KDNuggets-博客中文翻译-十二-
KDNuggets 博客中文翻译(十二)
原文:KDNuggets
使用 CountVectorizer 将文本文件转换为令牌计数
原文:
www.kdnuggets.com/2022/10/converting-text-documents-token-counts-countvectorizer.html
我们每天都在与机器互动——无论是询问“OK Google,设置早上 6 点的闹钟”还是“Alexa,播放我喜欢的播放列表”。但这些机器并不理解自然语言。那么当我们与设备交谈时会发生什么?它需要将语音即文本转换为数字,以便处理信息并学习上下文。在这篇文章中,你将学习一种使用 CountVectorizer 将语言转换为数字的流行工具。Scikit-learn 的 CountVectorizer 用于将文本语料库重新转换并预处理为令牌计数向量表示。

我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
它是如何工作的?
我们以一本流行儿童书的书名为例来说明 CountVectorizer 是如何工作的。
text = ["Brown Bear, Brown Bear, What do you see?"]
向量中有六个独特的词,因此向量表示的长度为六。该向量表示每个令牌/词在文本中的出现频率。

让我们添加另一个文档到我们的语料库中,以观察结果矩阵的维度如何增加。
text = ["Brown Bear, Brown Bear, What do you see?", “I love you to the moon and back”]
CountVectorizer 将生成以下输出,通过添加一个文档,矩阵从 1 X 6 变为 2 X 13。

矩阵中的每一列表示由语料库中的所有令牌组成的字典中的唯一令牌(单词),而每一行表示一个文档。上述示例有两个书名,即由两行表示的文档,每个单元格包含一个值,标识文档中对应的单词计数。由于这种表示方式,某些单元格在对应文档中令牌缺失时会有零值。
值得注意的是,随着语料库规模的增加,将巨大的矩阵存储在内存中变得不可管理。因此,CountVectorizer 将它们存储为稀疏矩阵,这是一种压缩形式的完整矩阵。
实操!
让我们选择《哈利·波特》系列的八部电影和一部《印第安纳·琼斯》电影进行演示。这将帮助我们了解 CountVectorizer 的一些重要属性。
首先导入 Pandas 库和来自 Sklearn > feature_extraction > text 的 CountVectorizer。
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
将文档声明为字符串列表。
text = [
"Harry Potter and the Philosopher's Stone",
"Harry Potter and the Chamber of Secrets",
"Harry Potter and the Prisoner of Azkaban",
"Harry Potter and the Goblet of Fire",
"Harry Potter and the Order of the Phoenix",
"Indiana Jones and the Raiders of the Lost Ark",
"Harry Potter and the Half-Blood Prince",
"Harry Potter and the Deathly Hallows - Part 1",
"Harry Potter and the Deathly Hallows - Part 2"
]
向量化
初始化 CountVectorizer 对象时设置 lowercase=True(默认值)以将所有文档/字符串转换为小写。接下来,调用 fit_transform 并将文档列表作为参数传递,然后将列和行名称添加到数据框中。
count_vector = CountVectorizer(lowercase = True)
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
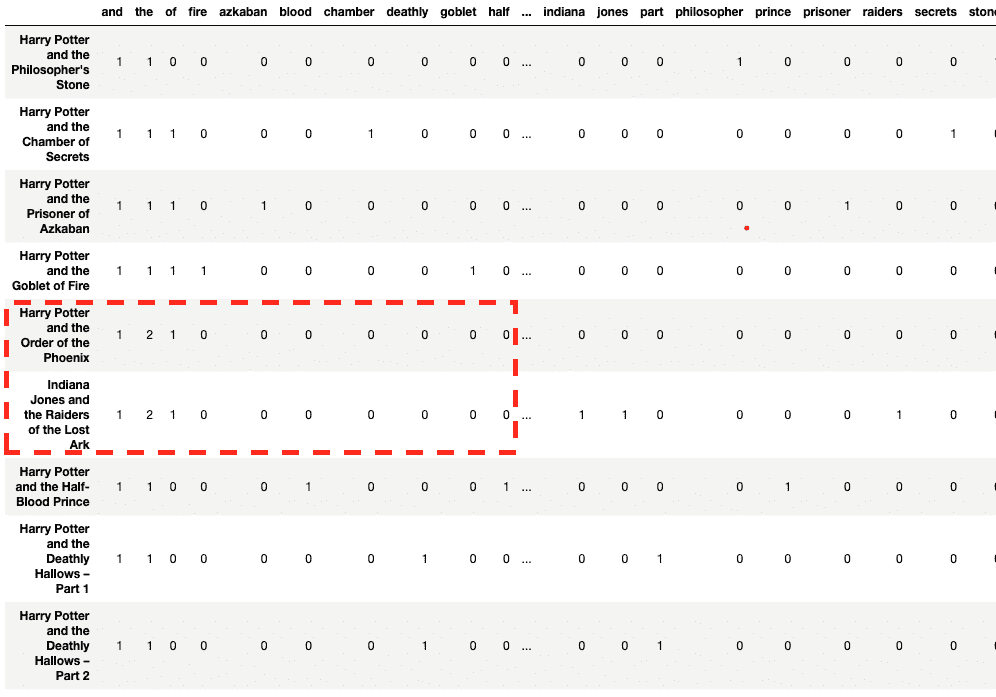
df
好消息!文档已转换为数字。但仔细观察会发现,“哈利·波特与凤凰令”与“印第安纳·琼斯与失落的圣杯”相比,与其他哈利·波特电影相似——至少在初步观察时是这样。
你一定在想像 ‘and’、‘the’ 和 ‘of’ 这样的令牌是否对我们的特征集添加了任何信息。这引导我们到下一步,即去除停用词。
stop_words
像 ‘and’、‘the’ 和 ‘of’ 这样的无用令牌称为停用词。去除停用词很重要,因为它们会影响文档的相似性,并不必要地扩展列的维度。
参数 ‘stop_words’ 删除这些预先识别的停用词——指定 ‘english’ 会删除特定于英语的停用词。你还可以显式添加一个停用词列表,即 stop_words = [‘and’, ‘of’, ‘the’]。
count_vector = CountVectorizer(lowercase = True, stop_words =
'english')
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
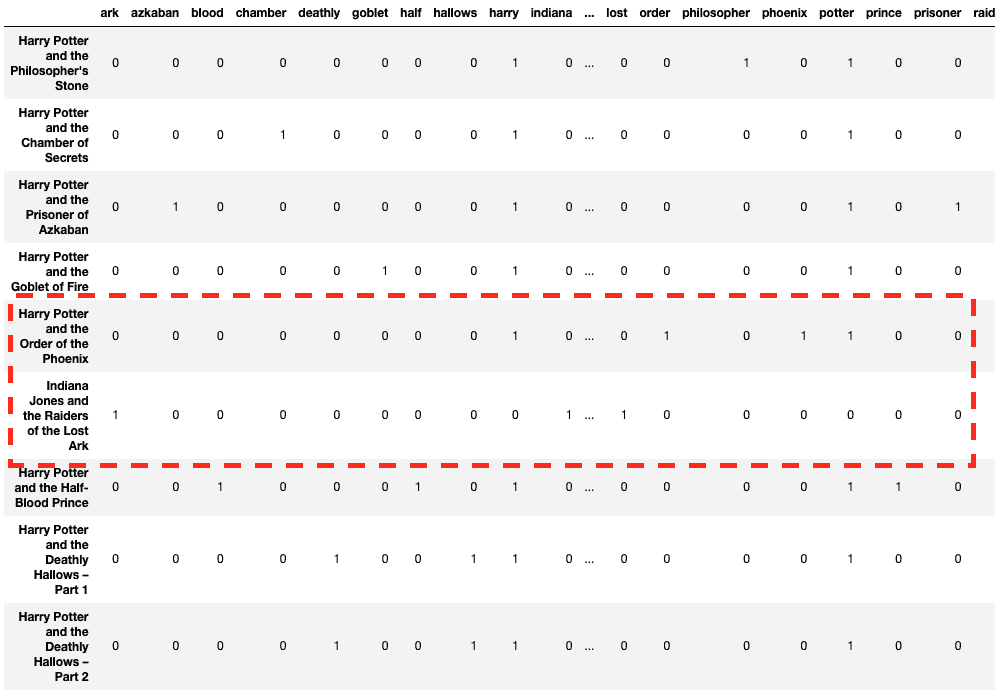
df
看起来更好!现在行向量看起来更有意义。
max_df
像 “Harry” 和 “Potter” 这样的单词不是“停用词”,但它们相当常见,对 Count Matrix 添加的信息很少。因此,你可以添加 max_df 参数来将重复的单词作为特征进行处理。
count_vector = CountVectorizer(lowercase = True, max_df = 0.2)
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
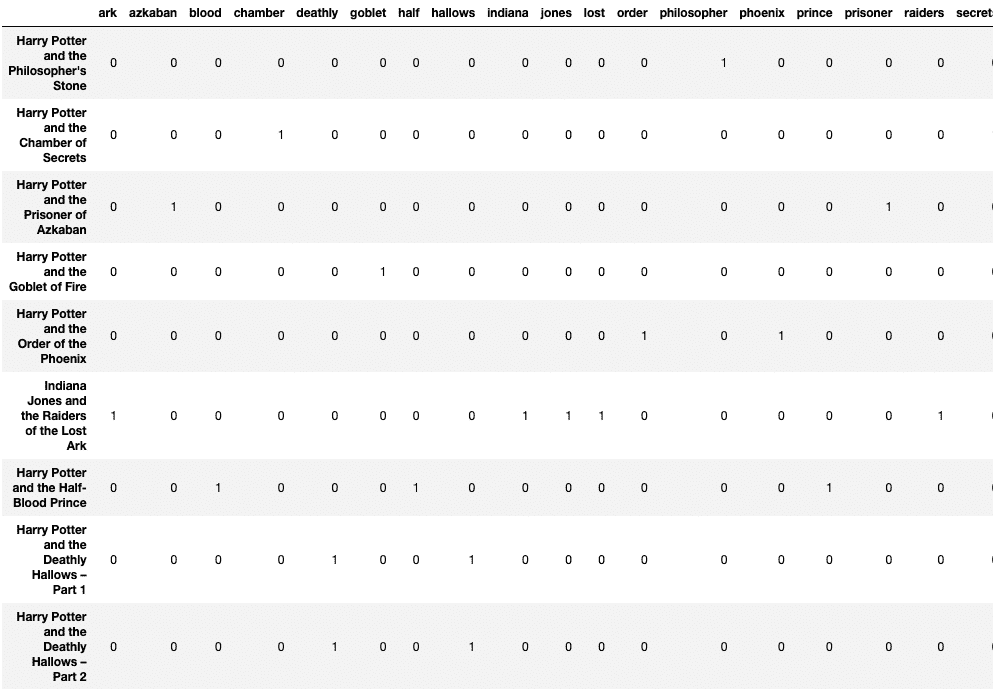
df
以下输出演示了停用词以及“harry”和“potter”从列中被删除:
min_df
它正好与 max_df 相反,表示应具有特定特征的最小文档数量(或比例和百分比)。
count_vector = CountVectorizer(lowercase = True, min_df = 2)
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
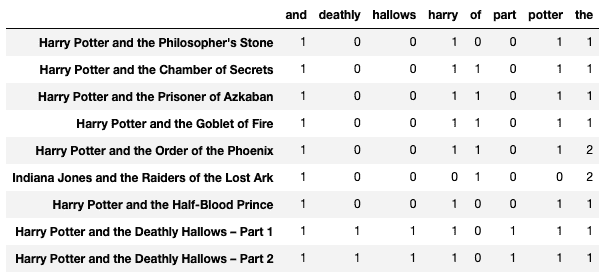
df
以下列(单词)在至少两个文档中出现。
max_features
它代表最常出现的特征/单词/列。
count_vector = CountVectorizer(lowercase = True, max_features = 4)
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
df
选择了下列四个最常出现的单词。
binary
binary 参数将文档中所有正出现的单词替换为‘1’。它表示单词或令牌的存在与否,而不是频率,并且在情感分析或产品评论等分析中非常有用。
count_vector = CountVectorizer(lowercase = True, binary = True,
max_features = 4)
count_vektor = count_vector.fit_transform(text)
count_vektor = count_vektor.toarray()
df = pd.DataFrame(data = count_vektor, columns = count_vector.get_feature_names())
df.index = text
df
与先前的输出进行比较后,名为“the”的列的频率表在下方结果中被限制为‘1’:

vocabulary_
它返回列的位置,并用于将算法结果映射到可解释的单词。
count_vector = CountVectorizer(lowercase = True)
count_vector.fit_transform(text)
count_vector.vocabulary_
上述代码的输出如下所示。
{
'harry': 10,
'potter': 19,
'and': 0,
'the': 25,
'philosopher': 17,
'stone': 24,
'chamber': 4,
'of': 14,
'secrets': 23,
'prisoner': 21,
'azkaban': 2,
'goblet': 7,
'fire': 6,
'order': 15,
'phoenix': 18,
'indiana': 11,
'jones': 12,
'raiders': 22,
'lost': 13,
'ark': 1,
'half': 8,
'blood': 3,
'prince': 20,
'deathly': 5,
'hallows': 9,
'part': 16
}
摘要
本教程讨论了文本预处理的重要性,即将其矢量化作为机器学习算法的输入。文章还展示了 sklearn 实现 CountVectorizer 的各种输入参数在一小组文档上的应用。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交汇点上工作,以提供业务价值和见解。她倡导以数据为中心的科学,是数据治理领域的领先专家,致力于构建值得信赖的 AI 解决方案。
相关主题
乳腺癌分类的卷积神经网络
原文:
www.kdnuggets.com/2019/10/convolutional-neural-network-breast-cancer-classification.html
评论
乳腺癌是全球女性和男性中第二常见的癌症。在 2012 年,它占所有新癌症病例的约 12%,以及所有女性癌症的 25%。
乳腺癌开始于乳房中的细胞失控生长。这些细胞通常形成肿瘤,肿瘤通常可以通过 X 光看到或触摸到。肿瘤是恶性的(癌症),如果细胞能生长到(侵入)周围组织或扩散(转移)到身体的远处区域。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
这里是一些快速事实:
-
美国约 1/8 的女性(约 12%)将在其一生中发展为侵袭性乳腺癌。
-
2019 年,预计美国将诊断出 268,600 例侵袭性乳腺癌新病例,以及 62,930 例非侵袭性(原位)乳腺癌新病例。
-
大约 85%的乳腺癌发生在没有乳腺癌家族史的女性身上。这些癌症通常是由于衰老过程和生活中的遗传突变,而不是遗传突变。
-
如果一名女性有一位一度亲属(母亲、姐妹、女儿)被诊断出患有乳腺癌,她患乳腺癌的风险几乎会翻倍。不到 15%的乳腺癌患者有家族成员被诊断为乳腺癌。
挑战
构建一个算法,通过观察活检图像自动识别患者是否患有乳腺癌。由于关系到人们的生命,算法必须极其准确。
数据
数据集可以从 这里 下载。这是一个二分类问题。我按如下方式拆分数据—
dataset train
benign
b1.jpg
b2.jpg
//
malignant
m1.jpg
m2.jpg
// validation
benign
b1.jpg
b2.jpg
//
malignant
m1.jpg
m2.jpg
//...
训练文件夹中每个类别有 1000 张图像,而验证文件夹中每个类别有 250 张图像。
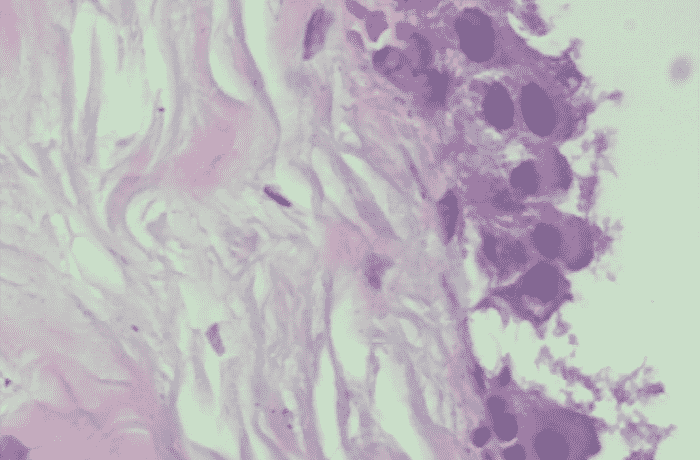
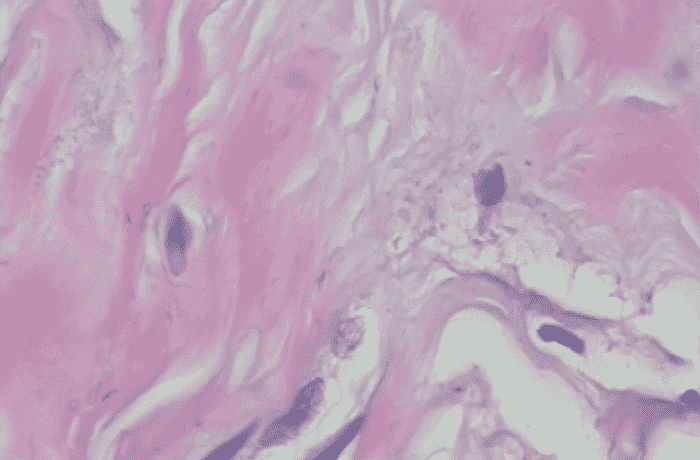
良性样本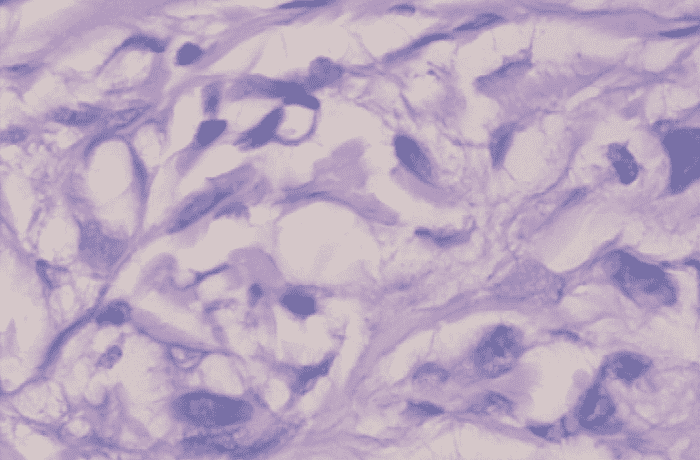
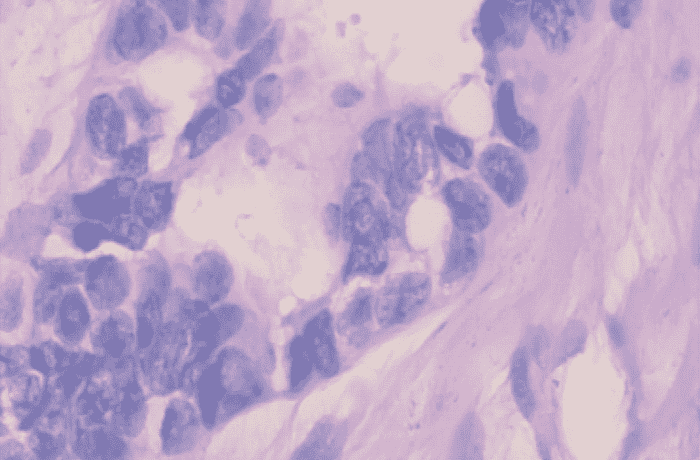
恶性样本
环境和工具
图像分类
完整的图像分类流程可以形式化为如下:
-
我们的输入是一个训练数据集,包括N张图像,每张图像都标记为 2 种不同类别之一。
-
然后,我们使用这个训练集训练一个分类器,让它学习每个类别的样子。
-
最后,我们通过让分类器预测一组从未见过的新图像的标签来评估分类器的质量。然后,我们将这些图像的真实标签与分类器预测的标签进行比较。
代码在哪里?
话不多说,我们开始写代码吧。完整的项目可以在 github 上找到 这里。
让我们先加载所有的库和依赖项。
接下来,我将图像加载到相应的文件夹中。
之后,我创建了一个由零组成的 numpy 数组用于标记良性图像,类似地,创建了一个由一组成的 numpy 数组用于标记恶性图像。我还打乱了数据集,并将标签转换为分类格式。
然后,我将数据集拆分为两个部分——训练集和测试集,分别包含 80%和 20%的图像。让我们看看一些示例的良性和恶性图像。
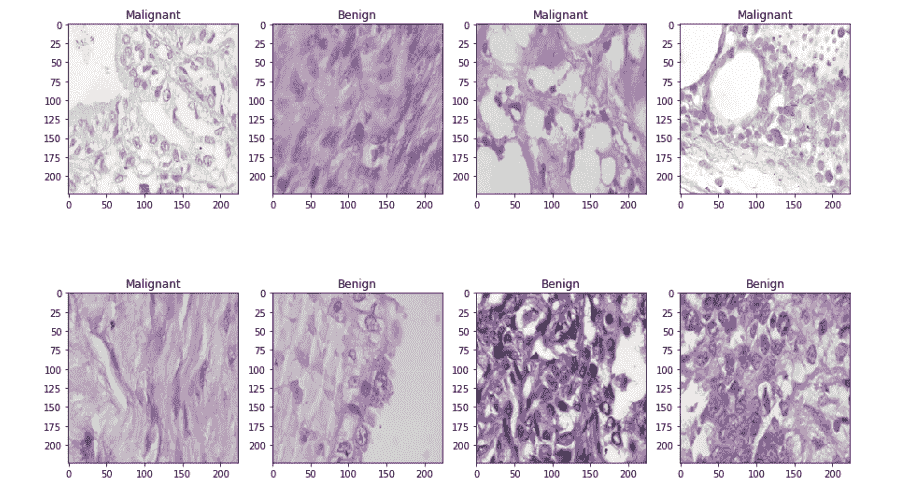
良性样本与恶性样本
我使用了 16 的批量大小。批量大小是深度学习中最重要的超参数之一。我倾向于使用较大的批量大小来训练我的模型,因为它允许通过 GPU 的并行性加速计算。然而,众所周知,过大的批量大小会导致较差的泛化效果。在一个极端的情况下,使用等于整个数据集的批量大小可以保证收敛到目标函数的全局最优解。然而,这会导致较慢的收敛速度。另一方面,使用较小的批量大小已被证明可以更快地收敛到良好的结果。这可以通过以下直观解释:较小的批量大小允许模型在必须查看所有数据之前开始学习。使用较小批量大小的缺点是模型不一定能收敛到全局最优解。因此,通常建议从较小的批量大小开始,利用更快的训练动态,并在训练过程中逐渐增加批量大小。
我还进行了数据增强。数据增强是一种有效的方法,可以增加训练集的规模。增强训练样本可以让网络在训练过程中看到更多的多样化,但仍具有代表性的数据点。
然后,我创建了一个数据生成器,以自动化的方式将数据从我们的文件夹中提取到 Keras 中。Keras 提供了方便的 Python 生成器函数来实现这一目的。
下一步是构建模型。这可以通过以下 3 个步骤描述:
-
我使用了 DenseNet201 作为预训练权重,它已经在 Imagenet 竞赛中进行了训练。学习率选择为 0.0001。
-
此外,我使用了全局平均池化层,后面跟着 50% 的 dropout 来减少过拟合。
-
我使用了批量归一化和一个包含 2 个神经元的全连接层用于 2 个输出类别,即良性和恶性,激活函数为 softmax。
-
我使用了 Adam 作为优化器,binary-cross-entropy 作为损失函数。
让我们看看每一层的输出形状和涉及的参数。

模型总结
在训练模型之前,定义一个或多个回调是很有用的。比较实用的有:ModelCheckpoint 和 ReduceLROnPlateau。
-
ModelCheckpoint:当训练需要很长时间才能取得好结果时,通常需要很多迭代。在这种情况下,最好仅在改进指标的纪元结束时保存表现最佳的模型副本。
-
ReduceLROnPlateau:当某项指标停止改善时,减少学习率。模型在学习停滞时通常会受益于将学习率减少 2-10 倍。这个回调监控一个量,如果在‘耐心’数量的纪元内没有看到改进,学习率将被减少。
ReduceLROnPlateau。
我训练了模型 20 个纪元。
性能指标
评估模型性能的最常见指标是准确率。然而,当你的数据集中只有 2% 是一个类别(恶性)而 98% 是另一个类别(良性)时,错误分类分数就没有意义了。你可以有 98% 的准确率,但仍然可能抓不到任何恶性病例,这会使模型表现很糟糕。
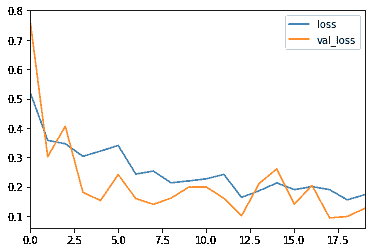
损失 vs 纪元 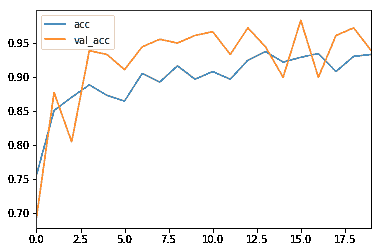
准确率 vs 纪元
精确度、召回率和 F1-Score
为了更好地了解错误分类,我们通常使用以下指标来更好地了解真正例(TP)、真正负例(TN)、假正例(FP)和假负例(FN)。
精确度 是正确预测的正观察值与总预测正观察值的比率。
召回率 是正确预测的正观察值与实际类别中所有观察值的比率。
F1-Score 是精确度和召回率的加权平均值。
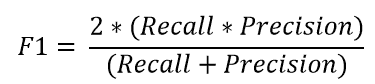
F1-Score 越高,模型越好。对于这三个指标,0 是最差的,而 1 是最好的。
混淆矩阵
混淆矩阵是分析分类错误时非常重要的指标。矩阵的每一行代表预测类别中的实例,每一列代表实际类别中的实例。对角线表示已正确分类的类别。这有助于我们不仅知道哪些类别被误分类,还知道它们被误分类为何种类别。
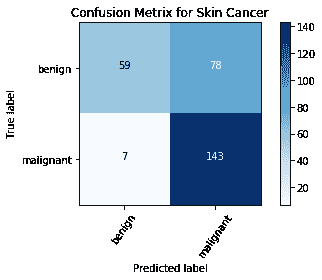
混淆矩阵
ROC 曲线
45 度线是随机线,其下的曲线面积(AUC)为 0.5。曲线距离这条线越远,AUC 越高,模型越好。模型的最高 AUC 为 1,此时曲线形成一个直角三角形。ROC 曲线还可以帮助调试模型。例如,如果曲线的左下角更接近随机线,则表明模型在 Y=0 时分类错误。而如果在右上角随机,则表明错误发生在 Y=1。
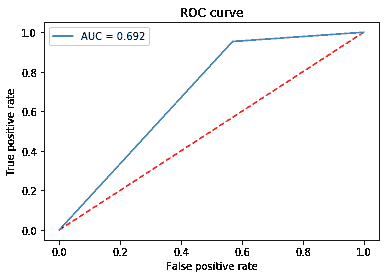
ROC-AUC 曲线
结果

最终结果
结论
尽管这个项目还远未完成,但看到深度学习在如此多样的现实问题中的成功是值得注意的。在这篇博客中,我展示了如何使用卷积神经网络和转移学习对一组显微镜图像进行良恶性乳腺癌分类。
参考文献/进一步阅读
转移学习一站式指南
在 Keras 中使用卷积神经网络(CNN)预测侵袭性导管癌
使用卷积神经网络对组织病理切片进行良恶性分类
尽管从组织病理图像中成功检测恶性肿瘤在很大程度上依赖于长期的...
深度学习确实可以在数据较少的情况下实现
离开前
对应的源代码可以在这里找到。
使用卷积神经网络的良性与恶性分类器 数据集可以从这里下载。 pip install…
联系方式
如果你想了解我最新的文章和项目,请关注我在 Medium 的账号。这些是我的一些联系信息:
祝阅读愉快,学习愉快,编码愉快!
个人简介:Abhinav Sagar 是 VIT Vellore 的大四本科生。他对数据科学、机器学习及其在现实世界问题中的应用感兴趣。
原文。经许可转载。
相关:
-
使用深度学习检测乳腺癌
-
如何轻松使用 Flask 部署机器学习模型
-
使用机器学习理解癌症
更多相关话题
卷积神经网络:使用 TensorFlow 和 Keras 的 Python 教程
原文:
www.kdnuggets.com/2019/07/convolutional-neural-networks-python-tutorial-tensorflow-keras.html
评论
卷积神经网络是深度学习在过去十年频繁上头条的原因之一。今天我们将训练一个图像分类器,利用 TensorFlow 的 eager API 来判断图像中是否包含狗或猫。
人工神经网络最近对多个行业产生了影响,因为它们在许多领域展现出了前所未有的能力。然而,不同的深度学习架构在每个领域都有所擅长:
-
图像分类(卷积神经网络)。
-
图像、音频和文本生成(GANs, RNNs)。
-
时间序列预测(RNNs, LSTM)。
-
推荐系统(玻尔兹曼机)。
-
大量其他内容(例如,回归分析)。
我们的前三推荐课程
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
今天我们将重点关注列表中的第一个项目,虽然每一个都值得单独写一篇文章。
什么是卷积神经网络?
在多层感知器(MLP),也就是普通神经网络中,每一层的神经元都连接到下一层的所有神经元。这种层被称为全连接层。
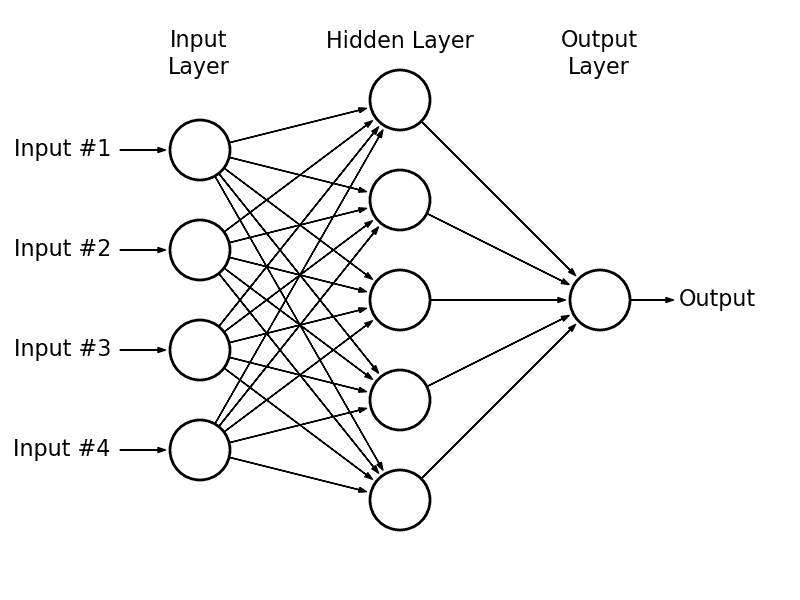
一个多层感知器。来源:astroml
卷积神经网络是不同的:它们具有卷积层。
在全连接层上,每个神经元的输出将是对上一层的线性变换,并与一个非线性激活函数(例如,ReLu 或 Sigmoid)组合。
相反,卷积层中每个神经元的输出仅是上一层子集的一个函数。
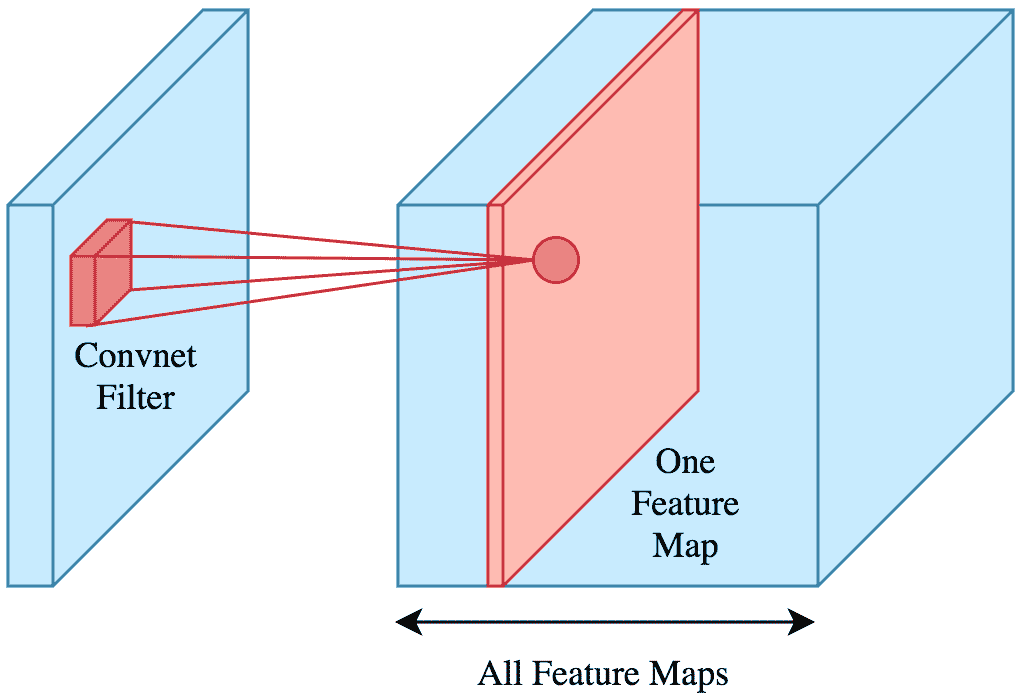
来源:Brilliant
卷积层上的输出将是对上一层的一个子集应用卷积的结果,然后是一个激活函数。
什么是卷积?
卷积操作,给定一个输入矩阵A(通常是前一层的值)和一个(通常小得多的)权重矩阵,称为卷积核或滤波器 K,将输出一个新的矩阵B。
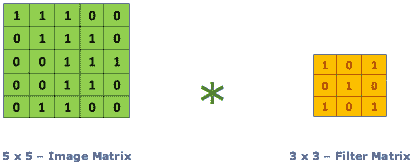
来源于@RaghavPrabhu
如果K是一个CXC矩阵,B中的第一个元素将是:
-
取A的第一个CXC子矩阵。
-
将每个元素乘以其在K中的相应权重。
-
将所有的乘积相加。
这最后两个步骤等同于将A的子矩阵和K展平,并计算结果向量的点积。
然后我们将K向右滑动以获取下一个元素,依此类推,重复这个过程直到A的每一行。
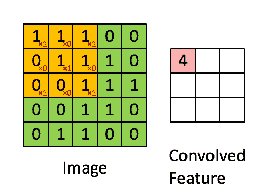
卷积可视化,来源于@RaghavPrabhu
根据我们的需求,我们可以选择仅从卷积核居中于Cth行和列的位置开始,以避免“越界”,或者假设“A 之外”的所有元素具有某种默认值(通常是 0)——这将决定B的大小是否小于A的大小或相同。
如你所见,如果A是一个NxM矩阵,那么现在B中的每个神经元的值将不再依赖于NM权重,而仅依赖于CC(少得多)个权重。
这使得卷积层比全连接层轻得多,帮助卷积模型学习得更快。
当然,我们在每一层会使用许多卷积核(每一层的输出是一个矩阵的堆叠)。然而,这仍然需要比我们老旧的多层感知机(MLP)少得多的权重。
为什么这样做有效?
为什么我们可以忽略每个神经元对大多数其他神经元的影响?因为整个系统的前提是每个神经元受其“邻居”强烈影响。然而,远处的神经元对它只有很小的影响。
这个假设在图像中是直观正确的——如果我们考虑输入层,每个神经元将是一个像素或像素的 RGB 值。这也是为什么这种方法在图像分类中效果如此之好的部分原因。
例如,如果我选择一张有蓝天的图片区域,附近的区域很可能也会显示蓝天,使用类似的色调。
像素的邻居通常会有类似的 RGB 值。如果没有,那么这可能意味着我们在图形或物体的边缘。
如果你用笔和纸(或计算器)进行一些卷积操作,你会发现某些卷积核会在某种边缘上增加输入的强度,而在其他边缘上则可能会减少它。
例如,考虑以下卷积核 V 和 H:

用于垂直和水平边缘的滤波器
V 过滤器处理垂直边缘(即上方和下方颜色差异很大的地方),而 H 过滤器处理水平边缘。注意其中一个是另一个的转置版本。
通过示例了解卷积
这是未经过滤的小猫图片:

如果我们分别应用水平和垂直边缘滤镜,会发生以下情况:

我们可以看到一些特征变得更加明显,而其他特征则逐渐消失。有趣的是,每个滤镜展示了不同的特征。
这就是卷积神经网络如何学习识别图像中的特征。
让它们自行调整内核权重要比任何手动方法都简单。想象一下尝试手动表达像素之间的关系!
为了真正理解每个卷积对图像的作用,我强烈建议你在 这个网站 上玩一玩。它比任何书籍或教程都对我帮助更大。去吧,收藏它。这很有趣。
好了,你已经学了一些理论知识。现在让我们进入实际操作部分。
如何在 TensorFlow 中训练卷积神经网络?
TensorFlow 是 Python 最受欢迎的深度学习框架。
我也听说过 PyTorch 很不错,尽管我从未有机会尝试。
我已经写过一个关于 如何使用 TensorFlow 的 Keras API 训练神经网络,重点讲解了 AutoEncoders。
今天会有所不同:我们将尝试三种不同的架构,看看哪一种效果更好。
和往常一样,所有代码都可以在 GitHub 上找到,你可以自己尝试或跟随操作。当然,我也会展示 Python 代码片段。
数据集
我们将训练一个神经网络来预测图像中是否包含狗或猫。为此,我们将使用 Kaggle 的 cats and dogs Dataset。它包含 12500 张猫的图片和 12500 张狗的图片,分辨率各异。
使用 NumPy 加载和预处理我们的图像数据
神经网络接收一个特征向量或矩阵作为输入,通常具有 固定尺寸。我们如何从图片中生成这个特征向量或矩阵?
幸运的是,Python 的图像库为我们提供了一种简单的方法,将图像加载为 NumPy 数组。即一个 HeightxWidth 的 RGB 值矩阵。
我们已经在 Python 中的图像滤镜 中做过这个,所以我将重用那段代码。
不过我们仍然需要解决固定尺寸的问题:我们为 输入层 选择什么 尺寸?
这很重要,因为我们需要调整每张图片的大小到所选择的分辨率。我们不希望扭曲长宽比过多,以免带来过多噪声给网络。
这是我们可以查看数据集中最常见的形状的方式。
我对前 1000 张图片进行了抽样,尽管当我查看 5000 张时结果没有变化。
最常见的形状是 375×500,不过我决定将其缩小到网络输入的 1/4。
这就是我们现在的图像加载代码的样子。
最后,你可以使用这段代码加载数据。我选择使用 4096 张图片作为训练集,1024 张作为验证集。然而,这只是因为我的 PC 由于 RAM 大小无法处理更多数据。
如果你在家尝试,可以将这些数字增加到最大值(例如训练集 10K 和验证集 2500)!
训练我们的神经网络
首先,作为一个基准,让我们看看普通MLP在这个任务上的表现。如果卷积神经网络如此革命性,我期望这次实验的结果会非常糟糕。
这是一个单隐层全连接神经网络。
本文的所有训练都使用了 AdamOptimizer,因为它是最快的。我仅为每个模型调整了学习率(这里是 1e-5)。
我训练了这个模型 10 个轮次,它基本上收敛到随机猜测。
我确保打乱训练数据,因为我按顺序加载它可能会导致模型偏差。
我使用了MSE作为损失函数,因为它通常更直观。如果你的 MSE 在二分类中是 0.5,你就相当于总是预测为 0。然而,具有更多层的 MLP 或不同损失函数表现没有更好。
从历史上看,其他成熟的监督学习算法,如Boosted Trees (使用 XGBoost),在图像分类上的表现甚至更差。
训练卷积神经网络
一个卷积层能带来多大好处?我们来给模型添加一个卷积层看看。
对于这个网络,我决定添加一个卷积层(24 个卷积核),然后是 2 个全连接层。
最大池化仅仅是将每四个神经元减少为一个神经元,取四者中的最高值。
仅经过 5 个训练轮次,它的表现已经好得多,比之前的网络要好。
通过 0.36 的验证 MSE,它已经比随机猜测好很多。然而,请注意,我不得不使用小得多的学习率。
此外,尽管它在更少的训练轮次中学到了更多,但每个训练轮次花费的时间要长得多。模型也变得相当沉重(200+ MB)。
我决定开始测量预测与验证标签之间的 Pearson 相关性。这个模型得分为 15.2%。
具有两个卷积层的神经网络
由于那个模型表现更好,我决定尝试一个更大的模型。我添加了另一个卷积层,并将两个层都做得更大(每个 48 个卷积核)。
这意味着模型可以从图像中学习更复杂的特征。但这也意味着我的 RAM 几乎要爆炸了。此外,训练时间也长得多(15 个周期需要半小时)。
结果非常出色。预测和标签之间的皮尔逊相关系数达到了 0.21,验证 MSE 低至 0.33。
让我们测量一下网络的准确率。由于 1 表示猫,0 表示狗,我可以说“如果模型预测的值高于某个阈值 t,那么预测为猫。否则预测为狗。”
尝试了 10 个直接阈值后,这个网络的最高准确率为 61%。
更大的卷积神经网络
既然增加模型的大小明显使模型学得更好,我尝试将两个卷积层都做得更大,每个128 个滤波器。
我保持了模型的其他部分不变,也没有改变学习率。
这个模型最终达到了 30%的相关性!它的最佳准确率为 67%,这意味着它在三分之二的情况下是正确的。
我仍然认为一个更大的模型可能会更好地拟合数据。
因此,对于下一次训练,我决定将全连接层的大小增加一倍,达到 512 个神经元。
不过,我确实将第一个卷积层的大小减少了一半,只保留了 64 个滤波器。
通常,我发现如果我把第一个卷积层做得更小,并在它们更深时增加其大小,我会得到更好的模型性能。
幸运的是,我的预测是正确的!
拥有两倍大小的全连接层的模型达到了0.75 的验证损失和42%的相关性。
它的准确率为 75%,这意味着它在 4 次中正确预测了 3 次!
这清楚地表明它学到了东西,即使这不是最先进的分数(更不用说打败人类了)。
这证明了,至少在这种情况下,增加全连接层的大小比增加卷积滤波器的数量效果更好。
我本可以继续尝试越来越大的模型,但收敛已经花了大约一个小时。
通常,模型的大小和时间限制之间存在权衡。
模型的大小限制了网络对数据的拟合程度(小模型会欠拟合),但我不想等 3 天让我的模型学习。
如果你有业务截止日期,通常也会面临相同的问题。
结论
我们已经看到卷积神经网络在图像分类任务上比普通架构明显更好。我们还尝试了不同的度量标准来衡量模型性能(相关性、准确率)。
我们了解了模型大小(防止欠拟合)和收敛速度之间的权衡。
最后,我们使用了 TensorFlow 的 eager API 来轻松训练深度神经网络,并使用 numpy 进行(尽管简单的)图像预处理。
对于未来的文章,我相信我们可以在不同的池化层、滤波器大小、步幅以及不同的预处理上进行更多实验。
你觉得这篇文章有用吗?你是否希望了解更多其他内容?是否有任何不够清楚的地方?请在评论中告诉我!
如果你有任何问题,或者想要联系我,请在Twitter、Medium或Dev.to找到我。
如果你想成为数据科学家,这里是我推荐的机器学习阅读清单。
个人简介:卢西亚诺·斯特里卡 是布宜诺斯艾利斯大学的计算机科学学生,同时也是 MercadoLibre 的数据科学家。他还在www.datastuff.tech上撰写关于机器学习和数据的文章。
原文。经许可转载。
相关:
-
3 本帮助我成为数据科学家的机器学习书籍
-
训练神经网络以模仿洛夫克拉夫特的写作风格
-
每个数据科学家都应该了解的 5 种概率分布
更多相关内容
Cookiecutter 数据科学:如何组织您的数据科学项目
原文:
www.kdnuggets.com/2018/07/cookiecutter-data-science-organize-data-project.html
 评论
评论
由 DrivenData 提供
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
为什么使用这个项目结构?
我们不是在谈论细枝末节的缩进美学或拘泥于格式标准——最终,数据科学代码质量关乎正确性和可重复性。
当我们考虑数据分析时,我们通常只关注最终报告、洞察或可视化。虽然这些最终产品通常是主要事件,但很容易专注于使产品看起来漂亮,而忽视生成它们的代码质量。因为这些最终产品是程序性生成的,代码质量依然重要!我们不是在谈论细枝末节的缩进美学或拘泥于格式标准——最终,数据科学代码质量关乎正确性和可重复性。
众所周知,良好的分析通常是非常零散和偶然探索的结果。尝试性实验和快速测试可能不起作用的方法都是获得好结果的过程的一部分,并且没有魔法弹药可以将数据探索转化为简单的线性进展。
话虽如此,一旦开始,它不是一个可以仔细考虑代码或项目布局结构的过程,因此最好从一个干净、逻辑的结构开始,并在整个过程中坚持使用。我们认为使用这样的标准化设置是一个相当大的胜利。原因如下:
其他人会感谢你
没有人在创建新的 Rails 项目之前坐下来考虑他们想把视图放在哪里;他们只是运行
rails new来获得像其他人一样的标准项目骨架。
一个明确定义的标准项目结构意味着新来者可以在不深入阅读大量文档的情况下开始理解分析。这也意味着他们不必在了解非常具体的内容之前阅读 100%的代码。
组织良好的代码往往是自我文档化的,因为组织本身为你的代码提供了上下文而无需过多开销。人们会感谢你,因为他们可以:
-
更容易与你合作完成这项分析。
-
从你的分析中学习过程和领域知识。
-
对分析得出的结论感到自信。
一个很好的例子可以在任何主要的网络开发框架中找到,比如 Django 或 Ruby on Rails。在创建一个新的 Rails 项目之前,没有人会坐下来考虑他们想把视图放在哪里;他们只需运行rails new来获取一个标准的项目骨架,因为这个默认的项目结构是合乎逻辑的且在大多数项目中合理标准化,对于从未见过特定项目的人来说,找出各种活动部分会容易得多。
另一个很好的例子是文件系统层级标准用于类似 Unix 的系统。/etc目录有一个非常具体的目的,/tmp文件夹也是如此,每个人(或多或少)都同意遵守这个社会契约。这意味着 Red Hat 用户和 Ubuntu 用户都大致知道在何处寻找某些类型的文件,即使在使用对方的系统时——或者说任何其他符合标准的系统!
理想情况下,当同事打开你的数据科学项目时,应该是这样的。
你会感谢自己。
曾经尝试过重现几个月前甚至几年前做过的分析吗?你可能写过代码,但现在很难判断你应该使用make_figures.py.old、make_figures_working.py 还是 new_make_figures01.py 来完成任务。以下是一些我们在存在主义恐惧中学会提出的问题:
-
我们是否应该在开始之前先将列 X 加入数据,还是这已经从其中一个笔记本中得到了?
-
说到这一点,我们需要先运行哪个笔记本才能运行绘图代码:是“处理数据”还是“清理数据”?
-
地理图表的 shapefiles 是从哪里下载的?
-
等等,无限重复。
这些问题类型是痛苦的,并且是项目组织不善的症状。一个好的项目结构鼓励采用使得重新回到旧工作变得更加容易的实践,例如关注点分离、将分析抽象为一个DAG,以及版本控制等工程最佳实践。
这里没有任何约束。
“愚蠢的一致性是小心眼者的鬼怪” — 拉尔夫·瓦尔多·爱默生(以及PEP 8!)
对几个默认文件夹名称不太满意?正在处理一个稍微非标准的项目,与当前结构不完全匹配?更愿意使用不同于(少数)默认值的包?
加油吧! 这是一个轻量级结构,旨在成为许多项目的良好起点。或者,正如 PEP 8 所说:
项目内的一致性更为重要。一个模块或函数内的一致性是最重要的。... 但要知道何时不一致——有时样式指南的建议不适用。遇到疑问时,运用你最好的判断。查看其他示例,决定什么看起来最好。并且不要犹豫去询问!
入门
考虑到这一点,我们创建了一个用于 Python 项目的数据科学 cookiecutter 模板。你的分析不必用 Python 进行,但模板确实提供了一些 Python 的样板代码,你可能需要删除(例如在src文件夹中,以及docs中的 Sphinx 文档骨架)。
需求
-
Python 2.7 或 3.5
-
cookiecutter Python 包 >= 1.4.0:
pip install cookiecutter
启动一个新项目
启动一个新项目就像在命令行中运行这个命令一样简单。无需先创建目录,cookiecutter 会为你完成这项工作。
cookiecutter https://github.com/drivendata/cookiecutter-data-science
示例
目录结构
├── LICENSE
├── Makefile <- Makefile with commands like `make data` or `make train`
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── external <- Data from third party sources.
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── docs <- A default Sphinx project; see sphinx-doc.org for details
│
├── models <- Trained and serialized models, model predictions, or model summaries
│
├── notebooks <- Jupyter notebooks. Naming convention is a number (for ordering),
│ the creator's initials, and a short `-` delimited description, e.g.
│ `1.0-jqp-initial-data-exploration`.
│
├── references <- Data dictionaries, manuals, and all other explanatory materials.
│
├── reports <- Generated analysis as HTML, PDF, LaTeX, etc.
│ └── figures <- Generated graphics and figures to be used in reporting
│
├── requirements.txt <- The requirements file for reproducing the analysis environment, e.g.
│ generated with `pip freeze > requirements.txt`
│
├── setup.py <- Make this project pip installable with `pip install -e`
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ │
│ ├── data <- Scripts to download or generate data
│ │ └── make_dataset.py
│ │
│ ├── features <- Scripts to turn raw data into features for modeling
│ │ └── build_features.py
│ │
│ ├── models <- Scripts to train models and then use trained models to make
│ │ │ predictions
│ │ ├── predict_model.py
│ │ └── train_model.py
│ │
│ └── visualization <- Scripts to create exploratory and results oriented visualizations
│ └── visualize.py
│
└── tox.ini <- tox file with settings for running tox; see tox.testrun.org
意见
项目结构中隐含了一些观点,这些观点源于我们在数据科学项目合作中的经验,有些是关于工作流程的,有些是关于简化工作生活的工具的。这些观点是该项目的基础——如果你有想法,请贡献或分享。
数据是不可变的
切勿编辑你的原始数据,特别是不要手动编辑,尤其是在 Excel 中。不要覆盖你的原始数据。不要保存原始数据的多个版本。将数据(及其格式)视为不可变的。你编写的代码应该将原始数据通过管道传递到最终分析中。你不需要每次都运行所有步骤来生成新的图表(见分析是一个 DAG),但任何人都应该能够仅使用src中的代码和data/raw中的数据重现最终产品。
此外,如果数据是不可变的,它不需要像代码那样进行源代码管理。因此,默认情况下,数据文件夹包含在 .gitignore 文件中。 如果你有少量数据,且很少更改,你可能希望将数据包含在仓库中。Github 目前会警告文件超过 50MB,并拒绝超过 100MB 的文件。其他存储/同步大数据的选项包括 AWS S3 及其同步工具(例如,s3cmd)、Git Large File Storage、Git Annex 和 dat。目前,我们默认要求使用 S3 存储桶,并使用 AWS CLI 将 data 文件夹中的数据与服务器同步。
笔记本用于探索和交流
像 Jupyter notebook、Beaker notebook、Zeppelin 等笔记本包以及其他文学编程工具对于探索性数据分析非常有效。然而,这些工具在再现分析结果时可能效果较差。当我们在工作中使用笔记本时,我们通常会将 notebooks 文件夹进一步细分。例如,notebooks/exploratory 包含初步探索,而 notebooks/reports 是更为完善的工作,可以导出为 html 文件到 reports 目录。
由于笔记本是源代码管理的挑战性对象(例如,json 的差异通常不可读,合并几乎不可能),我们建议不要直接在 Jupyter 笔记本上与他人协作。我们建议有效使用笔记本的两个步骤:
-
遵循一个命名规范,显示所有者和分析的顺序。我们使用
<step>-<ghuser>-<description>.ipynb的格式(例如,0.3-bull-visualize-distributions.ipynb)。 -
重构好的部分。不要在多个笔记本中编写执行相同任务的代码。如果这是数据预处理任务,将其放入
src/data/make_dataset.py的管道中,并从data/interim加载数据。如果是有用的工具代码,将其重构到src中。
现在,默认情况下,我们将项目转换为一个 Python 包(参见 setup.py 文件)。你可以导入你的代码并在笔记本中使用类似以下的单元格:
# OPTIONAL: Load the "autoreload" extension so that code can change
%load_ext autoreload
# OPTIONAL: always reload modules so that as you change code in src, it gets loaded
%autoreload 2
from src.data import make_dataset
分析是一个有向无环图(DAG)
在分析中,通常会有长时间运行的步骤来预处理数据或训练模型。如果这些步骤已经运行过(并且你将输出存储在类似于data/interim的目录中),你不希望每次都重新运行它们。我们更喜欢make来管理相互依赖的步骤,特别是那些长时间运行的步骤。Make 是 Unix 平台上常见的工具(并且在 Windows 上也可用)。遵循make文档、Makefile 约定和便携性指南将帮助确保你的 Makefile 在不同系统上有效运行。这里有一些 示例供你入门。许多数据人员,包括Mike Bostock,将make作为他们的首选工具。
还有其他一些管理 DAG 的工具是用 Python 编写的,而不是使用 DSL(例如,Paver、Luigi、Airflow、Snakemake、Ruffus或Joblib)。如果这些工具更适合你的分析,请随意使用它们。
从环境开始构建。
重现分析的第一步总是重现运行分析的计算环境。你需要相同的工具、相同的库以及相同的版本,以确保一切协调一致。
一种有效的方法是使用virtualenv(我们推荐使用virtualenvwrapper来管理虚拟环境)。通过在仓库中列出所有的需求(我们包含了一个requirements.txt文件),你可以轻松追踪重建分析所需的包。以下是一个好的工作流程:
-
在创建新项目时运行
mkvirtualenv。 -
使用
pip install安装分析所需的包。 -
运行
pip freeze > requirements.txt以固定用于重建分析的确切包版本。 -
如果你发现需要安装另一个包,重新运行
pip freeze > requirements.txt并将更改提交到版本控制系统中。
如果你对重建环境有更复杂的需求,可以考虑基于虚拟机的方法,如Docker或Vagrant。这两种工具使用基于文本的格式(Dockerfile 和 Vagrantfile),你可以轻松地将其添加到版本控制中,以描述如何创建一个具有所需要求的虚拟机。
保持秘密和配置不在版本控制中
你真的不希望在 Github 上泄露你的 AWS 秘密密钥或 Postgres 用户名和密码。言尽于此——请参见Twelve Factor App原则。这里有一种方法:
将你的秘密和配置变量存储在一个特殊的文件中
在项目根文件夹中创建一个.env文件。由于.gitignore,此文件不应被提交到版本控制仓库中。以下是一个示例:
# example .env file
DATABASE_URL=postgres://username:password@localhost:5432/dbname
AWS_ACCESS_KEY=myaccesskey
AWS_SECRET_ACCESS_KEY=mysecretkey
OTHER_VARIABLE=something
使用一个包来自动加载这些变量。
如果你查看src/data/make_dataset.py中的存根脚本,它使用了一个名为python-dotenv的包,将此文件中的所有条目加载为环境变量,因此可以通过os.environ.get访问。以下是从python-dotenv文档中改编的示例代码:
# src/data/dotenv_example.py
import os
from dotenv import load_dotenv, find_dotenv
# find .env automagically by walking up directories until it's found
dotenv_path = find_dotenv()
# load up the entries as environment variables
load_dotenv(dotenv_path)
database_url = os.environ.get("DATABASE_URL")
other_variable = os.environ.get("OTHER_VARIABLE")
AWS CLI 配置
使用 Amazon S3 存储数据时,管理 AWS 访问的简单方法是将访问密钥设置为环境变量。然而,在一台机器上管理多个密钥集(例如在多个项目中工作时),最好使用凭证文件,通常位于~/.aws/credentials。一个典型的文件可能如下所示:
[default]
aws_access_key_id=myaccesskey
aws_secret_access_key=mysecretkey
[another_project]
aws_access_key_id=myprojectaccesskey
aws_secret_access_key=myprojectsecretkey
在初始化项目时,你可以添加配置文件名;假设没有设置适用的环境变量,配置文件的凭证将作为默认值使用。
在更改默认文件夹结构时要保守
为了使这种结构适用于多种不同类型的项目,我们认为最好的方法是对你的项目更改文件夹保持宽容,但对所有项目的默认结构保持保守。
我们创建了一个folder-layout标签,专门用于提议添加、删除、重命名或移动文件夹的问题。更广泛地说,我们还创建了一个needs-discussion标签,用于需要进行仔细讨论和广泛支持的问题。
贡献
Cookiecutter Data Science 项目有其明确的观点,但不怕犯错。最佳实践在变化,工具在进化,经验在积累。这个项目的目标是让开始、结构化和共享分析变得更容易。 鼓励拉取请求和提交问题。我们很想知道什么对你有效,什么无效。
如果你使用了 Cookiecutter 数据科学项目,请链接回此页面或 给我们留言 并 告诉我们!
相关项目和参考文献链接
项目结构和可重复性在 R 研究社区中有更多讨论。如果你在使用 R,这里有一些项目和博客文章可能对你有所帮助。
-
项目模板 - 一个 R 数据分析模板
-
"设计项目" 在 Nice R Code 上
-
"我的研究工作流程" 在 Carlboettifer.info 上
-
"计算生物学项目的快速指南" 在 PLOS 计算生物学上
最后,感谢Cookiecutter项目 (github),它帮助我们减少了在编写模板代码上的时间,使我们能够将更多时间用于完成实际工作。
简介: DrivenData 是一家以使命驱动的数据科学公司,将数据科学、机器学习和人工智能的强大能力带到应对全球最大挑战的组织。DrivenData Labs (drivendata.co) 帮助以使命为导向的组织利用数据更聪明地工作,提供更有影响力的服务,并充分发挥机器智能的潜力。DrivenData 还举办在线机器学习竞赛 (drivendata.org),在这里,全球热情的数据科学家为社会影响构建算法。
原版。经授权转载。
相关:
-
与机器学习算法相关的数据结构
-
Python 正则表达式备忘单
-
Python 中的函数式编程介绍
更多相关话题
数据科学的核心
评论
作者:PG Madhavan, Ph.D.,算法学家 - 商业数据科学。
阅读了一些最近的博客后,我感到数据科学从业者对他们领域的性质感到一丝焦虑。数据科学到底是什么——这个问题似乎一直潜伏在表面下方……
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
作为一个年轻的研究和工作领域,数据科学的定义自然需要时间才能明朗。在此期间,看看这是否适合你……
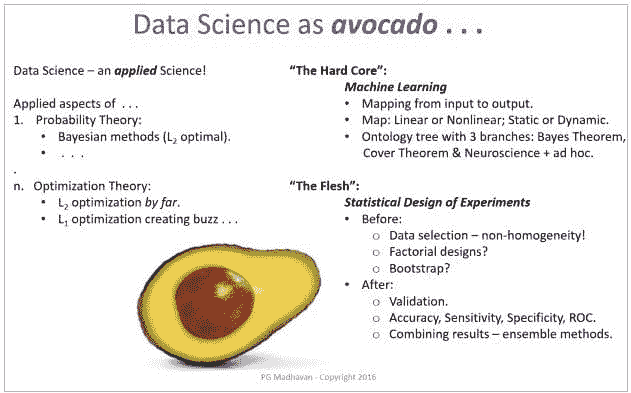
数据科学是许多理论的应用方面。我的方向是贝叶斯的,因此我把概率论放在首位。许多其他科学也起着重要作用——例如,物理学和统计力学就发挥了重要作用。我们已经很长时间习惯于 L2 优化(欧几里得距离度量),但目前在 L1 优化(出租车距离度量)方面有了越来越多的活动。L1 优化将我们从均方误差最优性的舒适区中推了出来,带来了 2 阶思维的挑战!
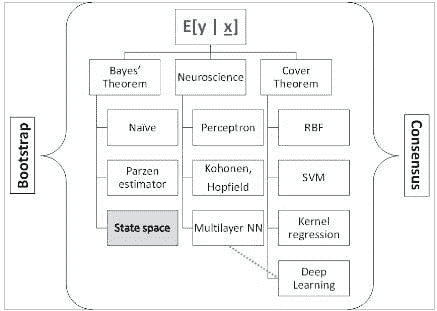
毫无疑问,数据科学的核心是机器学习(ML)——这个话题的确是“核心”!机器学习基本上关注于找到输入和输出向量空间之间极其重要的“映射”(有关该主题的完整开发,请参见“SYSTEMS Analytics: Adaptive Machine Learning workbook”)。有很多工具和技巧,使得对机器学习的全面理解可能会让人感到沮丧;所以我在下面整理了一个本体,组织了我们对机器学习的所有知识。重点是将大量材料分为 3 个主题:贝叶斯定理、覆盖定理和神经科学与特定方法。在机器学习实践中,这些方法被“自助”方法和“共识”方法“包裹”起来。
“鳄梨的核心”在大的括号内。
-
覆盖定理说明(来自Haykin, 2006):“在高维空间中非线性地转换的复杂模式分类问题,比在低维空间中更可能是线性可分的,前提是空间不是密集填充的。”
-
从输出的条件概率密度函数中估计条件期望值 E[ y | x],其中‘y’是输出,‘x’是输入,是硬核概率方法的核心内容。我个人最喜欢的是使用状态空间数据模型和卡尔曼滤波器来估计参数。
-
中间分支是一个由神经科学主导的“包罗万象”的领域,从感知机开始。深度学习是这种方法在本体论中最新的表现形式(结合了高维度)。
统计实验设计提供了周围的“实质”!
输入侧:自助方法
目标是最大化训练集信息的使用。
-
有许多方法:
-
自助训练集;有放回地抽样训练集。
-
蒙特卡罗方法;用于概率密度估计。
-
特征子空间。
-
统计学中的实验设计原则;“分组”、因子设计等。
-
还有更多。
-
输出侧:共识方法
使用独立的机器学习方法解决问题并结合结果。
-
结合“弱学习者”。
-
随机森林。
-
AdaBoost。
-
还有更多。
-
大多数机器学习工作倾向于学习输入和输出之间的静态映射,然后将其投入“生产”,隐含假设这种关系将保持不变!我挑战这种假设,并提供了在现实生活中动态变化的情况下最佳解决方法的方式,详见本博客:“对动态机器学习的需求:贝叶斯精确递归估计”。
机器学习映射的实际使用需要严格的实验设计框架(Box 等,一本老经典)。正如我们在上面的本体树中看到的,当你用强有力的统计实验学科围绕坚实的机器学习映射时,我们可以从数据科学中获得稳健、可重复且实际有用的结果!
在实现数据科学解决方案方面,数据科学是一项“团队运动”和“对抗性运动”。
没有数据科学就没有与数据的持续接触。数据会影响算法、代码、业务应用和日常使用。
数据科学解决方案的开发需要 (1) 一位具备深厚和广泛数学技能的算法专家,(2) 一位拥有数据库和云操作系统技能的编码员,以及 (3) 一位具有定量倾向的商业专业人员。我还没有遇到过具备这三种技能到所需深度的个人!同样重要的是,每种角色的个人气质差异明显。因此,快速的数据科学解决方案开发需要一个真实或虚拟的三人团队。数据科学解决方案的部署和操作通常可以由具备应用统计学思维的合格 STEM 毕业生完成(该人欣赏日常业务应用中的统计实验方面)。
数据科学的最佳时光尚未到来!还有其他科学可以挖掘以获取新技术,更多的计算能力意味着可以完成更多的任务,很快,由数据科学提供的强大“智能增强”将改变商业、工作和娱乐的性质,带来更好的变革——下一次“工业”革命!
 简介:PG Madhavan, Ph.D. 是一位数据科学专家 + 教练,在机器学习算法、产品和业务方面有着深厚且均衡的经验。
简介:PG Madhavan, Ph.D. 是一位数据科学专家 + 教练,在机器学习算法、产品和业务方面有着深厚且均衡的经验。
相关:
-
理论数据发现:利用物理学理解数据科学
-
构建数据科学投资组合:机器学习项目第一部分
-
如何为您的团队确定合适的数据科学家?
更多相关内容
新调查:你拥有哪些数据科学技能,哪些技能是你想要的?立即投票
原文:
www.kdnuggets.com/2020/08/core-hot-data-science-skills-poll.html
调查已结束 - 以下是结果:
我们分析了数据科学技能调查的结果,包括 8 个技能类别,超过 50% 的受访者掌握的 13 项核心技能,数据科学家希望学习的热门/新兴技能,以及数据科学家希望学习的顶级技能。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
新的 KDnuggets 调查提出了两个相关问题:
1. 你目前掌握哪些技能/知识领域(能够在工作或研究中使用的水平)?
2. 你希望添加或改进哪些技能?
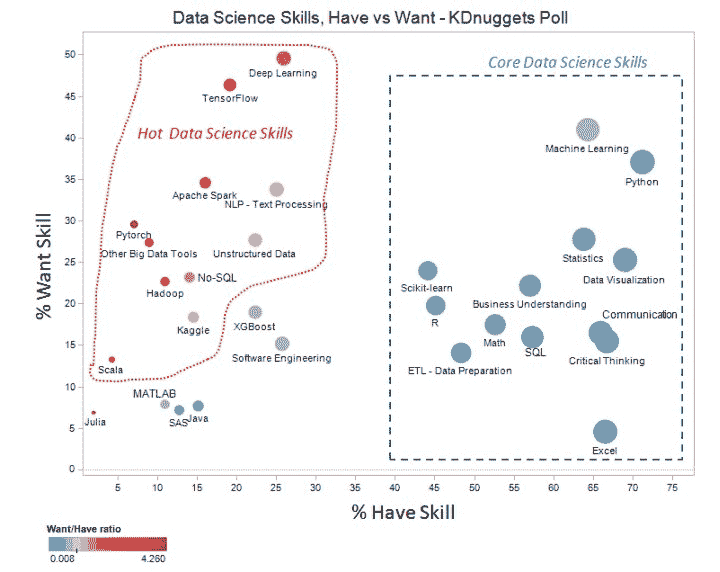 图 1. 来自 去年数据科学技能调查分析 的结果。
图 1. 来自 去年数据科学技能调查分析 的结果。
技能被收集到几个相关的子部分,读者被要求指出他们目前掌握哪些技能以及他们希望添加或改进哪些技能。请注意,你可能既有某项技能又希望改进它。
你可以 在这里阅读去年的调查分析。
更多相关主题
哪些数据科学技能是核心的,哪些是热点/新兴的?
原文:
www.kdnuggets.com/2019/09/core-hot-data-science-skills.html
评论最新的 KDnuggets 调查问卷
1. 你目前拥有哪些技能/知识领域(达到可以在工作或研究中使用的水平)? 和
2. 你想增加或改善哪些技能?
我们基于之前的 KDnuggets 文章和调查挑选了 30 项技能 - 见本文末尾的有用链接,以及外部来源。
总体而言(*),本次调查共收到超过 1,500 票 - 样本足够大,可以得出有意义的结论。平均每位受访者报告拥有 10 项技能,并希望增加或改善 6.5 项技能。
下图 1 显示了主要发现,X 轴显示拥有技能的百分比 - 对第一个调查问题的回答,Y 轴显示希望拥有技能的百分比 - 对第二个调查问题的回答。每个圆圈的大小与拥有该技能的受访者百分比成正比,而颜色则取决于 Want/Have 比例(红色为高 - 超过 1,蓝色为低 - 少于 1)。
注意:其他大数据工具 条目指的是除 Hadoop 或 Spark 外的大数据工具。
图 1:数据科学相关技能,拥有技能与希望增加或改善的技能
我们在此图表中注意到两个主要的集群。
集群 1,在图表右侧的蓝色虚线矩形中,包括超过 40% 受访者拥有的技能,且 Want/Have 比例小于 1。我们称之为核心数据科学技能。它们列在表 1 中。
表 1:核心数据科学技能,按 %Have 递减排序
| 技能 | %Have | %Want | %Want/ %Have |
|---|---|---|---|
| Python | 71.2% | 37.1% | 0.52 |
| 数据可视化 | 69.0% | 25.3% | 0.37 |
| 批判性思维 | 66.7% | 15.5% | 0.23 |
| Excel | 66.5% | 4.6% | 0.07 |
| 沟通技能 | 65.9% | 16.5% | 0.25 |
| 机器学习 | 64.3% | 41.0% | 0.64 |
| 统计学 | 63.8% | 27.8% | 0.44 |
| SQL/数据库编码 | 57.3% | 16.0% | 0.28 |
| 商业理解 | 57.0% | 22.2% | 0.39 |
| 数学 | 52.6% | 17.5% | 0.33 |
| ETL - 数据准备 | 48.3% | 14.1% | 0.29 |
| R | 45.1% | 19.8% | 0.44 |
| Scikit-learn | 44.1% | 24.0% | 0.54 |
其中,添加或改善欲望最强的技能是机器学习(41%)和 Python(37%)。增长最少的技能是 Excel - 只有 7% 的人希望增加或改善他们的 Excel 技能。
第二类(见图 1 左侧,并用红色边框标记)包括当前较不流行的技能(%Have< 30%),但正在增长,%Want/%Have 比例超过 1 - 见表 2。我们称之为热点/新兴数据科学技能。
表 2:热点/新兴数据科学技能,按 %Want/%Have 递减排序
| 技能 | %Have | %Want | %Want/ %Have |
|---|---|---|---|
| Pytorch | 7.0% | 29.6% | 4.26 |
| Scala | 4.2% | 13.3% | 3.14 |
| 其他大数据工具 | 8.9% | 27.4% | 3.08 |
| TensorFlow | 19.1% | 46.4% | 2.44 |
| Apache Spark | 16.0% | 34.6% | 2.16 |
| Hadoop | 10.9% | 22.7% | 2.08 |
| 深度学习 | 25.9% | 49.6% | 1.92 |
| No-SQL 数据库 | 14.0% | 23.2% | 1.65 |
| NLP - 文本处理 | 25.0% | 33.8% | 1.35 |
| Kaggle | 14.5% | 18.4% | 1.27 |
| 非结构化数据 | 22.3% | 27.7% | 1.24 |
有趣的是,尽管有观点认为 Hadoop 在下降,但在这次调查中,更多人想学习 Hadoop 而不是已经了解它,因此它可能仍会增长。
尽管 Julia 的需求/拥有比例为3.4,我们仍未将其列为热门/新兴技能,因为只有 2%的投票者选择了它,它目前还没有足够的支持。
剩余技能 - XGBoost、软件工程、Java、MATLAB、SAS 的拥有比例在 10%到 30%之间,但没有增长 - 需求/拥有比例 < 1。
表 3:其他数据科学技能,按拥有比例的降序排列
| 技能 | %拥有 | %需求 | %需求/ %拥有 |
|---|---|---|---|
| 软件工程 | 25.7% | 15.2% | 0.59 |
| XGBoost | 22.3% | 19.0% | 0.85 |
| Java | 15.1% | 7.7% | 0.51 |
| SAS | 12.7% | 7.2% | 0.57 |
| MATLAB | 10.9% | 7.9% | 0.73 |
| Julia | 2.0% | 6.9% | 3.44 |
这里是关于调查的更多细节。图 2 按拥有比例的降序排列了所有技能。
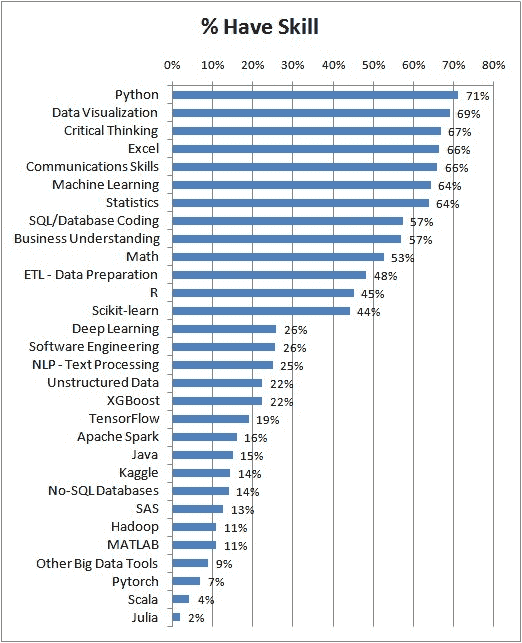
图 2:数据科学技能 KDnuggets 读者拥有的
图 3 显示了读者想要增加或改善的技能,以及他们拥有的技能的叠加。
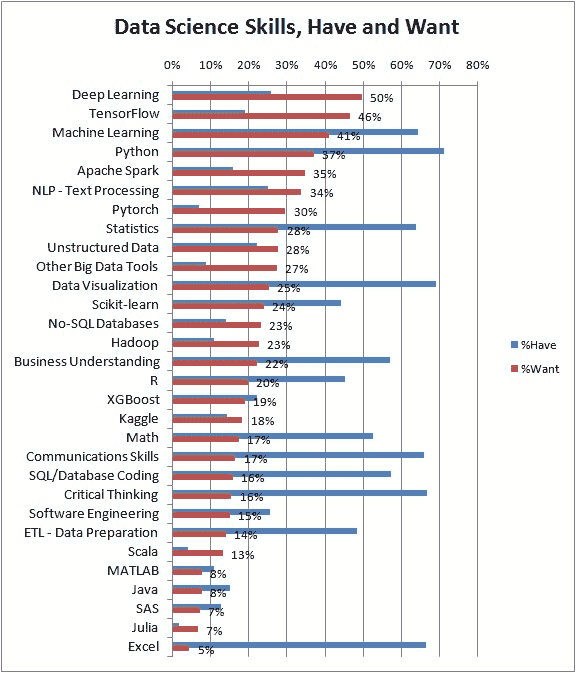
图 3:数据科学技能 KDnuggets 读者想要增加或改善(红色)和拥有(蓝色)
我们看到当前和有志成为数据科学家的顶级技能包括深度学习、Tensorflow、机器学习和 Python。
调查还询问了就业类型:
-
行业/自雇,64.4%
-
政府/非营利,7.2%
-
学术/大学,7.0%
-
学生,14.3%
-
其他/北美,7.1%
区域分布如下:
-
美国/加拿大,37.9%
-
欧洲,28.3%
-
亚洲,19.3%
-
拉丁美洲,6.1%
-
非洲/中东,4.8%
-
其他,3.5%
本次调查提供了初步分析,根据本帖的受欢迎程度,我们将进一步深入研究技能、就业类型和地区之间的关联。
注意:我们最初使用 Google 表单进行这项调查,但遭到机器人攻击,每个 Julia 和 MATLAB 的投票均超过 50,000 票。我们删除了机器人投票,同时保留了其他投票,并使用另一个平台重新启动调查,但不包括 Julia 和 MATLAB - 以避免再次攻击。最终 Julia 和 MATLAB 的结果是基于第一次调查版本中的有效投票估算的。
相关:
-
Python 引领数据科学和机器学习的 11 大平台:趋势与分析
-
Python 蚕食 R:2018 年分析、数据科学、机器学习的顶级软件:趋势与分析
-
成为摇滚明星数据科学家的 13 项顶级技能
-
数据科学家最需要的技能
-
我没有被聘为数据科学家。因此我寻找了谁在被雇佣的数据。
如何提升作为数据科学家的市场竞争力
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
使用 Biopython 进行冠状病毒 COVID-19 基因组分析
原文:
www.kdnuggets.com/2020/04/coronavirus-covid-19-genome-analysis-biopython.html
评论
新兴的全球传染病 COVID-19 由新型严重急性呼吸综合症冠状病毒 2 型 (SARS-CoV-2) 引起,自 2019 年 12 月底在中国首次发现以来,对全球公共卫生和经济带来了重大影响。
冠状病毒是一个庞大的病毒家族,能够引起范围广泛的疾病。第一个已知的由冠状病毒引起的严重疾病出现在 2003 年中国的严重急性呼吸综合症 (SARS) 疫情中。第二次严重疾病的爆发发生在 2012 年沙特阿拉伯的中东呼吸综合症 (MERS) 中。现在是 COVID-19 的持续爆发。
“通过比较已知冠状病毒株的可用基因组序列数据,我们可以确定 COVID-19 是通过自然过程起源的,”Scripps 研究所免疫学和微生物学副教授、论文通讯作者 Kristian Andersen 博士说。
因此,在这篇文章中,我们将解释和分析 COVID-19 DNA 序列数据,并尝试获取关于组成其蛋白质的尽可能多的见解。之后我们将把 COVID-19 DNA 与 MERS 和 SARS 进行比较,并理解它们之间的关系。
如果你对基因组学不熟悉,我建议你在继续之前查看 用机器学习和 Python 解密 DNA 测序 以获得 DNA 数据分析的基本理解。
冠状病毒是包膜病毒家族的一员,这些病毒在动物宿主细胞的细胞质中复制。它们通过具有 5′ 端帽结构和 3′ 聚腺苷酸化链的单链正义 RNA 基因组((+)ssRNA 分类的病毒),长度约为 30 kb 来识别。(已知最大病毒)。
现在,让我们使用 Python 来处理 COVID-19 DNA 序列数据。
首先,安装 Python 包如 Biopython 和 squiggle,它们将帮助你在 Python 中处理生物序列数据。
pip install biopython
pip install Squiggle
加载基本库:
import numpy as np
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import os
数据集可以从 Kaggle 下载。
我们将使用 Bio.SeqIO 来解析 DNA 序列数据(fasta)。它提供了一个简单统一的接口来输入和输出各种序列文件格式。
from Bio import SeqIOfor sequence in SeqIO.parse('/coronavirus/MN908947.fna', "fasta"):
print(sequence.seq)
print(len(sequence),'nucliotides')
所以它产生了序列及其长度。
GCAATGGATACAACTAGCTACAGAGAAGCTGCTTGTTGTCATCTCGCAAAGGCTCTCAATGACTTCAGTAACTCAGGTTCTGATGTTCTTTACCAACCACCACAAACCTCTATCACCTCAGCTGTTTTGCAGAGTGGTTTTAGAAAAATGGCATTCCCATC......AGAATGACAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA29903 nucliotides
将互补 DNA 序列加载到可比对的文件中
from Bio.SeqRecord import SeqRecord
from Bio import SeqIO
DNAsequence = SeqIO.read('/coronavirus/MN908947.fna', "fasta")
SeqIO.read() 将提供有关序列的基本信息。
SeqRecord(seq=Seq('ATTAAAGGTTTATACCTTCCCAGGTAACAAACCAACCAACTTTCGATCTCTTGT...AAA', SingleLetterAlphabet()), id='MN908947.3', name='MN908947.3', description='MN908947.3 Severe acute respiratory syndrome coronavirus 2 isolate Wuhan-Hu-1, complete genome', dbxrefs=[])
由于输入序列是 FASTA(DNA),而冠状病毒是 RNA 类型的病毒,我们需要:
-
将 DNA 转录为 RNA(ATTAAAGGTT… => AUUAAAGGUU…)
-
将 RNA 翻译为氨基酸序列(AUUAAAGGUU… => IKGLYLPR*Q…)
在当前的场景中,.fna 文件以 ATTAAAGGTT 开始,然后我们调用 transcribe(),所以 T(胸腺嘧啶)被替换为 U(尿嘧啶),因此我们得到的 RNA 序列以 AUUAAAGGUU 开始。
DNA = DNAsequence.seq#Convert DNA into mRNA Sequence
mRNA = DNA.transcribe() #Transcribe a DNA sequence into RNA.
print(mRNA)
print('Size : ',len(mRNA))
transcribe() 将 DNA 转换为 mRNA。
UAUUUUAGUGGAGCAAUGGAUACAACUAGCUACAGAGAAGCUGCUUGUUGUCAUCUCGCAAAGGCUCUCAAUGACUUCAGUAACUCAGGUUC...UAAUAGCUUCUUAGGAGAAUGACAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
Size : 29903
DNA 和 mRNA 之间的区别在于 碱基 T(胸腺嘧啶)被 U(尿嘧啶)取代。
接下来,我们需要使用 translate() 方法将 mRNA 序列翻译为氨基酸序列,我们会得到类似 IKGLYLPR*Q(这是所谓的 STOP 密码子,实际上是蛋白质的分隔符)的东西。
Amino_Acid = mRNA.translate(table=1, cds=False)
print('Amino Acid', Amino_Acid)
print("Length of Protein:",len(Amino_Acid))
print("Length of Original mRNA:",len(mRNA))
在下面的输出中,氨基酸由 * 分隔。
Amino Acid : IKGLYLPR*QTNQLSISCRSVL*TNFKICVAVTRLHA*CTHAV*LITNYCR*QDTSNSSIFCRLLTVSSVLQPIISTSRFRPGVTER*DGEPCPWFQRENTRPTQFACFTGSRRARTWLWRLRGGGLIRGTSTS*RWHLWLSRS*KRRFAST*TALCVHQTFGCSNCTSWSCYG...*SHIAIFNQCVTLGRT*KSHHIFTEATRSTIECTVNNARESCLYGRALMCKINFSSAIPM*F**LLRRMTKKKKKKKKKKLength of Protein : 9967
Length of Original mRNA : 29903
在我们的场景中,序列看起来像这样:IKGLYLPR*QTNQLSISCRSVL*TNFKICVAVTRLHA,其中:
IKGLYLPR 编码第一个蛋白质(每个字母编码一个氨基酸),QTNQLSISCRSVL 编码第二个蛋白质,以此类推。
请注意,蛋白质中的序列少于 mRNA 中的序列,因为 3 个 mRNA 用于生成一个蛋白质的单体,即氨基酸,使用下面的密码子表。* 用于表示终止密码子,在这些区域蛋白质已完成其完整长度。这些密码子经常出现,导致蛋白质长度较短,通常这些蛋白质在生物学上作用不大,将在进一步分析中被排除。
好的,首先了解什么是遗传密码和 DNA 密码子?
遗传密码 是由活细胞用来翻译编码在遗传物质(DNA 或 mRNA 的核苷酸三联体或 密码子)中的信息成蛋白质的一组规则。
标准遗传密码表通常表示为 RNA 密码子表,因为当细胞中的核糖体制造蛋白质时,是 mRNA 指导蛋白质合成。mRNA 序列由基因组 DNA 的序列决定。以下是一些密码子的特征:
-
大多数密码子指定一个氨基酸。
-
三个 “终止” 密码子标志着蛋白质的结束。
-
一个 “起始” 密码子 AUG 标志着蛋白质的开始,同时编码氨基酸甲硫氨酸。
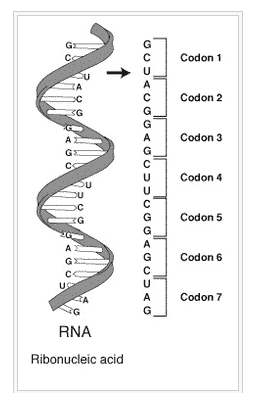
一系列密码子组成了信使 RNA(mRNA)分子的一部分。每个密码子由三个核苷酸组成,通常对应一个单独的氨基酸。这些核苷酸用字母 A、U、G 和 C 表示。这是 mRNA,使用 U(尿嘧啶)。DNA 则使用 T(胸腺嘧啶)。这个 mRNA 分子将指示一个核糖体根据这个代码合成蛋白质。来源
from Bio.Data import CodonTable
print(CodonTable.unambiguous_rna_by_name['Standard'])
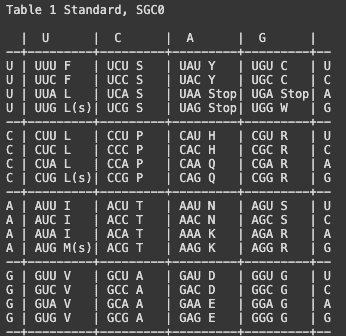
RNA 密码子表
现在让我们识别所有蛋白质(氨基酸链),基本上在终止密码子(由*标记)处进行分离。然后,移除任何少于 20 个氨基酸的序列,因为这是已知的最小功能性蛋白质(如果感兴趣)。
#Identify all the Proteins (chains of amino acids)
Proteins = Amino_Acid.split('*') # * is translated stop codon
df = pd.DataFrame(Proteins)
df.describe()
print('Total proteins:', len(df))def conv(item):
return len(item)def to_str(item):
return str(item)df['sequence_str'] = df[0].apply(to_str)
df['length'] = df[0].apply(conv)
df.rename(columns={0: "sequence"}, inplace=True)
df.head()# Take only longer than 20
functional_proteins = df.loc[df['length'] >= 20]
print('Total functional proteins:', len(functional_proteins))
functional_proteins.describe()
使用 ProtParam 的 Biopython 中的 Protparam 模块进行蛋白质分析。
ProtParam 中的可用工具:
-
count_amino_acids:简单地计算氨基酸在蛋白质序列中重复的次数。 -
get_amino_acids_percent:与之前的方法相同,只是返回整个序列的百分比数量。 -
molecular_weight:计算蛋白质的分子量。 -
aromaticity:根据 Lobry & Gautier (1994, Nucleic Acids Res., 22, 3174-3180)计算蛋白质的芳香性值。 -
flexibility:实现了 Vihinen et al. (1994, Proteins, 19, 141-149)的柔性方法。 -
isoelectric_point:此方法使用模块IsoelectricPoint来计算蛋白质的 pI 值。 -
secondary_structure_fraction:此方法返回一组氨基酸在螺旋、转角或片段中的比例。 -
螺旋中的氨基酸:V、I、Y、F、W、L。
-
转角中的氨基酸:N、P、G、S。
-
表中的氨基酸:E、M、A、L。
列表包含 3 个值:[螺旋、转角、片段]。
from __future__ import division
poi_list = []
from Bio.SeqUtils import ProtParam
for record in Proteins[:]:
print("\n")
X = ProtParam.ProteinAnalysis(str(record))
POI = X.count_amino_acids()
poi_list.append(POI)
MW = X.molecular_weight()
MW_list.append(MW)
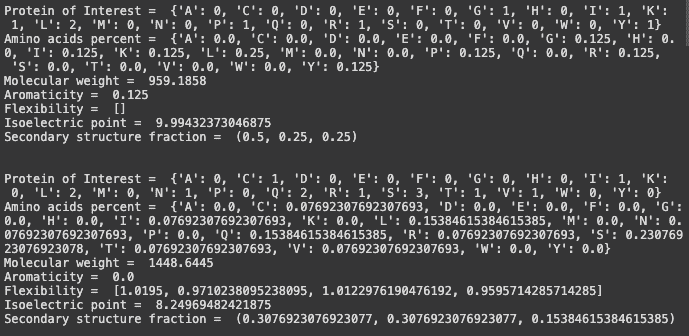
print("Protein of Interest = ", POI)
print("Amino acids percent = ",str(X.get_amino_acids_percent()))
print("Molecular weight = ", MW_list)
print("Aromaticity = ", X.aromaticity())
print("Flexibility = ", X.flexibility())
print("Isoelectric point = ", X.isoelectric_point())
print("Secondary structure fraction = ", X.secondary_structure_fraction())
绘制结果:
MoW = pd.DataFrame(data = MW_list,columns = ["Molecular Weights"] )#plot POI
poi_list = poi_list[48]
plt.figure(figsize=(10,6));
plt.bar(poi_list.keys(), list(poi_list.values()), align='center')
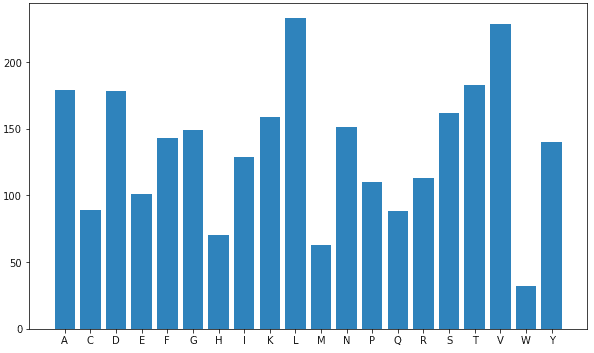
看起来这个蛋白质中的[**赖氨酸(L)**](https://www.sciencedirect.com/topics/medicine-and-dentistry/lysine)和[**缬氨酸(V)**](https://pubchem.ncbi.nlm.nih.gov/compound/Valine)数量较多,这表明有较多的α-螺旋。
现在让我们比较 COVID-19/COV2、MERS 和 SARS 之间的相似性。
加载 SARS、MERS 和 COVID-19 的 DNA 序列文件(FASTA)。
#Comparing Human Coronavirus RNA
from Bio import pairwise2SARS = SeqIO.read("/coronavirus/sars.fasta", "fasta")MERS = SeqIO.read("/coronavirus/mers.fasta", "fasta")COV2 = SeqIO.read("/coronavirus/cov2.fasta", "fasta")
序列长度:SARS:29751,COV2:29903,MERS:30119
在比较相似性之前,让我们分别可视化 COV2、SARS 和 MERS 的 DNA。
#Execute on terminal
Squiggle cov2.fasta sars.fasta mers.fasta --method=gates --separate
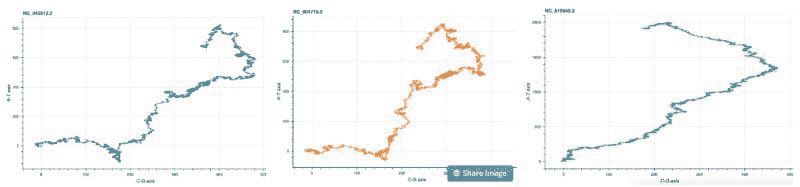
分别对 COV2、SARS 和 MERS 的 DNA 进行可视化。
我们可以观察到 COV2 和 SARS 的 DNA 结构几乎相同,而 MERS 的 DNA 结构与前两者有所不同。
现在让我们使用序列比对技术来比较所有 DNA 序列的相似性。
序列比对是将两个或多个序列(DNA、RNA 或蛋白质序列)按特定顺序排列的过程,以识别它们之间的相似区域。
识别相似区域使我们能够推断大量信息,如物种之间的保守性状、不同物种的遗传关系、物种的进化等。
两序列比对一次只比较两个序列,并提供最佳可能的序列比对。两序列比对易于理解,并且从结果序列比对中推断出的信息非常出色。
Biopython 提供了一个特殊的模块,Bio.pairwise2,用于使用两序列比对方法识别比对序列。Biopython 应用了最佳算法来找到比对序列,其表现与其他软件相当。
# Alignments using pairwise2 alghoritmSARS_COV = pairwise2.align.globalxx(SARS.seq, COV2.seq, one_alignment_only=True, score_only=True)print('SARS/COV Similarity (%):', SARS_COV / len(SARS.seq) * 100)MERS_COV = pairwise2.align.globalxx(MERS.seq, COV2.seq, one_alignment_only=True, score_only=True)print('MERS/COV Similarity (%):', MERS_COV / len(MERS.seq) * 100)MERS_SARS = pairwise2.align.globalxx(MERS.seq, SARS.seq, one_alignment_only=True, score_only=True)print('MERS/SARS Similarity (%):', MERS_SARS / len(SARS.seq) * 100)
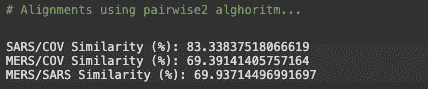
比较结果
完整病毒基因组(29,903 个核苷酸)的系统发育分析显示,COVID-19 病毒与一组SARS 类冠状病毒(贝塔冠状病毒属,萨尔贝科病毒亚属)关系最为密切(83.3% 核苷酸相似性),这些病毒之前在中国的蝙蝠中被发现。
绘制结果:
# Plot the data
X = ['SARS/COV2', 'MERS/COV2', 'MERS/SARS']
Y = [SARS_COV/ len(SARS.seq) * 100, MERS_COV/ len(MERS.seq)*100, MERS_SARS/len(SARS.seq)*100]
plt.title('Sequence identity (%)')
plt.bar(X,Y)
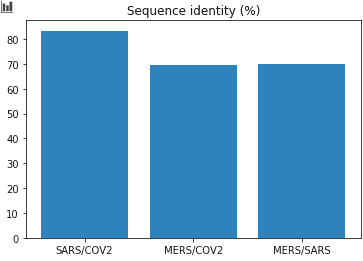
结论
我们已经看到了如何解读和分析 COVID-19 DNA 序列数据,并尝试获取尽可能多的关于构成其蛋白质的见解。在我们的结果中,我们发现该蛋白质中的[**亮氨酸(L**](https://www.sciencedirect.com/topics/medicine-and-dentistry/lysine)**)**和[**缬氨酸(V)**](https://pubchem.ncbi.nlm.nih.gov/compound/Valine)的数量较高,这表明该蛋白质中有较多的α-螺旋。
后来我们将 COVID-19 的 DNA 与 MERS 和 SARS 进行了比较。我们发现 COVID-19 与 SARS 关系密切。
这篇文章的内容就是这些。我希望你们喜欢阅读这篇文章,请在评论区分享你的建议/观点/问题。
感谢阅读!!!
个人简介: 纳格什·辛格·乔汉 是一位数据科学爱好者,关注大数据、Python 和机器学习。
原文。经许可转载。
相关:
-
通过机器学习探索生物信息学的世界
-
人工智能如何帮助管理传染病
-
数据科学家如何训练和更新模型以应对 COVID-19 复苏
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
当相关性优于因果关系时
原文:
www.kdnuggets.com/2021/08/correlation-better-causation.html
评论
作者 布列塔尼·戴维斯,Narrator.ai 数据主管

我们的前三名课程推荐
1. Google 网络安全证书 - 加快进入网络安全职业的步伐。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
“相关性不等于因果关系”
我不喜欢这个说法。不是因为它不准确(当然它是准确的)。我不喜欢它用来解除分析师武装的方式。这一句简单的话可以让任何分析在话语一出时陷入停滞。
当利益相关者说“是的……但相关性不等于因果关系”时,那就是“你的见解不够好,无法让我采取行动”的代名词。即终结者。
 来源:
来源: 这个流行的说法让决策者相信他们需要因果见解才能用数据做出决定。是的,在一个完美的世界里,我们只会依据因果见解行事。但实际上,这一要求并不合理。更多时候,当利益相关者要求“因果关系”来做决策时,往往需要过长时间,他们失去耐心,最终完全没有数据做决定。
考虑一下 A/B 测试。例如,这是团队目前应对因果关系要求的最常见方式。但 A/B 测试的正确执行出奇困难——正如无数统计学家挥手示意我们承认这一事实(比如 这个 和 这个)。悲哀的现实是,A/B 测试需要大量数据、完美的工程实施和高度的统计严谨性来正确完成……所以我们最终在没有有效结果的情况下发布新功能。
这种情况时常发生!但数据团队通过做出半心半意的因果证明尝试,最后依然根据直觉做决定,这并没有帮助我们。我们需要改变这种方法。
因果关系的缺点
现实是,证明因果关系是非常困难的。这不仅需要更高水平的统计严谨性,还需要大量精心收集的数据。这意味着你必须等待很长时间才能做出任何因果声明。这对其他因果推断方法也是如此,而不仅仅是 A/B 测试。
最终,因果关系在用数据做决策时是一个不切实际的要求。所以让我们停止尝试,找到另一种方法。让我们回到使用相关性上来。
我不是建议完全自由的尝试。我们不想得到那些“技术上相关”但没有合理解释的荒谬见解,比如这些。我说的是在商业环境中使用相关性,以最大化做出“最佳”决策的机会。并以这样的方式进行,使我们可以信任这些见解提供了关于任何给定决策如何影响我们关心的事物的合理期望。毕竟,这就是数据的目标。
解决方案:一种使用相关性来指导决策的启发式方法
要从相关性中获得可信的见解,我们希望最大化我们在数据中看到的相关关系实际上是因果关系的机会。我们可以通过遵循以下四个最佳实践来做到这一点。
1. 在测试相关性时要有意图
不要关联随机的事物。搜索足够长的时间,你必定会找到一个真正“令人惊讶”的相关性,就像这样。这种关系很可能是偶然的,这样你就浪费了你的时间和其他人的时间。统计学家将这种方法称为“p-hacking”。
 来源: https://www.tylervigen.com/spurious-correlations
来源: https://www.tylervigen.com/spurious-correlations
相反,要专注于已经存在关联的事物。一个很好的方法是关注客户的行动。如果你试图关联围绕客户行动的数据,你可以保证只探索那些实际以某种方式相关的行为。这听起来简单,但容易被忽视。例如,我们不应该看“我们推出课程的时间”如何影响客户报名的可能性,我们应该看“客户看到课程的时间”如何影响他们的报名可能性。因为我们从客户及其行动的角度来看所有行为,我们可以保证这些行动是相关的,增加了我们看到的相关关系也是因果关系的可能性。
2. 关联转化率,而不是总量
在大多数分析中,我们试图评估特定决策或变化将如何影响客户行为。客户行为最好用转化率来表示,而不是总量。如果我告诉你 10 人转化了,而 30 人转化了,这并不能告诉我客户的行为思维。如果我告诉你网站上 10%的人转化了,而 30%的人转化了,那么你就能更好地理解客户的转化意愿。
现在,设想一下将总电话咨询与总转化进行关联。我们可能会看到总电话咨询的增加与总转化的增加高度相关。显然是的,因为我们有更多的人在漏斗中,但我们直观地知道更多的电话咨询并不会引起更多的转化。它们只是因为受到另一因素(量)的影响而相关。通过查看转化率,我们可以更容易地挖掘出可以用来影响客户行为的见解。
你可能还想关联其他标准化指标(如平均订单价值),但如果可能的话,应避免这样做。这些指标可能具有更大的方差,这意味着你需要更多的数据来找到可靠的见解,或者你需要对指标进行降维(有效地将其转化为转化率),以减少方差,然后再进行分析。我现在不打算详细讨论这个,但我们将在未来的博客文章中涉及。在此期间,转化率始终是一个安全的选择。
3. 确保趋势在较长时间内保持一致
你的业务和客户总在变化,因此了解这一点很重要。我们通常会以聚合的方式查看相关性,将时间剥离出分析。然而,所有事物都在随时间变化,所以过去存在的相关性可能今天已经消失,如果不对数据进行时间上的分析,你将无法发现这一点。
由于历史行为是预测未来行为的最佳指标,我们需要查看数据随时间的变化情况,特别是我们分析的特征也在变化时。如果拥有 X 的人一直有更高的指标 Y,那么我们可以更容易地相信,当我们让更多人做 X 时,我们更有可能提高 Y。只要这种影响在时间上保持一致,我们就可以更有信心这些趋势在未来也是可靠的。
一个很好的例子是回顾你之前进行的 A/B 测试。当我们这样做时,我们发现其中一些测试在短时间内具有统计学意义,但随着时间推移并不一致。这是 A/B 测试中的 常见风险,因此许多专家建议进行常绿测试。不过这涉及很多工程复杂性,大多数团队最终没有设立。
 A/B 测试可以显示显著性,但对长期没有影响
A/B 测试可以显示显著性,但对长期没有影响
4. 始终监测结果
使用相关性的方法的缺陷在于我们可能会出错。虽然当我们遵循上述最佳实践时这种可能性较小,但仍然存在风险。但如果我们能迅速基于相关发现采取行动,并且密切监控结果,我们可以显著减少任何错误决策成为灾难的风险。顺便说一下,这同样适用于因果洞察。总是有风险事情不会按你预期的那样发展(像在这个警示故事中)。
在监测结果时,跟踪你所做的改变如何影响你想要实现的结果是很重要的。假设你发现使用折扣码的顾客与平均订单价值之间存在正相关。一旦你发现了相关趋势,你会希望将更多顾客慢慢转移到表现更好的群体中。然后,我们可以使用下面的图表来监控结果。
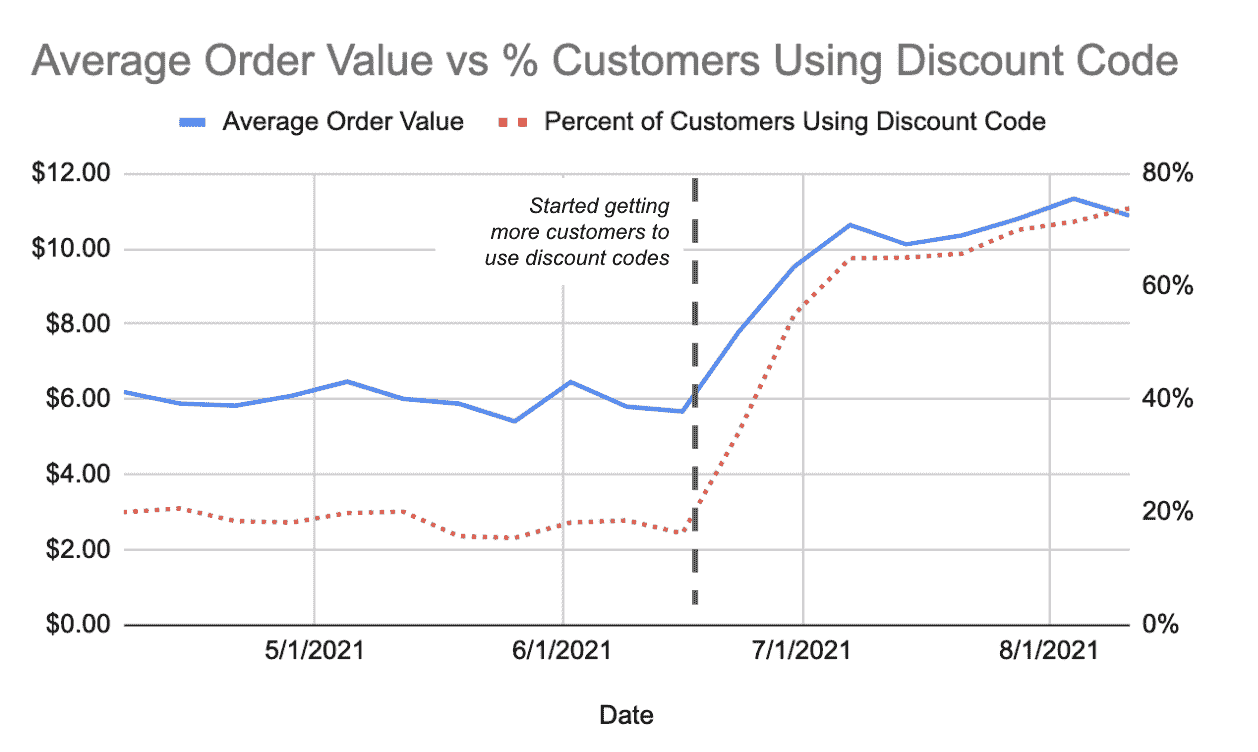
如果我们在做出更改时能跟踪这些数据,我们可以始终判断是否做出了正确的决策,并在未做对时快速纠正。
一种可重复、可靠的方法
我们可以自动化这种方法,分析结果将类似于下方的分析,使决策者能够更快地做出数据驱动的决策。
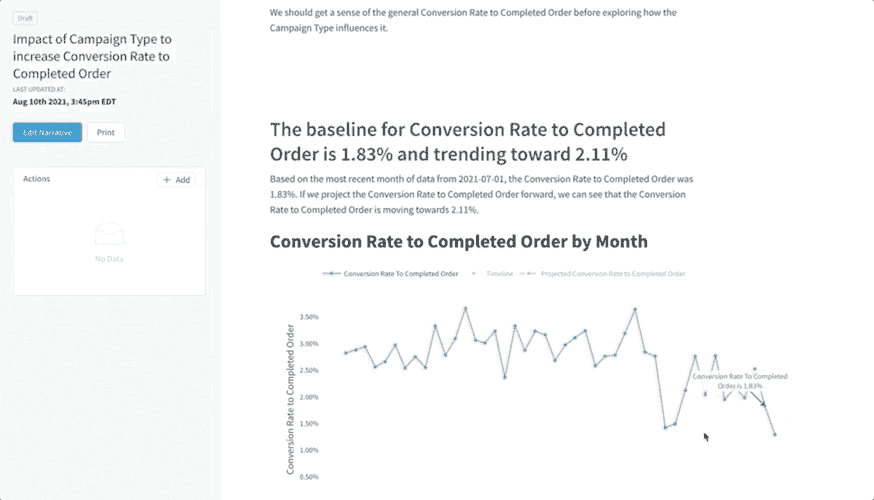 示例自动生成的分析由 叙述者 的分析按钮创建
示例自动生成的分析由 叙述者 的分析按钮创建
结论
实践中,我们需要准确的洞察力,并且必须迅速行动。等待两个月的分析以确定因果关系或等待四周的 A/B 测试完成并不实际。但是,如果我们能够迅速基于相关性做出行动,尤其是在这些相关性经过上述技术严格评估之后,我们将能做出更好的决策,更快地行动。因此,让我们淘汰“相关性不等于因果关系”这一说法,对相关性本身多一些信任。
简历: 布列塔尼·戴维斯 是 Narrator.ai 的数据主管。
原文。转载授权。
相关:
-
数据科学的 8 个基础统计概念
-
数据科学家必须了解的 10 个统计概念
-
你应该对预测变量的共线性有多担心?这要视情况而定…
更多相关话题
破解 SQL 面试
评论
由 Xinran Waibel, Netflix 数据工程师。

照片由 Green Chameleon 提供,来自 Unsplash。
SQL 是数据分析和数据处理最重要的编程语言之一,因此 SQL 问题总是数据科学相关职位面试的一部分,如数据分析师、数据科学家和 数据工程师。SQL 面试旨在评估候选人的技术和解决问题的能力。因此,不仅要基于样本数据编写正确的查询,还要考虑各种场景和边界情况,就像处理实际数据集一样。
我曾帮助设计和进行数据科学候选人的 SQL 面试问题,并且自己也经历了许多大型科技公司和初创公司的 SQL 面试。在这篇博客文章中,我将解释 SQL 面试问题中常见的模式,并提供如何在 SQL 查询中整洁处理它们的技巧。
提问
要顺利通过 SQL 面试,最重要的是确保你掌握了给定任务和数据样本的所有细节,通过提出尽可能多的问题来理解需求。这将节省你后来在解决问题上的时间,并使你能够妥善处理边界情况。
我注意到许多候选人往往直接进入解决方案,而没有对 SQL 问题或数据集有充分的理解。后来,当我指出他们解决方案中的问题时,他们不得不反复修改查询。最终,他们在迭代过程中浪费了很多面试时间,甚至可能没有找到正确的解决方案。
我建议把 SQL 面试当作与工作中的业务伙伴合作来对待。在提供解决方案之前,你需要收集所有关于数据请求的需求。
示例
找出薪资最高的前三名员工。
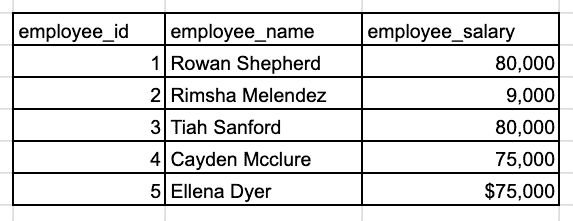
样本 employee_salary 表。
你应该询问面试官澄清“前三名”的定义。我是否需要在结果中包含确切的三名员工?如何处理平局情况?此外,仔细查看样本员工数据。薪资字段的数据类型是什么?是否需要在计算之前清理数据?
哪种 JOIN
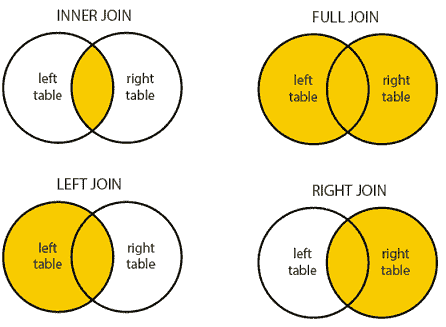
来源:dofactory.
在 SQL 中,JOIN 经常用于将多个表的信息结合起来。有 四种不同的 JOIN 类型,但在大多数情况下,我们只使用 INNER、LEFT 和 FULL JOIN,因为 RIGHT JOIN 不太直观,并且可以很容易地用 LEFT JOIN 替代。在 SQL 面试中,你需要根据给定问题的具体要求选择合适的 JOIN。
示例
找出每个学生修过的课程总数。(提供学生 ID、姓名和修课数。)
![]() *
*
 *
*示例学生和 class_history 表。
正如你可能注意到的,并不是所有出现在 class_history 表中的学生都在 student 表中,这可能是因为这些学生已不再在校。(在事务型数据库中,这其实很典型,因为记录通常在不活跃后会被删除。)根据面试官是否希望结果中包含不活跃学生,我们需要使用 LEFT JOIN 或 INNER JOIN 来结合两个表:
WITH class_count AS (
SELECT student_id, COUNT(*) AS num_of_class
FROM class_history
GROUP BY student_id
)
SELECT
c.student_id,
s.student_name,
c.num_of_class
FROM class_count c
-- CASE 1: include only active students
JOIN student s ON c.student_id = s.student_id
-- CASE 2: include all students
-- LEFT JOIN student s ON c.student_id = s.student_id

图片由 petr sidorov 提供,来自 Unsplash。
GROUP BY
GROUP BY 是 SQL 中最重要的函数,因为它广泛用于数据汇总。如果你在 SQL 问题中看到 sum、average、minimum 或 maximum 等关键词,这通常是一个很大的提示,表明你可能需要在查询中使用 GROUP BY。一个常见的陷阱是将 WHERE 和 HAVING 混合使用在与 GROUP BY 相关的数据过滤中——我见过很多人犯这个错误。
示例
计算每个学生每学年的平均必修课 GPA,并找出每学期符合院长名单要求的学生(GPA ≥ 3.5)。
![]() *
*
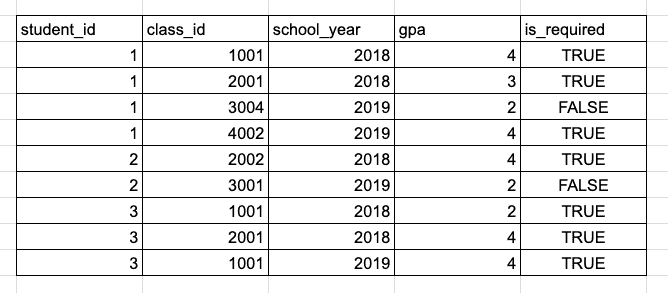 *
*示例 GPA 历史表。
由于我们在 GPA 计算中仅考虑必修课程,我们需要使用 WHERE is_required = TRUE 排除选修课程。我们需要每个学生每年的平均 GPA,因此我们将按 student_id 和 school_year 列进行 GROUP BY,并计算 gpa 列的平均值。最后,我们仅保留学生平均 GPA 高于 3.5 的行,这可以通过 HAVING 实现。让我们把一切整合在一起:
SELECT
student_id,
school_year,
AVG(gpa) AS avg_gpa
FROM gpa_history
WHERE is_required = TRUE
GROUP BY student_id, school_year
HAVING AVG(gpa) >= 3.5
请记住,每当在查询中使用 GROUP BY 时,你只能选择分组列和聚合列,因为其他列的行级信息已被丢弃。
有些人可能会疑惑 WHERE 和 HAVING 之间的区别,或者为什么我们不直接写 HAVING avg_gpa >= 3.5 而不指定函数。我将在下一节中详细解释。
SQL 查询执行顺序
大多数人从 SELECT 开始自上而下地编写 SQL 查询,但你知道 SELECT 是 SQL 引擎执行的最后几个函数之一吗?下面是 SQL 查询的执行顺序:
-
FROM, JOIN
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
DISTINCT
-
ORDER BY
-
LIMIT, OFFSET
再次考虑前面的例子。因为我们想在计算平均 GPA 之前筛选出可选课程,我使用了 WHERE is_required = TRUE 而不是 HAVING,因为 WHERE 在 GROUP BY 和 HAVING 之前执行。我不能写 HAVING avg_gpa >= 3.5 的原因是 avg_gpa 是作为 SELECT 的一部分定义的,因此在 SELECT 之前执行的步骤中无法引用它。
我建议在编写查询时遵循执行顺序,这对于那些在编写复杂查询时遇到困难的人很有帮助。

照片由 Stefano Ghezzi 提供,来自 Unsplash。
窗口函数
窗口函数 也经常出现在 SQL 面试中。常见的窗口函数有五种:
-
RANK/DENSE_RANK/ROW_NUMBER:这些函数通过对特定列进行排序来为每行分配一个排名。如果给定了任何分区列,行会在它所属的分区组内排名。
-
LAG/LEAD:它从指定顺序和分区组中检索前一行或后一行的列值。
在 SQL 面试中,理解排名函数的区别并知道何时使用 LAG/LEAD 是非常重要的。
示例
找到每个部门中薪资最高的前 3 名员工。

另一个示例 employee_salary 表。
当 SQL 问题要求“TOP N”时,我们可以使用 ORDER BY 或排名函数来回答问题。然而,在这个例子中,它要求计算“每个 Y 中的 TOP N X”,这强烈暗示我们应该使用排名函数,因为我们需要在每个分区组内对行进行排名。
以下查询准确地找到 3 名薪资最高的员工,无论是否有并列:
WITH T AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_salary DESC) AS rank_in_dep
FROM employee_salary)
SELECT * FROM T
WHERE rank_in_dep <= 3
-- Note: When using ROW_NUMBER, each row will have a unique rank number and ranks for tied records are assigned randomly. For exmaple, Rimsha and Tiah may be rank 2 or 3 in different query runs.
此外,根据如何处理并列情况,我们可以选择不同的排名函数。细节很重要!
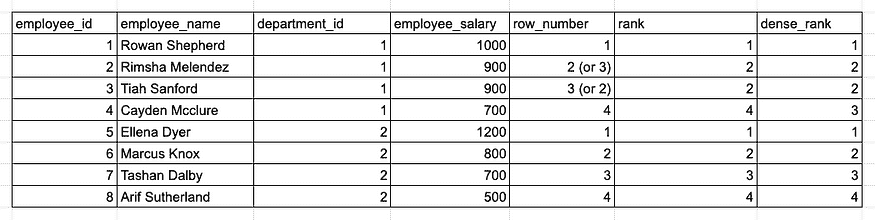
ROW_NUMBER、RANK 和 DENSE_RANK 函数的结果比较。

照片由 Héctor J. Rivas 提供,来自 Unsplash。
复制
另一个常见的 SQL 面试陷阱是忽略数据重复。虽然某些列在样本数据中似乎有不同的值,但候选人需要考虑所有可能性,就像他们在处理真实世界的数据集一样。例如,在前面的employee_salary表中,可能会有员工共享相同的姓名。
避免潜在重复问题的一种简单方法是始终使用 ID 列来唯一标识不同记录。
示例
使用employee_salary表计算所有部门每个员工的总工资。
正确的解决方案是通过employee_id进行分组,并使用SUM(employee_salary)计算总工资。如果需要员工姓名,可以在最后与员工表连接以检索员工姓名信息。
错误的方法是通过employee_name进行分组。
NULL
在 SQL 中,任何谓词都可能产生三种值之一:true、false 和NULL,一个保留的关键字表示未知或缺失的数据值。处理 NULL 数据集可能出乎意料地棘手。在 SQL 面试中,面试官可能会特别关注你的解决方案是否处理了 NULL 值。有时候,如果一个列不允许 NULL(例如 ID 列),这点是明显的,但对于大多数其他列,可能会存在 NULL 值。
我建议确认样本数据中的关键列是否允许 NULL,如果允许,请使用IS (NOT) NULL、IFNULL和COALESCE等函数来处理这些边界情况。
(想了解更多关于如何处理 NULL 值的信息?查看我关于 SQL 中 NULL 处理的指南。)
沟通
最后但同样重要的是——在 SQL 面试中保持沟通。
我面试过许多候选人,他们除了有问题时几乎不说话,这在他们最终提出完美解决方案的情况下是可以接受的。然而,在技术面试中,保持沟通通常是一个好主意。例如,你可以讨论你对问题和数据的理解,计划如何解决问题,为什么选择某些函数而不是其他替代方案,以及你考虑了哪些边界情况。
总结:
-
始终先提问以获取所需的详细信息。
-
仔细选择 INNER、LEFT 和 FULL JOIN。
-
使用 GROUP BY 来汇总数据,并正确使用 WHERE 和 HAVING。
-
理解三种排名函数之间的区别。
-
了解何时使用 LAG/LEAD 窗口函数。
-
如果你在创建复杂查询时遇到困难,可以尝试遵循 SQL 执行顺序。
-
考虑潜在的数据问题,如重复和 NULL 值。
-
与面试官沟通你的思路。
为了帮助你了解如何在实际的 SQL 面试中运用这些策略,我将在下面的视频中带你逐步解答一个 SQL 面试问题:
原文。经授权转载。
简介: Xinran Waibel 是一位经验丰富的数据工程师,位于旧金山湾区,目前在 Netflix 工作。她也是《Towards Data Science》、《Google Cloud》和《The Startup》在 Medium 上的技术作者。
相关:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
破解数据科学家面试
原文:
www.kdnuggets.com/2019/01/cracking-data-scientist-interview.html
评论
作者:Ajit Samudrala,Symantec 数据科学家
在 2018 年 8 月完成了我在 Sirius 的数据科学实习后,我开始寻找全职数据科学职位。我的初始搜索非常随意,简历和 Linkedin 个人资料也只是平庸。毫无意外地,我花了一个月才开始取得进展。经过 40 天的搜索,我收到了 Google 针对数据科学家的职位的首个回应。我激动不已,因为我甚至在最疯狂的梦想中都没想到会收到 Google 的电话。虽然我未能进入现场面试,但这是一次很好的学习经历。之后,我还与 Apple、SAP、Visa、Walmart、Nielsen、Symantec、Swiss Re、AppNexus、Catalina、Cerego 和另外 40 家公司进行数据科学家/机器学习工程师的面试。最终,我加入了 Symantec 在 Mountain View 的总部。我将以问答的形式总结我的经历,并试图揭穿初学者在成为数据科学家过程中可能存在的任何误解。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
1. 整个求职过程中最困难的部分是什么?
面试的反复无常。数据科学家是一个非常泛泛的术语;在我的求职过程中,我见过几种不同的类型。例如,我面试的 Google 职位主要集中在统计建模和实验设计。而与 Cerego 的面试则主要基于深度学习和自然语言处理。有些公司对软件开发和编码的重视程度与数据科学相当。我发现深度学习角色通常要求有相当的软件开发知识。
面试各种角色的问题在于,可能会变成一个无所不通但无所精通的人。我就经历过这种情况;我发现自己有时专注于统计学,一天后又转向机器学习/深度学习。虽然学习两个领域是好事,但要同时掌握这两个领域需要更长的时间。
2. 整个求职过程中最精彩的部分是什么?
我面试了从大公司到初创公司的各个领域。了解这些公司/团队如何利用数据科学解决业务问题让我大开眼界。我特别被几个用例震撼了,一个是在医疗保健领域,另一个是在机器人技术领域。在求职结束时,我感到会怀念与经理们的那些有趣的介绍。
3. 面试中主要需要哪些技能才能取得成功?
如第一个问题所建议的,每个角色所需的技能有所不同。尽管如此,我强烈推荐在 SQL、Python、机器学习/深度学习、统计学和分布式计算方面打下坚实的基础。掌握计算机科学基础知识,如算法和数据结构,尤其对面试技术公司时非常有帮助。一旦基础知识掌握到位,你可以深入研究你的兴趣领域。
4. 可能有成千上万的在线数据科学资源/导师/播客可供选择。我应该在哪里学习?
不要被数据科学/机器学习周围的各种喧嚣所迷惑。有许多机构、个人和书籍声称可以在 100 天或 3 个月内教授机器学习。虽然我不能对这些声明的真实性发表评论,但我强烈建议远离这些,并坚持使用 Coursera、MIT OpenCourseWare、斯坦福在线课程、NPTEL 等受欢迎且可靠的资源。此外,你无需花费任何费用就能从这些来源学习。
5. 除了学习概念,我应该把大部分时间花在什么地方?
花时间在 stats.stackexchange 和 Kaggle 上。利用 StackExchange 提升理论知识,用 Kaggle 进行应用实践。许多统计学/机器学习的概念并不十分直观,所以可以大胆搜索最基本的问题,如“随机森林是否总是比决策树表现更好?”,我敢打赌,有一些好心人可能在 StackExchange 上详细回答了许多类似的问题。
话虽如此,我发现许多数据科学面试已从测试理论知识转向通过家庭作业和案例研究来测试应用能力。Kaggle 非常有用,因为有许多精美的内核详细阐述了思考过程和解决方案的方法。
6. 如何在家庭作业和案例研究中表现出色?

大多数面试官更关注你的方法而非家庭作业的结果。所以,创造性和失败是可以接受的。
准备一个包含所有可重用函数的机器学习模板。在 Scikit-Learn 和 Matplotlib 上构建一个 API,以便你可以快速进行探索性数据分析(EDA)和构建基本模型。一旦完成了基本模型,你可以通过堆叠不同的模型、使用一个模型的预测来改善另一个模型,或其他任何可能引起面试官兴趣的疯狂尝试来开始发挥创意。如果成功了,那很好。如果失败了,你仍然会因为尝试不同的方法而获得好评。
关于案例研究,我认为最佳来源是 Google、Facebook、Twitter、eBay、Zillow 等公司的官方数据科学博客。通过阅读这些博客,你可以了解这些公司如何用机器学习/统计建模解决业务问题以及他们在过程中遇到的挑战。
7. 如何从人群中脱颖而出?

你可以用几种不同的方法来实现这一点。在我看来,培养阅读、消化和实施研究论文的能力会让你在众人中脱颖而出。尽管对初学者来说这是一个艰巨的任务,但从实现简单的组件的论文开始是一个不错的起点。起初,我曾经很难阅读研究论文,但几个月后,我至少能够从中实现基本的组件。
在流行的数据科学博客上写文章也可以帮助你获得一些额外的分数。选择一个未被广泛探索的话题或对一个概念给出独特的观点,以从你的工作中获得最大收益。
8. 领域专长的重要性如何?
在某些领域,面试官可能会非常重视领域专长。然而,对于一个入门级的数据科学家来说,我认为这不应该成为问题,你不必犹豫去申请任何领域的数据科学家职位。
9. 我是否应该申请技能要求过高的职位?
是的,你应该这样做。我曾收到一些职位的电话,这些职位的 JD 包含了一些不常见的术语,如 VAEs、GANs、Transformers、NLU、RF 学习、C++等。尽管破解这些可能很困难,但你仍然可以获得很好的学习经验。
10. 我是否应该做一些认证或投资时间学习一些工具?
虽然获得认证是好的,但我认为这在数据科学中不会给你的申请增加实质性的价值。关于工具,了解流行的部署工具是有益的。除此之外,花时间掌握开源框架,如 Hive、Kafka、Spark 等,是一种好方法。
11. 我的未来计划是什么?
我将继续从我的工作和才华横溢的同事那里学习。此外,我计划学习 RF 学习和 Java。如果有好的课程或书籍,请告诉我。我还会尽量在 Medium 上活跃,发布我的学习成果。
12. 随机提示
-
在面试中使用数据科学家的语言。
-
在家庭作业中编写干净且易于理解的代码。
-
练习 LeetCode 上的简单和中级问题,以备战白板面试。
-
如果失败不要灰心;在获得我的第一个工作机会之前,我经历了 43 次面试失败。
-
准备好面对面试的不确定性。许多公司仍未形成数据科学面试的标准流程。我参加的其中一个面试完全基于贝叶斯推断。
-
不要被互联网上阅读到的疯狂内容吓倒。大多数公司并不需要或使用这些内容。首先要掌握基础知识。
如果有我遗漏的常见问题,请在帖子下方评论。我会根据您的反馈不断更新帖子。您可以在 LinkedIn 上这里与我联系。
附言:本文针对初学者或首次转行进入数据科学领域的人。
个人简介:Ajit Samudrala 是 Symantec 的数据科学家。
原文。转载已获许可。
相关:
-
在接受那份华丽的数据科学工作之前再三思考
-
为什么你不应该成为数据科学通才
-
Netflix 数据科学面试问题: 如何通过 AI 面试
更多相关内容
机器学习中的博弈论速成课程:经典与新观念
原文:
www.kdnuggets.com/2020/03/crash-course-game-theory-machine-learning.html
评论

博弈论是数学中最迷人的领域之一,它影响了经济学、社会科学、生物学以及计算机科学等多个领域。关于博弈论的思考方式有很多种,但我发现一种虽然过于简化但非常有用的方式是:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
博弈论是带有激励的概率
游戏在人工智能(AI)的发展中扮演了关键角色。首先,游戏环境正在成为强化学习或模仿学习等领域的热门训练机制。理论上,任何多智能体 AI 系统都可以接受其参与者之间的游戏化互动。制定游戏原理的数学分支称为博弈论。在人工智能(AI)和深度学习系统的背景下,博弈论对实现多智能体环境中的关键能力至关重要,在这些环境中,不同的 AI 程序需要互动或竞争以实现目标。
博弈论的历史与计算机科学的历史息息相关。目前博弈论的许多研究可以追溯到计算机科学先驱如艾伦·图灵或约翰·冯·诺依曼的工作。由电影《美丽心灵》普及的著名纳什均衡是现代系统中许多人工智能交互的基石。然而,使用博弈论原理来建模人工智能宇宙时,往往超出了纳什均衡的范围。理解使用博弈论原理设计人工智能系统的影响,一个好的起点是理解我们在社会或经济交互中通常遇到的不同类型的游戏。
我们每天参与数百次基于游戏动态的互动。然而,这些游戏化环境的架构完全不同,参与者的激励和目标也各异。如何将这些原则应用于 AI 代理建模?这是一个推动整个 AI 研究领域(如多智能体强化学习)的挑战。
尽管游戏显然是博弈论的最直观体现,但这远不是这些概念唯一应用的领域。从这个角度来看,还有许多其他领域可以受到博弈论与 AI 结合的影响。事实上,大多数涉及多个“参与者”合作或竞争以完成任务的场景都可以通过 AI 技术进行游戏化和改进。尽管之前的陈述是一种概括,但我希望它传达了博弈论与 AI 是一种思考和建模软件系统的方法,而不是具体的技术。
为了使一个 AI 场景成为使用博弈论的良好候选者,它应该涉及多个参与者。例如,像 Salesforce Einstein 这样的销售预测优化 AI 系统并不是应用博弈论原则的理想候选者。然而,在多参与者环境中,博弈论可以极为有效。设计 AI 系统中的游戏动态可以总结为两个基本步骤:
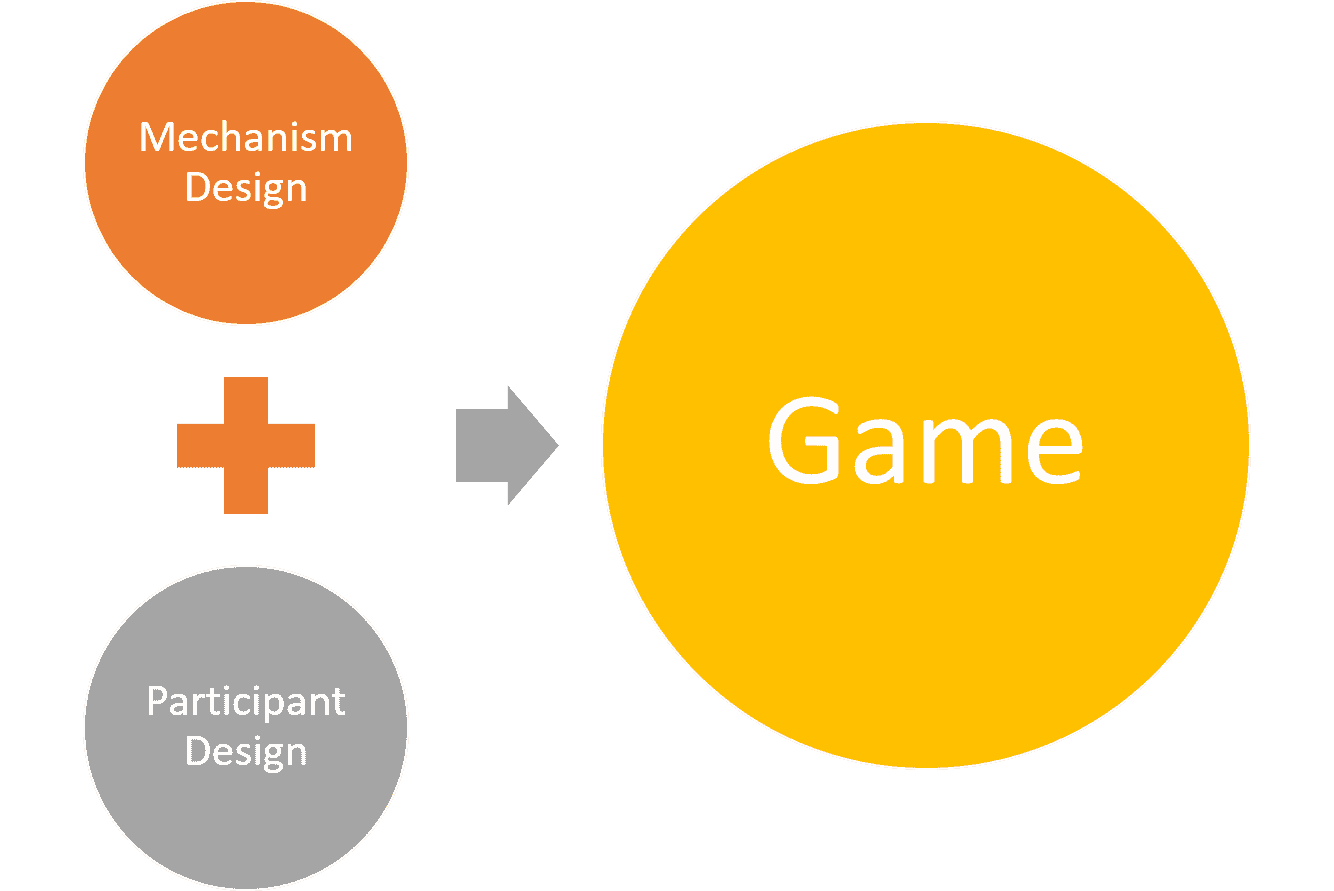
-
参与者设计: 博弈论可以用来优化参与者的决策,以获得最大效用。
-
机制设计: 反向博弈论专注于为一组智能参与者设计游戏。拍卖是机制设计的经典例子。
数据科学家应该了解的 5 种游戏类型
假设我们正在建模一个涉及多个代理的 AI 系统,这些代理将合作和竞争以实现特定目标。这是博弈论的经典例子。自 20 世纪 40 年代以来,博弈论一直专注于建模我们现在在多智能体 AI 系统中每天看到的最常见的互动模式。理解环境中的不同游戏动态是设计高效游戏化 AI 系统的关键要素。在高层次上,我喜欢使用五个要素标准来理解 AI 环境中的游戏动态:
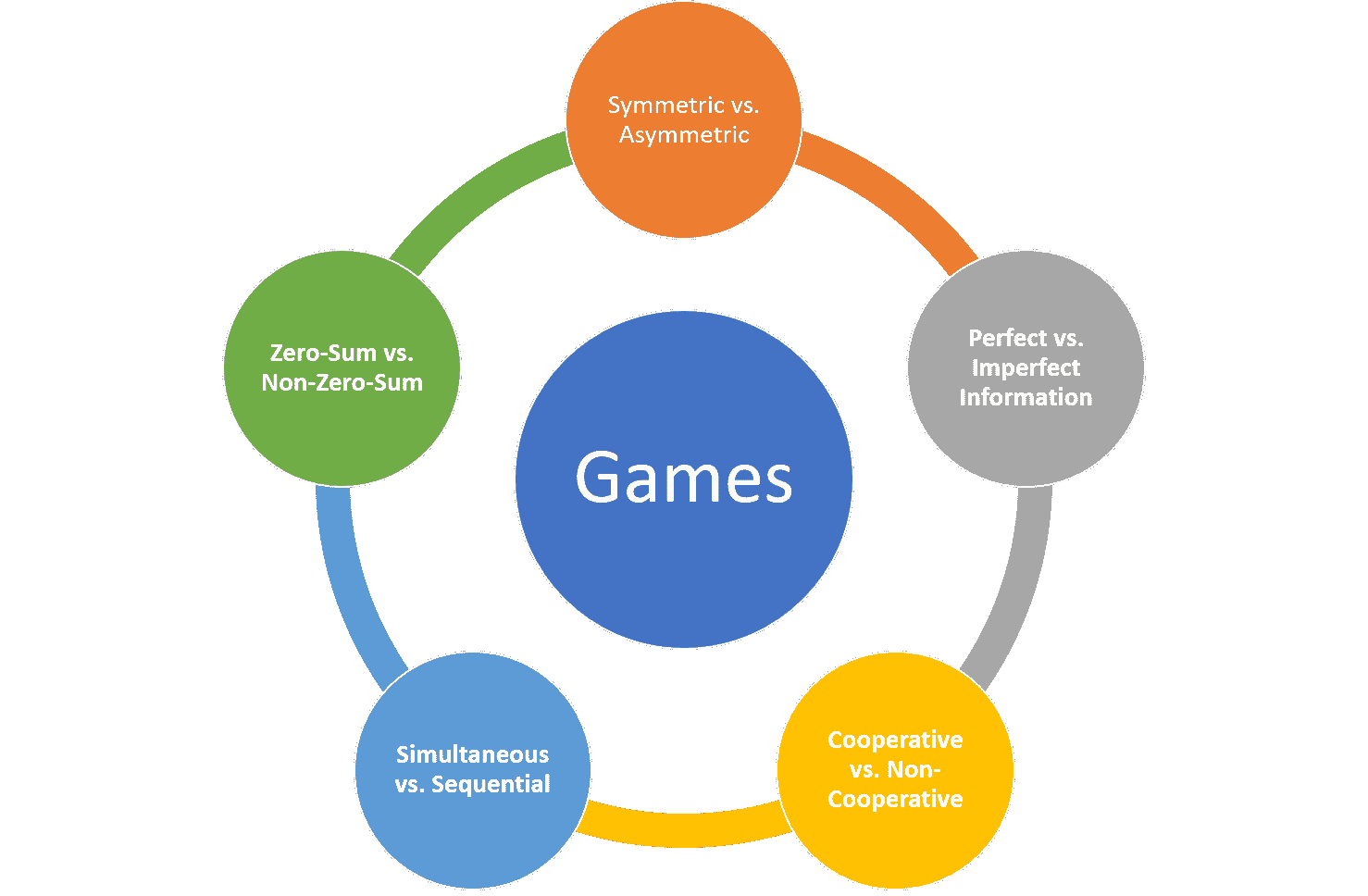
对称与不对称。
最简单的游戏分类之一是基于其对称性。对称博弈描述了一种环境,在这种环境中每个玩家有相同的目标,结果仅取决于所涉及的策略。棋类游戏是对称博弈的经典例子。我们在现实世界中遇到的许多情境缺乏数学对称的优雅,因为参与者通常有不同甚至冲突的目标。商业谈判是一个不对称博弈的例子,在这种博弈中,每一方有不同的目标,并从不同的角度评估结果(例如:赢得合同与最小化投资)。
完美信息与不完美信息
另一种重要的游戏分类是基于可用信息的类型。完美信息博弈指的是每个玩家都可以看到其他玩家的动作的环境。棋类游戏再次是完美信息博弈的一个例子。许多现代互动基于这样一种环境,即每个玩家的动作对其他玩家是隐藏的,博弈理论将这些情境分类为不完美信息博弈。从扑克牌游戏到自动驾驶汽车场景,不完美信息博弈无处不在。
合作博弈与非合作博弈
合作博弈环境是指不同的参与者可以建立联盟以最大化最终结果的环境。合同谈判通常被建模为合作博弈。不合作情境描述的是禁止玩家形成联盟的环境。战争是非合作博弈的终极例子。
同时博弈与顺序博弈
顺序博弈发生在一个玩家对其他玩家早期行动有信息的环境中。棋盘游戏大多本质上是顺序的。同时博弈则代表了两个玩家可以采取同时行动的情境。证券交易是同时博弈的一个例子。
零和博弈与非零和博弈
零和博弈指的是一种情境,其中一个玩家的获胜总是转化为其他玩家的损失。棋盘游戏是零和博弈的例子。非零和博弈通常出现在多个玩家可以从一个玩家的行动中获益的情境中。经济互动中多个参与者合作以增加市场规模就是非零和博弈的一个例子。
纳什均衡
对称博弈主宰了人工智能世界,其中大多数基于过去一个世纪最著名的数学理论之一:纳什均衡。
纳什均衡以 约翰·福布斯·纳什 的名字命名,这位美国数学家因在电影 《美丽心灵》 中由拉塞尔·克劳饰演而被铭记。基本上,纳什均衡描述了一种情况,其中每个玩家都选择了一种策略,并且没有玩家可以通过改变策略来获得更大的利益,同时其他玩家保持其策略不变。
纳什均衡是一个美丽且极其强大的数学模型,用于解决许多博弈论问题,但在许多不对称博弈环境中也存在不足。首先,纳什方法假设玩家具有无限的计算能力,而这在现实世界中几乎不可能发生。此外,许多纳什均衡模型未能考虑到风险这一概念,而风险在大多数不对称博弈和经济市场中是普遍存在的。因此,有许多不对称博弈场景很难使用纳什均衡进行实现。这在需要在解决方案的数学优雅性与实施的实际性之间找到正确平衡的多智能体 AI 系统中尤为重要。
对机器学习产生影响的博弈论新思想
多智能体 AI 系统是 AI 生态系统中最令人着迷的研究领域之一。近期在多智能体系统等领域的进展正在推动博弈论的边界,依赖于该领域的一些最复杂的思想。以下是一些在现代机器学习中非常常见的博弈论子学科的例子。
平均场博弈
平均场博弈(MFG) 是博弈论领域中相对较新的一个领域。MFG 理论在 2006 年由 Minyi Huang、Roland Malhamé 和 Peter Caines 在蒙特利尔,以及 Jean-Michel Lasry 和菲尔兹奖得主 Pierre-Louis Lions 在巴黎发表的一系列独立论文中首次提出。从概念上讲,MFG 包括用于研究具有大量理性玩家的微分博弈的方法和技术。这些代理不仅对自身状态(如财富、资本)有偏好,还对群体中其余个体的分布有偏好。MFG 理论研究这些系统的广义纳什均衡。
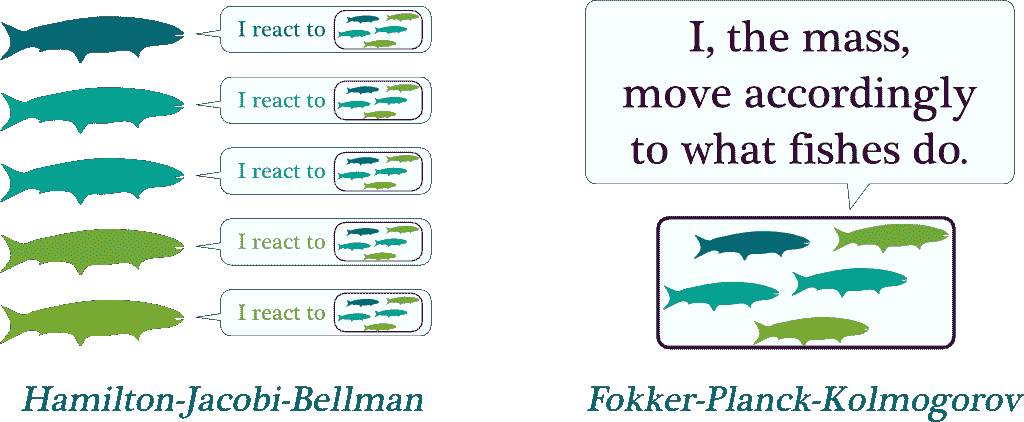
平均场博弈的经典例子是鱼群如何以协调的方式朝同一方向游动。从理论上讲,这种现象确实很难解释,但它的根源在于鱼对最近群体行为的反应。更具体地说,每条鱼并不关心其他鱼的个体行为,而是关心附近的鱼群整体的运动。如果我们将其转化为数学术语,鱼对鱼群的反应可以用哈密顿-雅可比-贝尔曼方程来描述。另一方面,鱼群行为的聚合决定了质量的运动,对应于福克-普朗克-科尔莫戈罗夫方程。均场博弈理论就是这两个方程的结合。
随机游戏
随机游戏可以追溯到 1950 年代,由诺贝尔经济学奖得主Lloyd Shapley引入。从概念上讲,随机游戏是由有限数量的玩家在有限状态空间上进行的,每个状态下,每个玩家选择有限个行动之一;这些行动的结果决定了每个玩家的奖励以及对后继状态的概率分布。
一个经典的随机游戏形式是哲学家就餐问题,其中有 n + 1 名哲学家(n ≥ 1)坐在一个圆桌旁,中间有一碗米饭。任何两个相邻的哲学家之间都有一根筷子,两个哲学家都可以使用。由于桌子是圆的,所以筷子的数量与哲学家的数量相同。要从碗里吃饭,哲学家需要同时获得他能接触到的两根筷子。因此,如果一个哲学家在吃饭,那么他的两个邻居不能同时吃饭。哲学家的生活非常简单,包括思考和吃饭;为了生存,哲学家需要不断地思考和吃饭。任务是设计一个协议,使所有哲学家都能生存。

演化博弈
演化博弈论(EGT)受达尔文进化理论的启发。EGT 的起源可以追溯到 1973 年,约翰·梅纳德·史密斯和乔治·R·普赖斯对竞赛的形式化分析,研究了策略的数学标准,以预测竞争策略的结果。从概念上讲,EGT 是将博弈论的概念应用于一个多样化策略的群体在时间上互动以形成稳定解决方案的情况,这个过程是通过选择和复制的演化过程来实现的。EGT 的主要思想是许多行为涉及到一个群体中多个代理的互动,而这些代理中的任何一个的成功取决于其策略如何与其他代理的策略互动。虽然经典博弈论关注的是静态策略,也就是说那些不会随时间变化的策略,但演化博弈论则不同于经典博弈论,它关注的是策略如何随着时间演变,以及哪些动态策略在这一演化过程中最成功。
EGT 的一个经典例子是鹰鸽博弈,该博弈模拟了鹰与鸽子之间对可分享资源的争夺。在游戏中,每个参赛者都会遵循以下两种策略中的一种:
-
鹰:发起攻击性行为,直到受伤或对手退却为止。
-
鸽子:如果对手发起攻击性行为,则立即撤退。
如果我们假设(1)每当两个个体都发起攻击性行为时,最终会发生冲突,并且两个个体受伤的可能性相同,(2)冲突的成本会将个体适应度降低一个常数值C,(3)当一只鹰遇到一只鸽子时,鸽子会立即撤退,鹰获得资源,以及(4)当两只鸽子相遇时,资源将被平分,那么鹰鸽博弈的适应度收益可以根据以下矩阵总结:
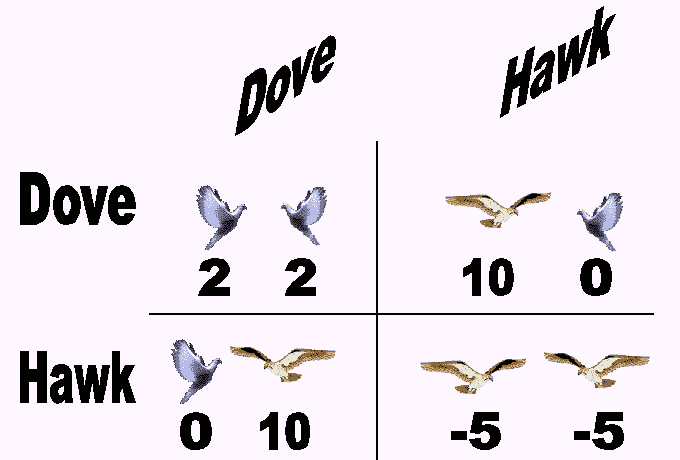
逆博弈论
在许多情况下,问题不是优化参与者在博弈中的策略,而是围绕理性参与者的行为设计博弈。这就是逆博弈论的作用。拍卖被认为是逆博弈论的一个主要例子。
博弈论正在经历一场由人工智能和多智能体系统进化推动的复兴。由计算机科学传奇人物如艾伦·图灵或约翰·冯·诺依曼制定的博弈论原则,如今已成为地球上一些最智能系统的核心,最近在人工智能领域的进展也在推动博弈论研究。随着人工智能的不断发展,我们应当看到博弈论领域出现新的、更具创新性的思想,这些思想将融入主流的深度学习系统中。
原文。经许可转载。
相关内容:
-
博弈论介绍(第一部分)
-
2020 年机器学习趋势
-
马尔可夫链介绍
更多相关话题
如何在深度学习中创建自定义实时图表
原文:
www.kdnuggets.com/2020/12/create-custom-real-time-plots-deep-learning.html
评论
图像来源:Pixabay
我们所说的实时图表是什么意思?
训练一个复杂的深度学习模型和一个大数据集可能是非常耗时的。随着训练轮次的增加,大量数字在屏幕上闪烁。你的眼睛(和大脑)会感到疲倦。
那个令人兴奋的准确度图表在哪里,不断更新你的进展情况?你怎么知道模型是否在学习有用的东西?以及,学习的速度有多快?
一个实时视觉更新会非常棒,不是吗?
毕竟,人类是视觉动物。
在这里,我们收集了一些有趣的事实,以强调在科学交流中使用视觉辅助工具的重要性...
说到视觉,我并不是指在你打开模型的详细输出时屏幕上滚动的大量数字。
不是这个。

我们要这个。
让我们看看如何实现这个目标。
那个令人兴奋的准确度图表在哪里,不断更新你的进展情况?你怎么知道模型是否在学习有用的东西?以及,学习的速度有多快?
我们所说的自定义图表是什么意思?
对于常规任务,有很多现成的工具。但许多时候,我们需要定制化的输出。
Tensorboard 很酷,但可能无法满足所有需求。
如果你在进行深度学习任务时使用 TensorFlow/Keras,可能你已经听说过或使用过 Tensorboard。它是一个非常棒的仪表板工具,你可以传递训练日志,并获得极佳的可视化更新。
在机器学习中,要改进某些东西,你通常需要能够衡量它。TensorBoard 是一个提供...
图像来源:Tensorboard
你可以非常轻松地使用 Tensorboard 获取标准的损失和准确度图表。如果你只想监控这些内容,而不关心其他内容,可以停止阅读本文,直接使用 Tensorboard。
但如果你有一个高度不平衡的数据集,并且你想绘制精准度、召回率和 F1 分数呢?或者,另一种不那么常见的分类指标,比如 马修斯系数?再或者,你只关心真正负样本和假负样本的比例,想创建你自己的指标?
如何在训练过程中看到这些非标准指标的实时更新?
Keras 有内置的混淆矩阵计算功能
幸运的是,Keras 提供了与混淆矩阵相关的四个基本量的基本日志——真正的正例 (TP)、假正例 (FP)、真正的负例 (TN) 和假负例 (FN)。这些来自 Keras Metrics 模块。
模块: tf.keras.metrics | TensorFlow Core v2.3.0
内置指标。
我们可以简单地在模型的训练日志中定义一个指标列表,并在编译模型时传递该列表。
**metrics** = [
tf.keras.metrics.TruePositives(name="tp"),
tf.keras.metrics.TrueNegatives(name="tn"),
tf.keras.metrics.FalseNegatives(name="fn"),
tf.keras.metrics.FalsePositives(name="fp"),
]
然后,
model.compile(
optimizer=tf.keras.optimizers.Adam(lr=learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(),
** metrics=metrics**,
)
所以,我们可以将这些度量(尽管它们是在训练数据集上计算的)作为训练日志的一部分。一旦得到这些度量,我们可以根据原理定义计算我们想要的任何自定义指标。例如,这里展示了一些非标准指标的公式,

图片来源: 维基百科
但是,我们如何从这些计算值创建自定义实时图表呢?
我们当然使用回调!
如何在训练过程中看到这些非标准指标的实时更新?
用于实时可视化的自定义回调
回调是一种神奇的工具类,可以在训练的某些点(或者每个纪元)被调用。简而言之,它们可以在训练过程中实时处理与模型性能或算法相关的数据。
这是 TensorFlow 官方的 Keras 回调页面。但为了我们的目的,我们必须编写一个自定义绘图类,它派生自基础 Callback 类。
模块: tf.keras.callbacks | TensorFlow Core v2.3.0
回调:在模型训练过程中在特定点调用的工具。
演示 Jupyter notebook
演示 Jupyter notebook 在我的 Github 仓库中 位于这里。这个仓库 包含许多其他有用的深度学习教程风格的笔记本。请随意加星或 fork。
一个不平衡的数据集

图片来源: Pixabay
我们为演示中的二分类任务创建了一个具有不平衡类别频率(负样本远多于正样本)的合成数据集。这种情况在实际数据分析项目中非常常见,它强调了需要一个用于自定义分类指标的可视化仪表盘的必要性,在这种情况下准确率不是一个好的指标。
以下代码创建了一个包含90% 负样本和 10% 正样本的数据集。
from sklearn.datasets import make_classificationn_features = 15
n_informative = n_featuresd = make_classification(n_samples=10000,
n_features=n_features,
n_informative=n_informative,
n_redundant=0,
n_classes=2,
**weights=[0.9,0.1]**,
flip_y=0.05,
class_sep=0.7)
下图显示了两个类别的样本数据分布。注意核密度图的失衡。
合成数据集按类别分布
回调是一类很棒的工具,可以在训练的某些点(或者每个周期)调用。
自定义回调类
自定义回调类主要执行以下操作,
-
初始化一系列列表以存储值
-
从模型中提取每个周期结束时的指标
-
从这些提取中计算分类指标
-
并将其存储在这些列表中
-
创建多个图表
这里是初始化,

这里是提取,

这里是计算,

这里是存储,

此外,我不会用标准的 Matplotlib 绘图代码来让你觉得枯燥,除了以下这部分,它在每次迭代时刷新你的 Jupyter notebook 图表。
from IPython.display import clear_output# Clear the previous plot
clear_output(wait=True)
此外,你不必每个周期都绘图,因为这可能会增加负担并减慢显示或机器的速度。你可以选择每隔 5 个周期绘制一次。只需将整个绘图代码放在一个条件下(这里epoch是你从训练日志中获得的周期数)
# Plots every 5th epoch
if epoch > 0 and epoch%5==0:
不用担心这些如何协同工作,因为演示笔记本仍然在这里供你使用。
结果
这里是一个典型的结果,显示了损失和精度/召回率/F1 分数的简单仪表板风格。注意,召回率开始时较高,但精度和 F1 分数对于这个不平衡的数据集较低。这些是你可以通过这种回调实时计算和监控的指标!

更多结果 — 概率分布!
你可以在每个周期结束时对模型(在那个点训练好的)进行任何计算,并可视化结果。例如,我们可以预测输出概率,并绘制它们的分布。
def on_epoch_end(self, epoch, logs={}):
# Other stuff
m = self.model
preds = m.predict(X_train)
plt.hist(preds, bins=50,edgecolor='k')
注意,开始时只有少数样本获得高概率,随着时间的推移,模型开始学习数据的真实分布。
摘要
我们展示了如何通过简单的代码片段创建一个实时深度学习模型性能的仪表板。按照这里概述的方法,你无需依赖 Tensorboard 或任何第三方软件。你可以创建自己的计算和图表,尽可能自定义。
请注意,上述方法仅适用于 Jupyter Notebook。对于独立的 Python 脚本,您需要进行不同的调整。
关于这个话题,还有另一篇精彩的文章,您可以在这里查看。
如何在 Keras 中绘制模型训练图 — 使用自定义回调函数和 TensorBoard
在处理犬种识别时,我开始探索不同的训练过程可视化方法……
您可能还喜欢……
如果您喜欢这篇文章,您可能还会喜欢以下我撰写的深度学习文章,
您是否在 Keras 深度学习模型中使用了“Scikit-learn 包装器”?
如何使用 Keras 的特殊包装类进行超参数调优?
我们展示了如何用几行代码展示深度 CNN 模型中各层的激活图……
我们展示了如何构建一个通用的工具函数来自动从目录中提取图像,并……
您可以查看作者的 GitHub** 代码库**,以获取机器学习和数据科学的代码、想法和资源。如果您和我一样,对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
Tirthajyoti Sarkar - 高级首席工程师 - 半导体、AI、机器学习 - ON…
通过写作让数据科学/机器学习概念易于理解:https://medium.com/@tirthajyoti 开源和……
原文。经授权转载。
相关内容:
-
用于比较、绘图和评估回归模型的简单 Python 包
-
初学者的 20 个核心数据科学概念
-
通过 Yann LeCun 的免费课程学习深度学习
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关内容
使用 Python 和 Dash 创建仪表盘
原文:
www.kdnuggets.com/2023/08/create-dashboard-python-dash.html
介绍
在数据科学和分析的领域中,数据的力量不仅在于提取洞察力,还在于有效地传达这些洞察力;这就是数据可视化发挥作用的地方。
数据可视化是信息和数据的图形化表现。它使用图表、图形和地图等视觉元素,使得更容易看出原始数据中的模式、趋势和异常值。对于数据科学家和分析师而言,数据可视化是一个重要工具,它有助于更快、更准确地理解数据,支持数据故事讲述,并有助于做出数据驱动的决策。
在这篇文章中,你将学习如何使用Python和Dash框架创建一个仪表盘来可视化 Netflix 的内容分布和分类。
什么是 Dash?
Dash 是一个由Plotly开发的开源低代码框架,用于在纯 Python 中创建分析性 Web 应用程序。传统上,为了实现这些目的,人们可能需要使用JavaScript 和 HTML,这需要你在后台(Python)和前端(JavaScript、HTML)技术方面都有专业知识。
然而,Dash 弥补了这一差距,使数据科学家和分析师能够仅使用 Python构建交互式、美观的仪表盘。这种低代码开发的特点使 Dash 成为创建分析仪表盘的合适选择,尤其是对于那些主要使用 Python 的人。
数据集分析
现在你已经了解了 Dash,让我们开始我们的实践项目。你将使用Netflix 电影和电视节目数据集,该数据集由Shivam Bansal创建,并可以在Kaggle上获得。
该数据集包含了截至 2021 年 Netflix 上可用的电影和电视节目的详细信息,如内容类型、标题、导演、演员、制作国家、发行年份、评级、时长等。
尽管数据集创建于 2021 年,但它仍然是发展数据可视化技能和理解媒体娱乐趋势的宝贵资源。
使用该数据集,你的目标是创建一个仪表盘,允许可视化以下几点:
-
地理内容分布:一张地图图表展示了内容生产在不同国家之间的年度变化。
-
内容分类:这个可视化将 Netflix 的内容分为电视节目和电影,以查看哪些类型最为突出。
设置项目工作区
让我们开始创建一个名为netflix-dashboard的项目目录,然后通过以下命令初始化和激活 Python 虚拟环境:
# Linux & MacOS
mkdir netflix-dashboard && cd netflix-dashboard
python3 -m venv netflix-venv && source netflix-venv/bin/activate
# Windows Powershell
mkdir netflix-dashboard && cd netflix-dashboard
python -m venv netflix-venv && .\netflix-venv\Scripts\activate
接下来,你需要安装一些外部包。你将使用pandas进行数据处理,dash创建仪表板,plotly绘制图表,以及dash-bootstrap-components为仪表板添加一些样式:
# Linux & MacOS
pip3 install pandas dash plotly dash-bootstrap-components
# Windows Powershell
pip install pandas dash plotly dash-bootstrap-components
清理数据集
在 Netflix 数据集中,你会发现director、cast和country列中有缺失值。将date_added列的string值转换为datetime以便于分析也会很方便。
要清理数据集,你可以创建一个新的文件clean_netflix_dataset.py,其中包含以下代码,然后运行它:
import pandas as pd
# Load the dataset
df = pd.read_csv('netflix_titles.csv')
# Fill missing values
df['director'].fillna('No director', inplace=True)
df['cast'].fillna('No cast', inplace=True)
df['country'].fillna('No country', inplace=True)
# Drop missing and duplicate values
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
# Strip whitespaces from the `date_added` col and convert values to `datetime`
df['date_added'] = pd.to_datetime(df['date_added'].str.strip())
# Save the cleaned dataset
df.to_csv('netflix_titles.csv', index=False)
开始使用 Dash
设置好工作空间并清理数据集后,你准备开始制作仪表板了。创建一个新的文件app.py,其中包含以下代码:
from dash import Dash, dash_table, html
import pandas as pd
# Initialize a Dash app
app = Dash(__name__)
# Define the app layout
app.layout = html.Div([
html.H1('Netflix Movies and TV Shows Dashboard'),
html.Hr(),
])
# Start the Dash app in local development mode
if __name__ == '__main__':
app.run_server(debug=True)
让我们解析一下app.py中的代码:
-
app = Dash(__name__):这一行初始化了一个新的 Dash 应用程序。可以把它看作是你应用的基础。 -
app.layout = html.Div(…):app.layout属性允许你编写类似 HTML 的代码来设计应用的用户界面。上述布局使用了html.H1(…)标题元素作为仪表板标题,并在标题下方添加了一个水平规则html.Hr()元素。 -
app.run(debug=True):这一行启动了一个开发服务器,在本地开发模式下提供你的 Dash 应用。Dash 使用Flask,一个轻量级的 web 服务器框架,将你的应用提供给 web 浏览器。
运行app.py后,你会在终端中看到一条消息,指示你的 Dash 应用正在运行并可以在127.0.0.1:8050/访问。打开此 URL 以在你的 web 浏览器中查看:
你的第一个 Dash 应用程序!
结果看起来很简单,对吧?别担心!这一部分旨在展示最基本的 Dash 应用结构和组件。你很快会添加更多功能和组件,使其成为一个令人惊叹的仪表板!
纳入 Dash Bootstrap 组件
下一步是编写仪表板布局的代码并为其添加一些样式!为此,你可以使用Dash Bootstrap Components (DBC),一个为 Dash 提供 Bootstrap 组件的库,使你能够开发具有响应式布局的样式化应用。
仪表板将以选项卡布局样式化,这提供了一种在同一空间内组织不同类型信息的紧凑方式。每个选项卡将对应于一个独特的可视化。
让我们继续修改app.py的内容以纳入 DBC:
from dash import Dash,dcc, html
import pandas as pd
import dash_bootstrap_components as dbc
# Initialize the Dash app and import the Bootstrap theme to style the dashboard
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = dbc.Container(
[
dcc.Store(id='store'),
html.H1('Netflix Movies and TV Shows Dashboard'),
html.Hr(),
dbc.Tabs(
[
dbc.Tab(label='Geographical content distribution', tab_id='tab1'),
dbc.Tab(label='Content classification', tab_id='tab2'),
],
id='tabs',
active_tab='tab1',
),
html.Div(id='tab-content', className='p-4'),
]
)
if __name__ == '__main__':
app.run(debug=True)
在这个修改后的布局中,你会看到新的组件:
-
dbc.Container:使用dbc.Container作为顶级组件将整个仪表板布局包裹在一个响应式和灵活的容器中。 -
dcc.Store:这个 Dash Core 组件允许你将数据存储在客户端(用户的浏览器)上,通过本地存储数据来提升应用性能。 -
dbc.Tabs和dbc.Tab:每个dbc.Tab代表一个独立的标签页,包含不同的可视化内容。label属性显示在标签页上,tab_id用于标识标签页。dbc.Tabs的active_tab属性用于指定 Dash 应用启动时的活动标签页。
现在运行app.py。生成的仪表板将具有 Bootstrap 样式布局,包含两个空标签页:
集成 Bootstrap 以实现标签样式布局
干得不错!你终于准备好将可视化内容添加到仪表板中。
添加回调和可视化
在使用 Dash 时,通过回调函数实现交互性。回调函数是在输入属性变化时自动调用的函数。之所以称为“回调”,是因为它是一个被 Dash 在应用发生变化时“回调”的函数。
在这个仪表板中,你将使用回调函数在选定的标签页中呈现相关的可视化,每个可视化将存储在components目录下的独立 Python 文件中,以便更好地组织和模块化项目结构。
地理内容分布可视化
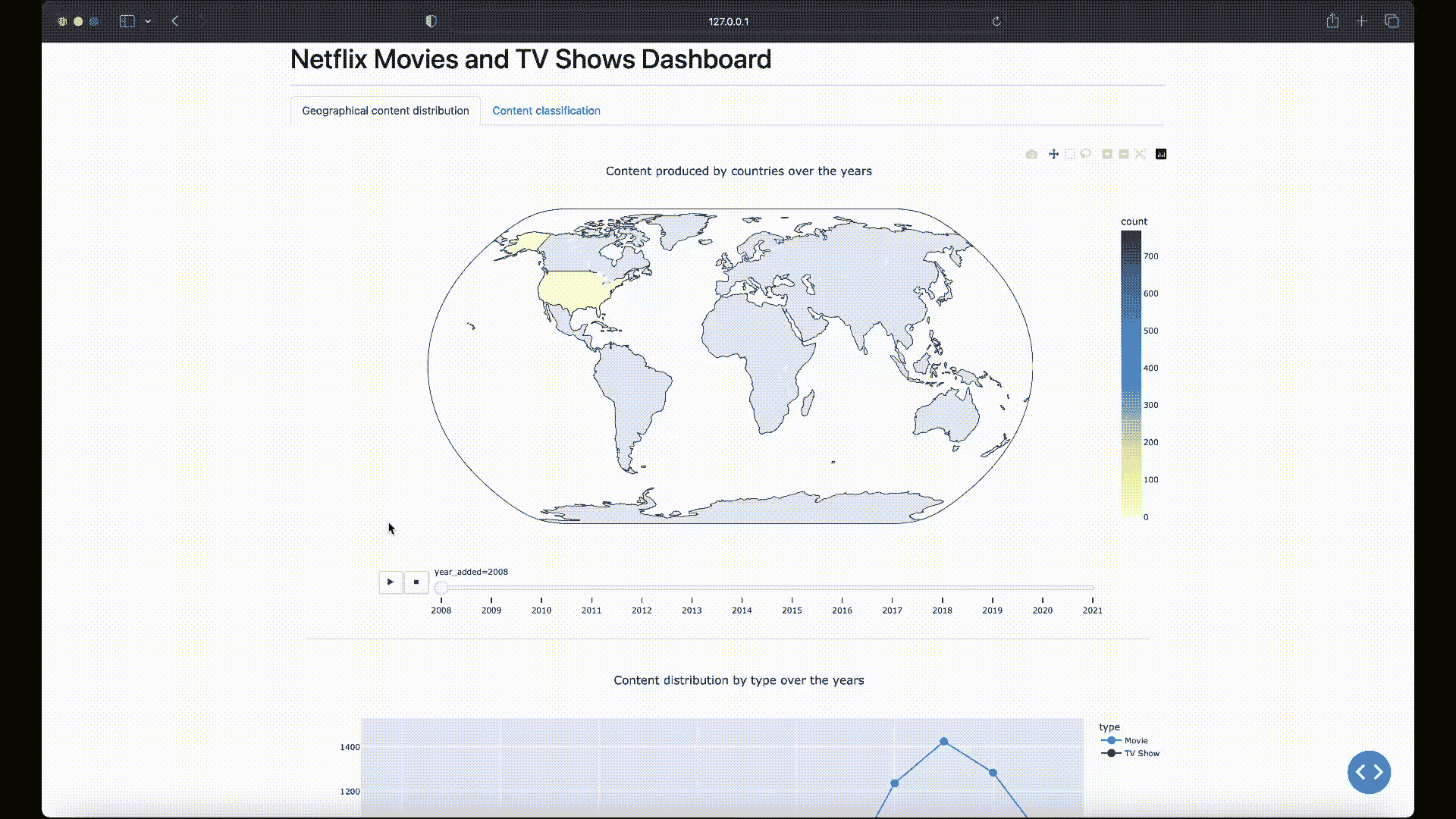
创建一个名为components的新目录,在其中创建一个geographical_content.py文件,该文件将生成一个区域图,展示 Netflix 的内容生产如何随年份在各国之间变化:
import pandas as pd
import plotly.express as px
from dash import dcc, html
df = pd.read_csv('netflix_titles.csv')
# Filter out entries without country information and if there are multiple production countries,
# consider the first one as the production country
df['country'] = df['country'].str.split(',').apply(lambda x: x[0].strip() if isinstance(x, list) else None)
# Extract the year from the date_added column
df['year_added'] = pd.to_datetime(df['date_added']).dt.year
df = df.dropna(subset=['country', 'year_added'])
# Compute the count of content produced by each country for each year
df_counts = df.groupby(['country', 'year_added']).size().reset_index(name='count')
# Sort the DataFrame by 'year_added' to ensure the animation frames are in ascending order
df_counts = df_counts.sort_values('year_added')
# Create the choropleth map with a slider for the year
fig1 = px.choropleth(df_counts,
locations='country',
locationmode='country names',
color='count',
hover_name='country',
animation_frame='year_added',
projection='natural earth',
title='Content produced by countries over the years',
color_continuous_scale='YlGnBu',
range_color=[0, df_counts['count'].max()])
fig1.update_layout(width=1280, height=720, title_x=0.5)
# Compute the count of content produced for each year by type and fill zeros for missing type-year pairs
df_year_counts = df.groupby(['year_added', 'type']).size().reset_index(name='count')
# Create the line chart using plotly express
fig2 = px.line(df_year_counts, x='year_added', y='count', color='type',
title='Content distribution by type over the years',
markers=True, color_discrete_map={'Movie': 'dodgerblue', 'TV Show': 'darkblue'})
fig2.update_traces(marker=dict(size=12))
fig2.update_layout(width=1280, height=720, title_x=0.5)
layout = html.Div([
dcc.Graph(figure=fig1),
html.Hr(),
dcc.Graph(figure=fig2)
])
上述代码通过'country'和'year_added'过滤和分组数据,然后计算每个国家在df_counts数据框中每年的内容生产量。
然后,px.choropleth函数使用df_counts数据框中的列作为其参数值来构建地图图表:
-
locations='country':允许你指定'country'列中包含的地理位置值。 -
locationmode='country names':这个参数“告诉函数”提供的locations是国家名称,因为 Plotly Express 也支持其他位置模式,如 ISO-3 国家代码或美国州名。 -
color='count':用于指定用于着色地图的数值数据。这里,它指的是'count'列,该列包含每个国家每年的内容生产量。 -
color_continuous_scale='YlGnBu':为地图中的每个国家构建一个连续的颜色比例,当color指定的列包含数值数据时。 -
animation_frame='year_added':这个参数在'year_added'列上创建动画。它在地图图表中添加一个年份滑块,允许你查看表示各国内容生产演变的动画。 -
projection='natural earth':这个参数没有使用df_countsDataFrame 中的任何列;然而,'natural earth'值用于设置地球世界地图的投影。
在层析图地图下方,还包含了一个带标记的折线图,展示了内容数量的变化情况,按类型(电视节目或电影)分类,显示多年变化。
为了生成折线图,创建了一个新的 DataFramedf_year_counts,该 DataFrame 通过'year_added'和'type'列对原始df数据进行分组,统计每种组合的内容数量。
然后使用px.line处理这些分组数据,其中'x'和'y'参数分别分配给'year_added'和'count'列,'color'参数设置为'type'以区分电视节目和电影。
内容分类可视化
下一步是创建一个名为 content_classification.py的新文件,该文件将生成一个树图图表,以从类型和类别的角度可视化 Netflix 的内容:
import pandas as pd
import plotly.express as px
from dash import dcc, html
df = pd.read_csv('netflix_titles.csv')
# Split the listed_in column and explode to handle multiple genres
df['listed_in'] = df['listed_in'].str.split(', ')
df = df.explode('listed_in')
# Compute the count of each combination of type and genre
df_counts = df.groupby(['type', 'listed_in']).size().reset_index(name='count')
fig = px.treemap(df_counts, path=['type', 'listed_in'], values='count', color='count',
color_continuous_scale='Ice', title='Content by type and genre')
fig.update_layout(width=1280, height=960, title_x=0.5)
fig.update_traces(textinfo='label+percent entry', textfont_size=14)
layout = html.Div([
dcc.Graph(figure=fig),
])
在上述代码中,数据加载后,对'listed_in'列进行调整,通过拆分和展开每个内容的多种类型来处理多个类型,为每个类型创建一个新行。
接下来,创建df_counts DataFrame,以'type'和'listed_in'列对数据进行分组,并计算每种类型-类别组合的数量。
然后,将df_counts DataFrame 中的列用作px.treemap函数参数的值,如下所示:
-
path=['type', 'listed_in']:这些是树图中表示的层次类别。'type'和'listed_in'列分别包含内容的类型(电视节目或电影)和类别。 -
values='count':树图中每个矩形的大小对应于'count'列,表示每种类型-类别组合的内容数量。 -
color='count':'count'列也用于为树图中的矩形着色。 -
color_continous_scale='Ice':当由color表示的列包含数字数据时,为树图中的每个矩形构建一个连续的颜色刻度。
在创建了两个新的可视化文件后,你当前的项目结构应该如下所示:
netflix-dashboard
├── app.py
├── clean_netflix_dataset.py
├── components
│ ├── content_classification.py
│ └── geographical_content.py
├── netflix-venv
│ ├── bin
│ ├── etc
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
└── netflix_titles.csv
实现回调函数
最后一步是修改app.py,以导入components目录中的两个新可视化,并实现回调函数,以在选择标签时渲染图表:
from dash import Dash, dcc, html, Input, Output
import dash_bootstrap_components as dbc
from components import (
geographical_content,
content_classification
)
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
app.layout = dbc.Container(
[
dcc.Store(id='store'),
html.H1('Netflix Movies and TV Shows Dashboard'),
html.Hr(),
dbc.Tabs(
[
dbc.Tab(label='Geographical content distribution', tab_id='tab1'),
dbc.Tab(label='Content classification', tab_id='tab2'),
],
id='tabs',
active_tab='tab1',
),
html.Div(id='tab-content', className='p-4'),
]
)
# This callback function switches between tabs in a dashboard based on user selection.
# It updates the 'tab-content' component with the layout of the newly selected tab.
@app.callback(Output('tab-content', 'children'), [Input('tabs', 'active_tab')])
def switch_tab(at):
if at == 'tab1':
return geographical_content.layout
elif at == 'tab2':
return content_classification.layout
if __name__ == '__main__':
app.run(debug=True)
回调装饰器@app.callback监听'tabs'组件的'active_tab'属性的变化,由Input对象表示。
每当'active_tab'发生变化时,switch_tab函数会被触发。这个函数检查'active_tab'的 id,并返回要在'tab-content' Div 中渲染的相应布局,如Output对象所示。因此,当你切换标签时,相关的可视化会出现。
最后,再次运行app.py以查看包含新可视化的更新仪表板:
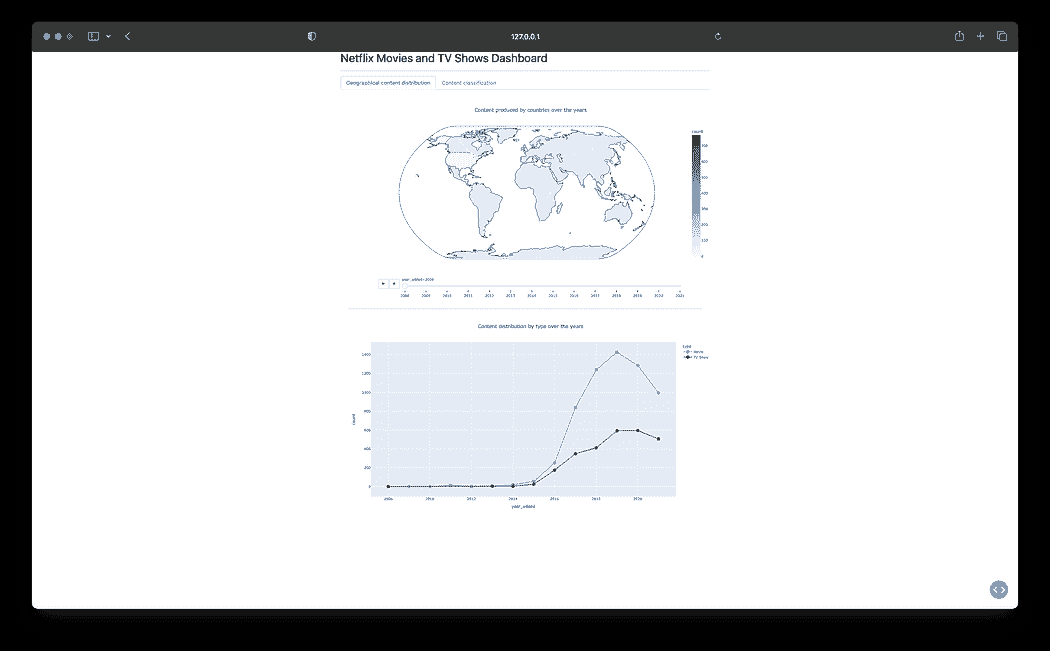
Netflix 电影和电视节目仪表板 — 最终结果
总结
本文教会了您如何创建一个仪表板来探索和可视化 Netflix 的内容分布和分类。通过利用 Python 和 Dash 的力量,您现在已经能够创建自己的可视化,从而为您的数据提供宝贵的洞察。
您可以在以下 GitHub 仓库查看此项目的完整代码:github.com/gutyoh/netflix-dashboard
如果您觉得这篇文章对您有帮助,并且想扩展对 Python 和数据科学的知识,考虑查看 Hyperskill 上的数据科学入门课程。
如果您对本博客有任何问题或反馈,请在下面的评论中告诉我。
赫尔曼·罗斯 是 Hyperskill Go 编程课程的技术作者,他将对教育科技的热情与赋能下一代软件工程师的使命融合在一起。同时,作为伊利诺伊大学厄本那-香槟分校的硕士生,他还深入数据领域。
原始. 经许可转载。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
进一步阅读此主题
如何为机器学习创建数据集
原文:
www.kdnuggets.com/2022/02/create-dataset-machine-learning.html

为什么为机器学习(ML)创建数据集很重要
一些非凡的事情正在发生。
算法领域的入门门槛正在逐日降低。这意味着任何拥有正确目标和技能的人都可以找到适用于机器学习(ML)和人工智能(AI)任务的优秀算法——计算机视觉、自然语言处理、推荐系统,甚至是自动驾驶。
开源计算已经取得了长足的进展,许多开源倡议推动了数据科学、数字分析和 ML 的发展。大学和企业研发实验室的研究人员每天都在创造新的算法和 ML 技术。我们可以放心地说,算法、编程框架、ML 包,甚至是学习这些技术的教程和课程已经不再是稀缺资源。
但高质量数据确实是稀缺的。数据集——经过妥善策划和标注的——仍然是稀缺资源。
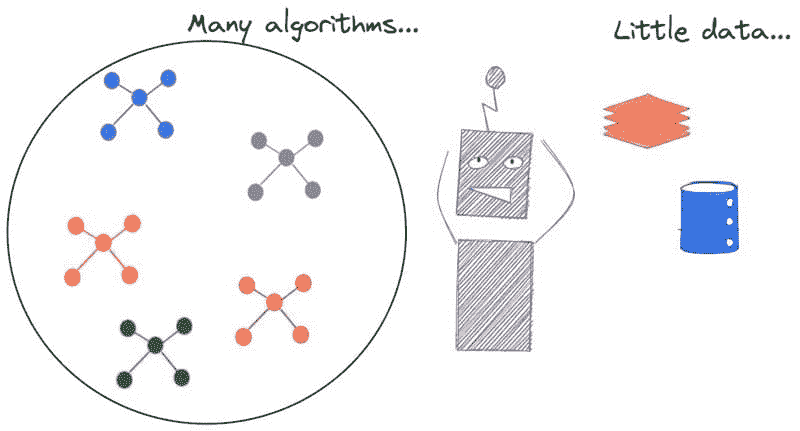
图 1:算法太多,但几乎没有好的数据集
高质量数据即使在基本 ML 任务中也很具有挑战性
通常,讨论的重点不是如何为你正在开发的酷炫 AI 驱动的旅行或时尚应用获取高质量数据。这类消费者、社交或行为数据的收集本身就存在问题。
每个应用领域都有其特定的数据需求挑战,例如,自主驾驶车辆所需的 LiDAR 数据需要特定的 3D 点云数据集来进行对象识别和语义分割,这些数据集非常难以人工标注。

图 2:一个 LiDAR 3D 点云数据集 - 训练时极难手动标注。图片 来源于此论文
然而,即使获得用于基本 ML 算法测试和构思的高质量数据集也是一种挑战。假设一位 ML 工程师从头开始学习,最理智的建议是从简单的小规模数据集入手,他/她可以将数据绘制在二维平面上,以直观地理解数据模式,并以直观的方式查看 ML 算法的内部工作方式。然而,随着数据维度的增加,视觉判断必须扩展到更复杂的领域——例如学习和样本复杂性、计算效率、类别不平衡等概念。
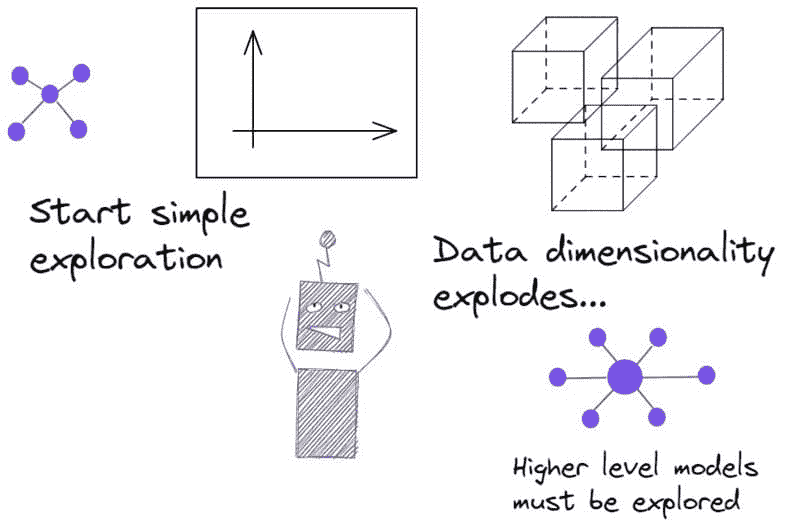
图 3:数据和机器学习模型的探索从简单开始——然后爆炸。数据集也必须不断演变。
合成数据集的救援
人们总是可以通过实验来评估和调整机器学习算法,获取真实数据集或生成数据点。然而,使用固定的数据集时,样本数量、潜在模式和正负样本之间的类别分离度都是固定的。这样的固定数据集无法测试或评估机器学习算法的许多方面。以下是一些例子:
-
测试数据和训练数据的比例如何影响算法的性能和鲁棒性
-
在不同程度的类别不平衡面前,指标的鲁棒性如何
-
必须进行哪些类型的偏差-方差权衡
-
算法在训练数据和测试数据中的各种噪声特征下的表现(即标签和特征集中的噪声)
合成数据集在所有这些情况下都能派上用场。合成数据是通过人工制造而非真实世界事件生成的信息。这种数据最适合用于模型的简单验证,但也用于帮助训练。合成数据集的潜在好处在于敏感应用——医学分类或金融建模,在这些领域中,获取高质量标注数据集通常是昂贵且禁止的。
适用于机器学习的好数据集的特征(合成的或真实的)
合成数据集是通过程序生成的,真实数据集则来源于各种渠道——社交或科学实验、医疗治疗历史、商业交易数据、网页浏览活动、传感器读数或自动摄像机或激光雷达拍摄的图像的人工标记。不论来源如何,数据集都应该具备一些理想的特征,以便对机器学习算法的开发和性能调整具有价值。
以下是一些例子:
-
数据集应具有数字、二进制或分类(有序或无序)特征的混合,并且特征的数量和数据集的长度应当具有一定的复杂性
-
对于合成数据,应该以可控的方式注入随机噪声
-
数据集必须具备一定的随机性
-
如果是合成的,用户应该能够选择多种统计分布来生成这些数据,即底层的随机过程/参数可以精确控制和调整
-
如果用于分类算法,则类别分离度应足够大,以实现良好的分类准确性,但也不应过大,以免使问题变得简单。对于合成数据,这应当是可控的,以便将学习问题设置为简单或困难
-
生成速度应相当高,以便对特定机器学习算法进行大量不同数据集的实验,即如果合成数据基于真实数据集的数据增强,则增强算法必须计算高效。
-
对于真实数据集,数据生成成本应低且过程应资源高效,以确保机器学习训练不会过度影响业务目标。
-
对于回归问题,可以使用复杂的非线性生成过程来获取数据——真实物理模型或物理过程的计算机模拟可以帮助实现这一目标。
回归、分类和聚类数据集创建用于机器学习
Scikit-learn 是基于 Python 的数据科学软件栈中最流行的机器学习库。除了优化的机器学习例程和管道构建方法外,它还拥有丰富的合成数据生成工具。我们可以创建各种数据集用于常规机器学习算法训练和调优。
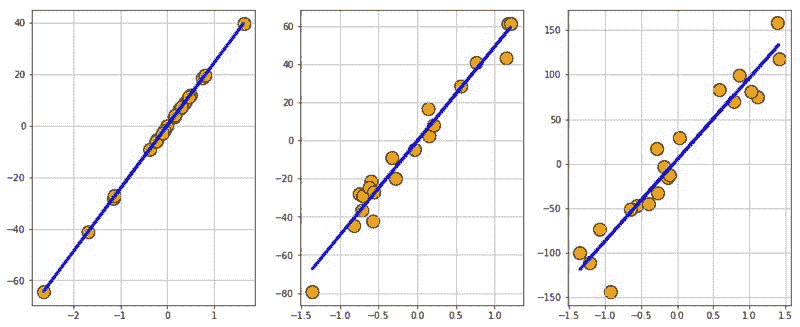
图 4:使用 Scikit-learn 创建的回归数据集。
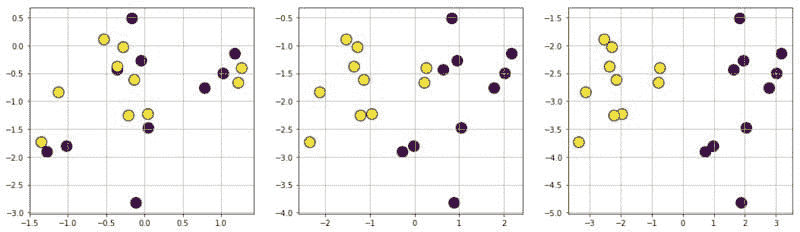
图 5:使用 Scikit-learn 创建的分类数据集。
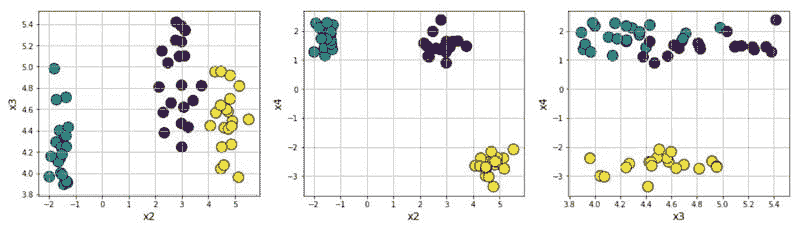
图 6:使用 Scikit-learn 创建的聚类数据集。
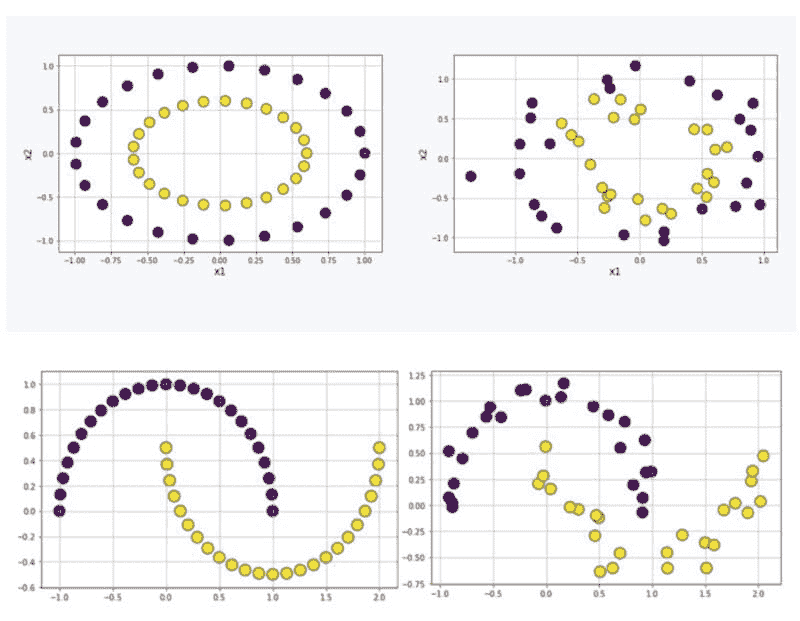
图 7:用于测试基于核的算法的非线性数据集。
高斯混合模型
高斯混合模型(GMM)是非常有趣的研究对象。它们在无监督学习和主题建模领域被广泛使用,特别是在大规模文本处理/自然语言处理任务中。即使在自动驾驶和机器人导航算法中,它们也有许多应用。只需少量代码,就可以创建有趣的数据集,模拟具有任意形状和复杂性的 GMM 过程。
以下是一些相同的合成数据示例:
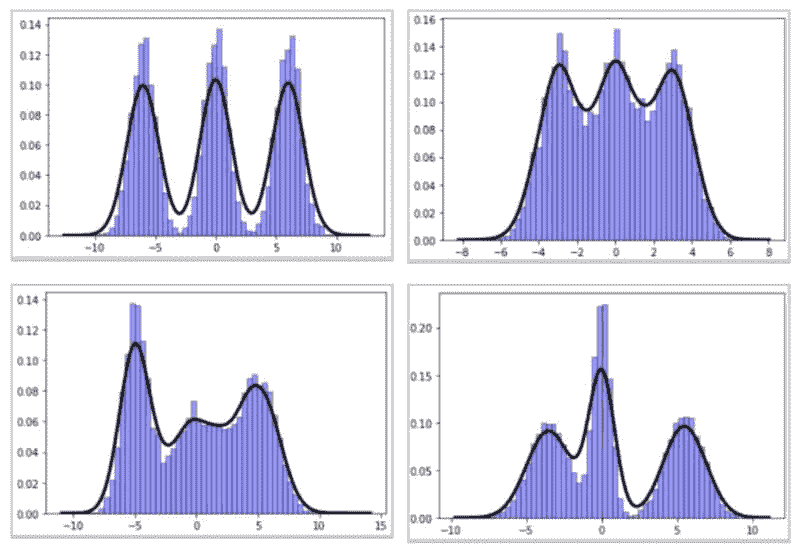
图 8:合成创建的高斯混合模型数据集。
从符号表达式生成数据集
通常,可能需要一种可控的方法来生成基于明确定义函数的机器学习数据集(涉及线性、非线性、理性或甚至超越项)。
例如,您可能希望评估各种核化支持向量机分类器在具有越来越复杂分隔符(从线性到非线性)的数据集上的效果,或展示线性模型在由有理或超越函数生成的数据集上的局限性。通过混合随机变量生成和符号表达式处理库如SymPy的力量,您可以创建与用户定义函数对应的有趣数据集。
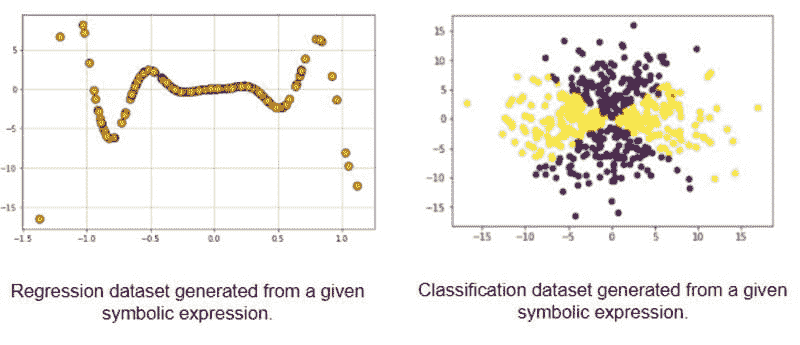
图 9:用于高级机器学习算法测试的符号函数生成数据集。
工业问题的时间序列/异常数据生成
时间序列分析在现代工业环境中有许多丰富的应用,其中众多传感器不断地从机器、工厂、操作员和业务流程中生成源源不断的数字数据。这种数字废料是工业 4.0革命的核心特征。
异常检测在这些数据流中是所有现代数据分析产品、服务和初创公司的核心内容。他们使用了从经过验证的时间序列算法到最新的基于神经网络的序列模型的所有技术。然而,在内部测试这些算法时,有时需要创建合成数据集,模拟时间序列中各种性质的异常。
本文深入探讨了这一理念,并展示了一些示例:在 Python 中创建具有异常签名的合成时间序列。
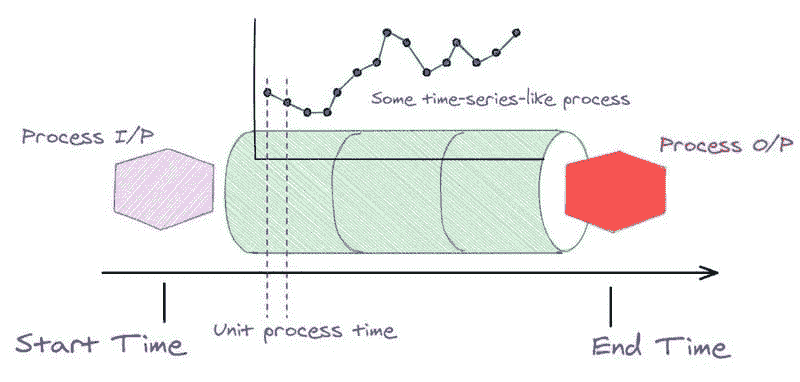
图 10:工业应用中时间序列数据集的核心生成过程。
可以生成各种规模的异常,
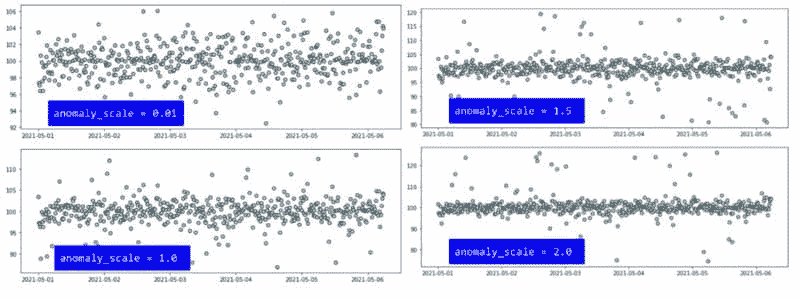
图 11:具有各种规模异常的时间序列。
数据漂移可能在任何方向和任何规模上发生。数据可能会改变其一个或多个统计属性——例如均值或方差。这也应该被建模并用于数据集生成。
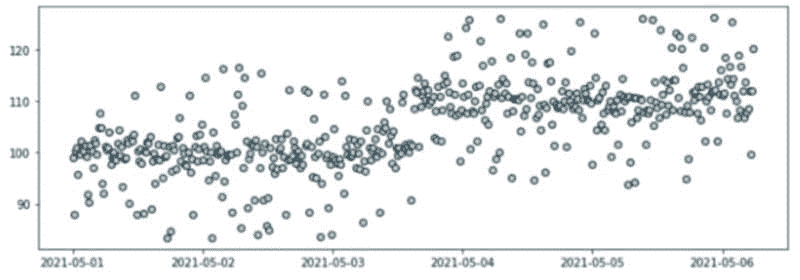
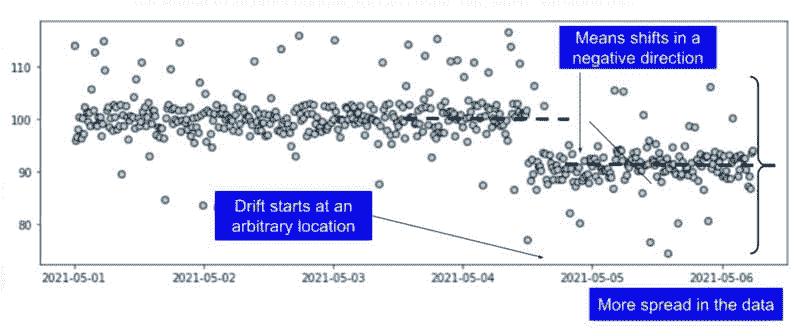
图 12:具有异常和数据漂移结合的时间序列数据集。
图像数据增强用于机器学习
已经有许多优秀的图像数据集可用于基本的深度学习模型训练和调整。然而,对于特定的任务或应用领域,机器学习工程师通常需要从相对较小的一组高质量图像开始,并通过巧妙的图像处理技术进行扩充。
这里有一篇博客详细讨论了图像数据的增强技巧作为示例:
基本上,可以使用增强技术从一些种子高质量图像创建各种深度和复杂性的图像数据集:
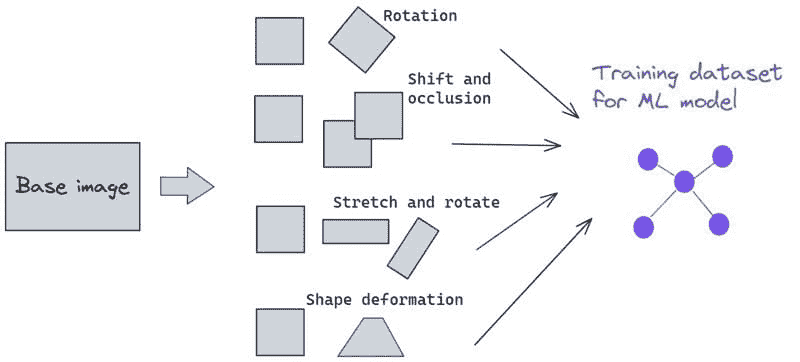
图 13:用于创建丰富且强健的数据集的图像数据增强,适用于深度学习训练。
还可以尝试各种噪声通道添加来扩增数据集,以使机器学习模型在噪声环境中表现良好。

图 14:图像数据增强,添加各种噪声通道。
总结
在本文中,我们讨论了创建高质量机器学习数据集的基本动机和一些期望的特性。业务流程、科学实验、医学和社交媒体历史——这些是并将继续是训练机器学习算法的最可信的真实数据来源。
然而,合成数据集因其在评估和优化机器学习算法中的强大功能和灵活性而越来越受到需求。
我们简要介绍了许多用于生成此类机器学习数据集的工具、框架和技术,以及它们如何精准地满足算法开发的需求。该领域将继续增长,并有助于开发和繁荣新的、令人兴奋的机器学习算法、框架和技术。
Kevin Vu 负责管理 Exxact Corp 博客,并与许多才华横溢的作者合作,这些作者撰写有关深度学习不同方面的文章。
原文。经授权转载。
相关主题
使用 Voila 和 Saturn Cloud 创建并部署仪表板
原文:
www.kdnuggets.com/2021/06/create-deploy-dashboards-voila-saturn-cloud.html
评论
由 Dhrumil Patel,NVIDIA 性能分析实习生
筛选和可视化银行交易数据
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
处理和训练大型数据集,将它们全部维护在一个地方,并将它们部署到生产环境中是一项具有挑战性的工作。但如果我告诉你,有一种方法只需点击几下即可处理所有这些问题,你会怎么想?
让我们了解如何轻松做到这一点。在本文中,我们将创建一个仪表板(使用 Python 和 Voila),它运行一个机器学习模型来去除欺诈交易,并用可视化显示剩余数据,并将其发布到 Saturn Cloud 的生产服务器以便更方便地访问。以下是文章的大纲,如果你已经了解相关细节,可以随意跳过某些部分。
-
什么是 Saturn Cloud?
-
创建仪表板(数据筛选和可视化)
-
部署仪表板(本地和生产)
-
结束语
什么是 Saturn Cloud
Saturn Cloud 是一个自动化 DevOps 和 ML 基础设施的机器学习平台。除此之外,他们使用 jupyter 和 dash 来扩展 Python 处理大量数据。以下是 Saturn Cloud 提供的一些其他功能:
-
你可以使用 Dask 在你需要的任意多台机器上并行运行代码
-
你可以轻松地在 GPU 上运行你的代码
-
你可以在不依赖于单独团队的情况下部署你的工作
-
它完全基于开源工具构建
-
它还可以在你的 AWS 账户中运行。此外,Saturn Cloud 连接到你现有的数据,你不需要移动它。添加所需的凭据,你就可以开始使用了。
-
你可以从 Google Colab 连接到 Dask。你也可以连接到任何可以托管 Python 的 GCP 服务。
这不是很酷吗?让我们学习如何使用 Saturn 在几个简单的步骤中创建一个仪表板并将其发布到生产环境中。
创建仪表板
Voila 101
在部署仪表盘之前,首先让我们使用 Python 和 Voila 创建一个基础仪表盘。使用 Voila 创建仪表盘有三个主要组件,分别是:
-
定义小部件(按钮点击或搜索字段以供交互)
-
为你在第 1 步中创建的交互式字段定义逻辑(事件处理程序)(基于类或基于函数)
-
一个输出小部件(你的结果将显示在这里)
以 虚假交易数据 为例,让我们构建一个仪表盘,它会在移除欺诈交易后提供筛选数据,并展示交易在不同货币下的多样性。假设你有一个能够识别欺诈交易的机器学习模型。为了简化本文,我们将仅使用一个 if 语句,但别担心,我会告诉你如何导入你自己的模型(如果你有的话)。
基础仪表盘
首先,你需要定义一个小部件。对于我们的用例,我们希望用户上传数据,并在移除欺诈交易后提供筛选数据和图表。我们将从定义上传按钮开始。
这里我们有两个按钮——一个用于上传文件(upload_file),另一个(upload_btn)让我们的事件处理程序(upload_btn_eventhandler)知道何时执行操作。我知道,你一定会想我们的事件处理程序在哪里?我们将在接下来定义它。但在此之前,input_widgets 只是将两个按钮组合在一起,并借助我们的输出小部件(upload_btn_output)来显示这些按钮。首先,让我们编写事件处理程序。

一旦我们点击上传按钮,我们的事件处理程序将接收文件并将其转换为 pandas 数据框,以便轻松处理数据。我通过句点分割文件名来找到文件的扩展名,然后根据文件是否为 Excel 或 CSV 来存储数据。现在进入最后一部分,输出小部件。如果你还记得,我们已经编写了一个名为 upload_btn_output 的输出小部件,所以我们就按这个名字来做。

现在,如果你还没有安装 voila,你需要安装它以便在本地运行,你可以在这里找到安装说明。但我将向你展示一种使用 Saturn Cloud 的简单方法。创建一个账户并登录,在他们的仪表盘上,你会看到“部署仪表盘”,点击它,然后启动 jupyter lab。现在,将我们刚刚创建的笔记本上传到 Saturn Cloud 的 jupyter lab 中。你可以在我的 GitHub 上找到完整的 jupyter notebook,这里。此外,你还可以选择 Saturn Cloud 提供的其他加速数据科学库和管道。

完成了吗?完美。现在复制 URL,粘贴到新标签页中,并将 …./your-username/dashboard/…. 替换为 /your-username/dashboard/voila,然后导航到 projects>examples>dashboard.ipynb 并运行它。你应该能够看到我们的上传按钮。
如果你遇到任何问题,或者想了解更多关于在 Saturn Cloud 上使用 Voila 创建仪表板的内容,请参考这个指南。

欺诈交易
目前我们还没有任何过滤后的数据,我们只是上传了一个文件并存储了其内容。让我们再写一些代码来处理欺诈交易。
我已经生成了一个包含假数据的 csv 文件,你可以在这里找到,随意使用。这里,我将删除超出特定阈值的值,视其为欺诈。如果所有金额 > 1000 的交易都是欺诈交易,我们可以通过在 upload_btn_eventhandler 中写入以下内容来实现。
如果你的数据在 AWS 等云端,完全不用担心。你只需要获取凭证即可开始。你可以通过使用 s3fs 库轻松完成,这是一种用于访问 AWS 文件系统的 Python 库。你可以在文档中了解更多信息。
使用预训练模型(额外)
如果你有一个预训练的模型想要使用,可以像我下面这样导入,但如果你只是想了解 Voila 的工作原理,并且对导入机器学习模型不感兴趣,可以跳过下面的代码。我们基本上是使用 joblib 加载计数向量化器和模型,然后进行预测。
过滤数据
太棒了,现在我们有了没有欺诈交易的干净数据。我们来添加一个功能,以便根据货币过滤交易吧?我们可以通过创建另一个逻辑来实现,就像我们为上传按钮创建的那样。现在我们只需传递我们创建的干净数据框。让我们看看代码:

我们在这里也会遵循相同的模式。首先,我们为货币列中的所有唯一值创建一个下拉框。然后,我们创建一个事件处理程序,它会调用另一个函数 common_filtering,该函数基本上会匹配货币并只给出那些货币匹配的值,换句话说,即过滤。然后我们将其显示到刚刚创建的输出小部件上。如果你使用的是我添加的相同数据文件,它应该是这样的。
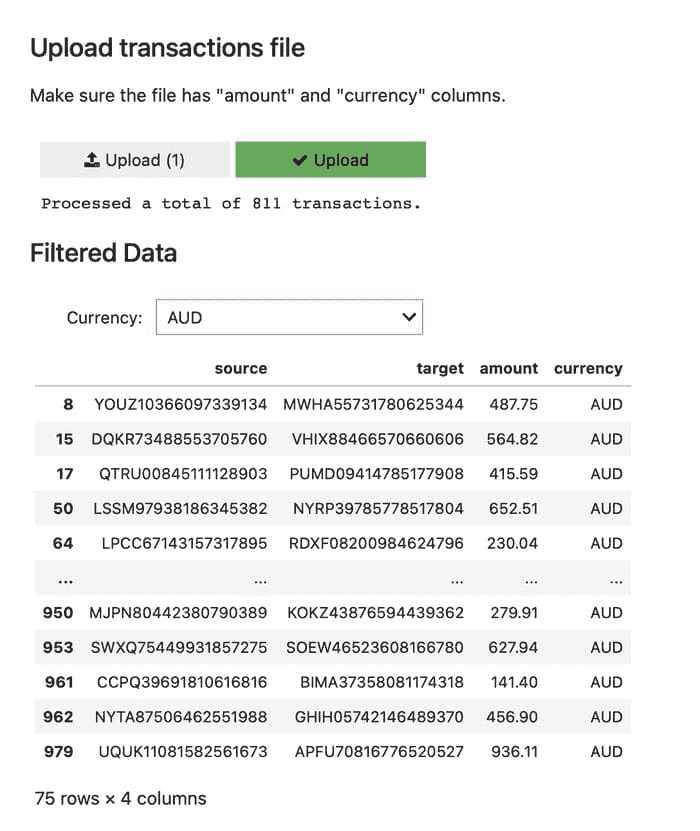
可视化
让我们继续可视化我们筛选后的数据。我们将制作一个货币计数的折线图,以查看交易在几个货币之间的分布情况。

首先,我们创建一个新的列计数,并计算每种货币的出现次数。然后我们将其作为plot_data传递,其中 X 轴保持货币,Y 轴保持计数。我们在这里使用 plotly——import plotly as px——并保留一个单独的辅助函数来调用绘图。如果一切顺利,你可以在仪表板上看到类似的柱状图。
然后,瞧(有点玩笑的意思),你有了一个工作中的仪表板。现在我们可以使用 Saturn Cloud 将其发布到生产中,这就像点击几下那么简单。
发布到生产
要创建部署,请访问项目页面并点击“创建部署”按钮。

创建部署
你将看到配置页面。正如你在下面看到的,你只需要设置一个名称和命令,你就可以开始了。然而;Saturn Cloud 上有很多选项可以探索,你可以在这里找到。
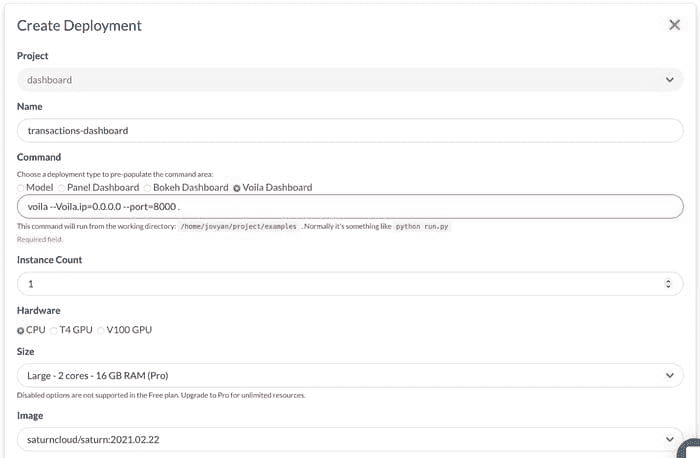
配置
现在配置已经准备好,你将能够看到仪表板,点击 URL 旁边的小播放按钮,一旦它激活,访问该 URL 以访问你的仪表板。
附录
在这篇文章中,我们介绍了 Saturn Cloud 是什么以及它如何加速你的端到端管道,如何使用 Voila 和 Python 创建仪表板,并仅通过几个简单步骤使用 Saturn Cloud 发布到生产中。拥有合适的工具对你帮助很大,如果你希望加速你的处理或数据科学管道,Saturn Cloud 就是其中之一。如果你有任何问题,可以通过twitter或Linkedin联系我,或者随时过来打个招呼。
个人简介:Dhrumil Patel (@Dhrumilcse) 是 NVIDIA 的性能分析实习生。他的兴趣在于处理大规模数据和使用现代框架(如 Django)进行 Web 应用开发。他还具备处理大量社交媒体数据的 NLP 实践经验。工作之外,他喜欢阅读书籍和折纸。
相关:
-
使用 Saturn Cloud 在 GPU 上为 Python 与 Pandas 加速
-
数据科学家,你需要了解如何编程
-
当良好的数据分析未能提供预期结果时
更多相关主题
如何通过 API 创建和部署一个简单的情感分析应用
原文:
www.kdnuggets.com/2021/06/create-deploy-sentiment-analysis-app-api.html
评论
图片来源:Reputation X
假设你已经为某个特定任务构建了一个 NLP 模型,无论是文本分类、问题回答、翻译还是其他什么。你已经在本地测试过,表现良好。你也让其他人测试过,表现依旧良好。现在你想将其推广到更大的受众,不管是你合作的开发团队、特定的终端用户群体,还是普通公众。你决定使用 REST API,因为这是你认为的最佳选项。接下来怎么办?
FastAPI 可能会有所帮助。FastAPI 是一个用于构建 Python API 的 Web 框架。我们将在本文中使用 FastAPI 构建一个 REST API,服务于一个 NLP 模型,该模型可以通过 GET 请求进行查询,并对这些查询作出响应。
在这个例子中,我们将跳过构建自己的模型,而是利用 HuggingFace Transformers 库的 Pipeline 类。Transformers 中充满了可以直接使用的 SOTA NLP 模型,还可以根据特定用途和高性能进行微调。该库的管道可以总结为:
这些管道是使用模型进行推理的一个极好的简单方式。这些管道是抽象了库中大部分复杂代码的对象,提供了一个简单的 API,专门用于几个任务,包括命名实体识别、掩码语言建模、情感分析、特征提取和问题回答。
使用 Transformers 库、FastAPI 和极少的代码,我们将创建并部署一个非常简单的 情感分析 应用。我们还将看到将这种方法扩展到更复杂的应用程序是相当简单的。
开始入门
如上所述,我们将使用 Transformers 和 FastAPI 来构建这个应用,这意味着你需要在系统上安装这些工具。你还需要安装 Uvicorn,这是 FastAPI 作为后端所依赖的 ASGI 服务器。我在我的 *buntu 系统上通过 pip 轻松安装了它们。
pip install transformers
pip install fastapi
pip install uvicorn
就这些,接下来…
分析情感
由于我们将使用 Transformers 来构建我们的 NLP 流水线,我们先来看看如何使其单独工作。这非常简单,只需将很少的基本参数传递给流水线对象即可开始。具体而言,我们需要定义一个任务——我们想做什么——和一个模型——我们将用来执行任务的东西。其实就这些。我们可以选择提供额外的参数或将流水线微调到我们的特定任务和数据,但对于我们的目的来说,直接使用现成的模型应该就足够了。
对我们来说,任务是sentiment-analysis,模型是[nlptown/bert-base-multilingual-uncased-sentiment](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment)。这是一个用于多语言情感分析的 BERT 模型,由 NLP Town 贡献到 HuggingFace 模型库。请注意,第一次运行该脚本时,会将大型模型下载到系统中,因此请确保有足够的空闲空间。
下面是设置独立情感分析应用的代码:
from transformers import pipeline
text = 'i love this movie!!! :)'
# Instantiate a pipeline object with our task and model passed as parameters
nlp = pipeline(task='sentiment-analysis',
model='nlptown/bert-base-multilingual-uncased-sentiment')
# Pass the text to our pipeline and print the results
print(f'{nlp(text)}')
调用流水线对象返回的是预测标签及其相应的概率。在我们的案例中,任务和模型的组合会产生 1(负面)到 5(正面)之间的标签,以及预测概率。让我们运行一下脚本看看它的表现。
python test_model.py
>>> [{'label': '5 stars', 'score': 0.923753023147583}]
这就是使用 Transformers 库及其 Pipeline 类将一些功能基本的 NLP 任务特定的现成模型启动并运行所需要的全部内容。
如果你想在我们继续将其通过 REST API 部署之前再多测试一下,可以尝试这个修改过的脚本,它允许我们从命令行传递文本,并以更好格式化的回复响应:
import sys
from transformers import pipeline
if len(sys.argv) != 2:
print('Usage: python model_test.py <input_string>')
sys.exit(1)
text = sys.argv[1]
# Instantiate a pipeline object with our task and model passed as parameters
nlp = pipeline(task='sentiment-analysis',
model='nlptown/bert-base-multilingual-uncased-sentiment')
# Get and process result
result = nlp(text)
sent = ''
if (result[0]['label'] == '1 star'):
sent = 'very negative'
elif (result[0]['label'] == '2 star'):
sent = 'negative'
elif (result[0]['label'] == '3 stars'):
sent = 'neutral'
elif (result[0]['label'] == '4 stars'):
sent = 'positive'
else:
sent = 'very positive'
prob = result[0]['score']
# Format and print results
print(f"{{'sentiment': '{sent}', 'probability': '{prob}'}}")
让我们运行几次,看看它的表现:
python model_test.py 'the sky is blue'
>>> {'sentiment': 'neutral', 'probability': '0.2726307213306427'}
python model_test.py 'i really hate this restaurant!'
>>> {'sentiment': 'very negative', 'probability': '0.9228281378746033'}
python model_test.py 'i love this movie!!! :)'
>>> {'sentiment': 'very positive', 'probability': '0.923753023147583'}
这具有更好的功能,因为我们不必将要分析的文本硬编码到程序中,并且我们还使结果更具用户友好性。让我们扩展这个更有用的版本,并将其作为 REST API 部署。
创建 API
现在是通过 FastAPI 部署这个非常简单的情感分析应用的时候了。如果你想了解更多关于 FastAPI 的信息以及如何使用这个框架格式化你的代码,请查看其文档。你需要知道的是,我们将创建 FastAPI 的一个实例(app),然后必须定义获取请求,将其附加到 URL,并通过函数为这些请求分配响应。
下面,我们将定义两个这样的 GET 请求;一个用于根 URL ('/'),显示欢迎信息,另一个用于接受字符串以进行情感分析 ('/sentiment_analysis/')。这两个请求的代码都非常简单;你应该能识别出'/sentiment_analysis/'请求调用的analyze_sentiment()函数中的大部分内容。
from transformers import pipeline
from fastapi import FastAPI
nlp = pipeline(task='sentiment-analysis',
model='nlptown/bert-base-multilingual-uncased-sentiment')
app = FastAPI()
@app.get('/')
def get_root():
return {'message': 'This is the sentiment analysis app'}
@app.get('/sentiment_analysis/')
async def query_sentiment_analysis(text: str):
return analyze_sentiment(text)
def analyze_sentiment(text):
"""Get and process result"""
result = nlp(text)
sent = ''
if (result[0]['label'] == '1 star'):
sent = 'very negative'
elif (result[0]['label'] == '2 star'):
sent = 'negative'
elif (result[0]['label'] == '3 stars'):
sent = 'neutral'
elif (result[0]['label'] == '4 stars'):
sent = 'positive'
else:
sent = 'very positive'
prob = result[0]['score']
# Format and return results
return {'sentiment': sent, 'probability': prob}
现在我们有了一个能够接受 GET 请求并进行情感分析的 REST API。在尝试之前,我们必须运行 Uvicorn 网络服务器,它将提供必要的后台功能。为此,假设你已将上述代码保存在名为 main.py 的文件中,并将 FastAPI 实例的名称保留为 app,运行以下命令:
uvicorn main:app --reload
你应该会看到这样的结果:
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [18271] using statreload
INFO: Started server process [18273]
INFO: Waiting for application startup.
INFO: Application startup complete.
按指示打开浏览器,访问 http://127.0.0.1:8000 ,你应该会看到:

如果你看到欢迎信息,恭喜,成功了!我们可以尝试使用浏览器地址栏进行一些请求,将下面引号中的内容粘贴到请求 URL 和查询字符串后面 (http://127.0.0.1:8000/sentiment_analysis/?text=):
“欢迎来到我的家!”

“我不喜欢你的猫”

“那部电影只是一般般”

很好,我们得到了结果!那如果我们想把它当作 API 来访问呢?在 Python 中,我们可以使用 requests 库。确保它已经安装,可以使用以下命令:
pip install requests
然后试试这样的脚本:
import requests
query = {'text':'i love the fettucine alfredo and would definitely recommend this restaurant to my friends!'}
response = requests.get('http://127.0.0.1:8000/sentiment_analysis/', params=query)
print(response.json())
保存后,执行脚本,你应该会得到如下结果:
python rest_request.py
>>> {'sentiment': 'very positive', 'probability': 0.8293750882148743}
这也成功了。太好了!
你可以在 这里 阅读更多关于 requests 库的信息。
结论
显然,我们本可以做得更多。数据预处理会很有用。进行错误检查也是明智的。作为确认,尝试使用一些奇怪的字符或不将冗长的请求用标点符号括起来,看看会发生什么。
下次我保证我们将扩展今天所做的内容,制作一些更强大、更有趣的东西。我已经在着手准备了。
相关内容:
-
使用 5 个重要的自然语言处理库入门
-
立即学习自然语言处理的神经网络
-
使用 TPOT 进行机器学习管道优化
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
了解更多相关主题
如何制定有效的 AI 战略
原文:
www.kdnuggets.com/2022/11/create-effective-ai-strategy.html

图片由 macrovector 提供,来源于 Freepik
介绍
数据是所有业务战略的核心。自从疫情爆发以来,数据生成速度前所未有,推动了整个世界的数字化。组织在其网络属性上的访问量呈指数增长,变得数据丰富。
现在,大多数组织希望利用这一数据资产来进一步改善业务并获得竞争优势。这可以通过多种方式实现——
-
通过了解用户的痛点来丰富用户体验
-
理解用户在其产品和服务中的价值
-
识别他们开始掉队的地方?
-
找出客户流失的原因——是页面加载问题还是缺乏更好的优惠或价格问题等?
-
或者,企业专注于提高内部运营效率,并希望通过数据驱动的成本削减措施。
什么是战略目标?
一旦确定了业务目标,管理层将其融入战略目标中,这些目标是企业希望在未来三到五年内实现的目标。无需多言,这是一个多年的过程,需要精心规划,以决定当前年份及其后续年份应选择哪些举措,以使企业能够实现其总体战略目标。
此外,战略家通过评估哪些任务为未来季度奠定基础,将年度目标拆分成每季度的目标。简而言之,战略家与跨学科团队的领导者共同确定依赖关系,制定每季度的目标和任务。
如何在多个倡议中进行优先排序?
为了实现业务目标,可以开展很多倡议,但你可能无法提前知道哪些举措能够以最优化和高效的方式创造业务价值。不能同时开展所有想法并对其进行后期分析以评估其效果。一次性执行所有倡议并评估其可行性在时间和资源上都是昂贵的。
这就是战略发挥作用的地方——它将宽泛的高层目标转化为细化且明确的路线图,以优先考虑关键项目。
许多人把策略与目标设定混淆,而实际上,策略是一个非常精心制定的计划,列出了行动项目,并成功地将策略从设计阶段推进到执行阶段。
策略的重要性
现在我们了解了什么是策略,让我们理解何时是固定战略要求并启动基础工作的正确时机。
这是一个典型的问题,即在设计最完美和最优化的策略所花费的时间与何时封存设计部分并开始策略执行之间的权衡。AI 策略的很大一部分特征来自于 AI 项目的实验性质。你可能在深入研究之前无法预见所有的需求、依赖关系和风险。因此,AI 策略需要不断重新优先排序,并且需要灵活性以及在项目进展到下一阶段时能够重新调整项目范围的能力。
可以理解的是,有时你必须从一个蓝图开始,而不是等到所有的信息和输入都完全准备好。这也被称为冷启动问题。
很难选择一个公开的声明来启动项目,而且这种担忧也是合理的。如果你在一开始就选择了错误的项目——你可能会失去热情,并在旅程的开始阶段感到气馁。可能需要六个月或一年时间来通过试错进行迭代,但在一到一年半之后,你的举措必须开始显现回报。过了一段时间,结束一个项目并从头开始一个新项目变得非常困难。
此外,新项目有时意味着对新技术的初期提升,这需要在内部专家的帮助下进行良好的战略规划,以帮助引入新技术。不仅仅是技术的采用至关重要,整体解决方案在组织内部的采纳也很关键。
这引出了我们的下一点,强调了需要倡导者来宣传你的解决方案的必要性,并在这段旅程中成为你的支持者。看到你的解决方案在企业中的采用会带来显著的信心提升。
制定有效的 AI 策略
AI 策略师是一个协调者,负责与包括业务、产品、数据科学和分析以及工程等多个团队合作。

来源: 图片由 tirachardz 提供于 Freepik
一个有效的 AI 策略要求策略师对 AI 项目的工作流程和关键基本驱动因素有清晰的了解,比如:
-
关注 AI 解决方案对最终用户的影响
-
理解伦理问题,如偏见或不公平的结果,或对敏感和私人信息的访问。
-
评估需要建模的过程是否可重复,以及数据是否存在供算法学习的模式。
-
提出的解决方案在技术方面是否具有可扩展性?
-
这是否跨越了各个领域,并在使用案例方面邀请广泛采用?
-
整个解决方案中哪些组件需要从头开发,哪些可以外包?
-
考虑实施策略所需的技术技能——这些技能是团队内部可用的,还是需要外部培训或招聘?
这篇文章阐明了战略的重要性,并重点介绍了在设计人工智能战略时的关键因素。旨在揭示复杂性并列出建立成功人工智能战略的基本支柱。
Vidhi Chugh 是一位人工智能战略家和数字化转型领袖,专注于产品、科学和工程交叉领域,致力于构建可扩展的机器学习系统。她是一位屡获殊荣的创新领袖、作者和国际演讲者。她的使命是将机器学习民主化,并打破术语,使每个人都能参与这一转型过程。
更多相关话题
使用 Tableau 创建高效的合并数据源
原文:
www.kdnuggets.com/2022/05/create-efficient-combined-data-sources-tableau.html
图片由编辑提供
你在 Tableau 上花费了大量时间和资源。现在,合并数据集的时机已经到来。需要合并 Excel 文件或 SPSS 文件吗?如何将多个数据源整合到一个 Tableau 数据源中,或者将外部数据与内部数据合并?使用本指南节省时间和精力,教你如何在 Tableau 中执行数据连接操作。
我们的前三名课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
那么,什么是 Tableau?
你可能听过“Tableau”这个词在不同的语境中出现,但你可能不清楚它的真正含义。
Tableau 是一套用于分析数据和实现商业目标的软件工具,通过全局视角来帮助你从数据中获取洞察,以便做出明智的决策,并规划业务发展方向。
从数据中获取洞察的最佳方法之一是构建 Tableau 中的数据表格。数据表格有助于合并数据源、深入分析数据并立即获得可视化的答案!
数据合并方法:概述
在 Tableau 中合并数据有两种方式:数据连接和数据混合。数据连接是指在同一来源(例如来自同一数据库的表格、同一工作簿中的 Excel 表格、同一目录中的文本文件)中处理多个表格或视图。在大多数情况下,Tableau 在进行数据连接时表现良好。
图 1 展示了使用内部数据连接技术的 Tableau 数据连接方法。图 2 则表示 Tableau 中的数据混合方法。
图 1 Tableau 中的数据连接(来源(tutorialspoint, n.d.))
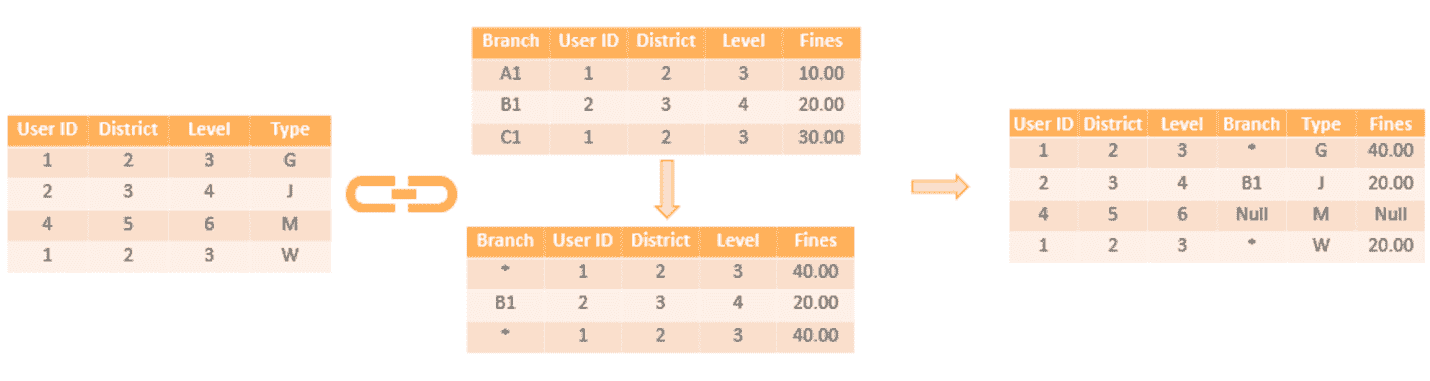
图 2 Tableau 中的数据混合(来源(Upasana, 2021, 12))
要使用数据连接,你需要知道两件事:如何在 SQL 中创建连接以及如何告诉 Tableau 连接的内容。通过数据连接,一旦你连接了需要合并的表格或视图,所有你需要做的就是添加一个额外的步骤,将连接两个表格的字段拖到“连接”架上。
Tableau 中的数据源
Tableau 中的数据源将你的源数据连接到 Tableau。它仅仅是你的数据的总和(无论是作为实时连接还是提取),连接的元数据、包含数据的表或工作表的名称,以及你在 Tableau 中对数据所做的修改。这包括计算、重命名的特征和默认布局等元数据,以及数据的集成方式。
图 3 Tableau 中的数据源(来源(Dmitry Anoshin, Teodora Matic, Slaven Bogdanovic, Tania Lincoln, 2019))
有效地合并数据源
Tableau 允许你创建高效的合并数据源,这样你只需做一次工作,然后可以将该数据源用于多个报告。
以下是创建这些数据源的一些技巧:
-
确保你的数据字段顺序相同
-
确保你的数据格式相同
-
如果可能,确保你的数据包含唯一标识符(例如客户 ID)
-
给同一表中的每个字段分配不同的颜色
-
给你的工作表起具有描述性的名称
-
给你的列起具有描述性的名称
如果你做到这些,你在 Tableau 中创建合并数据源时会非常轻松!
明智地合并表格
将工作簿中的表格数量限制到尽可能少,以创建更好的用户体验。如果你需要访问工作簿中的多个表格,可能需要创建可以用于每个分析场景的单独数据源。
使用联接的有效合并
联接很重要,因为它们允许我们将来自多个来源的信息合并到一个可视化中。它们通常用于在工作簿中的不同工作表之间联接数据,但你可以用联接做很多事情!你可以用它们来合并来自不同数据库的数据、计算机上的文件,甚至完全不同来源的数据!
在 Tableau 中处理多个表时,最佳方法是在数据连接窗口中定义联接。这样,你不是在定义一个特定的查询,而只是定义表之间的关联方式。

图 4 Tableau 中的联接(来源(Dmitry Anoshin, Teodora Matic, Slaven Bogdanovic, Tania Lincoln, 2019))
这些数据将由 Tableau 用于生成获取指定数据所需的具体查询。
作为基本的性能规则,联接的表格数量应最小化,只包括特定工作表/可视化所需的表格。(Eldridge, 2016)
使用混合数据的有效合并
如果你的数据包含许多独特的值,它将占用大量内存。如果你使用包含大量独特值的混合数据,应该使用 64 位版本的 Tableau Desktop。依赖于许多独特值的混合数据可能会花费更长时间进行计算。
使用数据集成
Tableau 10 中提供了一项新功能——数据集成,允许你结合来自多个来源的数据。数据集成适用于行级联接,而数据混合则作用于每个数据源的结果。如果你希望处理更多数据或更快地流动,必须使用数据集成。
调整详细信息级别
在开发精选的数据源时,考虑是否应该在特定的细节层级(LOD)进行汇总。如果是这样,考虑创建一个包含适当 LOD 的 LOD 表达式的新计算字段,以便于未来的开发者。
图 5 Tableau 中的详细信息示例(来源 (Dobiasz, 2019))
结论
数据处理并不容易。它可能是每个企业都在寻求的东西,但收集、分析数据以及确定其有效性可能是一项艰巨的任务。此外,每当企业需要使用数据时,这一过程必须重复进行。与其面临多个障碍和难题,不如直接告诉 Tableau 你希望如何准备数据。
你可以在 Tableau 中集成多个数据源,并创建一个综合仪表板。这将帮助你获得做出快速决策所需的洞察。
参考文献
-
Dmitry Anoshin, Teodora Matic, Slaven Bogdanovic, Tania Lincoln. (2019). Tableau 2019.x CookBook. SMTE Books.
-
Dobiasz, L. (2019, 11 3). the data school. 取自 https://www.thedataschool.com.au/wp-content/uploads/2019/11/LOD-expressions-1.jpg
-
Eldridge, A. (2016). Best Practices for Designing Efficient Tableau Workbooks.
tutorialspoint. (n.d.). Tutorials Point. 取自 tutorialspoint: https://www.tutorialspoint.com/tableau/images/data_join_1.JPG
-
Upasana. (2021, 12). edureka. 取自 edureka: https://www.edureka.co/blog/wp-content/uploads/2019/02/Data-Blending-with-Fines-Data-Blending-in-Tableau-Edureka.png
Neeraj Agarwal 是 Algoscale 的创始人,该公司是一家涉及数据工程、应用 AI、数据科学和产品工程的数据咨询公司。他在该领域拥有超过 9 年的经验,并帮助了从初创公司到财富 100 强公司等广泛的组织摄取和存储大量原始数据,以将其转化为可操作的洞察,促进更好的决策和更快的业务价值。
更多相关主题
-
Top 16 Technical Data Sources for Advanced Data Science Projects
-
Prepare Your Data for Effective Tableau & Power BI Dashboards
如何创建一个交互式 3D 图表并轻松与任何人分享
原文:
www.kdnuggets.com/2021/06/create-interactive-3d-chart-share.html
评论
由 Olga Chernytska,高级机器学习工程师
3D 图表有一个巨大的缺点。当创建一个 3D 图表时,你可以从不同的角度/尺度可视化数据,或者使用一个交互式库,这样你可以很好地理解数据。然而,这些图表在创建后很难分享。
人们通常将 3D 图表转换为单一的静态图像或一组从不同角度和不同尺度拍摄的图像。这种方法可能会丢失一些重要信息或难以理解,因此我们需要一个更好的选择。这个选择确实存在。
在这个简短的教程中,我将向你展示如何创建一个交互式 3D 图表并轻松与任何人分享——无论是数据科学家、开发人员、经理,还是没有任何编程环境的非技术朋友。共享的图表也将完全互动。
工作原理
你可能听说过 plotly,这是一个开源库,允许在 Jupyter Notebooks 中创建交互式图表。我使用过这个库,并且也将图表作为静态图像分享,直到我的同事向我展示了 plotly 的一个很棒的功能:
你可以将交互式图表保存为 HTML 文件——当在浏览器中打开时,它们是完全互动的。
演示
让我们创建一个简单的 3D 函数可视化——抛物线。首先,我们使用 numpy.meshgrid 在网格 (x,y) 上计算函数值。然后我们使用 plotly 绘制表面并将其保存为 HTML 文件。以下是相关代码(基于 文档)。
import numpy as np
import plotly.graph_objects as go
def parabola_3d(x, y):
z = x ** 2 + y ** 2
return z
x = np.linspace(-1, 1, 50)
y = np.linspace(-1, 1, 50)
xv, yv = np.meshgrid(x, y)
z = parabola_3d(xv, yv)
fig = go.Figure(data=[go.Surface(z=z, x=x, y=y)])
fig.write_html("file.html")
结果如下所示。这个 HTML 文件可以在任何浏览器中打开、嵌入到网站上,并通过消息传递工具发送。最好的地方是打开这个文件时,不需要 Jupyter Notebook 或 plotly 库。
 图像 1. 在浏览器中打开时 HTML 文件的样子。
图像 1. 在浏览器中打开时 HTML 文件的样子。
安装和更多
我记得 plotly 曾是一个过于复杂且功能非常有限的库,但在最近几年它变得非常酷。例如,现在有 13 种 3D 图表类型可用,还有数十种地图、统计、科学和金融的 2D 图表。
 图像 2. plotly 中可用的 3D 图表示例。 来源
图像 2. plotly 中可用的 3D 图表示例。 来源
如果您感兴趣并想尝试 plotly,这里有 文档 介绍如何安装它并构建您的第一个图表。绝对值得尝试!
简介:Olga Chernytska 是一家大型东欧外包公司的高级机器学习工程师;参与了多个顶级美国、欧洲和亚洲公司的数据科学项目;主要专注领域和兴趣是深度计算机视觉。
原文。经许可转载。
相关:
-
唯一真正需要的 Jupyter Notebook 扩展
-
直接使用 Pandas 获取交互式图表
-
数据讲述:大脑擅长视觉,但心灵被故事打动
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
相关主题
如何为您的数据项目创建采样计划
原文:
www.kdnuggets.com/2022/11/create-sampling-plan-data-project.html
在第一部分中,我们看到简单随机抽样(SRS)在实际操作中并不总是简单。
截至目前的故事
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持您组织的 IT
想象一下,你是一名data scientist,被聘用来估计下图中松树的平均高度,并描述其分布。你负责规划和分析,因此你可以在舒适的巢穴中操控一切,而一位热心的登山者会按照你的指示在森林中测量树木。
你绝对不会做的事情是指示登山者“完全随机选择 20 棵树。”(如果你有这个冲动,请回到第一部分。)

这片森林中的树木有多高?照片由Dan Otis拍摄,来源于Unsplash
相反,始终努力给出万无一失的指令,因为你永远不知道何时会出现一个野生的傻瓜。
始终努力给出万无一失的指令,因为你永远不知道何时会出现一个野生的傻瓜。
万无一失的指令
当我挑战我的学生给我更好的——更万无一失的——指令时,团队通常会提出老生常谈的建议:
“为每棵树分配一个唯一的编号,然后随机抽样这些编号。”
这已经更好了——至少不再包含“仅仅”这个词——但它仍然不是专业统计学家的级别答案。专业统计学家经历了足够多的挫折,知道细节决定成败。

照片由Sebastian Herrmann拍摄,来源于Unsplash
魔鬼在于(现实世界的)细节
在专业统计学家的思维中,那些看似无害的指令迅速演变成一整堆细节:
“亲爱的徒步旅行者,我提前向你道歉,但你必须一次走完整个森林,给所有树木编号……这就是为什么你如此喜欢徒步旅行!”
在我们甚至还没说完之前,我们的脑子已经在飞速运转:
用什么油漆?(写下来!)
等一下,我们可能需要多少桶油漆?(写下来!)
如果油漆用完了怎么办(因为我们不知道森林中有多少棵树)。(写下来!)
我们可以在哪里购买更多的油漆桶?离这里最近的城镇在哪里?(写下来!)
在我们工作期间,在哪里存放桶会更有效率?(写下来!)
我们如何确保合理标记这些树木,以便在抽到它们时能高效找到它们?(写下来!)
我们需要一个手推车吗?或者一些助手?(写下来!)
我们如何确保没有遗漏任何一棵树?(写下来!)
我们预计这将花费多长时间?(写下来!)
如果徒步旅行者在项目中途退出怎么办?(写下来!)
如果下雨了,油漆脱落怎么办?(写下来!)
这所有的费用是多少?(写下来!)
如果计划比预期更昂贵,我们的应对计划是什么?(写下来!)
我们的预算是多少?(写下来!)
替代抽样方案
啊,预算。随着你开始详细规划,你可能会发现你的理想方法不可行。在这种情况下,你有两个选择。
-
选择不同的抽样程序。SRS 并不是你唯一的选择,它甚至不一定是对你的需求最优的统计方法。它的主要优势是允许你使用初学者技术,但如果你发现实施 SRS 在现实中比雇用一个懂得高级方法的人更昂贵,那么这就是一个很好的选择。只要记住,使用其他抽样程序意味着你必须以不同于 STAT101 教给你的标准方式来分析数据(除非你选择下面的选项 2)。
-
假设** 远离问题。** 这是经典的绝望中的权宜之计,你会在 科学领域到处发现。这基本上就是说,你将进行分析,就好像某些事情是真的,即使你知道它们并非如此。这是哲学上不稳定的领域,只有决策者有权批准这样做,他可能会愿意接受一个低质量的决策程序来节省资源。如果你不是做 数据驱动决策的负责人,你没有权利做出这个决定。
但让我们设想一下,你的徒步旅行者非常渴望在森林里呆得越久越好(哇),以至于他们给你一个固定的项目费率。现在你可以负担得起让这个热爱户外的狂热者为你涂上所有的树木。是时候开始规划下一步:随机选择 20 棵树。
我们如何“仅仅”选择 20 棵树?一种简单的方法是,等到所有的树都被涂上独特的 ID,然后把所有的树木 ID 放入一个电子表格的列中,拖动=RAND()函数到相邻的列中,并按随机数列的顺序排序,然后选择顶部的前 20 个 ID。
现在我们对更多细节感到担忧:
标签应该是整数还是其他什么?(写下来!)
如果它们很难阅读怎么办?(写下来!)
我们确定随机数生成器是随机的吗?(写下来!)
如果我们忘记仅以值粘贴特殊怎么办?(写下来!)
我们计划带一台笔记本电脑去森林吗?哪一台?(写下来!)
如果没有 Wi-Fi,软件会正常工作吗?(写下来!)
笔记本电脑的电池能坚持多久?(写下来!)
我们需要备用笔记本电脑吗?(写下来!)
一旦我们有了 20 个随机选择的树木 ID——保存在哪里?(写下来!)——是时候向徒步旅行者道歉,可能需要再次在森林中徒步旅行。希望我们已经想出了一个高效的徒步策略来节省时间,因为可怜的徒步旅行者已经精疲力竭了。不过,还有更多的事情!
来自维基百科的高程测量高程计的插图:en.wikipedia.org/wiki/Hypsometer
徒步旅行者将如何进行测量?(写下来!)
我们应该使用什么工具?一个高程计?(写下来!)
我们如何确保徒步旅行者经过正确的培训以正确使用设备?(写下来!)
如果树木在坡道上或被遮挡,我们应该怎么办?(写下来!)
我们可能需要什么额外的设备?(写下来!)
测量结果将记录在哪里?纸上?笔记本电脑上?手机上?我们是否计划好如何携带这些数据,以及如果出现故障该怎么办?(写下来!)
徒步旅行者是否明白测量结果应该记录在树木 ID 旁边?
树高是徒步旅行者应该测量和记录的关于每棵树的唯一内容吗?当然,还有一些额外的信息可能有用且相对容易获取,包括时间、树木的物理特征、距离徒步旅行者起点的距离、在一个对阳光和土壤营养竞争相关的半径内的其他树木数量(那个半径是多少?)、树木的周长等等。(写下来!但如果你像我一样对树木了解甚少,请先咨询领域专家。)
如果我们为每个 ID 记录一堆额外的属性,它们应该如何记录?徒步旅行者应该使用什么数据模式?(写下来!)
我们如何检查错误?徒步旅行者是否需要进行额外的检查?(写下来!)
我们如何验证徒步旅行者是否正确地遵循了指示?(写下来!)
对于我们记录的每一个属性,单位或类别 应该由徒步旅行者使用?(写下来!)
在结束之前,我们会通读我们的文档,补充更多细节。如果你草率地编写详细说明,你会因为数据收集员带回来的混乱(因为它不会是你想要的)而恨他们。而你的数据收集员也会正当地恨你,因为你给了他们愚蠢的指示,还指望他们读懂你的心思。
有一天,数据收集员将会是你……然后你会恨自己。
抽样计划涵盖了数据收集的现实世界实际方面。
这就是我们在工作中艰难学习的方式。多年来我所养成的数据卫生习惯,源于对过去自己糟糕规划的愤怒。年轻时我主要关注数学。时光流逝后的我对现实世界的细节更感兴趣。我希望你能从我的错误中学习,这样你就不必重蹈覆辙。
请答应我,你不会再指示别人“只”做简单的随机抽样。

图片来源于 Brett Jordan 在 Unsplash
抽样计划
当你对细节足够担忧之后(写下来!),你面前的文档被称为抽样计划。
抽样计划涵盖了数据收集的现实世界实际方面,不使用它来记录现实世界的数据是极其业余的。如果你尝试跳过规划,你将面临一场非常昂贵的彩排,为即将到来的重新审视做好准备。
抽样方案
现在你已经写下了理论部分(抽样程序)和实践部分(抽样计划),你准备将它们合并成一个名为抽样方案的单一文档。
抽样计划 + 抽样程序 = 抽样方案
顺便提一下,当你从供应商那里购买数据时,应该始终要求提供完整的抽样方案(包括计划,而不仅仅是程序),以确保你理解你的数据实际含义。有关处理二级(继承的)数据的更多技巧,包括购买的数据,请查看我的指南 这里。
一个真正的专业人士在创建完整的抽样方案之前不会梦想到收集数据。不幸的是,由于数据课程的教学方式——理论多,实践少——往往需要一段时间才能让刚毕业的小白变成真正的专业人士。我们这些在行业中待久了的人可以通过为实践方面的注意加油来发挥作用。毕竟,如果细节都模糊不清,那所有的复杂数学又有什么意义呢?
感谢阅读!如何参加 AI 课程?
如果你在这里玩得开心,且你正在寻找一个为初学者和专家设计的有趣应用 AI 课程,这里有一个我为你准备的:
在这里享受整个课程播放列表: bit.ly/machinefriend
Cassie Kozyrkov 是谷歌的数据科学家和领导者,致力于将决策智能和安全可靠的 AI 民主化。
原文。经许可转载。
更多相关内容
使用 ChatGPT 迅速创建惊艳的数据可视化
原文:
www.kdnuggets.com/create-stunning-data-viz-in-seconds-with-chatgpt
图片来源:作者
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
数据可视化是任何从事数据工作的人必备的关键技能。但创建美观且信息丰富的数据可视化可能耗时且需要专业工具。这就是 ChatGPT 的用武之地。借助其最新更新,ChatGPT 使数据可视化比以往任何时候都更快、更容易。
最新更新显著提升了 ChatGPT 的体验。现在,你无需像原始 GPT-4、GPT4 高级分析版或 DALLE-3 之间切换,只需输入一个提示,ChatGPT 会自动解释你的请求并生成所需结果。
图片来源:ChatGPT
在这篇博客文章中,我们将探索如何使用简单的英文提示即时生成各种数据可视化。得益于 ChatGPT 的高级数据分析,你无需处理数据或运行 Python 代码。我们将从简单的饼图和条形图开始,然后使用实际数据集处理更复杂的可视化。
简单可视化
在这一部分,我们将编写一个简单的提示来生成图表。该提示包括以 Python 字典形式呈现的数据。
饼图
在我们创建提示之前,请确保你正在使用 GPT-4 模型,因为只有它支持生成可视化。
我们将编写一个提示来生成基于各种营养数据的饼图可视化。此外,我们请求 ChatGPT 使用更柔和的颜色组合,因为默认颜色比较鲜艳。
**Prompt: ** Generate a pie chart of values {"Vitamin A":5, "Vitamin B": 1, "Vitamin C": 4, "Water": 90} to keep the color combination light.
正如你所见,我们得到了很好的结果。
如果你想查看可视化背后的 Python 代码,你需要点击结果末尾的终端图标。

之后,会出现一个包含源代码的窗口,你可以修改和执行这些代码。然而,这一步不是强制性的,因为 ChatGPT 会直接运行代码并以图像形式显示可视化结果。你可以将这些图像保存用于演示或报告。
条形图
在下一部分,我们提供了汽车的 CO2 排放数据,并让 ChatGPT 施展魔法。
**Prompt: ** Generate a bar plot co2 emissions of values {"Car A":30, "Car B": 25, "Car C": 20}.
它已添加标题、x 轴和 y 轴标签,并确保了降序排列。完美!!!
探索性数据分析
与其过度控制 ChatGPT 的输出,不如让它独立创建结果,类似于各种 Python AutoViz 库。只需提供数据集并请求进行完整的探索性数据分析,以生成你需要查看的图表。
在我们的案例中,我们提供了一个顾客购物趋势数据集,该数据集提供了有关消费者行为和购买模式的宝贵见解。
**Prompt: ** Perform exploratory data analysis on customer shopping trends dataset and display only plots.
ChatGPT 提供了快速的结果,处理和分析消费者趋势在不到一分钟的时间内完成,而这个任务通常需要我至少 30 分钟的编码和运行时间。

你可以通过提供后续提示来改善结果,说明你感兴趣的可视化类型。
**Prompt: ** Improve the analysis by plotting a correlation chart, bar chart, pie chart, boxplot, and relplot.
如果你想看到多层次的复杂可视化,你需要特别要求 ChatGPT。
**Prompt: ** Use the dataset to plot various complex visualizations.
模型评估
数据可视化在模型评估中发挥了至关重要的作用。在这一部分,我们将使用 Kaggle 的糖尿病数据集,并要求 ChatGPT 训练和评估多个模型。为了最大化 ChatGPT 的能力,我们将请求它显示混淆矩阵、精准率-召回率和比较不同模型的图表。
**Prompt: ** Multiple machine learning models should be trained using the target column "Outcome", and the resulting model evaluation visualization should include a confusion matrix, precision-recall, and model comparison chart.
显然,ChatGPT 表现出色。尽管模型在数据集上的表现不佳,但我们对其快速而准确的数据可视化能力印象深刻。它可以用来快速分析数据集,或在面试或家庭作业中回答问题。

结论
ChatGPT 彻底改变了我们轻松创建数据可视化的方式。凭借其先进的数据分析能力,你可以使用简单的英文提示在几秒钟内生成令人惊叹和有信息量的数据可视化。
在这篇文章中,我们了解了 ChatGPT 如何即时生成各种图表,如饼图、条形图、相关矩阵,甚至是复杂的可视化图形如 relplots。
ChatGPT 在处理糖尿病数据集的机器学习模型训练以及生成评估指标和比较图表时也超出了预期。整个模型构建和可视化过程几乎只用了不到一分钟。
无论你需要简单的条形图、先进的模型分析,还是仅仅是快速理解数据集,ChatGPT 都能以最小的努力提供卓越的结果。随着能力的不断提升,现在是利用这个 AI 助手提升你的数据可视化技能的激动人心的时刻。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为遭受心理疾病困扰的学生构建一款 AI 产品。
更多相关话题
如何为你的数据科学项目创建令人惊叹的网页应用
原文:
www.kdnuggets.com/2021/09/create-stunning-web-apps-data-science-projects.html
评论
由 Murallie Thuwarakesh,Stax, Inc. 的数据科学家提供
图片由 Meagan Carsience 在 Unsplash 提供
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
网页开发不是数据科学家的核心能力。大多数数据科学家不会学习不同的技术来完成这项任务。这不是他们的强项。
然而,大多数数据科学项目也有一个软件开发组件。开发人员有时对问题有不同的理解,并且使用离散的技术。这通常会导致问题,并浪费双方团队的宝贵时间。
此外,像 Tableau 和 Power BI 这样的可视化工具更多地关注数据探索。然而,这只是完整数据科学项目的一部分。如果你需要集成机器学习模型,它们还远远不够完美。
Streamlit 允许你为数据科学项目开发网页应用。这个开源库的 API 完全用 Python 编写。因此,你不需要学习其他网页技术即可使用它。此外,它容易学习,修改起来也很灵活。
这篇文章是对 Streamlit 的介绍。我们将构建一个互动网页应用,它接受用户输入,运行 K-means 算法,并立即在网页界面上绘制结果。
在短文结束时,我们将涵盖
-
安装 Streamlit 并测试水温;
-
构建一个互动网页应用;
-
使用用户输入运行 K-means 算法;
-
使用缓存来提高性能,以及;
-
在云端部署它;
这里是 链接 到已部署版本。如果你想提前了解一下,请查看。
设置 Streamlit 以进行开发。
这个非凡的工具设置简单得令人难以置信,几乎所有 Python 用户都很熟悉它。使用 PyPI。
pip install streamlit
你也可以使用 conda 和其他流行的 Python 包管理工具。
完成后,你可以使用安装包中的 hello world 应用进行测试。在终端窗口中执行下面的命令以启动开发服务器。
streamlit hello
hello world 应用展示了你可以用 Streamlit 做的出色可视化。上述命令将启动一个本地开发服务器,并在默认浏览器中打开链接。你还可以在同一页面上找到源代码。此外,这个示例应用还提供了许多高级教程的链接,以便你进一步学习。
既然设置完成了,让我们创建一个与我们的机器学习模型互动的应用。
使用机器学习模型与 Streamlit 网页应用一起使用。
下面的应用程序使用 Pandas、Scikit-Learn、Matplotlib、Seaborn 和 Streamlit。在开始之前,请确保你已经安装了所有必要的包。如果没有,下面的命令会为你安装。
pip install pandas scikit-learn matplotlib seaborn streamlit
创建你的第一个网页应用
创建一个名为 ‘quickstart.py’ 的文件,内容如下。
# Imports
# -----------------------------------------------------------
import streamlit as st
import pandas as pd
# -----------------------------------------------------------
# Helper functions
# -----------------------------------------------------------
# Load data from external source
df = pd.read_csv(
"https://raw.githubusercontent.com/ThuwarakeshM/PracticalML-KMeans-Election/master/voters_demo_sample.csv"
)
# -----------------------------------------------------------
# Sidebar
# -----------------------------------------------------------
# -----------------------------------------------------------
# Main
# -----------------------------------------------------------
# Create a title for your app
st.title("Interactive K-Means Clustering")
# A description
st.write("Here is the dataset used in this analysis:")
# Display the dataframe
st.write(df)
# -----------------------------------------------------------
代码片段来自 作者。
上面的文件很简单。为了说明,我在文件中添加了几个部分。
在主应用部分,我们有三行。我们在页面上添加了一个标题和一个描述。然后我们在页面上显示数据框。 “st.write” 函数是一个全能解决方案。你可以将几乎任何东西传递给这个函数,Streamlit 足够智能,能够在 UI 中显示正确的小部件。要了解不同的 Streamlit 函数,这里有一个 备忘单。
让我们用下面的命令运行我们的初始应用。
streamlit run quickstart.py
和 hello 应用一样,这个命令将启动一个新的开发服务器。在你的浏览器中,你会看到下面的内容。
截图来自 作者。
恭喜你,你刚刚创建了第一个网页应用;不需要 HTML、CSS,也完全不需要 JavaScript。
但这只是初级阶段。一个网页应用可以做很多酷炫的事情。它可以实时与用户互动并更新内容。让我们看看如何实现它。
添加交互功能
在 Streamlit 网页应用中添加交互功能非常简单。Streamlit API 包含多个小部件。你可以使用它们来获取用户输入并将其值存储在一个变量中。其余部分就像其他任何 Python 程序一样。
让我们添加一个复选框来切换数据集的显示。毕竟,没有人会开发一个网页应用来查看原始数据。用下面的内容替换数据框显示(第 30 行)。
# Display the dataframe
df_display = st.checkbox("Display Raw Data", value=True)
if df_display:
st.write(df)
代码片段来自 作者。
如果你刷新浏览器,现在可以看到一个复选框来切换数据框的显示。
截图来自 作者。
但是,中间的切换按钮并不令人愉悦。让我们把它移到侧边栏。
向应用程序添加侧边栏
再次,这是一项轻松的操作。Streamlit API 具有侧边栏属性。你在主应用程序中创建的所有小部件在这个侧边栏属性中也可用。
通过使用 ‘st.sidebar’ 属性创建一个侧边栏变量。然后将我们在主应用程序部分添加的复选框分配移动到侧边栏部分。注意,我们现在使用的是 ‘st.sidebar.checkbox’ 而不是 ‘st.checkbox’。
# SIDEBAR
# -----------------------------------------------------------
sidebar = st.sidebar
df_display = sidebar.checkbox("Display Raw Data", value=True)
n_clusters = sidebar.slider(
"Select Number of Clusters",
min_value=2,
max_value=10,
)
# -----------------------------------------------------------
代码片段来自 作者。
在上面的代码中,我们还向侧边栏添加了一个滑块。这个小部件将捕获用户选择的聚类数量。下面是输出效果的样子。
截图来自 作者。
下一站,我们将使用用户选择的聚类数量运行 K 均值算法。
使用实时输入运行 K-Means。
使用以下代码扩展导入、辅助函数和主应用程序部分。
# Imports
# -----------------------------------------------------------
...
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme()
# -----------------------------------------------------------
# Helper functions
# -----------------------------------------------------------
...
def run_kmeans(df, n_clusters=2):
kmeans = KMeans(n_clusters, random_state=0).fit(df[["Age", "Income"]])
fig, ax = plt.subplots(figsize=(16, 9))
#Create scatterplot
ax = sns.scatterplot(
ax=ax,
x=df.Age,
y=df.Income,
hue=kmeans.labels_,
palette=sns.color_palette("colorblind", n_colors=n_clusters),
legend=None,
)
return fig
# -----------------------------------------------------------
# MAIN APP
# -----------------------------------------------------------
...
# Show cluster scatter plot
st.write(run_kmeans(df, n_clusters=n_clusters))
# -----------------------------------------------------------
代码片段来自 作者。
在上面的代码中,我们创建了一个运行 K-Means 算法的函数。它接受数据框和聚类数量作为参数,并返回一个 Matplotlib 图形。
K-Means 聚类的说明超出了本项目的范围。这是一个机器学习算法,这正是我们关心的。但是你可以参考我 之前的帖子 ,那里有相关的描述。
我们使用 n_clusters 变量,该变量捕获了上一节中的滑块值,作为 run_forecast 函数的第二个参数。
如果你刷新页面,你会看到一个仪表盘,它接收用户输入,运行机器学习算法,并立即更新 UI。
截图来自 作者。
即使你是一个经验丰富的开发者,与后端机器学习的这种互动和集成也是一项困难的任务。特别是如果你是一个不懂如何开发网页应用的数据科学家,这可能会占用你几周的时间。
通过缓存提高性能。
数据科学流程中的某些任务是耗时的。然而,这些任务对于相同的输入很少产生不同的结果。你可以使用 Streamlit 内置的缓存功能来存储它们的值以备将来使用。
虽然这听起来可能复杂,但使用 Streamlit 实现非常简单。你的耗时任务应该是一个函数,并且你用 @ts.cache 装饰器将其包装起来。只要输入参数相同且函数体未被修改,Streamline 就会从缓存中提取它。
在我们构建的应用程序中,我们调用外部 URL 以下载数据。如果这是一个实时 API,你可能不想缓存它。但在我们的情况下,它不是。因此,让我们通过替换以下代码行来缓存它。
# Load data from external source
@st.cache
def load_data():
df = pd.read_csv(
"https://raw.githubusercontent.com/ThuwarakeshM/PracticalML-KMeans-Election/master/voters_demo_sample.csv"
)
return df
df = load_data()
作者的 代码片段。
在第一次重新加载时,你可能会看到浏览器上显示“Processing load_data”的消息。但后续的重新加载不会出现这个提示。这是因为请求是从缓存中获取的,而不是从外部 URL 下载的。
在互联网上部署
如果你注意到了 Streamlit 控制台,你还会看到一个网络 URL。这意味着,如果你的防火墙允许,你的应用可以通过内部网访问。
如果你想在你的网络之外分享它,我们有很多选择。正如文档所说,Streamlit 应用在任何 Python 应用可以运行的地方都能工作。
-
Streamlit 推荐使用“Streamlit Sharing”选项。
你可以把你的代码放在 GitHub 仓库里,并配置 Streamlit Sharing 来提供你的应用。
Streamlit Sharing 是免费的,但目前仅限邀请。你可以为自己申请邀请。
-
你可以在云平台上部署它。这里有一篇 文章 显示了如何使用 AWS EC2 免费实例进行部署。
-
你可以 配置反向代理。像 Nginx 和 Apache 这样的代理服务器可以被配置来提供应用服务,并限制特定用户的访问。
一定要阅读 Streamlit 的社区指南 关于部署的内容,以探索你可以选择的众多选项。
下面是我如何在 Streamlit Share 上部署这个教程应用的。再一次,Streamlit 的便利性让我惊讶。
步骤 I:将你的代码放入 GitHub 公共仓库。 我已经将我的代码添加到这个 GitHub 仓库。我们需要确保它包含一个包含所有依赖项的 requirement.txt 文件。
步骤 II:使用你的 GitHub 账户登录 Streamlit。
步骤 III:在 Streamlit 控制台上创建一个新应用。 从下拉菜单中选择你的 GitHub 仓库或粘贴 URL。选择你想要用于部署的分支。最后,选择主文件名并点击部署。
作者截图。
大约一分钟内,我的应用 就在 Streamlit Share 上上线了。但部署时间可能会因项目需求而异。
请注意,Streamlit Share 目前是仅限邀请的。但我没等太久就获得了它。Streamlit 的 部署文档 包含了更多有用的信息。
结论
不用说,Streamlit 解决了数据科学项目中的一个关键问题。它赋予数据科学家构建 Web 应用程序以与其机器学习模型互动的能力。
在这篇介绍性文章中,我们探讨了如何将 Streamlit 与 K-Means 聚类结合使用。虽然这是一个简单的应用,但它展示了这项技术的核心概念。除了开发,我们还了解了如何轻松管理 Streamlit 中的缓存以提高性能。最后,我们讨论了部署选项。
Streamlit 远不止于此。请查看他们的 官方文档,其中包含了出色的教程。此外,他们的 API 速查表 对于快速开发也很有帮助。
Web 应用程序是一个绝妙的解决方案。但在某些情况下,你可能需要考虑其他方式来与 ML 模型交互。也许,构建一个命令行界面可能会有所帮助。
感谢阅读,朋友!看起来你我有很多共同的兴趣。我很愿意在 LinkedIn、Twitter 和 Medium 上与你联系。
还不是 Medium 会员?请使用此链接 成为会员。你可以享受成千上万的有深度的文章,并支持我作为推荐你的小佣金。
简介:Murallie Thuwarakesh (@Thuwarakesh) 是 Stax, Inc. 的数据科学家,并且是 Medium 上分析领域的顶级作家。Murallie 分享了他每天在数据科学领域的探索。
原文。转载已获许可。
相关:
-
数据科学家的 Streamlit 小贴士、技巧和窍门
-
使用 Streamlit 进行主题建模
-
构建一个应用程序来生成使用 TensorFlow 和 Streamlit 的逼真面孔
更多相关话题
如何创建无偏机器学习模型
原文:
www.kdnuggets.com/2021/07/create-unbiased-machine-learning-models.html
评论
作者:Philip Tannor,Deepchecks的联合创始人兼首席执行官。

图片由 Clker-Free-Vector-Images 提供,来源于 Pixabay
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
AI 系统在许多行业中变得越来越流行和核心。它们决定谁可能从银行获得贷款,个人是否应被定罪,甚至在不久的将来,我们可能会将生命托付给使用自动驾驶系统等技术。因此,迫切需要机制来驾驭和控制这些系统,以确保它们按预期行为。
一个近年来越来越受到关注的重要问题是公平性。虽然通常机器学习模型的评估基于准确性等指标,但公平性的观点是,我们必须确保我们的模型在性别、种族及其他选定属性上不带有偏见。
一个经典的关于 AI 系统种族偏见的例子是 COMPAS 软件系统,该系统由 Northpointe 开发,旨在协助美国法院评估被告成为再犯的可能性。Propublica 发布了一篇文章,称该系统对黑人有偏见,给他们更高的风险评级。

机器学习系统对非裔美国人的偏见? (来源)
在这篇文章中,我们将尝试理解机器学习模型中的偏见从何而来,并探索创建无偏模型的方法。
偏见从何而来?
“人类是最薄弱的环节”
—布鲁斯·施奈尔
在网络安全领域,常常说“人是最弱的环节”(Schneier)。这个观点在我们的案例中同样适用。实际上,偏见是由人类无意中引入到机器学习模型中的。
记住,机器学习模型的好坏取决于其训练数据,因此如果训练数据包含偏见,我们可以预期我们的模型也会模仿这些偏见。在自然语言处理(NLP)领域的词嵌入(word embeddings)中可以找到一些具有代表性的例子。词嵌入是学习得到的词的稠密向量表示,旨在捕捉一个词的语义信息,然后可以将这些信息输入到机器学习模型中用于不同的下游任务。因此,具有相似含义的词的嵌入预计应该是“接近”的。
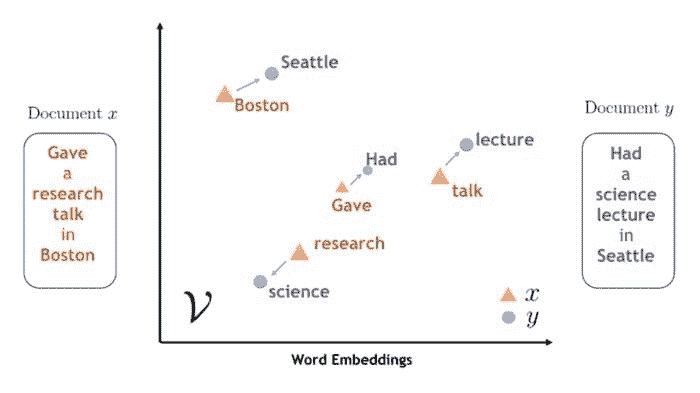
词嵌入可以捕捉词的语义含义。 (来源)
事实证明,嵌入空间可以用来提取词与词之间的关系,也可以用来找到类比。例如著名的king-man+woman=queen方程。如果我们将“doctor”替换为“king”,我们会得到“nurse”作为“doctor”的女性等价词。这一不良结果简单地反映了我们社会和历史中的性别偏见。如果在大多数现有文本中,医生通常是男性,护士通常是女性,那么我们的模型也会这样理解。
doctor = nlp.vocab['doctor']
man = nlp.vocab['man']
woman = nlp.vocab['woman']
result = doctor.vector - man.vector + woman.vector
print(most_similar(result))
Output: nurse
代码示例: man 对 doctor 的关系就像 woman 对 nurse 的关系 (根据 gensim word2vec) (来源)
文化特定倾向
当前,互联网上使用最多的语言是[英语]( https://www.statista.com/statistics/262946/share-of-the-most-common-languages-on-the-internet/#:~:text=As of January 2020%2C English ,percent%20of%20global%20internet%20users.)。数据科学和机器学习领域的大部分研究和产品也是用英语进行的。因此,许多用于创建大型语言模型的“自然”数据集往往反映了美国的思想和文化,并且可能对其他国籍和文化存在偏见。

文化偏见:GPT-2 需要积极引导才能在给定的提示下生成正面的段落。 (来源)
合成数据集
数据中的一些偏见可能是在数据集构建过程中无意中产生的。在构建和评估过程中,人们更可能注意到他们熟悉的细节。一个众所周知的图像分类错误例子是谷歌照片 将黑人误分类为猩猩。虽然这种单一的误分类可能对整体评估指标没有强烈影响,但这是一个敏感问题,并可能对产品及客户对产品的看法产生重大影响。

种族主义 AI 算法?将黑人误分类为猩猩。(source)
总之,没有哪个数据集是完美的。无论数据集是手工制作的还是“自然”的,它都可能反映其创建者的偏见,因此结果模型也会包含相同的偏见。
创建公平的机器学习模型
创建公平的机器学习模型有多种方法,这些方法通常属于以下阶段之一。
预处理
创建对敏感属性不偏见的机器学习模型的一个简单方法是从数据中去除这些属性,以便模型无法利用这些属性进行预测。然而,将属性划分为明确的类别并不总是很简单。例如,一个人的名字可能与其性别或种族相关,但我们不一定希望将这一属性视为敏感属性。更复杂的方法尝试使用降维技术来消除敏感属性。
在训练时
创建无偏见的机器学习模型的一个优雅方法是使用对抗去偏见。在这种方法中,我们同时训练两个模型。对抗模型被训练以预测受保护的属性,而预测器被训练以在原始任务上取得成功,同时使对抗模型失败,从而最小化偏见。
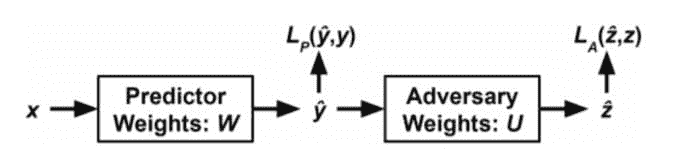
对抗去偏见的示意图:预测器损失函数由两个部分组成,即预测器损失和对抗损失。(source)
这种方法可以在不“丢弃”输入数据的情况下取得很好的去偏见效果,但它可能会遇到在训练对抗网络时通常出现的困难。
后处理
在后处理阶段,我们获得模型的预测结果作为概率,但我们仍然可以根据这些输出选择如何行动,例如,我们可以为不同的群体调整决策阈值,以满足我们的公平性要求。
确保模型公平性的一种后处理方法是查看所有组的 ROC 曲线下的交集。这个交集代表了所有类别可以同时实现的 TPR 和 FPR。请注意,为了满足所有类别的 TPR 和 FPR 相等的期望结果,可能需要故意选择在某些类别上得到较差的结果。
彩色区域是实现公平性分离标准时所能达到的范围。 (来源)
另一种在后处理阶段去偏差的方法涉及独立校准每个类别的预测。校准是一种确保分类模型的概率输出确实反映正标签匹配比例的方法。形式上,如果对于每个 r 值:
当模型经过适当校准后,不同保护属性值的误差率会相似。
结论
总结来说,我们讨论了机器学习世界中的偏差和公平性概念,我们看到模型的偏差通常反映了社会中的现有偏差。我们可以采取多种方法来强制执行和测试模型的公平性,希望使用这些方法能在全球范围内的人工智能辅助系统中实现更公正的决策。
进一步阅读
Alekh Agarwal, Alina Beygelzimer, Miroslav Dudík, John Langford, & Hanna Wallach. (2018). 公平分类的减少方法。
Brian Hu Zhang, Blake Lemoine, & Margaret Mitchell. (2018). 使用对抗学习减轻不必要的偏差。
Solon Barocas, Moritz Hardt, & Arvind Narayanan (2019). 公平性与机器学习。fairmlbook.org。
Ninareh Mehrabi, Fred Morstatter, Nripsuta Saxena, Kristina Lerman, & Aram Galstyan. (2019). 关于机器学习中的偏差和公平性的调查。
个人简介:Philip Tannor 是 Deepchecks 的联合创始人兼首席执行官。
相关内容:
-
保证隐私所需的数据保护技术
-
什么使人工智能值得信赖?
-
人工智能中的伦理、公平性与偏差
更多相关内容
如何在 Python 中为 NLP 任务创建词汇表
原文:
www.kdnuggets.com/2019/11/create-vocabulary-nlp-tasks-python.html
评论
在执行一个 自然语言处理任务 时,我们的文本数据转换大致按照以下方式进行:
我们的前三个课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
原始文本语料库 → 处理后的文本 → 分词文本 → 语料库词汇表 → 文本表示
请记住,这一切都发生在实际的 NLP 任务开始之前。
语料库词汇表是处理文本的储存区域,在其被转化为某种 表示形式 用于 即将到来的任务 之前,无论是分类,语言建模,还是其他任务。
词汇表有几个主要目的:
-
帮助预处理语料库文本
-
作为处理文本语料库在内存中的存储位置
-
收集并存储语料库的元数据
-
允许进行任务前的数据清理、探索和实验
词汇表有几个相关的目的,可以从几个不同的角度来理解,但主要的要点是,一旦语料库进入词汇表,文本就已经被处理,所有相关的元数据应当被收集和存储。
本文将逐步介绍一个有用的词汇表类的 Python 实现,展示代码中发生的事情,我们为什么这样做,以及一些示例用法。我们将从 这个 PyTorch 教程 开始,并在过程中进行一些修改。虽然这不会太依赖编程,但如果你对 Python 面向对象编程完全陌生, 我建议你先查看这里。
首先要做的是为句子开始、句子结束和句子填充的特殊标记创建值。当我们对文本进行分词(将文本拆分成其原子组成部分)时,我们需要特殊标记来划分句子的开始和结束,并在句子短于最大允许空间时填充句子(或其他文本块)的存储结构。稍后会详细介绍。
PAD_token = 0 # Used for padding short sentences
SOS_token = 1 # Start-of-sentence token
EOS_token = 2 # End-of-sentence token
上述内容表示,我们的句子开始标记(字面上是‘SOS’)在我们创建标记查找表时将占据索引位置‘1’。同样,句子结束标记(‘EOS’)将占据索引位置‘2’,而句子填充标记(‘PAD’)将占据索引位置‘0’。
接下来我们将为我们的词汇表类创建一个构造函数:
def __init__(self, name):
self.name = name
self.word2index = {}
self.word2count = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}
self.num_words = 3
self.num_sentences = 0
self.longest_sentence = 0
第一行是我们的__init__()声明,它要求self作为第一个参数(如查看此链接),并将一个词汇表的'name'作为第二个参数。
逐行来看,这些对象变量初始化的作用
-
self.name = name→ 这将被实例化为传递给构造函数的名称,用于引用我们的词汇表对象 -
self.word2index = {}→ 一个字典,用于保存词标记到相应词索引值,最终形式类似于'the': 7 -
self.word2count = {}→ 一个字典,用于保存语料库中每个词的计数(实际上是标记) -
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS"}→ 一个字典,保存了word2index的反向映射(词索引键到词标记值);特殊标记立即添加 -
self.num_words = 3→ 这将是语料库中词语的数量(实际上是标记) -
self.num_sentences = 0→ 这将是语料库中句子的数量(实际上是任何长度的文本块) -
self.longest_sentence = 0→ 这将是最长语料库句子的长度,以标记数量为单位
从上述内容,你应该能够看到我们目前关注的语料库元数据。尝试考虑一些你可能想要跟踪的额外语料库相关数据,这些数据我们尚未涉及。
既然我们已经定义了我们感兴趣的元数据,我们可以继续进行相关工作。填充词汇表的基本工作单元是向其中添加词语。
def add_word(self, word):
if word not in self.word2index:
# First entry of word into vocabulary
self.word2index[word] = self.num_words
self.word2count[word] = 1
self.index2word[self.num_words] = word
self.num_words += 1
else:
# Word exists; increase word count
self.word2count[word] += 1
如你所见,在尝试将一个单词标记添加到词汇表时,我们可能会遇到 2 种情况:要么该单词在词汇表中不存在(if word not in self.word2index:),要么存在(else:)。如果单词在词汇表中不存在,我们要将其添加到word2index字典中,将该单词的计数初始化为 1,将单词的索引(计数器中的下一个可用数字)添加到index2word字典中,并将总单词计数增加 1。另一方面,如果单词已经存在于词汇表中,则只需将该单词的计数器增加 1。
我们将如何将单词添加到词汇表中?我们将通过输入句子并进行分词处理来完成这项工作,逐一处理生成的标记。请再次注意,这些不一定是句子,命名这两个函数为add_token和add_chunk可能比add_word和add_sentence更为合适。我们将把重命名的工作留到另一天。
def add_sentence(self, sentence):
sentence_len = 0
for word in sentence.split(' '):
sentence_len += 1
self.add_word(word)
if sentence_len > self.longest_sentence:
# This is the longest sentence
self.longest_sentence = sentence_len
# Count the number of sentences
self.num_sentences += 1
这个函数接收一段文本,一个单一的字符串,并通过空白字符进行分割,以实现分词。这不是一种稳健的分词方法,也不是最佳实践,但目前足以满足我们的需求。我们将在后续文章中重新审视这个问题,并在我们的词汇类中构建更好的分词方法。在此期间,你可以在这里和这里了解更多关于文本数据预处理的内容。
在通过空白字符分割句子后,我们将句子长度计数器为每个传递给add_word函数处理并添加到词汇表中的单词增加 1(见上文)。然后我们检查该句子是否比我们处理过的其他句子更长;如果是,我们做个记录。我们还增加了到目前为止我们已经添加到词汇表中的语料库句子的计数。
然后我们将添加一对辅助函数,以便更容易访问我们两个最重要的查找表:
def to_word(self, index):
return self.index2word[index]
def to_index(self, word):
return self.word2index[word]
这两个函数中的第一个在适当的字典中根据给定的索引执行词到索引的查找;另一个函数则执行反向查找。这是基本功能,因为一旦我们将处理过的文本放入词汇表对象中,我们将希望在某个时候将其取出,并执行查找和引用元数据。这两个函数在这方面非常有用。
把这些内容综合在一起,我们得到以下结果。
让我们看看效果如何。首先,让我们创建一个空的词汇表对象:
voc = Vocabulary('test')
print(voc)
<main.Vocabulary object at 0x7f80a071c470>
然后我们创建一个简单的语料库:
corpus = ['This is the first sentence.',
'This is the second.',
'There is no sentence in this corpus longer than this one.',
'My dog is named Patrick.']
print(corpus)
['This is the first sentence.',
'This is the second.',
'There is no sentence in this corpus longer than this one.',
'My dog is named Patrick.']
让我们遍历语料库中的句子,并将每个句子中的单词添加到我们的词汇表中。请记住,add_sentence会调用add_word:
for sent in corpus:
voc.add_sentence(sent)
现在让我们测试一下我们所做的工作:
print('Token 4 corresponds to token:', voc.to_word(4))
print('Token "this" corresponds to index:', voc.to_index('this'))
这是输出结果,似乎效果不错。
Token 4 corresponds to token: is
Token "this" corresponds to index: 13
由于我们的语料库非常小,让我们打印出整个词汇表。注意,由于我们尚未实施任何有用的分词,只是基于空格分割,我们有一些标记以大写字母开头,还有一些带有尾随标点符号。我们将在后续中更恰当地处理这些问题。
for word in range(voc.num_words):
print(voc.to_word(word))
PAD
SOS
EOS
This
is
the
first
sentence.
second.
There
no
sentence
in
this
corpus
longer
than
one.
My
dog
named
Patrick.
让我们创建并打印出特定句子的对应标记和索引。注意这次我们尚未修剪词汇表,也没有添加填充或使用 SOS 或 EOS 标记。我们将这些添加到下次需要处理的项目清单中。
sent_tkns = []
sent_idxs = []
for word in corpus[3].split(' '):
sent_tkns.append(word)
sent_idxs.append(voc.to_index(word))
print(sent_tkns)
print(sent_idxs)
['My', 'dog', 'is', 'named', 'Patrick.']
[18, 19, 4, 20, 21]
就这样。即便我们有诸多显著的不足,但我们似乎仍拥有一套可能最终会有用的词汇表,因为它展示了许多核心的必要功能,这些功能将使其最终变得有用。
我们必须在下次处理的项目包括:
-
对我们的文本数据进行规范化(强制全部小写,处理标点符号等)
-
正确地对文本块进行分词
-
使用 SOS、EOS 和 PAD 标记
-
修剪我们的词汇表(在词汇表中永久存储之前的最小标记出现次数)
下次我们将实现此功能,并在更强大的语料库上测试我们的 Python 词汇表实现。然后,我们将把数据从词汇对象中转移到适用于 NLP 任务的有用数据表示中。最后,我们将对我们精心准备的数据执行 NLP 任务。
相关:
-
自然语言处理任务的数据表示
-
自然语言处理任务的主要方法
-
处理文本数据科学任务的框架
更多相关内容
我在 3 天内创建了一个 AI 应用程序
几周前,我开始玩 Chat GPT。我被惊呆了。我立即想用这个工具构建一些东西。我意识到这是一个千载难逢的黄金机会,正好在正确的时刻进入某个领域。
我为创建什么而苦思了几个星期。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
我希望它能成为世界上每个人都可以使用的东西。我过去的项目(不涉及 AI)都是小范围内的利基用例,我想构建一些比这更有意义的东西。我从所有的创业经历中学到的最大教训就是,今后要构建具有巨大市场潜力的东西。我经常构建一些很酷的东西,但只有相对少数人会需要使用。
所以我在 Google 趋势上搜索了全球流行的话题。很快,幸运的是,我发现“求职信”这个关键词在那一刻非常流行。这是一个“顿悟”时刻,因为我也在求职信方面遇到了痛点。
要么我讨厌做求职信,并且为那些我非常想要的工作而辛苦地完成它们,要么我干脆跳过那些需要求职信的工作,因为我对那些工作并不太感兴趣。
因此,我决定创建一个 AI 求职信生成器。
为了使它不同于市面上现有的任何求职信生成器(这些生成器在 AI 出现之前就存在),我意识到我需要一个其他人没有的关键功能。然后我意识到,大多数求职信生成器只要求你的技能。如果我的求职信生成器同时要求你的技能和职位描述中所需的技能呢?
结果是,我开始创建一个求职信生成器,让你将简历和职位描述粘贴到不同的表单中,然后将它们混合成一封酷炫的求职信。它会利用你的求职信和职位描述的文本,根据职位描述中所需的技能和经验相对于你简历上列出的技能和经验,为你撰写一封独特的求职信。简直是魔法!
我还是个新手编码员,但我在 ChatGPT 上制作整洁的提示方面经验丰富,所以我知道我能做到。
所以,我在 Open AI playground 上进行了两天的实验,尝试不同的提示,直到找到我认为最适合用我的简历和我在线找到的职位描述生成求职信的结果。我大约尝试了 1000 个不同的提示,涵盖了许多独特的最大令牌数、温度和惩罚组合。
接下来,为了创建我的应用,我需要学习如何编码一个网站,这样它可以以更用户友好的方式完成 Open AI playground 所做的一切。最重要的是,我需要有单独的表单框来输入简历和职位描述,不像 Open AI playground 只有一个表单框。
所以,我观看了一些关于创建“广告文案”AI 生成器的 YouTube 视频(在某种程度上类似于求职信生成器),并在一夜之间学会了如何在 bubble.io 上制作我的应用。作为最后一步,我只需要将 Open AI API 连接到我新网站上的输出表单即可。
从开始到完成,创建我的应用花了三天时间。它叫 Tally.Work (link)。快来看看吧!
最终结果还不错。有些人甚至觉得它在 HackerNews上很酷。现在,我在第一天就得到了成千上万的用户,我实际上花了大约 $100 在 Open AI 代币上(这是另一个问题)。
我意识到我应用程序生成的求职信确实看起来像是 AI 写的。不过没关系。AI(至少是我的提示)还没有达到那种水平。但总有一天,在不久的将来,它会达到那个水平。在那之前,我的工具可以作为求职信的初稿起点。用户可以使用我的工具来开始,然后编辑和添加内容,使求职信听起来更有人情味。
我还意识到 AI 将几乎完全消除诸如这些无用工作和繁琐任务。这不是很好吗?对吧?
我确实希望这个项目能够结束,因为正如我提到的,我不太喜欢求职信。如果这个项目(或类似的其他项目)成功,那么雇主将停止要求求职信,而这个应用程序将变得无用。正如我提到的,我讨厌求职信。
我希望这个项目的结果是我从中学到了很多经验,以便我可以构建一个更有趣的 AI 应用,希望它不会失败。
如果你想构建自己的 AI 应用,我的建议是直接开始。使用 Open AI playground ,无需编写代码,然后根据你的情况选择使用代码构建前端,或者使用像 bubble.io 这样的无代码构建器。关于这些的 YouTube 视频有很多,为什么不今天就开始呢?
Jeff Dutton 是多伦多地区为员工和雇主提供法律服务的就业律师。通过查看 个人博客 了解更多关于他的信息。
原文。经许可转载。
更多相关话题
创建 AI 驱动的解决方案:理解大型语言模型
原文:
www.kdnuggets.com/creating-ai-driven-solutions-understanding-large-language-models

编辑 | Midjourney & Canva 制图
大型语言模型是先进的人工智能类型,旨在理解和生成类似人类的文本。它们采用机器学习技术,特别是深度学习来构建。基本上,LLMs 是通过对来自互联网、书籍、文章和其他来源的大量文本数据进行训练,以学习人类语言的模式和结构。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
大型语言模型(LLMs)的历史始于早期的神经网络模型。然而,一个重要的里程碑是 Vaswani et al 在 2017 年推出的 Transformer 架构,详细内容见论文“注意力机制是你所需要的。”
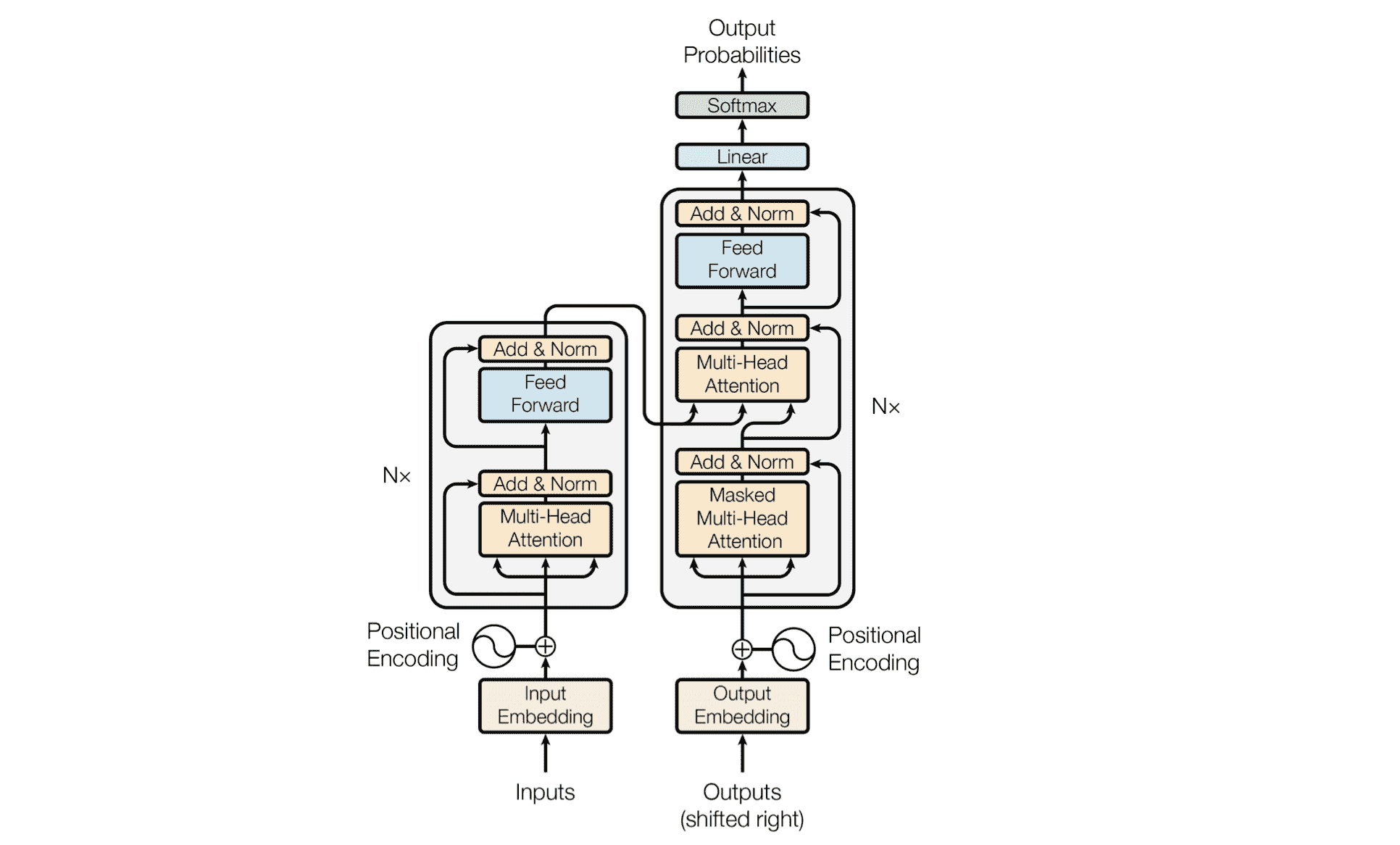
Transformer - 模型架构 | 来源: 注意力机制是你所需要的
这种架构提高了语言模型的效率和性能。2018 年,OpenAI 发布了 GPT(生成式预训练变换器),标志着高能力 LLMs 的开始。2019 年发布的 GPT-2 具有 15 亿参数,展示了前所未有的文本生成能力,并因其潜在的误用而引发了伦理问题。2020 年 6 月推出的 GPT-3,具有 1750 亿参数,进一步展示了 LLMs 的强大能力,使得从创意写作到编程辅助的各种应用成为可能。最近,OpenAI 的 GPT-4,于 2023 年发布,延续了这一趋势,提供了更强大的能力,尽管关于其规模和数据的具体细节仍然是专有的。
LLMs 的关键组件
LLMs 是复杂的系统,具有若干关键组件,使其能够理解和生成自然语言。关键要素包括神经网络、深度学习和变换器。
神经网络
大语言模型建立在神经网络架构上,这些计算系统受到人脑的启发。这些网络由互联的节点(神经元)层组成。神经网络通过根据接收到的输入调整神经元之间的连接(权重)来处理和学习数据。这一调整过程称为训练。
深度学习
深度学习是机器学习的一个子集,使用多层神经网络,因此被称为“深度”。它使大语言模型能够在大数据集中学习复杂的模式和表示,从而理解细微的语言上下文并生成连贯的文本。
转换器
转换器架构在 Vaswani 等人于 2017 年发表的论文“Attention Is All You Need”中首次提出,彻底改变了自然语言处理(NLP)。转换器使用注意力机制,使模型能够关注输入文本的不同部分,比以前的模型更好地理解上下文。转换器由编码器和解码器层组成。编码器处理输入文本,解码器生成输出文本。
大语言模型是如何工作的?
大语言模型通过利用深度学习技术和广泛的文本数据集来运作。这些模型通常采用转换器架构,如生成预训练变换器(GPT),其在处理文本输入等顺序数据方面表现出色。
这张图片展示了大语言模型(LLMs)如何进行训练以及它们如何生成回应。
在训练过程中,大语言模型通过考虑前面的上下文来预测句子中的下一个单词。这涉及对分词后的单词赋予概率分数,将其拆分为更小的字符序列,并将其转化为嵌入,表示上下文的数值。大语言模型在大量文本语料库上进行训练以确保准确性,使其能够通过零样本学习和自监督学习掌握语法、语义和概念关系。
训练完成后,大语言模型通过根据接收到的输入预测下一个单词,并从其获得的模式和知识中提取内容,自动生成文本。这导致连贯且上下文相关的语言生成,对于各种自然语言理解(NLU)和内容生成任务非常有用。
此外,提升模型性能涉及诸如提示工程、微调和基于人类反馈的强化学习(RLHF)等策略,以减轻偏见、仇恨言论以及训练过程中可能产生的事实错误回应,称为“幻觉”。这一方面对确保企业级大语言模型的安全和有效使用至关重要,防止组织面临潜在的法律责任和声誉损害。
大语言模型的应用案例
由于 LLMs 能够理解和生成类似人类的语言,因此它们在各个行业中有着广泛的应用。以下是一些常见的使用案例,以及作为案例研究的实际示例:
-
文本生成:LLMs 可以生成连贯且与上下文相关的文本,这使得它们在内容创作、讲故事和对话生成等任务中非常有用。
-
翻译:LLMs 能够准确地将文本从一种语言翻译成另一种语言,实现跨语言的无缝沟通。
-
情感分析:LLMs 能够分析文本以确定表达的情感,帮助企业了解客户反馈、社交媒体反应和市场趋势。
-
聊天机器人和虚拟助手:LLMs 可以为对话代理提供支持,使其能够以自然语言与用户互动,提供客户支持、信息检索和个性化推荐。
-
内容总结:LLMs 能够将大量文本压缩成简洁的摘要,使从文档、文章和报告中提取关键信息变得更加容易。
案例研究:ChatGPT
OpenAI 的 GPT-3(生成式预训练变换器 3)是开发出的最重要和最强大的 LLMs 之一。它拥有 1750 亿个参数,能够执行各种自然语言处理任务。ChatGPT是一个由 GPT-3 支持的聊天机器人示例。它可以就多个话题进行对话,从随意闲聊到更复杂的讨论。
ChatGPT 可以提供各种主题的信息,提供建议,讲笑话,甚至进行角色扮演。它通过每次互动进行学习,随着时间的推移改进其回应。
ChatGPT 已被集成到消息平台、客户支持系统和生产力工具中。它可以协助用户完成任务,回答常见问题,并提供个性化推荐。
使用 ChatGPT,企业可以自动化客户支持、简化沟通并提升用户体验。它提供了一种可扩展的解决方案,用于处理大量咨询,同时保持高水平的客户满意度。
开发基于 LLMs 的 AI 驱动解决方案
开发基于 LLMs 的 AI 驱动解决方案涉及多个关键步骤,从识别问题到部署解决方案。我们将这一过程简化为以下几个步骤:
这张图片展示了如何开发基于 LLMs 的 AI 驱动解决方案 | 来源:作者提供的图片。
确定问题和需求
明确阐述你想要解决的问题或希望 LLM 执行的任务。例如,创建一个用于客户支持的聊天机器人或一个内容生成工具。收集利益相关者和最终用户的见解,以了解他们的需求和偏好。这有助于确保 AI 驱动的解决方案有效地满足他们的需求。
设计解决方案
选择一个与项目要求相符的 LLM。考虑诸如模型大小、计算资源和任务特定能力等因素。通过微调参数和在相关数据集上训练,将 LLM 调整为您的特定用例。这有助于优化模型在应用中的性能。
如适用,将 LLM 与组织中的其他软件或系统集成,以确保操作和数据流畅。
实施和部署
使用适当的训练数据和评估指标来训练 LLM,以评估其性能。测试有助于在部署之前识别和解决任何问题或限制。确保 AI 驱动的解决方案能够扩展以处理不断增加的数据量和用户,同时保持性能水平。这可能涉及优化算法和基础设施。
建立机制以实时监控 LLM 的性能,并实施定期维护程序以解决任何问题。
监控和维护
持续监控已部署解决方案的性能,以确保其符合定义的成功指标。收集用户和利益相关者的反馈,以识别改进领域并迭代改进解决方案。定期更新和维护 LLM,以适应不断变化的需求、技术进步和用户反馈。
LLM 的挑战
虽然 LLM 提供了各种应用的巨大潜力,但它们也面临着若干挑战和考虑因素。其中一些包括:
伦理和社会影响:
LLM 可能继承训练数据中存在的偏见,导致不公平或歧视性的结果。它们可能生成敏感或私人信息,引发关于数据隐私和安全的担忧。如果没有得到适当的训练或监控,LLM 可能会无意中传播错误信息。
技术挑战
理解 LLM 如何做出决策可能具有挑战性,这使得信任和调试这些模型变得困难。训练和部署 LLM 需要大量的计算资源,这限制了小型组织或个人的可访问性。扩展 LLM 以处理更大的数据集和更复杂的任务可能在技术上具有挑战性且成本高昂。
法律和监管合规
使用大型语言模型(LLMs)生成文本引发了关于生成内容的所有权和版权的问题。LLM 应用程序需要遵守法律和监管框架,例如欧洲的 GDPR,以确保数据使用和隐私。
环境影响
训练 LLM 是高度耗能的,会产生显著的碳足迹,引发环境问题。开发更节能的模型和训练方法对于减轻广泛部署 LLM 的环境影响至关重要。在 AI 开发中关注可持续性对平衡技术进步与生态责任非常重要。
模型鲁棒性
模型鲁棒性指的是 LLM 在各种输入和场景中的一致性和准确性。确保 LLM 即使在输入有轻微变化的情况下也能提供可靠和值得信赖的输出,是一项重大挑战。团队们通过引入检索增强生成(RAG)技术来应对这一挑战,RAG 结合了 LLM 和外部数据源,以提高性能。通过将数据整合到 LLM 中,组织可以提高模型在特定任务中的相关性和准确性,从而提供更可靠和上下文适宜的回应。
LLM 的未来
近年来,LLM 的成就可谓非凡。它们在文本生成、翻译、情感分析和问答等任务上超越了先前的基准。这些模型已被集成到各种产品和服务中,推动了客户支持、内容创作和语言理解的进步。
展望未来,LLM 具有巨大的潜力进行进一步的进步和创新。研究人员正积极提升 LLM 的能力,以应对现有的局限性并推动可能性的边界。这包括改善模型解释性、减轻偏见、增强多语言支持以及实现更高效和可扩展的训练方法。
结论
总之,理解 LLM 对于解锁 AI 驱动解决方案在各个领域的全部潜力至关重要。从自然语言处理任务到聊天机器人和内容生成等高级应用,LLM 在理解和生成类似人类的语言方面展现了卓越的能力。
在构建 AI 驱动解决方案的过程中,我们需要以负责任的 AI 实践为重点,来处理 LLM 的开发和部署。这包括遵守伦理准则,确保透明度和问责制,以及积极与利益相关者互动,解决关切并促进信任。
Shittu Olumide 是一位软件工程师和技术作家,热衷于利用前沿技术创作引人入胜的叙述,具有敏锐的细节观察力和简化复杂概念的天赋。你还可以在 Twitter 上找到 Shittu。
更多相关内容
使用 Seaborn 创建美丽的直方图
原文:
www.kdnuggets.com/2023/01/creating-beautiful-histograms-seaborn.html

图片来源:Pixabay来自 Pexels
可视化是数据世界的重要部分,因为当信息以正确的方式呈现时,人们更容易理解。因此,任何数据人员都应该能够创建信息丰富且吸引人的可视化。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
直方图是最常见且实用的图表之一。直方图是一个用条形表示数据频率的图表,这些数据被划分为特定的区间。它通常用于可视化数值数据,以理解数据分布并识别趋势。
如何创建一个美丽的直方图图表?让我们学习一下。
使用 Seaborn 进行直方图可视化
对于我们的数据集示例,我们将使用 Seaborn 包中的 MPG 开放数据。
import seaborn as sns
mpg = sns.load_dataset('mpg')
mpg.head()
从我们的数据集示例中,我们可以快速使用 Seaborn 包开发一个简单的直方图图表。为此,我们需要使用 histplot 函数。
该函数默认以数值数据变量作为参数,输出是传递值的直方图。让我们尝试一下这个函数。
# Create a histogram of the "mpg" variable
sns.histplot(data=mpg, x="mpg")
从一行代码开始,我们得到了一个漂亮的直方图可视化。“mpg”变量的分布右偏,因为许多值集中在 15 到 25 之间。这是我们可以通过直方图获得的信息。
自定义直方图可视化
Seaborn 直方图的默认可视化效果很好,但我们可能希望更改直方图图表,使其更美观。
在这种情况下,可以使用 Seaborn 包的各种自定义选项。
基于分类列的多个直方图图示
有时,我们想要比较基于其他变量值的变量数值分布。为此,我们可以将要比较的变量名称传递给 hue 参数。
sns.histplot(data=mpg, x="mpg", hue = 'origin')
显示核密度估计 (KDE) 曲线
核密度估计(KDE)是一种使用密度函数估计数据概率的非参数方法。基本上,KDE 平滑直方图以显示分布。要显示 KDE 曲线,我们可以使用以下代码。
sns.histplot(data=mpg, x="mpg", kde=True)
更改箱的数量
直方图的绘制依赖于将变量值分箱的区间数。如果我们想要改变箱的数量,可以通过以下代码传递 bins 参数来实现。
sns.histplot(data=mpg, x="mpg", bins = 5)
也可以通过 binwidth 参数根据宽度来改变箱的数量。
sns.histplot(data=mpg, x="mpg", binwidth=5)
此外,还可以使用 binrange 参数限制最小和最大箱范围。
sns.histplot(data=mpg, x="mpg", binrange=(5, 30))
更改聚合统计量
默认情况下,Seaborn 假设直方图用于计算每个箱中的值。然而,我们可以改变聚合统计量。在 seaborn 中有几个选项可供选择,包括:
- 频率
显示观察值的数量除以箱宽度。
sns.histplot(data=mpg, x="mpg", stat = 'frequency')
- 概率
显示标准化值,使条形高度的总和为 1。
sns.histplot(data=mpg, x="mpg", stat = 'probability')
- 密度
显示标准化值,使直方图的总面积为 1。
sns.histplot(data=mpg, x="mpg", stat = 'density')
调整直方图美学
可以改变直方图的颜色和透明度。对于单个直方图,我们可以将颜色字符串值传递给 color 参数,将透明度值传递给 alpha 参数。
sns.histplot(data=mpg, x="mpg", color = 'red', alpha = 0.5)
如果我们有多个直方图,我们可以通过更改 palette 参数来改变整体配色方案。要了解 palette 参数中可以使用的值,可以查阅 文档。
sns.histplot(data=mpg, x="mpg", kde = True, palette = "Spectral", hue ='origin')
结论
直方图是可视化数值变量并获取分布趋势信息的一种图表。当我们需要展示数据中发生的情况时,它是一种有用的可视化工具。使用 Seaborn Python 包,我们可以轻松创建美丽的直方图并根据需要调整它们。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关内容
创建好的有意义的图表:一些原则
原文:
www.kdnuggets.com/2021/01/creating-good-meaningful-plots-principles.html
评论
作者:Vikrant Dogra,数据科学、分析和洞察专家

照片由 Luke Porter 提供,来自 Unsplash
图(或图表)是从数据中传达信息的本质方式,但好的图表很少见。我认为主要原因是创建图表时采用了被动的方法。但是,如果积极创建,运用数据调查和询问的原则,可以制作出合理且有意义的图表。
本文涵盖了一些创建有意义图表的原则。此外,它让你通过两个自定义的 web 应用程序亲身体验学习,这些应用程序允许你探索/设置各种选项,以创建信息丰富的散点图。
图表的组成部分
图通常包括主图区域(显示图表的地方)、坐标轴(例如 x 轴、y 轴)、坐标轴的描述,包括用于解释数据的标记/标签(例如刻度、刻度标签)以及在需要时,用于区分子组的图例。
图像来源于作者
好图表的特征
好图表应具有意义、自解释且易于记忆。因此,理想的方法应在某种程度上尝试模仿我们在脑海中思考、记忆和关联信息的方式。
以下是制作良好有意义图表的一些建议:
在所有情况下都不要创建图表
- 有时,简单的数据表可能比图表更有效。
根据输入数据使用正确的图表
-
通过一点积极思考,可以做到这一点。例如,许多人仍然混淆直方图和条形图。
-
由于可以用多种方式绘制任何给定的数据——尝试使用最佳图表,这有助于从数据中传达重要含义。
使图表易于阅读
-
关注重要的内容。降低其余内容的重点。
-
通常,工具提供的默认设置用于可视化/展示/业务智能并不理想。因此,你应该改进这些默认设置。
-
在需要时描述数据,以便你的图表可以在没有他人帮助的情况下被读取。
识别并使用相关的锚点/截断线
- 为了帮助人们快速理解图表中的信息——添加锚点或截断线,例如条形图中的均值(平均值)线。
突出偏离预期的情况、极端值/项目
- 通常,偏差是图表中感兴趣的内容——无论是平均值还是某些截断线,例如前 10% 或后 10%。
识别相似性
- 在某些情况下,兴趣可能在于理解相似性,例如两种分布之间的相似性。
有关详细建议,请阅读本文的:“共同点:改进图表的关注领域”部分。
不要仅仅绘制图表:在绘制时思考。
在这里,我涵盖了一些常见的图表类型,并解释了可能的改进方法:
条形图(用于分类变量)
作者提供的图片
-
不要仅依赖工具提示(即,将鼠标悬停在图表对象上以查看数据)来显示主要数据。例如,如果你通过条形图显示 4 个类别,那么你将需要使用工具提示 4 次来读取条形图的高度;对于 10 个类别,你将需要使用工具提示 10 次,……
-
在条形上显示数据(百分比或实际值,视情况而定)——这有助于任何人轻松比较这些数字,并在需要时进行一些简单的心理计算,例如比例、差异等。
-
如果表示的是百分比,说明这些百分比是否加起来为 100。这通常发生在类别相互独立或(在调查中)响应为单选时。
直方图(用于连续变量)
作者提供的图片
-
正确设置箱体(或类别间隔):箱体数量、箱体宽度。
-
如果可能,显示所有箱体的数据(频率或百分比)。如果不行,则仅显示重要的数据点,并补充数据的摘要,例如均值/中位数/众数。
密度/分布图
作者提供的图片
-
你必须展示一些超出曲线的东西,因为曲线仅给出数据的形状。
-
添加分布的摘要是一个好主意,例如均值/中位数/众数、集中度(例如,适当时——中间 67%、80%、95%)、统计测试结果指示的分布类型。
词云

作者提供的图片
-
这些图表视觉上很吸引人,但很难内化,因为除了前 2-3 个项目之外,无法对其进行排名,而且这些项目在词云中也是随机放置的。此外,仅凭词频的比例,无法在词云中比较两个词。
-
因此,设计一种方法来展示用于创建词云的数据(频率、百分比)——可以作为图中单词上的下标/上标,或作为附加的(已排序)频率表。
饼图
作者提供的图片
-
如果类别超过三个,使用条形图而不是饼图。
-
饼图的问题在数据科学社区已经很明确,但大多数商业界人士仍然喜欢饼图(及甜甜圈图)。这可能是因为饼图总是加起来 100%,而条形图可能不会。对于适合饼图的数据,我怀疑许多条形图的支持者(相对于饼图)忘记提到他们的条形图的列加起来是 100%。
箱线图
作者提供的图片
-
这些图非常适合理解数据的分布,并记住关键数字——前提是数字被显示。因此,显示重要值,即中位数、下/上四分位数、下/上须
-
此外,调查可能的异常值(超出须的数据显示点)是否存在模式
时间序列图
作者提供的图片
-
这些图自然会重复出现模式。因此,对于跨越多年的每月数据——可以按月份(x 轴)显示堆积(按年)的版本。这应该有助于读者注意到趋势和季节性。
-
如果存在周期,你可以通过显示一条跨越年份 x 月份的单线图来展示
散点图

作者提供的图片
在散点图中有许多数据点——核心意图是识别点中的模式。因此可以做很多事情,例如
-
拟合模型并附上置信区间。如果需要,请提及模型规范
-
帮助最终用户轻松读取数据点:独立为 X 和 Y 变量使用锚点/截断点,例如均值、中位数、四分位数、极值(例如底部/顶部 10%)。在显示这些线时,也尽量提及数值
-
突出显示感兴趣的数据点,例如为点着色,显示数据标签
-
甚至可以显示边际图,例如 x 变量和 y 变量下方的箱线图或直方图
共同点:改善图表的重点区域
在这里,我涵盖了图表的核心组件,并尝试提供通用建议,说明如何以及何时使用这些组件以实现有效绘图:
轴
轴:轴标题
-
使用方法:使用合理的标题——这意味着你通常需要改进默认的变量名称;标题必须易于理解,例如[模糊]距离与[清晰]距离(以英里为单位)
-
文本字体大小:使用易于阅读的字体大小,因为轴描述设置了阅读图表的背景
轴:刻度
-
是否需要:在数据为数值型时使用;否则避免使用。
-
文本字体大小:比轴标题字体小,因为这些重要性较低。你也可以通过使用灰色来减少这些文本的强调。
-
间隔:设置良好的刻度间隔是至关重要的。过度使用会使这些刻度无法读取图表。然而,适当的刻度数量可以帮助创建矩形块的心理图,以更快、更好地读取数据
轴:y 轴
- 是否需要:有时你可以去掉 y 轴线本身(包括标题和刻度)。例如,条形图(对于分类变量),如果你在条形上方显示数据标签,则不需要 y 轴线/标题/刻度。
图例
-
使用时机:仅在你想在图形中表示子组且无法通过图例区分时使用。
-
是否需要:这可能会使注意力从主要图形上分散。因此仅在必要时使用。
主要图形
主要图形:数据标签
- 使用时机:尽可能展示数据。例如,对于条形图;对于散点图,理想情况下仅显示极端值,例如底部 5%和顶部 5%。
主要图形:工具提示
-
如何不使用:避免仅使用工具提示来显示数据点的值。
-
如何使用:相反,使用工具提示有意义地增强关于数据点的信息
主要图形:颜色编码数据点
- 如何使用:使用不同的颜色突出显示重要/有趣的数据点
主要图形:注释
- 使用时机:通过注释添加更多层的信息。
增强
增强:参考/锚点
- 如何使用:显示表示例如均值、中位数、四分位数、极端 5%(低端和高端)、中间 80%等的锚点线
增强:突出显示差距
- 如何使用:也突出显示差距。例如,条形图中的两个柱子之间
增强:模型
- 使用时机:拟合模型(例如,在散点图中)以帮助理解变量之间的关系。还可以更好地解释数据点,即模型线的偏离。
增强:汇总数据
- 如何使用:大多数图形并不是设计用来统计汇总数据的——因此在主要图形下添加关键汇总统计数据将有助于丰富图形
DIY:创建自己的散点图
内化某物的最佳方式是通过实验,从这些实验中学习,通过尝试各种选项/组合并查看哪种方式对你最有效。
为了获得实践经验,我从头开始创建了两个几乎相同的散点图——一个使用 R,另一个使用 Python。我这样做是为了最小化关于 R 与 Python 的争论,并帮助你专注于实验核心概念,制作良好的有意义的图形。
为什么选择散点图?:它们是最具挑战性的图形之一,因为数据点很多——每个都单独表示。因此,制作有意义的散点图需要做很多工作。
关于这些绘图应用程序的一点说明:
散点图(使用 R):使用应用程序
基础图形使用R和ggplot2可视化库创建。该图形随后被转换为网络应用程序,使用R shiny并托管在shinyapps.io*
散点图- R 应用(作者提供的图片)
散点图(使用 Python):使用应用程序
基础图表使用python和plotly可视化库创建(为了生成本地回归模型,我使用了scikit-misc 库)。然后,使用streamlit.io将此图表转换为 Web 应用程序,并托管在heroku上。
散点图- Python 应用(作者提供的图片)
这两个图表具有反应性特征——你对规格的任何更改都会(几乎瞬间)反映在更新后的图表中。因此,上传你喜欢的测试数据集或使用默认数据集,释放你内心的孩子——尝试各种图表规格——本文中建议的以及其他的。然而,在探索结束时,制定出你自己创建有意义图表的规则。你可以随时修订/完善你的方法。
总结
本文探讨了创建良好图表的原则,但未涉及图表/表格之间的关系——通常在演示或仪表板中展示的内容。然而,我坚信,如果你掌握了创建良好图表的技巧,你可以轻松将这些经验转移到创建更好的仪表板中。
本文涵盖的原则旨在激发你积极思考如何创建有意义的图表。希望你以开放的心态阅读本文,尝试在提供的应用程序中进行各种设置实验,并努力融入你(绘图)的真正方向所接受的可能为你的图表创作方法增值的技巧。
简历:Vikrant Dogra 是一位数据科学、分析和洞察专家。
原文。已获授权转载。
相关内容:
-
数据科学、数据可视化与机器学习的顶级 Python 库
-
14 个数据科学项目来提升你的技能
-
TabPy: 结合 Python 与 Tableau
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持您组织的 IT
相关话题
使用 Matplotlib 和 Seaborn 创建可视化
原文:
www.kdnuggets.com/creating-visuals-with-matplotlib-and-seaborn

数据可视化在数据工作中至关重要,因为它帮助人们理解数据的变化。直接处理原始数据很困难,但可视化可以激发人们的兴趣和参与感。这就是为什么学习数据可视化对在数据领域取得成功非常重要。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
Matplotlib 是 Python 中最受欢迎的数据可视化库之一,因为它非常多功能,你可以从零开始几乎可视化任何东西。使用这个包,你可以控制可视化的许多方面。
另一方面,Seaborn 是一个建立在 Matplotlib 之上的 Python 数据可视化包。它提供了更简单的高级代码,并且包内含有多种内置主题。如果你想快速进行美观的数据可视化,这个包非常适合你。
在这篇文章中,我们将探索这两个包,并学习如何使用这些包来可视化你的数据。让我们开始吧。
使用 Matplotlib 进行可视化
如上所述,Matplotlib 是一个多功能的 Python 包,我们可以控制可视化的各种方面。这个包基于 Matlab 编程语言,但我们在 Python 中使用了它。
Matplotlib 库通常已经在你的环境中可用,特别是如果你使用 Anaconda。如果没有,你可以使用以下代码进行安装。
pip install matplotlib
安装后,我们将使用以下代码导入 Matplotlib 包进行可视化。
import matplotlib.pyplot as plt
让我们从使用 Matplotlib 进行基本绘图开始。首先,我会创建一些示例数据。
import numpy as np
x = np.linspace(0,5,21)
y = x**2
利用这些数据,我们将使用 Matplotlib 包创建一个折线图。
plt.plot(x, y, 'b')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.title('Sample Plot')
在上面的代码中,我们将数据传递给 matplotlib 函数(x 和 y),以创建一个简单的蓝色折线图。此外,我们使用上述代码控制轴标签和标题。
让我们尝试使用subplot函数创建多个 matplotlib 图表。
plt.subplot(1,2,1)
plt.plot(x, y, 'b--')
plt.title('Subplot 1')
plt.subplot(1,2,2)
plt.plot(x, y, 'r')
plt.title('Subplot 2')
在上面的代码中,我们并排创建了两个图表。subplot函数控制图表的位置;例如,plt.subplot(1,2,1)意味着我们将有两个图表在一行(第一个参数)和两列(第二个参数)。第三个参数用于控制我们现在引用的是哪个图表。所以plt.subplot(1,2,1)意味着单行双列图表中的第一个图表。
这就是 Matplotlib 函数的基础,但如果我们想对 Matplotlib 可视化进行更多控制,我们需要使用面向对象方法(OOM)。使用 OOM,我们可以直接从图形对象生成可视化,并调用指定对象的任何属性。
让我给你一个使用 Matplotlib OOM 的可视化示例。
#create figure instance (Canvas)
fig = plt.figure()
#add the axes to the canvas
ax = fig.add_axes([0.1, 0.1, 0.7, 0.7]) #left, bottom, width, height (range from 0 to 1)
#add the plot to the axes within the canvas
ax.plot(x, y, 'b')
ax.set_xlabel('X label')
ax.set_ylabel('Y label')
ax.set_title('Plot with OOM')
结果类似于我们创建的图表,但代码更复杂。一开始,这似乎是适得其反的,但使用 OOM 让我们几乎可以完全控制我们的可视化。例如,在上面的图表中,我们可以控制坐标轴在画布上的位置。
为了查看使用 OOM 与普通绘图函数的区别,我们将两个图表及其各自的坐标轴重叠在一起。
#create figure instance (Canvas)
fig = plt.figure()
#add two axes to the canvas
ax1 = fig.add_axes([0.1, 0.1, 0.7, 0.7])
ax2 = fig.add_axes([0.2, 0.35, 0.2, 0.4])
#add the plot to the respective axes within the canvas
ax1.plot(x, y, 'b')
ax1.set_xlabel('X label Ax 1')
ax1.set_ylabel('Y label Ax 1')
ax1.set_title('Plot with OOM Ax 1')
ax2.plot(x, y, 'r--')
ax2.set_xlabel('X label Ax 2')
ax2.set_ylabel('Y label Ax 2')
ax2.set_title('Plot with OOM Ax 2')
在上面的代码中,我们使用plt.figure函数指定了一个画布对象,并从该画布对象生成了所有这些图表。我们可以在一个画布中生成尽可能多的坐标轴,并在其中放置可视化图表。
也可以通过subplot函数自动创建图形和坐标轴对象。
fig, ax = plt.subplots(nrows = 1, ncols =2)
ax[0].plot(x, y, 'b--')
ax[0].set_xlabel('X label')
ax[0].set_ylabel('Y label')
ax[0].set_title('Plot with OOM subplot 1')
使用subplots函数,我们创建了图形以及坐标轴对象的列表。在上述函数中,我们指定了图表的数量和一行两列图表的位置。
对于坐标轴对象,它是一个包含所有可访问图表坐标轴的列表。在上面的代码中,我们访问了列表中的第一个对象来创建图表。结果是两个图表,一个填充了折线图,而另一个只有坐标轴。
因为subplots生成了一个坐标轴对象的列表,你可以像下面的代码一样对它们进行迭代。
fig, axes = plt.subplots(nrows = 1, ncols =2)
for ax in axes:
ax.plot(x, y, 'b--')
ax.set_xlabel('X label')
ax.set_ylabel('Y label')
ax.set_title('Plot with OOM')
plt.tight_layout()
你可以修改代码以生成所需的图表。此外,我们使用tight_layout函数,因为图表可能会重叠。
让我们尝试一些可以用来控制 Matplotlib 图的基本参数。首先,尝试更改画布和像素大小。
fig = plt.figure(figsize = (8,4), dpi =100)
参数 figsize 接受一个由两个数字(宽度,高度)组成的元组,结果与上述图类似。
接下来,让我们尝试为图添加图例。
fig = plt.figure(figsize = (8,4), dpi =100)
ax = fig.add_axes([0.1, 0.1, 0.7, 0.7])
ax.plot(x, y, 'b', label = 'First Line')
ax.plot(x, y/2, 'r', label = 'Second Line')
ax.set_xlabel('X label')
ax.set_ylabel('Y label')
ax.set_title('Plot with OOM and Legend')
plt.legend()
通过将标签参数分配给图并使用图例函数,我们可以将标签显示为图例。
最后,我们可以使用以下代码来保存我们的图。
fig.savefig('visualization.jpg')
直方图可视化了以箱体形式表示的数据分布。
还有许多线图之外的特殊图。我们可以使用这些函数访问这些图。让我们尝试几种可能对你的工作有帮助的图。
我们可以创建一个散点图来可视化特征关系,使用以下代码。
plt.scatter(x,y)
直方图
散点图
plt.hist(y, bins = 5)
箱线图
箱线图是一种将数据分布表示为四分位数的可视化技术。
plt.boxplot(x)
饼图
饼图是一种圆形图,用于表示分类图的数值比例,例如数据中分类值的频率。
freq = [2,4,1,3]
fruit = ['Apple', 'Banana', 'Grape', 'Pear']
plt.pie(freq, labels = fruit)
你还可以在 这里 查看 Matplotlib 库中的许多特殊图。
使用 Seaborn 进行可视化
Seaborn 是一个构建在 Matplotlib 之上的 Python 统计可视化包。Seaborn 的突出之处在于它通过优秀的样式简化了可视化的创建。这个包也与 Matplotlib 配合使用,因为许多 Seaborn API 依赖于 Matplotlib。
让我们尝试一下 Seaborn 包。如果你还没有安装这个包,可以使用以下代码进行安装。
pip install seaborn
Seaborn 内置了一个 API,可以获取用于测试包的样本数据集。我们将使用这个数据集来创建各种 Seaborn 可视化效果。
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()
使用上述数据,我们将探索 Seaborn 绘图,包括分布图、分类图、关系图和矩阵图。
分布图
我们将尝试的第一个图是分布图,用于可视化数值特征的分布。我们可以使用以下代码完成这项任务。
sns.displot(data = tips, x = 'tip')
默认情况下,displot 函数会生成一个直方图。如果我们想要平滑图形,可以使用 KDE 参数。
sns.displot(data = tips, x = 'tip', kind = 'kde')
分布图也可以根据 DataFrame 中的分类值进行拆分,使用 hue 参数。
sns.displot(data = tips, x = 'tip', kind = 'kde', hue = 'smoker')
我们甚至可以通过 row 或 col 参数进一步拆分图形。通过这些参数,我们可以生成多个图形,这些图形按照分类值的组合进行划分。
sns.displot(data = tips, x = 'tip', kind = 'kde', hue = 'smoker', row = 'time', col = 'sex')
另一种展示数据分布的方式是使用箱形图。Seaborn 可以通过以下代码轻松实现可视化。
sns.boxplot(data = tips, x = 'time', y = 'tip')
使用小提琴图,我们可以展示结合了箱形图和核密度估计(KDE)的数据分布。
最后,我们可以通过结合小提琴图和散点图将数据点展示到图中。
sns.violinplot(data = tips, x = 'time', y = 'tip')
sns.swarmplot(data = tips, x = 'time', y = 'tip', palette = 'Set1')
分类图
分类图是一种多种 Seaborn API 的可视化方法,适用于处理分类数据。让我们探索一些可用的图形。
首先,我们会尝试创建一个计数图。
sns.countplot(data = tips, x = 'time')
计数图会显示分类值的频率条形图。如果我们想要在图中显示计数数字,我们需要将 Matplotlib 函数结合到 Seaborn API 中。
p = sns.countplot(data = tips, x = 'time')
p.bar_label(p.containers[0])
我们可以通过使用 hue 参数进一步扩展图形,并用以下代码显示频率值。
p = sns.countplot(data = tips, x = 'time', hue = 'sex')
for container in p.containers:
ax.bar_label(container)
接下来,我们将尝试开发一个条形图。条形图是一种分类图,展示了数据的聚合以及误差条。
sns.barplot(data = tips, x = 'time', y = 'tip')
条形图使用分类特征和数值特征的组合来提供聚合统计数据。默认情况下,条形图使用平均聚合函数,并具有 95% 置信区间的误差条。
如果我们想要更改聚合函数,可以将函数传递给 estimator 参数。
import numpy as np
sns.barplot(data = tips, x = 'time', y = 'tip', estimator = np.median)
关系图
关系图是一种可视化技术,用于展示特征之间的关系。它主要用于识别数据集中存在的任何模式。
首先,我们将使用散点图来展示某些数值特征之间的关系。
sns.scatterplot(data = tips, x = 'tip', y = 'total_bill')
我们可以使用联合图将散点图与分布图结合起来。
sns.jointplot(data = tips, x = 'tip', y = 'total_bill')
最后,我们可以使用 pairplot 自动绘制数据框中各特征之间的成对关系。
sns.pairplot(data = tips)
矩阵图
矩阵图用于将数据可视化为颜色编码的矩阵。它用于查看特征之间的关系或帮助识别数据中的簇。
例如,我们有来自数据集的相关性数据矩阵。
tips.corr()
如果我们将这些数据表示为颜色编码的图,我们可以更好地理解上述数据集。这就是我们使用热图的原因。
sns.heatmap(tips.corr(), annot = True)
矩阵图还可以生成一个层次聚类图,推断数据集中的值,并根据现有相似性将它们分组。
sns.clustermap(tips.pivot_table(values = 'tip', index = 'size', columns = 'day').fillna(0))
结论
数据可视化是数据世界中的关键部分,它帮助观众快速理解我们的数据发生了什么。标准的 Python 数据可视化包是 Matplotlib 和 Seaborn。在本文中,我们学习了这些包的主要用途,除了 Matplotlib 和 Seaborn 外,还有哪些包可用于 Python 数据可视化,并介绍了几种可能帮助我们工作的可视化方式。
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰稿人。在 Allianz 印度尼西亚全职工作的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关内容
创建一个从音频中提取主题的 Web 应用程序
原文:
www.kdnuggets.com/2023/01/creating-web-application-extract-topics-audio-python.html

图片由israel palacio拍摄,来自Unsplash
这篇文章是如何构建一个使用 Python 转录和总结音频的 Web 应用程序的续集。在之前的帖子中,我展示了如何构建一个转录和总结你喜欢的 Spotify 播客内容的应用程序。文本的总结对听众来说是有用的,可以在听之前决定这一集是否有趣。
但音频中还有其他可能提取的功能。主题。主题建模是许多自然语言处理技术之一,它使自动提取来自不同来源的主题成为可能,比如酒店评论、招聘信息和社交媒体帖子。
在这篇文章中,我们将构建一个应用程序,使用 Python 从播客集中过滤主题并分析每个提取主题的重要性,配以优美的数据可视化。最后,我们将免费将 Web 应用程序部署到 Heroku。
要求
-
创建一个GitHub 仓库,这将用于将 Web 应用程序部署到 Heroku 生产环境!
-
在你的本地电脑上克隆代码库,使用
git clone <name-repository>.git。在我的案例中,我将使用 VS code,它是一个非常高效的 IDE,支持 Python 脚本,包含 Git 支持并集成了终端。请在终端中输入以下命令:
git init
git commit -m "first commit"
git branch -M master
git remote add origin https://github.com/<username>/<name-repository>.git
git push -u origin master</name-repository></username>
- 在 Python 中创建虚拟环境。
第一部分:创建提取主题的 Web 应用程序
本教程分为两个主要部分。在第一部分中,我们创建了一个简单的 Web 应用程序来提取播客中的主题。剩下的部分则专注于应用程序的部署,这是将应用程序随时分享给世界的重要步骤。让我们开始吧!
1. 从 Listen Notes 提取集的 URL
我们将要发现《Unconfirmed》的一期主题,名为“想在加密货币领域找工作?交易所正在招聘——第 110 期”。你可以在这里找到这一期的链接。正如你从电视和报纸上的新闻中可能了解到的,区块链行业正在迅猛发展,需要保持对该领域职位开放情况的更新。毫无疑问,他们会需要数据工程师和数据科学家来管理数据并从这些海量数据中提取价值。
Listen Notes 是一个播客搜索引擎和在线数据库,允许我们通过他们的 API 访问播客音频。我们需要定义一个函数从网页中提取节目的 URL。首先,你需要创建一个账户来检索数据,并订阅免费计划来使用 Listen Notes API。
然后,你点击你感兴趣的节目,并在页面右侧选择“使用 API 获取此节目”选项。按下后,你可以将默认的编码语言更改为 Python,并点击 requests 选项以使用该 python 包。之后,你复制代码并将其改编为一个函数。
import streamlit as st
import requests
import zipfile
import json
from time import sleep
import yaml
def retrieve_url_podcast(parameters,episode_id):
url_episodes_endpoint = 'https://listen-api.listennotes.com/api/v2/episodes'
headers = {
'X-ListenAPI-Key': parameters["api_key_listennotes"],
}
url = f"{url_episodes_endpoint}/{episode_id}"
response = requests.request('GET', url, headers=headers)
print(response.json())
data = response.json()
audio_url = data['audio']
return audio_url
它从一个单独的文件中获取凭据,secrets.yaml,该文件由一系列键值对组成,类似于字典:
api_key:{your-api-key-assemblyai}
api_key_listennotes:{your-api-key-listennotes}
2. 从音频中提取转录和主题
要提取主题,我们首先需要向 AssemblyAI 的转录端点发送一个 POST 请求,输入上一步中检索到的音频 URL。之后,我们可以通过向AssemblyAI发送 GET 请求来获取播客的转录和主题。
## send transcription request
def send_transc_request(headers, audio_url):
transcript_endpoint = "https://api.assemblyai.com/v2/transcript"
transcript_request = {
"audio_url": audio_url,
"iab_categories": True,
}
transcript_response = requests.post(
transcript_endpoint, json=transcript_request, headers=headers
)
transcript_id = transcript_response.json()["id"]
return transcript_id
##retrieve transcription and topics
def obtain_polling_response(headers, transcript_id):
polling_endpoint = (
f"https://api.assemblyai.com/v2/transcript/{transcript_id}"
)
polling_response = requests.get(polling_endpoint, headers=headers)
i = 0
while polling_response.json()["status"] != "completed":
sleep(5)
polling_response = requests.get(
polling_endpoint, headers=headers
)
return polling_response
结果将被保存到两个不同的文件中:
def save_files(polling_response):
with open("transcript.txt", 'w') as f:
f.write(polling_response.json()['text'])
f.close()
with open('only_topics.json', 'w') as f:
topics = polling_response.json()['iab_categories_result']
json.dump(topics, f, indent=4)
def save_zip():
list_files = ['transcript.txt','only_topics.json','barplot.html']
with zipfile.ZipFile('final.zip', 'w') as zipF:
for file in list_files:
zipF.write(file, compress_type=zipfile.ZIP_DEFLATED)
zipF.close()
下面是一个转录的示例:
Hi everyone. Welcome to Unconfirmed, the podcast that reveals how the marketing names and crypto are reacting to the week's top headlines and gets the insights you on what they see on the horizon. I'm your host, Laura Shin. Crypto, aka Kelman Law, is a New York law firm run by some of the first lawyers to enter crypto in 2013 with expertise in litigation, dispute resolution and anti money laundering. Email them at info at kelman law. ....
现在,我展示从播客的某一期提取的主题的输出:
{
"status": "success",
"results": [
{
"text": "Hi everyone. Welcome to Unconfirmed, the podcast that reveals how the marketing names and crypto are reacting to the week's top headlines and gets the insights you on what they see on the horizon. I'm your host, Laura Shin. Crypto, aka Kelman Law, is a New York law firm run by some of the first lawyers to enter crypto in 2013 with expertise in litigation, dispute resolution and anti money laundering. Email them at info at kelman law.",
"labels": [
{
"relevance": 0.015229620970785618,
"label": "PersonalFinance>PersonalInvesting"
},
{
"relevance": 0.007826927118003368,
"label": "BusinessAndFinance>Industries>FinancialIndustry"
},
{
"relevance": 0.007203377783298492,
"label": "BusinessAndFinance>Business>BusinessBanking&Finance>AngelInvestment"
},
{
"relevance": 0.006419596262276173,
"label": "PersonalFinance>PersonalInvesting>HedgeFunds"
},
{
"relevance": 0.0057992455549538136,
"label": "Hobbies&Interests>ContentProduction"
},
{
"relevance": 0.005361487623304129,
"label": "BusinessAndFinance>Economy>Currencies"
},
{
"relevance": 0.004509655758738518,
"label": "BusinessAndFinance>Industries>LegalServicesIndustry"
},
{
"relevance": 0.004465851932764053,
"label": "Technology&Computing>Computing>Internet>InternetForBeginners"
},
{
"relevance": 0.0021628723479807377,
"label": "BusinessAndFinance>Economy>Commodities"
},
{
"relevance": 0.0017050291644409299,
"label": "PersonalFinance>PersonalInvesting>StocksAndBonds"
}
],
"timestamp": {
"start": 4090,
"end": 26670
}
},...],
"summary": {
"Careers>JobSearch": 1.0,
"BusinessAndFinance>Business>BusinessBanking&Finance>VentureCapital": 0.9733043313026428,
"BusinessAndFinance>Business>Startups": 0.9268804788589478,
"BusinessAndFinance>Economy>JobMarket": 0.7761372327804565,
"BusinessAndFinance>Business>BusinessBanking&Finance>AngelInvestment": 0.6847236156463623,
"PersonalFinance>PersonalInvesting>StocksAndBonds": 0.6514145135879517,
"BusinessAndFinance>Business>BusinessBanking&Finance>PrivateEquity": 0.3943130075931549,
"BusinessAndFinance>Industries>FinancialIndustry": 0.3717447817325592,
"PersonalFinance>PersonalInvesting": 0.3703657388687134,
"BusinessAndFinance>Industries": 0.29375147819519043,
"BusinessAndFinance>Economy>Currencies": 0.27661699056625366,
"BusinessAndFinance": 0.1965470314025879,
"Hobbies&Interests>ContentProduction": 0.1607944369316101,
"BusinessAndFinance>Economy>FinancialRegulation": 0.1570006012916565,
"Technology&Computing": 0.13974210619926453,
"Technology&Computing>Computing>ComputerSoftwareAndApplications>SharewareAndFreeware": 0.13566900789737701,
"BusinessAndFinance>Industries>TechnologyIndustry": 0.13414880633354187,
"BusinessAndFinance>Industries>InformationServicesIndustry": 0.12478621304035187,
"BusinessAndFinance>Economy>FinancialReform": 0.12252965569496155,
"BusinessAndFinance>Business>BusinessBanking&Finance>MergersAndAcquisitions": 0.11304120719432831
}
}
我们已经获得了一个 JSON 文件,包含了 AssemblyAI 检测到的所有主题。本质上,我们将播客转录为文本,文本被拆分成不同的句子及其对应的相关性。对于每个句子,我们都有一个主题列表。在这个大字典的末尾,有一个从所有句子中提取的主题的总结。
值得注意的是,职业和求职是最相关的话题。在前五个标签中,我们还发现了商业和金融、初创企业、经济、商业和银行、风险投资以及其他类似的话题。
3. 使用 Streamlit 构建 Web 应用程序
部署的应用程序链接在这里
现在,我们将前面步骤中定义的所有函数放入主块中,在其中我们使用 Streamlit 构建我们的 Web 应用程序,Streamlit 是一个免费的开源框架,可以用 Python 编写几行代码来构建应用程序:
-
应用程序的主标题是通过
st.markdown显示的。 -
左侧面板侧边栏是使用
st.sidebar创建的。我们需要它来插入我们播客的集数 ID。 -
按下“提交”按钮后,将出现一个条形图,显示提取出的最相关的 5 个主题。
-
如果你想下载转录、主题和数据可视化,那里有一个下载按钮。
st.markdown("# **Web App for Topic Modeling**")
bar = st.progress(0)
st.sidebar.header("Input parameter")
with st.sidebar.form(key="my_form"):
episode_id = st.text_input("Insert Episode ID:")
# 7b23aaaaf1344501bdbe97141d5250ff
submit_button = st.form_submit_button(label="Submit")
if submit_button:
f = open("secrets.yaml", "rb")
parameters = yaml.load(f, Loader=yaml.FullLoader)
f.close()
# step 1 - Extract episode's url from listen notes
audio_url = retrieve_url_podcast(parameters, episode_id)
# bar.progress(30)
api_key = parameters["api_key"]
headers = {
"authorization": api_key,
"content-type": "application/json",
}
# step 2 - retrieve id of transcription response from AssemblyAI
transcript_id = send_transc_request(headers, audio_url)
# bar.progress(70)
# step 3 - topics
polling_response = obtain_polling_response(headers, transcript_id)
save_files(polling_response)
df = create_df_topics()
import plotly.express as px
st.subheader("Top 5 topics extracted from the podcast's episode")
fig = px.bar(
df.iloc[:5, :].sort_values(
by=["Probability"], ascending=True
),
x="Probability",
y="Topics",
text="Probability",
)
fig.update_traces(
texttemplate="%{text:.2f}", textposition="outside"
)
fig.write_html("barplot.html")
st.plotly_chart(fig)
save_zip()
with open("final.zip", "rb") as zip_download:
btn = st.download_button(
label="Download",
data=zip_download,
file_name="final.zip",
mime="application/zip",
)
要运行 web 应用程序,你需要在终端中输入以下命令行:
streamlit run topic_app.py
太棒了!现在应该会出现两个 URL,点击其中一个,网络应用程序就准备好了!
第二部分:将 Web 应用程序部署到 Heroku
一旦你完成了 web 应用程序的代码并检查其运行良好,下一步就是将其部署到互联网上的 Heroku。
你可能会想知道Heroku是什么。它是一个云平台,允许使用不同的编程语言开发和部署 web 应用程序。
1. 创建 requirements.txt、Procfile 和 setup.sh
然后,我们创建一个requirements.txt文件,包含脚本请求的所有 Python 包。我们可以使用这个神奇的 Python 库pipreqs自动创建它。
pipreqs
它将神奇地生成一个requirements.txt文件:
pandas==1.4.3
plotly==5.10.0
PyYAML==6.0
requests==2.28.1
streamlit==1.12.2
避免使用命令行pip freeze > requirements,就像这篇文章建议的那样。问题在于它会返回更多的 python 包,这些包可能并不是该特定项目所需的。
除了requirements.txt,我们还需要 Procfile,它指定了运行 web 应用程序所需的命令。
web: sh setup.sh && streamlit run topic_app.py
最后一个要求是有一个setup.sh文件,包含以下代码:
mkdir -p ~/.streamlit/
echo "\
[server]\n\
port = $PORT\n\
enableCORS = false\n\
headless = true\n\
\n\
" > ~/.streamlit/config.toml
2. 连接到 Heroku
如果你还没有在Heroku网站上注册,你需要创建一个免费的帐户才能使用其服务。还需要在本地 PC 上安装 Heroku。一旦完成这两个要求,我们就可以开始有趣的部分了!在终端中输入以下命令:
heroku login
按下命令后,Heroku 的窗口会出现在你的浏览器中,你需要输入帐户的电子邮件和密码。如果成功,你应该会看到以下结果:

所以,你可以返回到 VS 代码中,在终端上输入命令来创建你的 web 应用程序:
heroku create topic-web-app-heroku
输出:
Creating ⬢ topic-web-app-heroku... done
https://topic-web-app-heroku.herokuapp.com/ | https://git.heroku.com/topic-web-app-heroku.git
要将应用程序部署到 Heroku,我们需要这个命令行:
git push heroku master
它用于将代码从本地仓库的主分支推送到 heroku 远程。在使用其他命令将更改推送到你的仓库之后:
git add -A
git commit -m "App over!"
git push
我们终于完成了!现在你应该看到你的应用程序已经成功部署!
最后的思考
我希望你喜欢这个小项目!创建和部署应用程序真的很有趣。第一次可能有点令人生畏,但一旦完成,你不会后悔!我还想强调,对于小型项目和低内存要求的应用程序,最好将其部署到 Heroku。其他替代方案可以是更大的云平台框架,如 AWS Lambda 和 Google Cloud。GitHub 代码在 这里。感谢阅读。祝你有美好的一天!
尤金尼亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目专注于将持续学习与异常检测相结合。
原文。经许可转载。
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关内容
创造力在数据科学中至关重要
原文:
www.kdnuggets.com/2017/02/creativity-is-crucial-data-science.html
评论

数据科学可能不会被认为是最具创意的追求。
你将大量数据添加到一个仓库中,然后在另一端处理这些数据以得出结论。数据进,数据出,这里有什么创造性的空间?这不像是你在处理一块空白画布。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
对我来说,创造力的定义是你能够从无到有创造出某样东西。这需要巨大的想象力,看到表面统计数据之外的更深层结论是伟大的大数据专业人士的标志。
许多成功人士在与我们面谈时表现出创新思维。他们别无选择,塑造数据的独特而意外的方式是他们的工作。正如爱因斯坦从他的提琴演奏中获得灵感一样,许多顶尖数据科学家发现,当他们的创造力在流动时,他们常常找到最优雅的解决方案。这些数据创意者是最难找到的候选人之一——主要是因为其中的主观性。(另见之前的博客了解更多关于数据创意者的信息)
这实际上是我最喜欢的面试问题之一:
“你在职业生涯中做过的最具创意的事情是什么?”
在解释大量数据的无限方式中,人类创造力的作用不可低估。随着越来越多的人将人工智能视为解决所有数据需求的答案,我认为我们将面临一个瓶颈,人类总会拥有那个关键的优势。人工智能可能能够很好地解释数据(在短时间内),但永远无法做到卓越。为了做到这一点,创造力是缺失的关键。
从许多领先全球公司的员工文化来看,很明显,发挥员工的创造力是促使他们更紧密合作、彼此更有同理心的关键。数据科学并非孤立存在,它需要与业务中的其他领域相关联,以发挥最大影响力。以一种业务其他部门能够理解的方式创意包装数据是关键,这样他们才能看到全貌,从而支持寻找正确的解决方案。
然而,这个问题有一个大“但是”。要对数据进行创造性处理,需要决定深入挖掘其表面以下的内容,并承担相应的风险。接受数据的表面值通常就足够了,你会保住工作,也不会因奇怪的结论而激怒他人。当你创造性地提出不易被未受过训练的眼睛发现的东西时,你是在冒险,这需要勇气。然而,只要成功做到几次,你的团队就会给予你在未来继续这样做的自由。如果雇主文化对这种偏离思维的方式抵触,那会更难一些,但仍然是可能的。
当你以创造性的方式处理数据科学时,结果常常令人惊叹。
原文。经许可转载。
相关:
-
分析与数据科学专业人员的职业建议
-
为什么数据科学家和数据工程师需要理解云中的虚拟化
-
大数据和物联网并不会让商业更智能,分析和数据科学才会
更多相关主题
在不断发展的市场中对机器学习平台的关键比较
原文:
www.kdnuggets.com/2021/02/critical-comparison-machine-learning-platforms-evolving-market.html
评论
作者:Vivek Jain,Sigmoid

MLaaS 市场的发展
机器学习即服务(MLaaS)市场正蓬勃发展。预计到 2025 年将增长至 84.8 亿美元,年复合增长率为 43%。预计云计算的普及和更好地理解客户行为的需求将推动市场前进。鉴于公司今天可以从广泛的解决方案中选择以满足各种业务需求,MLaaS 模型在各行业中有明显倾斜。此外,物联网、自动化和人工智能驱动系统在各行业的普及将进一步放大 MLaaS 作为所有这些技术基础的需求。
数据卓越的三大机器学习平台
数据科学和机器学习平台为公司提供了开发、部署和监控机器学习算法的必备工具。这些智能平台将数据与智能决策算法结合在一起,包括语音识别、图像识别、自然语言处理(NLP)等功能。
市场上有多种机器学习平台。选择合适的解决方案可能是一项艰巨的任务——需要进行深入的研究和比较,不仅仅是解决方案和核心技术能力。为了让这个任务稍微简单一些,我们在一个地方汇总了三大机器学习平台以供审阅。
IBM Watson
IBM Watson Studio 或 Watson Machine Learning 实质上是 IBM 云服务的融合,专注于神经网络和机器学习模型的创建、训练和部署。通过利用 Watson Machine Learning 平台,公司可以开发分析模型,同时用自己的数据训练这些模型,并将它们集成到原生应用程序中。
微软 Azure
微软 Azure 机器学习解决方案为公司提供了一个协作平台,以开发、测试和部署预测数据解决方案。Azure 使创建机器学习模型的过程变得简单易行。这确保了开发的模型能够在短时间内被更大范围的受众访问。此外,这个平台还使数据科学家和工程师更容易开始挖掘预测数据。这使得它成为那些经验较少或没有经验的用户的理想选择。
谷歌云 AI
Google Cloud AI 是多个 Google AI/ML 项目(如 Tensor Flow、Kuberflow 和 Cloud ML Engine)的融合。它包括一整套机器学习服务,如数据准备、数据调优和数据训练。数据科学家可以利用该平台部署和共享 ML 模型,并协作改进。
三大机器学习平台的详细比较
| 功能 | IBM Watson | Microsoft Azure | Google Cloud AI |
|---|---|---|---|
| 支持的框架 | TensorFlow, Spark MLlib, scikit-learn, XGBoost, PyTorch, IBM SPSS, PMML | TensorFlow, scikit-learn, Microsoft Cognitive Toolkit, Spark ML | TensorFlow, scikit-learn, XGBoost, Keras |
| 内置算法 | 支持。包括可以大规模部署的 AutoAI 和机器学习算法。 | 不支持。更灵活于开箱即用的算法。 | 通过 最新更新支持。然而,实施仍处于测试阶段。 |
| 语音和文本处理 API | 识别 60 多种语言,翻译 21 种语言 | 识别 120 种语言,翻译 60 多种语言 | 识别 120 多种语言,翻译 100 多种语言 |
| 用户界面 | Watson UI 主要面向专业用户。普通数据科学家和业务分析师可能会觉得用户体验繁琐。 | Azure GUI 旨在可视化工作流程中的每一步。较少经验的 ML 团队可以探索 UI 以了解主要方法和模型。 | 易于使用的图形界面可以帮助经验较少的 ML 团队训练高质量模型。 |
| 采纳难易度 | Watson ML 平台可以轻松集成到现有的复杂分析和应用开发系统中。然而,该平台确实更面向专业 ML 团队。 | 完成项目的时间和精力投入有相当大的学习曲线。特别是对于经验较少的用户。 | Google ML 引擎高度灵活,除了 TensorFlow,还支持多种流行算法。此外,作为最受欢迎的数据可视化工具之一,Data Studio 满足数据科学家和营销人员的需求。 |
| 成本 | 定价层级明确:
-
精简版:按需付费 – 免费,5 个模型 / 每月 5,000 次预测 / 50 小时训练,批量部署
-
标准:按需付费 – 每月每 1,000 次预测$0.50 / 每容量单位小时$0.50
-
专业版:每月$1,000 / 每月 2,000,000 次预测 / 1,000 小时
| 带有 10gb 工作区存储的 ML 工作室对 Microsoft 账户用户免费。标准企业级工作区可按月$9.99 或每小时$1 的价格获取。 | AI Hub 和笔记本免费。其余部分需订阅(可通过合同谈判)。定价计算器可在网站上使用,但确切数字需联系 Google。 |
|---|
总结
在众多可用的 ML 平台中选择合适的一个可能是一个令人不知所措的任务。每种解决方案在算法、操作平台所需的技能以及执行的任务方面都有所不同。因此,如何选择一个能够全面满足您所有业务需求的平台,取决于您的公司通过机器学习程序打算实现的目标。诀窍在于将数据科学与您的长期业务目标正确对齐。一旦实现这一点,选择一个能够满足所有需求的平台将变得更加容易。
个人简介:Vivek Jain 是 [Sigmoid](http://<a href=)" rel="noopener" target="_blank">Sigmoid 的首席数据科学家,专长于实施 ML 解决方案,包括超个性化、深度神经网络、需求预测、文本分析等。
原文。经许可转载。
相关:
-
2020–2022 年云计算、数据科学和 ML 趋势:巨头之争
-
2020 年数据科学与机器学习现状:3 个关键发现
-
顶级语音处理 API 比较
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持组织中的 IT
更多相关话题
使用机器学习和计算机视觉检测作物疾病
原文:
www.kdnuggets.com/2020/06/crop-disease-detection-computer-vision.html
评论
由 Srinivas Chilukuri,ZS 纽约 AI 卓越中心
国际学习表示大会(ICLR)与国际农业研究咨询小组(CGIAR)联合开展了一项 挑战赛,全球超过 800 名数据科学家参与,通过近景图片检测作物疾病。该挑战的目标是构建一个机器学习算法,以准确分类植物是否健康、是否有茎锈病或叶锈病。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
小麦锈病是一种严重的植物病害,影响许多作物,减少产量,影响农民生计,并降低非洲的食品安全。该疾病在大规模监测时很难控制和根除。一个能够从任何图像中检测小麦锈病的准确图像识别模型,将使众包监测作物成为可能。
数据
图像数据来自多个来源。大部分数据由国际玉米和小麦改良中心 (CIMMYT) 及其在埃塞俄比亚和坦桑尼亚的合作伙伴在田间收集。其余数据来自谷歌图片上的公开图像。在此挑战中,禁止使用提供的数据以外的外部数据。以下是按类别分类的数据示例,即健康小麦、叶锈病和茎锈病。
健康小麦

叶锈病

茎锈病

图 1. 不同类别的示例图像
提供的训练 AI 模型的数据中共有 876 张图片(142 张健康,358 张叶锈病和 376 张茎锈病)。最终性能测试的数据有 610 张图片,标签未向参与者透露。
方法论
基于图片确定植物健康状态的最先进方法是一种称为卷积神经网络(CNN)的深度学习方法。整体建模过程需要几个步骤来有效地准备数据,使 CNN 模型能产生良好的结果。下图 2 展示了涉及的详细步骤。

图 2. 模型流程
在整个流程的各个步骤中,数据增强特别在提升模型性能方面发挥了重要作用。我们使用了多种数据增强技术 - 如下图所示。

a. 垂直和水平翻转
b. 光照标准化

c. 缩放和裁剪

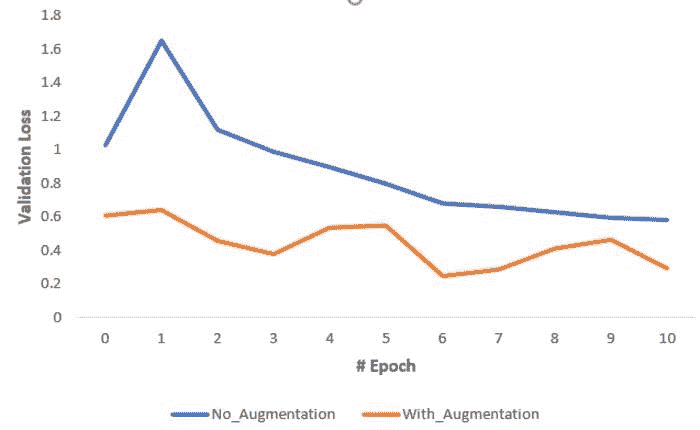
图 3. 数据增强示意图
接下来的关键步骤是 CNN 模型架构设计。我们使用了迁移学习来基于现有的ImageNet模型进行构建。虽然有多个预训练模型可用(例如 VGG、ResNet、InceptionV3、DenseNet、EfficientNet 等),我们选择了DenseNet201因为它的复杂性较低、参数较少且计算成本更为经济。
图 4. DenseNet201 模型架构
我们在达到最终性能之前,反复调整模型及不同的数据增强方法。作为参考,我们在图 5 中展示了模型性能在迭代过程中的演变。
图 5. 模型性能随迭代变化
结果
我们的最终得分是在测试数据集上获得的对数损失为 0.288,在 839 名参与者中排名第 53^(rd) 最终排行榜。在 610 张测试图像样本中,这相当于约 580 个正确分类的实例——换句话说,模型准确率为 95%。这对于实际使用来说相当好,并且考虑到我们仅在有限的比赛数据集上进行训练,通过添加更多的数据点可以进一步提高准确率。
性能非常出色,但[模型学到了什么]?
a. 模型说明
在竞赛环境之外,如果我们期望模型在实际应用中使用,解释模型为何对给定图像进行分类是很重要的。我们探索了一些使用可解释 AI 技术(称为梯度加权类别激活图(Grad-CAM))的示例,以突出模型基于哪些图像区域作出决策。图 6 展示了一些例子。
叶锈病:原始图像(左)和 Grad-CAM 热图图像(右)

茎锈病:原始图像(左)和 Grad-CAM 热图图像(右)

图 6. 使用 Grad-CAM 解释模型预测
从解释中我们可以看到,模型能够准确分类的原因在于它抓住了叶子和茎上的锈斑部分。
b. 通过深度梦境推断模型如何识别不同类别
一种可视化模型学习内容的方法是将网络倒置,并让其增强输入图像,以便引发特定的输出类别。假设你想知道什么样的图像会产生“香蕉”的分类,从一个充满随机噪声的图像开始,然后逐渐调整图像,直到它被神经网络认为是香蕉。这被称为深度梦境(Deep Dream)。

图 7. 让训练后的模型为香蕉类别生成图像的示例
我们在模型上应用了深度梦境方法,并生成了相应类别的图像。下面的图像分别说明了模型通常认为某一类别图像的样子。

图 8. 基于我们模型的所有类别的深度梦境结果
我们注意到对于不同的类别,模型发现了重要的区分模式:
-
健康小麦:主要颜色为绿色,具有叶状特征,没有锈斑相关的颜色如黄色/橙色
-
叶锈病:颜色混合,具有叶子状特征,并且叶子状特征上有锈斑相关的颜色(黄色/橙色)
-
茎锈病:具有管状模式,并且管状模式上有锈斑相关的颜色(黄色/橙色)
结论
在本文中,我们展示了如何将深度学习技术应用于基于近距离图像检测作物小麦锈病。除了良好的预测准确性,我们还展示了模型如何通过从类别激活图推断的解释来有效学习正确的表示。当扩展应用时,这种方法可以帮助数字监测作物健康,并可能显著提高农业生产力和产量。
ZS AI 团队在最终排行榜中排名前 6%,预测准确率为 95%。
简介:Srinivas Chilukuri 领导 ZS 纽约 AI 卓越中心。他拥有超过 15 年的经验,帮助各行业客户设计和实施 AI 解决方案。
相关:
-
使用 fast.ai 进行卫星图像分析以应对灾难恢复
-
利用 AI 识别塞伦盖蒂相机陷阱图像中的野生动物
-
农业中的机器学习:应用与技术
更多相关内容
CrowdFlower 2016 数据科学报告
原文:
www.kdnuggets.com/2016/04/crowdflower-2016-data-science-repost.html
 |
|---|
| 今年早些时候,我们对来自各种组织的数据科学家进行了调查。我们想了解什么最能促使他们成功,他们面临的最大挑战是什么,以及他们如何看待未来五年内该领域的发展。我们将所有这些内容汇总在一份便捷的免费报告中,你可以在这里下载。几个关键见解:
-
83% 的数据科学家认为目前数据科学家短缺
-
60% 的人表示他们花费最多的时间在清理和整理数据上
-
尽管如此,仍有 4/5 的数据科学家对目前的工作感到非常积极
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。 2. Google 数据分析专业证书 - 提升你的数据分析能力! 3. Google IT 支持专业证书 - 支持你的组织 IT 需求
完整报告包含更多详细信息,但我们希望让你了解一些我们认为最有趣的发现。如果你从事这个领域,请告诉我们下次应该询问什么。我们将非常感激。
|
| 下载报告 |
|
| |
|
|
|
更多相关话题
2017 年数据科学家报告现已发布
原文:
www.kdnuggets.com/2017/05/crowdflower-data-science-report-available.html
|
|
| |
|
|
| | |
|
|
|
|
|
| |
亲爱的 AI 爱好者,
我们的前三门课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯! 2. Google 数据分析专业证书 - 提升你的数据分析能力! 3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
连续三年,我们对来自各种组织的数据科学家进行了调查(今年接近 200 名)。我们继续问及去年的问题,如幸福感水平和对数据科学家的需求,以及有关调查参与者使用的数据特征的新问题。今年新增的内容包括关于 AI 世界的许多见解,特别强调成功的 AI 组成部分,如算法和训练数据。我们将所有内容汇编成一份免费报告,您可以在这里下载 这里。以下是我们的一些最喜欢的见解:
-
88% 的数据科学家报告称在他们的角色中非常开心或快乐(尽管有 3% 宁愿成为
摇滚明星 )。 -
数据科学家中,有 89% 每月至少被联系一次有关新工作机会,30% 有时每周多次。
-
72% 的数据科学家计划在未来 5 年内乘坐自动驾驶汽车。
完整报告详细描述了数据科学家、AI 计划以及数据本身的十几个关键见解。希望您和我们一样享受阅读这份报告的过程。
副总裁市场营销 | CrowdFlower
附言:28%的数据科学家宁愿摔断腿也不愿意意外删除他们的训练数据。了解更多关于训练数据的价值,请访问 Train AI 2017。使用代码BreakALeg28可享受注册费用 28%的折扣。
| |
| |
|
|
|
|
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
|
| |
|
| 立即尝试 CrowdFlower | 关于 CrowdFlower | |
|
| |
|
| 版权所有 © 2016 CrowdFlower Inc. | 2111 Mission St. San Francisco CA 94110 | |
|
| |
|
| |
|
|
更多相关话题
为什么数据分析师应该选择故事而非统计数据
原文:
www.kdnuggets.com/2019/09/crunch-data-analysts-stories-over-statistics.html
Sponsored Post.
数据讲故事是你在今天的数据经济中可以获得和发展的最重要的技能之一。这是将你的发现转化为能够激发变革和创造价值的东西的关键“最后一公里”沟通。Brent Dykes 具有超过 15 年的企业分析经验,并将在 Crunch Conference 上分享他对数据讲故事的见解。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
Crunch Conference: 什么对你的职业生涯产生了最强的影响?
Brent Dykes: Chip 和 Dan Heath 的书《Made to Stick: Why Some Ideas Survive and Others Die》对我的职业生涯产生了深远的影响。它的原则改变了我对沟通的思考方式。这也是第一本让我认识到故事相较于统计数据的力量的书。作为一个数据迷,我曾经认为逻辑和理性(事实!)是进行决策所需的全部。然而,这本书让我意识到讲故事为何如此重要。
CC: 对于进入该领域的分析师,你有什么建议?
BD: 我的建议是不要忘记分析过程中的“最后一公里”。在花费了大量的努力去发现关键见解之后,你必须有效地沟通这些见解,以便其他人(决策者)能够理解并被迫采取行动。数据专业人员常常在探索阶段表现出色,但在解释阶段却失败了。因此,他们的见解往往没有实质性的结果。掌握数据讲故事的艺术可以确保你在这一关键的最后一公里中取得成功。
CC: 你认为哪些流行词需要被淘汰,为什么?
BD: 我们可以放心地说,“大数据”一直只是“数据”。当然,这个术语可能代表了公司处理的数据量的显著变化,但在我看来,“大”这个强调削弱了它更具挑战性的方面(多样性、速度、真实性和价值)。我也从未喜欢过“公民数据科学家”这一术语。这一术语误导了商业用户成为“伪”数据科学家的能力。
阅读与 Brent 的完整采访 这里。Crunch 是最具启发性的数据显示会议之一,设有三个主题:数据科学、数据工程和商业智能。欢迎于 10 月 16-18 日在布达佩斯加入我们,届时将有来自 Facebook、Netflix 和 LinkedIn 的杰出讲者。使用折扣代码 ‘KDNuggets’ 可节省 $100 的会议票价。
更多相关话题
CSV 文件用于存储?不,谢谢。有更好的选择。
原文:
www.kdnuggets.com/2021/08/csv-files-storage-better-option.html
评论
由 Dario Radečić,NEOS 顾问

由 David Emrich 提供的照片,来源于 Unsplash
每个人和他们的祖母都知道什么是 CSV 文件。而 Parquet 却不那么为人所知。它是一种地板类型吗? 嗯,是的,但也不是——它是一种高效的数据存储格式,你今天将了解所有相关信息。
CSV 随处可见——从公司报告到机器学习数据集。这是一种简单直观的数据格式——只需打开一个文件,你就可以直接访问数据。实际情况并不像听起来那么好,原因稍后你将会了解到。
有许多 CSV 的替代方案——如 Excel、SQLite 数据库和 HDF——但其中一个特别突出。那就是 Parquet。
今天的文章回答了以下问题:
-
CSV 有什么问题?
-
什么是 Parquet 数据格式?
-
CSV 还是 Parquet?你应该使用哪一个?
CSV 有什么问题?
我喜欢 CSV 文件,你也可能喜欢。几乎任何软件都可以生成 CSV 文件,甚至是普通的文本编辑器。如果你对数据科学和机器学习感兴趣,只需访问 Kaggle.com——几乎所有的表格数据集都是这种格式。
CSV 是按行组织的,这意味着它们查询速度慢且难以高效存储。Parquet 则不是这样,它是一种按列组织的存储选项。对于相同的数据集,这两者之间的大小差异巨大,稍后你将看到。
加重伤害的是,任何人都可以打开和修改 CSV 文件。这就是为什么你绝不应该将这种格式用作数据库的原因。有更安全的替代方案。
但让我们专注于对公司真正重要的——时间和金钱。你可能会将数据存储在云中,无论是作为网络应用还是机器学习模型的基础。云服务提供商会根据扫描的数据量或存储的数据量来收费。这两者对 CSV 来说都不是好消息。
首先让我们看看亚马逊 S3 的存储定价。这些数字来自 这里:

图片 1 — 亚马逊 S3 不同数据格式的存储定价(作者提供的图片)
哎呀。Parquet 文件比 CSV 文件占用的磁盘空间要少得多(在 Amazon S3 上的大小),扫描速度也更快(扫描的数据)。因此,相同的数据集存储在 Parquet 格式中便宜了 16 倍!
接下来,让我们看看 Apache Parquet 的速度提升:

图片 2 — 不同数据格式的 Amazon S3 存储和查询价格比较(图片由作者提供)
再次强调——哇!如果你的原始 CSV 文件大小为 1TB,Parquet 将便宜 99.7%。
所以,当你的数据量很大时,CSV 绝对不是一个好的选择——无论是从时间还是成本的角度来看。
那么,Parquet 数据格式到底是什么?
它是一种用于存储数据的替代格式。它是开源的,并且遵循 Apache 许可协议。
CSV 和 Parquet 格式都用于存储数据,但它们的内部结构截然不同。CSV 是你所谓的 行存储,而 Parquet 文件将数据按列组织。
这意味着什么呢?假设你有以下数据:

图片 3 — 示例表数据(图片由作者提供)
这就是前一个表格在行存储和列存储中的组织方式:

图片 4 — 行存储 vs. 列存储(图片由作者提供)
简而言之,列存储文件更轻量,因为可以对每一列进行充分的压缩。与此不同的是,行存储通常包含多种数据类型。
Apache Parquet 旨在提高效率。列存储架构就是原因,它允许你快速跳过不相关的数据。这样查询和聚合都更快,从而节省硬件成本(换句话说,更便宜)。
简而言之,Parquet 是一种更高效的大文件数据格式。使用 Parquet 而非 CSV,你将节省时间和金钱。
如果你是 Python 爱好者,使用 Pandas 处理 CSV 文件应该很熟悉。接下来我们来看一下库如何处理 Parquet 文件。
实操 CSV 和 Parquet 比较
你将使用 NYSE 股票价格数据集 来进行这一实操部分。CSV 文件大小约为 50MB——并不大——但你会看到 Parquet 能节省多少磁盘空间。
首先,用 Python 的 Pandas 加载 CSV 文件:
import pandas as pddf = pd.read_csv('data/prices.csv')
df.head()
这就是它的样子:
图片 5 — NYSE 股票价格数据集的前几行 — CSV(图片由作者提供)
你需要使用 to_parquet() 函数来保存数据集。它的工作方式与 to_csv() 大致相同,因此使用起来不会有什么不同:
df.to_parquet('data/prices.parquet')
数据集现在已保存。让我们看看如何在比较文件大小之前加载它。Pandas 提供了 read_parquet() 函数来读取 Parquet 数据文件:
df_parquet = pd.read_parquet('data/prices.parquet')
df_parquet.head()
这就是数据集的样子:
图片 6 — NYSE 股票价格数据集的前几行 — Parquet(图片由作者提供)
两个数据集是完全相同的。命令 df.equals(df_parquet) 将在控制台上打印 True,所以可以用它来验证。
那么,文件大小是否有所减少?嗯,是的:
图 7 — NYSE 股票价格数据集中的 CSV 与 Parquet 文件大小对比(图像由作者提供)
这大约是磁盘空间使用量的四分之一。
对于 50MB 数据集这是否重要? 可能不重要,但在更大的数据集上,节省的空间也会增加。如果你将数据存储在云端并支付整体存储费用,这一点尤其重要。
这是一个值得考虑的问题。
*喜欢这篇文章吗?成为 Medium 会员 继续无限制地学习。如果你使用以下链接注册会员,我将获得部分会员费用,但对你没有额外费用: *https://medium.com/@radecicdario/membership
保持联系
简介: Dario Radečić 是 NEOS 的顾问。
原文。经许可转载。
相关:
-
5 个 Python 数据处理技巧与代码片段
-
如何查询你的 Pandas 数据框
-
Pandas 不够用?这里有一些处理更大、更快数据的 Python 替代方案
我们的 3 个最佳课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
RAPIDS cuDF 备忘单
原文:
www.kdnuggets.com/2023/05/cudf-data-science-cheat-sheet.html
RAPIDS cuDF
RAPIDS cuDF 是一个开源 Python 库,用于 GPU 加速的数据框(DataFrames)。cuDF 提供了类似于 Pandas 的 API,数据工程师、分析师和数据工程师可以利用 NVIDIA GPU 的强大性能,在大型数据集和时间序列数据上执行数据操作和分析任务,从而实现更快的数据处理和分析。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
开始使用 cuDF 非常简单,特别是如果您有使用 Python 和像 Pandas 这样的库的经验。虽然 cuDF 和 Pandas 提供了类似的数据操作 API,但在某些类型的问题中,cuDF 可以显著提升性能,包括大规模数据集、数据预处理和工程、实时分析,当然还有并行处理。数据集越大,性能提升越明显。
欲了解更多关于使用 cuDF 进行数据科学的信息,请查看我们最新的备忘单。
这份备忘单涵盖了 RAPIDS cuDF 的以下方面:
-
安装
-
读取数据
-
写入数据
-
选择数据
-
处理缺失数据
-
应用函数
-
处理数据
-
以及更多
立即查看 RAPIDS cuDF 备忘单,并尽快回来查看更多内容。
更多相关主题
人工智能的当前炒作周期
原文:
www.kdnuggets.com/2018/02/current-hype-cycle-artificial-intelligence.html
评论
前言
每个十年似乎都有其技术流行词:1980 年代有个人计算机;1990 年代有互联网和全球网页;2000 年代有智能手机和社交媒体;而在本十年则有人工智能(AI)和机器学习。然而,人工智能领域已有 67 年历史,这是五篇系列文章中的第三篇,其中:
-
本文讨论了人工智能当前的炒作周期。
-
第五篇文章讨论了 2018-2035 年可能对大脑、思想和机器的影响
时间线

介绍
在过去十年中,人工智能(AI)领域取得了显著进展。如[141]中所述,现在存在超过二十个领域,其中人工智能程序的表现至少与人类一样好(如果不是更好)。这些进展导致了人工智能领域的巨大兴奋,这与 1956-1973 年第一次人工智能炒作周期的繁荣阶段极为相似[56]。投资者正在为基于人工智能的研究和初创公司投资数十亿美元[143,144,145],而未来学家们也开始对强大人工智能的出现做出令人担忧的预测[149,150,151,152]。许多人质疑人类在就业市场中的未来,声称到 2033 年,美国 47%的工作可能面临被自动化取代的高风险[146],有些人甚至表示人工智能可能会导致人类的终结[141]。
在这篇文章中,我们认为人工智能的短期效果不太可能如这些声称的那样明显。导致四十多年前第一次人工智能繁荣阶段崩溃的一些障碍至今仍未解决,而且似乎需要严肃的理论进展才能克服这些障碍。此外,当前的基础设施不适合大规模地整合人工智能程序,这意味着人工智能系统不太可能很快大规模取代人类。因此,上述预测在未来十五年内不太可能实现,投资者可能无法从他们最近在人工智能领域的投资中获得预期的回报。
大胆的期望
最近对人工智能的炒作表现为两种形式:引人注目的预测和巨额投资,以下将讨论这两方面。
2035 年人工智能的力量预测
过去几年里,人们越来越相信人工智能是一个无尽的、神秘的力量,能够(或即将能够)超越人类并解决任何问题。例如,雷·库兹韦尔预测,“人工智能将在大约 2029 年达到人类水平,”[150],而格雷·斯科特则表示,“没有理由也没有办法让人类大脑在 2035 年之前赶上人工智能机器。”[152]。埃隆·马斯克表达了类似但更令人不安的情绪,他写道,“人工智能的进步速度……极其迅猛……发生严重危险事件的风险在五年时间框架内,最多十年,”[149],并进一步表示,“通过人工智能我们正在召唤恶魔”[152]。
人工智能将在大约 2029 年达到人类水平——雷·库兹韦尔,2014 年
尽管有人认为马斯克的视野过于极端,但研究人员仍然对强人工智能可能对人类未来的就业市场产生重大影响感到担忧。例如,2013 年,两位牛津大学教授弗雷和奥斯本发表了一篇名为[146]“就业的未来:工作岗位对计算机化的敏感程度如何?”的文章,试图分析未来二十年内可能计算机化的就业市场比例。他们估计,“47%的美国总就业属于高风险类别,意味着这些相关职业可能在未确定的几年内有可能实现自动化,也许在十年或二十年内。”继这项工作之后,许多咨询公司和智库撰写了若干篇预测,认为在未来二十年内,由于自动化,20%到 40%的工作岗位将会消失[147,148]。这些预测在许多企业的董事会和各国政府部门中引起了波澜。由于预计人工智能系统将把美国的劳动成本降低十倍,这些预测表明,企业通过雇佣人工智能程序而不是人类,可能会变得更加盈利;然而,这可能导致失业率达到惊人的比例,造成全球经济巨大的混乱。
初创企业的爆炸性增长和巨额投资
根据麦肯锡公司数据,2016 年非科技公司在人工智能上的支出介于 260 亿至 390 亿美元之间,科技公司在人工智能上的支出介于 200 亿至 300 亿美元之间[143]。类似地,基于人工智能的初创公司从 2012 年开始爆炸式增长,至今仍在持续。2017 年 12 月,AngelList(一个将初创公司与天使投资者和求职者连接起来的网站)列出了 3,792 家人工智能初创公司;2,592 名相关天使投资者;以及 2,521 个相关职位空缺。根据 Pitchbook,2007 年风险投资公司在人工智能初创公司上投资了 2.85 亿美元,2015 年为 40 亿美元,2016 年为 54 亿美元,2017 年 1 月至 10 月为 76 亿美元;2007 年至 2017 年间,风险投资在人工智能上的总投资超过 250 亿美元[144]。根据 CBInsights,仅 2016 年就有 658 家人工智能初创公司获得了资金,并积极推进他们的商业计划[145]。事实上,如今获得风险投资的业务计划大多数需要至少提到一些人工智能内容。

图 1:人工智能初创公司的风险投资(来源:Pitchbook)
第一次人工智能炒作周期 – 快速回顾
目前人工智能的炒作非常类似于 1956 年至 1973 年第一次人工智能炒作周期的繁荣阶段(在[56]中调查,这是本系列的第一篇文章)。事实上,继几项显著的人工智能进展(例如第一个自学程序——玩跳棋的程序,以及神经网络的引入[5,14])之后,政府机构和研究组织迅速向人工智能研究投资了大量资金[40,41,42]。在这种受欢迎程度的推动下,人工智能研究人员也迅速做出大胆的预测,预测强大的人工智能的出现。例如,1961 年,马文·明斯基写道:“在我们的有生之年,机器可能会在一般智能方面超过我们”[9]。
然而,这种兴奋并没有持续太久。到 1970 年代初,当人工智能的期望没有实现时,失望的投资者撤回了他们的资金;这导致了人工智能萧条期,那时人工智能的研究变得缓慢,甚至“人工智能”这个术语也被冷落。回顾起来,人工智能繁荣阶段的终结可以归因于以下两个主要障碍:
有限且昂贵的计算能力
1970 年代的计算能力非常昂贵,也不足以模仿人脑。例如,创建一个与人脑大小相当的人工神经网络(ANN)在 1974 年将消耗整个美国的 GDP[56]。
人类思维之谜
科学家们并不了解人脑的功能,尤其对创造力、推理和幽默背后的神经机制知之甚少。对机器学习程序应模仿什么的缺乏理解,对 AI 理论的发展构成了重大问题[38]。正如麻省理工学院教授休伯特·德雷福斯简洁地解释的那样,“这些程序缺乏四岁小孩的直觉常识,”而且没有人知道如何继续下去[154]。
上述第一个难题可以归类为机械性问题,而第二个则为概念性问题;这两者共同导致了四十年前第一个 AI 热潮的终结。到 1982 年,明斯基自己推翻了之前的乐观观点,称“我认为 AI 问题是科学史上最困难的问题之一”[155]。

图 2:人脑,其功能尚未完全理解
没有概念性突破
显然,尽管在 2011 年 IBM Watson 在《Jeopardy!》游戏中击败人类并非普通的壮举,但它只是对《Jeopardy!》中的各种问题提供了事实性回答。有关 IBM Watson 的一些后续声明和广告暗示它可以帮助解决一些更困难的人类问题(例如,帮助癌症研究和寻找替代疗法);然而,与 M. D. Anderson 癌症中心和其他医院的后续工作表明,它远未达到这样的期望[156, 157]。事实上,今天没有任何 AI 系统接近于 HAL 9000,一个在电影《2001 太空漫游》中被描绘为反派的人工智能计算机。
在过去四十年中,发生的实质性进展主要集中在上述第一个(机械)问题上。这里的促进原则是摩尔定律,它预测电子电路中的晶体管数量应该每两年大约翻一番;因此,自 1970 年代以来,计算的成本和速度提高了 1.1 百万倍[114,115,117]。这导致了普及且便宜的硬件和连接,使得几十年前在第一个炒作周期中发明的一些理论进展(如反向传播算法)和一些新技术在实践中表现得显著更好,主要通过繁琐的启发式应用和工程技能。
然而,仍然缺乏的是一个概念上的突破,以便为上述第二个问题提供见解:我们仍然不确定如何创建真正模仿智能生命的机器,以及如何赋予它“直觉”或“常识”或执行多项任务的能力(如人类)。这导致了即使是最现代的 AI 程序中也存在几个明显的缺陷(详见下文),使得它们在大规模使用中不具实用性。
任何足够先进的技术都与魔法无异 – 阿瑟·C·克拉克,1973
当前深度学习网络不够稳健
2015 年,Nguyen、Yosinki 和 Clune 检查了领先的图像识别深度神经网络是否容易出现误报 [158]。他们通过扰动模式生成了随机图像,并将原始模式及其变异副本展示给这些神经网络(这些网络使用了来自 ImageNet 的标记数据进行训练)。尽管这些扰动模式(其中八个如图 3 所示)本质上毫无意义,但这些网络以超过 99%的信心错误地将其识别为皇帝企鹅、海星等 [158]。

图 3:来源 – Nguyen、Yosinki 和 Clune 的研究文章 [158]
另一个研究小组展示了,通过佩戴某些迷幻眼镜,普通人可以欺骗面部识别系统,使其认为他们是名人;这将允许人们互相冒充而不被这种系统检测到 [159,160]。类似地,2017 年的研究人员在停车标志上贴了标签,这导致 ANN 将其误分类,这可能对自动驾驶汽车产生严重后果 [161]。在这些 AI 系统变得足够强大,不会被这些干扰欺骗之前,行业广泛采用它们将是不可行的 [162]。

图 4:来源 – 研究文章 [159] 和 [161]
机器学习系统仍然低效
机器学习算法需要数千到数百万张猫(以及非猫)的图片,才能开始准确区分它们。如果 AI 系统在与过去情况大相径庭的环境中运行(例如,由于股市崩盘),这可能会成为一个重大问题;因为 AI 系统可能没有足够大的数据集来进行充分训练,可能会导致失败。
深度学习网络难以改进
尽管深度学习算法有时能产生优越的结果,但它们通常是“黑箱”,即使是研究人员目前也无法建立一个理论框架来理解它们如何或为什么给出它们的答案。例如,Dudley 和他在 Mt. Sinai 医院的同事们建立的 Deep Patient 程序可以在很大程度上预测精神分裂症的发作,但 Dudley 遗憾地表示:“我们可以建立这些模型,但我们不知道它们如何工作” [109,141]。
由于我们不了解 AI 程序处理的数据与其最终回答之间的直接因果关系,系统地改进 AI 程序仍然是一个严重的复杂问题,通常需要通过试错法来完成。由于同样的原因,如果解决方案出现问题,修复起来也很困难[163,171]。考虑到这些问题以及人类被教导“治疗”原因(而非症状)的事实,许多行业在短期内可能难以依赖深度学习程序。例如,医生不太可能仅凭程序预测患者很快会变得精神分裂就给患者开药。确实,如果程序的预测不准确,而患者因不适当用药的副作用而生病,医生可能会面临指责,他或她唯一的辩护是对 AI 系统的信任是错误的。
摩尔定律可能在十年内终结
如前所述,摩尔定律预测电路中晶体管数量的指数增长,是我们在 AI 领域取得进展的最有影响力的原因。如今晶体管的尺寸最多可以减少到理论限制的一硅原子的 4,900 倍。在 2015 年,摩尔本人曾说:“我看到摩尔定律在接下来的十年内可能会消亡”[117]。因此,在摩尔定律消亡之前是否会开发出强大的通用 AI 系统尚不清楚。
AI 系统对人类社会的短期影响
不适应的基础设施
即使之前提到的 AI 系统问题得到解决,以下原因表明,企业、组织和政府的基础设施仍需付出大量努力以广泛地整合 AI 程序:
-
现代 AI 算法通常需要大量(几千个核心)的处理能力。然而,只有极少数组织在单个集群中安装了超过 100 个核心的并行计算基础设施,而安装更大规模的系统则既耗时又昂贵。原则上,组织可以将其数据发送到技术公司(如亚马逊云服务或谷歌云),这些公司可以提供更大规模的并行和分布式计算。然而,由于风险(例如数据泄露)和合规原因,许多组织无法使用这些服务。
-
大型企业中的数据通常分布在成千上万的不同数据库和位置;这些数据大多数是“嘈杂的”,如果人工智能系统使用这些数据的当前形式,很可能会失败。清理和协调数据是一项艰巨且耗时的任务,数据工程目前是部署人工智能系统的最大瓶颈,占用了超过 60%的时间和成本。大多数组织尚未开始大规模清理数据,而那些已经开始的组织预计需要两到五年才能完成。
-
上游或下游的变化(例如,法规或商业环境的变化)可能迫使人工智能系统重新配置、重新训练、重新验证和重新测试;如前所述,这可能会由于人工智能程序缺乏新训练数据而导致严重问题。

图 5:协调大数据就像解读各种不同的拼图块
短期人类工作的未来
尽管 Frey 和 Osborne 预测“47%的美国总就业属于高风险类别,……也许在十年或二十年内”[146],但大型科技公司的研究部门、战略公司和智库长期以来都低估了——至少低估了两倍——具体技术进步对人类社会产生影响所需的时间。原因在于,这些分析往往未能解决一个关键点:全球经济并非无摩擦——变化需要时间。人类对现代技术的适应很快,如果技术有助于他们,但如果技术对他们造成伤害,他们则非常抗拒,这种现象难以量化。
例如,在过去四十年里,通过外包,已经有了显著降低劳动成本的机会——在高工资国家降低了四倍。自 1979 年起,美国开始将制造业工作外包到工资较低的国家,但截至 2016 年,由于外包,美国累计损失的制造业工作岗位不到 800 万个[168]。类似地,美国的服务业工作外包始于 1990 年代,但美国累计损失了约 500 万个此类岗位。因此,由外包导致的工作岗位损失总计约为 1300 万个,占美国 1.61 亿劳动人口的 8%左右。如果全球经济是无摩擦的,那么根据 Frey 和 Osborne 的预测,47%的工作岗位本应被外包所取代。事实是,在过去 20 到 40 年里这种情况并没有发生,这对未来 15 年由于人工智能造成类似情况的说法提出了质疑,特别是在考虑到上述现代基础设施在纳入人工智能程序时的不足之处时。
此外,除非出现重大的概念性突破,否则之前提到的 AI 程序的缺陷也使得在未来十五年内自动化导致显著的失业不太可能。确实,AI 系统在其所学的领域表现很好,但如果其规则被微小扰动则很快会失败。如果他们的工作面临威胁,人们可以轻易利用这一点,例如,如果使用自动驾驶软件,出租车司机可能会与他人勾结,植入导致事故的恶意软件(或在停止标志上贴上标签,如前所述)。类似地,人工神经网络(ANNs)可以通过持续变异的恶意软件[161,162]攻击其防御系统被击败;不法分子可以利用这一点向 ANN 的训练集注入虚假数据,从而干扰 AI 系统的学习过程。尽管这些活动如果 AI 系统广泛使用肯定是非法的,但这种非法行为的风险和后果可能过于严重,以至于大规模 AI 的引入难以获得公众支持。
最后值得提到的一点是,未来十五年将会创造出额外的工作岗位,这些岗位在 Frey 和 Osborne 的分析[146]中并未考虑,也没有在随后的任何分析中考虑过[147,148]。
投资回报
由于上述原因,AI 系统的采用和实施可能比投资者预期的要慢。因此,不清楚融资者是否能从他们在过去十年中总计超过 250 亿美元的 AI 投资中获得回报,尤其是只有 11 家获得融资的私营公司市值超过 10 亿美元。事实上,自 2012 年以来,在 70 宗 AI 并购交易中,75%的交易价格低于 5000 万美元,且是“收购人才”(收购目的是人才而非商业表现);大多数由投资者资助的公司筹集不到 1000 万美元[169]。至少目前来看,短期内小额投资于 AI 可能会带来不错但不卓越的回报。然而,这与标准投资模型的建议大相径庭,该模型倡导投资者投入更多资金,并在 4-7 年内获得 8-14 倍的回报。
结论
过去几年来,人工智能领域开始进入一个新的炒作周期。最近在该领域的进展(见于[141])引起了研究人员和公众的兴趣,他们开始对强大人工智能的出现做出令人担忧的预测,同时金融家们也开始在人工智能研究和初创公司上投入巨额资金。这让人联想到四十五年前的第一次人工智能热潮。那时,人工智能领域也出现了许多显著的进展、大胆的预测和巨额的投资。最终,这一热潮阶段崩溃了,主要有两个原因。第一个是机械性的,因 1970 年代计算能力有限且成本高昂;第二个是概念性的,因缺乏对“直觉”和“人类思维”的理解,以及如何制造能模仿人类的计算机。
大部分由于摩尔定律,首个问题已得到实质性解决;在过去四十年中,硬件的成本和性能提高了超过一百万倍,使得能够使用普及且经济实惠的硬件来开发更好的人工智能程序。然而,第二个问题仍未解决。此外,即便是最现代的人工智能程序也存在主要缺陷,仍对扰动敏感、学习效率低且难以改进。即使这些问题得到解决,目前的商业和政府基础设施似乎也难以快速大规模地整合人工智能程序。因此,研究人员、投资者和公众对人工智能的大胆期望在接下来的十五年内实现的可能性不大。
尽管人工智能领域的许多兴奋点导致了显著的发展[141],但许多情况似乎也基于“非理性繁荣”[52]而非事实。我们似乎仍然需要重大突破,才能使人工智能系统真正模仿智能生命。正如约翰·麦卡锡在 1977 年指出的,创造类似人类的人工智能计算机将需要“概念突破”,因为“你需要的是 1.7 个爱因斯坦和 0.3 个曼哈顿计划,你首先需要的是爱因斯坦。我相信这需要 5 到 500 年”[43]。他的说法在四十多年后的今天似乎依然适用。

图 6:啮齿动物大脑的神经元映射(来源:[176])
然而,研究人员仍在开辟可能导致这些突破的路径。例如,由于人工神经网络(ANNs)和强化学习系统受到神经科学的启发,一些学者认为新的概念性见解可能需要通过生物学、数学和计算机科学的跨学科研究来实现。事实上,MICRoNS(来自皮层网络的机器智能)项目首次尝试对一个大约拥有 100,000 个神经元和约十亿个突触的啮齿动物大脑进行映射。美国政府(通过 IARPA)资助了这一数亿美元的研究计划,哈佛大学、普林斯顿大学、贝勒医学院和艾伦人工智能研究所的神经科学家和计算机科学家正在合作以实现成功[170]。MICRoNS 的计算目标包括学习执行复杂信息处理任务的能力,如一-shot 学习、无监督聚类和场景解析,最终目标是达到类似人类的熟练程度。如果成功,这个项目可能会为下一代 AI 系统奠定基础。
MICRoNS(来自皮层网络的机器智能)项目首次尝试对一个大约拥有 100,000 个神经元和约十亿个突触的啮齿动物大脑进行映射。如果成功,这个项目可能会为下一代 AI 系统奠定基础。
简介: 阿洛克·阿加瓦尔博士,是Scry Analytics, Inc的首席执行官和首席数据科学家。他曾在 IBM 研究院约克镇工作,创办了 IBM 印度研究实验室,并创立了 Evalueserve,该公司全球雇佣了超过 3,000 人。他于 2014 年创办了 Scry Analytics。
原文。经授权转载。
相关:
-
AI 的诞生与首个 AI 炒作周期
-
1983-2010 年 AI 复兴
-
AI 已与人类竞争的领域
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
自动化机器学习的现状
原文:
www.kdnuggets.com/2017/01/current-state-automated-machine-learning.html

自动化机器学习(AutoML)在过去一年中成为了一个相当引人关注的话题。一个最近的 KDnuggets 博客竞赛专注于这个话题,产生了一些有趣的想法和项目。在这段时间里,几款 AutoML 工具也引起了显著的关注,并获得了尊重和声誉。
本文将简要说明 AutoML,论证其合理性和采纳,介绍一对当代工具,并讨论 AutoML 预计的未来和方向。
什么是自动化机器学习?
我们可以讨论自动化机器学习是什么,也可以讨论自动化机器学习不是什么。
AutoML不是自动化数据科学。尽管存在重叠,机器学习只是数据科学工具包中的众多工具之一,它的使用实际上并不适用于所有数据科学任务。例如,如果预测是某个数据科学任务的一部分,机器学习将是一个有用的组件;然而,机器学习可能完全不涉及描述性分析任务。
即使是预测任务,数据科学也远不仅仅是实际的预测建模。数据科学家Sandro Saitta在讨论 AutoML 和自动化数据科学之间的潜在混淆时,这样说道:
这种误解源于对整个数据科学过程(例如,CRISP-DM)与数据准备(特征提取等)和建模(算法选择、超参数调整等)这些子任务之间的混淆,我称之为机器学习。
[...]
当你阅读有关自动化数据科学和数据科学竞赛的新闻时,缺乏行业经验的人可能会感到困惑,认为数据科学只是建模,并且可以完全自动化。
他绝对正确,这不仅仅是语义问题。如果你需要更多关于机器学习和数据科学(以及其他相关概念)之间关系的澄清,请阅读此文。
此外,数据科学家和领先的自动化机器学习倡导者Randy Olson指出,有效的机器学习设计要求我们:
- 始终为我们的模型调整超参数
- 始终尝试许多不同的模型
- 始终探索我们数据的多种特征表示
考虑到以上所有因素,如果我们将 AutoML 定义为算法选择、超参数调优、迭代建模和模型评估的任务,我们可以开始定义 AutoML 实际上 是什么。对此定义不会有完全一致的意见(例如,问 10 个人定义“数据科学”,然后比较你得到的 11 个答案),但这无疑会让我们起步正确。
我们为什么需要它?
在我们完成定义概念后,作为一个考虑 AutoML 可能带来好处的练习,让我们来看一下为什么机器学习是困难的。
来源:S. Zayd Enam
AI 研究员和斯坦福大学博士生 S. Zayd Enam 在一篇标题为 "为什么机器学习‘难’?" 的精彩博客文章中,最近写道(强调已添加):
[M]机器学习仍然是一个相对“困难”的问题。毫无疑问,通过研究推进机器学习算法的科学是困难的。这需要创造力、实验和毅力。在将现有算法和模型应用于你的新应用时,机器学习仍然是一个难题。
请注意,虽然 Enam 主要指的是机器学习研究,但他也触及了在用例中实施现有算法的问题(见强调)。
Enam 接着详细阐述了机器学习的困难,并专注于算法的性质(强调已添加):
这种困难的一个方面涉及建立对于应利用什么工具来解决问题的直觉。这需要了解可用的算法和模型以及每个算法和模型的权衡和限制。
[...]
难点在于机器学习是一个根本上困难的调试问题。机器学习的调试发生在两种情况下:1)你的算法不起作用或 2)你的算法效果不够好。[...] 算法第一次运行成功的情况非常少见,因此这往往是构建算法时花费最多时间的地方。
Enam 然后从算法研究的角度详细阐述了这个框架问题。然而,他所说的再次适用于… 应用 算法。如果一个算法不起作用,或者效果不够好,而选择和优化的过程变得迭代,这就暴露了自动化的机会,因此 自动化 机器学习。
我之前尝试过捕捉 AutoML 的本质如下:
如果 Sebastian Raschka 描述的那样,计算机编程是关于自动化的,而机器学习是“完全自动化自动化”,那么自动化机器学习就是“自动化自动化的自动化”。跟随我,在这里:编程通过管理重复任务来减轻我们的负担;机器学习允许计算机学习如何最佳地执行这些重复任务;自动化机器学习则允许计算机学习如何优化学习这些重复动作的结果。
这是一个非常强大的想法;虽然我们之前不得不担心调整参数和超参数,但自动化机器学习系统可以通过多种不同的方法学习调整这些参数以获得最佳结果。
AutoML 的理由源于这个想法:如果必须构建多个机器学习模型,使用各种算法和多个不同的超参数配置,那么可以自动化这些模型的构建,也可以自动化模型性能和准确性的比较。
很简单,对吧?
自动化机器学习工具的比较
现在我们知道什么是 AutoML,以及我们为什么要使用它……我们如何做它?以下是对一对现代 Python AutoML 工具的概述和比较,这些工具采用不同的方法,试图实现更多或更少相同的目标,即自动化机器学习过程。
Auto-sklearn
Auto-sklearn 是“一个自动化机器学习工具包,是 scikit-learn 估算器的直接替代品。”它也恰好是KDnuggets最近的自动化数据科学和机器学习博客竞赛的获胜者。
auto-sklearn 使机器学习用户免于算法选择和超参数调整。它利用了贝叶斯优化、元学习和集成构建的最新优势。通过阅读这篇在NIPS 2015上发表的论文,了解 auto-sklearn 背后的技术。
正如项目文档中的上述摘录所述,Auto-sklearn 通过贝叶斯优化来执行超参数优化,该过程通过迭代以下步骤进行:
- 构建一个概率模型以捕捉超参数设置与其性能之间的关系。
- 使用该模型通过权衡探索(在模型不确定的空间部分进行搜索)和开发(专注于预测表现良好的空间部分)来选择下一个要尝试的有用超参数设置。
- 使用这些超参数设置运行机器学习算法。
进一步解释这一过程的内容如下:
这一过程可以概括为联合选择算法、预处理方法及其超参数,如下所示:分类器/回归器和预处理方法的选择是顶级的、分类的超参数,并且根据它们的设置,所选方法的超参数变得有效。然后,可以使用贝叶斯优化方法来搜索这些组合空间,这些方法可以处理这样的高维、条件空间;我们使用基于随机森林的SMAC,它已被证明在这种情况下效果最佳。
就实用性而言,由于 Auto-sklearn 是 scikit-learn 估算器的直接替代品,因此需要一个功能正常的scikit-learn安装来利用它。Auto-sklearn 还通过共享文件系统上的数据共享支持并行执行,并可以利用 scikit-learn 的模型持久性能力。有效使用 Auto-sklearn 替代估算器只需以下 4 行代码即可获得机器学习管道,正如作者所述:
使用 Auto-sklearn 处理 MNIST 数据集的更详细示例如下:
另外值得注意的是,Auto-sklearn 赢得了ChaLearn AutoML 挑战赛的auto和tweakathon两个类别。
您可以阅读 Auto-sklearn 开发团队在最近的 KDnuggets 自动化数据科学和机器学习博客竞赛中的获奖博客提交这里,以及与开发者的后续采访这里。Auto-sklearn 是弗莱堡大学进行研究的结果。
Auto-sklearn 可以在其官方 GitHub 仓库找到。Auto-sklearn 的文档可以在这里找到,而其 API 可以在这里找到。
TPOT
TPOT 被“宣传”为“您的数据科学助手”(请注意,它并不是“您的数据科学替代品”)。这是一个 Python 工具,它“自动创建和优化使用遗传编程的机器学习管道。” TPOT 像 Auto-sklearn 一样,与 scikit-learn 配合使用,自我描述为 scikit-learn 的包装器。
正如之前在本文中提到的,两个突出的项目采用不同的方法实现类似的目标。虽然这两个项目都是开源的,使用 Python 编写,并旨在通过 AutoML 简化机器学习过程,但与使用贝叶斯优化的 Auto-sklearn 相比,TPOT 的方法基于 遗传编程。
尽管方法不同,但结果是一样的:自动化的超参数选择、使用各种算法建模以及探索多种特征表示,所有这些都导致了迭代模型构建和模型评估。
TPOT 的一个真正的好处是,它会为表现最佳的模型生成可直接运行的独立 Python 代码,形式为 scikit-learn 管道。这段代码代表了所有候选模型中表现最佳的,可以修改或检查以获取额外的见解,实际上可以作为 起点 而非仅仅作为 终点产品。
一个在 MNIST 数据上运行的 TPOT 示例如下:
此次运行的结果是一个管道,实现了 98% 的测试准确率,同时该管道的 Python 代码被导出到 tpot-mnist-pipeline.py 文件中,如下所示:
TPOT 可以通过其 官方 Github 仓库 获得,而其文档可以在 这里 查阅。
由 TPOT 首席开发者 Randy Olson 撰写的关于 TPOT 和 AutoML 的概述文章可以在 这里 找到。与 Randy 的后续采访可以在 这里 找到。
TPOT 是在 宾夕法尼亚大学生物医学信息学研究所 开发的,资助来自 NIH 资助 R01 AI117694。
当然,这些并不是唯一的 AutoML 工具。其他包括 Hyperopt (Hyperopt-sklearn)、Auto-WEKA 和 Spearmint。我敢打赌,未来几年还会有许多其他项目问世,包括研究型和工业级的。
自动化机器学习的未来
AutoML 未来会去向何处?
我最近就我的 2017 年机器学习预测 表达了意见:
[自动化机器学习] 将安静地成为一个重要的事件。也许对外界而言不如深度神经网络那样吸引眼球,但自动化机器学习将开始在 ML、AI 和数据科学中产生深远的影响,2017 年可能会成为这一点显现的一年。
在同一篇文章中,Randy Olson 还表达了他对 2017 年 AutoML 的期望。然而,Randy 还在最近的一次采访中陈述了以下内容:
在不久的将来,我认为自动化机器学习(AutoML)将会接管机器学习模型构建过程:一旦数据集以(相对)干净的格式存在,AutoML 系统将能够比 99%的人工更快地设计和优化机器学习管道。
[...]
然而,我可以自信地评论,AutoML 的一个长期趋势是,AutoML 系统将会在机器学习领域成为主流……
但是,AutoML 会取代数据科学家吗?Randy 继续说道:
我并不认为 AutoML 的目的是取代数据科学家,就像智能代码自动补全工具并不是为了取代计算机程序员一样。对我而言,AutoML 的目的是将数据科学家从重复和耗时的任务(例如机器学习管道设计和超参数优化)中解放出来,这样他们可以更好地将时间花在更难以自动化的任务上。
很好的观点。他的观点被 Auto-sklearn 的开发者所认同:
所有的自动化机器学习方法都是为了支持数据科学家,而不是取代他们。这些方法可以将数据科学家从麻烦的、复杂的任务(例如超参数优化)中解放出来,这些任务机器解决得更好。但分析和得出结论仍然需要由人类专家完成——特别是了解应用领域的数据科学家将仍然非常重要。
所以这一切听起来很令人鼓舞:数据科学家不会被大规模取代,AutoML 应该会帮助他们更好地完成工作。这并不是说 AutoML 已经完美。当被问及是否有改进的空间时,Auto-sklearn 团队表示:
尽管有几种方法用于调整机器学习管道的超参数,但到目前为止,对发现新的管道构建块的研究还很少。Auto-sklearn 使用一组预定义的预处理器和分类器,并按固定顺序进行操作。有效的方法来提出新的管道将是有帮助的。当然,人们可以继续这种思路,尝试自动发现新算法,如几篇最近的论文中所做的,例如《通过梯度下降学习学习》。
AutoML 的未来究竟会走向何处?很难确定。但毫无疑问,它将会有所发展,而且可能会比预期更早。虽然自动化机器学习的概念可能并非所有数据科学家都已熟悉,但现在正是加深了解的好时机。毕竟,如果你能在大众之前开始享受 AutoML 的好处,紧跟技术潮流,你不仅可以为不确定的未来保障工作,还能学会如何利用这些技术来现在就更好地完成工作。我认为没有比这更好的理由来建议你今天就开始学习 AutoML 了。
相关:
-
自动化机器学习:与 TPOT 首席开发者 Randy Olson 的访谈
-
自动化数据科学与机器学习:与 Auto-sklearn 团队的访谈
-
比赛获胜者:使用 Auto-sklearn 赢得 AutoML 挑战赛
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
数据科学职业的现状
原文:
www.kdnuggets.com/2022/10/current-state-data-science-careers.html

想要获得美国第#3 的最佳工作[职位]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm)?你应该成为数据科学家。被誉为 21 世纪的“最性感工作”,目前数据科学职业状态很好——并且有望变得更好。此外,现在任何人都可以通过学位、训练营或在线课程进入数据科学职业。
本文将概述数据科学职业的现状,查看工作可用性、薪资潜力、受重视的技能、职位以及你应该了解的雇主。我还会提供对数据科学职业未来的展望。
如果你是数据科学领域的从业者或希望进入数据科学职业,这篇文章将为你提供对该领域状况的全面分析。
1. 工作、工作、还是工作
数据科学职业最重要的指标之一是它在当前就业市场的表现。
总体来看,前景一片光明。虽然由于一些科技公司实施了招聘冻结和裁员,市场有些波动,但数据显示数据科学家的职业仍在蓬勃发展,尤其是与其他科技岗位相比。
职位数量
今天,Indeed.com显示超过 3 万个数据科学家职位空缺。如果我们将数据分析师和数据工程师也考虑在内,这个数字跃升至超过 7 万个职位空缺。

不想成为数据科学家?没关系——LinkedIn 查看了所有职位描述中提到“数据科学”的职位,显示美国范围内有超过 39 万个数据科学家职位空缺。这些技能在就业市场上依然非常有用。
潜在的估计增长
劳工统计局估计在未来十年内职位增长率将达到 36%,远高于他们跟踪的大多数其他职位——所有职位的平均增长率仅为 5%。
有趣的是,这比他们在 2020 年的预测有所增加——那时,他们预测十年的增长率为 31.4%。我们可以期待年年增长,这意味着将会有比 BLS 当前预测更多的数据科学职位。
失业率
另一个很好的方式来了解当前数据科学职业的状况是查看失业率。根据《美国新闻》的报告,每 100 名拥有数据科学技能的人中只有两人失业。全国失业率则比这高出 150% 多。
数据科学家的工作满意度
仅仅因为某个职业有很多空缺并不意味着它对你的心理健康和整体工作满意度是一个好选择。
然而,由于数据科学家受到富裕公司需求的推动,许多公司提供了令人难以置信的薪水、福利和高工作满意度。毕竟,如果他们不能让你满意,你可能会跳槽到竞争对手那里。
Glassdoor [报告]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm) 数据科学职位的工作满意度评分为 4.1 分(满分 5 分)。
数据科学家工作满意度如此之高的原因有几个因素:
-
工作责任重大。你将被依赖!你是公司中至关重要的一部分。这种责任感可以非常有回报。
-
成长空间。数据科学家的职业轨迹非常有前景,这对职业导向的人员来说令人兴奋。
-
优厚的福利。CareerKarma [报告]( https://careerkarma.com/blog/data-scientist-job-satisfaction/#:~:text=Data scientists receive high rewards ,for%20their%20skills%20and%20knowledge.) 90%的数据科学家对他们的医疗保障感到满意,79%对牙科福利感到满意,73%对视力保障感到满意。
-
选择多样。作为数据科学家,你几乎可以涉足任何数据领域。如今,这些领域已经涵盖了所有行业!
数据科学的薪资
作为数据科学家,薪酬非常丰厚,值得单独列出一个小标题。
总体而言,预计数据科学家的薪资很高——在美国,各地数据科学家的中位数基础薪水(不包括股票期权、401k 匹配、医疗保障或奖金)为100,864 美元。
让我们更详细地拆解一下。2022 年数据科学家的中位起薪为[$95k]( https://datasciencedegree.wisconsin.edu/data-science/data-scientist-salary/#:~:text=Despite a recent influx of ,median%20salary%20rises%20to%20%24195%2C000.)。对于中级数据科学家,你可以预期年薪为$130,000。如果你担任管理职位,预期你的薪水会接近$190,000。而如果你是资深数据科学家?你的基础数据科学年薪可以接近 25 万美元。

这不仅仅是因为数据科学工作位于高消费州。Indeed.com 显示,三分之二的数据科学家对他们的收入相对于生活成本感到满意。

2. 最佳数据科学家版
到现在为止,你应该已经看到数据科学职业的现状非常出色。我想进一步解析,以便你可以了解在这个领域内最好的情况。数据科学作为一个领域相当广泛。你应该考虑的包括许多顶级的数据科学家雇主、州以及数据科学领域内的职位。
雇主
我这里依据 Glassdoor 对“最佳”的定义——这些雇主之所以对数据科学家最为优秀,是因为他们在 Glassdoor 上的整体评分、数据科学家的平均工资以及职位空缺数量。
-
IBM。[IBM]( https://www.glassdoor.com/Overview/Working-at-IBM-EI_IE354.11 ,14.htm)作为雇主有超过 95k 条评论,平均评分为 4.1 分(满分 5 分)。关于数据科学职位的顶级评论提到出色的同事、丰富的协作机会以及良好的职业发展潜力。数据科学家的基础年薪为$127,041。
-
亚马逊。亚马逊拥有超过 100k 条评论,平均评分为 3.8 分(满分 5 分)。对数据科学家的正面评价包括所做工作的质量和薪酬水平。数据科学家的基础年薪为$131,545。
-
微软。微软拥有超过 40k 条评论,平均评分为 4.4 分(满分 5 分)。正面的评价提到良好的工作环境——以及你将与之合作的优秀人员。数据科学家的基础年薪约为$138,289。
我建议你查看完整的[列表]( https://www.glassdoor.com/Explore/top-data-scientist-companies_IO.4 ,18.htm)!
职位
在数据科学领域,如今有很多职业选择。如果你具备成为数据科学家的技能,你也可以选择从事这些工作。
1. 机器学习工程师
随着数据量的增大,机器学习变得越来越重要。公司们正试图建立管道和流程来管理这些数据的涌入,而机器学习是其中的一个工具。
你的工作职责将围绕创建和管理能够从公司大量数据中建立预测模型的自动化软件程序。
作为一名机器学习工程师,你可以期待获得$144k 的基础薪水,根据 ZipRecruiter。
2. 机器学习科学家
这里有一个微妙的区别:机器学习科学家创建的是算法,而不是软件。你将部署数据模型,构建和运行自动化,并进行深入研究。
根据 ZipRecruiter,你的基础工资将是$139k。
3. 人工智能工程师
另一个微妙的区别。作为数据科学家,你负责高级商业洞察。作为 AI 工程师,你负责创建推动基于 AI 的应用程序的模型。你需要掌握 R 和 Python,并且对统计学的掌握要达到顶尖水平。
作为人工智能工程师,你可以期待每年平均收入为$158k,根据 ZipRecruiter。
城市
在数据科学职业中,并非所有城市都相同。尽管数据科学家通常赚取六位数工资,但他们往往也生活在高消费和高税收的城市。
我查看了薪资排名前五的城市(数据来自 Indeed),然后计算了包括一居室公寓租金在内的每月生活成本(Numbeo)以及税后带回工资(SmartAsset)。这是我的结果:
1. 芝加哥,伊利诺伊州
这个城市拥有第五高的数据科学家薪水,但生活成本最低。如果你在芝加哥找到工作,你可以期待每月有$3,658.38 的盈余——在扣除租金、平均生活费用和税费之后。
2. 华盛顿特区
华盛顿特区按相同标准排名第二好的数据科学工作地点。扣除税费、租金和一般支出后,你可以期待每月带回$3,205.81。
3. 旧金山,加州
尽管这是仅次于纽约的第二昂贵居住地,旧金山排名第 3。你可以期待每月净收入约为$2,645.10。
4. 欧文,加州
排行榜上第四的最佳数据科学城市是欧文,加州。尽管租金和生活成本较低,但薪水却不相称。扣除税后、月度支出和租金,你的实际收入约为$2,522.80。
5. 纽约,纽约州
最后,纽约排名第五。虽然数据科学家的薪资在美国排名第二高,但纽约的租金价格与摩天大楼一样高。在你的$117k 年薪中,你可以预期在扣除租金、税费和生活费用后,每年仅剩$14k 的盈余。这每月只有$1,174.72。
3. 数据科学家所看重的技能是什么?
什么数据科学技能在职业生涯中最受重视?这是硬技能和软技能的结合。不要犯只关注编程方面的错误——你的商业敏锐度和团队合作能力与编写复杂的 SQL 查询同样重要。
为了掌握这些技能,我浏览了 Indeed 上的数据科学家职位描述,并记录了出现频率最高的技能。
硬技能
这些技能占据了工作的大部分。
编程: 你应该熟悉至少一种,最好是两种编程语言。尽管有很多新的流行编程语言,但雇主最常要求的三种传统语言是:Python、R 和 SQL。今天最重要的语言是 Python,但 R 在许多地方也被接受。为了管理数据库,你还应该熟悉 SQL。
数据分析: 这包括机器学习、深度学习、人工智能和应用统计学。
构建预测模型:作为数据科学家,你将负责构建预测模型。这是你最大的产品。数据科学家经常负责时间序列、预测和分类模型。
数据清理: 提取、清洗和转换数据。这是你工作的重要部分。虽然不光鲜,但却是必需的。
数据可视化:这与沟通技能有一些重叠,因为你最重要的任务之一是以决策者能够理解的方式展示你的发现——他们通常技术背景不深。
软技能
软技能在今天的数据科学家职业中至关重要。尤其是当这个角色需求增加时,预计你将与来自不同职业背景的人合作。作为数据科学家,你将公司中的业务和数据两方面联系起来。
实验设计: 这依赖于统计学知识,但很多实验设计是纯粹的常识。今天的数据科学工作需要你准备好解决问题。
沟通: 永恒的经典:你知道如何与不了解数据的人沟通吗?你将会做很多这样的工作。
指导: 你需要指导许多初级数据科学家、数据分析师或业务分析师。你帮助更多的新兴数据科学家,就能为公司提供更多价值。
协作:成为一个独立的数据科学团队的时代已经过去。今天,除了沟通,还要与公司不同部门的同事进行协作。你可能需要为人力资源部门创建一个人员流动预测模型,或者帮助财务团队进行预测。要准备好倾听。
4. 数据科学职业路径的未来是什么?
到现在为止,你已经了解了 数据科学职业 的现状。未来会怎样?
正如我上面所写的,美国劳工统计局 预测 增长:“预计数据科学家的就业将从 2021 年到 2031 年增长 36%,远快于所有职业的平均水平。”
为什么?越来越多的公司在做数据驱动的决策,这些公司的数据量也在增加。因此,负责管理所有数据的职位的需求也在增加。
随着远程工作变得越来越被接受,远程工作工具也越来越先进,我预计会有更多的数据科学家远程工作。
软技能将保持不变——主要集中在沟通和协作上。硬技能可能会发生变化。随着 AI 进军编程领域,你可能会发现你的批判性思维技能、设计用户友好图表的能力以及对业务运作的了解比 SQL 能力更重要。
摘要:数据科学职业的现状
总体而言,前景光明。
职位:预计会有更多职位出现,薪资和福利非常具有竞争力。
最佳选择:如今,对数据科学家来说,最佳雇主是 IBM、微软和亚马逊。最佳角色是机器学习工程师、机器学习科学家和 AI 工程师。最佳城市是芝加哥、华盛顿特区、旧金山、加州尔湾和纽约市。
需求技能集:对于硬技能,你需要展示编程、机器学习、应用统计、数据清理和可视化方面的熟练度。对于软技能,期望能够协作、指导、沟通,并应用业务知识。
未来:需求大、薪资高、可能会更多远程工作,并且更加关注高级技能。
希望你喜欢这篇对数据科学职业现状的全面了解。
内特·罗西迪 是一名数据科学家和产品战略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家通过顶级公司的真实面试问题准备面试。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
相关话题更多
Python 中的客户细分:实用方法
原文:
www.kdnuggets.com/customer-segmentation-in-python-a-practical-approach
作者提供的图片 | 使用 Excalidraw 和 Flaticon 创建
客户细分可以帮助企业量身定制营销工作并提高客户满意度。以下是方法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
从功能上讲,客户细分涉及将客户基础划分为不同的组或细分——基于共享的特征和行为。通过理解每个细分的需求和偏好,企业可以提供更个性化和有效的营销活动,从而提高客户保留率和收入。
在本教程中,我们将通过结合两种基本技术:RFM(最近性、频率、货币)分析和K 均值聚类,来探索 Python 中的客户细分。RFM 分析提供了评估客户行为的结构化框架,而 K 均值聚类则提供了一种数据驱动的方法,将客户分组到有意义的细分中。我们将使用来自零售行业的真实数据集:在线零售数据集来自 UCI 机器学习库。
从数据预处理到聚类分析和可视化,我们将逐步编写代码。让我们开始吧!
我们的方法:RFM 分析和 K 均值聚类
我们的目标是:通过将 RFM 分析和 K 均值聚类应用于这个数据集,我们希望获得关于客户行为和偏好的洞察。
RFM 分析是一种简单但强大的方法,用于量化客户行为。它基于三个关键维度来评估客户:
-
最近性 (R):特定客户最近一次购买的时间是什么时候?
-
频率 (F):他们多频繁购买?
-
货币价值 (M):他们花了多少钱?
我们将利用数据集中的信息计算最近性、频率和货币价值。然后,我们将这些值映射到通常使用的 RFM 评分尺度 1 - 5。
如果你愿意,可以使用这些 RFM 分数进行进一步的探索和分析。但我们将尝试识别具有相似 RFM 特征的客户细分。为此,我们将使用 K-Means 聚类,这是一种无监督的机器学习算法,将相似的数据点分组到簇中。
那么,让我们开始编码吧!
步骤 1 – 导入必要的库和模块
首先,让我们导入必要的库和特定的模块:
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
我们需要 pandas 和 matplotlib 来进行数据探索和可视化,并且需要来自 scikit-learn 的 KMeans 类来执行 K-Means 聚类。
步骤 2 – 加载数据集
如前所述,我们将使用在线零售数据集。该数据集包含客户记录:包括购买日期、数量、价格和客户 ID 的交易信息。
让我们从其 URL 中读取原本在 Excel 文件中的数据到 pandas 数据框中。
# Load the dataset from UCI repository
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx"
data = pd.read_excel(url)
另外,你可以 下载数据集 并将 Excel 文件读取到 pandas 数据框中。
步骤 3 – 探索和清理数据集
现在让我们开始探索数据集。查看数据集的前几行:
data.head()
data.head()的输出
现在在数据框上调用 describe() 方法,以更好地了解数值特征:
data.describe()
我们看到“CustomerID”列目前是浮点数值。当我们清理数据时,我们会将其转换为整数:
data.describe()的输出
还要注意数据集相当嘈杂。“Quantity”和“UnitPrice”列包含负值:
data.describe()的输出
让我们仔细查看这些列及其数据类型:
data.info()
我们看到数据集有超过 541K 条记录,其中“Description”和“CustomerID”列包含缺失值:
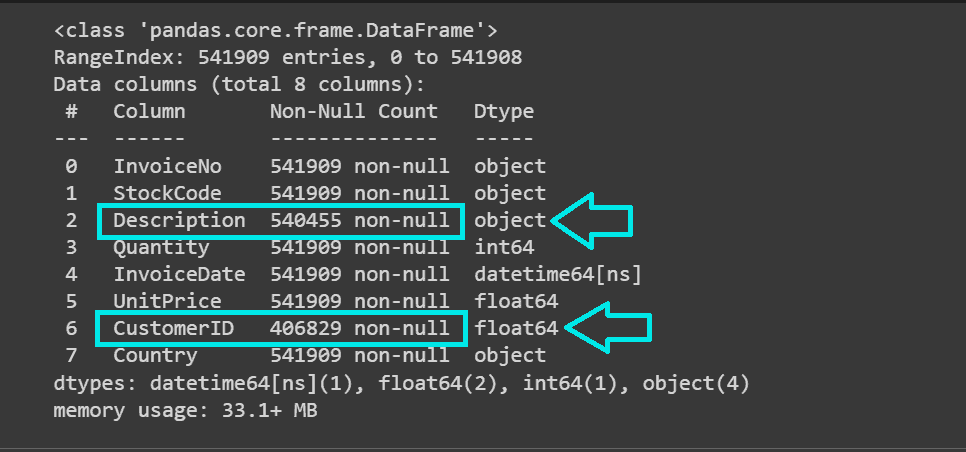
让我们统计每一列中的缺失值数量:
# Check for missing values in each column
missing_values = data.isnull().sum()
print(missing_values)
正如预期的那样,“CustomerID”和“Description”列包含缺失值:
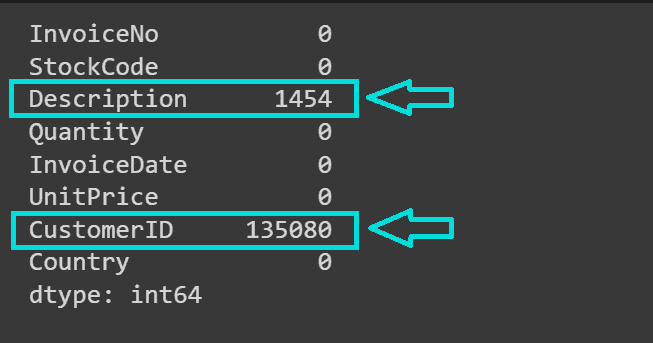
对于我们的分析,我们不需要“Description”列中的产品描述。然而,我们需要“CustomerID”以进行分析的下一步。所以让我们丢弃缺失“CustomerID”的记录:
# Drop rows with missing CustomerID
data.dropna(subset=['CustomerID'], inplace=True)
还要记住,“数量”和“单价”列的值应该严格为非负值。但它们包含负值。所以我们还会删除“数量”和“单价”中负值的记录:
# Remove rows with negative Quantity and Price
data = data[(data['Quantity'] > 0) & (data['UnitPrice'] > 0)]
我们还将“CustomerID”转换为整数:
data['CustomerID'] = data['CustomerID'].astype(int)
# Verify the data type conversion
print(data.dtypes)
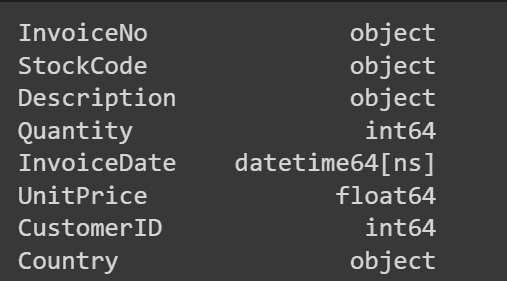
第四步 – 计算最近一次购买、购买频率和货币价值
让我们首先定义一个参考日期 snapshot_date,该日期比“发票日期”列中的最新日期晚一天:
snapshot_date = max(data['InvoiceDate']) + pd.DateOffset(days=1)
接下来,创建一个“总计”列,其中包含所有记录的数量*单价:
data['Total'] = data['Quantity'] * data['UnitPrice']
计算“最近一次购买”、“购买频率”和“货币价值”时,我们将按按 CustomerID 分组计算如下:
-
对于最近一次购买,我们将计算最近购买日期和参考日期(
snapshot_date)之间的差异。这给出客户最后一次购买的天数。所以较小的值表示客户最近进行了购买。但是当我们谈论最近分数时,我们希望最近购买的客户具有更高的最近分数,对吗?我们将在下一步处理中解决这个问题。 -
因为购买频率衡量客户购买的频率,所以我们将其计算为每个客户的唯一发票总数或交易次数。
-
货币价值量化了客户花费了多少钱。因此,我们将计算所有交易的货币总值的平均值。
rfm = data.groupby('CustomerID').agg({
'InvoiceDate': lambda x: (snapshot_date - x.max()).days,
'InvoiceNo': 'nunique',
'Total': 'sum'
})
让我们重新命名这些列以提高可读性:
rfm.rename(columns={'InvoiceDate': 'Recency', 'InvoiceNo': 'Frequency', 'Total': 'MonetaryValue'}, inplace=True)
rfm.head()
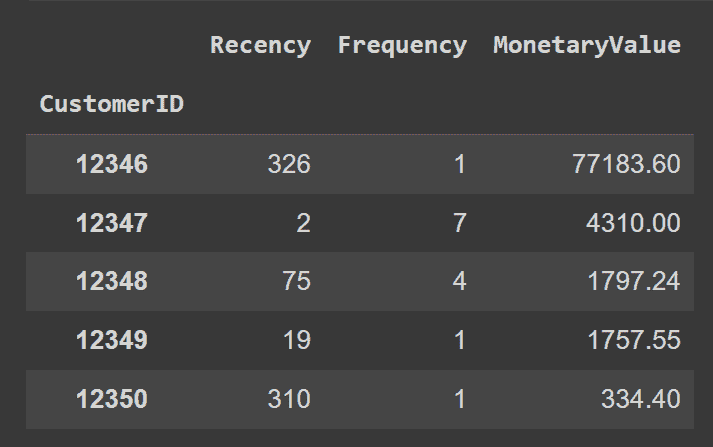
第五步 – 将 RFM 值映射到 1-5 规模
现在让我们将“最近一次购买”、“购买频率”和“货币价值”列映射到 1-5 的值范围内;即 {1,2,3,4,5}。
我们将基本上把值分配到五个不同的区间,并将每个区间映射到一个值。为了帮助我们确定区间边界,让我们使用“最近一次购买”、“购买频率”和“货币价值”列的分位数值:
rfm.describe()
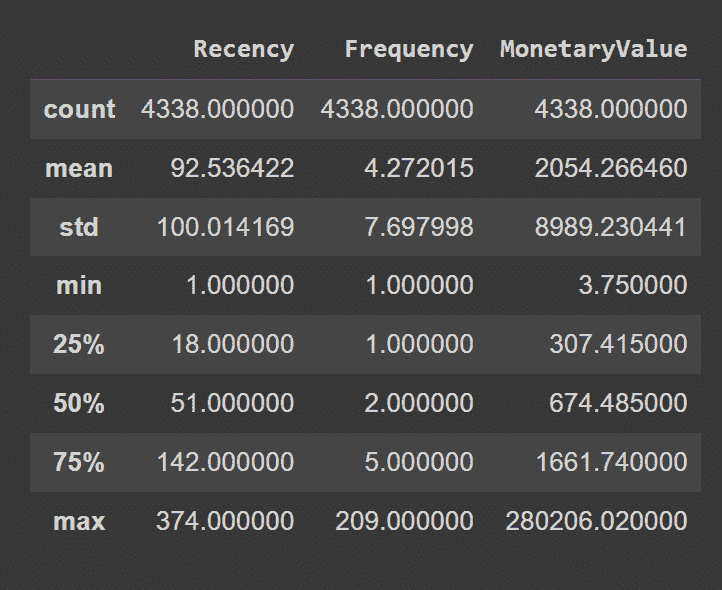
以下是我们定义自定义区间边界的方法:
# Calculate custom bin edges for Recency, Frequency, and Monetary scores
recency_bins = [rfm['Recency'].min()-1, 20, 50, 150, 250, rfm['Recency'].max()]
frequency_bins = [rfm['Frequency'].min() - 1, 2, 3, 10, 100, rfm['Frequency'].max()]
monetary_bins = [rfm['MonetaryValue'].min() - 3, 300, 600, 2000, 5000, rfm['MonetaryValue'].max()]
现在我们已经定义了区间边界,让我们将分数映射到 1 到 5(包括 1 和 5)之间的相应标签:
# Calculate Recency score based on custom bins
rfm['R_Score'] = pd.cut(rfm['Recency'], bins=recency_bins, labels=range(1, 6), include_lowest=True)
# Reverse the Recency scores so that higher values indicate more recent purchases
rfm['R_Score'] = 5 - rfm['R_Score'].astype(int) + 1
# Calculate Frequency and Monetary scores based on custom bins
rfm['F_Score'] = pd.cut(rfm['Frequency'], bins=frequency_bins, labels=range(1, 6), include_lowest=True).astype(int)
rfm['M_Score'] = pd.cut(rfm['MonetaryValue'], bins=monetary_bins, labels=range(1, 6), include_lowest=True).astype(int)
注意,基于区间的 R_Score 是 1(最近的购买)到 5(所有超过 250 天的购买)。但我们希望最近的购买具有 R_Score 为 5,而超过 250 天的购买具有 R_Score 为 1。
为了实现所需的映射,我们做:5 - rfm['R_Score'].astype(int) + 1。
让我们查看 R_Score、F_Score 和 M_Score 列的前几行:
# Print the first few rows of the RFM DataFrame to verify the scores
print(rfm[['R_Score', 'F_Score', 'M_Score']].head(10))
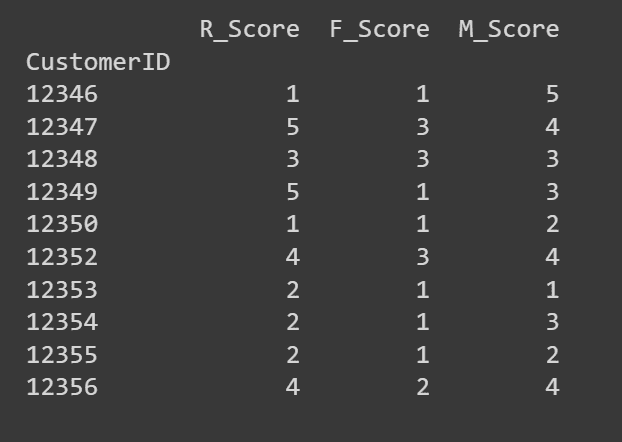
如果你愿意,可以使用这些 R、F 和 M 分数进行深入分析。或者使用聚类来识别具有相似 RFM 特征的群体。我们将选择后者!
第 6 步 – 执行 K 均值聚类
K 均值聚类对特征的尺度敏感。由于 R、F 和 M 值都在相同的尺度上,我们可以继续进行聚类,而无需进一步缩放特征。
让我们提取 R、F 和 M 得分来执行 K 均值聚类:
# Extract RFM scores for K-means clustering
X = rfm[['R_Score', 'F_Score', 'M_Score']]
接下来,我们需要找到最佳的集群数量。为此,让我们对一系列 K 值运行 K 均值算法,并使用肘部法来选择最佳 K:
# Calculate inertia (sum of squared distances) for different values of k
inertia = []
for k in range(2, 11):
kmeans = KMeans(n_clusters=k, n_init= 10, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
# Plot the elbow curve
plt.figure(figsize=(8, 6),dpi=150)
plt.plot(range(2, 11), inertia, marker='o')
plt.xlabel('Number of Clusters (k)')
plt.ylabel('Inertia')
plt.title('Elbow Curve for K-means Clustering')
plt.grid(True)
plt.show()
我们看到曲线在 4 个集群处出现拐点。因此,让我们将客户基础划分为四个细分市场。
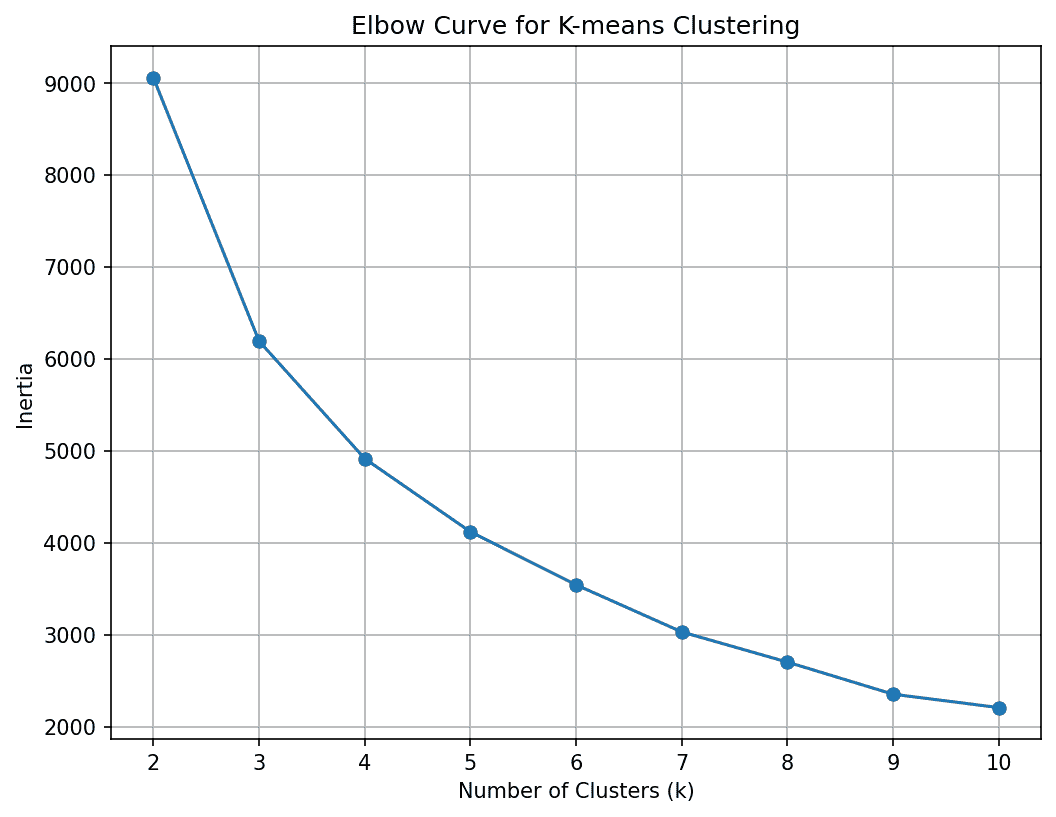
我们将 K 固定为 4。因此,让我们运行 K 均值算法以获取数据集中所有点的集群分配:
# Perform K-means clustering with best K
best_kmeans = KMeans(n_clusters=4, n_init=10, random_state=42)
rfm['Cluster'] = best_kmeans.fit_predict(X)
第 7 步 – 解释集群以识别客户细分
现在我们有了集群,接下来我们尝试根据 RFM 得分对它们进行描述。
# Group by cluster and calculate mean values
cluster_summary = rfm.groupby('Cluster').agg({
'R_Score': 'mean',
'F_Score': 'mean',
'M_Score': 'mean'
}).reset_index()
每个集群的平均 R、F 和 M 得分应该已经给你一个关于特征的概念。
print(cluster_summary)
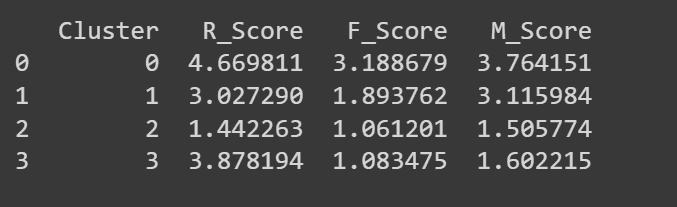
但让我们可视化集群的平均 R、F 和 M 得分,以便更容易解释:
colors = ['#3498db', '#2ecc71', '#f39c12','#C9B1BD']
# Plot the average RFM scores for each cluster
plt.figure(figsize=(10, 8),dpi=150)
# Plot Avg Recency
plt.subplot(3, 1, 1)
bars = plt.bar(cluster_summary.index, cluster_summary['R_Score'], color=colors)
plt.xlabel('Cluster')
plt.ylabel('Avg Recency')
plt.title('Average Recency for Each Cluster')
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend(bars, cluster_summary.index, title='Clusters')
# Plot Avg Frequency
plt.subplot(3, 1, 2)
bars = plt.bar(cluster_summary.index, cluster_summary['F_Score'], color=colors)
plt.xlabel('Cluster')
plt.ylabel('Avg Frequency')
plt.title('Average Frequency for Each Cluster')
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend(bars, cluster_summary.index, title='Clusters')
# Plot Avg Monetary
plt.subplot(3, 1, 3)
bars = plt.bar(cluster_summary.index, cluster_summary['M_Score'], color=colors)
plt.xlabel('Cluster')
plt.ylabel('Avg Monetary')
plt.title('Average Monetary Value for Each Cluster')
plt.grid(True, linestyle='--', alpha=0.5)
plt.legend(bars, cluster_summary.index, title='Clusters')
plt.tight_layout()
plt.show()
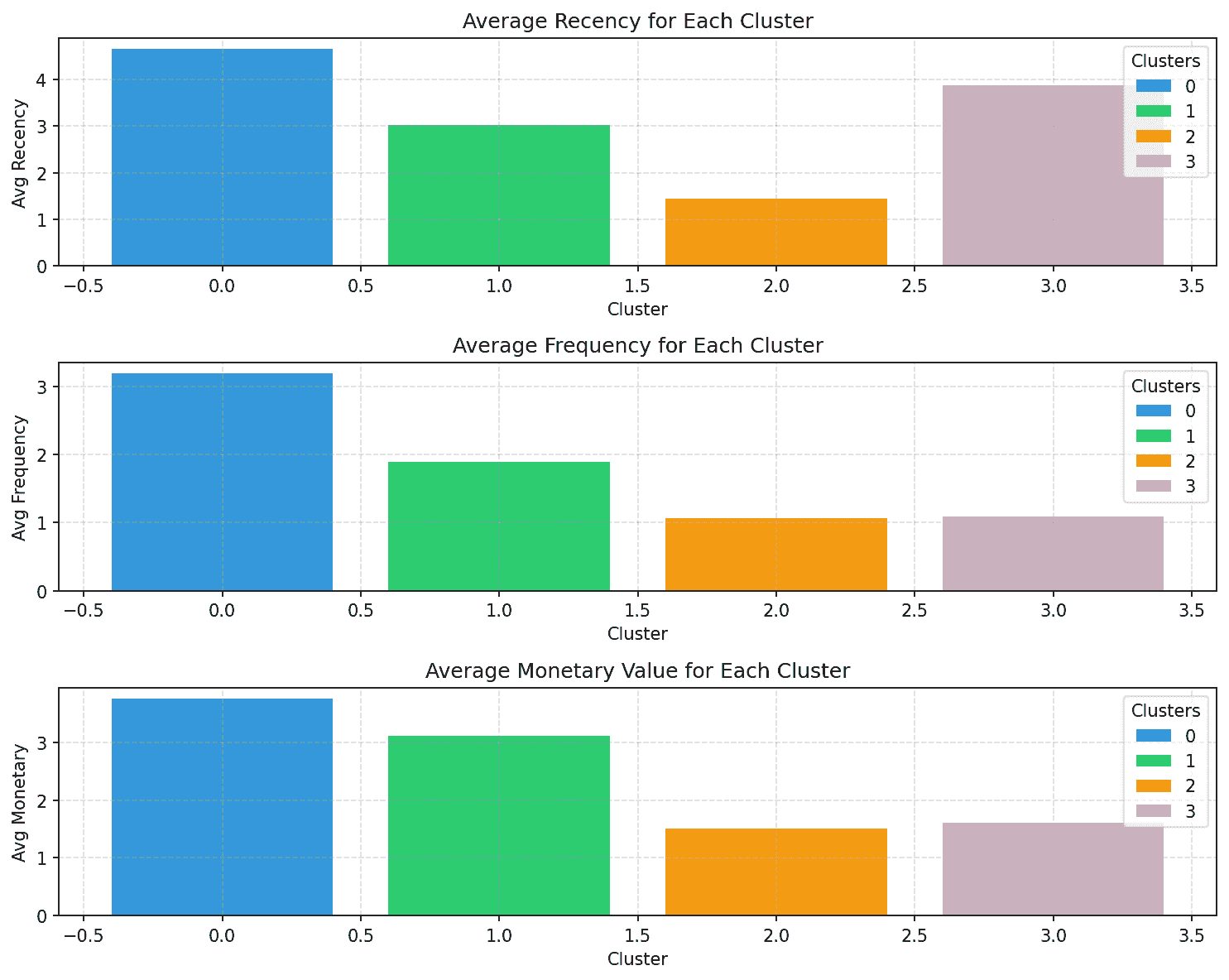
注意每个细分市场中的客户如何根据最近性、频率和货币价值来描述:
-
集群 0:在所有四个集群中,这个集群具有最高的最近性、频率和货币价值。我们称这个集群中的客户为冠军(或高消费客户)。
-
集群 1:该集群的特征是适中的最近性、频率和货币价值。这些客户的支出和购买频率仍然高于集群 2 和集群 3。我们称他们为忠实客户。
-
集群 2:这个集群中的客户倾向于花费较少。他们不经常购买,也没有最近进行过购买。这些客户可能是非活跃或高风险客户。
-
集群 3:该集群的特征是高最近性和相对较低的频率以及适中的货币价值。因此,这些是近期客户,他们可能会成为长期客户。
这里有一些如何定制营销工作的例子——以针对每个细分市场的客户——来增强客户参与度和留存率:
-
对冠军/高消费客户:提供个性化的特别折扣、优先访问和其他高级福利,以使他们感到被重视和欣赏。
-
对忠实客户:欣赏活动、推荐奖金和忠诚奖励。
-
对高风险客户:重新参与的努力,包括开展折扣或促销活动以鼓励购买。
-
对近期客户:针对性的活动,教育他们了解品牌,并对后续购买提供折扣。
理解不同细分市场中客户的百分比也是很有帮助的。这将进一步帮助简化营销工作并推动业务增长。
让我们使用饼图来可视化不同集群的分布:
cluster_counts = rfm['Cluster'].value_counts()
colors = ['#3498db', '#2ecc71', '#f39c12','#C9B1BD']
# Calculate the total number of customers
total_customers = cluster_counts.sum()
# Calculate the percentage of customers in each cluster
percentage_customers = (cluster_counts / total_customers) * 100
labels = ['Champions(Power Shoppers)','Loyal Customers','At-risk Customers','Recent Customers']
# Create a pie chart
plt.figure(figsize=(8, 8),dpi=200)
plt.pie(percentage_customers, labels=labels, autopct='%1.1f%%', startangle=90, colors=colors)
plt.title('Percentage of Customers in Each Cluster')
plt.legend(cluster_summary['Cluster'], title='Cluster', loc='upper left')
plt.show()
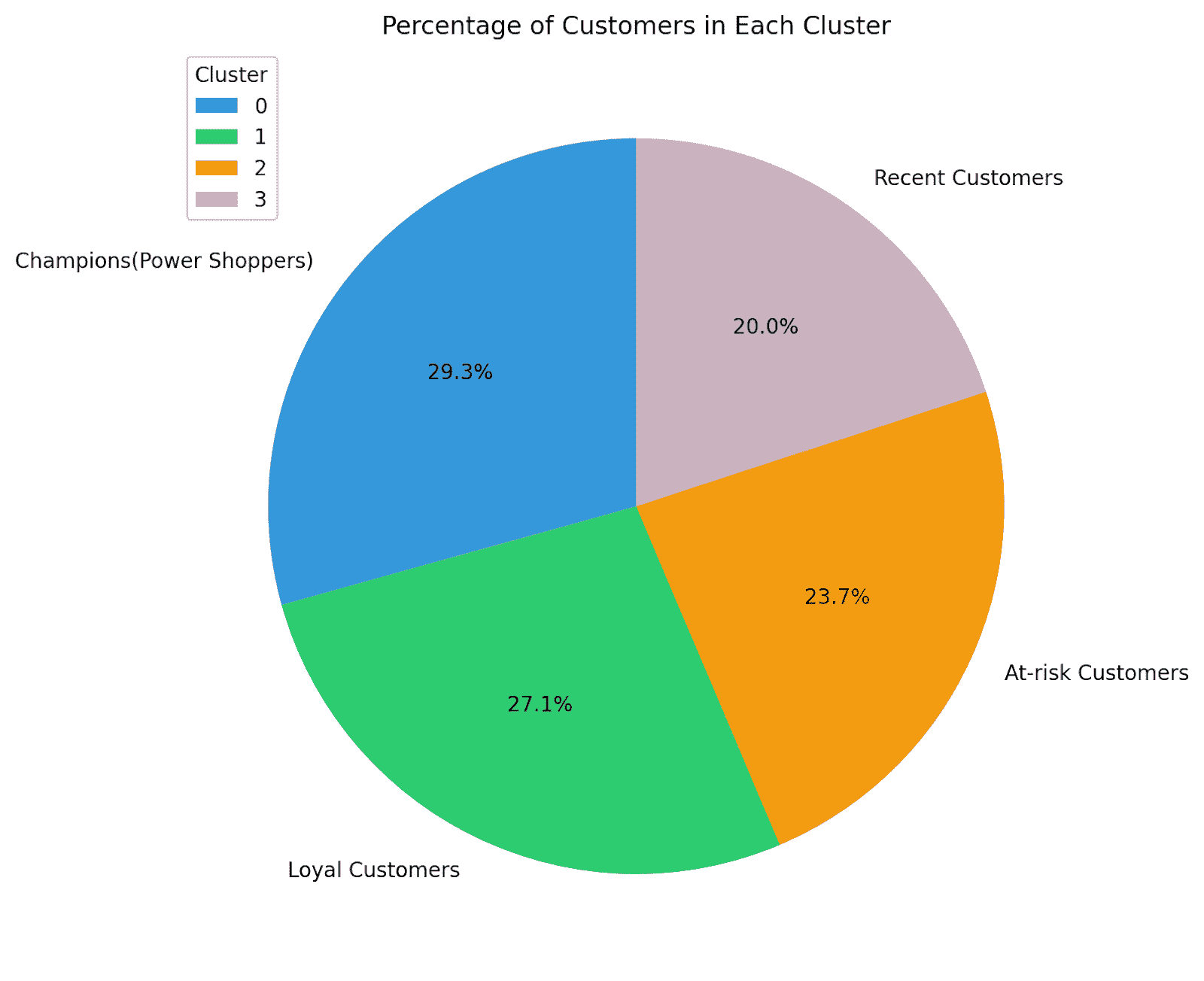
开始吧!在这个示例中,我们在各个细分市场中有相当均匀的客户分布。因此,我们可以投入时间和精力来留住现有客户、重新吸引高风险客户和教育新客户。
总结
就这样!我们从154K 个客户记录通过 7 个简单步骤分成了 4 个集群。我希望你能理解客户细分如何通过以下方式帮助你做出数据驱动的决策,从而影响业务增长和客户满意度:
-
个性化:细分允许企业根据每个客户群体的特定需求和兴趣来量身定制营销信息、产品推荐和促销活动。
-
改进目标定位:通过识别高价值和高风险客户,企业可以更有效地分配资源,将精力集中在最可能产生结果的地方。
-
客户保留:细分帮助企业通过了解什么因素让客户保持参与和满意,从而制定保留策略。
作为下一步,尝试将这种方法应用到另一个数据集上,记录你的过程,并与社区分享!但请记住,有效的客户细分和有针对性的活动需要对你的客户群有良好的理解——以及客户群的演变。因此,这需要定期分析以随着时间的推移优化你的策略。
数据集致谢
在线零售数据集在创意共享署名 4.0 国际(CC BY 4.0)许可证下许可:
在线零售。 (2015)。 UCI 机器学习库。 https://doi.org/10.24432/C5BW33 。
Bala Priya C**** 是来自印度的开发人员和技术作家。她喜欢在数学、编程、数据科学和内容创作的交叉点上工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等方式学习并与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
更多相关话题
使用 K 均值聚类进行客户细分
原文:
www.kdnuggets.com/2019/11/customer-segmentation-using-k-means-clustering.html
评论
客户细分是将市场细分为具有相似特征的离散客户群体。客户细分可以成为识别未满足客户需求的有力手段。利用上述数据,公司可以通过开发独特的吸引人产品和服务来超越竞争对手。
企业最常见的客户群体细分方式包括:
-
人口统计信息,如性别、年龄、家庭和婚姻状况、收入、教育和职业。
-
地理信息,这取决于公司的范围。对于本地化企业,这些信息可能涉及特定的城镇或县。对于较大的公司,这可能意味着客户所在的城市、州或甚至国家。
-
心理图谱数据,如社会阶层、生活方式和个性特征。
-
行为数据,如消费和消费习惯、产品/服务使用情况以及期望的收益。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
客户细分的优势
-
确定合适的产品定价。
-
制定定制化的营销活动。
-
设计一个最佳分销策略。
-
选择用于部署的具体产品特性。
-
优先考虑新产品开发工作。
K 均值聚类算法
-
指定簇的数量 K。
-
通过首先打乱数据集,然后随机选择 K 个数据点作为质心进行初始化。
-
不断迭代,直到质心没有变化,即数据点分配到簇的情况不再变化。
K 均值聚类,其中 K=3
挑战
您拥有一家超市购物中心,通过会员卡,您获得了一些基本的客户数据,如客户 ID、年龄、性别、年收入和消费评分。您希望了解客户,比如哪些是目标客户,以便可以传达给营销团队并相应地规划策略。
数据
该项目是 购物中心客户细分数据 竞赛的一部分,该竞赛在 Kaggle 上举行。
数据集可以从 kaggle 网站下载,网址在这里。
环境和工具
-
scikit-learn
-
seaborn
-
numpy
-
pandas
-
matplotlib
代码在哪里?
不再多言,让我们开始编码。完整项目可以在 github 上找到,网址在这里。
我开始加载所有库和依赖项。数据集中的列包括客户 id、性别、年龄、收入和消费评分。
我删除了 id 列,因为它似乎与上下文无关。还绘制了客户的年龄频率。
接下来,我制作了一个箱线图,以更好地可视化消费评分和年收入的分布范围。消费评分的范围明显大于年收入的范围。
我制作了一个条形图,以检查数据集中男性和女性人口的分布情况。女性人口明显超过男性。
接下来,我制作了一个条形图,以检查每个年龄组中客户的分布情况。显然,26-35 岁年龄组的客户数量超过了其他任何年龄组。
我继续制作了一个条形图,以可视化根据消费评分的客户数量。大多数客户的消费评分在 41-60 之间。
我还制作了一个条形图,以可视化根据年收入的客户数量。大多数客户的年收入在 60000 到 90000 之间。
接下来,我将簇内平方和(WCSS)与簇的数量(K 值)进行绘图,以找出最佳簇数量。WCSS 衡量观察值与其簇质心的距离总和,其公式如下。
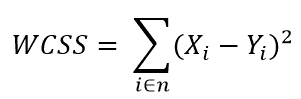
其中Yi是观察值Xi的质心。主要目标是最大化簇的数量,在极限情况下,每个数据点都成为自己的簇质心。
肘部法则
计算不同 k 值的簇内平方误差(WSS),并选择 WSS 首次开始减少的 k 值。在 WSS 与 k 的图中,这表现为一个肘部。
最优的 K 值通过肘部法则找到为 5。
最后,我制作了一个 3D 图,以可视化客户的消费评分和年收入。数据点被分成 5 个类别,并用不同颜色表示,如 3D 图所示。
结果
结论
K 均值聚类是最受欢迎的聚类算法之一,通常是从事聚类任务的实践者首先使用的工具,用以了解数据集的结构。K 均值的目标是将数据点分组为独特的、互不重叠的子组。K 均值聚类的一个主要应用是客户细分,以更好地理解客户,从而增加公司的收入。
参考文献/进一步阅读
客户细分的聚类算法背景 在今天竞争激烈的世界中,了解客户行为并根据...
[您所需的 K 均值聚类最全面指南
概述 K 均值聚类是数据科学中的一个简单而强大的算法。在现实世界中有大量的应用...](https://www.analyticsvidhya.com/blog/2019/08/comprehensive-guide-k-means-clustering/?source=post_page-----d33964f238c3----------------------)
[机器学习方法:K 均值聚类算法
2015 年 7 月 21 日 作者:EduPristine k 均值聚类(又称为细分)是最常见的机器学习...](https://www.edupristine.com/blog/beyond-k-means?source=post_page-----d33964f238c3----------------------)
离开之前
对应的源代码可以在这里找到。
[abhinavsagar/Kaggle-Solutions
Kaggle 竞赛的示例笔记本。显微镜图像的自动分割是医学...](https://github.com/abhinavsagar/Kaggle-Solutions?source=post_page-----d33964f238c3----------------------)
联系方式
如果你想跟踪我最新的文章和项目,关注我的 Medium。以下是我的一些联系方式:
祝阅读愉快、学习愉快、编码愉快。
个人简介:Abhinav Sagar 是 VIT Vellore 的高年级本科生。他对数据科学、机器学习及其在实际问题中的应用感兴趣。
原文。经授权转载。
相关:
-
R 用户的客户细分
-
如何使用 Flask 轻松部署机器学习模型
-
如何在 Python 中构建自己的逻辑回归模型
更多相关话题
在 Python 中自定义数据框列名
原文:
www.kdnuggets.com/2022/08/customize-data-frame-column-names-python.html

编辑图片
无论数据科学中的哪个职业,除了常规的数据清洗和模型构建外,个人还需要以易于业务理解的方式呈现结果。在本教程中,我们将探索四种场景,在这些场景中,你可以同时对所有数据框列应用不同的转换。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在深入探讨这些场景之前,让我们导入 pandas 库,并创建一个名为 df 的数据框,列名如下:
-
week_one_attendance
-
week_two_attendance
-
week_three_attendance
-
week_four_attendance
代码:
import pandas as pd
df = pd.DataFrame (data = [[0.10,0.20,0.70,0.80],[0.80,0.50,0.40,0.20],[0.50,0.10,0.20,0.10],[0.30,0.45,0.97,0.65]],
columns = ["week_one_attendance","week_two_attendance","week_three_attendance","week_four_attendance"])
df
输出:
让我们开始探索这些场景吧
场景 1
在下面的代码中,使用了for 循环来迭代数据框的所有列,在每次迭代中,每列都通过rename方法转换为大写。
代码:
for i in df.columns:
df.rename(columns = {i:i.upper()},inplace = True)
df.columns
输出:

场景 2
在下面的代码中,我们将声明一个名为columnnames的空字典,然后声明另一个名为count to 0的变量。
然后我们将使用for 循环来迭代数据框的所有列,在每次迭代中,count变量将增加 1。增加后的值将被用在fstring中生成新的列名。每次迭代时,原始列名和新列名将作为键值对添加到字典中。
在构建包含原始列名和新列名的字典 columnnames 后,我们将把字典传递给 rename 方法
代码:
columnnames = {}
count = 0
for i in df.columns:
count += 1
columnnames[i] = f"WEEK_{count}_ATTENDANCE"
columnnames
输出:
代码:
df.rename(columns = columnnames ,inplace = True)
df.columns
输出:

场景 3
在下面的代码中,我们将声明一个名为 columnnames 的空 字典
然后我们将使用 for loop 遍历数据框的所有列,每次迭代中,第一个下划线的出现将被替换为空格。每次迭代中,原始列名和新列名将作为键值对添加到字典中。
在构建包含原始列名和新列名的字典 columnnames 后,我们将把字典传递给 rename 方法
代码:
columnnames = {}
for i in df.columns:
x = i.replace('_','',1)
columnnames[i] = x
columnnames
输出:

代码:
df.rename(columns = columnnames ,inplace = True)
df.columns
输出:

场景 4
在下面的代码中,我们将声明一个名为 columnnames 的空 字典,然后声明另一个名为 count to 0 的 变量
然后我们将使用 for loop 遍历数据框的所有列,每次迭代中 count 变量将增加 1。增量值将被用于 fstring 中,以生成一个新列名,其中第一个和最后一个单词的位置被交换。每次迭代中,原始列名和新列名将作为键值对添加到字典中。
在构建包含原始列名和新列名的字典后,我们将把字典传递给 rename 方法
代码:
columnnames = {}
count = 0
for i in df.columns:
count += 1
columnnames[i] = f"ATTENDANCE_WEEK{count}"
columnnames
输出:

代码:
df.rename(columns = columnnames ,inplace = True)
df.columns
输出:

结论
相比于逐个手动更新每个列名,我们通过使用 for 循环和 Python 字符串的不同方法,能够同时更新数据框的所有列的值,从而节省了大量时间
Priya Sengar (Medium, Github) 是来自 Old Dominion University 的数据科学家。Priya 热衷于解决数据问题并将其转化为解决方案。
了解更多相关话题
通过集成 Jupyter 和 KNIME 来缩短实施时间
原文:
www.kdnuggets.com/2021/12/cutting-implementation-time-integrating-jupyter-knime.html
由 Mahantesh Pattadkal,KNIME 的数据科学家
数据科学家以在 3I 结构中创建自己的泡沫而闻名——实施、集成和创新。我个人倾向于最后两个 I:集成新技术以进行持续实验和创新以获得显著成果。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT 工作
我已经使用 Jupyter Notebook 工作了 4-5 年,并且对它非常熟悉。另一方面,我与我的队友 Paolo 分享了很多工作项目,他是构建 KNIME 工作流的专家。你可能会认为这会是个问题……其实不是!
KNIME Analytics 平台 和 Jupyter Notebook 都以其解决数据分析问题的视觉吸引力而著称(图 1)。Jupyter Notebook 通过网页浏览器提供了一个简化的脚本接口,支持 40 多种编程语言,但它最终仍然是一个主要受 Python 用户欢迎的编码平台。KNIME Analytics 平台完全在图形用户界面上运行,通过拖放操作和可视化编程进行控制。它通过以可视化和透明的工作流表示复杂的数据分析,提供了对逻辑和结构的快速理解。您还可以在 KNIME Analytics 平台中编写 Python 代码片段;Jupyter Notebook 用户体验简化了代码的输入和执行,结果是一个优化的编码人员 UI。现在,想象一下这两个平台的协同作用可以构建出无数可能的应用。
在这篇文章中,我们讨论了两个常见的生活场景,这些场景需要 Jupyter Notebook 与 KNIME Analytics 平台的协作,并展示了这种协作的简单性。
Jupyter Notebook 与 KNIME Analytics 平台的协作
在本节中,我们描述了两个场景以及如何:
-
在 KNIME 工作流中集成 Jupyter Notebook(场景 1)
-
将 KNIME 工作流集成到 Jupyter 代码中(场景 2)
在场景 1中,我的队友Paolo负责项目,并在时间压力下请求我帮助实施自定义数据转换,我在 Jupyter Notebook 中完成了这项工作。在这里,我将展示 Paolo 如何将我的 Jupyter 脚本集成到他的 KNIME 工作流中。
在场景 2中,我负责项目,仍然受到时间压力的影响,向 Paolo 请求帮助构建一个训练分类模型的工作流,他在 KNIME Analytics Platform 中提供了这个工作流。这里我将展示我如何将 Paolo 的工作流集成到我的 Jupyter Notebook 的 Python 脚本中。
图 1:这里展示了两个数据科学工具的用户界面:左侧是KNIME Analytics Platform,右侧是Jupyter Notebook。
在 KNIME 工作流中集成 Jupyter Notebook — 场景 1
利用机器学习进行航班延误预测
Paolo 被要求根据起飞延误对航班进行分类,数据集为Airline dataset。航班延误数据集中的每一行描述了一个航班,包括其出发地、目的地、计划起飞时间等。任何起飞延误超过 15 分钟的航班都被标记为“延误”。请求的任务是训练一个机器学习模型,分类一个航班是否会在起飞时延误,考虑所有其他合适的航班属性作为输入特征。
构建一个训练和评估机器学习模型的工作流的步骤通常是相同的:导入数据,转换和清洗数据,将其分为训练集和测试集,在训练集上训练选择的机器学习 (ML) 模型,将训练好的模型应用于测试集,并使用选择的评分指标对其性能进行评分。 Run Jupyter in KNIME 工作流将会大致类似于图 2(你可以从KNIME Hub下载)。
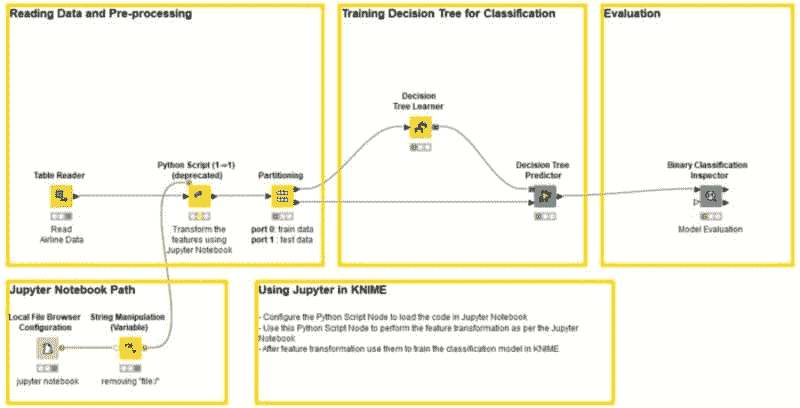
图 2. Run Jupyter in KNIME 训练工作流,用于训练和评估 ML 模型以预测航班的起飞延误。
数据清洗和数据转换部分通常非常耗时,因为这也取决于数据领域。Paolo 被时间压力所迫,问我是否可以实现这一部分。
对我来说,使用 Jupyter Notebook 来做这件事似乎很简单。然后,Paolo 可以通过 Python Script 节点将其导入他的工作流。我们一步一步来看这个过程。
-
步骤 1. 在 Jupyter Notebook 中编写 Python 代码。
-
步骤 2. 在 KNIME Analytics Platform 中设置 Python 环境
-
步骤 3. 执行 KNIME 工作流中的 Jupyter Notebook 代码。
步骤 1. 在 Jupyter Notebook 中编写 Python 代码
我在 Jupyter Notebook(图 3)中创建了一个名为 Custom_Transformation 的 Python 函数。该函数实现了一些基本的特征工程,并返回了包括转换特征在内的原始特征集。
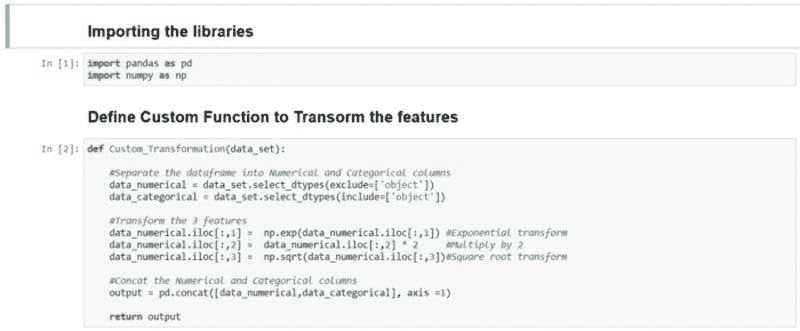
图 3. 用于特征转换的 Python 函数。
现在,我们需要将此代码导入到 Paolo 的 KNIME 工作流中。
步骤 2. 在 KNIME Analytics Platform 中设置 Python 环境
-
在 KNIME Analytics Platform 中,点击 文件 → 偏好设置 → KNIME → Python
-
在 Python 偏好设置页面(图 4a),创建一个新的 Conda 环境
-
根据系统上安装的 Python 版本,点击 新环境 来选择 Python 2 或 Python 3。
-
新 Conda 环境 对话框打开(图 4b)。现在你需要:
-
在黄色高亮显示的字段中输入环境名称
-
点击 创建新环境
-
环境创建后,在偏好设置页面(图 4a)中点击 应用 和 关闭。
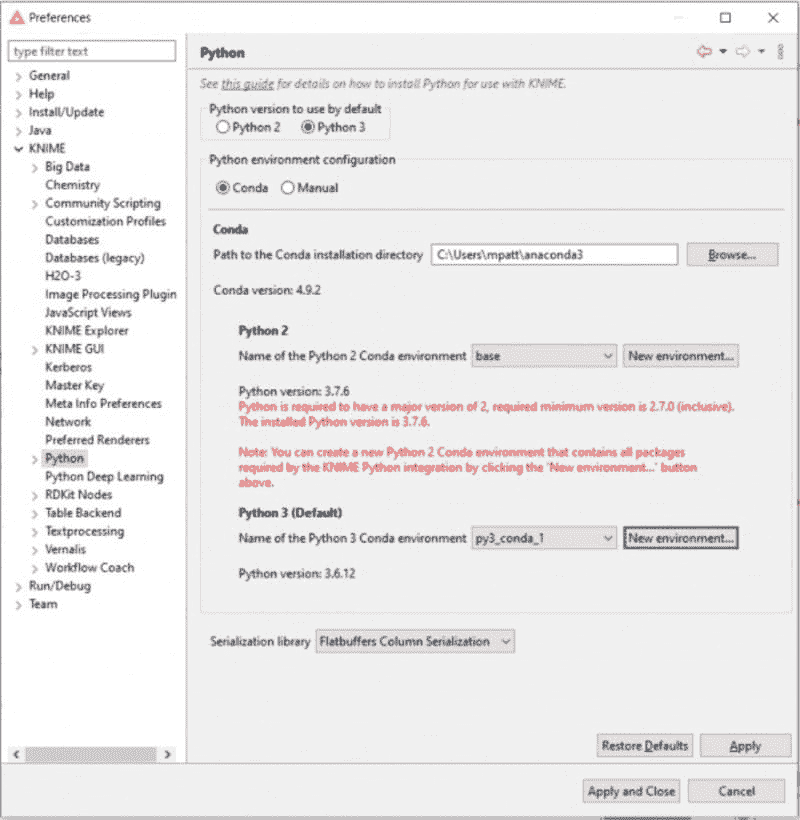
图 4a. Python 偏好设置窗口。
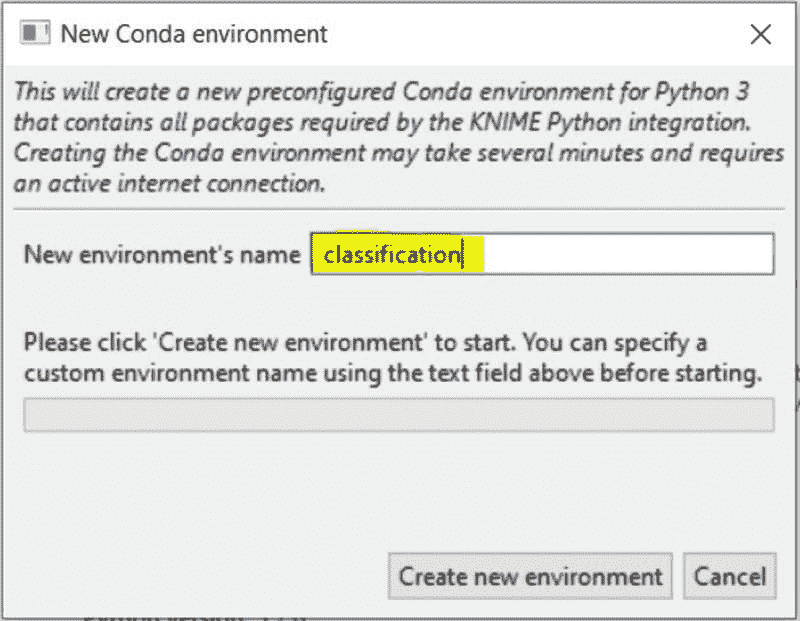
图 4b. 创建新 Conda 环境的对话框。
有关如何安装 KNIME 中的 Python 集成并使其正常工作,请查看我的文章 如何设置 Python 扩展。
步骤 3. 从 KNIME 工作流中执行 Jupyter Notebook 代码
在图 2 中的 KNIME 工作流中,我们引入了一个 Python Script 节点(Table Reader 节点后的第二个节点)。该节点加载并运行我在 Jupyter Notebook(图 5)中的代码。
脚本中的关键指令是:
My_notebook = knime_jupyter.load_notebook(...)
这行使用了 knimepy 指令
knime_jupyter.load_notebook
以定位 Jupyter Notebook 的 Custom_Transformation,并将 Jupyter 脚本加载到 my_notebook 变量中。
下一行执行该函数
Custom_Transformation
并将结果返回到一个名为的 pandas DataFrame
output_table
注意。 Jupyter Notebook 中的代码应始终提供 pandas DataFrame 类型的输出。
图 5. Python Script 节点的配置对话框。
运行 Python 脚本节点中的 Jupyter Notebook 的脚本如下所示:
#Copy input to output
notebook_location = flow_variables['path_to_jupy']
#Filename of the notebook
notebook_name = flow_variables['path_to_jupy (file name)']
#Path to the folder containing the notebook
notebook_directory = notebook_location.replace(notebook_name, "")
#Load the notebook as a Python module
my_notebook = knime_jupyter.load_notebook(notebook_directory, notebook_name)
#Call a function 'custom_transformation' defined in the notebook
output_table = my_notebook.Custom_Transformation(input_table)
执行 Python 脚本节点后,我们会在其输出中找到添加到原始特征中的转换特征,这些特征现在可以传递到 KNIME 工作流中的下一个节点。
将 KNIME 工作流集成到 Jupyter 代码中——场景 2
使用机器学习进行航班延误预测
我被要求实现一个部署应用程序,该程序使用以前在航班延误数据集上训练的模型来预测航班起飞延误。我想使用 Jupyter Notebook 开发这个应用程序。为了节省时间,我希望借用并整合 Paolo 的工作中的部署工作流。也就是说,我希望将 KNIME 工作流集成到我的 Jupyter Notebook 中。
这通过三个简单的步骤完成,类似于场景 1 中使用的三个步骤。
-
第一步。构建 KNIME 工作流
-
第二步。在 Jupyter Notebook 中设置 KNIME 环境
-
第三步。从 Jupyter Notebook 执行 KNIME 工作流
第一步。构建 KNIME 工作流
在我们的案例中,Paolo 已经通过 KNIME Hub 提供了 KNIME 工作流 在 Jupyter 中运行 KNIME。这个工作流部署了一个机器学习模型,用于预测航班起飞延误(图 6)。
第二步。在 Jupyter Notebook 中设置 KNIME 包
在 Command/Anaconda 提示符中,输入
pip install knime
这会安装最新的 knimepy 包。该包使 Jupyter Notebook 能够读取和运行 KNIME 工作流。
第三步。从 Jupyter Notebook 执行 KNIME 工作流
这是我在 Jupyter Notebook 中需要编写的内容(图 7 和图 8),以便导入和运行选定的 KNIME 工作流。
-
导入
knime包 -
导入 KNIME 可执行文件、工作区和 KNIME 工作流的路径
-
命令
knime.Workflow(...)可视化工作流。我使用它来双重检查 Jupyter 是否指向了预期的工作流(图 7) -
这个指令
wf.data_table_inputs[0]=data_set将存储为 DataFrame 的外部数据从 Jupyter 传递到 KNIME 工作流(图 7)。 -
wf.execute命令执行 KNIME 工作流 -
工作流执行后,结果默认存储在
wf.data_table_outputs[0]中(图 8)
注意。 确保从 Jupyter 执行的工作流在 KNIME 中没有同时打开。这会导致执行暂停,因为工作流已经在 KNIME 中打开进行编辑。*

图 6。在 Jupyter Notebook 中设置工作区并显示选定的 KNIME 工作流 在 Jupyter 中运行 KNIME。

图 7。执行工作流的代码。
从 KNIME Analytics Platform 4.3 开始,我还可以调用并执行驻留在 KNIME 服务器上的 KNIME 工作流,而不是在本地客户端安装中。这有三个主要优点:
-
改进的可扩展性: 在 KNIME Server 上执行可以利用来自本地另一台机器、云端服务器,甚至多个 KNIME 执行器的并行计算能力,或通过 KNIME Edge 进行计算。
-
更大的可访问性: 任何拥有凭证和互联网连接的人都可以从他们的 Jupyter Notebook 中使用部署在 KNIME Server 上的共享 KNIME 工作流。
-
更好的安全性和版本控制: 将 Jupyter Notebook 与 KNIME Analytics Platform 结合使用通常意味着背景不同的数据科学家在一个数据访问可能受到限制的组织中进行协作。KNIME Server 提供了一种安全且一致的方式来共享工作流、数据以及 Jupyter Notebook 的每次编辑。
对于之前的脚本唯一的更改是 KNIME 服务器上 KNIME 工作流的路径以及访问所需的用户名和密码,如图 8 所示。此脚本也可以在 GitHub 仓库中找到。此外,此案例中不再需要像之前那样指定 knime 执行器路径。

图 8. 从 Jupyter Notebook 执行工作流的代码片段。
协作是关键!
不需要在 Jupyter Notebook 和 KNIME Analytics Platform 之间做选择这一点是促进团队协作的一个优秀特点。通过混合和匹配 Jupyter Notebook 脚本和 KNIME 工作流片段,我们高效地创建了一套先进的应用程序,用于训练、应用和部署机器学习模型进行预测。
将这一策略与 KNIME Server 企业功能相结合,可以在具有不同背景和工具的数据科学家之间实现更大的协作。
协作始终是数据科学实验室中的关键因素,无论你是在寻找开源解决方案还是企业级解决方案,KNIME 软件都能以其在整合 Jupyter 和 其他许多工具 的灵活性来帮助你。
参考文献:
-
从 KNIME Hub 这里 下载 Run Jupyter in KNIME 和 Run KNIME in Jupyter 工作流。
-
阅读 Greg Landrum 关于 KNIME 和 Jupyter 的另一篇博客文章。
-
观看我们关于 增强 Jupyter Notebook 的视觉工作流网络研讨会 的录播。
个人简介:Mahantesh Pattadkal 是 KNIME 的数据科学家。他感兴趣的数据科学技术包括机器学习、自然语言处理、深度学习、预测建模和商业分析。他喜欢使用 Python、SQL、Tensorflow/Keras、Pytorch、Excel 和 R。
首次发表于 低代码高级数据科学。
原文。转载已获许可。
相关主题
tensorflow + dalex = 😃 ,或者如何解释一个 TensorFlow 模型
原文:
www.kdnuggets.com/2020/11/dalex-explain-tensorflow-model.html
评论
作者 Hubert Baniecki,MI2DataLab 的研究软件工程师。
我将展示如何使用 tensorflow 预测模型,并利用 dalex Python 包进行解释。这一主题的介绍可以在 解释模型分析:探索、解释和检查预测模型 中找到。
对于这个示例,我们将使用 世界幸福报告 的数据,并预测任何给定国家根据经济生产、社会支持等的幸福评分。

数据来源于世界幸福报告 (Kaggle.com)。
首先训练基础的 tensorflow 模型,并加入实验归一化层以获得更好的拟合。
下一步是创建一个 dalex 解释器对象,该对象以模型和数据作为输入。
现在,我们准备通过各种方法来解释模型:模型级别的方法解释全球行为,而预测级别的方法则专注于数据中的单个观察。我们可以从评估模型性能开始。

幸福回归任务的模型性能。
哪些特征最重要?让我们对比两种方法,其中一种在 shap 包中实现。
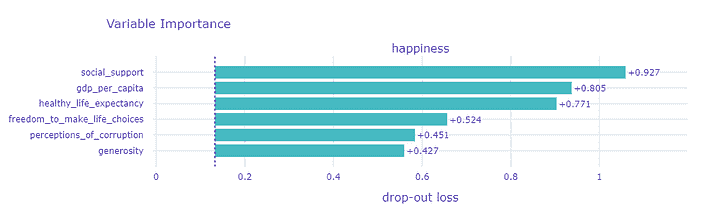
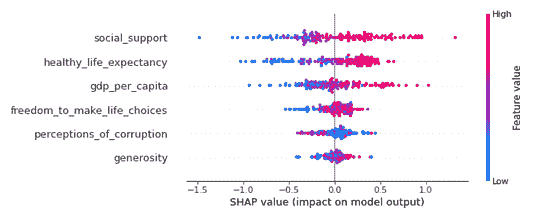
对比两种特征重要性方法,其中一种在 shap 包中实现。
变量与预测之间的连续关系是什么?我们使用部分依赖分析,指出并非总是越多越好。
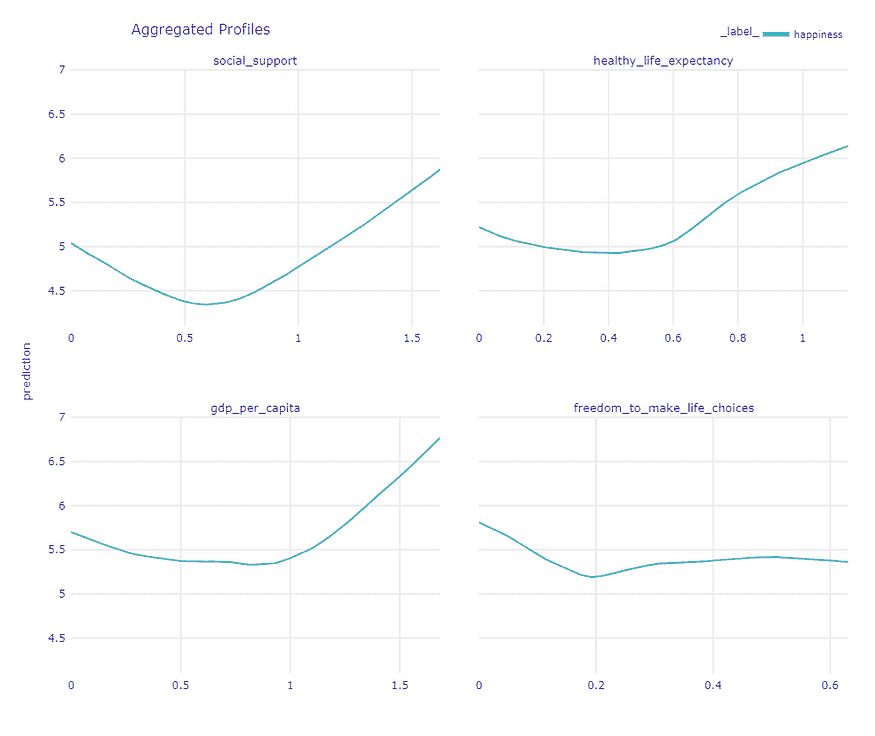
部分依赖分析(Partial Dependence profiles)展示了变量与预测之间的连续关系。
残差如何?这些图表对于可视化模型错误的地方非常有用。
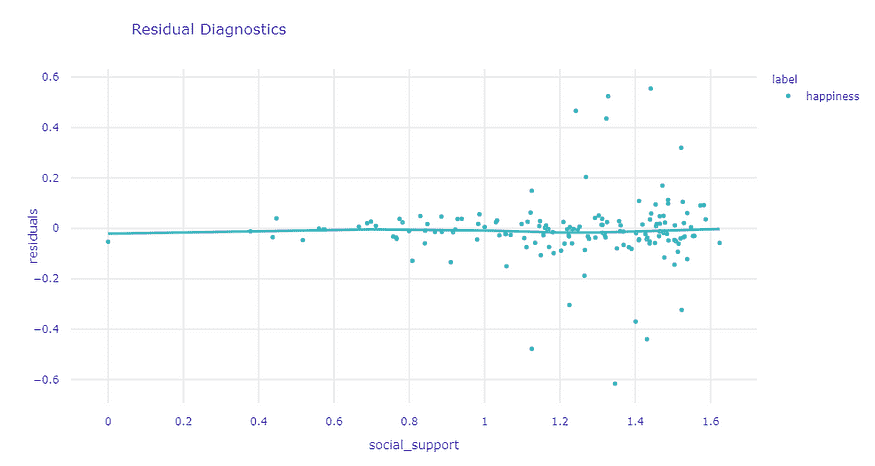
残差诊断可以帮助评估我们模型的弱点。
对于特定国家的变量归因,可以更加好奇,
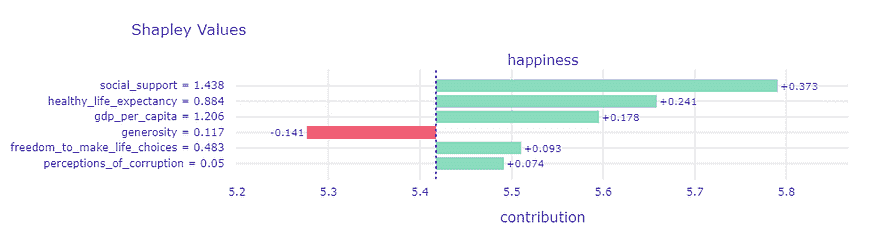
对波兰的变量归因。
或多个国家进行比较结果。
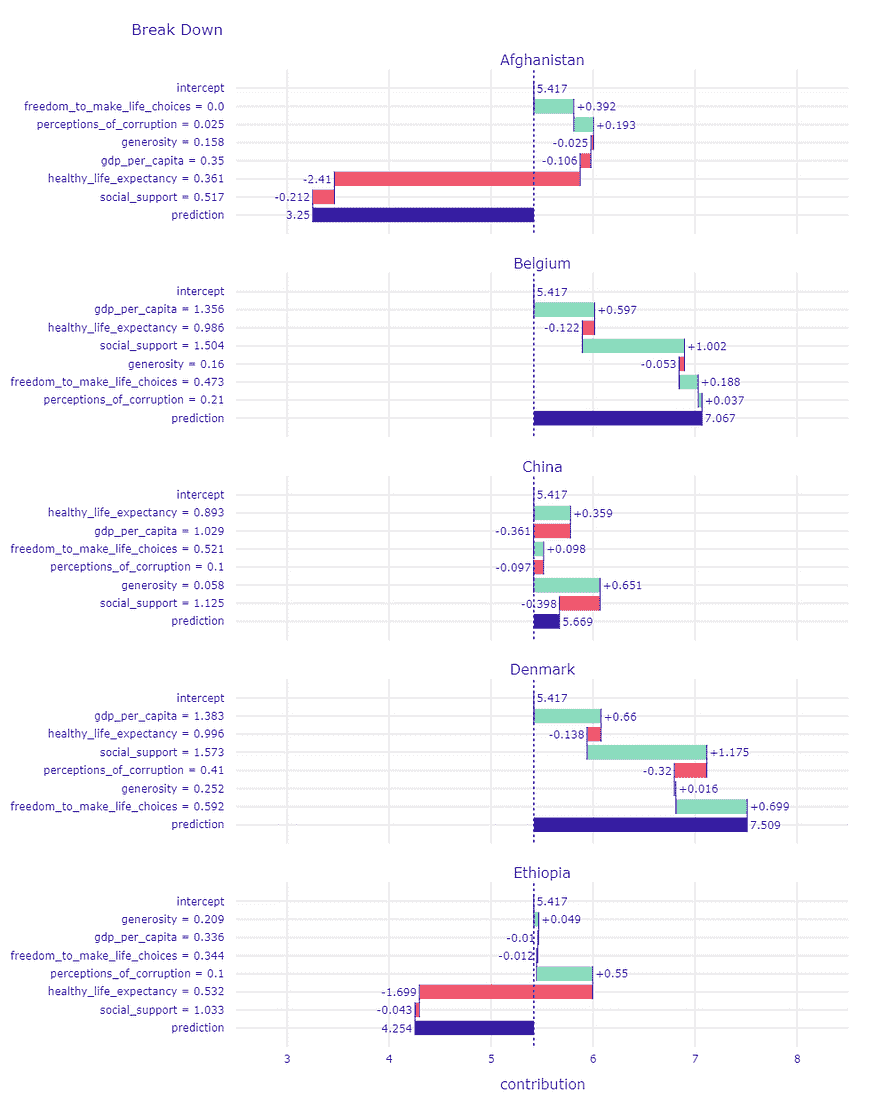
多个国家的变量归因。
如果你对替代逼近感兴趣,可以通过统一接口生成lime包的解释。
替代逼近 - 来自 lime 包的解释。
最后,如果需要一个可解释的模型,我们可以用易于理解的决策树来逼近黑箱模型。
基于黑箱模型预测值训练的决策树。
我希望这段旅程给你带来了一些快乐,因为如今解释预测模型变得更加易于访问和用户友好。当然,在 dalex 工具包中还有更多的解释、结果和图示。我们准备了各种资源,列在 包的 README 中。
这部分的代码可以在 dalex.drwhy.ai/python-dalex-tensorflow.html 找到。
pip install tensorflow dalex shap statsmodels lime scikit-learn
😃
原文。已获许可转载。
简介: Hubert Baniecki 是一名研究软件工程师,开发用于可解释 AI 的 R 和 Python 工具,并在解释性和人机交互的背景下研究机器学习。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 方面的工作
更多相关话题
Dask DataFrame 不是 Pandas
评论
由 Hugo Shi,Saturn Cloud 创始人
吸引力
你从中等大小的数据集开始。Pandas 做得相当好。然后数据集变大,因此你升级到更大的机器。但最终,你会在那台机器上耗尽内存,或者需要找到一种利用更多核心的方法,因为你的代码运行缓慢。此时,你将 Pandas DataFrame 对象替换为 Dask DataFrame。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
不幸的是,这通常不会顺利进行,结果会带来很多痛苦。你依赖于的一些 Pandas 方法在 Dask DataFrame 中未实现(我在看你,MultiIndex),这些方法的行为稍有不同,或者相应的 Dask 操作失败、内存耗尽并崩溃(我还以为不会这样!)
Pandas 是为单个 Python 进程设计的库。分布式算法和数据结构本质上是不同的。在 Dask DataFrame 方面可以做一些工作来改善这一点,但单个进程和机器集群总是会有非常不同的性能特征。你不应该试图抗拒这一基本事实。
Dask 是扩展你的 Pandas 代码的绝佳方法。盲目地将你的 Pandas DataFrame 转换为 Dask DataFrame 并不是正确的做法。 基本的转变不应是用 Dask 替代 Pandas,而是重用你为单个 Python 进程编写的算法、代码和方法。这才是本文的核心。一旦你调整了思维,其余的就不是火箭科学了。
有三种主要方式可以将你的 Pandas 代码与 Dask 结合使用
-
将你的大问题拆分成许多小问题
-
使用分组和聚合
-
将 dask 数据帧用作其他分布式算法的容器。
将你的大问题拆分成许多小问题
Dask DataFrame 由许多 Pandas DataFrame 组成。它非常擅长在这些 Pandas DataFrame 之间移动行,以便你可以在自己的函数中使用它们。这里的一般方法是以拆分-应用-合并模式来表达你的问题。
-
将大数据集(Dask DataFrame)拆分成较小的数据集(Pandas DataFrame)
-
对这些较小的数据集应用一个函数(Pandas 函数,而非 Dask 函数)
-
将结果合并回一个大数据集(Dask DataFrame)
有两种主要方法来拆分数据:
set_index 将 Dask DataFrame 的一列设为索引,并根据该索引对数据进行排序。默认情况下,它会估计该列的数据分布,以便生成大小均匀的分区(Pandas DataFrames)。
shuffle 将行分组,使得具有相同 shuffle 列值的行在同一分区内。这与 set_index 不同,因为结果没有排序保证,但你可以按多个列进行分组。
一旦你的数据被拆分,map_partitions 是将函数应用于每个 Pandas DataFrame 并将结果合并回 Dask DataFrame 的好方法。
但我有多个 DataFrame
没问题!只要你能以相同的方式拆分所有用于计算的 Dask DataFrame,你就可以继续。
一个具体的例子
我不会在这里深入代码。目标是为这个理论描述提供一个具体的例子,以获得对其样子的直观理解。假设我有一个包含股票价格的 Dask DataFrame,还有一个包含相同股票分析师估计的 Dask DataFrame,我想弄清楚分析师是否正确。
-
编写一个函数,该函数接受单一股票的价格和相同股票的分析师估计,并判断他们是否正确。
-
对股票价格调用
set_index,按股票代码排序。结果 DataFrame 的index将具有divisions属性,描述了每个分区包含哪些股票代码。(所有 B 之前的内容在第一个分区,B 和 D 之间的内容在第二个分区,等等)。使用股票价格divisions对分析师估计的 Dask DataFrame 调用set_index。 -
使用
map_partitions将函数应用于两个 Dask DataFrame 的分区。该函数将查看每个 DataFrame 中的股票代码,然后应用你的函数。
使用分组聚合
Dask 有一个出色的 Pandas 分组聚合算法。实际算法相当复杂,但我们在 文档 中有详细的描述。如果你的问题符合这种模式,你就找对地方了。Dask 在分组聚合的实现中使用了树形化简。你可能需要调整两个参数,split_out 控制结果最终分成多少个分区,split_every 帮助 Dask 计算树中的层数。可以根据数据的大小调整这两个参数,以确保不会耗尽内存。
使用 Dask 作为其他算法的容器

许多库都内置了 Dask 集成。dask-ml 与 scikit-learn 集成。cuML 有多节点多 GPU 实现的许多常见 ML 算法。tsfresh 用于时间序列。scanpy 用于单细胞分析。xgboost 和 lightgbm 都有 Dask 支持的并行算法。
结论
Dask 是扩展 Pandas 代码的绝佳方式。简单地将 Pandas DataFrame 转换为 Dask DataFrame 不是正确的方法。但 Dask 使你可以轻松地将大型数据集拆分成更小的部分,并利用现有的 Pandas 代码。
简介: Hugo Shi 是 Saturn Cloud 的创始人,这是一个用于扩展 Python、协作、部署任务等的首选云工作区。
原文。已获许可转载。
相关内容:
-
Pandas 不够?这里有几个处理更大、更快数据的好替代方案* 如果你会写函数,你就可以使用 Dask* 在 Python 中设置你的数据科学和机器学习能力
更多相关话题
Dask 和 Pandas 和 XGBoost:在分布式系统之间良好配合
原文:
www.kdnuggets.com/2017/04/dask-pandas-xgboost-playing-nicely-distributed-systems.html
作者:Matthew Rocklin,Continuum Analytics。
这项工作得到了Continuum Analytics、XDATA 计划和摩尔基金会的数据驱动发现计划的支持
编辑注: 如果你想了解 Dask 的介绍,可以阅读《介绍 Dask 的并行编程:与项目首席开发者的访谈》。要了解最新发布的更多信息,请参见Dask 0.14.1 版本。
总结
本文讨论了如何使用 Dask 分发 Pandas DataFrame,然后将它们交给分布式 XGBoost 进行训练。
更一般地说,它讨论了在相同共享内存进程中启动多个分布式系统的价值,并在它们之间顺利地交接数据。

引言
XGBoost 是一个深受喜爱的库,用于一种流行的机器学习算法类别——梯度提升树。它在商业中广泛使用,并且是 Kaggle 竞赛中最受欢迎的解决方案之一。对于更大的数据集或更快的训练,XGBoost 还配备了自己的分布式计算系统,可以扩展到集群中的多个机器上。太棒了。分布式梯度提升树需求量很大。
然而,在我们能够使用分布式 XGBoost 之前,我们需要做三件事情:
-
准备和清理我们可能很大的数据,可能需要大量的 Pandas 数据处理
-
设置 XGBoost 主节点和工作节点
-
将我们的清理后的数据从一堆分布式 Pandas DataFrame 传递给集群中的 XGBoost 工作节点
这实际上非常简单。这篇博客文章提供了一个快速示例,使用 Dask.dataframe 进行分布式 Pandas 数据处理,然后使用新的dask-xgboost包在 Dask 集群内设置 XGBoost 集群并进行交接。
在这个示例之后,我们将讨论一般设计及其对其他分布式系统的意义。
示例
我们有一个包含十个节点的集群,每个节点有八个核心(m4.2xlarges 在 EC2 上)
我们使用 dask.dataframe 加载 Airlines 数据集(只是一堆分布在集群中的 Pandas DataFrame),并进行一些预处理:
这从 S3 上的 CSV 数据中加载了几百个 pandas 数据框。我们随后不得不进行下采样,因为未来使用 XGBoost 的方式似乎需要大量的 RAM。我不是 XGBoost 专家,请原谅我的无知。最后我们有两个数据框:
-
df: 我们将从中学习航班是否延误的数据 -
is_delayed: 这些航班是否延误。
熟悉 Pandas 的数据科学家可能会对上述代码感到熟悉。Dask.dataframe 与 Pandas 非常 相似,但它在集群上运行。
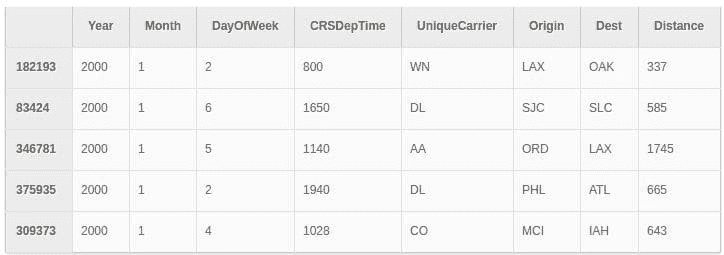
分类和独热编码
XGBoost 不愿意处理像 destination=”LAX” 这样的文本数据。相反,我们为每个已知的机场和航空公司创建新的指示器列。这将我们的数据扩展为许多布尔列。幸运的是,Dask.dataframe 有所有这些便利功能(谢谢 Pandas!)
这大大扩展了我们的数据,但使得训练变得更容易。
拆分和训练
很好,现在我们准备拆分我们的分布式数据框
启动一个分布式 XGBoost 实例,并在这些数据上进行训练
很好,我们能够在约一分钟内使用我们的十台机器在这些数据上训练一个 XGBoost 模型。我们得到的只是一个普通的 XGBoost Booster 对象。
我们可以在本地使用普通的 Pandas 数据
我们可以再次使用 dask-xgboost 来训练我们的分布式保留数据,得到另一个 Dask 系列。
评估
我们可以将这些预测带到本地进程,并使用普通的 Scikit-learn 操作来评估结果。

我们可能想要调整上述参数或尝试不同的数据来改进我们的解决方案。关键不是我们是否准确预测了航班延误,而是如果你是一个了解 Pandas 和 XGBoost 的数据科学家,上述的操作对你来说相当熟悉。在上述示例中没有太多新的材料。我们使用的工具和之前一样,只是规模更大。
分析
好的,现在我们已经展示了这如何工作,让我们稍微讨论一下刚刚发生了什么,以及这对分布式服务之间合作的总体意义。
dask-xgboost 的功能
dask-xgboost 项目相当小而且简单(200 TLOC)。在一个中央调度器和几个分布式工作节点的 Dask 集群中,它在运行 Dask 调度器的相同进程中启动一个 XGBoost 调度器,并在每个 Dask 工作节点中启动一个 XGBoost 工作节点。它们共享相同的物理进程和内存空间。Dask 被构建来支持这种情况,因此这相对简单。
然后,我们要求 Dask.dataframe 完全在 RAM 中生成,并询问所有组成的 Pandas 数据框所在的位置。我们告诉每个 Dask 工作节点将其拥有的所有 Pandas 数据框传递给其本地的 XGBoost 工作节点,然后就让 XGBoost 自己处理。Dask 不为 XGBoost 提供动力,它只是设置、提供数据,并让 XGBoost 在后台完成其工作。
人们常常问 Dask 提供了哪些机器学习功能,它们与 H2O 或 Spark 的 MLLib 等其他分布式机器学习库相比如何。对于梯度提升树,200 行的 dask-xgboost 包就是答案。Dask 不需要自己实现这样的算法,因为 XGBoost 已经存在,效果很好,并且为 Dask 用户提供了一个功能全面且高效的解决方案。
由于 Dask 和 XGBoost 都可以在相同的 Python 进程中运行,它们可以无成本地共享字节、互相监控等。这两个分布式系统以 NumPy 和 Pandas 在单个进程中协同工作的方式,在多个进程中共存。如果你希望轻松使用多个专门化服务,并避免大型单体框架,那么共享分布式进程与多个系统是非常有益的。
连接到其他分布式系统
前一段时间,我写了 一篇类似的博客文章,讲述了如何以与这里相同的方式托管 TensorFlow。设置 TensorFlow 与 Dask 并排运行,向其提供数据,并让 TensorFlow 处理事情也是非常简单的。
一般来说,这种“服务其他库”的方法是 Dask 在可能的情况下的操作方式。我们之所以能够覆盖今天的功能范围,是因为我们大量依赖现有的开源生态系统。Dask.arrays 使用 Numpy 数组,Dask.dataframes 使用 Pandas,现在 Dask 对梯度提升树的答案就是使分布式 XGBoost 的使用变得非常非常简单。瞧!我们获得了一个由其他专注的开发者维护的功能全面的解决方案,整个连接过程是在一个周末完成的(详情见 dmlc/xgboost #2032)。
自从这篇文章发布以来,我们收到了一些要求,希望支持其他分布式系统,如 Elemental,以及进行通用的 MPI 计算传递。如果我们能够用相同的进程集启动这两个系统,那么所有这些都是相当可行的。当你可以在相同的进程中将 numpy 数组从一个系统的工作节点传递到另一个系统的工作节点时,许多跨系统协作的挑战都会消失。
致谢
感谢 Tianqi Chen 和 Olivier Grisel 在 构建和测试 dask-xgboost 时的帮助。感谢 Will Warner 编辑这篇文章的帮助。
简介: 马修·罗克林 是一名开源软件开发者,专注于高效计算和并行计算,主要在 Python 生态系统内。他对许多 PyData 库做出了贡献,目前正在开发 Dask,一个并行计算框架。马修在芝加哥大学获得计算机科学博士学位,专注于数值线性代数、任务调度和计算代数。马修现居纽约布鲁克林,并受雇于 Continuum Analytics。
原文。经许可转载。
相关:
-
介绍 Dask 并行编程:与项目首席开发者的访谈
-
XGBoost:在 Spark 和 Flink 中实现最获胜的 Kaggle 算法
-
初学者 Pandas 推文分析指南
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
介绍 Dask-SearchCV:与 Scikit-Learn 的分布式超参数优化
原文:
www.kdnuggets.com/2017/05/dask-searchcv-distributed-hyperparameter-optimization-scikit-learn.html
作者:Jim Crist,Continuum Analytics。
介绍
去年夏天,我花了一些时间实验结合了 dask 和 scikit-learn(在这个 系列 博客 文章 中记录)。所做的工作产生的库非常初级,实际上没有什么成果。最近我重新开始了这项工作,很高兴地说,我们现在有了一个我可以满意的成果。这涉及到几个主要的变化:
-
范围的大幅缩减。之前的版本尝试实现模型和数据并行。由于不是机器学习专家,数据并行的实现方式不够严格。现在的范围缩小为仅实现超参数搜索(模型并行),这是我们可以做好的事情。
-
优化的图构建。结果发现,当人们被给予在集群中运行网格搜索的选项时,他们立即想要扩大网格大小。尽管代码变得更复杂,但我们现在可以处理极大的网格(例如,50 万候选者现在需要几秒钟构建图,而之前则需要几分钟)。需要注意的是,对于如此大小的网格,主动搜索可能会显著表现更好。相关问题:#29。
-
增强了与 Scikit-Learn 的兼容性。现在只有少数例外,
GridSearchCV和RandomizedSearchCV的实现应该可以直接替代它们的 scikit-learn 对应版本。
所有这些变化导致了名称的更改(之前是 dask-learn)。新库是 dask-searchcv。它可以通过 conda 或 pip 安装:
在这篇文章中,我将简要概述这个库,并讨论何时你可能会选择它而不是其他选项。
什么是网格搜索?
许多机器学习算法有超参数,可以通过调整这些参数来提高最终估计器的性能。网格搜索是一种优化这些参数的方法——它通过在这些参数的一个子集的笛卡尔积(即“网格”)上进行参数扫描,然后选择最佳结果的估计器。由于这涉及在相同的数据集上拟合多个独立的估计器,因此可以很容易地进行并行处理。
使用文本分类的示例
我们将重现 这个示例,使用来自 scikit-learn 文档的 news_groups 数据集。
设置
首先,我们需要加载数据:
Number of samples: 857
接下来,我们将构建一个管道来进行特征提取和分类。它由一个 CountVectorizer、一个 TfidfTransformer 和一个 SGDClassifier 组成。
所有这些都需要几个参数。我们只会对其中的一些进行网格搜索:
Number of candidates: 576
使用 Scikit-Learn 拟合
在 Scikit-Learn 中,网格搜索是使用 GridSearchCV 类进行的,并且可以(可选)使用 joblib 自动并行化。在这里,我们将跨 8 个进程进行并行化(即我机器上的核心数量)。
CPU times: user 39.1 s, sys: 12.7 s, total: 51.8 s
Wall time: 9min 12s
使用 Dask-SearchCV 拟合
Dask-SearchCV 中的 GridSearchCV 实现(几乎)可以直接替代 Scikit-Learn 版本。一些不常用的参数没有实现,同时也增加了一些新的参数。其中之一是 scheduler 参数,用于指定要使用的 daskscheduler。默认情况下,如果设置了全局调度器,则使用它;如果没有设置全局调度器,则使用线程调度器。
在这种情况下,我们将使用本地设置的分布式调度器,配置为 8 个进程,每个进程一个线程。我们选择这种设置的原因是:
-
我们使用的是 Python 字符串而不是 numpy 数组,这意味着某些任务会持有 GIL。这意味着我们至少需要使用几个进程以获得真正的并行性(这排除了线程调度器)。
-
对于大多数图,分布式调度器比多进程调度器更高效,因为它在数据移动方面更智能。由于分布式调度器在本地设置非常简单(只需创建一个
dask.distributed.Client()),因此当你需要多个进程时,使用它几乎没有缺点。
请注意,使用 Scikit-Learn 和 Dask-SearchCV 之间的变化相当小:
<Client: scheduler='tcp://127.0.0.1:64485' processes=8 cores=8>
CPU times: user 36.9 s, sys: 9.75 s, total: 46.7 s
Wall time: 7min 16s
为什么 dask 版本更快?
如果你查看上面的时间,你会注意到 dask 版本比 scikit-learn 版本快 ~1.3X。这并不是因为我们优化了 Pipeline 的任何部分,或者 joblib 存在显著的开销。原因很简单,就是 dask 版本的工作量更少。
给定一个较小的网格
以及与上述相同的管道,Scikit-Learn 版本大致如下(简化版):
作为一个有向无环图,它可能看起来像这样:
相比之下,dask 版本看起来更像是:
作为有向无环图,这可能看起来像是:
仔细观察,你会发现 Scikit-Learn 版本会多次使用相同的参数和数据拟合管道中的早期步骤。由于 Dask 比 Joblib 更具灵活性,我们能够在图中合并这些任务,并仅对任何参数/数据/估计器组合执行一次拟合步骤。对于那些早期步骤相对昂贵的管道,这在进行网格搜索时可能是一个重大优势。
分布式网格搜索
由于 Dask 将调度程序与图规范解耦,我们可以通过快速更改调度程序轻松地从单台机器切换到集群。我在这里设置了一个由 3 个 m4.2xlarge 实例组成的工作集群(每个实例有 8 个单线程进程),以及另一个实例作为调度程序。这通过 dask-ec2 工具的一个命令很容易实现:
要切换到使用集群而不是本地运行,我们只需实例化一个新客户端,然后重新运行:
<Client: scheduler='tcp://54.146.59.240:8786' processes=24 cores=24>
CPU times: user 871 ms, sys: 23.3 ms, total: 894 ms
Wall time: 2min 43s
速度大约提升了 3 倍,这符合我们预期的 3 倍工作节点。通过简单地更换调度程序,我们能够将网格搜索扩展到多个工作节点,从而提高性能。
下面你可以看到这个运行的 诊断图。这些图展示了 24 个工作节点随时间推移所执行的操作。我们可以看到我们在保持集群的工作量(蓝色)相对充足,闲置时间(白色)较少。虽然有一定的序列化(红色),但被序列化的值很小,因此这相对便宜。请注意,这个图也有点误导,因为红色框是绘制在正在运行的任务上,使其看起来比实际情况更糟。
使用 Joblib 的分布式网格搜索
为了对比,我们还将使用 joblib 运行 Scikit-Learn 网格搜索,后端为 dask.distributed。这也只需改变几行代码:
CPU times: user 12.1 s, sys: 3.26 s, total: 15.3 s
Wall time: 3min 32s
分析
在这篇文章中,我们对一个管道进行了 4 次不同的网格搜索:
| Library | Backend | Cores | Time |
+----------------+--------------+-------+----------+
| Scikit-Learn | local | 8 | 9min 12s |
| Dask-SearchCV | local | 8 | 7min 16s |
| Scikit-Learn | distributed | 24 | 3min 32s |
| Dask-SearchCV | distributed | 24 | 2min 43s |
从这些数字来看,我们可以看到无论是 Scikit-Learn 还是 Dask-SearchCV 实现,当增加更多核心时,都会扩展。然而,Dask-SearchCV 实现两种情况都更快,因为它能够合并冗余的 fit 调用,并避免不必要的工作。对于这个简单的管道,这节省的时间只有一两分钟,但对于更昂贵的转换或更大的网格,节省可能会很可观。
什么时候有用?
-
对于单个估计器(没有
Pipeline或FeatureUnion),Dask-SearchCV 的速度仅比使用带有dask.distributed后端的 Scikit-Learn 快一个小常数因子。在这些情况下,使用 Dask-SearchCV 的好处将是微乎其微的。 -
如果模型包含元估计器(
Pipeline或FeatureUnion),你可能会开始看到性能上的好处,特别是当管道中的早期步骤相对昂贵时。 -
如果你正在拟合的数据已经在集群上,那么 Dask-SearchCV 将(目前)更有效,因为它与远程数据配合得很好。你可以将 dask 数组、数据框或延迟对象传递给
fit,一切都能正常工作,无需将数据重新传回本地。 -
如果你的数据太大,Scikit-Learn 无法正常工作,那么这个库将不会对你有帮助。这个库仅用于以智能方式调度 Scikit-Learn 估计器在小到中等数据上的拟合。它并没有重新实现 Scikit-Learn 中的任何算法以扩展到更大的数据集。
未来的工作
目前我们仅镜像 Scikit-Learn 类 GridSearchCV 和 RandomizedSearchCV 来进行参数空间的被动搜索。虽然我们 可以处理非常大的网格,但在某些情况下,切换到主动搜索方法可能是最好的。可以使用 dask.distributed 中的异步方法构建类似的功能,我认为这会很有趣。如果你在这个领域有知识,请对 相关问题发表意见。
这项工作得到了 Continuum Analytics、XDATA 项目 和 摩尔基金会 的数据驱动发现计划的支持。同时感谢 Matthew Rocklin 和 Will Warner 对这篇文章草稿的反馈。
简介:Jim Crist 拥有明尼苏达大学机械工程的学士学位和(暂定)硕士学位。在拖延其论文的同时,他参与了科学 Python 社区。他目前是 Continuum Analytics 的软件开发人员。
原文。经许可转载。
相关:
-
Dask 与 Pandas 和 XGBoost:在分布式系统之间良好配合
-
介绍 Dask 并行编程:与项目首席开发者的访谈
-
科学 Python 入门(以及背后的数学)– Matplotlib
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
使用 Tableau 进行数据分析
原文:
www.kdnuggets.com/2021/04/data-analysis-using-tableau.html
评论
由 Juhi Sharma,产品分析师
图片由 Luke Chesser 拍摄,发布在 Unsplash
介绍
Kmart 是美国领先的在线零售商,作为其年度销售审查会议的一部分,他们需要根据 2019 年销售数据的洞察决定 2020 年的销售策略。
数据与 2019 年每个月的销售有关,任务是生成关键洞察,以帮助 Kmart 的销售团队做出关键的业务决策,最终优化其销售策略。
数据理解
-
数据属于 Kmart - 美国领先的在线零售商。
-
时间段 — 2019 年 1 月 — 2019 年 12 月
-
独特产品 — 19
-
总订单 — 178437
-
城市 — 9
-
KPI — 总销售额,总产品销售量
来源-作者
Tableau 工作表
来源:作者
2019 年销售最佳的月份是 12 月。12 月的总销售额为 $4619297。
来源:作者
2019 年销售了 31017.0 数量的 AAA 电池(4 包)。由于其是最便宜的产品,因此销售数量最多。
来源:作者
Macbook Pro 笔记本电脑的销售最高。
来源-作者
大约在晚上 7 点销售量最高。
Tableau 仪表板
来源-作者
我们可以在仪表板上应用城市、产品和时间段的筛选器。
基于分析的商业建议
-
公司应在 1 月和 9 月提供优惠和折扣,以增加 2020 年的销售额,因为这些月份在 2019 年的销售最低。
-
Austin、Portland 和 Dallas 的销售额相比其他城市较少。公司应寻找原因以提升 2020 年的销售额。
-
大约在中午 12 点和晚上 7 点展示广告是最合适的,以最大化客户购买产品的可能性。
-
AAA 电池(4 包)在 2019 年的销售量最多。公司应注意 AAA 电池(4 包)的库存。
-
公司可以根据 2019 年的洞察调整价格策略。
离开前
感谢阅读!如果您想联系我,可以通过 jsc1534@gmail.com 或我的LinkedIn 个人资料与我联系。
简历: Juhi Sharma (Medium) 热衷于通过数据驱动的方法解决商业问题,包括数据可视化、机器学习和深度学习。Juhi 正在攻读数据科学硕士学位,并拥有 2.2 年的分析师工作经验。
原文。经允许转载。
相关:
-
电子商务数据分析用于销售策略,使用 Python
-
Pandas Profiling: 一行魔法代码进行 EDA
-
TabPy: 结合 Python 和 Tableau
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关主题
从数据分析师到数据策略师:为产生影响而制定的职业路径
原文:
www.kdnuggets.com/2023/05/data-analyst-data-strategist-career-path-making-impact.html

图片来自 Dreamstudio.ai
如果你目前担任数据分析师或对该领域有浓厚兴趣,你可能已经听说了数据策略在商业世界中日益增长的重要性。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
随着越来越多的组织认识到数据驱动决策的价值,现在是探索从数据分析师角色转变为数据策略师角色的最佳时机。
在本文中,我们将讨论如何实现这一跃迁,并在你的职业生涯中创造更大的影响。
了解角色:数据分析师与数据策略师
在深入了解转换之前,我们先清楚地了解数据分析师与数据策略师之间的关键差异。虽然这两个角色对数据驱动的组织都至关重要,但它们各自服务于不同的目的。
数据分析师主要负责:
-
收集、处理和分析数据
-
识别模式和趋势以指导决策
-
创建可视化以传达发现
数据策略师则承担着更全面的角色:
-
开发和实施与业务目标对齐的数据策略
-
确保有效的数据治理、管理和安全
-
与各种利益相关者合作,以推动数据驱动的文化
获得数据策略师角色所需的技能
在许多组织中,数据策略仍然没有被很好地理解。根据你工作的地方,你可能需要在简历上展示一些创意来获得正确的经验。
要从数据分析师过渡到数据策略师,你需要在现有技能基础上进行扩展,并获得一些新能力。以下是一些需要提升的关键技能:
-
战略思维和问题解决:作为数据策略师,你将被期望看到全局,并理解如何利用数据推动业务增长。通过解决复杂的商业问题并找到数据驱动的解决方案来提升你的战略思维。
-
数据管理和治理:熟悉数据管理的最佳实践,包括数据质量、数据集成和数据架构。理解数据治理原则也有助于确保你组织的数据被负责任且安全地使用。
-
数据可视化和讲故事:掌握数据可视化和讲故事的艺术对于数据策略师至关重要,因为你需要以清晰而引人入胜的方式向非技术利益相关者传达复杂的数据洞察。
-
数据隐私和安全法规:保持对数据隐私和安全法规的了解,如 GDPR 和 CCPA,因为合规性是成功数据策略的关键方面。
获得数据策略经验
要从数据分析师转变为数据策略师,你需要一些实践经验。以下是获得这些经验的一些方法:
寻找机会在当前角色中参与数据策略项目。如果你的组织没有正式的数据策略,主动提出一个。
与其他数据专业人士合作,以扩展你的知识和经验。这可能包括与数据科学家、数据工程师和商业智能分析师合作。
寻求导师指导,从有经验的数据策略师那里获得宝贵的指导和支持,帮助你在职业转型过程中。
参加相关的研讨会、网络研讨会和会议,以保持对行业趋势和最佳实践的了解。
建立你的数据策略组合
创建一个引人注目的数据策略组合对展示你的技能和经验至关重要。以下是如何建立一个全面的组合,以突出你的能力和成就:
-
策划多样化的项目:展示一系列能够体现你处理各种数据策略挑战能力的项目。这可能包括与数据治理、数据管理、数据隐私或数据驱动决策相关的项目。
-
展示你的数据可视化和讲故事技能:包括能突出你以视觉吸引力和易于理解的方式呈现复杂数据洞察的工作示例。这可以涉及使用像 Tableau、Power BI 或 D3.js 这样的工具创建交互式仪表板或静态可视化。
-
强调你的数据策略成功:记录你参与的数据策略项目,并确保突出你工作的影响。用增加的收入、减少的成本或提高的效率等指标量化你的成就。
-
包括案例研究:提供详细的案例研究,概述你面临的具体挑战、你采取的数据驱动方法以及取得的成果。这将使潜在雇主更深入地了解你的问题解决能力和战略思维。
-
展示你对数据隐私和安全法规的理解:包括你成功应对数据隐私和安全问题的项目示例,展示你确保合规性和减轻风险的能力。
-
保持作品集的最新:定期更新你的作品集,增加新的项目和成就,并准备根据你申请的数据战略师职位的具体要求来调整内容。
网络和求职策略
网络是任何成功求职的关键方面,尤其是在转型为数据战略师这样的新角色时。以下是最大化你的网络努力和提升求职效果的一些建议:
利用你现有的网络:联系可能在数据战略领域有联系的同事、朋友和导师。他们可能会把你介绍给相关专业人士,推荐职位机会,或提供有价值的见解。
参与在线社区:参与数据战略相关的论坛、讨论组和社交媒体平台,如 LinkedIn。分享你的专业知识、提出问题,并参与讨论,以与其他数据专业人士建立关系。
参加行业活动和会议:寻找专注于数据战略的活动、研讨会和会议,以便与其他专业人士见面,了解最新趋势和最佳实践。务必向演讲者、讨论小组成员和其他与会者自我介绍,并在活动后跟进新的联系。
加入专业协会和组织:成为专注于数据战略的组织的成员,如数据战略网络或国际分析学会。这些组织通常为成员提供网络机会、资源和职位列表。
为数据战略项目做志愿者:将你的技能和专业知识提供给需要数据战略师输入的非营利组织或社区项目。这不仅有助于你建立作品集,还扩展了你的网络,并展示了你致力于利用数据做好事的承诺。
完善你的电梯演讲:在遇到新联系人时,准备简洁地描述你作为数据战略师的经验、技能和目标。这将使他人更容易理解你的价值,并可能将你与相关机会联系起来。
跟进并维护关系:在建立新联系后,务必进行跟进并保持联系。定期分享更新、文章或有趣的发现,以维护强大的职业网络,并在潜在的工作机会中保持关注。
通过扩展你的数据战略作品集并磨练你的网络和求职策略,你将能顺利从数据分析师过渡到数据战略师。
总结
通过建立在现有技能基础上,获得数据战略经验,并在强有力的作品集中展示你的成就,你将顺利在数据驱动的商业世界中产生影响。
记住,这个领域在不断发展,因此拥抱持续学习和适应性以保持领先于潮流。祝你在成为数据战略师的旅程中好运!
本·法雷尔 在一家大型国际银行全职担任数据战略负责人,并在业余时间在 Data Driven Daily (https://datadrivendaily.com) 撰写博客。他对从数据中获取最大价值充满热情,并帮助公司实施数据战略。
更多相关话题
数据分析师技能,助你晋升的必备技能
原文:
www.kdnuggets.com/2022/09/data-analyst-skills-need-next-promotion.html

图片来源:storyset on Freepik
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
我首先要承认,这个话题在许多不同的平台上已经被反复讨论过了。那么,我能提供什么是之前未曾提及的呢?
好吧,事实是,我比大多数 Medium 作者都要年长。虽然有些人礼貌地称我为“成熟”或“经验丰富”,但实际上我的观点是因为我足够长时间地经历了荧光色和渐变色在条形图上流行的时期。因此,我能提供的是经得起时间考验的建议。
数据可视化
作为分析师,你可能会花费至少 10 倍的时间分析数据,而不是向受众展示信息。因此,图形和其他视觉表现形式很重要,因为它能让即使是没有数据分析训练的人也能更好地理解。通过构建可视化图表,你可以帮助公司决策者一眼就能理解复杂的想法。
那么,如何提升这项技能呢?其实,有许多在线课程和专注于可视化的工具。然而,我不愿意推荐特定的技术或课程,因为世界变化如此之快,我希望提供经得起时间考验的建议。
因此,养成探索他人作品的习惯。建立一个名为“灵感”的书签文件夹,并将其填满博客链接。每周花 15 分钟浏览这些博客,为你的脑袋充电。
我还推荐购买几本书。Edward Tufte 是数据可视化的祖师爷,我也是 Nathan Yau 的粉丝,他在 FlowingData.com 上提供书籍、博客、课程和教程。我将他的两本书,Data Points 和 Visualize This,放在书架上以供灵感。
如何实际创建可视化的机制会随着实践而来。你们中的一些人会爱上 R 或 Python,其他人则会偏爱 Excel 或 Tableau。关键是让你的大脑充满可能性,这样你可以在构建之前想象出你想要的东西。
数据清理
数据科学家常说“构建机器学习模型的 80% 是准备和清理数据。”然而,这对于数据分析师来说也同样适用。不管实际的百分比是多少,事实是,处理数据的很大一部分时间用于清理数据。
清理数据很重要,因为未清理的数据可能会产生误导性的模式,并导致错误的结论。在我职业生涯早期,我负责提供第一次尝试解决问题的支持电话的百分比。当我向管理层展示结果时,其中一位坚持认为这些数字“没有意义”。当我进一步调查时,我发现电话数据中有一列叫做“status”,有时会填入一个“X”。显然,系统会为测试记录记录一个“X”,这应该被忽略。
数据清理技能随着实践和业务经验的增长而提高,这使得加速学习变得困难。一般来说,像 kaggle.com 或 zindi 这样的网站并不是练习数据清理的最佳场所,因为它们专注于数据科学,数据集通常已经相当干净。另一方面,像 data.ca.gov/ 或 data.gov/ 这样的政府网站是找到杂乱数据集的好地方。你也可以关注 TidyTuesday 项目,即使你不是 R 用户,也可以找到有趣的数据集,并熟悉实际中清理数据的步骤。
SQL
正如我提到的,我不愿推荐特定的工具或技术,因为环境变化非常迅速。可以肯定地说,Python 和 R 会继续存在,但 SQL 是另一个层次。SQL 是数据库的语言,因此学习 SQL 将始终是你操作和研究数据集的最直接方法。
如果你在一家允许下载 Excel 表格的公司工作——可以询问是否可以直接使用 SQL 访问数据库。一旦你熟悉了数据库结构,并能编写 SQL 以获取你想要的数据表示形式,你的工作效率和质量将会提升。
有许多资源可以帮助你提升 SQL 技能,CodeAcademy、Udemy和Udacity都是寻找实践课程的绝佳免费资源。SQL Generator和SQL Beautifier是值得常备的有用链接,可以帮助你学习。如果遇到技术问题,Stack Overflow有一个很棒的社区可以回答 SQL 相关的问题。
在 Rasgo,我们一直在大力回馈数据社区。我们最近的项目是推出免费的SQL Generator,它生成特定数据转换所需的 SQL 语法。我们发现人们在 Google 和 Stack Overflow 上搜索所需的 SQL 语法——浪费了大量本可以用于数据分析的时间。SQL Generator 是一个 SQL 查询模板,可以让你自定义列名和表结构,选择你想执行的操作,然后为你构建各种不同“风格”的 SQL 语法。再也不用担心 DATEDIFF()与 DATE_DIFF()之间的细微差别了!阅读这篇文章了解一些其他有用的在线工具。
批判性思维
批判性思维是最难掌握的技能之一,因为很少有课程或“一刀切”的方法来精通这一技能。批判性思维是一种有意识的努力,旨在挑战那些主宰我们思维的自动心理过程。
批判性思维不是你天生具备的,也不是一旦掌握就永远“开”的技能。相反,批判性思维是一种在你面临重要决策或分析时有意识地激活的能力。它是一种有目的的努力,旨在挑战、质疑和确认假设。
虽然有许多不同的资源可以帮助你提高批判性思维技能,但我想重点关注的是提问。如果你养成写下大量问题的习惯,你将会进行批判性思维。
假设你被要求查看客户流失情况以及是否最近有所改善。停下来问自己一些问题,例如:
-
流失率是如何计算的?为什么是这样?还有其他计算方式吗?
-
从客户的角度来看,什么是流失率?
-
这是否总是客户的选择?
-
哪些因素可能会影响?我可以测量这些因素吗?
-
这项任务的目标是什么?证明、反驳、展示、支持?
-
我可能忽略了什么?是否有已知的假设我无法验证/证明?
注意这条提问线是如何形成层层递进的。回答一个问题可能会引出更多的问题。这完全没问题。这就是要点!
例如,当我在一家电信公司担任分析师时,我被要求查找流失率突然在上个月增加的潜在原因(那时是四月)。我运用批判性思维,列出类似于上述列表的问题。
当我研究流失率计算方式时,我挑战自己考虑是否有其他方法来衡量流失率。长话短说,我发现:
-
公司使用“月末”数据来计算流失率。
-
三月份实际上是一个“财政”月份,涵盖了二月份。
-
二月是一年中最短的月份。
-
使用替代公式计算流失率表明,3 月份的流失率没有增加。
基本上,流失率的公式使得它在一年中最短的月份,也就是三月,会“激增”,这仅仅是因为数学运算的结果。
这个故事的寓意是,批判性思维有时会带你得出意想不到的结论。这也是你今天可以决定改善的东西;这并不是一种神秘的软技能,你必须天生具备!
沟通
另一方面,沟通是一项软技能。即使你是世界上最有才华和洞察力的数据分析师,如果你不能与他人沟通,那也无济于事。而且说的“他人”不幸的是指非技术人员。
作为分析师,你跨越两个不同的领域。在一个领域,你必须与同事和其他数据专家讨论技术细节。在另一个领域,你是业务决策者的翻译。你需要提供清晰、高层次的解释,以支持而不是混淆。
开始锻炼这项软技能的一种方法是参与社区活动。现在有很多在线社区、网站和论坛供数据分析师参与。我非常喜欢使用 slack 和 discord 渠道与他人互动,但这些平台通常很快就会冷却。我发现Locally Optimistic和DataTalks.Club是分析师们常聚集的稳定平台。你还可以通过开设博客来练习沟通技巧。Medium是一个很好的起点,在这里你可以发挥创造力并不断练习。
结论
关注最新趋势并提升让你具有市场竞争力的技能仍然很重要。例如,20 年前 VBA、宏、DAX 和 ASP 是提升晋升竞争力的优秀技能。如今,这些技能的相关性较低。希望我提供了一些关于过去 20 年中未曾改变的技能的有用建议,以帮助你避免迷失在细节中。如果你想联系我讨论旧时光,你可以在Locally Optimistic和DataTalks.Club找到我,或直接在Rasgo上联系我。
Josh Berry (@Twitter) 领导 Rasgo 的客户面向数据科学工作,自 2008 年起从事数据和分析职业。Josh 在 Comcast 工作了 10 年,建立了数据科学团队,并是内部开发的 Comcast 功能存储的主要负责人之一——这是市场上最早的功能存储之一。离开 Comcast 后,Josh 在 DataRobot 中对客户面向数据科学的发展起到了关键作用。在业余时间,Josh 对有趣的话题如棒球、F1 赛车、房地产市场预测等进行复杂分析。
原文。经许可转载。
更多相关内容
数据分析:分析数据的四种方法及其有效使用方式
原文:
www.kdnuggets.com/2023/04/data-analytics-four-approaches-analyzing-data-effectively.html

图片来自 Leeloo Thefirst
你是否曾希望拥有一个水晶球,能告诉你企业的未来?虽然我们不能承诺你看到未来的神秘景象,但我们确实有下一个最佳选择:数据分析。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
在今天这个数据驱动的世界中,企业收集和生成大量数据变得轻而易举。然而,仅仅拥有数据是不够的。
作为企业,你需要能够理解数据并以一种能够帮助你做出更好决策的方式使用它。这就是数据分析的作用。数据分析指的是检查数据以提取洞察和做出明智决策的过程。
根据统计数据,数据分析市场正在快速增长,预计到 2029 年将达到超过 6500 亿美元。这显示了数据分析在企业和全球经济中日益增长的重要性。
未来是数据驱动的。从预测客户行为到识别优化领域,数据分析可以帮助企业揭示隐藏在数据中的秘密,并推动更好的结果。但面对如此众多的工具和技术,知道从哪里开始可能会让人感到不知所措。
这篇文章将带你了解数据分析,并探讨分析数据的四种方法。通过阅读这篇文章,你将掌握利用数据的力量和做出明智决策的知识,这将使你的企业达到新的高度。
图片来自 HBS
描述性分析
描述性分析是一种数据分析类型,它专注于描述和总结数据以获得对过去发生了什么的洞察。它通常用于回答诸如“发生了什么?”和“多少?”的问题。
描述性分析可以帮助企业和组织理解他们的数据,并识别可以指导决策的模式和趋势。
下面是一些描述性分析的实际例子:
-
一家零售店可能会分析历史销售数据,以识别热门产品和趋势。例如,人们往往在二月份购买更多糖果。
-
患者数据可以被总结以识别常见的健康问题。例如,大多数人从十月到六月之间会得流感。
-
学生表现数据可以被分析以识别需要改进的领域。例如,大多数不及格微积分的学生经常迟到。
要有效地使用描述性分析,你需要确保数据的准确性和高质量。使用清晰简明的可视化工具以有效传达洞察也至关重要。
预测分析
预测分析使用统计学和机器学习技术来分析历史数据并预测未来事件。它通常用于回答诸如“可能会发生什么?”和“如果?”的问题。
预测分析非常有用,因为它可以帮助你规划未来。它可以帮助改善业务操作、降低成本并增加收入。例如,你可以预测销售基于季节性和以前的销售数据如何表现。如果你的预测分析告诉你销售在冬季可能会减少,你可以利用这些信息为这个季节设计一个有效的营销活动。
下面是一些实际的预测分析应用例子:
-
一家银行可能会使用预测分析来评估信用风险,并决定是否向客户发放贷款。在开放银行业务中,预测分析可以帮助建立针对每个客户的高度个性化行为模型,并以新的方式识别其信用状况。对客户而言,这可能意味着更好且更便宜的访问银行账户、信用卡和抵押贷款。
-
在营销中,预测分析可以帮助识别哪些客户最有可能响应特定的优惠。
-
在医疗保健中,预测分析可以用来识别有风险发展某种疾病的患者。
-
在制造业中,预测分析可以用来预测需求和优化供应链管理。
然而,有效使用预测分析也面临一些挑战。一个挑战是获取高质量数据,这对于准确预测至关重要。另一个挑战是选择合适的建模技术来分析数据并做出准确预测。最后,将预测分析结果传达给决策者可能是具有挑战性的,因为所使用的技术可能复杂且难以理解。
处方分析
处方分析是一种超越描述性和预测性分析的数据分析方法,它提供了应采取行动的建议。换句话说,这种方法涉及使用优化技术来确定最佳行动方案,考虑一组约束条件和目标。
它通常用于回答诸如“我们应该做什么?”和“我们如何改进?”的问题。
要有效实施它,需要深入理解所分析的数据以及模拟不同情景以确定最佳行动方案的能力。因此,这是四种方法中最复杂的一种。
处方分析可以帮助解决各种问题,包括产品组合、劳动力规划、营销组合、资本预算和容量管理。

图片由Pixabay提供
处方分析的最佳示例是在高峰时段使用谷歌地图获取路线。该软件考虑了所有交通方式和交通状况,以计算最佳路线。运输公司可能以这种方式使用处方分析来优化配送路线并降低燃料成本。特别是考虑到燃料成本的上升,这一点尤为重要。例如,在加拿大,平均每人每年花费约$2,000仅用于燃料,而在美国,家庭每年将近花费 2.24%的总收入用于燃料。
然而,与预测分析一样,使用处方分析也存在一些挑战。第一个挑战是获取高质量数据,这是准确分析和优化所必需的。另一个挑战是使用的优化算法的复杂性,这可能需要专门的技能和知识才能有效实施。
诊断分析
诊断分析是一种超越描述性分析的数据分析类型,用于识别问题或故障的根本原因。它回答诸如“为什么会发生?”和“是什么导致的?”的问题。例如,你可以使用诊断分析来确定为什么你的 1 月销售额下降了 50%。
诊断分析涉及探索和分析数据,以识别可以帮助解释问题或故障的关系和关联。这可以通过回归分析、假设检验和因果分析等技术来完成。
真实案例包括:
-
你可以使用诊断分析来识别生产过程中质量问题的根本原因。
-
你还可以利用它来找出客户投诉背后的原因,并提供有针对性的解决方案。
-
如果出现网络威胁,你还可以利用它来识别安全漏洞的来源并防止未来的攻击。
使用诊断分析有很多好处,比如识别问题和故障的根本原因,并制定有针对性的解决方案。但与之前两种数据分析方法一样,也存在一些挑战需要考虑。首先,获取高质量的数据和确保准确分析及洞察可能比较困难。其次,分析技术可能非常复杂,实施起来可能需要专业的技能和知识。
| 方法 | 定义 | 回答的问题 |
|---|---|---|
| 描述性 | 描述和总结数据,以获取有关过去发生情况的洞察。 |
-
发生了什么?
-
多少?
|
| 诊断性 | 确定问题或故障的根本原因 |
|---|
-
为什么会发生?
-
造成了什么?
|
| 预测性 | 分析历史数据并对未来事件做出预测。 |
|---|
-
可能会发生什么?
-
如果发生了什么?
|
| 处方性 | 基于分析提供建议的行动方案。 |
|---|
-
我们应该怎么做?
-
我们如何改进?
|
如何有效地使用这四种方法
虽然四种数据分析方法各有其优缺点,但为特定问题选择最合适的方法对于实现期望结果至关重要。选择方法时需要考虑的一些因素可能包括:
所处理问题的性质。不同的问题需要不同的方法。例如,你可以使用:
-
描述性分析总结客户反馈数据并识别客户需求模式
-
诊断分析用于识别影响销售业绩变化的因素
-
预测性分析预测产品的未来需求
-
处方性分析优化制造设施中的生产计划
可用数据的类型和质量。确保数据准确、完整和相关也很重要。这可能涉及清理、转换或其他准备工作,以确保数据适合所选择的方法。在许多情况下,数据准备可能是一个耗时且反复的过程,并且可能需要专业的工具或专长。
可用于分析的资源和技能。要进行有效的数据分析,还需要具备适当的技能和工具。这可能包括统计分析软件、编程语言和可视化工具。对于数据分析师,一些常见的技能可能会有用,包括数据清理、数据可视化、机器学习和统计推断。
结论
从上面的讨论中可以看出,数据分析是一个强大的工具,可以提供有价值的见解并推动业务增长。通过了解和利用四种不同的数据分析方法,企业可以更好地理解数据,做出更明智的决策。
然而,选择分析方法时,重要的是要仔细考虑您业务的具体需求和目标,并了解每种方法的优缺点。
终极地,通过选择正确的方法并有效地实施,企业可以获得竞争优势,实现长期成功。所以,勇敢地探索数据分析的激动人心的世界吧——可能性是无穷无尽的!
Nate Rosidi 是一名数据科学家,并从事产品战略工作。他还是一名兼职教授,教授分析课程,并且是 StrataScratch,一个帮助数据科学家准备顶级公司真实面试问题的平台的创始人。通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关主题
2023 年你需要了解的数据分析工具
原文:
www.kdnuggets.com/2023/05/data-analytics-tools-need-know-2023.html

作者图片
你可能想要转行到数据分析,或者这可能对你来说是一个全新的领域。不管怎样,准备好始终是关键。大多数进入新职业的人只关注最终目标:找到一份工作。然而,有些人过于专注于找到理想的工作,以至于忘记了他们需要掌握所需的技能和工具。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
什么是数据分析师?
数据分析师是指那些查看数据并提供报告和可视化的人,以解释数据。
数据分析师通常不会整天进行编码。他们的职责是利用技术思维以及 Excel、编码或 SQL 技能来识别趋势、模式和解决方案,以帮助企业做出决策。他们还负责将这些发现转化为可视化形式,呈现给相关利益方。
现在,让我们来看看数据分析师在工作中需要成功的必备工具。
作为数据分析师,你需要了解哪些工具?
Excel
-
工具类型:电子表格软件。
-
可用性:商业软件。
-
用途:数据整理和报告。
Excel 被许多来自不同行业的人频繁使用——它是大多数领域的基本工具。如果你还记得在学校时,你可能使用过它,但没有意识到它的全部功能。除了排序和组织数据,它还有计算和图表功能,非常适合数据分析。
虽然 Excel 很受欢迎,并且有很多有用的功能和插件,但它也有其缺点。由于其能力和处理能力,当处理大数据集时,运行速度非常慢,可能会导致计算错误和不准确。
Python
-
工具类型:编程语言。
-
可用性:开源。
-
用途:开发网站/软件、任务自动化、数据分析和数据可视化
Python 是一种通用编程语言,以其简单的语法而闻名,使得学习编程语言变得容易。由于其直观的语法,它目前是最受欢迎的编程语言。它包含多种库,例如NumPy,以帮助处理计算任务。
作为数据分析师,你可以使用 Python 来帮助你的数据分析,例如导入和过滤数据、统计测试、寻找数据之间的关联以及生成可视化。
R
-
工具类型:编程语言。
-
可用性:开源。
-
使用:统计分析和数据挖掘。
很多人在选择学习哪种编程语言时感到困惑——Python 还是 R。Python 以通用编程语言而闻名,而 R 是一种统计编程语言。
与 Python 相比,R 的语法更为复杂,但这是因为它专门构建用于处理重统计计算任务和创建数据可视化。
SQL
-
工具类型:标准化编程语言。
-
可用性:商业。
-
使用:与数据库通信
作为数据分析师,你将花费大量时间与数据库进行通信。它用于执行任务,如更新数据库中的数据或从数据库中检索数据。它提供了一种更简单的方式来扫描你的数据库,并通过几行代码探索新的发现。
Jupyter Notebook
-
工具类型:交互式创作软件。
-
可用性:开源。
-
使用:创建和共享代码/计算文档。
Jupyter Notebook 是一款开源软件,提供交互式计算,并且与不同的编程语言兼容。它可以创建和共享包含实时代码、方程式、可视化和文本的文档,供团队成员之间使用。
它的主要用途包括编程实践、跨项目协作、数据清洗、数据可视化和共享。它还与大数据分析工具如 Apache Spark 集成,接下来我们将讨论这个工具。
Apache Spark
-
工具类型:数据处理框架。
-
可用性:开源。
-
使用:大数据工作负载。
Apache Spark 是一个分析引擎,可以快速而有效地处理大规模数据。据知,Apache Spark 可以帮助你将工作负载运行速度提高 100 倍。作为数据分析师,你将使用它来处理各种数据集,分析非结构化的大数据,以及进行机器学习。
该框架与 Python、R、Java、Scala 和 SQL 等编程语言兼容。
Tableau
-
工具类型:数据可视化工具。
-
可用性:商业。
-
使用:连接数据,构建工作簿、故事和仪表板。
Tableau 是市场领先的商业智能工具之一,用于以简单的格式分析和可视化数据。如果你是一个没有精通编码技能的数据分析师,但仍然希望能够创建交互式可视化和仪表板来向利益相关者展示,Tableau 可以帮助你实现这一目标。
它包含如机器学习、统计学、自然语言和智能数据准备等功能。不仅让数据科学家生活更轻松,也让业务用户受益。
SAS
-
工具类型:统计软件套件。
-
可用性:商业。
-
用途:统计分析和数据可视化。
SAS 是一款命令驱动的软件,仅支持 Windows 操作系统。它代表统计分析系统(Statistical Analysis System),是一组协同工作的程序,用于存储和检索数据、修改数据、进行统计分析、以及创建可视化和报告。
该软件帮助你快速洞察数据,然后使用机器学习支持的自动分析,生成易于理解的报告,以支持决策过程。
KNIME
-
工具类型:数据集成平台。
-
可用性:开源。
-
用途:访问、融合、分析和可视化数据。
KNIME 是一个开源软件,允许你在任何复杂程度上构建分析。你可以使用:
-
KNIME Analytics Platform – 用于清理和收集数据、分析数据并通过可视化使其对所有人可访问。
-
KNIME Server – 部署工作流,并使其可供团队协作、管理和自动化。
微软 Power BI
-
工具类型:商业分析套件。
-
可用性:商业。
-
用途:将数据转化为视觉沉浸式和互动式的洞察。
微软 Power BI 允许你将数据转换为交互式可视化报告和仪表板,更加方便地分享你的发现。它支持与 Excel、文本文件、SQL 和云源的操作。你的数据在 Power BI 中是安全的,因为它使用敏感性标签、端到端加密和实时访问监控。
你可以在其产品范围内进行选择,如 Power BI Desktop、Power BI Pro、Power BI Premium、Power BI Mobile、Power BI Embedded 和 Power BI Report Server。
结论
随着你在数据分析师的旅程中不断前进,你会看到这些现有工具的进步和市场上新工具的出现。你的技能取决于你在未来 10 年中的定位。了解得越多,越好。
如果你仍然不确定数据分析的路径并需要更多指导,可以阅读:
- 2022 年顶级数据分析师认证课程
Nisha Arya 是一位数据科学家、自由技术写作者以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/能够促进人类寿命的延续。作为一名热心的学习者,她致力于拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
边框数据增强:重新思考用于目标检测的图像变换
原文:https://www.kdnuggets.com/2018/09/data-augmentation-bounding-boxes-image-transforms.html

由Ayoosh Kathuria,研究实习生
在获得深度学习任务的良好表现时,数据越多越好。然而,我们可能只有有限的数据。数据增强是一种应对数据短缺的方法,通过人工扩展数据集。事实上,这种技术已经证明非常成功,已成为深度学习系统的基本组成部分。
数据增强为何有效?
理解数据增强为何有效的一个非常直接的方式是将其视为一种人工扩展数据集的方法。正如深度学习应用中的情况一样,数据越多越好。
另一个理解数据增强为何如此有效的方法是将其视为对数据集添加噪声。这在在线数据增强的情况下尤为明显,即每次将数据样本馈送到训练循环中时都会随机增强。

左侧:原始图像,右侧:增强图像。
每次神经网络看到相同的图像时,由于施加了随机的数据增强,图像会有些许不同。这种差异可以看作是每次对数据样本添加的噪声,这种噪声迫使神经网络学习泛化特征,而不是对数据集进行过拟合。
GitHub 仓库
本文及整个增强库的内容可以在以下GitHub仓库中找到。
https://github.com/Paperspace/DataAugmentationForObjectDetection
文档
该项目的文档可以通过在浏览器中打开docs/build/html/index.html或访问这个链接找到。
本系列共有4部分。
边框对象检测
现在,许多深度学习库,如torchvision、keras以及GitHub上的专用库,提供了分类训练任务的数据增强。然而,对对象检测任务的数据增强支持仍然缺失。例如,用于分类任务的图像水平翻转增强将类似于上面显示的样子。
然而,对对象检测任务执行相同的增强也需要你更新边界框。例如,如下图所示。

水平翻转时的边界框变化
正是这种数据增强,或者说是数据增强技术需要我们更新边界框的检测等效方法,是我们将在这些文章中探讨的。具体来说,这里是我们将涵盖的增强列表。
-
水平翻转(如上所示)
-
缩放和平移
![]()
-
旋转
![]()
-
剪切
![]()
-
神经网络输入的缩放



技术细节
我们的小型数据增强库将基于Numpy和OpenCV。
我们将把增强定义为类,其实例可以被调用以执行增强。我们将定义一种统一的方法来定义这些类,以便你也可以编写自己的数据增强。
我们还将定义一个数据增强,它本身不做任何事,但结合数据增强,以便它们可以在序列中应用。
对于每种数据增强,我们将定义其两个变体,一个是随机的,一个是确定性的。在随机变体中,增强是随机发生的,而在确定性变体中,增强的参数(如旋转角度)保持不变。
示例数据增强:水平翻转
本文将概述编写增强的总体方法。我们还会介绍一些实用函数,帮助我们可视化检测和其他内容。让我们开始吧。
注释存储格式
对于每张图片,我们在一个numpy数组中存储边界框注释,数组具有N行和5列。这里,N表示图片中的对象数量,而五列表示:
-
左上角的x坐标
-
左上角的y坐标
-
右下角的x坐标
-
右下角的y坐标
-
对象的类别

存储边界框注释的格式
我知道很多数据集和注释工具以其他格式存储注释,因此,我将把它留给你,将数据注释存储的格式转换为上述描述的格式。
是的,为了演示目的,我们将使用以下图片,展示莱昂内尔·梅西对尼日利亚打进的精彩进球。
文件组织
我们将代码保存在两个文件中,data_aug.py和bbox_util.py。第一个文件包含数据增强的代码,而第二个文件包含辅助函数的代码。
这两个文件都将位于名为data_aug的文件夹中
假设你需要在训练循环中使用这些数据增强。我会让你找出如何提取图像并确保标注格式正确。
然而,为了简化操作,我们一次只使用一张图像。你可以轻松地将此代码放入循环中,或你的数据提取函数中以扩展功能。
克隆包含训练代码文件或需要进行数据增强的文件的 github 仓库。
git clone https://github.com/Paperspace/DataAugmentationForObjectDetection
我们的前三大课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌IT支持专业证书 - 支持你组织的IT需求
更多相关话题
-
数据科学中异常检测技术的初学者指南
,其中 N 是对象的数量,每个框由具有 5 个属性的行表示;即左上角坐标、右下角坐标以及对象的类别。 -
每种数据增强被定义为一个类,其中
__init__方法用于定义增强的参数,而__call__方法描述增强的实际逻辑。它接受两个参数,图像img和边界框注释bboxes,并返回转换后的值。
这就是本文的内容。在下一篇文章中,我们将处理Scale和Translate增强。这些不仅是更复杂的变换,因为涉及更多的参数(缩放和翻译因子),而且还带来了一些我们在HorizontalFlip变换中未曾遇到的挑战。例如,要决定在增强后如果部分框在图像之外时是否保留该框。
简历:Ayoosh Kathuria 目前在印度国防研究与发展组织实习,致力于提高颗粒视频中的目标检测精度。当他不在工作时,他要么在睡觉,要么在弹吉他演奏 Pink Floyd。你可以在 LinkedIn 上与他联系,或在 GitHub 上查看他的更多工作。
原文。已获许可转载。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
更多相关主题
数据复仇者……集结!
那如果……复仇者不是世界上最强大的超级英雄的集合,而是一群数据科学家呢?这听起来很有趣,对吧?
那如果……我花点时间写一些类似的东西呢?你会读它,对吧?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
对吧?

对于那些熟悉童年(或……不久前)漫画书的我们来说,复仇者是漫威漫画的首要超级英雄团队,将其他独立且能力超凡的个体聚集在一起,与地球上最危险的反派作斗争,赢得了我们的感激和崇拜,永远。对于那些不了解的人,复仇者并不是真正的固定超级英雄团队,其成员相当流动,多年来发生了剧烈变化。
但是如果为了乐趣(显然),我们将英雄的属性和性格与数据科学工具的超级功能进行匹配会怎么样?正如我们的英雄有他们的优点、缺点和偏好一样,数据科学家也是如此。复仇者成员的个性特征如何转化为分析领域?
考虑到这一点,我对自己编排了一些复仇者的新版本,并将他们的性格特征赋予他们设想中的超级数据科学家等同体。
顺便提一下,What If... 实际上是漫威宇宙中一个长期连载的漫画系列,虽然不定期,但其故事线非正统且通常“有趣”,挑战了漫威的现状。这种新颖和非传统的叙事方法实际上似乎非常适合数据科学。而且,随着故事创意的枯竭,未来的某一期或许会想象我们的英雄作为数据导向的专业人士。
所以,来吧,这些是地球上最强的分析师。数据复仇者……集结!
队长 执行美国
强大。正直。真正的领袖。美国队长显然是一个高管。我设想史蒂夫·罗杰斯——他的真实名字——会是复仇者公司的一位有能力的首席数据官。他可能不再亲自操作,但他在数据处理的艰难世界中成长,因此他理解那些在他手下工作的数据科学家所面临的日常挣扎。
或者,至少这是他告诉他们的。

绿巨人击碎……数据!
我对此的确定程度比对漫威明显优于 DC 的确定程度还要高,绿巨人绝对是那种会尝试使用 Map Reduce 算法解决每一个问题的数据科学家。想想看:Map Reduce 将问题拆解成更小的部分,然后利用蛮力进一步处理。绿巨人将他面前的一切映射出来,并减少瓦砾。
这是一种完美的匹配。当绿巨人平静并远离数据,假设他的布鲁斯·班纳形态时,他非常有洞察力,并看到一切事物的价值,但在面对手头的任务时,他会回到他最擅长的领域。
当然,Map Reduce 不能解决所有问题。但是,谁会告诉绿巨人这个呢?
被淹没的钢铁侠
鉴于托尼·斯塔克(钢铁侠的化名)令人印象深刻的科学、学术和企业背景,我认为钢铁侠更倾向于利用灵活的数据科学工具。因此,钢铁侠是个 Python 派的人。
处理数据?进行分析?使用库创建分类器?从头实现一些神经网络?建立和扩展一个生产就绪的系统?Python 确实可以做到这一切。托尼也喜欢原型,还能找出一种数据科学家喜欢的编程语言来做这一切吗?不,那另一种语言做不到。
当然,如果钢铁侠只开发生产系统,他可能会拿一本 C++的书,但他以自己是一个多面手的托尼为荣,因此他理解 Python 的价值。

雷神,Spark 之子
绿巨人可能强壮如野兽,但托尔则如神一般强大。此外,他知道没有一种算法方法可以解决他所有的问题。但他理解在他的问题解决方法中,运行在宇宙中最强大的数据处理引擎之上的单一框架的强大力量。此外,他在工作时非常专注,绝不允许任何人碰他的键盘。
托尔可能天生是阿斯加德人,但他选择了 Apache,每天依赖 Spark。
蜘蛛统计侠
网络喷射者曾在不同的时间成为复仇者和团队的亲密朋友。彼得·帕克,他的化名,是一个聪明好学的年轻人,具备高智商。他的科学头脑希望解决重要的问题,对实现这一雄心的琐碎实际问题不感兴趣。
你友好的邻里蜘蛛侠是一位分析师中的分析师。他并不真正关心构建生产系统或实现自己的算法,因此对他来说,软件仅仅是用来获取洞察力和解决问题的工具。R 是他首选的工具,因为它正好满足他的需求,仅此而已。他不介意学习 R 是多么困惑,因为他并非计算机科学背景出身,也不受其他编程语言实现方式的影响。
另外,他有些自满,并且有点聪明,因此人们不喜欢他。他更像是一个在后台、远离客户的数据科学家。

奇异博士的方法
在漫画中,斯蒂芬·斯特兰奇博士,医学博士,成为了至尊法师,整个宇宙的守护者。他利用魔法使敌人迷惑,同时解决问题。从这个意义上讲,奇异博士似乎会支持黑箱算法。更好的是,作为至尊法师,以及漫威宇宙中最强大的实体,几乎没有人真正理解他,也许他仅使用黑箱算法。
黑箱是他的一切首选。Iris 数据集?神经网络!天气数据集?随机森林!当他使用集成方法时,他更喜欢堆叠法。他会考虑支持向量机,但仅在维度非常高的情况下。
当其他数据复仇者遇到瓶颈,不知道如何解决问题时,他们会转向他那神秘难解的算法寻求解决方案。

(计算机?)视界
视界是一个由……嗯,这不重要的安卓机器人。他作为数据复仇者的角色是执行自动化机器学习以帮助其他人。视界采用混合贝叶斯和遗传算法的方法进行特征选择和模型构建,在并行训练和测试大量模型中,以获得最准确的结果,并帮助指引其他团队成员走正确的方向。
这里真正重要的一点是,视界并没有取代其他团队成员。他与更多肉体数据科学家是互补的,并没有试图接管他们的职业,让他们全部失业。眨眼,眨眼。
视界中没有“I”。
J.A.R.V.I.S.
J.A.R.V.I.S.(Just A Rather Very Intelligent System)是数据复仇者对 IBM 的 Watson 的专有模仿。他们决定尝试认知计算的水域,并从零开始实现了这样一个系统。
除了在公司内部满足自己客户的需求外,他们还实现了一个公开访问的 API,通过订阅可用,这也是数据复仇者现在的主要收入来源。API 经济在多年前就被托尼·斯塔克预见到了,他也确实从中获益。
额外奖励:数据科学项目准备的四大天王
为了稍微调侃理查德·里德及其团队,数据复仇者们保留这份实用检查清单,以确保新成员知道如何处理每项任务:
-
理解问题领域和提出的问题
-
调查数据
-
根据需要清理、准备和转换数据
-
从一个明确的框架内来解决问题
鉴于上述情况,我不禁认为,在现实中组建互补且有效的数据科学团队确实有其独特之处。我将把这个判断留给你自己。
文中提到的所有漫画人物以及使用的图像,均为漫威漫画公司的唯一和独占财产。
相关:
-
在建立数据创业公司时如何构建团队
-
大数据漫画解读当前隐私状态
-
8 个(简单的)步骤学习数据科学
更多相关内容
数据职业并不是一成不变的!揭示你在数据领域理想角色的技巧
原文:
www.kdnuggets.com/2021/04/data-careers-not-one-size-fits-all.html
评论
作者:莉莉安·皮尔森,世界级数据领导者和企业家的导师,Data-Mania 首席执行官
自从哈佛商业评论在 2012 年称数据科学家为“21 世纪最性感的职业”以来,似乎每个人和他们的妈妈都在争先恐后地提升数据科学技能。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
理由很充分!数据科学家的需求不断增加,薪资远超美国国家平均水平,根据2021 年罗伯特·哈夫技术薪资指南,美国数据科学家的中位数年薪为 129,000 美元。
但透过网络上的炒作,你是否真的应该追求数据科学家的角色?
通过指导数据专业人士,我注意到很多人进入数据科学领域时没有彻底研究它是否真正适合他们。他们做了大量工作以提升技能,却发现自己在数据科学职位上感到痛苦。
我知道,因为我曾经是这样的人。
我在 2012 年学习了数据科学技能,却意识到编码和构建数据解决方案并不能带给我我所寻找的满足感和幸福感。
到头来,数据科学的实施确实不适合我。我开始意识到,我需要做一些可以从工作中看到真实的积极影响的事情。
那我做了什么呢?
我从美国搬到泰国,创办了自己的数据业务 Data-Mania。让我告诉你,这真是非常有趣!

在你花费多年时间和精力追求数据科学之前,让我们先探索一些不同的选择。在数据的美妙世界中,有着无数的职业机会。
为了对最适合你的角色进行彻底分析,我们将考虑五个不同的因素:
-
当前技能
-
职业目标
-
个性
-
优先事项
-
激情
到本文结束时,你将对如何发掘你最终的数据梦想工作有一个明确的把握!
当前技能
首先,让我们分析一下你当前的技能。我发现大多数数据专业人士在一个主要领域都有扎实的技能。这些主要技能往往是:
-
数据分析技能
-
数据科学技能
-
数据工程
-
数据领导
如果你倾向于分析, 你擅长数据可视化、数据讲故事、仪表板设计——也许你在 Tableau 或 Power BI 中构建仪表板和可视化。你还能够使用 SQL 进行查询和检索数据。
如果你倾向于数据科学, 那么你有编程经验,并且掌握 Python 和 R。你对机器学习、预测建模、统计学和 SQL 有深刻的理解。
如果你倾向于数据工程, 你将具备 ETL 脚本编写和数据仓库的技能。随着你变得更加高级,你将会在分布式计算环境中工作,构建数据管道,维护数据系统,并使用 NoSQL。你还将懂得如何使用 C、C++、C#、Java、Scala 等语言进行编码,并设计利用 NoSQL 和 SQL 数据库的系统。
如果你倾向于数据领导, 那么你在领导项目和团队方面表现出色。你适合担任项目经理、产品经理或利益相关者管理等角色。你的超能力在于技术项目管理和数据战略领域!
职业目标
现在是时候思考你的大方向职业目标了。展望未来,你希望在数据职业生涯中达到什么位置?
你是否希望成为聚光灯下的领袖,领导盈利的数据项目?
你是否希望在幕后编码和构建数据解决方案,但又希望有更多的自主权?
或者你是否希望建立自己的产品,为自己工作——而不必对任何人负责?
因为这也是一种可能性!
个性
让我们聊聊个性类型。具体来说,你是内向还是外向呢?
如果你是内向型的,你会更愿意从事数据实施和编码工作。你会喜欢深入细节,而不受管理客户和团队成员的干扰。
如果你是外向型的,那么你在数据领导类型的角色中会表现得最好。你将能够运用你的沟通技巧来管理团队和项目,而不是自己亲自编写解决方案!
优先级
当我们谈论优先级时,我是指你职业生涯的哪个阶段。
根据你的阶段,你可能会有不同的优先级和需求。我喜欢通过 马斯洛需求层次理论 来思考这一点。
马斯洛需求层次理论指出,所有人都有自我实现的愿望,但为了优先满足内心的满足感,我们需要首先满足最基本的需求。

来源:简单心理学 -- https://www.simplypsychology.org/maslow.html
这些需求是:
-
生理需求
-
安全需求
-
爱与归属需求
-
自尊需求
-
自我实现需求
重要的是按顺序照顾好这些需求。
那么,这和你的数据职业有什么关系呢?
好吧,在我们职业生涯的开始,刚刚从学校毕业,许多人还背负着学生贷款时,我们通常会着眼于满足最基本的需求(生理和安全)。我们的优先事项是拥有一个栖身之处,并达到一个稳定的财务状态。
但一旦我们在职业生涯中取得进展,我们的需求也会改变。我们开始渴望认可、赞誉、晋升——换句话说,就是我们的自尊需求。最终,当我们获得了金钱和赞美后,常常会发现自己在寻找更多。这是数据专业人士寻求真正满足感和更大影响力的阶段。
问问自己:你现在最渴望从数据职业中得到什么?是金钱?是自由和赞誉?还是希望产生影响?
例如,数据实施工作通常是确保健康收入的最快途径。成为数据创业者或领导者可能需要更多的前期工作,但长期的满足感可能更大!
激情
想一想你对数据最热衷的是什么。
我社区的大多数人被以下四个领域之一吸引:
-
编码
-
与业务咨询
-
管理项目、产品和程序
-
设想和即兴发挥。
问问自己——什么是你最喜欢的?什么给你带来最多的能量?
如果你喜欢编码,你肯定会想考虑数据实施角色。但如果你更倾向于管理项目、程序和产品或与业务咨询,那就考虑数据领导角色。如果创新更符合你的兴趣,那你可能有创业的天赋!
拥有数据技能的世界是你的舞台。没有必要仅仅因为数据科学是最受关注的技术职业之一就限制自己。通过深入了解你的个性、激情、目标和技能,你将能够找到一份不仅薪水优厚,而且从长远来看带来真正满足感的工作。
如果你喜欢了解不同的数据职业路径,你一定会喜欢我的免费 数据超级英雄测验! 你将揭示你内心的数据超级英雄类型,并获得与数据技能、个性和激情独特组合直接对接的个性化职业建议。
参加测验 这里
简介: 莉莉安·皮尔森 帮助数据专业人士转变为世界级的数据领导者和企业家。迄今为止,她已向超过 100 万名数据专业人士传授 AI 知识。自 2008 年以来,她还为包括美国海军、国家地理和沙特阿美在内的大型组织提供战略规划服务。
相关:
-
是什么让我花了这么长时间才找到数据科学家工作
-
数据科学简历中的 7 个必备要素
-
为何许多数据科学家辞去优秀公司中的好工作
更多相关内容
数据目录已经死了;数据发现万岁
原文:
www.kdnuggets.com/2020/12/data-catalogs-dead-long-live-data-discovery.html
评论
由 Debashis Saha & Barr Moses 提供

图片由 Andrey_Kuzmin 提供,来源于 Shutterstock
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
随着公司越来越多地利用数据来推动数字产品、决策制定和创新,理解这些最关键资产的健康状况和可靠性是基本的。几十年来,组织依赖数据目录来推动数据治理。但这足够吗?
Debashis Saha,AppZen 的工程副总裁,曾任职于 eBay 和 Intuit,和 Barr Moses,Monte Carlo 的首席执行官兼联合创始人,讨论了为什么数据目录无法满足现代数据体系的需求,以及为什么需要一种新的方法——数据发现——来更好地促进元数据管理和数据可靠性。
这不是什么秘密:知道你的数据在哪里以及谁可以访问它,对理解数据对业务的影响至关重要。事实上,当涉及到构建 成功的数据平台 时,确保数据既有组织又集中,同时又容易被发现,是至关重要的。
类似于实体图书馆目录,数据目录 作为元数据的清单,提供给用户评估数据的可访问性、健康状况和位置所需的信息。在我们的 自助商业智能 时代,数据目录也成为数据管理和数据治理的重要工具。
不足为奇,对大多数数据领导者来说,建立数据目录是他们的首要任务之一。
至少,数据目录应该回答以下问题:
-
我应该在哪里寻找我的数据?
-
这些数据重要吗?
-
这些数据代表了什么?
-
这些数据是否相关且重要?
-
我如何使用这些数据?
尽管数据操作不断成熟,数据管道变得越来越复杂,传统的数据目录往往无法满足这些要求。
这就是为什么一些顶级数据工程团队正在创新他们的元数据管理方法 — 以及他们正在做什么:
数据目录的不足之处
尽管数据目录能够记录数据,但使用户“发现”并获取有关数据健康状况的有意义的实时洞察的根本挑战仍然未得到解决。
我们所知的数据目录无法跟上这一新现实,主要有三个原因:(1)缺乏自动化,(2)无法随着数据堆栈的增长和多样性进行扩展,以及(3)其不分布式的格式。
对自动化的需求增加
传统的数据目录和治理方法通常依赖数据团队进行繁重的手动数据录入,将更新目录的责任留给他们,随着数据资产的发展而更新。这种方法不仅耗时,而且需要大量的手动工作,这些工作本可以自动化,从而使数据工程师和分析师能够将时间用于真正推动进展的项目。
作为数据专业人士,理解数据状态是一场持续的斗争,这也突显了对更大、更多定制化自动化的需求。也许这个场景让你感到熟悉:
在利益相关者会议前,你是否经常发现自己急忙在 Slack 频道中寻找数据集,以搞清楚某个报告或模型的数据来源 — 以及为什么上周数据突然停止到达?为了应对这种情况,你和你的团队是否会聚集在一个房间里,开始白板绘制特定关键报告的所有上游和下游连接?
我会省略详细的描述,但它可能看起来是这样的:

你的数据血缘图看起来像是一场线条和箭头的风暴吗?我们也一样。图片由EgudinKa提供,来自Shutterstock。
如果这让你感到共鸣,你并不孤单。许多公司需要解决这种依赖关系拼图问题,开始了一个多年的过程来手动映射所有数据资产。有些公司能够投入资源构建短期解决方案,甚至开发内部工具,让他们能够搜索和探索数据。即使这能帮助你达到最终目标,但这对数据组织来说是一种沉重负担,耗费了数据工程团队的时间和金钱,这些本可以用于其他事情,比如产品开发或实际使用数据。
随数据变化而扩展的能力
当数据是结构化的时,数据目录效果很好,但在 2020 年,这种情况并不总是如此。随着机器生成的数据增加,公司在机器学习项目上的投资不断增加,非结构化数据变得越来越普遍,占所有新数据的90%以上。
通常存储在数据湖中,非结构化数据没有预定义的模型,必须经过多次转化才能可用和有用。非结构化数据非常动态,其形状、来源和意义在经过各种处理阶段(包括转化、建模和聚合)时不断变化。我们对这些非结构化数据所做的事情(即转化、建模、聚合和可视化),使得在其“理想状态”下进行目录记录变得更加困难。
除此之外,不仅仅是描述消费者访问和使用的数据,还需要基于数据的意图和目的来理解这些数据。数据生产者如何描述资产与数据消费者如何理解其功能将非常不同,即使是不同的数据消费者之间,对数据赋予的意义也可能存在巨大的差异。
例如,从 Salesforce 提取的数据集对数据工程师来说意义完全不同于对销售团队成员的意义。虽然工程师能理解“DW_7_V3”的含义,但销售团队可能会困惑,试图确定该数据集是否与他们在 Salesforce 中的“2021 年收入预测”仪表盘相关。情况还有很多类似的例子。
静态的数据描述本质上有限。到 2021 年,我们必须接受并适应这些新的和不断演变的动态,以真正理解数据。
数据是分布式的;目录则不是
尽管现代数据架构的分布(参见:数据网格)以及转向接受半结构化和非结构化数据作为常态,但大多数数据目录仍然将数据视为一维实体。随着数据的聚合和转化,它流经数据栈的不同元素,几乎无法进行文档记录。
传统的数据目录在数据摄取阶段管理元数据(有关数据的数据),但数据在不断变化,这使得随着数据在管道中演变,难以了解数据的健康状况。图像由 Barr Moses 提供。
如今,数据往往是[自描述的]( https://www.gartner.com/en/information-technology/glossary/self-describing-messages#:~:text=A message that contains data ,consists%20of%20tag%2Fvalue%20pairs.),包含了描述数据格式和意义的元数据与数据本身。
由于传统的数据目录不是分布式的,因此几乎不可能将其作为数据的中央真实来源。随着数据变得更加容易被各种用户访问,从 BI 分析师到运营团队,以及支持 ML、运营和分析的管道变得越来越复杂,这个问题只会加剧。
现代数据目录需要跨这些领域整合数据的意义。数据团队需要能够理解这些数据领域如何相互关联,以及汇总视图中的哪些方面是重要的。他们需要一种集中化的方法来回答这些分布式的问题——换句话说,就是一个分布式的、联合的数据目录。
从一开始就投资于正确的数据目录构建方法,将允许你构建一个更好的数据平台,帮助你的团队实现数据民主化和轻松探索数据,使你能够跟踪重要的数据资产并充分利用其潜力。
数据目录 2.0 = 数据发现
数据目录在你拥有严格模型时表现良好,但随着数据管道变得越来越复杂以及非结构化数据成为黄金标准,我们对这些数据的理解(例如它的功能、谁在使用它、如何使用它等)并不反映现实。
我们相信,下一代目录将具备学习、理解和推断数据的能力,使用户能够以自助服务的方式利用其洞察。但我们该如何实现这一目标?
数据发现可以通过提供分布式、实时的数据洞察,取代现代数据目录,同时遵守一套中央治理标准。图片由 Barr Moses 提供。
除了对数据进行目录化之外,元数据和数据管理策略还必须纳入数据发现,这是一种实时了解分布式数据资产健康的新方法。借鉴了 Zhamak Deghani 提出的分布式领域导向架构以及 Thoughtworks 的数据网格模型,数据发现认为不同的数据拥有者对其数据作为产品负有责任,并且负责促进不同位置之间的分布式数据的沟通。一旦数据被传递给特定领域并经过转化,该领域的数据拥有者可以利用这些数据满足其运营或分析需求。
数据发现通过提供基于数据如何被摄取、存储、聚合和使用的领域特定动态理解,取代了对数据目录的需求。与数据目录一样,治理标准和工具在这些领域中是联合的(允许更大的可访问性和互操作性),但与数据目录不同,数据发现提供对数据当前状态的实时理解,而不是其理想状态或“目录化”状态。
数据发现不仅可以回答数据理想状态下的问题,还可以回答当前数据在各个领域的状态问题:
-
哪个数据集是最新的?哪些数据集可以弃用?
-
这个表格上次更新时间是什么时候?
-
我所在领域中某个字段的含义是什么?
-
谁可以访问这些数据?这些数据上次被使用是什么时候?由谁使用的?
-
这些数据的上游和下游依赖关系是什么?
-
这些数据是生产级质量吗?
-
对于我所在领域的业务需求,哪些数据是重要的?
-
我对这些数据的假设是什么,它们是否得到了满足?
我们相信,下一代数据目录,也就是数据发现,将具有以下特性:
自助发现和自动化
数据团队应能够轻松使用数据目录,而无需专门的支持团队。自助服务、自动化和数据工具的工作流编排消除了数据管道各阶段之间的隔阂,并在此过程中使数据更容易理解和访问。更高的可访问性自然会导致数据采用率的增加,从而减轻数据工程团队的负担。
随着数据的演变,扩展性
随着公司摄取越来越多的数据以及非结构化数据成为常态,能够扩展以满足这些需求将对数据计划的成功至关重要。数据发现利用机器学习在数据资产扩展时获得全局视角,确保随着数据的演变而调整理解。这使得数据使用者能够做出更智能和明智的决策,而不是依赖过时的文档(即数据关于数据的过时情况,多么元!)或更糟的——凭直觉做决策。
数据血缘用于分布式发现
数据发现严重依赖自动化的表和字段级血缘,以映射数据资产之间的上游和下游依赖关系。血缘帮助在正确的时间提供正确的信息(这是数据发现的核心功能之一),并在数据资产之间建立联系,以便在数据管道出现故障时能更好地排除故障,这在现代数据堆栈发展以适应更复杂的用例时变得越来越常见。
数据可靠性以确保数据的黄金标准——始终如一
事实上,无论如何,你的团队可能已经在投资数据发现。无论是通过手动工作来验证数据、工程师编写的自定义验证规则,还是基于破碎数据或未被注意的隐性错误所做的决策成本。现代数据团队已经开始利用自动化方法来确保每个阶段的高可靠性数据,从数据质量监控到更全面的、端到端的data observability platforms来监控和警报数据管道中的问题。这些解决方案会在数据出错时通知你,以便你快速识别根本原因,快速解决问题,并防止未来的停机时间。
数据发现使数据团队能够相信他们对数据的假设与现实相符,从而在数据基础设施中实现动态发现和高度可靠性,无论领域如何。
接下来是什么?
如果坏数据比没有数据还糟糕,那么没有数据发现的数据目录比没有数据目录更糟。为了实现真正可发现的数据,重要的是你的数据不仅要“被编目”,还要准确、干净,并且在从摄取到消费的整个过程中完全可观测——换句话说:可靠。
有效的数据发现方法依赖于自动化和可扩展的数据管理,这与数据系统的新分布性质相适应。因此,为了真正实现组织中的数据发现,我们需要重新思考我们如何处理数据目录。
只有了解你的数据、数据的状态以及它是如何被使用的——在生命周期的所有阶段、跨领域——我们才能开始信任它。
想了解更多关于构建更好的数据目录的内容吗?请联系Debashis Saha或Barr Moses以及Monte Carlo 团队。
Debashis Saha 是 AppZen 的工程副总裁。在此之前,他曾担任 Intuit 和 eBay 的数据平台副总裁。
Barr Moses 是 Monte Carlo 的首席执行官兼联合创始人,这是一家数据可观测性公司。在此之前,她曾担任 Gainsight 的运营副总裁。
原文。经许可转载。
相关:
-
数据科学和机器学习:免费电子书
-
数据专业人士寻找数据集的 8 个地方
-
全面了解端到端的机器学习平台
更多相关内容
数据中心的人工智能:它是否真实?适合每个人吗?我们准备好了吗?
原文:
www.kdnuggets.com/2022/03/data-centric-ai-real-everyone-ready.html

图片来源:作者(在 Canva 上创建)
简而言之;
-
现代深度学习算法的兴起使世界不得不融入它的怀抱。
-
数据科学与人工智能的协同作用在行业巨头中正逐渐成为现实。
-
以数据为中心的人工智能正成为下一个重大趋势,我们应该做好准备!
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
今年早些时候,日益增长的人工智能社区开始深入思考从以模型为中心的方法转向以数据为中心的人工智能开发的可能性。为了跟上围绕数据为中心的人工智能项目的动向,我们从全球行业领导者和智库中提取了有价值的信息。
以数据为中心的人工智能概念
在过去的几十年里,人工智能发展的主导范式是模型或以软件为中心的方法。为了构建一个机器学习系统,你需要编写代码来实现你的算法和模型,然后利用这些代码进行数据训练,以提取有意义的洞见。在过去几十年里,我们大多数人下载了数据集,将数据集视为固定不变的,然后修改软件代码来理解数据。
尽管如此,近年来神经网络和其他算法取得了巨大的进步(得益于这种机器学习研究范式)。因此,许多应用程序的开源代码对某些人来说是一个有力的支持者,但对其他人却没有帮助。例如,GitHub是一个很好的开源软件示例,对一些人来说非常实用,但对其他人则不然。你可能会好奇为什么会这样?嗯,系统的应用情况就在这里发挥作用!
以数据为中心的方法适合每个人吗?
即使我们能够解决代码问题,考虑数据驱动的方法对你和我们所有人来说也更加有益。相反,我们应该将重点放在生成或创建正确的数据,以供学习算法使用。由著名计算机科学家和技术企业家 Andrew Ng 创办的 Landing AI,已经在计算机视觉领域的 MLOps 平台上工作了几年。Ng 是数据驱动概念的坚定信徒,也是深度学习爱好者。Ng 支持的概念在技术社区中获得了显著关注。数据科学与人工智能的协同概念正在行业巨头中实际应用。
数据驱动的人工智能可靠吗?
数据驱动的人工智能的预测分析使其成为未来的关键!社区的支持非常庞大,早期采用者也在不断增加。更有甚者,支持者开始鼓励他人参与并在实践中适应这一概念。
每当人工智能采用或提出新的技术方法时,通常是少数专家凭直觉进行实践。
例如,深度学习的兴起。长期以来,只有少数人以非常原始和手动的方式用 C++编写神经网络。最终,神经网络的理念变得更加广泛,许多人开始用 C++编写神经网络。大约在 2015/2016 年间,深度学习框架如 TensorFlow 和 PyTorch 被引入,使这些理念的应用变得更系统、更少出错。对于数据驱动的人工智能,已经有很多人凭直觉进行了多年实践。
对这一概念的广泛接受和支持预计将上升并主导机器学习生态系统。技术爱好者现在能够直观地工程化语音和自然语言处理数据。数据驱动的人工智能正成为下一个大事,我们应该为此做好准备!
曾经被视为徒劳无功的事情现在正成为现实!
世界是否准备好接受数据驱动的方法?
现代深度学习算法的兴起迫使世界接受这种方法。对于专家来说,理解算法的复杂方式使他们更容易专注于数据。
现在,代码已经更加成熟,并预计会迅速发展。
随着概念的快速发展变得迫在眉睫,概念的实际应用变得对业务生存至关重要。我们即将享受到使用成熟工具的动手经验,使这些理念的应用变得更加可重复、顺畅和系统化。

机器学习、人工智能和人类 由Freepik.com
如何为数据驱动的方法做好准备
现在开始为数据驱动的方法做好准备是明智的!Ng 分享了五个数据驱动人工智能开发的顶级技巧,旨在帮助技术社区应对技术进步的冲击:
-
标签一致性
-
噪声标签影响
-
发现不一致之处
-
澄清标签说明
-
结构化错误分析
有时,处理数据,或者简单地说数据清理,被视为一个预处理步骤。你可能听到过类似的说法!但在数据驱动的人工智能方法下,改进数据不仅仅是你做一次的预处理步骤。这是一个真正的重复算法训练和学习的工作。
数据改进是模型开发迭代过程的核心部分。专家认为,最佳实践是在多次开发和部署后监控和维护模型。系统地持续改进数据也是部署、监控和维护的核心部分。
但在数据驱动的人工智能方法下,改进数据不仅仅是你做一次的预处理步骤。这是一个真正的重复算法训练和学习的工作。数据改进是模型开发迭代过程的核心部分。
训练只是机器学习模型生命周期的一小部分。获取和准备高质量数据占据了机器学习过程的 80%;而训练部分则占据剩下的 20%。但这并不意味着训练部分比后者重要性低。
在学术研究和工业应用中,机器学习的训练方面具有重要意义。调查和研究表明,标签和数据注释对于准确和创新的人工智能至关重要,以及获取补充或外部数据,甚至生成新的数据——合成数据。
我们将走向何处?
机器学习领域的顶尖人物正将我们的注意力引向系统化数据工作的意义。在未来几年,世界将见证机器学习生态系统的范式转变。我们有一点是确定的;2010 年代专注于模型改进;而 2020 年代将专注于数据。
如何开始?
数据驱动的人工智能正在开创未来的发展,将有限的数据集转化为从概念到生产整合人工智能的运营和商业价值。我们相信这是实际情况;我们认为现在是通过与数据驱动的人工智能社区、资源、行业领袖、智库和思想领袖合作,开始学习和采用这一概念的时候了。
戈恩萨洛·马丁斯·里贝罗 是一位产品构建者,对初创企业和技术充满热情。他拥有计算机科学背景,但后来在管理领域发展自己。在初创企业和大型企业中构建了产品,领导过开发团队,现在正在为数据科学制定新标准,通过帮助公司变得以数据为中心并采纳有效的 AI。
更多相关话题
SQL 中的数据清理:如何为分析准备混乱的数据
原文:
www.kdnuggets.com/data-cleaning-in-sql-how-to-prepare-messy-data-for-analysis

使用 Segmind SSD-1B 模型生成的图像
想要开始使用 SQL 分析数据吗?那么,你可能需要稍等片刻。但为什么呢?
数据库表中的数据往往很混乱。你的数据可能包含缺失值、重复记录、异常值、不一致的数据条目等。因此,在使用 SQL 分析数据之前清理数据是非常重要的。
当你学习 SQL 时,你可以创建数据库表,修改它们,更新和删除记录。但在实际操作中,几乎不会出现这种情况。你可能没有权限修改表格、更新和删除记录。但你会有读取数据库的权限,并能够运行一系列 SELECT 查询。
在本教程中,我们将创建一个数据库表,填充记录,并查看如何使用 SQL 清理数据。让我们开始编码吧!
创建带有记录的数据库表
在本教程中,让我们创建一个如下的employees表:
-- Create the employees table
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
salary DECIMAL(10, 2),
hire_date VARCHAR(20),
department VARCHAR(50)
);
接下来,让我们向表中插入一些虚构的样本记录:
-- Insert 20 sample records
INSERT INTO employees (employee_id, employee_name, salary, hire_date, department) VALUES
(1, 'Amy West', 60000.00, '2021-01-15', 'HR'),
(2, 'Ivy Lee', 75000.50, '2020-05-22', 'Sales'),
(3, 'joe smith', 80000.75, '2019-08-10', 'Marketing'),
(4, 'John White', 90000.00, '2020-11-05', 'Finance'),
(5, 'Jane Hill', 55000.25, '2022-02-28', 'IT'),
(6, 'Dave West', 72000.00, '2020-03-12', 'Marketing'),
(7, 'Fanny Lee', 85000.50, '2018-06-25', 'Sales'),
(8, 'Amy Smith', 95000.25, '2019-11-30', 'Finance'),
(9, 'Ivy Hill', 62000.75, '2021-07-18', 'IT'),
(10, 'Joe White', 78000.00, '2022-04-05', 'Marketing'),
(11, 'John Lee', 68000.50, '2018-12-10', 'HR'),
(12, 'Jane West', 89000.25, '2017-09-15', 'Sales'),
(13, 'Dave Smith', 60000.75, '2022-01-08', NULL),
(14, 'Fanny White', 72000.00, '2019-04-22', 'IT'),
(15, 'Amy Hill', 84000.50, '2020-08-17', 'Marketing'),
(16, 'Ivy West', 92000.25, '2021-02-03', 'Finance'),
(17, 'Joe Lee', 58000.75, '2018-05-28', 'IT'),
(18, 'John Smith', 77000.00, '2019-10-10', 'HR'),
(19, 'Jane Hill', 81000.50, '2022-03-15', 'Sales'),
(20, 'Dave White', 70000.25, '2017-12-20', 'Marketing');
如果你能看出来,我使用了一小组名字来从中采样并构建记录的名字字段。不过,你可以在记录中更具创意。
注意:本教程中的所有查询都适用于MySQL。但你可以自由使用你选择的 RDBMS。
1. 缺失值
数据记录中的缺失值总是一个问题。因此,你必须相应地处理它们。
一种幼稚的方法是删除所有包含一个或多个字段缺失值的记录。然而,除非你确定没有其他更好的处理缺失值的方法,否则不应该这样做。
在employees表中,我们看到‘department’列中有一个 NULL 值(见 employee_id 13 的那一行),这表示该字段缺失:
SELECT * FROM employees;
你可以使用COALESCE()函数将‘Unknown’字符串用于 NULL 值:
SELECT
employee_id,
employee_name,
salary,
hire_date,
COALESCE(department, 'Unknown') AS department
FROM employees;
运行上述查询应给你以下结果:
2. 重复记录
数据库表中的重复记录可能会扭曲分析结果。我们选择了 employee_id 作为数据库表中的主键。因此,employee_data表中不会有重复的员工记录。
你仍然可以使用 SELECT DISTINCT 语句:
SELECT DISTINCT * FROM employees;
如预期的那样,结果集包含了所有 20 条记录:
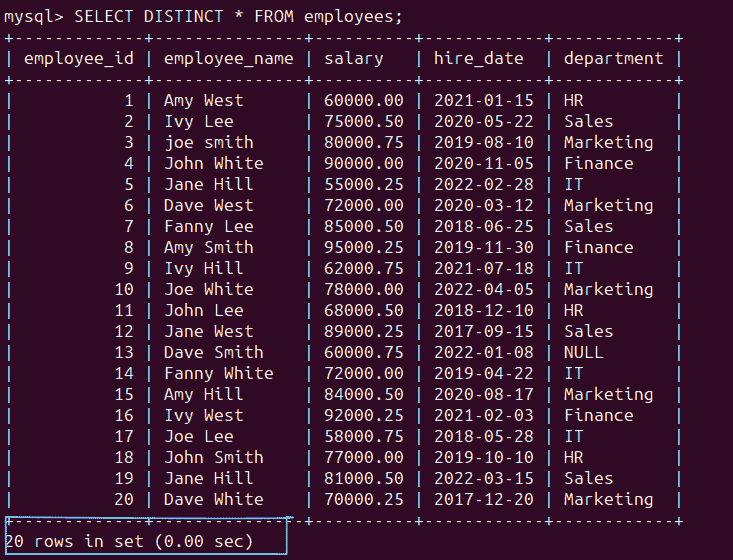
3. 数据类型转换
如果你注意到,‘hire_date’ 列当前是 VARCHAR 而不是日期类型。为了在处理日期时更方便,使用 STR_TO_DATE() 函数会很有帮助,如下所示:
SELECT
employee_id,
employee_name,
salary,
STR_TO_DATE(hire_date, '%Y-%m-%d') AS hire_date,
department
FROM employees;
在这里,我们仅选择了‘hire_date’列,并未对日期值进行任何操作。因此,查询输出应与之前的查询相同。
但如果你想执行例如添加偏移日期到值的操作,这个函数可能会有帮助。
4. 异常值
一个或多个数字字段中的异常值可能会影响分析。因此,我们应检查并移除异常值,以过滤掉不相关的数据。
但决定哪些值构成异常值需要领域知识和数据使用领域及历史数据的知识。
在我们的例子中,假设我们 知道 ‘salary’ 列的上限为 100000。因此,‘salary’ 列中的任何条目最多为 100000。超过此值的条目为异常值。
我们可以通过运行以下查询来检查这些记录:
SELECT *
FROM employees
WHERE salary > 100000;
如上所示,‘salary’ 列中的所有条目都是有效的。因此结果集为空:
5. 数据条目不一致
数据条目和格式不一致在日期和字符串列中尤为常见。
在 employees 表中,我们看到对应员工‘joe smith’的记录不是标题大小写。
但为了保持一致性,我们选择所有格式为标题大小写的名称。你需要使用 CONCAT() 函数与 UPPER() 和 SUBSTRING() 函数一起使用,如下所示:
SELECT
employee_id,
CONCAT(
UPPER(SUBSTRING(employee_name, 1, 1)), -- Capitalize the first letter of the first name
LOWER(SUBSTRING(employee_name, 2, LOCATE(' ', employee_name) - 2)), -- Make the rest of the first name lowercase
' ',
UPPER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 1, 1)), -- Capitalize the first letter of the last name
LOWER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 2)) -- Make the rest of the last name lowercase
) AS employee_name_title_case,
salary,
hire_date,
department
FROM employees;
6. 验证范围
在讨论异常值时,我们提到希望将‘salary’列的上限设为 100000,并将任何超过 100000 的工资条目视为异常值。
但同样重要的是,你不希望‘salary’列中出现任何负值。因此,你可以运行以下查询来验证所有员工记录的值是否在 0 到 100000 之间:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department
FROM employees
WHERE salary < 0 OR salary > 100000;
如上所示,结果集为空:
7. 派生新列
派生新列不一定是数据清洗步骤。然而,在实际操作中,你可能需要使用现有列来派生对分析更有帮助的新列。
例如,employees 表包含一个 'hire_date' 列。一个更有帮助的字段可能是 'years_of_service' 列,表示员工在公司工作的时间长短。
以下查询计算当前年份与 'hire_date' 年份之间的差异,以计算 'years_of_service':
SELECT
employee_id,
employee_name,
salary,
hire_date,
department,
YEAR(CURDATE()) - YEAR(hire_date) AS years_of_service
FROM employees;
你应该看到以下输出:
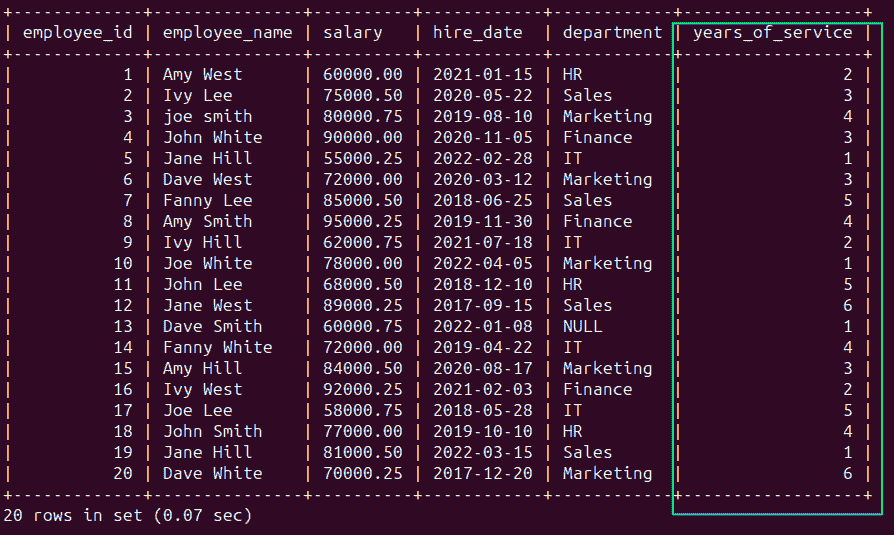
与我们运行的其他查询一样,这不会修改原始表。要向原始表中添加新列,你需要具有 ALTER 数据库表的权限。
总结
我希望你了解相关的数据清理任务如何提升数据质量并促进更相关的分析。你已经学会了如何检查缺失值、重复记录、不一致的格式、异常值等。
尝试启动你自己的关系数据库表,并运行一些查询以执行常见的数据清理任务。接下来,了解一下数据可视化的 SQL。
Bala Priya C是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交集处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、观点文章等与开发者社区分享她的知识。Bala 还创建了引人入胜的资源概述和编码教程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多内容
数据清洗与预处理入门
原文:
www.kdnuggets.com/2019/11/data-cleaning-preprocessing-beginners.html
评论
由 Sciforce 提供。
当我们团队的项目在今年的 CALL 共享任务挑战的文本子任务中获得第一名时,我们成功的关键因素之一是对数据的仔细准备和清理。数据清理和准备是任何 AI 项目中最关键的第一步。证据表明,大多数数据科学家将大部分时间 — 多达70% — 用于清理数据。
在这篇博客文章中,我们将引导你完成数据清理和预处理的初始步骤,从导入最流行的库到实际编码特征。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
数据清洗或数据清理是检测和纠正(或删除)记录集、表格或数据库中的损坏或不准确记录的过程,并指的是识别数据中不完整、不正确、不准确或不相关的部分,然后替换、修改或删除脏数据或粗糙数据。 //维基百科*
第一步:加载数据集

导入库
首先,你需要导入用于数据预处理的库。虽然有很多可用的库,但用于数据处理的最流行和重要的 Python 库是 Numpy、Matplotlib 和 Pandas。Numpy 是用于所有数学操作的库。Pandas 是导入和管理数据集的最佳工具。Matplotlib(Matplotlib.pyplot)是用于制作图表的库。
为了方便将来使用,你可以使用快捷别名导入这些库:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
将数据加载到 pandas 中
一旦你下载了数据集并将其命名为 .csv 文件,你需要将其加载到 pandas DataFrame 中,以便探索数据并执行一些基本的清理任务,去除那些会使数据处理变慢的信息。
通常,这些任务包括:
- 删除第一行:它包含了额外的文本而不是列标题。这些文本会阻碍 pandas 库正确解析数据集:
my_dataset = pd.read_csv(‘data/my_dataset.csv’, skiprows=1, low_memory=False)
- 删除我们不需要的文本解释列、网址列和其他不必要的列:
my_dataset = my_dataset.drop([‘url’],axis=1)
- 删除所有只有一个值或缺失值超过 50%的列,以便提高处理速度(如果你的数据集足够大,这样做仍然有意义):
my_dataset = my_dataset.dropna(thresh=half_count,axis=1)
另外,一个好的做法是将筛选后的数据集命名为不同的名称,以便与原始数据分开。这确保了你仍然保留了原始数据,以备需要时可以返回。
第 2 步。探索数据集

理解数据
现在你已经设置好了数据集,但你仍然应该花些时间来探索它并理解每一列代表的特征。对数据集进行手动检查是很重要的,以避免在数据分析和建模过程中出现错误。
为了简化过程,你可以创建一个包含列名、数据类型、第一行的值和数据字典描述的 DataFrame。
在你探索特征时,可以注意任何列:
-
格式不佳,
-
需要更多数据或大量预处理才能转化为有用特征,或者
-
包含冗余信息,
因为这些问题处理不当会影响你的分析。
你还应该注意数据泄漏,这可能导致模型过拟合。这是因为模型还会从在使用时无法获得的特征中学习。我们需要确保我们的模型只使用在贷款申请时能够获得的数据进行训练。
确定目标列
在探索过筛选后的数据集后,你需要创建一个因变量矩阵和一个自变量向量。首先,你应该根据你想要回答的问题决定使用哪个列作为建模的目标列。例如,如果你想预测癌症的发展情况,或信用是否会被批准,你需要找到一个包含疾病状态或贷款批准状态的列,并将其用作目标列。
例如,如果目标列是最后一列,你可以通过输入以下内容来创建因变量矩阵:
X = dataset.iloc[:, :-1].values
第一个冒号(:)表示我们想要获取数据集中的所有行。: -1 表示我们想要获取除最后一列外的所有数据列。.values 表示我们想要所有的值。
要拥有一个仅包含最后一列数据的自变量向量,你可以输入
y = dataset.iloc[:, -1].values
第 3 步。为机器学习准备特征

最后,到了为机器学习算法准备特征的数据清理工作。为了清理数据集,你需要处理缺失值和类别特征,因为大多数机器学习模型的数学基础假设数据是数值型的且没有缺失值。此外,scikit-learn库会在你尝试使用包含缺失值或非数值值的数据训练线性回归和逻辑回归模型时返回错误。
处理缺失值
缺失数据可能是数据不洁的最常见特征。这些值通常以 NaN 或 None 的形式存在。
这里是缺失值的几种原因:有时值缺失是因为它们不存在,或由于数据收集不当或数据录入错误。例如,如果某人未成年,而问题适用于 18 岁以上的人群,那么问题将包含缺失值。在这种情况下,为该问题填补一个值是不正确的。
填补缺失值的方法有几种:
-
如果你的数据集足够大且缺失值的比例很高(例如超过 50%),你可以删除包含数据的行;
-
如果处理的是数值型数据,你可以用 0 填补所有空变量;
-
你可以使用来自
scikit-learn库的 Imputer 类用数据的(均值、中位数、最频繁值)填补缺失值。 -
你还可以决定用同一列中紧接着的值填补缺失值。
这些决定取决于数据类型、你对数据的需求以及缺失值的原因。实际上,虽然某种方法很流行,但并不一定是正确的选择。最常见的策略是使用均值,但根据你的数据,你可能会找到完全不同的方法。
处理类别数据
机器学习仅使用数值型数据(浮点型或整数型)。然而,数据集通常包含需要转换为数值的对象数据类型。在大多数情况下,类别值是离散的,可以编码为虚拟变量,为每个类别分配一个数字。最简单的方法是使用 One Hot Encoder,指定你要处理的列的索引:
from sklearn.preprocessing import OneHotEncoder
onehotencoder = OneHotEncoder(categorical_features = [0])X = onehotencoder.fit_transform(X).toarray()
处理不一致的数据录入
不一致性发生在例如,当列中存在不同的唯一值但这些值本应相同时。你可以考虑不同的大小写处理方法、简单的打印错误和不一致的格式,以形成一个概念。移除数据不一致性的方法之一是去除条目名称前后的空格,并将所有字符转换为小写。
如果有大量不一致的唯一条目,手动检查最接近的匹配项是不可能的。你可以使用 Fuzzy Wuzzy 包来识别最可能相同的字符串。它接收两个字符串并返回一个比率。比率越接近 100,字符串统一的可能性就越大。
处理日期和时间
一种特定类型的数据不一致是日期格式的不一致,例如同一列中的 dd/mm/yy 和 mm/dd/yy。你的日期值可能不是正确的数据类型,这将使你无法有效地进行操作并从中获得洞察。这时你可以使用 datetime 包来修复日期的类型。
缩放和归一化
如果你需要指定一个量的变化不等于另一个量的变化,缩放是很重要的。借助缩放,你可以确保某些特征虽然很大,但不会被用作主要预测因子。例如,如果你在预测中使用一个人的年龄和薪水,一些算法会更关注薪水,因为它更大,这并没有意义。
归一化涉及将数据集转换为正态分布。一些算法如 SVM 在归一化数据上收敛得更快,因此归一化数据以获得更好的结果是有意义的。
有许多方法可以执行特征缩放。简而言之,我们将所有特征放在相同的尺度上,以便没有特征会被其他特征所主导。例如,你可以使用 StandardScaler 类来拟合和转换你的数据集:
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)As you don’t need to fit it to your test set, you can just apply transformation.sc_y = StandardScaler()
y_train = sc_y.fit_transform(y_train)
保存为 CSV
为了确保你仍然保留原始数据,将每个阶段或部分的最终输出存储在单独的 CSV 文件中是一个好习惯。这样,你可以在不重新计算所有内容的情况下对数据处理流程进行更改。
正如我们之前做的,你可以使用 pandas to_csv() 函数将 DataFrame 存储为 .csv 文件。
my_dataset.to_csv(“processed_data/cleaned_dataset.csv”,index=False)
结论
这些是处理大型数据集、清洗和准备数据以用于任何数据科学项目所需的基本步骤。你可能会发现其他形式的数据清洗也很有用。但现在我们希望你理解,在任何模型的构建之前,你需要正确地整理和清理数据。更好、更干净的数据能超越最好的算法。如果你在最干净的数据上使用一个非常简单的算法,你会得到非常令人印象深刻的结果。而且,更重要的是,执行基本预处理并不难!
原文。转载授权。
简介:SciForce是一家总部位于乌克兰的 IT 公司,专注于基于科学驱动的信息技术的软件解决方案开发。我们在许多关键的人工智能技术领域拥有广泛的专业知识,包括数据挖掘、数字信号处理、自然语言处理、机器学习、图像处理和计算机视觉。
相关:
更多相关话题
使用 Python 进行数据清洗备忘单
原文:
www.kdnuggets.com/2023/02/data-cleaning-python-cheat-sheet.html
数据清洗是数据科学项目中非常重要和关键的一步。机器模型的成功取决于你如何预处理数据。如果你低估并跳过数据集的预处理,模型将无法很好地执行,你将浪费大量时间去理解为什么它的表现没有你预期的那么好。
最近,我开始创建备忘单来加速我的数据科学活动,特别是关于数据清洗基础的总结。在这篇文章和备忘单中,我将展示数据科学项目中预处理步骤的五个不同方面。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
在这个备忘单中,我们涵盖了从检测和处理缺失数据、处理重复项及其解决方案、离群点检测、标签编码和类别特征的一热编码,到数据转换,如 MinMax 归一化和标准归一化。此外,本指南利用了 Pandas、Scikit-Learn 和 Seaborn 这三种最受欢迎的 Python 库提供的方法来显示图表。
学习这些 Python 技巧将帮助你从数据集中提取更多信息,从而使机器学习模型通过从清洗和预处理后的输入中学习而表现得更好。
更多相关主题
数据清洗:任何数据科学项目成功的秘密成分
原文:
www.kdnuggets.com/2020/07/data-cleaning-secret-ingredient-success-data-science-project.html
评论
由瑜吉塔·金哈,顾问和博主
在之前的几篇博客中,我们看到如何使用统计方法和可视化工具总结和分析数据。但原始数据需要处理才能转换为可用的格式。数据准备是数据科学中最重要和最初步的部分。这涉及数据预处理和数据整理。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
原始数据来自各种来源,通常不适合分析。例如,可能会有许多购物者的条目导致重复,或者在记录客户的电子邮件地址时可能会有拼写错误,或者一些调查问题可能被调查者遗漏了。使用未经清理的数据集,无论您尝试什么类型的算法,都不会得到准确的结果。这就是为什么数据科学家会花费大量时间进行数据清洗。
更好的数据胜过更复杂的算法。
尽管数据清洗的步骤和技术会因数据集的不同而有所不同,但以下步骤可以作为任何数据集类型的标准方法:
-
识别相关数据并移除不相关数据
-
修复不规则的基数和结构错误
-
异常值
-
缺失数据处理
正如在博客中讨论的,运行基础的描述性统计测试可以初步检查数据的缺失值、特征的变异性、特征的基数。
图 1:汇总统计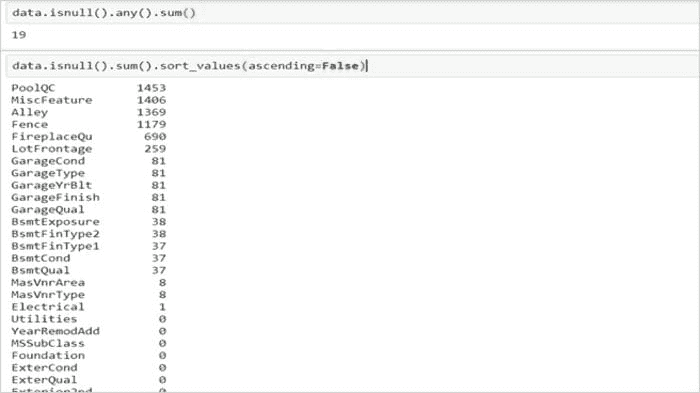
图 2:检查空值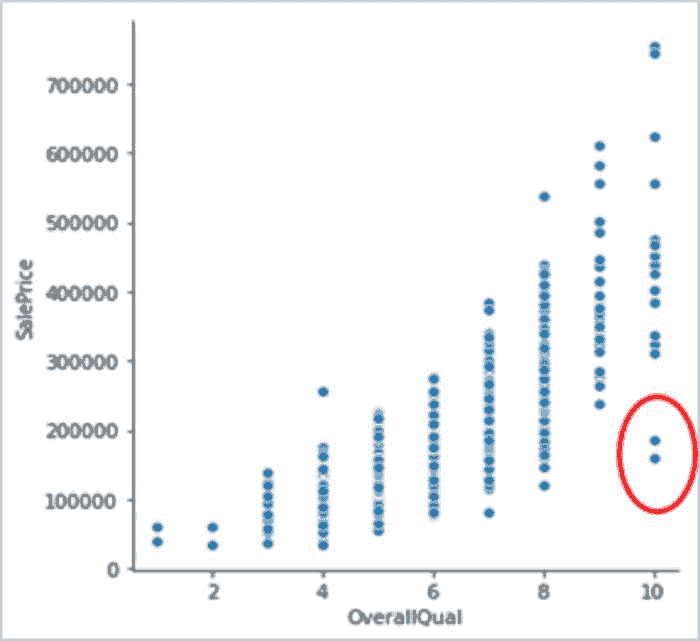
图 3:异常值用红色突出显示
识别相关数据并移除不相关数据
主要有两个检查应该进行,以识别不相关数据:
1. 重复条目
数据通常从多个来源收集并合并形成一个数据集。这可能导致观察值的重复。如果观察值(数量较少)重复几次可能不会有问题,但如果观察值重复过多,可能会导致错误行为。因此,最好删除重复的观察值,以获得更干净的数据集。

2. 无关观察值
数据集中可能包含对特定任务没有用的观察值。例如,如果你分析的是女性的购物行为,你将不需要数据集中男性的观察值——按行处理。
同样,你的数据可能有一个员工 ID 或姓名的列,这对预测帮助不大,可以删除——按列处理。
修复不规则的基数和结构性错误
-
删除具有 1 个基数的列(对于类别特征),或方差为零或非常低的列(对于连续特征)。这些特征提供的信息有限,对于构建预测模型不够有用。
-
类别列可能由于拼写错误或不一致的大小写而具有许多类。例如,性别列可能有许多类,如 male、female、m、f、M 和 F,这些仅代表两个水平——男性和女性。这些类应映射到适当的水平,其他水平应删除。条形图可用于突出显示此类问题。
-
确保数据以正确的数据类型表示,即数字以 int/float 存储,日期作为日期对象。
可能存在许多问题,如特征值中的空格,特征中的数据可能有混合的数据类型,例如一个数值列中可能有一些数字是数字格式,有些是字符串或对象。修复这些错误将导致数据集更加干净、易于解释和使用。
离群值
在之前的博客中,我们讨论了识别离群值的方法。总结来说,如果数据点位于以下位置,可以将其视为离群值:
-
高于Q3 + 1.5*IQR或低于Q1 - 1.5*IQR,如果数据遵循非高斯分布
-
如果数据遵循高斯分布,则离特征均值 2 或 3 个标准差(z-score)。
-
通过绘制箱线图、直方图或散点图(如图 3 所示)可视化单变量变量。
这些方法适用于对单变量或双变量(散点图)变量的初步分析,但对多变量数据或高维数据的价值不大。在这种情况下,应该利用先进的方法,如聚类、主成分分析(PCA)、局部离群因子(LOF)和高对比度子空间(HiCS)用于基于密度的离群值排名。
处理离群值的方法
1. 保留还是修剪
我们不应随意丢弃任何观察数据,因为这些信息可能对理解数据中的异常行为或异常现象非常有价值,除非我们确定这些离群点可能是由于测量误差,或者这些离群点的存在影响了模型的拟合。
图 4:在有离群点的情况下(左图),回归线似乎受到顶部极端点的影响。而在没有离群点的情况下(右图),回归线在去除极端点后更好地拟合了数据。
2. Winsorising 或修剪转换: Winsorising 用最近的非怀疑数据替换离群点。这也被称为修剪转换,因为我们将所有高于上限和低于下限的值修剪为这些阈值,从而限制离群点的值:
其中 fi 是特征 f 的具体值,lower 和 upper 是下限和上限,由上文讨论的 IQR 方法或 z-score 给出。
推荐在怀疑模型由于离群点的存在表现不佳时应用修剪转换。评估 Winsorising 影响的更好方法是比较在应用和未应用转换的数据集上训练的不同模型的性能。
3. 使用对离群点稳健的算法
基于树的算法和提升方法对离群点不敏感,因为它们使用的递归二叉分割方法固有的特性。这些算法在输入特征中存在离群点时是最好的选择。
如果目标变量中存在离群点,基于树的算法表现较好,但必须小心选择损失函数。原因是,如果我们使用均方误差函数,则差异会被平方,从而会极大影响下一个树,因为提升尝试拟合(损失的梯度)。然而,有更多稳健的错误函数可以用于提升树方法,如 Huber 损失和平均绝对偏差损失。
数据清理、描述性统计和探索性数据分析是数据科学生命周期中非常重要的部分。理解数据对于获得有关人口行为的高级见解至关重要,这也帮助你决定是否需要应用哪些转换,以及哪些算法能为你的特定业务问题提供最佳结果。
我们将在下一个博客中讨论如何处理缺失值。
参考文献:
www.r-bloggers.com/outlier-detection-and-treatment-with-r/
最初发布于 https://www.edvancer.in 2019 年 6 月 26 日。
简介:Yogita Kinha 是一位在 R、Python、机器学习以及统计计算和图形软件环境方面拥有经验的专业人士,具有 Hadoop 生态系统的实际操作经验,并在软件测试领域有测试与报告的经验。
原文。经授权转载。
相关:
-
如何处理数据集中的缺失值
-
如何准备你的数据
-
选择合适机器学习算法的简易指南
更多相关主题
数据清洗与 Pandas

作者提供的图片
介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
如果你对数据科学感兴趣,那么数据清洗可能对你来说是一个熟悉的术语。如果不是,让我来解释一下。我们的数据通常来自多个资源,并且不干净。它可能包含缺失值、重复项、错误或不需要的格式等。对这些混乱的数据进行实验会导致不正确的结果。因此,在将数据输入到模型之前,准备数据是必要的。通过识别和解决潜在的错误、不准确和不一致性来准备数据,这个过程称为 数据清洗。
在本教程中,我将带你深入了解使用 Pandas 清理数据的过程。
数据集
我将使用著名的 Iris 数据集。Iris 数据集包含了三种鸢尾花的四个特征的测量值:花萼长度、花萼宽度、花瓣长度和花瓣宽度。我们将使用以下库:
*** Pandas: 强大的数据处理和分析库
- Scikit-learn: 提供数据预处理和机器学习的工具
数据清洗步骤
1. 加载数据集
使用 Pandas 的 read_csv() 函数加载 Iris 数据集:
column_names = ['id', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
iris_data = pd.read_csv('data/Iris.csv', names= column_names, header=0)
iris_data.head()
输出:
| id | sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | Iris-setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | Iris-setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | Iris-setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | Iris-setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | Iris-setosa |
header=0 参数表示 CSV 文件的第一行包含列名(标题)。
2. 探索数据集
为了获得关于我们数据集的见解,我们将使用 pandas 中的内置函数打印一些基本信息。
print(iris_data.info())
print(iris_data.describe())
输出:
<class>RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 150 non-null int64
1 sepal_length 150 non-null float64
2 sepal_width 150 non-null float64
3 petal_length 150 non-null float64
4 petal_width 150 non-null float64
5 species 150 non-null object
dtypes: float64(4), int64(1), object(1)
memory usage: 7.2+ KB
None</class>
iris_data.describe() 的输出
info() 函数 对于了解数据框的整体结构、每列中的非空值数量和内存使用情况非常有用。而总结统计提供了数据集中数值特征的概述。
3. 检查类别分布
这是理解分类列中类别分布的重要步骤,这对于分类任务至关重要。你可以使用 pandas 中的 value_counts() 函数执行这一步。
print(iris_data['species'].value_counts())
输出:
Iris-setosa 50
Iris-versicolor 50
Iris-virginica 50
Name: species, dtype: int64
我们的结果显示数据集是平衡的,每个物种的表示数量相等。这为在所有 3 个类别之间进行公平评估和比较奠定了基础。
4. 删除缺失值
由于从info()方法中可以明显看出我们有 5 列数据没有缺失值,因此我们将跳过这一步。但如果遇到任何缺失值,请使用以下命令处理它们:
iris_data.dropna(inplace=True)
5. 删除重复项
由于重复项可能扭曲我们的分析,因此我们从数据集中删除它们。我们将首先使用以下命令检查它们的存在:
duplicate_rows = iris_data.duplicated()
print("Number of duplicate rows:", duplicate_rows.sum())
输出:
Number of duplicate rows: 0
我们的这个数据集没有重复项。不过,可以通过drop_duplicates()函数删除重复项。
iris_data.drop_duplicates(inplace=True)
6. 独热编码
对于分类分析,我们将对物种列执行独热编码。进行这一步的原因是机器学习算法更倾向于使用数值数据。独热编码过程将分类变量转换为二进制(0 或 1)格式。
encoded_species = pd.get_dummies(iris_data['species'], prefix='species', drop_first=False).astype('int')
iris_data = pd.concat([iris_data, encoded_species], axis=1)
iris_data.drop(columns=['species'], inplace=True)

图片来源:作者
7. 浮点值列的归一化
归一化是将数值特征缩放到均值为 0 和标准差为 1 的过程。进行此过程是为了确保特征对分析的贡献相等。我们将对浮点值列进行归一化,以实现一致的缩放。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
cols_to_normalize = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
scaled_data = scaler.fit(iris_data[cols_to_normalize])
iris_data[cols_to_normalize] = scaler.transform(iris_data[cols_to_normalize])
归一化后的 iris_data.describe() 输出
8. 保存清洗后的数据集
将清洗后的数据集保存到新的 CSV 文件中。
iris_data.to_csv('cleaned_iris.csv', index=False)
总结
恭喜你!你已经成功使用 pandas 清洗了第一个数据集。在处理复杂数据集时,你可能会遇到额外的挑战。然而,这里提到的基本技术将帮助你入门并准备数据以进行分析。
Kanwal Mehreen 是一位有志于成为软件开发者的人员,对数据科学和 AI 在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation 学者。Kanwal 喜欢通过撰写有关热门话题的文章分享技术知识,并热衷于提高女性在科技行业中的代表性。
更多相关内容
SQL 中的数据清理和整理
原文:
www.kdnuggets.com/2021/01/data-cleaning-wrangling-sql.html
评论
由Antonio Emilio Badia,路易斯维尔大学 CSE 系副教授。

我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
了解 SQL 被认为是数据科学家的基本技能之一,因为大量数据存在于(并持续被收集到)关系数据库中。数据分析的典型方法是从这些存储库中提取数据,并使用 R 或 Python 中的强大包/库进行分析。在这种方法中,SQL 仅用于数据的子集化和提取;基本的查询即可满足需求。
然而,实践者知道从原始数据到分析之间存在一个(漫长的过程:数据必须经过仔细准备,这是一项复杂的任务,通常包括标记的数据清理、数据整理或数据预处理等多个过程。一个问题是在哪个环境中进行这个过程。一些分析师更喜欢在 R 或 Python 中完成整个过程,因为它们都提供了丰富的支持,并且它们(尤其是 R)高度互动,而 SQL 缺乏丰富的包/库,使得在 R 或 Python 中许多操作变成了简单的一行代码,其语法也可能相当受限。另一方面,这种方法也有一些缺点:在处理非常大的数据集时,R 和 Python 可能会变得缓慢或遇到问题,而且包/库的多样性(许多功能重叠)在这些环境中增加了额外的复杂性。因此,在某些情况下,至少在 SQL 中进行部分数据清理和整理可能是有益的。正如我们所展示的,许多常见任务可以在 SQL 中完成而不会增加太多额外负担。为了说明这一点,我们提供了一个示例,重点介绍了缺失值的识别和替换。
缺失值在 SQL 中由 NULL 标记表示,但数据可能并不总是明确标记。假设有一个包含医学研究中患者信息的表Patients的数据集。一个属性是id,一个标识符,另外两个属性是Height和Weight,分别表示研究开始时每位患者的身高和体重。我们注意到一些体重值缺失,由-1 表示。然后我们按如下方式“清理”表:
UPDATE Patients
SET Weight = NULL
WHERE Weight = -1;
一旦完成这一点,我们可以使用谓词IS NULL来统一处理所有缺失值:查询
SELECT count(*)
FROM Patient
WHERE Weight IS NULL;
将精确告诉我们缺失了多少值。如果只有少量值缺失,我们可能想要丢弃不完整的数据。SQL 命令
DELETE FROM Patient
WHERE Weight IS NULL;
将消除缺少权重的行(观察值)。如果该属性被认为在后续分析中不重要,则命令
UPDATE TABLE Patient
DROP ATTRIBUTE Weight;
将从整个表中消除该属性——即,从所有行(观察值)中消除。如果我们更愿意填补缺失值,则命令:
UPDATE TABLE Patient
SET Weight = (SELECT avg(Weight) FROM Patient)
WHERE Weight IS NULL;
将所有缺失值替换为现有值的均值。更复杂的方法是从相关属性中填补缺失值。我们可能会想知道Height是否与体重相关;查询:
SELECT cor(Weight, Height)
FROM Patient;
将计算系统中两个属性之间的相关系数,其中存在内置的相关函数cor。即使在没有该函数的系统中,SQL 允许我们自己编写:
SELECT (avg(Weight * Height) - (avg(Weight)* avg(Height))) / (std(Weight) * std(Height))
FROM Patient;
因为均值(avg)和标准差(std)函数是普遍存在的。如果我们认为相关性足够高,我们可以使用kNN 算法来推断适当的值。在一般情况下,SQL 允许我们使用常见的距离函数(如欧氏距离或其他范数)计算数据集元素之间的距离,并按计算出的距离对结果进行排序,以便使用k最近邻来外推所需的值。在这个具体的例子中,计算非常简单:我们使用高度差的绝对值作为我们的距离,并以最近的 5 个邻居的平均权重作为我们新的填补权重:
SELECT id, avg(Weight)
FROM (SELECT P2.id, P.Weight
FROM Patient P, Patient P2
WHERE P2.Weight IS NULL and P.id <> P2.id
ORDER BY abs(P.Height - P2.Height)
LIMIT 5) as KNN;
GROUP BY id;
在此查询中,FROM 子查询计算两个不同数据点(患者)之间的距离,其中一个患者的体重缺失;按此距离排序(ORDER BY)并仅保留 5 个最近的结果(LIMIT);然后使用这 5 个邻居的体重平均值作为填补值(注意:平局的情况会被任意打破)。我们为每个缺失体重的数据点返回一个结果,因此我们提供了这样一个点的id。该结果可以在第二个查询中使用,类似于上面的第二个 UPDATE,来更改Patient中的数据值。
SQL 的一个额外优势是作为一个成熟的标准,能非常高效地处理非常大的数据集(回想一下,一个单独的查询优化器分析所有上述语句,并确定系统在当前数据和资源条件下执行 SQL 命令的最有效方式)。在从数据库中提取数据之前,能够进行一些数据清洗、整理和筛选,可能会使数据管道更简单、更高效。
简介: 安东尼奥·巴迪亚是路易斯维尔大学计算机科学与工程系的副教授。他在数据库领域的研究得到了 NSF(包括 CAREER 奖)的支持,并发表了 50 多篇论文。他教授数据库课程以及面向非计算机科学专业学生的数据管理和分析入门课程。他是《数据科学中的 SQL:使用关系数据库进行数据清洗、整理和分析,Springer》一书的作者,该帖子摘录自此书。
相关:
更多相关内容
从数据收集到模型部署:数据科学项目的 6 个阶段
原文:
www.kdnuggets.com/2023/01/data-collection-model-deployment-6-stages-data-science-project.html
图片由作者提供
数据科学是一个不断发展的领域。让我用两项不同的研究来支持这一点。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
第一个研究来源于Linkedin,完成于 2022 年。该研究展示了过去 5 年中增长最快的职位名称。机器学习工程师的职位是第四个增长最快的职位。它是数据科学的一个分支。
作为一名数据科学家,你必须构建自己的机器学习模型并将其投入生产。当然,你还应该了解网络爬虫,以及数据科学项目的所有其他阶段。你可以在文章的以下部分中找到这些内容。

图片来源:LinkedIn
第二项研究来自于[Glassdoor]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm)。它显示数据科学在美国 50 个最佳职位中排名前三。此外,这种情况在过去七年中一直保持不变。让我们看看这些统计数据。10,071 个职位空缺和 4.1/5 的职位满意度可能是它成为最佳职位之一的原因。此外,中位数基本工资为每年$120,000。
图片来源:[Glassdoor]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm)
现在,数据科学作为一个不断发展的领域变得更加明显。同时,行业需求也显得非常有前景。
由于这种需求,学习数据科学的选项正在增加。在线课程和网站是学习数据科学概念的流行方式。
选择正确的数据科学项目
掌握理论之后,做真实项目将使你为工作面试做好准备。这也有助于丰富你的作品集。
然而,初级开发者所做的项目常常存在重叠。例如,房价预测、识别鸢尾花或预测泰坦尼克号的幸存者。尽管这些项目很有用,但将这些项目包括在你的作品集中可能不是最好的选择。
为什么?
因为招聘人员查看你的简历的时间非常有限。这是另一项研究,应该让你更加意识到这一点。这是ladders进行的眼动追踪研究。这一职业网站显示,招聘人员平均只看你的简历 6 秒钟。

图片来自theladders
现在,我已经提到数据科学的受欢迎程度。由于其受欢迎程度,许多开发者已经迈出了一步。因此,这使得该领域竞争非常激烈。
为了让自己与众不同,你必须做出引人注目的新颖项目。你必须遵循某些阶段,以使这些项目达到最佳效果。这样,你不仅通过做不同于他人的项目脱颖而出,还通过全面而系统的工作吸引招聘人员的注意力并保持他们的关注。
这是项目阶段的概述。
图片由作者提供
现在我们来逐一查看。我还会给你不同项目和编码库的链接。在这种情况下,没有必要重新发明轮子。
1. 数据收集

图片由作者提供
数据收集是从不同来源收集数据的过程。在过去的 10 年中,来自不同来源的数据量不断增长。
到 2025 年,收集的数据量将增加到今天的近三倍。
这是 IDC 进行的研究,展示了不同类型的数据创建变化。
图片来自import.io
这意味着收集的数据量将继续增加。这是企业和开发者抓取更多数据的机会。
为什么你需要更多的数据?
数据收集后,最后阶段将是模型构建和部署到生产环境。因此,提高模型性能将非常重要。一个方法是通过收集更多数据来实现。在这里,主要关注的是如何随着数据量的增加来提升模型的性能。
图片来源于Deeplearning.AI
现在,已经有许多不同的技术来收集数据。在这里,我将解释其中的 3 种:从不同的文件源读取、网页爬取和 API。
从不同文件源收集数据
许多网站和公司会以良好的格式呈现数据。然而,在你的编码环境中读取这些数据需要几行代码。
例如,这个项目旨在分析那些负债累累却难以偿还的人群的数据。正如你所看到的,这个项目也从使用pandas 中的 read_csv函数读取数据开始。
现在你有了数据,可以进行这个项目所要求的探索性数据分析。
关于如何操作的更多细节,请参阅这里的视频。
有许多不同的网站可以找到开源数据。
这里有 4 种方法。
找到数据并使用 Python 函数读取它们,就像上面所做的那样。如果你的数据以其他格式(HTML、JSON、excel)存在,你也可以使用Pandas 函数来读取它们。
网页爬取
网页爬取是使用自动化工具通过网络抓取数据的过程。这意味着使用爬虫和抓取器。它们映射网站 HTML,然后按照给定的指令收集数据。
爬虫工具
网页爬虫会寻找可以从网站上获取的信息。它帮助你找到包含你想要抓取的信息的 URL。
爬虫
抓取器收集你预设的信息。每个抓取器都有一个选择器来定位你想从网站上获取的信息。
它是如何工作的?
通常,它们是一起工作的。首先,爬虫程序获取有关你的主题的信息并找到 URLs。然后,抓取程序通过使用选择器来定位你需要的信息。在最后一步,你抓取这些数据。
数据抓取 Python 库
在 Python 中,你可以通过使用不同的库来抓取数据。这里有 4 个库供你参考。
-
Selenium(这个不是官方文档,但我觉得更易读。)
这是Ken Jee 的视频。你可以看到他将数据科学项目分成不同步骤的 YouTube 系列。在第二个视频中,他解释了数据收集的重要性。然后,他使用 Selenium 从 Glassdoor 抓取数据,以对数据科学家的薪资进行数据分析。
API

作者提供的图片
API 代表应用程序编程接口,用于不同程序之间的通信。它帮助两个程序或应用程序之间传递信息。
YouTube 抓取 API
这是一个用于在下一个视频中收集数据的YouTube API。它允许你获取频道统计数据,例如总订阅者数和观看次数、视频名称、评论等。
在这个视频中,The Vu Data Analytics 频道使用 YouTube API 从 YouTube 抓取数据。
首先,数据会被处理。之后进行探索性数据分析、可视化等。
你可以看到与之前视频的一些相似之处,比如清理数据和进行解释性分析。这是正常的,因为大多数数据项目都会经历相同的阶段。但你在这些阶段中使用的数据和使用方式会提升你的项目并丰富你的作品集。
2. 构建数据管道
作者提供的图片
这是将你未结构化的数据转化为有意义版本的阶段。这里的管道术语侧重于转换。有时这个阶段也被称为数据清理,但可视化管道并将其分配到数据阶段是有意义的。
抓取数据后,数据通常不会处于最佳状态。这就是为什么改变其格式是必要的。例如,如果你有少量数据但包含许多NAs 或缺失值,将这些值填充为列的平均值将帮助你使用这些数据。
或者例如,如果你处理的是 日期时间列,你列的数据类型可能是对象。这会阻止你对该列应用日期时间函数。因此,你应该将这一列的数据类型转换为日期时间型。
拥有更多高质量的数据可以帮助你构建更有效的模型。
让我们给出一个机器学习中需要的转换示例。如果你构建一个模型,你的变量应该是数值型的。然而,有些数据包含类别信息。为了将这些变量转换为数值型,你应该进行 独热编码。
3. 数据探索

作者提供的图片
在进行项目时了解你的数据是非常重要的。为此,你必须首先使用不同的函数对数据进行探索。
下面是一些常用的 Pandas 函数,用于数据探索。
作者提供的图片
数据的初步查看
head( ) 函数让你有机会查看数据的前几行。同时,info( ) 函数会提供有关数据列的一些信息,例如长度和数据类型。
describe( ) 函数会提供描述性统计的总结。
shape( ) 函数会提供有关数据维度的信息,输出为行/列的元组。
astype( ) 函数帮助你改变列的格式。
此外,你可能不会仅仅处理一个数据集,因此合并数据也是你常用的操作。
4. 数据可视化

作者提供的图片
如果你可视化数据,从中提取有意义的信息会变得更容易。在 Python 中,你可以使用许多库来可视化数据。
你应该利用这个阶段来检测异常值和相关的预测变量。如果未被检测,它们会降低你的机器学习模型性能。
创建图形使得这种检测更容易。
异常值检测
异常值通常是由于异常情况发生的,它们不会帮助你的模型预测。检测异常值后需要将其从数据中移除。
这里我们可以看到这个分布图,它显示了人们在都柏林的 Airbnb 上愿意为一个房间支付的最高价格。
大多数人搜索每晚低于$200 的房间,尤其是在$100 左右每晚。然而,也有一些人搜索价格在 500-600 之间的房间。
在构建模型时,在某个层级对其进行筛选将帮助你更准确地预测行为。
相关图
图片由作者提供
这里,相关图检测相关的预测因子,这会降低你的模型性能。你可以看到图右侧的颜色刻度,显示了随着颜色密度的增加,相关性也增加,无论是负相关还是正相关。
5. 模型构建

图片由作者提供
这里你可以看到模型构建的不同阶段。
图片由作者提供
选择合适的算法
构建模型的第一步是选择使用哪种算法类型。当然,这取决于你的主题。
你是否处理数值数据并计划进行预测?那么你的选择将是回归。或者你想用分类算法对图像进行分类?这取决于你的项目。例如,异常检测通常是一个受欢迎的项目内容。它可以用于信用卡欺诈检测,并在后台使用聚类算法。当然,你也可以在项目中使用深度学习。
数据集拆分
评估模型的一种方法是测量其在模型不熟悉的数据上的性能。将数据拆分为训练集和测试集有助于实现这一点。
你使用训练数据集训练模型,然后使用测试集测试模型的性能,测试集包含模型不熟悉的数据。
在这个阶段,如果你已经知道将使用哪个模型,你可以跳过使用验证集。然而,如果你想尝试不同的模型以找出哪个最好,使用验证集是适合你的。
A/B 测试
在选择算法并划分数据集后,是时候进行 A/B 测试了。
有不同的算法。你如何确定哪个算法最适合你的模型?一个检查的方法是称为 A/B 测试的技术。在机器学习中,A/B 测试意味着你将尝试不同的模型,以找到最适合你的项目的那个。
尝试所有可能的算法,并找到表现最好的算法,然后继续使用它。
性能提升算法和技术

图片由作者提供
你的模型的性能通常可以通过使用不同的技术来提升。让我们重点讨论其中的三种。
图片由作者提供
降维
降维用于找到那些能比其他特征更好地表示数据的预测变量。这项技术使你的算法运行更快,模型预测效果更佳。
这里你可以看到在 sci-kit learn 库中应用降维技术的例子。
PCA
PCA 代表主成分分析,它帮助你确定需要多少个预测变量来解释数据集的某一百分比。
让我通过一个例子来解释一下,预计的交货时间是预测的。有 100 个预测变量,因此消除它们将有助于提升算法的速度,并使结果有更好的表现。这就是为什么应用 PCA 算法的原因。
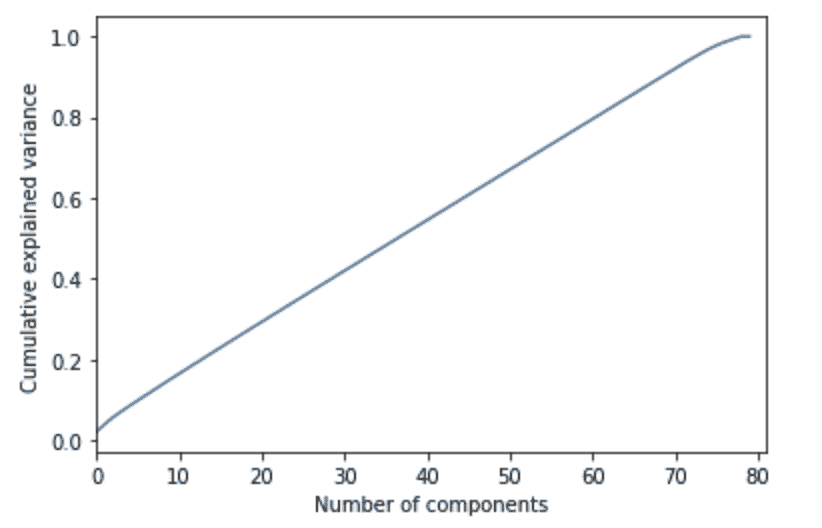
PCA 表明,至少需要 60 个代表性特征来解释 80%的数据集。这是代码,在 sci-kit learn 库中提供了解释。
超参数调优
在构建机器学习模型时,会有很多不同的参数可以用于预测。超参数调优帮助我们根据项目需求找到这些参数中的最佳值。
网格搜索
网格搜索帮助你找到最佳的参数值,以优化你的机器学习模型。
这里是 sci-kit learn 库中的代码,解释了什么是网格搜索,并提供了实现代码。
预处理
这有助于将变量缩放到相同的水平,这样你的预测算法就能更快地工作。
标准化器
主要思想是将预测变量的均值变为零,并将标准差调整为 1。 这里 是 sci-kit learn 库的代码,帮助你计算这一点。
模型评估指标

图片由作者提供
这一步帮助我们解读模型。这就是为什么不同算法有不同的评估指标。算法结果的解读会根据问题的类型有所不同:回归、分类或聚类。
回归
这是一种找出数值变量之间关系的技术。简单来说,我们将使用回归来预测数值变量。
这里是回归问题的两个评估指标。
均方误差(MSE)
均方误差是通过找到预测值和实际值之间的差异并对结果进行平方来计算的,适用于数据集中的每一个元素。
这里是公式。
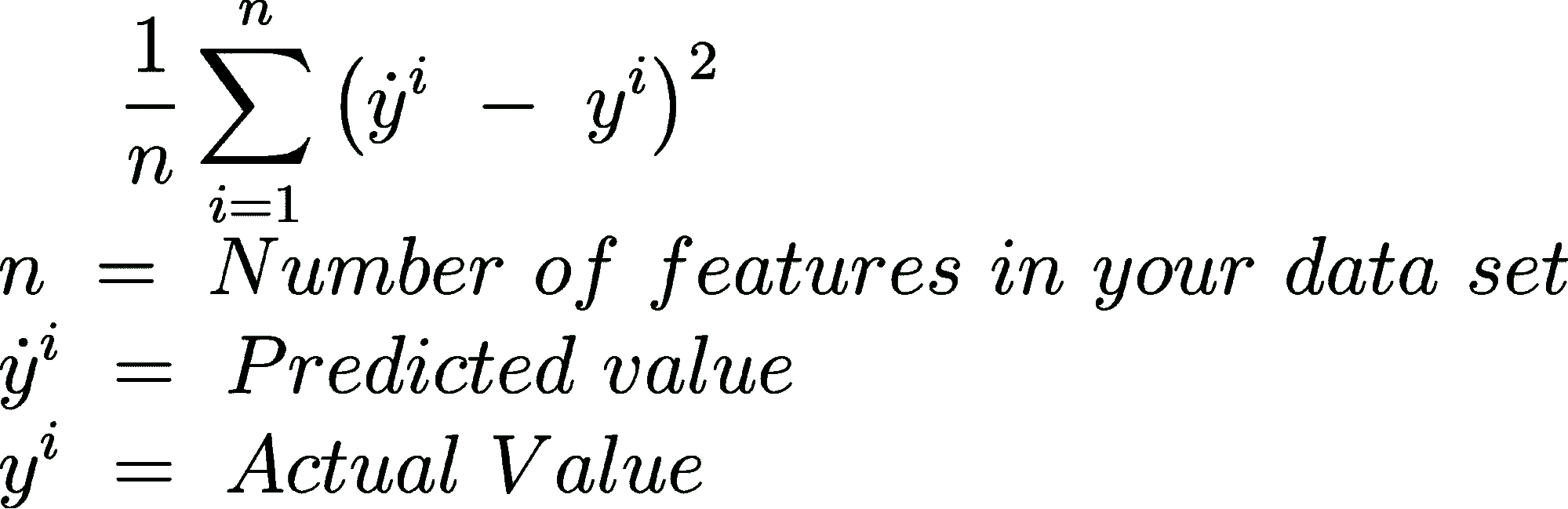
这里 是 Python 中使用 sci-kit learn 实现 MSE 的代码。
均方根误差(RMSE)
RMSE 是 MSE 的平方根。
这里是公式。
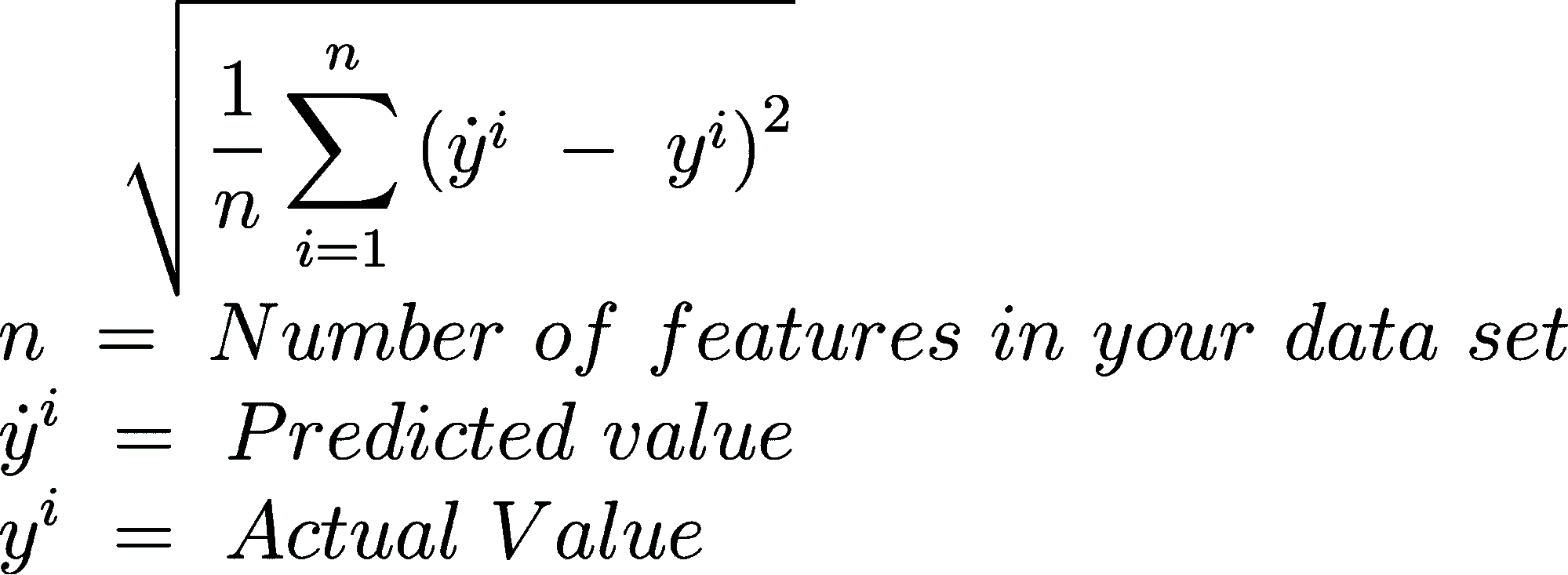
这里 是 Python 中使用 sci-kit learn 实现 RMSE 的代码。
分类
分类算法将数据分成不同的组,并相应地定义它们。
分类评估过程通常包括混淆矩阵,其中包括真实类别和预测类别。(真正例,假正例,真负例,假负例)
这里 是 sci-kit learn 中混淆矩阵的实现。
精度
这是用来评估正预测的准确性。
这里是公式。
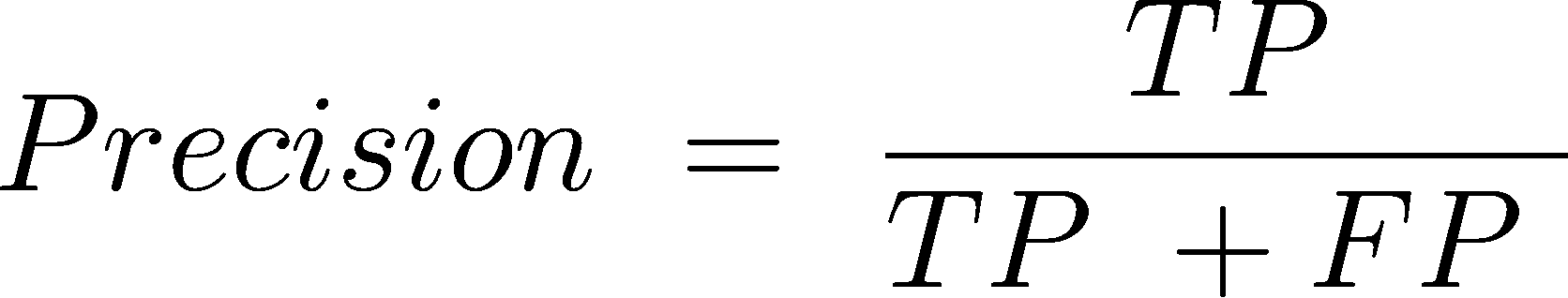
TP = 真正例
FP = 假正例
这里 是 Python 中使用 sci-kit learn 实现精度的代码。
召回率
召回率或敏感性,是算法正确分类的正例的比例。
这里是公式。
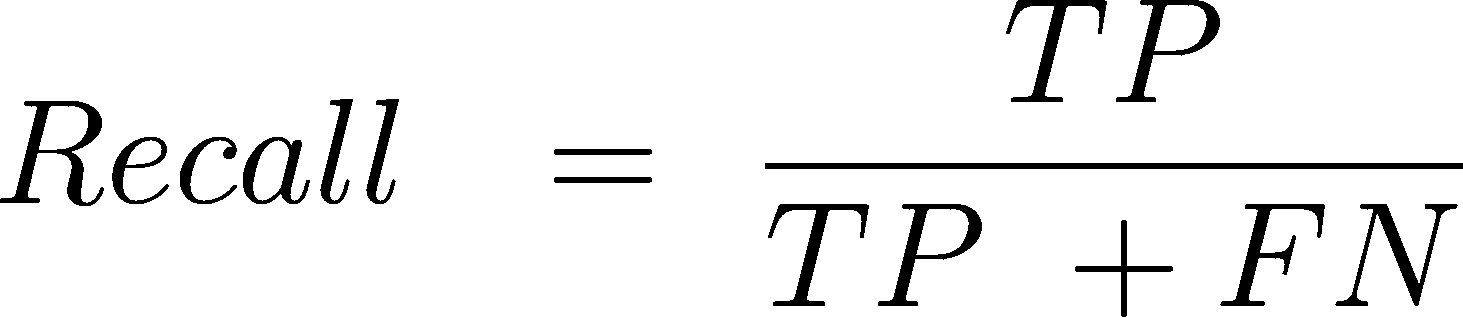
FN: 假阴性
这里 是使用 sci-kit learn 实现召回率的 Python 代码。
F1 分数
这是精确率和召回率的调和平均数。
这是公式
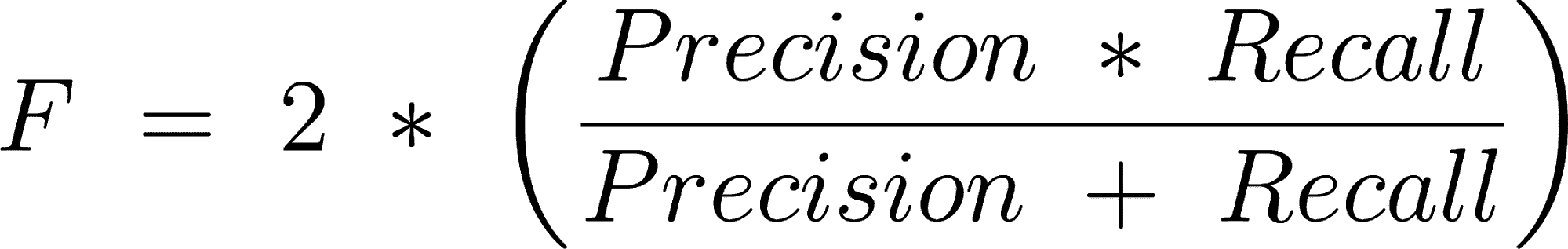
聚类
聚类的第一步是将数据点分组为一个簇。第二步是分配它们。
如果你选择了聚类算法,以下是两个评估指标来解释你模型的表现。我还添加了它们的公式和 sci-kit learn 库的链接。
纯度
纯度是正确分类的总数据点的百分比。
这是公式
要计算纯度,首先应计算 混淆矩阵。
RandIndex
它衡量两个簇之间的相似性。
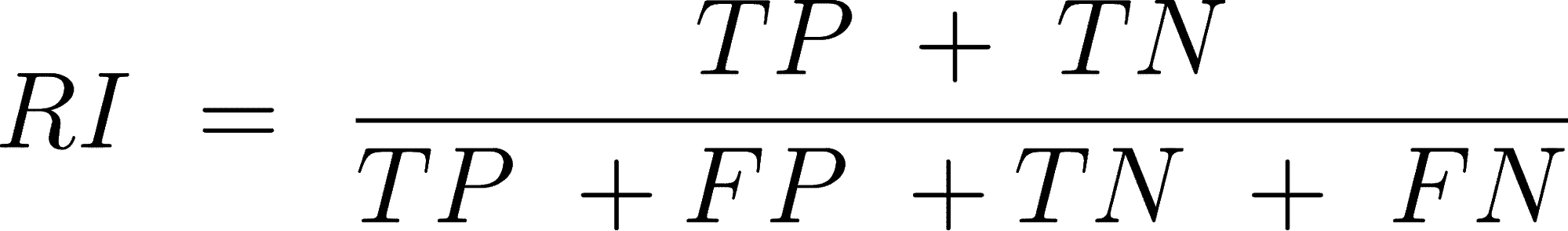
TP = 真阳性
FP = 假阳性
TN = 真阴性
FN = 假阴性
这里 是使用 sci-kit learn 实现 RandIndex 的 Python 代码。
6. 生产中的模型

作者提供的图片
在构建你的机器学习模型之后,是时候通过将模型展示给不同用户来查看其性能了。这儿我将说明如何通过使用 Python 中的两个不同库:Flask 和 Django 来实现。
此外,还有不同的选项来运行和托管你的模型,例如 Heroku、Digitalocean、pythonanywhere.com,你可以将它们用于自己的项目。
使用 Flask 的 Web 应用程序
Flask 是一个 Python 库,允许你编写 Web 应用程序。欲了解更多信息,请访问官方 网站。
假设你开发了一个 机器学习模型 来预测用户的体重,使用体测数据和年龄。
为此,你首先需要访问数据,以便构建多元线性回归。在这里,你可以访问体脂预测的开源 数据集,以创建一个预测体重的机器学习模型。
使用 pythonanywhere.com,你可以同时运行和托管你的模型。
使用 Django REST 的 API
我已经提到过 API 的定义,现在我将提及它的实现选项。你可以通过使用 Django REST 框架来编写你的 API。Django 类似于 flask,是一个微型 Web 框架。通过使用它,你还可以编写应用程序的后台和前台代码,同时编写 API。
让我们谈谈使用 Django REST 开发 API 的优势。
社区活跃,文档丰富。
此外,这里是其他 Python 框架;通过使用这些框架,你可以开发一个 API。
在这六个主要项目阶段之外,这里还有两个额外的阶段。
为你的应用程序添加订阅
你可以在你的 Web 应用程序中包含订阅计划。假设你开发了一个 OCR 算法,旨在通过图像处理从文档中提取信息,比如 Docsumo。
这里是他们定价系统的不同选项。

图片来自 docsumo.com
当然,在将你的 Web 应用程序转变为业务之前,还需要经历许多阶段,但最终目标可能是这样的。
要通过使用 API 获得收入,可以在 网站 上传你的 API,它还包含了成千上万的不同 API。
你可以通过添加不同的订阅选项来实现 API 的货币化,并在之后获得收入。
这是一个面部识别 api,它帮助你将文本转换为语音。这个 API 可能在后台使用 CNN 来识别面部。
图片来自 RapidAPI
如果你想开发一个面部识别算法,可以参考 Adem Geitgay 编写的 教程,该教程解释了面部识别的阶段,而无需深入,并通过开发自己的库使其更易于理解。
模型维护

图片由作者提供
将模型上传到生产环境后,它应该定期维护。由于模型将使用用户的信息,因此你的算法应该定期更新。
假设你构建了一个深度学习模型,用于预测用户照片中两个物体之间的距离。在训练模型时,你可能会使用高质量的图像。然而,现实生活中的数据可能不会达到你期望的质量。
在查看评估指标时,你可能会看到由于技术问题导致模型性能下降。当然,还有许多可能的解决方案来克服这个问题。
其中一种方法是向模型中的图片添加噪声。
这样,你的模型也将具备预测低质量图像的能力。
因此,为了保持模型的性能始终较高,需要定期进行类似的更新。同时,你还应定期关注客户反馈,以确保他们对你的工作感到满意,并排除他们的问题。
最后的想法
创建项目通常从数据收集开始。为了与众不同,使用我在文章中提到的一些或所有数据收集选项。此外,还可以使用不同的开源网站,以获取不同的数据集。
在收集数据、构建管道并将数据转换为正确格式后,接下来是从中提取有意义的信息,通过探索和可视化来完成。下一阶段是构建模型。
在这里,我们检查了模型构建和性能提升算法,以及评估指标。
当然,将模型部署到生产环境中有很多选择,我已经覆盖了一些。
遵循这些阶段将帮助你在项目中取得成功,丰富你的作品集,并获得潜在收入。
随着经验的积累,根据需要在这些阶段之间添加阶段是可以的。
在完成项目后,尝试将这些阶段映射到你的脑海中。因为详细解释这些阶段给面试官,也将帮助你在面试中表现出色并获得新工作。
内特·罗西迪 是一位数据科学家和产品战略专家。他还是一位兼任教授,教授分析学,并且是 StrataScratch 的创始人,这是一个帮助数据科学家准备面试的平台,提供来自顶级公司的真实面试问题。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
更多相关主题
通过维度缩减的数据压缩:3 种主要方法
原文:
www.kdnuggets.com/2020/12/data-compression-dimensionality-reduction.html
评论

照片来自 Anna Tarazevich ,来自 Pexels。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织中的 IT
为什么要减少数据的维度?
如果你在数据科学领域工作了一段时间,你一定听说过这个短语:
维度是一种诅咒。
这也被称为维度灾难。你可以在这里了解更多关于这个术语的信息。
总的来说,高维数据的一些常见缺点包括:
-
模型过拟合
-
聚类算法中的困难
-
非常难以可视化
-
你的数据中可能存在一些无用的特征
-
复杂且昂贵的模型
还有其他缺点,你可以在 Google 上搜索并查看详细信息。
在本文中,我们将讨论三种重要而著名的技术,这些技术将帮助你在减少数据维度的同时保持有用的特征或信息。
这三种基本技术分为两部分。
- 线性维度缩减
-
PCA(主成分分析)
-
LDA(线性判别分析)
- 非线性维度缩减
- KPCA(核主成分分析)
我们将讨论每种技术的基本思想、在 sklearn 中的实际应用,以及每种技术的结果。
PCA(主成分分析)
主成分分析是用于无监督数据压缩的最著名数据压缩技术之一。
PCA 帮助我们识别数据集中的模式,基于它们之间的相关性。或者简单来说,它是一种特征提取技术,通过这种方式将输入变量结合起来,使我们能够丢弃不重要的特征,同时保留数据集中重要的信息。PCA 找到最大方差的方向,并将数据投影到较低维度的空间中。新子空间的主成分可以解释为在新特征轴彼此正交的约束下的最大方差方向。
图片来源:Python 机器学习 repo.
这里,x1 和 x2 是原始特征轴,PC1 和 PC2 是主成分。
在使用 PCA 进行降维时,我们构建一个变换矩阵 W,其维度为 **d x k,这允许我们将样本向量 x 映射到一个新的 k 维特征子空间中,该子空间的维度比原始 d 维特征空间要少。
通常,k 远小于 d,因此第一个主成分具有最大的方差,以此类推。
PCA 对数据缩放非常敏感,因此在使用 PCA 之前,我们必须标准化特征,并将它们调整到相同的尺度。
PCA 在 Python 中从头实现很简单,且在 sklearn 中提供了内置函数。要查看从头实现的代码,请参考这个 repo。我们将回顾 sklearn 中的实现。
Sklearn 代码:
首先,我们必须导入数据集并进行预处理。
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases/wine/wine.data',
header=None)
print(df.head)
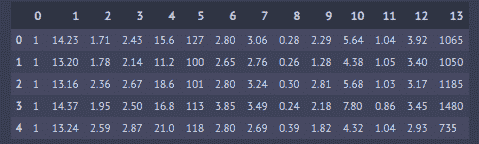
这是我们的数据框,其中第 0 列包含类别标签(1,2,3),第 1 到 13 列包含特征。让我们将它们分别分配给 X 和 y。
X = df.iloc[:, 1:] #all rows, columns starting from 1 till end
y = df.iloc[:, 0] #all rows, only 0th column
现在,让我们将数据集拆分为训练集和测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, random_state=0)
既然我们已经分割了数据集,让我们应用标准化缩放器来标准化我们的特征。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.transform(X_test)
现在,我们要做的就是对它执行 PCA。
from sklearn.decomposition import PCA
#pca = PCA()
现在,我们可以传递我们想要保留多少百分比的方差,或者主成分的数量。例如,如果我们想要保留数据的 80%信息,我们可以使用 pca = PCA(n_components=0.8),或者如果我们希望数据集中有 4 个特征,我们可以使用 pca = PCA(n_components=4)。
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train_std)
print(X_train_pca.shape)
我们可以看到,我们已经从 13 个特征减少到 2 个特征。为了检查我们保存了多少信息,我们可以做
pca.explained_variance_ratio_

为了可视化目的,我们使用了两个特征,因为两个特征可以很容易地进行可视化。我们可以看到,第一个特征有约 36%的信息,而第二个特征有约 18%的信息。因此,我们丢失了 11 个特征,但仍然保留了 55%的信息,这真的很酷。
让我们绘制这两个特征。
colors = ['r','b','g']
markers = ['s','x','o']
for l,c,m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_pca[y_train==l,0],
X_train_pca[y_train==l,1],
c=c, label=l, marker=m)
plt.title("Compressed Data")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.legend()
plt.tight_layout()
plt.show()
现在你可以应用任何机器学习算法,它将比最初在 13 个特征上训练的算法收敛得更快。
类似地,如果我想保留 80%的信息,我只需要做的是
pca1 = PCA(n_components=0.8)
X_train_pca = pca1.fit_transform(X_train_std)
X_test_pca = pca1.transform(X_test_std)
现在我们可以检查X_train_pca的维度。
X_train_pca.shape
>>> (142,5)
结果数据集的前 5 行是
X_train_pca[:6, :]
通过解释方差比
pca1.explained_variance_ratio_

如何选择 PCA 中的维度数
实际上,当你拥有良好的计算能力时,我们通常使用网格搜索来找到最佳超参数数量,也用它来找到提供最佳性能的主成分数量。
如果计算能力不足,我们必须在分类器性能和计算效率之间权衡,以选择主成分的数量。
通过线性判别分析(LDA)进行监督数据压缩
LDA 或线性判别分析是著名的监督数据压缩方法之一。正如“监督”这个词可能已经给你暗示的那样,它考虑了 PCA 中缺失的类别标签。它也是一种线性变换技术,就像 PCA一样。
LDA 使用的方法与 PCA相似,即我们将矩阵分解为特征值和特征向量,然后形成一个低维特征空间。然而,它使用了一种监督方法,意味着它考虑了类别标签。
在对数据应用 LDA 之前,我们假设数据是正态分布的,类别具有相同的协方差矩阵,并且训练样本彼此统计独立。一些研究论文证明,如果这些假设中的一个或多个假设稍微被违反,LDA 仍然表现良好。
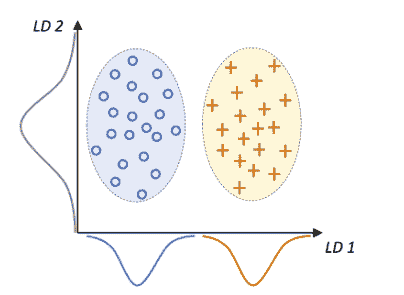
这个图形总结了 2 类问题的 LDA 概念,其中圆圈代表类别 1,+代表类别 2。线性判别 LD 1(x-轴)将很好地分离这两个正态分布的类别。而线性判别 LD 2 捕获了数据集中的大量方差,但由于无法获得任何类别区分信息,它会失败。
在 LDA 中,我们基本上是计算类内和类间散布矩阵。然后,我们计算散布矩阵的特征向量和相应的特征值,对其按降序排序,并选择前 k 个特征向量,这些特征向量对应于 k 个最大特征值,用于构建 d x k 维的变换矩阵 W。然后,我们将样本投影到新的特征子空间中。
我们可以使用以下公式计算 类内散布矩阵:
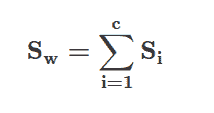
其中 c 是不同类别的总数,Si 是类 i 的个别散布矩阵,通过以下公式计算:
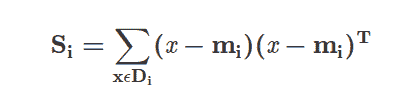
其中 mi 是存储类 i 的样本的均值特征值 μm 的均值向量。
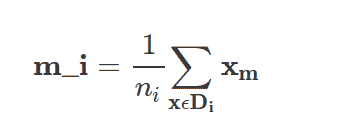
同样,我们可以计算类间散布矩阵 Sb:
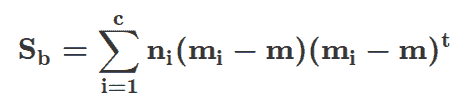
这里,m 是计算出的整体均值,包括所有 c 类别的样本。
在 Python 和 Numpy 中,整个工作并不难,很多人已经完成了。如果你想详细查看从零实现的细节,可以看看这个 repo。
让我们看看它在 Python 的 sklearn 中的实现。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# we have already preprocessed the dataset in PCA, we will use the same dataset
LinearDiscriminantAnalysis 是在 sklearn 的 discriminant_analysis 包中实现的一个类。你可以在 这里 查看文档。
第一步是创建一个 LDA 对象。
lda = LDA()
X_train_lda = lda.fit_transform(X_train_std, y_train)
X_test_lda = lda.transform(X_test_std)
这里需要注意的一点是,在 fit_transform 函数中,我们传递了数据集的标签,并且正如前面讨论的,这是一个监督算法。
这里我们没有设置 n_components 参数,因此它会自动决定从公式 min(n_features, n_classes — 1) 中选择。如果我们隐式提供了大于此的任何值,它将给我们一个错误。有关更多详细信息,请查看 文档。
我们可以通过以下方式检查结果形状
X_train_lda.shape
>>> (124, 2)
由于它是二维的,我们可以轻松地绘制所有类别。我们将使用上面相同的代码进行绘图。
colors = ['r','b','g']
markers = ['s','x','o']
for l,c,m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_lda[y_train==l,0],
X_train_lda[y_train==l,1],
c=c, label=l, marker=m)
plt.title("Compressed Data")
plt.xlabel("LD 1")
plt.ylabel("LD 2")
plt.legend()
plt.tight_layout()
plt.show()
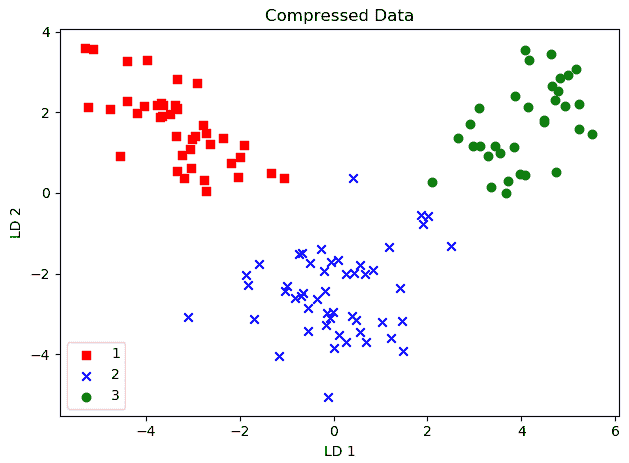
现在,由于我们已经压缩了数据,我们可以轻松地对其应用任何机器学习算法。我们可以看到这些数据是容易线性可分的,因此逻辑回归会给我们相当不错的准确性。
我们在使用 sklearn 的 LDA 时需要注意的一点是,我们不能像在 PCA 中那样以概率形式提供n_components。它必须是整数,并且必须满足条件min(n_features, n_classes — 1)。
LDA 与 PCA
你可能会遇到这样的想法:由于 LDA 也考虑了类标签作为其监督算法,结果在某些情况下显示 PCA 比 LDA 表现更好,比如在每个类包含少量示例的图像识别任务中(PCA Vs LDA, A. M. Martinez, and A. C. Kak, IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(2): 228-233, 2001)。
核 PCA
如前所述,PCA 和 LDA 都是线性降维技术。同样,大多数机器学习算法对数据的线性可分性做出假设,以便完美收敛。
但现实世界并不总是线性的,大多数时候,你必须处理非线性数据集。因此,我们可以看到线性降维技术可能不是这些数据集的最佳选择。
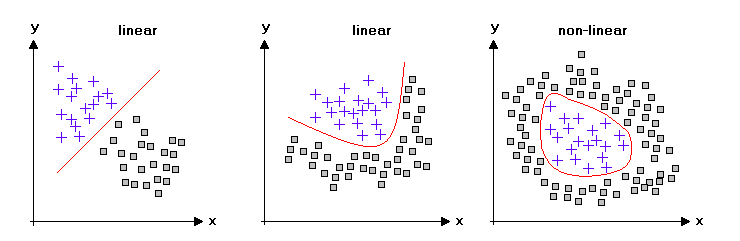
图片来源: statistics4u。
使用 KPCA,我们可以将非线性的数据显示到一个线性子空间中,在这个子空间上分类器表现得非常好。
KPCA 背后的主要思想是我们必须执行一个非线性映射,将数据转换到一个更高维的空间。
换句话说,我们将我们的d-维数据转换到这个更高的k-维空间,并定义一个非线性映射函数ϕ。
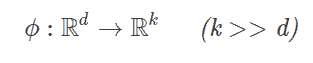
把ϕ看作一个函数,它通过一些非线性映射将原始d-维数据集映射到更大的k-维数据集上。
换句话说,我们执行一个非线性映射,将数据集转换到一个更高维度的空间,在那里我们使用标准 PCA 将数据投影回到一个较低维度的线性可分空间。
这种方法的一个缺点是计算成本非常高。为了克服这个问题,我们必须使用核技巧,通过它我们可以计算原始特征空间中两个高维特征向量之间的相似性。
现在,核技巧背后的数学细节和直觉很难用书面方式解释。我建议你观看加州理工学院的this视频,通过它你可以很好地理解 KPCA 和核技巧背后的数学直觉。
如果你想查看 Python 和 scipy 中的实现,我推荐你查看这个repo,其中逐步实现了这个过程。
我们将查看它在 Python 的 sklearn 中的实现。我们要做的是将一个非线性 2-D 数据集转换为线性 2-D 数据集。请记住,KPCA 会将其映射到更高维度,然后再映射到线性可分的较低维度。
from sklearn.datasets import make_moons #non-linear dataset
from sklearn.decomposition import KernelPCA
import matplotlib.pyplot as plt
import numpy as np
这里我们导入了重要的库和数据集。
X, y = make_moons(n_samples=100)
print(X.shape)
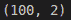
我们可以看到数据集有 100 行和 2 列。让我们查看数据集中类别的数量及其值。
print("Number of Unique Classes", len(np.unique(y)), "\nUnique Values are", np.unique(y))

由于我们有 2 个类别,我们可以轻松绘制它们。
#plotting the first class i.e y=0
plt.scatter(X[y==0,0], X[y==0,1],
color = 'red', marker='^',
alpha= 0.5)
#plotting the 2nd class i.e y=1
plt.scatter(X[y==1,0], X[y==1,1],
color = 'blue', marker='o',
alpha= 0.5)
#showing the plot
plt.xlabel("Axis 1")
plt.ylabel("Axis 2")
plt.tight_layout()
plt.show()
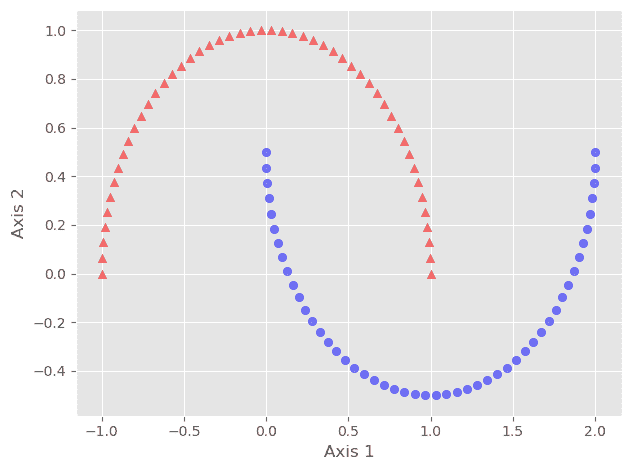
在这里我们可以看到两个类别并不线性可分。我们可以通过任何线性分类器来确认。
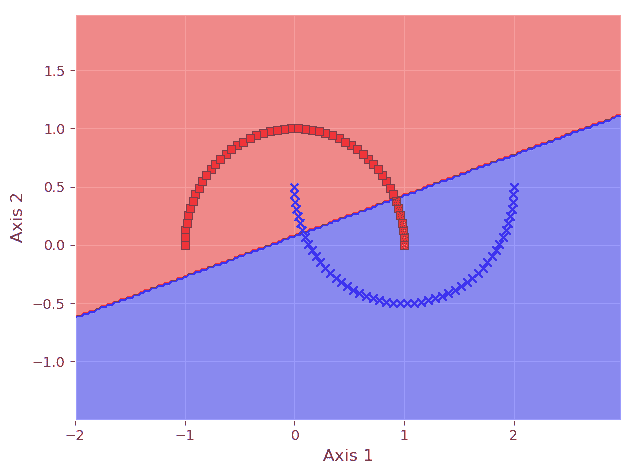
因此,为了使其线性可分,我们将其转换为更高维度,然后再映射回较低维度,全部使用 KPCA。
kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15) #defining the KenrelPCA object
这里我们使用了kernel='rbf'和gamma=15。有不同的核函数可供使用。它们包括linear、poly和rbf。同样,gamma是 rbf、poly 和 sigmoid 核的核系数。关于选择哪个核的详细答案可以在 stats.StackExchange 上阅读,点击这里。
现在我们只需对数据进行变换。
X_kpca = kpca.fit_transform(X) #transforming our dataset
让我们绘制图形以检查现在是否线性可分。
plt.scatter(X_kpca[y==0,0], X_kpca[y==0,1],
color = 'red', marker='^',
alpha= 0.5)
plt.scatter(X_kpca[y==1,0], X_kpca[y==1,1],
color = 'blue', marker='o',
alpha= 0.5)
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
plt.tight_layout()
plt.show()
我们可以看到我们的数据现在是线性可分的,甚至可以通过任何线性分类器来确认。
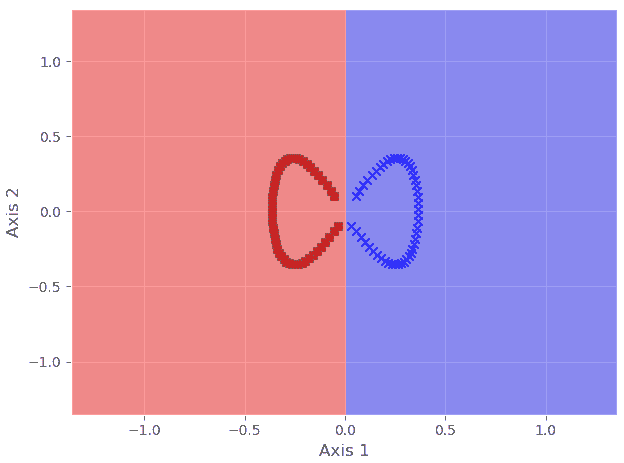
在这个例子中,我们通过使用 KPCA 将一个非线性数据集转换为线性数据集。在接下来的例子中,我们将减少之前在 PCA 和 LDA 中使用的葡萄酒数据集的维度。
kpca = KernelPCA(n_components=2)
X_train_kpca = kpca.fit_transform(X_train_std)
X_test_kpca = kpca.transform(X_test_std)
这将把我们之前的 13 维数据转变为 2 维线性可分的数据。我们现在可以使用任何线性分类器来获得良好的决策边界和良好的结果。
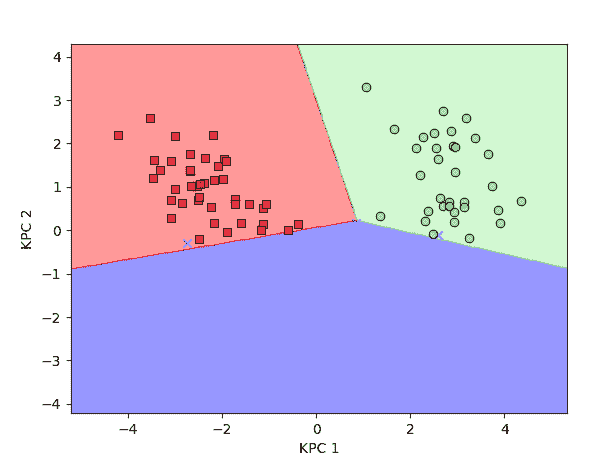
学习成果
在这篇文章中,你学习了 3 种维度降低技术的基础,其中 2 种是线性的,1 种是非线性的或使用了核技巧。你还学习了它们在最著名的 Python 库 sklearn 中的实现。
相关:
更多相关内容
AI 驱动世界中的数据工程格局
原文:
www.kdnuggets.com/2023/05/data-engineering-landscape-aidriven-world.html

图片来自 Bing 图像创作者
其中一个最大的影响是“提示工程”的广泛采用,这本质上是引导 AI 协助编码相关任务的技能。我看到安德烈·卡帕斯基在 Twitter 上开玩笑说:“最炙手可热的新编程语言是英语。”
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速通道进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
生成式 AI 还引发了一场淘金热,数十家非常早期的初创公司竞相开发一种 AI,可以查询数据仓库并用自然语言回答数据消费者提出的临时问题。蒙特卡罗首席技术官Shane Murray评论道:“这将极大简化自助分析过程,并进一步普及数据,但考虑到数据管道的复杂性,对于更高级的分析,超越基本的‘指标提取’会非常困难。”
穆雷提到:“当我评估数据工程候选人时,我关注的是他们的影响力和迅速上手的能力。”这可以体现在他们的主要工作中,也可以通过贡献开源项目体现。在这两种情况下,关键在于你做了什么影响,而不是你是否在那里。
如果你不喜欢变化,数据工程可能不适合你。穆雷提到,“这个领域几乎没有什么没经历过重塑。”显然,构建和维护数据管道的过程将变得更加容易,数据消费者访问和处理数据的能力也将随之提升。
然而,未改变的是数据生命周期。穆雷指出,“数据被生成,经过处理用于某个用途,然后被归档。”他还说:“尽管基础设施可能会变化,自动化将把时间和精力转移到左右两边,但人类数据工程师将继续在从数据中提取价值方面发挥关键作用,无论是架构可扩展且可靠的数据系统,还是作为某一数据领域的专业工程师。”
数据平台团队提供机会
我发现数据平台团队,现在在各种规模的数据团队中相当普遍,是数据工程师锻炼技能的绝佳场所。
默里进一步解释道:“在这里,你可以专注于业务运营中心的特定数据领域,如客户数据或产品/行为数据。在这个角色中,你应当力求理解从源头到分析用例的端到端问题,这将使你成为团队和业务的资产。”
“或者,你可以专注于数据平台的特定能力,如可靠性工程、商业智能、实验或特征工程。”默里指出。“这些角色通常对每个业务用例有更广泛但较浅的理解,但可能是从软件工程角色转向数据的一个更容易的跳跃。”
默里表示,我越来越常看到数据工程师的另一条路径是数据产品经理角色。如果一个人正在提升数据工程技能,但发现自己更倾向于与最终用户沟通,阐明需要解决的问题,并为团队提炼愿景和路线图,那么产品管理角色可能是一个未来的前景。
数据团队正在开始投资于这一技能集,随着我们转向将“数据作为产品”进行处理,从关键仪表盘和决策支持工具到对业务运营或客户体验至关重要的机器学习应用。“优秀的数据产品经理将理解如何构建一个可靠且可扩展的数据产品,同时应用产品思维来推动愿景、路线图和采纳,”默里确认道。
现代数据堆栈
默里阐述了现代数据堆栈正在迅速成为数据工程领域主流的流行技术栈。这个栈以基于云的数据仓库或数据湖为核心,辅以基于云的数据摄取、转化、编排、可视化和数据可观察性的解决方案。
其优势在于具有快速的价值实现时间,从根本上比前一代工具更具用户友好性,可以扩展到各种分析和机器学习用例,并能够扩展到现代世界中管理的数据的规模和复杂性。
“具体的解决方案将根据组织规模和特定数据使用案例有所不同,但通常最常见的现代数据堆栈包括 Snowflake、Fivetran、dbt、Airflow、Looker 和 Monte Carlo。可能还会有 Atlan 和 Immuta 分别用于数据目录和访问,” Murray 解释道。“较大的组织或那些有更多机器学习使用案例的组织通常会有更多地利用 Databricks 和 Spark 的数据堆栈。”
潜在的颠覆
“由 Snowflake 和 Databricks 引发的现代数据堆栈时代尚未达到整合的阶段,我们已经看到可能进一步颠覆现代数据管道现状的想法,” Murray 反思道。“在不久的将来,流数据的更广泛应用、零-ETL、数据共享以及统一的度量层将成为趋势。”零-ETL 和数据共享尤其有趣,因为它们有潜力简化现代数据管道的复杂性,这些管道具有多个集成点,因此也有失败的风险。
技术职位格局
预计技术行业的就业市场将在 2023 年经历重大变化,这一变化由大数据分析的增长推动。根据 Dice Media 的分析,这种变化将发生,因为全球大数据分析市场预计将以 30.7% 的惊人速度增长,到 2030 年预计达到 3462.4 亿美元的价值。这种增长预计将为数据工程师、商业分析师和数据分析师等领域的熟练专业人士创造大量机会。
“我坚信,数据工程工作将不仅仅是编写代码,更将涉及与业务利益相关者的更多沟通和设计端到端系统,”经验丰富的数据工程师和开源爱好者 Deexith Reddy 评论道。“因此,为了确保就业安全,必须同时关注数据分析的广度和数据工程的深度。”
生成性 AI 可能会使数据工程领域变得更具竞争力。然而,在我们的电话会议中,Reddy 还强调,参与开源项目对于建立强大的投资组合总是有益的,考虑到技术进步和最近的 AI 突破。
Reddy 进一步阐述了数据工程师在利用开源技术提升组织能力方面的关键角色。例如,数据工程师广泛采用了如 Apache Spark、Apache Kafka 和 Elasticsearch 等开源技术,数据科学家则使用 Kubernetes 来进行数据科学实践。这些开源技术帮助满足深度学习和机器学习负载以及 MLOps 工作流的计算需求。
公司通常会从这些开源项目中识别和招募顶尖贡献者,营造一个重视并鼓励开源贡献的环境。这种方法有助于留住技术熟练的数据工程师,并使组织能够从他们的专业知识中受益。
Saqib Jan 是一位作家和技术分析师,对数据科学、自动化和云计算充满热情。
更多相关主题
五个有趣的数据工程项目
评论
由德米特里·里亚博伊,Zymergen 的软件工程副总裁。
最近数据工程领域活动频繁,过去几年涌现出了大量有趣的项目和想法。这篇文章是对我认为数据工程师需要了解的五个项目的介绍。
DBT

DBT,或称“数据构建工具”,是对一个本质上简单的想法的清晰且执行良好的实现:用于执行重要工作的 SQL 语句应进行版本控制,并且最好能轻松参数化,可能相互引用。DBT 针对的是“数据分析师”,而不是数据工程师(尽管没有理由数据工程师不能使用它)。一切都在 SQL 中完成(嗯,还有 YAML)。
通过清晰地构建项目的布局、查询如何引用其他查询的工作方式以及配置中需要填充的字段,DBT 强制执行了许多优秀的实践,并大大改进了经常是混乱的工作流程。有了这些功能,它不仅可以运行你的工作流,还可以生成文档、帮助你运行验证和测试查询、通过包共享代码等。它提供了一个温和的上手方式,并为分析师提供了许多强大的工具,如果她选择利用这些工具,就可以充分发挥作用——如果不利用,就可以不干涉。
如果你或你生活中的某个人经常使用 SQL,他们需要了解一下 DBT。
Prefect

Prefect 是一个新兴的 AirFlow 挑战者:另一个数据管道管理器,它帮助设置 DAG 过程、参数化它们、适当响应错误条件、创建时间表和处理触发器等。如果你忽略它们稍显傲慢的营销(显然,Prefect 已经是“数据流自动化的全球领导者”,而 Airflow 只是一个“历史上重要的工具”),Prefect 有几个值得称道的地方,赢得了大量用户的赞誉:
-
它将实际的数据流与作业管理的调度/触发方面清晰分开,使得反向填充、临时运行、并行工作流实例等变得更容易实现。
-
它具有一个 neat 的功能性(以及类似 Airflow 的命令式风格)API来创建 DAG。
-
它避免了 Airflow 的 XCom 陷阱,即通过一种奇怪的侧通道在任务之间传递数据,这种方法偶尔会出现问题,而是依赖于透明的(除了在它出问题的时候)序列化和个别任务的显式输入/输出。
-
它使得 处理参数
你可以在 Airflow 中完成所有这些工作,但 Prefect 团队认为他们的 API 提供了更干净和直观的方式来解决这些及其他挑战。他们似乎赢得了不少赞同者。
Dask

人们还在忽视 Dask 吗?停止忽视 Dask 吧。
“Dask 是一个‘灵活的 Python 并行计算库’。如果你经常用 Python 进行数据工作,主要使用 NumPy / Scikit-learn / Pandas,你可能会发现引入 Dask 可以让事情变得非常顺畅。它轻量且快速,无论是在单机还是集群上都表现良好,它与 RAPIDS 协同工作,以获得 GPU 加速,并且相对于将你的 Python 代码迁移到 PySpark,可能会更容易进行扩展。他们有一份意外平衡的文档,讨论了 Dask 与 Spark 的优缺点,详细信息见 docs.dask.org/en/latest/spark.html。”
DVC

DVC 代表“数据版本控制”。这个项目邀请数据科学家和工程师进入一个受 Git 启发的世界,在这里,所有工作流版本都被跟踪,以及所有数据工件和模型,还有相关的指标。
说实话,我对“数据的 git”以及各种自动化数据/工作流版本控制方案持有一些怀疑态度:我过去看到的各种方法要么过于局部而不够有用,要么需要数据科学家在工作方式上做出过于剧烈的改变,才有可能被实际采纳。因此,我忽略了,甚至有意回避了查看 DVC。现在我终于看了一下……看起来也许这个方案有前途?与分支/版本关联的指标是一个很棒的功能。将类似 git 的分支概念与训练多个模型结合,使得价值主张变得清晰。它的实现方式是使用 Git 进行代码和数据文件索引存储,同时利用可扩展的数据存储进行数据管理,通过聪明的重用来降低整体存储成本,看起来是合理的。他们在 dvc.org/doc/understanding-dvc 上提到的很多内容都很真实。Thoughtworks 使用 DVC 作为他们的演示工具来 讨论“CD4ML”。
另一方面,我并不特别热衷于将管道定义交给 DVC —— Airflow 或 Prefect 或其他许多工具似乎在这方面提供了更多。对互联网资源的随意浏览揭示了多次提到将 DVC 与 MLFlow 或其他工具一起使用,但尚不清楚这如何运作以及会放弃什么。
不过,DVC 是每当出现“数据的 git”或“ML 的 git”问题时总会被提到的技术。它绝对值得关注和留意。
Great Expectations

Great Expectations 是一个非常好的 Python 库,允许你声明规则,期望某些数据集符合这些规则,并在遇到(生成或消费)这些数据集时进行验证。这些期望可能包括 expect_colum_values_to_match_strftime_format 或 expect_column_distinct_values_to_be_in_set。
将这些视为数据断言并没有错。期望可以使用多种常见的数据计算环境(Spark、SQL、Pandas)进行评估,并且可以与包括上述的 DBT 和 Prefect(当然还有 Airflow)在内的各种工作流引擎无缝集成。他们文档中的 介绍 和 期望词汇表 部分相当自解释。
除了提供定义和验证这些断言的方法外,Great Expectations 还提供了自动化数据分析工具,生成期望值并清理 HTML 数据文档。这有多酷?
这不是一个完全新颖的想法,但它似乎执行得很好,且该库正在获得关注。
奖励环节
也许这是后 Hadoop 时代的影响,也许是云计算的原因,也许只是因为 Python 终于有了类型提示,但确实很难将有趣的项目列表缩小到五个。这里是我个人非常希望花时间研究的一些项目,按照字母顺序排列,希望你这个坚持到现在的读者也会喜欢:
-
Amundsen 是来自 Lyft 的一个有趣的“数据发现和元数据平台”。每个自尊心强的科技独角兽似乎现在都有这样一个平台。我们能否停下来选出一个赢家?
-
Cadence 是一个“容错的有状态代码平台”,换句话说,就是一种将有关函数中长期状态的常见问题外包给其他人的方法。无论如何,抽时间观看这个视频,考虑一下它在你生活中的应用:
www.youtube.com/watch?v=llmsBGKOuWI -
Calcite 是解构数据库的核心,提供 SQL 解析器、数据库无关的查询执行规划器和优化器等功能。它 可以在这里找到,出现在许多支持 SQL 的“大数据”项目中(Hive、Flink、Drill、Phoenix 等)。
-
Dagster 是 GraphQL 的创始人开发的数据工作流引擎,旨在以 GraphQL 对前端工程师的影响方式来改变数据工程师的开发体验。这是个好东西,可能值得单独写一篇文章。
-
Json-Schema 并不是什么新东西,但出于某种原因,人们似乎不知道它的存在。它存在,它在不断发展,你应该定义和验证你的架构。这里有规格,这里有工具,你可以将它应用于现有的 JSON API 中,而不必羡慕 Avro/Thrift/Proto。
原文。已获授权转载。
相关:
了解更多此主题
数据工程技术 2021
原文:
www.kdnuggets.com/2021/09/data-engineering-technologies-2021.html
评论
由 Tech Ninja, @techninjathere 提供,开源、分析和云计算爱好者。

顶级工程技术的部分列表,图片由 KDnuggets 创建。
完整策划的数据工程新兴技术列表
-
Abacus AI,企业级 AI,带有 AutoML,与 DataRobot 类似。
-
Algorithmia,企业级 MLOps。
-
Amundsen,开源的数据发现和元数据引擎。
-
Anodot,实时监控所有数据,快速检测事件。
-
Apache Arrow,因其非 JVM、内存中、列式格式和矢量化而至关重要。
-
Apache Calcite,用于构建 SQL 数据库和数据管理系统的框架,不需要拥有数据。Hive、Flink 等使用 Calcite。
-
Apache HOP,促进所有数据和元数据的调度。
-
Apache Iceberg 是用于大规模分析数据集的开放表格式。
-
Apache Pinot,实时分布式 OLAP 数据存储。其增长令人印象深刻,虽然与 Druid 相似,但并不完全相同!
-
Apache Superset,开源 BI,提供许多连接器。
-
Beam,实现可以在任何执行引擎上运行的批处理和流处理数据作业。
-
Cnvrg,企业级 MLOps。
-
Confluent,Apache Kafka 及其生态系统。
-
Dagster,机器学习的数据调度器,非常注重编程,类似于 Airflow,但强调状态流。
-
DASK,纯 Python 的数据科学。
-
DataRobot,强大的 ML 平台,专注于企业 MLOps。
-
Databricks,凭借新的 SQL 分析和湖屋论文,期待更多令人惊叹的开源软件。
-
DataFrame Whale 是一个简单的数据发现工具。
-
Dataiku,企业级 AI/MLOps 平台。
-
Delta Lake, 在 Apache Spark 上的 ACID。
-
DVC,开源版本控制系统,适用于 ML 项目,MLOps 中的理想选择。
-
Feast,开源特征存储,现在与 Tecton 一起使用。
-
Fiddler,企业级可解释 AI。
-
Fivetran,数据集成管道。
-
Getdbt 正在通过提供简化的基于 SQL 的管道来精准匹配 Apache Spark 的需求。
-
Great Expectations,数据科学测试框架,它已经非常棒了!
-
Hopswork 开源 MLOps 功能存储。
-
Hudi 将事务、记录级更新/删除和变更流带入数据湖。
-
Koalas Pandas 在 Apache Spark 上。
-
Kubeflow 项目致力于在 Kubernetes 上创建简单、可移植和可扩展的机器学习工作流。
-
lakeFS 使你可以像管理代码一样管理数据湖。运行并行管道进行实验和数据的 CI/CD。
-
maiot-ZenML 开源 MLOps 框架,具有各种功能。
-
Marquez 开源元数据工具,具有出色的用户界面。
-
Metabase 一个开源 BI 工具,具有出色的可视化效果。
-
MLFlow 一个机器学习平台。
-
Montecarlodata 数据治理、数据发现或数据可观测性。
-
Nextflow 数据驱动的计算管道,旨在生物信息学领域,但可以超越该领域。
-
Pachyderm MLOps 平台,类似于 MLFlow。
-
Papermill 使笔记本参数化,使数据科学更加令人兴奋和易于访问。
-
Prefect 旨在使工作流管理比 Apache Airflow 更加简便和高效。
-
RAPIDS 数据科学在 GPU 上。
-
Ray 分布式机器学习,现在也支持流处理。
-
Starburst 通过使分布式数据的访问更快、更容易,释放其价值。
-
Tecton 企业功能存储。
-
Trino,即 PrestoSQL,现在与 Presto 明确分离,Trino 可以专注于功能开发。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业轨道。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持你的组织的 IT
按字母顺序重新排序,基于此原始文献。经许可转载。
相关:
更多相关话题
数据工程——数据科学的“表亲”,颇具挑战
原文:
www.kdnuggets.com/2021/01/data-engineering-troublesome.html
评论
作者:Lissie Mei,Visa 数据科学家。
我们总是认为数据科学是“21 世纪最性感的工作”。当涉及到从传统公司向分析公司转型时,公司的期待或数据科学家们都希望尽快进入数据分析的炫目世界。但情况总是如此吗?
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业之路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
一个麻烦的开始
自从我们 UC Davis 的实习团队开始与 Hilti,一家领先的电动工具及相关服务制造公司,合作以来,我们制定了几个精彩的蓝图:定价自动化、倾向模型……与这样一家伟大的公司合作对我们而言是一个宝贵的机会,我们迫不及待地想要发挥我们的分析技能以创造商业价值。但当我们开始接触数据时,我们发现,与数据驱动的公司如电子商务公司相比,从传统公司直接获取干净且结构化的数据是非常困难的。
由于我主要负责项目的数据清理和工程,我亲眼见证了由于数据准备不足,我们在分析进展中受到的阻碍。

我亲眼见证了由于数据准备不足,我们在分析进展中受到的阻碍。
我们直接与财务团队合作,但另一个团队,定价运营,实际上负责数据库的管理。最初,由于我们几乎无法及时请求和查询数据或联系相关人员,流程进展缓慢。此外,由于 Hilti 的销售数据较为敏感,公司缺乏安全的数据传输方式,每次数据请求都需要耗时的数据掩码处理。第三,数据工程的不足导致了多个参考表之间的不一致,我们几乎无法建立可靠的模型或得出结论。最后,我们必须处理各种数据类型:CSV、JSON、SQLite 等……虽然这是一个学习的好机会。
大约两个月后,我们准备好了所有的数据,每一个异常情况也都被讨论并解决。
深入探索时间!
我们精心开发的可视化框架和模型迫不及待想要尝试新数据。然而,当我们用实际数据展示第一个提案时,最尴尬的事情发生了。
猜猜怎么了?那些大数字似乎对不上。经过简短的讨论,我们意识到我们根本没有收到完整的数据。我们只关注了数据的细节,例如异常值和数据源之间的关系,却忘记了进行基本的检查,比如总和和计数。这是我将终身铭记的教训。真的!
数据工程为何如此重要
我从数据工程的经历中学到的最重要的一点是,那些在幕后工作的角色,如数据工程师,实际上掌握了创新的门户。当传统公司考虑利用数据时,最有效且最初的行动应该是改善数据工程流程。拥有优秀的数据工程师,公司可以构建一个健康且可扩展的数据管道,这使得数据分析师进行数据挖掘和发现商业洞察变得更容易。
我还了解到,为什么许多公司要求数据分析师掌握编程相关工具,比如 Python 和 Scala,除了分析工具如 SQL 和 Excel。通常,我们不能期待一个“全栈”分析师,但确实需要有能够与工程人员和管理人员沟通的人。尽管明确的工作分配对高效率很重要,但每个数据工具的专家确实很有吸引力。

全栈……有道理!
我期待自己未来能够学习前端和后端的知识,比如 Java、JavaScript、Kafka、Spark 和 Hive,我相信这些最终会成为我经验中的亮点。
原文。经授权转载。
相关:
相关话题
数据无处不在,它驱动着我们所做的一切!
原文:
www.kdnuggets.com/2020/08/data-everywhere-powers-everything.html
评论
由 Pradeep Adaviswamy 提供,Bahwan CyberTek 的区域分析经理

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
大自然赋予了我们火、水、空间、空气和土地这五大元素或资源,现在我们需要将数据也加入到这个列表中。
 自然也通过 DNA 处理自身的数据集,并且这些数据是有机组织的。现在我们有责任有效地利用我们拥有的数据。
自然也通过 DNA 处理自身的数据集,并且这些数据是有机组织的。现在我们有责任有效地利用我们拥有的数据。
我们都在大量生成数据,现在组织面临的挑战是策划和货币化这些数据,以便在市场上变得具有竞争力,实现生存,并为其产品和服务带来创新和盈利。
在本文中,我希望重点讨论公司如何启动以数据为中心的策略,以及如何在数据转型过程中取得成功。
一些组织拥有正确的“成分”(数据),他们需要提出正确的洞察以便利用这些数据;而另一些组织则拥有正确的用例,他们需要找到正确的“成分”(数据)来解决和实现这些用例。这两种方法都有效,关键在于他们的数据战略的整体成功,以实现最终的商业目标和目的。
数据货币化是新的全球经济,无论是老牌公司、大公司、小公司还是初创公司,都必须智能地捕获、存储、处理和消费数据。这必须是一个持续的反馈循环数据周期。有大量的工具和技术可以处理这个数据周期,但成功取决于组织的方向和治理。
行业研究和实地经验表明,永远不要采用“大干快上”的方法(‘大思考,小开始’),在建立企业数据项目时,始终设立临时检查点。组织不应认为拥有大数据/数据湖设置或人工智能实验室就能解决所有的数据分析需求。
如果公司采用以数据为中心的架构方法,并有一个全面的管理机构,那么将会繁荣,否则,仅仅拥有数据湖/中心是无法带领公司前进的。数据湖必须得到维护、策划和保护等,不能仅仅被视为企业数据存储解决方案,否则数据将会过时。

公司应始终致力于制定数据战略,这些数据战略应促进数据治理的民主化和企业数据素养,这可以成为整体业务绩效的催化剂,赋能用户,并带来自主性。
 组织不应鼓励团队走捷径,只追求眼前的成功(如果他们的整体愿景是长期的)。我将这种处理数据的捷径过程称为'数据乱穿马路'。如果公司想要进行商业智能、分析或数据科学,业务单元的领导应确保数据工程师、分析师和数据科学家不采取任何不科学的捷径。他们应避免在执行任务和构建 AI 模型时出现盲点。整体成功不应仅通过概念验证(PoC)或 AI 实验室原型结果来衡量,而应通过大规模部署和对业务及最终用户的影响来衡量。
组织不应鼓励团队走捷径,只追求眼前的成功(如果他们的整体愿景是长期的)。我将这种处理数据的捷径过程称为'数据乱穿马路'。如果公司想要进行商业智能、分析或数据科学,业务单元的领导应确保数据工程师、分析师和数据科学家不采取任何不科学的捷径。他们应避免在执行任务和构建 AI 模型时出现盲点。整体成功不应仅通过概念验证(PoC)或 AI 实验室原型结果来衡量,而应通过大规模部署和对业务及最终用户的影响来衡量。
数据领导者(如首席信息官、首席数据官、首席分析官等)应始终提出正确的数据问题,参与并监督数据策划、数据准备阶段及审查,以建立一个强大的组织数据语料库。这将为分析、数据科学/AI 模型构建和部署打下基础,同时与 AI 模型治理相结合。
一旦数据语料库准备好,组织可以获得合适的工具来构建和获取洞察。在数据分析的过程中,组织可能会遇到一些困难,比如在将数据策略付诸实践时可能面临的挑战(例如,挑战可能来自架构、数据基础设施、能力、运行成本、业务用户的期望、人员等)。这些挑战必须尽早解决和克服。
公司必须把数据视为其增长的关键,以便保持竞争力、变得更加智能、创新,并为任何无法预见的市场惊喜做好准备。
希望这篇文章的内容对你有帮助,并与你的经验和想法产生共鸣?欢迎分享你的想法、反馈和评论。
简介:Pradeep Adaviswamy 是 Bahwan CyberTek 的区域分析经理。他在解决方案设计与架构、大数据、商业智能、数据科学与分析、企业数据湖、数据管理与数据治理(DMBoK)、ETL、数据仓库、数据建模、数据可视化和人工智能等方面拥有约 17 年的经验。
原文。经许可转载。
相关:
-
每位数据科学家需要向商业领袖学习的内容
-
向您的大数据提出的 3 个关键数据科学问题
-
数据分析中的 5 大趋势
更多相关话题
机器学习的数据结构 – 第二部分:构建知识图谱
原文:
www.kdnuggets.com/2019/06/data-fabric-machine-learning-building-knowledge-graph.html
评论

介绍
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
在系列文章的最后:
[机器学习的数据结构。第一部分。
如何利用语义的新进展提高我们在机器学习中的表现。 towardsdatascience.com
[机器学习的数据结构。第 1-b 部分:图上的深度学习。
图上的深度学习日益重要。在这里,我将展示思考机器学习的基础... towardsdatascience.com
我已经在谈论数据结构的一般情况,并给出了一些数据结构中机器学习和深度学习的概念。同时也给出了我对数据结构的定义:
数据结构是支持公司中所有数据的平台。它的管理、描述、组合和普遍访问方式。该平台由企业知识图谱构成,以创建统一的数据环境。
如果你查看定义,它会说数据结构是由企业知识图谱形成的。因此,我们最好了解如何创建和管理它。
目标
一般
建立知识图谱理论和构建的基础。
细节
-
解释与企业相关的知识图谱概念。
-
关于建立成功的企业知识图谱提供一些建议。
-
展示知识图谱的例子。
主要理论
数据结构中的数据结构是通过知识图谱构建的,要创建知识图谱,你需要语义和本体来寻找有效的方式将数据链接起来,以独特地识别和连接具有共同业务术语的数据。
第一部分。什么是知识图谱?

medium.com/@sderymail/challenges-of-knowledge-graph-part-1-d9ffe9e35214
知识图谱由整合的数据和信息集合组成,并且还包含大量不同数据之间的链接。
关键在于,在这种新模型下,我们正在寻找答案。我们希望获得事实——这些事实来自哪里并不那么重要。这里的数据可以表示概念、对象、事物、人物,实际上可以是你脑海中想到的任何东西。图谱填补了概念之间的关系和连接。
在这种情况下,我们可以向数据湖提问:
这里有什么?
我们在这里的情况不同。一个可以建立框架来研究数据及其与其他数据关系的地方。在知识图谱中,以特定形式的本体表示的信息可以更容易被自动信息处理访问,如何最好地实现这一点是计算机科学如数据科学中的一个活跃研究领域。
所有数据建模声明(以及其他所有内容)在本体语言和知识图谱的世界中本质上都是渐进的。事后增强或修改数据模型可以通过修改概念来轻松完成。
通过知识图谱,我们正在构建一个人类可读的数据表示,这个表示唯一标识并连接了带有共同业务术语的数据。这个“层”帮助最终用户自主、安全、可靠地访问数据。
记得这个图像吗?

我之前提出过,数据结构中的洞察力可以被看作是其中的一个缺口。发现这种洞察力的自动化过程就是机器学习。
但这个结构是什么?它是由知识图谱形成的对象。就像在爱因斯坦的相对论中,结构是由时空的连续体(或离散体?)构成的,这里,结构是在你创建知识图谱时建立的。
构建知识图谱需要链接数据。链接数据的目标是以一种可以轻松消费并与其他链接数据结合的方式发布结构化数据,本体则是我们连接实体并理解它们关系的方式。
第二部分:创建成功的企业知识图谱

www.freepik.com/free-vector/real-estate-development-flat-icon_4167283.htm
不久前,Sébastien Dery 撰写了一篇关于知识图谱挑战的有趣文章。你可以查看一下:
[知识图谱的挑战
从字符串到事物——介绍 medium.com](https://medium.com/@sderymail/challenges-of-knowledge-graph-part-1-d9ffe9e35214)
来自伟大的博客cambridgesemantics.com
[学习 RDF
介绍 这组课程是对 RDF 的介绍,RDF 是语义网的核心数据模型和基础…… www.cambridgesemantics.com](https://www.cambridgesemantics.com/blog/semantic-university/learn-rdf/)
还有更多的资源,其中一个我在任何文章中都没有提到但非常重要的概念是三元组:主题、对象和谓词(或实体-属性-值)。通常,当你学习三元组时,它们实际上指的是资源描述框架(RDF)。
RDF 是三种基础语义网技术之一,另外两种是 SPARQL 和 OWL。RDF 是语义网的数据模型。
注意:哦,顺便提一下,几乎所有这些概念都是随着对万维网语义的新定义而来的,但我们将其用于一般的知识图谱。
我不打算在这里提供框架的完整描述,但我会给你一个它们如何工作的示例。请记住,我这样做是因为这是我们开始构建本体、链接数据和知识图谱的方式。
让我们看一个示例,看看这些三元组是什么。这与 Sebastien 的示例密切相关。
我们将从字符串“geoffrey hinton”开始。

这里我们有一个简单的字符串,它表示第一个边界,即我想了解更多的内容。
现在开始构建知识图谱,系统首先会识别到该字符串实际上指的是Geoffrey Hinton。然后,它会识别与此人相关的实体。
然后我们有一些与 Geoffrey 相关的实体,但我们还不知道它们是什么。
顺便提一下,如果你不认识这是Geoffrey Hinton:

然后系统会开始给关系命名:
现在我们有了命名的关系,我们知道我们的主要实体的连接类型。
该系统可以继续寻找连接的连接,从而创建一个巨大的图谱,代表我们“搜索字符串”的不同关系。
为此,知识图谱使用三元组。像这样:
要获得一个三元组,我们需要一个主题和对象,以及一个连接这两者的谓词。
正如你所看到的,我们有主体
这就是知识图谱形成的方式,以及我们如何使用本体论和语义来链接数据。
那么,我们需要什么来创建一个成功的知识图谱?来自 Cambridge Semantics 的 Partha Sarathi 写了一篇关于此的精彩博客。你可以在这里阅读:
自从 Google 在 2012 年通过一篇关于增强网页搜索的流行博客主流化知识图谱以来,企业们…… blog.cambridgesemantics.com
总结来说,他表示我们需要:
-
构思它的人: 你需要具备一些形式的业务关键领域专业知识和技术交集的人才。
-
数据多样性及其可能的高容量:企业知识图谱的价值和采用规模与其所涵盖的数据多样性成正比。
-
构建它的好产品: 知识图谱需要具备其他要求,包括良好的治理、安全性、与上游和下游系统的易连接性、可规模化分析性,并且通常需要适应云环境。因此,用于创建现代企业知识图谱的产品需要优化自动化,支持多种输入系统的连接器,提供基于标准的数据输出到下游系统,迅速分析任何数据量,并使治理用户友好。
你可以在这里阅读更多内容:
企业知识图谱帮助公司连接复杂的数据源。通过 Anzo®,你可以设计、构建…… info.cambridgesemantics.com
第三部分 知识图谱示例
Google:

Google 基本上是一个庞大的知识(不断扩展)图谱,他们基于此创建了也许是最大的数据结构。Google 拥有数十亿个事实,包括有关数百万个对象的信息及其之间的关系。它允许我们在其系统中进行搜索,以发现其中的见解。
在这里你可以了解更多:
LinkedIn:

我最喜欢的社交网络 LinkedIn 拥有一个庞大的知识图谱基础,建立在 LinkedIn 上的“实体”之上,如成员、职位、头衔、技能、公司、地理位置、学校等。这些实体及其之间的关系构成了职业世界的本体论。
洞察帮助领导者和销售人员做出业务决策,并提升 LinkedIn 的会员参与度:
engineering.linkedin.com/blog/2016/10/building-the-linkedin-knowledge-graph
记住,LinkedIn(以及几乎所有)知识图谱需要随着新成员注册、新职位发布、新公司、技能和职位在成员资料和职位描述中出现等情况进行扩展。
你可以在这里阅读更多内容:
作者:Qi He, Bee-Chung Chen, Deepak Agarwal engineering.linkedin.com](https://engineering.linkedin.com/blog/2016/10/building-the-linkedin-knowledge-graph)
金融机构的知识图谱:
概念模型用于协调来自不同来源的数据,并创建受管控的数据集以供业务使用。
在 这篇文章 中,Marty Loughlin 展示了平台 Anzo 如何帮助银行,你可以看到这项技术不仅与搜索引擎相关,而且能够处理不同的数据。
在那里,他展示了知识图谱如何帮助这种机构:
-
替代数据用于分析和机器学习
-
利率互换风险分析
-
交易监控
-
欺诈分析
-
特征工程与选择
-
数据迁移
还有更多内容。去看看吧。
结论

要创建知识图谱,你需要语义学和本体来找到一种有效的方式将数据链接起来,这样可以唯一标识并连接具有共同业务术语的数据,从而建立数据结构的基础。
当我们构建知识图谱时,需要形成三元组以使用本体和语义连接数据。同时,知识图谱的制造基本上依赖于三点:构思它的人、数据的多样性和一个良好的构建产品。
我们周围有许多我们甚至不知道的知识图谱。世界上最成功的公司正在实施和迁移他们的系统,以构建数据结构,并且当然包括其中的所有内容。
个人简介:Favio Vazquez 是一名物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是西班牙语数据科学出版物 Ciencia y Datos 的创作者。他喜欢新挑战,和优秀团队合作,以及解决有趣的问题。他是 Apache Spark 合作项目的一部分,帮助开发 MLlib、Core 和文档。他热衷于运用自己的知识和专长于科学、数据分析、可视化和自动学习,助力世界变得更美好。
原文。经许可转载。
相关链接:
-
我在敏捷数据科学研究中的最佳技巧
-
如何实时监控机器学习模型
-
2018 年 AI/机器学习进展:Xavier Amatriain 总结
更多相关主题
机器学习的数据织物——第一部分
原文:
www.kdnuggets.com/2019/05/data-fabric-machine-learning-part-1.html
评论 图片由Héizel Vázquez提供
图片由Héizel Vázquez提供
阅读第 1-b 部分:关于数据织物的深度学习:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
[机器学习的数据织物。第 1-b 部分:图上的深度学习。
图上的深度学习日益重要。在这里,我将展示机器学习的基本思路……towardsdatascience.com](https://towardsdatascience.com/the-data-fabric-for-machine-learning-part-1-b-deep-learning-on-graphs-309316774fe7)
介绍
如果你在线搜索机器学习,你会发现大约 2,050,000,000 个结果。是的,真的。很难找到适合所有用途或案例的描述或定义,但有一些很棒的定义。在这里,我将提出一种不同的机器学习定义,着重于一种新的范式——数据织物。
目标
概述
解释数据织物与机器学习的关系。
具体内容
-
给出数据织物及其创建生态系统的描述。
-
用几句话解释什么是机器学习。
-
提出一种在数据织物中可视化机器学习洞察的方法。
主要理论
如果我们能构建一个支持公司所有数据的数据织物,那么在其中获得的商业洞察可以被看作是一个凹痕。发现这个洞察的自动过程被称为机器学习。
第一部分:什么是数据织物?

我曾讨论过数据织物,并给出了一个定义(我会在下面再次提供)。
在谈论数据织物时,我们应提到几个词汇:图谱、知识图谱、本体论、语义、链接数据。如果你想要这些定义,请阅读上面的文章;然后我们可以说:
数据架构是支持公司所有数据的平台。它如何被管理、描述、组合和普遍访问。这个平台由企业知识图谱构成,以创建一个统一的一致的数据环境。
让我们把这个定义拆分开来。首先我们需要的是一个知识图谱。
知识图谱由整合的数据和信息集合组成,这些集合还包含大量不同数据之间的链接。关键在于,在这个新模型下,我们在寻找一个答案。我们想要的是事实——这些事实的来源并不重要。这里的数据可以表示概念、对象、事物、人物,实际上可以是任何你能想到的东西。图谱填充了这些概念之间的关系和连接。
知识图谱还允许你为图中的关系创建结构。通过它,可以建立一个框架来研究数据及其与其他数据的关系(记得本体论吗?)。
在这种情况下,我们可以向我们的数据湖提出这个问题:
这里有什么?
数据湖的概念也很重要,因为我们需要一个地方来存储我们的数据、管理它并运行我们的任务。但我们需要一个智能数据湖,一个了解我们拥有什么及如何使用它的地方,这就是拥有数据架构的一个好处。
数据架构应该是统一和一致的,这意味着我们应该努力将组织中的所有数据集中到一个地方,并真正管理和治理这些数据。
第二部分:什么是机器学习?
www.cognub.com/index.php/cognitive-platform/
机器学习已经存在了一段时间了。关于它有很多很好的描述、书籍、文章和博客,所以我不会用 10 段文字来让你感到乏味。
我只是想澄清一些要点。
机器学习不是魔法。
机器学习是数据科学工作流的一部分。但不是全部。
机器学习需要数据来存在。至少现在是这样。
好的,之后,让我给出一个稍微借用并个性化的机器学习定义:
机器学习是通过使用能够提取数据模式的算法,自动理解数据及其表示中的模式,而不需要专门为此编程,从而创建解决特定(或多个)问题的模型。
你可以同意这个定义,也可以不同意,目前文献中有很多很好的定义,我只是认为这个定义简单且对我想表达的内容很有用。
第三部分:在数据架构中进行机器学习
在爱因斯坦的引力理论(广义相对论)中,他在数学上提出了质量可以扭曲时空,而这种扭曲就是我们理解的引力。我知道如果你不熟悉这个理论,它可能听起来有些奇怪。让我试着解释一下。
在特殊相对论的“平坦”时空中,引力缺席,力学定律呈现出特别简单的形式:只要没有外力作用于物体,它将以恒定速度沿直线在时空中运动(牛顿的第一运动定律)。
但当我们有质量和加速度时,我们可以说我们在引力的作用下。正如惠勒所说:
时空告诉物质如何移动;物质告诉时空如何弯曲。

在上面的图像中,“立方体”是对时空结构的表示,当质量在其中移动时,它会扭曲它,“线条”的移动方式会告诉我们附近的物体如何在那个附近表现。所以引力就像是:
所以当我们有质量时,我们可以在时空中制造一个“凹痕”,在接近这个凹痕时,我们看到的就是引力。我们必须足够接近这个物体才能感受到它。
这正是我提出的机器学习在数据结构中的作用。我知道我听起来很疯狂。让我解释一下。
假设我们已经创建了一个数据结构。对我来说,最好的工具是 Anzo,正如我在其他文章中提到的。

你可以用 Anzo 构建一个叫做“企业知识图谱”的东西,当然也可以创建你的数据结构。
图谱的节点和边灵活地捕捉到每个数据源的高分辨率副本——无论是结构化还是非结构化。图谱可以帮助用户快速、互动地回答任何问题,让用户与数据对话以发现洞察力。
顺便说一下,这就是我对洞察力的描绘方式:
 图片来源:Héizel Vázquez
图片来源:Héizel Vázquez
如果我们有数据结构:
 图片来源:Héizel Vázquez
图片来源:Héizel Vázquez
我提议的观点是,洞察力可以被认为是数据结构中的一个凹痕。发现这个洞察力的自动过程就是机器学习。
 图片来源:Héizel Vázquez
图片来源:Héizel Vázquez
所以现在我们可以说:
机器学习是使用能够发现这些洞察力的算法的自动过程,这些算法没有被特别编程为此,以创建解决特定(或多个)问题的模型。
通过数据架构生成的洞察本身就是新数据,这些数据作为数据架构的一部分变得显而易见。也就是说,洞察可以扩展图谱,可能会产生进一步的洞察。
在数据架构中,我们面临一个问题,即尝试发现数据中的隐藏洞察,然后通过机器学习来发现它们。这在现实生活中会是什么样子?
Cambridge Semantics 的团队也有答案。Anzo for Machine Learning 解决方案用现代数据平台替代了这种繁琐且易出错的工作,旨在快速集成、协调和转换来自所有相关数据源的数据,形成优化的机器学习准备特征数据集。
数据架构提供了先进的数据转换功能,这对快速有效的特征工程至关重要,有助于从无关的噪声中分离出关键业务信号。
记住,数据优先,这一新范式通过内置的图数据库和语义数据层集成并协调所有相关的数据源——无论是结构化数据还是非结构化数据。数据架构传达了数据的业务背景和含义,使业务用户更容易理解和正确利用数据。
可重复性对数据科学和机器学习非常重要,因此我们需要一种简单的方法来重用协调的结构化和非结构化数据,通过管理数据集目录以及数据集成的持续方面,如数据质量处理,这正是数据架构所提供的功能。它还保留了机器学习数据集的数据端到端传承和来源,使得在生产中使用模型时容易找出所需的数据转换。
在接下来的文章中,我将给出一个在这个新框架下进行机器学习的具体示例。
结论
机器学习并不新颖,但有一种新的范式来实现它,也许它是该领域的未来(我真是太乐观了)。在数据架构中,我们有像本体、语义、层次、知识图谱等新概念;但所有这些都可以改善我们对机器学习的思考方式和实践。
在这个范式中,我们通过使用能够发现这些洞察而不需特别编程的算法,来在数据架构中发现隐藏的洞察,以创建解决特定(或多个)问题的模型。
感谢 Ciencia y Datos 的优秀团队对这篇文章的帮助。
感谢你阅读这篇文章。希望你在这里发现了一些有趣的内容 😃。如果这些文章对你有帮助,请与朋友分享!
如果你有问题,欢迎在 Twitter 上关注我:
[Favio Vázquez (@FavioVaz) | Twitter
来自 Favio Vázquez (@FavioVaz) 的最新推文。数据科学家,物理学家和计算工程师。我有一个…twitter.com](https://twitter.com/faviovaz)
和 LinkedIn:
[Favio Vázquez — 创始人 — Ciencia y Datos | LinkedIn
查看 Favio Vázquez 在 LinkedIn 上的个人资料,这是世界上最大的职业社区。Favio 有 16 个职位在列…www.linkedin.com](https://www.linkedin.com/in/faviovazquez/)
再见 😃
简介:Favio Vazquez 是一位物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一本用西班牙语出版的数据科学刊物。他喜欢迎接新挑战,和优秀的团队合作,以及解决有趣的问题。他是 Apache Spark 合作项目的一部分,参与 MLlib、Core 和文档的工作。他热衷于应用他的科学、数据分析、可视化和自动学习知识与专长,以帮助世界变得更美好。
原文。经许可转载。
相关:
-
我对敏捷数据科学研究的最佳建议
-
如何实时监控机器学习模型
-
人工智能/机器学习进展的年度回顾:Xavier Amatriain 2018 总结
更多相关内容
数据善用:以数据驱动的社会公益项目
原文:
www.kdnuggets.com/2014/07/data-for-good-data-driven-projects-social-good.html
由 Grant Marshall 撰写,2014 年 7 月
数据善用是一个新的非盈利组织,旨在展示那些更具利他主义的数据科学项目和资源。通过类似 Hacker News 或 Reddit 的格式,用户可以提交相关网站的链接,展示数据科学如何提供社会公益。发布到数据善用上的项目应对更广泛的受众友好,旨在向政府决策者展示数据能为他们做些什么。
图 1:数据善用项目标题的词云
网站上展示的项目种类繁多,涵盖了从 API、视频到展示城市如何利用数据平衡预算的报告等多个主题。如上所示,项目的重点是赋权“市民”或回馈“社区”。这些以社会为导向的术语主导了发布到网站上的项目标题,表明网站正致力于推广旨在提供社会公益的数据科学项目。
例如,网站首页上现在的危机网络是一个用于从多个来源以单一标准格式访问危机数据的 API。另一个适合发布到数据善用的例子是这个视频,展示了数据分析办公室如何利用数据科学解决纽约市非法油脂处理的问题。
图 2:数据善用过去两周的帖子数量
如上图所示(创建于 2014 年 7 月 22 日),尽管第一周的帖子数量每日不稳定(这些帖子主要来自两个独立用户),但在过去几天中,每日的帖子数量已经趋于稳定。此外,帖子现在来自各种用户,显示出该网站开始形成更为活跃的社区。这对网站来说是一个好兆头,希望这种社区参与的趋势能持续下去。
该项目恰逢数据科学提供社会公益的一个非常吉利的时机,KDD 2014 的主题是社会公益的数据科学,而DataKind则致力于将数据科学家与 NGO 连接起来以实现社会公益。将数据科学应用于改善社会的兴趣似乎正在上升。
总的来说,Data for Good 正在承担展示数据对社会能做什么这一崇高使命。如果他们继续成长,并且围绕该网站形成社区,Data for Good 可能会发展成为一个宝贵的资源,用于发现数据科学社区中面向社会的科学家所需的机会和资源。
相关内容:
-
KDD Cup 2014 – 预测 DonorsChoose.org 上的兴奋度
-
比尔及梅琳达·盖茨基金会资助:为社会公益提供大数据
-
美国开放数据行动计划及数据集
更多相关主题
数据治理与可观测性,解读
原文:
www.kdnuggets.com/2022/08/data-governance-observability-explained.html
数据治理和数据可观测性在组织中越来越受到采用,因为它们构成了一个详尽却易于操作的数据管道的基础。两三年前,组织的目标是创建足够的概念验证,以赢得客户对基于 AI 产品的信任,即使是一个简单的 AI 功能也会成为区分因素。它可以轻松地在竞争中占据优势。
然而,在今天的环境中,基于 AI 的功能已成为话题,并且成为保持竞争力的必要条件。这就是为什么今天的组织关注于建立一个坚实的基础,以使数据解决方案与常规软件的生产一样无缝且高效。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
因此,让我们深入了解数据可观测性和数据治理的来龙去脉,这两个是建立更强大数据基础的关键。
数据可观测性是什么?
数据可观测性是一个相对较新的术语,它解决了保持不断增长的数据可控的需求。随着创新的增长和在企业界的广泛采用,托管数据解决方案的技术栈变得更加高效。但与此同时,它们也变得更加复杂和精细,这使得它们难以维护。
组织面临的最常见问题是数据停机。数据停机是指数据不可靠的期间。这可能表现为数据错误、不完整数据或不同来源之间的数据差异。没有可靠的数据,就没有希望实现最先进的解决方案。
这就是数据可观测性发挥作用的地方,使数据维护变得可管理。这种新兴的需求催生了可观测性工程这一新兴领域,该领域有三个高级组件。简单来说,这些组件是数据可观测性用于聚合数据的格式:
-
指标: 指标是对在特定时间范围内测量的数据的累积度量。
-
日志: 日志是记录在不同时间点发生的事件。
-
追踪: 追踪是分布式环境中相关事件的记录。
为什么数据可观测性是必要的?
数据可观测性提供了预测数据行为和异常的额外优势,这有助于开发者提前设置资源和准备。数据可观测性的关键能力在于找出导致记录数据性能的根本原因。例如,如果欺诈检测模型的敏感度评分相对较低,数据可观测性将深入分析数据,探究为什么评分相对较低。
这一能力至关重要,因为与普通软件中大多数结果受代码控制不同,在机器学习软件中,大多数结果超出了解决方案的控制范围。这是因为数据是独立因素,只需一个异常事件就能使解决方案失效。一个这样的数据中断例子是疫情,它扰乱了就业率、股票趋势、投票行为等。
同样,很可能一个在某个数据组(例如,某个州的数据)上表现 consistently 的解决方案在另一个数据组上表现糟糕。
因此,了解性能背后的为什么在评估任何数据解决方案的输出时成为首要任务。
数据可观测性如何不同于数据监控?
可观测性通常被称为监控 2.0,但它是监控的一个更大的超集。可观测性更像是工程师的助手,通过考虑系统的深层状态来确定系统是否按预期工作。让我们回顾一下几个区分可观测性与监控的要点:
上下文
可观测性不仅仅跟踪/监控系统中的脉冲。它还考虑到那些影响系统功能的脉冲的上下文。
深度
监控跟踪系统的表面层脉冲以了解性能。相比之下,可观测性记录痕迹(或相关事件),建立必要的联系,并总体跟踪系统的深层内部状态。
行动
尽管监控的输出主要是反映系统性能或资源消耗的数字,但可观测性的输出则是行动建议。例如,监控会指出系统已经消耗了 100 GB 的内存。相比之下,可观测性会说明内存消耗是否不理想,以及是否需要开发者的干预来进行优化。
ML 监控与 ML 可观测性
可观测性已经是 DevOps 框架的一部分很长时间了。然而,在 MLOps 社区中,对其需求也越来越明显。此外,随着数据变得更加复杂,数据管道变得更复杂且难以跟踪。因此,当我们将可观测性融入机器学习世界时,定义 ML 监控和 ML 可观测性之间的关键区别是重要的。
观察能力的核心要素在 ML 观察能力中从头到尾得到体现。ML 监控仅收集关于解决方案的高级输出或成功指标的数据,如敏感度和准确性。之后,它会根据预设的阈值发送警报。
另一方面,ML 观察能力深入探讨记录的性能背后的原因。最后,通过评估数据行为,关联验证、测试和传入数据的见解,找出根本原因。
数据观察的支柱
数据观察力是几个关键特性或支柱的总和,这些支柱并行运行以改善数据健康:
图 1:数据观察的支柱 | 图片由作者创建
数据新鲜度
如广泛所知,任何 ML 解决方案都不及数据的好坏。因此,确保数据的新鲜性至关重要,因为旧的和不相关的数据会对组织的资源、硬件和劳动力造成负担。数据观察力寻求提供最佳路径来更新数据表,并帮助决定更新的最佳频率。
数据分布
数据分布是 ML 最基本的概念之一,因此被高度认为是数据观察力的支柱之一。数据分布是了解手头的数据是否在期望范围内的一种方式。换句话说,它是检查数据采样是否正确的方式。
数据量
正如其名,数据量只是跟踪数据的进出交易量。因此,应跟踪数据量的突然变化,并确保所有可用数据源的正常运行。
架构
架构是数据存储的框架。每个数据架构都被组织中的多个团队访问,每个团队具有不同的访问级别(编辑、查看等)。因此,数据的变化是不可避免的,必须通过适当的数据版本控制设施进行跟踪。需要记录谁进行了更改、何时进行更改以及为什么进行更改。此外,同时进行的更改如果架构没有能力处理这种情况,可能会导致数据不一致。
数据沿袭
数据沿袭,简单来说,就是数据的故事。它叙述了数据从 A 点到 B 点的过程。这是由于传入数据源的变化、架构中数据处理的差异,还是人工更改?一个强大的数据沿袭可以回答这些问题及更多问题。跟踪数据沿袭的主要目标是准确了解在数据出现问题时需要关注的地方。由于机器学习管道因涉及多个实验而复杂,实验跟踪 工具和平台在理解数据在多个实验、模型和数据版本中的使用和历程时非常有用。
数据隐私和安全
如前所述,数据访问通常因团队和个人而异。数据安全和隐私是确保数据健康的一些主要指标。数据更新中的一个新手错误或数据落入错误之手可能会破坏整个数据谱系,并对组织造成巨大的成本。
元数据
元数据是关于数据的信息。作为数据监控的超集,数据可观察性不仅仅查看数据以追踪干扰的根本原因,还观察元数据以发现数据变化的趋势。 元数据存储确保每个关键机器学习阶段的元数据被跟踪和存储,以易于阅读和访问的方式建立可靠且可重复的机器学习管道。
数据可观察性的支柱在构建和管理公司数据骨干的基础时至关重要。
一种良好的数据可观察性解决方案如何帮助您的组织?
在选择数据可观察性解决方案时,必须牢记数据可观察性的支柱。一个好的解决方案可以显著改善组织的数据生态系统健康。良好的解决方案改变组织动态的一些方式包括:
主动避免数据问题
由于数据可观察性通过元数据和性能检查跟踪数据行为的变化,它可以提前警告机器学习工程师,以防止关键数据情况的发生,并采取主动修复措施。
映射的辅助
一个好的数据可观察性解决方案不需要被告知它需要监控哪些指标。事实上,借助机器学习模型,它可以帮助识别关键指标、依赖关系、变量、进出资源。 元数据存储和实验跟踪功能对于保持高清晰度的映射是必需的。
监控静态数据
监控静态数据时,不需要将数据加载进来。这可以通过节省内存、处理器和时间等资源来节省大量成本。这也使得数据解决方案在不妥协性能的情况下变得可扩展。
背景
数据可观察性的关键能力之一是通过追踪和建立数据与结果之间的适当联系来找到根本原因。当你拥有一个 AI 助手,它指出某一特定行的错误及其原因时,它将背景带入视图,并使数据问题的修复更加迅速。
安全性
安全性,作为数据可观察性的支柱之一,自然是一个关键关注点,因为它可能在数据中造成巨大干扰。因此,数据可观察性确保了最佳的安全性和合规性。
自动配置
数据可观察性解决方案使用 ML 模型评估数据、元数据和 ML 解决方案,以确定环境、关键指标和潜在危机(如性能下降低于特定阈值)的因素。因此,它消除了维护和处理几乎总是变化的复杂规则的需求。
轻松适配
一个好的数据可观察性解决方案是灵活的,并且可以轻松集成到现有的 ML 堆栈中。除非 ML 堆栈组织较差,否则团队无需进行任何更改或重写模块。这很好,因为它节省了许多资源。它还允许评估不同的解决方案,并快速找到合适的解决方案。
数据可观察性是一个广阔的领域,上述要点仅涉及常见问题。因此,让我们深入探讨数据治理,看看它如何适应创建完美的数据管道。
什么是数据治理?
数据治理是一套标准和规则,旨在维护整个数据管道中的数据质量。由于 AI 和 ML 等新兴技术在很大程度上依赖于数据这一独立变量,因此认证数据质量至关重要。
重要的是要注意,数据治理不是数据管理,而是围绕最佳执行建立策略和政策,并分配适当的角色和职责。
数据治理的好处
在如今数据解决方案竞争日益激烈的环境中,数据治理是必不可少的。以下好处将更好地说明为什么如此:

图 2:数据治理的好处 | 作者创建的图像
端到端视图
数据治理致力于实现数据的单一真实。然而,数据往往在新兴组织中跨多个团队和利益相关者共享而没有任何跟踪措施。这导致多个数据版本,产生数据不一致和不满意的最终客户。为所有团队提供 360 度视图的单一真实来源是解决上述问题的关键。
更好的数据质量
数据治理确保数据完整且数据来源可靠。它还负责数据的正确性。
数据映射
多个团队经常访问用于特定解决方案的数据用于其他目的。例如,咨询团队可能访问数据转储以解决升级问题。因此,为了防止任何混淆,需要一个所有利益相关者或用户都可以参考的一致关键。
更好的数据管理
数据治理通过引入最新技术和自动化来提升现有的数据管理方法,以提高效率和减少错误。
安全性
数据治理处理数据安全问题,并解决所有合规性要求。这导致端到端数据管道的干扰最小,因为安全问题是主要障碍,并且需要很长时间才能解决。
数据治理挑战
数据治理是一个相对较新的学科,因此组织在初始设置阶段面临一些常见挑战。其中一些包括:
缺乏业务理解
数据通常被认为完全由 IT/开发团队拥有和管理。这存在一个主要缺陷,因为 IT 团队没有端到端的业务视角,无法做出关键决策。因此,在数据收集过程中,客户提供必要数据或从其他来源收集数据时,会存在差距。
如果缺少只有全面业务团队才能识别的功能,数据将会是次优的。除非整合业务理解,否则当利益相关者传达结果时,也会存在相当大的差距。
无法识别痛点
数据治理的工作是解决数据管道中的问题。然而,如果参与者无法识别优先事项和痛点,数据治理标准可能会因试错循环而花费更长时间。
缺乏灵活性
数据管理通常需要多个审批。例如,在处理客户请求时,可能发现客户的数据会占用大量空间,超过了可用硬件限制。这会启动层级审批链。即使这是一个简单的过程,但由于时间的重大影响,效率低下。
预算限制
数据解决方案通常需要大量内存和高处理能力等复杂资源。不幸的是,这些资源可能对团队来说是禁区,尤其是在数据团队仍处于新兴和发展的组织中。为了弥补预算和资源的不足,需要制定次优的解决方案,影响数据生态系统的健康。
如果我们深入探讨,将会发现许多新的和不同的挑战。每个组织都有不同的特性,面临各种各样的挑战。关键是开始行动,并在问题出现时加以解决。
数据治理工具
在选择数据治理工具时,最好从成本效益高和快速的选项开始。因此,可靠的开源解决方案或处理重负担的云平台非常适合用于测试。这些重负担包括轻松添加新功能、简单集成、即时可用的硬件或服务器能力等。
让我们看看在缩小数据治理工具范围时应该考虑的一些要点:
-
提升数据质量: 数据治理工具应能在无需干预的情况下清理、优化和验证数据。
-
无缝管理数据: 工具应集成高效的 ETL(提取、转换、加载)过程,以便轻松追踪数据血统。
-
记录数据: 文档是任何过程中的最被低估的参与者,即使它为团队保留和传递了最大的价值。记录数据是必要的,以便提高可重复性、可搜索性、访问性、相关性和连接性。
-
具有高度透明性: 工具应提供高度透明性给任何管理或使用它的人。它应该像一个助手一样,帮助用户明确任务、沟通点和不作为的影响。
-
审查数据: 数据、数据趋势、访问点和数据健康状况不断变化,需要密切监控。因此,定期审查可以保持数据的最新性,避免潜在的故障。
-
捕捉数据: 数据治理工具应自动发现、识别和捕捉关键数据点。
-
提供敏感洞察: 数据治理工具应理解数据,并最终提供关键洞察,以帮助制定数据管道中的下一步行动。
总的来说,在选择数据治理工具时,易用性也应成为主要关注点之一,因为用户与工具之间的高摩擦最终会拖慢过程。
15 个数据治理最佳实践
尽管最佳实践是主观的并且取决于组织的现状,但这里列出了开始时的十五个常见数据治理实践:
-
开始行动: 迈出第一步,从小处开始,制定增量计划。
-
定义目标: 增量计划必须有明确的目标,不仅分配给数据治理的参与者,还分配给每个过程和阶段。目标当然需要现实、可达成,并且朝着正确的方向展开。
-
通过所有权确保问责: 分配目标固然不够,每个数据治理参与者需要拥有过程并承诺他们的成功。认证所有权的最佳方法可能是将绩效 KPI 与过程关联起来。
-
强调团队成长: 为了让团队进步,并使个体玩家在层级之间的表现相当,高层过程所有者应直接对低层过程所有者负责。这可以激发问责制、团队合作,从而提高效率。
-
涉及利益相关者: 业务利益相关者的见解至关重要,以确保他们在没有模糊或困惑的情况下贡献自己的部分。因此,最好教育他们有关数据治理架构的知识。
-
融入业务理解: 理解业务目标和组织的目标对于构建组织的数据骨干至关重要。例如,公司是致力于短期成功还是长期持久?公司有何合规要求?公司期望从数据解决方案中获得多少利润?这些数据必须在制定数据治理政策之前收集。
-
融入框架: 数据治理必须合理地融入组织现有的框架和基础设施中。除非组织是初创公司并且能够承受流程调整,否则不推荐进行重大干扰。
-
优先级排序: 在实施数据治理过程中会出现大量问题。领导层应负责确定哪些问题需要尽早解决,哪些问题可以等待。
-
标准化: 在初期阶段,标准化数据流程可能是一项昂贵的过程,但从长远来看,它能大幅节省成本。标准化有助于解决多个方面的问题,包括消除数据差异、一次性数据接入、减少沟通中的来回反复、高效利用现有硬件等等。
-
定义指标: 我们能得到我们所衡量的结果,这一点在数据治理中同样适用。识别出可以定义过程成功与失败的关键指标,并非常小心地选择阈值。确保这些指标与业务 KPI 和结果直接相关。这将帮助业务团队更好地理解指标。
-
商业提案: 准备好一个商业提案,列出数据治理能为组织带来的优势和利益。预算谈判、上下线目标以及节省的时间应进行估算并呈现给相关部门。
-
无缝沟通: 确保团队之间的无缝沟通,因为高效的沟通是推动每个过程的关键杠杆。团队间的沟通常常复杂,因为人们不确定该联系谁。确保定义过程负责人,并保持任务的高度透明,以便个人可以迅速找到联系人。
-
确保合规: 遵循合规规则的预先规划策略有助于顺利推进。然而,在过程中的意外合规问题可能会很复杂,并且肯定需要大量时间处理。
-
引入专家: 一个由学习者和专家组成的团队能够驱动效率。外部专家带来行业内的数据治理额外知识,而内部人员则与他们合作,提供对组织动态的全方位视角。当两种知识结合时,可以激发出卓越的视角和洞察力。
-
准备备用计划: 考虑到预算请求未被批准或关键资源失效的情况。记录下应对这些情况的最快且高效的解决办法。
总的来说,重要的是要记住“一刀切”并不适用所有情况。因此,虽然了解行业最佳实践是很好的,但不建议回避实验,以找到最适合你组织和文化的做法!
结论
数据可靠性正成为日益关注的问题,原因在于数据量的不断增加和不可靠来源的增多。因此,作为机器学习解决方案核心的数据显示出极大的重要性。即使是最先进的解决方案,如果没有高质量的数据支持,也可能会失败。
组织在人工智能时代的头几年通过执行多个数据解决方案的概念验证后开始意识到这一点。不幸的是,结果是这些解决方案在特定数据集和特定时间内有效,但很快就会失败并变得不相关,即使重新训练也是如此。这就是为什么开发人员希望理解失败背后的原因,这可以通过主动监控和深入分析来明显实现。
因此,数据治理和数据可观测性在当今快速变化的竞争环境中变得至关重要。尽管它们是相对较新的学科,但它们与一些成熟的领域如云数据架构、虚拟框架、机器学习等交叉重叠。各行业的采纳率将很快使它们成为前沿领域。在此之前,让我们开始为即将到来的变革奠定基础吧!
参考资料
towardsdatascience.com/what-is-data-observability-40b337971e3e
www.montecarlodata.com/beyond-monitoring-the-rise-of-observability/
www.montecarlodata.com/automated-data-quality-testing-at-scale-with-sql-and-machine-learning-2/
www.montecarlodata.com/the-26-things-your-data-observability-platform-must-do/
www.montecarlodata.com/the-new-rules-of-data-quality/
www.montecarlodata.com/data-observability-in-practice-using-sql-1/
www.montecarlodata.com/demystifying-data-observability/
www.montecarlodata.com/data-observability-the-next-frontier-of-data-engineering/
www.montecarlodata.com/what-is-data-observability/
www.eckerson.com/articles/data-observability-a-crucial-property-in-a-dataops-world
blog.layer.ai/experiment-tracking-in-machine-learning/
profisee.com/data-governance-what-why-how-who/
www.talend.com/resources/what-is-data-governance/
Samadrita Ghosh 是 Censius 的产品营销经理
更多相关内容
数据导入与 Pandas:初学者教程
原文:
www.kdnuggets.com/2022/04/data-ingestion-pandas-beginner-tutorial.html

图片由作者提供
Pandas 是一个易于使用的开源数据分析工具,广泛用于数据分析、数据工程、数据科学和机器学习工程。它具有强大的功能,如数据清理与操作、支持流行的数据格式以及使用 matplotlib 的数据可视化。大多数数据科学学生只学习导入 CSV,但在工作中,你必须处理多种数据格式,如果这是你第一次做,事情可能会变得复杂。在本指南中,我们将重点介绍导入 CSV、Excel、SQL、HTML 和 JSON 数据集。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
SQL
要运行 SQL 查询,我们需要下载用于 Kaggle 科技行业心理健康 的 SQLite 数据库,许可证为 CC BY-SA 4.0。该数据库包含三个表:Questions、Answer 和 Survey。
SQL Schema | Kaggle
要从任何 SQL 服务器导入数据,我们需要创建连接(SQLAlchemy 可连接对象 / sqlite3),编写 SQL 查询,并使用 Pandas 的 read_sql_query() 函数将输出转换为数据框。在我们的案例中,我们将首先使用 sqlite3 包连接 mental_health.sqlite,然后将对象传递给 read_sql_query() 函数。最后一步是编写查询以从 Question 表中导入所有列。如果你是 SQL 新手,我建议你通过参加一个免费的课程来学习基础知识:Learn SQL | Codecademy。
import pandas as pd
import sqlite3
# Prepare a connection object
# Pass the Database name as a parameter
conn = sqlite3.connect("mental_health.sqlite")
# Use read_sql_query method
# Pass SELECT query and connection object as parameter
pdSql = pd.read_sql_query("SELECT * FROM Question", conn)
# display top 5 rows
pdSql.head()
我们已经成功将 SQL 查询转换为 Pandas 数据框。就是这么简单。
HTML
网络抓取在技术世界中是一项复杂且耗时的工作。你将使用 Beautiful Soup, Selenium,和 Scrapy 来提取和清理 HTML 数据。使用 Pandas read_html(),你可以跳过所有步骤,直接将网站上的表格数据导入数据框。这就是简单。在我们的案例中,我们将抓取 COVID-19 疫苗接种追踪器 网站,以提取包含 COVID19 疫苗接种数据的表格。
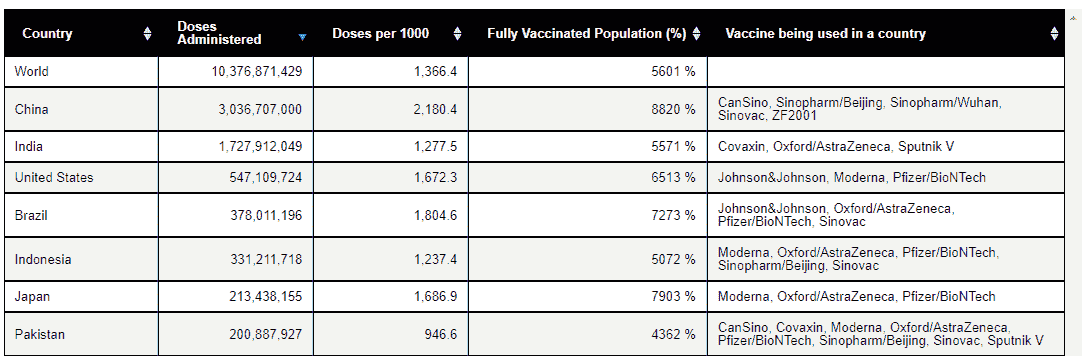
COVID19 疫苗接种数据 | 制药技术
仅使用pd.read_html()我们就能够从网站中提取数据。
df_html = pd.read_html(
"https://www.pharmaceutical-technology.com/covid-19-vaccination-tracker/"
)[0]
df_html.head()
我们的初始输出是列表,若要将列表转换为数据框,我们在末尾使用了[0]。这只会显示列表中的第一个值。
注意: 你需要对初始结果进行实验,以获得最终的结果。
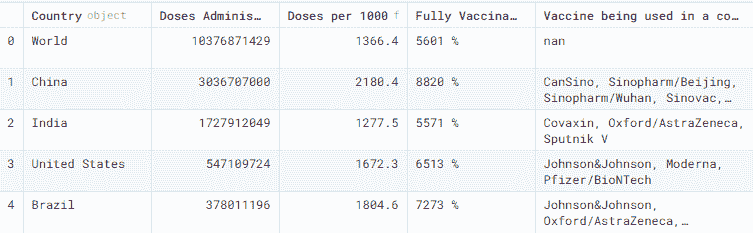
CSV
CSV 是数据科学中最常见的文件格式。它简单易用,可被多个 Python 包访问。你在数据科学课程中学到的第一件事就是导入 CSV 文件。在我们的案例中,我们使用的是 Kaggle 的 共享单车数据集,其遵循 CC0: 公共领域 许可证。CSV 中的值由逗号分隔,如下所示。

作者提供的图片
我们将使用read_csv()函数将数据集导入 Pandas 数据框。这个函数非常强大,因为我们可以解析日期、删除缺失值,并且只用一行代码就能进行大量数据清理。
data_csv = pd.read_csv("day.csv")
data_csv.head()
我们成功加载了 CSV 文件并显示了前五行。
Excel
Excel 表格在数据和业务分析专业人员中仍然很受欢迎。在我们的案例中,我们将使用 Microsoft Excel 将 美国总统与债务 数据集(由 kevinnayar 提供,遵循 CC BY 2.0 许可证)转换为.xlsx格式。我们的 Excel 文件包含两个工作表,但 Pandas 数据框是一个平面表,我们将使用sheet_name将选定的工作表导入 Pandas 数据框。
作者提供的图片
我们将使用read_excel()导入数据集:
-
第一个参数是文件路径。
-
第二是 sheet_name:在我们的案例中,我们正在导入第二个工作表。工作表编号从 0 开始。
-
第三是 index_col:由于我们的数据集包含索引列,为了避免重复,我们将提供index_col=<column_name>。
data_excel = pd.read_excel("US_Presidents.xlsx",sheet_name = 1, index_col = "index")
data_excel.head()

JSON
读取 JSON 文件相当棘手,因为有多种格式需要理解。有时,Pandas 无法导入嵌套 JSON 文件,因此我们需要执行手动步骤以完美导入文件。JSON 是科技行业最常见的文件格式。它受到网页开发者和数据工程师的青睐。在我们的案例中,我们将下载Spotify 推荐数据集,许可证为CC0: 公共领域。该数据集包含好歌曲和坏歌曲的 JSON 文件。对于这个例子,我们将只使用good.json 文件。正如我们所见,我们正在处理一个嵌套的数据集。

作者提供的图片
在进行任何数据处理之前,让我们使用read_json()函数在不带参数的情况下导入数据集。
df_json = pd.read_json("good.json")
df_json.head()
如我们所见,数据框只包含一列,而且数据杂乱无章。要调试此问题,我们需要导入原始数据集,然后进行解析。

首先,我们将使用json包导入原始 JSON 文件,并仅选择audio_features子集。最后,我们将通过使用json_normalize()函数将 JSON 转换为 Pandas 数据框。
这是成功的,我们终于将 JSON 解析为数据框。如果你处理的是多层嵌套 JSON 文件,尝试先导入原始数据,然后处理数据,以便最终输出为平面表格。
import json
with open('good.json') as data_file:
data = json.load(data_file)
df = pd.json_normalize(data["audio_features"])
df.head()
代码和所有数据集可以在 Deepnote.
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在精神健康方面遇到困难的学生。
更多相关话题
如何组织机器学习的数据标签化:方法和工具
原文:
www.kdnuggets.com/2018/05/data-labeling-machine-learning.html
评论
由 AltexSoft.
如果有数据科学名人堂,它一定会有一个专门的标签化部分。标签员的纪念碑可能是持着象征其艰巨和细致责任的大石头的阿特拉斯。ImageNet — 一个图像数据库 — 可能会有自己的纪念碑。九年来,它的贡献者手动注释了超过 1400 万张图像。仅仅想到这些就让人感到疲惫。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
虽然标签化不像发射火箭那样复杂,但它仍然是一项严肃的工作。标签化是监督学习数据预处理的不可或缺的阶段。这种模型训练方式使用了具有预定义目标属性(值)的历史数据。算法只能在有人进行映射的情况下找到目标属性。
标签员必须非常专注,因为每一个错误或不准确都会对数据集的质量和预测模型的整体性能产生负面影响。
如何获得高质量的标注数据集而不至于让自己变白头发?主要挑战在于决定谁负责标签化,估计需要多少时间,以及使用什么工具更好。
我们在关于机器学习项目的一般结构的文章中简要描述了标签化。在这里,我们将更详细地讨论标签化方法、技术和工具。
标签化方法
方法的选择取决于问题和训练数据的复杂性、数据科学团队的规模,以及公司可以分配用于实施项目的财务和时间资源。
内部标签
那句老话如果你想做得对,就自己动手做表达了选择内部标注方法的关键原因之一。这就是为什么当你需要确保尽可能高的标注准确性并且能够跟踪过程时,将这项任务分配给你的团队。尽管内部标注比下面描述的方法要慢得多,但如果你的公司拥有足够的人力、时间和财务资源,这是最好的选择。
假设你的团队需要进行情感分析。对公司在社交媒体和技术网站讨论区的评论进行情感分析,可以让企业评估其声誉和专业水平,并与竞争对手进行比较。这也提供了研究行业趋势的机会,以定义发展战略。
你需要收集和标注至少 90,000 条评论,以建立一个表现良好的模型。假设标注单条评论可能需要工人 30 秒,他或她需要花费 750 小时或几乎 94 个 8 小时的工作班次来完成任务。换句话说,大约需要三个月。考虑到美国数据科学家的中位小时工资为 36.27 美元,标注费用将为 27,202.5 美元。
你可以通过自动化数据标注来简化这个过程。这种训练方式涉及使用标注数据和未标注数据。数据集的一部分(例如 2,000 条评论)可以被标注以训练分类模型。然后,这个多类模型在剩余的未标注数据上进行训练,以找到目标值——正面、负面和中性情感。
针对金融、航天、医疗保健或能源等各个行业的项目实施通常需要专家对数据进行评估。团队会咨询领域专家关于标注原则。在某些情况下,专家会自己标注数据集。
Altexsoft 开发了 DoIGrind 应用程序旨在为荷兰初创公司Sleep.ai诊断和监测磨牙症。磨牙症是在清醒或睡眠状态下的过度磨牙或咬紧下颚。该应用程序基于噪声分类算法,该算法通过包含超过 6,000 个音频样本的数据集进行训练。为了定义与磨牙声音相关的录音,客户听取了样本并将其映射到属性上。这些特定声音的识别对于属性提取是必要的。
优势
可预测的良好结果和对过程的控制。 如果你依靠你的人,你就不会买到一只瞎猫。数据科学家或其他内部专家有兴趣做得很好,因为他们将与标注数据集一起工作。你还可以检查你的团队的进展,以确保它遵循项目的时间表。
缺点
这是一个缓慢的过程。 标注质量越高,所需时间就越长。你的数据科学团队将需要额外的时间来准确标注数据,而时间通常是有限资源。
众包
如果你可以通过众包平台直接开始工作,为什么还要花额外的时间来招募人员呢?
亚马逊机械土耳其 (MTurk) 是提供按需劳动力的领先平台之一。客户在此注册为请求者,创建和管理包含一个或多个 HIT(人工智能任务)的项目,在 机械土耳其请求者网站 上。该网站为用户提供了一个易于使用的界面来创建标注任务。MTurk 代表声称,借助其广泛的工人社区,标注数千张图像可能只需几小时而不是几天或几周。
另一个全球在线市场,Clickworker 拥有超过 100 万名承包商,准备承担图像或视频标注和情感分析任务。工作流程的初始阶段与 MTurk 类似。任务处理和分配阶段有所不同。注册雇主根据预定义的规格和要求下订单,平台团队制定解决方案并将所需的工作集发布在订单平台上,工作即开始。
优点
快速结果。 众包是一种合理的选择,适用于时间紧迫且数据集庞大、基本的项目,这些项目需要使用强大的标注工具。例如,计算机视觉项目中的汽车图像分类等任务不会耗费太多时间,可以由具备普通知识的员工完成。通过将项目分解为微任务来实现速度,这样自由职业者可以同时进行这些任务。这就是 Clickworker 组织工作流程的方式。MTurk 客户应该自己将项目分解为步骤。
经济实惠。 在这些平台上分配标注任务不会花费你很多钱。例如,亚马逊机械土耳其允许为每个任务设置奖励,这为雇主提供了选择的自由。例如,设置每个 HIT 的奖励为$0.05,每个项目一个提交,你可以用$100 标注 2,000 张图像。考虑到 HITs 的 20%费用(包括最多九个任务),最终费用为$120,适用于一个小数据集。
缺点
邀请他人为你的数据进行标注可能节省时间和金钱,但众包也有其陷阱,获取低质量数据集的风险是主要问题。
标注数据质量不一致。 日常收入依赖于完成任务数量的人可能会为了完成更多工作而忽略任务推荐。有时,由于语言障碍或工作分配,标注中的错误也会发生。
众包平台使用质量管理措施来应对这一问题,确保工人提供尽可能最好的服务。在线市场通过技能验证测试和培训、声誉评分监控、统计数据、同行评审、审计以及事先讨论结果要求等方式做到这一点。客户还可以要求多个工人完成特定任务,并在支付之前批准任务。
作为雇主,你必须确保你的方面一切正常。平台代表建议提供明确和简单的任务说明,使用简短的问题和要点,并给出标注任务的优秀和差劲的示例。如果你的标注任务涉及绘制边界框,你可以阐明你设定的每一条规则。

清晰展示图像标注的注意事项和禁忌
你必须指定格式要求,并告知自由职业者是否需要使用特定的标注工具或方法。要求工人通过资格测试是提高标注准确度的另一种策略。
外包给个人
加速标注的一个方法是通过多个招聘、自由职业和社交网络网站寻找自由职业者。
在UpWork平台上注册了不同学术背景的自由职业者。你可以通过技能、位置、小时费率、工作成功率、总收入、英语水平等筛选条件发布职位或寻找专业人才。
当涉及在社交媒体上发布招聘广告时,LinkedIn 拥有 5 亿用户,是首选网站。招聘广告可以在公司页面上发布或在相关小组中宣传。分享、点赞或评论将确保更多感兴趣的用户看到你的招聘信息。
在 Facebook、Instagram 和 Twitter 上发布帖子也有助于更快找到专业人才。
优点
你知道你雇佣的是谁。 你可以通过测试检查申请人的技能,以确保他们能够正确完成工作。由于外包涉及雇佣小型或中型团队,你将有机会控制他们的工作。
缺点
你需要建立工作流程。 你需要创建一个任务模板并确保其直观。如果你有图像数据,例如,你可以使用Supervising-UI, 该工具提供了一个标注任务的网络接口。此服务允许在需要多个标签时创建任务。开发者建议在本地网络中使用 Supervising-UI,以确保数据的安全性。
如果你不想创建自己的任务界面,可以为外包专家提供你偏好的标注工具。我们将在工具部分详细介绍。
你还需要编写详细且清晰的说明,以便外包工作人员能够理解并正确地进行标注。此外,你还需要额外的时间来提交和检查已完成的任务。
外包给公司
不需要雇佣临时员工或依赖于人群,你可以联系专门从事训练数据准备的外包公司。这些组织将自己定位为众包平台的替代选择。公司强调,他们的专业团队将提供高质量的训练数据。这样,客户的团队可以专注于更高级的任务。因此,与外包公司的合作就像是拥有一个外部团队一段时间。
外包公司,如CloudFactory、Mighty AI、LQA 和DataPure,主要为计算机视觉模型标注数据集。CrowdFlower 和CapeStart 也进行情感分析。前者不仅可以分析文本,还可以分析图像和视频文件。此外,CrowdFlower 的客户可以请求更复杂的情感分析方法。用户可以提出引导性问题,以了解人们为何以某种方式对产品或服务作出反应。
公司提供各种服务包或计划,但大多数不提供定价信息,直到收到请求。计划的价格通常取决于服务数量或工作小时数、任务复杂性或数据集的大小。
CloudFactory 允许根据服务价格计算工作小时数
优势
高质量的结果。 公司宣称他们的客户将获得无误差的标注数据。
劣势
这比众包更贵。 尽管大多数公司未具体说明工作成本,但 CloudFactory 的 定价 示例帮助我们理解,他们的服务价格略高于众包平台。例如,在众包平台上标记 90,000 条评论(每项任务价格为 $0.05)将花费 $4500。聘请一个 7 到 17 人的专业团队(不包括团队负责人)可能需要 $5,165–5200。
了解公司员工是否执行特定的标记任务。如果你的项目需要领域专家,确保公司招聘能够定义标记原则并及时纠正错误的人。
更多相关内容
数据湖与 SQL:数据天堂中的绝配
原文:
www.kdnuggets.com/2023/01/data-lakes-sql-match-made-data-heaven.html

图片来自作者
数据湖和 SQL 介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 加入网络安全职业的快速通道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
大数据是个大问题,而数据湖是存储和分析大型数据集的关键工具。但你如何处理所有这些信息?SQL 是解决方案。
数据湖是一个集中式的存储库,允许在任何规模下存储结构化和非结构化数据。SQL(结构化查询语言)是一种用于与数据库通信和操作的编程语言。它可以通过查询存储在数据湖中的关系数据库中的结构化数据,或者通过对数据湖中存储的非结构化数据应用模式并使用“按需模式”进行查询来管理数据湖中的数据。
使用 SQL 与数据湖结合,可以通过各种分析方式(如实时分析、批处理和机器学习)对结构化和非结构化数据进行组合和分析。
建立数据湖基础设施
建立数据湖基础设施涉及几个关键步骤:
确定数据湖的架构
在建立数据湖之前,了解你需要存储的数据类型以及原因非常重要,这包括数据量、安全要求和预算。这将帮助你确定数据湖的最佳设计和架构。
选择数据湖平台
亚马逊网络服务(AWS)湖泊构建、Azure 数据湖和谷歌云大数据查询是可用的数据湖平台之一。每个平台都有其独特的功能和能力,因此你必须决定哪个最适合你的需求。
定义数据治理和安全政策
任何数据湖都需要一个强大的数据治理和安全策略。这应包括数据访问、分类、保留和加密政策,以及监控和审计数据活动的程序。
建立数据摄取管道
数据摄取管道是将数据从源头传输到数据湖的过程。数据摄取管道可以通过多种方式设置,包括批处理、实时流处理和混合方法。
定义数据模式
数据模式是一种逻辑和有意义的数据组织方法。它有助于确保数据的一致存储,并且可以轻松查询和分析。
测试和优化数据湖
一旦你的数据湖正常运行,定期监控和维护它以确保其表现符合预期非常重要。这包括数据备份、安全和合规检查,以及性能优化等任务。
使用 SQL 将数据摄取到数据湖中
一旦你设置了数据湖基础设施,你可以开始将数据加载到其中。有几种方法可以使用 SQL 将数据摄取到数据湖中,例如使用 SQL INSERT 语句或使用基于 SQL 的 ETL(提取、转换、加载)工具。你也可以使用 SQL 查询外部数据源并将结果加载到数据湖中。
下面是一个如何使用 SQL 查询外部数据源并将结果加载到数据湖中的示例:
INSERT INTO data_lake (column1, column2, column3)
SELECT column1, column2, column3
FROM external_data_source
WHERE condition;
使用 SQL 转换数据湖中的数据
一旦你将数据摄取到数据湖中,你可能需要对其进行转换以使其更适合分析。你可以使用 SQL 对数据执行各种转换,例如过滤、聚合和连接来自不同来源的数据。
过滤数据: 你可以使用 WHERE 子句根据某些条件过滤行。
SELECT *
FROM data_lake
WHERE column1 = 'value' AND column2 > 10;
聚合数据: 你可以使用聚合函数,如 SUM、AVG 和 COUNT,来计算行组的汇总统计信息。
SELECT column1, SUM(column2) AS total_column2
FROM data_lake
GROUP BY column1;
连接数据: 你可以使用 JOIN 子句根据公共列将来自两个或多个表的行组合在一起。
SELECT t1.column1, t2.column2
FROM table1 t1
JOIN table2 t2 ON t1.common_column = t2.common_column;
使用 SQL 查询数据湖中的数据
要使用 SQL 查询数据湖中的数据,你可以使用 SELECT 语句来检索你想查看的数据。
下面是一个如何使用 SQL 查询数据湖中的数据的示例:
SELECT *
FROM data_lake
WHERE column1 = 'value' AND column2 > 10
ORDER BY column ASC;
你还可以使用各种 SQL 子句和函数来根据需要过滤、聚合和操作数据。例如,你可以使用 GROUP BY 子句按一个或多个列对行进行分组,并使用聚合函数,如 SUM、AVG 和 COUNT,来计算组的汇总统计信息。
SELECT column1, SUM(column2) AS total_column2
FROM data_lake
GROUP BY column1
HAVING total_column2 > 100;
处理数据湖和 SQL 的最佳实践
在处理数据湖和 SQL 时,有几项最佳实践需要记住:
-
使用基于 SQL 的 ETL 工具简化摄取和转换过程。
-
使用混合数据湖架构以支持批处理和实时处理。
-
使用 SQL 视图简化数据访问并提高性能。
-
使用数据分区来提高查询性能。
-
实施安全措施以保护你的数据。
结论
总之,数据湖与 SQL 是管理和分析大数据量的最佳组合。使用 SQL 将数据导入数据湖,在湖中转换数据,并查询以获取所需结果。
熟悉你使用的文件系统和数据格式,练习编写 SQL 查询,并探索基于 SQL 的 ETL 工具,以充分利用这一组合。掌握数据湖和 SQL 将帮助你有效地处理和理解你的数据。
感谢你抽出时间阅读我的文章。希望你觉得这篇文章信息丰富且引人入胜。
Sonia Jamil 目前在巴基斯坦最大的电信公司之一担任数据库分析师。除了全职工作外,她还从事自由职业。她的背景包括数据库管理方面的专业知识,以及在本地和基于云的 SQL Server 环境中的经验。她精通最新的 SQL Server 技术,对数据管理和数据分析有着强烈的兴趣。
更多相关内容
数据素养:使用苏格拉底方法
原文:
www.kdnuggets.com/2019/06/data-literacy-socratic-method.html
评论
由 Aarzoo Sidhu,The Data Thinker

我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
数据作为商业资产的增长价值是不容置疑的。它被描述为“新黄金”和“新石油”。全球范围内的组织,无论行业和规模,都在大量投资数据基础设施,以获取这一商品。
与黄金和石油因稀缺而珍贵不同,数据是无处不在的。因此,数据本身并不珍贵——它无处不在。价值在于组织能够有意义地与数据互动并从中提取商业洞察。而这其中正是存在着差距。
大多数非数据科学专家(或相关领域的专家)并不知道在面对数据时如何进行批判性思考。
数字中蕴含恐怖。亨普提·邓普蒂对爱丽丝说他掌控了自己使用的词语的信心,很多人不会将其扩展到数字上。
- Darrel Huff, 如何用统计数据说谎
Gartner 支持这种观点,并描绘了一个相当暗淡的未来:
到2020年,50%的组织将缺乏足够的人工智能和数据素养技能来实现业务价值。
如果数据没有提供商业价值,那么它就是无用的。它从新黄金变成了新垃圾(非常昂贵的垃圾)。因此,除了投资数据基础设施外,组织还需要优先考虑数据素养。
数据素养
在文献中,关于什么构成数据素养以及它如何与信息素养不同存在许多不同的观点。为了简化当前讨论,我喜欢麻省理工学院的定义:
数据素养包括读取、处理、分析和用数据进行论证的能力。 - R. Bhargava 和 C. D’Ignazio,设计数据素养学习者的工具和活动
与其采用基于课程或主题的方法来定义数据素养,这种基于技能的定义更具适应性和可扩展性。
现在我们有了定义,接下来我们来谈谈如何操作。
组织如何促进数据素养?在不同教育背景和经历的员工中,培养这些技能的最佳方法是什么?如何在职业发展中融入数据素养,而不仅仅是在正式教育系统中?
我不能教任何人任何东西。我只能让他们思考。
- 苏格拉底
苏格拉底式提问
关键是认识到,数据素养技能的核心是批判性思维技能。而且,好问题是发展批判性思维的关键。没有人比苏格拉底更了解这一点。他相信:
有纪律的提问练习使学者/学生能够审视观点并确定这些观点的有效性。
这种刺激高层次思维的方法被称为苏格拉底式提问(或苏格拉底研讨会)。
关键词“有纪律的”和“深思熟虑的”使苏格拉底式提问区别于一般的提问行为。组织和有目的的提问不仅有助于检查面前的信息,还能帮助反思对这些信息的思考(元认知)。这种反思性思维有助于追踪从信息到结论的路径,并揭示过程中做出的任何假设。
在他们的论文《苏格拉底式提问》中,Paul 和 Binker 这样描绘了苏格拉底式提问与批判性思维之间的联系:
使用苏格拉底式提问需要以下几点前提:所有的思考都有假设;做出主张或创造意义;有影响和后果;关注某些事物而忽略其他事物;使用某些概念或思想而非其他;由目的、问题或难题定义;使用或解释某些事实而非其他;相对清晰或模糊;相对深刻或肤浅;相对独白或多元对话。批判性思维是在有效、自我监控的意识下进行的思考。
- Richard Paul & A. J.A. Binker,批判性思维手册系列
此外,批判性思维基金会的 Linda Elder 和 Richard Paul 确定了以下六种刺激高层次思维的苏格拉底式问题。
-
澄清问题。
-
挑战假设的问题。
-
检查证据或理由的问题。
-
关于观点和视角的问题。
-
探索影响和后果的问题。
-
关于问题的问题。
苏格拉底式提问在数据素养中的应用
这种方法在全国的法学院中被用来教导如何揭露论证中的逻辑谬误。这个框架的美妙之处在于它可以适应任何感兴趣的主题。在我们的案例中,就是数据!
当个人用这种方法自己探讨信息时,它可以增强他们对数据的理解,揭示逻辑陷阱,并提供洞察。
苏格拉底式提问的一个更有效的应用是激发数据项目利益相关者之间的指导性讨论。通过一起检查数据并一起推理,团队可以为数据提供更多的背景,并构建更强的统计叙事,同时提高他们的数据素养技能。既然苏格拉底研讨会的目标是更好地思考,还有谁比数据思考者更适合领导讨论呢?
苏格拉底研讨会还可以帮助识别个人知识中的空白,促进好奇心,并培养智力谦逊。在讨论中发现的知识空白和数据素养主题,可以通过更传统的讲座和教程来加以补充。
示例问题
以下是每个类别的示例问题。并非每个示例问题都适用于所有情况,有些问题可能属于多个类别。主要目标应该是从所有六个类别中提问。
1. 澄清问题的问题。
-
我想用这个统计数据回答什么问题?
-
这个统计数据意味着什么?
-
单位是什么?
-
这个统计数据的基础数据是什么?
-
典型的数据点是什么样的?极端值是什么样的?
-
时间范围是什么?
-
图表显示了什么?x 轴和 y 轴是如何标记的?标题/图例是否合适?
2. 挑战假设的问题。
-
更高还是更低的值更好?
-
这是否符合我的预期?
-
我正在做哪些假设?
-
分析师做了什么假设?这些假设是否经过测试?
-
是否存在抽样偏差?期望偏差?选择偏差?幸存者偏差?确认偏差?预测偏差?轶事偏差?
3. 检查证据或理由的问题。
-
证据有多强?
-
统计显著性与商业相关性有何区别?
-
有什么缺失的?有缺失的数据吗?缺失的变异度测量吗?缺失的不确定性测量吗?
-
相关性有多强?如何探索因果关系?
-
什么会让我对这项分析更有/更少的信心?
4. 关于观点和视角的问题。
-
还有哪些额外的统计数据会有帮助?
-
如果统计数据支持对立观点,那它会是什么样的?
-
哪些冲突的观点有更多的证据?
-
如果这些数据都不可用,我会做出什么决定?
-
这个统计数据在我的竞争对手那里是什么样的?
-
我希望这个统计数据是什么?
5. 探索影响和后果的问题。
-
这一统计发现的意义是什么?对业务的影响?
-
其他统计数据是否支持这一发现?相反的统计数据会是什么样的?
-
我可以对这一发现采取行动吗?
-
它是否影响了当前的任何行动?
-
它是否影响了过去做出的任何决策?
-
如果存在不确定性,我应该如何在这种不确定性下行动?
-
这是否支持/反驳了我对这个问题已有的认识?
-
它如何与其他数据项目的相关发现联系起来?
6. 关于问题的问题。
-
最难回答的问题是什么?
-
是什么让这个问题变得难以回答?
-
是否有一个问题多次出现?
-
这个对话如何总结?

简介:Aarzoo Sidhu,具有生物统计学的正式教育背景和 8 年的数据管理与分析经验,《数据思考者》的作者,现在致力于超越数据科学,探索从数据到洞察的多条路径。
相关:
更多相关话题
为什么数据管理对数据科学如此重要?
原文:
www.kdnuggets.com/2022/08/data-management-important-data-science.html
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
数据是所有分析工具和机器学习算法的核心。它使领导者能够深入了解推动关键指标和客户满意度的因素。简单来说,数据在有效和智能使用时对任何组织都是一种资产。过去组织数据匮乏,缺乏利用数据力量的意识的时代已经过去。近年来,许多组织已经超越了数据限制,拥有了充足的数据来开始数据分析。
然而,数据的可用性单独并不能解决组织在数字化转型过程中面临的众多问题之一。他们需要数据管理系统,这些系统是 IT 和业务团队的结合体。

来源:性能图标矢量图由 rawpixel.com 创建
那么,让我们首先了解什么是数据管理。
数据管理
数据管理,顾名思义,涵盖了所有关于数据的内容——从数据的摄取、存储、组织到在组织内的维护。数据管理传统上由 IT 团队负责,但有效的数据管理只能通过 IT 团队与业务用户之间的跨部门协作来实现。业务需要向 IT 提供数据需求,因为他们对组织所希望实现的最终目标有更好的了解。
除了制定政策和最佳实践外,数据管理团队还负责一系列活动,如 这里 所述。让我们了解数据管理涵盖的范围:
-
数据存储和更新——谁将有权编辑数据,并假定数据所有权
-
高可用性和灾难恢复
-
数据归档和保留政策,以了解数据库存及其用途
-
本地和多云数据存储
-
最后也是最重要的,数据安全和隐私必须遵守监管要求。
自助分析 - 业务价值生成的加速器
便捷的数据访问和自助分析——数据民主化的核心支柱,显著提高了生成可操作见解和业务影响的速度。
让我再详细说明一下。想象一下,一个业务分析师向业务领导者提交了一份报告,重点解决一个特定目标,比如客户细分。如果业务需要知道一些在分析初稿中未捕获的额外细节,他们需要将这一请求通过整个数据周期反馈给分析师,并等待更新结果,然后才能采取行动。
如今显而易见的是,这会导致在获得足够的信息以赋能所有领导者和高管信任数据和分析、制定业务战略时的延误。这种延误不仅导致在竞争优势方面丧失商业机会,而且报告及数据也会在满足业务需求之前变得过时。
很好,我们现在已经理解了问题。让我们转到如何填补业务需求与所呈现分析之间的差距。现在,前述场景中有一个问题很明确——当前的情况是数据主要由分析师,即技术用户处理和使用。良好管理的数据系统使得非技术业务用户(通常的数据消费者)能够轻松获取他们需求的分析,并做出及时决策。
数据科学中的数据管理
到目前为止,我们已经理解了数据管理及其重要性,这一等式同样适用于数据科学项目和团队。
数据是所有机器学习算法的核心。数据科学是最普遍的组织数据消费者。我们需要更加重视上述强调的词汇——数据科学不拥有数据,它是潜在的(且希望如此!!!)良好管理和组织的数据的消费者。
为什么说数据可能需要管理——那是因为数据往往并不以正确的形式和状态存在。呼应数据科学社区的声音和关注,数据问题是让数据科学家时刻保持警惕的主要原因。
数据管理团队及整个组织需要采纳数据优先文化,并促进数据素养,以确保业务的关键战略资产,即数据,得到妥善管理和使用。
何时宣称一个组织拥有良好管理的数据系统?
这确实不是一个容易回答的问题。不能等待数据管理团队给出绿色信号,让数据科学团队开始将数据投入到他们的机器学习流程中。务实的做法是为强大且有效管理的数据团队奠定坚实的基础,并考虑到这是一个迭代过程。是的,就像机器学习算法的迭代性质一样,数据管理也是一个生命周期的方法。它随着数据科学团队与数据管理团队的合作,不断改进和完善最佳实践和指导方针而持续演变。
话虽如此,数据管理团队是数据相关政策、实践和数据访问协议的唯一负责人,拥有强大的数据治理框架。
随着疫情时代数据生成的增加,许多组织积极寻求通过各种方式来货币化数据,包括但不限于更好地了解最终用户、通过理解内部流程提升操作效率,或提供更好的最终用户体验。因此,近年来对数据及数据治理框架的关注急剧增加。
业务、数据管理和数据科学团队的结合
实现这种对齐的一个词是有效的数据治理政策。所有三个团队需要有强有力的沟通和反馈渠道。此外,团队对迭代和改进当前数据流程的接受度是组织强大数字化转型的关键加速器。
实际上,数据文化本身反映出数据责任不仅限于任何特定的团队或个人。这是组织中每个员工的共同责任,他们需要贡献力量,并建立最高标准的数据流程。
摘要
这篇文章专注于数据相关的所有内容。文章首先介绍了数据管理团队的一般角色和职责。在后半部分,文章重点讨论了数据管理在数据科学团队中的重要性,以及跨团队对齐如何在组织中建立有效的数据流程。
Vidhi Chugh 是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究交汇处工作,致力于提供业务价值和洞察。她倡导以数据为中心的科学,是数据治理的领先专家,致力于构建可信赖的 AI 解决方案。
更多相关话题
数据科学的数据管理原则
原文:
www.kdnuggets.com/data-management-principles-for-data-science

作者提供的图片
在你作为数据科学家的旅程中,你会遇到挫折,并且克服它们。你将学习到一个过程如何优于另一个过程,以及如何根据手头的任务使用不同的过程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
这些过程将协同工作,以确保你的数据科学项目尽可能高效,并在决策过程中发挥关键作用。
什么是数据管理?
其中一个过程是数据管理。在一个数据驱动的世界中,数据管理是组织利用数据资产并确保其有效性的一个重要元素。
数据管理是收集、存储、组织和维护数据的过程,以确保数据准确、可供需要的人访问,并在数据科学项目生命周期中保持可靠。就像任何管理过程一样,它需要由政策和技术支持的程序。
数据科学项目中的数据管理关键组件包括:
-
数据收集与获取
-
数据清理与预处理
-
数据存储
-
数据安全与隐私
-
数据治理与文档管理
-
协作与共享
如你所见,有一些关键组件。目前可能看起来有些令人生畏,但我将逐一讲解,以给你一个作为数据科学家需要预期的概述。
数据收集与获取
尽管现在有大量的数据存在,数据收集仍将是你作为数据科学家的职责之一。数据收集与获取是从各种来源(如网站、调查、数据库等)收集原始数据的过程。这个阶段非常重要,因为数据的质量直接影响到你的结果。
你需要识别不同的数据来源,并找到符合你要求的来源。确保你有适当的权限访问这些数据源,数据源的可靠性,以及格式是否与你的范围一致。你可以通过不同的方法收集数据,如手动数据输入、数据提取等。
在这些步骤中,你要确保数据的完整性和准确性。
数据清理与预处理
一旦你获得数据,下一步就是清理它 - 这可能会占用你大量时间。你需要仔细检查数据集,找出任何问题并加以修正。你在这一阶段的最终目标是标准化和转换数据,以便它准备好进行分析。
数据清理可以帮助处理缺失值、重复数据、错误的数据类型、异常值、数据格式、转换等问题。
数据存储
一旦你清理完数据,它的质量良好且准备好进行分析 - 就存储它吧!你不想丢失你刚刚花费的所有小时来清理数据并达到黄金标准。
你需要为你的项目和组织选择最佳的数据存储解决方案,例如数据库或云存储。同样,这将基于数据的体积和复杂性。你还可以设计架构,以便高效的数据检索和可扩展性。
另一个你可以实施的工具是数据版本控制和归档,它允许你维护所有历史数据及其任何更改,帮助保存数据资产并实现长期访问。
数据安全与隐私
我们都知道在当今时代数据的重要性,因此要不惜一切代价保护它!数据泄露和隐私侵犯可能会产生严重后果,你不想面临这个问题。
你可以采取一些步骤来确保数据安全和隐私,例如访问控制、加密、定期审计、数据生命周期管理等。你要确保你采取的任何保护数据的措施都符合数据隐私法规,例如 GDPR。
数据治理与文档管理
如果你想在数据生命周期中确保数据质量和问责制,数据治理和文档管理对于你的数据管理过程至关重要。这个过程包括制定政策、流程和最佳实践,以确保你的数据得到良好管理,并保护所有资产。其主要目的是提供透明度和合规性。
所有这些政策和流程应全面记录,以提供对数据如何结构化、存储和使用的洞察。这在组织内部建立信任,以及他们如何利用数据驱动决策过程,从而避免风险并发现新机会。
过程的示例包括创建全面的文档、元数据、维护审计跟踪和提供数据血缘。
协作与共享
数据科学项目涉及协作工作流程,因此你可以想象这会有多么混乱。你有一个数据科学家在处理同一个数据集,而另一个数据科学家则在进一步清理。
为了确保团队内的数据管理,始终沟通你的任务,以避免重叠,或某人拥有比其他人更好的数据集版本。
数据科学团队中的协作确保了数据对不同利益相关者的可访问性和价值。为了提高团队内部的协作和共享,你可以使用数据共享平台,使用诸如 Tableau 等协作工具,设置访问控制,并允许反馈。
数据管理工具和技术
好的,现在我们已经深入探讨了数据管理的关键组件,我将创建一个数据管理工具和技术的列表,以帮助你在数据科学项目生命周期中。
关系型数据库管理系统(RDBMS):
-
MySQL
-
PostgreSQL
-
Microsoft SQL Server
NoSQL 数据库:
-
MongoDB
-
Cassandra
数据仓库
-
Amazon Redshift
-
Google BigQuery
-
Snowflake
ETL(提取、转换、加载)工具:
-
Apache NiFi
-
Talend
-
Apache Spark
数据可视化和商业智能:
-
Tableau
-
Power BI
版本控制与协作:
-
Git
-
GitHub
数据安全和隐私:
-
Varonis
-
Privitar
总结
数据管理是数据科学项目的重要元素。把它看作支撑你城堡的基础。数据管理过程越好,结果就越好。我提供了一些文章,你可以阅读以了解更多关于数据管理的内容。
资源与进一步学习
-
5 个数据管理挑战及解决方案
-
前 5 大数据管理平台
-
免费数据管理与数据科学学习 CS639
-
为什么数据管理对数据科学如此重要?
尼莎·阿亚 是一位数据科学家、自由技术写作员以及 KDnuggets 的社区经理。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能够有益于人类生命的延续。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
数据管理:如何保持在客户心中的领先地位?
原文:
www.kdnuggets.com/2022/04/data-management-stay-top-customer-mind.html

如果你拥有或计划创业,你可能已经多次收到诸如“有效管理数据”和“更多关注客户”的建议。然而,如果你认为围绕数据管理和客户关系的炒作过多,那么是时候了解数据管理和客户满意度之间的关系,以及你如何利用这些知识帮助你的业务成功了。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
无论是通过市场营销活动还是客户服务电话,赢得客户的心都是必要的。然而,打动客户并不容易!在这个数字化商业世界中,产生了大量的客户数据。你必须了解客户的每一个细节,包括他们的兴趣和痛点,以便即时分析并向他们提供相关解决方案。
为了实现这一点,你组织中的每一个团队都必须有效地合作。通过实施以客户为中心的商业战略和有效的数据管理解决方案,你可以在业务中取得成功。
为什么你需要以客户为中心的方法?
在今天的数字商业世界中,客户有很多选择来比较和购买产品。要成为客户的首选,你必须首先了解他们,知道他们对你的产品或服务有什么期望,并迅速解决他们的问题。如果客户认为你不听取他们的需求,即使你拥有卓越的品牌价值,他们也会瞬间切换品牌。
根据 德勤 的研究,采取以客户为中心的方法的组织比那些不专注于客户的公司要有 60%的回报率。因此,什么是以客户为中心的战略?它就是将客户放在首位,了解他们的需求,并提供最佳解决方案。虽然采用以客户为中心的文化具有挑战性,但绝对值得付出努力。
如果你有一个以客户为中心的商业文化,问问自己这些问题,以查看你是否在正确的轨道上。
数据管理在以客户为中心的战略中的作用?
你可能会想,如果以客户为中心能够增加利润和声誉,为什么公司不去实施它。简短的答案是,大多数企业尝试以客户为中心但未能实现。然而,挑战在于几乎所有的客户数据来自多个接触点,并且在部门之间缺乏一致性和治理。
根据 哈佛商业评论 的一篇文章,组织中的数据中仅有 3%是高质量数据。差的数据和过时的数据不过是一些数字。为了有效地提供以客户为中心的体验,组织应当从收集相关客户数据开始,接着丰富、标准化,并使其能够立即提供给组织中的所有人。
在组织中手动完成所有这些工作需要时间和金钱,同时也容易出错。通过自动化的 数据管理解决方案
通过 utm_source=data_management_blog_Mar22&utm_medium=web&utm_campaign=blog,你可以在专注于提升客户生命周期价值和减少流失的同时,强化你的端到端客户数据管理。
数据管理解决方案如何有利于以客户为中心的战略
数据管理已经从简单的数据收集发展到分析和存储数据,以便于跟踪和访问。以下是数据管理解决方案的一些功能。
跟踪和访问你的数据
客户数据是跨多个部门收集并存储在不同的数据库中的。实现以客户为中心的文化的第一步是了解你提取的客户数据,数据存储的位置,信息属于哪个类别,谁收集了数据等等。如果你打算手动完成这些工作,你将陷入困境!
自动识别和分类带有元数据标签的数据可以让你快速确定谁、何时、何地、关于数据的内容以及客户数据的关联。当你的经理要求你检索关于客户的多个数据集时,你不必担心接下来的艰巨任务。借助正确的解决方案,你可以在几分钟内获得数据。实施有效的元数据管理解决方案不再是一个选择,而是一个必须的条件,以节省今天数字商业世界中的时间和人工劳动力。
检查并丰富数据质量
以下步骤确保数据是干净且最新的。数据质量和丰富性确保信息干净、去重、无错误且经过增强。"数据质量"这个词已经成为一个流行词。每个人都在谈论数据质量,每个人都希望实现 100%的数据质量。数据质量对于实现和维持以客户为中心的目标是否必要?是的,它至关重要!
正确的客户方法始于准确的数据。凭借精确的客户数据,你可以快速识别市场趋势、客户模式,并将正确的信息发送给正确的人,从而减少不必要的营销活动费用并提高客户终生价值。根据哈佛商业评论,将客户保留率提高 5%可以将利润提高 25%至 95%。一个由 AI 驱动的数据质量解决方案可以实时自动化数据分析、清理和丰富的过程,使你能够获得数据驱动的洞察,并有效地提高客户保留率。
无缝集成和存储数据
一旦你拥有了干净且丰富的数据,下一步是确保组织内的每个人、各个部门通过多种渠道访问这些数据。定义、管理和整合所有可用的客户数据对于创建黄金记录或关于客户的单一真实版本至关重要。数据集成解决方案是收集客户数据、将其转换为标准格式并存储在数据仓库或数据湖等集中位置的最佳选择。
数据集成为你提供了客户数据的完整视图。例如,如果销售部门清楚地了解所有关于客户的数据,他们将能够迅速做出明智的产品推荐。一个稳固的数据集成解决方案允许你随时无缝集成所有数据,为你提供统一的客户数据视图。
探索数据管理解决方案以实现以客户为中心的目标
在组织中创建以客户为中心的战略是困难的,但它是值得的。了解你的客户并快速响应他们的需求对于保留他们并最大化你的市场价值至关重要。
如果你在寻找和管理客户数据以实现以客户为中心的目标方面遇到困难,是时候开始使用数据管理解决方案了。智能且强大的数据管理解决方案如Xtract.io、Informatica、Talend等将通过几次点击处理所有客户数据,保护你的隐私,并帮助你获得创新的业务洞察。
请在评论区分享你的想法,以便我们开始一些有趣的讨论!
Abinaya Sundarraj 在数据解决方案公司 Xtract.io 担任市场营销顾问。她是一位热衷于阅读的人,喜欢撰写有关数据在各个行业中作用的文章。她相信宇宙为那些真正渴望的人提供一切。
更多相关主题
使用机器学习进行数据映射
原文:
www.kdnuggets.com/2019/09/data-mapping-using-machine-learning.html
评论
使用机器学习进行数据映射
从小型到大型企业,几乎每家公司都在争夺获得受众注意的机会。20 年前的常规营销活动现在已经不再奏效。为了走在前沿并超越竞争对手,你通常需要直接面向源头进行市场营销,尤其是当你的目标群体是千禧一代时。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
收集数据是许多企业学习如何定位其受众的一种方式。要直接向潜在买家进行市场营销,你需要了解他们的兴趣、需求、所在位置以及他们最有可能回应你的广告的地方。
虽然数据无法过于详细地描述个人,但它在了解群体方面非常有效。如果你能有效地利用数据,了解目标受众的行为不必困难。实现这一点的一种方式是通过数据映射。
什么是数据映射?
数据映射是一种将各种数据片段组织成一个可管理且易于理解的系统的方法。这个系统在存储时将数据字段与目标字段进行匹配。
简而言之,并非所有数据都遵循相同的组织标准。它们可能以你能想到的多种不同方式来表示电话号码。数据映射会识别电话号码的本质,并将它们都放在同一个字段中,而不是让它们以其他名称漂移。
通过这种技术,我们能够将组织的数据汇总成一个更大的图景。你可以发现你的目标受众主要生活在哪里,了解他们有什么共同点,甚至找出一些你不应触及的争议话题。
拥有这些信息后,你的企业可以做出更明智的决策,花费更少的资金,同时将产品和服务推向你的受众。
数据映射和机器学习
前面提到的识别电话号码的例子与一种叫做统一和数据清理的东西有很大关系。这些过程通常由机器学习驱动,而机器学习与人工智能不同。
机器学习使用模式和推断来提供预测,而不是执行单一任务,这比人工智能技术更多的是其一个子集。在前面的例子中,机器学习用于识别电话号码并将其分配到适当的类别以便于组织。
但机器学习不仅仅是识别电话号码。这项技术可以识别诸如缺失值或拼写错误等错误,并将来自同一来源的信息进行分组。
这就是数据清理和统一的真正含义——在没有任何人工输入的情况下清理所有数据,并以最完美和精确的形式呈现信息。这个过程节省时间,并且在信息的准确性方面更有效。
数据可以以几乎任何一个人或公司需要的方式显示。例如,地理空间数据是机器学习可以自动处理并创建的一种方式,而无需输入。地理空间数据基本上是将数据转换为地图并绘制出目标受众每天经过的物理位置和路线。这种技术可以为你的下一个广告活动提供独特的帮助。
为什么机器学习对数据映射很重要
机器学习使数据映射变得更加精确。如果没有这种技术,数据映射要么非常基础,要么完全手动完成。
假设我们采用基础的方法,一个简单的电子表格能够将信息输入并猜测其适当的类别。拼写错误不会被修正,缺失的值将保持缺失,某些信息可能会散落在随机的位置。
尝试手动完成数据映射将更糟。首先,一个人永远无法跟上信息的流动,更不用说已经隐藏在物联网中的信息积压。如果有人能够跟上流动,仍然会出现错误,因为大量数据会导致人类无法像机器一样发现连接。
为什么数据映射对你很重要
数据的使用是现代营销中极其重要的一部分。了解最佳的时间和地点来接触客户将使你能更高效地定位目标受众。
即使是那些可以在所有可能的媒体渠道上展示自己名字的大型行业,也会使用数据映射来节省成本,并对客户群体表现出更大的忠诚。
无论大或小,你都可以利用这些信息超越其他争夺客户注意力的竞争者。如今竞争激烈,因此走在前面并保持领先是一门每个人都在努力完善的艺术。数据映射可以帮助你尽早实现这一目标。
简介:凯拉·马修斯 在《The Week》、《数据中心杂志》和《VentureBeat》等刊物上讨论技术和大数据,并从事写作工作超过五年。要阅读凯拉的更多文章,订阅她的博客 Productivity Bytes。
相关:
-
6 个逐渐重视预测分析和预测的行业
-
如何说服你的老板数据分析的必要性
-
如何展示你的数据科学工作的影响
相关阅读
数据掩码:确保 GDPR 和其他合规策略的核心
原文:
www.kdnuggets.com/2023/05/data-masking-core-ensuring-gdpr-regulatory-compliance-strategies.html

图片由 Bing Image Creator 提供
隐私不是可以出售的产品,而是维护每个人完整性的宝贵资产。这只是促使 GDPR 和其他全球法规制定的众多因素之一。随着对数据隐私重要性的日益增加,数据掩码已成为各类组织维护个人信息安全和机密性的必要措施。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
数据掩码有一个使命——保护个人身份信息(PII)并尽可能限制访问。它匿名化并保护个人和敏感信息。因此,它适用于银行账户、信用卡、电话号码以及健康和社会安全细节。在数据泄露期间,没有个人身份信息(PII)会被暴露。您还可以在组织内设置额外的安全访问规则。
什么是数据掩码?
数据掩码,顾名思义,是一种通过用虚拟但现实的数据替代敏感数据来保护数据的技术。它在符合《通用数据保护条例》(GDPR)的情况下保护个人数据,确保数据泄露不会暴露个人的敏感信息。
由于数据掩码是数据保护策略的核心组成部分,它适用于各种数据类型,如文件、备份和数据库。它与加密、访问控制、监控等紧密配合,以确保端到端符合 GDPR 和其他规定。
我们为什么需要这项技术来符合 GDPR 和其他规定?
尽管数据脱敏在消除敏感数据暴露方面已被证明有效,但许多企业仍未遵循相关指南,面临违规风险。最受关注的案例是服装零售商 H&M,因为违反 GDPR 规范,被罚款 3500 万欧元。调查发现,管理层可以访问敏感数据,如个人的宗教信仰、个人问题等。这正是 GDPR 试图避免的情况,因此数据脱敏至关重要。
然而,像 BFSI(银行、金融服务和保险)和医疗保健等高度受监管的行业已经开始实施数据脱敏,以遵守隐私法规。这些法规包括支付卡行业数据安全标准(PCI DSS)和健康保险流通与问责法案(HIPAA)。
2018 年欧洲 GDPR 的实施引发了全球隐私法律的趋势,加利福尼亚州、巴西和东南亚等司法管辖区分别推出了 CCPA、CCPR、LGPD 和 PDPA 等法律,以保护个人数据。
数据脱敏可以为法规遵从提供多个好处,包括
-
保护敏感数据:数据脱敏可以通过用虚构但现实的数据替换敏感数据来保护敏感数据,如个人信息。这可以防止未经授权的访问或敏感数据的意外暴露。
-
遵守法规:数据脱敏可以用于匿名化个人数据,这有助于组织遵守如《通用数据保护条例》(GDPR)及其他数据隐私法律等法规。
-
审计和合规:数据脱敏可以提供敏感数据访问的可审计记录,这有助于组织展示其遵守监管要求的情况。
-
数据治理:数据脱敏可以作为数据治理工具;组织可以确保敏感数据仅用于预定目的,并由授权人员使用。
GDPR 的关键数据脱敏实践
数据最小化
数据脱敏中的数据最小化指的是只对保护敏感信息所需的最小量数据进行脱敏,同时仍允许数据用于其预期目的。这有助于组织在保护敏感数据的同时,平衡业务用途的需求。
例如,一个组织可能只需要对信用卡号码的最后四位数字进行脱敏,以保护敏感信息,同时允许数据用于金融交易。类似地,在个人数据中,仅对姓名和地址等特定字段进行脱敏,而保留性别和出生日期等其他字段,对于特定使用场景可能已足够。
假名化
假名化使用假名替代用户的识别信息,从而保护其隐私。这在确保符合通用数据保护条例(GDPR)方面非常有用,确保数据泄露不会揭示有关个人的敏感信息。
这种数据掩码技术用唯一的假名替代个人标识符,如姓名、地址和社会保险号码,同时保持性别和出生日期等非敏感属性不变。假名可以使用加密技术生成,如哈希或加密,以确保原始个人数据无法恢复。
它还符合对科学、历史和统计目的(分析)数据处理的安全和安全要求。这是确保符合 GDPR 数据保护设计原则的重要工具。
你可以优化你的 DevOps 功能。对于 DevOps,数据掩码提供了真实但安全的虚拟数据用于测试。这对依赖内部或第三方开发人员的组织尤其有益,因为它确保了安全性并减少了 DevOps 过程中的延迟。数据掩码使你能够在维护客户隐私的同时测试他们的数据。
针对 GDPR 及其他法规的数据掩码
将数据视为产品并使用掩码技术具有很多好处。2022 年,许多数据架构和产品平台因其创新方法而受到关注。例如,K2view 在业务实体级别执行数据掩码,确保一致性和完整性,同时保持引用完整性。
为确保最大安全性,每个业务实体的数据在其 Micro-Database 中进行管理,并由 256 位加密密钥保护。此外,Micro-Database 中的个人身份信息(PII)会实时掩码,遵循预定义的业务规则,提供额外的保护层。
参考资料
实施数据掩码技术可以帮助组织避免巨额罚款和声誉损害。然而,需要注意的是,数据掩码本身不足以实现 GDPR 合规,应与其他安全措施结合使用。
Yash Mehta 是国际公认的物联网(IoT)、机器对机器(M2M)及大数据技术专家。他撰写了多篇广受认可的数据科学、物联网、商业创新和认知智能方面的文章。他是名为 Expersight 的数据洞察平台的创始人。他的文章曾被最权威的出版物刊登,并被 IBM 和思科物联网部门评为最具创新性和影响力的连通技术行业作品之一。
更多相关话题
数据成熟度:AI 驱动创新的基石
原文:
www.kdnuggets.com/data-maturity-the-cornerstone-of-ai-enabled-innovation
图片来源于 Google DeepMind
在追求创新和确保竞争优势的过程中,企业正逐渐利用人工智能(AI)的力量作为一种变革性工具。人工智能承诺简化操作、提升决策过程,并揭示数据中隐藏的模式,这促使它在各行业迅速应用,尤其是在零售、制造和分销领域。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
然而,尽管有令人信服的可能性,实现人工智能的最大收益依赖于扎实的数据成熟度基础。不幸的是,许多企业由于各种因素面临实现这种成熟度的挑战。这些挑战通常包括:
-
数据孤岛现象
-
数据质量差
-
对数据资产和技能的透明度有限
-
组织惯性在重新建立技术作为业务数据需求的推动者与提供者之间的平衡
在这篇文章中,我将重点介绍克服这些挑战的建议策略,以建立一个强大的数据基础,进而扩展差异化的人工智能能力。
当前人工智能的状态及行业领袖如何引领前进
零售、制造和分销领域的领导者利用 AI 的强大功能取得了显著成果,从优化供应链到预测客户行为。生成式 AI 正在获得主流关注。最近的《财富》/德勤首席执行官调查发现,首席执行官们对生成式 AI 的潜力表现出广泛兴趣。在最近的一项调查中,79%的首席执行官对技术提升运营效率的潜力表示乐观,超过一半的首席执行官预期会出现新的增长途径。一部分人透露正在评估和实验生成式 AI,强调了积极利用尖端技术的主动态度。
在 AI 成熟度最高的行业领导者中,他们展示了差异化的能力来推动销售和优化运营。例如,亚马逊的 AI 推荐引擎根据客户的历史购买和浏览记录建议产品,这在推动销售方面发挥了重要作用。同样,沃尔玛成功地使用 AI 算法进行库存管理和需求预测,这意味着这家零售巨头正在利用 AI 确保产品在客户需要时随时可用。
然而,根据 Gartner 的 AI 成熟度模型,52%的中大型美国组织仍在实验 AI。
根据最近对 300 多位首席数据官的 AWS 调查,首席数据官在采纳 AI 和支持数字化转型方面扮演着至关重要的角色,并负责组织内的数据战略和治理,他们认为数据质量是充分发挥 AI 能力的最大障碍之一。
让我们深入探讨影响 AI 采纳的数据成熟度挑战以及如何克服这些挑战。
数据成熟度:AI 可扩展性的缺失环节
尽管 AI 的潜力不可否认,但许多企业由于数据相关的障碍而在扩展 AI 应用时遇到困难。随着组织开展雄心勃勃的 AI 计划,它们常常遇到阻碍及时实施和广泛采纳的重要障碍。组织必须优先考虑数据成熟度,以应对这些挑战,并充分实现 AI 的潜力。
数据成熟度指的是组织有效管理、治理和利用其数据资产的能力。它涵盖数据质量、治理、集成和分析能力。缺乏数据成熟度可能导致阻碍 AI 采纳和扩展的若干挑战,例如:
-
数据孤岛和碎片化: 分散在不同系统和格式中的数据会造成数据孤岛,可能阻碍公司范围内的整体利用。
-
数据质量问题: 不准确、不完整或不一致的数据可能导致缺陷的人工智能模型和不可靠的见解。
-
数据治理缺口: 如果没有适当的数据治理实践,企业可能会面临与数据安全、隐私和合规性相关的问题。
-
有限的数据分析能力: 无法从数据中提取有意义的见解可能会阻碍人工智能的开发和应用。
这些挑战凸显了数据成熟度在实现人工智能扩展性方面的关键作用。为了克服这些困难,企业必须采用全面的数据管理和治理方法。
解决关键挑战的规范性策略
DataArt 为企业提供了全面的战略和解决方案,以提升数据成熟度。我们推动合作伙伴走向一个数据民主化、灵活且目标驱动的软件生态系统,克服阻碍人工智能采纳的障碍。通过培养数据拥有、赋能和创新的文化,企业可以更好地利用人工智能的变革潜力,推动可扩展的、人工智能驱动的应用场景,将自己置于由数据驱动的卓越和持续增长所定义的未来前沿。
数据网格与数据产品的融合
数据网格和数据产品策略的出现预示着全球经济中的一种变革性范式转变。数据网格是一种新型架构方法,主张去中心化的数据拥有和管理,在单一企业中推动基于领域的数据架构。这一策略旨在通过将数据拥有权分配给领域特定团队,从而缓解集中数据湖或数据仓库的瓶颈。通过这种数据分发工作,数据网格使团队能够策划、拥有和发展他们的数据产品,促进灵活性和扩展性,同时保持数据治理和质量。
图 1:数据网格框架,通过业务领域驱动的数据产品实现快速价值实现。
同时,数据产品战略进一步巩固了人工智能扩展性的基础。该战略倡导将数据视为产品进行概念化、创建和管理,以满足组织内部特定用户的需求。每个数据产品都封装了有价值的见解、准备好的数据集或分析工具,旨在供各类利益相关者使用。这种方法培养了数据拥有的文化,赋予团队创新、协作的能力,并从精心策划的数据产品中提取可操作的见解,加速人工智能的采用。
例如,客户细分分析数据产品可以进一步用于创建流失数据产品,两者都可以用于营销目的,为客户生成超个性化的内容。如果没有数据产品或数据产品市场,团队将不得不从头开始构建这些分析能力。相反,每个新的用例可以重用和重新利用现有的数据产品,从而缩短开发时间,并产生更一致的输出。
数据民主化与有效的数据治理
随着各行各业的公司寻求更有效的数据管理方式,必须仔细考虑几个因素。数据民主化涉及使数据对数据科学家、商业分析师、领域专家、管理层和高管等利益相关者可访问和易于理解。此外,公司必须确保数据不仅可以随时获取、易于阅读,而且还要安全、合规,并具备透明的标准和控制措施。实施正确的安全性和合规性措施将帮助企业保护数据的完整性、隐私和合规性。
这种演变标志着组织如何利用数据的根本变化。历史上,IT 部门负责建立公司数据相关模块,如数据仓库和分析数据产品。通过实施 AI 驱动的数据民主化方法,IT 可以成为技术促进者,而不仅仅是控制数据访问和提供服务的角色。通过部署 AI 驱动的系统,IT 可以将资源集中在赋能用户独立浏览和获取公司数据的洞察上。这一过渡需要 IT 角色的根本转变,从守门人变成促进协作和创新的合作伙伴。
数据策划在确保组织内数据资产的质量、相关性和可用性方面发挥着关键作用。然而,由于数据来源的数量和多样性、功能孤岛以及人工努力的挑战,维护数据策划通常很困难。这是 AI 可以改善的领域之一。 AI 驱动的工具和算法可以自动化数据处理任务,从而实现更快的数据策划、数据清理和标准化,减少人工工作。 AI 算法可以识别数据中的模式并进行信息的上下文化,从而促进更准确的数据策划和分类。
通过采纳和实施这些策略,企业可以建立一个强大的数据成熟度基础,使其能够有效利用 AI 的力量,并在业务中扩展 AI 驱动的用例。此外,DataArt 可以帮助公司建立或改善连接技术、人员和流程的核心基础能力,如:
-
打破数据孤岛: 将来自不同来源的数据整合到一个集中存储库中,确保数据的一致性和可访问性。
-
建立数据治理: 实施一个定义数据所有权、访问控制、数据质量标准和数据使用政策的框架。
-
提升数据质量: 实施数据质量检查、清理过程和丰富技术,以提高数据的准确性和完整性。
-
培养数据素养: 对员工进行数据管理原则、数据分析技术和数据驱动决策的培训,以提升组织的数据利用能力。
-
投资于数据基础设施: 升级数据基础设施以处理日益增长的数据量、速度和种类,确保高效的数据存储、处理和分析。
-
拥抱 DataOps: 实施 DataOps 实践以自动化数据管理过程,实现快速数据交付和持续改进。
-
利用基于云的数据解决方案: 使用基于云的数据平台以在数据管理中获得可扩展性、灵活性和成本效益。
-
持续监控和改进: 监控数据质量、治理合规性和使用模式,以识别并解决新出现的挑战。
结论
数据成熟度不仅仅是技术要求;它是寻求释放 AI 变革潜力的企业的战略性必要条件。通过应对与数据成熟度相关的关键挑战,企业可以为由数据驱动的洞察和 AI 驱动的创新塑造未来铺平道路。
Oleg Royz 是 DataArt 的零售与分销副总裁。
更多相关主题
数据网格架构:重新定义数据管理
原文:
www.kdnuggets.com/2022/05/data-mesh-architecture-reimagining-data-management.html

由 GarryKillian 创建的连接点矢量 - www.freepik.com
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
数据被视为推动业务创新的驱动力。因此,企业不断探索数据的潜力,以使业务流程更直观,并为客户提供超个性化的体验。随着驱动型企业在当今数字世界中取得成功,对数据分析市场的投资预计到 2023 年将达到 1030 亿美元。随着企业急于从数据中获取更有价值和可操作的洞察,数据量和数据来源的增加也在快速增长和扩展。继续将来自不同来源的数据整合到一个集中位置(即数据湖或数据仓库)的数据管理策略变得越来越复杂,因为集中在数据仓库或数据湖中的数据需要由专业团队进行分析。
数据网格是一种新的 去中心化数据策略,将所有权归于每个业务领域,例如销售或客户支持。
数据网格的目标是建立来自不同领域的数据之间的一致性。这些领域被自主处理,以消除跨职能团队面临的数据可用性和访问性挑战。
数据网格将解决的问题
数据网格解决了传统大数据管理方法中显著存在的以下问题:
支持可扩展性
市场专家指出,传统的数据管理方法,包括数据仓库或数据 湖泊模型(data lake models) 扩展性差。随着数据量的增加,数据管理的复杂性也随之增加。在传统的数据湖架构中,来自不同来源的数据使得数据消费者难以解读。消费者必须回到数据生产者那里尝试理解数据。随着多个平台的集成增加,以及数据缺乏结构和所有权,时间的推移使得数据湖架构面临重大障碍。
数据网格架构倡导每个团队负责创建、处理和存储数据。这有助于其他领域避免单一中央企业级 数据仓库或数据湖 的瓶颈。集中数据的解耦使企业级扩展成为可能,当团队以速度和规模满足自身的数据需求时,迅速带来跨领域的创新。
数据质量的提升
集中式的数据管道使得团队对不断增长的数据量的质量控制减少,但数据网格架构允许每个团队使用自己的仓库和湖泊,创建和管理他们的领域数据,从而团队有更多的激励和所有权来确保数据产品的质量,确保在进一步分发前达到高标准。这种架构在企业内部带来了更多的问责制和团队间的协作。
更加关注组织变革
集中的整体数据储备还提供了一种跨多个技术和平台访问数据的架构,但它更多地集中于技术,而数据网格则专注于组织变革。数据网格生态系统将知识注入领域团队,鼓励领域团队在其专业领域内提供最佳业务价值。这种生态系统打破了一个常见的误解,即需要集中数据才能使其有用。由于数据来自不同来源的集中,数据的含义有时会被修改。数据网格可以解决这个问题,因为领域 团队将数据视为产品 并处理自己的数据管道。他们还能够提供数据产品,并集中提供。
让我们看一下企业在采纳数据网格架构之前需要考虑的几个关键因素
尺寸和业务需求
随着数据量和类型的增长,数据团队会感到不堪重负,企业从数据投资中获得的价值也会越来越少。因此,数据网格架构非常适合数据流来自多个来源、且这些来源各异且可变的大型企业。业务举措应与领域团队紧密对齐,以从领域特定的数据中获取有价值的见解。这种对齐有助于领域团队创造能够带来实际业务价值的高质量成果。
数据管理与所需专业知识
各领域处理数据的策略还需要企业范围内的协调和治理。现代工具可以帮助企业入门数据管理策略,但工具的选择仍需要专家的全面监督。
像 Cuelogic、Data Product Platform、IBM 等平台提供实施数据网格架构的服务。这些平台像传统的数据管理架构一样,整合来自所有来源的数据,将其制作成任意数量的数据产品,并创建数据网格。数据管理平台提供在任意数量领域间安全分发数据,并在任何层级提供数据质量控制、隐私和访问权限。
此类平台还对引导企业过渡到处理数据的新方式非常有用,并帮助它们避免在底层系统中发现的数据复杂性。
结论
数据网格架构为现有的数据管理架构带来了范式转变。它能够处理多样化和庞大的数据量,相比其他数据架构,它是一种更好的方法。数据网格中的领域特定结构有助于从不断增长的数据块中生成有价值的见解。团队对数据的拥有权转化为更大的数据实验和创新空间。Netflix 采用了数据网格架构,以整合和管理来自数百个不同数据存储的数据。参见这个YouTube 视频来了解 Netflix 数据网格。这种创建一个由领域团队组成的网络的新方式,能够帮助这些团队拥有自己的数据并将其视为产品,从而从数据操作中获得更多价值。
Yash Mehta 是一位物联网和大数据爱好者,他在 IDG、IEEE、Entrepreneur 等出版物上贡献了许多文章。他共同开发了像 Getlua 这样的平台,允许用户轻松地 合并多个文件。他还创立了一个研究平台,从专家那里生成可操作的见解。
更多相关话题
数据网格及其分布式数据架构
原文:
www.kdnuggets.com/2022/02/data-mesh-distributed-data-architecture.html

图片由 Ricardo Gomez Angel 提供,发布在 Unsplash
企业希望更快响应并提供卓越的客户体验,这需要对数据管理进行全面的重塑。迄今为止,技术已经解决了存储和处理大数据的问题。它还具备了将大数据进行深度分析的能力。与此同时,预计到 2025 年,先进数据管理解决方案的全球市场规模将达到 1229 亿美元。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
然而,数据来源类型和数量的日益多样化继续阻碍无缝的数据生命周期。迄今为止,数据管理领域主要是将数据捕获和流式传输到一个中心化的数据湖中。数据湖会进一步处理和清洗数据集。展望未来,数据专业人士找到了一种通过数据网格来解决数据来源扩展性的全新方法。
什么是数据网格?
数据网格是一种分布式架构解决方案,用于分析数据的生命周期管理。基于去中心化,数据网格消除了数据可用性和访问性的障碍。它使用户能够从多个来源捕捉和操作洞察,无论这些来源的地点和类型如何。随后,它执行自动化查询,而无需将数据传输到中心化的数据湖中。
数据网格的分布式架构去中心化了每个业务领域的所有权。这意味着每个领域都掌控着分析和运营用例的数据质量、隐私、新鲜度、准确性和合规性。
从中心化数据湖迁移到分布式网格
随着数据源数量的不断增加,数据湖无法进行按需集成。使用数据网格,将大量数据倾倒入数据湖的做法正处于过时的边缘。
新的数据管理框架确保了所有节点的协作参与,每个节点控制一个特定的业务单元。它通过遵循数据即产品的原则来实现这一点。这意味着每个数据集都被视为一个数字产品,包含干净、完整和有结论的数据集。这些数据集可以随时随地按需交付。对于一个快速增长的数据管理生态系统来说,数据网格是提供组织数据洞察的重要方法。
所有权的去中心化减少了对工程师和科学家的依赖。每个业务单元控制其自身的特定领域数据。然而,每个领域仍然依赖于中心化的标准化数据建模、安保协议和治理合规政策。
使用数据网格和数据结构
任何关于数据管理的讨论如果遗漏了数据结构架构,那将是不完整和无关的。关于数据结构和数据网格相互竞争的说法是一个误解。这是不正确的。Gartner 已经对这两个标题进行了并排讨论,并澄清了这一点。
数据结构是一种经典而相关的架构,推动了不同工业中的结构使用。它自动发现并提出管理架构,从而简化整个数据生命周期。它还支持验证数据对象和上下文引用,以便重新使用这些对象。数据网格通过利用当前的主题领域专长并为数据对象准备解决方案来实现这一点。
关于数据结构和数据网格相互竞争的说法是一个误解。这是不正确的。实际上,数据结构可能在从数据网格架构中提取最佳价值方面发挥重要作用。
使用基于实体的数据结构实施数据网格
以 K2View 的基于实体的数据结构架构为例。它为每个业务实体保存数据到一个独立的微型数据库,从而支持成千上万个这些数据库。此外,通过将‘业务实体’和‘数据作为产品’的概念融合,他们的结构支持数据网格设计模式的实施。在这里,数据结构创建了一个连接来自多个来源的数据集的集成层。这为操作和分析工作负载提供了全景视图。
实体基础结构标准化了所有数据产品的语义定义。根据规定,它建立了数据摄取方法和治理政策,以确保数据集的安全性。由于基础结构的支持,网格模式在实体级存储方面表现更好。
因此,对于网格分布式网络中的每个业务领域,都会部署一个专属的基础结构节点。这些特定于特定业务实体的领域拥有对服务和管道的本地控制,以便为消费者访问产品。
去中心化数据所有权模型
企业必须将来自多个来源的多种数据类型导入集中式存储库,如数据湖。在这里,数据处理通常消耗大量精力,并且容易出错。查询这种异构数据集进行分析会直接增加成本。因此,数据专业人士一直在寻找这种集中式方法的替代方案。凭借 Mesh 的分布式架构,他们能够实现每个业务实体的所有权去中心化。现在,这种模式减少了生成定性见解的时间,从而增加了核心目标的价值——快速访问数据并影响关键业务决策。
去中心化方法解决了更多问题。例如,传统数据管理中的查询方法可能会因数据量无法控制的增长而失去效率。这必然会迫使整个流程发生变化,并最终无法响应。因此,随着数据源数量的增加,响应时间急剧下降。这一直影响着提取数据价值和扩大业务成果的过程敏捷性。
通过去中心化,Mesh 将所有权分配给不同的领域,以应对数据量的挑战,并最终在其层面上、为其相关的数据集执行查询。因此,该架构使企业流程能够缩短事件与其消费分析之间的差距。企业能够在关键决策制定方面进行改进。
通过提供数据即服务架构,Mesh 带来了业务运营的敏捷性。它不仅减少了 IT 积压,还使数据团队只处理精简和相关的数据流。
因此,授权的消费者可以轻松访问他们各自的数据集,而无需了解其底层复杂性。
结论
从数字数据开始,Web 3.0 致力于去中心化企业流程。数据管理是这一方向上的一个重要用例。显然,集中式权威在处理爆炸性增长的数据方面已经超出了某个极限。期待 2022 年,它将把 Data Mesh 架构推向前沿。
Yash Mehta 是一位物联网和大数据爱好者,他在 IDG、IEEE、Entrepreneur 等刊物上发表了许多文章。他共同开发了像Getlua这样的平台,允许用户轻松地合并多个文件。他还创办了一个研究平台,从专家那里生成可操作的见解。
更多相关内容
哪些大数据、数据挖掘和数据科学工具常常一起使用?
原文:
www.kdnuggets.com/2015/06/data-mining-data-science-tools-associations.html
由 Gregory Piatetsky 撰写,发表于 2015 年 6 月 11 日,内容涉及 Apache Spark、数据挖掘软件、Excel、Hadoop、Knime、调查、Python、R、RapidMiner、SQL 评论
(与 Shashank Iyer 共同撰写。) 我们使用了 2015 KDnuggets 数据挖掘软件调查 的匿名数据,并对前 20 个工具进行了关联分析。数据集包含 2759 票,每票为一个或多个工具。在这篇文章的底部有一个链接可以下载匿名数据集。
我们使用了一种 Apriori 算法的版本来分析结果。
测量两个名义或二元特征之间关联显著性的方法有很多,例如卡方检验或 T 检验,但我们使用了一种简单的度量,我们称之为“提升度”,其定义为
提升度(X & Y)= pct (X & Y) / ( pct (X) * pct (Y) )
其中 pct(X) 是选择 X 的用户百分比。
提升度(X&Y)> 1 表示 X&Y 一起出现的频率高于它们独立时的预期频率,
如果 X 和 Y 的出现频率与它们独立时的预期频率相同,则提升度 = 1,
如果 X 和 Y 一起出现的频率低于预期,则提升度(Lift)< 1(负相关)。
注意,这一度量是对称的:提升度(X & Y)= 提升度(Y & X)
图 1 显示了前 10 大数据挖掘工具的热图。提升度值显示在各自的矩阵位置中,颜色梯度表示关联程度,从高到低。
如果提升度 > 1.2,方块为红色;如果小于 0.8,方块为蓝色;否则为灰色。
Spark 和 Hadoop 的提升度最高,达到了 3.31,其次是 Spark 和 Python(提升度 = 2.05)。我们还注意到 Excel 和 SQL 之间,以及 Tableau 和 SQL 之间存在较强的关联。
最低的关联度出现在 SAS base 和 KNIME(0.51),SAS base 和 RapidMiner(0.52),以及 KNIME 和 RapidMiner(0.56)之间。
图 1:前 10 大数据挖掘工具的关联矩阵热图
计算了一个类似的热图(图 2),显示了开源工具和商业工具之间的各种关联。
图 2: 开源工具与商业工具之间的混淆矩阵热图
为了可视化前 20 个最受欢迎工具之间的相关性,计算了图 3 中的网络图。
每个节点代表一个前 20 名工具,节点的颜色为红色:免费/开源工具,绿色:商业工具,紫红色:Hadoop/大数据工具。节点大小根据每个工具获得的投票百分比而变化。边缘大致分为两个部分——低关联到高关联,这在从浅粉色到深紫色的陡色渐变中显示。此分段还显示在每条边的权重中,较厚的边表示高关联,较细的边表示低关联。

图 3: 最受欢迎的 20 个工具的网络图(点击图表以获取更高分辨率的图像)
以下是图 3 网络图中数据的顶级、高级和低级关联。
表 1. 前 20 个工具中 20 个最高关联(提升)
| 工具 X | 工具 Y | 提升 |
|---|---|---|
| Alteryx | Tableau | 2.14 |
| Excel | Microsoft SQL Server | 2.15 |
| Excel | SQL | 1.93 |
| Hadoop | Spark | 3.31 |
| IBM SPSS Modeler | IBM SPSS Statistics | 6.18 |
| KNIME | Weka | 1.93 |
| MATLAB | Weka | 2.53 |
| Pig | Hadoop | 4.24 |
| Pig | Spark | 4.44 |
| Pig | scikit-learn | 2.25 |
| Pig | Unix shell/awk/gawk | 2.25 |
| Pig | Python | 2.09 |
| Python | scikit-learn | 3.12 |
| Python | Spark | 2.05 |
| Python | Unix shell/awk/gawk | 1.91 |
| SAS base | SAS Enterprise Miner | 6.39 |
| scikit-learn | Spark | 2.63 |
| scikit-learn | Unix shell/awk/gawk | 2.56 |
| SQL | Microsoft SQL Server | 2.38 |
| SQL | Unix shell/awk/gawk | 2.01 |
正如预期的那样,Excel 经常与 SQL 配对,Hadoop 与 Spark 配对,Pig 与 Hadoop 配对,IBM SPSS Modeler 与 IBM SPSS Statistics 配对。在不那么明显的关联中,我们看到 Pig 与 scikit-learn,Weka 与 KNIME 和 MATLAB。
表 2. 前 20 个工具中 20 个最低关联(提升)
| 工具 X | 工具 Y | 提升 |
|---|---|---|
| Alteryx | IBM SPSS Modeler | 0.54 |
| Alteryx | IBM SPSS Statistics | 0.17 |
| Alteryx | KNIME | 0.26 |
| Alteryx | MATLAB | 0.37 |
| Alteryx | Python | 0.55 |
| Alteryx | RapidMiner | 0.23 |
| Alteryx | SAS base | 0.28 |
| Alteryx | SAS Enterprise Miner | 0.24 |
| Alteryx | scikit-learn | 0.08 |
| Alteryx | Unix shell/awk/gawk | 0.08 |
| Alteryx | Weka | 0.11 |
| IBM SPSS Modeler | Unix shell/awk/gawk | 0.51 |
| IBM SPSS Statistics | scikit-learn | 0.34 |
| IBM SPSS Statistics | Spark | 0.54 |
| IBM SPSS Statistics | Unix shell/awk/gawk | 0.53 |
| KNIME | SAS base | 0.51 |
| KNIME | SAS Enterprise Miner | 0.48 |
| RapidMiner | SAS base | 0.52 |
| RapidMiner | SAS Enterprise Miner | 0.54 |
这里我们看到,Alteryx 用户几乎不使用其他工具(除了 Tableau),IBM SPSS 用户不使用 Unix,KNIME 和 RapidMiner 用户不使用 SAS。
最后,我们来看一下与 R 配套使用的工具。由于几乎一半的投票者使用了 R,没有工具与 R 的关联度超过 2,但以下是与 R 的提升值最高的工具。
表格 3. 最常与 R 关联的工具/软件
| 工具 | 提升 (工具, R) |
|---|---|
| Hive | 1.54 |
| Tableau | 1.42 |
| Python | 1.41 |
| Spark | 1.39 |
| scikit-learn | 1.36 |
| Unix shell/awk/gawk | 1.32 |
| MATLAB | 1.32 |
| SQLang | 1.30 |
| Weka | 1.30 |
| Microsoft SQL Server | 1.29 |
这是匿名数据集的链接(CSV 格式),包含 3 列
-
ord: 投票顺序
-
ntools: 工具数量
-
votes: 工具名称,用";"分隔。注意:为了匹配模式,R 被编码为 Rlang,SQL 被编码为 SQLang。
让我们知道你的发现!
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
数据挖掘与机器学习有何不同?
原文:
www.kdnuggets.com/2022/06/data-mining-different-machine-learning.html

我们生活在一个数据驱动、信息丰富的数字时代,企业时常见到新的技术术语和概念。随着越来越多的企业适应人工智能和机器学习,大数据和数据分析展示奇迹的可能性也大大增加。数据是一个关键工具;然而,数据量越大,组织获得洞察所需的时间就越长。
这就是为什么企业需要数据挖掘的原因。数据挖掘为企业开启了各种机会,因为它具有描述性和预测性的能力。数据挖掘在商业智能中的应用有助于未来的道路规划、产品开发和业务流程。此外,数据挖掘和机器学习都属于数据科学的一般范畴。
当涉及到数据挖掘和机器学习的应用时,它们之间有很多重叠,因此企业经常将这两者互换使用。令人感兴趣的是,尽管这两种技术具有类似的功能,但它们处理数据的方式却有所不同。我们不妨更详细地了解一下数据挖掘和机器学习,以便掌握它们的不同之处。
什么是数据挖掘?
数据挖掘从海量数据中提取关键信息。人们使用数据挖掘技术发现数据中的新、准确且有用的模式,以找出其意义和信息。
让我们详细拆解数据挖掘过程,看看专家如何实现功能并应对数据挑战。
-
理解业务目标: 包括定义目标、短期目标和当前业务状况。
-
理解获得的数据: 在这里,我们确定解决问题所需的数据类型。然后,从适当的来源收集所需的数据。
-
准备数据: 在这里,解决数据质量问题,如重复、数据损坏和缺失数据。然后以适当的格式展示数据。
-
建模数据: 这意味着应用算法来识别数据中的模式、洞察和更多有价值的信息。
-
评估数据: 在这里,企业检查获得的洞察是否达到了所需的目标和目的。
-
部署解决方案: 如果数据洞察与所需的业务目标一致,则作出决策。
正如这个过程所示,数据挖掘是一种有效解决复杂数据挑战的方法。那么,数据挖掘对您的业务还有哪些其他好处呢?
数据挖掘在业务中的好处
在今天竞争激烈的商业世界中,从数据中获取尽可能多的好处至关重要。这里是数据挖掘为企业提供的一系列广泛的好处。
-
与传统的数据处理方法如 BI 工具和软件系统相比,数据挖掘是一种成本效益高的解决方案。
-
企业通过数据挖掘方法进行有利可图的生产和操作调整。
-
数据挖掘适用于新的和遗留的系统,这意味着任何规模和大小的企业都可以实施其方法。
-
企业利用数据挖掘信息来访问风险模型、检测欺诈行为并提高产品安全性。
-
企业还可以快速启动自动化趋势和行为,并基于丰富的数据做出明智的决策。
数据挖掘与机器学习
如果你希望充分利用数据挖掘的潜力,使用“正确的工具来完成正确的工作”至关重要。虽然我们讨论了用于各种数据挖掘功能的不同工具和技术,其中一种工具是机器学习。
机器学习是数据挖掘的一种工具,包括发现算法以提高从数据中得出的经验的质量。数据挖掘使用机器学习设计的技术来预测结果,而机器学习是一个系统从有意识的数据集中学习的能力。
机器学习的演变揭示了一些需要手动处理的最棘手的问题。如今,机器学习和数据挖掘使得创建复杂的算法以处理大数据并提供有用的结果变得更加容易。
数据挖掘与机器学习
数据挖掘使用两个组件(数据库和机器学习)进行数据管理和数据分析技术。它帮助提取有价值的数据,从而为产品或服务提供出色的见解。
然而,机器学习仅使用算法并具备自我学习能力,以根据情境改变规则来寻找解决方案。
另一个显著的区别在于人工干预,数据挖掘需要不断的人力介入,而机器学习只需定义算法即可。由于机器学习是一个自动化过程,它会自行运行以生成准确的结果,而数据挖掘则不然。
数据挖掘受限于数据的组织和收集方式,并作为从复杂数据集中提取相关见解的手段。机器学习识别所有相关数据点之间的关联,以提供准确的结论,并最终塑造模型的行为。
例如, CRM 系统实施机器学习程序以增强其关系智能,以更好地理解客户。它可以分析过去的行动以提高转化率并改善客户满意度评分。这里有一个小的比较表格,帮助你更好地区分数据挖掘和机器学习。
| 比较基础 | 数据挖掘 | 机器学习 |
|---|---|---|
| 历史 | 它在 1930 年被引入,称为数据库中的知识发现。 | 它在 1950 年首次引入,用于 Samuel 的棋盘游戏程序。 |
| 起源 | 它起源于包含非结构化数据的传统数据库。 | 它起源于现有的数据和算法。 |
| 意义 | 它有助于从大型数据集中提取信息。 | 它从数据中引入了一个新算法。 |
| 责任 | 它用于从现有数据中获取规则。 | 它教会计算机学习和理解给定的规则。 |
| 特性 | 这更多的是一个手动过程,需要人工干预。 | 这是一个自动化过程,一旦设计实施后不需要人工干预。 |
| 实施 | 用户可以开发模型以使用数据挖掘技术。 | 用户可以在决策树、神经网络和人工智能的特定领域使用它。 |
| 应用与抽象 | 它用于聚类分析,数据从数据仓库中抽象出来。 | 它读取机器,并用于网络搜索、信用评分、垃圾邮件过滤、欺诈检测和计算机设计。 |
| 范围 | 我们可以在有限的领域应用它。 | 我们可以在广泛的领域使用它。 |
最终想法
数据挖掘过程有助于从历史数据中预测结果或从现有数据中找到新解决方案。机器学习克服了数据挖掘的问题,使其以更快的速度发展。此外,机器学习更准确且错误更少,使其能够做出自己的决策并解决问题。
然而,保持数据挖掘过程是至关重要的,因为它将定义特定业务的问题。数据挖掘和机器学习是推动业务发展的必要手段,需要更好地协同工作。
Sudeep Srivastava 是 Appinventiv 的首席执行官,他以乐观和精心计算的风险相结合的完美特质建立了自己,这一特质在 Appinventiv 的每个工作过程中都得到了体现。他建立了一个以挖掘移动行业未开发想法而闻名的品牌,花时间探索将 Appinventiv 带到技术与生活融合的地步。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
数据挖掘与机器学习:基础概念与算法:免费电子书
原文:
www.kdnuggets.com/2020/07/data-mining-machine-learning-free-ebook.html
评论
作者:Mohammed J. Zaki 和 Wagner Meira, Jr.
我们很高兴地宣布我们书籍的第二版 《数据挖掘与机器学习:基础概念与算法(第二版)》,由 Mohammed J. Zaki 和 Wagner Meira, Jr. 编著,剑桥大学出版社出版,2020 年。
整本书可以在线免费阅读,网站还包括视频讲座和其他资源。
本版新增了一个完全专门讨论回归和深度学习的部分。
描述与特点:
数据挖掘和机器学习中的基本算法构成了数据科学的基础,利用自动化方法分析模式和模型,应用于从科学发现到商业分析的各种数据。这本面向高级本科生和研究生课程的教科书提供了数据挖掘、机器学习和统计学的全面深入概述,为学生、研究人员和从业者提供了坚实的指导。该书奠定了数据分析、模式挖掘、聚类、分类和回归的基础。
本版包括一个新的回归部分,涵盖了线性回归、逻辑回归、神经网络、深度学习和回归评估的章节。该书内容自足,包含关键的数学概念和算法。它强调几何、代数和概率视角之间的相互作用,构建了数据挖掘和机器学习基础方法背后的关键直觉。
相关:
-
数据科学基础:免费电子书
-
理解机器学习:免费电子书
-
统计学习导论:免费电子书
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
了解更多内容
数据可观测性:使用 SQL 构建数据质量监视器
原文:
www.kdnuggets.com/2021/02/data-observability-building-data-quality-monitors-using-sql.html
评论
由 Ryan Kearns,斯坦福大学 和 Barr Moses,Monte Carlo 首席执行官兼联合创始人

图片由 faaiq ackmerd 提供,来源于 Pexels。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
在本系列文章中,我们将详细介绍如何从零开始创建自己的数据可观测性监视器,映射到数据健康的五大支柱。本系列的第一部分改编自 Barr Moses 和 Ryan Kearns 的 O'Reilly 培训,《管理数据停机时间:将可观测性应用于数据管道》,这是行业首个数据可观测性课程。相关练习可在这里找到,本文所示的改编代码可在这里获取。
从空值和重复行,到建模错误和模式变化,数据可能因多种原因而损坏。数据测试 通常是对抗不良数据的第一道防线,但如果数据在其生命周期中发生故障会发生什么?
我们将这种现象称为数据停机时间,指的是数据缺失、错误或其他不准确的时间段。数据停机时间 促使我们提出以下问题:
-
数据是否是最新的?
-
数据是否完整?
-
字段是否在预期范围内?
-
空值率是高于还是低于预期?
-
模式是否发生了变化?
为了在数据出现故障时触发警报并防止数据停机,数据团队可以借鉴我们软件工程领域朋友的成熟策略:监控和可观测性。
我们将数据可观测性定义为组织回答这些问题和评估其数据生态系统健康状况的能力。数据健康的关键变量反映了数据可观测性的五大支柱:
-
新鲜度:我的数据是否是最新的?是否存在数据未更新的时间间隔?
-
分布:我的数据在字段级别的健康状况如何?我的数据是否在预期范围内?
-
数据量:我的数据采集是否达到预期的阈值?
-
模式:我的数据管理系统的正式结构是否发生了变化?
-
数据源追溯:如果我的某些数据出现故障, upstream 和 downstream 受到什么影响?我的数据源之间是如何相互依赖的?
讨论数据可观测性是一个方面,但完全的处理应当揭开帷幕——数据可观测性在实际中是什么样的,底层代码是怎样的?
完全回答这个问题很困难,因为细节将取决于数据仓库、数据湖、BI 工具、首选语言和框架等选择。即便如此,使用像 SQLite 和 Jupyter 这样的轻量级工具来解决这些问题可能会很有用。
在这篇文章中,我们将通过一个数据生态系统的示例,创建自己的数据质量监测器,并探索数据可观测性在实际中的表现。
让我们来看看。
实践中的数据可观测性
本教程基于我们 O'Reilly 课程的练习 1。您可以使用 Jupyter Notebook 和 SQL 自行尝试这些练习。我们将在未来的文章中更详细地讨论,包括练习2、3和4*。
我们的示例数据生态系统使用了有关适居系外行星的 mock astronomical data。为了本练习的目的,我使用 Python 生成了数据集,将异常情况建模为我在生产环境中遇到的实际事件。该数据集完全免费使用,且如果您感兴趣的话,您可以在 utils folder 中找到生成数据的代码。
我使用的是SQLite 3.32.3,这应该使数据库能够通过命令提示符或 SQL 文件进行最小设置即可访问。这些概念扩展到任何查询语言,且这些实现可以轻松扩展到 MySQL、Snowflake 及其他数据库环境。
$ sqlite3 EXOPLANETS.db
sqlite> PRAGMA TABLE_INFO(EXOPLANETS);
0 | _id | TEXT | 0 | | 0
1 | distance | REAL | 0 | | 0
2 | g | REAL | 0 | | 0
3 | orbital_period | REAL | 0 | | 0
4 | avg_temp | REAL | 0 | | 0
5 | date_added | TEXT | 0 | | 0
EXOPLANETS 数据库条目包含以下信息:
0._id: 一个与行星对应的 UUID。
1. distance: 与地球的距离,以光年为单位。
2. g: 表面重力,作为 g,即重力常数的倍数。
3. orbital_period: 单次轨道周期的长度,以天为单位。
4. avg_temp: 平均表面温度,以开尔文度为单位。
5. date_added: 我们的系统发现该行星并自动将其添加到数据库的日期。
请注意,由于数据缺失或错误,某些行星的 distance、g、orbital_period 和 avg_temp 可能为 NULL。
sqlite> SELECT * FROM EXOPLANETS LIMIT 5;
请注意,此练习是追溯性的——我们在查看历史数据。在生产数据环境中,数据可观测性是实时的,并且应用于数据生命周期的每个阶段,因此实现方式会与这里的略有不同。
由于本练习的目的,我们将构建用于新鲜度和分布的数据可观测性算法,但在未来的文章中,我们将讨论其余的五大支柱——以及更多内容。
新鲜度
我们监控的数据可观测性的第一个支柱是新鲜度,它可以为我们提供关键数据资产最后一次更新的强有力指标。如果一个定期每小时更新的报告突然看起来非常陈旧,这种异常类型应能强烈指示我们某些地方出现了问题。
首先,请注意 DATE_ADDED 列。SQL 不存储关于单个记录添加时间的元数据。因此,为了在这种追溯性设置中可视化新鲜度,我们需要自己跟踪这些信息。
按 DATE_ADDED 列分组可以让我们了解 EXOPLANETS 的每日更新情况。例如,我们可以查询每天添加的新 ID 数量:
您可以通过在 the repository中运行 $ sqlite3 EXOPLANETS.db < queries/freshness/rows-added.sql 来自己执行此操作。我们会得到以下数据:
基于我们数据集的图示表示,EXOPLANETS 每天大约更新 100 条新条目,尽管有些天没有数据输入。
记住,对于新鲜度,我们要问的问题是“我的数据是否是最新的?”——因此,了解表更新中的这些间隙对于理解数据的可靠性至关重要。
新鲜度异常!
这个查询通过引入 DAYS_SINCE_LAST_UPDATE 的度量来实现新鲜度的操作化。(注意:由于本教程使用的是 SQLite3,MySQL、Snowflake 和其他环境中的 SQL 语法可能会有所不同。)
结果表显示“在日期 X,EXOPLANETS 中最近的数据是 Y 天前。”这是一种从表中的 DATE_ADDED 列中未显式提供的信息——但应用数据可观察性工具可以帮助我们揭示它。
现在,我们已经拥有检测新鲜度异常所需的数据。剩下的就是为 Y 设置一个 阈值 参数 —— 多少天是太久?参数将查询转变为检测器,因为它决定了什么算作异常(即:值得警报)什么不算。(关于设置阈值参数的更多信息将在后续文章中介绍!)
新鲜度异常!
返回给我们的数据代表了发生新鲜度事件的日期。
在 2020–05–14,表中最近的数据已经是 8 天前的了!这样的故障可能表示我们的数据管道出现了问题,如果我们将这些数据用于重要用途(如果我们在生产环境中使用这些数据,几乎可以肯定是这样),了解这些情况是很重要的。
特别注意查询的最后一行:DAYS_SINCE_LAST_UPDATE > 1;。
在这里,1 是一个 模型参数— 这个数字没有“正确”之说,虽然更改它会影响我们认为的事件日期。数字越小,我们捕捉到的真正异常越多(高 召回率),但这些“异常”可能并不反映实际的故障。数字越大,我们捕捉到的异常越可能反映真实的异常(高 精确度),但可能会错过一些。
对于这个示例,我们可以将 1 改为 7,从而只捕捉到 2020–02–08 和 2020–05–14 的两个最严重的故障。任何选择都会反映特定的使用案例和目标,这是一种重要的平衡,在将数据可观察性应用于生产环境时会反复出现。
下面,我们利用相同的新鲜度检测器,但使用DAYS_SINCE_LAST_UPDATE > 3;作为阈值。现在两个较小的停机未被检测到。
注意这两个未检测到的停机——这些必须少于 3 天的间隔。
现在我们可视化相同的新鲜度检测器,但DAYS_SINCE_LAST_UPDATE > 7;作为阈值。除了两个最大的停机外,其余都未被检测到。
就像行星一样,最佳模型参数位于“金发姑娘区”或在被认为过低和过高的值之间的“甜蜜点”。这些数据可观测性概念(以及更多!)将在以后的文章中讨论。
分布
接下来,我们要评估数据的字段级分布健康。分布告诉我们数据的所有期望值,以及每个值的出现频率。一个最简单的问题是,“我的数据有多少NULL”?在许多情况下,某种程度的不完整数据是可以接受的——但如果 10%的空值率变成了 90%,我们需要了解。
这个查询返回了大量数据!发生了什么事?
一般公式CAST(SUM(CASE WHEN SOME_METRIC IS NULL THEN 1 ELSE 0 END) AS FLOAT) / COUNT(*),按DATE_ADDED列分组,显示了SOME_METRIC在EXOPLANETS每日数据批次中的NULL值率。通过查看原始输出很难获得感觉,但可视化可以帮助揭示这一异常:
这些可视化清楚地表明,有一些空值率“峰值”事件我们应该检测。现在我们专注于最后一个指标AVG_TEMP。我们可以通过一个简单阈值最基本地检测空值峰值:
我们的第一个分布异常。
就检测算法而言,这种方法有点粗糙。有时,我们的数据模式简单到可以用这样的阈值解决。然而,在其他情况下,数据可能会很嘈杂或有其他复杂情况,如季节性,这就需要我们改变方法。
例如,检测 2020-06-02、2020-06-03 和 2020-06-04 似乎是多余的。我们可以过滤掉在其他警报之后立即出现的日期:
注意这两个查询中的关键参数是0.9。我们实际上是在说:“任何高于 90%的空值率都是一个问题,我需要知道。”
在这种情况下,我们可以(也应该)通过使用更智能的参数来应用滚动平均的概念,变得更加聪明。
一点澄清:注意在第 28 行,我们使用了AVG_TEMP_NULL_RATE — TWO_WEEK_ROLLING_AVG进行过滤。在其他情况下,我们可能需要对这个误差量取ABS(),但在这里则不需要——原因是NULL率的“激增”如果表示相对于之前的平均值的增加,那会更加令人担忧。监控NULL频率突然下降可能不太值得,而检测NULL率增加的价值则很明显。
当然,还有越来越复杂的异常检测指标,如Z-score和自回归建模,这些超出了本教程的范围。本教程仅提供了 SQL 中的基础框架,以进行字段健康监控;我希望它能给你自己数据上的一些启发!
接下来是什么呢?
本简短教程旨在展示“数据可观测性”并不像名字所暗示的那样神秘,通过全面了解数据健康,你可以在管道的每个阶段确保高数据信任度和可靠性。
实际上,数据可观测性的核心原则可以通过普通的 SQL“检测器”实现,只要保留一些关键的信息,如记录时间戳和历史表元数据。还值得注意的是,关键的机器学习驱动的参数调优对于随着生产环境增长的端到端数据可观测性系统是强制性的。
请继续关注本系列未来的文章,这些文章将重点关注分布和模式中的异常监控、数据可观测性中的血缘关系和元数据的作用,以及如何大规模监控这些支柱以实现更可靠的数据。
直到那时——祝你数据无停机!
有兴趣了解如何大规模应用数据可观测性吗?请联系Ryan、Barr及其余的Monte Carlo 团队。
Ryan Kearns是斯坦福大学的一名即将升入大四的学生,主修计算机科学和哲学。他目前是 Monte Carlo 的机器学习工程实习生。
Barr Moses是 Monte Carlo 的首席执行官兼联合创始人。此前,她曾担任 Gainsight 的运营副总裁。
原文。经许可转载。
相关:
-
SQL 中的数据清理和整理
-
实用统计推理的 10 个原则
-
数据科学与商业智能的区别,详解
更多相关话题
数据可观测性,第 II 部分:如何使用 SQL 构建自己的数据质量监控系统
原文:
www.kdnuggets.com/2021/02/data-observability-part-2-build-data-quality-monitors-sql.html
评论
作者:Barr Moses,Monte Carlo 的首席执行官兼联合创始人 & Ryan Kearns,Monte Carlo 的机器学习工程师
在这篇文章系列中,我们将讲解如何从零开始创建自己的数据可观测性监控系统,并映射到数据健康的五个关键支柱。第一部分可以在这里找到。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
本系列的第二部分改编自 Barr Moses 和 Ryan Kearns 的 O'Reilly 培训课程,管理数据停机时间:将可观测性应用于你的数据管道,这是业内首个数据可观测性的课程。相关的练习可以在这里找到,本文中展示的改编代码可以在这里找到。
随着世界对数据的需求增加,强大的数据管道变得更加必要。当数据出现问题时——无论是来自模式变化、空值、重复还是其他情况——数据工程师需要知道。
最重要的是,我们需要快速评估问题的根本原因,以免影响下游系统和用户。我们用“数据停机时间”来指代数据缺失、错误或其他不准确的时间段。如果你是一名数据专业人士,你可能会问以下问题:
-
数据是否是最新的?
-
数据是否完整?
-
字段是否在预期范围内?
-
空值率是否高于或低于预期?
-
模式是否发生了变化?
为了有效回答这些问题,我们可以借鉴软件工程师的做法:监控和可观测性。
为了帮助你回忆第一部分的内容,我们将数据可观测性定义为组织回答这些问题并评估其数据生态系统健康的能力。反映数据健康的关键变量,数据可观测性的五个支柱是:
-
新鲜度:我的数据是否是最新的?在何时数据没有更新?
-
分布:我的数据在字段级别上有多健康?我的数据是否在预期范围内?
-
数据量:我的数据接收是否达到预期阈值?
-
模式:我的数据管理系统的正式结构是否发生了变化?
-
血统:如果我的部分数据出现问题,哪些上游和下游的内容会受到影响?我的数据源之间如何相互依赖?
在这一系列文章中,我们感兴趣的是揭开面纱,研究数据可观测性在——代码中是如何表现的。
在第一部分中,我们探讨了前两个支柱:新鲜度和分布,并展示了如何通过少量的 SQL 代码将这些概念转化为操作性。这些问题可以称为更“经典”的异常检测问题——在数据持续流入的情况下,有没有什么看起来不对劲的?良好的异常检测确实是数据可观测性的一部分,但它不是全部。
同样重要的是上下文。如果发生了异常,那很好。但在哪里发生的?哪个上游管道可能是原因?哪些下游仪表盘会受到影响?我的数据的正式结构是否发生了变化?良好的数据可观测性取决于我们利用元数据来回答这些问题——以及许多其他问题——的能力,从而可以在问题变得更严重之前找出根本原因并解决它。
在这篇文章中,我们将探讨旨在提供这一关键上下文的两个数据可观测性支柱——模式和血统。我们将再次使用轻量级工具,如 Jupyter 和 SQLite,因此你可以轻松启动我们的环境,并尝试这些练习。让我们开始吧。
我们的数据环境
本教程基于练习 2 和 3,这是我们 O'Reilly 课程Managing Data Downtime的一部分。欢迎使用 Jupyter Notebook 和 SQL 自行尝试这些练习。我们将在未来的文章中详细讨论,包括练习4。
如果你阅读了第一部分 本系列文章,你应该对我们的数据比较熟悉。如之前所述,我们将处理mock 天文数据,有关宜居系外行星。我们使用 Python 生成了数据集,模拟了我在生产环境中遇到的实际事件的数据和异常。该数据集完全免费使用,utils 文件夹 包含生成数据的代码,如果你感兴趣的话。
我使用的是 SQLite 3.32.3,这使得数据库可以通过命令行提示符或 SQL 文件轻松访问。该概念适用于几乎任何查询语言,这些实现 可以扩展到 MySQL、Snowflake 以及其他数据库环境,所需更改极小。
再次查看我们的 EXOPLANETS 表:
$ sqlite3 EXOPLANETS.db
sqlite> PRAGMA TABLE_INFO(EXOPLANETS);
0 | _id | TEXT | 0 | | 0
1 | distance | REAL | 0 | | 0
2 | g | REAL | 0 | | 0
3 | orbital_period | REAL | 0 | | 0
4 | avg_temp | REAL | 0 | | 0
5 | date_added | TEXT | 0 | | 0
EXOPLANETS 数据库条目包含以下信息:
-
_id:与行星对应的 UUID。 -
distance:与地球的距离,单位为光年。 -
g:作为 g 的倍数的表面重力,g 是重力常数。 -
orbital_period:单个轨道周期的长度,单位为天。 -
avg_temp:表面平均温度,单位为开尔文。 -
date_added:我们的系统发现该行星并自动将其添加到数据库中的日期。
请注意,由于数据缺失或错误,distance、g、orbital_period 和 avg_temp 中一个或多个可能为 NULL。
sqlite> SELECT * FROM EXOPLANETS LIMIT 5;
请注意,这个练习是回顾性的——我们在查看历史数据。在生产数据环境中,数据可观测性是实时的,并应用于数据生命周期的每个阶段,因此会涉及到与这里做法稍有不同的实现。
看起来我们的最旧数据的日期是 2020–01–01 (注意:大多数数据库不会存储单个记录的时间戳,因此我们的 DATE_ADDED 列会为我们跟踪这一信息)。我们最新的数据……
sqlite> SELECT DATE_ADDED FROM EXOPLANETS ORDER BY DATE_ADDED DESC LIMIT 1;
2020–07–18
…似乎来自 2020-07-18。当然,这是我们在过去文章中使用的同一张表。如果我们想要探索更具上下文的模式和谱系支柱,我们需要扩展我们的环境。
现在,除了EXOPLANETS,我们还有一个叫做EXOPLANETS_EXTENDED的表,它是我们过去表的超集。可以把这些表看作是在不同时间点的同一个表。实际上,EXOPLANETS_EXTENDED包含的数据可以追溯到 2020-01-01……
sqlite> SELECT DATE_ADDED FROM EXOPLANETS_EXTENDED ORDER BY DATE_ADDED ASC LIMIT 1;
2020–01–01
…但也包含数据到 2020-09-06,比EXOPLANETS的数据更为广泛:
sqlite> SELECT DATE_ADDED FROM EXOPLANETS_EXTENDED ORDER BY DATE_ADDED DESC LIMIT 1;
2020–09–06
可视化模式变化
这些表之间还有其他不同之处:
sqlite> PRAGMA TABLE_INFO(EXOPLANETS_EXTENDED);
0 | _ID | VARCHAR(16777216) | 1 | | 0
1 | DISTANCE | FLOAT | 0 | | 0
2 | G | FLOAT | 0 | | 0
3 | ORBITAL_PERIOD | FLOAT | 0 | | 0
4 | AVG_TEMP | FLOAT | 0 | | 0
5 | DATE_ADDED | TIMESTAMP_NTZ(6) | 1 | | 0
6 | ECCENTRICITY | FLOAT | 0 | | 0
7 | ATMOSPHERE | VARCHAR(16777216) | 0 | | 0
除了EXOPLANETS中的 6 个字段外,EXOPLANETS_EXTENDED表还包含两个额外字段:
-
eccentricity:行星绕其宿主恒星的轨道偏心率。 -
atmosphere:行星大气的主要化学成分。
请注意,像distance、g、orbital_period和avg_temp一样,eccentricity和atmosphere也可能由于缺失或错误的数据而为NULL。例如,流浪行星具有未定义的轨道偏心率,许多行星根本没有大气层。
还要注意数据没有回填,这意味着表开始的数据(也包含在EXOPLANETS表中的数据)将没有偏心率和大气信息。
sqlite> SELECT
...> DATE_ADDED,
...> ECCENTRICITY,
...> ATMOSPHERE
...> FROM
...> EXOPLANETS_EXTENDED
...> ORDER BY
...> DATE_ADDED ASC
...> LIMIT 10;
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
2020–01–01 | |
两个字段的增加是一个模式 变化的例子——我们的数据的正式蓝图已经被修改。模式变化发生在对数据结构进行更改时,并且可能会令人沮丧地手动调试。模式变化可以指示有关数据的各种信息,包括:
-
新 API 端点的增加
-
假定已弃用但尚未…弃用的字段
-
列、行或整个表的增加或删除
在理想情况下,我们希望有这种变化的记录,因为它代表了我们管道可能出现问题的向量。不幸的是,我们的数据库并未自然配置来跟踪此类变化。它没有版本历史记录。
我们在第一部分中遇到过这个问题,当时我们查询单个记录的年龄,并添加了DATE_ADDED列来应对。在这种情况下,我们将做类似的操作,只不过是增加整个表:
sqlite> PRAGMA TABLE_INFO(EXOPLANETS_COLUMNS);
0 | DATE | TEXT | 0 | | 0
1 | COLUMNS | TEXT | 0 | | 0
EXOPLANETS_COLUMNS表通过记录EXOPLANETS_EXTENDED中在任何给定日期的列来“版本化”我们的模式。通过查看最初和最后的条目,我们可以看到列确实在某个时候发生了变化:
sqlite> SELECT * FROM EXOPLANETS_COLUMNS ORDER BY DATE ASC LIMIT 1;
2020–01–01 | [
(0, ‘_id’, ‘TEXT’, 0, None, 0),
(1, ‘distance’, ‘REAL’, 0, None, 0),
(2, ‘g’, ‘REAL’, 0, None, 0),
(3, ‘orbital_period’, ‘REAL’, 0, None, 0),
(4, ‘avg_temp’, ‘REAL’, 0, None, 0),
(5, ‘date_added’, ‘TEXT’, 0, None, 0)
]sqlite> SELECT * FROM EXOPLANETS_COLUMNS ORDER BY DATE DESC LIMIT 1;
2020–09–06 |
[
(0, ‘_id’, ‘TEXT’, 0, None, 0),
(1, ‘distance’, ‘REAL’, 0, None, 0),
(2, ‘g’, ‘REAL’, 0, None, 0),
(3, ‘orbital_period’, ‘REAL’, 0, None, 0),
(4, ‘avg_temp’, ‘REAL’, 0, None, 0),
(5, ‘date_added’, ‘TEXT’, 0, None, 0),
(6, ‘eccentricity’, ‘REAL’, 0, None, 0),
(7, ‘atmosphere’, ‘TEXT’, 0, None, 0)
]
现在,回到我们最初的问题:究竟是什么时候发生了模式变化?由于我们的列列表是按日期索引的,我们可以通过一个快速的 SQL 脚本来找到变化的日期:
这是返回的数据,我已重新格式化以提高可读性:
DATE: 2020–07–19
NEW_COLUMNS: [
(0, ‘_id’, ‘TEXT’, 0, None, 0),
(1, ‘distance’, ‘REAL’, 0, None, 0),
(2, ‘g’, ‘REAL’, 0, None, 0),
(3, ‘orbital_period’, ‘REAL’, 0, None, 0),
(4, ‘avg_temp’, ‘REAL’, 0, None, 0),
(5, ‘date_added’, ‘TEXT’, 0, None, 0),
(6, ‘eccentricity’, ‘REAL’, 0, None, 0),
(7, ‘atmosphere’, ‘TEXT’, 0, None, 0)
]
PAST_COLUMNS: [
(0, ‘_id’, ‘TEXT’, 0, None, 0),
(1, ‘distance’, ‘REAL’, 0, None, 0),
(2, ‘g’, ‘REAL’, 0, None, 0),
(3, ‘orbital_period’, ‘REAL’, 0, None, 0),
(4, ‘avg_temp’, ‘REAL’, 0, None, 0),
(5, ‘date_added’, ‘TEXT’, 0, None, 0)
]
使用此查询,我们返回了问题日期:2020–07–19。像新鲜度和分布可观察性一样,实现模式可观察性遵循一个模式:我们识别有用的元数据来指示管道健康,跟踪它,并构建探测器以警告我们潜在的问题。提供像EXOPLANETS_COLUMNS这样的额外表格是一种跟踪模式的方法,但还有许多其他方法。我们鼓励你思考如何为自己的数据管道实现模式变化检测器!
视觉化谱系
我们将谱系描述为数据可观察性的五大支柱中最全面的一项,这也是有充分理由的。
谱系通过告诉我们(1)哪些下游来源可能受到影响,(2)哪些上游来源可能是根本原因,从而为事件提供背景。虽然用 SQL 代码“可视化”谱系并不直观,但一个简单的示例可能会说明它的用途。
为此,我们需要再次扩展我们的数据环境。
介绍:HABITABLES
让我们向数据库中添加另一张表。到目前为止,我们一直在记录系外行星的数据。这里有一个有趣的问题:这些行星中有多少可能存在生命?
HABITABLES表格从EXOPLANETS中获取数据,以帮助我们回答这个问题:
sqlite> PRAGMA TABLE_INFO(HABITABLES);
0 | _id | TEXT | 0 | | 0
1 | perihelion | REAL | 0 | | 0
2 | aphelion | REAL | 0 | | 0
3 | atmosphere | TEXT | 0 | | 0
4 | habitability | REAL | 0 | | 0
5 | min_temp | REAL | 0 | | 0
6 | max_temp | REAL | 0 | | 0
7 | date_added | TEXT | 0 | | 0
HABITABLES中的一条记录包含以下内容:
-
_id:对应于行星的 UUID。 -
perihelion:在一个轨道周期内,离天体的最短距离。 -
aphelion:在一个轨道周期内,离天体的最远距离。 -
atmosphere:行星大气层的主要化学成分。 -
habitability:一个介于 0 和 1 之间的实数,表示行星可能存在生命的概率。 -
min_temp:行星表面上的最低温度。 -
max_temp:行星表面上的最高温度。 -
date_added:我们的系统发现该行星并自动将其添加到数据库中的日期。
像EXOPLANETS中的列一样,perihelion、aphelion、atmosphere、min_temp和max_temp的值也可以为NULL。实际上,对于EXOPLANETS中任何_id的eccentricity为NULL的记录,perihelion和aphelion也会是NULL,因为你使用轨道偏心率来计算这些指标。这解释了为什么在我们较旧的数据条目中这两个字段总是NULL:
sqlite> SELECT * FROM HABITABLES LIMIT 5;
因此,我们知道HABITABLES依赖于EXOPLANETS(或者同样地,EXOPLANETS_EXTENDED)中的值,EXOPLANETS_COLUMNS也是如此。我们数据库的依赖关系图如下所示:
图片由Monte Carlo提供。
非常简单的谱系信息,但已经很有用。让我们在这个图表的背景下查看HABITABLES中的一个异常,并看看我们能学到什么。
调查异常
当我们有一个关键指标,比如HABITABLES中的宜居性时,我们可以通过几种方式评估该指标的健康状况。首先,给定日期的新数据habitability的平均值是多少?
查看这些数据,我们看到情况不对。habitability的平均值通常在 0.5 左右,但在记录的数据后期降至约 0.25。
一个分布异常……但是什么导致了它?
这是一个明显的分布异常,但究竟发生了什么?换句话说,这个异常的根本原因是什么?
为什么我们不查看一下NULL率对于宜居性,就像我们在第一部分中做的那样?
幸运的是,这里没有看起来不正常的地方:
但这看起来并不对我们的问提有帮助。如果我们查看另一个分布健康指标——零值率,会怎样呢?
显然这里的情况更有问题:
从历史上看,habitability几乎从未为零,但在稍后的日期,它的零率平均接近 40%。这导致了字段平均值的下降。
一个分布异常……但是什么导致了它?
我们可以使用在第一部分中构建的分布检测器之一,来获取habitability字段中可观的零率的首次日期:
我通过命令行运行了这个查询:
$ sqlite3 EXOPLANETS.db < queries/lineage/habitability-zero-rate-detector.sql
DATE_ADDED | HABITABILITY_ZERO_RATE | PREV_HABITABILITY_ZERO_RATE
2020–07–19 | 0.369047619047619 | 0.0
2020 年 7 月 19 日是零率开始显示异常结果的第一天。请记住,这也是EXOPLANETS_EXTENDED的架构变更检测的那一天。EXOPLANETS_EXTENDED位于HABITABLES的上游,因此这两个事件很可能是相关的。
就是这样,谱系信息可以帮助我们识别事件的根本原因,并更快地解决问题。比较以下两个对HABITABLES事件的解释:
-
在 2020 年 7 月 19 日,
HABITABLES表中的宜居性列的零率从 0%跃升至 37%。 -
在 2020 年 7 月 19 日,我们开始在
EXOPLANETS表中跟踪两个额外的字段,eccentricity和atmosphere。这对下游表HABITABLES产生了不利影响,通常在eccentricity不为NULL时将字段min_temp和max_temp设置为极端值。反过来,这导致了habitability字段中零率的激增,我们检测到了平均值的异常下降。
解释(1)仅使用异常发生的事实。解释(2)使用血统,即表和字段之间的依赖关系,将事件置于背景中并确定根本原因。实际上,解释(2)中的一切都是正确的,我鼓励你在环境中进行实验,以自己理解发生了什么。虽然这些只是简单的示例,但拥有(2)知识的工程师将更快地理解和解决根本问题,这都归功于适当的可观测性。
下一步是什么?
跟踪模式变化和血统可以让你前所未有地了解数据的健康状况和使用模式,提供关于数据使用的谁、什么、哪里、为何以及如何的关键信息。事实上,模式和血统是理解数据停机的下游(以及往往是现实世界)影响时两个最重要的数据可观测性支柱。
总结:
-
观察我们数据的模式意味着理解我们数据的正式结构,以及它何时和如何发生变化。
-
观察我们数据的血统意味着理解管道中的上游和下游依赖关系,并将孤立事件放在更大的背景中。
-
这两个数据可观测性支柱都涉及跟踪适当的元数据,并以使异常情况可理解的方式转化数据。
-
更好的可观测性意味着更好地理解数据为何以及如何崩溃,从而减少检测时间和解决时间。
我们希望这一期的“数据可观测性背景”对你有帮助。
在第三部分之前,祝你没有数据停机!
想了解更多关于 Monte Carlo 数据可观测性方法的内容吗?请联系 Ryan、Barr*** 和 Monte Carlo 团队。***
Barr Moses 是 Monte Carlo 的首席执行官兼联合创始人,这是一家数据可观测性公司。在此之前,她曾担任 Gainsight 的运营副总裁。
Ryan Kearns 是 Monte Carlo 的数据与机器学习工程师,同时是斯坦福大学的高年级学生。
原文。经许可转载。
相关:
-
数据可观测性:使用 SQL 构建数据质量监控器
-
数据目录已死;数据发现万岁
-
SQL 中的数据清洗与处理
更多相关内容
数据管道、Luigi、Airflow:你需要知道的一切
原文:
www.kdnuggets.com/2019/03/data-pipelines-luigi-airflow-everything-need-know.html
评论
由 Lorenzo Peppoloni,Lyft

照片由 Gerrie van der Walt 提供,发布在 Unsplash
这篇文章基于我最近给同事讲解 Airflow 的讲座。
特别地,讲座的重点是:什么是 Airflow,你可以用它做什么,以及它与 Luigi 的不同之处。
为什么你需要一个 WMS
在公司中,移动和转换数据非常常见。
比如,你有大量的日志存储在 S3 上,你希望定期获取这些数据,提取和汇总有意义的信息,然后将其存储在分析数据库中(例如,Redshift)。
通常,这类任务最初是手动执行的,然后随着事情需要扩展,过程会自动化,例如用 cron 触发。最终,你会达到一个好老的 cron 无法保证稳定和可靠性能的地步。它已经不够用了。
这时你需要一个工作流管理系统(WMS)。
Airflow
Airflow 是在 2014 年由 Airbnb 开发的,后来开源了。2016 年,它加入了 Apache 软件基金会的孵化程序。
当被问到“Airflow 在 WMS 领域有什么不同?”时,Maxime Beauchemin(Airflow 的创建者)回答说:
一个关键的区别在于 Airflow 管道被定义为代码,并且任务是动态实例化的。
希望在这篇文章的最后,你能够理解,并且更重要的是,同意(或不同意)这一观点。
让我们首先定义主要概念。
作为 DAG 的工作流
在 Airflow 中,工作流被定义为具有方向性依赖关系的任务集合,基本上是一个有向无环图(DAG)。
图中的每个节点都是一个任务,边缘定义了任务之间的依赖关系。
任务分为两个类别:
-
操作符:它们执行某些操作
-
传感器:它们检查进程或数据结构的状态
现实中的工作流可以从每个工作流只有一个任务(你不必总是追求花哨)到非常复杂的 DAG,几乎无法可视化。
主要组件
Airflow 的主要组件是:
-
一个 元数据数据库
-
一个 调度器
-
一个 执行器
Airflow 架构
元数据数据库存储任务和工作流的状态。调度器使用 DAG 定义,加上元数据数据库中的任务状态,决定需要执行的内容。
执行器是一个消息队列进程(通常是 Celery),它决定哪个工作进程将执行每个任务。
使用 Celery 执行器,可以管理任务的分布式执行。另一种选择是将调度器和执行器运行在同一台机器上。在这种情况下,平行处理将通过多个进程来管理。
Airflow 还提供了一个非常强大的用户界面。用户能够通过网页 UI 监控 DAG 和任务执行,并直接与其交互。
读到 Airflow 采用 “设置并忘记” 方法是很常见的,但这是什么意思呢?
这意味着一旦设置了 DAG,调度器将自动根据指定的调度间隔安排其运行。
Luigi
理解 Airflow 最简单的方法可能是将其与 Luigi 进行比较。
Luigi 是一个用于构建复杂流水线的 Python 包,它是在 Spotify 开发的。
在 Luigi 中,与 Airflow 一样,你可以将工作流指定为任务以及它们之间的依赖关系。
Luigi 的两个基本构建块是 Tasks 和 Targets。目标是任务通常输出的文件,任务执行计算并消耗由其他任务生成的目标。
Luigi 流水线结构
你可以把它看作是一个实际的流水线。一个任务完成其工作并生成一个目标,第二个任务将目标文件作为输入,进行一些操作并输出第二个目标文件,依此类推。

咖啡休息(照片由 rawpixel 提供,来源于 Unsplash)
一个简单的工作流
让我们看看如何实现一个由两个任务组成的简单流水线。
第一个任务生成一个包含单词(在此情况下为“pipeline”)的 .txt 文件,第二个任务读取该文件并装饰行,添加“我的”。新行被写入一个新文件中。
Luigi 简单流水线
每个任务都指定为从 luigi.Task 派生的类,方法 output() 指定输出即目标,run() 指定任务执行的实际计算。
方法 requires() 指定任务之间的依赖关系。
从代码中可以很清楚地看到,一个任务的输入是另一个任务的输出,以此类推。
让我们看看如何在 Airflow 中做同样的事情。
Airflow 简单 DAG
首先,我们定义并初始化 DAG,然后将两个操作符添加到 DAG 中。
第一个是 BashOperator,它基本上可以运行任何 bash 命令或脚本,第二个是 PythonOperator,执行 Python 代码(为了展示,我在这里使用了两个不同的操作符)。
正如你所见,没有输入和输出的概念。两个操作员之间没有信息共享。确实存在在操作员之间共享信息的方法(你基本上是共享一个字符串),但作为一般规则:如果两个操作员需要共享信息,那么它们可能应该合并成一个。
更复杂的工作流
现在让我们考虑一下我们想同时处理更多文件的情况。
在 Luigi 中我们可以用多种方式做到这一点,但没有一种方式是特别直接的。
Luigi 管理多个文件的管道
在这种情况下,我们有两个任务,每个任务处理所有文件。依赖任务(t2)必须等到 t1 处理完所有文件后才能开始。
我们使用一个空文件作为目标来标记每个任务何时完成其工作。
我们可以通过编写并行的循环来增加一些并行化。
这个解决方案的问题在于 t2 可能会在 t1 开始产生输出后逐渐开始处理文件,实际上 t2 不必等到 t1 创建所有文件。
在 Luigi 中,一个常见的做法是创建一个包装任务并使用多个工作者。
这里是代码。
Luigi 使用多个工作者的管道
为了用多个工作者运行任务,我们可以在运行任务时指定 — workers number_of_workers。
现实中你常见的一种方法是委托并行化。基本上,你使用前面介绍的第一个方法,并在 run() 函数内部使用 Spark 等来实际处理。
让我们用 Airflow 来实现
你还记得最初的引言中提到 DAG 是如何用代码动态实例化的吗?
那这到底意味着什么呢?
这意味着通过 Airflow 你可以做到这一点
Airflow 通过多个文件实现并行 DAG
任务(和依赖项)可以通过编程方式添加(例如,在循环中)。相应的 DAG 如下所示。

并行 DAG
在这个阶段,你不需要担心并行化。Airflow 执行器从 DAG 定义中知道每个分支可以并行运行,这就是它所做的!
最终考虑
在这篇文章中我们讨论了很多点,我们谈到了工作流、Luigi、Airflow 以及它们之间的区别。
让我们快速回顾一下。
Luigi
-
它通常基于管道,任务的输入和输出共享信息并且互相连接
-
基于目标的方法
-
界面最小,没有用户与运行中的进程交互
-
没有自己的触发机制
-
Luigi 不支持分布式执行
Airflow
-
基于 DAG 的表示
-
通常,任务之间没有信息共享,我们希望尽可能并行化
-
没有强大的任务间通信机制
-
它有一个执行器,管理分布式执行(你需要设置它)
-
这种方法是“设定后忘记”,因为它有自己的调度程序
-
强大的 UI,你可以看到执行情况并与运行中的任务互动。
结论:在这篇文章中,我们查看了 Airflow 和 Luigi,以及这两者在工作流管理系统中的差异。我们看了一些非常简单的管道示例,并展示了如何使用这两种工具来实现它们。最后,我们总结了 Luigi 和 Airflow 之间的主要区别。
如果你喜欢这篇文章并且觉得有用,请随意????或分享。
祝好
个人简介:洛伦佐·佩波洛尼 是一位技术爱好者,终身学习者,拥有机器人学博士学位。他撰写有关他在软件和数据工程领域的日常经验。
原文。经许可转载。
相关:
-
数据科学管道初学者指南
-
数据科学家如何提高生产力
-
用 MLflow 管理你的机器学习生命周期 – 第一部分
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
数据预处理在深度学习中的作用
原文:
www.kdnuggets.com/2017/05/data-pre-processing-deep-learning-nuts-ml.html
由 Stefan Maetschke 博士撰写。
数据预处理是任何机器学习项目的基础部分,通常在数据准备上花费的时间比实际的机器学习更多。虽然一些预处理任务是特定问题的,许多其他任务,如将数据划分为训练集和测试集、样本分层或构建小批量是通用的。以下的标准管道展示了视觉领域深度学习的常见处理步骤。

读取器从文本文件、Excel 或 Pandas 表格中读取样本数据。然后,拆分器将数据分割成训练集、验证集和测试集,并在需要时进行分层抽样。通常,所有的图像数据无法一次性加载到内存中,加载器根据需求加载图像。这些图像通常会由变换器处理,如调整大小、裁剪或其他调整。此外,为了增加训练集,增强器通过随机增强(翻转、旋转等)图像来合成额外的图像。高效的基于 GPU 的机器学习要求通过批处理器将图像和标签数据分组到小批量中,然后传递给网络进行训练或推断。最后,为了跟踪训练进度,通常会使用记录器将训练损失或准确率写入日志文件。
一些机器学习框架,如 Keras,提供了这些预处理组件中的部分功能,并隐藏在 API 后面,如果适合当前任务,这会大大简化网络训练。请参阅以下 Keras 示例 来训练一个带增强的模型。
datagen = ImageDataGenerator( # augment images
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True)
datagen.fit(x_train)
model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=x_train.shape[0]
epochs=epochs,
validation_data=(x_test, y_test))
然而,如果需要一个 API 未提供的图像格式、增强或其他预处理功能怎么办?扩展像 Keras 这样的库并非易事,通常的做法是(重新)实现所需的功能——通常是以快速而粗糙的方式。但实现一个稳健的数据管道,按需加载、变换、增强和处理图像是具有挑战性和耗时的。
nuts-ml 是一个 Python 库,提供了称为nuts的常见预处理函数,这些函数可以自由排列并轻松扩展,以构建高效的数据处理管道。以下摘录自 nuts-ml 示例 显示了一个网络训练管道,其中 >> 操作符定义了数据的流动。
t_loss = (train_samples >> augment >> rerange >> Shuffle(100) >>
build_batch >> network.train() >> Mean())
print "training loss :", t_loss
在上述示例中,训练图像被增强,像素值被重新调整,并且样本在构建网络训练批次之前被打乱。最后,计算并打印每批次训练损失的均值。这个数据流的组成部分可以定义如下
rerange = TransformImage(0).by('rerange', 0, 255, 0, 1, 'float32')
augment = (AugmentImage(0)
.by('identical', 1.0)
.by('brightness', 0.1, [0.7, 1.3])
.by('fliplr', 0.1)))
build_batch = (BuildBatch(BATCH_SIZE)
.by(0, 'image', 'float32')
.by(1, 'one_hot', 'uint8', NUM_CLASSES))
network = KerasNetwork(model)
其中,rerange 是一种图像转换,它将像素值从范围 [0, 255] 转换到范围 [0, 1],augment 通过随机水平翻转和改变图像亮度来生成额外的训练图像,build_batch 构建由图像和一-hot 编码类标签组成的批次,而 network 将现有的 Keras 模型包装成可以插入管道的 nut。这个示例的完整代码可以在这里找到
nuts-ml 帮助更快速地构建深度学习的数据预处理管道。生成的代码更具可读性,并且可以很容易地修改以尝试不同的预处理方案。任务特定的函数可以轻松地作为 nuts 实现并添加到数据流中。例如,这里是一个调整图像亮度的简单 nut
@nut_function
def AdjustBrightness(image, c):
return image * c
... images >> AdjustBrightness(1.1) >> ...
nuts-ml 不进行网络训练,而是使用现有的库,如 Keras 或 Theano。任何接受 Numpy 数组的小批量用于训练或推理的机器学习库都是兼容的。有关 nuts-ml 的更多信息,请参见介绍部分并查看教程。
简历:Stefan Maetschke (PhD) 是 IBM Research Australia 的研究科学家,他在这里开发用于医学图像分析的机器学习基础设施和模型。
相关内容:
-
使用深度学习进行医学图像分析,第二部分
-
使用深度学习进行医学图像分析
-
负面图像上的负面结果:深度学习的主要缺陷?
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
更多相关内容
机器学习数据准备 101:为什么重要以及如何操作
原文:
www.kdnuggets.com/2019/10/data-preparation-machine-learning-101.html
评论
由Nandhini TS,Xtract.io
编码是成功商业模式的前提。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作。
我最近在 Quora 上发现了Alexandre Robicquet的回答,他的观点也在 Forbes 上发表。对于初学者来说,以下是他对“如何开始学习机器学习和人工智能”的建议:
他观点的简明版:
-
精通编码,特别是最适合机器学习的 python。除了编码专长,你还需要具备良好的分析和统计技能。
-
首先,你可以通过克隆 git 仓库或教程中的代码开始。但要成为一名优秀的 ML/AI 工程师,你必须了解并掌握你所做的工作。
-
不要发明一个解决方案再去寻找问题。相反,应当识别问题和挑战,以发明自动化解决方案。
(你可以在这里阅读他的回答)。
不仅仅如此。
如果你是编码爱好者,务必仔细检查你输入到算法中的数据质量和结构,因为它们在创造成功的分析模型中扮演着重要角色。
构建成功 AI/ML 模型有3 个维度:
算法、数据和计算。
虽然构建准确的算法和应用计算技能是过程的一部分,但这其中的基础是什么?
用正确的数据打下基础。
从基于 AI 的技术革命(如自动驾驶汽车)到构建非常简单的算法,你都需要以正确的形式获取数据。
实际上,特斯拉和福特通过行车记录仪、传感器和倒车摄像头收集数据,并对其进行分析,以构建无人驾驶和完全自动化的安全汽车。
收集数据后的下一步是准备数据,这将是本文的核心内容,并将在后续部分详细讨论。
在深入数据准备过程的概念之前,先让我们了解一下它的含义。作为 AI 创新背后的数据科学家,你需要理解数据准备的重要性,以达到你模型所需的认知能力水平。
让我们开始吧。
什么是数据准备?
数据是每个组织的宝贵资源。但是,如果我们不进一步分析这个陈述,它可能会自我否定。
企业使用数据的目的多种多样。从广义上讲,它用于做出明智的商业决策、执行成功的销售和营销活动等。但这些不能仅仅依靠原始数据来实现。
行业标准数据挖掘过程(来源:维基百科)
数据只有在经过清理、标记、注释和准备后才会成为宝贵资源。一旦数据经过各种适应性测试,它最终才会符合进一步处理的资格。这些处理可以有多种方法——数据输入到 BI 工具、CRM 数据库、为分析模型开发算法、数据管理工具等等。
现在,重要的是你从这些信息的分析中获得的见解必须准确可靠。实现这一结果的基础在于数据的健康。此外,无论是自行构建模型还是从第三方获取模型,你都必须确保整个过程中数据是标记过的、增强的、清理过的、结构化的——简而言之,这就是数据准备。
根据维基百科的定义,数据准备是将原始数据(可能来自不同的数据源)处理(或预处理)成可以方便且准确分析的形式,例如用于商业目的。数据准备是数据分析项目的第一步,可能包括许多离散任务,如加载数据或数据摄取、数据融合、数据清理、数据增强和数据交付。
数据准备在机器学习中的重要性
根据 Cognilytica 最近的一项研究,记录并分析了组织、机构和最终用户企业的反馈,以确定大量时间花费在标签标注、注释、清理、增强和数据丰富上,这些都是为机器学习模型准备的数据。
数据科学家 80%以上的时间都花在数据准备上。虽然这是一个好迹象,因为优质数据有助于构建分析模型,输出结果也更准确。但是,数据科学家理想的工作方式是将更多时间花在与数据互动、进行高级分析、训练和评估模型以及部署生产上。
只有 20%的时间用于过程的主要部分。为了克服时间限制,组织需要通过利用数据工程、标记和准备的专家解决方案,来减少在清理、增强、标记和丰富数据上所花费的时间(时间因项目复杂性而异)。
这引出了垃圾进,垃圾出的概念,即输出的质量由输入的质量决定。
数据准备过程
这里是针对机器学习模型的数据准备过程的简要概述:
数据提取 数据工作流的第一阶段是提取过程,通常是从非结构化来源(如网页、PDF 文档、缓存文件、电子邮件等)中检索数据。网络上提取信息的过程称为网络抓取。
数据分析 是审查现有数据以提高质量并通过格式带来结构的过程。这有助于评估数据的质量和一致性,符合特定标准。当数据集不平衡且未经过良好分析时,大多数机器学习模型都会失败。
数据清洗 确保数据干净、全面、无错误,并包含准确的信息,因为它有助于检测文本和数字中的异常值,也包括图像中的不相关像素。你可以消除偏差和过时的信息,确保数据的清洁。
数据转换 是将数据转换为统一格式。像地址、姓名和其他字段类型的数据以不同格式表示,数据转换有助于标准化和规范化这些数据。
数据匿名化 是从数据集中去除或加密个人信息以保护隐私的过程。
数据增强 用于多样化训练模型所用的数据。引入附加信息而不提取新信息,包括裁剪和填充,以训练神经网络。
数据采样 从大数据集中识别代表性子集,以分析和操作数据。
特征工程 是决定机器学习模型好坏的主要因素。为了提高模型的准确性,你需要将数据集合并成一个整体。
这里是一个例子:
假设有两列数据,一列是收入,另一列是输出分类(A、B、C)。输出 A、B、C 依赖于收入范围 $2k - $3K、$4k - $5K 和 $6K - $7K。新的特征将是收入范围,分配数值 1、2 和 3。现在,这些数值被映射到我们最初创建的 3 个数据集。
这里,收入范围是特征工程的一部分。
查看 MindOrks 关于特征工程的视频以进一步理解。
https://www.youtube.com/watch?time_continue=1&v=CXDfQdYpGGw
数据准备过程的另一个重要部分是标注。为了使这个概念简单易懂,让我以一种热饮,如茶为例。
现在,该项目的目标是识别特定类型茶叶中含有的咖啡因百分比或量。
红茶含有 20 毫克咖啡因
茶+牛奶含有 11 毫克咖啡因
草本茶含有 0 毫克咖啡因
格雷伯爵茶含有 40 毫克咖啡因
注意:(咖啡因百分比按 100 克茶计算)
因此,机器学习模型将为格雷伯爵茶分配一个数值,例如 1(它含有最高量的咖啡因),为红茶分配 2,依此类推。这引出了标记的概念,有助于识别数据集。
数据标记 - 数据准备的一个重要和不可或缺的部分
标注是将标签分配给一组未标记的数据,以使其在预测分析中更具可识别性。
这些标签指示照片中的动物是狗还是狐狸(见下图)。
标注帮助机器学习模型通过向模型提供数百万个标记数据来猜测和预测未标记的数据。

数据标记的一些用例:
-
图像分类/注释 包括图像的注释、描述、边界框定义等。
-
对话标记 一个典型的例子是聊天机器人,其中数据被标记并训练,使与用户的对话更加真实和相关。
-
情感分析 对数据进行标记,无论是文本还是图像,以理解内容的情感,例如推文的情况。
语音和文本 NLP 是对音频和文本源的标记。
-
人脸检测 标记图像集并进行训练以实现准确的检测和预测
-
从哪里开始?
数据准备是构建创新商业模型的必要前提。数据质量差和良好的模型是一个糟糕的组合,可能会毁掉你打算构建的模型的效率和性能。
市场上有很多数据准备解决方案可以帮助你节省时间并提高效率。尽管市场上有自助数据准备工具,但考虑到内部基础设施的可扩展性、从不同来源收集的大量数据、遵守各种数据规范和指南以及随需提供的专家帮助,托管服务相较于自助工具略有优势。
有几个数据准备即托管服务的供应商,比如Xtract.io、Informatica、Assetanalytix、Capestart等,你可以考虑这些供应商来帮助你开始数据准备工作。
如果你有任何问题或想分享的新信息,请在下方留言,以便我们引发一些有趣的讨论。
个人简介:Nandhini TS 是 Xtract.io 的产品营销专员——一家数据解决方案公司。她喜欢撰写关于数据对成功商业运营的力量和影响的文章。在空闲时间,她沉浸于发展副业和狂看恐龙纪录片中。
相关:
-
用 Python 掌握机器学习数据准备的 7 个步骤——2019 版
-
应对机器学习中数据不足的 5 种方法
-
数据科学项目准备的四大要素
更多相关主题
R 数据准备备忘单
原文:
www.kdnuggets.com/2021/10/data-preparation-r-dplyr-cheat-sheet.html
数据准备的重要性
我之前写过,不论我们愿意与否,数据准备是每个数据科学项目的重要组成部分。数据准备包括将数据以可重复的过程准备好以用于业务分析的任务,包括数据获取、数据存储和处理、数据清洗以及特征工程的早期阶段。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
数据团队可以使用至少三种常见工具来完成这些数据处理任务:
-
SQL,许多大数据平台如 Spark 支持的 SQL,非常适合从原始数据源如数据湖文件集合中进行粗略的数据过滤和收集。
-
Python 和 Pandas 库的使用正在日益普及,并且功能不断增强。
-
R,特别是使用 dplyr 包,提供了一套由大量开源 R 库支持的统一函数集合。
在这三者之间的选择很可能取决于你组织中可用的技能、可用的基础设施和代码库,以及需要使用的高级模型。本文将重点讨论使用 R 的原因,并提供一个实用的参考表。
dplyr 自 2016 年推出以来,具有一些重要功能,使其成为 R 中数据准备的优秀工具。
-
几乎适用于行业中任何数据源或文件格式的数据连接。
-
dplyr 被构建为一个和谐的包,简化了许多任务,这些任务如果需要将其他 R 包拼凑在一起,则可能会变得混乱或令人困惑。
-
脚本可以轻松集成版本控制和 Dev Ops 实践。
-
轻松将数据交给强大的 R 库,以便与 AI/ML 模型集成。
R 数据准备备忘单
以下快速参考备忘单指南将提供 dplyr 在数据准备每个步骤中的方法样例。这不是一个 dplyr 函数或选项的详尽列表,而是一个起点。
点击查看完整备忘单
十年前,R 是数据科学的唯一选择,但 Python 和 SQL 的竞争让它变得更好,因为一个生态系统中引入的功能很快会被复制或移植到另一个生态系统中。广泛的 R 用户社区有着确保其库活跃和发展的历史,确保你对 R 的投资在未来十年仍然具有相关性。未来某一天,也许 dplyr 和 Tidyverse 将不再是数据准备的最佳选择。但目前它们仍是极佳的选择(尽管有一些尴尬的语法元素,比如 %>% 管道!)。
Stan Pugsley 是一位驻盐湖城,犹他州的独立数据仓库和分析顾问。他还是犹他大学 - 埃克尔斯商学院的助理教授/讲师。你可以通过 电子邮件 联系作者。
更多相关主题
机器学习中的数据准备和原始数据
原文:
www.kdnuggets.com/2022/07/data-preparation-raw-data-machine-learning.html
随着可用数据量的巨大,分析和机器学习(ML)越来越多地被用来提取可以用于多种不同用途的关键信息。
例如,通过研究用户如何与电子商务网站互动,可以自动识别信用卡欺诈。但这仅在所有相关数据已被以适合机器学习算法的方式准备好时才有效。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
在这篇文章中,我将描述机器学习的数据准备技术。
原始数据
原始数据指的是由计算机收集的未经处理的原始数据。它通常体积庞大且复杂,难以分析。
在机器学习中,原始数据通常是从大量人群或传感器收集的,这些传感器收集有关某个对象或事件的信息。
当与特定类型的算法结合时,原始数据可以帮助计算机预测事件并做出决策,而无需人工干预。
数据准备
数据准备是清理数据的过程,包括去除无关信息和将数据转换为所需格式。数据准备是机器学习过程中的一个重要步骤,因为它使数据可以被机器学习算法使用,以创建准确的模型或预测。
简而言之,你需要收集一些原始数据,然后对其进行处理,使其对 ML 模型可理解。
数据准备的重要性
你用来构建模型的数据类型对模型的结果有很大影响。如果数据存在小的偏差或缺失信息,那么它可能会对模型的准确性产生很大影响。因此,拥有高质量的数据以用于训练模型是至关重要的。
实际上,研究人员发现 80%的数据工程工作都投入在数据准备上。因此,数据挖掘领域非常重视开发获取高质量数据的技术。 (张世超,张成奇,杨强,2003)
数据准备在以下三个方面至关重要:
-
现实世界的数据可能是嘈杂或不纯的
-
高级处理系统需要准确的数据
-
数据完整性产生高质量的趋势(Zhang, Shichao 和 Zhang, Chengqi 和 Yang, Qiang, 2003)
此外,数据准备会产生比源数据集更窄的数据集,这可以显著提升数据收集的性能。
原始数据中的问题
原始数据中可能存在许多问题,如噪声、数据冗余、不一致数据、异质数据等。(大数据上的机器学习:机遇与挑战,2017)。其中的一些问题如下所述:
数据冗余
重复可能发生在相同的数据多次出现的情况下。在你的机器学习系统中,重复的数据样本如果没有得到解决,可能会导致性能不佳。
数据冗余是指有多个信息源包含相同的数据。数据冗余并不总是一个问题,但在某些情况下可能会引起问题。
嘈杂数据
原始数据可能会有噪声。有时缺失或不正确的值,或者异常值,会扭曲其余数据。噪声数据带来了许多挑战。传统解决方案在大数据面前并不总是有效。它们不可扩展,如果使用简单的解决方案如均值,可能会丧失大数据的优势,因为这无法考虑数据的所有复杂性。
由于传感器故障造成的错误或缺失值可以通过预测分析进行替换。
数据异质性
大数据包含大量信息,包括文本、音频和视频文件。这些文件存储在不同的位置,并且以易于使用的格式存在。由于这些数据是从多个地方(例如 YouTube 上的手机视频)收集的,因此它们可以提供同一事物的不同视角。这些视角是异质的,因为它们是从不同群体的人那里收集的。
如果你想学习新知识,专家建议最好同时获取来自多个来源的信息。
数据准备技术
数据准备技术分为两种:传统和机器学习技术。
传统的数据预处理和准备工作是劳动密集型的、成本高昂且容易出错的;机器学习(ML)算法可以通过从大量、多样化和实时的数据集中学习来减少这种依赖。 (Bhatnagar, Roheet, 2018)
图 1 数据准备涉及的任务(来源(García, S., Ramírez-Gallego, S., Luengo, J., 2016))
数据处理的机器学习方法
实例减少
要从大型数据集中删除实例,可以使用一种叫做实例减少的过程。实例减少通过从数据集中移除实例或生成新实例来减少信息的数量。实例减少允许研究人员在不减少他们可以从数据中提取的知识和信息质量的情况下,减少非常大的数据集的大小。
缺失值的填补
处理缺失值的问题有不同的方法。首先,我们可以丢弃存在缺失值的实例。但这通常效果不佳,因为我们忽略了重要信息。另一种方法是对缺失值进行赋值。这通常使用建模数据集概率函数的机器学习技术来完成。然后可以应用最大似然程序来找到最佳的填补模型。
Paxata、Trifacta、Alteryx、Databricks、Qubole 和 Google AI 是一些最强大的数据准备工具。
结论
常见的数据预处理步骤有
-
格式化:将数据安排成所需的文件格式
-
清理:删除不完整和不一致的数据
-
采样:为快速处理取小部分数据
数据世界的导航可能对一些人来说很困惑,但希望本指南能帮助你更好地理解原始数据和处理数据之间的区别。学习如何准备数据的第一步将取决于你使用的数据类型。然而,确保数据尽可能准确和干净在建模时非常重要。在开始任何统计项目时,无论简单还是复杂,都要始终牢记这些数据准备提示。
参考文献
-
Bhatnagar, Roheet. (2018). 机器学习与大数据处理:技术视角与综述。
-
García, S., Ramírez-Gallego, S., Luengo, J. (2016). 大数据预处理:方法与前景。Big Data Anal 1。
-
大数据上的机器学习:机会与挑战。 (2017). 神经计算, 350-361。
-
张世超、张成奇、杨强. (2003). 数据挖掘的数据准备。应用人工智能, 375-381。
尼拉吉·阿加瓦尔 是 Algoscale 的创始人,这是一家涵盖数据工程、应用人工智能、数据科学和产品工程的数据咨询公司。他在该领域拥有超过 9 年的经验,曾帮助从初创公司到财富 100 强企业的各种组织摄取和存储大量原始数据,以便将其转化为可操作的见解,从而实现更好的决策和更快的业务价值。
更多相关话题
SQL 数据准备备忘单
原文:
www.kdnuggets.com/2021/05/data-preparation-sql-cheat-sheet.html
数据准备的重要性
无论我们喜欢与否,数据准备都是每个数据科学项目的重要部分。数据准备包括将数据以可重复的过程准备好以用于业务分析的任务,包括数据获取、数据存储和处理、数据清洗以及早期的特征工程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
马修·梅约: "为什么数据准备常被描述为数据相关任务中 80%的工作,你认为这是一种准确的概括吗?"
塞巴斯蒂安·拉什卡: "80%?我经常听到>90%!"
从 数据准备技巧、窍门和工具:与内部人士的访谈 中,KDnuggets
一个基本的问题是如何以及在哪里进行数据准备。选择不同工具和方法有其合理的理由:
-
你们的员工/同行最熟悉哪些工具或语言?
-
你是否需要一个可重复的流程,并定期运行?
-
你目前的大部分数据存储在哪里?
-
你处理的数据量和数据流速是多少?
-
目前有哪些云服务或本地资源可用于运行该过程?
-
哪些工具与贵组织当前的架构最兼容?
-
你的数据集是否包含需要特殊保护的私人元素(HIPA、FERPA、GDPR)?
对于许多组织来说,这些问题的答案将会引向 SQL。SQL 不仅在大多数组织中被广泛知晓和使用,而且还利用了现有的数据库资源、安全性和数据管道。如果你的原始数据在 SQL 基础的数据湖中,为什么要花时间和金钱将数据导出到新的平台进行数据准备?
SQL 数据准备备忘单
以下 快速参考备忘单指南 将展示 SQL 在数据准备各个步骤中的应用。这并不是 SQL 函数或选项的详尽列表,而是一个起点。
点击查看完整备忘单
关于为您的模型创建接口的最后一条建议。SQL 视图允许您以干净、安全、模块化的格式封装许多数据准备步骤的复杂性。与其在 Python 或 R 代码中嵌入长而复杂的查询,不如创建一个视图,以简单、可重用的格式访问这些代码。视图也是通过遮蔽或隐藏数据元素来对私密数据应用安全性的绝佳方式。
如果您已经投资了高性能的数据库许可证,为什么不利用它们在 SQL 中进行数据准备以支持数据科学呢?
斯坦·帕格斯利 是一位数据仓库和分析顾问,隶属于艾德·贝利技术咨询公司,公司总部位于犹他州盐湖城。他还是犹他大学厄克尔斯商学院的兼职教师。您可以通过电子邮件联系作者。
更多相关主题
数据专业人士如何在繁忙时刻依然给人留下深刻印象
原文:
www.kdnuggets.com/2021/10/data-professionals-impress-busy.html
评论
图片由 fauxels 提供,来源于 Pexels
即将到来的假日季节是作为数据专业人士留下深刻印象的理想时机。这是一年中最繁忙的时期,考虑到该领域的近期增长,公司领导可能会在 2022 年提拔一些员工。如果你现在能给人留下深刻印象,你很快就能进入职业生涯的下一阶段。
尽管在假日季节可能有很多晋升空间,但如何实现这一点并不总是明确的。抱着这种精神,这里有五种方法可以让你打动公司领导。
1. 展示对业务需求的理解
初级和高级数据专业人士之间的区别往往更多在于商业敏锐度,而不是技术专长。那些在这一领域取得成功的人了解为什么公司对数据科学感兴趣,以及如何在这些领域提供成果。假日季节也是展示这种理解的绝佳时机。
在疫情期间,75% 的美国购物者采纳了新的购物行为。零售公司需要在假日购物季节适应这些变化,你可以通过数据来帮助满足这一需求。利用第三方数据丰富第一方数据,并理解结果,将帮助这些合作伙伴在这些变化中取得成功。
当你理解这些业务/数据关系时,你可以提供更好的结果并打动客户。这些结果反过来会让你的上司印象深刻。展示你如何从数据中提供切实的业务效益,体现了你作为员工的价值。
2. 寻找提升生产力的方法
你还可以关注公司内部运营中的业务效益。数据分析和科学通常涉及大量手动工作。例如,高达80% 的 AI 项目时间用于标记和准备数据。所有这些缓慢的手动工作都有提升生产力的空间。
开始记录你日常工作中花费最多时间的流程,并与带来最多价值的流程进行比较。当你比较这些因素时,你可能会找到调整工作流程以提高团队效率的方法。你甚至可以尝试在一些自己的任务中实施这些变化,以观察它们的效果。
在找到潜在的改进领域后,将你的发现呈现给管理层。这展示了主动性和对公司底线的关注,这些都是领导层在高级员工中所期望的。
3. 寻找新的潜在客户
在这个假日季节,给公司带来价值的另一种方法是寻找潜在的新客户。数据科学是一个快速发展的领域,因此许多传统上不以数据为中心的行业现在将对这些服务感兴趣。接触这些公司可能为你的公司带来新的客户。
例如,卡车运输行业正慢慢地变得越来越以数据为中心。数据分析可以帮助车队节省燃料,减少设备停机时间等等,但将数据融入这些操作中是一个相对较新的趋势。你可以考虑这一领域或类似领域的公司,寻找你公司潜在的新客户。
这些新联系可以为你的公司带来更多收入,领导层无疑会欣赏这一点。主动出击将使你在这个假日季节脱颖而出。
4. 在工作之外提升你的技术技能
虽然软技能和商业知识通常是数据科学进步的最重要因素,但技术技能仍然很重要。如果你花时间在工作之外通过个人项目提升你的数据才能,你可以给管理层留下深刻的印象。
在空闲时间获得新认证可以展示主动性和对领域的尊重。这也向你的老板展示你对职业发展的认真态度。你可以通过寻找与公司业务相关且符合公司目标的个人项目来强调这些因素。
这些项目中一个重要的方面是你如何向上级展示你的进展。数据科学经理表示他们希望找到能简洁沟通的人担任高级数据科学家职位。如果你能简洁明了地展示你的个人项目,你可以展示出管理层所期望的。
5. 跟上数据趋势的发展
最后,通过展示对不断增长的数据科学趋势的关注,你可以在这个假日季节赢得赞誉。这是一个新兴且不断发展的领域,因此跟上这些变化对业务的成功至关重要。如果你能向老板展示你时刻关注这些发展,你可以留下持久的印象。
你可以通过阅读行业领先组织或数据科学论坛的更新来跟上这些趋势。如果你注意到任何增长或有前景的趋势,可以在公司领导面前提及,无论是在随意谈话还是相关会议中。如果你能展示出对这些发展有深入了解,可能会给他们留下深刻印象。
在 2022 年推进你的职业生涯
这个假日季节是给管理层留下深刻印象和提升职业生涯的绝佳时机。如果你想在 2022 年有所进步,按照这些步骤在年末给你的老板留下印象。
在数据科学领域的进步往往取决于展示你如何为公司带来价值。这些步骤将展示你的技能和知识,帮助你获得应得的职位。
简历:Devin Partida 是一位大数据和技术作家,同时也是 ReHack.com 的主编。
相关:
-
数据专业人士如何为简历增加更多变化
-
数据科学家如何在全球就业市场中竞争
-
如何成功成为自由职业的数据科学家
更多相关话题
数据质量维度:用伟大的期望确保您的数据质量
原文:
www.kdnuggets.com/2023/03/data-quality-dimensions-assuring-data-quality-great-expectations.html

图片由Mikael Blomkvist提供
数据质量在任何数据管理过程中都发挥着关键作用。组织依赖数据来指导决策和推动各种业务效率。然而,如果数据充满了不准确、错误或不一致之处,它可能会弊大于利。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
根据2020 年 Gartner 调查,数据质量差的平均成本为每年 1280 万美元。正如最新的数据质量状态报告所示,生产延迟(产品发布延迟)是数据质量差的一个明显症状。高质量、无错误的数据能提高从中得出的见解的可靠性和可信度。
为了提高数据质量,你需要一个测量框架。数据质量维度可以帮助你实现这个目标。维度使你能够衡量覆盖范围并识别需要进行数据质量测试的组件。
这篇文章介绍了数据质量的六个维度:完整性、一致性、完整性、及时性、唯一性和有效性。通过解决这些维度,你可以全面了解数据的质量,并识别需要改进的领域。这就是伟大的期望(GX)发挥作用的地方。
伟大的期望
伟大的期望(GX)是一个基于 Python 的开源工具,用于管理数据质量。它为数据团队提供了对数据进行分析、测试和创建报告的能力。该工具具有用户友好的命令行界面(CLI),使设置新测试和定制现有报告变得简单。
伟大期望可以与各种提取、转换和加载 (ETL) 工具如 Airflow 和数据库集成。有关集成的详细列表和官方文档可以在伟大期望的网站上找到。
GX 在其仓库中拥有许多期望。本文演示了如何使用单个期望来实现 GX 的数据质量维度。
数据
在开始实现之前,我们需要更多了解我们将使用的数据,以演示维度如何工作。
假设我需要创建一个数据集市分析,以找出销售部门在过去三年中每个区域的订单数量。
我们有一些订单的原始数据:
| 订单 ID | 订单日期 | 销售额 | 客户名称 | |
|---|---|---|---|---|
| 5955 | 2021-05-27 | 314.6217 | 安·钟 | |
| 21870 | 2022-08-28 | 996.9088 | 道格·比克福德 | |
| 3 | 2019-03-04 | 6025.7924 | 贝斯·佩奇 | |
| 19162 | 2021-04-11 | 403.5025 | 卡洛斯·索尔特罗 | |
| 12008 | 2022-11-29 | 4863.0199 | 弗雷德·沃瑟曼 | |
| 18630 | 201-09-16 | 4.9900 | 内奥拉·施奈德 | |
| 18378 | 2022-01-03 | 1566.3223 | 道格·比克福德 | |
| 15149 | 2020-03-12 | 1212.7117 | 米歇尔·隆斯代尔 | |
| 9829 | 2022-06-27 | 695.7497 | 尤金·巴查斯 | |
| 5188 | 2020-08-15 | 16426.6293 | 道格·比克福德 |
还有一些客户的原始数据:
| 客户名称 | 省份 | 区域 | 客户细分 |
|---|---|---|---|
| 安德鲁·艾伦 | 萨斯喀彻温省 | 努纳武特 | 消费者 |
| 特鲁迪·布朗 | 新斯科舍省 | 努纳武特 | 企业 |
| 迪奥尼斯·劳埃德 | 努纳武特 | 西部 | 企业 |
| 辛西娅·阿恩特森 | 西北地区 | 大西洋 | 企业 |
| 布鲁克·吉林厄姆 | 安大略省 | 安大略省 | 小型企业 |
| 亚历杭德罗·萨维利 | 新斯科舍省 | 努纳武特 | 消费者 |
| 哈罗德·帕夫兰 | 纽芬兰 | 大草原 | 企业 |
| 彼得·富勒 | 曼尼托巴省 | 魁北克省 | 消费者 |
| 伊昂尼亚·麦克格拉斯 | 魁北克省 | 魁北克省 | 家庭办公室 |
| 弗雷德·沃瑟曼 | 安大略省 | 大西洋 | 消费者 |
为了进行数据集市分析,我将使用基于客户名称(customer_regional_sales)的表:
在《伟大期望》中实现数据质量检查
为了本文的目的,使用了以下方法:
-
将数据保存在 3 个 CSV 文件中
-
使用 Pandas 读取 CSV
-
使用 Great Expectations 的
from_pandas方法来转换 Pandas dataframe。
import great_expectations as gx
import pandas as pd
df = pd.read_csv('./data/customer_regional_sales.csv',dtype={'Order ID': 'Int32'})
df_ge = gx.from_pandas(df)
这是对每个维度期望的一个良好示范。
伟大期望通过期望来评估数据。期望是以声明方式表达的陈述,可以被计算机评估,同时也对人类解释有意义。GX 具有 309 个期望,你还可以实现自定义期望。所有期望可以在这里找到。
完整性
完整性是数据质量的一个维度,衡量数据集中是否存在所有预期的数据。换句话说,完整性指的是数据集中是否存在所有必需的数据点或值,如果没有,缺少了多少。还需要检查该列是否存在。
GreatExpectations 有一个特定的 Expectation 用于检查完整性:
expect_column_values_to_not_be_null —— 期望列值不为空。
为了使值被视为例外,它们必须明确为空或缺失。例如,PostgreSQL 中的 NULL 或 Pandas 中的 np.NaN。仅仅有一个空字符串还不足以被视为 null,除非它已经被转换为 null 类型。
它可以应用于我们的用例:
df_ge.expect_column_values_to_not_be_null(
column = 'Customer Name',
meta = {
"dimension": "Completeness"
}
)
唯一性
唯一性是数据质量的一个维度,指的是数据集中每条记录代表一个唯一且不同的实体或事件的程度。它衡量数据是否没有重复或冗余记录,以及每条记录是否代表一个唯一且不同的实体。
expect_column_values_to_be_unique —— 期望每个列值都是唯一的。
df_ge.expect_column_values_to_be_unique(
column = 'Order ID',
meta = {
"dimension": 'Uniqueness'
}
)
接下来的维度需要更多的业务背景。
永久性
永久性是数据质量的一个维度,衡量数据随时间的相关性和准确性。它指的是数据是否是最新的。例如,我的要求是数据集应该包含过去四年的记录。如果数据集中有较旧的记录,我应该收到错误提示。
为了测试永久性,我使用 Expectation: expect_column_values_to_be_between
这将有效,因为我可以解析日期并进行比较。
import datetime
# Get the current date I use the start of the current year.
now = datetime.datetime(2023, 1, 1)
# Define the column to validate and the expected minimum date
min_date = now - datetime.timedelta(days=365*4)
# Create the expectation
df_ge.expect_column_values_to_be_between(
"Order Date"
min_value = min_date,
parse_strings_as_datetimes=True,
meta = {
"dimension": 'Timelessness'
}
)
Validity
Validity 是一个数据质量的维度,衡量数据是否准确并符合预期的格式或结构。由于无效数据可能会干扰 AI 算法对数据集的训练,因此组织应建立一套系统的业务规则来评估数据有效性。
例如,在美国,出生日期通常包括一个月份、一个日期和一个年份,而社会保障号码由十位数字组成。美国的电话号码以三位数的区号开始。因此,确定出生日期的具体格式可能更具挑战性。
在我的数据集中,日期列“Order Date”的格式是 YYYY-MM-DD,因此我应该检查该列中的所有值。
GX 有一个针对日期的 Expectation —— expect_column_values_to_be_valid_date。这个 Expectation 基于 dateutil 的“parse”方法。
如果你需要检查字符串的长度,那么你应该使用 Expectation —— expect_column_value_lengths_to_equal
使用正则表达式来处理我的日期格式是一种通用做法:
df_ge.expect_column_values_to_match_regex(
column = 'Order Date',
regex = '\d{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])',
meta = {
"dimension": "Validity"
}
)
我的愿景是,大多数 GX 仓库中的 Expectations 应该能够检查 Validity 维度。
一致性
一致性是数据质量的一个维度,指的是数据在数据集中的一致性和准确性。它衡量数据是否在逻辑上连贯,并符合预期的值、范围和规则。为了评估一致性,我通常将数据值与已知标准或值进行比较,并检查是否有差异或偏差。此外,我还使用统计方法来识别和纠正数据中的不一致。
作为我的数据集的一个示例,我创建了一个规则,即“Sales”列(表示每个订单的利润)不能为负。此外,我知道最大和为 25,000。
Great Expectations 提供了适用于此情况的 Expectation——expect_column_values_to_be_between。
df_ge.expect_column_values_to_be_between(
column = 'Sales',
min_value = 0,
max_value = 25000,
meta = {
"dimension": 'Consistency'
}
)
你也可以使用带有统计检查的 expectations:
expect_column_mean_to_be_between
expect_column_stdev_to_be_between
完整性
完整性确保数据的正确性和有效性,特别是当它被用于多个地方时。这包括检查数据在不同数据集之间的连接时是否准确和一致,并确保数据遵循业务设定的规则。
我有两个数据源和一个与这两个数据集相关的数据集。这意味着我必须检查在进行转换时数据是否丢失。对我来说,最重要的参数是订单 ID。我想确保所有订单都被放置在 customer_regional_sales 中。
Great Expectations 提供了几种解决方案:
-
使用 Expectation——expect_column_values_to_be_in_set。它期望每个列值都在给定的集合中。在这种情况下,我需要比较“orders”数据集中的订单 ID 与 customer_regional_sales 中的订单 ID。
df_expectations = pd.read_csv('./data/orders.csv', usecols=['Order ID'], squeeze = True ) df_ge.expect_column_values_to_be_in_set( "Order ID", value_set = df_expectations.tolist(), meta = { "dimension": 'Integrity' } )如果列 customer_regional_sales.order_id 与 orders.order_id 不相等,这个 Expectation 将会失败。
-
使用之前的 Expectation,但带有评估参数。你可以在官方文档中了解更多关于如何完成这项工作的内容。
-
使用 UserConfigurableProfiler 比较两个表。查看如何在官方文档这里中进行此操作。
-
最后,如果你想检查 Change Data Capture 的完整性,你需要使用 Data Quality Gate。DQG 允许你通过一键在 AWS 上部署带有 GX 的数据质量解决方案。请阅读我们关于此解决方案的案例研究,详见 AWS 技术博客。
结论
本文演示了如何使用 Great Expectations 库在数据中实现数据质量维度。通过使用 Expectations 验证数据,你可以确保数据符合多种数据质量维度的要求,包括完整性、有效性、一致性、唯一性等。虽然我已经覆盖了一些示例,但还有许多其他 Expectations 可供你使用,以满足你的具体业务需求。
通过改进数据质量方法,你可以避免代价高昂的错误,提高数据及其衍生洞察的准确性和可靠性。
如果你有任何问题或建议,请随时在下方留言或直接通过 LinkedIn 联系我。感谢阅读!
Aleksei Chumagin 是一位出色的 QA 专家,现担任 Provectus 的 QA 主管。Aleksei 在测试、编程和团队建设方面拥有丰富的经验。他在数据质量方面的专业知识使他成为 Provectus 团队的宝贵资产。Aleksei 是 Great Expectations 社区的积极贡献者。
了解更多相关信息
数据质量:优质的、劣质的与糟糕的
原文:
www.kdnuggets.com/2022/01/data-quality-good-bad-ugly.html

背景矢量由 rawpixel.com 创建 - www.freepik.com
仅仅用创可贴解决方案并不能解决问题的根源。创建数据可视化以使数据看起来更好,或对不干净的数据应用决策树,只是浪费时间。你可以创建世界上所有的模型,但如果你呈现的结果中一个个出现错误,那毫无用处。如果你的发现被视为圣经,公司基于这些发现做出重要决策,我们都不想处于那种不舒服的境地。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
错误或不干净的数据会导致错误的结论。理解和清理数据所花费的时间对结果的结果和质量至关重要。数据质量总是比复杂的华丽算法更胜一筹。
那么什么是数据质量?
数据质量是衡量数据集是否适合其特定用途及其可信程度的标准。它由准确性、完整性、一致性、有效性和时效性等特征组成。让我们简要地进一步解析这些特征。
-
准确性:这指数据与现实世界情境的匹配程度,使其可以使用。
-
完整性:一个数据集如果存在太多缺口或空白,将无法通过正确的分析来回答特定问题。
-
一致性:存储在一个位置的数据应当与存储在另一个位置的数据一致且不冲突。
-
有效性:这指数据的收集方式,定义业务规则和规范。它应当格式正确并在正确的范围内。
-
时效性:随时可用且易于访问的数据比随着时间推移变得不那么有用和准确的数据更有利于公司。
什么保证了数据质量?
可以使用特定的数据质量工具来改善和估算数据质量。例如:
-
数据剖析:这涉及到检查数据源,了解其结构及其潜在用途。
-
数据标准化:这是将数据转换为统一格式的过程,使分析师能够利用这些数据。
-
监控:对数据质量进行频繁检查至关重要。有特定工具可以检测和修正数据。
-
历史数据和实时数据:已经清理过的数据允许分析师将相同的数据质量框架应用于其他数据领域和应用程序。
实时数据质量在医疗保健领域的一个例子是确保患者数据的准确性和有效性。这对于文档记录、支付、风险管理和保护患者数据等方面至关重要。
数据质量的正面影响
-
决策:数据质量越高,公司和用户在基于输出结果做出重要决策时的信任度就越高。这反过来降低了公司做出错误决策的风险。
-
生产力:没有人愿意花费数小时修复数据错误。如果在初始步骤采取了正确措施,就可以让员工专注于下一步和其他责任。
-
目标:高质量的数据可以确保公司当前和未来目标的准确性,例如,市场营销团队更好地了解什么有效、什么无效。
-
合规:许多行业使用特定的指南来保持数据的隐私和安全,以防止任何泄露或潜在攻击。在金融领域,数据质量的缺乏可能会导致数百万美元的罚款或洗钱问题。
数据质量差的负面影响
-
输给竞争对手:如果你的竞争对手拥有比你更好的数据,提供给他们更多的见解可能导致错失机会,并对公司造成潜在的损害。不要让你的竞争对手超越你!
-
收入:基于不正确的数据做出的决策可能导致收入损失。例如,基于错误的 demographic 数据做出的政治决策可能会引发社会和财务问题。
-
声誉:每个人都希望提升和维护他们的声誉,尤其是当涉及到金钱时。基于糟糕数据做出的决策可能对公司造成严重损害,甚至可能失去投资者或公司本身。人们往往更容易记住坏的事情。
结论
在查看数据时,问自己这些问题:
1. 数据是如何收集的?
数据来源很重要。例如,这些数据是通过政府普查收集的,还是由某人手动创建并上传到 Kaggle 上的。收集来自上班路上不太感兴趣的人的数据,与发送调查问卷的网页链接让他们在自己时间里填写的方式是不同的。
2. 数据代表了什么?
数据是否能很好地代表你或公司所寻找的内容?使用基于巴黎的数据对法国的统计人口数据做出具体声明是不准确的。
3. 数据清理过程是怎样的?
有不同的方法来清理数据,选择一个特定的数据集或数据类型唯一的方法是很重要的。
4. 你在做什么来维护数据质量?
投资于合适的人才和基础设施,以维持和持续改善数据质量在技术领域中至关重要。
总是比直接面对一个可以避免的问题并花费时间和精力找解决方案要好。我总是说,做一次彻底,以后就不需要不断回头了。
尼莎·阿雅是一名数据科学家和自由职业技术写作者。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
主题更多内容
数据质量需求层级
原文:
www.kdnuggets.com/2022/08/data-quality-hierarchy-needs.html
马斯洛确定了人类需求的层级,从基础的生理需求如食物和住所开始,逐步上升到社会需求,最后到达创造力和自我实现。
数据团队有自己的需求层级,专注于确保数据的准确性。与大大小小的公司中的数据工程师和数据科学家合作过后,我将如何描述数据团队对数据质量的需求层级,从基础的数据新鲜度开始,我们首先确定是否拥有我们需要的数据。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT。
理想情况下,团队应具备工具来衡量这些层级中的数据质量。
数据团队的需求层级。
第 1 层:数据新鲜度
为了拥有高质量的数据,首先必须确保我们拥有数据。
你的管道运行了吗?如果是,什么时候?管道是否产生了新数据,还是产生了与上一次运行相同的数据?为了检查过时的数据,必须仔细且广泛地识别被卡住的数据流。很容易检测到没有更新,但在许多情况下,序列号或时间戳的移动并不意味着其他数据也已经移动。
第 2 层:数据量
一旦确定了数据的新鲜度,接下来需要关注的是数据量。我们可能会问如下问题:
-
数据量是否符合我们的预期?
-
如果数据量有所变化,它们是否符合我们在业务中已经观察到的趋势,例如周末或深夜活动较少?
在一些业务中,如零售商,节假日和节前可能会有不同的数据量。根据应用的不同,分析数据量可能需要考虑多个特征的强大数据模型。
第 3 层:数据模式
接下来是数据的布局:字段名称及其类型。在我与数据团队的工作中,我见过多种跟踪这些信息的方法,从使用存储在字符串字段中的 JSON 数据,到在支持的系统中使用子记录数据类型,例如 BigQuery。在决定采用何种方法时,有许多因素需要考虑,但通常关键关注点集中在缺失的数据列或关键字段上。
对于类型检查,我的建议是谨慎进行。在开发和生产环境中,许多字符串实际上是日期或数字。你可能需要考虑将类型“提升”到它们的最佳表示。这意味着在混合类型字段中,如果适用,你将为数值和字符串构建不同的模型。
第 4 层:数据值
最后,我们需要考虑数据值本身的内容。要评估数据质量,你需要推断类别,如果值的唯一性相对于总体大小较低。
对于字符串,我们计算了多种潜在模型,以便区分和捕捉新类型的字符串,而不被简单问题如值是否为 null 或字符串长度困扰。
第 5 层:使用元数据进行血统标记
调试数据流常常会引出这样的问题:“为什么这个字段有这个值?”
在过去构建数据管道的经历中,我一再遇到这个问题。我的解决方案是通过添加解释原因的字段来增强数据,在这些字段中我可以嵌入各种元数据:人类可读的解释、脚本文件名称和行号、其他变量,或我后来调试问题所需的任何信息。“我将其标记为缺货,因为两个数据源表示缺货,即使我们的第三个数据源说我们有 1,000 个”是检查单个记录时非常有用的信息。
不是每个人都有机会附加大量元数据,但如果你能做到这一点,你应该这么做。如果你考虑使用可以自动发现数据字段问题的工具,请注意,这些工具也可以分析你的新元数据字段,从而生成元数据警报,提醒你背后新的行为(如果需要的话)。
充分利用你的数据质量需求层级
这里需要记住的是,这个层级确实是一个层级。所有的事情都始于数据的新鲜度。如果你在层级的所有上层分析的数据都是陈旧的,你会对数据质量产生虚假的自信。你会认为今天的数据很好,实际上你只是重复分析上周三的数据。
一旦你确保了数据的新鲜度,你就可以确保你拥有所有数据,理解它的模式,等等。
- 我建议数据团队确保他们为每个层次提供了工具,并能够单独跟踪这些层次。然后,当所有层次都报告出色的结果时,你就会知道你已经满足了层次结构中的所有需求。对于繁忙的数据团队而言,这本身是一种超越。即使是马斯洛也会感到满意。
米奇·海尔是 Data Culpa, Inc.的首席技术官。他在零售数据、机器生成数据、计算机视觉和分析应用的数据管道工作中积累了超过十五年的经验。他还具有构建复杂数据中心环境解决方案的经验,并曾帮助开发数据领域、Pancetera(出售给量子公司)和 Conjur(出售给 CyberArk)的产品。米奇还是超过 25 项数据压缩、数据优化和数据安全发明的共同发明人。
了解更多相关话题
自然语言处理任务的数据表示
原文:
www.kdnuggets.com/2018/11/data-representation-natural-language-processing.html
我们之前详细探讨了 一些入门自然语言处理 (NLP) 主题,包括如何处理这些任务、预处理文本数据、入门流行的 Python 库等。我希望能转向探索不同类型的 NLP 任务,但有人指出我忽略了一个重要方面:自然语言处理的数据表示。
就像其他类型的机器学习任务一样,在 NLP 中,我们必须找到一种方法来将我们的数据(即一系列文本)表示给系统(例如文本分类器)。正如 Yoav Goldberg 提问 的那样,“我们如何以一种对统计分类器友好的方式编码这些分类数据?”这就引出了词向量。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
首先,除了“将单词转换为数字表示”,在进行数据编码时我们还对什么感兴趣?更确切地说,我们在编码什么?
我们必须从原始(或预处理过的)文本中的一组分类特征——单词、字母、词性标记、单词排列、单词顺序等——转化为一系列向量。实现文本数据编码的两种选择是稀疏向量(或独热编码)和密集向量。
这两种方法在几个基本方面有所不同。请继续阅读以了解讨论。
独热编码
在神经网络广泛应用于 NLP 之前——在我们称之为“传统” NLP 的领域——文本的向量化通常通过独热编码进行(请注意,这种做法仍然是许多练习中的有用编码方式,并未因神经网络的使用而过时)。对于独热编码,文本中的每个单词或标记对应一个向量元素。
我们可以考虑上面的图像,例如,作为一个向量的小片段,代表句子“女王走进了房间”。请注意,只有“女王”的元素被激活,而“国王”、“男人”等元素没有被激活。你可以想象,“国王曾经是一个男人,但现在是一个孩子”这句话的独热向量表示在上面显示的相同向量元素部分会有多么不同。
对语料库进行独热编码处理的结果是一个稀疏矩阵。考虑如果你有一个包含 20,000 个独特单词的语料库:在这个语料库中,一个仅包含 40 个单词的短文将被表示为一个具有 20,000 行(每个独特单词一个)的矩阵,矩阵中最多有 40 个非零元素(如果这 40 个单词中有大量非独特单词,则可能会更少)。这留下了大量的零,可能需要大量内存来存储这些稀疏表示。
除了潜在的内存容量问题,独热编码的一个主要缺点是缺乏意义表示。虽然我们可以通过这种方法很好地捕捉到文本中特定词汇的存在与缺失,但我们不能仅凭这些词汇的简单存在/缺失来确定任何意义。部分问题在于,我们使用独热编码时丢失了词语之间的位置关系或词序。这种顺序在表示词汇的意义时至关重要,下文会对此进行讨论。
提取词汇的相似性的概念也很困难,因为词向量在统计上是正交的。例如,考虑词对“狗”和“狗狗”,或“车”和“汽车”。显然,这些词对在不同方面是相似的。在一个线性系统中,使用独热编码,传统的自然语言处理工具,如词干提取和词形还原,可以用于预处理,以帮助揭示第一个词对之间的相似性;然而,我们需要更强健的方法来揭示第二个词对之间的相似性。
独热编码词向量的主要优点是它捕捉了词汇的二元共现(有时被描述为词袋模型),这足以执行广泛的自然语言处理任务,包括文本分类,这是这个领域最有用和最广泛的追求之一。这种类型的词向量对线性机器学习算法以及神经网络都很有用,尽管它们最常与线性系统相关。对线性系统也有用的独热编码变体,包括n-gram和TF-IDF表示形式。虽然它们与独热编码不同,但它们相似的是,它们是简单的向量表示,而不是下文介绍的嵌入。
密集嵌入向量
稀疏词向量似乎是一种完全可接受的表示某些文本数据的方式,特别是考虑到二元词共现。我们还可以使用相关的线性方法来解决一些 one-hot 编码的最大和最明显的缺点,如 n-grams 和 TF-IDF。但要深入理解文本的核心意义和标记之间的语义关系,仍然困难重重,词嵌入向量就是这样一种方法。
在“传统”自然语言处理(NLP)中,可以使用手动或学习的词性标注(POS)方法来确定文本中哪些标记执行了哪些类型的功能(名词、动词、副词、不定冠词等)。这是一种手动特征分配的形式,这些特征可以用于多种 NLP 功能的方法。例如,考虑命名实体识别:如果我们在文本段落中寻找命名实体,那么首先查看名词(或名词短语)以进行识别是合理的,因为命名实体几乎完全是所有名词的一个子集。
然而,假设我们将特征表示为密集向量——也就是说,将核心特征嵌入到一个大小为d维的嵌入空间中。如果愿意的话,我们可以将表示 20,000 个唯一词汇所用的维度数量压缩到 50 或 100 维。在这种方法中,每个特征不再具有自己的维度,而是被映射到一个向量中。
如前所述,意义与二元词共现无关,而与词汇的位置关系有关。这样想:如果我说“foo”和“bar”这两个词出现在一个句子中,那么确定它们的意义是困难的。然而,如果我说“那个 foo 叫了出来,吓到了年轻的 bar,”那么确定这些词的意义就容易多了。词语的位置及其与周围词语的关系是很重要的。
“你将通过一个词汇所伴随的词语来了解它。”
那么,这些特征究竟是什么呢?我们将其交给神经网络来确定词汇之间关系的重要方面。尽管人类对这些特征的解释可能不完全准确,但上面的图像提供了一个关于底层过程可能如何工作的见解,这与著名的King - Man + Woman = Queen 例子相关。
这些特性是如何学习的?这是通过使用一个 2 层(浅层)神经网络实现的——词嵌入通常与“深度学习”方法结合在一起,但创建这些嵌入的过程并不使用深度学习,尽管学习到的权重通常在之后的深度学习任务中使用。流行的原始word2vec嵌入方法 Continuous Bag of Words (CBOW)和 Skip-gram 与根据上下文预测一个词以及根据一个词预测上下文的任务相关(注意上下文是文本中的滑动窗口)。我们不关心模型的输出层;它在训练后被丢弃,嵌入层的权重随后用于后续的 NLP 神经网络任务。这个嵌入层类似于在 one-hot 编码方法中的结果词向量。
以上是用于 NLP 任务的两种主要文本数据表示方法。我们现在准备在下次探讨一些实际的 NLP 任务。
参考文献
-
自然语言处理,国家研究大学高等经济学院(Coursera)
-
自然语言处理,Yandex 数据学院
-
自然语言处理的神经网络方法,Yoav Goldberg
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计和优化、无监督学习、神经网络和机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。可以通过 editor1 at kdnuggets[dot]com 与他联系。
相关主题
使用 Python 进行数据缩放

图像由 Unsplash 提供
在机器学习过程中,数据缩放属于数据预处理或特征工程。在用于模型构建之前缩放数据可以实现以下目的:
-
缩放确保特征值在相同范围内
-
缩放确保用于模型构建的特征是无量纲的
-
缩放可用于检测离群值
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织 IT
数据缩放有多种方法。其中两个最重要的缩放技术是归一化和标准化。
使用归一化的数据缩放
当数据使用归一化进行缩放时,转换后的数据可以使用此方程计算
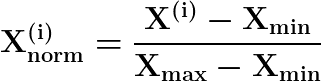
其中 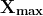 和
和 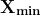 是数据的最大值和最小值。得到的缩放数据范围在 [0, 1] 之间。
是数据的最大值和最小值。得到的缩放数据范围在 [0, 1] 之间。
Python 实现归一化
使用归一化进行缩放可以使用下面的代码在 Python 中实现:
from sklearn.preprocessing import Normalizer
norm = Normalizer()
X_norm = norm.fit_transform(data)
设 X 为给定数据,具有 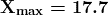 和
和 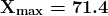 。数据 X 如下图所示:
。数据 X 如下图所示:
图 1. 数据 X 的箱线图,值在 17.7 和 71.4 之间。图像由作者提供。
归一化后的 X 如下图所示:
图 2. 归一化后的 X 值在 0 和 1 之间。图像由作者提供。
使用标准化的数据缩放
理想情况下,当数据呈正态分布或高斯分布时,应使用标准化。标准化的数据可以按如下方式计算:
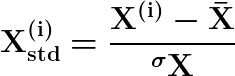
在这里,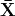 是数据的均值,而
是数据的均值,而 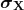 是标准差。标准化值通常应在[-2, 2]范围内,这代表 95%的置信区间。标准化值小于-2 或大于 2 的情况可以被视为异常值。因此,标准化可以用于异常值检测。
是标准差。标准化值通常应在[-2, 2]范围内,这代表 95%的置信区间。标准化值小于-2 或大于 2 的情况可以被视为异常值。因此,标准化可以用于异常值检测。
标准化的 Python 实现
使用标准化进行缩放可以通过以下代码在 Python 中实现:
from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(data)
使用上述描述的数据,标准化数据如下所示:
图 3. 标准化 X。作者提供的图片。
标准化均值为零。从上面的图中我们可以观察到,除了少数几个异常值,大多数标准化数据都在[-2, 2]范围内。
结论
总结一下,我们讨论了两种最流行的特征缩放方法,即标准化和归一化。归一化数据的范围在[0, 1],而标准化数据通常在[-2, 2]范围内。标准化的优点是它可以用于异常值检测。
本杰明·O·塔约 是一名物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中欧大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
数据科学 101:如何在 R 方面变得出色
原文:
www.kdnuggets.com/2016/11/data-science-101-good-at-r.html
由 Ari Lamstein 撰写。
最近我在我的 会员网站 上有几个人问了我以下问题:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我该如何在 R 方面变得出色?
这个话题出现的次数足够多,我可以概述一下我的想法。这样,下次有人提问时,我可以简单地将他们转发到这篇文章。

我的建议是面向那些想建立一个提升他们职业的在线作品集的人。这是我走过的道路,在某些方面,我只是说说对我有效的方法。
忽视 R
我的建议是完全停止考虑你在 R 方面的能力。相反,只需将其视为一个工具——一个实现目标的手段。这将使你能够将重点转移到
-
选择一个你关心的项目
-
发布你从研究中获得的结果
-
直接与重视你结果的人沟通
在我看来,这种关注点的变化改变了一切。
这些要点中的每一个都可以写成一本书。今天我将简单分享它们如何与我学习 R 的旅程相关。我会概述我如何从“R 作为一个副项目”转变为“R 开发者的职业”。这通常是那些问我这个问题的人真正想知道的。
我为什么以及如何学习 R
我并没有打算学习 R。
 几年前,我在一家房地产公司担任软件工程师。我在处理销售线索时需要分析数据。
几年前,我在一家房地产公司担任软件工程师。我在处理销售线索时需要分析数据。
MySQL 是我开始分析的一个很好的起点,但我需要做更多的工作。我开始学习 R,希望它能帮助我更好地分析数据。它确实做到了。
就我学习 R 的经历而言,我可能阅读了所有我能找到的资料。没有单一资源能准确告诉我我需要什么。许多资料详细介绍了对我完全无用的技术。从现在回想起来,温斯顿·张的R 图形 cookbook 和 Coursera 数据科学课程是我现在能记住名字的唯一资源。
在这种情况下,以上 3 点得到了满足,因为我有一份全职工作,我在分析与工作相关的数据,并且我与我的团队分享了结果。
自定义需求
在某个时候,我意识到自己有相当特殊的分析需求。我的主要分析单位是邮政编码,这本身就很不寻常。我还想将我们的内部数据与外部来源的人口数据进行融合,例如美国人口普查局。我在 R 生态系统中找不到完全符合需求的工具,所以我自己动手做了。这个项目最终变成了choroplethr。
由于我大部分职业生涯都是软件工程师,到目前为止的一切对我来说在某种程度上都是“正常”的。真正让我走出舒适区的是接下来的几个部分。
发布项目
尽管我在旧金山作为软件工程师工作了 10 多年,但我从未创建过开源项目。R 通过其包系统有着丰富的传统,这对我来说似乎是一个尝试新事物的好机会。
将项目从内部使用转变为其他人可以“现成”使用的状态是非常辛苦的工作。我真的不确定是否会有其他人使用这个项目。但当时我想,“如果这个项目能帮助到至少一个人,那就值得了。”
在 R 中没有准确测量包安装量的方法。但根据 metacran/cranlogs 应用程序的统计,截至本文撰写时,主要的choroplethr包已经被安装了 39,000 次。
营销项目
当我第一次发布choroplethr时,营销对我来说是一个禁忌词。现在我已经接受了它。
对不同的人来说,营销的意义各不相同。但对我而言,它主要意味着:
-
找到正在使用choroplethr的人,或者可能考虑使用它的人
-
了解他们为什么使用它。它如何融入他们项目的更广泛背景?
-
了解他们还有哪些其他问题,我可能能够帮助解决。
我主要使用内容营销来推广choroplethr。实际操作中,这意味着我有一个博客和一个让人们订阅我的邮件列表的方式。
电子邮件列表很重要。大多数访问网站的人离开后再也不会回来。如果你有他们的电子邮件地址,你可以在之后与他们讨论上述内容。
我的主要电子邮件订阅是Learn to Map Census Data in R,这是我关于如何使用choroplethr的免费电子邮件课程。目前已有几千人参加过这个课程。
货币化项目
在推出产品之前,最好先有潜在客户排队。理想情况下,你应该通过 Skype 与他们进行过几次访谈、调查过他们,或者至少通过电子邮件与他们保持联系。实际上,这些潜在客户已经在你的邮件列表中。这就是为什么我将“市场”列在“货币化”之前的原因。
我已经通过两种方式实现了choroplethr的货币化:
-
创建如何使用它的课程,并进行有关更广泛主题的一般教育
-
提供有关项目和更广泛主题的培训和咨询服务
我发现创建第一门课程改变了一切。除了课程的直接销售外,拥有一个付费的教育产品还带来了更高质量的咨询线索。
我最初不确定是否会有人购买的第一门课程,总收入达到了几千美元。
对初学者的建议
我分享自己的故事只是为了帮助那些问我“我怎么才能在 R 方面变得优秀?”的初学者。
我的回答是这是一个漫长的过程。但你今天可以做的两件事是:
-
选择一个你感兴趣的话题。
-
创建一个博客,并撰写你的第一篇帖子。那篇帖子可以介绍你自己并说明你计划研究的内容。
当然,话题可以更改。但我建议尝试将一个话题坚持至少 3 个月。对特定领域有深入了解会使你在寻求该领域信息的人眼中更有价值。
有问题吗?
如果你对我上面提到的内容有任何问题,或希望我深入撰写关于某个特定部分的未来文章,请随时通过下方的“联系”按钮与我联系。
如果你希望我为你提供个性化帮助,将这些材料应用到你自己的情况中,可以考虑加入我的membership site。
原始帖子。经许可转载。
简介: Ari Lamstein是一位软件工程师和数据分析师。他帮助客户进行软件工程和数据分析项目,编写开源软件并举办培训研讨会。详情请见arilamstein.com。
相关内容:
-
学习在 R 中绘制人口普查数据 – 免费电子邮件课程
-
R 图形画廊数据可视化集合
-
数据科学入门 – R
相关主题
数据科学适合我吗?14 个自我审查问题值得考虑
原文:
www.kdnuggets.com/2020/11/data-science-14-self-examination-questions.html
comments

我们的前三大课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
图片来源:Unsplash.
数据现在被认为是增长最快、价值数十亿的行业之一。因此,企业和组织正在尽可能利用他们已经拥有的数据,并确定他们还需要捕获和存储哪些数据。此外,对于数据科学家的需求仍然巨大,他们需要解读数据并揭示混乱商业问题的隐藏解决方案。一个 最近的研究 使用 LinkedIn 工作搜索工具显示,2020 年的大多数顶级技术职位都需要数据科学技能。
在数据科学充满激动人心的机会的背景下,自我教育是获得所需技能和经验的绝佳方式,这样可以在这个竞争激烈的领域中脱颖而出,并为你的雇主提供竞争优势。在投入数据科学领域之前,重要的是要审视以下问题,以评估数据科学是否真的适合你。
1. 什么是数据科学?
数据科学是一个涵盖多个子领域的广泛领域,如数据准备和探索、数据表示和转换、数据可视化和展示、预测分析、机器学习、深度学习、人工智能等。可以考虑数据科学能力的三个级别(基于一本优秀的机器学习教材《Python 机器学习》第三版的主题定义的 3 个级别),即:一级(基础水平);二级(中级水平);和三级(高级水平)。能力从一级到三级逐渐增加,如下图图 1所示。

图 1. 数据科学能力的三个级别。图片由 Benjamin O. Tayo 提供
2. 数据科学家做什么?
数据科学家利用数据来提取有意义的结论,并驱动机构或组织的决策。 他们的工作包括数据收集、数据转化、数据可视化和分析、构建预测模型,以及根据数据发现提供实施建议。 数据科学家在不同的领域工作,如医疗、政府、工业、能源、学术界、技术、娱乐等。 一些招聘数据科学家的顶级公司包括亚马逊、谷歌、微软、脸书、LinkedIn、Twitter、Netflix、IBM 等。
3. 数据科学家的就业前景如何?
数据科学家的就业前景非常积极。 IBM 预测 数据科学家的需求将在 2020 年增长 28%。 一项近期研究使用 LinkedIn 的职位搜索工具显示,2020 年大多数顶尖科技职位都需要数据科学、商业分析、机器学习和云计算技能(见图 2)。
图 2. 使用 LinkedIn 的职位搜索工具显示的全球技能类别职位数量。图片由 Benjamin O. Tayo 提供。
4. 数据科学家的收入是多少?
你作为数据科学家的收入取决于你工作的组织或公司、你的教育背景、工作经验年限以及你的具体职位。数据科学家的收入范围从$50,000 到$250,000, 中位数薪资约为$120,000。此文章讨论了更多关于数据科学家的薪资信息。
5. 我如何为数据科学职业做准备?
大多数数据科学或商业分析项目要求以下条件:
-
a) 高水平的定量能力
-
b) 解决问题的思维方式
-
c) 编程能力
-
d) 有效沟通的能力
-
e) 团队合作能力
因此,为了准备数据科学职业,你可以从攻读一个定量学科的学士学位开始,例如科学、技术、工程、数学、商业或经济学。
6. 我应该重点关注哪些编程语言?
如果你对学习数据科学基础感兴趣,你需要从某处开始。不要被数据科学家职位广告中提到的荒谬编程语言清单所压倒。虽然学习尽可能多的数据科学工具很重要,但建议一开始只学一两种编程语言。一旦你建立了坚实的数据科学基础,你可以挑战自己学习不同的编程语言或不同的平台和生产力工具来提升你的技能。根据这篇文章,Python 和 R 仍然是数据科学中使用的两大编程语言。我建议从 Python 开始,因为越来越多的学术培训项目和行业将其作为数据科学的默认语言。
7. 成为数据科学家需要多长时间?
如果你在分析学科如物理学、数学、工程学、计算机科学、经济学或统计学有坚实的基础,你基本上可以自学数据科学的基础知识。你可以从像 edX、Coursera 或 DataCamp 这样的免费在线课程开始。一级能力(见图 1)可以在 6 到 12 个月内达到。二级能力可以在 7 到 18 个月内达到。三级能力可以在 18 到 48 个月内达到。获得某一水平的能力所需的时间取决于你的背景以及你愿意投入的数据科学学习时间。通常,有分析学科背景的人,如物理学、数学、科学、工程学、会计或计算机科学的背景,所需的时间较少,而背景与数据科学不相符的人则需要更多时间。
8. 我是否有足够的耐心,即使在项目遇到瓶颈时也能继续工作?
数据科学项目可能非常漫长且要求高。从问题框定到模型建立和应用,这一过程可能需要几周甚至几个月,具体取决于问题的规模。作为一名数据科学家,遇到项目瓶颈是不可避免的。耐心、韧性和毅力是成功的数据科学职业生涯中必不可少的关键品质。
9. 我是否具备能够从模型中得出有意义结论的商业头脑,以便为我的组织做出重要的数据驱动决策?
数据科学是一个非常实用的领域。记住,你可能在处理数据和构建优秀的机器学习算法方面非常出色,但作为数据科学家,现实世界的应用才是最终的关键。每个预测模型必须在现实情况下产生有意义和可解释的结果。一个预测模型必须经过现实验证才能被认为是有意义和有用的。你作为数据科学家的角色是从数据中提取有意义的洞察,以用于数据驱动的决策,这些决策可以提高公司的效率、改善业务运作方式或帮助增加利润。
10. 我有良好的沟通技能吗?
数据科学家需要能够与团队成员或组织中的业务管理员沟通他们的想法。良好的沟通技能在这里扮演关键角色,能够将非常技术性的知识传达给对数据科学技术概念了解甚少的人。良好的沟通技能将帮助营造与数据分析师、数据工程师、现场工程师等其他团队成员的团结与合作氛围。
11. 我是终身学习者吗?
数据科学是一个不断发展的领域,因此要准备好接受和学习新技术。保持与领域发展联系的一种方式是与其他数据科学家建立网络。一些促进网络建设的平台有 LinkedIn、GitHub 以及 medium(Towards Data Science和Towards AI出版物)。这些平台对获取有关该领域最新发展的信息非常有用。
12. 我是团队合作者吗?
作为数据科学家,你将与数据分析师、工程师、管理员组成团队,因此需要良好的沟通技能。你还需要成为一个好的倾听者,特别是在早期项目开发阶段,你需要依赖工程师或其他人员来设计和构建一个好的数据科学项目。成为一个优秀的团队合作者将帮助你在商业环境中蓬勃发展,并保持与团队其他成员以及组织的管理员或董事的良好关系。
13. 我道德吗?
数据科学中必须考虑伦理和隐私。你需要了解项目的含义。对自己要诚实。避免操控数据或使用方法故意产生结果偏差。在所有阶段,包括数据收集和分析、模型构建、分析、测试和应用中,都要保持伦理。避免为了误导或操控受众而伪造结果。在解释数据科学项目的发现时,要保持伦理。
14. 学习数据科学的一些资源有哪些?
如果条件允许,你可以追求数据科学或商业分析的硕士学位。如果你无法负担硕士学位课程,你可以选择自学数据科学。一般来说,如果你在物理学、数学、经济学、工程学或计算机科学等分析学科中有扎实的背景,并且对探索数据科学领域感兴趣,最好的方式是从大规模开放在线课程(MOOCs)开始。然后在建立了坚实的基础之后,你可以寻求其他方式来提升自己的知识和技能,比如学习教材、参与项目以及与其他数据科学爱好者建立网络。
以下是推荐的 MOOCs 和教材,可以帮助你掌握数据科学的基础。
推荐的 MOOCs:
应用数据科学与 Python 专业(密歇根大学,通过 Coursera)
推荐的书籍:
从教材中学习可以提供比在线课程更精炼和深入的知识。这本书提供了数据科学和机器学习的绝佳入门,包含代码:《Python 机器学习》,作者为 Sebastian Raschka。github.com/rasbt/python-machine-learning-book-3rd-edition

作者以非常易于理解的方式解释了机器学习的基本概念。此外,书中包含代码,因此你可以实际使用这些代码进行练习和构建自己的模型。我个人发现这本书在我的数据科学之旅中非常有用。我会推荐这本书给任何数据科学爱好者。你所需要的只是基础的线性代数和编程技能,就能理解这本书。
还有很多其他优秀的数据科学教材,例如 Wes McKinney 的《Python for Data Analysis》、Kuhn 和 Johnson 的《Applied Predictive Modeling》以及 Ian H. Witten、Eibe Frank 和 Mark A. Hall 的《Data Mining: Practical Machine Learning Tools and Techniques》。
总结
总结一下,我们讨论了 14 个数据科学 aspirants 常见的重要问题。尽管不同个体的入门路径可能不同,但本文提供的答案可以为那些考虑数据科学领域的人提供一些指导。
相关:
更多相关主题
数据科学:大多数人未能交付的 4 个原因
原文:
www.kdnuggets.com/2018/05/data-science-4-reasons-failing-deliver.html
评论
作者:Nick Elprin,Domino Data Lab 的首席执行官兼联合创始人

当今组织面临的困境之一是:尽管数据科学被广泛认为是创新的关键驱动力,但很少有组织知道如何将数据科学的成果持续转化为商业价值。60%的公司计划在 2018 年将数据科学团队的规模翻倍。90%的人相信数据科学对商业创新有贡献。然而,实际能够量化所有模型的商业影响的公司不到 9%,只有 11%的公司能够声称拥有超过 50 个在生产中运作的预测模型。这些数据来源于最近对 250 多名数据科学领导者和从业者的调查。
这种脱节的根源是什么?在那些将数据科学视为技术实践的组织与那些进一步将数据科学视为贯穿整个业务结构的组织能力的组织之间存在差距。那些掌握了将算法驱动的决策制定嵌入业务核心所需的技术和管理实践的公司,获得的回报最多。它们可以被视为“模型驱动型”。(可以参考亚马逊、Netflix、Stitch Fix 和特斯拉作为例子。)

当然,说起来容易做起来难。让我们聚焦于组织在努力从数据科学投资中获取价值时出现的四个最棘手的挑战(顺便说一下,这些组织占大多数):
-
知识的孤岛。 雇佣数据科学家并不能保证你的组织能够从数据科学中获利。对于大多数公司而言,增加一个数据科学家到团队中并不会产生与之前的数据科学家相同的输出——你得到的是规模递减效益,而不是高效的数据科学团队所实现的指数效益。一个反复出现的主题是,数据科学家在个人笔记本电脑或其他孤立环境中工作时,常常会重复工作。他们无法看到其他人已经完成的工作,从而无法从中受益。例如,一家大型保险公司有数十位科学家在不协调的方式下解决相同的业务问题——导致了投资的损失和机会的错失。换句话说,拥有一群创建模型的个人和拥有一个能够利用集体知识、技能和过去工作来协作构建更好模型的动态团队之间是有区别的。
-
模型部署中的摩擦。 运作良好的数据科学团队在一个连续的迭代生命周期中运作——从研究到生产,再返回——并测量生产中模型的影响。不幸的是,研究过程往往与模型部署过程完全分开——而且当(如果)模型被部署时,没有与业务影响的关联。如果这与你的情况相符,那么你的组织可能无法对已部署的模型进行迭代以加以改进,更糟糕的是,未能衡量其模型的业务影响。一家主要的金融服务公司表示,他们“建造新的总部的时间比将一个模型投入生产的时间还要短。”
-
工具和技术不匹配。 IT 部门在过去十多年中致力于构建支持数据存储和处理的大数据基础设施——但这项基础设施不一定适合数据科学。数据科学家每月可能使用多达 3-5 种不同的工具或软件包,持续利用最新的软件包。仅在 2017 年,流行的开源编程语言 Python 就有超过 365,000 次更新!此外,数据科学工作要求访问弹性计算资源以执行特定实验,比如深度学习需要配备 GPU 的强大机器。缺乏弹性计算和最新工具限制了团队的敏捷性,制约了研究的进度——并导致了开发延迟。更糟糕的是,有时结果是影子 IT,就像一家大型全球银行的情况一样,因为批准新的 Python 软件包花费了太长时间,数据科学家最终带着个人笔记本电脑到工作场所并偷偷使用它们。
-
模型责任。 如果管理不当,生产中的模型可能会造成更多的损害而非好处。如果你在积极管理生产中的模型,你可能已经意识到这一点。一个未被严格监控或积极控制的模型可能会对业务造成严重的伤害,无论是合规性失败、收入损失,还是品牌或声誉的损害。例如,Knight Capital Group 在更新模型时出错后,在 45 分钟内损失了 4.4 亿美元。这是一个极端的例子,但它表明组织必须不断验证和监控其模型,以防止误用和性能退化。
如何应对这四个挑战将决定你们组织在未来五到十年中的发展。如果你认为你的公司在数据科学成熟度方面处于落后阶段,感到安慰的是,你并不孤单:实际上,约有 46%的调查参与者属于落后者类别。40%被认为是“有志向”的,仅有 14%则成功跻身前列,展示了将数据科学作为组织能力进行管理的能力。
现在还不晚。为了开始从数据科学中交付和衡量商业价值,你的组织必须围绕人员、流程和技术开发并实施一个一致且合理的框架。那些投入时间和精力建立这一框架,并成功将数据科学作为核心业务能力的公司,正获得回报。例如,Netflix 将模型整合到其业务的每个部分;他们估计,仅通过个性化和推荐模型就获得了十亿美元的增量价值。
信息很明确:成功实现数据科学并不容易。必须克服重大障碍。但最终,那些解决困难问题——如如何开发和部署高影响力的模型,以及如何真正用数据科学为企业提供支持——的组织,将在长期内更好地利用这些模型获得竞争优势。
个人简介:Nick Elprin是 Domino Data Lab 的首席执行官兼联合创始人。他于 2005 年获得哈佛大学计算机科学硕士学位。
相关:
更多相关话题
数据科学可以是敏捷的吗?将最佳敏捷实践应用于你的数据科学过程
原文:
www.kdnuggets.com/2021/01/data-science-agile-best-practices.html
评论
由Jerzy Kowalski,STX Next 的 Python 开发者。
我经常看到的观点是敏捷开发和数据科学不太适配。如果这是真的,那就意味着敏捷在数据科学家中并不受欢迎。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
由于我更倾向于进行严格分析而非轶事证据,我开始验证这个观点,并了解数据科学家是否使用敏捷。我发现他们确实在使用,但也可以使用得更多。
这促使我为将敏捷实践应用于数据科学项目提供了一个案例。结果就是这篇文章。
继续阅读以了解更多:
-
敏捷在数据科学家中有多受欢迎?
-
你可以做些什么来提升你的数据科学过程?
-
你应该将哪些最佳敏捷实践应用于数据科学?为什么?
-
在数据科学中实施敏捷有任何弊端吗?
使用敏捷的数据显示科学家占比是多少?
回答这个问题的一种可能方式是使用Stack Overflow 调查的结果。如果你想查看我分析的技术细节,我已经为你提供了一个jupyter notebook。
不幸的是,那里没有类似“你是否使用敏捷开发?”的问题,所以我选择了有关使用的协作工具的问题。我假设如果我发现了“Jira”作为答案,那么受访者很可能是在敏捷环境中工作。
别误解我的意思。我并不认为你必须使用 Jira 来进行敏捷开发——还有很多其他工具可供选择。如果你使用 Jira,这也不意味着你 100%是在进行敏捷开发。我只是做了一个我认为是“你是否使用敏捷开发”的最佳近似的假设。
回答“谁在使用敏捷?”这个问题要简单得多。“以下哪些描述了你?”正是我一直在寻找的答案之一,因为其中一个可能的答案是“数据科学家或机器学习专家。”
好了,理论讲解够了。现在让我们看看一些可视化数据吧!
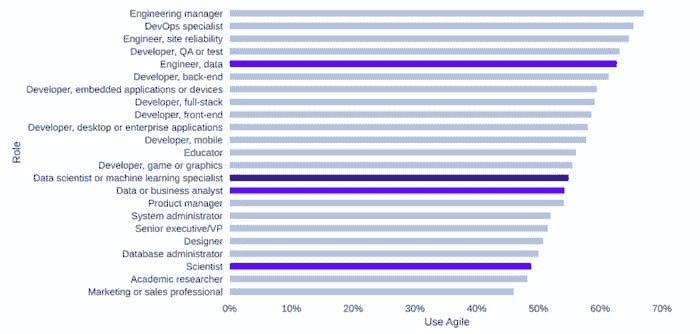
显然,数据科学家在这方面并不是行业领先者,因为只有 54.9%的人使用敏捷方法。类似角色的结果更差,数据工程师除外,他们在这方面接近最佳水平。此外,数据科学家与该群体中敏捷用户的比例之间在“工程性”方面存在正相关。
根据我的发现,我们不能说数据科学家对敏捷一无所知。但肯定还有改进的空间,所以让我们看看一些将敏捷方法融入数据科学项目的可能方式。
如何使你的数据科学工作更具敏捷性
有很多方法可以通过敏捷提升你的数据科学过程。让我们深入探讨两个我认为极其有价值的最佳实践,无论你是数据工程师、数据科学家还是软件工程师。
1. 分而治之
TL;DR:解决和管理较小的问题比试图一次性完成所有任务要容易。
我假设你至少有一些基本的任务定义系统。也许你使用像 Jira 或 Trello 这样的工具,或者在某个专用文档中使用待办事项列表。工具的选择其实不重要。
现在退一步思考一下你或团队中的其他人未能按时交付的任务。我相当肯定这些任务中有些是因为太大而无法在指定时间内完成。
我们为什么会创建庞大的任务?首先:常常会有一个巨大的诱惑让你尽快开始编码。当新的、令人兴奋的事物即将到来时,详细讨论实际需要做什么可能会显得无聊。小心,这是一种陷阱!除非你充分讨论任务,否则你会错过障碍,风险低估任务。
我们考虑以下场景:你正在开发一个识别热狗的系统,并且得到了一个庞大的图片集合用于训练模型。你脑海中的一个急躁的声音告诉你迅速在待办事项列表中创建一个新项目,称之为“提高模型准确性”,然后……开始编码。然后你被问到需要多长时间,你迅速回应:“三天。”
在与香肠的不平衡战斗了两周后,你发现自己正在向不满的利益相关者解释,由于许多标记为“热狗”的图片实际上是……香蕉,这比你最初假设的要困难得多。
如果你曾经花时间思考需要完成的任务,你可能会将其拆分为更小的部分。也许你会在初步数据集分析完成之前推迟三天的估计。
拆分任务时,记得要确保每个部分都能实际带来一些价值。下面的“模糊交付物”部分包含了更详细的指南。
最后但同样重要的是:较小的任务通常意味着更早的反馈。 如果在一天的数据集分析后,你告知你的利益相关者数据很混乱,那么他们可能会决定跳过这部分,让你去做一个更相关的任务。
2. 回顾
Scrum 是一个敏捷框架,帮助你组织交付产品的过程。Scrum 的一个组成部分是一系列旨在解决开发过程中可能出现的大多数问题的事件。
很难挑选出最有价值的形式,因为它们都是相辅相成的。但如果我必须说服一个 Scrum 怀疑者开始使用 Scrum 事件,我会从回顾开始。
回顾意味着专门留出时间来停下来反思哪些事情做得好,哪些事情做得不好。
这里是关键点:
-
给你的团队几分钟时间,思考一下最近在项目中发生的好事和坏事。让每个人写下他们想讨论的内容。
-
收集所有笔记,然后尝试找到并合并重复的内容。
-
再次给自己几分钟时间,对你认为最相关的话题进行投票。
-
现在是时候进行小组讨论,从获得最多票数的话题开始。尽量制定一个计划来改进这些痛点。
回顾可以采取多种形式,你可以自由提出新的形式。
说到工具:如果你有幸能面对面开会,那么老式的便利贴会很管用。如果不行,那么寻找一个在线解决方案就像谷歌“回顾工具”一样简单。
给自己一些时间来检视最近发生的事件和活动绝对是个好主意。我强烈建议你和你的团队一起尝试一下。
注意,Scrum 远不止是一两个花哨的会议!Scrum 指南无疑是获得关于 Scrum 的更广泛视角的最佳资源之一。希望阅读它能说服你尝试更多,甚至所有的组成部分。
最佳敏捷工程实践的好处:单元测试和测试驱动开发
除了过程级的敏捷改进,还有许多低层次的技术可以提升你的工作,包括代码审查、结对编程、持续集成——仅举几例。
我相信这些方法都适用于数据科学领域,但在这里我想重点关注两个:单元测试和测试驱动开发。 两者都是敏捷应用于软件工程的突出例子,而且根据最新的敏捷状态报告,它们都位列前十的敏捷工程实践中。
如果你不编写单元测试,那么你可能是在某个 REPL 环境中测试你的函数,或者编写临时脚本来完成工作。这种方法的问题在于,当你关闭 REPL 或删除测试脚本时,你的测试也会消失。
现在,假设你的测试被存储和共享。它们与许多其他测试一起周期性地运行,例如,在每次提交之前。你刚刚获得了一个保证你的函数按预期行为的保护措施。 如果任何更改使其失败,你将立即知道。
更重要的是,你可以将你的测试用例视为活的文档。你可能会同意,“示例”是大多数文档中最受欢迎的部分。现在你有了自己的“示例”部分:你的测试套件,解释如何使用函数以及预期的输出是什么。
此外,如果你在代码之前编写测试——这正是 TDD 的核心——你将获得更多好处。由于同时编写一个检查多个内容的测试是繁琐的,你最好保持简单,只检查给定输入是否返回正确的输出。因此,在编写函数时,你应该只专注于满足定义的需求。
这样,函数将保持为一个紧凑的、高度专业化的工具,而不是一段神秘的代码。我认为较小的函数通常更易于理解,所以可以公平地说,TDD 提供了更好的设计和增强的可读性。
将单元测试和测试驱动开发应用于数据科学
现在,让我们回答一个大问题:单元测试和 TDD 如何适用于数据科学的世界?好吧,如果你的日常工作包括使用像 NumPy 或 Pandas 这样的库进行数据整理,那么 TDD 完美适合!
考虑以下问题:你得到了一个 Pandas DataFrame,其中包含用分号分隔的多个值的字符串条目列:
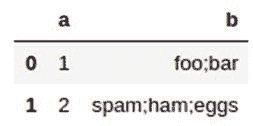
你的任务是转换 DataFrame,使每一行都具有单个 b 列条目。这类似于 Pandas 的explode,但输入是分号分隔的字符串。

我们有了样本输入,并且知道期望的输出。这就是编写测试所需知道的所有信息!让我们创建一个 test_utils.py 文件,并将我们的需求转化为代码:
import pandas as pd
from utils import explode_str_column
def test_explode_str_column():
input_df = pd.DataFrame(
{
"a": [1, 2],
"b": ["foo;bar", "spam;ham;eggs"]
}
)
column_to_explode = "b"
expected_df = pd.DataFrame(
{
"a": [1, 1, 2, 2, 2],
"b": ["foo", "bar", "spam", "ham", "eggs"]
},
index=[0, 0, 1, 1, 1]
)
actual_df = explode_str_column(input_df, column_to_explode)
如果你用pytest test_utils.py运行测试文件——自然,你需要安装pytest——它将失败,因为没有带有explode_str_column函数的utils模块。这没关系。当使用 TDD 时,你首先将需求定义为失败的测试,然后提供实现以使测试通过。
现在,让我们在新的 utils 模块中创建 explode_str_column 函数:
def explode_str_column(df, column):
df[column] = df[column].str.split(";")
return df.explode(column)
重新运行pytest test_utils.py,你会看到一个漂亮的绿色日志,说明你做得很好!

就这些!并不难或可怕,对吧?现在,作为某种家庭作业,你可以增强这个功能,以满足额外要求,比如处理不同的分隔符或避免修改输入的DataFrame。
记住从一个检查新需求的失败测试开始,然后编写解决方案。确保之前的测试没有失败!你还可以重构代码,使解决方案更清晰和/或性能更好。如果你完成了当前需求,应该为新的需求重复这个过程。
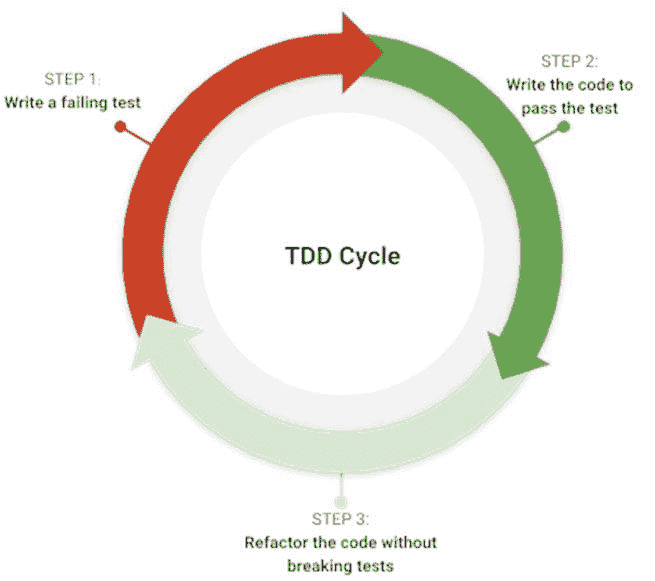
现在你知道如何通过单元测试和 TDD 使开发过程更敏捷了。使用这些技术可以解决数据操作问题,并为你提供更可靠、易读和设计更好的解决方案。
我确信在将这些方法融入你的日常工作后,你会看到越来越多的用例!
实施敏捷方法有哪些挑战和风险?
1. 模糊的交付成果
数据科学家在敏捷工作中的主要挑战是他们工作的输出往往很模糊。
让我们将其与网页开发人员进行比较。大多数时候,他们的任务非常具体,比如调整一个表单或添加一个新过滤器。这些任务的输出结果相当具体。用户可以点击新的界面项,提供的价值也相当容易识别。
现在,想想标准的数据科学任务,如原始数据清理、初步数据分析或改进预测模型。难点在于组织你的工作,使输出结果具有可展示性,并且理想情况下对最终用户可用。
这可能并不简单,但在开始任务之前回答以下问题应该会使其更容易:
- 谁是你的最终用户?
不要仅将最终用户视为客户。如果你有这些客户,那很好,但你还应该考虑所有将使用你软件的人。
- 你为什么需要“X”?
尝试理解你所做工作的理由。尽可能多地提出问题,以便早期发现风险。
- “X”将如何使用?
避免编写仅仅填补空白的脚本。创建一些对最终用户实际有价值的东西。也许这是一种 CLI 工具、一个包含有用分析的 jupyter notebook,或者一个小型库。为你的项目准备一个完成定义文档,将有助于明确什么可以被视为交付成果。
现在,将你的答案写在用户故事描述中。
最后,不要忘记应用我之前提到的“分而治之”方法。尽量找出最小的有价值的交付物。记住:你的工作成果不应该因为没有可点击的界面而变得模糊!
2. 研究和原型设计
原型设计的核心在于快速验证进一步的探索是否有意义。
起初,敏捷工程实践可能会让你感觉进展缓慢。对偶编程的要求是两位工程师:他们难道不能同时实现更多的代码吗?而且,为什么要关心测试?这只是更多的代码需要编写和维护——而且这需要时间!信不信由你,我确实听到过这样的论点……
令人遗憾的是,大多数原型代码最终都被丢弃了。这是不可否认的。那么,关心这种代码的质量是否值得?我认为是值得的。
原型经常变成被遗忘的脚本,存在于一些古老的仓库中。但时不时地,某个人(包括你!)可能会想要让它们重获新生。如果代码一团糟,那么复活将不会发生,或者会很痛苦。
如果你的原型成功了会怎样?我敢打赌,一旦你向更广泛的公众展示了有前景的结果,就会有人想要立刻使用它。不过,如果你创造了一个弗兰肯斯坦的怪物,你就得自己处理它。 尊重良好的实践在这种时候是值得的。
总结一下:在实现原型时,专注于相对较快地交付可工作的软件。但不要把它当作实现巨大功能或其他糟糕工作的绿灯。也许你可以减少重构代码的频率,不必追求 100%的测试覆盖率。允许自己不那么严格,但要尽量找到平衡。
最后的想法
说到底,很明显敏捷方法不仅仅适用于软件开发人员。数据显示,它在信息技术的其他领域也得到了广泛应用。
有很多敏捷实践可以有效地应用于各种问题,比如单元测试和测试驱动开发。
然而,数据科学领域的一些方面使得采用敏捷方法变得更加困难。我认为,工程责任越多,你成功应用敏捷实践的可能性就越大。另一方面,分析和研究的敏捷方法往往需要一种实质性的观念转变。
总的来说,我坚信无论你的项目性质如何,你都会从将敏捷方法融入你的过程中受益。我希望这些指导方针能帮助你迈出第一步。
个人简介: 耶日·科瓦尔斯基是一位 Python 爱好者,他利用自己最喜欢的编程语言解决机器学习和网络开发问题。耶日在可能的情况下传播函数式编程和 TDD 实践,并应用敏捷方法来改进软件开发过程。
相关:
更多相关主题
数据科学?敏捷?周期?我在高科技行业中管理数据科学项目的方法。
原文:
www.kdnuggets.com/2019/02/data-science-agile-cycles-method-managing-projects-hi-tech-industry.html
评论
由 Ori Cohen,Zencity.io 的数据科学负责人

奥地利阿尔卑斯山
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
敏捷软件开发已经在高科技行业中占据了主导地位。无论是以 Scrum、Kanban 还是 Scrumban 的形式实施,这些方法都是为了灵活应对,允许通过短周期的工作进行快速变化。虽然这些实施方法非常适合开发,但在某些方面与研究存在冲突,因此为了在研究中保持敏捷,我们需要调整敏捷的核心价值观,并将其与研究方法论对接,即创建一个利用敏捷价值观和思想但面向研究的工作实现。以下是我开发的一种方法,基于我个人管理数据科学研究团队的经验,并在多个项目中进行了测试。在接下来的章节中,我将从时间的角度审视不同类型的研究,比较开发和研究工作流程的方法,并最终提出我的工作方法论。
研究类型
我们通常会遇到三种类型的研究:
-
长期的,涉及学术界和像 IBM 或 FACEBOOK 这样的公司,即推动科学或技术进步的研究。
-
中期,即将在不久的将来对公司有贡献的战略项目。
-
短期项目,即公司产品的功能、客户项目、内部项目,如可重用的 API 或 POC。
短期或中期项目,在我看来,适用于任何与学术或公司相关的项目,这些项目旨在创建新算法或实现新功能,但受到行业限制,如时间、资源或资金。相比之下,长期研究通常是最令人畏惧的(尽管也有例外)。例如,在许多面试中,作为一名博士毕业生,我被问及是否可以在一个快节奏的初创公司中工作,并在短期内交付结果。
开发和研究之间的主要区别
让我们比较一下这两个领域的开发工作流程。
编程:在软件开发中,你将代码组织成函数、类(即面向对象编程),并可能使用设计模式等。你尝试设计一个清晰、可重用且易于维护的通用架构。在研究中,这个过程可以比作一个原型阶段,我们需要大量的灵活性,这使我们能够尽快尝试许多想法。对我和其他人来说,这归结为使用“Notebooks”——一个互动的 Python 环境,它通过将某些代码块分隔开来实现比传统 IDE 更快的原型设计,并保持持久的内存。我们不需要在没有必要时重新加载巨大的变量或重新计算算法,可以继续从上一个阶段工作。编程笔记本可以比作使用一个大的‘main’,分成多个单元格,每个单元格充当一个函数。传统编程 IDE 也不支持持久内存,试想在调试某个算法时读取一个巨大的数据集。
调试:调试过程有成熟的工具,你可以轻松地逐行跟踪,进入函数和类。在传统 IDE 中,你被迫重新加载数据集,每次重新启动调试过程时浪费宝贵的时间,而在笔记本中,数据集是持久的,整个过程中都保存在内存中(只要内核没有重置)。在笔记本中,调试过程包括使用 print(),因此,调试阶段确实相当简单。最终,当算法完成时,我们使用传统的软件开发工具,如 PyCharm,结合面向对象编程、设计模式进行重构,最后编写输入输出测试。
时间和进度管理:在常见的敏捷实施中,每个项目被分解为许多小的可交付任务,并且这些任务被给予一个短期估计。交付物被分组到周期中。这些小任务由团队成员拉取,直到完成,尽量在周期结束前完成所有任务。周期每 X 周重置一次。一般而言,研究任务较长,并且它们并不总是与短周期方法很好地匹配。例如,当我们启动一个模型时,可能需要几周才能获得理想的准确率。然而,这并不意味着在那些周内我们看不到其他方式的可测量结果,即特征与目标变量之间的相关性等。
既然我们已经讨论了软件开发和研究之间的一些主要区别,让我们来谈谈我的敏捷研究管理方法,并看看我如何尝试解决这些问题。
我的研究管理方法论
在研究中,我们考虑产品需求,分配特性,思考可能的算法解决方案,定义目标和关键绩效指标。事实是,我们没有一条清晰的路径通向那个目标,换句话说,我们不知道完成任务的确切路线。算法开发不仅仅是生产,它更多的是关于理解问题、评估选项、验证等。在实践中,我们根据直觉和经验测试许多不同的假设和想法,有些可能会有帮助,其他则可能不会。
我们首先为项目确定一个合理的截止日期,无论是两周、一个月还是更长时间,基本上是根据你的经验或估算认为所需的时间。不同项目之间的截止日期并不一致,因此难以放在严格的周期中。重要的是要记住,这些截止日期可能会变化,项目可能会比预期延长或提前结束。
我将每个项目分解为六个基本阶段(图 1.),这使我能够根据上下文对子任务进行分组。可以在图 1 中看到的这六个基本阶段列在下方,作为一个 Jira 面板。

图 1:应用研究或数据科学项目的六个阶段
项目阶段:
1. 文献综述
2. 数据探索
3. 算法开发
4. 结果分析
5. 评审
6. 部署
使用阶段方法,项目可以在各个阶段之间来回迭代,直到完成(图 2 中的蓝色和绿色箭头)。例如,我们完成了算法的编写,在‘结果分析’阶段我们发现需要回到‘数据探索’阶段并修改一个核心特征工程思路,项目将回到‘数据探索’并再次经历算法和结果分析阶段。

图 2:应用研究或数据科学项目的六个阶段覆盖在 Jira 看板上。展示了一个项目可以在不同阶段之间移动,无论是向前还是向后。
在每个阶段,我创建尽可能多的想法、假设或任务,即交付物。例如,在“文献综述”阶段,你可能有几个任务,比如在 Google Scholar 上查找论文、搜索 Github.com 或尝试在 Medium.com 上找到相关帖子。在“数据探索”阶段,你可能会探索特征工程、选择或今天所有可用的嵌入方法,从 word2vec、phrase2vec、sent2vec 到 Elmo、Bert 等。在“算法”阶段,我们可以测试几个经典的机器学习算法,尝试一些神经网络想法(CNN、LSTM、BI-GRU、多输入网络)、堆叠算法、集成方法等。在“结果分析”阶段,我们可以探索许多指标,如准确性、F1,检查模型的正确性等。在“审查”阶段,一名团队成员会审查我们的算法。最后,在“部署阶段”,我们将笔记本转换为清晰的基于类的 API,向 DevOps 团队暴露 init()、train()、predict()、upload_model() 和 download_model(),创建单元测试并以 Pip 包结束(我们使用的是 circleCI 和 Gemfury)。
我不对每个交付物分配估计,因为这增加了计划开销,安装了一个我想避免的僵化工作计划,并扰乱了研究过程中的创造力,即,我们不希望工作计划来管理我们,我们希望管理工作计划。我希望我的团队探索在创造性过程中出现和想到的不同解决方案,而不是坚持一个基本上只是愿望清单的预定计划。换句话说,过程中的数据、结果和洞察力会产生许多杰出的想法,从而使我的团队能够解决新颖的业务问题。
最终,我们探索许多可能引导我们实现目标的想法,但在每个阶段完成所有任务并不是强制性的,换句话说,如果我们对当前阶段感到满意,我们可以在没有完成所有其他任务的情况下进入下一阶段。另一方面,如果你对当前计划不满意,可以更改它、跳过或回退。
作为一个小团队的经理,我不希望承担子任务管理的额外负担。为了管理这些子任务,我使用了 JIRA 的 ‘smart-checklist 插件’,如图 3 所示。任务列表包含在每个项目框中,适当的任务可以在 UI 中标记为‘完成’或‘进行中’,显然,你只在项目框所在的阶段处理子任务。随着团队的成长,你可能会有专人负责维护每个子任务的详细信息,并可能需要使用 JIRA 内置的子任务管理功能,这会增加子任务管理的负担。我个人认为,我们的大多数子任务不需要全面跟踪,面板视图应尽可能干净和分组。

图 3:一个示例项目,其中每个主要阶段都有任务。
研究日常
项目管理不仅仅依赖于管理委员会,每日会议也是项目管理的重要方面。我的团队每天有一个小时的会议,通常在早上,类似于开发,我们尝试头脑风暴、同步,讨论昨天的工作,讨论遇到的问题,并谈论下一步。由于我们讨论的时间相对较长,我发现坐着开会更为合适,相比于站立式会议,即在沙发上讨论细节要更有益。这让我们能够分享想法,进行创意讨论,并不断改进,而无需等待周期结束后的反馈。
研究工作流程:
以下是我的研究工作流程方法的概述。
-
用符合项目期望、目标和 KPI 的合理项目截止日期替代周期方法论。
-
认识到一个项目在其生命周期中存在多个阶段。
-
认识到一个项目可以暂时返回到之前的阶段以尝试额外的想法。
-
将每个项目拆分为阶段性成果。
-
为每个阶段分配一个软截止日期。
-
认识到你的成果清单不需要整体完成,成果可以在项目过程中添加,这会影响截止日期。
-
在每个阶段,选择首先完成的最佳成果,当满意后,转到下一个研究阶段。
-
洗净、冲洗、重复。
版本开发
让我们简要讨论一下算法开发版本。我通常会努力实现项目目标和 KPI,但一个“足够好”的算法总比没有算法要好。因此,建议创建一个最小可行产品(MVP),完成过程,将其投入生产,然后决定下一版本的未来目标,这些目标可能来自产品部门、结果分析阶段或未完成的工作计划,如图 4 所示。
图 4:一个流程图,表示在利用研究阶段方法学工作流时的版本开发。
希望你能调整或使用这里提到的一些想法来管理数据科学研究项目。请记住,为了使这种方法有效,你的公司必须理解研究是一个不确定的过程,有些结果无法保证,但通过正确的项目管理方法,过程可以成功控制,以实现我们的目标。最后,如果你对从产品设计到模型完成和维护的项目工作流程感兴趣,Shay Palachy 写了一篇精彩的 文章。
我想感谢(按字母顺序排列)阿龙·尼瑟、盖·内舍尔、伊多·伊夫里、科比·希克里、摩西·哈达德、内塔内尔·大卫维茨、塞缪尔·杰弗罗金、西蒙·雷斯曼,感谢他们对敏捷方法论的宝贵见解、批评、校对和评论。
个人简介: Ori Cohen 拥有计算机科学博士学位,专注于机器学习。他领导着 Zencity.io 的数据科学团队,努力积极影响市民生活。
原文。经许可转载。
相关内容:
-
初创公司数据科学项目流程
-
从敏捷数据科学团队中获得实际世界的结果
-
通过深度学习加速敏捷过程
更多相关话题
9 个数据科学与分析职位趋势
原文:
www.kdnuggets.com/2020/09/data-science-analytics-job-trends.html
评论
由 Burtch Works 提供,分析与数据科学招聘
本文摘自我们新发布的 2020 年 Burtch Works 研究,分享了数据科学和分析领域的薪资、人口统计数据和其他招聘市场洞察。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域

1. 2021 年整体薪资数据的潜在影响
广泛的薪资削减可能会降低中位薪资
由于今年薪资削减影响了数据科学和分析团队,我们可能会看到对明年薪资的下行压力。奖金也可能受到负面影响。
裁员和休假可能影响职位提供和候选人谈判能力
目前,我们尚未看到由于当前危机而导致的职位提供低于预期的证据。从我们所见,大型公司至少目前仍在其规定的薪资范围内。然而,随着危机的持续,这种情况可能会发生变化,这可能会影响到 2021 年的薪资。由于裁员和休假打乱了许多候选人的职业计划,这也可能会影响他们协商更高薪资的能力,可能会暂时抑制薪资增长。
行业冲击的全面影响可能尚未显现
由于 COVID-19 的影响,许多行业和公司正遭受巨大冲击,市场可能会继续发生变化,因为一些在危机初期受到影响较小的组织现在开始裁员,包括一些咨询公司、广告公司、工业、软件、金融服务等。
托儿所和学校关闭导致对调整工作时间的请求增加
由于托儿所和学校关闭造成的干扰,我们听到一些经理说,他们看到对减少或调整工作时间的请求增加,这可能会对薪资产生影响。
2. 面试过程变得更快、更灵活
对于那些正在招聘的公司,我们看到面试过程变得更快,因为安排起来更容易。由于假期和旅行大多被搁置,许多候选人仍在远程工作,因此灵活性更高,特别是由于现场面试安排现在可以根据不同的日程安排进行调整,避免了接连安排的情况。
3. 由于远程工作,开始时间加快
由于远程工作当前的普及,这加快了候选人的启动时间,这些候选人通常需要 5 周时间来搬迁。雇主们已经开始运送计算机,以便更快地让人才上岗,立即处理数据项目,在许多情况下,搬迁由于安全问题被推迟了。

4. 技术评估优先考虑以便更早评估技术技能
鉴于面试过程已经基本转为完全虚拟,我们看到更强调在流程早期评估候选人的技术技能,通常甚至在安排与招聘经理的面试之前。这可能包括技术筛选和案例研究展示。
5. 对行业人口结构的影响
尽管一些行业和公司在产品或服务因 COVID-19 危机需求增加的情况下处于有利地位,但有些公司发现自己在应对旅行限制、封锁和需求迅速变化时挣扎。像零售、旅行或酒店业这样的行业可能会失去工作岗位,而技术领域可能会有所增加,因此我们将密切关注行业人口数据,以查看是否能在 2021 年的报告中发现任何变化。
6. 地点变化:候选人离开西海岸,对郊区办公室有利?
随着初创公司破产的增加以及一些公司宣布永久的远程工作策略,候选人离开西海岸的趋势可能会加速。这尤其影响了像湾区和西雅图这样的地区,这些地区近年来由于生活成本高和缺乏负担得起的住房而已经发生了变化。如果专业人士迁移到生活成本较低的地区,这可能会影响薪资,结果是薪资水平降低。是否封锁限制和避免公共交通,加上更有利的远程工作环境,会使郊区办公室受益,目前尚未可知。
7. 更多人才愿意变动,现在是招聘的有利时机
对于一些团队来说,危机对他们的招聘产生了积极影响。如果潜在的雇主以前无法接触到的人才因为被裁员、停职或因行业不确定性而愿意做出改变,这些人才可能会变得可用。我们已经看到,一些私募股权集团在危机期间为了准确把握商业决策时机,正在增加数据分析人才。
8. 随着远程工作增加,向云计算的过渡正在加速
由于远程工作的增加,越来越多的公司正在加快向云计算的过渡。因此,拥有云计算经验对于候选人保持市场竞争力将变得更加重要。
9. 数据科学与分析人才的持续竞争
尽管最近就业市场出现了扰动,但我们仍然看到对顶尖人才的激烈竞争,许多需求旺盛的候选人很快就会收到多个聘用通知。
通过下载我们的完整报告或查看下面的网络研讨会录制,了解更多关于这些趋势及其他趋势的信息!
原文。经授权转载。
相关:
更多相关话题
数据科学基础:集成学习器简介
原文:
www.kdnuggets.com/2016/11/data-science-basics-intro-ensemble-learners.html
算法选择对机器学习新手来说可能具有挑战性。构建分类器时,尤其是对初学者来说,通常采用考虑单一算法实例的解决方案方法。
然而,在特定情况下,将分类器链式或分组使用,利用投票、加权和组合技术以追求最准确的分类器,可能会更有用。集成学习器就是提供这种功能的分类器,它们以多种方式实现这一功能。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
本文将提供自助聚合、提升和堆叠的概述,这些方法可以说是最常用和最知名的基本集成方法。然而,它们并不是唯一的选项。随机森林是另一种集成学习器的例子,它在单一预测模型中使用大量决策树,通常被忽视并被视为一种“常规”算法。还有其他选择有效算法的方法,下面会介绍。
自助聚合
自助聚合的运作概念非常简单:建立多个模型,观察这些模型的结果,然后确定大多数结果。我最近在我的车的后轴组件上遇到了问题:我对经销商的诊断不太信服,因此我将车送到另外两个车库,他们都同意问题与经销商所建议的不同。瞧。自助聚合的实际应用。
我在这个例子中只访问了 3 个车库,但你可以想象如果我访问了几十个或几百个车库,准确性可能会提高,尤其是当我的车的问题非常复杂时。这对于自助聚合也适用,自助聚合的分类器通常比单一的组成分类器更准确。同时请注意,所使用的组成分类器类型并不重要;结果模型可以由任何单一分类器类型组成。
自助聚合是bootstrap aggregation的缩写,之所以这样命名是因为它从数据集中抽取多个样本,每个样本集被视为一个自助样本。这些自助样本的结果随后被聚合。
自助聚合 TL;DR:
-
通过模型的等权重来操作
-
通过多数投票来确定结果
-
对于一个数据集使用相同分类器的多个实例
-
通过带替换的抽样构建较小数据集的模型
-
当分类器不稳定时(例如决策树),效果最佳,因为这种不稳定性产生了具有不同准确度的模型,并从中得出多数结果
-
Bagging 通过引入人为的变异性来可能损害稳定模型,从而得出不准确的结论
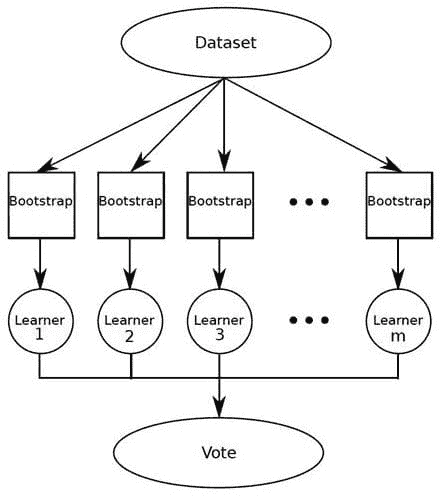
Boosting
Boosting 类似于 bagging,但有一个概念上的修改。与将模型赋予相等权重不同,boosting 为分类器分配不同的权重,并根据加权投票得出最终结果。
再考虑一下我的汽车问题,也许我过去去过某个特定的车库很多次,并且稍微比其他车库更信任他们的诊断。此外,假设我不喜欢之前与经销商的互动,并且对他们的见解信任度较低。我分配的权重将会反映这一点。
Boosting 简而言之:
-
通过加权投票来操作
-
算法以迭代方式进行;新模型受到之前模型的影响
-
新模型成为对早期模型分类错误的实例的专家
-
可以通过使用重采样而无需权重,概率由权重决定
-
如果分类器不是太复杂,则效果很好
-
也适用于弱学习者
-
AdaBoost(自适应提升)是一种流行的提升算法
-
LogitBoost(源自 AdaBoost)是另一种方法,它使用加性逻辑回归,并处理多类问题
Stacking
Stacking 与之前的两种技术略有不同,因为它训练多个单一分类器,而不是同一个学习者的不同版本。与 bagging 和 boosting 使用多种模型构建的同一分类算法(例如决策树)不同,stacking 使用不同的分类算法(可能是决策树、逻辑回归、人工神经网络或其他组合)来构建模型。
然后训练一个组合器算法,通过其他算法的预测来进行最终预测。这个组合器可以是任何集成技术,但逻辑回归通常被认为是执行这种组合的足够简单的算法。除了分类之外,stacking 还可以用于无监督学习任务,例如密度估计。
Stacking 简而言之:
-
训练多个学习者(与训练单个学习者的 bagging/boosting 相对)
-
每个学习者使用数据的子集
-
一个“组合器”在验证段上进行训练
-
Stacking 使用元学习者(与使用投票方案的 bagging/boosting 相对)
-
理论上难以分析(“黑魔法”)
-
Level-1 → 元学习者
-
Level-0 → 基本分类器
-
也可以用于数值预测(回归)
-
用于基本模型的最佳算法是平滑的全局学习者
虽然上述集成学习者可能是最知名和最常用的,但还有许多其他选项。除了堆叠,还有各种其他的元学习者。
数据科学新手容易犯的一个错误是低估算法领域的复杂性,以为决策树就是决策树,神经网络就是神经网络等。除了忽视算法家族的各种特定实现之间存在显著差异(查看过去几年神经网络领域的大量研究作为明确证据),还未意识到各种算法可以通过集成或介入的元学习者协同使用,从而在给定任务中实现更高的准确性,甚至解决单独无法解决的任务。任何你能想到的最新“人工智能”形式都采用了这种方法。不过,这是完全不同的话题。
相关:
-
数据科学基础:数据挖掘与统计学
-
数据科学基础:初学者的 3 个见解
-
机器学习关键术语解释
更多相关主题
数据科学基础:权力法则和分布
原文:
www.kdnuggets.com/2016/12/data-science-basics-power-laws-distributions.html
权力法则是一种强大的工具类别,可以帮助我们更好地理解周围的世界。
权力法则,也被称为尺度定律,本质上意味着某些现象的少数出现是频繁的或非常常见的,而相同现象的大多数出现则是不频繁的或非常罕见的;这些相对频率之间的确切关系在权力法则分布中有所不同。一些权力法则能够描述的广泛自然和人为现象包括收入差距、某种语言的词频、城市规模、网站规模、地震震级、书籍销售排名和姓氏受欢迎程度。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
全知的维基百科更正式地 定义 权力法则如下:
[A] 权力法则是一种功能关系,其中一个量的相对变化导致另一个量的相对变化成比例,与这些量的初始大小无关:一个量作为另一个量的幂变化。
将这个概念与钟形曲线进行对比,例如 正态分布,后者在描述或近似 许多现象 时是准确的。
一些非常简单的权力法则示例包括:
-
增加 x 的值 1,然后(并且总是)增加 y 的值 3
-
正方形的面积(边长翻倍,面积增加四倍)
-
英语中的词频 (齐夫定律;见下文)
本文将概述一些更受欢迎的权力法则,并举例说明它们所描述的内容,希望能引起新数据科学从业者的注意。为什么?因为我们调查、审查、接近和欣赏数据的方式越多,我们理解、分享和最终帮助他人理解数据的机会就越大。
齐夫法则以语言学家乔治·金斯利·齐夫命名,最初旨在描述文档集合中的单词频率之间的关系。它确实做得非常出色。如果一个文档集合中的单词按频率排序,y 用于描述第 x 个单词出现的次数,齐夫的观察可以简洁地表达为 y = cx^(-1/2)(项频率与项排名成反比)。
有趣的是,齐夫法则实际上还描述或近似了很多现象,超出了单词频率的范围。著名的例子包括不同国家城市的人口排名以及美国州的人口排名。
来源:www.dangreller.com/thats-just-not-normal-power-laws
你可以从误差率看出它并不完美,但仍是一个合理的近似。
帕累托原则,以经济学家维尔弗雷多·帕累托命名,表明可以近似认为某些特定现象的 80%效果是由 20%现象原因造成的。与这一原则相关的实际幂律是帕累托分布,该分布描述了硬盘驱动器错误率、人类定居点规模、陨石大小和石油储量发现等现象。
帕累托最初用这一原则著名地描述了财富分配,暗示社会财富的大多数(80%)由少数(20%)成员控制。具体数字可能会有所变化,但这一原则今天在经济学中仍被广泛应用和严格研究。
洛特卡法则,以数学家阿尔弗雷德·洛特卡命名,描述了特定学术领域中作者的出版频率。该法则指出,在特定时间段内,进行 x 次学术贡献的作者数量是仅进行一次贡献的作者数量的一个分数;观察值为 1 / x^a,其中 a 非常接近 2(但在学科领域中有所不同)。因此,我们可以近似地认为,1/4 的作者发表 2 篇论文的数量是发表 1 篇论文的数量的 1/4,发表 3 篇论文的数量为 1/9,发表 4 篇论文的数量为 1/16,依此类推。
上述知名定律没有涉及以下现象,这些现象也由幂律及其自定义指数近似描述,我鼓励你去探寻:
-
产品销售
-
网络图节点度数
-
网站大小
来源:www.technollama.co.uk/whatever-happened-to-the-long-tail
长尾理论,由克里斯·安德森在 2004 年《连线》杂志文章中推广,并在同名书籍中进一步阐述,是特定类型的幂律现象的体现。如果你读到这里仍然无法理解幂律如何在数据科学中实际应用(甚至更广泛的领域),我建议你深入探讨这一概念,虽然它并不像“发现”和推广所暗示的那样具有革命性,但确实有助于构建和应用对话。
存在许多幂律现象。此外,世界上还有各种现象之间的关系。调查和理解尽可能多的关系对于数据科学家理解他们研究的数据以及将其表达为他人能理解的形式非常有洞察力。然而,需警惕其反面;并非所有关系都可以用这种方式来近似,强行将数据强加于人为的描述中可能会产生误导。幂律(以及一般的描述性关系)应被视为你手中的另一种潜在工具。
相关:
-
数据科学基础:从数据中挖掘哪些类型的模式?
-
数据科学基础:集成学习者简介
-
数据科学基础:数据挖掘与统计学
更多相关话题
数据科学基础:从数据中可以挖掘出哪些类型的模式?
原文:
www.kdnuggets.com/2016/12/data-science-basics-types-patterns-mined-data.html
记住,数据科学可以被认为是根植于科学原理的数据相关任务的集合。虽然对于数据科学的确切定义或范围没有共识,但我谦虚地提供了我自己的尝试进行解释:
数据科学是一个多方面的学科,涵盖了机器学习和其他分析过程、统计学及相关数学分支,越来越多地借鉴高性能科学计算,最终目的是从数据中提取洞察,并利用这些新获得的信息讲述故事。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
至于数据科学与数据挖掘的关系,我曾表示“数据科学既与数据挖掘同义,也包括了数据挖掘的概念。”由于这篇文章将重点讨论从数据中挖掘的不同类型的模式,让我们转向数据挖掘。
数据挖掘功能可以分为 4 个主要的“问题”,即:分类和回归(合称:预测分析);聚类分析;频繁模式挖掘;以及异常值分析。当然,你也可以从其他方面来划分数据挖掘功能,例如,关注算法,从监督学习与无监督学习开始等等。然而,这是一种合理且被接受的方法来识别数据挖掘能够完成的任务,因此这些问题在下文中逐一介绍,重点关注每个“问题”能解决的内容。
分类
分类是监督学习的主要方法之一,涉及到如何对带有类别标签的数据进行预测。分类包括寻找一个描述数据类别的模型,然后用这个模型对未知数据进行分类。概念上的训练数据与测试数据对分类至关重要。
流行的分类算法用于模型构建,以及呈现分类器模型的方式,包括(但不限于):
-
决策树
-
支持向量机
-
神经网络
-
最近邻
分类的例子比比皆是。一些这样的机会包括:
-
在多个级别(低、中、高)识别信用风险
-
贷款批准(分类:贷款与否)
-
基于多个主题(政治、体育、商业、娱乐等)对新闻故事进行分类
例如,要对新闻故事进行分类,可以使用已标记的故事来建立模型,然后用未知类别的故事来测试模型,模型根据训练预测故事的主题。分类是数据挖掘的主要驱动力之一,其潜在应用几乎是无穷无尽的。
回归
回归类似于分类,因为它也是一种主流的监督学习形式,并且对于预测分析很有用。它们的区别在于,分类用于预测具有明确有限类别的数据,而回归用于预测连续的数值数据。作为监督学习的一种形式,回归中的训练/测试数据也是一个重要概念。线性回归是一种常见的回归“挖掘”形式。
回归有什么用?像分类一样,其潜力是无限的。一些具体的例子包括:
-
预测房价,因为房屋价格通常是在金融连续体上进行定价,而不是分类的
-
趋势估计,通过拟合趋势线来分析时间序列数据
-
健康相关指标的多变量估计,例如预期寿命
作为初学者,不要让非线性回归迷惑你:它只是最佳拟合线不是线性的,它取而代之的是另一种形状。这可以被称为曲线拟合,但本质上与线性回归和拟合直线没有不同,只不过用于估计的方法会有所不同。
聚类分析
聚类分析用于分析不包含预先标记类别的数据。数据实例通过最大化类内相似性和最小化不同类别之间的相似性来进行分组。这意味着聚类算法会识别并分组非常相似的实例,而不是分组那些彼此不太相似的实例。由于聚类不需要预先标记类别,它是一种无监督学习形式。
k-均值聚类可能是最著名的聚类算法示例,但并非唯一。存在不同的聚类方案,包括层次聚类、模糊聚类和密度聚类,还有不同的质心风格聚类方法(k-均值所属的家族)。
返回到文档示例,聚类分析可以将一组作者未知的文档根据其内容风格进行聚类,并且(希望)结果能够将它们的作者 - 或至少是类似作者 - 聚集在一起。在营销中,聚类可以特别有用,因为它可以帮助识别不同的客户群体,从而根据已知在这些群体中对类似客户有效的技术进行针对性营销。
其他示例?想象一下任何情况下,你可能有一个大数据集,这些实例没有明确的分类,但可能“自然”地展示出类似的特征集:描述动物类型的数据(腿数、眼睛位置、覆盖物);关于多种蛋白质的大量数据;描述各种族背景个体的遗传信息。所有这些情况(以及更多)都可以从允许无监督聚类算法找出哪些实例彼此相似,哪些实例彼此不同中受益。
频繁模式挖掘
频繁模式挖掘是一个已经使用了很长时间的概念,用来描述数据挖掘的一个方面,许多人认为这正是数据挖掘的精髓所在:对一组数据应用统计方法,以寻找该数据集中有趣且之前未知的模式。我们并不是要对实例进行分类或执行实例聚类;我们只是想学习在数据集和实例中出现的子集模式,哪些模式经常出现,哪些项目是关联的,哪些项目与其他项目相关。很容易看出为什么上述术语会混淆。
频繁模式挖掘最接近于市场篮分析,这是一种识别有限产品超集的子集,这些子集以一定的绝对频率和相关频率一起购买。这个概念可以推广到购买项目之外;然而,项目子集的基本原则保持不变。
异常分析
异常分析,也称为异常检测,与其他数据挖掘“问题”有些不同,通常不会单独考虑,原因有几个具体的方面。
首先,也是本讨论中最重要的一点,异常值分析并不像上述其他问题那样是独立的数据挖掘方法,而是可以利用上述方法来实现其自身目标(它是一种终极目标,而非手段)。其次,异常值分析也可以被视为描述性统计的一个练习,有些人认为这根本不是数据挖掘(认为数据挖掘按定义是预测统计方法)。然而,为了全面性,这里也包括了它。
异常值是指那些看起来与剩余数据或结果模型行为不太一致的数据实例。虽然许多数据挖掘算法故意不考虑异常值,或可以被修改以明确排除它们,但有时异常值本身可能就是重点。
这在欺诈检测中尤为明显,欺诈检测利用异常值来识别欺诈活动。如果你在纽约及其周边地区和在线频繁使用信用卡,主要用于微不足道的购买?今天上午在 Soho 的咖啡馆用了,晚上在上西区吃了饭,但在此期间在巴黎的实体店花费了几千美元购买电子设备?这就是你的异常值,这些数据会通过各种挖掘和简单的描述性技术被不懈追踪。
相关:
-
数据科学基础:初学者的 3 个见解
-
数据科学基础:集成学习者简介
更多相关主题
数据科学与大数据:两种截然不同的事物
原文:
www.kdnuggets.com/2015/07/data-science-big-data-different-beasts.html
由肖恩·麦克卢尔(ThoughtWorks)。

在今天的经济中,数据的重要性难以夸大。我们使用的工具和采取的行动消耗并生成我们世界的数字版本,所有这些都被捕获,等待使用。数据已成为大多数行业中真正感兴趣的资源,并被正确地视为竞争优势和颠覆性战略的入口。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
随着数据的兴起,出现了两种不同的努力,旨在利用其潜力。一种被称为数据科学,另一种是大数据。这些术语经常被互换使用,尽管它们在将数据的潜力带到组织门前时扮演着根本不同的角色。
尽管有人认为“数据科学”和“大数据”这两个术语仍然存在混淆,但这更多地与营销利益有关,而不是对这些术语在实际项目中的真实含义的诚实看待。数据科学旨在创建捕捉复杂系统潜在模式的模型,并将这些模型编码为可工作的应用程序。大数据则旨在收集和管理大量多样化的数据,以服务于大规模的网络应用程序和广泛的传感器网络。
尽管两者都有可能从数据中产生价值,但数据科学与大数据之间的根本区别可以用一句话来总结:
收集并不意味着发现
尽管这一声明显而易见,但在急于将公司的技术工具库填充数据智能技术的过程中,其真实性常常被忽视。价值往往被框架成仅通过收集更多数据来增加的东西。这意味着对数据焦点活动的投资更多地集中在工具而非方法上。工程车往往被摆在科学马之前,导致组织拥有一大套工具,却对如何将数据转化为有用的东西知之甚少。
将矿石送到空旷的车间
自铁器时代开始,铁匠们利用他们的技能和专长将原料转化为各种有价值的产品。通过使用特定领域的工具,铁匠将原材料锻造、拉伸、弯曲、冲压和焊接成有用的物品。经过多年的研究、试验和错误,铁匠学会了使用特定的气体、特定的温度、受控的气氛和各种矿石来源,以生产出符合其独特应用的定制产品。
随着工业革命的到来,能够更高效地将原材料转化为有价值的产品并进行规模化。但对规模化的关注并不是获取更多的材料,而是构建能够规模化和机械化转化专长的工具。随着这种机械化的发展,对工艺的理解变得更加重要,因为为了有效地操作、维护和在规模化中创新,必须深刻理解将原材料转化为能满足市场不断变化需求的产品的过程。
在数据的世界中,这种将原始资源转化为有价值的东西的专长被称为数据科学。之所以需要科学来将原始资源转化为有价值的东西,是因为从‘地面’中提取出的数据从未以有用的形式存在。‘原始数据’中充斥着无用的噪声、无关的信息和误导性的模式。将这些转化为我们所追求的珍贵事物,需要研究其属性并发现一个能捕捉我们感兴趣行为的有效模型。尽管存在噪声,拥有一个模型意味着一个组织现在拥有了进一步发现和创新的开端。对于他们的业务而言,这是一种独特的优势,赋予他们了解需要寻找的内容,以及对一个可以被机械化和规模化的世界的编码描述。
转化应当在收集之前进行规模化
没有行业会在没有相应专长的情况下投资资源的开采。在任何行业中,这都会被视为一个糟糕的投资。将矿石装上卡车却送到一个空荡荡的车间,几乎没有战略上的好处。
大数据的一个不幸方面是,我们往往需要查看最大的公司,以了解他们为在市场中竞争而设计的解决方案。但这些公司很少代表大多数组织面临的挑战。他们的主导地位通常意味着他们面临着非常不同的竞争,他们的工程工作主要是为了服务于大规模应用。这个工程对于日常操作至关重要,并且要满足高吞吐量和容错架构的要求。但它对于发现和转化所收集的数据成有价值的模型,捕捉市场运作背后的驱动因素的能力几乎没有说明。用数据来竞争的意义在于能够解释和预测组织的动态环境。
理解数据科学与大数据之间的区别对于投资于有效的数据战略至关重要。对于那些希望利用数据作为竞争资产的组织,最初的投资应集中在将数据转化为价值上。重点应放在数据科学上,以建立将数据从原始状态转化为相关性的模型。随着时间的推移,大数据方法可以与数据科学相辅相成。提取的数据种类的增加可以帮助发现新事物或改善现有模型的预测或分类能力。
填充车间所需的技能和专业知识,以将数据转化为有用的东西。带来的矿石将成为定义业务的产品。
简介: 肖恩·麦克卢尔,博士,是 ThoughtWorks 的高级数据科学家。
相关:
-
数据科学中的缺失 D
-
疑问与验证:数据科学的强大工具
-
2015 年预测:大数据和数据科学会发生什么?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号