PythonCentral-博客中文翻译-三-
PythonCentral 博客中文翻译(三)
Python 中的字符串是什么
原文:https://www.pythoncentral.io/what-is-the-string-in-python/
字符串是 Python 数据类型。在本文中,我们将了解什么是 python 中的字符串,如何在 Python 中反转、连接和比较字符串。为了从本文中获得最大收益,您需要具备 Python 的基础知识。如果你不点击查看我们的python 介绍。先说 python 中的字符串是什么。
Python 中的字符串是什么?
Python 字符串是一种数据类型。Python 没有字符数据类型。这就是为什么它有一个字符串,一个 Unicode 表示的字符列表。Python 将字符串作为字符数组来处理。
这意味着您也可以将所有列表函数应用于 string。声明一个 python 字符串非常简单,只需在单引号或双引号之间添加单词。这将告诉 Python 在内存中创建一个字符串长度的列表。让我们看一个定义 Python 字符串的例子。
text = 'Hello'
message = "Python string"
print(text)
print(message)
# output
'Hello'
"Python string"
上面的例子展示了如何在 python 中用单引号或双引号定义一个字符串。Python 字符串有一些利用字符串的函数。假设用户用他们的电子邮件注册了您的应用程序。您需要验证电子邮件字符串是小写的。以避免用户数据的重复。Python 提供了一个内置函数lower(),可以将字符串转换成小写。
email = "Email@Mail.com"
print(email)
# output
'Email@Mail.com'
print(email.lower())
# output
'email@mail.com'
我们提到字符串是一个列表,我们可以对它执行一些列表函数。这包括列表所具有的反向功能。
如何在 Python 中反转一个字符串
要在 python 中反转一个字符串,你需要理解 python 将字符串作为一个字符列表读取。相反的功能非常简单。首先,遍历字符串。从原始字符串的末尾开始创建一个新字符串。举个例子你就明白了。
text = 'Hello world'
new_text = ''
index = len(text)
while index > 0:
new_text += text[index -1]
index -= 1
print(text)
print(new_text)
# output
Hellow world
dlrow olleH
在上面的代码中,我们用字符串的长度创建了一个索引。使用循环从后向前遍历文本中的每一项。最后一部分是将字符添加到新字符串中,并减少计数器。这就解决了我们反串的问题。Python 支持更有效的方法来反转字符串。
text = 'Hello world'
new_text = text[::-1]
print(new_text)
# output
dlrow olleH
文本[::-1]代码做了什么?它对字符串进行切片,使其以字符串的长度开始,以零索引结束。这会反转字符串,并将其存储在 new_text 字符串中。您可能已经注意到,在前面的例子中,我们创建了一个空字符串,并开始向其中添加内容。这就引出了一个问题,如何连接 Python 的字符串?
在 Python 中连接字符串
串联 Python 的字符串是将字符串合并在一起。更简单的解释,如果你有 text_1 =“你好”,text_2 =“世界”。将它们串联起来就是我将它们合并,形成“Hello world”。在 Python 中有很多种连接字符串的方法。最简单的方法是使用加号。
text_1 = "Hello"
text_2 = "World"
print(text_1 + " " + text_2)
# output
Hello World
你的代码库越大,你就越需要定制连接。Python 提供了几个函数来帮助您以一种更优雅、更易读的方式连接字符串。第一种方法是 format()函数。
username = "John"
welcome_message = "Welcome {username} this is a test text".format(username=username)
print(welcome_message)
# output
Welcome John this is a test text
如果您需要添加空格,并且您有多个变量要添加到文本中,format 函数在大型测试中非常方便。你需要做的就是把变量名放在花括号里。Python 将从传递给 format 函数的参数中获取该变量的值。
第二种方法是使用 join 函数。如果您有一个列表,并且想要将列表数据连接成一个字符串,那么 join 函数非常有用。我们举个例子来了解一下。
full_name_parts = ['John', 'Jack', 'Watson']
full_name = "-"
full_name.join(full_name_parts)
print(full_name)
# output
John-Jack-Watson
您可以看到 join 函数遍历了列表,并将项目添加到 full_name 字符串中。它添加了中间带有-的项目。
第三种方法仅在 Python 3.6 及更高版本中可用。这是 f 弦法。这是 format 函数的一个更好的版本。
name = "Jack"
age = 72
f"Hi, {name}. You is {age}."
# output
'Hello, Eric. You are 74.'
f-string 方法允许您直接获取字符串中的变量值。如果你在字符串的开头添加了一个字符。
比较两个 Python 字符串
让我们假设您有一个存储用户名的应用程序。您希望每个用户的用户名都是唯一的。这意味着您需要验证这个名称不匹配任何其他注册的用户名。Python 提供了比较字符串的能力。一个基本的例子是:
name = input('Enter Your Name:')
saved_name = 'Jack'
if name == saved_name:
print('Sorry the name you entered is taken')
else:
print('Welcome {name}'.format(name=name))
# output
Sorry the name you entered is taken
# output
Welcome John
Python 将这两个字符串作为文本进行比较。这意味着如果用户输入小写的插孔名称,该条件将无效。这一点非常重要。你要知道 Python 是不做自动验证的。您需要手动实现所需的验证。这是一个非常简单的例子,在一个更现实的例子中,您将有一个数据库来确保名称是唯一的。
结论
Python 的字符串使用起来非常方便和有用。它有明确的形成和污染方法。您可以将它作为一个列表来使用。它支持不同的大多数 Python 列表内置的函数。要反转一个 Python 的字符串,你可以把它切片,以索引 0 结束。Python 中的连接字符串提供了不同的连接方法,可以根据您的需要进行选择。在 python 中比较字符串类似于比较两个整数。你可以在官方文档中了解更多关于 Python 字符串的知识。你可以在这里得到更多关于字符串函数的细节。
我的笔记本电脑需要什么规格来进行高效的 Python 编码?
原文:https://www.pythoncentral.io/what-specs-does-my-laptop-need-for-efficient-python-coding/

学习如何用 Python 编程是你做过的最好的决定之一。你会学到很多技能,这些技能会让你在职业生涯中走得更远。即使你不打算在你的职业生涯中使用编码,它也可以成为一个真正令人兴奋的爱好,给你的创造力一个完美的出口。
然而,一旦你决定开始编码,你需要确保你有合适的设备。不是任何设备都可以,即使你可以使用相对便宜的笔记本电脑。
当你买笔记本电脑时,别忘了给它上保险。如果您的设备被盗,笔记本电脑保险将为您承保。当你迫切需要更换日常编码用的笔记本电脑时,它可以帮你省下很多经济上的麻烦。
现在,让我们来了解一下您的笔记本电脑为获得出色的 Python 编码体验所需的规格。
随机存取存储
Python 需要多大的 RAM?虽然您可以使用 4GB 内存的笔记本电脑,但至少 8GB 内存的笔记本电脑才是最好的。4GB 将允许您完成工作,但是当您试图运行像 PyCharm 或 Visual Studio 代码这样的代码编辑器时,您将面临令人沮丧的延迟。
同样值得一提的是,你将能够运行任何使用大量系统内存的应用程序。你不希望你的内存不足扼杀你的创造力。
中央处理器
你需要一个合适的笔记本电脑 CPU 来进行 Python 编程。与 RAM 一样,您可以使用不太强大的 CPU,但是您会不断发现您的系统过载,浪费您大量的时间。
选择多核 CPU。英特尔酷睿 i5 应该是您的最低配置,尽管 i7 或第八代机型将最适合您。装有苹果 M1 和 M2 芯片的 Macbooks 也是不错的选择。
显示器(屏幕)
屏幕有多重要?比你想象的要多,因此你可能要比你计划的花费更多。在笔记本电脑的小屏幕上编码会对眼睛造成很大的伤害。选择至少 14 英寸、分辨率至少为全高清的屏幕。
你不一定要去买一个大的笔记本电脑,但是如果你有一个更小的设备,用一个外部显示器来补充它。这样,当你在家或在办公室时,你可以轻松地编写代码,当你外出时,仍然可以设法完成一些编程工作。
国家政治保卫局。参见 OGPU
从技术上来说,你不需要一个特别好的 GPU 来编码。使用集成的 GPU 绝对可以应付,尤其是在高端笔记本电脑上。然而,如果你计划在某个时候编写高质量的游戏,一个好的 GPU 最终将是必要的。即使在移动应用的开发中也是如此。
如果可以的话,请使用至少 4GB 的外部 GPU。像 GeForce 和 Quadro 这样的 NVIDIA 卡是理想的。
储存;储备
你当然可以用硬盘驱动器编码。但是在 2022 年,你真的没有理由吝啬你的硬盘。一个基本的固态硬盘应该是最低限度的,即使你不编码或使用你的笔记本电脑游戏。
并非所有 SSD 驱动器都生而平等。新的驱动器通常配备带有 NVMe 接口的 M.2 磁盘。你可以使用一个基本的固态硬盘驱动器,但你最好选择更强大的选项。你应该有至少 240GB 的存储容量。
键盘
你需要一个像样的键盘来编码,但任何选中以上所有选项的笔记本电脑都会附带一个足够好的键盘。如果你是从零开始构建你的笔记本电脑,不要在这方面吝啬。
操作系统(Operating System)
你的操作系统当然非常重要。然而,你可以使用任何主流操作系统的最新版本,这主要取决于个人偏好。如果你是 Linux 的粉丝,可以尝试使用 Ubuntu 发行版。
任何具备上述规格的笔记本电脑都非常适合用 Python 编码。如前所述,您可以设法用劣质设备编码。然而,考虑到编码在你的生活中变得多么重要,投资一个强大的设备是值得的。
用 Django 可以有效地解决什么类型的问题?
原文:https://www.pythoncentral.io/what-type-of-problem-can-be-effectively-solved-with-django/

Django 是编写 web 应用程序时使用的框架工具。开始时,你会注意到它的简单,这有助于事情进展得更快。
随着您添加现实世界的约束,数据模型变得更加复杂。你会发现你最初的策略不再有效。
随着您对问题了解的越来越多,请调整您的代码。Django 可能很快,但有时你最终会写出很慢的代码。
可能很难知道从哪里开始,尤其是当你的专业项目非常广泛的时候。在这种情况下,这是与 Django 发展公司合作的最佳时机,以获得你所要求的最好的专业结果。
请继续阅读本文,了解通过坚持不懈的努力、关注和一些调整,可以解决哪些常见的 Django 问题。学习阅读代码错误并找到它们的解决方案需要时间和练习。
Django 安装和使用中的常见问题
处理数据时,从数据位置开始调试,然后转到数据存储的界面,最后是视图和报告。
大多数性能问题都是由于试图访问数据库造成的。幸运的是,Django 详细总结了如何优化数据库。您只需从一开始就应用一个好的策略来高效地构建您的代码。
在寻求优化时,您的代码可能会变得不清晰。当面临清晰代码和性能提升之间的选择时,你能理解的代码应该放在第一位。你需要练习才能明白要改变什么。
工具
要解决问题,首先要识别它。有几件事你可以做。首先,理解 Django.db.connection,在当前连接中您有哪些查询。进入 shell 并使用命令 shell_plus 和标志–print-SQLon。
您的调试环境应该在后台运行中间件。它记录查询并引起对重复的注意。你可以在 Django-debug-toolbar 上找到这些信息。
意外查询
例如,在检查作者的 id 时,您本能地想要使用 author 字段。如果不需要 author 对象,可能就白做了一次额外的查询。万一以后用了作者值,也没关系。
通过使用列名称属性,使事情变得简单明了。
大小和存在命令
理解何时使用存在和 c 计数需要时间。当使用 Django 的 queryset 中的数据时,使用 Python 操作。当不使用数据时,请改用 queryset 方法。
在寻找 queryset 的大小时,做同样的事情。当你需要尺寸时使用计数,当你使用查询设置时使用长度。
如何得到你需要的东西
Django 固有地请求表中的所有列,并在 Python 项目中填充这些列。当您只需要表中列的子集时,使用值或值列表。通过这样做,您不必创建复杂的 python 对象。相反,您可以使用字典、值或元组。
如何处理多行
Django 捕捉在计算 querysets 时获得的值。如果您多次重复 queryset,它就可以工作,但是如果您只循环一次,它就不能很好地运行。
Django 将书籍加载到内存中,并遍历每一本书。您希望它保持一个 SQL 连接打开并读取每一行,然后在转到下一行之前调用 do_stuff 。在这种情况下,迭代器可以帮助您。迭代器允许你写线性数据。它很棒,因为当与值和值列表结合使用时,它在内存中保留的信息量最少。
迭代器在迁移信息并且必须改变表中的行时也很有帮助。它节省时间,避免了停机时间。
关系问题
Django 让您可以自然地与关系数据库交互。您可以随意使用精确且语义清晰的代码。因为 Django 使用延迟加载,所以它只在您需要时才加载作者。虽然这是一个积极的方面,但它可能会导致大量的查询。
Django 认识到了这个问题。它提供了两种解决方案:预取 _ 相关和选择 _ 相关。当用 Django 编写应用程序时,了解和使用它们是必不可少的。
当不使用时选择 _ 相关
一直使用 select_related 很有诱惑力,但有时并不合适。这可能意味着更多的工作不值得做。该命令为查询的每一行创建新的实例,这会消耗内存。当您查询 select_related 的相同值时,使用 querysets。另一种方法是翻转您的查询,使用预取相关的。
请记住,使用查询集时,您的更改会传播到查询集中的其他行。而 select_related 就不是这样了。
结论
Django 中出现的每个问题都至少有一个解决方案。您应该关注的是清晰的代码,以便以后进行优化。当你继续开发你的应用程序时,保持良好的卫生习惯,使用干净清晰的代码。
在 Python 文件中使用 Django 时,通过尝试遵循文档来避免错误。从养成使用资源的好习惯开始你的旅程,因为你以后会享受到好处。
初学者在哪里练习 Python 编程
原文:https://www.pythoncentral.io/where-to-practice-python-programming-for-beginners/

你知道如今编程是就业市场的热门趋势吗?有很多初学者和初级学习者想练习 Python。如果你是这个领域的新手,并且想学习如何成为一名更流利的 Python 开发者,你应该寻找更多的机会。为什么 Python 现在很重要?还有什么其他选择,为什么它们没有那么有效?让我们来看看使用 Python 的优势。
Python 简单来说是什么?有许多复杂的定义来帮助用户解释 Python 是什么。让我们抛开复杂的意思,用简单的英语来描述这种语言。所以,三言两语, Python 编程帮助 是指一种主要针对软件开发、网站建设、数据可视化、任务自动化而设计的编程语言。
Python 对新手的优势
为什么需要使用 Python?如果你试着用谷歌搜索今天开发人员最常用的语言和工具,你肯定会发现 Python 在列表的最上面。为什么这种语言如此流行?开发人员倾向于深入学习 Python 有几个原因。我们一起想办法。
1。新手很容易上手
如果你只是刚刚开始你的编程生涯的,你将需要一些容易获得并且不需要花费太多时间的东西。很多大三学生想从 C++开始,或者一次尝试几个选项。但不会带来好结果。如果你需要在一门语言上有好的和高质量的专业知识,那肯定是 Python。
2。你可以毫不费力地找到工作
为什么编程语言的选择会影响求职?问题是有些工具的需求比其他的少。所以,如果你正在积极地找工作,你会把它钉在一家公司的空缺上。问题是 Python 是一个广泛使用的工具。它可以在广泛的项目中实施。因此,公司,无论是软件公司还是其他类型的企业,都在急切地寻找新的人才。
3。Python 提供了很多机会
Python 被用于许多不同的项目和应用。如果你想成为市场的抢手货,并且知道如何在职业上提升自己,那么肯定有大量的机会可以做到这一点。使用 Python,你将能够开发软件和创建网站。有什么能比创建一个网站更赚钱呢?您还可以负责任务自动化或数据分析和可视化。

去哪里练习 Python 编程
如果你决定要获得更多关于这门语言的知识,并对自己进行测试,你应该小心现有的选择。让我们来看看你可以去实践编程经验的主要途径。
- 首先可以查一下自己的理论知识。平台为每个编程爱好者提供交互式问题和测验。你可以去网站上看看,自己测试一下。当你至少已经掌握了一些这门语言的专业知识时,最好还是这样做。
- 你可以查看一些实际的任务。网上有很多。如果你寻找一个技术性的任务生成工具,你会发现有很多种选择。这些是 选项,帮助你训练 你的技能,既实用又理论。
- 哪里可以练习 Python 专业知识?参加一个真实的项目怎么样?如果你在一个真实的项目中尝试自己,并敢于按计划做每件事,你会发现一个宝贵的机会。
你想让你的练习最完整、最有成效吗?那么你也许应该看看这些选项。它们非常适合所有年龄段的用户。不管你已经练习 Python 多久了,看看这些选项都是值得的。编程语言的专业性和专业知识始于定期和深入的实践。只有这样才是成功之路。
外卖
许多初学者想知道他们是否可以开始使用 Python 编程语言。对许多人来说这是一个很好的选择。在本文中,我们描述了选择 Python 作为编程任务的主要语言的三大原因。你想成为市场上收入高、要求高的专家吗?如果你学习 Python,你可以获得大量的工作机会,并获得适当的报酬。
为什么选择 Python 作为您在 Linux 上的第一种编程语言
原文:https://www.pythoncentral.io/why-choose-python-as-your-first-programming-language-on-linux/
由于 Windows 的使用在减少,Linux 正在迅速发展并变得越来越流行。许多程序员正致力于 Linux 的推广,他们为台式机开发新的程序,这些程序将等同于甚至优于 Windows 和 Mac OS X 应用程序。
用于 Linux 的编程语言有很多,而且每年都有新的出现。但并不是所有的都是程序员用的。几乎每一个现代 Linux 发行版中都有 Python,所以那些准备在 Linux 中编写第一个 Python 程序的人不需要安装任何额外的程序。要在 Linux 中编写您的第一个 Python 程序,请启动您最喜欢的 Linux 程序,并遵循本文的步骤。
具有简单语法和语义的可靠编程语言将确保快速学习,并有助于开发算法思维。第一语言应该是高水平和灵活的,这样学生就可以尝试解决问题的替代方案。同样重要的是,它应该支持现代设计方法,包括抽象、封装和面向对象的方法。我们来试着了解一下 Python 是否真的适合新手程序员。重要的是要记住编程语言可能因公司而异。但是如果你想做一名自由职业者,为 论文写作服务 或任何其他公司创建网站,从学习 Python 开始吧。
值得理解的是,第一门编程语言的选择并不总是决定一个学生未来的职业生涯,但它可以影响职业发展的方向,有利于未来的自主学习。
编程通常被视为开发思维的工具,并且能够影响人们解决问题的方式。这里可以与口语的 Sepir-Worf 假说相提并论,该假说认为语言决定思维。
选择第一编程语言的标准还可以包括:
- 范围和流行程度;
- 范式——面向对象或函数式编程;
- 句法简洁;
- 思想的优雅;
- 程序员群体的规模;
- 培训材料的可用性。
尽管对理想的第一语言缺乏共识,Python 符合大部分标准,可以被推荐为这样的选择。在这种情况下,值得考虑未来程序员所面临的任务,以及他或她所选择的整体学习策略。
Python 的范围
最近,脚本语言越来越受欢迎。用它们编写的软件比用传统的系统语言要多。Python 可用于所有主流平台:Windows、OS X、Linux、Unix、BeOS、Java。它广泛应用于科学计算、机器学习、web 开发、游戏和视觉效果创建、服务器管理以及其他一些领域。
Python 可以做许多开箱即用的有用的事情,并提供专业人员期望从核心编程语言中获得的所有基本工具和特性。有关如何使用 Python 来启发您学习它的更多示例,请查看本文。
社区和文档
Python 有一个来自世界各地的大型程序员社区,致力于学习、使用和开发它。有许多专门讨论 Python 的会议、聚会和黑客马拉松,这种语言有一个庞大且研究充分的 文档库 来帮助新手熟悉它并找到大多数问题的答案。Python 有大量适用于各种场合的标准库,甚至还有更多开源库供您在工作中使用。

Python 的简单性——语法和语义
得益于简单的正则语法,Python 程序通常可读性极强,易于理解。操作符在行尾结束,块结构缩进,程序看起来像可执行的伪代码。
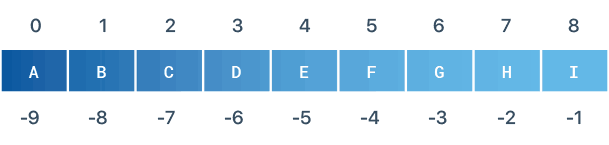
Python 最不寻常的特性之一是使用缩进来表示代码块。解释器有助于确保正确的格式,这使得编写不可读的代码更加困难。在其他语言中,缩进是一门艺术。在 Python 中,它是语法的重要部分。作为一个例子,这里有一个 Python 的线性搜索版本:
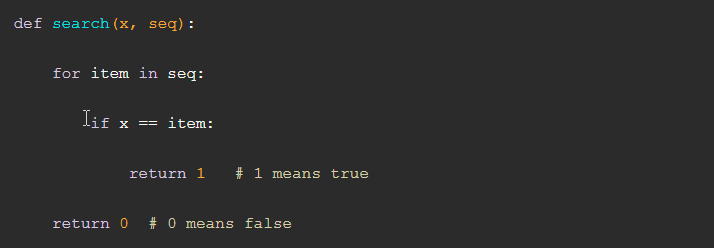
例如,如果将代表 的 行向左移动几个空格,就会导致语法错误。还要注意, : 用于表示代码块的开始。
除了基本的数字类型,Python 还提供了三种内置的数据结构:字符串、列表和字典。字符串和列表支持灵活的切片表示法,可以提取任何子串或子列表。
简单的程序真的很简单。比如 Python 中的 Hello World 是这样的:

语义上,Python 很简单。它是动态类型的,所以不需要变量声明。这减少了代码量,也消除了由于误解声明、定义和用法中的细微差别而导致的常见错误。Python 代码易于阅读,因为它在许多方面类似于日常英语。
Python 有一套最小但完整的简单控制结构:一个 if-elif-else 选择结构,一个确定的 for 循环,一个不确定的 while 循环。
Python 中的 为 循环就是例证。它允许控制变量取连续的值。它可用于枚举任何序列,如列表或字符串。列表项可以打印如下:

for 简单又安全,让你很早就可以进入,不用担心无尽的循环。
Python 的优缺点
我们已经在上面提到了 Python 的一些优点,我们建议将它们与缺点进行比较,以客观地评估作为第一个学习者的语言。
优势
- 简单易学。
- 简洁。
- 易于使用的语法和简单的语义。
- 可解释性。
- 广泛的可用性。
- 动态打字。
- 广泛的库支持。
- 大量文档和培训材料。
- 它是多平台的。
缺点
程序运行速度低:使用动态类型的语言逐行执行代码使得开发高性能的应用程序变得困难,但这通常可以通过提高开发人员的工作效率来弥补。
Python 程序使用大量内存:在创建优化的应用程序时,这可能是一个缺点。有关此问题的更多信息,请参见“Python 中的内存工作原理”。
编译时缺乏检查有时会导致运行时错误。这对于在运行或发布之前测试应用程序提出了更高的要求。
对比优缺点,Python 在弱硬件上对代码的速度有一定的限制。由于新手程序员通常不会编写高性能的应用程序,所以他们的产品没有如此严重的运行时限制。同时,Python 比编译的编程语言快好几倍,而可读性和语法、语义的简单性否定了可能的错误。

总结
Python 是一种简单、通用、有前途的编程语言。虽然它有一些缺点,但好处在很大程度上大于它们,尤其是对于新手程序员来说。脚本语言作为基本软件开发工具的流行是计算机编程中潜在的革命性变化。Python 是学习基础知识和开始职业生涯的理想工具。
为什么选择 Python

Python 已经在 IEEE Spectrum 的年度编程语言排名榜 之上好几年了。
如果你还没有开始学习 Python,那么理解它为什么会在全球开发者中流行是一个挑战。
因此,在这篇文章中,我列出了你应该考虑学习和使用 Python 的五大理由。
为什么是 Python?
Python 受欢迎背后最大的原因是它的。阅读和理解 Python 程序比用其他编程语言编写的程序要容易得多。
由于没有令人困惑的语法规则,程序员不必花太多精力编写代码。这使得像程序员一样思考变得容易多了。
对于程序员来说,用任何语言编写一个“Hello World”程序作为他们的第一个程序都是惯例。在 Java 中,基本程序的代码是这样的:
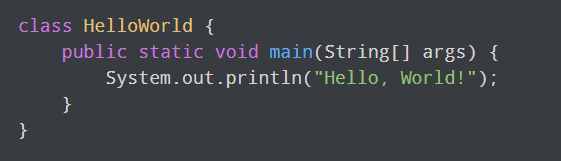
另一方面,Python 中的“Hello World”程序看起来是这样的:

这两种语言复杂程度的对比是惊人的。
此外,有了 Python,你不必担心让你的代码工作。
设置 Python 很容易——你所要做的就是访问 Python 官方网站,并在你的电脑上安装软件包。虽然如果你喜欢有一个好的界面来写代码,你可以得到一个 IDE,但是你不一定要这样做。您可以在 Windows 上使用命令提示符,或者在 macOS 和 Linux 上使用终端来运行您的程序。
Python 到底有多大用处?
Python 看起来很简单,但它远不是一种不灵活的语言。它用途广泛,在几个行业都有应用。大型科技公司,包括谷歌、Dropbox 和 Spotify,都使用 Python 开发各种应用程序。下面是不同公司的使用方法:
Dropbox
让用户管理云数据的 Dropbox 桌面客户端完全是用 Python 编写的,你会感到惊讶。服务器端代码也是用 Python 编写的,这使得它成为该公司使用的最重要的语言。这证明了 Python 的强大和出色的跨平台能力。
谷歌
谷歌已经成长为向大众提供的不仅仅是一个强大的搜索引擎,因此,该公司使用多种语言。除了 C++和 Go 之外,Python 是该公司使用最多的语言之一。
尽可能使用 Python 是谷歌的早期决定,并不难理解其中的原因。它支持快速实现功能,并且易于维护。
然而,由于 Python 没有那么快,谷歌软件栈中需要低延迟操作的部分是用 C++编写的。
Spotify
虽然该公司严重依赖 Java,但 Python 用于构建 web API 和交互式 API 控制台。交互式控制台使开发人员能够探索端点,而无需经历导航复杂界面的麻烦。
该语言在公司内部的其他应用包括:
- 数据分析
- 支付系统
- 内容管理系统
- DNS 服务器恢复系统
如你所见,这种语言在不同的公司有着广泛的应用。虽然 Python 可能没有 C++这样的低级语言快,但它是快速构建原型和实现特性的完美工具。
它还具有明显的多功能性。学习 Python 将使你能够创建几乎任何你想要的东西。
为什么要学习 Python?
易用性和多功能性是选择 Python 的两大原因。然而,学习 Python 是个好主意还有许多其他原因。
#1 一个积极支持的社区
Python 自 1991 年就出现了。它是有据可查的,并且被世界上一些最大的公司所使用。如果你碰巧遇到了这种语言的问题,很可能这个问题以前就已经解决了——仅仅是因为使用这种语言的开发人员数量太多。
简单的谷歌搜索通常足以回答你的任何问题。如果您在那里没有找到您的答案,您可以求助于详细的文档来获得解决方案。您也可以向 Stack Overflow 上的大型 Python 开发人员社区寻求帮助。
#2 多种编程范例
Python 提供的最大优势之一是它支持多种编程范式。它对面向对象、结构化、函数式和面向方面编程的支持使它非常灵活。
此外,这种编程语言以动态类型系统为特色,并拥有自动内存管理功能。这些特性使您能够使用 Python 构建大型、复杂的应用程序,而不必太担心约束。
#3 大数据应用
过去十年,数据科学和云计算的应用呈指数级增长。Python 对这些应用程序的支持帮助它一飞冲天。
Python 现在是处理大数据最常用的语言,仅次于 R,R 也用于创建人工智能系统。
Python 使得分析和组织数据变得非常容易。它的易维护性和可伸缩性帮助它把 R 推到了开发者偏好的第二位。
大数据库
该语言有几个软件包,如 NumPy 和 Pandas,使用户能够以不同的方式分析和使用数据,而无需从头开始编写程序。
由谷歌开发的 Tensorflow 是迄今为止最受欢迎的 Python 包,它能够构建机器学习算法。用户可以使用 pyspark 调用 spark 框架并处理大型数据集。
像这样的库使日常开发人员能够分析数据趋势,而不需要学习像 r 这样复杂的语言。
#4 庞大的套库
Tensorflow 和 Pandas 并不是 Python 自带的唯一的库。这种语言拥有大量的库,可以在开发的各个领域提供帮助。一些最著名的库包括:
- NumPy 和 SciPy: 为 web 开发的科学计算提供帮助。
- Scikit-Learn: 用于机器学习应用和自然语言处理。
- Keras: 它使得与神经网络一起工作变得更容易。
也有类似库的工具使 Python 能够与其他语言一起工作,并扩展其跨平台支持。
Python 的另一个优势是,你可以通过阅读 Python 标准库文档来了解几个库。
#5 几种开源框架和工具
Python 是开源的,这大大降低了开发成本。活跃的开发人员社区和缺乏严格的许可要求导致了一些强大的开源 Python 框架的开发。
任何开发人员都可以使用几十种强大的 Python 工具中的一种来满足他们确切的开发需求,而不会增加开发成本。
这些工具的可用性也有助于减少开发时间,因为团队不必编写代码来解决框架和工具为他们解决的问题。
Django、Flash 和 Bottle 是 web 应用程序开发人员可以用来简化和加速开发的许多工具中的一部分。另一方面,像 PyQT、PyGUI 和 Kivy 这样的框架有助于加速 GUI 应用程序的开发。
这些框架并不缺乏,而且很有可能你会找到一个框架来帮助你解决一个复杂的问题,而不需要写很多代码。
结论:2021 年 Python 值得学吗?
Python 是大学里最受欢迎的入门编程语言——现在你明白为什么了。
它很容易学习、阅读和使用,而且由于它是免费下载的,所以也很容易访问。对于一个发展中的开发者来说,这是一个完美的起点。
这种编程语言有着广泛的应用,可以用来做任何事情,从制作视频游戏到评估营销决策。活跃的社区和几个可用的库有助于加速软件开发。
但也许最重要的是,Python 在大型科技领域被广泛使用,这意味着学好它将带来几个经济上有回报的就业机会。
另外,学习编写 Python 程序将教会你一些细节,足以让你更轻松地掌握其他编程语言。
如果你正在寻找一门可以学习的编程语言,Python 是最好的选择。
好奇用 Python 可以做什么?下面就为 详细用法指南 提供帮助。
为您的第一个 Django 应用程序编写自动化测试
原文:https://www.pythoncentral.io/writing-automated-tests-for-your-first-django-application/
测试,测试和更多的测试
作为一名软件程序员,你经常听到别人谈论测试是任何项目中最重要的组成部分之一。当有适当的测试覆盖时,软件项目通常会成功。而当很少或没有时,它经常失败。你可能想知道:到底什么是测试?为什么大家都在不断强调它的重要性?
测试是检查代码正确性和完整性的简单程序或迷你程序。一些测试检查软件项目的微小细节- 当一个 POST 方法被调用时,一个特定的 Django 模型会被更新吗?,而其他人检查软件的整体运行——代码是否正确执行了我关于客户订单提交的业务逻辑?。不管多小,每个测试都很重要,因为它告诉你你的代码是否有问题。尽管对你的代码进行 100%的测试覆盖是相当困难的,并且需要付出大量的努力,但是你应该总是尽可能地用测试覆盖你的代码。
总体而言,测试:
- 节省您的时间,因为它们允许您测试应用程序,而无需一直手动运行代码。
- 帮助您验证和阐明软件需求,因为它们迫使您思考手头的问题,并编写适当的测试来证明解决方案可行。
- 让你的代码更健壮,对其他人更有吸引力因为他们能让任何读者看到你的代码在测试中被证明是正确运行的。
- 帮助团队一起工作,因为他们允许队友通过编写代码测试来验证彼此的代码。
编写您的第一个自动化 Django 测试
在我们现有的应用程序 myblog 的索引视图中,我们将返回用户在不到两天后发布的最新帖子。索引视图的代码附在下面:
def index(request):
two_days_ago = datetime.utcnow() - timedelta(days=2)
recent_posts = m.Post.objects.filter(created_at__gt=two_days_ago).all()
context = Context({
'post_list': recent_posts
})
return render(request, 'index.html', context)
这个视图中有一个小 bug。你能找到它吗?
似乎我们假设我们网站中的所有帖子都是过去“发布”的,即Post.created_at比timezone.now()早。然而,很有可能用户提前准备了一篇文章,并希望在未来的某个日期发布它。显然,当前代码也将返回那些未来的帖子。这可以在下面的代码片段中得到验证:
>>> m.Post.objects.all().delete()
>>> import datetime
>>> from django.utils import timezone
>>> from myblog import models as m
>>> future_post = m.Post(content='Future Post',
>>> created_at=timezone.now() + datetime.timedelta(days=10))
>>> future_post.save()
>>> two_days_ago = datetime.datetime.utcnow() - datetime.timedelta(days=2)
>>> recent_posts = m.Post.objects.filter(created_at__gt=two_days_ago).all()
# recent_posts contain future_post, which is wrong.
>>> recent_posts[0].content
u'Future Post'
在我们继续修复视图中的 bug 之前,让我们暂停一下,写一个测试来暴露这个 bug。首先,我们将一个新方法recent_posts()添加到模型Post中,这样我们就可以从视图中提取不正确的代码:
import datetime
从 django.db 导入模型作为 m
从 django.utils 导入时区
类 Post(m . Model):
content = m . CharField(max _ length = 256)
created _ at = m . datetime field(' datetime created ')
@ class method
def recent _ posts(cls):
two _ days _ ago = time zone . now()-datetime . time delta(days = 2)
return post . objects . filter(created _ at _ _ gt = two _ days _ ago)
然后,我们修改索引视图的代码,以使用来自模型Post的recent_posts()方法:
def index(request):
recent_posts = m.Post.recent_posts()
context = Context({
'post_list': recent_posts
})
return render(request, 'index.html', context)
现在我们将下面的代码添加到myblog/tests.py中,这样我们可以运行它来测试我们代码的行为:
import datetime
从 django.utils 导入时区
从 django.test 导入测试用例
从我的博客导入模型作为 m
类 PostModelTests(test case):
def setUp(self):
' ' '从未来创建帖子‘
超级(PostModelTests,self)。setUp()
self . Future _ Post = m . Post(
content = ' Future Post ',created _ at = time zone . now()+datetime . time delta(days = 10))
self . Future _ Post . save()
def tearDown(self):
' ' '从未来删除帖子。''
超级(PostModelTests,self)。tear down()
m . Post . objects . get(content = ' Future Post ')。删除()
def test _ recent _ posts _ not _ including _ future _ posts(self):
' ' ' m . post . recent _ posts()不应该返回未来的帖子。''
recent _ posts = m . post . recent _ posts()
self . assert notin(self . future _ post,recent_posts)
在这个测试用例中,我们想要验证未来的帖子不包含在从m.Post.recent_posts()返回的帖子列表中。现在,您可以通过以下方式运行测试:
$ python manage.py test
Creating test database for alias 'default'...
....................................................
======================================================================
FAIL: test_recent_posts_not_including_future_posts (myblog.tests.PostModelTests)
m.Post.recent_posts() should not return posts from the future.
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/user/python2-workspace/pythoncentral/django_series/article7/myblog/myblog/tests.py", line 23, in test_recent_posts_not_including_future_posts
self.assertNotIn(self.future_post, recent_posts)
AssertionError: unexpectedly found in []
-
在 11.877 秒内进行了 483 次测试
失败(失败=1,跳过=1,预期失败=1)
销毁别名“默认”的测试数据库...
由于来自未来的帖子在从recent_posts()返回的列表中,并且我们的测试抱怨了它,我们肯定知道在我们的代码中有一个 bug。
修复我们的测试用例错误
我们可以通过确保在recent_posts()的查询中m.Post.created_at早于timezone.now()来轻松修复这个错误:
class Post(m.Model):
content = m.CharField(max_length=256)
created_at = m.DateTimeField('datetime created')
@ class method
def recent _ posts(cls):
now = time zone . now()
two _ days _ ago = now-datetime . time delta(days = 2)
return post . objects . \
filter(created _ at _ _ gt = two _ days _ ago)。\
过滤器(created_at__lt=now)
现在,您可以重新运行测试,它应该会在没有警告的情况下通过:
$ python manage.py test
Creating test database for alias 'default'...
.................................................................................................................................................s.....................................................................................................................................x...........................................................................................................................................................................................................
----------------------------------------------------------------------
Ran 483 tests in 12.725s
OK (skipped=1,expected failures=1)
销毁别名“default”的测试数据库...
自动化测试案例总结和提示
在本文中,我们学习了如何为我们的第一个 Django 应用程序编写自动化测试。因为编写测试是最好的软件工程实践之一,它总是有回报的。这可能看起来违背直觉,因为您必须编写更多的代码来实现相同的功能,但是测试将在将来节省您的大量时间。
当编写 Django 应用程序时,我们将测试代码放入tests.py中,并通过运行$ python manage.py test来运行它们。如果有任何测试没有通过,Django 会将错误报告给我们,这样我们就可以相应地修复任何 bug。如果所有测试都通过了,那么 Django 显示没有错误,我们可以非常自信地说我们的代码工作正常。因此,对代码进行适当的测试覆盖是编写高质量软件的最佳方式之一。
为您的第一个 Python Django 应用程序编写模型
原文:https://www.pythoncentral.io/writing-models-for-your-first-python-django-application/
上一篇文章编写您的第一个 Python Django 应用程序是如何从头开始编写一个简单的 Django 应用程序的分步指南。在本文中,您将学习如何为新的 Django 应用程序编写模型。
软件架构模式
在我们深入代码之前,让我们回顾一下两个最流行的服务器端软件架构设计模式:模型-视图-控制器和表示-抽象-控制。
模型-视图-控制器
模型-视图-控制器 ( MVC )设计模式是一种软件架构模式,它将数据的表示与处理用户交互的逻辑分离开来。一个模型指定了存储什么样的数据。一个视图从一个模型中请求数据并从中生成输出。一个控制器提供逻辑来改变视图的显示或更新模型的数据。
呈现-抽象-控制
与 MVC ,表示-抽象-控制 ( PAC )是另一种流行的软件架构模式。PAC 将系统分成组件层。在每一层中,表示组件从输入数据生成输出;抽象组件检索并处理数据;而控制组件是表示和抽象之间的中间人,负责管理这些组件之间的信息流和通信。不像 MVC 中的视图直接与模型对话, PAC 的表示和抽象从不直接相互对话,它们之间的通信是通过控件进行的。与遵循 MVC 模式的 Django 不同,流行的内容管理系统 Drupal 遵循 PAC 模式。
姜戈的 MVC
虽然 Django 采用了 MVC 模式,但它与标准定义有点不同。即,
- 在 Django 中,模型描述了什么样的数据被存储在服务器上。因此,它类似于标准 MVC 模式的模型。
- 在 Django 中,视图描述了将哪些数据返回给用户。而标准的 MVC 视图描述了如何呈现数据。
- 在 Django 中,模板描述了如何将数据呈现给用户。因此,它类似于标准 MVC 模式的视图。
- 在 Django 中,控制器定义了框架提供的机制:将传入请求路由到适当视图的代码。因此,它类似于标准 MVC 模式的控制器。
总的来说,Django 偏离了标准的 MVC 模式,因为它建议视图应该包括业务逻辑,而不是像标准的 MVC 那样只包括表示逻辑,并且模板应该负责大部分的表示逻辑,而标准的 MVC 根本不包括模板组件。由于 Django 的设计与标准的 MVC 相比的这些差异,我们通常称 Django 的设计为模型-模板-视图+控制器,其中控制器经常被省略,因为它是框架的一部分。所以大部分时候 Django 的设计模式都叫 MTV 。
尽管理解 Django 的 MTV 模式的设计哲学是有帮助的,但最终唯一重要的事情是完成工作,Django 的生态系统提供了一切面向编程效率的东西。
创建模型
由于新的 Django 应用程序是一个博客,我们将编写两个模型,Post和Comment。一个Post有一个content字段和一个created_at字段。一个Comment具有一个message字段和一个created_at字段。每个Comment都与一个Post相关联。
from django.db import models as m
类 Post(m . Model):
content = m . CharField(max _ length = 256)
created _ at = m . Datetime field(' Datetime created ')
class Comment(m . Model):
Post = m . foreign key(Post)
message = m . TextField()
created _ at = m . Datetime field(' Datetime created ')
接下来,修改myblog/settings.py中的INSTALLED_APP元组,将myblog添加为已安装的应用。
INSTALLED_APPS = (
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.sites',
'django.contrib.messages',
'django.contrib.staticfiles',
# Uncomment the next line to enable the admin:
# 'django.contrib.admin',
# Uncomment the next line to enable admin documentation:
# 'django.contrib.admindocs',
'myblog', # Add this line
)
现在,您应该能够执行下面的命令来查看当您运行syncdb时将执行哪种原始 SQL。命令syncdb为INSTALLED_APPS中尚未创建表的所有应用程序创建数据库表。在后台,syncdb将原始 SQL 语句输出到后端数据库管理系统(在我们的例子中是 MySQL 或 PostgreSQL)。
$ python manage.py sql myblog
[/shell]
- MySQL 的实现
[shell]
BEGIN;
CREATE TABLE myblog_post (
id integer AUTO_INCREMENT NOT NULL PRIMARY KEY,
content varchar(256) NOT NULL,
created_at datetime NOT NULL
)
;
CREATE TABLE myblog_comment (
id integer AUTO_INCREMENT NOT NULL PRIMARY KEY,
post_id integer NOT NULL,
message longtext NOT NULL,
created_at datetime NOT NULL
)
;
ALTER TABLE myblog_comment ADD CONSTRAINT post_id_refs_id_648c7748 FOREIGN KEY (post_id) REFERENCES myblog_post (id);
提交;
[/shell]
[shell]
BEGIN;
CREATE TABLE "myblog_post" (
"id" serial NOT NULL PRIMARY KEY,
"content" varchar(256) NOT NULL,
"created_at" timestamp with time zone NOT NULL
)
;
CREATE TABLE "myblog_comment" (
"id" serial NOT NULL PRIMARY KEY,
"post_id" integer NOT NULL REFERENCES "myblog_post" ("id") DEFERRABLE INITIALLY DEFERRED,
"message" text NOT NULL,
"created_at" timestamp with time zone NOT NULL
)
;
提交;
[/shell]
SQL 转储看起来不错!现在,您可以通过执行以下命令在数据库中创建表。
$ python manage.py syncdb
Creating tables ...
Creating table myblog_post
Creating table myblog_comment
Installing custom SQL ...
Installing indexes ...
Installed 0 object(s) from 0 fixture(s)
注意,在前一个命令中创建了两个表myblog_post和myblog_comment。
与新模型玩得开心
现在,让我们深入 Django shell,享受我们全新的模型。要以交互模式运行我们的 Django 应用程序,请键入以下命令:
$ python manage.py shell
Python 2.7.2 (default, Oct 11 2012, 20:14:37)
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>>
前面的命令打开的交互式 shell 是一个普通的 Python 解释器 shell,您可以在其中针对我们的 Django 应用程序自由地执行语句。
>>> from myblog import models as m
>>> # No post in the database yet
>>> m.Post.objects.all()
[]
>>> # No comment in the database yet
>>> m.Comment.objects.all()
[]
>>> # Django's default settings support storing datetime objects with tzinfo in the database.
>>> # So we use django.utils.timezone to put a datetime with time zone information into the database.
>>> from django.utils import timezone
>>> p = m.Post(content='Django is awesome.', created_at=timezone.now())
>>> p
<Post: Post object>
>>> p.created_at
datetime.datetime(2013, 3, 26, 17, 6, 39, 329040, tzinfo=<UTC>)
>>> # Save / commit the new post object into the database.
>>> p.save()
>>> # Once a post is saved into the database, it has an id attribute which is the primary key of the underlying database record.
>>> p.id
1
>>> # Now we create another post object without saving it into the database.
>>> p2 = m.Post(content='Pythoncentral is also awesome.', created_at=timezone.now())
>>> p2
<Post: Post object>
>>> # Notice p2.id is None, which means p2 is not committed into the database yet.
>>> p2.id is None
True
>>> # Now we retrieve all the posts from the database and inspect them just like a normal python list
>>> m.Post.objects.all()
[<Post: Post object>]
>>> m.Post.objects.all()[0]
<Post: Post object>
>>> # Since p2 is not saved into the database yet, there's only one post whose id is the same as p.id
>>> m.Post.objects.all()[0].id == p.id
True
>>> # Now we save / commit p2 into the database and re-run the query again
>>> p2.save()
>>> m.Post.objects.all()
[<Post: Post object>, <Post: Post object>]
>>> m.Post.objects.all()[1].id == p2.id
True
现在我们已经熟悉了新的Post型号,将它与新的Comment一起使用怎么样?一个Post可以有多个Comment,而一个Comment只能有一个Post。
>>> c = m.Comment(message='This is a comment for p', created_at=timezone.now())
>>> c.post = p
>>> c.post
<Post: Post object>
>>> c.post.id == p.id
True
>>> # Since c is not saved yet, p.comment_set.all() does not include it.
>>> p.comment_set.all()
[]
>>> c.save()
>>> # Once c is saved into the database, p.comment_set.all() will have it.
>>> p.comment_set.all()
[<Comment: Comment object>]
>>> p.comment_set.all()[0].id == c.id
True
>>> c2 = m.Comment(message='This is another comment for p.', created_at=timezone.now())
>>> # If c2.post is not specified, then Django will raise a DoseNotExist exception.
>>> c2.post
Traceback (most recent call last):
File "<console>", line 1, in <module>
File "/Users/xiaonuogantan/python2-workspace/lib/python2.7/site-packages/django/db/models/fields/related.py", line 389, in __get__
raise self.field.rel.to.DoesNotExist
DoesNotExist
>>> # Assign Post p to c2.
>>> c2.post = p
>>> c2.save()
>>> p.comment_set.all()
[<Comment: Comment object>, <Comment: Comment object>]
>>> # Order the comment_set according Comment.created_at
>>> p.comment_set.order_by('created_at')
[<Comment: Comment object>, <Comment: Comment object>]
到目前为止,我们知道了如何使用每个模型的现有属性来创建、保存和检索Post和Comment。查询数据库找到我们想要的帖子和评论怎么样?原来 Django 为查询提供了一种稍微有点奇怪的语法。基本上,filter()函数接受符合“[字段]_ [字段属性] _[关系]=[值]”形式的参数。举个例子,
>>> # Retrieve a list of comments from p.comment_set whose created_at.year is 2013
>>> p.comment_set.filter(created_at__year=2013)
[<Comment: Comment object>, <Comment: Comment object>]
>>> # Retrieve a list of comments from p.comment_set whose created_at is later than timezone.now()
>>> p.comment_set.filter(created_at__gt=timezone.now())
[]
>>> # Retrieve a list of comments from p.comment_set whose created_at is earlier than timezone.now()
>>> p.comment_set.filter(created_at__lt=timezone.now())
[<Comment: Comment object>, <Comment: Comment object>]
>>> # Retrieve a list of comments from p.comment_set whose message startswith 'This is a '
>>> p.comment_set.filter(message__startswith='This is a')
[<Comment: Comment object>, <Comment: Comment object>]
>>> # Retrieve a list of comments from p.comment_set whose message startswith 'This is another'
>>> p.comment_set.filter(message__startswith='This is another')
[<Comment: Comment object>]
>>> # Retrieve a list of posts whose content startswith 'Pythoncentral'
>>> m.Post.objects.filter(content__startswith='Pythoncentral')
[<Post: Post object>]
>>> # Retrieve a list of posts which satisfies the query that any comment in its comment_set has a message that startswith 'This is a'
>>> m.Post.objects.filter(comment__message__startswith='This is a')
[<Post: Post object>, <Post: Post object>]
>>> # Retrieve a list of posts which satisfies the query that any comment in its comment_set has a message that startswith 'This is a' and a created_at that is less than / earlier than timezone.now()
>>> m.Post.objects.filter(comment__message__startswith='This is a', comment__created_at__lt=timezone.now())
[<Post: Post object>, <Post: Post object>]
您是否注意到最后两个查询有些奇怪?m.Post.objects.filter(comment__message__startswith='This is a')和m.Post.objects.filter(comment__message__startswith='This is a', comment__created_at__lt=timezone.now())返回两个Post而不是一个不奇怪吗?我们来核实一下有哪些帖子被退回来了。
>>> posts = m.Post.objects.filter(comment__message__startswith='This is a')
>>> posts[0].id
1
>>> posts[1].id
1
啊哈!posts[0]和posts[1]是同一个岗位!那是怎么发生的?因为原始查询是Post和Comment的连接查询,并且有两个Comment满足该查询,所以返回两个Post对象。那么,我们如何让它只返回一个Post?很简单,只需在filter()的末尾追加一个distinct():
>>> m.Post.objects.filter(comment__message__startswith='This is a').distinct()
[<Post: Post object>]
>>> m.Post.objects.filter(comment__message__startswith='This is a', comment__created_at__lt=timezone.now()).distinct()
[<Post: Post object>]
总结和建议
在本文中,我们为我们的博客网站编写了两个简单的模型Post和Comment。Django 没有编写原始的 SQL,而是提供了一个强大且易于使用的 ORM,允许我们编写简洁且易于维护的数据库操作代码。您应该深入代码并运行python manage.py shell来与现有的 Django 模型进行交互,而不是停留在这里。很好玩啊!
为您的第一个 Python Django 应用程序编写简单的视图
原文:https://www.pythoncentral.io/writing-simple-views-for-your-first-python-django-application/
在上一篇文章为您的 Python Django 网站激活管理应用中,我们学习了如何在您的网站中激活来自 Django 的内置管理应用。在本文中,我们将为您的网站编写简单的视图。
什么是视图?
在 Django 中,视图是一个端点,任何客户端都可以通过网络访问它来检索数据。例如,一些视图将使用模板呈现的数据提供给 web 服务器,web 服务器再将 HTML 页面提供给客户端。而其他视图向 web 服务器提供 JSON 数据,这些视图成为一个 RESTful API 的一部分。
在 Django 中,视图是简单的 Python 函数或方法,将数据返回到前端 web 服务器。当一个请求进来时,Django 通过检查域名后面的请求的 URL 来选择一个视图。当发出一个请求时,为了调用正确的视图,您需要将一个 URL 模式列表插入到myblog/urls.py中。URL 模式是基于字符串的正则表达式,它指定了视图的 URL 的一般形式。例如,r'^posts/(?P\d{4})/$'匹配域名后的部分遵循字符串“posts”后跟一个四位数的模式的所有 URL。
Django 网站的浏览量
在我们的博客网站上,我们将写出以下观点:
Post“索引”视图显示博客中最近的帖子或热门帖子的列表,就像 的主页一样Post“detail”视图显示了一个Post的细节,类似于 上的每一篇文章页面
在“索引”视图中,用户应该能够看到其他人制作的最新Posts列表。在“细节”视图中,用户应该能够看到一个Post的内容以及其他人制作的一个Comment列表。
索引视图
让我们编写您的第一个视图“索引”,它显示了最近Post的列表。使用以下内容创建一个文件myblog/views.py:
from django.http import HttpResponse
def index(request):
return HttpResponse('该页面显示最近发布的帖子列表。')
并修改文件myblog/urls.py:
from django.conf.urls import patterns, include, url
#取消对下面两行的注释,以启用 django.contrib 中的 admin:
import admin
admin . auto discover()
urlpatterns = patterns(',
#添加下面一行将根 URL 链接到函数 myblog.views.index()
url(r'^$',' my blog . views . index ',name='index ',
# url(r'^myblog/',include('myblog.foo.urls '),
#取消对下面的管理/文档行的注释以启用管理文档:
url(r'^admin/doc/',包括(' django.contrib.admindocs.urls '),
#取消注释下一行以启用 admin:
url(r'^admin/',include(admin.site.urls)),
)
现在您可以在浏览器中访问 127.0.0.1:8000 ,查看myblog.views.index() :
 返回的内容
返回的内容
因为myblog.views.index的返回值是一个字符串,所以这个页面显示了最近的文章列表,它显示在这个页面上。接下来,我们将修改函数myblog.views.index来返回一个不早于两天前发布的Post列表:
from datetime import datetime, timedelta
from django.http import HttpResponse
从我的博客导入模型作为 m
def index(request):
two _ days _ ago = datetime . utc now()-time delta(days = 2)
recent _ posts = m . post . objects . filter(created _ at _ _ gt = two _ days _ ago)。all()
返回 HttpResponse(recent_posts)
现在可以刷新 127.0.0.1:8000 看不到两天前没有帖子:
让我们使用管理站点的管理界面添加一个Post:

点击“保存”,文章管理页面将显示一篇新文章被添加,现在数据库中总共有三篇文章:

现在你可以刷新主页来查看返回的Post:

Django 视图模板
显然,只显示“文章对象”对用户没有太大的帮助,我们需要一个更有信息的页面来显示一系列的Post。这时模板将有助于把一个像当前这样无用的页面变成一个像样的页面。
用以下内容创建一个新文件myblog/templates/index.html:
{% if post_list %}
<ul>
{% for post in post_list %}
<li>
<a href="/post/{{ post.id }}/">{{ post.content }}</a>
<span>{{ post.created_at }}</span>
</li>
{% endfor %}
</ul>
{% else %}
<p>No post is made during the past two days.</p>
{% endif %}
并修改文件myblog/views.py以使用 Django 模板系统渲染 127.0.0.1:8000 的响应:
from datetime import datetime, timedelta
from django.http import HttpResponse
from django.template import Context, loader
从我的博客导入模型作为 m
def index(request):
two _ days _ ago = datetime . utcnow()-time delta(days = 2)
#检索不到两天前创建的帖子列表
recent _ posts = m . post . objects . filter(created _ at _ _ gt = two _ days _ ago)。全部()
#加载模板 my blog/templates/index . html
template = loader . get _ template(' index . html ')
# Context 是一个普通的 Python 字典,它的键可以在模板 index.html
Context = Context({
' post _ list ':recent _ posts
})中访问
return HttpResponse(template . render(context))
现在,您可以再次刷新主页,查看使用myblog/templates/index.html中的模板渲染的Post:

虽然视图索引()的当前代码可以工作,但是它比必要的要长一点。您可以使用 Django 快捷方式render来缩短代码:
from datetime import datetime, timedelta
from django.http import HttpResponse
from django.shortcuts import render
from django.template import Context
from myblog import models as m
def index(request):
two _ days _ ago = datetime . utc now()-time delta(days = 2)
recent _ posts = m . post . objects . filter(created _ at _ _ gt = two _ days _ ago)。all()
Context = Context({
' post _ list ':recent _ posts
})
# Render 接受三个参数:请求对象、模板文件的
#路径和 context
返回 render(request,' index.html ',context)
姜戈的详图
类似于index视图,detail视图显示了一个页面,该页面在类似于/post/1/detail.html的 URL 上呈现了关于Post的详细信息,其中1是一个Post的 id。
类似于index视图,您需要在编写detail视图之前编写 URL 模式。按照以下方式修改文件myblog/urls.py:
from django.conf.urls import patterns, include, url
#取消对下面两行的注释,以启用 django.contrib 中的 admin:
import admin
admin . auto discover()
urlpatterns = patterns(',
url(r'^$',' myblog.views.index ',name='index '),
#将视图函数 myblog.views.post_detail()映射到一个 url 模式
url(r'^post/(?p<post _ id>\ d+)/detail . html $ ',
'myblog.views.post_detail ',name='post_detail ',
# url(r'^myblog/',include('myblog.foo.urls '),
#取消对下面的管理/文档行的注释以启用管理文档:
url(r'^admin/doc/',包括(' django.contrib.admindocs.urls '),
#取消注释下一行以启用 admin:
url(r'^admin/',include(admin.site.urls)),
)
然后可以在myblog/views.py中实现视图功能:
from datetime import datetime, timedelta
from django.http import Http404, HttpResponse
from django.shortcuts import render
from django.template import Context
from myblog import models as m
def index(request):
two _ days _ ago = datetime . utc now()-time delta(days = 2)
recent _ posts = m . post . objects . filter(created _ at _ _ gt = two _ days _ ago)。all()
context = Context({
' post _ list ':recent _ post
})
return render(request,' index.html ',Context)
# post_detail 接受两个参数:普通请求对象和一个整数
#其值由 r'^post/(定义的 post_id 映射?p<Post _ id>\ d+)/detail . html $ '
def Post _ detail(request,Post _ id):
try:
Post = m . Post . objects . get(PK = Post _ id)
除 m.Post.DoesNotExist:
#如果没有帖子有 id post_id,我们抛出 HTTP 404 错误。
引发 http 404
return render(request,' post/detail.html ',{'post': post})
然后我们需要在myblog/templates/post/detail.html添加一个新的模板文件:
<div>
<h1>{{ post.content }}</h1>
<h2>{{ post.created_at }}</h2>
</div>
现在您可以访问 URL 帖子详细信息:

如果您访问的Post的id不在数据库中,我们的detail 视图将显示 HTTP 404 错误页面:

摘要
在本文中,我们编写了前两个视图。index视图显示了用户在不到两天前创建的posts的列表,detail视图显示了Post的详细内容。一般来说,写一部view的过程包括:
- 在
myblog/urls.py中为视图编写 URL 模式 - 在
myblog/views.py中编写实际视图的代码 - 在目录
myblog/templates/中写一个模板文件
为 Django 应用程序的视图编写测试
原文:https://www.pythoncentral.io/writing-tests-for-your-django-applications-views/
测试 Django 应用程序的视图
在我们的上一篇文章中,我们学习了如何为 Django 应用程序编写自动化测试,包括编写一个简单的测试来验证模型方法m.Post.recent_posts()的行为,并修复方法recent_posts()返回未来帖子的错误。
在本文中,我们将学习如何为像myblog.views.post_detail(request, post_id)这样的视图编写测试。为了做到这一点,我们将利用 Django 的测试客户端来模拟用户对视图执行操作。
Django 测试客户端
在接下来的代码片段中,我们将使用django.test.utils.setup_test_environment和django.test.client.Client来模拟用户与网站视图的交互。
>>> from django.test.utils import setup_test_environment
>>> # Set up a test environment so that response.context becomes available
>>> setup_test_environment()
>>> from django.test.client import Client
>>> client = Client()
>>> from django.test.client import Client
>>> client = Client()
>>> # GET the root path of our server
>>> response = client.get('/')
>>> # Inspect the status_code of our server's response
>>> response.status_code
200
>>> # Print the content of our server's response
>>> print(response.content)
过去两天没有帖子。
>>>从 myblog 导入 models as m
>>>from django . utils 导入 timezone
> > > #创建一个新的帖子以便下一个响应返回它
>>>m . Post . objects . Create(content = ' New Post ',created _ at = time zone . now())
>>>
>>>#打印我们服务器的新响应的内容,其中包括新的内容
'\n
- \n 新帖子\ n2013 年 8 月 14 日晚上 9:12\ n
\n \n
\n\n'
在前面的代码片段中,response.context是一个字典,包含了与 Django 服务器的当前请求-响应生命周期相关的所有键和值的信息。除非我们调用setup_test_environment()使当前 shell 成为测试环境,否则它不可用。这种设置测试环境的调用在tests.py中是不必要的,因为 Django 已经在python manage.py test中构建好了。
编写测试代码以验证 Post 详细视图
我们现有的帖子详细信息视图根据 URL 内部传递的 Post.id 值返回一个帖子:
# myblog/urls.py
urlpatterns = patterns('',
...
url(r'^post/(?P\d+)/detail.html$',
'myblog.views.post_detail', name='post_detail'),
...
# myblog/views.py 在 post/1/detail . html
def post _ detail(request,post _ id):
try:
post = m . post . objects . get(PK = post _ id)
除 m . post . doesnotexist:
raise http 404
return render(request,' post/detail.html ',{'post': post})
现在,我们可以编写测试用例来验证当 URL 中提供了post_id时,post_detail视图确实返回了一篇文章,并且当文章不存在时引发 404 错误。将以下代码插入myblog/tests.py:
import sys
from django.core.urlresolvers import reverse
# The function 'reverse' resolves a view name and its arguments into a path
# which can be passed into the method self.client.get(). We use the 'reverse'
# method here in order to avoid writing hard-coded URLs inside tests.
类 PostDetailViewTests(test case):
def setUp(self):
super(PostDetailViewTests,self)。setUp()
self . Post = m . Post . objects . create(content = ' New Post ',created_at=timezone.now())
def tear down(self):
super(PostDetailViewTests,self)。tearDown()
self.post.delete()
def test _ post_detail _ success(self):
response = self . client . get(reverse(' Post _ detail ',args=(self.post.id,))
# Assert self . Post 实际上是由 Post _ detail 视图返回的
self . Assert equal(response . status _ code,200)
self . Assert contains(response,' New Post ')
def test _ post_detail _ 404(self):
response = self . client . get(reverse(' post _ detail ',args=(sys.maxint,))
#断言 post _ detail 视图为不存在的帖子返回 404
self . Assert equal(response . status _ code,404)
测试 Django 视图摘要
在本文中,我们学习了如何为 Django 应用程序中的视图编写自动化测试。我们利用 Django 的测试客户端来模拟对服务器的GET请求,并检查返回的响应,以确保它们满足不同的用例。
为您的第一个 Python Django 应用程序编写上传帖子的视图
原文:https://www.pythoncentral.io/writing-views-to-upload-posts-for-your-first-python-django-application/
在上一篇文章中,我们编写了一个index视图来显示不到两天前创建的一系列posts和一个detail视图来显示一个post的详细内容。在本文中,我们将编写一个视图,允许用户上传一个post,并用 Django 内置的通用视图改进我们现有的index和detail。
上传视图
类似于我们在上一篇文章中所做的,为了编写上传视图,我们需要首先在myblog/urls.py中编写一个 URL 模式:
from django.conf.urls import patterns, include, url
#取消对下面两行的注释,以启用 django.contrib 中的 admin:
import admin
admin . auto discover()
urlpatterns = patterns(',
url(r'^$',' myblog.views.index ',name='index '),
url(r'^post/(?p<post _ id>\ d+)/detail . html $ ',
'myblog.views.post_detail ',name='post_detail ',
#将视图 myblog.views.post_upload 链接到 URL post/upload . html
url(r'^post/upload.html$',' myblog.views.post_upload ',name='post_upload ',
#取消对下面的管理/文档行的注释以启用管理文档:
url(r'^admin/doc/',包括(' django.contrib.admindocs.urls '),
#取消注释下一行以启用 admin:
url(r'^admin/',include(admin.site.urls)),
)
前面的 URL 模式指定myblog.views.post_upload应该处理任何指向 URL post/upload.html的请求。现在让我们编写实际的视图:
# Add the following import statements to the top of myblog/views.py
from datetime import datetime
from django.core.urlresolvers import reverse
from django.http import HttpResponseRedirect
#在 myblog/views.py 的末尾添加以下函数
def POST _ upload(request):
if request . method = = ' GET ':
return render(request,' post/upload.html ',{ })
elif request . method = = ' POST ':
POST = m . POST . objects . create(content = request。POST['content'],
created _ at = datetime . utc now())
#此时不需要调用 POST . save()——已经保存了。
return HttpResponseRedirect(reverse(' post _ detail ',kwargs = { ' post _ id ':post . id })
post_upload处理两种可能的情况。如果request是一个 GET 请求,post_upload只是返回一个 HTML 页面。如果是一个 POST 请求,post_upload()在数据库中创建一个新的Post对象,并返回一个在上下文中包含新的Post对象的 HTML 页面。
接下来,我们将为我们的视图编写模板myblog/templates/post/upload.html。这个模板将向用户呈现一个 HTML 表单。
<form action="{% url 'post_upload' %}" method="post">
{% csrf_token %}
<label for="content"></label>
<input type="text" name="content" id="content" />
<input type="submit" />
</form>
前面的模板文件使用 Django 的模板语言来指定页面的内容。每当 Django 将模板与上下文一起呈现时,模板呈现器就会处理{%和%}之间的代码,并且{% %}标记之外的任何内容都会作为普通字符串返回。为了查看渲染模板的实际输出,您可以在浏览器中检查其源代码:
<form action="/post/upload.html" method="post" _lpchecked="1">
<input type="hidden" name="csrfmiddlewaretoken" value="AGGNpA4NcmbuPachX2zrksQXg4PQ7NW0">
<label for="content"></label>
<input type="text" name="content" id="content">
<input type="submit">
</form>
现在您可以用python manage.py runserver shell 命令启动服务器,并访问 URL http://127.0.0.1:8000/post/upload.html:

现在您可以键入新的Post对象的内容:

然后点击“提交”,这将把您重定向到您的新帖子:

通用视图
到目前为止,我们在 Django 应用程序中编写了三个简单的视图:一个显示一列Posts的index视图;一个post_detail视图显示了一个Post对象的详细信息页面;和一个允许用户上传一个Post到数据库的post_upload视图。这些视图代表了 web 开发的一个常见案例:从数据库获取数据,使用模板呈现数据,并将呈现的模板作为 HTTP 响应返回给用户。由于这些类型的视图非常常见,Django 提供了一套generic视图,有助于在编写类似的视图时减少样板代码。
首先,我们将修改myblog/urls.py中的 URL 配置:
from django.conf.urls import patterns, include, url
#取消对下面两行的注释,以启用 django.contrib 中的 admin:
import admin
admin . auto discover()
从我的博客导入视图
urlpatterns = patterns(',
#取消对下面的管理/文档行的注释以启用管理文档:
url(r'^admin/doc/',包括(' django.contrib.admindocs.urls '),
#取消注释下一行以启用 admin:
url(r'^admin/',include(admin.site.urls)),
#使用通用视图替换以前的 post_index 和 post_detail viwes
url(r'^$'视图。PostIndexView.as_view(),name='post_index '),
url(r'^post/(?P < pk > \d+)/detail.html$ ',
观点。PostDetailView.as_view(),
name='post_detail '),
url(r'^post/upload.html',views.post_upload,name='post_upload '),
)
注意,post_detail接受一个参数pk,这是generic.DetailView获取主键是传入参数的Post对象所需要的。
然后,我们修改myblog/views.py:
from datetime import datetime, timedelta
from django.core.urlresolvers import reverse
from django.http import HttpResponseRedirect
from django.views import generic
从我的博客导入模型作为 m
def POST _ upload(request):
if request . method = = ' GET ':
return render(request,' post/upload.html ',{ })
elif request . method = = ' POST ':
POST = m . POST . objects . create(content = request。POST['content'],
created _ at = datetime . utc now())
#此时不需要调用 POST . save()——已经保存好了。
return HttpResponseRedirect(reverse(' post _ detail ',kwargs={'post_id': post.id}))
类 PostIndexView(泛型。ListView):
template _ name = ' index . html '
context _ object _ name = ' Post _ list '
model = m . Post
def get_queryset(self):
' ' '返回不到两天前创建的帖子'
two _ days _ ago = datetime . utc now()-time delta(days = 2)
返回 m . post . objects . filter(created _ at _ _ gt = two _ days _ ago)。全部()
类 PostDetailView(泛型。detail view):
template _ name = ' Post/detail . html '
model = m . Post
请注意,与以前的版本相比,这段代码要干净得多。generic.ListView提供了显示对象列表的概念,而generic.DetailView关心的是“显示一个特定的对象”。每个通用视图都需要知道它依赖于哪个模型,所以每个通用视图子类中都需要model属性。
因为generic.ListView和generic.DetailView接受合理的缺省值,比如在模板中使用的context_object_name和在数据库中查询的model,我们的代码变得更短、更简单,而不是太在意样板代码,比如加载和呈现模板。通用视图是一堆 Python classes,意在子类化以适应开发者的不同需求。
现在,您可以再次运行服务器,查看与我们之前的实现完全相同的输出。
总结和建议
在本文中,我们学习了如何编写一个视图来处理 POST 请求,以及如何使用generic视图来清理和提高视图的代码质量。Django 是不要重复自己(DRY) 原则的强烈支持者,该原则要求每条信息在系统中都应该有一个单一的、明确的和权威的表示。在 Django 的例子中,这意味着应该只有一个函数、一个类或一个模块负责一个特定的特性。例如,每个通用视图只处理一种类型的视图,并封装了特定类型视图的基本功能,因此子类可以在任何地方重用核心功能。Django 自己的实现和 API 严格遵循 DRY 原则,以最小化重复和不必要的样板代码。我们也应该遵循同样的原则,尽可能重用 Django 的generic视图。当您面临对通用视图进行子类化还不够的问题时,我建议您阅读 Django 关于如何实现通用视图的源代码,并尝试编写可重用的视图,而不是盲目地编写样板代码。
编写您的第一个 Python Django 应用程序
原文:https://www.pythoncentral.io/writing-your-first-python-django-application/
创建 Django 项目
上一篇文章介绍 Python 的 Django 介绍了 Django 框架的概况。在本文中,我们将从头开始编写一个简单的 Django 应用程序。第一步是使用 Django 的一个内置命令django-admin.py创建一个项目。在 Virtualenv 中,键入以下命令:
【shell】
django-admin . py start project my blog
django-admin.py是一个方便的 shell 可执行文件,它提供了一系列子命令来管理 Django 应用程序。在前面的例子中,子命令startproject在当前目录中创建一个 Django 项目目录结构:
myblog/
manage.py
myblog/
__init__.py
settings.py
urls.py
wsgi.py
myblog是 Django 项目myblog的父目录。它可以被重命名为你喜欢的任何名字,因为它只是一个容器。manage.py是一个命令行实用程序,可以让您以各种方式与 Django 项目myblog进行交互。这个实用程序对于调试或练习代码非常有帮助。myblog/myblog是包含项目实际 Python 包的目录。因为它是一个普通的 Python 包,所以可以使用普通的 Python 语法导入其中的任何模块或包。例如,import myblog.settings导入myblog包内的设置模块。myblog/myblog/settings.py是 Django 项目的设置或配置。它包含在整个项目中使用的全局配置列表。myblog/myblog/urls.py声明此项目的 URL 路由。它包含一个 URL 映射列表,告诉项目哪个视图函数如何处理 HTTP(S)请求。myblog/myblog/wsgi.py是在兼容 WSGI 的 web 服务器上运行 Django 项目的脚本。
既然我们有一个 Django 项目,就让我们来运行它吧!
python manage.py runserver
Validating models...
发现 0 个错误
2013 年 3 月 20 日- 21:15:27
Django 版本 1.5,使用设置‘my blog . settings’
开发服务器运行在 http://127.0.0.1:8000/
用 CONTROL-C 退出服务器
在你最喜欢的浏览器中访问http://127.0.0.1:8000/会显示一个欢迎页面。Django 应用程序的默认 IP 地址是127.0.0.1,只能从本地机器访问。如果你想在其他计算机上显示你的应用程序,你可以修改 ip 地址和端口,比如python manage.py runserver 0.0.0.0:8000,它允许你的 Django 应用程序监听所有的公共 IP。
在 Django 建立一个数据库
任何重要网站最重要的一个方面是数据库后端。由于数据库后端通常被配置为全局环境变量,Django 在myblog/settings.py中提供了一个方便的配置default项来处理各种数据库配置。
Django 和 MySQL
在包含 Django 应用程序的 Virtualenv 中,运行以下命令:
【shell】
pip install MySQL-python
这将安装 MySQL Python 驱动程序。Django 的对象关系映射(ORM)后端将使用这个驱动程序在原始 SQL 语句中与 MySQL 服务器通信。
然后,在 mysql shell 中执行以下语句,为 Django 应用程序创建一个用户和一个数据库。
【shell】
MySQL>创建用户‘python central’@‘localhost’标识为‘12345’;
mysql >创建数据库 myblog
mysql > GRANT ALL ON myblog。* TO ' python central ' @ ' localhost ';
现在,修改myblog/settings.py。
DATABASES = {
'default': {
# Add 'postgresql_psycopg2', 'mysql', 'sqlite3' or 'oracle'
'ENGINE': 'django.db.backends.mysql',
# Or the path to the database file if using sqlite3
'NAME': 'myblog',
# The following settings are not used with sqlite3
'USER': 'pythoncentral',
'PASSWORD': '12345',
# Empty for localhost through domain sockets or '127.0.0.1' for localhost through TCP
'HOST': '',
# Set to empty string for default
'PORT': '',
}
}
然后,运行下面的命令来初始化 Django 应用程序的数据库。
【shell】
python manage . py syncdb
创建表...
创建表 auth_permission
创建表 auth_group_permissions
创建表 auth_group
创建表 auth_user_groups
创建表 auth_user_user_permissions
创建表 django_content_type
创建表 django_session
创建表 django_site
您刚刚安装了 Django 的 auth 系统,这意味着您没有定义任何超级用户。您想现在创建一个吗?(是/否):是
用户名(留空使用‘我的用户名’):
邮箱:
密码:
密码(再次):
超级用户创建成功。
安装自定义 SQL...
安装索引...
从 0 个夹具安装了 0 个对象
最后,一个全新的 MySQL 数据库后端已经创建!您可以通过 django.contrib.auth.models 中的
【shell】
python manage . py shell
与新数据库进行交互导入用户
User . objects . all()
<用户:my username>
Django 和 PostgreSQL
像 MySQL 一样,我们在 virtualenv 中安装了一个 Python PostgreSQL 驱动程序。
【shell】
pip 安装 psycopg2
然后,在 PostgreSQL shell 中执行以下语句,为 Django 项目创建一个用户和一个数据库。
【shell】
postgres = #创建用户 pythoncentral,密码为‘12345’;
创建角色
postgres=#创建数据库 myblog
创建数据库
postgres=#将数据库 myblog 上的所有权限授予 pythoncentral
授予
现在,修改myblog/settings.py。
【python】
DATABASES = {
' default ':{
Add ' PostgreSQL _ psycopg 2 ',' mysql ',' sqlite3 '或' Oracle '
' ENGINE ':' django . db . backends . PostgreSQL _ psycopg 2 ',
如果使用 sqlite3
'NAME': 'myblog ',
以下设置不适用于 sqlite3
' USER ':' python central ','
然后,运行下面的命令来初始化 Django 应用程序的数据库后端。
【shell】
python manage . py syncdb
创建表...
创建表 auth_permission
创建表 auth_group_permissions
创建表 auth_group
创建表 auth_user_groups
创建表 auth_user_user_permissions
创建表 django_content_type
创建表 django_session
创建表 django_site
您刚刚安装了 Django 的 auth 系统,这意味着您没有定义任何超级用户。您想现在创建一个吗?(是/否):是
用户名(留空使用‘我的用户名’):
邮箱:
密码:
密码(再次):
超级用户创建成功。
安装自定义 SQL...
安装索引...
从 0 个夹具安装了 0 个对象
最后,您可以使用内置的 shell 与新的 Django 应用程序进行交互。
【shell】
python manage . py shell
from django . contrib . auth . models 导入用户
User . objects . all()
<用户:my username>
注意,当您查询所有的User对象时,Django 的 shell 对于数据库后端是不可知的。相同的代码User.objects.all()用于MySQL和PostgreSQL检索数据库中所有用户的列表。
Django 简介摘要
在本文中,我们创建了我们的第一个 Django 应用程序myblog,并针对一个MySQL后端和一个PostgreSQL后端进行了测试。使用 Django 的ORM,我们可以编写数据库CRUD(创建、读取、更新、删除)操作,而无需关心底层数据库后端。在本系列的后续文章中,我们将对几乎所有的数据库代码广泛使用 Django 的ORM。
你应该在 2021 年开始使用的 Python 技巧
原文:https://www.pythoncentral.io/x-python-tricks-you-should-start-using-in-2021/

Python 是一种面向对象的、复杂的编程语言,其语义在 2021 年将是活跃的、有效的。它建立在几个数据结构的高层次上,这些数据结构与动态语言类型相结合并将其绑定在一起。当您想要绑定和连接现有组件时,它被用作脚本和胶水来将它们绑定在一起,并敏捷地开发应用程序。
X Python 的把戏
即使在 2021 年,编程人员也应该学习 Python 语言。python 使用的语法简单、敏感。随着对机器学习语言和人工智能的需求不断增长,使用 Python 的趋势非常有预见性。它是一种用户友好的语言,具有简单的语法结构。
Python 为各种平台提供服务,就像 Java 选择最灵活高效的平台一样。许多著名的企业都在使用 Python,比如谷歌、脸书、IBM、Quora 等等。
这种动态编程语言注重用户友好和可读性的界面。在 2021 年,你应该学习一些技巧来获得 python 作业的帮助。我们向你展示了一些有用的技巧,你应该在 2021 年开始使用。
1。枚举
枚举是具有代表性的名称,必须是独特的,并且值是持久的。为了在类成员中存储多个数据,我们需要一个程序在任何地方使用它们。
示例代码
类别编号:
a,b,c = 5,6,7
打印(MyEnums.a) # 5
打印(MyEnums.b) # 6
打印(MyEnums.c) # 7
2。反向循环
这种反向循环的技巧将教你循环缺货的系列或任何列表。可以随便设置,不用设置循环从末尾开始。
示例代码
我的列表= [3,4,5,6,7]
对于反转的 x(my list):
打印(x)
输出
7
6
5
4
3
3。关联评估
对于单个 python 表示,可以通过连接操作符来连接多个比较。如果所有的比较都是正确的或错误的,它就为真。注意这与(2 < x) and (x < 9)和(6 < x)和(x<9)是一样的。x 只需要评估一次。
x = 7
2< x <9
真实的
6< x <9
错误的
以下情况也是允许的
2 < x > 3
对于连接两个以上的比较:
x = 7
y = 9
0 < x< 3 < y < 16
真实的
4。无循环打印“N”字符串
一个没有循环的有用技巧是打印“N”次字符串。这将节省时间和进一步的编码。
示例代码
String = "code "
打印(字符串* 5)
输出
代码代码代码
5。统一字典
为了将两本词典合二为一,这个技巧会对你有所帮助。
示例代码
X = {"a": 3}
Y = {"b": 4}
Z = {x,y}
Print (z) # {'a': 3,' b': 4}
6。排列词典
用于排列通过。Items()方法
x =
已排序(x. items())
[('u ',5),(' v ',2),(' w ',3)]
7 .。翻字典
您已经到了想要反转正在使用的字典的程度,使用最新字典的先前字典值。使用循环,您只需创建一行 python 代码,并创建一个新的字典来进一步处理。
dict1={"key4": 4," key5": 5," key6": 6," key7": 7}
dict2={v: k for k,v in dict1.items()}
打印(字典 2)
输出
{4: 'key4 ',5: 'key5 ',6: 'key6 ',7: 'key7'}
8。可变汇率
为了以简单的方式交换任意两个变量,可以对变量交换应用多重赋值,不包括添加第三个变量:
x,y = 4,6
x
four
y
six
x,y = y,x
x
six
y 4
9。代码运行时计算
为了提供最佳解决方案,如果您比较可变代码集,那么代码运行时计算就变得很重要。让我们借助时间模块来解释这一点
导入时间
startTime = time.time()
我们的关键代码从这里开始
X = 40
Y = 60
Z = x+y
打印(f "总和是: ",z)
我们的关键代码到此结束
endTime = time.time()
net = endTime – startTime
打印(f“所用时间:”净值)
产量
总数是 100 英镑
10。分类一个完整的列表
我们不时需要对列表中给出的项目的数据类型进行重新分类。为了加快这个过程,我们使用了 python 中的 map 函数。
列表 1 = [3,4,5,6,7]
打印(f "整数形式的列表: ",列表 1)
List2 = list(map(float,list1))
打印(f "浮动形式列表: ",列表 2)
产量
整数形式的列表:[3,4,5,6,7]
以浮点形式列出:[3.0,4.0,5.0,6.0,7.0]
结论
Python 是一种通用的动态编程语言,其中的技巧非常有用。随着时间的推移,python 的重要性大大增加,专家建议通过添加上述技巧来优化代码结构,以提高质量和改进。
尽管这些代码片段很容易被专业程序员理解,但初学者也可以利用它们。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号