PythonCentral-博客中文翻译-二-
PythonCentral 博客中文翻译(二)
Tweepy 简介,用于 Python 的 Twitter
原文:https://www.pythoncentral.io/introduction-to-tweepy-twitter-for-python/
Python 对于各种事物来说都是很棒的语言。非常活跃的开发人员社区创建了许多库,这些库扩展了语言并使使用各种服务变得更加容易。其中一个图书馆是 tweepy。Tweepy 是开源的,托管在 GitHub 上,支持 Python 与 Twitter 平台通信并使用其 API。关于库 Twython - 的介绍,请查看本文。
在撰写本文时,tweepy 的当前版本是 1.13。它于 1 月 17 日发布,与前一版本相比,提供了各种错误修复和新功能。2.x 版本正在开发中,但是目前还不稳定,所以大多数用户应该使用普通版本。
安装 tweepy 很简单,可以从 Github 库克隆:
git clone https://github.com/tweepy/tweepy.git
python setup.py install
或者使用简易安装:
pip install tweepy
这两种方式都为您提供了最新的版本。
使用 Tweepy
Tweepy 支持通过基本认证和更新的方法 OAuth 访问 Twitter。Twitter 已经停止接受基本认证,所以 OAuth 现在是使用 Twitter API 的唯一方式。
下面是如何使用 tweepy 和 OAuth 访问 Twitter API 的示例:
import tweepy
#消费密钥和访问令牌,用于 OAuth
Consumer _ key = ' 7 eyztcakinvs 3 T2 Pb 165 '
Consumer _ secret = ' a 44 r 7 wvbmw7 l 8 I 656y 4 l '
access _ token = ' z 00 xy 9 akhwp 8 vstj 04 l 0 '
access _ token _ secret = ' a1ck 98 w 2 nxxacmqmw 6 p '
# OAuth 进程,使用密钥和令牌
auth = tweepy。OAuthHandler(消费者密钥,消费者秘密)
auth.set_access_token(访问令牌,访问令牌 _ 秘密)
#使用认证创建实际接口
api = tweepy。API(授权)
# Sample 方法,用于更新状态
API . update _ status(' Hello Python Central!')
这段代码的结果如下:

基本身份验证和 OAuth 身份验证的主要区别在于消费者和访问密钥。使用基本认证,可以提供用户名和密码并访问 API,但自从 2010 年 Twitter 开始要求 OAuth 以来,这个过程变得有点复杂。必须在developer.twitter.com创建一个应用程序。
最初,OAuth 比基本 Auth 要复杂一些,因为它需要更多的努力,但是它提供的好处是非常有利可图的:
- Tweets 可以被定制为一个字符串来标识所使用的应用程序。
- 它不会泄露用户密码,使其更加安全。
- 管理权限更容易,例如,可以生成一组令牌和密钥,只允许从时间线读取,因此,如果有人获得这些凭据,他/她将无法编写或发送直接消息,从而将风险降至最低。
- 应用程序不回复密码,所以即使用户更改了密码,应用程序仍然可以工作。
登录到门户网站后,转到“应用程序”,可以创建一个新的应用程序,它将提供与 Twitter API 通信所需的数据。

这是一个拥有与 Twitter 网络对话所需的所有数据的屏幕。需要注意的是,默认情况下,应用程序没有访问直接消息的权限,因此,通过进入设置,将适当的选项更改为“读取、写入和直接消息”,您可以使您的应用程序能够访问每一个 Twitter 功能。
Twitter API
Tweepy 提供了对记录良好的 Twitter API 的访问。使用 tweepy,可以获得任何对象并使用官方 Twitter API 提供的任何方法。例如,User对象有自己的文档,遵循这些指导方针,tweepy 可以获得适当的信息。
Twitter API 中的类有Tweets、Users、Entities和Places。访问每一个都会返回一个 JSON 格式的响应,在 Python 中遍历信息非常容易。
# Creates the user object. The me() method returns the user whose authentication keys were used.
user = api.me()
print(' Name:'+user . Name)
print(' Location:'+user . Location)
print(' Friends:'+str(user . Friends _ count))
为我们提供了以下输出:
Name: Ahmet Novalic
Location: Gradacac,Bih
Friends: 59
这里记录了所有的 API 方法:https://docs.tweepy.org/en/stable/
Tweepy StreamingAPI
tweepy 的一个主要使用案例是监控 tweepy 并在事件发生时采取行动。其中的关键组件是StreamListener对象,它实时监控并捕捉推文。
StreamListener有几种方法,其中on_data()和on_status()是最有用的。下面是一个实现此行为的示例程序:
class StdOutListener(StreamListener):
''' Handles data received from the stream. '''
def on_status(self,status):
#打印推文的文本
print('推文文本:'+ status.text)
#状态对象中有许多选项,
#标签可以非常容易地访问。
对于 status . entries[' hash tags ']:
print(hash tag[' text '])
返回 true
def on_error(self,status _ code):
print(' get a error with status code:'+str(status _ code))
返回 True #继续监听
def on_timeout(self):
打印(' timeout ... ')
返回 True #继续收听
if _ _ name _ _ = = ' _ _ main _ _ ':
listener = StdOutListener()
auth = tweepy。OAuthHandler(消费者密钥,消费者秘密)
auth.set_access_token(访问令牌,访问令牌 _ 秘密)
stream = Stream(auth,listener)
Stream . filter(follow =[38744894],track=['#pythoncentral'])
因此,这个程序实现了一个StreamListener,代码被设置为使用 OAuth。创建了Stream对象,它使用该侦听器作为输出。作为 tweepy 中的另一个重要对象,Stream 也有许多方法,在本例中,filter()通过传递参数来使用。“follow”是其推文被监控的关注者列表,“track”是触发StreamListener的标签列表。
在这个例子中,我们使用我的用户 ID follow 和#pythoncentral hashtag 作为条件。运行程序并发布此状态后:

程序几乎立即捕捉到 tweet,并调用on_status()方法,该方法在控制台中产生以下输出:
Tweet text: Hello Again! #pythoncentral
pythoncentral
除了打印 tweet 之外,在on_status()方法中,还有一些额外的事情说明了 tweet 数据可以实现的可能性:
# There are many options in the status object,
# hashtags can be very easily accessed.
for hashtag in status.entities['hashtags']:
print(hashtag['text'])
这段代码遍历实体,选择“标签”,对于 tweet 包含的每个标签,它打印其值。这只是一个样本;tweet 实体的完整列表位于此处:https://developer . Twitter . com/en/docs/Twitter-API/data-dictionary/object-model/tweet。
结论
总而言之,tweepy 是一个很棒的开源库,它提供了对 Python 的 Twitter API 的访问。虽然 tweepy 的文档有点缺乏,也没有很多例子,但它严重依赖 Twitter API 的事实使它可能是 Python 最好的 Twitter 库,特别是考虑到对Streaming API 的支持,这是 tweepy 擅长的地方。像 python-twitter 这样的其他库也提供了许多功能,但是 tweepy 拥有最活跃的社区,并且在过去的一年中提交了最多的代码。
用于 tweepy 的额外资源可以在这里获得:
- 推特开发者
- 官方 tweepy 文档
- tweepy github 页面
- 邮件列表
- IRC, Freenode.net #tweepy.
Python 的 SQLAlchemy 入门教程
原文:https://www.pythoncentral.io/introductory-tutorial-python-sqlalchemy/
Python 的 SQLAlchemy 和对象关系映射
在编写任何 web 服务时,一个常见的任务是构建一个可靠的数据库后端。过去,程序员会编写原始的 SQL 语句,将它们传递给数据库引擎,并将返回的结果解析为普通的记录数组。如今,程序员可以编写对象关系映射 ( ORM )程序,以消除编写单调乏味、容易出错、不灵活且难以维护的原始 SQL 语句的必要性。
ORM 是一种编程技术,用于在面向对象编程语言的不兼容类型系统之间转换数据。通常,Python 等 OO 语言中使用的类型系统包含非标量类型,也就是说,这些类型不能表示为整数和字符串等基本类型。例如,一个Person对象可能有一个Address对象列表和一个与之相关的PhoneNumber对象列表。反过来,Address对象可以有一个PostCode对象、一个StreetName对象和一个StreetNumber对象与之相关联。虽然简单对象如PostCode s 和StreetName s 可以表示为字符串,但复杂对象如Address和Person不能仅用字符串或整数表示。此外,这些复杂对象还可能包含根本无法使用类型表达的实例或类方法。
为了处理管理对象的复杂性,人们开发了一类新的系统,称为 ORM 。我们之前的例子可以表示为一个带有一个Person类、Address类和PhoneNumber类的 ORM 系统,其中每个类映射到底层数据库中的一个表。一个 ORM 会为您处理这些问题,而您可以专注于系统逻辑的编程,而不是自己编写繁琐的数据库接口代码。
用 Python 编写数据库代码的老方法
我们将使用库 sqlite3 来创建一个简单的数据库,在下面的设计中有两个表Person和Address:

注意:如果您想了解如何使用 SQLite for Python,您可能想看看 Python 系列中的 SQLite。
在这个设计中,我们有两个表person和address,address.person_id是person表的外键。现在我们在一个文件sqlite_ex.py中编写相应的数据库初始化代码。
import sqlite3
conn = sqlite3.connect('example.db')
c = conn . cursor()
c . execute(' '
创建表 person
(id 整数主键 ASC,name varchar(250)NOT NULL)
' ' ')
c . execute(' '
创建表地址
(id 整数主键 ASC,street_name varchar(250),street_number varchar(250),
post _ code varchar(250)NOT NULL,person_id 整数 NOT NULL,
外键(person_id
c . execute(' '
INSERT INTO person VALUES(1,' python central ')
' ' ')
c . execute(' '
INSERT INTO address VALUES(1,' python road ',' 1 ',' 00000 ',1)
' ' ')
conn . commit()
conn . close()
请注意,我们在每个表中插入了一条记录。在您的 shell 中运行以下命令。
$ python sqlite_ex.py
现在我们可以查询数据库example.db来获取记录。在文件sqlite_q.py中编写以下代码。
import sqlite3
conn = sqlite3.connect('example.db')
c = conn . cursor()
c . execute(' SELECT * FROM person ')
print c . fetchall()
c . execute(' SELECT * FROM address ')
print c . fetchall()
conn . close()
并在您的 shell 中运行以下语句。
$ python sqlite_q.py
[(1, u'pythoncentral')]
[(1, u'python road', u'1', u'00000', 1)]
在前面的示例中,我们使用 sqlite3 连接提交对数据库的更改,使用 sqlite3 游标执行对数据库中的 CRUD (创建、读取、更新和删除)数据的原始 SQL 语句。尽管原始 SQL 确实完成了工作,但是维护这些语句并不容易。在下一节中,我们将使用 SQLAlchemy 的声明将Person和Address表映射到 Python 类中。
Python 的 SQLAlchemy 和声明性
编写 SQLAlchemy 代码有三个最重要的组成部分:
- 一个代表数据库中一个表的
Table。 - 将 Python 类映射到数据库中的表的
mapper。 - 一个定义数据库记录如何映射到普通 Python 对象的类对象。
SQLAlchemy 的声明允许在一个类定义中同时定义一个Table、mapper和一个类对象,而不必在不同的地方为Table、mapper和类对象编写代码。
以下声明性定义指定了sqlite_ex.py中定义的相同表格:
import os
import sys
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
from sqlalchemy import create_engine
Base = declarative_base()
类 Person(Base):
_ _ tablename _ _ = ' Person '
#这里我们为表 person
定义列#注意,每个列也是一个普通的 Python 实例属性。
id = Column(Integer,primary _ key = True)
name = Column(String(250),nullable=False)
class Address(Base):
_ _ tablename _ _ = ' Address '
#这里我们为表地址定义列。
#注意,每一列也是一个普通的 Python 实例属性。
id = Column(Integer,primary _ key = True)
street _ name = Column(String(250))
street _ number = Column(String(250))
post _ code = Column(String(250),nullable = False)
Person _ id = Column(Integer,foreign key(' Person . id ')
Person = relationship(Person)
#创建一个引擎,将数据存储在本地目录的
# sqlalchemy_example.db 文件中。
engine = create _ engine(' SQLite:///sqlalchemy _ example . db ')
#在引擎中创建所有表。这相当于原始 SQL 中的“Create Table”
#语句。
Base.metadata.create_all(引擎)
将前面的代码保存到文件sqlalchemy_declarative.py中,并在 shell 中运行以下命令:
$ python sqlalchemy_declarative.py
现在,应该在当前目录中创建一个名为“sqlalchemy_example.db”的新 sqlite3 db 文件。因为 sqlalchemy 数据库现在是空的,所以让我们编写一些代码将记录插入数据库:
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy _ 声明性导入地址、基、人
engine = create _ engine(' SQLite:///sqlalchemy _ example . db ')
#将引擎绑定到基类的元数据,以便可以通过 DBSession 实例
Base.metadata.bind = engine 访问
#声明
DBSession = session maker(bind = engine)
# DBSession()实例建立与数据库
#的所有对话,并代表加载到
#数据库会话对象中的所有对象的“暂存区”。在调用
# session.commit()之前,对
#会话中的对象所做的任何更改都不会持久化到数据库中。如果您对这些更改不满意,您可以通过调用
# session . roll back()
session = DBSession()来
#将它们全部恢复到上次提交时的状态
#在人员表中插入人员
新人员=人员(姓名= '新人员')
会话.添加(新人员)
会话.提交()
#在地址表中插入地址
new _ Address = Address(post _ code = ' 00000 ',person = new _ person)
session . add(new _ Address)
session . commit()
将前面的代码保存到本地文件sqlalchemy_insert.py中,并在您的 shell 中运行命令python sqlalchemy_insert.py。现在我们在数据库中存储了一个Person对象和一个Address对象。让我们使用sqlalchemy_declarative.py中定义的类来查询数据库:
>>> from sqlalchemy_declarative import Person, Base, Address
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///sqlalchemy_example.db')
>>> Base.metadata.bind = engine
>>> from sqlalchemy.orm import sessionmaker
>>> DBSession = sessionmaker()
>>> DBSession.bind = engine
>>> session = DBSession()
>>> # Make a query to find all Persons in the database
>>> session.query(Person).all()
[<sqlalchemy_declarative.Person object at 0x2ee3a10>]
>>>
>>> # Return the first Person from all Persons in the database
>>> person = session.query(Person).first()
>>> person.name
u'new person'
>>>
>>> # Find all Address whose person field is pointing to the person object
>>> session.query(Address).filter(Address.person == person).all()
[<sqlalchemy_declarative.Address object at 0x2ee3cd0>]
>>>
>>> # Retrieve one Address whose person field is point to the person object
>>> session.query(Address).filter(Address.person == person).one()
<sqlalchemy_declarative.Address object at 0x2ee3cd0>
>>> address = session.query(Address).filter(Address.person == person).one()
>>> address.post_code
u'00000'
Python 的 SQLAlchemy 概述
在本文中,我们学习了如何使用 SQLAlchemy 的声明编写数据库代码。与使用 sqlite3 编写传统的原始 SQL 语句相比,SQLAlchemy 的代码更加面向对象,更易于阅读和维护。此外,我们可以轻松地创建、读取、更新和删除 SQLAlchemy 对象,就像它们是普通的 Python 对象一样。
您可能想知道,如果 SQLAlchemy 只是原始 SQL 语句之上的一个抽象薄层,那么它不会给人留下深刻印象,您可能更喜欢编写原始 SQL 语句。在本系列的后续文章中,我们将研究 SQLAlchemy 的各个方面,并将其与原始 SQL 语句进行比较,当它们都用于实现相同的功能时。我相信在本系列的最后,您会确信 SQLAlchemy 优于编写原始 SQL 语句。
IPython 简介:增强的 Python 解释器
原文:https://www.pythoncentral.io/ipython-introduction-enhanced-python-interpreter/
简而言之,IPython 可以让你做各种真正强大的事情。它在科学家和数学家中非常流行,并且有很多他们非常欣赏的特性。它还有很多对其他使用 Python 的人非常有用的特性。
IPython 提供了许多简单的钩子供你定制和扩展它的工作方式。因为修改 IPython 的功能非常容易,所以很难准确定义它是什么。当你第一次安装它时,你会得到一个应用程序,它本质上是一个增强的 Python 交互式解释器。你可以在一个常规的互动会议上做所有你能做的事情,而且你还可以做更多。
IPython 魔法命令
你会注意到的第一个特性是彩色提示,一个绿色的In [1]:。颜色总是很酷,而且用得很好,但是 IPython 不仅仅是一个漂亮的堆栈跟踪。对标准 Python 会话的一个更强大的增强是使用了神奇命令——可以使用类似 shell 的语法调用的 Python 函数。你得到一堆内置的,一些非常聪明的,你可以很容易地定义自己的。要使用一个神奇的命令,你只需输入它的名字,然后输入任何参数,中间用空格隔开。例如:
magicname arg0 arg1
一些内置的魔法使 Python 会话的操作更像传统的 shell。你有cd、ls、cp等等。如果您喜欢使用这些命令,您可以像平常一样键入它们:
cd ~/scripts
如果您想使用没有魔法设置的 shell 命令,您只需砰的一声开始该行,并编写任何正常工作的命令:
!echo IPython
编辑 IPython 名称空间
我认为最有用的魔法之一是edit。如果您想编写任何中等复杂的 Python,您不希望在命令行中完成。在 IPython 中,不是像通常那样从文本编辑器开始,然后运行文件,而是相反的过程:我们在提示符下开始,并简单地从会话中调用编辑器。你可以使用任何你喜欢的编辑器,但是 Vim 规则。
你可以在提示符下输入“edit”来使用 edit。IPython 将用一个空的 tempfile 打开您的编辑器。当您保存并退出编辑器时,您编写的任何代码都会被注入到命名空间中。
例如,您可以在提示符下输入“edit ”,然后在编辑器中定义一个名为 spam 的函数,保存文件并退出编辑器,然后在提示符下调用 spam,传递您喜欢的任何参数。特别酷的是,如果你稍后在提示符下输入“edit spam ”, IPython 会重新打开任何包含垃圾邮件的 tempfile,这样你就可以对它进行更多的编辑。
还有一些方法可以将常规文件的内容注入到同一个名称空间中。当然,您可以使用编辑器的保存功能保存您构建的内容,或者只是从命令行将内容写入文件。还有一个名为 store 的魔术,您可以使用它使对象跨会话持久化。
能够轻松地以交互方式构建名称空间,并在进行过程中不断开发,这为您探索正在创建的对象并与之交互提供了更多的自由。这种方法非常适合编写 Python,通常可以快速地、以非常小的增量开发 Python。
配置 IPython 解释器
IPython 有一个强大的配置系统,本身就是纯 Python。您可以使用它来创建和管理任意数量的配置,定制 IPython 的每个特性,以及指定自动注入到新会话中的代码,进一步增强您完全定制您的解释器工作方式的能力。
几乎所有东西都是可配置的,如果你懂一点 Python,这很容易做到。
开发您的 IPython 环境
一旦您熟练使用 IPython,您应该查看 Python Central 上的其他文章,这些文章更详细地介绍了主要特性,包括定义您自己的神奇命令和配置会话。
随着时间的推移,随着您使用 IPython 越来越多,并向其中添加更多内容,您将开发出一个高度定制的控制台 IDE,方便地将您正在用 Python 做的其他事情包装起来。
从ipython.org那里拿一份,让我们知道你最终会把它带到哪里。
另外,要更深入地了解和回顾 IPython,请参阅文章IPython 回顾。
用 Python 编程,网络安全重要吗?
原文:https://www.pythoncentral.io/is-cyber-security-important-when-programming-with-python/

今年早些时候,Python 软件基金会(PSF)抢发 Python 更新 3.9.2 和 3.8.8,解决 关键安全漏洞 。其中一个漏洞包括远程代码执行,可以从世界任何地方利用该漏洞关闭系统。从理论上来说,这听起来很难利用,但实际上可以用来使机器脱机。
这一事件揭示了 Python 漏洞有多危险,Python 安全性有多重要。由于 Python 如此流行,它也吸引了寻求攻击易受攻击系统的犯罪分子的注意。攻击者最有可能找出许多应用程序的漏洞。
如果你是使用第三方 Python 模块(如 pip、dnspython 或任何其他开源库)的程序员或编码员,你可以肯定你的应用程序中存在安全风险。以下是您需要了解的关于 Python 漏洞和网络安全需求的所有信息。
为什么安全性对 Python 程序很重要?
截至 2021 年 5 月,根据 TIOBE 指数,Python 是全球第二大最受欢迎的编程语言,领先于 Java 和 C++。它受欢迎的主要原因之一是简单的代码语法,它模仿了英语。既然大家都在用 Python,那么在开发一个 app 或者写代码的时候必然会出现错误或者瑕疵。这些错误通常被称为漏洞,可能是危险的。
虽然了解这些漏洞背后的原因并避免这些错误以防止被利用是至关重要的,但有时甚至连最佳实践都被忽略了。这就是高效的网络安全系统发挥作用的地方,它可以保护您的敏感数据和服务器免受恶意攻击者的攻击。
需要网络安全的 Python 漏洞
与几乎所有的编码语言一样,网络安全对所有 Python 开发者来说都是至关重要的。对于处理敏感个人信息的大型数据库的开发人员来说尤其如此。我们不需要强调如果这样一个数据库被利用或被破坏,后果将是多么可怕。
和所有其他编程语言一样, Python 安全 面临 SQL 注入(SOLi)、XSS(跨站脚本)、跨站请求伪造等攻击的威胁。然而,Python 编程语言中最常见的五种最关键的攻击。让我们来看看。
LDAP 注入
LDAP(轻量级目录访问协议)是一种开放的跨平台协议,被许多企业所采用。它支持单点登录(SSO)环境,并充当用户身份验证的存储库。LDAP 注入攻击类似于 SQL 注入攻击。
通常,当应用程序没有正确过滤参数时,攻击者会利用 LDAP 查询中使用的参数。这导致了一个易受攻击的环境,黑客可以很容易地注入恶意代码。一旦代码被注入,就可能导致敏感数据被盗和暴露。一些黑客还可能使用高级 LDAP 注入方法来执行任意命令,以获得未经授权的权限。
XPath 注入
XPath 注入攻击通过用户提供的信息来构造 XML 数据的 XPath 查询。利用发送到网站的一条格式错误的信息,攻击者可以很容易地找出 XML 数据的结构,并访问受限数据。
如果 XML 数据用于身份验证,攻击者甚至可以获得更多访问网站的特权。
XPath 注入使用描述性语句,通过指定要查找和匹配的特定属性和模式,允许 XML 查询定位一组特定的信息。
对于使用 XML 的网站来说,接受某种形式的查询字符串输入来在页面上显示与相关的内容是很常见的。必须对这个输入进行清理,以防止弄乱 XPath 查询并返回错误的数据。
指令喷射
这种攻击的目标是利用易受攻击的应用程序在主机操作系统上执行任意命令。通过命令注入,罪犯可以将表单、cookies、HTTP 头或其他不安全的用户提供的数据传递给系统。恶意命令以易受攻击的应用程序的权限执行。这种类型的攻击主要是由于不安全的用户输入验证造成的。
导入功能漏洞
Python 流行的原因之一是因为导入数据的方便性和灵活性。但是,这也意味着应用程序容易受到攻击。
当使用 Python 编程和实现相对导入时,您的代码库会暴露给系统路径中的恶意模块,该恶意模块允许导入语句在恶意模块中执行代码,并造成等待被利用的安全漏洞。
为了防止这种情况发生,应该只允许可信数据通过输入函数传递到脚本的 stdin。最好的经验法则是将所有传入的数据视为不安全和不可信的。出于这个原因,Python 2 和更老的用户应该考虑使用 Python 3,Python 3 通过将导入函数视为原始输入来修复漏洞。
不安全的外部数据
不言而喻,任何来自外部来源的数据都是不可信的。最好避免将外部来源的数据包解析成 Python 代码。
这将避免通过子流程模块执行任意命令。另一个这样的漏洞是 YAML 文件,它会使您的应用程序暴露于攻击之下。这可以通过使用 py YAML safe _ load function(YAML . safe _ load)解析来自用户输入的 YAML 文件来避免。
总之
如您所见,Python 漏洞的世界是巨大的,攻击的严重性也同样糟糕。因此,您将需要某种形式的网络安全来防止任何违规行为的发生,并需要一种有效的工具来使 Python 代码免受任何安全或合规性问题的影响。
是时候学习 Python 了

随着电子商务的发展,许多人换了工作,成为程序员。这些天来,编程世界可以说是欣欣向荣。这个行业如此受欢迎,以至于它无法满足所有被轰炸的需求。尽管竞争激烈,但熟练的程序员总能找到出路。
如果你正在阅读这篇文章,我们假设你是一个寻求 python 家庭作业帮助的学生,或者你只是四处走走,试图弄清楚从头开始学习 python 并成为随需应变是否太晚了。我们可以肯定的是,学习 Python 没有不好的时候。你可以随时开始学习这门美丽的语言,并很快成为一名精致的专家。
下面,我们提供一些关于 Python 及其优势的一般信息,以及让你的学习和工作过程变得有趣、有意义和高效的技巧。
Python 是什么?
简单来说,Python 是一种通用的高级解释编程语言。这种语言在几十年前首次发布,但直到最近才成为焦点。Python 的伟大之处在于它支持许多编程范例,包含了最受欢迎的编程,如过程式、函数式和面向对象的编程。
为什么 Python 如此盛行?
选择 Python 而不是其他编程语言有很多原因。然而,最明显的是,Python 非常简单,非常高效,而且最重要的是,可读性强。那是什么意思?看,不同于普通的网页访问者、应用程序用户和客户,对于程序员来说,硬币有两个不同的面。除了观察最终产品,程序员还可以(显然也喜欢)检查初始代码,例如,应用、网页或游戏是如何工作的。当提到的任何产品或服务基于 Python 时,对于有能力的人来说都是容易阅读和理解的。
学习基础知识
我们希望你最终下定决心,准备开始你的学习之路。在我们看来,最好从以下几个方面开始你的旅程:
- Hello World: 这个短语是每个人都学习的基本命令,不管是什么编程语言。虽然这不会有很大的帮助,但这是一个向 Python 介绍自己并把 Hello,World 作为第一条学习线的好方法。
- 类型和变量:像任何程序员一样,你将不得不处理大量的数字,所以学习如何成功有效地处理它们是必须的。记住 Python 是面向对象的,每个变量都被当作一个对象。该语言支持两种类型的数字:整数和点数。
- 循环:循环在每一种编程语言中都是至关重要的。Python 使用两种类型的循环,命名为的*,而这些类型又依赖于两个函数,具体来说就是 range 和 xrange。*
除了上面提到的,其他基本命令还有列表、字典、对象和类、包和模块、条件、和字符串格式化。
找到你的位置
提高您的 Python 技能是一个陡峭的学习曲线。有时,你锻炼编程能力的动力会直线下降。但是一旦你找到了点燃你激情的东西,这种激情将带领你度过最黑暗的日子。
因为 Python 几乎应用于任何领域,所以在学习这门语言之前评估一下你的兴趣是合理的。拿一个清单,写下任何你觉得令人兴奋的事情。例如,您可能希望开始学习 Python,以便在以下领域运用您的知识:
- 比赛
- 数据处理
- 机器学习
- 自动化(脚本)
- 网页创建
- 移动应用
创建您自己的项目并参与其中
当你学习基本的 Python 命令时,我们鼓励你开始一个项目并在上面练习你的技能。你可以从不同的角度接近它,围绕它玩,包括和排除部分。例如,如果你有游戏编程的诀窍,一个好的项目想法是创建一个基于位置的游戏,其中玩家的主要目标是占领领土。你可以赋予玩家更多的能力,或者相反,减少玩家可以进行的一系列移动。无论你决定创造什么,都将有助于你锻炼大脑肌肉,提高编程技能。
交友挑战
提高你现有技能的最好方法之一是通过健康的竞争。幸运的是,使用 Python 这是完全可能的。您可以为 Python 用户找到大量编程挑战,并重温您的能力。除此之外,你还可以通过教授其他人 Python 的基础知识,处理更多的数据和流量,分析其他程序,加速他们的工作等等,来获得更多的挑战。
使用 Python 进行 Web 抓取的关键技巧
原文:https://www.pythoncentral.io/key-tips-for-web-scraping-with-python/

Python 是一种流行的高级通用编程语言,用于创建各种工具和解决方案,包括 web scrapers。事实上,Python 是有经验的开发者和学习者第四喜欢的语言。这种流行源于许多因素,例如语言的简单性(就易用性而言)、可伸缩性和大量预写代码库(库),这里仅举几例。
虽然 Python 被认为是易于使用和学习的,主要是因为它的语法和语义,但是您可以利用一些技巧来进一步简化这个过程。因此,本文将重点介绍使用 Python 进行 web 抓取的基本技巧。
什么是网页抓取?
Web 抓取,也称为 web 数据提取或 web 采集,是指从网站手动或自动收集数据的过程。值得指出的是,术语“网络搜集”的使用通常是指数据收集的自动化形式。自动网络数据提取是通过被称为网络抓取器的机器人来完成的。这些机器人处理一切事情,从向网站发送 HTTP 或 HTTPS 请求,解析数据(将其转换为结构化格式)到将其存储在文件中以供下载。
Web 抓取中的 Python
鉴于机器人的便利性,你可能想知道如何访问网页抓取器。如果你没有技术/编程背景,你会很高兴听到你可以购买或订阅现成的 web scraper。由一家主要关注此类机器人的公司创建和维护的现成 web 抓取工具提供了便利性和高级功能,这些功能只能来自开发人员的协作团队。
也就是说,如果你有广泛的技术背景,并且愿意投入一些时间和资源,你可以考虑使用 Python 从头开始创建一个 web scraper。如果这个选项对您有吸引力,值得指出的是,您可以从使用 Python 进行 web 抓取的几个关键技巧中获益。
使用 Python 进行网页抓取的技巧
在进行网络搜集时,您可以利用以下重要提示:
- 利用 Python 网络抓取库
- 避免常见的陷阱(反机器人/反刮擦技术)
- 阅读 robots.txt
- 设置超时参数
- 检查错误代码
- 评估网站是否有公共 API
- 使用多重处理包来提高网页抓取速度
1.Python Web 抓取库
有许多 Python web 抓取库。其中包括:
- Python 请求库:它包含预先编写的代码,使您能够发出 HTTP/HTTPS 请求。点击此处了解更多信息
- 美丽的汤:这是一个解析库
- lxml:这是一个解析库
- Scrapy:这是一个 Python 框架,处理结构化数据的请求、解析和保存
- Selenium:它旨在呈现 JavaScript 代码,并与其他库一起使用
使用 Python 库进行 web 抓取消除了从头创建一切的需要。例如,Python 请求库提供了一个包含许多 HTTP 方法的模板,包括 GET、POST、PATCH、PUT 和 DELETE。
2.避免常见的陷阱
现代网站采用防刮技术来保护存储在服务器上的数据。这些技术包括蜜罐陷阱、IP 拦截、验证码难题、登录和登录要求、标题等等。您可以使用无头浏览器、旋转代理、反检测浏览器或读取 Robots.txt 文件(将在下面讨论)来避免这些缺陷。
3.读取 robots.txt 文件
robots.txt 文件包含规定机器人不应访问的网页的说明。遵守这些准则可以防止 IP 阻塞。
4.设置超时参数
Python 请求库旨在发出请求,并且将无限期地等待响应,即使在服务器不可用的情况下也是如此。因此,建议设置超时参数。
5.检查错误代码
建议经常检查 web 服务器返回的状态代码以识别错误。这有助于确定您的请求是否超时或被阻止。此外,您的 Python 代码应该指出,如果 scraper 遇到错误代码,应该打印出什么内容。
6.检查公共 API
一些网站利用应用程序编程接口(API ),通过它您可以轻松方便地访问公开可用的数据。这样的公共 API 消除了创建刮刀的需要。
7.多重处理包
一个多重处理包使系统能够并行处理多个请求,从而加快网页抓取过程。当您处理大量网页时,这很方便。
结论
Python 是一种通用的编程语言,可以用来创建 web 抓取器。如果你想创建一个网页抓取器,这篇文章中强调的技巧可以增加你成功的机会。这些技巧包括检查错误代码和公共 API 的可用性、使用多处理器包、设置超时参数等等。
Python 中的 Lambda 函数语法(内联函数)
原文:https://www.pythoncentral.io/lambda-function-syntax-inline-functions-in-python/
Python 的语法相对方便且易于使用,但是除了语言的基本结构之外,Python 还附带了一些小的语法结构,使得某些任务特别方便。关键字/函数结构就是其中之一,创造者称之为“语法糖果”。在这里,我们将研究如何使用它们。
为了理解lambda关键字/函数及其构造,我们必须首先回顾一下 Python 中正则函数定义的工作方式。下面是函数定义的基本结构:
def basic(arg):
# Or whatever the function does
pass
# Or whatever the function returns
return arg
我们在这里定义的本质上是一个名为 basic 的空函数,它接收一个参数,什么也不做(pass 语句本质上是一个有效的“什么也不做”语句),然后返回给它的参数。这是大多数函数最基本的结构,但是最简单的函数定义将只包含这些语句中的一个——在一个语句中,它要么做某事(或传递),要么返回某事或None(一个return语句总是至少返回None实例,所以它实际上不能返回任何东西)。下面是这两种情况的样子:
def simple1(arg): pass
def simple2(arg): return arg
请注意,我们还通过将函数体语句放在与定义语句相同的行上,节省了一行。lambda函数结构正是这两种结构中的后一种,即一个返回某些东西的单语句函数,区别在于“return”关键字是隐含的,并不出现在构造中。现在我们知道了lambda函数是如何工作的(与一个单语句函数相同),让我们以lambda的形式构造 simple2 函数。为此,我们简单地使用lambda构造——如果我们将我们的lambda函数称为最简单的,它将是这样的:
simplest = lambda arg: arg
就是这样!现在我们有了最简单的和简单的 2 ,它们的行为方式完全相同,但是前者我们用的术语要少得多;然而,从技术上讲,我们只保存了两个角色,这有什么大不了的?
如果我们仔细查看lambda语句,我们会发现它实际上是一个语句,即返回一个函数(这就是为什么我们将它赋给一个变量),这就是lambda构造的真正力量所在,所以让我们来看一个利用这种力量的例子。
假设我们有一个三元组列表,如下所示:
tups = [
(1, 3, -2),
(3, 2, 1),
(-1, 0, 4),
(0, -1, 3),
(-2, 6, -5)
]
如果我们想要 tups 的排序版本,我们只需将它交给内置的sorted方法:
>>> sorted(tups)
[(-2, 6, -5), (-1, 0, 4), (0, -1, 3), (1, 3, -2), (3, 2, 1)]
如果我们只有想要按照每个元组中的第一个值排序,这没问题,但是如果我们想要按照第二个或第三个值排序呢?知道了内置的sorted方法是如何工作的,我们可以使用 key 参数来定义一个将返回所需值的函数(参见如何通过键或值对 Python 字典进行排序以了解关于sorted的一些背景知识)。下面是它如何查找每个元组中第二个值的排序:
>>> def sortkey(tup):
... return tup[1]
>>> sorted(tups, key=sortkey)
[(0, -1, 3), (-1, 0, 4), (3, 2, 1), (1, 3, -2), (-2, 6, -5)]
这工作得很完美,但是我们已经用光了额外的空间/行(如果在脚本文件中的话),和额外的内存用于一个只帮助排序我们的列表的单语句函数。如果使用不同的语言,我们可能别无选择,只能这样做(或者更糟),但幸运的是我们有lambda函数构造:-)。有了它,我们可以用更简单的形式定义相同的函数:
# Returns a function
>>> lambda tup: tup[1]
<function <lambda> at 0x02BD1230>
在最简单的的情况下,我们将由lambda构造/语句返回的 lambda 函数赋值,但是 lambda 构造的强大之处在于我们不需要这么做。相反,我们可以直接使用sorted中的语句作为键:
>>> sorted(tups, key=lambda tup: tup[1])
[(0, -1, 3), (-1, 0, 4), (3, 2, 1), (1, 3, -2), (-2, 6, -5)]
它的工作方式与sortkey相同,但是使用这种形式,过程更简单,节省了行和内存!
这就是lambda函数及其构造的强大之处,但最棒的是它也适用于你的脚本中需要这样一个函数的任何部分。这包括内置的排序/迭代函数(如sorted、map和filter)、类方法如re.sub(将repl参数作为函数)、实例方法(如list.sort)、Tkinter小部件的回调函数等。因此,不要犹豫,将lambda功能投入使用,探索它们能够做的一切!*
通过 Acire Python Snippets 项目学习 Python
原文:https://www.pythoncentral.io/learn-python-with-the-acire-python-snippets-project/
学习和使用代码片段总是学习和适应使用一门新语言的好方法。与 PHP 和 Java 等其他流行语言相比,Python 片段资源似乎少得多。如果您一直在试图寻找一些有用的 Python 片段来帮助您学习这门语言,请查看 Acire Snippets 项目。
该项目是一个交互式项目,不仅包含了一个有用的 Python 代码片段库,还允许您与代码片段进行交互,更改和定制它们,然后将它们作为一个很好的学习工具来运行。库中的所有代码片段都演示了如何执行常见和特定的任务,所以如果您刚刚开始使用 Python,这是一个很好的起点。如果你是一个更有经验的 Python 程序员,也可以选择提交你自己的代码片段来帮助教授他人。

Acire Snippet 项目具有多样化的代码段和代码库,每天都有新的代码段添加进来。它提供了对许多不同语言的支持(每次更新都会添加更多语言)。该项目也非常用户友好,使其易于浏览,玩,或重新安排片段,也非常容易提交自己的。
Python 中的列表理解
原文:https://www.pythoncentral.io/list-comprehension-in-python/
有时我们需要生成遵循一些自然逻辑的列表,比如迭代一个序列并在其中应用一些条件。我们可以使用 Python 的“列表理解”技术编写紧凑的代码来生成列表。我们可以循环遍历一个序列,并应用逻辑表达式。
首先,让我们来看一个特殊的函数range——顾名思义,它用于生成一个范围内的数字列表!尝试 Python IDLE 中的以下代码部分:
>>range(10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>range(5, 10)
[5, 6, 7, 8, 9]
>>range(0, 10, 2)
[0, 2, 4, 6, 8]
所以 range 实际上生成了一个列表。我们可以在 for 循环中使用它。看看下面的例子,我们生成了一个名为 myList 的列表:
myList = []
for i in range(0, 5):
myList.append(i**2)
print(myList)
上述代码片段将有以下输出:
[0, 1, 4, 9, 16]
我们还可以使用列表理解在一行代码中创建 myList :
myList = [ i**2 for i in range(0, 5) ]
很酷吧。让我们看另一个例子。给定一个列表输入列表,让我们创建一个输出列表,它将只包含输入列表中具有正索引的元素(索引 0,2,4,...).首先,让我们尝试使用一个循环来实现这一点:
inputList = ["bird", "mammal", "reptile", "fish", "insect"]
outputList = []
for i in range(0, len(inputList), 2):
outputList.append(inputList[i])
print(outputList)
现在让我们看看列表理解版本:
outputList = [inputList[i] for i in range(0, len(inputList), 2)]
print(outputList)
这两种技术将有相同的输出:
['bird', 'reptile', 'insect']
作为最后一个例子,给定一个整数列表,让我们找出奇数整数,并创建一个包含这些整数的新列表:
input = [4, 7, 9, 3, 12, 25, 30]
output = []
for x in input:
if not x%2 == 0:
output.append(x)
print(output)
将打印:
[7, 9, 3, 25]
使用列表理解方法完成的相同工作将是编写如下内容:
output = [x for x in input if not x%2 == 0]
print(output)
就是这样!现在我们可以描述语法了。我们由第三个大括号——“[&”——开始和结束,一切都要用大括号括起来。左大括号后面是一个 表达式 ,后面是一个 for 子句,然后是零个或多个for&if子句。
*列表理解总是返回一个列表,评估我们放在左括号后的 表达式 。
评估“for”子句的顺序
如果子句有一个以上的,它们将按照在循环中被求值的顺序被求值。例如,注意下面的列表理解,
output = [x**y for x in range(1, 5) for y in range(1, 3)]
类似于:
output = []
for x in range(1,5):
for y in range(1, 3):
output.append(x ** y)
两者都给出【1,1,2,4,3,9,4,16】作为输出。
现在我们已经学习了什么是列表理解,它的语法和一些显示它的用法的例子。问题是,为什么要用列表理解?在许多情况下,通过一起使用映射&λ函数,您可以在不使用列表理解的情况下获得相同的结果。然而,请注意,在大多数情况下,列表理解被认为比 map & lambda 函数放在一起更快。此外,列表理解使代码简洁易读——这是漂亮编码的必备条件。地图也帮助我们自然编码;例如,我们可以使用列表理解创建一个所有正数的列表,就像我们在数学课上思考的那样!*
Python 中的列表:如何在 Python 中创建列表
原文:https://www.pythoncentral.io/lists-in-python-how-to-create-a-list-in-python/
python 列表在 Python 中被广泛使用。列表是 Python 中最常用的数据结构之一。这是一个无序的数据存储。在本文中,我们将学习如何在 Python 中使用列表。你应该知道 Python 语法以及 Python 中的链表是什么。我们在上一篇文章中已经谈到了 python 字典的数据结构。
列表是一个顺序数据存储。按索引保存在列表中的项目。列表索引从 0 开始。这意味着一个简单列表 x = [1,2,3]。要获得第一个项目,您将需要通过索引的项目。这可能会令人困惑。别担心,我们会解释的。让我们从
用 Python 创建列表
在 Python 中定义列表有两种方法。第一个是在两个方括号之间添加您的项目。
举例:
items = [1, 2, 3, 4]
第二种方法是通过将项目传递给 Python list 内置函数来调用它。
举例:
Items = list(1, 2,3,4)
在这两种情况下,输出都将是
[1, 2, 3, 4]
该列表可以接受任何数据类型。你可以有一个整数和字符串的列表。python 中的列表不强制包含单一的项目类型。你可以列出不同的项目。
[1, 'name', {"key" : "value"}, list(1, 2, 3)]
T his 给你在列表中添加多种数据类型的灵活性。您可以在此列表中添加一个列表。这称为嵌套列表。 现在我们将数据存储到一个 python 列表中,是时候知道如何利用这些数据做更多的事情了。
在 Python 中向列表追加项目
列表是可变的数据结构。这意味着你可以创建一个列表并编辑它。您可以在创建的列表中添加、插入和删除项目。要向列表中添加项目,可以使用函数并传递要添加的值。append 函数会将项目添加到列表的末尾。该函数允许您在列表中想要的位置插入数据。它需要两个参数,索引和值。让我们看一个例子:
items = ["mobile", "laptop", "headset"]
# append the keyboard item to the list
items.append("keyboard")
print(items)
# output
['mobile', 'laptop', 'headset', 'keyboard']
# insert the mouse item to the list in before the laptop item
items.insert(1, "mouse")
print(items)
# output
['mobile', 'mouse', 'laptop', 'headset', 'keyboard']
Python 中的排序列表
我们上面提到 Python 列表是无序的。列表是这样存储在内存中的。你可以在这里看到 Python 列表的详细实现。
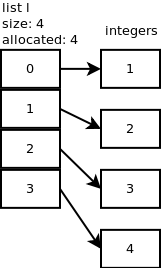
这意味着要访问列表中 item 的值,必须通过它的索引来调用它。更简单地说,如果我们有学生的名字列表 students = ["John "," Jack "," Christine"]并且你想得到第一个学生的名字。你需要知道这个学生名字的索引。在我们的例子中,它是零指数。student[0]的语法将是
让我们看一个真实世界的例子来清楚地理解它。
Students = ["John", "Jack", "Christine"]
for i in Students:
print(Students [i])
# Output
John
Jack
Christine
列表中有未排序的项目。要对它们进行排序,可以使用内置的 python 函数 sorted()。它将遍历列表项并对它们进行排序。
sorted()函数的用法非常简单。您需要将列表传递给排序函数。它将返回排序后的列表并改变原来的列表。
示例:
x = [4, 5, 1, 8, 2]
print(sorted(x))
# output
[1, 2, 4, 5, 8]
你会想到的第一个问题是它是如何工作的?它可以对整数进行排序。那么其他类型的数据字符串,字典呢..等等。排序函数在排序方面更具动态性。这意味着您可以传递您希望列表排序所基于的排序机制。我们可以传递给排序函数的第一个参数是 reverse。
注:由于
sorted()和sort()的不同,sort()改变了原来的列表。sorted()不改变原来的列表。它将返回新的列表。
Python 中的反向列表
排序功能可以颠倒列表顺序。将 reverse 键设置为 True 将使 Python 自动反转列表排序。让我们看一个例子。
chars = ["z", "y", "o", "b", "a"]
print(sorted(chars))
# output
['a', 'b', 'o', 'y', 'z']
chars = ["z", "y", "o", "b", "a"]
print(sorted(chars, reverse=True))
# output
['z', 'y', 'o', 'b', 'a']
这个例子向你展示了如何反转一个列表。在这个例子中,我们颠倒了列表的字母顺序。
高级排序
您可以通过在 key 参数中传递排序函数来为列表添加自定义排序。
chars = ["z", "y", "o", "b", "a"]
print(sorted(chars))
# output
['a', 'b', 'o', 'y', 'z']
words = ["aaaa", "a", "tttt", "aa"]
print(sorted(words, key=len))
# output
['a', 'aa', 'aaaa', 'tttt']
engineers = [
{'name': 'Alan Turing', 'age': 25, 'salary': 10000},
{'name': 'Sharon Lin', 'age': 30, 'salary': 8000},
{'name': 'John Hopkins', 'age': 18, 'salary': 1000},
{'name': 'Mikhail Tal', 'age': 40, 'salary': 15000},
]
# using custom function for sorting different types of data.
def get_engineer_age(engineers):
return engineers.get('age')
engineers.sort(key=get_engineer_age)
print(engineers)
# output
[
{'name': 'John Hopkins', 'age': 18, 'salary': 1000},
{'name': 'Alan Turing', 'age': 25, 'salary': 10000},
{'name': 'Sharon Lin', 'age': 30, 'salary': 8000},
{'name': 'Mikhail Tal', 'age': 40, 'salary': 15000}
]
在上面的例子中,我们使用 key 选项将排序方法传递给 sort 函数。我们在 chars 数组中使用的默认方法是基于顺序排序。在这个列表中,顺序是按字母顺序排列的。在单词列表中,我们有一个不同单词长度的列表。我们想按照单词的长度来排序。我们传递给排序函数的键是内置的len()函数。这将告诉 Python 根据单词长度对列表进行排序。
在工程师的例子中。这更可能是您需要在更真实的示例中解决的问题。您有一个工程师数据列表,并希望根据自定义方法对其进行排序。在我们的例子中,我们按照年龄对它进行了排序。
结论
Python List 是一个非常强大的数据结构。掌握它将使您摆脱 Python 中的许多日常问题。您可以创建包含一种或多种数据类型的列表。您可以追加列表并在所需的索引中插入数据。列表中使用最多的函数是 sorted 方法。您可以根据不同的标准对列表进行排序。你可以从 Python 官方文档中了解更多列表。
管理 Django 应用程序的静态文件
原文:https://www.pythoncentral.io/managing-static-files-django-application/
Django 的默认静态文件管理器
在每个 web 应用程序中,静态文件(如 css、Javascript 和图像)赋予网站独特的外观和感觉,使其脱颖而出。对于任何用户来说,一个漂亮、专业的网站比一个粗糙、未经修饰的网站更有吸引力。
在 Django 应用程序中,我们使用 Django 的默认静态文件管理组件来管理静态文件,比如django.contrib.staticfiles,它将所有静态文件收集到一个位置,这样它们就可以由前端 web 服务器提供服务,比如 apache 和在每个INSTALLED_APPS下寻找“静态”目录的AppDirectoriesFinder。
使用 Django 提供 CSS 和图像
首先,在我们的应用程序myblog中创建一个目录static,这样目录结构就变成了:
myblog/
static/
然后,在新的static目录中创建一个目录myblog,并在其下创建另一个static目录,这样目录结构就变成了:
myblog/
static/
myblog/
static/
这种目录结构可能看起来很奇怪,但它实际上是有意义的,因为 Django 的AppDirectoriesFinder将搜索INSTALLED_APPS或我们的myblog应用程序,并递归地找到它下面的静态目录。因此,位于myblog/static/myblog/static/style.css的样式表style.css可以在我们的模板文件中作为myblog/style.css引用。
现在,我们将以下代码插入myblog/static/myblog/static/style.css:
p {
color: red;
}
然后,我们修改模板文件来链接style.css文件,以测试文件的效果。
{% load staticfiles %}
{% if post_list %}
- [{ { post . content } }](https://www.pythoncentral.io/post/{{ post.id }}/)
{% else %}
过去两天没有帖子。
{% endif %}
现在,重新加载页面http://localhost:8000/,您将看到元素的文本变成红色:

然后我们可以在页面中添加一个 img 元素,该元素引用静态目录myblog/static/myblog中存储的jpg:
{% load staticfiles %}
{% if post_list %}
- [{ { post . content } }](https://www.pythoncentral.io/post/{{ post.id }}/)
{% else %}
过去两天没有帖子。
{% endif %}

[/html]
现在您可以刷新页面http://localhost:8000来查看主页上显示的新图像。

总结和提示
在本文中,我们学习了如何管理静态文件(图像、css、javascript 等)。)在我们的 Django 应用程序中。需要记住的一点是,Django 的内部静态文件管理器和目录查找器会自动查找myblog/static/myblog下的文件,所以最好把文件放在那个目录下,而不是直接放在myblog/里。通过将文件放入指定目录,Django 知道如何区分不同 app 之间的静态文件,比如myblog/style.css或myblog_version2/style.css。
在 Python 中测量时间–Time . Time()与 time.clock()
原文:https://www.pythoncentral.io/measure-time-in-python-time-time-vs-time-clock/
在我们深入 Python 中测量时间的区别之前,一个先决条件是理解计算世界中各种类型的时间。第一种类型的时间称为 CPU 或执行时间,它衡量 CPU 在执行一个程序上花费的时间。第二种类型的时间被称为挂钟时间,它衡量的是在计算机中执行一个程序的总时间。挂钟时间也称为运行时间。与 CPU 时间相比,挂钟时间通常更长,因为执行被测程序的 CPU 可能同时也在执行其他程序的指令。
另一个重要的概念是所谓的系统时间,它是由系统时钟测量的。系统时间代表计算机系统对时间流逝的概念。应该记住,操作系统可以修改系统时钟,从而修改系统时间。
Python 的time模块提供了各种与时间相关的函数。由于大多数时候函数都用相同的名称调用特定于平台的 C 库函数,所以这些函数的语义是平台相关的。
time . time vs . time . clock
时间测量的两个有用功能是time.time和time.clock。time.time以秒为单位返回自纪元以来的时间,即时间开始的点。对于任何操作系统,您都可以运行 time.gmtime(0)来找出给定系统上的纪元。对于 Unix,纪元是 1970 年 1 月 1 日。对于 Windows,纪元是 1601 年 1 月 1 日。time.time通常用于在 Windows 上对程序进行基准测试。虽然time.time在 Unix 和 Windows 上表现相同,但是time.clock有不同的含义。在 Unix 上,time.clock以秒为单位返回当前处理器时间,即目前为止执行当前线程所花费的 CPU 时间。在 Windows 上,它根据 Win32 函数QueryPerformanceCounter返回从第一次调用该函数以来经过的挂钟时间,以秒表示。time.time和time.clock的另一个不同之处在于,如果系统时钟在两次调用之间被调慢,那么time.time可能会返回一个低于前一次调用的值,而time.clock总是返回非递减值。
下面是一个在 Unix 机器上运行time.time和time.clock的例子:
在基于 Unix 的 OS 上
【python】
导入时间
打印(time.time()、time . clock())
1359147652.31 0.021184
time . sleep(1)
打印(time.time()、time . clock())
135914752.31
time.time()显示挂钟时间过去了大约一秒,而time.clock()显示花费在当前进程上的 CPU 时间少于 1 微秒。time.clock()比time.time()精度高很多。
在 Windows 下运行相同的程序会得到完全不同的结果:
在 Windows 上
>>> import time
>>> print(time.time(), time.clock())
1359147763.02 4.95873078841e-06
>>> time.sleep(1)
>>> print(time.time(), time.clock())
1359147764.04 1.01088769662
time.time()和time.clock()都显示挂钟时间过去了大约一秒。与 Unix 不同,time.clock()不返回 CPU 时间,而是返回比time.time()精度更高的挂钟时间。
给定time.time()和time.clock()的平台相关行为,我们应该使用哪一个来衡量程序的“精确”性能?嗯,看情况。如果程序预期运行在一个几乎为程序投入了足够多资源的系统中,例如,一个运行基于 Python 的 web 应用程序的专用 web 服务器,那么使用time.clock()测量程序是有意义的,因为 web 应用程序可能是运行在服务器上的主要程序。如果期望程序在同时运行许多其他程序的系统中运行,那么使用time.time()测量程序是有意义的。大多数情况下,我们应该使用基于挂钟的计时器来测量程序的性能,因为它经常反映生产环境。
time it 模块
Python 的timeit模块提供了一种简单的计时方式,而不是处理time.time()和time.clock()在不同平台上的不同行为,这往往容易出错。除了从代码中直接调用它,您还可以从命令行调用它。
例如:
在基于 Unix 的操作系统上
% python -m timeit -n 10000 '[v for v in range(10000)]'
10000 loops, best of 3: 365 usec per loop
% python -m timeit -n 10000 'map(lambda x: x^2, range(1000))'
10000 loops, best of 3: 145 usec per loop
在 Windows 上
C:\Python27>python.exe -m timeit -n 10000 "[v for v in range(10000)]"
10000 loops, best of 3: 299 usec per loop
C:\Python27>python.exe -m timeit -n 10000 "map(lambda x: x^2, range(1000))"
10000 loops, best of 3: 109 usec per loop
闲置中
>>> import timeit
>>> total_time = timeit.timeit('[v for v in range(10000)]', number=10000)
>>> print(total_time)
3.60528302192688 # total wall-clock time to execute the statement 10000 times
>>> print(total_time / 10000)
0.00036052830219268796 # average time per loop
>>> total_time = timeit.timeit('[v for v in range(10000)]', number=10000)
>>> print(total_time)
3.786295175552368 # total wall-lock time to execute the statement 10000 times
>>> print(total_time / 10000)
0.0003786295175552368 # average time per loop
timeit用的是哪个定时器?根据timeit的源代码,它使用了最好的定时器:
import sys
如果 sys.platform == 'win32':
#在 Windows 上,最佳计时器是 time . clock
default _ timer = time . clock
else:
#在大多数其他平台上,最佳计时器是 time . time
default _ timer = time . time
timeit的另一个重要机制是它在执行过程中禁用垃圾收集器,如下面的代码所示:
import gc
g cold = GC . isenabled()
GC . disable()
try:
timing = self . inner(it,self.timer)
最后:
if gcold:
gc.enable()
如果应该启用垃圾收集来更准确地测量程序的性能,例如,当程序分配和取消分配大量对象时,那么您应该在设置期间启用它:
>>> timeit.timeit("[v for v in range(10000)]", setup="gc.enable()", number=10000)
3.6051759719848633
除了非常特殊的情况,你应该总是使用模块timeit来测试一个程序。此外,值得记住的是,测量程序的性能总是依赖于上下文,因为没有程序是在具有无限计算资源的系统中执行的,并且从多个循环中测量的平均时间总是优于在一次执行中测量的时间。
Python 中的内存映射(mmap)文件支持
原文:https://www.pythoncentral.io/memory-mapped-mmap-file-support-in-python/
Python 中的内存映射文件是什么
从 Python 的官方文档中,请务必查看 Python 的 mmap 模块:
内存映射文件对象的行为类似于字符串和文件对象。然而,与普通的字符串对象不同,它们是可变的。
基本上,内存映射(使用 Python 的mmap模块)文件对象将普通文件对象映射到内存中。这允许您直接在内存中修改文件对象的内容。由于内存映射文件对象的行为也类似于可变字符串对象,因此您可以像修改字符列表的内容一样修改文件对象的内容:
obj[1] = 'a'-将字符‘a’分配给文件对象内容的第二个字符。obj[1:4] = 'abc'-从文件对象内容的第二个字符开始,将字符列表“abc”分配给三个字符。
简而言之,使用 Python 的mmap模块对文件进行内存映射,我们使用操作系统的虚拟内存来直接访问文件系统上的数据。内存映射不是通过系统调用如 open 、 read 和 lseek 来操作文件,而是将文件的数据放入内存中,这样就可以直接操作内存中的文件。这极大地提高了 I/O 性能。
用 Python 比较内存映射文件和普通文件
假设我们有一个大于 10 MB 的二进制文件 test.out ,并且有某种算法要求我们以这样一种方式处理文件数据,这种方式要求我们重复以下过程:
- 从当前位置开始,寻找 64 个字节,处理当前位置开始处的数据。
- 从当前位置开始,seek -32 字节并且处理当前位置开始处的数据。
数据的实际处理被一个pass语句代替,因为它不影响mmap和正常文件访问之间的相对性能比较。该算法会一直处理文件的数据,直到数据超过 10MB。使用普通文件对象执行算法的代码在文件 normal_process.py 中列出:
import os
import time
f = open('test.out ',' r ')
buffer _ size = 64
retract _ size =-32
start _ time = time . time()
while True:
f . seek(buffer _ size,os。SEEK_CUR)
#从当前位置开始处理一些数据
pass
f.seek(retract_size,os。SEEK_CUR)
#从当前位置开始处理一些数据
pass
if f . tell()>1024 * 1024 * 10:
break
end _ time = time . time()
f . close()
print('正常经过时间:{0} '。格式(结束时间-开始时间))
使用mmap处理文件数据的代码在文件 mmap_process.py 中列出:
import os
import time
import mmap
f = open('test.out ',' r')
m = mmap.mmap(f.fileno(),0,access=mmap。ACCESS _ READ)
buffer _ size = 64
retract _ size =-32
start _ time = time . time()
while True:
m . seek(buffer _ size,os。SEEK_CUR)
#从当前位置开始处理一些数据
pass
m.seek(retract_size,os。SEEK_CUR)
#处理从当前位置开始的一些数据
pass
if m . tell()>1024 * 1024 * 10:
break
end _ time = time . time()
m . close()
f . close()
print(' mmap 已用时间:{0} '。格式(结束时间-开始时间))
现在,您可以在 shell 中的一个简单 for 循环中比较 normal_process.py 和 mmap_process.py :
for i in {1..3}
do
python normal_process.py
python mmap_process.py
done
normal time elapsed: 0.355199098587
mmap time elapsed: 0.296804904938
normal time elapsed: 0.371860027313
mmap time elapsed: 0.290856838226
normal time elapsed: 0.355377197266
mmap time elapsed: 0.305727958679
如你所见, mmap_process.py 比 normal_process.py 平均快 17%,因为seek函数调用是直接针对 mmap_process.py 中的内存执行的,而它们是使用 normal_process.py 中的文件系统调用执行的。
用 mmap 修改 Python 中的内存映射文件
在下面的文件 mmap_write.py 中,我们修改了文件 write_test.txt 的内容,使用mmap和将更改刷新回磁盘:
import os
import mmap
f = open('write_test.txt ',' a+b')
m = mmap.mmap(f.fileno(),0,access=mmap。ACCESS _ WRITE)
m[0]= ' n '
# Flush 对文件的内存副本所做的更改回磁盘
m . Flush()
m . close()
f . close()
假设 write_test.txt 包含一行文字:
【shell】
$ cat write _ test . txt
mmap 是一个很酷的功能!
我们运行 python mmap_write.py 后,它的内容会变成(注意句子的第一个字符):
【shell】
$ cat write _ test . txt
nmap 是一个很酷的功能!
mmap 总结和建议
虽然mmap是一个很酷的特性,但是请记住mmap必须在进程的地址空间中找到一个连续的地址块,这个地址块足够大,可以容纳整个文件对象。假设您在一个没有足够的连续内存区域来容纳这些文件的系统上处理大文件,那么创建一个mmap将会失败。另外,mmap对某些特殊的文件对象不起作用,比如管道和 tty。
下表总结了何时应该使用mmap:
- 在多线程编程过程中,如果你有多个进程以只读方式从同一个文件中访问数据,那么使用
mmap可以节省大量内存。 mmap允许操作系统优化分页操作,这使得程序在页面中的内存能够被操作系统有效地重用。
合并排序:快速教程和实施指南
原文:https://www.pythoncentral.io/merge-sort-implementation-guide/
先决条件
要了解合并排序,您必须知道:
- Python 3
- Python 数据结构-列表
- 递归
什么是合并排序?
我们正在学习排序系列的第四个教程。之前的教程涵盖了冒泡排序、[插入排序](http://: https://www.pythoncentral.io/insertion-sort-implementation-guide/)和[选择排序](http://: https://www.pythoncentral.io/selection-sort-implementation-guide/)。如果你还没有读过这些,请照着我们将要建立的那些概念去做。像所有的排序算法一样,我们认为一个列表只有在升序排列时才被排序。降序被认为是最坏的未排序情况。
合并排序与我们目前所见的其他排序技术有很大不同。合并排序可用于对未排序的列表进行排序,或者合并两个已排序的列表。
对未排序的列表进行排序
这个想法是将未排序的列表分成更小的组,直到一个组中只有一个元素。然后,按排序后的顺序将两个元素分组,并逐渐增加组的大小。每次发生合并时,必须逐个比较组中的元素,并按照排序的顺序组合成一个列表。这个过程一直持续到所有元素被合并和排序。注意,当重组发生时,排序的顺序必须 始终 保持不变。
让我们用一个例子来看看,列表= [5,9,1,2,7,0]
分裂
Step 1: [5,9,1] [2,7,0]
Step 2: [5] [9,1] [2] [7,0]
Step 3: [5] [9] [1] [2] [7] [0]
注意: 在第二步中,我们正在处理组中的奇数个元素,所以我们任意拆分它们。所以,[5,9] [1] [2,7] [0]也是正确的。
合并
Step 4: [5,9] [1,2] [0,7]
Step 5: [1,2,5,9][0,7]
Step 6: [0,1,2,5,7,9]
为了更好的理解,请看这个动画。
合并两个排序列表
你可能认为交替地从两个排序列表中取出元素并把它们放在一起会产生一个排序列表。这是一个非常错误的想法。让我们看看为什么。
a = [1,3,4,9] b = [2,5,7,8]
如上所述,在合并两个列表时,我们得到了:[1,2,3,5,4,7,9,8]
很明显,合并后的列表是没有排序的。所以我们需要在制作一个大的排序列表之前比较这些元素。让我们看一个例子。
a = [1,3,4,9] b = [2,5,7,8]
Step 1: 1<2 new list → [1] a = [3,4,9] b = [2,5,7,8]
Step 2: 3>2 new list → [1,2] a = [3,4,9] b = [5,7,8]
Step 3: 3<5 new list → [1,2,3] a = [4,9] b = [5,7,8]
Step 4: 4<5 new list → [1,2,3,4] a = [9] b = [5,7,8]
Step 5: 9>5 new list → [1,2,3,4,5] a = [9] b = [7,8]
Step 6:9>7 new list → [1,2,3,4,5,7] a = [9] b = [8]
Step 7: 9>8 new list → [1,2,3,4,5,7,8] a = [9] b = []
Step 8: new list → [1,2,3,4,5,7,8,9]
如何实现归并排序?
现在你已经对什么是合并排序有了一个很好的理解,让我们来看看如何对一个列表进行排序的算法及其代码。
算法
- 递归地将未排序的列表分成组,直到每组有一个元素
- 比较每个元素,然后将它们分组
- 重复步骤 2,直到整个列表在过程中被合并和排序
代码
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:
mid = len(alist)//2
lefthalf = alist[:mid]
righthalf = alist[mid:]
#recursion
mergeSort(lefthalf)
mergeSort(righthalf)
i=0
j=0
k=0
while i < len(lefthalf) and j < len(righthalf):
if lefthalf[i] < righthalf[j]:
alist[k]=lefthalf[i]
i=i+1
else:
alist[k]=righthalf[j]
j=j+1
k=k+1
while i < len(lefthalf):
alist[k]=lefthalf[i]
i=i+1
k=k+1
while j < len(righthalf):
alist[k]=righthalf[j]
j=j+1
k=k+1
print("Merging ",alist)
alist = [54,26,93,17,77,31,44,55,20]
mergeSort(alist)
print(alist)
代码由互动 Python 提供。
结论
合并排序对大量和少量元素都有效,比冒泡、插入和选择排序更有效。这是有代价的,因为合并排序使用额外的空间来产生一个排序列表。归并排序的最坏情况运行时复杂度为o(nlog(n)),空间复杂度为 n 。尝试合并两个排序列表并在下面评论。本教程到此为止。快乐的蟒蛇!
用 Alembic 迁移 SQLAlchemy 数据库
原文:https://www.pythoncentral.io/migrate-sqlalchemy-databases-alembic/
蒸馏器
Alembic 是 SQLAlchemy 的一个轻量级数据库迁移工具。它是由 SQLAlchemy 的作者创建的,并且已经成为在 SQLAlchemy 支持的数据库上执行迁移的事实上的标准工具。
SQLAlchemy 中的数据库迁移
数据库迁移通常会更改数据库的模式,例如添加列或约束、添加表或更新表。它通常使用封装在事务中的原始 SQL 来执行,以便在迁移过程中出现问题时可以回滚。在本文中,我们将使用一个示例数据库来演示如何为 SQLAlchemy 数据库编写 Alembic 迁移脚本。
为了迁移一个 SQLAlchemy 数据库,我们为计划的迁移添加一个 Alembic 迁移脚本,执行迁移,更新模型定义,然后开始在迁移的模式下使用数据库。这些步骤听起来很多,但是它们做起来非常简单,这将在下一节中进行说明。
示例数据库模式
让我们创建一个 SQLAlchemy 数据库,其中包含一个部门和一个雇员表。
import os
from sqlalchemy 导入列,DateTime,String,Integer,ForeignKey,func
from sqlalchemy.orm 导入关系,back ref
from sqlalchemy . ext . declarative import declarative _ base
Base = declarative_base()
类 Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
类 Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
hired _ on = Column(DateTime,default=func.now())
db _ name = ' alem BIC _ sample . SQLite '
如果 OS . path . exists(db _ name):
OS . remove(db _ name)
从 sqlalchemy 导入创建引擎
引擎=创建引擎(' sqlite:///' + db_name)
从 sqlalchemy.orm 导入 session maker
session = session maker()
session . configure(bind = engine)
base . metadata . create _ all(engine)
在创建了数据库 alembic_sample.sqlite 之后,我们意识到我们忘记了在Employee和Department之间添加一个多对多关系。
移民
我们选择使用 alembic 迁移数据库,而不是直接更改模式,然后从头开始重新创建数据库。为此,我们安装 alembic,初始化 alembic 环境,编写迁移脚本来添加链接表,执行迁移,然后使用更新的模型定义再次访问数据库。
$ alembic init alembic
Creating directory /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic ... done
Creating directory /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic/versions ... done
Generating /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic/env.pyc ... done
Generating /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic.ini ... done
Generating /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic/script.py.mako ... done
Generating /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic/env.py ... done
Generating /home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic/README ... done
Please edit configuration/connection/logging settings in '/home/vagrant/python2-workspace/pythoncentral/sqlalchemy_series/alembic/alembic.ini' before proceeding.
$ vim alembic.ini #将以“sqlalchemy.url”开头的行更改为“sqlalchemy . URL = SQLite:///alem BIC _ sample . SQLite”
$ alem BIC current
INFO[alem BIC . migration]Context impl SQLiteImpl。
INFO [alembic.migration]将采用非事务性 DDL。
SQLite 的当前版本:///alembic_sample.sqlite:无
$ alem BIC revision-m " add department _ employee _ link "
生成/home/vagger/python 2-workspace/python central/sqlalchemy _ series/alem BIC/alem BIC/versions/1da 977 FD 3e 6 e _ add _ department _ employee _ link . py...完成的
$ alem BIC upgrade head
INFO[alem BIC . migration]Context impl SQL item pl。
INFO [alembic.migration]将采用非事务性 DDL。
信息【alembic.migration】运行升级无- > 1da977fd3e6e,添加部门 _ 员工 _ 链接
$ alem BIC current
INFO[alem BIC . migration]Context impl SQLiteImpl。
INFO [alembic.migration]将采用非事务性 DDL。
当前版本为 SQLite:///alem BIC _ sample . SQLite:None->1da 977 FD 3 E6 e(负责人),添加 department_employee_link
迁移脚本如下:
【python】
“”
添加部门 _ 员工 _ 链接
修订 ID: 1da977fd3e6e
修订:无
创建日期:2014-10-23 22:38:42.894194
'''
版本标识符,由 Alembic 使用。
修订版= '1da977fd3e6e'
下一版=无
从 alembic 导入操作
将 sqlalchemy 导入为 sa
def upgrade():
op . create _ table(
' department _ employee _ link ',
sa。列(
'部门标识',服务协议。
整数,撒。ForeignKey('department.id '),primary_key=True
),
sa。列(
'雇员标识',服务协议。整数,
sa。ForeignKey('employee.id '),primary_key=True
)
)
定义降级():
op.drop_table(
'部门 _ 员工 _ 链接'
)
现在数据库 alembic_sample.sqlite 已经升级,我们可以使用一段更新的模型代码来访问升级后的数据库。
import os
从 sqlalchemy 导入列、日期时间、字符串、整数、外键、func
从 sqlalchemy.orm 导入关系
从 sqlalchemy.ext.declarative 导入 declarative_base
Base = declarative_base()
class Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
employees = relationship(
' Employee ',
secondary = ' Department _ Employee _ link '
)
class Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
hired _ on = Column(DateTime,default = func . now())
departments = relationship(
Department,
secondary = ' Department _ Employee _ link '
)
class DepartmentEmployeeLink(Base):
_ _ tablename _ _ = ' department _ employee _ link '
department _ id = Column(Integer,ForeignKey('department.id '),primary_key=True)
employee _ id = Column(Integer,ForeignKey('employee.id '),primary _ key = True)
db_name = 'alembic_sample.sqlite '
从 sqlalchemy 导入创建引擎
引擎=创建引擎(' sqlite:///' + db_name)
从 sqlalchemy.orm 导入 session maker
session = session maker()
session . configure(bind = engine)
base . metadata . bind = engine
s = session()
IT = Department(name = ' IT ')
Financial = Department(name = ' Financial ')
s . add(IT)
s . add(Financial)
Cathy = Employee(name = ' Cathy ')
Marry = Employee(name = ' Marry ')
John = Employee(财务)
注意,我们并没有删除数据库 alembic_sample.sqlite ,而是执行了一个迁移来添加一个链接表。迁移后,关系Department.employees和Employee.departments按预期工作。
摘要
由于 Alembic 是专门为 SQLAlchemy 构建的轻量级数据库迁移工具,它允许您重用相同类型的数据库模型 API 来执行简单的迁移。然而,它不是一个万能的工具。对于特定于数据库的迁移,比如在 PostgreSQL 中添加触发器函数,仍然需要原始的 DDL 语句。
关于 Python 正则表达式的更多信息
原文:https://www.pythoncentral.io/more-about-python-regular-expressions/
在本系列的第一部分中,我们看了正则表达式的基本语法和一些简单的例子。在这一部分中,我们将了解一些更高级的语法和 Python 必须提供的一些其他特性。
正则表达式捕获组
到目前为止,我们已经使用正则表达式在一个字符串中进行了搜索,并使用返回的MatchObject来提取匹配的整个子字符串。现在我们来看看如何从匹配的子字符串中提取部分。
这个正则表达式:
\d{2}-\d{2}-\d{4}
将匹配以下格式的日期:
- 两位数的日期。
- 一个连字符。
- 两位数的月份。
- 一个连字符。
- 四位数的年份。
例如:
>>> s = 'Today is 31-05-2012'
>>> mo = re.search(r'\d{2}-\d{2}-\d{4}', s)
>>> print(mo.group())
31-05-2012
我们可以通过将这个正则表达式的各个部分放在括号中来捕获:
(\d{2})-(\d{2})-(\d{4})
如果 Python 匹配这个正则表达式,我们就可以分别检索每个捕获的组。
>>> mo = re.search(r'(\d{2})-(\d{2})-(\d{4})', s)
>>> # Note: The entire matched string is still available
>>> print(mo.group())
31-05-2012
>>> # The first captured group is the date
>>> print(mo.group(1))
31
>>> # And this is its start/end position in the string
>>> print('%s %s' % (mo.start(1), mo.end(1)))
9 11
>>> # The second captured group is the month
>>> print(mo.group(2))
05
>>> # The third captured group is the year
>>> print(mo.group(3))
2012
当您开始编写更复杂的正则表达式时,使用有意义的名称而不是数字来引用它们会很有用。语法是(...),其中...是要捕获的正则表达式,name 是要为组指定的名称。
>>> s = "Joe's ID: abc123"
>>> # A normal captured group
>>> mo = re.search(r'ID: (.+)', s)
>>> print(mo.group(1))
abc123
>>> # A named captured group
>>> mo = re.search(r'ID: (?P<id>.+)', s)
>>> print(mo.group('id'))
abc123
使用正则表达式重用捕获的组
我们还可以获取捕获的组,稍后在正则表达式中重用它们!(?P=name)表示匹配之前在命名组中匹配的任何内容。比如:
>>> s = 'abc 123 def 456 def 789'
>>> mo = re.search(r'(?P<foo>def) \d+', s)
>>> print(mo.group())
def 456
>>> print(mo.group('foo'))
def
>>> # Capture 'def' in a group
>>> mo = re.search(r'(?P<foo>def) \d+ (?P=foo)', s)
>>> print(mo.group())
def 456 def
>>> mo.group('foo')
def
Python 正则表达式断言
有时我们想匹配的东西只有后面有其他东西,这意味着 Python 在搜索字符串时需要提前查看。这被称为前瞻断言,语法为(?=...),其中...是需要跟随的内容的正则表达式。
在下面的例子中,正则表达式ham(?= and eggs)意味着匹配‘火腿’,但前提是它后面跟有‘和鸡蛋’。
>>> s = 'John likes ham and eggs.'
>>> mo = re.search(r'ham(?= and eggs)', s)
>>> print(mo.group())
ham
注意匹配的子串只有火腿,没有火腿鸡蛋。和鸡蛋部分只是对火腿部分进行匹配的要求。让我们看看如果不满足这个要求会发生什么。
>>> s = 'John likes ham and mushrooms.'
>>> mo = re.search(r'ham(?= and eggs)', s)
>>> print(mo)
None
>>> s = 'John likes ham, eggs and mushrooms.'
>>> mo = re.search(r'ham(?= and eggs)', s)
>>> print(mo)
None
可惜 Python 只做简单的字符匹配,只会匹配字符串火腿,只要后面跟和鸡蛋。人工智能和语义分析是另外一篇文章。🙂
我们还可以做否定前瞻断言,也就是说,一个元素只有在而不是后跟其他东西时才匹配。
>>> s = 'My name is John Doe.'
>>> # Syntax is (?!...)
>>> mo = re.search( r'John(?! Doe)', s)
>>> print(mo)
None
>>> s = 'My name is John Jones.'
>>> mo = re.search(r'John(?! Doe)', s)
>>> print(mo.group())
John
2022 年最流行的 web 开发框架
原文:https://www.pythoncentral.io/most-popular-frameworks-for-web-development-2022/
当开发人员开始开发一个数字产品时,他们不会从头开始编写代码。相反,他们求助于框架。在本文中,来自 Promodex 机构的专家将解释什么是框架以及使用它的好处。我们将讨论这两种框架的区别,并分享五种最流行的解决方案的简要特征。

什么是 Web 开发框架?
web 框架是用于构建数字产品的软件平台。它可以用于创建网站、web APIs 和其他类型的 web 资源。它具有一系列现成的组件,可以很容易地相互组合。例如,您可以在框架中找到应用程序模板和代码片段。所有这些元素都是标准化的。
使用 Web 开发框架的好处
框架使开发者能够实现以下目标:
- 促进和加快发展进程。专业人员挑选最合适的组件,并对其进行微调,以满足产品需求。
- 优化代码。程序员不得不写一长串代码的日子一去不复返了。现在,开发人员可以访问增强产品功能的简洁代码片段。
- 简化调试和维护。每个框架都有一个活跃的社区。每当你需要咨询时,同事们都会迫不及待地帮助你。
- 增强安全性。框架包含许多防止威胁的内置特性。
框架的主要缺点在于没有一个是完美的。每个解决方案都有其优点和缺点。您应该选择最符合您正在开发的产品需求的产品。

前端框架和后端框架的区别
前端框架也称为客户端框架。它们的后端也称为服务器端。前者用于创建最终用户与之交互的数字产品层。后者是构建网站的“隐形”层所必需的,以确保网站的功能性。
客户端框架尤其负责可伸缩性、SEO 优化和 UI/UX。服务器端解决方案负责网站的架构、URL 路由和安全性等方面。
React.js
从技术上讲,它是一个代码库,而不是一个成熟的框架。然而,它非常实用,非常受欢迎。它用于创建 JS 接口。它兼容多种编程语言和技术栈。
这个解决方案有内置的工具来促进搜索引擎优化。
React.js 迅速地将基于 HTML 的代码转换成网页的布局。只要修改了代码,界面就会更新。如果你需要提供一个移动应用,请使用 React Native。
另一方面,您应该准备好安装各种代码集合和其他补充组件来扩展 React 的默认功能。另外,它的文档对新手用户来说似乎很混乱。
角度
这个不适合移动格式。此外,它是以 HTML 为中心的,这使得模型-视图-控制器模式有点太复杂。
除了这两个缺点,Angular 还有很多优点,已经成为最流行的成熟框架。这是一个开源解决方案,免费插件和工具的范围不断扩大。它兼容所有最流行的浏览器,推荐用于具有复杂功能的产品。
Angular 是富互联网应用的绝佳选择。它们让您可以在浏览器上访问桌面功能。
vista . js
用于创建客户端零件。Vue 非常灵活,以其高速著称。它的默认功能可以说是基本的——但是你可以用 API、插件和库来扩展它。
该解决方案使您能够在单独的文件中编辑模板和样式。当您决定扩展产品时,将数据从一个代码库转移到另一个代码库会很容易。文件非常清楚。
使用 Vue.js 时,要做好应对两个不利的准备。首先,与其他框架相比,它的社区更小。其次,它有一个陡峭的学习曲线。即使你在 JS 方面很有经验,你以前的专业知识也很难派上用场。

Node.js
这个开源解决方案兼容多种操作系统。它对后端和前端部分同样有效。Node 的主要优势是它的快速性能。然而,它的模块通常是冗余的,这意味着你必须在编码上投入更多的时间。这个缺点的原因是,最初,JavaScript 是用来构建前端部分的。然后,人为修改,使之能够应对服务器端层。
Node.js 并不是处理 CPU 密集型任务的最佳选择。它一次只能完成有限数量的此类任务。
Ember.js
这个框架拥有异常丰富的功能。它以一个巨大的图书馆为特色。开发者很欣赏依靠手柄导航的机会。由于实时重新加载,请求处理速度非常快。
Ember 是一个相对年轻的开源解决方案,但它已经积累了一个庞大而活跃的社区。
至于缺点,这个框架比本文中提到的其他框架要慢。为了弥补这一点,你可以求助于附加组件。此外,开发新手通常很难习惯它的组件结构。
最终想法
开发人员使用框架来优化代码、加速开发过程、增强安全性和简化维护。数字产品的前端和后端部分有独立的框架。最受欢迎的解决方案有 React.js、Angular、Vue.js、Node.js 和 ember . js
如何在 Python 中实现矩阵相乘
在 Python 和大多数其他 OOP 编程语言中,将两个数相乘是一个非常简单的过程。然而,当你试图将两个矩阵相乘时,事情就变得有点复杂了。如你所知,矩阵基本上就是一个嵌套列表,或者是另一个列表中的多个列表。使用矩阵时,主列表中的每个列表都可以视为一行,行中的每个值都可以视为一列。矩阵可能是这样的:
x = [[4, 3], [88, 7], [56, 31]]
上例中的矩阵有三行,每行有两列。
如果你想将两个矩阵(x 和 y)相乘,你需要确保 x 中的列数等于 y 中的行数,否则这个等式将无法正常工作。出于本教程的考虑,让我们将两个各有三行、三列的矩阵相乘,即 3x3 矩阵。请记住,当您将两个矩阵相乘时,得到的矩阵的列数将与等式中最大的矩阵的列数一样多,因此,例如,如果您将 3×3 乘以 3×4,得到的矩阵将是 3×4。
出于本教程的目的,我们将 3x3 乘以 3x3。让我们看看下面的例子,看看它是如何工作的:
X = [[34,1,77],
[2,14,8],
[3 ,17,11]]
Y = [[6,8,1],
[9,27,5],
[2,43,31]]
result = [[0,0,0],
[0,0,0],
[0,0,0]]
for i in range(len(X)):
for j in range(len(Y[0])):
for k in range(len(Y)):
result[i][j] += X[i][k] * Y[k][j]
for r in result:
print(r)
在上面的例子中,我们首先要定义我们的矩阵。然后,我们需要定义一个结果矩阵,它将表示包含我们方程的答案的矩阵。因为我们的两个矩阵是 3x3,所以我们的结果矩阵也是 3x3。接下来,我们遍历 x 矩阵的行,然后是 y 矩阵的列(这是使用 y[0]完成的),最后遍历 y 矩阵的行。然后执行算术运算。
上面示例的输出如下所示:
r =[[367, 3610, 2428], [154, 738, 320], [193, 956, 429]]
这些基本信息应该足以让你自己开始学习矩阵乘法。一旦你掌握了像矩阵一样的乘法,一定要挑战自己,尝试那些列数和行数不相等的乘法。
Python 中数字的乘除运算
原文:https://www.pythoncentral.io/multiplying-dividing-numbers-python/
乘法是算术和编程领域的一项基本运算。我们可以在每个程序(或每个代码背后的逻辑)中找到它的用途,不管它有多基础。因此,程序员必须知道如何用 Python 将整数、小数、复数和字符串相乘,以创建高效而准确的代码。在本文中,我们将通过编码示例学习如何执行所有这些操作。
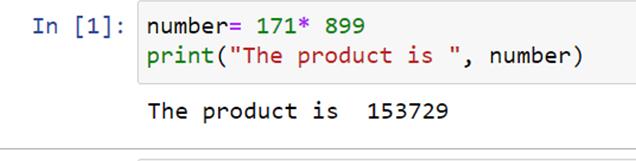
但是首先,让我们看看表示乘法运算的语法是什么。我们使用星号字符**' ***来执行乘法运算。我们来考虑一个例子,假设我们要把两个数字相乘,171 和 899。那么这个操作的代码就是:

上述代码的输出为:
我们可以看到,我们在 Python 中使用星号运算符来编写乘法代码。
Python 中的整数乘法
整数是一种仅由整数组成的数据类型,即整数中没有小数部分。例如 117,1,2,10 都是整数。整数相乘的语法很简单。我们写下要相乘的数字,并用星号运算符将它们分开。
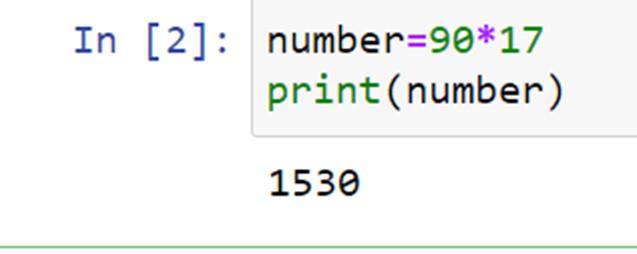
在上面给出的完整代码片段中,我们可以看到数字 90 和 17 相乘。
Python 中的乘法浮点数
浮点数数据类型的基本定义是它包含由分数组成的数字。它可以存储多达 17 个有效数字。浮点数的例子有 17.003、5.0098、70.0007 以及更多类似的数字。
浮点数相乘的语法与整数相同;我们将需要乘以星号运算符的数字分开并打印出来。
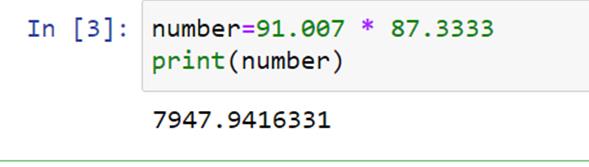
在这段代码中,我们使用星号运算符将两个浮点数 91.007 和 87.3333 相乘并打印出来。我们可以注意到乘法的输出也是一个浮点数。
Python 中的复数乘法
复数是形式为【a+bi】的虚数,其中“a”代表实数,“b”是虚数的系数。同样,“I”代表“iota”,它是-1 的平方根。在研究代码之前,让我们先讨论一下如何将复数相乘。例如,让我们考虑复数(3 + 4i)和(5 + 6i)。
该乘法的结果如下:
(3 * 5)+(3 * 6i)+(4 * 5i)+(4 I * 6i)
=15+ 18i+20i+ 24(i^2)
= -9+38i【自(i^2 =-1)】
我们用 【复数() 的方法对 Python 中的 复数进行乘法运算。
在 【复数() 的方法中,我们先写实部,然后写虚部,中间用逗号隔开。最好将每个复数存储在一个变量中,然后使用星号运算符对变量执行乘法运算。让我们对上例中考虑的数字进行乘法运算。
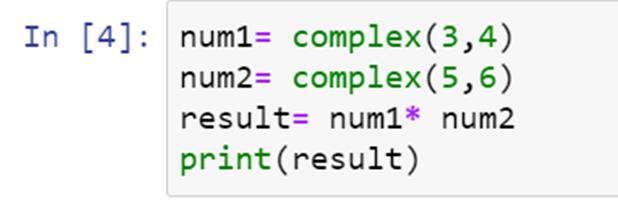
我们已经用 complex()方法写出了复数。数字存储在变量 num1 和 num2 中,然后执行乘法。
现在我们来看看输出是什么:

我们可以看到输出与我们在前面的例子中的计算相匹配。
Python 中的字符串与整数相乘
‘字符串乘以整数’是什么意思?假设我们想要多次显示一个字符串(一种数据类型的字符),那么我们可以将该字符串乘以它必须显示的次数,而不是一次又一次地写它,因此我们可以获得所需的输出。
在 Python 中用一个整数乘以一个字符串,我们使用【def()函数。在 def() 函数中,我们创建了另一个函数,其中我们提到了要重复的字符串变量,后跟它要重复的次数。然后我们返回相乘后的值。这里举个例子,我们取字符串“Hello World!”重复五次。
让我们看看完整代码的语法及其输出:

我们使用 def() 函数创建了 row() 函数。我们已经提到了字符串“Hello World!”作为第一个参数的 row() 函数然后将乘法数作为第二个参数。

我们可以看到输出显示了字符串五次。
使用 Python 中的函数将数字相乘
函数使程序简洁易懂。如果你的程序有很多乘法运算,那么为了节省时间和避免混乱,你可以使用函数来乘法。定义函数的步骤如下:
- 声明函数的参数。
- 使用该功能定义要执行的操作。
- 指定函数的返回值。
我们使用关键字 def 来声明一个函数。
让我们看看代码的语法是什么:

这里我们使用 def 关键字定义了一个函数 mult() 。这个函数的参数是 x 和 y,运算是 x 和 y 的乘法,返回的值是 x 和 y 的乘积,现在我们来看看这段代码的输出:
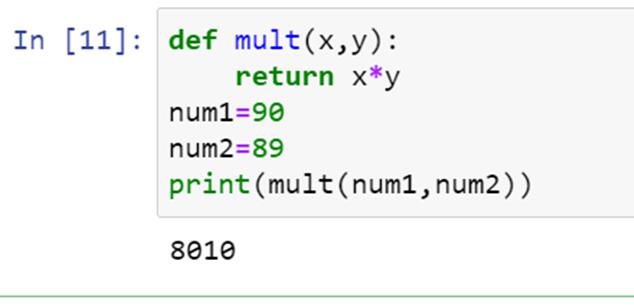
我们可以看到代码提供了输入数字的乘积作为输出。
Python 中的乘法列表
用 Python 将一个列表乘以另一个列表
我们要用 zip() 的方法在 Python 中把两个列表相乘。方法的作用是:提取列表中的元素。然后,我们将获得的元素相乘,并将它们添加到一个新的列表中。但是,我们必须确保列表长度相等,也就是说,两个列表的元素数量相等。
让我们看看如何编写这个操作的代码:

在这里,我们的两个列表分别是‘list 1’和‘list 2’。Multiply 是一个空列表,编译器将在其中追加乘积。使用 for 循环和 zip() 方法,我们获得每个列表的元素。元素相乘后,我们将乘积追加到空列表“multiply”中。
获得的输出为:

我们可以在结果中看到附加的产品。
列表元素相乘
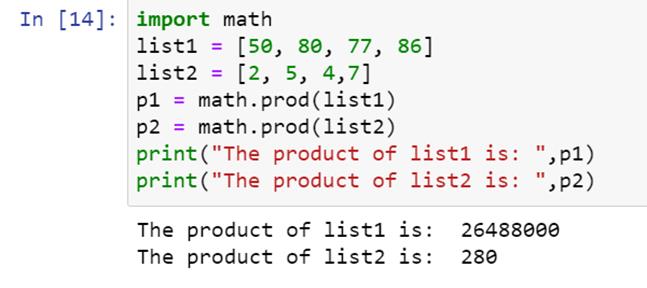
Python 的数学模块有一个 prod() 函数,让我们的乘法变得更简单。我们首先导入模块,然后编写如下代码:
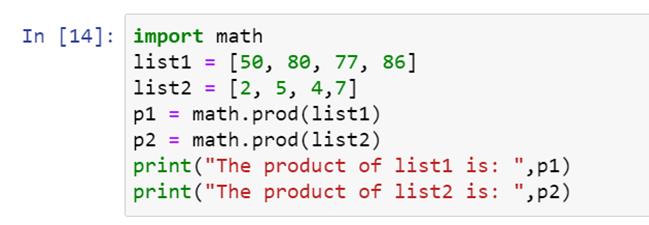
我们将得到列表元素的乘积作为输出:
遍历 Python 在列表元素乘法中的应用
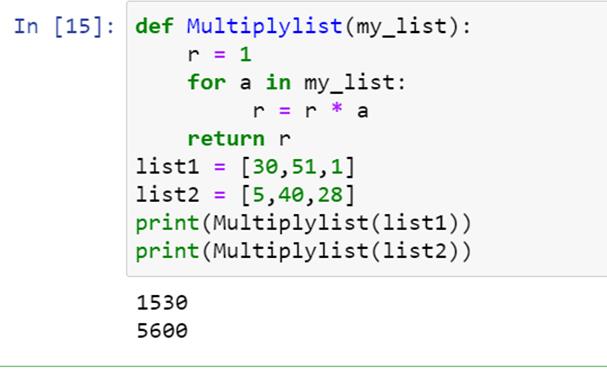
遍历方法是一种将列表元素相乘的迭代方法。迭代方法由循环语句组成。让我们看看如何使用循环语句来获得列表元素的乘积:
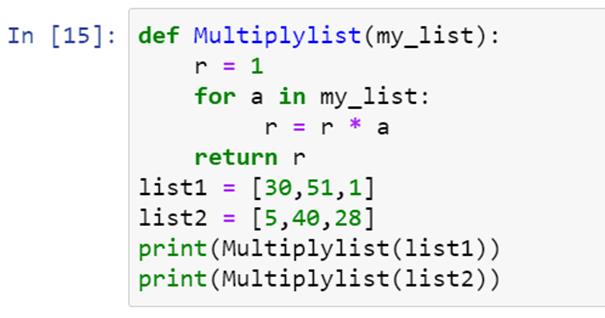
这里我们定义了一个函数 Multiplylist(),其中我们使用了一个循环语句“for”我们已经将变量 r 初始化为 1,使用循环快速地将元素一个接一个地相乘。最后,我们打印了产品清单。我们来看看输出:
你可以在这里了解更多关于 Python 中列表相乘的知识。
结论
Python 提供了各种方法来乘法数字。这些数字可以是整数或小数,也可以包含在列表中。对于每个乘法问题,Python 都有解决方案。通过包含函数,可以使代码高效而准确。我们希望这篇文章能帮助你 理解数字 相乘的不同方法,并在你的编码实践中毫不费力地使用它们。
新 PS Plus 透露:不如预期精彩?
原文:https://www.pythoncentral.io/new-ps-plus-revealed-not-as-exciting-as-expected/

在世界各地的游戏玩家翘首以盼之后,索尼在一篇 的博客文章 中发布了新的 PS Plus。它仍然被称为 PS Plus,但该公司现在已经将其与订阅服务 PS Now 合并。
乍看之下,这项新服务让游戏玩家更容易进入游戏,似乎是该公司对微软游戏通行证的回应。
竞争公司的服务为他们的用户群提供了每月付费的数百款游戏,并支持游戏流。
然而,现在 Game Pass 和 PS 之间已经有了足够的差异,进行一对一的比较是不合理的。我们将它们之间的差异分解如下。
PS Plus 用户关注的成本与游戏通票价格相比是多少
索尼将为其游戏机用户提供四个等级的 PS Plus 订阅服务:
- PS Plus Essential:【10 美元/月或 60 美元/年
- PS Plus Extra:【15 美元/月或 100 美元/年
- PS Plus Premium:【18 美元/月或 120 美元/年
- Ps Plus 豪华: 细节尚未公开
PS Plus Essential 提供了与该公司之前推出的 PS Plus 相同的优势。每月多花 5 美元,PS Plus Extra 将让游戏进入一个大的 PS4 和 PS5 游戏库。
PS Plus Premium 计划将为用户提供从老一代 PlayStation 游戏机上玩游戏的机会——包括 PSP 游戏——每月 18 美元。
虽然 PS Plus Deluxe 计划的定价细节尚未透露,但索尼指出,它的价格将低于 Premium 计划,并且不会在目录中包括 PS3 游戏。
另一方面,Game Pass 分为两层,PC 和 Xbox 的基础层价格为 10 美元/月,可以在不同的主机上访问大量的游戏。第二层是 Game Pass Ultimate,每月收费 15 美元,并提供其他一些额外服务。
随着 PS Plus Premium 的年费低于 Game Pass Ultimate 的年费,索尼的新游戏点播服务似乎更具吸引力。
PS Plus 上提供的游戏
Game Pass 提供超过 450 款游戏,其中超过三分之二的游戏可以在电脑上玩。此外,该公司的目录中有超过 100 款游戏,玩家可以在所有兼容设备上访问,包括手机。
另一方面,索尼的计划更加令人困惑。
PS Plus Extra 将提供 400 款 PS4 和 PS5 游戏,包括《死亡搁浅》、《蜘蛛侠》和《战神》等热门游戏。获得 PS Plus Premium 计划的用户将从旧款游戏机上获得 340 个额外的游戏。
有点令人惊讶的是,用户无法下载 PS3 游戏,需要进行流媒体播放。通过这种方式,索尼将 PS Now 服务与 PS Plus 合并,并希望通过以更低的成本提供更大范围的可下载游戏来吸引市场。
虽然这一举动看起来像是对 Game Pass 的反击,但假设它的定位像一个反击并不能捕捉到全貌。当然,这两种服务提供的是相同的东西,但 PS Plus 没有 Game Pass 提供的好处:第一天独家发行。
令人失望的是,PlayStation 玩家将无法通过他们的订阅访问新游戏,例如备受期待的《战神:拉格纳克》。
然而,PS Plus 每年比 Game Pass Ultimate 便宜得多,从某种意义上说,这是一笔更好的交易。
玩正反两面总是很有趣,但在一天结束时,重要的是要记住索尼并不真的需要与 Game Pass 竞争。该公司在第一方游戏发行方面一点也不吃力,令人兴奋的新游戏发行,如《地平线禁忌西部》取得了巨大成功。
再者,《战神》、《地平线:零黎明》等游戏的 PC 端口也获得好评。
这里的要点是,该公司为玩家提供了很棒的游戏优惠,并提供了一个玩老游戏的机会。这表明订阅服务的时代现在已经延伸到了游戏领域,而且还会持续下去。
NodeJS 与 Python:何时以及如何使用两者
原文:https://www.pythoncentral.io/nodejs-vs-python-when-how-to-use-both/

每个 web 开发人员都必须从某个地方开始。通常,这意味着参加一门课程,阅读几本相关的书籍,并对他们从头开始构建的第一个应用程序或网站进行测试。但是在所有这些步骤之前有一个要素——决定他们想要学习和使用哪些工具。
虽然说总有时间去学习新的技巧是完全合理的,但是决定你首先学习哪些技巧可以改变你整个职业生涯的形状。
NodeJS 和 Python 是数百万人在应用程序开发中使用的两个突出的解决方案。然而,尽管它们共享一些重叠的用例,但它们是完全不同的技术。
如果你曾经想知道哪一个更适合你的需要,不要再想了!下面,我们详细解释一下何时以及如何使用这两者。
什么是 node.js
NodeJS 是一个开源的 JavaScript 运行时环境。它基于 Chrome 的 V8 JavaScript 引擎,使用非阻塞、事件驱动的 I/O 模型。
从专业术语到通俗术语,它是一个允许 web 和应用程序开发人员构建可伸缩的服务器端应用程序的解决方案。如果你想开发和运行实时 web 应用程序,你很可能会搜索 NodeJS 开发服务或者自己使用这个平台。
您可以在 OS X、微软 Windows 和 Linux 操作系统上运行 NodeJS。这个因素使它成为一个高度通用的选项。
然而,与 Python 提供的多种用途相比,NodeJS 的灵活性减弱了。
Python 是什么?
Python 是一种开源的高级动态编程语言。正如我们在它的官方网站上看到的那样,它是“强大的”...而且快;与他人相处融洽;到处跑;&友好易学;是开放的。”
最重要的是,Python 是一种通用语言,这意味着您可以将它用于各种目的和项目。无论你是对建立网站和软件、机器学习、自动化还是数据分析感兴趣,Python 都是你最好的朋友。
将这种疯狂的灵活性与高度的易用性结合起来,您就会明白为什么它是领先的编程语言之一。
他们的优势是什么?
NodeJS 和 Python 提供了几个独特的优势来帮助您实现目标。以下是它们提供的最显著优势的简要说明。
NodeJS 的优势
- 可伸缩性 —如前所述,web 开发人员使用 NodeJS 来构建可伸缩的服务器端应用程序。虽然该平台缺乏清晰的编码标准,但它是一个以高吞吐量处理多个连接的非常好的解决方案。
- 简单 — NodeJS 也相对简单易学。无论您是将它用于客户端还是服务器端开发,很好地掌握它的基础知识都不会花费太多时间。
- 速度—V8 JavaScript 引擎的使用使 NodeJS 成为最快的代码执行库。此外,由于它的应用程序以片段形式输出数据,因此没有缓冲,这使得它的速度和效率更加令人印象深刻。
- 出色的生态系统 — NodeJS 提供了一个奇妙的生态系统,允许开发人员找到他们完成项目所需的支持。NPM 是世界上最大的软件注册中心,它提供了成千上万的软件包,你可以用来扩展它的功能。
Python 的优势
- 多功能性 —说到灵活性和多功能性,Python 是王者。您可以轻松地将其与 C、C++、COM、ActiveX、CORBA 和 Java 集成。最重要的是,它提供了一个全面的开源数据分析工具、测试工具和 web 框架库。
- 跨平台支持——你可以在任何操作系统上运行用 Python 编写的程序,包括最流行的微软 Windows 和 macOS。
- 直观性 —虽然 Python 非常强大,但学习起来并不困难。相反,它为所有感兴趣的人提供了相当低的准入门槛。
- GUI 支持 —使用 Python 的另一个好处是它有多个完全开发的 GUI 框架。例如 Tkinter、PyQt5 和 Pygame。
什么时候使用它们?
找到这些技术的最佳用例很大程度上取决于它们的属性,我们在上面已经描述过了。换句话说,为了充分利用 Python 和 NodeJS 的功能,您需要发挥它们的优势。
考虑到这一点,可以有把握地说,NodeJS 提供的速度和效率对于内存密集型活动可能会派上用场。Python 缺乏这些品质,这使得它不太适合开发依赖处理速度的高负载应用程序和电子商务网站。
另一方面, Python 擅长初学者友好性。它的语法和代码结构更简单,可读性更好,这使它比这个部门的 NodeJS 略胜一筹。有些人甚至在大学里教它。
多功能性也是如此——你可以使用 Python 进行几乎任何类型的开发。NodeJS 的使用领域更加有限。它最适合数据密集型实时应用。
两者之间另一个值得注意的区别是它们的架构。NodeJS 依赖于 JavaScript 解释器,而 Python 使用 CPython 作为解释器。它直接转化为它们的使用潜力。
NodeJS 旨在减少资源使用。因为它基于单线程事件循环模型,所以它允许相对轻量级的流程快速执行。
Python 更健壮一点。它将其代码转换成字节码,然后使用解释器将字节码转换成机器代码。这需要时间和资源,导致代码执行速度变慢。
然而,如果你担心 Python 的速度不够,你可以使用 PyPy 这样的解释器来增加速度。一旦用其中一个替换了默认的 CPython,您应该会注意到效率有了显著的提高。
底线
那么,NodeJS 与 Python 之争的最终结论是什么?在很大程度上,这取决于你的需求和喜好。
Python 是大型项目的绝佳选择,因为几乎可以用它做任何事情。如果你想在多个领域试试运气,比如机器学习、数值计算、网络编程和 web 应用,它是这项工作的最佳工具。
相反,对于小规模项目,NodeJS 是更好的选择。如果您想创建一个统一的运行时环境,它的独特属性将是理想的。它将允许您开发跨平台的 web、移动和桌面应用程序。
考虑您的需求,再次审视每个解决方案的突出品质,并选择更符合您愿景的解决方案。祝你好运!
Python 中的面向对象编程
原文:https://www.pythoncentral.io/object-oriented-programming-in-python/
面向对象是 Python 和许多其他语言的核心概念。理解这个概念,并很好地应用它,将使您能够构建更加优雅和易于管理的软件。
Python 中的面向对象编程是什么?
你会经常听到有人说,在 Python 中,一切都是对象。这几乎是真的,除了几个例外。表达式不是对象,但它总是表达一个对象。因为 Python 解释器将对 contact 上的任何表达式求值,所以只要它读取一个表达式,表达式本质上就是它求值的对象。名字也不是对象,但它总是引用一个对象。名称也在接触时被评估,评估到它们在那个时间点引用的任何对象。所以,最终,一切都是物体。
Python 的内置对象与自定义对象
每个对象都有特定的类型。Python 内置了一系列不同类型的对象,它们是预定义的,您也可以根据需要自己定义其他对象。内置类型有字符串、浮点、列表、函数、模块等。您可以使用这些内置类型做很多事情,但是如果您学会将它们结合起来,创建适合您的应用程序的自定义对象类型,您可以做更多的事情。你可以定义一个SpaceInvader类型,一个Employee类型,一个Account类型;它可以是任何东西。例如,一旦定义了一个Account类型,您就可以根据需要创建该类型的任意多个实例。同样,您可以根据需要拥有任意多个字符串,也可以根据需要拥有任意多个帐户。
数据与逻辑

数据与逻辑模型视图控制器
传统上,数据和逻辑之间有一个概念上的划分。像数字和字符串之类的东西是数据,像 if 分支和 while 循环之类的东西是逻辑,这两个东西应该分开。许多现代语言有不同的方法,结合数据和逻辑来创建对象。对象是一个单一的东西,它有存储数据的属性和定义逻辑的方法。几乎任何事物都可以被认为是一个对象,并根据它的属性和方法来定义。
对象的属性实际上只是赋予名称的值,而方法就像函数一样,所以如果你已经了解一点 Python,那么对象就很容易理解。
如果您想做一些银行业务,您可能想定义一些银行帐户对象。首先定义一个新的对象类型,我们称之为 Account。然后,你可以给它两个属性,一个叫做 fullname,它有一个字符串,这个人的名字,另一个叫做 balance,它有一个数字,可能是一个 float,它有一个当前余额。Account 类型还需要一个方法,我们称之为 transact,它通过增加或减少来改变 Account 对象的 balance 属性值。
乐高是面向对象的
那么,为什么从对象的角度思考会有用呢?想想用乐高搭建。乐高提供了原始的物体类型,砖块、瓦片、盘子等等,我们可以用它们来建造几乎任何建筑。如果你只想建造一个非常简单的模型,也许是一面墙,你可以拿起一块砖,然后添加一些小块,直到你得到你想要的。如果你想建造一些更复杂的东西,比如说一座城市,你需要用不同的方法来实现它。如果你只是不停地给不断膨胀的乐高积木块添加碎片,你最终只会得到一大堆乱七八糟的东西。相反,您需要从对象和接口的角度来考虑。

乐高元素是界面非常简单的物体;砖块与其他砖块或瓷砖或其他东西的接口并不复杂。它们可以夹在顶部或底部,没什么大不了的。因为它们有干净、简单的界面,所以很容易组合乐高元素来制作更复杂的物体,一面墙、一个烟囱、一个壁炉。重要的是确保你用简单的接口来构建这些新的对象。
设计良好的烟囱对象具有简单的接口,可以将它们附加到墙壁对象上。壁炉物体应该以简单的方式夹在烟囱和墙上。假设它设计得很好,你可以忘记你是如何制作壁炉的,你可能花了很长时间让它看起来刚刚好,但这已经不再相关,只有它的界面的复杂性是一个问题。只要你的壁炉容易固定,建造起来有多复杂都没有关系。这种复杂性被封装在壁炉对象中,只暴露了界面的复杂性。
如果您继续组合这些新对象来形成一个更复杂的对象,比如一个房子,您可以非常容易地将这个房子对象添加到您的城市对象中,同样假设是简单的接口。诸如此类。每个对象都应该由更原始的对象构成,所有的对象都有简单的接口,一路向下。
Python 中面向对象编程的对象
在 Python 中,如果你像上面讨论的那样定义了一个Account类型,你会很早就意识到只有账户持有人的名字和当前余额实际上是不够的,所以你可能会决定包括其他数据,比如账户持有人的家庭住址、出生日期、这类东西,以及账户开立日期等。然后,您可能需要方法来关闭帐户,修改帐户持有人的姓名,也许他们结婚了,这一切都可能变得有点太快了。然而,如果你从对象的角度考虑,很明显你会想把它分开一点。
我们总是可以定义一个新的Customer类型,它具有客户会有的属性和方法,然后定义一个帐户类型,它具有银行帐户的属性和方法。Account类型将有一个名为account_holder的属性,该属性将被分配给一个Customer类型的对象,而不仅仅是一个字符串或其他什么。
对象定义就像蓝图。首先定义一种新的对象类型,即对象定义,然后创建该类型的实例,这些实例就是对象本身。每个对象都是特定类型对象的一个实例。它将与同类型的所有其他对象具有相同的属性名称。例如,所有 account 类型的对象都有一个 account_holder 属性,但是,由于 Account 的所有实例都是独立的对象,所以每个实例都可以有不同的 account_holder 属性。
同样,一个对象的每个实例都具有与相同类型的所有其他实例相同的方法,但是调用一个实例的方法是特定于该实例的。每个字符串都有一个 upper 方法,因为它是一个字符串,字符串类型是用 upper 方法定义的。您可以对任何字符串调用 upper,但它只影响特定的字符串实例。
记住,一切都是物体。传递给函数的参数是对象,因此可以编写一个函数,将客户对象作为参数,引用它们的属性并调用它们的方法。您可以拥有一个 Account 对象列表,并像往常一样遍历该列表。您可以用内置类型的对象做的任何事情,也可以用您自己的类型来做。
这将在涵盖实际 Python 语法的文章中变得更加具体。这里的目的是尝试引入面向对象的范例,帮助你理解对象实际上是什么,同时也鼓励你思考如何更有效地使用它们。Python 的魔力始于 OOP。
Python 中的一行 if 语句(三元条件运算符)
原文:https://www.pythoncentral.io/one-line-if-statement-in-python-ternary-conditional-operator/
在现实世界中,我们周围发生的每一个行为都有特定的分类和条件。十二岁的人是孩子,而十三岁的人是青少年。如果天气宜人,你可以计划一次郊游。但是如果不是,你将不得不取消你的计划。这些条件也控制着编码世界。您将遇到各种编码问题,在这些问题中,您必须根据某些条件打印输出。
幸运的是,Python 有一个简单的命令和语法来解决这类问题。这些被称为条件语句。所以让我们开始讨论条件语句,它们的语法和应用。
基本 如果 语句(三元运算符)
很多编程语言都有一个 三元运算符 ,定义了一个条件表达式。最常见的用法是创建一个简洁、简单的依赖赋值语句。换句话说,如果条件为真,它提供一行代码来计算第一个表达式;否则,它会考虑第二个表达式。 源自 C 的编程语言通常有以下语法:

Python BDFL(Python 的创造者,吉多·范·罗苏姆)认为它是非 Python 语言,因为对于不习惯 c 语言的人来说,它很难理解。此外,冒号在 Python 中已经有了很多用途。于是,当 PEP 308 获批后,Python 终于收到了它的快捷条件表达式:

它首先评估条件;如果返回 True ,编译器会考虑 expression1 给出结果,否则expression 2。求值比较懒,所以只会执行一个表达式。
我们来看看这个例子:

这里我们定义了年龄变量,它的值是 15。现在我们使用 if-else 命令打印孩子是否是成年人。成年的条件是这个人的年龄应该是 18 岁或 18 岁以上。我们已经在 if-else 命令中提到了这个条件。现在我们来看看输出是什么:
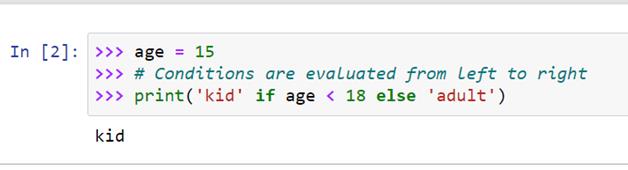
正如我们所看到的,我们已经基于年龄变量的值获得了输出“kid”。
我们也可以链接三元运算符:

在这里,我们合并了多个条件。这种形式是三元运算符的链式形式。让我们检查输出:

该命令与下面给出的程序相同:

编译器从左到右计算条件,这很容易用类似于 pprint 模块:的东西进行双重检查
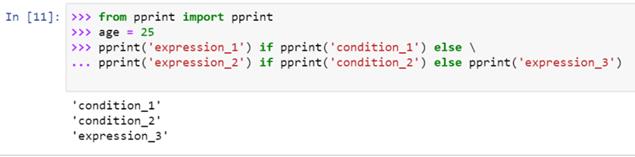
三元运算符的替代物
对于低于 2.5 的 Python 版本,程序员开发了几个技巧来模拟三元条件操作符的行为。他们一般都很气馁,但是知道他们是如何工作的还是很好的:
这些是在你的代码中强加条件的各种方法:
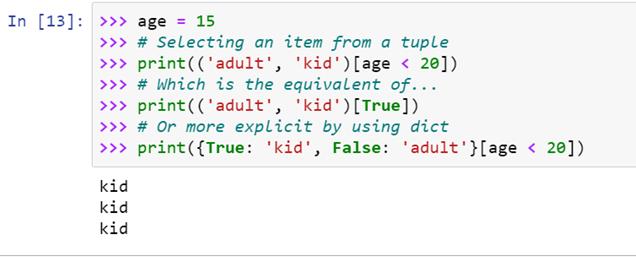
我们可以看到,对于各种输入,对于变量的确切值,得到相同的输出。
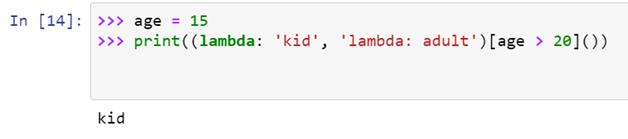
这种方法的问题是,无论条件如何,两个表达式都将被求值。作为变通办法,可以帮忙:
**
我们得到的输出如下:
另一种方法是使用‘and’或‘or’语句:
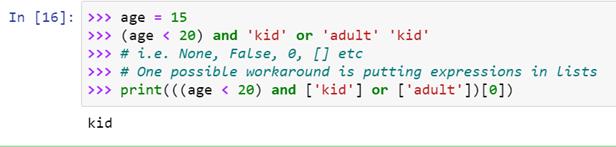
是的,大多数变通办法看起来都很糟糕。然而,有些情况下使用“and”或“or”逻辑比三元运算符更好。比如,当你的条件与其中一个表达式相同时,你可能想避免对它求值两次:
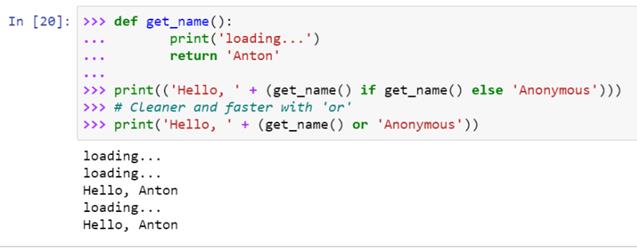
凹痕和块
Python 对编程语句的语法非常小心。当我们编写像 if-else 这样的复合语句时,我们必须保持适当的缩进和分块。if-else 语句的正确缩进语法如下:
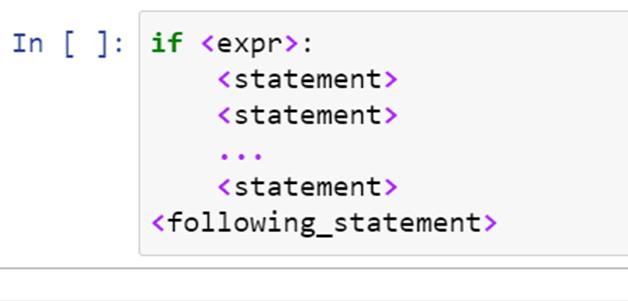
【if】下的语句被认为是一个“块”的一部分其他语句不是 if 块的一部分,在对“if”语句求值时不考虑这些语句。
如果你偏离了这个缩进,Python 会自动改变文本颜色,并在你运行代码时显示一个错误。让我们举一个例子,我们故意不同于适当的缩进:
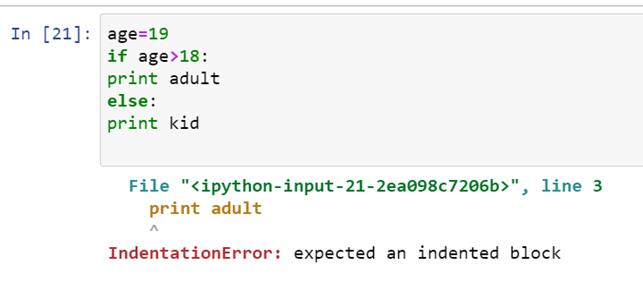
我们在这里可以看到 Python 给出了一个错误消息: “期望一个缩进块 ”
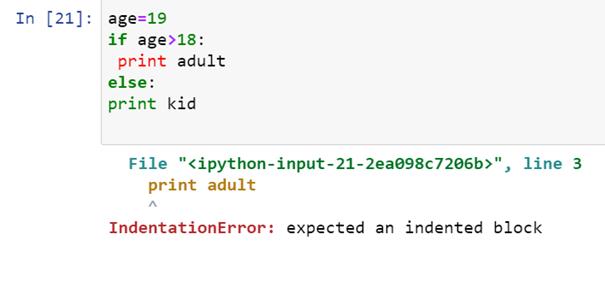
另外,注意第 3 行中“print”的颜色。所有其他文本都是绿色的,而“print”是红色的。颜色的变化是由于“print”的突然缩进造成的。
现在让我们纠正缩进:
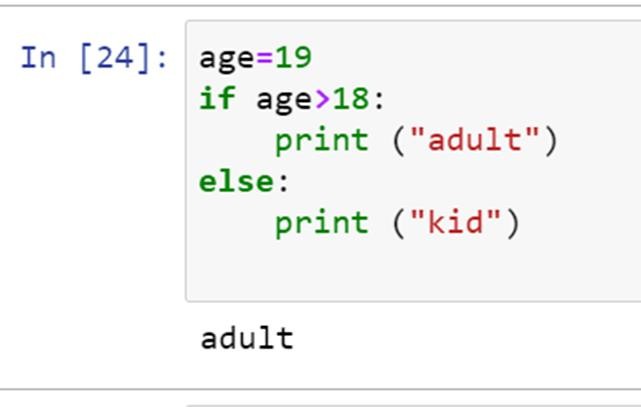
当我们维护了 Python 的缩进后,我们可以轻松地得到输出。
else和** elif 子句**
假设您的' if ' 条件为假,并且您有一个准备执行的替代语句。然后你就可以轻松地使用 else 子句了。现在,假设您有多个 if 条件,并且每个条件都有一个备选项。然后,你可以使用elif**子句并指定任意数量的情况。现在让我们为每种情况举一个例子:
的用法 从句:
if-else语句的语法很简单,在本教程中已经多次使用。让我们来看一个基本问题:有一个足球队的选择。候选人的资格最关键的条件是他应该年满 17 岁。如果他的年龄大于或等于十七岁,输出将是“你符合条件。”如果男孩小于 17 岁,结果将是“对不起”。你没有资格。”
现在让我们看看这个问题的代码:
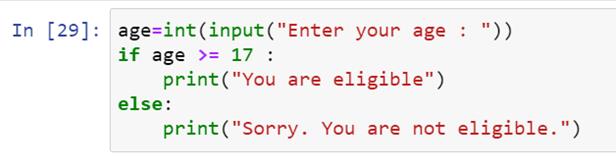
让我们运行这段代码,看看输出是什么:
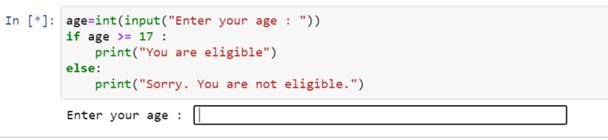
程序首先要求用户输入年龄。我们第一次进入十六岁的年龄。
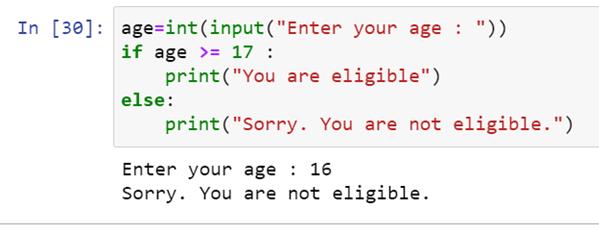
现在让我们输入 18 岁的年龄,观察输出。
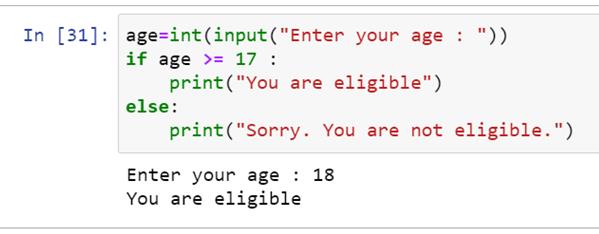
因此,我们可以看到代码评估输入的输入(“年龄”)并根据 if-else 条件检查值。如果条件为真,编译器会考虑“If”下的语句,而忽略其他语句。如果条件为假,编译器执行‘else,’下的语句,其他所有语句都被忽略。
使用 elif 从句:
当我们在打印输出之前需要检查多个条件时,我们使用这个子句。 elif 这个词紧凑为“else——if。”当我们使用the elif子句时,else子句是可选的。但是如果我们想使用else子句,那么必须只有一个子句,并且在程序的末尾也是如此。
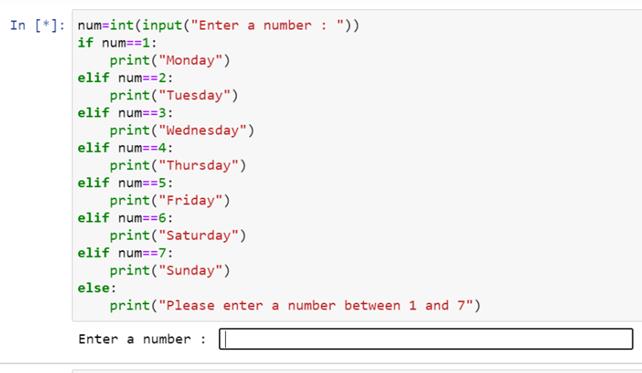
让我们来看一个问题。我们要求用户输入一个 1 到 7 之间的数字,并显示相应的工作日名称。我们来看看这个问题的程序。

上面给出的代码有 elif 以及 else 子句。
现在让我们检查输出:
程序首先要求用户输入一个数字。让我们输入四个。
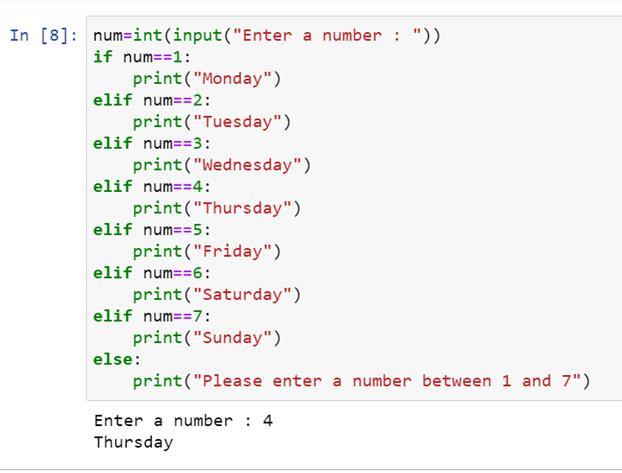
现在,让我们检查输入值 12 的输出。

因此,该代码适用于任何用户输入的输入值。
结论
条件支配着我们现实生活中的方方面面。为了在我们的虚拟编码世界中正确地模拟这些现实条件,我们这些程序员需要很好地掌握控制语句,如 if-else 。我们希望这篇文章能帮助你理解 Python 中的条件语句及其语法。本文讨论的各种问题将帮助你理解if-else语句的基本概念及其应用。****
使用 Python 的 Sublime Text 2 概述
原文:https://www.pythoncentral.io/overview-of-sublime-text-2-with-python/
每个开发人员的关键工具之一是一个良好的集成开发环境(IDE)。Python 是一种美丽的语言,得到了新兴开发人员社区的大力支持,他们不断创造出令人惊叹的库和扩展。这就是 Python 有众多 ide 的两个原因。它们包括商业插件,如 Komodo 和 PyCharm,用于其他 ide 的插件,如用于 Eclipse 的 PyDev,以及与 Python 安装捆绑在一起的轻量级插件 IDLE。然而,一些用户更喜欢使用文本编辑器来满足他们的几乎所有需求,包括开发。Sublime Text 2 是这些文本编辑器中的一个,在这里,我将展示在 Python 中使用 Sublime Text 2 的一些特性。
为什么选择文本编辑器
在开始,总是有两个论点,一个支持使用文本编辑器编码,一个反对。这不是本文的主题,但值得注意的是,这两个论点都有道理,并且根据用法和用户的熟练程度,其中一个会更合适。对于我的需求,以及通常从事相对较小规模项目(尤其是只包含一个文件的项目)的开发人员的需求,文本编辑器非常方便。它们提供的一些优势是:
- 重量很轻
- 可定制
- 有插件
- 支持跨平台开发
- 支持多种语言
介绍崇高文本 2
Sublime Text 2 是较新的文本编辑器之一。目前仍在开发中;因此,新的特性和错误修复经常出现。我个人使用 dev 频道的版本,这里的更新相对频繁:http://www.sublimetext.com/dev.崇高文本 2 是免费下载和评估的,许可证费用为 59 美元,但免费版本功能齐全。除了偶尔会出现一个弹出窗口之外,对产品来说没有太多的麻烦,特别是考虑到它的功能不受任何限制。
崇高具有伟大和创新的特点。它提供了各种各样的主题,大量的定制,插件架构(用 Python 编写),与完整的 ide 相比,它是轻量级的,可以在所有平台上使用,并且它还在不断地被开发。我使用它的原因和 Python 社区喜欢它的原因如下:
- 多个光标
- 片段
- 语法突出显示
- GIT 支持
- 全屏&无干扰模式
- 自动构建
Sublime 还提供了一个创新的控制台,可以通过 CTRL+SHIFT+P 访问:

它提供了各种选项,比如设置当前语法、管理插件、使用代码片段等等。包管理器提供了对许多插件的访问,包括 Python 插件,也可以通过这种方式访问。
为什么要用崇高文字 2?
下面列出了 Sublime 适合 Python 开发的一些关键特性。
1。代码片段(可从菜单和键盘快捷键中获得)
它们在跳转时提供自动选择,这减少了创建一些乏味的代码部分所需的时间和错误。

可以通过按 enter 键输入该代码片段,或者显示在文件中,如果您键入“for”后跟 tab,将自动创建该代码片段。

在上面的屏幕截图中,选择了“x ”,并且在使用 tab 键时将选择范围值,因此在使用代码片段时,tab 键跳转很快,并且集中在正确的位置。
2。语法突出显示和构建
它自动提供语法突出显示和构建,因此在创建文件时,通过使用 CTRL + B,您可以在编辑器的控制台中立即看到代码的输出。

3。在 SublimeROPE 插件的帮助下 Python 自动完成
SublimeROPE 也支持在其他文件中查找声明,这在处理较大的项目时非常方便。

SublimeROPE 还提供跳转到定义、显示文档和定位全局的功能,因此也支持基本的重构。

4。编辑器内部的 Python 解释器
SublimeREPL 提供了一个 Python 解释器(以及其他语言),可以在 Sublime Text 2 中运行。结合分屏视图,这变得非常方便。

5。棉绒
Sublime 2 支持错误检测程序/linters(如 pyflakes),可以与 SublimeLinter 插件完美集成。

6。缩进到空格的转换
这是每个 Python 程序员必须做的事情,因为空格是首选,有时在复制代码时,可能会发生混淆,这对 Python 非常不利。Python 的增强提议也表明了这一点,sublime 在一个简洁的界面中提供了这一点,并且有很好的可见结果,如下面的截图所示。


第 2 行中的空格(显示为点)和第 3 行中的空格(表示制表符)有明显的区别。有了“将缩进转换成空格”特性,这个问题就可以解决了,Python 也不会感到困惑。
总有改进的空间
但是,与成熟的 ide 相比,还有一些地方需要改进:
1。调试
对于大多数文本编辑器来说,这是一件痛苦的事情,尽管有一些东西可以提供帮助,比如 PdbSublimeTextSupport 0.2,它将 Sublime 与调试的 Python、pdb 集成在一起,但是像 Eclipse 这样的 ide 提供了更好的调试特性。
2。管理大型项目也是一个问题,但是 project browser 和 SublimeRope 提供了跨 project 中各种文件的自动完成功能,因此可以避免这个问题。
结论
总而言之,Sublime Text 2 是一个伟大的编辑器,它提供了非凡的定制选项。你可以根据自己的需要定制它,使用许多可用的插件,Python 和 Sublime 配合得很好。如果你对使用 Sublime Text 2 开发 Python 有一些建议或很好的设置,欢迎通过评论分享。
SQLAlchemy 表达式语言和 ORM 查询概述
原文:https://www.pythoncentral.io/overview-sqlalchemys-expression-language-orm-queries/
概观
在上一篇文章中,我们对 SQLAlchemy 和其他 Python ORMs 进行了比较。在本文中,我们将深入了解 SQLAlchemy 的 ORM 和表达式语言,并使用一个示例来展示它们强大的 API 和易于理解的 Python 结构。
SQLAlchemy ORM 不仅提供了将数据库概念映射到 Python 空间的方法,还提供了方便的 Python 查询 API。使用 ORM 在 SQLAlchemy 数据库中查找东西是令人愉快的,因为一切都很简单,查询结果和查询参数都以 Python 对象的形式返回。
SQLAlchemy 表达式语言为程序员提供了一个使用 Python 结构编写“SQL 语句”的系统。这些结构被建模为尽可能地类似底层数据库的结构,同时对用户隐藏了各种数据库后端之间的差异。尽管这些构造旨在用一致的结构表示后端之间的等价概念,但是它们并没有隐藏有用的后端特定的特性。因此,表达式语言为程序员提供了一种编写后端中立表达式的方法,同时允许程序员利用特定的后端特性,如果他们真的想这样做的话。
表达式语言补充了对象关系映射器。ORM 提供了将数据库概念映射到 Python 空间的抽象使用模式,其中模型用于映射表,关系用于通过关联表进行多对多映射,通过外键进行一对一映射,而表达式语言用于直接表示数据库中更原始的结构,而没有意见。
部门和员工的例子
我们用一个例子来说明如何在有两个表department和employee的数据库中使用表达式语言。一个department有很多个employees,而一个employee最多属于一个department。因此,数据库可以设计如下:
>>> from sqlalchemy import Column, String, Integer, ForeignKey
>>> from sqlalchemy.orm import relationship, backref
>>> from sqlalchemy.ext.declarative import declarative_base
>>>
>>>
>>> Base = declarative_base()
>>>
>>>
>>> class Department(Base):
... __tablename__ = 'department'
... id = Column(Integer, primary_key=True)
... name = Column(String)
...
>>>
>>> class Employee(Base):
... __tablename__ = 'employee'
... id = Column(Integer, primary_key=True)
... name = Column(String)
... department_id = Column(Integer, ForeignKey('department.id'))
... department = relationship(Department, backref=backref('employees', uselist=True))
...
>>>
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///')
>>>
>>> from sqlalchemy.orm import sessionmaker
>>> session = sessionmaker()
>>> session.configure(bind=engine)
>>> Base.metadata.create_all(engine)
在本例中,我们创建了一个内存 sqlite 数据库,其中包含两个表“department”和“employee”。列' employee.department_id '是列' department.id '的外键,关系' department.employees '包括该部门的所有雇员。为了测试我们的设置,我们可以简单地插入几个示例记录,并使用 SQLAlchemy 的 ORM 查询它们:
>>> john = Employee(name='john')
>>> it_department = Department(name='IT')
>>> john.department = it_department
>>> s = session()
>>> s.add(john)
>>> s.add(it_department)
>>> s.commit()
>>> it = s.query(Department).filter(Department.name == 'IT').one()
>>> it.employees
[]
>>> it.employees[0].name
u'john'
如你所见,我们在 IT 部门安插了一个叫约翰的人。
现在让我们使用表达式语言执行相同类型的查询:
>>> from sqlalchemy import select
>>> find_it = select([Department.id]).where(Department.name == 'IT')
>>> rs = s.execute(find_it)
>>> rs
> > > rs.fetchone()
(1,)
>>>RS . fetchone()#查询只返回一个结果,所以多得到一个都不返回。
>>>RS . fetchone()#由于前一个 fetchone()返回 None,所以获取更多会导致结果关闭异常
Traceback(最近一次调用 last):
File " ",第 1 行,在
File "/Users/xiaonuogantan/python 2-workspace/lib/python 2.7/site-packages/sqlalchemy/engine/result . py ",第 790 行,在 fetchone
self.cursor,self . context)
File "/Users/Users_ fetchone _ impl()
File "/Users/xiaonuogantan/python 2-workspace/lib/python 2.7/site-packages/sqlalchemy/engine/result . py ",第 700 行,in _fetchone_impl
self。_ non _ result()
File "/Users/xiaonuogantan/python 2-workspace/lib/python 2.7/site-packages/sqlalchemy/engine/result . py ",第 724 行,in _non_result
raise exc。ResourceClosedError("此结果对象已关闭。")
sqlalchemy . exc . resourceclosederror:此结果对象已关闭。
>>>find _ John = select([employee . id])。其中(employee . department _ id = = 1)
>>>RS = s . execute(find _ John)
> > > rs.fetchone() #员工约翰的 ID
(1),
>>>RS . fetchone()
由于表达式语言提供了模仿后端中立 SQL 的低级 Python 结构,这感觉上几乎等同于以 Python 方式编写实际的 SQL。
部门和员工之间的多对多
在我们之前的例子中,很简单,一个雇员最多属于一个部门。如果一名员工可能属于多个部门会怎样?难道一个外键不足以代表这种关系吗?
是的,一个外键是不够的。为了对department和employee之间的多对多关系建模,我们创建了一个新的关联表,它有两个外键,一个指向“department.id ”,另一个指向“employee.id”。
>>> from sqlalchemy import Column, String, Integer, ForeignKey
>>> from sqlalchemy.orm import relationship, backref
>>> from sqlalchemy.ext.declarative import declarative_base
>>>
>>>
>>> Base = declarative_base()
>>>
>>>
>>> class Department(Base):
... __tablename__ = 'department'
... id = Column(Integer, primary_key=True)
... name = Column(String)
... employees = relationship('Employee', secondary='department_employee')
...
>>>
>>> class Employee(Base):
... __tablename__ = 'employee'
... id = Column(Integer, primary_key=True)
... name = Column(String)
... departments = relationship('Department', secondary='department_employee')
...
>>>
>>> class DepartmentEmployee(Base):
... __tablename__ = 'department_employee'
... department_id = Column(Integer, ForeignKey('department.id'), primary_key=True)
... employee_id = Column(Integer, ForeignKey('employee.id'), primary_key=True)
...
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///')
>>> from sqlalchemy.orm import sessionmaker
>>> session = sessionmaker()
>>> session.configure(bind=engine)
>>> Base.metadata.create_all(engine)
>>>
>>> s = session()
>>> john = Employee(name='john')
>>> s.add(john)
>>> it_department = Department(name='IT')
>>> it_department.employees.append(john)
>>> s.add(it_department)
>>> s.commit()
在前面的例子中,我们创建了一个带有两个外键的关联表。这个关联表' department_employee '链接' department '和' employee ',关系Department.employees和Employee.departments是表之间的多对多映射。请注意,实现这一点的“魔术”是我们传递给Department和Employee模型类中的relationship()函数的参数secondary。
我们可以使用以下查询测试我们的设置:
>>> john = s.query(Employee).filter(Employee.name == 'john').one()
>>> john.departments
[]
>>> john.departments[0].name
u'IT'
>>> it = s.query(Department).filter(Department.name == 'IT').one()
>>> it.employees
[]
>>> it.employees[0].name
u'john'
现在让我们在数据库中再插入一名员工和另一个部门:
>>> marry = Employee(name='marry')
>>> financial_department = Department(name='financial')
>>> financial_department.employees.append(marry)
>>> s.add(marry)
>>> s.add(financial_department)
>>> s.commit()
要查找 IT 部门的所有员工,我们可以用 ORM 编写:
>>> s.query(Employee).filter(Employee.departments.any(Department.name == 'IT')).one().name
u'john'
或者表达语言:
>>> find_employees = select([DepartmentEmployee.employee_id]).select_from(Department.__table__.join(DepartmentEmployee)).where(Department.name == 'IT')
>>> rs = s.execute(find_employees)
>>> rs.fetchone()
(1,)
>>> rs.fetchone()
现在,让我们将员工 marry 分配到 IT 部门,这样她将属于两个部门。
>>> s.refresh(marry)
>>> s.refresh(it)
>>> it.employees
[]
>>> it.employees.append(marry)
>>> s.commit()
>>> it.employees
[, ]
为了找到 marry,即属于至少两个部门的所有雇员,我们在 ORM 查询中使用group_by和having:
>>> from sqlalchemy import func
>>> s.query(Employee).join(Employee.departments).group_by(Employee.id).having(func.count(Department.id) > 1).one().name
类似于 ORM 查询,我们也可以在表达式语言查询中使用group_by和having:
>>> find_marry = select([Employee.id]).select_from(Employee.__table__.join(DepartmentEmployee)).group_by(Employee.id).having(func.count(DepartmentEmployee.department_id) > 1)
>>> s.execute(find_marry)
> > > RS = _
>>>RS . fetchall()
[(2,)]
当然,一定要记得在完成后关闭数据库会话。
>>> s.close()
总结和提示
在本文中,我们使用了一个带有两个主表和一个关联表的示例数据库来演示如何用 SQLAlchemy 的 ORM 和表达式语言编写查询。作为一个精心设计的 API,编写查询就像编写普通的 Python 代码一样简单。由于表达式语言提供了比 ORM 更低级的 API,所以用表达式语言编写查询感觉更像是用 DBAPI(如 psycopg2 和 Python-MySQL)编写查询。然而,低级 API 提供的表达式语言比 ORM 更灵活,其查询可以映射到 Python 中的selectable SQL 视图,这在我们的查询变得越来越复杂时非常有用。在以后的文章中,我们将进一步探索如何利用表达式语言使编写复杂的查询变得愉快而不是痛苦。
将 Python Django 应用程序打包成一个可重用的组件
原文:https://www.pythoncentral.io/package-python-django-application-reusable-component/
通过编写和使用可重用的 Python Django 应用程序来节省时间
设计、开发和维护一个 web 应用程序并不简单。为了一个成功的 web 应用程序,许多特性和方面必须得到正确的处理。举几个例子,几乎每个 web 应用程序都具有的功能是用户管理、第三方 oauth 登录/注册和管理站点。由于在任何 web 应用程序中有如此多的常见问题需要一次又一次地解决,所以让它们成为可重用的组件/包是有意义的,这样新的 web 应用程序就可以简单地利用现有的代码来节省开发时间。
幸运的是, Python 包索引 ( pypi)提供了许多可以在自己的应用程序中使用的包。更具体地说, Django 包列出了所有你可以集成到自己项目中的可重用 Django 应用。找到并使用一个合适的 Django 包通常比自己编写一个更好、更省时。
在本文中,我们将学习如何使我们当前的myblog Django 应用程序成为一个可重用的 Django 包,以便您或其他人可以在他或她自己的项目中使用它。
包和应用程序
在我们开始之前,我们应该澄清一个关于软件包和应用程序的关键点。Python 包是易于重用的 Python 代码的逻辑组。一个包通常包含多个被称为模块的 Python 文件。
通常情况下,我们使用一个模块或者通过像import myblog.views或者from myblog import views那样导入一个包。为了让一个 Python 目录比如myblog变成一个包,我们把一个特殊的文件__init__.py放入其中,即使这个目录是空的。
Django 应用只是一个 Python 包,设计用于 Django 项目内部。通常,Django 应用遵循常见的 Django 约定,例如包括models.py、urls.py和views.py。
术语打包是指将 Django 应用打包成一个可部署的 Python 包,以便其他人可以轻松地将其集成到自己的项目中。
提取应用程序代码
在我们之前的教程之后,我们应用程序myblog的当前结构应该是这样的:
myblog/
manage.py
myblog/
__init__.py
admin.py
models.py
settings.py
static/
myblog/
background.jpg
style.css
templates/
index.html
post/
detail.html
upload.html
tests.py
urls.py
views.py
wsgi.py
首先,让我们在根myblog目录之外为myblog创建一个父目录。姑且称之为django-myblog:
django-myblog/
myblog/
manage.py
...
其次,让我们将myblog目录移动到django-myblog中:
django-myblog/
myblog/
__init__.py
...
myblog/
manage.py
第三,用以下内容创建一个文件django-myblog/README.rst:
=====
Myblog
=====
Myblog is a simple demo of Django's basic usage.
Quick start
-----------
1\. Add "myblog" to INSTALLED_APPS:
INSTALLED_APPS = {
...
'myblog'
}
2\. Include the myblog URLconf in urls.py:
url(r'^myblog/', include('myblog.urls'))
3\. Run `python manage.py syncdb` to create myblog's models.
4\. Run the development server and access http://127.0.0.1:8000/admin/ to
manage blog posts.
5\. Access http://127.0.0.1:8000/myblog/ to view a list of most recent posts.
第四,为你的可重用 app 创建一个许可文件django-myblog/LICENSE。通常 Django 应用程序是在 BSD 许可下发布的,但是你可以自由选择任何一个。
第五,创建django-myblog/setup.py来指定如何安装由分发使用的应用程序的指令。
import os
from setuptools import setup
README = open(OS . path . join(OS . path . dirname(_ _ file _ _),' README.rst '))。阅读()
#允许 setup.py 从任何路径运行
OS . chdir(OS . path . norm path(OS . path . join(OS . path . abspath(_ _ file _ _),os.pardir)))
设置(
name = 'django-myblog ',
version = '0.1 ',
packages = ['myblog'],
include_package_data = True,
license = 'BSD License ',
description = '一个简单的 django 应用程序演示',
long_description = README,
URL = ' HTTP://WWW . example . com/',
author = 'Your Name ',
author _ email = ' Your Name @ example . com ',
classifiers =[
' Environment::Web Environment ',
'Framework :: Django ',
'预定受众::开发者',
' licence::OSI Approved::BSD License ',# example licence
'操作系统::OS 独立',”
第六,创建django-myblog/MANIFEST.in来包含我们包中的文本文件和静态文件:
include LICENSE
include README.rst
recursive-include myblog/static *
recursive-include myblog/templates *
recursive-include docs *
注意我们还在MANIFEST.in中包含了一个目录docs。这个目录将包含我们将来可重用的应用程序的文档。现在,让我们创建一个空目录django-myblog/docs。
最后,我们构建我们的 Python 包:
$ python setup.py build
running build
running build_py
creating build
creating build/lib
creating build/lib/myblog
copying myblog/__init__.py -> build/lib/myblog
copying myblog/admin.py -> build/lib/myblog
copying myblog/models.py -> build/lib/myblog
copying myblog/settings.py -> build/lib/myblog
copying myblog/tests.py -> build/lib/myblog
copying myblog/urls.py -> build/lib/myblog
copying myblog/views.py -> build/lib/myblog
copying myblog/wsgi.py -> build/lib/myblog
running egg_info
writing django_myblog.egg-info/PKG-INFO
writing top-level names to django_myblog.egg-info/top_level.txt
writing dependency_links to django_myblog.egg-info/dependency_links.txt
reading manifest file 'django_myblog.egg-info/SOURCES.txt'
writing manifest file 'django_myblog.egg-info/SOURCES.txt'
在新的 Django Web 应用程序中使用 django-myblog
假设您要开始一个新的 Django 项目,它将使用myblog中的功能。您可以简单地重用我们刚刚在您的新项目中构建的django-myblog。
首先,让我们创建一个新的 Django 项目:
$ django-admin.py startproject mysite
其次,我们来修改一下mysite/settings.py:
INSTALLED_APPS = (
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.sites',
'django.contrib.messages',
'django.contrib.staticfiles',
'myblog', # Include 'myblog' into mysite
'django.contrib.admin', # Enable the admin site
'django.contrib.admindocs', # Enable the documentation for admin site
)
第三,让我们修改mysite/urls.py,将myblog的 URLconf 放在/blog下:
urlpatterns = patterns('',
...
url(r'^blog/', include('myblog.urls')),
)
第四,我们运行“python manage.py syncdb”来为myblog创建模型,并运行“python manage.py runserver”来启动服务器:
$ python manage.py syncdb
Creating tables ...
Creating table auth_permission
Creating table auth_group_permissions
Creating table auth_group
Creating table auth_user_groups
Creating table auth_user_user_permissions
Creating table auth_user
Creating table django_content_type
Creating table django_session
Creating table django_site
Creating table myblog_post
Creating table myblog_comment
您刚刚安装了 Django 的 auth 系统,这意味着您没有定义任何超级用户。您想现在创建一个吗?(是/否):是
用户名(留空使用‘小糯干滩’):root
邮箱:
密码:
密码(再次):
超级用户创建成功。
安装自定义 SQL...
安装索引...
从 0 个夹具安装了 0 个对象
$ python manage.py runserver
验证模型...
发现 0 个错误
2013 年 8 月 21 日- 12:03:10
Django 版本 1.5.1,使用设置‘my site . settings’
开发服务器运行在 http://127.0.0.1:8000/
用 CONTROL-C 退出服务器
最后,我们可以访问 http://127.0.0.1:8000/blog/来看看我们博客的主页:

总结和提示
在本文中,我们学习了如何将我们的myblog应用打包成一个可重用的组件,以及如何在一个新的 django 项目中使用它。编写可重用的 Django 应用程序总是一个好主意,因为您可以在新项目中重用相同的代码,从而节省大量时间。由于 Python 包索引 ( pypi)和 Django 包提供了可重用 Python 和 Django 应用程序的完整列表,所以在开始任何新项目之前,您应该检查一下它们。
熊猫数据框:创建和操作数据的教程
原文:https://www.pythoncentral.io/pandas-data-frame-a-tutorial-for-creating-and-manipulating-data/
Pandas DataFrames 是一种数据结构,以二维形式保存数据,类似于 SQL 或 Excel 电子表格中的表格,但速度更快,功能更强大。它们有行和列,也有对应于这些行和列的标签。
数据帧是一种无价的工具,它构成了机器学习、数据科学、科学计算以及几乎所有其他数据密集型领域的基石。
在本 Python 指南中,我们将看到如何在 Pandas 数据帧中创建和操作数据。
熊猫基础数据框
要使用数据帧,你必须首先导入熊猫,就像这样:
>>> import pandas as pd
让我们借助一个例子来理解数据帧的基础。假设你想用熊猫来分析求职者。除了跟踪他们的详细信息,包括他们的姓名、位置和年龄,您还想跟踪他们在公司指定的编程测试中的分数。
| | 名称 | 城市 | 年龄 | 测试分数 |
| 101 | 约翰 | Oslo | 25 | 88.0 |
| 102 | 丽莎 | 伯尔尼 | 32 | 79.0 |
| 103 | 基因 | 布拉格 | 35 | 81.0 |
| 104 | 凌 | 东京 | 29 | 80.0 |
| 105 | 布鲁斯 | 苏黎世 | 37 | 68.0 |
| 106 | 艾伦 | 哥本哈根 | 34 | 61.0 |
| 107 | 常 | 东京 | 32 | 84.0 |
如您所见,该表的第一行有列标签,可帮助您跟踪详细信息。另外,第一列有行标签,它们是数字。表格中的其他单元格用其他数据值填充。
既然背景已经确定,我们也知道需要创建什么样的数据框架,我们就可以研究如何去做了。
创建熊猫数据框架有很多方法。最突出的方法是用 DataFrame 构造函数提供标签、数据和其他细节。
在传递数据方面,你也可以有几种选择。除了将数据作为字典或 Pandas Series 实例传递之外,还可以将其作为二维元组、NumPy 数组或列表传递。您并不局限于这些方法——您可以使用 Python 提供的许多数据类型中的一种来传递数据。
假设你想用字典来传递数据。下面是代码的样子:
>>> data = {
... 'name': ['John', 'Lisa', 'Gene', 'Ling', 'Bruce', 'Alan', 'Chang'],
... 'city': ['Oslo', 'Bern', 'Prague', 'Tokyo',
... 'Manchester', 'Copenhagen', 'Hong Kong'],
... 'age': [41, 28, 33, 34, 38, 31, 37],
... 'test-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
... }
>>> row_labels = [101, 102, 103, 104, 105, 106, 107]
“数据”变量是一个内置的 Python 变量,指的是保存数据的字典。“row_labels”变量做了您期望它做的事情——它保存行的标签。
下面是创建数据帧的方法:
>>> df = pd.DataFrame(data=data, index=row_labels)
>>> df
name city age test-score
101 John Oslo 41 88.0
102 Lisa Bern 28 79.0
103 Gene Prague 33 81.0
104 Ling Tokyo 34 80.0
105 Bruce Manchester 38 68.0
106 Alan Copenhagen 31 61.0
107 Chang Hong Kong 37 84.0
至此,数据框已创建完毕。“df”变量保存对数据帧的引用。
使用 Python 数据框架
虽然我们创建的不是,但数据帧可能非常大。熊猫有两个命令。头()和。tail(),它允许您查看数据帧中的第一项和最后几项。
下面是你如何使用它们:
>>> df.head(n=2) # Outputs the first 2 rows
>>> df.tail(n=2) # Outputs the final 2 rows
“n”值是一个参数,它告诉命令要显示的角色数量。
也可以访问数据帧中的一列。你可以用同样的方法从字典中得到一个值:
>>> cities = df['city']
>>> cities # Returns the column
这是目前为止从熊猫数据框架中获取列的最方便的方法。但是在某些情况下,列名与 Python 标识符相同。
在这些情况下,你可以使用点符号来访问它,就像你访问一个类实例的属性一样:
>>> df.city # This will have the same result as the previous code
在上面的代码中,我们提取了与“city”标签对应的列,该列保存了所有求职者的位置。
有趣的是,Pandas DataFrame 中的每一列都是 pandas.Series 的一个实例。这是一个保存一维数据及其标签的数据结构。
你也可以像使用字典一样从一个系列对象中获取单个项目。这个想法是使用标签作为一个键,就像这样:
>>> cities[102]
要访问一整行,可以使用。loc[]访问器如下:
>>> df.loc[103]
name Gene
city Prague
age 33
test-score 81
Name: 103, dtype: object
创建熊猫数据帧的不同方式
本节将介绍四种最常见的创建数据框的方法。但是你可以在 官方文档 中找到在熊猫中创建数据帧的所有各种方法的细节。
在您尝试运行下面任何一个例子的代码之前,您需要导入 Pandas 和 NumPy:
>>> import numpy as np
>>> import pandas as pd
#1 带字典
使用字典创建数据帧时,其关键字成为列标签,值成为列。你可以这样定义一个:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
你可以使用 columns 参数来控制列的顺序。index 参数做同样的事情,只是针对行。
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 3
#2 带列表
Pandas 还提供了使用字典列表创建数据框架的灵活性:
>>> l = [{'x': 1, 'y': 2, 'z': 100},
... {'x': 2, 'y': 4, 'z': 100},
... {'x': 3, 'y': 8, 'z': 100}]
>>> pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
此外,您还可以灵活地使用嵌套列表来创建数据帧。但是在这样做的时候,最好是显式地指定行和/或列的标签,就像这样:
>>> l = [[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]]
>>> pd.DataFrame(l, columns=['x', 'y', 'z'])
x y z
0 1 2 100
1 2 4 100
2 3 8 100
值得注意的是,你也可以使用元组列表来代替上面的字典。
#3 带 NumPy 数组
以同样的方式将二维列表传递给 DataFrame 构造函数,也可以传递 NumPy 数组:
>>> arr = np.array([[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]])
>>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
>>> df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100
看起来这个例子和我们讨论过的嵌套列表例子是一样的。这种方法有一个优点。您可以选择使用“复制”参数。
默认情况下,NumPy 数组的数据不会被复制,导致数组中的原始数据被分配给 DataFrame。所以,如果你修改数组,数据帧也会改变:
>>> arr[0, 0] = 1000 # Changing the first item of the array
>>> df_ # Checking if the DataFrame is modified
x y z
0 1000 2 100
1 2 4 100
2 3 8 100
如果你想用 arr 中的值的副本而不是 arr 来创建你的 DataFrame,在 DataFrame 构造函数中提到“copy=True”。这样,即使 arr 被修改,数据帧也将保持不变。
#4 来自文件
Pandas 允许您在各种文件类型之间保存和加载数据和标签,包括但不限于 CSV、JSON 和 SQL。要将数据帧保存为 CSV 文件,可以运行以下命令:
>>> df.to_csv('data.csv')
一个 CSV 文件“data.csv”将出现在您的工作目录中。你也可以读取一个 CSV 文件,数据如下:
>>> pd.read_csv('data.csv', index_col=0)
这段代码将会给你与我们在这篇文章中创建的第一个相同的数据框架。请记住,代码的“index_col=0”部分表示行标签位于文件的第一列。
访问和修改数据帧中的数据
用存取器获取数据
The。loc[]访问器允许你通过标签获取行和列,比如:
>>> df.loc[10]
name John
city Oslo
age 41
test-score 88
Name: 10, dtype: object
你也可以使用。iloc[]访问器,用于按整数索引检索行或列。
>>> df.iloc[0] # Returns first row
name John
city Oslo
age 41
test-score 88
Name: 10, dtype: object
在大多数情况下,使用这些访问器都是有帮助的。Python 还有另外两个访问器:。在[]和。iat[]。但是自从。loc[]和。iloc[]支持切片和 NumPy 风格的索引,你可以用它们来访问列,比如:
>>> df.loc[:, 'city']
>>> df.iloc[:, 1]
也可以为列表或数组编写切片,而不是索引来检索行和列:
>>> df.loc[11:15, ['name', 'city']] # Slicing to get rows
>>> df.iloc[1:6, [0, 1]] # Lists to get columns
如您所知,您可以对列表、元组和 NumPy 数组进行切片,并根据需要跳过值。好的一面是。iloc[]支持这个列表。
>>> df.iloc[1:6:2, 0]
11 Lisa
13 Ling
15 Alan
Name: name, dtype: object
我们上面所做的切片从第二行开始,在索引为 6 的行之前停止,并且每隔一行跳过一行。
你不一定要使用切片构造来切片——你也可以使用 slice() Python 类来做。当然了,警察局。IndexSlice[]或 numpy.s []也可用于这些目的:
>>> df.iloc[slice(1, 6, 2), 0]
>>> df.iloc[np.s_[1:6:2], 0]
>>> df.iloc[pd.IndexSlice[1:6:2], 0]
虽然所有这些方法完成的是同样的事情,但你可能会发现根据你的情况使用其中一种更容易。
如果你想获取一个单一的值,你可以使用。在[]和。iat[],像这样:
>>> df.at[12, 'name']
>>> df.iat[2, 0]
# Output of both is 'Gene'
用访问器修改数据
您可以通过传递 Python 序列或 NumPy 数组来修改数据帧的一部分,就像这样:
>>> df.loc[:13, 'test-score'] = [40, 50, 60, 70] # Modifying the first four items in the test-score column
>>> df.loc[14:, 'test-score'] = 0 # Setting 0 to the remaining columns
>>> df['test-score']
10 40.0
11 50.0
12 60.0
13 70.0
14 0.0
15 0.0
16 0.0
Name: test-score, dtype: float64
你也可以使用负指数。iloc[]修改数据:
>>> df.iloc[:, -1] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0])
在数据帧中插入和删除数据
修改行
假设你想在数据框中添加一个新的人。下面是如何创建一个新的 Series 对象:
>>> rich = pd.Series(data=['Rich', 'Boston', 34, 79],
... index=df.columns, name=17)
>>> rich
name Rich
city Boston
age 31
test-score 79
Name: 17, dtype: object
>>> rich.name
17
您将需要使用“index=df.columns ”,因为对象的标签对应于 df 数据帧中的标签。
要将这个新的候选对象添加到 df 的末尾,可以使用。append()像这样:
>>> df = df.append(rich)
如果您以后需要删除这个新行,您可以使用。drop()方法:
>>> df = df.drop(labels=[17])
The。drop()方法返回删除了指定行的 DataFrame,但是您可以使用“inplace=True”来获取 None 作为返回值。
修改列
假设有第二次考试,你需要将每个考生的分数加到表格中。下面是如何在一个新列中添加分数:
>>> df['second-test-score'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0])
如果您使用过 Python 中的字典,您可能会发现这种插入列的方法很熟悉。这段代码将在“测试分数”列的右边添加一个新的“第二次测试分数”列。
您也可以在整个列中分配相同的值。你所要做的就是运行下面的代码:
>>> df['total-score'] = 0.0
虽然这种插入方法很简单,但它不允许在特定位置插入列。如果需要在表中的特定位置插入列,可以使用。insert()方法,像这样:
>>> df.insert(loc=4, column='soft-skills-score',
... value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0])) # Makes this new column the fourth column in the table
要从数据帧中删除一列,可以像使用 Python 字典一样使用 del 语句。
>>> del df['soft-skills-score']
数据帧的另一个类似于字典的特征是数据帧与。pop()。此方法移除指定的列并将其返回。
换句话说,你也可以用“df.pop('soft-skills-score ')”来代替 del。
但是您可能需要从表格中删除不止一列。在这种情况下,您可以使用。drop()函数。您需要做的就是指定要删除的列的标签。
另外,当您打算删除列时,您需要提供参数“axis=1”。但是请记住,该方法将返回没有指定列的 DataFrame。如果你想看到指定的列,你可以传递“inplace=True”
熊猫小组讲解:熊猫小组使用指南
原文:https://www.pythoncentral.io/pandas-groupby-explained-a-guide-on-using-pandas-groupby/
Python 是一个优秀的数据分析工具,因为它拥有丰富的以数据为中心的包生态系统。Pandas 是最受欢迎的软件包之一,它简化了数据的导入和分析。
在本指南中,我们将讨论。groupby()方法使用 split-apply-combine 以及如何访问组和转换数据。
什么是熊猫分组法?
Pandas 中的 GroupBy 方法旨在模拟 SQL 中 GROUP BY 语句的功能。Pandas 方法的工作方式类似于 SQL 语句,先拆分数据,然后按照指示聚合数据,最后再组合数据。
自。groupby()首先分割数据,Python 用户可以直接处理组。此外,聚合是在拆分后完成的,让用户可以完全控制聚合方式。
加载熊猫数据帧
为了理解如何使用 GroupBy 方法,首先加载一个样本数据集。您可以通过粘贴下面使用。read_csv()方法加载数据:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/datagy/data/main/sales.csv', parse_dates=['date'])
在了解 GroupBy 方法的对象如何工作之前,让我们使用。头()方法:
print(df.head())
你会注意到有一个日期栏显示交易日期。性别和地区列是保存销售人员数据的字符串类型列。sales 列表示各自的销售额。
熊猫如何按对象分组
创建一个 GroupBy 对象就像对 DataFrame 应用该方法一样简单。您可以传递单个列或一组列。这看起来是这样的:
print(df.groupby('region'))
# Output: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x7fb78815a4f0>
如你所见,它返回了一个 DataFrameGroupBy 对象,由于它是一个对象,我们可以探究它的一些属性。
group by 对象的属性
这些对象带有一个. ngroups 属性,存储分组中的组数。下面是计算对象中的组的方法:
print(df.groupby('region').ngroups)
# Output: 3
同样,你可以使用。属性来查找有关组的更多详细信息。属性输出类似字典的对象。对象将组作为键保存,这些键的值是组中行的索引。
要访问对象中的组,可以运行:
print(df.groupby('region').groups)
但是如果你只想找到对象的组名,你可以只返回字典的键,就像这样:
print(df.groupby('region').groups.keys())
# Output: dict_keys(['North-East', 'North-West', 'South'])
逐组选择熊猫
group by 方法允许您选择特定组中的所有记录。当您想了解一个组中的数据时,这是非常有用的。您可以通过使用。get_group()方法并传递组名。
例如,运行下面的语句将显示我们的样本数据集中“South”地区的数据:
print(df.groupby('region').get_group('South'))
通过拆分-应用-组合了解熊猫群体
GroupBy 方法利用一种称为分割-应用-组合的过程来提供数据帧的有用修改或聚合。这个过程是不言自明的,如下所示:
- 根据某些标准将数据分成组
- 功能独立应用于每组
- 结果被组合成一个数据结构
前面几节将带您了解如何使用?groupby()方法根据传递的标准将数据分组。因此,您已经熟悉了第一步。
分割数据背后的想法是将大数据分析问题分解成更小、更可行的部分。当你需要处理的问题比较小的时候,在把零件重新组装起来之前,对零件进行操作会比较容易。
虽然应用和合并步骤是不同的,并且是分开运行的,但是这个库让这两个步骤看起来像是一次完成的。
用 GroupBy 聚合数据
运行以下代码将聚合数据:
averages = df.groupby('region')['sales'].mean()
print(averages)
# Output:
# region
# North-East 17386.072046
# North-West 15257.732919
# South 24466.864048
# Name: sales, dtype: float64
让我们分解这段代码来理解它是如何工作的:
- df.groupby('region ')根据 region 列将数据分成组。
- ['sales']仅从组中选取区域列。
- The。mean()将 mean 方法应用于每个组中的列。
- 数据然后被组合成最终的数据帧。
具有 GroupBy 的其他聚合
现在您已经了解了拆分-应用-合并流程,下面是各种可用聚合函数的概述:
| 聚合方法 | 描述 |
| 。count() | 非空记录的数量 |
| 。max() | 组的最大值 |
| 。平均值() | 数值的算术平均值 |
| 。中位数() | 数值的中间值 |
| 。min() | 组的最小值 |
| 。模式() | 组中最频繁出现的值 |
| 。std() | 组的标准偏差 |
| 。sum() | 数值总和 |
| 【t0 . var()】 | 组的方差 |
您可以随意使用这些方法来处理数据。例如,如果您想计算每组的标准偏差,下面的代码可以做到:
standard_deviations = df.groupby('region')['sales'].std()
print(standard_deviations)
应用多个聚合
Pandas 库最强大的特性之一是它允许你通过。agg()方法。使用这种方法,可以将可调用列表传递给 GroupBy。下面是如何使用?agg()函数:
import numpy as np
aggs = df.groupby('region')['sales'].agg([np.mean, np.std, np.var])
print(aggs)
# Output:
# mean std var
# region
# North-East 17386.072046 2032.541552 4.131225e+06
# North-West 15257.732919 3621.456493 1.311495e+07
# South 24466.864048 5253.702513 2.760139e+07
The。agg()函数使您能够基于不同的组生成汇总统计数据。函数使得处理数据变得很方便,因为不需要使用。groupby()方法三次以获得相同的结果。
用分组方式转换数据
GroupBy 方法也使用户可以很容易地转换数据。简单地说,转换数据意味着执行特定于该组的操作。
这可能包括通过基于组分配值和使用 z 值标准化数据来处理缺失数据。
但是,这种转换与聚合和过滤有什么不同呢?与聚合和过滤过程不同,输出数据帧在转换后将始终具有与原始数据相同的维度。对于聚合和筛选来说,情况并非总是如此。
使用。transform()方法为原始数据集中的每条记录返回一个值。这保证了结果将是相同的大小。
利用。变换()
了解如何。transform()使用一个例子会更容易。假设您想计算一个地区总销售额的百分比。您可以传递“sum”可调用函数,并将该组的总和返回到每一行。然后,您可以将原始销售列除以总和,如下所示:
df['Percent Of Region Sales'] = df['sales'] / df.groupby('region')['sales'].transform('sum')
print(df.head())
有趣的是,您还可以在 GroupBy 中转换数据,而无需使用。transform()方法。您可以应用返回单个值而不聚合数据的函数。
例如,如果你应用。rank()方法,它将对每个组中的值进行排序:
df['ranked'] = df.groupby('region')['sales'].rank(ascending=False)
print(df.sort_values(by='sales', ascending=False).head())
运行这段代码将返回一个与原始数据帧长度相同的 Pandas 系列。然后,您可以将该系列分配给新列。
按分组过滤数据
过滤数据帧是使用。groupby()方法。但重要的是要知道这种方法不同于常规的筛选,因为 GroupBy 允许您应用基于组值聚合的筛选方法。
例如,您可以过滤您的数据框架,去掉一个组的平均销售价格低于 20,000 的行:
df = df.groupby('region').filter(lambda x: x['sales'].mean() < 20000)
print(df.head())
下面是这段代码的工作原理:
- 首先,代码根据“区域”列对数据进行分组。
- 接下来,该。filter()方法根据您传递的 lambda 函数过滤数据。
- 最后,如果“销售”列组中的平均值低于 20,000,lambda 函数就会计算出来。
以这种方式过滤数据,您就不需要在过滤出这些值之前确定每组的平均值。虽然在这个例子中,这种方式的过滤似乎是不必要的,但是在处理较小的组时,这种方式是非常宝贵的。
通过多列对数据帧进行分组
通过按多列对数据进行分组,您可以探索 GroupBy 方法的其他功能。在上面的所有例子中,我们传递一个表示单个列的字符串,并根据该列对 DataFrame 进行分组。
然而,GroupBy 也允许你传递一个字符串列表,每个字符串代表不同的列。这样,您可以进一步拆分数据。
让我们通过计算按“地区”和“性别”分组的所有销售额的总和来探索 GroupBy 的这一功能:
sums = df.groupby(['region', 'gender']).sum()
print(sums.head())
更有趣的是,这篇文章中提到的所有方法都可以以这种方式使用。您可以应用。rank()函数再次确定每个地区和性别组合的最高销售额,如下:
df['rank'] = df.groupby(['region', 'gender'])['sales'].rank(ascending=False)
print(df.head())
通过 GroupBy 使用自定义函数
GroupBy 方法最好的特性之一是你可以应用你自己的函数来处理数据。您可以选择使用匿名 lambda 函数,但也可以根据您的分析需要定义特定的函数。
让我们通过定义一个自定义函数来理解这是如何工作的,该函数通过计算最小值和最大值之间的差值来返回一个组的范围。以下是在将这样的函数应用到您的。groupby()方法调用:
def group_range(x):
return x.max() - x.min()
ranges = df.groupby(['region', 'gender'])['sales'].apply(group_range)
print(ranges)
# Output:
# region gender
# North-East Female 10881
# Male 10352
# North-West Female 20410
# Male 17469
# South Female 30835
# Male 27110
# Name: sales, dtype: int64
上面定义的 group_range()函数接受一个参数,在我们的例子中,这个参数是一系列“销售”分组。接下来,代码在返回最小值和最大值之间的差之前先找到这两个值。这样,它有助于我们看到组范围如何不同。
结论
GroupBy 函数简单易用,是最好的数据分析方法之一。使用该方法时需要记住的一些实用技巧包括:
- 当传递多个组关键字时,只有具有相同组关键字值的行彼此匹配才会被添加到组中。
- 将排序参数设置为 False 可以提高代码执行时间。
- 将分组步骤链接起来并应用一个函数可以减少代码行。
现在您已经了解了如何使用 GroupBy,是时候自己测试一下了,并享受快速简单的数据分析带来的好处。
优先队列:初学者指南
原文:https://www.pythoncentral.io/priority-queue-beginners-guide/
先决条件
要了解优先级队列,您必须知道:
- Python 3
- 线性队列
- Python 数据结构基本概念- 列表,元组
什么是优先级队列?
在你继续阅读本教程之前,我强烈推荐你阅读之前关于队列的教程,因为它会给你一个更好的基础,帮助你掌握这里的内容。
如果您想跟踪播放列表中最少播放的歌曲,您会怎么做?最简单的解决方案是对列表进行排序,但这既耗时又浪费。你只需要跟踪点击率最低的歌曲。最小堆或优先级队列可以帮助您做到这一点。
优先级队列,也称为堆队列,是抽象的数据结构。堆是二叉树,其中每个父节点的值小于或等于其任何子节点的值。换句话说,这种类型的队列跟踪最小值。因此,它有助于始终检索最小值。因此,它也被称为最小堆。因此,位置 0 保存最小/最小值。还有一个 max heap,操作也挺像的。
注意: 堆队列或优先级队列不对列表进行升序排序。它只是将最小的元素保持在第 0 个位置。其余的元素可以排序,也可以不排序。
如何实现优先级队列
要使用优先级队列,你必须导入 heapq 库。这是按如下方式完成的:
import heapq
导入 heapq 模块后,可以执行以下堆命令:
- heapify() -这个操作使你能够将一个常规的列表转换成一个堆。在执行这个操作时,最小的元素被推到位置 0。
h = [5,2,6,8,0,1,2,4]
heapq.heapify(h) #returns [0, 2, 1, 4, 5, 6, 2, 8]
注意:只有第一个元素在其正确的排序位置。
- heapq.heappush(heap,item)——这个操作将一个元素推入一个堆中。 堆 是指堆的名称,而 项 是指要添加到堆中的项。例如:
heapq.heappush(h,7)
print(h) #[0, 2, 1, 4, 5, 6, 2, 8, 7]
尝试添加一个负数,观察会发生什么。
- heapq . heap pop(heap)——这个操作用来返回堆中最小的元素。 堆 指堆的名称。
heapq.heappop(h) #returns 0
- heapq.heappushpop(heap,item)——顾名思义,这个命令向堆中添加一个项目,并返回最小的数字。这个命令比一个heap push()命令后跟一个heap pop()命令要高效得多。
heapq.heappushpop(h,3) #returns 0
print(h) #prints [1, 2, 2, 4, 5, 6, 3, 8, 7]
如果你用一个比堆的最小值小的数字尝试上面的命令,你会注意到同样的元素被弹出。比如:
heapq.heappushpop(h,0)#返回 0 print(h) #prints [1,2,2,4,5,6,3,8,7]
- heapq.heapreplace(heap,item)——上述问题可以通过执行该操作来解决,因为它返回最小的元素,然后添加新元素 。
heapq.heapreplace(h,0) #returns 1
print(h) #prints [0, 2, 2, 4, 5, 6, 3, 8, 7]
上述命令是你在处理堆时使用的主要命令,但也有其他通用命令,如merge()和 nsmallest()。 这些你可以自己去探索!
应用程序
优先级队列广泛应用于人工智能、统计、操作系统和图形等不同领域。
结论
尝试解决简介中讨论的音乐播放器问题。您将需要堆积一个元组列表,其中每个元组应该看起来像 (点击次数,歌曲 id,歌曲名称) 。 heapify 命令将根据元组的第一个元素跟踪 min,这就是为什么元组的第一个元素是命中数。把你的答案贴在下面。本教程到此为止。快乐的蟒蛇!
py2exe: Python 转 exe 简介
原文:https://www.pythoncentral.io/py2exe-python-to-exe-introduction/
py2exe 是一种将 Python 脚本转换成 Windows 的简单方法。exe 应用程序。它是一个基于 Distutils 的实用程序,允许您在 Windows 计算机上运行用 Python 编写的应用程序,而无需用户安装 Python。当您需要将程序作为独立的应用程序分发给最终用户时,这是一个很好的选择。py2exe 目前只能在 Python 2.x 中运行。
首先你需要从 sourceforge 官方网站下载并安装 py2exe
现在,为了能够创建可执行文件,我们需要在您希望可执行的脚本所在的同一文件夹中创建一个名为setup.py的文件:
# setup.py
from distutils.core import setup
import py2exe
setup(console=['myscript.py'])
在上面的代码中,我们将为myscript.py创建一个可执行文件。setup函数接收一个参数console=['myscript.py'],告诉 py2exe 我们有一个名为myscript.py的控制台应用程序。
然后,为了创建可执行文件,只需从 Windows 命令提示符(cmd)运行python setup.py py2exe。你会看到很多输出,然后会创建两个文件夹:dist和build。py2exe 使用build文件夹作为临时文件夹来创建可执行文件所需的文件。dist文件夹存储可执行文件和运行该可执行文件所需的所有文件。删除build文件夹是安全的。注意:运行python setup.py py2exe假设您的 path 环境变量中有 Python。如果不是这样,就使用C:\Python27\python.exe setup.py py2exe。
现在测试您的可执行文件是否有效:
cd dist
myscript.exe
GUI 应用程序
现在是时候创建一个 GUI 应用程序了。在这个例子中,我们将使用 Tkinter:
【python】
tkexample . py
' ' '一个非常基本的 Tkinter 例子'
从 Tkinter import *
root = Tk()
root . title('一个 Tk 应用')
Label(text= '我是标签')。pack(pady = 15)
root . main loop()
然后创建setup.py,我们可以使用以下代码:
【python】
setup . py
从 distutils.core 导入 setup
导入 py2exe
setup(windows =[' tk example . py '])
setup函数现在正在接收一个参数windows=['tkexample.py'],告诉 py2exe 这是一个 GUI 应用程序。再次创建在 Windows 命令提示符下运行python setup.py py2exe的可执行文件。要运行该应用程序,只需在 Windows 资源管理器中导航到dist文件夹,然后双击tkexample.exe。
使用外部模块
前面的例子是从 Python 标准库中导入模块。py2exe 默认包含标准库模块。然而,如果我们安装了第三方库,py2exe 很可能不包括它。在大多数情况下,我们需要显式地包含它。例如,一个应用程序使用ReportLab库来制作 PDF 文件:
# invoice.py
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.lib.units import mm
if _ _ name _ _ = = ' _ _ main _ _ ':
name = u ' Mr。约翰·多伊'
城市= '佩雷拉'
地址= '榆树街'
电话= '555-7241'
c =画布。Canvas(filename='invoice.pdf ',pagesize= (letter[0],letter[1]/2))
c . set font(' Helvetica ',10)
#打印客户数据
c.drawString(107*mm,120*mm,姓名)
c.drawString(107*mm,111*mm,城市)
c.drawString(107*mm,106*mm,地址)
c.drawString(107*mm
为了包含ReportLab模块,我们创建一个setup.py文件,将一个选项字典传递给setup函数:
# setup.py
from distutils.core import setup
import py2exe
setup(
console =[' invoice . py '],
options = {
' py2exe ':{
' packages ':[' reportlab ']
}
}
)
能够在其他计算机上运行可执行文件的最后一步是,运行可执行文件的计算机需要安装 Microsoft Visual C++ 2008 可再发行软件包。在这里可以找到一个很好的指南来解释如何做到这一点。然后只需将dist文件夹复制到另一台计算机并执行。exe 文件。
最后,请考虑以下建议:
- 大多数时候创建的可执行文件是向前兼容的:如果您在 Windows XP 中创建可执行文件,它将在 Vista 和 7 中运行。然而,它不是向后兼容的:如果你在 Windows 7 中创建可执行文件,它将不能在 Windows XP 上运行。
- 如果您导入了第三方库,请确保在交付软件之前测试所有的应用程序功能,因为有时会创建可执行文件,但缺少一些库。在这种情况下,当您尝试访问使用外部库的功能时,将会出现运行时错误。
- py2exe 自 2008 年以来就没有更新过,所以它不适合 Python 3。
如果你需要更多关于 py2exe 的信息,请访问官方网站。
PyInstaller:打包 Python 应用程序(Windows、Mac 和 Linux)
原文:https://www.pythoncentral.io/pyinstaller-package-python-applications-windows-mac-linux/
PyInstaller 是一个用于将 Python 脚本转换成独立应用程序的程序。PyInstaller 允许您在计算机上运行用 Python 编写的应用程序,而不需要用户安装 Python。当您需要将程序作为独立的应用程序分发给最终用户时,这是一个很好的选择。PyInstaller 目前只支持 Python 2.3 到 2.7。
PyInstaller 声称可以兼容很多现成的第三方库或包。完全支持 PyQt、Django 和 matplotlib。
首先,从官方站点下载并解压 PyInstaller。
PyInstaller 是一个应用程序,而不是一个包。所以没必要安装在你的电脑里。要开始,请打开命令提示符(Windows)或终端(Mac 和 Linux)并转到 PyInstaller 文件夹。
cd pyinstaller
现在假设你要打包 myscript.py,我把它保存到 pyinstaller 文件夹:
【python】
myscript . py
print(' Hello World!')
然后,为了创建可执行文件,只需运行python pyinstaller.py myscript.py,您将看到大量输出,一个名为myscript的文件夹将被创建,其中包含两个文件夹和一个文件。PyInstaller 使用build文件夹作为临时文件夹来创建可执行文件所需的文件。dist文件夹存储可执行文件和运行该可执行文件所需的所有文件。删除构建文件夹是安全的。名为myscript.spec的文件对于定制 PyInstaller 打包应用程序的方式很有用。
现在测试你的可执行文件是否有效:
[python]
cd myscript/dist/myscript
myscript
[/python]
[python]
cd myscript/dist/myscript
./myscript
[/python]
你现在应该看到一个“你好,世界!”印在屏幕上。
记住,运行python pyinstaller.py myscript.py假设您的 path 环境变量中有 Python。如果不是这样,就在 Windows 中使用C:\Python27\python.exe pyinstaller.py myscript.py。在 Linux 和 Mac OS X 的大部分时间里,Python 会出现在你的 path 环境变量中。
GUI 应用程序
现在是时候创建一个 GUI 应用程序了。在这个例子中,我们将使用 Tkinter:
【python】
tkexample . py
' ' '一个非常基本的 Tkinter 例子'
从 Tkinter import *
root = Tk()
root . title('一个 Tk 应用')
Label(text= '我是标签')。pack(pady = 15)
root . main loop()
要打包它,必须使用--windowed标志,否则应用程序将无法启动:
python pyinstaller.py --windowed tkexample.py
此时,您可以导航到 dist 文件夹,并通过双击它来运行应用程序。
Mac OS X 用户注意:如果你使用预装的 Python 版本,上面使用 Tkinter 的例子工作正常,如果你自己安装或更新 Python,你会发现运行打包的应用程序时会出现一些问题。
使用外部模块
前面的例子是从 Python 标准库中导入模块。默认情况下,PyInstaller 包含标准库模块。然而,如果我们安装了第三方库,PyInstaller 可能不会包含它。在大多数情况下,我们需要创建“钩子”来告诉 PyInstaller 包含这些模块。这方面的一个例子是一个使用 ReportLab 库制作 PDF 文件的应用程序:
【python】
invoice . py
from report lab . PDF gen 导入画布
from reportlab.lib.pagesizes 导入信件
from reportlab.lib.units 导入 mm
if _ _ name _ _ = = ' _ _ main _ _ ':
name = u ' Mr。约翰·多伊'
城市= '佩雷拉'
地址= '榆树街'
电话= '555-7241'
c =画布。Canvas(filename='invoice.pdf ',pagesize= (letter[0],letter[1]/2))
c . set font(' Helvetica ',10)
打印客户数据
c.drawString(107mm,120mm,姓名)
c.drawString(107mm,111mm,城市)
c.drawString(107mm,106mm,地址)
c.drawString(107*mm
“钩子”模块是一个具有特殊名称的 Python 文件,用于告诉 PyInstaller 包含一个特定的模块。在 Google 上搜索时,我找到了打包 ReportLab 应用程序所需的钩子这里,并把它们放在一个名为“hooks”的文件夹中:
+-hooks/
|-hook-report lab . pdf base . _ font data . py
|-hook-report lab . pdf base . py
|-hook-report lab . py
hook-reportlab.py和hook-reportlab.pdfbase.py为空文件,hook-reportlab.pdfbase._fontdata.py包含:
【python】
hook-report lab . pdf base . _ font data . py
hidden imports =[
' _ font data _ enc _ macexpert ',
'_fontdata_enc_macroman ',
'_fontdata_enc_pdfdoc ',
'_fontdata_enc_standard ',
'_fontdata_enc_symbol ' '
现在为了打包可执行文件,我们必须运行python pyinstaller.py --additional-hooks-dir=hooks/ invoice.py。additional-hooks-dir标志告诉 PyInstaller 在指定的目录中搜索钩子。
结论
如果您的脚本只从 Python 标准库中导入模块,或者导入官方支持的包列表中包含的模块,Pyinstaller 会工作得很好。使用这些受支持的包使得打包应用程序变得非常简单,但是当我们需要使用第三方不支持的模块时,要让它工作起来可能会很棘手。
PySide/PyQt 教程:交互式小部件和布局容器
原文:https://www.pythoncentral.io/pyside-pyqt-tutorial-interactive-widgets-and-layout-containers/
在上一期文章中,我们查看了为所有继承了QWidget的 Qt 小部件提供的一些功能,并且更深入地查看了一个特定的小部件QLabel。我们还通过一个例子展示了一个简单的 Python/Qt 应用程序的结构。然而,到目前为止,我们还不能做任何让用户非常满意的事情;我们的应用程序可以向它们显示文本。你可以称之为独白盒。我们需要一些方法让用户与我们的程序互动,把我们的独白变成对话。Qt 提供了丰富的交互式小部件,我们将在这里考虑一些更简单的小部件;我们将使用它们来探索如何在表单上布置小部件。在下一期中,我们将学习如何让我们的应用程序使用插槽和信号来响应用户交互;这一次,我们将讨论如何创建小部件并在表单上展示它们,包括一个使用我们所学内容的简单示例。
交互式小工具
Python/Qt 使得允许用户交互变得容易;它有一组非常简单、明智的小部件,并且它们很容易连接到您的应用程序的逻辑。我们来看几个。
小跟班
允许用户与应用程序交互的最简单的方法之一是让他们点击一个按钮。不出所料,Qt 有那些,叫做QPushButton。QPushButton构造函数有三个有效的签名:
QPushButton(parent=None)
QPushButton(text, [parent=None])
QPushButton(icon, text, [parent=None])
parent参数是一个QWidget,text是一个 Python 字符串或unicode,icon是一个QIcon。要创建一个标题为“Go”的属于some-form的按钮,我们要做:
go_button = QPushButton('Go', some_form)
如果我们想要一个快捷键,比如说 Alt-G,我们可以在 Go 中的 G 之前添加一个&符号:
go_button = QPushButton('&Go', some_form)
在大多数平台上,“G”还会带有下划线。
使用按钮还可以做其他一些事情。以上面的go_button为例,您可以通过调用:
go_button.setDefault(True)
你可以把它弄平:
go_button.setFlat(True)
将False传递给任何一个方法都会产生相反的效果。一个按钮被点击时会弹出一个菜单;为此,向按钮的setMenu方法传递一个QMenu对象。(我们将在以后的文章中研究菜单。)
文本框
Qt 的 textbox 控件叫做QLineEdit;它允许用户输入和/或编辑单行纯文本。它有两个构造函数签名:
QLineEdit(parent=None)
QLineEdit(text, [parent=None])
两者之间唯一的区别是,第二个将包含在QLineEdit中的文本设置为text。QLineEdit对象有很多方法,但是我们将关注一些最基本的方法。可以用text()方法检索其文本,用setText(text)设置,用setMaxLength(chars)设置可以输入的最大字符数。使用setReadOnly(True)可以使其为只读,并且可以使用setPlaceholderText(text)添加占位符文本。A QLineEdit有更高级的属性:可以设置验证器和输入掩码,处理选择和撤销历史,等等;我们稍后会谈到这一点。
组合框
QComboBox小部件用于向用户提供大量文本或文本/图标选择,用户必须从中选择一个。(对于多选,请参见QListView和QListWidget——我们就要到了。)它的构造函数只接收一个父级:
QComboBox(parent)
构建起来很简单,但是在中还没有任何东西。您可以通过多种方式之一添加项目。如果您的所有项目都是文本的,您可以使用addItems(texts),其中texts是一个字符串项目列表。要单独添加项目,您可以使用addItem,它有两个有效签名:
addItem(icon, text, [userData=None])
addItem(text, [userData=None])
其中icon是一个QIcon,text是一个unicode对象,userData是任何对象。您可以使用insertItem插入项目:
insertItem(index, icon, text, [userData=None])
insertItem(index, text, [userData=None])
或者,如果您的所有项目都是文本的,请选择insertItems(texts)。QComboBox 是一个灵活的小部件,用它可以做更多的事情,但这只是一个开始。
示例应用程序:概述
接下来,我们将学习如何将小部件组合到一个表单布局中——但是在此之前,让我们简要地看一下这一期的示例应用程序。

如您所见,这是一个非常简单的应用程序。用户可以选择一个称呼并输入他们想要问候的人(或其他实体)的姓名,当他们单击“建立问候”时,问候将显示在表单上的标签上。我们将在下一节中展示的就是这种形式。
布局管理
PySide 和 PyQt 有两种布局管理方法:绝对定位,开发人员必须指定每个小部件的位置和大小;使用布局容器,将小部件以多种排列方式之一放入表单中,并自动处理大小和位置。我们将使用这两种方法为上面描述的示例应用程序构建一个接口。
绝对定位
要设置小部件在窗口中的物理位置,可以使用小部件的move(x, y)方法;x和y分别是从表单左上角到小部件左上角的水平和垂直距离。这是我们的表单,使用绝对定位创建:
# Every Qt application must have one and only one QApplication object;
# it receives the command line arguments passed to the script, as they
# can be used to customize the application's appearance and behavior
qt_app = QApplication(sys.argv)
class AbsolutePositioningExample(q widget):
' ' ' py side 绝对定位的例子;主窗口
继承了 QWidget,这是一个方便的空窗口小部件。'
def __init__(self):
#将对象初始化为 QWidget
QWidget。__init__(self)
#我们必须自己设置主窗口的大小
#因为我们控制了整个布局
self.setMinimumSize(400,185)
self.setWindowTitle('动态迎宾')
#以此对象为父对象创建控件,并单独设置它们的位置;每一行都是一个标签,后跟
#另一个控件
#称呼选择器的标签
self . Salutation _ LBL = q Label(' Salutation:',self)
self . Salutation _ LBL . move(5,5) #从左上偏移第一个控件 5px
# self . Salutations =[' Ahoy ',
'Good day ',
'Hello ',【T6]' Heyo ',
'Hi ',
'Salutations ',
' was up ',
' Yo ']]
#在标签和组合框之间的
#最左边,以及在最右边的
# self . salutation . setminimumwwidth(285)
#将它放置在标签末端右侧五个像素处
self.salutation.move(110,5)
#收件人控件的标签
self . Recipient _ LBL = q label(' Recipient:',self)
# 5 像素缩进,比最后一对小部件低 25 像素
self.recipient_lbl.move(5,30)
#收件人控件是一个输入框
self . recipient = QLineEdit(self)
#添加一些幽灵文本来指示要输入什么样的内容
self . recipient . setplaceholdertext(";例如“world”或“Matey”";)
#与称呼宽度相同
self . recipient . set minimum width(285)
#与称呼缩进相同但低 25 像素
self.recipient.move(110,30)
# Greeting 小部件的标签
self . Greeting _ LBL = q label(' Greeting:',self)
#与其他小部件缩进相同,但低了 45 个像素,因此它具有
#物理分隔,表示函数的不同
self.greeting_lbl.move(5,75)
greeting 小部件也是一个标签
self.greeting = QLabel(',self)
#与其他控件一样缩进
self.greeting.move(110,75)
build 按钮是一个按钮
self . build _ button = q push button(&;建立问候,自我)
#放在右下角,比
#其他互动小工具
self . build _ button . setminimumwidth(145)
self . build _ button . move(250,150)
def run(self):
#显示表单
self.show()
#运行 Qt 应用程序
qt_app.exec_()
#创建应用程序窗口的实例并运行它
app = AbsolutePositioningExample()
app . run()
不用说,这在严肃的应用程序中会变得很麻烦。它也不能很好地响应调整大小;标签就放在指定的位置上。不仅如此,想象一下如果一个有视觉障碍的用户把他们的字体设置得特别大;您为控件设置的固定位置将不再适用。
布局容器
出于所有这些原因,布局容器比绝对定位使用得更频繁;它们更加灵活,可以减轻程序员计算精确位置的负担,并且可以调整布局以适应不同平台的 GUI 指南,如 Windows、GTK+、KDE 和 Mac OS X,以及不同用户的偏好。有五个主要的布局容器,每个容器都从 QLayout 开始:
- QHBoxLayout
- QVBoxLayout
- QGridLayout
- QStackedLayout
- QFormLayout
每个都有不同的目的。简单来说,QHBoxLayout和QVBoxLayout分别在水平和垂直方向一个接一个地排列小部件;QGridLayout将它们排列成任意大小的表格;QStackedLayout将它们一个接一个地排列起来,允许它们根据需要出现在最前面;而QFormLayout是一种特殊的两列网格排列,它提供了特殊的方法来排列第一列有标签、第二列有相关控件的常见表单。这些布局本身就足够有用,但是您的布局选项并不仅限于此:您还可以将布局嵌套在其他布局中,以便为您的用户界面创建更复杂、更灵活的模式。现在,我们将考虑垂直和水平的盒子布局和QFormLayout。
QVBoxLayout 和 qhboxlayout
盒子的布局相当简单。要使用一个作为顶级布局,您只需创建布局——其构造函数不需要参数——并使用名副其实的addWidget方法向其添加小部件。然后,将它设置为它所属的窗口的布局。例如:
T the window
win = QWidget()
#三个标签
LBL _ 1 = q label(";我们是";)
LBL _ 2 = q label(' stacked ')
LBL _ 3 = q label(' up)
# A 垂直方框布局
layout = QVBoxLayout()
#将小部件添加到布局中
layout . Add widget(LBL _ 1)
layout . Add widget(LBL _ 2)
layout . Add widget(LBL _ 3)
#将布局设置为窗口的布局
win.setLayout(layout)
一个QHBoxLayout可以被同样地使用,尽管它很少作为顶层布局。它是最常见的子布局。要将子布局添加到另一个布局,使用布局的addLayout方法,例如:
layout = QVBoxLayout()
sub_layout = QHBoxLayout()
# ...用小部件填充布局...
layout . add layout(sub _ layout)
盒子布局还有另一个有价值且常用的方法:addStretch。一个常见的布局有许多控件静态地位于一个盒子布局的一端,一些位于另一端,中间有灵活的空白空间。为此,在框的开头添加小部件,添加一个拉伸因子大于零的拉伸,即layout.addStretch(1);然后添加其余的小部件。
QFormLayout
除了每一行可以很容易地分成两列而不需要创建嵌套布局之外,QFormLayout与QVBoxLayout非常相似。这是使用表单布局的addRow方法完成的,该方法被大量重载。单参数版本:
addRow(QWidget)
addRow(QLayout)
在整个QFormLayout的末尾添加小部件或布局。双参数版本:
unicode, QLayout
unicode, QWidget
QWidget, QWidget
QWidget, QLayout
在第一列中添加初始元素作为“标签”,在第二列中添加第二个元素。unicode参数被用作QLabel的文本;QWidget可以是任何小部件。
方框布局示例
既然我们已经有了如何创建交互式小部件并以更灵活的布局排列它们的基本想法,让我们以更简单、更灵活的方式重新创建我们的界面。我们窗口的主布局将是一个QVBoxLayout,有两个子布局,一个QFormLayout包含所有带标签的控件,一个QHBoxLayout管理按钮在右下角的位置。我们将使用addStretch将QFormLayout与QHBoxLayout分开,并将按钮推到QHBoxLayout的最右侧。您可能会注意到,下面的代码与绝对定位示例相比没有什么变化;例如,在如何创建单个控件方面没有区别。
qt_app = QApplication(sys.argv)
class layout example(q widget):
' ' ' py side/PyQt 绝对定位的例子;主窗口
继承了 QWidget,这是一个方便的空窗口小部件。''
def __init__(self):
#将对象初始化为 QWidget,
#设置其标题和最小宽度
QWidget。_ _ init _ _(self)
self . setwindowtitle('动态迎宾')
self . setminimumwwidth(400)
#创建布局整个表单的 QVBoxLayout
self . layout = QVBoxLayout()
#创建管理带标签控件的表单布局
self . form _ layout = QFormLayout()
#我们希望提供的问候语
self.salutations = ['Ahoy ',
'Good day ',
'Hello ',
'Heyo ',
'Hi ',
'Salutations ',
'Wassup ',
'Yo']
#创建并填充组合框以选择称呼
self . salutation = QComboBox(self)
self . salutation . additems(self . salutations)
#将其添加到带有标签
self . form _ layout . addrow(&;称呼:',self.salutation)
#创建条目控件以指定收件人
#并设置其占位符文本
self . recipient = QLineEdit(self)
self . recipient . setplaceholdertext(";例如“世界”或“伙伴”";)
#将其添加到带有标签
self . form _ layout . addrow(&;收件人:',自我收件人)
#创建并添加标签以显示问候语文本
self.greeting = QLabel(',self)
self . form _ layout . addrow(' Greeting:',self.greeting)
#将表单布局添加到主 VBox 布局
self . layout . Add layout(self . form _ layout)
# Add stretch 将表单布局与按钮
self.layout.addStretch(1)分开
#创建一个水平的框布局来放置按钮
self.button_box = QHBoxLayout()
# Add stretch 将按钮推到最右边
self . button _ box . Add stretch(1)
#创建标题为
self . build _ button = q push button(&;建立问候,自我)
#将其添加到按钮框
self . button _ box . Add widget(self . build _ button)
#将按钮框添加到主 VBox 布局的底部
#将 VBox 布局设置为窗口的主布局
self.setLayout(self.layout)
def run(self):
#显示表单
self.show()
#运行 qt 应用程序
qt_app.exec_()
#创建应用程序窗口的实例并运行它
app = layout example()
app . run()
请特别注意这对程序员来说是多么容易。虽然代码并没有变短——并不是每一种便利都会减少输入,并且创建和嵌套布局会产生一些代码开销——但脑力劳动却少得多。开发者只需要得到一个产生期望效果的布局组合,并创建它们;可以单独创建和修改控件,很少考虑它们对其他控件布局的影响。下一期,我们将使用我们在这个例子中创建的接口,并让它实际上做一些事情。
PySide/PyQT 教程:QListView 和 QStandardItemModel
原文:https://www.pythoncentral.io/pyside-pyqt-tutorial-qlistview-and-qstandarditemmodel/
在我们的上一期中,我们讨论了 Qt 的QListWidget类,它允许用户制作简单的单列列表框。然而,对于更高级的列表控件,需要更灵活的小部件;因此,Qt 提供了QListView小部件,允许创建更多不同的项目。它是一个纯粹的表示小部件,显示由数据模型提供的信息。这将呈现的数据逻辑与执行呈现的小部件分离开来;有多个小部件可以显示来自相同模型结构的数据。
已经为您创建了一些专门的模型类型。例如,QStandardItemModel提供了有限的功能,这些功能比我们在上一期关于QListWidget的讨论中看到的要大一些;除了文本和图标,它还提供拖放功能、可检查项目和其他功能。自定义行为可以通过从QAbstractListModel继承来实现,这是一个通用的列表数据模型。
PySide/PyQt 的 qstandarditemmodel
我们将从讨论 QStandardItemModel 对QListView的使用开始。就像任何其他的QWidget一样,QListView被实例化了——对于我们遇到的每一个小部件,你是否已经厌倦了这一行?它读起来令人厌烦,但却是一个容易记住的对象模型;PyQt/Pyside 最大的优势之一是它的简单性、可记忆性和一致性。除此之外,QListView的构造函数接受一个可选的父类:
list = QListView(parent)
很简单。现在我们的列表需要一个模型来管理它的数据。我们将用我们的列表创建一个QStandardItemModel作为它的(可选)父节点:
model = QStandardItemModel(list)
QStandardItemModel还有其他构造函数签名,但它们与我们的单列列表无关;我们改天再讨论它们。
PySide/PyQt 的 QStandardItem
创建列表和模型是简单的部分;列表的主要工作是创建和填充模型。例如,让我们为列表创建一个项目:
item = QStandardItem()
我们可以方便地设置它的文本和图标:
item.setText('Item text')
item.setIcon(some_QIcon)
我们还可以创建已经设置了文本(和图标,如果需要)的项目:
textual_item = QStandardItem('Item text')
text_and_icon_item = QStandardItem(some_QIcon, 'Item text')
我们还可以使一个项目成为可检查的,在项目的最左边添加一个复选框:
item.setCheckable(True)
如果你希望你的复选框有三种状态——T0、T1 和 T2——使用 T3。
一个简短的 QStandardItem 示例
这是足够的背景知识,我们可以给出一个简单的关于QListView外观的例子,尽管它还不能做任何事情。我们将通过使我们的主窗口成为 QListView 来尽可能地简化;我们将进行与任何QWidget -as-a-window 示例相同的基本设置:
list = QListView()
list.setWindowTitle('Example List')
list.setMinimumSize(600, 400)
接下来,我们将创建我们的模型:
model = QStandardItemModel(list)
然后,我们将创建一些QStandardItem来填充我们的模型。为了向我的妻子致敬——我们今年夏天将迎来第三个孩子——我将列出她迄今渴望的食物。每个都有一个文本标题和一个复选框:
foods = [
'Cookie dough', # Must be store-bought
'Hummus', # Must be homemade
'Spaghetti', # Must be saucy
'Dal makhani', # Must be spicy
'Chocolate whipped cream' # Must be plentiful
]
对于 foods 中的 food:
#创建一个标题为
item = QStandardItem(food)的项目
#给它添加一个复选框
item.setCheckable(True)
#将项目添加到模型
model.appendRow(item)
最后,我们将我们的模型应用到QListView,显示窗口,并运行应用程序:
list.setModel(model)
list.show()
app.exec_()
完整的示例,加上经过删减的解释和注释,如下所示:
# Create a Qt application
app = QApplication(sys.argv)
#我们的主窗口将是一个 QListView
List = QListView()
List . setwindowtitle('示例列表')
list.setMinimumSize(600,400)
#为列表的数据创建一个空模型
model = QStandardItemModel(list)
#添加一些文字项目
食物=[
‘曲奇’,#必须是商店购买的
‘鹰嘴豆泥’,#必须是自制的
‘意大利面’,#必须是香辣的
‘达尔·马克哈尼’,#必须是辛辣的
‘巧克力鲜奶油’,#必须是大量的
]
对于 foods 中的 food:
#创建一个标题为
item = QStandardItem(food)的项目
#给它添加一个复选框
item.setCheckable(True)
#将项目添加到模型
model.appendRow(item)
#将模型应用到列表视图
list.setModel(model)
#显示窗口并运行 app
list . Show()
app . exec _()
运行时,它看起来会像这样:

添加简单的功能
这一切都很好,但它还没有做任何事情。让我们看看如何让一个带有QStandardItemModel的QListView响应用户交互。
你可能会想象每个QStandardItem会像一个QPushButton一样,当它被选择、检查、编辑等等时会发出信号——至少,如果你像我一样,那就是你所期望的。如果是这样,你就会像我一样,错了。实际上有一个信号可以表明QStandardItemModel中的项目发生了什么,那就是itemChanged(item)。正如您所看到的,它将已更改的项目带到它的插槽中,为了告诉它发生了什么,您需要检查该项目。我觉得这不太理想,但这就是我们所得到的。
您可以使用模型的item方法来检查未更改的项目;返回指定的从零开始的行中的项。(它也可以接受多列模型的一列,我们可能会在另一个时间看到。)
还有大量的信号表明模型结构的变化;这些都是继承自QAbstractItemModel的,可以在这里考察。我们将在稍后的QAbstractItemModel讨论中详细讨论它们,这完全是另一个话题;对于我们当前的例子,我们不需要它们中的任何一个。
让我们把我们的清单做成一个甜蜜的清单;您在购买和/或准备物品时核对物品,完成后,窗口关闭。(我知道,这是一个高度人为和构造的例子。)
首先,我们更改标题:
list.setWindowTitle('Honey-Do List')
然后,我们需要一个插槽来连接模型的itemChanged信号。我们将让它首先检查是否使用它的checkState方法检查了被更改的项目,以避免每次都检查所有的项目。如果它被选中,我们将查看其他的是否被选中;如果他们都是,我们就让QApplication退出:
def on_item_changed(item):
# If the changed item is not checked, don't bother checking others
if not item.checkState():
return
i = 0
#循环遍历这些项目,直到你没有得到任何项目,这意味着你已经通过了列表的结尾
而 model.item(i):
如果不是 model.item(i)。checkState():
返回
i += 1
app.quit()
然后,我们将把itemChanged信号接到我们的插槽上:
model.itemChanged.connect(on_item_changed)
这就是我们需要做的。以下是我们修改后的示例的完整代码:
# Create a Qt application
app = QApplication(sys.argv)
#我们的主窗口将是一个 QListView
List = QListView()
List . setwindowtitle(' Honey-Do List ')
List . setminimumsize(600,400)
#为列表的数据创建一个空模型
model = QStandardItemModel(list)
#添加一些文字项目
食物=[
‘曲奇’,#必须是商店购买的
‘鹰嘴豆泥’,#必须是自制的
‘意大利面’,#必须是香辣的
‘达尔·马克哈尼’,#必须是辛辣的
‘巧克力鲜奶油’,#必须是大量的
]
对于 foods 中的 food:
#创建一个标题为
item = QStandardItem(food)的项目
#给它添加一个复选框
item.setCheckable(True)
#将项目添加到模型
model.appendRow(item)
def on_item_changed(item):
#如果更改的项目没有检查,就不要费心检查其他的
如果没有 item.checkState():
return
#循环遍历这些项目,直到您没有得到任何项目,这意味着您已经通过了列表的结尾
i = 0
而 model.item(i):
如果不是 model.item(i)。checkState():
返回
i += 1
app.quit()
model . item changed . connect(on _ item _ changed)
#将模型应用到列表视图
list.setModel(model)
#显示窗口并运行 app
list . Show()
app . exec _()
这是一个QListView的简单应用。它可以做更多的事情,但是相同的模型可以用于其他小部件,我们将在另一个时间研究它的更多功能。下一次,我们将看一些完全不同的东西,Qt 中最让我兴奋的控件之一:QWebView,一个基于 WebKit 的控件,用于呈现 HTML/CSS/XML/XSLT 页面。
PySide/PyQt 教程:QWebView
原文:https://www.pythoncentral.io/pyside-pyqt-tutorial-qwebview/
QWebView 是一个非常有用的控件;它允许您显示来自 URL、任意 HTML、带有 XSLT 样式表的 XML 的网页、构造为 q 网页的网页以及它知道如何解释其 MIME 类型的其他数据。它使用 WebKit 网络浏览器引擎。WebKit 是一个最新的、符合标准的渲染引擎,被谷歌的 Chrome、苹果的 Safari 以及不久的 Opera 浏览器所使用。
创建和填写 QWebView
来自 QWebView 网址的内容
您可以像实例化其他QWidget一样实例化一个QWebView,并带有一个可选的父对象。然而,有许多方法可以将内容放入其中。最简单的——也可能是最明显的——是它的load方法,它需要一个QUrl;构建QUrl最简单的方法是使用 unicode URL 字符串:
web_view.load(QUrl('https://www.pythoncentral.io/'))
这将在QWebView控件中加载 的主页。等同于使用setUrl方法,就像这样:
web_view.setUrl(QUrl('https://www.pythoncentral.io/'))
用 QWebView 加载任意 HTML
还有其他有趣的方式将内容加载到QWebView中。您可以使用setHtml方法将生成的 HTML 加载到其中。例如,您可以这样做:
html = '''<html>
<head>
<title>A Sample Page</title>
</head>
<body>
<h1>Hello, World!</h1>
<hr />
I have nothing to say.
</body>
</html>'''
web_view.setHtml(html)
setHtml方法可以接受可选的第二个参数,即文档的基本 URL——基于这个 URL 解析文档中包含的任何相对链接。
其他 QWebView 内容类型
一个QWebView的内容不一定是 HTML 如果您有其他浏览器可查看的内容,您可以使用它的setContent方法将其放在一个QWebView中,该方法接受内容和可选的 MIME 类型以及一个基本 URL。如果省略 MIME 类型,会假设是text/html;MIME 类型的自动检测还没有实现,尽管它至少是初步计划的。我还没有找到 QWebView 可以处理的 MIME 类型列表,但是这里有一个处理 PNG 文件的例子:
app = QApplication([])
win = QWebView()
img = open('myImage.png ',' rb ')。read()
win.setContent(img,' image/png ')。
win.show()
app.exec_()
用 JavaScript 与 QWebView 交互
向用户呈现 web 风格的内容本身是有用的,但是这些内容可以与 JavaScript 交互,JavaScript 可以从 Python 代码启动。
一个QWebView包含一个QWebFrame对象,它的evaluateJavaScript方法现在对我们很有用。该方法接受一个 JavaScript 字符串,在QWebView内容的上下文中对其求值,并返回其值。
可以返回哪些值?QWebFrame 的 PySide 文档,就像 PyQt 和 Qt 本身的文档一样,在这一点上并不清楚。事实上,这些信息在网上根本看不到,所以我做了一些测试。
看起来字符串和布尔值只是简单的工作,而数字、对象、undefined和null的工作需要注意:
- 因为 JavaScript 缺少独立的整数和浮点数据类型,所以数字总是被转换成 Python 浮点。
- 对象作为 Python 字典返回,除非它们是函数或数组;函数作为无用的空字典返回,数组成为 Python 列表。
undefined变成了None,足够理智。null变得,不太理智地,“。没错——空字符串。
特别注意关于null和函数的行为,因为两者都可能导致看起来正确的代码行为错误。我看不到更好的函数选项,但是null尤其令人困惑;检测来自evaluateJavaScript的空值的唯一的方法是在将它返回给 Python 之前,在 JavaScript 端进行比较val === null。(正是在这一点上,我们集体为 JavaScript 考虑不周的类型感到悲伤。)
关于evaluateJavaScript的一个重要警告:它具有 JavaScript 内置eval的所有安全含义,应该谨慎使用,前端 JavaScript 编码人员很少表现出这种谨慎。例如,通过天真地构建一个字符串并将其发送到evaluateJavaScript来执行任意的 JavaScript 就太简单了。小心,验证用户输入,阻止任何看起来太聪明的东西。
在 QWebView 中评估 JavaScript 的示例
现在,让我们抛开谨慎,看一个简单的例子。它将显示一个允许用户输入名和姓的表单。将有一个被禁用的全名条目;用户不能编辑它。有一个提交按钮,但它是隐藏的。(现实生活中不要这样好吗?这种形式是可用性和文化敏感性的灾难,在公共场合展示几乎是一种侮辱。)我们将提供一个 Qt 按钮来填写全名条目,显示 submit 按钮,并将全名打印到控制台。下面是这个例子的来源:
# Create an application
app = QApplication([])
# And a window
win = QWidget()
win.setWindowTitle('QWebView Interactive Demo')
# And give it a layout
layout = QVBoxLayout()
win.setLayout(layout)
# Create and fill a QWebView
view = QWebView()
view.setHtml('''
<html>
<head>
<title>A Demo Page</title>
<script language="javascript">
// Completes the full-name control and
// shows the submit button
function completeAndReturnName() {
var fname = document.getElementById('fname').value;
var lname = document.getElementById('lname').value;
var full = fname + ' ' + lname;
document.getElementById('fullname').value = full;
document.getElementById('submit-btn').style.display = 'block';
return full;
}
</script>
</head>
<body>
<form>
<label for="fname">First name:</label>
<input type="text" name="fname" id="fname"></input>
<br />
<label for="lname">Last name:</label>
<input type="text" name="lname" id="lname"></input>
<br />
<label for="fullname">Full name:</label>
<input disabled type="text" name="fullname" id="fullname"></input>
<br />
<input style="display: none;" type="submit" id="submit-btn"></input>
</form>
</body>
</html>
''')
# A button to call our JavaScript
button = QPushButton('Set Full Name')
# Interact with the HTML page by calling the completeAndReturnName
# function; print its return value to the console
def complete_name():
frame = view.page().mainFrame()
print frame.evaluateJavaScript('completeAndReturnName();')
# Connect 'complete_name' to the button's 'clicked' signal
button.clicked.connect(complete_name)
# Add the QWebView and button to the layout
layout.addWidget(view)
layout.addWidget(button)
# Show the window and run the app
win.show()
app.exec_()
试着运行它。填写名字和姓氏,然后单击按钮。您应该会看到一个全名和一个提交按钮。查看控制台,您也应该看到全名打印在那里。
这是一个非常复杂的例子,但是我们可以做更多有趣的事情:在下一期文章中,我们将构建一个简单的应用程序,它将 HTML 和一些其他 Qt 小部件结合起来,有效地与 web API 一起工作。
PySide/PyQt 教程:QListWidget
原文:https://www.pythoncentral.io/pyside-pyqt-tutorial-the-qlistwidget/
Qt 有几个允许单列列表选择器控件的小部件——为了简洁和方便,我们称它们为列表框。最灵活的方法是使用 QListView,它在高度灵活的列表模型上提供了一个 UI 视图,这个模型必须由程序员定义;更简单的方法是使用 QListWidget,它有一个预定义的基于项目的模型,允许它处理列表框的常见用例。我们将从更简单的 QListWidget 开始。
qlistwidget
QListWidget的构造函数类似于许多 QWidget 派生的对象,并且只接受一个可选的parent参数:
self.list = QListWidget(self)
填充 QListWidget
用条目填充 QListWidget 很容易。如果您的项目是纯文本,您可以单独添加它们:
for i in range(10):
self.list.addItem('Item %s' % (i + 1))
或散装:
items = ['Item %s' % (i + 1)
for i in range(10)]
self.list.addItems(items)
您还可以使用QListWidgetItem类添加稍微复杂一些的列表项。可以单独创建一个QListWidgetItem,然后使用列表的addItem方法将其添加到列表中:
item = QListWidgetItem()
list.addItem(item)
更复杂的 QListWidget I tems
或者它可以以列表为父列表创建,在这种情况下,它会自动添加到列表中:
item = QListWidgetItem(list)
一个item可以通过它的setText方法设置文本:
item.setText('I am an item')
和一个使用其setIcon方法设置为QIcon实例的图标:
item.setIcon(some_QIcon)
您也可以在QListWidgetItem的构造函数中指定文本或图标和文本:
item = QListWidgetItem('A Text-Only Item')
item = QListWidgetItem(some_QIcon, 'An item with text and an icon')
上述每个构造函数签名也可以选择接受一个父级。
使用 QListWidget
QListWidget提供了几个方便的信号,可以用来响应用户输入。最重要的是currentItemChanged信号,当用户改变所选项目时发出;它的槽接收两个参数,current和previous,它们是当前和先前选择的QListWidgetItems。当用户点击、双击、激活或按下一项时,以及当所选项目组改变时,也有信号。
要获取当前选中的项目,您可以使用由currentItemChanged信号传递的参数,也可以使用 QListWidget 的currentItem方法。
关于 QIcons 的说明
定制QListWidgetItem的少数方法之一是添加一个图标,所以了解一下QIcons是很重要的。有许多方法可以建造一个QIcon;您可以通过以下方式创建它们:
- 提供文件名:
icon = QIcon('/some/path/to/icon.png')。 - 使用主题图标:
icon = QIcon.fromTheme('document-open')。 - 从一个
QPixMap:icon = QIcon(some_pixmap)。
和许多其他人。对不同方法的一些评论:首先,注意基于文件的创建支持广泛的但不是无限的文件类型集;您可以通过运行QImageReader().supportedImageFormats()找到您的版本和平台支持哪些。在我的系统上,它返回:
[PySide.QtCore.QByteArray('bmp'),
PySide.QtCore.QByteArray('gif'),
PySide.QtCore.QByteArray('ico'),
PySide.QtCore.QByteArray('jpeg'),
PySide.QtCore.QByteArray('jpg'),
PySide.QtCore.QByteArray('mng'),
PySide.QtCore.QByteArray('pbm'),
PySide.QtCore.QByteArray('pgm'),
PySide.QtCore.QByteArray('png'),
PySide.QtCore.QByteArray('ppm'),
PySide.QtCore.QByteArray('svg'),
PySide.QtCore.QByteArray('svgz'),
PySide.QtCore.QByteArray('tga'),
PySide.QtCore.QByteArray('tif'),
PySide.QtCore.QByteArray('tiff'),
PySide.QtCore.QByteArray('xbm'),
PySide.QtCore.QByteArray('xpm')]
如我所说,选择范围很广。在成熟的平台之外,基于主题的图标创建是有问题的;在 Windows 和 OS X 上你应该没问题,如果你在 Linux 上使用 Gnome 或 KDE 也一样,但是如果你使用不太常见的桌面环境,比如 OpenBox 或 XFCE,Qt 可能找不到你的图标;有一些方法可以解决这个问题,但是没有好的方法,所以你可能只能使用文本。
qlist widget 示例
让我们创建一个简单的列表小部件,显示目录中所有图像的文件名和缩略图图标。因为这些项目很简单,可以创建为一个QListWidgetItem,我们将让它从QListWidget继承。
首先,我们需要知道您的安装支持什么样的图像格式,这样我们的列表控件就可以知道什么是有效的图像。我们可以用上面提到的方法,QImageReader().supportedImageFormats()。在返回之前,我们将把它们都转换成字符串:
def supported_image_extensions():
''' Get the image file extensions that can be read. '''
formats = QImageReader().supportedImageFormats()
# Convert the QByteArrays to strings
return [str(fmt) for fmt in formats]
现在我们有了它,我们可以构建我们的图像列表小部件;我们称之为ImageFileWidget。它将从QListWidget继承,除了一个可选的parent参数之外,像所有的QWidgets一样,它将需要一个必需的dirpath:
class ImageFileList(QListWidget):
''' A specialized QListWidget that displays the list
of all image files in a given directory. '''
def __init__(self, dirpath, parent=None):
QListWidget.__init__(self, parent)
我们希望它有一种方法来确定给定目录中的图像。我们将给它一个_images方法,该方法将返回指定目录中所有有效图像的文件名。它将使用glob模块的glob函数,该函数对文件和目录路径进行 shell 风格的模式匹配:
def _images(self):
''' Return a list of file-names of all
supported images in self._dirpath. '''
#从空列表开始
images = []
#查找每个有效的
#扩展名的匹配文件,并将它们添加到图像列表中。
对于 supported_image_extensions()中的扩展:
pattern = os.path.join(self。_dirpath,
'*。% s ' % extension)
images . extend(glob(pattern))
返回图像
既然我们已经有了一种方法来确定目录中有哪些图像文件,那么将它们添加到我们的QListWidget中就很简单了。对于每个文件名,我们创建一个以列表为父的QListWidgetItem,将其文本设置为文件名,将其图标设置为从文件创建的QIcon:
def _populate(self):
''' Fill the list with images from the
current directory in self._dirpath. '''
#如果我们要重新填充,请清除列表
self.clear()
#为每个图像文件创建一个列表项,
#为自己的图像设置适当的文本和图标
。_ images():
item = QListWidgetItem(self)
item . settext(image)
item . seticon(QIcon(image))
最后,我们将添加一个方法来设置目录路径,每次调用它时都会重新填充列表:
def setDirpath(self, dirpath):
''' Set the current image directory and refresh the list. '''
self._dirpath = dirpath
self._populate()
我们将在构造函数中添加一行代码来调用setDirpath方法:
self.setDirpath(dirpath)
这就是我们ImageFileList类的最终代码:
class ImageFileList(QListWidget):
''' A specialized QListWidget that displays the
list of all image files in a given directory. '''
def __init__(self,dirpath,parent=None):
QListWidget。__init__(self,parent)
self . setdirpath(dirpath)
def setDirpath(self,dirpath):
' ' '设置当前图像目录并刷新列表'‘
自我。_dirpath = dirpath
self。_ 填充()
def _images(self):
' ' '返回 self 中所有
支持的图像的文件名列表。_dirpath。''
#从空列表开始
images = []
#为每个有效的
#扩展名找到匹配的文件,并将它们添加到 supported _ image _ extensions():
pattern = OS . path . join(self。_dirpath,
'*。% s ' % extension)
images . extend(glob(pattern))
返回图像
def _populate(self):
' ' '用 self 中的
当前目录中的图像填充列表。_dirpath。''
#如果我们要重新填充,请清除列表
self.clear()
#为每个图像文件创建一个列表项,
#为自己的图像设置适当的文本和图标
。_ images():
item = QListWidgetItem(self)
item . settext(image)
item . seticon(QIcon(image))
因此,让我们将ImageFileList放在一个简单的窗口中,这样我们就可以看到它的运行。我们将创建一个QWidget作为我们的窗口,在其中添加一个QVBoxLayout,并添加ImageFileList,以及一个入口小部件,它将显示当前选中的项目。我们将使用ImageFileList的currentItemChanged信号来保持它们同步。
我们将创建一个QApplication对象,传递给它一个空列表,这样我们就可以使用sys.argv[1]来传递图像目录:
app = QApplication([])
然后,我们将创建窗口,设置最小尺寸并添加布局:
win = QWidget()
win.setWindowTitle('Image List')
win.setMinimumSize(600, 400)
layout = QVBoxLayout()
win.setLayout(layout)
然后,我们将实例化一个ImageFileList,传递接收到的图像目录路径和我们的窗口作为它的父节点:
first = ImageFileList(sys.argv[1], win)
并添加我们的入口小部件:
entry = QLineEdit(win)
并将这两个小部件添加到我们的布局中:
layout.addWidget(first)
layout.addWidget(entry)
然后,我们需要创建一个槽函数,在当前项改变时调用;它必须接受参数curr和prev、当前和先前选择的项目,并且应该将条目的文本设置为当前项目的文本:
def on_item_changed(curr, prev):
entry.setText(curr.text())
然后,我们把它接到信号上:
lst.currentItemChanged.connect(on_item_changed)
剩下的就是显示窗口和运行应用程序:
win.show()
app.exec_()
我们的最后一部分,包装在标准的if __name__ == '__main__'块中,是:
if __name__ == '__main__':
# The app doesn't receive sys.argv, because we're using
# sys.argv[1] to receive the image directory
app = QApplication([])
#创建一个窗口,设置它的大小,给它一个布局
win = q widget()
win . setwindowtitle('图像列表')
win.setMinimumSize(600,400)
layout = QVBoxLayout()
win . set layout(布局)
#使用从命令行
lst = ImageFileList(sys . argv[1],win)传入的 image
#目录创建我们的 image filelist 对象之一
layout.addWidget(lst)
entry = QLineEdit(win)
layout.addWidget(条目)
def on_item_changed(curr,prev):
entry . settext(curr . text())
lst . currentitemchanged . connect(on _ item _ changed)
win.show()
app.exec_()
运行我们的整个示例要求您有一个装满图像的目录;我在我的 Linux 发行版的/usr/share/icons目录中使用了一个作为例子:
python imagelist.py /usr/share/icons/nuoveXT2/48x48/devices
但是你必须找到你自己的。几乎任何图像都可以。
很明显,QListWidget是一个非常简单的小部件,没有提供很多选项;对于很多用例来说,这是不够的。对于这些情况,您可能会使用一个QListView,我们将在下一期讨论这个问题。
PySide/PyQt 教程:使用内置信号和插槽
原文:https://www.pythoncentral.io/pyside-pyqt-tutorial-using-built-in-signals-and-slots/
在上一期中,我们学习了如何创建和设置交互式小部件,以及如何使用两种不同的方法将它们排列成简单和复杂的布局。今天,我们将讨论允许您的应用程序响应用户触发事件的 Python/Qt 方式:信号和插槽。
当用户采取一个动作时——点击一个按钮,在组合框中选择一个值,在文本框中输入——这个小部件发出一个信号。这个信号本身什么也不做;它必须连接到一个插槽,这个插槽是一个充当信号接收者的对象,如果给定一个信号,它就对其进行操作。
连接内置 PySide/PyQt 信号
Qt 部件内置了许多信号。例如,当一个QPushButton被点击时,它发出它的clicked信号。clicked信号可以连接到充当插槽的功能(仅摘录;运行它需要更多的代码):
[python]
@Slot()
def clicked_slot():
''' This is called when the button is clicked. '''
print('Ouch!')
创建按钮
BTN = q button(' Sample ')
将其点击的信号连接到我们的槽位
BTN . clicked . Connect(clicked _ slot)
[/python]
[python]
@pyqtSlot()
def clicked_slot():
''' This is called when the button is clicked. '''
print('Ouch!')
创建按钮
BTN = q button(' Sample ')
将其点击的信号连接到我们的槽位
BTN . clicked . Connect(clicked _ slot)
[/python]
注意在clicked_slot的定义上面使用了@Slot()装饰符;虽然不是绝对必要的,但它提供了关于如何调用clicked_slot的 C++ Qt 库提示。(关于 decorator 的更多信息,请参见Python decorator 概述文章。)稍后我们会看到更多关于@Slot宏的信息。目前来说,知道按钮被点击时会发出clicked信号,这个信号会调用它所连接的函数;有着少年般的幽默感,它会发出‘哎哟!’。
对于一个不那么幼稚(并且实际上是可执行的)的例子,让我们看看一个QPushButton如何发出它的三个相关信号,pressed、released和clicked。
[python]
import sys
from PySide.QtCore import Slot
from PySide.QtGui import *
...在此插入其余的导入内容
导入内容必须在所有其他内容之前...
创建一个 Qt app 和一个窗口
app = QApplication(sys.argv)
win = q widget()
win . setwindowtitle('测试窗口')
在窗口中创建一个按钮
btn = QPushButton('Test ',win)
@Slot()
def on_click():
' ' '告知按钮何时被点击'
打印('点击')
@Slot()
def on_press():
' ' '告知按钮何时被按下‘
印刷(‘按下’)
@Slot()
def on_release():
' ' '告知按钮何时释放‘
刊印(‘公布’)
将信号连接到插槽
BTN . clicked . Connect(on _ click)
BTN . pressed . Connect(on _ press)
BTN . released . Connect(on _ release)
显示窗口并运行 app
win . Show()
app . exec _()
[/python]
[python]
import sys
from PyQt4.QtCore import pyqtSlot
from PyQt4.QtGui import *
...在此插入其余的导入内容
导入内容必须在所有其他内容之前...
创建一个 Qt app 和一个窗口
app = QApplication(sys.argv)
win = q widget()
win . setwindowtitle('测试窗口')
在窗口中创建一个按钮
btn = QPushButton('Test ',win)
@ pyqtSlot()
def on _ click():
' ' '告知按钮何时被点击'
打印('点击')
@ pyqtSlot()
def on _ press():
' ' '告知按钮何时按下‘
印刷(‘按下’)
@ pyqtSlot()
def on _ release():
' ' '告知按钮何时释放‘
刊印(‘公布’)
将信号连接到插槽
BTN . clicked . connect(on _ click)
BTN . pressed . connect(on _ press)
BTN . released . connect(on _ release)
显示窗口并运行 app
win . Show()
app . exec _()
[/python]
当您运行应用程序并单击按钮时,它将打印:
pressed
released
clicked
按钮按下时发出pressed信号,松开时发出released信号,最后,当这两个动作都完成时,发出clicked信号。
完成我们的示例应用程序
现在,很容易完成上一期文章中的示例应用程序。我们将向LayoutExample类添加一个 slot 方法,该方法将显示构建的问候语:
[python]
@Slot()
def show_greeting(self):
self.greeting.setText('%s, %s!' %
(self.salutations[self.salutation.currentIndex()],
self.recipient.text()))
[/python]
[python]
@pyqtSlot()
def show_greeting(self):
self.greeting.setText('%s, %s!' %
(self.salutations[self.salutation.currentIndex()],
self.recipient.text()))
[/python]
注意,我们使用recipient QLineEdit的text()方法来检索用户在那里输入的文本,使用salutation QComboBox的currentIndex()方法来获取用户选择的称呼的索引。我们还使用了Slot()装饰符来表示show_greeting将被用作一个槽。
然后,我们可以简单地将构建按钮的clicked信号连接到该方法:
self.build_button.clicked.connect(self.show_greeting)
我们最后的例子,总的来说,看起来是这样的:
[python]
import sys
from PySide.QtCore import Slot
from PySide.QtGui import *
每个 Qt 应用程序必须有且只有一个 Qt application 对象;
它接收传递给脚本的命令行参数,因为它们
可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
class layout example(q widget):
' ' ' py side 绝对定位的例子;主窗口
继承了 QWidget,这是一个方便的空窗口小部件。''
def init(self):
将对象初始化为 QWidget,
设置其标题和最小宽度
QWidget。_ _ init _ _(self)
self . setwindowtitle('动态迎宾')
self . setminimumwwidth(400)
创建布局整个表单的 QVBoxLayout
self . layout = QVBoxLayout()
创建管理带标签控件的表单布局
self . form _ layout = QFormLayout()
自我.问候=[‘嗨’、
、【嗨】、
、【hey】、
、【Hi】、
、【wassup】、
、【yo】
创建并填充组合框以选择称呼
self.salutation = QComboBox(self)
self . Salutation . additems(self . salutations)
将其添加到带有标签
self . form _ layout . addrow(&Salutation:',self . Salutation)的表单布局中
创建条目控件以指定一个
收件人并设置其占位符文本
self . recipient = qline edit(self)
self . recipient . setplaceholdertext("例如' world '或' Matey ' ")
将其添加到带有标签
self . form _ layout . addrow(&Recipient:',self.recipient)的表单布局中
创建并添加标签以显示问候语文本
self.greeting = QLabel(',self)
self . form _ layout . addrow(' Greeting:',self.greeting)
将表单布局添加到主 VBox 布局
self . layout . Add layout(self . form _ layout)
Add stretch 将表单布局与按钮
self.layout.addStretch(1)分开
创建一个水平的框布局来放置按钮
self.button_box = QHBoxLayout()
Add stretch 将按钮推到最右边
self . button _ box . Add stretch(1)
创建标题为
self . Build _ button = q push button(&Build Greeting,self)的构建按钮
将按钮的点击信号连接到 show _ greeting
self . build _ button . clicked . Connect(self . show _ greeting)
将其添加到按钮框
self . button _ box . Add widget(self . build _ button)
将按钮框添加到主 VBox 布局的底部
将 VBox 布局设置为窗口的主布局
self.setLayout(self.layout)
@ Slot()
def Show _ greeting(self):
' ' '显示构造的问候语' '
self.greeting.setText('%s,%s!'%
(self . salutations[self . salutation . current index()],
self.recipient.text()))
def run(self):
显示表单
self.show()
运行 qt 应用程序
qt_app.exec_()
创建应用程序窗口的实例并运行它
app = layout example()
app . run()
[/python]
[python]
import sys
from PyQt4.QtCore import pyqtSlot
from PyQt4.QtGui import *
每个 Qt 应用程序必须有且只有一个 Qt application 对象;
它接收传递给脚本的命令行参数,因为它们
可用于定制应用程序的外观和行为
Qt _ app = QA application(sys . argv)
class layout example(q widget):
' ' ' py side 绝对定位的例子;主窗口
继承了 QWidget,这是一个方便的空窗口小部件。''
def init(self):
将对象初始化为 QWidget,
设置其标题和最小宽度。
QWidget。_ _ init _ _(self)
self . setwindowtitle('动态迎宾')
self . setminimumwwidth(400)
创建布局整个表单的 QVBoxLayout
self . layout = QVBoxLayout()
创建管理带标签控件的表单布局
self . form _ layout = QFormLayout()
自我.问候=[‘嗨’、
、【嗨】、
、【hey】、
、【Hi】、
、【wassup】、
、【yo】
创建并填充组合框以选择称呼
self.salutation = QComboBox(self)
self . Salutation . additems(self . salutations)
将其添加到带有标签
self . form _ layout . addrow(&Salutation:',self . Salutation)的表单布局中
创建条目控件以指定一个
收件人并设置其占位符文本
self . recipient = qline edit(self)
self . recipient . setplaceholdertext("例如' world '或' Matey ' ")
将其添加到带有标签
self . form _ layout . addrow(&Recipient:',self.recipient)的表单布局中
创建并添加标签以显示问候语文本
self.greeting = QLabel(',self)
self . form _ layout . addrow(' Greeting:',self.greeting)
Cdd 窗体布局到主 VBox 布局
self . layout . add layout(self . form _ layout)
Add stretch 将表单布局与按钮
self.layout.addStretch(1)分开
创建一个水平的框布局来放置按钮
self.button_box = QHBoxLayout()
Add stretch 将按钮推到最右边
self . button _ box . Add stretch(1)
创建标题为
self . Build _ button = q push button(&Build Greeting,self)的构建按钮
将按钮的点击信号连接到 show _ greeting
self . build _ button . clicked . Connect(self . show _ greeting)
将其添加到按钮框
self . button _ box . Add widget(self . build _ button)
将按钮框添加到主 VBox 布局的底部
self . layout . Add layout(self . button _ box)
将 VBox 布局设置为窗口的主布局
self.setLayout(self.layout)
@ pyqtSlot()
def Show _ greeting(self):
' ' '显示构造的问候语' '
self.greeting.setText('%s,%s!'%
(self . salutations[self . salutation . current index()],
self.recipient.text()))
def run(self):
显示表单
self.show()
运行 qt 应用程序
qt_app.exec_()
创建应用程序窗口的实例并运行它
app = layout example()
app . run()
[/python]
运行它,你将得到和以前一样的窗口,除了现在当 Build 按钮被按下时,它实际上生成我们的问候。(注意,可以将相同的方法添加到我们上次的绝对定位示例中,效果相同。)
既然我们已经知道如何将内置信号连接到我们创建的插槽,我们就为下一部分做好了准备,在下一部分中,我们将学习如何创建我们自己的信号并将它们连接到插槽。
PySide/PyQt 教程:创建自己的信号和插槽
原文:https://www.pythoncentral.io/pysidepyqt-tutorial-creating-your-own-signals-and-slots/
但是,您不必仅仅依赖 Qt 小部件提供的信号;你可以创造你自己的。信号是使用信号类创建的。一个简单的信号定义是:
[python]
from PySide.QtCore import Signal
tapped = Signal()
[/python]
[python]
from PyQt4.QtCore import pyqtSignal
tapped = pyqtSignal()
[/python]
然后,当对象被点击的条件满足时,调用信号的emit方法,信号被发出,调用它所连接的任何插槽:
thing.tapped.emit()
这有两个好处:首先,它允许你的对象的用户以熟悉的方式与它们交互;第二,它允许更灵活地使用对象,将对象上动作的定义效果留给使用它们的代码。
简单的 PySide/PyQt 信号发射示例
让我们定义一个简单的PunchingBag类,它只做一件事:当它的punch被调用时,它发出一个punched信号:
[python]
from PySide.QtCore import QObject, Signal, Slot
class PunchingBag(QObject):
' ' '代表一个出气筒;当你按下它时,它会发出一个信号,表明它被按下了。‘
拳打脚踢=信号()
def init(self):
将 PunchingBag 初始化为 QObject
QObject。init(self)
def punch(self):
' ' '出拳包' ' ' '
self . pucked . emit()
[/python]
[python]
from PyQt4.QtCore import QObject, pyqtSignal, pyqtSlot
class PunchingBag(QObject):
' ' '代表一个出气筒;当你按下它时,它会发出一个信号,表明它被按下了。‘
punched = pyqtSignal()
def init(self):
将 PunchingBag 初始化为 QObject
QObject。init(self)
def punch(self):
' ' '出拳包' ' ' '
self . pucked . emit()
[/python]
你可以很容易地看到我们做了什么。PunchingBag继承了QObject所以它可以发出信号;它有一个名为punched的信号,不携带任何数据;它有一个punch方法,除了发出punched信号之外什么也不做。
为了让我们的PunchingBag有用,我们需要将它的punched信号连接到一个做一些事情的插槽。我们将定义一个简单的函数,它在控制台上打印“Bag was punched ”,实例化我们的PunchingBag,并将其punched信号连接到插槽:
[python]
@Slot()
def say_punched():
''' Give evidence that a bag was punched. '''
print('Bag was punched.')
bag = PunchingBag()
将袋子的打孔信号连接到 say_punched 插槽
bag . punched . Connect(say _ punched)
[/python]
[python]
@pyqtSlot()
def say_punched():
''' Give evidence that a bag was punched. '''
print('Bag was punched.')
bag = PunchingBag()
将袋子的打孔信号连接到 say_punched 插槽
bag . punched . Connect(say _ punched)
[/python]
然后,我们打一下袋子,看看会发生什么:
# Punch the bag 10 times
for i in range(10):
bag.punch()
当您将其全部放入脚本并运行它时,它将打印:
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
Bag was punched.
有效,但不是特别令人印象深刻。然而,你可以看到它的用处:我们的出气筒非常适合任何你需要对出气筒做出反应的地方,因为PunchingBag把对出气筒做出反应的实现留给了使用它的代码。
载有数据的 PySide/PyQt 信号
创建信号时,您可以做的最有趣的事情之一是让它们携带数据。例如,您可以让一个信号携带一个整数,因此:
[python]
updated = Signal(int)
[/python]
[python]
updated = pyqtSignal(int)
[/python]
或者字符串:
[python]
updated = Signal(str)
[/python]
[python]
updated = pyqtSignal(str)
[/python]
数据类型可以是任何 Python 类型名称或标识 C++数据类型的字符串。由于本教程假定没有 C++知识,我们将坚持使用 Python 类型。
PySide/PyQt 信号发送圈
让我们用属性x、y和r定义一个圆,分别表示圆心的x和y位置,以及它的半径。您可能希望在调整圆大小时发出一个信号,在移动圆时发出另一个信号;我们将分别称它们为resized和moved。
有可能让与resized和moved信号连接的插槽检查圆的新位置或大小,并相应地作出响应,但是如果发送的信号可以包括该信息,则更方便,并且通过插槽函数需要较少的圆知识。
[python]
from PySide.QtCore import QObject, Signal, Slot
类 Circle(QObject):
' ' '表示一个由圆心的 x、y
坐标和半径 r 定义的圆,' ' '
调整圆大小时发出的信号,
携带其整数半径
调整大小=信号(int)
移动圆时发出的信号,携带
其圆心的 x、y 坐标。
moved = Signal(int,int)
def init(self,x,y,r):
将圆初始化为 QObject,这样它就可以发出信号
QObject。init(self)
“隐藏”这些值,并通过 properties
self 公开它们。_x = x
自我。_y = y
自我。_r = r
@property
def x(self):
返回 self。_x
@x.setter
def x(self,new_x):
self。_x = new_x
中心移动后,用新坐标
self.moved.emit(new_x,self.y)发出
移动信号
@property
def y(self):
返回 self。_y
@y.setter
def y(self,new_y):
self。_y = new_y
中心移动后,用新坐标
self.moved.emit(self.x,new_y)发出移动后的
信号
@property
def r(self):
返回 self。_r
@r.setter
def r(self,new_r):
self。_r = new_r
半径改变后,发射新半径的
调整大小信号
self . resized . emit(new _ r)
[/python]
[python]
from PyQt4.QtCore import QObject, pyqtSignal, pyqtSlot
类 Circle(QObject):
' ' '表示一个由圆心的 x、y
坐标和半径 r 定义的圆,' ' '
调整圆大小时发出的信号,
携带其整数半径
调整大小= pyqtSignal(int)
移动圆时发出的信号,携带
其圆心的 x、y 坐标。
moved = pyqtSignal(int,int)
def init(self,x,y,r):
将圆初始化为 QObject,这样它就可以发出信号
QObject。init(self)
“隐藏”这些值,并通过 properties
self 公开它们。_x = x
自我。_y = y
自我。_r = r
@property
def x(self):
返回 self。_x
@x.setter
def x(self,new_x):
self。_x = new_x
中心移动后,用新坐标
self.moved.emit(new_x,self.y)发出
移动信号
@property
def y(self):
返回 self。_y
@y.setter
def y(self,new_y):
self。_y = new_y
中心移动后,用新坐标
self.moved.emit(self.x,new_y)发出移动后的
信号
@property
def r(self):
返回 self。_r
@r.setter
def r(self,new_r):
self。_r = new_r
半径改变后,发射新半径的
调整大小信号
self . resized . emit(new _ r)
[/python]
请注意以下要点:
Circle继承了QObject,所以它可以发出信号。- 信号是用它们将要连接的插槽的签名创建的。
- 同一个信号可以在多个地方发出。
现在,让我们定义一些可以连接到圆圈信号的插槽。还记得上次我们说我们会看到更多关于@Slot装饰工的内容吗?我们现在有了携带数据的信号,所以我们将看看如何制作可以接收数据的插槽。要使一个插槽接受来自一个信号的数据,我们只需用与它的信号相同的签名来定义它:
[python]
A slot for the "moved" signal, accepting the x and y coordinates
@Slot(int, int)
def on_moved(x, y):
print('Circle was moved to (%s, %s).' % (x, y))
一个用于“调整大小”信号的槽,接受半径
@ Slot(int)
def on _ resized(r):
print(' Circle 被调整大小为半径% s . % r)
[/python]
[python]
A slot for the "moved" signal, accepting the x and y coordinates
@pyqtSlot(int, int)
def on_moved(x, y):
print('Circle was moved to (%s, %s).' % (x, y))
一个用于“调整大小”信号的槽,接受半径
@ pyqtSlot(int)
def on _ resized(r):
print(' Circle 被调整大小为半径%s.' % r)
[/python]
非常简单直观。要了解更多关于 Python decorators 的信息,你可能想看看文章- Python Decorators 概述来熟悉一下自己。
最后,让我们实例化一个圆,将信号连接到插槽,并移动和调整它的大小:
c = Circle(5, 5, 4)
#将圆圈的信号连接到我们的简单插槽
c . moved . Connect(on _ moved)
c . resized . Connect(on _ resized)
#将圆向右移动一个单位
c.x += 1
#将圆的半径增加一个单位
c.r += 1
当您运行结果脚本时,您的输出应该是:
Circle was moved to (6, 5).
Circle was resized to radius 5.
现在我们已经对信号和插槽有了更好的理解,我们准备使用一些更高级的小部件。在我们的下一期文章中,我们将开始讨论QListWidget和QListView,两种创建列表框控件的方法。
带 Tkinter 的 PySlices
在 Python 开发人员用 Python 创建的众多库和软件套件中,有一个是 Py 套件,这是一组用 wxPython 编写的工具,用于帮助 Python 爱好者进行编程。
这个套件中包括一个值得一提的 Python shell,名为 PySlices 。
也许这个 shell 最显著的特性是能够执行用笔记本风格的代码块编写的 Python 脚本,而不会干扰在同一个 shell 窗口中编写的其他代码块(此外还有一个“普通”shell 模式,可以在 Options > Settings 菜单中激活)。
这非常有用的一种方式是在使用利用了 Tkinter 库的脚本时。
使用 PySlices 与 Tkinter
为了说明 PySlices 的有用性,让我们检查一下我们在 Tkinter 文章的介绍中尝试一些代码的情况。在标准的 Python IDLE 中,如果我们希望在合并 select()方法来指定默认单选按钮时看到输出的不同,那么每当我们想要改变甚至像选择按钮“B”而不是按钮“A”这样小的事情时,我们都必须键入所有的代码来初始化我们的小部件——这个过程会非常乏味和烦人。
然而,如果我们使用 PySlices 来完成这个任务,让我们来看看这个过程会有什么不同:
步骤 1: 打开一个 PySlices 窗口(把所有的启动消息都折叠起来——节省了不少空间,看行号!)

步骤 2: 将示例中的代码输入下一个空白区域

步骤 3: 按快捷键组合之一(如 Shift-Return)运行

现在,我们可以很容易地看到代码的输出,如果我们想像前面提到的那样将默认的 RadioButton 从“A”更改为“B ”,只需编辑感兴趣的行并执行脚本。

不需要重启 shell 和/或重新初始化变量/对象来查看调整一个小部分的区别(在标准 Python IDLE 中可能需要这样做)。
使用 PySlices 与正则表达式
这个 shell 可以派上用场的另一种情况是调试正则表达式。比方说,我们想完成Python 正则表达式介绍文章中的前几个例子,而不必每次都重新键入正则表达式字符串和搜索行——与 Tkinter 例子一样,我们首先键入所有内容…

…点击快捷方式运行脚本(例如 Ctrl-Return)并查看输出…

…然后只更改重要的部分,并重新运行脚本以查看不同之处!

使用 Python IDLE,您还可以重复运行脚本,而不必重新键入所有代码,但是脚本必须在单独的窗口中编辑和执行,并且每个脚本都必须在运行前保存到磁盘,不管它有多小。使用 PySlices 你可以在一个窗口中编辑和运行多个脚本,并且在执行之前不必将每个脚本保存到它自己的文件中。这样做的缺点是,与 IDLE 不同, PySlices 不会在执行之前检查你的脚本是否有语法错误,所以如果/当这些或任何类型的错误发生时,它可能会对你大喊,但即使是这种云也有一线希望——就像你可以折叠你键入的代码块一样, PySlices 让你删除来自你的代码块的任何错误报告输出!
如果你想保存你在 PySlices 窗口中写的切片也很容易(它们保存到。 PySlices 格式——如果你只是想在普通的文本编辑器中通读的话,这都是文本),它们都保存在同一个文件中,而不是实际上必须将它们切片。无论是对于 Tkinter 库、正则表达式,还是日常脚本和 shell 使用, PySlices 都可以让您的 Python 脚本体验更加甜蜜。
Python for Android: Android 的原生对话框(SL4A)
原文:https://www.pythoncentral.io/python-android-androids-native-dialogs-sl4a/
Android has a series of built-in dialogs that allow applications to interact with users. They can be used to display things like spinners and progress bars, and they can also be used to prompt users to make some input, such as dates or strings.
All methods for creating dialog boxes exist in UIFacade of SL4A, and most methods needed to manage them. UI Facade also contains methods for creating webviews and using experimental FullScreenUI materials.
SL4A and native dialog box
The normal process when using a dialog box is to first create an appropriate dialog box object, then set any additional features you want it to have, and then present it to the user. It takes a few phone calls, but it's easy to do. Once it is displayed, there is a way to get the result from the dialog box and eliminate it. You can also update the progress dialog box during rendering.
Create Android dialog box
You use a dialogCreate* call to create a new dialog box. The standard dialog boxes are Alert, Input, Password, DatePicker, SeekBar, SpinnerProgress and HorizontalProgress.
For example, to create and present a date picker dialog box, you need to do the following. ...
【python】
从机器人导入 Android
droid = Android()
droid。dialogcreatedatepicker()
droid。dialogshow()
Note that all interactions with the dialog box are completed by calling the method of droid. This is only the result of the interface between SL4A and Android API. This droid object is a' God object', so everything is a method of droid. For simplicity, there is only one instance of a dialog box, so any dialogCreate* call will cause any existing dialog box to be destroyed.
Custom dialog box
You can use the dialogSet* call to set any additional functions of the dialog box. What you can customize depends on what kind of dialog box you create.
For example, you can use dialogSetPositiveButtonText to set the positive button text in a warning dialog box, and there are matching methods to set the neutral and negative button text. You can use any combination of these three methods in the alert dialog box.
Show dialog box
You use dialogShow to display a dialog box, and then you can use dialogDismiss to close the dialog box.
Get input
You can usually use dialogGetResponse to get any result, and it will block until the user responds to the dialog box. However, for some types of dialogs, you may need to use the eventPoll method of Events Facade to wait for dialog events. Some dialogs, such as menus, are persistent features of an application, and may generate multiple events over time, so they must be managed through Events Facade.
If you create a single-choice dialog box (radio button) or a multi-choice dialog box (checklist), you must pass a list of options for the user to choose from. You can use the dialogGetSelectedItems method to find out which options are selected. This method returns an integer list that maps to the index of the selected item in the selection list you passed in. Obviously, there is only one radio dialog box.
Say it again in Python ...
Suppose we need to ask users if they want to install a bunch of software packages, and then, suppose they want to install them, we want to create a progress bar to show how the installation process is going. Suppose we have five software packages to install.
[Python]
Import the system
从机器人创建机器人对象
导入 Android
droid = Android()
Create a reminder, set the title and message
droid. DialogCreateAlert (
' Install package?'
' You may want to use the wireless network to do this.'
)
设置几个按钮机器人。dialogsetpostivebuttontext(' Yes ')
droid。dialogsetnegativebuttontext(“否”)
Now present the dialog box to the user
droid.dialogshow ()
获取结果并关闭对话框
响应= droid。dialoggetresponse().结果
机器人。对话发现()
Check whether the user pressed a button, because the user can close
dialog boxes and check whether it is positive, otherwise we have finished
if it is not' which' in the response or ['which']! = 'positive': sys.exit()
Now that the check has been completed, create and present a new progress bar dialog box,
Set the title, message and maximum progress 5
Droid. DialogcreateHorizontalprogress (
' Install the software package ...',
' This should take a little time.' ,
5
呈现对话框 droid.dialogShow()
Start the installation now and update the progress bar along the way. ...
导入一对简约词
导入一些包安装功能作为安装
导入一些包列表作为包
安装每个包,对于包中的包,每次增加进度条
进度= 0
:
安装(打包)
进度+= 1
机器人。dialogsetcurrentprogress(进度)
整理并退出机器人。对话框溶解()
The screenshot on the right shows the confirmation dialog and the progress dialog. Of course, the actual look and feel of different devices will be slightly different.


Please note that if you only want to ask the user to enter some text, such as Python's "input" function or password, you can use the "dialogGetInput" and "dialogGetPassword" methods, which are just convenient wrappers and allow you to get these inputs in one call.
Event-based dialog box
The above example covers almost all the basics of SL4A using dialog boxes, and the API reference covers all the more detailed details. The only exception to the normal dialog operation (create-customize-render-read-close) is when using menu items. As mentioned above, menu items are added to the native menu of the application; Generally speaking, they are always available to users and can be clicked any number of times at any time, so their management is a little different.
For example, you can use addOptionsMenuItem to add an item to the options menu of an application. This method requires two parameters, one is a string that sets the text to be displayed on the item, and the other is a string that sets the name of the event generated whenever the item is clicked. You can choose to set the data passed with the event and set the icon to be displayed on the menu item. Again, see the API documentation for all the details.
This will be very meaningful if you have used the Events Facade before. Either way, it is not difficult to get started. The following example will block, so it needs another thread or something to play a greater role; This example only involves SL4A API.
# addoptions menuitem 采用两到四个参数:
# item_label,event_name,[event_data],[icon_name]
#以下调用向选项菜单添加了三个项目...droid.addOptionsMenuItem('Do A ',' a_event ','一些事件数据机器人。addoptions menuitem(' Do B ',' b_event ','其他一些数据. .)
droid。addoptions menuitem(' Quit ',' kill ',None,' ic_menu_revert))
If it is true:
# block until the event occurs, and then get the result
res = droid. eventwait (). result
# If it is a kill event, if RES ['name'] = =' kill': 【 is interrupted, exit the event cycle
.
# Otherwise, print event data
print(RES[' data '])
.
Python 基础:字符串和打印
原文:https://www.pythoncentral.io/python-basics-strings-and-printing/
字符串是 Python 中非常常用的类型,只需在字符两边加上引号就可以形成。引号内的任何内容都是字符串(单引号或双引号都是可以接受的)。要创建一个字符串,只需将引号中的这些字符作为变量的值,如下所示:
var = "I'm a string!"
打印一个字符串和创建一个字符串一样简单。当你打印一些东西时,你基本上是在定义一个输出。您可以打印任何想要的字符串,如下所示:
打印“我也是一串”
上面那行代码的输出很简单,“我也是一个字符串”。您可能已经知道,打印非常简单。您还可以通过打印变量来打印预定义的字符串或值,如下所示:
print var
正如你在上面看到的,var 已经被定义了,所以上面那行代码的输出会是,“我是一个字符串!”
Python 美汤示例:雅虎金融刮刀
原文:https://www.pythoncentral.io/python-beautiful-soup-example-yahoo-finance-scraper/
Python 为抓取网站提供了很多强大且易于使用的工具。Python 对抓取网站有用的模块之一被称为美汤。
在这个例子中,我们将为您提供一个漂亮的 Soup 示例,称为“web scraper”。这将从雅虎财经页面获取关于股票期权的数据。如果你对股票期权一无所知也没关系,最重要的是网站上有一个信息表,你可以在下面看到,我们希望在我们的节目中使用。下面是苹果电脑股票期权的清单。

首先,我们需要获得页面的 HTML 源代码。Beautiful Soup 不会为我们下载内容,我们可以用 Python 的urllib模块来完成,这是 Python 的标准库之一。
获取雅虎财务页面
[python]
from urllib.request import urlopen
options URL = ' https://finance . Yahoo . com/quote/AAPL/options '
options page = URL open(options URL)
[/python]
[python]
from urllib import urlopen
options URL = ' https://finance . Yahoo . com/quote/AAPL/options '
options page = URL open(options URL)
[/python]
这段代码检索 Yahoo Finance HTML 并返回一个类似文件的对象。
如果你进入我们用 Python 打开的页面,使用浏览器的“获取源文件”命令,你会发现这是一个庞大而复杂的 HTML 文件。使用BeautifulSoup模块简化和提取有用的数据将是 Python 的工作。BeautifulSoup是一个外部模块,因此您必须安装它。如果你还没有安装BeautifulSoup,你可以在这里获得。
美丽的汤示例:加载页面
以下代码将页面加载到BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(optionsPage)
美丽的汤例子:搜索
现在我们可以开始尝试从页面源(HTML)中提取信息。我们可以看到,选项在“符号”栏中有非常独特的名字,类似于AAPL130328C00350000。当你读到这篇文章时,这些符号可能略有不同,但是我们可以通过使用BeautifulSoup在文档中搜索这个唯一的字符串来解决这个问题。
让我们搜索这个特定选项的soup变量(您可能需要替换一个不同的符号,只需从网页上获取一个):
>>> soup.findAll(text='AAPL130328C00350000')
[u'AAPL130328C00350000']
这个结果还不是很有用。它只是我们搜索的 unicode 字符串(这就是“u”的意思)。然而BeautifulSoup以树格式返回内容,所以我们可以通过询问它的父节点来找到文本出现的上下文,如下所示:
>>> soup.findAll( text='AAPL130328C00350000')[0].parent
<a href="/q?s=AAPL130328C00350000">AAPL130328C00350000</a>
我们看不到表格中的所有信息。让我们试试更高一层。
>>> soup.findAll(text='AAPL130328C00350000')[0].parent.parent
<td><a href="/q?s=AAPL130328C00350000">AAPL130328C00350000</a></td>
再一次。
>>> soup.findAll(text='AAPL130328C00350000')[0].parent.parent.parent
<tr><td nowrap="nowrap"><a href="/q/op?s=AAPL&amp;k=110.000000"><strong>110.00</strong></a></td><td><a href="/q?s=AAPL130328C00350000">AAPL130328C00350000</a></td><td align="right"><b>1.25</b></td><td align="right"><span id="yfs_c63_AAPL130328C00350000"> <b style="color:#000000;">0.00</b></span></td><td align="right">0.90</td><td align="right">1.05</td><td align="right">10</td><td align="right">10</td></tr>
答对了。它仍然有点乱,但是你可以看到我们需要的所有数据都在那里。如果您忽略括号中的所有内容,您可以看到这只是一行中的数据。
optionsTable = [
[x.text for x in y.parent.contents]
for y in soup.findAll('td', attrs={'class': 'yfnc_h', 'nowrap': ''})
]
这段代码有点密,我们来一点一点拆开看。代码是列表理解中的列表理解。我们先来看看内在的:
for y in soup.findAll('td', attrs={'class': 'yfnc_h', 'nowrap': ''})
这使用了BeautifulSoup的findAll函数来获取所有带有td标签、一个yfnc_h类和一个nowrap的 nowrap 的 HTML 元素。我们选择这个是因为它是每个表条目中的唯一元素。
如果我们刚刚用类yfnc_h得到了td的值,我们将会得到每个表条目的七个元素。另一件要注意的事情是,我们必须将属性包装在字典中,因为class是 Python 的保留字之一。根据上表,它将返回以下内容:
<td nowrap="nowrap"><a href="/q/op?s=AAPL&amp;k=110.000000"><strong>110.00</strong></a></td>
我们需要更高一级,然后从该节点的父节点的所有子节点中获取文本。这就是这段代码的作用:
[x.text for x in y.parent.contents]
这是可行的,但是如果这是您计划频繁重用的代码,您应该小心。如果雅虎改变他们的 HTML 格式,这可能会停止工作。如果您计划以自动化的方式使用这样的代码,最好将它包装在一个 try/catch 块中,并验证输出。
这只是一个简单漂亮的 Soup 示例,让您了解如何用 Python 解析 HTML 和 XML。你可以在这里找到美汤文档。您会发现更多的搜索和验证 HTML 文档的工具。
Python 初学者到 Python Pro:需要掌握的 7 个基本技巧
原文:https://www.pythoncentral.io/python-beginner-to-python-pro-7-basic-tricks-to-master/

你到处听到教育不那么重要。一般来说,这种观点的起源在于这样一个事实,即学校、学院和大学很少向学生提供日后会派上用场的专业技能。虽然这并不完全正确,但教育系统已经或将让他们失望的想法是一半未来毕业生的普遍看法。
学生们常常抱怨学校里的科目毫无意义。或许,计划成为一名博客写手或 YouTuber 用户并不需要学校里的任何课程。至少乍一看是这样。想成为软件开发人员的学生该做些什么呢?某些学校确实教授编程。但那只是其中一个科目,其他的占用了你大部分的上学时间。
这就是传统作业被搁置的原因。学生们更热衷于在网上找一个 的大学家庭作业助手 ,这样他们就可以有额外的时间学习编程语言。而且有很多可以选择。有些人已经三十多岁了,而有些人是最近才出现的。重点关注哪一个?JavaScript,Elixir,C#?
这就是你的语言学研究可以派上用场的地方。由于其多功能性和简单性,英语已经成为一种国际语言。软件开发相当于通用语的是 Python。它可以用于各个方面,从基本的 web 开发到计算机科学和机器学习。如果你用的是 Spotify,这个应用是用 Python 开发的。
作为编程语言中的英语等价物意味着自学 Python 相当容易。只需阅读并开始编码。但是,在深入学习 Python 的 DIY 方法之前,您可以查看几个有用的学习语言的平台:
- 击球;
- 代码大战;
- SoloLearn
- Python 教程
- code academy;
现在,让我们看看从新手到高手学习 Python 的最佳方法。虽然这些技巧并不是火箭科学,但是要想知道从哪里开始却是相当棘手的。
-
Daily Code
当你学习新东西时,最重要的是持之以恒。因此,你需要每天练习。如果你想成为一名优秀的 Python 开发者,你至少需要花几个小时来编码。但不是一开始。你可以每天至少花半个小时开始编码。
这就像在一门新语言中学习新单词和语法结构一样。学习编程语言也是如此。学习如何编码,每天都编码。但是不要忘记不时地休息一下。重复很重要,但是当你把自己累坏了就没用了。
-
Take notes
虽然看起来很明显,但很多人在学习新东西时会忘记记笔记。记下应该做什么。记下哪些方面你失败了。而且,用纸笔做比较好。它将允许你预先计划代码,并且在使用计算机之前有一个你将要做的计划总是更好的。
-
Read other people's codes
成为 Python 开发人员的另一个重要方面,以及以后掌握技能的另一个重要方面是阅读其他开发人员写的代码。掌握你独特的编码风格的最好方法是向他人学习。它能给你带来新鲜的想法。你可以找出你做错了什么。此外,你可以了解到你在某些方面比其他人更好。
问题依然存在——去哪里找开发人员?你可以像大多数开发者一样,在 GitHub 上创建一个账户。你可以在那里找到数百名优秀的 Python 开发者,他们都分享自己的代码。因此,您可以查看 Python 编码的最佳示例,并改进您的风格。
-
Share your code
显然,如果你想确保你写的代码可读,你需要共享它们。你的 GitHub 账户再一次派上了用场。开始分享你的代码,其他开发者会给你提供建议。但是你应该准备好接受批评。有可能是你做错了,可能是你在用自己独特的风格写作,别人无法把握。
-
Read books about Python
即使是最有经验的 Python 开发人员也会阅读关于编码的书籍。在你的 DIY 之路上,你总能找到一些你没有发现的东西。令人高兴的是,有几十本关于 Python 的好书。从“Python 食谱”到“流畅的 Python”如果你想提高你的编程语言知识,有很多书值得一读。
-
Enrich your skill set
要成为一名优秀的开发人员并在市场上保持竞争力,您需要不断提高自己的技能。最好的选择是学习如何使用各种 Python 库。Python 是库方面的首选语言。你当然应该学习如何使用像 NumPy 和 SciPy 这样的库。但是还有更多。
Keras,TensorFlow,Matplotlib,知道的越多越好。您可以使用的库的数量使您成为一名多才多艺的开发人员。你可以通过与他们一起创建宠物项目并在 GitHub 上分享来展示你的库知识。
-
Learning AI and Machine Learning
用 Python 写的最有价值的应用可以在机器学习和 AI 领域找到。这就是为什么在这些领域中练习 Python 知识也是至关重要的。您可以从学习那些领域的项目所使用的算法开始,并在您自己的项目中实现它们。
最终想法
这些是如何开始学习 Python 并成为编程语言大师的主要方面。获得 Python 经验的最好方法是从事各种与该语言相关的自由职业。在您的 GitHub 帐户上分享这一体验。这会让你对未来的雇主更有吸引力。
Python 代码片段:求解二次方程
原文:https://www.pythoncentral.io/python-code-snippets-solving-quadratic-equation/
这里有一个使用 Python 的有趣方法:在一个函数中输入任意三个数字,你可以在毫秒内求解二次方程。我打赌你希望你在代数一课上就知道这个。
这个函数是由 Programiz 的人编写的,使用 Python 中的基本乘法和除法运算来求解二次方程。如果你不记得,要解二次方程,你必须取 b 的倒数,加上或减去 b 平方的平方根,减去 4 乘以 a 乘以 c 除以(除以)2 乘以 a。在二次方程中,a,b 和 c 可以是任何整数,正数或负数,只要 a 不等于零。在下面的例子中,a 等于 1,b 等于 5,c 等于 6,但是你可以把它们设置成你喜欢的任何数字。
以下是片段:
a = 1
b = 5
c = 6
# To take coefficient input from the users
# a = float(input('Enter a: '))
# b = float(input('Enter b: '))
# c = float(input('Enter c: '))
# calculate the discriminant
d = (b**2) - (4*a*c)
# find two solutions
sol1 = (-b-cmath.sqrt(d))/(2*a)
sol2 = (-b+cmath.sqrt(d))/(2*a)
正如你所看到的,这个代码片段找到了两个可能的解决方案(正如它的本意),因为你应该取 b 加上或减去 b 的平方的倒数,等等,这个等式解释了这一点。
该代码片段的输出如下:
print('The solution are {0} and {1}'.format(sol1,sol2))
现在你有了公式,加上你自己的数字,看看这个公式是否适合你。
Python 装饰者概述
Python 中的 Decorators 看起来很复杂,但是它们非常简单。你可能见过他们;它们是以'@'开头的函数定义前的奇数位,例如:
def decorator(fn):
def inner(n):
return fn(n) + 1
return inner
@ decorator
def f(n):
return n+1
请注意名为 decorator 的函数;它将一个函数作为参数,定义并返回一个新函数,该函数使用传递给它的函数。几乎所有的装饰者都有这种模式。@decorator符号只是一种调用现有函数的特殊语法,将新函数作为参数传递,并使用返回值替换新函数。
在上面的例子中,用f作为参数调用 decorator,它返回一个新函数来代替f。同样的效果可能不那么简洁地写出来:
def decorator(fn):
def inner(n):
return fn(n) + 1
return inner
def f(n):
返回 n + 1
f =装饰者(f)
所有的@符号都是为了使语法更加简洁。
查看工作中的 Python 装饰者
下面是一个简单的例子,它的输出说明了装饰器是如何工作的。
def wrap_with_prints(fn):
# This will only happen when a function decorated
# with @wrap_with_prints is defined
print('wrap_with_prints runs only once')
def wrapped():
#每次在
之前都会发生这种情况#被修饰的函数被调用
print('即将运行%s' % fn。__name__)
#这里是包装器调用装饰函数
fn()
#这将在每次
#装饰函数被调用
print('Done running %s' % fn。__name__)
包装退货
@ wrap _ with _ prints
def func _ to _ decorate():
print('运行被修饰的函数。')
func _ to _ decoration()
运行该示例时,输出将如下所示:
wrap_with_prints runs only once
About to run func_to_decorate
Running the function that was decorated.
Done running func_to_decorate
注意,装饰器(wrap_with_prints)只在创建装饰函数时运行一次,但是内部函数(wrapped)会在每次运行func_to_decorate时运行。
一个几乎实际的例子
Python 的函数就像任何其他 Python 对象一样;您可以将它们赋给变量,在函数调用中将它们作为参数传递,从其他函数返回它们,将它们放入列表和字典中,等等。(大家说 Python 有一级函数就是这个意思。)装饰器是利用这一事实来提供有用功能的一种简洁方式。
例如,假设我们有以下代码(您会将其识别为 fizzbuzz ):
def fizz_buzz_or_number(i):
''' Return "fizz" if i is divisible by 3, "buzz" if by
5, and "fizzbuzz" if both; otherwise, return i. '''
if i % 15 == 0:
return 'fizzbuzz'
elif i % 3 == 0:
return 'fizz'
elif i % 5 == 0:
return 'buzz'
else:
return i
对于范围(1,31)中的 I:
print(fizz _ buzz _ or _ number(I))
然后,假设我们想要记录函数的参数和返回值以便调试。(有更好的调试方法,您应该使用它们,但这对我们来说是一个有用的例子。)我们可以在函数中添加日志记录语句,但是如果我们有更多的函数,那就太麻烦了,而且更改正在调试的函数很可能会引入其他错误,这也是必须要调试的。我们需要一个保持函数完整的通用方法。
输入装饰师来拯救这一天!我们可以编写一个装饰函数来为我们记录日志:
def log_calls(fn):
''' Wraps fn in a function named "inner" that writes
the arguments and return value to logfile.log '''
def inner(*args, **kwargs):
# Call the function with the received arguments and
# keyword arguments, storing the return value
out = apply(fn, args, kwargs)
#在日志文件
中写入一行函数名、其
#参数和返回值,并打开(' logfile.log ',' a ')作为日志文件:
logfile.write(
')用 args %s 和 kwargs %s 调用%s,返回% s \ n“%
(fn。__name__,args,kwargs,out))
#返回返回值
返回出
返回内
然后,我们需要做的就是将我们的装饰器添加到fizz_buzz_or_number的定义中:
@log_calls
def fizz_buzz_or_number(i):
# Do something
运行该程序将生成如下所示的日志文件:
fizz_buzz_or_number called with args (1,) and kwargs {}, returning 1
fizz_buzz_or_number called with args (2,) and kwargs {}, returning 2
fizz_buzz_or_number called with args (3,) and kwargs {}, returning fizz
fizz_buzz_or_number called with args (4,) and kwargs {}, returning 4
fizz_buzz_or_number called with args (5,) and kwargs {}, returning buzz
# Do something
fizz_buzz_or_number called with args (28,) and kwargs {}, returning 28
fizz_buzz_or_number called with args (29,) and kwargs {}, returning 29
fizz_buzz_or_number called with args (30,) and kwargs {}, returning fizzbuzz
同样,有更好的调试方法,但这是装饰器可能用途的一个很好的例子。
更高级的用途
上面的装饰者是简单的例子;还有更高级的可能性。
多个装饰者
你可以连锁装修。例如,您可以使用 decorators 将函数返回的文本包装在 HTML 标签中——尽管我不建议这样做;请改用模板引擎。在任何情况下:
def b(fn):
return lambda s: '<b>%s</b>' % fn(s)
def em(fn):
return lambda s:'<em>% s</em>' % fn(s)
@ b
@ em
def greet(name):
回‘你好,% s!’% name
然后,调用greet('world')将返回:
<b><em>Hello, world!</em></b>
请注意,装饰器是按照从下到上的顺序应用的;函数先被em包装,然后结果被b包装。没有按照正确的顺序放置装饰器会导致混乱的、难以追踪的错误。
有争论的装饰者
有时,您可能希望将参数与要装饰的新函数一起传递给装饰函数。例如,您可能想要将前一个示例中的 HTML 标记包装 decorators b 和 em 抽象成一个通用的tag_wrap decorator,它将标记作为一个额外的参数,这样我们就不必为每个 HTML 标记都有单独的 decorator。可惜,你做不到。然而,你可以做一些看起来像是给装饰器传递参数的事情,并且有类似的效果:你可以写一个接受参数的函数,然后返回一个生成器函数:
def tag_wrap(tag):
def decorator(fn):
def inner(s):
return '<%s>%s' % (fn(s), tag)
return inner
return decorator
@ tag _ wrap(' b ')
@ tag _ wrap(' em ')
def greet(name):
回' Hello,%s!'% name
打印(问候('世界'))
这个例子的结果与上一个例子的结果相同。
让我们从外向内回顾一下tag_wrap做了什么。tag_wrap是一个接受标签并返回接受函数的函数装饰器的函数。当传递一个函数时,decorator 返回一个名为inner的函数,该函数接受一个字符串,将该字符串传递给传递给 decorator 的函数,并将结果包装在传递给tag_wrap的任何标签中。
这是一系列令人难以理解的定义,但是从一个库作者的角度来考虑它:对于不得不这么做的人来说这很复杂,但是对于包含它的库的用户来说,这非常简单。
现实世界中的装饰者
许多库的作者利用 decorators 来为库用户提供简单的方法,将复杂的功能添加到他们的代码中。例如,web 框架 Django 使用装饰器login_required,使视图需要用户认证——这无疑是以如此复杂的方式扩展功能的一种便捷方式。
另一个 Python web 框架 CherryPy 更进一步,它的工具处理认证、静态目录、错误处理、缓存等等。 CherryPy 提供的每一个工具都可以用一个配置文件来配置,通过直接调用工具,或者通过使用 decorators,其中一些“接受参数”,比如:
@tools.staticdir(root='/path/to/app', dir='static')
def page(self):
# Do something
它定义了一个名为“static”的静态目录,位于“/path/to/app”。
虽然这些 decorator 的设计是为了简化它们的使用,即使对于那些不完全理解它们如何工作的人来说也是如此,但是对 decorator 的全面理解将允许您更灵活、更智能地使用它们,并在适当的时候创建自己的 decorator,从而节省您的开发时间和精力,并简化维护。
Python 开发者简历写作指南
原文:https://www.pythoncentral.io/python-developer-resume-writing-guide/

本文作为指南,强调了 Python 开发人员简历中所需的技能以及创建令人印象深刻的简历的步骤。如今,招聘人员有数百份申请,如果你想获得面试机会,你的申请需要脱颖而出。因此,无论你是在考虑职业转型还是寻找新的职位,学习如何创建一份展示你的成就和能力的简历是至关重要的。
谁是 Python 开发者?
是一个开发团队中的人,擅长使用 Python 来创建和执行软件和其他产品。这些专家使用这种特殊的编程语言编写、评估和增强操作系统。由于 IT 行业的工作机会需求量很大,你的 Python 技能简历可能不足以吸引招聘者的眼球。你需要一切都完美无瑕。
现在的就业市场
寻找工作机会有时会令人望而生畏,完成每一份申请并为每一份招聘启事个性化你的简历可能会花费很多时间。由于 IT 行业与日俱增,你需要在每个层面上脱颖而出。
事实是,你必须根据你寻找的职位更新和重新整理你的简历。然而,如果你缺乏写简历的技巧,你将不会得到你想要的回应。这是因为面试官审查简历的时间很短。在这场疯狂的比赛中,你应该能够突出你所有好的方面,并利用每一个可能的杠杆。
有出路吗?
是的,有。为了被考虑,你必须有一份引人注目的简历,完美地总结了你的相关资格和专业经验。在面试开发人员职位的候选人时,公司会不断寻找具有优秀技术背景、精通 Python、扎实理解 web 框架、分析技能和其他相关资质的申请人。这些技能可以在一份写得很好的简历中突出出来,帮助你抓住招聘经理的兴趣。
然而,没有多少人能够同时成为一名完美的 IT 专家和一名优秀的作家,能够创作出一份引人注目、引人入胜的简历。通常情况下,都是非此即彼。嗯,这不是世界末日。现代科技让你可以在网上寻求帮助,眨眼之间就能解决这类问题。所以,无论你在写简历时遇到什么问题,都有一个简单的解决办法。你可以很容易地在 ResumeWritingLab 上找到它,因为这种工程简历写作服务是为了解决你在工作申请中可能遇到的任何困难而创建的。你可以节省宝贵的时间,得到一份一流的简历,让你得到尽可能多的工作机会。
然而,你需要能够备份你简历中的所有信息。这将有助于你避免欺诈,并在面试中保持正轨。以下部分是为 Python 开发者创建简历的分步指南。
决定 Python 体验简历格式
借助正确的简历格式,你的技能可以得到强调。此外,让面试官阅读你的申请并指出他们想要的关键细节可能会更好。时间性和功能性是撰写 Python 开发人员简历的最佳 简历 格式。
时序格式是最常见的结构。这意味着你的专业背景会在你的简历中连续出现。这一条特别适合在寻找的岗位上有丰富实际工作经验的求职者。
如果你没有任何相关的工作经验,功能性简历是非常好的。它是围绕你的个人能力和胜任能力而不是你的工作经历构建的。在这种简历结构下,技能和成就优先于专业素养。
添加联系方式和其他识别信息
保持当前和可访问的联系信息是必不可少的,应该始终放在首位。包括您的全名、电话号码、商务电子邮件地址、城市、邮政编码,以及任何与您在社交媒体网站或在线作品集上的个人资料相关的链接。
在总结前创建一个引人注目的专业陈述
在阅读简历的其余部分之前,一份专业的总结可以让招聘经理对你的能力和成就有一个简明的了解。客观陈述简要概括了你的职业目标和个人特点。你的目标应该解释你为什么想从事这个职业。这一段最多 2-3 句。
突出你的职业经历
让招聘经理清楚地了解你的职责和过去,这样他们就能看到你在过去职位上的表现。
突出你的技能
你的硬技能和软技能都应该列在你的简历上。前者是通过学习、专业经验或认证项目获得的,而后者是你可以培养的本能。硬技能的例子有:
- Python 编程语言的扎实知识
- 功能性和非功能性需求
- 软件原型
- 系统规格
- 敏捷方法
- 软件设计模式
- 测试和维护
- 了解 ORM 库
- 算法实现
软技能包括:
- 领导技能
- 分析技能
- 通讯技能
- 批判性思维技能
- 解决问题的技巧
- 人际关系技巧
使用申请者跟踪系统可识别的关键字和能力
招聘人员会收到大量的申请,他们通常只会审查最好的。在简历中加入职位描述中的关键词至关重要。根据你简历中的关键词与职位描述中的关键词的匹配程度,申请跟踪系统(ATS)将对候选人进行优先排序。仔细阅读职位描述,用最常用的术语列出所有技能,并把它们添加到你的简历中。
描述你的教育背景并添加证书
你还应该加上你的教育背景和长期获得的执照或证书,如果你有的话。从院校名称,毕业年份,学位头衔,以及你的绩点开始。添加您的证书或执照可以帮助您证明您致力于发展您的技术技能和知识。
结论
所以,你现在应该知道如何把 Python 放到简历上了。然而,写一份出色的简历需要适当的计划。认真对待这个过程,因为有一天你的职业生涯可能会依赖于它。准备好你的相关细节将会节省时间,并保证你在潜在雇主面前尽可能展现出最好的一面。
Python 词典
原文:https://www.pythoncentral.io/python-dictionary-operations-and-methods/
Python 字典(dict):概述
在内置的 Python 数据类型中,有一种非常通用的类型叫做字典。字典类似于列表和元组,因为它们充当您创建的其他对象或变量的存储单元。字典不同于列表和元组,因为它们保存的对象组没有任何特定的顺序,而是每个对象都有自己唯一的名,通常称为键。
存储在字典中的对象或值基本上可以是任何东西(甚至是定义为None的 nothing 类型),但是键只能是不可变的类型对象。例如字符串、元组、整数等。
注意:存储对象的不可变类型像元组可以只有包含其他不可变类型成为字典键。
创建 Python 字典
创建字典很容易,下面是一个空字典:
emptydict = {}
下面是一个有几个值的例子(注意{key1: value1, key2: value2, ...}结构) :
smalldict = {
'dlist': [],
'dstring': 'pystring',
'dtuple': (1, 2, 3)
}
也可以使用字典构造函数(注意用这种方法,键只能是关键字串):
smalldict = dict(dlist=[], dstring='pystring', dtuple=(1, 2, 3))
获取 Python 字典的值
要获取其中一个值,只需使用它的键:
>>> smalldict = {
'dlist': [],
'dstring': 'pystring',
'dtuple': (1, 2, 3)
}
>>> smalldict['dstring']
'pystring'
>>> smalldict['dtuple']
(1, 2, 3)
移除 Python 字典的键
要删除一个键:值对,只需用del关键字删除它:
>>> del smalldict['dlist']
>>> smalldict
{'dstring': 'pystring', 'dtuple': (1, 2, 3)}
向 Python 字典添加键
或者分配一个新的键,只需使用新的键:
>>> smalldict['newkey'] = None
>>> smalldict
{'dstring': 'pystring', 'newkey': None, 'dtuple': (1, 2, 3)}
覆盖 Python 字典键值对
注意:一个字典中所有的键都是唯一的,所以如果你给一个现有的键赋值,它会被覆盖!例如:
>>> smalldict['dstring'] = 'new pystring'
>>> smalldict
{'dstring': 'new pystring', 'newkey': None, 'dtuple': (1, 2, 3)}
在 Python 字典中交换键和值
如果您想将键换成值,您可以用值创建新的键,然后简单地删除旧的键:
>>> smalldict['changedkey'] = smalldict['newkey']
>>> del smalldict['newkey']
>>> smalldict
{'dstring': 'new pystring', 'changedkey': None, 'dtuple': (1, 2, 3)}
通过关键字搜索 Python 字典
要检查字典中是否存在键,只需使用 smalldict 中的键:
>>> 'dstring' in smalldict
True
注意:这是而不是检查一个值是否存在于字典中,只有一个键:
>>> 'new pystring' in smalldict
False
按值搜索 Python 字典
要检查给定的值,可以使用字典的标准方法之一values。
>>>'new pystring' in smalldict.values()
True
对于字典对象,还有许多更有用的方法和配方,但这些都是基本的。
请记住,key不一定是字符串,可以是您可以创建的任何不可变对象——值可以是任何东西,包括其他字典。不要害怕发挥创造力,发现你能用它们做什么!
Python 的 Django vs Ruby on Rails
原文:https://www.pythoncentral.io/python-django-vs-ruby-on-rails/
Python vs Ruby
Ruby 是一种动态的、反射的、面向对象的通用编程语言,它是在 20 世纪 90 年代中期设计和开发的。与将代码可读性看得比什么都重要的 Python 相比,Ruby 背后的哲学是程序员应该拥有编写简洁紧凑代码的灵活性、自由和权力。
Python 和 Ruby 之间最重要的区别在于,Python 的哲学要求程序员明确定义几乎所有东西,而 Ruby 允许程序员用从其他组件继承的隐式行为编写代码。例如,在 Ruby 中,实例方法中的self是隐式定义的,而 Python 要求self是实例方法中声明的第一个参数。
class Hello
def hello
'hello'
end
def call_hello
hello()
end
end
class Hello(object):
def hello(self):
return 'hello'
def call_hello(self):
return self.hello()
在上面的示例代码中,类Hello包含两个实例方法hello()和call_hello()。注意,Ruby 对call_hello()的定义只是调用了hello()方法,而没有像 Python 的定义那样引用self.hello()。
Ruby on Rails 概述
Ruby on Rails 是一个开源的 web 应用框架,运行在 Ruby 编程语言之上。就像 Django 一样,Rails 允许程序员编写与后端数据库对话的 web 应用程序来检索数据,并将数据呈现在客户端的模板中。
不出所料,Ruby 隐含的哲学也影响了 Rails 的设计方式。Django 强迫程序员显式地配置项目,并在代码中表达她的意图,与此不同,Rails 提供了许多程序员可以依赖的现成的隐式默认约定。与 Django 不同,Django 通常很灵活,不强制使用一种方式来做事情,Rails 认为做某些事情只有一种最好的方式,因此程序员很难修改 Rails 代码的逻辑和行为。
约定胜于配置
Rails 最重要的哲学是约定胜于配置(CoC),这意味着 Rails 项目有预定义的布局和合理的默认值。所有组件,如模型、控制器、静态 CSS 和 JavaScript 文件都位于标准子目录中,您只需将自己的实现文件放入这些目录中,Rails 就会自动获取它们。在 Django 中,您经常需要指定组件文件的位置。
CoC 是开发人员的一大胜利,因为它节省了反复输入相同配置代码的大量时间。然而,如果您想要定制您的项目的配置,您必须学习相当多的关于 Rails 的知识,以便在不破坏整个项目的情况下更改配置。
模型-视图-控制器和休息
Rails 是一个模型-视图-控制器(MVC)全栈 web 框架,这意味着控制器从模型中调用函数,并将数据返回给视图。尽管许多 web 框架也是基于 MVC 的,但 Rails 是独一无二的,因为它支持开箱即用的完整 REST 协议。使用标准的 HTTP 动词(如 GET、PUT、DELETE 和 POST)以统一的方式访问和处理所有模型对象。
为什么选择 Ruby on Rails
像 Django 一样,Rails 也使用模型来描述数据库表,使用控制器从模型中检索数据,并将数据返回给视图,视图最终将数据呈现为 HTTP 响应。为了将控制器映射到传入的请求,程序员在配置文件中指定路由。
自从 2005 年首次发布以来,Rails 在 web 程序员中越来越受欢迎。它易于使用和理解的技术栈和隐含的 CoC 哲学似乎允许敏捷的 web 程序员比其他框架更快地实现应用程序。因此,Rails 是 Django 的一个很好的替代方案。
Ruby on Rails 和 Django 的区别
到目前为止,Rails 看起来几乎和 Django 一样。因为 Django 的模型-模板-视图可以被视为模型-视图-控制器的变体,其中 Django 视图是 MVC 控制器,而 Django 模板是 MVC 视图,所以 Django 和 Rails 都支持 MVC 并提供通用的 web 框架功能。你可能会开始怀疑:Rails 和 Django 有什么区别吗?
最重要的区别是 Rails 推广了约定胜于配置的理念,这意味着开发者只需要指定应用程序中非常规的部分。例如,如果有一个名为Employee的模型类,那么如果开发人员没有提供一个显式的表名,那么数据库中相应的表将被命名为employees。如果开发人员希望表有不同的名称,这是非传统的,那么他或她需要在模型文件中为Employee显式指定表名。
Rails 运行在 Ruby 之上,Ruby 重视表现性并提供大量隐式行为,而 Django 运行在 Python 之上,后者重视显式性,可能会更冗长。例如,Rails 模型在每个模型对象上公开了一个隐式方法find_by,该方法允许程序员通过模型属性找到数据库记录。而 Django 并没有在其模型上公开这样的隐式方法。
除了像 Django 的django-admin.py createproject这样的常规项目生成脚本,Rails 还提供了一个强大的脚手架脚本,允许您直接从命令行生成一个新的控制器。
$ rails generate controller welcome index
create app/controllers/welcome_controller.rb
route get "welcome/index"
invoke erb
create app/views/welcome
create app/views/welcome/index.html.erb
invoke test_unit
create test/controllers/welcome_controller_test.rb
invoke helper
create app/helpers/welcome_helper.rb
invoke test_unit
create test/helpers/welcome_helper_test.rb
invoke assets
invoke coffee
create app/assets/javascripts/welcome.js.coffee
invoke scss
create app/assets/stylesheets/welcome.css.scss
上面的命令为您创建了几个文件和一个 URL 路由。大多数时候,你只需要在app/controllers/welcome_controller.rb的控制器实现文件和app/views/welcome/index.html.erb的视图实现文件中插入自定义逻辑。
与 Django 不同,Django 具有内置的用户认证和授权支持,Rails 不提供开箱即用的认证服务。幸运的是,有很多第三方认证库可用。你可以在 rails_authentication 查看它们。
Rails 的一个缺点是它的 API 比 Django API 变化更频繁。因此,Rails 通常不保留向后兼容性,而 Django 很少更改其 API 并保持向后兼容性。
托管支持和开发工具
由于不可否认的受欢迎程度,Django 和 Rails 都有优秀的主机提供商,比如 Heroku 和 T2 Rackspace。当然,如果您想自己管理服务器,您可以选择 VPS 提供商来托管您的 Django 或 Rails 应用程序。
如果你遇到了关于 Rails 的问题,官方网站rubyonrails.org提供了很好的资源在文档中查找信息,你也可以在社区论坛中提问。
总结和提示
Rails 和 Django 都是由高效编程语言支持的有效的 web 框架。归根结底,选择完全是主观和个人的,没有谁比谁更好。如果你要去一家使用这两种框架之一的公司工作,我建议和那家公司的开发人员谈谈,选择一个几乎所有人都感到兴奋的框架。
Python for Android:脚本层(SL4A)
原文:https://www.pythoncentral.io/python-for-android-the-scripting-layer-sl4a/
Android 的脚本层 SL4A 是一个开源应用程序,允许用一系列解释语言编写的程序在 Android 上运行。它还提供了一个高级 API,允许这些程序与 Android 设备进行交互,使访问传感器数据、发送短信、渲染用户界面等事情变得容易。
它真的很容易安装,可以在任何安卓设备上运行,所以你不需要 root 或者类似的权限。
目前脚本层支持 Python、Perl、Ruby、Lua、BeanShell、JavaScript 和 Tcl。它还提供对 Android 系统外壳的访问,这实际上只是一个最小的 Linux 外壳。
你可以从他们的网站上找到更多关于 SL4A 项目的信息。
为什么安卓的 SL4A 不一样
在 Android 上运行 Python 还有其他一些选择,其中一些非常好,但是没有一个提供脚本层的灵活性和特性。备选方案真正关注的是让您能够使用一些不受支持的语言创建和打包本机应用程序,有些做得非常好。例如,使用 Kivy ,你可以用 Python 创建一个应用程序,它可以运行在许多流行的操作系统、桌面和智能手机上,包括 Android。然而,因为它是多平台的,你无法直接访问 Android API,所以你无法使用许多让智能手机如此有趣的功能。
SL4A 是围绕 Android 操作系统设计的:它要求 Android 有用,但允许与操作系统更紧密地集成。
使用 SL4A,你仍然可以打包你的应用,如果你喜欢,你可以将它们发布到 Play 等应用商店,但这只是一个选项。将打包作为一个选项而不是一个目的的一个优点是,大多数 Python 脚本实际上都没有通过应用商店发布。它们应该被用作常规的 Python 程序。你通常只想写一点代码,保存它,然后运行它,并不断迭代。不得不不断构建应用程序是非常乏味的。
有了脚本层,您可以像在任何其他系统上一样开始工作,只是编辑和执行文件。
本系列主要关注 Python,Python 是 SL4A 上最受欢迎和最受支持的语言,但是其他语言也有非常有用的特性。例如,BeanShell 是一种编译为 Java 的高级语言,它能够绕过脚本层 API,直接访问 Android Java API。脚本层的 Ruby 和 JavaScript 解释器 JRuby 和 Rhino 也运行在 JVM 上,所以这些语言也可以这样做。有一个具备这些特性的环境是很好的。
投入:做好准备
SL4A 真的很好装。该应用程序以 APK 的形式发布,这是 Android 应用程序的标准格式,因此它可以以同样的方式安装。但是,在安装来自“未知来源”的应用程序之前,您需要在您的设备上允许这样做。如果您尚未安装,请打开设备的主设置菜单,打开安全菜单,然后通过选中未知来源选项“允许安装非市场应用程序”。现在您已经准备好安装脚本层了。
脚本层(SL4A)
如果您转到 SL4A 项目的主页,只需扫描页面上的条形码并在出现提示时确认下载,即可将脚本层 APK 的副本下载到您的设备上。如果你的设备上没有条形码扫描仪,任何应用商店都有一堆免费的扫描仪。
下载完 APK 后,您应该能够直接在设备的通知面板中安装它,下载内容将出现在通知面板中。您的设备可能略有不同,但只要您启用了从未知来源安装,就可以清楚地知道如何安装 APK。
一旦您安装了脚本层,您将能够打开它,用内置编辑器创建和编辑小 shell 脚本并运行它们。开始非常容易。
每当您第一次打开 SL4A 时,您会看到您的脚本目录的内容,它位于/sdcard/sl4a/scripts。这是您通常放置自己的脚本以便于访问的地方。如果你想构建更复杂的应用程序,或者如果你有很多简单的脚本,你可以在这里创建目录来帮助保持事情正常。
SL4A 解释器
SL4A 只将 shell 作为标准配置,但是在应用程序中安装其他解释器很容易。如果您打开 SL4A,然后点击您的设备主菜单按钮,SL4A 菜单将弹出。如果你按下 View,你会看到一个有三个选项的菜单,解释器,触发器和 Logcat。选择解释器会将您的视图从脚本目录移动到解释器列表。在此视图中点击设备的主菜单按钮将打开一个新菜单,其中有一个添加翻译的选项。在这里,您可以选择要安装的解释器,这将打开您的浏览器并为该解释器下载 APK。按照安装 SL4A 的相同方式安装该 APK。
每个解释器都作为一个独立的 Android 应用程序存在,并将作为一个应用程序出现在设备的菜单中。Python 解释器的应用叫做 Python for Android,或者简称 PY4A。每个解释器的应用程序至少有安装或卸载解释器的能力。PY4A 也可以管理。egg 文件,这为您提供了一种在脚本层安装 Python C 模块的简单方法,否则您只能使用纯 Python。任何 Python C 模块都必须首先针对 ARM 内核进行交叉编译,这是一个复杂的过程,但一些有用的包是从 Python for Android 项目页面预编译的,以及关于如何编译其他包的指令。
如果你还没有,打开 Python for Android 应用程序,点击安装按钮。您的脚本层现在支持 Python。
SL4A 上的 Python 库
如果你想添加新的模块来扩展设备的 Python 库,你必须做一些与你习惯的不同的事情。没有 root,你不能直接修改系统文件,所以脚本层在/sdcard/com.googlecode.pythonforandroid/extras/python有自己的包目录,这些包在你的 sdcard 上。您可以随时从该目录导入,对于您安装的每种语言,都存在类似的目录。
Python extras 目录预装了大量有用的模块,您可以将任何您喜欢的纯 Python 模块放在这里。
如果您将一个模块添加到 extras 目录,请确保它是可导入的 Python 模块本身。当你从存储库中获取一个库时,它通常会被构造成这样,应用程序的根目录包含一堆东西,如 READMEs、docs、tests 和 setup 文件,以及你需要的实际模块,可能是文件或目录。请记住,它必须是纯 Python,您必须解决任何依赖关系。
注意:如果你的设备上没有像样的文件浏览器,那就马上去抢一个。我通常使用免费的 ES 文件浏览器。如果你想认真研究黑客机器人,最好也早点在开发盒上安装 Android SDK。它包括一些工具,可以轻松完成一些常见的任务。这是一个相当复杂的工具包,但每个操作系统的指南都可以在网上找到,你将需要它来打包应用程序。
Android 的 SL4A Hello World:你的第一个脚本和 API
每当您添加一个新的解释器时,就会在脚本目录中自动安装一些示例脚本。这些是开始寻找代码示例的好地方,一旦完成,您可以安全地删除它们。
在 Python 中使用 SL4A 真的很简单。大多数脚本以下面两行开始:
from android import Android
droid = Android()
从这里开始,droid这个名字就是一个Android对象,并作为 Android 设备的挂钩。您可以使用它来访问整个脚本层 API。API 被划分为称为 facades 的部分,每个 facades 覆盖 API 的一些区域,比如网络视图、电话、WiFi、事件、相机、电池等等。
例如,您可以使用文本到语音外观让 droid 说话:
droid.ttsSpeak('Hello World')
注意 : Tasker 还支持 SL4A 脚本,因此您可以使用它来监控系统,并在满足特定条件时启动 Python 程序。
狂野西部:开放平台,无文档
原始 API 在网上有完整的文档记录。然而,关于如何使用它的信息很少。SL4A 和 PY4A 项目网站上有更多的信息,但还远远不够。就我个人而言,我认为开源开发者足够聪明,知道永远不要写文档~这样,他们可以通过写书谋生...
Paul Ferrill 所著的 Apress bookPro Android Scripting with SL4A 是学习正确使用脚本层的极好资源,并且使用 Python 作为示例语言。Apress 还发布了由 SL4A 项目的首席开发人员 Robbie Matthews 撰写的开始 Android 平板电脑编程。这本书更侧重于平板电脑,而不是 Python,但对于真正了解其主题的人来说,这仍然是一本很好的书。
还有 SL4A 和 PY4A 谷歌小组可以寻求帮助。他们可能会有点孤独,但是如果你把你的问题写得很好,你通常很快就会得到一个有用的回复。那里也有大量的存档材料。
这个 Python 中心系列旨在涵盖 Python 程序员需要了解的关于 Android 和脚本层的所有最重要的事情,以帮助您快速上手。而且,一如既往,我们真的很感谢社区对我们项目的投入,所以如果有什么你想看的,一定要让我们知道。
Python 生成器和 Yield 关键字
原文:https://www.pythoncentral.io/python-generators-and-yield-keyword/
乍看之下,yield语句用于定义生成器,代替函数的return向其调用者提供结果,而不破坏局部变量。与每次调用都以新的变量集开始的函数不同,生成器会从停止的地方继续执行。
关于 Python 生成器
因为yield关键字只用于生成器,所以首先回忆一下生成器的概念是有意义的。
生成器的思想是按需(即时)逐个计算一系列结果。在最简单的情况下,一个生成器可以被用作一个list,其中每个元素都被延迟计算。让我们比较一下做同样事情的列表和生成器——返回 2 的幂:
[python]
First, we define a list
the_list = [2**x for x in range(5)]
Type check: yes, it's a list
type(the_list)
<class 'list'>Iterate over items and print them
for element in the_list:
... print(element)
...
1
2
4
8
16How about the length?
len(the_list)
5Ok, now a generator.
As easy as list comprehensions, but with '()' instead of '[]':
the_generator = (x+x for x in range(3))
Type check: yes, it's a generator
type(the_generator)
<class 'generator'>Iterate over items and print them
for element in the_generator:
... print(element)
...
0
2
4Everything looks the same, but the length...
len(the_generator)
Traceback (most recent call last):
File "", line 1, in
TypeError: object of type 'generator' has no len()
[/python]
[python]
First, we define a list
the_list = [2**x for x in range(5)]
Type check: yes, it's a list
type(the_list)
<type 'list'>Iterate over items and print them
for element in the_list:
... print(element)
...
1
2
4
8
16How about the length?
len(the_list)
5Ok, now a generator.
As easy as list comprehensions, but with '()' instead of '[]':
the_generator = (x+x for x in range(3))
Type check: yes, it's a generator
type(the_generator)
<type 'generator'>Iterate over items and print them
for element in the_generator:
... print(element)
...
0
2
4Everything looks the same, but the length...
len(the_generator)
Traceback (most recent call last):
File "", line 1, in
TypeError: object of type 'generator' has no len()
[/python]
遍历列表和生成器看起来完全一样。然而,尽管生成器是可迭代的,但它不是集合,因此没有长度。集合(列表、元组、集合等)将所有值保存在内存中,我们可以在需要时访问它们。生成器动态地计算这些值,然后忘记它们,所以它对自己的结果集没有任何了解。
生成器对于内存密集型任务特别有用,在这种情况下,不需要同时访问内存密集型列表中的所有元素。在从不需要完整结果的情况下,逐个计算一系列值也很有用,可以向调用者提供中间结果,直到满足某些要求,进一步的处理停止。
使用 Python“yield”关键字
一个很好的例子是搜索任务,通常不需要等待找到所有结果。执行文件系统搜索时,用户会更乐意即时收到结果,而不是等待搜索引擎遍历每个文件,然后才返回结果。有没有人真的会在所有谷歌搜索结果中导航到最后一页?
由于不能使用列表理解来创建搜索功能,我们将使用带有yield语句/关键字的函数来定义一个生成器。yield指令应该放在一个地方,在那里生成器向调用者返回一个中间结果,并休眠直到下一次调用发生。让我们定义一个生成器,在一个巨大的文本文件中逐行搜索一些关键字。
def search(keyword, filename):
print('generator started')
f = open(filename, 'r')
# Looping through the file line by line
for line in f:
if keyword in line:
# If keyword found, return it
yield line
f.close()
现在,假设我的“directory.txt”文件包含一个巨大的姓名和电话号码列表,让我们查找名字中带有“Python”的人:
>>> the_generator = search('Python', 'directory.txt')
>>> # Nothing happened
当我们调用搜索函数时,它的主体代码不会运行。生成器函数将只返回生成器对象,充当构造函数:
[python]
type(search)
<class 'function'>
type(the_generator)
<class 'generator'>
[/python]
[python]
type(search)
<type 'function'>
type(the_generator)
<type 'generator'>
[/python]
这有点棘手,因为通常情况下,def search(keyword, filename):下面的所有东西都要在调用它之后执行,但在生成器的情况下不是这样。事实上,甚至有一个很长的讨论,建议使用“gen”,或其他关键字来定义一个生成器。但是,圭多决定坚持用“def”,就这样。你可以在 PEP-255 上看到动机。
为了让新创建的生成器计算一些东西,我们需要通过迭代器协议访问它,即调用它的next方法:
[python]
print(next(the_generator))
generator started
Anton Pythonio 111-222-333
[/python]
[python]
print(the_generator.next())
generator started
Anton Pythonio 111-222-333
[/python]
调试字符串被打印出来,我们没有查看整个文件就获得了第一个搜索结果。现在让我们请求下一场比赛:
[python]
print(next(the_generator))
generator started
Fritz Pythonmann 128-256-512
[/python]
[python]
print(the_generator.next())
generator started
Fritz Pythonmann 128-256-512
[/python]
生成器在最后一个yield关键字/语句上继续,并遍历循环,直到再次遇到yield关键字/语句。然而,弗里茨仍然不是合适的人选。接下来,请:
[python]
print(next(the_generator))
generator started
Guido Pythonista 123-456-789
[/python]
[python]
print(the_generator.next())
generator started
Guido Pythonista 123-456-789
[/python]
最后,我们找到了他。现在你可以打电话给他,用 Python 对伟大的generators说声“谢谢”!
更多生成器细节和示例
正如您可能注意到的,该函数第一次运行时,将从头开始,直到到达yield关键字/语句,将第一个结果返回给调用者。然后,每个其他调用将从离开的地方恢复生成器代码。如果生成器函数不再命中yield关键字/语句,它将引发一个StopIteration异常(就像所有 iterable 对象在耗尽/完成时一样)。
为了在后续调用中运行yield,生成器可以包含一个循环或多个yield语句:
def hold_client(name):
yield 'Hello, %s! You will be connected soon' % name
yield 'Dear %s, could you please wait a bit.' % name
yield 'Sorry %s, we will play a nice music for you!' % name
yield '%s, your call is extremely important to us!' % name
使用生成器作为传送带通常更有意义,链接功能可以有效地处理一些序列。一个很好的例子是缓冲:以大块获取数据,以小块进行处理:
def buffered_read():
while True:
buffer = fetch_big_chunk()
for small_chunk in buffer:
yield small_chunk
这种方法允许处理功能从任何缓冲问题中抽象出来。它可以使用负责缓冲的生成器一个接一个地获取值。
使用生成器的思想,即使是简单的任务也会更加高效。在 Python 2 中。x 是 Python 中一个常见的range()函数,通常被xrange()代替,后者是yields的值,而不是一次创建整个列表:
[python]
"range" returns a list
type(range(0, 3))
<class 'list'>xrange does not exist in Python 3.x
[/python]
[python]
"range" returns a list
type(range(0, 3))
<type 'list'>xrange returns a generator-like object "xrange"
type(xrange(0, 3))
<type 'xrange'>It can be used in loops just like range
for i in xrange(0, 3):
... print(i)
...
0
1
2
[/python]
最后,一个生成器的“经典”例子:计算 Fibonacci 数的前 N 个给定数:
def fibonacci(n):
curr = 1
prev = 0
counter = 0
while counter < n:
yield curr
prev, curr = curr, prev + curr
counter += 1
数字一直计算到计数器达到'n'为止。这个例子非常流行,因为斐波那契数列是无限的,很难放入内存。
到目前为止,已经描述了 Python 生成器最实用的方面。要了解更多详细信息和有趣的讨论,请看一下 Python 增强提案 255 ,其中详细讨论了该语言的特性。
快乐的蟒蛇!
Python 列表和元组
Python 列表和元组概述
Python 中最常用的两种内置数据类型是列表和元组。
列表和元组是序列数据类型组的一部分——换句话说,列表和元组以特定的顺序存储一个或多个对象或值。存储在列表或元组中的对象可以是任何类型,包括由关键字None定义的 nothing 类型。
列表和元组的最大区别是列表是可变的,而元组是不可变的。这意味着一旦创建了元组,就不能添加或删除对象,也不能改变顺序。然而,元组中的某些对象是可以改变的,我们将在后面看到。
创建 Python 列表或元组
创建列表或元组很容易,下面是一些空列表或元组:
# Lists must be surrounded by brackets
>>> emptylst = []
# Tuples may or may not be surrounded by parenthesis
>>> emptytup = ()
为了创建非空列表或元组,值用逗号分隔:
# Lists must be surrounded by brackets
>>> lst = [1, 2, 3]
>>> lst
[1, 2, 3]
# Tuples may or may not be surrounded by parenthesis
>>> tup = 1, 2, 3
>>> tup
(1, 2, 3)
>>> tup = ('one', 'two', 'three')
>>> tup
('one', 'two', 'three')
注意:要创建一个只有一个值的元组,在值后面添加一个逗号。
# The length of this tuple is 1
>>> tup2 = 0,
>>> tup2
(0,)
获取 Python 列表或元组值
与其他序列类型一样,列表和元组中的值由一个索引引用。这是一个数字,表示值的序列,第一个值从 0 开始。比如下面:
>>> lst[0]
1
>>> tup[1]
'two'
使用低于零的索引获得从列表或元组的末端开始的值:
>>> lst[-1]
3
>>> tup[-2]
'two'
切片 Python 列表和元组
通过对列表或元组进行“切片”,可以引用多个值(引用一个范围[start:stop]):
>>> lst[0:2]
[1, 2]
# Note an out-of-range stopindex translates to the end
>>> tup[1:5]
('two', 'three')
通过索引分配 Python 列表值
列表的值可以分配索引(只要索引已经存在),但不能分配给元组:
>>> lst[2] = 'three'
>>> lst
[1, 2, 'three']
>>> tup[2] = 3
Traceback (most recent call last):
File "<pyshell#68>", line 1, in <module>
tup[2] = 3
TypeError: 'tuple' object does not support item assignment
添加到 Python 列表
也可以用'+'操作符或标准的append方法将值添加到列表中(列表可以合并,或连接):
# concatenation, the same as lst = lst + [None]
>>> lst += [None]
>>> lst
[1, 2, 'three', None]
>>> lst.append(5)
>>> lst
[1, 2, 'three', None, 5]
列表的 Python del 关键字
可以使用关键字del从列表中删除值:
>>> del lst[3]
>>> lst
[1, 2, 'three', 5]
# Slicing deletion; no stop index means through the end
>>> del lst[2:]
>>> lst
[1, 2]
列表的赋值和删除方法不适用于元组,但串联有效:
# Note only tuples can be added to tuples
>>> tup += (4,)
>>> tup
('one', 'two', 'three', 4)
尽管元组不像列表那样是可变的,但是通过切片技术和一点创造性,元组可以像列表一样被操纵:
# Almost like slice deletion
>>> tup = tup[0:2]
>>> tup
('one', 'two')
>>> tup2 += tup
>>> tup2
# almost like index assignment
>>> tup2 = tup2[0:1] + (1,) + tup2[2:]
>>> tup2
(0, 1, 'two')
此外,如果一个元组包含一个列表,则该元组中列表的可变性被保留:
>>> tup3 = 0, 'one', None, []
>>> tup3[3].append('three')
>>> tup3
(0, 'one', None, ['three'])
除了这里描述的方法之外,还有更多针对列表和元组的方法,但是这些方法涵盖了最常见的列表和元组操作。而且记住,列表和元组可以嵌套(可以包含列表和元组,以及其他存储多组值的数据类型,比如字典),可以同时存储不同的类型,非常有用。
Python 的空等价物:None
原文:https://www.pythoncentral.io/python-null-equivalent-none/
什么是 null 或 None 关键字
null关键字常用于许多编程语言,如 Java、C++、C#和 Javascript。它是赋给变量的一个值。也许你见过这样的东西:
Javascript 中为空
var null_variable = null;
PHP 中为空
$null_variable = NULL;
Java 中为空
SomeObject null_object = null;
null关键字的概念是,它给变量一个中性,或“空”行为。注意,从技术上讲,null的行为在高级和低级语言之间是变化的,所以为了简单起见,我们将引用面向对象语言中的概念。
Python 的空等价物:None
Python 中null关键字的对等词是None。这样设计有两个原因:
- 许多人会认为“null”这个词有点深奥。对于编程新手来说,这并不是最友好的词语。同样,“无”指的是预期的功能——它什么也不是,也没有行为。
- 在大多数面向对象语言中,对象的命名倾向于使用 camel-case 语法。
ThisIsMyObject例。您很快就会看到,Python 的None类型是一个对象,并且表现得像一个对象。
将None类型赋给变量的语法非常简单。如下所示:
my_none_variable = None
为什么要用 Python 的 None 类型?
有很多例子可以说明为什么你会使用None。
通常你会想要执行一个可能有效也可能无效的动作。使用None是稍后检查动作状态的一种方式。这里有一个例子:
# We'd like to connect to a database. We don't know if the authentication
# details are correct, so we'll try. If the database connection fails,
# it will throw an exception. Note that MyDatabase and DatabaseException
# are not real classes, we're just using them as examples.
数据库连接=无
#尝试连接
尝试:
database = MyDatabase(db_host,db_user,db_password,db _ database)
database _ connect = database . connect()
除数据库例外:
通过
如果 database_connection 为 None:
打印('数据库无法连接')
否则:
打印('数据库可以连接')
另一个场景是你可能需要实例化一个类,这取决于一个条件。您可以将一个变量分配给None,然后可选地稍后将它分配给一个对象实例。然后你可能需要检查这个类是否已经被实例化了。这样的例子数不胜数——欢迎在评论中提供一些!
Python 的 None 是面向对象的
Python 是非常面向对象的,你很快就会明白为什么。请注意,Null关键字是一个对象,其行为就像一个对象。如果我们检查None对象是什么类型,我们得到如下结果:
>>> type(None)
<class>
>>> type(None)
<type>
从中我们可以发现三件事:
None是一个对象——一个类。非基本类型,如数字,或True和False。- 在 Python 3.x 中,
type对象被更改为新的样式类。然而None的行为是相同的。 - 因为
None是一个对象,我们不能用它来检查变量是否存在。它是一个值/对象,而不是用于检查条件的运算符。
检查变量是否为 None
有两种方法可以检查一个变量是否为None。一种方法是使用is关键字。另一种是使用==语法。这两种比较方法是不同的,稍后您会看到原因:
null_variable = None
not_null_variable = 'Hello There!'
# is 关键字
如果 null_variable 是 None:
print('null_variable 是 None ')
else:
print(' null _ variable 不是 None ')
如果非空变量为无:
打印('非空变量为无')
否则:
打印('非空变量为无')
# The = = operator
if null _ variable = = None:
print(' null _ variable is None ')
else:
print(' null _ variable is not None ')
if not _ null _ variable = = None:
print(' not _ null _ variable is None ')
else:
print(' not _ null _ variable is not None ')
这段代码会给我们以下输出:
【shell】
null _ variable is None
not _ null _ variable is not None
null _ variable is None
not _ null _ variable is not None
太好了,所以他们是一样的!嗯,算是吧。它们是基本类型。然而,上课时你需要小心。Python 为类/对象提供了覆盖比较运算符的能力。所以可以比较类,比如MyObject == MyOtherObject。本文不会深入讨论如何在类中覆盖比较操作符,但是它应该提供了为什么应该避免使用==语法检查变量是否为None的见解。
class MyClass:
def __eq__(self, my_object):
# We won't bother checking if my_object is actually equal
# to this class, we'll lie and return True. This may occur
# when there is a bug in the comparison class.
返回 True
my_class = MyClass()
如果我的类是无:
打印('我的类是无,使用 is 关键字')
否则:
打印('我的类不是无,使用 is 关键字')
if my _ class == None:
print(' my _ class is None,使用==语法')
else:
print(' my _ class is not None,使用= =语法')
这为我们提供了以下输出:
my_class is not None, using the is keyword
my_class is None, using the == syntax
有意思!所以你可以看到,is关键字检查两个对象是否完全相同。而==操作符首先检查类是否覆盖了操作符。对于 PHP 程序员来说,使用==语法与 Python 中的==相同,其中使用is关键字等同于===语法。
因此,使用is关键字来检查两个变量是否完全相同总是明智的。
Python 资源:书籍
每个人都以不同的方式学习,虽然一些开发人员喜欢以交互方式学习新的编码语言,但其他人可能希望在尝试编写任何代码之前有一个坚实的语言基础。如果你想学习 Python,并且喜欢通过阅读书籍来学习新的语言,请查看下面的列表以获得一些建议。
1。学习 Python

这本书有 1600 多页,所以不太适合胆小的人,但是如果你致力于学习 Python,这被认为是终极参考手册和教程之一。它已经出版了近 20 年,所以它肯定做对了什么。
2。 Python 速成班

这本书不像是一本参考手册,更像是一种基于项目的动手学习 Python 的方法,同时也为您提供了这门语言的全面基础。
3。敬酒不吃吃罚酒

该学习了...Hard Way 书籍是一个备受尊重和众所周知的系列的一部分,该系列教人们如何学习编码许多不同的语言。这本书可以在他们的网站上通过你的浏览器免费获得,但如果你喜欢,你也可以购买硬拷贝或数字下载。
4。 Python 编程

这本书是一本 Python 指南,给完全的初学者一个坚实的 Python 基础知识。这本书甚至吹嘘它有能力将完全的初学者变成 Python 大师。
5。巨蟒食谱

这本书是为更高级的 Python 用户而写的,他们希望用新的编码技术和技能来试验和拓宽他们的 Python 视野。
Python 资源:培训视频
原文:https://www.pythoncentral.io/python-resources-training-videos/
有时候,熟悉一门新语言或一项新技术的最好方法是先看别人做,然后自己跳进去试一试。如果你喜欢以这种方式学习,并且想要提高你的 Python 技能,请查看下面的任何培训视频或视频库,开始学习吧!
1。 Python 培训——Python 入门
这个受欢迎的视频由 YouTube 托管,带您了解 Python 的基本原理。在视频中,您将了解数据类型、变量以及其他对 OOP 语言很重要的术语和概念。
2。高级 Python 或者理解 Python

Besttechvideos.com 主持了一系列 Python 视频,包括这个带你了解一些高级 Python 主题和概念的流行视频。许多视频都是从 Python 演讲、活动或会议上传的。如果你访问 besttechvideos.com 并搜索“Python”这个词,你会找到几十个视频供任何水平的程序员欣赏。
3。PyVideo.org

PyVideo.org 是一个专门致力于探索和教授 Python 的大型视频库。与 BestTechVideos 一样,这些视频中有许多来自流行的 Python 会议或讲座。看看他们库中的视频,了解如何扩展您的 Python 概念和技术知识,甚至从任何层面提高您的 Python 编码技能。
Python 中的列表:如何实现就地反转
先决条件
要了解就地列表反转,您应该了解以下内容:
- Python 3
- Python 数据结构-列表
- 交换值
什么是到位列表冲销?
在之前的帖子中,你可能已经学会了如何用 Python 逆向读取列表,这很有趣。你可以在这里查看。然而,这个教程的动机是完全不同的。我们不会反向读取一个列表,而是将一个现有的列表改变成它的反向状态。注意,这是一种语言不可知的方法。
我们来看一个例子:
alist = [1,2,3,4,5,6,7]
print(alist[::-1]) #prints [7,6,5,4,3,2,1]
print(alist) #prints [1,2,3,4,5,6,7]
所以你只不过是在做 *alist[::-1]* 的时候以相反的顺序读。我们要实现的是让 *alist = [7,6,5,4,3,2,1]* 。
如何实现这一点?
这背后的想法是使用两个指针, 左 和 右 。 左 指针指向列表的第一个索引, 右 指针指向列表的最后一个索引。现在我们交换这些指针所指向的元素。然后,我们将指针移动到下一个索引。这种终止条件将是当左指针等于或越过右指针时。让我们看一个例子:
| 回合 | 列表 | 左 | 右 | 交换后列表 |
| 1 | 【1,2,3,4,5,6,7】 | 1 [0] | 7 [6] | 【7,2,3,4,5,6,1】 |
| 2 | 【7,2,3,4,5,6,1】 | 2[1] | 6[5] | 【7,6,3,4,5,2,1】 |
| 3 | 【7,2,3,4,5,6,1】 | 3[2] | 5【4】 | 【7,6,5,4,3,2,1】 |
| 4 | 【7,6,5,4,3,2,1】 | 4【3】 | 4【3】 | 停止自左==右 |
如你所见,现在名单颠倒了。
算法
- 左 指针指向第一个索引 右 指针指向最后一个索引
- 互换元素所指的 左 和 右 指针分别为
- 左指针递增 1,右指针递减 1
- 检查 左> =右 :
- 如果没有,重复步骤 2-4
- 如果是,停止。清单冲销完成
注意: 虽然这个算法是针对列表解释的,但是你也可以把它用在字符串上。在这种情况下,您可能需要通过类型转换将字符串转换为列表。不要忘记从列表格式重新构造字符串。这可以通过使用一些格式化命令来完成,比如 replace()。
代码
def reverse(alist):
#intializing pointers
left = 0
right = len(alist)-1
#condition for termination
while left<right:
#swapping
temp = alist[left]
alist[left] = alist[right]
alist[right] = temp
#updating pointers
left += 1
right -= 1
return alist
print(reverse([1,2,3,4,5]))
效率
你可能会想,你可以用反转的内容创建一个新列表,而不是经历所有这些麻烦。大概是这样:
alist = [1,2,3,4,5,6,7]
blist = list()
for item in alist[::-1]:
blist.append(item)
print(blist) #prints [7,6,5,4,3,2,1]
虽然上面的方法可行,但是你使用了额外的内存(【blist】)来存储反转列表。如果列表中的元素数量很大,这可能是一个严重的问题。这就是原地反转派上用场的时候了。就地反转的效率是 O(n ),因为我们至少访问列表中的所有元素一次。
结论
这是一个非常常见的面试问题。试着用同样的方法来解决这些难题,并在下面评论:
- 反串“你好”。输出应为“olleh”
- 把“我爱 Python Central”这句话倒过来。输出应该是“中央 Python love I”
- 检查“madam”是否是回文
我们将在未来的教程中使用这个概念,比如链表反转。本教程到此为止。快乐的蟒蛇!
Python 片段:如何生成随机字符串
原文:https://www.pythoncentral.io/python-snippets-how-to-generate-random-string/
Python 是一个非常有用的工具,可以用来创建随机字符串。可能有几十种不同的原因让你想要创建一个随机的字符和数字的字符串,但是其中一个最常见的原因是使用这个字符串作为密码。
Python 代码片段提供了这个非常有用的代码片段,用于生成随机字符串,作为一个密码生成器,可以很容易地在 Python 上运行的任何项目中使用。在代码片段中,密码生成器创建了一个最少 8 个字符、最多 12 个字符的随机字符串,其中包括字母、数字和标点符号。当字符串生成后,它被打印出来。那么您的用户(或您)就可以自由地使用它来满足他们的任何密码需求。
我们根据自己的喜好改编了这个片段,并把它放在下面。检查它,并随时使用它,修改它,或完全定制它。
import string
from random import *
min_char = 8
max_char = 12
allchar = string.ascii_letters + string.punctuation + string.digits
password = "".join(choice(allchar) for x in range(randint(min_char, max_char)))
print "This is your password : ",password
学习 Python 编写有效代码的初学者技巧
Python 入门
如果你是 Python 的新手,你可能会发现这篇文章非常有用。在这里,您将了解一些常见的 Python 入门提示和技巧,它们将使您能够编写简单高效的代码。
使用 Python 3 . 5 . 2 版本创建了本教程。
列表初始化
列表是 Python 中最常用的数据结构之一。如果你在过去已经声明了列表,你应该会这样做:
alist = list()
(or)
alist = []
如果你想将一个列表初始化为五个 0,你应该这样做:
alist = [0,0,0,0,0]
上面提到的方法对于短列表来说已经足够好了,但是如果你想将一个列表初始化为 20 个 0 呢?键入 0 二十次不是一种有效的方式。所以相反,你可以这样写:
alist = [0] * 20
print(alist)
Output: [0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Randint 命令
通常你会被要求生成随机数。Python 通过引入 randint 命令使这变得非常容易。该命令从您指定的范围内随机选择一个数字,使该过程快速而简单。R andint 需要从‘随机’库中导入,其中 可以这样做:
from random import randint
使用 randint 的sy 税为:
randint(<from_range>,<to_range>)
举个例子,如果你想打印 0 到 9(包括 0 和 9)之间的随机整数,可以这样做:
from random import randint
print(randint(0, 9))
Output: prints an integer between 0 and 9
注意,每次执行上面的命令,都会得到一个 0 到 9 之间不同的整数。
键入命令
当你接收来自用户的输入或者处理来自其他程序的输入时,知道你正在处理的输入的数据类型是非常有用的。这使您可以更好地控制可以执行的操作。 类型 命令标识变量的数据类型。
语法如下:
type(<variable_name>)
例如,如果你有一个名为 的列表变量 ,它是一个列表,那么执行下面的命令将返回:
alist = list()
type(alist)
Output: <class 'list'>
剥离命令
这是一个非常有用的命令,用于格式化以字符串形式接收的输入。 strip 命令删除字符串前后的空格。语法是:
<string>.strip()
比如你想去掉一个字符串前后的空格,应该这样做:
sample = “ Python “
sample.strip()
Output: Python
注意:只有前后的空格被删除,而不是两个单词之间的空格。例如:
sample = “ I love Python “
sample.strip()
Output: “I love Python”
使用 lstrip/rstrip 命令可以执行更多的操作,例如分别在字符串的左侧/右侧进行剥离。一定要靠自己进一步探索!
计数
我相信你会熟悉使用 作为 关键字的向前计数,它看起来像这样:
for i in range(0,5):
print(i)
Output: prints 0,1,2,3,4
然而,还有更多以 为 的关键词。它还能让你一步一步地数,甚至倒着数。语法 如下:
for i in range (<from_value>,<to_value>,<step>):
print(i)
例如,如果你想计算 0 到 10 之间的每一秒的数字,应该这样写:
for i in range(0,10,2):
print(i)
Output: prints 0,2,4,6,8
上面的命令将打印 0,2,4,6,8。请注意,如果没有指定步长,默认情况下步长为 1。
反向计数,命令如下:
for i in range(10,0,-1):
print(i)
Output: prints 10,9,8,7,6,5,4,3,2,1
如果步骤被指定为-2,那么上面的命令将打印 10,8,6,4,2。
一般提示
其他一些通用提示:
- 注释——尽可能地写注释,因为这将有助于你和他人更好地理解代码。单行注释可以这样写:
#<Single line comment>
段落注释可以这样写:
“””
<Paragraph comment>
“””
- 命名惯例——在命名变量时,要格外小心使用相关的名称。当其他人阅读您的代码时,在名称中指定数据类型会非常有用。如果您正在初始化一个名为“first name”的字符串,请确保在名称中包含数据类型,如“strFirstName”。这样,任何阅读您的代码的人都会立即理解变量“strFirstName”是 string 类型的。
- 行号——如果您使用 Python IDLE,请确保使用 ALT+G 命令到达特定的行。这有助于根据行号跟踪一行,当您有几行代码并抛出错误时,这是一个救命稻草。
结论
这些是从 Python 中精选出来的一些技巧,希望它们能让你的编码变得简单一些。还有很多东西需要学习,因为 Python 有大量的库,使得编码变得非常简单。所以继续探索,快乐的蟒蛇!
Python 工具:Pyflame
Pyflame 是优步工程团队带给我们的新工具(你可以在这里阅读这个想法的概念),许多 Python 程序员会发现它非常有用。该工具用于为 Python 流程生成火焰图。
Pyflame 通过使用 ptrace(2)系统调用来分析 Python 进程当前正在执行的堆栈跟踪。该工具仍然是最新发布的,已经被 web 开发社区所接受。安装简单,重量轻。创建 Pyflame 的目标是开发一个分析器,它将收集完整的 Python 堆栈,以一种可用于生成 flame 图的方式发出数据,具有较低的开销,并处理不明确用于分析的进程。如果做所有这些事情的能力听起来对你很有帮助,请确保在你的下一个项目中使用 Pyflame。
Python 技巧:存储多个值
原文:https://www.pythoncentral.io/python-tricks-storing-multiple-values/
在这篇文章中,我们将讨论如何在 Python 列表中存储和操作值。理解存储和使用值的所有方法对于掌握任何编码语言都是必不可少的,Python 也不例外。出于本文的目的,让我们以下面的列表为例:
l = [1, 2, 3, 4]
所以上面的列表叫做 l,它包含四个值,1,2,3,4。这应该是不言自明的。我们接下来要做的是学习如何快速方便地将列表中的每个值作为 Python 代码中的独立值进行存储。
假设您想将值 1、2、3 和 4 分别保存为变量 a、b、c 和 d。有许多不同的方法可以做到这一点,包括遍历列表,或者使用对应于每个值的索引手动遍历列表,但是实现这一点的最快方法是通过执行下面的简单步骤:
l = [1, 2, 3, 4]
a, b, c, d = l
这就是你需要做的。现在变量 a 的值是 1,b 是 2,c 是 3,d 是 4。
您可以使用任意多的值来实现这一点...当你用完字母表中的字母时,开始将它们组合成单词,并将变量存储为单词而不是字母。请记住,列表中各项的顺序就是它们保存到变量中的顺序,所以请确保按照正确的顺序编写它们(例如,如果在上面的代码片段中,您希望将值 3 保存为 d 而不是 c,只需将 d 放在第三个位置,将您喜欢的任何内容放在第四个位置...也许是 c?).
还有比这更简单或更容易的吗?大概不会。这是一个放在你后口袋里的好方法。
Python Unicode:编码和解码字符串(在 Python 2.x 中)
原文:https://www.pythoncentral.io/python-unicode-encode-decode-strings-python-2x/
This article is on Unicode with Python 2.x If you want to learn about Unicode for Python 3.x, be sure to checkout our Unicode for Python 3.x article. Also, if you're interested in checking if a Unicode string is a number, be sure to checkout our article on how to check if a Unicode string is a number.
字符串是 Python 中最常用的数据类型之一,有时您可能希望(或不得不)使用包含或完全由标准 ASCII 集之外的字符组成的字符串(例如,带有重音符号或其他标记的字符)。
Python 2.x 提供了一种称为 Unicode 字符串的数据类型,用于使用字符串编码和解码方法处理 Unicode 数据。如果你想了解更多关于 Unicode 字符串的知识,一定要查看维基百科上关于 Unicode 的文章。
注意:当执行一个包含 Unicode 字符的 Python 脚本时,必须在脚本的顶部加上下面一行,告诉 Python 代码是 UTF-8/Unicode 格式的。
# -*- coding: utf-8 -*-
Python Unicode:概述
为了弄清楚“编码”和“解码”是怎么回事,让我们看一个示例字符串:
>>> s = "Flügel"
我们可以看到我们的字符串 s 中有一个非 ASCII 字符,即“ü”或“umlaut-u”。假设我们处于标准的 Python 2.x 交互模式,让我们看看当我们引用字符串时会发生什么,以及当它被打印出来时会发生什么:
>>> s
'Fl\xfcgel'
>>> print(s)
Flügel
打印给了我们赋给变量的值,但是显然在这个过程中发生了一些事情,把我们输入解释器的内容变成了看似不可理解的东西。非 ASCII 字符ü被一组幕后规则翻译成一个代码短语,即“\xfc”。换句话说,它是由编码的。
在这一点上, s 是一个 8 位的字符串,对我们来说基本上意味着它不是一个 Unicode 字符串。让我们看看如何用相同的数据生成一个 Unicode 字符串。最简单的方法是在文字字符串前面加上“u”前缀,将其标记为 Unicode 字符串:
u = u"Flügel"
如果我们像对待s一样引用并打印u,我们会发现类似的东西:
>>> u
u'Fl\xfcgel'
>>> print(u)
Flügel
我们可以看到,我们的“umlaut-u”的代码短语仍然是“\xfc ”,并且它打印出来是一样的——那么这是否意味着我们的 Unicode 字符串的编码方式与我们的 8 位字符串 s 相同呢?为了弄清楚这一点,让我们看看当我们在u和s上尝试时encode方法做了什么:
>>> u.encode('latin_1')
'Fl\xfcgel'
>>> s.encode('latin_1')
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
s.encode('latin_1')
UnicodeDecodeError: 'ascii' codec can't decode byte 0xfc in position 2: ordinal not in range(128)
现在看起来编码 Unicode 字符串(用‘Latin-1’编码)返回了与字符串s相同的值,但是encode方法对字符串s不起作用。既然我们无法编码s,那解码呢?会给我们和u一样的价值吗?让我们来看看:
>>> s.decode('latin-1')
u'Fl\xfcgel'
毕竟这正是它的作用。那么,s是一个 8 位字符串,而u是一个 Unicode 字符串,这有什么区别呢?他们的行为方式是一样的,不是吗?在我们的“umlaut-u”示例中,除了 Unicode 字符串前面的“u”之外,似乎没有什么不同。
区别在于,Unicode 字符串u使用的是 Unicode 标准为字符“umlaut-u”定义的代码短语,而 8 位字符串s使用的是“latin-1”编解码器(规则集)为“umlaut-u”定义的代码短语。
好吧,嗯...这很好,但是...他们还是一样的,对吗?那么,这有什么关系呢?
为了说明区别及其重要性,让我们考虑一个新的 8 位字符串:
new_s = '\xe5\xad\x97'
与第一个不同,我们新的 8 位字符串是only代码短语——完全无法理解。
为什么我们不像最后一个 8 位字符串那样直接输入(或复制粘贴)字符呢?好吧,假设我们仍然使用标准的 Python 2.x console/IDLE,我们不能将这个值键入或粘贴到解释器中——因为如果我们这样做,它不会接受这个值。为什么?因为我们的new_s是一个亚洲文字字符的编码字符串(是的,只有一个字符),并且交互模式/IDLE 反对这样的输入(如果您的系统安装了合适的输入键盘,您可以尝试一下并找出答案)。
现在的问题是,我们如何将这些代码短语转换成它们应该显示的字符?在第一个例子中,在s上使用 print 语句效果很好,所以对于new_s应该也是一样,对吗?让我们看看我们未知的亚洲文字是什么:
>>>print new_s
å—
啊哦...那不对。首先,那不是亚洲文字。其次,不止是一个人物。简单地引用new_s会给出我们分配给它的字符串,而print似乎不起作用。让我们看看 Unicode 字符串是否能帮到我们。
要创建新的 Unicode 字符串new_u,我们不能使用第一个例子中的方法——要这样做,我们必须输入带有“u”前缀的字符串的文字字符(我们还没有看到我们的字符,无论如何交互模式/IDLE 不会接受它作为输入)。
然而,我们确实通过解码 s得到了u的值,所以同样地,我们应该能够通过解码new_s得到new_u的值。让我们像第一个例子那样尝试解码:
>>> new_u = new_s.decode('latin_1')
>>> new_u
u'\xe5\xad\x97'
很好,现在我们已经使用与第一个示例相同的方法存储了解码后的new_s字符串值,让我们打印我们的 Unicode 字符串,看看我们的脚本字符是什么:
>>> print(new_u)
å
哦...这不就是我们试图打印new_s字符串时得到的结果吗??那么使用 Unicode 字符串真的没有什么不同吗?
没那么快——有一个细节被有意掩盖以证明一点:我们用来解码字符串的编码与第一个例子相同,即“latin-1”编解码器。然而,8 位字符串new_s不是用“拉丁语-1”编码的,而是用“utf-8”编码的
好吧,所以除非明确告诉你,否则你真的没有办法知道,但这仍然说明了这一点:编码/编解码器/规则集在编码/解码字符串时会产生很大的不同。
使用正确的编码,让我们看看会发生什么:
>>> new_u = new_s.decode('utf_8')
>>> new_u
u'\u5b57'
>>> print(new_u)
字
终于!我们失踪已久的剧本角色找到了,看起来还不错。现在,尝试复制粘贴字符作为输入——你会发现它不起作用(我们仍然在谈论 Python 2.x 交互模式/IDLE)。
您可能还会注意到 new_u 的值有所不同,即它似乎只由一个代码短语组成(这次是以' \uXXXX '的形式)。这个 Unicode 标准为每个可能显示在屏幕上的字符或脚本字符的提供了一个唯一的代码短语。记住这一点,你也可以看出我们第一次试图解码 new_s,值是错误的(“u'\xe5\xad\x97 '”有 3 个代码短语,对于 Unicode 标准,这意味着 3 个独特的字符)。
好了,现在那些烦人的例子讲完了,让我们来回顾一下所有这些喧闹的要点:
- 字符串是 Python 中最常见的数据类型之一,有时它们会包含非 ASCII 字符。
- 当字符串包含非 ASCII 字符时,可以是 8 位字符串(编码字符串),也可以是 Unicode 字符串(解码字符串)。
- 要正确打印或显示一些字符串,需要对它们进行解码 (Unicode 字符串)。
- 编码/解码字符串时,编码/编解码器至关重要。
编码/编解码器就像你的字符串的 DNA——即使有相同的营养成分(输入),使用错误的 DNA(编解码器)会给你一个橘子,而你应该有一个苹果..
Python 与 Java:利弊
原文:https://www.pythoncentral.io/python-vs-java-pros-and-cons/

Java 和 Python 是目前市场上最流行的两种编程语言。这都归功于它们的自动化能力、多功能性和操作效率。但是,两种语言都有各自的优点和缺点。
它们既有许多共同点,也有许多不同点,这使得一些程序员根据自己的需要转向 Java,而另一些则转向 Python。
让我们检查一下这些语言的主要优缺点,并做一个比较。这将帮助你考虑合适的编程语言。请记住,不仅选择满足您需求的语言很重要,而且找到掌握这些技能的最合适的方法也同样重要。
Java 语言

Java 语言非常流行,并因被用于主要产品和服务的开发而闻名。与 C++等其他编程语言相比,它更容易学习,因为它遵循面向对象的概念。通过使用各种面向对象的编程概念,您可以系统地构建有效的应用程序。
首先,你可以在 CodeGym 上学习 Java,这将确保你像专家一样处理这种面向对象的编程语言。
Java 的优点
对于初学者来说相对容易掌握和完善。在时间紧迫或有截止日期的情况下,这种方法非常有效。
- 面向对象。
它是一种面向对象的编程语言。(OO)。它意味着与其他已知的编程语言(如 C#和 C++)共享概念。对象将较大的项目简化成较小的可管理的部分,增强了开发。它具有约束力,有助于提高安全性。
- 一次编写,随处运行。
该程序独立于底层的操作系统。这意味着只要 Java 虚拟机可用,你的代码就可以在 Mac、Windows、Linux 等平台上运行。这导致了更好的可及性。
- 多线程
Java 是一种多线程语言。由于大多数现代系统使用多线程 CPU,您可以将这一特性作为开发多功能应用程序的一个优势。
- 分布式计算
Java 提供了各种技术来链接像 CORBA 和 RMI 这样的资源,为多种目的提供构建创新的应用程序。
Java 的缺点
- 性能
Java 代码每次都由 Java 虚拟机(JVM)解释。这导致性能下降。Java 本质上缺乏实时数据处理。
- 内存管理
Java 提供了内置的内存管理来提高处理速度。垃圾收集可能会比手动工作效率更低,粒度更小。因此,Java 程序严重依赖内存存储。
- 代码可读性
由于复杂冗长的代码过程,Java 应用程序很容易变得冗长。如果开发人员没有足够的文档和注释,理解和分析可能会很耗时。
- 发牌
Oracle 为开发人员引入了一种新的商业许可。要使用 Java 8(或更新版本)的更新,用户必须每月支付订阅费,这增加了 Java 的长期成本。
Python 语言

Python 编程语言是一种面向对象的、解释性的高级编程语言,包括动态语义,即它自动区分分配给编程中使用的不同变量的值。对于初学者来说,变量和值可能会变得混乱,为了解决这个问题,你可以在 Python Central 上学习 Python。
Python 的优点
- 平滑的学习曲线
Python 对初学者非常友好,在大多数大学里被作为入门语言教授。它允许你专注于编程的概念、基本原理和基础,以抑制特定开发人员的心理。
- 高速发展
简洁的语法简化并加速了学习 Python 的过程,并在此基础上构建软件。预编码组件的包含提供了创建程序的现成构件。
- 对其他语言的可移植性和可扩展性
Python 是一种平台无关的语言,也就是说,你可以通过字节码和 Python 虚拟机在不同的系统上运行相同的代码,比如 Windows、Linux 或 macOS,Python 虚拟机在运行程序的实际 CPU 和开发人员之间充当中介。
- 多功能性加上适用于几乎一切的丰富工具集
Python 可以用于各种各样的任务,例如促进数据自动化、数据科学家、数据工程师、QA 工程师和 DevOps 专家的工作。
- 拥有庞大全球社区和大量人才库的免费技术
Python 可以免费用于商业和个人用途。它是一种开源语言,程序员可以自由使用。
Python 的缺点
- 速度限制
Python 的开发速度惊人,但在执行速度上却无法与 Java 和 C++相提并论。
用于检查和分配变量的解释器降低了程序的速度。
- 没有多线程
Python 基于全局解释器锁或 GIL 机制。它允许一次执行一个由字节码指令组成的序列。GIL 增强了单线程程序的性能,但限制了多线程程序同时运行多个工作流的能力。
- 高内存消耗
Python 中的垃圾收集器不会在对象变得不必要后立即将资源返回给系统。由于这个原因,Python 往往会耗尽内存。
- 移动和前端开发的困扰
没有智能手机支持 Python。所有 android 应用程序的开发都是用 Java 完成的,而 iOS 是用 Swift 和 Objective C 开发的。因此,Python 在不断增长的移动市场中缺乏坚持性。
对照表:Java 与 Python
让我们快速比较一下 Java 和 Python 的各种参数。
| 参数 | Java | Python |
| 语言水平 | 高的 | 高的 |
| 解释器/编译器 | 解释程序和编译程序 | 解释者 |
| 语言类型 | 结构语言;面向对象。 | 通用语言-结构性和过程性。 |
| 执行速度 | 速度比用 Python 快。 | 由于使用翻译,执行缓慢。 |
| 继承 | 提供部分多重继承。 | 提供单一和多重继承。 |
| 编码时使用类 | 绝对代码在类内。 | 使用的函数和变量可以在类外声明。 |
| 语法规范 | 非常特殊的时期。)、逗号(,)和分号。(😉. | 独立于强制使用分号(;) |
| 穿线 | 内置多线程支持。 | 支持多线程。 |
| 用途 | 信息技术、Android、大数据、研究、Web、桌面、银行、零售和桌面应用的进步。 | 用于推进大数据、人工智能、ML、GUI、基于机器人的桌面应用。 |
| 存储器访问 | Uses references, threads, and interfaces.不支持指针。 | Uses objects and blocks.没有使用接口和指针。 |
| 操作员超载 | 不支持运算符重载。 | 支持运算符重载。 |
| 期望结果的理想代码长度 | 极其冗长的代码。 | 最少的编码,大约。比 Java 小 4 倍。 |
| 对平台的依赖 | 独立于平台 | 独立于平台 |
| 库支持 | 大多数接口的库支持。 | 包括巨大的内置库。 |
结论
Python 和 Java 在很多方面都很相似,比如语言水平、对平台的依赖性等等。但是它们在执行速度及其限制、编码时类的使用以及其他一些方面有所不同。
两种语言中任何一种的操作和选择取决于用户的偏好以及可访问性。尽管获取信息对你自己来说可能会变得复杂。
这将加速你的学习曲线,给你所需要的动力。
现在你可以用上面分享的所有信息来选择哪种语言更适合你的需求。
Python While 循环
Python 中的 while 循环基本上只是一种构造代码的方法,当某个表达式为真时,代码会不断重复。要创建一个 while 循环,您需要一个目标语句和一个条件,目标语句是只要条件为真就会一直执行的代码。
while 循环的语法如下所示:
而条件
目标声明
然而,理解 while 循环的最好方法是看它在上下文中做了什么。在下面的例子中看看它是如何工作的:
count = 0
while (count < 4):
print count
count = count + 1
print "Bye!"
因此,上面 while 循环的输出应该如下所示:
0
1
2
3
Bye!
Count 从 0 开始,每执行一次循环,计数就按代码的指示增加 1(count = count+1)。由于这种情况,只有在 count 小于 4 时才会执行循环。所以在第四次执行后,count 变成了 4,循环被打破。然后下一行代码(打印“拜拜!”)可以执行。
Python 的计数方法
在 Python 中,count 方法返回对象在列表中出现的次数。count 方法的语法非常简单:
list.count(obj)
上面的例子代表了这个方法的基本语法。当您在上下文中使用它时,您需要将“list”关键字替换为包含您的对象的列表的实际名称,将“obj”关键字替换为您想要计数的实际对象。查看下面的示例,了解如何使用 count 方法的真实示例:
首先,从一个列表开始:
myList = ['blue', 'orange', 'purple', 'yellow', 'orange', 'green', 'pink'];
现在,要使用 count 方法对列表中的项目进行计数,您的代码应该如下所示:
myList.count('orange');
myList.count('pink');
您可能已经猜到,当您运行上面的代码时,输出将分别是 2 和 1。
使用 Python 的随机模块生成整数
原文:https://www.pythoncentral.io/pythons-random-module-to-generate-integers/
在 Python 中,random 模块允许您生成随机整数。当你需要随机选择一个数字或者从列表中随机选择一个元素时,经常会用到它。使用它实际上非常简单。假设您想要打印一个给定范围内的随机整数,比如 1-100。您应该这样编写代码:
import random
print random.randint(1, 100)
上面的代码将返回一个从 0 到 100 的随机数。要编写代码,只需通过圆括号参数传递想要从中抽取随机整数的数字范围。因此,如果您希望范围是 1-100,第一个参数是 1,最后一个参数是 100——非常简单!
Python 的 range()函数解释
原文:https://www.pythoncentral.io/pythons-range-function-explained/
Python 的 range()函数是什么?
作为一名有经验的 Python 开发人员,甚至是初学者,您可能听说过 Python range()函数。但是它有什么用呢?简而言之,它生成一个数字列表,通常用于通过for循环进行迭代。有许多使用案例。当你想执行一个动作 X 次时,你通常会想使用这个方法,在这种情况下,你可能关心也可能不关心索引。其他时候,您可能希望迭代一个列表(或另一个 iterable 对象),同时能够使用索引。
Python 2.x 和 3.x 中的range()函数工作方式略有不同,但是概念是相同的。不过,我们稍后会谈到这一点。
Python 的 range()参数
range()功能有如下两组参数:
range(stop)
stop:要生成的整数个数(整数),从零开始。range(3) == [0, 1, 2]如。
range([start], stop[, step])
start:序列的起始编号。stop:生成不超过本数的数。step:序列中各数字之间的差异。
请注意:
- 所有参数必须是整数。
- 所有参数都可以是正的或负的。
range()(以及一般的 Python)是基于 0 索引的,这意味着列表索引从 0 开始,而不是从 1 开始。访问列表第一个元素的语法是mylist[0]。因此由range()产生的最后一个整数直到但不包括stop。例如range(0, 5)生成从 0 到 5 的整数,但不包括 5。
Python 的 range()函数示例
简单用法
>>> # One parameter
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
>>> # Two parameters
>>> for i in range(3, 6):
... print(i)
...
3
4
5
>>> # Three parameters
>>> for i in range(4, 10, 2):
... print(i)
...
4
6
8
>>> # Going backwards
>>> for i in range(0, -10, -2):
... print(i)
...
0
-2
-4
-6
-8
迭代列表
>>> my_list = ['one', 'two', 'three', 'four', 'five']
>>> my_list_len = len(my_list)
>>> for i in range(0, my_list_len):
... print(my_list[i])
...
one
two
three
four
five
墙上有 99 瓶啤酒...
用下面的代码:
【python】
for I in range(99,0,-1):
if i == 1:
print('墙上 1 瓶啤酒,1 瓶啤酒!')
print('所以把它拿下来,传来传去,不要再在墙上挂啤酒了!')
elif i == 2:
print('墙上再来 2 瓶啤酒,再来 2 瓶啤酒!'打印('拿一瓶下来,传一传,墙上还有一瓶啤酒!')
else:
打印(' {0}瓶啤酒在墙上,{0}瓶啤酒!'。format(i))
print('所以把它拿下来,传来传去,{0}多瓶啤酒挂在墙上!'。格式(i - 1))
我们得到以下输出:
99 bottles of beer on the wall, 99 bottles of beer!
So take one down, pass it around, 98 more bottles of beer on the wall!
98 bottles of beer on the wall, 98 bottles of beer!
So take one down, pass it around, 97 more bottles of beer on the wall!
97 bottles of beer on the wall, 97 bottles of beer!
So take one down, pass it around, 96 more bottles of beer on the wall!
...
3 bottles of beer on the wall, 3 bottles of beer!
So take one down, pass it around, 2 more bottles of beer on the wall!
2 more bottles of beer on the wall, 2 more bottles of beer!
So take one down, pass it around, 1 more bottle of beer on the wall!
1 bottle of beer on the wall, 1 bottle of beer!
So take it down, pass it around, no more bottles of beer on the wall!
太棒了。终于可以看到 Python 的真正威力了:)。如果你有点困惑,请参考维基百科文章。
Python 的 range()与 xrange()函数
你可能听说过一个叫做xrange()的函数。这是 Python 2.x 中的一个函数,但是在 Python 3.x 中它被重命名为range(),而最初的range()函数在 Python 3.x 中被弃用。那么有什么不同呢?嗯,在 Python 2.x 中range()产生了一个列表,xrange()返回了一个迭代器——一个序列对象。我们可以在下面的例子中看到这一点:
[python]
range(1)
range(0, 1)
type(range(1))
* [Python 2.x](#)
```py
>>> range(1)
[0]
>>> type(range(1))
<type>
所以在 Python 3.x 中,range()函数有了自己的type。基本上,如果你想在一个for循环中使用range(),那么你就可以开始了。然而,你不能把它纯粹当作一个list物体来使用。例如,您不能对range类型进行切片。
当你使用迭代器时,for语句的每个循环都会动态产生下一个数字。而最初的range()函数在for循环开始执行之前就立即产生了所有的数字。最初的range()函数的问题是它在产生大量数字时使用了大量的内存。然而,数字越少,速度越快。注意,在 Python 3.x 中,您仍然可以通过将生成器返回给list()函数来生成一个列表。如下所示:
>>> list_of_ints = list(range(3))
>>> list_of_ints
[0, 1, 2]
在 Python 的 range()函数中使用浮点数
不幸的是,range()函数不支持float类型。然而,不要太早沮丧!我们可以很容易地用函数来实现它。有几种方法可以做到这一点,但这里有一个。
>>> # Note: All arguments are required.
>>> # We're not fancy enough to implement all.
>>> def frange(start, stop, step):
... i = start
... while i < stop:
... yield i
... i += step
...
>>> for i in frange(0.5, 1.0, 0.1):
... print(i)
...
0.5
0.6
0.7
0.8
0.9
1.0
太棒了。
Python 的 string.replace()方法–替换 Python 字符串
原文:https://www.pythoncentral.io/pythons-string-replace-method-replacing-python-strings/
替换 Python 字符串
通常你会有一个字符串(str object),在这里你会想要通过用另一段文本替换一段文本来修改内容。在 Python 中,一切都是对象——包括字符串。这包括str对象。幸运的是,Python 的string模块附带了一个replace()方法。replace()方法是string模块的一部分,既可以从str对象调用,也可以单独从string模块调用。
Python 的 string.replace()原型
string.replace()方法的原型如下:
string.replace(s, old, new[, maxreplace])
函数参数
s: Find and replace the string.- Old
: the old substring you want to replace.
* **New: The new substring that you want to place in the position of the old substring.***[max replace]: the maximum number of times you want to replace a substring.``
例子
从字符串模块直接导入字符串
our_str = 'Hello World'
import string
new_str = string.replace(our_str, 'World', 'Jackson')
print(new_str)
new_str = string.replace(our_str, 'Hello', 'Hello,')
print(new_str)
our_str = 'Hello you, you and you!'
new_str = string.replace(our_str, 'you', 'me', 1)
print(new_str)
new_str = string.replace(our_str, 'you', 'me', 2)
print(new_str)
new_str = string.replace(our_str, 'you', 'me', 3)
print(new_str)
这给了我们以下输出:
Hello Jackson
Hello, World
Hello me, you and you!
Hello me, me and you!
Hello me, me and me!
并使用来自str对象的string.replace()方法:
our_str = 'Hello World'
new_str = our_str.replace('World', 'Jackson')
print(new_str)
new_str = our_str.replace('Hello', 'Hello,')
print(new_str)
our_str = 'Hello you, you and you!'
new_str = our_str.replace('you', 'me', 1)
print(new_str)
new_str = our_str.replace('you', 'me', 2)
print(new_str)
new_str = our_str.replace('you', 'me', 3)
print(new_str)
这给了我们:
Hello Jackson
Hello, World
Hello me, you and you!
Hello me, me and you!
Hello me, me and me!
令人震惊的是,我们得到了相同的输出。
现在你知道了!Python 的string.replace()。
Python 的 time . Sleep()–暂停、停止、等待或休眠您的 Python 代码
原文:https://www.pythoncentral.io/pythons-time-sleep-pause-wait-sleep-stop-your-code/
假设你正在开发一个用户界面,你用你的代码来支持它。您的用户正在上传文档,您的代码需要等待文件上传的时间。同样,当你参观一个有自动门的建筑群时,你一定注意到当你进入建筑群时,门是静止的。只有当你进入建筑群时,门才会自动关闭。是什么导致了这两种情况下的延迟?
代码支持上述两种系统。正是编程语言的 延时函数 导致了所需的延时。我们还可以在 Python 代码中添加时间延迟。Python 的 time 模块允许我们在两个语句之间建立延迟命令。添加时间延迟的方法有很多种,在本文中,我们将逐步讨论每种方法。
Python 的 time . Sleep()–暂停、停止、等待或休眠您的 Python 代码
Python 的 时间 模块有一个很好用的函数叫做sleep()。本质上,顾名思义,它暂停您的 Python 程序。time . sleep()命令相当于 Bash shell 的sleep命令。几乎所有的编程语言都有这个特性。
功能
**使用该函数时,我们可以指定延时,编译器将执行固定的延时。 该函数的语法如下:
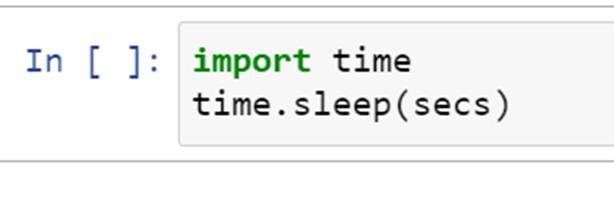
time.sleep()参数
- secs-Python 程序应该暂停执行的秒数。这个参数应该是一个 int 或者 float 。
使用 Python 的 time.sleep()
这里有一个快速简单的语法示例:

在这里,我们通过第一个命令指示系统等待五秒钟,然后等待 三百毫秒,等于 0.3 秒。 你可以在这里注意到,我们已经根据语法在括号内写了时间延迟的值。
现在让我们考虑另一个执行时间延迟的例子。

这里我们取了一个变量“a ”,它的值存储为 5。现在我们打印值“a ”,然后再次打印增加的值“a”。但是,两个语句的执行之间存在时间延迟。并且,我们已经指定使用time . sleep()函数。你一定观察到了,我们在代码的开头也导入了 time 模块。
现在我们来看看输出是什么:
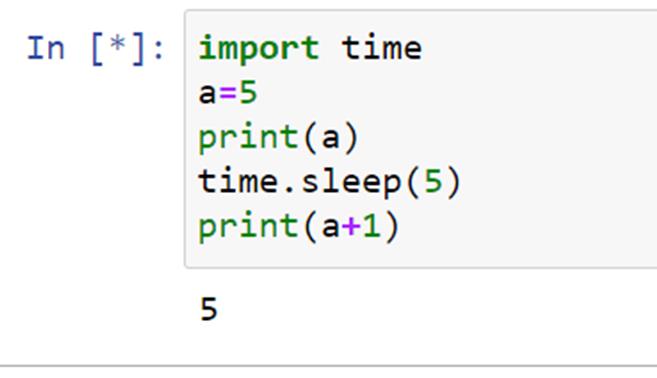
在这里,我们可以看到只有第一个命令被执行。现在五秒钟后的输出:

现在,经过五秒钟的延迟后,第二条语句也被执行。
睡眠的高级语法() 功能
**这里有一个更高级的例子。它接受用户输入,并询问您想要 【睡眠() 多长时间。它还通过打印出time . sleep()调用前后的时间戳来证明它是如何工作的。注意,Python 2.x 使用raw _ input()函数获取用户输入,而 Python 3.x 使用input()函数。现在让我们看看输入语法:
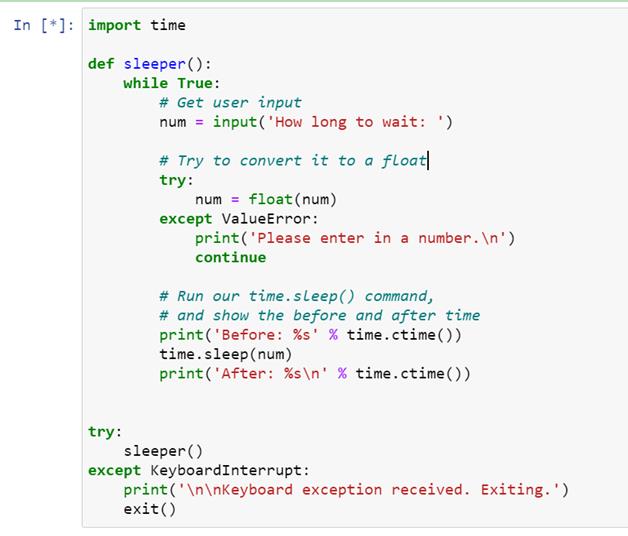
上面给出的代码询问用户要等待多长时间。我们已经在sleeper()函数中提到了这个输出的命令。然后,代码在代码执行开始时和代码实现后打印计算机时间。通过这种方式,我们可以看到延迟功能的实际功能。现在让我们看看输出:
系统要求我们输入,即我们希望系统等待多长时间。让我们输入 5 秒,观察最终的输出。
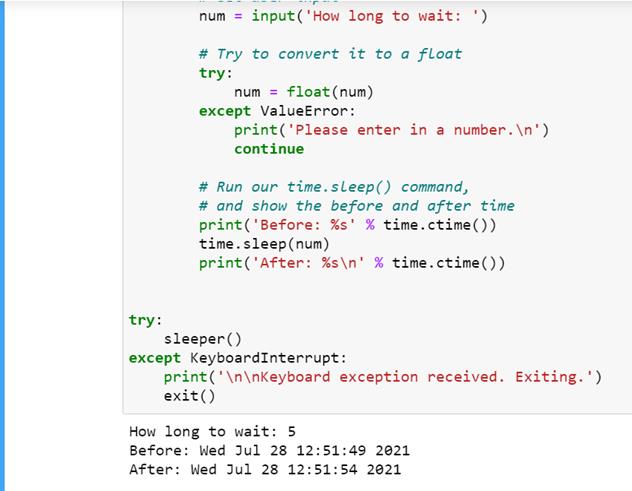
我们可以看到起始计算机时间(“之前”)和结束计算机时间(“之后”)有五秒钟的时间差。
time . sleep()的准确性
time . sleep()函数使用底层操作系统的sleep()函数。最终,这一功能有其局限性。例如,在标准的 Windows 安装中,您可以延迟的最小时间间隔是 10 - 13 毫秒。Linux 内核倾向于具有更高的滴答率,其时间间隔通常接近 1 毫秒。注意,在 Linux 中,可以安装RT _ PREEMPT补丁集,这样就可以拥有一个半实时内核。使用实时内核将进一步增加time . sleep()函数的准确性。但是,除非你想短暂的 睡眠 ,一般可以忽略这个信息。
使用装饰者添加time . sleep()命令
装饰器 用于创建调用高阶函数的简单语法。什么时候可以用装修工?假设我们不得不再次测试一个功能,或者用户不得不再次下载一个文件,或者你不得不在特定的时间间隔后检查一个接口的状态。您需要在第一次尝试和第二次尝试之间有一段时间延迟。因此,您可以在需要重复检查和需要时间延迟的情况下使用 decorators。
让我们考虑一个使用装饰者的例子。在这个程序中,我们将计算执行函数所花费的时间。

这里的time _ calc()是装饰函数,扩展并包含了其他函数,从而提供了简单的语法。让我们看看输出是什么。

使用线程添加time . sleep()命令
Python 中的多线程 相当于同时运行几个程序。当多线程与模块相结合时,我们可以快速解决复杂的问题。多线程功能可从 线程 模块获得。
让我们使用多线程和时间延迟来打印字母表歌曲。
这里一个线程被用来打印单个的字母。也有 0.5 秒的时间延迟。当你运行这个程序时,你会看到字母表歌曲的每一行都在 0.5 秒的延迟后被打印出来。我们来看看输出是什么:
延时练习题
-
打印两个延时报表:
在这个问题中,我们将打印两条语句,第一条是“大家好!”
第二个问题是“这是一个关于时间延迟的练习题。”我们将在这两个语句之间引入 5 秒的时间延迟。我们来看看这个问题的代码语法:
![Printing two statements 1]()
如你所见,基本步骤很简单。我们首先导入时间模块。接下来,我们给出第一条语句的打印命令。然后我们通过time . sleep()函数引入延时,然后我们给出打印以下语句的命令。我们来看看输出是什么:
![Printing two statements 2]()
此图显示了第一个输出。
![Printing two statements 3]()
现在,这个输出比前一个输出晚五秒钟获得。
-
显示日期和时间的程序:
让我们创建一个程序,在这个程序中,我们制作一个也能显示日期的数字钟。
该任务的代码如下:
![Program to display date and time 1]()
这里我们给出了显示日期和时间的命令。然后,我们添加了一秒钟的时间延迟,以便更新时间。该程序的输出如下:
![Program to display date and time 2]()




结论
时间延迟在用户界面中有着巨大的应用。对于程序员来说,知道如何在程序中增加时间延迟是很重要的。我们希望这篇文章能帮助你了解 Python 的时间模块。现在,您可以有效地在代码中添加时间延迟,并提高代码的生产率!****
快速排序:教程和实施指南
原文:https://www.pythoncentral.io/quick-sort-implementation-guide/
先决条件
要了解快速排序,您必须知道:
- Python 3
- Python 数据结构-列表
- 递归
什么是快速排序?
我们正在学习排序系列的第五个也是最后一个教程。前面的教程讲的是冒泡排序、[插入排序](https://www.pythoncentral.io/insertion-sort-implementation-guide/ )、选择排序和归并排序。如果你还没有读过,请照着我们将要建立的那些概念去做。像所有的排序算法一样,我们认为一个列表只有在升序时才被排序。降序被认为是最坏的未排序情况。
快速排序与我们目前看到的排序技术有很大的不同,也很复杂。在这种技术中,我们选择第一个元素,并将其称为。其思想是对元素进行分组,使枢轴左边的元素比枢轴小,而枢轴右边的元素比枢轴大。这是通过维护两个指针 左 和 右 来实现的。 左边的 指针指向枢轴后的第一个元素。让我们把 左边 所指的元素称为 lelement。 同理,右侧的指针指向列表右侧最远的元素。让我们称这个元素为relement。在每一步,比较 元素 与 枢轴 与 元素 与 枢轴。 记住 元素<枢轴 和 元素>枢轴 。如果不满足这些条件,则 元素 和 元素 被交换。否则, 左 指针递增 1, 右 指针递减 1。当 左> =右 时, 枢轴 与 元素 或 元素交换。**枢轴 元素将在其正确的位置。然后在列表的左半部分和右半部分继续快速排序。
让我们用一个例子来看看,列表= [5,9,6,2,7,0]
| 枢轴 | 左 | 右 | 比较 | 动作 | 列表 |
| 5 | 9 [1] | 0 [5] | 9>50 < 5 | Swap 0 and 9将 向左 增加 1递减 右 1 | 【5,0,6,2,7,9】 |
| 5 | 6 [2] | 7【4】 | 6>57 > 5 | 将 右 指针减少 1 个 指针,将 左 指针原样保留 | 【5,0,6,2,7,9】 |
| 5 | 6 [2] | 2【3】 | 6>52 < 5 | Swap 2 and 6将 向左 增加 1递减 右 1 | 【5,0,2,6,7,9】 |
| 5 | 6【3】 | 2【2】 | 停止(自 左>右 ) | 交换 5 和 2 | 【2,0,5,6,7,9】 |
同样,对左半部分[2,0]和右半部分[6,7,9]执行快速排序。重复此过程,直到整个列表排序完毕。即使我们可以看到右半部分已经排序,算法也无法知道这一点。
为了更好的理解,请看这个动画。
如何实现快速排序?
现在你已经对快速排序有了一个相当好的理解,让我们来看看这个算法及其代码。
算法
- 选择一个支点
- 设置左指针和右指针
- 比较一下指针元素(lelement)与 pivot指针元素(relelement)与pivot。
- 检查lelement<pivot和relement>pivot:
- 如果是,则左指针递增,右 指针指针递减
- 如果没有,互换 lelement 和 relement
- 当 左> =右、 将 支点 与或 右 指针互换。
- 在列表的左半部分和右半部分重复步骤 1 - 5,直到整个列表排序完毕。
代码
def quickSort(alist):
quickSortHelper(alist,0,len(alist)-1)
def quickSortHelper(alist,first,last):
if first<last:
splitpoint = partition(alist,first,last)
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)
def partition(alist,first,last):
pivotvalue = alist[first]
leftmark = first+1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:
leftmark = leftmark + 1
while alist[rightmark] >= pivotvalue and rightmark >= leftmark:
rightmark = rightmark -1
if rightmark < leftmark:
done = True
else:
temp = alist[leftmark]
alist[leftmark] = alist[rightmark]
alist[rightmark] = temp
temp = alist[first]
alist[first] = alist[rightmark]
alist[rightmark] = temp
return rightmark
alist = [54,26,93,17,77,31,44,55,20]
quickSort(alist)
print(alist)
代码由互动 Python 提供。
如何选择支点?
选择 中枢 非常关键,因为它决定了这个算法的效率。如果我们得到一个已经排序的列表,我们选择第一个元素为 pivot 那么这将是一场灾难!这是因为没有比 中枢 更大的元素了,这大大降低了 的性能。 为了避免这种情况,有几种方法可以用来选择 枢轴 的值。一种这样的方法是中位数法。在这里,我们选择第一个元素、最后一个元素和中间的元素。在比较了这三个元素之后,我们选择具有中间值的元素。让我们用一个例子来看看,list = [5,6,9,0,3,1,2]
第一个元素是 5,最后一个元素是 2,中间元素是 0。比较这些值,很明显,2 是中间值,这个选为。诸如此类的方法确保我们不会以最差的选择作为我们的 支点。 记住最差选择为是列表中最小或最大的值。
结论
快速排序最适用于小数量和大数量的元素。快速排序在最坏情况下的运行时间复杂度是 O(n2),类似于插入和冒泡排序,但可以改进为 O(nlog(n)),如前一节所述。与合并排序不同,它没有使用额外内存或空间的缺点。这就是为什么这是最常用的排序技术之一。本教程到此为止。快乐的蟒蛇!
快速提示:如何打印模块的文件路径
原文:https://www.pythoncentral.io/quick-tip-how-to-print-a-file-path-of-a-module/
Python 提供了一种非常容易和简单的方法来检索导入模块的文件路径。如果您试图快速找到文件路径,并且您正在处理一个具有多个子目录的项目,或者如果您正在使用主要通过命令行访问的脚本或程序,这将非常有用。如果您处于类似的情况,您可以使用下面的方法来查找模块的确切文件路径:
import os
print(os)
就是这样。每当您想知道代码中模块文件的确切位置时,就使用这个技巧。然后应该会为您打印出模块的准确文件路径。它可能看起来像这样:
<module 'os' from '/usr/lib/python2.7/os.pyc'>
快速提示:在 Python 中反转字符串
原文:https://www.pythoncentral.io/quick-tip-reversing-strings-in-python/
Python 中没有用于反转字符串的内置函数,但这并不意味着它不能完成。要在 Python 中反转一个字符串,需要使用一点扩展的 slice 语法,所以您必须在代码中添加类似下面这样的内容:[::-1]。
我们的意思是:
p = backwards
print p[::-1]
上面代码的结果应该如下:
sdrawkcab
这是因为在扩展的 slice 语法中,您告诉函数从哪里开始和结束(通过插入两个分号,您告诉函数从开头开始,在结尾结束),然后向后遍历字符串(通过使用-1...使用-2 仍然会向后打印,但会跳过每隔一个字母,所以结果会是:srwcb)。
亲自尝试一下,看看在 Python 中反向或向后迭代一个字符串是多么容易!
快速提示:如何使用 Python 转置矩阵
原文:https://www.pythoncentral.io/quick-tip-transpose-matrix-using-python/
你可能在数学课上记得这个,但是即使你不记得,也应该很容易理解。我们已经讨论了矩阵以及如何在 Python 中使用它们,今天我们将讨论如何快速简单地转置一个矩阵。当你转置一个矩阵时,你是在把它的列变成它的行。当你看到这样的例子时,就更容易理解了,所以看看下面的例子。
假设你的原始矩阵是这样的:
x = [[1,2][3,4][5,6]]
在该矩阵中,有两列。第一个由 1、3 和 5 组成,第二个由 2、4 和 6 组成。当你转置矩阵时,列变成行。因此,上述矩阵的转置版本将如下所示:
y = [[1,3,5][2,4,6]]
所以结果仍然是一个矩阵,但现在它的组织方式不同了,在不同的地方有不同的值。
在 Python 中自己转置一个矩阵实际上很容易。使用内置的压缩功能可以非常快速地完成这项工作。下面是它的样子:
matrix = [[1,2][3.4][5,6]]
zip(*matrix)
上面代码的输出就是转置矩阵。超级简单。
你也可以使用 NumPy 转置一个矩阵,但是为了这样做,必须安装 NumPy,这是一种更为笨拙的方法,可以实现与 zip 函数同样的目标,而且非常快速简单。
既然您已经理解了什么是转置矩阵以及如何自己去做,那么在您自己的代码中尝试一下,看看它为您自己的定制函数和代码片段增加了什么类型的通用性和功能性。理解如何使用和操作矩阵真的可以为你的编码技能增加很多维度,这是一个放在你口袋里的好工具。
快速提示:使用 Python 的比较运算符
原文:https://www.pythoncentral.io/quick-tip-using-pythons-comparison-operators/
就像在任何其他 OOP 语言中一样,Python 使用比较运算符来比较值。这些通常被称为布尔运算符,因为布尔一词表示使用比较运算符的结果是一个布尔值:真或假。下面是在 Python 中计算表达式、编写函数和比较值时可以使用的布尔值列表。看一看:
- == 表示您正在尝试辨别两个值是否相等——确保使用两个等号,而不是一个!
- != 表示您试图辨别两个值是否不相等。所以如果你有这样一个表达式:
7 != 10
您的答案将是布尔值:真。
- < 这个表示你在比较两个值,看第一个值是否小于第二个值,就像这样:
7 < 10
所以在这里,你的答案也是你的布尔值:真。
- > 这个运算符表示您正在比较两个值,看第一个值是否大于第二个值。所以在上面的例子中,用大于号代替左边的符号,你会得到一个布尔值 false,因为 7 不大于 10。
- < = 这个表示你在比较两个值,看看第一个值是小于还是等于第二个值。所以如果你有下面的表达式:
10 <= 10
您的答案将是布尔值 true,因为 10 等于 10(它不小于 10,但我们检查小于或等于)
- > = 你大概能猜出这个运算符是什么,但以防万一你猜不出来,它用来表示你正在比较两个值,看第二个值是否大于或等于第一个值。所以如果你把上面例子中的符号从小于或等于换成大于或等于,你仍然会得到相同的真值,因为 10 仍然等于 10。
快速提示:使用 Python 的 In 操作符
原文:https://www.pythoncentral.io/quick-tip-using-pythons-in-operator/
在 Python 中,单词“In”可以用作成员测试运算符。这是检查 Python 对象中是否存在某个值的好方法。请看下面的例子,了解它在上下文中的用法:
a = "学 Python 超级好玩!"
【超级】一
真实
上面的例子演示了如何使用“in”操作符。第二行代码(a 中的“super ”)检查字符串 a 中是否出现了字符组合“super ”(完全按照那个顺序)。正如您可能看到的,它确实出现在字符串 a 中,所以我们使用“in”操作符进行的成员资格测试的输出为真。当在这个上下文中使用时,in 操作符将总是返回一个布尔值(true 或 false),使用它是测试和检查某个值或字符集是否存在于任何对象中的一种非常有效的方法。
快速提示:在 Python 中使用集合
原文:https://www.pythoncentral.io/quick-tip-using-sets-in-python/
在 Python 中,集合是不包含任何重复条目的列表。使用 set 类型是确保列表不包含任何重复项的一种快速而简单的方法。下面是一个如何使用它来检查重复列表的示例:
a = set(["Pizza", "Ice Cream", "Donuts", "Pizza"])
print a
因为“Pizza”在列表中出现了两次,所以使用 set 将产生一个“Pizza”只出现一次的列表输出,如下所示:
set(['Pizza', 'Ice Cream', 'Donuts'])
如您所见,使用 set 类型是确保列表中的每个值都是独一无二的好方法。
用 Python 读写文件
原文:https://www.pythoncentral.io/reading-and-writing-to-files-in-python/
操纵文件是 Python 脚本的一个重要方面,幸运的是,这个过程并不复杂。内置的open函数是读取任何类型文件的首选方法,也可能是您需要使用的所有方法。让我们首先演示如何在一个简单的文本文件上使用这个方法。
为了清楚起见,让我们首先在标准文本编辑器(本例中为 MS Notepad)中编写文本文件字符串。当在编辑器中打开时,它看起来像这样(注意空的尾随行):

为了用 Python 打开我们的文件,我们首先必须知道文件的路径。在本例中,文件路径是相对于当前工作目录的。所以我们不需要在解释器中输入完整的路径。
>>> tf = 'textfile.txt'
用 Python 打开一个文件
使用这个变量作为open方法的第一个参数,我们将文件保存为一个对象。
>>> f = open(tf)
用 Python 读取文件
当我们引用我们的 file-object f时,Python 告诉我们状态(打开或关闭)、名称和模式,以及一些我们不需要的信息(关于它在我们机器上使用的内存)。
我们已经知道这个名字,我们没有关闭它,所以我们知道它是开放的,但模式值得特别注意。我们的文件f处于模式 r 中,用于读取。具体来说,这意味着我们只能从文件中读取数据,而不能编辑或向文件中写入新数据(对于text,它也处于t模式,尽管它没有明确说明这一点——这是默认模式,就像 r 一样)。让我们用read方法从文件中读取我们的文本:
>>> f.read()
'First line of our text.\nSecond line of our text.\n3rd line, one line is trailing.\n'
这看起来不完全像我们在记事本中输入的内容,但这是 Python 读取原始文本数据的方式。获取我们输入的文本(没有\n换行符,我们可以打印它):
>>> print(_)
First line of our text.
Second line of our text.
3rd line, one line is trailing.
注意我们如何在 Python IDLE 中使用_字符来引用最近的输出,而不是再次使用read方法。如果我们试着用read来代替,会发生什么:
>>> f.read()
''
发生这种情况是因为 read 返回了文件的全部内容,而不可见的位置标记(Python 如何跟踪你在文件中的位置)在文件的末尾;没什么可看的了。
部分读取 Python 中的文件
注意:如果你不想要文件的全部内容,你可以在read中使用一个整数参数;Python 将读取您为read指定的任意数量的字节作为整数参数。
要回到文件的开头(或文件中的任何地方),在f上使用seek(int)方法。通过回到开头,您可以使用read从头开始再次阅读内容:
>>> f.seek(0)
# We only read a small chunk of the file, 10 bytes
print(f.read(10))
First line
此外,要知道文件的当前位置,在f上使用tell方法,如下所示:
>>> f.tell()
10L
如果你不知道你的文件的大小或者你想要多少,你可能会发现这没什么用。
用 Python 逐行读取文件
然而,有用的是逐行读取文件的内容。我们可以用readline或readlines方法做到这一点——第一个方法一次读取一行,第二个方法返回文件中每一行的列表;两者都有一个可选的整数参数来指示要读取多少文件(多少字节):
# Make sure we're at the start of the file
>>> f.seek(0)
>>> f.readlines()
['First line of our text.\n', 'Second line of our text.\n', '3rd line, one line is trailing.\n']
>>> f.readline()
'First line of our text.\n'
>>> f.readline(20)
'Second line of our t'
# Note if int is too large it just reads to the end of the line
>>> f.readline(20)
'ext.\n'
逐行读取文件的另一种方法是将它视为一个序列并遍历它,如下所示:
>>> f.seek(0)
>>> for line in f:
>>> print(line)
First line of our text.
Second line of our text.
3rd line, one line is trailing.
用 Python 读取文件的特定行
我们可以使用readlines方法来访问文件中的特定行。
假设我们有一个名为test.txt的文件,包含以下文本:
one
two
three
four
我们可以这样理解第二行:
>>> test_file = open('test.txt', 'r')
>>> test_lines = test_file.readlines()
>>> test_file.close()
>>> # Print second line
>>> print(test_lines[1])
two
注意,它打印了两行,因为该行有一个行尾,而`print`添加了另一个行尾。可以用*剥离*的方法,比如`print(test_lines[1].strip())`。
**Python 文件写入模式**
这涵盖了文件的基本读取方法。在查看写入方法之前,我们将简要检查用`open`返回的 file-object 的其他*模式*。
我们已经知道了模式 *r* ,但是还有 *w* 和 *a* 模式(分别代表*写*和*追加*)。除此之外还有选项 *+* 和 *b* 。添加到模式中的 *+* 选项使文件为更新而打开,换句话说,就是从中读取或向其中写入。
使用这个选项,看起来似乎在 *r+* 模式和 *w+* 模式之间没有什么区别,但是这两者之间有一个*非常*重要的区别:在 *w* 模式中,文件被自动截断,这意味着它的**全部内容**被擦除——所以即使在 *w+* 模式中,文件一打开就会被完全覆盖,所以要小心。或者,您可以使用`truncate`方法自己截断打开的文件。
如果你想写到文件的末尾,只需使用*追加*模式(如果你也想从中读取,使用 *+* )。
*b* 选项表示以*二进制*文件打开文件(而不是默认的*文本*模式)。每当文件中有非常规文本的数据时(例如,打开图像文件时),请使用此选项。
现在让我们看看如何写入我们的文件。我们将使用 *a+* 模式,这样我们就不会删除已有的内容。首先让我们关闭文件`f`并打开一个新文件`f2`:
It's important to close the file to free memory
f.close()
f2 = open(tf, 'a+')
我们可以看到我们的`f`文件现在被关闭了,这意味着它没有占用太多的内存,并且我们不能对它执行任何方法。
**注意:**如果你不想在文件上显式调用`close`,你可以使用一个`with`语句来打开文件。`with`语句将自动关闭文件:
f remains open only within the 'with'
with open(tf) as f:
print(f.read())
First line of our text.
Second line of our text.
3rd line, one line is trailing.
This constant tells us if the file is closed
f.closed
True
用 *f2* ,让我们写到文件的末尾。我们已经处于追加模式,所以我们可以调用`write`:
f2.write('Our 4th line, with write()\n')
**用 Python 写多行到一个文件**
这样我们就写入了我们的文件,我们也可以用`writelines`写多行,这将把一个字符串序列(例如一个*列表*)作为行写入文件:
f2.writelines(['And a fifth', 'And also a sixth.'])
f2.close()
**注意:**的名字`writelines`是一个误称,因为**而不是**会自动在序列中的每个字符串末尾写换行符,我们将会看到。
好了,现在我们已经写好了文本并关闭了`f2`,所以当我们在文本编辑器中打开文件时,我们所做的更改应该会出现在文件中:

我们可以看到`writelines`方法并没有把我们的第五行和第六行分开,所以请记住这一点。
现在,您有了一个好的起点,开始编写脚本并探索在 Python 中读写文件时可以做些什么——不要忘记利用 Python 为字符串提供的所有广泛的格式化方法!
Python 的真实世界正则表达式
原文:https://www.pythoncentral.io/real-world-regular-expressions-for-python/
我们已经在这一系列文章中讨论了很多内容,所以现在让我们把它们放在一起,并通过一个实际应用程序来工作。
一个常见的任务是解析 Windows INI 文件,这些文件是键/值对,分成几个部分,如下所示:
[Section 1]
val1=hello world
val2=42
[Section 2]
val1=foo!
让我们首先编写一段 Python 代码,逐行读入测试文件:
for lineBuf in open('test.ini', 'r'):
print(lineBuf)
现在,我们将通过编写一些正则表达式来计算每行内容,从而扩展这一点。
识别章节标题
我们要做的第一件事是编写一个正则表达式,它将识别部分标题,即以方括号开始和结束的行。我们可以这样写一个正则表达式:^\[(.+)\]$
用简单的英语说:
- 匹配
^(行首)。 - 匹配一个
[字符(转义,因为[通常在正则表达式中有特殊含义)。 - 匹配在组中捕获的一个或多个字符(部分名称)。
- 匹配一个
]字符(其实没必要转义这个)。 - 匹配
$(行尾)。
如果我们更新代码来使用这个正则表达式:
sectionRegEx = re.compile(r'^\[(.+)\]$')
for lineBuf in open('test.ini', 'r'):
mo = sectionRegEx.search(lineBuf)
if mo:
print('Found a section: [%s]' % mo.group(1))
我们得到这样的输出:
Found a section: [Section 1]
Found a section: [Section 2]
似乎工作正常!
处理节标题中的空白
处理节标题中的空白会很方便,所以如果有人给我们一个如下所示的 INI 文件:
[Section 1]
val1=hello world
val2=42
[ Section 2 ] junk here!
val1=foo!
我们将能够正确处理奇怪的第二部分标题。现在,我们的代码没有找到它,所以让我们更新正则表达式来处理它:^\s*\[\s*(.+?)\s*\]
用简单的英语说:
- 匹配
^(行首)。 - 匹配
\s*(零个或多个空白字符)。 - 匹配一个
[字符。 - 匹配
\s*(零个或多个空白字符)。 - 匹配一个或多个字符(部分名称)。
- 匹配
\s*(零个或多个空白字符)。 - 匹配一个
]字符。
请注意,我们必须使+字符(捕获部分名称)非贪婪,以防止它匹配任何可能出现在结束]之前的尾随空格。我们也在结束]后停止匹配,因为我们不关心在它之后的线上是否有任何东西。
现在,我们的代码识别了格式古怪的节名:
sectionRegEx = re.compile(r'^\s*\[\s*(.+?)\s*\]')
for lineBuf in open('test.ini', 'r'):
mo = sectionRegEx.search(lineBuf)
if mo :
print('Found a section: [%s]' % mo.group(1))
这为我们提供了以下输出:
Found a section: [Section 1]
Found a section: [Section 2]
找到了第二个部分的标题,并清除了它的名称。
识别键/值对
下一步是编写一个识别键/值对的正则表达式,可能是这样的:^(.+)=(.+)$
用简单的英语说:
- 匹配
^(行首)。 - 匹配在组中捕获的一个或多个字符(密钥名)。
- 匹配
=字符。 - 匹配在组中捕获的一个或多个字符(键值)。
- 匹配
$(行尾)。
同样,我们希望这个正则表达式处理无关的空白,所以让我们把它改写成这样:^\s*(.+?)\s*=\s*(.+?)\s*$
我们更新后的代码现在看起来像这样:
sectionRegEx = re.compile(r'^\s*\[\s*(.+?)\s*\]')
keyValRegEx = re.compile(r'^\s*(.+?)\s*=\s*(.+?)\s*$')
for lineBuf in open('test.ini', 'r'):
mo = sectionRegEx.search(lineBuf)
if mo:
print('Found a section: [%s]' % mo.group(1))
mo = keyValRegEx.search(lineBuf)
if mo:
print('{%s} = {%s}' % (mo.group(1), mo.group(2)))
当我们打印键名和值时,我们用花括号将它们括起来,这样我们就可以看到它们是否被正确地剪裁了。
如果我们给它以下测试输入:
[Section 1]
val1=hello world
val2 = 42 = forty-two
[ Section 2 ] junk here!
val1=foo!
我们得到以下输出:
Found a section: [Section 1]
{val1} = {hello world}
{val2} = {42 = forty-two}
Found a section: [Section 2]
{val1} = {foo!}
为什么 Python 是最好的编程语言
原文:https://www.pythoncentral.io/reasons-why-python-is-the-best-programming-language/
如果你想知道谁会做我的 Python 作业,不要担心,因为你总能在网上找到专业的作业帮助服务。在专业网站上,专家可以为学生提供任何复杂程度的在线 Python 作业帮助。
网站助手以低廉的价格为学生提供服务,无论你在哪里学习,在学校,学院或大学。专业人士将根据既定的截止日期交付没有抄袭的优质解决方案。可以选择最适合自己的期限。您的家庭作业解决方案可以在 5 小时或 5 天内交付。
不用担心工作质量,因为每个帮工都有学位,都是高等教育机构毕业的。你甚至可以检查帮助者如何为其他学生做某类作业的例子。所有的专家都有在网上帮助学生完成家庭作业的长期经验。
最重要的是,你可以随时寻求援助。如果你突然忘记了,你甚至可以在晚上点一份作业解决方案。
应该从学习哪种编程语言开始?
如果你喜欢一个 STEM 主题,并且你已经决定你想把你的职业与它联系起来,你需要知道哪种编程语言会在你的工作中帮助你。最有可能的是,你将开始学习 Python 的编程语言。
Python 是最简单的编程语言之一,在 IT 界越来越受欢迎。Python 在编程语言中排名第四,仅次于经典的 Java、C 和 C ++。今天,每个程序员都必须拥有这个工具才能在自己的领域取得成功。
Python 是一种多用途编程语言,允许程序员编写可读性很好的代码。Python 的相对简洁性允许您创建一个比用另一种语言编写的程序要短得多的程序。
作为一种多平台编程语言,意味着 Python 程序可以在不同的操作系统上运行,而无需任何修改。
Python 的另一个优势是它的标准库,它与 Python 一起安装,包含用于操作系统、网页、数据库、各种数据格式的现成工具,用于构建程序的图形界面等等。
你可以用 Python 创建完全不同的程序;它们可以是小的脚本,也可以是复杂的系统。
最重要的是你可以免费使用 Python。因此,如果你不喜欢这个项目,你不会失去任何东西,也不会多付额外的钱。
对于不同的项目,这种编程语言还有许多其他好处。
Python 对于 web 开发来说很方便
据 web 开发人员称,Python 是备选语言中最方便的编程语言。
由于标准 web 开发任务的现成解决方案的应用程序的可用性,单个项目的速度提高了许多倍。稳定性应该理解为应用程序在任何条件下的可靠性。
Python 很可靠
美国银行选择 Python 来管理关键系统,美国证券交易委员会将 Python 作为一种语言来支持华尔街——听起来很有说服力。这种信任不是没有根据的:执行一项任务的几行代码使它不容易出现问题,并且易于调试。
Python 也用于在一些复杂的任务中扩展解决方案,结果可以在在线服务 YouTube、Dropbox、Reddit、Quora 和 Disqus 中看到。最初,这些资源有一个小而原始的功能。随着时间的推移,它们越来越受欢迎,它们引入了新的选项,Python 帮助快速、轻松地完成了这些工作。
Python 用于数据科学
无论您在 IT 领域选择哪条道路,数据都将是其中的一部分。分析技能的必要性不亚于编程技能,Python 在这两个领域都有应用。在 R 语言的层面上,Python 最常用于数据科学,Python 开发人员的空缺数量超过了 R 语言的类似职位。与 Python 不同,R 语言是用于研究和统计分析的特定工具。
数据并没有变小;对专家的需求越来越大,所以为了将来不迷失方向,现在就开始学习 Python 吧。由于编程语言总是有需求的,你可以很容易地找到一份掌握它的高薪工作。
哪些职业需要我的 Python 技能?
学习流行的编程语言为初学者打开了许多专业的大门。您可以在以下位置轻松开始您的职业生涯:
- 网络安全——防范黑客攻击、创建渗透系统的测试、安全系统分析以及软件开发。
- 物联网——又称物联网、智能家居。你可以买几个设备,在家试着配置或者专业做。
- 营销——从你的数据中提取和分析用户信息,或者使用脸书、谷歌和 Twitter 的 API。
- 科学-数学和统计层面的数据处理,从各个领域的实验室实验结果中提取信息部分。
- QA——通过从事自动化测试,你可以成为一名软件测试人员。
- 机器学习——Python 据说是机器学习的未来,我们也建议你以后多学一点。
Python 的一个可能的缺点是代码执行速度。Python 不是编译语言。Python 代码首先被编译成内部字节码,然后由 Python 解释器执行。在大多数情况下,与 c 等语言相比,使用 Python 会产生较慢的程序。
然而,现代计算机的计算能力如此之强,以至于对于大多数应用来说,开发速度比执行速度更重要,Python 程序通常会写得快得多。
此外,用 C 或 C ++编写的模块很容易扩展 Python。这种模块可用于执行程序中对处理器产生高负荷的部分。
你想获得编程博士学位的原因
原文:https://www.pythoncentral.io/reasons-why-you-might-want-to-get-a-phd-in-programming/

如果你已经完成了编程硕士学位,那么为什么不继续深造,获得博士学位呢?博士课程非常密集,但提供有用的信息。除了在教育上特别有用之外,它们还能让你的简历对雇主更有吸引力。
这篇文章将解释你可能想获得编程博士学位的一些其他原因:
速成班
人们避免完成博士学位的一个主要原因是课程的长度,通常是三到四年。然而,现在有许多课程提供商提供可以在线学习的两年制博士课程。这使得博士课程更容易被那些有其他任务的人所接受,比如工作或养育子女。如果速成课程对你有吸引力,那么你一定要深入研究。
智力优势
完成博士学位会让你比同领域的其他人更有智力优势,你可能会和他们竞争 T2 的工作。博士学位是你能获得的最高学位。这不仅意味着你会比你的同事或竞争对手更聪明,也意味着你更有资格。
此外,你的博士课程将让你有机会更深入地钻研编程,学习更多知识,探索你可能还不熟悉的领域。
Python 语言
你在攻读博士学位期间要完成的很多工作都将围绕 Python 这种高级编程语言展开。Python 支持多种编程范式,从过程式编程到函数式编程,是最容易学习的编程语言之一,但也是最难掌握的编程语言之一。完成编程博士学位的一个好处是,与你将来可能共事的人不同,你将会掌握它。
职业网络
完成博士学位后,你会遇到很多和你在同一领域工作的人,从学生到讲师。即使你没有积极地找工作,建立一个职业关系网也会被证明对你的未来特别有用。你的名字可能会被考虑用于你还没有申请的工作,以及奖学金。你会遇到世界上最优秀的程序员,你可能会在未来的项目中与他们合作。这也会让你更容易写一本关于编程的书,并为你的出版提供关系网。

专业研究
当你完成博士学位后,你将成为一名专业研究员。这将让你申请专业的研究工作,这是非常高的报酬和令人满意的。可以做学术研究员,也可以做产业研究员。在学术界做研究员也会给你机会教学生。
挑战自我
如果你已经完成了你的硕士学位,那么为什么不 挑战一下自己 去攻读你的博士学位呢?下定决心做某事并实现它是世界上最令人满意的事情之一。如果你能推动自己完成博士学位,那么绝对没有什么是你做不到的。
信用到期时的信用
当你为一家公司工作时,你就签字放弃你的工作。作为一名研究人员,在整个博士学位期间,你所完成的工作将完全属于你。这项工作可以发布供公众使用,这将导致你在其他人的工作中被引用、引述和赞扬。
没有其他资格能像博士一样享有如此高的声望。如果你认为你有所需要,那么为什么不去争取呢?唯一阻止你的是你自己。
Python 中的递归文件和目录操作(第 1 部分)
原文:https://www.pythoncentral.io/recursive-file-and-directory-manipulation-in-python-part-1/
如果您希望利用 Python 来操作系统上的目录树或文件,有许多工具可以提供帮助,包括 Python 的标准操作系统模块。下面是一个简单/基本的方法,可以帮助您通过文件扩展名找到系统中的某些文件。
如果您有在系统中“丢失”文件的经历,您不记得它的位置,甚至不确定它的名称,尽管您记得它的类型,这就是您可能会发现这个方法有用的地方。
在某种程度上,这份食谱结合了 Python 中的如何遍历目录树和递归目录遍历:制作你的电影列表!,但我们会对其稍作调整,并在第二部分中对其进行改进。
要编写这个任务的脚本,我们可以使用os.path模块中的walk函数或os模块中的walk函数(分别使用 Python 3.x 版或 Python 3.x 版)。
用 Python 2.x 中的 os.path.walk 进行递归
os.path.walk函数有 3 个参数:
- 一个武断的(但却是强制性的)论点。
visit-每次迭代时执行的函数。top-目录树的顶端行走。
然后遍历顶部的目录树,在每一步执行功能。让我们检查一下函数(我们将其定义为“step”),我们使用它来打印 top 下的文件的路径名,这些文件的文件扩展名可以通过arg提供。
下面是 step 的定义:
def step(ext, dirname, names):
ext = ext.lower()
for name in names:
if name.lower().endswith(ext):
print os.path.join(dirname, name)
现在让我们一行一行地分解它,但首先要指出的是,给 step 的参数是由用户直接通过os.path.walk函数、而不是传递的,这一点非常重要。walk 在每次迭代中传递的三个参数是:
ext-赋予os.path.walk的任意自变量。dirname-该迭代的目录名。names-dirname下所有文件的名称。
我们的 step 函数的第一行当然是我们的函数声明,包括将由os.path.walk直接传递的默认参数。
第二行确保我们的ext字符串是小写的。第三行开始我们的参数名循环,这是一个列表类型。第四行是我们如何检索带有我们想要的扩展名的文件名,使用字符串方法endswith来测试后缀。
最后一行打印通过后缀(扩展名)测试的任何文件的路径,将dirname参数连接到名称(带有适当的系统相关分隔符)。
现在,将我们的 step 函数与 walk 函数结合后,脚本看起来类似于这样:
# We only need to import this module
import os.path
# The top argument for walk. The
# Python27/Lib/site-packages folder in my case
topdir = '.'
# The arg argument for walk, and subsequently ext for step
exten = '.txt'
def step(ext, dirname, names):
ext = ext.lower()
for name in names:
if name.lower().endswith(ext):
print(os.path.join(dirname, name))
# Start the walk
os.path.walk(topdir, step, exten)
对于我的系统,我在 Python 2.7 的站点包中安装了wx_py,输出如下:
.\README.txt
.\wx-2.8-msw-unicode\docs\CHANGES.txt
.\wx-2.8-msw-unicode\docs\MigrationGuide.txt
.\wx-2.8-msw-unicode\docs\README.win32.txt
......
.\wx-2.8-msw-unicode\wx\tools\XRCed\TODO.txt
用 Python 3.x 中的 os.walk 进行递归
现在让我们用 Python 3.x 做同样的事情。
Python 3.x 中的os.walk函数工作方式不同,提供了比其他函数更多的选项。它需要 4 个参数,只有第一个是强制的。参数(及其默认值)依次为:
top
topdown(=True)
布尔型
onerror(=None)
followlinks(=False)
布尔型
我们现在唯一关心的是第一个。除了参数之外,walk 函数的两个版本的最大区别可能是 Python 2.x 版本自动遍历目录树,而 Python 3.x 版本生成一个生成器函数。这意味着 Python 3.x 版本只有在我们告诉它的时候才会进行下一次迭代,我们这样做的方式是通过一个循环。
我们将把os.walk生成器写入进入step函数的循环中,而不是像步骤那样定义一个单独的函数来调用。像 Python 2.x 版本一样,os.walk产生了 3 个值,我们可以在每次迭代中使用(目录路径、目录名和文件名),但是这次它们是三元组的形式,所以我们必须相应地调整我们的方法。除此之外,我们根本不会改变扩展名后缀测试,所以脚本最终看起来像这样:
import os
# The top argument for walk
topdir = '.'
# The extension to search for
exten = '.txt'
for dirpath, dirnames, files in os.walk(topdir):
for name in files:
if name.lower().endswith(exten):
print(os.path.join(dirpath, name))
因为我的系统的 Python32/Lib/site-packages 文件夹不包含任何特殊的内容,所以这个文件夹的输出结果只是:
.\README.txt
无论“topdir”和“exten”字符串被设置为什么,这都将以相同的方式工作;然而,这个脚本只是将文件名打印到窗口(在我们的例子中是 Python 的空闲窗口),如果有许多文件要打印,这会使我们的解释器(或 shell)窗口多行高——滚动起来有点麻烦。如果我们知道是这种情况,那么将结果写入我们可以随时查看的文本文件就容易多了。如果我们像这样加入一个with语句(比如在 Python 中的读写文件),我们可以很容易做到:
with open(logpath, 'a') as logfile:
logfile.write('%s\n' % os.path.join(dirname, name))
让我们先看看如何将它合并到 Python 2.x 版本的脚本中:
# We only need to import this module
import os.path
# The top argument for walk. The
# Python27/Lib/site-packages folder in my case.
topdir = '.'
# The arg argument for walk, and subsequently ext for step
exten = '.txt'
logname = 'findfiletype.log'
def step((ext, logpath), dirname, names):
ext = ext.lower()
for name in names:
if name.lower().endswith(ext):
# Instead of printing, open up the log file for appending
with open(logpath, 'a') as logfile:
logfile.write('%s\n' % os.path.join(dirname, name))
# Change the arg to a tuple containing the file
# extension and the log file name. Start the walk.
os.path.walk(topdir, step, (exten, logname))
正如我们在上面看到的,除了第三个变量logname和第三个参数os.path.walk之外,没有什么变化。with 语句已经取代了print语句。由于os.path.walk函数的性质,step需要打开日志文件,写入日志文件,每找到一个文件名就关闭日志文件;这不会导致任何错误,但有点尴尬。我们还必须注意,因为日志文件是在追加模式下打开的,所以它将而不是覆盖已经存在的日志文件,它将只将追加到文件中。这意味着如果我们在不改变logname的情况下连续运行脚本 2 次或更多次,每次运行的结果将被添加到同一个文件中,这可能是不希望的。
修改版 Python 3.x 脚本就没那么别扭了:
import os
# The top argument for walk
topdir = '.'
# The extension to search for
exten = '.txt'
logname = 'findfiletype.log'
# What will be logged
results = str()
or dirpath, dirnames, files in os.walk(topdir):
for name in files:
if name.lower().endswith(exten):
# Save to results string instead of printing
results += '%s\n' % os.path.join(dirpath, name)
# Write results to logfile
with open(logname, 'w') as logfile:
logfile.write(results)
在这个版本中,每个找到的文件的名称被附加到results字符串,然后当搜索结束时,结果被写入日志文件。与 Python 2.x 版本不同,日志文件以写模式打开,这意味着任何现有的日志文件都将被覆盖。在这两种情况下,日志文件都将被写入与脚本相同的目录中(因为我们没有指定完整的路径名)。
有了它,我们就有了一个简单的脚本,可以在文件树下找到某个扩展名的文件,并记录这些结果。在接下来的部分中,我们将在此基础上增加搜索多种文件类型、避免特定路径等功能。
Python 中的递归文件和目录操作(第 2 部分)
原文:https://www.pythoncentral.io/recursive-file-and-directory-manipulation-in-python-part-2/
在第 1 部分中,我们看了如何使用 os.path.walk 和 os.walk 方法在目录树下查找并列出特定扩展名的文件。前一个函数只出现在 Python 2.x 中,后一个函数在 Python 2.x 和 Python 3.x 中都可用。正如我们在上一篇文章中看到的,os.path.walk方法可能很难使用,所以从现在开始我们将坚持使用os.walk方法,这样脚本将更简单,并且与两个分支都兼容。
在第 1 部分中,我们的脚本遍历了topdir变量下的所有文件夹,但只找到一个扩展名的文件。现在让我们展开它,在选择的文件夹中的topdir路径下查找多个扩展名的文件。我们将首先搜索三种不同文件扩展名的文件:。txt,。我们的extens变量将是一个字符串列表,而不是一个:
extens = ['txt', 'pdf', 'doc']
字符.没有像之前一样包含在变量ext中,我们很快就会看到原因。为了保存结果(文件名),我们将使用一个以扩展名为关键字的字典:
# List comprehension form of instantiation
found = { x: [] for x in extens }
其他变量暂时保持不变;然而,脚本文件本身将被放在(并将从)我的系统的“Documents”文件夹中执行,所以topdir变量将成为那个路径。
之前我们用str.endswith方法测试了扩展。如果我们要再次使用它,我们必须遍历扩展名列表并用endswith测试每个文件名,但是我们将使用稍微不同的方法。对于行走过程中踩过的每个文件,我们将提取扩展,然后测试在扩展中的成员资格。下面是我们如何提取它:
for name in files:
# Split the name by '.' & get the last element
ext = name.lower().rsplit(“.”, 1)[-1]
与前一部分一样,我们将这一行放在 for 循环中,该循环与由os.walk返回的文件列表交互。在这一行中,我们结合了三个操作:改变文件名的大小写,拆分文件名,提取一个元素。在文件名上调用str.lower会将其变为小写。与extens中的所有琴弦相同。在 name 上调用str.rsplit,然后将字符串拆分成一个列表(从右边开始),第一个参数.对其进行分隔,并且只进行与第二个参数(1)一样多的拆分。第三部分([-1])检索列表的最后一个元素——我们使用它而不是索引 1,因为如果没有进行拆分(如果name中没有.),就不会引发IndexError。
现在我们已经提取了name的扩展名(如果有的话),我们可以测试它是否在我们的扩展名列表中:
if ext in extens:
这就是为什么在extens中.不在任何扩展名之前,因为ext永远不会有扩展名。如果条件为真,我们将把找到的名字添加到我们的found字典中:
if ext in extens:
found[ext].append(os.path.join(dirpath, name))
上面的行将把结果路径(dirpath连接到os.walk返回的name)追加到found中ext键的列表中。既然我们已经更改了搜索扩展和结果列表,我们还必须调整如何将结果保存到日志文件中。
在以前的版本中(使用os.walk),我们只是在logname打开一个文件,并将结果写入文件。在这个版本中,我们必须遍历结果中的多个类别,每个类别对应一个扩展。我们将把found中的每个结果列表连接到我们的结果字符串,我们现在将其标识为logbody。我们还将在日志文件中添加一个小标题,日志标题:
# The header in our logfile
loghead = 'Search log from filefind for files in {}\n\n'.format(os.path.realpath(topdir))
#我们的日志文件的正文
logbody = ' '
#循环搜索结果
以在 found:
#将来自 found dict
logbody += " < <结果的结果与扩展名“% s”>>" % search
#使用 str.join 将搜索时的列表转换为 str
log body+= ' \ n \ n % s \ n \ n ' % ' \ n '。加入(找到[搜索])
结果的格式可以是您喜欢的任何格式,但重要的是我们要遍历所有结果以获得完整的日志。在logbody完成之后,我们可以编写我们的日志文件:
# Write results to the logfile
with open(logname, 'w') as logfile:
logfile.write('%s\n%s' % (loghead, logbody))
注意:如果解决方案中的任何名称/路径包含非 ASCII 字符,我们必须将open模式更改为wb,并解码loghead和logbody(或者在 Python 3.x 中进行编码),以便成功保存logfile。
现在我们终于准备好测试我们的脚本了。在我的系统上运行它会产生这个日志文件(缩短的):
Search log from filefind for files in C:\Python27\Lib\site-packages
<< Results with the extension 'pdf' >>
.\GPL_Full.pdf
.\beautifulsoup4-4.1.3\doc\rfc2425-v2.1.pdf
.\beautifulsoup4-4.1.3\doc\rfc2426-v3.0.pdf
<< Results with the extension 'txt' > >
。\README.txt
。\soup.txt
。\ beautiful soup 4-4 . 1 . 3 \ authors . txt
。\ beautiful soup 4-4 . 1 . 3 \ copy . txt
...
。\ wx-2.8-MSW-unicode \ docs \ changes . txt
。\ wx-2.8-MSW-unicode \ docs \ migration guide . txt
。\ wx-2.8-MSW-unicode \ docs \ readme . win32 . txt
...
。\ wx-2.8-MSW-unicode \ wx \ tools \ XRCed \ todo . txt
<< Results with the extension 'doc' > >
这个日志告诉我们,在C:\Python27\Lib\site-packages目录中有几个 PDF 文件,许多文本文件,没有。doc”或 Word 文件。看起来效果不错,扩展搜索列表也很容易更改,但是如果我们不想在wx-2.8-msw-unicode树下的“docs”目录中搜索呢?毕竟,我们知道那里可能会有很多文本文件。我们可以通过在主循环中修改dirnames列表来忽略这个目录。因为我们可能想要忽略多个目录,所以我们将保留一个它们的列表(当然这将在循环之前进行):
# Directories to ignore
ignore = ['docs', 'doc']
现在我们有了列表,我们将在主遍历循环中添加这个小循环(在文件名循环之前):
# Remove directories in ignore
#目录名必须完全匹配!
for idir in ignore:
if idir in dirnames:
dirnames . remove(idir)
这将就地编辑dirnames,这样遍历循环的下一次迭代将不再包括在 ignore 中命名的文件夹。带有新行走循环的完整脚本现在如下所示:
import os
#文件中名称的第一个参数
topdir = ' . '
extens = ['txt ',' pdf ',' doc'] #要搜索的扩展名
found = {x: [] for x in extens} #找到的文件列表
#要忽略的目录
ignore = ['docs ',' doc']
logname = "findfiletypes.log"
print('开始搜索%s' % os.path.realpath(topdir)中的文件)
#遍历 os.walk 中的目录路径、目录名、文件的树
(top dir):
#删除忽略的目录
#目录名必须完全匹配!
for idir in ignore:
if idir in dirnames:
dirnames . remove(idir)
#遍历当前步骤的文件名
,查找文件名:
#用“.”分割文件名&获取最后一个元素
ext = name.lower()。rsplit(' . ', 1)[-1]
#如果 ext 匹配
如果 ext 在 ext:
中找到[ext]则保存全名。append(os.path.join(目录路径,名称))
#我们的日志文件中的标头
loghead = '在文件中搜索日志在{}中查找文件\n\n '。format(
OS . path . real path(top dir)
)
#我们日志文件的主体
logbody = ' '
#循环遍历在 found:
中搜索的结果
#将来自 found dict
logbody += " < <结果的结果与扩展名“% s”>>" % search
log body+= ' \ n \ n % s \ n \ n ' % ' \ n '。加入(找到[搜索])
#将结果写入日志文件
,打开(日志名,' w ')作为日志文件:
logfile.write('%s\n%s' %(日志头,日志体))
使用我们新的 ignored files 元素,日志文件看起来像这样(缩短了):
从filefind的日志中搜索C:\Python27\Lib\site-packages中的文件
<< Results with the extension 'pdf' >>
.\GPL_Full.pdf
<< Results with the extension 'txt' > >
。\README.txt
。\soup.txt
。\ beautiful soup 4-4 . 1 . 3 \ authors . txt
。\ beautiful soup 4-4 . 1 . 3 \ copy . txt
...
。\ beautiful soup 4-4 . 1 . 3 \ scripts \ demonstration _ markup . txt
。\ wx-2.8-MSW-unicode \ wx \ lib \ editor \ readme . txt
...
。\ wx-2.8-MSW-unicode \ wx \ tools \ XRCed \ todo . txt
<< Results with the extension 'doc' > >
我们的忽略列表正如我们所希望的那样工作,删除了wx-...-unicode中“docs”目录下的完整树。我们还可以看到,另一个忽略目录(“doc”)从我们的 PDF 结果中删除了另外两个 PDF 文件,对于这两个目录,我们不需要命名完整路径(因为这个名称无论如何都不会是dirnames中的完整路径)。这可能很方便,但是请记住,这种方法将删除与ignore列表中的名称匹配的名称下的树的任何部分(为了避免这种情况,如果您不介意麻烦地命名完整路径,请尝试同时使用dirpath和dirnames来指定要忽略的完整路径!).
现在我们已经完成了这个版本的文件/目录操作脚本,我们可以快速搜索任意树下的多个文件扩展名,并且只需双击就可以获得所有找到的文件扩展名的记录。如果我们只是想知道所有文件存在于哪里,这是很好的,但是由于它们可能不会都在同一个文件夹中,如果我们想将它们全部移动/复制到同一个文件夹中或者同时对它们做其他事情,浏览日志文件的每一行将是而不是更好的选择。这就是为什么在下一部分,我们将看看如何升级我们的脚本,以移动,复制/备份,或者擦除我们正在寻找的所有文件。
Python 中的递归文件和目录操作(第 3 部分)
原文:https://www.pythoncentral.io/recursive-file-and-directory-manipulation-in-python-part-3/
在本系列的第 2 部分中,我们扩展了我们的文件搜索脚本,使之能够在一棵树下搜索多个文件扩展名,并将结果(找到的匹配扩展名的文件的所有路径)写入日志文件。现在我们已经到了本系列的最后一部分,我们将在脚本中添加更多的功能(以函数的形式),以便能够移动、复制甚至删除搜索结果。
在查看移动/复制/删除函数之前,我们将首先获取将结果记录到文件中的子例程,并将其封装在一个函数中。下面是我们脚本的这一部分之前的样子:
# The header in our logfile
loghead = 'Search log from filefind for files in {}\n\n'.format(
os.path.realpath(topdir))
#我们的日志文件的正文
logbody = ' '
#在结果
中循环查找找到的搜索结果:
#用扩展名“% s”>>" % search result
log body+= ' \ n \ n % s \ n \ n“% ' \ n '连接找到的字典
logbody += " < <结果的结果。加入(找到[搜索结果])
#将结果写入日志文件
,打开(日志名,' w ')作为日志文件:
logfile.write(日志头)
logfile.write(日志体)
为了将它放入函数定义中,我们简单地将定义语句放在上面,添加适当的参数,并相应地缩进其余部分(注意found如何变成results以及logname如何变成logpath):
# Logging results for findfile
def logres(logpath, results):
# The header in our logfile
loghead = 'Search log from filefind for files in {}\n\n'.format(
os.path.realpath(topdir))
#我们的日志文件的正文
logbody = ' '
#在结果中循环搜索结果的结果
:
#将结果字典
logbody += " < <结果中的结果与扩展名“% s”>>" % search result
log body+= ' \ n \ n % s \ n \ n“% ' \ n '。加入(结果[搜索结果])
#将结果写入日志文件
,打开(日志路径,' w ')作为日志文件:
logfile.write(日志头)
logfile.write(日志体)
出于错误报告的目的,我们还将定义一个小函数来写一个错误日志,稍后我们将看到原因。下面是这个函数,它接受 3 个参数,并将字符串列表写入错误日志:
def logerr(logpath, errlist, act):
loghead = 'List of files that produced errors when attempting to %s:\n\n' % act
logbody = '\n'.join(errlist)
以 open(logpath,' w ')作为日志:
log . write(loghead+log body)
定义了两个日志记录函数后,我们现在将编写函数来对文件搜索的结果列表执行批处理操作。我们将首先看看如何对从原始位置找到的文件执行批量移动到目标目录。我们将用来实际移动文件的函数是来自shutil模块的move函数(想象一下:P),所以我们想把这个语句添加到脚本的开头:
# We'll use copy2 later
from shutil import move, copy2
对于我们的函数定义,不是直接作用于脚本中的found变量,而是让我们的方法接受一个结果字典并作用于它。如果我们需要的话,它还需要将它们移动到的目录的路径和错误日志路径。它还需要一个变量来存储错误(文件的路径字符串列表):
# Moving results
def batchmove(results, dest, errlog=None):
# List of results that produce errors
errors = []
在写函数定义的其余部分之前,关于move函数有一些重要的注意事项——首先,这个函数将把源参数移动到相同类型的目的地。这意味着如果源路径是一个目录,目标也将是一个目录,对于文件也是如此。其次,如果目标存在并且是一个文件,那么源必须是一个文件,否则功能将失败。换句话说,如果目的地是一个目录,那么源(无论是文件还是目录)都会被移动到目的地目录中,但是如果目的地是一个文件,那么源可能只是一个文件(我们不能将目录移动到文件中)。也就是说,我们需要做的就是确保batchmove的dest参数是一个现有的目录,所以我们将在测试后使用 try 语句:
# Make sure dest is a directory!
if os.path.isfile(dest):
print("The move destination '%s' already exists as a file!" % dest)
exit(input('Press enter to exit...'))
elif not os.path.isdir(dest):
try:
os.mkdir(dest)
except:
print("Unable to create '%s' folder!" % dest)
exit(input('Press enter to exit...'))
else:
print("'%s' folder created" % dest)
这样,如果移动失败,它会提醒用户并在退出前等待。检查完我们的目标目录后,我们可以添加函数的核心:遍历results并移动每个文件。循环如下:
# Loop through results, moving every file to dest directory
for paths in results.values():
for path in paths:
path = os.path.realpath(path)
try:
# Move file to dest
move(path, dest)
except:
errors.append(path)
print('File move complete')
results中的键只是搜索的文件扩展名,所以只需要值,对于值中当前paths列表中的每个path,我们试图将它移动到我们的目的地。如果移动失败,path被添加到错误列表中。当循环完成时,一条消息被打印到标准输出。
循环完成后,我们希望记录使用logerr方法遇到的任何错误,如下所示:
# Log errors, if any
if errlog and errors:
logerr(errlog, errors, 'move')
print("Check '%s' for errors." % errlog)
最后,我们将让脚本打印最后一条消息并退出:
exit(input('Press enter to exit...'))
综上所述,下面是我们的batchmove函数的样子:
# Moving results
def batchmove(results, dest, errlog=None):
#产生错误的结果列表
错误= []
#确保 dest 是一个目录!
if OS . path . is file(dest):
print("移动目的地' %s '已经作为文件存在!"% dest)
退出(输入('回车退出...'))
elif not OS . path . isdir(dest):
try:
OS . mkdir(dest)
except:
print("无法创建' %s '文件夹!"% dest)
退出(输入('按回车键退出...'))
else:
print("'%s '文件夹已创建" % dest ")
#循环遍历结果,将每个文件移动到目标目录
以获取结果中的路径。values():
以获取路径中的路径:
path = OS . path . real path(path)
try:
#将文件移动到目标目录
move(path,dest)
except:
errors . append(path)
print('文件移动完成')
# log errors,if any
if errlog and errors:
logerr(errlog,errors,' move ')
print(" Check ' % s ' for errors。"% errlog)
退出(输入('按回车键退出...')
现在我们有了batchmove函数,为了定义batchcopy函数,我们只需要将最内层循环的函数调用更改为copy2(以及相应的消息),因此完整的定义如下所示:
# Copying results
def batchcopy(results, dest, errlog=None):
# List of results that produce errors
errors = []
#确保 dest 是一个目录!
if OS . path . is file(dest):
print("复制目的地' %s '已经作为文件存在!"% dest)
退出(输入('回车退出...'))
elif not OS . path . isdir(dest):
try:
OS . mkdir(dest)
except:
print("无法创建' %s '文件夹!"% dest)
退出(输入('按回车键退出...'))
else:
print("'%s '文件夹已创建" % dest ")
#循环遍历结果,将每个文件复制到目标目录
作为结果中的路径。values():
作为路径中的路径:
path = OS . path . real path(path)
try:
#将文件复制到目标目录
copy2(path,dest)
except:
errors . append(path)
print('文件复制完成')
# Log errors,if any
if errlog and errors:
Log err(errlog,errors,' copy')
exit(input('按 enter 键退出... ')))
我们定义的这两个函数应该足够有用,不需要删除函数,但是如果我们想要一个,我们只需要从batchmove中移除dest检查,并将内部循环函数调用改为os.remove,如下所示:
# Deleting results -- USE WITH CAUTION!
def batchdel(results, errlog=None):
# List of results that produce errors
errors = []
#循环遍历结果,删除每个文件!
for path in results . values():
for path in paths:
path = OS . path . real path(path)
try:
# Delete File
OS . remove(path)
except:
errors . append(path)
print('文件删除完成')
# Log errors,if any
if errlog and errors:
Log err(errlog,errors,' delete')
exit(input('按 enter 键退出... ')))
这只是为了展示我们如何实现删除子例程,但实际上并不推荐这样做,因为 Python 删除的任何文件都会被永久删除(不会被发送到回收站!).简单地将文件移动到带有batchmove的文件夹中并从那里删除它们会更安全,但是当然这取决于你的选择:)。既然我们已经定义了这些函数,那么我们需要做的就是在搜索循环之后使用found作为results参数来调用它们,并且相应地调用我们想要的日志文件的路径,所以即使我们不知道文件在哪里,查找和移动它们也是轻而易举的事情!
递归 Python 函数例子:把你的电影列表!
原文:https://www.pythoncentral.io/recursive-python-function-example-make-list-movies/
This recipe is a practical example of Python recursive functions, using the os.listdir function. However it is not the most effective method to traverse a directory in Python. os.walk is generally considered the most Pythonic method. For a quick look at how to use os.walk, checkout the article this article for a os.walk example. If you are after a more in-depth look at os.walk, be sure to checkout the article Python's os.walk: An In-depth Guide
所以。有什么比在你的硬盘上制作一个视频文件列表更好的呢?
让我们列出一个文件夹中的所有视频文件,以及其中的所有其他文件夹!
Python 中的递归函数是什么?
递归是计算机科学中的一个概念。本质上,它把一个问题分成子问题。Python 中的递归一般与特定的函数、方法或对象有关,它调用自身来分解这些问题。例如,阶乘函数如下所示:
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
注意,factorial函数调用自己,将阶乘问题分解成子问题。
递归 Python 函数:我们编码吧!
让我们在一个函数中编写遍历代码,如下所示:
import os
def Print _ movie _ files(movie_directory,movie_extensions=['avi ',' dat ',' mp4 ',' mkv ',' vob']):
' ' '递归打印 movie _ directory 中扩展名为 movie_extensions 的文件''
#获取电影目录参数的绝对路径
电影目录= os.path.abspath(电影目录)
#获取电影目录中的文件列表
电影目录文件= os.listdir(电影目录)
#遍历电影目录文件中文件名的所有文件【T0:
file path = OS . path . join(电影目录,文件名)
#如果 os.path.isfile(filepath),检查它是否是一个正常的文件或目录
:
#检查文件是否有典型视频文件的扩展名
为 movie_extensions 中的 movie _ extension:
#不是电影文件,如果不是 file path . ends with(movie _ extension):
继续
#我们有一个视频文件!递增计数器
print _ movie _ files . counter+= 1
# Print 它的名字
Print(“{ 0 }”)。format(file path))
elif OS . path . isdir(file path):
#我们得到一个目录,进入其中做进一步处理
print _ movie _ files(file path)
代码和注释都是不言自明的。递归 Python 函数print_movie_files有两个参数:要搜索的目录路径。然后,它使用os.listdir方法获得这个目录中所有文件和文件夹的列表。我们使用一个for循环来处理list,,使用os.path.isfile方法检查文件路径是否是一个正常的文件或目录。如果是扩展名为movie_extensions的普通文件,会打印文件路径。如果filepath是一个目录,我们递归调用函数本身来进一步处理它。
调用递归 Python 函数
现在,我们在__main__范围内调用这个函数:
[python]
if name == 'main':
提供了目录参数,检查并使用是否是目录
if len(sys . argv)= = 2:
if OS . path . isdir(sys . argv[1]):
movie _ Directory = sys . argv[1]
else:
print('错误:“{0}”不是目录。'。format(sys . argv[1])
exit(1)
else:
将我们的电影目录设置为当前工作目录
movie_directory = os.getcwd()
打印(' \n -在“{0}”中查找电影- \n '。格式(电影目录))
将已处理文件的数量设置为零
print_movie_files.counter = 0
开始处理
print_movie_files(电影 _ 目录)
我们结束了。现在退出。
打印(' \n - {0}个电影文件在目录{1} -'中找到。格式
(print _ movie _ files . counter,movie_directory))
打印(' \ n 按回车键退出!')
等到用户按 enter/return,或者 尝试:
【input()
除键盘中断:
【exit(0)
[/python]
[python]
if name == 'main':
提供了目录参数,检查并使用是否是目录
if len(sys . argv)= = 2:
if OS . path . isdir(sys . argv[1]):
movie _ Directory = sys . argv[1]
else:
print('错误:“{0}”不是目录。'。format(sys . argv[1])
exit(1)
else:
将我们的电影目录设置为当前工作目录
movie_directory = os.getcwd()
打印(' \n -在“{0}”中查找电影- \n '。格式(电影目录))
将已处理文件的数量设置为零
print_movie_files.counter = 0
开始处理
print_movie_files(电影 _ 目录)
我们结束了。现在退出。
打印(' \n - {0}个电影文件在目录{1} -'中找到。格式
(print _ movie _ files . counter,movie_directory))
打印(' \ n 按回车键退出!')
等到用户按 enter/return,或者 try:
raw_input()
除键盘中断:
exit(0)
[/python]
运行脚本
- 下载并解压源代码 zip 文件(见下文),并将
list-movies.py复制到您希望搜索的目录中。 - -或- 将商品代码复制到一个新文件中,并将其作为
list-movies.py保存在您希望搜索的目录中。 - 电影所在的目录。例如
cd ~/Movies或cd C:\\Users\\Videos。 - 使用
/path/to/python list-movies.py运行list-movies.py脚本- Linux/OSX/Unix:
python list-movies.py - 视窗:
C:\\Python34\\python.exe list-movies.py
- Linux/OSX/Unix:
提示:在 Linux/OSX/Unix 上你可以将文件标记为可执行,在文件顶部添加一个 Python shebang 行,直接运行。例如。
cd ~/Desktop/list-movies.py
chmod +x ./list-movies.py
# Add "#/usr/bin/env python" to the top of the file
./list-movies.py # Run script, search files in current directory
./list-movies.py ~/Movies # Run script, search for files in ~/Movies
脚本中的代码将递归遍历(查找)其中的所有其他文件夹,并检查视频文件。如果您使用的是 Windows 并且安装了 Python IDLE,那么您只需双击该文件并检查输出。
同样,os.getcwd方法帮助我们获得当前工作目录(cwd),即脚本所在的目录。它调用我们刚刚编写的函数,还有一个计数器,它计算找到了多少个视频文件。最后,我们print我们拥有的所有信息,并等待用户使用input()或raw_input()函数终止程序的提示(当从 Python 2 升级到 Python 3 时,Python 将raw_input()函数的名称改为input())。
重置递归限制
原文:https://www.pythoncentral.io/resetting-the-recursion-limit/
Python 默认的递归限制是 1000,这意味着 Python 不会让一个函数对自身调用超过 1000 次,这对大多数人来说可能已经足够了。这种限制之所以存在,是因为允许递归发生 1000 次以上并不完全有利于轻量级代码。但是,如果您发现自己需要更高的递归限制,有一种方法可以覆盖默认限制,并将其重置为您选择的一个数字。不建议这样做,因为这样肯定会降低代码的速度,但是在需要这样做的时候,你可以这样做:
假设您想将限制设置为 1500。您真正需要的是将变量设置为 1500,后跟一行代码。
import sys
x=1500
sys.setrecursionlimit(x)
记住:只有在绝对必要的情况下才利用这种方法。
使用 Python 2.x 调整图像大小(批量调整)
The module we use in this recipe to resize an image with Python is PIL. At the time of writing, it is only available for Python 2.x. If you want to do more with image editing, be sure to checkout our article on how to watermark an image in Python
Python 是一种非常强大的脚本语言,你会惊喜地发现,你想要构建的许多常用函数都以库的形式存在。Python 生态系统非常活跃,充满了库。
举个例子,今天我将向你展示如何轻松地构建一个 Python 脚本,它将使用 Python 来调整一个图像的大小,我们将扩展它来将一个文件夹中的所有图像调整到你选择的尺寸。这是用 Python 的PIL (Python 映像库)。首先我们需要安装这个。
在 Windows 上安装 PIL
你可以在这里下载并安装 PIL 图书馆。
在 Mac 上安装 PIL
对于 MacPorts,您可以使用以下命令安装 PIL(对于 Python 2.7):
$ port install py27-pil
在 Ubuntu 上安装 PIL
在 Linux 上安装 PIL 往往因发行版而异,所以我们将只讨论 Ubuntu。要在 Ubuntu 上安装 PIL,请使用以下命令:
$ sudo apt-get install libjpeg libjpeg-dev libfreetype6 libfreetype6-dev zlib1g-dev
也可以使用pip,比如:
$ pip install PIL
好了,现在来看看调整图像大小的脚本!
用 Python 调整图像大小
要使用 Python 的 PIL 调整一幅图像的大小,我们可以使用以下命令:
from PIL import Image
宽度= 500
高度= 500
#打开图像文件。
img = Image.open(os.path.join(目录,图像))
#调整大小。
img = img.resize((宽度,高度),图像。双线性)
#保存回磁盘。
img.save(os.path.join(目录,'调整大小-' + image))
假设我们已经知道了宽度和高度。但是如果我们只知道宽度,需要计算高度呢?使用 Python 调整图像大小时,我们可以如下计算高度:
from PIL import Image
基底宽度= 500
#打开图像文件。
img = Image.open(os.path.join(目录,图像))
#使用相同的纵横比计算高度
width percent =(base width/float(img . size[0])
height = int((float(img . size[1])* float(width percent)))
#调整大小。
img = img.resize((baseWidth,height),Image。双线性)
#保存回磁盘。
img.save(os.path.join(目录,'调整大小-' + image))
简单!现在,我们向您展示如何使用 Python 批量调整图像大小。
使用 Python 批量调整图像大小
这是调用脚本的方式:
python image_resizer.py -d 'PATHHERE' -w 448 -h 200
首先,让我们导入让这个脚本工作所需的内容:
import os
import getopt
import sys
from PIL import Image
- 操作系统:让我们访问与电脑交互的功能,在这种情况下,从文件夹中获取文件。
- getopt :让我们轻松地访问最终用户传入的命令行参数。
- 图像:将允许我们调用
resize函数,该函数将执行应用程序的重载。
我们的批处理图像缩放器命令行参数
接下来,让我们继续处理命令行参数。我们还必须考虑到一个论点丢失的微小可能性。在这种情况下,我们将显示一条错误消息并终止程序。
# Let's parse the arguments.
opts, args = getopt.getopt(sys.argv[1:], 'd:w:h:')
#为需要的变量设置一些默认值。
目录= ''
宽度= -1
高度= -1
#如果传入了参数,请将其赋给正确的变量。
对于 opt,opts 中的 arg:
if opt = = '-d ':
directory = arg
elif opt = = '-w ':
width = int(arg)
elif opt = = '-h ':
height = int(arg)
#我们必须确保所有的参数都通过了。
如果 width == -1 或 height == -1 或 directory == '':
打印('无效的命令行参数。-d[目录]' \
'-w[宽度]-h[高度]都是必需的')
#如果缺少参数,请退出应用程序。
退出()
上面的评论是不言自明的。我们解析参数,用默认值设置变量的用法,并给它们赋值。如果一个或多个变量丢失,我们将终止应用程序。
很好,现在我们可以专注于这个脚本的目的了。让我们获取文件夹中的每个图像并对其进行处理。
# Iterate through every image given in the directory argument and resize it.
for image in os.listdir(directory):
print('Resizing image ' + image)
#打开图像文件。
img = Image.open(os.path.join(目录,图像))
#调整大小。
img = img.resize((宽度,高度),图像。双线性)
#保存回磁盘。
img.save(os.path.join(目录,'调整大小-' + image))
打印(“批处理完成。”)
Image.open 函数正在返回一个Image对象,这反过来让我们对它应用resize方法。为了简单起见,我们使用Image.BILINEAR算法。
这就是全部了。正如你所看到的,Python 是一种非常敏捷的语言,允许开发者专注于解决业务需求。
如何反转一个单链表
先决条件
要学习如何反转单链表,你应该知道:
- Python 3
- Python 数据结构-列表
- 到位清单冲正
- OOP 概念
- 第一部分和第二部分单链表
我们会学到什么?
在上一个教程中,我们讨论了什么是单链表,如何添加一个节点,如何打印所有节点,如何删除一个节点。如果您还没有阅读这些内容,我们强烈建议您先阅读,因为我们将基于这些概念进行构建。
本教程讲述了如何反转一个链表。 正如在之前的教程中所讨论的,你可以通过交换最后一个和第一个值来执行原地反转,依此类推。但是这里我们要讨论一种不同的方法。这个想法是颠倒链接。于是 4 - > 2 - > 3(人头指向 4,3 点指向无)就变成了 4 < - 2 < - 3(人头指向 3,4 点指向无)。这可以迭代和递归地完成。
我们将跟踪三样东西:当前元素、上一个元素和下一个元素。这是因为一旦我们颠倒了前一个节点和当前节点之间的链接,我们就无法移动到当前的下一个节点。这就是为什么必须跟踪当前的下一个节点。让我们看一个例子:
| 链表 | 上一个 | 货币 | nex | 反转后 |
| (h)4 - > 2 - > 3(无) | 无 | 4 | 2 | (无)4 - > 2 - > 3 |
| (无)4 - > 2 - > 3 | 4 | 2 | 3 | (无)4 < - 2 - > 3 |
| (无)4 < - 2 - > 3 | 2 | 3 | 无 | (无)4 < - 2 < - 3 |
| (无)4 < - 2 < - 3 | 3 | 无 | 无 | (无)4 < - 2 < - 3(h) |
注: 最后,我们将 头 指针指向上一个节点。
如何实现这一点?
既然你已经很好的掌握了链表反转,那我们就来看看相关的算法和代码吧。
迭代法
算法
- 设置为 无**当前 为 头**下一个 为下一个节点 当前
- 遍历链表,直到 当前 为 无 (这是循环的退出条件)
- 每次迭代时,将 当前 的下一个节点设置为 先前
- 然后,设置为 当前**当前 为 下一个 和 下一个 为其下一个节点(这是循环的迭代过程)
- 一旦变成了,设置头指针指向 前一个 节点。
代码
def reverseList(list):
#Initializing values
prev = None
curr = list.head
nex = curr.getNextNode()
#looping
while curr:
#reversing the link
curr.setNextNode(prev)
#moving to next node
prev = curr
curr = nex
if nex:
nex = nex.getNextNode()
#initializing head
list.head = prev
递归方法
算法
- 传递指针到此方法为 节点 。
- 检查 节点 的下一个节点是否为 无 :
- 如果是,这表明我们已经到达了链表的末尾。设置 头 指针指向本节点
- 如果没有,将 的下一个节点节点 传递给 反向 方法
- 一旦到达最后一个节点,就会发生逆转。
代码
def reverse(self,node):
if node.getNextNode() == None:
self.head = node
return
self.reverse(node.getNextNode())
temp = node.getNextNode()
temp.setNextNode(node)
node.setNextNode(None)
结论
也尝试使用原地反转来解决上述问题。反转是解决与链表相关的其他问题的基础,我们将在以后的教程中看到。快乐的蟒蛇!
回顾 bpython 和 DreamPie(替代 Python Shells)
原文:https://www.pythoncentral.io/review-of-bpython-and-dreampie-alternative-python-shells/
bpython 替代 Shell 评论
bpython 是一个比我们上次讨论的 IPython 更轻便的解决方案。IPython 扩展了 Python 本身的功能,并附带提供了交互特性,而 bpython 扩展了 Python shell 的交互特性——仅此而已。然而,在其预期目的的范围内,它是相当好的。它可以在 Windows、Linux 和 OS X 上运行。尽管在 Windows 上安装是一件非常痛苦的事情。
像 IPython 一样,bpython 提供了两个接口,一个使用 curses 的命令行接口和一个使用 GTK 的接口。对这两个版本的测试表明,GTK 界面受到的关注要少得多,命令行界面在测试版本(0.9.7.1)中更受欢迎。一些细节:在一行的末尾按下 Home 键会将光标放在提示的前面而不是后面,尽管当你输入时,它会正确地替换光标;使用深色 GTK 主题,代码完成菜单完全是黑色的;菜单功能没有快捷键。
bpython 代码完成和语法突出显示
bpython 的代码完成比 IPython 的 CLI 界面要好一些;它不是简单地显示一个列表供你输入,而是给你一个列表,你可以使用 Tab 和 Shift-Tab 滚动浏览。它还能优雅地处理极长建议列表的情况,尽管人们可能希望使用箭头键和上下翻页导航。GTK 界面也不方便——所有的条目都显示在一个列表中,一次只能显示大约 10 个条目,可以使用箭头键或 Tab 和 Shift-Tab 来导航;以这种方式浏览长长的列表是很困难的,因为你看不到足够远的未来来快速前进。简单有效地提供函数签名帮助。
bpython 在您键入时以及在源代码清单中突出显示语法。它使用 Pygments 干净、快速、有效地完成这项工作。使用的颜色可以通过创建一个主题文件来定制,非常简单;下载中有一个很好的例子 tarball 。
python 帮助
bpython 中的帮助相当少—您可以使用基本 python 交互模式提供的help函数,并且可以显示当前函数的源代码。
help函数的工作方式与默认的 Python 解释器完全一样,可以说相当不错。它使用一个分页器来显示请求帮助的项目的定义和 docstring,并且在结果中不突出显示语法。
显示函数或类定义的源代码在它工作时是有效的,尽管它似乎很难找到交互定义的函数的源代码。但是,它很好地展示了导入模块的源代码,并在页面中突出显示了它们的语法。
bpython 的其他功能
您可以使用 Ctrl-S 将交互式会话保存到文件中,或者使用 F8 将它发送到pastebin(bpython 开发人员自己的是硬编码的)。两者都工作得很好,尽管它们包含最初发出时产生错误的行;如果有排除它们的选项就好了。
还有一个不太直观的名字叫做 Rewind 函数,它获取到目前为止发出的所有行,弹出最后一行,重新评估剩余的。这对有副作用的代码来说是潜在的危险,尽管我发现它很有用,但它仍然让我毛骨悚然。我想这是基于“勇敢失败”的原则。
bpython 审查摘要
尽管到处都有缺点,尽管它有独特的功能选择,但我发现 bpython 非常有用;事实上,它非常有用,以至于我在所有的机器上都映射了一个快捷键来打开它。如果你像我一样发现 IPython 并不真正符合你的风格,那么试试 bpython 你可能会感到惊喜。
creampie 替代壳牌评论
dream pie——为什么 Python 的所有东西都必须有可笑的名字?—和 bpython 一样,专注于改进 python 的交互使用。它是由 IDLE 的一个贡献者编写的,IDLE 是 Python 默认提供的伪 IDE,包含了一些来自 IDLE 的代码。
DreamPie 的布局
DreamPie 的布局不像默认的 Python 交互式控制台,也不像我们已经讨论过的其他控制台。DreamPie 分为上下两部分,而不是用户输入代码并在交替的行上看到输出:代码在下一部分输入,当提交时,在上一部分进行评估。(对于 Scheme 程序员来说,感觉有点像drrack的界面,除了没有基于文件的文本编辑器部分。)
这种布局的优点是,在下半部分输入的代码在提交之前可以根据需要填充任意多的行;这允许多行编辑,这是其他交互式控制台经常缺乏的,并且消除了对 bpython 古怪的倒带功能的需要。例如,您可以输入完整的函数定义:
def some_func(n):
for i in range(n):
print n * scale
然后,当你意识到忘了第一行的scale参数时,你就不用重新输入整个函数了;你上去把第一行改成def some_func(n, scale)就可以了。完成后,按 Ctrl+Enter 提交整个块。
这确实是 DreamPie 的杀手锏——其他的都是小菜一碟。但它是美味的肉汁。请继续阅读。
DreamPie 语法突出显示和代码完成
哪里有语法,DreamPie 就突出它。它做得又快又好,代码窗口中正在进行的突出显示和评估窗口中的静态突出显示是一致的。简而言之,语法高亮是有效的。
这里讨论的所有交互式 Python shells 的代码补全在技术上是完美无缺的:它们都呈现了几乎相同的信息,以及完整的关键字、名称、模块名称、属性——一切。然而,DreamPie 在用户界面方面表现出色;浏览一长串的完成列表要容易得多,签名帮助也非常出色——在可用的地方,它会在一个可滚动的窗口中显示函数或类的完整源代码。
梦幻女郎的帮助
DreamPie 提供的帮助和 bpython 差不多,也就是说,不多。您可以使用help函数,完整源代码的调用提示和签名帮助很好,但这是它提供的所有 Python 帮助。文档也很少,但是菜单逻辑排列,功能性名副其实,菜单中列出了键盘快捷键;没有更多的文件,虽然一个方便的手册将不胜感激。
creampie 的其他功能
DreamPie 有一个经过深思熟虑的附加功能选择,其中一些非常有用。其中最有效的一个是仅复制代码功能;它允许用户在评估区域选择一个区域,只将代码复制到剪贴板,忽略评估结果。我发现自己经常使用这种方法,但是我希望有一个类似的方法将该区域的代码保存到一个文件中。(我已经提交了一个添加该功能的 pull 请求,但是尚未被接受或拒绝。)
您可以将历史记录保存到保留 DreamPie 界面突出显示和布局的 HTML 文件中,并从保存的 HTML 中导入历史记录。一个选项保存为纯文本也将受到赞赏,但不明显,如果它存在。
DreamPie 提供的另一个特性是多个选项卡,但是由于某种原因,唯一的选项卡区域是代码输入部分。我发现自己希望为每个代码输入标签设置单独的评估面板,但这可能会比它的价值更难实现。无论如何,这个特性在我的试验中并没有被证明是有用的。
创建审核摘要
DreamPie 干净、简单,并且大部分执行良好,仅代码输入和评估的划分就足以证明尝试它是正确的。我发现它很有效,没有错误,而且在所有操作系统上安装都很简单。
我能提供的最后一个建议是:如果您需要 IPython,您可能知道这一点,并且这是您显而易见的选择。bpython 和 DreamPie 的功能差不多,而且都很可靠,使用起来也很简单;唯一与众不同的特点是 bpython 提供的标准终端体验,而 DreamPie 提供的是分割窗口。如果你知道哪一个最符合你的喜好,就做出相应的选择;否则,两者都试试看。
无论如何,您都将拥有比默认 Python 控制台更好的体验。
IPython(替代 Python Shell)综述
原文:https://www.pythoncentral.io/review-of-ipython-alternative-python-shell/
关于 IPython 的介绍,请务必阅读文章IPython 简介:一个增强的 Python 解释器。
使用 Python 这样的解释型语言的好处之一是使用交互式 Python shell 进行探索性编程。它让您可以快速、轻松地进行尝试,而无需编写脚本并执行它,并且您可以在进行过程中轻松地检查值。shell 也有一些便利之处,包括逐行历史记录和用于阅读帮助的内置分页器。
不过,标准 Python shell 有一些限制:您最终会频繁地使用dir(x)来检查对象并找到您正在寻找的方法名。将您从 shell 中编写的代码保存到一个格式良好的方便文件中也很有挑战性。最后,如果您习惯了 IDE 的便利,您将会错过诸如语法高亮、代码完成、函数签名帮助等功能。此外,当使用 TkInter 以外的工具包测试 GUI 开发时,GUI 工具包的主循环会阻塞交互式解释器。
然而,Python 有一些替代的 shells,它们为基本接口的行为提供了一些扩展。IPython 可能是其中最古老的,它提供了一些非常深刻的功能,但忽略了一些肤浅的功能,而 bpython 和 DreamPie 是较新的,在 IPython 忽略的一些功能上做得很好。我们将从年龄先于美貌开始,逐一探讨。—使用 IPython。
IPython 概述
IPython 旨在实现几个目的:它希望成为常规 Python shell 的更强大的替代方案;作为您自己的 Python 程序的调试界面或交互式控制台;作为使用 Python 的编程系统的基础,例如科学编程或类似用途;并作为 GUI 工具包的交互界面。IPython 还开发了用于协作、交互式并行编程的工具。
IPython 运行在 Linux、Windows 和 OS X 上,可以使用easy_install或pip轻松安装。(如果您想使用可选的 Qt 接口,您还需要安装 PyQt)。一旦安装完成,您就可以通过从命令行执行ipython(或者,对于 Qt 版本,ipython qtconsole来启动它。以下是其功能概述:
IPython 代码完成和语法突出显示
IPython 提供了区分大小写的制表符补全,不仅包括对象和关键字的名称,还包括可用模块(包括当前工作目录中的模块)以及文件名和目录名。除了键入以外,没有其他方法可以选择其中一个选项,直到它成为唯一的选项。选项要么显示在光标下方的单行中,要么如果选项太多,则显示在几列中。
在 Qt 控制台中,当屏幕上有太多选择时,这种显示就成了一个问题。例如,如果你这样做:import gtk gtk.它会给你一个无法管理的可能选择的长列表,并把你的光标推离屏幕。不过,您可以通过按下q或Esc来恢复,这将清除选项视图并返回到您的光标处。在常规终端版本中,选项列表被打印到屏幕上,然后光标所在的行再次出现,这更容易使用,尽管很难浏览选项列表。
总而言之,使用 IPython 完成代码是准确和可行的,但没有想象中那么方便。
正在输入的代码的语法高亮显示在常规的控制台视图中不可用,但是在 Qt 控制台中提供了。然而,它不是特别可定制的。有三个选项,NoColor、Linux 和 LightBG,你可以使用 IPython 的%colors魔法在它们之间切换,例如:%colors linux切换到 Linux 着色方案。在页面中显示 Python 文件内容的%pycat%魔术在两个界面中都进行语法高亮显示。
IPython 魔法
你可能已经注意到上面提到的“魔法”;IPython 提供了各种控制或改变外壳行为的神奇功能。上面我们看到了%colors和%pycat,但是还有更多。以下是一些亮点:
- %自动呼叫:自动在呼叫中插入括号,如
range 3 5 - %debug :调试当前环境
- %edit :运行文本编辑器并执行其输出
- %gui :指定一个 gui 工具包,允许在其事件循环运行时进行交互
- %
- %loadpy :从文件名或 URL(!)
- %登录和%注销:开启和关闭登录
- %macro :为历史中的一系列行命名,以便重复
- %pylab :加载
numpy和matplotlib交互使用 - %quickref :加载快速参考指南
- %
- %
- %
- %
- %timeit :使用 Python 的
timeit来计时语句、表达式或块的执行
而那些,就像我说的,只是亮点。IPython 有很多功能,其中很多功能并不是立即可见的。不过,在线和内置的文档都很棒。
IPython 的帮助系统
IPython 的帮助系统特别方便——你只需键入你想看到描述的对象或函数的名字,然后加上?;IPython 将显示有问题的对象的文档字符串、定义、源、源文件等等。不够?用两个问号再试一次,你会得到更多。
例如,导入urllib2然后输入urllib2?会产生以下结果:
Type: module
Base Class: <type 'module'>
String Form:<module 'urllib2' from '/usr/lib/python2.7/urllib2.pyc'>
Namespace: Interactive
File: /usr/lib/python2.7/urllib2.py
Docstring: An extensible library for opening URLs using a variety of protocols
# ...删减了 350 个单词...
这是它的用法的一个例子:
import urllib2
#设置认证信息
authinfo = urllib2。HTTPBasicAuthHandler()
authinfo . add _ password(realm = ' PDQ Application ',uri = ' https://localhost:8092/site-updates . py ',user='username ',passwd = ' password ')
proxy _ support = URL lib 2。proxy handler({ ' http ':' http://proxy hostname:3128 ' })
#构建一个新的 opener,增加认证和缓存 FTP 处理程序
opener = urllib2 . Build _ opener(proxy _ support,authinfo,URL lib 2。CacheFTPHandler)
# Install it
URL lib 2 . Install _ opener(开启器)
f = URL lib 2 . urlopen(' http://www . python . org/')
请注意,我从结果中截取了 350 个单词的描述!输入urllib2??提供了上述所有内容以及该模块的完整源代码。
IPython 的帮助也适用于内置的神奇命令,它有一个内置的 IPython 概述(只需通过?访问),以及一个快速参考指南(%quickref)。简单来说,IPython 的帮助很大。
其他工具
IPython 提供了许多其他 Python shells 所没有的工具,包括用于并行编程和与多个 GUI 工具包交互工作的工具。
IPython 中的并行编程
IPython 的一个主要部分是它的并行编程结构,这是内置的,看起来非常强大——但这在很大程度上超出了本文的范围。(附带说明:默认情况下,IPython.parallel包的一些依赖项不会随 IPython 一起安装。)
交互式 GUI 编程
交互式 GUI 编程是 IPython 允许的活动之一,它非常适合这种活动。要启用它,请使用带有参数的%gui魔法函数,指定您正在使用哪个 GUI 工具包:
- %gui wx :启用 wxPython 事件循环集成
- %gui qt4|qt :启用 PyQt4 事件循环集成
- %gui gtk :启用 PyGTK 事件循环集成
- %gui tk :启用 tk 事件循环集成
- %gui OSX :启用 Cocoa 事件循环集成(需要%matplotlib 1.1)
- %gui :禁用所有事件循环集成
然后,您可以像往常一样构建您的 UI,除了当您调用工具包的主循环(例如 TkInter 中的root.mainloop()或 PyGTK 中的gtk.main())时,您的用户界面将在您继续交互发出命令时运行。
IPython 审查摘要
IPython 可以做的比我在这里描述的多得多——它包含很多功能,尽管它有一个相当长的学习曲线。它可能不适合所有人;对于许多人来说,我将讨论的其他选项之一可能提供了他们实际使用的所有功能,但复杂性要低得多,但它确实值得一看。让我们来讨论一下 bpython 和 DreamPie 。
搜索实现:线性和二进制
原文:https://www.pythoncentral.io/search-implementations-linear-binary/
先决条件
要了解线性和二分搜索法,你需要很好地理解:
- Python 3
- 基本 Python 数据结构概念-列表
简介
我们经常需要从给定的数据结构中找到一个元素,比如列表、链表或二叉树。有效的搜索技术可以节省大量时间并提高性能。在本教程中,我们将看到两个非常常用的搜索算法。
线性搜索
那么,如果你要在一个光线不好的房间里从书架上搜索“哈利·波特”,你会怎么做呢?你会从一端开始,一次拿一本书,检查它是不是哈利波特。你将使用蛮力方法检查每一本书,直到找到哈利波特或到达书架的尽头。最好的情况是哈利波特是第一本书,最坏的情况是这本书根本不在里面。无论哪种方式,你只能通过检查每一本书来了解这一点。这正是线性搜索。
二分搜索法
如果你要从一个按字母顺序排列的书架上寻找哈利波特,会怎么样?你会从头开始搜索吗?肯定不是!你可以从中间附近的某个地方开始,检查书籍的第一个字母,然后从那里向前或向后查找“H”标题。这意味着你不会看所有的书,从而节省时间。你也不需要翻遍整个书架来知道这本书是否在那里。在某一点上,你正在淘汰许多你永远不会看的书。二分搜索法与此类似。
注意: 可以对排序和未排序的项目进行线性搜索,但只能对排序后的项目集进行二分搜索法。
实施
现在你已经知道了什么是线性和二分搜索法方法,让我们看看这些搜索是如何在一系列数字上工作的。
线性搜索
给定列表 A = [6,3,9,0,5,8,2]查找 0 是否出现在该列表中。
算法
- 从列表 A 中一次取出一个数字
- 与 0 比较,检查是否匹配:
- 如果是,返回 True
- 如果不是,返回 False
- 如果列表结束,返回 False
代码
def linearSearch(ls,data):
for item in ls:
if item == data:
return True
return False
print(linearSearch([6,3,9,5,8,2],0))
二分搜索法
这个想法是不断比较元素和中间值。这样,每次搜索我们都会删除一半的列表。
算法
- 保持跟踪两个指针,第一个和最后一个,它们被递增或递减以限制要搜索的列表部分。
- 找到列表的中间元素:mid =(列表长度)/2
- 将中间元素与要查找的值进行比较
- 检查中间元素是否小于要查找的值:
- 如果是,该元素必须位于列表的后半部分
- 如果不是,元素必须位于列表的前半部分
- 重复第 1 步到第 3 步,直到找到元素或到达列表的末尾
注意: 列表继续被一分为二,中间的元素被比较,直到找到该元素或者没有其他元素可以比较。
代码
给定列表 B = [2,5,7,8,9,11,14,16]找出列表中是否有 14。
def binarySearch(ls,data):
first = 0
last = len(ls)-1
done = False
while first<=last and not done:
mid = (first+last)//2
if ls[mid] == data:
done = True
else:
if ls[mid] > data:
last = last-1
else:
first = first+1
return done
print(binarySearch([2,5,7,8,9,11,14,16],4))
| 回合 | 第一次 | 最后一次 | 中旬 | ls[mid] | 结果 |
| 1 | 0 | 7 | 3 | 8 | 8 < 14 |
| 2 | 4 | 7 | five | Eleven | 11 < 14 |
| three | six | seven | six | Fourteen | 14=14 |
注: 求 mid 元素,用“(first+last)//2”代替“(first+last)/2”。这给了我们整数,特别是当列表的长度是奇数时。在您的 Python IDLE 中尝试 9/2 和 9//2,以便更好地理解。
尝试一下 这个 动画可以更好地理解这两种搜索算法。尝试找到数组的第一个元素。哪个更快?
结论
从上面的解释中,很明显二分搜索法总是比线性搜索更快。如果你熟悉 o(n)符号,线性搜索是 o(n),二分搜索法是 log(n)
您可以在一个排序列表上执行线性搜索,也可以进行一个小的优化。一旦要查找的数字超过了要比较的元素,就可以停止搜索。例如,你想从列表[2,4,5,13,16,19]中搜索 12,一旦搜索到 13,你就可以停止,因为在一个排序列表中,12 不可能排在 13 之后。
在本教程中,我们只讨论了二分搜索法迭代法。尝试自己实现递归方法。此外,了解这些搜索的用途以及何时应用它们。本教程到此为止。快乐的蟒蛇!
从 Python 中的列表/元组/数据结构中随机选择一项
原文:https://www.pythoncentral.io/select-random-item-list-tuple-data-structure-python/
需要随机动作的最常见的任务之一是从一个组中选择一个项目,可以是字符串、unicode 或缓冲区中的一个字符,bytearray 中的一个字节,或者是列表、元组、集合或 xrange 中的一个项目。想要一个以上项目的样本也很常见。
随机选择一个项目时不要这样做
完成这些任务的一种简单方法包括如下内容:要选择单个项目,您可以使用来自random模块的randrange(或randint),该模块根据其参数指定的范围生成一个伪随机整数:
【python】
导入随机
items = ['here ',' are ',' some ',' strings ',
' which ',' we ',' will ',' select ',' one']
rand _ item = items[random . rand range(len(items))]
一种同样简单的选择多项的方法可能是使用random.randrange在列表理解中生成索引,比如:
【python】
rand _ items =[items[random . rand range(len(items))]
for item in range(4)]
[/Python]
这些都可以工作,但是如果您已经编写 Python 有一段时间了,您应该会想到,有一种内置的方法可以更简洁、更易读地完成这项工作。
请在选择项目时执行此操作
从 Python 序列类型(即str、unicode、list、tuple、bytearray、buffer、xrange中选择一项的 Python 方法是使用random.choice。例如,我们单项选择的最后一行是:
rand_item = random.choice(items)
简单多了,不是吗?有一个同样简单的方法从序列中选择 n 个项目:
rand_items = random.sample(items, n)
从set中随机选择
sets是不可转位,意味着set([1, 2, 3])[0]产生错误。因此random.choice不支持sets,而random.sample支持。
例如:
>>> from random import choice, sample
>>>
>>> # INVALID: set([1, 2, 3])[0]
>>> choice(set([1, 2, 3, 4, 5]))
Traceback (most recent call last):
File "", line 1, in <module>
File "<python-dist>/random.py", line 275, in choice
return seq[int(self.random() * len(seq))] # raises IndexError if seq is empty
TypeError: 'set' object does not support indexing
有几种方法可以解决这个问题,其中两种方法是首先将set转换成list,然后使用支持sets的random.sample。
示例:
>>> from random import choice, sample
>>>
>>> # Convert the set to a list
>>> choice(list(set([1, 2, 3])))
1
>>>
>>> # random.sample(), selecting 1 random element
>>> sample(set([1, 2, 3]), 1)
[1]
>>> sample(set([1, 2, 3]), 1)[0]
3
重复项目
如果序列包含重复值,则每个值都是独立的候选值。为了避免重复,一种方法是将list转换成set,然后再转换回list。例如:
>>> my_list = [1, 1, 2, 2, 3, 3, 4, 4, 5, 5]
>>> my_set = set(my_list)
>>> my_list = list(my_set) # No duplicates
>>> my_list
[1, 2, 3, 4, 5]
>>> my_elem = random.choice(my_list)
>>> my_elem
2
>>> another_elem = random.choice(list(set([1, 1, 1])))
选择排序:快速教程和实施指南
原文:https://www.pythoncentral.io/selection-sort-implementation-guide/
先决条件
要了解选择排序,您必须知道:
- Python 3
- Python 数据结构-列表
什么是选择排序?
我们正在学习排序系列的第三个教程。前面的教程讲的是冒泡排序和插入排序。如果你还没有读过,请照着我们将要建立的那些概念去做。像所有的排序算法一样,我们认为一个列表只有在升序时才被排序。降序被认为是最坏的未排序情况。
类似于插入排序,我们首先考虑要排序的第一个元素,其余的元素不排序。随着算法的进行,列表中已排序的部分将增长,未排序的部分将继续收缩。
选择排序是从列表中挑选最小的元素,并将其放入列表的排序部分。最初,第一个元素被认为是最小值,并与其他元素进行比较。在这些比较过程中,如果找到一个较小的元素,则认为它是新的最小值。完成一整轮后,找到的最小元素与第一个元素交换。这个过程一直持续到所有元素都被排序。
让我们用一个例子来看看,列表= [5,9,1,2,7,0]
5 被认为是已排序的,而元素 9,1,2,7,0 被认为是未排序的。
第一轮:
5 is the minimum
5<9: nothing happens
5>1: 1 is new minimum
1<2: nothing happens
1<7: nothing happens
1>0: 0 is the new minimum
Swap 0 and 5
alist = [0,9,1,2,7,5]
第二轮:
9 is the minimum
9>1: 1 is the new minimum
1<2: nothing happens
1<7: nothing happens
1<5: nothing happens
Swap 1 and 9
alist = [0,1,9,2,7,5]
第三轮:
9 is considered minimum
9>2: 2 is the new minimum
2<7: nothing happens
2<5: nothing happens
Swap 2 and 9
alist = [0,1,2,9,7,5]
第 4 轮:
9 is considered minimum
9>7: 7 is the new minimum
7>5: 5 is the new minimum
Swap 9 and 5
alist = [0.1.2.5,7,9]
第五轮:
7 is considered minimum
7<9: nothing happens
alist = [0.1.2.5,7,9]
注意: 即使在第 4 轮之后我们可以看到列表已经排序,算法也没有办法知道这一点。因此,只有在完全遍历了整个列表之后,算法才会停止。
为了更好的理解,请看这个动画。
如何实现选择排序?
现在你对什么是选择排序有了一个很好的理解,让我们来看看这个算法和它的代码。
算法
- 考虑要排序的第一个元素,其余元素不排序
- 假设第一个元素是最小的元素。
- 检查第一个元素是否小于其他元素:
- 如果是,什么都不做
- 如果否,选择另一个较小的元素作为最小值,并重复步骤 3
- 在完成列表的一次迭代后,用列表的第一个元素交换最小的元素。
- 现在认为列表中的第二个元素是最小的,以此类推,直到列表中的所有元素都被覆盖。
注意: 一旦一个元素被添加到列表的排序部分,它就决不能被接触和或比较。
代码
def selectionSort(alist):
for i in range(len(alist)):
# Find the minimum element in remaining
minPosition = i
for j in range(i+1, len(alist)):
if alist[minPosition] > alist[j]:
minPosition = j
# Swap the found minimum element with minPosition
temp = alist[i]
alist[i] = alist[minPosition]
alist[minPosition] = temp
return alist
print(selectionSort([5,2,1,9,0,4,6]))
结论
选择排序最适用于少量元素。插入排序的最坏情况运行时间复杂度是 o(n2 ),类似于插入和冒泡排序。本教程到此为止。快乐的蟒蛇!
使用 Python 发送电子邮件
Python 是一种众所周知的编程语言,在执行一个特殊的程序——解释器时,其源代码被部分转换成机器代码。许多人选择 Python 是因为它简单易学,可以跨多个平台工作。此外,python 软件通常可以免费下载,兼容各种类型的系统,加速开发。
和其他任何编程语言一样,Python 有自己的特点:
- 得益于基本语法,开发者可以轻松阅读和理解 Python 软件;
- 与其他编程语言相比,Python 可以使用更少的代码行来创建程序,从而帮助开发人员提高工作效率;
- Python 标准库足够大,包含几乎任何任务的可重用代码;
- Python 的另一个重要优势是可以很容易地与 C、C++、Java 等其他编程语言结合。

Python 有几个标准用例。它在编写服务器代码时很有用,因为它为复杂的服务器功能提供了许多由预写代码组成的库。数据科学家广泛使用 Python ML 库来运行机器学习模型,并构建分类器来高效地对数据 进行分类。最近,Python 也开始被积极地用于发送电子邮件。请阅读下面的内容,详细了解如何做到这一点。
如何使用 Python 发送 Gmail 邮件?
如今,电子邮件营销是任何商业推广策略的重要组成部分。许多人已经看到了电子邮件通讯的有效性。在此了解如何使用 Gmail 发送批量邮件。使用 Python 发送 Gmail 邮件也有几种方式。最流行的是通过 SMTP 协议。
SMTP
SMTP 是一种应用层协议。它用于在各种邮件服务器和外部服务(如移动设备上的邮件客户端)之间建立通信。SMTP 只是一种传递协议。因此,您无法使用它接收电子邮件。你可以发邮件。 IMAP 通常用于接收邮件。
包括 Gmail 在内的各种现代电子邮件服务不要求在内部邮件服务器上使用 SMTP。因此,该协议通常仅作为该服务通过 smtp.gmail.com 服务器的外部接口提供。邮件客户端主要在台式电脑或手机(雷鸟、Outlook 等)上使用。).
打开连接
Python 已经有了一个允许你连接到 SMTP 服务器的库。它叫 smtplib,是 Python 自带的。这个库处理协议的各个部分,比如连接、认证、验证和发送电子邮件。
使用 smtplib 库时,可以提供到邮件服务器的连接。这样的连接是不安全的。它没有加密。默认情况下使用端口 25。因此,创建更可靠的连接是值得注意的。
确保安全连接

当通过 SSL/TLS 保护到 SMTP 协议的连接时,它通过 465 端口,通常被称为 SMTPS。不言而喻,为什么要提供这样的连接。你可能明白这个问题的重要性。
在库 smtplib 中有几种方法可以保护 SMTP 连接。最流行的方法包括建立不安全的连接,随后切换到【TLS】。另一种选择是从一开始就创建一个安全的 SSL 连接。
创建电子邮件
建立安全连接后,您可以直接创建电子邮件。事实上,电子邮件是由换行符连接的普通文本行。大多数电子邮件包含“发件人”、“收件人”、“主题”和“文本”等字段。每行包含几个具有特定数据的字段。没有二进制协议(根据“请求-响应”模式传输数据),没有 XML,也没有 JSON。只有由字段分隔的行。要参数化字段,可以使用 Python 的字段格式。
Gmail 认证
使用 SMTP 发送 Gmail 电子邮件之前,您可能需要进行身份验证。如果您使用 Gmail 邮件服务作为您的 ISP,您需要获得 Google 的许可才能通过 SMTP 协议进行连接,该协议被评为不太安全的方法。如果您使用其他邮件提供商的服务,则不需要执行任何附加步骤。
用 Python 发送电子邮件
一旦你建立了 SMTP 连接并完成了谷歌认证,你就可以使用 Python 发送简单的邮件和带附件的邮件了。的使用。sendmail():是必需的。
结束语
发送、检查和回复电子邮件是一项相当耗时的任务,尤其是当你为大量的人或客户做这件事时,你只需要更改收件人的详细信息。然而,你可以在这方面自动化许多事情,从长远来看,这将节省你很多时间。自动化发送电子邮件的一种方式是通过 Python。要成功地使用它,只需经历几个简单的步骤就足够了,本文已经对此进行了详细描述。
尽量考虑我们所有的建议,提供可靠的 SMTP 连接,用 Python 发邮件一定会成功!
单链表:如何插入和打印节点
原文:https://www.pythoncentral.io/singly-linked-list-insert-node/
先决条件
要了解单链表,你应该知道:
- Python 3
- OOP 概念
什么是单链表?
在本教程中,我们将学习什么是单链表,以及可以对它们执行的一些非常基本的操作。
在我们进入什么是单链表的细节之前,我们必须了解什么是节点。这是因为节点是链表的构造块。一个节点由两部分组成:
- 数据部分-包含数据
- 地址部分-这是指向下一个节点位置的指针
在单链表中,每个节点的地址部分包含了下一个节点的位置信息。这就形成了一系列的链条或链环。链表的第一个节点由指针跟踪。最后一个节点指向 无 。
让我们看看下面的图表,以便更好地理解这一点:
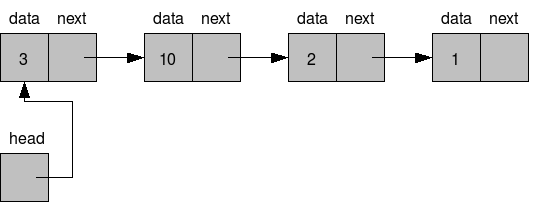
注:上图中最后一个元素 1 指向无。 尽管这些节点彼此相邻,但实际上,它们可能在也可能不在相邻的内存位置。
请看这个动画,它展示了链表的工作方式。
提示: 总是试图画出这些数据结构来获得清晰的理解。
如何创建单链表?
创建类
首先,你必须创建一个节点来创建一个单链表。为此,我们创建一个类【数据】 和next Node属性。如前所述, 数据 属性将包含数据,而next node将简单地指向链表中的下一个节点。我们将next node的默认值设为 None。 你可以用getter和setter方法来做到这一点。
既然已经创建了 节点 类,那么是时候创建linked list类了。这个只有一个属性,。默认情况下,这里会指向 无 。如果表头指向 None,则表示链表为空 。为了跟踪链表中节点的数量,我们可以在linked list类中添加一个size属性,并将其默认为 0。
插入节点
这是一个linked list类的方法。记住,为了使编码简单有效,我们总是将新节点添加到链表的开头。换句话说, 头 将始终指向最近添加的节点。如果我们将新节点添加到列表的末尾,我们需要做额外的工作来找到列表的末尾,然后添加它。这是一个浪费的操作。然而,如果你维护另一个指针,让我们称它为 尾指针使它指向最后一个节点,这是可以做到的。您可以在链表中的任意位置插入新节点。我们已经讨论了前一种方法,即在链表的开头插入。
假设我们需要将 7 添加到一个链表中,我们需要执行以下步骤:
- 创建一个以 7 为数据的节点对象,下一个节点指向 头 节点
- 将 头的 指针指向这个新节点
最后将 大小 属性加 1。如果插入成功,最好返回 True 。这样用户就知道发生了什么。
打印节点
这是一个linked list类的方法。要打印链表所有节点中的数据,我们需要一次遍历一个节点,并打印每个节点的数据部分。
编码单链表
class Node:
def __init__(self,data,nextNode=None):
self.data = data
self.nextNode = nextNode
def getData(self):
return self.data
def setData(self,val):
self.data = val
def getNextNode(self):
return self.nextNode
def setNextNode(self,val):
self.nextNode = val
class LinkedList:
def __init__(self,head = None):
self.head = head
self.size = 0
def getSize(self):
return self.size
def addNode(self,data):
newNode = Node(data,self.head)
self.head = newNode
self.size+=1
return True
def printNode(self):
curr = self.head
while curr:
print(curr.data)
curr = curr.getNextNode()
myList = LinkedList()
print("Inserting")
print(myList.addNode(5))
print(myList.addNode(15))
print(myList.addNode(25))
print("Printing")
myList.printNode()
print("Size")
print(myList.getSize())
单链表的优缺点是什么?
优势
- 这是一个动态数据结构,插入和删除都很简单,因为我们不需要移动元素。只要更新下一个指针就可以了。
- 使用链表可以很容易地实现堆栈和队列数据结构。
缺点
- 下一个指针用完了额外的内存。
- 随机访问是不可能的。您必须从头开始遍历链表才能到达特定的节点。
结论
本教程到此结束。在以后的教程中,我们将会看到如何从链表中移除一个元素,如何发现一个元素是否存在于链表中等等。快乐的蟒蛇!
SQLAlchemy 关联表
原文:https://www.pythoncentral.io/sqlalchemy-association-tables/
关联表
在我们之前的文章中,我们使用关联表来建模表之间的many-to-many关系,比如Department和Employee之间的关系。在本文中,我们将更深入地研究关联表的概念,看看我们如何使用它来进一步解决更复杂的问题。
部门员工链接和额外数据
在上一篇文章中,我们创建了以下 SQLAlchemy 模型:
import os
from sqlalchemy 导入列,DateTime,String,Integer,ForeignKey,func
from sqlalchemy.orm 导入关系,back ref
from sqlalchemy . ext . declarative import declarative _ base
Base = declarative_base()
class Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
employees = relationship(
' Employee ',
secondary = ' Department _ Employee _ link '
)
class Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
hired _ on = Column(DateTime,default = func . now())
departments = relationship(
Department,
secondary = ' Department _ Employee _ link '
)
class DepartmentEmployeeLink(Base):
_ _ tablename _ _ = ' department _ employee _ link '
department _ id = Column(Integer,ForeignKey('department.id '),primary _ key = True)
employee _ id = Column(Integer,ForeignKey('employee.id '),primary_key=True)
请注意,DepartmentEmployeeLink类包含两个外键列,足以模拟Department和Employee之间的多对多关系。现在我们再添加一列extra_data和两个关系department和employee。
import os
from sqlalchemy 导入列,DateTime,String,Integer,ForeignKey,func
from sqlalchemy.orm 导入关系,back ref
from sqlalchemy . ext . declarative import declarative _ base
Base = declarative_base()
class Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
employees = relationship(
' Employee ',
secondary = ' Department _ Employee _ link '
)
class Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
hired _ on = Column(DateTime,default = func . now())
departments = relationship(
Department,
secondary = ' Department _ Employee _ link '
)
class DepartmentEmployeeLink(Base):
_ _ tablename _ _ = ' Department _ Employee _ link '
Department _ id = Column(Integer,ForeignKey('department.id '),primary _ key = True)
Employee _ id = Column(Integer,ForeignKey('employee.id '),primary _ key = True)
extra _ data = Column(String(256))
Department = relationship(Department,backref = backref(" Employee _ assoc "))
Employee = relationship(Employee,
通过在DepartmentEmployeeLink关联模型上增加一个额外的列和两个额外的关系,我们可以存储更多的信息,并且可以更加自由地使用这些信息。例如,假设我们有一个在 IT 部门兼职的员工约翰,我们可以将字符串“兼职”插入到列extra_data中,并创建一个DepartmentEmployeeLink对象来表示这种关系。
>>> fp = 'orm_in_detail.sqlite'
>>> if os.path.exists(fp):
... os.remove(fp)
...
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///association_tables.sqlite')
>>>
>>> from sqlalchemy.orm import sessionmaker
>>> session = sessionmaker()
>>> session.configure(bind=engine)
>>> Base.metadata.create_all(engine)
>>>
>>>
>>> IT = Department(name="IT")
>>> John = Employee(name="John")
>>> John_working_part_time_at_IT = DepartmentEmployeeLink(department=IT, employee=John, extra_data='part-time')
>>> s = session()
>>> s.add(John_working_part_time_at_IT)
>>> s.commit()
然后,我们可以通过查询 IT 部门或DepartmentEmployeeLink模型来找到 John。
>>> IT.employees[0].name
u'John'
>>> de_link = s.query(DepartmentEmployeeLink).join(Department).filter(Department.name == 'IT').one()
>>> de_link.employee.name
u'John'
>>> de_link = s.query(DepartmentEmployeeLink).filter(DepartmentEmployeeLink.extra_data == 'part-time').one()
>>> de_link.employee.name
u'John'
最后,使用关系Department.employees添加 IT 员工仍然有效,如前一篇文章所示:
>>> Bill = Employee(name="Bill")
>>> IT.employees.append(Bill)
>>> s.add(Bill)
>>> s.commit()
链接与 Backref 的关系
到目前为止,我们在relationship定义中使用的一个常见关键字参数是backref。一个backref是将第二个relationship()放置到目标表上的常见快捷方式。例如,下面的代码通过在Post.owner上指定一个backref将第二个relationship()“帖子”放到user表格上:
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(256))
类 Post(Base):
_ _ tablename _ _ = ' Post '
id = Column(Integer,primary _ key = True)
owner _ id = Column(Integer,foreign key(' User . id ')
owner = relationship(User,backref = backref(' Post ',uselist=True))
这相当于以下定义:
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(256))
posts = relationship("Post", back_populates="owner")
类 Post(Base):
_ _ tablename _ _ = ' Post '
id = Column(Integer,primary _ key = True)
owner _ id = Column(Integer,foreign key(' User . id ')
owner = relationship(User,back _ populated = " posts ")
现在我们在User和Post之间有了一个one-to-many关系。我们可以通过以下方式与这两个模型进行交互:
>>> s = session()
>>> john = User(name="John")
>>> post1 = Post(owner=john)
>>> post2 = Post(owner=john)
>>> s.add(post1)
>>> s.add(post2)
>>> s.commit()
>>> s.refresh(john)
>>> john.posts
[, ]
>>> john.posts[0].owner
> > > John . posts[0]. owner . name
u ' John '
一对一
在模型之间创建one-to-one关系与创建many-to-one关系非常相似。通过在backref()中将uselist参数的值修改为False,我们强制数据库模型以one-to-one关系相互映射。
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(256))
类地址(Base):
_ _ tablename _ _ = ' Address '
id = Column(Integer,primary _ key = True)
Address = Column(String(256))
User _ id = Column(Integer,foreign key(' User . id '))
User = relationship(' User ',backref=backref('address ',uselist=False))
然后,我们可以按以下方式使用模型:
>>> s = session()
>>> john = User(name="John")
>>> home_of_john = Address(address="1234 Park Ave", user=john)
>>> s.add(home_of_john)
>>> s.commit()
>>> s.refresh(john)
>>> john.address.address
u'1234 Park Ave'
>>> john.address.user.name
u'John'
>>> s.close()
关系更新级联
在关系数据库中,参照完整性保证当one-to-many或many-to-many关系中被引用对象的主键改变时,引用主键的引用对象的外键也将改变。但是,对于不支持参照完整性的数据库,如关闭了参照完整性选项的 SQLite 或 MySQL,更改被引用对象的主键值不会触发引用对象的更新。在这种情况下,我们可以使用relationship或backref中的passive_updates标志来通知数据库执行额外的 SELECT 和 UPDATE 语句,这些语句将更新引用对象的外键的值。
在下面的例子中,我们在User和Address之间构造了一个one-to-many关系,并且没有在关系中指定passive_updates标志。数据库后端是 SQLite。
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(256))
类地址(Base):
_ _ tablename _ _ = ' Address '
id = Column(Integer,primary _ key = True)
Address = Column(String(256))
User _ id = Column(Integer,foreign key(' User . id '))
User = relationship(
' User ',backref=backref('addresses ',uselist=True)
)
然后,当我们改变一个User对象的主键值时,它的Address对象的user_id外键值将不会改变。因此,当你想再次访问一个address的user对象时,你会得到一个AttributeError。
>>> s = session()
>>> john = User(name='john')
>>> home_of_john = Address(address='home', user=john)
>>> office_of_john = Address(address='office', user=john)
>>> s.add(home_of_john)
>>> s.add(office_of_john)
>>> s.commit()
>>> s.refresh(john)
>>> john.id
1
>>> john.id = john.id + 1
>>> s.commit()
>>> s.refresh(home_of_john)
>>> s.refresh(office_of_john)
>>> home_of_john.user.name
Traceback (most recent call last):
File "", line 1, in
AttributeError: 'NoneType' object has no attribute 'name'
>>> s.close()
如果我们在Address模型中指定了passive_updates标志,那么我们可以更改john的主键,并期望 SQLAlchemy 发出额外的 SELECT 和 UPDATE 语句来保持home_of_john.user和office_of_john.user是最新的。
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
name = Column(String(256))
类地址(Base):
_ _ tablename _ _ = ' Address '
id = Column(Integer,primary _ key = True)
Address = Column(String(256))
User _ id = Column(Integer,foreign key(' User . id '))
User = relationship(
' User ',backref=backref('addresses ',uselist=True,passive_updates=False)
)
>>> s = session()
>>> john = User(name='john')
>>> home_of_john = Address(address='home', user=john)
>>> office_of_john = Address(address='office', user=john)
>>> s.add(home_of_john)
>>> s.add(office_of_john)
>>> s.commit()
>>> s.refresh(john)
>>> john.id
1
>>> john.id = john.id + 1
>>> s.commit()
>>> s.refresh(home_of_john)
>>> s.refresh(office_of_john)
>>> home_of_john.user.name
u'john'
>>> s.close()
摘要
在本文中,我们将深入探讨 SQLAlchemy 的关联表和关键字参数backref。理解这两个概念背后的机制对于完全掌握复杂的连接查询通常是至关重要的,这将在以后的文章中展示。
SQLAlchemy 表达式语言,更高级的用法
原文:https://www.pythoncentral.io/sqlalchemy-expression-language-advanced-usage/
概观
在上一篇文章 SQLAlchemy 表达式语言,高级用法中,我们通过包含User、ShoppingCart和Product的三表数据库了解了 SQLAlchemy 表达式语言的强大功能。在本文中,我们将回顾 SQLAlchemy 中物化路径的概念,并使用它来实现产品包含关系,其中某些产品可能包含其他产品。例如,DSLR 相机包是一种产品,其可以包含主体、三脚架、镜头和一组清洁工具,而主体、三脚架、镜头和该组清洁工具中的每一个也是一种产品。在这种情况下,DSLR 相机包产品包含其他产品。
物化路径
Materialized Path是一种在关系数据库中存储分层数据结构(通常是树)的方法。它可以用来处理数据库中任何类型的实体之间的层次关系。sqlamp是一个第三方 SQLAlchemy 库,我们将使用它来演示如何建立一个包含基于关系的分层数据结构的产品。要安装sqlamp,在您的 shell 中运行以下命令:
$ pip install sqlamp
Downloading/unpacking sqlamp
...
Successfully installed sqlamp
Cleaning up...
首先,让我们回顾一下我们在上一篇文章中所做的事情。
from sqlalchemy import Column, DateTime, String, Integer, ForeignKey, Float
from sqlalchemy.orm import relationship, backref
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
类 User(Base):
_ _ tablename _ _ = ' User '
id = Column(Integer,primary _ key = True)
name = Column(String)
class shopping cart(Base):
_ _ tablename _ _ = ' shopping _ cart '
id = Column(Integer,primary _ key = True)
owner _ id = Column(Integer,foreign key(User . id))
owner = relationship(
User,backref = backref(' shopping _ carts ',use list = True)
)
products = relationship(
' Product ',
secondary = ' shopping _ cart _ Product _ link '
)
defr})”。格式(购物车、自助)
class Product(Base):
_ _ tablename _ _ = ' Product '
id = Column(Integer,primary _ key = True)
name = Column(String)
#使用浮点数不是对货币值建模的正确方式。
#我们将在另一篇文章中探讨这个话题。
price = Column(Float)
shopping _ carts = relationship(
' shopping cart ',
secondary = ' shopping _ cart _ product _ link '
)
def _ _ repr _ _(self):
return '({ 0 }:{ 1 . name!r}:{1.price!r})”。格式(产品、自身)
类 ShoppingCartProductLink(Base):
_ _ tablename _ _ = ' shopping _ cart _ product _ link '
shopping _ cart _ id = Column(Integer,ForeignKey('shopping_cart.id '),primary _ key = True)
product _ id = Column(Integer,ForeignKey('product.id '),primary_key=True)
我们定义了四个模型,User表示一组用户,Product表示一组产品,ShoppingCart表示一组购物车,每个购物车都由一个User拥有并包含多个Product,还有ShoppingCartProductLink,它是一个连接Product和ShoppingCart的链接表。
然后,让我们将sqlamp引入模型类,看看我们如何使用它来为Product s 创建一个物化的路径。
import sqlamp
from sqlalchemy 导入列,DateTime,String,Integer,ForeignKey,Float
from sqlalchemy.orm 导入关系,back ref
from sqlalchemy . ext . declarative import declarative _ base
Base = declarative_base(元类=sqlamp。DeclarativeMeta)
类 User(Base):
_ _ tablename _ _ = ' User '
id = Column(Integer,primary _ key = True)
name = Column(String)
class shopping cart(Base):
_ _ tablename _ _ = ' shopping _ cart '
id = Column(Integer,primary _ key = True)
owner _ id = Column(Integer,foreign key(User . id))
owner = relationship(
User,backref = backref(' shopping _ carts ',use list = True)
)
products = relationship(
' Product ',
secondary = ' shopping _ cart _ Product _ link '
)
defr})”。格式(购物车、自助)
class Product(Base):
_ _ tablename _ _ = ' Product '
# _ _ MP _ manager _ _ 指定产品的哪个字段是物化路径管理器,
#用于管理产品的子代和祖先的查询。
_ _ MP _ manager _ _ = ' MP '
id = Column(Integer,primary _ key = True)
name = Column(String)
#使用浮点数不是对货币值建模的正确方式。我们将在另一篇文章中探讨这个话题。
price = Column(Float)
shopping _ carts = relationship(
' shopping cart ',
secondary = ' shopping _ cart _ product _ link '
)
#使用自引用外键引用包含此产品的父产品
#。
parent_id = Column(Integer,foreign key(' Product . id ')
parent = relationship(' Product ',remote _ side =[id])
def _ _ repr _ _(self):
return '({ 0 }:{ 1 . name!r}:{1.price!r})”。格式(产品、自身)
类 ShoppingCartProductLink(Base):
_ _ tablename _ _ = ' shopping _ cart _ product _ link '
shopping _ cart _ id = Column(Integer,ForeignKey('shopping_cart.id '),primary _ key = True)
product _ id = Column(Integer,ForeignKey('product.id '),primary_key=True)
注意,我们在Product模型中插入了一个新的外键parent_id和一个新的关系parent,并引入了一个新的类成员字段__mp_manager__。现在我们可以使用Product.mp来查询任何product的子代和祖先。
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///')
>>>
>>>
>>> from sqlalchemy.orm import sessionmaker
>>> DBSession = sessionmaker()
>>> DBSession.configure(bind=engine)
>>> Base.metadata.create_all(engine)
>>>
>>>
>>> camera_package = Product(name='DSLR Camera Package', price=1600.00)
>>> tripod = Product(name='Camera Tripod', price=200.00, parent=camera_package)
>>> body = Product(name='Camera Body', price=400.00, parent=camera_package)
>>> lens = Product(name='Camera Lens', price=1000.00, parent=camera_package)
>>> session = DBSession()
>>> session.add_all([camera_package, tripod, body, lens])
>>> session.commit()
>>> camera_package.mp.query_children().all()
[( :u'Camera Tripod':200.0 ), ( :u'Camera Body':400.0 ), ( :u'Camera Lens':1000.0 )]
>>> tripod.mp.query_ancestors().all()
[( :u'DSLR Camera Package':1600.0 )]
>>> lens.mp.query_ancestors().all()
[( :u'DSLR Camera Package':1600.0 )]
递归处理产品树
为了递归地遍历一棵Product树,我们可以调用sqlamp.tree_recursive_iterator并使用递归函数遍历树的所有后代。
>>> def recursive_tree_processor(nodes):
... for node, children in nodes:
... print('{0}'.format(node.name))
... if children:
... recursive_tree_processor(children)
...
>>> query = camera_package.mp.query_descendants(and_self=True)
>>> recursive_tree_processor(
... sqlamp.tree_recursive_iterator(query, Product.mp)
... )
DSLR Camera Package
Camera Tripod
Camera Body
Camera Lens
摘要
在本文中,我们使用前一篇文章的Product来说明如何使用sqlamp在 SQLAlchemy 中实现物化路径。通过简单地在Product中插入一个自引用外键和一个 mp_manager 字段,我们能够为Product实现一个分层数据结构。由于sqlamp是在 SQLAlchemy 之上编写的,它应该可以与 SQLAlchemy 支持的任何数据库后端一起工作。
SQLAlchemy 表达式语言,高级用法
原文:https://www.pythoncentral.io/sqlalchemy-expression-language-advanced/
表达语言
SQLAlchemy 的核心组件之一是表达式语言。它允许程序员在 Python 结构中指定 SQL 语句,并在更复杂的查询中直接使用这些结构。由于表达式语言是后端中立的,并且全面涵盖了原始 SQL 的各个方面,所以它比 SQLAlchemy 中的任何其他组件都更接近原始 SQL。在本文中,我们将使用一个三表数据库来说明表达式语言的强大功能。
数据库模型
假设我们想要对多个购物车进行建模,每个购物车都由一个用户创建,并存储多种产品。从规范中,我们可以推断出一个用户拥有多个购物车,一个购物车包含多个产品,一个产品可以包含在多个购物车中。因此,我们希望在ShoppingCart和Product之间建立多对多的关系,在User和ShoppingCart之间建立一对多的关系。让我们创建数据库模型:
from sqlalchemy import Column, DateTime, String, Integer, ForeignKey, Float
from sqlalchemy.orm import relationship, backref
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
类 User(Base):
_ _ tablename _ _ = ' User '
id = Column(Integer,primary _ key = True)
name = Column(String)
class shopping cart(Base):
_ _ tablename _ _ = ' shopping _ cart '
id = Column(Integer,primary _ key = True)
owner _ id = Column(Integer,foreign key(User . id))
owner = relationship(
User,backref = backref(' shopping _ carts ',use list = True)
)
products = relationship(
' Product ',
secondary = ' shopping _ cart _ Product _ link '
)
defr})”。格式(购物车、自助)
class Product(Base):
_ _ tablename _ _ = ' Product '
id = Column(Integer,primary _ key = True)
name = Column(String)
#使用浮点数不是对货币值建模的正确方式。
#我们将在另一篇文章中探讨这个话题。
price = Column(Float)
shopping _ carts = relationship(
' shopping cart ',
secondary = ' shopping _ cart _ product _ link '
)
def _ _ repr _ _(self):
return '({ 0 }:{ 1 . name!r}:{1.price!r})”。格式(产品、自身)
class ShoppingCartProductLink(Base):
_ _ tablename _ _ = ' shopping _ cart _ product _ link '
shopping _ cart _ id = Column(Integer,ForeignKey('shopping_cart.id '),primary_key=True)
product _ id = Column(Integer,ForeignKey('product.id '),primary _ key = True)
从 sqlalchemy 导入 create _ engine
engine = create _ engine(' SQLite:///')
从 sqlalchemy.orm 导入 session maker
DBSession = session maker()
DBSession . configure(bind = engine)
base . metadata . create _ all(engine)
创建用户、产品和购物车
现在让我们创建一个用户和几个产品。
>>> session = DBSession()
>>> cpu = Product(name='CPU', price=300.00)
>>> motherboard = Product(name='Motherboard', price=150.00)
>>> coffee_machine = Product(name='Coffee Machine', price=30.00)
>>> john = User(name='John')
>>> session.add(cpu)
>>> session.add(motherboard)
>>> session.add(coffee_machine)
>>> session.add(john)
>>> session.commit()
>>> session.close()
在继续之前,让我们验证一下现在数据库中有一个用户和三个产品。
>>> session = DBSession()
>>> cpu = session.query(Product).filter(Product.name == 'CPU').one()
>>> motherboard = session.query(Product).filter(Product.name == 'Motherboard').one()
>>> coffee_machine = session.query(Product).filter(Product.name == 'Coffee Machine').one()
>>> john = session.query(User).filter(User.name == 'John').one()
>>> session.close()
现在我们可以为用户John创建两个购物车。
>>> session = DBSession()
>>> cpu = session.query(Product).filter(Product.name == 'CPU').one()
>>> motherboard = session.query(Product).filter(Product.name == 'Motherboard').one()
>>> coffee_machine = session.query(Product).filter(Product.name == 'Coffee Machine').one()
>>> john = session.query(User).filter(User.name == 'John').one()
>>> john_shopping_cart_computer = ShoppingCart(owner=john)
>>> john_shopping_cart_kitchen = ShoppingCart(owner=john)
>>> john_shopping_cart_computer.products.append(cpu)
>>> john_shopping_cart_computer.products.append(motherboard)
>>> john_shopping_cart_kitchen.products.append(coffee_machine)
>>> session.add(john_shopping_cart_computer)
>>> session.add(john_shopping_cart_kitchen)
>>> session.commit()
>>> session.close()
使用表达式语言查询数据库
现在我们在数据库中有了一个用户、三个产品和两个购物车,我们可以开始使用表达式语言了。首先,让我们编写一个查询来回答这个问题:哪些产品的价格高于$100.00?
>>> from sqlalchemy import select
>>> product_higher_than_one_hundred = select([Product.id]).where(Product.price > 100.00)
>>>
>>> session = DBSession()
>>> session.query(Product).filter(Product.id.in_(product_higher_than_one_hundred)).all()
[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )]
>>> session.close()
然后,让我们编写一个查询来回答一个更复杂的问题:哪些购物车包含至少一个价格高于$100.00 的产品?
>>> shopping_carts_with_products_higher_than_one_hundred = select([ShoppingCart.id]).where(
... ShoppingCart.products.any(Product.id.in_(product_higher_than_one_hundred))
... )
>>> session = DBSession()
>>> session.query(ShoppingCart).filter(ShoppingCart.id.in_(shopping_carts_with_products_higher_than_one_hundred)).one()
( :John:[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )] )
>>> session.close()
然后,让我们编写一个查询来回答一个稍微不同的问题:哪些购物车中没有价格低于$100.00 的产品?
>>> products_lower_than_one_hundred = select([Product.id]).where(Product.price < 100.00)
>>> from sqlalchemy import not_
>>> shopping_carts_with_no_products_lower_than_one_hundred = select([ShoppingCart.id]).where(
... not_(ShoppingCart.products.any(Product.id.in_(products_lower_than_one_hundred)))
... )
>>> session = DBSession()
>>> session.query(ShoppingCart).filter(ShoppingCart.id.in_(
... shopping_carts_with_no_products_lower_than_one_hundred)
... ).all()
[( :John:[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )] )]
>>> session.close()
或者,前一个问题可以以不同的方式形成:我们如何找到所有产品价格都高于$100.00 的购物车?
>>> from sqlalchemy import and_
>>> shopping_carts_with_all_products_higher_than_one_hundred = select([ShoppingCart.id]).where(
... and_(
... ShoppingCartProductLink.product_id.in_(product_higher_than_one_hundred),
... ShoppingCartProductLink.shopping_cart_id == ShoppingCart.id
... )
... )
>>> session = DBSession()
>>> session.query(ShoppingCart).filter(ShoppingCart.id.in_(
... shopping_carts_with_all_products_higher_than_one_hundred)
... ).all()
[( :John:[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )] )]
>>> session.close()
现在,我们可以就Product.price上的聚合提出一种不同的问题。例如,我们可以问:哪些购物车中产品的总价格高于 200 美元?
>>> from sqlalchemy import func
>>> total_price_of_shopping_carts = select([
... ShoppingCart.id.label('shopping_cart_id'),
... func.sum(Product.price).label('product_price_sum')
... ]).where(
... and_(
... ShoppingCartProductLink.product_id == Product.id,
... ShoppingCartProductLink.shopping_cart_id == ShoppingCart.id,
... )
... ).group_by(ShoppingCart.id)
>>> session = DBSession()
>>> session.query(total_price_of_shopping_carts).all()
[(1, 450.0), (2, 30.0)]
>>> session.query(ShoppingCart).filter(
... ShoppingCart.id == total_price_of_shopping_carts.c.shopping_cart_id,
... total_price_of_shopping_carts.c.product_price_sum > 200.00
... ).all()
[( :John:[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )] )]
>>> session.query(ShoppingCart).filter(
... ShoppingCart.id == total_price_of_shopping_carts.c.shopping_cart_id,
... total_price_of_shopping_carts.c.product_price_sum < 200.00
... ).all()
[( :John:[( :u'Coffee Machine':30.0 )] )]
>>> session.close()
在前面的例子中,我们从构建一个 SQLAlchemy selectable total_price_of_shopping_carts开始,它的“列”是每个购物车的ShoppingCart.id和每个相应购物车中所有产品价格的总和。一旦我们有了这样一个selectable,就很容易编写查询来查找所有产品价格总和高于$200.00 的购物车。
潜在陷阱
到目前为止,我们的示例程序似乎运行得很好。但是,如果我们以非预期的方式编写和使用这些结构,从而意外地破坏了程序呢?SQLAlchemy 会通知我们程序有什么问题吗,以便我们调试它?
例如,列Product.price被定义为一个Float。如果我们创建一个带有字符串的price的Product对象会怎么样?SQLAlchemy 会因为价格输入的数据类型与定义不同而中断吗?让我们试一试。
>>> session = DBSession()
>>> cpu = Product(name='CPU', price='0.15')
>>> session.add(cpu)
>>> session.commit()
>>> cpu = session.query(Product).filter(Product.name == 'CPU').one()
>>> cpu.price
0.15
因此,带有字符串 price 的产品 CPU 被成功地插入到数据库中。用一个根本不是数字的字符串来表示价格怎么样?
> > > cpu_two = Product(name='CPU Two ',price = ' asdf ')
>>>session . add(CPU _ Two)
>>>session . commit()
...
sqlalchemy . exc . statement error:无法将字符串转换为浮点数:asdf(原始原因:ValueError:无法将字符串转换为浮点数:asdf) u'INSERT INTO product (name,price) VALUES(?, ?)'[{'price': 'asdf ',' name': 'CPU Two'}]
哎呀。现在 SQLAlchemy 引发了一个`StatementError`,因为“asdf”不能转换成一个`Float`。这是一个很好的特性,因为它消除了由粗心引起的潜在编程错误。
您可能还注意到,我们示例中的`filter()`方法使用了像`Product.name == 'CPU'`和`Product.price > 100.0`这样的表达式。这些表达式不是先被求值,然后将结果布尔值传递给`filter()`函数以获得实际的过滤结果吗?让我们用几个例子来验证`filter()`的行为。
session.query(Product).filter(True).all()
[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 ), ( :u'Coffee Machine':30.0 )]
session.query(Product).filter(Product.name='CPU').all()
File "", line 1
SyntaxError: keyword can't be an expression
session.query(Product).filter(Product.price > '100.0').all()
[( :u'CPU':300.0 ), ( :u'Motherboard':150.0 )]
从上面的例子中,我们看到`filter()`确实接受像`True`这样简单的布尔值,它返回数据库中的所有产品。但是,它不接受像`Product.name = 'CPU'`这样在过滤器上下文中含义不明确的表达式。像`Product`构造函数一样,它也将一个字符串值`'100.0'`转换成一个浮点数,并根据最终标准过滤产品表。
现在让我们检查几个 SQLAlchemy API 看起来不太直观的例子。首先,`select()`语句似乎只接受一列作为第一个参数,就像`select([Product.id])`一样。如果我们能写出类似`select(Product.id)`的东西不是很好吗?
products_lower_than_one_hundred = select(Product.id).where(Product.price < 100.00)
...
NotImplementedError: Operator 'getitem' is not supported on this expression
[/python]
Oops. SQLAlchemy does not like a single element as the first argument of select(). Remember, always pass in a list.
第二,一些 where 子句中的语法看起来不像 Pythonic 化的:ShoppingCart.products.any(Product.id.in_(product_higher_than_one_hundred))。如果我们能写出类似ShoppingCart.products.any(Product.id in product_higher_than_one_hundred))的东西不是很好吗?
>>> shopping_carts_with_products_higher_than_one_hundred = select([ShoppingCart.id]).where(
... ShoppingCart.products.any(Product.id in product_higher_than_one_hundred)
... )
...
TypeError: argument of type 'Select' is not iterable
因为 SQLAlchemy 的'Select'对象是不可迭代的,所以在in上下文中使用它不起作用。这看起来可能是一个缺点,但是它是有意义的,因为一个'Select'对象在 SQLAlchemy 中非常灵活。如示例所示,一个'Select'对象可以传递给任何一个filter()或where(),成为另一个'Select'对象的更复杂查询或事件的一部分。在这样的对象上支持iterable需要对底层实现进行大量的修改。
第三,query()的结果似乎是返回格式良好的对象,例如( :u'CPU':300.0 )作为一个Product对象的显示。它看起来不同于典型的物体,比如:
>>> class C:
... pass
...
>>> c = C()
>>> c
为什么?这是因为我们覆盖了`Product`的`__repr__()`方法,并且来自 Python 解释器的`print()`命令正在调用`Product`和`ShoppingCart`对象的结果数组上的`repr()`,这些对象调用每个相应类的实现的`__repr__()`。
最后,SQLAlchemy 为什么要实现自己的`Float`列类型?为什么他们不能重用 Python 内部的`float`类型?
简单来说,SQLAlchemy 是一个 ORM,ORM 使用定义的类型系统将 Python 结构映射到 SQL 结构,类型系统必须是数据库不可知的,这意味着它必须处理具有相同列类型的不同数据库后端。最长的答案是,模型中定义的每一列都必须由 SQLAlchemy 定义,定义/列类型实现自定义方法,这些方法由 SQLAlchemy 的低级 API 调用,以将 Python 构造转换为相应的 SQL 构造。
提示和总结
在本文中,我们使用了一个三表数据库来说明如何使用 SQLAlchemy 的表达式语言。需要记住的一点是,我们使用数学集合来指导我们编写 SQL 查询。每当我们遇到一个不小的问题,尤其是涉及多个表格的问题,我们应该分而治之,先回答问题的一部分。例如,问题“我们如何找到所有产品的价格总和高于$200.00 的购物车”可以分为以下几个部分:1 .我们如何计算产品价格的总和?(`func.sum()` ) 2。如何在一个`selectable`中列出所有的元组(`ShoppingCart.id`、`func.sum(Product.price)`)?3.我们如何使用`selectable`来编写实际的查询呢?
SQLAlchemy–一些常见问题
常见问题
在我们深入 SQLAlchemy 之前,让我们回答一系列关于 ORM 的问题:
- 能否阻止 SQLAlchemy 自动创建模式?相反,可以将 SQLAlchemy 模型绑定到现有的模式吗?
- 与编写原始 SQL 相比,使用 SQLAlchemy 时有没有性能开销?如果有,多少?
- 如果您没有足够的权限在数据库中创建表,SQLAlchemy 会抛出异常吗?
- 模式是如何修改的?它是自动完成的还是你写代码来完成的?
- 有没有对触发器的支持?
在这篇文章中,我们将回答所有的问题。一些问题将被详细讨论,而另一些问题将在另一篇文章中被总结和讨论。
SQLAlchemy 架构反射/自省
我们也可以指示一个Table对象从数据库中已经存在的相应数据库模式对象中加载关于自身的信息,而不是像前面的文章中所示的那样,使用Base.metadata.create_all(engine)从 SQLAlchemy 中自动创建一个模式。
让我们创建一个示例 sqlite3 数据库,其中一个表person存储一条记录:
import sqlite3
conn = sqlite3 . connect(" example . db ")
c = conn . cursor()
c . execute(' '
创建表人
(姓名文本,邮件文本)
' ' ')
c . execute(" INSERT INTO person VALUES(' John ',' John @ example . com '))"
c . close()
现在我们可以使用Table构造函数中的参数autoload和autoload_with来反映表person的结构。
>>> from sqlalchemy import create_engine, MetaData, Table
>>>
>>> engine = create_engine('sqlite:///example.db')
>>> meta = MetaData(bind=engine)
>>> person = Table("person", meta, autoload=True, autoload_with=engine)
>>> person
Table('person', MetaData(bind=Engine(sqlite:///example.db)), Column(u'name', TEXT(), table=), Column(u'email', TEXT(), table=), schema=None)
>>> [c.name for c in person.columns]
[u'name', u'email']
我们还可以使用MetaData.reflect方法反映数据库中的所有表。
>>> meta = MetaData()
>>> meta.reflect(bind=engine)
>>> person = meta.tables['person']
>>> person
Table(u'person', MetaData(bind=None), Column(u'name', TEXT(), table=), Column(u'email', TEXT(), table=), schema=None)
尽管反射非常强大,但它也有其局限性。记住反射构造Table元数据只使用关系数据库中可用的信息是很重要的。当然,这样的过程不能恢复实际上没有存储在数据库中的模式的某些方面。不可用的方面包括但不限于:
- 使用
Column构造函数的default关键字定义的客户端默认值、Python 函数或 SQL 表达式。 - 列信息,在
Column.info字典中定义。 Column或Table的.quote设定值。- 特定
Sequence与给定Column的关联。
SQLAlchemy 最近的改进允许反映视图、索引和外键选项等结构。像检查约束、表注释和触发器这样的结构没有被反映出来。
SQLAlchemy 的性能开销
由于 SQLAlchemy 在将变更(即session.commit())同步到数据库时使用工作单元模式,因此它不仅仅是像在原始 SQL 语句中那样“插入”数据。它跟踪对会话对象所做的更改,并维护所有对象的标识映射。它还执行相当数量的簿记,并维护任何 CRUD 操作的完整性。总的来说,工作单元自动化了将复杂对象图持久化到关系数据库中的任务,而无需编写显式的过程性持久化代码。当然,如此先进的自动化是有代价的。
因为 SQLAlchemy 的 ORM 不是为处理批量插入而设计的,所以我们可以写一个例子来测试它对原始 SQL 的效率。除了批量插入测试用例的 ORM 和原始 SQL 实现,我们还实现了一个使用 SQLAlchemy 核心系统的版本。由于 SQLAlchemy 的核心是原始 SQL 之上的一个抽象薄层,我们希望它能达到与原始 SQL 相当的性能水平。
import time
import sqlite3
from sqlalchemy . ext . declarative import declarative _ base
from sqlalchemy import Column,Integer,String,create _ engine
from sqlalchemy . ORM import scoped _ session,sessionmaker
base = declarative _ base()
session = scoped _ session(session maker())
类 User(Base):
_ _ tablename _ _ = " User "
id = Column(Integer,primary _ key = True)
name = Column(String(255))
def init _ db(dbname = ' SQLite:///example . db '):
engine = create _ engine(dbname,echo = False)
session . remove()
session . configure(bind = engine,autoflush=False,expire _ on _ commit = False)
base . metadata . drop _ all(engine)
base . metadata . create _ all(engine)
返回引擎
def test _ SQLAlchemy _ ORM(number _ of _ records = 100000):
init _ db()
start = time . time()
for I in range(number _ of _ records):
User = User()
User . NAME = ' NAME '+str(I)
session . add(User)
session . commit()
end = time . time()
print " SQLAlchemy ORM:在{1}秒内插入{0}条记录"。格式(
str(记录数),str(结束-开始)
)
def test _ sqlalchemy _ core(number _ of _ records = 100000):
engine = init _ db()
start = time . time()
engine . execute(
User。__ 表 _ _。insert(),
[{ " NAME ":" NAME "+str(I)} for I in range(number _ of _ records)]
)
end = time . time()
打印“SQLAlchemy Core:在{1}秒内插入{0}条记录”。格式(
str(记录数),str(结束-开始)
)
def init _ sqlite3(dbname = " sqlite3 . db "):
conn = sqlite3 . connect(dbname)
cursor = conn . cursor()
cursor . execute(" DROP TABLE IF EXISTS user ")
cursor . execute(" CREATE TABLE user(id INTEGER NOT NULL,name VARCHAR(255),PRIMARY KEY(id))"
conn . commit()
return conn
def test _ sqlite3(number _ of _ records = 100000):
conn = init _ sqlite3()
cursor = conn . cursor()
start = time . time()
for I in range(number _ of _ records):
cursor . execute(" INSERT INTO user(name)VALUES(?)",(" NAME " + str(i),))
conn . commit()
end = time . time()
打印" sqlite3:Insert { 0 } records in { 1 } seconds "。格式(
str(记录数),str(结束-开始)
)
if _ _ name _ _ = = " _ _ main _ _ ":
test _ sqlite3()
test _ sqlalchemy _ core()
test _ sqlalchemy _ ORM()
在前面的代码中,我们比较了使用原始 SQL、SQLAlchemy 的 Core 和 SQLAlchemy 的 ORM 向 sqlite3 数据库中批量插入 100000 条用户记录的性能。如果您运行该代码,您将得到类似如下的输出:
$ python orm_performance_overhead.py
sqlite3: Insert 100000 records in 0.226176977158 seconds
SQLAlchemy Core: Insert 100000 records in 0.371157169342 seconds
SQLAlchemy ORM: Insert 100000 records in 10.1760079861 seconds
注意,核心和原始 SQL 获得了相当的插入速度,而 ORM 比其他两个慢得多。尽管看起来 ORM 会导致很大的性能开销,但是请记住,只有当有大量数据需要插入时,开销才会变得很大。由于大多数 web 应用程序在一个请求-响应周期中运行小的 CRUD 操作,由于额外的便利和更好的可维护性,最好使用 ORM 而不是核心。
SQLAlchemy 和数据库权限
到目前为止,我们的示例在 sqlite3 数据库中运行良好,该数据库没有细粒度的访问控制,如用户和权限管理。如果我们想在 MySQL 或 PostgreSQL 中使用 SQLAlchemy 怎么办?当连接到数据库的用户没有足够的权限创建表、索引等时会发生什么??SQLAlchemy 会抛出数据库访问异常吗?
让我们用一个例子来测试当用户没有足够的权限时 SQLAlchemy 的 ORM 的行为。首先,我们创建一个测试数据库“test_sqlalchemy”和一个测试用户“sqlalchemy”。
$ psql
postgres=# create database test_sqlalchemy;
CREATE DATABASE
postgres=# create user sqlalchemy with password 'sqlalchemy';
CREATE ROLE
postgres=# grant all on database test_sqlalchemy to sqlalchemy;
GRANT
目前,测试用户“sqlalchemy”拥有对测试数据库“test_sqlalchemy”的所有访问权限。因此,我们希望数据库初始化调用成功,并将一条记录插入数据库“test_sqlalchemy”。
import time
import sqlite3
from sqlalchemy . ext . declarative import declarative _ base
from sqlalchemy import Column,Integer,String,create _ engine
from sqlalchemy . ORM import scoped _ session,sessionmaker
base = declarative _ base()
session = scoped _ session(session maker())
类 User(Base):
_ _ tablename _ _ = " User "
id = Column(Integer,primary _ key = True)
name = Column(String(255))
def init _ db(dbname):
engine = create _ engine(dbname,echo = False)
session . configure(bind = engine,autoflush=False,expire _ on _ commit = False)
base . metadata . create _ all(engine)
return engine
if _ _ name _ _ = = " _ _ main _ _ ":
init _ db(" PostgreSQL://sqlalchemy:sqlalchemy @ localhost/test _ sqlalchemy ")
u = User(name = " other _ User ")
session . add(u)
session . commit()
session . close()
执行完脚本后,您可以检查“user”表中是否有新的`User`记录。
$ psql test_sqlalchemy
psql (9.3.3)
Type "help" for help.
test _ sqlalchemy = # select * from " user ";
id |姓名
1 |其他 _ 用户
现在假设我们取消测试用户“sqlalchemy”的插入权限。那么我们应该预料到运行相同的代码将会失败并出现异常。
inside a psql shell
test_sqlalchemy=# revoke INSERT on "user" from sqlalchemy;
REVOKE
inside a bash shell
$ python permission_example.py
trace back(最近一次调用 last):
文件“permission _ example . py”,第 32 行,在
session.commit()
文件“/home/vagger/python central/local/lib/python 2.7/site-packages/sqlalchemy/ORM/scoping . py”,第 149 行,在 do
返回 getattr(self.registry(),name)(*args,**kwargs)
文件“/home......
File "/home/vagger/python central/local/lib/python 2.7/site-packages/sqlalchemy/engine/default . py ",第 425 行,在 do _ execute
cursor . execute(statement,parameters)
sqlalchemy . exc . programming error:(programming error)对关系用户的权限被拒绝
' INSERT INTO " user "(name)VALUES(%)(name)s)返回" user "。id' {'name': 'other_user'}
如您所见,抛出了一个异常,表明我们没有权限将记录插入到关系用户中。
SQLAlchemy 的模式迁移
至少有两个库可用于执行 SQLAlchemy 迁移:`migrate` [文档链接](https://sqlalchemy-migrate.readthedocs.org/en/latest/ "documentation link")和`alembic` [文档链接](http://alembic.readthedocs.org/en/latest/ "documentation link")。
由于`alembic`是 SQLAlchemy 的作者写的,并且是积极开发的,所以我们推荐你用它来代替`migrate`。`alembic`不仅允许您手动编写迁移脚本,它还提供了自动生成脚本的方法。我们将在另一篇文章中进一步探讨如何使用`alembic`。
SQLAlchemy 对触发器的支持
可以使用定制的 DDL 结构创建 SQL 触发器,并与 SQLAlchemy 的事件挂钩。虽然它不是对触发器的直接支持,但它很容易实现并插入到任何系统中。我们将在另一篇文章中研究自定义 DDL 和事件。
提示和总结
在本文中,我们从 SQL 数据库管理员的角度回答了一些关于 SQLAlchemy 的常见问题。虽然 SQLAlchemy 默认为您创建一个数据库模式,但是它也允许您反映现有的模式并为您生成`Table`对象。使用 SQLAlchemy 的 ORM 时会有性能开销,但在执行批量插入时这一点最明显,而大多数 web 应用程序执行相对较小的 CRUD 操作。如果您的数据库用户没有足够的权限在表上执行某些操作,SQLAlchemy 将抛出一个异常,显示您无法执行这些操作的确切原因。SQLAlchemy 有两个迁移库,强烈推荐使用`alembic`。尽管不直接支持触发器,但是您可以很容易地在原始 SQL 中编写它们,并使用自定义 DDL 和 SQLAlchemy 事件将它们连接起来。
SQLAlchemy ORM 示例
ORM 摘要
在以前的一篇文章中,我们简要地浏览了一个带有两个表department和employee的示例数据库,其中一个部门可以有多个雇员,一个雇员可以属于任意数量的部门。我们使用了几个代码片段来展示 SQLAlchemy 表达式语言的强大功能,并展示如何编写 ORM 查询。
在本文中,我们将更详细地了解 SQLAlchemy 的 ORM,并找出如何更有效地使用它来解决现实世界中的问题。
部门和员工
我们将继续使用前一篇文章中的 department-employee 作为本文中的示例数据库。我们还将向每个表中添加更多的列,以使我们的示例更加有趣。
from sqlalchemy import Column, DateTime, String, Integer, ForeignKey, func
from sqlalchemy.orm import relationship, backref
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
类 Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
class Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
# Use default = func . now()将雇员的默认雇佣时间
#设置为创建
# Employee 记录的当前时间
hired_on = Column(DateTime,default = func . now())
Department _ id = Column(Integer,foreign key(' Department . id ')
#雇员的当前时间
从 sqlalchemy 导入 create _ engine
engine = create _ engine(' SQLite:///ORM _ in _ detail . SQLite ')
从 sqlalchemy.orm 导入 session maker
session = session maker()
session . configure(bind = engine)
base . metadata . create _ all(engine)
注意,我们对 employee 表做了两处修改:1。我们插入了一个新列‘hired _ on ’,它是一个日期时间列,存储雇员被雇用的时间和,2。我们在关系Employee.department的backref中插入了一个关键字参数‘cascade ’,其值为 delete,all’。cascade 允许 SQLAlchemy 在部门本身被删除时自动删除该部门的雇员。
现在让我们写几行代码来使用新的表定义。
>>> d = Department(name="IT")
>>> emp1 = Employee(name="John", department=d)
>>> s = session()
>>> s.add(d)
>>> s.add(emp1)
>>> s.commit()
>>> s.delete(d) # Deleting the department also deletes all of its employees.
>>> s.commit()
>>> s.query(Employee).all()
[]
让我们创建另一个雇员来测试我们新的日期时间列“hired_on”:
>>> emp2 = Employee(name="Marry")
>>> emp2.hired_on
>>> s.add(emp2)
>>> emp2.hired_on
>>> s.commit()
>>> emp2.hired_on
datetime.datetime(2014, 3, 24, 2, 3, 46)
你注意到这个小片段有些奇怪吗?既然Employee.hired_on被定义为默认值func.now(),那么emp2.hired_on在被创建后怎么会是None ?
答案在于 SQLAlchemy 是如何处理func.now()的。func生成 SQL 函数表达式。func.now()在 SQL 中直译为 now() :
>>> print func.now()
now()
>>> from sqlalchemy import select
>>> rs = s.execute(select([func.now()]))
>>> rs.fetchone()
(datetime.datetime(2014, 3, 24, 2, 9, 12),)
正如您所看到的,通过 SQLAlchemy 数据库会话对象执行func.now()函数会根据我们机器的时区给出当前的日期时间。
在继续下一步之前,让我们删除department表和employee表中的所有记录,这样我们可以稍后从一个干净的数据库开始。
>>> for department in s.query(Department).all():
... s.delete(department)
...
>>> s.commit()
>>> s.query(Department).count()
0
>>> s.query(Employee).count()
0
更多 ORM 查询
让我们继续编写查询,以便更加熟悉 ORM API。首先,我们在两个部门“IT”和“财务”中插入几个雇员。
IT = Department(name="IT")
Financial = Department(name="Financial")
john = Employee(name="John", department=IT)
marry = Employee(name="marry", department=Financial)
s.add(IT)
s.add(Financial)
s.add(john)
s.add(marry)
s.commit()
cathy = Employee(name="Cathy", department=Financial)
s.add(cathy)
s.commit()
假设我们想找到名字以“C”开头的所有雇员,我们可以使用startswith()来实现我们的目标:
>>>s.query(Employee).filter(Employee.name.startswith("C")).one().name
u'Cathy'
让查询变得更加困难的是,假设我们想要查找姓名以“C”开头并且也在财务部门工作的所有雇员,我们可以使用一个连接查询:
>>> s.query(Employee).join(Employee.department).filter(Employee.name.startswith('C'), Department.name == 'Financial').all()[0].name
u'Cathy'
如果我们想搜索在某个日期之前雇用的员工,该怎么办?我们可以在 filter 子句中使用普通的 datetime 比较运算符。
>>> from datetime import datetime
# Find all employees who will be hired in the future
>>> s.query(Employee).filter(Employee.hired_on > func.now()).count()
0
# Find all employees who have been hired in the past
>>> s.query(Employee).filter(Employee.hired_on < func.now()).count()
3
部门和员工之间的多对多
到目前为止,一个Department可以有多个Employees,一个Employee最多属于一个Department。因此,Department和Employee之间是一对多的关系。如果一个Employee可以属于任意数量的Department呢?我们如何处理多对多的关系?
为了处理Department和Employee之间的多对多关系,我们将创建一个新的关联表“department_employee_link ”,其中外键列指向Department和Employee。我们还需要从Department中删除backref定义,因为我们将在Employee中插入一个多对多relationship。
import os
from sqlalchemy 导入列,DateTime,String,Integer,ForeignKey,func
from sqlalchemy.orm 导入关系,back ref
from sqlalchemy . ext . declarative import declarative _ base
Base = declarative _ Base()
class Department(Base):
_ _ tablename _ _ = ' Department '
id = Column(Integer,primary _ key = True)
name = Column(String)
employees = relationship(
' Employee ',
secondary = ' Department _ Employee _ link '
)
class Employee(Base):
_ _ tablename _ _ = ' Employee '
id = Column(Integer,primary _ key = True)
name = Column(String)
hired _ on = Column(
DateTime,
default = func . now())
departments = relationship(
Department,
secondary = ' Department _ Employee _ link '
)
class DepartmentEmployeeLink(Base):
_ _ tablename _ _ = ' department _ employee _ link '
department _ id = Column(Integer,ForeignKey('department.id '),primary _ key = True)
employee _ id = Column(Integer,ForeignKey('employee.id '),primary_key=True)
请注意,DepartmentEmployeeLink中的所有列“部门标识”和“员工标识”被组合在一起形成了表department_employee_link的主键,而类Department和类Employee中的relationship参数有一个指向关联表的附加关键字参数“次要”。
一旦我们定义了我们的模型,我们就可以按以下方式使用它们:
>>> fp = 'orm_in_detail.sqlite'
>>> # Remove the existing orm_in_detail.sqlite file
>>> if os.path.exists(fp):
... os.remove(fp)
...
>>> from sqlalchemy import create_engine
>>> engine = create_engine('sqlite:///orm_in_detail.sqlite')
>>>
>>> from sqlalchemy.orm import sessionmaker
>>> session = sessionmaker()
>>> session.configure(bind=engine)
>>> Base.metadata.create_all(engine)
>>>
>>> s = session()
>>> IT = Department(name="IT")
>>> Financial = Department(name="Financial")
>>> cathy = Employee(name="Cathy")
>>> marry = Employee(name="Marry")
>>> john = Employee(name="John")
>>> cathy.departments.append(Financial)
>>> Financial.employees.append(marry)
>>> john.departments.append(IT)
>>> s.add(IT)
>>> s.add(Financial)
>>> s.add(cathy)
>>> s.add(marry)
>>> s.add(john)
>>> s.commit()
>>> cathy.departments[0].name
u'Financial'
>>> marry.departments[0].name
u'Financial'
>>> john.departments[0].name
u'IT'
>>> IT.employees[0].name
u'John'
注意,我们使用Employee.departments.append()将一个Department添加到一个Employee的部门列表中。
要查找 IT 部门的员工列表,无论他们是否属于其他部门,我们可以使用relationship.any()函数。
>>> s.query(Employee).filter(Employee.departments.any(Department.name == 'IT')).all()[0].name
u'John'
另一方面,要查找 John 是其雇员之一的部门列表,我们可以使用相同的函数。
>>> s.query(Department).filter(Department.employees.any(Employee.name == 'John')).all()[0].name
u'IT'
总结和提示
在本文中,我们深入研究了 SQLAlchemy 的 ORM 库,并编写了更多的查询来探索 API。请注意,当您想要将删除从外键引用的对象级联到引用对象时,您可以在引用对象的外键定义的backref中指定cascade='all,delete'(如示例关系Employee.department中所示)。
Python 的 SQLAlchemy vs 其他 ORM
Update: A review of PonyORM has been added.
Python ORMs 概述
作为一门优秀的语言,除了 SQLAlchemy 之外,Python 还有很多 ORM 库。在本文中,我们将看看几个流行的替代 ORM 库,以更好地理解 Python ORM 的全貌。通过编写一个脚本来读写一个包含两个表person和address的简单数据库,我们将更好地理解每个 ORM 库的优缺点。
SQLObject
SQLObject 是一个 Python ORM,在 SQL 数据库和 Python 之间映射对象。由于与 Ruby on Rails 的 ActiveRecord 模式相似,它在编程社区中越来越受欢迎。SQLObject 的第一个版本发布于 2002 年 10 月。它在 LGPL 的许可下。
在 SQLObject 中,数据库概念以一种非常类似于 SQLAlchemy 的方式映射到 Python 中,其中表被映射为类,行被映射为实例,列被映射为属性。它还提供了一种基于 Python 对象的查询语言,使得 SQL 更加抽象,从而为应用程序提供了数据库不可知论。
$ pip install sqlobject
Downloading/unpacking sqlobject
Downloading SQLObject-1.5.1.tar.gz (276kB): 276kB downloaded
Running setup.py egg_info for package sqlobject
警告:未找到匹配“*”的文件。html'
警告:未找到匹配' * '的文件。css'
警告:没有找到与' docs/*匹配的文件。html'
警告:没有找到匹配' * '的文件。“tests”目录下的“py”要求已经满足(使用-升级来升级):form encode>= 1 . 1 . 1 in/Users/xiaonuogantan/python 2-workspace/lib/python 2.7/site-packages(来自 sqlobject)
安装收集的包:sqlobject
运行 setup.py install for sqlobject
将 build/scripts-2.7/SQL object-admin 的模式从 644 更改为 755
更改 build/scripts-2.7 的模式
警告:未找到匹配“*”的文件。html'
警告:未找到匹配' * '的文件。css'
警告:没有找到与' docs/*匹配的文件。html'
警告:没有找到匹配' * '的文件。“tests”目录下的“py”
将/Users/xiaonuogantan/python 2-workspace/bin/SQL object-admin 的模式更改为 755
将/Users/xiaonuogantan/python 2-workspace/bin/SQL object-convertOldURI 的模式更改为 755
成功安装 sqlobject
清理...
>>> from sqlobject import StringCol, SQLObject, ForeignKey, sqlhub, connectionForURI
>>> sqlhub.processConnection = connectionForURI('sqlite:/:memory:')
>>>
>>> class Person(SQLObject):
... name = StringCol()
...
>>> class Address(SQLObject):
... address = StringCol()
... person = ForeignKey('Person')
...
>>> Person.createTable()
[]
>>> Address.createTable()
[]
上面的代码创建了两个简单的表:person和address。要在这两个表中创建或插入记录,我们只需像普通 Python 对象一样实例化一个人和一个地址:
>>> p = Person(name='person')
>>> a = Address(address='address', person=p)
>>> p
>>>答
[/python]
为了从数据库中获取或检索新记录,我们使用附加到`Person`和`Address`类的神奇的`q`对象:
persons = Person.select(Person.q.name == 'person')
persons
list(persons)
[]
P1 = persons[0]
P1 = = p
True
addresses = address . select(address . q . person = = P1)
addresses
列表(地址)
[
]
a1 = addresses[0]
a1 == a
True
[/python]
暴风雨
Storm 是一个 Python ORM,在一个或多个数据库和 Python 之间映射对象。它允许开发人员跨多个数据库表构建复杂的查询,以支持对象信息的动态存储和检索。它是由 Ubuntu 背后的公司 Canonical Ltd .用 Python 开发的,用于 Launchpad 和景观应用程序,随后在 2007 年作为自由软件发布。该项目是在 LGPL 许可证下发布的,贡献者需要向 Canonical 分配版权。
像 SQLAlchemy 和 SQLObject 一样, Storm 也将表映射到类,将行映射到实例,将列映射到属性。与其他两个相比,Storm 的表类不必是特定于框架的特殊超类的子类。在 SQLAlchemy 中,每个表类都是sqlalchemy.ext.declarative.declarative_bas的子类。在 SQLObject 中,每个表类都是sqlobject.SQLObject的子类。
与 SQLAlchemy 类似,Storm 的Store对象充当后端数据库的代理,所有操作都缓存在内存中,一旦在存储上调用方法 commit,就将committed缓存到数据库中。每个存储拥有自己的映射 Python 数据库对象集,就像一个 SQLAlchemy 会话拥有不同的 Python 对象集一样。
Storm 的具体版本可以从下载页面下载。在本文中,示例代码是用 Storm 版编写的。
>>> from storm.locals import Int, Reference, Unicode, create_database, Store
>>>
>>>
>>> db = create_database('sqlite:')
>>> store = Store(db)
>>>
>>>
>>> class Person(object):
... __storm_table__ = 'person'
... id = Int(primary=True)
... name = Unicode()
...
>>>
>>> class Address(object):
... __storm_table__ = 'address'
... id = Int(primary=True)
... address = Unicode()
... person_id = Int()
... person = Reference(person_id, Person.id)
...
上面的代码创建了一个内存 sqlite 数据库和一个引用该数据库对象的存储库。Storm store 类似于 SQLAlchemy DBSession 对象,两者都管理附加到它们的实例对象的生命周期。例如,下面的代码创建一个人和一个地址,并通过刷新存储将这两个记录插入到数据库中。
>>> store.execute("CREATE TABLE person "
... "(id INTEGER PRIMARY KEY, name VARCHAR)")
> > > store.execute("创建表地址"
...”(id 整数主键,address VARCHAR,person_id 整数,“
..."外键(person_id)引用人员(id))")
> > > Person = Person()
>>>Person . name = u ' Person '
>>>打印人
> > > print "%r,%r" % (person.id,person.name)
None,u'person' #请注意,person.id 为 None,因为 person 实例尚未附加到有效的数据库存储。
>>>store . add(person)
>>>
>>>print " % r,%r" % (person.id,person.name)
None,u'person' #由于 store 还没有将 Person 实例刷新到 sqlite 数据库中,person.id 仍然是 None。
>>>store . flush()
>>>print " % r,%r" % (person.id,person.name)
1,u'person' #现在 store 已经刷新了 person 实例,我们得到了 person 的 id 值。
>>>Address = Address()
>>>address.person = person
>>>Address . Address = ' Address '
>>>print " % r,%r" % (address.id,Address . person,address.address)
None,,' Address '
>>>Address . person = = person
True
为了获取或检索插入的 Person 和 Address 对象,我们调用store.find()来找到它们:
>>> person = store.find(Person, Person.name == u'person').one()
>>> print "%r, %r" % (person.id, person.name)
1, u'person'
>>> store.find(Address, Address.person == person).one()
> > > address = store.find(Address,Address.person == person)。one()
> > > print "%r,%r" % (address.id,address.address)
1,u'address'
姜戈氏 ORM
Django 是一个免费的开源 web 应用框架,它的 ORM 被紧密地嵌入到系统中。在最初发布之后,Django 因其简单的设计和易于使用的网络特性而变得越来越受欢迎。它于 2005 年 7 月在 BSD 许可下发布。由于 Django 的 ORM 紧密地构建在 web 框架中,所以不推荐在独立的非 Django Python 应用程序中使用它的 ORM,尽管这是可能的。
Django 是最流行的 Python web 框架之一,它有自己专用的 ORM。与 SQLAlchemy 相比,Django 的 ORM 更适合直接的 SQL 对象操作,它公开了数据库表和 Python 类之间简单直接的映射。
$ django-admin.py startproject demo
$ cd demo
$ python manage.py syncdb
Creating tables ...
Creating table django_admin_log
Creating table auth_permission
Creating table auth_group_permissions
Creating table auth_group
Creating table auth_user_groups
Creating table auth_user_user_permissions
Creating table auth_user
Creating table django_content_type
Creating table django_session
您刚刚安装了 Django 的 auth 系统,这意味着您没有定义任何超级用户。您想现在创建一个吗?(是/否):否
安装自定义 SQL...
安装索引...
从 0 个固定设备
$ python manage.py shell
安装了 0 个对象
因为我们必须先创建一个项目才能执行 Django 的代码,所以我们在之前的 shell 中创建了一个 Django 项目“demo ”,并进入 Django shell 来测试我们的 ORM 示例。
# demo/models.py
>>> from django.db import models
>>>
>>>
>>> class Person(models.Model):
... name = models.TextField()
...
... class Meta:
... app_label = 'demo'
...
>>>
>>> class Address(models.Model):
... address = models.TextField()
... person = models.ForeignKey(Person)
...
... class Meta:
... app_label = 'demo'
上面的代码声明了两个 Python 类,Person和Address,每个类都映射到一个数据库表。在执行任何数据库操作代码之前,我们需要在本地 sqlite 数据库中创建表。
python manage.py syncdb
Creating tables ...
Creating table demo_person
Creating table demo_address
Installing custom SQL ...
Installing indexes ...
Installed 0 object(s) from 0 fixture(s)
为了将一个人和一个地址插入数据库,我们实例化相应的对象并调用这些对象的save()方法。
>>> from demo.models import Person, Address
>>> p = Person(name='person')
>>> p.save()
>>> print "%r, %r" % (p.id, p.name)
1, 'person'
>>> a = Address(person=p, address='address')
>>> a.save()
>>> print "%r, %r" % (a.id, a.address)
1, 'address'
为了获取或检索 person 和 address 对象,我们使用模型类的神奇的objects属性从数据库中获取对象。
>>> persons = Person.objects.filter(name='person')
>>> persons
[]
>>> p = persons[0]
>>> print "%r, %r" % (p.id, p.name)
1, u'person'
>>> addresses = Address.objects.filter(person=p)
>>> addresses
[
]
>>> a = addresses[0]
>>> print "%r, %r" % (a.id, a.address)
1, u'address'
[/python]
## 叫声类似“皮威”的鸟
peewee 是一个小型的、富有表现力的 ORM。与其他 ORM 相比,`peewee`专注于极简主义的原则,API 简单,库易于使用和理解。
pip install peewee
Downloading/unpacking peewee
Downloading peewee-2.1.7.tar.gz (1.1MB): 1.1MB downloaded
Running setup.py egg_info for package peewee
安装收集的包:peewee
运行 setup.py 安装 peewee
将 build/scripts-2.7/pwiz.py 的模式从 644 更改为 755
将/Users/xiaonuogantan/python 2-workspace/bin/pwiz . py 的模式更改为 755
成功安装 peewee
清理...
为了创建数据库模型映射,我们实现了映射到相应数据库表的一个`Person`类和一个`Address`类。
from peewee import SqliteDatabase, CharField, ForeignKeyField, Model
db = SqliteDatabase(':memory:')
class Person(Model):
... name = CharField()
...
... class Meta:
... database = db
...
class Address(Model):
... address = CharField()
... person = ForeignKeyField(Person)
...
... class Meta:
... database = db
...
Person.create_table()
Address.create_table()
为了将对象插入数据库,我们实例化对象并调用它们的`save()`方法。从对象创建的角度来看,`peewee`和 Django 很像。p = Person(name='person')
p.save()
a = Address(address='address', person=p)
a.save()
为了从数据库中获取或检索对象,我们从它们各自的类中`select`对象。person = Person.select().where(Person.name == 'person').get()
person
print '%r, %r' % (person.id, person.name)
1, u'person'
address = Address.select().where(Address.person == person).get()
print '%r, %r' % (address.id, address.address)
1, u'address'
## 波尼奥姆
[PonyORM](https://ponyorm.org/) 允许您使用 Python 生成器查询数据库。这些生成器被翻译成 SQL,结果被自动映射成 Python 对象。将查询编写为 Python 生成器使得程序员可以很容易地快速构造某些查询。
例如,让我们使用 PonyORM 查询 SQLite 数据库中以前的`Person`和`Address`模型。
from pony.orm import Database, Required, Set
db = Database('sqlite', ':memory:')
class Person(db.Entity):
... name = Required(unicode)
... addresses = Set("Address")
...
class Address(db.Entity):
... address = Required(unicode)
... person = Required(Person)
...
db.generate_mapping(create_tables=True)
现在我们在内存中有了一个 SQLite 数据库,两个表映射到了`db`对象,我们可以将两个对象插入到数据库中。
p = Person(name="person")
a = Address(address="address", person=p)
db.commit()
调用`db.commit()`实际上将新对象`p`和`a`提交到数据库中。现在我们可以使用生成器语法查询数据库。
from pony.orm import select
select(p for p in Person if p.name == "person")[:]
[Person[1]]
select(p for p in Person if p.name == "person")[:][0].name
u'person'
select(a for a in Address if a.person == p)[:]
[Address[1]]
select(a for a in Address if a.person == p)[:][0].address
u'address'
## sqllcemy(SQL 语法)
[SQLAlchemy](http://www.sqlalchemy.org/ "SQLAlchemy") 是在 MIT 许可下发布的 Python 编程语言的开源 SQL 工具包和 ORM。它最初于 2006 年 2 月发布,作者是迈克尔·拜尔。它提供了“一整套众所周知的企业级持久化模式,设计用于高效和高性能的数据库访问,适应于简单和 Pythonic 化的领域语言”。它采用了数据映射模式(像 Java 中的 Hibernate)而不是活动记录模式(像 Ruby on Rails 中的模式)。
SQLAlchemy 的工作单元原则使得有必要将所有数据库操作代码限制在特定的数据库会话中,该会话控制该会话中每个对象的生命周期。与其他 ORM 类似,我们从定义`declarative_base()`的子类开始,以便将表映射到 Python 类。
from sqlalchemy import Column, String, Integer, ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Person(Base):
... tablename = 'person'
... id = Column(Integer, primary_key=True)
... name = Column(String)
...
class Address(Base):
... tablename = 'address'
... id = Column(Integer, primary_key=True)
... address = Column(String)
... person_id = Column(Integer, ForeignKey(Person.id))
... person = relationship(Person)
...
在我们编写任何数据库代码之前,我们需要为我们的数据库会话创建一个数据库引擎。
from sqlalchemy import create_engine
engine = create_engine('sqlite:///')
一旦我们创建了一个数据库引擎,我们就可以继续创建一个数据库会话,并为之前定义为`Person`和`Address`的所有数据库类创建表。
from sqlalchemy.orm import sessionmaker
session = sessionmaker()
session.configure(bind=engine)
Base.metadata.create_all(engine)
现在,`session`对象变成了我们的工作单元构造器,所有后续的数据库操作代码和对象都将被附加到一个通过调用它的`__init__()`方法构建的 db 会话上。
s = session()
p = Person(name='person')
s.add(p)
a = Address(address='address', person=p)
s.add(a)
为了获取或检索数据库对象,我们从 db session 对象中调用`query()`和`filter()`方法。
p = s.query(Person).filter(Person.name == 'person').one()
p
print "%r,%r" % (p.id,p.name)
1、' person '
a = s . query(地址)。filter(Address.person == p)。一()
打印“%r,% r”%(a . id,a.address)
1、‘地址’
请注意,到目前为止,我们还没有提交对数据库的任何更改,因此新的 person 和 address 对象实际上还没有存储在数据库中。调用`s.commit()`将实际提交更改,即向数据库中插入一个新的人和一个新的地址。
s.commit()
s.close()
## Python ORMs 之间的比较
对于本文中介绍的每个 Python ORM,我们将在这里列出它们的优缺点:
### SQLObject
**优点:**
1. 采用了易于理解的 ActiveRecord 模式
2. 相对较小的代码库
**缺点:**
1. 方法和类的命名遵循 Java 的 camelCase 风格
2. 不支持数据库会话来隔离工作单元
### 暴风雨
**优点:**
1. 一个简洁、轻量级的 API,可以缩短学习曲线,实现长期可维护性
2. 不需要特殊的类构造函数,也不需要命令式基类
**缺点:**
1. 迫使程序员编写手动创建表的 DDL 语句,而不是从模型类中自动派生出来
2. Storm 的贡献者必须将他们贡献的版权给 Canonical 有限公司。
### 姜戈氏 ORM
**优点:**
1. 易于使用,学习曲线短
2. 与 Django 紧密集成,使其成为处理 Django 数据库时的 de-factor 标准
**缺点:**
1. 不能很好地处理复杂的查询;迫使开发人员回到原始 SQL
2. 与 Django 紧密结合;这使得它很难在 Django 上下文之外使用
### 叫声类似“皮威”的鸟
**优点:**
1. 一个 Django-ish API;使其易于使用
2. 轻量级实现;使其易于与任何 web 框架集成
**缺点:**
1. 不支持自动模式迁移
2. 编写多对多查询并不直观
### sqllcemy(SQL 语法)
**优点:**
1. 企业级 APIs 使代码健壮且适应性强
2. 灵活的设计;使得编写复杂的查询变得轻松
**缺点:**
1. 工作单元的概念并不常见
2. 一个重量级的 API 导致漫长的学习曲线
### 波尼奥姆
**优点:**
1. 用于编写查询的非常方便的语法
2. 自动查询优化
3. 简化的设置和使用
**缺点:**
1. 不是为同时处理数十万或数百万条记录而设计的
## 总结和提示
与其他 ORM 相比,SQLAlchemy 突出了它对工作单元概念的关注,这在您编写 SQLAlchemy 代码时非常普遍。最初,DBSession 的概念可能很难理解和正确使用,但稍后您会体会到额外的复杂性,它将与数据库提交时间相关的意外错误减少到几乎为零。在 SQLAlchemy 中处理多个数据库可能很棘手,因为每个数据库会话都被限制在一个数据库连接中。然而,这种限制实际上是一件好事,因为它迫使您认真考虑多个数据库之间的交互,并使调试数据库交互代码变得更容易。
在以后的文章中,我们将全面探索 SQLAlchemy 更高级的用例,以真正掌握其强大的 API。
堆栈教程:实现初学者指南
原文:https://www.pythoncentral.io/stack-tutorial-python-implementation/
先决条件
为了理解这个堆栈教程,你需要学习堆栈数据结构,这需要:
- Python 3
- 基本数据结构概念如列表(点击 此处 刷新列表概念)
- OOP 概念
什么是栈?
你好!如果你正在阅读这篇文章,你将会学到一个非常基本和最有用的数据结构概念。如果你懂其他语言,比如 C 或 C++,stack 的实现可能会很棘手(因为你必须跟踪指针!)但不是用 Python。Python 是如此神奇,以至于你可以使用列表来轻松地实现它们,但是你也将学习如何使用指针来采用一种语言不可知的方式来实现它们。但首先,让我们了解它们是什么。如果您已经熟悉了这一点,可以跳到实现部分。
当你听到书库这个词时,你首先想到的可能是一摞书,我们可以用这个类比来轻松解释书库!一些共性包括:
- 在书库的顶部有一本书(如果书库中只有一本书,那么这本书将被认为是最上面的书)。
- 只有拿走最上面的书,你才能拿到最下面的书。这里没有叠衣服游戏!(同时假设你一次只能举起一本书)。
- 一旦你一本书一本书地从上面拿走,就没有书剩下了,因此你不能再拿走更多的书。
看看这款名为 河内之塔 的有趣游戏,它完美地展示了堆栈是如何工作的。仔细阅读说明,关掉音乐(声音太大了!).

用编程的方式描述以上几点:
- 跟踪最顶端的元素,因为这将为您提供关于堆栈中元素数量以及堆栈是否为空/满的信息(如果堆栈为空,则 top 将被设置为 0 或负数)
- 最后进入堆栈的元素总是第一个离开(后进先出)
- 如果所有的元素都被移除,那么堆栈是空的,如果你试图从一个空的堆栈中移除元素,会抛出一个警告或错误信息。
- 如果堆栈已经达到最大限制,而你试图添加更多的元素,就会抛出一个警告或错误信息。
要记住的事情:
- 元素的进入和退出只发生在堆栈的一端(顶部)
- 将一个元素推入堆栈
- 从堆栈中取出一个元素
- 不允许随机访问——不能从中间添加或删除元素。
注意:始终跟踪顶部。这告诉我们堆栈的状态。
如何实现堆栈?
现在你知道什么是栈了,让我们开始实现吧!
栈实现使用列表
这里我们将定义一个类堆栈并添加方法来执行下面的操作:
- 将元素推入堆栈
- 从堆栈中弹出元素,如果为空则发出警告
- 获取堆栈的大小
- 打印堆栈的所有元素
class Stack:
#Constructor creates a list
def __init__(self):
self.stack = list()
#Adding elements to stack
def push(self,data):
#Checking to avoid duplicate entries
if data not in self.stack:
self.stack.append(data)
return True
return False
#Removing last element from the stack
def pop(self):
if len(self.stack)<=0:
return ("Stack Empty!")
return self.stack.pop()
#Getting the size of the stack
def size(self):
return len(self.stack)
myStack = Stack()
print(myStack.push(5)) #prints True
print(myStack.push(6)) #prints True
print(myStack.push(9)) #prints True
print(myStack.push(5)) #prints False since 5 is there
print(myStack.push(3)) #prints True
print(myStack.size()) #prints 4
print(myStack.pop()) #prints 3
print(myStack.pop()) #prints 9
print(myStack.pop()) #prints 6
print(myStack.pop()) #prints 5
print(myStack.size()) #prints 0
print(myStack.pop()) #prints Stack Empty!
注意:我们不担心堆栈的大小,因为它是由一个可以动态改变大小的列表来表示的。
使用数组的堆栈实现
Python 列表使得实现堆栈变得如此容易。然而,如果你想不可思议地实现堆栈语言,你必须假设列表就像数组(大小固定),并使用一个顶部指针来记录堆栈的状态。查看 这个 动画来了解它的工作原理。
算法
- 声明一个链表和一个整数 MaxSize,表示栈的最大大小
- Top 初始设置为 0
- 推送操作:
- 检查 Top 是否小于堆栈的 MaxSize
- 如果是,将数据追加到堆栈,并将 top 加 1
- 如果否,打印堆栈满信息
- 检查 Top 是否小于堆栈的 MaxSize
- 弹出操作:
- 检查 Top 是否大于 0:
- 如果是,从列表中弹出最后一个元素,并将 top 减 1
- 如果否,打印堆栈空消息
- 检查 Top 是否大于 0:
- 尺寸操作:
- 顶部指针的值是堆栈的大小
程序
class Stack:
#Constructor
def __init__(self):
self.stack = list()
self.maxSize = 8
self.top = 0
#Adds element to the Stack
def push(self,data):
if self.top>=self.maxSize:
return ("Stack Full!")
self.stack.append(data)
self.top += 1
return True
#Removes element from the stack
def pop(self):
if self.top<=0:
return ("Stack Empty!")
item = self.stack.pop()
self.top -= 1
return item
#Size of the stack
def size(self):
return self.top
s = Stack()
print(s.push(1))#prints True
print(s.push(2))#prints True
print(s.push(3))#prints True
print(s.push(4))#prints True
print(s.push(5))#prints True
print(s.push(6))#prints True
print(s.push(7))#prints True
print(s.push(8))#prints True
print(s.push(9))#prints Stack Full!
print(s.size())#prints 8
print(s.pop())#prints 8
print(s.pop())#prints 7
print(s.pop())#prints 6
print(s.pop())#prints 5
print(s.pop())#prints 4
print(s.pop())#prints 3
print(s.pop())#prints 2
print(s.pop())#prints 1
print(s.pop())#prints Stack Empty!
注:未添加元素 9,因此大小仍为 8。
除了上面描述的方法之外,您还可以添加方法来返回顶部元素,检查堆栈是否为空等等。
结论
堆栈的一个主要应用是在递归中。请务必查看这篇教程,了解什么是递归。一旦你熟悉了这个概念,试着用递归- 句子颠倒和平衡括号来解决这些难题。快乐的蟒蛇!
如何开始 Python 开发人员的职业生涯
原文:https://www.pythoncentral.io/starting-a-career-as-a-python-developer/

没有多少人知道成为专业开发人员的途径。然而,软件工程师和程序员在世界范围内需求量很大,不再是新闻。因此,作为一名开发人员工作无疑会有不错的报酬。你不需要成为 python 编程的专家,就可以开始开发人员的职业生涯;只要对这门语言有一个基本的了解,就能帮助你在这个领域找到初级 python 远程工作。你会在工作中提高自己的技能。
Python 是世界上最常用的编程语言之一。也是新手最容易快速学会的一种。Python 开发者利用 python 编程语言来设计、编码和执行项目。
Python 的调试、实现、开发都是由 python 开发者来完成的。
专业人士,如程序员、数据科学家、在线和移动应用程序开发人员、软件工程师等。,利用这种语言来创建所需的任务。创建的项目和应用程序是专门为满足开发者雇主的需求而设计的。一些 python 程序员甚至可能执行独立的工作来解决一些人的问题。
在这方面,我们与来自 job aggregator Jooble 的专业 python 开发人员合作,讨论作为 python 开发人员开始职业生涯的程序。让我们深入研究一下细节。
- 学会使用 Python
成为 python 开发者的第一步是学习使用 python 编码。有很多方法可以选择学习 python;你可以参加在线 python 课程,参加 python 编码训练营,甚至可以通过观看 YouTube 上的视频自学。
Python 使用广泛,对于没有编码背景的人来说相对容易。它是一种被广泛推荐给每个开发人员了解的语言,因为它在编码的几个方面都很有帮助。
- 提高你的技能
学会 python 编程后,有必要通过参与不同的项目来提高你的技能和能力,这将帮助你成为一名优秀的开发人员。这不仅有助于提高你对 python 的熟练程度和熟悉程度,还能给你提供将来急需的经验。
你可以通过建立网站、开发游戏应用等工作来磨练自己的技能。另一种方式是做自由职业者;这样做,你会提高自己的技能,会赚钱,会有信誉。
还有,几乎每个开发者都使用 GitHub 。在 GitHub 上,你可以搜索其他人的库,并为他们链接的项目做贡献。通过为已经完成的工作增加价值,这种技术证明了您具备成为 python 开发人员的素质。
- 推销自己
在你成功地学会了如何使用 python 编码之后,你必须推销自己,展示你的技能。你需要一份写得很好的简历,突出你的证书和技能。你还应该创建一个项目和任务组合,展示你为雇主做了什么。
结论
根据几份报告,由于对 python 程序员需求的增加,许多人对从事 python 开发感兴趣。专业开发人员也发现 python 有许多特性,使它在其他编程语言中脱颖而出。
尽管成为一名专业的 python 开发人员不需要任何特定的经验或背景,但是有几种方法可以让你开始职业生涯。然而,要想成功,你需要彻底理解 python。
在 Python 中交换值
在 Python 中交换两个变量的值实际上是一个非常简单的任务。Python 使得交换两个值变得相当容易,而不需要大量笨重的代码或奇怪的代码。使用下面的内置方法,看看交换两个数字有多容易:
x, y = 33, 81
print(x, y)
x, y = y, x
print(y, x)
第一个示例的结果是 33,81,而第二个示例的结果将被交换,因此结果为 81,33。这种交换可以用任何类型的变量来实现,不仅限于数字,也可以用于字符串。
Python 开发的文本编辑器与 ide:选择正确的工具
原文:https://www.pythoncentral.io/text-editors-vs-ides-for-python-development-selecting-the-right-tool/
你用来编程的语言和它的解释器或编译器只是你用来开发软件的一些工具。另一个重要的事情是你的编程环境。不像有些语言,你的选择是有限的,如 Delphi 或。NET 语言,有一两个明显更好的选择,Python 没有“标准”工具;Python 开发人员可以使用各种各样的编辑器和 ide。为自己选择合适的工具并不困难,但也不能掉以轻心:通过深入了解这些工具的特性,您可以充分利用它们,因此最好预先做出正确的选择,以避免浪费精力。
编辑器还是 IDE?
无论是面对面还是在讨论网站上,当有人问什么样的 IDE 最适合 Python 时,会有两种回答:一种是建议您最喜欢的 Python IDE,另一种是指出 IDE 对 Python 编程(或者在更极端的情况下,一般的编程)几乎没有什么帮助。我承认我的先入之见:我属于后一种阵营。我用 Emacs 处理几乎所有可以用文本表示的东西,我发现它非常高效和灵活。然而,我会试着抛开我的偏见,公正地讨论这件事。
语言方面的联系
在有些语言中,你会发现开发人员普遍认为 IDE 是必需的:Java、Delphi、C#和 VB.NET 就是明显的例子。所有这些语言都有一个共同的特点,那就是有大量的原始代码,这些代码对编译器来说是必需的,但对你的应用程序来说在语义上没有意义,而且必须是现成的;在 Java 和 C#中,你必须在调用函数之前定义一个类,而在 Delphi 中,你必须在一个地方定义一个函数的接口,在其他地方实现逻辑。ide 在这方面很棒;他们为你生成所有的样板代码。
Python(像 Perl、Go、Ruby 和 Lisp 等等)是不同的。样板文件较少;几乎你输入的每个字符都直接表达了你想要创建的功能。你可以说,低挂的 IDE 水果更少了。这使得 IDE 的使用成为一个更有争议的话题,Python 程序员在这个问题上的分歧也支持这个观点。
ide 会让程序员变得更糟吗?
IDE 的明显优势是它为您做了很多工作。当然,许多文本编辑器也可以配置成这样,但是 IDE 可以省去您这个麻烦。理想情况下,使用 IDE 比使用简单(或不太简单)的文本编辑器更有效率。那么为什么会有人继续抵制 IDEs 呢?
许多开发人员提出的支持文本编辑器的一个问题是,对 ide 的过度依赖阻碍了他们的用户深入学习他们的语言。这是有一定道理的。如果你依赖自动补全来提醒你函数、类和方法的名字,那就有你永远也学不会它们的危险;对于许多相当快的打字员来说,包括我自己,输入你知道的名字比使用自动补全要快。代码片段也是如此:如果你总是使用代码片段插入类定义,你可能永远也不会自己学会语法。
当然,如果你一直有你的 IDE,那也不一定是问题,不是吗?嗯,也许吧。从某种意义上来说,IDE 提供的功能越多,在某种程度上,对的约束就越多,因为一旦 IDE 为您解决了编码问题,它就会倾向于将您的解决方案限制在 IDE 提供的范围内。在某种程度上,这是真的,您的 IDE 可能会导致您选择不太理想的开发路径,仅仅是因为它工作得太好了。
适合您的工具
也就是说,许多 Python 程序员使用 ide,许多人不使用,他们都很有效率,并且对自己的选择很满意。在我看来,如果你对你最喜欢的文本编辑器感到满意,你可能会更好地使用它。如果你已经是一个 IDE 的人,你知道你想要什么;看看 IDEs。但如果你是骑墙派,你该如何选择?我认为一个很好的指标是你现在如何使用程序。你打字很快吗?你是一个键盘快捷键迷吗?你每次触摸鼠标都把它视为一次失败吗?如果您使用文本编辑器,尤其是像 Emacs 或 Sublime Text 这样高度可定制的编辑器,您可能会更高兴。如果另一方面。你是一个鼠标爱好者,你可能更喜欢 IDE。
另一个需要考虑的要点是你对编程语言的使用;如果您希望 Python 成为您的主要语言,很少使用其他语言,或者您希望使用 Python 作为您唯一的非 IDE 绑定语言,IDE 可能是一个好主意;您将会很好地使用它,它将会成为 Python 的一个有效工具。另一方面,如果你(像我一样)是一个语言爱好者,喜欢像左宗棠鸡这样的语言,你可能会想要使用文本编辑器;你可以用一个编辑器变得非常流利,你用它开发的技能将使你在所有语言中更有效率,尽管你可能没有使用任何特定语言的最方便的工具。
最后,如果你刚刚开始学习 Python,让我为简单的编辑器插上一个插头:你最好学习这种语言和它的库自己写,然后然后如果你认为 IDE 会加快你的工作,使用它。如果你走这条路,你会发现你学语言更快更彻底。
注意:我已经将我们的选择限制在跨平台编辑器和 ide 上,因为 Python 是一种跨平台语言,无论您多么喜欢您当前的操作系统,您都可能会发现自己在某个时候使用不同的操作系统,并且您会希望拥有自己熟悉的工具。此外,有这么多好的跨平台选项,将自己局限于单平台工具是愚蠢的。列出的所有选项都可以在 Windows、Linux 和 Mac OS X 上运行,有些还可以在数量惊人的其他平台上运行。
另外,我是从一个初级 Python 程序员的角度来考虑这个话题的。考虑到这一点,我在定制方面做得很少,除了高度可定制的编辑器,如 Emacs、Vim 和 Sublime Text。ide 尤其如此;我的立场是,如果一个工具应该是 Python 专用的,并且做所有的事情,那么它应该是开箱即用的,所以我主要在基本安装指令创建的状态下测试 ide。如果这对你来说不公平,请记住这是偏见的来源。
我们将从编辑开始。
基础知识:连接字符串
原文:https://www.pythoncentral.io/the-basics-concatenating-strings/
串联字符串基本上意味着将许多字符串加在一起形成一个更长的字符串。在 Python 中使用“+”符号可以很容易地做到这一点。
假设你有三根弦:
"I am", "Learning", "Python"
要连接它们,只需使用“+”符号将它们加在一起,就像这样:
>>> print "I am" + "Learning" + "Python"
你的输出应该是:“我在学 Python”。
您还可以在变量中连接字符串,如下所示:
string1 = "I am"
string2 = "Learning"
string3 = "Python"
>>> print string1 + string 3
在这种情况下,您的输出将是“我是 Python”。
基础知识:何时使用 del 语句
原文:https://www.pythoncentral.io/the-basics-when-to-use-the-del-statement/
使用 del 语句相对简单:它用于删除一些东西。它通常用于通过引用项目的索引而不是其值来从列表中删除项目。例如,如果您有以下列表:
list = [4, 8, 2, 3, 9, 7]
并且您想要删除索引为 4 的数字 9,因为它是列表中的第 5 个项目(索引从 0 开始),您可以使用 del 语句来执行此操作,如下所示:
del list[4]
因此,您的列表现在将如下所示:
list = [4, 8, 2, 9, 7]
可以用于开发的最好的 Python IDEs
原文:https://www.pythoncentral.io/the-best-python-ides-you-can-use-for-development/
This article was written by Sergio Tapia Gutierrez. If you're after another opinion by Jason Fruit, checkout our other IDE article Comparison of Python IDEs for Development. We also have a Review of Python's Best Text Editors.
IDE ( 集成开发环境)是程序员可以使用的最好的工具之一。它允许开发人员高效地工作,忘记样板文件。
虽然一些程序员对使用文本编辑器以外的任何东西的想法嗤之以鼻,但是当您正在处理一个包含许多文件的非常大的项目时,IDE 将具有使您作为开发人员的生活更加容易的特性。
一个好的 IDE 应该具备的一些特性是:
- 代码完成
- 语法突出显示
- 通用代码模板
- 源代码控制支持(例如 Subversion、Mercurial 或 Git
让我们看看哪些 Python IDE 是最好的,以及它们是如何相互比较的。

PyDev 的 Eclipse
PyDev 的 Eclipse

PyDev 的 Eclipse
PyDev 官方网站:http://pydev.org/
Eclipse 是一个非常通用的 IDE,已经存在很长时间了。这是经过时间考验的产品,非常可靠。Eclipse 就像一个沙盒 IDE 它可以支持任何语言,只要有人通过一个包来支持它。PyDev 就是这种情况,这个包允许您将 Eclipse 变成一个非常有用的 Python IDE。
这是一个完全免费 IDE,提供了大量的功能,例如:
- Django 一体化
- 代码完成
- 自动导入的代码完成
- 语法突出显示
- 代码分析
- 转到定义
- 重构
- 标记事件
- 调试器
- 远程调试器
- 令牌浏览器
- 交互式浏览器
- 单元测试集成
- 代码覆盖率
- 还有很多很多
我在我的 Windows 机器上用 Python 编码时使用了这个,它只需很少的配置就能工作。
Komodo Edit

Komodo Edit -可在 Windows、Linux 和 Mac 上使用。
科莫多编辑官网:http://www.activestate.com/komodo-edit
Komodo Edit 是一个非常干净、专业的 Python IDE。它没有绒毛,而是专注于把你需要的东西放在你面前。没有挖掘随机子菜单寻找一个选项。它的代码完成非常好,速度很快;它会在你输入的时候弹出,只需要很少的加载时间。
ActiveState 提供了他们 IDE 的商业版本,名为 Komodo IDE 。
两个版本之间的差异如下:

Komodo Edit vs. Komodo IDE
皮查姆

JetBrains 的 PyCharm
PyCharm 官方网站:http://www.jetbrains.com/pycharm/
PyCharm 是由 JetBrains 创建的 IDE。你可能记得这些人是 T2 ReSharper T3 的作者,这是. NET 开发者可以做的最好的投资之一。PyCharm 也不例外,JetBrains 延续了其优秀的血统,向开发者生态系统发布了另一个优秀的工具。
据说拥有绝对最好的代码完成技术,这至少值得您尝试一下。
- 跨平台
- 商业
- 自动代码完成
- 集成 Python 调试
- 错误标记
- 源代码管理集成
- 智能缩进
- 括号匹配
- 加行号
- 代码折叠
- 单元测试
节省时间的最佳 Python 库
原文:https://www.pythoncentral.io/the-best-python-libraries-to-save-time/
 机器学习和软件开发是所有用 Python 创建的开源项目的很大一部分。近年来,这些项目在开源开发领域创造了许多就业机会。用 Python 编写的最流行的开源项目有 TensorFlow、Keras、Scikit-learn、Flask、Django、Tornado、Pandas、Kivy、Matplotlib 和 Requests。1 . tensor flow .tensor flow 是一个开源软件库,用于各种任务的机器学习。该库由谷歌开发,以满足系统的需求,这些系统可以创建和训练神经网络,以检测和解码图像和相关性,类似于人类使用的教导和表示。
机器学习和软件开发是所有用 Python 创建的开源项目的很大一部分。近年来,这些项目在开源开发领域创造了许多就业机会。用 Python 编写的最流行的开源项目有 TensorFlow、Keras、Scikit-learn、Flask、Django、Tornado、Pandas、Kivy、Matplotlib 和 Requests。1 . tensor flow .tensor flow 是一个开源软件库,用于各种任务的机器学习。该库由谷歌开发,以满足系统的需求,这些系统可以创建和训练神经网络,以检测和解码图像和相关性,类似于人类使用的教导和表示。
- Keras
Keras 是用 Python 编写的开源神经网络库,能够在深度学习、TensorFlow、Theano 等软件上运行。它最初是为了用深度神经网络进行实验而创建的。Keras 的重点是模块化、可用性和可扩展性。
- Scikit-learn.
Scikit-learn 是一个库,它通过 Python 编程语言的一个接口为监督和非监督学习提供了各种算法。这个库是在“简化的 BSD 许可证”下发布的,并且发布了许多不同版本的 Linux,从而促进了 Scikit-learn 的商业和学术使用。
数据可视化的最佳 Python 库
数据是任何 研究论文写作的主要部分之一 ,但是很难高效地处理大量的数据。数据可视化使您能够更轻松地可视化信息。例如,通过创建一种信息地图。今天我们将看看可以在 Python 项目中使用的五个最好的数据可视化库。
- matplotlib
Matplotlib 是最流行的数据可视化 Python 库。可用于 Python 和 IPython shells、Python 脚本、web 应用服务器等。这是一个超过 10 年历史的 2D 图形图书馆,带有一个互动平台。 你可以将这个库用于各种用途,比如创建图表、直方图、功率谱、词干列表图、饼状图。Matplotlib 最大的优点是,您只需编写几行代码,其余的由它自己处理。 Metaplotilib 使用 Qt 和 GTK 等工具包,专注于静态图像和交互式图形的发布。
- Seaborn
Seaborn 数据可视化库也是基于 Matplotlib。如果您正在为您的工作寻找更高级的选项,请尝试这个 Python 库。 它带有一个功能齐全的界面,用于绘制有吸引力的、信息丰富的统计图形。它基于 KDE 的可视化 API 比其他类似的库更简洁。Seaborn 努力使可视化成为理解和探索数据的核心部分。Seaborn 与 PyData 栈完全集成,包括对 NumPy 和 pandas 数据结构的支持。
- 牛郎星。
这是一个基于流行的 Vega-Lite 可视化语法的声明性统计库。Altair 是一致的,有一个简单的 API。 使用这个数据可视化库,你可以用最少的代码创建美观高效的可视化效果。毕竟,在声明式库中,您只需要提到数据列与编码通道之间的一个链接,其余的将被自动处理。
- 阴谋地
Plotly 是一个基于网络的数据可视化工具包,它具有独特的功能,如树状图、3D 图和等高线图,这在其他库中并不常见。它有一个很棒的 API,提供了点状图、线状图、直方图、误差直方图、盒状图和其他可视化。
- ggplot
ggplot 是一个声明式图形创建系统。它基于 R 编程语言的图形语法,并与 Pandas 紧密集成。ggplot 只需要您声明如何映射要使用的变量,其余的自动处理。 如果你知道任何其他的图书馆应该在这个列表中占有一席之地,请在下面的评论中告诉我们。
Visual Studio 代码的最佳 Python 教程(一本写得很好的指南)
原文:https://www.pythoncentral.io/the-best-python-tutorial-for-visual-studio-code-a-well-written-guide/
开始您的 Python 之旅可能会非常激动人心,尤其是如果您以前从未安装过 IDE 的话。这个过程非常简单,不需要太多时间就可以完成。
在本指南中,我们将引导您安装 Visual Studio 代码和 Python 开发所需的扩展。我们还概述了如何输入代码、保存文件和运行程序。
为 Python 安装和配置 Visual Studio 代码
你可能听说过微软的 Visual Studio,但是除了名字之外,VS Code 与这个工具没有任何共同之处。由于它内置的对扩展的支持,你可以用 VS 代码编写多种语言的程序。
Windows、Mac、Linux 上都有 VS 代码,IDE 每月更新。
要在您的操作系统上安装该程序,请访问 官方网站 ,将鼠标悬停在下载按钮上的箭头上即可找到该工具的稳定版本。
在 Windows 上,运行安装程序并遵循安装说明将完成安装。在 Mac 上,您需要将下载的“Visual Studio Code.app”文件拖到 applications 文件夹中。
要在 Ubuntu 或 Debian 机器上安装 VS 代码,可以在终端中运行以下命令:
sudo apt 安装。/ <文件>。deb
VS 代码 Python 扩展
为了使 VS 代码能够与您选择的编程语言一起工作,您需要安装相关的扩展。安装 Python 扩展可以解锁 VS 代码中的以下特性:
- 自动 conda 使用和虚拟环境
- 使用智能感知完成代码
- Jupyter 环境和 Jupyter 笔记本中的代码编辑
- 代码片段
- 调试支持
- 林挺
- 支持 Python 3.4 及更高版本,以及 Python 2.7
- 单元测试支持
要安装扩展,按 Ctrl+Shift+X 打开扩展视图。您也可以通过单击活动栏上的扩展图标来完成此操作。
搜索“Python ”,点击安装按钮,从 VS 代码市场安装这个扩展。你也可以在这里 找到市集上的分机 。
用 VS 代码编写并运行 Python 程序
单击顶部栏上的文件,然后单击新建,打开一个新文件。您可以使用的快捷键是 Ctrl+n。
现在,您可以开始在新文件中输入代码。但是需要注意的是,VS 代码不会识别你写代码的语言。这是因为它不知道文件类型是什么。
您可以通过保存文件来激活 Python 扩展。“文件”菜单中提供了“保存”选项,但是您可以使用 Ctrl+S。py 扩展名附加在文件上,VS 代码会识别你的代码。
输入代码后,您可以在代码编辑器窗口内单击鼠标右键,然后单击“在终端中运行 Python 文件”来运行代码终端将出现在屏幕底部,显示程序的输出。
快速提示:Python 中列表和数组的区别
原文:https://www.pythoncentral.io/the-difference-between-a-list-and-an-array/
Python 中使用数组和列表来存储数据,但它们的用途并不完全相同。它们都可以用来存储任何数据类型(实数、字符串等),并且都可以被索引和迭代,但是两者之间的相似之处就不多了。列表和数组的主要区别在于可以对它们执行的功能。例如,您可以将一个数组除以 3,数组中的每个数字将被除以 3,如果您请求的话,结果将被打印出来。如果你试图将一个列表除以 3,Python 会告诉你做不到,并抛出错误。
它是这样工作的:
x = array([3, 6, 9, 12])
x/3.0
print(x)
在上面的示例中,您的输出将是:
array([1, 2, 3, 4])
如果您尝试对列表做同样的事情,结果会非常相似:
y = [3, 6, 9, 12]
y/3.0
print(y)
这几乎和第一个例子完全一样,除了你不会得到一个有效的输出,因为代码会抛出一个错误。
使用数组确实需要一个额外的步骤,因为它们必须被声明,而列表不需要,因为它们是 Python 语法的一部分,所以列表通常在两者之间使用得更多,这在大多数时候都很好。然而,如果你要对你的列表执行算术函数,你真的应该使用数组。此外,数组将更紧凑、更高效地存储数据,因此,如果您存储大量数据,也可以考虑使用数组。
str 和 repr 的区别
原文:https://www.pythoncentral.io/the-difference-between-str-and-repr/
str 和 repr 在 Python 中的用法非常相似,但它们不可互换。str 是一个内置函数,用于计算对象的非正式字符串表示形式,而 repr 必须用于计算对象的正式字符串表示形式。非正式和正式表述之间的明显差异与引号有很大关系。看看下面的例子:
【python】
x = 6
repr(x)
‘6’
str(x)
‘6’
y= '一个字符串'
repr(y)
y= '一个字符串' "
str(y)
y= '一个字符串'
[/python]
你可以在上面的例子中看到第一个例子(x)的输出是相同的,但是当你使用 repr 和 str 字符串而不是数字时,会有明显的区别。使用 repr 返回单引号和双引号内的输出,而 str 返回的输出与字符串声明时完全相同(在单引号内)。引号(以及 repr 和 str)很重要,因为非正式表示不能作为 eval 的参数调用,否则返回值就不是有效的 string 对象。如果需要调用输出作为 eval 的参数,请确保使用 repr 而不是 str。
Python 正则表达式的零星内容
原文:https://www.pythoncentral.io/the-odds-ends-of-python-regular-expressions/
在本系列的前两部分中,我们研究了正则表达式的一些相当高级的用法。在这一部分中,我们后退一步,看看 Python 在 re 模块中提供的一些其他函数,然后我们讨论一些人们经常犯的错误(哈!)制造。
有用的 Python 正则表达式函数
Python 提供了几个函数,使得使用正则表达式操作字符串变得很容易。
- 通过一条语句,Python 可以返回与正则表达式匹配的所有子字符串的列表。
例如:
>>> s = 'Hello world, this is a test!'
>>> print(re.findall(r'\S+', s))
['Hello', 'world,', 'this', 'is', 'a', 'test!']
\S表示任何非空白字符,所以正则表达式\S+表示匹配一个或多个非空白字符(例如一个单词)。
- 我们可以用另一个字符串替换每个匹配的子字符串。
例如:
>>> print(re.sub( r'\S+' , 'WORD', s))
WORD WORD WORD WORD WORD WORD
对re.sub的调用用字符串“WORD”替换正则表达式(如单词)的所有匹配。
- 或者,如果您想遍历每个匹配的子字符串并自己处理它,
re.finditer将遍历每个匹配,并在每次遍历时返回一个MatchObject。
例如:
>>> for mo in re.finditer(r'\S+', s):
... print('[%d:%d] = %s' % (mo.start(), mo.end(), mo.group()))
[0:5] = Hello
[6:12] = world,
[13:17] = this
[18:20] = is
[21:22] = a
[23:28] = test!
- Python 也有一个函数,使用正则表达式作为分隔符,将字符串分割成多个部分。假设我们有一个字符串,它使用逗号和分号作为分隔符,到处都是空格。
例如:
s = 'word1,word2 , word3;word4 ; word'
分隔符的正则表达式是:\s*[,;]\s*。
或者用简单的英语说:
- 零个或多个空白字符。
- 逗号或分号。
- 零个或多个空白字符。
这就是它的作用:
>>> s = 'word1,word2 , word3;word4 ; word5'
>>> print(re.split(r'\s*[,;]\s*', s))
['word1', 'word2', 'word3', 'word4', 'word5']
每个单词都已被正确拆分,并删除了空格。
常见的 Python 正则表达式错误
搜索多行字符串时不使用 DOTALL 标志
在正则表达式中,特殊字符.表示匹配任何字符。
例如:
>>> s = 'BEGIN hello world END'
>>> mo = re.search('BEGIN (.*) END', s)
>>> print(mo.group(1))
hello world
但是,如果被搜索的字符串由多行组成,。不匹配换行符(\n)。
>>> s = '''BEGIN hello
... world END'''
>>> mo = re.search('BEGIN (.*) END', s)
>>> print(mo)
None
我们的正则表达式说找到单词 BEGIN,然后是一个或多个字符,然后是单词 END ,所以发生的情况是 Python 找到了单词“BEGIN”,然后是一个或多个字符直到换行符,作为一个字符不匹配。然后,Python 查找单词“END ”,由于没有找到,正则表达式不匹配任何内容。
如果希望正则表达式匹配跨多行的子字符串,需要传入 DOTALL 标志:
>>> mo = re.search('BEGIN (.*) END', s, re.DOTALL)
>>> print(mo.group())
BEGIN hello
world END
搜索多行字符串时不使用 MULTILINE 标志
在 UNIX 世界中,^和$被广泛理解为匹配一行的开始/结束,但是只有在设置了MULTILINE标志的情况下,Python 正则表达式才是这样。如果没有,它们将只匹配被搜索的整个字符串的开头/结尾。
>>> s = '''hello
>>> ... world'''
>>> print(re.findall(r'^\S+$', s))
[]
为了获得我们期望的行为,传入MULTILINE(或简称为M标志:
>>> print(re.findall(r'^\S+$', s, re.MULTILINE))
['hello', 'world']
不重复不贪婪
运算符*和+和?分别匹配 0 个或更多的、 1 个或更多的、 0 个或 1 个重复,默认情况下,它们是贪婪的(例如,它们试图匹配尽可能多的字符)。
一个典型的错误是试图使用这样的正则表达式来匹配 HTML 标签:<.+&>
这看起来很合理——匹配开始的<,然后一个或多个字符,然后结束的>——但是当我们在一些 HTML 上尝试时,会发生这样的情况:
>>> s = '<head> <style> blah </style> </head>'
>>> mo = re.search('<.+>', s)
>>> print(mo.group())
<head> <style> blah </style> </style>
发生的事情是 Python 已经匹配了开始的<,然后一个或多个字符(head),然后结束的>,但是它没有就此停止,而是尝试看看它是否可以做得更好,让.字符匹配更多的字符。事实上它可以,它可以匹配所有的东西,直到字符串最后的>,这就是为什么这个正则表达式最终匹配整个字符串。
解决这个问题的方法是在.操作符后面加上一个?字符,使其成为非贪婪的(例如,使其匹配尽可能少的字符)。
>>> mo = re.search('<.+?>', s)
>>> print(mo.group())
<head>
现在,当 Python 到达第一个>(它关闭了初始的标记)时,它会立即停止,而不是尝试看看是否能做得更好。
`## 不区分搜索的大小写
默认情况下,正则表达式区分大小写。例如:
>>> s = 'Hello World!'
>>> mo = re.search('world', s)
>>> print(mo)
None
为了使搜索不区分大小写,传入IGNORECASE标志:
>>> mo = re.search('world', s, re.IGNORECASE)
>>> print(mo.group())
World
不编译正则表达式
Python 做了大量工作来准备一个正则表达式,所以如果你要经常使用一个特定的正则表达式,首先编译它是值得的。
例如:
>>> myRegex = re.compile('...')
>>> # This reads the file line-by-line
>>> for lineBuf in open(testFilename, 'r'):
... print(myRegex.findall(lineBuf))
现在 Python 只做一次准备工作,然后在每次循环中重用预编译的正则表达式,从而节省了大量时间。`
Python 编程语言——基本特性和主要优势
 无论现在有多少种编程语言在使用,其中哪一种是当今的领导者,Python 仍然是最爱之一。大多数软件开发人员在考虑将第二编程语言添加到简历中时都会选择 Python(以及 Python 开启的职业前景)。原因很简单——Python 确实很受欢迎,也很方便。由 Guido Van Rossum 在上个世纪(1991 年)创建的 Python 编码语言的目的是使编码更容易。它曾经只是 Perl 的替代品,但现在已经发展成为具有优秀代码可读性的通用语言。它允许开发人员用更少的步骤完成更多的工作,并且比 C++和 Java 简单。 Python 使用来自英语的关键词,甚至不需要深入的编程知识——一开始懂点数学就够了。简单性、开源性、种类繁多的库和令人印象深刻的范围使它成为目前世界上最流行的编程语言。
无论现在有多少种编程语言在使用,其中哪一种是当今的领导者,Python 仍然是最爱之一。大多数软件开发人员在考虑将第二编程语言添加到简历中时都会选择 Python(以及 Python 开启的职业前景)。原因很简单——Python 确实很受欢迎,也很方便。由 Guido Van Rossum 在上个世纪(1991 年)创建的 Python 编码语言的目的是使编码更容易。它曾经只是 Perl 的替代品,但现在已经发展成为具有优秀代码可读性的通用语言。它允许开发人员用更少的步骤完成更多的工作,并且比 C++和 Java 简单。 Python 使用来自英语的关键词,甚至不需要深入的编程知识——一开始懂点数学就够了。简单性、开源性、种类繁多的库和令人印象深刻的范围使它成为目前世界上最流行的编程语言。
Python 的特性决定了它的受欢迎程度
免费和开源
可以从官网免费下载 Python。它的源代码对用户是可用的,你可以使用它并改进它。一个庞大的 Python 社区支持这种语言,并增强了它的编程特性,使它更加方便。
健壮库
如前所述,这种语言包括丰富的现成模块和函数库,经过测试和润色。使用 Python,您可以在任何需要的时候参考这些库,并通过使用现成的模块来节省时间。没有必要从头开始编写代码,因为您可以使用库元素。
面向对象
面向对象编程(OOP)是 Python 最重要的特性之一。它建议将数据和功能绑定成一个单元并一起工作。其余的代码不会访问数据。简而言之,这种方法简化了执行过程、协议等的系统。Python 支持所有的 OOP 概念,并允许程序员在创建新产品时充分利用这种语言。
高层
用 Python 编码时,开发人员不需要单独记住系统的架构。内存管理也不是必须的。Python 会处理它。
可扩展和集成
Python 代码可以写成 C 和 C++语言。此外,您可以成功地将 Python 与其他编程语言集成在一起。
便携性
这种编程语言兼容所有平台。相同的代码可以在 Windows、Linux 和 Mac 上正确运行。您不需要在代码中实现任何特定的更改来调整它以适应特定的平台。在任何设备上继续进行您的项目。
解读
当你执行 Python 代码时,它一行一行地工作,一次一行。因此,您可以轻松地调试代码。此外,语法是合乎逻辑的,代码总是比其他语言提供的代码行要少。
可扩展
在你开发了代码块的逻辑之后,你可以克隆这个逻辑并将其应用到其他模块,无论是大的还是小的。可以应用所有特征或仅选择选项。 这些只是 Python 众多功能中的一部分,正是这些功能使得这种编程语言如此出众,受到了来自世界各地的专家们的喜爱,包括https://jatapp . com/services/application-development-services/。它适用于网站、桌面和移动应用程序、游戏和其他产品。此外,它还是自动化、数据科学、人工智能和机器学习领域的默认选择。
Python 编程的主要优势
巨头谷歌将 Python 作为其主要语言之一。例如,YouTube 是基于 Python 的。Pinterest、Reddit、Instagram 都依赖 Python 编码语言。它被 IBM、英特尔、NASA、网飞、Spotify 和脸书使用。 当然,所有这些行业领袖选择这种语言是有原因的——或者有很多原因。有了这样优秀的市场参与者的支持,Python 才能蓬勃发展。 我们已经定义了这种编码语言的特征。现在,让我们回顾一下它们给工作、编程例程和具体挑战带来了哪些实际好处。
提高生产率
这里应该提到的是,Python 并不是该领域最快的编码语言。已经够快了。然而,它不如 Java 和 c。尽管如此,使用这种语言可以使程序员大大提高他们的生产率。解释很简单。Python 以其简洁性,花更少的时间编写产品代码。访问现成的模块和函数将让程序员节省时间并消除可能的错误。同时,Python 的整体功能允许用它创建的应用程序具有快速的性能。
原型的最佳选择
由于许多初创公司都涉及专用应用程序,编程语言的选择至关重要。他们的全功能原型必须很快准备好。创业公司很少是独特的。比竞争对手更早上市可以决定产品的命运。 在这样的情况下,Python 成为了最有利的选择。它提供了出色的流程控制,可以快速创建复杂的跨平台应用程序。此外,它还提供了自己的单元测试。如果你是一家为初创公司开发应用程序的公司,Python 将会是你语言列表中的首选。
最适合竞争性编程的选项
竞争性编程阶段是工作申请的一部分,候选人应该展示他们的实际编程技能。速度往往是这个过程中的决定因素。它可以定义申请者是否进入面试阶段。在这种情况下,Python 竞争性编程可能是最好的变体,即使您通常专攻不同的语言。Python 的功能性使其适用于解决任何任务。简洁的语法和更少的代码确保了出色的速度。如果你不得不写 5 行代码而不是 25 行,你会更快地完成任务。顺便说一下,Python 专家在市场上需求量很大,你可以期待有吸引力的工作机会。
GUI 支持
使用图形用户界面(GUI)的可能性通常定义了编程语言的用户友好性。以可视化格式编写代码总是更方便。它还让程序员更好地控制代码的正确性。Python 提供了几个方便的 GUI,开发人员可以导入和应用。
代码编写和格式标准
PEP 是 Python 代码编写的基本标准。它确保代码始终保持可读。如果你把一个项目转移给另一个开发者,用 Python 探索代码不会有任何问题。语法保持清晰简洁,没有不必要的元素和表达式。 工作程序只会受益于此,这也是 Python 受欢迎的最大原因之一。此外,它有助于程序员更好的自我组织。Python 鼓励他们从一开始就编写清晰准确的代码。程序员甚至会遇到从这种语言切换到其他编码语言的问题。它们追求同样的清晰和简洁,但是没有其他编程语言能达到同样的水平。
大量的教材
如果你决定在你的公司实施 Python,不会有任何困难。有许多英语和其他语言的书籍、教科书和文章。 除了文字资料,YouTube 上还有大量免费的视频指南。您可以找到个人开发者的视频日志、网络研讨会和会议的记录以及其他信息来源。添加来自世界各地的 Python 专家参与的奇妙社区。其实现在学 Python 比几年前简单多了。 尽管 Python 可能并不完美——它也有缺点——但所有专家都发现 Python 编程的好处要大得多。此外,这种语言是最新的,并在不断改进。毫无疑问,将来问题会得到解决或补偿。
结论
现代软件开发公司使用多种语言,但 Python 肯定是其中之一。功能性、多功能性和简洁性是 Python 的明显优势,受到了所有程序员的称赞。它甚至已经超过了 Java 和 C. 这样的霸主,所以,如果你正在考虑作为第二种开始或学习的编程语言,选择 Python,它永远不会让你失望。
开发者可以用于视频编辑的 3 大 Python 库
原文:https://www.pythoncentral.io/the-top-3-python-libraries-developers-can-use-for-video-editing/
如果您自己完成所有步骤而不使用库,视频编辑过程被认为是一项非常困难的任务。了解有助于使视频编辑过程更快更简单的库的更多信息。我们将讨论三个能够简化和改进视频编辑过程的库。

使用 MoviePy 编辑视频
MoviePy 库是使用 Python 编码的开发人员最常用的库。你可以在其中执行任何基本的操作,比如插入标题、剪切或合并片段、处理视频,甚至创建效果。
模块中的所有操作都可以用一行代码来执行。编码尽可能简单,即使对新手来说也很清楚。值得注意的是,该代码可以在任何计算机上运行,并且受任何版本的 Python 支持。要开始编辑,你应该立即在你的机器上安装 Python 。
该库简单易用。即使是初学者也能很容易地弄清楚工作的算法和代码。它允许你快速创建你的剪辑和效果,并与任何版本的 Python 和任何操作系统。
使用 Scikit 编辑视频-视频
普通用户依赖各种视频编辑软件:如果他们想要简单的编辑,他们下载 Windows 版的 iMovie或 macOS 版的视频编辑工具。另一方面,编码器可以使用 Scikit-Video 等库快速轻松地编辑视频。
Scikit-Video 库包括一整套不同的视频处理和编辑算法,了解这个库将有助于你更好地学习 Python。使用它,您可以评估帧中的运动,控制质量并应用必要的过滤器。
Scikit-Video 是作为图像编辑版本的附加软件开发的,它拥有处理视频的所有可能的算法。
视频和图像之间的算法是匹配的,并且一些度量可以应用于视频帧和图像。但尽管如此,有些算法只能应用于视频,比如降噪。这个库是所谓的各种算法的集合,这些算法可以用于视频,也可以不专门用于视频,但可以用于编辑视频。
使用 vcdgear 编辑视频
VidGear 库以其轻便易用而闻名。程序员只需填写所需的代码行,只需几个步骤就可以快速轻松地完成复杂的视频处理任务。
VidGear 是三大 Python 库之一,可以帮助您快速轻松地对视频进行调整。该库进行了很好的优化,因此,它给面临编辑视频剪辑任务的网页设计师和程序员留下了极好的印象。除了速度之外,VidGear 可以可靠地处理所有错误,并且有许多有吸引力的选项。
以 MoviePy 为例说明如何用 Python 库编辑视频
最受开发者欢迎的库是 MoviePy。要开始使用,您需要在您的计算机上安装它。该库有许多功能,对于面临视频编辑任务的程序员和开发人员来说是最快和最有吸引力的。我们来详细分解一下 MoviePy 可以执行的功能:
- 合并视频文件。要从几个文件中制作一个视频,你需要在行中输入代码,并从文件夹中选择你要合并的视频。
- 折叠视频剪辑。使用 MoviePy,可以将屏幕分割成多个部分,每个部分都会播放一个新的视频。为此,输入 Python 代码并从打开的文件夹中打开必要的文件。
- 添加转场。MoviePy 常用来给视频添加各种翻译。你只需要输入代码,添加必要的动画,同时指定时间间隔。
既然您已经熟悉了 MoviePy 库可以执行的功能,以及您可以使用哪些 Python 技巧,那么让我们来看一个如何使用这个库来修剪和合并剪辑的示例。这个过程越简单越好,现在你就自己看吧!
- 原视频看完后,可以使用内置的方法,做很多事情。
- 要连接视频片段,你需要使用一个视频子剪辑,它将帮助你返回剪辑的剪切部分。
- 之后,您应该输入代码,返回从 start_secondsend_seconds 开始的视频中剪切的视频片段,并将所有片段精简为一个。
- 当你完成所有这些动作后,你可以从修剪过的片段列表中选择你需要的,你就可以创建一个联合视频了。
你已经看到这个程序很简单,是创建视频内容的好帮手。MoviePy 库将帮助您处理任何复杂的视频处理任务,并帮助您快速有效地剪切、粘贴或处理特定的视频片段。只需几个简单的步骤,你就可以轻松地成为 Python 开发者,获得成功的视频,并对结果尽可能满意。
结论
现在,您已经熟悉了所有三个有助于视频编辑的库,您可以利用它们进行成功而快速的编辑。最流行的是 MoviePy,它被数百万程序员和开发者使用。请记住,编辑剪辑是一个非常负责任的过程,通常会非常耗时,多亏了这个 Python 库,您将能够立即处理任何任务。
我们已经证明,您不必成为 Python 专业人员,也可以用简单的代码创建成功的视频。库的一个主要优点是对每个用户来说都很简单和容易访问,不管这个人是专家还是初学者。
Python 的禅:卓越编程的哲学
原文:https://www.pythoncentral.io/the-zen-of-python-a-philosophy-of-programming-excellence/
Python 的禅宗是由 Python 的创始人之一 Tim Peters 记录的 19 个观察的集合。虽然最初的集锦有 20 条格言,但吉多·范·罗苏姆认为最后一条是彼得斯开的一个奇怪的玩笑。
这个集合在 2004 年被标准化为 PEP 20,因为它极大地影响了 Python 社区的编程过程。在编写代码时记住这些观察并不是强制性的,但是它确实有助于确保代码的质量。
Python 包含了一个复活节彩蛋,你可以通过在解释器上运行“import this”来读取格言列表。
在本帖中,我们将讨论这些格言的含义,以及它们如何帮助你改进代码。
Python 之禅:崩溃
#1 漂亮比难看好
程序员是解决问题的专家,但是由于编写、记录和维护 Python 代码通常是团队工作,简单地为问题设计解决方案是不够的。理想情况下,代码需要是可读的和优雅的。
但是是什么让代码变得“美丽”呢?就像生活中一样,在 Python 编程中,美是主观的。然而,经验法则是代码必须易于被任何开发人员理解。
换句话说,如果一个程序运行得很好,并不意味着它是美丽优雅的。去掉不必要的条件,简化你的解决方案,会让你的代码变得漂亮。
#2 显性比隐性好
阅读这个观察,你可以得出结论,这是不言自明的。但是许多人在编码时没有实现它。
这句格言背后的意思是写冗长的代码比写间接的代码更好。Python 程序员需要竭尽全力确保他们代码的功能不会隐藏在难以理解的语言后面。
简单地说,你必须写出另一个没有程序知识的程序员也能理解的代码。
#3 简单胜于复杂
晚饭后拿出一个压力清洗机来清洗碗碟可能是一种解决方法,但它可能会损坏盘子。更不用说,这是一个愚蠢的解决问题的方法。
同理,编写复杂的代码来解决简单的程序也是不切实际的。Python 程序员必须避免使他们的解决方案过于复杂,即使它们看起来很聪明并且有效。
使你的程序复杂化最终会造成更大的损害,你的团队不会欣赏这一点。
#4 复杂比复杂好
虽然用压力清洗机洗碗不切实际,但如果你在洗车,使用压力清洗机可能是正确的方法。
前面的观察和这个提醒程序员,对于同一个问题,既有简单的解决方案,也有复杂的解决方案。但就像你不会用压力清洗机洗碗一样,你也不会用小擦洗器洗车。
这句格言的意思是,在大多数情况下,重视简单胜过复杂可能是正确的做法。尽管如此,当简单的解决方案不切实际时,您最好实现复杂的解决方案。
简单来说,Python 程序员应该记住简单性的限度。
#5 平比嵌套好
程序员通常有一种将事物组织成类别和子类别的诀窍,以区分他们程序的功能。许多程序员认为这是值得的,因为有序比混乱好。
然而,用这种方式组织代码会比组织更混乱。这并不是说将所有代码放在一个顶层模块中是个坏主意。但是,当您添加更多的子类别时,代码会变得越来越复杂。
坚持扁平的结构是保持程序简单的最好方法。
#6 疏比密好
程序员经常觉得有必要用过于复杂的代码来强调他们的技能。在一行代码中完成复杂的任务背后有一种完整的文化。
这并不是说俏皮话不好。在某些情况下,这样写解决方案是合理的。也就是说,这句格言表明程序员永远不应该为了在一行代码中包含所有功能而牺牲可读性。
#7 可读性计数
对于 Python 来说,可读性应该是重中之重。程序员只需编写一次代码,但许多人可能会多次阅读代码。
每个 Python 开发者都需要考虑到这一点。避免删除函数名和变量名中的元音字母,以确保代码始终清晰。
#8 特例不足以违反规则
Python 程序员需要遵循的最佳实践并不缺乏。这句格言表明,遵循规范比按照自己的方式编写代码更好,因为不一致会使代码不可读且难以处理。
#9 虽然实用性战胜了纯粹性
你可以把这看作是前面观察的延伸。虽然遵循最佳实践总是更好的,但是仅仅为了遵守规则而付出额外的努力也会使代码不可读。
如果你解决问题的方法比最佳实践所指出的方法更容易理解、更实用,那么破例背离最佳实践是更明智的做法。
#10 个错误永远不会悄无声息地过去
当一个程序返回 None 或一个错误代码,并且没有引发异常时,这个错误被称为无声错误。
这句格言背后的思想是,程序崩溃比抛出一个无声的错误并继续运行要好。这是因为沉默错误可能会导致复杂的错误,修复这些错误将更具挑战性。
#11 除非明确静音
这是上一课的延伸。在某些情况下,程序员可能想忽略程序抛出的错误。在这些情况下,最好显式地隐藏错误。
#12 面对暧昧,拒绝猜测的诱惑
程序员首先要学习的一件事是,计算机只做用户指示它们做的事情。换句话说,如果你的程序没有像你期望的那样运行,它只是在执行你的指令,而你的解决方案中有一个失误。
通过尝试许多不同的方法来解决不想要的行为,直到找到合适的方法,这不是正确的策略。它可能会掩盖问题,而不是解决问题。
这句格言指出,你必须拒绝盲目尝试不同解决方案的诱惑。您需要慢慢地浏览代码,并思考创建必要解决方案的逻辑。
应该有一种——最好只有一种——显而易见的方法来做这件事
如果你熟悉 Perl 编程语言,你可能知道它的格言:“有不止一种方法可以做到这一点!”
但是这句格言忽略了有几个选择通常会导致选择过多。当 Python 程序员找到几种方法来编写实现相同目标的代码时,也会出现这种情况。
投入额外的工作去学习问题的每一个解决方案是没有必要的。这句格言要求程序员缩小显而易见的解决方案并实现它。
#14 尽管这种方式一开始可能并不明显,除非你是荷兰人
这一课反映了 Tim Peters 的幽默感,因为 Python 的创造者 van Rossum 是荷兰人。
这一课看似轻松,但强调了一个重要的事实——程序员可能无法理解和回忆一门语言的规则,除非他们创造了这门语言。
拥有初学者的心态是提高编程技能的关键。
#15 现在总比没有好
它的意思是,如果一个程序陷入无限循环、崩溃或挂起,那么它比没有陷入无限循环、崩溃或挂起的程序更糟糕。
#16 虽然永远也不会比现在好
这句格言表明,等待一个程序完成执行比提前终止程序并根据错误的结果做出反应要好。
#17 如果实现很难解释,那就是个坏主意
有些程序员认为,如果他们能理解自己的代码,代码就足够好了。然而,如前所述,编程是一项团队活动。
如果你不能很容易地向你的队友解释你的解决方案,很可能这个解决方案太复杂了。
#18 如果实现容易解释,可能是个好主意
对上一课的扩展,这一课说如果代码易于解释,并不表明代码是好是坏。
名称空间是一个非常棒的想法——让我们多做一些吧!
在这最后一句格言中,提到了名称空间,它是组织分配给对象的名称的抽象。
这一课要说的是 Python 组织符号名称的方式是惊人的。
为 Python 函数计时
在之前的一篇文章中(在 Python 中测量时间- time.time() vs time.clock() ),我们学习了如何使用模块timeit对程序进行基准测试。因为我们在那篇文章中计时的程序只包括原始语句而不是函数,所以我们将探索如何在 Python 中实际计时一个函数。
不带参数的 Python 函数计时
模块函数timeit.timeit(stmt, setup, timer, number)接受四个参数:
stmt哪个是你要衡量的语句;它默认为“通过”。setup是在运行stmt之前运行的代码;它默认为“通过”。- 哪一次?计时器对象;它通常有一个合理的默认值,所以你不必担心它。
number这是您希望运行stmt的执行次数。
其中timeit.timeit()函数返回执行代码所用的秒数。
现在假设你想测量一个函数costly_func,实现如下:
def costly_func():
return map(lambda x: x^2, range(10))
您可以使用 timeit 来测量它的执行时间:
>>> import timeit
>>> def costly_func():
... return map(lambda x: x^2, range(10))
...
>>> # Measure it since costly_func is a callable without argument
>>> timeit.timeit(costly_func)
2.547558069229126
>>> # Measure it using raw statements
>>> timeit.timeit('map(lambda x: x^2, range(10))')
2.3258371353149414
请注意,我们使用了两种方法来测量这个函数。第一种方式传入 Python 可调用函数costly_func,而第二种方式传入原始 Python 语句costly_func。虽然第一种方式的时间开销比第二种方式稍大,但我们通常更喜欢第一种方式,因为它可读性更好,也更容易维护。
用参数计时 Python 函数
我们可以使用 decorators 来度量带有参数的函数。假设我们的costly_func是这样定义的:
【python】
def cost _ func(lst):
返回映射(lambda x: x^2,lst)
您可以使用如下定义的装饰器来度量它:
【python】
def wrapper(func,args, * kwargs):
def wrapped():
return func(* args,**kwargs)
return wrapped
现在您使用这个装饰器将带参数的costly_func包装成不带参数的函数,以便将其传递给timeit.timeit。
>>> def wrapper(func, *args, **kwargs):
... def wrapped():
... return func(*args, **kwargs)
... return wrapped
...
>>> def costly_func(lst):
... return map(lambda x: x^2, lst)
...
>>> short_list = range(10)
>>> wrapped = wrapper(costly_func, short_list)
>>> timeit.timeit(wrapped, number=1000)
0.0032510757446289062
>>> long_list = range(1000)
>>> wrapped = wrapper(costly_func, long_list)
>>> timeit.timeit(wrapped, number=1000)
0.14835596084594727
计时来自另一个模块的 Python 函数
假设您在另一个模块mymodule中定义了函数costly_func,既然它不是本地可访问的,那么您如何测量它的时间呢?嗯,你可以把它导入到本地名称空间或者使用setup参数。
# mymodule.py
def costly_func():
return map(lambda x: x^2, range(1000))
>>> timeit.timeit('costly_func()', setup='from mymodule import costly_func', number=1000)
0.15768003463745117
# OR just import it in the local namespace
>>> from mymodule import costly_func
>>> timeit.timeit(costly_func, number=1000)
0.15358710289001465
总结和提示
在本文中,我们学习了如何使用timeit.timeit测量 Python 函数的执行时间。通常,我们更喜欢将 Python 函数作为可调用对象导入并传递到timeit.timeit中,因为这样更易于维护。此外,请记住,默认的执行次数是 1000000,对于某些复杂的函数,这可能会大大增加总执行时间。
用 Python 创建 Google 工作表数据库的技巧
原文:https://www.pythoncentral.io/tips-for-creating-a-google-sheet-database-with-python/
你想学习如何用 Python 创建 Google sheet 数据库吗?如果是这样,你来对地方了。这篇博文将讨论一些可以帮助你开始的技巧。它还将提供一些例子,所以继续阅读开始。

使用正确的工具
用 Python 创建 Google sheet 数据库时,你需要做的一件事就是使用正确的工具。这意味着使用正确版本的 Python 和 Google Sheets。确保您使用的是 Python 版本 3 或更高版本。如果您使用的是旧版本的 Python,您将需要对其进行升级。至于 Google Sheets,你将需要使用版本的两个或更高版本。检查这些工具的版本的最简单的方法是去它们各自的网站寻找最新的版本。此外,花时间探索在线资源,在那里您可能会遇到一个可以自动化手动数据处理的工具。您可以使用 这个工具 来帮助您降低人为输入带来的错误风险。你也能更有效地利用你的时间。
变得有条理
你也应该变得有条理。这意味着你要清楚地知道你想要达到什么目标,以及你将如何去实现它。一种方法是创建一个大纲。这将有助于您确定需要收集哪些信息以及如何存储这些信息。您也可以使用这个大纲来创建一个路线图,引导您完成整个过程。此外,花时间创建一个专用文件夹,用于存储与项目相关的所有文件。这将有助于你跟踪每件事情,并在你需要的时候更容易找到你需要的东西。
遵循正确的步骤
用 Python 创建 Google sheet 数据库时,你需要做的另一件事是遵循正确的步骤。这意味着使用正确的命令来创建和填充数据库。第一步是创建一个新的 Google 工作表。从那里,你将需要创建一个新的 Python 脚本 。一旦创建了这两个文件,就可以开始填充数据库了。为此,您需要使用正确的 SQL 命令。如果您不熟悉这些命令,可以在网上找到它们的列表。最后,一旦您填充了数据库,您将需要保存它,以便以后可以访问它。
创建备份
最后但同样重要的是,你应该创建一个备份。这很重要,因为万一出现问题,它将帮助您恢复数据。 创建备份 有几种方法。一种方法是使用内置的 Google Drive 功能。另一种方法是将数据导出到外部存储设备。无论选择哪种方法,都要确保创建易于访问和使用的备份。

遵循这些提示,你将会很快用 Python 创建一个 Google sheet 数据库。记住慢慢来,输入数据时要小心。只要有一点耐心和努力,你将能够创建一个既可靠又易于使用的数据库。祝你好运!
2022 年 10 大 Python 在线课程
原文:https://www.pythoncentral.io/top-10-python-courses-online-in-2022/

简介
Python 已经成为全球使用最广泛、最容易访问的编码语言之一。对于 STEM 甚至其他学科的不同领域的许多人来说,它已经成为一种赋权工具。
获得这样一项基本技能是一个梦寐以求的机会,因为它提高了你的就业机会,更重要的是,为不同的问题提供了技术解决方案。无论是数据分析还是开发简单的程序来自动化琐碎的事情,Python 和它的包已经涵盖了一切。
现在,有人可能会问在哪里可以获得这些知识,为了回答这个问题,python central 的工作人员已经编译了一些在线课程的资源,这些课程是可访问的和全面的,足以让你精通 python。请注意,这个列表没有特定的顺序,它们都最适合不同的用途。请继续阅读,寻找答案!
好的 Python 课程由什么组成?
我们在选择课程时的标准是基于一些因素,如新手是否容易接触到,以及为寻求更多经验的熟练用户提供的有趣技巧。客观分析这一点的一些方法是保持对这几点的敏锐:
- 类比的用法:如果老师能够向没有数学背景的人解释“字符串”和“变量”这样的概念,这是一个好现象
- 更少的家庭作业,更积极的课堂作业:这有助于人们更经常地改正错误,而且因为他们可以倒带大多数录好的课,这也有助于他们复习。
- 行业经验:如果教师一直活跃在计算机编程行业,他们比普通的半职业教师更有可能有更多的锦囊妙计。
2022 年 10 大 Python 在线课程
# 1 Python 编程入门(Udemy)
这个两小时的简短入门课程是最适合初学者的 。 由加州大学伯克利分校的学生 Avinash Jain 创办的教育机构 Codex 制作,这个免费课程尽最大努力让一个没有编码经验的人熟悉 python 环境下代码的关键特性。您可以尽快完成这 15 个视频教程,因为每个教程只有 10 分钟。因此,这门课程可以非常快地完成。由于它是免费的,所以从初学者到基础知识一般的部分编码人员都可以使用。
导师 :阿维纳什·贾恩(Avinash Jain),Codex 的创始人,该机构旨在使代码知识民主化。
特色 :非常全面的课程持续时间非常短,因为它涵盖了许多需要进一步研究的主题,但它做得足够好,足以简化它,让任何外行人都知道事情的要点。也是免费的,是加分加一分。
| 课程名称 | Python 编程简介 |
| 讲师 | 阿维纳什·贾恩 |
| PythonCentral 专家评分 | 4.4 颗星 |
| 级别 | 初学者 |
| 成本 | 免费 |
| 总结 | 完全初学者的好课程 |
| Pro | 在不到两个小时的时间里教你基础知识 |
#2 完全初学者学习 Python 3.6(Udemy)
本课程的名称有点用词不当,因为本课程期望你对 Python 或编码有一些基本的了解。许多极其生动的细节被掩盖了,这门课在短时间内有效传授知识方面表现突出。本课程是 最适合中级或初级初学者 。这是一门 6 小时的课程,包括作业、现场问题和 39 个录音讲座,要求你也遵守你的控制台上的代码。这些讲座由经验丰富的 Michael S Russell 主持,他是一名业务分析师,拥有 20 年使用 Python 和其他编码语言处理大量数据的经验。
导师:Michael S . Russell,金融与银行学硕士,他是一位伟大的老师,能预见你的错误,也有精彩的技巧为半熟练或新手减轻工作量。
特色 :讲座都有字幕,通常有代码和 PowerPoint 的视频,这意味着它们是高质量和专业编辑的。它们在视觉上很容易理解,但我们也要说,老师以一种悠闲的节奏教学,在某种程度上,这实际上是好的,给了学生思考的空间。您还将学习如何操作 Jupyter 笔记本电脑。
| 课程名称 | 完全初学者学习 Python 3.6 |
| 讲师 | 迈克尔·拉塞尔 |
| PythonCentral 专家评分 | 4.4 颗星 |
| 级别 | 初级到中级 |
| 成本 | 免费 |
| 总结 | 涵盖 Python 基础知识的初学者坚实课程 |
| Pro | 带字幕的讲座,易于跟随 |
#3 Python 基础训练(LinkedIn 学习)
这是一个稍短的 5 小时课程,课程结构非常均衡,初学者开始时速度稍慢,最终加快速度。本课程适合 的初级初学者和半熟练的中级者。
讲师 : Bill Weinman,技术教育家和 Python 专家,在编写关于 C++、Java,当然还有 Python 等编码语言的内容方面有超过 25 年的经验。这种体验在讲座内容的质量上体现得淋漓尽致。
特色 :本课程经过认证,最后提供证书,作为你简历的附件有效。这门课程很有声望,比尔·魏因曼已经教了很多人编程。因此,即使是这个 5 小时的课程,对于那些希望雇佣自由职业者来完成某些编码任务的公司来说也是有价值的。你在 5 个小时内学会了循环、模块和世界上所有的东西,在每章结束时完成了章节划分和测验。
| 课程名称 | Python 基础训练 |
| 讲师 | 比尔·魏因曼 |
| PythonCentral 专家评分 | 4.7 颗星 |
| 级别 | 初学者 |
| 成本 | LinkedIn 学习订阅 |
| 总结 | 适合 Python 新手的 5 小时课程 |
| Pro | 包括一个练习和 11 个小测验 |
# 4 Python 3:Python 编程初学者指南(SkillShare)

这是一门更全面的课程,内容超过 8 小时,外加 9 个不同的项目,帮助您磨练技能并获得实践经验。本课程最适合 初学者和中级程序员。 它专注于开发应用程序的框架,所以这是一个中心焦点,这并不坏,因为开发一个应用程序包含了 Python 的大多数主要工具和应用程序,并使您熟悉所有这些。
导师 :托尼·斯汤顿,精通多种编码语言,就职于 IT 部门。
特色 :在课程结束时提供证书,但最好的部分是课程给你的奖金 9 个不同的项目,以应用在 8 小时的讲座和测验中获得的技能,因为没有指导方针,你可以自由地以你喜欢的方式处理问题。
| 课程名称 | Python 3:Python 编程初学者指南 |
| 讲师 | 托尼·斯汤顿 |
| PythonCentral 专家评分 | 4.7 颗星 |
| 级别 | 初学者 |
| 成本 | SkillShare Premium 订阅 |
| 总结 | 由知识渊博、引人入胜的讲师讲授的简短而甜蜜的初级 Python 课程 |
| Pro | 周末学习 Python 的绝佳课程 |
#5 100 天代码:2022 年完整 Python Pro boot camp(Udemy)
《100 天的代码》是网上最实用、最紧张、最全面的 Python 课程之一,由于信息量太大,要跟上它有点困难,这是出了名的。因此,新人通常需要 100 多天才能完成这门课程。这门课程最适合于 中级程序员和想拓展 Python 其他用途的程序员。
数据科学家和 Python 的狂热用户 Angela Yu 博士精通 Python 的几乎每一种用法,因此她的课程似乎为所有技能水平的人提供了一些东西。
特色 :超过 60 小时的内容、项目等,使其成为最全面的在线课程之一。它是有报酬的,但提供结业证书。如果你对你的教学质量不满意,它还提供 30 天的退款保证。
| 课程名称 | 100 天代码:2022 年完整的 Python Pro 训练营 |
| 讲师 | 于安琪博士 |
| PythonCentral 专家评分 | 4.7 颗星 |
| 级别 | 初学者 |
| 成本 | $84.99 |
| 总结 | 全面的 Python 课程,让初学者在 100 天内成为专业人员 |
| Pro | 由伦敦顶级编程训练营伦敦 App Brewery 的首席讲师授课 |
#6 使用 Python 的数据摄取(LinkedIn Learning)
这是清单上第一批更适合 高级或高级中级程序员的课程之一。 这部分是因为本课程侧重于数据管理和应用 Python 统计分析技术。这门课程非常适合那些必须处理大量数据并且可能还不精通这门语言的生物科学家。
导师: Miki Tebeka,数据专家,资深编码老师。
特色 :面向需要学习 STEM 语言的科学家和人员,因为它是专门为处理数据密集型文件而构建的,并学习如何用 Python 分离和管理它们。还提供了许多模板和其他资源。它还提供了一个证书。
| 课程名称 | 使用 Python 摄取数据 |
| 讲师 | 云母条 |
| PythonCentral 专家评分 | 4.2 颗星 |
| 级别 | 中级 |
| 成本 | LinkedIn 学习订阅 |
| 总结 | 面向中级 Python 程序员的优秀数据科学课程 |
| Pro | 简短的课程;讲授 ML 从业者可能在中发现的真实场景 |
#7 巨蟒圣经(Udemy)
这是一门有趣且以应用为基础的 9 小时课程,使用 11 个有趣的项目进行结构化,教你基础和高级技术,因此最适合 中级或初级编码人员。
指导老师 : Ziyad Yehia,来自物联网学院,一个在世界各地教授人们如何编码的机构。
特色: 11 个有趣的项目将在你学会解决它们所需的概念后由你来处理。在 10 多个小时的课程中,你已经自己用 Python 编写了 11 个应用程序,这是值得称赞的。
| 课程名称 | Python 圣经 |
| 讲师 | Ziyad Yehia |
| PythonCentral 专家评分 | 4.7 颗星 |
| 级别 | 初级到中级 |
| 成本 | $129.99 |
| 总结 | 10 小时的课程将帮助你建立 11 个项目的投资组合 |
| Pro | 讲师以有趣的方式教授 Python 的原理和方法 |
#8 用 Python 构建工具(LinkedIn Learning)
这门特定的课程集中于构建工具,这些工具可以自动化重复的任务,最适合于 中级和后期初学者。 这门课程很棒,因为它可以帮助传统上不从事 STEM 的人,也可以帮助其他领域的人,因为对许多人来说,琐碎的计算任务仍然很耗时。
导师 : Scott Simpson,编程老手,IT 行业专家,作家,教师。
特色 :专注于构建自动化工具,帮助排序、管理电子表格和其他较小任务的工具,可以帮助零售业、商业甚至科学家和社会学家。
| 课程名称 | 用 Python 构建工具 |
| 讲师 | 斯科特·辛普森 |
| PythonCentral 专家评分 | 4.5 颗星 |
| 级别 | 中级 |
| 成本 | LinkedIn 学习订阅 |
| 总结 | 一个小时的课程,教你如何用 Python 自动完成任务 |
| Pro | 从长远来看能帮你节省大量时间的实用课程 |
#9 完整的 Python 课程:初学者到进阶(SkillShare)

这个 16 小时的课程经过精心编排和研究,对 的初学者、中间用户或老手都有帮助。 从很多方面来说,这是一门重要的课程,因此它忽略了一些细节,但可以通过有趣的项目和讲座帮助你学习 Python。
讲师: Joseph Delgadillo,科技作者和自学成才的 Python 专家、教育家和讲师,编码教育公司 JTDigital 的创始人。
特色 :两个可以自由运用你的概念的项目,脚本编写、Django 框架和 GUI 设计都是本课程很酷的部分。
| 课程名称 | 完整的 Python 课程:初学者进阶 |
| 讲师 | 约瑟夫·德尔加迪略 |
| PythonCentral 专家评分 | 4 颗星 |
| 级别 | 初学者 |
| 成本 | SkillShare Premium 订阅 |
| 总结 | 关于初级 Python 开发人员入门所需了解的一切的深入课程 |
| Pro | 经济实惠的 Python 速成班 |
# 10 Python A-Z:Python 用于数据科学的真实练习
这是一个 11 小时的超具体但简短的课程,内容是关于应用 Python 技术,你们大多数人在数据科学和机器学习的基础 Python 课程后可能会拥有,并使用基于人工智能的技术为自己构建有用的自动化工具。本课程适用于 高级或后期中级程序员。
导师 :基里尔·叶列缅科,世界上最大的在线 Python 辅导和编程语言学院之一 Agency 的创始成员。
特色 :关注数据科学,大数定律,Jupyter 笔记本,循环,数据分析技术。这个课程提供了一个证书,并且被大公司作为你简历的一个真实特征。你还会学到矩阵和数据框架,这很有用。
| 课程名称 | Python A-Z:带实际练习的数据科学 Python |
| 讲师 | 基里尔·叶列缅科 |
| PythonCentral 专家评分 | 4.6 颗星 |
| 级别 | 初学者 |
| 成本 | $84.99 |
| 总结 | 面向数据分析和数据科学的 Python 编程综合课程 |
| Pro | 清晰的解释和富有挑战性的作业让你为工作中可能出现的任何情况做好准备 |
结论
虽然所有这些课程都填补了一些空白或提供了适合您需求的特定类型的教育,但我们认为#5 100 days of code 仍然是整体上最好的,也是网上最全面的 Python 课程之一。#2 学习 Python 3.6 对初学者来说是最好的,但是有一个更尖锐的学习曲线。
有些课程是付费的,详情可在会员链接上找到。您的决定完全取决于您的需求以及您希望使用 Python 实现什么。
面向初学者的 5 大免费 Python 资源
原文:https://www.pythoncentral.io/top-5-free-python-resources/
作为初学者学习 Python 可能有点让人不知所措。你从哪里开始?你怎么知道你得到了最好的信息?一旦你掌握了基本知识,你会做什么?如果你最近发现自己在问这些问题中的任何一个,那么你来对地方了。在这篇文章中,我们为刚开始学习 Python 的人整理了一些最好的免费 Python 学习资源(并非所有这些资源都适合绝对的编码初学者,但有些是,所以如果你是这样的人,请继续阅读!).
1。Codecademy

Codecademy 非常适合绝对的初学者。他们的免费代码教程非常受欢迎,这是有原因的。在本教程中,通过一些免费的实践课程,您将会对编写 Python 代码有一个很好的了解。
2。敬酒不吃吃罚酒

《艰难地学习 Python》是一本免费的在线电子书,它为你提供了大量 Python 代码的基础知识。这本书涵盖了从最基本的(当你第一次开始时如何设置)到超级复杂的(如何构建一个游戏)的一切。
3。谷歌的 Python 类

谷歌的 Python 课程对于那些希望从专业角度学习这门语言的人来说是一个很好的资源。这门课不是为完全的编码初学者开设的,但是那些有一点编码知识的人将能够使用 Google 在这门课中提供的视频、讲座、书面材料和代码练习来学习 Python。
4。一个字节的 Python

《Python 的一个字节》是一本免费的电子书,适合完全的初学者。这本书将为您提供一个全面的课程,介绍您需要了解的关于 Python 的所有知识,为您新获得的技能更上一层楼打下坚实的基础。
5。tuts plus

这个 TutsPlus 教程为您提供了几十种不同的资源,可以用来学习 Python,它甚至为您提供了一个教学大纲,以便您可以确保知道使用什么资源,以及您应该在编码之旅的哪个阶段使用它。对于编码新手和编码老手都是完美的。
现实世界中的 5 大 Python 应用
原文:https://www.pythoncentral.io/top-5-python-applications-in-the-real-world/

根据可信的统计数据收集者 Statista 的说法,Python 在编码者中排名第三。第一名和第二名分别是 JavaScript 和 HTML/CSS,这是设计 IT 产品的必备技能。让我们仔细看看 Python,以及它给我们带来的机遇!
Python 是一种语法清晰可读的语言,是一种通用的高级编程语言。这便于创建不同的 IT 产品,从 web 应用程序到人工智能学习算法和平台。
这种动态的解释性语言也服务于其他线下行业。Python 的生产没有任何限制。你可以请众多 dev 或者 手机 app 开发服务 为你编写完美的 IT 产品。
因此,你可以在哪里用 Python 进行设计?
-
Web page development
Python 框架 Django 和 Flask 已经成为 web 开发的主流。它用于创建在后端服务器上运行的网站逻辑。
这些框架简化了生成用户在浏览器中看到的 HTML 页面、数据库查询和地址处理的过程。Python 中使用的类比其他任何编码语言都更方便、更简短。
-
Data analysis and visualization
Matplotlib 是一个综合性的可视化库,用于绘制二维 2D 图形。Python 更新版本的创建是为了尽可能简单明了地与任何数据库进行交互。
特别是,该语言的工作环境包含一个编程接口,用于使用 SQL 查询直接在脚本中处理数据库。如果您需要将 Python 代码用于 Oracle 和 MySQL 数据库,只需对其进行最小的修改。
-
Process automation
许多开发人员使用 Python 作为一种方便的工具来完成小脚本。这使得各种流程自动化,丰富了每个办公室和公司的日常工作。一个简单的例子与电子邮件系统的处理方式有关。
当然,这可以手动完成。要收集统计数据并进行分析,您需要计算包含特定关键字的电子邮件的数量。然而,您可以创建一个简单的脚本来计算每个标题或标签。
-
Machine learning
Python 非常适合这个目的。人们通过用 Python 编写的系统获得了识别人脸和声音的能力。同样,它也符合深度学习和神经网络专业人士的需求。
有机器学习的框架和数据库。最流行的两个是双重的:scikit-learn 和 TensorFlow。Scikit-learn 是 Python 编程语言的开源机器学习软件库。后者是更低级的库。它允许你创建自定义算法。
-
System Programming and Management
Python 拥有管理其运行的各种操作系统服务的接口——Linux、Windows 等。因此,使用 Python 编写面向 PC 的可移植应用程序非常方便。有了它,您可以加快打开和搜索文件夹中的文件,启动程序,计算和其他典型的任务。
Python 的主要优势是入门门槛低。换句话说,几乎任何人都可以学习用这种语言编程。因此,如果你想开始编码,就找一个可靠的课程并开始练习。
作者简介:Anastasiia Lastovetska 是一名科技作家,在mls dev工作,是一家从零开始构建 web &移动 app 解决方案的软件开发公司。她研究技术领域,创建关于应用程序开发、UX/用户界面设计、技术&商业咨询的优秀内容。
为你的 Web 开发雇佣一个有才华和负责任的 Python 程序员的八大技巧

在你寻找 Python 开发人员时,你要确保你只雇佣那些在他们的工作中是最好的,并且有几年经验和完成项目的 Python 开发人员。因此,你应该慢慢来,因为这是一个巨大的决定。
尽管如此,你不需要担心。我们列出了雇佣 Python 程序员的十大技巧。
雇佣 Python 开发者的技巧
1。定义你的目标和需求
在你试图寻找一个 Python 开发者之前,花一些时间定义你的需求和目标。你需要哪种类型的程序员?什么样的能力和特质对你来说是重要的?你的消费计划是什么?
如果你花时间清楚地定义你的需求,你将能够更有效地缩小搜索范围,并通过避免与缺乏你所要求的资格的程序员进行面试来节省时间。
2。寻找合适的 Python 程序员
一旦你断定你需要招聘一名 Python 程序员,研究步骤就开始了。你必须为这项工作找到理想的人选,这意味着你必须选择既有才华又有责任心的人。
您可以采取几个步骤来确保找到 Python。首先,寻找使用 web 工具的合格程序员。这是一个寻找 Python 程序员的绝佳地点,因为他们通常聚集在许多软件开发论坛和网站上。
你也可以向你的朋友和同事寻求建议。如果你认识的某个人曾经和一个出色的 Python 程序员一起工作过,他们可能会让你和他们接触。
3。评估过去的工作和投资组合
当面试潜在的 Python 开发人员时,查看他们以前的工作和投资组合以了解他们的才能和专业知识是至关重要的。
如果他们没有投资组合,这并不总是一个交易破坏者,但值得注意。你可以向他们询问他们做过的其他项目,如果他们没有任何例子,那就是危险信号。
确定他们的工作是否与你雇佣他们的项目相关也很重要。例如,如果你正在找人构建一个 web 应用程序,可以看看他们的 web 开发组合。如果他们缺乏相关经验,他们可能不是这个职位的最佳人选。
4。面试时提问
面试过程对于了解候选人并确定他们是否适合这个职位至关重要。通过问正确的问题,您可以确定他们的经验和技能程度。
在面试中,要问的一些关键问题包括:告诉我你不得不调试一段复杂代码的时候。到底是什么问题,您是如何解决的?你能给我演示一下你创造的复杂算法吗?你做过的最具挑战性的项目是什么?你认为一个伟大的 Python 程序员应该具备哪些品质?
这些类型的问题会让你更好地了解候选人的能力,以及他们是否适合这份工作。
5。考虑他们的工作承诺
当你想雇佣 Python 开发者时,最重要的标准之一就是这个人是否致力于长期发展。因此,询问他们的工作承诺和他们对工作的期望。如果他们只是在寻找一个临时职位,他们可能不适合你的团队。
然而,如果他们正在寻找有发展空间的长期工作,这是一个很好的指标。你想雇佣一个致力于公司成功的人,并且会长期为公司效力。
6。检查他们的参考资料
查看你考虑雇佣的任何 Python 程序员的参考资料。当我们说推荐人时,我们不仅仅指他们以前的工作。
请求查看他们的工作示例,无论是代码示例、他们写的博客,还是他们参与的个人项目。如果他们拒绝透露他们以前的任何工作,这是一个主要的危险信号。
当回顾他们以前的工作时,密切关注代码质量。是否组织良好,简单易懂?有什么注释描述了代码的作用吗?这是一个你很难理解的混乱吗?
你还应该向他们以前共事过的人索取推荐信,无论他们是同事、导师,甚至仅仅是朋友。这些人可以向你提供一个体面的概念,告诉你如何使用有问题的 Python 编码器,以及你是否可以信任他们。
7 .。思考超越编码技巧
首先,你需要确保你考虑雇佣的 Python 程序员精通计算机科学基础。他们必须能够描述数据结构和算法。如果他们做不到,他们可能不是你所需要的优秀程序员。
一个好的 Python 程序员除了会编码,还会解决问题。他们应该能够将问题分解成更小的部分,然后一次解决一个。
最后,确保你选择的 Python 程序员是一个有能力的沟通者。他们应该能够以一种可理解的方式向你描述他们的代码。如果他们做不到这一点,当你需要修改他们的代码时,几乎肯定会有问题。
8。考虑成本
当你想雇佣一个 Python 程序员时,你最不想做的事情就是打破你的预算。同时,你也不想降低你的报价,最终和一个不合格的或者对工作不感兴趣的人在一起。
那么,你如何取得正确的平衡呢?最好的办法是考虑一下你所在地区的 Python 程序员的普遍工资是多少,然后再加上 10-20%。这有助于确保你不仅雇佣了一个合格的人,还雇佣了一个有动力为好的结果而工作的人。
当然,任何规则都有例外。如果你是为一个特别困难或高风险的项目招聘,你可能需要让交易变得更好。然而,总的来说,这应该为您提供了一个不错的起点。
结论
雇佣一名优秀的 Python 程序员对你的商业成功至关重要,按照上面列出的步骤,你一定能雇佣到 Python 程序员。因此,这个指南将帮助你雇佣 Python 开发者,不管你在做什么样的项目。
想要获得高薪工作,你应该知道的几个面试问题
在 Indeed.com 有超过 38,000 个招聘信息 对于 Python 开发者来说,很明显这些知识渊博的编程专业人士需求量很大。此外,根据 PYPL 流行指数,Python 仍然高居榜首,占据了28.52%的市场份额。
Python 被用在许多不同的编程场景中,并被世界上最大的公司所利用,它将继续存在,一些业内人士甚至认为它是编程语言的未来。
尽管如此,不管你有多有经验或知识多渊博,面试一个开发人员的角色都是令人紧张的。
面试官希望应聘者对编程概念有深刻的理解,并表现出解决复杂问题的能力。虽然对 Python 开发人员的需求很高,但是被雇佣也不是件容易的事。
如果你很快就要参加 Python 面试,这份顶级 Python 面试问题列表将有助于确保你在开始面试前已经覆盖了所有的基础。
在这篇文章中,我们涵盖了从面向新生的 Python 面试问题到高级 Python 编程面试问题的所有内容。
Python 新鲜人面试问题
#1 什么是 Python?它有什么好处?
Python 是一种解释型通用编程语言,以其高级语法而闻名。在合适的库的帮助下,它可以用来构建许多不同种类的应用程序。此外,Python 允许面向对象编程,并拥有自动内存管理等特性。
这些品质使这种语言成为构建解决现实世界问题的应用程序的理想语言。
Python 提供了两个主要的好处:
- Python 有一个易读易懂的语法,便于学习和调试。这种简单性有助于降低企业的程序维护成本。此外,开发人员可以使用 Python 编写脚本,第三方包支持为开发人员提供了重用代码的灵活性。
- Python 是动态类型的,加上高级数据结构,使其成为快速应用开发的首选语言。
#2“动态类型化”是什么意思?
在编程中,“键入”指的是类型检查。类型检查是确保开发人员想要执行的操作的数据类型相互兼容的过程。
Python 是一种强类型语言,这意味着代码如:
"1"+2
会抛出一个类型错误。代码中的 1 是一个字符串,而 2 是一个数字,Python 不隐式转换数据类型。换句话说,强类型语言不允许类型强制。
相比之下,使用弱类型语言(如 JavaScript)运行相同的代码将输出字符串“12”
类型检查分两个阶段进行:
- 静态: 程序执行前检查数据类型。
- 动态: 程序执行过程中检查数据类型。
由于 Python 是一种解释型语言,程序语句是一行一行地动态执行的。这使得 Python 成为一种动态类型语言。
#3 什么是解释语言?
解释编程语言是按顺序一行接一行地执行语句的语言。运行程序不需要编译。除了 Python,JavaScript、PHP 和 Ruby 等语言也是解释型语言。
#4 人教版 8 是什么意思,是什么让它变得重要?
Python 增强提案(PEP)是由该语言的开发者向社区提供的设计文档。除了提供设计信息,这些文档还描述了该语言的新特性及其内部流程。
PEP 8 是一个特定的 PEP 文档,概述了 Python 的风格指南。开源社区的开发者需要在他们的项目中遵循这些指南,使得 PEP 8 成为每个开发者的主要指南之一。
# 5 Python 中的“作用域”是什么意思?
对象的作用域是对象保持相关的代码块。每个 Python 对象都有一个作用域,Python 的名称空间唯一地标识了程序中的所有对象。
除了对象,名称空间还有一个作用域,程序员可以在其作用域内使用名称空间中的对象,而无需添加前缀。在代码执行期间,范围是在不同的级别上定义的。不同的范围是:
- 局部作用域,指函数中可访问的局部对象。
- 全局范围,指的是在整个执行过程中可访问的对象。
- 模块级作用域,指当前模块中可访问的对象。
- 最外层的作用域,指程序中可以使用的所有内置对象。Python 最后搜索最外层范围内的对象,这样它就可以找到引用的名称。
需要注意的是,使用内置关键字,如 全局 ,可以将局部范围对象视为全局范围对象。
#6 什么是元组和列表?它们有什么不同?
在 Python 中,列表和元组都是序列数据类型,这意味着它们存储对象的集合。程序员可以在列表和元组中存储不同的数据类型。
程序员在定义列表时,会使用方括号:
mylist = ["John", 7, 0.38]
另一方面,程序员在定义元组时使用括号:
mytuple = ("Andy", 3, 0.29)
列表和元组的主要区别在于列表是可变对象,而元组是不可变对象。
换句话说,程序员可以通过添加或删除数据来修改列表。然而,一旦元组被声明,程序员就不能以任何方式修改它。
# 7 Python 内置的数据类型有哪些?
Python 包括几种数据类型;然而,当声明任何类型的变量时,不需要定义数据类型。也就是说,理解 Python 中的数据类型是至关重要的,因为忽略数据类型之间的兼容性会导致程序执行过程中的类型错误。
使用 type()和 isInstance()之类的函数,可以检查变量中存储了什么类型的数据。
Python 中有许多不同类别的对象:
无类型
none 数据类型在 Python 中定义了空值。它被设计用作布尔等式运算。它使用“None”关键字定义。
数字类型
整数、浮点数和复数是 Python 中可用的三种数字数据类型。布尔数据类型被认为是整数子类型。
| 类名 | 使用 |
| int | 将整数文字存储为整数 |
| 浮动 | 存储带小数或指数的文字和浮点数 |
| 复杂 | 以 A + Bi 形式存储复数;属性包括 real 和 imag |
| bool | 存储真值或假值 |
可以使用标准库中的“分数”和“小数”类分别存储有理数和小数。
序列类型
官方 Python 文档指出有三种序列数据类型:列表、元组和范围对象。
| 类名 | 使用 |
| 列表 | 它是一个可变序列,用于存储元素的集合 |
| 元组 | 它是一个不可变的序列,用于存储元素的集合 |
| 范围 | 表示执行过程中产生的不可变序列 |
| str | 它是一个不可变的 Unicode 码位序列,用于存储文本 |
标准的 Python 库也包含了 bytearray 之类的类来存储二进制数据。
程序员可以用 中的 和 而不是 运算符遍历存储在序列数据类型中的元素。这些运算符与值比较运算符具有相同的优先级。
映射类型
映射对象使程序员能够将散列值映射到随机对象。截至 2021 年,映射类型只有一种: 字典 。dictionary 数据类型是可变的,它存储一个逗号分隔的键和值对列表。
一个程序员会实现这样一个字典:
a = dict(name = "Kate", age = 16, country = "Finland")
设定类型
集合数据类型存储可散列对象的无序集合。Python 目前只内置了两种 set 类型: set 和 frozenset 。
set类型是可变的,程序员可以对其使用 add()和 remove()等方法。另一方面,顾名思义, frozenset 数据类型是不可变的,声明后不能修改。
| 类名 | 使用 |
| 设置 | 不同散列对象的可变无序集合 |
| frozenset | 不同可散列对象的不可变集合 |
需要注意的是,由于 frozenset 是不可变的,所以它是可散列的,这使得程序员可以将它用作字典键。Frozensets 也可以用作集合的元素。
设置的数据类型是不可变的,不能作为字典键使用。
模块
模块是内置的数据类型,支持属性访问,这是一种特殊的操作。属性访问定义了 mymod 。 myobj ,其中 mymod 为模块, myobj 为符号表中的名称。
模块的符号表存储在 dict module 的特殊属性中。但是不可能直接分配给这个模块。
可调用类型
这些数据类型是应用函数调用的类型。因此,这些数据类型包括用户定义的函数、生成器函数、实例方法和一些精选的内置函数、方法和类。
#8 什么是 pass 关键字?
pass关键字用于填充可能在程序运行时执行的空代码块。换句话说,该关键字表示对程序中尚未编写的代码块的空操作。
# 9 Python 语言中的模块和包是什么?他们提供什么好处?
模块是任何扩展名为. py 的 Python 文件。它可以包含已定义的类、函数或变量。这些文件可以使用 导入 关键字导入并初始化到程序中。如果不需要使用整个模块,程序员也可以使用 中的 和 import 关键字导入模块的部分内容。
模块的概念是它们有助于避免不同程序中全局变量之间的冲突。
同样,包有助于避免不同模块名称之间的冲突。包只是支持模块名称空间的层次结构的工具。
用 Python 创建一个包很简单,因为使用了系统固有的文件结构。要创建一个包,程序员必须简单地将模块放入一个文件夹中。文件夹名用作包名。
要从一个包中导入一个模块,程序员必须在包名后面加上模块名,并在它们之间加一个点。
也可以导入整个包。但是,这样做并不会将模块导入到本地名称空间,因此这个操作没有用。
模块化的好处
模块和包是 Python 机制,支持 Python 中的模块化编程。模块化提供了几个优势:
- 简单: 当开发人员在一个模块上工作时,他们可以把全部精力放在解决问题的一小部分上。有了模块化,开发更容易,错误更少。
- 可维护性: 使用模块的想法是为了加强问题不同领域之间的逻辑界限。当模块以相互依赖最小的方式编写时,以后对一个模块的修改破坏其他模块的可能性就最小化了。
- 可重用性: 一个模块中的功能可以在应用程序的其他部分重用,没有任何麻烦。
- 作用域: 模块有自己的名称空间,这有助于避免程序不同部分中相似标识符的混淆。
什么是全局、私有和受保护的属性?
全局变量是用 Global 关键字声明的公共变量,赋予它们一个全局范围。
受保护的属性是可以从定义它的类外部访问和修改的属性。然而,一个负责任的开发者应该避免这些行为。受保护的属性有一个下划线作为标识符的前缀(例如,“_john”是受保护的属性)。
私有属性在标识符后面有一个双下划线,不能从类外部访问或修改。尝试访问或修改这些标识符会导致 AttributeError。
# 11 Python 中的“自我”是什么?
程序员用 self 来表示类的一个实例,访问类的属性和方法。需要注意的是,与 C++中不同的是, self 在 Python 中并不是一个关键字。然而, self 将属性与开发者的参数绑定在一起,因此像关键字一样使用。
# 12 _ _ init _ _ 代表什么?
init 是一个构造函数方法,在创建新的对象或实例时会自动调用。它的功能是为对象或方法分配内存。每个类都有一个与之关联的 init 方法,这有助于将类的属性和方法与存在的局部变量区分开来。
# 13 Python 中的 break 和 continue 是做什么的?
将 break 语句添加到循环的末尾会终止循环,并将控件放在循环体的末尾。
与 break 语句一样,continue 也是一个跳转语句。但是,continue 语句不是终止循环,而是跳过循环的当前迭代。控制流向循环的下一次迭代。
#14 什么是单元测试?
单元测试包括单独测试程序的不同部分。应用程序通常包含几个协同工作的不同组件。
然而,如果应用程序不能正常运行,查明应用程序的哪个部分导致了问题就变得很困难。也有可能是应用程序的多个组件运行不正常。
单元测试是用来单独测试应用程序的每个组件的框架。它有助于确定应用程序的哪些部分可能对其失败负责。
# 15 docstring 的作用是什么?
文档字符串是一个多行字符串,帮助开发人员记录一段代码。docstring 描述了一个方法是如何工作的。
#16 什么是切片?
切片的意思是拿走某物的一部分。切片用于删除列表的一部分。切片的语法是[start : stop : step]。“开始”定义了列表必须被切片的起点。“stop”是要切片的最后一个元素的索引。“步长”值定义了要跳跃的步数。
Python 允许对列表、字符串、数组和元组进行切片。
Python 中的数组和列表有什么不同?
数组是相同类型数据的集合,比列表消耗更少的内存。
列表是不同类型数据的集合。这些数据类型消耗大量内存。
面向经验丰富的开发人员的 Python 面试问题
# 18 Python 如何管理内存?
Python 内存管理器处理 Python 中的内存管理。该组件以仅为 Python 保留的私有堆空间的形式分配内存。
换句话说,所有的对象都存储在这个私有堆中。虽然数据是不可访问的,但是程序员可以使用一些 API 函数来处理私有堆空间。
除了 PMM,Python 还有内置的垃圾收集特性来为私有堆空间释放内存。
什么是名称空间,为什么要使用它们?
名称空间是将“名称作为键”映射到“对象作为值”的字典,有助于确保程序中的对象名称被识别为唯一的。名称空间是允许 Python 开发人员在没有任何冲突的情况下使用对象的组件。
由于名称空间本质上是字典,多个名称空间可以将相同的名称映射到不同的对象。名称空间可以分为三种类型:
- 本地命名空间: 为函数调用临时创建,当函数返回输出时被 Python 清除。顾名思义,它包括函数内部的本地名称。
- 全局命名空间: 当一个程序导入一个包,并且这个包一直使用到执行结束时,就创建了全局命名空间。它包含给定项目中使用的包或模块的名称。
- 内置名称空间: 这个名称空间包括 Python 内置的函数名。它还包括各种异常的名称。
名称空间的生命周期取决于它们所关联的对象的范围。当一个对象的范围结束时,相应的名称空间的生命周期也结束了。
由于这个原因,从外部名称空间访问内部名称空间对象在 Python 中是不可能的。
什么是范围解析?
一个程序可能有两个不同的对象,它们具有相同的名称和作用域,但功能不同。范围解析是确定检查命名空间的顺序的过程。这个过程使 Python 能够很容易地区分看似相似的对象。
Python 使用范围解析的一个很好的例子是,它必须区分“math”和“cmath”模块中两个名称相似的函数。
#21 装饰器在 Python 中有什么用?
装饰函数是一种 Python 函数,它在不改变函数结构的情况下向程序中的现有函数添加功能。这些函数是以自底向上的方式调用的。
装饰函数之所以如此有用,是因为除了让函数更有用之外,它们还可以接受函数的参数,并在将参数传递给函数之前对其进行修改。
这是通过使用内部嵌套函数来封装数据并确保装饰函数不会全局出现来实现的。
#22 什么是 lambda,它有什么用?
在 Python 中,lambda 是一个匿名函数,可以接受无限数量的参数。但是,这个函数只能有一个表达式。
开发人员在短时间内需要匿名函数的情况下使用 lambda 函数。这些函数既可以赋给变量,也可以包装在另一个函数中。
#23 解释如何在 Python 中复制对象
Python 中的赋值语句不会复制对象。它通过将现有对象绑定到目标变量的名称来工作。
开发人员可以使用复制模块创建对象的副本。复制模块使程序员能够以两种不同的方式复制一个对象:
- 浅拷贝: 它创建一个对象的按位拷贝,其值与原始值相同。如果任何值引用其他对象,则复制这些对象的引用地址。
- 深度复制: 它以递归的方式将源对象的所有值复制到目标对象。源对象引用的对象也会被复制。
# 24 range 和 xrange 函数有什么不同?
在功能上,range()和 xrange()函数是相似的,因为它们都生成一个整数序列。但是,range()函数返回一个列表,xrange()函数输出一个 xrange 对象。
换句话说,xrange()函数不生成静态列表,而是动态生成值。因此,xrange()函数通常与对象类型生成器一起使用。这种同时使用生成器和 xrange()函数的技术被称为“屈服”。
在有限内存上运行的应用程序中,让步技术是非常宝贵的。运行 range()函数会占用太多内存,导致“内存错误”
需要注意的是,xrange()在 Python 3 的所有版本中都被否决了。在 Python 3 中,range()与 xrange()具有相同的功能。另一方面,在 Python 2.x. 中,开发人员仍然更喜欢使用 xrange()而不是 range()
#25 定义酸洗和拆线
标准的 Python 库内置了序列化。序列化的过程包括将对象转换为可存储的格式。这样做是为了以后反序列化该对象以获得原始对象。
系列化的过程也称为腌制。在这个过程中,任何对象都可以序列化为字节流,并作为文件转储到内存中。这是使用 pickle.dump()函数完成的。
这个过程很快,但是 Python 在这个过程中在压缩上做出了妥协。换句话说,pickle 对象可以进一步压缩。
pickle 模块最大的优点是它跟踪序列化的对象,并且 pickle 对象可以跨 Python 版本移植。
unpick 是 pick 的逆操作,它反序列化字节流,重新模拟一个对象并将其加载到内存中。这是使用 pickle.load()函数执行的。
# 26 Python 中的生成器是什么?
生成器是一个函数,它一个接一个地返回一个可迭代的项目集合。这些函数通常用于创建迭代器,但是生成器使用 yield 关键字返回生成器对象,而不是使用 return 关键字。
#27 什么是 PYTHONPATH?
这是一个环境变量,程序员必须设置它来添加额外的目录。Python 将在这些目录中寻找包和模块。PYTHONPATH 环境变量特别有用,因为它使程序员能够在全局默认位置之外维护 Python 库。
#28 什么是 help()和 dir()函数?
运行 help()函数显示模块、类、方法、关键字等的文档。如果程序员不向函数传递任何参数,控制台上会出现一个交互式帮助实用程序。
dir()函数返回一个有效方法和属性的列表,这些方法和属性与它所调用的对象相关联。该函数对不同的对象表现不同,因为它试图生成最相关的数据,而不是完整的信息。
当用于库对象或模块时,该函数返回模块中的所有属性。当用于类对象时,它返回所有基本和有效属性的列表。最后,如果没有传递参数,函数将返回当前范围内的属性。
你好。py 文件不同于。pyc 文件?
。py 和。pyc 文件以完全不同的格式存储程序。而。py 文件有一个程序的源代码。pyc 文件存储程序的字节码。编译. py 文件时会生成字节码。。pyc 文件只为您导入的文件生成。这些不是为您运行的所有文件生成的。
在执行任何程序之前,Python 解释器会检查编译后的文件是否可用。如果存在. pyc 文件,则执行该文件。但是如果它不存在,Python 会寻找一个. py 文件并执行它。
简单来说,. pyc 文件会节省一个程序员的编译时间。
#30 解释解释过程
Python 既不解释也不编译,因为解释和编译都是实现的两个方面。由于这个原因,Python 被认为是一种字节码解释的语言。
Python 程序存储为。py 文件,程序被编译以产生被称为“字节码”的指令供虚拟机处理。这个字节码存储为。pyc 文件。
Python 解释器是虚拟机的实现。通常,字节码由 CPython(官方解释器)或 JIT 编译器解释。
#31 什么是按值传递和按引用传递?
按值传递和按引用传递是传递参数的两种不同方法。
按值传递方法包括传递对象的副本。这意味着如果复制的对象被更改,原始项目将保持不受影响。
另一方面,通过引用传递涉及到作为参数传递对对象的引用。如果修改了新对象,原始对象也会改变。Python 通过引用传递参数。
#32 定义迭代器
迭代器是一个将自身状态(在迭代中所处的位置)存储在自身中的对象。对象由 iter()方法初始化,而 next()方法返回序列中的下一项。当 next()函数到达迭代器的末尾时,它抛出 StopIteration 异常。
# 33 Python 中文件是如何删除的?
OS . remove()函数提供了删除 Python 文件的最简单方法:
import os
os.remove("XYZFile.csv")
print("File Deleted")
函数的作用是:根据分隔符将一个字符串分割成一个字符串列表。join()函数与 split()函数相反,它根据分隔符连接字符串列表并返回单个字符串。# 34 split()和 join()函数是什么?
*args 和**kwargs 有什么不同?
“* args”是在函数定义期间使用的特殊语法,用于传递变长参数。星号表示语法中的可变长度,并且习惯上使用“args”。
“* * kwargs”也是一种特殊的语法;但是,它与*args 不同。它用于在函数定义期间传递可变长度的关键字参数。带关键字的参数是在传递给函数时有名称的变量。
这个语法实际上是一个变量名和它们各自值的字典。通常使用“kwargs”位,但程序员可以使用任何其他名称。
#36 负指标有什么用?
从列表、元组或字符串末尾开始的索引称为负索引。这些用于从列表、字符串或元组的末尾获取元素。“Arr[-1]”表示数组中的最后一个元素,“Arr[-2]”是倒数第二个元素,依此类推。
Python 面向对象编程面试问题
创建一个类并解释它是如何工作的
关键字“ 类 ”在 Python 中创建了一个类,然后可以用它来创建对象、访问名称属性以及创建和使用方法。
|
class Pet:
def __init__(self, name, age):
self.name = name
self.age = age
p1 = Pet("Snowy", 3)
print(p1.name)
print(p1.age)
|
# 38 Python 中什么是继承?
继承使一个类能够访问另一个类的所有方法和属性,并且是使 Python 代码易于重用的特性之一。
继承消除了开发人员在应用程序中重复复制和使用大量代码的需要,使得编程更加复杂和有目的。
从另一个类继承的类被称为派生类或子类。另一方面,子类从其继承属性和方法的类被称为父类或超类。
在 Python 中,继承有许多不同的种类:
- 在单一继承中,一个父类提供对一个子类的成员访问。
- 多级: 在这种继承中,父类 X 的成员由子类 Y 继承,然后,派生类 Z 从类 Y 继承成员,换句话说,X 是 Z 的祖父,Y 作为中间类。
- 在这种类型的继承中,一个子类继承多个超类的成员。父类的所有成员都由派生类继承。
- 当一个父类向几个子类提供对其成员的访问时,这就是所谓的层次继承。
如何使用访问说明符?
在 Python 中,诸如 public、private 和 protected 这样的访问说明符不是直接实现的。变量的访问限制是通过在变量名前加单下划线或双下划线来定义的。如果变量名前没有下划线,Python 默认将它们识别为公共变量。
#40 程序员不创建实例可以调用父类吗?
如果基类是一个静态方法或者被另一个子类实例化,父类可以被调用而不需要创建实例。
#41 什么是空班?
没有任何已定义成员的类是空类。 pass 关键字用于定义这类,空类的对象可以在类之外创建。
新修改量和覆盖修改量有什么不同?
新 修饰符指示编译器使用新的实现来代替基类函数。 覆盖 在程序员想要覆盖子类内的基类函数时很有帮助。
什么是最终确定?
Finalize 是一个内置的方法,它在调用垃圾收集方法之前释放非托管资源并清理 Python。这是最有用的内存管理方法之一。
#44 如何检查给定的类是否是子类?
Python 在标准库中提供了一种方法来帮助程序员确定一个类是否是子类。issubclass()方法使得判断一个类是否是另一个子类的子类变得容易。
也可以使用 Python 内置的 isinstance()方法检查一个对象是否是一个类的实例。
Python 熊猫面试问题
熊猫是什么?
这是一个开源的 Python 库,使得高性能的数据操作更容易实现。这个库的名字来自“面板数据”,它有多维数据。Wes McKinney 在 2008 年首次发布了 Pandas,它因其在数据分析方面的应用而受到欢迎。
程序员可以使用 Pandas 库完成数据分析的所有五个步骤。
熊猫的数据框架是什么?
数据帧是可变的 2D 表格结构。这些用于用行和列表示数据。您可以使用以下语法使用 pandas 库创建一个数据帧:
import pandas as pd
dataframe = pd.DataFrame(data, index, columns, dtype)
数据表现为序列、列表、地图、字典等形式。在这里,
- index 是可选参数,代表行标签的索引
- columns 也是可选参数,但它代表列标签
- dtype 是可选的,表示每一列的数据类型
如何组合熊猫数据帧?
有三种简单的方法来组合数据帧:
- Append():Append()方法将数据帧水平堆叠
- Concat(): 该方法垂直堆叠数据帧。当数据帧具有相同的列和相似的字段时,效果最好。
- Join(): 它从具有一个或多个公共列的不同数据帧中提取数据。
如何确定数据帧中的值是否丢失?
isnull()和 isna()方法有助于识别数据帧是否缺少任何值。缺失的值可以用 0 或列的平均值替换。
什么是重新索引?
将一个数据帧装入一个新索引的过程,可选地使用一些填充逻辑,被称为重新索引。如果前一个索引中缺少某个值,则在该位置放置“NaN”或“n a”。
如果新索引等同于旧索引,则不返回任何对象。但是,如果新索引不同于原始索引,则返回一个新对象。
copy 值为 false,通常用于更改数据帧中行和列的索引。
如何从数据帧中删除行、列和索引?
del df . index . name 语句按名称删除索引。另一方面,drop()方法对于删除行或列很有用。
程序员将轴参数传递给 drop 方法。如果值为 0,该方法将删除该行。但是如果值为 1,该方法将删除该列。
将 inplace 值设置为 True 可以就地删除行或列,无需重新分配即可完成任务。使用 drop_duplicates()方法可以很容易地从数据帧中删除重复项。
当从各种来源导入数据时,熊猫图书馆能识别日期吗?
图书馆可以识别日期,但不能自动识别。首先,程序员在从数据源读取数据时必须添加 parse_dates 参数。如果我们从一个 CSV 文件中读取数据,它可能有不同的日期时间格式,这是 Pandas 库无法处理的。
在这种情况下,该库为程序员提供了创建自定义解析器的灵活性。使用 lambda 函数可以很容易地构建解析器。
Numpy 面试问题
什么是 NumPy?
NumPy 是最流行的基于 Python 的包之一,它被认为非常有用,因为它用于处理数组。该库易于使用,是开源的,具有优化的工具,使其能够以卓越的速度执行 N 维数组处理。
该库被明确地设计为处理复杂的数组,并执行统计、代数和三角计算。因此,该库最常用于执行科学计算和广播功能。
除了帮助执行上述所有计算,使用 NumPy,程序员还可以执行:
- 堆叠
- 搜索、分类和计数
- 矩阵运算
- 复制和查看数组
- 按位运算
# 53 NumPy 数组比列表好吗?
Python 列表是高效的数据结构,使程序员能够执行一系列不同的功能。然而,在计算矢量化运算时,列表也有一些限制。这些操作包括执行元素式加法和乘法。
除非拥有每个元素的数据类型信息,否则 Python 列表不起作用。这种对信息的需求导致了开销,因为每次对列表中的任何元素执行操作时,都会运行类型调度代码。
NumPy 数组处理 Python 列表的这些限制,使它们非常适合在计算矢量化运算时使用。NumPy 数组几乎比 Python 列表快 30 倍,因为它们的同质性允许它们被密集地打包到计算机的内存中。
由于这个原因,使用 NumPy 数组时释放内存也比使用 lists 时释放内存更快。
如何高效地从文本文件中加载数据?
numpy.loadtxt()方法可以自动读取文件的页眉和页脚。如果文件中有注释,它也会读取注释。
loadtxt()方法以高效著称。当它进展缓慢时,程序员通常会将文件的格式更改为 CSV 文件,以帮助 Python 更有效地加载数据。
根据 NumPy 版本的不同,该方法有多种替代方案。
该方法支持以下文件格式:
- 这些文件很大,但却是可移植的,可读的。通常,从这些数据库加载数据很慢。
- 原始二进制: 没有元数据的不可移植文件,但数据加载速度很快。
- Pickle: 这些文件是可移植的,但是比 CSV 和二进制文件慢。性能取决于 NumPy 版本。
- HDF5: 代表“高性能厨房水槽”这种文件格式支持 PyTables 和 H5PY 格式。
- 。npy: 是 NumPy 的原生二进制格式。它的简单、高效和可移植性得到了认可。
#55 如何使用 NumPy 将 CSV 数据加载到数组中?
genfromtxt()方法使得将 CSV 数据加载到数组中变得容易。但是,分隔符必须设置为逗号。
from numpy import genfromtxt
csv_data = genfromtxt(‘example_file.csv', delimiter=',')
#56 如何用一行反转一个 NumPy 数组?
使用切片语法可以很容易地反转 NumPy 数组,并将结果存储在另一个数组中。
reversed_array = arr[::-1]
Python 库面试问题
Python 中的包和模块有什么不同?
在 Python 中,一个模块是一个单独的文件,它可以将其他模块(文件)作为对象导入。相比之下,包是包含各种子包和模块的文件夹或目录。
程序员通过用。py 扩展名。这些文件包含可以跨模块重用的类和方法。
#58 最有用的 Python 模块有哪些?
模块是保存有 Python 代码的文件。py 扩展,这些可以包含变量、函数和类。最有用的内置模块包括:
- 数学
- 随机
- datetime
- 缝好了
- os
- JSON
#59 如何生成随机数?
随机 模块来自标准 Python 库,允许程序员生成随机数。首先,导入模块,然后调用 random()方法。方法生成一个介于 0 和 1 之间的随机浮点值。
import random
print(random.random())
该模块也可用于生成指定范围内的随机数。将某个范围的开始、结束和步长放入 randrang()方法将在该范围内生成一个随机数。
import random
print(random.randrange(5,100,2))
#60 酸洗和拆洗有什么区别?
pickle 进程将 Python 对象转换成二进制,unpickling 进程将二进制形式的数据转换成对象。
酸洗对象有助于存储磁盘和外部存储位置。另一方面,取消拾取的对象将数据作为可以在 Python 中使用的对象进行检索。
pickle模块方便了 Python 中的 pickle 和 unpicking。pickle.dump()方法将 Python 对象转储到内存中,并使用 pickle.load()方法对数据进行解拾取。
什么是 GIL?
全局解释器锁是一种互斥锁(一种锁定机制),有助于限制对 Python 对象的访问。GIL 还有助于确保正确的线程同步并避免死锁。
GIL 是 Python 中支持多任务处理的主要组件。我们可以通过一个例子来理解它是如何做到这一点的。让我们假设一个系统中有三个线程。
线程一次获取一个 GIL。当 I/O 操作完成时,GIL 由第一个线程释放,并由另一个线程获取。这个循环一直持续到所有线程都完成执行。
在进程中的任何时刻都没有 GIL 的线程继续处于等待状态。只有获得了 GIL,才能执行死刑。
什么是 PIP?
Python 安装程序包是一个命令行工具,用于安装 Python 模块。其无缝界面使得安装各种模块变得简单。
该工具在互联网上搜索你想要安装的包,找到后,将它安装到 Python 的工作目录中。这个过程不需要用户交互。
哪些工具可以帮助识别 bug 并执行静态分析?
有许多工具可以用来发现 Python 代码中的错误,PyChecker 是许多程序员的首选。当 PyChecker 发现错误时,它会发出问题警报,并指出错误的复杂性。
Pylint 是一个流行的林挺工具,用于检查模块是否符合编码标准。该工具支持几个插件,这些插件使定制功能能够满足开发人员的需求。
#64 主要功能是什么?
“main”函数被认为是程序中跨编程语言执行的起点。然而,在 Python 中,解释器逐行解释文件,并不显式提供 main()函数。
也就是说,在 Python 中可以很容易地模拟 main()函数的执行。想法是使用 name 属性定义一个 main()函数。name 变量内置于 Python 中,指向当前模块的名称。
#65 什么是烧瓶?
Flask 是一个 Python 微框架,它使用 Jinja2 和 Werkzeug 作为依赖项。Flask 提供了一些其他框架没有的优势:
- 它没有使用太多对外部库的依赖
- 外部依赖性的缺乏使得微框架异常轻便。这也导致需要发布的安全补丁更少。
- 内置开发服务器和高性能调试器
当开发者退出 Python 时,并不是所有的内存都被释放。为什么?
Python 有一个有效的清理机制,当用户退出 Python 时,它会自动运行。这种机制试图释放或销毁所有对象。
但是一些 Python 模块有对对象的循环引用。有时,从全局命名空间引用的对象也不会被释放,因为释放或销毁这些由 C 库保留的部分是不可能的。
# 67 Flask 比 Django 好吗?
【Flask 和 Django 都将浏览器中键入的 URL 映射到函数;然而,这两个框架之间有一些关键的区别。
烧瓶更容易使用,但不需要用户做太多的跑腿工作。因此,Flask 用户必须手动指定 Flask 的详细信息。
另一方面,Django 有用户可以分析和使用的预写代码。这消除了程序员使用框架时需要做的大量工作。
虽然 Flask 和 Django 都同样有用,但是开发者的选择取决于他们对自己喜欢做的工作的偏好。
烧瓶、金字塔和姜戈有什么不同?
Flask 是一个适用于小型应用的现成的微框架。它使用外部库。
金字塔是为大型应用程序设计的高度可配置的工具。它为用户提供了使用工具的选择,还提供了选择数据库、模板风格等的灵活性。
Django 是为大型应用程序构建的,它带有一个 ORM,使得从关系数据库和应用程序模型传输数据成为可能。
#69 什么是狗堆效应?
缓存过期,网站同时收到客户端多个请求的事件。使用信号量锁可以避免该事件。
结论
浏览这篇文章中的问题不足以通过面试。你必须练习回答这些问题,并且每天提高你的编程技能。如果你保持专注,破解任何 Python 面试都不会太有挑战性。****
了解 Python SQLAlchemy 的会话
原文:https://www.pythoncentral.io/understanding-python-sqlalchemy-session/
什么是 SQLAlchemy 会话?会话是做什么的?
SQLAlchemy 的核心概念之一是Session。一个Session建立并维护你的程序和数据库之间的所有对话。它代表所有已加载到其中的 Python 模型对象的中间区域。它是启动对数据库查询的入口点之一,查询结果被填充并映射到Session中的唯一对象。唯一对象是Session中唯一具有特定主键的对象。
一只Session的典型寿命如下:
- 构建了一个
Session,此时它不与任何模型对象相关联。 Session接收查询请求,其结果被持久化/与Session相关联。- 构建任意数量的模型对象,然后添加到
Session,之后Session开始维护和管理这些对象。 - 一旦对
Session中的对象进行了所有的修改,我们可以决定将Session中的修改commit到数据库中,或者将Session中的修改rollback。Session.commit()表示到目前为止对Session中的对象所做的更改将被保存到数据库中,而Session.rollback()表示这些更改将被丢弃。 Session.close()将关闭Session及其对应的连接,这意味着我们已经完成了对Session的操作,并希望释放与之关联的连接对象。
通过示例了解 SQLAlchemy 会话
让我们用一个简单的例子来说明如何使用Session将对象插入数据库。
from sqlalchemy import Column, String, Integer, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
类 User(Base):
_ _ tablename _ _ = ' User '
id = Column(Integer,primary _ key = True)
name = Column(String)
从 sqlalchemy 导入 create _ engine
engine = create _ engine(' SQLite:///')
从 sqlalchemy.orm 导入会话标记
#构造一个 sessionmaker 对象
session = sessionmaker()
#将 sessionmaker 绑定到引擎
session . configure(Bind = engine)
#在数据库中创建所有由 base 的子类定义的
#表,例如用户
Base . metadata . Create _ all(engine)
创建和保持会话对象
一旦我们有了一个session,我们就可以创建对象并将它们添加到session中。
# Make a new Session object
s = session()
john = User(name='John')
#将用户 john 添加到会话对象
s.add(john)
#将新用户 John 提交到数据库
s.commit()
让我们插入另一个用户 Mary,并在插入过程的每一步检查新对象的id。
>>> mary = User(name='Mary')
>>> print(mary.id, mary.name)
(None, 'Mary')
>>> s.add(mary)
>>> print(mary.id, mary.name)
(None, 'Mary')
>>> s.commit()
>>> print(mary.id, mary.name)
(1, u'Mary')
注意在调用s.commit()之前mary.id是None。为什么?因为对象mary在构造并添加到s时还没有提交到数据库,所以它没有底层 SQLite 数据库分配的主键。一旦新对象mary被s提交,它就会被底层 SQLite 数据库赋予一个id值。
查询对象
一旦数据库中有了 John 和 Mary,我们就可以使用Session查询他们。
>>> mary = s.query(User).filter(User.name == 'Mary').one()
>>> john = s.query(User).filter(User.name == 'John').one()
>>> mary.id
2
>>> john.id
1
如您所见,被查询的对象具有来自数据库的有效的id值。
更新对象
我们可以像更改普通 Python 对象的属性一样更改Mary的名称,只要我们记得在最后调用session.commit()即可。
>>> mary.name = 'Mariana'
>>> s.commit()
>>> mary.name
u'Mariana'
>>> s.query(User).filter(User.name == 'Mariana').one()
>>>
>>> mary.name = 'Mary'
>>> s.commit()
>>> s.query(User).filter(User.name == 'Mariana').one()
Traceback (most recent call last):
......
sqlalchemy.orm.exc.NoResultFound: No row was found for one()
>>> s.query(User).filter(User.name == 'Mary').one()
删除对象
现在我们有两个`User`对象保存在数据库中,`Mary`和`John`。我们将通过调用会话对象的`delete()`来删除它们。
s.delete(mary)
mary.id
2
s.commit()
mary
Mary . id
2
T5>玛丽。_ sa _ instance _ state . persistent
False # Mary 不再持久存在于数据库中,因为她已经被会话删除
由于`Mary`已被会话标记为删除,并且该删除已被会话提交到数据库中,我们将无法再在数据库中找到`Mary`。
mary = s.query(User).filter(User.name == 'Mary').one()
Traceback (most recent call last):
......
raise orm_exc.NoResultFound("No row was found for one()")
sqlalchemy.orm.exc.NoResultFound: No row was found for one()
会话对象状态
因为我们已经看到了一个`Session`对象的运行,所以了解会话对象的四种不同状态也很重要:
* *Transient* :不包含在会话中的实例,还没有被持久化到数据库中。
* *Pending* :一个已经添加到会话中但还没有持久化到数据库中的实例。它将在下一个`session.commit()`保存到数据库中。
* *Persistent* :持久化到数据库中的实例,也包含在会话中。您可以通过将模型对象提交到数据库或从数据库中查询它来使其持久化。
* *Detached* :一个实例已经被持久化到数据库中,但是没有包含在任何会话中。
让我们用`sqlalchemy.inspect`来看看一个新的`User`对象`david`的状态。
from sqlalchemy import inspect
david = User(name='David')
ins = inspect(david)
print('Transient: {0}; Pending: {1}; Persistent: {2}; Detached: {3}'.format(ins.transient, ins.pending, ins.persistent, ins.detached))
Transient: True; Pending: False; Persistent: False; Detached: False
s.add(david)
print('Transient: {0}; Pending: {1}; Persistent: {2}; Detached: {3}'.format(ins.transient, ins.pending, ins.persistent, ins.detached))
Transient: False; Pending: True; Persistent: False; Detached: False
s.commit()
print('Transient: {0}; Pending: {1}; Persistent: {2}; Detached: {3}'.format(ins.transient, ins.pending, ins.persistent, ins.detached))
Transient: False; Pending: False; Persistent: True; Detached: False
s.close()
print('Transient: {0}; Pending: {1}; Persistent: {2}; Detached: {3}'.format(ins.transient, ins.pending, ins.persistent, ins.detached))
Transient: False; Pending: False; Persistent: False; Detached: True
注意在插入过程的每个步骤中,`david`的状态从*瞬时*到*分离*的变化。熟悉对象的这些状态是很重要的,因为轻微的误解可能会导致程序中难以发现的错误。
作用域会话与普通会话
到目前为止,我们从`sessionmaker()`调用构建的用于与数据库通信的会话对象是一个普通的会话。如果您第二次调用`sessionmaker()`,您将获得一个新的会话对象,其状态独立于前一个会话。例如,假设我们有两个按以下方式构造的会话对象:
from sqlalchemy import Column, String, Integer, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
类 User(Base):
_ _ tablename _ _ = ' User '
id = Column(Integer,primary _ key = True)
name = Column(String)
从 sqlalchemy 导入 create _ engine
engine = create _ engine(' SQLite:///')
从 sqlalchemy.orm 导入 session maker
session = session maker()
session . configure(bind = engine)
base . metadata . create _ all(engine)
构造第一个会话对象
s1 = session()
构造第二个会话对象
s2 = session()
然后,我们将无法同时向`s1`和`s2`添加同一个`User`对象。换句话说,一个对象最多只能附加一个唯一的`session`对象。
jessica = User(name='Jessica')
s1.add(jessica)
s2.add(jessica)
Traceback (most recent call last):
......
sqlalchemy.exc.InvalidRequestError: Object '' is already attached to session '2' (this is '3')
然而,如果会话对象是从一个`scoped_session`对象中检索的,那么我们就没有这样的问题,因为`scoped_session`对象为同一个会话对象维护了一个注册表。
session_factory = sessionmaker(bind=engine)
session = scoped_session(session_factory)
s1 = session()
s2 = session()
jessica = User(name='Jessica')
s1.add(jessica)
s2.add(jessica)
s1 is s2
True
s1.commit()
s2.query(User).filter(User.name == 'Jessica').one()
请注意,s1和s2是同一个会话对象,因为它们都是从一个维护同一个会话对象的引用的scoped_session对象中检索的。
总结和提示
在本文中,我们回顾了如何使用SQLAlchemy的Session以及模型对象的四种不同状态。由于工作单元是 SQLAlchemy 中的一个核心概念,所以完全理解并熟悉如何使用Session和模型对象的四种不同状态是至关重要的。在下一篇文章中,我们将向您展示如何利用Session来管理复杂的模型对象并避免常见的错误。
如何使用 Python 将华氏温度转换为摄氏温度
原文:https://www.pythoncentral.io/use-python-convert-fahrenheit-celsius/
没有多少简单的技巧可以让你在头脑中轻松地将华氏温度转换为摄氏温度(反之亦然)。除非你对数字很在行,否则这些公式不是你可以用心算算出来的。如果你不擅长数字,有计算器可以帮你。或者,如果您愿意,可以使用 Python 来求解公式。这些公式包括加法、减法、乘法和除法——其中一些我们在之前的教程中已经介绍过了,所以如果你需要复习,一定要去看看。
让我们从华氏温度转换成摄氏温度的公式开始。为了做到这一点,我们需要从华氏温度值中减去 32,然后将这个数字除以 1.8。下面看看它在 Python 中的样子。
fahrenheit = 82
celsius = (fahrenheit - 32) / 1.8
所以上例的输出是 27.8。所以 82 华氏度相当于 27.8 摄氏度。相当整洁。
但是如果你想把摄氏温度转换成华氏温度呢?这样做的方法与上面例子中的公式非常相似。要将摄氏温度转换成华氏温度,你需要做与上面例子相反的事情。摄氏度需要乘以 1.8,然后在这个数字上加 32。下面的例子展示了它在 Python 中的表现。
celsius = 10
fahrenheit = (celsius * 1.8) + 32
这个可能更容易在你的脑海中实现。上面例子的输出是华氏 50 度。
这些公式可用于将任何数值从华氏温度转换为摄氏温度或从摄氏温度转换为华氏温度。作为 Python 方程,它们可能会派上用场,或者在为您的项目编写函数时,您会发现它们很有用。自己尝试一下,看看它能帮助你更好地在头脑中进行转换!
如何使用 Python 进行字符串相乘
原文:https://www.pythoncentral.io/use-python-multiply-strings/
我们已经学习了如何在 Python 中使用乘法,但是你知道 Python 可以用来乘除了数字以外的东西吗?事实上,你可以用 Python 来乘字符串,仔细想想,这其实挺酷的。你可以拿一个字符串,用一点点 Python 就可以把它翻倍,三倍,甚至四倍。
我们可以用几种不同的方法来对字符串进行乘法运算,这取决于你希望如何对相乘后的字符串进行格式化。看看下面的代码片段,看看它是如何工作的:
简单地将一个字符串相乘,这是最直接的方法:
2*'string'
上面代码的输出将是:
stringstring
这显然是可行的,但是如果你不想让相乘后的字符串读起来像一个巨大的字符串,这就不够完美了。如果你想让你的字符串被分开,而不仅仅是作为一个长单词来读,你必须改变代码,把你的字符串变成一个元组,就像这样:
4*('string',)
上面代码的输出将是:
('string', 'string', 'string', 'string')
更清晰。
您还可以使用 Python 将单词、字符串或元组集合相乘。查看下面的代码片段,看看它是如何做到的:
3*('good', 'morning')
上面代码的输出如下所示:
('good', 'morning', 'good', 'morning', 'good', 'morning)
正如您可能已经开始看到的,使用 Python 对字符串进行乘法运算一点也不复杂。很酷的一点是,你可以用你用来乘数字的相同概念(我们方便的*符号)来乘单词和其他类型的对象。遗憾的是,同样的概念对除法的作用并不像对乘法一样,但是你可以对加法做一些类似的事情——但那是另一个教程了!
如何使用队列:初学者指南
先决条件
要了解队列数据结构,您首先应该很好地理解以下内容:
- Python 3
- 基本数据结构概念如列表(点击 此处 刷新列表概念)
- OOP 概念
简介
本教程将帮助你理解队列数据结构以及如何实现它。这些概念经常在面试中被检验,并且有广泛的应用。与其他语言相比,队列的 Python 实现相对简单。在这里,您将学习如何以 Pythonic 的方式和语言不可知论者的方式来做这件事。
队列是一个简单的数据结构概念,可以很容易地应用到我们的日常生活中,比如你在星巴克排队买咖啡。基于这个例子我们来做几个观察:
- 人们从一端进入队伍,从另一端离开
- 先到的人先离开,最后到的人最后离开
- 一旦所有人都得到服务,就没有人在排队等候离开了

现在,让我们以编程的方式来看以上几点:
- 队列从两端开放,意味着从后面添加元素,从前面移除元素
- 先添加的元素先被删除(先进先出)
- 如果所有的元素都被删除,那么队列是空的,如果你试图从一个空的队列中删除元素,会抛出一个警告或错误消息。
- 如果队列已满,并且您向队列中添加了更多元素,则必须抛出警告或错误消息。
需要记住的事情:
- 队列中的入口点和出口点是不同的。
- 入队——将元素添加到队列中
- 出列——从队列中删除一个元素
- 不允许随机访问——不能从中间添加或删除元素。
实施
我们将看到三种不同的实现方式。一种是使用列表,另一种是使用库 【德奎】 ,最后一种是使用数组 。让我们一个一个来看看...
-
Queue Implementation Usage List
这里我们将定义一个类队列并添加方法来执行下面的操作:
- 将元素放入队列的开头,如果队列已满,则发出警告
- 从队列末尾将元素出队,如果为空则发出警告
- 评估队列的大小
- 打印队列的所有元素
class Queue:
#Constructor creates a list
def __init__(self):
self.queue = list()
#Adding elements to queue
def enqueue(self,data):
#Checking to avoid duplicate entry (not mandatory)
if data not in self.queue:
self.queue.insert(0,data)
return True
return False
#Removing the last element from the queue
def dequeue(self):
if len(self.queue)>0:
return self.queue.pop()
return ("Queue Empty!")
#Getting the size of the queue
def size(self):
return len(self.queue)
#printing the elements of the queue
def printQueue(self):
return self.queue
myQueue = Queue()
print(myQueue.enqueue(5)) #prints True
print(myQueue.enqueue(6)) #prints True
print(myQueue.enqueue(9)) #prints True
print(myQueue.enqueue(5)) #prints False
print(myQueue.enqueue(3)) #prints True
print(myQueue.size()) #prints 4
print(myQueue.dequeue()) #prints 5
print(myQueue.dequeue()) #prints 6
print(myQueue.dequeue()) #prints 9
print(myQueue.dequeue()) #prints 3
print(myQueue.size()) #prints 0
print(myQueue.dequeue()) #prints Queue Empty!
在任何需要的地方调用 printQueue()方法,以确保它在工作。
注意:你会注意到我们并没有从开头移除元素,而是在结尾添加元素。其原因将在下面的“使用阵列实现”一节中介绍。
-
Use deque's queue to realize
Deque 是一个库,它在导入时提供现成的命令,例如用于入队的 append() 命令和用于出队的 popleft() 命令。
#Importing the library
from collections import deque
#Creating a Queue
queue = deque([1,5,8,9])
#Enqueuing elements to the Queue
queue.append(7) #[1,5,8,9,7]
queue.append(0) #[1,5,8,9,7,0]
#Dequeuing elements from the Queue
queue.popleft() #[5,8,9,7,0]
queue.popleft() #[8,7,9,0]
#Printing the elements of the Queue
print(queue)
在队列清空后,尝试使用 popleft() 命令,看看会得到什么。张贴你可以处理这个问题的方法。
注意: 实现 2 效率更高,因为链表中的插入操作开销很大!这是因为每当在位置 0 插入一个元素时,所有其他元素都必须移动一个位置(这类似于坐在长凳上的人向下推以容纳另一个人)。我们将在后面的教程中详细讨论操作的效率。
-
Use the array queue to realize
Python 列表使得实现队列变得如此容易。然而,如果你想不可思议地实现队列语言,你必须记住以下几点:
- 元素从队列的末尾添加,从队列的开头移除。
- 像对待数组一样对待列表(大小固定)——我们可以通过虚拟地限制列表的大小来实现。这是通过确保列表不会超出固定的限制或大小来实现的。
- 使用尾指针来记录添加到队列中的元素——尾指针总是指向下一个可用空间。例如,当队列中有三个元素时,Tail 将指向第四个位置。当队列已满时,尾指针将大于声明的大小。
- 使用 Head 指针来标记从队列中移除的元素——Head 指针将指向下一个要出列的元素。例如,如果队列中有三个元素,头指针将指向第一个元素。在一个出列操作之后,头指针将指向队列中的第二个元素。实际上,没有元素会从队列中删除。这是因为一旦删除了一个元素,列表会自动将所有其他元素向左移动一个位置。这意味着位置 0 将总是包含一个元素,这不是实际队列的工作方式。
- 使用一个重置方法——这个方法被调用来重置队列、尾部和头部。例如,如果队列中有三个元素,那么 Head = 0,Tail = 4。现在,如果我们让所有三个元素出队,队列将是空的,这意味着 Head = Tail = 4。所以如果你将一个元素加入队列,它会发生在位置 4,这是不正确的。因此,有必要将这些指针重置为 0。请注意,由于我们实际上并没有删除元素,所以列表仍然包含“已删除”的元素,因此也需要创建一个新的列表。
算法
- 声明一个列表和一个整数 MaxSize,表示队列的虚拟最大大小
- 头部和尾部初始设置为 0
- 尺寸方法
- 计算队列中元素的数量-> Size = Tail - Head
- 重置方法:
- 将尾部和头部重置为 0
- 创建新队列(将队列初始化为新列表)
- 入队操作:
- 检查大小是否小于 MaxSize:
- 如果是,将数据添加到队列中,然后将 Tail 增加 1
- 如果否,打印队列满消息
- 检查大小是否小于 MaxSize:
- 出列操作:
- 检查大小是否大于 0:
- 如果是,从列表中弹出第一个元素,并将 Head 增加 1
- 如果没有:
- 呼叫重置方法
- 打印队列空消息
- 检查大小是否大于 0:
程序
class Queue:
#Constructor
def __init__(self):
self.queue = list()
self.maxSize = 8
self.head = 0
self.tail = 0
#Adding elements
def enqueue(self,data):
#Checking if the queue is full
if self.size() >= self.maxSize:
return ("Queue Full")
self.queue.append(data)
self.tail += 1
return True
#Deleting elements
def dequeue(self):
#Checking if the queue is empty
if self.size() <= 0:
self.resetQueue()
return ("Queue Empty")
data = self.queue[self.head]
self.head+=1
return data
#Calculate size
def size(self):
return self.tail - self.head
#Reset queue
def resetQueue(self):
self.tail = 0
self.head = 0
self.queue = list()
q = Queue()
print(q.enqueue(1))#prints True
print(q.enqueue(2))#prints True
print(q.enqueue(3))#prints True
print(q.enqueue(4))#prints True
print(q.enqueue(5))#prints True
print(q.enqueue(6))#prints True
print(q.enqueue(7))#prints True
print(q.enqueue(8))#prints True
print(q.enqueue(9))#prints Queue Full!
print(q.size())#prints 8
print(q.dequeue())#prints 8
print(q.dequeue())#prints 7
print(q.dequeue())#prints 6
print(q.dequeue())#prints 5
print(q.dequeue())#prints 4
print(q.dequeue())#prints 3
print(q.dequeue())#prints 2
print(q.dequeue())#prints 1
print(q.dequeue())#prints Queue Empty
#Queue is reset here
print(q.enqueue(1))#prints True
print(q.enqueue(2))#prints True
print(q.enqueue(3))#prints True
print(q.enqueue(4))#prints True
注意: 元素 9 没有被添加到队列中,因此队列的大小保持为 8
除了上面描述的方法,你还可以添加一些方法来返回队列开始的元素,检查队列是否为空等等。
结论
本教程到此结束。一定要学会队列的应用。另外,请继续关注 PythonCentral,了解更多关于其他类型队列的信息,比如循环队列和优先级队列。快乐的蟒蛇!
在 Python 中使用 Break 和 Continue 语句
原文:https://www.pythoncentral.io/using-break-and-continue-statements-in-python/
在 Python 中,break 语句用于退出(或“中断”)使用“for”或“while”的条件循环。循环结束后,代码将从紧跟 break 语句的那一行开始。这里有一个例子:
even_nums = (2, 4, 6)
num_sum = 0
count = 0
for x in even_nums:
num_sum = num_sum + x
count = count + 1
if count == 4
break
在上面的示例中,当 count 变量等于 4 时,代码将中断。
continue 语句用于跳过循环的某些部分。与 break 不同,它不会导致循环结束或退出,而是允许忽略循环的某些迭代,如下所示:
for y in range(7)
if (y==5):
continue
print(y)
在这个例子中,除了数字 5 的之外,循环的所有迭代(数字 0-7)都将被打印,因为通过使用 continue 语句,循环被指示在 y 等于 5 时跳过 y。
自己练习一下,看看如何使用 break 和 continue 语句。理解这两个语句的区别和用途将使您能够编写更加简洁高效的代码。
在 Python 中使用指数
到目前为止,您可能已经知道如何用 Python 对和进行乘除运算。Python 中的乘法相当简单,也很容易做到。但是使用指数呢?例如,你如何计算一个数的二次幂?如果你不确定,你可能会发现答案很简单。要计算一个数的另一个数的幂,需要使用“**”运算符。两个数相乘只使用一个符号,一个数的另一个数的幂的运算符使用两个:。
让我们看一个例子。要找到 4 的平方(4 的 2 次方是另一种说法),您的代码应该是这样的:
4**2
很简单,对吧?
要打印上面等式的结果,别忘了使用 print 命令。:
print(4**2)
代码的输出将是:
16
下面的片段将会给你一个我们如何在真实环境中使用指数的例子。在代码片段中,我们使用匿名函数(lambda)对数字 0-5 进行二次幂运算,并打印结果。
squares = 5
result = list(map(lambda x: 2 ** x, range(terms)))
for i in range(squares):
print("2 raised to the power of",i,"is",result[i])
所以上面代码片段的输出应该是:
2 raised to the power of 0 is 1
2 raised to the power of 1 is 2
2 raised to the power of 2 is 4
2 raised to the power of 3 is 8
2 raised to the power of 4 is 16
2 raised to the power of 5 is 32
要自己使用该代码片段并获得不同的结果,请更改 squares 变量的值(这将根据您选择的数字的大小给出更多或更少的结果),或将 2 值更改为另一个数字。如果您正在寻找一种方法来理解如何在 Python 中正确处理指数,这段代码片段是探索这种技能的一个很好的选择。
在 Python 中使用模来检查闰年
原文:https://www.pythoncentral.io/using-modulo-check-leap-year-python/
我们已经在的上一课中讨论过模(%)运算符,但是作为一个快速复习,模是一个用于计算一个数除以另一个数的余数的运算符。因此,如果你有一个等式,比如 6 % 3,答案将是 0,因为 3 平均地进入 6,没有余数。理解模的关键在于,它不是用来计算两个数相除的答案,而是用来计算余数。所以在 10 % 3 的例子中,答案应该是 2,因为 3 除以 10 ^ 3,余数是 2。
使用模运算符的一个很酷的方法是计算一年是否是闰年。你可能知道,闰年每 4 年发生一次,而且总是在 4 的倍数的年份,例如,2000 年、2004 年、2008 年、2012 年和 2016 年是最近的闰年。尽管闰年总是偶数年,但并不是每个偶数年都是闰年,因为它每 4 年而不是每 2 年发生一次。出于这个原因,检查一个数字是偶数还是奇数的代码不能用于这个特定的目的。
要检查一个数字是否是闰年,我们必须看它是否能被 4 整除。为此,我们使用模来查看一个数除以 4 是否有余数 0。如果是的话,那一定是闰年。如果不是,那就不可能是一个。查看下面的代码,看看它是如何工作的:
year = 2020
if (year % 4) == 0:
print("{0} is a leap year")
else:
print("{0} is not a leap year")
这个简单的代码可以处理您输入的任何年份,以确定它是否是闰年。如果你用 2017 年、2018 年或 2019 年试试,你会发现这几年都不是闰年。然而,如果你像上面的例子一样尝试 2020 年,你会发现,事实上,这是一个闰年。所以上面代码的输出是:
2020 is a leap year
使用 Python 显示日历
原文:https://www.pythoncentral.io/using-python-display-calendars/
这里有一个关于 Python 的有趣的东西,你可能已经熟悉了,也可能还不熟悉:它有一个内置的日历函数,你可以用它来显示尽可能多的日历。当您导入该函数时,您可以使用它以标准日历格式显示任何一年中的一个月(顶部是一个月,后面是 7 列天)。因为是内置功能,所以设置起来其实相对容易简单。
与任何其他内置函数一样,要使用它,首先需要导入它,如下所示:
import calendar
到目前为止一切顺利。接下来,您需要分别使用变量 yy 和 mm 来设置您想要显示的年份和月份。因此,如果您想查看 2016 年 2 月,您需要将 yy 变量设置为 2016,将 mm 变量设置为 2,如下所示:
yy = 2016
mm = 2
记住:不要写出你试图访问的月份的名称。使用月份的数字表示作为变量值。因此,如果您试图访问十月份,您应该使用值 10。如果您想访问 April,应该是 4。对于年份,确保你写的是完整的一年,而不仅仅是最后两位数字,因为这是一种常见的写日期的方式。
我们快完成了。要显示日历,您必须使用以下语法打印它:
打印(日历.月(年,月))
这就是以标准日历形式显示您选择的月份所需的全部代码——这真的非常简单。查看以下内容,将所有代码作为一个片段。
import calendar
yy= 2016
mm = 2
print(calendar.month(yy, mm))
使用 Python 内置的日历功能,摆弄一下日期,看看您能想象出多少个月!
在您的第一个 Django 应用程序中使用 Python Django 的模型表单
原文:https://www.pythoncentral.io/using-python-django-modelform-first-django-application/
姜戈的模型
在我们之前的文章如何使用 Python Django 表单中,我们学习了如何创建 Django 表单对象,并在模板中使用它们来完成常见的任务,比如数据验证和 HTML 生成。在本文中,我们将学习如何使用 Django 的ModelForm直接从模型创建表单。与普通的 Django 表单对象相比,ModelForm对象将自己绑定到 Django Model上,从而免除了手工创建表单对象的责任。
为模型文章创建模型表单
在接下来的代码片段中,我们定义、创建并打印一个 PostForm 对象。
>>> from myblog import models as m
>>> from django.forms import ModelForm
>>> class PostForm(ModelForm):
... class Meta:
... model = m.Post
...
>>> post = m.Post.objects.all()[0]
>>> post
>>> form = PostForm(instance=post)
>>> form.as_p()
u'
Content:
New Post
\n
Datetime created:
2013-08-14 21:12:30
'
如您所见,ModelForm对象的as_p方法返回的输出与我们之前的表单对象的as_p方法完全相同。因此,我们可以简单地用一个ModelForm对象替换 post upload 视图中的表单对象。
# myblog/forms.py
...
from myblog import models as m
...
class PostModelForm(forms.ModelForm):
class Meta:
model = m.Post
# myblog/views.py
from myblog.forms import PostForm, PostModelForm
from myblog.forms import PostForm, PostModelForm
def post_form_upload(request):
if request.method == 'GET':
form = PostModelForm()
else:
# A POST request: Handle Form Upload
# Bind data from request.POST into a PostForm
form = PostModelForm(request.POST)
# If data is valid, proceeds to create a new post and redirect the user
if form.is_valid():
content = form.cleaned_data['content']
created_at = form.cleaned_data['created_at']
post = m.Post.objects.create(content=content, created_at=created_at)
return HttpResponseRedirect(reverse('post_detail', kwargs={'post_id': post.id}))
return render(request, 'post/post_form_upload.html', {
'form': form,
})
现在,您可以刷新页面 http://127 . 0 . 0 . 1:8000/post/form _ upload . html,查看新的ModelForm对象是否与之前的表单对象呈现相同。

我们的空表单页面。
自定义模型表单对象
我们可以定制字段列表,排除某些我们想对用户隐藏的数据库字段,而不是向用户公开模型的所有字段。例如,Comment.created_at可能是一个字段,其值应该默认为django.utils.timezone.now(),而不是由用户提供。
# myblog/forms.py
class CommentModelForm(forms.ModelForm):
class Meta:
model = m.Comment
exclude = ('created_at',)
# Python shell
>>> from myblog.forms import CommentModelForm
>>> form = CommentModelForm()
>>> form.as_p()
u'
Post:
---------
\n
Message:
\r\n
'
注意Comment.created_at没有列在form.as_p的输出中。
我们可以执行的另一种定制是改变默认的字段类型或者与某些模型字段相关联的小部件。例如,PostModelForm.content使用 HTML input元素呈现,这是任何CharField的默认 Django HTML 小部件。我们可以改为使用一个textarea元素。
# myblog/forms.py
class PostModelForm(forms.ModelForm):
class Meta:
model = m.Post
widgets = {
'content': forms.Textarea(attrs={'cols': 80, 'rows': 20})
}
现在您可以刷新页面http://127.0.0.1:8000/post/form_upload.html并注意到表单字段Content现在呈现为一个textarea元素,而不是一个input元素。

使用我们的文本区
总结和提示
在本文中,我们学习了如何使用和定制 Django 的ModelForm对象来公开 Django Model的有限接口,如Post或Comment。使用ModelForm比使用Form更有利,因为前者将Model对象紧密地集成到其核心功能中,减轻了程序员手工创建表单的一些责任。
使用 Python 检查列表中的数字
原文:https://www.pythoncentral.io/using-python-to-check-for-number-in-list/
今天的 Python 片段是通过“in”关键字带给你的。在 Python 中,我们可以将 In 关键字用于许多不同的目的。根据今天的片段,我们将使用它来检查一个特定的数字是否在列表中。
首先,假设我们有一个名为 coolNumbers 的列表。看看下面的列表:
coolNumbers = [3, 1, 88, 7, 20, 95, 26, 7, 9, 34]
现在,假设我们希望能够识别列表中是否有某些数字。例如,也许我们想知道 26 是否在列表中。下面是我们如何做的,使用 in 关键字(确保这些代码行在你已经声明了列表之后出现在你的 Python 文件中):
if 26 in coolNumbers:
(print: "26 is a cool number")
这就是使用 in 关键字检查一个数字是否在列表中所要做的全部工作。很直观。如果在列表中找到该数字,将打印短语“26 是一个很酷的数字”。但是如果您要找的号码不在您的列表中呢?假设您正在寻找数字 29,如果它不在列表中,您希望将它添加到列表中,因为众所周知,29 是一个非常酷的数字。您实际上可以使用“not in”关键字来检查列表中的某个号码是否是而不是。结合 if 语句,您可以检查问题中的数字是否不在您的列表中,如果是这样,您可以确保它被添加。你可以这样做:
if 29 not in coolNumbers:
coolList.append(29)
这就够了。这个过程不仅非常简单,而且像许多 Python 代码一样,非常直观。自己做一个很酷的数字列表(包括所有你认为很酷的数字),看看你是否能识别和添加你自己的整数。
使用 Python 检查奇数或偶数
原文:https://www.pythoncentral.io/using-python-to-check-for-odd-or-even-numbers/
使用 Python 进行计算和算术相当容易。Python 可以执行的一种很酷的算法是计算一个数除以另一个数的余数。为此,您需要使用模运算符(也称为百分号:%)。当您在两个数字之间放置一个模时,它会计算第一个数字除以第二个数字的余数。如果第二个数与第一个数相等,则没有余数,计算出的答案是 0。如果第二个数字与第一个数字不相等,那么将返回某种数字作为答案。
看看下面的等式,看看它是如何工作的:
6 % 3
10 % 3
在第一个例子中,3 均匀地进入 6(正好 2 次),所以等式的答案是 0。在第二个例子中,3 不等于 10。它三次进入 10,余数为 1。记住,你不是在试图寻找 10 除以 3 的答案——模是用来寻找这个等式的余数的。也就是 2。所以上面方程的答案分别是 0 和 2。
在上下文中使用模的一个很好的方法是用它来测试是奇数还是偶数。如果一个数能被 2 整除而没有余数,那么根据定义,这个数是偶数。如果这个数除以 2 得出一个余数,那么这个数一定是奇数。要用 Python 术语表达这个概念,请参见下面的代码片段:
if (num % 2 == 0): #number is even -- insert code to execute here
else: #number is odd -- insert code to execute here
上面的代码基本上说明了如果一个数除以 2 的余数等于零,这个数就是偶数。如果不是,数字是奇数。该代码片段可用于根据所讨论的数字是偶数还是奇数来执行许多不同的函数——在显示“在此插入代码”的地方插入您的函数,为代码片段添加一些功能。
使用 Python 找到三个数字中的最大值
原文:https://www.pythoncentral.io/using-python-to-find-the-largest-number-out-of-three/
这里有一个有用的片段,它将向您展示如何使用 Python 从任意三个给定的数字中找出最大的数字。基本上,该代码片段通过使用 if... 否则如果...else 语句将这三个数字相互比较,并确定哪个数字最大。查看下面的代码片段,了解它是如何工作的:
number1 = 33
number2 = 67
number3 = 51
if (number1 > number2) and (number1 > number3):
biggest = num1
elif (number2 > number1) and (number2 > number3):
biggest = number2
else:
biggest = number3
print("The biggest number between",number1,",",number2,"and",number3,"is",biggest)
在上面的例子中,我们知道 num2 (67)是最大的数字。所以第二个陈述(elif)是正确的,因为 num2 大于 num1 和 num3。因此,执行代码的结果将是下面的输出:“33、67 和 51 之间的最大数是 67。”这是可行的,因为 67 被设置为 elif 语句之后的“最大”变量。
这个代码应该与任何三个数字一起工作,以确定哪个是最大的。如果您希望您的用户能够自己输入数字,只需在代码中插入这三行代码来代替其他 num1、num2 和 num3 声明:
num1 = float(input("Enter first number: "))
num2 = float(input("Enter second number: "))
num3 = float(input("Enter third number: "))
摆弄代码,看看你是否能让它与任何不同数字的组合一起工作(你应该能!).
使用 Python 的 Pass 语句
原文:https://www.pythoncentral.io/using-pythons-pass-statement/
在 Python 中,pass 语句很像注释,被认为是空语句,这意味着它不会导致任何 Python 操作。注释和 pass 语句之间的唯一区别是,虽然注释被解释器完全忽略,但是 pass 语句不会(但是,像注释语句一样,不会因为 pass 而执行任何东西)。
使用 pass 的一个好方法是保留未准备好或尚未编写的代码。它经常代替循环或函数。要使用它,您只需要在通常插入任何其他代码的地方键入单词“pass”(如循环或函数)。要在上下文中查看它,请查看下面的示例:
count = 0
while (count < 4):
pass
如你所见,我们有一个 while look,它将在计数小于 4 时执行一些代码。假设这是您的代码,但是您还没有完成 while 循环的编写,并且想要转移到其他内容,稍后再回到它。这是使用 pass 语句的最佳时机。你的代码实际上不会做任何事情,但是至少你已经设置好了它,正确格式化了它,并且当你的代码完成时,它已经准备好了。
当然,您也可以在这里使用注释来提醒未来的自己您对函数的计划,但是如果您正在寻找一个更简单的解决方案,实现 pass 语句比写出整个注释更快更容易——它只需要四个字符和大约 0.4 秒的时间。只要确保不要忘记稍后返回并添加您想要的函数、循环或其他代码片段,否则您可能会在执行代码时遇到一些真正的问题。
使用 Python 的 Tabnanny 模块来清理代码
原文:https://www.pythoncentral.io/using-pythons-tabnanny-module-for-cleaner-code/
Tabnanny 是 Python 中的一个模块,用于检查源代码中的模糊缩进。这个模块很有用,因为在 Python 中,空白不应该是模糊的,如果你的源代码包含任何奇怪的制表符和空格的组合,tabnanny 会让你知道。
您可以通过两种方式之一运行 tabnanny,要么使用命令行,要么在您的程序中运行它。从命令行运行它将如下所示:
$ python -m tabnanny .
这将产生指定在哪个文件和哪个行中发现了错误的结果。如果您想查看正在扫描的所有文件的更多信息,请在编写命令时使用-v 选项:
$ python -m tabnanny -v .
要在程序中运行 tabnanny,您需要将它与函数一起使用。check(),它应该看起来像这样:
import sys
import tabnanny
tabnanny.check(file_or_dir)
只要你使用 tabnanny 来检查你所有的代码,你就不会有任何缩进错误的问题。因为这个过程通常非常快,而且几乎不需要任何编码来完成,所以这是一个显而易见的过程。
使用 Sparts 编写 Python 代码
原文:https://www.pythoncentral.io/using-sparts-to-write-python-code/
Sparts 是脸书开发的一个 Python 库,用于消除骨架代码。该库的主要目的是使实现服务变得容易,而不必编写多余的代码,因此您可以非常快速地创建原型。要学习 Sparts 的基础知识,请务必阅读文档。
Sparts 的工作方式是将任何服务分成两部分,核心“服务”和“任务”。任务通常指后台/离线处理,而服务包括任何共享功能。因此,要创建任何新的自定义逻辑,您只需子类化 VService (sparts.vtask.VService)并运行其 initFromCLI()即可。另一方面,任务(sparts.vtask.VTask)用于触发程序采取行动。没有它们,服务类将毫无用处。
总之,Sparts 核心的服务和任务结合在一起,使您的生活变得更加轻松,并且在将新服务实现到您的产品中或创建新原型时,需要编写更少的代码。在这里为你自己检查一下。
使用 Python 临时文件模块
原文:https://www.pythoncentral.io/using-the-python-tempfile-module/
在用 Python 编程时,可能会有这样的时候,您需要以文件的形式使用或操作一些数据,但是还没有写入文件。自然地,想到的第一个解决方案是打开一个新的或现有的文件,写入数据并最终保存它(如果您不熟悉如何做,可以看看文章在 Python 中读取和写入文件)。然而,也可能出现这样的情况,一旦脚本运行完毕,您就不再需要或想要这些文件了,因此,不希望它留在您或其他任何人的文件系统中。
这就是 tempfile 模块派上用场的地方,它提供了创建临时文件的函数,当脚本退出时,您不必去手动删除这些文件。让我们看几个简单的例子来说明使用临时文件的基本方法。
用 tempfile 创建一个临时文件就像用内置的 open()方法创建一个常规文件一样,只是不需要给临时文件命名。我们将打开一个,向其中写入一些数据,然后读回我们所写的内容。
# Importing only what we'll use
from tempfile import TemporaryFile
t = TemporaryFile()
data = 'A simple string of text.'
现在我们有了要写入的临时文件 t 和数据字符串——我们没有指定文件的模式,所以它默认为‘w+b ’,这意味着我们可以读取和写入任何类型的数据。在接下来的三行中,我们将把数据写入文件,然后读回我们写的内容。
[python]
t.write(bytes(data, 'UTF-8'))
Makes sure the marker is at the start of the file
t.seek(0)
print(t.read().decode())
A simple string of text.
[/python]
[python]
t.write(data)
Makes sure the marker is at the start of the file
t.seek(0)
print(t.read())
A simple string of text.
[/python]
就像其他文件对象一样,我们可以向临时文件对象写入数据,也可以从临时文件对象中读取数据。同样,区别和优点是,一旦临时文件对象被关闭,就没有它的踪迹了。这在使用 with 语句时尤其有利,该语句会在语句完成时自动执行关闭文件的简单清理工作:
[python]
with TemporaryFile() as tempf:
data = (data + '\n') * 3
Write the string thrice
tempf.write(bytes(data, 'UTF-8'))
tempf.seek(0)
print(tempf.read().decode())
[/python]
[python]
with TemporaryFile() as tempf:
Write the string thrice
tempf.write((data + '\n') * 3)
tempf.seek(0)
print(tempf.read())
[/python]
我们得到以下输出:
A simple string of text.
A simple string of text.
A simple string of text.
并检查文件句柄是否已关闭:
>>> # Test to see if the file has been closed
>>> print(tempf.closed)
True
这基本上是临时文件的要点。它和其他文件对象一样简单易用。
tempfile 模块还提供了 NamedTemporaryFile()方法,该方法提供了一个临时文件,该文件在文件系统中总是有一个明确且可见的名称(当然,直到它被关闭)。文件名可以通过它的 name 属性来访问(如果我们的文件 t 是一个 NamedTemporaryFile,我们将使用 t.name 来访问该信息)。此外,这种类型的临时文件提供了在关闭时实际保存文件而不是删除文件的选项。
如果你需要创建一个临时目录,这个模块也提供了 mkdtemp()方法来实现;然而,与 TemporaryFile 和 NamedTemporaryFile 对象不同,临时目录 不会在没有您手动删除它们的情况下被 删除——它们唯一的临时之处是,它们默认存储在由 tempfile.tempdir 的值定义的临时文件夹中。尽管如此, tempfile 提供的创建临时文件和目录的工具还是非常有用的,所以不要犹豫尝试一下。
使用 YAPF(另一种 Python 格式化程序)
原文:https://www.pythoncentral.io/using-yapf-yet-another-python-formatter/
另一个 Python 格式化程序 (YAPF)是编写 Python 的一个有价值的工具。YAPF 是一个开源的 Python 格式化程序,它使编写干净的 Python 代码变得容易得多,所以你可以花更多的时间编写代码,而不用担心代码看起来怎么样。使用这个格式化程序的一个很大的优点(除了漂亮的代码之外)是,它使得由任意数量的开发人员编写的 Python 代码集成到一个文件甚至一个大的目录或项目中变得非常容易。
正如你将在他们的 github 页面上看到的,YAPF 会拿走你丑陋的代码:

并将其重新格式化成组织良好的代码:

YAPF 不是一般的重新格式化程序,因为它会重新格式化你的整个文件,而不仅仅是把你的代码一行一行地格式化成一个好看的模板。它实际上重新组织和重构了您的 Python,不仅仅是为了让它看起来更好,而是为了帮助优化性能。如果你写了很多 Python,它确实是你可以使用的不可或缺的工具。
用 Decorators 验证 Python 函数参数和返回类型
原文:https://www.pythoncentral.io/validate-python-function-parameters-and-return-types-with-decorators/
概观
所以前几天我和 Python decorators 一起玩(和你一样)。我一直想知道是否可以让 Python 验证函数参数类型和/或返回类型,就像静态语言一样。有些人会说这很有用,而其他人会说由于 Python 的动态特性,这从来都不是必需的。我只是把它破解了一下,看看这是否可行,并认为看看你能用 Python 做什么是非常酷的。所以我将把政治排除在外:-)。欢迎在评论中发表你的想法。
本文假设您至少对装饰者及其工作方式有基本的了解。
下面的代码验证了顶级函数参数和返回类型的type。然而,它不会查看数据结构下的类型。例如,您可以指定第二个参数必须是一个元组。但是,您不能验证子值,例如:(<type 'int'>, <type 'str'>)。如果有人能成功,我倒要看看!
所以让我们开始吧!
验证程序异常
在我们开始用实际代码验证函数参数并返回type之前,我们将添加一些自定义异常。请注意,这不是必需的,我只是希望它能够抽象出一些消息,并创建更干净的代码。我们将创建以下例外:
ArgumentValidationError:当一个函数的参数的type不是它应该的时候。InvalidArgumentNumberError:提供给函数的参数个数不正确。InvalidReturnType:返回值错误时type。
每个异常都有一个定制的错误消息,所以消息的数据被传递给构造函数方法:__init__()。让我们看一下代码:
class ArgumentValidationError(ValueError):
'''
Raised when the type of an argument to a function is not what it should be.
'''
def __init__(self, arg_num, func_name, accepted_arg_type):
self.error = 'The {0} argument of {1}() is not a {2}'.format(arg_num,
func_name,
accepted_arg_type)
def __str__(self):
返回 self.error
class InvalidArgumentNumberError(value error):
' ' '
当提供给函数的参数数量不正确时引发。
注意,这个检查只从 validate_accept()装饰器中指定的参数数量
开始执行。如果 validate_accept()
调用不正确,那么这个
可能会报告一个错误的验证。
'''
def __init__(self,func_name):
self.error = '无效的{0}()'参数个数。格式(函数名)
def __str__(self):
返回 self.error
class invalid returntype(value error):
' ' '
顾名思义,返回值是错误的类型。
'''
def __init__(self,return_type,func_name):
self.error = '对于{1}()'无效的返回类型{0} '。格式(返回类型,
函数名)
def __str__(self):
返回 self.error
相当直接。注意,ArgumentValidationError异常需要参数arg_num,以指定第 n 个具有错误type的参数。这需要一个序数:如第一、第二、第三等。所以我们的下一步是创建一个简单的函数来将一个int转换成一个序数。
序数转换器
def ordinal(num):
'''
Returns the ordinal number of a given integer, as a string.
eg. 1 -> 1st, 2 -> 2nd, 3 -> 3rd, etc.
'''
if 10 <= num % 100 < 20:
return '{0}th'.format(num)
else:
ord = {1 : 'st', 2 : 'nd', 3 : 'rd'}.get(num % 10, 'th')
return '{0}{1}'.format(num, ord)
[/python]
We've called it ordinal() just to keep things simple, where it takes one int argument. But how does it work? For numbers 6 - 20, the number suffix (in order from 6 - 20) is always "th". However outside of that range:
- 如果最后一个数字以 1 结尾,则后缀为“st”。
- 如果最后一个数字以 2 结尾,则后缀为“nd”。
- 如果最后一个数字以 3 结尾,则后缀为“rd”。
- 否则(当最后一个数字> = 4 时),后缀将为“th”。
在本例中,我们使用了一个%字符,也就是modulus操作符。当除以一个数时,它提供给我们余数。在这种情况下,如果我们将一个数除以 10,就会得到最后一位数字。注意,我们也可以使用str(num)[-1]。然而,这是低效的,丑陋的。
现在,到实际的验证器了!
功能参数验证
我们将从向函数参数验证器(decorator)展示代码开始,并从那里开始。这两个验证函数非常相似,但是有一点不同。
def accepts(*accepted_arg_types):
'''
A decorator to validate the parameter types of a given function.
It is passed a tuple of types. eg. (, <type>)</type>
注意:它不做深度检查,例如检查类型的
元组。传递的参数只能是类型。
' ' '
def accept _ decorator(validate _ function):
#检查验证器
#函数的参数个数是否与提供给实际函数
#进行验证的参数个数相同。我们不需要
#来检查要验证的函数是否有正确的
#数量的参数,因为 Python 会自动完成这个
#(也有一个类型错误)。
@ func tools . wraps(validate _ function)
def decorator _ wrapper(* function _ args,**function_args_dict):
如果 len(accepted_arg_types)不是 len(accepted_arg_types):
抛出 InvalidArgumentNumberError(validate _ function。__name__)
#我们使用 enumerate 来获取索引,因此我们可以将类型不正确的
#参数传递给 ArgumentValidationError。
for arg_num,(actual_arg,accepted _ arg _ type)in enumerate(zip(function _ args,accepted _ arg _ types)):
if not type(actual _ arg)is accepted _ arg _ type:
ord _ num = ordinal(arg _ num+1)
raise ArgumentValidationError(ord _ num,
validate_function。__name__,
accepted_arg_type)
return validate _ function(* function _ args)
return decorator _ wrapper
return accept _ decorator
好吧!那到底是什么?注意,对于常规装饰器,有一个函数返回一个函数。通常,子函数会在调用函数包装之前和/或之前做一些事情。然而在我们的例子中,我们使用了元装饰器。这些将 decorator 模型向前推进了一步,它们本质上是一个带有子 decorator 的 decorator,子 decorator 接受被检查函数的函数参数。相当困惑!但是一旦你明白了,它们就很简单了。
我们使用的是zip()函数,它返回一个元组列表。它让我们同时遍历两个列表。在我们的例子中,允许的函数参数和实际的函数参数。然后zip()呼叫被enumerate()打包。enumerate()函数本身返回一个enumerate对象。每次调用enumerate.next()函数时(例如在我们的for语句中),它都会返回一个tuple。这是loop-index, (list-1-element, list-2-element)的形式。这样我们就可以得到参数的索引,如果需要的话可以传递给异常。然后使用isinstance()函数来比较所需参数和实际参数的类型。你也可以使用if type(accepted_arg) is type(actual_arg),但是我发现这种方式在语法上更简洁。
需要考虑的一点是:在我们的add_nums()函数被调用后,从技术上讲,装饰器返回的是值,而不是add_nums()。所以如果你看从add_nums()返回的对象,它实际上将是装饰者。因此,它将有一个不同的名称,你会失去你的文件字符串。这也许没什么大不了的,但是很容易解决。幸运的是functools.wraps()函数来帮忙了,它本身就是一个装饰器。要使用它,您必须导入functools模块,并在您的验证装饰器上添加装饰器。
返回类型验证
现在进入返回type验证。它在这里,在所有的荣耀中。
def returns(*accepted_return_type_tuple):
'''
Validates the return type. Since there's only ever one
return type, this makes life simpler. Along with the
accepts() decorator, this also only does a check for
the top argument. For example you couldn't check
(, <type>, <type>).
In that case you could only check if it was a tuple.
'''
def return_decorator(validate_function):
# No return type has been specified.
if len(accepted_return_type_tuple) == 0:
raise TypeError('You must specify a return type.')</type></type>
@ func tools . wrapps(validate _ function)
def decorator _ wrapper(* function _ args):
#指定了多个返回类型。
if len(accepted _ return _ type _ tuple)>1:
raise type error('您必须指定一个返回类型。')
#因为装饰器接收到一组参数
#并且只返回一个对象,所以我们只需要
#获取第一个参数。
accepted _ return _ type = accepted _ return _ type _ tuple[0]
#我们将执行函数,
#看看返回类型。
return _ value = validate _ function(* function _ args)
return _ value _ type = type(返回值)
如果 return_value_type 不被接受 _return_type:
抛出 invalid return type(return _ value _ type,
validate_function。__name__)
return 返回值
return 装饰器 _ 包装器
return 装饰器
可以看到,它类似于参数验证函数(validate_accept)。然而,由于它不需要迭代所有的值,我们只需要检查类型是否相同。
我们的功能是验证
我决定使用一个非常简单的示例函数。因为最终,不管它有多复杂,它还是会以同样的方式工作。没必要把事情弄得比应该的更复杂!已经实现了两个。一个带有名为add_nums_correct的正确return type,另一个返回名为add_nums_incorrect的str。这样我们就可以测试return验证器是否工作。
@accepts(int, int)
@returns(int)
def add_nums_correct(a, b):
'''
Adds two numbers. It accepts two
integers, and returns an integer.
'''
返回 a + b
@accepts(int,int)
@ returns(int)
def add _ nums _ incorrect(a,b):
'''
将两个数相加。它接受两个
整数,并返回一个整数。
' ' '
返回“Not an int!”
所以让我们检查一下,看看它是否有效。
>>> # All good.
>>> print(add_nums_correct(1, 2))
3
>>> # Incorrect argument type (first).
>>> add_nums_correct('foo', 5)
Traceback (most recent call last):
File "Validate Function Parameter and Return Types with Decorators.py", line 196, in
add_nums_correct('foo', 5)
File "Validate Function Parameter and Return Types with Decorators.py", line 120, in decorator_wrapper
accepted_arg_type)
__main__.ArgumentValidationError: The 1st argument of add_nums_correct() is not a <type>
>>>
>>> # Incorrect argument type (second).
>>> add_nums_correct(5, 'bar')
Traceback (most recent call last):
File "Validate Function Parameter and Return Types with Decorators.py", line 200, in <module>
add_nums_correct(5, 'bar')
File "Validate Function Parameter and Return Types with Decorators.py", line 120, in decorator_wrapper
accepted_arg_type)
__main__.ArgumentValidationError: The 2nd argument of add_nums_correct() is not a <type>
>>>
>>> # Incorrect argument number.
>>> add_nums_correct(1, 2, 3, 4)
想学 Python?以下是开始的方法
原文:https://www.pythoncentral.io/want-to-learn-python-heres-how-to-start/
Python 是一种功能强大的编程语言,如今被广泛应用于许多行业。如果你想学习 Python,你来对地方了!在这篇博文中,我们将讨论如何开始学习 Python,并为您提供一些有助于您学习这门语言的资源。我们开始吧!

Python 是什么?
Python 是由吉多·范·罗苏姆在 20 世纪 80 年代创造的一种编程语言。如今,它是一种被广泛使用的语言,它的许多特性使它成为对初学者有吸引力的选择。Python 易于读写,它有一个大型的标准库,可用于数据分析和机器学习等任务。Python 也是一种流行的 web 开发语言,可以用来创建服务器端应用程序。
如果你对学习 Python 感兴趣,网上有很多资源。你可以找到教程、书籍和视频来帮助你开始学习这门语言。你也可以加入一个 兼职编程训练营 来学习更多的编程语言和其他编程技能。对于那些想学习编码的人来说,Python 是一个很好的选择,它可以用于各种任务。所以花时间去学习更多的相关知识绝对是值得的。
为什么要学 Python?
Python 是一种通用语言,你可以在 web 应用程序的后端、前端或整个堆栈上使用。Python 对于 数据科学 和人工智能应用也很棒。此外,Python 相对于其他编程语言来说,相对容易学习。这就是为什么许多初学者在学习编码时会从 Python 开始。
如何入门 Python
首先,你需要下载并安装 Python。可以从 Python 官方网站(python.org)获取 Python 的最新版本。我们推荐使用 Python 的 Anaconda 发行版,它附带了许多对数据科学和机器学习有用的包。一旦安装了 Anaconda,就可以通过打开 Anaconda Navigator 并选择“Environments”选项卡来创建 Python 环境。从这里,您可以创建一个新的 Python 环境,并使用 conda 包管理器安装包。
帮助你学习 Python 的资源
我们建议查看官方的 Python 文档,其中包含了一个优秀的初学者教程。您还可以在网上找到许多学习 Python 的资源,包括书籍、视频和课程。我们最喜欢的资源之一是 Jake VanderPlas 的 Python 数据科学手册。这本书涵盖了数据科学和机器学习的广泛主题,如果你对这些领域感兴趣,这是学习 Python 的好方法。如果你想更深入地研究 Python,我们推荐你看看你最喜欢的 Python 包的源代码。这是了解有经验的 Python 程序员如何编写代码的一个很好的方式,它可以为您的项目提供一些思路。
原来如此!关于如何开始学习 Python 的一些提示。希望这有所帮助,给你一点方向。记住一次专注于一项任务,把事情分成可管理的小块。很快,你就会像专业人士一样编写 Python 代码了!
在 Python 2.x 中为您的图像添加水印
The module we use in this recipe to resize an image with Python is PIL. At the time of writing, it is only available for Python 2.x. Also, if you wish to do other things with images, checkout our article on how to resize an image with Python.
当您拍摄照片并将其发布到互联网上时,添加水印来防止和阻止未经授权的复制或图像盗窃通常是很方便的。
下面是一个简单的 Python 脚本,它使用PIL模块给你的图像添加水印。它使用系统字体给图像添加可见的文本水印。
from PIL import Image, ImageDraw, ImageFont, ImageEnhance
import os, sys
FONT = 'Arial.ttf'
我们从导入PIL模块开始,加载 Truetype 字体‘arial . TTF’。默认情况下,它会在同一个文件夹中搜索字体,然后查看你的字体目录(例如 C:/Windows/Fonts)
def add_watermark(in_file, text, out_file='watermark.jpg', angle=23, opacity=0.25):
我们定义了一个函数add_watermark并声明了一些默认参数。
in_file–输入文件名。text–水印文本。out_file–输出文件名(默认:watermark.jpg)。angle–水印的角度(默认:23 度)。opacity–不透明度(默认值:0.25)
img = Image.open(in_file).convert('RGB')
watermark = Image.new('RGBA', img.size, (0,0,0,0))
首先,我们打开输入文件并创建一个相似尺寸的水印图像。两个文件都需要处于RGB模式,因为我们正在使用阿尔法通道。
size = 2
n_font = ImageFont.truetype(FONT, size)
n_width, n_height = n_font.getsize(text)
从字体大小 2 开始,我们创建文本并获得文本的宽度和高度。
while (n_width+n_height < watermark.size[0]):
size += 2
n_font = ImageFont.truetype(FONT, size)
n_width, n_height = n_font.getsize(text)
通过增加字体大小,我们搜索不超过图像尺寸(宽度)的文本长度。
draw = ImageDraw.Draw(watermark, 'RGBA')
draw.text(((watermark.size[0] - n_width) / 2,
(watermark.size[1] - n_height) / 2),
text, font=n_font)
使用正确的字体大小,我们使用 header 部分中声明的系统字体将文本绘制到水印图像的中心。
watermark = watermark.rotate(angle, Image.BICUBIC)
然后我们使用Image.BICUBIC(算法)近似旋转图像(默认为 23 度)。
alpha = watermark.split()[3]
alpha = ImageEnhance.Brightness(alpha).enhance(opacity)
watermark.putalpha(alpha)
在 alpha 通道上,我们通过默认值 0.25 来降低水印的不透明度(例如:降低亮度和对比度)。(注意:值 1 返回原始图像)。
Image.composite(watermark, img, watermark).save(out_file, 'JPEG')
最后,我们将水印重新合并到原始图像中,并保存为一个新的 JPEG 文件。
整个代码如下:
from PIL import Image, ImageDraw, ImageFont, ImageEnhance
import os, sys
字体= 'Arial.ttf '
def add_watermark(in_file,text,out_file='watermark.jpg ',angle=23,opacity = 0.25):
img = image . open(in _ file)。convert(' RGB ')
watermark = image . new(' RGBA ',img.size,(0,0,0,0))
size = 2
n _ FONT = image FONT . truetype(FONT,size)
n_width,n _ height = n _ FONT . getsize(text)
while n _ width+n _ height<watermark . size[0]:
size+= 2
n _ FONT = image FONT . truetype(FONT,size)
n _ nDraw(水印,' RGBA ')
draw . text(((watermark . size[0]-n _ width)/2,
(watermark . size[1]-n _ height)/2),
text,font = n _ font)
watermark = watermark . rotate(角度,图像。双三次)
alpha = watermark . split()【3】
alpha = image enhance。亮度(alpha)。enhance(不透明度)
watermark . put alpha(alpha)
image . composite(水印,img,水印)。保存(输出文件,“JPEG”)
if _ _ name _ _ = ' _ _ main _ _ ':
if len(sys . argv)<3:
sys . exit('用法:% s<input-image><text><output-image>' \
'<angle><opacity>' % OS . path . basename(sys . argv[0])
add _ watermark(* sys . argv[1:])【T4
快速有效地学习 Python 的方法
原文:https://www.pythoncentral.io/ways-to-learn-python-fast-efficiently/

Python 是二十一世纪流行的编程语言。了解 Python 可以帮助你在计算机工程专业上取得进步。
然而,作为开始,我们经常在选择最佳教育旅程时遇到问题,我们通常会浪费大量时间试图找出哪种资源是最好的。当大多数开发人员开始发现新事物时,他们经常会在他们的计算机或 USB 驱动器上积累各种课程,这不是一个好习惯。
我们将讨论快速学习 Python 的各种方法。
-
First, understand the jargon.
在我们学习它之前,我们必须先掌握如何或在哪里使用这个句法。Python 在多种领域实现,包括网站开发、数据研究、机器学习、系统工程。因为很难一次了解所有的主题,所以我们必须专注于我们需要掌握的关键原则,并适当地继续下去。
-
covers the following basic knowledge of python.
最起码,你和你的导游必须掌握基本知识。如果你不理解它们,你将很难处理复杂的挑战、计划或使用实例。
-
Set a learning goal for yourself.
在开始学习 Python 之前,为自己制定一个学习目标。当你牢记自己的目标时,你开始学习时遇到的问题就会更容易克服。此外,你会意识到为了达到你的目标,应该集中精力或浏览哪些学习材料。例如,如果您希望学习 Python 进行数据处理,您需要执行任务、构建函数并理解有助于数据分析的 Python 模块。
- [ Anaconda accelerates the configuration of Python.
您可以从 Python Software Foundation 网页安装 Python 安装文件,然后获取和检索增加的库,或者您可以下载 Anaconda 软件包,其中也包括您需要的几个软件包,特别是如果您打算使用 Python 进行数据处理或预测分析。
-
Virtual learning Python with the help of Python teacher.
在线 Python 导师 可以辅助你学习基本的 Python 编程原理,以及更复杂的 Python 编程主题。导师可以提供广泛的学科和水平,让你选择一个完全适合你的需求。
大多数导师会与您建立免费视频通话,讨论您的要求,并了解您的独特要求。Python 实际上正在成为一门流行的在线辅导课程,非常适合在在线课堂上讲授。
学生现在可以在一个共享的代码编辑器中实时展示他们的进度,让教育工作者有机会同时提供帮助。此外,学习者可以更轻松地在屏幕上完成他们的编码挑战,因为他们可以考虑一切,而不必担心有人在背后监视。这使个人感觉更舒服,从而提高理解和记忆。
-
With your discovery, put it into practice.
Python 也不例外,学习某样东西最简单的方法就是将其付诸实践。如果你通过在线课程或教科书理解它,你应该接触它。
打开你的笔记本电脑,配置你的编码设置,然后开始编码。例如,如果你已经学习了条件循环,用它们来创建一个数字乐透。
为了获得更好的结果,你也可以用 if-else 表达式来调整它。如果你正在采用一个新的 Python 库,你可以把它变成一个小小的冒险,这将极大地增强你对这个想法的理解。
-
Consider picking up a Python library.
掌握一个或多个补充 Python 的 Python 库很有帮助。库是充当“催化剂”的专用功能集如果没有自定义代码,您就必须构建自定义代码来完成特定的工作。举例来说,Pandas 是一个著名的用于修改表中数据的库。Numpy 是一个 Python 库,帮助在数组上执行算术和科学运算。
-
Make a timetable for learning Python and stick to it.
大多数人跳过这一步,导致困难或停工。现在需要做的就是制定一个时间表。建立至少两周的时间来展开你的学习,并保证你有足够的机会来反思 Python 的基础, 在 IDE 中练习编码,并调试代码。
排除错误是学习 Python 或任何计算机程序的困难和乐趣的一部分。在最初的两周之后,你会惊讶于自己的进步。你将有足够的经验去学习你选择的供应商提供的更复杂的东西。
-
Associate with people who are eager to learn.
虽然编程看起来是一项孤独的工作,但在团队中完成时会更有效。在 Python 中创建项目时,将自己与同样在实践的其他人联系起来是至关重要的。你将能够提供你在旅途中学到的技巧和技术。
结论
虽然 Python 是一门简单易懂的语言,但即使对于业余爱好者 T2 来说,掌握这门语言的所有基本思想也需要一些时间。
利用上述方法,你可以快速理解 Python 的基本原理和特定领域的信息。
标准的 Python 手册也是一个极好的信息来源。关键的重点应该是把你学到的东西付诸实践;没有快速改善的方法。
你能用 python 做什么:使用指南
原文:https://www.pythoncentral.io/what-can-you-do-with-python-usage-guide/
先决条件
你应该知道 python 的基本语法。你应该在你的机器上安装 Python。在本文中,我们将了解更多关于
- 你能用 python 做什么?
- 如何学习 Python?
- 什么时候学 Python
- python 程序员挣多少钱
你能用 Python 做什么?
Python 是一种通用语言。您可以在任何类型的应用程序中使用它。您可以将它作为一种脚本语言来解决一些日常问题。
使用 Python 编写脚本
我们举个例子。如果你喜欢摄影,你可能有一个图像命名的问题。在漫长的一天拍摄后,你回到了你的工作室。您过滤了图像并将选定的图像放入一个目录中。该目录包含不同名称的不同图像。您需要通过用特定的格式命名所有图像来简化您的工作。假设图像名称将由地名和序列号组成。这使您可以轻松搜索图像。通过使用 Python,您可以创建一个简单的脚本,该脚本将遍历该文件夹中所有 JPEG 类型的文件,并对其进行重命名。
未排序的图像
让我们看一个例子:
import os
def main():
path = input("Enter folder path: ")
folder = os.chdir(path)
for count, filename in enumerate(os.listdir()):
dst ="NewYork" + str(count) + ".jpeg"
os.rename(src, dst)
if __name__ == '__main__':
main()
正如你所看到的,Python 是一个高效的自动化工具。这有助于将你的注意力集中到重要的事情上。
用 Python 还能做什么?你可以用 python 做一个 FTP 服务器。使用命令
python3 -m http.server 8000
您可以运行 python 服务器。您可以通过本地网络访问该服务器。您可以从不同的设备打开浏览器。键入您的network ip : 8000。您可以访问该文件夹中的所有文件。您可以使用它从同一网络中的不同设备传输文件。
Python 在日常生活中如此简单的用法会让它变得更简单。谈论引导我们走向
Python 在基于 web 的应用程序中的使用
Python 在 web 开发中非常流行,有 Flask 和 Django 这样的框架。如果你想建立自己的电子商务商店。你可以使用 Django 框架。安装后,您将有一个现成的项目结构来构建您的网站。让我们看看安装 Django 有多容易。
# checking django version
$ python -m django --version
# if you don't have django installed you can install it using pip
$ python -m pip install Django
注意:如果没有安装 pip,您应该按照我们的文章安装它。
安装 Django 后,现在你可以创建你的项目了。
$ django-admin startproject my-eCommerce-Website
您将拥有如下所示的项目结构
my-eCommerce-Website/
manage.py
my-eCommerce-Website/
__init__.py
settings.py
urls.py
asgi.py
wsgi.py
继续姜戈项目。您应该安装您的项目应用程序
$ python manage.py startapp store
在您的 Django 项目中,您将拥有所有的应用程序。每个应用程序都有不同的文件夹。
my-eCommerce-Website/
manage.py
my-eCommerce-Website/
__init__.py
settings.py
urls.py
asgi.py
wsgi.py
你可以在 Django 的官方文档中了解更多关于他们的信息。您会发现,开始使用 Python 进行 web 开发非常容易。
Python 在数据科学、游戏和移动开发等不同领域有不同的用途。我们在上一篇里详细讲过。
如何学习 Python?
学习 Python 是一个持续的过程。有些人喜欢课程,有些人喜欢实践经验。你从哪里学习真的不重要。您将需要应用您所学的知识来构建有用的 Python 应用程序。我们在上一篇文章中谈到了学习它的各种资源。在这里检查一下。如果你已经知道它的基本语法。你现在的重点应该是学习如何构建 python 的应用程序。
这取决于您想要构建的应用程序的类型。如果您正在寻找构建一个基于 web 的应用程序。推荐弗拉斯克和姜戈。
你在哪里可以学习烧瓶?
- 烧瓶文件有一个获取说明部分。学习 Flask 的基础知识很有帮助。
- Coursera 刚刚发布了学习 Flask 的新课程。它会引导你了解所有烧瓶的细节。
- 教程点有条不紊烧瓶教程。
在上述所有资源中,您将构建一个 Flask 应用程序。这将给你带来使用 Flask 的实践经验。
你什么时候能学会姜戈?
- Django 文档是学习 Django 的详细资源。用它的启动导轨。
- Django 是最流行的 Python 框架。Coursera 创建了一个全专精来学习它。
- 教程点创建了一个有组织的学习 Django 的资源。叫做姜戈教程。
同样,来源是什么并不重要。你需要自己试着写代码,构建一个项目。这会帮助你建立你的投资组合。
如果你正在寻找建立机器学习项目。Udacity 和 Coursera 是学习它的绝佳资源。
在哪里可以学习机器学习?
- Udacity 有一门关于机器学习的入门课程。它会引导你通过机器学习和人工智能。
- 斯坦福大学在 Coursera 上也有一个很棒的课程来学习机器学习。由吴恩达主持。他是机器学习和人工智能领域的顶尖人物之一。
- 如果你喜欢阅读。教程点有一个关于机器学习的教程。它会给你所需的知识来了解更多关于机器学习的知识。
什么时候学习 Python
学习 Python 作为基础不会花很多时间。可能需要两到四周的时间才能适应。学习 Python 之上的其他框架可能需要时间。这取决于领域和框架的难度。学习如何用 Flask 或 Django 构建应用程序可能需要 4 到 6 周的时间。对于机器学习来说,可能需要更长的时间。机器学习是一个更复杂的领域。需要更多的时间去学习。请注意,根据您的学习过程,时间可能会有所不同。请记住,像机器学习或数据科学这样的领域需要数学背景。这可能需要更长的学习时间。
Python 程序员挣多少钱?
Python 应用于不同的行业。这样用它找工作就容易了。就你的工资而言,很多因素会控制这一点。
- 你的经历
- 你的国家
- 公司业务规模
- 您正在构建的应用程序类型
这就是为什么你对它了解得越多越好。以获得与你的经验相符的期望薪资的准确数字。你应该检查一下玻璃门。这将帮助你了解你所在地区基于技能的平均人数。
结论
Python 有很多有用的用法。它基于您想要构建的应用程序的类型。学习 Python 是一个持续的过程。您对 python 了解得越多,您可以构建的应用程序就越多。会帮你更快找到工作,增加工资。
Python 从 C++中学到了什么:编程语言是如何被创造出来的?
原文:https://www.pythoncentral.io/what-did-python-learn-from-c-how-was-the-programming-language-created/

被高薪和无限的职业发展机会所吸引,许多人对开始他们的编程生涯感到兴奋。最艰难的选择来了:学什么编程语言。许多人从最常用的编程语言中进行选择,如 Python 语言 、Java、JavaScript 等等。在本文中,我们将重点关注 Python 的历史和这种语言的细节。
Python 语言需求量很大
如果你问“Python 是一门好的第一语言吗?”答案是肯定的。根据统计数据,因为流行增加了相关性,更多的公司可能会使用 Python。最终,这将增加对 Python 专业知识的需求。如果您对编码感兴趣,可以从 Python 开始。
如果你想知道一些开发者关于如何增强你的在线隐私的秘密,试着下载用于 PC 的 VPN,这将是最安全的选择。我们建议您查看不同提供商的服务,并选择一家可靠的提供商,如【VeePN】服务提供商,该提供商为您的不同类型的设备提供应用和扩展。现在是时候深入了解 Python 及其特性了。
即使你不是程序员,学习 Python 在很多情况下都会对你有好处。在蓬勃发展的科技行业,如大数据、机器学习和数据安全,Python 已经是王者。Python 在高校也有使用。所有这些领域都大量使用 Python。他们甚至使用自己的一套库,这些库作为代码扩展运行,可以添加这些代码来创建功能。
Python 简史
20 世纪 80 年代末,第一次概念化了 Python。它最初是作为 ABC 编程语言的模拟语言创建的,这种语言在荷兰也很流行。Python 的异常处理和对 Amoeba 操作系统的关注是它相对于 ABC 语言的两个主要优势。“Python”这个词不是指蛇。它以英国电视节目《巨蟒剧团》的名字命名。
Python 2.0 于 2000 年问世。在这个迭代中,它主要是一个开源项目。列表理解、完整的垃圾收集器和 Unicode 支持都是这个 Python 版本的特性。
Python 的关键特征
- 高层。Python 是为那些喜欢将自己写的代码转换成低级编程语言的程序员设计的,因为它是高级的。为了让 Python 具有可移植性——并且在各种类型的计算机上几乎不需要修改就能运行——它还需要在执行前进行处理。
- 面向对象。Python 使用强大的面向对象的方法来组织代码,这使得可以从对象和类的角度考虑问题。Python 也支持过程化方法。可以被其他开发人员重用的编码模式可以减少开发工作中的重复。
- 解读。Python 不需要在执行前编译程序。因此,您不需要使用编译器来将输入数据转换为已编译的类文件。而是执行 a.py 文件。Python 字节码的编译也是自动的,完全隐式的。
- 通用。Python 可以用于构建几乎任何应用程序,包括各种活动的几乎任何领域。Python 既可以用于短期任务,如测试过程,也可以用于长期任务,如长期产品开发和路线图规划。
正因为如此,除了软件开发人员之外,计算机语言在包括物理、数学、系统工程、数据处理和数学在内的各种学科的专家中也很有名。此外,Python 是一种对初学者来说用户友好的脚本语言。
Python 真的那么好学吗?
对于新手来说,最伟大的编程语言之一就是 Python。它的语法与英语相当,阅读和理解起来相当简单。即使您以前从未键入过一行代码,您也可以花一点时间和精力来学习如何编写 Python。
编程涉及大量数学是一个普遍的想法。Python 并不要求你是一个数学家专家才能使用它。有数学基础知识是有益的。通过将问题分成更小的部分来创造性地解决问题比编写 Python 更重要。
学习 Python 需要多少时间
学习 Python 的基础通常需要两到六个月的时间。然而,你可以很快获得足够的知识来创建你的第一个简短程序。学习如何使用 Python 的大量库可能需要几个月甚至几年的时间。
为了完成你的预定任务,你对 Python 的了解程度将决定你需要花多长时间来学习 Python。例如,如果你的目标是自动化工作中的某项任务,而不是为了成为一名数据分析师而学习 Python,你可能会更快地学习 Python。
学习 Python 的最终想法
学习 Python 是成为程序员最快也是最简单的方法之一。这种语言是最简单也是最需要的语言之一,因为它允许在各种行业中创建不同类型的应用程序。不要忘记在编码时使用 VPN 应用程序,因为它们对增强你的在线安全性非常有帮助。
什么是单点登录,它是如何工作的?
原文:https://www.pythoncentral.io/what-is-a-single-sign-on-and-how-does-it-work/

创造一个安全可靠的工作环境对现代企业来说非常重要。由于远程和混合工作模式将长期存在,公司需要比以前更加重视网络安全。尽管“网络安全”一词可能会让一些人联想到复杂性,但大多数解决方案都比想象的要简单。相反,这些网络安全解决方案大多旨在降低复杂性并为公司提供增强的安全性。除了这些好处之外,它们还有很多好处。
提到网络安全,首先想到的是密码。密码管理对企业至关重要。然而,这可能是一个困难的过程。跟踪员工、客户和同事使用的所有密码可能非常耗时。此外,如果密码被泄露,恶意行为者可能会访问组织存储的敏感和机密数据。因此,密码、身份和访问控制对于拥有远程员工的企业至关重要。
虽然密码管理似乎是一个困难的过程,但有一些替代方法,如单点登录,可以在提高效率的同时最大限度地降低复杂性。本文将讨论单点登录服务及其与身份管理的关系。
什么是单点登录?
单点登录 是一项技术和服务,它使个人能够通过单一的凭证组合来利用各种应用和服务。该识别系统将许多登录屏幕合并成一个统一的屏幕。用户只需输入一次验证数据即可使用所有网络功能。利用单点登录技术的用户在一台服务器上注册,然后立即登录到其他功能,而不管他们使用的是什么服务、软件或域。
这个识别系统在消费者访问该公司的软件和应用程序时为他们提供了一致的界面。个人只需提供一次验证数据就可以使用公司的全部网络功能,而不是为每个产品或软件记住几个密码组合。Sing Sign-On 将个人重定向到一个验证面板,当他们试图使用需要授权的功能时,可能需要提供登录凭据。如果用户以前执行过此步骤,系统不会要求他们提供任何进一步的身份验证凭据来利用网络功能、应用程序和他们希望的其他功能。
它是如何工作的?
单点登录以共享 id 的概念为中心,这是指在可信任的自动化技术之间交换个人特征。如果一个平台授权给一个人,他们会立即被允许加入其他与该平台有公认联系的项目。这是 CAS 和 OAuth 等协议支持的后续 SSO 服务的基础。
如果个人使用其单点登录应用程序加入系统功能,则会生成一个身份验证令牌并保存在他们的设备或单点登录软件中。个人访问的任何后续功能都将通过单点登录服务进行验证,然后单点登录服务将路由个人的令牌来验证他们的 id 并授予他们访问权限。由于它在某种程度上规范了个人 id,SSO 被认为是 身份管理最佳实践 的基本步骤之一。
单点登录协议类型
SSO 是更广泛的联合身份管理概念的一个组成部分。这一概念表明在两个或多个结构域或 IM 系统之间形成了公认的键。单点登录在这种方法的架构中很常见。有几种单点登录协议,包括:
1-安全访问标记语言— SAML
SAML 是一种既定的标准,它允许各方(尤其是 IdP 和 SAML SP)共享验证和登录信息。SAML 允许 SP 在不进行身份验证的情况下运行,而是将识别信息传递给内部和外部消费者。它允许跨系统(通常是应用程序或服务)与 SP 共享访问详细信息。SAML 允许在公共云和其他支持 SAML 的系统之间进行安全的跨域通信,以及在本地或另一个云中的各种替代身份管理解决方案。
2-开放授权— OAuth
OAuth 是一种开放访问授权标准,被互联网用户广泛用于向企业或网络提供对他们在其他网站上的数据的访问,而不会泄露他们的凭证。个人可以利用开放许可来允许应用程序在另一个服务中使用他们的信息,而不必明确验证他们的有效性。OAuth 规定了分离的服务器和服务如何在不暴露原始的、关联的、单一登录凭证的情况下,授权对它们的资产进行验证。在验证行话中,这被称为安全、第三方、用户代理、委托验证。
3- OpenID 连接— OIDC
建立在 OAuth 2.0 框架上的 OIDC 是一个自由开放的验证系统。该框架面向消费者,允许他们使用单点登录(SSO)来利用使用 OpenID 提供商(OPs)来确认其 ID 的第三方网站,如电子邮件提供商或社交网络。OpenID 是为联合验证开发的,这意味着它允许第三方使用现有帐户代表客户验证客户。
4-基于 Kerberos 的单点登录
Kerberos 是一种提供相互认证的协议,在这种协议中,个人和服务器在不安全的连接上验证对方的合法性。它通过利用令牌授予服务来控制验证和软件程序,如电子邮件客户端和服务器。消费者通过首先与密钥分发中心(KDC)验证来连接服务,之后他们从 KDC 接收他们希望使用的特定服务的安全服务票。
遗言
随着远程和混合工作安排的日益流行,安全连接到公司服务器变得越来越重要。虽然密码、验证和授权管理可能看起来是困难的过程,但是诸如单点登录之类的服务可以帮助企业降低复杂性,并使其员工的访问过程更加容易。
此外,由于个人只需要一个密码,单点登录使他们更容易开发、记忆和使用更强的密码。此外,通过集中密码输入,单点登录允许公司和企业成功地管理密码安全程序。
Python 中的元组是什么
学习 Python 中的内置函数和数据类型是在你被认为精通这门语言之前你需要取得的更重要的知识飞跃之一。
元组是 Python 中四种内置数据类型之一,理解它的工作原理应该不会太难。
下面是元组的分类,它们是如何工作的,以及它们与列表和字典有何不同。
Python 中的 Tuple 是什么?
如上所述,元组是 Python 内置的四种数据类型之一。另外三种数据类型分别是列表、 集合、 和字典。每种数据类型都有其特点,在使用时也有其独特的缺点。
Python 元组的特征有:
- 元组是有序的、索引的数据集合。与字符串索引类似,元组中的第一个值的索引为[0],第二个值的索引为[1],依此类推。
- 元组可以存储重复值。
- 一旦数据被分配给一个元组,其值就不能改变。
- 元组允许你在一个变量中存储多个数据项。您可以选择在一个元组中只存储一种数据,也可以根据需要混合存储。
如何创建和使用元组?
在 Python 中,元组是通过将数据的值或“元素”放在圆括号“()”内来分配的必须用逗号分隔这些项目。
Python 官方文档 声明,在圆括号内放置项目是可选的,程序员可以声明元组而不使用它们。然而,在声明元组时使用圆括号被认为是最佳实践,因为它使代码更容易理解。
一个元组可以有任意数量的值,并且这些值可以是任意类型。
下面是一些声明元组的例子:
tuple1 = (1, 3, 5, 7, 9);
tuple2 = "W", "X", "c", "d";
tuple3 = ('bread', 'cheese', 1999, 2019);
你也可以通过在括号之间不放值来创建一个空的元组,就像这样:
tuple1 = ();
创建一个只有一个值的元组在语法上有点棘手。当声明一个只有一个值的元组时,在结束括号之前必须包含一个输入值的逗号。
tuple1 = (1,);
这是为了让 Python 明白,你是在试图创建一个元组,而不是一个整数或字符串值。
访问元组项
在 Python 中,你可以通过各种方式访问元组。你要记住的重要一点是 Python 元组索引就像 Python 字符串索引——它们都是从 0 开始索引的。
因此,就像字符串索引一样,元组可以被连接、切片等等。Python 中访问元组的三种主要方式是索引、负索引和切片。
方法#1:步进
访问元组时,索引操作符就派上了用场。要访问元组中的特定元组,可以使用“[]”运算符。请记住,索引是从 0 而不是 1 开始的。
换句话说,一个有五个值的元组将有从 0 到 4 的索引。如果试图访问元组现有范围之外的索引,将会引发“IndexError”
此外,在索引操作符中使用浮点类型或其他类型来访问元组中的数据会引发“类型错误”
这里有一个使用索引访问元组的例子:
tuple1 = (1, 3, 5, 7, 9);
print(tuple1[0])
*# Output: 1*
你也可以把元组放在元组里面。这被称为嵌套元组。要访问一个元组中另一个元组的值,必须链接索引操作符,就像这样:
tuple1 = ((1, 3), (5, 7));
print(tuple1[0][1])
print(tuple1[1][0])
*# Output:
# 3
# 5*
方法#2:负步进
有些语言不允许负索引,但 Python 不是其中之一。
换句话说,元组中的索引“-1”指的是列表中的最后一项,索引“-2”指的是倒数第二项,依此类推。
下面是如何在 Python 中使用负索引来访问元组元素:
tuple1 = (1, 3, 5, 7);
print(tuple1[-1])
print(tuple1[-2])
*# Output:
# 7
# 5*
方法#3:切片
通过切片访问元组值意味着使用切片操作符访问元素,切片操作符是冒号("😊。
切片是这样工作的:
tuple1 = ('p','y','t','h','o','n');
*# To print second to fourth elements*
print(tuple1[1:4])
*# Output: ('y','t','h')*
*# To print elements from the beginning to the second value*
print(tuple1[:-4])
*# Output: ('p','y')*
*# To print elements from the fourth element to the end*
print(tuple1[3:])
*# Output: ('h','o','n')*
*# To print all elements from the beginning of the tuple to the end* print(tuple1[:])
*# Output: ('p','y','t','h','o','n')*
切片是访问元组中值的有效方法。如下所示,可视化元组中的元素可以使您更容易理解范围并在代码中编写适当的逻辑。

改变元组
虽然 Python 列表是可变的,但元组不是。这是元组的主要特征之一——一旦元组元素被声明,它们就不能被更改。
这里有一个例子:
tuple1 = (1,2,3,4,5)
tuple1[0] = 7
*# Output: TypeError: 'tuple' object does not support item assignment*
然而,元组可以在其中存储可变元素,比如列表。如果存储的元素是可变的,您可以更改嵌套在元素中的值。下面举个例子来演示:
tuple1 = (1,2,3,[4,5])
tuple1[3][0] = 7
print(tuple1)
*# Output: (1,2,3,[7,5])*
虽然元素的值一旦分配就不能更改,但是元组可以完全重新分配。
tuple1 = (1,2,3,[4,5])
tuple1 = ('p','y','t','h','o','n');
print(tuple1)
*# Output: ('p','y','t','h','o','n')*
改变元组的唯一方式是通过连接。串联是组合两个或多个元组的过程。可以使用+和*运算符连接元组。
*# Concatenation using + operator*
tuple1 = (('p','y','t')+('h','o','n'));
print(tuple1)
*# Output: ('p','y','t','h','o','n')*
*# Concatenation using * operator*
tuple2 = (("Repeat",)* 3)
print(tuple2)
*# Output: ('Repeat', 'Repeat', 'Repeat')*
删除元组
Python 不允许程序员改变元组中的元素。这意味着您不能删除元组中的单个项。
然而,使用关键字“del”可以完全删除一个元组
tuple1 = ('p','y','t','h','o','n')
del tuple1[2]
*# Output: TypeError: 'tuple' object doesn't support item deletion*
del tuple1
print(tuple1)
*# Output: NameError: name 'my_tuple' is not defined*
可用于元组的方法
使用元组时,有两种方法可以提供额外的功能。这两种方法是计数法和指数法。
这里有一个例子,演示了如何使用这两种方法:
tuple1 = ('p','y','t','h','o','n')
print(tuple1.count('y'))
*# Output: 1
# Since there is only one 'y' in the tuple*
print(tuple1.index('y'))
*# Output: 1
# Since the index of 'y' is 1*
元组操作
元组的工作方式很像字符串,并响应您可以对它们执行的所有常规操作。但是,当对它们执行操作时,结果是元组而不是字符串。
除了连接和重复,程序员还可以对元组执行其他一些操作。
例如,你可以检查一个元组的长度:
tuple1 = ('p','y','t','h','o','n')
print(len(tuple1))
还可以比较元组的元素,提取元组中的最大值和最小值:
tuple1 = (1,2,3,4,5)
tuple2 = (5,6,7,8,9)
tuple1[4] == tuple2[0]
*# Output: True*
print(max(tuple1))
*# Output: 5*
print(min(tuple1))
*# Output: 1*
您也可以使用“成员测试”来检查一个条目是否存在于一个元组中下面是一个成员资格测试的例子:
tuple1 = (1,2,3,4,5)
1 in tuple1
*# Output: True*
'1' in tuple1
*# Output: False*
7 in tuple1
*# Output: False*
您可以使用 for 循环来遍历元组中的项。例如:
for name in ('Kathy', 'Jimmy'):
print('Hello', name)
Python 中列表和元组的相似性
元组和列表在一些不同的方面是相似的,我们已经在这一节讨论了如何相似。
存储
元组和列表相似的一个主要原因是你可以在两者的一个变量中存储多个条目。此外,元组和列表都可以为空。
这两者之间的主要区别是语法上的:你必须用圆括号来声明一个元组,用方括号来声明一个列表。
通过键入变量名并在末尾添加括号,可以创建一个空元组。或者,您可以使用 tuple()构造函数来创建元组。
重要的是要记住,如果你使用构造函数创建一个元组,你将需要使用双括号来正确地向 Python 表明你的意图。
此外,如果你用一个条目创建一个元组,你需要在条目后添加一个逗号。如果您忘记添加逗号,Python 不会将代码识别为元组。
列表也以类似的方式工作。您可以通过键入所需的列表名称并在其末尾添加方括号来创建列表。或者,您可以使用 list()构造函数来创建列表。
虽然你可能认为你需要在列表中添加一个项目后添加一个逗号,但事实并非如此。Python 会识别出它是一个列表,而不需要你添加一个尾随逗号。
通常,存储在列表和元组中的项目本质上是相似的,并且倾向于以某种方式彼此相关。
如果你正在创建一个包含字符串、整数或布尔值序列的列表或元组,你需要做的就是用逗号将它们分开。但这并不是说不能创建包含不同数据类型的列表和元组。
只需确保在添加字符串时使用撇号,在添加布尔值时将 T 和 F 的 True 和 False 大写。另外,请注意,您可以在列表和元组中添加重复项。
开箱
元组和列表的另一个相似之处是它们都支持解包。当您创建一个列表或元组时,Python 会将许多值“打包”到一个变量中。
解包的思想是 Python 使你能够给单个变量分配单个值。
然而,不管你是使用列表还是元组,你必须确保你创建的变量数量与列表或元组中的值数量相同。如果不这样做,Python 会抛出一个错误。
索引
列表和元组之间的最后一个相似之处是,它们都是项目的有序集合。换句话说,数据的存储顺序一旦设定就不可改变。
元组和列表中的值都可以通过引用数据的索引值来访问。在 Python 和大多数其他编程语言中,索引从零开始。因此,列表或元组中的第一个值的索引为 0,第二个值的索引为 1,依此类推。
列表和元组之间的差异
元组和列表具有相同的功能——它们使你能够在其中存储不同种类的数据。然而,两者之间有一些主要的区别。
从语法上来说,元组在圆括号内有值。但是,如果您想用 Python 表示一个列表,您必须将值放在方括号(“[]”)中。
另一个关键的区别是,虽然你可以在赋值后改变列表中的元素,但是元组中的值不能改变。
元组被分配给一个内存块,而列表使用两个内存块。因此,在元组上迭代比在列表上迭代更快。
如何在元组和列表之间选择
由于在元组上迭代更快,如果你正在构建一个需要更快迭代的解决方案,选择使用元组而不是列表是一个好主意。
此外,如果你正在解决的问题不需要改变元素,使用元组是理想的。但是,如果项目需要更改,您将需要使用列表。
你可以在我们关于 Python 列表 的 指南中学习使用 Python 中的列表。
辞书:第三种收藏类型
字典是另一种数据类型,也作为一个集合。然而,与列表和元组不同,字典是键值对的哈希表。
其他数据类型和字典的另一个关键区别是字典是无序的。此外,字典是可变的,这意味着您可以添加、更改或删除其中的元素。要声明 dictionary 对象,必须使用花括号(“{}”)。
要学习创建和使用字典对象,请查看我们的 如何用 Python 创建字典的帖子。
结论
元组是方便的数据类型,可以作为解决复杂问题的强大工具。现在,您已经阅读了本指南,了解了它们是什么以及它们是如何工作的。
为了巩固您对这个强大的内置 Python 函数的了解,您只需编写一些包含元组的代码。
什么是 Python 游戏编程?
原文:https://www.pythoncentral.io/what-is-python-game-programming/

介绍
Python 已经成为娱乐部门制作视频游戏的一个有竞争力的选择。这不仅仅是因为 Python 在其他技术领域的广泛使用,或者是因为它是开源的,可以免费下载。
Python 是一种用于视频游戏制作的编程语言,因为它是一种高度灵活和强大的工具。它使游戏创作中最常见的活动变得快速而简单。有几个资源像计算机编程课程可以帮助你学习如何成功地使用它,这可能会帮助你知道如何有效地使用它。
强烈建议使用 Python 创建游戏,原因有几个,包括以下几点。
为什么 Python 是游戏创作的最佳编程语言?
清晰语法
Python 的流行可能部分归因于该语言相对简单的语法。由于代码易于阅读和理解,这种编程语言是构建视频游戏的绝佳选择。当试图设计一个游戏时,代码不仅易于理解,而且易于编写,这是有益的,因为它减少了在这个过程中花费的时间和精力。
它有一个简单的语法,这有助于概念或逻辑的无缝执行,调试变得更容易访问,并且容易添加功能的能力使它成为开发游戏的一个好选择。
灵活的对象定向
灵活的对象定向是赋予一类或一类对象特征或特性的过程。此后,这些特征被传递给从它们生成的任何附加类别。因此,如果一个程序员想要创建一个动物类型的类,他们将首先建立某些标准特性,比如 eat()和 sleep()。那么,来自不同地方的任何其他特征可能具有相似的属性。
Python 的许多美妙之处之一是该语言在面向对象方面的高度适应性。因此,程序员可以构建新对象并编辑现有对象,而无需编写太多代码。因为游戏创作者经常需要创造新的东西,改变现有的东西,所以 Python 是游戏开发的绝佳选择。
代码可重用性
Python 重用大部分代码的能力是用这种编程语言构建游戏的另一个主要好处。
Python 是一种面向对象的编程语言,这意味着它可以获取一段准备好的代码,并在任何需要的地方使用它。这种灵活性让 Python 受益匪浅。这是一个巨大的好处,最终会导致游戏中代码行数的显著减少。如果代码行更少,那么在整个项目中重写相同原则所花费的时间就会更少,开发整个软件所花费的时间也会更少。
更重要的是,通过允许您使用 Python 广泛的代码库生态系统,它使您能够利用其他开发人员产生的代码。这些库可以用来访问其他开发者发布的代码。面向对象编程可以在各种编程语言中找到。
另一方面,Python 库的丰富性和广度意味着,对于您试图解决的任何问题,很有可能其他人已经创建了可以处理它的代码。这是因为 Python 是一种流行的编程语言。这是非常好的,不仅减少了游戏中的总工作量,也提高了处理各种问题的技能。
基于游戏的库和框架
Python 是最流行的游戏编程语言之一,因为它在用于游戏创作时通常支持 2D 和 3D 视觉效果。这使得 Python 成为最流行的游戏编程语言之一。它提供了对各种库和框架的访问,这使得游戏创作成为一个简单的过程。
Kivy、Pyglet、Pymunk、PySDL2、PyOpenGL、Pygame、PyODE 和许多其他库在视频游戏制作中经常使用。此外,有大量的教程可以帮助新手通过开始阶段。
动态打字
Python 的动态类型能力使它比其他编程语言更有竞争力。正因为如此,开发人员不需要提前定义变量,这样既节省了时间,又免去了麻烦。当涉及到游戏创作时,动态类型是有益的,因为它使开发和测试游戏更快。
Python 不需要类型声明,由于这种语言的灵活性,一想到某个想法就尝试一下是可行的。例如,如果你在半夜醒来,有了一个想法,你可以马上测试它。因为每个数据类型都是在运行时动态决定的。Python 程序员在使用变量之前从来不需要进行强制转换。
广泛的社区支持
当谈到创建视频游戏时,拥有一个鼓励和帮助的社区是你所能拥有的最基本的东西之一。关于围绕计算机语言建立的社区,Python 拥有最大和最活跃的用户群之一。如果你在寻找一个问题的解决方案时遇到了困难,那么很有可能社区中的其他人已经遇到并克服了同样的挑战。
由于 Python 社区的规模和范围,寻找和雇佣 Python 开发人员既简单又划算。此外,这些资源包括大量开源教程和其他教学材料。即使你不打算雇佣开发人员,你仍然可以立即开始你的项目。
能够整合人工智能
人工智能在游戏业务中的应用变得更加关键。如果你想改进你的游戏,你应该做什么?你可以利用深度学习和其他类型的机器学习的能力。Python 已经被证明是创造人工智能的一个有价值的工具。许多库,如 TensorFlow、Keras 和 Theano,都是由希望在游戏中包含基于人工智能的元素的程序员开发的。
此外,开发人员可以跨不同平台使用 Python。因此,你的游戏可以建立在一个单一的平台上,可以很容易地移植到其他平台上。此外,Python 是一种节省成本的编程语言,因为它是免费和开源的。
稳定可靠的性能
导入模块是 Python 中一个常见且重要的功能,它允许开发人员从其他来源获取数据,并在他们的项目中重用这些数据。这种方法使开发人员能够重用数据。因为只有必要的模块从不同的源导入并与原始文件集成,所以模块导入功能也节省了空间。这是因为一个单独的项目不需要拥有它工作所必需的所有数据。
Python 以其可靠高效的性能而闻名。因此,即使很多事情同时发生,你的游戏速度也不会受到影响。当设计基于动作的视频游戏时,拥有一个可以同时处理信息而不会滞后或冻结的系统是很有帮助的。一个值得注意的例子是任天堂著名的马里奥赛车 8 豪华版视频游戏系列。这款游戏在全球售出了 4500 多万份,这一事实证明了这种编程语言的能力。
易于故障排除
Python 使得游戏开发调试过程更加简单,这也是支持使用 python 的最有说服力的理由之一。搜索和纠正代码中出现的问题的行为被称为“调试”
Python 已经是最容易理解和编写的编程语言之一,所以它比其他语言更容易调试是有道理的。然而,这并不是它比其他语言更容易调试的唯一原因。
Python 是一种被称为解释语言的编程语言。这表明代码在运行前没有编译。相反,它会立即运行,而无需事先收集。它有优点也有缺点,但最重要的优点之一是,如果代码中有错误,代码的执行将会暂停。将显示一条错误消息。
专注于一个特定的问题,解决它,然后继续前进,这对于保持对调试过程的控制有很大的帮助。
易于扩展
除此之外,扩展 Python 也很简单。Python 可以在未来的任何时候为你的游戏添加新的特性或关卡。因为代码易于理解和编写,所以它有助于开发新的更新。它使开发人员能够专注于工作,而不是纠结于语言。
例如,如果一个项目包括来自游戏玩家和玩家的持续输入,它必须是可伸缩的。这是因为随着用户数量的增长,开发人员必须更加努力才能满足需求。
此外,当一大群人一起处理同一个项目时,使用 Python 有几个好处。它提供了一个标准化的设置,所有开发团队成员都可以通过阅读和创建相同的代码来轻松协作。
结论
使用 Pygame 的 Python 已经被用于构造几个知名的游戏,包括 Frets on Fire。Pygame 再次成为使用 Python 编程语言制作游戏的最广泛使用的库之一。业余程序员和游戏开发行业的专业人员都使用它来创建游戏。
类似地,编程语言 Python 被用来开发坦克的游戏世界。即时动作游戏,四名玩家对抗四名其他玩家的团队战斗,以及拥有超过 100 辆精彩模拟坦克的强大推进系统是游戏的一些亮点。
这些游戏清楚地展示了通过使用 Python 计算机编程可以带来的巨大体验。由于代码与 Windows、Mac OS X 和 Linux 兼容,专门从事 Python web 开发的企业可以为消费者提供通过 web 交付的引人入胜的游戏体验。
什么是 Python:安装指南
原文:https://www.pythoncentral.io/what-is-python-installation-guide/
先决条件
如果你是 Python 新手,请务必阅读我们的前一篇文章。它兼容所有不同的操作系统。这很容易设置,事实上,如果你使用的是 Linux 系统,你会预装 python。在这篇文章中,你会知道:
- 如何检查 python 版本?
- 如何下载 Python?
- Python 版本 2.x 和 3.x 的区别
- 如何建立一个现成的 python 环境。
如何检查 Python 版本?
一些操作系统预装了 Python,比如 macOS 或 T2 Ubuntu。其他操作系统如 Windows 没有开箱即用的安装。
为了检查 Python 是否安装在中,请在 macOS 或 Linux 中打开终端。编写以下命令:
python --version
输出:
Python 3.7.2
如果你用的是 windows。打开 CMD 并写下:
python -v
检查 Python 版本的另一种方法是编写python。它应该打开 Python 外壳或者引发一个错误。

如果你的操作系统没有安装 Python。
如何下载 Python?
Python 最好的特性之一是它的兼容性。它可以很容易地安装在任何操作系统。您可以通过命令行或 GUI 安装它。
在基于 Linux 的操作系统中安装 Python 非常容易。在这种情况下,我们将检查 Ubuntu 的安装。在其他 Linux 发行版中也差不多。
-
安装依赖项。
$ sudo apt-get install software-properties-common $ sudo add-apt-repository ppa:deadsnakes/ppa -
更新操作系统软件包管理器
sudo apt-get update -
安装最新版本
$ sudo apt-get install python3.8
请注意,python 的版本将取决于您的发行版。比如在 Fedora 25 上安装一个Python36的包来获得 Python 3.6。
如何在 windows 中安装它:
- 访问官网。
- 导航到下载>窗口。
- 选择您的版本。
- 打开。exe 文件。
- 单击立即安装。
- 继续下一步。
- 完成安装,然后单击关闭。
为 windows 设置 python
windows 安装的最后一步。
如何在 macOS 中安装 Python:
- 执行上述步骤
- 从下载部分选择 MacOS X
- 点击 macOS 安装程序。
- 打开下载的文件。
- 单击以继续使用推荐的设置。
- 完成后,你就可以安装了。
macOS 中的安装过程
Python2.x 和 3.x 有什么区别?
如果你试图开始学习 Python,你会发现有两个版本。2.x 和 3.x 有什么区别?
Python 就像任何其他有版本的语言一样。版本控制的目标是跟踪更新。每个版本都有自己的特色。为什么我们要对任何语言的更新进行版本控制?
目标是能够跟踪更新。在软件行业,更新语言会有副作用。该更新可能包含不推荐使用的功能或语法更改。自动更新会导致项目失败。版本控制帮助我们指定我们的项目将运行的版本。这导致了更少的错误,并增加了项目的生命周期。版本号由两部分组成。像这样(2.7 或者 3.8)。第一个数字指的是一个重大变化。可能导致不赞成某些功能或语法更改的更改。第二个数字是指一个小的更新或修复。每次更新都有一个变更日志。有了这个 changelog,开发人员可以跟踪变更以更新他们的项目。总是建议使用该语言的最新版本。
在 Python 中,有 2.x 和 3.x 两个版本,区别是主要的。将 2.x 项目更新为 3.x 将导致语法错误。2.x 和 3.x 有什么区别?你应该学哪一个?
整数除法:
用 2.x 除两个整数不会有浮点值。
# Python 2.x
print 5 / 2
output:
# 2
# Python 3.x
print(5 / 2)
output:
# 2.5
打印功能:
3.x 括号中的打印功能是强制性的。Python2.x 括号中的打印函数是可选的。
# Python 2.x
print "Hi weclome to python 2.x"
output:
# Hi weclome to python 2.x
# Python 3.x
print("Hi weclome to python 3.x")
output:
# Hi weclome to python 3.x
Unicode:
在 2.x 中,隐式字符串类型是 ASCII。但是在 3.x 中是 UNICODE。
print('sample word')
print(b'sample word')
# Python 2.x
output:
# <type 'str'>
# <type 'str'>
# Python 3.x
output:
# <class 'str'>
# <class 'bytes'>
在 2.x 中两者是同一类型。但是在 3.x 中它们是不同的类型。这并不意味着 Python2.x 不支持 Unicode。它支持不同语法的 Unicode】。
范围和 xrange:
Python3.x 中不赞成使用语句xrange,你可以查看我们关于范围函数的完整文章。
# Python 2.x
for x in xrange(1, 5):
print(x)
output:
# 1 2 3 4
# Python 3.x
for x in xrange(1, 5):
print(x)
output:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'xrange' is not defined
It should be
for x in range(1, 5):
print(x)
output:
# 1 2 3 4
错误处理:
Python3.x 中的错误异常处理要用as来定义。
# Python 2.x
try
variable_name
except NameError, err:
print err, 'ops defined before assign.'
# output:
(NameError("name 'variable_name' is not defined",), 'ops defined before assign.')
# Python 3.x
try:
variable_name
except NameError, err:
print err, 'ops defined before assign.'
output:
File "<ipython-input-1-942e89fbf9ab>", line 3
except NameError, err:
^
SyntaxError: invalid syntax
It should be:
try:
variable_name
except NameError as err:
print(err, 'ops defined before assign.')
注意:Python2.7 支持结束。如果你是 python 新手,建议从 Python3.x 开始。
如何设置一个现成的 python 环境?
python 的不同版本使得为所有项目设置一个单一的设置是不现实的。如果你有一个 python2.x 项目,它不能在你的 python3.x 环境中工作。您需要将每个项目与其包隔离开来。这个概念被称为虚拟环境。这是一个独立的环境,有一个特定的版本来运行您的项目。使用虚拟环境将有助于您轻松处理不同的项目。你需要它来激活环境。
如何搭建虚拟环境?
安装虚拟环境 ubuntu
-
确保您已经安装了它。
-
更新您的软件包管理器
sudo apt update -
安装 pip 软件包管理器。
$ sudo apt install -y python3-pip -
安装基本工具。
$ sudo apt install -y build-essential libssl-dev libffi-dev python3-dev -
安装虚拟环境。
$ sudo apt install -y python3-venv -
创建一个虚拟环境。
$ python3 -m venv <env_name> -
激活虚拟环境。
$ source <env_name>/bin/activate
现在你有一个孤立的操场。任何已安装的包都将在这个虚拟环境中。如果你完成了,你可以简单地写deactivate去激活环境。
结论
您可以在任何操作系统上轻松安装 python。通过其版本控制系统,您可以为您的项目选择正确的版本。总是建议使用最新版本。你应该知道版本之间的区别。更新项目取决于您使用的版本。建议每个项目都使用虚拟环境。它帮助你在同一台机器上运行多个项目。
Python 编程是用来做什么的?Python 为企业带来的好处
原文:https://www.pythoncentral.io/what-is-python-programming-used-for-benefits-of-python-for-business/
 编程语言使我们能够开发有用的程序和产品,以及高效的数字解决方案。许多企业使用编程来自动化他们的业务流程、评估他们的绩效、分析客户数据以及许多其他事情。而且,尽管今天使用了许多不同的编程语言,Python 仍然是最简单和最有益的语言之一。在本文中,我们将讨论 Python 编程的用途以及如何在您的业务中使用它。除了开发基于 web 的应用程序和提高项目效率,Python 的优势还包括创建交互式用户界面、网络安全程序以及各种分析工具和数据集等。继续阅读,了解 Python 编程如何帮助您的企业。
编程语言使我们能够开发有用的程序和产品,以及高效的数字解决方案。许多企业使用编程来自动化他们的业务流程、评估他们的绩效、分析客户数据以及许多其他事情。而且,尽管今天使用了许多不同的编程语言,Python 仍然是最简单和最有益的语言之一。在本文中,我们将讨论 Python 编程的用途以及如何在您的业务中使用它。除了开发基于 web 的应用程序和提高项目效率,Python 的优势还包括创建交互式用户界面、网络安全程序以及各种分析工具和数据集等。继续阅读,了解 Python 编程如何帮助您的企业。
Python 编程的主要用途
Python 是最流行的编程语言之一,这要归功于它的简单性和灵活性。由于其广泛的库、框架和其他工具,它可以用于任何类型的项目。这种编程语言的主要目的是开发简单高效的应用程序,可用于任何类型的业务。Python 在各个领域的使用导致了许多框架和库的产生,这些框架和库非常易于使用。由于大量用于数据分析、机器学习、web 开发和其他领域的库,这种编程语言的用户数量在不断增长。
Python 为企业带来的宝贵优势
安全系统
出于安全目的使用 Python 在乌克兰的开发者中变得越来越流行。网络安全和渗透测试咨询专家经常使用它来编写脚本或编写恶意软件。这是基于这样一个事实,即 Python 的简单语法允许网络罪犯更容易地进行他们的活动,这为企业带来了一系列全新的安全风险。幸运的是,在同一种编程语言中,创建了高级安全解决方案,可以基于行为分析和异常检测来识别可疑活动。
Web 开发
Python 被领先的互联网巨头使用,如 YouTube、网飞、Reddit、Quora、Dropbox 等。内容管理系统(CMS)网站 Django 是最受欢迎的网站之一,Instagram 和 Pinterest 等公司都在使用它。你也可以使用 Python 来开发电子商务商店或购物车。这种语言非常通用,也适合开发移动应用程序。例如,优步在移动设备上使用 Python 实现其后端功能。
数据分析
Python 中有很多工具可以用于数据分析。其中有熊猫、NumPy、Numpy、SciPy、Matplotlib、Scikit-Learn、Seaborn、Statsmodels 等。这有助于您比使用 R 或 Excel 更快地处理数据。
数据可视化
数据可视化在商业领域变得越来越重要,因为它可以帮助企业更好地理解他们的行为模式,改善他们与客户的关系。而且,由于 Python 很好地支持数据可视化,许多公司将它作为营销策略中的一种工具。
数据科学和机器学习
随着数据成为全球业务流程中越来越重要的一部分,公司正在寻找将数据整合成有意义的信息的方法,以帮助他们提高绩效并获得超越竞争对手的优势。这就是机器学习的用武之地。Python 已经成为该领域的领先技术之一,因为它可以用于训练算法和创建神经网络。使用这种编程语言也很容易从数据中获得洞察力,并将它们应用到现实世界的业务问题中。
在商业中使用 Python 编程的其他优势
除了上面列出的五个领域, Python 在商业中还有许多其他用途,例如:
- 文本处理。它使人们能够解析文本文件,甚至使用正则表达式在其中进行搜索。
- 数据压缩。Python 允许你比 ZIP 更好地压缩数据。
- 网络编程。你可以使用 Python 来编写像 CGI 脚本这样的网络程序,以及创建像代理服务器、代理、防火墙等网络工具。
- 多亏了 Pygame 库,你可以使用 Python 创建动画图像或视频。Pygame 对游戏开发特别有用。
- 桌面应用程序。使用 Tkinter 库,您可以用 Python 创建功能齐全的桌面应用程序。
- 你可以用 Python 开发视频游戏,创建自动交易系统,以及许多其他事情。
最后
正如您所看到的,在 Python 的帮助下,您可以为您的业务创建许多有用的工具,包括仪表板、交互式用户界面和许多其他东西。此外,您可以使用这种编程语言来开发在各种设备上工作的定制软件,包括移动设备。除此之外,Python 使您能够创建能够更准确地识别可疑活动的安全系统。在它的帮助下,您还可以更有效地分析数据,并创建对客户更有吸引力的可视化效果。总而言之,如果您正在寻找提高工作效率和自动化工作流程的方法,Python 可能是您企业的一个有价值的选择。
python 有什么用途:python 初学者指南
先决条件
如果你期待学习 python,你可能会发现这篇文章非常有用。在这里,您将了解 Python。它是用来做什么的?在哪学的?
要更多地了解任何一种语言,你需要了解一点它的历史。通过了解它的历史,你会对语言的主要焦点和发展方向有更多的了解。
根据 StackOverflow 2019 年的调查,Python 是最受欢迎的编程语言之一。在本文中,我们将了解更多关于
- python 的历史
- 学习需要多长时间
- python 的主要用法
- 去哪里免费学 python
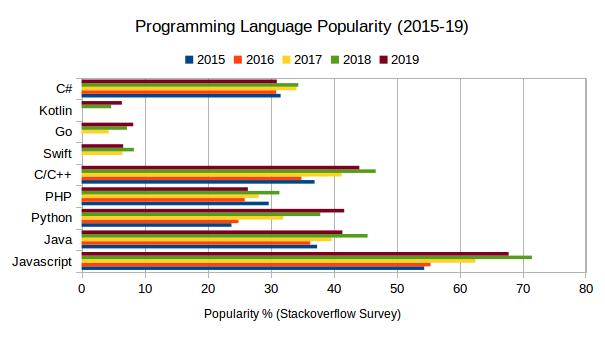
编程语言流行度图表根据stack overflow2019调查
python 的历史
Python 是一种 解释为高级通用 编程语言 。由 吉多·范·罗苏姆创作并于 1991 年首次公映。Guido 的 python 目标是成为开源的交互式编程语言。他想鼓励其他开发者使用它。Python 基于 C 语言,在性能上对 python 有帮助。CPython 的目标是将 Python 脚本翻译成 C 语言,并对解释器进行直接的 C 级 API 调用。Python 的代码可读性使其对长期项目非常有用。对于不同的公司都是不错的选择。除了在大型商业项目中使用 python 之外,开发人员开始将 python 用于辅助项目。现在你知道 python 的主要目标了。Python 注重可读性和性能。Python 支持不同的操作系统。让我们开始看看它的主要用法。
python 的主要用法
面向对象和函数式编程等多种编程范式的支持,以及背后庞大的社区,正在帮助语言适应不同的开发领域。再来说说 Python 的流行用法。
网页开发
在 Web 开发中,有许多编程语言可供选择。Python 在 web 开发中被广泛采用,有 Django、Flask 和 Pyramid 等框架。或者使用 scrappy、BeautifulSoup4 等从不同网站获取数据的废弃工具。
Django 是最大的 python web 框架。这是一个鼓励快速开发的 MVC(模型-视图-控制器)框架。它提供了具有标准架构的结构良好的文件。Django 给你开箱项目:
- 具有大量定制的可扩展架构。
- 包含项目配置的设置模块。
- ORM(对象关系映射器)将你的 python 代码转换成 SQL。
- 带有用户管理系统的管理门户。
- HTML 渲染的模板引擎。
- 内置表单验证。
- 漏洞防范,如 SQL 注入、跨站点脚本、点击劫持和密码管理
你可以在我们对 Django 的介绍中了解更多关于 Django 的信息。
Flask 是一个微框架,之所以这么叫是因为它不需要安装特定的工具或库。它没有默认的数据库或表单验证,您可以完全控制项目架构。您可以根据需要添加工具。Flask 是大型项目或基于微服务的项目的快速解决方案。这并不意味着 Flask 不是可伸缩项目的好选择。烧瓶是一个简单的选择
- 需要详细定制的项目
- 微服务系统。
- 用最少的配置快速创建 web 应用程序。
注:我们在之前的文章中对 Django 和其他框架做了充分的比较。Python 的用途不仅仅是构建 web 应用程序,还包括机器学习和数据科学等其他领域。
机器学习和数据科学
Python 非常擅长资源管理(RAM、CPU 和 GPU)。数据科学家和机器学习工程师正在将它与如下库一起使用:
- 张量流,机器学习的端到端 python 平台。它处理复杂的计算。它用于自然语言处理、语音识别,具有开箱即用的用户友好响应。
- Pytorch,一个生产就绪的机器学习库。它利用机器 CPU 和 GPU 来支持应用程序加速计算
- NumPy, Python 最流行的复杂数学运算库。它有很多线性代数方程,比如傅立叶变换。
数据科学和机器学习最近在学术研究和公司中被大量使用。你需要一个好的数学背景,并且你已经准备好开始学习它了。
自动化脚本
开发人员和安全工程师正在使用它来编写自动化脚本,以帮助他们的日常工作。查看我们关于使用 python 和 boto 访问 AWS 服务的文章
除了不擅长的移动和游戏之外,你可以在几乎所有的应用程序中使用它。
学习需要多长时间?
显然,学习一门新语言的时间并不是对每个人都是固定的。它被设计成像英语一样可读。我们可以说,学习它的基础知识并开始使用它可能需要大约 2 周的时间。
下面是 python 语法的一个例子
# define variables
language = "english"
# check type the type
type(language) # str
# python boolean
is_readable = True
# List Data structure
numbers = [1, 2, 3, 4, 5]
# conditional statment
If language == "english":
print("Welcome to english language")
else:
print("Invalid language")
# iteration and for loop
for num in numbers:
print("current number is : ", num)
# we can use ptyhon funtions to isolate logic
def get_number_type(number):
if number % 2 == 0:
return "Even number"
else:
return "Odd number"
# calling function
number_type = get_number_type(2)
print(number_type)
# Output : Even number
number_type = get_number_type(3)
print(number_type)
# Output : Odd number
上面的代码是一个易于阅读的 Python 代码的例子。这就是 Python 易学的原因。查看干净 python 代码的技巧。
去哪里免费学 python?
有大量的资源可以免费学习,我们将列出最好的学习资源。
- 文档 文档教程
- Udacity 课程python 编程入门
- Coursera 专精 Python 为大家带来
- Tutorialspoint 教程
- W3Schools 教程
- Sololearn 课程
结论
从上面的解释来看,很明显你可以在不同的应用中使用 python。python 在不同的行业和领域有着广泛的用途。它兼容所有的操作系统。如果你想以编程开始你的职业生涯,这是一个好的开始。对于在日常工作中需要几个脚本的数学家来说,Python 是一个非常有用的工具。如果您正在寻找可伸缩的 web 应用程序,python 也是一个不错的选择。
Python 中 str 和 repr 有什么区别
原文:https://www.pythoncentral.io/what-is-the-difference-between-str-and-repr-in-python/
Python 中 str 和 repr 的用途
在我们深入讨论之前,让我们来看看 Python 的官方文档中关于这两个函数的内容:
object.__repr__(self):由repr()内置函数和字符串转换(反引号)调用,计算对象的“正式”字符串表示。
object.__str__(self):由str()内置函数和 print 语句调用,计算对象的“非正式”字符串表示。引用自 Python 的数据模型
从官方文档中,我们知道__repr__和__str__都是用来“表示”一个对象的。__repr__应该是“正式”代表,而__str__是“非正式”代表。
那么,Python 默认的任何对象的__repr__和__str__实现是什么样子的呢?
例如,假设我们有一个int x和一个str y,我们想知道这两个对象的__repr__和__str__的返回值:
>>> x = 1
>>> repr(x)
'1'
>>> str(x)
'1'
>>> y = 'a string'
>>> repr(y)
"'a string'"
>>> str(y)
'a string'
虽然int x的repr()和str()的返回值是相同的,但是您应该注意到str y的返回值之间的差异。认识到str对象的默认实现__repr__可以作为eval的参数调用,返回值将是有效的str对象,这一点很重要:
>>> repr(y)
"'a string'"
>>> y2 = eval(repr(y))
>>> y == y2
True
而__str__的返回值甚至不是一个可以被 eval 执行的有效语句:
>>> str(y)
'a string'
>>> eval(str(y))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1
a string
^
SyntaxError: unexpected EOF while parsing
因此,如果可能的话,对象的“正式”表示应该可以被 eval() 调用并返回相同的对象。如果不可能的话,比如对象的成员引用自己,导致无限循环引用,那么__repr__应该是明确的,包含尽可能多的信息。
>>> class ClassA(object):
... def __init__(self, b=None):
... self.b = b
...
... def __repr__(self):
... return '%s(%r)' % (self.__class__, self.b)
...
>>>
>>> class ClassB(object):
... def __init__(self, a=None):
... self.a = a
...
... def __repr__(self):
... return "%s(%r)" % (self.__class__, self.a)
...
>>> a = ClassA()
>>> b = ClassB(a=a)
>>> a.b = b
>>> repr(b)
RuntimeError: maximum recursion depth exceeded while calling a Python object
你可以用不同的方式定义ClassB.__repr__,而不是完全遵循__repr__对ClassB的要求,这将导致无限递归问题,其中a.__repr__调用b.__repr__,而b.__repr__调用a.__repr__,后者调用b.__repr__,,如此循环往复。尽可能多地显示对象信息的方法与有效的 eval-constrained__repr__一样好。
>>> class ClassB(object):
... def __init__(self, a=None):
... self.a = a
...
... def __repr__(self):
... return '%s(a=a)' % (self.__class__)
...
> > > a = class a()
>>>b = class b(a = a)
>>>a . b = b
>>>repr(a)
<class ' _ _ main _ _。主要的,主要的。class '>(a = a))"
>>>repr(b)
"<class ' _ _ main _ _。>(a = a)
因为__repr__是对象的官方表示,所以您总是希望调用"repr(an_object)"来获得关于对象的最全面的信息。然而,有时__str__也是有用的。因为__repr__可能太复杂而无法检查所讨论的对象是否复杂(想象一个对象有十几个属性),__str__有助于快速概述复杂的对象。例如,假设您想要检查一个冗长日志文件中间的datetime对象,以找出用户照片的datetime不正确的原因:
>>> from datetime import datetime
>>> now = datetime.now()
>>> repr(now)
'datetime.datetime(2013, 2, 5, 4, 43, 11, 673075)'
>>> str(now)
'2013-02-05 04:43:11.673075'
现在的__str__表示看起来比从__repr__生成的正式表示更清晰、更易读。有时候,能够快速理解对象中存储的内容对于理解复杂程序的“大”图景是很有价值的。
Python 中 str 和 repr 之间的问题
需要记住的一个重要问题是,容器的__str__使用包含的对象的__repr__。
>>> from datetime import datetime
>>> from decimal import Decimal
>>> print((Decimal('42'), datetime.now()))
(Decimal('42'), datetime.datetime(2013, 2, 5, 4, 53, 32, 646185))
>>> str((Decimal('42'), datetime.now()))
"(Decimal('42'), datetime.datetime(2013, 2, 5, 4, 57, 2, 459596))"
因为 Python 更喜欢明确性而不是可读性,所以元组的__str__调用调用包含的对象的__repr__,即对象的“正式”表示。虽然正式表示比非正式表示更难阅读,但它是明确的,并且对错误更健壮。
Python 中 str 和 repr 之间的提示和建议
- 为你实现的每个类实现
__repr__。不应该有任何借口。 - 对于你认为可读性对不模糊性更重要的类,实现
__str__。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号