 3']) |
但是如果提供了零个、一个或两个以上的参数,程序将抛出一个错误。
现在,我们来看一个使用 nargs 的*值的例子。假设您构建了一个接受数字并返回其总和的 CLI 应用程序。它看起来像这样:
# sum.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("numbers", nargs="*", type=float)# The numbers argument will only accept floating point numbers
args = parser.parse_args()
print(sum(args.numbers))
因为我们已经使用了*值,所以不管你传递了多少个值(或者没有传递任何值),程序都将返回总和。
相比之下,将+值赋给 nargs 只会强制参数接受最少一个值。下面是一个 CLI 应用程序的例子,它接受一个或多个文件并打印它们的名称。
# files.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("files", nargs="+") # The files argument needs a minimum of one value
args = parser.parse_args()
print(args)
如果你给这个程序提供一个或多个文件,它将返回一个带有文件名的名称空间,比如:
| $ python files . py hello world . txt命名空间(files=['helloWorld.txt']) |
但是,如果没有提供文件,它将抛出如下错误:
| $ python files.py用法:files.py [-h] files [files...]files.py: error:需要以下参数:files |
余数值使 nargs 能够在命令行捕获剩余的输入值。让我们来看看它是如何工作的:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('value')
parser.add_argument('remaining', nargs=argparse.REMAINDER)
args = parser.parse_args()
print(f'Initial value: {args.value}')
print(f'Leftover values: {args.remaining}')
向这个程序传递一些字符串将导致第一个字符串被第一个参数捕获。第二个参数将捕获剩余的字符串。下面是运行它时的输出结果:
| > python nargs.py 你好读者第一个值:良好其他值:['天','到','你','读者'] |
nargs 参数提供了很大的灵活性,但是当你的应用程序有多个命令行选项和参数时,它可能很难使用。
当涉及到不同的 nargs 值时,您可能很难组合选项和参数。让我们用一个例子来看看如何:
# cooking.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("vegetables", nargs="+")
parser.add_argument("spices", nargs="*")
args = parser.parse_args()
print(args)
你会期望“蔬菜”接受一个或多个项目,而“香料”接受零个或多个项目。但这并不是你运行程序时会发生的:
| $ python cooking.py 茄子辣椒黄瓜名称空间(蔬菜=['茄子','辣椒','黄瓜'],调料=[]) |
我们得到这个输出,因为解析器没有任何方法来确定哪个值需要分配给哪个参数或选项。
在本例中,您可以通过将两个参数都转换为选项来解决这个问题。这样做很简单,只需在参数后面添加两个连字符。
然后,您可以运行以下命令来获得正确的输出:
| $ python cooking.py -蔬菜茄子黄瓜-香料辣椒名称空间(蔬菜=['茄子','黄瓜'],香料=['辣椒']) |
这个例子表明,在用 nargs 组合参数和选项集时必须小心。
设置默认值
将“默认”参数与。add_argument()方法,可以为参数和选项提供适当的默认值。
当您的目标选项或参数需要一个有效值时,即使用户没有提供输入,使用该参数也会非常有用。
让我们回到我们在这篇文章前面写的自定义 ls 命令。假设应用程序现在需要让命令列表显示当前目录的内容,如果用户没有提供目标目录的话。
下面是这个程序的样子:
# ls.py version5
import argparse
import datetime
from pathlib import Path
# ...
general = parser.add_argument_group("general output")
general.add_argument("path", nargs="?", default=".")
# ...
如你所见,我们已经将“默认”参数设置为“.”字符串,表示当前目录。另外,nargs 被设置为“?”它删除了对输入值的约束,并且只接受单个值(如果提供了任何值的话)。
运行程序,看看它是如何工作的!
提及允许输入值的列表
argparse 模块提供了提供值列表的可能性,并且只允许这些值与特定的参数和选项一起工作。
该模块通过您可以提供给。add_argument()方法。您需要为此参数提供您的可接受值列表。
假设您正在构建一个需要接受 t 恤尺寸的 CLI 应用程序。这里有一个程序将定义一个"- size "选项和一些可接受的值:
# size.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--size", choices=["S", "M", "L", "XL"], default="M")
args = parser.parse_args()
print(args)
如您所见,我们使用了“choices”参数来提供可接受值的列表。如您所料,CLI 应用程序将只接受这些值。
如果用户试图提供一个不在列表中的值,会发生什么情况:
| $ python choices.py - size A用法:choices.py [-h] [ - size {S,M,L,XL}]choices . py:error:argument-size:无效选择:' A'(从‘S’、‘M’、‘L’、‘XL’中选择) |
但是如果提供了一个有效值,程序将打印名称空间对象,就像前面讨论的例子一样。
更有趣的是,“choices”参数可以接受不同数据类型的值。因此,如果您需要接受整数值,您可以定义一个可接受值的范围。
让我们看看如何使用 range()来做到这一点:
# weekdays.py
import argparse
my_parser = argparse.ArgumentParser()
my_parser.add_argument("--weekday", type=int, choices=range(1, 8))
args = my_parser.parse_args()
print(args)
这个应用程序将自动检查用户以“选择”参数形式提供给命令行的 range 对象的任何值。
如果提供的数字超出范围,应用程序将抛出如下错误:
| $ python days.py - weekday 9用法:days.py [-h] [ - weekday {1,2,3,4,5,6,7}]days.py:错误:参数-工作日:无效选择:9(从 1、2、3、4、5、6、7 中选择) |
在 Argparse 中创建和定制帮助消息
argparse 模块最好的特性之一是为您的应用程序生成帮助消息和自动使用消息。
用户可以使用-h 或- help 标志来访问这些消息。默认情况下,这些标志集成到所有 argparse CLIs 中。
在本文的前几部分,你看到了如何将描述和结束消息集成到你的 CLI 应用程序中。
现在,让我们继续我们的定制 ls 命令示例,看看如何通过“help”和“metavar”参数为各个参数和选项提供增强的消息。
# ls.py version6
import argparse
import datetime
from pathlib import Path
# ...
general = parser.add_argument_group("general output")
general.add_argument(
"path",
nargs="?",
default=".",
help="take the path to the target directory (default: %(default)s)",
)
detailed = parser.add_argument_group("detailed output")
detailed.add_argument(
"-l",
"--long",
action="store_true",
help="display detailed directory content",
)
# ...
我们已经讨论过像%(prog)这样的格式说明符在 argparse 中没有任何问题。但是在这个阶段,同样值得注意的是,您可以使用 add_argument()的大部分参数作为格式说明符。这些包括但不限于%(类型)和%(默认)
执行我们现在重新设计的应用程序会产生以下输出:
| $ python ls.py -h用法:ls [-h] [-l] [path]这个程序列出了一个目录的内容选项:-h,- help 显示该帮助信息并退出一般输出:path 取目标目录的路径(默认:。)详细输出:-l,- long 显示详细目录内容感谢您使用 ls |
正如你所看到的,当运行带有-h 标志的应用程序时,现在-l 和 path 都会显示描述性的帮助消息。尽管“path”在它的帮助信息中有默认值,但它仍然是有用的。
argparse 中的默认用法消息已经足够好了,但是如果您愿意,可以使用 metavar 参数对其进行改进。
当选项或参数接受输入值时,参数变得特别方便。您可以为解析器用来生成帮助消息的输入值指定描述性名称。
让我们后退一步,用-h 开关运行前几节中的 point.py 示例。下面是输出:
| $ python point.py -h用法:point . py[-h][-COORDINATES COORDINATES]选项:-h,- help 显示此帮助信息并退出-坐标坐标坐标 |
argparse 模块使用选项的原始名称在帮助和用法消息中指定相应的输入值。
但是在上面的输出中,“坐标”出现了两次,这可能会使用户误以为坐标需要提供两次。
你可以这样处理这种不确定性:
# point.py
import argparse
parser = argparse.ArgumentParser()
parser.add_argument(
"--coordinates",
nargs=2,
metavar=("X", "Y"),
help="take the Cartesian coordinates %(metavar)s",
)
args = parser.parse_args()
print(args)
在上面的代码中,一个具有两个坐标名的元组值被赋给了 metavar。另外,我们还为适当的选项添加了自定义消息。
运行上面的代码将得到以下输出:
| $ python coordinates.py -h用法:coordinates . py[-h][-coordinates X Y]选项:-h,- help 显示此帮助信息并退出-坐标 X Y 取笛卡尔坐标(' X ',' Y') |
处理您的 CLI 应用程序的执行如何终止
CLI 应用程序必须在特定情况下终止,例如出现错误和异常时。
处理异常和错误的最常见方式是退出应用程序并显示退出状态或错误代码。状态或代码向操作系统或其他应用程序指示应用程序由于某些执行错误而终止。
一般来说,当一个命令以零代码退出时,它在终止前成功地完成了它的任务。另一方面,非零代码表示命令未能完成其任务。
这个表示成功的系统非常简单。但是,这使得指示命令失败的任务变得复杂。退出状态和错误代码没有明确的标准。
操作系统或编程语言可能使用简单的小数、十六进制、字母数字串或完整短语来描述错误。
Python 中使用整数值来描述 CLI 应用程序的系统退出状态。如果返回“无”退出状态,则意味着退出状态为零,终止成功。
如你所料,非零值表示异常终止。大多数系统需要范围在 0 到 127 之间的退出代码。如果该值超出范围,则结果未定义。
使用 argparse 构建 CLI 应用程序时,您不必考虑返回成功操作的退出代码和命令语法错误。
然而,当应用程序由于其他错误而突然终止时,您需要返回适当的退出代码。
ArgumentParser 类提供了两种在出错时终止应用程序的方法。
你可以使用。exit(status=0,message=None)方法,该方法结束应用程序并返回指定的状态和消息。或者,您可以使用。error(message)方法,该方法打印提供的消息,并使用状态代码“2”终止应用程序
无论您使用哪种方法,状态都将打印到标准错误流中,这是一个用于错误报告的专用流。
使用。当您想自己指定状态代码时,exit()方法是正确的方法。您可以使用。error()方法在任何情况下。
让我们稍微编辑一下我们的自定义 ls 命令程序,看看如何退出:
# ls.py version7
import argparse
import datetime
from pathlib import Path
# ...
target_dir = Path(args.path)
if not target_dir.exists():
parser.exit(1, message="The target directory doesn't exist")
# ...
代码末尾的条件语句检查目标字典是否存在。如您所见,我们没有使用“raise SystemExit(1)”,而是使用了“ArgumentParser.exit()”
这个简单的决定使得代码更加关注 argparse 框架。
当你运行程序时,你会发现当目标目录不存在时,程序就会终止。
如果您使用的是 Linux 或 macOS,您可以检查\(?Shell 变量,并确认您的应用程序已返回“1”,表示执行中有错误。在 Windows 上,您需要检查\)LASTEXITCODE 变量的内容。
在您构建的 CLI 应用程序中保持状态代码的一致性是一个很好的方法,可以确保您和您的用户轻松地将您的应用程序集成到命令管道和 shell 脚本中。
如何使用 Pip(安装、更新、卸载软件包的简单指南)
原文:https://www.pythoncentral.io/how-to-use-pip-simple-guide-to-install-update-uninstall-packages/
Python 包包含大量代码,你可以在不同的程序中重复使用。它们消除了编写已经编写好的代码的需要,因此对于程序员和其他广泛使用 Python 的职业来说非常方便,比如机器学习工程师 T2 和数据分析师。 可以将 matplotlib、numpy 等包导入到项目中。每个包都附带了几个可以在代码中使用的函数。然而,在使用一个包之前,您需要使用 pip 来安装它,pip 是 Python 的默认包管理器。 你还需要了解如何更新软件包,卸载不需要的软件包。这本简明指南涵盖了你需要知道的一切。
Pip 操作说明
安装 pip
如果你使用 python.org 上的安装程序在电脑上安装 Python,pip 会和 Python 一起安装。 如果你在虚拟环境中工作或者使用未被再发行商修改的 Python 版本,Pip 也会被自动安装。再发行商通常会从 Python 安装中删除 ensurepip 模块。 如果使用的是 Python 的修改版,可以使用 get-pip.py 或 ensurepip 安装 pip。这在 Windows 和 macOS 机器上都可以工作。然而,用 python.org 安装程序建立一个新的 Python 环境通常更容易。
使用不同版本的画中画
如果你已经在电脑上安装了 Python2 和 Python3,那么除了使用 pip 命令之外,你应该还能使用 pip2 和 pip3。 Pip 可以设置为在一台机器上运行 Python2 或 Python3。两者都不行。例如,如果您将 pip 设置为与 Python3 一起工作,那么您用它安装的包将不能在 Python2 上工作。 pip2 可用于 Python2 中的包管理,pip3 可用于 Python3 中的包管理。
检查已安装软件包的详细信息
如果您不确定是否安装了 pip,您可以使用 pip show 命令来查找任何已安装软件包的详细信息。pip 显示的语法是:
pip show <package-name>
如果机器上安装了 pip,运行代码来查找 pip 的许可证和依赖项应该会得到如下类似的结果:
pip show pip
Name: pip
Version: 18.1
Summary: The PyPA recommended tool for installing Python packages.
Home-page:
| 1
| |
(https://pip.pypa.io/)
Author: The pip developers
Author-email: pypa-dev@groups.google.com
License: MIT
Location: /usr/local/lib/python2.7/site-packages
Requires:
Required-by:
请记住,上面的代码显示了 pip 命令在…/python2.7/site-中安装包。但是,根据环境的不同,pip 也可以在 Python3 上使用。
### **列出所有已安装的软件包**
Pip 还能让你生成一个在你的计算机上为 Python 安装的包的列表。 在解释器上输入“pip list”应该会得到类似的输出:
pip list
Package Version
future 0.16.0
pip 18.1
setuptools 39.2.0
six 1.11.0
wheel 0.31.1
您可以改变命令的输出格式,只输出最新的包、过期的包或没有依赖关系的包。你也可以使用 pip 冻结命令。该命令不会输出 pip 和包管理包,如车轮和设置工具。
pip freeze
future0.16.0
six1.11.0
**安装包** 用 pip 安装包很容易。如果您想要安装的软件包已经在 PyPI 中注册,您需要做的就是指定软件包的名称,就像这样:
pip install
运行这个命令将会安装最新版本的软件包。您也可以使用 pip install 一次安装多个软件包。
pip install <package_name_1> <package_name_2> <package_name_3> ...
Pip 还允许您使用语法安装特定版本的软件包:
pip install
### **从 GitHub/本地驱动器安装**
有时,PyPI 上一些包的新版本没有及时更新。在这种情况下,开发人员从本地目录或 GitHub 库安装它。 使用 pip install 从本地目录安装软件包,指定包含 setup.py 文件的路径,如下:
pip install path/to/dir
您可以从以下网站安装软件包。whl 和。zip 文件,只要它们包含 setup.py 文件。
pip install path/to/zipfile.zip
要从 Git 存储库中安装一个包,可以使用下面的命令:
pip install git+
要指定标签或分支并安装软件包的特定版本,请在存储库的 URL 末尾加上一个“@”,然后输入软件包的标签。 记住,要用这种方法从 GitHub 安装软件包,你需要在你的系统上安装 git。要安装 git,您也可以从 GitHub 下载要安装的包的 zip 文件,并以这种方式安装。
### **更新包**
您可以使用- upgrade 选项和 pip install 将软件包更新到最新版本:
pip install --upgrade
or
pip install -U
### **更新画中画**
您可以毫不费力地使用 pip 更新 pip。当 pip 的更新可用时,如果您运行 pip 命令,您将看到一条消息,说明“您使用的是 pip 版本 xy.a,但是版本 xy.b 可用。” 您可以运行“pip 安装-升级 pip”来安装和使用新版 pip。 要使用该命令更新 pip2 或 pip3,只需用 pip 版本替换第一个 pip。
pip3 install --upgrade pip
or
pip2 install --upgrade pip
### **卸载软件包**
用 pip 卸载软件包就像用它安装软件包一样简单。您可以使用以下命令卸载软件包:
pip uninstall
除了允许您同时安装多个软件包,pip 还允许您一次卸载多个软件包。您必须使用命令:
pip uninstall
当您使用 pip 删除包时,会要求您确认是否要删除文件。如果您不希望提示您要卸载的软件包,您可以在“pip 卸载”后使用- yes 或-y 选项
### **检查依赖性**
pip check 命令允许您检查和验证已安装的软件包是否具有兼容的依赖关系。 当您在一台所有包都具有所需依赖关系的机器上运行该命令时,屏幕上会出现一个“没有发现不符合要求”的提示。 另一方面,如果一个依赖包没有安装或者有版本不匹配,pip 检查会输出这个包和依赖。如果您看到这样的消息,请使用 pip install -U. 更新相应的软件包
了解如何使用 pytest 测试 python 应用程序,点击这里查看文章。**
如何使用 Print 获得更高效的代码
原文:https://www.pythoncentral.io/how-to-use-print-for-more-efficient-code/
如果您还没有充分利用 Python 代码,这里有一个快速提示可以帮助您提高 Python 代码的效率。如果你想打印一个列表中用逗号分隔的所有值,有几种不同的方法:有复杂的方法,也有简单的方法。这里有一个复杂方式的例子:
food = ["pizza", "tacos", "ice cream", "cupcakes", "burgers"]
print(', '.join(str(x) for x in food))
上面代码的输出将是:
pizza, tacos, ice cream, cupcakes, burgers
print 语句中的代码并不简洁高效。如果您想以简单有效的方式打印同一列表中的所有值,请尝试使用 print 语句:
print(*food, sep=", ")
上面的 print 语句的输出将与第一个示例中的输出完全相同:
pizza, tacos, ice cream, cupcakes, burgers
以这种方式打印列表将确保您的代码看起来干净并且尽可能高效地执行。
如何使用 Python Django 表单
原文:https://www.pythoncentral.io/how-to-use-python-django-forms/
Django 形式
什么是 HTML 表单?它有什么样的用例?
网页上的 web 表单、web 表单或 HTML 表单允许用户输入发送到服务器进行处理的数据。表单可以类似于纸张或数据库表单,因为 web 用户使用复选框、单选按钮或文本字段来填写表单。例如,表单可用于输入运输或信用卡数据以订购产品,或者可用于从搜索引擎检索搜索结果。
HTML 表单是从客户端应用程序向服务器发送数据的最常见方式。在本文中,我们将学习如何使用 Django 的表单库来处理 HTML 表单。
使用 Django 表单库的好处
在之前的一篇文章中,为您的第一个 Python Django 应用程序编写上传帖子的视图,我们学习了如何使用request.POST变量从 HTML 表单中检索数据。然而,仅仅检索数据是不够的,因为我们可能希望处理数据验证,并避免在模板中手动编写 HTML 表单。
幸运的是,Django 的表单库提供了以下好处:
- 从表单小部件自动生成 HTML 表单。
- 根据一组规则验证提交的数据。
- 如果有错误,重新显示 HTML 表单。
- 将提交的数据转换成 Python 兼容的类型。
基本概念
在我们深入讨论编写表单的细节之前,我们需要了解以下概念:
- Widget :一个 Python 类,将自己呈现为 HTML 形式。
- 字段:验证数据的 Python 类,例如限制最大字符数的
CharField。 - 表单:字段的集合。
- 表单资产:与呈现表单相关联的 CSS 和 Javascript。
设计正确的话,Form库与其他 Django 组件是分离的,比如数据库层甚至模板。通过将Form库与 Django 的其余部分分离,我们可以独立于应用程序的其余部分编写和测试表单,这增加了应用程序的可维护性。
表单和视图
现在让我们继续创建一个表单对象,它表示myblog/forms.py中的一个Post。
from django import forms
类后置形式(形式。形式):
内容=形式。CharField(max _ length = 256)
created _ at = forms。DateTimeField()
然后我们创建一个新的视图,返回我们在上下文中的表单。
from myblog.forms import PostForm
def POST _ Form _ Upload(request):
if request . method = = ' GET ':
Form = PostForm()
else:
# A POST 请求:处理表单上传
form = PostForm(request。POST) #从请求绑定数据。投寄成一种邮件形式
#如果数据有效,则继续创建新的帖子并重定向用户
If form . is _ valid():
content = form . cleaned _ data[' content ']
created _ at = form . cleaned _ data[' created _ at ']
post = m . post . objects . create(content,
created _ at = created _ at)
return httpresponseredict(reverse(' post _ detail ',
kwargs={'post_id': post.id})
return render(request,' post/post_form_upload.html ',{
'form': form,
})
然后我们创建一个新的模板,在myblog/templates/post_form_upload.html的 HTML 页面中呈现我们的表单。
<form action='/post/form_upload.html' method='post'>{% csrf_token %}
{{ form.as_p }}
<input type='submit' value='Submit' />
</form>
最后,我们修改myblog/urls.py以追加以下条目:
urlpatterns = patterns('',
...
url(r'^post/form_upload.html$',
'myblog.views.post_form_upload', name='post_form_upload'),
...
)
现在我们可以访问 URL http://localhost:8000/post/form_upload.html来看看我们新的帖子表单页面:

我们的空表单页面。
填写表格并点击“提交”会将您重定向到新帖的详细信息页面:

我们的表格填好了。

提交后我们的页面。
因为“内容”和“创建者”字段都是必填的,所以当您试图上传一个空字段时,会出现一个错误。

所需输入误差..
总结和提示
在本文中,我们学习了如何使用 Django 的表单库来处理 HTML 表单。虽然手工创建 HTML 表单是常见的做法,但是创建 Django 的表单对象可以提供更好的可维护性、可读性和功能性。在下一篇文章中,我们将学习如何使用 Django 的ModelForm从模型中自动生成表单。
如何在 Mac 上使用 Python

Python 是一个强大的编程工具,但当你在 Mac 上使用它时,它就变成了另一种野兽。这是一种非常适合 Mac 的语言,因为它克服了传统的编程障碍,以便使编码过程更人性化,更容易理解。
但是纯粹的简单并没有让 Python 变得容易学习。仍然有一个陡峭的学习曲线要处理,所以我们甚至要涵盖基础知识,如如何在 Mac 上安装 Python。目标是直接进入主题,所以让我们看看如何在 macOS 上实际使用 Python。
入门
麦金塔电脑自带预建的 Python 2.7 版本,所以如果最新版本不是强制性的,你甚至不必为技术程序而烦恼。然而,大多数用户想要最新的 Python 3 版本,他们可以从官方网站 python.org 下载。当你访问网站并点击下载按钮时,你会得到几样东西:
- 您笔记本电脑的应用程序文件夹中有一个名为 Python 3.9 的新文件夹。这个目录包含 IDLE,又名文本编辑器,是 Python 的现成解决方案。除此之外,您将获得 Python Launcher,一个管理 Python 脚本的工具。在 IDLE 中,您可以找到包含所有 Python 文档的帮助菜单。
- 包含库和 Python 可执行文件的框架。该框架被标记为/Library/Frameworks/Python . framework。一旦安装 Python,程序本身将与您的 shell 路径共享该框架的位置。
谨记,想要保留 Python 预装版本的用户千万不要更改或修改原有框架,因为它完全在苹果的掌控之中。即使您下载了较新的程序,两个版本也会同时保留在您的计算机上。
运行 Python 脚本
我们已经提到了 Python 的原生集成开发环境,又名 IDLE,因为这是新客户在 Mac 上开始使用 Python 的最简单方式。但是在你用 Python 开始一些繁重的工作之前,你需要记住一件事——程序可能需要很强的处理能力,你应该总是寻找 有用的提示 当你编程太辛苦时,如何给你的 Mac 降温。
在 Mac 上运行 Python 脚本有两种基本方式:
- 来自终端窗口的命令
- 来自取景器
前一种解决方案更常见,因为它更简单,但我们将同等讨论这两种方案。终端和 Finder 都需要一个文本编辑器来创建脚本。典型的 macOS 有各种标准的命令行编辑器,如 emacs 或 vim,但您可以通过使用 BBEdit 或 text Mate 等替代编辑器来选择更高级的功能。
如果你使用终端窗口,你必须确保 shell 搜索路径包含/usr/local/bin。这是最基本的条件,没有它你无法继续下去。使用 Finder,事情变得有点复杂,这也是大多数人避免使用它的原因。有两个选项可以考虑:
- 将脚本拖到 Python 启动器
- 将 Python Launcher 设置为在 Mac 上运行脚本的主要应用。您可以在 Finder info 窗口中通过连按启动器来完成此操作。之后,您可以用许多不同的方式控制和管理脚本。
小心 GUI
对于没有经验的用户来说,Python 和 Mac 有许多小陷阱,其中最重要的是图形用户界面( GUI )。也就是说,任何一种拥有 GUI 并与 Aqua 窗口管理器通信的程序都需要一种特殊的方法。
为了启动一个新的脚本,你必须使用 python 而不是 python 来改变这个过程。这是一个简单的技巧,但它让许多新程序员感到茫然和困惑。如果您想在程序中添加新的 Python 包,可以用几种方法。
第一个选项是使用标准安装模式(python setup.py install)安装一个包。第二种选择是使用安装工具扩展或 pip 包装。
底线
Python 和 Mac 是一种天然的结合,让两种工具都能发挥出最大的潜力。我们向您简要介绍了如何在 Mac 上使用 Python,但是现在轮到您开始工作并深入探究 Python 编码的秘密了。你准备好试一试了吗?
如何使用 Python 将英里转换成公里
原文:https://www.pythoncentral.io/how-to-use-python-to-convert-miles-to-kilometers/
令人沮丧的是,无论是测量距离、重量、温度等,整个地球都无法在一个测量系统上达成一致...每个人都行驶在道路的哪一边也是如此)。如果每个国家都使用相同的计量单位,那么这些公式将是无用和过时的,但在此之前,了解如何将英里转换为公里可能是一个好主意,反之亦然。如果你是一个 Python 开发者,那么知道如何用 Python 写公式可能会特别有用。继续阅读,看看它是如何做到的。
将英里换算成公里并不特别困难。为了在你的头脑中做一个粗略的估计,你真正需要记住的是一英里大约等于 1.6 公里(或者一公里大约是一英里的 2/3)。当试图使用公式找到正确的换算时,我们必须使用更精确的换算系数,它等于 0.62137119。
要把英里换算成公里,公式非常简单。你需要做的就是用里程数除以换算系数。要查看用 Python 写出来的效果,请查看下面的示例:
miles = 30
conversion_factor = 0.62137119
kilometers = miles / conversion_factor
print kilometers
在上面的例子中,您只需要声明两个变量:miles 和 conversion_factor,miles 可以是您需要的任何数字,conversion _ factor 的值必须始终保持不变,以便获得正确和准确的转换。上面代码的输出将是 48.2803202,因此 30 英里大约等于 48 公里。
要将公里转换为英里,您将采用类似的方法。进行此转换时,您需要将公里值乘以转换系数。有关在 Python 中进行这种转换的示例,请参见下面的示例:
kilometers = 6
conversion_factor = 0.62137119
miles = kilometers / conversion_factor
print miles
上面示例的输出将是 3.72822714,因此 6 公里大约等于 3 加 3
如何使用 Python 来帮助你学习数据科学
原文:https://www.pythoncentral.io/how-to-use-python-to-help-you-with-data-science/

Python 是一种编程语言,在过去几年里越来越受欢迎。由于它的灵活性和易用性,许多人正在将它用于数据科学。在这篇博文中,我们将向您展示如何开始使用 Python 进行数据科学研究。我们将讲述这门语言的基础知识,并给你一些如何有效使用它的建议。因此,如果您有兴趣了解更多关于 Python 或一般数据科学的知识,请继续阅读!
关于 Python
Python 对于数据科学来说是一种很好的语言,因为它简单易学,并且有大量的库可供你在项目中使用。即来自 Zuar 公司 的专业人士说“Python 的语法简单且一致,这使得它非常适合编写脚本。最流行的数据科学库是 NumPy,它提供了处理数据的强大工具。
另一个流行的库是 pandas,它提供了高性能的数据结构和分析工具。此外,还有许多其他库可以用于数据科学,如 matplotlib、seaborn 和 sci-kit-learn。
了解基础知识
在开始使用 Python 进行数据科学研究之前,理解这门语言的基础是很重要的。这包括了解如何编写代码,以及如何使用不同的可用库。如果您是编程新手,那么我们建议查看我们的 Python 初学者指南。一旦掌握了基础知识,就可以开始学习更多关于数据科学的知识。
受益于 Python 的库

Python 的一大优点是有很多库可供你在项目中使用。这意味着您不必从头开始编写所有内容,您可以利用他人已经编写的现有代码。这可以节省你很多时间,也意味着你可以专注于 你的项目 中对你最重要的部分。几乎所有的东西都有图书馆,所以无论你想做什么,总有一个图书馆能帮到你。例如,如果你想做机器学习,那么你可以使用 scikit-learn 库。如果你想做自然语言处理,那么你可以使用 NLTK 库。如果你想做数据可视化,那么你可以使用 matplotlib 或者 seaborn 库。
有效使用 Python 的技巧
一旦你学会了 Python 的基础知识,并且利用了它的库,你就可以开始在数据科学中更有效地使用它。这里有一些你可以使用的提示:
Jupyter Notebooks 是一款非常棒的数据科学工具,因为它允许你在交互式环境中编写和执行 T2 代码。这意味着您可以试验您的代码,并立即看到结果。Jupyter Notebooks 也非常适合与他人分享您的代码,因为您可以将其导出为 HTML 文件。
熊猫图书馆是最受欢迎的数据科学图书馆之一,它非常强大。然而,学习如何有效地使用它是很困难的。我们建议查看一些可用的在线资源,如官方文档或熊猫食谱。
网上有许多很好的资源可以帮助你了解更多关于 Python 的数据科学知识。我们建议查看 Dataquest、Kaggle 和 Stack Overflow 等网站。
建立数据科学项目
现在,您已经学习了 Python 的基础知识,并且利用了它的库,您可以开始构建自己的数据科学项目了。首先,我们建议查看我们关于如何用 Python 构建机器学习模型的教程。这将引导您完成构建机器学习模型的过程,并向您展示如何有效地将 Python 用于数据科学。
一旦你建立了一个机器学习模型,你就可以开始从事其他项目,比如自然语言处理或数据可视化。有许多不同的方法可以将 Python 用于数据科学,因此我们建议进行试验,看看哪种方法最适合您。
这些只是你需要了解的关于数据科学 Python 的一些事情。如果您有兴趣了解更多信息,我们建议您查看上面列出的一些资源。只需一点点努力,您就能在数据科学项目中有效地使用 Python。或者,您可以报名参加数据科学课程,以最大限度地发挥您的全部潜力。
如何通过 Pyenv 使用 Python 版本管理
原文:https://www.pythoncentral.io/how-to-use-python-version-management-with-pyenv/
有没有想过开发团队如何为支持多个 Python 版本的项目做出贡献?仔细想想,跨多个 Python 版本测试一个项目似乎是一项繁重的工作。
但是谢天谢地,在现实中,这很容易做到。使用 pyenv 可以相对容易地管理多个 Python 版本。
在本指南中,我们将带您了解什么是 pnenv,它是如何工作的,以及如何使用它来管理 Python 版本。
pyenv 是什么?它是如何工作的?
pyenv 最初以“Pythonbrew”的名字发布,它是一个版本管理工具,使 Python 用户能够管理项目中的 Python 版本。如果您的机器安装了多个 Python 版本,那么您可能已经在机器上安装了 pyenv。
该工具使您能够利用新的 Python 特性,并为在各种 Python 版本上工作的项目做出贡献。需要注意的是,在 Python 版本之间切换时,可能会出现几个问题。
例如,如果您从 Python 3.7 切换到 3.9,特性会有很大的不同,3.7 的特性集要小得多。pyenv 的好处在于,它有助于弥合这些特性之间的差距,并克服因缺乏特性而产生的问题。
pyenv 工作背后的基本理念是直接使用垫片。
Shims 是轻量级的可执行文件,pyenv 使用它们将您的命令从您的机器上安装的所有版本传递到您的项目设计运行的正确 Python 版本。
当您安装 pyenv 时,垫片被引入到环境路径所在的目录中。这样,当 Python 命令运行时,pyenv 会拦截它并将其定向到适当的填充程序。
在这个过程的这一点上,它识别你的项目需要的 Python 版本,然后将命令传递给正确的 Python 版本。
pyenv 的安装要求
像任何其他应用程序一样,编程语言的解释器也接收更新。更新可能会改进一系列功能,涉及补丁,引入错误修复,或添加新功能。
要在机器上使用 pyenv 进行 Python 版本管理,机器需要安装 Python。此外,pyenv 需要 shell 路径才能正常工作。
让我们回顾一下激活 pyenv 以便在您的机器上安装的步骤:
- 访问 官方 Python 网站 并安装在你的机器上。
- 根据需要设置 shell——要使 pyenv 能够导航 Python 版本并选择合适的版本,它必须使用 shell 的 PATH 变量。PATH 的作用是根据命令确定 shell 需要在哪里搜索文件。因此,您必须确保 shell 找到 pyenv 正在运行的 Python 版本,而不是它默认检测到的版本(通常是系统版本)。
- 当 shell 准备好,并且路径设置正确时,您必须激活环境。我们将在接下来的两节中探讨如何做到这一点。
pyenv global
pyenv global 的主要功能是确保 pyenv 可以在使用不同操作系统的机器上使用所有 Python 版本,开发团队使用这些操作系统来创建项目。
你可以为你正在处理的任何项目设置一个目录,根据它正在处理的 Python 版本来命名。pyenv 还为开发人员提供了创建和管理虚拟环境的灵活性。
这些特性适用于 Linux 发行版和 OS X,不依赖于 Python。因此,采取全球方法在用户一级有效。换句话说,不需要使用任何 sudo 命令来使用它。
需要注意的重要一点是,可以使用其他命令覆盖 global。但是,您可以使用一个命令来确保默认情况下使用特定的 Python 版本。例如,如果开发人员想默认使用 3.9,他们可以运行下面的命令:
$ pyenv global 3.9
上面一行会改变~/中的版本。pyenv/版本到 3.9。正如您可能已经猜到的那样,pyenv 全局并不是专门为某些依赖项和应用程序而设置的,而是为整个项目而设置的。
您也可以运行上面的命令来查看项目是否在 Python 版本上运行。
pyenv 本地
该命令有助于检查哪个 Python 版本适用于特定的应用程序。因此,如果您运行以下命令:
$ pyenv local 2.7.
该命令将在当前目录下创建一个. python 版本的文件。
如果在机器和环境上安装并激活了 pyenv,运行该命令将为您创建 2.7 版本。
使用 pyenv
参与 Python 项目的开发人员和测试人员都需要利用几个 Python 版本来发布一个项目。一遍又一遍地改变 Python 版本是耗时的、具有挑战性的,而且是彻头彻尾的烦人,会减慢进度。
由于这个原因,pyenv 被开发人员和测试人员视为必不可少的工具。它自动在 Python 版本之间切换,使得构建和测试 Python 项目更加方便。
如前所述,该工具使管理 Python 版本变得容易。以下是使用 pyenv 的关键步骤:
- 安装正在为其构建项目的所有 Python 版本。
- 在计算机内设置机器的默认 Python 版本。
- 针对项目设置本地 Python 版本。
- 创建一个虚拟环境,以便正确使用 pyenv。
常见错误:“pyenv 不更新 Python 版本”
当您设置 pyenv 环境时,您可能会遇到一个错误,显示一条类似“pyenv global x.x.x 没有更新 Python 版本”的消息
不要担心,因为当有人设置 pyenv 时,这种错误在 macOS 和 Linux 机器上出现是很常见的。
通过在~/中添加下面一行代码,很容易解决这个错误。zshrc 文件:
eval "$(pyenv init -)"eval "$(pyenv init --path)"
使用 pyenv 迁移包
迁移包包括在 Python 版本之间移动 Python 库或包。
该过程包括根据选择标准转移所有相关的设置、依赖关系和程序。有了 pyenv,就没有什么可担心的了,因为它允许您通过内置的二进制包来完成它。
如果你在 Windows 或 Linux 机器上,你所要做的就是在你的终端上输入以下命令:
git clone https://github.com/pyenv/pyenv-pip-migrate.git $(pyenv root)/plugins/pyenv-pip-migrate
该命令会将最新的 pyenv 版本安装到上述目录中。您可以在 macOS 机器上通过启动 Homebrew 并运行命令来做同样的事情:
$ brew install pyenv-pip-migrate
用 pyenv 列出并安装所有 Python 版本
我们已经在这篇文章中简要介绍了如何安装 pyenv,所以让我们来看看如何用这个工具安装 Python。
请记住,如果您按如下所述安装 Python,您将看到一个 Python 版本列表,您可以在项目中进行切换。
pyenv 提供了一些命令,向您展示您可以安装的 Python 版本。要获得在您的机器上使用 pyenv 的 Python 版本列表,您可以运行命令:
$ pyenv install --list | grep " 3\.[678]"
您可以期待类似这样的输出:
| 3.6.03.6-开发3.6.13.6.23.6.33.6.43.6.53.6.63.6.73.6.83.7.03.7-开发3.7.13.7.23.8-开发 |
开发人员可能会意识到上面的 Python 版本列表包含了“Cython”,这是 Python 的一个超集,旨在执行类似 C 语言的功能。
超集从 C 语言中获取语法,可以像 C 语言一样快速运行。默认情况下,当您安装 Python 时,您正在安装它的 Cython 版本。
在命令中," 3\ "part 定义了您想要显示的 pyenv 的子版本。
假设您想要安装 Python 解释器的 Jython 版本。您可以稍微修改一下我们之前使用的命令并运行它。应该是这样的:
$ pyenv install --list | grep "jython"
运行该命令的结果如下:
| jython-devjython-2.5.0jython-2.5-devjython-2.5.1jython-2.5.2jython-2.5.3jython-2.5.4-rcljython-2.7.0jython-2.7.1 |
Jython 是 Python 的一个实现,设计用于在 Java 上运行。它以前被称为 JPython,提供了在 Python 上运行基于类的程序的好处,这些程序本来是要在 JVM 上运行的。
您也可以不使用附加参数而运行 pyenv - list。这将允许您找到 Python 的实现,并查看 pyenv 工具能够获取的所有版本。
用 pyenv 切换 Python 版本
当您准备更改 Python 版本或安装一个不在您机器上的新版本时,您可以运行命令:
$ pyenv install -v 3.9.3
该命令将下载您指定的 Python 版本,将它与收集到的包一起安装,并让您知道它是否安装成功以及安装在哪里。
你应该知道的 pyenv 命令
pyenv 可以使用许多命令,这些命令允许您对许多 Python 版本执行一系列检查。当测试人员和开发人员团队需要在 Python 版本之间来回切换时,pyenv 提供的命令变得非常有价值。
这里快速浏览了许多可用的命令:
- pyenv 命令: 该命令显示 pyenv 可以使用的所有命令和子命令的列表。
- pyenv global: 您可以使用这个命令来设置将在所有 shells 中使用的全局 Python 版本。使用命令会将版本名称组合到~/中。pyenv/版本文件。可以用特定于应用程序的覆盖全局 Python 版本。python 版本文件。或者,您也可以指定环境变量 PYENV_VERSION 来完成此操作。
- pyenv help: 它输出一个你可以用 pyenv 使用的所有命令的列表,以及这些命令要完成的任务的简短解释。如果您需要某个命令的详细信息,您应该运行这个命令。
- pyenv install: 在这篇文章的前面,我们已经介绍了在用 pyenv 列出 Python 版本时如何使用 install 命令。该命令允许您安装一个特定的 Python 版本,您可以使用以下标志属性:
- 它显示了所有可安装 Python 版本的列表。
- -g:你可以用这个标志构建一个调试 Python 版本。
- -v:打开详细模式,允许您将编译状态打印到 stdout。
- pyenv local:local 命令允许你设置一个特定于应用的本地 Python 版本。它通过向。python 版本文件。该命令允许您通过设置 PYENV_VERSION 或使用 pyenv shell 命令来覆盖全局 Python 版本。
- pyenv shell: 使用 shell 中的 PYENV_VERSION 环境变量,您可以仅为 shell 设置 Python 版本。该命令不仅会覆盖全局版本,还会覆盖特定于应用程序的 Python 版本。
- pyenv 版本: 你可以使用该命令显示当前安装在机器上的所有 Python 版本。
- pyenv which: 这个命令允许你找到你的机器的可执行文件的完整路径。如前所述,pyenv 利用了垫片,该命令允许您查看可执行 pyenv 运行的路径。
结论
有了这个指南,你应该能够通过最大限度地使用 pyenv 工具,毫不费力地为 Python 项目做出贡献。它允许您在几个 Python 版本之间移动,并在最新和最老的 Python 版本上测试您的项目——所有这些都不会干扰开发系统。
您可以在 Linux、Windows 和 macOS 上使用 pyenv,并检查您机器的当前 Python 版本。还可以用 pyenv 安装新版本的 Python。我们已经介绍了如何在 Python 版本之间切换并利用它们不同的特性。
如何使用 Python 的 If 语句
原文:https://www.pythoncentral.io/how-to-use-pythons-if-statement/
在 Python 中,If 语句包含基于特定条件是否为真而执行的代码。例如,如果您想打印一些东西,但是您希望打印文本的执行取决于其他条件,您将需要使用 if 语句。
If 语句的基本语法如下:
if(condition) : [code to execute]
简单 if 语句的语法相当简单。确保条件可以是真或假,比如变量等于、不等于、小于或大于某个值(请记住,这种情况下的“等于”符号是这样的:==)要了解它在上下文中的用法,请看看下面的示例。
var=40
if(var == 40) : print "Happy Birthday!"
print "end of if statement"
您可能会猜到,上面代码的输出如下:
Happy Birthday!
end of if statement
生日快乐!因为这是在 var 等于 40 的条件下执行的代码,事实上 var 等于 40。本例中使用了 if 语句的 End 来表示 if 语句已经结束。如果 var 不等于 40,那么只打印“If 语句结束”,属于 if 语句的代码不会被执行,因为只有当 if 条件为真时才允许执行。
如何使用 Python 的 len()方法
原文:https://www.pythoncentral.io/how-to-use-pythons-len-method/
Python 的 len()方法可以用来轻松找到字符串的长度。这是一种简单快捷的测量字符串长度(字符数)的方法,无需编写大量代码。使用 len()方法的语法相当简单,很难出错——即使是初学 Python 的程序员也应该能够掌握它。要了解其工作原理,请查看以下代码片段:
str = "hey, I'm a string, and I have a lot of characters...cool!"
print = "String length:", len(str)
所以要找到字符串“str”的长度,需要通过 len()方法传递。你的答案是字符串中的字符数,包括标点和空格。字符串“str”中的字符数是 57,包括空格、逗号、句点、撇号和感叹号。因此,上述代码的输出如下所示:
String length: 57
len()方法还会计算字符串中包含的数字、空格和标点符号,如下例所示:
str = "I'm 26 years old."
print = "String length:", len(str)
上述代码的输出如下,其中 str 字符串有 17 个字符,包括空格、撇号、数字和句点:
String length: 17
len()方法除了字符串名称之外不接受任何参数,所以这是唯一可以通过它传递的东西。这不是一个特别通用的方法,但是对于这个特定的目的来说,它确实很方便,并且在您的编码冒险中,您可能会遇到许多不同的原因,在这些原因中,您需要找到字符串的长度。您还可以在 if 语句中使用此方法,根据字符串包含(或不包含)的字符数来执行某些代码。
如何使用 Python 的 xrange 和 range
原文:https://www.pythoncentral.io/how-to-use-pythons-xrange-and-range/
Python 有两个创建列表的方便函数,或者一个整数的范围,帮助进行for循环。
这些功能是xrange和range。但是你可能已经猜到了!🙂
Python 中 xrange 和 range 的区别
在开始之前,先说一下xrange和range的不同之处。
在很大程度上,xrange和range在功能上是完全相同的。它们都提供了一种生成整数列表的方法,供您随意使用。唯一的区别是range返回一个 Python list对象,而xrange返回一个xrange对象。
那是什么意思?好问题!这意味着xrange并不像range那样在运行时生成静态列表。它用一种叫做产生的特殊技术创造出你需要的值。这项技术用于一种叫做发生器的物体。如果您想更深入地了解生成器和 yield 关键字,请务必查看文章 Python 生成器和 yield 关键字。
好的,现在那个是什么意思?又一个好问题。即意味着如果你有一个非常大的范围,比如说十亿,那么xrange就是要使用的函数。如果你有一个真正对内存敏感的系统,比如你正在使用的手机,这一点尤其正确,因为range将使用尽可能多的内存来创建你的整数数组,这会导致MemoryError并使你的程序崩溃。这是一只渴望记忆的野兽。
也就是说,如果您想多次迭代列表,使用range可能更好。这是因为xrange必须在每次访问索引时生成一个整数对象,而range是一个静态列表,整数已经“在那里”可以使用。
好了,现在说点好的。
xrange 函数是做什么的?
利用 Python 的 xrange()函数生成一个数列,使其类似于 range()函数。但是这两个函数的主要区别在于,xrange()函数只在 Python 2 中可用,而 range()函数在 Python 2 和 3 中都可用。
xrange()函数的语法是:
【xrange(开始、结束、步进)
参数用于定义一个从开始到结束的数字范围,起始数字包含在内,最终数字不包含在内。
三个参数的含义如下:
- 开始: 它指定了数字序列的开始位置。
- 结束: 它指定了编号序列的结束位置。
- 步: 它指定了序列中数字的区别。
值得注意的是,虽然起始位置和步长值可以选择定义,但编号序列的最终位置必须始终定义。
range 函数有什么作用?
当 range()函数中定义了一个数字范围时,它返回定义范围内的数字序列。当程序员需要执行一个动作指定的次数时,通常使用内置函数。
Python 3 中的 range()函数本质上是 Python 2 中 xrange()函数的重命名版本。该函数通常与 for 循环一起使用,因此,希望使用该函数的程序员必须了解 for 循环是如何工作的以及如何使用它。
range()函数的一个常见用例是用于迭代序列类型。
range()函数的语法是:
【启动、停止、步进】
用户可以使用参数决定数字序列的开始和结束位置以及数字之间的差异。使用所有参数不是强制性的-只有 停止 参数是强制性的。
参数的含义与 xrange()函数中参数的含义基本相同:
- 开始: 是整数,是数列的起点。
- Stop: 必须返回之前的数列的整数。数字序列以值“停止–1”结束
- 步: 定义数列中数字之间增量的是整数值。
range 和 xrange 的优点
使用 range()函数的主要优点是效率更高。它可以快速多次迭代相同的数字序列。
相比之下,xrange()函数需要为数字序列的每次迭代重建 integer 对象。
range()函数使用实整数对象;因此,它在使用内存方面表现不佳。也就是说,xrange()函数不能在所有需要真实列表的情况下使用,因为它不支持切片或列表方法。
继续讨论 xrange()函数的主要优点——xrange()对象。不管定义的范围有多大,xrange()对象都占用相同的内存量。
它被称为不透明序列类型,产生与相应列表相同的值,而不同时存储数字。就性能而言,xrange()函数在迭代一个大的数字序列时性能更好。
使用 xrange 功能的不同方式
使用 xrange()函数有三种不同的方法:只使用停止参数,同时使用开始和停止参数,以及使用所有参数。
#1 使用带有 Stop 参数的 xrange 函数
由于 start 和 step 参数是可选的,所以可以只使用 stop 参数来定义 xrange()函数。如果 Python 用户只传递一个参数,Python 会假设它是停止值,而 start 和 step 参数的默认值分别设置为 0 和 1。
例如,如果要打印从 0 到 9 的数字序列,必须将“10”作为 stop 参数传递给 xrange()函数。由于停止值是一个排他值,该函数将只生成 9 之前的数字。
n = xrange(10)
print(list(n))
需要 print 语句,因为 xrange(10)的输出必须显式转换成列表。上面脚本的输出将是:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
#2 使用带有开始和停止参数的 xrange 函数
当用户向 xrange()函数传递两个参数时,Python 假设这些值表示起始值和终止值。因为没有定义 step 参数,所以它默认为 1。
假设你想打印一个从 10 到 19 的数字序列。为此,您必须将起始值定义为 10,因为起始参数是包含性的。另一方面,由于停止值是唯一的,所以必须将“20”作为参数传递。
n = xrange(10,20)
# converting n into a list and printing the list
print(list(n))
脚本的输出将是:
[10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
#3 使用带有开始、停止和步进参数的 xrange 函数
当用户将所有三个参数传递给 xrange()函数时,不考虑任何参数的默认值。
例如,如果你想打印 20 到 30 之间的数字,你必须传递 20 作为开始参数,31 作为停止参数,1 作为步长。
n = xrange(20,31,1)
# converting n into a list and printing the list
print(list(n))
脚本将打印数字序列:
[20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30]
范围功能的不同使用方式
就像 xrange()函数一样,range()函数有三种用法:
#1 范围(停止)
如果用户只向 range()函数传递一个参数,Python 会假设它是停止值。Python 然后生成一个从 0 到停止值之前的数字的数字序列。
例如,要打印从 0 开始到 9 结束的十个数字,必须运行以下代码:
for i in range(10):
print(i, end=' ')
# Output 0 1 2 3 4 5 6 7 8 9
需要注意的是,起始值默认为 0,步长值默认为 1。此外,如果停止值设置为 0 或任何负值,range()函数将返回一个空序列。
#2 范围(启动、停止)
当用户向 range()函数传递两个参数时,Python 假定参数是 start 和 stop。该函数生成一个序列,从起始值开始,到 stop–1 结束。
例如,如果你想打印一个从 10 到 15 的数字序列,你可以使用下面的脚本:
for i in range(10, 16):
print(i, end=' ')
# Output 10 11 12 13 14 15
需要注意的是,步长值默认为 1,如果停止值小于开始值,range()函数返回一个空序列。
#3 范围(开始、停止、步进)
当用户将所有三个参数传递给 range()函数时,它将返回一个数字序列,该序列从起始值开始,以步长值为增量,在终止值之前结束。
例如,如果您想打印一个从 10 开始到 45 结束的序列,序列中的数字之间的增量为 5,您可以使用下面的脚本:
for i in range(10, 50, 5):
print(i, end=' ')
# Output 10 15 20 25 30 35 40 45
需要注意的是,如果步长值设置为 0,Python 将抛出 ValueError 异常。
如何使用 Python 的 range 和 xrange
那么我们如何使用range和xrange?下面是一个最简单的例子:
[python]
>>> for i in xrange(10):
... print(i)
...
0
1
2
3
4
5
6
7
8
9
[/python]
太好了!很简单。注意,你也可以用range代替这里的xrange,但是我个人更喜欢xrange。可能是前面那个性感的“x”吧。🙂
好了,解释时间。函数xrange和range总共接受三个参数,但是其中两个是可选的。参数是“开始”、“停止”和“步进”。“start”是你希望列表开始的整数,“stop”是你希望列表停止的整数,“step”是你的列表元素的增量。
Python 的 xrange 和奇数范围
假设我们只想要奇数。我们可以这样做:
[python]
>>> for i in xrange(1, 10, 2):
... print(i)
...
1
3
5
7
9
[/python]
我们告诉 Python,我们希望第一个元素是 1,最后一个元素比 10 小 1,我们希望每个元素增加 2。非常简单的东西。
Python 的 xrange 和带负数的 range
好吧,那么如果我们想要一个负面清单呢?
简单。这里有一个例子:
[python]
>>> for i in xrange(-1, -10, -1):
... print(i)
...
-1
-2
-3
-4
-5
-6
-7
-8
-9
[/python]
就是这样!我们要做的就是把“开始”、“停止”、“步进”改成负数。太棒了。请注意,对于负面清单,您必须这样做。尝试使用xrange(-10)将不起作用,因为xrange和range使用默认的“步长”1。
另一个 Python xrange 和 range 示例
这里还有一个 100 到 120 之间偶数的例子:
[python]
>>> for i in xrange(100, 120, 2):
... print(i)
...
100
102
104
106
108
110
112
114
116
118
[/python]
对于xrange和range来说差不多就是这样。如果你想从技术上了解这两个函数的功能,请查阅 Python 文档中关于 xrange 和 range 的内容。
请注意,如果“开始”大于“停止”,则返回的列表将为空。此外,如果“步长”大于“停止”减去“开始”,那么“停止”将被提升为“步长”的值,并且列表将包含“开始”作为其唯一的元素。
这里有一张更清晰的图片:
[python]
>>> for i in xrange(70, 60):
... print(i)
...
# Nothing is printed
>>> for i in xrange(10, 60, 70):
... print(i)
...
10
[/python]
不赞成使用 Python 的 xrange
再补充一点。在 Python 3.x 中,xrange函数已经不存在了。在 Python 2.x 中,range函数现在做xrange做的事情,所以为了保持代码的可移植性,你可能想坚持使用range来代替。当然,你可以一直使用 Python 提供的 2to3 工具来转换你的代码,但是这会带来更多的复杂性。
之所以把xrange去掉,是因为基本上总是用起来比较好,性能影响可以忽略不计。所以 Python 3.x 的range函数是来自 Python 2.x 的 xrange
你可以在这里找到 PEP 文档来解释它被删除的原因。
完毕,士兵。完毕。
如何使用 Enumerate()函数
原文:https://www.pythoncentral.io/how-to-use-the-enumerate-function/
在 Python 中,enumerate()函数用于遍历列表,同时跟踪列表项的索引。要看到它的实际效果,首先你需要列出一个清单:
pets = ('Dogs', 'Cats', 'Turtles', 'Rabbits')
那么您将需要这行代码:
for i, pet in enumerate(pets):
print i, pet
您的输出应该如下所示:
0 Dogs
1 Cats
2 Turtles
3 Rabbits
如您所见,这些结果不仅打印出了列表的内容,还打印出了它们对应的索引顺序。您还可以使用 enumerate()函数创建索引/值列表的输出,其中的索引根据您的代码进行更改。
对于我,宠物在列举(pets,7):
打印我,宠物
这段代码更改了函数,以便为列表中的第一个值分配索引号 7,以便进行枚举。在这种情况下,您的结果将如下:
7 Dogs
8 Cats
9 Turtles
10 Rabbits
如何使用 Python 地图功能(逐步)
原文:https://www.pythoncentral.io/how-to-use-the-python-map-function-step-by-step/
映射是一种允许开发人员处理和转换 iterable 中的元素而无需显式声明 for 循环的方法。这就是 map()函数的用武之地。它允许开发人员将 iterable 的每一项转换成新的 iterable。
map()函数是支持函数式编程风格的两个内置 Python 方法之一。
在本文中,我们将讨论 map()函数的工作原理,如何使用该函数来转换各种可迭代对象,以及如何将该函数与其他 Python 工具相结合来执行更复杂的转换。
请记住,这篇文章假设读者理解了 for 循环、函数和可迭代的工作原理。
什么是 map()函数?
Python 程序员有时会遇到这样的问题,他们需要对一个 iterable 的所有元素进行相同的操作,并从中创建一个新的 iterable。
通常,开发人员会为此使用 for 循环,但是使用 map()函数也有助于达到同样的效果。
与 for 循环非常相似,map()函数也遍历所提供的 iterable 的元素。然后它输出一个迭代器,其中的转换函数已经应用于所提供的 iterable 的每个元素。它具有以下签名:
map(function, iterable[, iterable1, iterable2,..., iterableN])
分解一下:
函数 应用于iterable的每个元素,之后创建一个新的迭代器,按需产生转换后的项。 函数 可以是接受与传递给 map()函数的 iterables 数目相同的参数数目的任何方法。
需要注意的是,签名中的第一个参数是一个函数对象。换句话说,它要求你传递一个函数而不调用它。第一个参数是转换函数,负责将原始元素转换成转换后的元素。
参数可以是任何类型的 Python 函数,而不仅仅是内置函数,包括类、用户定义函数和 lambda 函数。
现在,我们用一个例子来理解 map()函数。假设您需要一个程序,它接受一个数值列表作为输入,并输出一个包含原始列表中每个数字的平方值的列表。
如果您决定对此使用 for 循环,解决方案将如下所示:
numberList = [3, 6, 9]
squareList = []
for num in numberList:
squareList.append(num ** 2)
squareList
# Output: [9, 36, 81]
上面代码中的 for 循环遍历 numberList 中的所有数字,并对每个值应用指数运算。结果存储在 squareList 列表中。
然而,如果您使用 map()函数来开发一个解决方案,实现将如下所示:
def square(number):
return number ** 2
numberList = [3, 6, 9]
squareList = map(square, numberList)
list(squareList)
# Output: [9, 36, 81]
在上面的代码中,square()是转换函数,它将列表中的每个数字“映射”到各自的平方值。调用 map()函数会将定义的 square()函数应用于 numberList 中的值。结果是一个保存平方值的迭代器。
然后,在 map()上调用 list()函数,创建一个保存平方值的列表对象。
map()函数使用 C 语言,比 Python 中的 for 循环更高效。但除了效率之外,使用该功能还有另一个优势——更低的内存消耗。
Python for 循环将整个列表存储在系统内存中,但 map()函数并非如此。map()函数按需为列表元素提供服务,一次只在系统内存中存储一个元素。
注意: 在 Python 2.x 中 map()函数返回一个列表,但在 Python 3.x 中,它返回一个 map 对象。map 对象充当迭代器,根据需要返回列表元素。因此,您需要使用 list()方法来创建 list 对象。
在 int()函数的帮助下,你也可以使用 map()函数将一个列表中的所有元素从字符串转换成整数。你可以这样做:
stringNumbers = ["32", "58", "93”]
integers = map(int, stringNumbers)
list(integers)
# Output: [32, 58, 93]
在上面的例子中,map()函数将 int()方法应用于 stringNumbers 列表中的每一项。调用 list()函数背后的想法是,它将耗尽 map()函数返回的迭代器。
然后 list()函数将迭代器转换成一个列表对象。请记住,在此过程中不会修改原始序列。
map()如何与不同的功能配合使用
如前所述,map()适用于所有类型的 Python 可调用程序,前提是可调用程序接受参数并能返回有用的值。例如,您可以使用实现 call()方法的类和实例,以及类、静态和实例方法。
这里有一个例子供你考虑:
numberList= [-2, -1, 0, 1, 2]
#Making the negative values positive
absoluteValues = list(map(abs, numberList))
list(map(float, numberList))
# It prints [-2.0, -1.0, 0.0, 1.0, 2.0]
words = ["map", "with", "different", "functions"]
list(map(len, words))
# It prints [3,4,9, 9]
涉及 map()函数的一个更常见的趋势是使用 lambda 函数作为主要参数。当开发人员需要提供一个基于表达式的函数来映射()时,lambda 函数特别有用。
让我们后退一步,用 lambda 函数重新实现前面讨论的平方值示例。这是如何工作的:
numberList = [5, 10]
squareList = map(lambda num: num ** 2, numberList)
list(squareList)
#Output: [25,100]
从上面的例子可以清楚地看出,lambda 函数是与 map()结合使用的最有用的函数,并且经常被用作 map()函数的第一个参数,以快速处理和转换 iterables。
使用 map()处理多个输入的可重复项
如果您向 map()提供几个 iterables,转换函数将需要与 iterables 传递的一样多的参数。函数的每次迭代都会将每个 iterable 中的一个值作为参数传递给 函数 。当到达最短迭代的末尾时,迭代停止。
例如,考虑以下 map()与 pow()函数的使用:
listOne = [2, 4, 6]
listTwo = [1, 2, 3, 7]
>>> list(map(pow, listOne, listTwo))
# Output: [2, 16, 216]
如果你熟悉 pow()函数,你会知道它接受两个参数——我们称之为 a 和 b——并返回 a 的 b 次方。
在上面的例子中,a 的值是 2,b 在第一次迭代中是 1。到了第二次迭代,a 值是 4,b 是 2,依此类推。观察输出,您会看到输出的 iterable 与最短的 iterable 一样长,在本例中是 listOne。
使用这种技术,你可以通过各种数学运算来合并包含数值的可重复项。
使用 map()转换字符串的可重复项
如果你的一些解决方案涉及到处理包含字符串对象的 iterables,你可能需要使用某种转换函数来转换这些对象。在这些情况下,map()函数可以派上用场。
在本节中,我们将讨论两种不同的场景,在这两种场景中,map()对于转换 string 对象的 iterables 非常有用。
使用 str 类的方法
当开发人员需要操作字符串时,他们通常使用内置 str 类下的方法。这些方法有助于将字符串转换成新字符串。如果您正在处理包含字符串的 iterables,并且希望以相同的方式转换所有的字符串,那么您可以使用 map()函数:
stringList = ["this", "is", "a", "string"]
list(map(str.capitalize, stringList))
list(map(str.upper, stringList))
list(map(str.lower, stringList))
# Output:
# [‘This', 'Is, A', 'String']
# ['THIS, 'IS', 'A', 'STRING']
# ['this', ‘is', a', 'string']
您可以使用 str 和 map()方法对 stringList 列表中的每个元素执行各种转换。在大多数情况下,开发人员会找到不接受任何附加参数的有用方法。这些方法包括上面代码中的方法和其他一些方法,如 str.swapcase()和 str.title()。
有时,开发人员也使用接受额外参数的方法,比如 str.strip()函数,它接受一个去掉空格的 char 参数。这里有一个如何使用这种方法的例子:
spacedList = ["These ", " strings", "have ", " whitespaces "]
list(map(str.strip, spacedList))
#Output: ['These', 'strings', 'have', 'whitespaces']
如上面的代码所示,str.strip()方法使用默认的 char 值,map()方法从 spacedList 的元素中删除空白。
然而,如果你需要给方法提供参数,并且不想依赖默认值,使用 lambda 函数是正确的方法。
让我们来看另一个例子,它使用 str.strip()方法从列表元素中删除省略号而不是空格:
dotList = ["These..", "...strings", "have....", "..dots.."]
list(map(lambda s: s.strip("."), dotList))
# Output: ['These', 'strings', 'have', 'dots']
这里,lambda 函数调用。strip()(在“s”对象上),从字符串中移除点前面和后面的点。
当开发人员需要处理含有尾随空格或其他需要从文本中删除的不需要的字符的文本文件时,这种处理字符串的方法非常方便。
在这种情况下,开发人员也可以使用不带自定义 char 参数的 str.strip()方法——它从文本中删除换行符。
从字符串中删除标点符号
文本处理问题以各种形式出现,在某些情况下,当文本被拆分成单词时,不需要的标点符号会留在文档中。
解决这个问题的一个简单方法是创建一个自定义函数,通过包含常用标点符号的正则表达式从单个单词中删除这些标点符号。
使用 sub()方法可以实现这个函数——这是 Python 标准库的“re”模块下的一个正则表达式函数。这里有一个示例解决方案:
import re
def punctationRemove(word):
return re.sub(r'[!?.:;,"()-]', "", word)
punctationRemove("...Python!")
# Output: 'Python'
函数有一个正则表达式模式,用于保存英语中常见的标点符号。注意撇号(')没有出现在正则表达式中,因为保留像“I'll”这样的缩写是有意义的。
代码中的 re()函数通过用空字符串替换匹配的标点符号来删除标点符号。最后,它返回单词的干净版本。
但是这个转换函数只是解决方案的一半——您现在需要使用 map()函数将这个函数应用于文本文件中的所有单词。一种方法是将字符串提供给变量,比如“text”,然后将 text.split()函数的返回值存储在 words 变量中。
如果你打印单词变量,你会发现它是一个列表,将字符串中的单词作为单独的字符串项保存。此时您也许能够推断出最后一步——运行 map 函数,并将标点符号移除函数和单词列表传递给它。
记得把这个 map 函数放在 list()函数中,打印出去掉标点符号的单词列表。
您提供给程序的单词可能带有标点符号。对 map()函数的调用将标点符号移除()函数应用于每个单词,移除所有标点符号。因此,第二个列表包含所有被清理的单词。
用 map()变换数字项
在处理包含数值的可重复项时,map()方法很有可能派上用场。有了它,开发人员可以执行广泛的算术和数学运算,包括将字符串转换为整数或浮点数等。
使用幂运算符是最常见的数学运算之一,用于转换包含数值的可重复项。下面是一个带有转换函数的程序的例子,它接受一个数字并返回这个数字的平方和立方:
def exponent(x):
return x ** 2, x ** 3
numList = [3, 4, 5, 6]
list(map(exponent, numList))
# Output: [(9, 27), (16, 64), (25, 125), (36, 216)]
exponent()函数从用户处接受一个数字,并返回平方值和立方值。注意,输出包括元组,因为 Python 将返回值作为元组来处理。对该函数的每次调用都返回一个二元组。
接下来,当 exponent()函数作为参数传递给 map()方法时,它返回一个保存已处理数字的元组列表。
这只是 map()方法可能实现的数学转换的一个例子。使用 map()可以完成的其他任务包括从 iterable 的每个元素中添加和减去特定的常数。但是您也可以使用像 sin()和 sqrt()这样的函数,它们是 Python 标准库的数学模块和 map()的一部分。
下面是一个如何将 factorial()方法与 map()一起使用的示例:
import math
numbersList = [1, 2, 3, 4]
list(map(math.factorial, numbersList))
# Output: [1, 2, 6, 24]
在这个例子中,numbersList 列表被转换成一个新的列表,其中保存了原始列表中数字的阶乘值。在代码中使用 map()函数没有任何限制。确保你对这个函数有所思考,并想出你自己的程序来巩固你对它的理解。
如果你觉得这篇文章有帮助,你可能想看看这篇关于 FastAPI 的文章。
如何使用 Python Zip 函数(快速简单)
原文:https://www.pythoncentral.io/how-to-use-the-python-zip-function-fast-and-easy/
Python 的 zip()函数可以帮助开发人员从多种数据结构中对数据进行分组。元素按照它们出现的顺序连接;有了它,您可以同时迭代不同的数据结构。所有这些都没有使用一个嵌套循环!
如果这是你想要实现的目标,你需要学会使用 zip()。该功能最大的优点是使用起来并不复杂。
在本指南中,我们将带您了解如何使用 zip()并并行迭代不同的数据结构。
Python 中的 zip()是什么?
在 Python 中,zip()同时合并几个被称为 iterables 的对象。它通过创建一个新对象来实现这一点,该对象的元素都是元组。
可迭代的元素保存在这些元组中。让我们看一个简单的例子来理解 zip()函数。
假设我们有两个包含名字的元组,就像这样:
names1 = ("Jack", "Theo", "Jose")
names2 = ("Duncan", "Chris", "Anthony")
所以,如果要对这些元组的元素进行配对,可以使用 zip()。函数是这样循环的:
print(zip(names1,names2))
当然,打印功能将帮助我们了解使用 zip 时会发生什么。运行这段代码,您会看到它返回一个特定的 zip 对象。代码的输出看起来会像这样:
<zip object at 0x7f7991fc4cc0>
现在,让我们来看看如何将这个 zip 对象转换成一个列表。就写这么简单:
print(list(zip(names1,names2)))
再次运行代码,您将看到输出:
| [( 【杰克】 , 【邓肯】 ),( 【西奥】 , 【克里斯】 ),( 【何塞】【安东尼】)】 |
到目前为止,我们已经介绍了这个函数的基本工作原理。我们将在接下来的章节中讨论 zip 函数的几个细节。
如果你想看看官方对 zip()函数的定义, 这里是官方 Python 文档页面的链接 。请注意,您还可以在文档中找到 zip()函数的源代码,如果您想了解该函数的技术工作方式,这将很有帮助。
对各种数据结构使用 zip()函数
在上一节的示例程序中,我们探讨了如何使用 zip()函数将两个列表合并成一个对象——zip 对象。对象的元素是长度为 2 的元组。
要利用 zip()函数的功能,您必须理解该函数可以处理所有类型的数据结构。在这一节中,我们将探索 zip()是如何做到这一点的。
使用 zip()和元组
向 zip()函数传递两个元组类似于向它传递列表。因此,代码应该是这样的:
names1 = ("Jack", "Theo", "Jose")
names2 = ("Duncan", "Chris", "Anthony")
print(list(zip(names1,names2)))
运行代码,输出将是:
| [( 【杰克】 , 【邓肯】 ),( 【西奥】 , 【克里斯】 ),( 【何塞】【安东尼】)】 |
很明显,对列表和元组使用 zip()函数实际上没有区别。方便!
使用 zip()和字典
虽然您可以将 zip()与字典一起使用,但您需要注意一些限制。
让我们通过一个例子来深入了解本质:
names1 = {"mom":"Sonia", "dad":"Jesse"}
names2 = {"firstChild":"Andrew", "secondChild": "Kayla"}
print(list(zip(names1,names2)))
花一分钟思考一下代码输出应该是什么。
默认情况下,zip()函数将字典的键缝合在一起。因此,运行代码将给出以下输出:
| [( 【妈妈】 , 【第一胎】 ),( 【爸爸】 , 【二胎】 )] |
然而,zip()函数也允许您“压缩”字典的值。要做到这一点,您必须在将 dictionary 对象传递给 zip()时调用它们的 values 方法。
让我们继续前面的例子,看看如何做到这一点:
names1 = {"mom":"Sonia", "dad":"Jesse"}
names2 = {"firstChild":"Andrew", "secondChild": "Kayla"}
print(list(zip(names1.values(),names2.values())))
代码的输出现在看起来像这样:
| 【(【索尼娅】【安德鲁】)【杰西】【凯拉】)】 |
从 zip()返回不同的数据结构
zip()的一个好处是,除了允许你传递不同的数据结构,它还允许你导出不同的数据类型。
向后滚动一点,回想一下 zip()的默认输出是一个特殊的 zip 对象。
之前,我们在 list 函数中包装了 zip()函数来输出一个列表。所以,您也可以使用 dict 和 tuple 来返回字典和元组,这并不奇怪。
我们来看一个例子:
names1 = ("Jack", "Theo", "Jose")
names2 = ("Duncan", "Chris", "Anthony")
print(tuple(zip(names1,names2)))
运行这段代码的结果看起来会像这样:
| (【杰克】 、 【邓肯】 )、( 【西奥】 、 【克里斯】 )、( 【何塞】 、 【安东尼】) |
我们也可以使用 dict 函数,就像这样
names1 = ("Jack", "Theo", "Jose")
names2 = ("Duncan", "Chris", "Anthony")
print(dict(zip(names1,names2)))
输出将如下所示:
| 【杰克】 : 【邓肯】【西奥】 : 【克里斯】【何塞】 : 【安东尼】 } |
使用带有两个以上参数的 zip()函数
本指南中的所有示例都包含两个可迭代变量,但是 zip()理论上可以使用无限个变量。在这一节中,我们将探索 zip()函数的这一功能。
让我们从定义三个变量来创建一个 zip 对象开始:
india_cities = ['Mumbai', 'Delhi', 'Bangalore']
africa_cities = ['Lagos', 'Cape Town', 'Tunis']
russia_cities = ['Moscow', 'Samara', 'Omsk']
现在,将三个对象压缩在一起就像将它们传递到 zip()中一样简单,就像这样:
print(list(zip(india_cities, africa_cities, russia_cities)))
代码的输出将如下所示:
| (【孟买】 , 【拉各斯】【莫斯科】 ), 【德里】【开普敦】【萨马拉】 , 【班加罗尔】 |
显然,向 zip()传递三个参数会创建一个新的数据结构。该结构的元素是长度为 3 的元组。
请记住,这延伸到更大的数字。简单地说,如果您向 zip()传递“n”个参数,它将创建一个新的数据结构,其中包含长度为“n”的元组元素
zip()如何处理不同长度的参数
在本指南中,我们只涉及了 zip()函数如何处理相同长度的数据结构。首先,我们处理了长度为 2 的结构,在上一节中,处理了长度为 3 的列表。
但是当我们将不同长度的参数传递给 zip()函数时会发生什么呢?
Python zip()函数非常灵活,接受不同长度的参数。让我们在这一节中探索函数的这一能力。
如果你回过头来打开 zip()函数的官方 Python 文档,函数的定义会让事情变得清楚。功能描述说:
“当最短的输入 iterable 用尽时,迭代器停止。”
换句话说,zip()函数输出的长度将总是等于 最小的 自变量的长度。
这里有一个例子来验证这一点。假设我们有两组人:一组是男人,一组是女人。你想让他们两人一组,这样他们就可以上双人舞蹈课——也许是萨尔萨舞。
现在,让我们用 zip()函数写一些代码,看看它如何帮助我们:
menGroup = ['Devin', 'Bruce', 'Jimmy', 'Eddie']
womenGroup = ['Gina', 'Mila', 'Friday']
print(list(zip(menGroup,womenGroup)))
很明显,menGroup 变量比 womenGroup 变量多包含一个元素。因此,我们可以预期 zip()函数会删除 menGroup 变量中的最后一个元素。
运行这段代码,我们将得到以下结果:
| [( 【德文】 , 【吉娜】 ),( 【布鲁斯】 , 【米拉】 ),( 【吉米】【星期五】) |
不出所料,埃迪没有得到萨尔萨舞比赛的参赛资格。让我们期待另一位女士的加入吧!
用 zip()函数循环多个对象
zip()函数最有用的一个方面是它允许你并行迭代多个对象。更重要的是,所涉及的语法容易记忆和使用!
我们用一个例子来理解用 zip()循环。假设你们两个列表:一个有学生的名字,另一个有成绩。下面是代码的样子:
studentList = ['Devin', 'Bruce', 'Jimmy']
gradeList = [97, 71, 83]
在本例中,让我们假设学生列表的排序位置与他们的成绩列表相同。现在,让我们编写代码来打印每个学生的姓名及其相应的成绩。
for student, grade in zip(studentList, gradeList):
print(f"{student}'s grade is {grade}")
运行这段代码的结果如下:
| 德文的成绩是 97布鲁斯的成绩是 71 分吉米的成绩是 83 分 |
Python 3 和 2 在 zip()函数上的区别
需要注意的是,zip()在 Python 2 和 3 中的工作方式不同。zip()函数返回 Python 2 中的元组列表,这个列表被截断为最短输入 iterable 的长度。
因此,如果您调用一个没有参数的 zip()函数,输出将是一个空列表,如下所示:
zipping = zip(range(3), 'WXYZ')
zipping # Holding the list object
[(0, 'W'), (1, 'X'), (2, 'Y')]
type(zipping)
zipping = zip() # Creating empty list
zipping
[]
正如所料,在上面的代码中调用 zip()会给出一个元组列表的输出。列表在“Y”处被截断,不带参数调用 zip()会返回一个空列表。
但是在 Python 3 中 zip()并不是这样工作的。在 Python 3 中,不带参数调用 zip()会返回一个迭代器。
如果开发者需要,迭代器对象产生元组。但是元组只能被遍历一次。迭代以 StopIteration 异常结束,该异常在最短的输入 iterable 用尽时引发。
请记住,虽然 Python 3 中返回了迭代器,但它是空的。我们来看一个例子:
zipping = zip(range(3), 'WXYZ')
zipping # Holding an iterator
type(zipping)
list(zipping)
zipping = zip() # Create an empty iterator
zipping
next(zipping)
运行这段代码将产生输出:
| 回溯(最近呼叫最后一次):文件<字符串>,行 7 , < 模块 >停止迭代 |
在这种情况下,调用 zip()函数会返回一个迭代器。第一次迭代在 c 处被截断,而第二次迭代引发 StopIteration 异常。
Python 3 的好处在于它可以模拟 Python 2 中 zip()的行为。它通过将返回的迭代器封装在对 list()的调用中来实现这一点。这样,它遍历迭代器,返回一个元组列表。
如果您使用的是 Python 2,请注意向 zip()函数传递长输入 iterables 会导致不合理的高内存消耗。因此,如果您需要传递长输入的 iterables,请使用 itertools.izip(*iterables)。
该函数生成一个迭代器,从可迭代对象中聚集元素。因此,使用它与在 Python 3 中使用 zip()具有相同的效果。我们来看一个例子:
from itertools import izip
zipped = izip(range(3), 'WXYZ')
zipped
list(zipped)
在上面的代码中,调用了 itertools.izip()函数,它创建了一个迭代器。当返回的迭代器被 list()消耗时,它输出一个元组列表,就像 Python 3 中的 zip()函数一样。当它到达最短输入迭代器的末尾时,它停止。
如果你同时使用 Python 2 和 3,并且喜欢用两种语言编写代码,那么这里有一些你可以使用的代码:
try:
from itertools import izip as zip
except ImportError:
pass
在这段代码中,izip()函数在 itertools 中是可用的。因此,在 Python 2 中,该函数将在别名 zip 下导入。否则,程序将引发一个 ImportError 异常,这样您就知道您使用的是 Python 3。
上面的代码使你能够在你写的所有代码中使用 zip()函数。当代码运行时,Python 会自动选择正确的版本。
既然您已经理解了 ins 和 out of zip()函数,那么是时候打开指关节,喝杯咖啡,开始编写现实世界的解决方案了!
如何使用 Twython (Twitter) Python 库
原文:https://www.pythoncentral.io/how-to-use-the-twython-twitter-python-library/
Python 是一种非常通用的语言,具有非常多样化的库生态系统。这就是为什么他们的座右铭是“包括电池”-男孩,他们是对的!使用 Python,你可以与包括脸书、Twitter 和 LinkedIn 在内的各种社交网络联系和互动。
今天,我想向您展示如何使用 Twython 和 Python 在 Twitter 上执行一些基本任务。
Twython 是一个非常健壮、成熟的 Twitter 库。已经维持了 2 年多。它由其核心团队积极维护,并定期从社区收到补丁。这不是一个 alpha 状态库;它经过测试,并在许多商业应用中使用。
你可以在这里找到 Twython 的 Github 页面:https://github.com/ryanmcgrath/twython。您将在库页面上看到库的源代码和贡献者列表。他们还提供了一个简单的。py 文件下载给你使用。
安装 Python 的 Twython
简单安装将为您获取最新版本,并将其安装在 Python 能够访问的地方。
如果你不熟悉简易安装,这是一个与setuptools捆绑在一起的简易 Python 模块(easy_install),可以让你自动下载、构建、安装和管理 Python 包。官方 Python 3.x 和 Python 2.x 发行版中包含了简易安装。
安装 Easy Install 后,只需运行下面的命令,让它下载并打包最新版本的 Twython:
easy_install twython
创建 Twython 对象
让我们从导入库并创建一个 Twython 对象开始。我们将在所有与 Twitter 的交互中使用这个对象。
from twython import Twython
twitter = Twython()
获取 Twitter 用户的时间表
在我们的第一个演示中,我们将执行开发人员希望从 Twitter 获得的最常见的功能之一:获取用户的时间表。作为一个例子,我将搜索我自己的时间线。方法如下:
from twython import Twython
twitter = Twython()
# First, let's grab a user's timeline. Use the
# 'screen_name' parameter with a Twitter user name.
user_timeline = twitter.getUserTimeline(screen_name="pythoncentral")
在 Twython 中打印用户推文
现在我们有了用户的时间线,我们可以使用 Twython 来显示单个 Tweets。因为user_timeline变量只是一个集合,你可以跳过或获取你需要的 Tweets 数量。
# And print the tweets for that user.
for tweet in user_timeline:
print(tweet['text'])
运行 Twython 脚本
保存您的脚本(在我的例子中,它被命名为twythonExample.py),并使用 Python 命令运行它:
python twythonExample.py
您应该会在控制台上看到一些推文。如果没有,请仔细检查 Twython 库是否正确安装在 Python 安装的 Libs 文件夹中。
代码本身是不言自明的;每条推文中都有丰富的数据。在本例中,我们将进入并打印“text”元素。
使用 Twython,让 Twitter 交互更简单!
更多 Twython 的东西来尝试
获取 Gravatar 图像
现在让我们尝试获取用户的 Gravatar 图像。
from twython import Twython
twitter = Twython()
抓取用户的 Gravatar 图标非常简单。你也可以决定你想要多大尺寸的 gravatar。
print(twitter.getProfileImageUrl('pythoncentral', size='bigger'))
print(twitter.getProfileImageUrl('pythoncentral'))
如您所见,我们可以请求特定大小的 gravatar,或者如果您只是想要默认大小,则根本不需要请求大小。
用 Twython 搜索 Twitter
来点推特搜索怎么样?Twython 让这个问题变得无关紧要。
from twython import Twython
twitter = Twython()
# Some basic search functionality.
print(twitter.search(q='pythoncentral'))
您应该会在控制台上看到一组 Tweets 结果,其中包含您编写的查询。最重要的是,这个过程真的很快,在搜索过程中开销最小。
获取每日和每周的 Twitter 趋势
最后,Twython 提供了一种获取每日和每周趋势的方法。两者都很容易调用:
from twython import Twython
twitter = Twython()
# Displaying the Daily Trends.
trends = twitter.getDailyTrends()
print(trends)
# Displaying the Weekly Trends.
weeklyTrends = twitter.getWeeklyTrends()
printweeklyTrends
Twython 是一个非常强大的库,有一个很棒的贡献者团队已经为它工作了很长时间。如果您在 Python 中有任何 Twitter 需求,我会强烈推荐这个库。
如何使用 Unittest 为 Python 中的函数编写测试用例
原文:https://www.pythoncentral.io/how-to-use-unittest-to-write-a-test-case-for-a-function-in-python/
从 Python 2.1 开始,unittest 模块就是 Python 标准库的一部分。顾名思义,它帮助开发人员为他们的代码编写和运行测试。
单元测试包括通过测试最小的可测试代码片段来检查代码的缺陷。这些微小的代码块被称为“单元”以这种方式测试代码有助于验证程序的每一部分——包括用户可能没有意识到的助手函数——都做了它应该做的事情。
除了帮助发现 bug,单元测试还有助于防止代码随着时间的推移而退化。
由于这些原因,TDD 驱动的开发团队发现模块是必不可少的,并且这些团队确保所有的代码都有一些测试。
请记住,单元测试不同于集成和回归测试,在集成和回归测试中,测试的目的是检查程序的不同部分是否能一起工作并产生预期的结果。
简单地说,编写单元测试是防止代码失败的好方法。
在本指南中,我们将带领您使用 unittest 模块编写测试。您需要对 Python 函数有一个基本的了解,才能有效地从本指南中学习。
单元测试的主要思想
回想高中:
数学问题涉及使用一套不同的算术程序来得出不同的解决方案。然后将这些解决方案结合起来,得到正确的最终答案。
我们中的许多人会再次通读解决方案,以确保每一步都做对了。更重要的是,检查我们没有写错任何东西或犯错误,并且每一步结束时的计算都是正确的。
对我们的步骤和计算的检查捕捉到了我们在单元测试中所做的事情。在编码过程中犯错误是写出好代码的一部分——就像在数学中得到正确答案的一部分一样。
但是回到旧代码并疯狂地检查它来验证它的正确性并不是正确的方法。这可能会非常令人沮丧。
假设你写了一小段简单的代码来确定一个矩形的面积。为了检查代码是否正确工作,您可以传递各种数字,并查看计算是否正确。
单元测试会为你带来同样的检查过程。
单元测试是回归测试的一个标准且关键的组成部分,有助于确保代码在发生变化时能按预期执行。此外,测试有助于确保程序的稳定性。
因此,当对程序进行更改时,您可以运行预先编写的相应单元测试,以检查它现有的功能不会影响代码库的其他部分。
单元测试的主要好处之一是它有助于隔离错误。如果您要运行整个项目的代码并收到几个错误,调试代码将会非常乏味。
单元测试的输出使得确定代码的任何部分是否抛出错误变得简单。调试过程可以从那里开始。
这并不是说单元测试总是有助于发现错误。但有一点是肯定的。在您检查集成测试中的集成组件之前,这些测试为寻找 bug 提供了一个方便的起点。
现在你已经完全理解了使用单元测试背后的动机,让我们来探索如何实现它们,并使它们成为你开发管道的一部分。
Python 中单元测试的基础知识
也称为 PyUnit,单元测试模块基于 Erich Gamma 和 Kent Beck 创建的 XUnit 框架设计。
你会在其他几种编程语言中找到类似的单元测试模块,包括 Java 和 c
正如你可能知道的,单元测试既可以手动完成,也可以在工具支持下自动完成。自动化测试更快,更可靠,并且减少了测试的人力资源成本,这也是为什么大多数开发团队更喜欢单元测试的原因。
unittest 模块的框架支持测试套件、夹具和测试运行程序,从而实现自动化测试。
单元测试的结构
在单元测试中,一个测试有两个部分。一部分涉及管理测试“夹具”的代码,第二部分是测试本身。
通过子类化 TestCase 并添加一个适当的方法或覆盖来编写一个测试。这里有一个例子:
import unittest
class SimpleTest(unittest.TestCase):
def test(self):
self.failUnless(True)
if __name__ == '__main__':
unittest.main()
上面的 SimpleTest 类有一个 Test()方法,如果 True 变为 False,该方法将失败。
运行单元测试
运行单元测试的直接方法是在测试文件的底部写下如下内容:
if __name__ == '__main__':
unittest.main()
然后,您可以从命令行运行该脚本。您可以期待这样的输出:
| 。-在 0.000 秒内运行 1 次测试OK |
输出开始处的单点表示测试已通过。
单元测试的输出将总是包括测试运行的次数。它还将包括每个测试的状态指示器。但是如果您想要更多关于测试的细节,您可以使用-v 选项。
单元测试的结果
单元测试的输出可以表明以下三种情况之一:
- 好的——这意味着你的测试已经通过。
- 失败——这意味着存在 AssertionError 异常,测试没有通过。
- ERROR——这意味着测试引发了除 AssertionError 之外的异常。
现在你已经熟悉了 Python 中单元测试的基础知识。我们现在将学习如何通过例子实现单元测试。
定义测试用例
TestCase 类是 unittest 中最重要的类之一。类提供了基本的代码结构,您可以使用它在 Python 中测试函数。
这里有一个例子:
import unittest
def put_fish_in_aquarium(list_of_fishes):
if len(list_of_fishes) > 10:
raise ValueError("The aquarium cannot hold more than ten fish")
return {"tank_1": list_of_fishes}
class TestPutFishInAquarium(unittest.TestCase):
def test_put_fish_in_aquarium_success(self):
actual = put_fish_in_aquarium(list_of_fishes=["guppy", "goldfish"])
expected = {"tank_1": ["guppy", "goldfish"]}
self.assertEqual(actual, expected)
下面是这段代码中发生的事情的分类:
unittest 模块被导入以使其对代码可用。接下来,定义需要测试的功能。在这种情况下,该函数被称为 put_fish_in_aquarium。
编写这个函数是为了接受一个鱼的列表,如果这个列表有十个以上的条目,它就会产生一个错误。
接下来,该函数返回鱼缸的字典映射,在代码中定义为“tank_1”,到鱼的列表。
TestPutFishInAquarium 类被定义为 unittest.TestCase 的子类,类中定义了 test _ put _ fish _ in _ aquarium _ success 方法。该方法使用某个输入调用 put_fish_in_aquarium 函数,然后验证返回值是否与预期的返回值相同。
让我们继续探索执行这个测试的步骤。
执行测试用例
假设上一节中的代码保存为“test_fish_in_aquarium.py”。要执行它,请在命令行中导航到包含 Python 文件的目录,然后运行命令:
python -m unittest test_put_fish_in_aquarium.py
在上面的代码行中,我们用代码行的“python -m unittest”部分调用了 unittest Python 模块。这一行中的下一个字符定义了文件的路径,将之前编写的测试用例作为一个参数。
当您运行该命令时,命令行将提供以下输出:
| 输出。-在 0.000 秒内运行 1 次测试OK |
如你所知,测试已经通过了。
让我们来看一个失败的测试。
我们已经更改了下面代码中“expected”变量的值,以使测试失败:
import unittest
def put_fish_in_aquarium(list_of_fishes):
if len(list_of_fishes) > 10:
raise ValueError("The aquarium cannot hold more than ten fish")
return {"tank_1": list_of_fishes}
class TestPutFishInAquarium(unittest.TestCase):
def test_put_fish_in_aquarium_success(self):
actual = put_fish_in_aquarium(list_of_fishes=["guppy", "goldfish"])
expected = {"tank_1": ["tiger"]}
self.assertEqual(actual, expected)
要运行代码,您可以运行我们之前描述的相同命令行条目。输出将如下所示:
| 输出F= = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = =FAIL:test _ put _ fish _ in _ aquarium _ success(test _ put _ fish _ in _ aquarium。-回溯(最近呼叫最后一次):文件“test_put_fish_in_aquarium.py”,第 13 行,在 test _ put _ fish _ in _ aquarium _ success 中self.assertEqual(实际,预期)assertion error:{ ' tank _ 1 ':[' guppy ','金鱼']}!= {'tank_1': ['tiger']}- {'tank_1': ['孔雀鱼','金鱼']}+ { '坦克 _1': ['老虎']}-在 0.001 秒内完成 1 项测试失败(失败次数=1) |
注意现在输出的开头是“F”而不是“a”它表示测试失败。
测试出现异常的功能
unittest 模块的一个好处是,你可以用它来验证一个测试是否会引发 ValueError 异常。当列表中有太多条目时,将引发异常。
让我们通过添加一个新的测试方法来扩展我们已经讨论过的同一个例子:
import unittest
def put_fish_in_aquarium(list_of_fishes):
if len(list_of_fishes) > 10:
raise ValueError("The aquarium cannot hold more than ten fish")
return {"tank_1": list_of_fishes}
class TestPutFishInAquarium(unittest.TestCase):
def test_put_fish_in_aquarium_success(self):
actual = put_fish_in_aquarium(list_of_fishes=["guppy", "goldfish"])
expected = {"tank_1": ["tiger"]}
self.assertEqual(actual, expected)
def test_put_fish_in_aquarium_exception(self):
excess_fish = ["guppy"] * 25
with self.assertRaises(ValueError) as exception_context:
put_fish_in_aquarium(list_of_fishes=excess_fish)
self.assertEqual(
str(exception_context.exception),
" The aquarium cannot hold more than ten fish."
)
代码中定义的新测试方法调用了 put_fish_in_aquarium 方法,就像我们定义的第一个方法一样。但是,该方法调用包含 25 个“guppy”字符串的函数。
新方法使用 with self.assertRaises(...)上下文管理器,它是 TestCase 方法的默认部分,用于检查 put_fish_in_aquarium 方法是否因为这个字符串列表太长而拒绝它。
我们期望出现的异常类 ValueError 是 self.assertRaises 的第一个参数,涉及的上下文管理器绑定到某个名为 exception_context 的变量。
此变量有一个异常属性,其基础值 Error 由 put_fish_in_aquarium 方法引发。当调用 ValueError 上的 str()来检索它所拥有的消息时,它会返回预期的异常。
再次运行测试,您将看到以下输出:
| 输出..-在 0.000 秒内运行 2 次测试OK |
因此,测试通过了。重要的是要记住单元测试。除了 assertRaises 和 assertEqual,TestCase 还提供了几个方法。我们在下面定义了一些值得注意的方法,但是你可以在文档 中找到支持的断言方法 的完整列表。
| 方法 | 断言 |
| assertEqual(a,b) | a == b |
| assertFalse(a) | bool(a)为假 |
| assertIn(a,b) | a 在 b 中 |
| 阿松酮(a) | a 无 |
| assertinotone(a) | a 不是无 |
| assertNotEqual(a,b) | 答!= b |
| assertNotIn(a,b) | a 不在 b |
| assertTrue(a) | bool(a)为真 |
到目前为止,我们已经介绍了一些可以引入到代码中的基本单元测试。让我们继续探索 TestCase 提供的其他工具,您可以使用它们来测试您的代码。
设置方法
TestCase 支持的最有用的方法之一是 setUp 方法。它允许您为单独的测试创建资源。当您有一组在每次测试之前都需要运行的公共准备代码时,使用这种方法是理想的。
通过设置,您可以将所有的准备代码放在一个地方,无需在每次测试中反复重复。这里有一个例子:
import unittest
class FishBowl:
def __init__(self):
self.holding_water = False
def put_water(self):
self.holding_water = True
class TestFishBowl(unittest.TestCase):
def setUp(self):
self.fish_bowl = FishBowl()
def test_fish_bowl_empty_by_default(self):
self.assertFalse(self.fish_bowl.holding_water)
def test_fish_bowl_can_be_filled(self):
self.fish_bowl.put_water()
self.assertTrue(self.fish_bowl.holding_water)
上面的代码有一个鱼缸类,holding_water 实例最初设置为 False。但是,您可以通过调用 put_water()方法将其设置为 True。
TestFishBowl 方法在 TestCase 子类中定义,并定义设置。这个方法实例化了 FishBowl 的一个新实例,分配给 self.fish_bowl。
如前所述,设置方法在每个单独的方法之前运行,因此,为 test _ fish _ bowl _ empty _ by _ default 和 test_fish_bowl_can_be_filled 创建一个新的 FishBowl 实例。
这两个中的第一个验证 holding_water 为假,第二个验证调用 put_water()后 holding_water 为真。
运行这段代码,我们将看到输出:
| 输出..-在 0.000 秒内运行 2 次测试OK |
如你所见,两项测试都通过了。
注意: 如果有几个测试文件,一次运行完会更方便。您可以在命令行中使用“python -m unittest discover”来运行多个文件。
拆卸方法
tear down 方法是 setUp 方法的对应物,使您能够在测试后删除数据库连接并重置对文件系统所做的修改。这里有一个例子:
import os
import unittest
class AdvancedFishBowl:
def __init__(self):
self.fish_bowl_file_name = "fish_bowl.txt"
default_contents = "guppy, goldfish"
with open(self.fish_bowl_file_name, "w") as f:
f.write(default_contents)
def empty_tank(self):
os.remove(self.fish_bowl_file_name)
class TestAdvancedFishBowl(unittest.TestCase):
def setUp(self):
self.fish_bowl = AdvancedFishBowl()
def tearDown(self):
self.fish_bowl.empty_bowl()
def test_fish_bowl_writes_file(self):
with open(self.fish_bowl.fish_bowl_file_name) as f:
contents = f.read()
self.assertEqual(contents, "guppy, goldfish")
上面代码中的 AdvancedFishBowl 类创建了一个名为 fish_bowl.txt 的文件,然后将字符串“guppy,金鱼”写入其中。该类还有一个 empty_bowl 方法,用于删除 fish_bowl.txt 文件。
在代码中,您还可以找到 TestAdvancedFishBowl TestCase 子类的 setUp 和 tearDown 方法。
您可能会猜到 setUp 方法创建了 AdvancedFishBowl 的一个新实例,并将其分配给 self.fish_bowl。
另一方面,tearDown 方法调用 self.fish_bowl 上的 empty_bowl 方法。通过这种方式,它可以确保每次测试结束后都删除 fish_bowl.txt 文件。因此,每个测试都重新开始,而不会受到前一个测试所做的更改和结果的任何影响。
test _ fish _ bowl _ writes _ file 方法验证“孔雀鱼,金鱼”被写入 fish _ bowl . txt。
运行代码将得到以下输出:
| 输出。-在 0.000 秒内运行 1 次测试OK |
如何写出好的单元测试?
有一些提示要记住,这将帮助你写出好的单元测试:
#1 仔细命名你的测试
需要注意的是,在 Python 中,当测试方法以单词“test”开头时,TestCase 会识别它们
因此,以下测试将不起作用:
class TestAddition(unittest.TestCase):
def add_test(self):
self.assertEqual(functions.add(6, 1), 9)
你可以写 test_add,这样就可以了。但是 add_test 就不行了。这很重要,因为如果你写的方法前面没有“test ”,你的测试总是会通过的。这是因为它根本没有运行。
有一个你认为已经通过的测试比根本没有测试要糟糕得多。犯这种错误会彻底搞乱 bug 修复。
使用长名字是最好的方法。名字越具体,以后就越容易找到 bug。
#2 开始时做简单的测试,慢慢积累
编写首先想到的单元测试是正确的方法,因为它们肯定很重要。
这个想法是编写测试来检查你的功能是否正常工作。如果这些测试通过了,你就可以开始编写更复杂的测试了。但是永远不要急着写复杂的测试,直到你写了检查代码基本功能的测试。
#3 边缘情况
为边缘案例编写测试是进行单元测试的一个很好的方法。假设你在一个程序中处理数字。如果有人输入否定会怎么样?还是浮点数?
更奇怪的是,如果输入为零,会发生什么吗?
Zero 以破解代码而闻名,所以如果你在和数字打交道,测试它是明智的。
#4 编写相互独立的测试
永远不要编写相互依赖的测试。它忽略了单元测试的要点,并且很有可能会使以后的 bug 测试变得乏味。
由于这个原因,unittest 模块有一个内置的特性来防止开发人员这样做。同样需要注意的是,该模块并不保证测试会按照您指定的顺序运行。
然而,您可以使用 setUp()和 tearDown()方法来编写在每次测试之前和之后执行的代码。
避开断言。IsTrue
使用断言。IsTrue 不是一个好主意,因为它没有提供足够的信息。它只告诉你值是真还是假。使用 assertEqual 方法会更有帮助,因为它会给你更多的细节。
#6 你的一些测试会漏掉的东西
编写好的测试需要练习,即使你很擅长,也有可能会遗漏细节。
事实是,即使是最好的开发人员也无法想到程序失败的所有方式。然而,编写好的测试提高了在代码破坏之前捕捉到代码破坏错误的机会。
因此,如果你在代码中遗漏了什么,也不用担心。回到测试文件,为您偶然发现的情况编写一个新的断言。这确保您在将来不会错过它——即使是在您复制函数和测试文件的项目中。
今天编写的有用的测试类和将来编写的好函数一样有用。
结论
使用 unittest 模块是开始测试的最好方法之一,因为它涉及到编写简短的、可维护的方法来验证你的代码。
有了这个模块,编写测试不再费时费力,因为测试对所有 CI 渠道都至关重要。测试有助于在事情发展到修复 bug 成为主要的时间和成本支出之前捕捉 bug。
该模块无疑使测试变得更加容易和容易。开发人员不需要花时间学习或依赖外部测试框架。Python 内置的几个命令和库有助于确保应用程序按预期工作。
然而,随着你积累了更多编写测试的经验,你可以考虑转向其他更强大的测试框架,比如 pytest。这些框架往往具有高级特性,可以帮助你充实你的测试。
如何使用 Python 验证电子邮件地址
原文:https://www.pythoncentral.io/how-to-validate-an-email-address-using-python/
这个片段向您展示了如何使用 Python 的 awesome isValidEmail()函数轻松验证任何电子邮件。验证电子邮件意味着您正在测试它是否是一封格式正确的电子邮件。虽然这段代码实际上并不测试电子邮件是真是假,但它确实确保了用户输入的电子邮件是有效的电子邮件格式(包含字符、后跟@符号、后跟字符和“.”的特定长度的字符串)其次是更多的字符。
用于验证的代码实际上非常简单,非常类似于使用任何其他 OOP 语言执行这个特定任务的方式。看看下面的片段,自己看看。
import re
def isValidEmail(email):
if len(email) > 7:
if re.match("^.+@([?)[a-zA-Z0-9-.]+.([a-zA-Z]{2,3}|[0-9]{1,3})(]?)$", email) != None:
return True
return False
if isValidEmail("my.email@gmail.com") == True :
print "This is a valid email address"
else:
print "This is not a valid email address"
这段代码可以在任何 Python 项目中用来检查电子邮件的格式是否正确。它需要被修改以用作表单验证器,但是如果您希望验证任何表单提交的电子邮件地址,您绝对可以将它作为一个起点。
HTML 解析器:如何抓取 HTML 内容
先决条件
需要了解以下内容:
- Python 3
- 基本 HTML
- Urllib2(非强制但推荐)
- 基本的 OOP 概念
- Python 数据结构-列表、元组
为什么要解析 HTML?
Python 是广泛用于从网页中抓取数据的语言之一。这是收集信息的一种非常简单的方法。例如,它对于快速提取网页中的所有链接并检查它们的有效性非常有帮助。这只是许多潜在用途的一个例子...所以继续读下去吧!
下一个问题是:这些信息是从哪里提取的?要回答这个,我们来举个例子。进入网站【NYTimes】点击页面右键。选择 查看页面来源 或者直接按键盘上的Ctrl+u键。将打开一个新页面,其中包含许多链接、HTML 标记和内容。这是 HTML 解析器为纽约时报抓取内容的来源!
什么是 HTML 解析器?
HTML 解析器,顾名思义,就是简单地解析一个网页的 HTML/XHTML 内容,并提供我们要找的信息。这是一个用各种方法定义的类,可以覆盖这些方法来满足我们的需求。注意,要使用 HTML 解析器,必须获取网页。正因如此,HTML 解析器经常与 urllib2 一起使用。
要使用 HTML 解析器,你必须导入这个模块:
from html.parser import HTMLParser
HTML 解析器中的方法
- HTML Parser . feed(data)-HTML 解析器读取数据就是通过这个方法。此方法接受 unicode 和字符串格式的数据。它不断处理获得的数据,并等待缓冲不完整的数据。只有在使用这个方法输入数据之后,才能调用 HTML 解析器的其他方法。
- HTMLParser.close() - 调用这个方法来标记 HTML 解析器输入提要的结束。
- HTMLParser.reset() - 该方法重置实例,所有未处理的数据都将丢失。
- html parser . handle _ starttag(tag,attrs) - 这个方法只处理开始标签,像 < title > 。tag 参数指的是开始标记的名称,而 attrs 指的是开始标记内的内容。例如,对于标签 < Meta name="PT" > ,方法调用将是 handle_starttag('meta ',[('name ',' PT')])。注意,标记名被转换成小写,标记的内容被转换成键、值对。如果一个标签有属性,它们将被转换成一个键、值对元组并添加到列表中。例如,在标签中,方法调用将是 handle_starttag('meta ',[('name ',' application-name '),(' content '。《纽约时报》)])。
- html parser . handle _ end tag(tag)-这个方法与上面的方法非常相似,除了它只处理像 < /body > 这样的结束标记。因为在结束标记中没有内容,所以这个方法只有一个参数,就是标记本身。比如 < /body > 的方法调用会是:handle_endtag('body ')。类似于 handle_starttag(tag,attrs)方法,这也将标记名转换为小写。
- html parser . handle _ startendtag(tag,attrs) - 顾名思义,这个方法处理的是开始结束标签,比如,<a href = http://nytimes . com/>。参数 tag 和 attrs 类似于 HTMLParser.handle_starttag(tag,attrs)方法。
- html parser . handle _ data(data)-该方法用于处理类似 < p > ……的数据/内容。< /p > 。当您想要查找特定的单词或短语时,这尤其有用。这种方法结合正则表达式可以创造奇迹。
- html parser . handle _ comment(data)-顾名思义,这种方法是用来处理类似 <的评论的!- ny times - > 并且方法调用类似于 html parser . handle _ comment(‘ny times’)。
咻!这需要处理很多东西,但是这些是 HTML 解析器的一些主要(也是最有用的)方法。如果你感到头晕,不要担心,让我们来看一个例子,让事情变得更清楚一点。
【HTML 解析器是如何工作的?
既然你已经具备了理论知识,让我们来实际测试一下。要尝试以下示例,您必须安装 urllib2 或按照以下步骤安装它:
- 安装pip
- 安装 urllib - pip 安装 urllib2
from html.parser import HTMLParser
import urllib.request as urllib2
class MyHTMLParser(HTMLParser):
#Initializing lists
lsStartTags = list()
lsEndTags = list()
lsStartEndTags = list()
lsComments = list()
#HTML Parser Methods
def handle_starttag(self, startTag, attrs):
self.lsStartTags.append(startTag)
def handle_endtag(self, endTag):
self.lsEndTags.append(endTag)
def handle_startendtag(self,startendTag, attrs):
self.lsStartEndTags.append(startendTag)
def handle_comment(self,data):
self.lsComments.append(data)
#creating an object of the overridden class
parser = MyHTMLParser()
#Opening NYTimes site using urllib2
html_page = html_page = urllib2.urlopen("https://www.nytimes.com/")
#Feeding the content
parser.feed(str(html_page.read()))
#printing the extracted values
print(“Start tags”, parser.lsStartTags)
#print(“End tags”, parser.lsEndTags)
#print(“Start End tags”, parser.lsStartEndTags)
#print(“Comments”, parser.lsComments)
或者,如果您不想安装 urllib2,可以直接将一串 HTML 标记提供给解析器,如下所示:
parser = MyHTMLParser()
parser.feed('<html><body><title>Test</title></body>')
当您处理大量数据时,一次打印一个输出以避免崩溃!
注意:如果你得到错误: IDLE 不能启动进程,在管理员模式下启动你的 Python IDLE。这应该能解决问题。
异常情况
HTMLParser。当 HTML 解析器遇到损坏的数据时,这个异常被抛出。这个异常以三种属性的形式给出信息。 msg 属性告诉您错误的原因, lineno 属性指定错误发生的行号, offset 属性给出构造开始的确切字符。
结论
关于 HTML 解析器的这篇文章到此结束。一定要自己尝试更多的例子来提高自己的理解能力!如果您需要开箱即用的电子邮件解析器或 pdf 表格解析解决方案,我们的姐妹网站可以满足您的需求,直到您掌握 python mojo。请务必阅读一下 BeautifulSoup ,它是Python 中另一个帮助抓取 HTML 的神奇模块。但是,要使用这个模块,您必须安装它。坚持学习,快乐 Pythoning 化!
插入排序:快速教程和实现指南
原文:https://www.pythoncentral.io/insertion-sort-implementation-guide/
先决条件
要了解插入排序,您必须知道:
- Python 3
- Python 数据结构-列表
什么是插入排序?
我们正在学习排序系列的第二个教程。前面的教程讲了冒泡排序,这是一个非常简单的排序算法。如果你还没有读过,你可以在这里找到它。像所有的排序算法一样,我们认为一个列表只有在升序时才被排序。降序被认为是最坏的未排序情况。
顾名思义,在插入排序中,一个元素被比较并插入到列表中正确的位置。要应用这种排序,必须考虑列表的一部分要排序,另一部分不排序。首先,考虑第一个元素是排序的部分,列表中的其他元素是未排序的。现在,将未排序部分中的每个元素与排序部分中的元素进行比较。然后将其插入已分类零件的正确位置。 记住,列表的排序部分始终保持排序。
让我们用一个例子来看看,list = [5,9,1,2,0]
第一轮:
sorted - 5 and unsorted - 9,1,2,0
5<9: nothing happens
alist = [5,9,1,2,0]
第二轮:
sorted - 5, 9 and unsorted - 1,2,0
1<9: do nothing
1<5: insert 1 before 5
alist = [1,5,9,2,7,0]
第三轮:
sorted -1, 5, 9 and unsorted - 2,0
2<9: do nothing
2<5: do nothing
2>1: do nothing
insert 2 before 5
alist = [1,2,5,9,0]
注: 即使我们很清楚 2 小于 5 但大于 1,算法也无从得知这一点。因此,只有在与排序部分中的所有元素进行比较后,它才会使插入位置正确。
第四轮:
sorted -1, 2, 5, 9 and unsorted - 0
0<9: do nothing
0<5: do nothing
0<2: do nothing
0<1: insert 0 before 1
alist = [0,1,2,5,9]
为了更好的理解,请看这个动画。
如何实现插入排序?
现在你已经对插入排序有了一个很好的理解,让我们来看看这个算法和它的代码。
算法
- 考虑要排序的第一个元素,其余元素不排序
- 与第二个元素比较:
- 如果第二个元素<第一个元素,将该元素插入排序部分的正确位置
- 否则,保持原样
- 重复 1 和 2,直到所有元素排序完毕
注意: 随着排序部分中元素数量的增加,来自未排序部分的新元素在插入前必须与排序列表中的 所有 元素进行比较。
代码
def insertionSort(alist):
for i in range(1,len(alist)):
#element to be compared
current = alist[i]
#comparing the current element with the sorted portion and swapping
while i>0 and alist[i-1]>current:
alist[i] = alist[i-1]
i = i-1
alist[i] = current
#print(alist)
return alist
print(insertionSort([5,2,1,9,0,4,6]))
取消对 print 语句的注释,查看列表是如何排序的。
结论
插入排序最适用于少量元素。插入排序的最坏情况运行时间复杂度是 o(n2 ),类似于冒泡排序。然而,插入排序被认为比冒泡排序更好。探究原因并在下面评论。本教程到此为止。快乐的蟒蛇!
在 Windows、Mac 和 Linux 上安装 PySide 和 PyQt
原文:https://www.pythoncentral.io/install-pyside-pyqt-on-windows-mac-linux/
在上一篇文章中,我向大家介绍了 Qt 及其 Python 接口,PyQt 和 PySide 现在你已经对它们有所了解,选择一个并安装它。我推荐 PySide 有两个原因:首先,本教程是根据 PySide 构思的,可能会涵盖一些在 PyQt 中没有完全实现的主题;第二,它的许可对你将来的使用更加灵活。然而,这两种方法都可以。
下面将向您展示如何在 Windows、Mac 和 Linux 上安装 PySide 和 PyQt。二进制安装程序可用于大多数常见平台;链接和设置说明概述如下:
视窗
PySide 或 PyQt 的安装是通过一个简单的点击式安装程序来完成的。对于 PySide,从releases.qtproject.com获得适合你的 Python 版本的二进制文件。运行安装程序,确认 Python 安装的位置(应该可以正确地自动检测到)并选择一个安装目录,您应该在几秒钟内完成 PySide 安装。
PyQt 非常相似,除了您只能选择部分安装而不是完整安装:不要。你会想要例子和演示。它们值这个空间。从河岸获取 PyQt 安装程序。
麦克 OS X
安装 PySide 的 Mac OS X 二进制文件可以从 Qt 项目中获得。
对于 PyQt,使用由 PyQtX 项目提供的二进制文件。为您的 Python 版本选择完整版本,它提供 Qt 和 PyQt,除非您确定您已经在正确的版本中安装了 Qt;然后使用最少的安装程序。
如果你正在使用自制软件,你可以:
brew install pyside
或者
brew install pyqt
从命令行。您也可以使用 MacPorts:
port-install pyNN-pyside
更改NN以匹配您的 Python 版本。同样,您可以:
port-install pyNN-pyqt4
安装 PyQt。
Linux(基于 Ubuntu 和 Debian)
对于基于 Debian 和 Ubuntu 的 Linux 发行版,安装 PySide 或 PyQt 很简单;只是做:
sudo apt-get install python-pyside
从命令行。对于 PyQt:
sudo apt-get install python-qt4
或者,使用 Synaptic 安装您选择的python-pyside或python-qt4。
Linux(基于 CentOS 和 RPM)
对于大多数基于 RPM 的发行版,使用yum安装 PySide 或 PyQt 也很简单;只是做:
yum install python-pyside pyside-tools
以 root 身份从命令行安装 PySide。为了 PyQt,做
yum install PyQt4
现在您已经安装了 PySide 或 PyQt,我们几乎可以开始学习使用它了——但是首先,我们必须讨论编辑器和 ide。我们将在下一期文章中这样做。
安装 Python:Windows、Mac 和 Linux 的详细说明
原文:https://www.pythoncentral.io/installing-python-detailed-instructions-for-windows-mac-and-linux/

目录:
- 简介
- Python for windows–安装
- Python for MAC OS-安装
- Python for Linux–安装
- 结论
- 常见问题解答
简介:
Python 是世界上最流行的编程语言之一,有超过 800 万开发人员在使用它。Python 的无处不在意味着如果你现在就努力学习它,你将会在未来几年收获巨大的收益。因此,如果您想开始学习 Python,请继续阅读以了解如何在您的机器上安装它!探索 Python 教程 了解更多信息。
在 Windows 上安装 Python
-
目前有两个不同版本的 Python 在使用——Python 2 和 Python 3。这些版本在语法和功能上有所不同。每个版本都有可用的子版本。您必须决定要下载哪个版本的 Python。
-
到 Python 官网的“Python for Windows”板块-。在那里,您可以找到所有可供下载的 Python 版本。例如,最新版本是 Python 3.10.4。点击下载,你会看到一个各种可执行安装程序的列表,每一个都有不同的系统要求。选择一个与您的机器规格兼容的,并下载它。
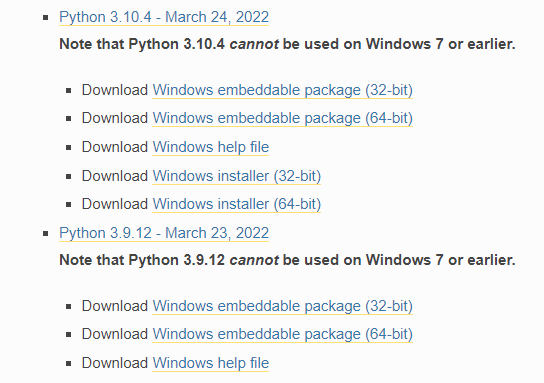
- 一旦给出运行安装程序的选项,选择对话框底部的两个复选框——“为所有用户安装启动器”和“将 Python[您选择的版本]添加到路径中”。然后点击“立即安装”
-
安装完成后,你会看到一个对话框,通知你“安装成功”然后,您可以验证 Python 确实已经成功安装在您的计算机上。
-
打开命令提示符,键入“Python”如果安装确实成功,将显示您选择下载的 Python 版本。
- 最后,您需要验证 Pip 是否已经与 Python 一起成功安装。Pip 是 Python 的一个强大的系统管理包,因此它是检查您是否能够成功下载它们的理想工具。要验证 Pip 的安装,请打开命令提示符并输入“Pip-V”。如果 Pip 安装正确,将出现以下输出:

在 MacOS 上安装 Python
- 从 Python 官网下载可执行安装程序。如果您访问 https://www.python.org/downloads/macos/的,它会自动检测您的操作系统并选择针对您的系统规格优化的安装程序。如果不起作用,只需点击您喜欢的 Python 版本的链接,手动选择安装程序。
- 下载完安装程序后,双击软件包开始安装 Python。安装程序将显示一个软件向导,指导您完成安装所需的不同步骤。在某些情况下,您可能需要输入 Mac 密码,让系统知道 Python 是在您的许可下安装的。
-
首先,你会被要求同意 Python 许可证,也就是 Python 软件基础许可证版本 2。然后,只需点击“安装”开始下载!
-
安装完成后,你会看到 Python 文件夹。您可以验证 Python 和 IDLE(Python 的集成开发环境)是否安装正确。为此,双击空闲文件;如果安装成功,您将看到下面的 Python shell:
-
在同一个文件夹中,您会找到一个名为“安装证书”的文件 Python 使用一组 SSL 根证书来验证安全网络连接的身份。您需要从第三方提供商那里安装这些证书的当前和管理包。双击安装证书以快速下载必要的 SSL 证书。
-
最后,你可以在空闲时执行一个简单的程序,看看是否一切正常。
注意: 如果你使用的是苹果 M1 Mac,如果你还没有安装的话,你首先需要安装 Rosetta。这是一个使基于英特尔的功能能够在苹果硅 MAC 上运行的包。下载后,它会在后台自动运行。您可以通过命令行给出以下命令来安装它:“/usr/sbin/software update-install-Rosetta-agree-to-license。”
查看 Python 在线培训 &认证课程,让自己获得 Python 行业级技能认证。
为 Linux 安装 Python
-
要安装 Python for Linux,你需要一台运行 Debian 或 Fedora 操作系统的电脑,至少要有 2GB 内存和 5GB 磁盘空间。你还需要 sudo 进入系统。
-
在大多数 Linux 版本上,比如 Debian,Python 已经安装好了。您可以通过打开命令提示符并输入“python-v”或“Python-version”来检查 Python 是否已安装如果未安装 Python,输出将显示“未找到命令‘Python’”
- 要从包管理器安装 Python,输入以下命令:“sudo apt-get install python3.9”(安装时用自己喜欢的版本替换 3.9)。键入“Y”并按 enter 键继续。包管理器将为您安装 Python。

或者,您可以从源代码构建 Python。为此,请遵循以下步骤:
-
获取源代码。你可以从 Python 的官方 GitHub 库克隆它。
-
配置代码。配置脚本包括许多标志,如 prefix、- enable-optimizations 等。要配置特定的标志,请导航到克隆源代码的 CPython 目录,然后在终端上运行以下命令。/configure-prefix = $ HOME/python 3.9 . "
-
最后,是构建过程。运行 make 工具启动构建过程,然后运行 make install 命令将构建文件放在 configures–prefix 指定的位置。最终输出如下:
结论
Python 是目前最流行的编程语言之一,这是有道理的。它的易用性、开源支持和更高的生产率使它成为许多开发人员的最爱。它与 Windows、Mac 和 Linux 的兼容性只是促进了它的广泛使用。
我们希望这篇文章能够回答你关于在你选择的操作系统上下载 Python 的所有问题!
常见问题:
- 最新的 Python 版本是什么?
Python 3.10 是最新版本,它包含了许多新特性和优化。其当前发布版本是 3.10.4。它具有库特性、语法特性、解释器改进和类型特性。
- Python 与 windows 11 的兼容性?
我们可以在 Windows 11 上安装最新版本的 Python。要在 Windows 11 上安装最新版本的 Python,请访问 Python 下载网站,并从稳定版本部分选择 Windows Installer (64 位)。下载完成后,导航到下载文件夹,双击安装程序,并在 windows 上安装最新的 python 版本。
- Python 可以在任何操作系统上使用吗?
Python 是一种跨平台的编程语言,可以在 Windows、macOS 和 Linux 上工作。说到选择操作系统,这主要是个人喜好的问题。根据 2020 年的一项调查,45.8%的开发人员使用 Windows,27.5%使用 macOS,26.6%使用 Linux。
- 为什么 Python 需要这么长时间才能启动?
在 Windows 上,Python 通常很容易启动,但有报告称 Python 意外地需要很长时间才能启动。问题机器上运行不正常的病毒检查软件可能是问题的根源。当配置为监控所有文件系统读取时,一些病毒扫描程序已经被识别为启动两个数量级的启动开销。检查您的程序上的防病毒软件的配置,以确保它们都以相同的方式配置。
- 如何才能发现 Python 中的 bug 以及发现 bug 的工具?
PyChecker 是一个检测 Python 源代码中 bug 的程序。PyChecker 以多种方式运行。它从导入每个模块开始。如果存在导入错误,则无法处理该模块,导入提供了一些基本的模块信息。每个函数、类和方法的代码都被检查潜在的缺陷。 查看进阶 Python 面试问题 轻松破解面试。
- Linux 适合 Python 吗?
Python 在 Linux 上非常容易使用,因为它的安装步骤比在 Windows 上少。在 Linux 中工作时,在 python 版本之间切换也很简单,Python 学习不会受到操作系统的影响。
- Python 在 mac 上的使用?
理论上,运行 macOS 的 Mac 上的 Python 与运行任何其他 Unix 平台的 Python 有着显著的关联。然而,还有一些额外的特性值得一提,比如 IDE 和包管理器。
作者简介
赛普里亚·拉武里 是一名数字营销人员,也是一名充满激情的作家,他正与全球顶级在线培训提供商MindMajix合作。她还拥有 IT 和高要求技术的深入知识,如商业智能、机器学习、销售力量、网络安全、软件测试、QA、数据分析、项目管理和 ERP 工具等。
使用自制软件在 Mac 上安装 Python
原文:https://www.pythoncentral.io/installing-python-on-mac-using-homebrew/
Python 是一种广受欢迎的高级编程语言,因其可读性、简单性和灵活性而备受赞誉。世界各地的开发人员使用它来构建各种各样的应用程序,包括 web 应用程序、数据分析工具、科学模拟等等。
如果你是 Mac 用户,想要开始学习或使用 Python,你需要在你的电脑上安装它。在 Mac 上安装 Python 有几种不同的方法,但是使用自制软件是最简单和最方便的选择之一。
在本文中,我们将解释什么是家酿,如何在 Mac 上安装它,以及如何使用它来安装 Python。我们开始吧!
什么是自制?
家酿是一个命令行实用程序,允许您在 macOS 上安装和管理开源软件。它类似于 apt-get(用于 Ubuntu)或 yum(用于 CentOS)这样的包管理器。有了 Homebrew,你可以轻松地在 Mac 上安装包括 Python 在内的各种开源软件。
使用自制软件的一个好处是,它可以很容易地安装和管理同一软件的多个版本。例如,如果您正在处理一个需要旧版本 Python 的项目,您可以使用 Homebrew 安装该特定版本,而不会影响系统上默认安装的 Python 版本。
自制软件的另一个优点是它将软件安装在与系统其他部分分开的位置,这有助于避免冲突,保持系统整洁。
如何用自制软件在 Mac 上安装 Python?
在使用 Homebrew 安装 Python 之前,您需要安装 Homebrew 本身。以下是如何做到这一点:
第一步进入发射台>其他>终端启动终端 app。
第 2 步在终端窗口中运行以下命令,并按下 return 按钮,在 Mac 上安装 Homebrew:
/bin/bash-c " $(curl-fsSL https://raw . githubusercontent . com/home brew/install/HEAD/install . sh)"
第 3 步完成家酿安装,你将被提示输入您的管理员密码。要继续,只需输入并再次按下 return 即可。
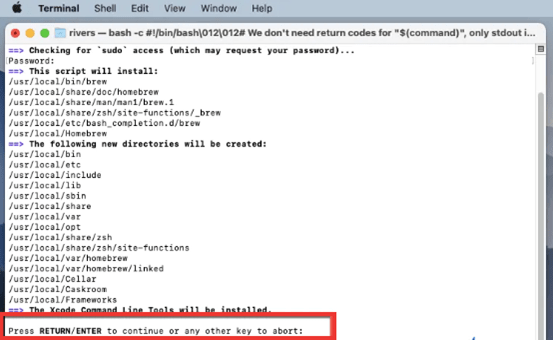
步骤 4:推迟直到安装完成。程序的实时更新将显示在终端窗口中。
安装家酿后,最好对其进行更新,以确保您拥有最新版本。要更新 Homebrew,请在终端中运行以下命令:
brew 更新
就是这样!您现在已经成功地在 Mac 上安装了 Homebrew。你可以用自制软件在你的 Mac 上安装 Python。
步骤 5 在终端窗口运行 brew install pyenv 命令,在 Mac 上安装 pyenv。借助这个 PyEnv 实用程序,您可以在不同的 Python 版本之间切换。
步骤 6 设置 pyenv 后,使用 pyenv install 3.11.1 命令在 Mac 设备上安装 Python 3。(这里 3.11.1 是 Python 目前拥有的版本号。您可以用需要的版本号替换版本号。)
如何检查 Python 是否成功安装在 Mac 上?
有几种不同的方法可以检查 Python 是否成功安装在 Mac 上。一种方法是打开终端窗口,输入命令“ Python - version ”。这将显示您的系统上当前安装的 Python 版本。
检查 Mac 上是否安装了 Python 的另一种方法是使用 Finder 应用程序来搜索 Python 可执行文件。您可以打开 Finder,从菜单栏中选择“转到”,然后选择“转到文件夹”在“转到文件夹窗口中,输入“ /usr/local/bin/python ”,按下“转到”按钮。如果您的系统上安装了 Python,这将打开包含 Python 可执行文件的文件夹。如果文件夹不存在或收到错误消息,这意味着您的系统上没有安装 Python。
还可以通过在终端窗口中使用“python”命令启动交互式 Python 会话来检查您的 Mac 上是否安装了 Python。如果安装了 Python,这将打开一个 Python 提示符,您可以在其中输入 Python 命令。如果未安装 Python,您将会收到一条错误消息,指出找不到该命令。
结束语
使用 Homebrew 在 Mac 上安装 Python 是在您的系统上设置 Python 开发环境的一个简单过程。无论您是刚刚开始使用 Python,还是经验丰富的程序员,这种方法都可以帮助您快速入门并使用 Python。
通过使用 Homebrew 安装 Python,您可以利用其强大的包管理功能,轻松安装和管理多个版本的 Python,以及其他开源软件包。如果你打算在你的 Mac 上使用 Python,通过 Homebrew 安装它绝对值得考虑。
PySide/PyQt 简介:基本部件和 Hello,World!
原文:https://www.pythoncentral.io/intro-to-pysidepyqt-basic-widgets-and-hello-world/
这一部分介绍了 PySide 和 PyQt 的最基本的要点。我们将谈一谈它们使用的对象种类,并通过几个非常简单的例子向您介绍 Python/Qt 应用程序是如何构造的。
首先,Qt 对象的基本概述。Qt 提供了许多类来处理各种各样的事情:XML、多媒体、数据库集成、网络等等,但是我们现在最关心的是可见的元素——窗口、对话框和控件。Qt 的所有可见元素都被称为小部件,是一个公共父类QWidget的后代。在本教程中,我们将使用“widget”作为 Qt 应用程序中任何可见元素的通称。
Qt widgets are themable. They look more-or-less native on Windows and most Linux setups, though Mac OS X theming is still a work in progress; right now, Python/Qt applications on Mac OS X look like they do on Linux. You can also specify custom themes to give your application a unique look and feel.
第一个 Python/Qt 应用程序:Hello,World
我们将从一个非常简单的应用程序开始,它显示一个带有标签的窗口,标签上写着“Hello,world!”这是以一种容易掌握的风格编写的,但不可模仿——我们稍后会解决这个问题。
# Allow access to command-line arguments
import sys
#从 PySide 导入 Qt
的核心和 GUI 元素。来自 PySide 的 QtCore import *
。QtGui 导入*
#每个 Qt 应用程序必须有且只有一个 Qt application 对象;
#它接收传递给脚本的命令行参数,因为它们
#可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
#用我们的文本
label = QLabel('Hello,world!')
#将其显示为独立的小部件
label.show()
#运行应用程序的事件循环
qt_app.exec_()
# Allow access to command-line arguments
import sys
# SIP 允许我们选择希望使用的 API
导入 SIP
#使用更现代的 PyQt API(Python 2 . x 中默认不启用);
#必须在导入任何提供指定 API 的模块之前
sip.setapi('QDate ',2)
sip.setapi('QDateTime ',2)
sip.setapi('QString ',2)
sip.setapi('QTextStream ',2)
sip.setapi('QTime ',2)
sip.setapi('QUrl ',2)
sip.setapi('QVariant ',2)
#从 PyQt4 导入所有 Qt
。Qt 导入*
#每个 Qt 应用程序必须有且只有一个 Qt application 对象;
#它接收传递给脚本的命令行参数,因为它们
#可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
#用我们的文本
label = QLabel('Hello,world!')
#将其显示为独立的小部件
label.show()
#运行应用程序的事件循环
qt_app.exec_()
对我们所做工作的高度概括:
- 创建 Qt 应用程序
- 创建小部件
- 将其显示为一个窗口
- 运行应用程序的事件循环
这是任何 Qt 应用程序的基本轮廓。无论打开多少个窗口,每个应用程序都必须有且只有一个QApplication对象,它初始化应用程序,处理控制流、事件调度和应用程序级设置,并在应用程序关闭时进行清理。
创建的小部件没有父部件,这意味着它显示为一个窗口;这是应用程序的启动窗口。如图所示,然后调用QApplication对象的exec_方法,这将启动应用程序的主事件循环。
关于这个例子的一些细节:
- 注意,
QApplication的构造函数接收sys.argv作为参数;这允许用户使用命令行参数来控制 Python/Qt 应用程序的外观、感觉和行为。 - 我们的主要小部件是一个
QLabel,它仅仅显示文本;任何小部件——也就是继承自QWidget的任何东西——都可以显示为一个窗口。3.
A note on the PyQt version: there's a fair amount of boilerplate code preceding the creation of the QApplication object. That selects the API 2 version of each object's behavior instead of the obsolescent API 1, which is the default for Python 2.x. In the future, our examples for both PySide and PyQt will omit the import section for space and clarity. But don't forget that it needs to be there. (Actually, all of the sip lines could have been omitted from this example without any effect, as could the PySide.QtCore import, as it doesn't use any of those objects directly; I've included them as an example for the future.)
两个基本部件
让我们来看两个最基本的 Python/Qt 小部件。首先,我们将回顾它们所有的父代,QWidget;然后,我们将看一个继承自它的最简单的小部件。
QWidget
QWidget 的构造函数有两个参数,parent QWidget和flags QWindowFlags,这两个参数由它的所有后代共享。小部件的父部件拥有该小部件,当父部件被销毁时,子部件在其父部件被销毁时被销毁,并且其几何形状通常受到其父部件的几何形状的限制。如果父控件是None或者没有提供父控件,则小部件归应用程序的QApplication对象所有,并且是一个顶级小部件,即一个窗口。如果窗口显示,参数flags控制部件的各种属性;通常,默认值 0 是正确的选择。
通常,您会像这样构造一个QWidget:
widget = QWidget()
或者
widget = QWidget(some_parent)
一个QWidget经常被用来创建一个顶层窗口,因此:
qt_app = QApplication(sys.argv)
#创建一个小部件
widget = QWidget()
#将其显示为独立的 widget
widget.show()
#运行应用程序的事件循环
qt_app.exec_()
QWidget类有许多方法,但大多数方法在另一个小部件的上下文中讨论更有用。然而,我们很快就会用到的一个方法是setMinimumSize方法,它接受一个QtCore.QSize作为它的参数;一个QSize代表一个小部件的二维(宽×高)像素度量。
widget.setMinimumSize(QSize(800, 600))
另外一个可以被所有 widgets 使用的QWidget方法是setWindowTitle;如果小部件显示为顶层窗口,这将设置其标题:
widget.setWindowTitle('I Am A Window!')
QLabel
我们已经在“你好,世界!”中使用了一个QLabel应用程序,但我们将仔细研究它。它主要用于显示纯文本或富文本、静态图像或视频,通常是非交互式的。
它有两个类似的构造函数,一个与QWidget相同,另一个采用一个text unicode 字符串来指定显示的文本:
label = QLabel(parent_widget)
或者
label = QLabel('Hello, world!', parent_widget)
默认情况下,标签的内容靠左对齐,但是可以使用QLabel的setAlignment方法将其更改为任意的PySide.QtCore.Qt.Alignment,如下所示:
label.setAlignment(Qt.AlignCenter)
您也可以使用QLabel的setIndent方法设置缩进;缩进是从内容对齐的一侧以像素为单位指定的;例如,如果对准是Qt.AlignRight,缩进将从右边开始。
要在QLabel中换行,请使用QLabel.setWordWrap(True);称之为“T2”式的文字转换。
A QLabel有更多的方法,但这是一些最基本的。
更高级的“你好,世界!”
既然我们已经研究了QWidget类及其后代QLabel,我们可以对我们的“Hello,world!”更能说明 Python/Qt 编程的应用程序。
上次我们只是为小部件创建了全局变量,我们将把窗口的定义封装在一个继承自QLabel的新类中。在这种情况下,这似乎有点枯燥,但是我们将在后面的例子中扩展这个概念。
# Remember that we're omitting the import
# section from our examples for brevity
#创建 QA application 对象
Qt _ app = QA application(sys . argv)
class HelloWorldApp(QLabel):
' ' '一个显示文本“Hello,world!”' '
def __init__(self):
#将对象初始化为 QLabel
QLabel。__init__(self,“你好,世界!”)
#设置大小、对齐方式和标题
self . Set minimumsize(QSize(600,400))
self.setAlignment(Qt。
self.setWindowTitle('你好,世界!')
def run(self):
' ' '显示应用程序窗口并启动主事件循环' ' ' '
self.show()
qt_app.exec_()
#创建应用程序的实例并运行它
HelloWorldApp()。run()
到目前为止,我们已经准备好在下一期中进行一些真正的内容,在下一期中,我们将讨论更多的小部件、布局容器的基础以及信号和插槽,它们是 Qt 允许应用程序响应用户动作的方式。
Python GUI 开发概述(Hello World)
原文:https://www.pythoncentral.io/introduction-python-gui-development/
Python 非常适合各种跨平台应用程序的快速开发,包括桌面 GUI 应用程序。然而,在开始用 Python 开发 GUI 应用程序时,需要做出一些选择,本文提供了在正确的道路上出发所需的信息。我们将讨论 Python 有哪些重要的 GUI 工具包,它们的优点和缺点,并为每个工具包提供一个简单的演示应用程序。
演示“hello world”应用程序概述
这个演示应用程序很简单:一个包含组合框的窗口,显示“hello”、“goodbye”和“heyo”选项;可以在其中输入自由文本的文本框;以及一个按钮,当单击该按钮时,将打印由组合框和文本框的值组合而成的问候语,例如“Hello,world!”—到控制台。以下是示例应用程序的模型:

注意,这里讨论的所有工具包都适用于我们的简单应用程序的类似面向对象的方法;它是从顶级 GUI 对象(如应用程序、窗口或框架)继承的对象。应用程序窗口由一个垂直布局小部件填充,它管理控件小部件的排列。Python 的其他 GUI 工具包,如早已过时的 pyFLTK 或简单的 easygui,采用了不同的方法,但这里讨论的工具包代表了 Python GUI 库开发的主流。
我试图为每个工具包提供惯用的代码,但是我对其中的一些并不精通;如果我做了任何可能误导新开发人员的事情,请在评论中告诉我,我会尽最大努力更新示例。
选择 Python GUI 工具包
有几个工具包可用于 Python 中的 GUI 编程;有几个是好的,没有一个是完美的,它们是不等价的;有些情况下,一个或多个优秀的工具包并不合适。但是选择并不困难,对于许多应用程序来说,您选择的任何 GUI 工具包都可以工作。在下面的工具包部分中,我试图诚实地列出每种工具的缺点和优点,以帮助您做出明智的选择。
一个警告:网上可获得的许多信息——例如,在 Python wiki 的 GUI 文章或 Python 2.7 FAQ 中——都是过时的和误导的。这些页面上的许多工具包已经有五年或更长时间没有维护了,其他的则太不成熟或没有正式的使用记录。另外,不要使用我见过到处流传的选择你的 GUI 工具包页面;它的加权代码使得除了 wxPython 之外几乎不可能选择任何东西。
我们将看看四个最流行的 Python GUI 工具包:TkInter、wxPython、pyGTK/PyGobject 和 PyQt/PySide。
TkInter
TkInter 是 Python GUI 世界的元老,几乎从 Python 语言诞生之日起,它就与 Python 一起发布了。它是跨平台的,无处不在的,稳定可靠,易于学习,它有一个面向对象的,出色的 Pythonic API,它可以与所有 Python 版本一起工作,但它也有一些缺点:
对主题化的有限支持
在 Python 2.7/3.1 之前,TkInter 不支持主题化,所以在每个平台上,它的定制窗口小部件看起来都像 1985 年左右的 Motif。从那以后,ttk 模块引入了主题窗口小部件,这在一定程度上改善了外观,但保留了一些非正统的控件,如 OptionMenus。
小部件精选
Tkinter 缺少其他工具包提供的一些小部件,比如非文本列表框、真正的组合框、滚动窗口等等。一些额外的控制由第三方提供,例如 Tix 来弥补不足。如果您考虑使用 TkInter,请提前模拟您的应用程序,并确保它可以提供您需要的所有控件,否则您可能会在以后受到伤害。
Tkinter 中的演示应用程序/Hello World
import Tkinter as tk
类示例 App(tk。frame):
' ' ' TkInter 的一个应用实例。实例化
并调用 run 方法运行。'
def __init__(self,master):
#使用父级的构造函数
tk.Frame 初始化窗口. __init__(self,
master,
width=300,
height=200)
#设置标题
self.master.title('TkInter 示例')
#这允许大小规范生效
self.pack_propagate(0)
#我们将使用灵活的包装布局管理器
self.pack()
#问候语选择器
#使用 StringVar 访问选择器的值
self.greeting_var = tk。string var()
self . greeting = tk。OptionMenu(self,
self.greeting_var,
'你好',
'再见',
' heyo ')
self . greeting _ var . set('你好')
#收件人文本输入控件及其 string var
self . recipient _ var = tk。string var()
self . recipient = tk。Entry(self,
text variable = self . recipient _ var)
self . recipient _ var . set(' world ')
go 按钮
self.go_button = tk。按钮(self,
text='Go ',
command=self.print_out)
#将控件放在表单
self.go_button.pack(fill=tk。x,边=tk。BOTTOM)
self . greeting . pack(fill = tk。x,边=tk。TOP)
self . recipient . pack(fill = tk。x,边=tk。顶部)
def print_out(self):
' ' '打印从用户
的选择中构造的
的问候语'【T3]打印(' %s,%s!'% (self.greeting_var.get()。title(),
self . recipient _ var . get())
def Run(self):
' ' '运行应用' ' ' '
self.mainloop()
app = ExampleApp(tk。tk()
app . run()
wxPython
注意,在撰写本文时,wxPython 仅适用于 Python 2.x
Python 的创始人吉多·范·罗苏姆这样评价 wxPython:
wxPython 是最好、最成熟的跨平台 GUI 工具包,但有许多限制。wxPython 不是标准 Python GUI 工具包的唯一原因是 Tkinter 先出现了。
至少,他说过一次,很久以前;吉多·范·罗苏姆到底做了多少 GUI 编程呢?
无论如何,wxPython 确实有很多优点。它有大量的小部件,在 Windows、Linux 和 OS X 上的本地外观和感觉,以及足够大的用户群,至少那些明显的错误已经被发现了。它不包含在 Python 中,但是安装很容易,并且它适用于所有最新的 Python 2.x 版本;wxPython 可能是目前最流行的 Python GUI 库。
尽管它并不完美;它的文档非常糟糕,尽管这个示范性的演示应用程序本身就是无价的文档,但它却是你能得到的所有帮助。我个人觉得 API 不和谐,令人不快,但其他人不同意。尽管如此,你几乎不会在使用 wxPython 的项目中发现它不能做你需要的事情,这是对它的一个很大的推荐。
wxPython 中的演示应用程序/Hello World
[python]
import wx
class ExampleApp(wx。frame):
def _ _ init _ _(self):
每个 wx 应用程序必须创建一个应用程序对象
才能使用 wx 做任何其他事情。
self.app = wx。应用程序()
设置主窗口
wx.Frame.init(self,
parent=None,
title='wxPython Example ',
size=(300,200))
可用的问候语
self.greetings = ['hello ',' goodbye ',' heyo']
布局面板和 hbox
self.panel = wx。Panel(self,size=(300,200))
self.box = wx。BoxSizer(wx。垂直)
Greeting 组合框
self.greeting = wx。ComboBox(parent=self.panel,
value='hello ',
size=(280,-1),
choices=self.greetings)
将问候语组合添加到 hbox
self . box . Add(self . greeting,0,wx。TOP)
self.box.Add((-1,10))
收件人条目
self.recipient = wx。TextCtrl(parent=self.panel,
size=(280,-1),
value='world ')
将问候语组合添加到 hbox
self . box . Add(self . recipient,0,wx。顶部)
添加填充以降低按钮位置
self.box.Add((-1,100))
go 按钮
self.go_button = wx。按钮(self.panel,10,'& Go ')
为按钮
自身绑定一个事件。绑定(wx。EVT _ 按钮,自我.打印 _ 结果,自我.去 _ 按钮)
使按钮成为表单
self.go_button 的默认动作。SetDefault()
将按钮添加到 hbox
self . box . Add(self . go _ button,0,flag=wx。ALIGN_RIGHT|wx。底部)
告诉小组使用 hbox
self . panel . set sizer(self . box)
def print_result(self,*args):
' ' '打印从
用户所做的选择中构造的问候语'
打印(' %s,%s!'% (self.greeting.GetValue()。title(),
self.recipient.GetValue()))
def run(self):
' ' '运行 app ' '
self。Show()
self.app.MainLoop()
实例化并运行
app = example app()
app . run()
[/python]
pyGTK/pyGobject
pyGTK 是一个基于 GTK+ 的跨平台小部件工具包,GTK+ 是一个广泛使用的 GUI 工具包,最初是为图像处理程序 GIMP 开发的。pyGobject 是 pyGTK 的新版本,它使用 Gobject 内省并支持 GTK3 的特性。这两个版本的 API 密切相关,它们的功能和缺点也相似,因此对于我们的目的来说,可以将它们视为一体。pyGTK 的开发者推荐使用 pyGobject 进行新的开发。
pyGTK 只在 Windows 和 Linux 上使用本地小部件。虽然 GTK+支持本地窗口部件和 OS X 窗口,但 pyGTK 仍在开发中;目前,它在 Mac 上的外观和感觉模仿了 Linux。然而,小部件是主题化的,有大量非常吸引人的主题。pyGTK 在 Python 2.x 上也是最成功的;新版本开始支持 Python 3,但并不完整,尤其是在 Windows 上。安装 Windows 以前需要从不同的来源下载多个软件包,但最近一体化的二进制安装程序已经可用。
从积极的一面来看,pyGTK 是稳定的,经过良好的测试,并有一个完整的小部件选择。它还有出色的文档,如果你喜欢这类东西,还有一个出色的可视化 GUI 生成器,叫做 Glade 。它的 API 简单明了,大部分都很简单,只有少数例外,并且有相当好的示例代码。pyGTK 的底线是:它是一个可靠且功能强大的 GUI 工具包,但存在跨平台不一致的问题,并且不如其他同样优秀的替代产品受欢迎。
关于选择 pyGTK 的一个特别注意事项:如果你的应用程序涉及各种简单的、基于文本的列表框,pyGTK 的设计将会引起问题。与其他工具包相比,它严格的关注点分离和模型-视图-控制器划分使得列表框的开发异常复杂。当我刚接触 Python GUI 开发时,没有注意到这一点使我在一个重要的项目上落后了很多。
pyGTK/pyGobject 中的演示应用程序/Hello World
import gtk
class ExampleApp(gtk。window):
' ' ' pyGTK 的一个示例应用。实例化
并调用 run 方法运行。'
def __init__(self):
#初始化窗口
GTK . window . _ _ init _ _(self)
self . set _ title(' pyGTK Example ')
self . set _ size _ request(300,200)
self.connect('destroy ',gtk.main_quit)
#垂直构造布局
self.vbox = gtk。VBox()
#问候语选择器-注意使用便利的
# type ComboBoxText 如果可用,否则便利的
# function combo_box_new_text,后者已被弃用
if (gtk.gtk_version[1] > 24 或
(gtk.gtk_version[1] == 24 和 GTK . GTK _ version[2]>10)):
self . greeting = GTK。combobox text()
else:
self . greeting = gtk . combo _ box _ new _ text()
#修复方法名以匹配 GTK。combobox text
self . greeting . append = self . greeting . append _ text
#添加问候语
地图(self.greeting.append,['hello ',' goodbye ',' heyo'])
#收件人文本输入控件
self.recipient = gtk。entry()
self . recipient . set _ text(' world ')
go 按钮
self.go_button = gtk。按钮(' _Go')
#连接 Go 按钮的回调
self . Go _ button . Connect(' clicked ',self.print_out)
#将控件置于垂直布局
self . vbox . pack _ start(self . greeting,False)
self . vbox . pack _ start(self . recipient,False)
self . vbox . pack _ end(self . go _ button,False)
#将垂直布局添加到主窗口
self.add(self.vbox)
def print_out(self,*args):
' ' '打印从
用户所做的选择中构造的问候语'
打印(' %s,%s!'%(self . greeting . get _ active _ text()。title(),
self . recipient . get _ text())
def Run(self):
' ' '运行 app'
self.show_all()
gtk.main()
app = example app()
app . run()
PyQt/PySide
Qt 不仅仅是一个小部件工具包;它是一个跨平台的应用程序框架。PyQt,它的 Python 接口,已经存在好几年了,而且稳定成熟;随着 API 1 和 API 2 这两个可用 API 的出现,以及大量不推荐使用的特性,它在过去几年中已经有了一些改进。此外,即使 Qt 可以在 LGPL 下获得,PyQt 也是在 GNU GPL 版本 2 和 3 或相当昂贵的商业版本下获得许可的,这限制了您对代码的许可选择。
PySide 是对 PyQt 弊端的回应。它是在 LGPL 下发布的,省略了 PyQt 4.5 之前的所有不推荐使用的特性以及整个 API 1,但在其他方面几乎与 PyQt API 2 完全兼容。它比 PyQt 稍不成熟,但开发得更积极。
无论您选择哪种包装器,Python 和 Qt 都能完美地配合工作。更现代的 API 2 是相当 Pythonic 化和清晰的,有非常好的文档可用(尽管它的根源在 C++ Qt 文档中是显而易见的),并且产生的应用程序在最近的版本中看起来很棒,如果不是非常原生的话。这里有您可能想要的每一个 GUI 小部件,Qt 提供了更多——处理 XML、多媒体、数据库集成和网络的有趣类——尽管对于大多数额外的功能,您可能最好使用等效的 Python 库。
使用 Qt 包装器的最大缺点是底层 Qt 框架非常庞大。如果您的可分发包很小对您很重要,那么选择 TkInter,它不仅很小,而且已经是 Python 的一部分。此外,虽然 Qt 使用操作系统 API 来使其小部件适应您的环境,但并不是所有的部件都是严格的原生部件;如果原生外观是您的主要考虑因素,wxPython 将是更好的选择。但是 PyQt 有很多优点,当然值得考虑。
PyQt/PySide 的演示应用程序/Hello World
注意:对于 Qt,我用过 PySide 示例代码将使用 PyQt 运行,只有几行不同。
import sys
from PySide.QtCore import *
from PySide.QtGui import *
class ExampleApp(QDialog):
' ' '一个 PyQt 的示例应用。实例化
并调用 run 方法运行。'
def __init__(self):
#创建一个 Qt 应用程序——每个 PyQt 应用程序都需要一个
self . Qt _ app = QA application(sys . argv)
#可用的问候语
self.greetings = ['hello ',' goodbye ',' heyo']
#调用当前对象上的父构造函数
QDialog。__init__(自身,无)
#设置窗口
self.setWindowTitle('PyQt 示例')
self.setMinimumSize(300,200)
#添加垂直布局
self.vbox = QVBoxLayout()
#问候语组合框
self . greeting = QComboBox(self)
#添加问候语
列表(map(self.greeting.addItem,self.greetings))
#收件人文本框
self . recipient = QLineEdit(' world ',self)
# Go 按钮
self . Go _ button = q push button(&Go ')
#将 Go 按钮连接到其回调
self . Go _ button . clicked . Connect(self . print _ out)
#将控件添加到垂直布局中
self . vbox . Add widget(self . greeting)
self . vbox . Add widget(self . recipient)
#一个非常有弹性的间隔符,用于将按钮压到底部
self . vbox . Add stretch(100)
self . vbox . Add widget(self . go _ button)
#使用当前窗口的垂直布局
self.setLayout(self.vbox)
def print_out(self):
' ' '打印由用户选择的
构建的问候语'
打印(' %s,%s!'%(self . greetings[self . greeting . current index()]。title(),
self.recipient.displayText()))
def run(self):
' ' '运行应用程序并显示主窗体'
self . show()
self . Qt _ app . exec _()
app = example app()
app . run()
Python 类介绍(第 2 部分,共 2 部分)
原文:https://www.pythoncentral.io/introduction-to-python-classes-part-2-of-2/
在本系列的第一部分中,我们看了在 Python 中使用类的基础知识。现在我们来看看一些更高级的主题。
Python 类继承
Python 类支持继承,这让我们获得一个类定义并扩展它。让我们创建一个继承(或从第一部分中的例子派生出)的新类:
class Foo:
def __init__(self, val):
self.val = val
def printVal(self):
print(self.val)
类 derived Foo(Foo):
def negate val(self):
self . val =-self . val
这定义了一个名为DerivedFoo的类,它拥有Foo类所拥有的一切,还添加了一个名为negateVal的新方法。这就是它的作用:
>>> obj = DerivedFoo(42)
>>> obj.printVal()
42
>>> obj.negateVal()
>>> obj.printVal()
-42
当我们重新定义(或覆盖)一个已经在基类中定义的方法时,继承变得非常有用:
class DerivedFoo2(Foo):
def printVal(self):
print('My value is %s' % self.val)
我们可以按如下方式测试该类:
>>> obj2 = DerivedFoo2(42)
>>> obj2.printVal()
My value is 42
派生类重新定义了printVal方法来做一些不同的事情,每当调用printVal时都会使用这个新版本。这让我们可以改变类的行为,这通常是我们想要的(因为如果我们想要原始的行为,我们只需要使用原始的类)。注意,该方法的新版本调用旧版本,并且调用以基类的名称为前缀(否则 Python 会认为您调用的是新版本)。
Python 提供了几个函数来帮助您确定一个对象是什么类:
- 检查一个对象是否是指定类的一个实例,或者是一个派生类。
例如以下内容:
>>> print(isinstance(obj, Foo))
True
>>> print(isinstance(obj, DerivedFoo))
True
>>> print(isinstance(obj, DerivedFoo2))
False
- 检查一个类是否派生自另一个类
例如以下内容:
>>> print(issubclass(DerivedFoo, Foo))
True
>>> print(issubclass(int, Foo))
False
Python 类迭代器和生成器
Python 的for语句将循环遍历任何可迭代的,包括内置的数据类型,如数组和字典。例如:
>>> arr = [1,2,3]
>>> for x in arr:
... print(x)
1
2
3
当我们定义自己的类时,我们可以使它们可迭代,这将允许它们在 for 循环中工作。我们通过定义一个返回一个迭代器(一个跟踪我们在循环中的位置的对象)的__iter__方法和一个返回下一个可用值的__next__方法来实现这一点。请注意,Python 3.x 和 Python 2.x 的next方法的语法是不同的。对于 Python 3.x,您必须使用__next__方法,而对于 Python 2.x,您必须使用next方法。
这里有一个简单的例子,可以让你在一个数据结构上向后迭代。下面是类的定义:
[python]
class Backwards:
def init(self, val):
self.val = val
self.pos = len(val)
def iter(self):
回归自我
def next(self):
如果 self.pos < = 0:
提升 StopIteration,我们就完成了
self.pos = self.pos - 1
return self.val[self.pos]
[/python]
[python]
class Backwards:
def init(self, val):
self.val = val
self.pos = len(val)
def iter(self):
回归自我
def next(self):
我们完成了
如果 self.pos < = 0:
提高 StopIteration
self.pos = self.pos - 1
return self.val[self.pos]
[/python]
这是一个迭代类的例子:
>>> for x in Backwards([1,2,3]):
... print(x)
3
2
1
该类跟踪两件事,被迭代的数据结构和下一个要返回的值。__iter__方法只是返回对对象本身的引用,因为这是用来管理循环的。当 Python 遍历对象时,它会重复调用next方法来获取下一个值,直到没有剩余值时抛出StopIteration异常。
这是一个非常简单的例子,但是它的大部分是锅炉板代码(获取每一项并跟踪我们在循环中的进度),每次我们想要创建一个 iterable 类时都是一样的。然而,Python 又一次拯救了我们,它给我们提供了一种方法,使用生成器来消除所有这些重复的管理代码。
一个生成器是一种特殊的函数,它返回一个 iterable 对象,这个对象自动地记住它在一个循环中的位置。这是同一个例子,这次使用了一个发生器。
该功能可定义如下(注意:使用yield关键字):
def backwards(val):
for n in range(len(val), 0, -1):
yield val[n-1]
我们可以这样使用发电机:
>>> for x in backwards([1,2,3]):
... print(x)
3
2
1
如果你以前从未见过这种事情,你可能真的很难理解它,但是最简单的方法就是像这样阅读backwards函数:
- 在传入的值上向后循环。
- 在每一遍中,
yield下一个值,即暂时停止执行循环,并将下一个值返回给调用者。它做它想做的任何事情,然后当它再次调用我们时,我们从我们停止的地方继续循环。
作为对象的 Python 类
一个类描述了该类的实例看起来像什么,也就是说,它们将有什么方法和成员变量。在内部,Python 在自己的对象中跟踪每个类的定义,我们可以修改这个对象。这意味着我们可以动态地改变类的定义,甚至在运行时创建一个全新的类!
让我们从一个简单的类定义开始:
class Foo:
def __init__(self, val):
self.val = val
让我们来看看用法:
>>> obj = Foo(42)
>>> obj.printVal()
AttributeError: Foo instance has no attribute 'printVal'
哎呀!我们得到一个错误,因为这个类没有一个printVal方法。
好了,再加一个:-)。我们可以这样定义它:
def printVal(self):
print(self.val)
我们可以将函数添加到类中,如下所示:
>>> Foo.printVal = printVal
>>> obj.printVal()
42
我们定义了一个名为 printVal 的方法,它是独立的(也就是说,它是在类之外定义的),但是它看起来像一个类方法(也就是说,它有一个 self 参数)。然后,我们将它添加到类定义(Foo.printVal = printVal)中,这使得它变得可用,就好像它是原始类定义的一部分一样。
如果我们想删除它,我们可以使用普通的del语句:
>>> del Foo.printVal
>>> obj.printVal()
AttributeError: Foo instance has no attribute 'printVal'
为了在运行时创建一个全新的类,我们使用了type方法:
>>> obj = MyNewClass()
NameError: name 'MyNewClass' is not defined
>>> MyNewClass = type('MyNewClass', (object,), dict())
>>> obj = MyNewClass()
>>> print(obj)
<__main__.MyNewClass object at 0x01D79DCC>
type调用的第二个参数是我们想要从中派生的类的列表,而第三个参数是组成类定义的方法和成员变量的字典(您可以在这里定义它们,或者如上所述动态添加它们)。
要理解 Python 中的生成器和 yield 关键字,请查看文章 Python 生成器和 yield 关键字。
Python 类简介(第 1 部分,共 2 部分)
原文:https://www.pythoncentral.io/introduction-to-python-classes/
类是一种将相关信息组合成一个单元的方式(也称为对象,以及可以被调用来操作该对象的函数(也称为方法)。例如,如果您想跟踪一个人的信息,您可能想记录他们的姓名、地址和电话号码,并且能够将所有这些作为一个单元来操作。
Python 有一种稍微特殊的处理类的方式,所以即使你熟悉像 C++或 Java 这样的面向对象的语言,深入研究 Python 类仍然是值得的,因为有一些东西是不同的。
在我们开始之前,理解类和对象之间的区别是很重要的。一个类仅仅是对事物应该是什么样子,什么变量将被分组在一起,以及什么函数可以被调用来操纵这些变量的描述。使用这个描述,Python 可以创建这个类的许多实例(或对象),然后可以独立操作这些实例。把一个类想象成一个 cookie cutter——它本身并不是一个 cookie,但是它描述了一个 cookie 的样子,可以用来创建许多单独的 cookie,每个 cookie 都可以单独食用。好吃!
定义一个 Python 类
让我们从定义一个简单的类开始:
class Foo:
def __init__(self, val):
self.val = val
def printVal(self):
print(self.val)
这个类被称为Foo,像往常一样,我们使用缩进来告诉 Python 类定义在哪里开始和结束。在这个例子中,类定义由两个函数定义(或者说方法)组成,一个叫做__init__,另一个叫做printVal。还有一个成员变量,没有明确定义,但我们将在下面解释它是如何创建的。

The diagram shows what the class definition looks like - 2 methods and 1 member variable. Using this definition, we can then create many instances of the class.
可以看到这两种方法都采用了一个名为self的参数。它没有有可以被称为self,但这是 Python 的惯例,虽然你可以称它为this或me或其他什么,但如果你称它为self之外的任何东西,你会惹恼其他 Python 程序员,他们将来可能会看你的代码。因为我们可以创建一个类的许多实例,当调用一个类方法时,它需要知道它正在处理哪个实例,这就是 Python 将通过self参数传入的内容。
__init__是一个特殊的方法,每当 Python 创建一个新的类实例(即使用 cookie cutter 创建一个新的 cookie)时,都会调用这个方法。在我们的例子中,它接受一个名为val的参数(而不是强制 self ),并在一个成员变量中复制一个参数,也称为val。与其他语言不同,在其他语言中,变量必须在使用前定义,Python 在第一次赋值时动态创建变量,类成员变量也不例外。为了区分作为参数传入的val变量和val类成员变量,我们给后者加上了 self 前缀。所以,在下面的语句中:
self.val = val
self.val指的是属于调用方法的类实例的 val 成员变量,而val指的是传递给方法的参数。
这有点令人困惑,所以让我们来看一个例子:
obj1 = Foo(1)
这将创建我们类的一个实例(即使用 cookie cutter 创建一个新的 cookie)。Python 自动为我们调用__init__方法,传入我们指定的值(1)。所以,我们得到了其中的一个:

我们再创建一个:
【python】
obj 2 = Foo(2)
除了将2传递给__init__方法之外,会发生完全相同的事情。
我们现在有两个独立的对象,val 成员变量有不同的值:

如果我们为第一个对象调用printVal,它将打印出其成员变量的值:
>>> obj1.printVal()
1
如果我们为第二个对象调用printVal,它将打印出的值,它的成员变量:
>>> obj2.printVal()
2
标准 Python 类方法
Python 类有许多标准方法,比如我们在上面看到的__init__,当类的一个新实例被创建时,它会被调用。以下是一些比较常用的方法:
__del__:当一个实例将要被销毁时调用,这允许你做任何清理工作,例如关闭文件句柄或数据库连接__repr__和__str__:都返回对象的字符串表示,但是__repr__应该返回一个 Python 表达式,可以用来重新创建对象。比较常用的是__str__,可以返回任何东西。__cmp__:调用比较对象与另一个对象。注意,这只在 Python 2.x 中使用,在 Python 3.x 中,只使用了丰富的比较方法。比如__lt__。__lt__、__le__、__eq__、__ne__、__gt__、__ge__:调用将一个对象与另一个对象进行比较。如果定义了这些函数,它们将被调用,否则 Python 将退回到使用__cmp__。__hash__:调用计算对象的散列,用于将对象放置在数据结构中,如集合和字典。__call__:让一个对象被“调用”,例如,你可以这样写:obj(arg1,arg2,...)。
Python 还允许你定义方法,让一个对象表现得像一个数组(所以你可以这样写:obj[2] = "foo"),或者像一个数字类型(所以你可以这样写:print(obj1 + 3*obj2))。
Python 类示例
下面是一个简单的实例,这个类模拟了一副扑克牌中的一张牌。
[python]
class Card:
Define the suits
DIAMONDS = 1
CLUBS = 2
HEARTS = 3
SPADES = 4
SUITS = {
CLUBS: 'Clubs',
HEARTS: 'Hearts',
DIAMONDS: 'Diamonds',
SPADES: 'Spades'
}
定义特殊牌的名称
值= {
1: 'Ace ',
11: 'Jack ',
12: 'Queen ',
13: 'King'
}
def init(self,suit,value):
保存花色和卡值
self.suit =花色
self.value =值
def lt(self,other):
将该卡与另一张卡进行比较
(如果我们较小,则返回 True;如果
较大,则返回 false;如果我们相同,则返回 0)
如果 self.suit < other.suit:
返回 True
elif self . suit>other . suit:
返回 False
if self.value < other.value:
返回 True
elif self . value>other . value:
返回 False
返回 0
def str(self):
如果 self.value 在 self 中,则返回 self 的字符串描述
。值:
buf = self。VALUES[self . value]
else:
buf = str(self . value)
buf = buf+' of '+self。套装
return buf
[/python]
[python]
class Card:
Define the suits
DIAMONDS = 1
CLUBS = 2
HEARTS = 3
SPADES = 4
SUITS = {
CLUBS: 'Clubs',
HEARTS: 'Hearts',
DIAMONDS: 'Diamonds',
SPADES: 'Spades'
}
定义特殊牌的名称
值= {
1: 'Ace ',
11: 'Jack ',
12: 'Queen ',
13: 'King'
}
def init(self,suit,value):
保存花色和卡值
self.suit =花色
self.value =值
def cmp(self,other):
将该牌与另一张牌进行比较
(如果我们较小则返回< 0,>如果
较大则返回> 0,如果我们相同则返回 0)
如果 self . suit<other . suit:
return-1
elif self . suit>other . suit:
return 1
elif self . value<other . value:
return-1
Eli
def str(self):
如果 self.value 在 self 中,则返回 self 的字符串描述
。值:
buf = self。VALUES[self . value]
else:
buf = str(self . value)
buf = buf+' of '+self。套装
return buf
[/python]
我们首先定义一些类常量来表示每种服装,并定义一个查找表,以便于将它们转换成每种服装的名称。我们还为特殊牌(a、j、q 和 k)的名称定义了一个查找表。
构造函数或__init__方法接受两个参数,suit 和 value,并将它们存储在成员变量中。
每当 Python 想要将一个Card对象与其他对象进行比较时,就会调用特殊的 cmp 方法。约定是,如果一个对象小于另一个对象,则该方法应该返回负值,如果大于另一个对象,则返回正值,如果两者相同,则返回零。注意,传入进行比较的另一个对象可以是任何类型,但是为了简单起见,我们假设它也是一个Card对象。
每当 Python 想要打印出一个Card对象时,就会调用特殊的__str__方法,因此我们返回一个人类可读的卡片表示。
下面是实际运行的类:
>>> card1 = Card(Card.SPADES, 2)
>>> print(card1)
2 of Spades
>>> card2 = Card(Card.CLUBS, 12)
>>> print(card2)
Queen of Clubs
>>> print(card1 > card2)
True
注意,如果我们没有定义一个自定义的__str__方法,Python 将会给出自己的对象表示,如下所示:
<__main__.Card instance at 0x017CD9B8>
所以,你可以明白为什么总是提供你自己的__str__方法是个好主意。🙂
私有 Python 类方法和成员变量
在 Python 中,方法和成员变量总是公共的,即任何人都可以访问它们。这对于封装来说不是很好(类方法应该是唯一可以改变成员变量的地方,以确保一切都保持正确和一致),所以 Python 有一个约定,以下划线开头的类方法或变量应该被认为是私有的。然而,这只是一个惯例,所以如果你真的想在课堂上胡闹,你可以,但是如果事情发生了,你只能怪你自己!
以两个下划线开头的类方法和变量名被认为是该类的私有,即一个派生类可以定义一个相似命名的方法或变量,它不会干扰任何其他定义。同样,这仅仅是一个约定,所以如果你决定要查看另一个类的私有部分,你可以这样做,但是这样可以防止名字冲突。
我们可以利用 Python 类的“一切都是公共的”特性来创建一个简单的数据结构,将几个变量组合在一起(类似于 C++ POD 或 Java POJO):
class Person
# An empty class definition
pass
>>> someone = Person()
>>> someone.name = 'John Doe'
>>> someone.address = '1 High Street'
>>> someone.phone = '555-1234'
我们创建一个空的类定义,然后利用 Python 会在首次分配成员变量时自动创建成员变量这一事实。
使用 Boto 在 AWS 上介绍 Python
原文:https://www.pythoncentral.io/introduction-to-python-on-aws-with-boto/
亚马逊网络服务为我们提供了廉价、便捷的云计算基础设施。那么我们如何在上面运行 Python 呢?
在 Amazon EC2 上设置 Python
EC2 是亚马逊的弹性计算云。它是用于在 AWS 上创建和操作虚拟机的服务。您可以使用 SSH 与这些机器进行交互,但是使用设置为 web 应用程序的 IPython HTML Notebook 要好得多。
您可以手动设置 IPython 笔记本服务器,但是有几个更简单的选项。
- NotebookCloud 是一个简单的 web 应用程序,使您能够从浏览器创建 IPython 笔记本服务器。它真的很容易使用,而且免费。
- 来自麻省理工学院的 StarCluster 是一个与亚马逊合作的更强大的库,它使用配置文件来简化创建、复制和共享云配置。它支持 IPython 开箱即用,并且在线提供了额外的配置文件。
两个选项都是开源的。
您不需要使用 IPython 或 Amazon EC2 来使用 AWS,但是这样做有很多好处。
无论您是在 EC2 上运行您的机器,还是只想使用普通机器上的一些服务,您通常都需要一种方法让您的程序与 AWS 服务器进行对话。
Python Boto 库
AWS 有一个广泛的 API,允许你编程访问每一个服务。有很多库可以使用这个 API,对于 Python,我们有 boto。
Boto 为几乎所有的亚马逊网络服务以及其他一些服务提供了一个 Python 接口,比如 Google Storage。Boto 是成熟的、有据可查的、易于使用的。
要使用 Boto,您需要提供您的 AWS 凭证,特别是您的访问密钥和秘密密钥。这些可以在每次连接时手动提供,但是将它们添加到 boto 配置文件更容易,这样 boto 就可以自动提供密钥。
如果您希望为您的 boto 设置使用一个配置,您需要在~/.boto 下创建一个文件。如果您希望在整个系统范围内使用这个配置,您应该在/etc/boto.cfg 下创建这个文件。ini 格式,至少应该包含一个凭据部分,如下所示:
[Credentials] aws_access_key_id = <your access key> aws_secret_access_key = <your secret key>
您可以通过创建连接对象来使用 boto,这些对象表示到服务的连接,然后与这些连接对象进行交互。
from boto.ec2 import EC2Connection
conn = EC2Connection()
注意,如果没有在配置文件中设置 AWS 键,您需要将它们传递给任何连接构造函数。
conn = EC2Connection(access_key, secret_key)
创建您的第一台 Amazon EC2 机器
现在,您有了一个连接,您可以使用它来创建一个新机器。您首先需要创建一个安全组,允许您访问您在该组中创建的任何机器。
group_name = 'python_central'
description = 'Python Central: Test Security Group.'
group = conn . create _ security _ group(
group _ name,description
)
group.authorize('tcp ',8888,8888,'[0 . 0 . 0 . 0/0【T1 ')](http://0.0.0.0/0)
现在您有了一个组,您可以使用它创建一个虚拟机。为此,您需要一个 AMI,一个 Amazon 机器映像,这是一个基于云的软件发行版,您的机器将使用它作为操作系统和堆栈。我们将使用 NotebookCloud 的 AMI,因为它是可用的,并且已经用一些 Python 好东西进行了设置。
我们需要一些随机数据来为该服务器创建自签名证书,这样我们就可以使用 HTTPS 来访问它。
import random
from string import ascii_lowercase as letters
#以正确的格式创建随机数据
data = random.choice(('UK ',' US'))
对于范围(4)中的 a:
data+= ' | '
对于范围(8)中的 b:
data+= random . choice(letters)
我们还需要创建一个散列密码来登录服务器。
import hashlib
#您选择的密码放在这里
password = 'password '
h = hashlib . new(' sha1 ')
salt =(' % 0 '+str(12)+' x ')% random . getrandbits(48)
h . update(password+salt)
密码= ':'。join(('sha1 ',salt,h.hexdigest()))
现在,我们将散列密码添加到数据字符串的末尾。当我们创建一个新的虚拟机时,我们将把这个数据字符串传递给 AWS。机器将使用字符串中的数据创建一个自签名证书和一个包含您的散列密码的配置文件。
data += '|' + password
现在,您可以创建服务器了。
# NotebookCloud AMI
AMI = 'ami-affe51c6'
conn.run_instances(
AMI,
instance_type = 't1.micro ',
security _ groups =[' python _ central '],
user_data = data,
max_count = 1
)
要在线查找服务器,您需要一个 URL。你的服务器需要一两分钟的时间来启动,所以这是一个休息和烧水的好时机。
要获得 URL,我们只需轮询 AWS,看看服务器是否已经分配了公共 DNS 名称。以下代码假设您刚刚创建的实例是您的 AWS 帐户上的唯一实例。
import time
while True:
inst =[
I for r in conn . get _ all _ instances()
for I in r . instances
][0]
dns = inst。__dict__['公共域名']
如果 dns:
#我们希望这个实例 id 用于以后的
instance _ id = I . _ _ dict _ _[' id ']
中断
time.sleep(5)
现在,将 dns 名称转换成正确的 URL,并让浏览器指向它。
print('https://{}:8888'.format(dns))
现在,您应该自豪地拥有了一台全新的 IPython HTML 笔记本服务器。请记住,您需要上面提供的密码才能登录。
如果您想终止实例,您可以使用下面的代码行轻松完成。请注意,要做到这一点,您需要实例 id。如果遇到问题,您可以随时访问 AWS 控制台,并在那里控制您的所有实例。
conn.terminate_instances(instance_ids=[instance_id])
玩得开心!
Python 正则表达式简介
原文:https://www.pythoncentral.io/introduction-to-python-regular-expressions/
在 Python 中,在一个字符串中搜索另一个字符串相当容易:
>>> str = 'Hello, world'
>>> print(str.find('wor'))
7
如果我们确切地知道我们要找的是什么,这很好,但是如果我们要找的东西不是那么明确呢?例如,如果我们想搜索一年,那么我们知道这将是一个 4 位数的序列,但我们不知道这些数字将会是什么。这就是正则表达式的用武之地。它们允许我们基于我们所寻找的内容的一般描述来搜索子字符串,例如搜索 4 个连续数字的序列。
在下面的例子中,我们导入了包含 Python 正则表达式功能的re模块,然后用我们的正则表达式(\d\d\d\d)和我们想要搜索的字符串调用search函数:
>>> import re
>>> str = 'Today is 31 May 2012.'
>>> mo = re.search(r'\d\d\d\d', str)
>>> print(mo)
<_sre.SRE_Match object at 0x01D3A870>
>>> print(mo.group())
2012
>>> print('%s %s' % (mo.start(), mo.end())
16 20
在一个正则表达式中,\d表示任意位,所以\d\d\d\d表示任意位,任意位,任意位,或者说白了,连续 4 位。正则表达式大量使用反斜杠,反斜杠在 Python 中有特殊的含义,所以我们在字符串前面加了一个 r 使其成为一个原始字符串,它阻止 Python 以任何方式解释反斜杠。
如果re.search找到匹配我们正则表达式的东西,它返回一个匹配对象,其中保存了关于匹配内容的信息。在上面的例子中,我们打印出匹配的子字符串,以及它在被搜索的字符串中的开始和结束位置。
注意 Python 没有匹配日期(31)。它会匹配前两个字符,即与前两个\d匹配的 3 和 1 ,但是下一个字符(一个空格)不会匹配第三个\d,所以 Python 会放弃并继续搜索字符串的剩余部分。
匹配一组字符
让我们试试另一个例子:
>>> str = 'Today is 2012-MAY-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str)
>>> print(mo.group())
2012-MAY-31
这一次,我们的正则表达式包含新元素[A-Z]。方括号表示与其中一个字符完全匹配。例如,[abc]表示 Python 将匹配一个 a 或 b 或 c ,但不匹配其他字母。由于我们想要匹配 A 和 Z 之间的任何字母,我们可以写出整个字母表([ABCDEFGHIJKLMNOPQRSTUVWXYZ]),但是谢天谢地,Python 允许我们使用连字符([A-Z])来缩短这个字母。所以,我们的正则表达式是\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d,意思是:
- 寻找(或匹配)一个数字(4 次)。
- 匹配一个'-'字符。
- 匹配 A 和 Z 之间的一个字母(三次)。
- 匹配一个'-'字符。
- 匹配一个数字(2 次)。
如上例所示,Python 找到了嵌入在字符串中的日期。
不幸的是,我们的正则表达式目前只处理大写的月份名称:
# The month uses lower-case letters
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str)
>>> print(mo)
None
有两种方法可以解决这个问题。我们可以传入一个标志,表示搜索应该不区分大小写:
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Z][A-Z][A-Z]-\d\d', str, re.IGNORECASE)
>>> print(mo.group())
2012-May-31
或者,我们可以扩展字符集来指定更多的字符:[A-Za-z]表示大写 A 到大写 Z,或者小写 A 到小写 Z 。
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d\d\d\d-[A-Za-z][A-Za-z][A-Za-z]-\d\d', str)
>>> print(mo.group())
2012-May-31
正则表达式的重复
上一个例子中的正则表达式开始变得有点笨拙,所以让我们看看如何简化它。
在正则表达式中,{n}(其中 n 是数字)表示重复前面的元素 n 次。所以我们可以重写这个正则表达式:
\d\d\d\d-[A-Za-z][A-Za-z][A-Za-z]-\d\d
变成这样:
\d{4}-[A-Za-z]{3}-\d{2}
这意味着:
- 匹配任意数字(4 次)。
- 匹配一个'-'字符。
- 匹配字母 A-Z 或 a-z (3 次)。
- 匹配一个'-'字符。
- 匹配任意数字(2 次)。
这就是它的作用:
>>> str = 'Today is 2012-May-31'
>>> mo = re.search(r'\d{4}-[A-Za-z]{3}-\d{2}', str)
>>> print(mo.group())
2012-May-31
当指定应该匹配多少重复时,我们有很大的灵活性。
- 我们可以指定一个范围,例如
{2,4}表示匹配 2 - 4 次重复。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d{2,4}', str)
>>> print(mo.group())
1234
- 我们可以忽略上限值,例如
{2,}表示“匹配 2 次或更多次重复”。
>>> str = "abc12345def"
>>> mo = re.search(r'\d{2,}', str)
>>> print(mo.group())
12345
常见重复的简写
有些类型的重复非常常见,它们有自己的语法。
{1,}表示匹配前一个元素一次或多次,但这也可以用特殊的+操作符来写(例如\d+)。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d+', str)
>>> print(mo.group())
12345
{0,}表示匹配前一个元素零次或多次,但这也可以用*操作符来写(如\d*)。
>>> str = 'abc12345def'
>>> mo = re.search(r'\d*', str)
>>> print(mo.group())
呀,发生什么事了?!为什么这个什么都没打印出来?嗯,你必须小心操作符,因为它会匹配零或更多的重复。在这种情况下,Python 看着被搜索字符串的第一个字符,对自己说这是数字吗?没有。我匹配了零个或多个数字吗?是(零),所以正则表达式已经匹配了。*如果我们看看MatchObject告诉我们的:
>>> print('%s %s' % (mo.start(), mo.end()))
0 0
我们可以看到这正是所发生的,它在被搜索的字符串的最开始匹配了一个空的子字符串。让我们稍微改变一下我们的正则表达式:
>>> str = 'abc12345def'
>>> mo = re.search(r'c\d*', str)
>>> print(mo.group())
c12345
现在我们的正则表达式说匹配字母 c,然后零个或多个数字,这就是 Python 随后找到的。
{0,1}表示匹配前一个元素 0 或 1 次,但这也可以用?操作符来写(如\d?)。
>>> str = 'abc12345def'
>>> mo = re.search(r'c\d?', str)
# Note: the \d was matched 1 time
>>> print(mo.group())
c1
>>> mo = re.search(r'b\d?', str)
# Note: the \d was matched 0 times
>>> print(mo.group())
b
在下一篇文章中,我们将继续讨论正则表达式的更多高级用法。
Python 的 Django 简介
原文:https://www.pythoncentral.io/introduction-to-pythons-django/
什么是 Web 开发
Web 开发是一个宽泛的术语,指的是任何涉及到为互联网或内部网创建网站的工作。web 开发项目的最终产品各不相同,从由静态网页组成的简单站点到与数据库和用户交互的复杂应用程序。web 开发涉及的任务清单包括 web 设计、 web 内容开发、客户端-服务器脚本、 web 服务器和网络配置和电子商务开发。通常,web 开发意味着构建网站的非设计方面:编码。
大型企业通常有数百人在 IT / web 开发部门工作。例如,一所大学经常需要大量的 web 开发人员、图形设计人员、信息系统架构师来处理其庞大的基于 web 的基础设施,以便学生可以注册课程,教授可以上传考试分数等等。相比之下,较小的公司和个人通常需要一两个 web 开发人员和/或图形设计人员来为他们创建网站。
什么是 Web 框架
为了从事 web 开发项目,程序员需要利用众多 web 框架中的一个来编写代码,这些代码专用于作为高效且可伸缩的 web 服务器来管理内容并向最终用户提供服务。
web 框架是一个软件库,旨在帮助任何网站的开发。通过将常见的 web 功能打包到自身中,web 框架允许程序员使用开箱即用的代码和基础结构来创建网站,以便他们可以专注于构建面向业务逻辑的网站功能,而不是反复编写处理常见 web 编程任务的代码。例如,大多数 web 框架为数据库访问、模板引擎和 web 会话管理提供了库。如果没有 web 框架,无论何时开始一个新项目,人们都将被迫编写相同的模板代码来处理这些常见任务。
姜戈是什么
Django 是一个免费的开源 Python web 框架。在 2005 年首次发布后,它作为 web 开发的de-factor框架,越来越受 Python 程序员的欢迎。Django 强调组件的可重用性和可插拔性,这样不同的代码就可以即插即用,形成一个内聚的 web 系统。
Django 宣扬的另一个原则是干(不要重复自己)。 DRY 旨在减少软件开发中各种重复的信息。例如,我们应该将服务器的静态文件夹的地址赋给应用程序的设置文件中定义的一个常量,这样我们就可以在将来轻松地更改它,而不是在代码的任何地方将服务器的静态文件夹写成一个原始字符串。
除了为常见的 web 任务(如数据库交互和会话管理)提供库之外,Django 还提供了一个内置的admin站点,允许网站的程序员和管理员通过 GUI 界面轻松地创建、读取、更新和删除数据库记录。
由 Django 支持的网站
以下是由 Django 支持的网站的非独家列表:
- pinterest.com:图钉板风格的照片分享网站。
- bitbucket.org:代码分享网站。
- instagram.com:照片分享网站。
- addons.mozilla.com:火狐浏览器的插件管理网站。
- disqus.com:社区博客评论托管网站。
如你所见,Django 完全有能力托管一些最受欢迎的社交分享网站,如 Pinterest 和 Instagram,以及一些最关键的网站,如 Bitbucket。由于 Django 推广和维护的最佳软件实践,大公司也开始采用新技术,并慢慢地从 J2EE 转移出去。
Django 与其他 Python Web 框架的比较
当然,Django 并不是唯一的 Python web 框架。其他流行的 Python web 框架有:
- Flask :开源的微型 web 框架,只提供 web 开发的核心库。它不提供数据库抽象、表单验证或任何其他可由第三方组件提供的组件。与 Django 不同,Flask 提供的开箱即用组件的数量保持在最低限度,这就是它被称为微型 web 框架的原因。
- 金字塔:一个受 Zope、Pylons 和 Django 启发的开源极简网络框架。它严格遵循 MVC (模型-视图-控制器)模式和持久性不可知。与 Django 相比,Pyramid 提供了一个额外的 URL 映射机制,称为 URL 遍历,它通过预定义的字典数据结构将 URL 映射到视图。
- Web2py:受 Ruby-on-Rails 启发的开源宏 Web 框架。它遵循 Ruby-on-Rails 关于配置方法的约定,并为各种组件和库提供了合理的缺省值。与 Django 相比,web2py 是不同的,因为它为程序员处理几乎所有的事情,同时提供更少的配置选项。
请注意,这些框架之间没有排名。无论你选择哪种 web 框架,最终最重要的问题是由你自己或你的团队来回答:我喜欢使用这个框架吗?一个易于使用的 web 框架能让任何程序员发挥出最高的效率。因此,选择一个你喜欢的框架,用它来创建优雅的网站。
摘要
在本文中,web 开发和 Django 的前景以鸟瞰图的形式呈现。除了学习 web 开发和 Django 的一般基础知识,我们还将 Django 与其他 Python web 框架进行了比较,得出的结论是,无论你选择哪个框架,都应该选择一个你爱用的框架。
Python 的 TkInter 介绍
原文:https://www.pythoncentral.io/introduction-to-pythons-tkinter/
在 Python 体验的某个阶段,您可能想要创建一个具有图形用户界面或 GUI(大多数人发音为“gooey”)的程序。有许多针对 Python 的工具包可以实现这一点,包括 Python 自己的原生 GUI 库 TkInter。在 Tkinter 中设置 GUI 并不复杂,尽管最终取决于您自己设计的复杂性。在这里,我们将通过一些简单的 GUI 示例来看看 Tkinter 模块的常用部分。在进入示例之前,让我们简要介绍一下 Tkinter 库必须提供的常用小部件(GUI 的构建块)。
简而言之,Tkinter 的所有小部件要么向 GUI 提供简单的输入(用户输入),要么从 GUI 输出(信息的图形显示),或者两者兼而有之。下面是最常用的输入和输出小部件的两个表格,并附有简要描述。
常用于输入的 Tkinter 小部件:
| 小工具 | 描述 |
| 进入 | 入口小部件是最基本的文本框,通常是一个单行高的字段,用户可以在其中键入文本;不允许太多格式 |
| 文本 | 让用户输入多行文本,并存储文本;提供格式选项(样式和属性) |
| 纽扣 | 用户告诉 GUI 执行命令的基本方法,例如对话框中的“确定”或“取消” |
| 单选按钮 | 让用户从列表中选择一个选项 |
| 复选按钮 | 允许用户从列表中选择多个选项 |
常用于输出的 Tkinter 小部件:
| 小工具 | 描述 |
| 标签 | 通过文本或图像显示信息的最基本方式 |
| 照片图像/位图图像 | 这些更像是类对象,而不是真正的小部件,因为它们必须与标签或其他显示小部件结合使用;它们分别显示图像和位图 |
| 列表框 | 显示文本项列表,用户可以从中突出显示一个(或多个,具体取决于配置) |
| 菜单 | 为用户提供菜单 |
尽管上面的小部件被分为“输入”和“输出”两类,但实际上它们都是双重的输入和输出,尤其是当回调(或事件绑定)开始起作用的时候。我们稍后将进一步研究回调和事件绑定,现在我们将看看上面应用程序中列出的一些小部件的例子。
要使用 Tkinter 模块,我们必须将其导入到我们的全局名称空间中。这通常是通过这样的语句来实现的:
[python]from tkinter import *[/python]
[python]from Tkinter import *[/python]
但是,为了保持名称空间的整洁,最好不要这样做。相反,我们将使用这种形式:
[python]import tkinter as tk[/python]
[python]import Tkinter as tk[/python]
这使我们能够访问模块,而不必每次都键入完整的模块名。当我们引用它时,你可以看到这一点:
>>> tk
<module 'Tkinter' from 'C:\Python27\lib\lib-tk\Tkinter.pyc'>
好了,我们现在准备好制作我们的 GUI 了——但是在此之前,让我们简单地想象一下我们希望它是什么样子,并检查一下内部 GUI 结构。现在我们将保持我们的设计简单,一个输出部件和一个输入部件——一个Label部件和一个Entry部件。
每个 Tkinter 小部件都由另一个被称为“父”的小部件管理或属于另一个小部件(属于另一个小部件的小部件被称为该小部件的“子部件”)。GUI 中唯一没有父窗口的小部件是主(或根)窗口。所有其他小部件都应该是根窗口的子窗口。此外,小部件通常物理上位于其父部件内部。这是基本结构。现在让我们开始建立我们的。第一步是创建我们的根窗口:
root1 = tk.Tk()
Tkinter Tk 对象是我们的根窗口,我们可以用子窗口填充它。首先是我们的标签。
label = tk.Label(root1, text='our label widget')
很快,我们有了一个标签。我们使用的第一个参数是父节点的名称(root1)。第二个参数是标签的标准关键字选项,用于设置它将显示的文本(如果有的话)。
接下来,我们初始化我们的输入小部件,条目:
entry = tk.Entry(root1)
初始化标签和条目小部件并设置好我们想要的选项后,剩下的就是告诉 Tkinter 将它们放在屏幕上它们的父窗口中。尽管我们设置了父类和选项,但是除非我们明确地告诉 Tkinter 显示它们,否则我们的小部件不会显示。
为了顺利处理这个过程,Tkinter 提供了一些内置的图形组织者,称为几何管理器。下表描述了每个可用的几何管理器。
| 几何图形管理器 | 描述 |
| 包装 | 用于用小部件填充父级空间 |
| 格子 | 将它管理的小部件放在父网格中。每个小部件在网格中都有自己的盒子或单元格(T0 )( T1 ),尽管它们可以通过一些选项覆盖多个 T2 单元格(T3) |
| 地方 | 允许明确设置窗口的大小和位置;主要用于实现自定义窗口布局,而不是普通布局 |
正如我们从第三个管理器的描述中看到的,pack 和 grid 管理器是用于常规公共布局的管理器,我们将在这个 GUI 中使用 pack。我们希望我们的标签在条目的顶部,所以我们将首先打包它,并使用一个选项将其设置在顶部,然后再打包条目(它将自动显示在标签下方):
label.pack(side=tk.TOP)
entry.pack()
搞定了。现在可以看到我们的小部件了。然而,您会注意到,如果您处于 Python 2.7 空闲状态,还没有 GUI 出现。就像任何其他小部件一样,必须告诉 Tkinter 显示根窗口,但是对于根窗口而不是几何管理器,必须调用主 Tk 循环,如下所示:
root1.mainloop()
现在我们应该可以看到一个新窗口,看起来像这样...

这可能会因您的设置/环境而有所不同,但不会相差太多。有了输入框,我们可以在窗口中键入我们想要的任意多的文本,尽管它不会做任何事情,只是呆在那里,因为我们没有让它做任何其他事情(即使我们点击“Enter”,标签也是一样)。
让我们关闭这个窗口,看一个有更多小部件的例子。我们还将快速了解一下事件绑定和网格管理器。请注意,在我们关闭 GUI 后,我们的根窗口及其所有子窗口将变得不可用,如果您尝试再次启动 root1 的主循环,或者尝试更改 label 的配置,您会发现这一点。
对于我们的第二个 GUI,我们将有一个标签和 3 个单选按钮。我们将像以前一样从根窗口开始,然后初始化标签:
root2 = tk.Tk()
label2 = tk.Label(root2, text='Choose a button')
我们现在有了根窗口和标签,但是在初始化 Radiobutton 之前,我们将创建一个 Tkinter 变量对象来跟踪每个 radio button 保存的值:
# Object of the Tkinter StringVar class
buttonstr = tk.StringVar()
现在我们将创建三个单选按钮,并将它们的值连接到我们的 buttonstr 变量:
buttonA = tk.Radiobutton(root2, text='Button A', variable=buttonstr, value='ButtonA string')
buttonB = tk.Radiobutton(root2, text='Button B', variable=buttonstr, value='ButtonB string')
buttonC = tk.Radiobutton(root2, text='Button C', variable=buttonstr, value='ButtonC string')
创建了 Radiobuttons 后,我们现在将检查当我们使用回调将方法连接到每个 Radiobuttons 时会发生什么。回调用于告诉 GUI 在小部件激活时执行一些命令或动作。我们将使用回调来打印每个单选按钮被选中时的值:
def showstr(event=None):
print(buttonstr.get())
我们刚刚定义的这个函数只不过是打印使用 get()方法访问的 StringVar 的值。我们现在可以通过使用command选项在 Radiobuttons 中引用这个函数作为回调:
buttonA.config(command=showstr)
buttonB.config(command=showstr)
buttonC.config(command=showstr)
好了,现在我们所有的小部件都初始化了,我们将设置它们在网格管理器中显示:
label2.grid(column=0, row=0)
buttonA.grid(column=0, row=1)
buttonB.grid(column=0, row=2)
buttonC.grid(column=0, row=3)
我们使用选项column和row告诉 grid 小部件的确切位置,但是如果我们不这样做,grid 会以默认顺序显示它们(列是零)。事不宜迟,我们现在将运行我们的 GUI。
root2.mainloop()
它应该是这样的:

注意:在我们选择一个单选按钮之前,似乎所有的单选按钮都被选择了——这仅仅是因为我们没有用 select()方法选择一个默认的单选按钮。如果我们在第一个按钮上使用这个方法,它将显示如下:
buttonA.select()
root2.mainloop()

现在,如果我们选择任何一个单选按钮(例如,A然后C然后B,那么我们应该会看到每个按钮的回调结果:
>>> root2.mainloop()
ButtonA string
ButtonC string
ButtonB string
除了用于将功能链接到窗口小部件的命令选项的回调之外,事件绑定可用于将某些用户“事件”(例如击键和鼠标点击)链接到缺少命令选项的窗口小部件。让我们用我们的第一个 GUI 例子来尝试一下。在所有其他设置都相同的情况下,就在打包输入框之后和启动 root1 主循环之前,我们将为“Enter”键设置一个事件绑定,这样如果按下它,输入框中的文本将被打印到空闲窗口。我们首先需要一种方法来完成这项工作:
# Prints the entry text
def showentry(event):
print(entry.get())
现在我们有了显示条目文本的方法,我们必须绑定事件(当用户点击“Enter”键且输入框处于焦点时):
>>> entry.bind('<Return>', showentry)
'29748480showentry'
在这一行中,我们使用了bind方法(每个小部件都可以使用)来连接我们的键盘事件(第一个参数)和我们的方法(第二个参数)。还要注意,对于return键,我们的事件名称是,而不是,因为这标志着 Tkinter 中完全不同类型的事件。我们可以忽略返回的函数名后面的短数字串,这对我们来说没有任何特殊意义。
如果我们现在运行根窗口的主循环,在我们的输入框中键入一些文本,并点击Enter键,Python 将显示我们键入的内容(试试看!).同样的功能可以用于 Tkinter GUI 中的任何小部件,并且可以用bind_all和bind_class方法同时绑定多个小部件。以同样的方式不受unbind、unbind_all和unbind_class方法的约束。
这就结束了我们对 Python Tkinter 库的介绍——它提供的工具与其他可用的第三方包相比是基本的,但是不要害怕使用它来发挥创造力!
Python 中的 SQLite 简介
原文:https://www.pythoncentral.io/introduction-to-sqlite-in-python/
SQLite3 是一个非常容易使用的数据库引擎。它是独立的、无服务器的、零配置的和事务性的。它非常快速和轻量级,并且整个数据库存储在单个磁盘文件中。它在许多应用中被用作内部数据存储。Python 标准库包括一个名为“sqlite3”的模块,用于处理该数据库。这个模块是一个符合 DB-API 2.0 规范的 SQL 接口。
使用 Python 的 SQLite 模块
要使用 SQLite3 模块,我们需要在 python 脚本中添加一条 import 语句:
import sqlite3
将 SQLite 连接到数据库
我们使用函数sqlite3.connect来连接数据库。我们可以使用参数“:memory:”在 RAM 中创建一个临时 DB,或者传递一个文件名来打开或创建它。
# Create a database in RAM
db = sqlite3.connect(':memory:')
# Creates or opens a file called mydb with a SQLite3 DB
db = sqlite3.connect('data/mydb')
当我们使用完数据库后,我们需要关闭连接:
db.close()
创建(CREATE)和删除(DROP)表格
为了对数据库进行任何操作,我们需要获得一个游标对象,并将 SQL 语句传递给游标对象来执行它们。最后,提交变更是必要的。我们将创建一个包含姓名、电话、电子邮件和密码列的用户表。
# Get a cursor object
cursor = db.cursor()
cursor.execute('''
CREATE TABLE users(id INTEGER PRIMARY KEY, name TEXT,
phone TEXT, email TEXT unique, password TEXT)
''')
db.commit()
要删除表格:
# Get a cursor object
cursor = db.cursor()
cursor.execute('''DROP TABLE users''')
db.commit()
请注意,提交函数是在 db 对象上调用的,而不是在游标对象上。如果我们输入cursor.commit,我们将得到AttributeError: 'sqlite3.Cursor' object has no attribute 'commit'
将数据插入数据库
为了插入数据,我们使用光标来执行查询。如果需要 Python 变量的值,建议使用“?”占位符。不要使用字符串操作或连接来进行查询,因为非常不安全。在本例中,我们将在数据库中插入两个用户,他们的信息存储在 python 变量中。
cursor = db.cursor()
name1 = 'Andres'
phone1 = '3366858'
email1 = 'user@example.com'
# A very secure password
password1 = '12345'
name 2 = ' John '
phone 2 = ' 5557241 '
email 2 = ' John doe @ example . com '
password 2 = ' abcdef '
# Insert user 1
cursor . execute(' ' ' Insert INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 1,电话 1,电子邮件 1,密码 1))
打印('插入第一个用户')
# Insert user 2
cursor . execute(' ' ' Insert INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 2,电话 2,电子邮件 2,密码 2))
打印('插入第二个用户')
db.commit()
Python 变量的值在元组内部传递。另一种方法是使用“:keyname”占位符传递字典:
cursor.execute('''INSERT INTO users(name, phone, email, password)
VALUES(:name,:phone, :email, :password)''',
{'name':name1, 'phone':phone1, 'email':email1, 'password':password1})
如果需要插入几个用户使用executemany和一个带有元组的列表:
users = [(name1,phone1, email1, password1),
(name2,phone2, email2, password2),
(name3,phone3, email3, password3)]
cursor.executemany(''' INSERT INTO users(name, phone, email, password) VALUES(?,?,?,?)''', users)
db.commit()
如果您需要获得刚刚插入的行的 id,请使用lastrowid:
id = cursor.lastrowid
print('Last row id: %d' % id)
用 SQLite 检索数据(选择)
要检索数据,对 cursor 对象执行查询,然后使用fetchone()检索单个行,或者使用fetchall()检索所有行。
cursor.execute('''SELECT name, email, phone FROM users''')
user1 = cursor.fetchone() #retrieve the first row
print(user1[0]) #Print the first column retrieved(user's name)
all_rows = cursor.fetchall()
for row in all_rows:
# row[0] returns the first column in the query (name), row[1] returns email column.
print('{0} : {1}, {2}'.format(row[0], row[1], row[2]))
光标对象作为迭代器工作,自动调用fetchall():
cursor.execute('''SELECT name, email, phone FROM users''')
for row in cursor:
# row[0] returns the first column in the query (name), row[1] returns email column.
print('{0} : {1}, {2}'.format(row[0], row[1], row[2]))
要使用条件检索数据,请再次使用“?”占位符:
user_id = 3
cursor.execute('''SELECT name, email, phone FROM users WHERE id=?''', (user_id,))
user = cursor.fetchone()
更新(UPDATE)和删除(DELETE)数据
更新或删除数据的过程与插入数据的过程相同:
# Update user with id 1
newphone = '3113093164'
userid = 1
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
#删除 id 为 2
Delete _ userid = 2
cursor . execute(' ' '从 id =?'的用户中删除'',(删除用户标识,))
db.commit()
使用 SQLite 交易
事务是数据库系统的一个有用属性。它确保了数据库的原子性。使用commit保存更改:
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
db.commit() #Commit the change
或者rollback回滚自上次调用commit以来对数据库的任何更改:
cursor.execute('''UPDATE users SET phone = ? WHERE id = ? ''',
(newphone, userid))
# The user's phone is not updated
db.rollback()
请记住总是调用commit来保存更改。如果您使用close关闭连接或者与文件的连接丢失(可能程序意外结束),未提交的更改将会丢失。
SQLite 数据库异常
最佳实践是始终用 try 子句或上下文管理器围绕数据库操作:
import sqlite3 #Import the SQLite3 module
try:
# Creates or opens a file called mydb with a SQLite3 DB
db = sqlite3.connect('data/mydb')
# Get a cursor object
cursor = db.cursor()
# Check if table users does not exist and create it
cursor.execute('''CREATE TABLE IF NOT EXISTS
users(id INTEGER PRIMARY KEY, name TEXT, phone TEXT, email TEXT unique, password TEXT)''')
# Commit the change
db.commit()
# Catch the exception
except Exception as e:
# Roll back any change if something goes wrong
db.rollback()
raise e
finally:
# Close the db connection
db.close()
在这个例子中,我们使用了 try/except/finally 子句来捕捉代码中的任何异常。finally关键字非常重要,因为它总是正确地关闭数据库连接。请参考这篇文章,了解更多关于例外的信息。请查看:
# Catch the exception
except Exception as e:
raise e
这被称为一个无所不包的子句,这里只是作为一个例子,在实际应用中你应该捕捉一个特定的异常,如IntegrityError或DatabaseError,更多信息请参考 DB-API 2.0 异常。
我们可以使用连接对象作为上下文管理器来自动提交或回滚事务:
name1 = 'Andres'
phone1 = '3366858'
email1 = 'user@example.com'
# A very secure password
password1 = '12345'
try:
with db:
db . execute(' ' ' INSERT INTO users(name,phone,email,password)
VALUES(?,?,?,?)“”,(姓名 1,电话 1,电子邮件 1,密码 1))
除了 sqlite3。IntegrityError:
打印('记录已经存在')
最后:
db.close()
在上面的例子中,如果 insert 语句引发了一个异常,事务将被回滚并打印消息;否则事务将被提交。请注意,我们在db对象上调用execute,而不是cursor对象。
SQLite 行工厂和数据类型
下表显示了 SQLite 数据类型和 Python 数据类型之间的关系:
None类型转换为NULLint类型转换为INTEGERfloat类型转换为REALstr类型转换为TEXTbytes类型转换为BLOB
行工厂类sqlite3.Row用于通过名称而不是索引来访问查询的列:
【python】
db = sqlite3 . connect(' data/mydb ')
db . row _ factory = sqlite3。row
cursor = db . cursor()
cursor . execute(' ' '从用户中选择姓名、电子邮件、电话' ')
对于游标中的行:
row['name']返回查询中的姓名列,row['email']返回电子邮件列。
打印(' {0} : {1},{2} '。格式(行['姓名'],行['电子邮件'],行['电话'])
db . close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号