KDNuggets-博客中文翻译-十三-
KDNuggets 博客中文翻译(十三)
原文:KDNuggets
2021 年你应该开始阅读的数据科学书籍
原文:
www.kdnuggets.com/2021/04/data-science-books-start-reading-2021.html
评论
作者 Przemek Chojecki,Contentyze CEO
数据科学无疑是目前最热门的职业选择之一。许多公司(其中许多公司拥有数据科学部门)正在招聘数据科学家。成为数据科学家是一个重大成就。如果你已经是统计学家并希望提升自己,这也是一个磨练专业技能的绝佳机会。
我们的前三课程推荐
 1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
本文讨论了适用于任何水平的数据科学热门书籍。

2021 年你应该开始阅读的数据科学书籍
初学者数据科学水平
如果你刚刚开始探索数据科学,可以查看以下这些书籍:

从零开始的数据科学书籍
在 《从零开始的数据科学》 这本书中,数据科学的概念是以易于理解的方式呈现给陌生的学习者的。你甚至不需要了解 Python 就可以开始。我强烈推荐你从这本书开始。

《Python 机器学习简介》
如果你愿意从初学者水平学习机器学习,并渴望了解更多内容,那么这本名为《Python 机器学习简介》的书是一个绝佳选择。请记住,你不需要已经掌握 Python。

数据科学职位
然后,为了成为一名合格的数据科学家,你可以看看我写的书《数据科学职位:如何成为数据科学家》,这本书提供了一个全面的逐步指南。
通过我在多个组织担任项目经理、数据科学分析师或首席技术官的经验,我能够看到招聘数据科学家和发展数据科学团队的过程。本书将告知你:
-
成为数据科学家首份工作的必备条件,
-
你应学习的技能,
-
你在面试中应展示的内容,
以及更多内容。
中级数据科学水平
如果你读过一两本数据科学书籍,并且自己做过一些数据科学任务,现在你习惯于处理数据,这里有一些书籍可以深化你对数据科学的理解。

《Python 数据分析》
《Python 数据分析》 建议使用 NumPy 和 pandas。此外,《Python 数据分析》是一个知识渊博的数据科学家可能会欣赏的绝妙资源。它也对 Python 语言的功能进行了适当的介绍。

Python 数据科学手册
《Python 数据科学手册》 是所有标准 Python 库的完美指南。强烈推荐 Pandas 库、Scikit-Learn 库和 NumPy 数学库。
这本详尽的工作手册将为数据科学家和数据挖掘人员提供处理数据的有效方法。数据科学家会喜欢其中的多种插图、对每个过程背后算法的简明解释,以及附属网站上的工具。这无疑是目前唯一详尽且最新的 Python 科学计算资源。
你将学习如何使用以下内容:
-
Jupyter 和 iPython 是可以用来进行数据处理的 Python 框架。
-
Numpy: 需要构建一个密集且有效的数据数组,用于 Python 中的数据处理。
-
Pandas 结合了强大的向量和 DataFrame,以便在 Python 中分析和检索带标签/列的数据。
-
Matplotlib 是一个 Python 绘图库,提供了多种功能用于绘图和数据可视化。
-
Scikit-learn: 是一个流行的 Python 机器学习库,提供了复杂的机器学习算法和高效的实现。

《Python 机器学习》书籍
Python 机器学习 介于中级和高级机器学习阶段之间。它适合所有该领域的专家以及其他人。它从机器学习和深度学习的温和介绍开始,然后转向更高级的方法。一本了不起的书!

动手实践机器学习:Scikit-Learn 和 TensorFlow (第 2 版)
动手实践机器学习:Scikit-Learn 和 TensorFlow (第 2 版) 是一本宝贵的资源,能够获得更多成果!这本书讨论了所有基础知识(分类过程、降维),甚至涉及神经网络和深度学习。

Python for Finance 书籍
如果你对金融和数据科学感兴趣,Python for Finance 是必读书籍。这本书强调了利用数据科学方法来评估资本市场,并且提供了几个出色的示例来证明这一点。它是一个极其现实的产品,通常适合那些不经常从事金融工作的人。
专家级数据科学水平
对于那些在数据科学方面有一定经验的人来说,阅读大量的科学研究文章比阅读书籍更为合适。这是因为这种方法更为现实,并且可以将深度学习融入到你的程序中,以超越传统统计学。

深度学习与 Python
深度学习与 Python 这本书的作者是 Keras 库的开发者之一,Keras 是 Python 最著名的机器学习库之一。这本书以实用的方法开始,因为你可以立即学习几种有用的技巧。它通常非常实际,因为你可以在阅读后立即应用于活动中。这是深度学习的终极必读书籍。

深度学习
深度学习 是一本关于深度学习算法的绝佳参考书。它包含了有限的编码量,并且对如何解决机器学习问题有很好的见解。该书被该领域的专家频繁引用。

如果你对数学感兴趣,那么你一定会喜欢 机器学习:概率视角。它是对机器学习过程背后数学的真正深入探索。
不,我不建议一口气读完。我的建议是享受一杯咖啡,坐下来,慢慢阅读。
如何在 2021 年成为数据科学家?
就这些了。希望这些书籍能帮助你成为更优秀的数据科学家!
如果你在寻找第一份入门级数据科学工作却不知道从哪里开始,请报名参加我的 数据科学工作课程。一旦你进入课程,我可以在我们的学习小组中直接回答你的问题,帮助你成为初级数据科学家。
如果你喜欢这篇文章,请查看我关于成为数据科学家的其他帖子:
[加入我的技术新闻通讯]
数据科学,人工智能,机器学习](https://creative-producer-9423.ck.page/c3b56f080d)
简介:Przemek Chojecki 是 Contentyze 的 CEO,文本编辑器 2.0,数学博士,福布斯 30 位 30 岁以下杰出人物。
原文。经许可转载。
相关:
-
2021 年 15 本免费的数据科学、机器学习与统计学电子书
-
另外 10 本免费必读机器学习与数据科学书籍
-
数据科学与机器学习:免费电子书
更多相关内容
数据科学与商业:学习预期价值框架的 3 个理由
原文:
www.kdnuggets.com/2018/07/data-science-business-expected-value-framework.html
 评论
评论
实施数据科学在商业中的最困难且最关键的部分之一是量化投资回报率或 ROI。在这篇文章中,我们强调了学习预期价值框架的三个理由,该框架将机器学习分类模型与 ROI 连接起来。此外,我们会指向我们最近发布的新视频,预期价值框架:使用 H2O 建模员工流失,这是我们旗舰课程的一部分:数据科学与商业 (DS4B 201)。该视频概述了使用 H2O 减少员工流失并计算 ROI 的步骤,将关键的 H2O 功能与过程联系起来。最后,我们将讨论一些与将预期价值应用于商业中的机器学习分类问题相关的预期价值框架常见问题。
学习预期价值框架的 3 个理由
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
如果你想将数据科学与机器学习分类器的 ROI 联系起来,这里有你需要了解预期价值的 3 个理由。我们将使用与员工流失(也称为员工离职或员工流失)相关的DS4B 201 课程中的示例。
原因 #1: 分类机器学习算法经常最大化错误的指标
F1 是平衡精度和召回率的阈值(换句话说,它在减少假阳性和假阴性方面寻求一个相对平衡的阈值)。问题在于,在商业中,假阳性(类型 1 错误)和假阴性(类型 2 错误)相关的成本很少相等。实际上,在许多情况下,假阴性的成本要高得多(可能是 3 倍或更多!)。
示例: 员工流失的类型 1 和类型 2 错误成本
我们开发了一个预测算法,该算法发现员工在加班过多时离职的可能性是正常情况的 5 倍。

从 H2O + LIME 结果计算预期流失成本我们开发了一个建议,使用极其强大的 H2O 分类模型以及 LIME 来减少加班,并解释结果。像许多算法一样,我们默认通过处理类型 1 和类型 2 错误来优化。这会以大致相同的比例错误分类离职员工(类型 2 错误)和留任员工(类型 1 错误)。估计减少加班对员工的成本是如果员工离职,生产力损失的 30%。然而,错误减少留任员工的加班成本是类型 1 错误的 30%或 3 倍,还把它们当作相同处理! 商业问题的最佳阈值几乎总是低于 F1 阈值。这引出了你需要了解期望值框架的第二个理由。
理由 #2: 解决方案是最大化期望值
当我们需要使用商业成本来计算期望值时,我们可以通过迭代计算来找到最大化商业问题期望利润或节省的最佳阈值。通过在不同的阈值下迭代计算节省金额,我们可以查看哪个阈值优化了目标方法。
在详细的示例中,我们可以看到,在阈值优化结果中,最大节省($546K)发生在阈值 0.149 处,这比在最大 F1 阈值下的节省($470K)节省了 16%。值得一提的是,最大化 F1 的阈值是 0.280,对于包含总人口 15%的测试集来说,由于不够优化,导致了$76K 的额外成本($546K - $470K)。将这种低效扩展到整个数据集(训练数据 + 测试数据),这是每年错失的$500K 机会!
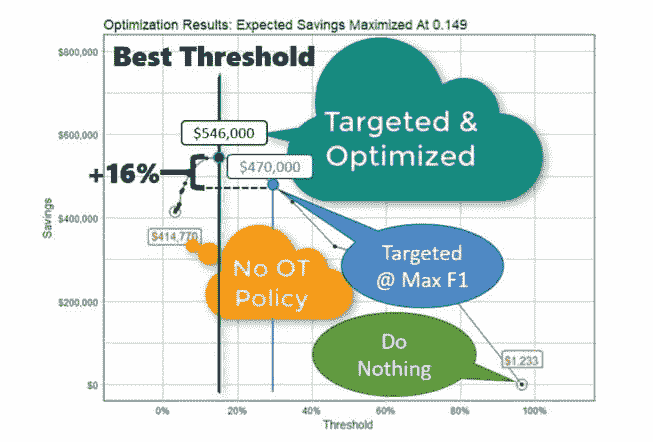
然而,模型基于多个假设,包括平均加班百分比、每位员工的预期净利润等等。
理由 #3: 期望值可以测试假设中的变异性
我们可以使用灵敏度分析以及期望值。我们测试模型假设对员工离职期望利润(或节省)的影响。
在下面的人力资源示例中,我们测试了平均加班百分比和每位员工的净收入的一系列值,因为我们对未来的估计可能存在偏差。在下面显示的敏感性分析结果中,我们可以在盈利能力热图中看到,只要平均加班百分比小于或等于 25%,实施有针对性的加班政策就能为组织节省资金。
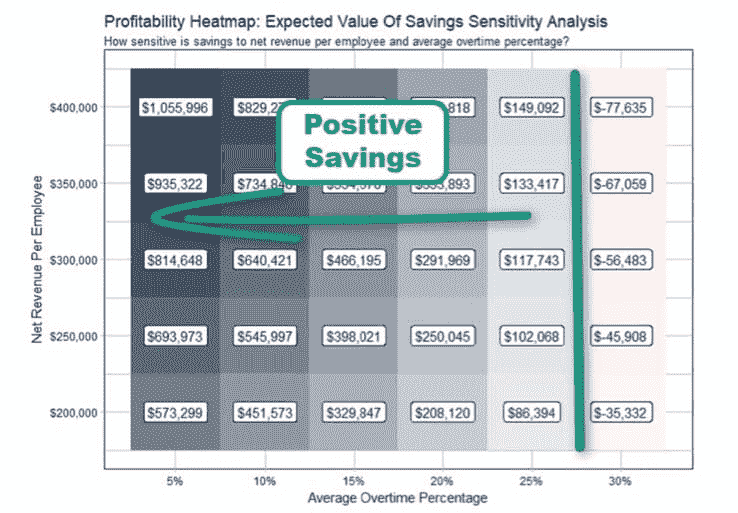
敏感性分析结果(盈利能力热图)
哇!我们不仅可以测试最大化商业案例的最佳阈值,还可以使用期望值测试每年和每人变化的输入范围。如果你有兴趣了解如何将期望值框架应用于你的业务,我们会展示如何操作,提供代码,并展示在我们在**数据科学商业课程(DS4B 201 课程)****中的其他行业应用实例。
简介: Matt Dancho 是一位数据驱动的决策者。热衷于学习新工具、开发软件和与人合作以获取见解并做出更好的决策。喜欢与团队和个人合作以推动运营卓越。驻扎在美国宾夕法尼亚州州立大学。
相关:
更多相关话题
数据科学职业:7 个期望与现实
原文:
www.kdnuggets.com/2022/06/data-science-career-7-expectations-reality.html

在即将开始数据科学职业路径的人们的期望与数据科学家实际做的事情之间存在巨大差距。有些期望得到了满足,但许多新数据科学家发现他们的工作与他们预期的完全不同。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
这部分是因为数据科学是一个快速发展的领域。今天的流行词汇可能在明天就变成过时技术。另一个原因是因为它是一个广泛的领域——数据科学家发现他们必须在工作中扮演许多角色。此外,面试阶段通常存在一些误导:雇主对员工的需求非常迫切,因此会过分美化职位描述。而且,数据科学领域如此广泛,它包括数据清理、整理、机器学习、基础统计和数据可视化。

让我们来看看数据科学家的期望与他们实际面临的现实。
期望 #1:数据科学家的收入很高。
一般认为数据科学家需求很高,所以薪水也很丰厚。实际上,你的数据科学薪资在很大程度上取决于你生活的地方、你为谁工作、你处于职业生涯的哪个阶段以及你所在的行业。
那么 数据科学家赚多少钱 呢?薪资可以达到六位数,但 $60k-70k 范围的薪资也很常见。一些初级职位的平均薪资不到 $50k。尽管如此,大多数薪资水平仍然非常具有竞争力,并且附带许多福利。
期望 #2:你将通过关键见解影响你的业务。
许多人会告诉你,成为一名数据科学家不仅仅是与你处理数字和 Python 的技能有关。成为一名优秀的数据科学家意味着你具备商业洞察力。你知道这些数字意味着什么。你将把这些重要的洞察传达给公司领导团队的关键成员。
现实情况是,和其他任何角色一样,你必须屈服于政治。有时你所做的工作会对业务产生实际影响。你会开发出一个真正影响公司底线的算法。但是,往往情况下,甚至更多的是,你会制作一个电子表格、数据可视化,或者只是为一个需要数据用于明天演示的高管处理一些数字。Deliveroo 数据科学家 Jonny Brooks-Bartlett 写道:“你必须不断地做一些临时工作,比如从数据库中提取数据,以便在正确的时间将数据提供给正确的人,做一些简单的项目,以便让正确的人对你有正确的看法。”
期望 #3:全都是机器学习、人工智能和算法。
例如,目前人工智能在数据科学中是一个非常流行的流行词。新的数据科学家可能自然地认为他们将构建前沿算法,并从事机器学习工作。
然而,如上所述,很多工作只是临时的与数据相关的工作。这涉及大量的 ETL 和数据清理。虽然你的一部分时间肯定会花在令人兴奋的概念和技术上,但大部分时间不会。
此外,你的雇主通常会期望你尽快开始使用极其有限且笨拙的数据构建 AI 模型。Monica Rogati 在她关于如何避免招聘数据科学家的指南中 写道:“[新招聘的数据科学家] 预计需要投入一些精力来收集和清理数据——但他们没想到会如此复杂和混乱,缺失或难以访问的情况如此之多。”这完美地概括了作为新数据科学家是什么样的体验。
期望 #4:你可以在线学习所有你需要的知识。

有一种感觉是,训练营或 Coursera 课程将教会你成为 数据科学家 所需的一切。现实情况,如同几乎所有其他工作一样,是你需要在工作中进行大量学习。有一些沟通技巧和领导本能是你从 Coursera 课程中无法获得的。
对于数据科学家来说,这也更为真实,那就是工作取决于你如何对待它。许多初创公司雇佣数据科学家是因为投资者要求这样做。缺乏技术知识的创始人对你能做什么一无所知,所以你需要自己搞清楚并定义角色。(并且准备好在过程中遇到许多误解。)
期望 #5:一切都是数字。
作为数据科学家,你期望你的工作是纯粹的数学。你收集数据、进行分析、创建数据产品,并处理数字。但请记住,你的雇主并不像你一样中立。正如数据科学可以被意外地用于不良目的一样,数据科学家也可能如此。
我们都对亚马逊臭名昭著的反女性人工智能招聘工具有所了解。一些数据科学家开发了那个模型。一个更具道德灰色地带的例子是优步的 Greyball 项目,该项目帮助优步司机躲避执法,避免被罚款。同样,这个产品并不是像雅典娜从特拉维斯·卡兰尼克的额头上直接跳出来的。真实的人们是将其构建出来的。
作为数据科学家,你可能会被要求做一些值得怀疑的事情。公司并不一定是为了善意而存在;它们大多数是为了盈利。特别是当你正在开发可能影响许多人的产品时,保持对所需完成任务的分析思维是值得的。
期望 #6:你将被重视、理解和支持。
正如许多数据科学家所知,工作的现实是没有指导、基础设施不足,而且对你实际做的事情了解甚少。“数据科学家可能是为了编写智能机器学习算法来推动洞察,但因为他们的第一份工作是整理数据基础设施和/或创建分析报告,所以做不到这一点,” 布鲁克斯-巴特利特写道。特别是如果你在创业公司工作,你通常需要做大量的预数据科学工作来完善你的工具、架构和技术。而且 IT 团队并不总是合作。
此外,同事们会认为你能处理任何与“数据”相关的请求,无论当时流行的数据术语是什么。六七年前,数据科学家们会被要求用 Hadoop 存储和处理数据。C-suite 级别的高管可能会要求你处理“深度学习”相关的工作。同时,你也会被要求发送一个带有简单 VLOOKUP 公式的 Excel 表格。
“最终,你不再像你想象的那样构建复杂的算法和预测模型。你现在花费所有时间来提升 SQL 和数据准备技能,从系统中提取数据并转换为不同格式,向利益相关者展示这些数据,以便他们可以利用这些数据做出商业决策,”Natassha Selvaraj在讨论为什么这么多数据科学家离职时写道。
虽然数据科学家确实很抢手,但对这个角色的困惑如此之多,以至于你不总能获得完成工作的支持或基础设施。
期望 #7:你会热爱你的工作。
正如 Selvaraj 所指出的,许多数据科学家正在离职,但许多人仍然享受他们的生活。Glassdoor [列出]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm)它为美国第 3 大最佳工作,工作满意度相对较高(5 分中 4.1 分)。一项 KDNuggets 调查发现大多数数据科学家对他们的工作仍然感到满意。
像任何工作一样,做数据科学家可能会很乏味。它可能伴随有意外的任务。它可能具有挑战性。但它也可能非常有趣。作为数据科学家,你将被要求突破你的极限,并有机会对你的公司产生真正的影响(即使你也需要做一些琐碎的工作)。
一旦你度过了适应新角色的成长 pains,你将有权创建一个你喜欢的工作。“我处于一个可以只做数据科学的职位,”BullCityPicker在 Reddit 上写道,“极少的无聊会议,大量的‘别打扰我’时间,还有我选择有趣项目的自由。我为此得到很高的薪水。我有很多自主权,能够不断学习新东西,感到非常满意。”
成为数据科学家的现实是什么?
总结来说,作为数据科学家,你:
-
有机会赚很多钱——但这并不保证。
-
可能会影响最终结果——但如果你希望别人听你说话,你需要与他人友好相处。
-
将从事前沿技术——同时做大量枯燥的 SQL 查询。
-
仅通过在线学习就能做好准备——但你必须通过被扔进深水区来学习某些技能。
-
创建真正影响人的数据驱动产品——但这些影响既可能是负面的,也可能是正面的。
-
被你的同事和公司重视——但你也会遭到深刻误解和常常得不到足够的支持。
-
会喜欢你的工作——如果它适合你的话。
换句话说,数据科学家就像其他工作一样。这份工作与其他工作不同的是,数据科学也受到了被称为“21 世纪最性感的工作”营销的影响。这导致你和你的雇主之间产生了很多误解和期望不匹配的问题。
如果你知道期望是什么,并且仍然感兴趣,那么这将是一个非常有回报的职业路径。
内特·罗西迪 是一名数据科学家和产品战略专家。他还是一名讲授分析课程的兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备来自顶级公司的真实面试问题。你可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
了解更多相关话题
数据科学已经改变,而非消亡!

作者提供的图像
随着技术的不断发展和人工智能在我们日常生活中的应用,许多人担心工作岗位的流失。甚至有人说数据科学在消亡。许多人表示,机器学习正在取代数据科学,并称数据科学是一个饱和的领域。随着 ChatGPT 等工具的广泛使用以及它们在编码任务等方面的应用,我们在质疑数据科学是否在消亡。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
但真的是这样吗?真的在消亡吗?
当然不是。我们获得的数据越来越多,这些数据产生了推动决策的宝贵洞察。这些洞察无法由计算机生成,我们需要它们来进行数据科学。可以建立机器学习模型,并利用数据发现有价值的洞察,但关键因素是对数据的需求以及如何处理数据。
而要理解如何处理数据,你需要人类。你需要数据科学家!但是什么发生了变化?
数据科学的变化
由于生成式 AI 的发展以及每个人都想进入科技行业的热潮,数据科学中的各种元素正在发生变化。让我们回顾一下数据科学中的一些变化。
技能
诸如探索性数据分析这样的任务曾经提供了重要的洞察,现在发生了巨大的变化。它通常需要数据科学家和数据分析师的帮助。然而,现在有了像 ChatGPT 这样的工具以及快速的数据科学课程——每个人都相信自己能编码,并且在 Python 中技术熟练。
然而,这并不是真的。如果你具备正确的技能组合,并且在如 Python 等编程语言中非常熟练,你将会脱颖而出。组织仍会寻找高素质的数据科学家来完成任务,而不是 ChatGPT 的回答或那些只参加过快速数据科学课程的人。
作为一名数据科学家,你的工作将是适应当前的市场。不断学习和提升技能是你保持竞争力并被真正重视的方式。
这包括不断学习不同的软件架构、库、框架、编程语言等。
构建完整应用程序
许多人正在使用 ChatGPT 来帮助他们完成编码任务。但需要理解的是,ChatGPT 可以帮助你构建完整应用程序的模块,但无法将这些模块整合起来构建整个基础。
组织将需要一个了解所有不同模块及其如何组合的人。他们能够将所有模块拼凑在一起,因为他们了解每个模块的作用,并将它们结合起来构建基础。
这并不意味着 ChatGPT 没有帮助——它确实有。许多程序员利用 ChatGPT 来帮助他们处理代码块,这加快了他们的代码编写过程。同时,它也通过学习新知识帮助提高程序员的技能,使他们在编码中更加熟练。
所以,作为一名数据科学家,你需要掌握更多的知识,甚至是所有的知识。你需要了解数据科学的每一个元素,以及如何构建一个完整的应用程序。
角色的融合
数据科学中的角色会有很多,但需要注意的是,许多角色将会融合。你以前可能是数据分析的首选人选,但现在你需要成为一个全能型人才,并在整体数据科学中成为专家。例如,你将运用你的分析技能来构建应用程序。
原因在于越来越多的组织在考虑工作角色的效率,以及他们实际需要多少人。例如,我应该雇用一个擅长创建和展示数据可视化的人,还是找到一个能够做所有事情的数据科学家?从商业角度来看,你知道公司会选择谁。
我能给你的最好建议就是在你擅长的领域做到非常出色。做到你能做到的最好,以免感到被挤出。
职业市场
数据科学的就业市场已经发生了变化。多年来,许多人试图通过快速培训营和一些 Jupyter Notebook 项目进入技术行业。不幸的是,这在当前市场中已经不再有效。具备熟练的技能组合、丰富的经验以及对数据科学的高级理解是至关重要的。
理解机器学习架构和高级数据分析是你需要完善的领域!你需要脱颖而出!
总结
我希望这篇博客能帮助你理解数据科学世界的变化,以及如果你想进入或在该领域发展——你需要做什么!与其感到被挤出,你只需要了解下一步需要做什么,以保持竞争力!
Nisha Arya 是一位数据科学家、自由技术作家和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及数据科学相关理论知识。她还希望探索人工智能如何对人类寿命产生好处。作为一个热衷的学习者,她致力于扩展自己的技术知识和写作技能,同时帮助引导他人。
相关阅读
数据科学备忘单 2.0
评论
由 Aaron Wang,麻省理工学院商业分析硕士 | 数据科学。
这个数据科学备忘单涵盖了一个学期的初级机器学习内容,基于麻省理工学院的机器学习课程 6.867 和 15.072。你应该至少具备基本的统计学和线性代数知识,尽管初学者仍然会发现这个资源有用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
灵感来源于 Maverick 的 数据科学备忘单(因此名字中有 2.0),可以在 这里 找到。
涵盖的主题:
-
线性和逻辑回归
-
决策树和随机森林
-
支持向量机
-
K-最近邻
-
聚类
-
提升
-
降维(PCA、LDA、因子分析)
-
自然语言处理
-
神经网络
-
推荐系统
-
强化学习
-
异常检测
-
时间序列
-
A/B 测试
这个备忘单将不定期更新新的改进信息,因此考虑在 GitHub 仓库 上关注或加星,以保持最新状态。
未来的补充(欢迎提供想法):
-
数据插补
-
生成对抗网络
为什么这个备忘单中没有涵盖 Python/SQL?
我计划让这个资源主要涵盖算法、模型和概念,因为这些内容变化不大且在各个行业中都很常见。技术语言和数据结构通常因工作职能而异,刷新这些技能可能在键盘上更有意义,而不是纸上。
许可证
欢迎在课堂、复习课中分享这个资源,或者分享给任何可能觉得有用的人 😃
本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可

图像用于教育目的,由我创建,或借自我的同事 这里。
原始。经许可转载。
简介: 亚伦·王 目前在 MIT 攻读商业分析硕士学位,专注于商业与数据科学的交叉点。亚伦对 AI/ML 在技术领域的未来充满热情,愿意聊聊相关机会。
相关:
更多相关主题
在云端使用 Dask 进行数据科学
评论
由 Hugo Bowne-Anderson,Coiled 数据科学推广负责人和市场营销副总裁
在数据科学和机器学习中,扩展大数据分析的能力变得越来越重要,并且增长迅速。幸运的是,像 Dask 和 Coiled 这样的工具使得人们可以轻松而迅速地做到这一点。
我们的前 3 个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析水平
3. Google IT Support Professional Certificate - 支持你的组织 IT
Dask 是在 PyData 生态系统和 Python 中扩展分析的热门解决方案。这是因为 Dask 设计用于并行化任何 PyData 库,因此可以无缝地与 PyData 工具配合使用。
扩展 分析以利用单个工作站的所有核心是开始处理大数据集时的第一步。
接下来,为了利用云上的集群(如 Azure、Google Cloud Platform、AWS 等),你可能需要 扩展 计算。
继续阅读,我们将:
-
使用 pandas 展示数据科学工作流中的常见模式,
-
利用 Dask 扩展工作流,利用单个工作站的核心,并且
-
演示如何将我们的工作流扩展到云端,使用 Coiled Cloud。
所有代码 在这里查看 github。
注意:在开始之前,考虑一下是否真的需要扩展你的计算。在开始之前考虑让 pandas 代码更高效。通过绘制学习曲线来衡量更多数据是否会提升模型表现。
PANDAS 和 ETL:数据科学中的常见模式
首先,我们将使用 pandas 在内存数据集上介绍一个常见的数据科学模式。这是 NYC 出租车数据集的 700 MB 子集,总体约为 10 GB。
我们希望看到扩展的光芒四射,因此我们选择了一个相对乏味的工作流。现在我们读取数据,处理数据,创建特征,并将其保存为 Parquet(不可读但比 CSV 高效得多)。
# Import pandas and read in beginning of 1st file
import pandas as pd
df = pd.read_csv("data_taxi/yellow_tripdata_2019-01.csv")
# Alter data types for efficiency
df = df.astype({
"VendorID": "uint8",
"passenger_count": "uint8",
"RatecodeID": "uint8",
"store_and_fwd_flag": "category",
"PULocationID": "uint16",
"DOLocationID": "uint16",
})
# Create new feature in dataset: tip_ratio
df["tip_ratio"] = df.tip_amount / df.total_amount
# Write to parquet
df.to_parquet("data_taxi/yellow_tripdata_2019-01.parq")
这在我的笔记本电脑上大约花了 1 分钟,这是我们可以容忍的分析等待时间(也许)。
现在我们想对整个数据集执行相同的分析。
DASK: 扩展你的数据科学
数据集的 10GB 大小超过了我的笔记本电脑的 RAM,因此我们不能将其存储在内存中。
相反,我们可以编写一个 for 循环:
for filename in glob("~/data_taxi/yellow_tripdata_2019-*.csv"):
df = pd.read_csv(filename)
...
df.to_parquet(...)
然而,我的笔记本电脑上的多个核心通过这种方法没有得到充分利用,这也不是一种优雅的解决方案。这里就需要 Dask 来实现单机并行处理。
导入 Dask 的几个方面,我们将启动一个本地集群并启动一个 Dask 客户端:
from dask.distributed import LocalCluster, Client
cluster = LocalCluster(n_workers=4)
client = Client(cluster)
client
然后我们导入 Dask DataFrame,懒惰地读取数据,并执行 ETL 管道,就像之前用 pandas 做的那样。
import dask.dataframe as dd
df = dd.read_csv(
"data_taxi/yellow_tripdata_2019-*.csv",
dtype={'RatecodeID': 'float64',
'VendorID': 'float64',
'passenger_count': 'float64',
'payment_type': 'float64'}
)
# Alter data types for efficiency
df = df.astype({
"VendorID": "UInt8",
"passenger_count": "UInt8",
"RatecodeID": "UInt8",
"store_and_fwd_flag": "category",
"PULocationID": "UInt16",
"DOLocationID": "UInt16",
})
# Create new feature in dataset: tip_ratio
df["tip_ratio"] = df.tip_amount / df.total_amount
# Write to Parquet
df.to_parquet("data_taxi/yellow_tripdata_2019.parq")
在我的笔记本电脑上大约需要 5 分钟,我们可以称其为可接受的(我想)。但是,如果我们想做一些稍微复杂的事情(这是我们常做的!),这段时间将迅速增加。
如果我可以访问云上的集群,现在就是利用它的时候!
但首先,让我们反思一下我们刚刚解决了什么:
-
我们使用了一个 Dask DataFrame——一个大型虚拟数据框,按索引划分为多个 Pandas DataFrame
-
我们正在使用一个本地集群,包含:
-
一个 调度器(负责组织和分配工作/任务给工作者),以及,
-
工作者,用于计算这些任务
-
-
我们已经启动了一个 Dask 客户端,它是“集群用户的用户界面入口”。
总之——客户端存在于你编写 Python 代码的地方,客户端与调度器进行通信,传递任务。
COILED: 扩展你的数据科学
现在我们所期待的时刻到了——是时候跃入云端了。如果你可以访问云资源(如 AWS)并知道如何配置 Docker 和 Kubernetes 容器,你可以在云中启动一个 Dask 集群。然而,这将是耗时的。
进入一个方便的替代方案:Coiled,我们将在这里使用它。为此,我登录了 Coiled Cloud(目前 Beta 是免费的计算!),安装了 coiled,并进行了身份验证。请随意跟随并自己操作。
pip install coiled --upgrade
coiled login # redirects you to authenticate with github or google
然后我们进行必要的导入,启动一个集群(大约需要一分钟),并实例化我们的客户端:
import coiled
from dask.distributed import LocalCluster, Client
cluster = coiled.Cluster(n_workers=10)
client = Client(cluster)
接下来我们导入我们的数据(这次来自 s3),并执行我们的分析:
import dask.dataframe as dd
# Read data into a Dask DataFrame
df = dd.read_csv(
"s3://nyc-tlc/trip data/yellow_tripdata_2019-*.csv",
dtype={
'RatecodeID': 'float64',
'VendorID': 'float64',
'passenger_count': 'float64',
'payment_type': 'float64'
},
storage_options={"anon":True}
)
# Alter data types for efficiency
df = df.astype({
"VendorID": "UInt8",
"passenger_count": "UInt8",
"RatecodeID": "UInt8",
"store_and_fwd_flag": "category",
"PULocationID": "UInt16",
"DOLocationID": "UInt16",
})
# Create new feature in dataset: tip_ratio
df["tip_ratio"] = df.tip_amount / df.total_amount
# Write to Parquet
df.to_parquet("s3://hugo-coiled-tutorial/nyctaxi-2019.parq")
在 Coiled Cloud 上这花了多久?30 秒。 即使对于这个相对简单的分析,这也比我的笔记本电脑上所需的时间少了一个数量级。
很容易看出在单一工作流中进行这组分析的强大之处。我们不需要切换上下文或环境。而且,当我们完成后,可以简单地从 Coiled 切换回本地工作站的 Dask 或 pandas。云计算在需要时非常棒,但在不需要时可能会带来负担。我们刚刚经历了一个负担要少得多的体验。
你需要更快的数据科学吗?
你现在可以免费开始使用 Coiled 集群。Coiled 还处理安全、conda/docker 环境和团队管理,因此你可以专注于数据科学和工作。立即开始使用 Coiled Cloud。
简介: Hugo Bowne-Anderson Hugo Bowne-Anderson 是Coiled的首席数据科学传播官和市场营销副总裁(@CoiledHQ, LinkedIn)。他在数据科学家、教育者、传播者、内容营销员和数据战略顾问方面具有丰富经验,涉及工业界和基础研究。他还在耶鲁大学和冷泉港实验室等机构、SciPy、PyCon 和 ODSC 等会议以及 Data Carpentry 等组织中教授数据科学。他致力于传播数据技能、数据科学工具的使用以及开源软件,无论是个人还是企业。
相关:
-
Dask 中的机器学习
-
为什么以及如何在大数据中使用 Dask
-
Dask 中的 K-means 聚类:猫咪图片的图像滤镜
更多相关话题
数据科学命令行:探索数据
原文:
www.kdnuggets.com/2018/02/data-science-command-line-book-exploring-data.html
评论
 数据科学的工具多种多样,涵盖了各种生态系统。Python 和 R 是一些比较受欢迎的编程环境,但还有许多其他选项,包括大量的编程和脚本语言、GUI 和基于 web 的工具。
数据科学的工具多种多样,涵盖了各种生态系统。Python 和 R 是一些比较受欢迎的编程环境,但还有许多其他选项,包括大量的编程和脚本语言、GUI 和基于 web 的工具。
一种较少考虑的攻击方式是严格的命令行方法。确实,你可能使用命令行来执行 Python 脚本,运行 C 程序,或调用 R 环境……或进行其他操作。但从终端运行整个过程呢?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
回答这个问题的是Jeroen Janssens,他是现在免费提供的书籍《数据科学命令行》的作者。书籍的网站上:
本指南展示了命令行的灵活性如何帮助你成为更高效、更有生产力的数据科学家。你将学会如何将小而强大的命令行工具结合起来,以快速获取、清理、探索和建模你的数据。
...
发现为什么命令行是一种灵活、可扩展且可延展的技术。即使你已经熟练使用 Python 或 R 处理数据,通过利用命令行的强大功能,你的数据显示工作流将得到显著提升。
除了编写关于数据科学命令行工具的详尽调查外,Jeroen 还准备了一个Docker 镜像,其中包含 80 多种相关工具,这些工具在书中都有涉及。
第七章《数据科学命令行》一书的标题为“探索数据”,重点介绍在OSEMN 模型的第三步中使用命令行工具。
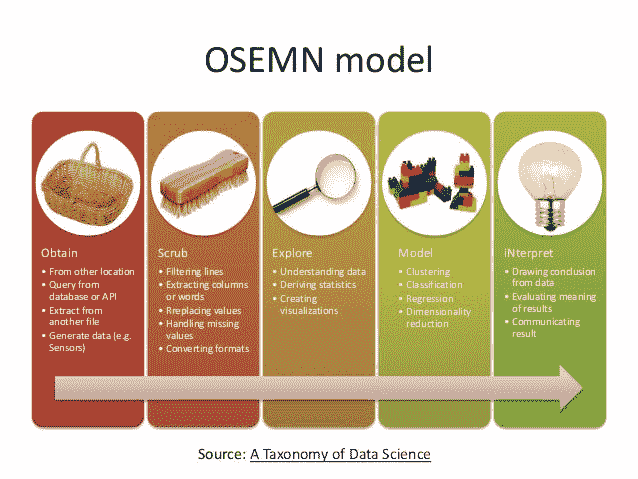
OSEMN 模型(来源)。
你可以从三个视角探索数据。第一个视角是检查数据及其属性。在这里,我们想知道,例如,原始数据是什么样的,数据集有多少数据点,以及数据集具有哪些特征。
探索数据的第二种视角是计算描述性统计。这种视角对于了解单个特征非常有用。一个优势是输出通常简洁且为文本格式,因此可以在命令行上打印出来。
第三个视角是创建数据的可视化。从这个视角我们可以深入了解多个特征如何相互作用。我们将讨论一种在命令行上打印的可视化创建方式。然而,可视化最适合在图形用户界面上显示。可视化相对于描述性统计的一个优势是它们更灵活,并且可以传达更多的信息。
这里快速展示了你在命令行中探索数据时可以完成的任务。
首先,你需要安装python3-csvkit:
$ sudo apt install python3-csvkit
然后,下载一个 CSV 文件进行操作:
$ wget https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
我们可以使用head打印iris.csv的前几行:
$ head iris.csv
sepal_length,sepal_width,petal_length,petal_width,species
5.1,3.5,1.4,0.2,setosa
4.9,3,1.4,0.2,setosa
4.7,3.2,1.3,0.2,setosa
4.6,3.1,1.5,0.2,setosa
5,3.6,1.4,0.2,setosa
5.4,3.9,1.7,0.4,setosa
4.6,3.4,1.4,0.3,setosa
5,3.4,1.5,0.2,setosa
4.4,2.9,1.4,0.2,setosa
很方便。但使用csvlook(python3-csvkit的一部分),你会得到一个更表格化的视图:
$ head iris.csv | csvlook
|---------------+-------------+--------------+-------------+----------|
| sepal_length | sepal_width | petal_length | petal_width | species |
|---------------+-------------+--------------+-------------+----------|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 5 | 3.4 | 1.5 | 0.2 | setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | setosa |
|---------------+-------------+--------------+-------------+----------|
更好。想查看整个文件吗?虽然我一直将cat的输出传输到more中:
$ cat iris.csv | more
... Jeroen 提倡使用less,这是一个更通用的命令行工具,操作风格类似于vi文本编辑器。它允许使用一系列单键命令在文本文件中移动。试试看('q'表示退出):
$ iris.csv csvlook | less -S
想知道数据集的属性名称吗?很简单,使用特殊的编辑器sed:
$ < iris.csv sed -e 's/,/\n/g;q'
sepal_length
sepal_width
petal_length
petal_width
species
很好。那么更多的属性元数据呢?
$ csvstat iris.csv
1\. sepal_length
Nulls: False
Min: 4.3
Max: 7.9
Sum: 876.5000000000002
Mean: 5.843333333333335
Median: 5.8
Standard Deviation: 0.8253012917851412
Unique values: 35
5 most frequent values:
5.0: 10
6.3: 9
5.1: 9
6.7: 8
5.7: 8
...
数据集中的唯一属性值计数如何?
$ csvstat iris.csv --unique
1\. sepal_length: 35
2\. sepal_width: 23
3\. petal_length: 43
4\. petal_width: 22
5\. species: 3
根据你对命令行的熟悉程度或依赖程度(或愿意成为的程度),你可以深入了解更高级的概念,如创建包含多个顺序执行命令的 bash 脚本。然而,这将从“命令行”数据科学转向更熟悉的脚本编写领域,但使用的是 bash 而不是例如 Python。你也可以做一些介于两者之间的事情,比如创建一个包含 bash 片段的库作为函数,并将它们添加到你的.bashrc配置文件中,以便在命令行上重复调用它们处理不同的数据。可能性仅受限于你的想象力和技能。
这只是《命令行中的数据科学》第七章中的一部分,而这本书只是触及了书中蕴含的丰富信息。
无论你怎么看,拥有命令行技能都是无价的。在这种情况下,你应该给这本书一个机会。
相关:
-
使用 Python 掌握数据准备的 7 个步骤
-
文本数据预处理的一般方法
-
Python 中的探索性数据分析
进一步了解这个话题
《命令行中的数据科学:免费电子书》
原文:
www.kdnuggets.com/2022/03/data-science-command-line-free-ebook.html

图片由作者提供
去年年底,我非常渴望了解关于 MLOps 的一切,最终目标是建立一个端到端的机器学习系统。像其他好奇的人一样,我报名参加了 Noah Gift 主办的 MLOps 事件。他在推广他的书和 Coursera 上的教程。我惊讶于自己从未学习过命令行工具以及它们在自动化中的重要性。在问答环节中,我告诉他我对这些工具的痴迷,他建议我参加他的 DataCamp 迷你课程:Python 中的命令行自动化。这门课程让我对数据管道、数据编辑、创建脚本以及如何在终端中用一行代码实现与 Python 中 15 行代码相同的结果有了新的看法。因此,我继续寻找有关命令行的最佳资料,最后找到了 Jeroen Janssens 的《命令行中的数据科学》(Amazon)。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
关于本书

获取免费电子书 | 在 GitHub 上收藏 | 在亚马逊上购买
本书通过编程示例解释了如何利用 Unix 强大工具执行与数据科学相关的所有任务。本书适合所有数据专业人士、工程师、系统管理员和研究人员。免费的电子书是互动式的,几乎没有时间就能掌握所有核心主题。我读过电子书、PDF 和纸质书,但这种阅读方式简直是一个新境界。它就像是在阅读你最喜欢的库的文档,但更好。
本书内容包括:
-
获取数据
-
创建命令行工具
-
清理数据
-
使用 Make 的项目管理
-
探索数据
-
并行管道
-
数据建模
-
多语言数据科学
在这本书中,你将学习如何使用 API、数据集和电子表格来提取数据。接着,进行数据清理和操作。之后,你将学习如何使用rush进行数据分析和可视化。你还将学会管理数据科学工作流程、创建并行管道以及构建机器学习模型(回归、分类)。除了核心主题,你还会学到如何利用 Unix 的强大工具提升你进行快速数据分析的效率。
我喜欢如何使用csvsql对 CSV 文件运行 SQL 查询,以及如何使用rush绘制各种图表。我从未见过任何机器学习工程师使用命令行工具进行数据预处理、创建模型和评估结果。当我第一次读到建模部分时,我感到怀疑,我知道他们必须使用 Python 或 R 脚本进行训练,但令我惊讶的是,作者使用了vw进行训练和评估。
特殊功能
这本书有许多突出的特点,但其中一些令人震惊的特性将在本评论中提到。
数据分析
一行代码的数据分析结合强大工具和 SQL 查询是我从未想象过的。这本书解释了多种提取和分析数据的方法,如使用 grep、header、trim 和 csvsql。
$ seq 5 | header -a val | csvsql --query "SELECT SUM(val) AS sum FROM stdin"
sum
15.0
数据可视化
这本书展示了如何使用rush进行任何基于R的数据分析。运行复杂的统计函数,探索数据,然后使用ggplot以任何形式可视化数据。书中还教你如何创建自己的工具,以优化当前的工作流程。
$ rush plot --x tip --fill time --geom density tips.csv > plot-density.png
$ display plot-density.png
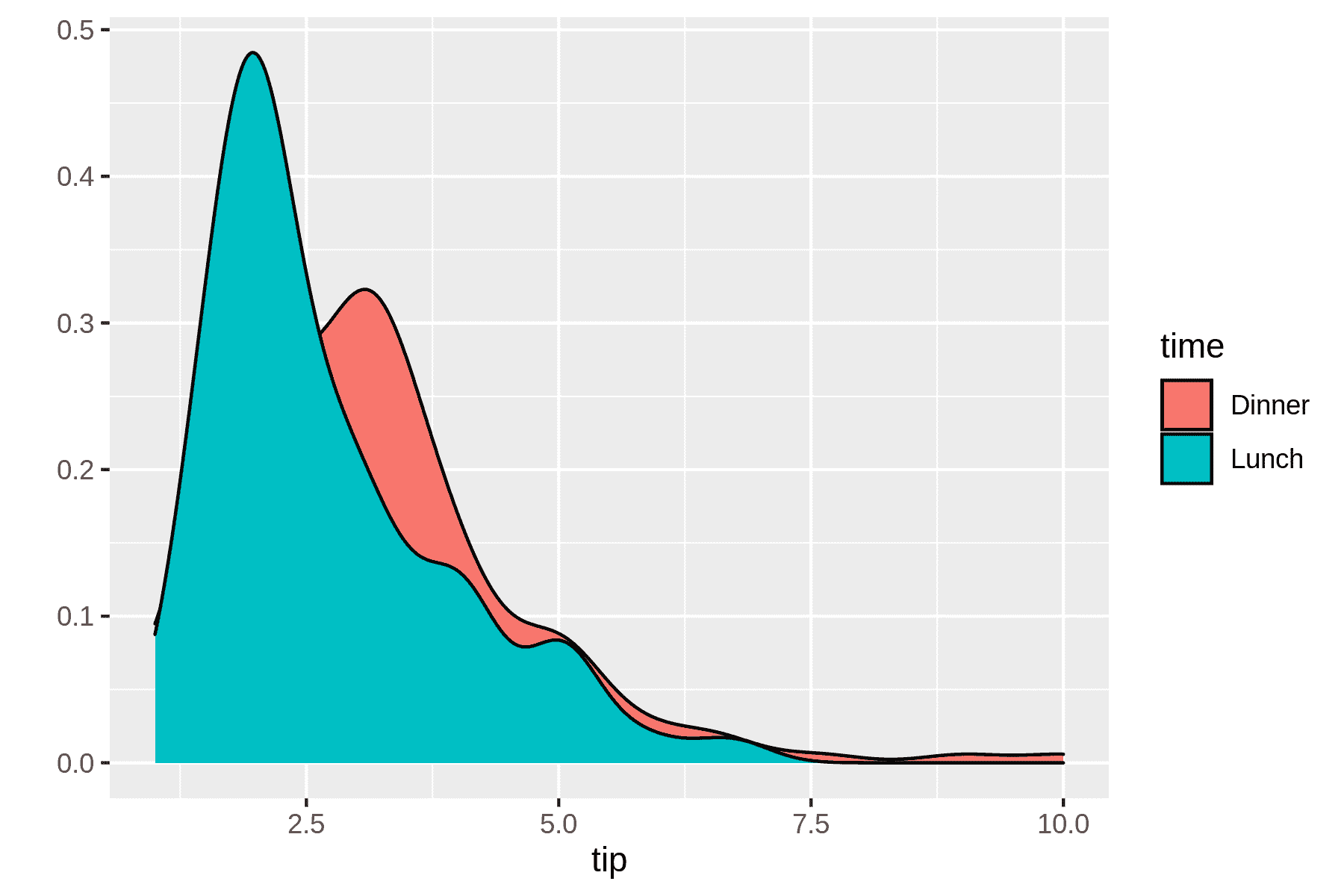
模型训练
我仍然对如何使用vw进行回归分析以及如何使用skll训练分类模型感到惊讶。我不想透露太多,因为你需要亲自体验才能理解。
$ skll -l classify.cfg 2>/dev/null
这些工具接受多个参数,并使用相同的算法训练模型。没有什么不同,只是我们用一行脚本完成所有这些。在 Python 中,我们需要写至少 20-30 行代码才能获得类似的结果。
$ < output/wine_summary.tsv csvsql --query "SELECT learner_name, accuracy FROM s
tdin ORDER BY accuracy DESC" | csvlook -I
│ learner_name │ accuracy │
├────────────────────────┼───────────┤
│ LogisticRegression │ 0.9953125 │
│ RandomForestClassifier │ 0.9953125 │
│ KNeighborsClassifier │ 0.99375 │
│ DecisionTreeClassifier │ 0.984375 │
GNU 并行管道
如果你正在处理大型文件或下载大型数据集,parallel将减少运行任何计算过程的时间。它将允许你并行化和分配命令及管道。parallel的最佳之处在于,你不需要修改当前的工具就能运行并行任务。
$ seq 0 2 100 | parallel "echo {}² | bc" | trim
0
4
16
36
64
100
144
196
256
324
... with 41 more lines
结论
数据科学是一个令人兴奋的领域,而命令行工具使其更加有趣,因为它简化了复杂性,并提供了用一行代码执行任务的新方法。书中完美地解释了这些强大工具的必要性以及如何利用它们改进当前的数据科学工作流程。如果你决定阅读这本书,我建议你通过编写脚本并自行测试来学习。书中还指导你拉取并运行 docker 镜像,以便你无需手动安装 Unix 强大工具。
这本免费 电子书 遵循 CC BY-NC-ND 4.0 许可协议。你也可以在 亚马逊购买纸质版。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专家,他热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些受心理疾病困扰的学生。
更多相关主题
数据科学中最常用、最令人困惑和滥用的术语
原文:
www.kdnuggets.com/2015/02/data-science-confusing-jargon-abused.html
评论
大数据正当红。全球网络设备系统每秒产生数 TB 的数据。负担得起的存储使得记录看似任意数量的信息成为可能。机器学习算法以及分布式计算,越来越能够从这些信息中提取可操作的智能。但“大数据”究竟意味着什么?
随着数据科学重要性的提升,与之相关的术语体系也在不断扩展。虽然许多术语定义明确,但其他术语则是流行词汇,在媒体中无处不在,却缺乏具体意义。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在这篇文章中,我将从多个角度, namely 理论家、实证数据科学家和新闻稿的夸张表述,提供对数据科学流行词的看法,这些表述往往被主流媒体盲目重复。

大数据
理论家: 大数据是一个定义不明确的术语。它可能比中等规模数据大,但又比巨型数据小。
数据科学家: 与长期主导机器学习研究的玩具数据集不同,今天的大数据足够庞大,无法方便地适应单台工作站的主内存。分析大数据需要利用分布式计算和并行算法。简而言之,大数据 是指比单台机器的主内存能容纳的数据更多的数据。
新闻稿: 大数据对软件开发人员而言是一个宝贵的资源,对现代企业来说,像水对地球生存一样必要。大数据利用云计算的力量生成多彩的图表,否则你在今天的经济中就会像恐龙一样过时。你是否有大数据策略来跟上硅谷的步伐?
云计算
理论家: 云指的是远程计算。幸运的是,对分布式系统的兴趣激发了对可并行算法的关注。
数据科学家: 分布式计算资源的可用性大大扩展了数据科学社区的能力。我们可以在数十台或数百台虚拟机上同时训练模型。我们可以使用 Hadoop 等工具分配计算资源。所有这些都无需在硬件上进行重大前期资本投资。
新闻稿: 云。服务。平台。谷歌,亚马逊,脸书,Azure。云无处不在。一切都在向云端迁移。一切都生活在云端。甚至云本身也在云端。公共云,私人云,元云。你的业务有云战略吗?
深度神经网络
理论家: 深度神经网络指的是一种图形模型,其中数据通过一层层的节点进行计算。‘神经’这个词可能会误导人。尽管这些系统的经验表现令人印象深刻,但其数学属性仍然不甚了解。
数据科学家: 受到生物学的启发,深度神经网络由接收兴奋性或抑制性输入的节点组成,边缘模拟突触。这些模型在涉及机器感知和自然语言的许多任务中实现了最先进的性能。
新闻稿: 深度学习是一项激进的新技术,利用大脑的力量赋予机器类人的智能。这项变革性技术可能加速奇点的到来,催生出能够思考、感受、吸收人类知识总和并殖民半人马座α星的类人机器人一代。

隐私
理论家: 长期以来,“隐私”缺乏具体定义。在过去几年中,已经在数据库查询机制的背景下提出了一些隐私的数学定义。差分隐私量化了个人信息由于其包含在数据库中而泄露的概率。
数据科学家: 在互联网上,很可能没有人正在做任何保护你隐私的工作。我们是为了从数据库中提取信息而获得报酬的,而不是为了防止信息泄露而加固它们。为什么要在数据中添加噪音呢?这会使我们的算法性能看起来更差。隐私并不存在。
新闻稿: 你的信息经过四重加密,采用银行级的 Fort Knox 安全保护!没有人,甚至我们的 CEO 都无法查看你的私人信息。使用我们的产品,知道隐私是我们的首要任务!

预测编码 / 数据分析
理论家: 预测编码是文档分类的重新品牌化,用于向律师销售电子发现产品。数据分析是数据分析的同义词。
数据科学家: 当我们向一家律师事务所推介一个用户友好的二分类工具,以帮助通过线性模型和词袋表示法检索相关文档时,他们并未感到满意。在下一个演示文稿中,我们描述了“预测编码”,我们的突破性“数据分析”技术用于“知识大脑”。
新闻稿: 预测编码代表了人工智能与法律工作流程之间的变革性协同,以前所未有的规模为客户带来成功。最先进的预测编码数据分析将使你的竞争对手过时。
 Zachary Chase Lipton 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部资助下,他对机器学习的理论基础和应用都感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习。
Zachary Chase Lipton 是加州大学圣地亚哥分校计算机科学工程系的博士生。在生物医学信息学部资助下,他对机器学习的理论基础和应用都感兴趣。除了在 UCSD 的工作外,他还曾在微软研究院实习。
相关:
-
(深度学习的深层缺陷)’s 深层缺陷
-
差分隐私:如何使隐私与数据挖掘兼容
-
Geoff Hinton AMA:神经网络、大脑和机器学习
了解更多
专业数据科学课程
原文:
www.kdnuggets.com/2021/03/data-science-curriculum-professionals.html
评论
由 布洛克·陶特,Odyssey Energy Solutions 的数据与系统专家。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
作者提供的图示。
如果你终于决定从 Excel 的复制粘贴转向可重复的数据科学,那么你需要知道最佳的路线。好消息是,有大量免费的资源可以帮助你,还有很棒的在线社区可以帮助你。坏消息是,选择哪些资源可能会让人感到不知所措。这里有一个直截了当的指南,你可以毫无遗憾地跟随,这样你就可以花更少的时间担心路径,更多的时间在上面跋涉。它基于我从一个从未上过统计课的可再生能源项目工程师到主要数据平台负责人的经历中学到的教训。
你在这里
在这段旅程的起点,你可以发现一群因必要而非激情进行数据分析的受过教育的个人。他们接受过工程师和商业分析师的培训,使用最简单的软件来运行他们的方程式。电子表格之所以美妙,是因为它们非常直观。你可以在每一步方程式中真实地看到并在隐喻中感受到数字。构建一个主电子表格是一个亲密的过程。(不相信我?试试看当他们展示他们的新模板时,你批评他们的颜色方案。)然而,一旦从原型转到全规模数据分析,电子表格很快会遇到局限性。一旦遇到需要整整一天时间才能修复的循环引用,开始计划在需要打开大文件或花一周时间尝试重建别人完成的分析时,你就该考虑转变了。在你旅程的第一步中,你需要去除电子表格的手动步骤,加快速度,并简化公式的跟踪。你需要开始编程。
第一次旅行:选择编程语言
现在你面临着人生中最重要的决定。大多数有抱负的数据科学家永远无法跨越这个巨大的障碍。你打算先学习哪种编程语言?为了减轻你的焦虑,你应该知道实际上没有错误的答案;这就像在选择一只小狗和一辆新车之间(或者对某些人来说,是猫和摩托车)。虽然有很多编程语言可以选择,但在目前的阶段,我只能推荐两个:Python 和 R。
你可以花几个月的时间阅读关于哪个更好的文章,但它们最终都说同样的话。所以,减轻你的负担,让这成为你最后一次纠结于这个话题。这份指南直截了当,记住吗?我会直白地告诉你。
如果你要与任何人合作,并且他们已经做出了这个选择,那就选择相同的语言。这样生活会更轻松。假设你是为你的团队开辟这条道路(这很棒),我可能推荐你选择 R。这种语言专门设计用于让非计算机程序员的生活更轻松,学习社区也非常棒。更重要的是,RStudio IDE(集成开发环境;你将在这里编辑代码)比使用 Python 更容易入门。(对于那些在大学里使用过 Matlab 的人来说,感觉就像是在使用 Matlab。)尽管如此,Python 是软件工程师更受欢迎的语言,在你开始构建机器学习应用程序时,实际世界中使用的频率也更高。
我个人开始是为了普通计算机编程目的自学 Python,并且在很多令人沮丧的东西上遇到了麻烦(比如该死的 PATH 变量),这使得进展开始时非常缓慢。当我开始学习数据科学时,我切换到了 R,并且真的很喜欢这种体验。最近,我深入研究了 Python 的数据科学包,现在在两者之间频繁切换(这实际上非常容易)。
如果你想更深入了解这个话题,你应该阅读 这篇文章 ,文章更详细地探讨了这个话题。然后,你应该选择一个并开始学习。
第二段征程:基础统计和整洁数据
一旦你选择了编程语言,你需要选择 IDE 和学习材料。如果你选择了 R,请使用 RStudio 并阅读 Garrett Grolemund 和 Hadley Wickham 的《R For Data Science》(通常缩写为 R4DS)。如果你选择了 Python,请下载 JupyterLab(使用 Anaconda)并阅读 Jake VanderPlas 的《Python Data Science Handbook》。这两本书都可以在网上免费获取。
这两本书将带你从完全新手提升到超越电子表格的能力,使你能够处理各种项目。所以,去做吧。拿一个让你非常沮丧的数据分析过程(也许是需要将数据从一堆 CSV 文件复制到一个模板中,也许是一个需要许多电子表格和在它们之间复制/粘贴数据的过程,等等),并编写一个 R/Python 脚本来完成它。当你遇到障碍时,向社区寻求支持。
推动我前进的最大一步是理解整洁数据的概念。因此,我建议阅读 Hadley Wickham 的《整洁数据》一文,并在你的代码中运用其原则。
此外,做数据分析最有趣的部分就是创建令人惊叹的可视化。确保你花大量时间玩弄你的图表。这些图表将帮助你让其他人看到你的代码比他们的电子表格更好。
最后,由于你现在正在进行更深入的数据分析,复习稳健统计学的原则可能会很有帮助。我推荐 David Spiegelhalter 的《统计学的艺术》。这本书不是教科书,而是讲解统计学数学背后的思维方式,对于编程者来说,比深入探讨数学本身更有用。
首个目的地
你做到了!通过这些非常简单的步骤,你现在可以称自己为数据分析师了。此时,你可以做 Excel 中能做的一切,甚至更多。数据分析现在快得多,你自动化了乏味的工作,制作图表的乐趣大大增加。对于许多人来说,这已经是你想要达到的最远目标。然而,接下来的几个步骤将看起来非常诱人。如果你觉得之前很有趣,等你做出第一个仪表板时就会更加精彩。
第三站:仪表板
查看 Shiny R 画廊 (shiny.rstudio.com/gallery/)。或者,如果你是 Python 爱好者,可以看看 Dash Enterprise 应用画廊 (dash-gallery.plotly.host/Portal/)。这些是仪表板,你可以将所有数据分析结果汇集在一个地方,让你的商业领导者惊叹于你的工作,并做出数据驱动的明智决策。(不错的口号,对吧?)进一步说,仪表板可以是 Web 应用,允许你的团队其他成员通过 GUI(图形用户界面)运行你的代码。你的团队当前使用的软件是否让你抓狂?你可以重新创建它,但量身定制以完全符合你的需求,真正减少点击次数。该程序的输出可能是一个漂亮的 PDF 报告。
简而言之,仪表盘很棒。你想要掌握制作这些仪表盘的技能。从将你的一个分析结果转化为仪表盘开始,然后逐步建立。使用 R 的 Shiny 包和 Python 的 Dash 包。还有大量文档可以帮助你,包括 Hadley Wickham 的《Mastering Shiny》一书,但与基础数据科学书籍不同,我不一定推荐完全读完这些书。只需开始编码,并在不确定如何做时使用它们。再说一次,学习社区是你的朋友。
第四阶段:包、GitHub、开源、环境
现在你的同事对你的仪表盘赞不绝口,羡慕你的自动化脚本,你将需要开始协作。一开始,你可能会通过电子邮件或文件共享与他人分享你的代码。类似地,每当你开始一个新的分析时,你很可能会复制上一个分析,然后在不同地方做些修改以适应新的数据。这是每个人的起点,但很快就会变得混乱。此外,你希望有更好的方法来跟踪代码的变化并允许其他人共同编辑。为了解决这些问题,你需要将代码转换为一个包,并将其托管在 GitHub 上。这样,每个人都可以访问代码,甚至可以将其开源,允许你与全球合作。
学习如何做到这一点的最佳资源是 Hadley Wickham 的《R Packages》和官方 Python Packaging 文档(packaging.python.org/overview/)。GitHub 的指南也是学习如何使用其平台的极好资源(guides.github.com/)。
当你第一次为团队构建应用程序时,管理本地环境会让你感到非常沮丧。我指的是,每个人的计算机上安装了不同的文件和操作系统中的细微差别,导致在他们的“环境”中运行的代码与在你的环境中行为不同。这是一件非常混乱的事情,涉及到计算机科学而非基础数据科学。我尽可能避免学习环境管理,但一旦我开始学习,它确实让我的生活变得容易多了。不管是主动学习还是出于必要,你都需要自己掌握这一技能。我从未找到过学习这方面的优秀资源,所以我在这里做了一个推荐你阅读的资源。
第二个目的地
你现在已经将数据分析技能提升到了一个新水平。你可以为开源代码做出贡献,并且现在具备了排查同事问题所需的技能。你可以领导一个高效的数据分析团队。拥有这些能力后,你正在寻找真正推动业务价值的方法,以便高层管理者不能再忽视你的工作。
第五阶段:高级统计与机器学习
如果你想真正为公司带来价值,你需要超越简单的线性回归和计算平均值。你需要开始深入研究高级统计和(提醒词!)机器学习。这一步是比较陡峭的。盲目尝试开源机器学习模型是可能的,但这有点像玩火。你真的需要理解你在做什么,否则计算机可能会将你的动机转化为一些疯狂的东西。我不是说你必须理解每个模型中所有的数学,但你应该对这些数学试图实现的目标感到舒适。你还应该开始从数据中提取更大的推论,识别出你未受过训练的眼睛所遗漏的模式。你应该学习更多统计的细微差别,以确保你得出的结论是负责任的。这部分确实是关于大权力需要大责任的。好好学习这些工具,你就可以做得更好。
最好的机器学习资源是 Coursera 上的机器学习课程,由斯坦福大学教授、机器学习名人 Andrew Ng 教授讲授。你可以在 GitHub 上找到 Python 和 R 的作业,而不是他在课程中使用的 Octave(编程语言)。紧接着这个课程的另一个极好的课程是 MIT 的深度学习入门(6.S191)课程。它是 MIT 课程,每年在课程结束后公开。该课程使用 Python 和一个叫 TensorFlow 的包。(注意,深度学习是一种机器学习,机器学习是一种人工智能。你说的内容部分取决于你想给谁留下深刻印象。)
在 Coursera 上有一门很好的高级统计课程,约翰斯·霍普金斯大学的“统计推断”(使用 R),或者密歇根大学的“用 Python 进行推断统计分析”。
第六步:云计算,数据管道
在某些时候,本地托管所有的处理过程将不再有意义。这可能是由于所需的计算能力、需要将来自多个来源的数据汇总到一个位置,或需要一个持续运行的应用程序而不是一次性分析。在这种情况下,你将转向云计算,这意味着你还必须找到将数据导入云中的方法。此时,你可能会从数据分析师/科学家过渡到数据工程师。这涉及到很多内容,其中大部分是特定于云托管提供商的。为了避免这种情况,你可以使用类似 RStudio Cloud 的工具,它会为你处理所有麻烦的工作。否则,你需要重新学习许多计算机科学概念,如分区、复制和网络。
要深入了解云服务,我写了 这篇文章。其他一些有用的资源包括 Google Cloud Labs(或类似的 Amazon、Microsoft 等材料)以及 Martin Kleppmann 的书《设计数据密集型应用》。
对于那些希望利用云计算能力但不打算实际托管应用程序的人,你绝对应该查看 Google Colab Notebooks。这些工具允许你在云端运行 Jupyter 笔记本,而不是在自己的计算机上,无需任何复杂的设置。它非常适合共享代码,同时也不必处理本地环境问题。
第三目的地
你已经达到了数据科学的圣地。你可以申请的职位有生产数据科学家或机器学习工程师。你现在具备了为大科技公司工作的技能,同时你在所在行业的专业知识也让你区别于普通数据科学家,这使得你的才能非常有吸引力。利用这些来清楚地为你的公司带来价值,这样你才能被认可你的真正价值。
伟大的未来
你可以考虑无数条下一步的路径。你可以深入研究神经网络和开源 AI 库,将人工智能带到你的行业。或者你可以投入到前端编码中,学习 JavaScript、HTML 和 CSS,将你开始构建的 web 应用提升到一个新的水平。或者你可以精通数据可视化和设计,更好地传达你的分析结果。或者你可以做其他无数的事情。因为你已经学会了如何在云端进行数据科学,天空不再是你的限制。
原文。经许可转载。
简介: 布罗克·陶特 是一位在可再生能源行业工作的工程师和数据科学家。
相关:
更多相关话题
数据科学课程路线图
原文:
www.kdnuggets.com/2019/12/data-science-curriculum-roadmap.html
(额外作者列表)
评论
我们在收到来自学术伙伴的多个请求后,冒险建议了一条课程路线图。作为一个团队,我们的大部分时间都花在了行业中,尽管我们中的许多人也曾在学术领域度过了一段时间。以下是一些广泛的建议,每种实施都不可避免地需要大量调整。考虑到这一点,以下是我们的课程推荐。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多的应用而非理论
我们想强调的是,准备学生将知识应用于行业环境中的单一最重要因素是以应用为中心的学习。使用现实数据回答实际问题是最佳准备方式。它将抽象概念与实际操作结合起来,同时教会数据机制和数据直觉,这在孤立情况下是不可能做到的。
以此为基础,我们提供了一系列主题,以便为数据科学实践做好准备。
课程原型
数据科学和数据中心的学术项目类型与我们在工作中识别的主要技能领域非常相似。有些项目强调工程,有些项目强调分析,还有些项目强调建模。这些的区别在于,分析关注我们能从数据中学到什么,建模关注估计我们希望拥有的数据的问题,而工程则关注如何使一切运行得更快、更高效、更稳健。
也有一些通用数据科学项目,在一定程度上涵盖了所有这些领域。此外,还有相当多的领域特定项目,教授特定领域的工程、分析和建模技能的子集。

这些项目模型的课程推荐会有所不同。然而,它们都会包含一些核心主题。分析、工程和建模中心的项目将有各自额外的主题领域。一般课程将包括一些分析、工程和建模课程的内容,但可能不会深入到相同的程度。学生通常会从这三个领域的任何组合中自行选择课程。
领域特定项目的课程看起来与一般项目类似,唯一不同的是,主题,甚至整个课程,将专注于该领域的特定技能。例如,一个侧重于精算的 数据分析项目可能包括保险公司最常用的软件工具、时间序列和稀有事件预测算法,以及在保险行业中被广泛接受的可视化方法。学生可以通过基于实际领域特定数据的项目来最佳地实践他们的技能。强烈建议参与实际项目或实习。在设计这些项目时,机构也可能考虑提供跨学科的学位和项目。领域特定项目通常结合了来自多个部门或学院的课程。
这是我们建议在每个领域中包含的主要主题,并列出了一些特别重要的子主题。
基础主题
-
编程
-
文件和数据操作
-
脚本编写
-
绘图
-
-
基本数据库查询
-
概率与统计
-
概率分布
-
假设检验
-
置信区间
-
统计显著性
-
-
代数
-
数据伦理
-
数据解释与沟通
-
演讲
-
技术写作
-
针对非技术受众的数据概念
-
分析主题
-
高级统计
-
实验设计
-
统计功效
-
A/B 测试
-
贝叶斯推断
-
因果推断
-
-
微积分
-
应用
-
成本效益权衡
-
实用意义
-
-
可视化
工程主题
-
软件工程
-
协作开发
-
版本控制与可重复性
-
数据流处理
-
生产工程
-
流水线建设
-
调试和单元测试
-
-
软件系统与基础设施
-
并行与分布式处理
-
客户-服务器架构
-
云计算
-
-
计算复杂性
-
数据结构
-
数据库
-
设计
-
数据建模
-
高级数据库查询
-
-
数据管理
-
安全
-
隐私
-
治理
-
合规
-
建模主题
-
线性代数
-
监督学习
-
分类
-
回归
-
-
无监督学习
-
聚类
-
降维
-
-
神经网络
-
多层感知器
-
卷积神经网络
-
循环神经网络
-
-
特征工程
-
自然语言处理
-
计算机视觉
-
算法设计
-
优化
请注意,对于每个主题和子主题,有许多有效的方法可以将其拆分为课程。您机构的最佳方式将取决于许多因素,包括学期长度、每堂课的小时数、现有的部门界限、讲师的可用性以及学生预期的学习速度。这些建议假设一个为期两年的硕士课程,主要目标是为学生准备就业和持续职业发展,尽管它们也可以根据其他项目的范围进行扩大或缩小。
应该重申的是,注重应用的教学将更好地为学生准备职业职位。理论越是扎根于具体实例中,具体技能在解决更大问题的背景下被练习得越多,学生对如何运作以及在哪里应用的理解就越深刻。
原文。经许可转载。
相关:
-
2019 年 5 大著名深度学习课程/学校
-
应对数据科学技能日益增长的需求
-
我在数据科学硕士课程中学到的 7 件事
更多相关内容
自学数据科学课程
原文:
www.kdnuggets.com/2020/02/data-science-curriculum-self-study.html
评论

照片由 Kelly Sikkema 提供,来自 Unsplash。
作为数据科学教育者,许多对数据科学感兴趣的人联系我寻求如何进入数据科学领域的指导。本文将讨论建立数据科学必备技能所需学习的推荐主题。
这里提出的主题,如果深入学习,将提供开始从事数据科学所需的最基本背景。这个课程大纲也可以用于设计数据科学入门级的大学课程。
请记住,仅仅通过课程获得的知识并不会使你成为数据科学家。课程学习必须配合一个顶点项目或实习。Kaggle 比赛可以用作顶点项目,因为它们提供了在真实数据科学项目上工作的机会。
以下列表呈现了学习入门数据科学的基本主题。
1. 数学基础
(I)多变量微积分
大多数机器学习模型是基于具有多个特征或预测变量的数据集构建的。因此,熟悉多变量微积分对于构建机器学习模型非常重要。你需要熟悉以下主题:
-
多变量函数
-
导数和梯度
-
步骤函数、Sigmoid 函数、Logit 函数、ReLU(整流线性单元)函数
-
代价函数
-
函数绘制
-
函数的最小值和最大值
(II)线性代数
线性代数是机器学习中最重要的数学技能。数据集表示为矩阵。线性代数用于数据预处理、数据转换和模型评估。你需要熟悉以下主题:
-
向量
-
矩阵
-
矩阵的转置
-
矩阵的逆
-
矩阵的行列式
-
点积
-
特征值
-
特征向量
(III)优化方法
大多数机器学习算法通过最小化目标函数来执行预测建模,从而学习必须应用于测试数据的权重以获得预测标签。你需要熟悉以下主题:
-
代价函数/目标函数
-
似然函数
-
误差函数
-
梯度下降算法及其变体(例如,随机梯度下降算法)
2. 编程基础
Python 和 R 被认为是数据科学领域的顶级编程语言。你可以选择只专注于一种语言。Python 在工业界和学术培训项目中被广泛采用。作为初学者,建议你只专注于一种语言。
这里是一些需要掌握的 Python 和 R 基础主题:
-
基础 R 语法
-
R 编程的基础概念,如数据类型、向量运算、索引和数据框
-
如何在 R 中执行操作,包括排序、使用 dplyr 进行数据处理,以及使用 ggplot2 进行数据可视化
-
R studio
-
Python 的面向对象编程方面
-
Jupyter notebooks
-
能够使用 Python 库,如 NumPy、pylab、seaborn、matplotlib、pandas、scikit-learn、TensorFlow、PyTorch
3. 数据基础
学习如何处理各种格式的数据,例如,CSV 文件、pdf 文件、文本文件等。学习如何清理数据、填补数据、缩放数据、导入和导出数据,以及从互联网抓取数据。一些相关的包包括 pandas、NumPy、pdf tools、stringr 等。此外,R 和 Python 包含多个内置数据集,可用于练习。学习数据转换和降维技术,如协方差矩阵图、主成分分析(PCA)和线性判别分析(LDA)。
4. 概率与统计基础
统计和概率用于特征可视化、数据预处理、特征转换、数据填补、降维、特征工程、模型评估等。以下是你需要熟悉的主题:
-
平均数
-
中位数
-
众数
-
标准差/方差
-
相关系数和协方差矩阵
-
概率分布(二项分布、泊松分布、正态分布)
-
p 值
-
贝叶斯定理(精确度、召回率、正预测值、负预测值、混淆矩阵、ROC 曲线)
-
A/B 测试
-
蒙特卡罗模拟
5. 数据可视化基础
学习良好数据可视化的基本组件。良好的数据可视化由几个组件组成,这些组件必须组合在一起才能产生最终产品。
a) 数据组件: 决定如何可视化数据的一个重要第一步是了解数据的类型,例如,分类数据、离散数据、连续数据、时间序列数据等。
b) 几何组件: 在这里你决定什么样的可视化适合你的数据,例如,散点图、折线图、柱状图、直方图、Q-Q 图、平滑密度图、箱线图、配对图、热图等。
c) 映射组件: 在这里,你需要决定使用哪个变量作为 x 变量,哪个作为 y 变量。这一点尤为重要,特别是当你的数据集是多维的,具有多个特征时。
d) 尺度组件: 在这里,你决定使用什么样的尺度,例如,线性尺度、对数尺度等。
e) 标签组件: 这包括坐标轴标签、标题、图例、使用的字体大小等。
f) 伦理组件: 在这里,你需要确保你的可视化展示了真实的故事。你需要在清理、总结、操控和生成数据可视化时保持意识,确保你的可视化不会误导或操控你的观众。
重要的数据可视化工具包括 Python 的 matplotlib 和 seaborn 包,以及 R 的 ggplot2 包。
6. 线性回归基础
学习简单和多重线性回归分析的基础知识。线性回归用于具有连续结果的监督学习。执行线性回归的一些工具如下所示:
Python:NumPy、pylab、sci-kit-learn
R:caret 包
7. 机器学习基础
a) 监督学习(连续变量预测)
-
基础回归
-
多重回归分析
-
正则化回归
b) 监督学习(离散变量预测)
-
逻辑回归分类器
-
支持向量机(SVM)分类器
-
K 最近邻(KNN)分类器
-
决策树分类器
-
随机森林分类器
-
朴素贝叶斯
c) 无监督学习
- K 均值聚类算法
机器学习的 Python 工具:Scikit-learn、Pytorch、TensorFlow。
8. 时间序列分析基础
用于预测模型的时间依赖性场景,例如预测股票价格。分析时间序列数据有 3 种基本方法:
-
指数平滑
-
ARIMA(自回归积分滑动平均),是指数平滑的推广
-
GARCH(广义自回归条件异方差性),是一种用于分析方差的类似 ARIMA 的模型。
这三种技术可以在 Python 和 R 中实现。
9. 生产力工具基础
掌握如何使用基本的生产力工具,如 R studio、Jupyter notebook 和 GitHub 至关重要。对于 Python,Anaconda Python 是最佳的生产力工具。高级生产力工具,如 AWS 和 Azure,也是需要学习的重要工具。
10. 数据科学项目规划基础
学习如何规划项目的基础知识。在构建任何机器学习模型之前,重要的是仔细规划你希望模型实现的目标。在深入编写代码之前,重要的是了解待解决的问题、数据集的性质、要构建的模型类型、如何训练、测试和评估模型。项目规划和组织对提高数据科学项目的生产力至关重要。以下提供了一些项目规划和组织的资源。
数据科学自学的有用资源
数据可视化的艺术——使用 Matplotlib 和 Ggplot2 进行天气数据可视化
数据科学 101——包含 R 和 Python 代码的简短课程
原文。已获许可转载。
相关:
更多相关话题
数据科学数据架构
原文:
www.kdnuggets.com/2015/09/data-science-data-architecture.html/2
数据流
图 2 展示了分析应用的数据流。图片的左侧描述了数据库,右侧描述了分析堆栈:红点表示调度实例,蓝点表示实际分析过程。顶部部分“Dev”表示模型开发环境,而下部框“Prod”表示模型生产环境。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作

在模型开发环境中,数据库被分为三个部分(或模式):
-
一个暂存区(或对数据科学家而言)只读环境,其中 IT 可以提供数据。为了确保没有混淆已交付的内容(从质量和数量的角度),此区域必须为只读。
-
数据科学的游乐场(或沙盒)。这是一个免费的区域,用于模型实验,回答临时问题,并开发报告和见解。
-
模型开发环境的下部表示预生产阶段。这是一个数据科学家与 IT 部门密切合作的区域。数据科学家和 IT 操作员的讨论围绕模型的交接过程展开。此外,IT 操作员需要了解模型的数据需求,并为模型准备操作环境。模型交接给操作团队需要配备审计结构。
下面描述的数据流支持数据科学家的完整工作流程:从临时报告到支持多个部门的模型。如前所述,流程从数据在只读(暂存)区域中可用开始。这里的数据是首次交付(数据科学家天生好奇,总是寻找新的数据源)和定期安排的数据交付(例如,每月的新客户、使用情况、交易等)的混合。最初,数据以原始形式到达,并被以这种形式进行探索。IT 和数据科学家之间的进一步合作可能会导致对某些数据聚合或选择的请求。定期数据交付由计划任务拾取,为数据科学数据集市准备数据。理想情况下,这是一个基于变更历史的数据集市,包含回答 90%临时问题的数据,并能够生成建模数据。另一种选择是存储每月快照,但这使得基于时间的选择和模型变得更加困难。请注意,演示环境旨在包含转换后的暂存区域数据,而不是原始数据的副本。此外,演示环境应理想上仅包含来自暂存区域的数据,以防止无法复制的模型。
从数据集市中,数据科学家创建两种类型的数据用于建模:分析数据和操作数据。分析数据指的是用于构建模型的数据。它是历史数据,并且在训练/测试/验证中被适当地拆分。操作数据指的是进行评分所需的数据。请注意,由于演示环境仅包含历史数据,因此操作数据仅指数据的格式,而不是其时效性。这一点非常重要,因为我遇到过多次情况,数据科学家以为需要最新的数据才能对模型进行评分(在开发环境中)。这给 IT 部门带来了不合理的压力,要求在开发环境中以高频率提供数据,并且未能将模型开发与模型生产分开所带来的所有不利后果。
一旦模型构建完成,即经过训练、测试、验证并确认在操作数据上得分,模型可以进入预生产阶段。与其将其作为一个独立的环境,不如在开发环境中专门保留一个区域。就模型存储而言,它可以是模型库中的一个文件夹;就数据库而言,最佳实践是不允许数据科学家创建所需的表,而是将表创建语句提供给 IT 部门,以便讨论命名规范等。IT 部门创建表之后,数据科学家可以将操作测试数据插入表中,以展示模型在预生产中的得分。这一点很重要,以便识别任何被忽视的依赖关系。
为了让模型在生产环境中运行,IT 部门需要在生产环境中提供操作数据。这有两个途径。首先,由于 IT 部门确切知道他们放置在只读暂存区中的内容,他们可以将其提供到生产环境中。模型的数据准备工作就交给数据科学家,他们作为模型评分作业的一部分完成这项工作。当向 IT 部门解释这个场景时,他们通常希望接管,并使用他们首选的 ETL 工具提供模型所需的确切数据。数据科学家则负责以 IT 部门可以重建的方式记录数据转换。通常这并非易事,因为数据科学家会提出非常有创意的数据转换方法,这可能难以在 ETL 工具中归档。实际上,这通常是选择折中之路:IT 部门提供半成品数据,数据科学工作流完成其余部分,然后进行模型评分。
最佳实践是不要让数据科学家将模型迁移到生产环境中。可以由具有强 IT 背景和对 IT 政策了解的某位数据科学团队成员担任 IT-数据科学联络员,并协助迁移工作。
数据科学需要 IT 部门和数据科学家之间的紧密互动。这是一个自下而上的过程,并且是敏捷的。这意味着,在进行分析之前,不能将其写成需要逐字遵循的规范列表。通常,数据科学家会先调查数据样本,并结合对业务的理解,然后确定模型构建和数据交付的需求。这是一个迭代的过程,随着洞察的深入,会出现新的或修改的数据需求。一个理解这一过程并能够参与其中的 IT 部门,可以极大地促进数据科学的成功及其对业务的提升。
总结性评论
文章讨论了 IT 架构如何支持数据科学家的工作流程。我发现这种架构适用于许多将数据科学作为非核心业务的公司(如金融机构、零售业、电信业和制造业等行业,而不是专注于深度学习的公司)。我也意识到技术的迅速变化,例如用 Hadoop 等替代传统数据库。在这些情况下,我发现,在训练环境中对数据库建模(或至少将数据库作为模型开发环境的一部分)往往提供了最大的灵活性。数据科学的价值来自于能够操作数据以确定分析的下一步。任何能够增强这种能力的架构都将导致数据科学的更好结果,从而促进更好的决策制定。
原文。
简历: Olav Laudy 是 IBM Analytics 亚太区首席数据科学家。
相关:
-
数据需求层级
-
自动统计学家及数据科学所渴望的自动化
-
数据科学的尴尬真相
更多相关话题
-
如何使用 Apache Kafka 构建可扩展的数据架构
构的范式转变](https://www.kdnuggets.com/exploring-data-mesh-a-paradigm-shift-in-data-architecture)
什么是数据科学,数据科学家做什么?
原文:
www.kdnuggets.com/2017/03/data-science-data-scientist-do.html
介绍
哈佛称什么职业为21 世纪最性感的工作?没错,就是数据科学家。
啊,是的,那神秘的数据科学家。那么,数据科学家的秘密武器到底是什么,这个“性感”的人每天在工作中到底做些什么呢?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
本文旨在帮助定义数据科学家的角色,包括典型的技能、资格、教育背景、经验和职责。由于数据科学家角色没有一个标准化的定义,而且理想的经验和技能组合在一个人身上相对较少,因此这一定义显得有些宽泛。
这一定义可能会更加混淆,因为有些角色有时被认为是相同的,但通常却大相径庭。这些角色包括数据分析师、数据工程师等。稍后会详细讨论。
下面是一个图示,展示了数据科学家可能借鉴的一些常见学科。数据科学家在每个学科上的经验和知识水平,通常沿着从初学者到熟练者,再到专家的理想状态变化。

由 Calvin.Andrus(原创作品)CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)),通过 Wikimedia Commons
尽管这些以及其他学科和专业领域(这里未展示)都是数据科学家角色的特征,但我喜欢将数据科学家的基础看作是建立在四个支柱上的。其他更具体的专业领域可以从这些支柱中衍生出来。
现在让我们讨论一下这些课程。
数据科学专业知识的支柱
尽管数据科学家通常来自许多不同的教育和工作经历背景,但大多数数据科学家应该在四个基本领域中表现出色,或者在理想情况下成为专家。这四个领域按优先级或重要性排序如下:
-
业务领域
-
统计与概率
-
计算机科学与软件编程
-
书面和口头沟通
还有其他非常期望的技能和专业知识,但在我看来,这四项是主要的。本文将称这些为数据科学家的支柱。
现实中,人们通常在这些支柱中的一两个方面很强,但通常在所有四个方面都不均衡。如果你遇到一个在所有方面都是真正专家的数据科学家,那么你基本上遇到了一只独角兽。
基于这些支柱,数据科学家应该能够利用现有的数据源,并在需要时创建新的数据源,以提取有意义的信息和可操作的见解。这些见解可以用来推动业务决策和变更,以实现业务目标。
这是通过商业领域的专业知识、有效的沟通和结果解释,以及利用所有相关的统计技术、编程语言、软件包和库、数据基础设施等来完成的。
数据科学维恩图
可以找到许多不同版本的数据科学家维恩图,以帮助可视化这些支柱(或变体)及其相互关系。David Taylor 写了一篇关于这些维恩图的优秀文章,标题为数据科学维恩图之战。我强烈推荐阅读。
这是我最喜欢的数据科学家维恩图之一,由 Stephan Kolassa 创建。你会注意到图表中的主要椭圆形与上述支柱非常相似。

Farcaster 在英语维基百科 [GFDL (http://www.gnu.org/copyleft/fdl.html) 或 CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0)],通过 Wikimedia Commons
这就是这个过程的概要。那么这些支柱在这里如何发挥作用呢?
数据科学家的支柱、技能和教育深入分析
我们已经讨论了业务领域和沟通支柱,这代表了商业敏锐性和顶级的沟通技巧。这对于发现和目标阶段非常重要。在数据科学家通常需要向关键利益相关者(包括高管)展示和沟通结果时,这也非常有帮助。
因此,强大的软技能,特别是沟通(书面和口头)和公众演讲能力是关键。在传达和交付结果的阶段,关键在于数据科学家能够以易于理解、引人入胜和有见地的方式呈现结果,同时使用适合其受众的语言和术语水平。此外,结果应该始终与最初推动项目的商业目标相关联。
对于所有列出的其他阶段,数据科学家必须具备强大的计算机编程技能,以及统计学、概率论和数学知识,以便理解数据、选择正确的解决方案、实施解决方案并进行改进。
一个重要的话题是现成的数据科学平台和 API。可能会有人认为这些平台可以相对容易地使用,因此不需要在某些领域具有显著的专业知识,也就不需要一位强大且全面的数据科学家。
虽然确实许多现成的产品可以相对容易地使用,根据所解决的问题可能会获得相当不错的结果,但在数据科学的许多方面,经验和技能至关重要。
其中包括具备以下能力:
-
根据具体问题定制方法和解决方案,以最大化结果,包括根据需要编写新算法和/或显著修改现有算法的能力
-
访问和查询多种不同的数据库和数据源(RDBMS、NoSQL、NewSQL),以及将数据集成到以分析为驱动的数据源中(例如,OLAP、数据仓库、数据湖等)
-
找到并选择最佳的数据源和数据特征(变量),包括根据需要创建新的特征(特征工程)
-
了解所有可用的统计、编程和库/包选项,并选择最佳方案
-
确保数据具有高完整性(优质数据)、质量(正确的数据),并处于最佳状态,以保证结果准确、可靠且具有统计意义
- 避免与垃圾进垃圾出相关的问题
-
选择并实施最佳的工具、算法、框架、语言和技术,以最大化结果并根据需要进行扩展
-
选择正确的性能指标,并应用适当的技术以最大化性能
-
探索如何利用数据在没有来自上层的指导和/或交付物要求的情况下实现业务目标,即数据科学家作为创意提供者
-
跨部门有效合作,并与公司所有部门和团队协作
-
区分好结果和坏结果,从而降低由于错误结论和随后的决策可能带来的风险和财务损失
-
了解产品(或服务)客户和/或用户,并以他们为中心创建想法和解决方案
在教育方面,成为数据科学家没有单一的路径。许多大学创建了专门的数据科学和分析项目,大多数为硕士学位水平。一些大学和其他组织也提供认证项目。
除了传统的学位和认证项目外,还有一些训练营,这些训练营从几天到几个月不等,还有在线自学课程和聚焦于数据科学及相关领域的大规模在线开放课程(MOOC),以及自我驱动的实践学习。
无论选择哪条学习路径,数据科学家应该具备高级的定量知识和高度的技术技能,主要涉及统计学、数学和计算机科学。
数据科学中的“科学”
科学一词通常与科学方法同义,也许你们已经注意到,上述过程与科学方法这一表达所特征化的过程非常相似。
这里有一张图像,展示了科学方法作为一个持续过程的可视化效果。

由 ArchonMagnus(原创) [CC BY-SA 4.0 (http://creativecommons.org/licenses/by-sa/4.0)],通过维基共享资源
一般来说,传统科学家和数据科学家都会提出问题和/或定义问题,收集和利用数据来得出答案或解决方案,测试解决方案以查看问题是否解决,并根据需要迭代以改进或最终确定解决方案。
数据科学家 vs. 数据分析师 vs. 数据工程师
如前所述,数据科学家的角色经常与其他类似角色混淆。主要有两个相关角色是数据分析师和数据工程师,这两者之间有显著的区别,也与数据科学有所不同。
让我们更详细地探讨这两个角色。
数据分析师
数据分析师与数据科学家共享许多相同的技能和责任,有时也有类似的教育背景。这些共享的技能包括:
-
访问和查询(例如,SQL)不同的数据来源
-
处理和清理数据
-
总结数据
-
理解和使用一些统计和数学技术
-
准备数据可视化和报告
然而,一些关键区别在于,数据分析师通常不是计算机程序员,也不负责统计建模、机器学习以及数据科学过程中的许多其他步骤。
使用的工具也通常不同。数据分析师经常使用如Microsoft Excel(可视化、数据透视表等)、Tableau、SAS、SAP和Qlik等用于分析和商业智能的工具。
分析师有时会执行数据挖掘和建模任务,但通常使用如IBM SPSS Modeler、Rapid Miner、SAS和KNIME等可视化平台。另一方面,数据科学家则通常使用R和Python等工具执行这些相同的任务,并结合相关的语言库。
最后,数据分析师在与高级业务经理和高管的互动中往往有显著差异。数据分析师通常从上层获取问题和目标,进行分析,然后报告他们的发现。
然而,数据科学家倾向于自己提出问题,依据对哪些业务目标最重要以及数据如何用于实现这些目标的了解。此外,数据科学家通常使用更高级的统计和建模技术、数据可视化,并以更具商业驱动的叙事方式强调报告。
数据工程师
在大数据时代,数据工程师变得越来越重要,可以被视为一种数据架构师。他们不太关注统计、分析和建模,更多关注数据架构、计算和数据存储基础设施、数据流等。
数据科学家和大数据应用使用的数据通常来自多个来源,并必须以优化分析、商业智能和建模的方式进行提取、移动、转换、集成和存储(例如,ETL/ELT)。
因此,数据工程师负责数据架构和设置所需的基础设施。因此,他们需要是熟练的程序员,具备与DevOps角色非常相似的技能,同时具备强大的数据查询编写能力。
这个角色的另一个关键方面是数据库设计(RDBMS、NoSQL和NewSQL)、数据仓储和设置数据湖。这意味着他们必须非常熟悉许多可用的数据库技术和管理系统,包括与大数据相关的那些技术(例如,Hadoop和HBase)。
最后,数据工程师通常还会处理非功能性基础设施要求,如可扩展性、可靠性、耐用性、可用性、备份等。
数据科学家的工具箱
我们将以对一些典型工具的概述结束,这些工具属于数据科学家的所谓工具箱。
由于计算机编程是一个重要组成部分,数据科学家必须熟练掌握R、Python、SQL、Scala、Julia、Java等编程语言。通常不需要在所有这些语言中都成为专家,但R、Python和SQL确实是关键,而像Scala这样的语言在大数据领域也越来越重要。
对于统计、数学、算法、建模和数据可视化,数据科学家通常会尽可能使用现有的包和库。一些较为流行的包括Scikit-learn、e1071、Pandas、Numpy、TensorFlow、Matplotlib、D3、Shiny和ggplot2。
对于可重复的研究和报告,数据科学家通常使用诸如Jupyter、iPython、Knitr和R markdown等笔记本和框架。这些工具非常强大,因为代码和数据可以与关键结果一起交付,以便任何人都可以执行相同的分析,并在需要时进行扩展。
如今,数据科学家还应该能够使用与大数据相关的工具和技术。最受欢迎的例子包括Hadoop、Spark、Hive、Pig、Drill、Presto、Mahout等。
最后,数据科学家应该知道如何访问和查询许多顶级的RDBMS、NoSQL和NewSQL 数据库管理系统。一些最常见的包括MySQL、PostgreSQL、Redshift、MongoDB、Redis、Hadoop和HBase。
总结
哈佛对数据科学家的评价是正确的。这是一个极其重要且需求旺盛的角色,对企业实现其财务、运营、战略等目标的能力有着显著影响。
公司会收集大量数据,而这些数据往往被忽视或未充分利用。通过有意义的信息提取和可操作见解的发现,这些数据可以用于做出关键业务决策,并推动重大业务变革。它还可以用于优化客户成功及随后的获取、留存和增长。
如前所述,数据科学家可以对企业的成功产生重大积极影响,但有时也可能无意中造成财务损失,这也是为什么雇用一位顶尖数据科学家至关重要的众多原因之一。
希望这篇文章有助于揭示数据科学家的角色以及其他相关角色。
干杯!
亚历克斯·卡斯特鲁尼斯是Why of AI的创始人兼首席执行官,也是《AI for People and Business》的作者。他还是西北大学 Kellogg / McCormick MBAi 项目的兼职教授。
原文。经许可转载。
相关:
-
机器学习:完整详尽的概述
-
数据科学与大数据的解释
-
人工智能、深度学习与神经网络的解释
相关主题
数据科学定义幽默:一系列关于数据科学定义的古怪名言
原文:
www.kdnuggets.com/2022/02/data-science-definition-humor.html

由 Rupa Mahanti,顾问
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
数据科学是一个广泛的学科,涉及几乎所有的业务领域,从金融到公用事业,从制造业到医疗保健和生命科学。数据科学是当前数字世界中最流行的流行词之一。然而,围绕这一术语存在很多混乱,不同的人对这个术语有不同的定义。以下是一些关于数据科学定义的幽默而富有洞察力的名言,希望能让你开心一笑。
“数据科学的第一个规则是:不要问如何定义数据科学。”
―乔希·布卢姆 (Azam 2014)
“关于数据科学:它是一个跨学科的、非学科性的领域,人们以有趣的方式完成工作,但他们自己都不知道该怎么称呼。”
―凯瑟琳·卡森 (Azam 2014)
“定义数据科学就像定义互联网——问 10 个人,你会得到 10 个不同的答案。”
―米凯拉·S·帕克、阿林·E·伯吉斯和菲利普·E·伯恩 (Parker et al. 2021)
“数据科学不过是统计学在不同领域中的新瓶装旧酒版本。”
―兰迪·巴特利特 (Bartlett 2015)
“‘数据科学’这个术语实际上是一个同时意味着一切和什么都不意味着的术语。”
―尼克·亚当斯 (Azan 2014)
“数据科学完全是基于你拥有的数据——或者经常是你没有的数据——提出有趣的问题。”
―莎拉·贾维斯 (Darmody 2020)
“‘数据科学’的定义就是‘数据科学家’所做的事情。”
―哈兰·D·哈里斯 (Harris 2011)
“数据科学是数据的土木工程。”
―凯西·奥尼尔和瑞秋·舒特 (O’Neil and Schutt 2013)
“数据科学有一个有趣的特点,就是它是少数几个让从业者没有特定领域的研究领域之一。”
―米哈伊尔·梅夫 (Mew 2021)
“数据科学是使数据变得有用的科学。”
―卡西·科齐科夫 (Kozykorv 2018)
“数据科学并不在于数据的数量,而在于数据的质量。”
―朱安·李 (Coresignal 2021)
“数据科学的座右铭:如果一开始不成功,那就称之为版本 1.0。”
“数据科学很像做饭。虽然原料在开始时可能很吸引人,但只有当你真正开始切割、剁碎,并最终端出美味的菜肴时,乐趣才开始。大多数时候,你会得到一道菜,但在数据科学的世界里,我们称之为数据洞见。”
―理查德·科内利乌斯·苏万迪 (Suwandi 2020)
“数据科学是 80%处理数据,20%抱怨处理数据。”
―理查德·科内利乌斯·苏万迪 (Suwandi 2020)
“数据科学是艺术和科学的结合,仅受限于数据科学家探索的自由程度以及他们的创造能力。”
“数据科学的实际操作是一种红牛助力的黑客技术和浓缩咖啡激发的统计学的结合。”
“而且数据科学不仅仅是统计学,因为当统计学家完成了理论上的完美模型时,如果他们的工作依赖于此,很少有人能将制表符分隔的文件读入 R 中。”
―迈克·德里斯科尔 (O’Neil and Schutt 2013)
“数据科学:一个扩展统计学技术领域的行动计划。”
―威廉·克里夫兰 (Cleaveland 2001)
“学习数据科学就像去健身房,只有持续不断地做,你才会有所收益。”
—莫埃兹·阿里 (Suwandi, 2022)
“许多人把数据科学视为一项工作,但更准确的说法是,它是一种思维方式,一种通过科学方法提取洞见的手段。”
—Thilo Huellmann (Coresignal 2021)
笑声确实是最好的药,数据专业人士的生活中也确实需要更多的幽默。下次当你计划在数据领域进行演讲或展示时,最好以一些有趣或古怪的数据名言开场,以引起同事和客户的兴趣。它们不仅能轻松气氛,还会提供一些没有人会想到的有用建议,因为它们非常搞笑。为了享受更多这样的名言,可以看看这本书——数据幽默:有趣的数据、大数据、统计学和数据科学名言、双关语及妙句。
Rupa Mahanti 是一名顾问及《数据幽默:有趣的数据、大数据、统计学和数据科学名言、双关语及妙句》一书的作者。数据幽默:有趣的数据、大数据、统计学和数据科学名言、双关语及妙句。
更多相关主题
数据科学学位与课程:价值判断
原文:
www.kdnuggets.com/data-science-degrees-vs-courses-the-value-verdict

作者提供的图片
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
如果你想在数据科学领域找到工作,而你第一次没有获得计算机科学、数据科学或数学学位,你现在可能在考虑你的选择。你可以回到学校获得那个学位,或者尝试完成一个认证的数据科学课程或训练营。
两者都昂贵且耗时,但学位比大多数课程或训练营要昂贵和耗时得多。这个价格对雇主来说值得吗?让我们通过每种课程提供的内容来详细分析一下。
传统路径:数据科学学位
标准路线是获得数据科学、计算机科学或数学的学位(甚至两个)。这种结构化的学习将教会你在数据科学工作中表现出色所需的知识。
学位的一个好处是它可以让你扎实而全面地学习该主题。它提供了真正的深度和对理论概念的深刻理解,这些是你从密集的训练营或在线课程中无法获得的。
学位涵盖广泛而深入的主题,包括高级数学、统计学、计算机科学基础、数据结构、算法、机器学习、数据可视化,甚至可能包括近年来变得更加实用的人工智能、深度学习和大数据技术等专业领域。
这样广泛而深入的学习意味着你真正理解了基础知识。你不仅仅是一个代码工蜂;你明白如何以及何时使用特定的统计工具或进行特定的分析。
不仅如此,学位还具有分量。许多大学就像品牌名称,雇主会认可并钦佩。例如,拥有 MIT 数学学位的求职者会以积极的方式脱颖而出。
不过,正如我之前提到的,学位通常需要四年时间,尽管也有更短、更专注的选项。例如,如果四年太长,你可以选择一个加速课程或一个专注于数据科学的硕士学位,这通常需要一到两年时间。
这些替代方案有点像大学学位的速成版,提供了更集中、侧重于工作所需的课程——数据科学、机器学习和统计技能。对于那些已经毕业并希望立即转行进入数据科学职位而不愿花费四年时间的人来说,它们可能是一个有吸引力的选择。
现代途径:在线课程和训练营
正如你所知道的,数据科学领域非常强劲且持续增长(不,没有泡沫)。这些领域的毕业生数量与职位空缺的数量不匹配。这意味着,虽然没有学位获得工作确实不容易,但也不是不可能——雇主只是希望你证明你的技能。
一种方法是通过结合在线课程、证书和训练营来做到这一点。这条路径更加灵活。你甚至可以兼职进行,同时进行现有工作。
与标准学位相比,这些课程的课程设置更具实用性,并根据当前的就业市场需求进行设计。它们包括类似实际数据科学工作的动手项目,教授你在标准职位描述中可能会看到的具体技能,如 Python、R、机器学习算法和数据可视化工具的熟练使用。这种方法对那些喜欢直接应用而非坐在讲堂里的学习者尤其有用。
许多训练营只持续几个月,通常在结束时提供某种工作安置机会。它们很昂贵,有时达到数万美元,但如果它们能帮助你在不到一年内找到六位数的工作,这可能会有很高的投资回报率。
问题在于,这条路线并没有提供完整的、整体的视角。你可能能够用优秀的项目充实你的简历,但在面试中可能会因为被问到训练营未涵盖的基础问题而表现不佳。

作者通过 supermeme.ai 创建
这就是为什么单一的训练营不够;你通常需要通过审计(或支付)Coursera 或 EdX 课程,或者进行自学、研究和实践来补充。
填补空白
学位无疑提供了无与伦比的深度和声望。但是,通过课程和训练营获得的敏捷性和实用技能不仅是一个值得的替代方案,而且实际上可能使你更好地为职场做准备。虽然学位是传统的,但它们也具有更大的惯性——课程和训练营可以比学位更快地响应不断变化的就业市场。此外,学位课程更加注重理论,对诸如面试准备等技能的重视较少。

作者创建于 supermeme.ai
也就是说,如果你选择课程和训练营的混合组合,你将错过从专注于一个主题一年的深度知识和学科信心。
幸运的是,我们推荐了一些资源,可以帮助你弥补这一差距,确保无论你选择了学位路径还是训练营方向,都能展现出全面且合格的候选人形象。
进一步了解数据科学主题
你可以通过两种方式进行。其一,你可以查看数据科学学位的课程大纲,并列出你想要学习的所有内容。其二,你可以从后向前推——选择一个理想的工作岗位,写下你想要学习的所有职位要求。无论哪种方式,编制你想要学习的主题列表。
有了这个列表,你可以利用以下资源来完善你的学习:
-
Coursera 和 edX: 如果你不想支付课程费用,你可以旁听课程以学习材料,尽管你无法获得结业证书。Coursera 和 edX 提供大量关于数据科学和数学理论与基础主题的全面课程。
-
可汗学院: 提供免费的课程,包括统计学和概率等大学级别的课程。
-
麻省理工学院开放课程: 你完全可以利用麻省理工学院这个品牌!这是一个宝贵的资源,提供了来自麻省理工学院的免费讲座和课程材料,涵盖计算机科学和数据科学的高级主题。
-
学术期刊和论文:这可能有点深奥,但阅读研究论文是深入理解高级数据科学主题的好方法,更重要的是,跟上当前研究趋势。一些论文需要付费获取,但许多可以在线免费获取。从 Google Scholar 开始。
为一个主题练习技能
如你所知,仅仅在简历上写“精通统计学”并不够,还需付出更多努力。

作者创建于 supermeme.ai
你需要应用你实际的数据科学技能,从编码到项目实施,并且要有项目来证明这一点。以下是一些资源,可以为你的简历增加额外的光彩。注意:这些资源对于学位型候选人尤其有用,因为学位通常比课程和训练营提供的实际项目机会要少。
-
DataCamp: 提供以编程、数据分析和机器学习等实际技能为重点的互动课程。
-
GitHub: 让你参与真实世界的项目,与他人合作,以获得实际经验并展示你的编码和项目管理技能。
-
Kaggle: 提供一个平台,让你与其他新人竞争,解决现实世界的问题,访问数据集,并与全球社区合作。
成功面试
无论你选择了学位还是训练营,你都需要在面试中表现出色才能获得工作。你应该准备数据科学工作面试,关注技术问题以及展示你的项目工作。以下是一些资源:
-
StrataScratch: 曾经希望你能提前知道面试官会问你什么吗?StrataScratch(我创办的)收集了 1000 多个真实的面试问题,包括编码和非编码问题,以及最佳答案,让你能够练习和准备面试官可能问你的任何问题。
-
会议和研讨会:建立联系和网络的重要性不可低估。参加这些活动,无论是亲自还是虚拟,了解最新趋势,与专业人士建立联系,甚至可能找到可以提供建议和面试见解的导师。
-
LeetCode: 提供大量编码挑战和问题,以提升你的算法和编码技能,这对于技术面试至关重要。
-
Glassdoor:提供关于公司特定面试问题和流程的见解,以及候选人对面试经历的评价。
最后的想法
如果你是一个有抱负的数据科学家,最好的做法是评估自己的现状。如果你有时间和资金可以用于学位,那是一个很好的选择,只要你将深厚的理论知识与实际操作和面试准备结合起来。如果你需要选择训练营或课程,那也是一个越来越有竞争力的选项——只要确保你完全掌握了相关概念。
两种选择都是可行的,但其中一种可能比另一种更适合你。希望这个价值指南能帮助你选择适合你的选项,并填补你需要的空白,从而获得理想的工作。
Nate Rosidi 是一名数据科学家,并且从事产品策略工作。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶尖公司的真实面试问题。Nate 撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖 SQL 的所有内容。
更多相关主题
数据科学与残疾
评论
2012 年在英国是一个重要的年份。全国洋溢着民族自豪感。联合杰克在大多数英国街道上高高飘扬,气氛热烈,因为我们举办了可以说是有史以来最好的奥运会。在比赛期间,我们见证了残疾运动员在残奥会和特殊奥运会上显著的崛起和应得的公众认可。塔尼·格雷-汤普森、艾莉·西蒙兹和李·皮尔森现在和莫·法拉赫、布拉德利·威金斯一样,可能会在酒吧和朋友们讨论的英国最佳奥运选手中被提及。之前存在的任何污名都被打破了,我们的英雄运动员带回了一个又一个金牌。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT

由于奥运会,我们现在看到社会对残疾群体变得更加理解和包容,但联合国报告称世界上大约 15% 的人口遭受某种类型的残疾,越来越多人觉得我们需要做得更多,以帮助改善残疾人士的生活。
数据科学和人工智能在过去几年中成为技术的前沿,许多从业者对生活采取了更具慈善性质的观点,支持那些身心障碍者。
机器学习在支持自闭症谱系障碍(ASD)患者方面发挥着重要作用。这种状况大约影响每 100 人中的 1 人,其中男性比女性更容易被诊断出此病。它在大约 3 岁时影响儿童,导致他们在处理或参与人际互动或情感方面遇到困难,这使得融入其他儿童的群体非常困难。然而,伦敦知识实验室在将一组 ASD 儿童引入一款名为 Andy 的虚拟自主机器人方面取得了巨大成功。实验发现,儿童们与 Andy 互动非常积极,专心倾听,问答交流比与成年人更为自如。类似地,一款名为 Milo 的人工智能机器人已经在美国 50 多所学校推广,鼓励 ASD 儿童更加愿意面对面互动,在某些情况下,甚至允许与机器人进行身体接触,这是大多数 ASD 患者难以想象的。虽然目前没有公认的 ASD 治疗方法,但该实验为 ASD 儿童及成人的家庭带来了希望,期待他们有一天能够自如地与人工智能软件交谈,从而提升与他人互动的信心。
智能假肢是数据科学应用的另一个领域,旨在使残疾人的生活更加便捷。对于许多截肢者或失去一个或多个肢体功能的人来说,选择非常有限,而且通常非常原始,关注基本功能而非日常可用性。然而,由赛格威发明人 Dean Kamen 领导的 Deka 研究公司,首创了一款名为“Luke”臂的假肢(以致敬卢克·天行者命名)。这一技术的独特之处在于它更接近于人手内部的工作原理,机械等效的肌腱、肌肉和骨骼使用户具有更自然的运动范围,比过去 20 年更常见的钩子和爪子要接近人类手臂。该臂可以通过多种方式控制:通过附着在臂基部的微小神经末梢,或通过佩戴者鞋中的控制器。该项目获得了美国陆军研究办公室的显著资金支持,但大规模生产的假肢仍可能极为昂贵,有些估算约在 50,000 美元左右。尽管这可能不是每个需要假肢的人都能接受的答案,但这里展示的运动范围和技术复杂性为未来的类似技术带来了光明前景,届时可能会以更低的成本提供,并具有更多用途。
由世界上最著名的科学家之一斯蒂芬·霍金教授带到显著位置的技术——电子增强和替代通信系统(AAC)已成为那些由于运动神经元病或脑瘫等疾病而无法说话的人的生活中不可或缺的一部分。在这个市场上的最新创新之一,仍然与霍金自 1986 年起使用的‘Equaliser’设备紧密相关的是 DynaVox EyeMax。该设备利用计算机视觉技术,通过前置摄像头跟踪用户眼睛在命令屏幕上的运动,甚至可以编程使用特定的语调以防止言语被误解。它有潜力利用自然语言处理为许多失去语言能力的人提供发言功能,但该技术也有一些限制;每个设备必须为各自的用户单独编程,包括兴趣地点、朋友和家人的名字及其他独特信息,并且设备的费用通常不被健康保险覆盖。然而,预计未来将深度学习技术融入设备中应能减少编程所需的时间,这可能会使设备的成本降至更实惠的水平。
不仅仅是专业医疗公司认识到利用数据科学技术改善残疾人生活的财务和慈善价值。谷歌最近宣布,他们希望提升其智能手机和其他设备的可访问性,以帮助那些视力、听力或灵活性受限的用户。一个令人兴奋且独特的发展是为谷歌智能手机设计的盲文系统,它允许用户通过蓝牙将盲文设备连接到手机上。此外,Android 系统现在可以通过类似于斯蒂芬·霍金在轮椅上使用的‘开关’来控制。根据谷歌的说法,这为以前无法访问这些技术的新用户群体打开了大门,并允许用户使用与朋友相同的硬件,而不是使用定制的、可能不那么吸引人的设备。这些发展具有巨大的财务激励,因为 Switch Access 和 BrailleBack 都可以免费从 Android 上下载,这意味着与许多为残疾群体设计的技术不同,价格不再是障碍。总体而言,谷歌的贡献为其他技术公司树立了一个基准,促使他们跟随其在为残疾人士生产负担得起且易于使用的平台方面的领导,我们期待看到下一步是谁。
最后,有些东西目前确实更处于“概念验证”阶段,但对未来展现了巨大的潜力。2011 年,来自维吉尼亚理工大学 RoMeLa 机器人与机制实验室的 Dennis Hong 博士首创了一款设计用于让盲人或视力部分受损的人能够独立驾驶的汽车。该系统结合了能够学习预定路线并感知障碍物和行人的机器学习软件,以及一系列集成在压力垫手套中的传感器,能够告诉驾驶员他们应该去哪里,以及是否有需要避免的障碍物。在同年 TED 演讲中,Hong 博士展示了这款汽车,一名盲人在 Daytona Speedway 安全地完成了整个预定路线的驾驶。必须指出的是,有几个原因导致该系统无法立即实施,最少的是需要将路线精确输入到汽车的计算机中,以便传感器能够指导驾驶员,而这对每条道路来说并不现实。然而,它在数据科学和机器学习领域显示了巨大的进展,对盲人和部分视力受损群体来说是一个巨大的飞跃。
在将数据科学与残疾之间的关系标记为成功之前,必须解决几个问题。首先,当前出现的技术创新是否足够先进,可以现在就为那些有残疾的人带来益处,还是实际的突破可能要在 5 到 10 年后才会到来?同样,这些选项在经济上是否都是可行的,不是对生产者而言,而是对消费者而言,后者可能因收入有限而收入有限?此外,数据科学提供的创新是否仅限于让残疾人士的生活更轻松,还是例如,深度学习是否有可能被用来识别导致某些残疾的基因,从而给医生提供研究和限制这些基因的机会?
数据科学的未来看起来非常光明,因为几项创新已经在全球范围内对残疾人士的生活产生了显著的影响。下一步,无论是进入遗传学研究、深度学习集成还是其他领域,都取决于许多主要公司是否会超越财务报表,转而致力于改善全球数百万残疾人士的生活。希望不必等到下一届奥运会才会实现这一点。
原文。
相关内容:
-
埃博拉分析与数据科学教训
-
数据科学如何预测并减少不良出生结果
-
数据科学如何抗击疾病
更多相关内容
数据科学是否是一个即将消亡的职业?
图片由cottonbro studio提供
介绍
我们的前三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业的捷径。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
我最近阅读了一篇文章,描述了数据科学作为一个过度饱和的领域。文章预测,机器学习工程师将在未来几年取代数据科学家。
根据这篇文章的作者,大多数公司用数据科学来解决非常类似的业务问题。因此,数据科学家不再需要提出解决问题的新方法。
作者接着说,解决大多数数据驱动组织中的问题只需要基本的数据科学技能。这一角色很容易被一个机器学习工程师取代——一个具备基本数据科学算法知识的人员,同时还拥有部署机器学习模型的知识。
我在过去一年里阅读了许多类似的文章。
一些人表示,数据科学家的角色将被如 AutoML 之类的工具取代,而另一些人则将数据科学称为一个“即将消亡的领域”,将很快被数据工程和机器学习操作等角色取代。
作为与数据行业不同领域紧密合作的人,我希望就这个话题提供我的意见,并回答以下问题:
-
数据科学是否是一个即将消亡的职业,未来几年是否还会有需求?
-
自动化工具是否会使数据科学家失业?
-
数据科学是否已经过度饱和,未来是否会被新的角色取代?
-
数据科学家对组织来说是否有价值?他们如何为企业创造价值?
数据科学家是否还需要?
大多数组织中的数据科学工作流程非常相似。许多公司雇佣数据科学家来解决类似的业务问题。大多数建立的模型不要求你提出新颖的解决方案。
你在这些组织中解决数据驱动问题时采用的大多数方法可能已经被使用过,你可以从网上丰富的资源中借鉴灵感。
此外,像 AutoML 和 DataRobot 这样的自动化工具的兴起使得预测建模变得更加容易。
我在一些商业用例中使用 DataRobot,它是一个很棒的工具。它会遍历许多值,并为你的模型选择最佳参数,以确保你获得最准确的模型。
如果预测建模随着时间的推移变得更简单,那么为什么公司仍然需要数据科学家呢?为什么不使用自动化工具和机器学习工程师的组合来管理整个数据科学工作流程呢?
答案很简单:
首先,数据科学从来不是关于重新发明轮子或构建高度复杂的算法。
数据科学家的角色是通过数据为组织增值。在大多数公司中,这仅涉及构建机器学习算法的极小一部分。
其次,总会有一些问题是自动化工具无法解决的。这些工具有一套固定的算法供你选择,如果你发现一个需要多种方法组合来解决的问题,你将需要手动解决。
尽管这种情况并不常见,但仍然会发生——作为一个组织,你需要雇用足够熟练的人来处理这些问题。此外,像 DataRobot 这样的工具不能进行数据预处理或模型构建前的繁重工作。
人情味
作为一个曾为初创公司和大型公司创建数据驱动解决方案的人,情况与处理 Kaggle 数据集的体验非常不同。
没有固定的问题。通常,你会有一个数据集,并且会给你一个商业问题。你需要找出如何利用客户数据来最大化公司的销售额。
这意味着数据科学家所需的不仅仅是技术或建模技能。你需要将数据与当前的问题联系起来。你需要决定哪些外部数据源可以优化你的解决方案。
数据预处理既漫长又繁琐,这不仅因为它需要强大的编程技能,还因为你需要对不同的变量及其与当前问题的相关性进行实验。
你需要将模型的准确性与诸如转化率这样的指标联系起来。
模型构建并不总是这个过程的一部分。有时,简单的计算可能足以完成像客户排名这样的任务。只有某些问题需要你实际进行预测。
最终,数据科学家为组织提供的价值在于他们将数据应用于现实世界的用例的能力。无论是构建分割模型、推荐系统,还是评估客户潜力,除非结果是可解释的,否则对组织没有实际的好处。
只要数据科学家能够借助数据解决问题,并弥合技术与商业技能之间的差距,这一角色就会继续存在。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。您可以通过 LinkedIn 与她联系。
了解更多相关主题
时尚中的数据科学
评论
作者 Preet Gandhi,纽约大学数据科学中心

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
背景
你小时候常去的多少家商店现在已经不复存在了?还记得 Sears、Zellers、American Apparel、Wet Seal、The Limited 等吗?许多其他知名零售商如 Aeropostale、Bebe、A&F、Guess、J.C Penney、Payless、Rue2 等也在全国范围内关闭了数百家门店,以应对销售下滑。福布斯估计,在 2017 年最后一个季度,21 家零售商关闭了 3,591 家门店。它们无法与电商部门竞争,因为越来越多的消费者选择在家舒适地在线购物,而不是亲自去零售店。零售商被迫利用数据来升级其基础设施和服务,以为客户提供更好的体验。许多 Macy’s、Coach、Kate Spade、Nordstrom 等公司的招聘信息显示了零售和时尚巨头在面对竞争时的严重性和迫切性。

介绍
时尚行业是一个竞争激烈且动态变化的市场。趋势和风格瞬息万变。一季的系列或趋势需要来自最具创意的头脑的数千个工时,而最终的成功取决于时尚专家、博客作者和名人的简单“热”或“冷”判断。数据科学可以在历史数据上进行应用,以预测哪些趋势会变得“火爆”,从而潜在地节省大量时间和金钱。例如,利用以往销售数据训练良好的模型,可以帮助我们预测 Kanye West 的新 Yeezy 第 6 季系列是否会成功。数据科学家可以使用预测算法、视觉搜索、从照片中捕捉结构化数据、自然语言处理等概念。
数据来源
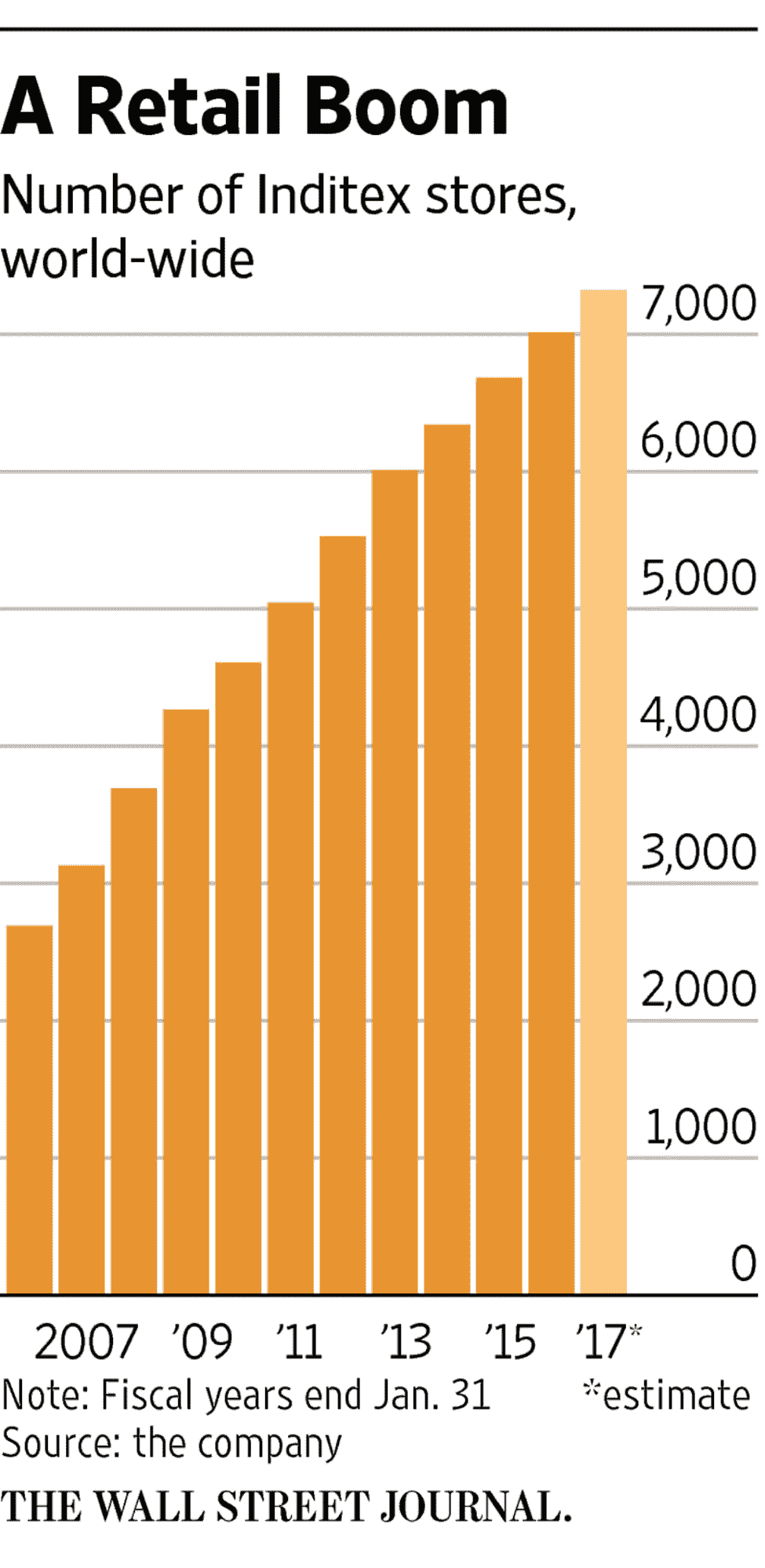 时尚和零售行业的数据非常丰富。来自零售商和百货商店关于顾客消费习惯的大量历史数据是传统来源。随着社交媒体的出现,帖子互动、Instagram 趋势、Twitter 标签、最受欢迎的时尚博主的穿衣风格、名人时尚风格、流行名人的“点赞/反应”等,提供了丰富的见解数据。在发布系列之前测试反应的一种新技术是将照片发布在社交媒体(Facebook、Twitter、Instagram、Pinterest)上,并研究评论,以便在推出之前对系列进行修改。这里使用情感分析来获取公众意见的见解。这些网站的公开 API 是开放和易于使用的。数据可以通过这些 API 实时抓取并转换为可用的形式。在线数据源是原始的和未审查的,反映了公众意见。如果正确利用,这些数据具有很大的潜力。你在网上找到的大多数数据都是非结构化的:文本、图像、音频和 YouTube 视频。非结构化数据在原始形式下可能具有挑战性,需要清理和转换。
时尚和零售行业的数据非常丰富。来自零售商和百货商店关于顾客消费习惯的大量历史数据是传统来源。随着社交媒体的出现,帖子互动、Instagram 趋势、Twitter 标签、最受欢迎的时尚博主的穿衣风格、名人时尚风格、流行名人的“点赞/反应”等,提供了丰富的见解数据。在发布系列之前测试反应的一种新技术是将照片发布在社交媒体(Facebook、Twitter、Instagram、Pinterest)上,并研究评论,以便在推出之前对系列进行修改。这里使用情感分析来获取公众意见的见解。这些网站的公开 API 是开放和易于使用的。数据可以通过这些 API 实时抓取并转换为可用的形式。在线数据源是原始的和未审查的,反映了公众意见。如果正确利用,这些数据具有很大的潜力。你在网上找到的大多数数据都是非结构化的:文本、图像、音频和 YouTube 视频。非结构化数据在原始形式下可能具有挑战性,需要清理和转换。
一个有趣的数据来源是顾客在商店内的 wifi 信号。跟踪顾客的行为模式,以查看他们停留的时间、顺序访问的区域、回访的频率以及在每个区域停留的时间。这种数据可以用于安排商店内的系列,并将经常一起购买的商品放置在一起。
例如:Zara
Zara 是时尚界最受欢迎和成功的商店之一。他们采用了“快时尚”的概念,即从设计一个系列到将其运送到商店的整个过程最多需要三周。这个品牌的成功归功于这一动态概念,其中零售商研究顾客的选择和偏好,以创建迎合他们口味的系列。他们创造顾客渴望的产品,而不是销售他们设计的产品。顾客自己可能不知道他们具体在寻找什么,但 Zara 的聪明商业分析师和数据科学家利用数据来创建一个系列,使顾客会自动喜欢,因为这正是他们的“口味”。此外,Zara 在全球范围内都有商店,顾客的不同人口统计特征意味着像尺寸、体型、颜色偏好和数量等简单因素会有很大差异。生产适量的正确产品有助于减少浪费。
关键问题领域
1. 颜色选项
通过大数据,我们可以找到顾客偏好的颜色,以策划畅销系列。特定风格的颜色范围、颜色组合等可以从销售数据和在线零售数据中挖掘出来。许多时候,顾客会购买一件衣服的某种颜色,然后换成另一种颜色。退换货的数据可以用来生产更多的受欢迎颜色的商品。
2. 男装还是女装?
每个设计师的目标受众或性别不同,以增加他们的知名度或销售量。设计师需要决定每个系列中的商品数量及所需的多样性。他们有一套固定的资源,如预算和展示空间,并需要数据支持的指导方针来决定每个类别分配多少。这在许多商店如 Forever21、H&M 等很常见,通常看到女性商品占据两三层空间,而男性商品仅占一层。这些零售商知道要为特定客户类别提供更多选项以增加销售。这些见解来源于历史销售数据。

3. 将时装秀风格转变为零售商品
很多在时装秀上展示的风格在现实生活中并不“适穿”。时装秀上的趋势往往被夸张,过于奢华,不适合零售。服装需要经过修改才能在商店中销售。训练算法以建议哪些特征如颜色、面料、剪裁、长度、组合等需要更改,可以确保产品在上架时销售良好。此外,每个国家/地区的口味不同。因此,每个产品必须根据当地偏好进行调整。
4. 服装价格
对于每件服装,设计师需要了解顾客愿意为其支付的价格,考虑到质量、风格、受欢迎程度和品牌价值。大数据应被用于平均之前的销售数据,以生成建议价格。竞争品牌的数据也可以用于设定价格,使其既不太高,又能带来良好的收入。
5. 揭示新的产品类别
品牌需要寻找市场上成功的新产品以及那些盈利潜力不大的产品。设计师需要考虑制作独特新产品是否会被顾客接受或拒绝。例如,创意鲜艳的印花可能适合瑜伽裤,但可能被认为对运动鞋过于花哨。大数据可以用于决定进入哪个类别以及是否继续销售某个特定的旧产品。
6. 店铺安排

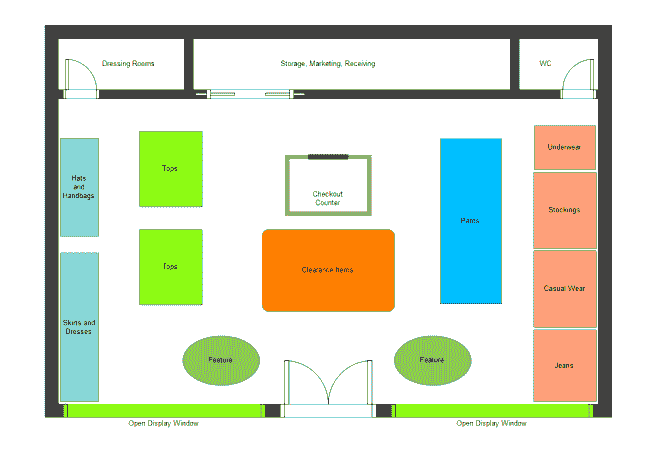
顾客在购物时会表现出特定的行为,这些行为可以被研究以便将商品安排在一种增加大多数商品销售机会的方式中。关联数据挖掘可以帮助我们决定将产品如何分组,以便顾客可能会挑选到大多数商品。你可能已经注意到,在许多服装店中,配饰通常被放置在我们站在结账区域附近的位置,这会促使顾客购买这些配饰。Wi-Fi 数据可以用来跟踪顾客在商店中的移动,从而以最佳方式安排库存。
结论
毋庸置疑,我们可以说数据驱动的决策将在竞争激烈的时尚世界中为你提供优势。在创建任何产品之前,需要参考数据以查看其经济可行性和前景。选择性地使用你的数据来创建和转换你未来的顾客肯定会购买的产品线,将有助于零售商在电子商务的浪潮中生存下来。有些人可能会说,AI 可能会使创意变得单调,因为它只是创造顾客想要的东西。但这就是为什么结果应该仅用来补充人类的创造性洞察,而不是完全替代它。不过,在正确的时间以正确的价格创造正确的产品也无伤大雅。
简历: Preet Gandhi 是纽约大学数据科学中心的硕士生。她对大数据和数据科学充满热情。可以通过 pg1690@nyu.edu 联系她。
相关:
-
机器学习和机器人技术正在转变的 4 个行业
-
酒店行业的大数据分析
-
应用数据科学:解决预测性维护业务问题 第二部分
更多相关话题
数据科学在电影行业中的应用
原文:
www.kdnuggets.com/2019/07/data-science-film-industry.html
评论
作者:弗兰基·沃拉斯。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
制作电影时涉及到无数因素,从确定制作成本到开发有针对性的营销活动。数据科学参与了几乎每一个步骤,数据科学领域的专业人士可以从电影行业中学到很多东西。
流媒体服务在数据科学革命的前沿。包括亚马逊、Hulu 和 Netflix 在内的制作公司分析大数据中的模式,以决定他们创作的内容类型,并提供个性化的观影推荐。通过这种方式,数据科学可以在前所未有的层次上帮助娱乐的制作和营销。
数据科学领域也在各种电影中作为重要主题出现。像艾伦·图灵和约翰·纳什这样的现实创新者的故事近年来被改编成主要电影,与那些使用预测分析、机器学习和人工智能作为中心情节的虚构故事并肩而立。
社会对数据科学影响的迷恋表明,关于这一主题的电影肯定会增多。此外,制作公司将继续利用这些技术更好地理解个人的观影习惯和偏好,以创作更受大众欢迎的内容。
电影成功指标与相关数据

图片来源:Pexels
技术可以告诉电影制作人他们应如何制作和营销任何一部电影。从选角决定到甚至营销中使用的颜色,电影的每一个方面都可以影响销售。利用技术,我们可以预测客户的偏好,并确定如何优化内容以达到最大的潜力。
预测观众对电影的期望几乎可以保证该电影的成功。在 2018 年,被华特迪士尼公司收购的 20 世纪福克斯公司发布了一篇论文,概述了如何使用机器学习分析电影预告片的内容。在这一过程中收集的数据用于比较预告片,并预测其他可能引起观众兴趣的电影。
20 世纪福克斯使用 Google 服务器和开源 AI 框架 TensorFlow 创建了 Merlin,一个“实验性的电影观众预测和推荐系统”。在 Merlin 的试运行中,该工具分析了超级英雄金刚狼的起源故事“Logan”的预告片,以预测“Logan”观众可能感兴趣的其他电影。在预测的 20 部电影中,11 部是正确的。
实际排名前五的电影都在预测名单中:X 战警: apocalypse;约翰·威克 2;奇异博士;蝙蝠侠大战超人:正义黎明;自杀小队。一般来说,观众在寻找一部以“坚韧的男性动作主角”为特色的超级英雄电影。
尽管其数据解释并不完美,Merlin 是过去十年软件开发演变的一个典型例子。为了让程序员更好地专注于改进 AI 算法,未来的软件开发必须包括旨在减少重复任务所花费时间的节省措施。由于 AI 设计用于专注于单一任务,它是提高程序数据分析准确性的理想起点。
大数据在分析中的作用
当大数据首次出现于 2010 年左右时,它有效地改变了将数据分析转化为有用洞察和利润的方法。大数据通常来源于外部,利用从互联网、公共数据源等收集的信息来做出更准确的预测。在娱乐行业中,大数据可以用于提供个性化的用户体验,并减少流媒体网站观众的流失率。
在用户可以选择的电影和电视节目种类繁多的情况下,留住观众对流媒体服务和电影制作公司至关重要。高流失率表明公司做错了什么,结合机器学习,大数据可以帮助公司识别问题领域。
在流媒体服务中,用户界面在观众留存中发挥着重要作用。例如,如果观众推荐不准确,可能会导致观众转向其他平台寻求娱乐。流媒体服务非常清楚积极用户体验的重要性。
为了保持观众的参与度,Netflix 开发并持续改进其自适应流媒体算法以优化流媒体质量并创造个性化用户体验。流媒体巨头会调整媒体的音频和视觉质量,以优化体验。他们还使用预测缓存,以便视频播放得更快或质量更高。例如,如果观众在观看一部系列剧,下一集将会被部分缓存。
与此同时,推荐系统基于显性和隐性信息。“显性数据是你字面上告诉我们的:你对《王冠》点赞,我们就知道了,”Netflix 产品创新副总裁 Todd Yellin 告诉 Wired。 “隐性数据实际上是行为数据。你没有明确告诉我们‘我喜欢《不可破的金米·施密特》’,你只是 binge 观看了它并在两个晚上内看完了,所以我们从行为上理解这一点。大多数有用的数据是隐性的。”
如果利润有所显示,Netflix 的算法无疑是成功的:自 2015 年以来,Netflix 的利润增长了超过 30%,年收入达到 166.14 亿美元。
电影行业中的预测分析

图片来源: Pexels
Merlin 和类似程序对预测分析的影响范围广泛,但需要更大范围的数据才能找到准确的模式。在过去几十年里,研究人员收集了数千部电影和电视节目的数据,以寻找可行的预测指标。在许多类别中发现了相关性,包括角色类型、情节复杂性、明星效应、预算和“buzz”,即围绕某部电影的社交讨论和市场推广。
Buzz 的显著特点在于,可以从许多来源获得有关这种现象的信息,例如社交媒体和评论。然而,围绕一部影片的 buzz 只是整体分析图景中的一小部分。数据分析必须在电影的每个生命周期阶段中使用,从开发到后期制作和发行。
预测分析可以帮助生产者、制作公司和高管做出战略决策、预测趋势,并更好地理解观众习惯。知情决策对电影制作过程至关重要,而获取高质量、高可用性的数据是客户保留和利润的关键s。数据科学家应注意电影行业利用预测分析和大数据的各种方式,并将这些知识带到其他行业和商业环境中。
个人简介: 弗兰基·华莱士是一位来自西北地区的自由撰稿人,他为多种在线博客撰稿。华莱士目前居住在爱达荷州的博伊西,是蒙大拿大学的应届毕业生。
相关:
更多相关话题
数据科学如何推动欺诈预防
原文:
www.kdnuggets.com/2022/09/data-science-fuels-fraud-prevention.html

图片由 Tima Miroshnichenko 提供
就像一个俄克拉荷马州的超级农场主被一个水力压裂公司接触一样,大多数电子商务公司并不知道他们所坐拥的潜在价值有多大。在这种情况下,我们谈论的不是自然资源,而是数据。数据挖掘被誉为新的石油热潮已经有 15 年了,但提炼原始数据的方法仍在不断探索中,我们可以用它来推动的机制也在不断发现中。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
许多电子商务公司熟悉利用他们从访问流量中收集的数据来进行客户细分和定向营销等功能。当然,这些都是利润收益清单上的首要想法,但产生令人印象深刻的利润的一部分也包括减轻欺诈带来的损失——这是一个逐年增加的关注点。数据科学也为此提供了动力。
利用数据增强您的欺诈解决方案
无论您转向哪个安全提供商,它提供的保护层都会从数据开始。一般来说,欺诈解决方案希望查看的数据点将从任何电子商务网站想要收集的信息开始。这些信息可能在数字市场中主动提供,意味着用户在提示时选择自行提供信息。常见的例子包括在网站上注册账户或订阅新闻通讯。这通常会产生如下数据点:
-
姓名
-
电子邮件地址
-
电话号码
-
物理地址
-
出生日期
或者,用户的数据点可能是被动收集的,用户没有有意、知情的参与:
-
IP 地址和其他连接信息
-
他们与网站的互动,包括花费的时间和其他行为生物识别数据
-
用于连接网站的设备的识别信息,一个设备指纹
单独来看,这些数据点可能无法提供有关单个客户的太多洞见。然而,拥有这些信息的公司能够较好地了解其访问者的合法性。欺诈软件可以利用这些数据点进行丰富化,将相对匿名的数据框架转变为完整的数字档案。
丰富你的欺诈打击能力
几乎所有使用身份验证来减少损失的欺诈解决方案都会大量依赖数据丰富化——即利用已知的数据点来扩展到相关的、更有用的数据点。通过这种方法,单一的(虽然重要)信息,如电话号码,可能会变成社交媒体上的帖子、照片以及朋友和家人。这些扩展的数据可以通过多种方式收集:
-
[封闭源数据]( https://www.e-education.psu.edu/geointmooc/node/2016#:~:text=Closed source data is government ,considered%20more%20accurate%20and%20reliable.),或用户在注册或入职过程中自己提交的个人识别信息,这些信息无法在开放互联网的其他地方找到。
-
专有数据库中的聚合用户数据是另一种封闭源数据。许多欺诈预防解决方案利用庞大的数据库来交叉验证进入的流量。这些数据库可能包括历史上的良好或不良用户、欺诈交易行为、声誉数据,甚至信用历史,一些公司使用的专有数据库中数据参考点可能达到数十亿。
-
OSINT 数据,即开放源智能,是可以从公开可访问的来源中收集的数据集合,如与电子邮件或电话号码相关联的账户和注册信息、社交媒体上的图片和帖子、传统新闻来源、公共记录如结婚或逮捕、地理位置数据等。
在初步收集的数据点经过这种丰富化处理后,欺诈软件现在拥有一个更易于评估、更具决定性的用户档案。在审查档案时,会根据发现情况给每个用户分配一个欺诈评分。例如,通过 VPN 连接等潜在的欺诈指标会增加评分。一旦达到预定义的阈值,大多数解决方案提供自动阻止用户进程或将案件提升到人工处理的功能。
定义公司风险容忍度阈值是执行主动反欺诈计划的一部分——最有效的一种。就像你地板下的欺诈者一样,关于自己公司的数据越多,安全性就可以越高。设定明确的目标——例如,阻止 ATO 攻击——至关重要,清理你的数据并相应地标记它也同样重要。清理数据是关键。
在防止欺诈方面,这种数据准备对于支持几乎所有欺诈解决方案 AI 的机器学习算法至关重要。这些算法,无论依赖于什么模型,需要训练以为特定公司生成准确的结果。训练教会软件识别系统中欺诈者和良好客户之间的微妙差异,逐渐提高准确性,识别什么是合格的,什么是可疑的异常值。如果没有训练,信任机器学习算法自主运行是一项风险决定,但经过良好训练的算法可能只需很少的人工监督,从而释放资源。
数据驱动的欺诈调查示例
一个用户来到你的电子商务平台,注册一个新账户,并开始他们的购物之旅。他们的用户数据看起来合法,因为他们填写了注册表单的每个部分,包括有效的电话号、电子邮件地址、姓名和位置。
然后你的欺诈软件介入,以防万一。通过对与提供的凭证相关的 OSINT 数据进行查找,程序注意到这个用户的电子邮件地址似乎是新的,而且他们的电话号码没有与任何社交网络关联——在 2022 年非常不寻常。虽然这个用户可能只是对社交媒体漠不关心,但大多数欺诈系统可以定制以标记这样一个异常用户为潜在可疑对象,并在其旅程被升级到人工审查时暂停处理。
专门的欺诈团队中的人工审查员介入,仔细查看此用户。最初,审查员倾向于将此用户标记为欺诈的假阳性,尽管他们的数字存在感很小。尽管仍有些犹豫,他们决定放大视角,查看软件报告的数据趋势分析。这一分析讲述了不同的故事。
该软件自动从汇总数据中提取洞察,注意到该用户的设备指纹与 70 个其他用户几乎相同。此外,通过运行速度检查,程序显示所有这些用户在网站上停留的时间相似,并且所有用户都在过去 72 小时内访问过该网站。此外,对所有这些账户的IP 分析显示,其位置与注册时声称的地址非常不同,并且许多这些 IP 来源于之前被标记为可疑的数据中心代理。
欣慰的是,他们没有简单地给这个用户绿灯,欺诈团队成员阻止了所有具有相同资料的交易。他们设置了一个自定义规则以检测匹配该资料的未来连接,然后享受了一顿因充实而令人愉快的午餐。
关键要点
首先,任何电子商务业务最大的收获应该是,针对进站流量的欺诈预防解决方案对遏制系统内的欺诈是至关重要的。欺诈技术越来越复杂,根据 UK Finance 的数据,仅去年英国就因欺诈损失了£24 亿。
第二个关键点是要意识到,任何欺诈解决方案在获得模型的最佳数据时将最为有效。虽然提供一个低摩擦、低流失的购物体验对于每个电子商务部门都很重要,但这种体验必须与公司对欺诈损失的承受能力相衡量。通过要求额外的身份信息给客户旅程增加一点摩擦,不应导致巨大的投资回报率下降。此外,这可能会对你的客户群体提供更有洞察力的视角,正如前面讨论的那样,这些视角是驱动你欺诈缓解和希望中的利润的燃料。
Gergő Varga 自 2009 年以来一直在各种公司打击在线欺诈——甚至共同创办了自己的反欺诈初创公司。他是《Dummies 欺诈预防指南——SEON 特别版》的作者。他目前在 SEON 担任内容宣传员,利用他的行业知识保持市场营销的敏锐,协调不同部门以了解欺诈检测的前线情况。他住在匈牙利布达佩斯,是哲学和历史的狂热读者。
更多相关话题
数据科学游戏 – 学生竞赛
数据科学竞赛,一项学生竞赛。
每年,协会组织一场国际数据科学挑战赛,以促进学生在这一领域的技能。挑战赛分为两个阶段,团队由四名学生组成,其中最多允许一名博士生。挑战的第一步是在线进行的,提供排名。这个排名基于不同团队对问题解决方案的表现,前 20 名团队可以参加挑战赛的第二阶段。同一所大学的两个团队不能被选中进入最终阶段。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
20 支入选的团队将在一个周末内处理由数据科学竞赛合作伙伴提供的数据,并在专业人士和数据科学专家面前展示他们的结果。颁奖典礼在合作伙伴的见证下结束挑战。

团队
我们的团队主要由数据科学家和来自巴黎萨克雷大学的学生组成。
重要信息
任何完成硕士或博士学位的学生都可以参加。我们邀请您查看条款和条件以获取更多细节。挑战赛将分为两个不同的阶段:
-
在线阶段在 Kaggle 上进行:任何团队(由 4 名学生组成)都可以申请。这个第一阶段将是有选择性的,将在 6 月举行。
-
最终阶段在巴黎举行,特别是在 Cap Gemini 的 Château Les Fontaines。第一阶段的前 20 名团队(每所大学 1 支团队:如果同一所大学有多支团队进入前 20 名,则仅选择最佳的团队)将在九月的整个周末进行竞争。
由学术研究人员和“Platine”成员代表组成的评审团将为最佳和最具创新性的工作颁发额外奖项。

下一位会是谁?
2015 年 6 月,20 支团队在整个周末竞争,挑战由谷歌·凯捷提供,地点为豪华的尚特勒·莱·丰丹。问题是预测 Youtube 视频标签。来自 5 个不同国家的 5 支团队因最佳成绩获得了我们的高级合作伙伴奖励。
| 大学 | 国家 | 2015 年数据科学排名 |
|---|---|---|
| 莫斯科国立大学 | 俄罗斯 | 1 |
| 拉萨比恩扎大学 | 意大利 | 2 |
| 巴黎高科电信学院 | 法国 | 3 |
| 阿姆斯特丹大学 | 荷兰 | 4 |
| 伦敦帝国学院 | 英国 | 5 |
相关:
-
在 Kaggle 数据科学竞赛中成功的 10 个步骤
-
KDD 杯竞赛的现状与未来
-
如何在不阅读数据的情况下主导数据科学竞赛
了解更多主题
数据科学历史与概述
原文:
www.kdnuggets.com/2020/11/data-science-history-overview.html
评论
由朱利亚诺·利戈里,全球首席信息官及数字化转型经理。
什么是数据科学?用简单的话说?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
“数据科学”这一术语最近才出现,专门指定一种新职业,旨在解读海量的大数据。但解读数据有着悠久的历史,科学家、统计学家、图书馆员、计算机科学家等已讨论了多年。
如今,作为一个业务领域的数据科学确实非常复杂,由于其显著的受欢迎程度,有许多对数据科学的描述,例如:
数据科学涉及分析数据并从中提取有用的知识。建立预测模型通常是数据科学家的最重要活动(格雷戈里·皮亚特斯基,KDnuggets,
www.kdnuggets.com/tag/data-science)。数据科学涉及分析大数据,以提取与可能性和误差估计的相关性(布罗迪,2015 年)。
数据科学是一门新兴学科,它借鉴了统计方法和计算机科学的知识,以为各种传统学术领域提供有影响力的预测和见解(哈佛数据科学计划
datascience.harvard.edu)。
然而,用简单的话说,数据科学家只是尝试从大量数据中获取洞察,以帮助公司做出更聪明的业务决策。我们还将数据科学定义为一种通过数据推断可操作见解的方法论。
数据科学使用各种数据导向技术,包括SQL、Python、R和Hadoop等。然而,它还广泛使用统计分析、数据可视化、分布式架构等,以从数据集提取意义。通过数据科学应用提取的信息用于指导业务流程和实现组织目标。
为了完成这一部分,我们还将提供数据挖掘、人工智能、机器学习和深度学习的简单定义,因为这些概念与数据科学及彼此相关。
-
数据挖掘旨在理解和发现数据中新的、以前未见的知识。
-
人工智能(AI)关注于让机器变得智能,旨在创建一个像人类一样行为的系统。
-
机器学习是人工智能的一个子集。机器学习旨在开发能够从历史数据中学习并通过经验改进系统的算法。
-
深度学习是机器学习(ML)的一个子集,在这个过程中,数据通过多个非线性变换来计算输出。

图 1 人工智能、机器学习、深度学习和数据科学之间的关系。
数据科学利用数据挖掘、机器学习、人工智能技术。
例如,深度学习需要在更强大的环境中运行 Jupyter。幸运的是,像 Saturn Cloud 这样的平台允许用户管理 Jupyter 开发环境。实际上,通过管理环境的资源,用户可以在必要时启用更多的 CPU、GPU 和内存。因此,专为云计算设计的平台允许保持环境成本低廉,使数据科学家只需为所使用的资源付费。
数据科学简史
数据科学彻底改变了我们世界的多个不同方面。让我们来看看数据科学的起源及其发展历程。
-
在 1962 年,约翰·W·图基在《数据分析的未来》中写道——数据科学历史上的第一个里程碑被全球公认为聪明的美国数学家约翰·图基。约翰·图基在统计学上的影响巨大,但最著名的词汇归功于他的是与计算机科学相关的术语。实际上,他是第一个引入“bit”一词作为“binary digit”缩写的人。
-
在 1974 年,彼得·瑙尔出版了《计算机方法简明调查》,这本书调查了各种应用领域的数据处理方法。术语“数据科学”变得更加明确,他给出了自己的定义:“处理数据的科学,一旦数据被建立,数据与其代表的内容的关系就委托给其他领域和科学。”
-
在 1977 年,国际统计计算协会(IASC)成立。
-
在 1989 年,格雷戈里·皮亚特基-夏皮罗组织并主持了第一次知识发现数据库(KDD)研讨会。
-
在 1994 年,《商业周刊》发布了一篇关于“数据库营销”的封面故事。
-
在 1996 年,国际分类学会(IFCS)会议上,第一次将“数据科学”一词纳入会议标题(“数据科学、分类和相关方法”)。同年,乌萨马·法亚德、格雷戈里·皮亚特基-夏皮罗和帕德雷克·史密斯发表了《从数据挖掘到知识发现数据库》。
-
1997 年,在他担任密歇根大学 H.C.卡佛统计学讲席教授的开幕讲座上,Jeff Wu 呼吁将统计学重新命名为“数据科学”,并将统计学家重新命名为“数据科学家”。

图 2 数据科学的历史。
自 21 世纪初以来,数据储备呈指数级增长,这在很大程度上要归功于高效且经济的处理和存储技术的出现。实时收集、处理、分析和展示数据和信息的能力为我们提供了前所未有的机会进行新的知识发现。为了处理这些海量数据,数据科学家需要高性能和大量的技术组合,以便在几秒钟内加快任务和数据处理速度。
由于有强大的平台可用,数据科学家如今可以利用人工智能、机器学习和深度学习等颠覆性技术。
数据科学实践中的挑战
尽管分析的采用增加了,但也带来了自己的一系列挑战。Kaggle 于 2017 年对 16000 名数据专业人士的样本进行的研究显示了他们职业中面临的 10 大最困难挑战:
-
脏数据(36% 报告)
-
数据科学人才短缺(30%)
-
公司政治(27%)
-
缺乏明确的问题(22%)
-
数据无法访问(22%)
-
结果未被决策者使用(18%)
-
向他人解释数据科学(16%)
-
隐私问题(14%)
-
缺乏领域专业知识(14%)
-
组织规模小,无法负担数据科学团队(13%)
这些挑战显得尤为突出。然而,我们需要意识到,每当一个新领域取得进展时,新的挑战也需要得到解决。我们必须拥抱变革,并确信这些变化有助于我们确保持续改进,获取新技能,拓展知识,探索新方法。
谁是数据科学家?
如上所述,随着操作数据的不断增长和新技术的出现,我们越来越需要具有分析敏锐性的专业人才,从海量数据中提取有价值的信息和见解,并做出精准决策。我们将这种类型的专家称为“数据科学团队”或简单称为“数据科学家”。
数据科学家是一个分析数据的专家,应该精通解决现代世界复杂问题所需的技术技能。今天新兴的技术,如人工智能、物联网、5G、机器人技术、区块链等,都严重依赖数据,只有那些能够操作数据并将其转化为有利产品的人,才能引领未来的数字业务。
因此,数据科学家在每个公司和组织的业务发展战略中扮演着至关重要的角色。正如托马斯·H·德文波特和 D.J.帕蒂尔所说,数据科学家是 21 世纪最性感的职业。
数据科学工具面向数据科学家
提供了丰富的软件工具支持数据科学家深入探索数据科学领域。如今,现有的平台使数据科学家能够使用他们最熟悉的工具(Python、Jupyter 和 Dask)进行大规模工作。通常,这些服务通过安全且可扩展的基础设施提供,以便在云环境中运行数据科学和机器学习工作负载。数据团队可以在自动化 DevOps 和 ML 基础设施工程下,以大规模在 Python 中开发和部署数据科学模型。
这些平台支持许多有用的 Python 库。
“Python 库是函数和方法的集合,使数据科学家可以执行许多操作而无需编写代码。”
-
NumPy 是一个为 Python 编程语言提供大规模、多维数组和矩阵支持的库。
-
Seaborn 是一个基于 matplotlib 的 Python 数据可视化库。
-
TensorFlow 是一个免费的开源软件库,用于跨多个任务的数据流和可微分编程。
-
PyTorch 是一个基于 Torch 库的开源机器学习库。
-
Numba 是一个开源 JIT 编译器,使用 LLVM 将 Python 和 NumPy 的子集翻译为快速的机器代码。
-
SciPy 是一个免费且开源的 Python 库,用于科学计算和技术计算。
-
Pandas 是一个为 Python 编程语言编写的数据处理和分析的软件库。
-
Scikit-learn 是一个免费的 Python 编程语言机器学习库。
-
Matplotlib 是一个用于 Python 编程语言及其数值数学扩展 NumPy 的绘图库。
-
Bokeh 是一个 Python 数据可视化库,提供高性能的交互式图表和绘图。

图 3 Python 库。
例如,广受认可的数据科学平台 Saturn Cloud 提供了一个全 Python 的端到端分析平台,在 AWS 上运行。包括:
-
Dask 允许组织扩展 Python 并显著减少运行时间。
-
协作工具、模型部署能力和机器学习生命周期的工具套件。
-
Prefect 提供了一个工作流编排框架,消除了开发者和数据科学家的手动工作。
-
与 Docker 和 Kubernetes 等服务的集成,使数据科学家能够构建自定义镜像,以满足他们最佳的开发期望。
-
Jupyter Notebooks 用于部署、管理和扩展 PyData 堆栈。
我们要去哪里?前景。
正如约翰·图基所预测的:“数据分析的未来可以涉及巨大的进步、克服真正的困难以及为所有科学和技术领域提供巨大服务。” 在过去的几年里,我们见证了许多数据驱动的技术创新,5G 超快的互联网速度、机器学习、云计算和区块链概念,这个显著的清单远非穷尽。数据的爆炸以及技术能力的增长只是一个开始,我们的生活正在随着技术创新变得“更智能”,这些创新很快可能会融入人类生活的各个方面。
原文。已获许可转载。
相关内容:
更多此类话题
数据科学与冒名顶替综合症
原文:
www.kdnuggets.com/2017/09/data-science-imposter-syndrome.html
评论
我不是一个真正的数据科学家。
我从未使用过深度学习框架,比如 TensorFlow 或 Keras。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
我从未接触过 GPU。
我没有计算机科学或统计学学位。我的学位是机械工程学,真是奇怪。
我不知道 R。
但我还没有放弃希望。阅读了一些职位发布后,我发现成为真正的数据科学家只需五个博士学位和 87 年的工作经验。
如果这听起来很熟悉,你要知道你并不孤单。你不是唯一一个担心自己还能伪装成数据科学家的时间有多长的人。你不是唯一一个对下一个面试被笑出来而做噩梦的人。
冒名顶替综合症是一种感觉,认为你领域中的其他人都比你更有资格,你永远不会被雇佣,或者如果已经被雇佣,那你是招聘过程中的一个错误。尽管统计上看这种感觉不太可能,但我们中的大多数人感到低于平均水平。根据我与同事的交谈,我估计我们中有 9 成在某一时刻遭受过冒名顶替综合症。(如果这对你来说完全陌生,我建议你阅读 Kruger 和 Dunning 的“无能而无意识”一书。)

即便是伊沃克有时也会感到像冒名顶替者。(图片由 Diane Rohrer 提供。)
真正的数据科学家是什么样的
“数据科学”是一个激发了很多兴奋的术语,就像一个磁铁,吸引了许多相关的子领域。我们称之为数据科学的领域仍然相对年轻,但对于个人来说,已经过于广泛,无法在每个角落都成为专家。根据我的经验,通才的数据科学独角兽是一种神话中的生物。我们中的任何人都无法涵盖所有领域。那么我们该如何继续?
前进的道路有两条:通才和专家。
一个好的通才
-
对数据科学的每个部分都具有表面上的熟悉感,
-
认识到所有的术语和技术词汇,
-
对解决特定问题所需的工具和专长有一个良好的概念,并且
-
在技术评审中提出有见地的问题。
一个好的专家
-
深入理解一个领域,
-
能够将他们的专业领域解释给非专家,
-
理解不同方法之间的权衡,
-
了解当前的研究和新工具,并且
-
可以快速使用他们的工具来产生高质量的结果。
一名通才不一定了解算法的细节和工具的使用技巧。他们会告诉你数据清洗很关键,但可能无法列举替代缺失值的方法之间的权衡。他们会告诉你 Spark 是加速计算的好方法,但可能无法建议你使用最佳设置。
一名专家不一定对自己领域之外的内容了解很多。他们会知道如何在 5 亿个数据点上运行线性回归的最佳架构,但可能无法解释朴素贝叶斯分类器。他们会敏锐地把握平方损失、铰链损失和逻辑损失之间的权衡,但可能无法从 Hive 表中查询数据。
另一种描述通才和专家的方法是“广度”与“深度”。他们都是技术精通的,但他们的专长分布不同。我们每个人都是部分通才和部分专家。随着职业的发展,你会找到最适合你的混合方式。
这种区分在招聘数据科学家时也很有帮助。具体要求具有深度神经网络研究经验或金融数据可视化背景的求职者,将比要求“全栈”数据科学家更有效地吸引符合需求的申请者。
如何证明你是一个真正的数据科学家
传统上,我们通过高级学位来确立在某个领域的资格。不幸的是,对大多数人来说,数据科学领域的高级学位非常稀缺。我们没有一张纸作为盾牌,当有人质疑我们的资格时。因此,我们该怎么做呢?我们如何回答批评者、面试官、同事,甚至是我们内心最严厉的声音?
以木工为例。假设你想在厨房里安装一个定制的橱柜。三位木匠前来询问这项工作。第一位木匠展示了她的证书。她说:“我在城市顶级的橱柜制造商那里做了七年的学徒。”第二位木匠打开了她的工具箱,说:“我的凿子是最新设计的,没有人能比我的刨子更锋利。”第三位木匠递给你一个小盒子,樱桃色且光滑完美。当你用指尖拉动把手时,一个抽屉无声地滑出。她说:“这是我做的。”
认证、工具和作品集都是建立资历的热门方式。我不会争论哪一种优于另一种,但作品集对数据科学家特别有效。认证较少且尚未标准化。列出我们使用过的算法和计算机语言并不能传达我们对它们的熟悉程度或我们能用它们做什么。 构建项目 向非技术观众展示了我们能为他们做什么,并向技术面试官和同事展示了我们的专业知识。当然,这不能保证你会在第一次面试中得到工作。但即使没有,这也是正常的。 继续面试。
成为真正的数据科学家的感受
请注意,无论是全能型还是专门型的数据科学家都有很多不知道的事情。这意味着即使是真正的数据科学家也会大部分时间感到迷茫。我们的项目负责人会问我们不知道答案的问题。 同事会轻松地谈论我们从未听说过的算法。队友会写出我们完全无法解读的代码。文章会引用我们不知道存在的“热门”子领域。档案论文会抛出我们如同象形文字般难以理解的方程式。实习生会指出我们推理中的根本缺陷。这没关系。你没有做错。这没关系。
我们的目标不是积累答案,而是提出更好的问题。如果你在提出问题并利用数据寻找答案,那么你就是一名数据科学家。就这样。
原文。经许可转载。
相关内容:
-
KDnuggets 顶级博主:与顶级数据科学家 Brandon Rohrer 的访谈
-
数据科学口袋指南
-
如何获得数据科学工作:一个非常具体的指南
更多相关话题
数据科学如何改善高等教育
原文:
www.kdnuggets.com/2018/11/data-science-improving-higher-education.html
评论

大数据为高等教育提供了巨大的机会。越来越多的高校以及政府正在使用数据科学来改进教育机构在招聘、学生互动和预算等方面的方式。
我们的前三大课程推荐
1. Google 网络安全证书 - 加入网络安全领域的快速通道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
以下是数据科学正在改善高等教育的六种方式。
1. 提高毕业率
几乎所有大学的主要目标之一是提高毕业率。有很多策略可以实现这一目标,数据可以帮助学校确定哪种策略最适合它们。
分析关于辍学学生与完成学业学生的数据,可以帮助学校识别出最有可能离开的学生特征。它还可以使学校为这些学生提供资源,以减少他们辍学的风险。
费城的天普大学一直在使用数据来提高其毕业率。它发现那些收入适中并获得部分佩尔助学金的学生最有可能辍学,即使与那些获得全额佩尔助学金的最低收入学生相比也是如此。它还发现,拥有四年高中外语学习经历的学生较不容易辍学。
使用这些数据,天普大学向处于风险中的学生提供了经济援助,并启动了帮助改善学生校园归属感的举措。该校的四年毕业率已从 20%上升到 44%,六年毕业率从 59%上升到 70%。
2. 改进招聘策略
数据还可以帮助学校吸引学生报名并入学。学校越来越多地使用数据来决定针对哪些潜在学生,从而制定他们的宣传活动和个性化的营销内容。
为了寻找潜在学生,许多学校会分析当前年份的学生特征,然后针对具有相似特质的高中生。学校还可以分析哪些学生毕业并取得了最成功的成绩,以确定哪些类型的人可能最适合该大学。
例如,圣路易斯大学意识到需要扩大其地理覆盖范围,这是基于其学生通常来自的地区高中毕业生数量预计将下降。它使用了高中生在注册 SAT 或 ACT 时填写的大学偏好问卷中的信息。
它寻找那些适合该大学的学生,并表明他们愿意为上学而旅行。
3. 优化支出
当学校追踪支出并努力计算各种投资的回报时,它们会生成大量的数据点,用于优化支出。通过结合来自多个学校的数据,国家教学成本与生产力研究,也称为德拉华成本研究,帮助学校发现更有价值的见解。
大约 700 所大学和学院参与德拉华成本研究,该研究使学校能够将其提供一个小时的教学成本与其他机构的成本进行比较。它还提供了其他方面的数据,如教学负担以及常规教员进行的教学量。
德拉华成本研究项目允许参与的机构定义其同伴群体,以获取最符合其目标的比较。以这种清晰定义的方式访问个性化数据,使信息更具实用性和可操作性。教育机构可以利用这些数据优化成本,提高与其他大学的竞争力。
4. 提升校园安全
在校园内增加摄像头可能有助于威慑潜在的犯罪分子并提高校园安全,但手动分析视频录像也非常耗时。然而,将数据分析系统整合到安全系统中可以大大简化这一过程,并以其他方式提高安全性。
启用分析功能的安全系统,例如塔尔萨大学的系统,可以定义搜索条件,比如嫌疑人穿的衣物。系统会自动开始提取匹配这些条件的数据。安全团队还可以设置高风险情况的警报,以便他们知道在什么时间监控哪些摄像头。
例如,如果一辆车在夜间驶入停车场,保安团队会收到警报,告诉他们检查哪个监视器。然后,如果他们发现任何可疑的情况,他们可以更快地派出团队。
5. 缩小公平差距
数据科学还可以帮助学术机构改善面临独特挑战的群体的成果,包括少数族裔、低收入和第一代学生。在过去几年中,乔治亚州立大学在这方面已成为领军者,这部分归功于其对数据的使用。现在,从乔治亚州立大学毕业的黑人学生的学士学位数量超过了美国其他非营利学校。
学校成功的秘诀在于一个以数据为基础的辅导系统。该程序使用算法来监控学生的表现。如果系统检测到学生的工作开始出现问题,他们的辅导员将会主动联系他们提供帮助。学校还为那些发现自己难以支付学费的学生提供小额资助。
6. 提高学生参与度
与学校和校园更有互动的学生更有可能按时毕业,并且可能会有更好的大学经历和对大学的认知。跟踪参与度指标可以帮助学校联系那些没有参与的学生。
例如,诺丁汉特伦特大学跟踪进入建筑物的卡片刷卡记录、图书馆使用情况、虚拟学习环境使用情况和电子作业提交。学校发现,基于这些指标参与度低的学生中有四分之三 未能从第一年顺利过渡到第二年。
根据这些发现,学校开发了一个程序,辅导员会联系那些两周内没有参与的学生。这有助于在低参与度对学生产生更严重影响之前,将他们引导到正确的方向上。
从改善学生成果到帮助学校变得更具竞争力,数据科学在高等教育中的作用日益增长。利用数据改善教育的趋势不会在短时间内放缓。
简介: 凯拉·马修斯 在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上讨论技术和大数据,并且已有五年以上的写作经验。要阅读凯拉的更多文章,订阅她的博客 Productivity Bytes。
相关:
-
你是否应该无偿提供你的数据技能?
-
在两年内提高你的数据科学技能的 8 种方法
更多相关内容
数据科学的不便之处
原文:
www.kdnuggets.com/2015/05/data-science-inconvenient-truth.html
评论作者:卡米尔·巴尔托查(lastminute.com)
-
![数据清理]() 数据从来不会是干净的。
数据从来不会是干净的。 -
你将花费大部分时间来清理和准备数据。
-
95%的任务不需要深度学习。
-
在 90%的情况下,广义线性回归会解决问题。
-
大数据只是一个工具。
-
你应该接受贝叶斯方法。
-
没有人关心你是怎么做的。
-
学术界和商业界是两个不同的世界。
-
演示至关重要——成为 Power Point 的高手。
-
所有模型都是错误的,但有些是有用的。
-
数据科学没有完全自动化的解决方案。你需要亲自动手。
 数据从来不会是干净的。
数据从来不会是干净的。简介:卡米尔·巴尔托查 是 lastminute.com 的数据科学负责人,数据处理、数据系统架构和人工智能领域的专家。
原始文章。
(编辑:你认为的数据科学的不便之处是什么?请评论)
相关:
-
采访:亚历山德罗·加利亚尔迪,Glassdoor 论数据科学家的有趣与无聊之处
-
自动统计学家与数据科学渴望的自动化
-
数据科学家对商学院的建议
进一步了解此主题
数据科学实习面试问题
原文:
www.kdnuggets.com/2020/08/data-science-internship-interview-questions.html
评论
由Jay Feng,数据科学负责人兼Interview Query联合创始人。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
数据科学是一个有吸引力的领域。它有利可图,你可以有机会参与有趣的项目,并且总是能学习到新知识。因此,进入数据科学领域竞争非常激烈。开始你的数据科学职业生涯的最佳方式之一是通过数据科学实习。
在这篇文章中,我们将探讨总体所需的知识水平、典型面试流程的组成部分以及一些示例面试问题。注意,“总体”一词被强调,因为具体内容因公司而异。
数据科学实习面试中期望具备什么?
数据科学实习面试和全职数据科学家的最大区别在于,你通常不需要了解关于机器学习或深度学习概念的极其具体细节。
然而,你需要具备能够在其基础上进行构建的基本构件——这包括 Python、R 或 SQL、统计学和概率基础以及基本的机器学习概念。
以下是使你成为有吸引力候选人的基本知识和技能列表:
Python 或 R

Python 数据科学库来自TechVidan.
你应该有脚本语言的编程经验,理想情况下是 Python 或 R。如果你是 Python 程序员,你还应该对流行的库如Scikit-learn和Pandas有基本了解。
你应该知道的: 你应该知道如何编写基本函数,并对各种数据结构及其用途有基本理解。你还应该了解 Scikit-learn 的一些基本(但重要)功能,如 test_train_split 和 StandardScaler。对于 Pandas,你应该能够像使用 SQL 编写查询一样,熟练操作 DataFrames。
例如,你可能需要构建一个简单的机器学习模型来预测产品的销售数量。在这种情况下,如果你是 Python 用户,了解 Scikit-Learn 库将非常有用,因为它提供了许多现成的函数,比如上面提到的那些。
如何准备: 尝试在 Kaggle 上做数据科学项目或在 Interview Query 上完成家庭作业,以了解你可能需要完成的项目。
为了更好地了解 Scikit-Learn,构建一个简单的机器学习模型或浏览其他人完成的一些数据科学项目会是一个好主意。
最后,尝试在 Interview Query 上练习 Python 问题,以了解他们可能会问你什么。
SQL

SQL 数据库来自HackersAndSlackers。
你不需要在关系数据库方面有太多经验,但至少应该了解 SQL 的工作原理。 如果你争取一个数据科学实习,那么你很可能会在一个拥有大量数据的公司工作。你将被期望自己浏览这些数据以解决问题。
你应该知道的: 你应该能够编写基本查询,并知道如何使用 SQL 查询操作数据。公司在其家庭作业案例研究中常常会涉及 SQL,因此你需要对 SQL 非常熟悉。
示例问题:
编写一个 SQL 查询以获取Employee表中的第二高薪水。例如,给定以下 Employee 表,查询应返回200作为第二高薪水。如果没有第二高薪水,则查询应返回null。
+----+----------+
| Id | Salary |
|---|
+----+----------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+----------+
如何准备: Mode 提供了一个很好的学习基础 SQL 的资源,你可以在这里找到。此外,还有大量的 SQL 练习题和案例研究可以在网上找到。
统计学与概率论

图片来源于Unsplash。
你应该对基础统计学和概率论有一定了解。这些概念是大多数机器学习和数据科学概念的基础。同时,许多数据科学职位的面试问题与统计学相关。
你应该知道的: 你应该对基本概念有扎实的理解,包括但不限于概率基础、概率分布、估计和假设检验。统计学的一个非常常见的应用是条件概率——例如,给定一个客户购买了产品 C,那么他购买产品 B 的概率是多少?
如何准备:如果这些概念对你来说很陌生,你可以利用一些免费的资源,比如可汗学院或乔治亚理工学院。
机器学习概念

机器学习来自 Forbes。
虽然你不需要成为专家,但你应该对基本的机器学习模型和概念有较好的理解。如果职位描述中提到你会负责构建模型,这一点尤为重要。
你应该知道的内容:这包括但不限于线性回归、支持向量机和聚类等概念。理想情况下,你应该对这些概念有基本的理解,并了解何时使用各种机器学习方法。
例如,你可能需要对一个产品的价格点实施线性回归,以确定销售数量。也就是说,作为实习生,你不会被要求将机器学习模型投入生产或部署。
领域知识
你应该对你申请的领域有领域知识(如果没有,你应该学习)。
例如,如果你申请的是市场部门的数据科学职位,了解不同的营销渠道(如社交媒体、联盟、电视)以及核心指标(如 LTV、CAC)会是一个好主意。
数据科学实习面试过程

图片来自 Unsplash。
再次强调,面试过程最终取决于你申请的公司。但一般来说,大多数(如果不是所有)公司在面试过程中都会有一些常见的步骤,我将在下文中解释。
你作为实习生能做的最糟糕的事情就是不研究公司及其文化使命和价值观。
初步筛选
通常,初步筛选(通常是电话筛选)由公司的人力资源或招聘经理进行。其目的是让面试者对角色有更好的了解,而面试官可以更好地了解面试者。
你应该预期他们会询问你对这个角色和公司的兴趣,你认为自己为什么适合这个职位,以及与你过去经历相关的问题。在极少数情况下,你也可能会被问到一两个简单的技术问题。
面试官只是确保你对公司真正感兴趣,你是一个良好的沟通者,并且没有任何明显的警示信号。
家庭作业案例
现在许多数据科学实习公司会要求你完成一个带回家挑战。这意味着他们会给你一定的时间来完成他们提供的案例研究,这通常反映了你在实际角色中会遇到的那种问题。
这样做是为了了解你如何解决问题(即你的思考过程)以及你是否具备完成问题所需的基本知识。案例示例包括清理数据集和构建机器学习模型以进行给定预测,或查询数据集和分析数据,或两者的结合。
现场面试
最后是现场面试,可能包括一轮到多达六轮的面试。这些面试包括行为性和技术性的面试问题。你也可能需要在某一轮中当场完成一个案例。
虽然他们会尽力确保你对成功履行该角色所需的基本知识有深入的理解,但他们也会评估你的行为、动机,最终判断你是否适合团队。确保你表现得最好,但不要忘记做你自己!
面试问题
以下是 10 个你应该了解的面试问题示例:
-
什么是 p 值?
-
什么是正则化,它试图解决什么问题?
-
你如何将年龄和收入之间的关系转化为线性模型?
-
如果你有两个相同重量的骰子,得到和为 4 的概率是多少?
-
在整理和清理数据集时,你会采取哪些步骤?
-
什么是交叉验证,它为什么必要?
-
举一个例子说明当准确率不是衡量机器学习模型效果的最佳指标时的情况。
-
INNER JOIN 和 OUTER JOIN 有什么区别?
原文。经许可转载。
相关:
更多相关内容
数据科学面试指南 - 第一部分:结构
原文:
www.kdnuggets.com/2022/04/data-science-interview-guide-part-1-structure.html
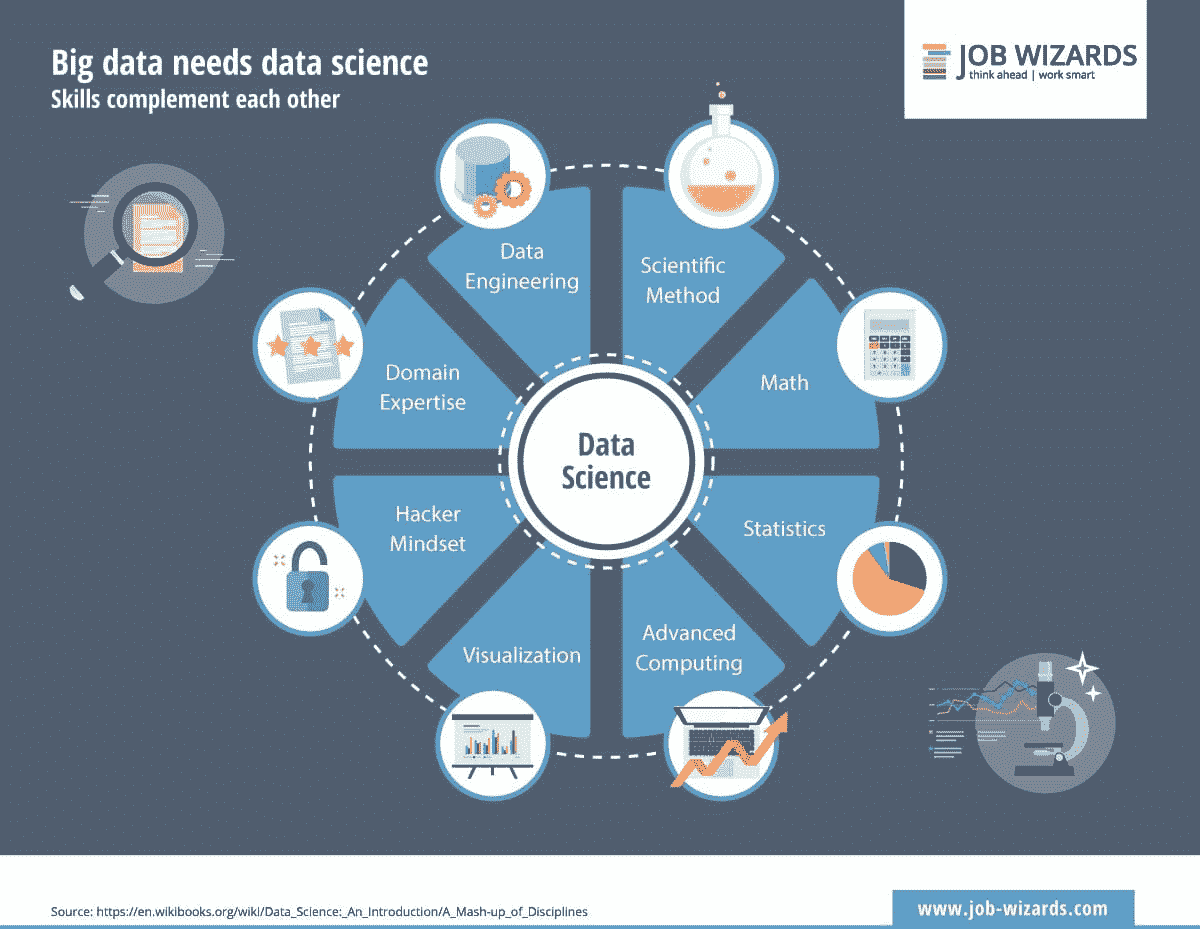
来源:WikiBooks
数据科学是一个广泛的领域,包括各种各样的领域。主要方面包括数学、计算机科学和领域专长。
根据 IGotAnOffer 的说法,数据科学家面试中通常会问的问题可以分为五类。这是通过分析来自领先科技公司的 300 多个数据科学面试问题得出的。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
这五类问题包括:
-
编程 (38%) - 这将测试你的问题解决能力以及你如何使用算法、SQL 等来操作数据。
-
统计学 (21%) - 这将测试你对统计学整体的理解,以及你如何在解决问题的任务中应用统计学。
-
机器学习 (17%) - 这将测试你理解机器学习理论的能力,如何构建模型,如何将其应用于特定问题/任务,并且如何改进它。
-
与业务相关 (12%) - 这将测试你对技术知识的理解,以及这些知识如何用于推动业务和确定正确的决策。
-
行为面试 (13%) - 这将测试你的特征,并确定你是否适合公司。
编程
数据科学面试的编程部分占最高比例,达 38%。面试的三分之一以上将基于编程,这是正常的,因为你正在面试数据科学职位。
编程问题旨在分析和评估候选人在计算机科学及其基础知识方面的能力。它可以涵盖以下主题:
-
数据结构:数组、字典、栈/队列、字符串、树/二叉树等。
-
算法:二分查找、递归、排序等。
-
SQL:约束条件、主键/外键、联接等。
示例问题包括:
-
如何反转一个整数?
-
编写一个程序,使用你选择的编程语言打印从 1 到 50 的数字。
-
SQL 中的不同连接是什么?
统计学
统计学是数据科学的重要组成部分。统计学帮助数据科学家分析大型复杂数据集。它在机器学习中被广泛应用于改进模型。
理解流行的统计术语及其在数据科学任务中的应用将帮助你在数据科学领域取得成功。它可以涵盖以下话题:
-
概率分布
-
假设检验
-
建模
这些话题将围绕概率和统计展开。示例问题包括:
-
描述 A/B 测试
-
P 值通俗来说是什么?
-
t 检验是什么?
机器学习
随着机器学习模型在日常生活中的应用,它成为了数据科学的重要方面,我们如何不断改进以便在商业等领域实施。
数据科学家以解决问题和创建模型著称,因此在数据科学面试中,面试官将测试你构建模型的能力、整体工作流程及如何改进。
这可以涵盖以下话题:
-
人工智能
-
模型构建、验证和解释
-
算法的类型
-
机器学习的使用案例
示例问题包括:
-
监督学习和无监督学习之间有什么区别?
-
列出 5 种监督学习算法
-
包装和提升之间有什么区别?
-
如何减少模型的过拟合?
商业相关
数据如此有价值的原因在于它可以让人们更深入理解数据,并帮助做出重要决策。
将技术知识应用于商业案例场景将帮助面试官了解你如何利用技能改善和发展公司。
这可以涵盖以下话题:
-
产品的性能和局限性
-
商业的短期和长期目标
示例问题包括:
-
影响产品 X 销售下降的变量是什么?
-
变量 J 会在接下来的 6 个月内提升产品 X 的性能吗?
-
你会建议我们做什么来提高准确性?
-
根据指标的输出,我们应该做出什么决策?
行为
尽管大多数技术职位需要强硬技能,但软技能同样重要。你的软技能将决定你是否适合这个角色。
在行为阶段,利用简历中的元素阐述自己将使你更成功。
例如,一些公司可能更倾向于一个高度独立且几乎不需要互动的候选人。面试官会浏览你的简历,并询问你在之前公司中的工作经历以及你的工作方式。你将理解他们需要一个独立的员工,并可以挖掘你过去的独立经验。
示例问题包括:
-
你为什么选择成为数据科学家?
-
你认为你能为公司带来什么?
-
你最成功的项目是什么?为什么?
-
你最不成功的项目是什么?为什么?你会如何改进它?
-
你如何处理多任务?
我们已经讨论了数据科学面试的 5 个类别,下一步是为面试做准备。

掌握数据科学面试是我推荐的第一本数据科学面试书籍。它由前 Facebook 员工Kevin Huo和Nick Singh编写。
本书包括 201 个真实的数据科学面试问题,这些问题曾被 Facebook、Google、Amazon、Netflix 等公司提问。书中包含详细的逐步解决方案,以帮助你更好地理解。
主题包括概率、统计学、机器学习、SQL 与数据库设计、编码(Python)、产品分析和 A/B 测试。
Nisha Arya是一位数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何/可以如何有利于人类生命的长寿。她是一位热衷学习的人,寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
数据科学面试指南 – 第二部分:面试资源
原文:
www.kdnuggets.com/2022/04/data-science-interview-guide-part-2-interview-resources.html

来源: Maya Maceka 通过 Unsplash
以下是一些资源列表,帮助你为数据科学面试做好准备,或者用于提升你的技术技能,或是开始学习数据科学。这些资源可以帮助你实现所有目标。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
Seattledataguy
Seattledataguy 汇编了一份数据科学学习指南,帮助人们为面试做好准备。这个 Excel 表格:数据科学面试指南 是由曾在亚马逊、Facebook 等大公司面试过的人创建的。
如果你想使用这个表格,你可以复制一份,并按照学习指南添加个人笔记。
主题包括:
-
机器学习算法
-
概率与统计
-
产品与实验设计
-
编程
-
SQL
Udacity 免费面试准备课程
Udacity 提供免费的面试准备课程,确保你能获得理想的技术职位。这些课程涵盖了数据科学的不同方面,包括:
codeacademy 课程
Codeacademy 也是一个提供帮助你进行面试准备的课程的平台。然而,这些课程不是免费的;你需要注册 Pro 版的 codeacademy 计划。当你完成任何 Pro 计划的课程,包括面试准备课程时,还会获得一份证书。
包括的课程有:
Udemy 课程
Udemy 提供了广泛的课程,能够在你的数据科学之旅中提供帮助。然而,有一些课程专门为指导你通过数据科学面试准备阶段而精心策划。这些包括:
Krish Naik - YouTuber
Krish Naik 是 iNeuron 的联合创始人,目前拥有 542K 订阅者。他有超过 10 年的经验,并讲解数据科学、机器学习、深度学习及更多领域的理论和应用。他在 YouTube 频道上有三种不同类型的会员;数据科学材料、数据科学指导和项目实时数据科学。
他有一个面试问题的播放列表,这些包括:
他有更多详细的播放列表:
备忘单
备忘单是以通俗易懂的方式学习复杂主题的好方法。与其我列举所有备忘单,不如阅读Abid Ali Awan(@1abidaliawan)发表在 KDnuggets 上的两篇文章。你将能找到学习数据科学和准备面试所需的每一份备忘单。
-
数据科学备忘单完整合集 – 第一部分
-
数据科学备忘单完整合集 – 第二部分
上述提供的资源将帮助你在数据科学面试中取得最佳结果。然而,你可以做一些准备工作来使过程更加顺利。
研究角色和公司
了解更多关于你申请的角色和公司的信息将对你大有帮助。确保你理解角色的要求,以及你是否符合这些要求。表现过度总比表现不足要好。
如果职位描述中列出了你不熟悉或需要复习的特定任务,你可以在面试前利用时间进行准备。
对公司及其目标进行额外的研究会给面试官留下深刻印象,因为这表明你渴望了解他们更多信息。
优势和劣势
了解自己在软技能和硬技能上的优点和缺点,将为你提供更好的改进指南。诚实地评估你的技术技能,并且直言不讳你缺乏的技能,将帮助面试官更好地理解你如何能为公司带来益处。
对每一项技能都说“是”只会让你在工作中陷入困境,当被要求做一项你没有经验的任务时,推销自己很重要,但撒谎并不会帮助你。
如果你没有他们正在寻找的特定技能,但后来获得了第二次面试的机会,利用这段时间通过学习更多关于该技能的知识来打动他们。
提问
面试官喜欢提问的人。这让他们可以更多地与你互动,教你关于他们公司的情况,并了解你是什么样的人。
这些问题可以与您面试的职位相关。这个职位是替代性的角色吗?会提供培训吗?我的典型工作日会是什么样的?团队有多少人?我将与谁密切合作?公司在寻找什么样的候选人?
你也可以问一些更个人化的问题,例如:你喜欢公司什么?你认为公司可以改进哪些方面?
所有这些问题都可以让面试官和面试者更好地了解彼此,以及他们是否适合这个角色。提问没有坏处,所以尽管问吧!
结论
希望《数据科学面试指南》第一部分和第二部分对你有所帮助。祝你面试顺利,希望你能获得你想要的工作!
尼莎·阿亚是一名数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/能够促进人类寿命的不同方式。作为一个热衷学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
数据科学面试指南
原文:
www.kdnuggets.com/2018/04/data-science-interview-guide.html/2
评论
机器学习模型
现在我们有了最佳特征,是时候训练我们的实际模型了!机器学习模型分为两大类:监督学习和无监督学习。监督学习是当标签可用时。无监督学习是当标签不可用时。明白了吗?监督标签!带点双关意味。话虽如此,千万不要混淆监督学习和无监督学习的区别!!!这个错误足以让面试官取消面试。此外,另一个新手常犯的错误是运行模型前没有标准化特征。虽然有些模型对这个问题具有抵抗力,但很多模型(如线性回归)对尺度非常敏感。因此,经验法则是:使用前务必标准化特征!!!
线性与逻辑回归
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
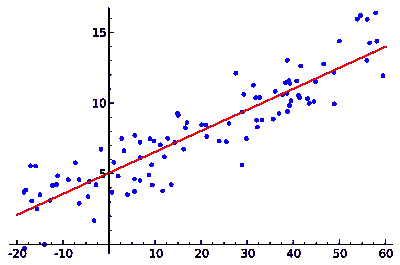
线性回归和逻辑回归是最基本且最常用的机器学习算法。在进行任何分析之前,务必先进行线性/逻辑回归作为基准!一个常见的面试失误是直接从更复杂的模型如神经网络开始分析。神经网络无疑具有很高的准确性。然而,基准测试是重要的。如果你的简单回归模型已经有 98%的准确率并且非常接近过拟合,那么使用更复杂的模型并不是明智的选择。值得注意的是,线性回归用于连续目标,而逻辑回归用于二元目标(主要因为 sigmoid 曲线将特征输入强制到 0 或 1)。
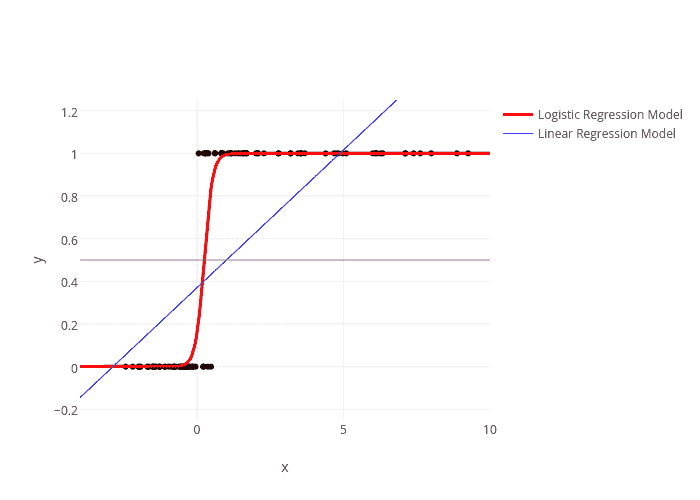
我建议同时掌握逻辑回归和线性回归(包括单变量和多变量)。除了为面试做准备,线性回归模型还被用作各种其他机器学习模型的基础。因此,这是一项长期投资。
决策树与随机森林
比线性回归模型稍复杂的模型是决策树。决策树算法根据信息增益在不同特征上进行划分,直到遇到纯叶子(即只有一个标签的记录集)。可以通过在一定数量的划分后停止决策树来防止出现纯叶子(修复过拟合问题的常用策略)。
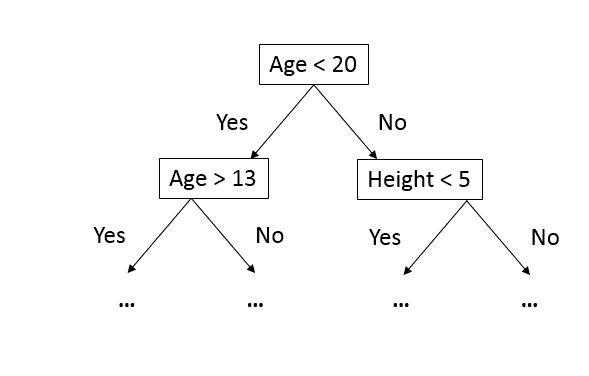
计算用来划分树的信息增益是很重要的。常见面试问题!确保你知道如何计算信息增益!!! 常见的信息增益计算函数有基尼系数和熵。
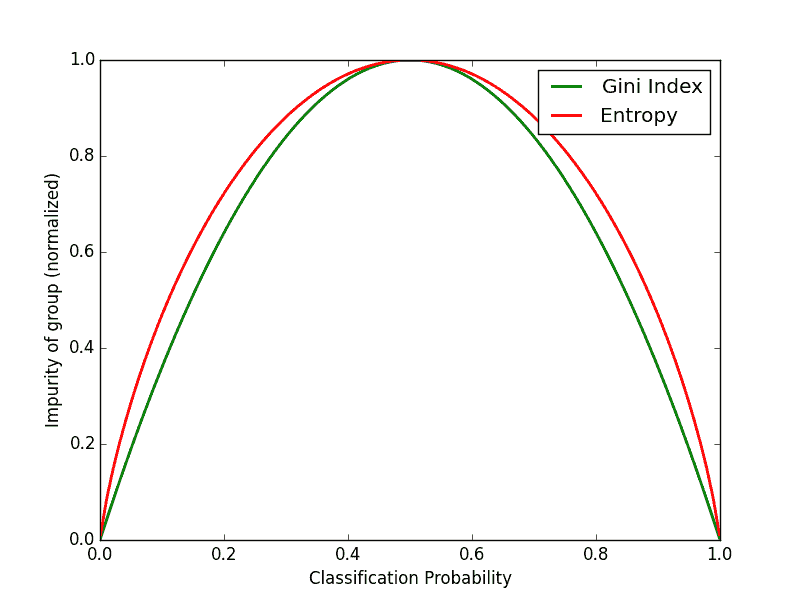
上述曲线中重要的是,熵对信息增益的值更高,因此会比基尼系数引起更多的划分。
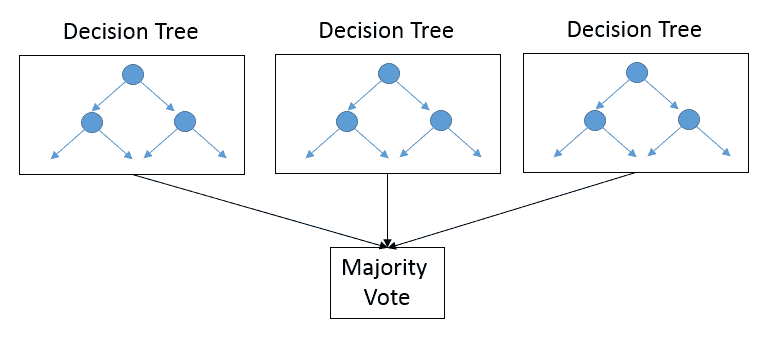
当决策树不够复杂时,通常会使用随机森林(它只是多个决策树在数据子集上生长,最终进行多数投票)。如果树的数量没有正确确定,随机森林算法可能会过拟合。有关决策树、随机森林和基于树的集成模型的更多信息,请查看我的其他博客:在 Scikit-Learn 上学习决策树和集成模型
K-Means
K-Means 是一种无监督学习模型,用于将数据点分类到不同的簇中。提供簇的数量,使得模型会不断调整质心,直到迭代地找到最佳簇中心。
簇的数量是通过肘部曲线来确定的。
簇的数量可能很难确定(尤其是当曲线没有明显的拐点时)。另外,要注意 K-Means 算法是局部优化而非全局优化。这意味着你的簇将取决于初始化值。最常见的初始化值是在 K-Means++中计算的,其中初始值尽可能远离彼此。有关 K-Means 和其他无监督学习算法的更多细节,请查看我的其他博客:基于聚类的无监督学习
神经网络
神经网络是现在大家都在关注的一个热门算法。
虽然我无法在这个博客上涵盖所有复杂的细节,但了解基本机制以及反向传播和梯度消失的概念是非常重要的。同样重要的是认识到神经网络本质上是一个黑箱。如果案例研究要求你构建一个可解释的模型,选择不同的模型或准备好解释你如何找到权重对最终结果的贡献(例如图像识别过程中隐藏层的可视化)。
集成模型
最后,单一模型可能无法准确地确定目标。某些特征需要特殊的模型。在这种情况下,会使用多个模型的集成。以下是一个示例:
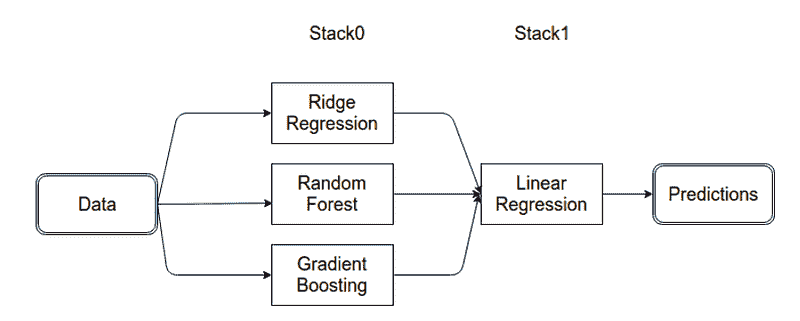
这里,模型以层或堆栈的形式存在。每一层的输出是下一层的输入。
模型评估
分类评分
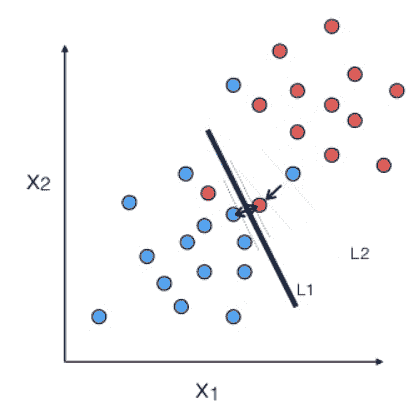
评估模型性能的最常见方法之一是计算记录被准确预测的百分比。
学习曲线
学习曲线也是评估模型的常见方法。在这里,我们旨在查看我们的模型是否过于复杂或不够复杂。
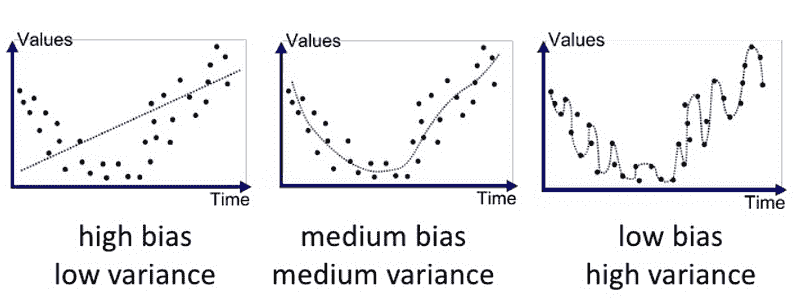
如果模型不够复杂(例如我们决定在模式不是线性的情况下使用线性回归),我们会遇到高偏差和低方差的问题。当我们的模型过于复杂(例如我们决定在简单问题上使用深度神经网络)时,会导致低偏差和高方差。高方差是因为结果会随着训练数据的随机化而变化(即模型现在非常不稳定)。在面试过程中不要混淆偏差和方差的区别!!!为了确定模型的复杂性,我们使用如下所示的学习曲线:
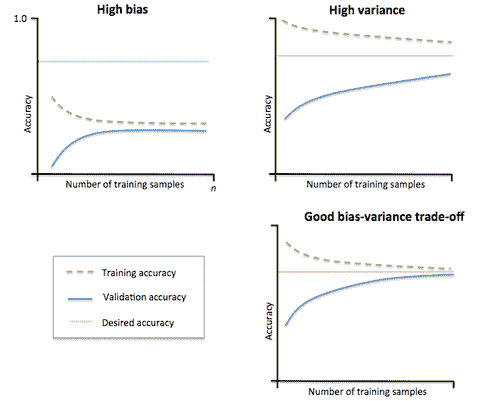
在学习曲线上,我们在 x 轴上变化训练-测试分割,并计算模型在训练集和验证集上的准确性。如果它们之间的差距过大,则说明模型过于复杂(即过拟合)。如果曲线中的任何一条都没有达到期望的准确度,而且曲线之间的差距过小,则数据集偏差较大。
ROC
当处理具有严重类别不平衡的欺诈数据集时,分类评分并没有多大意义。相反,接收者操作特征(ROC)曲线提供了更好的替代方案。
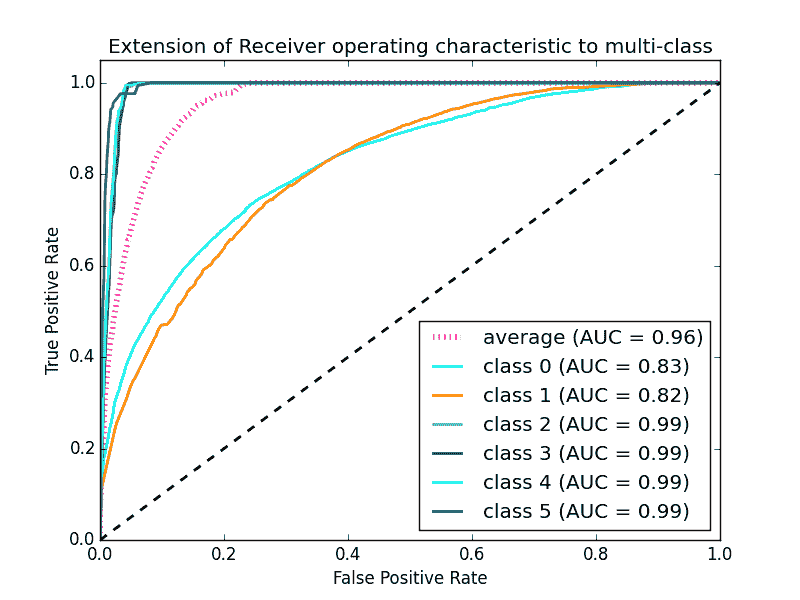
45 度线是随机线,其中曲线下面积(AUC)为 0.5。曲线离此线越远,AUC 越高,模型越好。模型的最高 AUC 值为 1,此时曲线形成直角三角形。ROC 曲线也可以帮助调试模型。例如,如果曲线的左下角接近随机线,则意味着模型在 Y=0 时误分类。而如果在右上角是随机的,则意味着错误发生在 Y=1。此外,如果曲线有尖峰(而不是平滑),则表明模型不稳定。在处理欺诈模型时,ROC 是你的最佳朋友。
额外材料
关于本课程:机器学习是让计算机在没有明确编程的情况下行动的科学。在…www.coursera.org](https://www.coursera.org/learn/machine-learning)
这个专业化课程由华盛顿大学的领先研究人员提供,将带你进入令人兴奋的…www.coursera.org](https://www.coursera.org/specializations/machine-learning)
来自 deeplearning.ai 的深度学习。如果你想进入人工智能领域,这个专业化将帮助你做到这一点。深度…www.coursera.org](https://www.coursera.org/specializations/deep-learning)
个人简介:Syed Sadat Nazrul 正在利用机器学习来抓捕网络和金融犯罪分子,并在夜晚写有趣的博客。
原文。已获授权转载。
相关:
-
成为数据科学家的两个方面
-
如何在数据科学面试中生存
-
数据科学家招聘指南
更多相关内容
数据科学面试学习指南
原文:
www.kdnuggets.com/2020/01/data-science-interview-study-guide.html
评论
作者 Ben Rogojan,SeattleDataGuy。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
数据科学面试,如同其他技术面试一样,需要充分的准备。为了确保你能够应对统计学、编程和机器学习的连续问题,需要涵盖多个主题。
在开始之前,我想分享一个提示。
我注意到公司进行的数据科学面试有几种类型。
一些数据科学面试非常以产品和指标为导向。这些面试更多关注像你会使用什么指标来展示你应该改进产品的地方等产品问题。这些问题通常与 SQL 和一些 Python 问题搭配出现。
另一种数据科学面试往往混合了编程和机器学习。
如果你不确定将面对哪种类型的面试,我们建议询问招聘人员。有些公司非常擅长保持面试的一致性,但即便如此,团队也可能会根据他们的需求有所不同。以下是我们注意到的一些公司数据科学面试的例子。
Airbnb — 产品导向,指标诊断,指标创建,A/B 测试,大量行为问题,以及家庭作业材料。
Netflix — 产品感觉问题,A/B 测试,实验设计,指标设计
Microsoft — 编程为主,二叉树遍历,SQL,机器学习
Expedia — 产品、编程、SQL、产品感觉、关于 SVM、回归和决策树的机器学习问题
由于这种差异,我们创建了一个清单,以跟踪你学习过的主题领域以及你仍需覆盖的内容。
首先,确保你能解释基本的数据科学算法。
机器学习算法
-
逻辑回归 — 视频
-
A/B 测试 — 视频
-
决策树 — 博客
-
SVM — 博客
-
如何使用 SVM — 视频
-
主成分分析:PCA — 博客
-
主成分分析 — 视频
-
AdaBoost — 博客
-
AdaBoost — 视频
-
机器学习中的梯度提升算法的温和介绍 — 博客
-
梯度提升第一部分:回归主要思想 — 视频
-
K-Means 聚类 — 智能数学 — 视频
-
贝叶斯网络 — 博客
-
神经网络 — 博客
-
降维算法 — 博客
-
kNN 算法如何工作 — 视频
概率与统计
在大型科技公司,偶尔会收到概率或统计学的问题。虽然这些问题不一定需要复杂的数学,如果你有一段时间没有考虑独立和依赖概率,那么复习基础公式是很有帮助的。

概率视频
概率测验
概率面试问题
这些问题大多数都与我们被问过的问题相似,或者直接取自于glassdoor.com。
-
一个骰子被掷了两次。第一次掷出 3 和第二次掷出奇数的概率是多少?
-
在任何 15 分钟的时间间隔内,有 20%的概率能看到至少一颗流星。在一个小时的时间段内看到至少一颗流星的概率是多少?
-
爱丽丝有两个孩子,其中一个是女孩。另一个孩子也是女孩的概率是多少?你可以假设世界上男性和女性的数量相等。
-
你可以将 12 个人分成 3 个 4 人团队的方式有多少种?
统计学预测
统计学概念
统计学是一个广泛的概念,所以不要过于纠结于这些视频的细节。相反,确保你能在表面层面解释这些概念。
统计学测验后
产品与实验设计

产品意识是数据科学家必备的重要技能。了解在新产品上应该测量什么及其原因,有助于确定产品是否表现良好。有趣的是,有时候某些指标朝着你期望的方向发展,可能并不总是好事。人们在你的网站上花费更多时间,可能是因为网页加载时间更长或其他类似的用户面临问题。这就是为什么指标很棘手,以及你测量什么是重要的。
产品与实验设计概念
产品与指标问题
-
一个重要指标下降,你会如何深入分析原因?
-
你会使用什么指标来量化 YouTube 广告的成功(这也可以扩展到其他产品,如 Snapchat 滤镜、Twitter 直播、Fortnite 新功能等)
-
你如何衡量一个产品/产品功能的成功或失败
-
Google 发布了其搜索算法的新版本,他们使用了 A/B 测试。在测试过程中,工程师发现新算法没有正确实施,返回了不相关的结果。在测试过程中发生了两件事:
-
治疗组的人比对照组执行了更多的查询。
-
治疗组的广告收入也更高。
为什么治疗组的人比对照组执行了更多的搜索?这里可能有不同的答案。
问题 4 来源于 Zarantech; 我们非常喜欢这个问题,并认为它很好地展示了事情如何可能出错。
编程
仅仅因为数据科学并不总是需要大量编程,并不意味着面试官不会要求你遍历二叉树。因此,确保你问问面试官预期会遇到什么问题。不要被这些问题吓倒。做几个练习,以防在面试中感到意外。
视频前问题
算法与数据结构
视频前问题
在查看关于数据结构和算法的视频内容之前,考虑尝试以下问题。这将帮助你了解需要关注的重点。
数据结构视频
算法视频
字符串操作
SQL
学习后问题
现在你已经学习了一些内容,并观看了一些视频。让我们尝试一些更多的问题吧!
SQL — 问题
一般来说,面试中至少会有一个以 SQL 为重点的部分。此外,面试官可能会带你了解整个产品开发过程,选择需要跟踪的指标,然后进行查询以衡量该指标的有效性。
SQL — 视频
后续 SQL 问题
结论
技术面试可能会很艰难。不论是针对软件工程师、数据工程师还是数据科学家。我们希望这份学习指南能帮助你跟踪进展!
如果你认为我们遗漏了什么,或者有其他你认为有帮助的资源,请告知我。谢谢!
原文。经许可转载。
简介:Ben Rogojan是位于西雅图的数据科学家兼工程师,拥有丰富的经验,设计了 ETL 管道、数据库、网站以及其他初创公司和成熟公司的软件产品。Ben 目前在一家健康分析公司担任数据工程师。
相关:
更多相关内容
如何获得数据科学面试机会:寻找工作、联系关卡管理者和获取推荐
评论
获得面试机会对许多工作岗位来说自然至关重要,数据科学岗位也不例外。虽然关于这一话题的资源肯定不乏,但实用且可操作的建议却很少。在我开始求职时,我知道超过 70%的求职者通过某种形式的网络关系找到工作。我知道我应该“联系招聘人员并建立我的网络以进入这个领域”。但即便知道了这些,我仍然面临一个重要问题:怎么做?
我第一次寻找数据科学工作是在 2017 年 2 月快要完成研究生学业的时候。我尝试了所有可能获得面试机会的方法,包括……
-
在 LinkedIn、GlassDoor 和 Indeed 上提交了数百份申请
-
在所有社交网络上联系(校友、共同朋友)的人以获取推荐
-
在 Google 上进行研究,并尝试了所有推荐的内容(除了创建自己的数据科学职位),比如“获得数据科学面试的十大方法”、“获取数据科学工作的 5 个技巧”和“如何获得数据科学工作:一个极其具体的指南”。
-
花费了大量时间创建、格式化和完善我的简历
在以全职工作的投入(即每天至少花费 8 小时)进行三个月的求职之后,我终于通过 AngelList 获得了第一次面试机会。
我第二次寻找数据科学工作的时间是在 2018 年 12 月被当时的初创公司裁员之后。这一次,我使用 50 份申请和 18 个推荐,在一个月内获得了10 次面试机会(总共花费了不到 30 小时)。这种巨大的差异并不是因为我有更多的工作经验。实际上,我第二次的市场竞争力并没有明显提高。这种剧烈的变化是因为我第一次做得完全错误!这不是因为关于获得数据科学面试的文章具有误导性或不准确,而是它们只告诉我应该做什么,而没有告诉我如何去做。
在这篇文章中,我不仅会分享应该做什么(只有 3 种方式而不是 10 种),还会分享如何有效地执行这些方式以获得面试机会。你将在这篇文章中找到策略、脚本和其他免费资源,这些将帮助你在求职过程中保持条理和有序。具体来说,这个博客解答了以下问题:
-
我应该在哪里寻找数据科学工作?
-
我该如何联系关卡管理者?
-
我该如何获得推荐?
-
什么样的数据科学简历才算优秀?
在我们开始之前,你是否更喜欢看视频?可以观看这个 YouTube 视频,而不是阅读。
三种方法
获得面试的三种方式是:原始申请、联系守门人和获取推荐。原始申请就是简单地将你的简历提交到职位空缺上。虽然这是一个简单的方法,但效率通常较低。联系守门人可能更有效,但需要更多的努力。获得推荐是最有效的方法,但也需要最多的时间和精力(假设你还没有认识愿意推荐你的人)。下面的图示展示了这三种方法在努力/时间和效果方面的视觉效果。
图片由Emma Ding提供 | 获得面试的三种方式
原始申请:搜索的地方很重要!
当我们首次想到检查工作机会时,通常会立即转向流行的在线招聘网站,如 LinkedIn、GlassDoor 或 Indeed。第一次找工作时,我在 LinkedIn 提交了数百份申请,但零回复。事实上,一些正在转行的朋友也发现他们在 LinkedIn 上没有收到回复。当我开始第二次找工作时,我没有在 LinkedIn 上提交任何申请。
为什么?问题在于每个职位发布后,往往在一周内会收到数百份申请。如果你仅仅依赖这些热门的招聘网站,你获得回应的机会会非常渺茫。你正在与大量候选人竞争!
不幸的是,近年来,LinkedIn 已成为一个服务于希望接触具有特定经验和资格的潜在候选人的招聘平台。它不是一个服务于缺乏经验的求职者的平台,因为你必须与数百(有时是几千)名申请者竞争一个职位。
解决这个问题的一种方法是在不太流行的网站上申请。使用那些尚未成为主流的网站。怀疑?Edouard Harris 在他的博客文章中很好地解释了为什么“公司更关注通过不那么知名渠道申请的候选人”。这里列出了一些我和我认识的人尝试过并证明有帮助的网站。还有一些网站是专门与数据科学相关的。
-
KDnuggets 工作
-
数据科学中心 — 分析人才(以美国为中心)
-
DataJobs(以美国为中心)
-
Icrunchdata(以美国为中心)
此外,还有一些较小的在线招聘网站,其回应率高于前三大招聘网站。
-
AngelList — 我就是通过它找到的第一份数据科学工作!
每当在任何招聘网站上申请时,尽量向招聘人员发送个性化的说明。研究公司(通过公司网站、谷歌和 Glassdoor),并解释为什么你是这个职位的最佳人选。个性化将大大提高你获得回应的机会。
联系门卫:迎接更多面试机会

照片由 Austin Distel 提供,来源于 Unsplash
尽管我推荐的网站的回应率通常高于大型招聘网站,但招聘人员的回复仍可能需要数周时间,因为他们总是有一堆简历要审阅。现在你可能需要尝试第二种方法——直接联系门卫。我发现使用这种方法比原始申请更快获得回应。
门卫指的是你有意在其中工作的公司里的技术招聘人员或数据科学家。大公司通常有专门负责招聘数据科学家的技术招聘人员,但小公司的数据团队可能更加自给自足。如果你能够赢得门卫的青睐,这可能会使你在招聘过程中取得进展。
以下是赢得门卫青睐的几个步骤:
-
编制你感兴趣的公司个人列表(即使目前没有职位空缺)。
-
通过访问公司网站或使用 LinkedIn 查找门卫的联系方式(同一公司可能有多个门卫)。
-
制作一个能够吸引门卫注意的邮件提案。
-
如果一周左右没有收到回复,请发送跟进邮件,并继续跟进直到收到拒绝为止。
邮件提案应简洁而完整。你的邮件可能会被转发到其他人那里,没有人会为你复制和粘贴多个邮件,所以提案需要涵盖所有内容。一个好的邮件提案包括两个部分:
-
第一部分是简短的介绍(2~3 句话),包括你的意图、对你经验的简要描述以及你对公司的兴趣。再次强调,对公司进行一些研究将大大帮助你以具体的方式表达兴趣。
-
第二部分是关于你最有影响力的项目。确保这部分内容有趣、易读且易于分享。
为了简化问题,这里有一个模板。

这个邮件模板更新自通过艰难的方式学到的教训:破解数据科学面试,作者是 Greg Kamradt
如果你在几天内收到回复,那很好!但如果在一周左右没有收到回复,给门卫发一封跟进邮件。根据我和我朋友的经验,跟进邮件的回复率高于第一次发送的邮件。这是我用来发送跟进邮件的模板:

这个邮件模板更新自如何跟进求职申请:邮件模板,作者是 Alex Cavoulacos
虽然你可以使用这两个模板作为起点,但不要直接复制。如果门卫看到完全相同的邮件模板,会留下负面印象。你可以更改内容,可以让它更长或更短。只要记住,主要目的是展示你的兴趣并发送所有必要的信息。
获取推荐:在你梦想公司面试的最佳方式

图片由Christina @ wocintechchat.com在Unsplash提供
在第一次找工作时,我联系了校友、拥有共同朋友的人,甚至是随机的人以获取推荐。然而,最终没有得到任何推荐。相比之下,在第二次找工作时,我的网络中的人们在我还没有请求之前就主动告诉我他们愿意推荐我。
随着时间的推移,我了解了一些关于请求推荐的误解。获取推荐是让某个熟悉你工作的人给他们的公司提供一个热情的推荐。这不是去烦扰你在 LinkedIn 或其他地方找到的陌生人。此外,大多数情况下,后者的方法并不起作用。
获取推荐与联系门卫的不同之处在于,它从与技术公司员工建立关系开始,无论他们的职业是什么。无论他们是产品经理、软件工程师、产品设计师,还是其他任何职位。建立关系是非常重要的。Haseeb Qureshi 有一篇很棒的博客文章讲述了如何打入科技行业。特别是在网络建设方面的部分非常精彩。Qureshi 说……
……人们**讨厌**当你要求他们给你一份工作。
给你一份工作?为什么?他们不了解你。他们为什么会给你工作?他们为什么会浪费时间在你身上?
信息性面试的力量在于,它不是让事情围绕你展开,而是让它围绕他们展开。人们喜欢谈论自己,他们喜欢教别人,他们想要帮助他人。但他们不想被陌生人烦扰寻求帮助。
如果你持续这样做,人们会看到你的好奇心和真诚。他们会相信你的故事,并且愿意推荐你。
这可能听起来工作量很大,特别是当你之前没有做过的时候,但实际上只需要 4 个步骤来正确建立关系:
-
请人喝咖啡。在疫情期间这可能不容易做到,因此你可以请求一个简短的 Zoom 聊天。
-
进行信息性面谈。你需要展示对对方及其工作以及他们公司的兴趣。
-
第二天通过电子邮件感谢他们并进行跟进。你不希望仅仅建立一次性的联系。关系需要维护。
-
一旦有人愿意推荐你,你需要使推荐过程顺利进行。不要问“你们公司有没有职位空缺”,而是自己查看公司网站,找到最适合你的职位。然后准备一封电子邮件,附上你的简历、职位链接、你经验的描述,以及你为何适合该职位的解释。
这些具体的步骤使我在第二次求职时获得了18 个推荐。如果你遵循所有这些步骤,你将会获得强有力的推荐!这不仅会帮助你在第一次求职时,还会对未来的求职有帮助。
下面是一个冷邮件模板,你可以用作首次联系的参考。这里的重点是让邮件变得个性化,展示你的真实兴趣。

这个邮件模板更新自如何进入科技行业由 Haseeb Qureshi 提供。
再次强调,世界很小。不要照搬完全相同的脚本。花时间定制你的信息,因为从长远来看,这样的努力是值得的。
优秀简历的特点

图片由Scott Graham提供,来自Unsplash。
根据你的目标和可用时间,你可以选择一种或多种方法来获得面试。但无论你使用哪种方法,良好的简历是关键。这是吸引招聘人员的关键因素。
简历是你成就的总结。它应该简洁,因此不是展示你所有知识或技能的地方。添加过多内容只会让人感到信息过载。因此,在你的数据科学简历中,你需要突出与数据科学相关的最重要的内容,如工作经验、培训和相关技能。当招聘人员或招聘经理看到你的简历时,他们应该立刻感受到你在数据科学领域有丰富的经验,并且你是一个合格的候选人。
这里是我在测试自己的简历、与许多招聘人员和招聘经理交谈以及审查其他人的简历后制定的一些简历书写规则。
避免红旗:
-
一份好的简历始终保持在 1 页长。 招聘人员和招聘经理每天收到很多简历,他们通常只有不到一分钟的时间浏览一份简历并做出决定。如果你的简历有多页,他们可能甚至不会看第二页。
-
不要有拼写错误。 让朋友进行同行评审,确保在发送之前没有拼写错误或语法错误。
改善你的简历:
-
有选择性和精心编排。 从你影响力最大的经历、项目和技能开始。在经历和项目部分,确保每一项不超过四个要点。第一个要点应始终是最具影响力的点,以业务指标来衡量,例如用户保留率或转化率的改善,跳出率或成本的减少等。
-
简洁明了。 你的简历展示了你的沟通能力,为了证明你能有效沟通,你应该注意去除冗余的短语和重新组织冗长的表达。
让你的简历脱颖而出:
-
不要只是说,要展示数字和指标。 在描述你的经历和项目时,展示你通过业务指标来衡量的贡献。展示处理的数据规模和类型,并引用你使用的确切技术。具体化使你的简历更值得信赖。
-
不要对所有职位发送相同的简历。 为每个申请添加定制化的调整总是值得的。至少,如果你注意到职位描述中提到了重要的关键词和技能,请在简历中使用这些关键词,并突出你的相关技能。编造内容是不行的,但完全可以重新组织你的技能和经历,以适应职位描述的背景。
最后的思考
说到底,获得数据科学面试是困难的,尤其是对初学者而言。当你努力了几个月却没有收到任何回应时,这可能会让人灰心。希望这篇文章能为那些正在寻找工作的有志数据科学家们带来一些启示。如果你需要更多建议,可以随时通过这里联系我,我很乐意提供帮助!
感谢阅读!
如果你喜欢这篇文章并想支持我……
-
订阅我的YouTube 频道!
-
关注我在Medium上!
-
在Linkedin上联系!
-
是什么激励我开始使用 Medium 和 YouTube?请看下面的答案(剧透:一次裁员!)
获得 100%面试到录用率的秘诀
简介: Emma Ding 是 Airbnb 的数据科学家和软件工程师。
原文。经许可转载。
相关内容:
-
我如何在失业两个月后获得 4 份数据科学职位的录用,并使收入翻倍
-
如何获得数据科学家的工作
-
如何在没有任何工作经验的情况下获得第一份数据科学工作
更多相关主题
物联网(IoT)的数据科学:与传统数据科学的十个区别
原文:
www.kdnuggets.com/2016/09/data-science-iot-10-differences.html
评论
介绍
在过去的二十年中,超过六十亿个设备已经联网。所有这些连接的“事物”(统称为 - 物联网)每天生成超过 2.5 万亿字节的数据。相当于每天填满 57.5 亿台 32 GB 的 iPad(来源:Gartner)。这些数据必然会在未来几年内显著影响许多商业流程。因此,物联网分析(物联网的数据科学)的概念预计将推动物联网的商业模式。根据《福布斯》,强大的分析技能更有可能在物联网中取得 3 倍的成功。我们在物联网的数据科学课程中涵盖了许多这些理念。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
物联网的数据科学有相似之处,但也有一些显著的差异。这里是物联网的数据科学与传统数据科学的 10 个区别。
图片来源:Postscapes。
-
硬件和无线层的工作
-
边缘处理
-
物联网垂直领域使用的具体分析模型
-
物联网的深度学习
-
物联网的预处理
-
传感器融合在物联网中的作用
-
实时处理与物联网
-
物联网的隐私、保险和区块链
-
人工智能:机器间互相教导(云机器人)
-
企业的物联网和人工智能层
1) 硬件和无线层的工作
这可能听起来很明显,但很容易被低估。物联网涉及处理各种设备以及各种无线技术。这是一个快速变化的生态系统,有新技术如 LoRa、LTE-M、Sigfox 等。5G 的部署将带来重大变化,因为我们将拥有局部和广域连接。每个垂直领域(我们跟踪智能家居、零售、医疗保健、智慧城市、能源、交通、制造业和可穿戴设备)也有一套特定的物联网设备和无线技术。例如,对于可穿戴设备,你会看到使用蓝牙 4.0,但对于工业物联网,你可能会看到保证服务质量的蜂窝技术,如 GE 与 Verizon 的 Predix 联盟。
2) 边缘处理
在传统的数据科学中,大数据通常存储在云端。但物联网并非如此!许多供应商如思科和英特尔称之为边缘计算。我在之前的文章中详细介绍了边缘分析和物联网的影响:物联网边缘分析的演变。
3) 在物联网垂直领域使用的具体分析模型
物联网需要强调不同的模型,这些模型也取决于物联网垂直领域。在传统的数据科学中,我们使用各种算法 (数据科学家使用的顶级算法)。对于物联网,时间序列模型通常被使用。这意味着:ARIMA、Holt Winters、移动平均。不同之处在于数据量的大小,但也包括这些模型的更复杂的实时实现,例如 (pdf) : ARIIMA: 减少能耗的机器学习架构的实际物联网实现。不同的物联网垂直领域使用的模型也有所不同。例如在制造业:预测性维护、异常检测、预测和缺失事件插值是常见的。在电信领域,传统模型如客户流失模型、交叉销售、增销模型、客户生命周期价值等可能会将物联网作为输入。
4) 物联网的深度学习
如果将相机视为传感器,深度学习算法如 CNN 在安全应用中有许多应用,例如来自 hertasecurity。强化学习也在物联网中有应用,我在 Brandon Rohrer 的文章中讨论了 强化学习与物联网。
5) 物联网的预处理
物联网数据集需要不同形式的预处理。Sibanjan Das 和我在 深度学习 - 物联网与 H2O 中提到过。
深度学习算法在物联网分析中发挥着重要作用。来自机器的数据是稀疏的和/或具有时间性。即使我们信任来自特定设备的数据,设备在不同条件下的行为也可能不同。因此,捕捉算法的数据预处理/训练阶段的所有场景是困难的。持续监测传感器数据也是繁琐且昂贵的。深度学习算法可以帮助减轻这些风险。深度学习算法可以自主学习,使开发者能够专注于更好的事物,而无需担心训练它们。
6)传感器融合在物联网中的作用
传感器融合涉及将来自不同传感器和来源的数据结合起来,使得结果信息的不确定性比单独使用这些来源时要小。(摘自维基百科)。在这种情况下,“不确定性减少”可以意味着更准确、更完整、更可靠,或指基于综合信息得出的新视角。传感器融合一直在Aerospace等应用中发挥关键作用:
在航空航天应用中,加速度计和陀螺仪通常被耦合到一个惯性测量单元(IMU)中,该单元根据多个传感器输入测量方向,称为自由度(DOF)。由于严格的精度和漂移公差以及高可靠性,航天器和飞机的惯性导航系统(INS)可能花费数千美元。
但我们越来越多地看到自驾车和无人机中的传感器融合,在这些情况下,来自多个传感器的输入可以结合起来推断关于事件的更多信息。
7)实时处理和物联网
物联网涉及快速和大数据。因此,实时应用自然与物联网形成协同效应。许多物联网应用如车队管理、智能电网、推特流处理等具有基于快速和大数据流的独特分析需求。这些包括:
-
实时标记: 随着来自各种来源的非结构化数据流动,提取信号的唯一方法是对数据进行分类。这可能涉及与动态模式概念的工作。
-
实时聚合: 每当你在滑动时间窗口内聚合和计算数据时,你就是在进行实时聚合:找到过去 5 秒钟的用户行为日志模式,并将其与过去 5 年的数据进行比较,以检测偏差。
-
实时时间关联: 例如:基于位置和时间识别新兴事件,从大规模流媒体社交媒体数据中进行实时事件关联(以上摘自logtrust)。
8)物联网的隐私、保险和区块链
我曾经在欧盟参加过一次会议,其中提出了“芯片的沉默”这一概念。这个引人注目的标题源于电影《沉默的羔羊》。这个想法是:当你进入一个新环境时,你有权知道所有监控你的传感器,并且可以有选择地开关它们。这可能听起来很极端,但确实反映了今天隐私讨论中占主导地位的布尔(开或关)思维。然而,未来关于物联网的隐私讨论可能会更加细致入微,尤其是当隐私、保险和区块链一起考虑时。
根据AT Kearney,保险公司已经将物联网视为一个重要的机会。像伦敦劳合社这样的组织也在寻求通过引入新技术来应对大规模系统性风险,这些技术由城市区域传感器例如无人机推动。将区块链引入物联网创造了其他可能性——例如,IBM 表示:
将区块链概念应用于[物联网]提供了迷人的可能性。从产品完成最终组装的那一刻起,它可以由制造商注册到一个代表其生命周期开始的通用区块链中。销售后,代理商或最终客户可以将其注册到一个区域区块链(社区、城市或州)中。
9) 人工智能:机器相互学习(云机器人)
我们之前提到过深度学习和物联网的可能性,我们说深度学习算法在物联网分析中扮演重要角色,因为机器数据稀疏且/或具有时间性元素。设备在不同条件下的行为可能不同。因此,捕捉所有场景以用于数据预处理/训练阶段的算法是困难的。深度学习算法可以通过让算法自我学习来帮助缓解这些风险。这一机器自我学习的概念可以扩展到机器教其他机器。 这个想法并不那么离谱。
以世界上最大的工业机器人制造商 Fanuc 为例。Fanuc 机器人通过观察和强化学习在一夜之间自我学习执行任务。Fanuc 的机器人使用强化学习进行自我训练。大约八小时后,它的准确率达到 90%或以上,这几乎与专家编程相同。如果多个机器人同时工作并共享所学内容,这一过程可以加速。这种分布式学习的形式被称为云机器人。
10) 企业的物联网和人工智能层
我们可以在企业内部更广泛地扩展“机器教其他机器”的想法。企业正在获得一个“人工智能层”。企业中的任何实体都可以训练其他“同伴”实体。这可能是建筑物向其他建筑物学习,或者飞机、油井甚至打印机!培训可以是动态的和持续的(例如,一个建筑物了解能源消耗并“教导”下一个建筑物)。物联网是企业物联网系统的数据关键来源。目前,这种方法的最佳例子是 Salesforce.com 和 Einstein。强化学习是推动企业物联网和人工智能层的关键技术。
“到 2016 年底,全球收入最高的 100 家企业软件公司中,将有超过 80 家将认知技术整合到他们的产品中。”(来源:Deloitte)
远离人工智能寒冬,我们似乎突然进入了人工智能的春天。在这个人工智能春天中,物联网突然有了明确的商业模式。
结论
从上述讨论中,我们看到数据科学在物联网中的许多相似之处,但也有显著的差异。存在明显的差异(例如在硬件和无线网络的使用上)。但对我来说,最令人兴奋的发展是物联网推动了如无人机、自动驾驶汽车、企业人工智能、云机器人等令人兴奋的新兴领域。我们在物联网数据科学课程中涵盖了许多这些想法。
这一批次中只剩下最后几个名额。
更多相关主题
不常见的数据科学职位指南
评论
由Frederik Bussler,Apteo 增长营销部门提供

我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
照片由Jake Kokot提供,来源于Unsplash。
找到一个数据科学工作是否就像学习 Python 和 Jupyter 等技能、参与 Kaggle 比赛、获得认证、并在求职网站上提交简历一样简单?
错误。
最近,Kaggle 的独立用户达到了500 万。在其他社区中,Towards Data Science 每月获得2000 万次浏览。AI 研究员 Andrew Ng 在他的 Coursera 课程中有400 万名学习者。
与此同时,全球只有17,100名机器学习工程师。截止撰写本文时,LinkedIn 上有2,100个开放的机器学习工程师职位。其中,大约80个职位在 FAANG 公司。
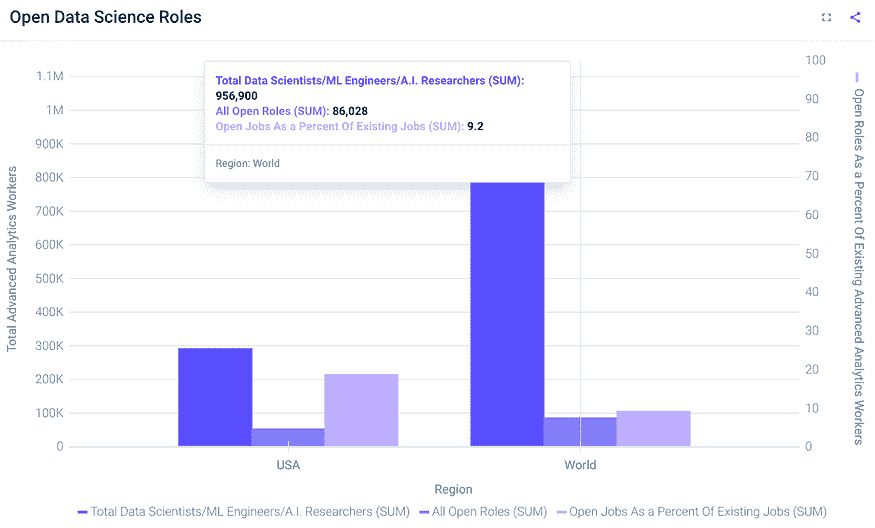
“开放的数据科学职位”由 Apteo 的“数据科学职业趋势”仪表盘提供。
公平地说,如果我们包括一般的数据科学和 AI 研究员角色,全球共有86,000个空缺职位。然而,称数据科学为“竞争激烈”可能是对今年的轻描淡写。
数据科学社区与数据科学就业机会。作者可视化展示。
红海 vs. 蓝海战略
在商业中,一个竞争激烈的领域被称为“红海”,在这个拥挤的空间里鲨鱼在争夺。相比之下,“蓝海”则指的是未开发的、没有竞争对手的市场空间。

图标由 Freepik 提供,来自 flaticon.com。由作者编辑。
作为一个未来的数据科学家,你的目标是竞争于蓝海。以下是四种方法。

红海与蓝海策略。由作者创建。
1. 使用小众平台和社区
我是 LinkedIn 的超级粉丝。事实上,在完成了 100 多门 LinkedIn 学习课程后,我曾 被 LinkedIn 特别推荐,我的帖子获得了 超过 10,000 条评论,并且我有超过 20,000 个连接。不过,仅依赖 LinkedIn 是一种红海策略 (⚠️)。

LinkedIn 帖子,由 LinkedIn 提供。
LinkedIn 拥有大约 六分之一亿 用户。这意味着,如果你仅在 LinkedIn 上进行网络连接,并通过 LinkedIn 申请工作,你将与 大量 人竞争。
作为一个使用 LinkedIn 招聘的人,好的职位发布可能会迅速涌入大量申请者,以至于很难浏览所有申请,更不用说给每个人反馈了。
这就是为什么,除了 LinkedIn 之外,我建议你还使用一些小众平台,比如 Shapr、Y Combinator 的 Work At A Startup、Lunchclub.AI(注:这是我的邀请链接,但我不会从中获利)、像 Wizards 这样的 Slack 社区,以及 Meetup 或 Eventbrite 上的线下社区。
这些都是免费的。
紧密的社区使你更容易脱颖而出。例如,Shapr 和 Lunchclub 是专注于一对一连接的专业网络。
2. 网络以避免“黑洞效应”
我曾经遇到一个会议参加者开玩笑说:“网络连接是新的不工作的方式。”虽然这很有趣,但我在那次活动中也遇到了一个新客户。
网络连接与第一个要点类似,但这里我专指申请工作的时间。

照片由 Chuttersnap 提供,来自 StockSnap。
你可能听说过有人提交 数百 份工作申请却没有任何回应的故事。也许你自己也经历过这种现象。
尽管有些人通过这种方式找到了工作,但提交简历到某些招聘门户网站的可能性越来越大,意味着你永远不会收到回复。如我所提,招聘经理正被申请者淹没。
这就像把你的简历扔进了黑洞。
问问自己:如果你必须在一个完全陌生的人和一个你被介绍的人之间做出决定,你会选择谁?
因此,招聘经理和高管几乎总是选择与他们有某种联系的申请者,即使只是通过共同的熟人介绍。
你建立的网络越多,你与潜在雇主的共同联系就会越多,获得介绍也就会更容易。

LinkedIn“共同联系”。由作者创建。
这是一个你可以用来请求共同联系介绍的超级简单模板:
首先,关注他们最新的帖子,然后发消息。
嘿 Connector_name,
希望你一切顺利。由于我们在同一行业,并且与[@name]在[@company]有共同联系,我希望你能通过 LinkedIn 介绍我。我最近申请了他们的[job posting title]。
我写了一条草稿信息,你可以复制/粘贴给他们以便轻松介绍:
你好 [@name],
我注意到你正在招聘一个[job posting title]。
我想向你介绍[@Frederik Bussler]作为潜在候选人,他在这个领域有[achievement_1]和[achievement_2]。Frederik 有兴趣与你讨论这个职位。你想要一个简短的介绍吗?
谢谢,
Connector_name
3. 专业化
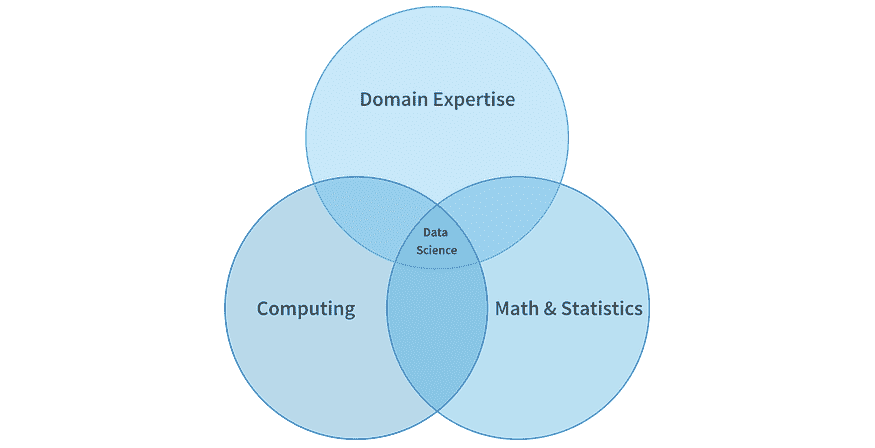
数据科学韵图,由作者创建。
数据科学是一个多学科领域,其中一个重要组成部分是领域专业知识。
例如,沃尔玛[使用预测模型]( https://corporate.walmart.com/newsroom/innovation/20170807/5-ways-walmart-uses-big-data-to-help-customers#:~:text=In many industries%2C big data ,our%20stores%20and%20e%2Dcommerce.)来预测某些时间段的需求。如果数据科学岗位的招聘经理必须在“Python 专家”和“零售预测建模专家”之间做出选择,显然更专业的候选人会胜出,其他条件相同的情况下。
亚马逊的推荐引擎负责亚马逊高达35%的收入,他们不断招聘数据科学人才以壮大这只金蛋。如果你曾经在推荐引擎上工作过——即使只是作为一个副项目——那会给你带来比更通用的申请者更大的优势。
学习专业化技能——具体选择哪种专业取决于你的个人兴趣——是一个改变游戏规则的因素。
4. 实践项目 > 证书

证书在 2020 年非常流行。如果你使用 LinkedIn,你肯定注意到那些臭名昭著的“证书帖子”。
用户展示了他们来自 Coursera、EdX、在线学习门户、LinkedIn Learning 以及其他无数来源的证书。我也有这样的过错——正如我提到的,我参加了 100 多门 LinkedIn Learning 课程,并获得了几乎每所常春藤大学的证书来自几乎每所常春藤大学。
尽管如此,依赖证书是一种红海战略(⚠️)。当数以百万计的人拥有与你相同的证书时,你就需要差异化。

比较数据科学工作与 Andrew Ng 的 Coursera 学生。由作者创建。
实践项目,即分析你感兴趣的数据,将给你带来巨大的优势。
你可以参考上面提到的data science career trends仪表盘以及其他公开工作区来获得灵感。
结论
数据科学是一个竞争日益激烈的领域,但你可以通过使用小众平台、扩大你的专业网络、专注于你感兴趣的领域,并与世界分享独特项目来脱颖而出。
原始。经许可转载。
相关:
更多相关话题
数据科学职位报告 2019:Python 大幅上升,TensorFlow 快速增长,R 使用量翻倍超过 SAS
评论
作者 Bob Muenchen,分析分析世界。
在我持续追踪数据科学软件的普及度的过程中,我刚刚更新了我的就业市场分析。为了避免你阅读整个文档,我在这里复制了该部分内容。
职位广告
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
测量数据科学软件的普及度或市场份额的最佳方法之一是计算那些将知识作为要求的职位广告数量。职位广告信息丰富且有资金支持,因此它们可能是衡量每种软件当前受欢迎程度的最佳指标。职位需求的变化图表为我们提供了未来可能会变得更加流行的良好线索。
Indeed.com 是美国最大的招聘网站,使其职位广告收集成为最好的选择。正如他们的联合创始人兼前首席执行官 Paul Forster 所述,Indeed.com 包括“来自 1000 多个独特来源的所有职位,包括主要的招聘网站 – Monster、CareerBuilder、HotJobs、Craigslist – 以及数百份报纸、协会和公司网站。” Indeed.com 还拥有出色的搜索功能。它曾经有一个职位趋势图表工具,但这个工具显然已经关闭。
使用 Indeed.com 搜索职位很容易,但以确保在不同包之间公平比较的方式搜索软件则具有挑战性。一些软件仅用于数据科学(例如 SPSS、Apache Spark),而其他软件既用于数据科学职位,也用于更广泛的报告撰写职位(例如 SAS、Tableau)。通用语言(例如 Python、C、Java)在数据科学职位中被广泛使用,但绝大多数使用这些语言的职位与数据科学无关。为了公平比较,我制定了一个协议,将每个软件的搜索范围仅限定于数据科学家的职位。该协议的详细信息在另一篇文章中描述,* 如何搜索数据科学职位 *。本节中的所有图表都使用这些程序来进行所需的查询。
我在 2019 年 5 月 27 日和 2017 年 2 月 24 日收集了本节讨论的职位数量。有人可能会认为单一天的样本可能不太稳定,但大量的职位来源使得 Indeed.com 的职位数量相当一致。使用相同协议收集的 2017 年和 2014 年的数据的相关系数为 r=.94,p=.002。
图 1a 显示 Python 以 27,374 个职位领先,其次是 SQL 的 25,877 个职位。Java 和 Amazon 的机器学习 (ML) 工具的职位数量大约低 25%,在 17,000 个左右。R 和 C 变体排在其后,大约有 13,000 个职位。人们常常比较 R 和 Python,但在获得数据科学职位方面,R 的职位只有 Python 的一半。当然,这并不意味着这些职位是相同的。我仍然看到更多的统计学家使用 R 和机器学习领域的人更喜欢 Python,但 Python 的确正在蓬勃发展!从 Hadoop 开始,职位数量逐渐下降。R 也常常与 SAS 进行比较,SAS 只有 8,123 个职位,而 R 有 13,800 个。
图 1a 的比例尺非常宽,以至于底部的包 H20 看起来似乎为零,而实际上它有 257 个职位。
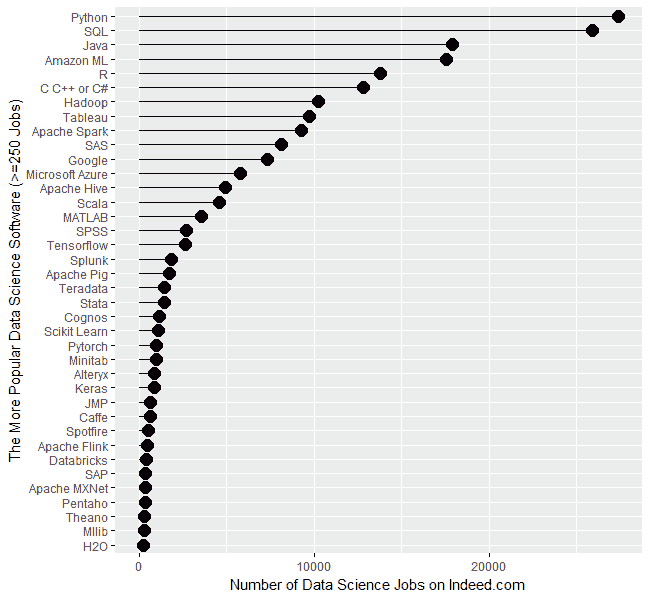
图 1a。更受欢迎的软件的数据科学职位数量。
为了比较不太受欢迎的软件,我在图 1b 中将它们单独绘制。Mathematica 和 Julia 是这个集合的领先者,每个大约有 219 个职位。古老的 FORTRAN 语言仍然顽强地保有 195 个职位。开源的 WEKA 软件和 IBM 的 Watson 紧随其后,各有大约 185 个职位。从 XGBOOST 开始,职位数量呈现出相当稳定的缓慢下降趋势。
有几个工具使用工作流界面:Enterprise Miner、KNIME、RapidMiner 和 SPSS Modeler。它们的职位数量都在 50 到 100 个之间。在许多其他受欢迎度指标中,RapidMiner 超过了非常相似的 KNIME 工具,但在这里后者的职位数量多出 50%。Alteryx 也是基于工作流的工具,但它已从其他工具中脱颖而出,在图 1a 上显示有 901 个职位。
图 1b. 低于 250 个广告的数据科学软件工具的职位数量。
在解释图 1b 中的尺度时,看似零的确实是零。从 Systat 开始,没有一个软件包的工作列表超过 10 个。
重要的是要注意,图 1a 和图 1b 中显示的值是单一时间点的快照。更受欢迎的软件的职位数量每天变化不大。因此,图 1a 中显示的软件的相对排名在接下来的一两年内不太可能发生太大变化。图 1b 中显示的不太受欢迎的软件包的职位数量非常低,它们的排名更有可能从月到月发生变化,但与主要软件包相比,它们的位置应该保持更稳定。
接下来,让我们看看 2017 年到现在(2019 年)工作的变化。图 1c 显示了那些在 2017 年时至少有 100 个职位列表的软件包的百分比变化。如果没有这样的限制,软件从 2017 年的 1 个职位增加到 2019 年的 5 个职位将有 500%的增长,但仍然不会引起太大兴趣。工作市场正在升温或增长的软件以红色显示,而那些降温的软件以蓝色显示。
图 1c. 从 2017 年到 2019 年职位列表的百分比变化。仅显示 2017 年时至少有 100 个职位的软件。
Tensorflow 是来自 Google 的深度学习软件,其增长最快,达到 523%。接下来是 Apache Flink,一个分析流数据的工具,增长为 289%。H2O 紧随其后,增长为 150%。Caffe 是另一个深度学习框架,其 123%的增长反映了人工智能算法的流行。
Python 显示出“仅”97%的增长,但其受欢迎程度已经如此之高,以至于其增加的 13,471 个职位超越了许多其他软件包的总职位数!
Tableau 显示出类似的增长率,尽管增加的职位数相对较少,为 4,784 个。
从 Julia 语言开始,我们看到增长放缓。我惊讶于 SAS 和 SPSS 的职位仍在增长,尽管分别仅为 6%和 1%。
原文。已获得许可转载。
简介: 罗伯特·A·穆恩琴(Robert A. Muenchen)是一个拥有 35 年经验的 ASA 认证专业统计师™,目前担任田纳西大学 OIT 研究计算支持(前身为统计咨询中心)经理。他是《R for SAS and SPSS Users》一书的作者,并与约瑟夫·M·希尔比(Joseph M. Hilbe)共同编写了《R for Stata Users》,Bob 也是 r4stats.com 的创建者,这是一个受欢迎的网站,致力于分析数据科学软件的趋势,评审这些软件,并帮助人们学习 R 语言。
相关:
了解更多此话题
数据科学如何在 COVID-19 期间保障人们的安全
原文:
www.kdnuggets.com/2020/08/data-science-keeping-people-safe-covid-19.html
评论
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
COVID-19 大流行已经肆虐了几个月,可能还会持续几个月。在这一持续的危机中,人们需要资源以保持尽可能长时间的安全。数据科学及其相关技术正在实现这些行动,在全球安全中发挥着至关重要的作用。
艰难时期往往是人们在平静日子里夸耀的系统的试金石。COVID-19 大流行也不例外,数据科学已经充分证明了其价值。数据,更重要的是,人们使用数据的方式,正在塑造和完善应对 COVID-19 安全的方式。
让我们更详细地看看这是如何发生的:
1. 影响法律政策
数据分析是制定有效政策以遏制病毒传播的核心。政治家们不能指望制定任何有效的预防措施,如果他们不了解 COVID-19 在他们所在地区的传播情况。另一方面,如果他们求助于数据科学家,他们可以获得做出明智决策所需的知识。
各国政府利用这些资源的程度有所不同,但这些资源确实存在。疾病控制与预防中心(CDC)分析各种数据池以向当局提供如病例趋势、住院率和死亡率报告等指标。随着各州开始重新开放,这些分析变得越来越有价值。
2. 衡量医疗方法的有效性
关于病毒,医疗专业人士仍有很多未知,因此 COVID-19 的安全措施仍在发展中。随着医生对疾病了解的加深,他们发现一些旧有的做法效果并不理想。例如,大多数医生已经放弃了羟氯喹,转而使用像瑞德西韦和地塞米松这样的药物。
数据科学不仅能建议医疗方法,还能显示当前方法是否有效。随着当局继续实施新做法,他们需要关注数据,以了解这些方法是否有用。更好的数据分析可以提供关于哪些有效、哪些无效的更具决定性的答案。
3. 确保物流链中的产品质量
供应链是许多生活方面的支柱,尤其是在疫情期间。最后一公里的配送增加了十倍以上,因为人们选择在线订购必需品,而不是外出购物。随着更多易腐食品如生鲜通过邮件运输,公司需要数据科学来确保产品质量。
一些运输冷冻商品的容器需要在零下 20 到零下 65 摄氏度之间操作,否则可能会影响内部物品。数据科学家可以帮助公司创建智能监测系统,以确保这些容器保持适当的环境。如果没有合适的数据工具,运输中的食品、疫苗和植物可能会在途中变质。
4. 对抗虚假信息
在疫情的混乱中,虚假信息也出现了爆发。错误的信息可能威胁到 COVID-19 的安全,但数据科学可以提供帮助。社交媒体用户生成的数据量过多,人工审核员难以监控,但基于机器学习的分析工具可以标记可能虚假的信息。
机器学习数据工具可以学习识别有害语言,如仇恨言论或呼吁暴力的言论。同样,这项技术也可以突出可能虚假或误导的声明。通过将社交媒体帖子与数据集和科学公认的真相进行比较,这些工具可以发现并标记虚假信息。
5. 启用和改进接触追踪
COVID-19 安全的一个关键步骤是接触追踪。一些最有效的接触追踪实例利用了数据科学技术。像韩国这样的国家已经建立了分析政府感染数据的系统,以提醒用户是否可能接触到病毒。
这些应用需要使用数据科学技术,如数据获取、清洗和掩蔽,才能正常工作。数据科学家可以将他们的专业知识提供给应用开发者和研究人员,以帮助创建一个有效的接触追踪网络。借助这些工具,各个领域可以更好地控制病毒传播。
数据科学在全球混乱中提供信息
在各种应用中,数据科学提供了一个重要的资源——信息。如果当局和公民要对大流行作出适当反应,他们需要全面了解情况。数据科学使人们能够从原始数据中绘制出更为一致的图景,从而增强抗击 COVID-19 的能力。
个人简介:德文·帕蒂达是一位大数据和技术作家,同时还是ReHack.com的主编。
相关:
-
可视化受 COVID-19 影响的欧洲国家的流动趋势
-
数据科学家开发了更快的方式来减少污染,降低温室气体排放
-
医疗保健中的 AI 和机器学习
更多相关话题
277 个数据科学关键术语,解释详尽
原文:
www.kdnuggets.com/2017/09/data-science-key-terms-explained.html

本文展示了一系列与数据科学相关的关键术语,并提供简明扼要的定义,分为 12 个不同的主题。从大数据开始,一直到自然语言处理,这些定义涵盖了机器学习、数据库、Apache Hadoop 等多个方面。虽然可能需要一些时间,但一旦你掌握了这些术语,你应该对数据科学中的重要术语有一个清晰的了解。如果定义对你来说过于简略,也不用担心;在适当的地方有丰富的链接供你进行扩展阅读。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
20 个大数据关键术语,解释详尽
大数据。如果你以某种方式来到这个网站,并且自从它开始流行至少十多年以前以来从未听说过这个术语,我真的不知道该说什么。
但仅仅听说过这个术语,或者参与(或反对)其随意使用,并不意味着你真正了解它的含义或其完全涵盖的内容。实际上,试图在一篇文章中详尽描述大数据是什么是毫无意义的,原因之一是没有公认的详尽描述,也不应该有。然而,收集一些与大数据相关的关键术语并不是个坏主意,因为这为进一步的工作奠定了共同的基础。
12 个机器学习关键术语,解释详尽
这是 KDnuggets 系列文章中的第一篇,提供相关术语(以机器学习为例)的简明解释,专门采用简洁明了的方式,适合那些希望隔离和定义术语的人。经过一些思考,我们确定这些基础但富有信息的文章在过去没有得到足够的曝光。
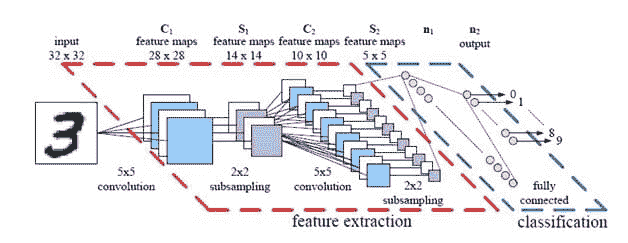
所以,让我们从机器学习及相关主题开始了解吧。
10 个聚类关键术语解释
聚类是一种数据分析方法,它将数据点分组,以“最大化类内相似性和最小化类间相似性”(由Han, Kamber & Pei提出),而不使用预定义的点标签(即一种无监督学习技术)。本文介绍了聚类分析中常用技术的关键术语。
14 个深度学习关键术语解释
深度学习是一个相对较新的术语,尽管它在最近的在线搜索量激增之前就已经存在。由于在多个不同领域的令人难以置信的成功,深度学习在研究和行业中正经历着激增。深度学习是应用深度神经网络技术的过程——即具有多个隐藏层的神经网络架构——来解决问题。深度学习是一种过程,类似于数据挖掘,使用深度神经网络架构,这些架构是特定类型的机器学习算法。
16 个数据库关键术语解释
数据需要被策划、呵护和管理。它需要被存储和处理,以便将其转化为信息,并进一步精炼成知识。存储数据的机制,继而促进这些转化,显然是数据库。
本文介绍了 16 个关键的数据库概念及其简洁、直接的定义。

15 个描述性统计学关键术语解释
尽管统计学是数据科学的核心工具集,但往往被更实用的技术技能,如编程,所忽视。即使是机器学习算法,依赖于数学概念如代数和微积分——更不用说统计学了!——也常常被当作一个比实际需要的更高层次来处理,这可能导致“数据科学家”对其职业的一个关键方面缺乏基本理解。

11 个预测分析入门关键术语解释
本文汇编了 PAW 创始人 Eric Siegel 的畅销获奖书籍《预测分析:预测谁会点击、购买、撒谎或死亡的力量》(修订版,2016 年)中包含的关键定义,这本书已经被 35 多所大学作为教科书采用——但阅读起来像流行科学,被称为“大数据的《怪诞经济学》”。
20 个云计算关键术语解释
云计算主要使公司能够更快地部署其应用程序,而无需过多的维护,这些维护由服务提供商管理。这也导致了更好的计算资源利用,根据业务的需求和要求进行调整。
虽然互联网充满了与云相关的术语,但这里有一些相当基础但重要的术语,任何人都应该了解这些术语。了解这些关键术语将帮助你理解行业发展和未来的云计算趋势。
16 Hadoop 关键术语解析
Hadoop 是一个由 Apache 基金会管理的非常强大的开源平台。Hadoop 平台建立在 Java 技术之上,能够在分布式集群环境中处理大量异构数据。其扩展能力使其非常适合分布式计算。
Hadoop 生态系统由 Hadoop 核心组件和其他相关工具组成。在核心组件中,Hadoop 分布式文件系统(HDFS)和 MapReduce 编程模型是两个最重要的概念。在相关工具中,Hive 用于 SQL,Pig 用于数据流,Zookeeper 用于服务管理等都是重要的。我们将详细解释这些术语。

13 Apache Spark 关键术语解析
Apache Spark 之所以如此受欢迎,其中一个原因是 Spark 为数据工程师和数据科学家提供了一个强大的统一引擎,该引擎既快速(在大规模数据处理上比 Apache Hadoop 快 100 倍),又易于使用。这使得数据从业者能够以更大规模互动解决机器学习、图计算、流处理和实时交互查询处理问题。
在这篇博客文章中,我们将讨论在使用 Apache Spark 时遇到的一些关键术语。
12 物联网关键术语解析
物联网(IoT)是一个概念,旨在允许互联网基础的通信在物理对象、传感器和控制器之间发生。本文将以直白的方式定义物联网的 12 个关键术语。
18 自然语言处理关键术语解析
本文旨在提供一个入门角色,采取简明的方式定义一些关键的自然语言处理术语。虽然阅读后你不会成为语言学专家,但我们希望你能更好地理解一些 NLP 相关的讨论,并获得如何进一步学习这些主题的视角。
这里有 18 个精选的自然语言处理术语,简明定义,并提供了适当的进一步阅读链接。
相关:
-
机器学习算法:简明技术概述 – 第一部分
-
深度学习与神经网络概述:初学者的基本概念
-
数据科学概述:初学者的基本概念
更多相关内容
数据科学最后一公里
作者:Joel Horwitz(Alpine Data Labs),2014 年 6 月。
数据科学通常被称为开发者、统计学家和业务分析师的结合体。用更随意的术语来描述,它更恰当地被称为黑客技术、领域知识和高级数学。Drew Conway 在他的博客文章中很好地描述了这些能力。近期的关注点主要集中在建立分析沙箱的早期阶段,以提取数据、格式化、分析并最终创造洞察(见下图 1)。
许多先进的分析供应商专注于这一工作流程,这与过去 30 年商业智能的历史背景有关。例如,新进入这个领域的 Trifacta 最近宣布了一轮 2500 万美元的融资,它将预测分析应用于数据,以帮助改进特征创建步骤。这是一个非常值得关注的领域,因为约 80%的工作都花费在去除数据偏差、寻找真正重要的变量(信号/噪声比)和识别最适合数据的模型(线性回归、决策树、朴素贝叶斯等)上。不幸的是,大多数创建的洞察往往无法超越我所称的“数据科学最后一公里”。
 图 1. 简单的数据科学工作流程。
图 1. 简单的数据科学工作流程。
什么是数据科学最后一公里?这是将发现的洞察转化为高度可用格式或集成到特定应用中的最终工作。这一最后一公里有很多例子,以下是我认为的最佳例子。
示例 1. 报告、仪表盘和演示文稿
多亏了商业智能社区,我们现在习惯于期望在仪表盘格式中查看我们的洞察,其中图表和图形相互叠加。像 Tableau 和 Platfora 这样的新型可视化分析工具通过使得将看似不相关的指标进行对比变得更加简单,进一步丰富了图形的混合。不要误解我的意思,仪表盘永远会有其存在的价值。
一般而言,指标的报告频率应仅限于能够采取行动的频率。
在英特尔,我们每天早上 7 点举行站立会议,回顾关键指标,并帮助团队确定每日优先事项。对于更复杂的分析,例如引入新流程或生产工具,我们会根据项目安排单独的会议。在这里,可视化格式定义得非常明确,甚至有一个称为 SPC(统计过程控制)的行业标准。每个业务都有用于报告指标的标准图表,此外,还有一个明确的方法来绘制数据。
我最喜欢的有关数据展示最佳设计实践的书籍之一是爱德华·塔夫特(Edward Tufte)所著。我以前的老板和导师推荐了这本书 《定量信息的视觉展示》,它改变了我的生活。我最喜欢的视觉之一是书中如何展示法国的火车时刻表。
1880 年代的法国火车时刻表,来自 Marlena Compton 博客。
演示文稿、报告和仪表盘是数据“消亡”的地方。定期审查这些图表并将建议应用于业务、产品或运营在季度甚至年度基础上是很常见的做法。
示例 2. 模型
数据科学输出被组织吸收的另一种方式是作为模型的输入。根据我的经验,这主要是通过 Excel 来完成的。我感到非常惊讶的是,居然没有更多其他应用程序来简化这个过程?也许是因为这些知识被锁在高度专业化的分析师脑海中?无论原因是什么,这似乎是一个主要的破坏领域,有很大的需求来标准化这个过程,并打破孤岛。我最喜欢的一句名言来自一位前同事。我们在一个漫长的周末分析新产品战略业务模型时,他说:“当他们告诉我我将处理模型时,这绝不是我想象中的样子。” 无论你是在运营、财务、销售、市场营销、产品、客户关系还是人力资源领域,准确建模你的业务意味着你很可能能够预测其成功。
示例 3. 应用
最后,可能也是我最喜欢的例子是那些围绕我们周围的数据科学构建的产品,而我们甚至没有意识到。其中一个我能想到的最古老的例子是天气预报。我们得到的是 7 天的天气预报,形式是阳光、云朵、雨滴,以及由冗长的解释性舞者管理的绿屏,而不是报告雨的原始概率数据、气压、风速、温度以及许多其他影响预测的因素。
另一个例子是信用评级的衍生指数(FICO)、股票市场指数、Google 的页面排名,或者购买意愿值,或其他一些用于显著效果的单一值。这些指数并不会全盘报告,尽管如果你尝试,可以找到它们。(例如,访问 pagerank.chromefans.org/ 查看任何网站的 Google 页面排名)。相反,它们被打包成像搜索、产品推荐等多种产品化格式,弥合习惯与原始数据之间的差距。对我来说,这是我最关注的领域,因为这是推动数据融入我们决策过程的最后一英里工作。
大数据如何适应这种情景?大数据旨在通过更多的数据提高准确性。众所周知,最好的算法会因数据输入量的增加而失效。然而,对大型数据集进行复杂的统计和分析并不是一件简单的事。过去几年里,很多初创公司围绕这一点建立了框架,但需要相当多的编码技能。只有少数公司提供了更易于接触的大数据数据科学应用方法。
一个已经建立了可视化且高度健壮的规模分析方式的公司是 Alpine Data Labs。它拥有大量的本地统计模型,你可以将这些模型混合搭配,快速生成与顶级算法相媲美的复杂算法,所需时间仅为几分钟,而非几个月。很难想象几年前我们还在每季度手动调整算法。亲自查看 start.alpinenow.com,了解我们取得了多大的进展。
总结来说,我认为我们需要将重点转回数据科学的应用,以免感到失望。我个人已经在考虑如何以数据为核心价值构建新产品,而不是作为后续决定的附加部分。关于这个主题还有很多内容要写,期待听到你的想法。
随时通过 Twitter @JSHorwitz 联系我
相关帖子:
-
Trifacta – 通过自动化和机器学习解决数据整理问题
-
将牌堆排成:大数据中的下一个机会波
-
大数据策略:数据化
-
为即将到来的数据洪流准备行业:PAW-制造业 2014
更多相关主题
数据科学入门(无数学)
原文:
www.kdnuggets.com/2017/04/data-science-layman-no-math-added.html
作者:安娜琳·吴(剑桥大学)和肯尼斯·苏(斯坦福大学)。
想开始学习数据科学吗?还是想读一本好书?
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
Numsense! 数据科学入门 是一本面向没有统计学或计算机科学背景的读者的入门数据科学书籍。它避免使用术语,以简单而简明的方式呈现关键算法。为了帮助你理解,每个算法还配有真实世界的例子和直观的视觉图。
我们的承诺:无数学内容。
探索超过 10 种经典算法和方法的关键概念,包括:
-
A/B 测试
-
异常检测
-
关联规则
-
聚类
-
决策树和随机森林
-
回归分析
-
社会网络分析
-
神经网络
为了帮助你复习所学内容,我们还包括了:
-
比较算法优缺点的备忘单
-
每章总结
-
常用术语的词汇表
这本书适合谁?
你!但实际上,任何对数据科学感兴趣的人——无论是监督分析师的业务经理,寻找数据新见解的顾问,进入这个领域的学生,还是任何有好奇心的人。
我为什么要对数据科学感兴趣?
你已经看到数据科学如何彻底改变了我们的生活和工作方式。谷歌利用它生成与你搜索查询相关的结果,亚马逊则利用它推荐你可能喜欢的产品。最近,数据科学算法还被用于推动数字个人助理和自主驾驶汽车的发展。了解这些算法的工作原理对于欣赏它对我们未来的潜在影响至关重要。
阅读这本书对我的工作有什么价值?
数据科学算法可以应用于广泛的领域——无论是客户画像还是医学诊断,这些算法都能为你提供关键洞察,帮助你做出更具战略性的决策。
别人怎么说?
"... 熟悉 Annalyn Ng 和 Kenneth Soo 的工作已久,书中所承诺的内容自然也就不让人惊讶。这确实是面向外行的数据科学书籍,而书中描述的通常复杂的数学——以高层次呈现——故意没有详细讲解。但不要被误导:这并不意味着内容有任何削减。事实上,书中信息内容扎实,其优势在于它的精简和简洁。"
马修·梅奥
数据科学家及 KDnuggets 副编辑
"... Numsense! 是对关键数据科学算法的便捷图形描述,适合新数据科学家的入门、与分析师合作的商务人士的概述,或是任何想了解自己数据如何处理的人的刺激阅读。
大卫·斯蒂尔韦尔
心理测量中心副主任,
大数据分析与定量社会科学讲师,
剑桥大学贾奇商学院
点击这里获取你的副本
更多相关话题
我目前的数据科学学习历程
原文:
www.kdnuggets.com/2021/01/data-science-learning-journey.html
评论
Arnuld on Data,自由职业数据科学家
埃里克·韦伯(没错,就是那个看起来很帅、带着可爱狗狗的家伙)最近在LinkedIn上写了一篇关于他希望在开始数据科学职业生涯时少做的 10 件事的文章。这篇文章是我对这 10 点的经历。首先,你应该去阅读他的文章。下面是截图:

首先,这将不是一篇“内容”帖子。
已经有很多相关文章和博客帖子了,可以查看它们。在这里,我们将讨论你希望成为数据科学家并被行业关注时的重点和方向。
1) 以为我需要学习所有东西
是的,这个问题确实花费了你很多时间和精力。这个障碍是你应该立即解决的。我在开始时挣扎过,但几个月后,它就消退了。我将这个突破归功于我每天阅读的习惯。
我继续阅读 LinkedIn 上的帖子(特别是埃里克·韦伯本人发的帖子)。此外,我每天花一到两个小时,甚至更多,阅读 Towards Data Science、Medium、KDnuggets 以及不同数据科学家和机器学习工程师的个人博客。这教会了我数据科学在工业工作中的重要性:你用自己的技能为组织创造了多少价值。你通过构建你感兴趣的东西或解决一个问题来定义价值。你通过回答这个问题来选择学习的内容,这将帮助你了解该学什么,不该学什么。
我花了几个月才意识到这一点(我猜是 6 个月)。随着我们逐步进行这些点,我会将这些月份加在一起,看看我们本可以节省多少时间。

2) 准备面试小知识。
是的,这又是一个困难,主要因为几个原因:
-
关于数据科学家的定义,没有一个公认的标准。只有对他的工作职责有一个模糊的了解,以及这些职责与数据分析师或机器学习工程师的职责有什么不同。
-
然后是令人困惑的职位描述。由于没有一致的数据科学家定义,你会看到要求你精通一切的描述:机器学习、软件工程、Python、R、多年统计学、微积分、线性代数、Big-O,等等。看着这些职位描述,你会觉得自己需要 50 岁以上才能申请这些工作。
不要被这些描述所困扰。不要过于在意职位描述。大多数情况下,“面试问答”是数据科学新颖性与人才招聘、数据科学和软件工程团队之间沟通不畅的结合体。与其感到不知所措,不如专注于如何突破它。
破解这个问题的一种方法是看现实。如果你认识任何现实生活中的数据科学家、数据分析师和机器学习工程师(在现实世界中),与他们谈谈他们的工作将是一个很好的主意。如果你不认识任何人,你可以随时查看博客和文章。
我在这个领域没有认识的专业人士。所以我通过阅读博客和文章来学习。我发现公司面试了很多“知道”东西的人,但真正“构建”东西的人却很少。所以专注于构建东西,而不仅仅是学习和教育(例如,部署和生产是两个主要方面)。我花了 5-6 个月才意识到这一点。
目前已经过去了 6 + 6 = 12 个月。
3) 试图模仿别人的道路
啊,这是我最喜欢的 😃 因为这是我浪费最多时间的地方。
-
Tetiana Ivanova 在 6 个月内找到了工作。
-
Kelly Peng 在辞去数据分析师职位后,在一年内找到了a job in one year。
-
Natassha Selvaraj 找到了工作,而且她还在大学学习。
-
Mikko Koskinen 甚至没有计划成为数据科学家。
-
Thomas Hepner 在其他领域感到迷茫,而一年后他成为了行业中的数据科学家。
图片由 Edward Jenner 提供,来自 Pexels。
看看 我的个人资料,我在软件开发(C 语言)方面有 4.5 年的经验,并且现在做了 8 个月的数据科学,但仍然无法回答这个问题:
你最喜欢的机器学习算法是什么,为什么?
是的,我同意我的情况看起来像 Big-O的最坏情况:O(n^n)。
我阅读了数以百计和千计(不,我不是夸张)的博文和文章,了解那些获得数据科学职位并改变行业的人。我追踪并模仿了他们的数据科学旅程,从他们的思维模式到课程选择,甚至是某些书籍中某些章节的选择,像一个完美的 碳拷贝。而我仍然未能回答上面的问题,因为我甚至不知道为什么我会喜欢某个机器学习算法而不是另一个。毕竟,我只是盲目地消化所有模型,以“变得像他们”之名。
两天前我放弃了,决定跟随我认为我应该做的事。(令人惊讶的是,我今天遇到了 Eric 的帖子。就像宇宙在试图告诉我我走在正确的道路上,这条道路属于我)
我认为我们每个人都必须个性化我们的旅程。我们的环境、才能、经验、态度、工作伦理、背景和学习能力,都各不相同且独特。这就是为什么也许追随别人路径永远不会有效。
所以我决定实验并开辟自己的道路成为数据科学家。这并不是说我会停止阅读其他人的经历,我仍会阅读,但我不会盲目地跟随和试图复制到我的生活中,而是将它们作为指南针,作为指导机制。这花了我 8 个月。虽然晚了总比不做好。
6 + 6 + 8 = 20 个月。

图片由 Gerd Altmann 提供,来自 Pixabay。
4) 关注完美的解决方案。
我的计算机编程经验解决了这个问题。我在行业中花了半个十年编写代码为雇主创造收入,这已经教会我“完成”比“完美”更重要。找到别人遇到的问题并构建解决方案实际上是唯一重要的事情。单纯的学习和教育并不重要。
6 + 6 + 8 + 0 = 20 个月
5) 学习我很少使用的高级统计。
回到 2018 年,我花了很多时间学习数据科学的数学和统计。我花了 4 个月时间学习:
-
Khan Academy 上的代数 I 和 II。
-
来自 Arizona State University at edX 的大学级代数与问题解决。
-
MIT 大图景微积分来自 YouTube
-
Calculus Made Easy 由 Silvanus P. Thompson 编写。从 Project Gutenberg 免费获取。
-
MIT Calculus 1A: Differentiation 微积分 1A:微分。
-
来自 Calculus-1 at Khan Academy 的极限与积分微积分。
-
阅读不同的统计学书籍 以获得统计思维方式
真是个错误 😦 。从我今天所知道的来看,我只需要这个:
-
统计学基础。不是统计学本身,而是机器学习和数据分析所需的特定主题。
-
贝叶斯定理基础
-
线性代数基础(仅涉及一些小内容,如矩阵乘法和转置等)
-
大 O 符号基础(查看 Interview Cake’s Explanation)
是的,没有什么花哨的,只有基础知识。所有花哨的东西可以在你找到工作后再做。在此之前,你可以使用 Python 或 R 库。与其像在学校或大学一样试图学习数学公式,不如尝试学习如何使用 Python 中的库调用,例如使用 Scipy 计算 t 检验,并学习理解它所需的数学:
3.1. Statistics in Python - Scipy lecture notes
简单的线性回归。给定两个观测数据集,x 和 y,我们想要检验 y 是线性的假设...
好吧,花了 8 到 10 个月:
6 + 6 + 8 + 0 + 10 = 30 个月

由 Vlad Dediu 拍摄,来自 Pexels
6) 认为 R 与 Python 的辩论需要只选择一个。
我在这方面挣扎了:
-
从 R for Data Science 由 Hadley Wickham 开始。读了几章,然后放弃了,因为我读到 Python 在工业界越来越受欢迎。
-
我从 Python 开始,尝试了几本书,然后回到了 R,因为 ggplot 比 matplotlib 看起来更好。
-
然后我回到了 Python,因为它更有软件工程的感觉。
-
回到 R 语言,因为 tidyverse 作为一个包在数据分析和可视化方面比 Python 的工具显得更成熟。
当我从一家向我寻求 R 相关工作的公司获得一个家庭作业任务时,这个问题解决了。在使用 R 和 Python 完成家庭作业后,我再也不想碰 R 了。根据我的经验,Python 更适合软件工程实践,而软件工程实践在编写实际工业数据科学代码时确实是必要的。这与进行软件开发几乎一样。从那时起我完全转向 Python。个人而言,如果我需要使用其他语言,我会选择Julia。大约花了 4 到 6 个月的时间。
6 + 6 + 8 + 0 + 10 + 4 = 34 个月
7) 花大量时间思考非结构化数据
我在“数学错误”之后犯了这个错误。我花了几个月时间考虑 SQL 和 NoSQL。我们看待事物时,从自己的视角出发,认为这就是它的意义。例如,我们都知道这是数据时代,每天生成数以百万计的兆字节数据。大部分是非结构化的。我猜我应该学习 NoSQL。但几乎所有的职位描述都只提到 SQL。然后我开始考虑学习 SQL。

由Mika Baumeister拍摄,来源于Unsplash
我既没有学会 SQL,也没有学会 NoSQL。这就是对一件事犹豫不决如何浪费几个月的时间。
我开始转变视角,不再从自己的方式解读,而是研究那些找到数据科学工作的人及他们学了什么。他们都列出了 SQL 作为技能。所以我转向了 SQL。一个好的起点是SQLBolt。
我不会考虑任何时间浪费,因为即使我没有学到任何东西,我也用那些时间去学习其他东西。所以,到目前为止的方程式是:
6 + 6 + 8 + 0 + 10 + 4 + 0 = 34 个月
8) 思考技术,而不是业务
这是一个需要严肃心态转变的领域,我也需要这样的变化。我的计算机编程背景使我成为一个 100%技术型的人,真的不知道如何做一个超越团队工作的成员。贡献团队是我的社交和沟通技能的终点。
我起初并不知道这一点,但多亏了我的阅读习惯,我发现了许多数据科学的特点,这些特点使其与其他技术职位存在差异。我克服这一点的一种方式是与我认识或遇到的人谈论大数据。通过向我的朋友和其他人解释数据科学、机器学习概念。但由于我的自由职业工作和数据科学学习需要我花很多时间在电脑前,我没有太多机会使用这种方法。
图片由Lorenzo Cafaro提供,来自Pixabay。
数据科学不仅仅是编程,数据科学不仅仅是网页开发,它不仅仅是关于分析数据和构建模型。这只是故事的一半。数据科学的另一半是能够与不太懂技术的人进行沟通。业务利益相关者、管理层决策者和客户是你将要面对的三种不同类型的非技术人员。因此,如果我们把它看作是“另一个技术工作”,那么与人合作将是一个大问题。有一本关于沟通数据洞察的优秀书籍,标题为“Storytelling With Data*”,作者是Cole Nussbaumer Knaflic。这本书几乎是必读的。
还有另一个方面。业务问题。你构建的模型、你做的比较以及你取得的准确度,它如何对业务有所帮助?你看,如果一个数据科学家不能为业务带来一些利润、好处或附加价值,那么他的工作是没有意义的。如果你像我一样来自技术背景,这很难掌握并变得擅长。技术心态在这种情况下所做的,就是让你的思维仅仅集中在构建模型和分析数据上,因为这就是我们的工作。我们没有业务背景。
我没有很好的解决方案,因为我没有任何个人经验。所以请带着怀疑的态度参考我的建议。也要自己搜索。我只能阅读博客、帖子和文章来理解该做什么。我也不认识任何产品经理(我见过一两个 IT 服务经理,但我不确定这是否算作)。我遇到的唯一方法是双重的:
-
阅读案例研究、产品案例研究。这就是产品经理的工作。所以如果你认识任何产品经理(甚至是项目经理),你应该和他们谈谈他们的产品/项目如何为公司带来了价值。
-
阅读像《Cracking the PM Interview》这样的书籍,由盖尔·拉克曼·麦克道维尔和杰基·巴瓦罗。
不理解这一点会让你在技术技能上花费大量时间,如果你是程序员或软件开发人员的话。浪费了 6 个月:
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 = 40 个月
9) 尝试跟上所有论文
你需要避免的另一个陷阱。我在这方面卡住了一段时间。我想自己实现一两篇论文,但现在我总是首先关注“构建一些东西”。学习你开始构建某物所需的最少知识。
是的,所有那些论文看起来确实非常令人印象深刻,也很美丽。论文大多关于学术。你要在行业中找到工作。学术和行业不完全匹配,只有两个可能的例外:
-
你在寻找一个行业内的研究职位。在这种情况下,你的作品集将仅限于 10%到 20%的雇主。
-
你想为四大公司工作,即 Facebook、Amazon、Google 和 Microsoft。
除了上述内容,我看不到偏离我目标的任何意义,即在一家优秀的一级或二级公司找到数据科学家的职位。不要误解我的意思,我喜欢做研究。事实上,在大学时,我曾想攻读微内核研究的博士学位。研究工作需要耗费大量的时间和精力。我认为更好的生活方式是找到职业上的平衡:在个人兴趣和市场/行业需求之间的平衡。避免偏向任一方面。

与其跟进所有的论文,更好的平衡学习的方法是:
-
学习使用 Pandas 进行数据清洗的基础知识(Kaggle 数据集已经为你完成了 90%的工作。在现实生活中,你需要做所有的清洗工作。学会抓取一些数据并清理它)
-
学习机器学习建模的基础知识,以及为什么选择某个模型而不是另一个。不同的模型适合不同领域的问题,例如医疗保健与金融。
-
学习如何将模型部署到生产环境中(当你使用Streamlit、Heroku和Voila时,你会对实际工作的感觉有所了解。我已经实现了熊检测模型,使用 Voila 这里)。
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 + 10 = 50 个月
10) 认为做事只有一种方法
这是一个大问题。我觉得我一生都在与这个问题挣扎。有些人天生就具备这种能力,而有些人则没有。我倾向于认为,也许聪明的人不会有这个问题(我遇到或读过的聪明人,他们没有)。像我这样的人花了一生的时间去克服它。这是一种囚禁,相信我。生活在“只有一种做事方法”的思维模式中是非常令人沮丧的。如果你看看现实生活中的故事,创意没有任何限制。

这更多的是一种个人发展障碍,而不是技术障碍,因为无论你从事哪个领域,这个问题都会出现,它与技术完全无关。我仍在努力解决这个问题。我迄今为止找到的解决方案是,当我无法解决问题时,我会离开计算机,去散步(如果是傍晚)或阅读一本完全无关的书(如果不是傍晚,例如一些非小说类的书籍),或者骑摩托车,完全忘记这个问题。然后我会在稍后回来,尝试从不同的文章或博客帖子中学习相同的内容,同时不参考我卡住的原始点。只是从其他人那里获得对相同问题的新视角。
我无法给这个问题设定时间限制。我为此困扰了一辈子:
6 + 6 + 8 + 0 + 10 + 4 + 0 + 6 + 10 + 生活 = 50 + 生活
所以,我浪费了将近 50 个月?
其实不是。
当谈到我浪费时间的地方时,这些点彼此重叠。实际上是 12 个月。2019 年 12 月到 2020 年 11 月。开始的几个月,我甚至不知道自己需要做什么。直到 2020 年 3 月事情才开始有意义。我认为如果事情对我更清晰,我本可以节省 4 到 6 个月,但这只是一个粗略的估计,一些非常聪明的人告诉我:解决障碍需要的时间就是需要的时间。让我重申一下:
我们每个人都有个人的数据科学旅程。我们的环境、才能、经验、态度、工作伦理、背景和学习能力都是不同和独特的。这就是为什么追随别人的路径可能从来不起作用的原因。这就是为什么你需要不断推动自己学习你所能学到的东西,保持对行业动态的了解,并不断纠正你的路径(就像智能手机上的地图应用不断纠正我们并指引方向一样)
额外内容 — 你的心理状态
在我理解逻辑回归比线性回归更适合什么类型的问题之前,我一直在尝试学习神经网络。在机器学习变得有意义之前,我就在做深度学习。在我看来,这主要是因为:
-
关于人工智能和深度学习的媒体炒作
-
我专注于打造一些伟大而真正令人印象深刻的东西
-
认为每个人都在做这个,如果我想找到一份工作,就需要做得比他们更好。毕竟,市场竞争如此激烈。
-
专注于大四
-
我对医疗保健数据很感兴趣,《实用深度学习教程》中有关于医学影像诊断的章节。你可以在这里查看一个例子。
深度学习和人工智能在媒体上随处可见。我们往往认为我们需要比其他人更优秀,而其他人已经在撰写带有华丽公式和大量代码的高数学博客。你不信?那就看看这个吧。当这样的人已经掌握了深度学习和数据科学时,谁会来找我们呢?
是的,它如此普遍,以至于有了专门的名称。它叫做“冒名顶替综合症”。去读一读吧。我曾以为只有我一个人受苦。但后来我意识到这非常普遍。是的,市场竞争激烈,由于当前疫情,许多人失去了工作。我在 LinkedIn 上看到过几位数据科学家和机器学习工程师失业的帖子。我甚至看到他们字面上恳求“点赞和分享”以寻找工作。这真的很令人心碎。每个人都值得过上好生活。

图片由Engin Akyurt提供,来自Pexels。
从积极的一面来看,这场疫情扰乱了世界,它让许多企业停滞不前,而有些企业的客户数量却激增(比如播客和视频会议服务)。在如此破坏性的时期,我们需要更加坚韧地应对痛苦和困境,并找到增强我们决心的方法。我相信我们出生在某一年并不是偶然,这也是我们处于这场疫情中的原因。我认为我们应该从中学习,我们应该从这些时光中创造出更美好的生活。祝你在数据科学学习的旅程中好运,希望我们能继续互相学习,使自己变得更好。
简历:Arnuld 是一名具有 5 年 C、C++、Linux 和 UNIX 经验的工业软件开发人员。在转向数据科学并担任数据科学内容编写者超过一年后,Arnuld 目前作为自由职业数据科学家工作。
原文。经许可转载。
相关:
-
我在 Coursera 上的数据科学在线学习之旅
-
2021 年免费学习数据科学的途径
-
从软件工程师到机器学习工程师的旅程
更多相关话题
2021 年数据科学学习路线图
原文:
www.kdnuggets.com/2021/02/data-science-learning-roadmap-2021.html
评论

尽管日期发生了变化,但新的一年给每个人带来了重新开始的希望。如果你再加上一点计划、一些清晰的目标和学习路线图,你将拥有一个充满成长的年份。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
本文旨在通过提供学习框架、资源和项目创意来加强你的计划,帮助你建立一个展示数据科学专长的扎实作品集。
仅供参考:我根据自己在数据科学领域的个人经验准备了这份路线图。这并不是唯一的学习计划。你可以根据自己感兴趣的特定领域或研究方向调整这份路线图。此外,这个路线图是以 Python 为基础的,因为我个人更喜欢它。
什么是学习路线图?
学习路线图是课程的延伸。它绘制了一个多层次的技能图谱,详细说明了你想要磨练的技能,你将如何在每个层级测量结果,以及技巧来进一步掌握每项技能。
我的路线图根据每个层级的复杂性和在实际应用中的普遍性分配权重。我还添加了一个估计时间,帮助初学者完成每个层级的练习和项目。
这里有一个金字塔,描绘了按复杂性和行业应用排序的高级技能。
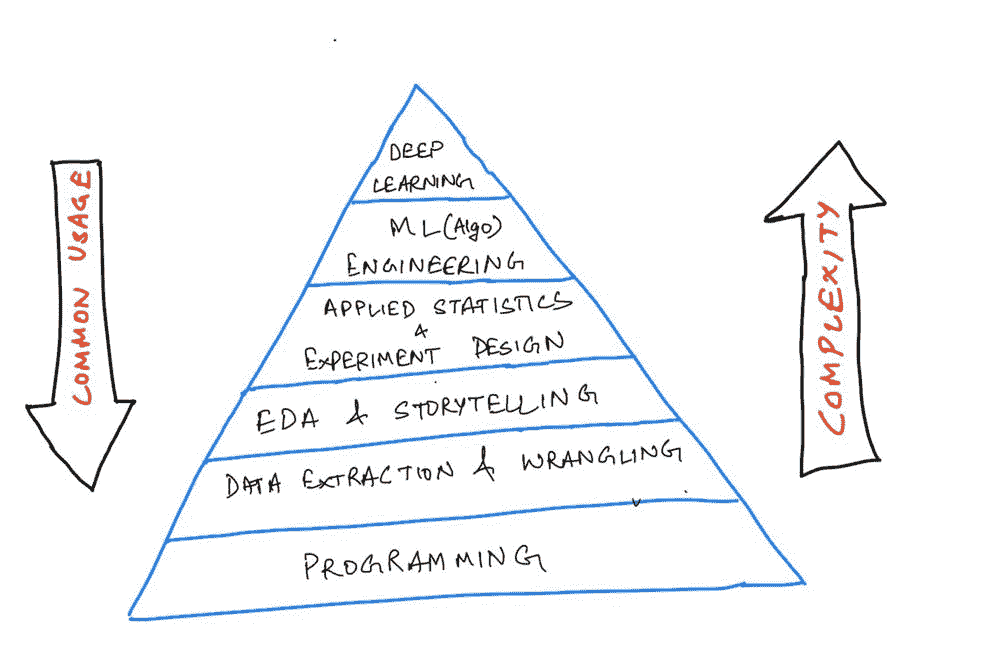
数据科学任务按复杂性排序。
这将标志着我们框架的基础。我们现在需要深入每一层,以更具体、可测量的细节完善我们的框架。
具体性来自于检查每一层中的关键主题和掌握这些主题所需的资源。
我们将能够通过将学到的知识应用到多个现实世界的项目中来衡量所获得的知识。我已经添加了一些项目创意、门户和平台,供你用来衡量你的能力。
重要说明: 每天处理一天的内容,每天一个视频/博客/章节。这是一个广泛的范围,不要给自己带来过多压力!
让我们深入探讨这些层次,从基础开始。
1. 如何了解编程或软件工程
(估计时间:2-3 个月)
首先,确保你拥有扎实的编程技能。每个数据科学职位描述都会要求至少一种编程语言的专业知识。
需要了解的具体编程主题包括:
-
常见的数据结构(数据类型、列表、字典、集合、元组)、编写函数、逻辑、控制流程、搜索和排序算法、面向对象编程,以及使用外部库。
-
SQL 脚本:使用连接、聚合和子查询查询数据库
-
熟悉使用终端、Git 的版本控制和使用 GitHub
学习 Python 的资源:
-
learnpython.org [免费]— 一个免费的初学者资源。它从零开始涵盖了所有基本编程主题。你可以使用互动式终端来并行练习这些主题。
-
Kaggle [免费]— 一个免费的互动式 Python 学习指南。它是一个简短的教程,涵盖了数据科学中的所有重要主题。
-
freeCodeCamp 的 Python 认证 [免费] – freeCodeCamp 提供了几个基于 Python 的认证课程,如科学计算、数据分析和机器学习。
-
freecodecamp 在 YouTube 上的 Python 课程 [免费] — 这是一个 5 小时的课程,你可以跟随这个课程来练习基本概念。
-
中级 Python[免费]— Patrick 在 freecodecamp.org 上提供的另一个免费课程。
-
Coursera Python for Everybody Specialization [收费] **— **这是一个涵盖初学者级概念、Python 数据结构、从网络收集数据以及使用 Python 操作数据库的专业化课程。
学习 Git 和 GitHub 的资源:
-
Git 和 GitHub [免费] 指南:完成这些教程和实验室,以对版本控制有扎实的掌握。这将有助于你进一步参与开源项目。
-
这里有一个 Git 和 GitHub 快速入门课程 在 freeCodeCamp 的 YouTube 频道上
学习 SQL 的资源:
-
这里有一个 SQL 和数据库课程 在 freeCodeCamp 的 YouTube 频道上
-
Treehouse 提供了一个 很好的 SQL 入门课程。
通过解决大量问题和完成至少两个项目来衡量你的专业水平:
-
在这里解决大量问题: HackerRank (适合初学者)和 LeetCode (解决简单或中等难度的问题)
-
从网站/API 端点提取数据 — 尝试编写 Python 脚本,从允许抓取的数据网页(如 soundcloud.com)中提取数据。将提取的数据存储到 CSV 文件或 SQL 数据库中。
-
游戏如石头剪子布、旋转纱线、猜单词、掷骰子模拟器、井字棋等。
-
简单的网页应用程序,如 YouTube 视频下载器、网站屏蔽器、音乐播放器、抄袭检测器等。
将这些项目部署到 GitHub Pages 或仅在 GitHub 上托管代码,以便你学习如何使用 Git。
2. 如何学习数据收集和数据清洗(整理)
(预计时间:2 个月)
数据科学工作的一个重要部分是寻找能够帮助你解决问题的适当数据。你可以从不同的合法来源收集数据 — 抓取(如果网站允许)、API、数据库和公开的代码库。
一旦你拥有数据,分析师通常会发现自己在清理数据框、处理多维数组、进行描述性/科学计算以及操作数据框以汇总数据。
数据在“现实世界”中很少是干净和格式化的。Pandas 和 NumPy 是你可以使用的两个库,帮助你从脏数据转换为可分析的数据。
当你开始熟悉编写 Python 程序时,可以随时开始学习使用像pandas和numpy等库。
学习数据收集和清洗的资源:
-
关于 在 Python 中使用 NumPy 和 Pandas 进行数据处理的实用教程 来自 HackerEarth。
-
Kaggle pandas 教程 [免费] — 一个简短而精炼的动手教程,将引导你掌握常用的数据处理技能。
-
Coursera 上的 Python 数据科学入门课程 — 这是应用数据科学与 Python 专业课程的第一个课程。
数据收集项目创意:
-
从你选择的网站/API(对公众开放)收集数据,并将数据转化为来自不同来源的汇总文件或表格(数据库)。示例 API 包括 TMDB、quandl、Twitter API 等等。
-
选择任何公开可用的数据集,并在查看数据集和领域后定义一系列你希望探索的问题。利用 Pandas 和 NumPy 对数据进行清洗,以找出这些问题的答案。
3. 如何学习探索性数据分析、商业敏锐度和讲故事
(预计时间:2–3 个月)
下一阶段需要掌握的是数据分析和讲故事。数据分析师的核心职责是从数据中提取洞见,并用简单的术语和可视化方式将其传达给管理层。
讲故事部分要求你在数据可视化方面非常熟练,并具备出色的沟通技巧。
需要学习的具体探索性数据分析和讲故事的主题包括:
-
探索性数据分析 — 定义问题、处理缺失值、异常值、格式化、过滤、单变量和多变量分析。
-
数据可视化 — 使用如 matplotlib、seaborn 和 plotly 等库绘制数据。了解如何选择合适的图表来传达数据中的发现。
-
开发仪表板 — 许多分析师仅使用 Excel 或类似 Power BI 和 Tableau 的专业工具来构建汇总/聚合数据的仪表板,以帮助管理层做出决策。
-
商业敏锐度:练习提出正确的问题,这些问题真正针对商业指标。练习编写清晰简洁的报告、博客和演示文稿。
获取更多数据分析学习资源:
-
在这个freeCodeCamp YouTube 频道上的免费课程中学习使用 Python 进行数据分析。
-
Python 数据分析 — 由 IBM 提供的 Coursera 课程。该课程涵盖了数据清洗、探索性分析以及使用 Python 进行简单模型开发。
-
数据可视化 — 由 Kaggle 提供的另一门互动课程,让你练习所有常用的绘图方法。
-
通过以下书籍培养产品感知和商业头脑:Measure what matters、Decode and conquer、Cracking the PM interview**。
数据分析项目想法
-
在 电影数据集上的探索性分析以寻找制作盈利电影的公式(将其作为灵感来源),使用来自医疗、金融、WHO、过往人口普查、电子商务等的数据集。
-
利用上面提供的资源构建仪表板(jupyter notebooks、excel、tableau)。
4. 如何学习数据工程
(预计时间:4–5 个月)
数据工程支撑着研发团队,使研究工程师和科学家在大数据驱动的公司中能够访问干净的数据。数据工程是一个独立的领域,如果你只想专注于统计算法方面的问题,可以选择跳过这一部分。
数据工程师的职责包括构建高效的数据架构,简化数据处理,维护大规模的数据系统。
工程师使用 Shell (CLI)、SQL 和 Python/Scala 来创建 ETL 管道,自动化文件系统任务,并优化数据库操作,以提高其性能。
另一个关键技能是实施这些数据架构,这需要对像 AWS、Google Cloud Platform、Microsoft Azure 等云服务提供商有很高的熟练度。
学习数据工程的资源:
-
Udacity 数据工程纳米学位— 就资源汇总列表而言,我还没遇到过结构更好的数据工程课程,该课程从零开始涵盖了所有主要概念。
-
GCP 上的数据工程、大数据和机器学习专项课程 — 你可以完成 Google 在 Coursera 上提供的这一专项课程,该课程带你了解 GCP 提供的所有主要 API 和服务,帮助你构建完整的数据解决方案。
数据工程项目想法/认证准备:
-
AWS 认证机器学习(300 美元)— AWS 提供的一个监考考试,这将使你的个人资料更具分量(但不保证任何东西),需要对 AWS 服务和机器学习有一定的理解。
-
专业数据工程师 — 由 GCP 提供的认证。这也是一项监考考试,评估你设计数据处理系统、在生产环境中部署机器学习模型以及确保解决方案质量和自动化的能力。
5. 如何学习应用统计学和数学
(预计时间:4–5 个月)
统计方法是数据科学的核心部分。几乎所有的数据科学面试都主要关注描述性和推断统计学。
人们常常在没有清楚了解解释这些算法工作的基础统计和数学方法的情况下开始编写机器学习算法。这显然不是最佳的学习方法。
你应该在应用统计学和数学中关注的主题:
-
描述统计学 — 能够总结数据是很强大的,但并不总是必要。学习位置估计(均值、中位数、众数、加权统计、修剪统计)和变异性来描述数据。
-
推断统计学 — 设计假设检验、A/B 测试、定义业务指标、分析收集的数据和实验结果,使用置信区间、p 值和α值。
-
线性代数、单变量和多变量微积分 ,以理解机器学习中的损失函数、梯度和优化器。
学习统计学和数学的资源:
-
在这个免费的 8 小时课程中学习大学级统计学 ,课程在 freeCodeCamp 的 YouTube 频道上提供。
-
[书籍] 数据科学的实用统计 (强烈推荐) — 一本详细介绍所有重要统计方法的指南,包含清晰简洁的应用/示例。
-
[书籍] 裸统计学 — 一本非技术性的详细指南,帮助理解统计学对我们日常事件、体育、推荐系统等许多实例的影响。
-
Python 中的统计思维 — 一门基础课程,帮助你开始统计思维。该课程还有第二部分。
-
描述统计学入门 — 由 Udacity 提供。包括解释广泛使用的定位和变异性测量(标准差、方差、中位绝对偏差)的讲解视频。
-
推论统计学,Udacity——该课程包括视频讲座,教你如何从数据中得出可能并不立即显而易见的结论。它侧重于发展假设,并使用常见的测试,如 t 检验、方差分析(ANOVA)和回归分析。
-
这里有一份数据科学统计指南来帮助你走上正确的道路。
统计项目想法:
-
解决上述课程提供的练习,然后尝试处理一些公共数据集,在这些数据集中应用这些统计概念。提出类似于“在 0.05 显著性水平下,是否有足够证据表明波士顿的母亲生育时的平均年龄超过 25 岁?”的问题。
-
尝试设计并与同伴/小组/班级一起进行小实验,让他们与应用程序互动或回答问题。在一段时间后,一旦你收集到足够的数据,就对这些数据应用统计方法。这可能非常难以实现,但应该非常有趣。
-
分析股票价格、加密货币,并围绕平均收益或其他指标设计假设。确定你是否能通过临界值拒绝零假设或未能拒绝零假设。
6. 如何学习机器学习和人工智能
(预计时间:4–5 个月)
在深入掌握所有上述主要概念后,你现在应该准备好开始使用高级机器学习算法。
学习主要有三种类型:
-
监督学习——包括回归和分类问题。学习简单线性回归、多重回归、多项式回归、朴素贝叶斯、逻辑回归、KNN、树模型、集成模型。了解评估指标。
-
无监督学习——聚类和降维是无监督学习中两个广泛使用的应用。深入研究主成分分析(PCA)、K 均值聚类、层次聚类和高斯混合模型。
-
强化学习(可跳过)——帮助你构建自我奖励系统。学习优化奖励,使用 TF-Agents 库,创建深度 Q 网络,等等。
大多数机器学习项目要求你掌握我在这篇博客中解释的许多任务。
学习机器学习的资源:
-
这里有一个免费的完整课程使用 ScikitLearn 的 Python 机器学习在 freeCodeCamp YouTube 频道上。
-
[书籍] 动手学习机器学习:Scikit-Learn、Keras 和 TensorFlow 第 2 版——这是我最喜欢的机器学习书籍之一。书中不仅涵盖了理论数学推导,还通过示例展示了算法的实现。你应该完成每章末尾给出的练习。
-
Andrew Ng 的机器学习课程——任何想学习机器学习的人都必修的课程。毫无疑问!
-
机器学习简介——Kaggle 的互动课程。
-
游戏 AI 和强化学习简介——Kaggle 上另一个关于强化学习的互动课程。
对于那些有兴趣进一步深入深度学习的人,你可以从完成 deeplearning.ai 提供的专业化课程和《动手学习》书籍开始。从数据科学的角度来看,除非你打算解决计算机视觉或 NLP 问题,否则这并不是特别重要。
深度学习值得拥有一份专门的路线图。我将很快创建一个包含所有基础概念的路线图。
跟踪你的学习进度
我还为你在 Notion 上创建了一个学习跟踪器。你可以根据自己的需求自定义它,并用来跟踪你的进度,方便访问所有资源和项目。
此外,这是这个博客的免费视频版本:
这只是数据科学广泛领域的一个高级概述。你可能需要深入研究这些主题,为每个类别制定一个基于概念的详细计划。
原文。经许可转载。
相关:
更多相关内容
完整的数据科学 LinkedIn 个人资料指南
原文:
www.kdnuggets.com/2019/11/data-science-linkedin-profile-guide.html
评论
由 Dan Lewins,Big Cloud 的社交媒体经理。
到目前为止,全球注册的数据科学 LinkedIn 个人资料已经超过了 830,000 个。尽管如此,在线上目前有如此多的数据科学家,但人才短缺依然是一个严重的问题。事实上,根据 O'Reilly Media 的报告,几乎一半的欧洲公司都在为填补数据科学职位而挣扎。Indeed 的招聘实验室的研究显示,自 2013 年以来,数据科学职位空缺总体增加了 256%,其中 2018 年 12 月以来年增长率达 31%。数据科学是一个庞大而复杂的行业,涵盖了许多子领域。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
职位的变动通常需要如此具体的技能集,以至于这些职位平均空缺时间长达 45 天。那么,这对你作为数据科学、工程或机器学习领域的专业人士意味着什么?你是一个抢手货。无论是初创公司、独角兽公司还是大企业,都会希望与您合作。我们可以保证这一点。对招聘专家来说,他们希望能够识别出能为组织提供独特技能的候选人。优化你在 LinkedIn 上的技能集是至关重要的,你应该立即开始!
仍然不相信吗?
LinkedIn 拥有超过 5.75 亿的注册用户,其中每月活跃的用户超过 2.6 亿,毫无疑问,它是#1 的职业社交平台。你有机会与行业中的影响者、决策者和领导者建立联系。
这个社交网络平台缩短了候选人与客户之间的距离,这导致了超过 75%的专业人士现在使用 LinkedIn。这将影响他们在职业变动时的决策。
当像 LinkedIn 这样的平台被大量同领域的专业人士填满时,你需要专注于使自己在竞争中脱颖而出。
“大数据就像青少年时期的性行为:每个人都在谈论它,没人真的知道怎么做,每个人都认为别人正在做,所以每个人都声称自己在做。” – Chris Lynch, Vertica Systems
随着 LinkedIn 活跃用户数量的不断增长,确保你充分利用这个平台比以往任何时候都更重要。正如 Work It Daily 的创始人兼首席执行官 J.T. O'Donnell 所说,“LinkedIn 个人资料是‘我们管理的。它与 Twitter、Instagram 或 Facebook 没有什么不同。它直接代表了我们。’”
这份数据科学 LinkedIn 个人资料指南将帮助你创建一个优化且吸引人的个人资料,使猎头和招聘人员对你的专业技能感兴趣。
为什么你应该保持 LinkedIn 个人资料的最新状态
保持 LinkedIn 个人资料最新的好处是显而易见的。然而,你可能会想知道,如果你没有积极寻找新的机会,为什么还需要保持更新。你也可能会想知道,如果你已经在使用 LinkedIn 申请职位,为什么没有看到你期望的结果。
无论你属于哪个类别,你都应该考虑利用你的个人资料作为记录你的角色职责、项目和完成的活动的理想平台。为什么?因为这样做可以让他人完全了解你的技能和经验,这可能正是他们所寻找的。
让我们更详细地看看这个问题。
假设你在个人资料描述中将自己描述为一个团队合作者。对大多数雇主而言,能够作为团队的一部分工作是一个强制性要求。
giphy.com/gifs/fresh-off-the-boat-jessica-huang-constance-wu-kt1smiAtPsh0c
利用 LinkedIn 记录你日常工作中的细节,给你机会证明你实际上非常适合团队合作。
假设你正在担任数据科学家的职位。你的标准角色要求可能看起来像这样:
– 作为首席数据策略师,我识别并整合可以通过我们的产品能力利用的新数据集。我还与工程团队密切合作,制定和执行数据产品的开发策略。
– 执行分析实验以帮助解决各种问题,对各个领域和行业产生真正的影响。
– 识别相关数据源和数据集,以满足客户业务需求,并收集大量的结构化/非结构化数据集和变量。
– 设计和利用算法及模型来挖掘大数据存储,进行数据和错误分析以改进模型,并清理和验证数据以确保其一致性和准确性。
– 分析数据中的趋势和模式,并以明确的目标解释数据。
– 通过与软件开发人员和机器学习工程师合作,将分析模型投入生产。
– 向利益相关者传达分析解决方案,并根据需要实施对操作系统的改进。
听起来很简单,对吧?
关键是要思考一下你有多少次在数据科学家角色之外工作过。
我们都有过为了支持同事或其他部门而参与某个任务或项目的经历。这不属于我们的核心职责,但这些时刻提供了展示你额外付出和作为团队成员支持业务的理想机会。
那这在你的个人资料上是什么样的呢?这里有一个来自数据科学副总监的例子:

当招聘人员能够清晰地了解你所从事的所有工作时,你的个人资料会立即变得更有吸引力。这包括你在个人资料中列出的角色中的成就。
当然,你可能已经包含了最新的职位头衔,但如果能清晰地列出你的角色职责,就能让招聘人员更好地了解你的技能和专长。这使得你更有可能被需要你专长的组织挖掘!
如何优化你的数据科学 LinkedIn 个人资料
现在我们已经了解了为什么你应该使用 LinkedIn,接下来我们来看看个人资料布局的每个部分。是时候充分利用 LinkedIn 的所有功能了!
个人资料头部
你的个人资料头部是访问你页面的访客首先看到的内容。你会惊讶于有多少个人资料没有包含任何个人资料或头部图像。这对招聘和人力资源专业人士来说是一个直接的障碍。不包含任何图像的个人资料会给人一种你在平台上不活跃的印象。你会看起来好像不会回应你可能收到的任何沟通。
过去为了找到完美的头像而在父母家的阁楼里翻找家庭宝丽来照片的日子已经过去了。现在,大多数智能手机,如 iPhone,都配有“人像”模式,可以在几秒钟内拍出专业的个人照片。当然,拍摄头像照片时你还需要考虑一些因素。
虽然你可能有互联网上最好的撅嘴,但 LinkedIn 不是你周末自拍或你最珍贵的猫咪朋友的照片展示地。
那我接下来该做什么?
网上有很多资源可以教你如何使用手机快速拍摄专业照片,比如这个逐步教程。
以完美的头像向你的观众展示你是谁,是以更具亲和力的方式介绍自己的第一步,鼓励他人了解你。
除了展示你最灿烂的笑容外,你还需要确保有一张最好与您的专业领域相关的头部图像。
让我们看一个例子:
Alyesha Sayle 是 Big Cloud recruitment 的高级技术招聘顾问。Alyesha 专注于全球数据科学、机器学习和人工智能组织的招聘。Alyesha 寻找的理想候选人应具备语言技术、可解释人工智能和人力分析方面的专业技能。

对于一个不认识 Alyesha 的人来说,这些信息可能很多,但当访问她的 LinkedIn 个人资料时,我们能够清楚地了解 Alyesha 的工作内容,因为她的个人资料被有效地优化,以传达她的工作角色和她所在的公司。
现在我们了解了 Alyesha 的工作内容和所在行业后,我们更有可能想要探索她的个人资料,以进一步了解她的过去和现在的职业角色。
“关于”部分
“关于”部分紧随你的标题之后。这提供了一个机会,详细解释你的角色、技能和经验。你应该利用这个部分展示在简历中包括的亮点,并且这些亮点对潜在雇主感兴趣。
将“关于”部分视为仅仅是一个总结。请记住,在你的照片之后,这是雇主首先看到的个人资料部分,所以确保这一部分的准确性非常重要。一个好的或坏的简介可能会决定你是否能获得宝贵的机会或失去机会。请用第一人称写作,而不是第三人称。招聘人员常常评论用第三人称写作会显得缺乏专业性,这会让人感觉不够亲切。
活动
你知道吗,你的 LinkedIn 个人资料展示了你在整个平台上的最近活动?默认情况下,你与 LinkedIn 上其他用户的四个最新互动将显示在个人资料中的活动动态中。
这些活动对访问你页面的任何人都是可见的,在与其他 LinkedIn 用户和组织沟通时,值得记住这一点。
这是你最近活动在个人资料中的呈现方式:

这对招聘人员有什么好处?
向你的观众展示你在 LinkedIn 上的活动可以展示许多信息。例如,访问你页面的用户可以看到你与谁建立了联系,你讨论了哪些话题,以及你涉及的行业。建议你记住,在 LinkedIn 上发布任何内容时,你的评论对所有人都是可见的。
在发布内容或评论时,如果你对某个话题表达个人观点,最好避免负面活动。这可能会影响你在招聘人员寻找新职业机会时的形象。
数据科学 LinkedIn 经验和工作历史
现在,这一部分是你将在个人资料中列出大部分信息的地方。你可以列出你曾工作过的每一个角色。你还可以包括多媒体资产,如照片、视频和提供你角色证明的链接。
当你填写个人资料的这一部分时,同时更新你的简历是明智的。拥有最新的简历会增加你通过 LinkedIn 的 EasyApply 功能申请职位时的吸引力。不仅如此,你还可以将简历直接上传到新机会。不过不用担心,我们通过创建你唯一需要的简历模板让这部分变得简单。
大多数 LinkedIn 用户会包括详细说明其角色的基本信息。他们会列出所在公司的名称和在该公司工作的时间范围。重要的是不要错过在此处详细说明你的角色和职责的机会。扩展你的经验和职业发展,以使自己在竞争中脱颖而出。
没有人愿意在访问 LinkedIn 个人资料时阅读冗长的内容。保持描述简洁明了,避免冗长的句子和段落。
记住,LinkedIn 上数据科学专业人士的数量已经饱和。会有那些与你拥有类似经验和技能的人,因此你需要有意识地保持你的个人资料清晰简洁。直截了当地陈述你的专长,避免在列出时混淆各个领域。 Ryan Swanstrom 的报告展示了 LinkedIn 个人资料中数据科学家、软件工程师和数据工程师技能的对比。

数据科学家、软件工程师和数据工程师在 LinkedIn 上列出的技能对比。
当然,在我们行业内的某些角色之间总会有技能的交叉。然而,如果你的技能在每个相关角色中都被清晰列出,并详细说明了它们是如何应用的,那么审查你个人资料的招聘人员会更清楚它们的具体应用情况。
但为什么我需要添加这些信息?
需要考虑的是,在你繁忙的日程中,你可能忽视了工作中的某些方面。某些任务或项目可能不符合你工作描述上的内容,但如果它们支持雇主所寻找的专业领域,请使用它们!详细描述你过去和现在的角色能为招聘人员提供最详细的洞察。你在帮助他们深入了解你为什么是一个完美的候选人来担任一个激动人心的新职位。这将增加你被联系的可能性,同时确保你在尽可能展示自己。
将这一部分视为记录你每个角色工作内容的机会。这将为你提供一个参考的地方,供你随时回顾和反思。这在你职业生涯的后期可以成为一个很好的资源,因为你将拥有个人进步的记录。
我应该如何具体操作?
让我们看几个例子来更好地理解:
在这里,我们将以 Big Cloud 招聘公司的社交媒体经理为例。
示例 1: 在这里我们可以看到这个人正在 Big Cloud 担任社交媒体经理。公司标志和品牌已包含在内,但没有分享这个特定角色的具体内容。这使得招聘人员需要做很多猜测来确定你的优势和专业领域。

示例 2: 在这里,我们可以看到这个人担任 Big Cloud 的社交媒体经理。他们详细说明了这个角色的具体内容。额外的贡献在角色描述中有记录。这展示了项目的完成情况,进一步支持了这个角色。

当然,根据你的职业,可能并不总是适合你披露角色的每一个细节。然而,你能提供的更多信息可能会对你长期有利。这将增加你在申请职位时成为成功候选人的机会——这才是最终目标,对吧?
数据科学 LinkedIn 技能与推荐
在展示你的优势时,LinkedIn 个人资料上的技能和推荐部分非常有价值。在这里,你可以通过同行的确认突出你的专业领域。
例如;如果你是一名数据科学专业人士,你的技能可能包括以下几项:
-
C/C++
-
Python
-
HTML/CSS/JS
-
Java/Android
-
TensorFlow
-
R
-
SQL
-
Keras
-
jQuery
-
Tableau
-
AWS
-
MATLAB
-
Hadoop
-
Spark
推荐
口碑仍然是并且永远是最重要的推荐方式之一。努力通过个人推荐来展示你的能力、个性和职业道德。将这视为一个展示自己不仅仅是屏幕上另一个面孔的机会。
注意任何由你的同事和上司撰写的推荐。包括以前与你合作过的人的推荐,可以为雇主提供实时的推荐。这将进一步展示你的专业履历和能力。
以下是你的推荐在个人资料上的显示方式:

书面的推荐仅会来自你已连接的个人。只有在你批准后,它们才会在你的个人资料上可见。
虽然拥有许多推荐是好的,但我们建议只批准那些展示你技能的推荐。与工作态度或你在领域内的知识相关的推荐也是很好的!招聘人员将使用推荐来验证你在特定角色中的表现能力。
列出数据科学的 LinkedIn 兴趣
到现在为止,你应该对你在更新 LinkedIn 个人资料之前提交的许多职位申请的情况有了一个不错的了解。

我们认为,你在个人资料上投入的努力越多,你将看到更多的机会。你已经完成了页面设置的这一步,但问题是,你还可以如何利用 LinkedIn?这就是兴趣的作用所在。
你的 LinkedIn 新闻动态会根据你进行个性化调整。你不仅会看到网络中连接的人的帖子,还会看到你加入或关注的群组和社区的活动。加入群组是结识与你有共同兴趣的新人的好方法。它不一定是专业性的!例如,你可以分享对 Elon Musk 雄心壮志的日常记录的共同兴趣。
在社区中不要害羞,利用它们作为建立网络和学习新事物的机会。我们建议从这里开始。
你会发现很多人分享关于他们专业领域的见解和意见。有些人可能会提出你知道答案的问题。利用 LinkedIn 提供帮助、进行对话,并发表你的观点。
另外需要注意的是,你的兴趣对访问你个人资料的人是可见的。这为你的受众提供了一个额外的机会,让他们更多地了解你。
我已经准备好了,那些数据科学招聘人员在哪里?
是不是只有我们这样觉得,在等待事情发生时会听到蟋蟀的叫声?
现在你已经为你的个人资料重新装修一新,我们来检查一些基本设置。
谁可以联系到你?
为了确保招聘人员能够联系到你,你需要确保在个人资料上启用了特定的设置。
这是你的联系设置应该如何显示:

允许招聘人员通过 InMail 联系你是至关重要的,如果你希望收到新的职位信息。如果你没有启用这个功能,你可以确定不会有很多猎头联系你。
谁可以找到我?
如果你不告诉招聘人员你正在寻找新的机会,你将不会听到回应。
你的 LinkedIn 求职偏好应该如下:

数据科学、机器学习和人工智能职位申请中重要的是什么?
现在我们已经覆盖了如何最大限度地利用你的 LinkedIn 资料,让我们深入探讨数据科学招聘过程。Big Cloud 招聘团队集体拥有超过 20 年的人才搜索经验。具体来说,专业人士在数据科学、机器学习和人工智能组织中工作。
我们与招聘团队坐下来,以深入了解如何避免在数据科学简历中常见的错误。从猎头的角度来看,我们审视了在审查职位申请时最吸引人的信息。
问:你在数据科学家简历中看到的最常见错误是什么?
问:流行词汇游戏。仅列出你能清楚展示有经验的技能。更好的是,在项目描述的背景下支持你的技能。如果没有证据表明你在某个项目中应用了你的经验,这意味着你不适合你申请的角色。你会惊讶于我收到的许多来自数据科学家的申请中没有提到他们参与的项目。– Alyesha Sayle – 高级技术招聘专员(语言技术、可解释 AI 和人员分析)
个人简介中包含大量文字令人不悦且不必要。我更愿意看到一个对关键工作目标和经验有简洁概述的个人简介。此外,不接受 InMails 的候选人犯了一个大错。如果你对新机会持开放态度,但不接受 InMails,你可能会错过新的、令人兴奋的角色。花时间检查你是否已优化设置,以便招聘人员可以联系到你。– Tom Harris – 首席顾问(数据科学、机器学习、深度学习、计算机视觉和人工智能)
问:你能多快判断一个数据科学候选人是否适合这个角色?
答:在浏览申请者的个人资料时,通常在前 5 至 10 秒内就会显而易见。一个优秀的候选人会花时间完善自己的个人资料,并清晰地传达他们的专业经验。当候选人明显地在个人资料中注入一些个性时,令人耳目一新。这几乎总是鼓励我继续阅读他们的信息。如果候选人列出了他们参与的项目的例子,那也是一个巨大的加分项。这意味着我可以将他们推荐到更相关、更有趣的职位,并且不会浪费任何人的时间。 – Nicholas Jackson – 数据科学招聘专家(机器学习、深度学习、计算机视觉与人工智能)
问:你希望在 LinkedIn 个人资料中看到每个职位多少信息?
答:对我来说,我只需要每个职位用 3 至 4 句话描述,并列出他们所使用的技术,无论是在个人资料摘要中还是在关键词列表中。如果每个职位下没有列出相关信息,我很可能会转到下一个申请者。 – Chris Harrison – 高级顾问(数据科学、机器学习、人工智能、深度学习、NLP 与大数据)
申请者提供的信息越多越好。你的个人资料信息越少,你的账户被认为适合潜在新职位的机会就越小。这意味着你可能是一个优秀的候选人,但由于个人资料没有反映你的真实情况和能力,可能不会被联系到。 Chris Bradbury – (深度学习与计算机视觉招聘专家)
问:你在寻找哪些特定技能使候选人更有可能成功?
答:在数据科学领域,大多数组织都在寻找具备核心行业标准技能的候选人。有太多申请职位的候选人缺乏或没有提及关键技能,如 Python、数据科学、机器学习和 AWS。如果你在个人资料中包含这些内容,将会有很大不同。此外,阅读别人以第三人称谈论自己通常不太令人愉快。 – Dan Kettle – 高级技术招聘专家(数据科学、机器学习与人工智能)
问:你会推荐什么方法给希望在求职时脱颖而出的数据科学 LinkedIn 候选人?
A. 有一点总是让我印象深刻,那就是候选人是否包含了自己网站或 Github 个人资料的链接。如果你有这两个链接,最好都包含上。当我审阅申请时,能够直接查看申请人的背景和能力总是让我印象深刻,我会更倾向于联系那些考虑加入这些信息的候选人 —— 杰斯·伯金 – 高级技术候选人招聘专员(机器学习、自然语言处理与对话式人工智能)
问:当你审阅工作申请时,LinkedIn 上的数据科学家发表的出版物对你重要吗?
A. 绝对是的。候选人常常在简历上包含他们的出版物详情,如果在审阅申请后我联系候选人,我通常会询问这些出版物的详细信息。我认为数据科学申请者利用 LinkedIn 的文章写作功能会非常有益,因为这有助于提高你是谁的认识,并在浏览个人资料时给招聘人员更多的经验洞察 —— 卡斯滕·杨 – 人工智能专家招聘(机器学习/深度学习、计算机视觉、自然语言处理与机器人)
Big Cloud 的顶级数据科学 LinkedIn 技巧
– 避免在个人资料写作中使用技术术语和流行词汇。尽量保持你的写作尽可能贴近人性。你的目标是传达你的专业知识和个性,同时保持对你的职业资料的清晰和简洁描述。
– 在你的写作中注入个性。你的目标不仅是传达你的优势和能力,还要展示你作为个体的特质。记得保持专业,并避免分享负面观点,这可能会影响你被新雇主接触的机会。
– 在你的个人资料中加入多媒体。每个经历条目都允许你提供网站链接,并可以上传图片,以增强条目的可视性。充分利用这些功能来帮助你的个人资料更具视觉吸引力。
– 包括课外活动、志愿经历以及额外的口头/书面语言能力。
– 创建你自己的内容 —— LinkedIn 允许你上传文档。通过撰写围绕你专长领域的文章、对行业趋势的反应以及事件支持来展示你的专业知识,从而吸引行业内的关注。如果你已经发表了与机器学习、深度学习、人工智能和数据科学相关的文章,可以将这些文章重新利用并上传到你的 LinkedIn 个人资料中,以支持网络的增长。
– 利用数据科学 LinkedIn 小组。使用小组将允许你加入社区并与其他相关领域的人建立联系。参与小组活动将带来新的方式,让你被发现并考虑新的就业机会。
– 列出你的成就和你想联系的人。利用个人简介中的每一行来推销你所做的事情和你能提供的价值。
原文。经授权转载。
相关内容:
更多相关话题
数据科学与机器学习与数据分析与商业分析
原文:
www.kdnuggets.com/2018/05/data-science-machine-learning-business-analytics.html
评论
数据科学。这个流行词汇被许多人试图定义,取得了不同的成功。
思考这个问题会让人涉及到与数据科学相关的所有其他领域——商业分析、数据分析、商业智能、高级分析、机器学习,最终是人工智能。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
在处理这个问题时,我们在365 Data Science意识到“绝对定义”的数据科学需要大量的‘数据科学’背景知识才能理解,这本身就是一个递归问题……这里的假设是,统计学家或程序员比说历史学家或语言学家更容易理解数据科学,因为前者以某种形式接触过数据科学。
这引出了一个观点,即“相对定义”的数据科学可能更有用,这里是我们提出的方案。
这是一个欧拉图,描绘了上述所有领域。每种颜色代表一个不同的领域(混合颜色表示交集),图中有时间线和示例用法。
图 1:矩形的位置、大小和颜色显示了概念上的相似性和差异性,而非复杂性
由于所有这些信息可能会令人不知所措,我们从头开始。
商业
为了避免过度简化问题,我们假设“商业”一词不需要定义。商业活动的一些例子包括:
-
商业案例研究
-
定性分析
-
初步数据报告
-
使用可视化进行报告
-
创建仪表板
-
销售预测

它们舒适地坐在蓝色矩形中。
数据
这就是实际的欧拉图开始的地方。如果我们将数据纳入图中,将会有两个大领域及其交集,或总共三个部分。
根据我们最初的术语选择,我们可以将最后四个术语移到商业和数据的交集区域,目前在图中表示为紫色区域。这是因为‘初步数据报告’,‘可视化报告’,‘创建仪表板’和‘销售预测’都是数据驱动的业务活动。
它们可以与‘商业案例研究’和‘定性分析’相对立,因为这些是基于商业但基于过去的知识、经验和行为。所有这些都是重要的,但正如你很快会看到的——实际上并不是数据科学。

分析与分析
分析指的是将你的问题分解成易于消化的部分,方便你逐个研究并检查它们之间的关系。
分析,另一方面,是对分析中获得的组成部分应用逻辑和计算推理。在这样做时,人们寻找模式,并经常探索她可以如何在未来利用这些模式。
因此,与其说商业和数据,我们不如使用商业分析和数据分析。
时间
在进一步讨论之前,让我们引入一个时间线,因为它对于后续的分段至关重要。
我们将采用三个状态——过去、现在和未来。
图表上将有一条线穿过,表示任何分析问题的当前时刻。左侧的一切将指代面向过去的分析。右侧的一切将指代预测性分析。
我们分析的最后两个部分已经展示了这个点的全貌。
‘销售预测’被移到右侧,因为它的名字意味着一个面向未来的分析过程。广义上讲,‘定性分析’是利用你的直觉和经验来规划你的下一步行动——因此另一个面向未来的术语。
数据科学
对大多数读者来说,这就是文章的顶峰。数据科学是一个离不开数据的领域。因此,它完全属于 数据分析的范畴。
它与商业分析的关系如何呢?
好吧,事实证明,所有既是数据分析又是商业分析的东西确实是数据科学。
但有一点需要说明。存在一些数据科学过程并不是直接和立刻的商业分析,但却是数据分析。例如,‘钻探作业优化’需要数据科学工具和技术。数据科学家可能会每天都做这些事情。然而,在‘石油业务’领域中,我们不能真的说它直接与商业分析相关。
基于‘相对定义’的概念,为了更好地说明这些观点,“数字信号处理”是数据分析的一部分,但不是数据科学或商业分析的一部分。数据、编程和数学都会涉及,但并不像我们在数据科学中使用它们那样。
为了保持一致性,让我们用时间线来结束——数据科学既在这条线的左侧,也在右侧(就像其他领域一样)。
这引出了一个问题:是否存在仅以过去为导向的领域?
商业智能
商业智能(BI)是分析和报告历史数据的过程。
这是以过去为导向的吗?不一定,但没有涉及预测分析。回归、分类和所有其他通常的预测方法是数据科学的一部分,但**不是商业智能。这就是分界线所在。
此外,商业智能完全是数据科学的一个子集。因此,当一个人处理描述性统计、报告或过去事件的可视化时,她同时在做 BI 和数据科学。
机器学习和人工智能
在这里,定义会变得有些模糊,因为仅仅解释机器学习和人工智能会导致失去文章的重点。此外,关于机器学习是什么,有很多资源,尤其是在 KDnuggets 上。
人工智能(AI)是机器表现出的任何类似于自然(人类)智能的形式,如计划、学习、解决问题等。
机器学习(ML)是机器在没有明确编程的情况下预测结果的能力。
机器学习(ML)是一种人工智能(AI)的方法,但两者常常被混淆,因为实际上机器学习是我们人类迄今为止开发的唯一可行的人工智能路径。因此,当我们谈论公司正在使用的人工智能的实际应用时,我们实际上是在谈论机器学习。
在我们的图表中,这两个术语的适配方式如下。
机器学习完全属于数据分析,因为它不能在没有数据的情况下进行。它也与数据科学重叠,因为它是数据科学家工具箱中最好的工具之一。最后,只要没有涉及预测分析,它也参与商业智能。
在数据科学中,机器学习的实例包括“客户保留”、“防欺诈”和“创建实时仪表盘”(也属于商业智能的一部分)。显著的例子包括“语音识别”和“图像识别”。这两者可以被认为是在数据科学之内或之外,因此我们把它们放在了边界上。
为了全面解释所有关系,机器学习完全在人工智能之内,但人工智能本身有一些与商业分析和数据分析无关的子领域!我们选择的一个例子是“符号推理”。
高级分析
我们分析的最后一个领域是高级分析。它不是数据科学术语,而是营销术语。它用于描述“难以处理”的分析。从主观上看,对初学者来说,图中的一切都是高级的。虽然这不是最好的术语,但它确实有助于汇总我们在整篇文章中使用的所有“正确”术语。
移除 AI 并添加高级分析,这就是我们得到的结果。
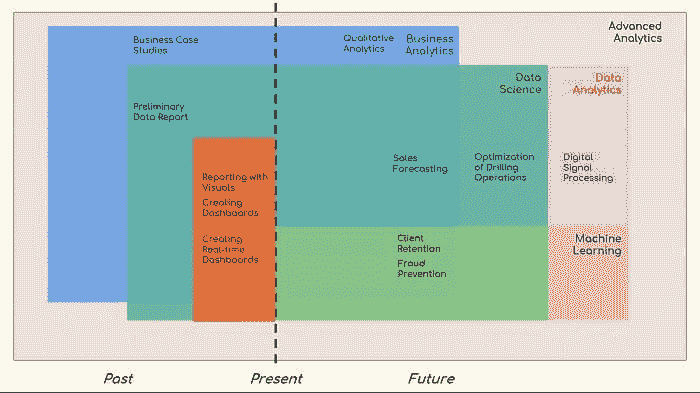
在本文的术语中,我们的高级分析分析已完成。
这是一个动画 gif,比较了这些定义。

简介: Iliya Valchanov 是 365 Data Science 的联合创始人。
相关:
更多相关内容
50+ 个数据科学、机器学习备忘单,已更新
原文:
www.kdnuggets.com/2016/12/data-science-machine-learning-cheat-sheets-updated.html
评论
本文更新了 Bhavya Geethika 的一篇非常受欢迎的文章 50+ 个数据科学、机器学习备忘单。如果我们遗漏了一些受欢迎的备忘单,请在下方评论中添加。

Python、R 及 Numpy、Scipy、Pandas 的备忘单
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
数据科学 是一个多学科领域。因此,在数据科学世界中有成千上万的包和数百个编程函数!有志的数据爱好者无需了解所有内容。备忘单或参考卡是一个汇总了最常用命令的工具,帮助你更快地学习该语言的语法。以下是一些经过深思熟虑并总结在几个紧凑页面中的最重要备忘单。
精通数据科学涉及统计学、数学、编程知识,尤其是 R、Python 和 SQL,然后将这些结合起来,利用业务理解和人类直觉——这是驱动决策的终极因素。
以下是按类别划分的备忘单:
Python 备忘单:
Python 是初学者的热门选择,但仍然足够强大,可以支持一些世界上最受欢迎的产品和应用程序。其设计使编程体验几乎像用英语书写一样自然。Python 基础或 Python 调试器备忘单覆盖了入门所需的重要语法。社区提供的库,如 numpy、scipy、sci-kit 和 pandas,广泛依赖,而 NumPy/SciPy/Pandas 备忘单提供了这些库的快速复习。
-
DaveChild 的 Python 备忘单 来自 cheatography.com
-
Python 基础参考表 来源:cogsci.rpi.edu
-
[NumPy / SciPy / Pandas 备忘单]( https://s3.amazonaws.com/quandl-static-content/Documents/Quandl+-+Pandas ,+SciPy,+NumPy+Cheat+Sheet.pdf)
-
OverAPI.com Python 备忘单
-
Python 3 备忘单 作者:Laurent Pointal
R 的备忘单:
R 的生态系统扩展如此之大,以至于需要大量的参考。R 参考卡涵盖了 R 世界的大部分内容。Rstudio 还发布了一系列备忘单,以便为 R 社区提供便利。ggplot2 的数据可视化似乎是一个受欢迎的选择,因为它在你创建结果图表时非常有用。
在 cran.r-project.org 上:
在 Rstudio.com 上:
其他:
-
DataCamp 的 数据分析(data.table 方法)
MySQL 和 SQL 的备忘单:
对于数据科学家来说,SQL 的基础知识与其他任何语言一样重要。PIG 和 Hive 查询语言与 SQL——原始结构化查询语言密切相关。SQL 备忘单提供了一个 5 分钟的快速指南,然后你可以深入探索 Hive 和 MySQL!
Spark、Scala、Java 备忘单:
Apache Spark 是一个用于大规模数据处理的引擎。对于某些应用,如迭代机器学习,Spark 可以比 Hadoop(使用 MapReduce)快多达 100 倍。Apache Spark 备忘单解释了它在大数据生态系统中的位置,讲解了基本的 Spark 应用程序的设置和创建,并解释了常用的操作和动作。
-
Dzone.com 的 Apache Spark 参考卡
-
DZone.com 的 Scala 参考卡
-
Openkd.info 的 Scala on Spark 备忘单
-
Java 备忘单 由 MIT.edu 提供
-
Java 备忘单 由 Princeton.edu 提供
Hadoop 和 Hive 备忘单:
Hadoop 作为一种非传统工具,解决了被认为无法解决的问题,通过提供一个开源软件框架来进行大规模数据的并行处理。探索 Hadoop 备忘单以发现使用 Hadoop 命令行时的有用命令。SQL 和 Hive 函数的组合是另一个值得关注的内容。
Django Web 应用框架备忘单:
Django 是一个免费的开源 Web 应用框架,使用 Python 编写。如果你是 Django 新手,可以查看这些备忘单,快速了解概念,并深入学习每一个。
机器学习备忘单:
我们经常花时间思考哪种算法最好?然后再回到我们的厚厚的书本中查找参考!这些备忘单提供了关于数据的性质和你正在解决的问题的思路,然后建议你尝试某种算法。
-
机器学习备忘单 于 scikit-learn.org
-
Scikit-Learn 备忘单:Python 机器学习 来自 yhat(由 GP 添加)
-
预测学习模式备忘单 于 Dzone.com
-
方程式和技巧 机器学习备忘单在 Github.com
-
监督学习迷信 Github.com 的备忘单
Matlab/Octave 备忘单
MATLAB(MATrix LABoratory)由MathWorks于 1984 年开发。Matlab d 一直是学术界用于数值计算的最流行语言。它适用于处理几乎所有可能的科学和工程任务,配备了多个高度优化的工具箱。MATLAB 不是开源工具,但有一个免费的GNU Octave 重新实现版,它遵循相同的语法规则,使大多数代码与 MATLAB 兼容。
跨语言参考备忘单
相关:
-
50+ 数据科学与机器学习备忘单
-
数据科学备忘单指南
-
按受欢迎程度排名的前 20 个 R 包
更多相关话题
数据科学与机器学习:免费电子书
原文:
www.kdnuggets.com/2020/12/data-science-machine-learning-free-ebook.html
评论
我们已经有一段时间没有与读者分享免费电子书了,但本周我们发现了另一部值得关注的作品,并希望在假期学习季节(这绝对是一个存在的事情)来临之前与大家分享。
今天我们分享数据科学与机器学习:数学与统计方法,由 D.P. Kroese、Z.I. Botev、T. Taimre 和 R. Vaisman 合著。该书去年出版,除了可以免费下载 PDF 外,还可以购买印刷版(和 Kindle 版)。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
数据科学与机器学习:数学与统计方法是一本以实践为导向的教材,重点介绍使用 Python 进行数据科学和实施机器学习模型。它很好地解释了相关理论,并根据需要介绍了必要的数学,结果使得这本实用书的节奏非常适中。
根据其网站,这本书的raison d'être 实际上与我的看法有些不符:
本书的目的是提供一本易于理解但内容全面的教科书,旨在帮助学生更好地理解数据科学中丰富的思想和机器学习算法背后的数学和统计学。
我相信这是同一枚硬币的另一面:当我看到这本书的优势在于教授实用技巧并用必要的理论和基础数学加以强化时,可以明确地说,它实际上专注于理论和基础数学,并通过实际应用来强化这些内容。
我会说可能平分秋色。
无论你支持哪种方法,这本书的目录如下:
-
导入、总结和可视化数据
-
统计学习
-
蒙特卡洛方法
-
无监督学习
-
回归分析
-
正则化和核方法
-
分类
-
决策树和集成方法
-
深度学习
这里涵盖了许多相关主题,并且逻辑顺序合理。我特别喜欢从蒙特卡罗方法过渡到无监督学习的过程,以及这种过渡发生在引入监督学习概念之前。尽管分类在长远来看可能更有用(至少目前似乎如此),但我第一次接触机器学习时,分类的影响远远不如聚类,因此在我看来,其先行引入可能对其他新学习者同样具有吸引力。
为确保本书对即使是最新的数据科学和机器学习学生也足够自给自足,本书包括了足够且有用的附录:
-
线性代数与泛函分析
-
多变量微分与优化
-
概率与统计
-
Python 基础
通过阅读这本书,你不会成为一个完整的数据科学专家,但这并不是它的目标。通过学习《数据科学与机器学习:数学与统计方法》,你将获得该领域基础知识的坚实基础,在此基础上可以添加更多前沿的方法和算法。
我最喜欢的机器学习书籍之一,是我首次接触该主题时使用的书籍,名为《数据挖掘:实用机器学习工具与技术》,也称为 Weka 书。我作为初学者非常喜欢它如何将实践和理论结合起来,根据需要介绍和解释数学,以学习当时呈现的实际实施。我发现这本书有类似的格式,具有使用 Python 代替 Weka 工具包的优势,至少在今天,Python 的实现路径要更为相关。
我推荐这本书给任何学习数据科学和机器学习基础知识的人,并且希望按照所描述的展示格式进行学习。
相关:
-
理解机器学习:免费的电子书
-
统计学习导论:免费的电子书
-
数据挖掘与机器学习:基本概念与算法:免费的电子书
更多相关主题
数据科学,机器学习:2017 年的主要发展及 2018 年的关键趋势
原文:
www.kdnuggets.com/2017/12/data-science-machine-learning-main-developments-trends.html
评论今年我们再次询问了该领域的杰出领导小组
数据科学、机器学习、预测分析的主要发展是什么?你期望 2018 年有哪些关键趋势?
主要主题包括人工智能和深度学习——这两者既有实际进展也有炒作,机器学习,安全,量子计算,AlphaGo Zero,等等。阅读 Kirk D. Borne、Tom Davenport、Jill Dyche、Bob E. Hayes、Carla Gentry、Gregory Piatetsky-Shapiro、GP Pulipaka、Rexer Analytics 团队(Paul Gearan、Heather Allen 和 Karl Rexer)、Eric Siegel、Jeff Ullman 和 Jen Underwood 的观点。
还可以阅读大数据:2017 年的主要发展及 2018 年的关键趋势和去年的预测。
有不同的观点?在文章末尾评论。

Kirk D. Borne, @KirkDBorne,BoozAllen 首席数据科学家,博士天体物理学家。顶级数据科学和大数据影响者。
 2017 年我们看到大数据让位于人工智能成为技术炒作周期的中心。这种对人工智能的过度媒体和从业者关注包括了正面消息(越来越强大的机器学习算法和人工智能应用于众多行业,包括汽车、医学影像、安全、客户服务、娱乐、金融服务)和负面消息(机器威胁到我们的工作和接管我们的世界)。我们还见证了围绕数据的价值创造创新增长,包括更大规模的 API 使用、即服务产品、数据科学平台、深度学习以及主要供应商的云机器学习服务。数据、机器学习和人工智能的专业应用包括机器智能、规范分析、旅程科学、行为分析和物联网。
2017 年我们看到大数据让位于人工智能成为技术炒作周期的中心。这种对人工智能的过度媒体和从业者关注包括了正面消息(越来越强大的机器学习算法和人工智能应用于众多行业,包括汽车、医学影像、安全、客户服务、娱乐、金融服务)和负面消息(机器威胁到我们的工作和接管我们的世界)。我们还见证了围绕数据的价值创造创新增长,包括更大规模的 API 使用、即服务产品、数据科学平台、深度学习以及主要供应商的云机器学习服务。数据、机器学习和人工智能的专业应用包括机器智能、规范分析、旅程科学、行为分析和物联网。
在 2018 年,我们应看到超越人工智能炒作的趋势。将是验证人工智能价值、衡量其投资回报率并使其可操作的时候。我们将看到这些发展领域与 2017 年的重点领域没有太大不同,包括流程自动化、机器智能、客户服务、超个性化和劳动力转型。我们还将见证物联网的成熟度增长,包括更高的安全特性、模块化平台、访问传感器数据流的 API 和边缘分析接口。同时,我们可能会看到数字双胞胎在制造、公共事业、工程和建筑行业变得更加主流。我还相信,在 2018 年,将有更多从业者迎接挑战,向怀疑的公众传达人工智能的积极益处。
汤姆·达文波特,是巴布森学院的 IT 和管理学杰出教授,国际分析学会的共同创始人,麻省理工学院数字经济倡议的研究员,以及德勤分析的高级顾问。
2017 年的主要发展:
-
企业人工智能进入主流: 许多大型、成熟的公司正在进行人工智能或机器学习项目。一些公司有超过 50 个使用各种技术的项目。这些大多是“低垂的果实”项目,目标相对有限。趋势是远离拥有“变革性”产品的大型供应商,转向开源、自己动手类型的项目。当然,这意味着公司必须招聘或培养高水平的数据科学技能。
-
机器学习应用于数据集成: 数据分析和管理中最古老的挑战现在正通过机器学习得到解决。集成和整理数据的劳动密集型方法正被“概率匹配”技术所取代——或至少被增强——通过对不同数据库中的相似数据元素进行匹配。这个工具的使用——通过工作流和专家众包来增强——可以将数据集成的时间减少十倍。
-
![开源]() 保守型公司接受开源: 传统上保守的公司,如银行、保险和医疗行业的公司,如今正积极接受开源分析、人工智能和数据管理软件。一些公司积极鼓励员工避免使用专有工具,而其他公司则让个人自由选择。成本是转变的一个原因,但性能的提升和吸引最近大学毕业生更为普遍。
保守型公司接受开源: 传统上保守的公司,如银行、保险和医疗行业的公司,如今正积极接受开源分析、人工智能和数据管理软件。一些公司积极鼓励员工避免使用专有工具,而其他公司则让个人自由选择。成本是转变的一个原因,但性能的提升和吸引最近大学毕业生更为普遍。
 保守型公司接受开源: 传统上保守的公司,如银行、保险和医疗行业的公司,如今正积极接受开源分析、人工智能和数据管理软件。一些公司积极鼓励员工避免使用专有工具,而其他公司则让个人自由选择。成本是转变的一个原因,但性能的提升和吸引最近大学毕业生更为普遍。
保守型公司接受开源: 传统上保守的公司,如银行、保险和医疗行业的公司,如今正积极接受开源分析、人工智能和数据管理软件。一些公司积极鼓励员工避免使用专有工具,而其他公司则让个人自由选择。成本是转变的一个原因,但性能的提升和吸引最近大学毕业生更为普遍。2018 年的发展:
-
![]() 我们已经进入了“后算法”时代:历史上,分析师和数据科学家需要对使用何种算法有相当的了解。但分析和机器学习过程的自动化使得可以考虑一百种或更多不同的算法。重要的是模型或模型集合的表现如何。这当然促进了“公民数据科学家”的崛起。尽管这种发展可能最终会有一些令人担忧的故事,但目前还没有出现。
我们已经进入了“后算法”时代:历史上,分析师和数据科学家需要对使用何种算法有相当的了解。但分析和机器学习过程的自动化使得可以考虑一百种或更多不同的算法。重要的是模型或模型集合的表现如何。这当然促进了“公民数据科学家”的崛起。尽管这种发展可能最终会有一些令人担忧的故事,但目前还没有出现。 -
独立 AI 初创公司的吸引力开始减弱: 在风险资本资助的刺激下,过去几年成立了数百家 AI 初创公司。大多数解决相对狭窄的问题。然而,即使它们有效,集成到现有的流程和系统中仍然是大多数组织的主要挑战。因此,成熟的公司更倾向于开发自己相对易于集成的 AI“微服务”,或从那些将 AI 内容嵌入其交易系统的供应商那里购买。
 我们已经进入了“后算法”时代:历史上,分析师和数据科学家需要对使用何种算法有相当的了解。但分析和机器学习过程的自动化使得可以考虑一百种或更多不同的算法。重要的是模型或模型集合的表现如何。这当然促进了“公民数据科学家”的崛起。尽管这种发展可能最终会有一些令人担忧的故事,但目前还没有出现。
我们已经进入了“后算法”时代:历史上,分析师和数据科学家需要对使用何种算法有相当的了解。但分析和机器学习过程的自动化使得可以考虑一百种或更多不同的算法。重要的是模型或模型集合的表现如何。这当然促进了“公民数据科学家”的崛起。尽管这种发展可能最终会有一些令人担忧的故事,但目前还没有出现。吉尔·迪奇、@jilldyche,SASBestPractice 的副总裁。畅销商业书籍作者。
现在几乎每个人和他们的兄弟都有人工智能或机器学习的产品。2017 年证明了亮眼的新物品被重新打磨,许多供应商——其中许多甚至不是我所谓的“AI 邻近”——准备好擦亮和展示他们的产品集。讽刺的是,由于其新颖性,许多这些供应商可能会超越已有的产品。
 2018 年将会看到更多关于 AI/ML 的商业对话和使用案例。为什么?因为管理者,大多数是有问题要解决的商业人士,不在乎神经网络是否在稀疏数据上挣扎。他们对自然语言处理中的词汇推理挑战不感兴趣。他们想要加速供应链,知道客户将会做什么/购买什么/说什么,并且仅仅告诉计算机他们想知道什么。这是大规模的处方分析,能够以最小的采用摩擦来提供这些服务的供应商可以主宰世界。
2018 年将会看到更多关于 AI/ML 的商业对话和使用案例。为什么?因为管理者,大多数是有问题要解决的商业人士,不在乎神经网络是否在稀疏数据上挣扎。他们对自然语言处理中的词汇推理挑战不感兴趣。他们想要加速供应链,知道客户将会做什么/购买什么/说什么,并且仅仅告诉计算机他们想知道什么。这是大规模的处方分析,能够以最小的采用摩擦来提供这些服务的供应商可以主宰世界。
卡拉·根特里,Analytical Solution 的数据科学家, @data_nerd。
 2017 年是大家开始讨论机器学习、人工智能和预测分析的年份,不幸的是,许多这些公司/供应商只是“追逐流行词”,并没有真正的背景去实现他们所宣传的……如果你查看任何上述提到的“热门话题”在 Twitter 上的讨论,你会发现一堆来自去年谈论社交媒体营销的同一群人的帖子!这些领域的经验需要时间和才能,而不仅仅是“行动号召”和流行词……如常所说,经验确实重要!
2017 年是大家开始讨论机器学习、人工智能和预测分析的年份,不幸的是,许多这些公司/供应商只是“追逐流行词”,并没有真正的背景去实现他们所宣传的……如果你查看任何上述提到的“热门话题”在 Twitter 上的讨论,你会发现一堆来自去年谈论社交媒体营销的同一群人的帖子!这些领域的经验需要时间和才能,而不仅仅是“行动号召”和流行词……如常所说,经验确实重要!
我认为 2018 年是我们关注数据科学和预测分析领域领导者的一年,这不仅仅是因为它很流行,而是因为它能对你的业务产生巨大的影响。预测招聘可以节省数百万的人员流动成本;人工智能和机器学习可以在几秒钟内完成你以前需要几天的工作!我们同意技术可以带我们达到新的高度,但也要记得做一个有良知的人。作为数据科学家或算法编写者,你有责任避免造成伤害,无论是法律上的,还是在人性和伦理实践上的,要保持透明和公正。
Bob E. Hayes @bobehayes,研究员和作家,《Business Over Broadway》的出版者,拥有工业-组织心理学博士学位。
数据科学和机器学习能力的实践正被越来越多的行业和应用所采纳。
在 2017 年,我们见证了人工智能能力的重大进展。虽然之前的深度学习模型需要大量数据来训练算法,但神经网络和强化学习的使用表明,创建高性能算法不再需要数据集。DeepMind 运用了这些技术,并通过自我对弈创建了 Alpha Go Zero,这一算法超越了之前的算法。
随着人工智能在刑事司法、金融、教育和工作场所等领域的持续增长,我们需要为算法建立标准,以评估它们的准确性和偏差。对人工智能社会影响的关注将继续增长(见这里和这里),包括制定人工智能可以使用的规则(例如,避免“黑箱”决策)以及理解深度学习算法如何做出决策。
 即使在互联网时代诞生的公司(例如 imgur、Uber)中,安全漏洞也将继续上升。因此,我们将看到对安全方法进行彻底改革的努力,增加区块链(一个虚拟账本)的可见性,作为改善公司如何保护其客户数据的可行方式。
即使在互联网时代诞生的公司(例如 imgur、Uber)中,安全漏洞也将继续上升。因此,我们将看到对安全方法进行彻底改革的努力,增加区块链(一个虚拟账本)的可见性,作为改善公司如何保护其客户数据的可行方式。
Gregory Piatetsky-Shapiro,KDnuggets 的总裁,KDnuggets的创始人,数据科学家,KDD 会议和 SIGKDD 的联合创始人,知识发现和数据挖掘的专业组织。
2017 年的主要发展:
-
![]() AlphaGo Zero 可能是 2017 年人工智能领域最重要的研究突破
AlphaGo Zero 可能是 2017 年人工智能领域最重要的研究突破 -
数据科学的自动化程度不断提高,更多工具提供自动化机器学习平台。
-
人工智能的炒作和期望的增长速度甚至超过了人工智能和深度学习的成功增长。
 AlphaGo Zero 可能是 2017 年人工智能领域最重要的研究突破
AlphaGo Zero 可能是 2017 年人工智能领域最重要的研究突破2018 年的关键趋势
-
GDPR(欧洲通用数据保护条例)于 2018 年 5 月 25 日生效,将对数据科学产生重大影响,其要求包括解释权(你的深度学习方法能否解释为什么这个人被拒绝了信用?)以及防止偏见和歧视。
-
谷歌 DeepMind 团队将跟进 AlphaGo Zero 的惊人成果,并在一个几年前许多人认为计算机无法完成的任务上取得另一个超人类表现。
(注意:下一个 DeepMind 的突破发生在 2017 年 12 月,AlphaZero在仅 4 小时内掌握了国际象棋,该自我学习程序在国际象棋、围棋和将棋中达到了超人类表现。)
-
我们将看到更多的自动驾驶汽车(和卡车)进展,包括首次出现的问题(如拉斯维加斯的自动驾驶班车不知道要让路)被解决(下次它会让路)。
-
人工智能泡沫将继续,但我们将看到震荡和整合的迹象。
Dr. GP (Ganapathi) Pulipaka, @gp_pulipaka 是 DeepSingularity LLC 的首席执行官兼首席数据科学家。
机器学习、深度学习、数据科学发展,2017 年
-
AlphaGo Zero 引入了一种新的强化学习形式,其中 AlphaGo 成为自己的教师,无需人工干预和历史数据集。
-
![]() Python(1.65 M GitHub 推送)、Java(2.32 M GitHub 推送)和 R(163,807 GitHub 推送)是 2017 年最受欢迎的编程语言。
Python(1.65 M GitHub 推送)、Java(2.32 M GitHub 推送)和 R(163,807 GitHub 推送)是 2017 年最受欢迎的编程语言。 -
在 CPU 上处理大规模大数据以执行神经网络功能可能会在长期内带来巨大的能源成本。谷歌发布了第二代 TPU。TPU 的精密设计工程包括将协处理器附加到常见的 PCIe 总线,并附有处理流量的指令,使用乘法累加器(MACs)重用寄存器中的值进行数学计算,并节省数十亿美元的能源。
-
Nvidia 发布了基于 Volta 架构的 Tesla GPU,用于超级充电深度学习和机器学习,每个 GPU 的峰值性能达到 120 万亿次浮点运算。
-
从 D-Wave 量子退火计算机的炒作中脱身,转向具有 20 量子比特能力的量子计算机,使用 QISKit 量子编程栈在 Python 中进行编程。
 Python(1.65 M GitHub 推送)、Java(2.32 M GitHub 推送)和 R(163,807 GitHub 推送)是 2017 年最受欢迎的编程语言。
Python(1.65 M GitHub 推送)、Java(2.32 M GitHub 推送)和 R(163,807 GitHub 推送)是 2017 年最受欢迎的编程语言。机器学习、深度学习、数据科学趋势 - 2018 年。
-
McAfree Labs 2018 年的威胁研究报告显示,对抗性机器学习将用于网络入侵检测、欺诈检测、垃圾邮件检测和恶意软件检测,在无服务器环境中以极高的机器速度进行。
-
HPE 将开发点积引擎,并推出自己的神经网络芯片,用于高性能计算,支持来自深度神经网络、卷积神经网络和递归神经网络的推理。
-
![]() 量子机器学习的未来依赖于具有 10 个或更多状态和 100 多个维度的量子比特,而不是只能采用两种可能状态的量子比特。将制造出大量带有量子比特的微芯片,从而创造出极其强大的量子计算机。
量子机器学习的未来依赖于具有 10 个或更多状态和 100 多个维度的量子比特,而不是只能采用两种可能状态的量子比特。将制造出大量带有量子比特的微芯片,从而创造出极其强大的量子计算机。 -
2018 年物联网和边缘计算与机器学习的障碍将降低。地理空间智能将在应用于手机、RFID 传感器、无人机、无人机和卫星的突破性算法的推动下跃升。
-
自我监督学习和自主学习将为机器人提供动力,采用新颖的深度学习技术进行控制任务,使机器人能够与其周围的地面环境和水下环境进行交互。
 量子机器学习的未来依赖于具有 10 个或更多状态和 100 多个维度的量子比特,而不是只能采用两种可能状态的量子比特。将制造出大量带有量子比特的微芯片,从而创造出极其强大的量子计算机。
量子机器学习的未来依赖于具有 10 个或更多状态和 100 多个维度的量子比特,而不是只能采用两种可能状态的量子比特。将制造出大量带有量子比特的微芯片,从而创造出极其强大的量子计算机。Paul Gearan、Heather Allen 和 Karl Rexer,Rexer Analytics的负责人,该公司是一家领先的数据挖掘和高级分析咨询公司。
尽管商业智能软件的普及和有效使用仍面临许多障碍,但对于没有研究或分析背景的人来说,这一承诺仍面临许多困难。虽然像 Tableau、IBM 的 Watson、Microsoft Power BI 等软件已经取得了一些进展,但根据 Rexer Analytics 在 2017 年收集的数据,仅有略超过一半的受访者表示自助工具正在被数据科学团队之外的人使用。当这些工具被使用时,大约 60%的时间会报告遇到挑战,最常见的主题是对分析过程的理解失败和结果的误解。
 对于 2018 年,实现这些“公民数据科学”工具的承诺,以扩展分析的使用和力量,产生有效且有意义的结果至关重要。正如我们经验所示,综合多学科团队的方法仍然是最佳选择:为没有数据分析训练的员工和高管提供探索和可视化假设的工具很重要。但同样重要的是,团队要与经过专业训练的数据科学专家一起开发模型和解释结果,以理解特定分析技术的应用和局限性。
对于 2018 年,实现这些“公民数据科学”工具的承诺,以扩展分析的使用和力量,产生有效且有意义的结果至关重要。正如我们经验所示,综合多学科团队的方法仍然是最佳选择:为没有数据分析训练的员工和高管提供探索和可视化假设的工具很重要。但同样重要的是,团队要与经过专业训练的数据科学专家一起开发模型和解释结果,以理解特定分析技术的应用和局限性。
Eric Siegel, @predictanalytic,预测分析世界会议系列创始人。
在 2017 年,机器学习中的三个高速趋势持续全速前进,我预计它们在 2018 年也会如此。其中两个是积极的,另一个则是玫瑰的不可避免的刺:
1) 机器学习的商业应用在各个行业中的采纳范围持续扩大 —— 例如在市场营销、金融风险、欺诈检测、员工优化、制造业和医疗保健等领域。要一目了然地了解这些广泛的活动范围以及哪些领先公司正在实现价值,请查看预测分析世界 2018 年 6 月拉斯维加斯会议,这是首个“Mega-PAW”以及全美唯一的 PAW 商业会议。
2) 深度学习蓬勃发展,无论是热度还是实际价值。 这套相对新的先进神经网络方法将机器学习提升到一个新的潜力层次——即在大信号输入问题上实现高性能,如图像分类(自动驾驶汽车、医学图像)、声音(语音识别、说话人识别)、文本(文档分类),甚至是“标准”业务问题,例如,通过处理高维点击流。为了推动其在各行业领域的商业化部署,我们将推出深度学习世界,配合 PAW Vegas 2018。
3)不幸的是,人工智能仍然被过度宣传和“过度神化”(这个双关语归功于模型机构的埃里克·金 😃。虽然专家从业者有时使用术语 AI 特指机器学习,但分析供应商和记者更常用它来暗示那些明显不切实际的能力,并培养更多幻想而非现实的期望。正如亚瑟·C·克拉克曾经著名地提出,“任何足够先进的技术都与魔法无异”,但这并不意味着我们想象或在科幻小说中包含的任何“魔法”都可以或将被技术实现。你的逻辑是倒置的。人工智能将拥有自己的意志,可能会恶意或鲁莽地对人类构成生存威胁,这是一种鬼故事——这种鬼故事进一步推动了机器的拟人化(甚至是神化),许多供应商似乎希望这能提高销售。朋友们、同事们和国人们,我敦促你们减少对“人工智能”的关注。这只会增加噪音和混乱,最终会引发反弹,就像所有“虚幻软件”销售一样。
杰夫·乌尔曼,斯坦福大学 W·阿施曼计算机科学荣誉教授。他的研究兴趣包括数据库理论、数据库集成、数据挖掘以及利用信息基础设施的教育。
最近我参加了一次会议,与我的两位最老的同事约翰·霍普克罗夫特和阿尔·阿霍重聚。(编辑:见经典教科书数据结构与算法,作者:阿霍、霍普克罗夫特和乌尔曼)。在我的演讲中,我没有什么新内容,但阿尔和约翰都在关注一些可能对 KDnuggets 读者真正感兴趣的事情。
约翰(霍普克罗夫特)谈到了深度学习算法的分析。他做了一些实验,观察了在不同顺序下对相同数据进行系列训练时网络节点的行为(或类似实验)。他发现了在每个生成的网络中,某些节点基本上做着相同的事情的情况。还有其他情况,其中无法将节点与节点映射,但一个网络中的小组节点与另一个网络中的另一个节点组产生相同的效果。这项工作还处于起步阶段,但我认为可能会在明年继续保持的一个预测是:
对深度学习网络的细致分析将推进对深度学习如何真正工作的理解,以及其用途和陷阱。
然后,Al Aho 谈到了量子计算。许多全球最大的公司,如 IBM、微软、谷歌,都在投入大量资金建设量子计算机。对于这些设备有许多不同的方法,但 Al 兴奋的是他的前学生在微软的工作,他正在开发一套编译器和模拟器,用于设计量子算法并进行测试,虽然不是在一个真正存在的机器上,而是在模拟器上。这让我想起了 1980 年代的集成电路设计工作。当时我们也有从高级语言到电路的编译器,这些电路先是被模拟,而不是制造(至少在最初是这样)。这种方法的优势在于你可以尝试不同的算法,而不需要花费巨大的物理电路制造费用。当然,在量子世界中,这不仅仅是“缓慢且昂贵”,而且可能“根本不可能”,我们目前还不知道。Al 实际上和我一样对量子计算是否很快实现持怀疑态度,但毫无疑问资金将会投入,算法将会设计。例如,Al 指出去年在更高效的量子算法用于线性代数方面取得了有趣的进展,如果实现,这肯定会引起数据科学家的兴趣。所以这是另一个预测:
量子计算,包括数据科学中的算法,将在未来几年受到更多关注,即使真正能够在足够大规模下运行的量子计算机从未实现或还需要几十年。
我会再添加一个我自己更平凡的预测:
- 从 Hadoop 迁移到 Spark 的趋势将继续,最终导致人们几乎忘记 Hadoop。
Jen Underwood、@idigdata、Impact Analytix, LLC 的创始人,是一位公认的分析行业专家,拥有产品管理、设计和超过 20 年的“动手”数据仓库、报告、可视化及高级分析解决方案开发经验。
当我回顾 2017 年时,我会温馨地记住那一年智能分析平台的出现。从分析机器人到自动化机器学习,数据科学的各个方面都出现了大量复杂的智能自动化能力。数据集成和数据准备平台已经变得足够智能,可以即插即用数据源,在数据管道出现错误时自行修复,甚至根据从人类互动中学到的知识自行管理维护或数据质量任务。增强分析产品开始兑现将机器学习普及的承诺。最后,拥有预打包的最佳实践算法设计蓝图和部分自动化特征工程能力的自动化机器学习平台在数字时代的分析武器库中迅速成为游戏规则改变者。
 明年我预计自动化人工智能将在更多的分析和决策过程中无缝整合。随着组织的适应,我预计会出现大量关于如何做出自动化决策的问题,以及如何在我们不完美的世界中负责任地引导这些系统。即将到来的欧盟通用数据保护条例合规截止日期将进一步提高我们需要打开分析黑箱、确保正确使用并尽职管理个人数据的需求。
明年我预计自动化人工智能将在更多的分析和决策过程中无缝整合。随着组织的适应,我预计会出现大量关于如何做出自动化决策的问题,以及如何在我们不完美的世界中负责任地引导这些系统。即将到来的欧盟通用数据保护条例合规截止日期将进一步提高我们需要打开分析黑箱、确保正确使用并尽职管理个人数据的需求。
相关内容:
更多相关话题
企业的数据科学与机器学习平台
原文:
www.kdnuggets.com/2017/05/data-science-machine-learning-platforms-enterprise.html
评论
作者:Ahmad AlNaimi,Algorithmia。

TL;DR 一个具有弹性的 数据科学平台 对于大型公司中的集中式数据科学团队是必需的。它帮助他们在 PB 规模下集中、重用和生产化他们的模型。我们为此目的构建了Algorithmia Enterprise。
你已经构建了那个 R/Python/Java 模型。它运行良好。接下来呢?
“一切始于你的 CEO 听说了机器学习和数据是新石油的说法。数据仓库团队有人刚刚提交了 1PB Teradata 系统的预算,而 CIO 听说 Facebook 使用便宜的 Hadoop 商品存储,超级便宜。一场完美的风暴爆发了,现在你被要求建立一个数据优先的创新团队。你雇佣了一组数据科学家,大家都很兴奋,开始找你寻求一些数字魔法来‘Googlify’他们的业务。你的数据科学家没有任何基础设施,花费所有时间为高管构建仪表板,但投资回报是负面的,大家都怪你没有在他们的盈亏表上倾注足够的独角兽血。” – Vish Nandlall (source)
在 PB 规模上共享、重用和运行模型不是数据科学家的工作流程的一部分。这种低效在企业环境中被放大,因为数据科学家需要与 IT 协调每一步,持续部署是一团糟(如果不是不可能的话),重用性低,随着公司不同部门开始“Googlify”他们的业务,问题越来越严重。
数据科学与机器学习平台旨在满足这种需求。它作为一个基础层,供三个内部利益相关者协作:产品数据科学家、中央数据科学家和 IT 基础设施。
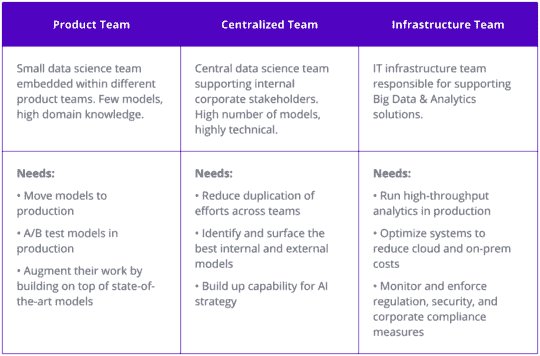
图 1:一个数据科学平台服务于三个利益相关者:产品、中央和基础设施。它对于大型公司来说是必需的,这些公司对机器学习有复杂且不断增长的依赖。
在这篇文章中,我们将涵盖:
-
谁需要 数据科学与机器学习 (DS & ML) 平台?
-
什么是数据科学与机器学习平台?
-
如何区分平台?
-
平台的例子
你需要一个数据科学平台吗?
这并不适合每个人。拥有一个或两个用例的小团队最好是围绕共享和扩展自己开发解决方案(或使用私有托管解决方案)。如果你是一个有许多内部客户的中央团队,你很可能正在遭受以下一种或多种症状:
症状 #1 你在拆分代码库
你的数据科学家创建了一个模型(假设是用 R 或 Python 编写的),并希望将其接入生产环境,以便作为 Web 或移动应用的一部分使用。你的后端工程师们,使用 Java 或 .NET 构建了他们的基础设施,最终会在他们选择的技术栈中重新编写这个模型。现在你有两个代码库需要调试和同步。随着时间的推移,当你构建更多模型时,这种低效率会加剧。
症状 #2 你在重新发明轮子
无论是像预处理函数这样的小功能,还是像完整训练模型这样的大功能。你的团队产出的越多,当前团队成员、过去团队成员,特别是项目之间系统性重复工作的可能性就越大。
症状 #3 你在努力招募最佳人才
你公司每个角落都有数据科学或机器学习的想法,以保持领先,但你只有少数几个天才专家,他们一次只能处理一个挑战。你会雇佣更多的人,但数据科学和机器学习人才稀缺,顶尖人才像顶级 NFL 四分卫一样昂贵。
症状 #4 你的云账单激增(P2 实例太多了!)
你已经将模型部署在一个网络服务器后面。在深度学习的世界里,你可能会需要一个支持 GPU 的机器,比如 AWS EC2 上的 P2 实例(或 Azure N-Series 虚拟机)。为每一个生产化的深度学习模型运行这些机器可能会迅速变得昂贵,特别是对于负载波动较大或难以预测的模式。
什么是数据科学与机器学习平台?
这涉及到除训练之外的一切。数据科学与机器学习平台关注的是模型在训练阶段之后的生命周期。这包括:模型的注册,显示模型从一个版本到下一个版本的传承,将它们集中起来以便其他用户可以找到它们,并将它们作为自包含的工件提供,这些工件可以随时插入任何数据管道中。

库 vs. 注册表
像 scikit-learn 和 Spark MLlib 这样的工具包含了一系列独特的算法。这就是一个库。数据科学与机器学习平台则是一个注册表。它包含来自不同来源的多个算法实现,每个算法都有自己的版本(或传承),这些实现同样是可发现和可访问的。注册表的用户将能够轻松找到并比较不同算法实现的输出。
训练与推理
数据科学家会使用适合问题的工具。有时这些工具是 scikit-learn 和 Keras 的组合,是 Cafe 和 Tensorflow 模型的集成,或者是用 R 编写的 H2O 脚本。一个平台不会指定工具,但能够注册和操作这些模型,无论它们是如何训练或组合的。
手动与自动部署
将模型部署到生产环境中有多种方式,最终结果大多是一个 REST API。不同的方法引入了许多风险,包括不一致的 API 接口设计、不一致的认证和日志记录,以及消耗开发运维资源。一个平台应该能够通过最小的步骤自动化这些工作,通过一致的 API 和认证暴露模型,并减少对开发运维的操作负担。
如何区分数据科学与机器学习平台?
从表面上看,所有的数据科学平台听起来都一样,但关键在于细节。以下是一些比较的数据点:
支持的语言
R 和 Python 是大多数数据科学和机器学习项目的必备语言。Java 也很重要,因为像deeplearning4j和H2O 的 POJO模型提取器等库。C++在科学计算或HPC中尤其相关。其他运行时是可选的,取决于你的使用场景和非数据科学同事使用的主要技术栈,如 NodeJS/Ruby/.NET。
CPU 与 GPU(深度学习)
随着深度学习在数据科学和机器学习领域的日益突出,随着该领域的成熟和模型库的增长,这种趋势只会增加。尽管 TensorFlow 很受欢迎,但它并不总是向后兼容,Caffe 可能需要特殊的编译标志,而 cuDNN 实际上是另一个需要管理的 GPU 集群复杂层。如果能够完全容器化和生产化异构模型(无论是代码、节点权重、框架还是底层驱动程序)并在 GPU 架构上运行,这将是平台的一个强大差异化因素,甚至是强制性要求。
单版本与多版本控制
版本控制是能够列出模型随时间变化的历史,并独立访问每个版本。当模型被版本化时,数据科学家可以衡量模型的漂移。单版本架构为该模型(当前稳定版本)暴露一个 REST API 端点,只有作者能够从其控制面板“切换”模型。多版本架构除了为稳定版本暴露一个 REST API 端点外,还暴露每个先前版本,使它们同时可用,这消除了向后兼容性挑战,并使后端工程师能够实施部分推出或实时 A/B 测试。
垂直与水平扩展
将模型作为 REST API 提供是不够的。垂直扩展是将模型部署到更大的机器上。水平扩展是将模型部署到多台机器上。无服务器扩展,如Algorithmia 企业版实现的,是通过将模型封装在专用容器中,根据需求在计算集群中即时部署该容器,并在执行后立即销毁容器以释放资源。无服务器计算带来了扩展和经济 效益。
单租户 vs. 多租户
处理敏感或机密模型时,共享硬件资源可能会成为挑战。单租户平台会在相同资源(机器实例、虚拟内存等)中运行所有生产模型。多租户平台则将模型作为虚拟隔离的系统(通过为每个模型使用容器或虚拟机)进行部署,并可能提供额外的安全措施,如防火墙规则和审计跟踪。
固定 vs. 可互换数据源
数据科学家可能需要在模型上运行来自 S3 的离线数据,而后端工程师则同时在同一模型上运行来自 HDFS 的生产数据。固定数据源平台要求模型作者实现两个数据连接器:HDFS 和 S3。可互换数据源平台则要求作者实现一个通用数据连接器,作为多个数据源的适配器,并为未来可能出现的数据源做好模型兼容性准备。在 Algorithmia 企业版中,这被称为 Data API。
示例数据科学与机器学习平台
这绝非详尽无遗的列表。如果你有建议,请随时给我们留言或发送通知。
原始文章。经许可转载。
个人简介:Ahmad AlNaimi 是一位具有行动偏向的跨学科问题解决者。喜欢将创意从概念阶段推进到原型阶段再到早期应用。软件工程师和早期业务开发专家。
相关:
-
DataScience.com 新更新旨在成为行业领先的数据科学平台
-
Gartner 数据科学平台 – 深入分析
-
Forrester 与 Gartner 对数据科学平台和机器学习解决方案的比较
我们的 3 个推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关主题
数据科学机器,或‘如何进行特征工程’
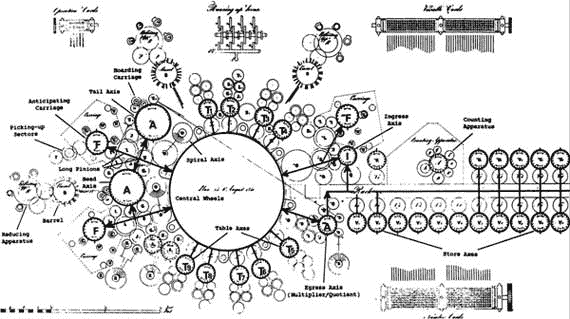 麻省理工学院硕士生马克斯·坎特的最新研究实现了他所称之为“数据科学机器”的技术。坎特和他在CSAIL的论文导师卡利扬·维拉马查内尼合作撰写了一篇关于数据科学机器(DSM)及其基础创新——深度特征合成算法的论文,该论文将于下周在 IEEE 国际数据科学与高级分析会议上发布。他们的论文《深度特征合成:自动化数据科学工作》现已在线发布。坎特和维拉马查内尼简明地描述 DSM 为“一个从原始数据中生成预测模型的自动化系统”,它将作者们创新的特征工程方法与端到端数据科学管道相结合。迄今为止,DSM 在其参加的数据科学竞赛中击败了 68.9%的团队。也许最值得注意的是,取得这一成功率的提交通常在 12 小时内完成,而不是需要几个月的人工工作。DSM 的基础是观察到数据科学竞赛问题通常具有以下共同特性:它们是结构化和关系型的,它们建模人类与复杂系统的互动,并且尝试预测某些人类方面的内容。深度特征合成 与任何数据科学问题一样,特征必须首先从现有变量中识别出来,或从现有变量中创建出来。虽然特征工程在非关系数据(如文本和图像)领域取得了显著进展,但坎特和维拉马查内尼指出,这一任务仍然是数据科学管道中最依赖人工干预的任务,即使对于经验丰富的数据科学家来说也可能是困难且耗时的。如果要真正实现自动化,这一任务也必须最接近人类的效率。DSM 的特征工程算法深度特征选择(DFS)专门用于关系型数据集,用于自动化识别和生成洞察性特征。DFS 以关系表为输入,能够处理这种数据结构中包含的各种数据类型。成功的 DFS 算法旨在像数据科学家一样思考,将洞察性问题转化为输入特征。DFS 算法遍历关系,并在此过程中应用特征选择函数,逐步创建最终特征。DFS 在执行这一遍历时,将数学函数的计算叠加到特定深度,这也是 DFS 名称的由来。根据输入数据类型,DSM 在两个不同层次上应用多个数学函数:实体和关系。实体层特征关注于转换和翻译函数,例如更改数据表示、四舍五入数字,以及将现有的广义属性提取为更多且更简洁的属性。关系层特征关注于表中实体之间的关系(比如你的主键和外键)。这些特征函数能够从其他表中提取相关数据以与给定特征关联(例如,找到与订单相关的最大项目价格或项目数量),这些数据可能作为有用特征输入到模型中。机器学习路径 为启动 DSM 的机器学习路径,首先选择一个输入特征作为目标值,用于形成预测问题。通过元数据选择适当的特征,称为预测变量,以帮助预测过程。DSM 然后创建一个数据预处理、特征选择、降维、建模和评估的路径,所有这些都被参数化并在必要时可供重用。参数优化通过Copula 过程完成,并通过观察相关性来减少特征数量。减少后的特征集在样本数据上进行测试,通过不同的组合来优化预测准确性。通过使用自动调节功能(作者认为这是其性能绝对关键的因素),DSM 在所有三个竞赛中提高了其得分。讨论 所有这些似乎基本上表明:DSM 利用智能关系型数据库的关系遍历来帮助构建和建立候选特征,通过寻找相关值来缩小特征集,并在等同于蛮力特征工程的组合中,应用迭代特征子集到样本数据中,同时重新组合以优化,直到找到最佳解决方案。为了测量 DSM 的性能,它被投入到 2014 年 KDD Cup、IJCAI 和 2015 年 KDD Cup 等竞赛中,如前所述,它击败了超过 2/3 的人类竞争者。坎特和维拉马查内尼声称,即使在表现最差的时候(IJCAI),DSM 仍能以类似于人类竞争者的方式构建预测问题,证据是它在任务中沿用类似的数据建模途径。在同一竞赛中,它与获胜者的 AUC 差距约为 0.04,表明 DSM 捕捉到了竞赛数据集中的主要方面。坎特和维拉马查内尼认为,虽然它目前不能与最高表现的人类科学家竞争,但 DSM 仍然有其与他们并肩的作用。尽管在每场比赛中有许多人战胜了 DSM,但它能够以相当少的努力(在某些情况下少于 12 小时,而不是几个月)击败大多数人。他们建议,考虑到这一点,它可以用来设定基准以及激发创造力。通过前置特征工程和生成潜在顶级特征集,能够让人类在数小时内重新思考问题,有效地从 DSM 解决方案出发,继续前进。需要注意的是,虽然 DSM 令人印象深刻,但它并不是第一个旨在自动化机器学习的系统。其他例子包括许多自动构建广告竞标模型的系统,或KXEN Model Factory(现在是 SAP 的一部分),它在 2010 年就已经提供了自动化模型构建。此外,DSM 显然并不适用于所有类型的数据,它是一个专注于关系型数据集的系统。尚未证明它在不符合先前识别的数据科学竞赛问题模式的关系型数据集上有效。DSM 已经衍生出一个名为FeatureLab的初创公司,称其为“界面上的洞察”,坎特担任首席执行官。该网站声明“利用你的数据,无需更多数据科学家”,并声称它是“寻求增加数据科学资源的公司的最佳解决方案”。这些都是大胆的声明,尤其是考虑到 DSM 的个别部分并不能真正算作突破。FeatureLab 很可能会在“商业智能”服务平台的云雾中迷失。但大数据依然存在,特征工程在过去 12 个月里一直是机器学习的热门话题。DSM 可能正是其特定技术组合在恰当的时间点上,导致了对数据科学的新思考方式。哈佛计算机科学教授玛戈·塞尔茨(Margo Seltzer)在谈到 DSM 时表示:“我认为他们做的事情将迅速成为标准——非常迅速。”如果情况确实如此,FeatureLabs 可能会处于良好的位置。你可以在这里阅读更多关于坎特和维拉马查内尼的数据科学机器的信息。简介:马修·梅奥 是一名计算机科学研究生,目前正在从事机器学习算法的并行化研究。他还是数据挖掘学生、数据爱好者和有志于成为机器学习科学家的人员。相关链接:
麻省理工学院硕士生马克斯·坎特的最新研究实现了他所称之为“数据科学机器”的技术。坎特和他在CSAIL的论文导师卡利扬·维拉马查内尼合作撰写了一篇关于数据科学机器(DSM)及其基础创新——深度特征合成算法的论文,该论文将于下周在 IEEE 国际数据科学与高级分析会议上发布。他们的论文《深度特征合成:自动化数据科学工作》现已在线发布。坎特和维拉马查内尼简明地描述 DSM 为“一个从原始数据中生成预测模型的自动化系统”,它将作者们创新的特征工程方法与端到端数据科学管道相结合。迄今为止,DSM 在其参加的数据科学竞赛中击败了 68.9%的团队。也许最值得注意的是,取得这一成功率的提交通常在 12 小时内完成,而不是需要几个月的人工工作。DSM 的基础是观察到数据科学竞赛问题通常具有以下共同特性:它们是结构化和关系型的,它们建模人类与复杂系统的互动,并且尝试预测某些人类方面的内容。深度特征合成 与任何数据科学问题一样,特征必须首先从现有变量中识别出来,或从现有变量中创建出来。虽然特征工程在非关系数据(如文本和图像)领域取得了显著进展,但坎特和维拉马查内尼指出,这一任务仍然是数据科学管道中最依赖人工干预的任务,即使对于经验丰富的数据科学家来说也可能是困难且耗时的。如果要真正实现自动化,这一任务也必须最接近人类的效率。DSM 的特征工程算法深度特征选择(DFS)专门用于关系型数据集,用于自动化识别和生成洞察性特征。DFS 以关系表为输入,能够处理这种数据结构中包含的各种数据类型。成功的 DFS 算法旨在像数据科学家一样思考,将洞察性问题转化为输入特征。DFS 算法遍历关系,并在此过程中应用特征选择函数,逐步创建最终特征。DFS 在执行这一遍历时,将数学函数的计算叠加到特定深度,这也是 DFS 名称的由来。根据输入数据类型,DSM 在两个不同层次上应用多个数学函数:实体和关系。实体层特征关注于转换和翻译函数,例如更改数据表示、四舍五入数字,以及将现有的广义属性提取为更多且更简洁的属性。关系层特征关注于表中实体之间的关系(比如你的主键和外键)。这些特征函数能够从其他表中提取相关数据以与给定特征关联(例如,找到与订单相关的最大项目价格或项目数量),这些数据可能作为有用特征输入到模型中。机器学习路径 为启动 DSM 的机器学习路径,首先选择一个输入特征作为目标值,用于形成预测问题。通过元数据选择适当的特征,称为预测变量,以帮助预测过程。DSM 然后创建一个数据预处理、特征选择、降维、建模和评估的路径,所有这些都被参数化并在必要时可供重用。参数优化通过Copula 过程完成,并通过观察相关性来减少特征数量。减少后的特征集在样本数据上进行测试,通过不同的组合来优化预测准确性。通过使用自动调节功能(作者认为这是其性能绝对关键的因素),DSM 在所有三个竞赛中提高了其得分。讨论 所有这些似乎基本上表明:DSM 利用智能关系型数据库的关系遍历来帮助构建和建立候选特征,通过寻找相关值来缩小特征集,并在等同于蛮力特征工程的组合中,应用迭代特征子集到样本数据中,同时重新组合以优化,直到找到最佳解决方案。为了测量 DSM 的性能,它被投入到 2014 年 KDD Cup、IJCAI 和 2015 年 KDD Cup 等竞赛中,如前所述,它击败了超过 2/3 的人类竞争者。坎特和维拉马查内尼声称,即使在表现最差的时候(IJCAI),DSM 仍能以类似于人类竞争者的方式构建预测问题,证据是它在任务中沿用类似的数据建模途径。在同一竞赛中,它与获胜者的 AUC 差距约为 0.04,表明 DSM 捕捉到了竞赛数据集中的主要方面。坎特和维拉马查内尼认为,虽然它目前不能与最高表现的人类科学家竞争,但 DSM 仍然有其与他们并肩的作用。尽管在每场比赛中有许多人战胜了 DSM,但它能够以相当少的努力(在某些情况下少于 12 小时,而不是几个月)击败大多数人。他们建议,考虑到这一点,它可以用来设定基准以及激发创造力。通过前置特征工程和生成潜在顶级特征集,能够让人类在数小时内重新思考问题,有效地从 DSM 解决方案出发,继续前进。需要注意的是,虽然 DSM 令人印象深刻,但它并不是第一个旨在自动化机器学习的系统。其他例子包括许多自动构建广告竞标模型的系统,或KXEN Model Factory(现在是 SAP 的一部分),它在 2010 年就已经提供了自动化模型构建。此外,DSM 显然并不适用于所有类型的数据,它是一个专注于关系型数据集的系统。尚未证明它在不符合先前识别的数据科学竞赛问题模式的关系型数据集上有效。DSM 已经衍生出一个名为FeatureLab的初创公司,称其为“界面上的洞察”,坎特担任首席执行官。该网站声明“利用你的数据,无需更多数据科学家”,并声称它是“寻求增加数据科学资源的公司的最佳解决方案”。这些都是大胆的声明,尤其是考虑到 DSM 的个别部分并不能真正算作突破。FeatureLab 很可能会在“商业智能”服务平台的云雾中迷失。但大数据依然存在,特征工程在过去 12 个月里一直是机器学习的热门话题。DSM 可能正是其特定技术组合在恰当的时间点上,导致了对数据科学的新思考方式。哈佛计算机科学教授玛戈·塞尔茨(Margo Seltzer)在谈到 DSM 时表示:“我认为他们做的事情将迅速成为标准——非常迅速。”如果情况确实如此,FeatureLabs 可能会处于良好的位置。你可以在这里阅读更多关于坎特和维拉马查内尼的数据科学机器的信息。简介:马修·梅奥 是一名计算机科学研究生,目前正在从事机器学习算法的并行化研究。他还是数据挖掘学生、数据爱好者和有志于成为机器学习科学家的人员。相关链接:
-
数据科学中书本上没有的 3 件事
-
数据维度减少的七种技术
-
2015 年 8 月的分析、大数据、数据挖掘、数据科学收购和初创公司汇总
更多相关话题
利用数据科学使清洁能源更加公平
原文:
www.kdnuggets.com/2022/03/data-science-make-clean-energy-equitable.html

图片由 Pedro Henrique Santos 提供,来源于 Unsplash
数据科学在应对气候变化的斗争中扮演着越来越重要的角色。它可以用于预测清洁能源系统的供需情况,以及 确定 哪些建筑物需要进行能源效率升级。当我们运用数据科学开发应对气候变化的创新解决方案时,我们应该小心不要复制或加剧现有的不平等,或创造新的不平等。
我们的前三推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT
气候变化的影响,从极端天气到严重干旱,将在最贫困、最缺乏应对能力的国家和社区中造成更大冲击。不幸的是,我们正在开发的许多解决方案也存在不公平性。仍使用煤炭和煤油烹饪的贫困家庭无法负担太阳能屋顶和节能家电。低收入父母在工作和育儿之间疲于奔命,几乎没有时间去充电站充电,且可能没有车库或车道在家充电。
当我们使用数据科学来帮助应对气候变化时,我们应该寻求既环保又公平的解决方案。例如,许多社区没有可靠的公共交通。根据蒂埃拉·比尔斯博士,加州大学洛杉矶分校土木与环境工程助理教授,关于交通需求的数据通常不可用或不准确,尤其是对老年人或残疾人等面临出行问题的群体。新的地理定位数据源和直接从用户处收集出行偏好的方法可以提供更全面的交通需求图景。数据科学可以帮助我们优化路线规划,并为服务不足的地区创建按需公交线路和拼车匹配服务。
数据科学支持公平解决方案的另一个领域是清洁、可靠能源的获取。全球有高达 7.6 亿人缺乏电力,还有更多人经历频繁的中断。根据能源专家马新博士,TotalEnergies Ventures 亚太平台总监,数据科学的进步可以帮助我们扩展和民主化能源获取。例如,微电网和小型电网可以通过实现小规模的本地发电,为偏远和服务不足的社区提供能源,而不依赖于传统电网。数据科学用于基于天气模式预测能源供应,并监测和优化太阳能电池板和电池的状态。近年来,微电网和小型电网已经为全球超过 1100 万人提供了电力。
这些例子来源于我主持的去年秋季的C3E 会议,展示了数据科学的深思熟虑的使用如何支持公平的清洁能源解决方案。3 月 7 日,讨论将继续由我的同事珍妮·萨卡尔博士在全球女性数据科学会议上主持,该会议将在斯坦福大学和在线进行。以下是这些小组讨论启发的一些教训,关于数据科学家如何帮助将公平付诸实践。
1) 考虑公平的多个维度。 过去,推动公平的努力通常集中在为人们提供平等的资源和机会。然而,当人们起点不平等时,平等的访问权很少能带来公平的结果。公平是一个更广泛的框架,部分关注利益和负担如何在不同群体(如种族、收入、性别等)以及地理区域(如城乡差异、全球北方与南方)之间分配。它还考虑了人们的行动能力,提出诸如:在决策时谁被代表?人们是否有权力改变他们的情况和塑造他们的社区?在用公平的视角查看数据集时,询问被测量的内容、由谁测量以及目的是什么,以及数据中包含了谁而不包含谁。同样,边缘化群体在数据科学和数据驱动决策中的代表性也至关重要,以确保他们参与会影响他们社区的决策。
2) 理解你想解决的问题的人性方面。 在任何数据科学项目开始时,明确表达你的目标很重要,而不仅仅是收集一堆数据并套用算法。如果你不了解你试图解决的问题的人类影响,你就无法制定公平的响应。例如,劳伦斯伯克利国家实验室的研究人员正在处理屋顶太阳能安装的数据。只有将这个数据集与人口统计数据结合,他们才得以洞察公平问题,例如谁在(或不在)安装太阳能,原因是什么,以及哪些障碍阻碍了在太阳能渗透较少的群体中的采用。
3) 留意“数据沙漠”并努力纠正它们。 如果人们在我们关于某个问题的数据中没有被代表,他们在解决方案设计时将会是隐形的。例如,如果你正在开发清洁能源系统的供需模型,但没有关于偏远农村地区的电力需求的数据,结果系统可能不适合这些地区。有一些有效的技术方法来处理稀疏或混乱的数据,但我们不应该仅仅通过统计技术来修补数据沙漠。相反,我们需要确保数据收集代表所有相关的人和地方。我们需要广泛思考如何获取更多、更好的数据,并推动私营、研究和政府部门的数据开放。这通常需要精心设计的利益相关者和社区参与。
4) 认识到现有数据的局限性。 数据展示了人们在现有资源和限制下的行为,而不是他们理想中想要或需要的东西,或是在不同激励下会做的事情。例如,电力供应不稳定的地区可能因缺乏需求而表现出低能源使用,而不是因为人们不安装电器或参与其他活动,如果他们能保证获得稳定的电力供应,他们可能会这样做。我们不应该假设人们现在的行为就是他们在一个更公平的世界中希望采取的方式。
5) 小心不要通过大数据掩盖不平等现象。 尽管大数据现在非常流行,但它并不是我们唯一应该关注的尺度。不平等问题往往是局部的、细节性的。这些微小的信号可能在庞大的数据集中被忽略。例如,通勤者的平均旅行时间可能掩盖了那些唯一的出行选择是两小时多阶段旅程的异常情况。你可以通过使用分解数据的技术来避免掩盖不平等现象,从而尽可能地精细化数据。例如,BEAM 模型等基于代理的模型可以让你在个体层面上查看人们的行为和偏好。
6) 寻找创新的方法来收集社区需求的数据。 边缘化群体通常在现有数据来源中代表性不足。寻找创造性的方法来收集这些社区的定量和定性数据,并收集他们对数据收集和分析过程的意见。新的数据收集工具如移动应用和在线调查可以提供帮助,但要小心技术工具不会进一步忽视那些接入有限的人群。直接与边缘化群体接触,与关键利益相关者和社区成员合作,以了解他们对要问的问题、要收集的数据和要设计的解决方案的看法,这是至关重要的。
这些只是我们可以利用数据科学以更公平的方式应对气候变化的一些方法。目前,存在大量的“公平洗牌”现象。组织声称考虑公平性,但实际上并未真正挑战现状。相反,公平性需要在整个数据科学过程中占据核心地位,从数据收集和问题分析到解决方案设计和实施。这是我们如何建设一个既更环保又更公正的世界的方法。
Margot Gerritsen 博士 是斯坦福大学能源资源工程系的教授。她是数据科学中的女性(WiDS)的共同创始人和联合主任,该计划旨在激励和教育全球的数据科学家,无论性别如何,并支持该领域的女性。如果你想深入了解如何利用数据科学以公平的方式应对气候变化等关键问题,WiDS 邀请你参加他们 2022 年 3 月 7 日在斯坦福大学及全球线上举办的年度会议。
更多主题
数据科学与 DevOps 相遇:使用 Jupyter、Git 和 Kubernetes 的 MLOps
原文:
www.kdnuggets.com/2020/08/data-science-meets-devops-mlops-jupyter-git-kubernetes.html
评论
作者:Jeremy Lewi,谷歌软件工程师 & Hamel Husain,GitHub 高级机器学习工程师
问题
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
Kubeflow 是一个快速发展的开源项目,使在 Kubernetes 上部署和管理机器学习变得简单。
由于 Kubeflow 的爆炸性流行,我们接收了大量的 GitHub 问题,这些问题必须被分类并转交给合适的主题专家。下图展示了过去一年中新开启的问题数量:
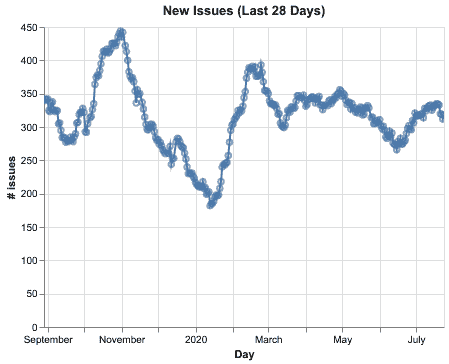
图 1: Kubeflow 问题数量
为了应对这种流量,我们开始投资一个叫做 Issue Label Bot 的 GitHub 应用程序,它使用机器学习来自动标记问题。我们的 第一个模型 是通过使用 GitHub 上流行的公共代码库集合来训练的,只预测了通用标签。随后,我们开始使用 Google AutoML 来训练一个特定于 Kubeflow 的模型。新模型能够以 72% 的平均精度和 50% 的平均召回率预测 Kubeflow 特定标签。这大大减少了与 Kubeflow 维护相关的问题管理的繁琐工作。下表包含了对 Kubeflow 特定标签在保留集上的评估指标。以下的 精度和召回率 与我们为适应需求而调整的预测阈值一致。
| 标签 | 精度 | 召回率 |
|---|---|---|
| area-backend | 0.6 | 0.4 |
| area-bootstrap | 0.3 | 0.1 |
| area-centraldashboard | 0.6 | 0.6 |
| area-components | 0.5 | 0.3 |
| area-docs | 0.8 | 0.7 |
| area-engprod | 0.8 | 0.5 |
| area-front-end | 0.7 | 0.5 |
| area-frontend | 0.7 | 0.4 |
| area-inference | 0.9 | 0.5 |
| area-jupyter | 0.9 | 0.7 |
| area-katib | 0.8 | 1.0 |
| area-kfctl | 0.8 | 0.7 |
| area-kustomize | 0.3 | 0.1 |
| area-operator | 0.8 | 0.7 |
| area-pipelines | 0.7 | 0.4 |
| area-samples | 0.5 | 0.5 |
| area-sdk | 0.7 | 0.4 |
| area-sdk-dsl | 0.6 | 0.4 |
| area-sdk-dsl-compiler | 0.6 | 0.4 |
| area-testing | 0.7 | 0.7 |
| area-tfjob | 0.4 | 0.4 |
| platform-aws | 0.8 | 0.5 |
| platform-gcp | 0.8 | 0.6 |
表 1: 各种 Kubeflow 标签的评估指标。
鉴于新问题的到来速度,定期重新训练我们的模型变成了一个优先事项。我们认为,持续重新训练和部署我们的模型以利用这些新数据对于保持模型的有效性至关重要。
我们的解决方案
我们的 CI/CD 解决方案如 图 2 所示。我们不显式地创建一个有向无环图(DAG)来连接 ML 工作流中的各个步骤(例如预处理、训练、验证、部署等)。相反,我们使用一组独立的控制器。每个控制器声明性地描述世界的期望状态,并采取必要的行动使实际状态与之匹配。这种独立性使我们可以使用最适合每个步骤的工具。更具体地说,我们使用
-
用于开发模型的 Jupyter 笔记本。
-
GitOps 用于持续集成和部署。
-
Kubernetes 和托管云服务用于基础设施。

图 2: 展示了我们如何进行 CI/CD。我们目前的管道由两个独立操作的控制器组成。我们通过描述我们希望存在的模型(即我们的模型“新鲜”的含义)来配置 Trainer(左侧)。Trainer 定期检查训练模型是否足够新鲜,如果不够新鲜则训练一个新模型。同样地,我们配置 Deployer(右侧)来定义部署模型与训练模型集合同步的含义。如果未部署正确的模型,它将部署一个新模型。
有关模型训练和部署的更多细节,请参考 下面的驱动部分。
背景
使用协调器构建弹性系统
协调器是一种被证明对构建弹性系统极其有用的控制模式。协调模式 是 Kubernetes 工作原理的核心。图 3 展示了协调器的工作原理。协调器通过首先观察世界的状态来工作;例如,当前部署了什么模型。然后协调器将其与世界的期望状态进行比较并计算差异;例如,标签为“version=20200724”的模型应该被部署,但当前部署的模型标签为“version=20200700”。协调器随后采取必要的行动将世界驱动到期望状态;例如,打开一个拉取请求以更改部署的模型。

图 3. 我们的部署器应用的 Reconciler 模式示意图。
Reconciler 已被证明在构建弹性系统方面极为有用,因为一个良好实现的 Reconciler 提供了高度的信心,无论系统如何扰动,它最终都会恢复到期望的状态。
无 DAG
控制器的声明性特征意味着数据可以通过一系列控制器流动,而无需显式创建 DAG。与其使用 DAG,不如将一系列数据处理步骤表示为一组期望的状态,如下图 4 所示:
图 4: 说明了管道如何从独立的控制器中产生,而无需明确编码一个有向无环图(DAG)。这里我们有两个完全独立的控制器。第一个控制器确保每个元素 a[i] 都应该有一个元素 b[i]。第二个控制器确保每个元素 b[i] 都应该有一个元素 c[i]。
与许多传统的 DAG 基础工作流相比,这种基于 Reconciler 的范式提供了以下优势:
-
抗故障能力:系统持续寻求实现并维持期望的状态。
-
工程团队自主性的增加: 每个团队可以自由选择适合其需求的工具和基础设施。Reconciler 框架只要求控制器之间有最少的耦合,同时仍允许编写表达力强的工作流。
-
经过实战检验的模式和工具:这个基于 Reconciler 的框架并没有发明新的东西。Kubernetes 拥有丰富的工具生态系统,旨在简化控制器的构建。Kubernetes 的流行意味着有一个庞大且不断增长的社区熟悉这种模式及其支持工具。
GitOps:通过拉取请求进行操作
GitOps,如图 5 所示,是一种管理基础设施的模式。GitOps 的核心思想是源代码控制(不一定是 git)应当是描述基础设施配置文件的真实来源。然后,控制器可以监视源代码控制并在配置更改时自动更新你的基础设施。这意味着要进行更改(或撤销更改),你只需打开一个拉取请求。
图 5: 要推送 Label Bot 的新模型,我们创建一个 PR 更新配置映射,以存储我们想要使用的 Auto ML 模型的 ID。当 PR 被合并后, Anthos Config Management(ACM) 会自动将这些更改部署到我们的 GKE 集群。因此,后续的预测将使用新模型。 (图片由 Weaveworks 提供)
综合起来:Reconciler + GitOps = 机器学习的 CI/CD
有了这些背景知识,我们接下来深入探讨如何通过结合 Reconciler 和 GitOps 模式来构建 CI/CD 以支持机器学习。
我们需要解决三个问题:
-
我们如何计算世界的期望状态与实际状态之间的差异?
-
我们如何进行必要的更改,以使实际状态与期望状态匹配?
-
我们如何构建一个控制循环来持续运行 1 和 2?
计算差异
为了计算差异,我们只需编写执行我们需要的操作的 lambda 函数。因此,在这种情况下,我们编写了两个 lambda 函数:
-
第一个 lambda根据最近模型的年龄来确定是否需要重新训练。
-
第二个 lambda通过将最近训练的模型与在源代码控制中检查的配置映射中的模型进行比较来确定模型是否需要更新。
我们将这些 lambda 函数封装在一个简单的 Web 服务器中并部署到 Kubernetes 上。我们选择这种方法的原因之一是我们希望依赖 Kubernetes 的git-sync将我们的仓库镜像到 pod 卷中。这使得我们的 lambda 函数变得非常简单,因为所有的 git 管理都由一个运行git-sync的 side-car 处理。
执行
为了应用必要的更改,我们使用 Tekton 将我们用来执行各个步骤的不同 CLI 连接在一起。
模型训练
为了训练我们的模型,我们有一个Tekton 任务:
该笔记本从 BigQuery 中提取 GitHub Issues 数据,从 BigQuery 并生成适合导入到Google AutoML的 GCS 上的 CSV 文件。然后,笔记本启动一个AutoML任务来训练模型。
我们选择 AutoML 是因为我们希望专注于构建一个完整的端到端解决方案,而不是在模型上进行迭代。AutoML 提供了一个竞争性的基准,我们可以在未来尝试改进。
为了轻松查看执行的笔记本,我们将其转换为 HTML 并上传到GCS,这使得公开提供静态内容变得容易。这允许我们使用笔记本生成丰富的可视化来评估我们的模型。
模型部署
要部署我们的模型,我们有一个 Tekton 任务:
-
使用 kpt 更新我们的 configmap 为所需值。
-
运行 git 将我们的更改推送到一个分支。
-
使用一个包装器来操作 GitHub CLI (gh) 来创建 PR。
控制器确保每次只有一个 Tekton 管道在运行。我们配置我们的管道始终推送到相同的分支。这确保我们只会打开一个 PR 来更新模型,因为 GitHub 不允许从同一分支创建多个 PR。
一旦 PR 合并,Anthos Config Mesh 会自动将 Kubernetes 清单应用到我们的 Kubernetes 集群。
为什么选择 Tekton
我们选择 Tekton 是因为我们面临的主要挑战是顺序运行一系列 CLIs 在不同的容器中。Tekton 对此非常合适。重要的是,Tekton 任务中的所有步骤都在同一个 Pod 上运行,这允许使用 Pod 卷在步骤之间共享数据。
此外,由于 Tekton 资源是 Kubernetes 资源,我们可以采用相同的 GitOps 模式和工具来更新我们的管道定义。
控制循环
最后,我们需要构建一个控制循环,定期调用我们的 lambdas 并根据需要启动 Tekton 管道。我们使用 kubebuilder 创建了一个 简单的自定义控制器。我们控制器的协调循环将调用我们的 lambda 来确定是否需要同步,如果需要的话,使用哪些参数。如果需要同步,控制器会触发 Tekton 管道来执行实际更新。下面是我们的 自定义资源 的示例:
apiVersion: automl.cloudai.kubeflow.org/v1alpha1
kind: ModelSync
metadata:
name: modelsync-sample
namespace: label-bot-prod
spec:
failedPipelineRunsHistoryLimit: 10
needsSyncUrl: http://labelbot-diff.label-bot-prod/needsSync
parameters:
- needsSyncName: name
pipelineName: automl-model
pipelineRunTemplate:
spec:
params:
- name: automl-model
value: notavlidmodel
- name: branchName
value: auto-update
- name: fork
value: git@github.com:kubeflow/code-intelligence.git
- name: forkName
value: fork
pipelineRef:
name: update-model-pr
resources:
- name: repo
resourceSpec:
params:
- name: url
value: https://github.com/kubeflow/code-intelligence.git
- name: revision
value: master
type: git
serviceAccountName: auto-update
successfulPipelineRunsHistoryLimit: 10
自定义资源指定了端点needsSyncUrl,用于计算是否需要同步的 lambda 和一个 Tekton PipelineRunpipelineRunTemplate,描述了在需要同步时创建的管道运行。控制器处理详细信息;例如,确保每个资源每次只有一个管道在运行,垃圾回收旧的运行等……所有繁重的工作都由 Kubernetes 和 kubebuilder 为我们处理。
注意,出于历史原因,kind ModelSync 和 apiVersion automl.cloudai.kubeflow.org 与控制器实际执行的内容不完全一致。我们计划在未来修复这个问题。
构建您自己的 CI/CD 管道
我们的代码库距离成熟的、易于重用的工具还很遥远。尽管如此,它是公开的,可以作为构建自己管道的有用起点。
以下是一些入门指引:
-
使用 Dockerfile 来构建您自己的 ModelSync 控制器
-
修改 kustomize 包 以使用你的镜像并部署控制器
-
根据你的用例定义一个或多个 lambda 函数
-
你可以参考我们的 Lambda 服务器 作为示例
-
我们用 Go 编写了我们的代码,但你可以使用任何你喜欢的语言和 web 框架(例如 flask)
-
-
定义适合你的用例的 Tekton 流水线;我们的流水线(见下文链接)可能是一个有用的起点
-
Notebook Tekton 任务 - 使用 papermill 运行 notebook 并上传到 GCS
-
PR Tekton 任务 - Tekton 任务用于打开 GitHub PR
-
-
根据你的用例定义 ModelSync 资源;你可以参考我们的资源作为示例
-
ModelSync 部署规范 - YAML 用于持续部署标签机器人
-
ModelSync 训练规范 - YAML 用于持续训练我们的模型
-
如果你希望我们清理这些内容并在未来的 Kubeflow 版本中包含,请在问题 kubeflow/kubeflow#5167 中发言。
下一步
血统跟踪
由于我们没有明确的 DAG 表示 CI/CD 流水线中的步骤顺序,因此理解我们的模型的血统可能会很具挑战性。幸运的是,Kubeflow Metadata 通过使每个步骤记录其生成的输出所使用的代码和输入的信息变得容易,解决了这个问题。Kubeflow 元数据可以轻松恢复和绘制血统图。下图展示了我们 xgboost 示例 的血统图示例。
图 6: 我们 xgboost 示例 的血统跟踪 UI 截图。
我们的计划是让我们的控制器自动将血统跟踪信息写入元数据服务器,以便我们可以轻松了解生产中的内容的血统。
结论

构建 ML 产品是团队合作的成果。为了将模型从概念验证阶段转变为已发布的产品,数据科学家和 DevOps 工程师需要协作。为了促进这种协作,我们认为允许数据科学家和 DevOps 工程师使用他们首选的工具非常重要。具体来说,我们希望支持以下工具:数据科学家、DevOps 工程师和 SRE。
-
Jupyter 笔记本用于模型开发。
-
GitOps 用于持续集成和部署。
-
Kubernetes 和托管云服务作为基础设施。
为了最大限度地提高每个团队的自主性并减少对工具的依赖,我们的 CI/CD 过程采用了去中心化的方法。我们的方法不是明确地定义一个连接步骤的 DAG,而是依赖于一系列可以独立定义和管理的控制器。我们认为这自然适用于责任可能在团队之间分配的企业;数据工程团队可能负责将网络日志转换为特征,建模团队可能负责从特征中生成模型,而部署团队可能负责将这些模型推向生产环境。
深入阅读
如果你想了解更多关于 GitOps 的内容,我们建议你查看 Weaveworks 的这个指南。
要学习如何构建自己的 Kubernetes 控制器, kubebuilder 书籍 提供了一个端到端的示例。
Jeremy Lewi 是谷歌的软件工程师。
Hamel Husain 是 GitHub 的高级机器学习工程师。
原文。已获得许可转载。
相关:
-
我从 200 种机器学习工具中学到的东西
-
在边缘设备上实施 MLOps
-
端到端机器学习平台的概览
更多相关内容
数据科学对我们心理发展的作用
原文:
www.kdnuggets.com/2019/02/data-science-mental-development.html
评论
由 Syed Sadat Nazrul,分析科学家

我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力。
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求。
情感是人类社会的基本元素。如果你仔细考虑,任何值得分析的事物都受到人类行为的影响。网络攻击受到不满员工的高度影响,他们可能会忽视应有的谨慎,或从事 内部滥用。股市依赖于经济气候的影响,而经济气候本身取决于大众的整体行为。在沟通领域,众所周知 我们所说的只占信息的 7%,其余 93%则编码在面部表情和其他非言语线索中。整个心理学和行为经济学领域都致力于这一领域。尽管如此,有效测量和分析情感的能力将使我们以显著的方式改善社会。例如,加州大学旧金山分校的心理学教授 保罗·艾克曼 在他的书中,撒谎:市场、政治和婚姻中的欺骗线索 描述了如何通过面部表情来帮助心理学家发现潜在的自杀意图,即使患者在隐瞒这种意图。这听起来像是面部识别模型的工作?神经映射呢?我们能否有效地从神经冲动中映射情感状态?改善认知能力又如何?甚至是情感智力和有效沟通?利用我们拥有的大量非结构化数据来解决世界上许多问题是大有作为的。
尽管如此,像所有数据科学问题一样,我们需要深入探讨建模情感的核心挑战:
-
如何框定问题?我们的模型类别应是什么?我们优化的目标是什么?
-
我们应该收集哪些数据?我们在寻找哪些相关性?哪些方面需要更深入地探讨?
-
获取此类数据是否存在任何问题?社会和文化对获取情感数据的看法是什么?需要遵守哪些隐私法规?数据安全又如何保障?
想了解如何有效设计 AI 产品,请阅读我的数据科学家和 AI 产品 UX 设计指南。在这篇博客中,我旨在概述 AI 如何帮助我们未来的心理发展,并讨论一些当前的解决方案。
医疗保健
患者对医生撒谎并不少见。男性和女性的信任障碍源于尴尬和与医生接触时间太少。一项数字健康平台的研究, ZocDoc,揭示了近一半(46%)的美国人因为尴尬或害怕被评判而避免告诉医生健康问题。约三分之一的人表示,他们因无法找到合适的机会或在预约期间时间不足(27%),或因医生没有提问或特别询问是否有困扰他们的事(32%)而隐瞒了细节。这对自杀领域产生了重大影响。根据世界卫生组织(WHO)的数据,每年多达 80 万人死于自杀,60%的人面临严重的抑郁症。尽管抑郁症使患者更容易进行自杀行为,但区分自杀性抑郁症和普通抑郁症并不容易。
Deena Zaidi 在她的博客中,机器学习利用面部表情区分抑郁症和自杀行为*, *描述了一位自杀专家如何通过对风险因素的深入评估,准确预测患者未来的自杀想法和行为,与不了解患者的人的准确性相当。这与根据抛硬币做决定没有区别。虽然使用监督学习模型读取面部表情的技术仍在开发中,但这一领域已显示出很大的潜力。

从 SVM 结果分析的杜氏(上)与非杜氏(下)笑容有助于检测自杀风险(来源: Laksana 等人研究自杀意念的面部行为指标)。
一份报告,与南加州大学、卡内基梅隆大学和辛辛那提儿童医院医疗中心的科学家合作撰写,研究了非语言面部行为以检测自杀风险,并声称发现了一种区分抑郁症和自杀患者的模式。使用 SVM,他们发现面部行为描述符如涉及眼轮匝肌收缩的微笑百分比(杜氏笑容)在自杀和非自杀群体之间具有统计学意义。
认知能力
认知能力是我们进行从最简单到最复杂任务所需的脑基技能。它们与我们如何学习、记忆、解决问题和集中注意力的机制关系更大,而不是与任何实际知识有关。人们都希望提高认知能力。谁不希望更好地记住名字和面孔,更快地掌握困难的抽象概念,并且能更好地“看到联系”呢?
Elevate 应用程序在 Apple Store
目前,有一些应用程序可以帮助我们训练认知能力。其中一个例子是 Elevate,它由脑力游戏组成,用户可以在合适的难度级别上玩,以提高心理数学、阅读和批判性思维能力。 最佳认知功能 的价值是如此显而易见,以至于详细说明可能是多余的。我们不断推陈出新,以超越我们的五感来更深刻地理解周围的世界。例如,在图像识别领域,AI 已经能够 “看”得比我们更清楚,通过观察远超 RGB 光谱的变量,从而帮助我们突破自身的视觉限制。然而,当我们可以进入虚拟世界时,为什么要局限于二维屏幕来可视化三维物体呢?

Nanome.AI 开发了用于分析抽象分子结构的增强现实技术
增强现实让我们感觉仿佛已经传送到了另一个世界。当我想到这个问题时,计算材料科学和生物学是我立即想到的领域。作为过去的一名计算材料科学家,我知道可视化复杂的分子结构对于许多研究人员来说是一项挑战。Nanome.AI帮助在增强现实中可视化这些复杂的结构。更进一步,已经有很多初创公司在解剖学领域使用增强现实培训外科医生。
平行坐标图可视化 7 维空间
数据可视化和降维算法的新术语不断出现,帮助我们更好地体验周围的世界。例如,我们有了平行坐标,它允许我们在高维空间中进行可视化和过滤,而t-SNE则因能够将复杂空间降维到二维或三维空间而广受欢迎。
情商
情商是意识到、控制和表达自身情绪的能力,以及审慎和富有同理心地处理人际关系的能力。每个人都会经历情绪,但只有少数人能够准确识别它们的发生。这可能是因为缺乏自我意识,或者只是我们有限的情感词汇。很多时候,我们甚至不知道自己想要什么。我们努力以特定的方式与周围的人建立联系,或消费某种产品,只是为了体验一种非常独特的情感,而我们无法描述它。我们的感受远不止于幸福、悲伤、愤怒、焦虑或恐惧。我们的情绪是上述所有情绪的复杂组合。理解自身情绪以及他人情绪的能力对情感健康和维持积极关系至关重要。
大脑活动的分布模式预测了使用 fMRI 扫描检测到的离散情绪的体验,顶部显示活动模式,底部显示灵敏度范围(来源:解码人脑中的自发情绪状态,Kragal 等)
随着神经映射的创新,我们将更好地理解作为人类的自我以及我们能够达到的各种情感状态。监督学习已经提供了一些常见情感的识别。通过对脑波进行无监督学习,我们可能会更好地理解复杂的情感模式。例如,一个简单的异常检测算法或许可以揭示新的情感模式或需要关注的显著情感压力点。这些研究有可能揭示改进我们情感智力的创新方法。

准确解读微表情如何有助于在商业交易中进行谈判的演示(来源:TED 演讲:如何通过身体语言和微表情预测成功 — Patryk & Kasia Wezowski)
即使是帮助预防自杀的监督图像识别模型也可以让个人读取与他们交谈者的情感。例如,一个关于微表情的 TED 演讲展示了如何通过注意某些面部表情来估算商业谈判中的理想价格点。该 TED 演讲还提到,能够更好地解读微表情的销售人员比无法做到这一点的销售人员多销售 20%。因此,这 20%的优势可能通过投资于能够揭示谈话者情感的眼镜来实现。
情感智力包括理解我们自己的情感以及对周围人的情感更为敏感。通过对我们情感状态的深入研究,我们或许可以发现一些我们从未体验过的新情感。在正确的手中,AI 可以作为我们的延伸,帮助我们与生活中珍视的人建立有意义的联系。
体验与想象力
想象力是形成新想法、图像或对外部对象的概念的能力或行为,这些对象当前不在感官范围内。AI 对我们体验和想象力的影响将源于更好的认知能力和情感智力的综合。简单来说,接触到更丰富的认知能力和情感智力将使我们能够体验到今天普通思维无法轻易构思的想法。
牛津大学的哲学教授,尼克·博斯特罗姆,在他的论文《当我长大后为什么想成为超人类》中描述了如何通过新体验模式来提升我们的体验和想象力。假设我们今天的体验模式被表示在空间 X 中。10 年后,假设这些体验模式被表示在空间 Y 中。空间 Y 将比空间 X 大得多。这个未来的空间 Y 可能拥有我们传统的快乐、悲伤和愤怒之外的新情感。这种新空间 Y 甚至可以让我们更准确地理解反映我们想表达的抽象思想。我们每个人都有可能以文森特·梵高在最狂野的想象中也无法想象的方式来看待世界!
Y 的新领域实际上可以解锁超越我们当前想象的新世界。未来的人们将以比我们今天更丰富的方式思考、感受和体验世界。
沟通
当你缺乏情感智力时,很难理解自己给他人的印象。你会感到被误解,因为你传达信息的方式别人无法理解。即使经过练习,情感智能高的人也知道他们并不能完美地沟通每一个想法。人工智能有可能通过增强自我表达来改变这一点。

谷歌眼镜可以将德语翻译成英语(来源:谷歌收购 Word Lens 制造商以提升翻译功能)
10 年前,我们的大多数沟通仅限于电话和电子邮件。今天,我们可以使用视频会议、增强现实以及社交媒体上的各种应用程序。随着我们认知能力和情感智力的提升,我们可以通过更高分辨率和更低抽象级别的成语来表达自己。谷歌眼镜可以即时翻译外语文本。我已经在早些时候提到过谷歌眼镜可能用于阅读微表情。然而,为什么要将我们的沟通仅限于我们可以“看到”的内容呢?

通过向头戴设备传送电脉冲来控制无人机(来源:脑控无人机比赛:佛罗里达大学举办独特的无人机比赛)
佛罗里达大学的学生实现了仅用意念控制无人机。我们甚至可以使用振动游戏机来利用触觉,使得《马里奥卡丁车》游戏更加逼真。现今的增强现实仅限于我们的视觉和听觉。在未来,增强现实可能会使我们能够嗅觉、味觉和触摸我们的虚拟环境。除了接触我们的五感外,我们对某些情境的情感反应可能还会通过 AI 的力量进行微调和优化。这可能意味着在《灵异鬼照片》中分享主角的恐惧,感受《艾玛》中的心碎,或对《宝可梦》的冒险感到兴奋。
一些潜在的关注点
虽然我已经列举了利用 AI 读取情感、帮助我们理解自己和周围人的所有积极面,但我们不能忽视潜在的挑战:
-
数据安全:根据世界隐私论坛的报告,被盗医疗凭证的街头价值大约为 50 美元,而被盗信用卡信息或社会保障号码的街头价值仅为 1 美元。同样,心理健康信息也是敏感的个性化数据,可能被黑客利用。正如黑客们试图窃取我们的信用卡和健康保险信息一样,访问情感数据在黑市上也可能有很高的回报。
-
政府数据法规:对于任何高度敏感的个性化数据,不同国家有不同的法规需要遵守。在美国,医疗相关数据需要遵守HIPAA法规,而财务应用相关的数据则需要遵守PCI标准。如果我们放眼全球,欧盟有GDPR,中国则有SAC。
-
伦理边界:与任何新技术一样,社会可能对其情感数据的访问感到不快。让我们面对现实吧。我们可能对医生检查我们的情感数据以改善健康状况表示接受,但对保险公司试图收取更高保费则不太能接受。同样,我们曾经对美国通过操控大众心理进行选举舞弊的怀疑。然而,伦理规范在很大程度上取决于给定社会的“正常”标准。某些目前不可接受的东西在未来可能会被接受。尽管数据科学在某些领域的应用可能让公众感到不适,但如防止信用欺诈的欺诈分析、反洗钱以及像亚马逊和 Netflix 这样的推荐系统的市场分析等其他应用则完全可以接受。在引入新想法时,社会接受度将高度依赖于所收集数据用于解决的问题类型。有关 AI 产品开发的更多细节,请查看我关于数据科学家和 AI 产品的 UX 设计指南的博客。
简介: Syed Sadat Nazrul 白天使用机器学习追捕网络和金融犯罪分子,夜晚则撰写有趣的博客。
原文。经授权转载。
相关:
-
接收者操作特性曲线解析(Python 版)
-
数据科学面试指南
-
数据科学家的 DevOps:驯服独角兽
更多相关话题
数据科学最低要求:开始从事数据科学所需掌握的 10 项核心技能
原文:
www.kdnuggets.com/2020/10/data-science-minimum-10-essential-skills.html
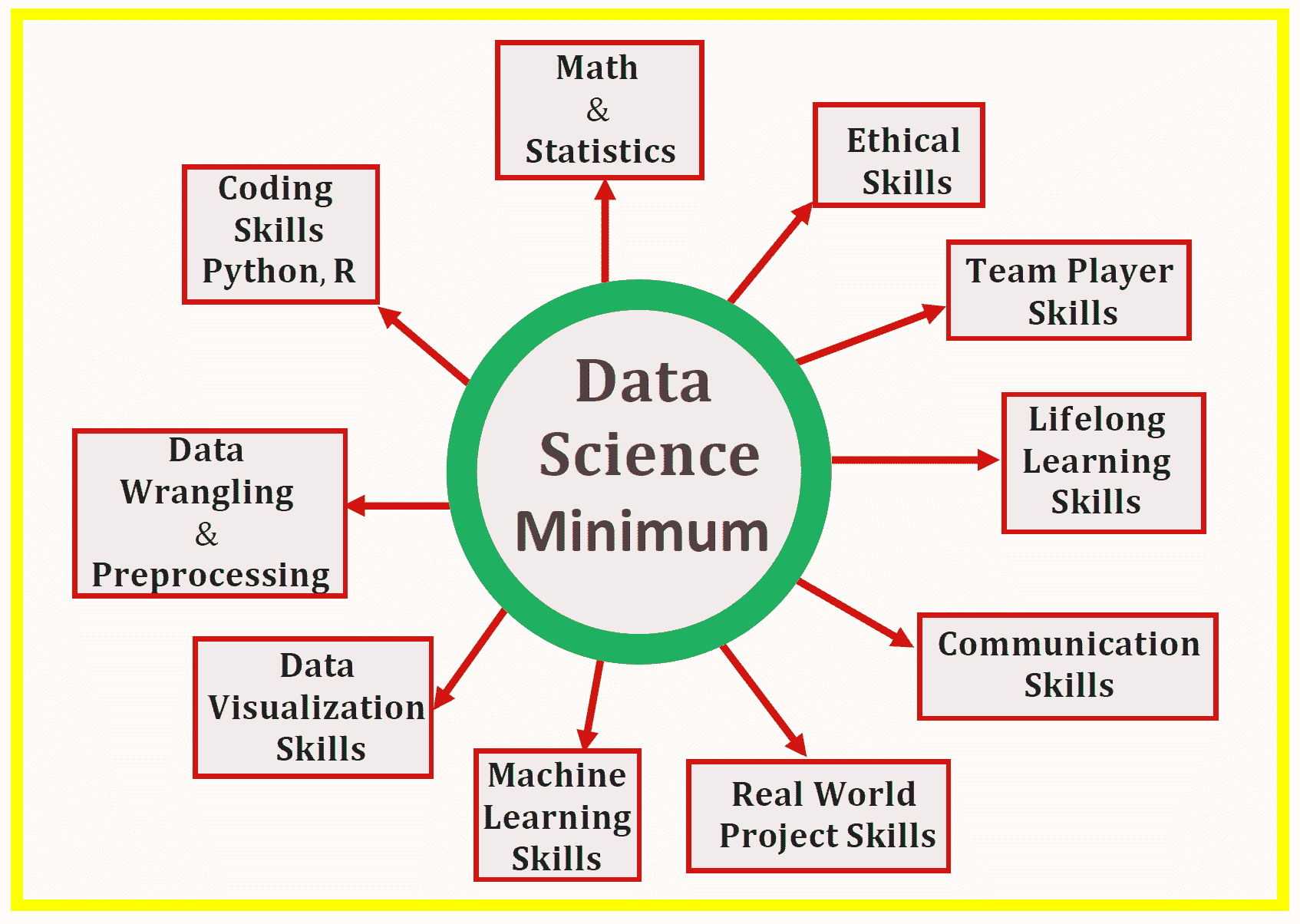
数据科学是一个广泛的领域,包括数据准备与探索、数据表示与转换、数据可视化与展示、预测分析和机器学习等多个子领域。对于初学者来说,提出以下问题是很自然的:我需要掌握哪些技能才能成为数据科学家?
本文将讨论 10 项数据科学家实践所需的核心技能。这些技能可以分为两类,即技术技能(数学与统计、编码技能、数据整理与预处理技能、数据可视化技能、机器学习技能以及实际项目技能)和软技能(沟通技能、终身学习技能、团队合作技能和伦理技能)。
数据科学是一个不断发展的领域,但掌握数据科学的基础将为你提供必要的背景,以便你追求深度学习、人工智能等高级概念。本文将讨论 10 项数据科学家必备的核心技能。
1. 数学和统计技能
(i) 统计学和概率
统计和概率用于特征可视化、数据预处理、特征转换、数据填补、降维、特征工程、模型评估等。以下是你需要熟悉的主题:
a) 平均值
b) 中位数
c) 模式
d) 标准差/方差
e) 相关系数和协方差矩阵
f) 概率分布(二项分布、泊松分布、正态分布)
g) p 值
h) 均方误差(MSE)
i) R2 分数
j) 贝叶斯定理(精确度、召回率、正预测值、负预测值、混淆矩阵、ROC 曲线)
k) A/B 测试
l) 蒙特卡洛模拟
(ii) 多变量微积分
大多数机器学习模型是基于具有多个特征或预测变量的数据集构建的。因此,熟悉多变量微积分对于构建机器学习模型至关重要。以下是你需要熟悉的主题:
a) 多变量函数
b) 导数和梯度
c) 步骤函数、Sigmoid 函数、Logit 函数、ReLU(修正线性单元)函数
d) 成本函数
e) 函数绘图
f) 函数的最小值和最大值
(iii) 线性代数
线性代数是机器学习中最重要的数学技能。数据集被表示为矩阵。线性代数用于数据预处理、数据转换和模型评估。以下是你需要熟悉的主题:
a) 向量
b) 矩阵
c) 矩阵的转置
d) 矩阵的逆
e) 矩阵的行列式
f) 点积
g) 特征值
h) 特征值
(iv) 优化方法
大多数机器学习算法通过最小化目标函数来执行预测建模,从而学习必须应用于测试数据的权重,以获得预测标签。你需要熟悉的主题包括:
a) 成本函数/目标函数
b) 似然函数
c) 误差函数
d) 梯度下降算法及其变体(例如随机梯度下降算法)
了解更多关于梯度下降算法的信息,请访问:机器学习:梯度下降算法如何工作。
2. 必要的编程技能
编程技能在数据科学中至关重要。由于 Python 和 R 被认为是数据科学中最受欢迎的两种编程语言,对这两种语言的基本知识至关重要。有些组织可能只要求具备 R 或 Python 中的一种技能,而不是两者。
(i) Python 技能
熟悉 Python 中的基本编程技能。以下是你应该掌握的最重要的包:
a) Numpy
b) Pandas
c) Matplotlib
d) Seaborn
e) Scikit-learn
f) PyTorch
(ii) R 语言技能
a) Tidyverse
b) Dplyr
c) Ggplot2
d) Caret
e) Stringr
(iii) 其他编程语言的技能
一些组织或行业可能需要以下编程语言的技能:
a) Excel
b) Tableau
c) Hadoop
d) SQL
e) Spark
3. 数据处理和预处理技能
数据对于任何数据科学分析至关重要,无论是推断分析、预测分析还是处方分析。模型的预测能力取决于构建模型时使用的数据质量。数据有不同的形式,如文本、表格、图像、语音或视频。通常,用于分析的数据需要被挖掘、处理和转换,以适合进一步分析。
i) 数据处理:数据处理过程是任何数据科学家至关重要的一步。在数据科学项目中,数据很少能够轻易获取用于分析。数据更可能存在于文件、数据库中,或从网页、推文或 PDF 等文档中提取。了解如何处理和清理数据将使你能够从数据中提取出其他隐藏的关键见解。
ii) 数据预处理:了解数据预处理非常重要,涉及的主题包括:
a) 处理缺失数据
b) 数据填充
c) 处理分类数据
d) 编码分类标签用于分类问题
e) 特征变换和降维技术,如主成分分析(PCA)和线性判别分析(LDA)。
4. 数据可视化技能
理解良好数据可视化的基本组成部分。
a) 数据组件:决定如何可视化数据的一个重要第一步是了解数据的类型,例如,类别数据、离散数据、连续数据、时间序列数据等。
b) 几何组件:在这里你决定什么样的可视化适合你的数据,例如,散点图、折线图、条形图、直方图、QQ 图、平滑密度图、箱线图、对角图、热图等。
c) 映射组件:在这里你需要决定使用什么变量作为 x 变量,什么作为 y 变量。这一点很重要,尤其是当你的数据集是多维的,具有多个特征时。
d) 比例组件:在这里你决定使用什么样的比例尺,例如,线性尺度、对数尺度等。
e) 标签组件:这包括轴标签、标题、图例、字体大小等。
f) 伦理组件:在这里,你需要确保你的可视化讲述了真实的故事。你需要在清理、总结、操控和生成数据可视化时意识到自己的行为,并确保你没有利用可视化来误导或操控观众。
5. 基本机器学习技能
机器学习是数据科学的一个非常重要的分支。理解机器学习框架非常重要:问题框定、数据分析、模型构建、测试与评估、模型应用。了解更多关于机器学习框架的信息,请参见:机器学习过程。
以下是需要熟悉的重要机器学习算法。
i) 监督学习(连续变量预测)
a) 基本回归
b) 多重回归分析
c) 正则化回归
ii) 监督学习(离散变量预测)
a) 逻辑回归分类器
b) 支持向量机分类器
c) K-最近邻(KNN)分类器
d) 决策树分类器
e) 随机森林分类器
iii) 无监督学习
a) KMeans 聚类算法
6. 来自现实世界数据科学项目的技能
仅仅从课程作业中获得的技能不足以让你成为数据科学家。一个合格的数据科学家必须能够展示成功完成现实世界数据科学项目的证据,该项目应包括数据科学和机器学习过程中的每个阶段,如问题框定、数据获取与分析、模型构建、模型测试、模型评估和模型部署。现实世界的数据科学项目可以在以下内容中找到:
a) Kaggle 项目
b) 实习
c) 来自面试
7. 沟通技巧
数据科学家需要能够与团队的其他成员或组织中的业务管理人员沟通自己的想法。良好的沟通技巧在这里起着关键作用,它能帮助将非常技术化的信息传达给对数据科学技术概念几乎没有了解的人。良好的沟通技能将有助于与数据分析师、数据工程师、现场工程师等其他团队成员培养团结和合作的氛围。
8. 成为终身学习者
数据科学是一个不断发展的领域,因此要做好拥抱和学习新技术的准备。与其他数据科学家建立网络是保持对该领域发展动态了解的一种方式。一些促进网络联系的平台包括 LinkedIn、GitHub 和 Medium(Towards Data Science和Towards AI出版物)。这些平台对于获取关于该领域最新发展的信息非常有用。
9. 团队合作技能
作为一名数据科学家,你将与数据分析师、工程师、管理人员等团队成员一起工作,因此你需要良好的沟通技能。你还需要成为一个好的倾听者,特别是在项目初期阶段,你需要依赖工程师或其他人员来设计和规划一个好的数据科学项目。作为一个优秀的团队成员将帮助你在商业环境中取得成功,并与团队其他成员以及组织的管理员或主管保持良好关系。
10. 数据科学中的伦理技能
理解项目的含义。对自己保持真实。避免操纵数据或使用会故意产生偏见的方式。确保在数据收集、分析、模型构建、分析、测试和应用的所有阶段都遵循伦理原则。避免伪造结果以误导或操控受众。解释数据科学项目结果时要保持伦理。
总结一下,我们讨论了从事数据科学工作所需的 10 项基本技能。尽管数据科学是一个不断发展的领域,但掌握数据科学的基础将为你提供必要的背景,使你能够进一步探索深度学习、人工智能等高级概念。
本杰明·O·泰奥 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
原文。经许可转载。
更多相关话题
数据科学 MOOC 过于肤浅
原文:
www.kdnuggets.com/2020/07/data-science-moocs-superficial.html
评论

I. 介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
数据科学、机器学习和分析被认为是最热门的职业路径之一。行业、学术界和政府对熟练的数据科学从业者的需求迅速增长。因此,持续的“数据热潮”吸引了来自物理学、数学、统计学、经济学和工程学等多种背景的专业人士。数据科学家的就业前景非常乐观。 IBM 预测 数据科学家的需求将于 2020 年激增 28%。
对数据科学从业者需求的不断增长催生了大规模开放在线课程(MOOC)的激增。最受欢迎的 MOOC 提供商包括以下几个:
a) edx: www.edx.org/
b) Coursera: www.coursera.org/
c) DataCamp: www.datacamp.com/
d) Udemy: www.udemy.com/
e) Udacity: www.udacity.com/
f) Lynda: www.lynda.com/
由于 MOOC 越来越受欢迎,每个数据科学 aspirant 自然应该问自己这样一个问题:数据科学 MOOC 适合我吗?
为了回答这个问题,让我们探讨一下 MOOC 的优缺点。
II. MOOC 的优势
大多数 MOOC 是免费的在线课程,任何人都可以报名。MOOC 提供了一种经济实惠且灵活的学习新技能的方式。MOOC 涵盖了领导力、分析学、数据科学、机器学习、职业技能、工程学、商业与管理、人文学科、计算机科学等广泛的在线课程。这些课程通常由全球顶尖大学提供,如 MIT、哈佛大学、加州大学伯克利分校、密歇根大学、洛桑联邦理工学院、香港理工大学、昆士兰大学等。有些课程也由大型企业如 IBM、谷歌和微软提供。MOOC 的最大优势是能够向领导者和专家学习,以及有机会参加世界顶尖大学的课程。
III. 数据科学 MOOC 的缺点
大多数数据科学 MOOC 是入门级课程。这些课程适合那些已经在相关学科(物理学、计算机科学、数学、工程学、会计)中具有坚实背景的人,旨在进入数据科学领域。在我数据科学的旅程中,我发现以下 3 个数据科学专业课程在质量和严谨性方面都是最好的。
b) 分析学:基本工具与方法(乔治亚理工 X,通过 edX)
c) 应用数据科学与 Python 专业课程(密歇根大学,通过 Coursera)
如果你对探索数据科学领域感兴趣,我建议你从 MOOC 开始。然后,在建立了坚实的数据科学基础之后,你可以使用下一部分讨论的方法来进一步提升你在该领域的知识。
IV. 超越 MOOC 培训的提升数据科学知识的步骤
以下步骤将帮助你提升数据科学知识和技能,超越 MOOC 培训的范围。
a) 从教科书中学习
从教科书中学习可以获得比在线课程更精细和深入的知识。这本书提供了对数据科学和机器学习的极好介绍,包括代码:《Python 机器学习》,作者:Sebastian Raschka。作者以非常易于理解的方式解释了机器学习的基本概念。此外,还包括代码,你可以实际使用这些代码进行练习和构建自己的模型。我个人发现这本书在我的数据科学家之路上非常有用。我会推荐这本书给任何数据科学追求者。你只需具备基础的线性代数和编程技能即可理解这本书。其他优秀的数据科学教科书还有 “Python 数据分析”(作者:Wes McKinney)、“应用预测建模”(作者:Kuhn & Johnson)、“数据挖掘:实用的机器学习工具和技术”(作者:Ian H. Witten、Eibe Frank & Mark A. Hall)等。
b) 与其他数据科学追求者建立网络
根据我的个人经验,通过与其他数据科学追求者合作,每周进行关于数据科学和机器学习的各种话题讨论,我学到了很多。与其他数据科学追求者建立网络,在 GitHub 上分享你的代码,或在 LinkedIn 或 Medium 上展示你的技能,这将帮助你在短时间内学习大量的新概念和工具。你还会接触到新的做事方式、新的算法和技术。
c) 将知识应用于现实世界的数据科学问题
请记住,仅仅依靠在线课程是无法让你成为数据科学家的。在建立了坚实的数据科学基础之后,你可以寻求实习机会或参与 Kaggle 比赛,实战真实的数据科学项目。
V. 总结与结论
总结来说,我们讨论了数据科学 MOOC 的优缺点。如果你在物理学、数学、经济学、工程学或计算机科学等分析学科有扎实的背景,并且对探索数据科学领域感兴趣,最好的方式是从 MOOC 开始。然后,在建立扎实的基础之后,你可以寻找其他方式来增加你的知识和专业技能,例如学习教科书、参与项目和与其他数据科学追求者建立网络。
额外的数据科学/机器学习资源
原文。已获得许可转载。
相关:
更多相关话题
数据科学在 10 年内不会消失,但你的技能可能会
原文:
www.kdnuggets.com/2021/06/data-science-not-becoming-extinct-10-years.html
评论
Ahmar Shah 博士,科学家,学术(医疗保健中的数据科学)

图片由michael podger提供,来源于Unsplash
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
作为一名从事数据科学工作超过十年的专业人士,看到有人预言这个领域将在 10 年内消失,我感到非常沮丧。通常给出的理由是新兴的AutoML工具将消除从业者开发自己算法的需求。
我发现这样的观点特别令人沮丧,因为它使初学者不认真对待数据科学,无法在其中取得成功。坦率地说,看到关于这个领域的预言是一种对数据科学社区的不公,因为需求只会进一步增加!
为什么任何理智的人会投资他们有限的时间和精力去学习一些很快就会消失的东西呢?
让我告诉你一件事。如果有一个领域让你有最好的机会真正退休,那就是数据科学。就这么简单。我将给你四个关键理由,说明为什么数据科学不会很快消失。我还会给你建议,以确保你在 10 年内仍然保持在数据科学的前沿。
数据科学不会消失,但如果你不与时俱进,你的技能可能会。让我们深入探讨。
1. 数据科学存在了几个世纪
让我们从科学开始。我不需要说服你,科学已经存在了几个世纪。科学的本质是从数据中学习。我们观察世界上的事物(收集数据),然后创建一个模型(传统上称为理论)来总结和解释这些观察结果。我们创建这些模型来帮助我们解决问题。
数据科学的本质是完全相同的。收集数据,通过创建模型从中学习,然后使用这些模型来解决问题。多年来,各个学科开发并完善了许多执行这一过程的工具。根据领域的重点不同,描述这一组工具和程序的名称也有所不同。目前获得广泛关注的术语是数据科学。
然而,与以前相比,现在的不同之处在于数据的量和我们可用的计算能力。当我们只有几个数据点和少量维度时,手动将其记录在纸上并拟合一条直线(回归)或识别模式是可行的。现在,我们可以廉价地从多个来源(多特征)收集大量数据。拥有大量数据点和维度时,人力无法或不切实际地拟合一条直线(或聚类)。
如果收集数据和开发模型以解释数据的实践已经存在了几个世纪,你认为为什么它会在未来 10 年内消失?
如果有什么不同的话,我们将收集更多种类的数据,并且需要新的方式来创造性地结合这些数据以解决问题。
2. 开发模型只是现实世界项目的一个很小部分
“自动化机器学习”下的一些工具正在获得关注,其中一些可能会导致数据科学的民主化。然而,大多数此类工具将有助于加速在清理过的数据输入上的不同算法的测试和实施。
但将干净的数据输入模型的能力绝非易事。
实际上,许多与数据科学相关的调查指出了数据科学家在数据收集和清理上花费的时间的不成比例。以 Anaconda(数据科学家使用的领先分发工具之一)的年度调查为例,该调查显示数据科学家花费 66%的时间在数据加载、清理和可视化上,仅有 23%的时间用于模型训练、选择和评分。我的个人经验也是如此。
了解算法如何在后台工作并理解其细微差别并非易事,许多在线课程正是花时间解释这些。然而,这种对算法的专注只会创造一种虚假的错觉,好像数据科学全是关于模型的。许多经验丰富的从业者开始看到过度强调模型,而忽视数据清理的问题。领域内的领先专家安德鲁·吴(Andrew Ng)鼓励数据科学界转向以数据为中心的方法,而不是我们目前在数据科学项目中普遍采用的以模型为中心的方法。在他的深度学习新闻简报中,他指出:
有一个常见的笑话,说 80%的机器学习实际上是数据清理,好像这是个较低级的任务。我的观点是,如果 80%的工作是数据准备,那么确保数据质量是机器学习团队的重要工作。
这种情况因网站如Kaggle的存在而进一步恶化,那里参与者提供的是干净的数据,任务仅限于开发不同的模型,以最大化预先确定的性能指标。(Kaggle 对于它的功能来说确实很棒!)
真实世界的项目涉及许多问题,这些问题并不都是从仔细清理的数据或定义明确的问题开始。在大多数项目中,我们事先不一定知道哪些特征会相关、数据需要多频繁地收集以及需要回答的正确问题是什么。欢迎来到真实世界!
新的自动化工具的出现将继续使不同模型的实施变得简单且易于访问。然而,它无法解决现实世界项目中更具挑战性的问题。许多此类问题是依赖于背景的,并不适合自动化。
3. 真实世界的数据科学项目需要迭代开发
也许是受到数据科学热潮的驱动,我曾经遇到有人来找我,说他们有数据,希望我应用“数据科学”来解决他们的问题(这些问题可能也不一定明确)。我敢打赌,许多非数据科学家会把它视为某种魔法(一个你可以输入数据然后得到输出的工具)。
远非如此,真实项目有需要平衡的权衡。这需要一个迭代的方法,首先部署初始模型,然后随着更多数据的收集,监控性能以进行进一步的优化。
任何部署的模型只有在按预期使用时才有用。这并不能保证。需要有熟练的人工元素来持续监控和诊断部署模型的使用,并提出适当的解决方案来优化它。然而,监控部分不一定会被自动化,甚至可能不是定量的。可能会发生非常意外和奇怪的事情,你可能无法预测。
伦敦大都会面部识别系统
不久前,伦敦大都会警察测试了一个实时的面部识别系统。该系统配有摄像头,可以扫描购物中心和公共广场上的人,提取各种面部特征,然后与观察名单上的嫌疑人进行比对。系统随后会显示任何匹配结果,以供警官审查,并决定是否需要拦截(在某些情况下,还可能进行逮捕)。关于该系统操作的独立报告引发了重大关注,并指出了几个局限性。在 6 次试验中识别出的 42 名嫌疑人中,只有 8 名(仅 19%)是正确的匹配。
有大量文献记录了data science 算法存在偏见,这使得它们不够完善,需要进一步发展。按照目前的情况,我们甚至还没有到模型被广泛部署和使用的阶段。因此,我们甚至没有足够的模型漂移或出现问题的案例来进一步自动化这些工具。到目前为止,我们能做的最好的事情是识别模型部署后的问题(例如,银行业,医疗保健,警务)。
*这是最先进的技术。 我们开发和部署模型,但它们却证明是不够的,不适合目的。我们现在正处于只看到使用不适当模型的早期后果的阶段。是否有任何自动化的解决方案来应对这一问题?没有!
即使是手动操作,我们也面临挑战!
4. 数据科学之所以是科学,有其原因
这是我最喜欢的观点。平凡、重复、无认知需求的任务已经面临自动化的风险。然而,这种破坏只导致了更多需要人类创造力和解决问题能力的工作。我们的记忆很糟糕,但我们人类在识别模式以解决问题方面是非常卓越的。
“你的头脑是用来产生想法的,不是用来保存它们的。”——大卫·艾伦
数据科学是因为有科学而存在的。这是关于解决问题。我们面临的问题需要创造性和独创性的解决方案。我们正是擅长这方面,这是一项极具吸引力的技能。数据科学的应用场景只会增加。这只是因为我们正在收集更多数据,并且我们拥有更多计算能力来在小芯片上实施复杂的数学运算。
让我展示一下实现当今最著名的机器学习算法有多么简单。
想象一下,你已经有了经过仔细清理的输入变量 (X) 和输出变量 (Y),准备输入到模型中。使用 Scikit-learn(一个知名的开源 Python 机器学习库),我们可以用以下两行代码实现决策树:
**from** **sklearn** **import** tree
tree.DecisionTreeClassifier.fit(X,Y)
我们可以用以下两行代码实现支持向量机:
**from** **sklearn** **import** svm
svm.SVC.fit(X,y)
你看到模式了吗?我们只需更改函数名称,就可以得到模型。真正的数据科学家不会坐着从头实现这些算法。他们会使用行业中成熟的库,比如 Scikit-learn。
但你真的认为大多数数据科学家在做这些工作,并因这一技能而被聘用吗?改变模型中的一个词,然后运行并报告结果?不!
然而,如果你作为数据科学家只关注这些,那么很快这个技能的需求将会消失。
实现一个模型是大多数人如果知道工具的话都能做到的,而且培训人们也很容易。困难的部分是:
-
知道何时使用某种工具
-
为什么某种工具表现不佳
-
哪些步骤可能有助于提高性能
-
在给定问题中哪些权衡是重要的
-
洞察力和将上述所有与总体目标联系起来的能力
-
具备与领域专家沟通的能力
上述技能是通过处理现实世界中具有挑战性的项目获得的。它们需要时间,学习过程也在认知上是有挑战的。然而,随着我们收集更多数据,面对行业特定的独特挑战和竞争,这些技能将变得越来越重要(而不是 更少!)。
我列出的技能属于解决问题和创造力的永恒领域。这些技能将继续受到高度追捧,因为它们无法被自动化。
最终思考
你应当有一个首选工具,学习它、掌握它,并随着经验的积累了解其细节。然而,确保你能够利用机会参与挑战性的项目,在这些项目中你可以发挥你的创造力和解决问题的技能。
不必担心数据科学会很快灭绝。这种担忧只会让你无法享受你的旅程,并且会使你对这个领域半心半意。如果你相信这种末日预言,你将错失有前景的机会,使你的技能停滞不前。确实,你的需求也会随之消失!
“无论你认为自己能还是不能,你都是对的。” 亨利·福特
然而,如果你继续从事具有挑战的数据科学项目(从数据收集到模型部署),你将在 10 年内站在这个领域的前沿,你的需求只会增加!
选择权在你手中。 ????
简介: Ahmar Shah, PhD 是一名科学家和学术人员。Ahmar 领导一个学术团队,基于爱丁堡大学医学学院的 Usher Institute,专注于医学领域的数据驱动创新。
原文。经许可转载。
相关:
-
数据科学家,你需要学会编程
-
数据科学家在 10 年内会灭绝吗?
-
未来 5 年会出现数据科学工作短缺吗?
更多相关话题
NYC 出租车行程的数据科学:分析与可视化
原文:
www.kdnuggets.com/2017/02/data-science-nyc-taxi-trips.html
由 Indu Khatri,约克大学 Schulich 商学院。
当你决定处理真正的“Big Data”时,感觉就像梦想成真。让我为之狂热的数据是 NYC 出租车行程数据。感谢开放源代码技术的支持者,他们帮助了许多像我这样的新兴数据科学家学习和发展技能。NYC 出租车与豪华车委员会分享了近 11 亿次的纽约出租车行程信息(从 2009 年 1 月到 2015 年 6 月)。委员会发布了更新版的 13 亿次出租车行程数据(包括 2016 年 6 月之前的额外行程)。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
我很快就意识到,当我尝试在我的 Acer 笔记本上探索这些数据时,它完全无能为力。作为计算机科学家和内心的商业女性,我在寻找一个能帮助我在这个数据集上测试数据科学技能的替代方案。像往常一样,Google 解决了我的问题!我使用了 Google BigQuery,它在云中存储了大量数据集,可以通过 SQL 查询进行探索。正如 Google 所说:“BigQuery 是 Google 完全托管的、PB 级别的、低成本的分析数据仓库。”(BigQuery 文档)。
为了进行我的分析,我可以访问 NYC 出租车与豪华车委员会上传的多个 CSV 文件,地址是:www.nyc.gov/html/tlc/html/about/trip_record_data.shtml。我本可以使用 ETL 过程从这些多个 CSV 文件中提取数据并加载到 BigQuery 中,但 Google 已经为我完成了这项工作。如果你对手动过程感兴趣,请参考这个精彩的博客:tech.marksblogg.com/billion-nyc-taxi-rides-bigquery.html。
BigQuery 提供了公共数据集,可以免费探索并集成到我们的软件应用中(在超过限制后可能收费——你可以查看定价计算器)。BigQuery 的 NYC TLC Trips 公共数据集包含了 2015 年之前的行程信息。这些数据包括了 NYC 黄色出租车记录的行程。以下是数据的链接:
我决定以如下方式继续我的分析:
1. 探索了 2015 年的 TLC 黄出租车行程数据
以下是数据的表格描述。
| 表格 ID | bigquery-public-data:new_york.tlc_yellow_trips_2015 |
|---|---|
| 表格大小 | 18.7 GB |
| 行数 | 146,112,989 |
2. 使用 BigQuery 的 StandardSQL 分析数据集
这是我用于分析的查询的简要概览:
3. 使用 Tableau 进行解释性分析
我正在展示我的 Tableau 故事,展示了三个主要仪表板的自解释分析。
第一个仪表板讨论了以下趋势:
-
每月总旅行次数,
-
每小时总旅行次数,
-
每小时黄出租车的平均速度,
-
每小时黄出租车的平均行驶距离
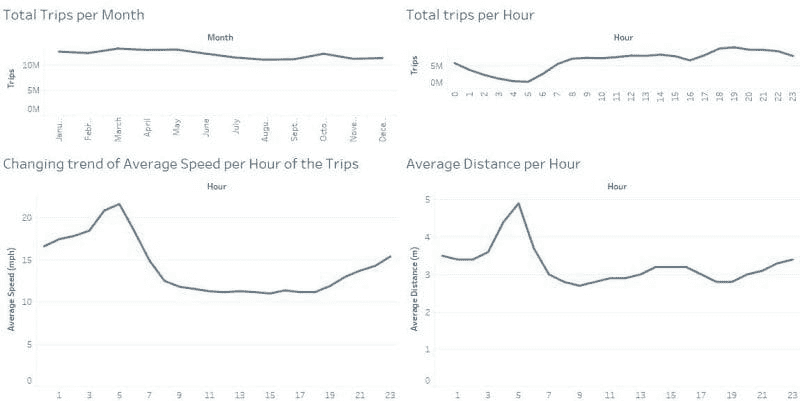
第二个仪表板讨论了以下出租车行程相关信息:
-
热力图显示了给予司机的小费百分比(数据分为 24 小时的 7 周时间段),
-
5 个不同小费区间内的总行程百分比
第三个仪表板讨论了以下趋势:
-
以某个平均速度进行的总出租车行程的百分比。大多数平均速度在 5.50 到 39 mph 之间,
-
以某个平均距离进行的总出租车行程的百分比。大多数行程都在短距离内
PS:接下来的任务是进行预测分析。我计划建立一个多元回归模型来预测新行程的小费百分比。希望你觉得有帮助。请分享你的评论和建议!
个人简介: Indu Khatri 是一位大数据和机器学习爱好者,拥有计算机科学背景,并在 Accenture 和 Cerner 工作期间获得了多个奖项。她目前在 Schulich 商学院(约克大学,托伦托,加拿大)攻读商业分析硕士学位。
相关内容:
-
通过数据可视化提升工程智能的 Uber 案例
-
纽约出租车黑客马拉松——在公共出租车数据集中寻找隐私风险
-
汽车制造商必须围绕大数据进行合作
更多相关话题
我如何在被解雇后 2 个月获得 4 个数据科学职位,并将收入翻倍
原文:
www.kdnuggets.com/2021/01/data-science-offers-doubled-income-2-months.html

图片由安娜·施韦茨提供
在这场前所未有的疫情时期,许多人发现他们的职业生涯受到了影响。这包括一些我曾经合作过的最有才华的数据科学家。为了帮助一些被裁员的亲密朋友找到新工作,我分享了我的个人经历,我认为将这些经历公开分享是值得的。毕竟,这不仅仅涉及我和我的朋友。任何因为疫情被裁员的数据科学家,或者正在积极寻找数据科学职位的人,都可以在这里找到一些他们能感同身受的内容,我希望这能为你的求职提供最终的希望。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT 需求
如果你曾经在面试、面试准备、谈判等方面感到困惑,我也曾经历过这些,我希望能提供帮助。如果你认为我能在任何方面让你的求职之旅更轻松,请通过这里与我联系!这是我的故事。希望你能从中找到一些有用的建议和鼓励。
被解雇
在 2018 年 12 月,我的经理通知我,我将在 2019 年 1 月被裁员。三个月前,我当时初创公司的工程副总裁给我们的人力资源负责人写了一封信。这封信解释了我为何是公司中的顶尖表现者之一,并倡导增加我的薪水。这帮助我获得了 33%的薪资涨幅。我自然感到受到了激励,渴望在一个重要项目上突破下一个里程碑。公司和我的未来看起来都很光明。正是在这个成功的时刻,我被告知我受到了公司整体成本削减措施的影响。我在 1 月 15 日被解雇了。
被迫开始寻找新工作是非常令人畏惧的。浏览了市场上的数据科学职位空缺后,我很快意识到自己的知识差距。我在 B2B 初创公司所做的工作(混合了初级数据工程和机器学习)与许多职位要求完全无关,比如产品感知、SQL、统计学等。我知道一些基础知识,但不确定如何填补向更高级技能的差距。然而,即便是这个问题似乎也不如更紧迫的问题重要,比如我到底如何才能获得面试机会?我在初创公司只有 1.5 年的工作经验,缺乏统计学或计算机科学相关的学位。随之而来的还有更多问题。如果我在失去签证状态之前找不到工作怎么办?如果经济在我找到新工作之前出现下滑怎么办?尽管有很多担忧,但选择不多。我必须找到一份新工作。
准备求职
面对感到压倒性的任务,我需要一些信息来决定我的下一步行动。在做了一些研究后,我意识到市场上超过一半的数据科学职位是以产品为驱动的职位(‘产品分析’),其余的则是以建模或数据工程为导向的职位。我还注意到,除了产品分析之外的职位通常要求更高。例如,大多数建模职位要求博士学位,工程职位则要求计算机科学背景。显然,不同轨道的要求差异很大,因此每个轨道的准备工作也会有所不同。
有了这些知识,我做出了一个重要决定:准备所有的职位轨道将会是非常繁重的,而且可能效果也不佳。我需要专注于一个方向。我选择了产品分析,因为根据我的背景和经验,我更有可能获得这个方向的面试机会。当然,并不是每个数据科学家都有我这样的背景和经验,所以我在下面总结了大公司数据科学职位的三大类一般要求。了解这些基本要求节省了我很多时间,我相信它也会对其他寻找数据科学职位的人有所帮助。然而,我还要补充的是,对于小型初创公司,面试可能会更少结构化,并且需要三者的混合技能。
产品分析(市场占比约 70%)
-
要求:实际的产品发布经验;强大的商业洞察力;高级 SQL 技能
-
示例:Airbnb 的数据科学家,分析师;Lyft 的数据科学家;Facebook 的数据科学家;Google 的产品分析师
建模(市场占比约 20%)
-
要求:机器学习知识(不仅要了解如何使用,还要了解其基础数学和理论);强大的编程能力
-
示例:Lyft 的数据科学家,算法;Airbnb 的数据科学家,算法;Amazon 的应用科学家;Facebook 的研究科学家
数据工程(市场占比 ~10%)
-
要求:端到端的数据科学家,具备数据工程技能;了解分布式系统;MapReduce 和 Spark;具有与 Spark 实际工作经验;强大的编码能力
-
示例:Airbnb 的数据科学家;某些初创公司的数据科学家
根据我自己的经验,本文的其余部分主要针对那些准备进入产品分析岗位的人。稍后回来查看我关于数据工程岗位准备的文章。
求职开始
一旦我知道自己将被裁员,我做的第一件事就是广泛而积极地申请其他工作。我使用了所有我知道的招聘网站,包括 GlassDoor、Indeed 和 LinkedIn。我还向我认识的每一个人请求推荐。然而,由于接近年底,我直到 2019 年 1 月才收到任何回应。
请求推荐被证明比自己申请要有效得多。在大约 50 份原始申请中,我只获得了 3 次面试,而在 18 次推荐中,我获得了 7 次面试。总体来看,很明显我在这个市场上并不被视为强有力的候选人。
面试:概述
尽管每个公司的面试结构不同,但大多数公司遵循了一个大致的框架:
-
招聘人员的初次电话
-
1 或 2 轮技术电话筛选(TPS)或一个带回家作业
-
一个 4 ~ 5 小时的现场面试,通常包括 3 ~ 4 轮技术面试和与招聘经理的行为面试
大约一半(4/10)的公司在面试前或面试时都有一个带回家的作业。带回家作业消耗了很多精力。通常,一个 8 小时的带回家作业让我在提交后至少需要半天的休息。因此,我尽力安排面试时间。带回家作业后的第二天早上没有面试。了解基本结构可以在很大程度上让你感到更轻松,能够应对寻找新工作的过程。
面试前
在面试中,每个机会对我来说都至关重要。虽然我知道有些人通过面试学习,通过许多面试变得更好,并通常在最后几家公司获得录用,但我觉得我不能采用这种方法。当我在 2017 年毕业时,我从 500 份原始申请中只获得了 4 次面试。我没有期待在 2019 年获得更多。因此,我的计划是充分准备每一次面试。我不会让任何机会白白浪费。
被裁员的一个好处是我可以全职准备面试。每天我都制定了学习计划,集中精力于两到三件事。不再多。从之前的面试中,我了解到深入理解可以让你在面试中给出更全面的回答。在面试时尤其如此,当你比平时更紧张和焦虑时,拥有深入的知识会有所帮助。那时候你不希望尝试伪造答案。
在描述我自己的经验时,我忍不住想到一个常见的误解:没有实际经验就无法获得产品/实验的知识。我坚决不同意这个观点。我之前没有任何产品或 A/B 测试的经验,但我相信这些技能可以通过阅读、听讲、思考和总结来获得。毕竟,这就是我们在学校里学习的方式。实际上,随着我认识越来越多的高级数据科学家,我继续发现这种方法是常见的,即使对于有多年经验的人也是如此。你被面试的内容可能与你实际从事的工作无关,但你可以通过其他方式获得所需的知识。
以下是你可以期待的基本情况。通常,在 TPS 中会问到产品和 SQL 相关的问题。现场面试包括几轮问题,包括产品意识、SQL、统计、建模、行为以及可能的演讲。接下来的几个小节总结了我在准备面试时使用的最有用的资源(均为免费)。一般来说,GlassDoor是了解公司特定问题的一个好来源。一旦我看到这些问题,我就明白了公司需要什么以及我在满足这些需求方面的不足之处。我随后能够制定一个计划来填补这些空白。
针对特定学科的准备

图片由 Andrew Neel 提供,来源于 Unsplash
以下六个小节是我如何为产品分析职位面试中出现的特定内容做准备的。在解释我自己的准备过程中,我希望能让后来的求职者更顺利地前行。
产品意识
作为一家初创公司的数据科学家,我主要负责开发和部署机器学习模型以及编写 spark 作业。因此,我几乎没有获得任何产品知识。当我看到一些在GlassDoor上发布的真实面试问题时,例如“如何衡量成功?”或“如何通过当前用户的行为验证新功能?”,我完全不知道如何处理这些问题。当时,这些问题看起来过于抽象和开放。
为了学习产品感觉,我使用了基本的阅读和总结策略,借助下面列出的资源。这些阅读帮助我建立了产品知识。因此,我创建了一种结构化的方法(我自己的“框架”)来回答任何类型的产品问题。然后,我将我的知识和框架付诸实践,这就是学习任何技能所必需的:实践。我写出了涉及产品感觉的问题的答案。我大声朗读我的答案(甚至用手机录音),并利用录音来微调我的答案。很快,我不仅能够在面试中假装懂行,而且实际上真的掌握了内容。
资源:
SQL
我第一次参加 SQL TPS 考试失败了,那是一家我非常感兴趣的公司。显然,需要有所改变。我再次需要练习,因此我花时间练习 SQL 问题。最终,我能够在一天内完成以前需要整整一周的问题。实践使完美!
资源:
统计学与概率
为了准备这些类型的问题,我复习了基础统计学和概率,并做了一些编程练习。虽然这可能看起来很庞大(两个主题都有很多内容),但作为产品数据科学家的面试问题从未难过。下面的资源是一个很好的复习方法。
资源:
-
可汗学院提供了一门入门级的统计学与概率课程,涵盖了这两个领域的基础知识。
-
这本在线统计学书籍涵盖了所有基本的统计推断。
-
哈佛大学提供了一个统计学 110: 概率课程,这是一门关于概率的入门课程,包含实际问题。如果你更喜欢阅读而不是听讲,宾夕法尼亚州立大学提供了一个概率论导论课程,里面有很多例子。
-
我还在 HackRank 上完成了10 天统计学以巩固我的理解。
-
有时候,统计面试中会问到 A/B 测试的问题。Udacity 有一个很好的 课程 涵盖了 A/B 测试的基础知识,而 Exp Platform 有一个更简洁的 教程 讲解这一主题。
机器学习
没有计算机科学学位的我开始找工作时对机器学习了解有限。我曾在之前的工作中上过一些课程,并复习了这些课程的笔记以备面试。然而,尽管建模问题现在越来越频繁,但产品数据科学家的面试问题主要是如何应用这些模型,而不是基础数学和理论。不过,以下是一些有用的资源,可以在面试之前提升你的机器学习技能。
资源:
-
起步时,我推荐这个免费的 应用机器学习课程 由 Andreas Mueller 主讲
-
Coursera - 机器学习 由 Andrew Ng 主讲
-
Udacity - 机器学习工程师纳米学位
演示
一些公司要求候选人展示拿回家的作业或他们最自豪的项目。还有一些公司在行为面试中询问最具影响力的项目。然而,无论形式如何,关键是使你的演示既有趣又具有挑战性。
这听起来很不错,但你怎么做呢?我主要的建议是考虑所有细节,例如从高层目标和成功指标,到 ETL,再到建模实现细节、部署、监控和改进。细节的累积能够形成一个出色的演示,而不是一个大创意。这里有一些值得重新思考的问题,帮助你达到理想的演示效果:
-
这个项目的目标和成功指标是什么?
-
你如何决定是否启动这个项目?
-
你怎么知道客户是否从这个项目中受益?受益的程度如何?
-
你如何测试?如何设计你的 A/B 测试?
-
最大的挑战是什么?
在展示项目时,你希望能够吸引观众。为了使我的演示有趣,我经常分享有趣的发现和项目中的最大挑战。但确保吸引观众的最佳方式是练习。大声地不断练习。我曾经在家人面前练习演讲,以确保对材料的掌握和沟通的流畅。如果你能吸引你认识的人,面试官作为被动听众就没有机会了。
行为问题
尽管容易沉迷于准备技术面试问题,但不要忘记行为问题同样重要。我面试过的所有公司在现场面试中至少有 1 轮行为面试。这些问题通常分为这三类:
-
为什么选择我们?/ 你在工作中最看重什么?
-
自我介绍/为什么离开你当前的工作?
-
你职业生涯中的最大成功/失败/挑战。其他版本:告诉我一个你解决冲突的例子,或你曾说服过你的经理或产品经理的事情。
行为问题对数据科学家来说非常重要。所以要做好准备!了解公司的使命和核心价值有助于回答第一类问题。像第 2 和第 3 个问题可以通过讲述故事来回答——3 个故事足以回答所有行为问题。确保你在面试时有几个好的故事。类似于产品问题,我通过大声讲述、录音和听取,反复练习来微调我的回答。听到一个故事是确保其有效性的最佳方式。
获取 100%现场面试转正率的秘诀

图片由 Campaign Creators 提供,来自 Unsplash。
面试前的晚上通常是压力巨大、忙碌的。我总是试图在这期间迅速掌握更多技术知识,同时复习统计学笔记,并考虑回答产品问题的框架。当然,正如我们在学校学到的那样,这些都不是特别有用。结果主要取决于之前的准备量,而不是一晚的临时抱佛脚。因此,准备很重要,但在面试当天你可以遵循一些规则,以确保面试的成功。
-
在回答问题前务必澄清问题。 确保通过用你自己的话重复问题来理解你被问到的内容。如果你在没有澄清问题的情况下直接回答,这就是一个红旗。
-
组织所有问题的回答。 用要点写下你的思路。这向面试官展示了你有系统性地处理问题的方法,并帮助面试官后续写出评价。
-
当你不知道答案时不要慌张。如果你对某个领域不熟悉也没关系。在这种情况下,你可以先做一些假设,但要确保沟通你正在做假设,并询问这些假设是否合理。有时候要求更多时间完全没问题。如果你想不出答案而脑袋一片空白怎么办?谈谈你在相关问题上的经验。
-
态度很重要。 公司在寻找愿意倾听并能够接受不同意见的人。你需要展示自己是一个容易合作的人。保持谦虚和尊重。倾听并澄清。为房间带来你的积极能量,并尽力进行良好的对话。
-
研究公司。 熟悉公司的产品。问问自己如何改进这些产品,以及可以用什么指标来衡量这些产品的成功。通过阅读公司的博客,了解数据科学家在每家公司做什么也很有帮助。进行这种研究可以在面试中引发更深入、更好的对话。
使用这些规则,我在现场面试中得到了以下反馈:
-
以非常有条理的方式回答产品问题
-
演讲内容非常有条理,经过深思熟虑
-
展现了对我们产品的深厚兴趣,并提供了有价值的改进建议
谈判
在收到口头邀请后,下一步是与招聘人员一起确定数字。在这里我坚持一个规则 - 永远谈判。但怎么谈?
Haseeb Qureshi 提供了一份非常有用的谈判工作邀请指南(包含脚本!),我在我的邀请谈判阶段严格遵循了这些规则。每一条规则都非常正确。我与所有给我提供邀请的公司进行了谈判。邀请的平均涨幅为 15%,最高的邀请总值上涨了 25%。谈判有效,所以不要害怕尝试!
收获
-
大量的练习是关键。
-
失败是生活的一部分,也是求职过程的一部分。不要过于严肃对待它。
-
找到适合你的减压方式。
概述
在减掉 11 磅体重和经历了大量的哭泣和尖叫(求职是压力很大的过程,承认这一点没关系)后,我终于在被解雇后的两个月内收到了 4 个邀请。其中 3 个邀请来自我从未梦想过加入的公司:Twitter、Lyft 和 Airbnb(最终我选择了加入 Airbnb),另一个邀请来自一家医疗保健初创公司。在这两个月的忙碌期结束时,我总共收到了 10 次面试、4 次现场面试和 4 个工作邀请,给我带来了 40%的 TPS 到现场面试率和 100%的现场面试到邀请率。

图片由Emma Ding提供 | 从被解雇到加入梦想公司的时间线
我非常幸运,在被裁员后得到了家人和朋友的大力支持和帮助,这对我获得梦想公司的工作至关重要。这很困难。具有讽刺意味的是,找工作也是一项繁重的工作,但一切都是值得的。
我写这篇博客是因为我知道我曾经感到多么的困惑。准备面试需要做很多准备工作。我希望这篇文章能为其他需要工作的数据专家提供更清晰的指导,如果你想要更多建议,请随时通过这里联系我。我很感激现在能有一份很棒的工作,我也很乐意帮助你达到你的目标!
更新
自从我三周前发布这篇文章以来,我收到了数百个关于数据科学面试的问题。因此,我决定制作一系列视频来帮助你获得梦想的数据科学职位。如果你感兴趣,可以查看我的 YouTube 频道!
欢迎!我是艾玛·丁。我是 Airbnb 的数据科学家/数据工程师,当我不忙的时候……我制作视频和撰写文章……
艾玛·丁 是 Airbnb 的数据科学家和软件工程师。
原文。已获许可转载。
更多相关话题
我在 Coursera 上的数据科学在线学习之旅
原文:
www.kdnuggets.com/2020/11/data-science-online-learning-journey-coursera.html
评论
由 Ruben Winastwan,数据科学爱好者

图片由 Caleb Jones 提供,来源于 Unsplash
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
介绍:我的背景
是在 2016 年,我在完成机械工程学士学位后,直接开始攻读计算力学硕士学位。那时,我对编程了解有限,更别说了解数据科学和机器学习了。
启程的契机发生在我硕士学习期间,当时我需要构建一个对象检测和对象跟踪算法的经典计算机视觉项目,使用 Python、C++和 OpenCV。那个项目确实迫使我艰难地学习 Python 和 C++,以及如何正确编写干净的代码。
长话短说,我发现自己对计算机视觉领域非常着迷,这引发了我的执念:我想成为一名计算机视觉工程师。
但当我阅读计算机视觉工程师职位的招聘要求时,高期望变成了泡影:他们期望候选人了解机器学习和深度学习,特别是卷积神经网络(CNN)。

计算机视觉工程师的常见职位描述
那时,我甚至不知道什么是机器学习,更别提 CNN 了。尽管我的学习计划涉及了编程、数学和统计,但我们从未讨论过机器学习。
经过一些研究,我发现如果你想了解 CNN,你需要首先了解一般的深度神经网络(DNN)。如果你想了解 DNN,你需要首先了解经典的神经网络。如果你想了解神经网络,你需要首先了解机器学习。如果你想了解机器学习,你需要首先了解数据科学的基础。

这就像一个视频游戏,我需要逐步升级,直到达到我想要的主题。此外,我是自下而上的方法的忠实粉丝,因此我决定首先学习数据科学的基础。
当时的问题是:当我的学习计划没有提供相关课程时,我怎么能学习所有这些内容呢?
我需要自己学习所有这些内容。
那时我第一次知道 Coursera 的存在。
那为什么是 Coursera 呢?
首先,我并不打算在这篇文章中推荐 Coursera。我只是发现它们是对我来说最好的在线学习平台,因为有许多来自知名机构的数据科学和机器学习课程。此外,你还可以选择免费旁听课程,并仍然获得学习材料的访问权限。
更重要的是,如果你真的想追求这个专业的证书,总体费用比 Udacity Nanodegree 便宜得多,尤其是如果你还在读书的话。
好了,说了这么多,我们来看看我的学习路径吧。
我的数据科学学习路径
我们都同意,一切的最难部分总是在开始时。就像我想涉足数据科学时一样。我不断问自己一个问题:我从哪里开始?
经过一些研究,我终于制定了我的在线学习课程,这里是我在 Coursera 上按时间顺序进行的课程或专业列表。
IBM 数据科学

我决定从基础层面开始学习数据科学,因为我不想错过一些重要概念。这就是我选择将 IBM 数据科学作为我第一门专业课程的原因。
在参加这门课程之前,你不需要对数据科学、统计学、机器学习或编程有任何先前的知识。这门专业的第一门课程被称为‘什么是数据科学?’。我的意思是,你不会找到比这更基础的了,对吧?
这个专业有 9 门课程。它从数据科学的概念和方法开始,然后深入讲解 Python 和 SQL 编程。接着,它将带你进入数据科学的核心——统计学、数据分析、数据可视化和机器学习。
完成这个专门化课程后,你不会成为数据科学方面的专家,因为这个专门化课程不会详细讲解每一个主题。然而,它给了我数据科学的一个很好的概述,并帮助我决定接下来应该学习什么。
感谢这个专门化课程,我能够为我的数据科学和机器学习在线学习之旅制定了如下路线图:
-
SQL
-
统计学
-
数据可视化
-
机器学习
-
深度学习
这使我进入了我所学习的下一个专门化课程。
现代大数据分析与 SQL

这是由 Cloudera 提供的一个专门化课程,重点是利用 SQL 进行大数据分析。这个专门化课程总共有 3 门课程。
如我们所知,如今的数据量过于庞大,无法存储在传统的数据库管理系统中,因此处理分布式集群中的数据的知识和实践经验非常重要。这门课程将教你正是这些内容。
我特别喜欢这个专门化课程的实践性。通过 Cloudera 提供的虚拟机,我们有机会应用 SQL 查询来检索或存储数据,使用 Apache Hive、Apache Impala、MySQL 或 PostgreSQL。即使你完成了专门化课程,你仍然可以重新访问虚拟机,这样你总能复习你的 SQL 技能并玩弄数据。
如果你对 SQL 一无所知,不用担心,因为这个专门化课程将从基础开始教你。
从数据到洞察:Google Cloud Platform

我修这门课程是为了补充我从 Cloudera 的之前专门化课程中学到的材料。虽然 Cloudera 的专门化课程更多地集中于在分布式集群中应用 SQL,这个专门化课程让我能够在云端应用 SQL。
这个专门化课程将教你如何在 Google Cloud Platform (GCP) 的 BigQuery 中检索或存储数据。你将有机会使用 Google 公共数据集,如 Google Analytics,并自己实施 SQL 查询。
除此之外,我喜欢这个专门化课程的另一个原因是,你将学到的不仅仅是 SQL 和 BigQuery。你还会学习如何使用 Google Data Studio 创建互动数据可视化仪表板,以及如何在 BigQuery 中直接创建一个简单的回归或分类机器学习模型。
在完成这个专门化课程后,我继续学习了数据科学和机器学习背后最重要的概念之一,即统计学。
使用 R 统计

我们可以达成共识,统计学是数据科学的核心。由于我之前已经了解统计学,我选择了这个专门化,希望能够刷新统计学的基础理论。但最终,我获得的比预期要多。
这个专门化确实教会了你关于统计学的所有必要知识,从概率基础理论、推断统计学,到频率主义和贝叶斯观点的回归理论。
我喜欢这个专门化的两点:
-
所有最终项目都具有投资组合价值,这意味着你需要做真实的统计数据分析工作,并且不要指望在 1 或 2 小时内完成它们。完成专门化后,你将拥有 3 或 4 个投资组合价值的项目,可以放在你的简历中。
-
你需要使用 R 来完成每门课程的项目。这对我来说很好,因为我之前从未使用过 R。我认为学习一种新的编程语言从长远来看是有益的,而 R 绝对是一个很好的数据科学和统计工具箱,可以加入到你的技能库中。
完成专门化后,我觉得我想深入研究一下贝叶斯统计学,特别是关于马尔可夫链蒙特卡罗的方法。这就是为什么我在这个专门化之后又选修了一门关于统计学的课程,那就是……
贝叶斯统计:技术与模型

如果你想全面了解贝叶斯统计学的概念,我认为这将是适合你的课程。在这门课程中,你将学习关于马尔可夫链蒙特卡罗的概念,以及如何使用贝叶斯概念解决回归问题。
我特别喜欢这门课程的地方在于理论与实践的平衡。
每个材料都会首先讲解理论,然后进行演示,讲师会向你展示如何在代码中实现你刚刚学到的理论。在这门课程中,你将学习如何在 R 和 JAGS 中实现贝叶斯统计学。
本课程的最终项目也具有投资组合价值,并且与上述的 R 统计学专门化非常相似。你将被要求使用贝叶斯概念在 R 中进行统计分析工作。
完成课程后,我决定继续学习下一个主题,即数据可视化。
Tableau 数据可视化

通常情况下,当涉及到数据可视化时,我会使用 Python,借助 Matplotlib、Seaborn 或 Plotly。然而,我想学习一些新东西——我想学会如何使用商业智能工具进行数据可视化,无论是 PowerBI 还是 Tableau。然后我发现了这个专门化。
如果你对 Tableau 不熟悉并想学习如何用它来可视化数据,我会推荐这门专业。
这个专业包含 5 门课程和一个 Capstone 项目。前三门课程将为你提供数据可视化最佳实践的理论理解,以及如何用数据讲故事。第四门课程基本上就是让你动手使用 Tableau,你将学习如何创建交互式数据可视化仪表板和故事。
我非常喜欢这门专业的地方是,当你注册这门专业时,你会获得 6 个月免费使用 Tableau Desktop 的权限。
这意味着你可以在本地机器上探索 Tableau 的许多功能,并用它创建很多有趣的可视化。如果许可证在 6 个月后过期,你将有机会再延续 6 个月。
机器学习

到目前为止,我已经学习了数据科学概述、使用 SQL 进行大数据分析、统计学和数据可视化最佳实践。接下来,终于到了学习机器学习的时机。
作为机器学习的完全初学者,我决定参加安德鲁·吴的机器学习课程,因为我知道这是 Coursera 上最著名的机器学习课程。
这完全是合理的。我相信对于初学者来说,我找不到比这更好的机器学习课程了。
这门课程将教你经典的监督学习和无监督学习算法的概念,如线性回归、逻辑回归、支持向量机(SVM)、K 均值聚类以及人工神经网络。不仅如此,安德鲁还给了我们在实践中应用机器学习系统的技巧和窍门。
基本上,我喜欢这门课程的一切。
我喜欢安德鲁·吴在教学中对各种机器学习算法的热情。我喜欢他如何轻松地向我们解释和简化复杂的机器学习概念。我也喜欢编程作业,以及我们有机会从零开始实现神经网络算法。
如果你是机器学习的新手,对我来说这是你应该开始学习的最佳课程。
深度学习

最终,我越来越接近实现我的初衷——了解卷积神经网络的概念。
我仍然记得当我发现安德鲁·吴是这门深度学习专业的老师时的兴奋感。在完成机器学习课程后,毫不犹豫地选择这门专业对我来说并不是一个困难的决定。
这个专业化课程结构非常合理。第一个课程将教你有关深度神经网络的概念,而你已经在之前的机器学习课程中学习了经典的神经网络。接下来,它会介绍卷积神经网络和序列模型的重要概念。
Andrew Ng 一如既往地在教授有关深度学习算法的难点概念方面表现出色。编程作业很有趣,让你可以实现各种深度学习算法,TensorFlow 也是目前行业中最常用的深度学习框架之一。
然而,这个专业化课程中的大多数编程作业仍然是在 TensorFlow 1 中实现的,现在已经相当过时了。
DeepLearning.AI TensorFlow 开发者专业证书

我相信在 DeepLearning.AI 将名称改为 TensorFlow 开发者专业证书 之前,这个专业化课程曾被称为 TensorFlow 实践。
不管怎样,我之所以在完成深度学习专业化课程后立即选择这个专业化课程,是因为我想学习如何实现 TensorFlow 2 以应用于各种深度学习算法。这个专业化课程完全达到了这一目标。
这个专业化课程完全是实践操作。你不会在其中找到有关深度学习的理论,因为它的重点是借助 TensorFlow 实现深度学习算法。因此,建议在参加这个专业化课程之前,你已经了解深度学习的概念。
它让你获得了构建用于图像分类、情感分析、诗歌生成和时间序列预测的深度学习模型的实践经验。
作为额外的福利,如果你未来想获得 TensorFlow 开发者证书,这个专业化课程也是你备考的最佳资源。我最近完成了认证,我可以说这个专业化课程是最好的备考资源。如果你对我获得认证的经历感兴趣,可以在下面的链接中阅读。
我对参加考试的总体体验、我的备考方式以及如果重新参加考试我会做的不同之处…
结语
我认为你应该知道,单独上数据科学和机器学习课程是不够的,无论你的目标是获得数据科学职位还是掌握某些数据科学概念。和我一样,尽管学习了与 CNN 相关的课程,并不意味着我已经掌握了它。
这些课程是你获得感兴趣主题基础知识的绝佳资源。参加课程只是起点,接下来发生的事情完全取决于你。
将你从课程中获得的知识付诸实践,才能真正巩固你的新技能。在参加这些课程期间或之后,做一些个人项目,将代码上传到 GitHub,并通过博客分享你学到的项目或学习材料。
祝你在数据科学学习之旅中一切顺利!
个人简介:Ruben Winastwan 是一名数据科学爱好者,专注于机器学习和计算机视觉。
原文。经许可转载。
相关内容:
-
MIT 免费课程:计算思维与数据科学入门
-
提升数据科学技能必修的在线课程
-
2020 年最佳机器学习课程前 10 名
更多相关内容
数据科学被高估了,这里是原因

图片来自 freepik
人们已经为数据科学大肆宣扬了大约 10 年,自从《哈佛商业评论》称其为“21 世纪最性感的职业”以来。我自己也被这种炒作所吸引,这也是我 4 年前攻读该学科学位的原因。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
随着时间的推移,我意识到数据科学被过度炒作了。这一领域被过度美化,以至于那些真正不了解其内容的人也在谈论这个词汇。
你一定听过“85%的生产化机器学习模型将失败”这一说法。这是研究公司 Gartner 的预测,老实说,如果这个数字更高我也不会感到惊讶。就我个人而言,我过去曾参与过多个失败的数据科学项目。
失败的数据科学投资可能会给组织带来巨大的费用,特别是如果基于预测算法的结果做出错误的业务决策。
在这篇文章中,我将突显出围绕数据科学的炒作所引发的一些主要问题以及如何克服这些问题。
人们往往将机器学习奉为神明
机器学习并不是解决所有问题的万能方案,这一点对利益相关者和非技术管理者至关重要。并非所有问题都可以用机器学习解决,也并非所有问题都应该用机器学习解决。
我曾与一位高级教授(他并不专攻数据科学)合作完成我的顶点项目。我们的学院与一家希望实施网络安全解决方案以过滤恶意流量的公司合作。
数据以日志文件的形式提供,而他们没有给我们足够的数据。
我们清理了数据并尝试构建一个仪表盘来分析数据点。我们的教授坚持让我们使用机器学习模型。他说这样会给客户留下深刻印象。
我们说这行不通。数据不够。
他没有听。
我们要求更多的数据。
他说这不可能,我们必须使用现有的资源。
我们构建了模型并进行了展示,他对演示过程中看到的高准确率很满意。数据集不平衡,所以我们的模型只预测了一个类别。他不知道这一点。我们尝试解释,但似乎对他没有影响。
任何在数据行业工作超过一个月的人可能都经历过类似的情况,尽管可能没有那么极端。
高层管理、利益相关者和业务团队通常来自非技术背景。听到“数据科学”和“机器学习”等术语时,他们的期望往往会升高。数据科学家需要让他们回到现实,清楚地解释什么是可能的,什么是不可能的。
在不需要时使用机器学习
我明白了。即使在真正不需要的情况下,建议构建机器学习模型也是很诱人的。我也会这样做。许多人,尤其是非技术人员,常常将数据科学等同于机器学习。
然而,作为数据科学家,直到你确定机器学习建模是最佳选项之前,不要开始构建预测算法。
构建机器学习模型,特别是在大量数据上,是计算密集型的,可能会给组织带来不必要的开支。
如果问题可以通过硬编码逻辑或在电子表格中进行简单计算来解决,为什么要浪费时间构建机器学习模型呢?
这是一个 例子 ,展示了数据科学家用机器学习解决非机器学习问题的情况:
Hiren 最近被聘为印度顶级银行之一的数据科学家。他构建了一个 KNN 算法,以识别银行应该关注的最盈利的行业细分。他强调,他们应该关注他们投资组合中的 33 个行业中的 2 个。
结果让业务团队成员失望,因为他们已经知道了这些。他们能够通过简单的草率计算得出相同的结论。
对他来说,花时间构建一个提供完全相同结果的机器学习模型是不必要的。
Hiren 随后决定深入挖掘并了解更多业务需求,以便他可以更好地利用自己的数据科学专业知识为团队做出贡献。在掌握了一些领域知识后,他意识到公司将从客户级别的推荐中受益,而不是行业级别。
他不仅仅告诉公司应该针对哪些行业,还能够识别这些行业中最有利可图的客户。这些是业务团队尚未掌握的洞察,因为从大量客户数据集中提取意义对他们来说要复杂得多。
上述故事在尝试构建数据科学解决方案时教会了我们两个关键的教训:
-
如果有更简单的解决方案,请不要使用机器学习。
-
只有在理解业务需求后才开始构建预测模型。否则,你将花费时间在一个没有人使用的华丽算法上。
招聘没有数据的 数据科学家
当数据科学在 2012 年急剧流行时,公司开始大规模招聘数据科学家。他们中的大多数人没有建立数据管道,但期望数据科学家能够进来并开始创造价值。
不出所料,这并没有发生。
大多数数据科学家不知道如何构建数据管道。他们使用的是可以从现有预处理数据库中轻松提取的数据。
这导致了双方的许多沮丧。
数据科学家准备好开始构建机器学习模型,但无法做到这一点。公司在数据科学团队上投入了大量资金,却没有从中获得任何业务收益。
仅仅因为炒作而决定进入数据科学领域,这些组织浪费了大量的时间和金钱。
那么……数据科学的职业仍然值得追求吗?
以上问题都源于对数据科学的过度炒作。学生往往过于急于进入这个领域,因为他们想学习一个高度需求的技能。雇主开始大规模招聘数据科学家,但没有完全理解这个角色。
这些不匹配的期望导致双方都感到非常沮丧。
数据科学家确实倾向于过分强调预测建模,而在大多数情况下,简单的数据分析就足够了。
当机器学习算法未能达到雇主的期望时,这会导致非常不愉快的工作情况。
然而,如果各方的期望达成一致,追求数据科学职业仍然可以是极其值得和令人满足的。如果你拥有数据科学技能,以下是一些找到合适公司的建议:
-
确保公司有一个数据团队。这意味着组织的数据素养很高,你被要求达成奇怪期望的机会更小。
-
采访你的雇主。询问你的招聘经理关于这个角色的真正职责;公司拥有多少数据,目前数据是如何存储的,以及你需要带来什么价值。
"请记住,上述建议主要适用于初级数据科学家。高级数据科学家、顾问或经理可能会被聘请来帮助实施公司的数据科学流程,即使在没有结构化数据管道的阶段也是如此。"
一旦你在一家你感到舒适的公司找到工作,务必时刻质疑机器学习是否真的是正确的方法。在提出解决方案之前,尽量全面理解业务问题,否则解决方案可能与利益相关者无关。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在LinkedIn上与她联系。
更多相关内容
数据科学“按数字上色”与假设开发画布
原文:
www.kdnuggets.com/2018/11/data-science-paint-by-numbers-hypothesis-development-canvas.html
评论
当我还是个孩子的时候,我喜欢“按数字上色”的套件。任何能够在画线之间上色的人都可以成为伦勃朗或达芬奇(我们可以稍后讨论强迫孩子们“保持在界线内”的长期影响)。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
设计领域正在使用设计画布应用“按数字上色”的概念。设计画布概述了在特定主题下的重要内容,然后允许“画家”填入正确的信息。设计画布是一个单页操作模板,旨在捕捉成功执行所需的所有不同视角,具体取决于要解决的问题。一个很好的画布示例是 商业模式画布,感谢 Strategyzer(见图 1)。

图 1: 商业模式画布,感谢 Strategyzer
商业模式画布迫使组织“填入”你业务的价值主张、成本结构、收入来源、供应商网络和客户细分。转眼间,每个人都可以成为杰克·韦尔奇!
现在,你已经准备好从大数据 MBA 的角度迈出下一步,通过基于商业模式画布来完善业务用例——或假设——这正是我们可以更有效地利用数据和分析来优化业务的地方。下一步涉及新创建的假设开发画布。
介绍数据科学按数字上色
大多数数据科学项目中投资不足的一个领域是对假设或用例的彻底和全面的发展;也就是说,我们试图通过数据科学工作证明什么,以及我们如何衡量进展和成功。
为了满足这些要求,我们开发了假设开发画布——一个“按数字绘画”的模板,我们将在执行数据科学工作之前填充,以确保我们彻底理解我们要实现的目标、业务价值、我们如何衡量进展和成功、与假设相关的障碍和潜在风险。假设开发画布旨在促进业务利益相关者与数据科学的合作(见图 2)。

图 2:假设开发画布
假设开发画布包括以下内容:
-
假设的描述和目标——组织试图预测的内容及其相关目标(例如,减少计划外的操作停机时间 X%,提高客户保留率 X%,减少过时和过剩的库存 X%,提高准时交付率 X%)。
-
从财务、客户和运营角度来看假设的商业价值;即成功解决假设后的粗略投资回报率(ROI)。
-
衡量成功和进展的 KPI,以及与 KPI 潜在的二级和三级影响相关的风险探索。有关 KPI 的二级和三级影响的更多细节,请参见博客“错误衡量的意外后果”。
-
决策——需要做什么、何时、何地、由谁等——以支持和推动行动和自动化,支持假设的业务、客户和运营目标。
-
需要探索的潜在数据来源,包括简要描述及业务利益相关者认为可能是合适数据来源的原因。
-
与假阳性和假阴性(I 型和 II 型错误)相关的风险;与分析模型错误的情景相关的风险。
视觉工作坊加速了业务利益相关者和数据科学团队之间的合作,以确定支撑数据科学工作成功的假设需求。
机器学习画布(大数据 MBA 版本)
现在为了完成整个循环,我介绍机器学习画布。我在网站“机器学习画布”上偶然发现了 Louis Dorard 的机器学习画布 v0.4。Louis 已将他的画布免费提供,我也将根据我们的独特数据科学需求,对他的画布进行相应的添加(见图 3)。

图 3:机器学习画布(大数据 MBA 版本)
为了我们的数据科学工作,我们需要在面板中添加内容:
-
处方:一旦我们有了预测,我们该如何处理这个预测?
-
自动化:我们如何利用规范性洞察来自动化标准程序?
总结
成功的数据科学参与需要在整个开发过程中与业务利益相关者密切合作,以:
-
理解和量化金融、运营和客户价值创造的来源(这涉及经济学)。
-
彻底了解将要衡量进展和成功的 KPI 和指标,特别是这些 KPI 和指标的潜在的二次和三次影响。
-
头脑风暴可能会产生更好业务和运营绩效预测的变量和指标(数据来源)。
-
对假设相关的奖励/收益和成本/风险进行编码(包括与假阳性和假阴性相关的风险和成本)。
-
与业务利益相关者密切合作,以了解从预测分析的角度“足够好”实际上是什么时候的“足够好”。
我们现在拥有三个设计画布,不仅可以将我们的商业模型与数据科学和机器学习工作关联起来,而且数据科学团队现在可以直接“看到”他们的工作如何影响商业模型。

图 4:将商业模型与数据科学和机器学习关联起来
引用著名的美国哲学家兼兼职场地管理员卡尔·斯帕克勒的话:“现在我有了这些,这很好。”
相关:
-
打造数据科学团队的制胜计划
-
使用混淆矩阵量化错误成本
-
创建智能的 3 个阶段
更多相关主题
数据科学诗
评论
由 Igor Korolev, DO, PhD,Brainformatika

图片来源。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
数据科学非常酷,
它充满了许多有用的工具。
R、Python 和 Excel,
Tableau、SAS 和 SQL。
定义问题,收集数据
然后你会发现有用的见解。
提取、转换、加载和清理
在大屏幕上进行可视化。
跟随领域专家的指导,
创建数据所需的特征。
选择要运行的机器学习算法
回归、随机森林,
神经网络带来终极乐趣。
将数据分成训练集和测试集
找到最有效的参数
使用 AUC、召回率和精度进行评估
提供有助于决策的见解
数据科学需要批判性思维和学习
但它可能会有深远的影响和回报。
更多相关话题
一个能让你找到工作的数据科学作品集
原文:
www.kdnuggets.com/2021/09/data-science-portfolio-job.html
评论

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
当我获得第一个数据科学实习时,我还没有毕业。我正在攻读计算机科学学位,但在向雇主展示任何成绩单或学术记录之前,就已经获得了这份工作。我是在自学数据科学的四个月左右才得到了这个角色。
现在,我已经过渡到同一公司的全职角色。
我能获得这份工作的唯一途径就是借助我的数据科学作品集。
仅在过去一年里,我就收到了来自世界各地组织的多个数据科学工作邀请。
我目前正在做一些自由职业的工作,同时也全职工作,要是没有我为自己建立的作品集,我绝不会有这些机会。
当我刚开始自学数据科学时,我在 Kaggle 上尝试了一些数据集——简单的,如波士顿房价数据集和泰坦尼克号数据集。
随着时间的推移,厌倦感开始显现。这些项目有着非常相似的结构,话题也没有真正激发我的兴趣。
我想从事一些我觉得有趣的工作,于是我上网寻找令我兴奋的话题的数据集。
一段时间后,我想出了一个数据科学项目的想法。然而,我无法找到满足我开始构建项目所需的所有信息的现成数据集。
我不得不通过 APIs 和网络爬虫工具自己收集数据,清理数据,然后构建数据框架。这整个过程帮助我了解了从网上收集数据的不同技术。
这个项目证明比我想象的要困难得多,但我在过程中学到了很多。我开始更好地掌握 Python 及其库。
一旦我完成了几个项目,我就想在我的 GitHub 仓库中分享它们。
然而,我并不满足于仅仅分享项目的源代码。我想分享我的发现和我用来收集数据的技术。我想讲述我所做的所有工作的故事。
我开始撰写解释创建项目步骤的文章。我将这些文章提交给数据科学出版物。
在创建了大约 3 到 4 个项目后,我建立了一个作品集网站。这个网站包括了项目的基本描述,以及相关的源代码和我写的文章。
这是一种将我所有工作的成果集中展示的方式,以便任何拥有我网站链接的人都能看到我所做的一切。
我的作品集网站是我在学习数据科学的头几个月内获得实习机会的唯一原因。

照片来自 Firmbee.com 在 Unsplash。
在实习期间,我有一些闲暇时间。我利用这些时间学习工作之外的技能,构建项目,并撰写相关文章。
随着我通过写作开始接触更广泛的受众,招聘人员和数据科学家们根据我写的项目联系了我。我开始自由职业,并为客户按合同基础构建数据科学项目。
这对我来说是一个很好的方式来提升技能,获取超出日常工作范围的知识。
我也获得了多次技术写作机会,并且偶尔以自由撰稿人的身份为出版物写作。
我的作品集包含了我所做的项目、我的博客、推荐信和我合作过的客户。大多数这些机会都是因为我通过写作与世界分享我的工作。
如果你是数据科学行业的初学者,我建议你学习新知识并写作。编写关于你刚刚学到的概念的教程。
如果你有一个数据科学项目的想法,就将其付诸实践。这可能需要几天、几周甚至几个月的时间。
一旦你成功建立了项目,将其分享给全世界。将其分解为通俗易懂的术语,解释你所做的一切。
这将引起招聘人员的兴趣,当你申请数据科学职位时,它还将使你与那些简历上仅有在线证书的其他申请者区分开来。
创建项目也是学习和提升数据科学技能的好方法。如果你上过一两门数据科学课程,那么现在是时候通过构建你热衷的项目来运用你的编程和机器学习技能了。
相关:
了解更多相关话题
一个能让你在 2022 年获得工作的数据科学作品集
原文:
www.kdnuggets.com/2022/10/data-science-portfolio-land-job-2022.html

图片来源:编辑
如果你正在阅读这篇文章,很可能以下一项或多项陈述适用于你:
-
你没有数据科学硕士学位,也没有相关领域的经验。
-
每个你遇到的数据科学职位招聘信息都要求至少 2-3 年的相关经验。但如果没有经验,没人愿意雇佣你,你怎么获得经验呢?
-
你已经参加了无数的数据科学在线课程,它们都教给你类似的内容。你最终陷入了一个陷阱,你并没有真正学到新的东西,只是觉得自己在学习。
-
你甚至创建了数据科学项目,并将其包含在你的作品集中,希望它们能为你在该领域找到工作,但这些项目没有成功。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
如果以上任何陈述与你有关,那么你可能在以下四点上做错了:
1. 你参加了太多的在线课程
每次你参加一个新的针对初学者的在线课程并将其添加到简历上时,你是在告诉雇主你在这个领域还是新手。这使得你看起来缺乏经验,可能会对你的作品集造成比好处更多的伤害。
我见过很多数据科学候选人在简历上列出超过十个类似的在线课程,却没有任何项目或现实应用来展示他们学到的技能。
这里是你应该做的事情
参加一到两个数据科学在线课程,并基于所学技能创建项目。如果你在构建这些项目时发现自己在特定领域缺乏专业知识,那么参加一个填补你知识空白的课程。
这样,你不仅能更快地学习,还能在简历上展示广泛的技能,而不是列出十个教授相同内容的课程。
2. 你没有从人群中脱颖而出
大多数申请者的另一个错误是,他们在简历上列出相同类型的项目。
像鸢尾花分类和泰坦尼克号生存预测这样的项目非常受欢迎。
由于其简单性,这些是大多数人在学习数据科学时创建的第一个项目。如果你将这些项目添加到简历中,你是在告诉雇主你缺乏经验和创造力。
其他数百名申请者已经创建了相同的项目并在他们的作品集中提到这些项目。既然你的简历与 80%的其他数据科学 aspirants 没有区别,为什么你会获得工作邀请?
相反,你应该这样做
创建展示各种技能的数据科学项目,例如数据分析、机器学习和数据预处理。如果你需要灵感来创建独特的项目,可以查看我最好的 5 个数据科学作品集项目。
现实世界的数据通常是脏的,需要从外部来源收集,而不像 Kaggle 数据集那样已经结构化和预处理。
创建一个端到端的数据科学项目是个好主意,涉及通过 API 或网络抓取技术收集数据。
这向雇主展示了你的编程技能足够强大,可以处理现实世界的数据科学用例。
3. 你做的研究不够
许多求职者倾向于向每个开放的数据科学职位投递简历,认为这会增加他们找到工作的机会。
然而,这样做实际上会降低你的就业机会。你可能会收到一封通用的拒绝邮件,或者根本没有来自你申请公司的回复。
这是因为你在申请时没有考虑公司实际在寻找什么。每个空缺职位都是独特的,不同公司雇佣数据科学家的原因各不相同。
例如,一家电子商务公司可能会在其市场部门雇佣数据科学家,建立一个推荐系统,鼓励客户在网站上进行更多购买。
另一方面,一家科技公司可能会雇佣数据科学家来帮助他们的产品团队引入新功能并衡量产品成功。
尽管这两个职位的职位名称都是“数据科学家”,但它们的工作范围却不同。如果你用相同的简历申请每个职位而没有考虑公司的用例,这一点会表现出来。
相反,你应该这样做
选择几个你想申请的公司。阅读关于它们的信息,并对它们所在的行业进行一些研究。
然后,尝试创建与该行业相关的项目。这告诉招聘经理你会为他们增值,因为你已经做过类似他们用例的项目。
你甚至可以更进一步,联系那些已经在你想加入的公司工作的数据科学家。通过 LinkedIn 或电子邮件与他们联系,尝试了解他们参与的项目类型。
然后,你可以创建一些相关的项目,以使你的简历在其他申请者中脱颖而出。
4. 你没有发挥你的优势
几个月前,一位有志成为数据科学家的求职者联系了我。她希望能在数据科学领域找到一份工作,但未能成功。
我审阅了她的简历,并立即意识到问题所在。
这位申请者来自市场营销背景,只参加过一次数据科学 Bootcamp。
她在简历中突出的技能包括编程、机器学习和统计。
任何阅读到那份简历的雇主都能看出她在上述科目上的知识有限,因为从三个月的 Bootcamp 中能学到的知识是有限的。
她应该这样做
这位申请者的优势在于她的市场营销领域知识。
由于有市场营销背景,她应该创建一些与市场营销分析相关的项目。
大多数市场营销专家无法处理大量数据。他们缺乏技术和分析技能。
由于她已经拥有市场营销领域的专业知识,她只需掌握一些 Python、Excel 和 SQL 技能。然后,她应该使用这些工具创建一些市场营销数据分析项目,并将它们包含在她的作品集中。
这本来可以很容易地为她在分析领域找到一份工作。
然后,在该领域有一两年的经验后,她可以从数据分析转型为数据科学。
数据科学是一个需要应用统计知识以及强大的分析和编程能力的领域。对大多数人来说,没有正式的资格认证,很难立即获得数据科学的职位。
因此,首先进入门槛较低的领域,如数据工程或分析,然后逐渐过渡到数据科学,是有意义的。
我的数据科学作品集如何让我在该领域找到工作
我在没有硕士学位的情况下成功获得了多个数据科学领域的职位。
在我的第一次数据科学实习之后,我成为了同一公司的高级顾问,现在在一家跨国公司担任预测分析师。
我获得这些工作不是因为我是最符合条件的申请者,而是因为我展示了对这个领域的真正兴趣。雇主寻找的是对工作充满热情的申请者,因为技能可以随着时间的推移得到提升。
我创建了自己感兴趣的主题的数据科学项目,并撰写了相关的博客文章。我将我的作品发布在我的数据科学博客和作品集网站上。
然后,我在简历上包含了我的网站和博客链接。我在简历的“项目”部分突出了一些我最好的项目,并写了几行说明。
在获得我的第一个实际数据科学职位后,我积累了一些该领域的经验,这帮助我创建了更大、更有趣的项目。随着我继续在线发布我的工作,雇主们开始联系我进行 自由项目。
我被聘请来为公司收集大量数据,建立机器学习模型,进行市场研究,并参与自由写作项目。所有这些任务都在我的数据科学家日常工作之上。
建立强大的在线存在感是获得工作机会的关键。许多有才华的人因为雇主不知道在哪里找到他们而未被发现。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在 LinkedIn 上与她联系。
更多相关话题
数据科学作品集项目创意(可能让你找到工作,也可能不会)
原文:
www.kdnuggets.com/2021/10/data-science-portfolio-project-ideas.html
评论
有哪些数据科学作品集项目创意可以帮助你找到工作?
当雇主招聘数据科学家时,他们通常寻找的是能够为他们的业务创造收入和机会的人。仅仅了解编程、机器学习、统计学等是不够的,获取数据科学工作也需要一个作品集来展示你的数据科学技能。一个全面的数据科学作品集可以展示你所有的技能,使你有资格获得该职位。一个解释得当的数据科学作品集应展示你沟通、协作、推理数据、主动性以及技术技能的能力。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求

数据科学作品集的重要性
-
数据科学作品集比简历更有价值,因为你可以利用作品集记录你的项目、代码和数据集。
-
通过作品集,你可以展示你的数据科学技能。
-
作品集让你能够与其他专业人士建立联系。
-
它也会增加你获得数据科学工作的机会。

构建数据科学作品集最重要的部分是弄清楚要在作品集中添加什么。在你的数据科学作品集中,你需要在 GitHub、你的网站或博客上拥有一些项目。每个项目都应该结构清晰,以便招聘经理可以快速评估你的技能。在这篇博客中,我们将介绍一些应该出现在你作品集中的数据科学项目创意。
数据科学作品集项目创意
在将项目添加到你的作品集之前,你需要了解应该添加哪些数据科学项目以及需要避免哪些。这就是我们现在要讨论的数据科学作品集项目创意。
你应该添加那些与你角色相匹配的项目。例如,如果你打算申请分析师职位,构建使用数据清洗和讲故事的项目可能对你有用。
你的数据科学作品集应该包含 3-5 个项目,以展示你的能力:
-
沟通
-
与利益相关者和团队成员协作
-
拥有技术能力
-
理解数据
-
积极主动
-
拥有领域专业知识
数据清洗项目
你应该添加能够展示你数据清洗技能的项目。找到一个混乱的数据集,然后清理数据并进行基本分析。尝试寻找并处理一些非结构化数据,以提高你的技能。你还可以通过 API 或网页抓取收集自己的数据。
数据可视化和讲故事的项目
包含那些能够展示你技能的项目:
-
讲故事
-
提供真实的见解
-
说服行动
在这里你需要演示和解释你的代码在做什么,因此数据可视化和良好的沟通技巧非常有用。
构建端到端项目
构建端到端项目是向招聘经理展示你具备提取见解和向他人展示见解的技能的最佳方式。这表明你知道如何处理和处理数据,然后生成一些输出。
真实数据和网页抓取
你可以使用真实数据进行分析,而不是预先清理过的数据。数据收集、清洗、准备和转换是数据科学工作的真实部分。网页抓取也是获取有趣数据的好方法。
尝试选择有趣的分析
不论你发现什么,选择有趣的数据都是一个好主意。最好的作品集项目更注重处理有趣的数据,而不是展示复杂的建模。
数据科学作品集中不应包括的项目
建议你的作品集中不要包含常见项目。你需要避开最常见的项目创意来建立你的作品集。尝试提出一些真正能够使你与众不同的项目。
以下是一些最常见的项目,如果你在数据科学作品集中包含它们,可能会对你不利:
-
在泰坦尼克号数据集上进行生存分类。
-
MNIST 数据集上的数字分类。
-
使用虹膜数据集进行花卉物种分类。
这些是最常见的项目,可能对你帮助不大。你无法通过这些数据集与他人区分开来。你必须确保列出新颖的项目,以便从众多项目中脱颖而出。
具体数据来源的创意
一些很棒的数据来源包括 - Reddit、Tumblr、体育、维基百科、非营利组织、大学网站等。还有一些难度较大的来源,因为它们有严格的 API 政策 - Facebook、Yelp、Foursquare、LinkedIn 和 Craigslist。
一旦你有了一些有趣的项目可以添加到你的数据科学作品集中,你的下一步就是以最佳方式展示你的工作。为了增加你数据科学项目的权重,你可以使用 GitHub URL,撰写关于你成就的博客,并使用 BI 工具创建仪表盘。
原文。转载已获许可。
相关:
更多相关话题
使用数据科学预测和防止现实世界问题
原文:
www.kdnuggets.com/2021/04/data-science-predict-prevent-real-world-problems.html
评论
各行各业的人们越来越感兴趣于利用数据科学来了解改善决策的重要趋势。数据科学在预测事件和防止不良后果方面也发挥了重要作用。以下是一些发人深省的例子。

图片来自 Gerd Altmann Pixabay
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
1. 阻止网络攻击
许多行业现在都有广泛的在线存在。然而,定向网络攻击可以迅速阻碍整个公司,迫使员工暂时转向纸质记录,或处理文件或门户的访问丧失。
然而,数据科学可以帮助公司 IT 团队掌握并阻止威胁。例如,关联规则学习(ARL)基于某些特征来评估风险。它允许管理人员根据是否与过去的问题有共同点来预测可能的问题。
当数据科学帮助发现异常值时,预防也变得可能。假设系统发现一个来自外国的未知 IP 地址的人在深夜试图访问公司网络。它可以自动拒绝该个人的访问,直到人工进行更仔细的检查。
2. 改善执法政策
对有色人种的持续警察暴力问题导致了对执法部门进行重大变革的呼声。然而,大多数人不知道如何推进。
一个名为 Campaign Zero 的组织使用数据驱动的方法来提出未来警务的新政策框架。该组织的研究人员审查了 600 份警察工会合同。结果显示,84% 的文件包含至少一项条款,使得追究警察责任变得困难。
数据还显示哪些地点的警察部门与黑人男性死亡的案件相关联,这些案件的比例高于全国谋杀率。应用数据分析的另一种方法是评估哪些警官的不当行为或投诉事件高于平均水平。警察局长可以据此做出部门决策,以预测和防止不必要的暴力。
3. 保持输出水平高
人们特别感兴趣的是数据科学如何帮助那些成功几乎完全依赖于实现一致输出的行业。在这些情况下,意外事件或误导性的判断可能导致利润骤降和客户不满。
然而,数据科学也可以支持制造厂等设施中使用的预防性维护程序。研究表明,80% 的维护技术人员宁愿预防问题,也不愿意应对问题。当工厂领导使用连接传感器将数据传输到分析平台时,他们可以预测部件何时会故障或通过提醒相关人员关注不利趋势来防止问题发生。
在澳大利亚,政府官员认为数据科学可能是改善采矿行业结果的关键。寻找新的高质量矿床的困难意味着公司通常会进行成本高昂的勘探工作,但结果却不尽如人意。数据科学可以在这方面提供帮助,同时也能监控已建立矿井的通风系统。工人的安全性将得到提升,而公司则能避免过高的成本。
4. 帮助健身设施吸引客户
许多人都能与加入健身房并兑现健身承诺但随着时间推移变得不再热衷的情境产生共鸣。数据科学可以预测导致动机丧失的原因,并防止其发生。它还可以帮助为会员提供个性化的推荐。
一家名为 CIPIO 的风险投资科技公司帮助健身房老板将数据转化为可操作的策略。记录可能显示某位会员只参加了瑜伽课程,并且他们的出勤率逐渐变得不稳定。系统可以建议健身房工作人员通知该会员有关一个将瑜伽与短时间高强度心肺训练结合的课程。这个建议可能通过提供不同的机会来引起兴趣。
这样的工具还可以显示更广泛的趋势,例如大多数会员在哪几个月结束订阅。如果数据显示这种情况通常发生在三月,俱乐部可以提供额外的激励措施,以减少会员流失的可能性。它还可以预测对新特定类型课程的可能兴趣,例如适合老年人或受伤者的椅子锻炼。
5. 避免缺货情况
当消费者打算购买某物却发现货架空空时,他们自然会感到沮丧。这就是为什么许多零售商现在利用大数据来预测需求并防止库存短缺。数据分析系统可以查看社会趋势、天气模式、区域偏好和其他细节,以评估人们购买的可能性。
这种方法还可以将适当数量的商品发送到正确的位置,例如具有全国性网点的连锁店。数据可能显示在科罗拉多州对运动服的需求迅速增加,而在阿肯色州这种销售下降或保持平稳。零售商可以利用这些信息保持商店的适当库存。
一些大型节日,如英国的格拉斯顿伯里,也依赖数据科学来预测结果和防止失望。研究人员分析数据,以了解某一年是否可能有比平常更多或更少的降雨。这些信息帮助零售商知道应该带什么样的商品。相同的方法使供应商能够确定最受欢迎的食品和饮料,以便更好地准备。
数据科学具有丰富的潜力
大多数商业领袖知道了解不良事件整体可能性的的重要性,并尽力阻止它们发生。数据科学可以使这些目标更可管理,无论是在这里的例子中还是在其他地方。
虽然无法确定地预测未来,但数据科学可以追踪趋势并从中提取有意义的见解。无论行业或服务的受众如何,它都可以帮助商业决策者平稳运营行业,同时减少不良结果。
简介:德文·帕提达是一位大数据和技术作家,同时也是ReHack.com的主编。
相关内容:
-
预测分析在劳动行业的潜力
-
数据科学家开发了更快的方式来减少污染,减少温室气体排放
-
自动化如何改善数据科学家的角色
更多相关内容
数据科学预测未来
原文:
www.kdnuggets.com/2018/06/data-science-predicting-future.html
评论
数据科学中的预测分析依赖于解释性数据分析,这正是我们在前一篇文章中讨论的内容 - 数据科学的数据的什么、哪里和如何。我们讨论了数据科学中的数据,以及商业智能(BI)分析师如何利用它来解释过去。
事实上,一切都是相互关联的。一旦 BI 报告和仪表板准备好,并且从中提取出洞察,这些信息就成为预测未来值的基础。而这些预测的准确性取决于所使用的方法。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
回顾传统数据与大数据在数据科学中的区别,或参考我们关于数据科学的第一篇文章。
我们可以对预测分析及其方法做出类似的区分:传统数据科学方法与机器学习。一者主要处理传统数据,另一者则处理大数据。

数据科学中的传统预测方法:它们是什么?
传统的预测方法包括线性回归分析、逻辑回归分析、聚类分析、因子分析和时间序列等经典统计方法。这些方法的输出将输入到更复杂的机器学习分析中,但让我们先逐一回顾它们。
一个快速的旁注。数据科学行业中的一些人也将这些方法称为机器学习,但在本文中,机器学习指的是更新、更智能、更好的方法,如深度学习。

线性回归
在数据科学中,线性回归模型用于量化分析中不同变量之间的因果关系。比如房价与房屋大小、邻里环境和建造年份之间的关系。该模型计算系数,通过这些系数你可以预测一栋新房的价格,只要你有相关的信息。
逻辑回归
由于不可能将所有变量之间的关系表达为线性关系,数据科学利用如逻辑回归等方法来创建非线性模型。逻辑回归处理的是 0 和 1。例如,公司在筛选过程中应用逻辑回归算法来过滤求职者。如果算法估计一个潜在候选人在公司一年内表现良好的概率超过 50%,它会预测 1,即成功申请。否则,它会预测 0。
聚类分析
当数据中的观察值根据某些标准形成组时,就会应用这种探索性数据科学技术。聚类分析考虑到一些观察值具有相似性,并促进了发现新的重要预测因素,这些因素可能并不在数据的最初概念化中。
因子分析
如果聚类是关于将观察值分组,那么因子分析则是关于将特征分组。数据科学利用因子分析来降低问题的维度。例如,如果在一个 100 项的问卷中,每 10 个问题属于一个通用态度,因子分析将识别这 10 个因子,这些因子可以用于回归,从而提供更可解释的预测。数据科学中的许多技术都是这样集成的。
时间序列分析
时间序列是一种流行的方法,用于跟踪特定值随时间的发展。经济学和金融领域的专家使用它,因为他们的主题是股票价格和销售量——这些变量通常是相对于时间进行绘制的。
数据科学如何在传统预测方法中找到应用?
相应技术的应用范围极广;数据科学正在逐步进入越来越多的行业。尽管如此,有两个突出的领域值得讨论。
用户体验(UX)与数据科学
当公司推出新产品时,他们通常会设计测量客户对该产品态度的调查问卷。在 BI 团队生成仪表板后分析结果包括将观察值分组到不同的区域(例如地区),然后单独分析每个区域,以提取有意义的预测系数。这些操作的结果通常证实了结论,即产品在每个区域需要进行轻微但显著不同的调整,以最大化客户满意度。
预测销售量
这是时间序列分析发挥作用的类型。销售数据已被收集到某个日期,数据科学家希望了解下一销售周期或一年后可能发生的情况。他们应用数学和统计模型并进行多次模拟;这些模拟为分析师提供了未来的情景。这是数据科学的核心,因为基于这些情景,公司可以做出更好的预测并实施适当的策略。
谁使用传统的预测方法?
数据科学家。但请记住,这个头衔也适用于使用机器学习技术进行分析的人。许多工作在不同的方法论之间流动。
数据分析师则是准备高级分析类型的人,这些分析解释了已经出现的数据模式,并忽略了预测分析的基础部分。
机器学习和数据科学
机器学习是数据科学的最先进方法。这是完全正确的。
机器学习相对于任何传统数据科学技术的主要优势在于其核心存在算法。这些是计算机用来寻找尽可能适合数据的模型的方向。机器学习和传统数据科学方法之间的区别在于我们不给计算机指示如何找到模型;它采用算法并利用其方向自主学习如何找到所述模型。与传统数据科学不同,机器学习需要较少的人为干预。事实上,机器学习,尤其是深度学习算法非常复杂,以至于人类无法真正理解“内部”发生了什么。
明确来说,我们必须注意到,机器学习方法超越了传统方法。例如,监督学习有两个子类型——回归和分类(例如多项逻辑回归)。自然,许多传统方法也属于‘机器学习’这个总称。这是合乎逻辑的,因为线性回归是许多其他方法的基础,包括深度神经网络。
聚类和主成分分析(PCA),另一方面,是无监督学习算法(对于 PCA 的争论甚至比回归更激烈)。
无论如何,传统方法和机器学习的区别或多或少是主观的。有些人画了界限,有些人则没有。在我们的框架中,传统方法的简单性(某种程度上的优雅)是区分的主要原因。有关这一问题的有趣观点可以在这里探讨:www.kdnuggets.com/2017/06/regression-analysis-really-machine-learning.html
最后,深度学习相比传统方法计算开销非常大。为了给你一些背景,我见过一些线性回归是在纸上手动计算的工作。
对我来说,界限在于:你能否创建一个 CNN 并在合理的时间内在纸上解决它?实际上不能,所以这就是我所称之为机器学习的东西。
在数据科学中,机器学习是什么?
机器学习算法类似于一个试错过程,但特别之处在于每次试验至少和之前一次一样好。但请记住,为了学得好,机器必须经历数十万次试错,每次错误的频率逐渐减少。
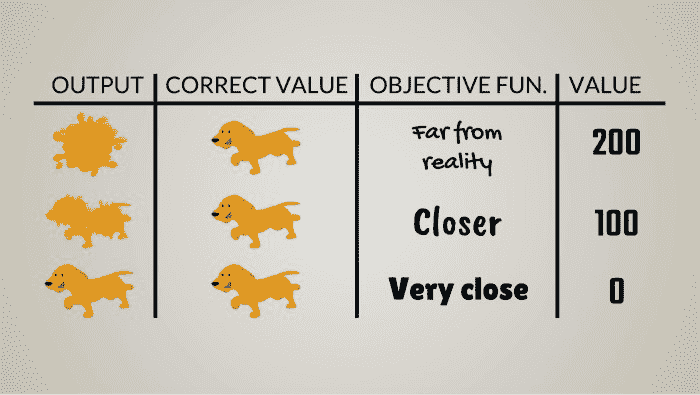
一旦训练完成,机器将能够将其所学到的复杂计算模型应用于新数据,仍然可以进行高度可靠的预测。
机器学习主要有三种类型:有监督学习、无监督学习和强化学习。
有监督学习
有监督学习依赖于使用标记数据。机器获得与正确答案相关的数据;如果机器的表现没有得到正确答案,优化算法会调整计算过程,计算机会进行另一次试验。请记住,通常机器一次处理 1000 个数据点。
支持向量机、神经网络、深度学习、随机森林模型和贝叶斯网络都是有监督学习的实例。
无监督学习
当数据过大,或者数据科学家在标记数据的资源上面临过多压力,或者他们完全不知道标签是什么时,数据科学便会诉诸于无监督学习。这包括将未标记的数据提供给机器并要求其从中提取见解。这通常会导致数据根据其属性被划分为特定的方式。换句话说,它被聚类了。
无监督学习在发现数据中的模式方面非常有效,特别是那些传统分析技术下人类可能会遗漏的东西。
数据科学通常结合使用有监督学习和无监督学习,其中无监督学习对数据进行标记,而有监督学习找到最佳模型以适应数据。其中一个例子是半监督学习。
强化学习
这是一种机器学习类型,其重点在于性能(如走路、看、阅读),而不是准确性。每当机器的表现优于之前时,它都会获得奖励;但如果表现不佳,优化算法不会调整计算。想象一下小狗学习命令。如果它执行命令,它会得到奖励;如果不执行命令,就得不到奖励。因为奖励很美味,所以狗会逐渐改进执行命令的能力。也就是说,与其最小化错误,强化学习更注重最大化奖励。
机器学习在数据科学和商业领域的应用在哪里?
欺诈检测
通过机器学习,特别是监督学习,银行可以利用历史数据,将交易标记为合法或欺诈,并训练模型以检测欺诈活动。当这些模型检测到任何微小的盗窃概率时,它们会标记交易,并实时阻止欺诈行为。
客户留存
借助机器学习算法,企业组织可以预测哪些客户可能会购买他们的商品。这意味着商店可以高效地提供折扣和‘个性化服务’,从而减少营销成本并最大化利润。几个突出的名字浮现在脑海:谷歌和亚马逊。
谁在数据科学中使用机器学习?
如上所述,数据科学家深度参与机器算法的设计,但舞台上还有另一位明星。
机器学习工程师。这是一个专门寻找将最先进的计算模型应用于解决复杂问题(如商业任务、数据科学任务、计算机视觉、自动驾驶汽车、机器人等)的专家。
数据科学中的编程语言和软件
处理数据和数据科学时需要两大类工具:编程语言和软件。
数据科学中的编程语言
掌握编程语言使数据科学家能够设计可以执行特定操作的程序。编程语言最大的优势在于我们可以重用创建的程序,以多次执行相同的操作。
R、Python 和 MATLAB,结合 SQL,覆盖了处理传统数据、商业智能和传统数据科学时使用的大部分工具。
R 和 Python 是所有数据科学子学科中最受欢迎的工具。它们最大的优势在于能够处理数据,并且与多种数据和数据科学软件平台集成。它们不仅适用于数学和统计计算;它们还具有很强的适应性。
SQL 是王者,尤其在处理关系型数据库管理系统时,因为它是为此目的专门创建的。SQL 在处理传统历史数据时最具优势,例如在准备 BI 分析时。
MATLAB 是数据科学中第四个不可或缺的工具。它非常适合处理数学函数或矩阵操作。
数据科学中的大数据当然借助 R 和 Python 来处理,但从事这一领域的人通常也精通其他语言,如 Java 或 Scala。这两种语言在合并来自多个来源的数据时非常有用。
除了上述提到的语言外,JavaScript、C 和 C++ 通常在涉及机器学习的数据科学分支中被使用。它们比 R 和 Python 更快,并提供更大的自由度。
数据科学中的软件
在数据科学中,软件或软件解决方案是为特定业务需求调整的工具。
Excel 是一个适用于多个类别的工具——传统数据、BI 和数据科学。类似地,SPSS 是一个非常著名的工具,用于处理传统数据和应用统计分析。
另一方面,Apache Hadoop、Apache Hbase 和 Mongo DB 是用于处理大数据的软件。
Power BI、SaS、Qlik 和尤其是 Tableau 是用于商业智能可视化的顶级软件示例。
在预测分析方面,EViews 主要用于处理计量经济学时间序列模型,而 Stata 用于学术统计和计量经济学研究,其中回归、聚类和因子分析等技术被不断应用。
这就是数据科学
数据科学是一个含糊的术语,涵盖了从处理数据——传统数据或大数据——到解释模式和预测行为的所有内容。数据科学通过传统方法如回归和聚类分析或通过非传统的机器学习技术来进行。
这是一个广阔的领域,我们希望你更接近理解它是多么包罗万象并与人类生活紧密交织。

简历:Iliya Valchanov 是 365 Data Science 的联合创始人。
相关内容:
更多相关内容
数据科学、预测分析在 2016 年的主要发展及 2017 年的关键趋势
原文:
www.kdnuggets.com/2016/12/data-science-predictive-analytics-main-developments-trends.html
评论我们最近向一些数据科学和预测分析领域的领先专家询问了他们对 2016 年最重要的发展以及他们对 2017 年关键趋势的期望。
另见之前的帖子 大数据:2016 年的主要发展和 2017 年的关键趋势。AI & 机器学习主要发展和关键趋势的总结将于下周发布。
一些主要的主题包括 2016 年美国总统选举中的民调失败、深度学习、物联网、对价值和投资回报率的更多关注,以及“大众”行业对预测分析的日益采纳。
这是专家对数据科学、预测分析在 2016 年的主要发展及 2017 年的关键趋势的看法。

Kirk D. Borne,BoozAllen 的首席数据科学家,天体物理学博士,顶级数据科学/大数据影响者。
在 2016 年,我看到几个重要的数据科学相关发展,包括
-
公民数据科学家的出现,并伴随着自助分析和数据科学工具的增长;
-
深度学习 被应用于各种用例(包括文本分析)
-
在客户呼叫中心和客户服务接触点出现了由人工智能驱动的聊天机器人;
-
组织对从大数据和数据科学中看到实际投资回报和效益的要求增加,更关注“价值证明”而不是“概念证明”;
-
机器智能成为广泛用例中流程、产品和技术的重要组成部分:联网汽车、物联网、智慧城市、制造业、供应链、处方性机器维护等。
2017 年,我们预计边缘分析用例将得到更大扩展:将机器学习嵌入传感器或靠近数据采集点 -- 机器学习可能通过 API 或在靠近数据采集器的处理器中调用,或集成到传感器芯片架构中。发现的模式、趋势、异常和新兴现象(BOI:行为兴趣)将促进许多领域更好更快的预测和处方分析应用:网络安全、数字营销、客户体验、医疗保健、紧急响应、发动机性能、自动驾驶车辆、制造业、供应链等。
汤姆·达文波特,Babson College 杰出教授,国际分析研究所联合创始人,以及德勤分析的高级顾问。
2016 年进展
-
分析团队的去中心化:经过一段时间的整合,组织开始将分析工作分散到业务部门和职能部门,在许多情况下尝试保留一定程度的企业协调。
-
专有与开源技术的组合: 许多大型公司正在利用专有和开源的分析及大数据技术—通常是在一个应用程序中组合使用。
-
认知技术的碎片化: 大型、单一的认知技术已被拆分成一系列单功能的 API,这些 API 可以组合成完整的系统。
-
模糊的定量角色: 定量分析师、数据科学家和认知应用开发者之间的区别变得越来越模糊;明确的角色和职位已成过去。
2017 年趋势
-
操作认知应用:认知技术将从“科学项目”转向操作应用。
-
模型假设的质疑: 2016 年总统选举中的民意调查失败将使更多管理者质疑分析模型背后的假设。
-
认知工具的分类: 更多组织将理解和分类可用的不同认知工具,并将其应用于适当的业务问题。
-
推动透明度: 战略性和受监管的机器学习应用的所有者将推动这些应用的更大透明度,并避免使用不够透明的算法。
塔玛拉·达尔,SAS 新兴技术总监。
今年的“大数据”事件是美国选举周期,因为它将大数据/数据科学/预测分析的讨论带到了公共领域。虽然这些不是大多数人使用的术语,但在美国,我们近距离体验了数据:它的角色、用途和误用、解读和误解,以及正确与错误的洞察。
随着数据继续渗透到我们职业和个人生活的每个方面,得益于物联网,私人和公共部门将受到压力,确保数据的收集、使用和分析是安全、可靠和伦理的。如果公司处理不当,他们将不复存在。
约翰·埃尔德,Elder Research 的创始人兼主席,美国最大的分析咨询公司。
一年前,《科学》杂志将“2015 年度最佳科学突破提名奖”授予了一项尝试复制 100 个顶级实验的研究。然而,研究人员只能复制 39 个实验。尽管如此,这也比流行病学领域的记录要好很多,后者中那些发表的医学“发现”仅有 5-35% 的准确率。我相信,大多数虚假相关的问题都源于糟糕的数据科学。用目标随机化等重采样程序替代过时的显著性公式,可以更好地校准随机结果出现的可能性,尤其是考虑到研究人员和挖掘软件所进行的大规模搜索。出版标准需要新的标准,但结果会更加可靠,节省大量资源,甚至挽救生命。
安东尼·戈德布鲁姆,Kaggle 的联合创始人兼首席执行官,Kaggle 是领先的数据科学竞赛平台。
像 Airbnb、Climate Corporation(现为孟山都)和 Opendoor 这样的公司是数据科学如何产生巨大影响的极佳例子。他们建立了强大的数据科学团队,影响了公司内部的决策。在 2017 年,我们将看到这些公司引领采用解决数据科学中一些重大痛点的工具和流程:特别是共享和协作数据科学工作流,并推动模型投入生产。2016 年,学术研究的热点话题从深度神经网络转向强化学习和生成模型。
在 2017 年,我们应该开始看到这些技术用于实际的商业用例。强化学习的一些有前景的领域包括算法交易和广告定向。
更多相关主题
-
2021 年最佳 ETL 工具
向“我们如何通过分析改善业务”。这意味着要投资于业务理解的开发,例如使用决策建模,以及将分析模型部署到生产系统中(以及所有相关的组织变革)。
相关内容:
-
大数据:2016 年的主要发展及 2017 年的关键趋势
-
2017 年数据科学趋势
-
Kobielus 对 2017 年数据科学的预测
相关主题更多信息
数据科学入门:初学者的基本概念
原文:
www.kdnuggets.com/2017/08/data-science-primer-basic-concepts-for-beginners.html

数据科学究竟是什么?
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
数据科学是一个多面向的学科,包括机器学习及其他分析过程、统计学及相关的数学分支,越来越多地借鉴高性能科学计算,最终目的是从数据中提取洞察,并利用这些新发现的信息讲述故事。
对这个多面向的学科感到陌生?不确定从哪里开始?这是一个针对数据科学新手的简短且不太技术化的主题概述,从有监督学习与无监督学习等基础知识到幂律分布和认知偏见的重要性。
数据科学基础:初学者的 3 个见解
对于数据科学初学者,3 个基本问题进行了概述:有监督学习与无监督学习、决策树剪枝,以及训练集与测试集。
数据科学基础:数据挖掘与统计学
当我第一次接触数据挖掘和机器学习时,我承认:我认为这是一种魔法。能做出准确的重大预测?这是巫术!然而,好奇心很快让你发现一切都是光明正大的,可靠的科学和统计方法承担着责任。
但这会导致短期内更多的问题。机器学习。数据挖掘。统计学。数据科学。 这些概念和术语有时重叠且显得重复。虽然有很多尝试去澄清这些(永远不安定的)不确定性,但这篇文章将探讨数据挖掘与统计学之间的关系。
数据科学基础:从数据中可以挖掘出什么类型的模式?
数据挖掘功能可以分为 4 个主要“问题”,即:分类和回归(合称为预测分析);聚类分析;频繁模式挖掘;以及异常值分析。我想你也可以用其他方式来拆分数据挖掘功能,比如关注算法、从监督学习与非监督学习开始等等。然而,这是一种合理且被接受的方法来识别数据挖掘可以完成的工作,因此这些问题每个都在下面进行讨论,重点是每个“问题”可以解决什么。
数据科学基础:集成学习者介绍
本文将概述 bagging、boosting 和 stacking,这些是最常用且最著名的基本集成方法。然而,它们并不是唯一的选择。随机森林是另一种集成学习器,它在一个预测模型中使用多个决策树,通常被忽视并被视为“常规”算法。还有其他选择有效算法的方法,下面也会讨论到。
数据科学基础:幂律与分布
也称为缩放律,幂律基本上意味着某些现象的少量发生是频繁或非常常见的,而相同现象的大量发生则是不频繁或非常罕见的;这些相对频率之间的确切关系在幂律分布中有所不同。幂律能够描述的自然发生和人为现象的广泛范围包括收入差距、某语言的词频、城市规模、网站规模、地震的震级、书籍销量排名和姓氏的受欢迎程度。
数据科学基础:认知偏误四个关键点
一些具体的认知偏误如何(并且确实会)在现实世界中干扰的例子包括:
相关:
-
机器学习算法:简明技术概述 - 第一部分
-
掌握 Python 机器学习的 7 个步骤
-
数据科学难题,解释
更多相关主题
数据科学过程生命周期
原文:
www.kdnuggets.com/2021/09/data-science-process-lifecycle.html
评论
由莉莉安·皮尔森(Lillian Pierson, P.E.),世界级数据领导者和企业家的导师,Data-Mania 首席执行官
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
如果你在执行数据项目,确保你的项目顺利进行并为公司带来利润可能会感受到很大的压力。
目前行业的数据项目失败率高达 80% (根据 Gartner 的数据),难怪数据专业人员感到压力山大。
这就是我认为数据行业如此错误的地方。
问题
数据和人工智能行业正在蓬勃发展。公司在数据项目上投资数百万 - 然而从上面的统计数据可以看出,通常无法从投入中获得真正的回报。
为什么会这样?
好吧,我们可以整天制定战略 - 但我观察到的一个主要问题,我相信这可能显著导致低回报,是数据工作者缺乏战略和业务知识。
你看,作为一名数据实施工作者,你可能对“如何做”非常着迷。你喜欢沉浸在细节中。你花时间构建复杂的模型,解决代码问题,开发技术解决方案 - 而且你热爱这份工作。
但我有一个重要的问题要问你。
你是否总是知道你为什么要这样做?
我曾经也是一名数据科学家。虽然现在我花时间在泰国苏梅岛发展我的数据创业公司 Data-Mania,但你曾经可以在我的办公隔间里找到我忙于构建模型。
我知道陷入细节中的难处。
当你过于专注于技术和编码时,很容易忽视实际的商业目标和愿景。你可能会开始原地踏步,跑题,并且整体上导致业务效率低下 - 通常却没有注意到。
更不用说,在没有清晰了解自己在公司愿景中的位置和没有前进策略的情况下执行项目,可能会令人感到沮丧和低效。没有人喜欢在看不到成果的情况下连续工作数小时。
数据专业人士感到迷茫并不意外。在我与一小组领导和企业主进行的2020 年数据调查中,87%的企业主报告说他们没有明确的、可重复的盈利数据项目的流程。
数据专业人士如何在没有强有力的领导和指导框架的情况下出色地完成工作?
我们需要确保作为数据实施人员,我们保持对最终目标的关注。作为领导者,我们需要确保数据实施人员从一开始就被纳入整体战略中。
如果你准备好确保你参与的数据项目始终保持在正轨上并且盈利,那么让我们深入探讨数据科学过程生命周期框架。
数据科学过程生命周期 - 它是什么
本质上,数据科学过程生命周期是一个可以用来管理数据实施的结构。
这使数据实施人员能够看到他们的角色首次进入项目整体图景的地方,并确保有一个连贯的管理结构。
为了开始,我首先想与大家分享微软的 Azure 数据科学过程生命周期,然后分享我认为我们如何改进它。
微软将他们的过程生命周期分为四个类别:
-
商业理解
-
数据获取和理解
-
建模
-
部署
这个框架在解决上述问题上迈出了巨大的一步:巨大的低效、离题项目、范围蔓延,等等。
这个过程中的一个完整节点——商业理解——确保技术和数据实施人员在实际尝试解决问题之前理解商业问题。
不过,我认为这个生命周期可以得到改进。
我认为这个过程没有充分强调技术人员试图解决的商业问题。通过这个框架,四个节点中的只有一个教育数据实施人员商业敏锐度。
在深入项目之前进行快速检查是一个好的起点,但还不够。
为什么需要更深入
数据实施人员需要对项目背后的大背景有透彻的理解。
这样考虑一下。
如果你正在执行数据项目,你就是那个密切关注现场的人。你能获得经理和高层可能无法得到的技术和数据解决方案的内部视角。
当你完全了解业务愿景并获得了更高层次的洞察时,你将能够发现之前可能忽视的东西。无论是业务问题解决效率低下,还是可能更早实现目标的策略,你都会开始从新的视角审视你的工作。
如何改进数据过程生命周期
我建议在这个框架上增加一个第五个职能单元,称之为数据策略单元。
如果你在心里想着,“等一下,我对数据策略一无所知。”
不要害怕。
我绝对不是建议数据实施人员要负责从零开始创建数据策略。相反,这将是一种自上而下的方法。
这个单元将确保所有技术和数据实施团队对业务问题、目标和愿景有深入的理解——以确保他们每天进行的工作是推动这一愿景的。
这个单元也将作为一个 sanity check。
作为一名有多年经验的注册工程师,我深知在项目中陷入细节是多么容易。你需要有一个框架来回归,以便知道如何做出决策。
通过实施这个过程,数据实施人员将不再在项目中感到迷茫,避免走岔路或将过多时间花费在对整体目标没有贡献的努力上。
让我们全面审视一下我‘全新升级’的框架,加入数据策略单元:
-
商业理解
-
数据策略
-
数据获取与理解
-
建模
-
部署
将这一部分添加到框架中,确实会成为一种双赢的局面。
数据实施人员将会从他们的项目中获得更大的成就感和满足感,因为他们保持正轨,并为业务创造更大的成功。
商业领导者实际上将从他们投入大量精力的数据项目和员工中获得真实的投资回报。
而整个数据行业将会繁荣发展!
简介:莉莲·皮尔森(Lillian Pierson, P.E.) 是一位首席执行官及数据领导者,致力于支持数据专业人士发展成为世界级的领导者和企业家。迄今为止,她已经帮助教育了超过 130 万名数据专业人士,涵盖人工智能和数据科学。莉莲与 Wiley & Sons 出版社合作出版了 6 本数据书籍,并与 LinkedIn Learning 合作开设了 5 门数据课程。她为全球各类组织提供支持,从联合国和国家地理到爱立信和沙特阿美,涵盖了所有领域。她是一位注册工程师,保持良好信誉。自 2007 年以来,她一直担任技术顾问,自 2018 年起成为数据业务导师。她偶尔在全球峰会和数据隐私与伦理论坛中志愿提供专业知识。
相关:
-
如何几乎在一夜之间从数据自由职业者转型为数据企业家
-
数据职业不是一刀切的!揭示你在数据领域理想角色的技巧
-
数据分析师与数据科学家的 7 大区别
更多相关话题
数据科学流程,重新发现
原文:
www.kdnuggets.com/2016/03/data-science-process-rediscovered.html
上周,KDnuggets 的 热门推文 是对 数据科学家的工作流程或过程是什么? 的 Quora 回答。这个回答由自称为“神经科学家转数据科学家”的 Ryan Fox Squire 撰写,采用了数据科学流程来描述这种工作流程。
数据科学流程
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
数据科学流程是一个用于处理数据科学任务的框架,由 哈佛大学 CS 109 的 Joe Blitzstein 和 Hanspeter Pfister 制定。CS 109 的目标,正如 Blitzstein 本人所述,是向学生介绍数据科学调查的整体过程,这一目标应能提供对框架本身的一些洞察。
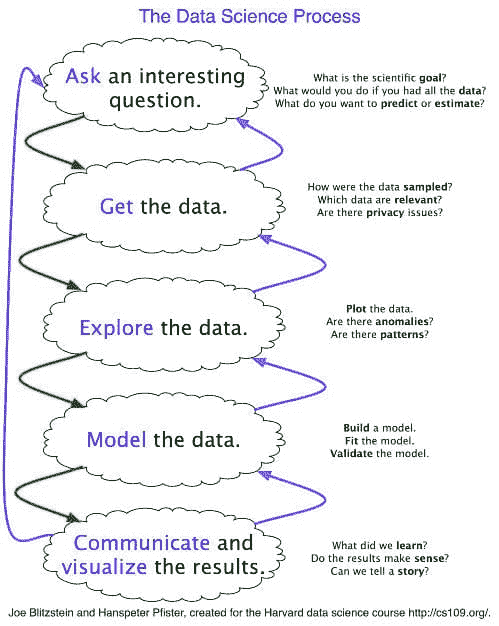
以下是 Blitzstein 和 Pfister 框架的一个示例应用,关于每个阶段的技能和工具,由 Ryan Fox Squire 在他的回答中提供:
第 1 阶段:提出问题
-
技能:科学、领域专长、好奇心
-
工具:你的大脑、与专家交流、经验
第 2 阶段:获取数据
-
技能:网络爬虫、数据清洗、查询数据库、计算机科学知识
-
工具:python, pandas
第 3 阶段:探索数据
-
技能:了解数据,提出假设,模式?异常?
-
工具:matplotlib, numpy, scipy, pandas, mrjob
第 4 阶段:建模数据
-
技能:回归、机器学习、验证、大数据
-
工具:scikits learn, pandas, mrjob, mapreduce
第 5 阶段:传达数据
-
技能:演讲、口语、视觉效果、写作
-
工具:matplotlib, adobe illustrator, powerpoint/keynote
Squire 然后(正确地)得出结论,数据科学工作流是一个非线性、迭代的过程,并且需要许多技能和工具来覆盖整个数据科学过程。Squire 还表示,他喜欢数据科学过程,因为它强调了提出问题以指导工作流的重要性,以及随着对数据的熟悉不断迭代问题和研究的重要性。
数据科学框架是一个创新的框架,用于解决数据科学问题。不是吗?
接下来,我们看看 CRISP-DM。
CRISP-DM
与 Blitzstein & Pfister 提出的数据科学过程相比,并且由 Squire 进一步阐述,我们快速查看了事实上的官方(但无疑已过时)的数据挖掘框架(已扩展到数据科学问题),即跨行业数据挖掘标准过程(CRISP-DM)。尽管该标准不再积极维护,它仍然是一个受欢迎的框架,用于指导数据科学项目。
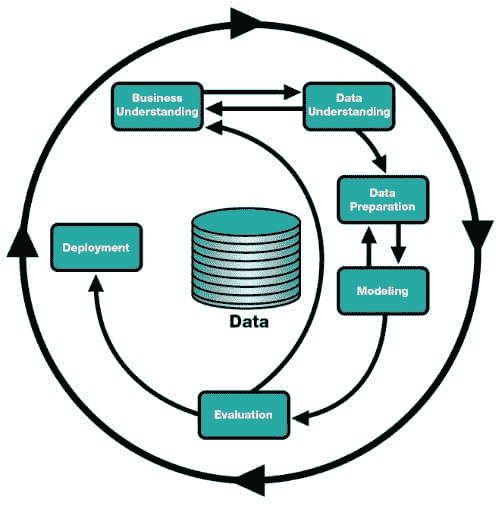
CRISP-DM 由以下步骤组成:
-
业务理解
-
数据理解
-
数据准备
-
建模
-
评估
-
部署
你可以在这些模型中看到相似之处:我们首先提出一个问题或寻求对某种特定现象的洞察,我们需要一些数据进行检查,这些数据必须以某种方式进行检查或准备,这些数据用于创建一个合适的模型,然后对生成的模型进行处理,无论是“部署”还是“传达”。尽管与 Blitzstein & Pfister 的数据科学过程相比,CRISP-DM 的工作流允许迭代性的问题解决,而且明显是非线性的。
就像标准本身不再维护一样,它的网站也没有维护。然而,你可以在其维基百科页面上获取有关 CRISP-DM 的更多信息。对于那些不熟悉 CRISP-DM 的人,这个视觉指南是一个很好的起点。
所以 CRISP-DM 显然是调查数据科学问题的基础框架,对吗?
KDD 过程
与 CRISP-DM 出现的同时,KDD 过程已经完成了开发。KDD(知识发现数据库)过程,由 Fayyad、Piatetsky-Shapiro 和 Smyth 提出,是一个以“应用特定的数据挖掘方法进行模式发现和提取”为核心的框架。该框架包含以下步骤:
-
选择
-
预处理
-
转换
-
数据挖掘
-
解释
如果你认为“数据挖掘”一词类似于之前框架中的“建模”一词,那么 KDD 过程也相似。请注意此模型的迭代性质。

讨论
重要的是要注意,这些并不是此领域唯一的框架;SEMMA(用于样本、探索、修改、建模和评估),来自 SAS,以及面向敏捷的游击分析都值得提及。还有许多公司和行业中各种数据科学团队和个人无疑使用的内部流程。
那么,数据科学过程是对 CRISP-DM 的全新解读,CRISP-DM 只是 KDD 的再加工,还是一个全新的独立框架?嗯,是的,也不是。
就像数据科学可以被视为数据挖掘的现代版本一样,数据科学过程和 CRISP-DM 可能被视为 KDD 过程的更新。需要明确的是,即使如此,也并不意味着它们变得不必要;对这些过程呈现方式的更新可能对新一代从更新的语言和“新”的框架视角来看待这些过程有所帮助,因此值得关注。
每一个JavaScript 库都值得吗?我不是这个领域的专家,但我会说可能不值得。虽然这并不是一个完美的类比,但基本观点是,在技术中,工具的使用经常会有所重叠。人们对新奇的事物和不同的东西很感兴趣,因此,即使新包装的术语与之前的术语完全相同或相对相似,也可以起到心理和实际的作用。
数据科学过程及其前身 CRISP-DM 基本上是 KDD 过程的再加工。这并非出于恶意或阴暗的含义;这并不是指责或指指点点。这只是一个简单的事实陈述:前面的东西影响后面的东西。最终,我们用于进行数据科学的任何框架或过程或步骤,只要它对我们有效并提供准确的结果,就值得使用。即使这恰好是数据科学过程,或者 CRISP-DM,或者 KDD 过程,或当你进入 Kaggle 比赛,或者你的老板让你对小部件数据进行聚类,或你尝试最新的深度学习研究论文时所采取的步骤。
马修·梅奥 (@mattmayo13) 是一位数据科学家,也是 KDnuggets 的主编,KDnuggets 是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他的联系方式是 editor1 at kdnuggets[dot]com。
更多相关主题
数据科学过程
评论
由 Springboard 提供。
在 Springboard,我们的数据学生经常问我们诸如“数据科学家做什么?”或者“数据科学的一天是什么样的?”之类的问题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
这些问题很棘手。答案可能因角色和公司而异。
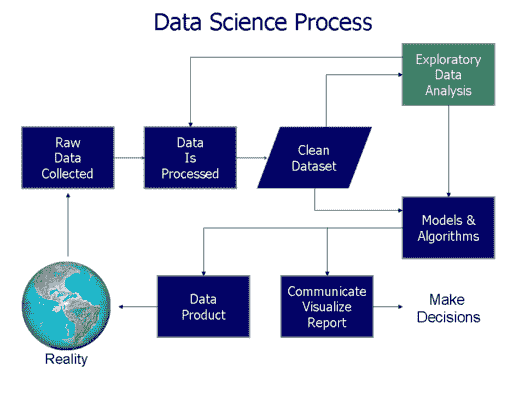
图 1: 数据科学过程,来源: 维基百科
所以我们问了 Raj Bandyopadhyay,Springboard 的数据科学教育总监,看他是否有更好的答案。
结果发现,Raj 使用了一个非常有用的框架,这不仅是理解数据科学家做什么的一种方式,也是一种拆解任何数据科学问题的备忘单。
Raj 将其称为“数据科学过程”,他在短短的 5 天电子邮件课程中详细阐述了这个过程。以下是他的洞察总结。
步骤 1: 确定问题
在你解决问题之前,首先要做的是准确地定义问题是什么。你需要能够将数据问题转化为可操作的内容。
你经常会从有问题的人那里得到模糊的信息。你需要培养将稀缺信息转化为可操作输出的直觉——并提出其他人没有问的问题。
比如说你在为公司销售副总裁解决问题。你应该从了解他们的目标和数据问题背后的原因开始。在你开始考虑解决方案之前,你需要和他们一起明确问题。
做这件事的一个好方法是提出正确的问题。
然后,你应该弄清楚销售流程的样子以及客户是谁。你需要尽可能多的背景信息,这样你的数字才能转化为洞察。
你应该提出以下问题:
-
谁是客户?
-
他们为什么购买我们的产品?
-
我们如何预测客户是否会购买我们的产品?
-
表现良好的细分市场和表现不佳的细分市场有什么不同?
-
如果我们不主动向这些群体销售产品,我们将损失多少资金?
针对你的问题,销售副总裁可能会透露他们想了解为什么某些客户群体的购买量低于预期。他们的最终目标可能是确定是否继续投资这些客户群体,或将其降级。你需要根据这个问题调整你的分析,并挖掘出能够支持任何结论的洞察。
在这个阶段结束时,你需要拥有解决问题所需的所有信息和背景。
步骤 2:收集解决问题所需的原始数据
一旦你定义了问题,你需要数据来提供转变问题的解决方案所需的洞察。这个过程涉及思考你需要什么数据,并找到获取这些数据的方法,无论是查询内部数据库还是购买外部数据集。
你可能会发现你的公司将所有销售数据存储在 CRM 或客户关系管理软件平台中。你可以将 CRM 数据导出为 CSV 文件以进行进一步分析。
步骤 3:处理数据以进行分析
现在你拥有了所有原始数据,你需要在进行任何分析之前对数据进行处理。数据往往会比较混乱,特别是当数据维护不善时。你可能会看到会破坏分析的错误:设为 null 的值实际上是零、重复值和缺失值。你需要仔细检查数据,以确保能够获得准确的洞察。
你需要检查以下常见错误:
-
缺失值,例如没有初次联系日期的客户
-
被破坏的值,例如无效条目
-
时区差异,可能你的数据库没有考虑到用户的不同时区
-
日期范围错误,例如会有不合理的日期,比如销售开始之前的注册数据
你需要查看文件行列的汇总,并抽取一些测试值以查看你的值是否合理。如果你发现有些值不合理,你需要删除这些数据或用默认值替换它们。你需要在这里运用直觉:如果客户没有初次联系日期,是否合理说没有初次联系日期?还是需要找销售副总裁询问是否有人有关于客户缺失的初次联系日期的数据?
一旦你完成了这些问题的处理和数据清理,你就准备好进行探索性数据分析(EDA)了。
步骤 4:探索数据
当你的数据清理完成后,你应该开始动手玩弄数据!
这里的难点不在于提出测试的想法,而在于提出可能转化为洞察的想法。你的数据科学项目有一个固定的截止日期(你的销售副总裁可能在急切等待你的分析结果!),因此你需要优先考虑你的问题。
你需要查看一些有趣的模式,这些模式可以帮助解释为什么该群体的销售减少。你可能会注意到他们在社交媒体上活动不多,很少有人拥有 Twitter 或 Facebook 账户。你还可能会发现他们大多数年龄比你的普通受众要大。由此你可以开始追踪可以更深入分析的模式。
第 5 步:进行深入分析
这个步骤是你需要运用你的统计、数学和技术知识,并利用所有数据科学工具来分析数据并找出每一个见解的地方。
在这种情况下,你可能需要创建一个预测模型,将你的表现不佳的群体与平均客户进行比较。你可能会发现年龄和社交媒体活动是预测谁会购买产品的重要因素。
如果你在构建问题时提出了许多正确的问题,你可能会意识到公司一直在大力投入社交媒体营销,信息传递的目标是年轻受众。你会知道某些人口统计群体更喜欢通过电话而非社交媒体进行联系。你开始看到产品的市场推广方式显著影响了销售:也许这个问题群体并不是无药可救的!将战术从社交媒体营销转变为更多的面对面互动,可能会对一切产生积极的变化。这是你必须向销售副总裁提出的。
你现在可以将所有这些定性见解与定量分析的数据结合起来,编织一个能促使人们行动的故事。
第 6 步:沟通分析结果
重要的是销售副总裁要理解你发现的见解为什么重要。最终,你被召唤来在整个数据科学过程中创造解决方案。有效沟通将是你提案能否转化为行动或无行动的关键。
你需要在这里编写一个引人入胜的故事,将你的数据与他们的知识结合起来。你可以从解释年长人群表现不佳的原因开始。你将这些与销售副总裁给出的答案和从数据中发现的见解结合起来。然后你提出解决问题的具体方案:我们可以将一些资源从社交媒体转移到个人电话中。你将所有这些结合成一个叙述,解决销售副总裁的困境:她现在清楚如何恢复销售并实现她的目标。
她现在准备根据你的提案采取行动。
在数据科学过程中,你的日常工作会因你所在的位置而有很大变化,你肯定会接到超出标准流程的任务!你也会经常同时处理不同的项目。
如果你希望系统地思考数据科学,了解这些步骤是很重要的,更何况如果你打算开始从事数据科学职业。
如果是这样的话,你可能会想查看我们免费的 40 页《数据科学入门指南》!
即使你并不打算进入这个领域,通过回到基础并彻底理解它们,你在数据科学领域的职业生涯也将得到改善。我们很欢迎你对数据科学过程的任何反馈。
相关内容:
-
数据科学与残疾
-
数据科学如何预测和减少不良出生结果
-
预测分析——一碗汤的故事
更多相关话题
数据科学即产品 – 为什么如此困难?
评论
由 Tad Slaff,Picnic Technologies 数据科学产品负责人。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在 Picnic,我们将自己视为科技对食品杂货的回应。从仅限应用程序的商店、20 分钟的配送窗口到及时供应链,技术和底层数据对 Picnic 的成长至关重要。
作为 Picnic 内的数据科学团队,我们的任务是将数据驱动的决策提升到一个新水平。我们负责构建具有智能、上下文和授权的自动化系统,以实现每年数千万欧元的业务影响决策。
然而,构建这些系统是困难的。而将它们投入生产并被业务使用则更为困难。让我们来看看在 Picnic 将我们的数据科学项目产品化需要什么,我们亲切地称之为‘数据科学即产品’。
为什么这如此困难?
2019 年 7 月的一项研究发现,87% 的数据科学项目未能投入生产。有许多原因被提及,包括缺乏领导支持、数据源孤岛和缺乏协作。除了这些问题,还有一些固有的方面使得数据科学和机器学习项目与其他软件开发有所不同。
首先,数据科学,尤其是机器学习,存在于概率和不确定性的世界中。一个基于机器学习的支付欺诈模型的典型输出可能是,‘该订单欺诈的概率为 73% +/- 5%,置信区间为 95%’。我们在业务方面的对口人员生活在确定的世界中,‘我们希望阻止所有欺诈订单’。在这两个世界之间进行转换并不是一项容易的任务。
此外,数据科学项目中存在的非线性(通常)不会出现在“传统”软件开发中。我们在开始构建模型之前不知道它的表现如何。可能需要一周、三个月,或者可能无法达到令人满意的性能水平。这使得制定一个包含时间表和业务希望看到的交付物的漂亮项目计划变得非常困难。
最后,将模型投入生产时,模型信任的重要性难以夸大。当与业务部门合作将模型生产化时,我们进入了他们是专家的领域。在许多情况下,我们希望自动化一个手动过程或替代一组精心设计的业务规则。虽然这些规则并不完美,但它们是由深刻理解业务的人所制定的。交付一个黑箱机器学习算法并告知业务它将取代他们当前的工作方式是一个具有挑战性的任务。最终,业务部门拥有模型试图自动化的任何过程的盈亏,我们作为数据科学家需要说服他们将生计交给我们的模型。
根据我们的经验,成功生产化模型涉及多个领域,可以通过以下因素实现:
-
用例选择
-
商业对齐
-
敏捷(数据科学)开发
用例选择
“我想如果你只有一把锤子,确实很容易把所有问题都当成钉子来处理。” — 亚伯拉罕·马斯洛
机器学习可以解决的问题宇宙是巨大的。你在客户成功、供应链、分销、金融等方面有无数的用例。考虑到 Picnic 美丽维护的数据仓库中高质量数据的获取如此简单,确定从哪里开始是很困难的。选择正确的用例对数据科学项目的成功至关重要。
那你打算如何决定选择哪个用例?
-
具有最大商业价值的那个?
-
“低垂的果实”来实现快速胜利?
-
与公司战略目标一致的那个?
在 Picnic,我们考虑了这些因素,但关键的决定因素归结为一件事:
我们对机器学习是否是解决这个问题的最佳方法有多大的信心?
(还记得我说过我们数据科学家习惯于概率思维吗?)
我们希望确保数据科学家的时间得到最有效的利用。假设有一个有吸引力的问题可以产生巨大的价值,但通过几个精心设计的业务规则可以获得 80%的价值。让数据科学团队花几个月时间来获得额外的 10%是否是资源的最佳利用?可能不是。
使用我们的数据科学禅原则作为指导,我们可以将用例选择标准分解为几个组成部分:
-
我们是否有足够的干净、高质量的数据来建模这个问题?
-
是否有一个明确的客观标准(或损失函数)供我们优化?
-
商业部门是否准备好让这个过程自动化?
-
它如何融入生产系统?该产品团队是否有足够的带宽来实施它?
-
是否有关于成功实施机器学习以解决此类问题的案例研究、研究论文或其他资源?
-
是否有任何偏见或伦理问题需要解决?
如果对这些问题有任何疑虑,我们将重新考虑是否这是我们团队应接手的最佳项目。
无论你有多少资源可以投入到问题上,如果没有正确的使用案例,成功的机会也很低。
业务对齐
如果首先记录下所有未知因素,完美的项目计划是可能实现的。——比尔·兰利
确保项目目标的一致性看起来既简单又明显。商业部门希望更准确的预测。你相信你可以超越现有系统。问题出在哪里?
问题在于,这不仅仅是关于模型的性能。
假设你构建了一个出色的模型,并设置了一个每日执行的任务。结果可能是商业部门需要能够在一天内更新他们的预测。突然之间,你需要一个实时服务。你的模型在大多数文章/段落/地区上表现良好,但这个季度有一个新产品推出。现在你的模型在没有历史数据的情况下做出预测(冷启动问题(cold start problem)说你好)。
机器学习项目需要商业部门对系统的运作有一定的理解。他们需要了解机器学习模型的固有优势和劣势,如何处理边界情况,以及使用了哪些特征。
除此之外,你需要知道模型将如何使用。预期的输出是什么?预测将如何被消耗?如果模型无法运行,会有备用机制吗?在开始开发之前知道这些问题的答案可以避免许多头疼的问题、紧张的讨论和熬夜的重做工作。
模型信任的问题再次出现。如果商业部门不信任你的模型输出怎么办?
你可以展示所有的 ROC 曲线、F1 分数和测试集性能,但如果模型做出的前几次预测恰好是错误的,它会有机会恢复吗?之前存在的基本业务规则并不完美,但商业部门知道哪些情况它工作良好,哪些情况不工作,然后可以相应地进行干预。你的模型(希望)具有操作影响,如果商业部门不信任它们,那么它们将不会被使用。就是这么简单。
关于模型信任的讨论虽然不舒服,但却至关重要。你需要事先了解业务需要什么条件才能在生产中使用你的模型。至少,双方需要决定并签署一个包含性能指标的评估期。
数据科学家与业务部门之间期望的差异导致了许多数据科学项目的终结。对话需要在花费几个月的工作之前进行。你的模型的生命周期可能取决于此。
敏捷数据科学开发或……
MVP 优于 POC。
“当你在筹集资金时,它是 AI。当你在招聘时,它是 ML。当你在实施时,它是线性回归。当你在调试时,它是 printf()。” — 巴伦·施瓦茨
*  *
*
德雷克同意,MVP 优于 POC。
敏捷开发已成为软件开发的实际标准,但尚未进入数据科学领域。如今的数据科学项目往往采取“建好了他们就会来”的心态。数据科学家与业务部门讨论问题,决定优化的指标,并询问如何获取数据。然后他们离开,花费几个月时间构建一个美观且稳健的模型,并展示最终产品。然后……
…它不会被使用。敏捷开发有效的核心原因同样适用于数据科学:它需要以客户为中心。
有效的方法是跳过概念验证(POC),因为它往往停留在数据科学家的笔记本电脑上,转而专注于创建最小可行产品(MVP)。
对于最小可行产品(MVP),目标是尽可能快地构建一个端到端的解决方案。你构建数据管道,从一个基本的基准模型(也称为线性回归或逻辑回归)开始,并向最终用户展示预测。一个实际的例子可以参见我们如何利用机器学习找到最佳投放时间。
这成为软件开发实际标准的原因同样适用于机器学习。我们正在尽力遵循敏捷宣言的核心原则:
专注于可工作的软件
- 不要花时间对可能永远不会被使用的模型进行微调。将时间用于构建一个可行的
客户协作
- 大幅缩短市场时间,使你的‘客户’看到的输出与更复杂的系统相似。你可以从那里进行迭代和改进。
响应变化
- 在第二周而不是第二季度发现什么有效更为合适。也许你计划整合的内部系统没有办法暴露你需要的数据。对需求保持灵活,尽早并频繁地交付可工作的代码。
数据科学项目的难点不在于建模。难点在于其他所有事情。通过专注于 MVP,你可以更快地将工作系统投入生产,输出预测。你会更早发现问题,并在几周内为客户提供一个崭新的模型,而不是几个月。
最终,我们的目标不是为了构建模型而构建模型。我们在构建一个包含模型的产品。我们可以借鉴数十年的产品开发经验来实现这一目标。
结论
基于机器学习的产品开发并不容易。你需要处理所有的软件开发组件,同时核心还需应对机器学习的复杂性。这是一个新领域,没有现成的蓝图来指导如何做好它。通过确保你选择了正确的用例,与业务对齐,并遵循经过验证的敏捷软件开发实践,你可以为成功做好准备。
在 Picnic,技术、数据和机器学习是我们的核心。我们拥有一支极具才华的数据科学家团队,一个可扩展的自助数据科学平台,以及业务部门的全力支持,以将我们的模型投入生产。
原文。经许可转载。
相关内容:
更多相关内容
数据科学编程语言及其使用时机
原文:
www.kdnuggets.com/2022/02/data-science-programming-languages.html
使用编程语言是数据科学不可或缺的。数据科学的广泛性和可用编程语言的数量使得决定使用哪种语言以及何时使用变得相当困难。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
我的办法是向你展示编程在数据科学中最常见的使用案例。从那里开始,我将介绍最适合特定使用案例的编程语言。当然,我不能分析所有的编程语言,我需要缩小范围。
我之所以这样做,多亏了一项特定的调查。
编程语言在数据科学中的使用时机
当谈到编程语言的受欢迎程度时,我们将使用 Anaconda(Python 的发行版)2021 年的调查。
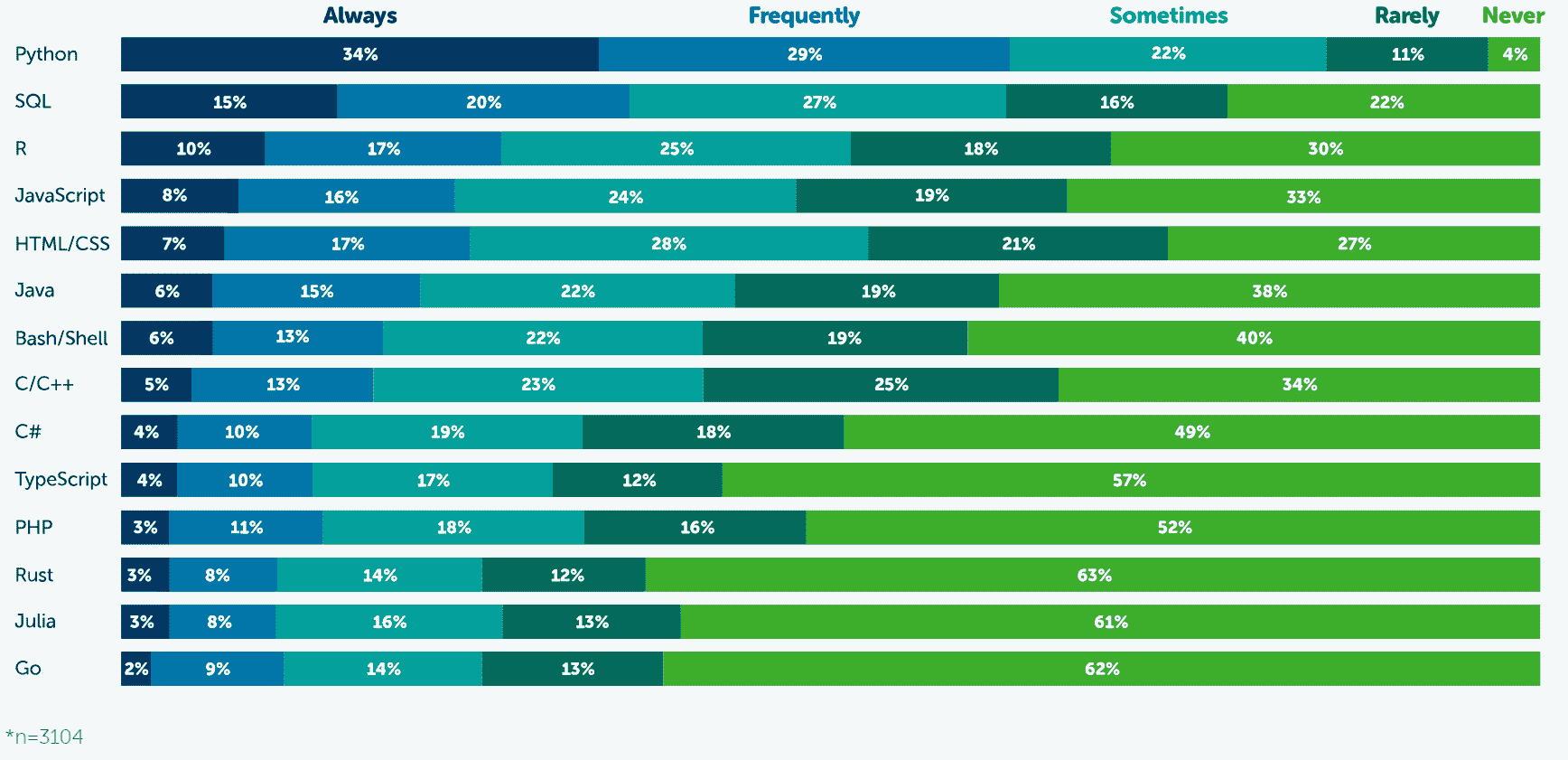
来源:www.anaconda.com/state-of-data-science-2021
调查显示了最受欢迎的数据科学编程语言的使用频率。样本量为 3,104,比较安全地得出结论,这些编程语言反映了数据科学中的受欢迎程度。一些其他的列表包含了其他语言,但我们将坚持这个列表来分析每一种语言。
问题是,这些编程语言在数据科学中什么时候使用?如果你不知道什么时候使用它,告诉你‘使用这种语言’是没有意义的。
数据科学家的工作通常包括以下阶段:
-
数据提取和处理
-
统计分析
-
数据可视化
-
建模/机器学习(ML)
-
模型部署
-
自动化
数据提取和处理
数据提取意味着从数据库或其他来源获取数据。
一旦获取数据,你需要对其进行清理,以确保你拥有正确和合适的数据。通过清理,你可以去除错误、不一致、重复的数据,替换不完整的数据,并相应地格式化数据。
数据清理之后是数据处理。这意味着你要修改数据,使其更易读和有条理。
希望你不会认为应该手动完成这些任务。有一些编程语言非常适合执行这些任务。它们是:
-
SQL
-
Python
-
R
这是它们擅长的概述:

SQL
优点: SQL 的主要目的是处理数据和数据库。因此,它在数据提取和操作(在一定程度上)方面非常理想,特别是在处理关系型数据库时。数据检索速度快,相对简单。语法也经过标准化。
缺点: 数据操作相对有限
Python
优点: 由于内置的分析工具,非常适合处理数据。它是一个开源语言,因此其受欢迎程度和活跃的社区为你提供了大量的分析库。易于使用,复杂的数据操作可以用更少的代码完成。
缺点: 不适合数据提取,但其库在一定程度上弥补了这一不足。
R
优点: 由数学家和数据科学家为数学家和数据科学家设计。再一次,开源语言为数据操作提供了大量的 R 包。它是为处理大量数据而设计的。
缺点: 尽管可以在 R 中提取数据,但由于其复杂性和相对较慢,适用性不强。
统计分析
数据科学周期的下一阶段是统计分析。一旦你收集了数据并根据需要进行了操作,你需要对其进行分析。这样做的目的是在数据中发现模式,然后转化为洞察、预测和报告。
最适合的编程语言是:
-
R
-
Python
-
Java
-
JavaScript
-
Julia
这是它们在统计分析方面表现的概述:

R
优点: 统计分析是 R 的主要目的,因此它在这方面表现出色。它提供了大量的数据分析工具,用于进行复杂的统计计算。可以处理大量的数据。
缺点: 作为一种相对较老的语言,有时可能会很慢,并需要更多的代码行。
Python
优点: 其数据分析库使其在大多数统计分析中表现出色。库设计用于处理高数据量。比 R 更快。
缺点: 在统计分析方面的库数量不如 R 多。
Java
优点: Swift 编程语言;比 R 和 Python 都要快。它可以在没有任何特殊软件的情况下运行,只需 Java 虚拟机(JVM)。这还提供了与许多分析框架一起工作的机会,例如 Kafka、Hadoop、Hive 或 Apache Spark,它们都在 JVM 上运行。以下是一些有关 Java 统计的建议以及使用哪些库。
缺点: 不像 R 那样适合高强度的统计分析。
JavaScript
优点: 它提供了一些统计分析的可能性。结合其可以在任何计算机(有 JVM)上运行的能力,它可能适合一些较轻的统计分析。你可以在Stack Overflow 上找到一些 JavaScript 库的推荐。
缺点: 尽管有一些用于统计分析的库,但它们的可能性范围相对有限,尤其是与 R 相比。
Julia
优点: 其语法简单,数学操作的书写方式非常接近现实世界。它也比 Python 快。它可以调用其他编程语言的库,例如 Python 的。对于描述性统计,以下是Julia 的标准统计库和其他库,这里是一些附加库和有用示例。如果你需要概率统计,Julia 也有大量相关包,这显示统计确实是这个编程语言的核心。甚至有一本关于 Julia 统计的书。
缺点: 相对不那么流行,导致社区和库的范围较小。也不像 R 那样适合高强度的统计分析。
数据可视化
一旦你分析了数据,你需要展示你的见解。你通常需要向非技术人员展示,因此不能指望他们查看无限的数据、表格和计算。你希望他们理解你,而最简单的方法就是创建一些吸引人的数据可视化,以便一目了然地解释一切(几乎)。
你会希望使用擅长此类工作的编程语言:
-
R
-
Python
-
JavaScript
-
Julia
它们在数据可视化中的表现如下:
R
优点: 数据可视化是统计分析的延伸,这个统计编程语言在这方面也表现出色。提供了大量的可视化包。它们允许在小空间内展示非常有信息量的可视化。允许使用地理地图。
缺点: -
Python
优点: 对数据可视化也很有帮助,因为它提供了大量用于此目的的库。
缺点: 它提供的库仍然比 R 的要弱一些。
JavaScript
优点: 提供了大量的数据可视化库,这使得它非常适合此目的。再者,它可以在任何机器上运行,因此你不需要额外的软件来创建或展示你的见解。
缺点: -
Julia
优点: 对数据可视化相对较好,因为它提供了一些用于此目的的包。
缺点: 仍然是相对较新的语言,因此库的数量不像 Python 那样庞大。
建模/机器学习(ML)
现在你已经准备好了数据并进行分析,一切都准备好构建模型了。这包括选择建模技术,然后编写算法。编写算法是机器学习中的一个关键部分;模型训练的效果取决于它。是的,你编写算法的能力决定了模型在发现模式和提供业务预测方面的表现。
那么哪些数据科学编程语言在这个任务中能为你提供最多的帮助呢?它们是:
-
Python
-
R
-
Java/JavaScript
-
C/C++
-
Julia
-
TypeScript
我尝试根据优缺点评估它们的适用性:

Python
优点: Python 的简洁性使得编写复杂的机器学习代码变得容易。由于其库的灵活性也很高。说到库,有很多(而且很强大的!)库可以帮助你获得非常高质量的机器学习。
缺点: 无。
R
优点: 特别适合那些编程能力稍逊的专家。其强大的计算能力非常适合复杂的机器学习。还提供了大量优秀的机器学习专用包。
缺点: 可能会很慢。不太适合真正硬核的神经网络。同时不太适合部署到生产环境中。
Java/JavaScript
优点: 非常快速(比 Python 快)且在重负载数据处理方面可靠。有高质量的框架支持不同的机器学习技术和算法。
缺点: 不像 Python 那样灵活。
C/C++
优点: 代码易于机器读取。提供了内存管理和其他性能参数的可能性。由于其速度以及许多机器学习库都是用 C/C++编写的(甚至 Python 库也是),使其非常适合复杂的机器学习用例。非常适合程序员。这里有一些相当好的Java、JavaScript 和 C++的机器学习库推荐。
缺点: 它的优点也是它的陷阱。它是一种代码密集型编程语言,对于那些编码经验较少的人来说,可能比较难以学习。此外,调试复杂算法通常也非常困难。不够灵活,因此如果仍在实验参数,效果不佳。
Julia
优点: 为机器学习计算和统计任务开发。对于没有重编程背景的用户来说,它非常快速且易于学习。可能拥有最好的机器学习、线性代数、微分方程、数学优化、并行和分布式计算以及自动微分库。非常多才多艺,这意味着其代码可以在 C、Python 和 R 中执行。
缺点: 仍然相对较小的社区在贡献其库。
TypeScript
优点: 它是 JavaScript 的超集。对于那些已经熟悉 JavaScript 并希望摆脱一些缺陷的用户来说非常理想。拥有强大的机器学习库,例如 Kalimdor、TensorFlow Deep Playground、R.js、Machinelearn.js、Machine-learning 或 ML Classifier UI。它运行在浏览器或 JS 引擎上,因此非常适合基于浏览器的机器学习。其静态类型选项允许在模型部署之前发现代码中的错误。
缺点: 相较于 JavaScript,需要更多的代码行。因此,其性能可能较慢。
模型部署
任何数据科学家的重要任务之一是部署他们创建的模型。这是模型和你之前工作的真正影响所在。它不再是玩笑,因为部署模型意味着它进入了现有业务环境的生产。这意味着真实的人将使用它,它在提供洞察方面的表现将极大地影响业务决策和现实世界。
要让模型供人们使用,你必须创建一些应用程序(无论是移动端还是基于 Web 的)、桌面软件或 API。一些最佳的数据科学编程语言包括:
-
Python
-
Java
-
JavaScript
-
C#
-
HTML/CSS
-
PHP
-
Rust
-
GoLang
他们执行任务的方式如下:
Python
优点: 作为一种通用编程语言,毫无疑问,它非常适合部署模型。它尤其适合软件开发和构建基于 Web 的应用程序。其普遍的优势是有大量优质的库。这也使它在这里表现出色,Django、Pyramid、TurboGears 和 Flask 是一些推荐的库。它非常富有表现力、灵活且易于使用,使得创建应用程序更快。由于代码逐行执行,代码调试变得更加容易,错误发生时不会继续执行代码。Python 的主要优势之一是其可移植性,这意味着它可以在多个平台上完美运行。
缺点: 可能比其他编程语言运行速度较慢。它几乎完全不适合移动应用开发。它使用了大量的内存,因此在同时执行多个内存消耗较大的任务时应当小心。由 Python 构建的应用程序需要详细的测试,因为它是一种动态类型语言,意味着变量可以改变其数据类型。
Java
优点: 仍然是开发圈中广泛使用的编程语言。它适用于任何类型的软件,无论是移动应用还是基于网页的应用。其中一个原因肯定是它的跨平台性,这意味着除了 JVM 外不需要额外的软件。在实践中,你只需编写一次代码,然后可以在任何环境中运行。它的语法相当简单,这使得部署模型更为方便。此外,它是面向对象的程序;代码可以很容易地升级、适应和重用。Java 的主要优势之一是其相对较高的安全性,因为它没有指针并且有一个安全管理器。这使得在安全性是主要关注点之一时,Java 被高度推荐。
缺点: 速度可能是它的主要缺点。Java 也比较消耗内存,且在运行垃圾回收器时,可能会降低性能。此外,它也不太适合轻松地构建美观且用户友好的图形界面。
JavaScript
优点: 其主要优点之一是速度。作为一种解释型语言,不需要编译,因此运行速度较快。此外,它是一种客户端脚本,这意味着它在浏览器上运行,无需连接到服务器,这有助于提升速度。它与其他编程语言配合良好,使得在更大的系统中部署模型变得合适。语言相当简单,使得部署模型和代码调试更加容易。具有很好的界面,使得创建吸引人且实用的图形用户界面变得容易。
缺点: 由于用户可以看到代码,因此存在安全性问题。
C#
优点: 作为一种通用编程语言,与 Python 类似,它在构建各种类型的应用程序时非常灵活,适用于不同平台。作为一种基于面向对象原则的语言(例如 Java),这自然使得构建应用程序变得更容易,测试和升级也需要更少的代码行数。这也得益于 C# 的类型安全性,意味着变量在代码中不能更改其数据类型。它具有强大的内存备份,因此应该不会有内存泄漏问题。
缺点: 速度 - 当用 C# 编写时,应用程序有时可能运行较慢。它需要 .NET 平台以实现跨平台灵活性。
HTML/CSS
优点: HTML 适用于专门用于显示网页的基于网页的应用程序。每个浏览器都支持它,并且由于它在浏览器中运行,因此不需要安装额外的软件。它是一种非常简单的语言,这使得它非常快速。它还允许使用模板,使数据科学家可以轻松地将其模型部署到网页应用中。
缺点: 单独使用时,通常只适用于基本的网页应用。这可以通过与 CSS 结合使用来改进。HTML 的安全性也相当有限,如果安全性是你的主要关注点之一,则不推荐使用。通常需要与其他编程语言结合使用以创建动态网页。
PHP
优点: 这是一种服务器端脚本语言,这意味着应用程序不是在网页浏览器上运行,而是在网页服务器上运行。这一关键特性使其非常适合创建互动和动态的网站及应用程序。它也很容易嵌入 HTML 代码。因此,PHP 不依赖于应用程序运行的平台。由于使用自己的内存,它的运行速度较快。不需要大量的代码,因此制作复杂的网页应用变得比较容易,尤其是在调试时。PHP 是一种非常稳定的编程语言,确保你的模型功能得到充分转化为用户体验。它还拥有广泛的库,增强了数据展示,并能轻松连接到数据库,使其非常适合展示模型的工作。值得一提的是,PHP 的语法与 C 语法相同,因此如果你有 C 语言的知识,将会很容易使用它。
缺点: 如果你担心安全性,PHP 可能会有所不足。然而,它的社区多年来通过提供各种工具和框架来解决这个问题。这种编程语言可能不适合大型应用或轻松使用多个功能,可能导致性能不佳。由于 PHP 不够模块化,也可能会很难维护和升级。由于缺乏调试工具,调试也相当困难。
Rust
优点: Rust 设计时考虑了应用的安全性和性能。难怪这两个领域是这种数据科学编程语言的亮点。它适合开发桌面程序或移动应用,但主要是为了制作基于网页的应用。支持 C 和 C++,所以如果你有这些编程语言的经验,你也可以利用 Rust 相比之下的优势,并与其他语言轻松集成。它在创建应用程序的简易性(动态类型的优点)和代码可维护性(静态类型的优点)之间取得了平衡。Rust 也被认为是最安全的编程语言之一。它提供了对已部署应用的低级控制,因此你可以真正优化其性能。
缺点: 这是一个相对较新的语言,因此其库可能不如其他一些语言的库那么好。底层控制使得它更适合用于后端而非前端。
GoLang
优点: 其主要优势是稳定性。它基于 C 语言,因此如果你有 C 语言经验,你可以轻松学习它并受益于其优势。该语言非常快,因为它是编译语言。它配备了大量旨在简化编码的工具,这使得它非常适合快速构建应用程序。它是一种非常可扩展的语言,非常适合在较长时间内部署模型并进一步开发。GoLang 的标准库提供了测试支持。如果你想构建一个稍微复杂一点的应用程序,GoLang 可以成为一个不错的选择。它非常擅长处理多任务。作为一种新语言,它被设计为与云计算紧密配合。
缺点: 作为编译语言及其所带来的速度意味着你可能需要写相对较多的代码行来完成即使是比较简单的任务。这是其简单性的权衡,因此该语言偶尔不适合 hardcore 程序员。
自动化
另一个任务,涉及并影响所有其他任务,在数据科学中越来越重要的是自动化。这是一个包罗万象的任务,旨在自动化数据科学家的手动工作。这是因为许多数据科学家的工作包括手动、重复和繁琐的工作,他们可以更有目的地使用这些时间。
然而,并不是所有的数据科学家工作都可以被自动化。目前,只有机器学习可以完全自动化。提取和处理数据、数据分析及其可视化只能部分自动化。模型部署也是如此。
这并不意味着你不能尝试至少自动化你工作的部分。我将看看一些最好的数据科学编程语言:
-
Python
-
Bash/Shell
-
Java
-
C#
-
Julia
-
R
看看它们的排名:
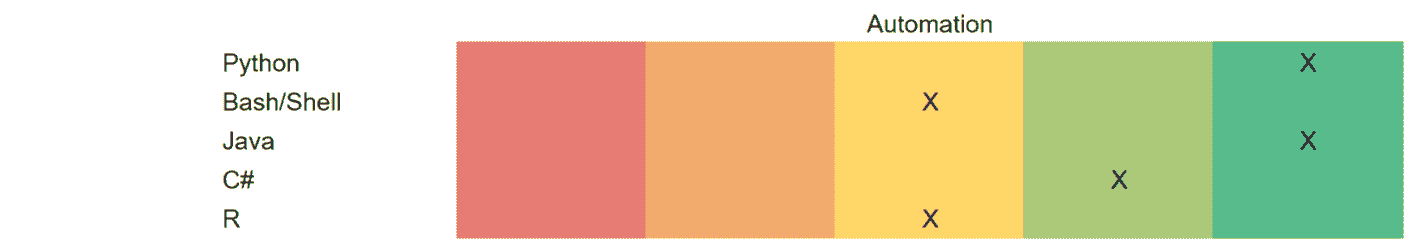
Python
优点: 它是一种通用语言,因此也适用于自动化。使 Python 在数据科学中表现良好的特点,同样使其适用于自动化。它的简单性、表现力以及为机器学习和自动化提供的大量极其可靠的库是其主要优势。它们带来了灵活性,而 Python 的平台独立性只会增加这一点。它适合于自动化数据科学工作的所有部分。这里是 一些关于如何使用 Python 进行自动化的建议。
缺点: 不太适合移动平台。
Bash/Shell
优点: 为自动化 Linux 上的重复任务而创建(它也可以在 Windows 10 上运行),毫无疑问,它非常适合自动化。它的主要用途是数据提取和数据科学中的数据处理,这使它非常适合构建数据管道。如果你在 Medium 上,Towards Data Science 博客有一篇关于使用 Bash 自动化枯燥工作的文章。
缺点: 不适合自动化数据科学家工作的其他部分。作为一种通用自动化语言,它的使用也不那么普遍。
Java
优点: 在 Python 缺乏的地方,Java 表现出色:它非常适合移动应用程序。这一点并不令人惊讶。Java 作为一种脚本语言,专门设计用于自动化任务执行。它的代码也非常容易更改和更新,非常适合工作流参数经常变化的动态环境。支持帮助自动化的框架。此外,它可以在任何安装了 JVM 的机器上运行,并且非常快速。这里有一些你可以玩耍并与 Java 代码集成的 ETL 工具。
缺点: 缺乏灵活性。
C#
优点: 一般来说,它是最好的自动化语言之一,特别是如果你想自动化构建模型。为什么?因为有一个模型构建器,正如微软文档所说,它“使用自动化机器学习来探索不同的机器学习算法和设置”。为此,它使用 C#代码。
缺点: 它依赖于平台。
R
优点: 作为统计分析和可视化的王者之一,这是一个完美的工具来自动化数据科学过程中的这部分。特别是当过程涉及到大量统计分析时,其质量比速度更为重要。如果你对自动化探索性数据分析感兴趣,这里有一些可能对你有帮助的 R 包。
缺点: 如果速度至关重要,那么 R 可能不如其他数据科学编程语言好。作为一种整体自动化语言,它的使用也不那么普遍。
如何选择学习哪些数据科学编程语言?
简单,学习最适合的那个。哪个是最适合的?就是那个符合你要求的。
你必须问自己最重要的问题是:我需要编程做什么?如果你不问自己(并回答)这个问题,你可能会试图教一头大象爬树。
你在工作中主要做什么?你希望在当前或未来的工作中做些什么?作为学生,你对哪些方面感兴趣,你希望你的职业发展方向是什么?
当然,你可以随意选择一种数据科学编程语言,只因为你有时间并且想学习。然而,大多数时候,选择取决于你的工作要求或将来的需求。因此,了解每个数据科学职位的内容是至关重要的。
例如,如果你是业务分析师、数据建模师、数据库管理员或数据分析师,你可能只需要SQL就足够了。这是因为你主要从事数据提取和处理工作。
如果你是数据分析师,SQL已经很好了。不过,你可能还需要了解Python,以进行一些较复杂的统计工作和自动化,也许还需要其他适合自动化的语言。
除了SQL和Python,市场营销科学家、BI开发人员、统计学家或量化分析师也可能需要了解R。如果你的工作更多是分析和可视化数据而不是提取数据,添加Python和/或R到SQL中会变得更加重要。
另一方面,数据架构师可能希望学习Python、Java或任何其他适合构建应用程序的数据科学编程语言。
作为数据科学家,你在数据科学周期的各个步骤中都会涉及到一定程度。你可能会希望增加Java/JavaScript、C语言或其他适合机器学习、模型部署和自动化的语言。
数据工程师主要关注数据的提取、转换和加载。除了SQL和其他用于这些操作的语言,他们可能还会使用用于自动化的语言。
如果你是机器学习工程师,这意味着你专注于构建和部署机器学习模型。所以你可能需要在建模/机器学习、模型部署和自动化部分增加一些额外的学习编程语言。
软件工程师专注于软件开发,因此他们可能不需要对其他用途的编程语言有广泛的知识。
数据科学家是否有理想的编程语言组合?
我通常不会声称某事物的流行本质上意味着它也很好。然而,在这种情况下,编程语言的流行反映了它们在数据科学中的适用性。
是的,前三种最受欢迎的编程语言几乎构成了数据科学中的理想组合。查看文章开头的图表中的前三种语言,你会发现它们。没错,数据科学的神圣三位一体是Python、SQL和R。
再次提醒,你在数据科学中的工作是决定性的最重要因素。基于此,你可能还会偏好其他语言,或者你可能不需要这三种数据科学编程语言中的某一种。
尽管如此,这些语言的普及意味着市场对熟练掌握它们的数据科学家的需求很高。
这种高需求是有原因的。原因是:Python、SQL 和 R 都非常擅长它们所做的工作。使用它们,你能够在任何阶段的数据科学项目中进行高质量的工作。这三者在数据提取和处理方面都表现出色。对于统计分析和可视化,你可以使用 Python 或 R。机器学习也是如此。而在部署模型或自动化某些过程时,你可以再次使用 Python,对你完成的工作感到满意。
如果你还想了解 MATLAB 和 SAAS,请查看这篇“前五大数据科学编程语言”的帖子。

总结
在这里没有显著的结论。除非没有一种最佳的数据科学编程语言。相反,请使用下面的概述来轻松找到最适合你的编程语言。
内特·罗西迪 是一名数据科学家和产品战略专家。他还是一名讲授分析学的兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶级公司的真实面试问题为面试做准备。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关话题
数据科学项目流程(初创公司)
原文:
www.kdnuggets.com/2019/01/data-science-project-flow-startups.html
评论
作者:Shay Palachy,数据科学家与顾问
最近,一个我正在咨询的初创公司(BigPanda)要求我对数据科学项目的结构和流程发表意见,这让我思考了它们的独特之处。初创公司的经理和不同团队可能会发现数据科学项目与软件开发项目之间的差异不直观且令人困惑。如果这些基本差异没有明确指出并加以说明,可能会导致数据科学家与同事之间的误解和冲突。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
相应地,来自学术界(或高度研究导向的行业研究小组)的研究人员在进入初创公司或较小公司时可能会面临自己的挑战。他们可能会发现将产品和业务需求、更紧张的基础设施和计算约束以及客户反馈纳入其研究和开发过程中是具有挑战性的。
因此,本帖的目的是展示我在近年来的工作过程中识别出的特征项目流程。希望这能帮助数据科学家及与他们合作的人,以一种反映其独特性的方式来结构数据科学项目。
这个流程是针对小型初创公司设计的,在这些公司中,一个小团队的数据科学家(通常是一个到四个)会由一个人领导,进行短期和中期项目。更大的团队或那些以机器学习为主、深科技初创公司可能仍会发现这个结构有用,但这些公司的流程通常较长,并且在许多情况下结构不同。
图 1:数据科学项目流程(初创公司)
我将这个过程分为三个并行的方面:产品、数据科学和数据工程。在很多情况下(包括我曾经工作过的大多数地方),可能没有数据工程师来执行这些职责。在这种情况下,数据科学家通常负责与开发人员合作,帮助处理这些方面。或者,数据科学家可能会进行这些准备工作,如果他们恰好是所有神奇生物中最稀有的:全栈数据科学家!✨????✨。因此,你可以根据你的环境将数据工程师替换为数据科学家。
在时间轴上,我将过程分为四个不同的阶段:
-
定义
-
研究
-
(模型)开发
-
部署
我将按顺序逐一讲解这些内容。
1. 定义阶段
定义数据科学项目的范围比其他类型的项目更为关键。
1.1. 产品需求
一个项目应始终从产品需求开始(即使最初的想法是技术性或理论性的),该需求应由产品/业务/客户成功人员在某种程度上进行验证。产品人员应该有一个关于这个特性(大致上)应该如何呈现的想法,并且现有或新客户将愿意为此付费(或者它将防止流失/推动订阅/推动其他产品的销售/等)。
产品需求不是完整的项目定义,而应当被描述为一个问题或挑战;例如,“我们的客户需要一种了解他们预算支出方式的方法”,或者“我们无法让我们的老用户继续服药,这增加了流失率”,或者“客户愿意为一个能够预测他们运营的机场高峰时段的产品支付更多费用”。
1.2. 初步解决方案构思
在这个阶段,数据科学家与负责的产品人员、数据工程师及其他相关方一起,为可能的解决方案提出不同的粗略方案。这包括一般方法(例如,无监督聚类 vs 增强树分类 vs 概率推断)和要使用的数据(例如,我们数据库中的这个特定表,或我们尚未监控或保存的一些特定用户行为,或一个外部数据源)。
这通常也涉及到一定程度的数据探索。你不能在这里深入探讨,但任何有前景的“触手可及的成果”都可以帮助引导创意生成。
数据科学家应该主导这个过程,并通常负责提供大部分解决方案的想法,但我建议你利用所有参与这个过程的人来进行解决方案的构思;我曾幸运地得到过由后端开发人员、首席技术官或负责的产品人员提供的最佳解决方案想法。不要假设不同的、较少理论导向的背景会使人们不适合参与这一阶段;额外的思维和观点总是有价值的。
1.3. 数据准备和可访问性
团队现在应当对希望用于探索可能解决方案的数据有一个清晰的了解(或至少是第一个这样的数据集或来源)。因此,提供数据访问并为探索和使用准备数据的过程应该与下一阶段同时开始。
这有时可能需要将生产数据库中的大型数据集导出到其备用/探索对应的数据库中,或者如果在研究阶段时间的可用性不是关键的话,导出到较冷的存储(例如对象存储)。相反,这也可能意味着将来自非常冷的存储的大型数据导出回表格或文档形式,以便进行快速查询和复杂计算。无论是哪种情况,这一阶段是启动研究阶段所必需的,通常会花费比预期更多的时间,因此这是启动这一阶段的最佳时机。
1.4. 范围与关键绩效指标(KPIs)
这一阶段涉及共同决定项目的范围和关键绩效指标(KPIs)。
KPIs 应首先以产品术语定义,但比之前详细得多;例如,针对前面提到的三个产品需求,它们可能变成“客户现在可以使用一个具有 CTR 统计和按类别预测的仪表板”,或“65 岁以上用户错过的用药天数将在接下来的两个季度内减少至少 10%”,或“客户将收到机场高峰时段的每周预测,粒度至少为一小时,且准确率至少为±50%”。
这些 KPIs 应当被转化为可测量的模型指标。幸运的话,这些将是非常严格的指标,例如“预测广告的预期 CTR,准确率至少为 X%且在至少 Y%的案例中适用,适用于任何运行时间至少为一周的广告,及任何具有超过两个月历史数据的客户”。然而,在某些情况下,可能需要使用更宽泛的指标,例如“使用生成的扩展查询进行主题探索所需的时间将缩短,和/或结果质量将提高,相比于原始查询”。当模型旨在辅助某些复杂的人工功能时,这一点尤其如此。
从技术上讲,即便这些指标也可以被严格定义(在学术研究中,通常如此),但根据资源和时间限制,我们可能会通过人类反馈来近似这些指标。在这种情况下,每次反馈迭代可能会花费更长时间,因此我们通常会尝试找到额外的硬性指标来指导我们完成大部分即将进行的研究迭代,昂贵的反馈则可能每隔几次迭代或者在重大变更时才会进行一次。
最后,范围在这里尤其重要,因为研究项目往往会拖延,并且随着研究过程中新可能性的出现或当被审视的方法只能部分满足需求时,自然扩展其规模和范围。
范围限制 1: 我发现明确限制范围更具生产力;例如,如果你决定基于多臂赌博机模型是最有前景的方法,你可以将项目范围定义为单次两/三周的模型开发迭代,无论模型准确度如何(例如,只要超过 60%)。然后,如果提高准确度是有价值的(在某些情况下可能发现其价值较低),开发第二个模型可能会被视为一个独立的项目。
范围限制 2: 另一种范围限制的变体是使用逐渐增加的复杂度;例如,第一个项目可能旨在部署一个只需要提供一个相当大的广告文案和颜色变化候选集供客户成功人员使用的模型;第二个项目可能尝试构建一个提供较小建议集的模型,客户可以自己查看;最后一个项目可能尝试构建一个突出单一选项的模型,排名其下几个选项,并为每个变体添加 CTR 预测和人口统计覆盖。
这已经是对软件工程的巨大改动,通常软件工程中组件的迭代是为了增加规模而不是复杂性。
尽管度量与产品价值的函数可能是阶跃函数,这意味着在某些 X 值以下的任何模型对客户都没有用;在这些情况下,我们将倾向于迭代,直到达到该阈值。然而,虽然这个 X 在某些情况下可能非常高,我相信产品/业务人员和数据科学家往往会高估这个阶跃的高度;很容易就会说任何低于 95% 准确率的模型(例如)没有价值,无法销售。然而,在许多情况下,仔细审查和挑战产品假设可以导致非常有价值的产品,这些产品在技术上可能不那么苛刻(至少在产品的第一次迭代中)。
1.5. 范围与 KPI 批准
最后,负责的产品人员需要批准定义的范围和 KPI。数据科学家的工作是确保每个人理解范围的含义——包括了什么和优先级——以及产品 KPI 与指导模型开发的更难度量之间的关系,包括这些度量与前者的近似程度。明确说明这一点可以防止模型开发的消费者——产品和业务人员——在模型开发期间或之后才意识到优化了错误的度量。
范围定义的总体备注
在许多地方,这个阶段被跳过,数据科学家急于开始挖掘数据并探索可能解决方案的有趣论文;根据我的经验,这几乎总是最糟糕的选择。跳过这个阶段可能导致在开发有趣的模型上花费数周或数月的时间,这些模型最终无法解决实际需求,或在某些可以事先明确的 KPI 上失败。
2. 研究阶段
2.1. 数据探索
这就是乐趣开始的地方!在定义范围之后开始这个阶段的主要优势在于,我们的探索可以由我们已决定的实际硬性 KPI 和模型指标来引导。
像往常一样,这里需要在探索和利用之间取得平衡;即使在明确的关键绩效指标(KPI)下,也有必要在一定程度上探索一些看似无关的途径。
到目前为止,数据工程师应该已经提供了最初所需的数据集。然而,在这个阶段,通常会发现一些数据的不足,可能需要将额外的数据源添加到工作集中。数据工程师应该对此做好准备。
最后,尽管这里将其与文献和解决方案审查阶段分开讨论,实际上它们通常是并行进行的或交替进行的。
2.2. 文献与解决方案审查
在这一阶段,既要审查学术文献,也要审查现有的代码和工具。平衡再次变得重要;既要在探索和利用之间取得平衡,又要在深入研究材料的细节和快速提取要点及可能用途之间取得平衡。
对于学术文献,深入探讨形式证明和前期文献的选择很大程度上取决于时间限制和项目背景:我们是在为公司核心能力构建坚实基础,还是在为一次性问题制定解决方案?我们是否计划将我们的工作以学术论文的形式发表?你是否计划成为该领域的团队专家?
例如,假设一位数据科学家开始一个项目,旨在帮助销售部门更好地预测潜在客户的产生或流失,她觉得自己对许多常见解决方案所基于的随机过程理论只有浅薄的理解。对此感受的适当回应可能会大相径庭;如果她在一家算法交易公司工作,她肯定应该深入研究这些理论,甚至可能需要参加在线课程,因为这对她的工作非常相关;另一方面,如果她在一家专注于自动肝脏 X 光扫描肿瘤检测的医学影像公司工作,我会说她应该尽快找到适用的解决方案并继续前进。
对于代码和实现,应该追求的理解深度取决于技术方面,其中一些可能在过程后期才会发现,但许多也可以事先预测。
例如,如果生产环境仅支持部署用于后台的 Java 和 Scala 代码,而解决方案预计以 JVM 语言提供,则数据科学家需要在此研究阶段深入探讨她找到的基于 Python 的实现,因为在模型开发阶段继续使用它们会涉及将它们转换为 JVM 语言。
最后,在回顾文献时,要记住,不仅仅是选择的研究方向(或几个方向)需要向团队其他成员展示。相反,还应简要回顾该领域和所有考察过的解决方案,解释每个方向的优缺点及选择的理由。
2.3. 技术有效性检查
提出可能的解决方案时,数据工程师和任何参与的开发人员需要在数据科学家的帮助下,估计该解决方案在生产中的形式和复杂性。产品需求和建议解决方案的结构和特性应有助于确定合适的数据存储、处理方式(流处理还是批处理)、可扩展性(水平和垂直)以及成本的大致估算。
在此阶段进行此重要检查是因为某些数据和软件工程可以与模型开发并行进行。此外,建议的解决方案可能会在工程方面不够适用或过于昂贵,此时应尽快识别并处理。当技术问题在模型开发开始之前得到考虑时,研究阶段获得的知识可以用来提出可能更符合技术限制的替代解决方案。这也是为什么研究阶段必须提供解决方案概览的另一个原因,而不仅仅是单一的解决方案方向。
2.4. 范围与关键绩效指标验证
再次,产品经理需要批准建议的解决方案,现在用更技术化的术语表述,是否符合定义的范围和关键绩效指标。可能的技术标准通常具有易于检测的产品影响,包括响应时间(及其与计算时间的关系)、数据的新鲜度以及有时的缓存中计算(与查询和批处理频率相关)、领域适应的难度和成本(包括数据成本),以及解决方案的可组合性(例如,数据和模型结构是否允许将国家级模型轻松拆分为地区级模型,或将几个这样的模型组合成一个大陆级模型),虽然还有许多其他标准。
3. 开发阶段
3.1. 模型开发与实验框架设置
开始模型开发所需的设置数量和复杂性在很大程度上取决于基础设施和数据科学家可获得的技术支持。在较小的公司或尚未习惯于支持数据科学研究项目的地方,设置可能仅仅是数据科学家打开一个新的代码库和启动一个本地的 Jupyter Notebook 服务器,或者请求一个更强大的云计算机来运行计算。
在其他情况下,这可能涉及编写自定义代码以实现更复杂的功能,如数据和模型版本控制或实验跟踪和管理。当这些功能由某些外部产品或服务提供时(现在越来越多这样的产品出现),可能需要进行一些设置,比如链接数据源、分配资源和设置自定义包。
3.2. 模型开发
一旦基础设施到位,实际的模型开发可以正式开始。这里对模型开发的定义范围因公司而异,取决于数据科学家所交付的模型与生产中部署的服务或特性之间的关系和差距。考虑这种差距的各种方法可能会在一定程度上通过考虑一个光谱来捕捉。
在一个极端情况下,一切都被认为是模型:从数据聚合和预处理,到模型训练(可能是周期性的),模型部署,服务(可能包括扩展)以及持续监控。另一方面,另一个极端是仅将模型类型和超参数的选择,通常还包括高级数据预处理和特征生成,视为模型。
公司的位置在光谱上的位置取决于许多因素:数据科学家偏好的研究语言;相关的库和开源软件的可用性;公司支持的生产语言;是否有专门从事数据科学相关代码的数据工程师和开发人员;以及数据科学家的技术能力和工作方法。
如果有一个非常全栈的数据科学家,并且有足够的支持来自专门的数据工程师和开发人员——或者,替代地,如果有足够的现有基础设施专门用于数据湖的操作和自动化、模型服务、扩展和监控(可能还包括版本控制)——那么可以采用更广泛的模型定义,并且在模型开发的大部分迭代中使用端到端的解决方案。
这通常意味着首先构建完整的数据处理管道,从数据源到可扩展的服务模型,中间包括数据预处理、特征生成和模型本身的简单占位符。然后在数据科学部分进行迭代,同时保持限制范围在现有基础设施上可用和可部署的内容。
这种端到端的方法可能需要更多时间来设置,每次对模型类型和参数的迭代测试也可能需要更长时间,但它节省了后续产品化阶段的时间。
我个人非常喜欢这种方法,但它的实施和维护复杂,并且并不总是适用。在这种情况下,管道的开始和结束部分会留到产品化阶段。
3.3. 模型测试
在开发模型时,模型的不同版本(以及随之而来的数据处理管道)应该持续地根据预设的硬指标进行测试。这可以大致估计进展情况,也使数据科学家能够决定模型是否足够好,以值得进行整体 KPI 检查。请注意,这可能具有误导性,因为从 50%提升到 70%准确度在许多情况下比从 70%提升到 90%准确度要容易得多。
图 2:模型失败意味着需要迭代,但方法失败可能会让你回到研究阶段。
当测试显示模型偏离目标时,我们通常会调查模型及其输出,以指导改进。然而,有时性能差距非常大,不同的研究方向变体都未能达到预期——这就是方法失败。这可能需要改变研究方向,将项目送回研究阶段。这是数据科学项目中最难接受的方面:实际存在回退的可能性。
另一种方法失败的可能结果是目标的改变。幸运的话,这种改变可以是产品方面的小变动,但在技术上以更简单的方式重新陈述目标。
例如,与其尝试生成一篇文章的一句总结,不如选择文章中最能总结内容的一句话。
最终可能的结果当然是项目取消;如果数据科学家确信所有研究途径都已探索完毕,而产品经理确信无法围绕现有性能构建有效的产品,那么可能是时候转到另一个项目了。不要低估识别无法挽救的项目和做出终止决定的能力;这是快速失败方法论的重要部分。
3.4. KPI 检查
如果预设的硬指标是唯一的 KPI,并且完全捕捉了所有产品需求,那么这一阶段可能只是形式上的,当最终模型展示出来且开发阶段宣告结束时。但这通常不是情况。
在更常见的情况下,硬指标是实际产品需求的良好近似,但不是完美的。因此,这一阶段是确保无法自动检查的软指标也得到满足的机会。这是与产品和客户成功团队共同完成的。如果你还能直接检查客户的实际价值——例如,在与设计合作伙伴合作时——那么这是你为迭代找到的最佳指南。
例如,假设我们正在处理一个复杂的任务,例如从大量语料库中提取相关文档。团队可能已经决定尝试提高结果集的质量,专注于返回文档的内容和主题的方差,因为客户感觉系统倾向于将非常相似的文档聚集在前几名结果中。
模型开发可能已经通过一些可测量的内容方差指标取得进展——每个模型根据它返回的前 20 个文档的多样性进行评分,给定一组测试查询;也许你会测量文档主题在某些主题向量空间中的总体距离,或者仅仅是唯一主题的数量或显著词分布的平坦度。
即使数据科学家选择了一个能显著改善这一指标的模型,产品和客户成功团队也应该查看测试查询的大量实际结果;他们可能会发现难以量化但可以解决的问题,例如模型通过提升一些重复出现的无关话题来增加结果的方差,或者通过包括来自不同来源(例如新闻文章与推文,它们使用了非常不同的语言)的相似主题的结果。
当产品人员确信模型达到了项目的声明目标(到令人满意的程度)时,团队可以继续推进产品化。
4. 部署阶段
4.1. 解决方案产品化与监控设置
如前所述,这一阶段依赖于公司对数据科学研究和模型服务的处理方法,以及几个关键技术因素。
产品化:在可以在生产中使用研究语言的情况下,这一阶段可能涉及将模型代码调整为可扩展的方式;这一过程的复杂程度取决于模型语言的分布式计算支持、特定的库和自定义代码。
当研究语言和生产语言不同,这可能还涉及将模型代码包装在生产语言的包装器中,将其编译为低级别的二进制文件或在生产语言中实现相同的逻辑(或找到这样的实现)。
可扩展的数据摄取和处理也需要进行设置,特别是在这种情况没有被纳入模型的情况下。这可能意味着,例如,将在单个核心上运行的 Python 函数转变为一个数据流通过的管道,或变成定期运行的批处理任务。如果数据被大量重复使用,有时会设置一个缓存层。
监控: 最后,需要设置一种持续监控模型性能的方法;在少数情况下,当生产数据源是恒定的时,这可能可以安全跳过,但我认为在大多数情况下,你无法确保数据源分布的稳定性。因此,设置这样的性能检查不仅可以帮助我们发现开发和产品化过程中可能遗漏的模型问题,更重要的是,可以发现数据源分布中的变化——通常称为协变量偏移——这可能会随着时间的推移降低一个完全良好的模型的性能。
例如,假设我们的产品是一个检测皮肤标记并评估是否建议用户去看皮肤科医生的应用程序。当市场上出现一款流行的新手机,其配备的相机与我们数据中的相机显著不同时,我们的数据可能会发生协变量偏移。
4.2. 解决方案部署
如果一切设置正确,那么这个阶段可以总结为,希望按下一个按钮,将新模型——以及为其提供服务的任何代码——部署到公司的生产环境中。
部分部署: 然而,为了测试模型的有效性(例如,减少客户流失或增加每用户的平均月支出),模型可能会以只对部分用户/客户群体暴露的方式进行部署。这使得可以直接比较用户基础中的两个(或更多)组之间对任何可测量的 KPI 的影响。
另一个你可能不希望将模型部署给所有人的原因是,如果模型是为特定客户或客户群体的需求开发的,或者如果它是一个高级功能或特定计划的一部分。或者,模型可能具有某种用户或客户的个性化元素;这有时可以通过实际拥有一个考虑客户特征的单一模型来实现,但有时需要为每个客户训练和部署不同的模型。
无论情况如何,这些情景都增加了部署模型的复杂性,并且根据公司现有的基础设施(例如,如果你已经将一些产品功能部署到客户的子集),可能需要你的后端团队进行大量额外的开发。
当模型需要部署到最终产品上时,比如用户手机或可穿戴设备,这个阶段会更加复杂,此时模型的部署可能只会作为下一次应用程序或固件更新的一部分进行。
生成偏差: 最后,所有部分部署的情况实际上对数据科学团队来说是一个紧迫的问题,因为这自然会对模型将开始积累的未来数据引入偏差——模型将开始在具有可能独特特征的用户子集的数据上运行。根据产品和具体的偏差特征,这可能对模型在实际应用中的表现产生重大影响,也可能对在此期间积累的数据上训练的未来模型产生影响。
例如,在设备更新的情况下,较早更新应用程序/固件的用户往往属于某些特定的人群(较年轻、更懂技术、收入较高等)。
4.3. KPI 检查
我在这里增加了另一个 KPI 检查,因为我认为在验证了部署后实际使用的性能和对产品及客户需求的成功响应之前,不能将解决方案标记为交付完成。
这可能意味着在部署后几周内筛选和分析结果数据。然而,当涉及实际客户时,这也必须包括产品或客户成功人员与客户坐在一起,试图理解模型对他们使用产品的实际影响。
4.4. 解决方案交付
用户和客户都很满意。产品团队成功地围绕模型构建或调整了他们想要的产品。我们完成了。祝酒词已祝,欢呼声已响,一切顺利。
解决方案已交付,我会在此时称项目完成。然而,它确实以一种特定的方式继续存在——维护。
维护
设置了健康检查和持续性能监控后,这些可能会触发短时间的项目工作。
当某些情况看起来可疑时,我们通常从查看数据(例如协变量偏移)开始,也许还会模拟模型对我们怀疑导致问题的各种情况的响应。这些检查的结果可能会使我们介于几个小时的小代码修改和模型重新训练,以及完整的模型开发迭代之间(如本帖开头的图所示),在严重的情况下,有时甚至需要回到研究阶段尝试完全不同的方向。
最后总结
这是数据科学项目流程的建议。它也非常具体,范围有限——为了简洁性和可视性——显然不能覆盖实际中存在的各种变体。它也代表了我的经验。
出于这些原因,我很希望听到你对运行、领导或管理数据科学项目的反馈、见解和经验,无论这些项目的规模如何,或者你所在的数据科学团队的规模如何。
对于这个话题的另一个精彩视角,我推荐阅读我的朋友 Ori 关于数据科学敏捷开发的文章。我还要感谢Inbar Naor、Shir Meir Lador (@DataLady)和@seffi.cohen 的反馈。
简历:Shay Palachy 是一名数据科学家和数据科学顾问。他也喜欢参与社区和开源项目。
原文。经允许转载。
相关内容:
-
机器学习项目的端到端指南
-
机器学习项目清单
-
用 MLflow 管理你的机器学习生命周期——第一部分
更多相关内容
数据科学项目基础设施:如何创建它
原文:
www.kdnuggets.com/2021/08/data-science-project-infrastructure.html
评论

任何数据科学项目的主要起点是商业或任何其他现实生活中的问题。这是你在决定数据科学项目应该如何时需要记住的最重要的一点。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 相关工作
当你为项目构建数据科学基础设施时也是一样。你是在为其他人使用而构建你的项目及其基础设施。因此,我不会过多涉及基础设施的技术细节。我将在这里提供一些建议,如果你想要构建一个有目的的数据科学项目,你应该牢记这些建议。当然,这也包括一些技术建议。
遵循这些建议将使问题解决保持在你项目的核心位置,这正是它应有的状态。它们还将帮助你建立 展示你技能所需的唯一数据科学项目。
建立稳固的数据科学项目基础设施的四个步骤
构建一个稳固的数据科学基础设施并不容易,尤其是当你经验不足时。但为了确保安全,请使用此清单确保你走在正确的道路上:
-
使用 API 和其他技术获取真实数据
-
使用(云)数据库存储数据
-
构建一个模型
-
部署你的模型
通过遵循这些步骤,你将通常遵循所谓的 OSEMN 框架。这是一个概述你数据科学项目应该经过的过程的框架:
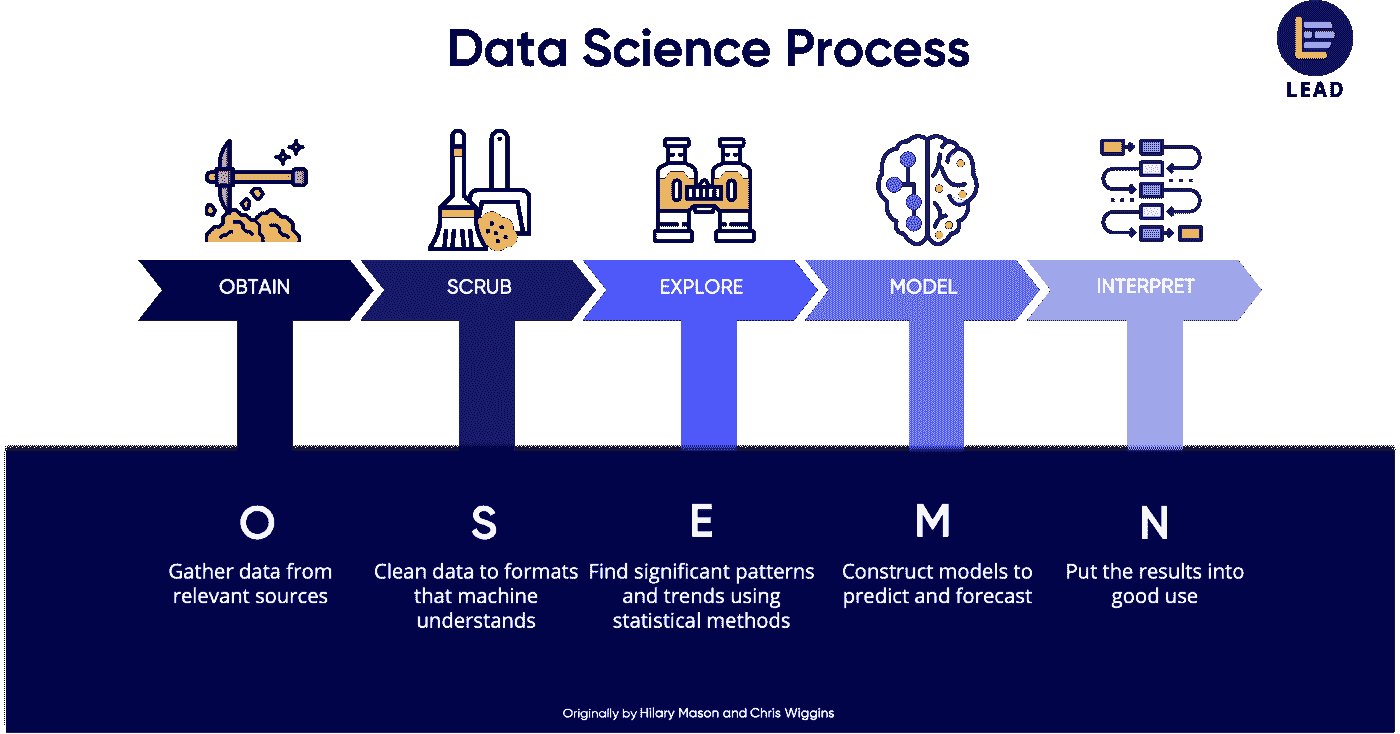
来源:TOWARDS DATA SCIENCE
现在我将详细说明每一点。
使用 API 和其他技术获取真实数据
你是在用你的项目解决实际问题,对吧?使用真实数据来做这些事情是很自然的。我指的是用户生成的数据,这些数据是实时更新的,比如流数据。如果你使用这些数据,你的项目将变得不那么理论化。你正在处理的是今天相关的数据,需要不断更新,这也考验了你处理这些数据的能力。这才是挑战所在,而不是仅仅在一些历史数据集上进行实践,尽管那也有其目的。
主要的问题是你如何以及在哪里获取真实的数据。你通过使用 API 来获取这些数据。为了获取所需的真实数据,你必须知道如何使用、配置和设置 API。有一种简单的方法可以帮助你可视化 API 是什么以及它们的功能:
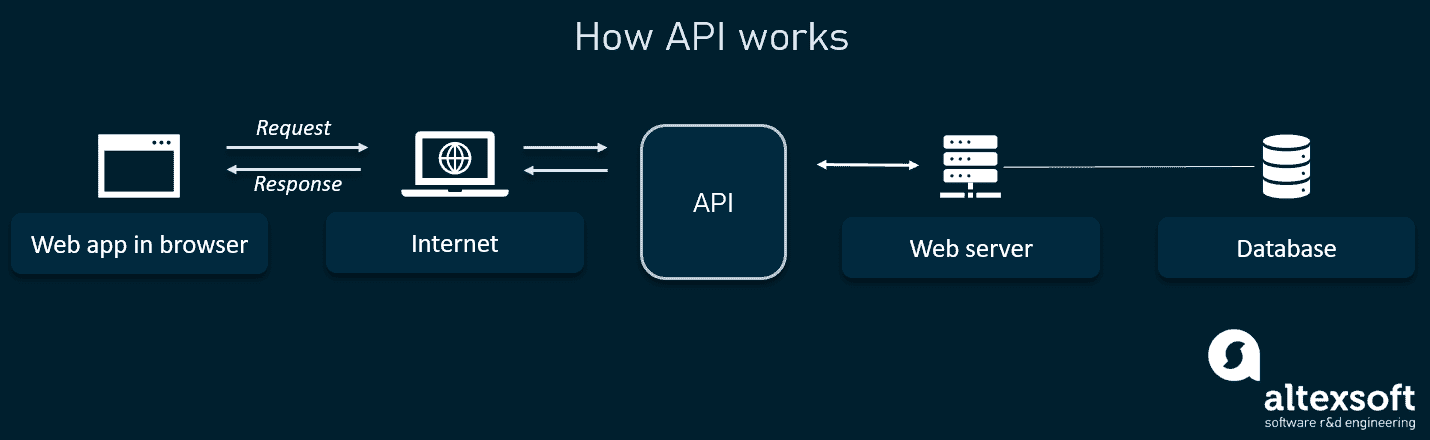
来源:ALTEXSOFT
一些受欢迎的 API 有:
使用这些技术将允许你获取的数据包括:
-
实时更新
-
每条记录的数据和时间戳
-
地理位置
-
数字和文本数据
了解如何使用 API 是数据科学行业中极力推荐的技能之一。首先,用静态数据构建机器学习模型是没有意义的。这就是为什么你(可能)需要知道如何使用 API。它们将允许你自动化数据更新。如果你使用 API,你可以避免创建集成层,因为 API 也是不同系统之间的通信平台。如果你掌握了 API,你还可以在以后部署你的模型,甚至构建将使用这些实际数据的应用程序。
这篇 Springboard 文章 清楚地解释了什么是 API 以及哪些 API 推荐给数据科学家。每个推荐都有 API 文档和教程的链接以及一些在线资源用于实践 API。
使用 API 时,你还需要使用其他技术,例如:
-
帮助你进行 API 调用的库
-
数据结构如 JSON 和字典,用于从 API 收集和保存数据
一旦你获得了数据,你需要将其存储在某个地方,对吧?这是在构建基础设施中的另一个重要步骤。
使用云数据库存储数据
由于你处理的是实时数据,建议你将数据存储起来。否则,你将不得不不断从 API 中提取所有数据,包括你已经拥有的数据以及此期间出现的新数据。
当你使用数据库存储数据时,你只需提取新数据,清理它,并将其附加到数据库中已存在的干净数据中。一些最受欢迎的云数据库是:
但为什么你特别应该使用云数据库?假设你在做一个相对较大的项目,并且有大量自动更新的实时数据,在这种情况下,云数据库将允许你以相对便宜的方式存储这些数据,并具有几乎无限的存储容量。例如,Amazon Web Services 和 Google Cloud 也提供运行机器学习算法的可能性。如果你使用内部数据存储,你将无法做到这一点。而且你也不必担心备份和数据可用性。
如果你为某家公司工作,尤其是那些生成大量数据的大公司,你很可能需要精通(或至少想要学习)云计算。公司之所以转向云数据库,正是因为你也应该这样做的原因。即使你现在还不是数据科学家,也不意味着你不能成为。看看这个 如何获得数据科学职位的指南,我相信它会帮助你实现目标。
Pupuweb 上的一篇精彩文章值得阅读,如果你想了解云数据库的基本特征、其提供者、优缺点,以便决定哪个选项最适合你。
如果你不想自己学习云数据库,可能可以尝试一个在线课程。我认为 这个 Coursera 课程 可能是一个很好的起点。这是杜克大学的课程,而且是免费的。如果你参加这个课程,你将与 Amazon Web Services、Azure 和 Google Cloud Platform 合作。
建立模型
一旦你有了前两个基础设施元素,就可以开始建立模型。当你建立回归或机器学习模型时,你需要再次记住模型应该解决实际问题。要建立这样的模型,你应该问自己以下问题:
-
我试图通过这个模型完成什么?为什么我选择了这个模型而不是其他模型?
-
我如何清理数据,为什么这样做?
-
我将对数据执行什么验证测试,以使其适合模型?
-
模型的假设是什么,我将如何验证它们?
-
我应该如何优化模型?我应该做出哪些权衡决策?
-
我应该如何实施测试/控制?
-
模型中的基础数学是什么,它是如何工作的?
使你能够提出好问题的主要工具是经验。然而,要获得经验,你需要建立一些模型。为了建立这些模型,你还需要一些技术工具来帮助你。构建机器学习模型的主要工具类别包括:
-
机器学习工具包
-
机器学习平台
-
分析解决方案
-
数据科学笔记本
-
云原生机器学习服务(MLaaS)
首先,我推荐这篇Forbes 文章来熟悉每个类别所提供的内容。
如果你掌握了 Python 编程、数学和统计学知识,并且有一定的机器学习基础,一些课程可以进一步提升你的模型构建技能。例如,AT&T 提供了一个免费的 Udacity 课程,专注于构建优秀模型所需的关键问题。
通常认为数据科学家的唯一工作就是构建模型。虽然这并不完全正确,但这确实非常重要。所以我不需要强调你为什么应该擅长构建模型。
尽管构建模型看似是你基础设施拼图的最后一块,但实际上并非如此。
还需进行最后一步。确保你构建的模型确实能达到其目的,即解决现实中的问题。
部署你的模型
这是构建任何数据科学项目基础设施时非常重要的一部分。这最后一步真正考验了你的模型及其目的。你可以通过让其他人成为你项目的一部分来实现这一点。允许他们使用你的模型及其产生的见解。
请记住,你的工作是通过将数据转化为见解,再将见解转化为建议来帮助他人。你如何接触到其他人?理想情况下,你会部署你的模型。你可以使用如 Django或 Flask等应用框架来实现这一点。或者,你可以使用云服务提供商如 Amazon Web Services 或 Google Cloud。
你可以将你的见解以简单的仪表盘形式展示给用户,用户可以进行交互。或者,也许它可以是一个 API,用户可以连接到该 API 以获取你的见解和建议。
为什么部署模型是一个重要的步骤以及你应该掌握的技能?它将导致业务流程中有时会出现根本性的变化。曾经手动执行的任务将由基于算法的解决方案接管。只有通过部署,你的模型才能实现其解决现实问题的目的。部署模型将展示你作为数据科学家的更广泛技能:不仅是你的技术技能,还包括对业务及其流程的理解。
再次,这需要通过经验来获得。如果你缺乏经验,弥补一点技术知识总是明智的。因此,如果你已经学会了如何使用 API 和云服务来获取和存储模型数据,你也可以使用它们来部署模型。
如果你真的想将应用框架添加到你的技能中,我只能鼓励你。有大量的 Flask 和 Django 书籍、教程和资源可以帮助你掌握这些工具。
如果你缺乏数据科学项目的想法,这里有一个建议,看看 这八个你可以尝试的项目。 只需遵循本文中的四条指南,你应该没问题。
总结
创建数据科学基础设施时,构建项目的主要要点包括:
-
时刻牢记,你的工作不仅仅是构建一个模型,而是解决一个实际问题。
-
你的项目基础设施应专注于帮助你解决一个问题。
-
项目基础设施的四个主要组件应包括:
-
输入数据的 API
-
(云) 数据库
-
模型
-
洞察的 API
以这种方式构建数据科学基础设施,你将确保你的项目产生了影响。
原文. 已获许可转载。
简介: 奈特·罗西迪 是一名数据科学家和产品经理。
相关:
更多相关主题
数据科学项目手册
原文:
www.kdnuggets.com/2017/03/data-science-project-playbook.html
评论
作者:Matthew Coffman, High Alpha。
本文是对"塑造产品战略的四大关键思想"的跟进。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
Slack 数据工程部负责人Josh Wills对数据科学持务实的观点。
鉴于我们多么频繁地听到或讨论机器学习和人工智能作为初创公司区分自身的方式,我一直在努力找出可以让初创公司识别和创建有价值的数据科学项目的初步步骤。我最近参加了MLconf 2016,这是一个汇集了学术界、产品领导者和实践数据科学家的活动。
我发现这次经历既令人鼓舞又让人谦逊,看到了更大和更成熟的公司如何应对这些挑战。讲座内容涵盖了各种方案、反思和建议。由于我更偏向工程思维,有些内容超出了我的理解。不过,总体而言,我从讲者和其他与会者那里学到了很多。我带着一些关于我们作为初创产品领导者如何最佳应对数据科学挑战的思考离开了。我想尝试将这些想法组织成一本其他人可以用来入门的手册。
第一步:了解数据科学领域
当然,数据科学/机器学习/人工智能已经成为一个独立的行业,并取得了关键的规模。各种平台、工具和算法的供应商不乏其人,可以应对几乎任何应用。另一方面,找到有能力处理你挑战的专家则是另一回事。大公司之间的竞争激烈,争夺彼此的数据科学家。这给我们这些希望打造下一个伟大的聊天机器人或洞察驱动应用的人留下的机会不多。
如果你很幸运已经在团队中有一名数据科学家,那么让这个人成为你规划和执行项目的合作伙伴。同时,理解数据科学家在构建和扩展应用程序的其他复杂部分时,往往没有其他工程师那样的专业知识和经验。确保在项目规划中让数据科学家和工程师都参与,以最大限度地确保成功。
在没有与主题专家建立关系的情况下,产品领导者如何仍然追求对其应用程序有意义的数据驱动功能?我主张采用一种极其实用的方法——与大多数其他产品规划过程一样,为一系列权衡做好准备。幸运的是,工具和平台的高度竞争环境意味着几乎任何理想化的功能都可以实现。因此,产品领导者的重点需要放在寻找正确的功能和权衡其影响上。
第二步:识别 MVDP
Josh Wills,Slack 的数据工程主管,在会议上做了一个非常有趣的演讲。Slack 有很多有趣的方式来审视产品,特别是他们非常专注于解决问题而不是仅仅销售产品。每一分努力都集中在解决客户的具体业务问题上。
作为产品领导者,我们经常使用最小可行产品的概念来确定解决客户问题所需的最低工作量。Josh 提倡最小可行数据产品作为平衡“可能的愿景与必要性”的一种方式。Slack 选择了一小部分功能——例如频道推荐——然后努力找出验证它是否改善了客户体验的最低努力、最容易测量的方法。
最小可行数据产品需要以下条件才能成功:
-
为客户提供真实价值——增强或加深他们与产品的关系
-
可用且充足的数据——即使是最好的算法也无法在没有数据的情况下执行
-
交付的实际性——换句话说,团队是否能在现有资源和现成解决方案的情况下交付能力?
产品领导者可以从头脑风暴功能开始,优先考虑那些对客户价值最大的功能。与工程领导者(以及可能的数据科学专业人士)合作,讨论实现特定功能所需的数据和资源。
不要害怕缩小范围——这里的目标是构建能够迅速证明功能对客户有价值的东西。一旦确定了这一价值,就可以在其基础上添加更多的复杂性。然而,对于数据科学项目而言,尤其重要的是在前期防止过多的复杂性,以减少项目无法启动的可能性。
第三步:寻找工程友好的解决方案
我们的工程和产品团队在构建和交付功能方面表现出色,但他们可能还没有足够的经验和专业知识来完全独立完成这些工作。数据科学家提供对特定数据集的可能性、构建功能的正确工具/技术的更高层次的理解,然后(同样重要的是)如何将其投入生产。幸运的是,互联网上充满了可以帮助公司推出数据科学功能的课程、学习材料、应用程序和 API,即使他们没有自己的数据科学家。
现在,几乎每种算法和技术都可以现成使用。我们工程团队的真正关注点应集中在数据准备和加载、模型/算法/工具的训练和选择,以及将这些工具实施到生产环境中。团队不应该从头开始构建任何东西——那是浪费宝贵的资源。
在确定了最低可行的数据产品后,是时候寻找最实用的方法来构建该功能。虽然没有工具或平台适合每一种用例,但有一些良好的起点可以供你的团队利用:
-
通用机器学习平台/预测服务: Google Prediction API、Amazon Machine Learning API、Microsoft Azure Machine Learning API 和 BigML 是一些服务的例子,这些服务提供 API,你的工程师可以将数据输入到预构建或定制的模型中,这些模型可以快速测试并插入到你的应用程序中。这类服务适用于预测用户行为、标记大数据集中的用户或产品、优先排序数据集等。
-
特定用途的人工智能平台:这一领域似乎具有最大的动力——在互联网搜索你的用例可能会发现各种针对开发者解决特定问题的新应用程序。主要供应商包括 IBM Watson(语音识别、图像识别、翻译)和 Google Cloud(语音、文本、图像及其他服务),每天都有许多新兴初创公司涌现。
-
博客、目录和机器学习社区新闻: 与其他开发领域一样,互联网提供了一个健康的起点,其他团队在数据科学项目中分享了他们的成功和失败。我推荐 KDnuggets 和O’Reilly作为知识探索的良好起点。
在所有可能的情况下,无论构建什么,都很可能包括工具和平台的组合。这就是为什么专注于只做团队需要交付的最小客户价值的工作是有帮助的——只要所有各方都围绕这一目标保持一致,这将有助于防止数据科学项目失控。
第四步:衡量和迭代
就像任何其他功能一样,从一开始就需要明确如何衡量客户满意度。鉴于数据科学项目的额外复杂性,创建一个紧密的客户反馈和功能迭代循环更加重要。由于对数据和潜在复杂模型的巨大依赖,团队可能难以准确找出某个功能效果不如预期的原因。产品领导者在了解每次迭代预期的工作量方面发挥着重要作用,并可能需要在额外工作的价值方面做出判断。有时,如果发现需要的工作量过大或结果仍然不可预测,可能需要完全放弃某个功能。
一个优秀的产品领导者与客户和数据保持着严谨的关系。在测试新的数据科学驱动功能时,观察这两个来源的反馈是至关重要的。
结论:无法回头
Josh Wills 强调观察到,对许多公司来说,数据科学工作只是他们产品投资组合的一部分。他继续说,在大多数情况下,那些工作中的一两个将为所有其他工作支付费用。开始数据科学真的很困难——他称之为一种信仰行为。他说像 Facebook、Google 和 Amazon 这样的公司已经过了最初的困难,现在数据科学几乎驱动着他们所做的一切。机器学习和数据科学是这些公司用来创造价值的工具,而用户体验成为通过自动化提供见解和机会以使客户生活更轻松的功能。
从实际的角度来看,产品领导者可以开始将数据科学功能整合到自己的应用程序中。尽管追赶大公司可能是一个挑战,但我们需要专注于我们自己客户的需求,并以最合理的方式改善他们的体验。
简介:Matthew Coffman 领导 High Alpha 的产品部门,这是一个专注于构思、启动和扩展下一代企业云公司的风险投资工作室。他与其投资组合公司合作,建立团队、规划技术,并解决能够帮助他们更快增长的问题。他非常高兴能成为印第安纳波利斯技术社区的一部分!
原文。经许可转载。
相关:
-
为数据团队奠定基础
-
从敏捷数据科学团队中获得现实世界的成果
-
创造力在数据科学中的重要性
更多相关主题
Rotten Tomatoes 电影评分预测的数据科学项目:第一种方法
 作者提供的图像
作者提供的图像
毫无疑问,预测娱乐行业中电影的成功与否可以决定一个制片厂的财务前景。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您所在组织的 IT
准确的预测使制片厂能够在营销、发行和内容创作等各个方面做出明智的决策。
最好的是,这些预测可以通过优化资源配置来最大化利润和最小化损失。
幸运的是,机器学习技术提供了一个强大的工具来解决这个复杂的问题。毫无疑问,通过利用数据驱动的洞察,制片厂可以显著改善其决策过程。
这个数据科学项目曾作为 Meta(Facebook)招聘过程中的家庭作业。在这项家庭作业中,我们将了解 Rotten Tomatoes 如何将电影标记为“烂片”、“新鲜”或“认证新鲜”。
为此,我们将制定两种不同的方法。
作者提供的图像
在我们的探索过程中,我们将讨论数据预处理、各种分类器以及潜在的改进,以提高模型的性能。
到本篇文章结束时,您将了解到如何利用机器学习来预测电影的成功以及如何将这些知识应用于娱乐行业。
但在深入之前,让我们先了解一下我们将要处理的数据。
第一种方法:基于数值特征和类别特征预测电影状态
在这种方法中,我们将结合数值特征和类别特征来预测电影的成功。
我们将考虑的特征包括预算、类型、时长和导演等因素。
我们将采用几种机器学习算法来构建我们的模型,包括决策树、随机森林以及具有特征选择的加权随机森林。
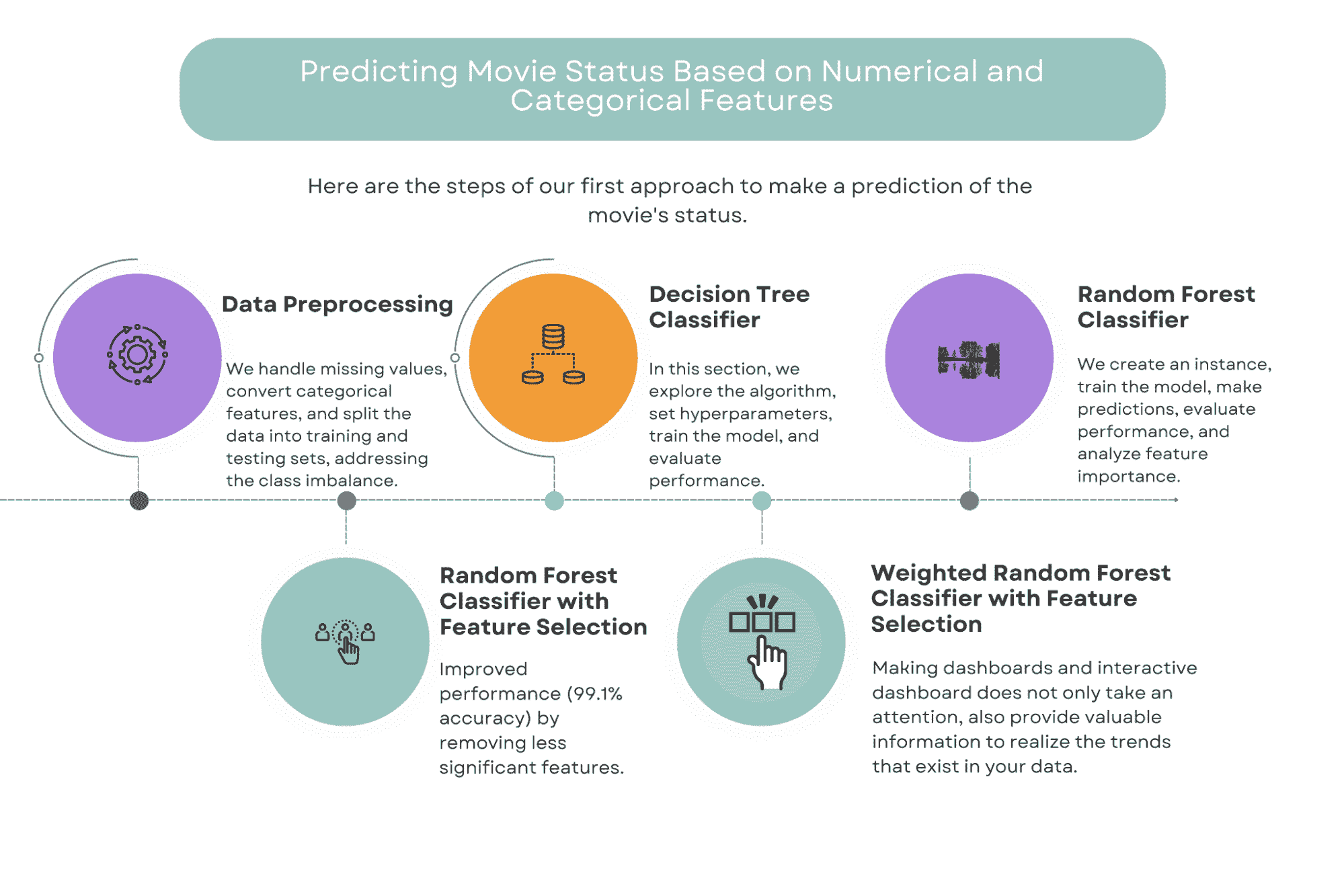
图片来自作者
让我们读取数据并看一眼。
这是代码。
df_movie = pd.read_csv('rotten_tomatoes_movies.csv')
df_movie.head()
这是输出结果。
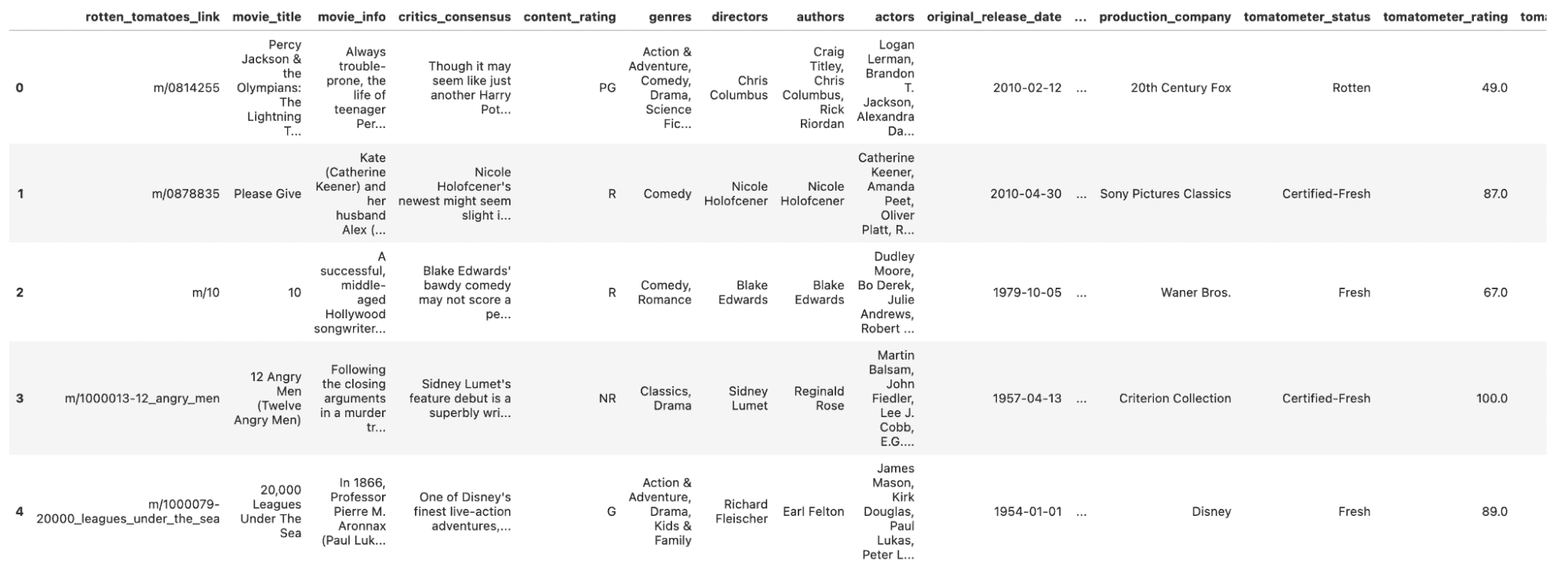
现在,让我们开始数据预处理。
我们的数据集中有很多列。
让我们来看看。
为了更好地理解统计特征,让我们使用 describe()方法。 这是代码。
df_movie.describe()
这是输出结果。

现在,我们对数据有了一个快速概览,让我们进入预处理阶段。
数据预处理
在开始构建模型之前,预处理数据是至关重要的。
这涉及到通过处理类别特征并将其转换为数值表示来清理数据,并对数据进行缩放,以确保所有特征具有相等的重要性。
我们首先检查了 content_rating 列,以查看数据集中唯一的类别及其分布。
print(f'Content Rating category: {df_movie.content_rating.unique()}')
然后,我们将创建一个条形图,以查看每个内容评级类别的分布。
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是完整的代码。
print(f'Content Rating category: {df_movie.content_rating.unique()}')
ax = df_movie.content_rating.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是输出结果。
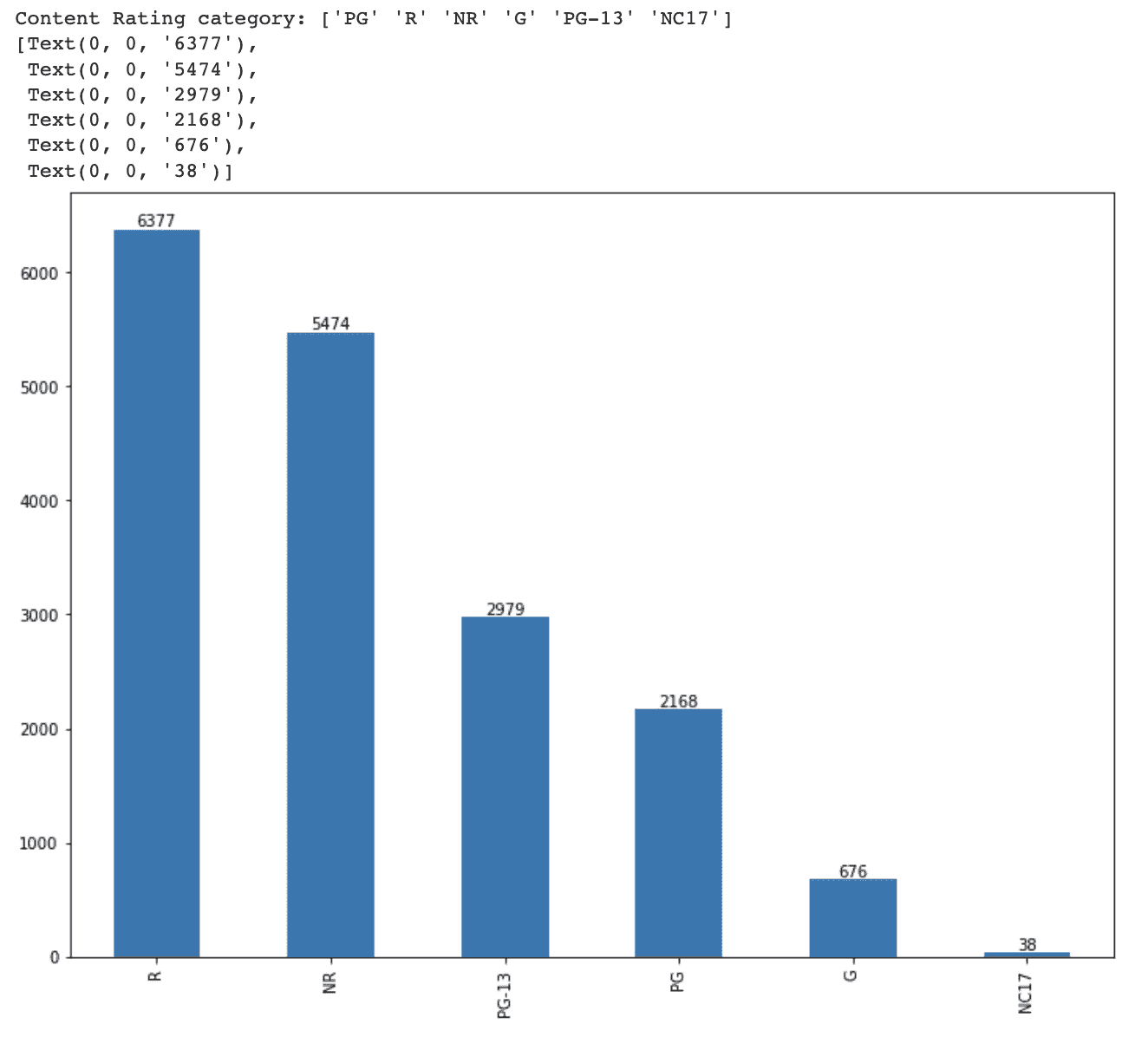
将类别特征转换为数值形式对我们的机器学习模型至关重要,因为这些模型需要数值输入。对于此数据科学项目中的多个元素,我们将应用两种普遍接受的方法:有序编码和独热编码。当类别表示一个强度的程度时,有序编码更好,而当没有提供幅度表示时,独热编码更为理想。对于“content_rating”资产,我们将使用独热编码方法。
这是代码。
content_rating = pd.get_dummies(df_movie.content_rating)
content_rating.head()
这是输出结果。
让我们继续处理另一个特征,audience_status。
这个变量有两个选项:‘Spilled’和‘Upright’。
我们已经应用了独热编码,现在是时候使用有序编码将这个类别变量转换为数值型变量了。
由于每个类别表示一个程度,我们将使用有序编码将这些类别转换为数值。
如前所述,首先找出唯一的受众状态。
print(f'Audience status category: {df_movie.audience_status.unique()}')
然后,让我们创建一个条形图,并在条形上方打印值。
# Visualize the distribution of each category
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是完整的代码。
print(f'Audience status category: {df_movie.audience_status.unique()}')
# Visualize the distribution of each category
ax = df_movie.audience_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是输出结果。
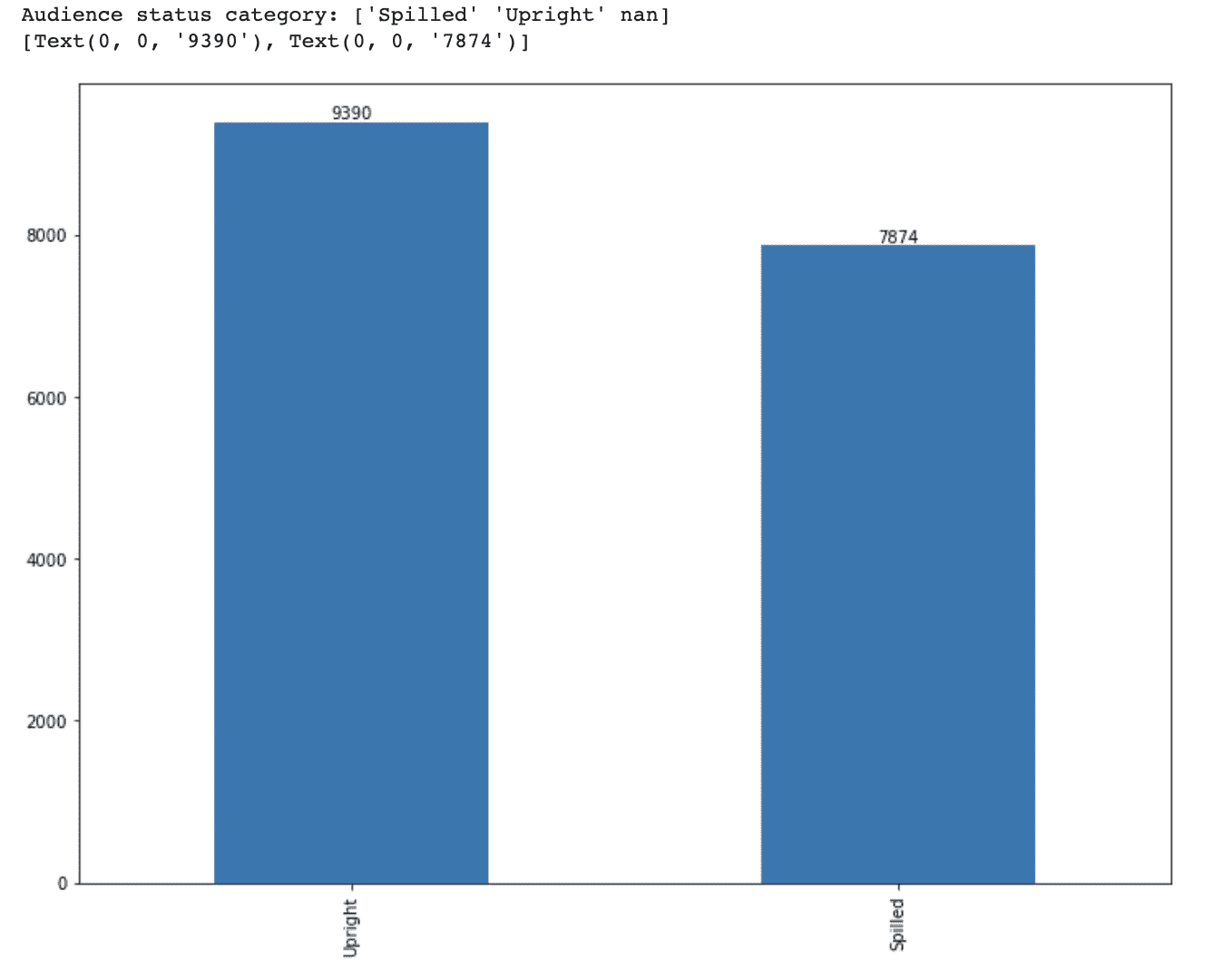
好的,现在是时候使用 replace 方法进行序数编码了。
然后让我们使用 head() 方法查看前五行。
这是代码。
# Encode audience status variable with ordinal encoding
audience_status = pd.DataFrame(df_movie.audience_status.replace(['Spilled','Upright'],[0,1]))
audience_status.head()
这是输出结果。
由于我们的目标变量 tomatometer_status 有三个不同的类别,“腐烂”、“新鲜”和“认证新鲜”,这些类别也表示一个量级的顺序。
这就是为什么我们会再次进行序数编码,将这些分类变量转换为数值变量。
这是代码。
# Encode tomatometer status variable with ordinal encoding
tomatometer_status = pd.DataFrame(df_movie.tomatometer_status.replace(['Rotten','Fresh','Certified-Fresh'],[0,1,2]))
tomatometer_status
这是输出结果。
在将分类数据转换为数值数据后,现在是时候合并两个数据框了。我们将使用 Pandas 的 pd.concat() 函数,并使用 dropna() 方法删除所有列中包含缺失值的行。
接下来,我们将使用 head 函数查看新形成的数据框。
这是代码。
df_feature = pd.concat([df_movie[['runtime', 'tomatometer_rating', 'tomatometer_count', 'audience_rating', 'audience_count', 'tomatometer_top_critics_count', 'tomatometer_fresh_critics_count', 'tomatometer_rotten_critics_count']], content_rating, audience_status, tomatometer_status], axis=1).dropna()
df_feature.head()
这是输出结果。

很好,现在让我们使用 describe 方法检查数值变量。
这是代码。
df_feature.describe()
这是输出结果。

现在让我们使用 len 方法检查数据框的长度。
这是代码。
len(df)
这是输出结果。

在移除缺失值的行并进行机器学习构建所需的转换后,我们的数据框现在有 17017 行。
现在让我们分析目标变量的分布情况。
正如我们从一开始一直在做的那样,我们将绘制一个条形图,并将值放在条形的顶部。
这是代码。
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是输出结果。
我们的数据集包含 7375 部“腐烂”、6475 部“新鲜”和 3167 部“认证新鲜”的电影,这表明存在类别不平衡问题。
这个问题将稍后解决。
暂时让我们将数据集拆分为测试集和训练集,使用 80% 对 20% 的拆分比例。
这是代码。
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status'], axis=1), df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'Size of training data is {len(X_train)} and the size of test data is {len(X_test)}')
这是输出结果。
决策树分类器
在这一部分,我们将探讨决策树分类器,这是一种常用于分类问题的机器学习技术,有时也用于回归。
该分类器通过将数据点分成分支来工作,每个分支都有一个内部节点(包括一组条件)和一个叶节点(具有预测值)。
按照这些分支并考虑条件(True 或 False),数据点被分隔到适当的类别中。过程如下所示。
作者提供的图像
当我们应用决策树分类器时,可以调整多个超参数,如树的最大深度和叶节点的最大数量。
在第一次尝试中,我们将叶节点的数量限制为三个,以使树简单易懂。
首先,我们将创建一个最多有三个叶节点的决策树分类器。然后,在我们的训练数据上训练这个分类器,并用来生成测试数据上的预测。最后,我们将检查准确度、精确度和召回率指标,以评估我们有限决策树分类器的性能。
现在让我们一步步实现决策树算法,使用 sci-kit learn。
首先,让我们使用 scikit-learn 库中的 DecisionTreeClassifier() 函数定义一个最多有三个叶节点的决策树分类器对象。
random_state 参数用于确保每次运行代码时都产生相同的结果。
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)
然后是时候在训练数据(X_train 和 y_train)上训练决策树分类器,使用 .fit() 方法。
tree_3_leaf.fit(X_train, y_train)
接下来,我们使用训练好的分类器和预测方法对测试数据(X_test)进行预测。
y_predict = tree_3_leaf.predict(X_test)
在这里,我们打印预测值与测试数据实际目标值的准确度分数和分类报告。我们使用 scikit-learn 库中的 accuracy_score() 和 classification_report() 函数。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
最后,我们将绘制混淆矩阵,以可视化决策树分类器在测试数据上的表现。我们使用 scikit-learn 库中的 plot_confusion_matrix() 函数。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap='cividis', ax=ax)
这是代码。
# Instantiate Decision Tree Classifier with max leaf nodes = 3
tree_3_leaf = DecisionTreeClassifier(max_leaf_nodes= 3, random_state=2)
# Train the classifier on the training data
tree_3_leaf.fit(X_train, y_train)
# Predict the test data with trained tree classifier
y_predict = tree_3_leaf.predict(X_test)
# Print accuracy and classification report on test data
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot confusion matrix on test data
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree_3_leaf, X_test, y_test, cmap ='cividis', ax=ax)
这是输出结果。
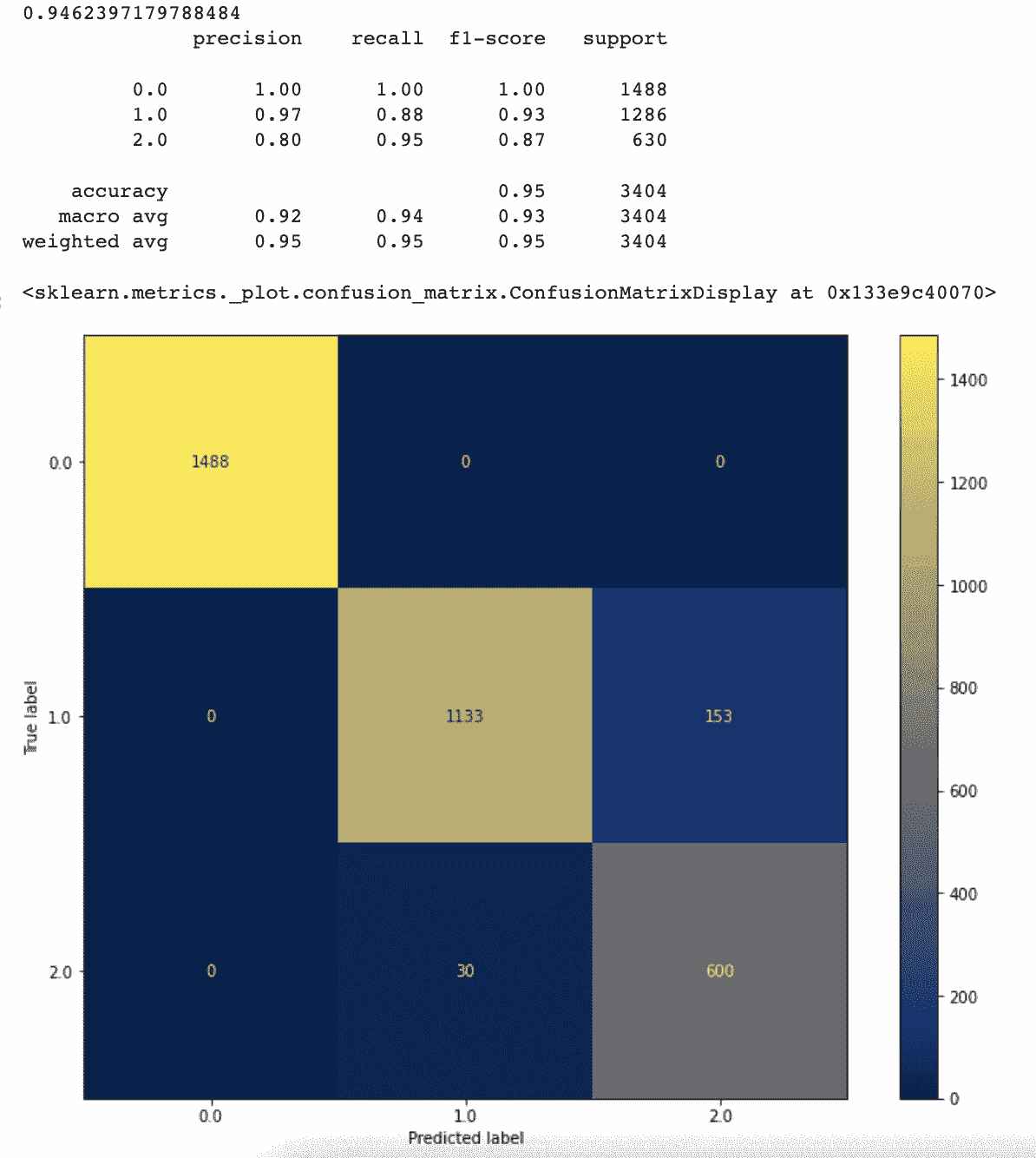
从输出结果可以清楚地看到,我们的决策树表现良好,特别是考虑到我们将其限制为三个叶节点。一个简单分类器的优点是决策树可以被可视化且易于理解。
现在,为了理解决策树如何做出决策,让我们通过使用 sklearn.tree 的 plot_tree 方法来可视化决策树分类器。
这是代码。
fig, ax = plt.subplots(figsize=(12, 9))
plot_tree(tree_3_leaf, ax= ax)
plt.show()
这是输出结果。
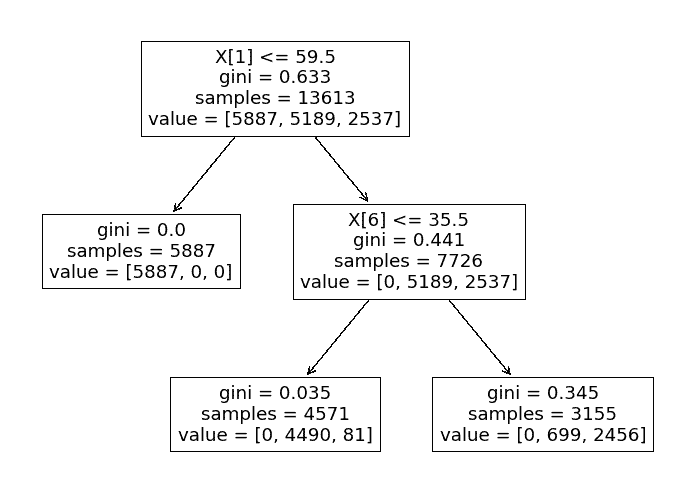
现在让我们分析这个决策树,找出它如何进行决策过程。
具体而言,算法使用'tomatometer_rating'特征作为每个测试数据点分类的主要决定因素。
-
如果'tomatometer_rating'小于或等于 59.5,则数据点被标记为 0('Rotten')。否则,分类器会继续到下一个分支。
-
在第二个分支中,分类器使用'tomatometer_fresh_critics_count'特征来分类剩余的数据点。
-
如果该特征的值小于或等于 35.5,则数据点被标记为 1('Fresh')。
-
如果不是,则标记为 2('Certified-Fresh')。
-
这一决策过程与 Rotten Tomatoes 用来分配电影状态的规则和标准紧密对齐。
根据 Rotten Tomatoes 网站,电影被分类为
-
如果他们的 tomatometer_rating 为 60%或更高,则标记为‘Fresh’。
-
如果低于 60%,则标记为'Rotten'。
我们的决策树分类器遵循类似的逻辑,若电影的 tomatometer_rating 低于 59.5,则分类为'Rotten',否则为'Fresh'。
然而,在区分'Fresh'和'Certified-Fresh'电影时,分类器必须考虑更多的特征。
根据 Rotten Tomatoes,电影必须满足特定标准才能被分类为'Certified-Fresh',例如:
-
Tomatometer 评分至少为 75%的电影。
-
至少要有五条来自顶级评论家的评论。
-
广泛上映的电影至少要有 80 条评论。
我们的有限决策树模型仅考虑了来自顶级评论家的评论数量,以区分'Fresh'和'Certified-Fresh'电影。
现在,我们理解了决策树的逻辑。因此,为了提高其性能,让我们遵循相同的步骤,但这次我们将不添加最大叶节点参数。
这是我们代码的逐步解释。这次我不会像之前那样过多扩展代码。
定义决策树分类器。
tree = DecisionTreeClassifier(random_state=2)
在训练数据上训练分类器。
tree.fit(X_train, y_train)
使用训练好的树分类器预测测试数据。
y_predict = tree.predict(X_test)
打印准确率和分类报告。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
情节混淆矩阵。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)
太好了,现在让我们一起查看它们。
这是完整代码。
fig, ax = plt.subplots(figsize=(12, 9))
# Instantiate Decision Tree Classifier with default hyperparameter settings
tree = DecisionTreeClassifier(random_state=2)
# Train the classifier on the training data
tree.fit(X_train, y_train)
# Predict the test data with trained tree classifier
y_predict = tree.predict(X_test)
# Print accuracy and classification report on test data
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot confusion matrix on test data
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(tree, X_test, y_test, cmap ='cividis', ax=ax)
这是输出结果。
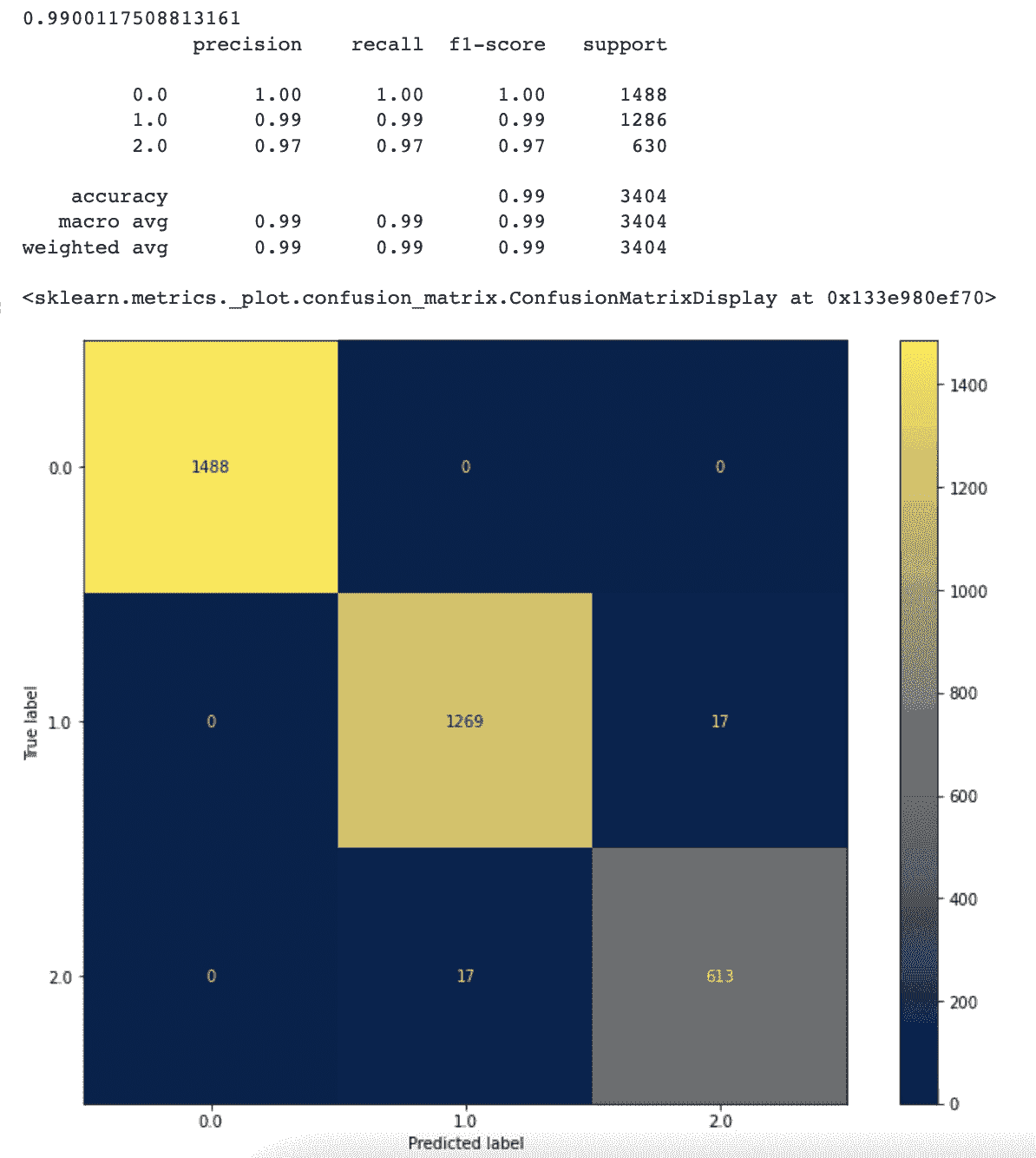
移除最大叶节点限制后,我们分类器的准确率、精确度和召回率都提高了。分类器现在的准确率达到 99%,而之前为 94%。
这表明当我们允许分类器自行选择最佳叶节点数量时,它的表现更好。
尽管当前结果看起来非常出色,但仍有更多的调优空间,以达到更好的准确率。在接下来的部分中,我们将探讨这个选项。
随机森林分类器
随机森林是由多个决策树分类器组合而成的集成算法。它使用 bagging 策略来训练每个决策树,其中包括随机选择训练数据点。由于这种技术,每棵树在训练数据的不同子集上进行训练。
Bagging 方法因使用自助法来抽样数据点而著名,使得同一数据点可以被多个决策树选择。
作者提供的图像
使用 scikit-learn,应用随机森林分类器非常简单。
使用 Scikit-learn 设置 随机森林算法 是一个简单的过程。
算法的性能,如决策树分类器的性能,可以通过更改超参数值来提高,比如决策树分类器的数量、最大叶子节点数和最大树深度。
我们首先使用默认选项。
让我们再次逐步查看代码。
首先,让我们使用 scikit-learn 库中的 RandomForestClassifier() 函数实例化一个随机森林分类器对象,并将 random_state 参数设置为 2,以确保结果可重复。
rf = RandomForestClassifier(random_state=2)
然后,使用 .fit() 方法在训练数据(X_train 和 y_train)上训练随机森林分类器。
rf.fit(X_train, y_train)
接下来,使用训练好的分类器对测试数据(X_test)进行预测,使用 .predict() 方法。
y_predict = rf.predict(X_test)
然后,打印预测值与测试数据的实际目标值的准确率得分和分类报告。
我们再次使用 scikit-learn 库中的 accuracy_score() 和 classification_report() 函数。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
最后,让我们绘制一个混淆矩阵来可视化随机森林分类器在测试数据上的表现。我们使用 scikit-learn 库中的 plot_confusion_matrix() 函数。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)
这里是完整的代码。
# Instantiate Random Forest Classifier
rf = RandomForestClassifier(random_state=2)
# Train Random Forest Classifier on training data
rf.fit(X_train, y_train)
# Predict test data with trained model
y_predict = rf.predict(X_test)
# Print accuracy score and classification report
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot confusion matrix
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)
这里是输出结果。
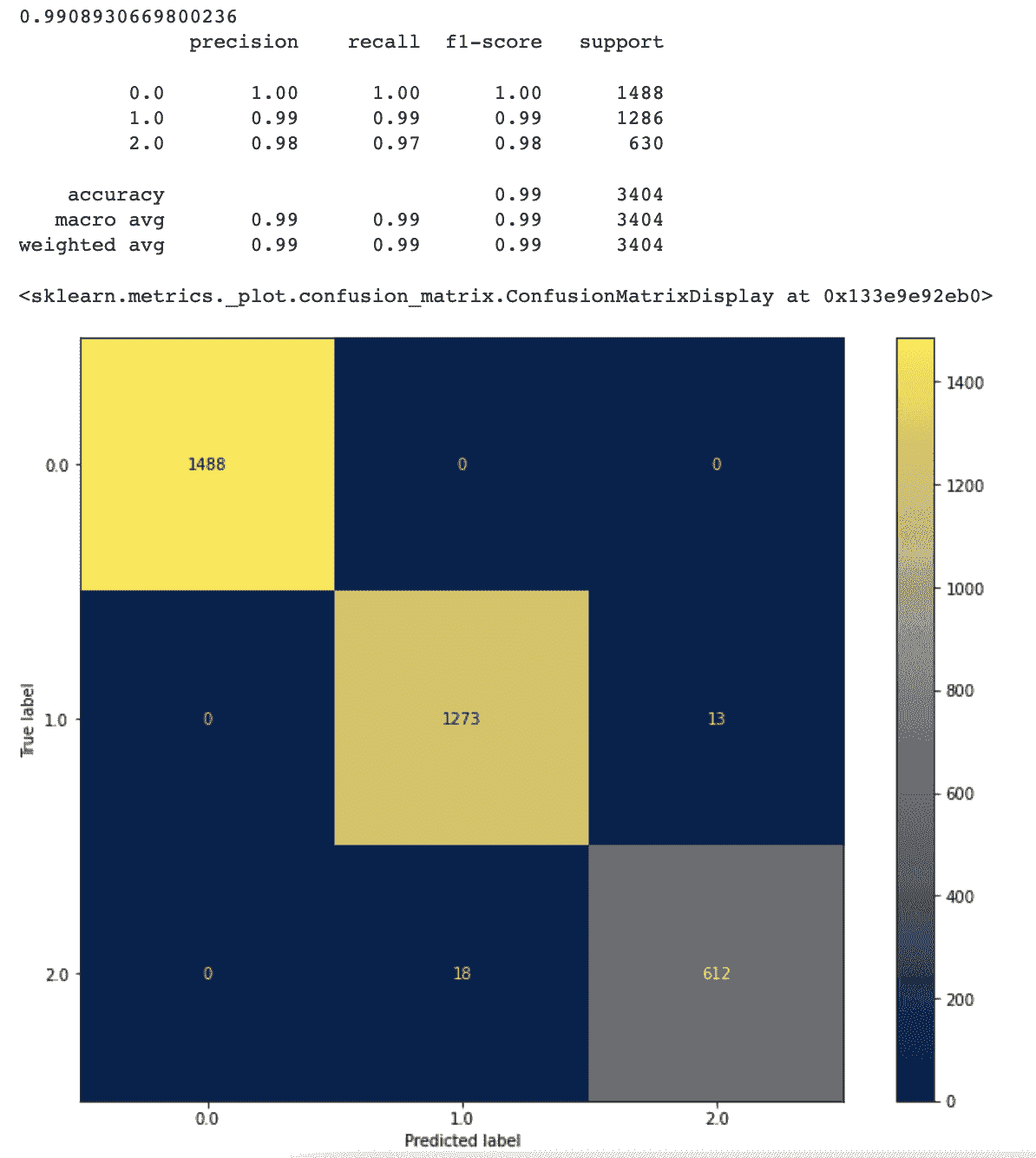
准确率和混淆矩阵结果显示,随机森林算法优于决策树分类器。这展示了像随机森林这样的集成方法相较于单个 分类算法 的优势。
此外,基于树的方法允许我们在模型训练后识别每个特征的重要性。因此,Scikit-learn 提供了 feature_importances_ 函数。
太好了,再次让我们一步步查看代码以理解它。
首先,使用 Random Forest Classifier 对象的 feature_importances_ 属性来获取数据集中每个特征的重要性分数。
重要性分数表示每个特征对模型预测性能的贡献程度。
# Get the feature importance
feature_importance = rf.feature_importances_
接下来,特征重要性按重要性降序打印出来,以及对应的特征名称。
# Print feature importance
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')
然后,为了从最重要到最不重要的特征进行可视化,让我们使用 numpy 中的 argsort()方法。
# Visualize feature from the most important to the least important
indices = np.argsort(feature_importance)
最后,创建一个水平条形图来可视化特征重要性,y 轴上从最重要到最不重要排列特征,x 轴上显示对应的重要性分数。
这个图表让我们可以轻松识别数据集中最重要的特征,并确定哪些特征对模型性能的影响最大。
plt.figure(figsize=(12,9))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
这是完整的代码。
# Get the fature importance
feature_importance = rf.feature_importances_
# Print feature importance
for i, feature in enumerate(X_train.columns):
print(f'{feature} = {feature_importance[i]}')
# Visualize feature from the most important to the least important
indices = np.argsort(feature_importance)
plt.figure(figsize=(12,9))
plt.title('Feature Importances')
plt.barh(range(len(indices)), feature_importance[indices], color='b', align='center')
plt.yticks(range(len(indices)), [X_train.columns[i] for i in indices])
plt.xlabel('Relative Importance')
plt.show()
这是输出。
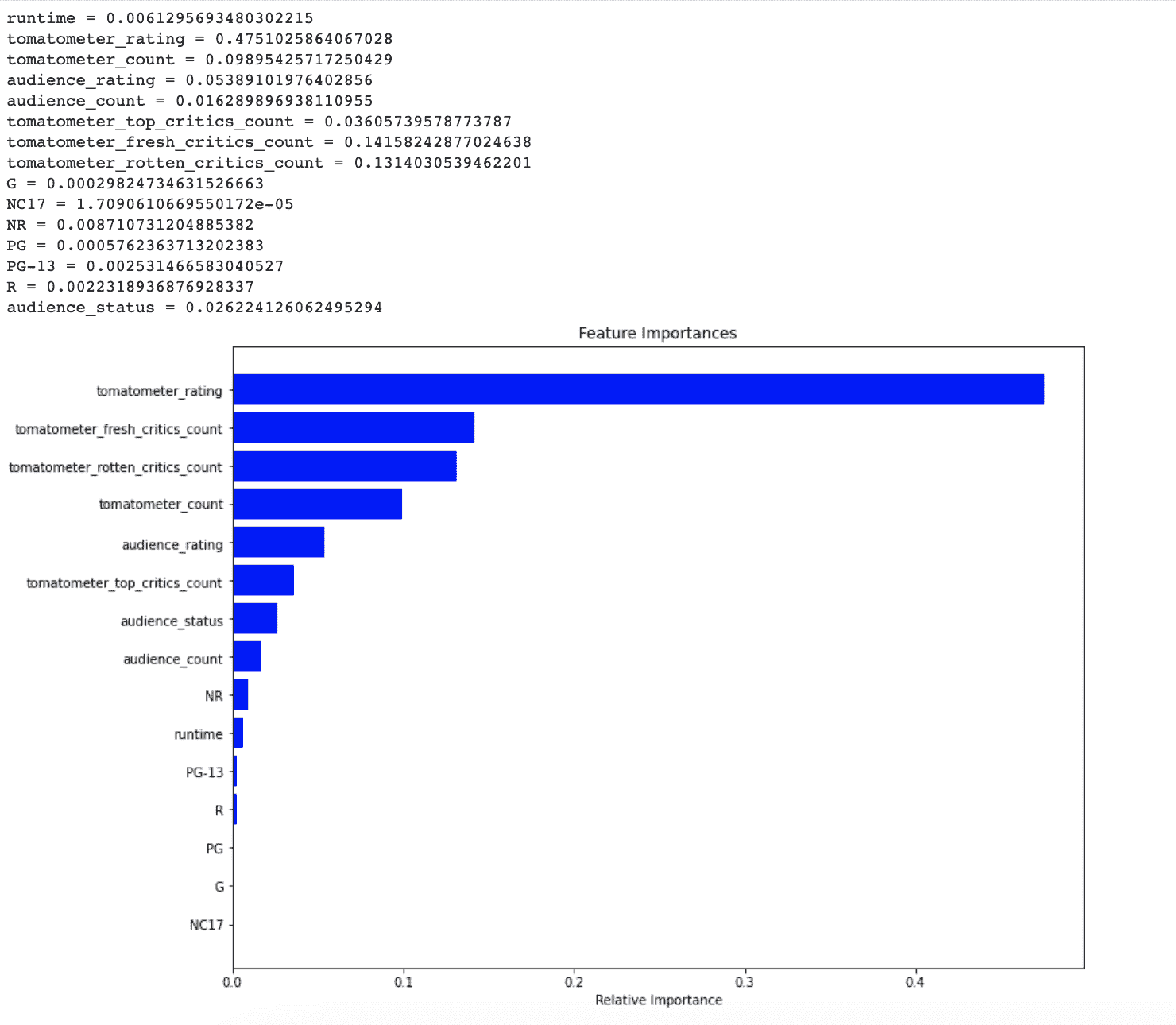
从这个图中可以看出,模型在预测未见数据点时没有考虑 NR、PG-13、R 和 runtime 这些特征。在下一部分,我们将看看解决这个问题是否能提高模型的性能。
随机森林分类器与特征选择
这是代码。
在最后一部分,我们发现一些特征被我们的随机森林模型认为在预测中不太重要。
因此,为了提升模型的性能,让我们排除这些不太相关的特征,包括 NR、runtime、PG-13、R、PG、G 和 NC17。
在以下代码中,我们将首先获取特征重要性,然后将数据集拆分为训练集和测试集,但在代码块内部我们去除了这些不太重要的特征。然后我们将打印出训练集和测试集的大小。
这是代码。
# Get the feature importance
feature_importance = rf.feature_importances_
X_train, X_test, y_train, y_test = train_test_split(df_feature.drop(['tomatometer_status', 'NR', 'runtime', 'PG-13', 'R', 'PG','G', 'NC17'], axis=1),df_feature.tomatometer_status, test_size= 0.2, random_state=42)
print(f'Size of training data is {len(X_train)} and the size of test data is {len(X_test)}')
这是输出。
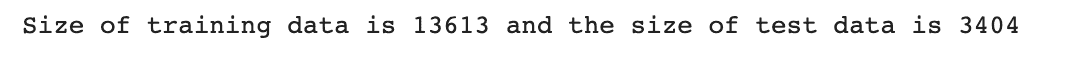
太好了,由于我们去除了这些不太重要的特征,让我们看看性能是否有所提升。
因为我们做了太多次这个,所以我快速解释一下以下代码。
在以下代码中,我们首先初始化一个随机森林分类器,然后在训练数据上训练随机森林。
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train, y_train)
然后,我们使用测试数据计算准确性分数和分类报告并打印出来。
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
最后,我们绘制混淆矩阵。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)
这是完整的代码。
# Initialize Random Forest class
rf = RandomForestClassifier(random_state=2)
# Train Random Forest on the training data after feature selection
rf.fit(X_train, y_train)
# Predict the trained model on the test data after feature selection
y_predict = rf.predict(X_test)
# Print the accuracy score and the classification report
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
# Plot the confusion matrix
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, X_test, y_test, cmap ='cividis', ax=ax)
这是输出。
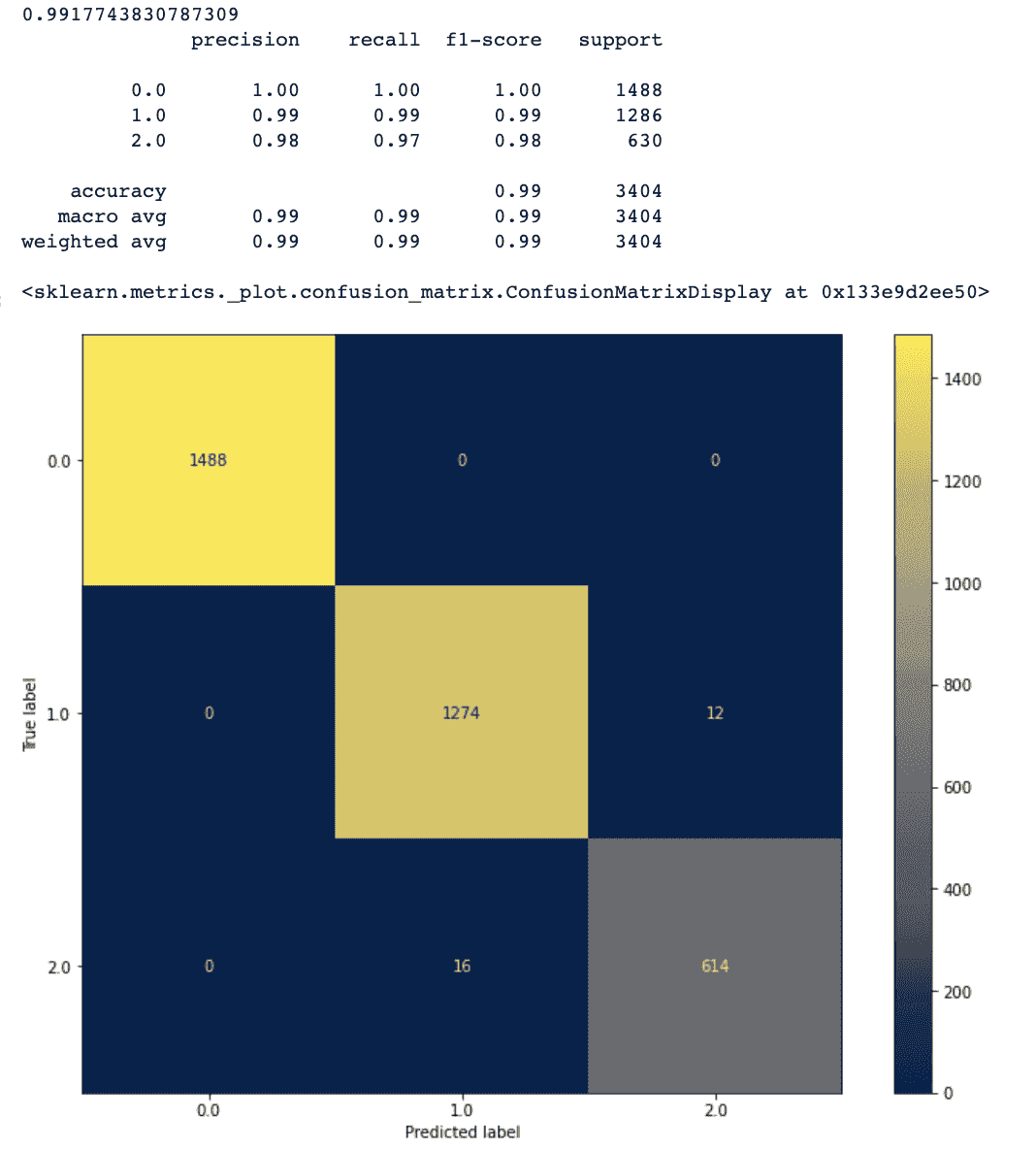
看起来我们新的方法效果相当好。
经过特征选择后,准确率提高到了 99.1%。
与之前的模型相比,我们的模型的假阳性和假阴性率也有所降低。
这表明,特征的数量增多并不总是意味着模型更好。一些不重要的特征可能会产生噪音,这可能是降低模型预测准确度的原因。
既然我们的模型性能已经提升到这个程度,让我们探索其他方法来检查是否能进一步提高。
带特征选择的加权随机森林分类器
在第一部分,我们意识到我们的特征有些不平衡。我们有三个不同的值,'Rotten'(由 0 表示)、'Fresh'(由 1 表示)和'Certified-Fresh'(由 2 表示)。
首先,让我们看看我们特征的分布。
这是可视化标签分布的代码。
ax = df_feature.tomatometer_status.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是输出。
很明显,‘Certified Fresh’特征的数据量远少于其他特征。
为了解决数据不平衡的问题,我们可以使用 SMOTE 算法等方法来过采样少数类,或在训练阶段向模型提供类别权重信息。
这里我们将使用第二种方法。
为了计算类别权重,我们将使用 scikit-learn 库中的compute_class_weight()函数。
在这个函数中,class_weight参数被设置为'balance'以处理类别不平衡,而classes参数被设置为 df_feature 中tomatometer_status列的唯一值。
y参数设置为 df_feature 中tomatometer_status列的值。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)
然后,创建一个字典来将类别权重映射到其相应的索引。
这是通过使用dict()函数和zip()函数将类别权重列表转换为字典完成的。
range()函数用于生成与类别权重列表长度对应的整数序列,然后用作字典的键。
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()
最后,让我们看看我们的字典。
class_weight_dict
这是完整的代码。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature.tomatometer_status),
y = df_feature.tomatometer_status.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dict
这是输出。
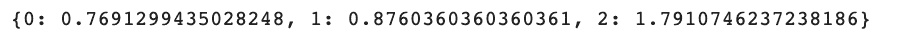
类别 0('Rotten')的权重最小,而类别 2('Certified-Fresh')的权重最大。
当我们应用随机森林分类器时,现在可以将这些权重信息作为参数包括进来。
剩余的代码与之前做过的许多次相同。
让我们用类别权重数据构建一个新的随机森林模型,在训练集上训练它,预测测试数据,并显示准确率和混淆矩阵。
这是代码。
# Initialize Random Forest model with weight information
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
# Train the model on the training data
rf_weighted.fit(X_train, y_train)
# Predict the test data with the trained model
y_predict = rf_weighted.predict(X_test)
#Print accuracy score and classification report
print(accuracy_score(y_test, y_predict))
print(classification_report(y_test, y_predict))
#Plot confusion matrix
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, X_test, y_test, cmap ='cividis', ax=ax)
这是输出。
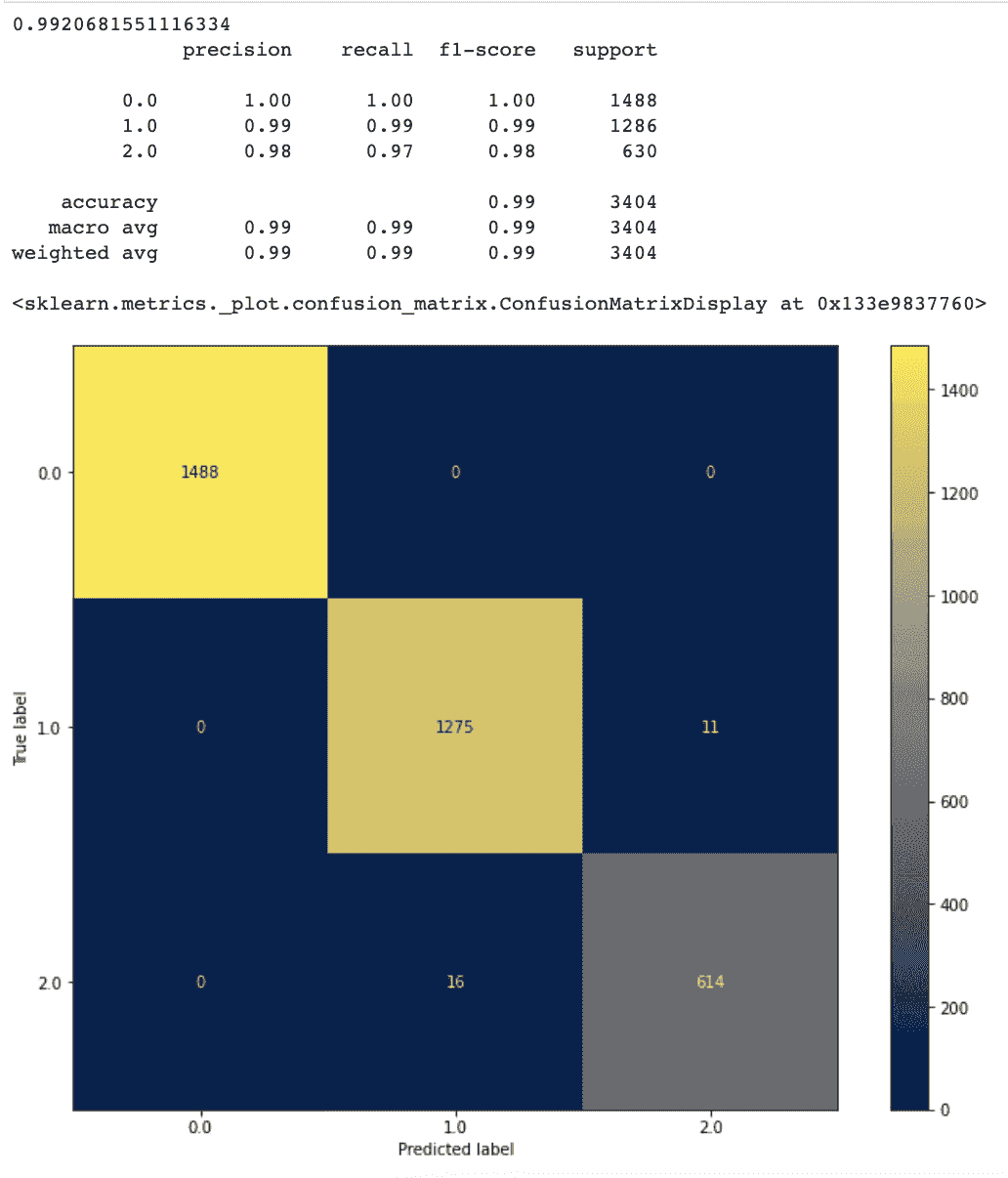
当我们添加类别权重时,模型的性能有所提升,现在准确率达到 99.2%。
“Fresh”标签的正确预测数量也增加了一次。
使用类别权重来解决数据不平衡问题是一种有效的方法,因为它鼓励我们的模型在训练阶段更加关注权重较高的标签。
该数据科学项目链接: platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
Nate Rosidi 是一名数据科学家,专注于产品策略。他也是一位讲授分析学的兼职教授,并且是StrataScratch,一个帮助数据科学家准备顶级公司面试真实问题的平台的创始人。在Twitter: StrataScratch或LinkedIn上与他联系。
更多相关主题
烂番茄电影评分预测数据科学项目:第二种方法
这个数据科学项目曾在 Meta(Facebook)的招聘过程中作为家庭作业使用。在这个家庭作业中,我们将发现烂番茄如何进行“烂片”、“新鲜”或“认证新鲜”的标签。
数据科学项目链接:platform.stratascratch.com/data-projects/rotten-tomatoes-movies-rating-prediction
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
为此,我们将开发两种不同的方法。
作者提供的图片
在我们的探索过程中,我们将讨论数据预处理、各种分类器,以及可能的改进以增强我们模型的性能。
到本帖结束时,你将了解如何使用机器学习预测电影成功,以及这些知识如何应用于娱乐行业。
但在深入之前,让我们先了解一下我们将处理的数据。
第二种方法:基于评论情感预测电影状态
在第二种方法中,我们计划通过评估评论的情感来预测电影的成功。我们将特别应用情感分析来评估评论的整体情感,并根据这种情感将电影分类为“新鲜”或“烂片”。
然而,在开始情感分析之前,我们必须先准备我们的数据集。与之前的策略不同,这种方法涉及处理文本数据(评论),而不是数值和分类变量。对于这个挑战,我们将继续使用随机森林模型。让我们在继续之前,仔细查看一下我们的数据。
首先,让我们读取数据。
这是代码。
df_critics = pd.read_csv('rotten_tomatoes_critic_reviews_50k.csv')
df_critics.head()
这是输出。

作者图片
很好,让我们开始数据预处理。
数据预处理
在这个数据集中,我们没有电影名称和相应的状态。对于这个数据集,我们有 review_content 和 review_type 变量。
这就是为什么我们将把这个数据集与之前的数据集在 rotten_tomatoes_link 上合并,并选择必要的特征进行索引括起来,如下所示。
这是代码:
df_merged = df_critics.merge(df_movie, how='inner', on=['rotten_tomatoes_link'])
df_merged = df_merged[['rotten_tomatoes_link', 'movie_title', 'review_content', 'review_type', 'tomatometer_status']]
df_merged.head()
这是输出结果。

在这种方法中,我们将只使用 review_content 列作为输入特征,将 review_type 作为真实标签。
为了确保数据可用,我们需要过滤掉 review_content 列中的任何缺失值,因为空评论不能用于情感分析。
df_merged = df_merged.dropna(subset=['review_content'])
过滤掉缺失值后,我们将可视化 review_type 的分布,以便更好地理解数据的分布。
# Plot distribution of the review
ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这个可视化将帮助我们确定数据中是否存在类别不平衡,并指导我们选择适合的模型评估指标。
这是完整的代码:
df_merged = df_merged.dropna(subset=['review_content'])
# Plot distribution of the review
ax = df_merged.review_type.value_counts().plot(kind='bar', figsize=(12,9))
ax.bar_label(ax.containers[0])
这是输出结果。
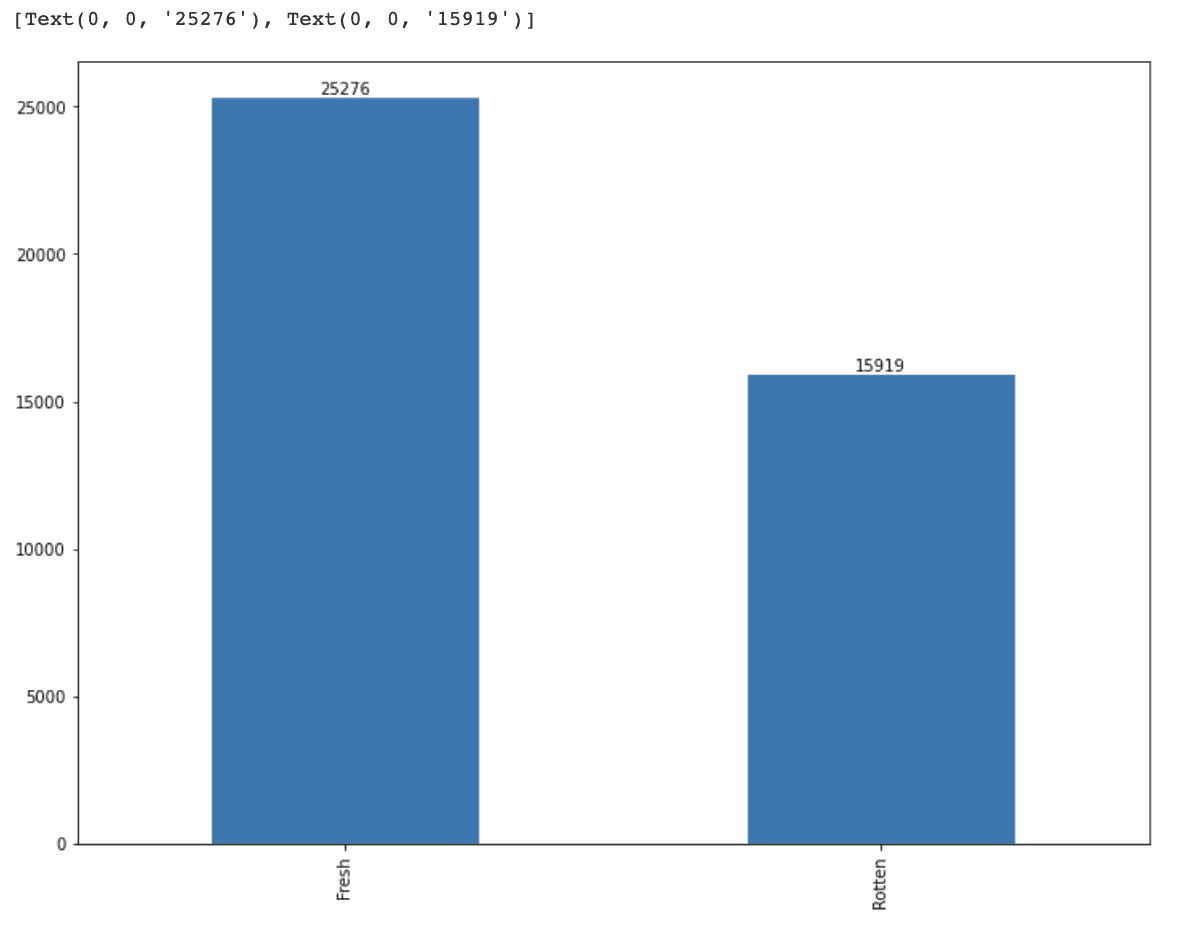
看起来我们在特征之间存在不平衡问题。
而且,我们的数据点也太多了,这可能会降低我们的速度。
所以,我们将首先从原始数据集中挑选 5000 条记录。
df_sub = df_merged[0:5000]
然后我们将进行有序编码。
review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1]))
最后,我们将创建一个数据框,包含使用 Python 的 concat() 方法编码的标签和评论内容,并通过使用 head() 方法查看前 5 行。
df_feature_critics = pd.concat([df_sub[['review_content']]
,review_type], axis=1).dropna()
df_feature_critics.head()
这是完整的代码。
# Pick only 5000 entries from the original dataset
df_sub = df_merged[0:5000]
# Encode the label
review_type = pd.DataFrame(df_sub.review_type.replace(['Rotten','Fresh'],[0,1]))
# Build final DataFrame
df_feature_critics = pd.concat([df_sub[['review_content']]
,review_type], axis=1).dropna()
df_feature_critics.head()
这是输出结果。

很好,现在作为这一部分的最终步骤,让我们将数据集分成训练集和测试集。
X_train, X_test, y_train, y_test = train_test_split( df_feature_critics['review_content'], df_feature_critics['review_type'], test_size=0.2, random_state=42)
默认随机森林
为了在机器学习方法中使用 DataFrame 中的文本评论,我们必须将其转换为可处理的格式。在自然语言处理(NLP)中,这被称为标记化,我们将文本或单词转换为 n 维向量,然后使用这些向量表示作为机器学习算法的训练数据。
为此,我们将使用 scikit-learn 的 CountVectorizer 类将文本评论转换为标记计数矩阵。我们首先通过创建输入文本的唯一术语字典开始。
例如,根据两个评论"This movie is good"和"The movie is bad",算法将创建一个唯一短语的字典,如;
然后,根据输入文本,我们计算字典中每个单词出现的次数。
["this", "movie", "is", "a", "good", "the", "bad"]。
例如,输入"This movie is a good movie"将生成一个向量[1, 2, 1, 1, 1, 0, 0]
最后,我们将生成的向量输入到我们的 Random Forest 模型中。
我们可以通过在向量化文本数据上训练我们的 Random Forest 分类器来预测评论的情感,并将电影分类为“新鲜”或“腐烂”。
以下代码实例化一个 CountVectorizer 类,将文本数据转换为数值向量,并指定一个单词必须出现在至少一个文档中才能包含在词汇表中。
# Instantiate vectorizer class
vectorizer = CountVectorizer(min_df=1)
接下来,我们将使用实例化的 CountVectorizer 对象将训练数据转换为向量。
# Transform our text data into vector
X_train_vec = vectorizer.fit_transform(X_train).toarray()
然后,我们实例化一个具有指定随机状态的 RandomForestClassifier 对象,并使用训练数据拟合随机森林模型。
# Initialize random forest and train it
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train_vec, y_train)
现在是时候使用训练好的模型和转换后的测试数据进行预测了。
然后我们将打印出包含评估指标如精确度、召回率和 f1-score 的分类报告。
# Predict and output classification report
y_predicted = rf.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
最后,我们创建一个指定大小的新图形来绘制混淆矩阵,并绘制混淆矩阵。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax
这是完整代码。
# Instantiate vectorizer class
vectorizer = CountVectorizer(min_df=1)
# Transform our text data into vector
X_train_vec = vectorizer.fit_transform(X_train).toarray()
# Initialize random forest and train it
rf = RandomForestClassifier(random_state=2)
rf.fit(X_train_vec, y_train)
# Predict and output classification report
y_predicted = rf.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax
这是输出。
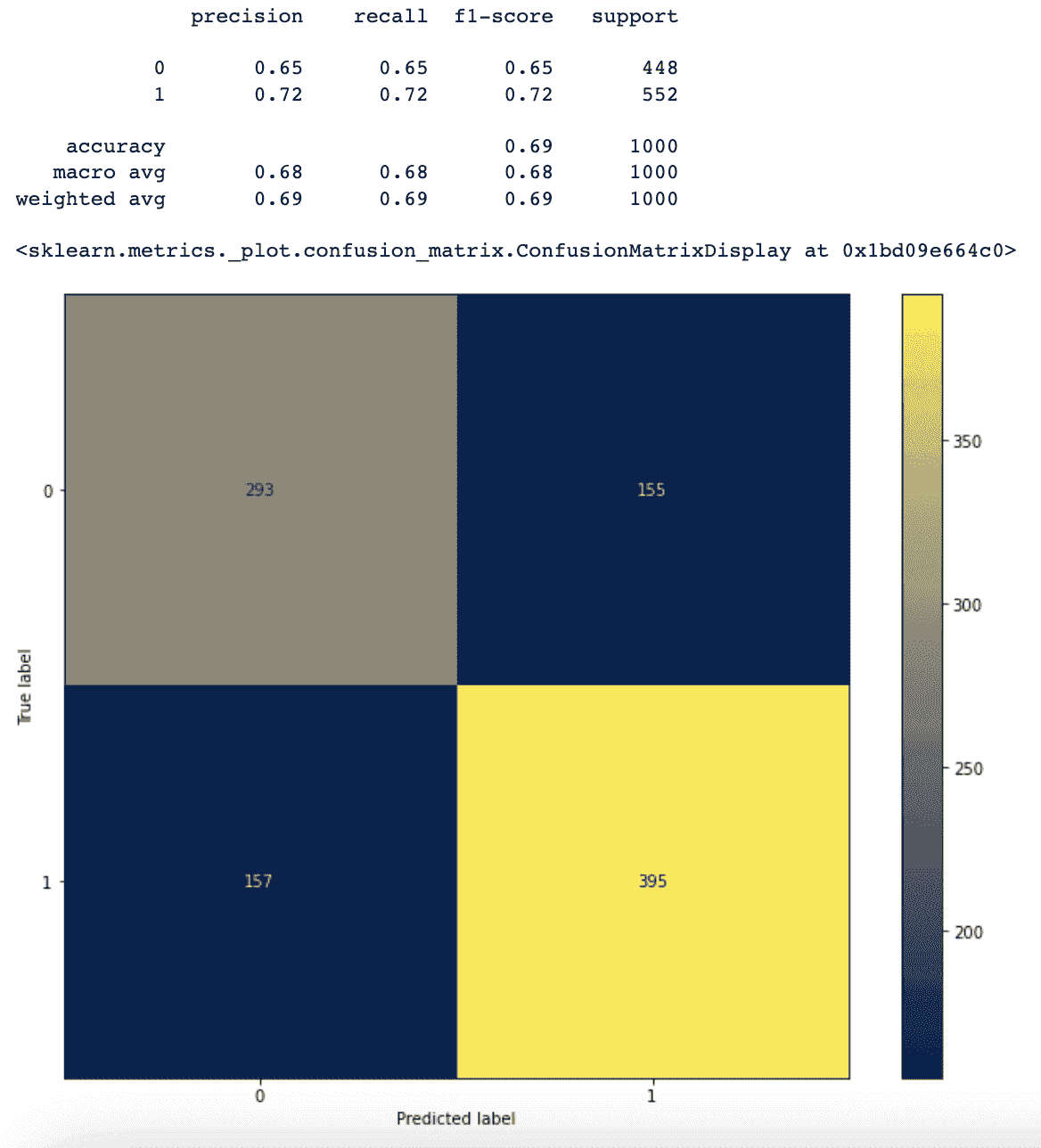
加权随机森林
从我们最新的混淆矩阵可以看出,我们模型的表现还不够好。
然而,由于处理的数据点数量有限(5000 而非 100000),这可能是预期中的结果。
让我们看看是否可以通过解决类别不平衡问题来提高性能。
这是代码。
class_weight = compute_class_weight(class_weight= 'balanced', classes= np.unique(df_feature_critics.review_type),
y = df_feature_critics.review_type.values)
class_weight_dict = dict(zip(range(len(class_weight.tolist())), class_weight.tolist()))
class_weight_dict
这是输出。
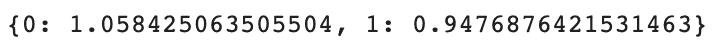
我们现在在向量化的文本输入上训练我们的 Random Forest 分类器,但这次包括了类权重信息,以提高评估指标。
我们首先创建 CountVectorizer 类,并像之前一样将文本输入转换为向量。
并将我们的文本数据转换为向量。
vectorizer = CountVectorizer(min_df=1)
X_train_vec = vectorizer.fit_transform(X_train).toarray()
然后我们将定义一个具有计算类权重的随机森林并进行训练。
# Initialize random forest and train it
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
rf_weighted.fit(X_train_vec, y_train)
现在是时候通过使用测试数据进行预测并打印出分类报告了。
# Predict and output classification report
y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
最后一步,我们设置图形大小并绘制混淆矩阵。
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)
这是完整代码。
# Instantiate vectorizer class
vectorizer = CountVectorizer(min_df=1)
# Transform our text data into vector
X_train_vec = vectorizer.fit_transform(X_train).toarray()
# Initialize random forest and train it
rf_weighted = RandomForestClassifier(random_state=2, class_weight=class_weight_dict)
rf_weighted.fit(X_train_vec, y_train)
# Predict and output classification report
y_predicted = rf_weighted.predict(vectorizer.transform(X_test).toarray())
print(classification_report(y_test, y_predicted))
fig, ax = plt.subplots(figsize=(12, 9))
plot_confusion_matrix(rf_weighted, vectorizer.transform(X_test).toarray(), y_test, cmap ='cividis', ax=ax)
这是输出。
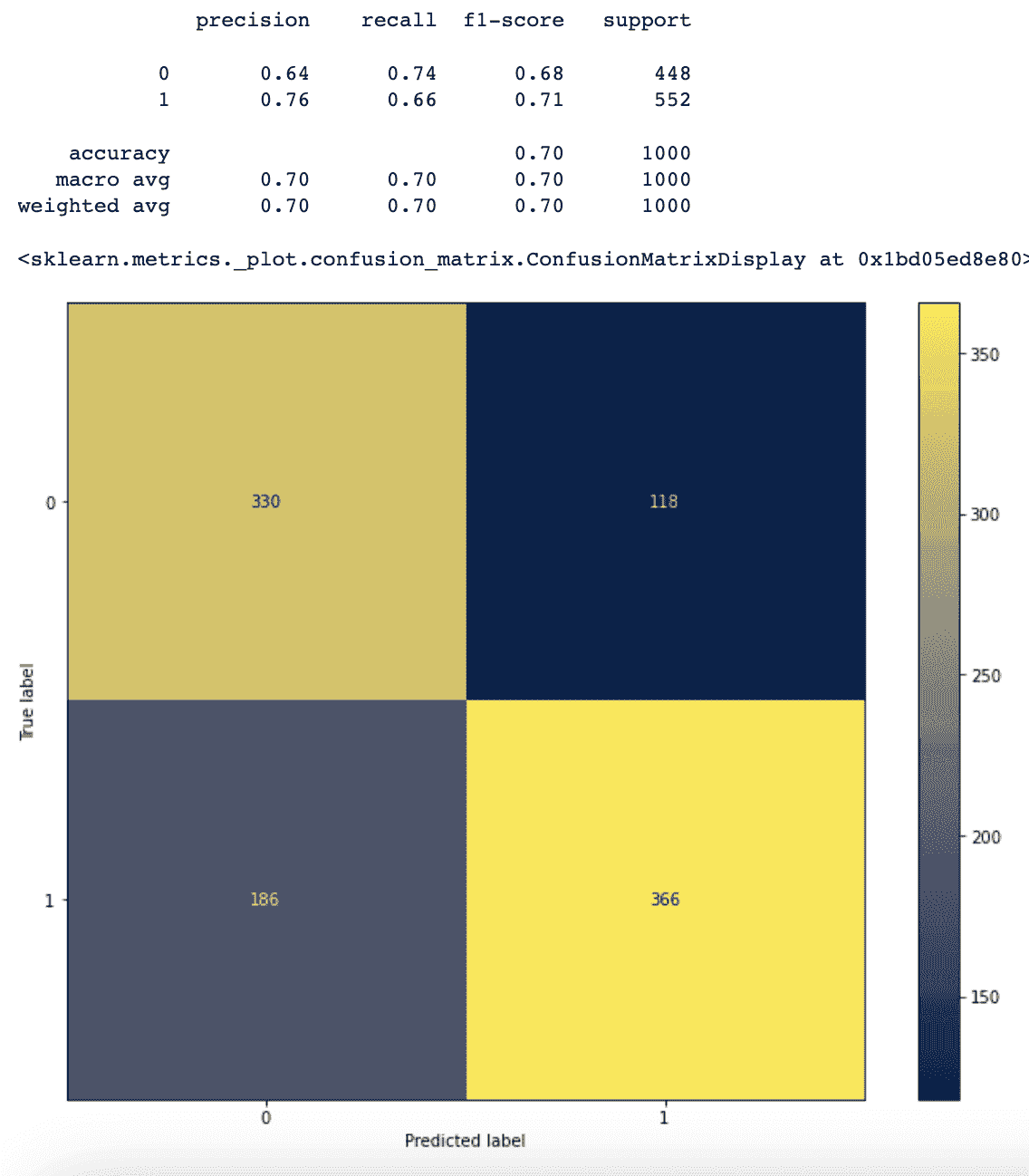
现在我们模型的准确性略高于没有类权重的模型。
此外,由于类 0('Rotten')的权重大于类 1('Fresh')的权重,模型现在在预测 'Rotten' 电影评论方面表现更好,但在预测 'Fresh' 电影评论方面表现较差。
这是因为模型更关注被分类为 'Rotten' 的数据。
电影状态预测
现在我们已经训练了模型来预测电影评论的情感,让我们使用随机森林模型来预测电影状态。我们将通过以下阶段来确定电影的状态:
-
收集某部电影的所有评论。
-
利用我们的随机森林模型来估计每个评论的状态(例如,'Fresh' 或 'Rotten')。
-
根据总的评论状态来分类电影的最终状态,使用 Rotten Tomatoes 网站上给出的基于规则的方法。
在以下代码中,我们首先创建一个名为 predict_movie_statust 的函数,它接受一个预测作为参数。
然后,根据 positive_percentage 值,我们确定电影状态,将 'Fresh' 或 'Rotten' 分配给预测变量。
最终,它将输出带有电影状态的正面评论百分比。
这是代码。
def predict_movie_status(prediction):
"""Assign label (Fresh/Rotten) based on prediction"""
positive_percentage = (prediction == 1).sum()/len(prediction)*100
prediction = 'Fresh' if positive_percentage >= 60 else 'Rotten'
print(f'Positive review:{positive_percentage:.2f}%')
print(f'Movie status: {prediction}')
在这个例子中,我们将预测三部电影的状态:Body of Lies、Angel Heart 和 The Duchess。让我们从 Body of Lies 开始。
'Body of Lies' 预测
如上所述,首先收集 Body of Lies 电影的所有评论。
这是代码。
# Gather all of the reviews of Body of Lies movie
df_bol = df_merged.loc[df_merged['movie_title'] == 'Body of Lies']
df_bol.head()
这是输出。

太好了,在这个阶段,我们应用加权随机森林算法来预测状态。然后我们在之前定义的自定义函数中使用它,该函数接受一个预测作为参数。
这是代码。
y_predicted_bol = rf_weighted.predict(vectorizer.transform(df_bol['review_content']).toarray())
predict_movie_status(y_predicted_bol)
这是输出。

这是我们的结果,让我们通过与 ground_truth 状态进行比较来检查结果是否有效。
这是代码。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Body of Lies'].unique()
这是输出。

看起来我们的预测非常有效,因为我们预测的电影状态是 Rotten。
'Angel Heart' 预测
在这里我们将重复所有步骤。
-
收集所有评论
-
进行预测
-
比较
首先,收集 Anna Karenina 电影的所有评论。
这是代码。
df_ah = df_merged.loc[df_merged['movie_title'] == 'Angel Heart']
df_ah.head()
这是输出。

现在是时候使用随机森林和我们的自定义函数进行预测了。
这是代码。
y_predicted_ah = rf_weighted.predict(vectorizer.transform(df_ah['review_content']).toarray())
predict_movie_status(y_predicted_ah)
这是输出。

让我们进行比较。
这是代码。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'Angel Heart'].unique()
这是输出。
我们的模型再次预测正确。
现在再试一次。
'The Duchess' 预测
首先,让我们收集所有评论。
这里是代码。
df_duchess = df_merged.loc[df_merged['movie_title'] == 'The Duchess']
df_duchess.head()
这是输出结果。

现在是时候进行预测了。
这里是代码。
y_predicted_duchess = rf_weighted.predict(vectorizer.transform(df_duchess['review_content']).toarray())
predict_movie_status(y_predicted_duchess)
这是输出结果。

让我们将预测结果与实际情况进行比较。
这里是代码。
df_merged['tomatometer_status'].loc[df_merged['movie_title'] == 'The Duchess'].unique()
这是输出结果。

电影的实际标签是 '新鲜',这表明我们模型的预测是错误的。
但可以注意到,我们模型的预测值非常接近 60%的阈值,这表明对模型进行微调可能会将预测结果从 '烂' 改变为 '新鲜'。
显然,我们上面训练的随机森林模型并不是最佳模型,因为仍有改进的潜力。在下一部分,我们将提供许多建议,以提高我们模型的性能。
性能改进建议
-
增加你拥有的数据量。
-
设置随机森林模型的不同超参数。
-
应用不同的机器学习模型以找到最佳模型。
-
调整用于表示文本数据的方法。
结论
在本文中,我们探索了两种不同的方法来根据数值和分类特征预测电影状态。
我们首先进行了数据预处理,然后应用决策树分类器和随机森林分类器来训练我们的模型。
我们还尝试了特征选择和加权随机森林分类器。
在第二种方法中,我们使用了默认的随机森林和加权随机森林来预测三部不同电影的状态。
我们提供了改进模型性能的建议。希望本文对您有所帮助。
如果你想要一些初学者级别的项目,可以查看我们的帖子 “数据科学项目想法(适合初学者)”。
Nate Rosidi 是一位数据科学家,专注于产品策略。他还是一位兼职教授,教授分析课程,并且是 StrataScratch、一个帮助数据科学家准备面试的在线平台的创始人。可以在 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关信息
数据科学项目雇主希望看到:如何展示业务影响
原文:
www.kdnuggets.com/2018/12/data-science-projects-business-impact.html
评论
作者:约翰·沙利文, DataOptimal
找工作并不容易,你需要让自己脱颖而出。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
我喜欢的一种策略是建立展示业务影响的投资组合项目。
预测花卉类型可能对初学者有用,但在现实世界中,你将直接或间接地处理一些针对业务方面的工作。
我将逐步讲解如何构建一个在 R 中预测客户流失的模型,以展示显著的业务影响。
以下是过程的简要概述:
-
确定项目范围
-
准备数据
-
适配模型
-
进行预测
-
展示业务影响
-
确定项目范围
在任何实际的数据科学项目开始时,你需要通过提出一系列问题来开始。
以下是几个好的开始:
-
你试图解决什么问题?
-
你的潜在解决方案是什么?
-
你将如何评估你的模型?
假设你在电信行业工作,并且你可以访问客户数据。你的老板来找你,问道,“我们如何利用现有数据改善业务?”这问题相当模糊,所以这是我如何回答上述问题来制定策略以回答老板问题的方式:
你试图解决什么问题?
在查看了你的数据后,你注意到获取新客户的成本是留住现有客户的五倍。现在更具体的问题是,“我们如何提高客户留存率以降低成本?”
你的潜在解决方案是什么?
为了提高客户留存率,我们需要识别潜在的不满客户。如果我们能在客户生命周期的早期进行干预,我们可以提供折扣或替代服务,试图阻止不满客户流失。由于我们有客户数据的访问权限,我们可以构建一个机器学习模型,尝试预测可能会流失的不满客户。为了简化,我们将只使用逻辑回归模型。
你将如何评估你的模型?
我们将使用一系列机器学习评估指标(ROC,AUC,灵敏度,特异性)以及以业务为导向的指标(成本节约)。
- 准备数据
下一步是准备数据。
这个工作流程会因项目而异,但在我们的示例中,我将使用以下工作流程:
-
导入数据
-
快速查看
-
清理数据
-
拆分数据
我省略了完整的探索阶段,因为我希望未来专门写一篇文章来讨论它。探索阶段与建模阶段一样重要,甚至更重要。
要查看包含所有步骤的完整代码,请查看原始帖子。这里是 R 语言中前两步的快速快照:
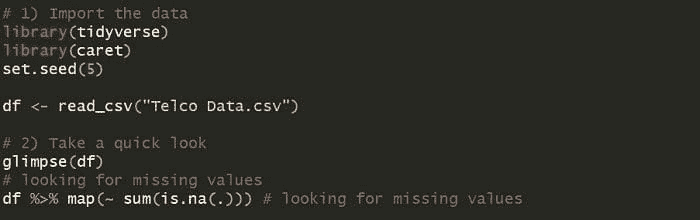
虽然未显示,但在清理步骤中,我使用中位数填补了缺失值。这是一种简单的方法,但你绝对应该查看更严格的统计方法。
在最后一步,我将数据拆分为训练集和测试集,分别使用 75%和 25%的数据。这总是一个好的做法,有助于防止过拟合。
- 拟合模型
为了实现逻辑回归模型,我们将使用广义线性模型(GLM)函数,即 GLM。
有不同类型的广义线性模型,其中包括逻辑回归。为了指定我们要执行二元逻辑回归,我们将使用参数“family=binomial”。

- 进行预测
现在我们已经拟合了模型,是时候看看它的表现如何了。
为此,我们将使用“测试”数据集进行预测。我们将传入前一节的“拟合”模型。为了预测概率,我们将指定“type=response”。

我们将设置响应阈值为 0.5,因此如果预测概率高于 0.5,我们将把这个响应转换为“是”。
下一步是将字符响应转换为 因子类型。这样可以确保编码对于逻辑回归模型是正确的。

我们稍后将更详细地查看阈值,所以不用担心为什么我们设置为 0.5。
最终步骤是评估我们的模型。
一个有用的工具是混淆矩阵。它显示了每个类别的正确和错误预测的数量。


敏感性(真实正类率)和 特异性(真实负类率)也是“confusionMatrix”函数报告的有用指标。

另一个有用的指标是 接收者操作特征(ROC)曲线下面积,也称为 AUC。
ROC 是一个很好的工具,因为它绘制了真实正类率(TPR)与假正类率(FPR)在阈值变化时的关系。以下是如何使用“ROCR”库来绘制它:
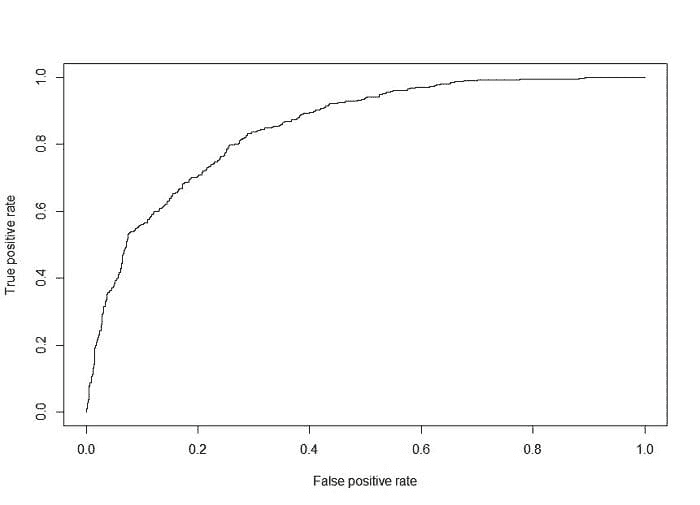
使用此图的一个有用方法是计算曲线下面积,也称为 AUC。AUC 的值范围从 0 到 1,1 为最佳。以下是计算 AUC 的 R 代码:


我们的模型的 AUC 为 0.85,这相当不错。如果我们只是随机猜测,我们的 ROC 将是 45 度的直线。这将对应于 AUC 为 0.5。至少,我们的表现优于随机猜测,所以我们知道我们的模型至少添加了一些价值!
- 展示业务影响
最终步骤是将我们迄今为止所做的一切转化为业务影响。
让我们先对成本做一些假设。我们假设在电信行业获取新客户的成本是 $300。我们之前提到的数据表明,获取新客户的成本是保留现有客户的五倍,所以我们的保留成本将是 $60。
这是这些成本与四种预测类型相关的简要总结:
-
错误负类(预测客户不会流失,但实际上他们会):$300
-
真正正类(预测客户会流失,并且他们确实会):$60
-
假正类(预测客户会流失,但实际上他们不会):$60
-
真阴性(预测客户不会流失,而他们确实不会流失):$0
如果我们将每种预测类型的数量乘以相关成本并求和,我们得到以下成本公式:
成本 = FN($300) + TP($60) + FP($60) + TN($0)
让我们计算在不同阈值(0.1, 0.2, 0.3,…,0.9, 1.0)下每位客户的成本。在初始化阈值向量“thresh”后,我可以循环遍历每个阈值并进行预测。由于我在按客户计算成本,因此我将按测试集中的总数据点数量进行除法。
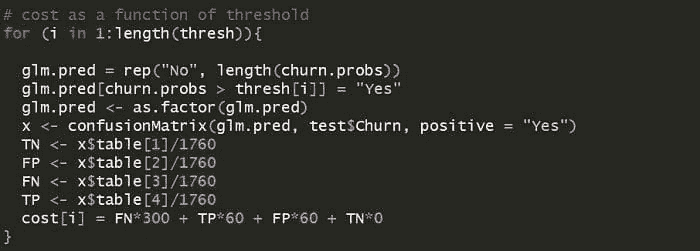
最后,我将结果放入数据框中,连同我称之为“简单”模型的内容。这是我们之前的逻辑回归模型,默认阈值为 0.5。

图表显示,客户的最低成本约为$40,阈值为 0.2。
假设我们的公司目前使用的是“简单”模型,该模型在 0.5 的阈值下每位客户的成本约为$48。
如果我们有大约 500,000 的客户基础,那么从简单模型切换到优化模型每年可节省$4MM 的成本!这种成本节省是雇主们非常希望看到的显著业务影响。
结论
在求职过程中,脱颖而出的最佳方法之一是构建展示真实业务影响的作品集项目。
如果你能提出聪明的商业问题并像现实世界中的数据科学家一样完成项目,你将立即对雇主更具价值。
欲了解完整的逐步教程和 R 代码,请查看原始帖子。
一如既往,确保在你的 GitHub 页面和 LinkedIn 个人资料上记录你的工作。
保持积极,继续构建项目,你将顺利找到工作。祝你求职顺利!
个人简介:约翰·沙利文是数据科学学习博客DataOptimal的创始人。你可以在 Twitter 上关注他 @DataOptimal。
资源:
相关:
更多相关话题
数据科学项目可以帮助你解决现实世界问题
原文:
www.kdnuggets.com/2022/11/data-science-projects-help-solve-real-world-problems.html

作者提供的图片
实践项目是学习数据科学和机器学习的最佳方式。数据科学作业将使你接触到这一领域的各个方面,并帮助你通过实际的 SQL、R 或 Python 经验磨练技能。它不仅会帮助你提升数据科学技能并获得自信,还能让你制作出引人注目的简历。本文将讨论各种适合初学者的数据科学项目创意,帮助你建立强大的数据科学组合。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
随着今天数据的指数增长,数据科学已成为最受追捧的领域。现今的公司如果有效利用数据科学,将获得竞争优势。这导致了所有公司对数据分析师和数据科学家的职位空缺增加。为了在这个领域找到工作,通过建立数据分析项目来展示你的技能是个不错的主意。在我们开始讨论这些项目之前,让我们看看为什么数据科学项目能帮助你找到工作,以及为什么你应该拥有一个令人印象深刻的数据科学项目组合。
为什么你应该建立一个数据科学项目组合?
如果你对数据科学领域真正感兴趣,你应该对数据科学解决了什么样的问题及如何解决这些问题有一个基本的了解。如果你想进入这个领域,你需要了解解决特定数据科学问题所需的技能。在线课程和书籍只能带你到一定的水平,但如果你真的想进入这个领域,你应该了解数据是如何用于解决实际问题的。要理解这一点,参与项目是获取进入数据科学所需的所有技能的唯一途径。
数据科学项目将帮助你理解解决问题所需的各种步骤:
-
定义问题并将其拆分为更小的步骤
-
数据收集
-
探索性数据分析
-
模型构建
-
数据可视化和讲故事
图片来自作者
问题定义
这是任何数据科学项目的第一步。任何数据科学项目都从这一步开始,你需要清晰地理解和定义问题。这是数据科学项目生命周期中最重要的方面之一。例如,如果你想投资特斯拉股票,但你想了解零售投资者如何看待这家公司,以及总体情绪如何?那么你需要清晰地定义这个问题。在这个例子中,你的问题陈述是:“了解特斯拉在零售投资者中的感知如何?”
一旦你确定了问题,你需要了解解决该问题需要什么类型的数据。
数据收集
一旦你确定了问题,下一步是数据收集。你需要识别可以解决你在第一步中定义的问题的数据来源。你可能需要使用 API 从一个或多个来源获取数据。
以第一点讨论的示例为例,假设你打算投资特斯拉股票,但想了解零售投资者对这家公司的总体情绪。为了解决这个问题,你需要收集零售投资者对这家公司评论的信息。你决定去推特上查看人们对这些公司不同公告的反应。你可以浏览单独的推文并理解情绪,因为会有数百万条推文可供查看。
在这种情况下,你需要获取谈论特斯拉的推文数据。为了获取这些数据,你将创建一个推特开发者账户,并使用 Python 通过 Twitter API 提取推文。这些将是解决任何项目所需的数据收集步骤。在大多数公司中,有专门的数据工程师负责数据收集,但有时数据科学家也需要具备这些使用 API 收集信息的技能。
探索性数据分析
这是数据科学项目生命周期中的另一个重要步骤。探索性数据分析旨在理解数据,识别所需的列,删除冗余列,处理缺失值,检测异常值,并识别数据中的模式。
在上述讨论的 Twitter 示例中,你需要清理推文,删除冗余信息,仅保留分析所需的相关推文,了解推文随时间的变化以寻找季节性等。这个步骤用于理解和探索数据,并在数据不符合需求时进行修改。
模型构建
一旦你定义了问题、收集了数据并使用 EDA 技术进行了初步分析,你将开始进入模型构建阶段。当你定义一个问题时,你会意识到这个问题是否可以通过监督学习或无监督学习算法来解决。根据问题的需求,你需要了解使用什么模型。
这一阶段需要一些时间来理解哪个模型对你的问题最为相关。市场上有许多模型可以用来解决同样的问题,因此,你需要根据模型的准确性来评估这些模型。评估是一个耗时的过程,因为这个步骤涉及大量的试验和错误。一旦你的模型构建完成并且表现足够好,你就可以开始进行数据可视化和讲故事。
在上述讨论的 Twitter 示例中,你可以使用标记的数据集(每条推文的信息标记为正面/负面/中性)来训练机器学习模型。模型训练完成后,你需要输入一条新推文来测试该模型的性能。一旦你测试了多个样本,你可以检查假阳性和假阴性的数量来了解模型的表现。你需要尝试其他模型,以比较不同分类算法的准确性。
数据可视化与讲故事
如果你认真进行分析但无法有效地传达故事,那么它是没有用的。将从数据中发现的见解传达给非技术观众是数据科学家所需的最重要的技能之一。有许多工具和技术可用于讲故事。你可以使用 Tableau 或 Power BI 来帮助你构建更好的可视化效果。
现在我们已经讨论了数据科学项目中需要采取的步骤,让我们关注一些你可以参与的实际数据科学项目。
数据科学项目创意
互联网上有许多资源可以帮助你入门数据分析和数据科学项目。在本节中,我们将讨论一些你可以用于解决实际问题的项目创意。第一步将是识别数据来源,我们也会讨论这一点。

图片由作者提供
倾向建模
一种称为“倾向建模”的方法旨在预测网站用户、潜在客户或客户采取特定行动的可能性。这是一种统计方法,通过考虑所有可能影响客户行为的独立因素和混杂因素,来识别客户进行某项行动的概率。

图片由作者提供
例如,营销团队可以使用倾向模型来了解和确定潜在客户转化为付费客户的概率或可能性。它也可以用来了解现有客户从平台上流失的可能性。因此,倾向建模可以帮助公司明智地分配资源,从而获得更好的结果,降低成本。例如,公司可以通过倾向建模识别哪些客户更可能对电子邮件做出回应,从而只向这些特定客户发送电子邮件,这将节省时间和资源。在 kaggle 上有一个很好的数据集用于倾向建模,以了解客户购买特定产品的倾向。
实际案例
许多公司使用倾向建模。倾向建模可以应用于许多场景,如确定购买倾向、流失倾向、参与倾向或预测客户终身价值。
这种方法主要被 Facebook/Meta、Google、Amazon 等公司的营销团队使用。营销团队严重依赖客户倾向分数来决定是否投资于特定的客户群体。因此,拥有一个倾向建模项目在你的作品集中是必须的。在 kaggle 上有一个很好的倾向建模示例,以了解哪些客户可以通过他们的营销活动来进行目标。
文本分析
随着技术进步和数字化,信息量巨大的现象出现。在所有这些信息中,互联网中有大量的文本数据。公司利用这些文本数据了解客户对其公司的看法,以及他们对产品的评价,从而调整策略。在 kaggle 上有一个很好的项目,可以对电影评论数据集进行情感分析。
作者提供的图片
在文本分析中有许多领域,其中之一是自然语言处理(NLP)。NLP 用于将文本数据分解成机器可读的格式,标记化文本数据,从数据中提取含义,并识别洞察。自然语言处理有许多应用;例如,理解客户的情感,构建对话代理或聊天机器人,开发类似 Alexa 或 Siri 的服务,构建语言翻译引擎等等。因此,在你的作品集中有与自然语言处理相关的项目是一个好主意。
现实世界的例子
在今天的世界中,几乎所有公司都使用文本分析或自然语言处理来了解他们的客户并开发创新产品。例如,Facebook/Meta 大量使用文本分析。与主要以视频和照片形式存在数据的 Instagram 不同,Facebook 的数据大多是文本数据。他们使用这些文本数据自动将帖子分类到不同类别,并自动删除有攻击性的帖子。实际上,Facebook 开发了一种名为 Deep Text 的内部工具,用于分析和提取帖子含义,从而自动识别攻击性帖子并将其从平台上删除。
除了 Facebook,还有许多公司使用文本分析和机器学习为客户构建创新解决方案。例如,亚马逊开发了 Alexa,这是一个智能虚拟助手。Alexa 能够准确地回应客户查询,因为它在后台使用复杂的机器学习算法,首先将语音转换为文本,然后使用 NLP 识别文本的含义,再利用机器学习模型预测最佳的回应,然后将回应转换为音频输出。
因此,文本分析或自然语言处理被大多数创新公司在当今世界中使用,拥有一个 NLP 项目在你的作品集中,将有助于你在下次面试中脱颖而出。
推荐引擎
推荐系统是一类扩展的网络应用,旨在根据用户的历史数据识别用户的响应,并推荐用户最有可能采取的新产品或新行动。推荐引擎可以分为两个主要组别:基于内容的系统和协同过滤系统。
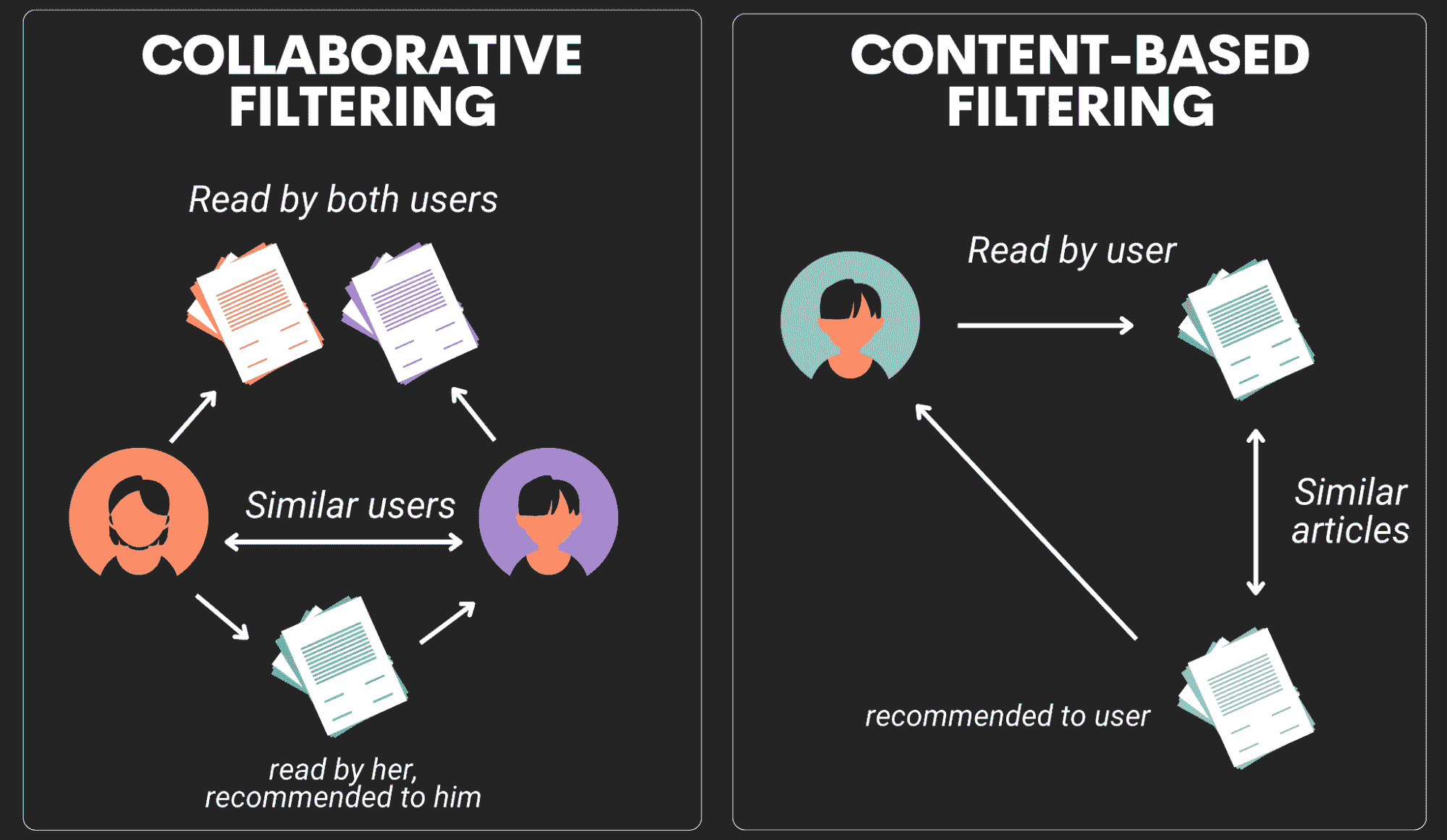
作者图像
基于内容的系统:在这些引擎中,推荐是基于物品的内容。例如,如果你在 Netflix 上观看了很多科幻电影,那么 Netflix 会推荐你一些来自惊悚类别的新电影,这些电影可能具有类似的类别。
协同过滤系统:在这些引擎中,推荐是基于两个用户之间的相似性。如果两个用户相似,他们可能会收到相似的推荐。例如,根据历史数据,如果用户 1 和用户 2 观看了相似的电影,那么推荐系统会向用户 1 推荐一部用户 2 可能看过的新电影。因此,推荐给用户的物品是类似用户所偏好的。
学习任何概念的最佳方式是通过做项目,在 Python 中构建一个时尚推荐引擎是一个非常好的选择。
现实世界的例子
最常见的推荐系统之一是 Netflix,它根据客户的历史使用情况推荐新电影、节目和纪录片。亚马逊也使用推荐系统,根据客户的购买或浏览历史推荐类似的产品。
利用其收集的大量数据,Netflix 创建了一个推荐引擎,几乎能实时运作。Netflix 收集每个用户的信息,然后根据他们观看、搜索、添加到观看列表等内容对用户进行排名。这类数据被包含在大数据中,所有数据都存储在数据库中,机器学习算法可以利用这些数据创建模式,揭示观众的偏好。由于每个用户可能有不同的口味,这些模式可能与另一个用户匹配,也可能不匹配。推荐系统根据这些评分向每位客户呈现用户可能观看的电视剧或电影。
聊天机器人
被称为聊天机器人(chatbots)、谈话机器人(chatter-bots)或对话代理(conversational agents)的软件程序,通常用来代替人工代理来协助客户。你是否曾访问过一个客户服务网站,与一名代表聊天,然后发现你实际上是在与一个“机器人”交谈?所以你知道聊天机器人是什么了!

图片由作者提供
聊天机器人通常通过独立应用程序或基于网页的应用程序供用户访问。如今,客户服务是聊天机器人在现实世界中最常用的领域。聊天机器人通常接管以前由实际人类执行的工作,如客户服务代表或支持人员。
聊天机器人是复杂的计算机程序,分析客户文本聊天以确定合适的回答。所有这些机器人都利用自然语言处理(NLP),这通常包括两个步骤:自然语言理解,将客户提供的文本转化和解构;和机器学习模型,帮助机器人理解和提取句子的含义。客户文本的回应在第二步中形成,称为自然语言生成,使用第一步创建的含义。创建聊天机器人的基础通常是 NLP。
真实世界的例子
近年来,人工智能(AI)引发了一波变革。它已成为每个行业的标准技术。顾客愿意与聊天机器人互动,如果它们实现得当,如一些大型企业使用的成功聊天机器人示例和案例研究所展示的那样。因此,实施适当的机器人策略并根据使用案例定制聊天机器人对整个客户体验至关重要。
许多公司已经实现了成功的聊天机器人用于处理基本查询:
-
Dominos 已通过 Facebook Messenger 实现一个聊天机器人以确保顺畅的订单相关问题回答系统。
-
HDFC 银行已实现一个聊天机器人来回答客户关于金融的基本问题。
还有许多其他公司建立了聊天机器人,因此,将此项目纳入您的作品集是一个好主意。
总结
进入数据分析和数据科学领域,非常重要的是建立一个项目作品集,这将帮助您理解问题解决过程,并在下次面试中建立一个强有力的案例。本文讨论了构建项目对获得数据科学家所需相关技能的关键性。我们讨论了解决数据科学问题的步骤:问题定义、数据收集、探索性数据分析、模型构建和数据可视化与讲故事。
你可以通过实际项目经验来获得所有这些技能。我们还讨论了一些现实世界的项目想法以及公司如何在今天的世界中利用它们。在 StrataScratch,你可以参与由许多公司提供的小项目,这些项目被称为 家庭作业。因此,抓住机会,开始实践,为你的下一个面试准备好你的作品集。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名副教授,教授分析学,并且是 StrataScratch、一个帮助数据科学家准备面试的在线平台的创始人。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关话题
2022 年能让你获得工作的数据科学项目
原文:
www.kdnuggets.com/2022/05/data-science-projects-land-job-2022.html

正如数据行业的从业者无数次提到的,构建数据科学项目是进入该领域最简单的方法之一,尤其是当你没有硕士学位时。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
在我 2020 年写的上一篇文章中,我提供了一些数据科学项目的想法,你可以将这些项目添加到你的作品集中,以增加获得工作的机会。距离那时已经过去两年了。
在行业工作了一段时间,与数据科学招聘经理交谈,并审阅了简历后,我对应该添加到简历中的项目类型有了略微不同的看法。
在这篇文章中,我将为你提供有关应添加到你的作品集中的项目类型的建议,包括哪些项目应添加,哪些不应添加。一些项目实际上对你的简历有害,展示这些项目可能会导致你的申请被淘汰。
我还将提供一些项目想法,包括教程和源代码作为参考材料。确保你不要完全照搬这些项目——稍微修改代码并加入你自己的独特创意,最重要的是,确保你理解你在做什么。数据科学面试官几乎总是会要求你解释过去的项目和源代码,如果你不了解自己的工作,将很难通过面试阶段。
你应添加哪些项目到你的作品集中,哪些项目应避免?
做:创建能通过数据解决问题的项目
我经常看到人们构建数据科学项目时忽略了最终目标。
我曾经查看过一个候选人的 GitHub 资料,看到数百行 EDA 和五颜六色的图表。它看起来不错,但我不知道他的目标是什么。坦白说,我觉得他自己也不知道,因为他无法准确解释他试图通过分析实现什么。
这个候选人犯了一个常见的错误?—?他过于专注于展示他知道如何构建不同类型的图表、预处理和操控数据。过多关注代码、库和工具,而不是关注从分析中得出实际结果。
大多数招聘经理并不真正关心你使用的库和工具。他们想了解你的思维过程,以及你为什么决定采取这种方法来解决问题。他们想知道你在得出结果的过程中遇到了哪些困难,以及你应用了哪些方法来克服这些困难。
如果你能够带领他们了解整个数据科学项目,并解释你做了什么和为什么这么做,你将给雇主信心,证明你的推理能力。这表明无论你使用什么程序或库,你都能解决出现的任何问题。
不要:创建过度使用的项目
泰坦尼克号生存预测、波士顿房价预测和鸢尾花分类是你不应该在简历中展示的项目。
虽然这些项目是提升你机器学习技能的好方法,但它们太简单且常见,不适合在简历上展示。这些数据科学项目非常流行,其他候选人可能也会在他们的申请中展示这些项目。
如果招聘经理审阅了 50 份简历,而你展示了与 40 个其他候选人相同的项目,你的简历很可能会被丢弃,因为你没有从人群中脱颖而出。
由于这些项目相对简单,雇主可能会觉得你的数据科学知识很浅显,仅停留在表面。
数据科学项目来建立你的作品集
以下是一些能够增强你简历并帮助你在面试中脱颖而出的项目示例:
1. 流失预测
客户流失率是指消费者停止与组织进行业务的比率。高客户流失率对公司不利,如果他们能预测到用户即将停止购买,他们会采取措施防止这种情况发生。
这是数据科学在组织中的最流行应用之一。
如果你在简历中展示一个客户流失预测模型,你将吸引招聘经理的注意,因为这是一个他们熟悉的用例。这帮助你在展示没有实际业务相关性的项目的其他候选人中脱颖而出。
这里有一个我在线找到的教程,你可以跟随它来学习如何预测客户流失。一旦你理解了代码并熟悉流失预测模型的工作原理,我建议从头开始构建你自己的算法。不要在没有充分理解的情况下复制别人的代码,否则你会发现很难通过面试或回答与项目相关的问题。
2. 客户细分
客户细分是将公司的目标受众划分为不同用户组的过程。每个组的模式会相似。
我推荐创建这样的项目,因为它也是组织中常见的数据科学用例,并且能为公司增加商业价值。
你可以跟随我创建的客户细分教程,使用 Kaggle 的 Mall Customer Segmentation dataset 进行编码。我进行了探索性数据分析、预处理,并最终建立了一个模型,将购物中心的客户细分为不同的用户组。我还提供了如何接触这些个人的建议,以及他们可能感兴趣的产品类型。
3. 出租车行程时间预测
共享出行公司如 Uber 经常需要预测出租车到达时间以及车辆到达目的地所需的时间。
这是一个为组织增加价值的机器学习应用,并且在你的简历上看起来很棒。你可以使用 Kaggle 上的 NYC Taxi Trip Duration dataset 来进行这个项目。
这个数据集已经有一些现有的解决方案来预测出租车行程时间,你可以使用 this 代码笔记本作为参考来构建你的模型。
额外的求职数据科学职位技巧
1. 总是优先考虑质量而非数量
在你的简历中,最好有 2 到 3 个完整的端到端项目,而不是 10 个简单的常见项目。招聘经理通常会要求你详细介绍一个完整的数据科学项目以及你是如何实施的。确保这个项目不如《泰坦尼克号》或《虹膜花预测》那样简单。
2. 在简历中包括不同类型的项目
我上面列出的项目主要集中在机器学习上。确保还展示涉及数据收集、预处理和 EDA 的项目,因为许多数据科学职位要求的技能集不仅仅限于模型构建。
3. 具有创造性和原创性
招聘经理每天都会浏览数百份申请。为了真正让自己脱颖而出,你需要具备创造力。展示讲述故事的项目?——一些他们可能以前没有见过的项目。这里有一些我创建的独特作品集项目的示例,它们帮助我获得了第一份数据科学工作。
尝试进入一个全新的领域可能会让人感到不知所措,尤其是当你没有任何正式的培训背景时。然而,借助大量的在线课程、教程和互联网上发布的源代码,你几乎可以学到关于该领域的所有知识,从而获得数据科学职位。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在LinkedIn上与她联系。
更多相关内容
数据科学难题 — 2020 年版
原文:
www.kdnuggets.com/2020/02/data-science-puzzle-2020-edition.html
评论
关于数据科学韦恩图的一些看法(原始来源:Saurav Dhungana)
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
新的一年已经到来,让我们重新审视数据科学难题的现状。数据科学领域中最重要的组成概念是什么?它们如何相互结合?这些概念中哪些在上一期之后变得更为重要,哪些则变得不那么重要?
由于距离我上次处理这个特定话题已经过去了几年,出于兴趣和比较的目的,值得看看这个。我们将首先回顾一下上次的概念定义,然后看看自那时以来情况有何变化。
我们从被认为是数据科学革命最初驱动因素的大数据开始。2017 年我所说的:
大数据仍然对数据科学很重要。无论你选择什么比喻,大数据都是继续推动数据科学革命的原材料。
关于大数据,我相信从商业角度来看,数据获取和保留的正当性、大数据项目开始提供实际财务回报的期望,以及与数据隐私和安全相关的挑战,将成为不仅仅是 2017 年,而且在未来的大数据重要话题。简而言之,现在是时候从大数据中获得丰厚回报,并对其进行严格保护了。
然而,正如其他人所言,大数据现在“就是如此”,也许不再是一个值得特别关注的实体,尽管它在过去十年中获得了很多关注。
虽然我通常不赞成对大多数关键术语进行大写处理,但“大数据”似乎之前需要这种处理,因为它具有近乎传奇的地位和品牌名称般的地位。请注意这次我已经撤销了这种地位,这与大数据不再是顶级数据科学术语的想法相一致。如最后一句话所暗示的,往前看,大数据仅仅是“数据”,我们可以将这一段摘录重新表述为,"数据是继续推动数据科学革命的原材料"。
看,现在我们都应该意识到数据对数据科学过程的重要性(这在名称中就已经体现了)。无论我们的数据是大还是小,或者处于数据规模光谱的其他位置,从一开始就不需要区分。我们都想对数据进行科学分析并提供价值,无论数据多还是少。“大数据”可能为我们提供更多或独特的分析和建模机会,但这似乎类似于在一开始就区分我们指甲的大小,以便知道需要带什么大小和类型的锤子来完成某项工作。
数据无处不在。大多数数据是大的。现在是时候不再强调这一点,就像我们不再说“智能”手机一样。现在的手机基本上都是智能的,特别指出这一点更多的是在讲述你自己,而不是手机。
然而,我坚持认为,随着时间的推移,数据隐私和安全相关的挑战只会变得越来越重要,我们还可以将伦理学纳入其中,尽管认真对待这些话题超出了本文的范围。
这是我上次关于机器学习作为数据科学组件的说法:
机器学习是数据科学的主要技术驱动因素之一。数据科学的目标是从数据中提取洞见,而机器学习是使这一过程能够自动化的引擎。机器学习算法不断促进计算机程序从经验中自动改进,这些算法在各种不同领域变得越来越重要。
我坚持这一观点,并且只会论证机器学习不仅是数据提取的主要技术驱动因素之一,它是唯一的主要技术驱动因素。
数据科学有很多方面;我们在本文中讨论了其中的几个。然而,当考虑从通过描述性统计或这些统计数据的可视化或某种业务智能报告——所有这些都可以在适当情况下提供非常有用和宝贵的启示——看不见的数据中提取洞见时,机器学习是自然的选择,这一路径本身就蕴含了自动化。
机器学习与数据科学并不完全等同;然而,鉴于机器学习在从数据中提取见解的依赖性,你可以理解那些经常混淆这两个概念的人。
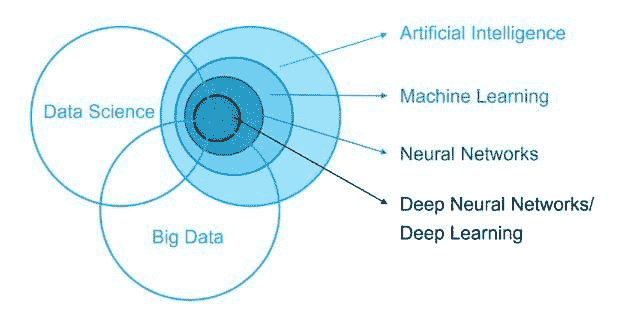
关于数据科学领域的一些主要组件如何契合的看法(来源:OmniSci)
那么深度学习怎么样呢?
深度学习也是一个过程;它是应用深度神经网络技术——具有多个隐藏层的神经网络架构(这是一种特殊类型的机器学习算法)来解决问题。作为一个过程,深度学习与神经网络的关系类似于数据挖掘与“传统”机器学习的关系(这是一种有些缺乏细微差别的比较,但在非常高的层面上我支持这种说法)。
深度学习是一种特定类型的机器学习,即利用深度神经网络进行洞察提取。神经网络在许多领域——特别是计算机视觉和自然语言处理——仍然提供最先进的结果,这也是它们常常被与机器学习区别对待的原因。虽然它们只是一个工具,但这个工具在特定的数据科学任务中往往表现出特别的实用性。
自从之前的数据科学难题文章以来,深度学习从在计算机视觉领域中占据主导地位并将目标瞄准自然语言处理,到现在已经完成了对 NLP 的全面覆盖。正如在计算机视觉中一样,深度学习算法现在并不是解决问题的唯一算法,但它们无疑已成为众多子任务中的首选之一,这也是有充分理由的。
数据科学与人工智能的关系似乎在过去三年中发生了相当大的变化。人工智能在那时似乎使用得要少得多。如今,每个机器学习和数据科学初创公司似乎都在从事人工智能业务,还有许多其他公司完全没有使用 AI。
那么人工智能是什么呢?注意,这里指的不是人工通用智能,即创造一种能够迅速适应新问题的智能,类似于人类智能。以下是我三年前对 AI 的看法:
在我看来,AI 是一个标准,是一个不断变化的目标,是一个无法达到的理想。
但这并不意味着人工智能不值得追求;人工智能研究带来的回报以灵感和动力的形式出现。然而,正如你可能已经注意到的,人工智能有一个认知问题。正如数据挖掘曾经是一个引起许多人恐惧的主流术语(主要与隐私侵犯有关),人工智能从完全不同的角度使大众感到恐惧,这种恐惧类似于天网式的恐慌。我不知道我们该感谢媒体、埃隆·马斯克、人工智能与深度学习及其成功的混淆,还是其他完全不同的原因,但我认为结果是不可避免的:这种认知问题是真实存在的,未接触者变得越来越恐惧。
还有这一点:尽管机器学习、人工智能、深度学习、计算机视觉和自然语言处理(以及这些“智能”技术的其他各种应用)都是独立且不同的领域和应用领域,即便是从业者和研究人员也不得不承认,除了过去常见的困惑和混淆外,还有一些不断演变的“概念蔓延”现象。这是可以理解的;这些领域最初都是其他领域(计算机科学、统计学、语言学等)的小众子学科,因此它们的不断演变是可以预见的。虽然在某种程度上确保所有应该对这些领域有基本理解的人确实具备这种理解很重要,但就其在数据科学等领域的应用而言,我谦虚地认为,过于深入语义上的争论从长远来看对从业者并没有太大益处。
到 2030 年,人工智能和机器智能将与现在大相径庭,缺乏对这一不断演变的技术集合及其研究的基本理解,或者对其作为数据科学家的应用不持开放态度,将对你的长期成功产生不利影响。
正如我上面提到的,深入探讨人工智能到底是什么定义并不是我愿意做的事。我对什么可以被技术上归类为“人工智能”有一个模糊的概念,你也是如此;我们的模糊概念可能有所不同。我对人工智能的看法及其主要好处的根本性认识在于它的不可达性。人工智能代表了一组模糊定义的宏伟目标,我们离这些目标越近,就会被更宏伟的目标取代。
这就引出了数据科学:
数据科学是一个多方面的学科,它包括机器学习和其他分析过程、统计学及相关数学分支,并日益借鉴高性能科学计算,最终目的是从数据中提取洞察,并利用这些新获得的信息讲述故事。
我仍然喜欢这个定义。它简洁明了,把事情汇聚在一起,在我看来无需进一步阐述。不过我确实写了它,所以可能有些偏颇。
最后,我们来谈谈统计学。统计学如何融入数据科学的广阔领域?这是 Diego Kuonen 在我发布上一篇关于这一主题的文章三年后的看法:
.@mattmayo13,难道 #统计学 不是拼图纸吗?
“#数据科学 拼图”
t.co/9E1zqJoDx6#大数据 #机器学习 #深度学习 #人工智能 #分析 #物联网 pic.twitter.com/zjcHkUChKO— Diego Kuonen 教授 (@DiegoKuonen) 2017 年 1 月 25 日
他是对的!如果数据科学是一个拼图,就像一个拼图,拼图纸在比喻上就是数据科学立足的基础。统计学就是那个基础。
这些就是数据科学的顶级概念,至少是我看到的。显然,这些并不是领域中唯一重要的方面。数据可视化等许多其他方面未被包含在此,许多人会争辩说这些也应当被包括在内。然而,我坚持我的选择,并将其他概念留待下次讨论。
最后,我要强调这只是一个人的观点,基于我过去几年对我的思维模型的调整。这不是事实,但这是我的看法,虽然我相信会有很多人不同意。
相关:
-
数据科学难题,再探讨
-
数据科学难题解析
-
机器学习难题解析
更多相关主题
数据科学难题,解释
原文:
www.kdnuggets.com/2016/03/data-science-puzzle-explained.html/2
由Matthew Mayo撰写,KDnuggets 主编,2016 年 3 月 10 日,发表于人工智能、数据挖掘、数据科学、深度学习、解释、机器学习
数据挖掘
Fayyad, Piatetsky-Shapiro & Smyth 将数据挖掘定义为“应用特定算法从数据中提取模式”。这表明,在数据挖掘中,重点在于算法的应用,而非算法本身。我们可以将机器学习与数据挖掘的关系定义为:数据挖掘是一个过程,在此过程中,机器学习算法被用作工具来提取数据集中潜在的有价值模式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
数据挖掘,作为机器学习的姊妹术语,也是数据科学的重要组成部分。在数据科学这个术语爆炸之前,实际上数据挖掘作为谷歌搜索术语享有更大的成功。查看比上述图形所示时间更久的谷歌趋势,数据挖掘曾经更加流行。然而,如今,数据挖掘似乎在机器学习和数据科学之间作为一个概念存在。如果接受上述解释,即数据挖掘是一个过程,那么将数据科学视为数据挖掘的超集以及继承术语是有意义的。
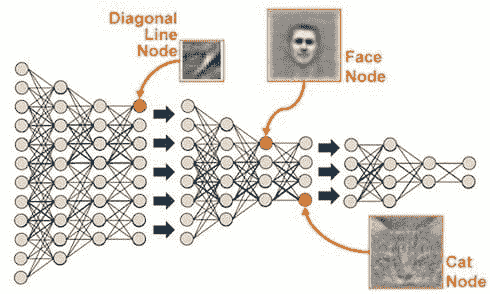
深度学习
深度学习是一个相对较新的术语,尽管在最近的网络搜索中出现了剧增。深度学习因其在多个领域取得的巨大成功而享受着研究和行业的激增,它是应用深度神经网络技术的过程——即具有多个隐藏层的神经网络架构——来解决问题。深度学习是一个过程,就像数据挖掘一样,它使用深度神经网络架构,这些架构是特定类型的机器学习算法。
深度学习最近取得了一系列令人印象深刻的成就。鉴于此,至少在我看来,重要的是要牢记以下几点:
-
深度学习不是万灵药——它不是一个适用于所有问题的万能解决方案。
-
它不是传说中的万能算法——深度学习不会取代所有其他的机器学习算法和数据科学技术,或者说,至少到目前为止,它还没有证明这一点。
-
适度的期望是必要的——虽然最近在各种分类问题上取得了巨大进展,特别是在计算机视觉、自然语言处理、强化学习等领域,但当代深度学习并不能扩展到解决像“解决世界和平”这样非常复杂的问题上。
-
深度学习和人工智能并不是同义词
深度学习可以为数据科学提供大量的附加过程和工具来帮助解决问题,从这个角度来看,深度学习是数据科学领域中一个非常有价值的补充。
人工智能
大多数人发现对人工智能进行精确、甚至广泛的定义是困难的。我不是人工智能研究员,所以我的回答可能与某些人的看法大相径庭,甚至可能会让其他领域的人感到不满。我多年来对人工智能这一概念进行了许多思考,我得出的结论是,人工智能,至少是我们在考虑时通常想到的那个概念,并不存在。
在我看来,人工智能是一个标准,是一个不断变化的目标,是一个无法实现的理想。每当我们走向人工智能的成就时,这些成就似乎总是会被称作其他东西。
我曾经读过类似这样的说法:如果你在 1960 年代问一位 AI 研究人员他们对人工智能的定义,他们可能会一致认为,一个可以放在口袋里的小设备,能够帮助预测我们的下一步动作和愿望,并且随时可以获得所有人类知识,这样的设备就是真正的人工智能。然而,我们今天都使用智能手机,极少有人会把它们称作人工智能。
人工智能在数据科学中适合什么位置?嗯,正如我所说的,我不认为人工智能是任何实际存在的东西,所以很难说它适合在哪里。但在与数据科学和机器学习相关的许多领域中,人工智能提供了动机,有时这种动机与实际的价值同等重要;计算机视觉和现代深度学习研究都受益于人工智能精神,即使不是无限期地。
人工智能可能是一个最有资金投入但在其名字行业中却从未实际产生任何东西的研究与开发工具。虽然我认为从人工智能直接过渡到数据科学可能不是理解这两者关系的最佳方式,但在某种形式下,许多两者之间的中介步骤已经由人工智能开发和完善。

数据科学
那么,在讨论这些相关概念及其在数据科学中的位置后,究竟什么是数据科学?对我来说,这是最难精确定义的概念。数据科学是一个多面向的学科,涵盖了机器学习和其他分析过程、统计学及相关的数学分支,并越来越多地借鉴高性能科学计算,最终目的是从数据中提取洞察力,并利用这些新发现的信息讲述故事。这些故事通常伴随图像(我们称之为可视化),并且旨在服务于行业、研究,甚至只是为了我们自己,目的是从数据中获取一些新的想法。
数据科学运用各种不同领域的工具(请参阅你上面读到的所有内容)。数据科学既与数据挖掘同义,也包含了包括数据挖掘的概念。
数据科学产生各种不同的结果,但它们都有一个共同的方面——洞察力。数据科学不仅包括这些,还可能对你来说是完全不同的东西……而且我们还没有涉及数据的获取、清洗、整理和预处理呢!顺便问一下,什么是数据?数据总是很大吗?
我认为我的数据科学难题的构想,至少是可以用上述图表表示的版本,与本文顶部的皮亚特斯基-沙皮罗的维恩图相吻合。我还建议它与德鲁·康威的数据科学维恩图基本一致,尽管我有一个保留意见:我相信他那非常有理有据且有用的图表实际上是指数据科学家,而不是数据科学。这可能是在斤斤计较,但我不认为数据科学的{领域 | 学科 | 概念}本身包括黑客技能;我认为这是一种科学家具备的技能,用来使他们能够做数据科学。诚然,这可能是在钻研语义问题,但在我看来是有道理的。
当然,这并不是整个领域的全貌,该领域在不断发展。例如,我记得不久前读到,数据挖掘曾是商业智能的一个子领域!即使存在意见分歧,我真的无法想象今天这还是一个有效的观点(老实说,几年前很难接受)。
就这样:你的一些最喜欢的术语被以你不会原谅我的新方式扭曲了。如果你现在非常愤怒,迫不及待地想告诉我我有多么错误,请记住这篇文章的要点:你刚刚读到的是一个人的观点。在这个精神下,欢迎在评论中提出你(可能是激烈且尖锐的)对立观点。否则,我希望这篇文章要么让新读者了解数据科学这一难题,要么迫使他们重新审视自己心中的数据科学难题。
相关:
-
真正的数据科学家请站出来
-
十大数据挖掘算法解析
-
商业领袖的数据分析解析
相关主题
数据科学拼图,再次审视
原文:
www.kdnuggets.com/2017/01/data-science-puzzle-revisited.html
评论
去年我写了一篇概述文章,定义了与数据科学相关的多个关键概念——包括数据科学本身——并尝试解释这些部分如何拼接成一个所谓的“数据科学拼图”。随着新年的开始,以及过去一年取得的进展、洞见和成就被纳入我们的集体职业展望,我认为重新审视这个拼图是明智的,注意并整合任何可能有助于重新排列拼图的变化和更新,并在适当的时候提供一些附加评论。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
大数据在数据科学中仍然重要。无论你选择什么比喻,但无论怎么看,大数据仍然是推动数据科学革命的原材料。
关于大数据,我相信从商业角度看,数据获取和保存的合理性、期望大数据项目开始提供实际的财务回报,以及与数据隐私和安全相关的挑战,将成为不仅是 2017 年,而且是未来大数据的重大故事。简而言之,是时候从大数据中获得丰厚的回报,并对其进行大力保护了。
然而,正如其他人所评论的,大数据现在“只是存在”,也许不再是值得特别关注的实体,它已经获得了近十年的特别关注。
机器学习是数据科学的主要技术驱动因素之一。数据科学的目标是从数据中提取洞见,而机器学习是实现这一过程自动化的引擎。机器学习算法不断促进计算机程序从经验中自动改进,这些算法在各种不同领域变得越来越重要。
我相信(而且我并不是唯一的一个)自动化机器学习将越来越成为一种工业级的强大力量,辅助数据科学家完成各种机器学习和建模任务,但还不会取代数据科学家……至少现在还不会。对模型的解释 仍然是必要的,虽然人眼的细微差别和精细度不能完全外包给机器学习管道,但大部分的算法和特征选择可以,多个模型的评估和比较以寻找最佳拟合也是如此。
我以前提到过机器学习和数据挖掘之间复杂的关系(我假设大多数人对此有所了解)。我认为这两个学科之间的界限比过去更模糊了(如果这可能的话)。我之前强调了机器学习是一个促进数据挖掘过程的工具;然而,随着机器学习成为一个更主流的术语,我预见到它们的加速普及和混淆。
深度学习也是一个过程;它是将深度神经网络技术——具有多个隐藏层的神经网络架构(这些是特定类型的机器学习算法)——应用于解决问题的过程。作为一个过程,深度学习对于神经网络而言,就像数据挖掘对于“传统”机器学习一样(这是一种略显欠缺细微差别的比较,但在一个非常高的层面上,我仍然支持这个观点)。
尽管深度学习在过去一年中引起了极大的关注和夸大的成功,但它仍然没有像人们想象的那样普及。然而,我确实看到它(缓慢地)在未来几年中成为数据科学家的一个常用工具。尽管如此,随着它成为一种常用的分类技术,记住深度学习不是万灵药变得越来越重要,它在广泛(多数?)情况下甚至不是一个有效的选择。此外,深度学习和人工智能并不等同。
当我想到人工智能时,以下观点对我来说仍然是真实的:
在我看来,人工智能是一个标准,一个不断变化的目标,一个无法实现的目标。
但这并不意味着人工智能不值得追求;人工智能研究带来的回报以启发和激励的形式体现。然而,如你所见,人工智能存在认知问题。正如数据挖掘曾是一个主流术语,让许多人感到恐惧(主要与隐私入侵有关),人工智能从完全不同的视角恐吓大众,这种视角引发了类似 SkyNet 的恐惧。我不知道是感谢媒体、埃隆·马斯克、将人工智能与深度学习及其成功混淆,还是其他原因,但我认为结果是不可避免的:这一认知问题是真实存在的,未接触者正变得恐惧。
还有这一点:尽管机器学习、人工智能、深度学习、计算机视觉和自然语言处理(以及这些“智能”技术的各种其他应用)都是各自独立的领域和应用领域,即使是从业者和研究人员也不得不承认,这些领域正在经历一种不断发展的“概念蔓延”,超出了以往的常规混乱和困惑。这没关系;这些领域最初都是其他领域(计算机科学、统计学、语言学等)的细分学科,因此它们的持续演变是可以预期的。虽然确保所有应该对这些领域差异有基本理解的人确实具备这种理解在某种程度上是重要的,但在数据科学等领域应用这些技术时,我谦虚地认为,过于深入语义上的细节对从业者的长期利益不大。
人工智能和机器智能 到 2030 年将与现在大相径庭,对这一不断发展的技术集合和支撑它们的研究缺乏基本理解,或者在作为数据科学家时对其应用缺乏开放性,将对你的长期成功产生不利影响。
我之前将数据科学定义为:
数据科学是一个多面向的学科,涵盖了机器学习和其他分析过程、统计学及相关数学分支,越来越多地借鉴高性能科学计算,最终目的是从数据中提取洞察并利用这些新获得的信息讲述故事。
我实际上对这个定义还是很满意的。特别是,我发现过去一年中,数据科学和数据挖掘之间存在相当大的混淆。虽然这并非定论,我仍然坚持以下观点:
数据科学使用了来自各种相关领域的各种工具(见上文)。数据科学既与数据挖掘同义,也包括数据挖掘的概念。
因此,尽管原始数据科学难题图示并非完全过时,我还是根据上述讨论点进行了如下修改:
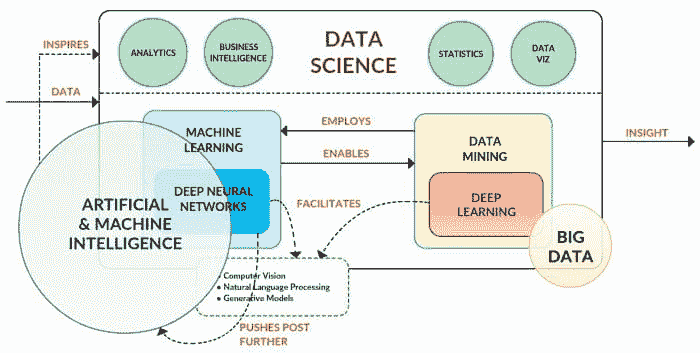
特别地,请注意以下几点:
-
大数据作为一个独立的实体已变得不再重要(大数据不再是新兴事物;它只是现实)。
-
人工智能、机器学习和深度学习之间的关系总是在某种程度上发生变化,并将持续被重新考虑。
-
人工智能向人工与机器智能领域的蜕变,反映了认知与智能技术的重要性增加。
-
自然语言处理、计算机视觉和生成模型与一个新的人工与机器智能关系领域联系更为密切,反映了现实情况。
-
机器学习和数据挖掘与神经网络和深度学习之间的关系没有发生变化;然而,展示功能关系可能会变得比突出类似关系(如当前所示)更为重要(至少在我看来更为重要)。
-
尽管我提到过高性能科学计算及其在数据科学中的作用,但它在图示中并未显示;鉴于分布式和并行计算能力(包括 GPU 并行性)的重要性增加,以及对原始计算资源的需求,我预计明年可能会有所变化。
我相信数据科学将继续发展,并将新的工具和技术纳入其工具箱,一旦这些工具对该行业的作用变得明显。尽管我仍然不完全满意数据科学这个术语,但毫无疑问,它确实存在、真实,并受到许多人的热烈欢迎,并且它的采用率只会随着时间的推移而增加。
再次提醒你,在对上述内容感到不满之前,请将其视为:仅仅是一个人的观点。
相关:
-
数据科学难题的解释
-
预测科学与数据科学
-
为什么我们需要数据科学
更多相关话题
-
数据科学基础:你需要知道的 10 项必备技能
数据科学:现实与期望
原文:
www.kdnuggets.com/2022/03/data-science-reality-expectations.html
-
当你告诉别人你是数据科学家时,这会带来很多假设和高期望。每个公司对数据科学家的定义都是独特的,这取决于他们的期望。
-
我在 2019 年 9 月完成了为期 9 个月的 Bootcamp 后,深入了解了数据科学的世界。课程包括线性代数、统计学、应用建模、SQL、机器学习、计算机科学和生产部署(例如 git、Flask、AWS)。我很兴奋能够参与到一个以惊人速度发展的领域。特斯拉有了自动驾驶汽车,Instagram 正在创造疯狂的算法,几乎每家公司都在其商业计划中实施数据使用。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
-
在完成了 Bootcamp 后,我以为会得到大量数据,需要在变量之间找出模式。这将涉及大量的数据清理和机器学习模型的实施,以更好地理解当前和未来的输出。我看到几乎每个行业都有数据科学家的职位空缺,从明显的像亚马逊到新兴的像主要护肤品牌。我相信自己进入了一个每家公司都需要的职业,虽然这是真的,但现实却有所不同。
-
我对数据科学家的角色有很多假设和期望。然而,在我在行业中的近几年以及与其他数据科学家、机器学习工程师和分析师交谈后,我开始看到数据科学未能满足行业期望的方式。
-
接下来我将逐一讲解每个要点。
1. 缺乏数据科学领导力

Jehyun Sung 来自 Unsplash
-
我相信,为了让任何事情成功,你需要有一个合适的团队,每个成员都具备特定的技能。当所有成员的技能结合在一起时,成功的机会就会大大增加。
-
在大多数公司中,负责数据科学和使用数据科学进行决策的高层管理人员,对实际的数据科学知识和理解几乎没有或完全没有教育背景。
作为数据科学家,这使你处于什么境地?在进行数据科学工作流时,总会有被阻碍或需要领域专家建议的时候。与没有数据科学知识的高管交流会使你的工作生活变得困难,因为解决问题的责任将落在你身上。
当公司实施自上而下的管理方式时,这就成为一个主要问题。这种方式是在最高层进行决策,并传达给团队其他成员。许多数据驱动的公司仍然严重依赖这种方法,这导致了等级制度和整体员工满意度的问题。作为数据科学家,你可能没有参与决策过程的机会,也没有得到足够的重视和尊重。你会非常沮丧,因为清理数据、构建模型和生成准确输出都是你投入的时间和精力。
2. 孤狼:非自愿
这一点与上面提到的有关。过去十年中,数据驱动的初创公司急剧增加。有些初创公司一开始就表现良好并高效运营,但大多数公司员工少于 100 人。
排除高管、董事总经理、HR 团队等后,只有少数员工擅长数据分析、数据可视化、机器学习和 SQL。如果你是团队中的主要数据科学家,你很可能会被来自不同团队成员的多个请求压得喘不过气来。
在这种情况下,拒绝这些请求并无妨。工作过多会开始影响你和你的健康。此时,公司应理解公司的成长,并开始考虑扩展数据团队。
3. 数据科学家并非无所不知

Patrick Tomasso via Unsplash
数据科学家的面试过程通常非常复杂。可以查看 simplilearn 来查看前 60 名数据科学面试问题及答案:从基础到技术。在过去,我被问过有关 SQL、线性回归和逻辑回归、决策树等问题。
你可以想象,准备数据科学面试是多么令人畏惧,你需要掌握广泛的概念!然而,不要让这阻碍你追求数据科学的职业生涯。了解的背景越多,你的机会就越大。继续练习顶级面试问题,直到你感到自信。你可以向招聘经理询问面试过程的详细信息,这将有助于你准备。
一旦你获得了数据科学家的职位,你可能会被要求在几乎没有或没有方向的情况下解决问题。这可能是因为团队成员对数据科学没有了解,或者误以为数据科学家什么都知道。我的建议是,与数据团队中的其他成员,如软件工程师和分析师密切合作,以获得支持。如果你不幸是团队中唯一的数据人员,拥有一位专家或高度熟练的导师来提供建议是一个不错的选择。
结论
本文的目的并不是要劝阻任何人追求数据科学职业,而是为了让大家更好地理解这份工作的内容。
我希望在我进入第一个商业数据科学职位之前,有人给我提供详细的分解和建议。虽然在工作中学习这些东西对你成长有帮助,但如果你能带着这些知识去工作并做好准备,将会让你的生活更轻松。
本文旨在帮助公司了解他们可能存在的问题以及如何改进。公司的总体目标是高效且成功的,而对我来说,这从员工开始。
Nisha Arya 是一名数据科学家和自由撰稿人。她特别感兴趣于提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能在促进人类寿命方面的不同方式。她是一个热衷学习者,致力于拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
销售电话的数据科学:3 个可操作的发现
原文:
www.kdnuggets.com/2017/01/data-science-sales-calls-actionable-findings.html
comments
作者:Juliana Crispo, Gong.io
人工智能正在改变世界,销售也不例外。
今天我很高兴与你分享销售研究领域的一项重大进展,这将有助于提高你的成交率。
我有幸与Gong.io的数据科学团队合作,进行了一项新的全面研究,分析了超过 70,000 个 B2B SaaS 销售电话。
你没听错。据我了解,这是迄今为止最大规模的销售研究。
(继续阅读或观看我与 Gong CEO 的对话来了解这些发现。)
对我们来说,我们将销售成功定义为推进,或者将交易从“演示”推进到“提案”再到“成交”的速度。
在我们深入讨论实际可操作的建议之前,来一个现代销售小测验:
如果在销售对话中早早提到竞争对手,你是否应该担心?
在你演示之前,是否应该让客户进行一段长时间的谈话?多长时间算太长?
讨论你的公司超过 2 分钟对你的成交率有何影响?
虽然你可能对上述问题进行猜测,但我们现在有分析来支持我们的主张。
结论 #1 — 在你演示之前提到竞争对手是一个好迹象。
根据分析的销售电话数据,如果在流程的早期阶段提到竞争对手至少 1 次,你的机会推进的概率实际上增加了 49%。
但有一个条件。
在你的销售过程中,稍后提到竞争对手会产生相反的效果。
当我将自己对公司平均 25%+的成交率的经验与我知道的那些在入职培训中平均只有 10%成交率的公司进行比较时,这在事后看来似乎很明显。
成交率较高的公司会投资于对新代表的竞争对手教育。相反,我看到那些轻描淡写竞争对手教育的公司成交率较低。
结论是什么? 了解你在市场中的竞争地位,并准备好与潜在买家讨论。这可能意味着你推进交易的概率差异高达 50%。
结论 #2 — 让你的客户进行至少 4 分钟的“长时间谈话”。
如果你能让潜在客户至少谈论 4 分钟,你的交易推进的概率会增加。
如果你只能让客户在直线上谈 50 秒钟,成交的机会将低于平均水平。
我知道那些经验丰富的卖家会想,“唉,朱莉安娜……”但听我说。现在你有数据支持你。
我在与较新的销售人员或创始人会面时看到的一个常见挑战是,他们经常告诉我,一旦买家已经告诉他们他们的问题,他们会感到不舒服,不愿问更多的澄清问题。
就像他们觉得自己“太好奇”或者“太年轻”或“经验不足”而不敢向高管提这些问题一样。
如果这听起来像是你,那就是一个你今天需要从心理中消除的限制性信念。
毕竟,你每天和这个高管的同行交流的次数比他们还多,这使你成为自己领域的专家。
在下一次通话中,我挑战你深入挖掘,看看你能让他们多开放一点。如果你不确定从哪里开始,这份关于痛点发现问题的演示文稿可以帮助你在销售对话中提问得更聪明。
警告:短小的澄清问题,如“你能详细说明一下吗?”或“你能给我一个例子吗?”,或者“多讲讲……”不会打破你的客户交流,但会帮助延长交流时间。
要点 #3 — 不要谈论你的公司超过 2 分钟。
当我看到下面的图表时,我就像……哈利路亚。
2 分钟推销悬崖的理由。
Gong.io 从这 72,326 通电话中发现,如果你推销你的公司超过 2 分钟,你基本上是在把你的成交率推下悬崖。
根据现代买家旅程变化的速度,我预测这 2 分钟的悬崖数字在未来一年内将减少——尤其是在技术销售领域。
数据表明,如果你在通话中花费 10%时间讨论你的公司,你的成交机会将是同行的 1/4。
这意味着,如果你团队中最顶尖的销售代表的成交率为 24%,而你是一个话多的人,那么你的成交率可能仅为 6%。
所以,是的,你确实可以把你的成交率从悬崖上谈下来。
要点是什么? 将你的公司推销时间缩短到最多 2 分钟。多于此,你的成交率将受到影响。
原文。经许可转载
简历: 朱莉安娜·克里斯波 是创业销售训练营的创始人,这是一所技术驱动的销售学校,拥有来自谷歌、Salesforce 和 LinkedIn 等 128 家公司的 2000 多名学生。她被 Tradecraft 评为技术销售和 BD 领域的 50 位顶级影响者之一,她的工作曾被《福布斯》、《财富》、《赫芬顿邮报》等媒体报道。
相关内容:
-
销售电话的数据科学:预示问题或成功的惊人词汇
-
微软正在变成 M(ai)crosoft
-
60 天环游世界:让深度语音在普通话中发挥作用
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
销售电话的数据科学:意外的词汇揭示了问题或成功的信号
原文:
www.kdnuggets.com/2016/09/data-science-sales-calls-words-trouble-success.html
评论
作者:Amit Bendov,Gong.io 的首席执行官和联合创始人。

将近一个世纪以来,对泰坦尼克号可能安息的地点理论层出不穷。由前沿深海测绘船 Argo 拍摄的标志性照片终结了这一辩论。类似地,直到最近,宇宙的年龄仍然不确定。通过显示宇宙的膨胀率,哈勃望远镜提供了一个估计:137.5 亿年。
偶尔会出现一个图像,它终结了数十年的理论、信念和观点。
这些图像令人震惊,且往往与您预期的样子不太一样。
当我们看到从分析大量销售电话数据库中得出的惊人初步结果时,我们就是这种感觉。
尽管这不是揭示宇宙秘密一样深奥的问题,但如何进行成功的销售对话是一个古老的问题,每天影响着数百万人。对此也没有缺乏意见:亚马逊上有超过 13,000 本关于销售的书籍。
首先,关于数据的一点背景。
-
来自 18 家美国 B2B 公司的超过 25,000 小时的销售电话记录。
-
电话记录被分离为扬声器、转录、清理(机器转录相当“嘈杂”),然后使用人工智能和机器学习来寻找各种模式。(有趣的想法:一个人仅仅听这些电话就需要 12 年。)
-
电话记录与相应的交易历史记录(“机会”)进行了匹配,以确定交易结果和速度。
注意:有几十个因素可能影响交易的成功与否。有些与卖方相关,有些与买方相关。在这篇文章中,我会挑选两个有用的买方信号。将来我会分享一些销售人员常说的内容。
所以这是第一个信号:你的交易什么时候结束?
在几乎任何初始对话中,销售人员都会试图了解交易的时间框架。
她可能会问“你预计什么时候开始这个项目?”或“这个计划的时间表是什么?”
对于回答的变体有数百种可能性,从“哦,我们昨天就需要这个”到“2017 年下半年”。
结果发现,最具指示性的词之一是"probably"。比如“可能在二月”或者“可能在第一季度末之前”。提到这个词与交易时间的相关性很高。事实上,当客户在讨论时间时使用“probably”一词时,预测的准确性高达 73%。不过,在你过于兴奋之前,我需要提醒你:这是相关性,不是因果关系。我们了解这一区别,对吧?😃 这并不意味着交易会成功。只是说如果成功的话,时间可能是准确的。
现在你可能可以看到为什么这对我们来说是一个“阿戈时刻”。我曾认为“probably”有些负面。谁会想到这个词实际上是一个积极的信号?这就是机器学习的力量:事实,而不是意见。
由于这是相关性的,我们只能猜测原因:“我们昨天就需要这个”,并不是一个很有深度的回答,也并不真正有意义。同样的,“我相信明年某个时候”也没有多大意义。但“可能在三月”是一个更谨慎、更深思熟虑的回答。因此,他们很可能是认真的。
现在来看一个沉默的杀手:“反信号”。
在慢速交易的通话中出现的顶级短语之一是"to figure out"。比如“我们需要弄清楚我们的策略……”或者“我需要与团队讨论,然后我们需要弄清楚……”,特别是在结束通话并讨论下一步时。
在这里,这也并不意味着交易已经结束,但表明有一个障碍,所以要保持警惕。你可能还需要将交易的成功概率估计在你通常范围的下限。
这也是我未曾想到的顶级信号,但一旦我们看到它,它就显得完全合乎逻辑。另一个阿戈时刻。
目前就这些了,大家 - 我希望你们会觉得有用。
简介:Amit Bendov是 Gong.io 的首席执行官兼联合创始人。他在高速增长的科技创业公司中拥有超过 20 年的高级领导经验;管理研发、市场营销和销售,涉及北美、欧洲和亚太地区的全球企业。他的履历包括将科技公司从零销售到成功退出/IPO,从小团队到大组织,从默默无闻到炙手可热的公司。
原文。经授权转载。
相关:
-
环游世界 60 天:在普通话中让深度语音工作
-
采访:Ali Vanderveld,Groupon 关于分析驱动销售团队的关键要素
-
微软正在变成 M(ai)crosoft
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
了解更多相关主题
我的数据科学六个月成功故事
原文:
www.kdnuggets.com/2023/04/data-science-six-months-success-story.html
几天前,我庆祝了学习数据科学六个月,我可以告诉你这是我今年做出的最佳决定。
对于一个习惯于反复尝试的我来说,数据科学是我很高兴决定尝试的职业,因为我从未像对待它一样如此有意识地对待过任何事情。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如果有人在一年前告诉我,我会知道如何从 Twitter 上抓取和分析推文,并构建可以讲述数据故事的仪表板,我可能会怀疑,但我对自己在过去六个月中学到的许多东西和取得的里程碑感到惊讶。
我将在本文中分享一些我在过去六个月中学到的东西和帮助我保持专注和忠于旅程的技巧。
初期阶段
当我决定追求数据科学职业时,我做的第一件事是观看了一些YouTube 视频并大量研究数据科学家的发展路线图及最佳学习方式。我列出了需要学习的工具清单,并寻找可以免费学习的平台。我最初开始时选修了IBM 数据科学课程但最终大部分时间都花在了Datacamp上,这得益于Ingressive for good提供的奖学金。
另一件我做的事是为了责任感而让自己暴露在外。害怕吗?是的,我非常害怕,因为这个女孩尝试了很多事情并半途而废。但我决心将这件事进行到底,因此给自己设定了一个时间框架,在六个月内学会基础知识。我甚至没有考虑在六个月内找工作,目标是为了在这六个月内学到很多东西,以帮助我开始这条职业道路。
我在 Twitter 上发表了一条帖子声明了我的意图,并将其固定在我的个人资料上,这样我每天上线查看个人资料时,它都会提醒我。
另一件事是祈求神的恩典和指导。是的,我为此祈祷,并且我开始了这段与神同行的旅程。我非常重视神因素,并相信这是我成功的秘密成分。
此外,我制定了一个适合我的计划,早晨的时间是我阅读的最佳时机,这对我来说很容易,因为这时我没有电脑,只能在手机上学习。手机是我早晨起来后第一个拿起的东西,感谢耶稣,然后直接进入 Datacamp,直接进入 Python 学习。
在一个月内,我在 Datacamp 完成了四门 Python 课程,我非常兴奋并期待更多。




我在旅程的第一个月完成的四门课程的成就声明。
五月
我在五月制定了计划,希望完成更多课程,我努力工作,以至于那个月我在 Datacamp 上完成了 16 门 Python 课程。


我还加入了20 数据分析项目与 Octave 合作,虽然我还没有学到足够的知识来构建项目,但我冒险加入并向其他人学习。

20 数据分析项目
到了五月底,我完成了第一个项目——超市销售仪表盘。虽然不是特别出色,但这是我学习的垫脚石,开启了成长的世界。
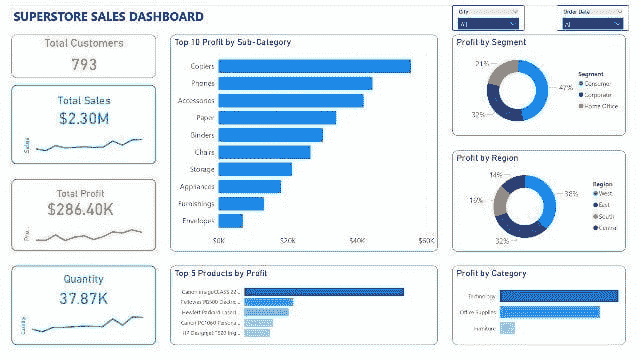
超市销售仪表盘
到了六月初,我完成了 Datacamp 上的数据科学家 Python 路径,并立即开始学习 SQL。
我参与了另一个项目,对过去诺贝尔奖获奖者的分析,这次做得更好。我在学习上保持了一致性,并且成长也很稳定。
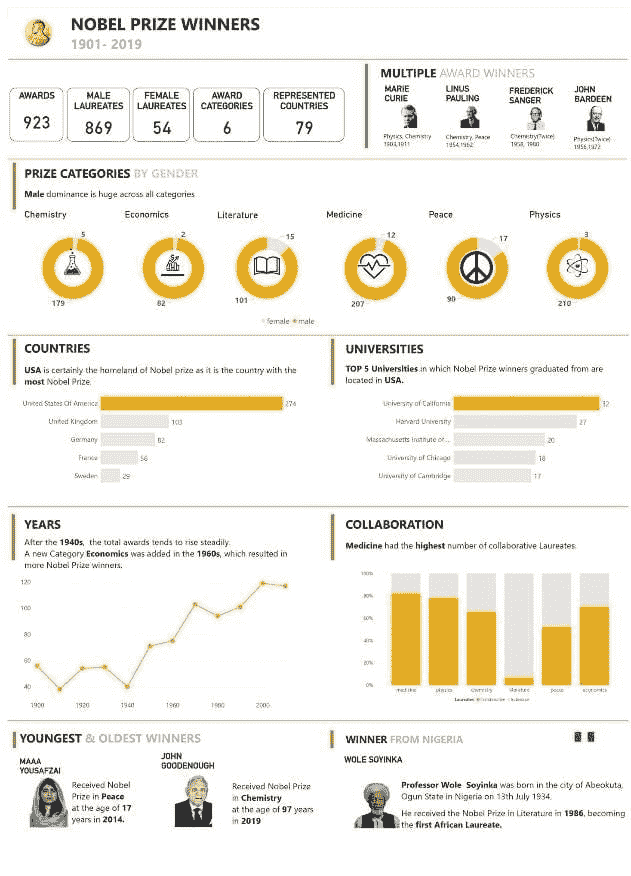
过去诺贝尔奖获奖者的分析
我还加入了 Stanbic IBTC 培训项目学习 Azure,这对我来说是一次艰难却令人兴奋的旅程。

到了六月底,我在 Datacamp 上获得了超过 1,000,000 的学习经验值。
七月
在七月,我完成了一个实际改变了我学习旅程的项目——拉各斯真实主妇情感分析项目。这个项目让很多人对我的旅程产生了兴趣,我收到了许多招聘人员的私信,他们希望与我合作。
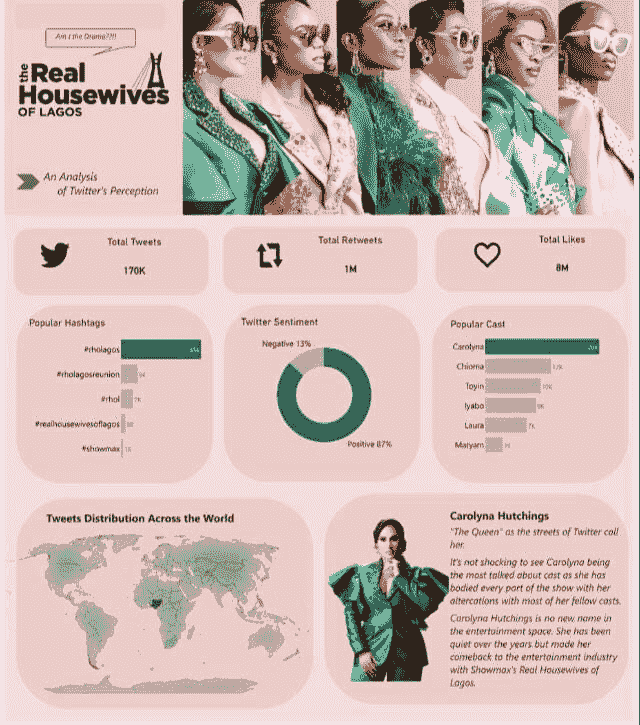
到七月底,我获得了我的第一个职位,成为一家尼日利亚初创公司的数据分析师。
八月
在八月,我获得了 Datacamp 认证。

我还参加了两门微软考试:DP 900-Azure 数据基础和 DP 300-Azure 数据库管理员,并且都通过了。


我还赢得了 Datacamp 每日 XP 学习者挑战赛,以及 Ingressive for good 组织的#55daysof 数据挑战。
九月
到九月时,我在 Datacamp 上连续学习了 150 天。我在 10 天后失去了这个连续记录??。这是一个艰难的时刻。
从那时起,学习、重学和成长就像过山车一样,我对未来充满了期待。现在是时候重新评估我所处的状态以及下一步的计划了。
学习点
在这段旅程中,我学到的一件事是任何事都是可行的。只要你有学习的意愿,并且准备好付出努力,一切都是完全可以实现的。在此,我还别出心裁地给你提出一个挑战。我挑战你在本月每天坚持学习,选择一项技能或工具,进行学习活动,并评估你的成长。
另一件我学到的事是,每天坚持会有回报,一致性在我的旅程中是一个重要的因素。我在过去的六个月里每天都坚持……虽然有些天我可能没怎么学习,但在其他日子我会非常努力,但我始终坚持。
此外,努力工作是我六个月成功故事中的另一个决定性因素。我全力以赴。当我开始这段旅程时,我每天学习 11 小时。我会在白天花费至少四小时,虽然是间歇性的,而不是一次性完成,通过手机学习概念。然后,我会花费整夜时间在借来的笔记本电脑上练习我所学到的内容。
另一个真正帮助我的建议是分享我的旅程,每天上线谈论我的经历是我成长的关键因素。
与该领域其他数据专业人士建立网络,并成为数据社区的一部分是另一个关键因素,我在 Twitter 上有很多被动导师,他们影响了我的旅程。
在我的旅程中,我还学会了接受倦怠是正常的,有时候我会醒来感到非常没有动力,并且怀疑自己是否在正确的道路上。在这样的日子里,我不会逼自己太狠,只做一个 Datacamp 上的练习就够了。我不会因为没有拼命而自怨自艾,而是在感觉非常有动力的日子里,我会额外努力弥补失去的时间。
也有过一些日子我感觉自己像个骗子,冒名顶替综合症严重打击了我,我觉得自己只是学习而什么都不知道。我不得不努力提升自信心。我写下了很多自我肯定的话,并在怀疑自己时大声朗读它们。
我旅程中的亮点
赢得了 #I4GDatacamp 奖学金。
成功进入 Stanbic IBTC 培训生项目。
获得我的第一个数据分析师职位。
赢得了 I4G #55daysofdata 挑战。
赢得了 Datacamp XP 学习者挑战。
在 Datacamp 上庆祝获得超过一百万 XP。
在 Datacamp 上庆祝连续 150 天的记录。
从 Ingressive for Good 赢得了一台笔记本电脑。
我的旅程中的低光点
在 Datacamp 上失去了连续记录。
每发送一次笔记本电脑申请就收到大量的拒绝邮件。
我的路线图
Python — 前四个月积极学习
Power BI — 从第二个月开始学习
SQL — 从第四个月开始学习
Azure — 从第三个月开始学习
电子表格 — 从第五个月开始学习。
我的资源和平台
我知道这篇文章很长,但我希望它能激励某人坚持自己的旅程并继续努力。可能需要一段时间,但下一个我将阅读的成功故事就是你的。
Tina Okonkwo 是一位数据分析师,对用数据讲故事充满热情。她为那些追求数据分析职业的人提供辅导和指导。她的目标是将我的数据分析旅程分享给更广泛的受众,并帮助他人开启他们的数据分析之旅。
原文。经允许转载。
更多相关内容
2016 年的数据科学技能
评论
作者:Seamus Breslin, Solas Consulting
数据科学家在 2016 年需求很高。现在“数据科学家”被称为今年的最热门职位,你是否具备所需的技能?获得数据科学家职位并不容易,尤其是在大公司,因为可能会有许多类似的候选人竞争同一职位。然而,有些技能是雇主寻找的,可能会让你在竞争中脱颖而出。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在我看来,2016 年需要的顶级数据科学技能如下:
SQL
SQL 仍然是成功的数据科学家所需的最重要工具之一,因为大多数企业存储的数据都在这些数据库中。
CrowdFlower 最近对 LinkedIn 上的 3,490 个数据科学职位进行了分析,SQL 是他们分析中提到的超过一半职位的技能,这意味着 SQL 是最常被提及的技能。
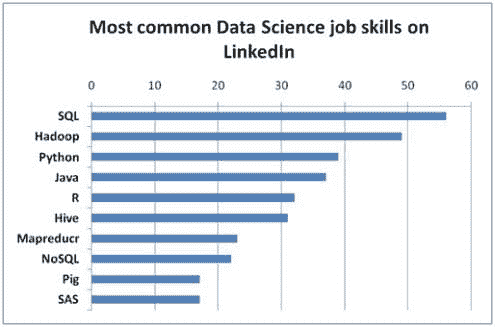
图 1. 根据 Crowdflower 的数据科学工作技能最常见的技能
数据可视化
依赖数据驱动决策的公司极度依赖数据科学家通过分析数据来可视化和传达故事的能力,因为数据科学家需要将数据驱动的洞察力传达给公司内的技术人员和非技术人员。
沟通技能
沟通仍然像以往一样重要,也是数据科学专业人员必备的另一项技能。例如,沟通在通过演示文稿分享结果或发布结果时至关重要。他们应该能够与高级管理层沟通,以便用他们的语言表达数据,并将数据转化为决策和行动。
Hadoop
学习 Hadoop 和大数据分析将使你在竞争中脱颖而出。大数据在企业中的一个主要障碍是缺乏 Hadoop 相关技能。
Spark
Spark 位于那些为了满足对大数据建模和分析日益增长需求而不断发展的技术前沿。
Spark 是一项在大数据领域越来越受到关注的技能,因为它的速度和易用性。
Python
Python 是另一个需求上升的领域。这种编程语言帮助工程师用比 Java 或 C++更少的代码创建概念,因此被视为更高效、出错率更低,并有可能创建更清晰的程序。
还对 Python 不够信服?Python 不仅易于学习,还有一个不断增长的大型活跃社区。如果你遇到编码问题,社区中有各种专家可以提供帮助。根据一项研究,Python 仍然是数据科学的首选工具。
统计学
这是你作为数据科学家所能提供的核心内容。统计学始终是数据科学家的一个重要组成部分,因此他们能够决定最合适的统计技术来解决不同类别的问题并应用相关技术,非常重要。
R
人们常说,数据科学中的 80%工作是数据处理。尽管如此,R 使得数据处理变得简单,因为 R 拥有一些最优秀的数据管理工具。
R 是金融和分析驱动型公司(如谷歌、Facebook 和 LinkedIn)的重要工具,因此如果你还没有深入了解 R,那么值得进一步研究。
创造力
任何人都可以按部就班。2016 年的企业希望创新,以在销售和对消费者展示的形象上与竞争对手区分开来。
创造力是将上述技术技能应用于实践的能力,并以不同于遵循预先得出的公式的方式,创造有价值的东西。

个人简介:西默斯·布雷斯林是Solas Consulting的创始人兼董事总经理,拥有超过 11 年的 IT 行业经验。Solas 专注于招聘数据、BI、SQL、Oracle、Java 和.Net 专业人士。
相关:
-
回顾成为数据科学家前三个月的经历
-
约翰·施基特卡:SAP 谈我们需要什么样的数据科学家
-
数据科学家是适合你的职业道路吗?诚恳的建议
了解更多相关话题
利用你的数据科学技能创造 5 种收入来源
原文:
www.kdnuggets.com/2023/03/data-science-skills-create-5-streams-income.html
数据科学近年来已成为一种需求旺盛的技能,其应用不仅限于企业部门。它为个人创造多个收入来源开辟了新的途径。
在这篇文章中,我将介绍如何利用你的数据科学技能创造五种不同的额外收入来源。从咨询到写作,再到销售在线课程,我们将探索数据科学如何用于赚取额外现金。本文将为那些希望扩展收入组合并最大化其数据科学技能的人提供有价值的见解。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作

图片由Katie Harp拍摄,来源于Unsplash
1. 数据科学写作
你可以利用数据科学技能产生收入的第一个途径是数据科学写作。写作是技术领域被忽视的技能,它实际上非常有价值,能够帮助你创造额外和被动收入。一个很好的开始博客的选择是Medium,这样可以提升你的技能并开始建立受众。
这将帮助你通过Medium 合作伙伴计划来生成收入,如果你能每月达到 100k 次浏览量,那么每月收入可达 1000 $。如果你专注于此,通常可以在不到一年的时间内实现。
此外,你还会开始收到来自其他网站和在线博客的写作邀请。这将非常有利可图,因为你可以为一篇文章收取 100 $ 及以上的费用。你可以查看这份数据科学博客列表,这些博客会为你的文章付费。
使用数据科学技能你可以写很多主题:
-
数据科学实用指南与教程
-
数据科学项目
-
数据科学技能学习计划
-
数据科学职业建议
我真正喜欢写作的一点是,它不仅能帮助你创造良好的收入,还能帮助你建立个人品牌,展示你的数据科学技能。此外,这还可以在任何地方、任何时间以你自己的节奏完成,并且之后可以创造许多机会,正如你将在接下来的部分中看到的那样。
另一个重要方面是开始自己的新闻通讯。即使是免费的,这也会非常有帮助。之后,你可以利用邮件列表来宣传你的产品,例如课程和电子书。一个开始新闻通讯的好地方是substack。
2. 销售数据科学电子书
利用你的数据科学技能生成的第二种收入来源是销售数据科学电子书。在进行一段时间的数据科学博客之后,你可以开始这个收入来源。主要原因是博客会打破你与技术写作之间的隔阂,并提升你的写作技能。
此外,你还会知道人们真正感兴趣的主题是什么,哪些是不感兴趣的。现在你拥有了技能、受众和市场理解,可以利用这些来写出真正让人们愿意阅读的电子书。
你可以在如 Gumroad 等在线平台上开始销售你的电子书。如果你做得非常好,你可以在之后将书籍出售到亚马逊,以便销售纸质版。为了宣传你的书籍,你可以使用前面提到的新闻通讯。此外,我非常推荐建立自己的网站,并在上面销售你的产品。
我在撰写电子书时偏好的方法是首先在自己的博客或 Medium 上将其写成一系列文章,然后再将其转换为电子书。这样,你可以避免一次性写完整本书而没有得到任何反馈或基于文章统计数据和人们互动情况对书籍成功的指示。
3. 数据科学 YouTube 频道
你可以通过建立一个数据科学 YouTube 频道来生成第三种收入来源。你可以在通过在线发布内容和每周撰写博客建立强大声誉和在线个人品牌后,采取这一步。
已经发布的博客不仅能帮助你建立良好的品牌,从而在发布视频时拥有广泛的受众。此外,你可以将大部分视频建立在之前写的文章上,并将其作为视频脚本。这样,你不会花费太多时间准备脚本和视频代码。这个技巧将节省你大量时间,并帮助你制作更多视频。
我也相信录制 YouTube 视频会对下一个收入来源大有帮助。你将打破你与摄像机之间的隔阂,变得更加自信,也会获得编辑视频和制作互动视频的实际技能。此外,你的受众将与你建立良好的沟通,并且对购买你的课程有更多信心,因为他们之前看过你的解释。
4. 销售数据科学课程
利用你的数据科学技能可以生成的第四个收入来源是创建并销售数据科学课程。由于制作高质量课程在时间和资源上非常昂贵,我真的建议你等到有了大量受众再去销售你的课程。
一个重要的建议是尽量制作与个人品牌相一致的更专业化课程。例如,尽量避免非常竞争的课程,如机器学习基础、数据科学家的 Python 等。相反,专注于与你之前关注的话题相关的更专业化主题。例如,我已经写了超过 10 篇关于如何优化 Python 代码和编写更高效 Python 代码的文章。我的文章得到了很好的反馈,我建立了一个强大的品牌,可以提供关于如何编写优化 Python 代码的很好的建议。因此,转化成短课程是一个非常合理的步骤。
最后的建议是尽量为每门课程准备电子书。这样你将组织好内容,只需花时间制作视觉内容。
以下是你可以用来销售和货币化你课程的平台列表:
5. 数据科学指导
你可以用来货币化数据科学技能的最终方法是通过指导和咨询。一旦你建立了强大的个人品牌并且有了大量受众,你可以提供有偿的长期指导和一次性咨询。
你可以提供项目评审、简历和作品集反馈、模拟面试和学习计划咨询。此外,还可以提供长期指导,帮助你的学员从职业生涯的某一点 A 到达点 B。
我个人使用两个主要的平台进行指导:Calendly和Mentorcruise。我使用 Calendly 进行一次性指导,因为它在时间安排和支付选项上提供了很大的灵活性。我使用 Mentorcruise 进行长期指导,因为该平台会处理我和学员之间的一切事务,并确保我们双方都能从指导过程中获益。
在本文中,我与你分享了利用数据科学技能建立副业的经验,从写数据科学博客开始,再到出版数据科学电子书、建立 YouTube 频道、创建数据科学在线课程,最后进行指导和咨询。当然,还有其他方法,如构建数据科学产品、自由职业和数据科学竞赛。然而,我试图分享自己的经验,以便根据实际经验提供信息。
Youssef Rafaat 是一位计算机视觉研究员和数据科学家。他的研究专注于开发用于医疗保健应用的实时计算机视觉算法。他还在营销、金融和医疗保健领域担任数据科学家超过 3 年。
了解更多主题
最受欢迎的数据科学和数据挖掘技能
原文:
www.kdnuggets.com/2014/12/data-science-skills-most-demand.html
由Gregory Piatetsky,KDnuggets 于 2014 年 12 月 15 日在 数据科学技能,数据科学家,Hadoop,纽约-纽约,Python,R,SAS,技能,SQL 评论 今年数据科学家的需求持续强劲。尽管“数据科学家”职位趋势显示该关键词在 2013 年达到峰值,并在 2014 年保持平稳,但这可能反映了职位名称的变化以及数据科学家成为主流职业。
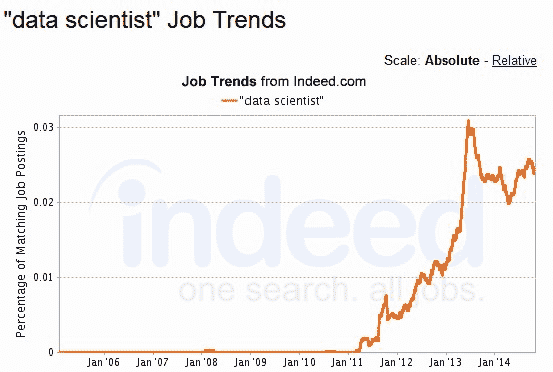
许多文章已经讨论了 数据科学技能 - 也可以参见本文底部。
KDnuggets 职位板 www.kdnuggets.com/jobs/ 在 2014 年接收到了历史最高的职位数量(迄今约 245 个),这是一个足够大的样本来分析和量化需求技能。
大约 85%的 KDnuggets 2014 职位来自美国,但也有来自其他 14 个国家的职位:加拿大、中国、爱沙尼亚、德国、印度、以色列、卢森堡、马耳他、葡萄牙、塞尔维亚、新加坡、瑞士、荷兰和英国。
大约 33%的职位标题为“数据科学家”,高于 2013 年的 25%和 2012 年的 19%。
第二常见的职位标题是工程师 - 有许多不同版本,如 BI 工程师、机器学习工程师、软件工程师等 - 见下面的词云。

接下来我们通过检查招聘广告中的常见关键词来了解最受欢迎的技能。
最常见的术语是:
-
团队,88%的招聘广告中提到
-
商业,73%
-
分析,64%
-
设计,63%
-
开发,62%
-
统计学,61%
-
统计,61%
-
研究,61%
-
机器学习,53%
-
数据挖掘,52%
-
建模,49%
-
解决方案,47%
这表明数据科学家职位是一个专注于商业分析的团队合作,研究、设计和开发发挥了重要作用。统计学、机器学习和数据挖掘几乎被用作同义词。
观察到对应于更具体技能/语言的术语
-
SQL,54%的招聘广告中提到
-
Python,46%
-
R,44%
-
SAS,36%
-
Hadoop,35%
-
Java,32%
-
优化,23%
-
C++,21%
-
可视化,20%
-
MATLAB,18%
-
BI 或商业智能,17%
-
分布式,16%
-
回归,16%
-
非结构化,16%
-
Hive,16%
-
移动,15%
NoSQL 在 11%的职位广告中被提及。
下面的美国地图显示了美国境内工作的分布情况,圆圈的大小对应工作数量,颜色对应 SAS(蓝色)与 R(红色)工作的比率对数。
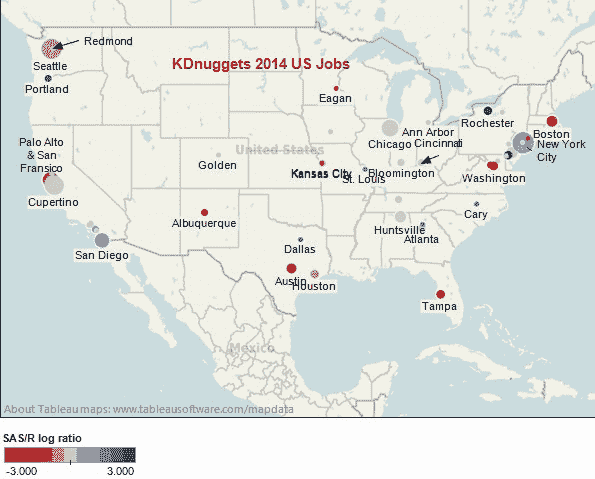
下一张图显示了美国城市中 SAS 与 R 的分布情况。
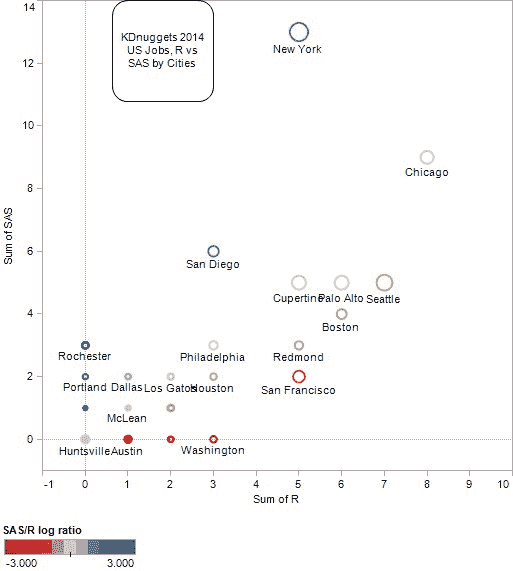
我们看到纽约、圣地亚哥、罗切斯特、波特兰和达拉斯的 SAS 工作数量多于 R,而西雅图、波士顿、雷德蒙和旧金山则更倾向于 R。芝加哥、库比蒂诺和帕洛阿尔托的 R 和 SAS 工作数量大致相等。
我们还通过测量顶级语言/系统之间的互动进行了分析
提升度 = 实际的 X 和 Y 配对的工作数 / 如果 X 和 Y 独立分布时的期望工作数。
我们看到 R 和 Python 之间的配对最强(提升度为 1.61),但 R 和 SAS 之间的配对也很强。唯一的负提升度是 SAS 与 Hadoop 之间 - 这些组合不太可能被同时要求。

最后,我们查看了教育情况。
几乎所有职位都要求有研究生学位(硕士),并且 48%的职位要求或偏好博士学位。
你认为数据科学家最需要哪些技能?
相关:
-
成为数据科学家所需的 9 项必备技能
-
澳大利亚分析专业技能和薪资报告
-
招聘数据科学家:需要关注什么?
-
2015 年预测 - 数据科学家的未来发展方向?
-
数据科学技能与商业问题
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关主题
-
[2022 年最需求的人工智能技能]( https://www.kdnuggets.com/2022/08/indemand-artificial-intelligence-skills-learn-2022.html )
顶级科技公司数据科学 SQL 面试问题
原文:
www.kdnuggets.com/2021/10/data-science-sql-interview-questions.html
评论

结构化查询语言,通常称为 SQL,是最强大的数据工具之一,使我们能够处理和分析大规模的数据。因此,任何使用大量数据的公司都将受益于拥有扎实 SQL 基础的员工。SQL 可以在公司每个层面上广泛使用,并且能够使用 SQL 可以确立一个人在数据处理方面的基本能力。在任何与数据相关的角色中,即使是基础的 SQL 能力也为候选人增加了额外的价值:能够根据个人需求查询数据是一项宝贵的技能,即使是在如产品经理或业务分析师等数据相关性较低的角色中。同时,在任何数据科学角色中,强大的 SQL 技能几乎是硬性要求。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
当然,还有许多其他方法可以大规模地存储和检索数据,包括 Spark、Hadoop/HIVE、Snowflake、Python 库 Pandas,甚至 Excel 和 Google Sheets。然而,每种方法都有其自身的局限性,没有一种能够在灵活性、可扩展性和易用性上超越 SQL,成为数据科学行业的标准。
面试中可能会出现各种问题,但 SQL 几乎是你可以期待被考核的基础内容,特别是针对数据相关的职位。我们将探讨一些你需要了解的关键概念和想法,以准备这些 SQL 面试问题,重点是 FAANG 公司的要求,然后在实际面试中走一遍几个 SQL 问题。
让我们开始吧。
数据科学 SQL 面试概念和问题
大型科技公司,即 FAANG(Facebook、Apple、Amazon、Netflix、Google),是数据科学职位的主要雇主,任何对数据行业感兴趣的人自然会关注这些公司的职位。但 FAANG 公司在面试中提出的 SQL 问题与其他公司有什么不同?通常,FAANG 公司将面试问题组织为案例研究,以测试你在其产品背景下的分析技能。例如,Google 可能会有分析其搜索引擎或电子邮件账户使用情况的 SQL 问题,而 Facebook 可能会涉及平台活动,如用户评论和好友关系。
在你面试的任何公司中,确保你在使用公司平台和产品方面至少有一定的舒适度是很重要的。对于强调这一点的 FAANG 公司来说,这一点尤为重要。虽然你可能凭借对代码的了解合理地回答标准的 SQL 面试问题,但能够理解你所处理的内容,从而讨论场景、权衡甚至潜在的边界情况,这样可以在面试中留下更深刻的印象。
数据科学 SQL 面试问题的类型
让我们深入探讨面试中涉及的 SQL 特定问题。SQL 面试问题通常可以分为三种不同的类别:基础定义、报告和抽象问题解决。
基础 SQL 定义
面试中最基础的 SQL 问题以定义为主。这些问题直接测试你对 SQL 基础知识的掌握,例如使用常见函数如 SUM、MIN/MAX 和 COUNT。通常,这些问题会询问关于 SQL 功能的基本定义,例如区分不同类型的连接或连接与并集的不同。这些问题也可能要求你编写某些短小的查询,可能需要从一小组表中提取和汇总基本信息以完成简单的功能。
通常,这些最早的问题会引导你创建基础查询,这些查询构成了可以进一步扩展成更复杂问题的框架。
报告与洞察
接下来是 SQL 报告问题,这些问题通常测试你编写日常数据分析工作中所需的常见查询的能力,例如识别和提取关键指标和数据,如日活跃用户(DAU)、月活跃用户(MAU)、增长率、时间变化百分比和留存率等常见报告关键绩效指标(KPI)。
之前的基本 SQL 定义,包括如 MIN 和 MAX 等聚合函数,将是必需的,同时还需要能够连接数据集并使用公共表表达式(CTEs)和子查询创建自己的视图。在更高级的报告层次中,常常会测试百分位数和排名,使用如 NTILE 和 RANK 等函数。通常,这些问题与窗口分区结合,这些是高级技术报告概念。
根据面试的结构,这可以在之前基本 SQL 定义的问题基础上构建,增加那些已覆盖概念的复杂性。在这些问题中,理解你所给的数据和你期望的输出是非常重要的。如果给出多个表,它们将需要一些连接,而问题中的限制因素意味着你需要了解应该应用哪些过滤器。
在之前的博客文章中,我们深入探讨了需要准备的SQL 面试问题。我们还曾写过一些流行公司提问的SQL 窗口函数类型。
用 SQL 解决问题
在最高级、最先进的层次是问题解决 SQL 问题。这些是开放性的、通常含糊不清的问题,测试你如何用 SQL 解决问题。与之前的报告 SQL 面试问题有些相似,但这些问题增加了模糊性的复杂性,你不仅需要考虑要报告的 SQL 输出,还要考虑如何提取特定的数据以及你想要提取的数据到底是什么。
这些类型的面试问题通常可以进一步细分为 ETL 和数据库设计问题。ETL 代表“提取、转换、加载”,这是一个将数据从一个源复制到另一个源或上下文的通用数据处理程序,包括所需的数据提取、转换和上传。数据库设计是根据数据库模型组织数据,这个模型是通过数据分类和识别这些数据点之间的关系来创建的。
ETL 可以是构建数据科学基础设施的起点,第一步是收集数据并将其转换为可用格式。虽然这些概念通常在数据工程专门的面试中进行测试,但大多数数据科学家仍然需要具备创建、插入和更新表的扎实基础。与 API 的工作将是技能发展的额外步骤,为数据科学工作流中的下一步——创建模型和仪表盘——奠定基础。
解决问题的 SQL 问题比之前的报告问题复杂得多,除了根据既定参数查询和返回数据之外,你还必须在不同来源和上下文之间转换数据,有时甚至需要设计整个数据管道。当然,考虑到面试设置的时间限制,任何问题的答案的复杂性自然会受到限制,仅覆盖一般步骤或宽泛的理论。
查看我们的视频 解决复杂的 SQL 面试问题。我们还在视频 你需要的唯一数据科学项目中讨论了数据科学基础设施管道。
最后,请记住面试过程中还会问到非 SQL 问题。这些问题包括个人或行为问题、产品感觉和商业案例、数据分析以及其他语言如 R 和 Python 的编码问题,还有人工智能和建模问题。我们在 顶尖 5 家数据科学公司终极指南中涵盖了 FAANG 各公司的整体面试流程。
数据科学 SQL 面试问题:FAANG 各公司提出的问题
显然,每个公司根据其自身的价值观和产品,甚至是团队和角色的不同,关注点和重点都不同。我们将探讨 FAANG 的一些面试问题,这些公司是业内最大的 数据科学 雇主之一。虽然我们会讨论一些问题的解决方案,但在查看答案之前,一定要自己尝试解决这些问题,或者至少花一分钟考虑一下你会如何解决这个问题,然后再深入了解解决方案。
社交媒体集团除了 SQL 还会问很多产品感觉的问题。Facebook 旗下的各种社交媒体平台意味着其面试问题将集中在这些平台至关重要的指标上,特别是用户活动。我们来看看:
过去 30 天每个用户的评论数量

这个来自 Facebook 的数据科学 SQL 面试问题测试了你基于日期条件过滤数据的能力。查看下面的视频,获取一些如何解决该问题的提示。
活跃用户的比例

问题链接
每个国家的排名方差

首先,让我们看看我们获得的表格:
fb_comments_count
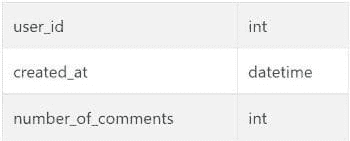
fb_active_users

为了回答这个数据科学 SQL 面试问题,我们是否需要澄清一些内容?措辞可能有些令人困惑,因此在面试过程中,如果你有一点不确定,一定要提问澄清。“基于评论数量的排名上升”在两个月之间的意思是,国家在一个月到另一个月之间用户评论数量的增加。例如,澳大利亚用户在 2019 年 12 月的评论数量为 5,而在 2020 年 1 月增加到 6,因此澳大利亚的排名会有所上升。(可以在 StrataScratch 平台上查看这些表格!)
除此之外,考虑一下我们可能需要处理的任何边界情况。一个大问题可能是如果用户没有任何位置数据,从而导致国家列的空值。我们可以通过过滤掉这种情况的行来处理。此外,也可能有些国家在前一个月(2019 年 12 月)没有评论,但在后一个月(2020 年 1 月)有评论。根据我们创建连接的方式,这将产生一个额外的空值,我们需要在最后的步骤中加以考虑。
现在,让我们考虑一下输出应该是什么样的。我们寻找的是一个简单的国家列表,但这个列表将基于隐藏的数字,这些数字过滤出在两个月之间“基于评论数量的排名上升”的条件。那么我们需要做什么才能实现这一点?
首先,我们需要隔离每个月的评论数量。幸运的是,评论数量已经在表 fb_comments_count 中汇总,因此这个初步步骤将是两个表之间的直接连接。由于单个用户不重要,我们将按国家分组并汇总评论数量。
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE country IS NOT NULL
GROUP BY country
注意到问题的措辞,为了简化,我们将根据每个国家评论的总数来分配排名。根据提示,我们被告知要避免排名之间的间隙,因此我们将使用 DENSE_RANK 函数,而不是 RANK 函数。虽然 RANK 和 DENSE_RANK 通常会根据其他值的比较为等级分配相同的排名,但 DENSE_RANK 会使用下一个顺序排名值,而不是像 RANK 那样跳过到下一个值。例如,RANK 会是 [1, 2, 2, 4, 5],而 DENSE_RANK 会是 [1, 2, 2, 3, 4]。
现在让我们把它添加到查询中。
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE country IS NOT NULL
GROUP BY country
不过,目前这个查询实际上返回的是所有用户评论活动的汇总,而我们实际上想要将两个具体的时间段进行划分和比较。接下来,我们将分开 2019 年 12 月和 2020 年 1 月的评论。我们可以使用 WITH 头来创建两个单独的月份的用户评论活动表。例如,2019 年 12 月的活动会如下所示:
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2019-12-31' and created_at >= '2019-12-01'
AND country IS NOT NULL
GROUP BY country
下一步显而易见的是,通过调整我们 WHERE 语句过滤的日期值,将 2019 年 12 月的代码移到 2020 年 1 月,并将两个部分合并在一起。在到达这一步之前,我们想要建立我们查询的完整骨架。因此,我们将暂时使用单独月份的 WITH 语句的占位符伪代码以提高可读性。请注意,12 月和 1 月的表将具有相同的列,并且可以通过唯一的国家名称进行连接。此外,我们正在寻找 1 月 2020 年排名高于 2019 年 12 月排名的情况,这在数值上意味着较低的值。
WITH dec_summary as (CODE BLOCK),
jan_summary as (CODE BLOCK)
SELECT j.country
FROM jan_summary j
LEFT JOIN dec_summary d on d.country = j.country
WHERE (j.country_rank < d.country_rank)
现在在我们将所有完全编写的代码重新整合之前,还有最后一步:正如我们之前提到的,我们还想捕捉到一个边缘情况,即 2019 年 12 月可能没有用户评论活动。根据我们的表连接方式,2019 年 12 月的dec_summary表中不会有列值。由于我们从jan.summary表开始,这意味着我们 LEFT JOIN 到 1 月汇总的 12 月值将导致 12 月值为 null。因此,我们必须添加额外的 null 条件作为 OR,这样结果就是:
WITH dec_summary as (CODE BLOCK),
jan_summary as (CODE BLOCK)
SELECT j.country
FROM jan_summary j
LEFT JOIN dec_summary d on d.country = j.country
WHERE (j.country_rank < d.country_rank)
OR d.country is NULL
最后,让我们将这些全部整合在一起吧!
with dec_summary as (
SELECT
country,
sum(number_of_comments) as number_of_comments_dec,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2019-12-31' and created_at >= '2019-12-01'
AND country IS NOT NULL
GROUP BY country
),
jan_summary as (
SELECT
country,
sum(number_of_comments) as number_of_comments_jan,
dense_rank() over(order by sum(number_of_comments) DESC) as country_rank
FROM fb_active_users as a
LEFT JOIN fb_comments_count as b
on a.user_id = b.user_id
WHERE created_at <= '2020-01-31' and created_at >= '2020-01-01'
AND country IS NOT NULL
GROUP BY country
)
SELECT j.country
FROM jan_summary j
LEFT JOIN dec_summary d on d.country = j.country
WHERE (j.country_rank < d.country_rank)
OR d.country is NULL
查看我们的 Facebook 数据科学家面试指南。我们在有关 了解 Facebook 数据科学家面试流程的文章中也讨论了更广泛的面试流程。
亚马逊
这家跨国科技公司被说在面试问题中非常重视建模,例如捕捉客户行为和保留。亚马逊也有许多产品在其公司旗下,当然,你在面试中实际被问到的问题会根据你申请的具体团队或职位有所不同。也就是说,让我们来看几个关于亚马逊电子商务最知名产品的数据科学 SQL 面试问题:
订单总成本

首先,让我们看一下我们提供的表:
客户

订单
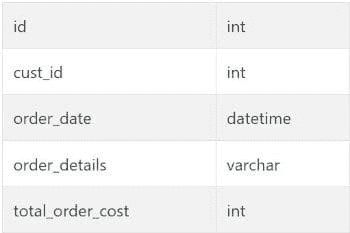
一如既往,首先问自己一些关键问题:这个问题的输出应该是什么样的?我们是否需要再次确认任何细节?问题明确指出了它的要求:我们需要按字母顺序获取客户 ID、客户名称和订单总费用。这应该是对我们给定的客户和订单表的直接连接,我们可以按客户 ID 和名称分组,然后求和他们的订单总费用。
让我们首先进行连接:
SELECT customers.id,
customers.first_name,
FROM orders
JOIN customers ON customers.id = orders.cust_id
接下来,我们需要汇总每个客户订单的总费用,这里是 total_order_cost 的 SUM。因此,我们将对其他相关列进行分组,然后提取我们订单费用字段的 SUM。
SELECT customers.id,
customers.first_name,
SUM(total_order_cost)
FROM orders
JOIN customers ON customers.id = orders.cust_id
GROUP BY customers.id,
customers.first_name
ORDER BY customers.first_name ASC;
最后,问题要求我们按客户的名字字母顺序排列,这需要在查询末尾简单地使用 ORDER BY:
SELECT customers.id,
customers.first_name,
SUM(total_order_cost)
FROM orders
JOIN customers ON customers.id = orders.cust_id
GROUP BY customers.id,
customers.first_name
ORDER BY customers.first_name ASC;
就这样!
下面查看一些来自 Amazon 的额外数据科学 SQL 面试问题:
查找用户购买

营销活动成功 [高级]

这个数据科学 SQL 面试问题涉及处理复杂逻辑并实现多个场景和边界情况。查看下面的视频,了解如何处理这个高级 SQL 面试问题。
查看我们的文章 Amazon 数据科学家面试问题。我们还在我们的 Amazon 数据科学家面试指南 中讨论了更广泛的面试过程。
这家跨国科技公司也被认为会询问许多建模问题,并且额外的产品问题更侧重于业务方面。同样,问题的具体类型和重点将根据你申请的团队和职位而有所不同。
让我们看看一些来自 Google 的 SQL 数据科学面试问题。
总 AdWords 收入

用户电子邮件标签

问题链接
再次,让我们从查看提供的表格开始。
google_gmail_emails

google_gmail_labels

和往常一样,我们首先了解我们期望的输出,然后获得可能需要的任何澄清或考虑任何潜在的边缘情况。在这里,我们想返回带有标签的电子邮件,这些标签存储在单独的表中,因此我们将从简单的连接开始。由于我们专注于每个用户,并计算他们从每种标签收到的电子邮件数量,我们可以通过对 user 和 label 列进行分组,然后分别计数开始:
SELECT mails.to_user,
labels.label,
COUNT(*) AS cnt
FROM google_gmail_emails mails
INNER JOIN google_gmail_labels labels ON mails.id = labels.email_id
GROUP BY mails.to_user,
labels.label
注意我们使用 COUNT 函数而不是 SUM 函数,因为 COUNT 忽略了空值。如果使用 SUM,对于包含空值的任何分组值,我们将得到空白输出。然后可以使用这个必需的连接作为我们 SELECT 的表,并且我们可以根据各个标签单独进行划分。我们想要来自每个标签的数字,通过一些基本的探索或对 Gmail 的一般熟悉,我们知道这些标签是“Promotion”、“Social”和“Shopping”。从这里开始,我们可以为每个不同的标签整理各自的 COUNTS,这将需要一个类似于上述的外部 GROUP。我们将使用一些伪代码以便于阅读,然后再完全整合上述代码:
SELECT
to_user,
SUM(CASE
WHEN label = 'Promotion' THEN cnt
ELSE 0
END) AS promotion_count,
SUM(CASE
WHEN label = 'Social' THEN cnt
ELSE 0
END) AS social_count,
SUM(CASE
WHEN label = 'Shopping' THEN cnt
ELSE 0
END) AS shopping_count
FROM (CODE BLOCK)
GROUP BY to_user
ORDER BY to_user
最后,我们在初始连接表中进行写入。
SELECT
to_user,
SUM(CASE
WHEN label = 'Promotion' THEN cnt
ELSE 0
END) AS promotion_count,
SUM(CASE
WHEN label = 'Social' THEN cnt
ELSE 0
END) AS social_count,
SUM(CASE
WHEN label = 'Shopping' THEN cnt
ELSE 0
END) AS shopping_count
FROM (SELECT mails.to_user,
labels.label,
COUNT(*) AS cnt
FROM google_gmail_emails mails
INNER JOIN google_gmail_labels labels ON mails.id = labels.email_id
GROUP BY mails.to_user,
labels.label)
GROUP BY to_user
ORDER BY to_user
就是这样!
活动排名
查看我们的 成为 Google 数据科学家的终极指南。我们还在 Google 数据科学家面试指南 中讨论了更广泛的面试过程。
我们在另一篇博客文章 高级 SQL 面试问题 中也涵盖了流行公司提出的其他 SQL 问题。
最后的提醒
既然我们已经介绍了一些 FAANG 公司各自的数据科学 SQL 面试问题,接下来我们简要回顾一下在准备大型面试时提升 SQL 能力的最佳实践。建立 SQL 技能至关重要,因为它们对任何处理数据的角色都可能很重要。能够阅读和理解他人的代码,甚至提取自己的数据,都是极其强大的能力。
建立这些 SQL 能力的良好第一步就是来到这里!获得实际的 SQL 经验非常有帮助,因为你将超越你从课堂或类似培训中获得的理论框架,进行实际操作。
在你练习 SQL 数据科学面试问题时,先尝试在不运行代码编辑器的情况下构建解决方案。花大约 15 分钟思考你编写的原始代码,尽力确保没有语法错误或漏洞。你甚至可以通过在纸上实际写下代码而不是在代码编辑器中工作来强化这一过程。如果遇到困难,可以快速查看提示。
在实际工作环境中,你通常可以反复运行任何你想测试的代码,以解决可能出现的每一个错误。以这种方式工作是巩固 SQL 知识的好方法,通过训练自己在第一次尝试时能够得到最全面的答案。此外,在面试过程中处理这些数据科学 SQL 面试问题时,第一时间得到一个好的、稳固的答案非常重要。虽然不需要百分之百完美,但代码中充满小的语法错误会给面试官留下不好的印象。
还需要注意的是,在极端情况下,反复运行代码可能也不切实际,例如当你处理的数据库非常大,每个查询都需要很长时间才能完成时。大型查询运行几个小时后才发现你不小心做了错误的连接,这可能导致大量的时间浪费。
接下来,在你在短期内尽可能确信代码中没有更多错误后,在代码编辑器中进行实际运行。查看任何弹出的错误或问题,这些是你在前一步中可能遗漏的,并进行必要的更改。记录你遗漏的内容也是一个好习惯,并且在处理多个练习 SQL 面试问题时,观察是否有揭示你知识空白、问题习惯或常见问题的模式。
最后,将你的工作与其他可用解决方案进行比较,以便比较方法和了解潜在的优化。首先是官方解决方案,你应该问自己几个问题。
-
你是否还有其他方法可以进一步优化你的代码?
-
你的代码中是否存在低效的地方?
-
解决问题的替代方法与你的方法有何不同?它们是否是你可以从中学习的更好方法?
此外,阅读每个问题的讨论线程,识别与问题相关的任何主题,如边界案例或替代方法,甚至是与给定场景类似的问题。
从那里开始,你已准备好在数据科学面试中迎接任何 SQL 问题。
原文。经许可转载。
简介: 内森·罗西迪是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的的平台,提供来自顶级公司的真实面试问题。
相关:
更多相关主题
如何在预算内设置你的数据科学技术栈

数据科学可能是一个昂贵的投资。物理基础设施和设备、云托管服务、数据库访问等都可能迅速累积成可观的费用。这可能会使你在行业中起步变得困难。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
大多数小企业每年在数据分析上花费超过 10,000 美元,但大多数个人无法负担。无论你是独立工作还是为公司设置技术栈,你都需要一个更实惠的选项。以下是如何在不花费过多的情况下设置你的技术栈。
1. 寻找提供免费服务层的服务提供商
服务提供商如网络托管公司是数据科学中一个重要但常常昂贵的部分。值得庆幸的是,许多服务提供商也为入门用户提供免费的或低成本的服务层。即使是像 AWS 这样的行业领导者,也提供类似 S3 和 AWS Lambda 的免费功能,但有使用限制。
你不能在免费服务层中使用提供商的所有服务,可能会有存储或访问频率的限制。确定你项目的需求,然后比较各种选项,以找到最适合你的需求的方案。
2. 优选基于网页的软件
在购买软件工具时,尽量选择基于网页的选项而不是传统的本地应用程序。如果你将大部分或所有操作转移到网络上,你对物理设备的需求就不会那么高。这样,你可以减少在计算机、服务器或其他基础设施上的开支,因为你不需要那么多的存储或处理能力。
在寻找基于网页的选项时,确保了解它们的收费方式。许多 Kubernetes 操作的计费选项按集群每小时收费,这可能会迅速变得昂贵。确保选择的即服务选项不会比本地解决方案更贵。
3. 重新思考必要性
另一种降低栈成本的方法是排除一些选项。许多功能和过程可能很昂贵,但你可能不需要它们。例如,网站托管的费用通常在1000 美元到 4000 美元之间,但你不一定需要一个独特的域名。
在审查预算和目标时,重新考虑你是否需要列表上的每一项。有些功能可能很有用,但对最终产品的影响不大,所以最好现在先不考虑它们。
4. 使用开源数据库
数据科学的另一个高成本方面是你的数据库。收集自己的数据很慢,需要大量基础设施成本,许多公开的数据库也很昂贵。你可以通过在开源数据库上训练程序来避免这些成本。
许多开源数据库会免费提供有限的访问权限。一些服务提供商的免费套餐,如 Supabase,甚至会提供免费且完全的访问权限,通常基于开源选项。不过,在使用这些开源数据库时,一定要检查它们的安全性,并在处理前清理数据。
5. 从小做起
最后,你可以通过调整你的雄心来降低成本。大型、开创性或颠覆性的项目可能会有超出预算的复杂性和存储需求。首先关注较小、需求较少的项目,计划在获得更多收入后扩展。
较小的项目会让有限的免费资源的相对效用显得不那么限制。如果你能等到赚更多的钱再扩展,免费的数据库和托管工具可以帮助你走得更远。
数据科学不一定要昂贵
数据科学起初可能会让人觉得难以接受,特别是考虑到一些企业在这方面的花费。尽管这些开支可能会非常庞大,但对新数据科学操作来说并不一定如此。
遵循这五个步骤将帮助你建立你的栈而不需要花费太多。如果你已经有一些工具,甚至可以免费开始工作。然后,你可以开始扩展你的操作,未来转向更大的项目。
德文·帕蒂达是一位大数据和技术作家,同时也是ReHack.com的主编。
主题扩展
数据科学统计学 101
原文:
www.kdnuggets.com/2016/07/data-science-statistics-101.html
作者:Jean-Nicholas Hould,JeanNicholasHould.com。
对于没有定量背景的有抱负的数据科学家来说,学习统计学可能是一个令人生畏的过程。无论你是计算机科学本科生、寻求职业转换的开发人员,还是 MBA 毕业生,统计学通常是数据科学中最令人生畏的部分。作为一名商学院毕业生,对我来说也是如此。
我们的三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求

统计学是一个严肃的学科,有些人一生都在研究它。作为一名有抱负的数据科学家,你应该如何学习统计学?你需要了解什么?学习统计学的最佳方法是什么? 下面是你应该如何进行的。
从简单开始
理解简单的统计概念可以带来极大的价值。在许多数据科学项目中,你不需要高级的统计知识就能得出重要结论。因此,你应该专注于学习统计学的基础知识,将其应用到工作中,并从那里扩展。
你需要了解的两个主要统计分支是描述性统计和推断性统计。通过正确理解这些,你可以获得大量的价值。
描述性统计
描述性统计以定量方式描述一组信息。它们总结了观察到的数据。与推断统计不同,它们并不推断有关更大人群的事实。它们仅仅描述了收集到的数据集。
你过去肯定接触过这些统计数据。在描述性统计中,一些常见的测量指标评估集中趋势 (均值、中位数、众数…),其他则评估数据集的变异性 (标准差…)。
推断性统计
推断统计使我们能够根据样本数据集推断关于总体的属性。它们利用样本得出超出收集数据的结论。
在实际的数据科学中,推断统计在比较转化率、分析如 A/B 测试等实验时被大量使用。
在线课程
对我来说,在线课程是学习基础知识的绝佳选择:
这些课程是互动式的,包括练习和视频。我认为它们是入门这一领域的非常好方式。它们将为你提供足够的知识,使你可以开始对统计学感到更加自信。
书籍
总的来说,我推荐这本书 《裸统计学:剥去数据的恐惧》。这本书由查尔斯·惠兰撰写,涵盖了描述性/推断统计学等主题,并提供了每个领域的良好概述。通过一些非常具体和轻松的例子,它使统计学不再神秘。
从这里开始
记住,学习这些概念的最佳方式是将你的知识应用于具体的例子。一旦你开始将这些概念融入到你的分析中,我建议你阅读一本统计学手册,比如 《统计学全书》 并加深你的知识。
简介:让-尼古拉斯·霍尔德 是一位来自 加拿大蒙特利尔的数据科学家。JeanNicholasHould.com 的作者。
原始链接。已获转载许可。
相关:
更多相关主题
数据科学、统计学和机器学习词典
原文:
www.kdnuggets.com/2022/05/data-science-statistics-machine-learning-dictionary.html

Pisit Heng 通过 Unsplash
作为一名新的数据科学家,理解办公室技术术语和行话可能会很困难。本文将为你提供在数据科学之旅中最常用的术语。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
A
算法 - 一组用于解决特定任务的可重复指令。
AngularJS - 一个开源 JavaScript 库,允许开发者创建单页应用程序。由 Google 和 AngularJS 社区管理。
Anaconda - 是一个开源数据科学发行版,简化了包和部署。主要用于 Python 和 R 编程语言的用户。
Apache Spark - 一个开源计算框架和库集,用于实时的大规模数据处理。
人工智能 - 是计算机或计算机控制的机器人执行通常由人类完成的任务的能力,因为这些任务需要人类智能。
B
反向传播(Backpropagation) - 有时缩写为“backprop”。它是告诉神经网络在预测时是否出错的信使,通过反复调整权重来实现。
集成学习(Bagging) - 也称为自助法,是一种通过使用从数据子集创建的多个模型的预测组合来进行预测的技术。
贝叶斯定理 - 一种用于确定条件概率的数学公式。
贝叶斯网络 - 一种概率图模型,旨在建立一个保持已知条件依赖关系和在其他所有情况下的条件独立性的模型。
偏差 - 是由于机器学习过程中不正确的假设而产生的系统性误差。
大数据 - 是由于其巨大的多样性、不断增长的体量和速度而变得非常不切实际的数据。
二元变量 - 在变量的上下文中,这些变量只有两个唯一值,如“是”和“否”
二项分布 - 是一种用于计算具有固定试验次数的实验概率的方法。
提升 - 是一个顺序过程,其中模型通过从前一个模型中学习来纠正错误。
C
分类变量 - 具有离散定性值的变量,如种族或宗教。
卡方检验 - 一种统计方法,用于测试和比较观察结果与预期结果。
分类 - 是通过识别对象属于哪个类别来预测标签的过程。
聚类 - 一种无监督算法过程,用于将数据点划分为特定的组。
计算机视觉 - 一种 AI 形式,使计算机能够以类似于人类视觉的方式可视化、处理和识别图像/视频。
置信区间 - 一种统计方法,用于基于样本结果估计一个特定类别的总体百分比。
混淆矩阵 - 用于描述分类模型性能的表格。
连续变量 - 是具有无限个值的变量,如速度和距离。
凸函数 - 如果图上的任何两点之间的线段位于图形上方或图形上。
相关性 - 是两个或多个变量之间协方差/关系的比率。
成本函数 - 一种统计方法,用于定义和测量模型的错误。
协方差 - 用于测量两个随机变量之间关系的量度。
交叉熵 - 用于测量一组事件的两个概率分布之间的差异。
交叉验证 - 一种统计技术,通过将数据分为两个部分来评估和比较机器学习算法。
D
数据工程师 - 负责设置和维护组织数据基础设施的数据专业人员。
数据挖掘 - 从结构化和非结构化数据中提取有用信息的过程。
数据科学 - 为分析过程准备数据,包括清洗、操作、算法开发等,以执行高级数据分析。
仪表板 - 用于跟踪、分析和显示信息管理工具。
性能。构建仪表板的最常用工具包括 Excel 和 Tableau。
数据库 - 是一个有结构的数据集合,以可访问的方式组织。常见的数据库语言是 SQL。
数据增强 - 一种通过对现有数据进行轻微调整来增加数据量的技术。
决策树 - 一种非参数监督学习方法,用于分类和回归,旨在通过学习从数据特征中推导出的简单决策规则来构建预测目标变量值的模型。
深度学习 - 一种机器学习方法,教计算机做自然流露的事情。它训练算法在给定一组输入的情况下预测输出。
因变量 - 被测量并受到自变量影响的变量。
降维 - 减少训练数据中输入变量数量的过程。
E
提前停止 - 一种避免过拟合的技术,用于训练机器学习模型时采用迭代方法。
探索性数据分析 - 是数据初步调查中的关键过程,通过可视化或统计分析提供更多见解。
ETL - 是提取、转换和加载的流行缩写。ETL 系统从源系统中提取数据,确保其质量并呈现数据。
评估指标 - 用于衡量机器学习模型质量的指标,如 AUC。
F
假阴性 - 真实的预测被错误地预测为假。
假阳性 - 错误的预测被错误地预测为真实。
特征减少 - 是减少特征数量的过程,以提高计算密集型任务的效率而不丢失信息。
特征选择 - 是通过选择相关特征来减少输入变量数量的过程,以用于模型中。
F-得分 - 是衡量模型在数据集上准确度的指标。
G
GPU - 代表图形处理单元,是一种专门的处理器,可处理用于机器学习、视频编辑和游戏应用的数据块。
梯度提升 - 是依赖于使用之前的模型来改进下一个模型,并最小化整体预测误差的过程。
梯度下降 - 是一种优化算法,帮助找到给定函数的局部最小值/最大值。
H
Hadoop - 一个开源框架,用于高效存储和处理大数据集。
层次聚类 - 一种将相似数据点分组为称为簇的算法。
直方图 - 组织一组数据点在连续变量中的图形表示。
留出样本 - 从数据集中随机抽取的样本,未用于模型拟合过程。
超参数调整 - 发现机器学习算法的最佳超参数的过程。
I
自变量 - 可以操作或对因变量产生直接影响的变量。
迭代 - 重复特定数量次的语句/代码块的过程,依次生成输出。
J
JavaScript - 一种脚本语言,用于创建交互式网页内容,如应用程序和浏览器。
Jupyter Notebook - 一个基于网页的交互式计算平台,用于创建和分享计算文档。
K
K 均值 - 一种无监督学习算法,通过距离将数据点分组到最近的质心。
Keras - 由 Google 开发的开源软件库,用于实现神经网络。
K-近邻 (KNN) - 一种监督学习算法,用于回归和分类任务。它通过计算当前训练数据点之间的距离来对测试数据集进行预测。
Kubernetes - 一个开源平台,用于自动化应用程序的部署、扩展和管理。
L
标记数据集 - 具有“标签”、“类别”或“标记”的数据。
套索回归 - 通过收缩或正则化来避免过拟合,以最小化预测误差的过程。
线性回归 - 用于对连续因变量进行预测,利用自变量进行预测。
逻辑回归 - 用于预测分类因变量,使用自变量对输出进行分类,输出只能在 0 和 1 之间。
对数损失 - 测量分类模型的性能,其中输出是介于 0 和 1 之间的概率值。
长短期记忆网络 - 一种能够学习和记忆长期依赖关系的递归神经网络。LSTM 旨在长时间记住过去的信息。
M
机器学习 - 是一种模型利用历史数据作为输入预测新输出值的过程,用于识别和学习数据分析中的模式。
机器学习操作 (MLOps) - 机器学习工程的核心功能,专注于将机器学习模型投入生产,并随后维护和监控它们的过程。
管理信息系统 (MIS) - 由硬件和软件组成的计算机系统,作为组织运营的支柱。
最大似然估计 - 一种概率框架,用于获得更稳健的参数估计。
均值 - 是所有数字的平均值。
均绝对误差 - 也称为 L1 正则化,计算标签数据和预测数据之间误差平方的均值。
均方误差损失 - 也称为 L2 正则化,告诉你回归线与数据点集的接近程度。
中位数 - 是从小到大排序的列表中的中间值。
众数 - 数据集中出现频率最高的值。
模型选择 - 从已知模型集中选择统计模型的过程。
蒙特卡洛方法 - 一种数学技术,用于估计不确定事件的可能结果。
多类分类 - 具有多个目标变量类别的分类问题。
多层感知器 - 是一种前馈人工神经网络,其中一组输入被送入神经网络以生成一组输出。
多变量分析 - 比较和分析多个变量之间相互依赖性的过程。
N
朴素贝叶斯 - 使用假设数据点属性之间独立的分类器的过程,基于贝叶斯定理。
NaN - 代表“not a number”,指的是未定义或未表示的数值数据类型。在数据集中,这将被视为缺失或不正确表示。
自然语言处理 - 计算机能够检测和理解人类语言的能力,通过语音和文本与我们人类一样。
神经网络 - 由神经元组成的网络,包含三种不同的层:输入层、一个或多个隐藏层,以及输出层。
NoSQL - 代表“Not only SQL”,是一种提供数据存储和检索的数据库。
名义变量 - 一种用于命名、标记或分类被测量特定属性的变量类型。
正态分布 - 是一种概率分布函数,表示在钟形图中随机变量的分布。
归一化 - 一种将数据缩放到[0, 1]范围内的技术。
NumPy - 一个用于 Python 的库,提供多维数组对象处理、线性代数和矩阵计算函数的数学功能。
O
独热编码 - 一种将分类变量转换为机器学习和深度学习算法可用的形式的过程,以提高模型的预测和准确性。
序数变量 - 是具有某种排序形式的离散值的变量。
异常值 - 是在样本中远离整体模式的观测值。
过拟合 - 指统计模型完全适应其训练数据。当函数过于精确地拟合有限的数据点集时,发生建模错误。
P
Pandas - 一个用于数据处理和分析的开源 Python 库。
参数 - 是定义系统的一组可测量因素,并且是从过去的训练数据中学习到的模型部分。
精确度 - 是模型对实际正例的总数以及正预测的质量的衡量。
预测建模 - 通过分析给定输入数据集中的模式,使用数学方法预测未来事件或结果的过程。
预测变量 - 用于对因变量进行预测的变量。
预训练模型 - 是由其他人创建的模型,能够解决类似的问题,而不是从头开始构建模型。
主成分分析 - 一种用于通过提高模型可解释性来减少数据集维度的技术,而不降低信息损失。
概率分布 - 是描述所有可能值及其发生的统计函数。
P 值 - 是样本数据结果由偶然发生的概率,因此较低的 P 值是好的。
R
R - 一种开源编程语言,也是一个用于统计计算、机器学习和数据可视化的软件环境。
随机森林 - 由许多决策树组成的一种集成学习方法,用于分类、回归和其他任务,包含多个决策树。
回归 - 一种用于研究自变量或特征与因变量或结果之间关系的技术。
正则化 - 用于解决统计模型中过拟合问题的一种技术。
强化学习 - 目的是训练模型,通过一系列为特定问题创建的解决方案和/或决策来返回最优解。
Ruby - 一种开源编程语言,主要用于构建网络应用程序。
S
Scikit-learn - 一个为 Python 用户提供的库,包含机器学习和统计建模的工具,如分类、回归、聚类和降维
SQL - 代表结构化查询语言,用于通过执行如更新数据、检索数据等任务来管理数据库。
标准差 - 告诉你数据围绕均值的变动情况
标准误差 - 告诉你计算出的不同均值的变动情况
随机梯度下降 - 旨在通过逐步调整网络的权重来最小化成本函数。
监督学习 - 一种算法在标记数据集上进行学习并分析训练数据的学习类型
支持向量机 - 一种监督学习模型,通过创建一个线性或超平面将数据分成不同的类别
T
T 分布 - 一种描述样本均值与总体均值之间标准化距离的概率分布,类似于正态分布。
T 值 - 组间和组内的方差,其中较大的 T 值意味着组间差异较大,而较小的 T 值则意味着组间差异较小。
TensorFlow - 是一个开源库,用于深度学习应用,使得通过数据流图构建具有多层的大规模神经网络模型变得简单。
分词 - 将文本字符串分割成称为标记的单元的过程,是自然语言处理的一部分。
迁移学习 - 一种机器学习方法,其中从一个任务中获得的知识可以作为另一个任务的基础点进行重用。
真阳性 - 你预测为正且实际为正
真阴性 - 你预测为负且实际为负
T 检验 - 一种用于通过找出两个总体均值的差异来比较两个总体的检验。
第一类错误 - 决定拒绝原假设,但可能是错误的。
第二类错误 - 决定保留原假设,但可能是错误的。
U
欠拟合 - 一种建模错误,无法对训练数据建模或对新数据进行泛化,在训练集上表现不佳。
无监督学习 - 模型在未标记的数据上进行学习,推断出更多隐藏结构,以产生准确可靠的输出。
V
方差 - 用于测量一组数字的分布。
向量 - 用于以数学和易于分析的形式表示被称为特征的数值特征。
X
XGBoost - 一个开源库,提供了一个正则化的梯度提升框架,支持 C++、Java、Python、R 等编程语言。
Z
Z 检验 - 一种统计检验方法,用于计算两个总体均值是否存在差异。
结论
这些并不是所有的术语,但这些是最流行的术语。如果有遗漏的,请随时在评论中补充。希望这些对你有帮助!
尼莎·阿里亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及数据科学相关的理论知识。她还希望探索人工智能如何及能够如何促进人类寿命的延续。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
数据科学战略探索:将数据科学战略与组织战略对齐
原文:
www.kdnuggets.com/2018/11/data-science-strategy-safari-aligning-data-science-strategy.html
评论
作者:托马斯·约瑟夫,Aspire Systems
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
回到我还是管理学生的时候,激励我的是亨利·明茨伯格、布鲁斯·阿尔斯特兰德和约瑟夫·兰佩尔的经典之作《战略探索》。战略探索描述了战略的不同视角,如附加矩阵中所总结的那样。
图 1 : 战略制定的多个方面
这些战略的多个方面确实在定义我对战略的看法方面发挥了重要作用。毫无疑问,彼得·德鲁克和迈克尔·波特等领域伟大人物的著作也塑造了我的思考过程和对战略管理的观点。然而,使这本书成为我最喜欢的书单上的书籍的原因是,作者从不同的角度看待了战略管理领域。这篇文章的标题来自于对明茨伯格开创性工作的灵感。在这篇文章中,我尝试带你们进行一次数据科学战略制定过程的探索之旅。
数据科学战略制定:重大问题
在制定数据科学战略时,值得提出的一个问题是:随着数据科学在影响业务结果方面取得的巨大进展,数据科学战略应该引领组织战略,还是像其他职能战略一样,与组织战略对齐?在我看来,像其他职能战略一样,数据科学战略也应与组织战略对齐。如果数据科学领域无法用于支持组织实现其总体目标,那么它将毫无意义。因此,我坚信数据科学战略必须从组织战略中派生出来。那么,下一个问题是如何定义与组织战略对齐的数据科学战略?为了回答这个问题,让我们解读战略对齐框架。
数据科学战略探险:对齐是关键
战略对齐是一个过程,通过这个过程,一个组织的能力、资源和行动与计划中的组织目标保持一致。数据科学已经成为组织必须构建的一个关键能力,以在这个数字化互联的时代中获得优势。然而,同样重要的是,数据科学参与的输出,即预测、建议、推论研究等,必须与组织希望追求的战略目标整体方案相契合。这可以通过遵循对齐框架的过程来实现。图 2 展示了数据科学战略对齐框架。
图 2:数据科学战略对齐框架
战略对齐框架可以总结为以下步骤:
-
分析业务价值链中的关键功能。
-
在每个功能中,识别关键绩效指标。
-
从每一个绩效指标中推导出预测或推论用例,这将有助于实现这些绩效指标。创建一个与每个绩效指标对齐的用例网络。
-
对每个用例,识别影响该用例的业务因素。
-
对每个因素识别相关的数据点。
-
识别生成这些数据点的系统和子系统,并找出将它们连接以实现用例的方法。
这些步骤可以根据其价值分为“战略对齐”步骤和“操作对齐”步骤。前四个属于第一个类别,剩下的两个属于后者。
让我们看看保险公司战略对齐框架的表现。以价值链中的单一功能‘客户管理’为例。
图 3:保险公司的对齐过程
客户管理功能的分析流程如图 3 所示。为了确保数据科学战略与组织目标对齐,过程的第一步是为价值链中的每个功能识别关键绩效指标(KPI)。对于我们正在分析的‘客户管理’功能,一个对顶线和底线有重大影响的关键 KPI 是“提高客户保留率”。
确定了关键绩效指标后,对其进行对齐将涉及推导出有助于实现这一绩效指标的数据科学用例。对于客户管理职能,一个有助于提高客户保留率的用例是预测保费续保的概率。该用例的输出可以用于针对续保概率较低的客户开展定向营销,从而实现 KPI 的目标。除了与 KPI 直接相关的用例外,我们还应推导出相关用例,以促进实现该 KPI。例如,确定了需要针对的客户后,了解如何具体地针对他们也很有价值,比如预测最佳的联系时间和渠道,或预测给他们特定优惠的最佳价格点。
类似地,我们必须查看所有的职能、每个职能中的关键指标,并推导出所有主要和相关的预测用例。这些用例可以形成一个相互关联的网络,称为战略对齐图(SAM)。下面的图 4 是一个代表性的 SAM,描绘了业务价值链、其关键职能、用例的相互关联网络及其对应的类别(自然语言处理、推理、机器学习/深度学习、其他人工智能等)。一个全面的 SAM 将形成将数据科学项目与组织战略对齐的蓝图,并指示不同用例/模型之间的相互依赖。此外,它还将有助于了解为组织增值所需的各种数据科学能力。
图 4:战略对齐图
现在我们已经了解了创建 SAM 的过程,让我们深入探讨数据科学战略的操作方面。
一旦我们拥有了对组织至关重要的用例的相互关联网络,接下来的任务就是使数据获取和集成策略与整体战略对齐。为了使数据获取策略与整体战略对齐,我们首先需要了解实施 SAM 中所描绘的用例所需的数据点类型,以及数据点的特征,如格式、速度、频率、生成这些数据点的数据系统等。一种有效的方法是查看每个用例,识别影响每个用例的业务因素,然后逐步向下探讨。
对于我们特定的用例,即预测续保率,一些对续保率有影响的因素包括:
(a) 竞争 (b) 定价 (c) 客户体验与期望 & (d) 渠道效果等
必须通过与业务/领域团队的密切讨论来识别如上所述的各种因素。识别了影响每个用例的各种因素后,下一步任务是识别与每个因素相关的数据点。图 5 中描绘了影响续约率的因素相关的一些主要数据点。
图 5:与因素相关的数据点
与每个因素相关的数据点的需求决定了数据源和集成策略。从上述描绘的各种数据点可以看出,数据需求可能来自组织内部,也可能来自外部来源。例如,与竞争相关的数据点很可能需要从外部来源获取。其他数据点主要可以从组织内部的各种系统中获得。
此外,因素分析还有助于确定与每个用例相关的数据类型。与识别的数据点相关的一些数据类型如下。
-
传统的 RDBMS 数据(例如:人口统计数据、客户记录、保单交易等)
-
文本数据(客户评论)
-
语音(呼叫中心数据)
-
日志文件(渠道使用指标、渠道 Cookies 等)
为了全面了解数据需求,需要通过不同的方面来看待每一个因素。需要从以下列出的各种方面来看待每个因素。
-
数据点是什么?
-
数据类型的多样性如何?
-
数据来源是什么?
-
外部还是内部?
-
这些数据点生成和捕获的频率是多少?
-
如何将它们连接起来以实现用例?
从数据需求衍生出的这些综合视角将有助于将数据工程策略的不同组件,如数据获取、数据集成、数据预处理和清洗、数据存储等,与整体组织战略对齐。
总结
看到数据科学战略对齐框架的实际应用后,不禁会想我们是否可以将该框架与 Mintzberg 的《战略探险》的某些观点进行类比。这个框架中包含的过程步骤有学习、认知和规划策略学校的元素。然而,最终这个框架像其他任何框架一样,旨在将个人的思维过程结构化,以实现特定目标。它的最终目标是确保你的数据科学工作与整体组织目标和战略对齐。
简介:Thomas Joseph 是 Aspire Systems 的高级数据科学家,负责扩展数据科学的影响力并实现卓越的交付。
原文。经授权转载。
相关:
-
应用数据科学:解决预测性维护商业问题
-
数据科学家的思维方式 – 第一部分
-
数据科学家的思维方式 – 第二部分
更多相关话题
数据科学 - 需要系统工程方法
原文:
www.kdnuggets.com/2017/10/data-science-systems-engineering-approach.html
评论
背景
系统工程的学科起源于 1940 年代的贝尔实验室,并通过军事及 NASA 的复杂项目部署逐渐流行起来
根据国际系统工程理事会的说法,“系统工程是一门工程学科,其责任是创建和执行一种跨学科流程,以确保在整个系统的生命周期中以高质量、可信赖、成本效益和符合进度要求的方式满足顾客和利益相关方的需求。”
我们的前三个课程推荐
1. Google 网络安全证书 - 畅享网络安全职业快车道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
系统工程涵盖诸如:跨学科功能,端到端管理,复杂系统,生命周期管理,形式化需求工程,可靠性,后勤等方面。系统工程还采用了“系统的系统”方法。系统工程问题采用以下步骤解决(根据 INCOSE):阐述问题,调查替代方案,建模系统,集成,推出系统,评估性能,重新评估。他们通常还涉及与系统思维基本思想相关的系统模式的工作。
那么,这些思想与数据科学有何关联呢?随着数据科学变得更加复杂,问题的性质要求更加全面的方法/系统思维方法。这尤其适用于深度学习等领域
数据科学中系统思维的需求
下面是数据科学中应用系统思维的两个例子
1 机器学习在实际应用中只起到了很小的作用
在论文机器学习系统中的隐藏技术债务中,Google 的一个团队表示,在现实世界的 ML 系统中,只有很小一部分是由 ML 代码组成的,如中间的小黑盒所示。所需的周围基础设施是庞大而复杂的。
文章继续说道
-
机器学习系统之所以复杂,是因为它们不仅存在维护传统代码的问题,还有一系列机器学习特定的问题。
-
复杂模型侵蚀了边界。不幸的是,通过规定具体的预期行为来强制执行机器学习系统的严格抽象边界是困难的。事实上,仅当期望的行为在没有依赖于外部数据的软件逻辑的情况下无法有效表达时,才需要机器学习。
-
Map-Reduce 对于迭代的机器学习算法来说是一个不好的抽象。
-
数据测试、可再现性和过程管理都增加了机器学习系统的复杂性。
2)TensorLayer
TensorLayer 是一项全新的开源计划,旨在解决部署实际深度学习模型的不断增长的复杂性。《TensorLayer: 一种高效深度学习开发的多功能库》(https://arxiv.org/abs/1707.08551)涵盖了许多系统工程问题。
tensorlayer 的体系结构如下所示。
如您所见,机器学习只是一个组件。如果您考虑采用端到端(系统工程)方法,则 tensorlayer 提供了四个模块:
-
一个层模块,提供了神经元层的参考实现,可以灵活地相互连接以构建神经网络,
-
一个模型模块,可帮助管理模型生命周期中产生的中间状态,
-
一个数据集模块,管理可以被离线和在线学习系统使用的训练数据,
-
一个工作流模块,支持并行训练任务的异步调度和故障恢复。
这克服了深度学习中日益增长的互动性问题,开发人员不得不花费大量时间来集成组件以进行神经网络的实验、管理中间训练状态、组织与培训相关的数据以及在不同事件中实现超参数调整。这样,整合应用程序(如 DRLs、GANs、模型交叉验证和超参数优化)的部署将更加容易。
结论
随着数据科学作为一门学科的成熟,我看到需要解决更加复杂和整体化的问题。为了实现这些目标,我们可以借鉴现有的系统工程等学科。我在牛津大学物联网数据科学课程中讨论了这些问题。
相关文章:
-
人工智能和物联网之间的动态关系
-
2 月最热门的 /r/MachineLearning 帖子:牛津深度自然语言处理课程;Scikit-learn 结果的数据可视化
-
物联网(IoT)数据科学与传统数据科学的十个不同之处[/2016/09/data-science-iot-10-differences.html "Data Science for Internet of Things (IoT): Ten Differences From Traditional Data Science 的永久链接")
有关此主题的更多信息
数据科学工具插图学习指南
原文:
www.kdnuggets.com/2020/08/data-science-tools-illustrated-study-guides.html
评论
双胞胎兄弟和教育者 Afshine 和 Shervine Amidi,曾创建了极好的 机器学习 和 深度学习 学习资源,这次再次携手,为一系列数据科学工具提供了一套插图学习指南。
这套 插图学习指南 是基于 Afshine 目前正在教授的 MIT 课程,尽管兄弟俩是共同创建了这些资源的。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
这些指南具体涵盖了什么内容?它们被分为四个不同的类别,每个类别包含一个到三个相关的指南。下面的链接会重定向到这些指南的在线版本;PDF 版本可在稍后找到。
数据检索
该指南涵盖的概念包括:过滤、条件和数据类型;连接类型;聚合、窗口函数;表格操作
数据处理
这些指南涵盖的概念包括:过滤、条件和数据类型;连接类型;聚合、窗口函数;数据框架转换;R 和 Python 之间的转换简化
数据可视化
这些指南涵盖的概念包括:散点图、折线图、直方图;箱线图、地图;自定义图例;R 与 Python 之间的轻松转换
工程技巧

本指南涵盖的概念包括:使用 Git 进行版本控制;使用 Bash 进行终端操作;掌握 Vim 编辑器
如果你更喜欢这些资源的 PDF 版本,可以在 这里 找到各个下载链接。
或者,你可以访问一个包含所有这些材料的 "超级学习指南" 文档。
这些 数据科学工具插图学习指南 是熟悉所涵盖概念的绝佳资源。再次感谢 Afshine 和 Shervine 提供的另一个详尽资源。
相关:
-
机器学习备忘单
-
深度学习备忘单
-
Pytorch 初学者及 Udacity 深度学习纳米学位的备忘单
更多相关内容
数据科学工具受欢迎程度,动画展示
原文:
www.kdnuggets.com/2020/06/data-science-tools-popularity-animated.html
评论
作者:Greg Hamel,作家 | 机器学习竞赛专家。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
下方的动画图表展示了根据 KDnuggets 从 2000 年到 2019 年的软件调查结果的十大最受欢迎的数据科学工具(见下表)。KDnuggets 是一个领先的数据科学和分析博客,过去 20 年来通过一系列年度用户调查收集了数据科学和数据挖掘工具的受欢迎程度。调查受访者被询问了他们在过去一年中用于项目的数据科学工具。
请注意,视频中显示的数值表示过去一年中使用特定数据科学工具的用户比例。一个受访者可能会报告使用多个数据科学工具,因此这些工具的总和不需要达到 100%。用户通常会报告使用更广泛的工具,因此图表上的数值呈上升趋势。
视频:根据 KDnuggets 从 2000 年到 2019 年的调查,十大数据科学工具随时间变化的受欢迎程度
注意:调查包含了 20 到 90 个选项,但上面的影片仅显示了每年的前 10 名。
编辑:KDnuggets 在 2020 年没有进行数据科学软件调查,但以下是之前 KDnuggets 在分析、数据挖掘、数据科学软件方面的调查结果:
-
开源数据科学/机器学习生态系统的 6 个组件;Python 是否已经超越 R?,2018 年 6 月
-
Python 蚕食 R:2018 年分析、数据科学、机器学习的顶级软件 - 趋势与分析,2018 年 5 月
-
分析、数据科学、机器学习软件调查的新领导者、趋势和惊喜,2017 年
-
R 和 Python 在顶级分析和数据科学软件中对决,2016 年
-
R 领先于 RapidMiner,Python 紧随其后,大数据工具增长,Spark 点燃,2015 年
-
RapidMiner 继续领先,2014 年
-
RapidMiner 和 R 争夺第一名,2013 年
-
KDnuggets 2012 年调查:分析、数据挖掘、大数据软件使用情况
-
KDnuggets 2011 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2010 年调查:使用的数据挖掘/分析工具
-
KDnuggets 2009 年调查:使用的数据挖掘工具
-
KDnuggets 2008 年调查:使用的数据挖掘软件
-
KDnuggets 2007 年调查:数据挖掘/分析软件工具
更多相关主题
数据科学如何改变移动应用开发?
原文:
www.kdnuggets.com/2023/03/data-science-transform-mobile-app-development.html

图片由 Mikael Blomkvist 提供
数据是当今数字时代的新力量。随着各行各业和企业使用移动应用进行各种用途,大量的数据被产生。面对如此巨大的数据量,企业需要有效且智能的方式来驱动有用的洞察,进一步提升业务增长。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
公司在移动应用开发中使用数据科学以获得更高的成果。因此,它正在颠覆应用开发行业。在本文中,我们将讨论数据科学如何帮助开发者和企业转变移动应用开发。
但在我们继续之前,让我们首先了解一下
什么是数据科学?
数据科学是从数据中获取有意义和目的驱动的洞察与分析的研究领域。这是一种多学科的方法,结合了人工智能、计算机工程、数学和统计学的多个原则,以分析大量数据。数据科学涉及编程以及数学和统计学知识,以提取目标导向的数据洞察或分析。因此,当数据科学与行业领域或商业细分市场结合使用时,有助于提升商业智能和性能。
数据科学在移动应用开发中是如何工作的?
数据科学主要是计算机编程。它专注于开发人工智能和机器学习模型,以自动分析大规模数据。数据科学家负责构建数据处理管道、准备应用分析、设计架构和创建机器学习模型。
这些机器学习模型随后交给应用开发者,以集成到移动应用中。因此,数据科学在移动应用开发中主要关注数据摄取、人工智能与机器学习模型的开发以及将其部署到移动应用中。数据科学还帮助应用开发者转换和重新部署机器学习模型,以适应新标记的数据或任何其他模型输入的变化。
然而,这里的移动应用开发人员负责创建和维护移动应用程序。数据科学主要作为集成自动化数据分析模型的组件。因此,数据科学家和应用开发人员在移动应用开发过程中携手合作。由于机器学习和人工智能可以改变移动应用,数据科学在应用开发中的使用具有巨大潜力。
数据科学如何改变移动应用开发?
数据科学在移动应用开发中发挥了重要作用。移动应用通常会收集大量的数据和分析。特别是在电子商务、商业和企业规模的情况下,移动应用必须处理大量数据。然而,为了处理如此多的数据,移动应用通常集成了 API 或云服务。
但是,这些技术仅用于收集信息。因此,迫切需要一种有效或智能的技术解决方案,不仅能够处理大数据,还能够协助提供业务驱动的洞察。以下是将数据科学整合到移动应用开发中的进一步好处:
1. 理解用户行为
对于任何业务,成功取决于他们如何更好地理解目标受众。在当前移动驱动的世界中,人们大量依赖使用移动应用和智能手机来访问在线服务。企业通过收集客户数据来衡量他们对产品和服务的偏好和兴趣。
在这种情况下,数据科学赋予移动应用智能地收集信息并得出对业务智能有用的洞察。这帮助应用所有者和利益相关者准确分析用户行为,并调整他们的商业战略。因此,企业能够更有效地实现目标并避免潜在的失败。
2. 解码隐藏问题
这是在移动应用开发中使用数据科学的主要优势之一。它帮助开发人员和应用开发公司发现开发过程中可能被忽视的问题。通常,移动应用中的错误或缺陷在部署后才会被注意到。因此,开发团队和应用所有者不得不花费不必要的精力和增加成本。
在这里,数据科学有助于发现移动应用中的隐藏或潜在问题。它使用编程算法检测无结构和不相关数据中的模式。许多开发人员在安卓应用开发中使用数据科学来检测最终部署前的漏洞和技术故障。因此,数据科学有助于检测隐藏问题,确保开发过程的完美。
3. 改善开发过程
数据科学不仅仅关乎分析。它涉及编程和开发自动化功能,这些功能可以提升应用开发过程。有了数据科学,开发人员可以实施预测分析和机器学习模型来开发应用程序。
这可以帮助提升从数据收集到获取有用见解的各种操作。因此,数据科学使得应用开发公司和开发人员能够加快部署和处理过程,从而减少时间、精力和成本。
4. 提供个性化的用户体验
用户体验是决定应用性能和成功的最关键因素之一。用户对你的应用的感受也会塑造品牌形象。因此,企业总是关注他们的应用提供的用户体验。他们试图结合创新功能和吸引人的设计来吸引用户。
然而,尽管做出了这些努力,许多移动应用仍难以吸引和留住用户。但通过在移动应用开发中使用数据科学,企业可以为应用用户提供更好、更个性化的用户体验。结果,他们可以改善品牌印象和客户留存率。
结论
数据科学是一种智能且具有颠覆性的技术。它赋予移动应用智能和自动化的数据分析能力,从而得出有意义的、更好的商业见解。有了数据科学,应用开发变得更加高效和以结果为导向。
随着其使用的不断增加,其未来看起来十分光明。但是,由于这一阶段仍处于演变过程中,最好在专家的帮助下实施这项技术,参考移动应用开发公司。他们将帮助你成功地将数据科学集成到你的应用项目中。
Ishan Gupta 是 RipenApps 的首席执行官兼联合创始人,RipenApps 是一家领先的网页和移动应用开发公司,专注于安卓和 iOS 应用开发。向全球中小企业提供功能丰富的移动和网页应用解决方案,改变了全球商业。
更多相关话题
热点还是冷门:2015 年的数据科学趋势
2015 年的倒计时已经开始。在 2014 年取得巨大进展之后,数据科学准备迎接 2015 年出现并主导的新趋势。虽然这些趋势中的一些被广泛接受,但另一些则稍显争议。只有时间才能揭示真正的赢家。在那之前,我们都需要自己决定相信 2015 年的哪个趋势。
CrowdFlower,一个由人驱动的数据增强平台,最近发布了一份有趣的信息图,基于他们的数据科学家对 2015 年的期望。以下是他们报告中的一些见解:
首席数据科学家将在 2015 年成为决策的主导者,而首席信息官(CIO)则退居幕后。

“大数据”这个术语将让位于“丰富数据”——这并不令人惊讶,因为我们已经看到 2014 年有很多文章批评“大数据”术语的过度使用,使其基本上变得毫无意义。像“创新”或“颠覆”一样,“大数据”今天被用于几乎所有与数据科学相关的事情,这种情况肯定需要停止。
随着开源在大数据技术中的主导地位,开放数据预计将在 2015 年变得更加重要。人们越来越意识到解锁数据仓库中的数据并使其自由、便捷地可获取的价值。

在 2014 年,我们看到数据科学家职位在各个部门中建立。在 2015 年,我们预计这些数据科学家将开始合作(无论是在组织内部还是跨组织),以从数据中获取更大的价值。
迄今为止,大数据的进展主要受到企业利润驱动的影响。但现在我们开始看到大数据用于社会公益的价值。我们预计 2015 年会有更多此类倡议和会议,比 2014 年更多。

数据民主化——任何人,而不仅仅是数据科学家或技术爱好者,都能分析和使用数据,这种能力在 2015 年可能成为一种颠覆性力量。2014 年的多个软件发布专注于分析的广泛消费者化,我们尚未看到用户将如何利用这种能力(结合开放数据倡议)。

更多详细信息和完整的信息图可以在这里找到:www.crowdflower.com/blog/data-science-2015-whats-hot-whats-not
相关:
-
2015 年预测 – 数据科学家接下来会怎样?
-
2015 年大数据顶级趋势
-
2015 年预测:大数据和数据科学将会发生什么?
更多相关话题
数据科学入门:面向软件工程师的入门教程系列
原文:
www.kdnuggets.com/2017/05/data-science-tutorial-series-software-engineers.html
作者:Harris Brakmić,软件工程师。
编辑说明:这是针对新手的数据科学多部分教程的概述。作者给这个系列起了一个不同的——自嘲的——标题;以平常心看待,并认识到该系列的方法和内容是从软件工程的角度对数据科学各个方面进行全新审视的开始。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
PySpark 控制台。
要使用 Python 进行一些严肃的统计工作,应该使用像 Continuum Analytics 提供的合适发行版。当然,也可以手动安装所有所需的软件包(Pandas、NumPy、Matplotlib 等),但要注意复杂性和包依赖关系的繁琐。在本文中,我们将使用 Anaconda 发行版。在 Windows 上的安装非常简单,但要避免使用多个 Python 安装(例如,同时使用 Python3 和 Python2)。最好让 Anaconda 的 Python 二进制文件成为您的标准 Python 解释器。
模式无处不在,但许多模式无法立即被识别。这是我们在数据库、数据仓库和其他数据孤岛中深挖的原因之一。本文将使用 Pandas 的数据框架中的几种方法,并生成图表。我们还将创建数据透视表,并通过 ODBC 查询 MS SQL 数据库。在这种情况下,SqlAlchemy 将成为我们的助手,我们将看到即使是像我们这样的“失败者”也可以轻松合并和筛选 SQL 表,而无需触及 SQL 语法。不论任务是什么,首先总需要一个强大的工具集。比如我们将在这里使用的 Anaconda 发行版。我们的数据源将包括包含 Reddit 评论的 JSON 文件或像 Northwind 这样的 SQL 数据库。许多 90 年代的孩子都使用 Northwind 来学习 SQL。
所有可用子版块的最高评分评论。
所以,让我们谈谈我在过去两篇文章中忘记提到的一些 Pandas 特性。
根据其定义,Spark 是一个快速、通用的大规模数据处理引擎。好吧,有人会说:但我们已经有 Hadoop 了,那我们为什么还要使用 Spark?对于这样的问题,我会回答说 Hadoop 是 EJB 的再发明,我们需要一些更灵活、更通用、更具扩展性并且……比 MapReduce 快得多的东西。Spark 以非常快的速度处理批处理和流处理。
从我非科学家的角度来看,我会将机器学习定义为人工智能研究的一个子集,它开发出能够从数据中获得知识并基于这些知识做出预测的自学习(或自我改进?)算法。然而,机器学习不仅仅局限于学术界或某些“开明的圈子”。我们每天都在使用机器学习,却没有意识到它的存在和实用性。机器学习在实际应用中的几个例子包括:垃圾邮件过滤器、语音识别软件、自动文本分析、“智能游戏角色”或即将到来的自动驾驶汽车。所有这些实体都基于某些机器学习算法做出决策。
Spark 堆栈中的数据框。
在开始使用数据框之前,我们首先需要准备运行在 Jupyter(以前称为“IPython”)中的环境。在你下载并解压 Spark 包后,你会在 python/pyspark 目录下找到一些重要的 Python 库和脚本。这些文件在你启动控制台中的 PySpark REPL 时会用到。如你所知,Spark 支持 Java、Scala、Python 和 R。基于 Python 的 REPL 称为 PySpark,提供了通过 Python 脚本控制 Spark 的良好选项。
在本文中,我们将探讨微软的 Azure 机器学习环境以及如何将云技术与 Python 和 Jupyter 结合使用。正如你所知道的,我在整个文章系列中广泛使用了这些技术,因此我对数据科学友好的环境有着强烈的看法。当然,这并不是说其他编程环境或语言,如 R,不好,因此你的意见可能会与我大相径庭,这没关系。此外,AzureML 也提供了非常好的 R 支持!因此,随时可以根据你的需要调整本文的所有内容。在开始之前,先说几句我为什么会想到写关于 Azure 和数据科学的文章。
在完成我的数据科学和机器学习基础课程时,我发现 Azure ML 内置支持 Jupyter 和 Python,这对我来说非常有趣,因为这使得 Azure ML 成为理想的实验平台。他们甚至将其中一个工作区域称为“实验”,因此可以预期良好的 Python(和 R)支持以及许多现成的模块。和其他技术爱好者一样,我迅速决定撰写一篇文章,描述 Azure ML 的一些关键部分。
简介: 哈里斯·布拉克米奇 (@brakmic) 是 Advarics GmbH 的软件开发工程师。他使用 Ractive、React、Backbone 和 DevExtreme 开发 Web 应用,并使用 C# 开发基于 Azure 的后台系统。
相关:
-
机器学习:全面详细概述
-
MXNet Python API 介绍
-
入门数据科学:你需要知道的事项
更多相关主题
如何进入数据科学:为有志数据科学家提供的终极问答指南
原文:
www.kdnuggets.com/2019/04/data-science-ultimate-questions-answers-aspiring-data-scientists.html
评论
作者:Admond Lee

那么……你想成为一名数据科学家?很好。你是一个自我驱动的人,对数据科学充满热情,并希望通过解决复杂问题为公司带来价值。很棒。但你在数据科学方面没有零经验,也不知道如何入门这个领域。我明白。我也经历过这个阶段,真的非常理解你。这就是为什么这篇文章专门献给你——充满热情和抱负的数据科学家——回答最常见的问题和挑战。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
如果数据是“新石油”,那么数据科学家的功能就像一个石油炼厂,将数据转换为能够节省成本和创造资本的洞察
下面所有的问题不是我提出的,而是你们——充满活力的数据科学社区。非常感谢你们对我之前的LinkedIn 帖子的支持,包括我从电子邮件和其他渠道收到的问题!请注意,下面的问题没有特定顺序,因此可以跳到你觉得合适的部分。
我希望通过分享我的经验,这篇文章能够揭示如何追求数据科学职业,并给你一些通用的指南,以使你的学习之旅更加愉快。让我们开始吧!
当前数据科学技能差距的趋势是什么?
国际数据公司(IDC)预测,全球大数据和商业分析的收入将在 2020 年超过$210 亿。
根据2018 年 8 月美国 LinkedIn 工作报告,2015 年时数据科学技能人才的过剩。三年后,趋势发生了巨大的变化,越来越多的公司面临数据科学技能人才的短缺,因为大数据被越来越多地用于生成洞见和做出决策。
从经济学角度来看,这一切都与供给和需求有关。
好消息是:现在“形势”发生了变化。坏消息是:尽管数据科学领域的工作机会增加了,许多有志成为数据科学家的求职者仍然面临着由于技能缺口相对于当前市场需求的挑战,导致难以找到工作。
在接下来的部分中,你将看到如何提升数据科学技能,弥补“差距”,在众多候选人中脱颖而出,最终增加获得梦想工作的机会。
问题与答案

1. 需要哪些技能,以及如何补充这些技能?
我会非常诚实地告诉你。学习所有数据科学的技能几乎是不可能的,因为范围实在太广。总会有一些技能(技术性/非技术性)是数据科学家不了解或未曾学习的,因为不同的企业需要不同的技能。
一般来说——根据我从其他数据科学家那里获得的经验和学习——要成为数据科学家,必须掌握一些核心技能。
技术技能。数学和统计学、编程以及商业知识。尽管无论使用何种编程语言都能表现出卓越的编程能力,但作为数据科学家,我们应该能够用商业上下文的语言解释我们的模型结果,并辅以数学和统计学。
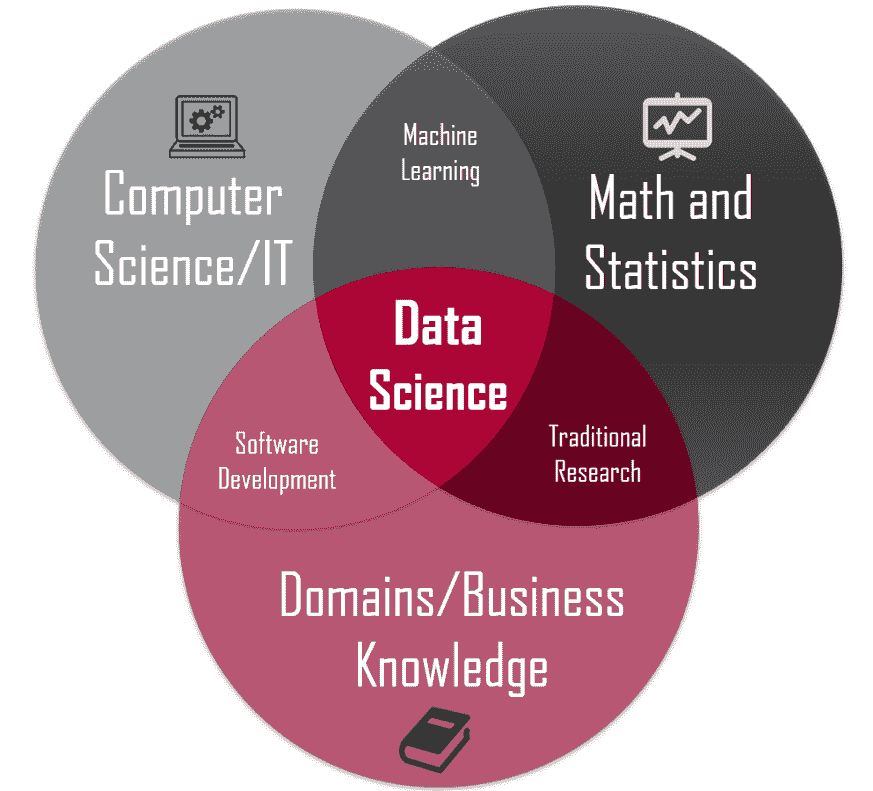
我仍然记得当我刚开始学习数据科学时,我读了这本教科书——统计学习导论——R 语言应用。我强烈推荐这本教科书给初学者,因为这本书专注于统计建模和机器学习的基本概念,并提供了详细且直观的解释。如果你是一个数学硬核爱好者,也许你会更喜欢这本书:统计学习的要素。
要学习编程技能,特别是对于没有先前经验的初学者,我建议专注于学习一种语言(个人来说,我更喜欢 Python!????),因为这些概念也适用于其他语言,且 Python 更易于学习。Python 或 R 的重要性和用途在数据科学中一直是一个争论的话题。就个人而言,我认为应该关注如何帮助企业解决问题,而不论使用哪种语言。
最后,我不能强调足够的是,理解业务知识是极其重要的,正如我在我的一篇文章中提到的(你可以在这里参考)。
软技能。事实上,软技能比硬技能更重要。惊讶吗?我希望不会。
LinkedIn 调查了 2,000 位商业领袖,他们希望员工在 2018 年掌握的软技能有:领导力、沟通、协作和时间管理。我坚信这些软技能在数据科学家的日常工作中发挥着至关重要的作用。特别是,我在沟通技能的重要性上吃了不少苦头,你可以在这里阅读。
2. 如何在众多的训练营和在线课程中选择合适的?
随着围绕 AI 和数据科学的炒作,很多人纷纷加入这股热潮,涌现出大量的 MOOC、训练营、在线课程和工作坊(免费/付费),希望能“赶上潮流”。
资源很多,要有策略。
那么问题是:如何选择对你合适的学习材料?
我的筛选和选择适合自己的在线课程/工作坊的方法:
-
理解没有单一最佳课程可以涵盖你所需的所有材料。一些课程在某些领域有重叠,购买不同课程但大部分教学材料重复是不值得的。
-
首先了解你需要学习什么。千万不要仅仅因为华丽和吸引人的标题就进入一个课程。记得之前提到的技术技能吗?查看数据科学家的职位描述,你会发现公司对一些技能有共同的要求。现在你知道了所需技能和你缺乏的技能。太棒了。去寻找能帮助你提升知识(理论和实践)的课程吧。
-
在线研究不同平台提供的最佳课程。一旦你筛选出几门符合需求的课程,在掏钱报名之前,务必查看其他人的评价(非常重要!)。另一方面,很多免费课程也可以在 Coursera、Udemy、Lynda、Codecademy、DataCamp、Dataquest 和其他平台找到。我是否也提到了 YouTube? 是的,你明白了。
-
提示: 一些平台可能会提供财政援助来补贴你的课程费用(如 Coursera 等)。试试吧!
-
一些个人最喜欢的课程,对我帮助巨大:
-
机器学习 由 Coursera 的联合创始人 Andrew Ng 教授。
-
Python 数据科学与机器学习训练营 由 Jose Portilla 教授。
-
深度学习 A-Z™:动手构建人工神经网络 由 Kirill Eremenko 和 Hadelin de Ponteves 教授。
-
Python 数据科学基础培训 由 Lillian Pierson 教授。
-
终极动手 Hadoop——掌控大数据! 由 Frank Kane 教授。
-
3. 从开源资源学习是否足够成为数据科学家?
我认为,从开源资源中学习足以让你开始数据科学的学习,任何进一步的学习则是为了进一步发展数据科学家的职业生涯,这也取决于业务需求。
4. 初学者(来自完全不同的背景)是否应该先通过阅读材料来了解基础知识?你会推荐哪本书?

学习没有固定的路径,所有道路通向罗马。阅读材料无疑是了解基础的好开始,我也是这样做的!
只要注意不要试图阅读和记忆数学和算法的琐碎细节。因为很可能,你会在编码时遇到实际问题时,忘记所有内容而没有真正应用这些概念。
只需了解和掌握足够的基础知识即可启动,然后继续向下一个步骤前进。务实一点。不要试图掌握一切,因为完美主义往往是不知不觉中拖延和无法前进的最佳原因。
以下是一些我建议阅读的书籍,用于理解 Python、机器学习和深度学习的基础知识(希望有所帮助!):
5. 如何平衡理解商业问题(制定解决方案)和发展技术技能(编码、核心数学知识等)?
我开始时先发展我的技术技能,然后再去理解商业问题和制定解决方案。
商业问题告诉你是什么和为什么。要解决一个商业问题,首先必须了解如何解决这个问题。而“如何”来自于技术技能。同样,方法取决于情况,我的建议主要基于个人经验。
6. 我们如何克服作为数据科学家职业生涯初期的挑战?
许多有志的数据科学家(包括我)面临的一个主要挑战是数据科学是信息的海洋。我们很容易因为接收到来自不同方向的各种建议和资源(在线课程、研讨会、网络研讨会、聚会等等)而失去焦点。保持专注。知道你拥有的和你需要的,并全力以赴。
在我的数据科学旅程中,挑战无数,但这些挑战也塑造了今天的我。我会尽力解释我面临的主要挑战以及如何克服它们:
-
当我刚开始时,被众多资源搞得很困惑。 我通过艰难的方式筛选出干扰。听数据科学家的播客和观看他们的网络研讨会,阅读大量关于如何在这一领域发展职业的数据科学文章,尝试不同的在线课程,参与 LinkedIn 上的数据科学社区并从中学习。最终,我只专注于那些对我有帮助的资源,并在这篇文章中分享了它们。
-
曾经有一段时间我差点放弃。 当学习曲线过于陡峭,我开始怀疑自己时,放弃的念头出现了。我真的能做到这一点吗?我真的走在正确的道路上吗?激情和耐心让我重新找回方向,坚持不懈地努力奋斗。
你的工作将占据你生活的大部分,唯一真正让你感到满意的方式是做你认为伟大的工作。而做伟大工作的唯一方法就是热爱你所做的事情。
— 史蒂夫·乔布斯
- 获得数据科学家职位(或类似工作但不同职位)。我希望我能早些阅读由Favio Vázquez撰写的这些文章——如何获得数据科学家的职位? 和 获得数据科学家职位的两面性。由于就业市场竞争激烈,获得工作对我来说并不容易。我提交了大量简历却无济于事。我深思熟虑,认为肯定有什么地方出了问题。我改变了我的方法,开始建立网络:参加聚会和研讨会,在网上分享我的学习经验,接触职业招聘会上的潜在雇主,并以更系统的方式进行分享,在提交简历后进行跟进等等。情况开始发生变化,机会也开始敲响我的门。
7. 如何在简历中呈现我的工作经验,以便我会被录用,并且我的经验会被认可?
我相信这里存在一个误解——你不会仅仅凭借简历上的经验就被录用。事实上,你的简历是获得下一个阶段申请——面试的第一张入场券的方式之一。
因此,学习如何在简历中写出工作经验对获得入场券确实很重要。研究表明,平均招聘人员在决定申请者是否适合职位之前,会扫描简历六秒。换句话说,要通过简历测试,你的简历只有六秒钟的时间给潜在雇主留下正确的印象。就个人而言,我参考了以下资源来打磨我的简历:
8. 什么样的作品集可以帮助我们获得数据科学或机器学习领域的第一份工作?

在我第一篇 Medium 文章中,我提到了建立作品集的重要性。如果没有一个好的作品集,拥有一个精致的简历也不足以让你获得面试机会。
在雇主第一次浏览你的简历后,他们想了解你更多的背景,这就是你的作品集发挥作用的地方。虽然你可能会想知道如何从头开始建立一个作品集,但可以从记录你的学习历程开始。通过社交媒体平台(LinkedIn、Medium、Facebook、Instagram、个人博客——都可以)分享你的学习经验、错误、收获——技术性或非技术性——。
对在摄像机前讲话感兴趣? 那就开始制作视频(采访其他有抱负的/成熟的数据科学家)并分享在 YouTube 上。擅长写作? 那就开始在不同平台上写你感兴趣的主题。如果你对视觉和写作不感兴趣,那么联系他人并进行播客。
我的意思是: 利用互联网建立你的作品集和获得关注的机会确实丰富,或者可能引起未来雇主的注意。
我做过的最好的决定之一是与数据科学社区在LinkedIn互动,并在Medium上记录我的学习历程。我在 LinkedIn 上通过紧密联系的数据科学社区,在这种有利于分享和学习的环境中学到了最多。
渐渐地,我学会了(还在学习中!)如何利用我从不同来源获得的经验在 LinkedIn 上建立我的作品集。在这个过程中,我收到了来自不同招聘人员的职位机会信息,甚至有机会和他们中的一些人喝咖啡聊聊天!
— 更多资源 —
此时,你可能会想,为什么我一下子分享了这么多资源。好吧,我的简单秘诀是:收藏我觉得有用的网站和文章,并时不时参考它们。
这证明是极其有用的,当我需要一些参考和复习时非常方便。我可以分享整个收藏的网站列表,但这对于这篇文章来说可能太长了(或许在其他文章中吧)。
尽管如此,我还是列出了一些有用的资源:
-
Towards Data Science,Quora,DZone,KDnuggets,Analytics Vidhya,DataTau,fast.ai
关注激励人心的数据科学家和专业人士

LinkedIn 上的数据科学社区非常棒,我强烈建议你关注下面提到的激励人心的数据科学家和专业人士:
最后的想法

你已经到达这里了?!感谢阅读。
这是迄今为止最长的一篇文章,还有很多我迫切想与你分享的内容(也许在下一篇文章中,谁知道呢?????)。
不要让任何人用他们的时间表催促你
希望我的分享已经解答了你心中的疑问。无论何时你在数据科学之旅中遇到障碍,请记住你并不孤单,我们都在这里作为社区的一部分来帮助你。只要联系我,我会非常乐意帮助你!
现在你已经找到了你的问题的答案(如果你还有其他问题,请在下面留言),是时候为实现你作为数据科学家志向的终极目标采取巨大的行动了。没有哪一步行动是微不足道的。只需一步步向前推进。当你濒临放弃时,坚持是关键。
一如既往,如果你有任何问题或意见,请随时在下面留下反馈,或者你可以通过LinkedIn与我联系。到那时,下一个帖子见! ????
你可以在LinkedIn、Medium、Twitter和Facebook上与他联系,或在这里预约电话咨询。
简介:Admond Lee 是一名大数据工程师,行动中的数据科学家。他被誉为帮助初创企业创始人和各种公司通过深度数据科学和行业专业知识解决问题的备受追捧的数据科学家和顾问之一。
原文。经授权转载。
相关:
-
选择最佳机器学习课程的完整指南
-
如何在数据科学、AI、大数据领域工作
-
关于数据科学职位申请的秘密
更多相关话题
数据科学如何被用来理解 COVID-19
原文:
www.kdnuggets.com/2020/04/data-science-understand-covid-19.html
评论 
来源:联合国
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
COVID-19 的迅速传播和全球影响可能让人感到无助和恐惧,因为新型冠状病毒的升级迫使他们改变日常生活的许多方面。
然而,人们可以通过了解数据科学家如何努力学习 COVID-19 的更多信息,在这些不确定的时期中感受到一丝希望。
数据科学可以提供冠状病毒结果的准确图景
医疗专业人士和其他人必须获取有关冠状病毒情况每日变化的正确且最新的信息。包括约翰斯·霍普金斯大学、IBM 和 Tableau 在内的多个组织,已发布互动数据库,提供实时病毒情况的视图。
这些来源中的许多都引用了由可信机构如美国疾病控制与预防中心 (CDC) 和世界卫生组织 (WHO) 提供的数据。它们还包括这些机构的直接链接,以便人们可以快速、轻松地获取可靠的信息。
使用这些数据库可以告知人们确认病例、死亡人数和康复人数。无论一个人是参与抗击冠状病毒的前线工作者还是试图保持知情的普通公民,他们都可以在一个地方获得全部或大部分所需的信息。
数据科学家设计了一种更快捷的接触者追踪处理方式
接触者追踪是一种有效的方式来减缓 COVID-19 的传播。它涉及在个人确诊后与其密切接触的人取得联系,并告知他们进行自我隔离。尽管接触者追踪非常耗时,但随着越来越多的人认真对待社交距离,它变得越来越容易。
数据科学家和医学专家们在牛津大学联合合作,以提高接触者追踪的效率。参与项目的专家们指出,数学模型显示传统的公共卫生接触者追踪方法速度不够快,无法彻底减缓 COVID-19 的传播。
他们创建了一个基于手机的解决方案,以消除人们手动拨打联系人电话的需要。相反,这些联系者会收到确认自我隔离需要的短信。研究人员澄清,如果这种方法能获得国家领导人的支持而不是由独立应用开发者主导,它将最为有效。
目前没有国家使用这种方法。然而,鉴于手机的市场渗透率和人们对接收短信的熟悉程度,很容易理解这种方法为何有意义。
每个人都可以在帮助科学家抗击冠状病毒中发挥作用
许多 COVID-19 患者只有轻微症状或根本没有症状。此外,经典症状包括发烧和咳嗽——这两种问题并不局限于冠状病毒。这些因素可能使人们更容易无意中传播疾病。但开发人员创建了一个利用数据共享帮助医学专家了解更多关于病毒的信息的应用程序。
这个应用程序叫做 Covid Symptom Tracker,已有至少 200,000 名用户。即使人们没有症状或不认为自己的症状与 COVID-19 相关,他们也可以并且应该与应用程序互动。研究人员对冠状病毒了解得越多,他们就越能有效应对。
人们通过应用程序进行简短的每日症状检查。他们还提供年龄和邮政编码,并披露任何既往疾病。这些信息帮助科学家确定受影响或有风险的群体。应用程序不会将用户数据用于商业目的,但会将数据提供给致力于阻止冠状病毒的人员,包括一些卫生组织的工作人员。
数据科学家利用机器学习更快地寻找可能的治疗方法
除了限制 COVID-19 传播的竞争外,科学家们还在尽快揭示有效的治疗方法。哥伦比亚大学数据科学项目的两名毕业生转向机器学习以提供帮助。实验室中抗体发现的典型过程需要数年时间。然而,这种方法仅需一周即可筛选出具有高成功可能性的治疗性抗体。
采用这种方法的团队表示,这种方法的成本也低于传统方法。人类仍然是过程的一部分,因为他们必须测试机器学习算法识别出的最有前景的基因序列。然而,使用这种加快的方法可能在有效找到对冠状病毒患者有效的干预措施方面至关重要。
数据科学可以帮助追踪传播情况
数据科学专家还得出结论,图数据库在展示 COVID-19 的传播方式方面发挥了重要作用。图数据库显示了人、地点或事物之间的链接。科学家们将每个实体称为节点,而它们之间的连接则是“边”。结果提供了事物之间关系的可视化表示(如果有的话)。
在冠状病毒爆发的早期,中国的数据科学家创建了一个名为 Epidemic Spread 的图数据库工具。它允许用户输入与他们所经历的旅行相关的识别信息 如航班号或汽车牌照。数据库随后会告知这些用户是否有确诊的冠状病毒病例的人员曾进行过相同的旅行,并可能将其传播给同乘的乘客。
对抗 COVID-19 的进展
尽可能多地了解冠状病毒将挽救生命。这只是数据科学家用他们的技能来帮助的迷人方式之一。
简介: 凯拉·马修斯 讨论技术和大数据,曾在《The Week》、《The Data Center Journal》和《VentureBeat》等出版物上发表文章,并从事写作工作超过五年。要阅读更多凯拉的文章,订阅她的博客 Productivity Bytes。
相关内容:
-
数据科学家最佳免费流行病学课程
-
5 种数据科学家应对 COVID-19 的方式以及 5 种应避免的行动
-
COVID-19 可视化:有效可视化在疫情叙事中的力量
更多相关话题
数据科学志愿服务:帮助的方式
comments
由 Susan Sivek 提供, Alteryx。
Alteryx 最近介绍了两个从 Alteryx for Good 数据挑战赛中受益的非营利组织,该挑战赛于 2 月在悉尼的 Alteryx Inspire 会议上举办。此次比赛由 Alteryx 合作伙伴 RXP 共同赞助,为这些宝贵的组织带来了新的分析方法和见解。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
尽管 AFG 比赛的主要目标是帮助组织满足数据需求,但参与也使学生受益,他们获得了处理实际问题的新技能,并扩展了个人网络。(你可以在 这个播客节目 中听到他们的经历!)
无论你处于哪个职业阶段,你都可以参与“数据公益”活动和项目。不论你是在数据领域已有成就还是正在追求这样的职业,这里都有许多机会供你贡献。你将获得新领域的经验、新的作品集项目和与其他数据爱好者的新联系,同时你会为自己参与到一个好的事业中而感到自豪!

虽然有许多通用的技术相关事业可供参与,但我们在这里将重点关注那些主要以数据为导向的事业。
组织的项目
加入由知名组织主办的短期或长期分析或数据科学项目或合作,以推进一个好的事业:
-
DataKind (美国) 和 Data for Good (加拿大):提供全球数据科学和分析咨询、项目管理、活动策划等志愿机会。
-
Data Science for Social Good: 评估“社会公益”组织所需的数据科学项目,并将志愿者与项目对接。
-
Catchafire: 为非营利组织提供一个发布基于技能的志愿者需求的地方,包括数据分析项目。
-
Statistics Without Borders: 组织数据专业人士通过他们的统计专业知识帮助国际事业。
-
联合国志愿者: 招募来自各个背景的志愿者,协助支持全球和平与发展的项目——目前包括集中在空间/GIS 和数据可视化的机会。

黑客马拉松和竞赛
当然,你可以参加数据竞赛来寻求名声和(也许)一些财富……但为何不选择一个也能造福他人的竞赛呢?以数据为重点的黑客马拉松(也称为数据马拉松或数据挑战)可以提供这两者。这些活动由不同的组织规划和协调,参与者人数、奖金和资源的规模各不相同。以下是一些可以找到这些活动的地方:
-
Alteryx 社区!例如,女性分析小组最近动员了参与Women in Data Hackathon,这是与 TrueCue 合作举办的。看到社区成员团结合作,无论是长期的社区成员还是较新的ADAPT参与者,都非常棒。该黑客马拉松的注册已经关闭,但请留意未来的机会。其他在线社区,如 LinkedIn 和 Facebook 上的数据专业人士小组,也可能分享类似活动的帖子。
-
Kaggle competitions: 确实,许多 Kaggle 竞赛关注于盈利公司数据和需求,但有时也有机会研究非营利组织的数据并为他们提供解决方案。例如,这个竞赛关注于城市中的社会和环境问题,解决可持续性问题。另一个竞赛由医疗组织协调,侧重于基于图像分析诊断肺栓塞。这两个竞赛都提供了丰厚的现金奖!
-
DrivenData 提供了带有奖金的竞争性数据科学竞赛和面向那些寻求温和数据竞赛入门的“练习”机会。主题范围从癌症诊断到仇恨言论表情包再到野生动物保护。
-
Devpost 也提供了一些专注于为某个事业分析数据的竞赛,有些竞赛还提供奖金。请仔细查看指南,因为有些竞赛要求学生身份或在特定地点居住。甚至还有专门针对高中生的竞赛,所以如果你正在早早开始数据探索,不妨了解一下!
你也可能有机会以评委、导师或教练的身份参与活动。通过我们自己的Alteryx for Good项目,我最近担任了由信息系统与商业分析学生协会在奥克兰大学举办的数据案例竞赛的评委。看到这些出色的学生运用他们的 Alteryx 技能、批判性思维和分析思维应对挑战,真是令人振奋和有趣。

开源机会
即使你对数据科学和编程还比较陌生,也可以考虑为开源工具提供帮助,以使数据科学对每个人都更好。这值得你花时间,你将学到很多课程,向世界分享你的贡献,并为你的工作经验增加新的内容。(阅读一些技巧来选择项目并在简历上展示你的工作。)
选择你自己的数据问题冒险
有很多具有挑战性的问题等着你去解决,即使你更喜欢独立操作或者不能承诺参加竞赛或组织。想出你自己的项目,并找到可以帮助你以某种方式解决问题的公开数据,无论是通过建模、数据可视化、应用程序构建、数据讲述还是其他方法。例如,我们最近分享了与COVID-19相关的数据源列表和种族不公问题的数据源列表,但还有许多其他可能性。
你也可能有一个想要帮助的非营利组织。无论你想用什么工具帮助他们,考虑一下如何最好地接触他们以及如何进行合作,如在此指南中探讨的那样。

用你的 Alteryx 技能帮助他人
如果你已经掌握了 Alteryx 技能,可以考虑注册Alteryx for Good Co-Lab。该项目将 Alteryx 专家与需要数据帮助或教学或使用 Alteryx 的非营利组织和教育工作者连接起来。
无论你的背景和技能水平如何,总有一个值得帮助的好原因,感激你的时间、精力和专业知识——你也将从中受益。
原文。经许可转载。
简介: 苏珊·卡瑞·赛维克,博士,是一位作家和数据迷,喜欢用日常语言解释复杂的想法。在担任了 15 年的新闻学教授和学术研究员后,苏珊将重点转向了数据科学和分析,但仍然喜欢以创意方式分享知识。她欣赏美食、科幻小说和狗。
相关内容:
更多相关主题
数据科学与商业智能的解释
原文:
www.kdnuggets.com/2021/02/data-science-vs-business-intelligence-explained.html
评论
定义数据科学和商业智能这两个术语以及它们之间的关系,一直是热烈讨论的主题。虽然这些术语相关,但未能掌握它们背后的独立而明确的概念可能会带来重大后果。
例如,未来几年将出现数十万个数据科学(DS)和商业智能(BI)职位。候选人的数量可能显得极其稀少或意外庞大,这取决于你对每个职位所需技能的相关性和实用性的判断。BI 专家能否成功转型为 DS 角色?DS 对 BI 职位是否重要?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在 2021 年,商业高管将评估数十亿美元的新项目。哪些项目获得批准,哪些被搁置,将受到高管及其团队对这两个术语理解和定义的影响。项目负责人通常会迅速将行业流行词附加到他们的项目上,以跟随最新趋势,但这些项目是否只是旧想法的重新包装?
图 1 提供了 BI 和 DS 全景的一个视角:
 图 1: BI 和数据科学的全景图。
图 1: BI 和数据科学的全景图。
基础没有改变
数据管理和数据可视化仍然是理解和规划业务的核心。这些涉及捕获、清理、标准化、整合、可视化和安全管理数据的技术和流程。Excel 不够用。漂亮的仪表盘也不够。你必须长期承诺将数据作为资产,并且需要有纪律性来建立和维护数据湖和数据仓库环境。
关键点在于,任何没有坚实数据基础的 DS 或 BI 项目都将无法持续。任何建立在手动、不一致流程上的过程都会缓慢、不可靠且资源密集。最终,这些过程需要通过专业 IT 帮助来成熟,否则将因自身重量而崩溃。
商业智能
自 1980 年代以来,几乎每家公司都尝试使用计算机和数据库来管理和理解他们的历史数据。然而,问题在于——经过近 40 年,没有人真正掌握它。每年,公司都会增加或更换软件系统,而 IT 部门很少跟得上,因此企业不断优先处理项目,以查看哪些数据受到关注,哪些数据被忽视(抱歉,市场部门)。
你可以通过商业智能的图表、仪表盘、数据库图示和数据集成项目来识别它。这很昂贵且令人沮丧——但却是不可或缺的。
商业智能相对于数据科学具有永久的优势,因为它有具体的数据点;少量、简单的假设;自解释的指标;以及自动化的过程。此外,商业智能永远不会消失。它将始终是一个不断发展的过程,因为你永远不会停止改变你的业务或升级和更换源系统。
数据科学
从数据的后视镜中查看是重要且有帮助的,但它是有限的,永远无法让你到达目标的地方。在某些时候,你需要展望未来。商业智能需要与数据科学相辅相成。
数据科学是复杂且精密的规划和优化形式。例子包括:
-
实时预测客户最有可能购买的产品。
-
在商业微事件和微响应之间形成一个加权网络,以便可以在没有人工干预的情况下做出决策,然后随着每一个结果更新该网络,使其在行动中不断学习。
-
按 SKU 级别进行预测,按日统计每笔销售。
-
识别和预测稀有事件,例如信用卡欺诈,并向客户和/或员工发送自动通知。
-
根据几十种属性和行为创建客户群体,然后用定制的消息进行针对性营销。
传统规划是在离散的、由人类主导的会议中完成的,而数据科学技术应该将规划和优化步骤嵌入到软件中,并作为自动化过程的一部分运行。模型使用历史数据进行训练,留出一部分数据以验证预测的准确性。如果结果令人满意,那么模型将被部署并进行监控,通常使用商业智能报告。
为数据科学项目寻找业务支持是一项挑战,因为这些技术难以解释和可视化。这些项目难以管理,通常涉及非结构化或半结构化数据、复杂的假设、统计模型、走入死胡同的探索性项目,以及有限或混淆的可视化。
结果是,试点项目可能启动缓慢且难以维持。由于工作的不可预测性,你所取得的结果可能会时断时续。预测未来永远不会简单。
虽然 BI 项目通常由单个人完成,但 DS 项目需要不同领域的员工广泛合作,包括数据工程师、统计学家、业务专家和软件开发人员。每个职位的技能都需要多年的掌握。数据科学家通常在统计学方面具有深厚的专业知识,但软件开发技能仅处于基础水平,业务专长有限。数据科学团队需要与 IT 和业务部门合作,以创建真正集成的解决方案。
让一切运转起来
根本问题在于,术语之间的区别在于你是否需要回顾(BI)或展望(数据科学)。BI 收集数据以了解过去的事件。数据科学生成数据以建模尚未发生的事件。
了解这些实践之间的差异对于批准或拒绝提议的项目、招聘具有 BI 或 DS 项目所需技能的员工以及设计能够支持两者的数据管理平台至关重要。我们应避免将它们视为竞争性的倡议或会过去的潮流。数据科学和商业智能将长期存在,并将成为充分利用其潜力的业务的重要区分因素。
简介:Stan Pugsley 是一位数据仓库和分析顾问,隶属于位于盐湖城的Eide Bailly 技术咨询。他还是犹他大学埃克尔斯商学院的兼职教师。你可以通过电子邮件联系作者。
原文。经许可转载。
相关:
-
机器学习难题解释
-
什么是数据科学?
-
分析与统计学之间的区别是什么?
更多相关话题
数据科学与决策科学
原文:
www.kdnuggets.com/2019/05/data-science-vs-decision-science.html
评论
由 ActiveWizards 提供

我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
数据科学已经成为一个广泛使用的术语和流行词。它是一个代表多个学科组合的广阔领域。然而,还有一些相邻的领域值得关注,不应与数据科学混淆。其中之一就是决策科学。它的重要性不容小觑,因此了解这两个领域的实际差异和特征是有用的。数据科学和决策科学相关但仍是独立的领域,因此在某些方面,它们可能难以直接比较。
一般来说,数据科学家是专门从事在数据被收集、处理和结构化之后从中寻找见解的专家。决策科学家则将数据视为做出决策和解决商业问题的工具。为了展示其他差异,我们决定准备一个信息图表,将数据科学与决策科学按照几个标准进行对比。让我们深入了解一下。
从定义上讲,数据科学似乎是一个跨学科领域,它使用科学算法、方法、技术和各种方法来提取有价值的见解。因此,它的主要目的是揭示数据中的见解,以便进一步应用于各个行业的利益。相比之下,决策科学是将复杂的定量技术应用于决策过程。它的目的是将数据驱动的见解与认知科学的元素结合,应用于政策规划和开发。因此,对于这两者而言,数据同样重要,但机制却大相径庭。
现在,让我们进入应用领域。数据科学在零售、快速消费品、娱乐、媒体、医疗保健、保险、电信、金融、旅游、制造、农业、体育等众多行业中得到应用。决策科学则涉及更理论化的商业和管理、法律和教育、环境监管、军事科学、公共卫生和公共政策等领域。
专家在这些领域面临的关键挑战也有所不同。例如,数据科学家面临脏数据问题、开发资源获取困难、安全问题等挑战。决策科学家则寻找克服可靠数据缺乏、复杂数据环境带来的困难以及应用技术复杂性的新方法。他们应具备数学、金融和分析方面的知识,以做出正确的决策。
最后,让我们考虑未来趋势,洞察数据科学和决策科学的进一步发展和前景。根据我们的预期,数据科学将继续朝着自动化方向发展,进一步演变并广泛使用聊天机器人和虚拟助手。增强现实元素的使用将变得普遍,工业的机器人化将进一步推进,强化学习的受欢迎程度也会增加。相比之下,决策科学将继续推动我们向自动化决策和数据赋能方向发展。它肯定会在行业中取得重要地位和广泛应用,从而增加对专业人才的需求。
结论
数据科学可以是决策科学的一个重要组成部分,且商业所有者经常将数据科学视为解决所有问题和担忧的方案。然而,仅仅使用数据科学是不够的。真相存在于数据科学和决策科学之间。
我们尝试展示数据科学和决策科学的共性、差异和具体特点。如果你对这张信息图有一些想法或意见,欢迎在评论区分享,以便进一步讨论。
简介:ActiveWizards 是一个专注于数据项目(大数据、数据科学、机器学习、数据可视化)的数据科学家和工程师团队。核心专业领域包括数据科学(研究、机器学习算法、可视化和工程)、数据可视化(d3.js、Tableau 等)、大数据工程(Hadoop、Spark、Kafka、Cassandra、HBase、MongoDB 等),以及数据密集型 web 应用开发(RESTful APIs、Flask、Django、Meteor)。
原文。经许可转载。
相关:
-
如何进入数据科学领域:针对有志于成为数据科学家的终极问答与详细指南
-
对新数据科学家的建议
-
如何在数据科学、人工智能、大数据领域工作
该主题的更多内容
数据科学与 Optimus 第一部分:简介
原文:
www.kdnuggets.com/2019/04/data-science-with-optimus-part-1-intro.html
评论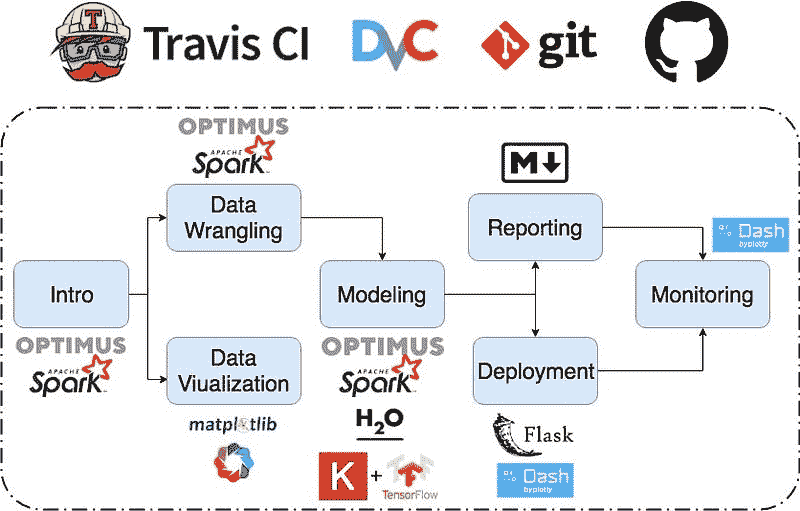
如果你不认识这些图标也不用担心,我会在下一篇文章中解释它们 😃
数据科学已经达到了新的复杂性和当然也很棒的水平。我已经做了很多年,我希望人们能有一条清晰易懂的路径来完成他们的工作。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
我已经讨论了数据科学及其他内容有一段时间了,现在是时候动手一起编程了。
这是关于使用 Optimus、Spark 和 Python 进行数据科学的系列文章的开始。
什么是 Optimus?

如果你一直关注我,你会知道我和Iron-AI团队创建了一个名为 Optimus 的库。
Optimus V2 的创建旨在使数据清理变得轻而易举。API 的设计非常适合新手,同时对使用过 pandas 的人也非常熟悉。Optimus 扩展了 Spark DataFrame 的功能,添加了.rows和.cols属性。
使用 Optimus,你可以清理数据、准备数据、分析数据、创建分析器和图表,并进行机器学习和深度学习,所有这些都是分布式的,因为在后台我们有 Spark、TensorFlow、Sparkling Water 和 Keras。
它非常容易使用。它就像 pandas 的进化版,加上了一些 dplyr,并结合了 Keras 和 Spark。你用 Optimus 创建的代码可以在本地机器上运行,只需简单更改主节点,它也可以在本地集群或云端运行。
你会看到许多有趣的功能被创建来帮助数据科学周期的每一步。
Optimus 非常适合作为敏捷数据科学方法论的辅助工具,因为它可以帮助你完成几乎所有的步骤,并且可以轻松连接到其他库和工具。
如果你想了解更多关于敏捷数据科学方法论的内容,请查看这个:
[创建以 ROI 为驱动的数据科学实践的敏捷框架]
数据科学是一个令人惊叹的研究领域,正受到学术界和工业界的积极发展……www.business-science.io](http://www.business-science.io/business/2018/08/21/agile-business-science-problem-framework.html)
安装 Optimus
安装过程非常简单。只需运行命令:
pip install optimuspyspark
然后你就准备好开始了。
运行 Optimus(以及 Spark、Python 等)

创建一个数据科学环境应该是简单的。无论是尝试新东西还是用于生产。当我开始思考这些系列文章时,我惊讶于发现准备一个可重复的数据科学环境有多么困难,尤其是使用免费的工具。
一些参赛者包括:
[Google Colaboratory
colab.research.google.com](https://colab.research.google.com/)
[微软 Azure 笔记本 - 在线 Jupyter 笔记本
提供在微软 Azure 云端运行的 Jupyter 笔记本的免费在线访问。 notebooks.azure.com](https://notebooks.azure.com/)
[首页 - cnvrg
cnvrg.io](https://cnvrg.io/)
但毫无疑问对我来说最优秀的是 MatrixDS:
[由数据科学家为数据科学家建立的社区
matrixds.com](https://matrixds.com/)
使用这个工具,你可以获得免费的 Python 环境(带 JupyterLab)和 R 环境(带 R Studio),还有 Shiny 和 Bokeh 等展示工具,甚至更多功能。而且全免费。你将能够运行仓库中的所有内容:
[FavioVazquez/ds-optimus
如何使用 Optimus、Spark 和 Python 进行数据科学。 - FavioVazquez/ds-optimus github.com](https://github.com/FavioVazquez/ds-optimus)
在 MatrixDS 内部,通过简单的项目分叉:
[MatrixDS | 数据项目工作台
MatrixDS 是一个在任何规模上构建、共享和管理数据项目的地方。 community.platform.matrixds.com](https://community.platform.matrixds.com/community/project/5c5907039298c0508b9589d2/files)
只需创建一个帐户,你就可以开始使用。
旅程
如果你不知道这些标志是什么,不用担心,我会在下一篇文章中解释 😃
上述路径是我将如何构建不同博客、教程和系列文章的结构。我现在必须告诉你,我正在准备一个全面的课程,涵盖一些商业科学的工具,详情请见:
[商业科学大学
从虚拟研讨会中学习,带你了解整个数据科学业务过程中的问题解决…… university.business-science.io](https://university.business-science.io/)
第一部分在 MatrixDS 和 GitHub 上,因此你可以在 GitHub 上 Fork 并在 MatrixDS 上 Forklift。
[MatrixDS | 数据项目工作台
MatrixDS 是一个在任何规模上构建、共享和管理数据项目的地方。 community.platform.matrixds.com](https://community.platform.matrixds.com/community/project/5c5907039298c0508b9589d2/files)
在 MatrixDS 上点击 Forklift:
如何使用 Optimus、Spark 和 Python 进行数据科学。 - FavioVazquez/ds-optimusgithub.com](https://github.com/FavioVazquez/ds-optimus)
这是笔记本,但请在平台上查看:)
有更新请在 Twitter 和 LinkedIn 关注我:).
简介:Favio Vazquez 是一位物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是西班牙语数据科学出版物 Ciencia y Datos 的创始人。他喜欢新挑战、与优秀团队合作和解决有趣的问题。他参与了 Apache Spark 的合作,帮助开发 MLlib、Core 和文档。他热衷于应用其在科学、数据分析、可视化和自动学习方面的知识和专业技能,帮助世界变得更美好。
原文。经许可转载。
相关:
-
10 分钟实用 Apache Spark
-
数据管道、Luigi、Airflow:你需要知道的一切
-
4 个原因说明你的机器学习代码可能很糟糕
更多相关内容
使用 Optimus 进行数据科学 第二部分:设置你的 DataOps 环境
原文:
www.kdnuggets.com/2019/04/data-science-with-optimus-part-2-setting-dataops-environment.html
评论
欢迎回到使用 Optimus 的数据科学系列。在第一部分:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
[使用 Optimus 进行数据科学. 第一部分:介绍。
通过 Python、Spark 和 Optimus 拆解数据科学。 towardsdatascience.com
我们开始这个旅程时讨论了 Optimus、Spark 和创建我们的环境。为此,我们使用了 MatrixDS:
数据社区的工作台 matrixds.com
只需点击下方即可访问该仓库:
MatrixDS 是一个用于构建、分享和管理任何规模数据项目的地方。 community.platform.matrixds.com
然后在 MatrixDS 上点击“叉车”:
GitHub 上也有一个仓库:
如何使用 Optimus、Spark 和 Python 进行数据科学。 — FavioVazquez/ds-optimus github.com
你只需要克隆它。
DataOps

来自 DataKitchen 的优秀团队:
DataOps 可以加速数据分析团队创建和发布新分析结果给用户的能力。它需要敏捷的思维方式,并且还必须得到一个自动化平台的支持,该平台将现有工具整合到 DataOps 开发管道中。DataOps 涵盖了整个分析过程,从数据获取到洞察交付。
所以对我来说,DataOps(数据操作)可以被看作这些领域的交集:
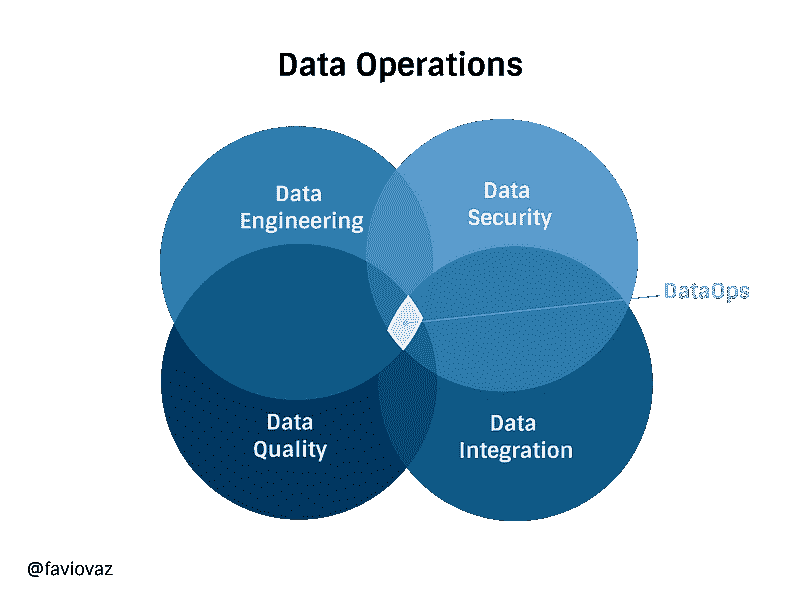
其功能组件包括:
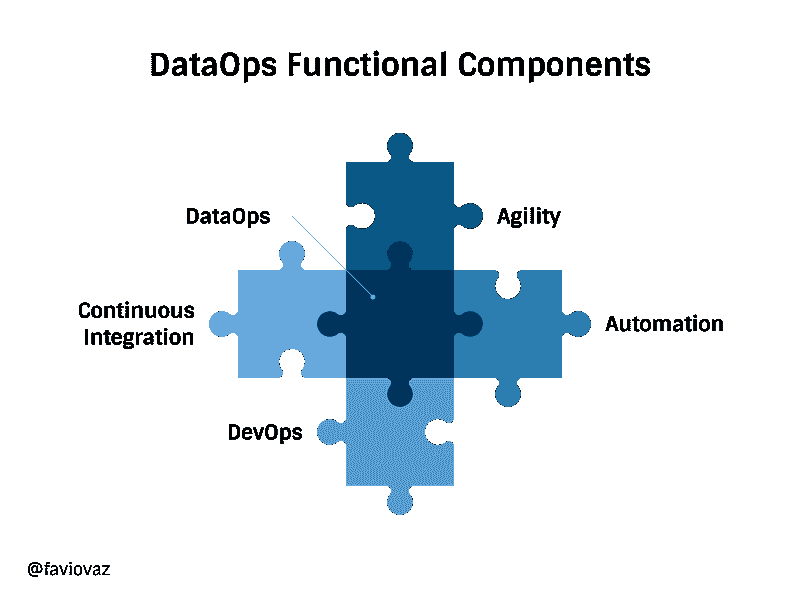
你可以在我的朋友 Andreas Kretz 的出版物中阅读更多关于这些主题的信息:
[数据科学的管道工
数据科学背后的工程与大数据社区 medium.com](https://medium.com/plumbersofdatascience)
在 MatrixDS 上设置环境

我们将在平台上使用以下工具创建一个简单(但强大的)DataOps 环境:TravisCI、DVC、Git 和 GitHub。
Git:

Git 是一个免费的开源分布式版本控制系统,设计用于以速度和效率处理从小型到大型项目的所有任务。
在数据科学中,git 就像我们内部的一个记忆力超强的经理。它会记住你做过的所有事情,如何做的,以及仓库中每个文件的历史记录。
Git 在 MatrixDS 中默认安装,但我们需要设置两个配置。首先,打开一个新的终端并输入:
git config --global user.name "FIRST_NAME LAST_NAME"
设置你的姓名,然后
git config --global user.email "MY_NAME@example.com"
设置你的电子邮件。
我建议你在这里输入的电子邮件与 GitHub 上的电子邮件相同。
要开始使用这个仓库,只需克隆它:
git clone **https://github.com/FavioVazquez/ds-optimus.git**
然后进入目录:
cd ds-optimus
因为这是一个已经存在的 Git 仓库,你不需要初始化它,但如果你是从头开始,你需要输入:
git init
在你希望放置仓库的文件夹中。
DVC:
DVC 或数据版本控制是一个开源版本控制系统,适用于机器学习项目和数据科学项目。这个视频解释得更好:
因为我们使用 Python,我们将通过以下步骤安装 DVC:
pip install --user dvc
根据文档的说明,为了开始使用 DVC,你需要首先在项目目录中初始化它。DVC 不要求使用 Git,也可以在没有任何源代码管理系统的情况下工作,但为了获得最佳体验,我们推荐在 Git 仓库上使用 DVC。
重要提示:
目前在 MatrixDS 上 DVC 的一些配置存在错误,因此为了运行 DVC,你必须在不同的文件夹中进行,而不是在 /home/matrix 中。为此,请执行以下操作(假设你将原始项目保存在默认文件夹中):
cd /home/
sudo mkdir project
cd project
cp -r ../matrix/ds-optimus/ .
cd ds-optimus
所以要开始在我们的仓库中使用 DVC,只需输入:
dvc init
如果由于某种原因,这在 MatrixDS 上不起作用,请为 Linux 安装 DVC:
wget https://dvc.org/deb/dvc.list
sudo cp dvc.list /etc/apt/sources.list.d/
sudo apt-get update
sudo apt-get install dvc
如果由于某种原因你遇到错误:
W: chown to root:adm of file /var/log/apt/term.log failed - OpenLog (1: Operation not permitted)
执行一个
sudo su
然后输入:
apt-get install dvc
好的,所以如果你在这个仓库上运行了 dvc init,你会看到:
Adding '.dvc/state' to '.dvc/.gitignore'.
Adding '.dvc/lock' to '.dvc/.gitignore'.
Adding '.dvc/config.local' to '.dvc/.gitignore'.
Adding '.dvc/updater' to '.dvc/.gitignore'.
Adding '.dvc/updater.lock' to '.dvc/.gitignore'.
Adding '.dvc/state-journal' to '.dvc/.gitignore'.
Adding '.dvc/state-wal' to '.dvc/.gitignore'.
Adding '.dvc/cache' to '.dvc/.gitignore'.
You can now commit the changes to git.
+-----------------------------------------------------------------+
| | | |
| DVC has enabled anonymous aggregate usage analytics. | | |
| Read the analytics documentation (and how to opt-out) here: | | |
| https://dvc.org/doc/user-guide/analytics | | |
| | | |
+-----------------------------------------------------------------+
What's next?
------------
- Check out the documentation: https://dvc.org/doc
- Get help and share ideas: https://dvc.org/chat
- Star us on GitHub: https://github.com/iterative/dvc
然后提交你的工作(如果你更改了文件夹,可能需要重新配置 Git):
git add .
git commit -m "Add DVC to project"
Travis CI:

Travis CI(持续集成)是我最喜欢的 CI 工具。持续集成是指经常合并小的代码更改,而不是在开发周期结束时合并大量更改。目标是通过在较小的增量中开发和测试来构建更健康的软件。
这里的隐藏概念是对你正在做的工作进行自动测试。当我们编程时,我们一直在做很多事情,我们在测试新事物,尝试新库等等,搞砸的情况并不少见。CI 帮助你解决这个问题,因为你将开始你的工作,用 Git 提交一部分内容,你应该有必要的测试来查看你新编写的代码或分析是否对你的项目产生影响(无论是好是坏)。
关于 Travis 和 CI 工具还有很多需要了解的内容,但这里的计划是使用它,你会在过程中学习到。所以你首先需要做的是访问:
travis-ci.org](https://travis-ci.org/)
并使用你的 GitHub 个人资料创建一个账户。
然后你将前往(在这里我假设你已经成功地从 GitHub 上 fork 了这个仓库),然后在 travis-ci.org/account/repositories 你将选择** ds-optimus:**
然后激活这个仓库
如果一切顺利,你会看到类似这样的内容:
目前这是空的,因为我们还没有任何东西可以测试。这没关系,我们会在接下来的文章中处理这个问题。但现在我们需要创建一个基本的文件来触发“travis 构建”。
为此我们需要一个 .travis.yml 文件,它应该包含以下基本内容:
language: python
python:
- "3.6"
# Before upgrade pip and pytest
before_install:
- pip install --upgrade pip
- pip install pytest
# command to install dependencies
install:
- pip install -r requirements.txt
# command to run tests
#script: pytest
正如你所看到的,我们还需要一个 requirements.txt 文件,在我们这个例子中,它现在只会包含 optimus。
如果你在 GitHub 上有项目的 fork,请确保将我的 master 添加为上游,因为文件已经在那里。
如果你不知道如何添加上游仓库,以下是方法:
这篇文章演示了如何在执行操作时保持下游仓库与上游仓库的同步… medium.com
然后我们需要推送一个包含“.travis.yml”的提交到项目中。
然后当你再次访问 Travis 时,你将看到你的第一次构建:
现在它会给我们一个错误,因为我们还没有创建任何要运行的测试:
但不要担心,我们稍后会解决这个问题。
感谢查看更新,并开始为这个项目设置环境。如果你有任何问题,请在这里写信给我:
法比奥·巴斯克斯 - 创始人 / 首席数据科学家 - Ciencia y Datos | LinkedIn
加入 LinkedIn ‼️‼️ 重要说明:由于 LinkedIn 的技术限制,我现在只能接受连接请求…www.linkedin.com](https://www.linkedin.com/in/faviovazquez/)
简介: 法比奥·巴斯克斯 是一名物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一本西班牙语的数据科学出版物。他喜欢新的挑战,和优秀的团队合作,并解决有趣的问题。他参与了 Apache Spark 的合作,帮助 MLlib、Core 和文档工作。他热爱运用自己的科学知识和专业技能,帮助世界变得更美好。
原文。经允许重新发布。
相关:
-
10 分钟内掌握实用 Apache Spark
-
数据管道、Luigi、Airflow:你需要知道的一切
-
你的机器学习代码可能糟糕的 4 个原因
更多相关主题
如何在没有学位的情况下进入数据科学
原文:
www.kdnuggets.com/2020/11/data-science-without-degree.html
评论

本文适合以下几类人群:
-
你没有高等教育学位,但你对数据科学感兴趣。
-
你没有 STEM 相关的学位,但你对数据科学感兴趣。
-
你在一个完全与数据科学无关的领域工作,但你对数据科学感兴趣。
-
你只是对数据科学感兴趣,并希望了解更多相关知识。
你可能会想,“我真的有机会吗?”
答案是,“是的,这是可能的。”
好消息是,你已经通过了第一步,那就是你对数据科学感兴趣。 现在这将不是一条容易的路,因为你是一个黑马,但把它作为每天激励自己的动力。
此外,我将提供一些我希望自己在刚开始时能够得到的建议。
首先,关于我自己一点……
我有一个商学学位,但从大学二年级开始就对机器学习产生了兴趣。因此,我自学了今天所知道的大部分内容,并有幸在一些数据分析/数据科学岗位上工作过。
我为什么告诉你这些?我想让你明确,我曾经也处于与你类似的境地!
记住,这是一个长期目标,因此你应该期望长期见到结果。如果你愿意全身心投入,我建议至少坚持一年,然后再决定是否继续。
说到这里,让我们深入探讨一下:
进入数据科学归结为两件事,成长和展示你的技能。
1) 发展你的数据科学技能
不久前,我写了一篇文章,“如果我能重新开始,我会如何学习数据科学。” 在这篇文章中,我将学习内容按主题进行了划分,即统计学与数学、编程基础和机器学习。
在这篇文章中,我将根据你的理解水平对应该学习的内容进行划分。
Level 0: 基础知识
你必须从基础知识开始,构建块,或者你想怎么称呼它都可以。但相信我,基础越扎实,你的数据科学之旅就会越顺利。
特别是,我建议你在以下主题中建立基础:统计学与概率论、数学和编程。
统计学和概率论: 如果你读过我以前的文章,可能已经听过千万次,但数据科学家实际上只是现代的统计学家。
-
如果你对统计学和数学几乎没有接触,我推荐Khan Academy 的统计学和概率论课程。
-
然而,如果你对微积分和积分有一定的了解,我强烈推荐你学习乔治亚理工学院的课程“统计方法”。虽然它讲解的证明较多,难度略高,但它会帮助你理解每个概念的复杂性。
数学: 根据你在高中时对数学的关注程度,决定了你需要花多少时间学习基础数学。你应该学习三个领域:微积分、积分和线性代数:
-
微积分在优化相关的任何内容中都是必不可少的(在数据科学中相当相关)。我推荐可汗学院的微积分课程。
-
积分在概率分布和假设检验中至关重要。我推荐学习可汗学院的积分课程。
-
线性代数在深度学习中尤其重要,但即便如此,对于其他基础机器学习概念,如主成分分析和推荐系统,也很有用。惊喜惊喜,你可以猜到我推荐哪个课程。链接在这里。
编程: 就像对数学和统计有基本了解很重要一样,掌握编程的核心基础将使你的生活变得轻松许多,特别是在实现阶段。因此,我建议你在深入研究机器学习算法之前,花时间学习基本的SQL和Python。
-
如果你完全没有 SQL 的基础,我建议你学习Mode 的 SQL 教程,因为它非常简洁且全面。
-
类似地,如果你完全没有 Python 的基础,Codecademy是一个很好的资源来熟悉 Python。
第 1 级:专业化
一旦你掌握了基础知识,你就可以开始专业化。此时,你可以决定是否专注于机器学习算法、深度学习、自然语言处理、计算机视觉等领域……
-
如果你想了解更多关于机器学习算法和实现的知识,我建议你查看Kaggle 的机器学习入门、斯坦福的机器学习课程或Udemy 的机器学习 A-Z 课程。查看一下,看看哪个最适合你!
-
如果你想深入了解深度学习,可以查看ai 的专门化课程。这是值得投资的!
-
如果你想深入了解 NLP,这里有 来自斯坦福大学和牛津大学的 5 个免费自然语言处理课程。
你可以专注的领域有很多,所以在做出决定之前,请多做探索!
第二级:实践
和其他任何事情一样,你必须练习你所学的知识,因为你会失去你不用的知识!以下是我推荐的 3 个资源,用于练习和提升你的技能。
-
Leetcode 是一个很棒的资源,帮助我学习了许多技能和技巧。我在找工作时大大依赖了这个资源,它是我会一直回去的资源。最好的部分是,它通常有推荐的解决方案和讨论板块,因此你可以学习到更高效的解决方案和技巧。
-
Pandas 练习题:这个资源是一个专门为 Pandas 提供练习题的仓库。通过完成这些练习题,你将学会:过滤和排序数据,汇总数据,使用 .apply() 操作数据,等等。
-
Kaggle 是世界上最大的 data science 社区之一,提供了数百个数据集供你选择。通过 Kaggle,你可以参加竞赛或仅仅利用可用的数据集来创建自己的机器学习模型。
2)展示你的数据科学技能
学习数据科学是一回事,但人们常常忘记的是推销自己——你最终会想展示你所学的内容。如果你没有与数据科学相关的学位,这一点尤其重要。
一旦你完成了几个个人数据科学项目,下面是一些展示它们和推销自己的方法:
你的简历
首先,利用你的简历展示你的数据科学项目。我建议创建一个名为“个人项目”的部分,在这里列出你完成的两到三个项目。
同样,你可以在 LinkedIn 的“项目”部分添加这些项目。
Github 仓库
我强烈建议你创建一个 Github 仓库,如果你还没有的话。既然我们谈到了 Github,学习 Git 也是一个好主意。在这里,你可以包含你所有的数据科学项目,更重要的是,你可以与其他人分享你的代码。
如果你有一个 Kaggle 账户并在 Kaggle 上创建笔记本,这也是一个很好的替代方案。
一旦你有了活跃的 Kaggle 或 Github 账户,确保在你的简历、LinkedIn 和你的网站(如果有的话)上提供你的账户网址。
个人网站
说到网站,我强烈建议以网站形式建立数据科学作品集。HTML 和 CSS 非常容易学习,这将是一个有趣的项目!如果你没有时间,像 Squarespace 这样的工具也会很有效。
在 Medium 上写博客
我可能有些偏见,因为这个方法对我很有效,但这并不意味着我不能推荐博客写作!借助像 Medium 这样的平台,你可以撰写项目 walkthroughs,例如我在葡萄酒质量预测上的文章。
非营利机会
最后,利用非营利的数据科学机会。我遇到了一篇由 Susan Currie Sivek 撰写的有用文章, 提供了几个你可以参与真实数据科学项目的组织。
原文。经许可转载。
相关:
更多相关主题
数据科学家类型
评论
观看原版 Metis DemystifyDS 会议演讲及问答
当你第一次进入数据科学领域时,或者即使你已经在其中待了一段时间,你也可能会被工具的数量和所需技能的广泛范围所压倒。关于成为数据科学家所需条件的博客文章往往变成了你尚未掌握的技能和尚未学习的工具的清单。这令人气馁。而且这也是适得其反的。

我的目标是为你提供一张地图,以帮助你在数据科学广阔的领域中导航。这个目标是帮助你优先考虑你想学习的内容和想做的事情,以免你感到迷失。
这些想法不仅仅是我的。这些想法基于与这里列出的数据科学家进行的一系列访谈,他们来自几个不同的公司,以及来自学术数据科学项目的贡献者。基础思想被总结在 一个公共文档中,作为一个行业数据科学家对学术数据科学项目的资源——一个虚拟行业咨询委员会的尝试。你从中获得的任何见解,我都归功于这个小组,而任何错误或不准确之处可能只是我个人的原因。总的来说,这是许多人深思熟虑后的观点的汇编。

数据科学之所以感觉如此庞大,是因为它不再是一个单一领域。实际上,它有三个独立的支柱。数据分析,将原始信息转化为可以行动的知识或驱动决策的知识。数据建模,使用我们拥有的数据来估计我们希望拥有的数据。然后是数据工程,将这些分析和建模活动整合起来,使一切运行得更快、更稳健,并且处理更大数量的数据。

这三个领域都是独立的。它们需要不同的技能和工具。让我们更深入地探讨每一个。
数据分析
数据分析有几个方面,即将数据转化为我们可以用来做决策的信息。

领域知识 是将业务需求或实际问题转化为问题的能力。这涉及到在答案的准确性和寻找答案所需的时间与金钱之间做出权衡。领域知识对于解释数据也是绝对必要的,它不仅包括理解呈现的数字和标签,还包括了解它们在现实世界中的反映,以及我们对其准确性可以做出的现实假设。
将信息转化为行动的另一个重要部分是研究。这可以像执行正确的 Google 搜索和阅读几份文档一样简单。通常,这涉及到对现有过程进行仪器化,例如日志记录代码,或在生产线上添加传感器,或进行调查。对于某些应用,研究涉及实验的精心设计。这需要使用复杂的统计工具来规划将收集哪些信息、如何收集以及如何在事后分析。
最后,数据分析的一个重要部分是解释。在面对大量数据时,我们如何总结、汇总、可视化它,并利用统计摘要从大量的数据中提炼出知识。特别是,我想强调可视化的艺术。将数字转化为易于解释并传达有用信息的图像是一种艺术,也是一门科学。它涉及到对人类视觉感知和理解的直觉感受。
数据建模
数据建模也有几个主要的子类别。这通常被称为机器学习。它不过是创建一个数据的简化描述,你可以用它来对未测量的数据进行估算。机器学习的三个主要子类是监督学习、无监督学习和自定义模型开发。

监督学习 使用标记的示例来发现模式。这些可以是分类标签,例如:这个客户在购买后一个月内是否重新访问了我们的网站,是或否?示例也可以用数字进行标记。例如:一个视频获得了多少次观看?使用大量带标签的示例,配有其类别或值,监督学习算法可以提取出潜在的模式。如果标签是分类的,这被称为分类。如果这些标签是数值的,这被称为回归。此外,有时目标不是对未来示例进行特定预测,而只是确定它们是否符合先前看到的模式。这被称为异常检测。
机器学习的第二个主要领域叫做无监督学习,这表明数据没有标签。我们不知道结果或正确答案。在无监督学习中,目标是发现数据分布中的模式。在聚类中,会识别出彼此之间比与数据集其他部分距离更近的数据点组。这些是数据中的自然分组。可以用来找到在超市购买类似物品的顾客。
在降维中,也会识别出那些倾向于以相似或协调的方式表现的变量组,例如共同作用以产生期望特征的基因。在降维中,聚类的不是数据点,而是变量。不是表的行,而是列。
在应用数据建模中,自定义算法开发非常常见。监督学习和无监督学习方法都是通用的。它们开始时对数据来源、数据含义和数据领域假设非常少。通用算法可以凭借强大的统计能力处理这些情况。当你拥有大量的数据时,它们表现最佳。
然而,在实际应用中,我们往往没有足够多的数据,也没有足够的数据来依赖于简单的机器学习技术。当这种情况发生时,我们就需要进行自定义算法开发。我们在算法中加入我们已知或可以合理假设的领域信息。例如,在农业行业,一个重要的建模问题是预测玉米田的产量,即收获谷物的总重量。这是一个极其复杂的系统,涉及土壤质地和化学成分、遗传学、温度和湿度等因素的相互作用。而且需要一年时间才能收集一个数据点。使用简单的机器学习方法来学习完整的作物模型是不现实的。然而,地质学家、化学家、生物学家、气象学家和遗传学家都对这个系统的各个部分进行了调查和描述。通过整合已知的信息并做出合理的假设,可以创建一个可处理的作物模型。
数据工程
数据工程是数据科学的第三个支柱。它有几个主要领域。数据管理是存储、移动和处理数据的过程。对于几千或甚至几百万个数据点的数据集来说,这很简单。但当单个数据点变得非常复杂,例如个体的基因组,或数据点数量达到数十亿或数万亿时,数据就不再适合放入笔记本电脑的 RAM 中,需要使用全新的工具。

数据工程师的另一个重要任务是将在原型中表现良好的代码准备好在更广泛的环境中运行。 在 Jupyter notebook 中构建模型是一回事,但要使其能够处理每一个客户请求,代码需要与公司其余的代码库兼容,并且需要能够以适当的格式接收数据和发布结果。任何故障或失败都需要优雅地处理,系统需要对恶意或不良用户进行保护。从平稳运行的原型到生产代码之间的差距很大,数据工程的一部分工作就是缩小这个差距。
在数据管理和生产中,软件工程扮演着重要角色。这不仅仅是构建符合你要求的代码,还能够在当前团队中共享和维护,适应未来的变化,并随着需求的发展进行扩展或缩减。这是一门工艺,拥有大量的工具和专业技能。
数据机制
还有一个意外的第四个支柱,即数据机制。这是每个人都需要做但没人愿意谈论的繁琐工作。它包括数据格式化,确保你的数据类型一致,从字符串中提取所需信息,确保使用的字符串有效,优雅地处理错误。它还包括值解释,以可解释和一致的方式处理日期和时间,正确响应缺失值,确保计量单位的一致性和文档记录。它还包括数据处理的基础:查询、切片和连接。这让你能够从可用的大数据湖中提取你需要的子集进行操作。

现在我们有了四个支柱:数据分析、数据建模、数据工程和数据机制。这对你作为数据科学家意味着什么?这些领域都是非常不同的。我认为一个数据科学家至少应当接触到所有这些技能领域。这意味着你不一定是专家,甚至不一定擅长这些领域,但你知道它们是什么,知道该问哪些问题以及进行哪些 Google 搜索。
初级数据科学家可能在这些支柱中都有一点经验。

以此为基础,我们可以讨论一些数据科学家的原型。我希望这些能对你规划培训和职业发展有所帮助。
原型
一种前进的路径是成为数据科学通才——在分析、建模、工程和机制方面发展扎实的混合能力。各方面的良好平衡能让你广泛了解各种范围的问题。这可能意味着你需要为一些项目与专业人士合作。但这将很好地为你成为技术领袖或数据高管奠定基础。

提个警告:可能会倾向于忽视数据机制或假设某个更初级的人员会处理这些问题。这样的人是数据科学家明星。这是一个反模式。这是你不想成为的,也不想雇用的。机制工作可能会很琐碎。有些日子它会占用你大部分时间。但你永远无法摆脱对它的需求。拥抱机制任务,学习完成它们所需的技能,并继续前行。

也有一些专业原型,强调三个主要领域中的每一个。
如果你选择强调数据分析,你可以成为侦探,一个善于发现正确数据并利用这些数据得出结论的高手。侦探对建模和工程方法非常熟悉,并以轻量级的方式使用它们。分析是他们的重点。

另一个数据科学家的原型是预言家,他掌握了建模的技能和机器学习的工具。他们可能接触过分析和工程,但他们的重点是建模——无论是通用的机器学习模型还是定制的领域特定模型。

最后,你可以选择强调数据工程,成为制造者。这个人帮助一切运转得更快、更可靠。他们的工作仍然需要一些分析和建模,以及绝对需要一些机制工作,但他们将专注于工程任务。制造者是那些将好想法转化为具体机械的人。
最后是独角兽。这个人是每个领域的高手。这是数据科学的理想状态。除了它并不存在之外。成为某一领域的高手需要很长时间。成为三者中的每一个领域的高手本质上是将三种职业叠加在一起。这并非不可能,但这是条漫长的道路,而这条路的途中会经过其他原型作为中转站。

因此,最有用的职业规划原型是
-
通才,精通一切,
-
侦探,一个分析的高手,
-
预言家,建模的高手,
-
制造者,一个工程的高手。
另一种表示这些角色的方式是使用一个三维图,其中有分析、建模和工程的坐标轴。你可以看到侦探、预言者和创作者分别接近各个坐标轴。全才则是三者的平衡,坐落在空间的中间。我想要完全明确的是,我并不是在暗示这些角色之间存在任何等级或价值判断。它们各自都是宝贵的,并且具有不同的功能。让你的偏好和兴趣引导你在选择它们时。
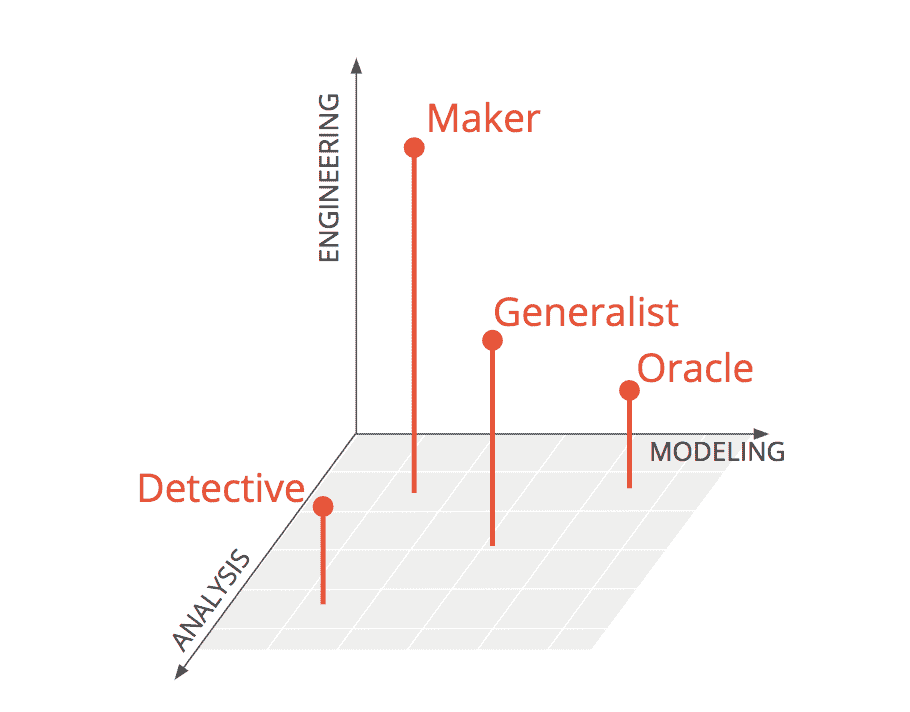
职位发布
数据科学专业没有被普遍接受的分类法。在找工作时,我建议忽略职位名称。没有可靠的方法可以在职位名称和角色之间进行转换。我还建议不要过于关注列出的具体工具。相反,要关注所暗示的技能。通过阅读暗示,发现他们想要的是哪种角色。职位描述听起来更像是创作者吗?全才?侦探?基于此,你可以决定这个特定的职位是否适合你。
同样,当发布职位时,请要求具体的技能。不要要求所有技能。也不要要求一个独角兽。你不会找到的。
我希望你从中得到的,比其他任何事情都要多的是,你不需要在所有领域都是专家才能成为一个伟大且成功的数据科学家。选择一个方向并深入即可。
祝好运!如果你还没有选择好自己的路径,希望这些信息能帮助你规划,并祝你在过程中取得巨大成功。
原文。已获许可转载。
相关:
-
数据科学家最需求的技术技能
-
数据科学面试学习指南
-
成为顶尖数据科学家的 13 项技能
更多相关话题
数据科学家解析:技能、认证和薪资
原文:
www.kdnuggets.com/data-scientist-breakdown-skills-certifications-and-salary

图片来源:作者
由于 ChatGPT 等平台的使用,我们中的许多人对数据科学家的需求感到担忧。在过去几年中,公司在科技行业裁员,而大家都在问 AI 是否是背后的原因。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
在今天的文章中,我们将具体讨论数据科学,尽管面临挑战,但拥有数据科学技能的人拥有更有前景的职业寿命。
根据365datascience的研究,数据科学家占主要科技公司裁员人数的 3%。其他科技专业人士,如软件工程师,受影响更多,约为 22%。
仅这一统计数据就展示了数据科学家在推动科技行业发展中的关键作用。
数据科学家的角色是什么?
数据科学家的工作角色专注于统计学、机器学习和人工智能。他们的商业目标是能够使用不同的数据策略,将原始数据转化为可以在决策过程中使用的业务洞察。
这可以从简单的数据分析到构建机器学习模型。
数据科学家擅长数学、统计学和计算机科学,精通如 Python 或 R 等编程语言。
如何成为数据科学家
如上所述,要成为数据科学家,你需要对数学和统计学有良好的基础理解,并掌握一门编程语言。
计算机科学怎么样?我不需要学位吗?
在某些情况下是的,具体取决于你所在的地区。例如,在英国,许多公司希望有大学学位。然而,随着数据科学家需求的持续增长,组织认识到供给不足,并且非常愿意接纳拥有正确认证和技能的人。
那这些认证是什么呢?
数据科学家薪资
那么薪资情况如何呢?
根据[Glassdoor]( https://www.glassdoor.co.uk/Salaries/us-data-scientist-salary-SRCH_IL.0 ,2_IN1_KO3,17.htm?countryRedirect=true),截至 2024 年 4 月 12 日,美国数据科学家的平均工资为$157,000,范围在$132,000 到$190,000 之间。
请注意,在这个数据中,仅有 37.8%的职位公告了薪资。作为技术行业的一员,我遇到过年薪在$160,000–$200,000 之间的美国数据科学家。
但是,薪资高度依赖于一系列因素:
影响数据科学家薪资的因素
-
地理位置 - 通常生活成本较高的地区如伦敦或纽约薪资也会较高。不过,远程工作的增加使全球的数据科学家有机会获得更好的薪资。
-
经验 - 自然地,经验越丰富,你的薪资会越高。获得正确的经验和技能作为数据科学家将帮助你提高薪资,因为你在已经高需求的市场中变得更具竞争力。
-
行业 - 你所工作的行业也会影响你的薪资。技术、金融和医疗等行业日常利用数据的程度越来越高,需要数据科学家来解读这些数据。
总结
数据科学家的需求将继续增长,如果你希望转行进入技术行业并寻求更高的职业稳定性,数据科学是适合你的选择。
不用担心没有大学的相关资格,你可以通过上述认证获得相同的经验和技能,并找到工作!
尼莎·阿亚是一名数据科学家、自由技术写作员,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,并围绕数据科学提供理论知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何有利于人类寿命的延续。作为一个热衷于学习的人,尼莎寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
数据科学家职业路径从新手到首份工作
原文:
www.kdnuggets.com/2021/11/data-scientist-career-path-first-job.html
comments
我们最近有一篇博客文章,我讨论了18 种学习数据科学的在线资源。显然,18 种资源对一个人来说太多了,并且根据你的经验水平和你在旅程中的位置,并不是所有平台对你都相关。
因此,我想做的是将你的数据科学之旅或成为数据科学家的职业路径分解成不同的阶段,依据经验和目标,推荐一些在线资源,以帮助你在成为数据科学家的职业路径中的当前阶段。
我所做的就是与社区中的一些数据科学家交流,询问他们的职业历程,并收集了一些对他们职业生涯有所帮助的在线资源推荐。然后,我将这些信息与我的数据科学家职业路径和我使用的资源进行了匹配。
我想做的是与您分享一个从完全新手到获得数据科学工作的一套四步数据科学旅程,以及每一步你可以使用的资源。
数据科学家职业路径的四个阶段
我从与社区交流以及反思自己旅程中收集到的信息是,你作为数据科学家的职业路径可以分为四个不同的阶段。从完全新手到获得数据科学工作,这四个阶段是:

1. 学习语法和工具
学习语法和工具是数据科学家职业路径中的首次接触。
在这个阶段你的目标是:
-
了解数据科学中的一些问题是什么
-
查看你是否喜欢这类问题
-
查看你是否喜欢编码
-
查看你是否喜欢数据科学家将使用的平台和工具
这个阶段的重点是学习如何编码、统计和数学、建模、所有的理论,并测试你将用于工作的工具和平台。在这个阶段,每个人都是初学者。所以,你可能刚刚从大学毕业,或者还在学校,或者可能转行,但你可能只有一两门编程课程,或者根本没有编程经验,但这个阶段是为了让你了解平台、代码和数据科学类型的问题。
所以你希望利用的在线资源来学习和接触数据科学实际上位于下图中你作为初学者的底部部分:
我自己从 Mode Analytics 开始,这帮助我在一定程度上学会了 SQL 和 Python,然后我转到下一个平台以提升到更高的水平。但在第一阶段,任何一个上面图表中的平台都能帮助你获得编码和数据科学问题的初步了解。
除了 Mode Analytics,我还建议完成 Coursera 或 Udemy 提供的数据科学课程,以便你能接触到更多内容,了解自己是否对数据科学感兴趣。

现在你已经学会了工具,并对数据科学中会遇到的问题有了些了解,你想要脱离教程模式,进入更复杂的内容。这就带你进入了第二阶段。
2. 尝试更复杂的内容
在第二阶段,你需要从教程模式中脱离,进入更专业的行业话题或数据科学领域。
对我来说,DataCamp 帮助我摆脱了教程模式。他们提供了许多专业话题,让我可以利用数据科学知识,如开发机器学习模型,并将其应用到我感兴趣的特定行业中。
如果你查看下面图表中的其他推荐,我们不仅有 DataCamp,还有像 CodeAcademy、StrataScratch 和 LeadCode 等在线资源。

所有这些平台都能帮助你在专业领域提升技能,这些技能可以应用到数据科学或软件开发中。
在数据科学职业路径的这一阶段,你不仅要脱离教程模式,进入更复杂的内容,同时你也在尝试了解数据科学职业的真正含义。
为了进一步了解这一点,我和一些同事在数据科学社区中从 YouTube、Reddit 和其他讨论论坛中学习。
观看 YouTube 视频或浏览 Reddit 帖子的目的是了解其他数据科学家遇到和暴露的问题。这可以帮助你理解数据科学职业可能的感受以及未来可能的经历。
总之,数据科学职业路径中的第二阶段是关于摆脱教程模式,进入更复杂和复杂的数据科学话题,这些话题你最终可以应用到你的工作中。此外,还包括去 Reddit 等讨论论坛,或观看其他数据科学家的 YouTube 视频,以了解他们的经历,这将帮助你设想自己在数据科学职业中的状态。
现在你在数据科学和编码方面有了一些进步,并且了解了一点作为数据科学家的职业前景,你也很兴奋想要成为其中的一员。让我们继续前进,进入数据科学家职业路径的第三阶段。
3. 认真对待
数据科学职业路径中的第三步适用于那些已经决定将数据科学作为职业并且最终认真对待的人。现在,你需要做的是离开像 DataCamp 这样的教育平台,投入到可以全面检验你技能的项目中。
对于这个用例,你可以尝试一些非教育平台,如 Kaggle,来进行一些项目,并与其他数据科学家进行排名竞争。

如果你觉得不想做 Kaggle,而是想参加一个在线或面对面的数据科学训练营,那么 General Assembly 是一个非常受欢迎的选择,他们会教你如何进入数据科学领域。
显然,一旦你完成了 Kaggle 或结营后,你会想要准备面试以成为数据科学家。你确实应该尝试使用像 LeetCode 或 StrataScratch 这样的面试准备平台。
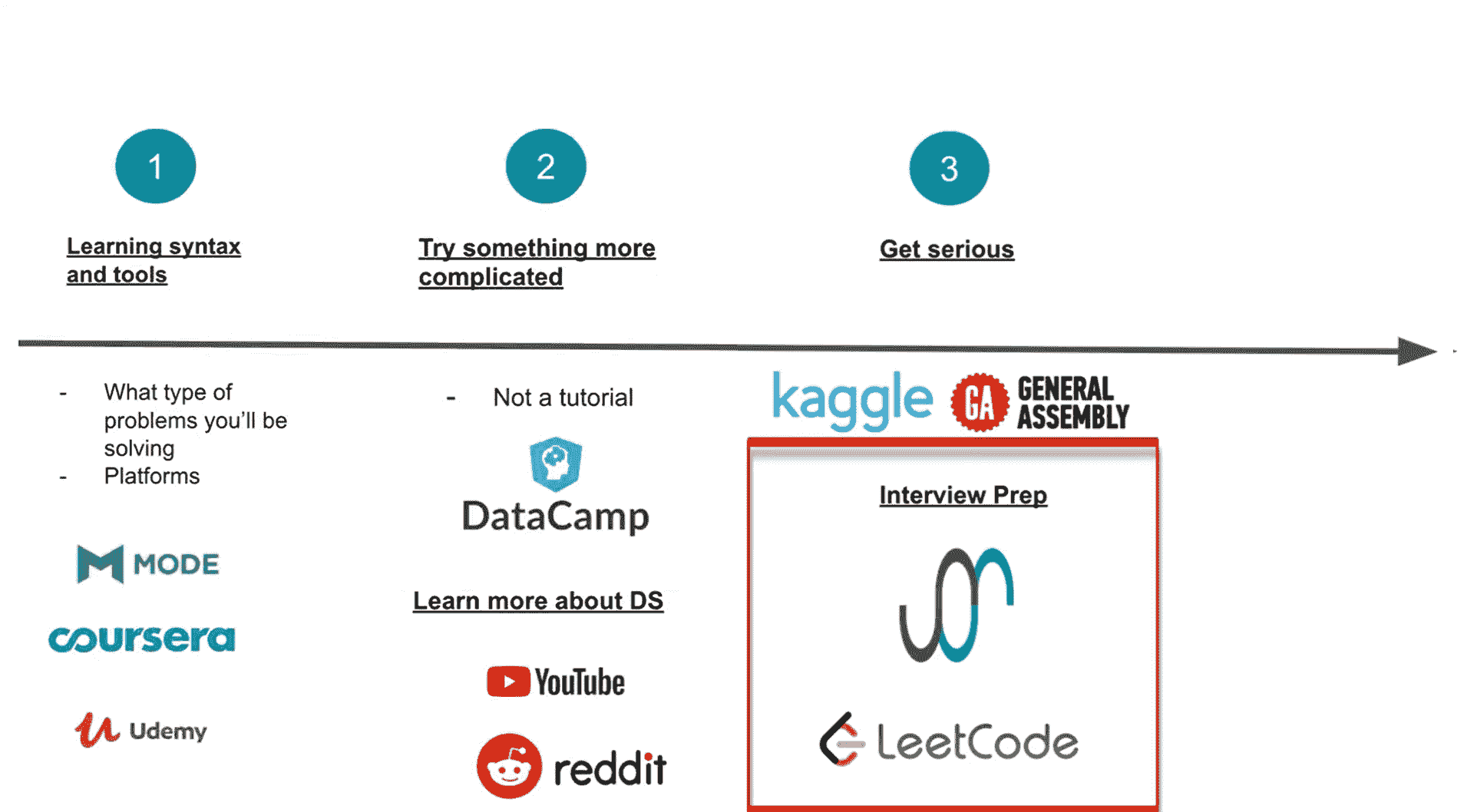
在这些平台上,你会找到大量来自真实公司的data science interview questions,这些问题可以为你提供成功面试所需的实践。
在这个阶段,目标是更加认真地对待成为数据科学家。你应该提高自己的技能,以便能够进行项目工作,产生有意义的影响,并且能够迅速且没有太多困难地回答和解决数据科学面试中的问题。因此,你需要在一些项目和面试问题上进行大量练习。
现在唯一缺少的就是找到一份工作,并获得薪水,成为数据科学家,这将引领我们进入数据科学家职业路径的第四步。
4. 第一份工作
如果你之前没有任何行业或专业经验,或者没有作为数据科学家的工作经历,跳出第三阶段可能会很困难。所以,你需要认真对待第三阶段。尽可能多地准备和学习,以便你了解编码和回答这些技术问题。这将使你能够在获得第一份工作时运用这些技能。
在这个阶段,你需要了解自己对哪些类型的项目感兴趣。作为数据科学家,有许多不同类型的角色和数据科学家。
你可能每天都在创建推荐引擎,你可以将东西部署到生产环境中或保留在开发服务器上,你可以创建数据管道,你也可以做更多像研发类型的分析或其他事情。在最初的几年里,你可能会做所有这些工作,然后随着你专业化并在职业中成长,你可能会做得更少,只专注于某些角色。
在数据科学家职业路径的这一阶段,作为你的第一份工作,关键是了解你喜欢什么,以及你作为数据科学家喜欢做的角色和责任是什么。
结论
现在我们已经讨论了典型的数据科学家职业路径,我必须说,并非所有的数据科学之旅都是相同的。这实际上是我从与社区中几位数据科学家交谈以及对我自己经历的反思中总结出的常见阶段和主题的集合。
我猜测你现在可能处于第一个到第三个阶段,并且你正在尝试找到第一份数据科学工作的方法。因此,我建议你根据你所处的阶段,选择一些在线资源来帮助你在这个阶段,并帮助你达到下一个水平。第四阶段是我们希望成为专业数据科学家的地方。
希望这些信息对你有帮助,并且你能理解自己在这段旅程中的位置以及需要做些什么才能进入下一个阶段或水平。
原文。经许可转载。
相关:
相关话题
成为数据科学家的挑战

Christopher Gower 通过 Unsplash
全球组织都在寻找新的方法来组织、处理和释放数据的全部潜力,并将其转化为高价值的商业洞察。因此,我们可以说数据是新的石油。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
希捷 预计到 2025 年,生成的数据量将达到 163 泽字节;是 2017 年数据量的十倍。因此,你可以想象数据科学家的需求会飙升。2012 年,LinkedIn 发布数据科学家的增长率达到 650%。这一职业在最佳工作排名中名列前茅,并且薪资最高。
每个行业都能从数据科学中受益,因此没有理由让组织错过这一机会。哈佛商业评论将数据科学标记为 21 世纪“最性感”的职业。
尽管这是 21 世纪“最性感”的职业,但每个职业都有其挑战。你可能会想,一个需求如此高的工作,挑战和问题应该会少一些,因为这些岗位在组织中至关重要。然而,按照金融时报的说法,许多公司似乎未能创造出能够应对数据专家激增的职位。许多数据专家正在努力晋升或实现职业愿望。根据 Stack Overflow 的调查,13.2%的数据科学家在寻找新的工作,因为他们对目前的角色不满意。
那么,为什么会这样?数据科学家面临的挑战是什么?
1. 数据准备
数据很少是完美或干净的,这导致数据科学家花费近 80%的时间来清洗和准备数据,参考Forbes。这篇文章的标题是《最耗时、最不愉快的数据科学任务》,因此你可以想象为什么 13.2%的数据科学家在寻找新工作。如果你大部分时间都花在提高数据质量,使其准确一致,然后再进行分析;这可能会变得非常疲惫、单调和耗时。
减少准备数据所花费的时间以及数据科学家缺乏动力的一个方法是采用新兴的 AI 驱动的数据科学技术,如增强分析。增强分析自动化手动数据清洗和准备任务,使数据科学家能够更高效地工作,并将时间花在他们更愿意做和喜欢做的分析等其他任务上。
2. 数据安全

FLY:D via Unsplash
随着组织转向使用云数据管理,网络攻击变得越来越突出。这可能对处理政府数据和需要保护的公共信息的组织来说是一个非常大的问题。
造成的问题有:
-
机密数据被滥用
-
由于网络攻击的增加,监管标准已经扩展了数据同意和利用流程。这给处理数据的数据科学家带来了更多的工作。
为了减少这些问题的发生,组织应该实施额外的安全措施和先进的机器学习驱动的安全平台来保护数据。同时确保组织遵循数据保护规则和法规,以避免审计和罚款;这些会给组织带来不良声誉。
3. 多数据源
当数据不易获得时,会花费大量时间搜索数据、验证数据的可靠性以及手动输入数据。这可能导致错误、重复以及整体数据质量差,从而做出错误的决策。
拥有一个集成多个数据源的集中平台,为数据科学家和其他可能需要数据的人提供即时访问。这为数据科学家节省了大量时间和精力,改善了整体工作流程。
4. 理解业务问题
在收集数据、整理数据和进行任何形式的分析之前;数据科学家必须理解需要解决的问题。他们是数据的科学家,因此他们将重新构建数据以寻找解决方案;所以他们对问题有一个良好的理解是至关重要的。
理解业务问题是数据科学工作流程的第一阶段。如果工作流程的第一阶段经过正确思考,当数据科学家进入数据准备和分析阶段时,它始终可以作为参考点。
5. 全才
许多组织存在一个很大的误解,认为数据科学家能做所有事情。作为数据科学家,你需要收集和清洗数据、构建模型和分析数据。如上所述,80%的数据科学家时间用于清洗和准备数据,因此可以想象,在此之后,构建模型和分析数据所投入的努力。
对数据科学家要求过高会导致数据团队运作无效。他们会失去动力,被工作量压倒,可能会想要辞职。其他同事需要理解每位数据科学家的角色、优点和缺点。此外,这种误解认为数据科学家非常聪明,能做任何事情,能够完成分配的任务。
结论
数据科学家将继续成为市场上最受欢迎的职业之一。随着数据科学家数量的迅速增加,要在这个角色中取得成功,不仅需要卓越的技术技能,还需要非技术技能,如理解组织的需求,以一种能够向利益相关者证明分析结果有用且能为公司带来好处的方式进行沟通。
尼莎·阿娅 是一名数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何/可以促进人类寿命的不同方式。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
为什么数据科学家必须了解变革管理
原文:
www.kdnuggets.com/2018/02/data-scientist-change-management.html
评论
Jurjen Helmus,阿姆斯特丹应用科学大学(HvA)。
本周我受邀为一组变革管理人员做了一次关于数据科学的客座讲座。我们讨论了预测性维护对劳动力的社会影响,以及如何从变革管理的角度处理这一概念的实施。在讲座结束时,我意识到应该是数据科学家了解变革管理,而不是相反。这可能使数据科学家发现的改进的实施更加高效,因为这解决了行为变革问题:这是我们实施想法和实现目标的最大障碍之一。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
变革管理模型
变革管理可能被视为与数据科学对立的领域。数据科学是困难的,而变革是软性的。变革管理并不是解决混乱问题,而是关于变革的过程,数据科学则是关于在处理混乱数据后提供解决方案。变革管理的核心理念之一是变革作为一个过程的一部分出现,而不是在突然或预测的时间出现。变革来自人们对变革的接受。
我们在讲座中讨论的一个变革管理模型指出,“变革是由于对新现实的反应而导致的行为变化的结果。”变革是结果而不是起点。目标是你要朝着的方向,变革是实现这些目标所必需的。但要实现目标,必须从后向前思考,回到需要实施干预的点,以创造新的现实。
这就是我意识到的:创造新的现实通常是我们数据科学家在做的事情——基于我们对系统行为的洞察——基于数据集。
成功的变更实施并非从新的现实开始:它从与那些需要对新现实作出反应的人们合作开始。我总结出,对于我们数据科学家来说,拥抱变更管理的概念并在实施结果之前寻求这种方法的合作可能会更有效。
案例 - 预测性维护
让我通过具体案例来阐明我的想法。设想一个生产相对简单产品的工厂。维护和检修由技术部门进行。生产线上的同事和维护部门的员工每天都与机械设备打交道,因此他们了解并感知设备的状态。以詹姆斯为例,他是一位 45 岁的维护工程师,在公司工作超过 25 年。他通过旋动螺栓和手臂就能感知是否需要维护。当然,机械设备有时会故障,但这也在所难免。
现在预测性维护出现了。数据科学家们开始着手预测即将进行的维护,以便在设备故障被感知之前发现问题。请注意,组织内开始进行数据科学工作本身就是一种干预。项目结束时,确实为许多设备创建了一个预测模型,能够在故障发生前 3 周以 97%的准确率预测组件的故障。预测表明,生产故障减少 85%是可以实现的。
挑战 - 实施
这时变更管理就显得重要了。实施后会发生什么变化?行为可能需要改变,但还有更大的问题:预测性维护是一种现实的变化。在旧的现实中,设备会在出现故障的情况下进行维护,或者在预防性维护的情况下,设备会定期维护。在新的现实中,设备甚至在人工感知能力之前就可能由算法进行维护。在新的现实中,未出现故障的设备也会被修理。
这可能引发技术同事的问题,比如“我的技能仍然需要吗?”
因此,成功实施预测性维护的结果是由于对新现实的反应而行为发生的变化。挑战在于不仅仅关注核心数据科学项目,还要使新的现实被接受。这需要在数据科学启动之前或同时进行一系列干预。
干预的最佳实践
那么,变更管理的最佳实践是什么,它们应该如何使用?首先要认识到的是,变更在数据科学家开始分析之前就已经开始了。任何包含智能预测算法的项目都涉及到聪明且技术娴熟的员工。因此,在展示任何结果之前,与这些员工进行互动。项目经理可能认为人们希望为比自己更大的目标做出贡献。在预测性维护的情况下,追求零生产故障可能会激励员工,而不是使他们退缩。
接下来要认识到,领域知识需要成为数据科学项目的一部分。因此,让来自工作一线的员工参与项目,让他们分享他们对机器或任何分析主题的了解。这样,你员工的技能得到了认可。他们知道你知道他们很有能力。被倾听的重要性不容低估。
同时,在项目期间以及项目结束时,要与技术娴熟的员工一起测试。挑战你的员工熟悉预测算法。此外,让他们进行人机对抗:谁知道哪些机器最需要服务。
此外,关注更宏观的视角。在任何公司中实施数据科学并不是要挤掉员工,而是使我们所做的事情更有效、更高效。我期望在实施之后,仍然会对熟练的员工有需求。
简历: Jurjen Helmus(1980 年)在阿姆斯特丹应用科技大学(HvA)工作。他协调“城市技术中的大数据”这一辅修课程。此外,他正在阿姆斯特丹大学进行博士研究,建立用于电动车充电基础设施的基于代理的仿真模型。
相关内容
进一步阅读
数据科学家 vs 数据分析师 vs 数据工程师
原文:
www.kdnuggets.com/2022/01/data-scientist-data-analyst-data-engineer.html

信息图向量由 stories 创建 - www.freepik.com
2022 年最受欢迎的数据相关职业解析
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
三年多前,我面临一个将伴随我一生的决定——“我将来要做什么工作?”我刚刚完成了高等教育,刚从高中毕业。
在与朋友和家人进行长时间讨论后,我决定追求被称为“21 世纪最性感的工作”的职位。我决定攻读数据科学本科专业。
当时,我选择了数据科学,因为我对自己的选择并不清楚。我听说了一个流行的领域,它承诺灵活的工作时间和丰厚的薪水,于是决定专注于此。
然而,在数据行业工作了一年多后,我意识到数据科学只是我可以选择的众多职业路径之一。
数据行业中还有许多不那么热门但需求高、薪资丰厚的职位。
在这篇文章中,我将描述数据行业中三种最有前景的职业选择——数据分析、数据科学和数据工程。
数据工程师
数据工程师是数据行业中被忽视的英雄。他们整合大量数据,并建立可扩展的管道,使其他数据专业人士可以轻松访问。
数据科学家无法建立机器学习模型,而没有数据工程师完成的数据准备工作。
随着公司开始认识到建立可扩展数据框架的重要性,数据工程师的需求在过去几年中增长了。
数据工程师是这个列表中三种角色中最具技术性的。他们设计数据库模式,管理系统中的数据流,并执行质量检查以确保数据的一致性。
要成为数据工程师,你需要具备软件设计、数据库架构、DevOps 和数据建模方面的技能。你还需要对 SQL 有很强的掌握。数据工程职位描述中通常要求了解 Python 和 Bash 等脚本语言。
数据分析师
数据分析师是那些组织数据以识别可以支持决策趋势的个人。
这些人利用他们的技术和领域知识来提出可以帮助企业增长的建议。
以下是数据分析师工作流程的一个简单例子:
-
ABC 商店希望更好地了解他们的客户基础。
-
他们希望根据品牌忠诚度和每次购买的金额等因素将客户细分为不同的群体。然后,他们将通过不同的促销活动吸引每个客户群体。
-
数据分析师可以根据客户购买行为识别趋势并执行这种细分。
-
例如,有一组客户曾经每月光顾 ABC 商店(第一组)。然而,在过去的几个月里,他们突然停止了购买。这意味着他们可能决定转向竞争品牌购物,或者他们根本不再需要这个产品。
-
第二组客户只有在特定产品打折时才光顾 ABC 商店(第二组)。他们不是常客,仅对某个产品的促销活动做出反应。
-
这两组客户需要不同的接触方式。第一组客户表现出品牌忠诚度,这需要通过个性化信息和礼品卡等策略来重新获得。
-
另一方面,第二组客户应该通过基于他们经常购买的产品的特定促销活动来进行定位。
数据分析师通常执行上述描述的任务。
为了识别客户价值并像上述那样对其进行分组,分析师需要对公司的产品供应有深入了解。他们还需要在商业和市场营销等领域具备专业知识。
数据科学家
数据科学家的工作范围经常与数据分析师的工作范围混淆,这是因为他们的技能集有很大的重叠。
然而,这些角色之间的主要区别在于数据科学家构建机器学习模型,而数据分析师则不构建。
数据科学家需要具备与分析师非常相似的技能。他们需要了解如何收集和转换数据,创建
可视化,执行分析任务,并通过数据解决业务问题。
除了以上列出的所有技能外,数据科学家还需要知道如何创建预测模型。
以下是数据科学家工作流程的一个例子:
-
ABC 商店希望了解他们客户的终身价值。数据科学家将执行上述所有分析。
-
然后,他们将进一步构建一个聚类模型,将这些客户细分为不同的群体。
-
为了根据每个客户的偏好提出个性化的产品推荐,数据科学家还可以在每个细分群体中构建一个推荐系统。
结论
数据科学非常受欢迎,围绕这个领域有很多炒作。然而,数据行业还有其他快速发展的职业,在薪资和需求方面同样具有前景。
数据科学家、工程师和分析师在数据生命周期中同样重要。组织需要这些领域的专业知识,以便做出具有商业价值的数据驱动决策。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
相关话题
数据科学家、数据工程师及其他数据职业解析
原文:
www.kdnuggets.com/2021/05/data-scientist-data-engineer-data-careers-explained.html
木桌照片由 freepik 创建 - www.freepik.com
数据相关的职业领域可能令人困惑,不仅对于新手,对于那些在该领域有一定工作经验的人也如此。
然而,针对新手,我发现那些有意进入数据领域的人经常(也理应)对需要了解哪些内容来决定自己适合什么角色缺乏一般性理解。在这篇文章中,我们将探讨五种不同的数据职业类型,并希望提供一些建议,帮助你在这个广阔而复杂的领域中起步。
我们将专注于行业角色,而不是研究角色,以避免增加额外的复杂层次。我们还将省略如首席数据官等高管职位,主要因为如果你已达到这个职业阶段,这篇文章的信息可能对你并不需要。
所以这里有五种数据职业类型,附有描述和区分它们的相关信息。
数据架构师
数据架构师专注于工程和管理数据存储及其中的数据。
数据架构师关注于管理数据和工程化支持这些数据的基础设施。在这种角色中,通常不需要进行数据分析(除非是为了性能调整进行数据存储分析),并且可能不需要使用像 Python 和 R 这样的编程语言。然而,对关系型和非关系型数据库的深入了解无疑是必需的。选择适合数据存储的存储方案,以及数据转换和加载,将是必要的。数据库、数据仓库和数据湖等存储环境,这些都是数据架构师的领域。这一角色很可能对硬件,特别是与存储相关的硬件有最深入的理解,并且可能对云计算架构有最好的了解。
SQL 和其他数据查询语言——如 Jaql、Hive、Pig 等——将是宝贵的,并且在数据基础设施设计和实施后,可能会成为数据架构师日常工作的主要工具之一。验证数据的一致性以及优化数据访问也是这一角色的重要任务。数据架构师将具备维护适当的数据访问权限、确保基础设施稳定性以及保证数据可用性的专业知识。
这与数据工程师角色的区别在于重点:数据工程师关注于构建和维护数据管道(见下文),而数据架构师关注于数据本身。然而,这两个角色可能会有重叠:ETL;任何可能变换或移动数据的任务,特别是从一个存储到另一个存储;启动数据在管道中的旅程。
和本文中的其他角色一样,你可能不会看到“数据架构师”这一职位的广告,而是看到相关的职位名称,例如:
-
数据库管理员
-
Spark 管理员
-
大数据管理员
-
数据库工程师
-
数据经理
数据工程师
数据工程师专注于工程和管理支持数据及数据管道的基础设施。
什么是数据基础设施?它是允许从数据存储中检索数据、以某种特定方式(或一系列方式)处理数据、在任务之间移动数据(以及任务本身)的软件和存储解决方案的集合,当数据正在分析或建模的过程中,以及这些分析或建模之后的任务。这是数据从其源头到最终有用位置及其后续的整个过程的路径。数据工程师肯定熟悉DataOps及其在数据生命周期中的集成。
数据基础设施从何而来?它需要设计和实施,而数据工程师负责这项工作。如果数据架构师是汽车维修工,负责保持汽车的最佳运行状态,那么数据工程可以被视为设计汽车所需的道路和服务中心,以便汽车能够顺利行驶并进行必要的更改以继续下一段旅程。这两种角色对汽车的功能和移动至关重要,当你从点 A 驾驶到点 B 时,它们同样重要。
说实话,数据工程和数据管理所需的一些技术和技能是相似的;然而,这些学科的从业者在不同的层次上使用和理解这些概念。数据工程师可能对关系数据库中的数据访问安全有基础知识,而数据架构师则具备专家级知识;数据架构师可能对组织在数据科学家对数据进行建模之前所需的转换过程有一些了解,而数据工程师则对这一转换过程非常熟悉。这些角色各自使用自己的语言,但这些语言或多或少是相互可理解的。
你可能会发现类似的职位名称被广告宣传,例如:
-
大数据工程师
-
数据基础设施工程师
数据分析师
数据分析师专注于数据的分析和展示。
在此背景下,我使用数据分析师来指代那些专注于描述性统计分析和数据展示的角色。这包括报告、仪表板、关键绩效指标、业务表现指标的准备工作,以及涵盖任何被称为“商业智能”的内容。该角色通常需要与(或查询)关系型和非关系型数据库以及其他数据框架进行互动。
前面提到的角色主要涉及设计基础设施以管理和促进数据的流动,以及管理数据本身,而数据分析师主要关注从现有数据中提取信息并处理这些数据。这与以下两个角色——机器学习工程师和数据科学家形成对比,后者都专注于从数据中获取超出数据表面信息的见解。如果我们可以将数据科学家与推断统计学家进行类比,那么数据分析师就是描述统计学家;这里是当前数据,这里是它的样子,以及我们从中得到的信息。
数据分析师在所展示的角色中需要一套独特的技能。数据分析师需要了解各种不同的技术,包括 SQL 和关系数据库、NoSQL 数据库、数据仓库以及商业和开源报告与仪表盘包。除了了解一些上述技术外,对这些技术的局限性的理解同样重要。由于数据分析师的报告通常具有临时性,了解在做出这一决定之前,无需花费大量时间进行的操作是重要的。如果分析师知道数据如何存储以及如何访问,他们也能知道哪些请求——通常来自完全不了解这些的人——是可服务的,哪些不是,并能建议数据如何以有用的方式提取。迅速适应的能力对数据分析师来说可能是关键,这可以区分优秀和卓越。
相关职位包括:
-
商业分析师
-
BI 分析师
机器学习工程师
机器学习工程师开发和优化机器学习算法,并实施和管理(接近)生产水平的机器学习模型。
机器学习工程师是那些设计和使用预测性及相关性工具来利用数据的人。机器学习算法允许在高速下应用统计分析,那些运用这些算法的人不满足于让数据以当前形式自说自话。数据的审问是机器学习工程师的工作方式,但需要具备足够的统计理解,以知道何时过度,何时提供的答案不可信。
统计学和编程是机器学习研究人员和从业者的一些最大资产。数学如线性代数和中级微积分对那些使用更复杂的算法和技术的人,如神经网络,或从事计算机视觉工作的人很有用,同时了解学习理论也是有用的。当然,机器学习工程师必须了解一系列机器学习算法的内部工作原理(算法越多越好,理解越深越好!)。
一旦机器学习模型足够好以投入生产,机器学习工程师可能还需要将其投入生产。希望做到这一点的机器学习工程师需要了解 MLOps,这是一种处理机器学习模型生产化过程中问题的正式方法。
相关职位:
-
机器学习科学家
-
机器学习从业者
-
<特定机器学习技术> 工程师,例如自然语言处理工程师、计算机视觉工程师等。
数据科学家
数据科学家主要关注数据、从数据中提取的洞察力以及数据所讲述的故事。
数据架构师和数据工程师关注的是数据的基础设施,包括数据的存储和传输。数据分析师关注的是从现有数据中提取描述性事实。机器学习工程师则专注于推进和使用现有工具,以利用数据进行预测和关联分析,并使得生成的模型广泛可用。数据科学家主要关注数据、从数据中提取的洞察力以及数据所讲述的故事,不论完成这些任务需要什么技术或工具。
数据科学家可能会使用上面提到的任何技术,具体取决于他们的角色。这也是“数据科学”相关的最大问题之一;这个术语并没有特指任何具体内容,却涵盖了所有内容。这个角色是数据领域的万金油,知道(或许)如何启动一个 Spark 生态系统;如何对存储在其中的数据执行查询;如何将数据提取并存储在非关系数据库中;如何将非关系数据提取到平面文件中;如何在 R 或 Python 中处理这些数据;如何在初步探索性描述分析后进行特征工程;如何选择合适的机器学习算法对数据进行预测分析;如何统计分析预测任务的结果;如何将结果可视化以便非技术人员易于理解;以及如何向高管讲述数据处理管道的最终结果。
这只是数据科学家可能具备的一组技能之一。然而,无论如何,这个角色的重点在于数据以及从中获取的洞察力。领域知识通常也是此角色的重要组成部分,这显然不是这里可以教授的内容。数据科学家需要关注的关键技术和技能包括统计学(!!!)、编程语言(特别是 Python、R 和 SQL)、数据可视化以及沟通技能——以及上述典型角色中提到的所有其他内容。
数据科学家和机器学习工程师之间可能存在很多重叠,至少在数据建模(即:预测分析过程)及相关领域中尤其如此。然而,对于这些角色之间的差异,常常存在混淆。要详细了解数据工程师和数据科学家之间的关系——这对角色也可能有显著的重叠,可以参考这篇 Mihail Eric 的精彩文章。
记住,这些只是五种主要数据职业角色的原型,它们在不同组织之间可能有所不同。享受你理想数据职业的旅程吧!
马修·梅奥 (@mattmayo13) 是数据科学家兼 KDnuggets 的主编,这是一份开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关话题
数据科学家与数据工程师薪资对比
原文:
www.kdnuggets.com/2021/10/data-scientist-data-engineer-salary.html
评论

图片由 Ryan Quintal 提供,来源于 Unsplash [1]。
目录
-
介绍
-
数据科学家
-
数据工程师
-
总结
-
参考文献
介绍
注意:本文是第三篇,属于一个关于流行数据/技术职位薪资报告的系列文章。我会在文章末尾链接其他两篇文章。
本文旨在提供一种指南,让这些领域的专业人士能够对照自己当前的薪资,而不是将角色进行比较以判断谁应该获得更多的薪水。尽管这听起来有些老生常谈,但在请求更高薪水时,记住以下两点仍然很重要:提出要求不会有害,而有时候,你得不到的往往是你没有要求的。请记住这些数据更具一般性,你可以根据具体情况查看你的薪资水平。这些数值更像是一个方向性的指南供你参考。
数据科学家和数据工程师拥有一些共同的技能和经验,但也存在一些关键差异,这些差异可能导致薪资的不同。话虽如此,让我们直接进入以下两个角色的一些真实薪资示例。
数据科学家

图片由 Copernico 提供,来源于 Unsplash [2]。
由于我已经写过一些关于数据科学薪资的文章,我将在这里包括一些重要信息,以及几个不同的示例。
下面是作为数据科学家可能会看到的一些预期职位,这些职位的薪资可能会有显著变化:
入门级数据科学家 → 数据科学家 → 高级数据科学家
首席数据科学家 — 数据科学经理 — 数据科学总监
除了这些职位外,还有一些资历等级,如 I、II 和 III。
接下来,我将展示各个职位的薪资范围以及所需的年限或期望年限。
请注意,这些角色的薪资基于美国平均水平(基于 PayScale [3]):
-
平均整体数据科学家 →
96,455 美元 -
平均入门级数据科学家 →
85,312 美元(1 年) -
平均早期数据科学家 →
95,121 美元(1–4 年) -
平均中期数据科学家 →
109,696 美元(5–9 年) -
平均经验数据科学家 →
136,051 美元(10–19 年)
我是否同意这些数字?
不。
如果你阅读了之前的文章,下面是我将包含的不同城市及其相关技能的薪资报告。
-
密歇根州安娜堡 →
88,197 美元 -
马萨诸塞州剑桥 →
110,213 美元 -
科罗拉多州丹佛 →
92,924 美元
这里是具体的城市和技能:
-
北卡罗来纳州夏洛特 + 自然语言处理(NLP) →
70,000 美元 -
北卡罗来纳州夏洛特 + Tableau 软件 →
79,096 美元 -
乔治亚州亚特兰大 + Java →
80,000 美元
城市的平均薪资似乎更符合现实,而与城市相关的具体技能薪资则显得过低。我认为原因是,当你按照特定技能筛选时,你会剥离掉所有其他技能。因此,一个解决办法可能是找到该城市的平均薪资,然后比较上述技能之间的差异,以获得更现实的薪资估算。
我认为有趣的是,自然语言处理技能的薪资不如 Tableau,但我认为自然语言处理可能过于专业且可能较少被误解,而 Tableau 被广泛理解,大多数数据科学家不会将其添加到简历中,因为它更偏向于数据分析师——当你了解你的薪资或编辑简历时,可能需要考虑这一点——简而言之,不要做出假设,力求使你的技能独特。
我认识的数据科学家中使用 Java 的人不多,但我发现报告中包含这种技能作为选项是有趣的,也许市场上确实有 Java 的需求,我不确定具体原因(可能是软件工程师转型为数据科学家)。
数据工程师

图片来源于Fotis Fotopoulos在Unsplash[4]。
现在我们已经对数据科学薪资有了一个良好的了解,包括不同因素如位置和技能,让我们更深入地探讨数据工程师薪资的具体情况。
在所有这些薪资比较中,数据工程师和数据科学家的薪资范围似乎更为接近,正如下文所示。
作为数据工程师,以下是一些可能会显著影响薪资的预期职位:
数据工程师 → 高级数据工程师 → 数据工程经理
高级软件工程师 — 数据科学家(是的,专注于数据工程)
除了这些职位,还有一些高级别,如 I、II 和 III。
接下来,我将展示各职位的薪资范围以及所需的年限或期望年限。
请注意,这些角色基于美国的平均水平(基于PayScale[5]):
-
数据工程师的整体平均薪资 →
92,519 美元 -
入门级数据工程师平均薪资 →
77,350 美元(1 年) -
初级数据工程师平均薪资 →
87,851 美元(1–4 年) -
中级数据工程师平均薪资 →
103,467 美元(5–9 年) -
经验丰富的数据工程师平均薪资 →
117,918 美元(10–19 年)
我是否同意这些数据?
不。
我认为每个职位的薪资至少应该调整一次,因为早期职业阶段的薪资应该是中级或经验丰富的数据工程师的薪资,这还取决于你所居住的地点——所以让我们深入探讨具体位置的平均薪资。
-
纽约,纽约 →
104,615 美元 -
西雅图,华盛顿 →
105,076 美元 -
旧金山,加州 →
123,859 美元 -
奥斯汀,德克萨斯州 →
96,290 美元
这些城市的平均薪资比整体平均薪资更有意义。最有趣的是旧金山的差异,但这仍然是预期中的情况,因为那里的生活成本非常高。
现在,让我们看看这些城市的具体技能:
-
纽约,纽约 + Scala →
121,755 美元 -
西雅图,华盛顿 + 大数据分析 →
107,442 美元 -
旧金山,加州 + Apache Hadoop 技能 →
123,672 美元 -
奥斯汀,德克萨斯州 + 亚马逊网络服务(AWS) →
97,436 美元
在所有这些薪资中,旧金山在增加技能时薪资有所下降——这表明在查看个性化报告时,你可能需要添加所有技能,而不仅仅是一个。纽约在添加 Scala 技能后薪资涨幅最大,我个人也同意这一点,因为 Scala 是一项很棒且相当难掌握的技能。
总结
薪资具有几个特征,这些特征可以使其增加或减少。我们刚刚讨论了两个因素:经验年限、地点(城市)和技能。还需要考虑其他因素,包括但不限于:面试本身、简历本身、谈判技巧、奖金、股份、教育和认证。
总结一下,以下是数据科学家与数据工程师薪资的主要区别:
* 美国数据科学家平均薪资 96,455 美元 * 美国数据工程师平均薪资 92,519 美元 * 这两个角色的薪资范围可能是最相似的 * 数据科学家更多关注从现有的、打包的机器学习算法中创建模型,而数据工程师则更多利用 SQL 进行与数据相关的 ETL/ELT * 薪资受多个因素影响,其中最重要的可能是资历、城市和技能
希望你觉得我的文章既有趣又有用。如果你同意或不同意这些薪资比较,请随时在下方评论。为什么同意或不同意?你认为关于薪资还有哪些其他重要因素需要指出?这些因素当然可以进一步澄清,但我希望我能对数据科学家和数据工程师薪资之间的差异提供一些见解。
最后,我可以再次问同样的问题,你认为远程职位会如何影响薪资,特别是当城市在确定薪资时是如此重要的因素?
感谢阅读!
我与这些公司没有任何关联。
请随时查看我的个人资料,
Matt Przybyla,以及其他文章,您还可以通过以下链接订阅我的博客,以接收电子邮件通知,或者通过点击屏幕顶部的订阅图标(在关注图标旁边),如果您有任何问题或意见,请在 LinkedIn 上与我联系。
订阅链接: datascience2.medium.com/subscribe
我还写了一篇类似的文章,讨论了机器学习工程师薪资与数据科学家薪资的差异,您可以在 这里 [6] 找到,还有数据科学家与数据分析师薪资的差异,您可以在 这里 [7] 查阅。本文概述并突出了各自薪资的相似特征。请记住,对于这两篇文章,这些薪资不是我的,而是由 PayScale 和其他实际的数据科学家、数据工程师、数据分析师及机器学习工程师报告的。因此,这些文章基于真实数据讨论,旨在帮助您更好地理解哪些因素(一般来说)会影响职位的薪资增减。
再次说明,这些薪资数据来自 PayScale,如果您需要更具体的估算,您可以使用 薪资调查 [8]。
参考文献
[1] 照片由 Ryan Quintal 拍摄,发表于 Unsplash,(2019)
[2] 照片由 Copernico 拍摄,发表于 Unsplash,(2020)
[3] PayScale, 数据科学家薪资,(2021)
[4] 照片由 Fotis Fotopoulos 拍摄,发表于 Unsplash,(2018)
[5] PayScale, 数据工程师薪资,(2021)
[6] M.Przybyla, 数据科学家与机器学习工程师薪资,(2021)
[7] M. Przybyla, 数据科学家与数据分析师薪资,(2021)
[8] PayScale, PayScale 薪资调查,(2021)
简介:Matthew Przybyla 是 Favor Delivery 的高级数据科学家,同时也是一名自由技术作家,特别是在数据科学领域。
原始内容。经许可转载。
相关:
-
我们不需要数据科学家,我们需要数据工程师
-
没有数据工程技能的数据科学家将面临严峻现实
-
数据科学家、数据工程师及其他数据职业的解释
更多相关话题
数据科学家认为数据是他们的头号问题。这就是为什么他们错了。
原文:
www.kdnuggets.com/2020/09/data-scientist-data-problem-wrong.html
评论
由詹姆斯·泰勒,数字决策和从 AI 及机器学习中实现业务影响的首席执行官及权威。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
我经常看到一些文章或帖子将数据整合或准备视为数据科学项目面临的关键问题。这总是让我困惑,因为这不是我们的真实经验——在与采用预测分析、机器学习或 AI 的财富 500 强公司合作时,我们并未看到这样的情况。但我想我找出了原因。问题如下:
数据科学家认为的“数据科学项目”实际上不是数据科学项目。
让我用一些来自伟大研究的数据来说明这一点。早在 2016 年,《经济学人信息部》对“断链:为什么分析投资还未见成效”进行了调查,下图显示这些数据似乎支持数据问题是头号问题的论点。

哇——非常清楚,数据整合/准备是最大的问题,报告此问题的项目几乎是下一个问题的两倍。
事实上,这只是调查数据的一个子集。以下是完整的数据集:

数据整合和准备仅排在第 4 位。问题定义/框架、解决方案方法/设计和行动/变更管理的排名都更高。这是我们的经验。
在大型、成熟的“成人”公司中,数据科学项目失败有一个或两个原因:
-
他们正在解决错误的问题。他们正在构建一种分析工具,但这种工具并不是业务所需的,无法解决真正的业务问题,或者设计得不适合业务环境。
-
因为他们无法对所构建的模型采取行动。他们不能通过改变决策和采取行动来利用分析工具。
这说明了问题所在。
问题在于数据科学家认为他们的项目从数据开始,到分析结果的沟通结束。如果这是你的关注点,那么数据就是你的首要问题。
但这不是数据科学项目的起点,也不是终点。它们必须以业务为起点和终点。这意味着从一个业务问题开始 - 业务希望改进的业务决策 - 并以该问题得到解决为结束 - 业务行为发生改变(更好)。如果这是你的关注点,那么你的问题不是数据,而是问题定义和操作化 - 使分析工作在现实生活中得以实现。
这是在这些阶段中展示的差异。在左边,是许多数据科学家认为他们的项目涉及的内容;在右边,是实际涉及的内容。

底线:如果你的数据科学团队告诉你数据是他们的首要问题,那么他们就是在做错了。
我之前写过关于这个问题的文章 - 查看这篇关于研究本身的文章以及这篇关于采用决策建模作为更好的方式来定义你的数据科学团队尝试解决的问题。你可能还会喜欢我们最近的白皮书和关于构建分析企业的视频。
原文。经许可转载。
相关:
更多相关主题
数据科学家的困境:冷启动问题 – 十个机器学习示例
原文:
www.kdnuggets.com/2019/01/data-scientist-dilemma-cold-start-machine-learning.html
评论
作者:Kirk D. Borne,Booz Allen。

来源:www.yuspify.com/blog/cold-start-problem-recommender-systems/
古代哲学家孔子被认为说过“研究你的过去以了解你的未来。”这一智慧不仅适用于生活,也适用于机器学习。具体来说,标签数据(过去的事物)的可用性和应用对于标记之前未见的数据(未来的事物)是监督机器学习的基础。
如果没有过去数据中的标签(诊断、类别、已知结果),那么我们如何在标记(解释)未来数据方面取得进展?这将是一个问题。
在无监督机器学习中也出现了一个相关问题。在这些应用中,没有关于标签训练数据存在的要求或假设——我们本质上是在对数据中的模式进行参数化或特征化(例如,趋势、相关性、细分、聚类、关联)。
许多无监督学习模型如果事先知道哪些参数化选择最佳,可能会更容易收敛并更有价值。如果我们不能知道这一点(即因为它确实是无监督学习),那么我们至少希望知道我们的最终模型在解释数据方面是最佳的(以某种方式)。
在这两种应用(监督学习和无监督学习)中,如果我们没有这些初步的见解和验证指标,那么如何启动模型构建并朝着最佳解决方案前进?
这个挑战被称为冷启动问题!解决这个问题的办法很简单(有点):我们做一个猜测——一个初始猜测!通常,这将是一个完全随机的猜测。
听起来真是……真是……随机!我们如何知道这是否是一个好的初始猜测?我们如何从这个随机的初始选择中推进我们的模型(参数化)?我们如何知道我们的进展是否朝着更准确的模型方向发展?怎么做?怎么做?怎么做?
这可能是一个真正的挑战。当然,没有人说“冷启动”问题会很容易。任何曾经在冰冻的早晨尝试启动一辆非常寒冷的汽车的人,都知道冷启动挑战的痛苦。在这样的早晨,没有什么比这更令人沮丧的了。但在这样的早晨,没有什么比发动机启动、汽车开始前进并逐渐提升性能的那一刻更令人振奋和鼓舞的了。
面对机器学习中的冷启动问题的数据科学家的经历可能非常相似,尤其是在我们的模型开始取得进展并表现出不断提高的性能时的兴奋感。
我们将在最后列出几个例子。但在此之前,让我们讨论一下目标函数。这才是真正解锁冷启动挑战中性能的关键。这是我们将列举的大多数例子中的神奇成分。
目标函数(也称为成本函数或收益函数)提供了模型性能的客观衡量。它可能像模型正确分类标签的百分比(在分类模型中),或模型曲线与数据点偏差的平方和(在回归模型中),或相对分离的簇的紧凑度(在聚类分析中)一样简单。
目标函数的价值不仅在于它的最终值(即, 给我们一个定量的整体模型性能评分),它的巨大(也许是最大的)价值体现在指导我们从最初的随机模型(冷启动零点)到最终成功(希望是最优)的模型。在这些中间步骤中,它作为评估(或验证)指标。
通过在步骤零(冷启动)测量评估指标,然后在对模型参数进行调整后再次测量,我们可以了解这些调整是否导致了更好的模型性能或更差的表现。然后,我们知道是否继续在相同方向上调整模型参数,还是转向相反方向。这被称为梯度下降。
梯度下降方法基本上是找出性能误差曲线的斜率(即, 梯度),当我们从一个模型进展到下一个模型时。正如我们在小学代数课上学到的,我们需要两个点来找出曲线的斜率。因此,只有在运行并评估两个模型后,我们才能得到两个性能点——然后最新点的曲线斜率会指导我们下一个模型参数调整的选择:要么(a)继续在与上一步相同的方向上调整(如果性能误差减少),以继续下降误差曲线;要么(b)在相反方向上调整(如果性能误差增加),以转向并开始下降误差曲线。
注意,爬山算法与梯度下降是相反的,但本质上是相同的。爬山算法不是最小化误差(成本函数),而是最大化准确性(收益函数)。同样,我们测量两个模型的性能曲线的斜率,然后向表现更好的模型的方向前进。在这两种情况下(爬山算法和梯度下降),我们希望达到一个最优点(最大准确性或最小误差),然后宣布这是最佳解决方案。当我们记得我们从一个初始的随机猜测开始(作为冷启动)时,这真是令人惊讶和满足的。
当我们的机器学习模型有许多参数(对于深度神经网络,这些参数可能有成千上万),计算变得更加复杂(可能涉及多维梯度计算,称为张量)。但原则是相同的:定量发现每一步模型构建进展中,需要对每一个模型参数进行哪些调整(大小和方向),以便朝着目标函数的最优值(例如,最小化误差、最大化准确性、最大化拟合优度、最大化精确度、最小化假阳性等)前进。在深度学习中,和典型的神经网络模型一样,估计这些对模型参数调整的方法(即,对每个网络节点之间的边权重)被称为反向传播。这仍然是基于梯度下降的。
对于梯度下降、反向传播,或许所有的机器学习方法,可以这样理解:“机器学习是一组从经验中学习的数学算法。良好的判断来自经验,而经验则来自于错误的判断。” 在我们的例子中,随机冷启动模型的初始猜测可以视为“错误的判断”,但随后经验(即,来自于如梯度下降等验证指标的反馈)会带来“良好的判断”(更好的模型),进入我们的模型构建工作流程。
以下是数据科学中冷启动问题的十个例子,其中机器学习的算法和技术在模型向最优解的进展中产生了良好的判断:
-
聚类分析(如 K-Means 聚类),其中初始的聚类均值和聚类数量事先未知(因此最初是随机选择的),但可以利用聚类的紧凑性来评估、迭代并改进一组聚类,逐步进展到最终的最优聚类集(即,最紧凑且分离最好的聚类)。
-
神经网络中,网络边上的初始权重是随机分配的(冷启动),但使用反向传播迭代模型到达最优网络(具有最高分类性能)。
-
TensorFlow 深度学习,使用与简单神经网络相同的反向传播技术,但在非常高维的深度网络层和边缘权重的参数空间中使用张量来计算权重调整。
-
回归分析使用数据点与模型曲线之间偏差的平方和来找到最佳拟合曲线。在线性回归中,存在一个封闭形式的解(可以从线性最小二乘技术中推导出来)。非线性回归的解通常不是一个封闭形式的数学方程组,但偏差平方和的最小化仍然适用 —— 梯度下降可以用于迭代工作流来寻找最佳曲线。请注意,K 均值聚类实际上是piecewise regression的一个例子。
-
非凸优化,其中目标函数具有许多山峰和谷底,因此梯度下降和爬山算法通常只会收敛到局部最优,而不是全局最优。像遗传算法、粒子群优化(当梯度无法计算时)和其他evolutionary computing方法用于生成大量随机(冷启动)模型,然后对每个模型进行迭代,直到找到全局最优(或直到时间和资源耗尽,然后选择你找到的最好的一个)。[参见下图,该图说明了遗传算法的一个示例用例。另请参阅图形下方的 NOTE 关于遗传算法,这同样适用于其他进化算法,表明这些算法并不是专门的机器学习算法,而实际上是元学习算法]。
-
kNN (k-最近邻)是一种监督学习技术,其中数据集本身成为模型。换句话说,将新的数据点分配到特定组(该组可能有或没有类别标签或特定含义)仅仅是基于找到哪些现有数据点类别(组)在对新数据点的最近邻进行投票时占多数。需要检查的最近邻的数量是某个数 k,可以最初是任意的(冷启动),然后进行调整以提高模型性能。
-
朴素贝叶斯分类,它将贝叶斯定理应用于具有类别标签的大数据集,但其中一些属性和特征的组合在训练数据中没有表示(即,一个冷启动挑战)。通过假设不同的属性是数据项的相互独立特征,可以估计新数据项的类别标签的后验概率,该数据项具有在训练数据中找不到的特征向量(属性集)。这有时被称为贝叶斯信念网络(BBN),是另一个示例,其中数据集成为模型,不同属性的个别出现频率可以指示不同属性组合的预期出现频率。
-
马尔可夫建模(序列信念网络)是 BBN 对序列的扩展,这些序列可以包括网络日志、购买模式、基因序列、语音样本、视频、股票价格或任何其他时间序列、空间序列或参数序列。
-
关联规则挖掘,它搜索发生频率高于随机抽样的数据集预期的共现关联。关联规则挖掘是另一个示例,其中数据集成为模型,没有关于关联的先验知识(即,冷启动挑战)。这种技术也称为市场篮子分析,已用于简单的冷启动客户购买推荐,但也用于如tropical storm (hurricane) intensification prediction等特殊用例。
-
社交网络(链接)分析,其中网络中的模式(例如,中心性、覆盖范围、分离度、密度、社群等)编码关于网络的知识(例如,网络中最权威或最有影响力的节点),通过应用如PageRank的算法,未提前了解这些模式(即,冷启动)。
最后,作为额外补充,我们提到一个特殊情况——推荐引擎,其中冷启动问题是一个持续研究的主题。研究挑战是找到对新客户或新产品的最佳推荐,这些客户或产品以前未见过。查看这些与此挑战相关的文章:
我们在开头提到孔子及其智慧。这是另一种形式的智慧: rapidminer.com/wisdom/—RapidMiner智慧会议。会议非常精彩,提供了许多优秀的教程、用例、应用程序和客户评价。我很荣幸在他们 2018 年在新奥尔良的会议上担任主旨发言人,主题是“清除数据科学和机器学习中的迷雾:一些不寻常地方的常见嫌疑犯”。你可以在这里找到我的幻灯片演示: KirkBorne-RMWisdom2018.pdf

注意: 遗传算法(GAs)是元学习的一个例子。它们本身不是机器学习算法,但 GAs 可以应用于机器学习模型和任务的集合中,以在一组局部最优解中找到最优模型(或许是全局最优模型)。
原始版本。转载已获许可。
个人简介: Kirk D. Borne 是 Booz Allen Hamilton 的首席数据科学家和执行顾问。
资源:
相关:
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
想成为数据科学家?不要从机器学习开始
原文:
www.kdnuggets.com/2021/01/data-scientist-dont-start-machine-learning.html
评论

照片由Will Porada拍摄,来自Unsplash。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
大多数人听到“数据科学”这个词时首先想到的通常是“机器学习”。
这对我来说就是这样。我对数据科学的兴趣是因为我第一次接触了“机器学习”这一概念,它听起来真的很酷。所以当我在寻找学习数据科学的起点时,你可以猜到我从哪里开始了(提示:它和豆子搅拌押韵)。
这是我最大的错误,这也引出了我的主要观点:
如果你想成为数据科学家,不要从机器学习开始。
请耐心听我讲完。 显然,要成为一名“完整”的数据科学家,你最终需要学习机器学习的概念。但你会惊讶于在没有它的情况下你能走多远。
那么,为什么你不应该从机器学习开始呢?
1. 机器学习只是数据科学家工作的一部分(而且这一部分非常小)。

图片由作者创建。
数据科学和机器学习就像是正方形和矩形。机器学习是(数据科学的一部分),但数据科学不一定是机器学习,就像正方形是矩形,但矩形不一定是正方形。
实际上,我认为机器学习建模仅占数据科学家工作的大约 5-10%,大部分时间是在其他方面度过的,这一点我会在后面详细说明。
TLDR: 如果你首先专注于机器学习,你将投入大量时间和精力,却收获甚微。
2. 完全理解机器学习需要先掌握其他几个相关学科的初步知识。
从根本上说,机器学习是建立在统计学、数学和概率论之上的。就像你首先学习英语语法、修辞语言等来写好一篇文章一样,你必须先掌握这些基础模块,然后才能学习机器学习。
举几个例子:
-
线性回归是大多数训练营首先教授的第一个“机器学习算法”,实际上它更像是一个统计学
-
主成分分析仅在矩阵和特征值(线性代数)的概念下才能实现。
-
朴素贝叶斯是一种完全基于贝叶斯定理的机器学习模型(概率)。
因此,我将总结两点。第一,学习基础知识将使学习更高级的主题变得更容易。第二,通过学习基础知识,你将已经掌握了几个机器学习的概念。
3. 机器学习不是每个数据科学家问题的答案。
许多数据科学家,包括我自己,都在这方面挣扎。和我最初的观点类似,大多数数据科学家认为“数据科学”和“机器学习”是密不可分的。因此,当面对问题时,他们考虑的第一个解决方案就是机器学习模型。
但并非每个“数据科学”问题都需要一个机器学习模型。
在某些情况下,使用 Excel 或 Pandas 进行简单分析就足以解决当前问题。
在其他情况下,问题可能与机器学习完全无关。你可能需要使用脚本清理和处理数据,构建数据管道,或创建互动仪表板,这些都不需要机器学习。
那么你应该做什么呢?
如果你读过我的文章“如果我要重新开始数据科学,我会怎么学”,你可能会注意到我建议学习数学、统计学和编程基础。我仍然坚持这一点。
正如我之前所说,学习基础知识将使学习更高级的主题变得更容易,通过学习基础知识,你将已经掌握了几个机器学习的概念。
我知道如果你在学习统计学、数学或编程基础时,可能会觉得自己在成为“数据科学家”的道路上没有进展,但学习这些基础知识只会加速你未来的学习。
你必须先学会走路,才能跑步。
如果你想要一些实际的下一步行动,这里有几个建议:
-
从统计学开始。在这三个基础模块中,我认为统计学是最重要的。如果你对统计学感到畏惧,数据科学可能不适合你。我建议查看乔治亚理工学院的课程统计方法或可汗学院的视频系列。
-
学习 Python 和 SQL。如果你更喜欢 R,那也可以。我个人从未使用过 R,所以没有意见。你对 Python 和 SQL 的掌握越好,数据收集、处理和实施将会越轻松。我也建议你熟悉 Python 库,如 Pandas、NumPy 和 Scikit-learn。我还推荐你学习二叉树,因为它是许多高级机器学习算法(如 XGBoost)的基础。
-
学习线性代数基础。 当你处理任何与矩阵相关的工作时,线性代数变得非常重要。这在推荐系统和深度学习应用中很常见。如果这些内容是你未来想学习的内容,不要跳过这一步。
-
学习数据处理。 这占数据科学家工作的一半以上。更具体地说,了解更多关于特征工程、探索性数据分析和数据准备的知识。
感谢阅读!
这是一篇带有主观看法的文章,所以你可以根据自己的需求选择阅读。我总体的建议是,机器学习不应成为你学习的重点,因为这不是一个很好的时间利用方式,并且对你在职场上成为成功的数据科学家帮助不大。
话虽如此,祝你在未来的努力中好运!
原文。经允许转载。
相关内容:
相关话题更多内容
为什么数据科学家和数据工程师需要了解云中的虚拟化
原文:
www.kdnuggets.com/2017/01/data-scientist-engineer-understand-virtualization-cloud.html/2
隔离与安全
将一个团队的工作与另一个团队的工作分开很重要,以便他们能够实现业务所需的服务水平协议(SLA)。在虚拟化领域,这种分离是通过将服务器和虚拟机分组到各自的资源池中来实现的,以限制它们对外部工作负载的影响。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
示例:一家医疗保健公司中的不同团队使用一个 Hortonworks 集群进行某些分析工作,同时在同一基础设施上运行 MapR 集群进行其他分析目的。
在专门构建的虚拟机中可以部署分布式防火墙,以排除对某些集群和数据的访问,这些集群和数据可能位于相同的基础设施上。由于这些分布式防火墙位于虚拟机中,它们可以随工作负载一起移动,而不受物理边界的限制。
性能
数据科学家需要在时间限制内找到他们查询的答案。执行其工作的系统性能对这个群体至关重要。
为了测试数据科学程序在虚拟机上的性能,VMware 工程师在 Spark 集群上执行了一组机器学习(ML)算法,其中集群中的每个节点都保存在虚拟机中。这些测试也在没有虚拟化的相同服务器上执行,并对测试结果进行了比较。以下是一个结果示例。

这些类型的系统最初使用大量示例数据来训练模型,以便模型能够识别数据中的某些模式。这些示例集在上述设置中范围从 7 亿到 21 亿条记录。每个示例都有 40 个特征或数据记录的不同方面(例如交易金额和信用卡购买的到期日期)。
模型在大量示例上训练完成后,会被呈现一个新的事务实例。例如,这可能是一个信用卡交易或客户申请新信用卡。分析模型需要将该事务分类为良好或欺诈。通过使用统计技术,模型对此问题给出二元答案。这种类型的分析称为二元分类。也测试了几种其他机器学习算法。
结果显示,这些在 vSphere 上运行的 ML 算法表现良好,在某些情况下,比相同测试代码的裸金属实现性能更佳。有关这些工作负载和观察到的结果的详细技术描述请参见 www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/bigdata-perf-vsphere6.pdf
云部署的虚拟化选择
数据科学家/数据工程师以及基础设施管理团队在开始在云中部署分析基础设施软件时,面临的技术选择在此处突出显示。
-
正确调整虚拟机的规模
-
将虚拟机放置到最合适的主机服务器上
-
虚拟机中不同软件角色的配置
-
将计算资源分配给不同的团队
-
快速供应
-
在基础设施级别监控应用程序
虚拟机的规模调整
在创建虚拟机时,你选择内存量、虚拟 CPU 数量、存储布局和网络配置——如果需要,之后也可以更改。这些都是软件构造,而非硬件构造,因此更容易更改。在大数据实践中,我们已经看到最低值为 4 vCPUs,对于运行 Hadoop/Spark 类型工作负载的高端虚拟机,一般经验值为 16 vCPUs。虽然能够利用超过 16 vCPUs 的应用程序很少见,但仍然是可行的。例如,这些应用程序的代码高度并行化,并且有大量的并发线程。
虚拟机所需的内存量可以与物理内存一样大,尽管我们看到现代工作负载的配置内存通常为 256Gb 或 512Gb。经典 Hadoop 工作节点的基本操作可以适应 128Gb 内存边界。这些大小将由应用平台架构师决定,但对最终用户、数据科学家和数据工程师来说,了解每台虚拟机适用的约束条件也很重要。根据硬件容量,这些数字可以迅速扩展,以查看在新条件下工作是否更快完成。
将虚拟机放置到服务器上
在某些云环境中,你可以选择将虚拟机适配到主机服务器及其包含的机架上;在其他环境中则不能。如果你被提供了这种选择,你可以做出决策来优化应用程序的性能。例如,在私有云中,你可以选择不对服务器的物理内存或物理 CPU 进行过度分配,即不要将虚拟机的数量或虚拟机资源的配置设得过大。避免这种对物理资源的过度分配通常有助于那些资源密集型的应用程序,如数据分析应用程序的性能。
这里的一个相关问题是,任何一个物理主机服务器上应该有多少个虚拟机。在我们的虚拟化测试工作中,每台服务器上两个到四个适当大小的虚拟机可以作为一个起点得到良好的结果——随着对平台和工作负载经验的增加,这个数字可以进一步增加。在你能够看到服务器硬件类型和配置的情况下,虚拟机的大小应尊重 NUMA 边界,以便从机器上获得最佳的性能。上述提到的虚拟化最佳实践文档在这方面提供了详细的技术建议。
虚拟机中的不同软件角色
在大多数现代分布式数据平台中,软件过程角色被分为“主节点”和“工作节点”。控制过程运行在前者上,而驱动个别任务的执行程序则运行在工作节点上。你为这些不同的角色创建一个模板虚拟机(一个“黄金主机”),然后根据你需要的该角色实例的数量复制或克隆该虚拟机。可能会有一个选项,将分析软件组件本身安装到模板虚拟机中,从而在实例化克隆或集群成员时节省重复安装的时间。这些节点在集群的生命周期中可以通过供应商的管理工具随时进行新的软件服务的自定义。我们也可以以相同的方式从集群中退役某些角色,例如当我们需要更少的工作节点来执行分析工作时。
将计算资源组分配给不同的团队
云虚拟化方法的一个固有价值是硬件资源的池化,这样可以将总 CPU/内存的部分聚合力量分配给特定的目的和团队。虚拟化包括“资源池”的概念,能够保留一定的计算和内存资源用于此目的(跨多个机器)。一个部门的虚拟机集合存在于其资源池的有限空间内,而另一个部门则存在于另一个资源池。这些资源池在物理上可能是相邻的。根据需要,计算资源可以动态分配给一个或另一个。这使得拥有来自不同团队竞争请求的数据科学部门的管理者对资源分配有了更多控制权,取决于每个团队项目工作的需求和相对重要性。
快速供应
为数据科学家创建一组虚拟机当然比提供新的物理机器更快速,从而提高了生产工作的时间。虚拟机集合的进一步扩展和收缩灵活性更为重要。在我们所见的大型分析应用部署中,初期的快速扩展从 20 个节点(虚拟机)迅速增加到一个集群中的 300 多个节点。随着时间的推移和新类型负载的出现,这种大型基础设施可能会收缩,以便在同一硬件集合中容纳新的基础设施,尽管被分隔到不同的资源池中。这种灵活性是虚拟化的功能。以前为各个团队划定的严格所有权边界在这里被打破了。
基础设施级别的应用监控
数据科学家/工程师想知道为什么查询需要这么长时间才能完成。我们对各种类型数据库的历史都非常了解这一现象。SQL 引擎是今天大数据基础设施上最受欢迎的层之一——实际上,几乎每个供应商都有一个。不断需要找到效率低下或结构不良的查询,这些查询占用了系统资源。虚拟机和资源池最初提供了对这些异常查询的隔离。但更进一步,如果云服务提供商允许的话,能够在基础设施级别查看代码的效果提供了有价值的数据,以追踪其影响并优化执行时间。
云基础设施在不断发展
在我们的开场白中,我们提到了公共云、私有云和混合云。对跨这些云类型使用通用基础设施和管理工具有广泛的兴趣。当这些基础元素在私有云和公共云中相同时,应用程序可以根据业务需求的最佳匹配存在于任意云中。实际上,应用程序可以以有序的方式从一个云迁移到另一个云,而无需进行更改。数据科学家/工程师的界限会变得模糊,因为一个特定的分析工作项目可能从公共云中的实验开始,随着其成熟,迁移到私有云以优化其性能。反向迁移也可能发生。2016 年底宣布,完整的 VMware 软件定义数据中心产品组合将在 AWS 上作为服务运行。这种跨私有云和公共云的通用基础设施扩展了数据科学家/数据工程师的灵活性和选择性。VMware Cloud on AWS 上的分析工作负载现在可以以本地方式访问 AWS 上的 S3 存储,在共同的数据中心内,从而降低数据访问的延迟。
在本文中,我们已经看到,对于数据科学家和数据工程师来说,理解虚拟化构造的价值,因为他们将分析部署到各种云平台上。虚拟化是这些数据工作者需要了解的关键使能层,以便获得最佳结果。
大数据/Hadoop 在 VMware vSphere 上的参考资料
部署指南:
-
虚拟化 Hadoop - 部署指南
www.vmware.com/bde 在资源 -> 入门,或更直接地:
www.vmware.com/files/pdf/products/vsphere/Hadoop-Deployment-Guide-USLET.pdf
-
使用 Isilon 存储在 vSphere 上部署虚拟化的 Cloudera CDH - EMC/Isilon 的技术指南
hsk-cdh.readthedocs.org/en/latest/hsk.html#deploy-a-cloudera-hadoop-cluster
或在 community.emc.com/docs/DOC-26892 查找最新版本
-
使用 Isilon 存储在 vSphere 上部署虚拟化的 Hortonworks HDP - EMC/Isilon 的技术指南
hsk-hwx.readthedocs.org/en/latest/hsk.html#deploy-a-hortonworks-hadoop-cluster-with-isilon-for-hdfs
参考架构:
-
Cloudera 参考架构 - Isilon 版本
-
Cloudera 参考架构 – 直接附加存储版本
-
使用 Cisco UCS 和 EMC Isilon 的大数据:构建 60 节点 Hadoop 集群(使用 Cloudera)
-
在 VMware vSphere 上部署 Hortonworks 数据平台 (HDP) – 技术参考架构
案例研究:
-
Adobe 在 VMware vSphere 上部署 Hadoop 作为服务
www.vmware.com/files/pdf/products/vsphere/VMware-vSphere-Adobe-Deploys-HAAS-CS.pdf
-
在大规模基础设施中虚拟化 Hadoop – EMC 技术白皮书
-
Skyscape Cloud Services 在 vSphere 上部署 Hadoop 云服务
-
在 VMware IT 中虚拟化大数据 – 从小规模开始
blogs.vmware.com/vsphere/2015/11/virtualizing-big-data-at-vmware-it-starting-out-at-small-scale.html
性能:
-
vSphere® 6 上的大数据性能 – 优化虚拟化大数据应用的最佳实践(2016 年)
www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/bigdata-perf-vsphere6.pdf
-
使用 VMware vSphere® 6 在高性能服务器上的虚拟化 Hadoop 性能(2015 年)
-
虚拟化的 Hadoop 性能与 VMware vSphere 5.1
www.vmware.com/resources/techresources/10360
上述两篇技术论文中包含了一些非常有用的最佳实践。
-
在 vSphere 5 上虚拟化 Hadoop 性能的基准案例研究
-
事务处理委员会 – TPCx-HS 基准测试结果(Cloudera 在 VMware 上的性能,由 Dell 提交)
-
ESG 实验室评审:VCE vBlock 系统与 EMC Isilon 适用于企业 Hadoop
labs.vmware.com/flings/big-data-extensions-for-vsphere-standard-edition
其他 vSphere 特性与大数据:
-
使用 VMware vSphere 5 故障容错保护 Hadoop
www.vmware.com/files/pdf/techpaper/VMware-vSphere-Hadoop-FT.pdf
-
朝向弹性大象 – 为云环境启用 Hadoop
labs.vmware.com/vmtj/toward-an-elastic-elephant-enabling-hadoop-for-the-cloud
-
Apache Flume 和 Apache Scoop 数据导入到 VMware vSphere 上的 Apache Hadoop 集群
www.vmware.com/files/pdf/products/vsphere/VMware-vSphere-Data-Ingestion-Solution-Guide.pdf
-
Hadoop 虚拟化扩展 (HVE):
www.vmware.com/files/pdf/Hadoop-Virtualization-Extensions-on-VMware-vSphere-5.pdf
VMware 首席技术官与 Cloudera 首席技术官的访谈视频和 Adobe 参考视频:
hwww.youtube.com/playlist?list=PL9MeVsU0uG662xAjTB8XSD83GXSDuDzuk
简介:贾斯廷·穆雷 (@johjustinmurray) 是 VMware 加州帕洛阿尔托的技术营销架构师。他自 2007 年以来在 VMware 从事过各种技术和联盟角色。贾斯廷与 VMware 的客户和现场工程师合作,制定使用虚拟化技术进行大数据的指南和最佳实践。他在各种会议上讲解了这些主题,并在 博客、白皮书及其他材料中发表过文章。
相关:
-
云计算关键术语解释
-
机器学习趋势与人工智能的未来
-
介绍云托管深度学习模型
更多相关内容
数据科学家必备的探索性数据分析指南
原文:
www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html

Bing Image Creator 提供的图像
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
探索性数据分析(EDA)是每个数据科学项目开始时最重要的任务。
本质上,这涉及到彻底检查和描述您的数据,以发现其潜在的特征、可能的异常以及隐藏的模式和关系。
对数据的理解将是指导您机器学习管道接下来的步骤的终极关键,从数据预处理到模型构建以及结果分析。
EDA 的过程基本包括三个主要任务:
-
步骤 1: 数据集概述和描述性统计
-
步骤 2: 特征评估和可视化,以及
-
步骤 3: 数据质量评估
如你所猜测的,每项任务可能需要相当全面的分析,这将让你像疯子一样切片、打印和绘制你的 pandas 数据框。
除非你选择了合适的工具。
在这篇文章中,我们将深入探讨 有效 EDA 过程的每个步骤,并讨论为什么你应该将[ydata-profiling](https://github.com/ydataai/ydata-profiling) 变成你的终极工具来掌握它。
py`` To **demonstrate best practices and investigate insights**, we’ll be using the [Adult Census Income Dataset](https://www.kaggle.com/datasets/uciml/adult-census-income), freely available on Kaggle or UCI Repository (License: [CC0: Public Domain](https://creativecommons.org/publicdomain/zero/1.0/)). # Step 1: Data Overview an Descriptive Statistics When we first get our hands on an unknown dataset, there is an automatic thought that pops up right away: *What am I working with?* ## We need to have a deep understanding of our data to handle it efficiently in future machine learning tasks As a rule of thumb, we traditionally start by characterizing the data relatively to the number of *observations*, number and *types of features*, overall *missing rate*, and percentage of *duplicate* observations. With some pandas manipulation and the right cheatsheet, we could eventually print out the above information with some short snippets of code: Dataset Overview: Adult Census Dataset. Number of observations, features, feature types, duplicated rows, and missing values. Snippet by Author. All in all, the output format is not ideal… If you’re familiar with pandas, you’ll also know the standard *modus operandi* of starting an EDA process — `df.describe()`:  Adult Dataset: Main statistics presented with **df.describe()**. Image by Author. This however, only considers **numeric features**. We could use a `df.describe(include='object')` to print out some additional information on **categorical features** (count, unique, mode, frequency), but a simple check of existing categories would involve something a little more verbose: Dataset Overview: Adult Census Dataset. Printing the existing categories and respective frequencies for each categorical feature in data. Snippet by Author. However, we can do this — *and guess what, all of the subsequent EDA tasks!* — **in a single line of code**, using `[ydata-profiling](https://github.com/ydataai/ydata-profiling):` ```` 成人普查数据集的概况报告,使用 ydata-profiling 生成。摘录作者提供。**上述代码生成了数据的完整概况报告**,我们可以利用这些报告进一步推进我们的 EDA 过程,而无需编写更多代码!接下来,我们将通过报告的各个部分。关于**数据的总体特征**,我们寻找的信息都包含在***概述*部分**中:  ydata-profiling: 数据概况报告 — 数据集概述。图片由作者提供。我们可以看到我们的数据集包含**15 个特征和 32561 个观察值,**,其中**23 条重复记录,以及总体缺失率为 0.9%**。此外,数据集已被正确识别为**表格数据集**,且相当异质,呈现出**数值和分类特征**。对于**时间序列数据**,这类数据具有时间依赖性,并展示出不同类型的模式,`ydata-profiling`会在报告中加入[其他统计数据和分析](https://towardsdatascience.com/how-to-do-an-eda-for-time-series-cbb92b3b1913)。我们可以进一步检查**原始数据和现有的重复记录**,以便对特征有一个整体的了解,然后再进行更复杂的分析:  ydata-profiling: 数据概况报告 — 样本预览。图片由作者提供。**从简要的样本预览**中,我们可以立即看到,尽管数据集总体上缺失数据的比例较低,但**某些特征可能会受到影响**程度较大。我们还可以识别出某些特征具有相当**数量的类别**,以及具有 0 值的特征(或者至少有大量的 0)。  ydata-profiling: 数据概况报告 — 重复行预览。图片由作者提供。**关于重复行**,考虑到大多数特征代表了多个可能“同时符合”的类别,发现“重复”观察值并不奇怪。然而,也许**“数据异味”**可能是这些观察值共享相同的`age`值(这是可以理解的)和完全相同的`fnlwgt`,考虑到所展示的值,这似乎更难以置信。因此需要进一步分析,但我们**很可能会在后续阶段删除这些重复项**。总体而言,数据概述可能是一个简单的分析,但却是**极其重要的**,因为它将帮助我们定义即将到来的任务。# 第 2 步:特征评估和可视化在对整体数据描述进行初步了解后,我们需要**深入分析数据集的特征**,以获取其个别属性的见解 — **单变量分析** — 以及它们的交互和关系 — **多变量分析**。这两个任务都高度依赖于**调查适当的统计数据和可视化**,这些统计数据和可视化需要**针对特征类型**(例如,数值型、分类型)**和我们希望剖析的行为**(例如,交互、相关性)进行定制。## 让我们来看一下每项任务的最佳实践。## 单变量分析分析每个特征的个体特征至关重要,因为它将帮助我们决定其**对分析的相关性**以及**所需的数据准备类型**,以实现最佳结果。例如,我们可能会发现一些极端值,这些值可能指示**不一致性**或**异常值**。我们可能需要对**数值数据**进行**标准化**,或根据现有类别的数量对分类特征进行**独热编码**。或者,我们可能需要执行额外的数据准备,以处理那些**偏移或偏斜**的数值特征,如果我们打算使用的机器学习算法期望特定的分布(通常是高斯分布)。最佳实践因此要求对描述性统计和数据分布等个体属性进行彻底调查。**这些将突出出后续任务的需要,包括异常值移除、标准化、标签编码、数据填充、数据增强和其他类型的预处理。**让我们更详细地研究`race`和`capital.gain`。*我们能立即发现什么?*  ydata-profiling: 数据概况报告(race 和 capital.gain)。图片由作者提供。**对`capital.gain`的评估是直接的:** py Given the data distribution, we might question if the feature adds any value to our analysis, as 91.7% of values are “0”. **Analyzing ****race**** is slightly more complex:** There’s a clear underrepresentation of races other than `White`. This brings two main issues to mind: * One is the general tendency of machine learning algorithms to **overlook less represented concepts**, known as the problem of [small disjuncts](https://towardsdatascience.com/data-quality-issues-that-kill-your-machine-learning-models-961591340b40), that leads to reduced learning performance; * The other is somewhat derivative of this issue: as we’re dealing with a sensitive feature, this “overlooking tendency” may have consequences that directly relate to ***bias* and *fairness* issues**. Something that we definitely don’t want to creep into our models. Taking this into account, maybe we should **consider performing data augmentation** conditioned on the underrepresented categories, as well as considering **fairness-aware metrics for model evaluation**, to check for any discrepancies in performance that relate to `race` values. **We will further detail on other data characteristics that need to be addressed when we discuss data quality best practices (Step 3).** This example just goes to show how much insights we can take just by assessing each individual feature’s *properties*. **Finally, note how, as previously mentioned, different feature types call for different statistics and visualization strategies:** * **Numeric features** most often comprise information regarding mean, standard deviation, skewness, kurtosis, and other quantile statistics, and are best represented using histogram plots; * **Categorical features** are usually described using the mode, median, and frequency tables, and represented using bar plots for category analysis.  ydata-profiling: Profiling Report. Presented statistics and visualizations are adjusted to each feature type. Screencast by Author. Such a detailed analysis would be cumbersome to carry out with general pandas manipulation, but fortunately `ydata-profiling` **has all of this functionality built into the** `ProfileReport` for our convenience: no extra lines of code were added to the snippet! ## Multivariate Analysis For Multivariate Analysis, best practices focus mainly on two strategies: analyzing the **interactions** between features, and analyzing their **correlations**. ## Analyzing Interactions Interactions let us **visually explore how each pair of features behaves**, i.e., how the values of one feature relate to the values of the other. For instance, they may exhibit *positive* or *negative* relationships, depending on whether the increase of one’s values is associated with an increase or decrease of the values of the other, respectively.  ydata-profiling: Profiling Report — Interactions. Image by Author. Taking the interaction between `age` and `hours.per.week`as an example, we can see that the great majority of the working force works a standard of 40 hours. However, there are some “busy bees” that work past that (up until 60 or even 65 hours) between the ages of 30 and 45\. People in their 20’s are less likely to overwork, and may have a more light work schedule on some weeks. ## Analyzing Correlations Similarly to interactions, **correlations let us** **analyze the relationship **between features. Correlations, however, “put a value” on it, so that it is easier for us to determine the “strength” of that relationship. This “strength” is **measured by correlation coefficients** and can be analyzed either numerically (e.g., inspecting a **correlation matrix**) or with a **heatmap**, that uses color and shading to visually highlight interesting patterns:  ydata-profiling: Profiling Report — Heatmap and Correlation Matrix. Screencast by Author. Regarding our dataset, notice how the correlation between `education` and `education.num` stands out. In fact, **they hold the same information**, and `education.num` is just a binning of the `education` values. Other pattern that catches the eye is the the correlation between `sex` and `relationship` although again not very informative: looking at the values of both features, we would realize that these features are most likely related because `male` and `female` will correspond to `husband` and `wife`, respectively. **These type of redundancies may be checked to see whether we may remove some of these features from the analysis** (`marital.status` is also related to `relationship` and `sex`; `native.country` and `race` for instance, among others).  ydata-profiling: Profiling Report — Correlations. Image by Author. **However, there are other correlations that stand out and could be interesting for the purpose of our analysis.** For instance, the correlation between`sex` and `occupation`, or `sex` and `hours.per.week`. **Finally, the correlations between **`income`** and the remaining features are truly informative**, **specially in case we’re trying to map out a classification problem.** Knowing what are the *most correlated* features to our target class helps us identify the* most discriminative* features and well as find possible data leakers that may affect our model. From the heatmap, seems that `marital.status` or `relationship` are amongst the most important predictors, while `fnlwgt` for instance, does not seem to have a great impact on the outcome. **Similarly to data descriptors and visualizations, interactions and correlations also need to attend to the types of features at hand.** In other words, different combinations will be measured with different correlation coefficients. By default, `ydata-profiling` runs correlations on `auto`, which means that: * **Numeric versus Numeric** correlations are measured using [Spearman’s rank](https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient) correlation coefficient; * **Categorical versus Categorical **correlations are measured using [Cramer’s V](https://en.wikipedia.org/wiki/Cram%C3%A9r%27s_V#:~:text=In%20statistics%2C%20Cram%C3%A9r%27s%20V%20(sometimes,by%20Harald%20Cram%C3%A9r%20in%201946.); * **Numeric versus Categorical** correlations also use Cramer’s V, where the numeric feature is first discretized; And if you want to check **other correlation coefficients** (e.g., Pearson’s, Kendall’s, Phi) you can easily [configure the report’s parameters](https://ydata-profiling.ydata.ai/docs/master/pages/advanced_usage/available_settings.html#correlations%0A). # Step 3: Data Quality Evaluation As we navigate towards a *data-centric paradigm* of AI development, being on top of the **possible complicating factors** that arise in our data is essential. With “complicating factors”, we refer to *errors* that may occurs during the data collection of processing, or [*data intrinsic characteristics*](https://towardsdatascience.com/data-quality-issues-that-kill-your-machine-learning-models-961591340b40) that are simply a reflection of the *nature* of the data. These include *missing* data, *imbalanced* data, *constant* values, *duplicates*, highly *correlated* or *redundant* features, *noisy* data, among others.  Data Quality Issues: Errors and Data Intrinsic Charcateristics. Image by Author. Finding these data quality issues at the beginning of a project (and monitoring them continuously during development) is critical. **If they are not identified and addressed prior to the model building stage, they can jeopardize the whole ML pipeline and the subsequent analyses and conclusions that may derive from it.** Without an automated process, the ability to identify and address these issues would be left entirely to the personal experience and expertise of the person conducting the EDA analysis, which is obvious not ideal. *Plus, what a weight to have on one’s shoulders, especially considering high-dimensional datasets. Incoming nightmare alert!* This is one of the most highly appreciated features of `ydata-profiling`, the **automatic generation of data quality alerts**:  ydata-profiling: Profiling Report — Data Quality Alerts. Image by Author. **The profile outputs at least 5 different types of data quality issues**, namely `duplicates`, `high correlation`, `imbalance`, `missing`, and `zeros`. Indeed, we had already identified some of these before, as we went through step 2: `race` is a highly imbalanced feature and `capital.gain` is predominantly populated by 0’s. We’ve also seen the tight correlation between `education` and `education.num`, and `relationship` and `sex`. ## Analyzing Missing Data Patterns Among the comprehensive scope of alerts considered, `ydata-profiling` is especially helpful in **analyzing missing data patterns**. Since missing data is a very common problem in real-world domains and may compromise the application of some classifiers altogether or severely bias their predictions, **another best practice is to carefully analyze the missing data **percentage and behavior that our features may display:  ydata-profiling: Profiling Report — Analyzing Missing Values. Screencast by Author. From the data alerts section, we already knew that `workclass`, `occupation`, and `native.country` had absent observations.** The heatmap further tells us that there is a direct relationship with the missing pattern** in `occupation` and `workclass`: when there’s a missing value in one feature, the other will also be missing. ## Key Insight: Data Profiling goes beyond EDA! So far, we’ve been discussing the tasks that make up a thorough EDA process and how **the assessment of data quality issues and characteristics **— **a process we can refer to as Data Profiling** — is definitely a best practice. Yet, it is important do clarify that [**data profiling**](https://towardsdatascience.com/awesome-data-science-tools-to-master-in-2023-data-profiling-edition-29d29310f779)** goes beyond EDA. **Whereas we generally define EDA as the exploratory, interactive step before developing any type of data pipeline, **data profiling is an iterative process that **[**should occur at every step**](https://medium.com/towards-artificial-intelligence/how-to-compare-2-dataset-with-pandas-profiling-2ae3a9d7695e)** of data preprocessing and model building.** # Conclusions **An efficient EDA lays the foundation of a successful machine learning pipeline.** It’s like running a diagnosis on your data, learning everything you need to know about what it entails — its *properties*, *relationships*, *issues* — so that you can later address them in the best way possible. **It’s also the start of our inspiration phase: it’s from EDA that questions and hypotheses start arising, and analysis are planned to validate or reject them along the way.** Throughout the article, we’ve covered **the 3 main fundamental steps that will guide you through an effective EDA,** and discussed the impact of having a top-notch tool — `ydata-profiling` — to point us in the right direction, and **save us a tremendous amount of time and mental burden.** **I hope this guide will help you master the art of “playing data detective”** and as always, feedback, questions, and suggestions are much appreciated. Let me know what other topics would like me to write about, or better yet, come meet me at the [Data-Centric AI Community](https://discord.gg/W2wBzyMvU2) and let’s collaborate! **[Miriam Santos](https://www.linkedin.com/in/miriamseoanesantos/)** focus on educating the Data Science & Machine Learning Communities on how to move from raw, dirty, "bad" or imperfect data to smart, intelligent, high-quality data, enabling machine learning classifiers to draw accurate and reliable inferences across several industries (Fintech, Healthcare & Pharma, Telecomm, and Retail). [Original](https://medium.com/towards-data-science/a-data-scientists-essential-guide-to-exploratory-data-analysis-25637eee0cf6). Reposted with permission. ### More On This Topic * [Collection of Guides on Mastering SQL, Python, Data Cleaning, Data…](https://www.kdnuggets.com/collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis) * [Exploratory Data Analysis Techniques for Unstructured Data](https://www.kdnuggets.com/2023/05/exploratory-data-analysis-techniques-unstructured-data.html) * [7 Steps to Mastering Exploratory Data Analysis](https://www.kdnuggets.com/7-steps-to-mastering-exploratory-data-analysis) * [A Comprehensive Guide to Essential Tools for Data Analysts](https://www.kdnuggets.com/a-comprehensive-guide-to-essential-tools-for-data-analysts) * [Essential Machine Learning Algorithms: A Beginner's Guide](https://www.kdnuggets.com/2021/05/essential-machine-learning-algorithms-beginners.html) * [The Essential Guide to SQL’s Execution Order](https://www.kdnuggets.com/the-essential-guide-to-sql-execution-order) py` `````
数据科学家的认知偏见指南:免费电子书
原文:
www.kdnuggets.com/2023/05/data-scientist-guide-cognitive-biases-free-ebook.html
如果你有兴趣探讨认知偏见的主题,并深入了解这些偏见如何影响你的日常生活以及作为数据科学家的实践,那么免费的电子书《清晰思考:数据科学家理解认知偏见的指南](https://datasciencehorizons.com/thinking-clearly-data-scientist-guide-understanding-cognitive-biases/)可能是一个很好的资源。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
数据科学地平线最新提供的这本电子书涵盖了多个著名的偏见,提供了它们如何干扰日常逻辑推理的概述,管理这些偏见和减轻其影响的方法,以及与数据科学实践相关的具体问题。
来源于数据科学地平线:
认知偏见是可以影响我们思维、决策和判断的心理捷径,常常导致错误或误解。作为数据科学家,我们也难以避免这些偏见,它们可能影响我们工作的质量和从数据中获得的见解。这本全面的电子书探讨了各种认知偏见,并提供了实用策略,帮助你识别和克服这些偏见对数据科学工作产生的影响。
这里仅是本书中涵盖的偏见的一个小预览:
了解确认偏见如何导致挑选数据并强化已有信念,发现抵消这种偏见的策略。
探索自利偏见及其对自我评估和人际互动的影响,并学习如何更平衡地理解你的经历和个人成长。
理解光环效应及其对感知和判断的后果,并发现减少其对评估影响的方法。
深入研究群体思维及其在决策和问题解决中的危险,揭示预防和应对其影响的策略。
揭示负面偏见及其对情感健康和决策的影响,并学习在数据科学工作中管理和克服这种偏见的技巧。
认知偏见无处不在。你有,我有,我们都有。减少这些偏见对我们逻辑思维干扰的关键在于能够识别它们,并制定策略来保持其影响。这个免费资源旨在帮助你做到这一点。
现在下载 清晰思考:数据科学家的认知偏见理解指南,你的事后偏见最终会告诉你这是绝对正确的决定 😃
马修·梅奥 (@mattmayo13) 是数据科学家和 KDnuggets 的主编,这是一份开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关内容
数据科学家的 Python 高效编码指南
原文:
www.kdnuggets.com/2021/08/data-scientist-guide-efficient-coding-python.html
评论
由Dr. Varshita Sher,数据科学家
在这篇文章中,我想分享一些我在过去一年中从配对编程中吸收的编写更清晰代码的技巧。一般来说,将它们作为我日常编码例程的一部分,帮助我生成了高质量的 Python 脚本,这些脚本随着时间的推移容易维护和扩展。
有没有想过为什么高级开发者的代码看起来比初级开发者的代码好得多?继续阅读,来弥合这个差距……
我将提供实际的编码场景来说明如何使用这些技巧,而不是给出通用的示例!这是一个Jupyter Colab Notebook,如果你想跟着一起操作!
1. 在处理for循环时使用tqdm。
想象一下遍历一个大型的可迭代对象(列表、字典、元组、集合),却不知道代码是否已经运行完成!真糟糕,对吧!在这种情况下,请确保使用tqdm构造来显示进度条。
例如,在我读取存在于 44 个不同目录中的所有文件时(这些路径已经存储在名为fpaths的列表中),以显示进度:
from tqdm import tqdmfiles = list()
fpaths = ["dir1/subdir1", "dir2/subdir3", ......]
for fpath in tqdm(fpaths, desc="Looping over fpaths")):
files.extend(os.listdir(fpath))

使用 tqdm 与 “for” 循环
注意:使用*desc*参数来为循环指定一个简短的描述。
2. 在编写函数时使用类型提示。
简单来说,就是在 Python 函数定义中明确声明所有参数的类型。
我希望有具体的用例来强调何时使用类型提示,但事实是,我经常使用它们。
这是一个假设的函数update_df()示例。它通过附加一行包含来自模拟运行的有用信息(例如使用的分类器、得分的准确率、训练-测试分割大小以及该特定运行的额外备注)的数据帧来更新给定的数据帧。
def update_df(**df: pd.DataFrame**,
**clf: str**,
**acc: float**,
**remarks: List[str] = []**
**split:float** = 0.5) -> **pd.DataFrame**:
new_row = {'Classifier':clf,
'Accuracy':acc,
'split_size':split,
'Remarks':remarks}
df = df.append(new_row, ignore_index=True)
return df

几点需要注意:
-
函数定义中的
->符号后面的数据类型(def update_df(.......) **->** pd.DataFrame)表示函数返回值的类型,即在这种情况下是 Pandas 的数据框。 -
如果有默认值,可以像往常一样以
param:type = value的形式指定。(例如:split: float = 0.5) -
如果一个函数没有返回任何内容,可以自由使用
None。例如:def func(a: str, b: int) -> None: print(a,b) -
要返回混合类型的值,例如,假设一个函数可以在标志
option设置时打印语句,或者在标志未设置时返回一个int:
from typing import Union
def dummy_args(*args: list[int], option = True) -> Union[None, int]:
if option:
print(args)
else:
return 10
注意:从 Python 3.10 开始,*Union** 不再是必需的,因此你可以直接这样做:*
def dummy_args(*args: list[int], option = True) -> None | int:
if option:
print(args)
else:
return 10
-
在定义参数类型时,你可以尽可能具体,就像我们对
remarks: List[str]所做的那样。我们不仅指定它应该是一个List,而且它应该仅仅是str类型的列表。为了好玩,尝试在调用函数时传递一个整数列表到
remarks。你会看到没有错误返回!为什么会这样? 因为 Python 解释器不会根据你的类型提示执行任何类型检查。
尽管如此,包含它仍然是一个好的实践!我觉得它在编写函数时能带来更多的清晰度。此外,当有人调用这样的函数时,他们会看到输入参数的清晰提示。

带类型提示的函数调用提示
3. 使用 args 和 kwargs 处理参数数量未知的函数。
想象一下:你想写一个函数,接收 一些 目录路径,并打印每个目录中的文件数量。问题是,我们不知道用户会输入 多少 个路径!可能是 2 个,也可能是 20 个!所以我们不确定应该在函数定义中定义多少个参数。显然,写一个像 def count_files(file1, file2, file3, …..file20) 这样的函数会很傻。在这种情况下,args 和(有时 kwargs)非常有用!
Args 用于指定未知数量的 位置 参数。
Kwargs 用于指定未知数量的 关键字 参数。
Args
这是一个函数 count_files_in_dir() 的示例,它接收 project_root_dir 和一个任意数量的文件夹路径(在函数定义中使用 *fpaths)。作为输出,它会打印每个这些文件夹中的文件数量。
def count_files_in_dir(project_root_dir, *fpaths: str):
for path in fpaths:
rel_path = os.path.join(project_root_dir, path)
print(path, ":", len(os.listdir(rel_path)))

计算 Google Colab 目录中的文件数量
在函数调用中,我们传入了 5 个参数。由于函数定义期望一个 必需 的位置参数,即 project_root_dir,它会自动知道 "../usr" 必须是这个参数。其余的参数(在这个例子中是四个)都被 *fpaths 吸收,用于计算文件数量。
注意:这种吸收技术的正确术语是“参数打包”,即剩余参数被打包成 **fpaths*。
Kwargs
让我们来看一下必须接收未知数量的 关键字 参数的函数。在这种情况下,我们必须使用 kwargs 而不是 args。以下是一个简短的(无用的)示例:
def print_results(**results):
for key, val in results.items():
print(key, val)

使用方式与*args非常相似,但现在我们能够将任意数量的关键字参数传递给函数。这些参数作为键值对存储在**results字典中。从这里开始,可以使用.items()轻松访问字典中的项。
我在工作中发现了kwargs的两个主要应用:
- 合并字典(有用但较少有趣)
dict1 = {'a':2 , 'b': 20}
dict2 = {'c':15 , 'd': 40}
merged_dict = {**dict1, **dict2}
*************************
{'a': 2, 'b': 20, 'c': 15, 'd': 40}
- 扩展现有方法(更有趣)
def myfunc(a, b, flag, **kwargs):
if flag:
a, b = do_some_computation(a,b)
actual_function(a,b, **kwargs)
注意:查看matplotlib 的绘图函数使用[*kwargs*](https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.plot.html#matplotlib-pyplot-plot)* 来指定图表的可选修饰,如线宽和标签。*
这里有一个实际使用**kwargs扩展方法的案例,来自我最近的一个项目:
我们通常使用 Sklearn 的train_test_split()来拆分X和y。在处理其中一个 GAN 项目时,我需要将生成的合成图像拆分为与拆分真实图像及其相应标签所用的相同的训练测试集。此外,我还希望能够传递任何其他通常传递给train_test_split()的参数。最后,stratify必须始终传递,因为我在处理人脸识别问题(并希望所有标签都在训练集和测试集中存在)。
为此,我们创建了一个名为custom_train_test_split()的函数。我包含了一些打印语句来展示内部发生的情况(并省略了一些片段以简化说明)。
def custom_train_test_split(clf, y, *X, stratify, **split_args): *print("Classifier used: ", classifier)
print("Keys:", split_args.keys())
print("Values: ", split_args.values())
print(X)
print(y)
print("Length of passed keyword arguments: ", len(split_args))*
trainx,testx,*synthetic,trainy,testy = train_test_split(
*X,
y,
stratify=stratify,
**split_args
) *######### OMITTED CODE SNIPPET #############
# Train classifier on train and synthetic ims
# Calculate accuracy on testx, testy
############################################*
*print("trainx: ", trainx, "trainy: ",trainy, '\n', "testx: ",
testx, "testy:", testy)* *print("synthetic: ", *synthetic)*
注意:在调用此函数时,为了便于理解,我使用了虚拟数据替换了实际的图像向量和标签(见下图)。不过,代码同样适用于真实图像!

图 A 使用函数定义中的 kwargs 调用函数
注意事项:
-
在函数调用语句中使用的所有关键字参数(除了
stratify),将作为键值对存储在**split_args字典中。(要验证,请查看蓝色输出。)你可能会问为什么不使用
stratify?这是因为根据函数定义,它是一个必需的仅限关键字参数,而不是一个可选的参数。 -
所有非关键字(即位置)参数(如
"SVM"、labels等)在函数调用中会存储在函数定义中的前三个参数,即clf、y和*X(是的,传递的顺序很重要)。然而,在函数调用中我们有四个参数,即"SVM"、labels、ims和synthetic_ims。那第四个参数该存储在哪里?记住我们在函数定义中使用了
*X作为第三个参数,因此传递给函数的所有参数在前两个参数之后都被打包(浸泡)到*X中。(要验证,请检查绿色输出)。 -
当在我们的函数中调用
train_test_split()方法时,我们实际上是在使用*运算符解包X和split_args参数(*X和**split_args),以便将所有元素作为不同的参数传递。
也就是说,
train_test_split(*X, y, stratify = stratify, **split_args)
相当于写
train_test_split(ims, synthetic_ims, y, stratify = stratify, train_size = 0.6, random_state = 50)
- 当存储
train_test_split()方法的结果时,我们再次打包synthetic_train和synthetic_test集合到一个单独的*synthetic变量中。

要检查里面有什么,我们可以使用*运算符再次解包它(见粉色输出)。
注意:如果你想深入了解使用***运算符进行打包和解包,请查看这篇文章。
4. 使用预提交 hooks。
我们编写的代码通常很凌乱,缺乏适当的格式,比如尾随空格、尾随逗号、未排序的导入语句、缩进中的空格等。
虽然可以手动修复所有这些问题,但使用pre-commit hooks可以节省你大量的时间。简单来说,这些 hooks 可以通过一行命令进行自动格式化——pre-commit run。
这里有一些来自官方文档的简单步骤来开始并创建一个[.pre-commit-config.yaml](https://pre-commit.com/index.html#2-add-a-pre-commit-configuration)文件。它将包含你关心的所有格式化问题的hooks!
作为纯个人偏好,我倾向于保持我的.pre-commit-config.yaml配置文件简单,并使用Black 的预提交配置。
注意:需要记住的一点是,文件必须被暂存,即在执行*pre-commit run*之前使用*git add .*,否则你会看到所有文件都会被跳过:
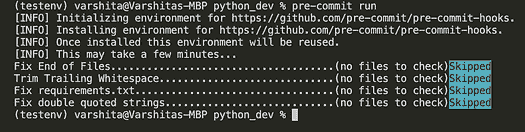
5. 使用.yml 配置文件来存储常量。
如果你的项目包含大量配置变量,例如数据库主机名、密码、AWS 凭证等,请使用.yml文件来跟踪所有这些变量。你可以在任何 Jupyter Notebook 或你希望的脚本中使用这个文件。
由于我大部分工作是为客户提供模型框架,以便他们可以在自己的数据集上重新训练它,我通常使用配置文件来存储文件夹和文件的路径。这也是确保客户在运行你的脚本时只需更改一个文件的好方法。
让我们在项目目录中创建一个fpaths.yml文件。我们将存储需要存放图像的根目录。此外,还会存储文件名、标签、属性等的路径。最后,我们还存储合成图像的路径。
image_data_dir: path/to/img/dir *# the following paths are relative to images_data_dir*
fnames:
fnames_fname: fnames.txt
fnames_label: labels.txt
fnames_attr: attr.txt
synthetic:
edit_method: interface_edits
expression: smile.pkl
pose: pose.pkl
你可以像这样阅读这个文件:
# open the yml file
with open(CONFIG_FPATH) as f:
dictionary = yaml.safe_load(f)
# print elements in dictionary
for key, value in dictionary.items():
print(key + " : " + str(value))
print()
注意:如果你想深入了解,这里有一个精彩的 教程 来帮助你入门 yaml。
6. 奖励:有用的 VS-Code 扩展
虽然确实有很多不错的 Python 编辑器,但我必须说 VSCode 是我见过的最好的 (对不起,Pycharm)。为了更好地利用它,考虑从市场中安装这些扩展:
- 括号配对着色器——允许用颜色识别匹配的括号。
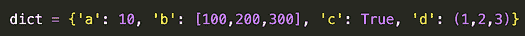
- 路径智能感知——允许自动补全文件名。
- Python Docstring 生成器——允许为 Python 函数生成 docstring。
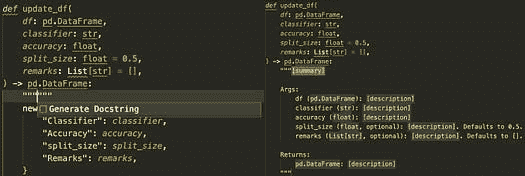
使用 VSCode 扩展生成 docstring
技巧:使用*"""** 在你编写了函数并使用了类型提示之后生成 docstring。这样生成的 docstring 将包含更多信息,如默认值、参数类型等(见上图右侧)。*
- Python Indent——(我最喜欢的;由 Kevin Rose 发布) 允许对多行代码/括号进行正确的缩进。
来源:VSCode 扩展市场
- Python 类型提示——允许在编写函数时自动补全类型提示。
- TODO tree:(第二喜欢) 追踪在编写脚本时插入的所有
TODO。
追踪项目中插入的所有 TODO 注释
- Pylance——允许代码自动补全、参数建议(还有很多其他功能,能更快地编写代码)。
恭喜你离成为专业 Python 开发者更近了一步。我打算在学习到更多有趣的技巧时更新这篇文章。如有更简单的方法完成本文提到的某些任务,请随时告知我。
下次再见 😃
数据科学面试中逐步解释你的 ML 项目的指南。
面试官最喜欢的问题 - 你会如何“扩展你的 ML 模型”?
使用 Pandas 进行时间序列分析
Podurama: 播客播放器
阅读 Varshita Sher 博士的每一篇故事(以及 Medium 上其他成千上万的作者的故事)
简介:Varshita Sher 博士 是艾伦·图灵研究所的数据科学家,同时也是牛津大学和 SFU 校友。
原文. 已获得授权转载。
相关:
-
编写干净 R 代码的 5 个技巧
-
Python 数据结构比较
-
GitHub Copilot 开源替代品
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
数据科学家 Docker 入门指南
原文:
www.kdnuggets.com/2018/08/data-scientist-guide-getting-started-docker.html
评论
介绍
Docker 是一个日益流行的工具,旨在简化在容器中创建、部署和运行应用程序的过程。容器非常有用,因为它们允许开发人员将应用程序及其所需的所有组件(如库和其他依赖项)打包在一起,并作为一个整体进行分发。虽然软件工程师经常使用 Docker,但数据科学家如何开始使用这个强大的工具呢?在我们进入入门指南之前,让我们先讨论一些你可能想要在数据科学中使用 Docker 的原因。
为什么选择 Docker?
可重复性
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT 需求
Docker 最大的吸引力之一是其可重复性。除了共享 Docker 镜像本身,你理论上还可以共享一个 Python 脚本,将结果嵌入 Docker 中。然后,某位同事可以运行这个脚本,亲自查看 Docker 镜像中的内容。
时间
你可以节省大量时间,因为你不必安装单独的包,因为它们都包含在 Docker 镜像中。此外,Docker 容器启动时间约为 50 毫秒,比运行传统虚拟机要快得多。
灵活性
这是一个非常灵活的工具,因为你可以快速运行 Docker 库中创建的任何软件。
构建环境
Docker 对于在将构建环境托管到实际服务器之前进行测试非常有用。你可以将 Docker 容器配置成与服务器的环境相同,从而简化测试过程。
分发
数据科学家可能会花费数小时来准备机器以适应特定的框架。例如,设置一个 Caffe 环境有 30 多种独特的方法。Docker 提供了一个一致的平台来共享这些工具,从而减少了寻找特定操作系统安装程序和库的时间浪费。
可访问性
Docker 生态系统——docker compose 和 docker machine——使其对任何人都容易访问。这意味着公司中不熟悉内部代码的成员仍然可以运行它。非常适合销售团队成员或高层管理人员展示你正在构建的新数据科学应用!
入门指南
希望我们已经向你展示了使用 Docker 的好处,现在是时候开始了。首先,你需要前往 Docker 网站安装软件的一个版本。
为了确保它已正确安装,打开命令行并输入 docker version。这应该显示如下内容:

现在我们已经安装了 Docker,让我们研究一个相对简单、常见的示例:
docker run -p 8000:8000 jupyter/notebook
对于刚接触 Docker 的人来说,这看起来可能有点吓人,所以让我们来拆解一下:
docker run——这个命令找到镜像(在这个示例中是 jupyter notebook),加载一个容器,然后在该容器中运行一个命令。
-p 8000:8000——‘p’关键字代表端口,因此这部分命令是打开主机和容器之间的端口,格式为 -p <host_port>:<container_port>。
jupyter/notebook——要加载的镜像。除了 Jupyter notebook,你还可以浏览官方的Docker 库,查找数千种最受欢迎的软件工具。
一旦你运行了这个命令并导航到 localhost:8000/,你应该会看到以下内容:

非常简单,对吧?考虑到你通常需要下载 Python、运行时库和 Jupyter 包,通过 Docker 运行这些是极其高效的。
好了,现在已经启动运行了,让我们深入了解如何在主机和容器之间共享 Jupyter 笔记本。首先,我们需要在主机上创建一个目录来存储笔记本,我们称之为 /jupyter-notebooks。运行 Docker 命令时共享目录与端口的工作方式类似,我们需要添加以下内容:
-v ~/jupyter-notebooks:/home/joyvan jupyter/notebook
所以,我们在这里做的是将 <host_directory>:<container_directory> 进行映射(例如,将主机上的 ~/jupyter-notebooks 映射到容器上的 /home/joyvan)。这个容器目录来自 Jupyter Docker 文档,是此类镜像指定的工作目录。
将其与之前运行的命令结合起来,完整的命令应该是这样的:
docker run -p 8000 :8000 -v ~/jupyter-notebooks:/home/joyvan jupyter/notebook
现在简单地启动本地主机服务器,创建一个新的笔记本,并将其从“未命名”重命名为“示例笔记本”。最后,检查你本地机器上的 ~/jupyter-notebooks 目录,你应该会看到:Example Notebook.ipynb。瞧!
Dockerfile
Dockerfile 是一个文本文件,其中包含用于自动创建 Docker 镜像的命令。这是一种有效的方式来保存 Docker 命令并通过 Docker build /path/to/dockerfile 命令按顺序执行它们。
我们的 Jupyter notebook 示例的 Dockerfile 如下所示:
FROM ubuntu:latest
RUN apt-get update && apt-get install -y python3 \ python3-pip
RUN pip3 install jupyter
WORKDIR /home/jupyter
COPY /src/jupyter ./
EXPOSE 8000
ENTRYPOINT ["jupyter", "notebook", "--ip=*"]
现在,让我们讨论每一部分:
FROM ubuntu:latest
这告诉 Docker 新镜像的基础应该是什么,在这个例子中是 ubuntu。:latest 只是抓取最新版本。如果你想测试旧版本,可以输入版本号。
RUN apt-get update && apt-get install -y python3 \ python3-pip
这一行确保系统是最新的,然后安装 python3 和 pip3。
RUN pip3 install jupyter
这会安装 Jupyter。
WORKDIR /home/jupyter
COPY /src/jupyter ./
设置 Docker 镜像容器的工作目录,然后从本地主机复制所需的文件。
EXPOSE 8000
类似于之前的 -p,这会暴露 8000 端口。
ENTRYPOINT ["jupyter", "notebook", "--ip=*"]
启动 Jupyter notebook。
Dockerfile 非常有用,因为它们允许其他团队成员轻松运行 Docker 容器。
结论
正如你所看到的,我们成功地让 Docker 在数据科学中快速运行了一个工作用例。我们只是触及了你可以做的事情的表面,但得益于 Docker 的出色库,可能性是无穷的!掌握 Docker 不仅可以帮助你进行本地开发,还能在与数据科学团队合作时节省大量时间、金钱和精力。请继续关注 KDnuggets,我们很快将发布一篇 Docker 备忘单文章。
相关:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号