KDNuggets-博客中文翻译-九-
KDNuggets 博客中文翻译(九)
原文:KDNuggets
2020 年最佳 GIS 课程
评论 来源
来源
地理信息系统分析是对空间关系和模式的分析。随着物联网(IoT)的兴起,空间组件被融入社会,更多的数据可以连接,并且很可能具有时空组件。
我们的前三个课程推荐
 1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
 2. 谷歌数据分析专业证书 - 提升你的数据分析技能
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
2020 年,GIS 分析在主流数据科学领域中出现得越来越频繁。由于新冠疫情,分析师们纷纷使用地图 API 来快速可视化并总结他们的发现。相比于金融、制造和营销,GIS 在数据科学领域并不是大众的默认选择。
1. Mike Miller 在 Udemy 上的课程
这不是一门课程,而是一个提供各种关于 GIS 课程的讲师。
Mike Miller 是一位 GIS 网页程序员,他提供 YouTube 教程,并在 Udemy 上有一系列关于使用 php、QGIS、PostGIS 和 leaflet.js 等技术的 GIS 应用程序网页编程课程可供购买。
2. Esri 提供的免费课程

对于 GIS 领域的人来说,Esri 无需多介绍。Esri 是 GIS 软件 ArcGIS 的主要服务提供商。与 QGIS 和 CARTO 一起,它是市场上前三大 GIS 软件之一。
在 ESRI 课程网站中,简单地筛选可用的免费课程。来自 ESRI 的课程自然会围绕使用 ArcGIS 进行,因此你需要获取该软件才能参加这些课程。
3. UC Davis 地理信息系统(GIS)专业化课程

这门课程与 Esri 合作开发,使用 ArcGIS。在整个课程中,学生可以学习基础的空间分析以及卫星影像分析。这是一个面向初学者的课程。
4. 延世大学的空间数据科学与应用
 来源
来源
这门课程将探讨 GIS 的数据科学方面,并使用 QGIS、R、POSTGIS、POSTGRESQL 和 Hadoop 等多种技术。该课程将使用更多开源软件如 QGIS 和 R,因此可以被更广泛的受众访问。
该课程面向的是中级水平的学生,需要你已经参加过更基础或初级的课程才能跟上进度。
相关:
-
R、SQL 和 Tableau 中的犯罪数据地理时间序列预测入门
-
OpenStreetMap 数据到 ML 训练标签用于目标检测
-
Python、Selenium 和 Google 用于地理编码自动化:免费和付费
更多相关话题
最佳 Instagram 账号推荐:数据科学、机器学习与人工智能
原文:
www.kdnuggets.com/2022/08/best-instagram-accounts-follow-data-science-machine-learning-ai.html

图片由编辑提供
很多人使用 Instagram —— 如果它还不是,那么它肯定是最顶尖的社交媒体应用之一。我做的一件事就是关注关于数据科学、机器学习和人工智能的 Instagram 账号。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
我也关注其他类型的内容,但当我看到代码、需要解决的问题或理论知识时,这会刺激我的大脑。这让我理解我知道什么以及我需要进一步学习的内容。
我整理了这篇博客,以帮助你找到应该关注的 Instagram 账号,从而获取最佳的数据科学、机器学习和人工智能内容。
@GitHub
如果你还没有使用 GitHub,GitHub 是一个用于版本控制、软件开发和协作的代码托管平台。他们的页面涵盖了所有相关的软技能和硬技能——使其成为数据科学初学者的好 Instagram 页面。当你点击他们简历中的链接时,你可以进一步探索每个帖子以及详细的博客——适合喜欢简化和详细信息的人。
@itsthatlady.dev
如果你刚刚进入开发行业,需要一些额外的指导 —— @itsthatlady.dev 的 Kadesha 是一个很棒的 Instagram 账号。她提供职业建议和各种资源给技术新手。她会指导你应选择哪些最佳路径,包括哪个地点适合工作、应该参加哪些培训项目等等。如果你想要一些互动性更强的内容,有人与你对话 —— 这是适合你的页面!
@madewithcode
由 Google 创建的 Instagram 页面,旨在激励女孩编程。我们都知道技术行业男性主导,这使得女性在进入行业时感到不太舒适。该页面庆祝在技术行业中的女性,并展示她们如何激励各年龄段的女性进入这一行业。他们还与 Teen Vogue 合作,鼓励高中和大学女生更有兴趣追求技术职业。
@NvidiaAI
如果你对 AI 特别感兴趣,并且想了解 Nvidia 当前的进展——这是一个有趣的页面。它会为你提供关于他们新产品的丰富内容,介绍他们的成就以及可能的未来方向。他们还会发布即将举行的活动和工作坊,这是一种保持信息更新、建立网络和发展职业生涯的好方式。你还可以了解到其他人如何使用 NvidiaAI 创新他们当前的业务,使用 #IAMAI 标签,可能会指导你找到适合你的商业方向或创业目标。
@learn.machinelearning
如果你在寻找直接的机器学习知识,并且对学习更多感兴趣——这是一个理想的页面。Uday Kiran 是该页面的创始人,他们的目标是帮助人们入门机器学习。内容涵盖了机器学习的一切,从如何入门到机器学习的解释,甚至是像 Google 和 Snapchat 这样的公司如何使用机器学习。你还可以通过测验来测试你的知识,获取项目创意和技巧!
@machinelearning
另一个学习机器学习的页面是 machinelearning!他们的目标是以直观的方式呈现机器学习。他们也可以在 Medium 和 YouTube 上找到。我个人喜欢他们内容在格式和展示上的一致性。他们提供关于各种主题的简洁但信息丰富的幻灯片,例如统计学、数学、数据科学等!他们有超过 100 篇帖子,以及在 Medium 和 YouTube 上的内容供你学习。
@python.learning
如果你选择了 Python 作为你的编程语言,这是一个值得关注的 Instagram 页面。它为你提供了职业信息、不同的课程、机器学习的理论知识以及更多内容。更棒的是,为了让你的编程职业生涯更加顺利,它还不断更新一些幽默的段子,帮助你度过学习新编程语言的过渡期。边学习边笑一笑是没有问题的。
@neuralnet.ai
如果你对神经网络和提升深度学习知识感兴趣——你找到了你的页面!类似于 @machinelearning,这个页面的表现一致性吸引了我的注意。他们提供了良好的可视化,内容简单但重要,有助于你扩展深度学习的知识。他们还有一个 GitHub 页面、用于测试你对深度学习理解的测验,并且引导你阅读他们认为最好的机器学习书籍:动手实践机器学习:Scikit-Learn、Keras 和 TensorFlow。
结论
如果你偶尔在 Instagram 上浏览,关注其中一些页面将帮助你保持在技术领域的领先地位,并帮助你弄清楚下一步该做什么。Instagram 上还有很多其他页面,如果你知道哪些好的页面,请在下面的评论中分享,以便其他人可以改进他们在数据科学、机器学习和人工智能方面的旅程。
尼莎·阿利亚 是一名数据科学家和自由撰稿人。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能在延长人类寿命方面的不同方式。作为一个热衷于学习的人,她寻求拓宽自己的技术知识和写作技能,同时帮助引导他人。
更多相关主题
2022 年数据科学最佳学习资源
原文:
www.kdnuggets.com/2022/01/best-learning-resources-data-science-2022.html

作者图片 | 照片由 jannoon028 提供
当我开始我的数据科学职业生涯时,我对从哪里开始、学习什么或哪些课程最好感到困惑。简单的谷歌搜索无法帮助你,你可能会浪费很多时间寻找合适的资源。在经历了这种困难之后,我向自己承诺要简化事情,以帮助他人。这个博客包含了帮助你快速启动职业生涯的最佳书籍、课程、平台、认证和社交网络的列表。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作。
书籍

作者图片
有些人喜欢阅读书籍,因此今年有一些有趣的书籍可供选择。在我们跳到书单之前,花点时间问问自己喜欢哪种编程语言。大多数人会选择Python,但R和Julia也非常受欢迎,因为它们都是为数据科学设计的。
初级水平: 数据分析的 Python:使用 Pandas、NumPy 和 IPython 进行数据整理
中级水平: 数据科学实用统计学
R 爱好者: 数据科学中的 R
未来语言: Julia 数据科学
课程

作者图片
我的旅程开始于 Codecademy 和 DataCamp 的课程,这些课程教会了我 Python、R、SQL 和统计学的基础知识。我强烈建议初学者尝试任何数据科学课程,并尽量按时完成。
以下列表包含免费课程、付费课程和短期教程。这些课程将帮助你建立坚实的基础,以便开始进行实际的数据项目。
免费课程
付费课程
-
Udacity: 学习成为数据科学家在线课程
-
DataCamp: Python 数据科学家轨迹
-
Coursera: IBM 数据科学专业证书
-
Codecademy: 数据科学家职业路径
教程
平台

作者提供的图像
如果我在开始数据科学之旅之前就知道Kaggle,我的生活会更轻松。这些平台提供示例、简单的指南以及进行实验的能力。你可以从笔记本中学习,或与专家数据科学社区讨论想法。
如果你想在数据科学和机器学习领域取得成功,只需在 Kaggle 上创建一个账户,并开始参与各种讨论。同时,创建一个GitHub账户,从更大的开发者社区中学习。
附加: 使用 Paperswithcode 和 DAGsHub 学习应用机器学习。
博客

图像来自 freepik
数据科学博客提供了关于特定工具、新概念和适合初学者的教程的简短信息。在完成几个课程后,我立刻爱上了 Towards Data Science 和 Analytics Vidhya 上易于跟随的博客。它们仍在帮助我在数据分析和机器学习方面不断进步。
认证

作者提供的示例证书
如果你没有数据科学学位,认证将为你在求职市场上提供优势。目前大多数平台都提供认证考试,许多认证是值得的。
这些认证考试将考察你在数据分析、编程技能、统计思维、建模和展示方面的能力。
数据社交网络

作者提供的图片 | 元素来源于 freepik
你如何保持对不断变化的数据科学领域的更新?通过关注专家、影响者或加入数据科学社交网络。这些社交网络包括 Discord(Learn AI Together)、LinkedIn、Twitter、Dev.to 和 Reddit(r/datascience)。
结论
我收到了很多直接消息和邮件,询问“如何开始学习数据科学。”大多数人说,他们认为如果能够学会基础知识,就能开始赚取六位数的薪水,这种心态是错误的。因此,如果你是为了错误的理由去做这件事,我建议你在这里停止,开始寻找你喜欢的事物。这个过程会变得困难,你会失去方向。简而言之,你将浪费时间和金钱去做你不喜欢的事情。
在这篇博客中,我们了解了最佳的学习资源和平台。开始关注 Twitter 或 LinkedIn 上的数据影响者,在 Kaggle 上创建一个账户,从一个免费的课程开始,然后完成一个付费课程,以深入了解机器学习和最佳编码实践。
"数据科学需要奉献和努力工作。"
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,喜欢构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络为那些面临心理健康困扰的学生开发一个 AI 产品。
更多相关内容
Scikit-learn 的最佳机器学习框架和扩展
原文:
www.kdnuggets.com/2021/03/best-machine-learning-frameworks-extensions-scikit-learn.html
评论
很多包实现了 Scikit-learn 估算器 API。
如果你已经熟悉 Scikit-learn,你会发现这些库的集成非常简单。
使用这些包,我们可以扩展 Scikit-learn 估算器的功能,我将在这篇文章中展示如何使用其中一些。
数据格式
在这一部分,我们将探索可以用于处理和转换数据的库。
Sklearn-pandas
你可以使用这个包将 ‘DataFrame’ 列映射到 Scikit-learn 转换中。然后你可以将这些列组合成特征。
要开始使用这个包,通过 pip 安装 ‘sklearn-pandas’。‘DataFrameMapper’ 可用于将 pandas 数据帧列映射到 Scikit-learn 转换中。我们来看看怎么做。
首先,创建一个虚拟 DataFrame:
data =pd.DataFrame({
'Name':['Ken','Jeff','John','Mike','Andrew','Ann','Sylvia','Dorothy','Emily','Loyford'],
'Age':[31,52,56,12,45,50,78,85,46,135],
'Phone':[52,79,80,75,43,125,74,44,85,45],
'Uni':['One','Two','Three','One','Two','Three','One','Two','Three','One']
})
DataFrameMapper 接受一个元组列表——第一个项的名称是 Pandas DataFrame 中的列名。
第二个传递的项是将应用于该列的转换类型。
例如,‘LabelBinarizer’ 可以应用于 ‘Uni’ 列,而 ‘Age’ 列则使用 ‘StandardScaler’ 进行缩放。
from sklearn_pandas import DataFrameMapper mapper = DataFrameMapper([
('Uni', sklearn.preprocessing.LabelBinarizer()),
(['Age'], sklearn.preprocessing.StandardScaler())
])
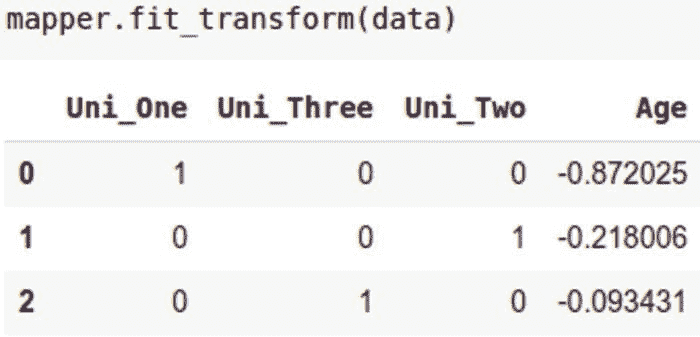
在定义映射器之后,接下来我们使用它来拟合和转换数据。
mapper.fit_transform(data)
映射器的 transformed_names_ 属性可用于显示转换后的结果名称。
mapper.transformed_names_

传递df_out=True给映射器将把结果返回为 Pandas DataFrame。
mapper = DataFrameMapper([
('Uni', sklearn.preprocessing.LabelBinarizer()),
(['Age'], sklearn.preprocessing.StandardScaler())
],df_out=True)
Sklearn-xarray
这个包将来自 xarray 的 n 维标记数组与 Scikit-learn 工具结合起来。
你可以将 Scikit-learn 估算器应用于 ‘xarrays’,而不会丢失它们的标签。你还可以:
-
确保 Sklearn 估算器与 xarray DataArrays 和 Datasets 之间的兼容性,
-
使估算器能够更改样本数量,
-
具有预处理转换器。
Sklearn-xarray 基本上是 xarray 和 Scikit-learn 之间的桥梁。为了使用其功能,通过 pip 或 ‘conda’ 安装 ‘sklearn-xarray’。
该包具有包装器,可以让你在 xarray DataArrays 和 Datasets 上使用 sklearn 估算器。为了说明这一点,首先我们创建一个 ‘DataArray’。
import numpy as np
import xarray as xr
data = np.random.rand(16, 4)
my_xarray = xr.DataArray(data)

从 Sklearn 中选择一种转换应用于此 ‘DataArray’。在这种情况下,我们来应用 ‘StandardScaler’。
from sklearn.preprocessing import StandardScaler
Xt = wrap(StandardScaler()).fit_transform(X)

包装的估算器可以无缝地在 Sklearn 管道中使用。
pipeline = Pipeline([
('pca', wrap(PCA(n_components=50), reshapes='feature')),
('cls', wrap(LogisticRegression(), reshapes='feature'))
])
在拟合此管道时,您只需传入 DataArray。
类似地,DataArrays 可以在交叉验证网格搜索中使用。
为此,您需要从 ‘sklearn-xarray’ 创建一个 ‘CrossValidatorWrapper’ 实例。
from sklearn_xarray.model_selection
import CrossValidatorWrapper from sklearn.model_selection
import GridSearchCV, KFold
cv = CrossValidatorWrapper(KFold())
pipeline = Pipeline([
('pca', wrap(PCA(), reshapes='feature')),
('cls', wrap(LogisticRegression(), reshapes='feature'))
])
gridsearch = GridSearchCV(
pipeline, cv=cv, param_grid={'pca__n_components': [20, 40, 60]}
)
之后,您将把 ‘gridsearch’ 拟合到 ‘DataArray’ 数据类型中的 X 和 y。
自动化机器学习
是否有工具和库可以将 Sklearn 集成以更好地进行自动化机器学习?是的,有一些例子。
Auto-sklearn
通过这个,您可以使用 Scikit-learn 进行自动化机器学习。对于设置,您需要手动安装一些依赖项。
$ curl https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt | xargs -n 1 -L 1 pip install
接下来,通过 pip 安装 ‘auto-sklearn’。
使用此工具时,您无需担心算法选择和超参数调整。Auto-sklearn 会为您处理这些。
这是得益于最新进展在贝叶斯优化、元学习和集成构建领域。
要使用它,您需要选择一个分类器或回归器,并将其拟合到训练集上。
from autosklearn.classification
import AutoSklearnClassifier
cls = AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)
Auto_ViML – 自动化变体可解释机器学习(发音为 “Auto_Vimal”)
给定某个数据集,Auto_ViML 尝试不同的模型和特征,最终选定表现最佳的模型。
该软件包还会在构建模型时选择最少数量的特征。这会为您提供一个更简单且易于解释的模型。该软件包还:
-
通过建议更改缺失值、格式和添加变量来帮助您清理数据;
-
自动分类变量,无论是文本、数据还是数字;
-
当详细信息设置为 1 或 2 时,会自动生成模型性能图;
-
让您使用 ‘featuretools’ 进行特征工程;
-
当 ‘Imbalanced_Flag’ 设置为 ‘True’ 时,处理不平衡数据
要查看实际效果,请通过 pip 安装 ‘autoviml’。
from sklearn.model_selection import train_test_split, cross_validate
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=54)
train, test = X_train.join(y_train), X_val.join(y_val)
model, features, train, test = Auto_ViML(train,"target",test,verbose=2)
TPOT – 基于树的管道优化工具
这是一个基于 Python 的自动化机器学习工具。它使用遗传编程来优化机器学习管道。
它探索多个管道以便选出最适合您的数据集的管道。
通过 pip 安装 ‘tpot’ 开始进行尝试。运行 ‘tpot’ 后,您可以将生成的管道保存到文件中。文件将在探索过程完成后或当您终止过程时导出。
下面的代码片段展示了如何在数字数据集上创建分类管道。
from tpot import TPOTClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75, test_size=0.25, random_state=42)
tpot = TPOTClassifier(generations=5, population_size=50, verbosity=2, random_state=42)
tpot.fit(X_train, y_train)
print(tpot.score(X_test, y_test))
tpot.export('tpot_digits_pipeline.py')
Feature Tools
这是一个自动特征工程的工具。它通过将时间序列和关系数据集转换为特征矩阵来工作。
通过 pip 安装‘featuretools[complete]’以开始使用它。
深度特征合成(DFS)可以用于自动特征工程。
首先,你需要定义一个包含数据集中所有实体的字典。在‘featuretools’中,实体是一个单独的表。然后,定义不同实体之间的关系。
下一步是将实体、关系列表和目标实体传递给 DFS。这将为你提供特征矩阵及其对应的特征定义列表。
import featuretools as ft
entities = {
"customers" : (customers_df, "customer_id"),
"sessions" : (sessions_df, "session_id", "session_start"),
"transactions" : (transactions_df, "transaction_id", "transaction_time")
}
relationships = [("sessions", "session_id", "transactions", "session_id"),
("customers", "customer_id", "sessions", "customer_id")]
feature_matrix, features_defs = ft.dfs(entities=entities,
relationships = relationships,
target_entity = "customers")
Neuraxle
你可以使用 Neuraxle 进行超参数调优和 AutoML。通过 pip 安装‘neuraxle’以开始使用它。
除了 Scikit-learn,Neuraxle 还兼容 Keras、TensorFlow 和 PyTorch。它还具有:
-
并行计算和序列化,
-
通过提供对这类项目至关重要的抽象来处理时间序列。
要使用 Neuraxle 进行自动化机器学习,你需要:
-
一个定义好的管道
-
一个验证分割器
-
通过‘ScoringCallback’定义评分指标
-
选择的‘hyperparams’仓库
-
选择的‘hyperparams’优化器
-
一个‘AutoML’循环
完整的示例请查看这里。
实验框架
现在是时候介绍几个你可以用于机器学习实验的 SciKit 工具了。
SciKit-Learn 实验室
SciKit-Learn 实验室是一个命令行工具,你可以用来运行机器学习实验。要开始使用它,请通过 pip 安装skll。
在那之后,你需要获取一个SKLL格式的数据集。
接下来,为实验创建一个配置文件,然后在终端中运行实验。
$ run_experimen experiment.cfg
当实验完成时,多个文件将存储在结果文件夹中。你可以使用这些文件来检查实验。
Neptune
Scikit-learn 与 Neptune 的集成让你可以使用 Neptune 记录你的实验。例如,你可以记录你的 Scikit-learn 回归器的总结。
from neptunecontrib.monitoring.sklearn import log_regressor_summary
log_regressor_summary(rfr, X_train, X_test, y_train, y_test)
查看这个笔记本以获取完整示例。
模型选择
现在让我们转移话题,看看专注于模型选择和优化的 SciKit 库。
Scikit-optimize
这个库实现了基于序列模型的优化方法。通过 pip 安装‘scikit-optimize’以开始使用这些功能。
Scikit-optimize 可以通过基于贝叶斯定理的贝叶斯优化来进行超参数调优。
你可以使用‘BayesSearchCV’根据这一理论获得最佳参数。一个 Scikit-learn 模型作为第一个参数传递给它。
from skopt.space import Real, Categorical, Integer
from skopt import BayesSearchCV
regressor = BayesSearchCV(
GradientBoostingRegressor(),
{
'learning_rate': Real(0.1,0.3),
'loss': Categorical(['lad','ls','huber','quantile']),
'max_depth': Integer(3,6),
},
n_iter=32,
random_state=0,
verbose=1,
cv=5, n_jobs=-1,
)
regressor.fit(X_train,y_train)
适配后,你可以通过‘best_params_’属性获得模型的最佳参数。
Sklearn-deap
Sklearn-deap 是一个用于实现进化算法的包。它减少了你找到最佳模型参数所需的时间。
它并不会尝试每一种可能的组合,而是只演化出结果最佳的组合。通过 pip 安装‘sklearn-deap’。
from evolutionary_search import EvolutionaryAlgorithmSearchCV
cv = EvolutionaryAlgorithmSearchCV(estimator=SVC(),
params=paramgrid,
scoring="accuracy",
cv=StratifiedKFold(n_splits=4),
verbose=1,
population_size=50,
gene_mutation_prob=0.10,
gene_crossover_prob=0.5,
tournament_size=3,
generations_number=5,
n_jobs=4)
cv.fit(X, y)
生产用模型导出
继续前进,现在我们来看看可以用来导出模型以供生产的 Scikit 工具。
sklearn-onnx
sklearn-onnx 实现了将 Scikit-learn 模型转换为ONNX。
要使用它,你需要通过 pip 获取‘skl2onnx’。一旦你的管道准备好,你可以使用‘to_onnx’函数来转换模型为 ONNX 格式。
from skl2onnx import to_onnx
onx = to_onnx(pipeline, X_train[:1].astype(numpy.float32))
Treelite
这是一个用于决策树集合的模型编译器。
它处理各种基于树的模型,如随机森林和梯度提升树。
你可以用它导入 Scikit-learn 模型。这里的‘model’是一个 scikit-learn 模型对象。
import treelite.sklearn
model = treelite.sklearn.import_model(model)
模型检查和可视化
在这一部分,我们将探讨可以用于模型可视化和检查的库。
Dtreeviz
dtreeviz 用于决策树的可视化和模型解释。
from dtreeviz.trees import dtreeviz
viz = dtreeviz(
model, X_train, y_train,
feature_names=boston.feature_names,
fontname="Arial", title_fontsize=16,
colors = {"title":"red"}
)
Eli5
eli5 是一个可以用于调试和检查机器学习分类器的包。你还可以用它来解释这些分类器的预测。
例如,Scikit-learn 估算器权重的解释可以如下所示:
import eli5
eli5.show_weights(model)
其他 SciKit 工具
dabl– 数据分析基础库
dabl 提供了常见机器学习任务的样板代码。它仍在积极开发中,因此不推荐用于生产系统。
import dabl
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
sc = dabl.SimpleClassifier().fit(X_train, y_train)
print("Accuracy score", sc.score(X_test, y_test))
skorch
Skorch 是 PyTorch 的 Scikit-learn 封装器。
它允许你在 Scikit-learn 中使用 PyTorch。它支持多种数据类型,如 PyTorch Tensors、NumPy 数组和 Python 字典。
from skorch import NeuralNetClassifier
net = NeuralNetClassifier(
MyModule,
max_epochs=10,
lr=0.1,
iterator_train__shuffle=True,
)
net.fit(X, y)
最后的思考
在本文中,我们探讨了一些扩展 Scikit-learn 生态系统的流行工具和库。
如你所见,这些工具可以用于:
-
处理和转换数据,
-
实现自动化机器学习,
-
执行自动特征选择,
-
进行机器学习实验,
-
选择适合你问题的最佳模型和管道,
-
导出模型以供生产…
…以及更多!
尝试在您的 Scikit-learn 工作流程中使用这些包,您可能会惊讶于它们的便利性。
个人简介:德里克·穆伊提是一位数据科学家,对分享知识充满热情。他通过 Heartbeat、Towards Data Science、Datacamp、Neptune AI、KDnuggets 等博客积极贡献于数据科学社区。他的内容在互联网上的观看次数已超过百万。德里克还是一名作者和在线讲师。他还与各个机构合作,实施数据科学解决方案以及提升员工技能。您可能想查看他的Python 完整数据科学与机器学习训练营课程。
原文。经许可转载。
相关:
-
数据科学、数据可视化和机器学习的顶级 Python 库
-
深度学习、自然语言处理和计算机视觉的顶级 Python 库
-
在 TensorFlow 中修剪机器学习模型
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
更多相关主题
最佳稀疏数据机器学习模型
原文:
www.kdnuggets.com/2023/04/best-machine-learning-model-sparse-data.html

作者提供的图片
稀疏数据是指特征值为零的数据集。这会在不同领域造成问题,特别是在机器学习中。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
稀疏数据可能由于不适当的特征工程方法而发生。例如,使用一热编码创建大量虚拟变量。
稀疏性可以通过计算数据集中零值的比例与总元素数的比率来衡量。解决稀疏性问题将影响你的机器学习模型的准确性。
此外,我们应区分稀疏性和缺失数据。缺失数据仅意味着某些值不可用。在稀疏数据中,所有值都是存在的,但大多数值为零。
此外,稀疏性对机器学习带来了独特的挑战。具体来说,它会导致过拟合、丢失有用数据、内存问题和时间问题。
本文将探讨与稀疏数据相关的这些常见问题。然后,我们将介绍处理这些问题的技术。
最后,我们将应用不同的机器学习模型于稀疏数据,并解释为什么这些模型适用于稀疏数据。
在整个文章中,我将主要使用 scikit-learn 库,如果你希望修改代码和参数,我也会提供官方文档链接。
现在让我们开始讨论稀疏数据的常见问题。
稀疏数据的常见问题
稀疏数据可能对数据分析提出独特的挑战。我们已经提到了一些最常见的问题,包括过拟合、丢失有用数据、内存问题和时间问题。
现在,让我们详细查看每一项。

作者提供的图片
过拟合
过拟合发生在模型变得过于复杂,开始捕捉数据中的噪声而不是潜在模式时。
在稀疏数据中,可能有大量特征,但只有少数特征与分析实际相关。这会使得识别哪些特征重要、哪些不重要变得困难。
结果可能导致模型对数据中的噪声过拟合,并在新数据上表现不佳。
如果你对机器学习不熟悉或想了解更多,你可以参考scikit-learn 关于过拟合的文档。
丢失有用数据
稀疏数据的一个最大问题是它可能导致潜在有用信息的丢失。
当我们拥有非常有限的数据时,识别数据中的有意义模式或关系变得更加困难。这是因为任何数据集固有的噪声和随机性在数据稀疏时更容易掩盖重要特征。
此外,由于可用数据的数量有限,我们更有可能错过数据中一些真正有价值的模式或关系。特别是在由于采样不足而导致数据稀疏的情况下,这一点尤其真实。在这种情况下,我们甚至可能未意识到丢失了数据点,因此可能无法意识到我们正在丢失有价值的信息。
这就是为什么如果移除过多特征,或者数据压缩过度,可能会丢失重要信息,从而导致模型准确性降低。
内存问题
内存问题可能由于数据集的巨大规模而出现。稀疏数据通常导致许多特征,存储这些数据可能需要计算上的高开销。这可能限制一次能处理的数据量,或者需要大量计算资源。
这里你可以查看使用 scikit-learn 进行数据缩放的不同策略。
时间问题
时间问题也可能由于数据集的巨大规模而发生。稀疏数据可能需要更长的处理时间,特别是当处理大量特征时。这可能限制数据处理的速度,在时间敏感的应用中可能会有问题。
处理稀疏特征的方法有哪些?

作者提供的图片
稀疏数据在数据分析中带来了挑战,因为其非零值出现频率较低。然而,有几种方法可以缓解这个问题。
一个常见的方法是移除导致数据集稀疏的特征。
另一个选项是使用主成分分析(PCA)来减少数据集的维度,同时保留重要信息。
特征哈希是一种可以采用的技术,它涉及将特征映射到固定长度的向量。
T-分布随机邻域嵌入(t-SNE)是另一种有用的方法,可以用来可视化高维数据集。
除了这些技术,选择一个适合处理稀疏数据的机器学习模型,如 SVM 或逻辑回归,也是至关重要的。
通过实施这些策略,可以有效解决数据分析中与稀疏数据相关的挑战。
现在我们先从减少稀疏数据的策略开始,然后我们将深入探讨模型。
移除它!
在处理稀疏数据时,一种方法是移除包含大多数零值的特征。这可以通过设置每个特征中非零值的百分比阈值来完成。任何低于该阈值的特征都可以从数据集中移除。
这种方法可以帮助减少数据集的维度,并提高某些机器学习算法的性能。
代码示例
在这个示例中,我们设置了数据集的维度以及稀疏度,稀疏度决定了数据集中有多少值为零。
然后,我们生成具有指定稀疏度的随机数据,以检查我们的方法是否有效。在此步骤中,我们计算稀疏度以供之后比较。
接下来,代码设置要移除的零的数量,并随机移除数据集中特定数量的零。然后,我们重新计算修改后的数据集的稀疏度,以检查我们的方法是否有效。
最后,我们重新计算稀疏度以查看变化。
这是代码。
import numpy as np
# Set the dimensions of the dataset
num_rows = 1000
num_cols = 100
# Set the sparsity level of the dataset
sparsity = 0.9
# Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data < sparsity] = 0
# Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements
print(f"The sparsity of the dataset before removal {sparsity:.4f}")
# Set the number of zeros to remove
num_zeros_to_remove = 50000
# Remove a specific number of zeros randomly from the dataset
zero_indices = np.argwhere(data == 0)
zeros_to_remove = np.random.choice(
zero_indices.shape[0], num_zeros_to_remove, replace=False
)
data[
zero_indices[zeros_to_remove, 0], zero_indices[zeros_to_remove, 1]
] = np.nan
# Calculate the sparsity of the modified dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements
print(
"Sparsity after removing {} zeros:".format(num_zeros_to_remove), sparsity
)
这是输出结果。

PCA
PCA 是一种流行的降维技术。它识别数据的主成分,这些主成分是数据变化最大的方向。
然后可以使用这些主成分在较低维度的空间中表示数据。
在稀疏数据的背景下,PCA 可以用来识别数据中包含最多变异的最重要特征。
通过仅选择这些特征,我们可以减少数据集的维度,同时保留大部分重要信息。
你可以使用 scikit-learn 库来实现 PCA,我们将在接下来的代码示例中这样做。这里是官方文档,如果你想了解更多信息。
代码示例
要对稀疏数据应用 PCA,我们可以使用 Python 中的 scikit-learn 库。
该库提供了一个 PCA 类,我们可以使用它来拟合 PCA 模型并将数据转换为较低维度的空间。
在接下来的代码的第一部分,我们创建一个数据集,如同在前一部分中一样,具有给定的维度和稀疏度。
在第二部分,我们将应用 PCA 将数据集的维度减少到 10。之后,我们将重新计算稀疏度。
这是代码。
import numpy as np
# Set the dimensions of the dataset
num_rows = 1000
num_cols = 100
# Set the sparsity level of the dataset
sparsity = 0.9
# Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data < sparsity] = 0
# Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements
print(f"The sparsity of the dataset before removal {sparsity:.4f}")
# Apply PCA to the dataset
pca = PCA(n_components=10)
data_pca = pca.fit_transform(data)
# Calculate the sparsity of the reduced dataset
num_zeros = (data_pca == 0).sum()
total_elements = data_pca.shape[0] * data_pca.shape[1]
sparsity = num_zeros / total_elements
print(f"Sparsity after PCA: {sparsity:.4f}")
这是输出结果。

特征哈希
处理稀疏数据的另一种方法叫做特征哈希。这种方法通过哈希函数将每个特征转换为固定长度的值数组。
哈希函数将每个输入特征映射到固定长度数组中的一组索引。如果多个输入特征映射到相同的索引,则将这些值相加。特征哈希对于存储大型特征字典可能不可行的大型数据集非常有用。
我们将在下一部分一起讨论这个内容,但如果你想深入了解,这里可以查看 scikit-learn 库中特征哈希器的官方文档。
代码示例
在这里,我们再次使用相同的方法来创建数据集。
然后我们使用 scikit-learn 的 FeatureHasher 类对数据集应用特征哈希。
我们使用n_features参数指定输出特征的数量,并使用input_type参数指定输入类型为字典。
然后我们使用 FeatureHasher 对象的 transform 方法将输入数据转换为哈希数组。
最后,我们计算结果数据集的稀疏度。
这是代码。
import numpy as np
# Set the dimensions of the dataset
num_rows = 1000
num_cols = 100
# Set the sparsity level of the dataset
sparsity = 0.9
# Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data < sparsity] = 0
# Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements
print(f"The sparsity of the dataset before removal {sparsity:.4f}")
# Apply feature hashing to the dataset
hasher = FeatureHasher(n_features=10, input_type="dict")
data_dict = [
dict(("feature" + str(i), val) for i, val in enumerate(row))
for row in data
]
data_hashed = hasher.transform(data_dict).toarray()
# Calculate the sparsity of the reduced dataset
num_zeros = (data_hashed == 0).sum()
total_elements = data_hashed.shape[0] * data_hashed.shape[1]
sparsity = num_zeros / total_elements
print(f"Sparsity after feature hashing: {sparsity:.4f}")
这是输出结果。
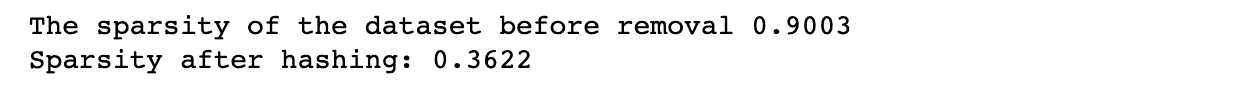
t-SNE 嵌入
t-SNE(t-分布随机邻域嵌入)是一种非线性降维技术,用于可视化高维数据。它在减少数据的维度的同时保持其全局结构,已成为机器学习中可视化和聚类高维数据的热门工具。
t-SNE 特别适用于处理稀疏数据,因为它可以有效地降低数据的维度,同时保持其结构。t-SNE 算法通过计算高维和低维空间中数据点之间的成对距离来工作。然后,它最小化这些距离在高维和低维空间中的差异。
为了在稀疏数据上使用 t-SNE,数据必须首先转换为密集矩阵。这可以通过各种技术完成,如 PCA 或特征哈希。数据转换完成后,t-SNE 可以用来获得数据的低维嵌入。
此外,如果你对 t-SNE 感兴趣,这里是 scikit-learn 的官方文档,可以查看更多信息。
代码示例
以下代码首先设置数据集的维度和稀疏度级别,生成具有指定稀疏度级别的随机数据,并计算应用 t-SNE 之前数据集的稀疏度,正如我们在前面的示例中所做的那样。
它然后对具有 3 个组件的数据集应用 t-SNE,并计算 t-SNE 嵌入的稀疏度。最后,它打印出 t-SNE 嵌入的稀疏度。
这是代码。
import numpy as np
# Set the dimensions of the dataset
num_rows = 1000
num_cols = 100
# Set the sparsity level of the dataset
sparsity = 0.9
# Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data < sparsity] = 0
# Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements
print(f"The sparsity of the dataset before removal {sparsity:.4f}")
# Apply t-SNE to the dataset
tsne = TSNE(n_components=3)
data_tsne = tsne.fit_transform(data)
# Calculate the sparsity of the t-SNE embedding
num_zeros = (data_tsne == 0).sum()
total_elements = data_tsne.shape[0] * data_tsne.shape[1]
sparsity = num_zeros / total_elements
print(f"Sparsity after t-SNE: {sparsity:.4f}")
这是输出结果。

稀疏数据的最佳机器学习模型
既然我们已经解决了处理稀疏数据的挑战,我们可以探索专门为稀疏数据设计的机器学习模型。
这些模型可以处理稀疏数据的独特特征,例如大量特征中有许多零和有限的信息,这使得传统模型很难实现准确预测。
通过使用专门为稀疏数据设计的模型,我们可以确保预测结果更加精准可靠。
现在我们来谈谈适合稀疏数据的模型。
SVC(支持向量分类器)
SVC(支持向量分类器)与线性核可以很好地处理稀疏数据,因为它使用训练点的子集,即支持向量,进行预测。这意味着它可以高效地处理高维稀疏数据。
你也可以使用支持向量进行回归。
如果你想了解更多关于支持向量算法的内容,包括分类和回归,我在 这里解释了支持向量机。
逻辑回归
这也可以很好地处理稀疏数据,因为逻辑回归使用正则化项来控制模型复杂性,这有助于防止在稀疏数据集上的过拟合。
如果你想了解更多关于逻辑回归以及其他分类算法的信息,请查看 机器学习算法概述:分类。
KNeighboursClassifier
该算法可以很好地处理稀疏数据,因为它计算数据点之间的距离,并且能够处理高维数据。
你可以在 这里的机器学习算法 查看 KNN 和其他你需要了解的数据科学算法。
MLPClassifier
MLPClassifier 在输入数据标准化时可以很好地处理稀疏数据,因为它使用梯度下降进行优化。
这里你可以看到 MLP 分类器的实现,以及其他算法,借助 ChatGPT 的帮助。
决策树分类器
当特征数量较少时,它可以很好地处理稀疏数据。如果你对决策树不了解,我在 这里解释了决策树和随机森林,这是我们分析稀疏数据模型的最终模型。
RandomForestClassifier
RandomForestClassifier 在特征较少时可以很好地处理稀疏数据。

图片由作者提供
现在,我将展示这些模型在生成的数据上的表现。但是,我会添加另一个算法,以查看这些算法是否会超越这个通常不适合稀疏数据的算法。
代码示例
在本节中,我们将测试多个机器学习模型在稀疏数据集上的表现,这是一种包含大量空值或零值的数据集。
我们将计算数据集的稀疏性,并使用 F1 分数评估模型。
然后,我们将创建一个包含每个模型 F1 分数的数据框,以比较它们的表现。此外,我们将过滤掉在评估过程中可能出现的任何警告。
import numpy as np
from scipy.sparse import random
import numpy as np
from scipy.sparse import random
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.exceptions import ConvergenceWarning
import warnings
# Generate a sparse dataset
X = random(1000, 20, density=0.1, format="csr", random_state=42)
y = np.random.randint(2, size=1000)
# Calculate the sparsity of the dataset
sparsity = 1.0 - X.nnz / float(X.shape[0] * X.shape[1])
print("Sparsity:", sparsity)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Train and evaluate multiple classifiers
classifiers = [
SVC(kernel="linear"),
LogisticRegression(),
KMeans(
n_clusters=2,
init="k-means++",
max_iter=100,
random_state=42,
algorithm="full",
),
KNeighborsClassifier(n_neighbors=5),
MLPClassifier(
hidden_layer_sizes=(100, 50),
max_iter=1000,
alpha=0.01,
solver="sgd",
verbose=0,
random_state=21,
tol=0.000000001,
),
DecisionTreeClassifier(),
RandomForestClassifier(),
]
# Create an empty DataFrame with column names
df = pd.DataFrame(columns=["Classifier", "F1 Score"])
# Filter out the specific warning
warnings.filterwarnings(
"ignore", category=ConvergenceWarning
) # Filter warning that mlp classifier will possibly print out.
for clf in classifiers:
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
f1 = f1_score(y_test, y_pred)
df = pd.concat(
[
df,
pd.DataFrame(
{"Classifier": [type(clf).__name__], "F1 Score": [f1]}
),
],
ignore_index=True,
)
df = df.sort_values(by="F1 Score", ascending=True)
df
这里是输出结果。
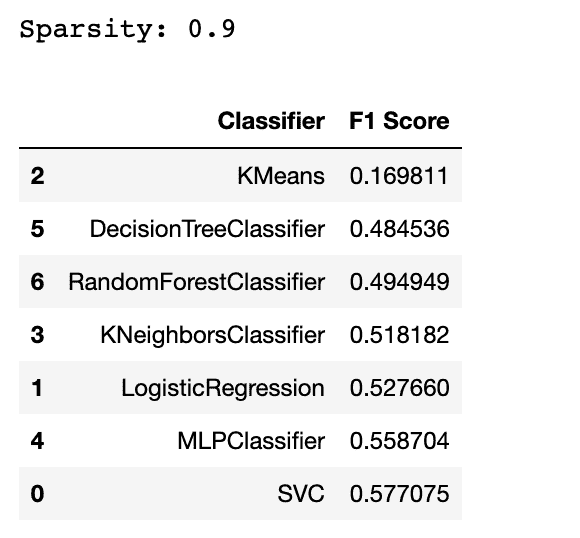
到目前为止,你可能会发现一个不适合稀疏数据的算法。没错,答案是 KMeans。但为什么呢?
KMeans 通常不适合稀疏数据,因为它基于距离度量,这在高维稀疏数据中可能会出现问题。
也有一些算法我们甚至不能尝试。例如,如果你试图将 GaussianNB 分类器包含在这个列表中,你会遇到错误。它提示 GaussianNB 分类器期望的是密集数据而不是稀疏数据。这是因为 GaussianNB 分类器假设输入数据遵循高斯分布,因此不适合稀疏数据。
结论
总结来说,处理稀疏数据可能会面临各种问题,比如过拟合、丢失有效数据、内存和时间问题。
然而,有几种方法可以处理稀疏特征,包括移除特征、使用 PCA 和特征哈希。
此外,某些机器学习模型如 SVM、Logistic Regression、Lasso、Decision Tree、Random Forest、MLP 和 k-最近邻适合处理稀疏数据。
这些模型已被设计为高效处理高维和稀疏数据,使它们成为处理稀疏数据问题的最佳选择。使用这些方法和模型可以提高模型的准确性,节省时间和资源。
Nate Rosidi 是一位数据科学家和产品战略专家。他还担任分析学兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。可以通过 Twitter: StrataScratch 或 LinkedIn 与他联系。
了解更多
最佳机器学习 YouTube 视频(10 分钟以内)
原文:
www.kdnuggets.com/2020/06/best-machine-learning-youtube-videos-under-10-minutes.html
评论
机器学习教育内容通常以学术论文或博客文章的形式呈现。这些资源非常宝贵。然而,它们有时可能篇幅较长,耗时较多。如果你只是想学习基本概念,而不需要所有背后的数学和理论,简洁的机器学习视频可能是更好的选择。此列表中的 YouTube 视频涵盖了诸如机器学习是什么、自然语言处理基础、计算机视觉的工作原理以及视频游戏中的机器学习等概念。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
1. 机器学习是什么? | 机器学习基础
上传日期: 2018 年 9 月 19 日
频道: Simplilearn
Simplilearn 的视频清晰简明地解释了许多机器学习的基本概念。在视频中,Simplilearn 解释了监督学习、无监督学习和强化学习之间的区别。此外,他们简要介绍了 K 近邻算法。视频使用了良好的视觉效果、图表和简单的示例。最后,视频包含了一个快速的测验和对一些最有趣的机器学习应用的简短概述。
2. 自然语言处理(NLP)基础
上传日期: 2018 年 6 月 6 日
频道: SparkCognition
AI 解决方案提供商 SparkCognition 在这段不到五分钟的视频中解释了 NLP 的基础知识。他们能够在如此短的时间内传递如此多的信息令人赞叹。

NLP – 停用词
该视频使用了出色的视觉效果和动画,以帮助创建清晰简明的解释。它简要地涉及了结构化数据与非结构化数据、停用词以及 NLP 如何改善搜索引擎。最后,SparkCognition 解释了企业如何利用 NLP 分析数据,提升运营效率和安全性。
3. 计算机视觉的工作原理
上传日期: 2018 年 4 月 19 日
频道: Google Cloud Platform
计算机视觉是机器学习领域最大的研究领域之一。Google 的这个视频提供了对计算机视觉工作原理的深入但简洁的解释。在视频中,他们解释了计算机如何看待图像以及机器学习模型如何被训练以识别物体。
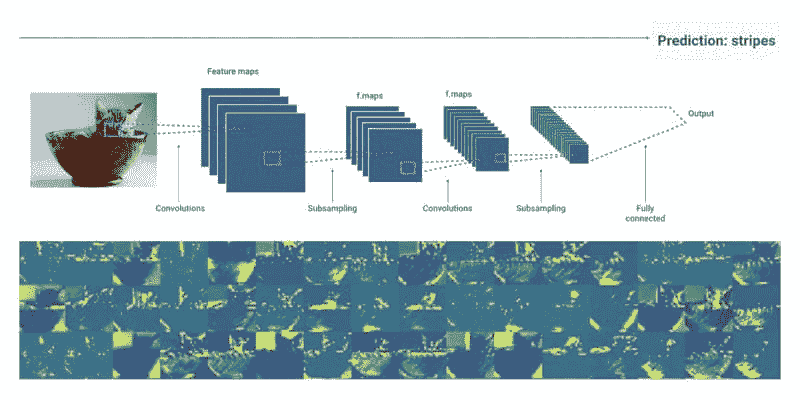
CNNs
此外,视频简要解释了卷积神经网络(CNN)以及它们如何使用labeled training data进行预测和提高准确性。最后,视频还提到 CNNs 擅长理解空间特征,但在处理时间特征时存在困难。视频时长刚过七分钟,Google 成功地用出色的视觉辅助展示了大量信息。
4. 多智能体捉迷藏
上传日期: 2019 年 9 月 17 日
频道: OpenAI
来自 OpenAI 的这个实验非常有趣,展示了多智能体竞争如何导致智能行为。
在这个视频中,OpenAI 解释了他们如何用简单规则和初步工具构建一个虚拟的捉迷藏世界。在这个世界里,他们放置了多个角色,分为躲藏者和寻找者。在经过数百万轮游戏后,代理开始通过强化学习学会利用工具来获得优势。他们开始合作,找到创造性的方法来赢得比赛。最终,他们甚至学会了利用编程中的漏洞来作弊取得胜利。有关实验的更多评论视频可以在Two Minute Papers频道找到。
5. MarI/O – 游戏中的机器学习
上传日期: 2015 年 6 月 13 日
频道: SethBling
在这个视频中,Twitch 主播和计算机程序员 SethBling 介绍了 MarI/O,这是一款他开发的 AI 程序,学会了如何玩《超级马里奥世界》。
Seth 展示了程序的游戏技能,并解释了神经网络的基础知识和 MarI/O 的 24 小时进化学习系统。他讲解了神经网络如何被训练以玩游戏,神经网络看到什么,以及它如何学习做出决策并随着时间的推移进化。
每个视频不到 10 分钟,非常适合在通勤或午休时观看,同时增强你对机器学习基础知识的了解。观看以上视频后,你应该能更好地理解机器学习是什么、自然语言处理和计算机视觉的基础知识,以及游戏中的机器学习。
想了解更多关于机器学习的文章吗?请查看20 Best YouTube Channels for AI and Machine Learning以及下面的相关资源。
个人简介:Limarc Ambalina 是一位驻东京的作家,专注于 AI、科技和流行文化。他曾为包括 Hacker Noon、Japan Today 和 Towards Data Science 在内的多个出版物撰稿。
原文。经许可转载。
相关:
-
5 篇关于面部识别的机器学习论文
-
10 篇必读的机器学习文章(2020 年 3 月)
-
5 篇关于情感分析的必读论文
更多相关内容
2019 年欧洲最佳数据科学与分析硕士课程
原文:
www.kdnuggets.com/2019/04/best-masters-data-science-analytics-europe.html/2
荷兰
-
代尔夫特理工大学计算机科学硕士学位 - 数据科学与技术方向在本课程的数据科学与技术方向中,你将学习如何工程化和开发能够处理和解释海量数据集的系统,以提取重要信息。将解决数据分析的基本和实际问题,包括数据和软件的安全性、信息可视化、数据驱动的决策和高性能计算算法等。 (24 个月课程,欧盟:$4,567,非欧盟:$32,574 全额学费,计算机科学排名:75)
-
JADS 联合硕士数据科学与创业为期两年的硕士课程在数据科学和创业领域真正实现了跨学科的商业、技术和分析的结合。它综合了埃因霍温理工大学和蒂尔堡大学的独特优势:埃因霍温的技术专长与蒂尔堡的商业、法律和社会见解。 (24 个月课程,欧盟:$4,860,非欧盟:$35,540 全额学费)
-
莱顿大学统计科学硕士学位: 数据科学这一专业方向使你更好地理解统计模型,特别是与数据科学相关的模型,包括它们在广泛的实证研究中的应用和解释。凭借这些知识,你将能够批判性地研究科学研究并开发新的模型和技术。本课程将讨论的数据挖掘、机器学习、网络、模式识别和深度学习。数据科学:计算机科学选项可用,点击此处了解更多信息。 (24 个月课程,欧盟:$4,589,非欧盟:$41,111 全额学费,计算机科学排名:275)
-
拉德布德大学计算机科学硕士:数据科学在本课程中,你将学习如何利用计算机将数据转化为知识,并将这些知识转化为解决方案。 (24 个月课程,欧盟:$4,589,非欧盟:$25,769 全额学费,计算机科学排名:325)
-
阿姆斯特丹大学信息系统硕士:数据科学方向。在这个为期一年的项目中,你将掌握数据科学所用的理论和工具。我们将教你如何在不同领域(如医疗保健、媒体与通信、智能城市、生命科学和数字人文学科)使用这些工具处理数据。(12 个月项目,欧盟:$4,589,$16,433 全部学费,计算机科学排名:75)
-
新 阿姆斯特丹大学商业数据科学硕士。你对数据科学和商业感兴趣吗?你是否拥有分析思维和智力好奇心?如果是,这个硕士课程适合你。(12 个月项目,欧盟:$4,589,$16,433 全部学费,计算机科学排名:75)
-
蒂尔堡大学数据科学商业与治理硕士课程,重点关注数据分析和数据挖掘领域的知识和专业技能,同时涵盖大数据的经济、管理和法律视角。满足政府组织、公司和学术界对具有分析技能的员工日益增长的需求。(12 个月项目,欧盟:$2,339,非欧盟:$16,287 全部学费,计算机科学排名:575)
-
蒂尔堡大学商业分析与运营研究硕士课程,教授通用的数据科学和优化方法,使你能够在各种应用中解决决策问题。(12 个月项目,欧盟:$2,339,非欧盟:$16,287 全部学费,计算机科学排名:575)
-
新 马斯特里赫特大学决策数据科学硕士。你是否喜欢为复杂问题提出优雅的解决方案?你是否觉得从大量数据中提取模式具有挑战性?那么你应该考虑攻读数据科学决策硕士。(24 个月项目,法定学费:$2,345,机构学费:$18,917 全部学费,计算机科学排名:575)
挪威
- 新 挪威生命科学大学(NMBU)数据科学硕士。在挪威生命科学大学(NMBU)的数据科学项目中,你将学习如何将信息学、数学和统计学与数据分析结合起来,以应对大数据挑战。(24 个月项目,免费学费)
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 支持
波兰
-
新 华沙经济学院的高级分析 – 大数据硕士学位。该项目的毕业生可以在制造公司、银行、保险和电信公司、公共行政及专注于高级数据分析的研究中心担任高级数据分析师。该项目还为学生进行研究和攻读第三周期学习做准备。(24 个月项目,欧盟:全学费$7,979,非欧盟:全学费$10,783)
-
新 科兹敏斯基大学的大数据分析硕士学位。科兹敏斯基大学的金融与会计硕士项目中的大数据分析专业是一个为期两年的英语授课项目,与全球公司行业专家合作进行。(24 个月项目,欧盟:全学费$2,998)
葡萄牙
- 新 Nova IMS 的数据科学与高级分析硕士学位。数据科学与分析的受欢迎程度在过去几年中稳步增长,无论是在行业还是学术界。数据科学与高级分析硕士学位(数据科学专业)旨在培养市场导向的人才,他们希望将有效的分析模型应用于不同的商业问题,解读结果及其对业务的影响,以便做出数据驱动的决策来优化业务流程。(24 个月项目,全学费$7,822,计算机科学排名:125)
俄罗斯
-
诺沃西比尔斯克国立大学的大数据分析硕士学位。数据科学中的创新项目导向培训由构思和塑造大数据世界未来的头脑和双手主导。您的文凭将只显示“理学硕士”,因为我们的“巫师”学位尚未正式确立。(24 个月项目,全学费$11,681,计算机科学排名:325)
-
ITMO 大学的机器学习与数据分析硕士课程。机器学习与数据分析硕士课程是俄罗斯为数不多的提供数据科学教育的课程之一,数据科学在信息时代变得越来越重要。学生将学习如何使用最新工具和分析方法来分析实际数据。这是学习数据收集、存储和检索、机器学习算法和数据挖掘技术、数据可视化和建模最佳实践的绝佳机会。(24 个月课程,俄罗斯学生:$3,280,非俄罗斯学生:$3,587 全部学费,CS 排名:125)
-
乌拉尔联邦大学的适应性数据分析硕士课程该课程的毕业生将有资格在适应性数据分析和大数据领域的不同产业、领域和所有权形式、机构和组织中从事职业,包括金融、信用和保险机构、市政当局和政府、学术及机构研究组织。(24 个月课程,$5,750 全部学费,CS 排名:575)
-
全新 国家研究大学的应用统计与神经网络分析硕士课程。国家研究大学 - 高等经济学院(HSE)的应用统计与网络分析硕士课程适合希望通过获得应用统计研究生学位来提升统计知识和资质的学生,无论其主要学习领域如何。(24 个月课程,$10,508 全部学费,CS 排名:225)
西班牙
-
IE 人文科学与技术学院的商业分析与大数据硕士课程的两个硕士学位是创新性的学位,旨在培养新一代数据驱动和创新导向的专业人才,具备追求成功商业分析与大数据职业生涯所需的所有技能。(10 个月课程,$39,538 全部学费)
-
巴塞罗那科技学院的大数据解决方案硕士课程 大数据与创新分析硕士课程将帮助你成为能够在任何组织中发现见解并推动创新的国际专业人士。你将学习如何从数据中提取相关见解,并利用最先进的分析和数据技术为任何类型的组织或行业生成战略解决方案。(9 个月课程,$29,095 全部学费,CS 排名:125)
-
巴塞罗那经济研究生院数据科学硕士。该项目为毕业生设计和构建数据驱动的决策系统提供了准备,提供了预测、描述和规范分析的全面培训。(9 个月项目,$20,780 全部学费)
-
巴塞罗那大学数据科学基础硕士。该项目提供了进行数据建模和分析所需的算法和数学基础,通过实践导向的课程,培养应对数据项目的专业技能。它强调理解数据科学背后算法的基础,并能够修改和创建符合数据项目需求的新特定算法。(12 个月项目,欧盟:$3,291,非欧盟:$5,683 全部学费,计算机科学排名:175)
-
全新 马德里卡洛斯三世大学大数据分析硕士。马德里卡洛斯三世大学的大数据分析硕士项目旨在对与数据分析相关责任的专业人员进行(再)培训,特别是那些涉及公司内大数据量评估的人员。(12 个月项目,欧盟:$3,291,非欧盟:$5,683 全部学费,计算机科学排名:175)
瑞典
-
斯基夫德大学数据科学硕士。该项目重点关注三个主要领域:智能数据分析、编程和决策支持。示例课程包括人工智能、数据挖掘、编程、可视分析和商业智能。(12 个月或 24 个月,欧盟:免费,非欧盟:$30,900 全部学费)
-
林雪平大学统计学与机器学习硕士。该项目专注于利用统计学的力量构建高效模型、做出可靠预测和优化决策的现代机器学习和数据库管理方法。该项目为学生提供了在劳动力市场上最受重视的独特技能。(24 个月项目,欧盟:免费,非欧盟:$23,446 全部学费)
-
全新 哥德堡大学应用数据科学硕士。数据科学关注于从大量数据中提取意义。由于大数据集的日益可用以及这些数据所带来的机会和挑战,这一领域近年来迅速发展。(24 个月项目,欧盟:免费,非欧盟:$30,537 全部学费,计算机科学排名:425)
-
新 查尔姆斯理工大学数据科学硕士。随着数字革命的到来,数据科学和人工智能(AI)已成为我们生活和社会的重要组成部分。凭借在机器学习方面的坚实基础,以及对数据科学和 AI 多样化问题的理解,你将拥有广泛的职业选择。数据科学课程由查尔姆斯理工大学提供。(24 个月课程,欧盟:免费,非欧盟:学费$30,327)
瑞士
-
洛桑联邦理工学院数据科学硕士。该项目为你提供从基础到实施的全面教育,从算法到数据库架构,从信息理论到机器学习。该硕士课程由计算机与通信科学学院、数学研究所和工程学院合作提供,为期两年,全部用英语授课。(24 个月课程,学费$2,532,计算机科学排名:24)
-
ETH 数据科学硕士。ETH 提供的专门数据科学硕士项目,与数学系以及信息技术和电气工程系合作,提供高质量的教育,培养下一代数据科学家。该课程为期两年,全部用英语授课。(24 个月课程,学费$2,320,计算机科学排名:9)
-
日内瓦大学商业分析硕士课程。该项目旨在支持学生在不确定的情况下管理、分析和使用数据,以便在战略、战术和操作决策中做出明智的选择;为学生在数字化转型中高效领导做好准备,为企业和社会创造价值;并弥合大学教育与职业需求之间的差距。(24 个月课程,学费$2,025)
-
新 苏黎世大学数据科学硕士。数据科学主要学习项目的核心包括信息学领域的选修模块以及一个硕士项目。(24 个月课程,学费$2,965,计算机科学排名:125)
-
新 卢塞恩应用科学与艺术大学的应用信息与数据科学硕士课程。该跨学科硕士课程为学生应对数字经济的技术和管理挑战做好准备。课程为所有与数据相关的职能、商业领域、公司和组织开辟了广泛的就业和发展机会。(24 个月项目,$2,965 全额学费)
土耳其
-
新 伊斯坦布尔塞希尔大学的数据科学硕士课程。伊斯坦布尔塞希尔大学的数据科学(含论文)研究生项目旨在通过培养明天的数据科学家来填补预计的数据科学技能缺口。(24 个月项目,$8,000 全额学费)
-
新 TED 大学的应用数据科学硕士课程。自 2000 年代初以来,数据科学这一概念以惊人的速度获得认可,旨在扩展统计学的应用范围,近年来已成为本世纪最需要的专业领域之一。在 TED 大学的应用数据科学项目中了解更多。(18 个月项目,$8,000 全额学费)
英国
-
帝国理工学院的商业分析硕士课程是一个为期一年的全日制课程,旨在为数据和证据驱动的决策制定未来做好准备。您将从领先的从业者和世界级的教师那里学习如何应用最新的学术思想和分析、计算工具,以帮助做出商业决策。(12 个月项目,$36,897 全额学费,计算机科学排名:15)
-
爱丁堡大学的数据科学硕士课程旨在吸引希望在工业界或公共部门建立数据科学家职业的学生,以及希望在进一步培训(如我们的数据科学 CDT)之前探索该领域的学生。(12 个月项目,欧盟:$17,992,非欧盟:$40,026 全额学费,计算机科学排名:21)
-
伦敦大学学院的数据科学硕士课程将为学生提供分析工具,以运用现代计算方法设计复杂的技术解决方案,并强调严谨的统计思维。该课程结合了从入门级别开始的核心统计和机器学习方法培训,以及涵盖统计计算和建模更多专业知识的选修课程。(12 个月项目,欧盟:$18,018,非欧盟:$37,040,计算机科学排名:37)
-
伦敦经济学院的数据科学硕士课程提供数据科学方法的培训,强调统计学视角。你将接受理论方面的全面基础培训,以及数据科学的技术和实际技能。(12 个月课程,欧盟:$36,579,非欧盟:$37,299 全额学费,计算机科学排名:125)
-
伦敦城市大学的数据科学硕士课程适合拥有数量化本科背景或能展示数量化技能的学生。学生通常处于职业生涯的早期阶段,涵盖经济学、统计学和计算机科学等多种职业。学生将对数据充满好奇,并希望学习新技术以提升职业生涯,并参与当前激动人心的行业发展。该课程包括一些复杂的编程任务,由于课程的应用性质,许多学生拥有数学或统计学背景,并享受与算法打交道。(12 个月课程,欧盟:$12,712,非欧盟:$22,816 全额学费,计算机科学排名:375)
-
南安普顿大学的数据科学硕士课程将培训学生成为熟练的数据科学家。你将获得数据挖掘、机器学习和数据可视化等领域的高级知识,包括最新的技术、编程工具包以及工业和社会应用场景。(12 个月课程,欧盟:$12,060,非欧盟:$31,943 全额学费,计算机科学排名:125)
-
伦敦大学金史密斯学院的数据科学硕士课程将提供分析未来商业、数字媒体和科学中关键大数据的技术和实际技能。(12 个月课程,欧盟:$13,220,非欧盟:$19,609 全额学费,计算机科学排名:525)
-
巴斯大学的数据科学硕士课程在此课程中,你将学习到具有普遍相关性的强大统计基础,并发展对概率机器学习技术的专业知识。你将获得在实践中应用这些知识的核心软件技术的专业技能,解决小型和大型数据集的挑战。(12 个月课程,欧盟:$12,386,非欧盟:$28,683 全额学费,计算机科学排名:375)
-
伦敦国王学院的数据科学硕士课程。该课程是一个跨学科的学习项目,将为您提供在数据收集、整理、策划和分析方面的高级技术和实践技能。它还考察数据科学家的职业、法律和伦理责任。这是一个理想的学习路径,适合有定量学科背景的毕业生或具备相关工作经验的人。(12 个月课程,欧盟:$12,907,非欧盟:$33,246 全部学费,计算机科学排名:75)
-
格拉斯哥大学的数据科学硕士课程。该数据科学硕士课程为您提供了对大型数据集分析和使用的全面基础,并结合开发项目的经验,为您在大数据和 IT 行业中担任负责职位做好准备。除了学习反映前沿技术和国际认可学术人员专长的一系列课程外,您还将进行一个重要的编程团队项目,并培养自己在数据科学项目中的能力。(12 个月课程,欧盟:$10,430,非欧盟:$27,405 全部学费,计算机科学排名:125)
-
东伦敦大学的数据科学硕士课程。该数据科学硕士课程旨在为希望在数据中心、主要是定量领域的广泛专业学科和就业领域中建立专业知识和就业机会的学生提供机会。因此,跨学科方法是课程实施的核心。(12 个月课程,欧盟:$11,186,非欧盟:$17,288 全部学费)
-
卡迪夫大学的数据科学与分析硕士课程。该课程旨在提供处理、收集、存储和分析大量复杂数据集所需的全面技能。您将由数学学院和计算机科学与信息学学院的专家授课,这将使您从不同的角度了解该主题,并可接触到两个学院的广泛模块。(12 个月课程,欧盟:$12,190,非欧盟:$28,227 全部学费,计算机科学排名:275)
-
兰卡斯特大学数据科学硕士。该课程在多学科学习方面具有独特的专注。有效的数据科学需要从多个学科中汲取技能,因此我们的课程由计算机与通信学院、数学与统计系以及兰卡斯特大学管理学院联合提供。(12 个月课程,欧盟:$12,190,非欧盟:$26,727 全部学费,计算机科学排名:175)
-
全新 埃塞克斯大学大数据与文本分析硕士。埃塞克斯大学的大数据与文本分析课程帮助你获得大规模处理文本数据的实际知识,以将这些数据转化为有意义的信息,并有机会参与来自实际行业需求的项目,这些需求由我们的工业合作伙伴提出。(12 个月课程,欧盟:$11,786,非欧盟:$22,894 全部学费,计算机科学排名:375)
-
全新 南威尔士大学数据科学硕士。在南威尔士大学的数据科学课程中,你将学习如何应用高级分析技能和知识来解决一系列现实世界的问题。(12 个月课程,$17,470 全部学费,计算机科学排名:375)
-
全新 利兹贝克特大学数据科学硕士。数据和信息被认为是当今社会经济、商业和文化生活的核心。利兹贝克特大学的数据科学课程将为你提供先进的信息和分析技能,以在数字知识经济中取得成功。(12 个月课程,$17,470 全部学费)
-
全新 布鲁内尔大学伦敦数据科学与分析硕士。布鲁内尔大学伦敦的数据科学与分析课程与 SAS(市场领先的商业分析软件和服务提供商,也是商业智能市场最大的独立供应商)联合举办。(12 个月课程,欧盟:$13,220,非欧盟:$24,407 全部学费)
乌克兰
- 全新 乌克兰天主教大学计算机科学硕士,数据科学方向。计算机科学硕士数据科学方向课程由乌克兰天主教大学提供。(18 个月课程,$6,300 全部学费)
当然,如果你认为我们遗漏了应该添加到此列表中的课程,请在下方评论告知我们。你可以在 此链接 上找到关于其他欧洲国家和其他项目的更多详细信息。
资源:
相关内容:
更多相关内容
2019 年最佳数据科学与分析硕士课程 – 在线
原文:
www.kdnuggets.com/2019/04/best-masters-data-science-analytics-online.html
评论
数据科学与分析是一个非常热门的领域,对数据科学家的需求仍在强劲增长。许多大学参与其中,并创建了许多该领域的学位,主要是硕士学位。
回到 2017 年,我们进行了一系列关于这些学位的最佳文章,涵盖了美国、欧洲和在线课程。幸运的是,我们现在更新了这些全面的列表,并添加了更多的硕士课程。第一个这些列表已经发布 - 2019 年最佳数据科学与分析硕士 - 欧洲。在这篇文章中,我们将专注于在线硕士课程。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
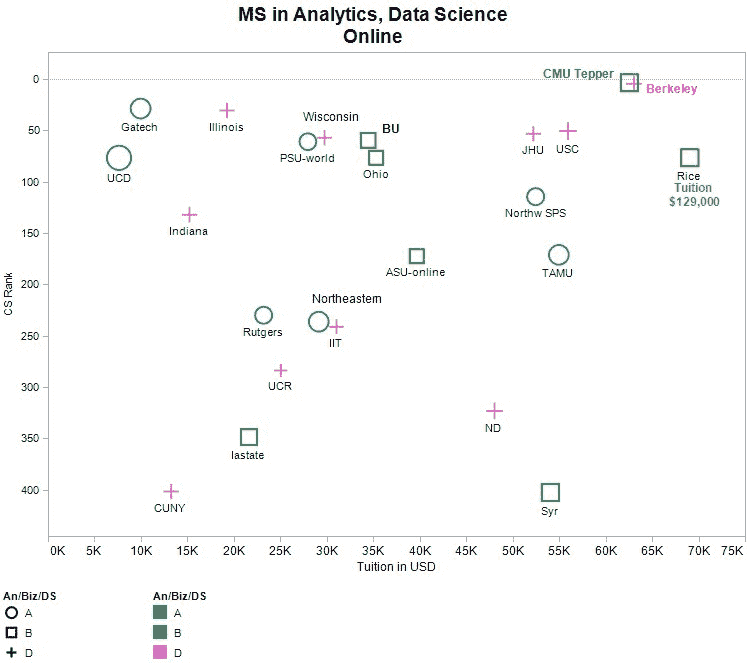
CS 排名是顶级大学的计算机与信息系统研究生项目排名前 1-50。它们提供前 50 所学校的单独 CS 排名,然后是下一组 450 所学校的范围(51-100、101-150 等)。为了区分排名相同范围的学校,我们在范围的起始位置添加了 Top Universities 排名除以 10 的值。当然,这个排名在计算上并不是 100% 科学的,但它确实给出了提供这些课程的学校的一个很好的概念。
我们包括了 2017 年版本的信息,以便你了解这些学校在过去几年中的变化。像往常一样,如果我们遗漏了任何内容,请在评论区告诉我们,我们将相应地更新表格。
| CS 排名(2017) | 大学,学位 | 描述 | 学期学分 | 学费(2017) |
|---|---|---|---|---|
| 3 (3) | CMU Tepper 商业分析硕士 | MSBA 旨在帮助拥有技术背景的个人深化分析技能,并晋升到高级商业分析师职位。 | 24 | $67575 ($62500) |
| 4 (4) | 加州大学伯克利分校 信息与数据科学硕士 | 在线提供的信息与数据科学硕士(MIDS)课程为数据科学专业人士培养成为该领域的领导者。通过融合跨学科课程、经验丰富的教师、成功的同行网络和在线学习的灵活性,认证的 datascience@berkeley 项目将加州大学伯克利带到你所在的任何地方。 | 2027 学分 | $66150 ($62991) |
| 24 (28) | 乔治亚理工学院 分析硕士 | 分析硕士是一个跨学科的学位项目,结合了乔治亚理工学院在统计学、运筹学、计算机科学和商业领域的优势,通过结合世界级的谢勒商学院、计算学院和工程学院的专业知识,毕业生将学会以独特和跨学科的方式整合技能,从而深入了解分析问题。 | 2436 学分 | $9900 ($9900) |
| 31 (30) | 伊利诺伊大学香槟分校 数据科学计算机科学硕士 | 这个完全在线的专业硕士学位使学习者获得了伊利诺伊大学教员的知识,他们在数据科学领域做出了开创性的研究。MCS-DS 毕业生将特别适合进入今天行业中薪资高、需求大的职业轨道。 | 17.532 学分 | $19200 ($19200) |
| 44 (50) | 南加州大学 计算机科学硕士(数据科学) | 计算机科学硕士(数据科学)课程为学生提供计算机科学的核心背景,以及在获取、存储、访问、分析和可视化大型、异构和实时数据方面的算法、统计和系统专业知识,这些数据涉及包括能源、环境、健康、媒体、医学和交通在内的多种现实世界领域。 | 2432 学分 | $55886 ($55886) |
| 75 (56.5) | 威斯康星大学 数据科学硕士 | 在数据科学竞争激烈的领域,硕士学位是顶级公司高级职位的要求。在线 UW 数据科学硕士课程是忙碌成人的明智选择,适合那些希望提升职业生涯或开始全新职业,但没有时间参加校园课程的人。 | 17.512 课程 | $30600 ($29700) |
| 75 (59.1) | 波士顿大学大都会学院 应用商业分析硕士 | 计算机信息系统硕士(MS)项目旨在为希望将信息系统的技术能力与管理和组织问题知识结合的学生提供设计。 | 18-2440 学分,兼职学费 | $34400 ($34400) |
| 125 (52.7) | 约翰斯·霍普金斯大学 数据科学硕士 | 严谨的课程聚焦于计算机科学、统计学和应用数学的基础,同时融入实际案例。学生可以选择在线学习或在约翰斯·霍普金斯应用物理实验室的先进设施中实地学习,从实践工程师和数据科学家那里获得知识。毕业生准备好在涉及数据管道和存储、统计分析以及从数据中提取故事的专业职位中取得成功。 | 17.510 门课程 | $53740 ($52170) |
| 125 (60.3) | 宾夕法尼亚州立大学 数据分析职业硕士 | 在全面的基础课程中,教学重点放在大数据和数据库设计过程中。你可以学习数据管理技术和用于描述性、规范性和预测性分析的数据分析技术,以在各种学科中利用竞争优势。 | 17.530 学分 | $29250 ($27900) |
| 125 (113.8) | 西北大学 SPS 数据科学硕士 | 数据科学与商业战略的结合创造了对能够做出数据驱动决策的专业人才的需求,从而推动组织前进。你可以在西北大学的在线数据科学硕士项目中建立在当今数据驱动的世界中所需的基本分析和领导技能。 | 1812 门课程 | $53148 ($52410) |
| 125 (229.3) | 罗格斯大学 分析与数据科学硕士 | 商业与科学硕士学位的分析专业为学生的数据驱动决策做准备。它将计算机科学、统计学、机器学习、数据挖掘和大数据领域结合起来。学生将获得多种技能,包括分析大型数据集的能力、开发支持决策的建模解决方案的能力以及深入理解数据分析如何推动商业决策。 | 18-24 | $23136 ($23136) |
| 125 (NEW) | 都柏林大学 数据分析硕士及专业文凭 | 该课程将帮助你分析和理解通过自由获取的在线信息的大量数据集。这是一项极其宝贵的技能,受到雇主的强烈需求。 | 3690 学分 | \(7575 (\)) |
| 175 (170.5) | 德克萨斯农工大学 分析学硕士 | 统计学系提供的兼职分析学硕士课程提供来自排名靠前的梅斯商学院的课程,面向具有强大定量技能的在职专业人士,例如拥有科学、数学、商业和工程学位的本科生。 | 24 | $65000 ($54904) |
| 175 (171.9) | 亚利桑那州立大学 商业分析硕士 | 亚利桑那州立大学的 W.P. Carey 商业分析硕士(MS-BA)学位为你发展成长的职业领域提供了所需的工具,同时给予你按自己的时间表学习的灵活性。 | 1633 学分 | $39622 ($39622) |
| 175 (235.6) | 诺斯伊斯特大学 分析学专业硕士 | 分析学硕士项目帮助满足雇主的需求,通过核心课程和整合的实践学习机会,为学生提供端到端的分析教育。该项目使学生深入理解数据处理的机制(即数据的收集、建模和结构化),并具备识别和传达数据驱动洞察的能力,这些洞察最终会影响决策。 | 2445 学分小时 | $34200 ($29070) |
| 175 (NEW) | 俄亥俄大学 商业分析硕士 | 这个在线商业分析硕士课程超越了传统工具和方法。它传授你深入挖掘组织数据并用以做出关键商业决策所需的高级分析技能。 | 16-20 | \(35250 (\)) |
| 175 (NEW) | 莱斯大学 商业分析硕士 | 在莱斯商学院,你将建立有效开展业务所需的基础——然后学习如何跨团队思考和工作,以最大化组织内每个部门的产出。 | 24 | \(129000 (\)) |
| 225 (131.4) | 印第安纳大学布卢明顿 数据科学硕士 | 提供广泛的课程,涵盖数据挖掘、云计算、健康与医学、网络安全、高性能计算、机器学习和人工智能等主题,你可以根据自己的兴趣定制课程。 | 18 | $15172 ($15172) |
| 275 (322.6) | 圣母大学 数据科学硕士 | 该项目以方便的在线格式提供卓越的学术教育,优化了复杂定量材料的学习。它包含由圣母大学教职工授课的小班实时课程,面对面的专属沉浸周以及圣母大学所知名的个人关注学生成功。 | 21 | $48000 ($48000) |
| 325 (240.5) | 伊利诺伊理工学院 数据科学硕士 | 在伊利诺伊理工学院的数据科学硕士项目中,你将学习如何使用高级数学、统计学和计算机科学来探索数据。特别是,你将学习如何分析数据、可视化结果,并清晰地表达发现。完成该项目后,你将能够思考需要解决的实际问题,而不仅仅是寻找技术解决方案。 | 16 | $30985 ($30985) |
| 325 (402) | 锡拉丘兹大学 商业分析硕士 | BusinessAnalytics@Syracuse 是锡拉丘兹大学马丁·J·惠特曼管理学院提供的在线商业分析硕士项目。该项目帮助以数据为驱动的思考者发展或提升解读复杂数据的能力,并指导其组织做出更明智、更具操作性的决策。 | 2436 学分 | $54000 ($54000) |
| 375 (NEW) | 利物浦大学 大数据分析硕士 | 利物浦大学在线大数据分析硕士课程旨在提供使你能够利用大数据和分析的潜力来转变业务决策和规划的技能。 | 24-3390 学分 | \(变化 (\)) |
| 425 (283.3) | 加州大学河滨分校 数据科学硕士 | 在线工程硕士(数据科学专业)项目可以教你如何从大量数据中提炼出有价值的见解。课程设计旨在使毕业生能够开发高效的技术,以识别、分析和可视化数据组中的隐藏模式,从而提取关键信息。 | 13 | $24990 ($24990) |
| 425 (348.1) | 爱荷华州立大学 商业分析硕士 | 商业分析硕士是一个跨学科的研究生项目,旨在帮助在职专业人士应对“大数据”环境中的数据分析和商业智能挑战。该项目的开发旨在满足当今企业和组织面临的激烈全球竞争和不断的技术干扰的需求。 | 2130 学分,混合在线-校园 | $24000 ($21570) |
| 525 (1020.1) | 俄勒冈州立大学 数据分析硕士 | 该 45 学分的硕士学位项目具有跨学科课程,提供统计学、计算机科学和数学的扎实基础知识。你还可以选择健康分析的研究生选项。 | 17.545 学分 | $23445 ($23445) |
| 575 (1036.1) | 密苏里大学 数据与分析硕士 | 密苏里大学的数据与分析硕士学位是一个 34 学分的在线交付跨学科项目。我们欢迎来自各种学术背景的学生,成为密苏里及区域性相关行业中的高效数据科学家。我们的项目通过在多个学科中提供独特的课程重点,反映了数据科学不断发展的领域。 | 2434 学分 | $34000 ($34000) |
| 1000 (401.1) | CUNY SPS 数据科学硕士 | 数据科学硕士(以前为数据分析硕士)在线学位项目帮助学生获得进入或在快速增长的数据科学领域中晋升所需的证书和技能。 | 17.530 学分 | $13200 ($13200) |
| 1000 (1023.5) | 美国大学 商业分析硕士 | Kogod 商学院的分析硕士(MSAn)项目培养学生成为数据分析方面的专家。学生将学习如何利用数据解决各种组织和业务挑战,涉及财政绩效和运营效果。 | 1533 学分 | $54186 ($54186) |
| 1000 (1026.1) | 俄克拉荷马大学 数据科学与分析硕士 | 俄克拉荷马大学提供的在线数据科学与分析硕士学位由计算机科学学院和工业与系统工程学院合作开发。 | 1433 学分 | $26103 ($26103) |
| 1000 (1046.1) | 科罗拉多大学 商业分析硕士 | 商业分析教你使用数学模型来增强职场决策能力。这让你理解更常见的建模程序类型——大数据预测建模、数据分析、预测、运营管理及其他高级定量方法,从而学会基于数据做出决策。 | 2430 学分 | $39450 ($39450) |
| 1000 (1056.1) | 奥克拉荷马州立大学 商业分析硕士 | 提供在多平台环境中进行数据分析的实际应用,包括深入接触 SAS(r)工具以及使用 Python、R、SQL、Tableau 等其他工具和编程语言的培训。此外,该项目非常重视软技能和商业洞察力的发展。 | 2433 学分在线,37 学分校园 | $奥克拉荷马州居民: 13365, 非奥克拉荷马州居民: 33990 ($14175) |
| 1000 (n/a) | 贝克学院 商业智能 MBA | 我们的商业智能 MBA 项目旨在为希望了解更多信息资源的经理设计。你将能够上由经验丰富的商业经理和 IT 专业人士主讲的课程,帮助你全面了解商业世界。 | 17.538 学分小时 | $17100 ($17100) |
| 1000 (n/a) | 贝伊帕斯大学 应用数据科学硕士 | 贝伊帕斯的应用数据科学项目引导学生学习统计主题,从最大似然、假设检验和调查抽样,到重采样方法、时间序列分析和贝叶斯分析,再到各种回归方法,最终深入探讨支持向量机、树基方法、神经网络、图模型、EM 算法和集成学习等机器学习方法。 | 12-2436 学分 | $29340 ($29340) |
| 1000 (n/a) | 贝尔维尤大学 商业分析硕士 | 贝尔维尤大学的商业分析硕士课程旨在满足对能够利用前沿专业知识将大数据转化为战略资产的领导者的需求。 | 17.536 学分小时 | $20700 ($20340) |
| 1000 (n/a) | 布兰查德斯顿科技学院 应用数据科学与分析硕士 | 该项目与行业合作伙伴共同设计。我们硕士课程的毕业生将具备在数据科学和大数据分析为关键组成部分的行业中就业的能力,如保险、零售、制药、生物技术、商业、旅行、电信、政府和情报等部门。 | 24 兼职 | $2320 ($2320) |
| 1000 (n/a) | 卡佩拉大学 分析硕士 | 卡佩拉的分析硕士课程培养数据分析专业人员处理、理解和转化数据,以开发解决实际问题的方案,同时有效地向组织提供洞察和沟通结果。 | 1248 学分 | $25020-33360 ($32400) |
| 1000 (n/a) | 中央康涅狄格大学 数据挖掘硕士 | 数据挖掘硕士课程使学生能够在大型数据集中过滤出有趣且有用的模式和趋势。课程提供最先进的数据建模方法,帮助学生为信息时代的职业做好准备。 | 17.533 学分 | $21681 ($21681) |
| 1000 (n/a) | 科罗拉多技术大学 计算机科学硕士 - 数据科学 | CTU 的计算机科学硕士 - 数据科学方向专注于从结构化或非结构化数据中提取洞察和知识的方法、流程和系统。在 MSCS 课程的核心基础上,方向课程旨在为有意从事数据科学领域的人提供基础和专注的知识。 | 2448 学分,6 学期 | $28080 ($28080) |
| 1000 (n/a) | 德保罗大学 预测分析硕士 | 预测分析硕士课程应对了数据科学家日益增长的需求,这些科学家需要具备技术和分析技能的完美结合,以应对大数据分析的挑战。课程强调技术能力和实际经验,并为学生提供高级数据挖掘、多变量统计、机器学习和数据库处理技能。 | 17.552 学分小时 | $43160 ($43160) |
| 1000 (n/a) | 数据科学技术学院 信息系统与大数据工程人工智能硕士 | 这个为期 9 个月的高级硕士课程(3 个月的课程,6 个月的实习),秋季和春季有两个入学机会,旨在为你打开大数据工程职位的大门,结合数学与计算机科学的卓越,这是所有行业都在寻找的。 | 9 | $7900 ($4640) |
| 1000 (n/a) | 数据科学技术学院 应用数据科学与大数据硕士 | 这个为期 6 个月的课程和 6 个月实习的应用硕士课程,秋季和春季有两个入学机会,旨在为你打开大数据分析职位的大门,这是所有行业都在寻找的。 | 6 | $7900 ($7680) |
| 1000 (n/a) | 达科他州立大学 分析学硕士 | 通过该项目,你将获得并磨练成为分析和数据科学专业人士所需的技能。 | 1030 学分 | $13320 ($13320) |
| 1000 (n/a) | 埃尔姆赫斯特学院 数据科学硕士 | 埃尔姆赫斯特的数据科学硕士项目采取全面的方法,课程整合了统计学、计算机科学和商业,这些技能领域对在新兴的大数据领域取得成功至关重要。 | 2410 课程,30 学分兼职 | $25350 ($25350) |
| 1000 (n/a) | 全帆大学 商业分析硕士 | 全帆大学的商业智能理学硕士项目教你如何收集和分析大数据,以更好地服务于客户需求。通过技术作为解读的视角,你将创建视觉表现,传达对任何行业至关重要的信息。 | 1236 学分 | $28008 ($28008) |
| 1000 (n/a) | 拉萨尔大学 分析学硕士 | 我们的压缩课程格式允许你一次专注于一个主题领域,同时在不到两年的时间内完成课程。每门课程长度为八周,允许你每学期完成两门课程。我们的学期有秋季、春季和夏季。该项目的学生将发展定义和协调大数据源、模拟预测模型和可视化结果的策略。学生将与来自不同行业的内部和外部数据源进行工作。 | 2030 学分 | $26250 ($26250) |
| 1000 (n/a) | 路易斯大学在线 数据科学硕士 | 路易斯大学的数据科学硕士在线学位旨在提供提升的数学和计算机科学技能,以应对围绕大数据分析的问题。路易斯大学的数据科学硕士在线项目为你提供数据挖掘、数据可视化、预测分析和数据管理的技能。 | 2433 学分 | $26235 ($26235) |
| 1000 (n/a) | 圣路易斯大学 商业数据分析硕士 | 该项目旨在帮助学生获得可立即应用于工作场所的实用知识,由一支活跃的专业人士团队授课,使用当前商业新闻驱动的真实案例。MSBDA 为当前从业者和职业转换者提供了获得研究生级别资格证书的机会,授予高质量的在线学位。 | 17.530 学期学时 | $22950 ($22950) |
| 1000 (n/a) | 凤凰大学 信息系统硕士与研究生商业分析证书 | 通过我们的信息系统硕士与研究生商业分析证书(MIS/BA),你将发展所需的统计分析、数据关系管理和分析编程技能,帮助企业做出基于证据的决策。 | 17.542 credits | $29316 ($31080) |
| 1000 (n/a) | 雷吉斯大学 数据科学硕士 | 受我们的耶稣会传统启发,雷吉斯大学的数据科学硕士项目为你准备了一个需求旺盛的数据分析职业,帮助你从数据中提取见解,并以社会负责的方式沟通这些见解如何影响你工作的企业和你周围的世界。 | 17.536 credits | $25560 ($25560) |
| 1000 (n/a) | 圣玛丽学院 数据科学硕士 | 我们主要的在线项目将为你提供所需的数学和计算深度,以精炼别人仅仅使用的工具。你将建立一个坚实的数学基础——在不断变化的世界中一种持久的技能——使你能够应对现在和未来的复杂数据挑战,无论你使用什么编程语言。 | 2436 credits | $31946 ($28944) |
| 1000 (n/a) | 南达科他州立大学 数据科学硕士 | SDSU 的数据科学硕士项目是一个 30 学分的项目,设计为在一个日历年内完成,从 6 月到 5 月,尽管学生可以根据需要多花一年时间完成。为了方便起见,暑期课程提供在线学习,学生可以在夏季在线开始项目,并在随后的学年在校园内完成。 | 1230 credits | $13320 ($13320) |
| 1000 (n/a) | 圣约瑟夫大学 商业智能与分析硕士 | 圣约瑟夫大学的在线商业智能与分析硕士(MSBIA)——这是首批完全在线提供的商业智能与分析硕士学位之一——由商业智能和分析行业中心的专家设计和提供。你可以从三个职业发展方向中选择:通用方向、数据分析或编程语言。 | 2430 credits | $17520 ($17520) |
| 1000 (n/a) | 南卫理公会大学 数据科学硕士 | DataScience@SMU 是一个为当前和未来的数据科学专业人士设计的在线数据科学硕士课程。通过互动课程、协作小组活动和在线面对面课堂,你将获得做出有意义的数据驱动决策所需的技术、分析和沟通技能。 | 20-28 | $57084 ($57084) |
| 1000 (n/a) | 南新罕布什尔大学 数据分析硕士 | 我们的数据分析硕士在线课程专注于数据分析在广泛行业中的战略和高级应用。课程涵盖数据挖掘、可视化、建模、优化及数据的伦理使用。 | 1512 学分 | $22572 ($22572) |
| 1000 (n/a) | 滑铁卢大学 数据分析硕士 | SRU 的数据分析硕士学位为 33 学分,可以在全日制 10 个月或兼职 2 年内完成。该项目的一个特别显著特点是其与专业证书项目标准的对齐验证。 | 1033 学分 | $16269 ($16269) |
| 1000 (n/a) | 阿拉巴马大学亨茨维尔 管理科学-商业分析硕士 | MSMS-BA 课程旨在满足课程质量、教师卓越和项目相关性的最高标准,符合商学院的 AACSB 国际认证标准 - 高等商学院协会。 | 1230 学分 | $21810 ($21810) |
| 1000 (n/a) | 马里兰大学大学学院 数据分析硕士 | 马里兰大学大学学院的数据分析硕士课程结合了技术和商业学科的学习,使你成为一名具有强大职业潜力的数据分析师。你将学习如何管理和操控数据、创建数据可视化,并做出战略性的基于数据的推荐以影响业务成果。 | 17.536 学分 | $24984 ($24984) |
| 1000 (n/a) | 维拉诺瓦大学 分析硕士 | 与其他结合现有学位课程的项目不同,我们的分析课程专门设计以满足当前商业需求。课程涉及数据管理、商业智能、预测和处方模型及其在所有业务职能中的应用,我们的项目可以为你在分析领域的成功做好准备。 | 24 | $43400 ($43400) |
| 1000 (n/a) | 西弗吉尼亚大学 商业数据分析硕士 | 西弗吉尼亚大学商学院提供的在线商业数据分析硕士课程,帮助学生在统计技术、数据挖掘、数据库利用及分析工具方面获得专业知识。“大数据”正在推动企业和非营利组织的决策,并创造对数据分析技能的需求。 | 17.530 学分 | $30690 ($29790) |
| 1000 (NEW) | 莫拉维安研究生在线 预测分析硕士 | 莫拉维安研究生在线的预测分析硕士课程通过提供个性化的学生支持、由实际行业指导的课程以及一对一的职业指导,帮助学生成功提升职业发展。 | - | 未说明 |
| 1000 (NEW) | 北中部大学 数据科学硕士 | 这个数据科学硕士课程旨在帮助学生深入理解这一新兴的跨学科领域。学生将获得包括数据生命周期在内的广泛知识基础,并学习如何将大量非结构化数据处理成组织可以利用的可用数据集。 | 23 | $30530 |
| 1000 (NEW) | 爱丁堡纳皮尔大学 数据科学硕士课程 | 数据科学是商业和公共部门的一个主要增长领域,且目前缺乏具备所需数据科学知识和技能的专业人士。该以工作为基础的硕士数据科学课程旨在解决这一短缺问题。 | 24-33 180 学分 | $9060 |
| 1000 (NEW) | 德雷克塞尔大学 数据科学硕士 | 在当今就业市场中最快速增长的领域之一脱颖而出,德雷克塞尔大学的在线数据科学硕士学位课程将帮助你通过创建机器学习算法来分析和处理数据,从而解决公司问题。 | 2445 学分 | $56925 |
| 1000 (NEW) | 梅里马克学院 数据科学硕士 | 在课堂上学习可以实际应用于工作的技能。梅里马克学院的在线数据科学硕士学位课程教授学生使用最新工具和分析方法解决问题。 | 1632 学分 | $28320 |
| 1000(新) | 梅里马克学院 商业分析硕士 | 通过在工作中立即使用的适用技能来利用你的时间。梅里马克学院的在线商业分析硕士学位课程教学生解决问题和可视化数据集,使用最新的行业工具和分析方法。 | 1632 学分 | $28320 |
| 1000(新) | 特拉华大学 应用统计硕士 | 特拉华大学的在线应用统计硕士课程(ASTAT)将学生培养成数据专业人士,能够满足对统计学专业知识日益增长的需求。我们的学生从受尊敬的大学获得高质量、负担得起且相关的教育,并准备好在数据科学、大数据、商业分析和相关职业中取得成功。 | NA 根据要求提供 | NA - 根据要求提供 |
| 1000(新) | 瓦尔纳自由大学 数据科学硕士 | 瓦尔纳自由大学“切尔诺里泽茨·赫拉巴尔”提供的数据科学硕士课程专注于计算机科学的前沿问题,符合国际、欧洲和国家标准与要求。我们的目标是培养更多数据科学领域的专业人才,以满足软件公司的需求。 | 12 | $5391 |
| 1000(新) | 约翰逊与威尔斯大学 数据分析硕士 | 事实是:今天的企业依赖数据。通过这个硕士课程为自己在数据分析领域的成功职业做好准备。你将通过这个在线数据分析硕士学位获得数据挖掘、分析、管理和可视化、预测、建模、优化和仿真的专业知识。 | 2432 学分 | $23744 |
| 1000(新) | 肯特州立大学 数字科学(数据科学)硕士 | 数字科学硕士(MDS)学位是为来自各种背景的毕业生设立的职业硕士项目。入学不要求有数字科学学士学位,学生可以在秋季或春季学期入学。 | 1232 学分 | $21524 |
资源:
相关:
了解更多相关内容
美国/加拿大最佳分析学、商业分析、数据科学硕士课程
原文:
www.kdnuggets.com/2019/05/best-masters-data-science-analytics-us-canada.html
 评论
评论
数据科学和分析是一个非常热门的领域,对数据科学家的需求仍在强劲增长。许多大学介入并创建了许多相关学位,主要是硕士学位。
这是更新后的分析学、数据科学硕士课程条目:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
回到 2017 年,我们曾经发布了一系列文章,探讨了美国、欧洲和在线的最佳学位。幸运的是,我们现在已经更新了这份全面的名单,并添加了许多新的硕士课程。
我们已经发布了我们权威的在线硕士指南以及欧洲的指南,这篇文章将重点介绍美国和加拿大的项目。
包含了 CS 排名,这是前 50 名大学的计算机与信息系统研究生课程排名。虽然这个排名在计算方式上并非 100%科学,但它确实提供了关于提供这些课程的学校的良好参考。未出现在排名中的大学被标记为 NA。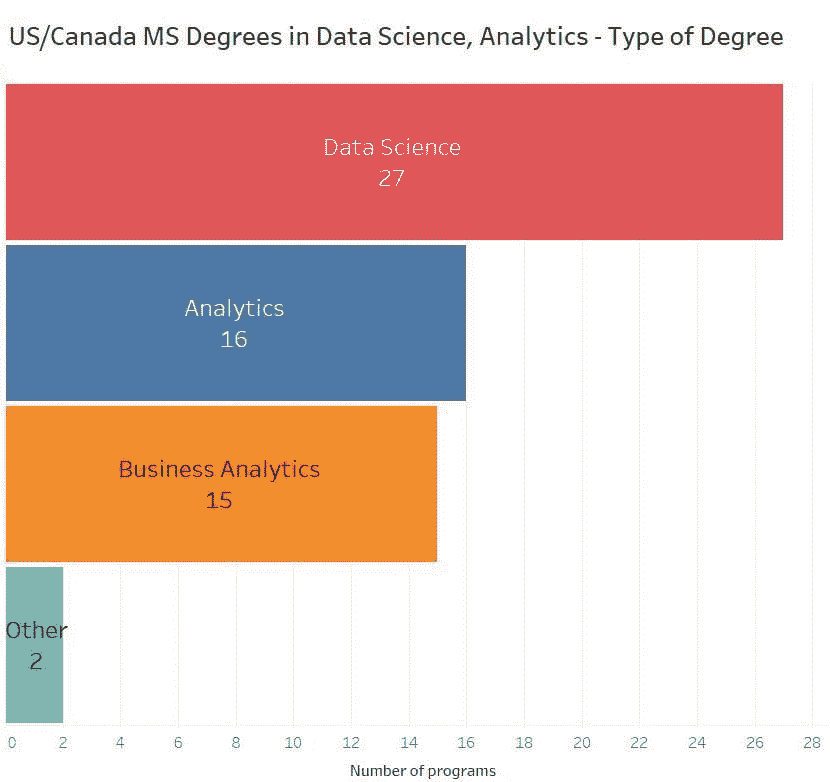
我们包含了 2017 年版本的信息,以便您了解这些学校在过去几年中的变化。和往常一样,请在评论区告诉我们如果我们遗漏了任何内容,我们会相应地更新列表。
-
麻省理工学院商业分析硕士学位。该项目专为计划从事数据科学行业的在读学生或近期大学毕业生量身定制,也适合寻求职业发展或转行的人员,特别是工程师、数学家、物理学家、计算机程序员及其他高科技专业人士。(12 个月课程,整个课程学费 77,350 美元(2017 年学费为 57,350 美元),计算机科学排名:1(2017 年计算机科学排名:1))
-
斯坦福大学统计学硕士:数据科学数据科学方向通过硕士核心课程和编程要求,培养扎实的数学、统计、计算和编程技能,同时通过数据科学及相关领域课程的通用和专门选修课程提供基础的数据科学教育。(24 个月课程,每年 32,658 美元(32,658 美元/年),计算机科学排名:2(2))
-
卡内基梅隆大学计算数据科学硕士该项目使你掌握开发下一代大规模信息系统部署中涉及的技术层面以及分析这些系统生成的数据所需的技能和知识。(16 个月课程,整个课程 76,500 美元(75,484 美元),计算机科学排名:3(3))
-
哈佛大学数据科学硕士学位该项目将提供在统计建模、机器学习、优化、大规模数据集管理与分析以及数据获取方面的扎实准备。该项目还将关注可重复的数据分析、协作问题解决、可视化和沟通,以及数据科学中的安全和伦理问题。(18 个月课程,全程学费 44,816 美元(44,816 美元),计算机科学排名:7(6))
-
多伦多大学应用计算硕士(数据科学方向)由计算机科学系和统计科学系共同提供,教授计算机科学与统计学交汇处的数据科学。(16 个月课程,公民学费 26,000 美元(11,320 美元),国际学生学费 56,000 美元(27,590 美元),每年,计算机科学排名:11(10))
-
华盛顿大学数据科学硕士学位该硕士项目为你提供从大型、嘈杂且异质的数据集中提取知识的技术技能——大数据——以提供可供人们和组织使用的见解。在此项目中,你将深入掌握管理、建模和可视化大数据的技能,以满足今天工业、政府、非营利和研究组织日益增长的需求。(17.5 个月课程,46,575 美元(46,125 美元)全程学费,计算机科学排名:17(16))
-
哥伦比亚大学的数据科学硕士该项目允许学生将数据科学技术应用于他们感兴趣的领域,基于四门基础课程。我们的学生有机会进行原创研究,纳入一个顶点项目,并与行业合作伙伴和教职工互动。(18 个月课程,全额学费$58,080($58,080),计算机科学排名:18(29))
-
纽约大学的数据科学硕士这是一个高度选择性的项目,面向具有数学、计算机科学和应用统计学强大背景的学生。该学位专注于开发新的数据科学方法。课程提供两种结构化研究生项目的方式,让学生有机会通过不同方向追求专业化。(24 个月课程,全额学费$62,028($62,028),计算机科学排名:20(32))
-
滑铁卢大学的数学硕士(统计学或计算机科学)这两个学位不同,但都提供数据科学专业化。在这些项目中,你将学习应用和开发方法,以从可用数据中获得洞察,理解、预测和改进商业战略、产品和服务、市场营销活动、医学、公共卫生与安全以及其他众多领域。(18 至 24 个月课程,加拿大居民$11,466($11,466),国际学生$30,666($30,666),全额学费,计算机科学排名:22(31))
-
乔治亚理工学院的分析学硕士这是一个跨学科的学位项目,结合了乔治亚理工学院在统计学、运筹学、计算机科学和商业领域的优势,通过结合 Scheller 商学院、计算机学院和工程学院的世界级专业知识,毕业生将学会以独特和跨学科的方式整合技能,从而深入洞察分析问题。(24 个月课程,提供在线选项,本州居民$43,416($43,416),外州学生$59,940($59,940),在线课程$9,900($9,900),计算机科学排名:24(28))
-
不列颠哥伦比亚大学的数据科学硕士是一个由 UBC 计算机科学系和统计系共同开发的专业课程,旨在满足这一需求,为学生提供快速通道进入优秀职业。通过使用描述性和规范性技术,学生从非结构化和结构化的数据中提取和分析数据,然后以帮助组织基于数据做出明智决策的方式传达这些分析结果。(10 个月课程,$31,836($24,033)本州居民;$43,709($32,675)国际学生,计算机科学排名:28(23))
-
德克萨斯大学奥斯汀分校的商业分析硕士学位 这是一个 10 个月的项目,将教会你如何利用大量数据并将其用于构建更好的商业模式。(10 个月的项目,州内 $43,000($43,000),州外 $48,000($48,000)全项目,CS 排名:29(26))
-
宾夕法尼亚大学的数据科学工程硕士学位 数据科学学位课程可以在一到两年内完成。它结合了机器学习、大数据分析和统计学等核心主题的前沿课程,以及各种选修课程,并提供在选择的领域专长 – 深度领域 – 应用这些技术的机会。(12 或 24 个月的项目,全学费 $67,660($67,660),CS 排名:34(39))
-
南加州大学的计算机科学硕士学位(数据科学) 该项目为学生提供计算机科学的核心背景,并在获取、存储、访问、分析和可视化大规模、多样化和实时数据方面提供算法、统计和系统方面的专门知识。这些数据与包括能源、环境、健康、媒体、医学和交通等各种现实世界领域相关。该项目既提供现场课程也提供在线课程。(24 个月的项目,州内 $55,886($55,886),州外 $63,634($63,634),在线 $61,984($61,984)全学费,CS 排名:44(50))
-
加州大学圣地亚哥分校的数据科学与工程高级研究硕士学位 在这个项目中,工程专业人员将软件程序员、数据库管理员和统计学家的技能结合起来,创建数据的数学模型,识别趋势/偏差,然后以有效的可视化方式展示,使他人能够理解。(24 个月的项目,全学费 $39,121($39,100),CS 排名:46(38))
-
马里兰大学学院公园分校的商业分析硕士学位 该项目深入探讨了大数据的理解及其对商业的优势利用。作为华盛顿特区地区最好的项目之一,MSBA 涵盖了网络安全、信息系统、供应链和交通、社交媒体和网络分析、预测以及定量分析等主题。(16 个月的项目 $49,892($49,042)州内,$62,762($62,422)州外全学费,CS 排名:50(47))
-
新 密歇根大学的商业分析硕士学位 商业分析硕士课程培训学生利用数据和统计信息制定商业策略。(12 个月的项目,州内 $21,241,州外 $48,579 全学费,CS 排名:50)
-
威斯康星大学麦迪逊分校的统计学-数据科学硕士。利用统计思维的力量将帮助你将数据放入上下文中,并将其含义传达给他人。你将通过现实的战略规划会议来提升分析、推理和沟通技巧。因此,MS-DS 将使你在与专业人士和商业领袖的团队合作中,具备坚实的技能,并能够领导基于数据推理的讨论。(12 个月或 24 个月项目,州内学费 $23,820 ($23,820),州外学费 $48,810 ($48,810),计算机科学排名:75(75))
-
波士顿大学城市学院的应用商业分析硕士。该项目全面覆盖了在数据驱动的商业决策过程中使用的最先进的概念、技术和工具。无论是在线学习、校园学习还是两者结合,学生将获得使用各种分析模型和决策支持工具的实践经验,并将其应用于营销、运营、产品和技术创新、金融服务等领域的大数据集和互联数据输入。(18 个月或 24 个月项目,每学期 $25,490 ($25,490),计算机科学排名:75(75))
-
印第安纳大学布鲁明顿分校的数据科学硕士。通过广泛的课程选择,如数据挖掘、云计算、健康与医学、网络安全、高性能计算、机器学习和人工智能,你可以根据兴趣定制课程。(18 个月项目,现场学习:州外 $43,717 ($43,717),州内 $15,172 ($15,172);在线学习:州外 $21,457 ($21,457),州内 $13,470 ($13,470),计算机科学排名:75(125))
-
新 芝加哥大学的分析学硕士。该硕士课程基于应用统计学的核心,为学生提供高级分析培训,以发展从大数据中提取洞见和构建自动化人工智能系统的能力。(12 个月项目,全学费 $4,640,计算机科学排名:75)
-
约翰斯·霍普金斯大学的数据科学硕士。严格的课程重点关注计算机科学、统计学和应用数学的基础,同时结合现实世界的例子。通过在线和在约翰斯·霍普金斯应用物理实验室的现代设施现场学习,学生从实践中的工程师和数据科学家那里学习。毕业生准备好在涉及数据管道和存储、统计分析以及提取数据故事的专业工作中取得成功。(17.5 个月项目,全学费$52,170,CS 排名:125(75))
-
马萨诸塞大学安姆赫斯特分校的计算机科学硕士(数据科学方向)。该项目旨在满足对数据科学领域扩展和增强培训的需求。它要求完成数据科学理论、数据科学系统、数据分析和统计课程。它教你开发和应用方法来收集、整理和分析大规模数据,并利用这些分析进行发现和决策。(24 个月项目,州内学费$25,000,州外学费$46,400,CS 排名:125(75))
-
西北大学的分析硕士。该项目教授学生在当今竞争激烈、数据驱动的世界中推动商业成功的技能。借助著名教授和来自主要公司的讲师的专业知识,我们将数学和统计学研究与先进的信息技术和数据管理教学相结合。(15 个月项目,每季度$18,040(全学费$52,239),CS 排名:125(125))
-
西蒙弗雷泽大学的大数据专业硕士。学生将很好地准备成为数据科学家/程序员、数据解决方案架构师和首席数据官,能够提供影响战略决策的见解。该项目具有挑战性,适合在计算机科学或定量领域(如工程或物理)有强大能力的学生。(16 个月项目,居民学费$27,592,国际学费$32,898,CS 排名:125(125))
-
北卡罗来纳州立大学的分析硕士。如果你擅长数学和统计编程,并且对数据工作充满热情,那么这个项目适合你。MSA 独特地设计了,使像你这样的个人能够从大量和多样的数据中提取并有效沟通可操作的见解。(10 个月项目,州内学费$23,460,州外学费$43,466,CS 排名:125(125))
-
弗吉尼亚大学的数据科学硕士 我们严格的职业硕士项目通过将课堂学习与在行业、学术界和政府合作伙伴处进行的实际项目相结合,为学生准备好领导数据科学前沿领域。 (11 个月项目,$25,534($25,534)州内,$40,626($40,626)州外,CS 排名:175(175))
-
德克萨斯 A&M 大学的分析硕士 这是一个兼职硕士学位,提供来自排名靠前的梅斯商学院的课程,面向具有强大定量技能的在职专业人士,例如理科、数学、商业和工程领域的学士学位持有者。提供在线和现场选项。 (24 个月项目,$65,000($54,904)学费全额,CS 排名:175(175))
-
亚利桑那州立大学的商业分析硕士 该项目为你进入动态扩展的数据驱动分析和战略业务决策领域做好准备。你将获得帮助公司利用数据获取竞争优势所需的技能。ASU 还提供在线项目,你可以在这里找到更多信息。 (9 个月项目,$10,970($10,970)州内,$21,888($21,888)州外,$23,508($23,508)国际学费全额,CS 排名:175(175))
-
女王大学的管理分析硕士 在这个项目中,你将从北美一些最优秀的管理教育者那里学习。此外,还会有几次课程包括行业专家和从业者。这确保了你能够从当前在行业中工作的人的角度了解最新趋势和实践。 (16 个月项目,$63,500($44,600)居民,$80,000($67,750)国际,学费全额,CS 排名:175(175))
-
新 伊利诺伊大学芝加哥分校(UIC)的商业分析硕士。商业分析硕士提供了一个全面的方法,学生在数据管理、机器学习和预测分析方面发展专业知识,同时建立坚实的商业技能背景。学生获得分析大型数据集并通过数据可视化、统计建模和数据挖掘技术生成洞察的技能。该项目课程强调行业经验、曝光度和跨多个分析项目的合作。 (12 个月项目,$5,830 州内,$11,950 州外,CS 排名:175)
-
全新 密歇根州立大学的商业分析硕士。如今的数据比以往任何时候都多,分析已成为每个重大商业决策的一部分。通过密歇根州立大学的商业分析硕士课程,你可以成为这一新兴转型和领先新行业的重要组成部分。(12 个月项目,本州生全学费$36,000,外州生全学费$39,000,CS 排名:175)
-
明尼苏达大学的数据科学硕士。该项目通过汇集数据收集和管理、数据分析、可扩展的数据驱动模式发现及其基本概念,提供了大数据及其分析的坚实基础。(18 或 24 个月项目,本州生每学期$8,364($8,364),外州生每学期$12,942($12,942),CS 排名:225(125))
-
罗格斯大学的分析与数据科学硕士课程。该项目为学生的数据驱动决策制定做好准备。它将计算机科学、统计学、机器学习、数据挖掘和大数据等领域结合在一起。学生将获得多种技能,包括分析大数据集的能力、开发建模解决方案以支持决策的能力以及深入理解数据分析如何推动商业决策。提供在线选项。(24 个月项目,$23,136($23,136)本州生,$28,128($28,128)外州生全学费,CS 排名:225(225))
-
东北大学的专业分析硕士。该项目帮助满足雇主的需求,提供一个全面的分析教育,包括核心课程和综合实践学习机会。该项目为学生提供了对数据工作机制的深刻理解,以及识别和传达数据驱动洞察的能力,最终影响决策。提供在线选项。(24 个月项目,全学费$34,200($29,070),CS 排名:225(225))
-
伊利诺伊理工学院的数据科学硕士。在这个项目中,你将学习使用高级数学、统计学和计算机科学探索数据。你将学习如何分析数据、可视化结果并表达发现。你将带着解决实际问题的能力而非仅仅找到技术解决方案的能力离开该项目。提供在线选项。(16 个月项目,全学费$30,985($30,985),CS 排名:225(225))
-
新 加州大学戴维斯分校商业分析硕士。在为期一年的课程中,你将受益于我们与位于旧金山和硅谷的前沿大数据公司深厚的联系。(12 个月课程,全额学费$57,200,计算机科学排名:225)
-
爱荷华州立大学商业分析硕士。该项目是一个跨学科的研究生课程,面向在“海量数据”环境中处理数据分析和商业智能的在职专业人士。它旨在满足今天面临激烈全球竞争和不断技术变革的企业和组织的需求。在线提供。(21 个月课程,全额学费$24,000($21,570),计算机科学排名:325(325))
-
新 乔治梅森大学数据分析硕士。该证书课程旨在帮助有兴趣解决如何将商业分析、网络防御/取证、能源、金融、基因组学、医疗保健、情报、执法或运输等应用中产生的大量数据转化为有意义的信息的学生。该项目面向那些可能在大数据应用领域发展的研究生。(12 个月课程,本州学生全额学费$15,826,外州学生全额学费$37,333,计算机科学排名:325)
-
新 中佛罗里达大学数据分析硕士(大数据)。数据分析硕士是一个 30 学分的跨学科项目,旨在培养学生开发算法和计算机系统,以促进从大量数据中发现信息。它将利用大数据分析的技术方面,包括算法设计、编程、获取、管理、挖掘、分析和解释数据。(12 个月课程,全额学费$36,300,计算机科学排名:375)
-
新 乔治城大学公共政策数据科学硕士。该课程独特地结合了数据科学与定量公共政策分析,为毕业生提供前沿的计算、分析和领导能力。(12 个月课程,全额学费$54,570,计算机科学排名:425)
-
美国大学商业分析硕士学位。该项目旨在培养学生成为数据分析专家。学生将学习如何利用数据解决与财政绩效和运营效益相关的各种组织和商业挑战。在线提供。(15 个月课程,全额学费$54,186($54,186),计算机科学排名:NA(325))
-
圣玛丽大学的计算与数据分析硕士。MSc CDA 课程的主要重点是培养高素质的计算和数据分析专业人士,以推动创新和组织成功。MSc CDA 通过实践学习机会和行业互动,帮助学生为数据科学行业中的有利可图的职业做好准备。(16 个月课程,$19,000($17,000)本地生,$35,000($33,000)国际生全额学费,CS 排名:NA)
-
俄克拉荷马大学的数据科学与分析硕士。该课程的毕业生将具备设计和构建工具以提取、吸收和分析数据的技能,以及预测和提升企业在各个领域未来表现的系统理解。课程由计算机科学学院和工业与系统工程学院合作提供。(14 个月课程,$32,500($26,103)全额学费,CS 排名:NA)
-
科罗拉多大学丹佛分校的商业分析硕士。商业分析教你使用数学模型来增强工作场所的决策能力。这使你理解更常见的建模程序——大数据预测建模、数据分析、预测、运营管理及其他高级定量方法——从而基于数据做出决策。提供在线和晚间课程选项。(24 个月课程,$39,450($39,450)全额学费,CS 排名:NA)
-
贝尔维尤大学的商业分析硕士。该课程旨在满足对能通过前沿专业知识将大数据转化为战略资产的领导者的需求。提供在线课程。(24 个月课程,$20,700($20,340)全额学费,CS 排名:NA)
-
德保罗大学的预测分析硕士。该课程应对了对数据科学家的需求,要求具备技术和分析技能,以应对大数据分析的挑战。课程强调技术熟练度和实践经验,提供数据挖掘、多变量统计、机器学习和数据库处理方面的高级技能。(17.5 个月课程,$43,160($43,160)全额学费,CS 排名:NA)
-
雷吉斯大学的数据科学硕士。受耶稣会传统的启发,该项目为您准备了一份有需求的职业,分析数据,从中获取见解,并以社会负责的方式沟通其对您工作的业务及周围世界的影响。 (24 个月项目,$25,560($25,560)全额学费)
-
南达科他州立大学的数据科学硕士。这是一个 30 学分的项目,设计为在一个日历年内完成,即从 6 月到 5 月,尽管学生如果愿意,可以花费超过一年完成。为了方便起见,夏季课程可以在线学习,以便学生可以在夏季在线开始项目,并在随后的学年内在校园完成。 (12 个月项目,$13,320($13,320)全额学费,计算机科学排名:NA)
-
阿拉巴马大学亨茨维尔分校的管理科学-商业分析硕士。该项目旨在满足最高的课程质量、师资优秀和项目相关性标准,符合 AACSB 国际商学院联合会的认证要求。 (12 个月项目,$21,810($21,810)全额学费,计算机科学排名:NA)
-
密歇根大学迪尔伯恩分校的数据科学硕士。课程包括必修核心课程和技术选修课程,提供在当前就业市场高度需求的各个数据科学领域建立知识和职业技能的机会。 (18 至 24 个月项目,州内$20,490($20,490)全额学费,州外$35,280($35,280)全额学费,计算机科学排名:NA)
-
旧金山大学的数据科学硕士。该项目提供技术课程以及通过为期九个月的实习项目获得的无与伦比的实践经验。学生每周两天在位于湾区及其他地区的合作公司现场工作。课程受到来自 Facebook、Eventbrite、Buzzfeed 等数据科学家顾问委员会的影响,涵盖了机器学习、数据获取、统计建模、数据库管理、数据可视化、自然语言处理和深度学习等主题。 (12 个月项目,$48,825($48,825)全额学费,计算机科学排名:NA)
-
田纳西大学查塔努加分校计算机科学-数据科学硕士课程。该硕士课程旨在培养学生在专业思维和直觉方面的技能,使学生能够做出合理的专业评估和决策。毕业生应能够在商业、政府和教育的研究、开发和规划层面承担责任,或继续进行更进一步的正式培训。(24 个月课程,本州学费$20,040,外州学费$32,236,计算机科学排名:NA)
-
全新 克拉克大学商业分析硕士课程。通过掌握商业中最受欢迎的领域,迎接大数据的潮流——加速你的职业发展。(12 个月课程,全额学费$55,770,计算机科学排名:NA)
-
全新 新罕布什尔大学分析硕士课程。大数据是个大问题,各行各业——从职业体育队(想想《点球成金》和选秀)到医疗保健(基因编码和疾病预防)——都需要分析和数据科学专家。在仅仅 12 个月内,你可以成为其中的一员。(12 个月课程,本州学费$14,170,外州学费$27,810,计算机科学排名:NA)
-
全新 托马斯·爱迪生大学数据科学与分析硕士课程。托马斯·爱迪生州立大学(TESU)与 Statistics.com 的统计教育研究所合作,提供完全在线的数据科学与分析硕士学位课程,专门针对在职成人的独特需求进行设计。(12 个月课程,本州学费$7,519,外州学费$9,967,计算机科学排名:NA)
-
全新 耶希瓦大学数据分析与可视化硕士课程。在耶希瓦大学的 30 学分数据分析与可视化硕士课程中,你将开发一个适合工作的项目组合,并加深对数据科学和可视化的核心原则、模式和实践的理解。(12 个月课程,全额学费$32,070,计算机科学排名:NA)
资源:
相关:
更多相关内容
轻松找到最匹配的数据分布
原文:
www.kdnuggets.com/2021/10/best-matching-distribution-data-effortlessly.html
评论
我们的目标是什么?

图片来源:由作者准备,使用了 Pixabay 图片(免费使用)
你有一些数据点。最好是数值型的。
你想找出这些数据可能来自哪个统计分布。经典的统计推断问题。
当然,有严格的统计方法可以实现这个目标。但是,也许你是一个忙碌的数据科学家。或者是一个更忙的程序员,他恰好被分配了这个数据集,需要迅速编写一个应用端点,以找到最匹配数据的分布。以便另一个机器学习应用可以使用基于此分布生成的一些合成数据。
简而言之,你没有很多时间,想要找到一种快速的方法来发现最匹配的数据分布。
基本上,你希望对多个分布运行一批自动化的拟合优度(GOF)测试,并快速总结结果。
当然,你可以从头开始编写代码,使用例如 Scipy 库逐一运行标准 GOF 测试,针对多个分布进行测试。
或者,你可以使用这个小巧但实用的 Python 库——distfit 来为你完成繁重的工作。
Distfit——一个用于自动拟合数据分布的 Python 库
根据他们的网站,**distfit** 是一个用于单变量分布概率密度拟合的 Python 包。它通过残差平方和(RSS)和其他 GOF 测量来确定在 89 种理论分布中最好的拟合。
让我们看看如何使用它。这是 演示笔记本。
按照常规安装,
pip install -U distfit
生成测试数据并进行拟合
生成一些正态分布的测试数据,并将它们拟合到 distfit 对象中。
基本上,你希望对多个分布运行一批自动化的拟合优度(GOF)测试,并快速总结结果
拟合效果如何?
那么,拟合效果如何?
注意,在上面的代码中,模型dist1对生成分布或其参数(即正态分布的loc或scale参数)没有任何了解,也不知道我们调用了np.random.normal来生成数据。
我们可以通过一段简单的代码一次性测试拟合优度和估计参数,
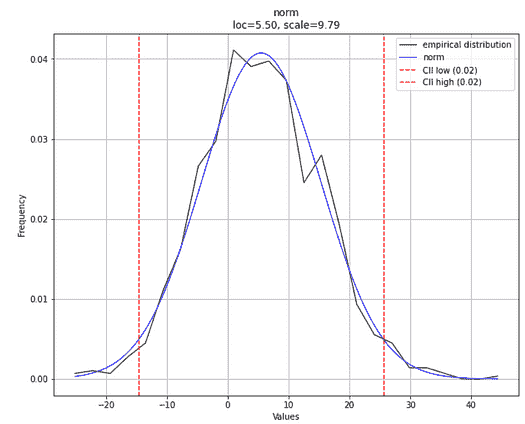
dist1.plot(verbose=1)
这是预期的图(注意,由于生成数据的随机性质,图形在你的情况下肯定会有所不同)。
注意图例副标题中拟合过程估计的**loc**和**scale**参数。这些参数值与我们之前设置的值非常接近,不是吗?估计的分布类型显示为norm,即正态分布。完全正确。
作者创建的图像
关于拟合模型的更多信息
使用另一行代码,你可以获取所有拟合到数据(内部)并测试拟合优度的分布的摘要。
dist1.summary
你会得到如下结果,
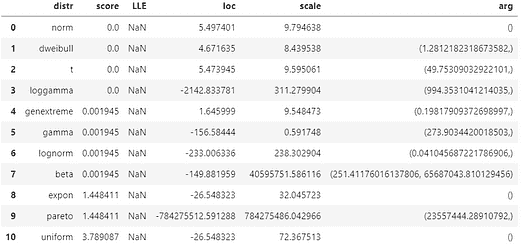
作者创建的图像
这显示了所有测试过的各种分布的参数。它还显示了**score**,表明拟合优度**——即预期数据和给定数据之间的距离,数值越低越好。请注意,在这个模型中有多个分布的得分相同且为零,但根据内部逻辑,正态分布被选择为最可信的分布。
为什么在这个摘要中只有 10 个分布?因为默认情况下,它使用最受欢迎的 10 个分布的列表进行扫描。你可以在初始化distfit对象时将确切的列表作为参数指定。
使用 Scipy 内部
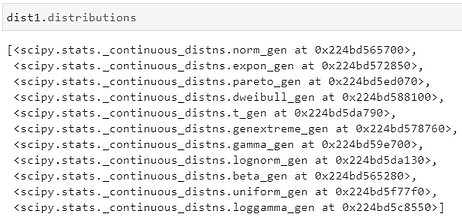
如果你输入dist1.distributions,你将看到用于拟合过程的函数列表,这些函数来自 Scipy 包。
不要仅仅停留在拟合阶段,还要生成合成数据
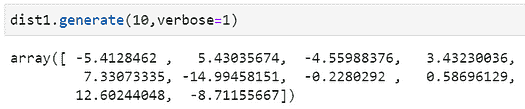
作为附加功能,distfit模型提供了一个 API,可以基于最佳拟合分布轻松生成数据。在这里,我们生成了 10 个随机变量,loc=5.5和scale=9.79(如之前拟合的)。
需要注意的事项
如果两个或多个分布的数据形状相似度很高,估计可能会出错。特别是,当样本量(训练数据)较小时。
例如,让我们从Beta 分布生成一些数据,参数选择使得它们看起来几乎像正态分布。如果我们选择α和β相等或接近相等,我们可以实现这一点。然后,如果你拟合 1000 个数据点,你可能会得到正态分布作为最佳拟合分布。

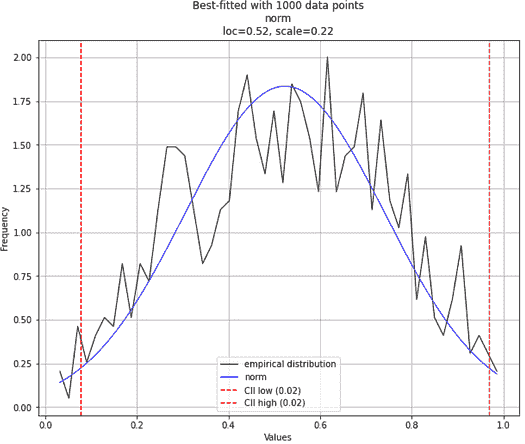
作者创建的图像
然而,如果你将样本量扩展到 10,000 个点,你很可能会得到正确的答案。
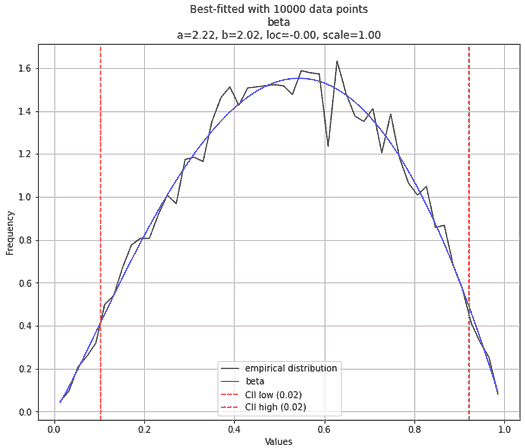
作者创建的图像
你可以做的其他事情
你可以选择使用哪种统计测试(RSS、Kolmogorov-Smirnov 等)来确定最佳拟合。
你还可以指定确切的列表来遍历分布。
你可以使用distfit.predict方法来预测响应变量的概率。
我们只展示了连续分布拟合的例子。你也可以对离散分布进行拟合。
为什么这是“高效数据科学”的一个例子?
我认为使用像distfit这样的工具包是高效数据科学的一个绝佳例子。
我在这篇文章中写了什么是高效的数据科学。本质上,它意味着以更高的速度、更稳健的方式进行相同的数据科学活动。
你可以用 Scipy 函数从头编写纯 Python 代码,循环遍历各种分布,并对你拥有的数据进行 GOF 测试。但既然已经有人为这个任务编写了一个优秀的库(配有高质量的文档),你为什么还要浪费时间呢?
这就是为什么你可以在想要将单变量数据拟合到最佳分布并一次性获取所有统计属性时考虑使用distfit。
你可以查看作者的GitHub库,以获取机器学习和数据科学的代码、创意和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或关注我在 Twitter 上。
原文。已获许可转载。
简历: Tirthajyoti Sarkar 是 Adapdix Corp 的数据科学/机器学习经理。他定期为 KDnuggets 和 TDS 等出版物撰写与数据科学和机器学习相关的各种主题。他撰写了数据科学书籍,并为开源软件做出贡献。Tirthajyoti 拥有电子工程博士学位,目前正在攻读计算数据分析硕士学位。可以通过 tirthajyoti at gmail[dot]com 联系他。
相关:
-
用 Python 创建带有异常签名的合成时间序列
-
如何在 Python 中进行“无限制”数学运算
-
用合成数据教 AI 分类时间序列模式
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关话题
更新的在线分析、商业分析、数据科学硕士学位
原文:
www.kdnuggets.com/2020/09/best-online-masters-data-science-analytics-online.html
评论
当前的疫情深刻改变了许多事情,但对 AI 和数据科学教育的需求并没有减少。变化在于在线教育的转变加速了。
现在有更多大学提供在线学位,包括 AI、数据科学和机器学习,因此我们将此目录主要限制在那些拥有顶级大学计算机科学排名的大学。特别感谢 Asel Mendis 收集了本博客中使用的大部分数据。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
我们在 2017 年和 2019 年发布了类似的名单。
这是我们 2020 年最佳在线硕士学位项目的目录,包括 AI、商业分析、数据分析、数据科学和机器学习。
CS 排名是Top Universities 计算机与信息系统研究生项目的排名。他们为前 50 所学校提供了单独的排名,然后为接下来的 450 所学校提供了范围(51-100、101-150 等)。
下图 1 展示了排名与学费的关系,适用于排名<500 的学校。排名范围内,我们取了该范围的中点。 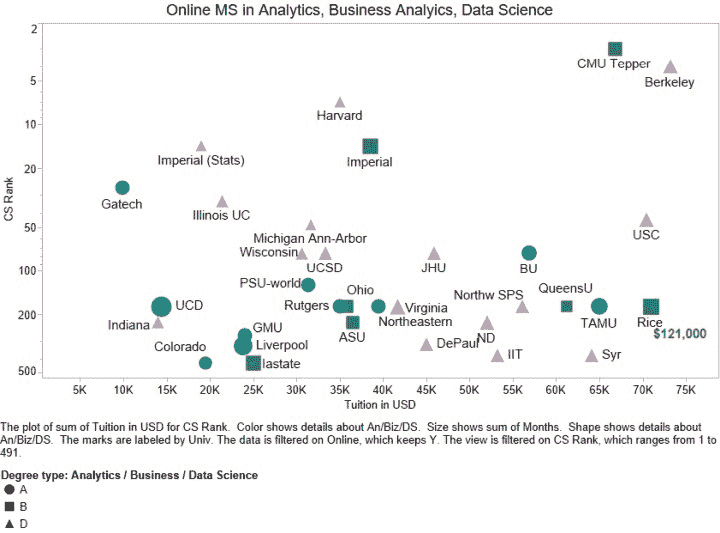
图 1:顶级在线分析、商业分析、数据科学硕士学位。
仅显示了 Top Universities 计算机科学排名<500 的学校。
形状/颜色对应学位类型:蓝色圆形代表分析,绿色方形代表商业,紫色三角形代表数据科学。形状的大小对应教育的时长。
一些观察:
-
这份名单中的几乎所有学校都来自美国,除了 DSTI(法国)、帝国学院(英国)、利物浦大学(英国)、UCD(爱尔兰)和女王大学(加拿大)。
-
尽管我们没有 2019 年的所有学费数据,但我们看到许多学校在 2020 年提高了学费。这一趋势无法持续太久。
-
我们没有看到学校排名与学费之间的明显相关性。
一些商业分析项目非常昂贵(Rice 的学费为 121,000 美元),而乔治亚理工学院仅需 9,900 美元。鉴于在线获得优质教育的便利和众多选择,许多顶级以外的学校是否能够继续收取如此高的在线教育学费仍然值得怀疑。
最受欢迎的学位名称是“数据科学”,在超过一半的情况下使用。
调查的学校中,数据分析占比为 17%,商业分析占比为 9%。
以下是学位名称的频率(去除 MS、MSc、硕士等):
-
数据科学,35
-
数据分析,11
-
商业分析,6
-
分析,2
-
分析与数据科学,2
-
人工智能,1
-
CS 和定量方法,1
-
数据科学与人工智能,1
-
管理分析,1
-
管理信息系统,1
-
硕士统计学(数据科学),1
-
信息学专业研究,1
-
战略分析,1
下表提供了 64 个顶级在线硕士项目的详细信息。
在一些情况下,当没有 CS 顶级大学排名时,
我们为整个大学提供了全球排名前列的大学排名。
表 1:顶级在线分析、商业分析、数据科学硕士学位。
| CS 排名 2020 | 大学,学位 | 描述 | 时长 | 学费(美元) |
|---|---|---|---|---|
| 3 | CMU Tepper 商业分析硕士 | MSBA 旨在为有技术背景的人士提供深入分析技能,并晋升为高级业务分析师职位。 | 18-24 个月 | 66820 |
| 4 | UC Berkeley 信息与数据科学硕士 | 在线授课的信息与数据科学硕士(MIDS)项目培养数据科学专业人士成为该领域的领军人物。通过融合跨学科课程、经验丰富的教师、成就斐然的同侪网络和灵活的在线学习,这一认证项目将 UC Berkeley 带到你身边,无论你身在何处。 | 20 | 73224 |
| 7 | 哈佛大学 数据科学硕士 | 此学位让你深入理解数据科学方法,包括预测建模、数据挖掘、机器学习、人工智能、数据可视化和大数据。 | 12 | 35000 |
| 14 | 伦敦帝国学院 商业分析硕士 | 你将学习如何应用最新的学术思维和分析及计算工具来帮助做出商业决策。尽管我们的项目建立在严格的技术和定量培训基础上,但也高度应用。选修课程和项目专注于某一行业,给予你根据个人兴趣调整课程的机会。 | 校内 12 个月,在线 22 个月 | 38500 |
| 14 | 伦敦帝国学院 数据科学硕士(MSc Statistics (Data Science)) | 课程将关注与大规模科学数据处理相关的各种工具和技术,包括机器学习理论、数据转换与表示、数据可视化以及使用分析软件。 | 12 | 19000 |
| 27 | 乔治亚理工学院 分析学硕士(MS in Analytics) | 通过乔治亚理工学院的在线分析学硕士(OMS Analytics),你可以建立并增强你的专业知识,使自己对众多公司更具价值。我们的跨学科方法为你提供了向一些最具知识的商业智能、统计学和运筹学领域的专家学习的机会,以及大数据和高性能计算领域的专家。 | 12-24 | 9900 |
| 33 | 伊利诺伊大学厄本那-香槟分校 数据科学计算机硕士(Master of Computer Science in Data Science) | 本课程通过聚焦数据科学的课程,要求完成 32 学分的研究生课程,每门课程 4 学分,共八门研究生课程。MCS-DS 包括机器学习、数据挖掘、数据可视化和云计算的必修课程。 | 12-18 | 21440 |
| 44 | 南加州大学 应用数据科学硕士(MS in Applied Data Science) | 我们的学生沉浸于数据分析的整体领域、分析师和/或数据科学家的角色,以及信息学技能可以应用于关键组织任务的领域。他们理解数据管理、数据可视化、数据挖掘和人工智能技术(特别是机器学习)对分析过程的重要性,以及这些技术如何应用于现实世界的挑战。 | 18-24 | 70471 |
| 48 | 密歇根大学 应用数据科学硕士(Master of Applied Data Science) | 应用数据科学硕士(MADS)项目将为你提供从头到尾管理数据科学的全面准备,适用于各种现实世界情境。该项目在灵活的在线格式中融合了理论、计算和应用。MADS 项目包括数据收集、处理、分析、可视化、报告和干预的学习和应用。它将使你能够学习如何用数据得出结论并做出决策,同时关注数据使用的伦理问题。 | 12 | 31688 |
| 75 | 波士顿大学 应用数据分析硕士学位 | 适合中期职业 IT 专业人士或具有计算机科学背景的学生,该项目专注于分析培训,提供坚实的数据分析知识,并在学术严谨的框架内考察最新行业工具和方法的呈现及应用。 | 16-24 | 56864 |
| 75 | 约翰斯·霍普金斯大学 数据科学硕士学位 | 严谨的课程设置专注于计算机科学、统计学和应用数学的基础,同时结合实际案例。通过在线学习和在约翰斯·霍普金斯应用物理实验室的先进设施中现场学习,学生可以向实践中的工程师和数据科学家学习。 | 12-24 | 45950 |
| 75 | 普渡大学 商业分析硕士学位 | 适合希望利用对技术和分析专业知识日益增长需求的在职专业人士。 | 12-24 | 32064 |
| 125 | 宾夕法尼亚州立大学世界校园 数据分析专业研究生硕士学位 | 该项目通过大学内三个学术部门的强大合作关系提供,给你提供了从具有多样背景的教师那里受益的机会。凭借广泛的经验,我们的教师可以教授你如何在大规模和超大规模及不同领域中使用统计学、计算机科学、机器学习和软件工程来收集、分类、分析和建模数据。 | 12-24 | 31380 |
| 175 | 诺斯伊斯特大学 信息学专业研究生硕士学位 | 本项目通过平衡的课程设置,结合信息科学知识和技术技能培训,以及对商业基础和 IT 创新战略思维的理解,帮助学生在 IT 应用和管理职位上取得成功。通过将计算技能和应用与信息战略、数据治理、伦理和商业智能的实际挑战相结合,学生在信息技术管理、系统设计与开发、信息安全、人机交互、数据分析、云计算和网络服务及企业架构等领域获得能力。 | 18 | 39500 |
| 175 | 西北大学 数据科学硕士 | 数据科学硕士项目的学生获得了在当今数据密集型世界中成功所需的关键技能。他们学习如何利用关系型和文档数据库系统及基于开源系统(如 R、Python 和 TensorFlow)构建的分析软件。他们学会了如何使用传统统计学和机器学习方法进行可靠的预测。 | 12-24 个月 | 56100 |
| 175 | 俄亥俄大学 商业分析硕士 | 这个在线商业分析硕士项目超越了传统的工具和方法。它传授了你需要的高级分析技能,以深入挖掘组织数据并利用这些数据做出关键的商业决策。 | 16-20 个月 | 35820 |
| 175 | 皇后大学 全球管理分析硕士 | 针对寻求掌握将分析应用于商业需求的全球专业人士。了解不仅如何有效使用数据,还如何构建和管理复杂项目并领导高绩效团队。 | 12 个月 | 61200 |
| 175 | 莱斯大学 商业分析硕士 | 在莱斯商学院,你将建立有效开展业务所需的基础,然后学习如何跨团队思考和工作,以最大化组织内每个部门的产出。 | 24 个月 | 121,000 |
| 175 | 罗格斯大学 分析与数据科学硕士 | 商业与科学硕士学位中的分析课程为数据驱动的决策制定做好准备。它将计算机科学、统计学、机器学习、数据挖掘和大数据领域结合在一起。学生将获得各种技能,包括分析大数据集的能力、开发建模解决方案以支持决策的能力,以及对数据分析如何驱动商业决策的透彻理解。 | 18-24 个月 | 35000 |
| 175 | 德克萨斯农工大学 分析硕士 | 分析硕士项目的使命是将工作专业人士转变为能够使用现代分析技术协作解决商业问题的领导者。 | 24 个月 | 65000 |
| 175 | 都柏林大学 数据分析硕士和专业文凭 | 本课程将帮助你分析和理解通过大量自由获取的在线信息定期创建的大数据集。这是一项极其有价值的技能,雇主对这一技能的需求很高。 | 36 个月 | 14437 |
| 175 | 弗吉尼亚大学 数据科学硕士 | 弗吉尼亚大学数据科学学院的新在线数据科学硕士(MSDS)课程扩展了我们前沿课程的可及性,超越了夏洛茨维尔。数据科学在几乎所有行业中的应用是 21 世纪最重要的任务之一。我们很高兴欢迎来自地区、国家和全球的新一届多样化学生。 | 24 | 41728 |
| 225 | 亚利桑那州立大学 商业分析硕士 | 如果你想站在大数据的前沿,在线商业分析硕士将教你如何操控、解析和分析静态数据。你将深入了解大数据和数据分析,同时学习如何利用数据为业务关键解决方案提供支持。 | 16 | 36500 |
| 225 | 印第安纳大学 数据科学硕士 | 该项目旨在为中期职业人士提供便利和灵活性。你将在一个易于访问和直观的格式中,获得你选择主题的深入专业知识。 | 12-18 | 14000 |
| 225 | 圣母大学 数据科学硕士 | 圣母大学在线数据科学硕士项目由应用与计算数学与统计系(ACMS)提供,并得到门多萨商学院、信息技术办公室和赫斯堡图书馆教职员工的参与。 | 21 | 52000 |
| 275 | 乔治·梅森大学 数据分析工程硕士 | 数据分析工程(DAEN)硕士项目是乔治·梅森大学沃尔根诺工程学院的一个跨学科项目。该项目为学生提供了广泛的数据分析算法、工具和流程的知识和经验,并专注于灵活且广泛的课程,以帮助毕业生解决各种现实世界的问题。 | 12-24 | 24000 |
| 115 全球 | 德保罗大学 数据科学硕士 | 我们的在线学习项目模拟了课堂体验,提供 100%软件、教师顾问、职业服务及广泛校友网络的访问。了解如何管理和分析复杂数据,开发数据科学模型以支持决策,并有效地向非技术观众传达分析结果。 | 12-24 | 44980 |
| 325 | 利物浦大学 人工智能硕士 | 该项目将为你提供开发、设计和评估各种用途的智能系统所需的技能。 | 30 | 23895 |
| 375 | 伊利诺伊理工学院 数据科学硕士 | 数据科学硕士项目的学生深入探讨给定问题的基本前提,学习重新构建问题,并确定结果是否合理。他们通过探索和改进现有数据的结构、创建和评估模型、构建和测试假设来实现这一目标。他们学习如何分析数据、可视化结果,同样重要的是,如何清晰地表达他们的发现。 | 12-24 | 53262 |
| 375 | 锡拉丘兹大学 应用数据科学硕士 | 应用数据科学硕士的跨学科课程专注于四个关键学习能力:数据采集和组织、技术分析、可视化和沟通以及实际应用。每个能力为学生提供了一个发展资源和演示作品集的机会,同时在一个或多个感兴趣领域中增长他们的专业知识。 | 12-24 | 64152 |
| 223 全球 | 科罗拉多州立大学全球 数据分析硕士 | 学生通过商业智能和数据分析准备成为组织领导者。作为 CSU Global 的数据分析硕士(MSDA)学生,你将提升与各种核心业务职能——会计、金融、物流、管理和战略——相关的决策技能。 | 12-18 | 19500 |
| 425 | 爱荷华州立大学 商业分析硕士 | 商业分析硕士是一个面向在职专业人士的跨学科研究生项目,解决“大数据”环境中处理数据分析和商业智能的挑战。该项目旨在满足当今企业和组织在激烈的全球竞争和不断的技术变革中的需求。 | 21 | 25000 |
| 525 | 德雷克塞尔大学 数据科学硕士 | 德雷克塞尔大学的在线数据科学硕士课程是计算机科学和信息系统的结合。通过课程,你将学习如何操作和总结数据;深入挖掘数据和文本;确定趋势;并将你的发现编织成一个能够清晰传达给组织的故事。 | 12 | 60390 |
| 525 | 加州大学河滨分校 数据科学硕士 | 在线工程硕士学位,专注于数据科学,能够教会你从大量数据中提炼有价值的见解。课程设计使毕业生能够开发高效的技术,以识别、分析和可视化数据组中的隐藏模式,提取关键信息。 | 13 | 29988 |
| 575 | 密苏里大学 数据科学与分析硕士 | MU 的在线数据科学与分析硕士学位将为你提供将大数据转化为智能数据所需的知识、工具和经验。如果你希望帮助各行各业的公司解决复杂的数据问题,这可能是适合你的学位。 | 12-18 | 37878 |
| 575 | 俄勒冈州立大学 数据分析硕士 | 在俄勒冈州立大学的在线数据分析硕士项目中,你将探索有趣且具有挑战性的真实数据问题,同时装备自己以应对大规模数据的量化工具。 | 12-18 | 25200 |
| 575 | 德州理工大学 数据科学硕士 | 我们为期一年的数据科学硕士课程已获得 STEM 认证。学生将学习如何使用先进技术、操作大数据,并利用统计方法解读数据。掌握这些技能后,学生将获得将理解转化为组织战略所需的商业技能。 | 12 | 25064 |
| 446 全球 | 布兰迪斯大学 战略分析硕士 | 布兰迪斯大学一贯被《美国新闻与世界报道》评为全国顶尖大学,拥有培养变革者的悠久历史。我们为专业人士设计的前沿、100% 在线课程,均衡关注数据的艺术与科学。通过我们的战略分析硕士项目,你将掌握将数据分析转化为有洞察力、数据驱动故事所需的技术和战略技能,以影响关键决策者。 | 12-24 | 35350 |
| 725 全球 | 沃斯特理工学院 数据科学硕士 | 我们便捷的在线格式并不是唯一的好处;我们提供量身定制的数据科学学习路径。除了教授数据科学基础的核心课程外,你还可以从各种选修课程中选择,为未来的数据科学事业做好准备。 | 12-24 | 53130 |
| 775 全球 | 俄克拉荷马州立大学 商业分析与数据科学硕士 | 一个 37 学分的 STEM 项目,通过将课堂上获得的知识应用于解决现实世界的商业问题,提供实际的数据分析经验,使用软件包括 Alteryx、Colab、PowerBI、Python、R、SAS、Tableau 等。 | 36 个月(兼职) | 11880 |
| na | 奥斯汀佩大学 计算机科学与定量方法硕士 | 与在线数据科学学位类似,奥斯汀佩大学的课程将计算机科学、数学和商业分析结合起来,以帮助制定业务和组织决策。 | 12-18 | 17000 |
| na | 贝帕斯大学 应用数据科学硕士 | 贝帕斯大学的应用数据科学项目带领学生学习从最大似然、假设检验和调查抽样,到重抽样方法、时间序列分析和贝叶斯分析,各种回归方法,以及最终详细讲解支持向量机、树基方法、神经网络、图模型、EM 算法和集成学习等机器学习方法。 | 12-24 月 | 29340 |
| na | 贝尔维尤大学 数据科学硕士 | 贝尔维尤大学的在线数据科学硕士学位旨在让你掌握策划、分析和从大型数据集中发现相关信息的能力。你将学习到解决几乎任何领域复杂问题所需的工具、方法和系统。虽然不需要数据科学或计算经验,但具有一些数学、计算和统计学背景会有所帮助。 | 12-18 | 17850 |
| na | 卡布里尼大学 数据科学硕士 | 在这个完全在线的学位项目中,学生获得了为数据导向的职业做准备的基本技能,如商业智能分析师、数据挖掘分析师、IT 项目经理和数据库管理员。 | 24 个月 | 25380 |
| na | 科罗拉多技术大学 计算机科学硕士 - 数据科学 | 计算机科学硕士(MSCS)学位课程包括核心课程,旨在提供计算机科学最重要学科如计算机算法、操作系统、数据库、安全和网络,以及软件工程的相关和高级教学。 | 12-24 | 29280 |
| na | CUNY 职业研究学院 数据科学硕士 | 该项目的学习目标和严格的实践课程围绕雇主需求设计。在项目期间,学生使用流行的编程语言如R和Python构建越来越复杂的项目组合,反映当前 IT 工作场所的经验和需求。学生构建预测和规范性模型,进行演示练习,并在便捷的在线环境中审阅彼此的工作,确保他们具备当今市场上最受重视的专业知识。 |
12-18 | 16635 |
| na | 达文波特大学 数据分析硕士 | 该课程为已经熟悉数据分析和新入门者提供了数据挖掘、数据可视化、沟通和预测分析的技能。你还将掌握现代数据仓库和云计算等备受追捧的技能,并精通行业标准软件,如SQL、R Programming、IBM SPSS Statistics、IBM SPSS Modeler、Tableau、RStudio等。 |
12-18 | 26460 |
| na | 丹佛大学 数据科学硕士 | 在线数据科学硕士课程包括 15 门课程,为学生提供编程、数据挖掘、机器学习、数据库管理和数据可视化等关键能力的知识和技能。 | 18-24 | 64080 |
| na | 数据科学技术学院 (DSTI) 应用数据科学与 AI 硕士 | 该课程将使你深入理解人工智能技术的主要科学基础,专注于建模而非数据科学 API 和框架的调查。该应用硕士课程在应用数学及其实现方面具有“深度优先”的特点,由“法国数学学派”的教授主讲。 | 12 | 8700 欧元 |
| na | 数据科学技术学院 (DSTI) 应用数据分析硕士 | 该课程将通过数据分析增强决策能力,从而提升你的商业技能和职业机会。在此应用硕士课程中,你将掌握进行分析所需的技术和工具,并提供相关且结构化的报告,提高公司项目的投资回报率。 | 12 | 5700 欧元 |
| na | 数据科学技术学院 (DSTI) 人工智能数据工程应用硕士 | 该课程将让你深入了解大数据与 IT 方面的知识,以及数据科学。课程将提供追求成功职业生涯所需的基础,包括计算机科学和数学理解,以及实际项目。 | 12 | 8700 euro |
| na | 埃尔姆赫斯特学院 数据科学硕士 | 我们采取全面的方法,将分析和机器学习与业务整合。这个创新课程赋予你在统计学、分析方法和编程工具方面的技术能力,同时提升你重要的业务技能。结果是:一个全面的知识基础,让你能够掌握那些让他人困惑的信息,在任何专业环境中创造真实的业务价值。 | 24 | 26550 |
| na | 刘易斯大学 数据科学硕士 | 在线数据科学硕士课程为你提供数据挖掘、数据可视化、预测分析和数据管理的技能。刘易斯大学的在线数据科学硕士学位旨在为你提供更高的数学和计算机科学技能,以应对大数据分析中遇到的问题。 | 12-18 | 31590 |
| na | 马里兰大学全球校区 数据分析硕士 | 马里兰大学全球校区的数据分析硕士课程旨在满足对能够将不断增长的机构数据转化为有价值资产的高技能专业人才的日益增长的需求。你将获得使用各种分析工具的实践经验,学习如何管理和操作数据,创建数据可视化,并提出数据驱动的战略建议以影响业务结果。 | 12 | 17280 |
| na | 玛丽维尔大学 数据科学硕士 | 我们在顶级雇主的建议下建立了我们的课程,这些雇主在各行业中使用数据科学,因此我们的课程重点关注现代数据科学工具箱中最需要的技能,如多种编程语言的计算机编程、机器学习、预测建模和大数据分析。 | 12-18 | 27540 |
| na | 梅里马克学院 数据科学硕士 | 该课程通过工程学院和商学院的合作提供,将数据科学家所需的工程技能与将数据集转化为利益相关者可用的见解的商业智慧相结合。 | 12-16 | 30464 |
| na | 北中大学 数据科学硕士 | 我们的数据科学硕士项目旨在帮助学生深入理解这一新兴的跨学科领域。学生将获得包括数据生命周期在内的广泛知识,学会如何将大量非结构化数据处理成组织可以利用的可用数据集。 | 23 | 31970 |
| na | 俄克拉荷马州立大学 管理信息系统硕士 | MIS 项目不要求未来的学生拥有商业背景或学位。33-34 学时的课程包括 22 学时的核心课程(兼职学生为 21 学时核心课程)和一个选修/选项领域,以便学生可以专注于 MIS 的兴趣领域。除非另有说明,否则所有课程均可通过在线学习选项获得。 | 12-18 | 17127 |
| na | 雷吉斯大学 数据科学硕士 | 从保险到银行,再到医疗保健,几乎每个行业都认识到数据及其分析和解释的重要性。数据科学硕士学位将为你在预测分析、统计、数据可视化和数据工程等领域的热门职业机会做好准备。 | 12-18 | 34200 |
| na | 罗切斯特理工学院(RIT)数据科学硕士 | 鼓励学生与数据科学、分析和基础设施领域的专家合作,提供解决实际问题的实践经验。课程包括学生选择选修课程的机会,以追求数据科学广泛领域及其各种应用领域中的多种职业路径。该项目为所有背景的学生,无论是科学、工程还是商业背景,都提供了从事数据科学职业的准备。 | 24 | 35730 |
| na | 圣母大学圣玛丽学院(IN)数据科学硕士 | 在我们的数据科学硕士项目中,一个职业科学硕士(PSM)项目,你将发展成一名具有深厚分析技能的专业从业者。成为一个全面的个人,具备数据科学的深厚知识,同时具备有效沟通和项目管理的能力。 | 24 | 29700 |
| na | 南方卫理公会大学(SMU)数据科学硕士 | 旨在为当前和未来的数据科学专业人士提供所需的高级技能,以管理、分析、挖掘和理解复杂数据,从而在组织中做出战略决策。 | 20-28 | 57084 |
| na | 新罕布什尔大学 (SNHU) 数据分析硕士 | 让你深入学习这一领域,磨练当前劳动力市场上最受追捧的技能之一。你将学习如何使用高级统计技术和工具进行数据和信息管理,以收集和分析大数据集。你还将学习如何应用你的计算、分析和建模技能,为关键利益相关者提供决策支持。 | 15 | 22572 |
| na | 圣地亚哥大学 应用数据科学硕士 | 应用数据科学硕士项目由数据科学专家与关键行业和政府利益相关者紧密合作开发,提供深入的实践和技术培训,旨在使毕业生在这一重要且快速发展的领域获得职业成功。 | 12-24 | 33300 |
| na | 威斯康星大学 数据科学硕士 | 该数据科学硕士项目将教你如何利用最新工具和分析方法 harness 大数据的力量。创新的虚拟实验室让你可以远程访问软件工具和编程语言,如 R、Python、SQL Server 和 Tableau,从而节省购买和安装这些应用程序的成本、时间和麻烦。 | 12-18 | 30600 |
| na | Utica College 数据科学硕士 | Utica 的 30 学分在线数据科学硕士项目将帮助你在组织和社会背景下考虑数据,从而影响各种组织和行业的战略和政策制定。 | 24 | 24900 |
| na | Walsh College 数据分析硕士 | 让你掌握评估、解释和转化信息的知识和技能,以解决复杂的商业问题,并帮助组织实施战略性的数据驱动解决方案。对于没有技术背景的学生,MSDA 包括对数据库、编程和网络的介绍。 | 18-24 | 25500 - 31450 |
| na | 西部 governors 大学 (WGU) 数据分析硕士 | 拥有你的 M.S. 数据分析学位,你将成为数据挖掘、管理、映射和处理的专家,使你能够提高收入潜力并最大化职业发展机会。 | 18-24 个月 | 10620 |
我们希望此列表对你有用,如果我们遗漏了什么,请在评论中添加。
相关
-
2019 年最佳数据科学与分析硕士 – 欧洲版
-
数据科学 MOOCs 过于肤浅
-
4 门免费的数学课程,提升你的数据科学技能
更多相关内容
人工智能、分析、数据科学、机器学习最佳播客前 10 名
原文:
www.kdnuggets.com/2019/07/best-podcasts-ai-analytics-data-science-machine-learning.html
评论
在日常通勤或休息时间收听播客是保持在数据科学领域最新并确保你不断学习的高效有效方式。
以下的 KDnuggets Top 10 列表 突出了截至 2019 年最活跃和受欢迎的播客,这些播客包含数据科学和机器学习的对话。我们审查了更多的播客,因此此列表仅包括在 iTunes 上评分最高(4.5+)、评论最多且当前月份内至少有一集的新播客。所有节目描述均改编自播客列表。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织

我们还分享了一些新的和引人注目的播客,这些播客要么太新,无法与大名单竞争,要么已经有一段时间没有发布,但仍然是绝佳的资源,或涵盖更广泛的话题。 你仍然应该考虑查看这些节目,因为它们可能会带来一些对你下一次大数据冒险至关重要的知识点!
告诉我们你对我们精选内容的看法,并请分享你认为应考虑在未来最佳播客列表中的最爱播客。
播客前 10 名
#1. 数据怀疑者 由 Kyle Polich 主持 | 276 集,2014 – 2019,iTunes
包含有关数据科学、统计学、机器学习和人工智能的访谈和讨论,重点是应用批判性思维和科学方法来评估主张的真实性和方法的有效性。
最新一集: (20 min.) 与 Prasanth Pulavarthi 的访谈,讨论 Onyx 格式用于深度神经网络。
#2. 数据故事 由 Enrico Bertini 和 Moritz Stefaner 主持 | 143 集,2012 – 2019,iTunes
关于数据分析、可视化及相关话题的最新发展讨论。
最新一期:(42 分钟)Evan Peck 是本期节目的嘉宾,他将谈论他和他的学生最近发表的关于“数据是个人的”研究。该研究包括对宾夕法尼亚州乡村的 42 次访谈,目的是查看不同教育背景的人们如何对一组不同的数据可视化进行排名。
#3. 与 Lex Fridman 的人工智能,MIT AI | 34 集,2018 – 2019,iTunes
关于智能和人工智能的本质的对话,在 MIT 及其以外,从深度学习、机器人学、AGI、神经科学、哲学、心理学、认知科学、经济学、物理学和数学的角度出发。
最新一期:(44 分钟)Chris Urmson 曾是 Google 自动驾驶汽车团队的首席技术官,是 Carnegie Mellon 大学 DARPA 大挑战和 DARPA 城市挑战的关键工程师和领导者。今天,他是 Aurora Innovation 的首席执行官,这是他与 Sterling Anderson(前 Tesla Autopilot 总监)和 Drew Bagnell(Uber 前自主性和感知负责人)共同创立的自动驾驶软件公司。
#4. Linear Digressions 由 Udacity 提供 | 237 集,2014 – 2019,iTunes
通过有趣(且常常非常不寻常)的应用探索机器学习和数据科学。
最新一期:(16 分钟)如果你是 Google 或 Netflix,并且你有一个推荐或搜索系统作为你的主打产品,那么测试算法改进的最佳方法是什么?A/B 测试是测试用户对软件变化响应的经典答案,但在返回排名列表的算法上下文中思考 A/B 测试的意义时,事情会变得很复杂。这就是我们本周讨论交错测试的原因——这是一种简单的 A/B 测试修改,使得两种算法之间的对决变得更加容易,并且它允许你用比传统 A/B 测试少得多的数据来进行测试。
#5. TWiML&AI 由 Sam Charrington 主持 | 300 集,2016 – 2019,iTunes
This Week in Machine Learning & AI 专为机器学习和人工智能爱好者的高度目标化受众量身定制。涵盖机器学习、人工智能、深度学习、自然语言处理、神经网络、分析和深度学习等技术。
最新一期:(75 分钟)扎克里·利普顿,特普商学院助理教授,专注于机器学习在医疗保健中的应用,以帮助医生进行诊断和治疗。我们讨论了医疗领域的监督学习、分布变化下的鲁棒性、跨行业机器学习系统的伦理问题以及“公平洗白”的概念。
#6. SuperDataScience 来自 Kirill Eremenko | 250 期,2017 – 2019,iTunes
将全球最具启发性的数据科学家和分析师带给您,帮助您在数据科学领域建立成功的职业生涯。数据呈指数增长,从事分析工作的人薪资也在不断上升。这个播客可以帮助您学习如何迅速提升您的分析职业生涯。
最新一期:(66 分钟)与 Webfor 的数字战略创始人兼主任凯文·盖奇的聊天。您将了解数字助手是什么以及它们的未来发展方向,借助像谷歌的雷·库兹韦尔这样的专家。您将听到凯文对“可测量的东西会被管理”的哲学以及这对营销和数据科学的意义。您还将了解为什么网站变得越来越不重要,如何将细分市场逐渐过渡到个性化,创建令人惊叹的客户体验,磁盘配置文件、自然语言处理、计算机视觉及其在未来营销中的作用。
#7. Talking Machines 来自 Tote Bag Productions | 84 期,2015 – 2019,iTunes
凯瑟琳·戈尔曼和尼尔·劳伦斯带来与领域专家的清晰对话、对行业新闻的深入讨论以及对您的问题的有用回答。机器学习正在改变我们可以向周围世界提出的问题,我们在这里探讨如何提出最佳问题以及如何利用这些答案。
最新一期:(45 分钟)我们讨论了边际似然性和交叉验证,凯瑟琳对 PosterSession.ai仍然感到兴奋,我们发明了 Deep Quaggles,并听取了波士顿大学伊莱恩·恩索西教授的对话。
#8. AI 播客 由 NVIDIA 提供 | 90 集,2016 年 – 2019 年,iTunes
我们与一些世界领先的 AI 专家联系,解释它是如何工作的,如何发展,以及它如何与人类所有领域交织在一起。AI 计算公司 NVIDIA 制作了这个播客。
最新一集:(24 分钟)有人说风格永不褪色,而现在借助 AI,找到个人的时尚感将变得更加容易。时尚电商初创公司 Stitch Fix 正在努力在 AI 驱动的决策与人类判断之间建立无缝平衡。我们与 Stitch Fix 首席算法官布拉德·克林根伯格聊了聊公司如何利用 AI 来帮助我们更好地穿着。
#9. 数字分析权威小时 由迈克尔·赫布林、蒂姆·威尔逊和莫·基斯主持 | 126 集,2015 年 – 2019 年,iTunes
参加任何会议,你都会听到人们说,最有价值的讨论是在展会后的酒吧里发生的。阅读任何商业杂志,你会发现有文章提到类似于“商业分析是目前最热门的职业类别,而且存在显著的人才、流程和最佳实践的缺乏。”在这种情况下,会议是 eMetrics,酒吧是……多个,参会者包括迈克尔·赫布林、蒂姆·威尔逊和吉姆·凯恩(名誉主持人)。经过几杯啤酒和几个小时关于数字分析前沿的讨论,他们意识到他们可能有一些可以回馈社区的东西。这个播客就是其中的一项贡献。每一集都是一个封闭的话题和一个开放的论坛——目标是让听众享受迈克尔、蒂姆和莫分享他们的想法和经验,并希望能从中获得一些可以在第二天的工作中尝试的东西。
最新一集:(45 分钟)你有没有想过,喝一两杯酒,拿起麦克风,在公共论坛上发表你的抱怨,会是个好主意?好吧,我们这样做了!这一集的录制是在拉斯维加斯的营销分析峰会(MAS)上,在现场观众面前进行的(没有笑声录音!没有 canned applause!)。莫、迈克尔和蒂姆使用了一个“什么让我们恼火?”的应用程序来讨论分析师面临的一系列挑战和挫折。他们(当然是莫和蒂姆)在其中几个问题上存在分歧,但他们也偶尔提出了一些应对挑战的方法。
#10. 工业中的人工智能 由丹尼尔·法吉拉(Daniel Faggella)主办 | 99 集,2017 – 2019,iTunes
通过与药品、银行、零售和国防等领域的顶尖人工智能和机器学习专家及研究人员的访谈,了解在企业中人工智能的可能性及其应用现状。发现趋势,了解当前有效的做法,并学习如何在人工智能变革的时代适应和蓬勃发展。
最新一期:(21 分钟)当我们调查观众感兴趣的内容时,最常选择的答案是“商业智能”。作为后续,我们询问他们商业智能对他们的意义,他们的回答归结为了解企业已经收集的数据。这种广泛的定义触及了商业智能与人工智能之间区别的核心。界限开始变得模糊。我们本周的嘉宾是 Qlik 的高级总监 Elif Tutuk。Tutuk 谈论了商业智能如何演变,以及在许多商业智能功能转变为人工智能的背景下,我们现在如何定义它。Tutuk 讨论了人工智能如何融入商业智能,以及这可能为企业带来什么。
新的与引人注目的提及
- WiDS(女性数据科学家) 由斯坦福大学的玛戈特·盖里岑(Margot Gerritsen)教授主办 | 10 集,2018 – 2019,iTunes
数据科学正在改善从医疗保健到地震学、到人权等多个领域的结果。听听数据科学领域的女性领导者分享她们的建议、职业亮点和沿途的经验教训。
最新一期:(33 分钟)Meltem Ballan,一位在通用汽车从事联网汽车工作的数据科学家,解释了数据科学如何改变汽车行业。
采访数据科学、机器学习和人工智能领域的顶尖和新兴人物,讨论推动该领域发展的趋势和业务用例。
最新一期:(63 分钟)2019 年 6 月,200 多名数据科学家齐聚纽约 Viacom 总部,听取主要行业参与者对什么构成有效数据驱动策略的看法。Formulated.by 的高级内容顾问 Q McCallum 深入探讨了数据科学主要关注的议题,并与 DSS NYC 演讲者 Lauren Lombardo(尼尔森公司高级数据科学家)和 Sergey Fogelson(Viacom 数据科学与建模副总裁)进行了对话。听他们讨论当前的实践以及人工智能的增长将如何影响广告。
今天的领军人物与主持人 Byron Reese 探讨 AI。
最新一期:(30 分钟)在这一期中,Byron 与嘉宾 Chris Duffey 讨论了创造力的本质以及机器智能如何与创意概念互动。
讲解机器学习和人工智能的高级基础知识,包括基本直觉、算法和数学。每期节目都提供了高质量的精心挑选资源,讨论编程语言和框架以及深度学习,详细介绍每期节目的内容。
最新一期:(42 分钟)强化学习概念介绍。
与《怪诞经济学》书籍的合著者 Stephen J. Dubner 一起发现一切的隐藏面。每周,《怪诞经济学电台》告诉你你一直以为你知道的事情(但其实不知道)以及你从未想到想知道的事情(但现在知道了)——从睡眠经济学到如何在几乎任何领域变得出色。Dubner 采访诺贝尔奖得主、挑衅者、知识分子、企业家和各种各样的其他人。特别节目包括“首席执行官的秘密生活”系列以及一个现场游戏节目“告诉我一些我不知道的事”。
最新一期:(52 分钟)我们都知道我们的政治系统是“破碎的”——但这是否真的如此?有人说,共和党和民主党构成了一个非常成功的行业,他们勾结起来扼杀竞争、抑制改革并使国家分裂。那么,你打算怎么做呢?
- Talk Python To Me 由 Michael Kennedy 主持 | 222 集,2015 – 2019,iTunes
我们涵盖广泛的 Python 及相关话题,我们的目标是带你了解你所熟知和喜爱的 Python 包和框架背后的故事。
最新一期:(67 min.)我们如何让孩子们对编程感兴趣?通过嵌入式设备使编程变得具体可感知。你知道吗,在孩子们学习了 BBC micro:bit 后,90%的孩子认为编程适合每个人,而 86%的人表示这让计算机科学的话题更有趣?
相关内容:
更多相关主题
最佳机器学习播客
原文:
www.kdnuggets.com/2021/04/best-podcasts-machine-learning.html
评论
由理托布拉塔·戈什,深度学习顾问和大四物理本科生。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
图片由Icons8 Team提供,来源于Unsplash。
播客是了解新领域和工具的绝佳方式,同时也能让你保持对自己关心领域的更新。
我也相信,主要围绕访谈的播客是了解 AI 领域明星和超级英雄的绝佳方式。你可以一窥他们的思维方式、正在做什么以及如何解决特定问题。
我还认为,通过收听播客你能获得独特的内容,其他地方无法获取这些内容。
在这篇文章中,我不会深入探讨为什么我认为播客很棒以及机器学习学习者和从业者应该收听它们。
这里是我强烈推荐给机器学习学习者和专业人士的播客。
1. 梯度异议
来自 Weights and Biases,由Lukas Biewald主办
这是一个机器学习播客,专注于“来自解决现实世界问题的机器学习专家的故事。”
Lukas 以他自己的风格主持播客。他提出了非常有意义的问题,并对主题了解颇深。播客节目非常信息丰富、简洁明了且引人入胜。
-
每集长度:通常为 30-60 分钟
-
目前为止最喜欢的一集:Peter Norvig,谷歌研究总监——奇点在观察者的眼中
2. DeepMind: The Podcast
来自 DeepMind,由Hannah Fry主办
Hannah Fry 是一位出色的主持人,表现堪比任何专业播客主持人。这使得这个播客与其他播客有所不同。Hannah Fry 是一位数学家,具有主持播客的经验。她对 AI 充满热情,且对这个播客也充满热情。这个播客可能有一个团队在背后工作,音效和音乐也暗示了这一点。他们还让体验变得非常有趣。
这个播客关注 DeepMind 的工作,并邀请那些在 DeepMind 内部处理这些问题的人。问题和解决方案用简单的语言描述。充满激情的主持人还会给你一个关于问题的大致概况以及未来的发展方向。这个播客结构非常好,设计精良,且非常信息丰富和启发性强。
-
每集时长:30 分钟
-
目前最喜欢的集数:Episode 2: Go to Zero
3. Lex Fridman Podcast
由 Lex Fridman 主持
Lex Fridman 是一位专注于自动驾驶汽车和人机交互的 AI 研究员。他还在 MIT 教学。他作为播客主持人的独特之处在于,他非常关注嘉宾工作的长期目标和深远影响。他对诸如意识和 AGI 概念等深层次的事物感兴趣。他提出深刻、基础的问题,并让我们了解嘉宾对这些问题的看法。
他播客中的话题超越了 AI 的领域。他曾邀请过 Roger Penrose、Richard Dawkins 和 Noam Chomsky 等嘉宾。他的访谈中有很大一部分关于 AI。他的访谈通常很长,因此有更多的时间深入详细地讨论话题。我非常喜欢这一点。
-
每集时长:60–180 分钟
-
目前最喜欢的集数:David Silver: AlphaGo, AlphaZero, and Deep Reinforcement Learning | Lex Fridman Podcast #86
4. Chai Time Data Science
由 Sanyam Bhutani 主持
Sanyam Bhutani 是一位社区型人物。就是这样。作为 h2o.ai 的数据科学家,他撰写博客,主持访谈,并与 Machine Learning Tokyo 一起主持读书俱乐部和其他俱乐部。他还在 fast.ai 社区中非常活跃。他从不通过内容获利!当他在播客中采访嘉宾时,他不仅仅是为了采访提问,也是为了学习!我喜欢他好奇、谦逊的提问方式。
这个播客邀请了许多 Kaggle 竞赛的获胜者和大师。主持人谈论嘉宾的经历、职业以及当前的研究、项目和兴趣。然后是 Kaggle!他经常采访特定竞赛的获胜者,并询问他们对这些特定竞赛的思考和方法。这些内容对于参与 Kaggle 竞赛或有兴趣为任何项目开发完整流程的人来说非常有帮助。看到来自不同背景的多样化人群赢得 Kaggle 竞赛,并在这个播客上谈论他们的职业、生计和 Kaggle,非常有趣。
-
每集时长:30–90 分钟
-
到目前为止最喜欢的集数: Chris Deotte | 成为 4x Kaggle 大师的秘密 | 讨论与笔记
5. 机器学习街头讲座
由Yannic Kilcher、Dr. Tim Scarfe* 和 *Keith Dugger 主持
这是列表中唯一一个有多位主持人的播客。Yannic 以其论文讲解视频和墨镜而闻名。Dr. Scarfe 和 Keith 也保持着在线存在,并参与深度学习。
这个播客故意保持一种黑客、开源的氛围。从他们选择的背景、呈现风格以及更多方面都可以看出这一点。他们深入研究研究主题并采访与之相关的人。多位主持人的存在为对话增添了价值,而不是成为负担。听众可以从多个角度听取意见,并了解多种观点。嘉宾也更有可能揭示研究的不同方面。
-
每集时长:90–120 分钟
-
到目前为止最喜欢的集数:#040 — 对抗样本
+1. Google 演讲、微软研究院 和 TED/TEDx
当然,你已经注意到标题中的“+1”了。我将这些资源合并在一起,因为前两个资源中的所有内容都没有专注于 ML 或 AI。尽管 TED 有一些基于这个主题及更广泛主题的演讲,但它在 ML、数据科学和 AI 方面有一些非常好的演讲。
如果你访问微软研究院的 YouTube 页面,你会看到许多会激发你兴趣的播放列表。例如,AI 杰出讲座系列 包含了许多引人深思的 AI 演讲。Talks at Google 也是如此。
TED 上有很多关于数据科学、人工智能及其影响的演讲。而且 TED 在这些领域爆发之前的几年就已经在涵盖数据分析、人工智能等话题。我记得曾经听过一场演讲,通过讲故事使数据更有意义 | Ben Wellington,这是在 2015 年发表的,强调了数据分析如何既有创意又简单地揭示许多重要见解,并且通过影响政府政策来改善生活。还有另一场我想提到的演讲是:Daphne Koller:我们从在线教育中学到了什么。Coursera 的联合创始人给我们提供了关于在线教育的许多深刻见解,以及数据在其中的核心作用。这是数据如何改变像教育这样根本的事物并积极影响数百万生活的又一例证。
- 每集时长:混合
结论
近年来关于和机器学习相关的播客经历了爆炸性增长。在这种信息泛滥的情况下,不要感到不知所措。我听了很多关于机器学习/数据科学的播客,并决定这些是最好的。
原始文章。已获许可转载。
简介: Ritobrata Ghosh 是一名深度学习顾问,同时也是一名自由职业者和大四物理本科生。他对通过机器学习解决实际问题感兴趣,特别是在计算机视觉这一广泛领域,通过探索深度强化学习和生成对抗网络来实现。他的 Twitter 和 LinkedIn 账户可以关注。
相关:
更多相关主题
创建领域特定 AI 模型的最佳实践
原文:
www.kdnuggets.com/2022/07/best-practices-creating-domainspecific-ai-models.html

图片由Andrea De Santis提供,Unsplash
大规模通用 AI 实施作为解决某些 B2B 问题的优秀基础构件,大多数组织已经或正在利用这些模型。然而,对即时投资回报的渴望、创建快速失败的原型以及提供以决策为中心的成果,推动了领域特定 AI 项目的需求。
用例和主题专业知识有帮助,但数据科学家和分析师需要调整 AI 实施周期,以解决需要更多具体性和相关性的问题。构建这样的 AI 模型时遇到的最大障碍是找到高质量的领域特定数据。以下是一些领域特定模型适配的最佳实践和技术,这些方法在我们身上一次次取得了成功。
数据很重要,但重要吗?
首先挖掘你的组织,发现尽可能多的相关领域特定数据资产。如果这是一个直接涉及你的业务和行业的问题,你很可能拥有可以利用的未开发的数据资产。如果发现数据资产不足,不必灰心。有多种策略和方法可以帮助创建或增强特定数据集,包括主动学习、迁移学习、自我训练以改善预训练和数据增强。以下是一些详细信息。
主动学习
主动学习是一种半监督学习方法,通过查询策略选择特定实例进行学习。使用领域专家和人工环节机制对这些选择的实例进行标注,有助于在更快的时间内将过程优化为有意义的结果。此外,主动学习需要较少的标注数据,从而降低了人工标注成本,同时仍能实现更高的准确性。
这里有一些建议,帮助在数据有限的情况下实现主动学习:
-
首先,将数据集分为种子数据和未标记数据。
-
标记种子数据,并用它来训练学习模型。
-
根据查询功能,从未标注的数据中选择实例进行人工标注(最关键的步骤)。查询策略可以基于不确定性采样(如最小置信度、边缘采样或熵)、委员会查询(如投票熵、平均 Kullback-Leibler 散度)等。
-
将新标注的数据添加到种子数据集中,并重新训练学习模型。
-
重复前两步,直到达到停止标准,例如查询实例的数量、迭代次数或性能改进。
迁移学习
这种方法利用源领域的知识在目标领域学习新知识。这个概念存在已经有一段时间了,但在过去几年中,当人们谈论迁移学习时,往往谈论神经网络,可能是因为那里有成功的实施案例。
以 ImageNet 为例,以下是一些经验教训:
-
使用预训练网络作为特征提取器。确定导出哪些层的特征取决于你的数据与基础训练数据集的相似程度。差异将决定你的策略,如下文所述。
-
如果领域不同,只使用神经网络的低级特征。这些特征可以导出,并作为分类器的输入。
-
如果领域相似,移除神经网络的最后一层,使用剩余的完整网络作为特征提取器。或者将最后一层替换为一个新的层,该层与目标数据集的类别数匹配。
-
尝试解冻基础网络的最后几层,并以较低的学习率(例如 1e-5)进行微调。目标领域和源领域越接近,需要微调的层数就越少。
自训练以改进预训练(Jingfei Du 等,2020)
这种组合提供了一种方法,能够最大限度地利用来自下游任务的有限标记数据。同时,它也有助于充分利用大量易获得的未标记数据。其工作原理如下。
-
对预训练模型(例如 RoBERTa-Large)进行微调,以适应目标下游任务的标记数据,并将微调后的模型用作教师。
-
使用查询嵌入从未标记的数据集中提取任务特定数据,并从数据集中选择最近邻。
-
使用教师模型对在第 2 点中检索的领域内数据进行标注,并从每个类别中选择得分最高的前 k 个样本。
-
使用第 3 步中生成的伪数据对新的 RoBERTa-Large 进行微调,并提供学生模型。
数据增强
数据增强包括一系列低成本、高效的技术,从现有数据中生成新数据点。上一节自训练中的第 2 点也涉及数据增强,这对整个过程至关重要。
其他 NLP 应用的技术包括回译、同义词替换、随机插入/交换/删除等。对于计算机视觉,主要的方法包括裁剪、翻转、缩放、旋转、噪声注入、调整亮度/对比度/饱和度以及 GAN(生成对抗网络)。
确定使用哪种方法取决于你的用例、初始数据集质量、现有领域专家和可用的投资。
5 个额外的提示来帮助领域特定 AI 的优化
你会发现需要继续优化你的领域特定 AI。以下是我们从定制实现以满足特定用例中的经验中学到的一些经验教训。
-
在开始你的概念验证(POC)之前,进行适当的数据探索,以检查数据的质量和数量问题。了解数据是否符合实际应用场景(例如下游任务,如命名实体识别(NER)、关系抽取、问答等),其变化和分布,以及其准确性水平。对于分类问题的变化和分布——分类结构、每一层的类别数量、每个类别的数据量、平衡与不平衡等——所有这些都很重要。你发现的内容将影响你的数据处理方法和选择以改进领域特定模型性能的方法论。
-
根据你的用例和数据特征选择适当的算法/模型。还要考虑速度、准确性和部署等因素。这些因素的平衡很重要,因为它们决定了你的开发是否可能停留在 POC 阶段或有实际应用和产品化的潜力。
例如,如果你的模型最终会部署到边缘设备上,虽然大模型可能具有更高的预测准确性,但不应选择它们。鉴于边缘设备的计算能力,运行这样的模型并不现实。
从一个强大的基线模型开始每一个开发/领域适应。考虑使用 AutoML 快速检查算法在领域特定数据集上的适用性,然后根据观察结果进行优化。
-
数据预处理是任何 NLP 项目的关键部分。由于领域特定的要求以及选择的特征化方法和模型,所采取的步骤应根据具体情况确定。通用的流程可能无法提供最佳结果。
例如,某些步骤如去除停用词/标点符号和词形还原,可能并不总是对深度学习模型必要。它们可能会导致上下文的丧失;然而,如果你使用的是 TF-IDF 和机器学习模型,它们可能会很有用。将流程模块化,以便在定制以满足用例需求时可以重用一些常见步骤。
-
如果有可用的领域特定预训练语言模型,请利用它们。一些知名模型包括 SciBERT、BioBERT、ClinicalBERT、PatentBERT 和 FinBERT。这些领域特定的预训练模型可以帮助实现更好的表示和上下文化的嵌入。如果这些模型在你的领域不可用,但你有足够的计算资源,可以考虑使用领域内高质量的未标注数据训练你自己的预训练模型。
-
考虑整合领域特定的词汇和规则。在某些情况下,它们可以提供更高效和更准确的结果,并避免模型迭代问题。创建这些词汇和定义规则可能需要相当大的努力和领域专业知识,这些都需要平衡。
总结
将 AI 定向满足领域特定需求和挑战需要在整个过程中保持严谨,不仅在方法和资源方面。好消息是,公司对解决特定挑战并解决这些挑战的解决方案越来越感兴趣,这反过来为数据科学家和 AI 开发人员提供了最佳实践,以期为他们的应用提供更快的投资回报。
Cathy Feng 领导着 Evalueserve 的 AI 实践,指导公司进入数据分析的下一个时代。她对教育人们了解 AI 及其业务应用充满热情,她的努力促成了为麦当劳、英特尔和先正达等公司创建特定领域的 AI 应用程序。
更多相关话题
机器学习 ETL 的最佳实践
原文:
www.kdnuggets.com/best-practices-for-building-etls-for-ml
机器学习工程的一个关键部分是构建可靠且可扩展的数据提取、转换、丰富和加载的过程。这是数据科学家与机器学习工程师最密切合作的组成部分之一。通常,数据科学家会提出一个粗略的数据集设计方案。理想情况下,不是在 Jupyter notebook 上。然后,机器学习工程师加入这个任务,以帮助使代码更具可读性、效率和可靠性。
机器学习 ETLs 可以由多个子 ETL 或任务组成,并且可以以非常不同的形式体现。一些常见的例子:
-
基于 Scala 的 Spark 任务读取和处理存储在 S3 中的 Parquet 文件格式的事件日志数据,并通过 Airflow 每周计划。
-
Python 进程通过计划的 AWS Lambda 函数执行 Redshift SQL 查询。
-
复杂的 pandas 重处理通过 Sagemaker 处理作业执行,使用 EventBridge 触发器。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
ETL 中的实体
我们可以在这些类型的 ETL 中识别不同的实体,我们有源(原始数据存储的位置)、目标(最终数据制品存储的位置)、数据 处理(数据如何被读取、处理和加载)和触发器(ETL 如何被启动)。
-
在源部分,我们可以有如 AWS Redshift、AWS S3、Cassandra、Redis 或外部 API 等存储位置。目标也是如此。
-
数据处理 通常在临时的 Docker 容器中运行。我们可以通过使用 Kubernetes 或其他 AWS 管理服务,如 AWS ECS 或 AWS Fargate,再增加一层抽象。甚至可以使用 SageMaker Pipelines 或 Processing Jobs。通过利用特定的数据处理引擎,如 Spark、Dask、Hive、Redshift SQL 引擎,你可以在集群中运行这些过程。同时,你还可以使用 Python 进程和 Pandas 进行简单的单实例数据处理。除此之外,还有一些其他有趣的框架,如 Polars、Vaex、Ray 或 Modin,它们可以用于处理中间解决方案。
-
最受欢迎的 触发器 工具是 Airflow。其他可用的工具有 Prefect、Dagster、Argo Workflows 或 Mage。

我是否应该使用框架?
框架是一组抽象、约定和开箱即用的工具,可以用于创建更统一的代码库,当应用于具体问题时。框架对于 ETLs 非常方便。正如我们之前描述的那样,有很多非常通用的实体可以被抽象或封装,以生成全面的工作流。
我构建内部数据处理框架的进展步骤如下:
-
首先建立一个连接不同 源 和 目标 的库。在你进行的不同项目中,根据需要实现这些连接器。这是避免 YAGNI 的最佳方式。
-
创建简单且自动化的开发工作流,使你能够快速迭代代码库。例如,配置 CI/CD 工作流以自动测试、代码检查和发布你的包。
-
创建实用工具,如读取 SQL 脚本、启动 Spark 会话、日期格式化函数、元数据生成器、日志记录工具、获取凭据和连接参数的函数,以及警报工具等。
-
在构建工作流的内部框架与使用现有框架之间进行选择。在考虑内部开发时,复杂性范围非常广泛。你可以从一些简单的约定开始构建工作流,最终可能会构建一些基于 DAG 的库,如 Luigi 或 Metaflow。这些是你可以使用的流行框架。
构建 “Utils” 库
这是你的数据代码库的一个关键和核心部分。所有的处理过程将使用这个库来将数据从一个源移动到另一个目标。一个扎实且经过深思熟虑的初始软件设计是关键。
但我们为什么要这样做呢?主要原因是:
-
重用性:在不同的软件项目中使用相同的软件组件可以提高生产力。这个软件组件只需开发一次。然后,它可以集成到其他软件项目中。但这个想法并不新鲜。我们可以追溯到1968 年的一次会议,其目标是解决所谓的软件危机。
-
封装:库中不同连接器的所有内部细节不需要展示给最终用户。因此,提供一个可理解的接口就足够了。例如,如果我们有一个数据库连接器,我们不希望连接字符串暴露为连接器类的公共属性。通过使用库,我们可以确保对数据源的安全访问得到保障。审查此部分
-
更高质量的代码库:我们只需开发一次测试。因此,开发者可以依赖于这个库,因为它包含了一个测试套件(理想情况下,测试覆盖率非常高)。在调试错误或问题时,我们可以忽略,至少在初次检查时,问题是否出在库中,只要我们对测试套件有信心。
-
标准化 / “观点”:拥有一个连接器库在某种程度上决定了你开发 ETL 的方式。这是好的,因为组织中的 ETL 将具有相同的数据提取或写入方式。标准化有助于更好的沟通、更高的生产力以及更好的预测和规划。
在构建这种类型的库时,团队承诺在一段时间内维护它,并承担在需要时实施复杂重构的风险。需要进行这些重构的原因可能包括:
-
组织迁移到不同的公共云。
-
数据仓库引擎发生变化。
-
新的依赖版本破坏了接口。
-
需要进行更多的安全权限检查。
-
新团队进来,对库的设计有不同的意见。
接口类
如果你想让你的 ETL 与来源或目的地无关,创建基类的接口类是一个好的决定。接口作为模板定义。
例如,你可以有抽象类来定义DatabaseConnector所需的方法和属性。让我们展示一个简化的示例,说明这个类可能的样子:
from abc import ABC
class DatabaseConnector(ABC):
def __init__(self, connection_string: str):
self.connection_string = connection_string
@abc.abstractmethod
def connect(self):
pass
@abc.abstractmethod
def execute(self, sql: str):
pass
其他开发者可以从DatabaseConnector子类化并创建新的具体实现。例如,可以以这种方式实现MySqlConnector或CassandraDbConnector。这将帮助最终用户快速理解如何使用任何从DatabaseConnector子类化的连接器,因为它们都将具有相同的接口(相同的方法)。
mysql = MySqlConnector(connection_string)
mysql.connect()
mysql.execute("SELECT * FROM public.table")
cassandra = CassandraDbConnector(connection_string)
cassandra.connect()
cassandra.execute("SELECT * FROM public.table")
简单的接口与命名良好的方法非常强大,有助于提高生产力。因此,我建议花时间仔细思考这一点。
正确的文档
文档不仅仅指代码中的docstrings和内联注释。它还指你关于库的周边解释。对包的最终目标进行明确的陈述,以及对贡献的要求和指南进行清晰的解释是至关重要的。
例如:
*"This utils library will be used across all the ML data pipelines and feature engineering jobs to provide simple and reliable connectors to the different systems in the organization".*
或者
*"This library contains a set of feature engineering methods, transformations and algorithms that can be used out-of-the-box with a simple interface that can be chained in a scikit-learn-type of pipeline".*
对库有一个清晰的使命有助于贡献者的正确理解。这就是为什么开源库(例如:pandas、scikit-learn 等)在这些年中获得了如此大的受欢迎程度。贡献者接受了库的目标,并承诺遵循规定的标准。我们在组织中也应该做得类似。
在任务陈述之后,我们应该开发基础的软件架构。我们希望接口的样子是什么?我们应该通过接口方法中的更多灵活性(例如:更多的参数导致不同的行为)还是通过更细粒度的方法(例如:每个方法都有非常具体的功能)来覆盖功能?
在此之后,制定风格指南。概述首选的模块层次结构、所需的文档深度、如何发布 PR、覆盖要求等。
关于代码中的文档,docstrings 需要充分描述函数的行为,但我们不应仅仅复制函数名称。有时,函数名称已经足够表达其功能,此时 docstring 解释其行为就显得多余。保持简洁准确。举个简单的例子:
❌不行!
class NeptuneDbConnector:
...
def close():
"""This function checks if the connection to the database
is opened. If it is, it closes it and if it doesn’t,
it does nothing.
"""
✅是的!
class NeptuneDbConnector:
...
def close():
"""Closes connection to the database."""
说到内联注释,我总是喜欢用它们来解释一些可能看起来奇怪或不规则的事情。此外,如果我必须使用复杂的逻辑或花哨的语法,最好在该片段上方写一个清晰的解释。
# Getting the maximum integer of the list
l = [23, 49, 6, 32]
reduce((lambda x, y: x if x > y else y), l)
此外,你还可以包含指向 Github 问题或 Stackoverflow 回答的链接。这非常有用,特别是当你需要编写一些奇怪的逻辑来解决已知的依赖问题时。当你实施了从 Stackoverflow 获得的优化技巧时,这也是非常方便的。
在我看来,这两者——接口类和清晰的文档——是让共享库长时间保持活力的最佳方法。它将抵御懒散和保守的新开发者,同时也能适应充满活力、激进且意见明确的开发者。更改、改进或革命性的重构将会顺利进行。
将软件设计模式应用于 ETL
从代码的角度来看,ETL 应该有 3 个明显区分的高级功能。每个功能与以下步骤之一相关:提取、转换、加载。这是 ETL 代码最简单的要求之一。
def extract(source: str) -> pd.DataFrame:
...
def transform(data: pd.DataFrame) -> pd.DataFrame:
...
def load(transformed_data: pd.DataFrame):
...
显然,将这些函数命名为这样并不是强制的,但它会提高可读性,因为这些术语是广泛接受的。
DRY(不要重复自己)
这是一个伟大的设计模式之一,为连接器库提供了正当理由。你写一次,并在不同的步骤或项目中重用它。
函数式编程
这是一种编程风格,旨在使函数“纯”或无副作用。输入必须是不可变的,给定这些输入,输出总是相同的。这些函数更容易在隔离环境下进行测试和调试。因此,为数据管道提供了更好的可重复性。
应用函数式编程到 ETL 时,我们应该能够提供幂等性。这意味着每次运行(或重新运行)管道时,应该返回相同的输出。具有这种特性,我们可以自信地操作 ETL,确保重复运行不会生成重复数据。你曾经多少次需要创建一个奇怪的 SQL 查询来删除错误 ETL 运行中插入的行?确保幂等性有助于避免这些情况。Maxime Beauchemin,Apache Airflow 和 Superset 的创始人,是函数式数据工程*的知名倡导者。
SOLID
我们将使用类定义的引用,但这一部分也可以应用于一等函数。我们将使用重度面向对象编程来解释这些概念,但这并不意味着这是开发 ETL 的最佳方式。没有具体的共识,每家公司都有自己的方法。
关于单一职责原则,你必须创建只有一个变化原因的实体。例如,将职责分隔到两个对象中,例如SalesAggregator和SalesDataCleaner类。后者可能包含特定的业务规则来“清理”销售数据,而前者则专注于从不同系统中提取销售数据。这两个类的代码可能会因为不同的原因而变化。
对于开放-封闭原则,实体应该可以扩展以添加新功能,但不应开放以进行修改。想象一下,SalesAggregator接收了一个StoresSalesCollector作为组件,用于从实体店提取销售数据。如果公司开始在线销售并且我们想获取这些数据,我们会声明SalesCollector对于扩展是开放的,只要它也能接收另一个具有兼容接口的OnlineSalesCollector。
from abc import ABC, abstractmethod
class BaseCollector(ABC):
@abstractmethod
def extract_sales() -> List[Sale]:
pass
class SalesAggregator:
def __init__(self, collectors: List[BaseCollector]):
self.collectors = collectors
def get_sales(self) -> List[Sale]:
sales = []
for collector in self.collectors:
sales.extend(collector.extract_sales())
return sales
class StoreSalesCollector:
def extract_sales() -> List[Sale]:
# Extract sales data from physical stores
class OnlineSalesCollector:
def extract_sales() -> List[Sale]:
# Extract online sales data
if __name__ == "__main__":
sales_aggregator = SalesAggregator(
collectors = [
StoreSalesCollector(),
OnlineSalesCollector()
]
sales = sales_aggregator.get_sales()
里氏替换原则,或行为子类型并不容易直接应用于 ETL 设计,但对于我们之前提到的实用程序库却适用。这个原则试图为子类型设定规则。在使用超类型的程序中,理论上可以用一个子类型来替代它,而不会改变程序的行为。
from abc import ABC, abstractmethod
class DatabaseConnector(ABC):
def __init__(self, connection_string: str):
self.connection_string = connection_string
@abstractmethod
def connect():
pass
@abstractmethod
def execute_(query: str) -> pd.DataFrame:
pass
class RedshiftConnector(DatabaseConnector):
def connect():
# Redshift Connection implementation
def execute(query: str) -> pd.DataFrame:
# Redshift Connection implementation
class BigQueryConnector(DatabaseConnector):
def connect():
# BigQuery Connection implementation
def execute(query: str) -> pd.DataFrame:
# BigQuery Connection implementation
class ETLQueryManager:
def __init__(self, connector: DatabaseConnector, connection_string: str):
self.connector = connector(connection_string=connection_string).connect()
def run(self, sql_queries: List[str]):
for query in sql_queries:
self.connector.execute(query=query)
在下面的例子中,我们看到任何DatabaseConnector的子类型都符合 Liskov 替换原则,因为其任何子类型都可以在ETLManager类中使用。
现在,让我们谈谈接口隔离原则。它指出,客户端不应依赖于它们不使用的接口。这对于DatabaseConnector设计非常有用。如果你在实现DatabaseConnector,不要用在 ETL 上下文中不会使用的方法来过载接口类。例如,你不需要grant_permissions或check_log_errors等方法。这些方法与数据库的管理使用有关,而这并不是我们关注的内容。
另一个重要的原则是依赖倒置原则。这个原则指出,高层模块不应该依赖于低层模块,而应该依赖于抽象。这个行为在上面的SalesAggregator中得到了明确的体现。注意,它的init方法不依赖于StoreSalesCollector或OnlineSalesCollector的具体实现。它基本上依赖于一个BaseCollector接口。
一个优秀的 ML ETL 应该是什么样的?
我们在上面的例子中重度依赖面向对象的类,以展示如何将 SOLID 原则应用于 ETL 作业。然而,关于构建 ETL 时最好的代码格式和标准,没有普遍的共识。它可以有非常不同的形式,更多的是一个拥有内部良好文档化的观点框架的问题,而不是试图制定一个行业范围内的全球标准。
因此,在这一部分,我将尝试专注于解释一些使 ETL 代码更易读、更安全、更可靠的特征。
命令行应用程序
所有数据处理本质上都是命令行应用程序。在用 Python 开发 ETL 时,总是提供一个参数化的 CLI 接口,以便可以从任何地方执行它(例如,可以在 Kubernetes 集群下运行的 Docker 容器)。有许多工具可以构建命令行参数解析,如 argparse、click、typer、yaspin 或 docopt。Typer 可能是最灵活、易用且对现有代码库侵入性最小的。它由著名的 Python 网络服务库 FastApi 的创作者开发,其 Github 星标数不断增长。文档很出色,并且正变得越来越符合行业标准。
from typer import Typer
app = Typer()
@app.command()
def run_etl(
environment: str,
start_date: str,
end_date: str,
threshold: int
):
...
要运行上述命令,你只需要做:
python {file_name}.py run-etl --environment dev --start-date 2023/01/01 --end-date 2023/01/31 --threshold 10
处理与数据库引擎计算的权衡
构建基于数据仓库的 ETL 时,通常建议将尽可能多的计算处理推送到数据仓库。如果你拥有一个根据需求自动扩展的数据仓库引擎,这完全没问题。但并非每个公司、情况或团队都具备这种条件。一些机器学习查询可能非常长,并容易超载集群。通常需要从非常不同的表中汇总数据,回溯多年的数据,执行时间点子句等。因此,将所有计算都推送到集群并不是最好的选择。在某些情况下,将计算隔离到进程实例的内存中可能更安全。这是没有风险的,因为你不会影响集群,从而可能会破坏或延迟业务关键查询。这对于 Spark 用户来说是显而易见的,因为所有计算和数据都分布在执行器上,因为他们需要的大规模。但如果你在使用 Redshift 或 BigQuery 集群时,总是要注意可以将多少计算委托给它们。
跟踪输出
机器学习 ETL 生成不同类型的输出工件。一些是 HDFS 中的 Parquet 文件,S3 中的 CSV 文件,数据仓库中的表,映射文件,报告等。这些文件可以用于训练模型、丰富生产数据、在线获取特征等多个选项。
这非常有帮助,因为你可以使用工件的标识符将数据集构建作业与训练作业链接。例如,当使用 Neptune track_files() 方法时,你可以跟踪这些类型的文件。这里有一个非常清晰的例子 here 你可以使用。
实现自动回填
想象一下,你有一个每日 ETL,它获取前一天的数据以计算用于训练模型的特征。如果由于任何原因你的 ETL 一天未能运行,第二天它运行时,你将丢失前一天计算的数据。
为了解决这个问题,最好查看目标表或文件中最后注册的时间戳。然后,ETL 可以对那些滞后的两天执行。
开发松散耦合的组件
代码非常容易改变,而依赖数据的过程更是如此。构建表的事件可能会演变,列可能会改变,大小可能会增加等。当你的 ETL 依赖于不同的数据源时,将它们在代码中隔离总是好的。这是因为如果你需要将两个组件分开作为两个不同的任务(例如:一个需要更大的实例类型来处理,因为数据增加了),如果代码不是混乱的,将更容易做到。
使你的 ETL 幂等
在源表或过程本身出现问题的情况下,通常会多次运行相同的过程。为了避免生成重复的数据输出或半填充的表格,ETL 应该是幂等的。也就是说,如果你不小心用相同的条件运行相同的 ETL 两次,第一次运行的输出或副作用不应受到影响(ref)。你可以通过应用删除-写入模式来确保这一点,管道会先删除现有数据,然后再写入新数据。
使你的 ETL 代码简洁
我总是喜欢将实际实现代码与业务/逻辑层进行明确的分离。当我构建 ETL 时,第一层应被视为一系列步骤(函数或方法),明确说明数据发生了什么。拥有多个抽象层并不坏。如果你需要维护 ETL 多年,这将非常有帮助。
总是将高层次和低层次的函数彼此隔离。发现类似的情况非常奇怪:
from config import CONVERSION_FACTORS
def transform_data(data: pd.DataFrame) -> pd.DataFrame:
data = remove_duplicates(data=data)
data = encode_categorical_columns(data=data)
data["price_dollars"] = data["price_euros"] * CONVERSION_FACTORS["dollar-euro"]
data["price_pounds"] = data["price_euros"] * CONVERSION_FACTORS["pound-euro"]
return data
在上面的示例中,我们使用了高层次的函数,如“remove_duplicates”和“encode_categorical_columns”,但同时我们明确展示了一个实现操作,用于通过转换因子转换价格。将这两行代码移除并用一个“convert_prices”函数替换,会不会更好?
from config import CONVERSION_FACTOR
def transform_data(data: pd.DataFrame) -> pd.DataFrame:
data = remove_duplicates(data=data)
data = encode_categorical_columns(data=data)
data = convert_prices(data=data)
return data
在这个例子中,可读性不是问题,但假设你将一个长达 5 行的 groupby 操作嵌入到“transform_data”中,与“remove_duplicates”和“encode_categorical_columns”一起。在这两种情况下,你都混合了高层次和低层次的函数。强烈建议保持一致的分层代码。有时候,为了保持函数或模块 100% 一致性分层,是不可避免且过度工程的,但这是一个非常有益的目标。
使用纯函数
不要让副作用或全局状态使你的 ETL 变得复杂。纯函数如果传入相同的参数,会返回相同的结果。
❌下面的函数不是纯函数。你正在传递一个与另一个从外部源读取的函数连接的 dataframe。这意味着表格可能会发生变化,因此,每次函数被调用时,返回的 dataframe 可能会不同,即使使用相同的参数。
def transform_data(data: pd.DataFrame) -> pd.DataFrame:
reference_data = read_reference_data(table="public.references")
data = data.join(reference_data, on="ref_id")
return data
要使这个函数成为纯函数,你需要执行以下操作:
def transform_data(data: pd.DataFrame, reference_data: pd.DataFrame) -> pd.DataFrame:
data = data.join(reference_data, on="ref_id")
return data
现在,当传递相同的“data”和“reference_data”参数时,函数将产生相同的结果。
这是一个简单的例子,但我们都见过更糟的情况。依赖全局状态变量的函数、根据某些条件更改类属性状态的方法,可能会改变 ETL 中其他即将出现的方法的行为,等等。
最大限度地使用纯函数可以实现更具功能性的 ETL。正如我们在前面的几点中已经讨论的,它带来了巨大的好处。
尽可能多地参数化
ETL 会发生变化。这是我们必须接受的事实。源表定义、业务规则、期望结果、实验的精细化、ML 模型对更复杂特征的需求等都会发生变化。
为了在我们的 ETL 中拥有一定的灵活性,我们需要深入评估在哪里投入大部分精力来提供参数化执行。参数化是一种特性,通过简单的接口只需更改参数即可改变过程的行为。该接口可以是 YAML 文件、类初始化方法、函数参数甚至 CLI 参数。
一种简单直接的参数化方式是定义 ETL 的“环境”或“阶段”。在将 ETL 投入生产之前,最好拥有一个“测试”、“集成”或“开发”隔离环境,以便我们可以测试我们的 ETL。该环境可能涉及不同的隔离级别,可以从执行基础设施(开发实例与生产实例隔离)、对象存储、数据仓库、数据源等开始。
这是一个明显的参数,可能是最重要的。但我们还可以将参数化扩展到与业务相关的参数。我们可以参数化运行 ETL 的窗口日期、可能更改或细化的列名、数据类型、过滤值等。
适量记录日志
这是 ETL 中最被低估的属性之一。日志对于检测生产执行异常或隐性错误、解释数据集非常有用。记录提取数据的属性总是很有用。除了代码中的验证以确保不同的 ETL 步骤成功运行,我们还可以记录:
-
来源表、API 或目标路径的引用(例如:“从
item_clicks表中获取数据”) -
预期模式的变化(例如:“
promotion表中有一个新列”) -
获取的行数(例如:“从
item_clicks表中获取 145234093 行”) -
关键列中的空值数量(例如:“在 Source 列中发现 125 个空值”)
-
数据的简单统计(例如:均值、标准差等)(例如:“CTR 均值:0.13,CTR 标准差:0.40”)
-
类别列的唯一值(例如:“Country 列包含:‘Spain’,‘France’和‘Italy’”)
-
去重的行数(例如:“移除 1400 行重复数据”)
-
计算密集型操作的执行时间(例如:“聚合耗时 560 秒”)
-
ETL 不同阶段的完成检查点(例如:“丰富过程成功完成”)
Manuel Martín**** 是一位拥有超过 6 年数据科学经验的工程经理。他曾担任数据科学家和机器学习工程师,现在负责 Busuu 的 ML/AI 实践。
更多相关内容
数据科学中使用笔记本的最佳实践
原文:
www.kdnuggets.com/2018/11/best-practices-notebooks-data-science.html
评论
作者 Armin Wasicek,Sumo Logic

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
在数据科学领域,笔记本已成为一种重要工具——它们是由个人或团队创建的活跃文档,用于编写和运行代码、显示结果以及分享成果和见解。
像其他故事一样,数据科学笔记本遵循其类型的特定结构。通常有四个部分——(1) 开始时定义数据集,(2) 继续清理和准备数据,(3) 使用数据进行建模,(4) 解释结果。本质上,笔记本应记录实验为何启动、如何进行以及展示结果的解释。
为了说明笔记本的功能,让我们退一步了解其结构,讨论人类速度与机器速度,探索笔记本如何提高生产力,并概述编写笔记本的五个最佳实践。
笔记本的结构
一个笔记本将计算分为称为段落的单独步骤。每个段落包含输入和输出部分。每个段落单独执行,并修改笔记本的全局状态。状态可以定义为所有相关变量、记忆和寄存器的集合。段落中不得包含计算,但可以包含文本或可视化来说明代码的工作原理。
人类速度与机器速度
笔记本的力量在于其能够分段并减缓计算速度。计算机程序的常规执行速度是机器速度。机器速度意味着当程序被提交给处理器执行时,它会尽可能快地从头到尾运行,只在 IO 或用户输入时才会阻塞。因此,程序的状态变化非常快,以至于人类无法观察或修改。程序员通常会附加调试器,在所谓的断点处停止程序并读取和分析其状态。因此,他们会将执行速度减慢到人类速度。
笔记本使得查询状态变得更加明确。某些段落专注于计算进展,即推进状态,而其他段落则仅用于读取和显示状态。此外,在执行过程中可以通过覆盖某些变量来回滚状态。也可以简单地终止当前执行,从而删除状态并重新开始。
笔记本作为提升生产力的工具
笔记本通过促进逐步改进来提高生产力。修改代码和仅重新运行相关段落的成本很低。因此,在开发笔记本时,用户会建立状态,然后在该状态上进行迭代,直到取得进展。与之相对,运行一个独立的程序将需要更多的设置时间,并且可能会受到副作用的影响。笔记本更有可能将所有状态保存在工作内存中,而每次运行独立程序时都需要重新建立状态。
这需要更多的时间,并且所需的 IO 操作可能会失败。在内存中迭代程序状态被证明是非常高效的。这对于数据科学家尤其如此,因为他们的程序通常处理大量数据,这些数据需要加载到内存中以及进行可能耗时的计算。
从组织的角度来看,笔记本是知识管理的宝贵工具。它们被设计成自包含、可共享的知识单元,并能为以下方面进行修正:
-
知识转移
-
审计和验证
-
协作
编写笔记本的最佳实践
所以,有兴趣实施笔记本吗?在开始这个过程时,有几个要点需要考虑:
#1 一个笔记本,专注于一个主题。
笔记本包含了完整的程序、数据和思想记录,以传递给其他人。为此,它们需要保持专注。虽然将所有内容放在一个地方很诱人,但这可能会让读者感到困惑。不如写两个或更多的笔记本,而不是在一个笔记本中过载。
#2 状态是明确的。
一个常见的困惑来源是程序状态在段落之间通过隐藏变量传递。代表两个后续段落之间接口的变量集合应该明确列出。应该避免引用除前一个段落外的其他段落的变量。
#3 将代码分模块
笔记本整合了代码,但它不是代码开发的工具。代码开发工具是集成开发环境(IDE)。因此,笔记本应只包含粘合代码和一个核心算法。所有其他代码应在 IDE 中开发、单元测试、版本控制,然后通过库导入到笔记本中。模块化及其他良好的软件工程实践在笔记本中依然有效。实践表明,过多的代码会使笔记本变得杂乱,分散注意力于原始目的或分析目标。
#4 使用明确变量并整理代码
笔记本的目的是为了分享和供他人阅读。如果我们没有提出好的、自我解释的名称,其他人可能不容易跟上我们的思路。整理代码也是很重要的。笔记本在质量上要求比传统代码更高。
#5 标记图表
一幅图胜千言。然而,图表需要一些文字来标记轴线、描述线条和点,以及理解其他重要信息,如样本大小等。没有这些信息,读者可能难以把握图表的比例或重要性。此外,图表容易从笔记本中复制粘贴到其他文档或聊天中,这样它们会失去原始笔记本的上下文。
总结 - 思维过程的分段是笔记本强大功能的来源。在解决问题时逐步改进能提升生产力。笔记本应该提供最先进的用户体验,并结合机器学习框架,以释放数据的价值。
简历: Armin Wasicek 是 Sumo Logic 的高级软件工程师,专注于高级分析。此前,他在学术界和工业界度过了许多年愉快的研究生涯。他的兴趣包括机器学习、安全性和物联网。Armin 拥有奥地利维也纳技术大学的博士和硕士学位,并曾在加州大学伯克利分校担任 Marie Curie 研究员。
相关:
-
数据科学编程最佳实践
-
如何在 Google Cloud 上设置免费的数据科学环境
-
为什么称自己为数据科学家?
更多内容
使用 OpenAI GPT 模型的最佳实践
原文:
www.kdnuggets.com/2023/08/best-practices-openai-gpt-model.html

图片来源:rawpixel.com 于 Freepik
自从 GPT 模型发布以来,每个人都在不断使用它。从提出简单问题到开发复杂的编码,GPT 模型可以迅速帮助用户。这就是为什么模型随着时间的推移会变得越来越强大的原因。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
为了帮助用户获得最佳输出,OpenAI 提供了他们的 最佳实践 用于使用 GPT 模型。这来自于许多用户对该模型的不断实验和找到的最佳使用方式。
在本文中,我将总结你在使用 OpenAI GPT 模型时应知道的最佳实践。这些实践是什么?让我们深入了解。
GPT 最佳实践
GPT 模型的输出质量仅取决于你的提示。通过明确的指示你想要什么,它将提供你期望的结果。一些提升 GPT 输出质量的建议包括:
-
在提示中包含详细信息以获得相关答案。 例如,与其使用“给我代码来计算正态分布”的提示,不如写成“请提供标准分布计算的 Python 代码示例。在每个部分中放置注释,并解释每段代码为何如此执行。
-
提供角色或示例,并增加输出的长度。 我们可以为模型提供角色或示例,以便更好地澄清。例如,我们可以传递系统角色参数,以教师讲解学生的方式来解释某些内容。通过提供角色,GPT 模型将以我们所需的方式呈现结果。如果你想更改角色,这里有一段示例代码。
import openai
openai.api_key = ""
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
messages=[
{
"role": "system",
"content": """
When I ask to explain something, bring it in a way that teacher
would explain it to students in every paragraph.
""",
},
{
"role": "user",
"content": """
What is golden globe award and what is the criteria for this award? Summarize them in 2 paragraphs.
""",
},
],
)
提供示例结果也是一个好方法,以指导 GPT 模型如何回答你的问题。例如,在这段代码中,我传递了我如何解释情感的方式,GPT 模型应模仿我的风格。
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
messages=[
{
"role": "system",
"content": "Answer in a consistent style.",
},
{
"role": "user",
"content": "Teach me about Love",
},
{
"role": "assistant",
"content": "Love can be sweet, can be sour, can be grand, can be low, and can be anything you want to be",
},
{
"role": "user",
"content": "Teach me about Fear",
},
],
)
- 指定完成任务的步骤。 提供详细的步骤说明,以便获得最佳输出。详细分解 GPT 模型应如何操作的指令。例如,我们在这段代码中提供了带前缀和翻译的两步指令。
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
messages= [
{
"role": "system",
"content": """
Use the following step-by-step instructions to respond to user inputs.
step 1 - Explain the question input by the user in 2 paragraphs or less with the prefix "Explanation: ".
Step 2 - Translate the Step 1 into Indonesian, with a prefix that says "Translation: ".
""",
},
{
"role": "user",
"content":"What is heaven?",
},
])
-
提供参考、链接或引用。如果我们已经有了各种问题的参考资料,我们可以利用这些作为 GPT 模型提供输出的基础。提供任何你认为与问题相关的参考列表,并将其传入系统角色。
-
给 GPT 时间来“思考”。提供一个查询,让 GPT 详细处理提示,然后再匆忙给出不正确的结果。这一点尤其重要,如果我们传递给助手角色一个错误的结果,我们希望 GPT 能够进行批判性思考。例如,下面的代码展示了我们如何要求 GPT 模型对用户输入更具批判性。
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
messages= [
{
"role": "system",
"content": """
Work on your solution to the problem, then compare your solution to the user and evaluate
if the solution is correct or not. Only decide if the solution is correct once you have done the problem yourself.
""",
},
{
"role": "user",
"content":"1 + 1 = 3",
},
])
- 让 GPT 使用代码执行以获得精确结果。 对于更复杂的计算,GPT 可能无法正常工作,因为模型可能提供不准确的结果。为了解决这个问题,我们可以要求 GPT 模型编写和运行代码,而不是直接计算。这样,GPT 可以依赖代码而不是其计算结果。例如,我们可以提供如下输入。
res = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
max_tokens=100,
temperature=0.7,
messages= [
{
"role": "system",
"content": """
Write and execute Python code by enclosing it in triple backticks,
e.g. ```code goes here```py. Use this to perform calculations.
""",
},
{
"role": "user",
"content":"""
Find all real-valued roots of the following polynomial equation: 2*x**5 - 3*x**8- 2*x**3 - 9*x + 11.
""",
},
])
结论
GPT 模型是现有的最佳模型之一,以下是一些最佳实践来提高 GPT 模型的输出:
-
在提示中包含详细信息以获得相关回答
-
提供角色或示例,并添加输出的长度
-
指定完成任务的步骤
-
提供参考、链接或引用
-
给 GPT 时间来“思考”
-
让 GPT 使用代码执行以获得精确结果
Cornellius Yudha Wijaya 是数据科学助理经理和数据撰写员。在全职工作于 Allianz Indonesia 的同时,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
相关主题
初学者和高级程序员的最佳 Python 书籍
原文:
www.kdnuggets.com/2021/05/best-python-books-beginner-advanced.html
评论
作者:Claire D. Costa,Digitalogy LLC 的内容编写员和策略师

图片由 Christina Morillo 提供,来源于 Pexels
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
“编码 Python 的乐趣在于看到简洁、可读的类,用少量清晰的代码表达大量动作,而不是堆积如山的琐碎代码,这些代码让读者感到厌烦。”
— Guido van Rossum
Python 的流行性和多用途特性使其成为各种项目的完美编程语言。此外,这种流行性和公司广泛采用导致了行业对熟练 Python 开发者的强烈需求。
现在,实际上有大量的资源,比如书籍、YouTube 频道、播客、GitHub 仓库、在线课程和网站,这些资源广泛覆盖了 Python 的各种主题。
Python 书籍
只需慢慢来,不要伤害大脑。
互联网充满了各种方便的媒介来学习 Python 的所有知识。虽然我们之前讨论了更广泛采用的媒介,但书籍仍然是学习者的永恒热门选择。书籍在 Python 学习者中如此受欢迎的原因在于,它们允许读者按自己的时间和节奏吸收和实践内容。
跟随我们,我们将深入探讨更多为各技能水平学习者准备的知名 Python 书籍。
1. 思考 Python
-
作者:艾伦·B·道尼
-
出版社: O'Reilly
-
难度等级: 初学者

《思考 Python》的封面
“对于所有的活产儿,平均妊娠期为 38.6 周,标准差为 2.7 周,这意味着我们应该预期 2–3 周的偏差是很常见的。”
— 艾伦·B·道尼
《Think Python》 无疑是了解 Python 编程基础的最佳书籍之一。该书通过采取更渐进的教学方法,为初学者提供了一个优秀的 Python 入门点。
最新版的书籍更新了所有代码示例,使其与 Python 3 相对应,以提供最新的学习体验。书中还包含了大量练习、案例研究和详细的主题解释。《Think Python》的主要亮点列在下面:
-
为初学者提供从浏览器开始学习 Python 的知识。
-
清晰定义了 Python 中的概念。
-
强调调试,以教会读者快速发现、解决和避免错误。
2. 《Python 编程:计算机科学导论》
-
作者: 约翰·M·泽尔
-
出版社: 富兰克林,贝德尔
-
难度等级: 初学者

书籍《Python 编程:计算机科学导论》的封面
由于 Python 的易用性和简单性,它可以成为初学者的绝佳第一编程语言。同样,《Python 编程:计算机科学导论》 的编写目标是尽可能简化 Python 的基础知识,以便初学者能够更容易地掌握。
作者将这本书定位为大学教材,因此作者采取了更传统的教学方法,专注于问题解决、程序设计和编程作为核心技能。因此,如果你是大学生并且想学习 Python,我们推荐你试试这本书。该书的主要亮点列在下面:
-
专注于使用易于使用的图形包,以鼓励使用此类 GUI 包
-
提供大量有趣的示例和章节末练习
-
专注于帮助读者掌握基础知识,而不会让他们感到 Python 主题过于复杂
3. 《Django 初学者:使用 Python 和 Django 构建网站》
-
作者: 威廉·S·文森特
-
出版社: WelcomeToCode
-
难度等级: 初学者

书籍《Django 初学者:使用 Python 和 Django 构建网站》的封面
Django 已成为现代开发人员中最受欢迎的 Web 应用开发框架之一。Django 基于 Python 构建,证明了它能够提供构建出色 Web 应用所需的一切,而无需深入核心 Python。
从一个简单的 Hello World 开始,《Django 初学者:使用 Python 和 Django 构建网站》完美地提供了逐步教学方法,教你如何构建完整的 Django 应用。书中还专注于教授维护安全性、自定义外观和有效测试应用的最佳实践。
除了 Hello World 应用外,本书涵盖的其他应用包括:
-
一个页面应用
-
一个留言板应用
-
一个博客应用
-
一个报纸应用
4. 《Python 口袋参考:口袋里的 Python》
-
作者: 马克·卢茨
-
出版商: O'Reilly
-
难度级别: 中级

书名《Python 口袋参考:口袋里的 Python》的封面
“在 Python 思维方式中,显式优于隐式,简单优于复杂。”
― 马克·卢茨
《Python 口袋参考:口袋里的 Python》并不是一本全面的 Python 学习资源,而是为开发者提供关于众多 Python 主题的即时参考。作者希望这本书能作为其他更全面 Python 书籍的补充,这些书籍提供教程、代码示例和其他学习材料。
该书的最新版本涵盖了 Python 3.4 和 2.7 中的所有必知内容,同时也介绍了两个版本之间的差异。马克的口袋参考书面向有一定 Python 编程经验的开发者。书中涉及多个主题,例如:
-
常用的标准库模块和扩展
-
用于创建和处理对象的语法
-
面向对象编程工具
-
内置对象类型,如数字、字典等
-
特殊操作符重载方法
5. 《Python 机器学习:使用 Python、scikit-learn 和 TensorFlow 2 进行机器学习和深度学习》
-
作者: 塞巴斯蒂安·拉施卡 & 瓦希德·米尔贾利
-
出版商: Packt Publishing
-
难度级别: 中级

书名《Python 机器学习:使用 Python、scikit-learn 和 TensorFlow 2 进行机器学习和深度学习》的封面
感谢 Python, 机器学习的普及 在近年来飙升。《Python 机器学习:使用 Python、scikit-learn 和 TensorFlow 2 进行机器学习和深度学习》旨在为具备编程语言基础知识的 Python 开发者和数据科学家提供,他们渴望创建令人印象深刻的机器学习和深度学习驱动的智能解决方案。如果你是其中之一,这本书将是你的理想之选。
说到这本书的内容,除了必要的介绍外,第三版提供了大量关于机器学习主题的内容,例如:
-
训练简单的机器学习算法
-
使用 Scikit-learn 包进行分类
-
构建良好数据集的步骤
-
将机器学习模型嵌入应用程序
6. 《Python 深度学习》
-
作者:François Chollet
-
出版社:Manning Publications
-
难度级别:中级

《Python 深度学习》封面
“Python 深度学习”是一本出色的书籍,简化了使用 Python 进行深度学习的复杂性。本书的作者正是著名的深度学习 Python API Keras的创造者。François 的书籍使用 Keras 作为连接深度学习和 Python 世界的桥梁,通过直观的解释和实际的例子逐步构建你对这一主题的理解。
这本书被分为几个部分,涵盖了大部分关于机器学习和 神经网络的入门内容,以及深度学习在现实世界挑战和任务中的实际应用,例如:
-
计算机视觉
-
文本和序列
-
最佳实践
-
生成对抗深度学习
7. 《Python 精要:桌面快速参考》
-
作者:Alex Martelli, Anna Ravenscroft & Steve Holden
-
出版社:O’Reilly
-
难度级别:中级

《Python 精要:桌面快速参考》封面
无论你是过去曾经使用过 Python,还是一位希望学习 Python 的资深开发人员,你都会发现“Python 精要:桌面快速参考”异常有用。该书涵盖了 Python 世界中一系列广泛使用的话题,并作为 Python 编程语言的快速参考。
本书作者将其分为五个部分,涵盖了从基础到核心功能以及更高级的内容。以下是对这五个部分的简要说明:
-
第一部分:介绍和解释 Python 解释器
-
第二部分:涵盖核心 Python 语言及其内置主题
-
第三部分:
-
第四部分:涵盖网络和 Web 编程与 Python
-
第五部分:涵盖扩展 Python 程序、分发以及从 v2 到 v3 的迁移
8. 《Python 编程:强大的面向对象编程》
-
作者:Mark Lutz
-
出版社:O’Reilly
-
难度级别:中级

《Python 编程:强大的面向对象编程》封面
假设你已经非常清楚地理解了 Python 的入门主题,那么接下来做什么呢?
接下来最明显的事情就是通过开发一个简单而实用的 Python 应用程序来测试你新获得的知识。
如果你在寻找特定领域的示例,我们强烈推荐 Lutz 的书《编程 Python:强大的面向对象编程》。这本书非常适合中级 Python 开发者,并深入讲解了以下各种广泛应用的教程:
-
Python 的简要快速介绍
-
使用系统工具和文件、目录进行系统编程
-
使用 Tkinter 进行 GUI 编程
-
使用客户端和服务器端脚本、网络脚本以及电子邮件客户端进行互联网编程
9. 使用 Python 进行自然语言处理:使用自然语言工具包分析文本
-
作者: Steven Bird、Ewan Klein 和 Edward Loper
-
出版社: O’Reilly
-
难度等级:高级

书籍《使用 Python 进行自然语言处理:使用自然语言工具包分析文本》的封面
自然语言处理 已成为现代设备的重要组成部分,因为它们在提供预测文本、手写识别、人性化语言翻译等智能功能方面发挥了关键作用。书籍《使用 Python 进行自然语言处理:使用自然语言工具包分析文本》为那些初涉编程世界或对 Python 不熟悉的人提供了充足的学习资源。
这本书更适合对 Python 基础有扎实掌握的开发者,因为它包含了大量详细的示例和练习。它使用 Python 库 NLTK 来教授以下主题:
-
NLP 介绍
-
访问文本和词汇资源
-
处理原始文本
-
词汇的分类和标记
-
文本分类
结论
学习 Python 可以为你打开一系列有利可图的机会。如果你渴望获得本世纪最热门和高薪的职位,我们建议你深入了解 Python 的概念。本文中提到的书籍在以读者友好的方式解释即使是最复杂的 Python 主题方面做得非常出色。
我们是否涵盖了你最喜欢的书籍?我们很想听听你的想法。
感谢阅读!
个人简介:Claire D. Costa 是 Digitalogy 的内容创作者和市场推广员,Digitalogy 是一个技术采购和定制匹配市场,根据全球用户的具体需求,将他们与经过筛选的顶级开发者和设计师联系起来。
原文。已获得许可转载。
相关:
-
最佳免费的数据科学电子书:2020 年更新
-
你应该知道的最佳 Python IDE 和代码编辑器
-
2021 年你应该开始阅读的数据科学书籍
更多相关话题
最佳 Python 课程:分析总结
原文:
www.kdnuggets.com/2022/01/best-python-courses-analysis-summary.html
介绍
如果我们询问:“十大最佳 Python 课程是什么?”数据揭示了什么?收集了来自顶级平台的几乎所有课程,显示出有很多选择,共有超过 3000 个课程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
本文总结了我的分析并呈现了前三大课程。有关完整的文章,包括重现我结果所需的所有代码,请参见原文:根据数据分析的十大最佳 Python 课程。
TL;DR: 胜出者
在所有收集的课程中,分析显示这些是前三名:
如果你只是想了解推荐的课程,可以查看前三名。然而,如果你对生成这些排名的数据显示和方法感兴趣,请继续阅读完整总结。
妥协与假设
数据分析需要采用还原主义的方法来看待世界。通常,数据必须被选择,因为它与期望的属性有较好的相关性。这些妥协和假设是必要的,但同样重要的是能够说明我们所做的假设。这样,其他人可以对你的方法进行批评并理解其局限性。
假设:
-
谷歌搜索引擎排名是对反向链接数量和质量的公平反映
-
课程页面的受欢迎程度与其独特链接的数量正相关
-
课程页面的受欢迎程度与其流量正相关
-
分析中使用的平台选择是全面的
-
对页面中“Python”或顶级关键字的数据过滤没有排除相关课程或包含不相关课程
局限性:
-
使用的基础 Ahrefs计划提供了 Google 上的前 50 个搜索结果,而不是所有可能的结果集
-
Ahrefs 的域名评分只是 Google 秘密算法的估计
数据准备
准备数据以进行分析通常是最具挑战性的步骤。在这种情况下,我:
1. 将每个课程平台导出为单独的 CSV 文件。
我们已经知道我们需要进一步过滤数据以排除某些无关的页面,但那是后话。
2. 确保我们的 Python 环境中有所需的库:pandas,matplotlib/seaborn,以及scipy。
这些库将有助于探索和可视化数据。
3. 创建一个空的 DataFrame,并将每个文件合并到该 DataFrame 中。
由于每个 CSV 都有自己的索引,我们需要重置索引以为合并后的数据框创建一个新索引。
4. 检查数据以构建有意义的过滤器
这处理了第 1 点提到的问题。
5. 删除重复项
例如,URL 可以是" http"或"https",可能有或没有 www。
6. 应用特征工程创建了一个引用域和流量之间的交互项。
计算流量和引用域的 z 分数,使用 scipy 库创建一个新属性:两个 z 分数的平均值。
7. 进行了另一轮清理
例如,Codecademy 的 Python 2 课程排名第一,但被 Python 3 所取代。解决方案:我们保留了 Codecademy 的位置并切换了推荐课程。目前,人类的常识是这种分析中的一个关键输入。
数据可视化
正如通常情况一样,数据可视化在数据准备阶段就开始了。这有助于了解是什么使得情况变得复杂。
例如,一旦课程按其流量和引用域进行绘制,就很明显我们仍然需要进行一些主要的清理(如第 7 步所述)以移除不相关的课程。以下图表显示了一些进入数据中的无关课程:
进行可视化通常需要创建一个新的数据框,将数据分组为你所需的格式。例如,按平台分组的 Python 课程和流量条形图:
上述图表带来了一个有趣的观察:一个平台上的 Python 相关课程越多,并不一定意味着流量越多。这似乎证实了质量比数量更重要的格言。
定性分析
定量分析给出了我们的排名。对于一些免费的课程的定性分析,我将它们合并起来并分享了我的看法。
1. 通过 Codecademy 学习 Python
证书:✔ 测验:✔ 项目:✔ 互动:✔
一门扎实的初级课程,解决 Python 问题,涵盖其他课程常常完全忽略的基础主题。
2. Udacity 的 Python 编程入门
视频:✔ 测验:✔
尽管这门初级课程没有给我留下像其他课程那样的深刻印象,但仍然提供了很好的价值。例如,与 Codecademy 不同的是,每节课都有录制的讲座。
3. 适合所有人的编程(Python 入门) by Coursera
证书:✔(需支付)视频:✔ 测验:✔
这门课程的视频比我试用的其他课程更有条理和趣味。课程的节奏和难度起初较低,但最终会使你达到中级水平的 Python 知识。Python 学习环境特别设计得很好。
结论
Codecademy 的课程看起来是开始 Python 学习的安全选择。但无论你选择哪个课程,都要尽可能多地进行项目实践。找到一个你感兴趣的问题,并持续编程,直到你有解决方案。展示你的解决方案,帮助他人,甚至将其作为职业。使用 Python —— 以及编程的一般性 —— 为自己和他人创造价值,是一个奖励性的反馈循环,将不断激励你前进和提升。
我们希望这篇文章能帮助你在 Python 学习之路上前进。查看 原文 以获取更多细节、完整代码以及其他前 10 名的内容。
布伦丹·马丁 是创始人兼主编,LearnDataSci。LearnDataSci 使数据科学学习在线上对每个人都可及。每月的文章旨在帮助在线学习者对数据科学和机器学习主题有直观的理解,这些主题对数据科学职业至关重要。
更多相关话题
你应该了解的最佳 Python IDE 和代码编辑器
原文:
www.kdnuggets.com/2021/01/best-python-ide-code-editors.html
评论
由 Claire D. Costa,Digitalogy LLC 的内容撰写者和策略师。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
照片由 luis gomes 提供,来自 Pexels。
Python 是对程序员需要多少自由的实验。自由过多,则没有人能读懂他人的代码;自由过少,则表达能力受到威胁。 - Guido van Rossum
自从其创建以来,Python 已迅速演变成一种多功能的编程语言,成为从 web 应用程序到被部署到人工智能、机器学习、深度学习等多个不同项目的选择。
Python 拥有许多特点,例如其简单性、大量的包和库,以及相对较快的程序执行速度,仅举几例。
GitHub 的第二大热门语言,也是机器学习中最受欢迎的语言。
对于程序员来说,代码编辑器或 IDE 是接触任何编程语言的第一步,因此选择它们是前进过程中最关键的步骤之一。在本文中,我们将探讨一些顶级 Python IDE 和代码编辑器,以及你应该或不应该选择它们作为下一个项目的理由。
根据 StackOverflow 的数据,Python 是增长最快的主要编程语言:Stack Overflow 开发者调查 2019
什么是集成开发环境(IDE)?
IDE 代表 [集成开发环境](https://press.rebus.community/programmingfundamentals/chapter/integrated-development-environment/#:~:text=An integrated development environment (IDE,IDEs have intelligent code completion.),不仅包括用于管理代码的标准代码编辑器,还提供了一整套调试、执行和测试工具,这是软件开发的绝对必要条件。有些 IDE 还配备了内置的编译器和解释器。以下是一些标准功能,常见的 IDE 在单一专用环境中提供:
-
语法高亮
-
构建自动化
-
版本控制
-
可视化编程
-
代码格式化和补全
-
代码重构
-
支持与外部工具的集成
IDE 与代码编辑器
代码编辑器或集成开发环境(IDE)是任何程序员最基本的软件,它是他们一天的开始和结束。为了实现其最大潜力,最佳的起点是一个可以基本支持 Python 的代码编辑器或 IDE,但这还不全是。**许多 **编程语言 可以完全不依赖 IDE,而有些则依赖 IDE。
代码编辑器 — 代码编辑器是程序员用于应用开发的核心软件。可以将其视为一个简单的文本编辑器,但具有额外的编程特定的高级功能,例如:
-
语法高亮
-
代码格式化
-
拆分文件查看和编辑
-
即时项目切换
-
多重选择
-
跨平台支持
-
轻量级
IDE — 另一方面,IDE 配备了一套工具,这些工具不仅帮助开发应用程序,还帮助进行测试、调试、重构和构建自动化。不用说,在大多数情况下,IDE 可以提供代码编辑器的所有功能,但代码编辑器无法替代 IDE。
2020 年最佳 Python IDE 和代码编辑器
选择合适的工具至关重要。同样,在开始一个新项目时,作为程序员,你在选择完美的代码编辑器或 IDE 时有很多选择。市场上有许多 Python 的 IDE 和代码编辑器,在本节中,我们将讨论一些最佳的选项及其优缺点。
- PyCharm

图像来源 — PyCharm。
-
类别: IDE
-
首次发布日期: 2010
-
平台兼容性: Windows、macOS、Linux
-
适合人群: 中级到高级 Python 用户
-
支持的语言: Python、Javascript、CoffeeScript 等
-
价格: Freemium(免费限制功能社区版本,付费全功能专业版本)
-
下载: PyCharm 下载链接
-
使用 PyCharm Python IDE 的流行公司 — Twitter、HP、Thoughtworks、GROUPON 和 Telephonic。
由 JetBrains 开发,PyCharm 是一个 跨平台 IDE,提供了版本控制、图形调试器、集成单元测试等多种功能,并且非常适合用于 Web 开发和数据科学任务。借助 PyCharm 的 API,开发者可以创建自定义插件,为 IDE 添加新功能。其他功能包括:
-
代码补全
-
实时更新代码更改
-
Python 重构
-
支持全栈 Web 开发
-
支持如 matplotlib、numpy 和 scipy 等科学工具
-
支持 Git、Mercurial 等
-
提供了付费版和社区版
优点 —
-
可以提高生产力和代码质量
-
高度活跃的社区支持
缺点 —
-
加载速度可能较慢
-
为最佳兼容性,要求对现有项目更改默认设置
-
初始安装可能较困难
参考截图
图片来源 — PyCharm。
- Spyder
图片来源 — Spyder。
-
类别:IDE
-
首次发布年份:2009
-
平台兼容性:Windows、macOS、Linux
-
适用对象:Python 数据科学家
-
价格:免费
-
下载:Spyder 下载链接
Spyder 提供对 NumPy、SciPy、Matplotlib 和 Pandas 等包的支持。面向科学家、工程师和数据分析师,Spyder 提供了高级的数据探索、分析和可视化工具。这个跨平台 IDE 的功能包括:
-
代码补全
-
语法高亮
-
通过分析器进行代码基准测试
-
多项目处理
-
查找文件功能
-
历史日志
-
内置控制台用于内部检查
-
支持第三方插件
优点 —
-
包含对众多科学工具的支持
-
提供了出色的社区支持
-
互动控制台
-
轻量级
缺点 —
-
附带执行依赖
-
对新手来说可能有些挑战
参考截图
图片来源 — Spyder。| spyder-ide/spyder
- Eclipse + Pydev

-
类别:IDE
-
首次发布年份:2001 — Eclipse,2003 — Pydev
-
平台兼容性:Windows、macOS、Linux
-
适用对象:中级到高级 Python 用户
-
支持语言:Python(Eclipse 支持 Java 和许多其他编程语言)
-
价格:免费
-
下载:PyDev 下载链接
-
使用 PyDev 和 Eclipse Python IDE 的知名公司 — Hike、Edify、Accenture、Wongnai 和 Webedia。
Eclipse 是最顶尖的 IDE 之一,支持包括 Python 在内的广泛编程语言的应用开发。最初用于开发 Java 应用,通过插件引入对其他编程语言的支持。用于 Python 开发的插件是 Pydev,提供了额外的好处,如:
-
Django、Pylint 和单元测试集成
-
互动控制台
-
远程调试器
-
跳转到定义
-
类型提示
-
自动补全代码和自动导入
优点 —
-
易于使用
-
程序员友好的功能
-
免费
缺点 —
-
复杂的用户界面使得使用起来具有挑战性
-
如果你是初学者,那么使用 Eclipse 会很困难
参考截图

图片来源 — Pydev。
- IDLE

图片来源 — Python。
-
类别:IDE
-
首次发布年份:1998
-
平台兼容性:Windows、macOS、Linux
-
适用对象:初学 Python 用户
-
价格:免费
-
下载:IDLE 下载链接
-
使用 IDLE Python IDE 的热门公司 — 谷歌、维基百科、CERN、雅虎和 NASA。
IDLE 的全称是集成开发和学习环境,已与 Python 一起捆绑使用超过 15 年。IDLE 是一个跨平台 IDE,提供了一组基本功能,以保持简洁。提供的功能包括:
-
带有彩色代码、高亮输入、输出和错误信息的 Shell 窗口
-
支持多窗口文本编辑器
-
代码自动补全
-
代码格式化
-
文件内搜索
-
带有断点的调试器
-
支持智能缩进
优点 —
- 适合初学者和教育机构
缺点 —
- 缺少更高级 IDE 提供的功能,如项目管理能力
- Wing

图片来源 — Wing。
-
类别:IDE
-
首次发布年份:2000 年 9 月 7 日
-
平台: Windows、Linux 和 Mac
-
适用对象:中级到高级 Python 用户
-
价格:每用户每年 $179 的商业使用费,永久商业使用许可证每用户 $245
-
下载:Wing 下载链接
-
使用 Wing Python IDE 的热门公司 — Facebook、谷歌、英特尔、苹果和 NASA
功能丰富的 Python IDE Wing 旨在通过引入智能功能如智能编辑器和简单的代码导航来加快开发速度。Wing 有 101、Personal 和 Pro 三个版本,其中 Pro 版本功能最为丰富,也是唯一付费的。Wing 的其他显著功能包括:
-
代码补全、错误检测和质量分析
-
智能重构功能
-
互动调试器
-
单元测试集成
-
可自定义界面
-
支持远程开发
-
支持 Django、Flask 等框架
优点 —
-
与版本控制系统如 Git 配合良好
-
强大的调试能力
缺点 —
-
缺乏吸引人的用户界面
-
Cloud9 IDE

图片来源 — AmazonCloud9。
-
类别: IDE
-
**首次发布年份: **2010
-
平台: Linux/MacOS/Windows
-
**使用 Cloud9 Python IDE 的流行公司 — **Linkedin、Salesforce、Mailchimp、Mozilla、Edify 和 Soundcloud。
Amazon Web Services的一部分,Cloud9 IDE 让你可以通过浏览器访问基于云的 IDE。所有代码都在亚马逊的基础设施上执行,提供了无缝且轻量的开发体验。功能包括:
-
需要最少的项目配置
-
强大的代码编辑器
-
代码高亮、格式化和补全功能
-
内置终端
-
强大的调试器
-
实时配对编程功能
-
即时项目设置,覆盖大多数编程语言和库
-
通过终端畅通访问多个 AWS 服务
优点 —
-
使无服务器应用程序的开发变得轻松
-
异常强大且全球可访问的基础设施
缺点 —
-
完全依赖互联网访问
-
Sublime Text 3

图片来源 — Sublime。
-
**类别: **代码编辑器
-
**首次发布年份: **2008
-
**平台兼容性: **Windows、macOS、Linux
-
**适用对象: **初学者、专业人士
-
**支持语言: **Python 和 C#
-
**价格: **免费增值
-
**下载: **Sublime text 3 下载链接
-
**使用 Sublime Text Python IDE 的流行公司 — **Starbucks、Myntra、Trivago、Stack 和 Zapier。
Sublime Text 是最常用的跨平台代码编辑器之一,支持多种编程语言,包括 Python。Sublime 提供多种功能,如丰富的主题进行视觉自定义、干净且无干扰的用户界面,并支持通过插件扩展核心功能的包管理器。其他功能包括:
-
通过包管理器获取最新插件
-
文件自动保存
-
宏功能
-
语法高亮和代码自动补全
-
同时代码编辑
-
跳转到任何位置、定义和符号
优点 —
-
简洁的用户界面
-
分屏编辑
-
快速且高性能的编辑器
缺点 —
-
令人烦恼的弹出窗口要求购买 Sublime 许可证
-
繁杂的快捷键数量
-
复杂的包管理器
-
Visual Studio Code

图片来源 — Visual Studio Code。
-
**类别: **IDE
-
**首次发布年份: **2015
-
**平台兼容性: **Windows、macOS、Linux
-
适用对象: 专业人士
-
支持语言:所有主要编程语言(Python、C++、C#、CSS、Dockerfile、Go、HTML、Java、JavaScript、JSON、Less、Markdown、PHP、PowerShell、Python、SCSS、T-SQL、TypeScript)
-
价格:免费
-
使用 Visual Source Code(Python IDE)的热门公司 — The Delta Group、TwentyEight, Inc.、Focus Ponte Global、Creative Mettle 和 National Audubon Society, Inc.
由微软开发, Visual Studio Code 是一款备受推崇的跨平台代码编辑器,具有高度的可定制性,并允许在多种编程语言中进行开发,包括 Python。它为程序员提供了丰富的功能,如智能调试、可定制性、插件支持等。主要亮点包括:
-
内置对 Git 和版本控制的支持
-
代码重构
-
集成终端
-
智能感知用于更智能的代码高亮和自动完成
-
直观的代码调试功能
-
无缝部署到 Azure
优点 —
-
定期更新,活跃的社区支持
-
免费
缺点 —
-
插件数量庞大,找到合适的插件可能有挑战
-
对大文件的处理能力平平
-
启动时间较长
参考截图
图片来源 — Visual Studio Code。
- Atom

图片来源 — Atom。
-
类别:代码编辑器
-
首次发布年份:2014
-
平台兼容性:Windows、macOS、Linux
-
适合人群:初学者、专业人士
-
支持语言:Python、HTML、Java 和其他 34 种语言。
-
价格:免费
-
下载:Atom 下载链接
-
使用 Atom(Python IDE)的热门公司 —埃森哲、Hubspot、Figma、Lyft 和 Typeform。
由 GitHub 开发, 这是源代码托管和软件版本控制领域的领先者,Atom 是一个轻量级的跨平台代码编辑器,支持 Python 和许多其他编程语言。Atom 提供了许多以插件形式呈现的功能,增强了其核心特性。它基于 HTML、JavaScript、CSS 和 Node.js,底层框架为 Electron。提供的功能包括:
-
通过内置的包管理器支持第三方包
-
支持开发者协作
-
超过 8000 个功能和用户体验扩展包
-
支持多窗格文件访问
-
智能代码自动完成
-
自定义选项
优点 —
-
轻量级代码编辑器
-
社区驱动的开发和支持
缺点 —
-
最近的更新增加了内存使用
-
使用前需要在设置中进行一些调整
-
Jupyter

图片来源 — Jupyter。
-
类别:集成开发环境(IDE)
-
首次发布年份:2015 年 2 月
-
浏览器兼容性:Chrome、Firefox、Safari
-
价格:免费
-
下载:Jupyter 下载链接
-
**使用 Jupyter Python IDE 的知名公司 — **Google、Bloomberg、Microsoft、IBM 和 Soundcloud。
也被称为Project Jupyter,它是一个开源和跨平台的 IDE,许多数据科学家和分析师更倾向于使用它而不是其他工具。非常适合处理 AI、ML、DL 等技术以及包括 Python 在内的多种编程语言。Jupyter 笔记本提供了无缝的代码、文本和方程式创建与共享,用于各种目的,包括分析、可视化和开发。提供的功能包括:
-
代码格式化和高亮
-
通过电子邮件、Dropbox 轻松分享
-
生成交互式输出
-
与大数据兼容良好
-
可以从本地和云机器运行
优势 —
-
需要最少的设置
-
适合快速数据分析
劣势 —
- 缺乏经验的用户可能会觉得 Jupyter 复杂
参考截图

图片来源 — Jupyter。
如何为自己选择最佳 Python IDE 和代码编辑器
选择正确的 IDE 或代码编辑器可能意味着在快速开发中节省时间,或者由于鲁莽的决策而浪费时间。我们在前一部分提到了许多 IDE 和代码编辑器及其一些显著的特性。如果您对选择哪个来进行下一个 Python 项目感到困惑,我们建议您快速阅读一下。毕竟,没有一套合适的 IDE 和代码编辑器,程序员会是什么样的呢?
注意:为了消除各种问题,我想提醒您,这篇文章只是我个人想要分享的意见,您有权与其不同意。
原文。已获得许可转载。
简介: Claire D. Costa 是 Digitalogy 的内容创作者和营销人员,Digitalogy 是一个技术采购和定制匹配市场,根据全球用户的具体需求,将他们与经过筛选的顶级开发人员和设计师连接起来。
相关:
更多相关主题
最适合数据科学的 Python IDE 是什么?
原文:
www.kdnuggets.com/2018/11/best-python-ide-data-science.html
评论
作者 Saurabh Hooda,Hackr.io

版权: Hitesh Choudhary 通过 Unsplash
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
Python 由 Guido van Rossum 创建,首次发布于 1991 年。这种解释型高级编程语言用于通用编程。Python 解释器可在包括 Linux、MacOS 和 Windows 在内的多个操作系统上使用。
编辑: 这里是最受欢迎的 Python IDE/编辑器,基于 KDnuggets 投票,灵感来源于此博客。
凭借近 30 年的运作历史,Python 在编程社区中赢得了巨大的受欢迎程度。虽然使用 IDLE 或 Python Shell 编写 Python 代码对于小型项目很有效,但在处理完整的机器学习或数据科学项目时却不够实用。
在这种情况下,你需要使用一个 IDE(集成开发环境)或专用的代码编辑器。由于 Python 是领先的编程语言之一,提供了大量的 IDE。因此,问题是,“哪个是最好的 Python IDE?”
显然,没有单一的 Python IDE 或代码编辑器可以被冠以“最佳”称号。这是因为每个 IDE 都有其自身的优点和缺点。此外,在众多的 IDE 中进行选择可能会耗费时间。
不用担心,我们会为你提供帮助。为了帮助你选择合适的 IDE,我们整理了一些主要的 Python IDE,这些 IDE 专为处理数据科学项目而设计。这些 IDE 包括:
Atom
平台 – Linux/macOS/Windows
官方网站 – atom.io/
类型 – 通用文本编辑器
Atom 是一个免费的开源文本和源代码编辑器,支持多种编程语言,包括 Java、PHP 和 Python。文本编辑器支持用 Node.js 编写的插件。尽管 Atom 支持多种编程语言,但它对 Python 表现出了特别的热爱,具有有趣的数据科学功能。
Atom 带来的最伟大的特性之一是对 SQL 查询的支持。然而,你需要首先安装 Data Atom 插件才能访问这一功能。它支持 Microsoft SQL Server、MySQL 和 PostgreSQL。此外,你可以在 Atom 中可视化结果,而无需打开其他窗口。
另一个对 Python 数据科学家有利的 Atom 插件是 Markdown Preview Plus。它提供了编辑和可视化 Markdown 文件的支持,让你可以预览、渲染 LaTeX 方程等。
优点:
-
活跃的社区支持
-
与 Git 的极佳集成
-
支持管理多个项目
缺点:
-
在旧版 CPU 上可能会出现性能问题
-
遭遇 迁移问题
Jupyter Notebook
平台 – Linux/macOS/Windows
官方网站 – jupyter.org/
类型 – 基于 Web 的 IDE
Jupyter Notebook 源自于 2014 年的 IPython,是一个基于服务器-客户端结构的 Web 应用程序。它允许你创建和操作被称为 notebook 的文档。对于 Python 数据科学家来说,Jupyter Notebook 是必备的,因为它提供了最直观和互动的数据科学环境之一。
除了作为 IDE 操作外,Jupyter Notebook 还可以作为教育或演示工具。此外,它对于刚刚开始数据科学的人员来说是一个完美的工具。你可以轻松查看和编辑代码,制作令人印象深刻的演示文稿。
通过使用 Matplotlib 和 Seaborn 等可视化库,你可以在与代码相同的文档中显示图形。此外,你可以将整个工作导出为 PDF、HTML 或 .py 文件。与 IPython 一样,Project Jupyter 是一系列项目的总称,包括 Notebook 自身、Console 和 Qt 控制台。
优点:
-
允许从笔记本创建博客和演示文稿
-
确保可重复的研究
-
在运行代码之前编辑代码片段
缺点:
- 复杂的安装过程
PyCharm
平台 – Linux/macOS/Windows
官方网站 – www.jetbrains.com/pycharm/
类型 – 专为 Python 设计的 IDE
PyCharm 是一个专为 Python 设计的 IDE。PyCharm 对 Python 就像 Eclipse 对 Java 一样。这个功能全面的集成开发环境提供了免费版和付费版,分别称为 Community 和 Professional 版本。它是安装最快的 IDE 之一,之后的设置也很简单,深受数据科学家青睐。
对于喜欢 IPython 或 Anaconda 发行版的用户,PyCharm 可以轻松集成 Matplotlib 和 NumPy 等工具。这意味着你可以在数据科学项目中轻松使用数组查看器和交互式图。除此之外,IDE 还支持 JavaScript、Angular JS 等。这使得它也适合 Web 开发。
安装完成后,PyCharm 可以直接用于编辑、运行、编写和调试 Python 代码。要开始一个新的 Python 项目,你只需打开一个新文件并开始编写代码。除了提供直接的调试和运行功能外,PyCharm 还支持源代码控制和完整的项目。
优点:
-
活跃的社区支持
-
实际上是 Python 开发的首选,无论是数据科学还是非数据科学项目
-
无论是新手还是资深用户都很容易使用
-
更快的重新索引
-
无需外部要求即可运行、编辑和调试 Python 代码
缺点:
-
可能加载较慢
-
默认设置可能需要调整才能使用现有项目
Rodeo
平台 – Linux/macOS/Windows
官方网站 – rodeo.yhat.com/
类型 – Python 专用 IDE
带有橙色的标志暗示这个 Python IDE 是专门为数据分析开发的。如果你有一些 RStudio 的使用经验,你会知道 Rodeo 与它有许多相似之处。对于不了解 RStudio 的人来说,它是最受欢迎的 R 语言集成开发环境。
像 RStudio 一样,Rodeo 的窗口被分为四个部分,即文本编辑器、控制台、变量可视化环境和绘图/库/文件。令人惊讶的是,Rodeo 和 RStudio 与 MATLAB 有很大相似性。
Rodeo 的最佳之处在于它为初学者和资深用户提供了相同级别的便利。由于 Python IDE 允许你在创建的同时查看和探索,Rodeo 无疑是那些刚开始用 Python 从事数据科学的人最好的 IDE 之一。这个 IDE 还拥有内置教程和辅助材料。
优点:
-
很大的自定义空间
-
实时查看和探索你正在创建的内容
-
通过自动补全和语法高亮功能更快地编写代码,并支持 IPython
缺点:
-
很多错误
-
支持不够活跃
-
存在内存问题
Spyder
平台 – Linux/macOS/Windows
官方网站 – www.github.com/spyder-ide/spyder
类型 – Python 专用 IDE
Spyder 是一个开源的专用 Python IDE。其独特之处在于它针对数据科学工作流程进行了优化。它配有 Anaconda 包管理器,这是Python 编程语言的标准发行版。Spyder 具备所有必要的 IDE 功能,包括代码自动补全和集成文档浏览器。
专为数据科学项目构建,Spyder 拥有平滑的学习曲线,让你能够迅速上手。在线帮助选项允许你在开发项目的同时查找有关库的具体信息。此外,这款专为 Python 设计的 IDE 与 RStudio 相似。因此,当从 R 转向 Python 时,这是一个不错的选择。
Spyder 对 Python 库(如 Matplotlib 和 SciPy)的集成支持进一步证明了该 IDE 专为数据科学家设计。除了值得称赞的 IPython/Jupyter 集成,Spyder 还具有一个独特的“变量浏览器”功能,允许以表格形式显示数据。
优点:
-
代码自动补全和变量探索
-
易于使用
-
适合数据科学项目使用
-
界面整洁
-
主动的社区支持
缺点:
-
对非数据科学项目能力不足
-
对于高级 Python 开发者来说过于基础
如何选择最佳的 Python IDE?
这完全取决于你需要满足的要求。然而,这里有一些通用建议:
-
刚开始使用 Python 时,选择一个自定义和附加功能较少的 IDE。干扰越少,开始得越容易。
-
将 IDE 功能与你的期望进行比较
-
尝试多个 IDE 将帮助你更好地了解哪个最适合特定需求。
个人简介:Saurabh Hooda 曾在全球电信和金融巨头担任多种职务。在 Infosys 和 Sapient 工作十年后,他创建了自己的第一个创业公司 Leno,解决超本地图书共享问题。他对产品营销和分析感兴趣。他最新的项目Hackr.io推荐了最佳的数据科学教程和每种编程语言的在线编程课程。所有教程都由编程社区提交和投票。
相关:
-
数据科学编程最佳实践
-
5 个“干净代码”技巧将显著提高你的生产力
-
初学者数据可视化与探索使用 Pandas
更多相关话题
构建生成式 AI 应用程序的最佳 Python 工具备忘单
原文:
www.kdnuggets.com/2023/08/best-python-tools-generative-ai-cheat-sheet.html
新一代的声音
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
KDnuggets 发布了一个富有洞察力的新备忘单,突出了构建生成式 AI 应用程序的顶级 Python 库。
正如读者无疑意识到的那样,生成式 AI 目前是数据科学和机器学习中最热门的领域之一。像 ChatGPT 这样的模型凭借其从简单提示中生成出令人惊叹的高质量文本的能力,捕捉了公众的想象力。
由于其多功能性、丰富的库生态系统以及与 PyTorch 和 TensorFlow 等流行 AI 框架的轻松集成,Python 已成为开发生成式 AI 应用程序的首选语言。KDnuggets 的这份新备忘单 提供了数据科学家在构建生成式应用程序时应了解的关键 Python 库的快速概览,从文本生成到人机聊天界面及其他领域。
要了解更多关于生成式 AI 应用程序构建中使用哪些 Python 工具的信息,查看我们的最新备忘单。
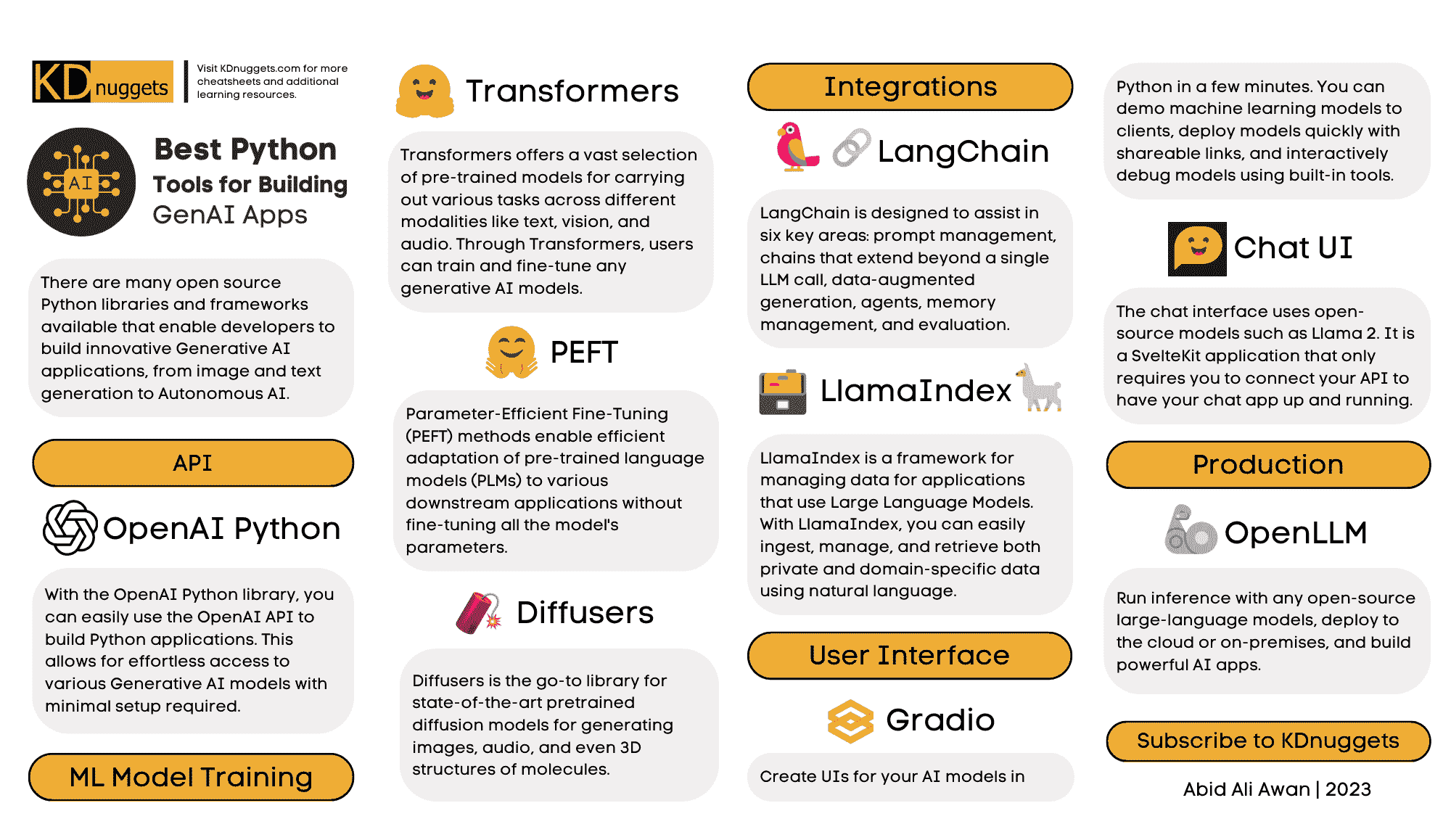
目前有许多开源的 Python 库和框架可以使开发人员构建创新的生成式 AI 应用程序,从图像和文本生成到自主 AI。
涵盖的一些亮点包括 OpenAI 用于访问诸如 ChatGPT 的模型,Transformers 用于训练和微调,Gradio 用于快速构建演示模型的用户界面,LangChain 用于将多个模型链接在一起,以及 LlamaIndex 用于摄取和管理私有数据。
总体来说,这份备忘单将大量实用指南浓缩成一页。无论是希望开始使用生成式 AI 的初学者,还是经验丰富的从业者,都可以从这份精简的参考资料中受益,它提供了最好的工具和库。KDnuggets 团队在编译和视觉组织数据科学家需要的信息方面做得非常出色,为构建下一代 AI 应用程序提供了极大的便利。
立即查看,并请继续关注以获取更多信息。
了解更多此话题
找到数据科学项目所需数据集的 3 个最佳网站
原文:
www.kdnuggets.com/2020/04/best-sites-datasets-data-science.html
评论
由Angelia Toh, Self Learn Data Science 的联合创始人。

我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
在您的数据科学学习旅程中,您不可避免地会需要寻找数据集。特别是当我们提倡在‘如何在 2020 年成为数据科学家’中进行数据科学项目时,您应该始终关注那些可以进行实验的有趣数据集。在这里,我们列出了 3 个最佳网站,供您获取数据科学项目的数据集。
1. Kaggle

您现在应该对 Kaggle 非常熟悉了。公司们一直在 Kaggle 上发布他们的数据,以利用社区的力量来解决现实生活中的问题。这使得 Kaggle 成为寻找具有实际问题陈述的数据集的理想场所。如果您想练习构建机器学习模型而不必麻烦地生成或标记数据,Kaggle 是最适合您的地方。此外,Kaggle 的笔记本部分允许用户分享他们的代码和模型,这些都可以作为极好的学习资源。我强烈推荐初学者在 Kaggle 上找到他们的第一个数据科学项目。
2. Google Dataset Search
2020 年初刚刚推出的 Google Dataset Search 是最全面的数据集搜索引擎。它声称可以索引超过 2500 万个在线数据集,并且自 2018 年 9 月推出以来,已帮助科学家和研究人员更好地定位数据集。具备按数据类型、更新时间等条件进行筛选的功能,Google Dataset Search 已成为我们大多数人的首选。
如果数据集可以在网上找到,您一定可以通过搜索引擎找到它。
3. Data.gov

在寻找数据科学数据集时,你可能会想查看你的政府发布的公开数据。这些数据如果得到有效利用,可能会带来对整个社区有益的解决方案。Data.gov 是一个由美国政府提供的开放数据湖,政府的数据被发布以促进科学社区内的研究和发展。在 Data.gov 上,数据按健康、能源或教育等主题分类,使得导航和查找所需数据变得容易。
如果你不是美国居民呢?试着用你喜欢的搜索引擎搜索“data your country”。通常,你会找到你所在国家政府发布数据的网站。例如,这里 是印度的数据网站,而 这个 是英国的数据网站。
使用这些网站,你将能够找到任何你感兴趣的数据集。记住,实践数据科学是最好的学习方式。所以保持这些网站的访问,你肯定会需要它们。
简介:Angelia Toh,‘Impossible’ 只是提醒我‘I’m possible’。永远不要停止学习 | 自学数据科学家,自学数据科学的共同创始人。
相关:
更多相关主题
2022 年数据专业人士市场 AWS 技能的最佳方法
原文:
www.kdnuggets.com/2021/11/best-ways-data-professionals-market-aws-skills.html
评论
照片由 Carl Heyerdahl提供,发布在Unsplash上
确保潜在雇主了解你的能力在你试图在其他数据专业人士中脱颖而出时至关重要。熟悉亚马逊网络服务(AWS)越来越有用。以下是今天的就业市场中推广你的 AWS 技能的五种方法。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
1. 提及参与比赛
就像网络安全专业人士经常组队处理对网络和设备的模拟攻击一样,拥有 AWS 技能的人可以参加帮助他们利用现有技能并学习新技能的比赛。
在一个你可能没预料到的例子中,国家橄榄球联盟(NFL)有一个年度比赛,数据专业人士使用 AWS 创造与比赛及其相关统计数据相关的新机会。
NFL 的高级足球数据和分析总监 Michael Lopez 说:“我们对 NFL 及其合作伙伴不断以创新的方式利用数据和分析推动我们的比赛感到非常自豪,而 Big Data Bowl 的成功是这一进化的重要部分。”
该活动还具有导师指导部分。它将 12 名初级数据科学家与一些 NFL 的分析专家配对。参与这样的活动表明你渴望在大规模上检验你的 AWS 技能。
2. 讨论特定于 AWS 的认证
即使你已经认为自己拥有高度先进的 AWS 技能,总是有更多的东西可以学习。你的知识可以通过保持数据存储和使用要求的合规性来增强整个组织。
例如,根据 PCI 要求 6.5,客户仍然需要对他们开发的任何 AWS 应用程序负责,并负责对团队进行相关工具的培训。更具体地说,公司必须解决常见的软件漏洞。花时间获得 AWS 认证可以向雇主展示你拥有最新的知识,并准备好应用这些知识。
基于云的技能对今天的社会运作至关重要。人们使用云应用程序保持生产力并与团队成员协作。许多用于监督警务、医疗保健、交通运输和其他基本事务的系统都在云中运行。AWS 提供数字徽章,你可以用来展示你的认证,使雇主更容易注意到它们。
3. 在 AWS 中构建作品集
作品集是展示你作为数据专业人员所做工作的绝佳方式。虽然作品集不能完全替代简历,但它们是很好的补充,因为它们能展示项目的视觉方面。
一种有效的方式来推销你的技能是将 AWS 作为你的主要产品来构建作品集。这样,你不仅展示了你的总体能力,还具体证明了你能够以有意义的方式应用 AWS 专业知识。
一些你可以用于构建作品集的 AWS 工具是免费层的一部分。在任何情况下,你都可以以最小的成本开始。
4. 通过连接提升技能
真正关心提升技能的人通常会寻找能帮助他们成长的机会。虽然你确实可以通过足够的专注自学,但通常和志同道合的人聚集在一起更有价值。交换建议和意见让你在分享自己所知的同时,也能吸收他人的知识。
你也不一定需要旅行。例如,在 2021 年 6 月,举办了一场针对女性技术人员的AWS 虚拟会议。虽然该活动在澳大利亚和新西兰举行,但全球各地的人们都可以参加。
这些主题和活动涉及了点对点网络、职业发展、人工智能等方面。如果你之前参加过 AWS 活动,值得利用这些机会来推销自己。这样做可以向雇主展示你对职业发展的承诺以及保持知识更新的努力。
5. 在简历中突出 AWS
增强你的简历是一个更传统但仍然有效的方式来突出你的 AWS 能力并吸引雇主的兴趣。与其仅仅将 AWS 列为工具和平台部分的要点,不如用有用的背景来支持你的技能。提供尽可能多的具体信息,并在适用时关注 AWS 项目的积极成果。
还值得花更多时间描述你拥有的、需求高于平均水平的特定 AWS 技能。例如,一项调查发现,DevOps 是有志成为 AWS 专业人士简历上的顶尖技术技能。
由于商业领袖越来越常迁移到云端或在多云环境中维持工作负载,提及你在管理多个云或协助迁移方面的任何具体经验将会对你有所帮助。
自信地推销自己
使自己对潜在雇主尽可能吸引可能是一个令人畏惧的任务。这通常是因为许多申请者不愿意夸大自己的才能。然而,了解雇主确实需要具备 AWS 技能并理解云环境复杂性的人员是至关重要的。
云计算将长期存在。这些提示将帮助你说服雇主你拥有帮助他们公司成功的知识。
简介:德文·帕提达是一位大数据和技术作家,同时也是ReHack.com的主编。
相关:
-
数据专业人士如何在忙碌时依然给人留下深刻印象
-
数据专业人士如何为简历增添更多变化
-
数据科学家如何在全球就业市场中竞争
更多相关主题
如何更好地利用数据科学促进业务增长
原文:
www.kdnuggets.com/2022/08/better-leverage-data-science-business-growth.html

关于世界如何变化以及如何与之开展业务的讨论很多,我们生活在一个前所未有的时代,一切都不再如从前。主要的“罪魁祸首”是技术进步,随之而来的是全球流通的数据量,以及这些数据以某种方式等待被使用。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
但,这种变化是否深刻到动摇了商业的基础?当你深入了解时,一切其实没有改变。正如保罗·西蒙所写,“在经历了不断的变化后,我们或多或少还是一样的。”这也适用这里吗?
我们不否认数据对商业世界的影响。然而,商业的成功仍然归结为两个问题,你需要回答:
-
针对谁?
-
什么?
针对谁,或者说你的客户是谁?这仍然是任何业务的起始点。你的产品可能很完美(或者你这么认为!),但如果没人购买它,那也无所谓。商业的关键是销售。因此,你需要找到那些愿意以对你和他们都合适的价格购买你产品的人。
你销售的是什么,换句话说,就是你的产品。这是你业务的另一个基础。你想销售的东西从一个想法开始。但在产品进入市场之前,需要进行复杂的工作,包括产品的开发、设计、质量检查、包装、定价、营销策略等。
业务中的这两种力量是交替的,你的客户影响你的产品,反之亦然。
然后进入第三部分,数据的影响得到充分体现。这是你做事的方式。你可以使用传统方法:依赖所谓的商业直觉,这样你不需要任何数据,一切都顺利,直到突然出现严重问题。
或者你可以采用‘现代方法’,即使用数据科学来帮助你做出业务决策。这里的关键词是‘帮助’。数据科学正是做到这一点的工具。它仅仅是一个工具,可以帮助你做出更好的业务决策,并将不良决策降到最低。数据科学不会取代人的理性,它不会代替你做决定,也绝对不完美。但它可以帮助你做出明智的决定,让你的商业直觉在数据无助的情况下发挥作用。
如何将数据科学融入这些业务基础中以推动业务增长?我们将来看一些例子。
客户分析
如果不了解你的客户,你就不知道他们想要什么和需要什么。了解这些对确定提供哪些产品至关重要。没有这些,就没有销售,更谈不上业务增长。
根据Qualtrics的报告,有五种技术将影响市场研究行业:
-
高级数据分析
-
自动化统计分析
-
自然语言处理
-
文本分析
-
物联网(IoT)
根据你处理的分析类型,这些技术的使用程度有所不同。
客户细分
来源: https://www.garyfox.co/customer-segmentation/
技术使你能够以一种直到最近才可能实现的方式对客户进行细分。要做到这一点,你需要收集大量的数据。
这可以从简单的地理区域划分开始,你可以收集如客户所在国家、城市和 IP 地址等数据。
然后你可以包括人口统计数据,如客户的年龄、收入、婚姻状况、性别、教育背景和种族。
当然,客户购买你产品的意愿不仅仅取决于他们的位置或年龄。你可以更进一步,收集关于他们的个性、生活方式、兴趣和观点的数据。
这已经是相当大量的数据,高级数据分析和自动化统计分析可以帮助你处理这些数据。数据科学可以使这种细分变得比你手动细分数据要快得多、准确得多、详细得多。
自然语言处理和文本分析在这里也可以发挥作用。越来越多的数据以音频文件或社交媒体(以及互联网的一般形式)上的文本形式被收集,包括帖子、评论、评价、短信等。想象一下逐条阅读每一个客户的评论,这几乎是不可能的!
数据科学允许根据这些数据进行更复杂的细分。你可以根据客户的行为进行细分,这使得基于综合数据创建客户画像成为可能。从这里可以分析客户的行为或言论,并预测和影响他们的行为。这是一个你比客户更了解他们自己的层次。
客户定位
一旦你对你的(潜在)客户了如指掌,你就可以更有信心地针对他们。这意味着在正确的时间和正确的价格向他们提供合适的产品。根据你的数据,你知道你不会向喜欢阅读哲学书籍的人推荐惊悚小说。但如果你有一部伊曼努尔·康德的《实践理性批判》的优秀新译本,可能正合他们的胃口。
他们的社会地位是什么?收入是多少?也许他们想买这本书但目前买不起?针对首批购买者的特别优惠怎么样?
这都是客户细分的扩展。它不仅有助于将你当前的产品提供给正确的市场,还可以朝另一个方向发展——即,决定开发新产品来进入其他市场细分。
保持顾客(满意)
保持客户与获取新客户同样重要。如果你在获取新客户的同时,现有客户却以更快的速度流失,那你就是在做错事!这没有增长!而且,如果客户知道你在保持他们方面做得不好,会使得新客户不愿意购买你的产品或使用你的服务。
顾客希望看到一种让他们感到被理解的个人化方式。你有机会通过使用你所拥有的大量数据来了解他们。
你还想奖励他们的忠诚。给他们一些额外的东西。否则,他们会转向竞争对手。
你想了解他们对产品或服务的满意度。他们希望产品设计、功能、质量和价格方面得到哪些改进。谁不喜欢时不时享受一些特别的优惠和福利呢?
再次,数据在这里发挥着重要作用。你可以利用它来计算明确告诉你客户忠诚度的指标。
例如,净推荐值(Net Promoter Score)表示客户对你的品牌的感受,以及他们是否愿意向家人和朋友推荐它。
另一个衡量忠诚度的方式可能是重复购买。公司内部定义了重复购买的标准,包括购买次数和每次购买之间的时间。然后你可以调查为什么有些客户留在你这里而有些客户没有。如果趋势是负面的,你可以扭转它。如果是积极的,你可以继续保持并在这个趋势上做得更好。
数据科学使你能够量化参与度水平。这个指标并不关注购买,但可以反映客户的满意度。它可能包括数据,如关注你社交媒体的客户数量,喜欢和评论你的帖子,分享帖子,评价你的产品或服务等。分享比点赞更好吗?评论比分享更好吗?评论是正面的还是负面的?赋予这些可能意味着一切或什么都不意味着的信息的价值,这就是数据科学的作用。例如,通过确定评论的“情感”,无论是高度积极、积极、中立、消极还是极度消极。你可以为此校准机器学习算法。速度更快,结果更一致。算法的世界观不会因为喝了一杯早晨咖啡而有所不同。
其中一个关键指标是流失率,它给出了新获得客户与保留客户的比例。这也可以帮助你检测是否存在客户流入或流出及其原因。如果没有这个指标,你只能猜测。但当你找到问题的原因时,解决其影响会更容易。
客户忠诚度指数更关注于客户的意图(未来)而非过去。换句话说,他们有多大可能推荐你、再次购买你的产品并尝试你的其他产品?
所有这些指标都帮助你了解自己在客户忠诚度方面的现状。从这里开始,你可以着手改善。你可以通过向客户提供个性化的优惠、忠诚度计划、折扣、新产品等来实现这一点。
产品开发
知道提供什么与向谁提供是紧密相连的。客户想要什么在每一个产品开发过程中都得到了体现。
了解客户的需求,你可以识别市场上的缺失。是全新的产品吗?是现有产品但增加了一些额外功能吗?也许是相同的功能但更具用户友好性?或者仅仅是设计上的不同,以便吸引客户?
在产品开发中使用数据科学可以更快地对市场和客户需求的变化做出反应,这反过来使你的业务有可能实现那些你本来会错过的销售。
来源: https://www.netsolutions.com/insights/everything-about-new-product-development/
看着产品开发的步骤,你可以很容易地想象到数据科学可以帮助几乎每一个阶段。
产品创意分析
例如,分析创意的可行性及其市场潜力,你的竞争对手是谁,以及如何有所不同。这包括产品功能、设计、包装、定价和营销策略。
在筛选创意时,你必须考虑客户的需求、你是否能提供这些需求以及成本是多少。你拥有的这个伟大创意是否可行且有市场?一旦分析了所有数据,你可以开始开发和测试你的概念。
产品概念开发
当你开发和测试概念时,你应该再次考虑对客户的好处、市场上是否有类似产品、你的竞争对手是谁以及他们在做什么。
你能提供一些不同的东西来夺取竞争对手的市场份额或在他们之间占据一席之地吗?收集的关于客户对你概念创意的反应的数据可以告诉你你做对了什么。当然,你还可以通过获取客户的想法来改进你的概念。
市场营销策略
说到市场营销,细分再次出现。你的(潜在)客户是谁?根据你的回答,你应该调整产品设计、包装、定价、市场营销方式和分销方式,以满足客户需求。
产品开发或制造
在识别市场后,可以根据收集的数据及其分析开发产品。这意味着根据你的概念创建功能、设计产品并进行测试。
使用机器学习加快产品设计和工程,提高产品测试的精确度和自动化水平。
依靠数据科学来完全或部分自动化产品开发过程,从而降低你的成本,从创意到产品上市所需的时间,以及产品的质量。
这在数字产品方面尤其真实。但如果你在制造业,产品开发过程是类似的。同样,数据科学可以提供极大的帮助。你仍然需要开发产品、设计它、测试其质量并决定如何以及向谁市场推广。
产品改进
虽然这不严格属于数据开发的部分,但它必须不断改进,以使产品获得市场份额并保持市场份额。必须添加新功能或改进现有功能,以跟上竞争和不断变化的客户口味。
为了解决这个问题,数据科学可以通过其推荐引擎帮助你预测用户对产品(或产品的特定元素)的评分。这样,你可以找出如何改进与产品相关的任何方面,并提高客户满意度,从而支持你的增长。
市场营销分析
这与客户分析紧密相关,但也有额外的维度。
首先,你需要将客户进行细分,以便你可以将市场营销策略量身定制到特定的细分市场。一刀切的方法在这里行不通!
在市场营销分析中,根据 Dr. Alan Zhang,你需要处理:
-
客户生命周期
-
市场营销渠道
客户生命周期是与客户分析共享的方面。
然而,市场分析的一个额外元素是分析营销渠道。数据科学用于确定每个客户群体应使用哪些营销渠道、何时是最适合的目标时机、使用哪些营销活动等。
必须使用指标来评估营销决策。根据所选择的渠道和策略,点击率、跳出率、转化率、独立访客数、投资回报率等指标可以帮助你评估和改进你的营销决策。
内部流程
向正确的市场提供正确的产品,正如我们所看到的,也是一个可以通过数据科学优化的内部流程。还有其他一些内部流程虽然不直接与这两个业务基础相关,但同样重要,并且可能产生巨大的影响。
库存管理和分销
为了满足客户需求,你必须建立库存管理系统。通过数据科学,你可以实时获取库存信息。从那里,你可以向客户提供有关特定产品的可用性和位置的准确资讯。你可以停止积压那些销售不佳的产品,同时避免某些高需求产品的持续缺货问题。
你可以战略性地找到最佳的仓库和商店位置及规模、库存量、员工人数等。这不仅能让你迅速响应客户需求的变化,还能预测这些变化。
分销方面也是如此。你是否想使用自己的车队将产品送到客户手中?或者应该使用其他公司的服务?成本在这里扮演了重要角色,但交货时间也是关键。不仅客户收到产品的速度更快,而且通过数据分析,你的交货时间估算也能更加准确。然后你可以利用实际交货时间来检测流程中的不足。分析可能会导致决定使用自己的车队、雇用更多或更少的司机、优化配送路线、寻找新的运输方式、预测燃料成本、交通堵塞、延误等。这一切可以保持你的成本低,同时实现客户对可靠性和速度的期望。
与此相关的是,如果你在制造业中,使用数据科学来预测故障率,并调整生产线以应对需求的增加或减少。
人力资源
显而易见的是,要利用数据科学来推动业务增长,你需要数据科学家。不仅仅是他们,还需要一整套不同职位的专家,这些专家在公司成长过程中将变得必不可少。你怎么知道需要哪些技能? 新员工表现如何?你只看重专业技能,还是员工的个性也很重要?同样重要的是,如何留住优秀员工?
人力资源管理可以从数据科学中受益。使用对候选人数据的算法可以帮助你确定适合的候选人,包括他们的教育背景、专业技能和个性。这样,你可以预测哪些候选人最有可能成为顶尖表现者。这大大改变了依靠直觉招聘的旧方式。
通过在培训和发展中使用数据科学,你可以摆脱一刀切的做法。员工各不相同。他们学习的方式不同(例如,有些人喜欢理论或实践方法),兴趣(例如,有些人渴望成为领导者,而有些人想更好地完成工作)或动机(例如,有些人更受金钱驱动,有些人则被学习新知识激励)也各异。为每个人量身定制培训和发展计划将使他们的潜力得到最大限度的发挥,同时保持他们的快乐。你只能从愿意留在公司并且满意的高质量员工中获益。
人力资源也可以在劳动力预测中使用数据科学。招聘是一个昂贵且耗时的过程。数据科学有助于预测劳动力需求的增加。这是业务增长的功能,但还需要考虑其他因素。知道你需要更多员工是一回事,了解员工的个人特征则是另一回事。就业市场的情况如何?你需要的人才是否存在?如果存在,他们的薪资是多少?使用数据科学可以预测这些变量,并通过在合适的时间招聘合适的人才来支持你的增长。
报告
小公司可能甚至不需要复杂的报告。将大部分数据保存在脑海中是很容易的,你大致知道自己的位置,可以自信地依靠直觉。然而,随着公司成长,你会意识到没有任何报告来导航你的业务会越来越像是在夜间、雾中、下雪时戴着眼罩驾驶。
拥有一个从数据源、经过分析到报告的数据管道,从而使你能够做出业务决策,变得至关重要。数据工程师、数据库设计师和管理员、数据分析师、统计学家以及 BI 开发人员,在拥有合适的工具的情况下,能够为你创造奇迹。
你可能会从基础知识开始,只将数据用于描述性目的。换句话说,你可以找出发生了什么。
从那时起,你可以以越来越复杂的方式使用数据。不仅仅是了解发生了什么,你还可以预测未来会发生什么,应该做些什么来使某些事情发生(或不发生),甚至发现数据集之间的未知联系,并弄清楚事情发生的原因和方式。
这难道不是任何想要增长的企业都希望了解的内容吗?
摘要
从我们的角度来看,数据和数据科学对业务运营产生了巨大影响,同时又没有改变什么。公司仍然需要拥有产品或服务,并且必须销售才能生存和发展。然而,企业可以提供的产品类型、它们如何开发这些产品以及如何接触客户正在发生彻底的变化。
数据对业务运作产生了关键影响。然而,数据本身毫无意义,除非将其转化为信息和洞察。为此,你需要数据科学家。毫不奇怪,数据科学家多年来一直供不应求。他们的专业知识和不断增长的数据科学工具可以改变你业务的几乎每个方面:从产品设计、开发、测试和制造,到营销、定价、库存管理、分销、招聘和报告。
抵抗这种变化就像是在自残。
内特·罗西迪 是一位数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是StrataScratch,一个帮助数据科学家准备顶级公司面试问题的平台的创始人。可以通过Twitter: StrataScratch或LinkedIn与他联系。
了解更多相关话题
通过 CI 改进笔记本:自动测试图机器学习文档
评论
由 Huon Wilson,CSIRO Data61

照片由 Martin Adams 提供,来源于 Unsplash
构建数据科学库就像在两个世界之间行走:数据科学由 Python 笔记本主导,这是一种快速便捷的浏览器代码实验和演示方式,而软件工程则专注于使软件可靠和可重复。StellarGraph 使用持续集成来保持两者的优点。
StellarGraph 是一个开源、用户友好的 Python 库,用于 图机器学习,基于 TensorFlow 和 Keras 构建。它提供了 大量演示 功能的方式,即 Jupyter 笔记本,帮助数据科学家和其他人开始解决实际问题。这些演示可以直接在 GitHub 上查看,甚至有链接可以在 Binder 和 Google Colab 云服务中自动运行。
随着 StellarGraph 1.0 版本计划于本月晚些时候发布,我们已经开发了自动化流程,以确保我们的演示能够工作——并将继续工作——即使我们对库进行重大改进。
在这篇文章中,我们将详细介绍支持我们保持库的演示内容最新和信息丰富的持续集成(CI)。
工作原理
StellarGraph 的笔记本 CI 主要有三种工作方式:
-
验证每个笔记本是否 最新并成功运行,使用 papermill 来 保持 CI 快速,以提供良好的开发者体验
-
提供链接到 nbviewer 以 方便地查看失败,在浏览器中以良好渲染的方式显示
-
通过确保每个笔记本都有指向云服务的链接和相同的格式来检查我们是否提供了 一致的体验,使用 black 和自定义代码。
让我们深入了解每一个细节。
高速度;可靠性;人类——选择两个
文档和示例在准确时最为有用。StellarGraph 是一个活跃的项目,拥有不断的改进和修复;这些改进使我们能够使笔记本更好,有些变化需要调整一个或两个笔记本。所有这些都必须做到完美。
我们的目标是确保每个演示每次都能正常工作,遵循“不是火箭科学”软件工程原则。在逐个拉取请求的基础上保持笔记本的正常工作要容易得多。如果我们不保持它们的更新,我们可能需要很长时间才能发现它们已损坏,更不用说诊断原因并修复它们了。
我们非常小心,并根据需要更新和重新运行笔记本,但人类很容易犯错误。StellarGraph 拥有 40 多个笔记本,每周合并约 25 个拉取请求。这意味着即使是低错误率也会导致大量损坏的笔记本。
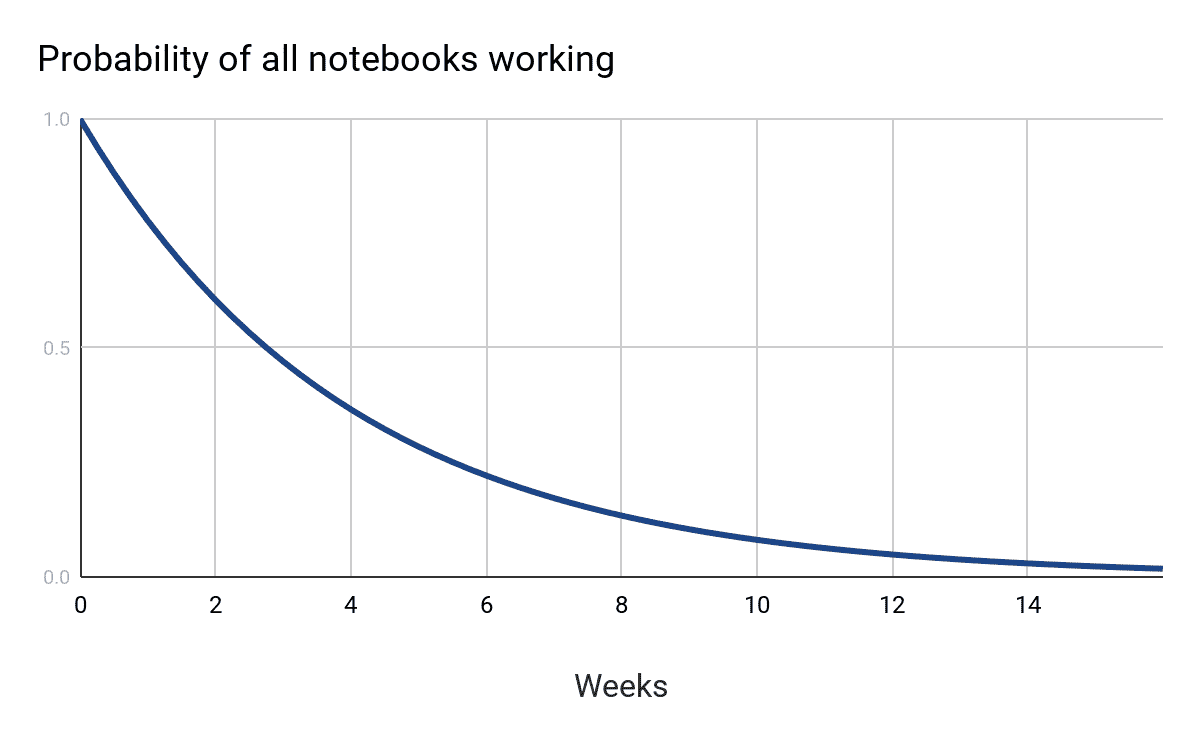
软件退化:每周有 25 个拉取请求,每个拉取请求破坏笔记本的几率即使很低(1%),所有笔记本在一周后正常工作的概率会降到零。
例如,假设每个拉取请求只有 1% 的概率使某些笔记本停止工作。即使是很小的几率,这意味着所有笔记本在一周后正常工作的概率只有 78%,一个月后则低于 40%。
我们尝试通过手动代码审查来保持笔记本的正常运行,使用ReviewNB 应用程序。ReviewNB 提供比原始 JSON 更有用的差异,使得讨论良好和不那么好的更改变得容易。然而,人类是容易犯错的,可能会遗漏问题。此外,代码审查仅突出显示已编辑的笔记本;它不会突出显示应该编辑的笔记本!
自动运行笔记本
为了帮助我们人类,我们还利用计算机来检查笔记本:CI 检查它们在每个拉取请求和每次合并时是否正常运行,除了单元测试之外。但 CI 最有效的方式是快速,而我们的大多数笔记本展示了重量级机器学习,这还不够快。
减少 CI 时间的最简单方法是并行工作。几乎所有的笔记本仅依赖于 StellarGraph 库,因此它们可以独立执行。我们并发地运行它们,使用并行作业在Buildkite CI上,但这仍然不够:一些笔记本单独运行时间过长。
我们使用papermill来执行我们的笔记本,因为它支持参数化:在 CI 上运行时,我们的笔记本会训练其模型较短时间,或者计算较短的随机游走,或进行其他优化。
Papermill 的参数化功能允许我们在不需要在每个演示中添加丑陋的“我们在 CI 上吗”条件代码的情况下完成这一点。对于需要参数化的笔记本,我们只需稍作重构,使其包含一个需要调整的参数的单个单元格。然后,可以通过a YAML 文件和参数 _file 选项替换新值。
这些笔记本在 CI 上暂时运行,因此模型的准确性并不是很重要。主要需要的是执行每一个代码路径,以验证一切是否正常。我们优化参数,使其尽可能小,同时仍然能处理每个边界情况,例如只将训练周期减少到两个而不是一个,以捕捉在周期之间发生的任何问题。
如果出现问题,比如函数参数更改或甚至内存不足,笔记本将无法运行,我们的测试也会失败。这立即告诉我们需要更多的更改以保持一切正常。
使用 Buildkite 构件和注释来突出显示错误
CI 帮助我们看到何时出了问题,但更好的方式是了解确切的问题。Papermill 通过记录笔记本的所有 stdout 和 stderr 输出来提供帮助;但深入查看冗长的 CI 日志是麻烦的。此外,这些日志通常缺乏足够的上下文,难以轻松理解问题,尤其是与笔记本的渲染视图相比,错误附加到单个单元格中,以及任何其他相关的单元格。
运行笔记本后,CI将结果笔记本附加到执行它的步骤,无论是否通过。如果执行失败,这个输出笔记本将包括异常或其他错误。
我们使用的是一个Buildkite 上的公共管道,因此构件是公开可见的,这意味着拉取请求的作者——或任何其他人——可以点击并下载它们以检查问题。
当笔记本在 CI 中失败时,会自动添加一个链接来查看失败的笔记本* 到 nbviewer,并且该链接会自动添加到构建中。*
我们还大量使用 Buildkite。 Nbviewer 可以渲染任何公共的 Jupyter 笔记本 URL,包括这些文档。我们的 CI 创建了直接在浏览器中查看它们的链接,对于那些失败的笔记本, 会添加注释 在构建的顶部,附上该链接。理解问题只需查看失败的构建并点击一个高亮的链接即可。
一致的演示体验
StellarGraph 致力于为每个演示提供一致的体验,因为这使得:
-
StellarGraph 的用户可以在不同的演示之间切换,而无需理解每一个的独特之处。
-
StellarGraph 的开发者可以编写和编辑笔记本,因为过程的更多部分有预期的行为,避免了如格式化等浪费时间的操作。
-
自动化工具帮助我们维护演示文稿,因为输入的笔记本更加结构化。
笔记本中的 Binder 按钮,例如在使用 GCN 的介绍性节点分类演示中,能在不到一分钟的时间内将读者直接带到一个可执行环境。
这项工作的基础是 一个自定义脚本 ,该脚本使用 nbconvert 来运行一些笔记本预处理器。这些预处理器会执行如下任务:
-
使用 black 格式化代码
-
重新编号单元执行次数 从 1 开始,这样编辑者可以根据需要多次运行和重新运行笔记本,直到它正常工作,并且笔记本在发布时仍显示“ In [1], Out [1], In [2], Out [2], …”。
-
插入适当的链接 到 Binder 和 Google Colab 云服务,这样查看 GitHub 上演示的人就可以迅速切换到执行它们。
这个脚本通过一个命令直接应用所有格式,使得开发者可以轻松保持笔记本的一致性。不幸的是,便捷仅仅是部分解决方案;要求人们记住去做这件事意味着它偶尔会被忘记。
这里的解决方案与运行笔记本时相同:在 CI 中检查格式。我们的脚本通过一种模式支持这一点,它将笔记本重新格式化到一个临时路径,然后 与原始笔记本比较 :它们应该是相同的。

当 笔记本格式不正确时,CI 构建会注释带有这些笔记本的列表以及修复命令。
如果有差异,脚本将 添加注释 到 构建 上,建议适当的修复命令。
结论
StellarGraph 以 其演示 为傲,我们依靠自动化来保持它们的优质,即使在一个高速发展的项目中,如我们向 1.0 版本发布的过程中。通过 ReviewNB,我们获得了很好的审查体验,并在笔记本无法运行或格式不合适时会收到警报。所有这些都发生在任何更改被提交之前,问题会通过方便的链接和建议修复方案在 Buildkite CI 中标记出来。
我们的所有代码都是 开源的,因此我们希望通过分享,其他人可以将数据科学和软件工程的世界结合起来,并看到两者的好处。
通过我们对 使用图卷积网络的节点分类 的演示,开始使用 StellarGraph 库进行图机器学习。
StellarGraph 中的 CI 工作主要由Tim Pitman完成,Huon Wilson提供了贡献。格式化脚本主要由Andrew Docherty编写,Tim 和 Huon 扩展了该脚本。Denis Khoshaba保持我们的 CI 和基础设施顺利运行。为了使 papermill 在 CI 上表现得更好,Huon贡献了几处调整*。
该工作得到了 CSIRO Data61 的支持,这是澳大利亚领先的数字研究网络。
简介: Huon Wilson 是一名软件工程师,拥有扎实的数学和统计学背景,具有编译器等低级系统编程领域的丰富经验,熟悉 C++、C 及 Rust 等编程语言。更高层次上,他在 R 和 Python 中有数值编程经验,了解大多数语言范式和许多其他软件工程领域。
原文。已获许可转载。
相关:
-
图形神经网络模型校准以获得可信预测
-
可扩展的图形机器学习:我们能攀登的高峰?
-
图形机器学习与用户体验:一段未开发的爱情故事
我们的 Top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
更多相关内容
我们如何更好地解决分析问题?
原文:
www.kdnuggets.com/2020/03/better-solve-analytics-problems.html
评论
由Rajneet Kaur,数据科学家提供

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
我该如何开始?
我可以用数据回答哪些问题?
解决方案框架应该包含哪些组件?
根据我作为分析经理/导师的经验,我经常会被问到这个问题。我们处理大量新的分析和数据科学项目。问题定义和解决方案开发是成为顾问的关键因素。结构化问题定义阶段对于项目成功至关重要,但可能看起来像是一个创意过程。
从一个框架开始,
我的市场营销教授曾经说过,当一位学生询问如何开始案例研究时。他的建议在经历了大量的项目、客户和角色后,我仍然认为非常适用。
开始阶段往往是最艰难的,业务框架可以帮助使项目启动和临时分析变得更加容易。通过从一个或多个框架开始,然后进行定制,可以实现很多目标。你的客户很可能已经了解这些框架,因此理解分析内容会更容易。讲故事也会变得更简单。
虽然详细的集合可以在这个链接中查看,这里是一个可以使用的框架的起始清单:
-
分析:RFM、假设检验、石川/鱼骨图(因果关系)
-
市场营销:AIDA(客户购买旅程)、4P、PLC、CLV、细分:任何 22 或 33 矩阵,如 BCG、安索夫矩阵以及其他如帕累托矩阵
-
一般业务:SWOT(内部)、PESTLE(外部)、波特的 5/6 力、3Cs
虽然石川图和 4P 可以用于根本原因分析,AIDA 和 PLC 可以很好地进行队列/生命周期分析。优化是另一个常见的分析领域,帕累托分析和象限分析非常有帮助。
让我们用一些例子来演示 4P 的使用,它是最简单的,也是我最喜欢的根本原因框架之一。这个框架可以有效地用于每周或每月的业务健康监测的纠正措施,比如在案例 1 中:

从上述分析中,我们发现整体支出的 ROAS 在逐年下降。进一步分析表明,线下渠道的贡献在减少。基于这些客户行为模式,你的组织决定将营销预算从线下转移到线上。线下支出需要减少三分之一,你需要决定如何最大限度地保持提升效果。
我们接下来使用帕累托 - 帕累托是最直观的框架之一,重点在于“少数重要”的概念。虽然它也被称为 80-20 法则,即 20%的驱动因素应涵盖 80%的价值,但你可以随意- 更改数值阈值。

几周后,我们决定进一步优化支出。假设我们发现不同地点对线下促销的反应不同。让我们看看如何通过象限分析将每一笔营销资金优化到极致:

一个或多个商业框架可以结合使用,并根据业务驱动因素进一步调整以获得有效的输出。从简单到最复杂,商业框架可以在分析及其他生活领域中发挥作用。我最早的几次面试是通过 BCG 的自我分析破解的,将我的“个人生活”作为明星,将“学术”作为现金牛,将我的“干净”橱柜(当然是讽刺的!)作为我的狗,而职业生涯则是问号。
请回信分享你在解决分析和数据科学项目中的观点、经验或挑战。
简介:Rajneet Kaur 是一位充满激情且结果导向的营销和数据科学高管,拥有 6 年的商业和技术经验。
原文。经授权转载。
相关:
-
如何利用数据分析测量人流量
-
增强科学家第一部分:机器学习在 SEM 图像分类中的实际应用
-
如何向老板推销数据分析的必要性
更多相关话题
梦与现实之间:生成文本与幻觉
原文:
www.kdnuggets.com/between-dreams-and-reality-generative-text-and-hallucinations

由 DALL-E 生成的图像
在数字时代,人工智能的奇迹改变了我们互动、工作甚至思考的方式。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
从策划我们的播放列表的语音助手到预测市场趋势的算法,AI 已经无缝地融入我们的日常生活。
但和任何技术进步一样,它也不乏曲折。
大型语言模型或 LLM 是一个训练过的机器学习模型,根据你提供的提示生成文本。为了生成好的回应,模型利用了训练阶段所保留的所有知识。
最近,大型语言模型(LLMs)展示了令人印象深刻且不断增长的能力,包括对任何类型用户提示生成令人信服的回应。
然而,即使 LLMs 具有生成文本的惊人能力,仍然很难判断这些生成内容是否准确。
这正是通常所说的幻觉。
但这些幻觉是什么,它们如何影响 AI 的可靠性和实用性?
大型语言模型幻觉之谜
在文本生成、翻译、创意内容等方面,LLMs 都是高手。
尽管是强大的工具,LLM 确实存在一些显著的缺陷:
-
使用的解码技术可能会产生乏味、缺乏连贯性或容易陷入单调重复的输出。
-
他们的知识基础本质上是“静态”的,这带来了无缝更新的挑战。
-
一个常见问题是生成的文本要么是无意义的,要么是不准确的。
最后一点被称为幻觉,这是一个从人类延伸到 AI 的概念。
对于人类而言,幻觉代表了尽管是虚构的却被感知为真实的体验。这一概念也扩展到 AI 模型中,其中幻觉文本看似准确,即使它是虚假的。
在大型语言模型的背景下,“幻觉”指的是模型生成的文本不正确、无意义或不真实的现象。

图片来源于 Dall-E
LLMs 的设计不同于数据库或搜索引擎,因此它们在回答时不参考特定的来源或知识。
我敢打赌你们大多数人可能在想……这怎么可能呢?
嗯……这些模型通过在给定提示的基础上生成文本。生成的回答并不总是直接基于特定的训练数据,而是为了与提示的上下文对齐。
简而言之:
它们可能自信地输出事实不准确或根本没有意义的信息。
解密幻觉的类型
识别人类的幻觉一直是一个重大挑战。考虑到我们有限的可靠基准对比能力,这一任务变得更加复杂。
尽管来自大型语言模型的输出概率分布等详细见解可以帮助这个过程,但这些数据并不总是可用,这增加了复杂性。
幻觉检测问题仍未解决,是持续研究的课题。
-
明显的虚假信息: LLMs 可能会虚构不存在的事件或人物。
-
过于准确的信息: 可能会过度分享,导致敏感信息的传播。
-
无意义的内容: 有时,输出可能完全是胡言乱语。
为什么会出现这些幻觉?
为什么会出现这些幻觉?
根本原因在于训练数据。LLMs 从大量数据集中学习,这些数据集有时可能是不完整、过时或甚至矛盾的。这种模糊性可能导致它们产生误导,把某些词汇或短语与不准确的概念联系起来。
此外,大量的数据意味着 LLMs 可能没有明确的“真相来源”来验证其生成的信息。
利用幻觉为你所用
有趣的是,这些幻觉可以是一种伪装的福音。如果你寻求创造力,你会希望 LLMs 如 ChatGPT 能够幻觉。

图片由 DALL-E 生成
想象一下请求一个独特的幻想故事情节,你会希望得到一个全新的叙事,而不是现有故事的复制品。
同样,在头脑风暴时,幻觉可以提供大量多样的创意。
缓解虚幻
意识到这一点是应对这些幻觉的第一步。以下是一些控制幻觉的策略:
-
一致性检查: 生成多个对同一提示的回应并进行比较。
-
语义相似性检查: 使用 BERTScore 等工具来衡量生成文本之间的语义相似性。
-
在更新数据上进行训练: 定期更新训练数据以确保相关性。你甚至可以对 GPT 模型进行微调,以提升其在某些特定领域的表现。
-
用户意识:教育用户关于潜在幻觉及交叉验证信息的重要性。
最后一个,但并非最不重要的… 探索!
这篇文章为 LLM 幻觉奠定了基础,但对你和你的应用程序的影响可能会大相径庭。
此外,你对这些现象的解释可能与实际情况不完全一致。全面理解和评估 LLM 幻觉对你工作的影响的关键在于深入探讨 LLM。
结论
AI,特别是 LLM 的发展过程,就像是在未开发的水域航行。虽然广阔的可能性令人兴奋,但必须警惕那些可能使我们偏离方向的幻影。
通过理解这些幻觉的本质并实施减轻它们的策略,我们可以继续利用 AI 的变革力量,确保其在不断演变的数字环境中的准确性和可靠性。
Josep Ferrer**** 是来自巴塞罗那的分析工程师。他毕业于物理工程,目前在应用于人类移动的数据科学领域工作。他是一个兼职内容创作者,专注于数据科学和技术。Josep 撰写关于 AI 的所有内容,涵盖了这一领域的持续爆炸性应用。
更多相关主题
超越编码:为何人文关怀至关重要
原文:
www.kdnuggets.com/beyond-coding-why-the-human-touch-matters

作者提供的图片
软技能在 2024 年的兴起。
如果我们展望技术的未来和软件开发的不同元素,就会发现这不仅仅是技术能力的问题。过去几年,自动化和人工智能主导了软技能的发展。
然而,这些自动化过程所欠缺的是无形的能力,如沟通、同理心和情感智力。
我们正生活在数字时代的到来之中。组织正在打造需要销售的产品——这需要出色的销售技巧。他们希望不断开发产品——这需要你能够有效地与利益相关者沟通。他们希望工作流程尽可能顺利——这要求你在团队中无缝协作。他们希望变得更大更好——这要求你具有创造力。
组织重视能够以协作方式领导并且能够以同情心解决问题的个人。
技术专业人员需要的软技能
技术专业人员远程工作的情况非常普遍。这自然会减少将团队成员聚集在一起更协作地工作的能力。然而,自疫情以来,公司将公司文化置于首位。越来越多的组织希望建立更加多元和包容的工作环境。
我还会链接一些能够帮助你提高各项软技能的优质课程。
沟通
链接:提高沟通技能
作为技术专业人员,你不仅需要与计算机沟通,还需要与团队沟通。技术专业人员与计算机约会并完全忽略团队的情况是很正常的。
在组织中,口头和书面沟通是非常重要的。你的团队成员需要了解你正在做什么以及他们如何提供帮助。
批判性思维
链接:职业的批判性思维技能
组织希望在市场上成为最好的。在日常工作中,作为技术专业人员,你会遇到各种问题,需要找到创新和有效的解决方案。
批判性思维使你能够跳出框框,从多种方式处理问题,直到你决定哪种解决方案最好。拥有创意角度将使你能够更有效地解决问题,并向利益相关者展示你持续改进组织整体业务目标的能力。
同理心
链接:情感和社交智力
在远程工作的环境中,加上使用生成性 AI 工具来帮助完成日常任务——很难意识到同理心的重要性。你的电脑没有感情,但你的团队成员和客户有。
同理心让你能够从他人的角度理解问题,而不是仅仅假设“代码有问题”。他们的大脑没有问题,他们只是从不同的角度看待问题,需要同理心来解决它。
组织
链接: 职业和个人成功的软技能专门化
组织自己不仅对你的职业生涯重要,对你的个人生活也很重要。缺乏组织可能导致你的项目比你预期的更快陷入困境。
跟踪所有正在执行的任务,并提供额外的信息和达成截止日期,将使你和你的团队享受工作,而不是感受到在两周内完成任务的压力。
组织自己和团队将使你更高效,并拥有一个富有成效的团队。
时间管理
链接: 更聪明地工作,而不是更辛苦: 个人和职业生产力的时间管理
在科技行业工作意味着你通常需要在紧迫的截止日期下工作,几乎没有灵活性。结合良好的自我组织,时间管理将帮助你达成这些截止日期。
了解处理特定任务所需的时间还将帮助你在一周内更好地组织自己。例如,清理数据占用了我 35%的时间,因此我会在一周的开始时先进行这项工作,以便在周末之前完成分析并向利益相关者展示。
总结
 
软技能变得越来越重要,你不应忽视它们。提升你的软技能将使你从一个优秀的程序员成长为一个令人推荐的杰出程序员,也有助于你获得晋升。
人际交往技能很重要!
 
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及基于理论的数据科学知识。Nisha 涉及广泛的主题,并希望探索人工智能如何有利于人类生命的长久。作为一个热衷的学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助他人。
更多相关信息
超越猜测:利用贝叶斯统计进行有效文章标题选择

图片由作者提供
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
一个好的标题对于文章的成功至关重要。人们通常只用一秒钟的时间(如果我们相信 Ryan Holiday 的书籍《[相信我,我在撒谎]( https://en.wikipedia.org/wiki/Trust_Me ,_I%27m_Lying)》)来决定是否点击标题打开整篇文章。媒体对优化 点击率 (CTR) 情有独钟,点击率是标题被点击的次数与标题展示的次数之比。具有吸引点击的标题会增加点击率。媒体通常会选择点击率更高的标题,因为这样可以产生更多的收入。
我并不特别关注挤压广告收入。更重要的是传播我的知识和专业技能。然而,观众的时间和注意力有限,而互联网上的内容几乎是无限的。因此,我必须与其他内容创作者竞争,以获得观众的注意力。
我该如何为下一篇文章选择一个合适的标题?当然,我需要一组选项供选择。希望我可以自己生成这些选项或请 ChatGPT 帮忙。但接下来我该怎么办?作为数据科学家,我建议进行 A/B/N 测试,以数据驱动的方式理解哪个选项最好。但也有问题。首先,我需要迅速决定,因为内容会很快过时。其次,可能没有足够的观察数据来发现点击率的统计显著差异,因为这些值相对较低。因此,除了等待几周来决定,还有其他选择。
希望有解决方案!我可以使用一种“多臂老丨虎丨机”机器学习算法,该算法会根据我们观察到的观众行为数据进行调整。选择集中的某一选项被点击的次数越多,我们可以分配给该选项的流量就越多。在本文中,我将简要解释什么是“贝叶斯多臂老丨虎丨机”,并演示如何使用 Python 在实践中应用它。
什么是贝叶斯多臂赌博机?
多臂赌博机是机器学习算法。贝叶斯类型利用汤普森采样来选择选项,这基于我们对点击率概率分布的先验信念,这些信念会根据新数据进行更新。所有这些概率论和数学统计学的术语可能听起来复杂且令人生畏。让我尽可能少用公式来解释整个概念。
假设只有两个标题可以选择。我们对它们的点击率(CTR)毫无头绪。但我们希望找到表现最好的标题。我们有多个选择。第一个是选择我们更相信的标题。这是多年来行业中的运作方式。第二个是将 50%的流量分配给第一个标题,将 50%分配给第二个标题。这种方法随着数字媒体的兴起变得可能,你可以精确决定在观众请求阅读文章列表时显示的文本。通过这种方法,你可以确保 50%的流量分配给了表现最好的选项。这是极限吗?当然不是!
有些人在文章发布后的几分钟内就会阅读这篇文章。有些人则需要几个小时或几天。这意味着我们可以观察到“早期”读者对不同标题的反应,并将流量分配从 50/50 调整为更多地分配给表现更好的选项。过一段时间后,我们可以再次计算点击率(CTR),并调整分配比例。在极限情况下,我们希望在每个新观众点击或跳过标题后调整流量分配。我们需要一个科学且自动的框架来适应流量分配。
这就是贝叶斯定理、贝塔分布和汤普森采样的用武之地。
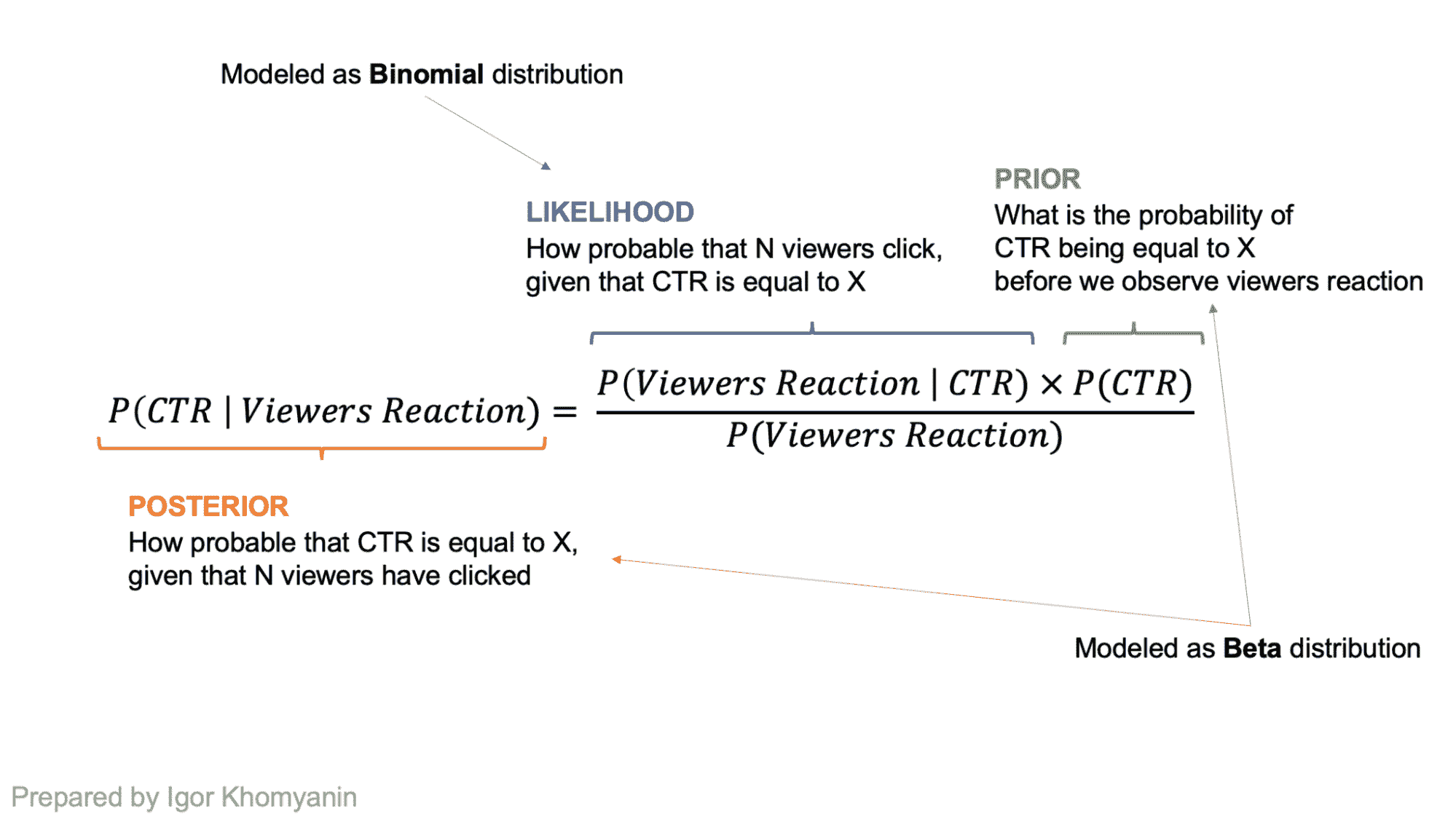
假设一篇文章的点击率是一个随机变量“theta”。按设计,它的值在 0 到 1 之间。如果我们没有先验信念,它可以是 0 到 1 之间的任何一个数,且概率相等。在观察到一些数据“x”后,我们可以调整我们的信念,并通过贝叶斯定理得到一个新的“theta”分布,该分布会偏向于 0 或 1。
点击标题的人数可以建模为一个二项分布,其中"n"是看到标题的访问者数量,"p"是标题的 CTR。这是我们的似然性!如果我们将先验(我们对 CTR 分布的信念)建模为一个贝塔分布并采用二项似然性,则后验分布也将是一个具有不同参数的贝塔分布!在这种情况下,贝塔分布被称为对似然性的共轭先验。
证明这一事实并不难,但需要一些数学练习,这在本文中不相关。请参考这里的精美证明:

贝塔分布的范围在 0 到 1 之间,这使其成为建模 CTR(点击率)分布的理想选择。我们可以从"a = 1"和"b = 1"作为建模 CTR 的贝塔分布参数开始。在这种情况下,我们对分布没有任何信念,使得任何 CTR 都是同等可能的。然后,我们可以开始添加观察到的数据。如你所见,每一次"成功"或"点击"都将"a"增加 1,每一次"失败"或"跳过"都将"b"增加 1。这会使 CTR 的分布偏斜,但不会改变分布的家族,它仍然是贝塔分布!
我们假设 CTR 可以建模为贝塔分布。然后,有两个标题选项和两个分布。我们如何选择向观众展示什么?因此,算法被称为"多臂老丨虎丨机"。当观众请求标题时,你"拉动两个臂"并采样 CTR。之后,你比较这些值并展示具有最高采样 CTR 的标题。然后,观众要么点击,要么跳过。如果标题被点击,你将调整此选项的贝塔分布参数"a",代表"成功"。否则,你将增加此选项的贝塔分布参数"b",意味着"失败"。这会使分布偏斜,对于下一个观众,选择此选项(或"臂")的概率与其他选项相比会有所不同。
经过几次迭代,算法将对 CTR 分布进行估计。从该分布中采样将主要触发最高 CTR 的选项,但仍允许新用户探索其他选项并重新调整分配。
好吧,这一切在理论上都是可行的。它真的比我们之前讨论过的 50/50 拆分更好吗?
用 Python 构建模拟
创建模拟和构建图表的所有代码可以在我的GitHub Repo中找到。
如前所述,我们只有两个标题可供选择。我们对这些标题的点击率没有先验信念。因此,我们从 a=1 和 b=1 开始,为两个 Beta 分布设定初始值。我将模拟一个简单的流量假设为观众队列。我们确切知道在向新观众展示标题之前,前一个观众是“点击”还是“跳过”。为了模拟“点击”和“跳过”动作,我需要定义一些真实的点击率。设定它们为 5%和 7%。需要强调的是,算法对这些值一无所知。我需要它们来模拟点击;你会在现实世界中有实际的点击。我将为每个标题抛掷一个超级偏向的硬币,其正面出现的概率为 5%或 7%。如果抛出正面,则为点击。
然后,算法是直接的:
-
根据观察到的数据,为每个标题获取 Beta 分布。
-
从两个分布中采样点击率。
-
了解哪个点击率(CTR)更高,并抛掷相关的硬币。
-
了解是否有点击发生。
-
如果有点击,则将参数“a”增加 1;如果有跳过,则将参数“b”增加 1。
-
重复直到队列中有用户。
为了了解算法的质量,我们还将保存一个值,表示暴露于第二个选项的观众份额,因为它具有更高的“真实”点击率。我们将使用 50/50 分配策略作为基线质量的对比。
作者提供的代码
在队列中有 1000 名用户之后,我们的“多臂老丨虎丨机”已经对点击率有了很好的了解。
这里有一个图表显示了这种策略能带来更好的结果。在 100 名观众之后,“多臂老丨虎丨机”超过了 50%观众的第二个选项份额。由于越来越多的证据支持第二个标题,算法将更多流量分配给了第二个标题。几乎 80%的观众都看到了表现最好的选项!而在 50/50 的分配中,只有 50%的观众看到了表现最好的选项。
贝叶斯多臂老丨虎丨机展示了额外的 25%观众看到表现更好的选项!随着数据的增加,这两种策略之间的差异只会加大。
结论
当然,“多臂老丨虎丨机”并不完美。实时采样和服务选项的成本很高。最好拥有良好的基础设施以在期望的延迟下实现整个过程。此外,你可能不希望通过更改标题来让观众感到困惑。如果你的流量足够进行快速 A/B 测试,那就做吧!然后,手动更改一次标题。然而,这个算法可以应用于媒体以外的许多其他领域。
我希望你现在理解了什么是“多臂赌博机”以及它如何用于在适应新数据的情况下在两个选项之间进行选择。我特别没有关注数学和公式,因为教科书会更好地解释这些内容。我打算介绍一种新技术,并激发对它的兴趣!
如果你有任何问题,请随时通过 LinkedIn 联系我。
所有代码的笔记本可以在我的 GitHub 仓库 中找到。
Igor Khomyanin**** 是 Salmon 的数据科学家,曾在 Yandex 和 McKinsey 担任数据相关职位。我专注于使用统计学和数据可视化从数据中提取价值。
更多相关话题
超越人类界限:超级智能的崛起
原文:
www.kdnuggets.com/beyond-human-boundaries-the-rise-of-superintelligence

图片来源:Dall-E
在技术迅速发展的世界中,有一个话题脱颖而出,吸引了科学家、技术爱好者和大众的想象力:
人工智能的崛起。
当我们站在一个新时代的面前,这个问题显得尤为重要:
AI 的未来会是怎样的?
跟随我,让我们一起发现一切!
AI 革命
AI 已经取得了长足的进步,从简单的规则基础算法到模仿人类认知解决问题和做决定的深度学习模型。
图片来源:作者
AI 技术根据其模仿人类特征的能力分为三大类。
1. 人工窄智能(ANI)或具备专门能力的 AI
ANI,通常被称为弱 AI 或窄 AI,专注于特定应用或任务。它被设计用于执行单一任务,并尝试在有限的变量、限制和场景范围内模仿人类行为。
ANI 的例子在技术中随处可见,如 iPhone 上的 Siri 语音和语言处理或自动驾驶车辆中的视觉识别能力。
2. 人工通用智能(AGI)或等同于人类水平的 AI
AGI,也称为强 AI 或深度 AI,指的是机器理解、学习和使用智能来解决复杂问题的能力,类似于人类。AGI 基于‘心智理论’框架,使其能够感知其他智能实体的情感、信念和思维过程。
AGI 仍然是一个理论概念,但已引起主要科技公司的极大兴趣。例如,微软通过 OpenAI 投资了 10 亿美元于 AGI。如今,我们已经拥有 ChatGPT-4,它能够处理广泛的问题并展示更高水平的认知技能,代表了一种早期形式的 AGI。
3. 人工超级智能(ASI)或超越人类智力的 AI
ASI 代表了一种超越人类智力的 AI 形式,能够在每项任务中超越人类。ASI 不仅能够理解人类情感和体验,还被设想拥有自己的情感、信念和欲望。
虽然 ASI 目前是一个理论概念,但其预计的决策和问题解决能力预计将远远超越人类能力。
在深入探讨这种超级智能之前,让我们稍微回顾一下……
AI 的未来在早期过去是什么样的?
人工智能的概念多年来在恐惧和迷人之间摇摆,早于实际术语的出现。普遍的看法是,真正的人工智能必须模仿人类形式,这掩盖了人工智能实际上已经运作了相当一段时间的现实。
显著的成就,比如在国际象棋中超越人类技能,仅仅是冰山一角。自 1980 年代以来,人工智能一直是各个行业的重要组成部分。

加里·卡斯帕罗夫与深蓝棋手对弈的画面。
1990 年代,随着概率和贝叶斯方法的出现,机器学习经历了变革。这些进展为一些当前最普遍的人工智能应用奠定了基础,包括处理庞大数据集的能力。
这一能力扩展到对原始文本进行语义分析,使得网络用户可以通过输入简单查询,轻松地在数十亿个网页中找到所需的信息。
对超级智能的探索
超级智能不仅仅是以闪电般的速度处理数据。它涉及到在每一个智力方面的全面提升,从推理和创造力到自我改善。
想象一个机器在创新、思考和学习方面超越人类能力的世界。我们现在还不在这样的世界中,但随着技术的进步,这种情景可能比我们想象的更近。
最近的进展,例如 OpenAI 的 GPT-4,展示了人工智能的快速发展。考虑到在机器学习或量子计算等领域经历的所有突破,超级智能的出现变得越来越有可能。
这引出了我们要讨论的内容……
超级智能的潜力与风险
超级智能的好处是无穷无尽的。从医学领域的基于人工智能的疾病预测,到金融或气候变化,假设的超级智能可以提升人类社会。然而,现有的人工智能水平已经带来了一些重大影响,因此超级智能可能会使这些情况变得更加严重:
1. 转变工作场所
忘掉旧有的观念,即人工智能仅会影响低技能工作。得益于生成式人工智能的进步,如 DALL-E 和 Mid-Journey,即使是创造性职业也感受到了压力。
这些人工智能系统可以迅速生成艺术、文学和视频。它们的速度如此之快,已经开始超越人类记者编写基础新闻文章的能力。
这种转变引发了关于未来工作的重大问题,尤其是在我们曾认为免受自动化影响的领域。
2. 应对知识产权迷宫
人工智能的崛起在知识产权领域掀起了风暴。当一个人工智能创作一首歌曲或一个标志时,谁拥有这些作品?
-
程序员?
-
人工智能本身?
-
提供训练数据的创作者?
随着人工智能系统在现有内容上进行训练,现在能够生成极具说服力的虚假内容,这一问题变得越来越复杂。这一困境甚至引发了法律纠纷,[例如 Getty Images 起诉 Stability AI 关于照片使用的问题。]( https://apnews.com/article/getty-images-artificial-intelligence-ai-image-generator-stable-diffusion-a98eeaaeb2bf13c5e8874ceb6a8ce196#:~:text=In a lawsuit filed early ,to%20build%20a%20competing%20business.%E2%80%9D)
3. 虚假信息挑战
人工智能以低成本和高效率生成逼真的虚假内容是把双刃剑。这项技术可能大幅扩大虚假信息在网上的传播,随着虚假内容变得越来越复杂,这一担忧也在不断增加。
4. 决策中的人工智能
政府和企业越来越依赖人工智能来决策,如社会福利和执法等领域。这些系统分配的风险评分可能对人们的生活产生重大影响。
然而,问题在于:未加控制的人工智能可能会复制甚至加剧现有的社会偏见。
人类必须保持参与,指导人工智能的决策,以防止不公平的结果。
为人工智能时代做准备
权力越大,责任越大。随着人工智能的快速进步,我们需要跟上步伐。政策制定者、行业专家和开发者需要就人工智能的规则和法规进行合作。
确保这些智能系统与人类价值观和伦理对齐至关重要。如果没有适当的检查和制衡,未加控制的人工智能可能导致反乌托邦的结果,机器可能会支配人类。决策者必须迅速制定政策,以跟上这一不断发展的技术。
此外,人工智能的公平使用和分配是一个紧迫的问题。超级智能人工智能可能会赋予控制它的人巨大的权力,导致财富和影响力的不平等。确保人工智能的有益和公平使用是社会必须正视的挑战。
这引出了…
奇点理论
奇点理论最早由约翰·冯·诺依曼在 1958 年提出。对于那些不熟悉这一概念的人来说,它描述了一个假设的时刻,即人工智能要么发展出自我意识,要么获得如此先进的能力,以至于超越了人类的控制。
图片来源:克雷格·贝拉米
在这种情况下,人工智能将以指数级的速度自主提升,远远超出人类的理解或控制。
然而,这一概念极具争议。
对这一理论的批评者认为,它低估了人类思维的能力,同时高估了人工智能的潜在能力。如果这种事件发生,其时间也成为科学家和技术专家之间争论的话题。
所以我们还不必惊慌!
以乐观态度迎接未来
人工智能发展的轨迹充满希望。通过采取平衡的方法,我们可以利用人工智能进步的好处,同时有效应对其挑战。
当我们站在历史的关键时刻时,我们必须以兴奋、谨慎和责任心迎接这一超级智能的曙光。
我们如何为即将到来的事物做好准备?
答案在于提高意识和持续自我教育。人工智能在自动化例行任务方面的非凡能力不仅节省时间,还让人类能够从事更复杂和富有创意的工作。
以医疗保健为例:人工智能对医学图像的解读能力可能挽救生命。同样,在交通领域,人工智能的作用日益增长,这在特斯拉等自驾车的受欢迎程度上得到了体现。
未来的发展预示着更加复杂的汽车技术。此外,人工智能正在简化物流和供应链,提高效率,降低成本。
Josep Ferrer是一位来自巴塞罗那的分析工程师。他拥有物理工程学位,目前在应用于人类流动性的数据科学领域工作。他还是一名兼职内容创作者,专注于数据科学和技术。Josep 撰写有关人工智能的所有内容,涵盖了这一领域的持续爆炸性发展。
了解更多相关话题
超越 Numpy 和 Pandas:解锁鲜为人知的 Python 库的潜力
原文:
www.kdnuggets.com/2023/08/beyond-numpy-pandas-unlocking-potential-lesserknown-python-libraries.html
图片由 OrMaVaredo 提供,发布在 Pixabay
Python 是世界上使用最广泛的编程语言之一,为开发者提供了广泛的库。
无论如何,当谈到数据处理和科学计算时,我们通常会想到像 Numpy、Pandas 或 SciPy 这样的库。
在这篇文章中,我们介绍了三种你可能感兴趣的 Python 库。
1. Dask
介绍 Dask
Dask 是一个灵活的并行计算库,支持大规模数据处理的分布式计算和并行处理。
那么,我们为什么应该使用 Dask 呢?正如他们在 他们的网站上所说的:
Python 已经成长为数据分析和通用编程中的主导语言。这种增长得益于像 NumPy、pandas 和 scikit-learn 这样的计算库。然而,这些包并未设计用于超越单一机器的规模。Dask 的开发目的是将这些包及其相关生态系统本地扩展到多核机器和分布式集群,以处理超出内存的数据集。
因此,Dask 的一个常见用途是 他们说的:
Dask DataFrame 用于 pandas 通常需要的情况,通常是当 pandas 因数据大小或计算速度而失败时:
操作大型数据集,即使这些数据集无法全部加载到内存中
通过使用多个核心加速长时间计算
对大型数据集进行分布式计算,使用标准的 pandas 操作,如 groupby、join 和时间序列计算
因此,当我们需要处理巨大的 Pandas 数据框时,Dask 是一个不错的选择。这是因为 Dask:
允许用户在笔记本电脑上操作 100GB 以上的数据集,或在工作站上操作 1TB 以上的数据集
这确实是一个相当令人印象深刻的结果。
在幕后发生的情况是:
Dask DataFrame 协调了许多按索引排列的 pandas DataFrame/Series。Dask DataFrame 按 行 进行分区,通过索引值对行进行分组以提高效率。这些 pandas 对象可能存储在磁盘上或其他机器上。
因此,我们有了这样的结果:
Dask 和 Pandas 数据框之间的区别。图像由作者提供,自 Dask 网站上引用的图像自由改编。
Dask 一些实际功能
首先,我们需要安装 Dask。可以通过 pip 或 conda 来安装:
$ pip install dask[complete]
or
$ conda install dask
特性一:打开 CSV 文件
我们可以展示 Dask 的第一个特性:如何打开一个 CSV 文件。我们可以这样做:
import dask.dataframe as dd
# Load a large CSV file using Dask
df_dask = dd.read_csv('my_very_large_dataset.csv')
# Perform operations on the Dask DataFrame
mean_value_dask = df_dask['column_name'].mean().compute()
所以,正如代码所示,我们使用 Dask 的方式与 Pandas 非常相似。特别是:
-
我们使用
read_csv()方法,完全与 Pandas 一样。 -
我们像在 Pandas 中一样截取一列。实际上,如果我们有一个名为
df的 Pandas 数据框,我们可以这样截取一列:df['column_name']。 -
我们对截取的列应用
mean()方法,类似于 Pandas,但这里我们还需要添加compute()方法。
同样,即使打开 CSV 文件的方法与 Pandas 相同,在底层 Dask 也在轻松处理超出单台机器内存容量的大型数据集。
这意味着我们看不到任何实际的区别,除了一个大型数据框不能在 Pandas 中打开,而在 Dask 中可以。
特性二:扩展机器学习工作流
我们可以使用 Dask 创建一个具有大量样本的分类数据集。然后,我们可以将其拆分为训练集和测试集,用 ML 模型拟合训练集,并计算测试集的预测结果。
我们可以这样做:
import dask_ml.datasets as dask_datasets
from dask_ml.linear_model import LogisticRegression
from dask_ml.model_selection import train_test_split
# Load a classification dataset using Dask
X, y = dask_datasets.make_classification(n_samples=100000, chunks=1000)
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Train a logistic regression model in parallel
model = LogisticRegression()
model.fit(X_train, y_train)
# Predict on the test set
y_pred = model.predict(X_test).compute()
这个例子强调了 Dask 即使在机器学习问题中也能处理巨大数据集的能力,通过将计算分配到多个核心上。
特别是,我们可以使用 dask_datasets.make_classification() 方法为分类案例创建一个 “Dask 数据集”,并可以指定样本数量和块数(甚至非常大!)。
与之前相似,预测结果通过 compute() 方法获得。
**NOTE:**
in this case, you may need to intsall the module dask_ml.
You can do it like so:
$ pip install dask_ml
特性三:高效的图像处理
Dask 利用的并行处理能力也可以应用于图像。
特别是,我们可以打开多个图像,调整大小,然后保存调整大小后的图像。我们可以这样做:
import dask.array as da
import dask_image.imread
from PIL import Image
# Load a collection of images using Dask
images = dask_image.imread.imread('image*.jpg')
# Resize the images in parallel
resized_images = da.stack([da.resize(image, (300, 300)) for image in images])
# Compute the result
result = resized_images.compute()
# Save the resized images
for i, image in enumerate(result):
resized_image = Image.fromarray(image)
resized_image.save(f'resized_image_{i}.jpg')
所以,过程如下:
-
我们使用方法
dask_image.imread.imread("image*.jpg")打开当前文件夹(或你可以指定的文件夹)中的所有 “.jpg” 图像。 -
我们使用方法
da.stack()将所有图像调整为 300x300,使用列表推导式。 -
我们使用
compute()方法计算结果,正如之前所做的那样。 -
我们使用
for循环保存所有调整大小的图像。
2. SymPy
介绍 Sympy
如果你需要进行数学计算和运算,并且希望坚持使用 Python,你可以尝试 Sympy。
的确:既然我们可以使用我们钟爱的 Python,为什么还要使用其他工具和软件呢?
根据他们在 网站 上写的内容,Sympy 是:
一个用于符号数学的 Python 库。它旨在成为一个功能齐全的计算机代数系统(CAS),同时保持代码尽可能简单,以便易于理解和扩展。SymPy 完全用 Python 编写。
但是为什么使用 SymPy?他们建议:
SymPy 是…
- 免费: 根据 BSD 许可证,SymPy 既是言语上的自由,也是酒精上的自由。
- 基于 Python: SymPy 完全用 Python 编写,并使用 Python 作为语言。
- 轻量级: SymPy 仅依赖于 mpmath,一个纯 Python 库用于任意浮点算术,使其易于使用。
- 一个库: 除了作为交互工具使用,SymPy 还可以嵌入到其他应用程序中,并通过自定义函数进行扩展。
所以,它基本上拥有所有 Python 爱好者喜爱的特性!
现在,让我们看看它的一些特性。
SymPy 的一些功能演示
首先,我们需要安装它:
$ pip install sympy
**PAY ATTENTION:**
if you write *$ pip install* *simpy* you'll install another (completely
different!) library.
So, the second letter is a "y", not an "i".
功能一:解代数方程
如果我们需要解代数方程,可以这样使用 SymPy:
from sympy import symbols, Eq, solve
# Define the symbols
x, y = symbols('x y')
# Define the equation
equation = Eq(x**2 + y**2, 25)
# Solve the equation
solutions = solve(equation, (x, y))
# Print solution
print(solutions)
>>>
[(-sqrt(25 - y**2), y), (sqrt(25 - y**2), y)]
所以,这就是过程:
-
我们用方法
symbols()定义方程的符号。 -
我们用方法
Eq编写代数方程。 -
我们用方法
solve()解方程。
当我在大学时,我使用了不同的工具来解决这些问题,我必须说 SymPy,如我们所见,是非常易读和用户友好的。
但是,确实:这是一个 Python 库,那么它会有什么不同呢?
功能二:计算导数
计算导数是我们在数据分析中可能需要的另一项任务。通常,我们可能因为各种原因需要进行计算,SymPy 确实简化了这个过程。实际上,我们可以这样做:
from sympy import symbols, diff
# Define the symbol
x = symbols('x')
# Define the function
f = x**3 + 2*x**2 + 3*x + 4
# Calculate the derivative
derivative = diff(f, x)
# Print derivative
print(derivative)
>>>
3*x**2 + 4*x + 3
如我们所见,这个过程非常简单且自解释:
-
我们用
symbols()定义我们导数的函数符号。 -
我们定义函数。
-
我们用
diff()计算导数,指定函数和我们计算导数的符号(这是一个绝对导数,但在有x和y变量的函数的情况下,我们还可以进行偏导数)。
如果我们进行测试,我们会看到结果在 2 到 3 秒内到达。因此,它也相当快。
功能三:计算积分
当然,如果 SymPy 能够计算导数,它也能计算积分。让我们来做:
from sympy import symbols, integrate, sin
# Define the symbol
x = symbols('x')
# Perform symbolic integration
integral = integrate(sin(x), x)
# Print integral
print(integral)
>>>
-cos(x)
在这里,我们使用方法 integrate(),指定要积分的函数和积分变量。
难道这不更简单吗?!
3. Xarray
介绍 Xarray
Xarray 是一个扩展 NumPy 功能的 Python 库,使我们能够处理带标签的数组和数据集。
正如他们在 他们的网站上 说的:
Xarray 使得在 Python 中处理带标签的多维数组变得简单、高效和有趣!
同样:
Xarray 在原始类似 NumPy 的多维数组之上引入了维度、坐标和属性的标签,这使得开发者的体验更加直观、简洁且不易出错。
换句话说,它通过在数组维度上添加标签或坐标来扩展 NumPy 数组的功能。这些标签提供了元数据,并使多维数据的更高级分析和操作成为可能。
例如,在 NumPy 中,数组是通过基于整数的索引来访问的。
在 Xarray 中,每个维度都可以有一个关联的标签,使得根据有意义的名称来理解和操作数据变得更加容易。
例如,与其用arr[0, 1, 2]访问数据,我们可以在 Xarray 中使用arr.sel(x=0, y=1, z=2),其中x、y和z是维度标签。
这使得代码更易读!
那么,让我们看看 Xarray 的一些功能。
Xarray 的一些功能演示
和往常一样,安装方法如下:
$ pip install xarray
特性一:使用标记坐标
假设我们想创建一些与温度相关的数据,并希望用纬度和经度等坐标标记这些数据。我们可以这样做:
import xarray as xr
import numpy as np
# Create temperature data
temperature = np.random.rand(100, 100) * 20 + 10
# Create coordinate arrays for latitude and longitude
latitudes = np.linspace(-90, 90, 100)
longitudes = np.linspace(-180, 180, 100)
# Create an Xarray data array with labeled coordinates
da = xr.DataArray(
temperature,
dims=['latitude', 'longitude'],
coords={'latitude': latitudes, 'longitude': longitudes}
)
# Access data using labeled coordinates
subset = da.sel(latitude=slice(-45, 45), longitude=slice(-90, 0))
如果我们打印它们,会得到:
# Print data
print(subset)
>>>
<xarray.dataarray longitude:="">array([[13.45064786, 29.15218061, 14.77363206, ..., 12.00262833,
16.42712411, 15.61353963],
[23.47498117, 20.25554247, 14.44056286, ..., 19.04096482,
15.60398491, 24.69535367],
[25.48971105, 20.64944534, 21.2263141 , ..., 25.80933737,
16.72629302, 29.48307134],
...,
[10.19615833, 17.106716 , 10.79594252, ..., 29.6897709 ,
20.68549602, 29.4015482 ],
[26.54253304, 14.21939699, 11.085207 , ..., 15.56702191,
19.64285595, 18.03809074],
[26.50676351, 15.21217526, 23.63645069, ..., 17.22512125,
13.96942377, 13.93766583]])
Coordinates:
* latitude (latitude) float64 -44.55 -42.73 -40.91 ... 40.91 42.73 44.55
* longitude (longitude) float64 -89.09 -85.45 -81.82 ... -9.091 -5.455 -1.818</xarray.dataarray>
那么,让我们一步步看一下这个过程:
-
我们已将温度值创建为 NumPy 数组。
-
我们将纬度和经度值定义为 NumPy 数组。
-
我们使用
DataArray()方法将所有数据存储在 Xarray 数组中。 -
我们使用
sel()方法选择了一部分纬度和经度,这个方法可以选择我们想要的子集值。
结果也很容易读取,因此标记在很多情况下确实很有帮助。
特性二:处理缺失数据
假设我们正在收集与全年温度相关的数据。我们想知道我们的数组中是否有一些空值。以下是检查的方法:
import xarray as xr
import numpy as np
import pandas as pd
# Create temperature data with missing values
temperature = np.random.rand(365, 50, 50) * 20 + 10
temperature[0:10, :, :] = np.nan # Set the first 10 days as missing values
# Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50)
# Create an Xarray data array with missing values
da = xr.DataArray(
temperature,
dims=['time', 'latitude', 'longitude'],
coords={'time': times, 'latitude': latitudes, 'longitude': longitudes}
)
# Count the number of missing values along the time dimension
missing_count = da.isnull().sum(dim='time')
# Print missing values
print(missing_count)
>>>
<xarray.dataarray longitude:="">array([[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
...,
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10],
[10, 10, 10, ..., 10, 10, 10]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0</xarray.dataarray>
因此,我们得出有 10 个空值。
另外,如果我们仔细观察代码,我们可以看到,我们可以将 Pandas 的方法应用于 Xarray,如isnull.sum(),它统计了缺失值的总数。
特性一:处理和分析多维数据
当我们有可能标记数组时,处理和分析多维数据的诱惑很大。那么,为什么不尝试一下呢?
例如,假设我们仍在收集与特定纬度和经度相关的温度数据。
我们可能想计算温度的均值、最大值和中位数。我们可以这样做:
import xarray as xr
import numpy as np
import pandas as pd
# Create synthetic temperature data
temperature = np.random.rand(365, 50, 50) * 20 + 10
# Create time, latitude, and longitude coordinate arrays
times = pd.date_range('2023-01-01', periods=365, freq='D')
latitudes = np.linspace(-90, 90, 50)
longitudes = np.linspace(-180, 180, 50)
# Create an Xarray dataset
ds = xr.Dataset(
{
'temperature': (['time', 'latitude', 'longitude'], temperature),
},
coords={
'time': times,
'latitude': latitudes,
'longitude': longitudes,
}
)
# Perform statistical analysis on the temperature data
mean_temperature = ds['temperature'].mean(dim='time')
max_temperature = ds['temperature'].max(dim='time')
min_temperature = ds['temperature'].min(dim='time')
# Print values
print(f"mean temperature:\n {mean_temperature}\n")
print(f"max temperature:\n {max_temperature}\n")
print(f"min temperature:\n {min_temperature}\n")
>>>
mean temperature:
<xarray.dataarray longitude:="">
array([[19.99931701, 20.36395016, 20.04110699, ..., 19.98811842,
20.08895803, 19.86064693],
[19.84016491, 19.87077812, 20.27445405, ..., 19.8071972 ,
19.62665953, 19.58231185],
[19.63911165, 19.62051976, 19.61247548, ..., 19.85043831,
20.13086891, 19.80267099],
...,
[20.18590514, 20.05931149, 20.17133483, ..., 20.52858247,
19.83882433, 20.66808513],
[19.56455575, 19.90091128, 20.32566232, ..., 19.88689221,
19.78811145, 19.91205212],
[19.82268297, 20.14242279, 19.60842148, ..., 19.68290006,
20.00327294, 19.68955107]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
max temperature:
<xarray.dataarray longitude:="">
array([[29.98465531, 29.97609171, 29.96821276, ..., 29.86639343,
29.95069558, 29.98807808],
[29.91802049, 29.92870312, 29.87625447, ..., 29.92519055,
29.9964299 , 29.99792388],
[29.96647016, 29.7934891 , 29.89731136, ..., 29.99174546,
29.97267052, 29.96058079],
...,
[29.91699117, 29.98920555, 29.83798369, ..., 29.90271746,
29.93747041, 29.97244906],
[29.99171911, 29.99051943, 29.92706773, ..., 29.90578739,
29.99433847, 29.94506567],
[29.99438621, 29.98798699, 29.97664488, ..., 29.98669576,
29.91296382, 29.93100249]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0
min temperature:
<xarray.dataarray longitude:="">
array([[10.0326431 , 10.07666029, 10.02795524, ..., 10.17215336,
10.00264909, 10.05387097],
[10.00355858, 10.00610942, 10.02567816, ..., 10.29100316,
10.00861792, 10.16955806],
[10.01636216, 10.02856619, 10.00389027, ..., 10.0929342 ,
10.01504103, 10.06219179],
...,
[10.00477003, 10.0303088 , 10.04494723, ..., 10.05720692,
10.122994 , 10.04947012],
[10.00422182, 10.0211205 , 10.00183528, ..., 10.03818058,
10.02632697, 10.06722953],
[10.10994581, 10.12445222, 10.03002468, ..., 10.06937041,
10.04924046, 10.00645499]])
Coordinates:
* latitude (latitude) float64 -90.0 -86.33 -82.65 ... 82.65 86.33 90.0
* longitude (longitude) float64 -180.0 -172.7 -165.3 ... 165.3 172.7 180.0</xarray.dataarray></xarray.dataarray></xarray.dataarray>
我们也以清晰可读的方式得到了我们想要的结果。
再次如前所述,为了计算温度的最大值、最小值和均值,我们使用了应用于数组的 Pandas 函数。
结论
在这篇文章中,我们展示了三个用于科学计算和运算的库。
虽然 SymPy 可以替代其他工具和软件,使我们能够使用 Python 代码进行数学计算,但 Dask 和 Xarray 扩展了其他库的功能,帮助我们在遇到其他最著名的 Python 数据分析和处理库存在困难的情况下提供帮助。
费德里科·特罗塔 从小就热爱写作,在学校时就写侦探故事作为班级考试的一部分。由于他的好奇心,他发现了编程和 AI。由于对写作的强烈热情,他无法避免开始写作这些话题,因此决定转行成为一名技术作家。他的目标是通过写作来教育人们有关 Python 编程、机器学习和数据科学的知识。了解更多关于他的内容,请访问 federicotrotta.com。
原文。经授权转载。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关内容
超越独热编码:类别变量的探索
原文:
www.kdnuggets.com/2015/12/beyond-one-hot-exploration-categorical-variables.html
评论
作者:威尔·麦金尼斯。
在机器学习中,数据至关重要。用于根据数据进行预测的算法和模型很重要,也非常有趣,但机器学习仍然受到“垃圾进,垃圾出”这一理念的制约。考虑到这一点,让我们来看一下这些输入数据的一个小子集:类别变量。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求

类别变量 (wiki) 是那些表示固定数量可能值的变量,而不是连续数量的变量。每个值将测量分配到这些有限组或类别中的一个。这些变量与有序变量不同,有序变量之间的距离应相等,无论类别数量如何,而有序变量则具有某种固有的排序。例如:
-
有序变量:低、中、高
-
类别变量:乔治亚州、阿拉巴马州、南卡罗来纳州……,纽约
我们稍后使用的机器学习算法倾向于需要数字而不是字符串作为输入,因此我们需要某种编码方法来进行转换。
插一句话:在这篇文章中还有一个概念会经常出现,那就是维度的概念。简单来说,就是数据集中列的数量,但它对最终模型有着重要的影响。在极端情况下,“维度灾难”的概念讨论了在高维空间中某些事物可能会停止正常工作。即使在相对低维的问题中,具有更多维度的数据集也需要更多的参数来使模型理解,这意味着需要更多的行来可靠地学习这些参数。如果数据集中的行数是固定的,而添加额外的维度却没有为模型提供更多的信息,这可能会对最终模型的准确性产生不利影响。
回到眼前的问题:我们想将分类变量编码为数字,但我们担心这个维度问题。显而易见的答案是直接为每个类别分配一个整数(假设我们事先知道所有可能的类别)。这称为序数编码。它不会给问题增加任何维度,但暗示了一个可能并不存在的变量顺序。
方法论
为了了解效果如何,我编写了一个简单的 Python 脚本来测试常见数据集上的不同编码方法。首先是过程概述:
-
我们收集一个包含分类变量的分类问题的数据集
-
我们使用某种编码方法将 X 数据集转换为数值
-
我们使用 scikit-learn 的交叉验证分数和 BernoulliNB()分类器来生成数据集的分数。这在每个数据集上重复 10 次,使用所有分数的均值。
-
我们存储数据集的维度、均值分数以及编码数据和生成分数的时间。
这在来自 UCI 数据集库的几个不同数据集上重复进行:
我尝试了 7 种不同的编码方法(4-7 的描述摘自statsmodel 的文档):
-
序数:如上所述
-
独热编码:每个类别一个列,每个单元格中填入 1 或 0,表示该行是否包含该列的类别
-
二进制:首先将类别编码为序数,然后将这些整数转换为二进制代码,然后将该二进制字符串的数字分成单独的列。这种编码以比独热编码更少的维度编码数据,但会有一些距离扭曲。
-
总和:比较给定水平的因变量均值与所有水平因变量的总体均值。也就是说,它使用每一个前 k-1 水平和水平 k 之间的对比。在这个例子中,水平 1 与所有其他水平进行比较,水平 2 与所有其他水平进行比较,水平 3 与所有其他水平进行比较。
-
多项式:对于 k=4 水平的多项式编码,系数包括线性、二次和三次趋势。这里的分类变量被假设为由一个基础的、等间距的数值变量表示。因此,这种编码仅用于具有相等间距的有序分类变量。
-
后向差分:将一个水平的因变量均值与前一个水平的因变量均值进行比较。这种编码可能对名义变量或序数变量有用。
-
Helmert:对一个水平的因变量均值与所有前一个水平的因变量均值进行比较。因此,‘逆’这个名字有时用来与前向 Helmert 编码区分。
结果
蘑菇
| 编码 | 维度 | 平均得分 | 耗时 | |
|---|---|---|---|---|
| 0 | 序数 | 22 | 0.81 | 3.65 |
| 1 | 独热编码 | 117 | 0.81 | 8.19 |
| 6 | Helmert 编码 | 117 | 0.84 | 5.43 |
| 5 | 后向差分编码 | 117 | 0.85 | 7.83 |
| 3 | 求和编码 | 117 | 0.85 | 4.93 |
| 4 | 多项式编码 | 117 | 0.86 | 6.14 |
| 2 | 二进制编码 | 43 | 0.87 | 3.95 |
汽车
| 编码 | 维度 | 平均得分 | 耗时 | |
|---|---|---|---|---|
| 10 | 求和编码 | 21 | 0.55 | 1.46 |
| 13 | Helmert 编码 | 21 | 0.58 | 1.46 |
| 7 | 序数 | 6 | 0.64 | 1.47 |
| 8 | 独热编码 | 21 | 0.65 | 1.39 |
| 11 | 多项式编码 | 21 | 0.67 | 1.49 |
| 12 | 后向差分编码 | 21 | 0.70 | 1.50 |
| 9 | 二进制编码 | 9 | 0.70 | 1.44 |
拼接
| 编码 | 维度 | 平均得分 | 耗时 | |
|---|---|---|---|---|
| 14 | 序数 | 61 | 0.68 | 5.11 |
| 17 | 求和编码 | 3465 | 0.92 | 25.90 |
| 16 | 二进制编码 | 134 | 0.94 | 3.35 |
| 15 | 独热编码 | 3465 | 0.95 | 2.56 |
结论
这绝不是一项详尽的研究,但似乎二进制编码在保持合理一致性的情况下表现良好,没有显著的维度增加。正如预期,序数编码表现一直很差。
如果你想查看源代码、添加或建议新的数据集或编码方法,我已经将所有内容(包括数据集)上传到 GitHub:github.com/wdm0006/categorical_encoding。
可以直接在那儿贡献,或在这里评论提出建议。
原始.
相关:
-
数据挖掘 Medicare 数据 – 我们能发现什么?
-
机器学习的 5 个部落 – 问题与答案
-
欺诈检测解决方案
更多相关话题
超越天网:打造 AI 演进的下一前沿
原文:
www.kdnuggets.com/beyond-skynet-crafting-the-next-frontier-in-ai-evolution
图片来源:Google DeepMind
在快速技术发展的时代,人工智能(AI)作为一种变革性力量,具有重塑行业和提升我们日常生活的潜力。AI 能力的核心在于数据——驱动其学习和决策过程的生命线。数据的可靠性不可过分强调,因为它是 AI 算法有效执行的基础。此外,确保数据的可获取性和维护道德隐私实践也成为影响 AI 未来成功的关键因素。
可靠数据:知情决策的支柱
现代企业在做出知情决策时,严重依赖 AI 生成的见解,涉及库存管理、客户支持、产品开发和广告活动等。然而,旧谚语“垃圾进,垃圾出”依然真实。糟糕的数据可能导致误导性结论和不良决策,造成财务损失和错失机会。
在考虑虚假信息或虚假宣传的潜在影响时,数据的可靠性变得尤为关键。在虚假信息如野火般传播的时代,基于不可靠数据训练的 AI 算法可能会无意中放大和延续虚假信息。这突显了建立严格的数据质量标准和健全的事实核查程序的重要性,以确保 AI 的输出是准确的。
普及有价值的数据洞察
在 AI 领域,源自数据的有价值洞察通常集中在大型科技公司手中。然而,AI 的潜在应用远远超出科技巨头。从医疗保健、农业到交通运输和金融,AI 驱动的解决方案可以革新行业,并造福各种规模的公司。这就是为什么每个人都应该获得 AI 使用的数据洞察,而不仅仅是少数几个人。
解锁 AI 对更广泛社会利益的潜力需要使数据访问民主化。中小企业、研究人员、初创公司甚至个人都应该有机会利用 AI 驱动的洞察。想象一个未来,在那里当地农民可以利用 AI 预测最佳收获时间,或小型零售商可以使用 AI 做出有关新店位置的明智决策。这个愿景需要从数据囤积转向数据共享。
消费者隐私与大科技公司的竞争优势
在消费者隐私和商业利益之间取得平衡,对于确保 AI 驱动的洞察能惠及整个社会而不损害个人权利或使企业处于不利地位至关重要。然而,深入探讨大科技公司与消费者数据隐私之间的关系,揭示了一个更复杂的故事。虽然这些公司将自己表现为保护个人数据的倡导者,但更深入的观察表明,他们的动机可能更多是为了获得竞争优势,而不仅仅是出于道德关切。
推动数据隐私背后隐藏的可能实际上是一个战略商业计划。一些大科技公司不仅保留用户数据以保护它,而且利用这些数据来完善自己的产品和商业模型,同时阻止竞争对手访问相同的数据。这使他们在市场中具有独特优势,实现个性化体验和有针对性的广告,而竞争对手无法匹敌。因此,数据隐私成为确保和巩固市场主导地位的一种手段。
然而,这种策略模糊了伦理责任和商业优势之间的界限。它提出了一个问题,即这些努力是否真正优先考虑用户的福祉,还是为了维持强大的市场地位而进行的精心计算的举动。无论他们的意图是源于真正的关切还是战略性收益,结果将决定未来几年 AI 等技术将如何影响我们的生活。
为伦理和包容性 AI 铺平道路
掌握 AI 全潜力的旅程始于认识到数据的关键作用。优质的数据是 AI 创新的基础,确保其可及性和可靠性至关重要。为了充分释放 AI 的能力,我们必须使所有类型的企业、组织和个人都能享受到洞察的民主化。
通过培养合作文化,遵守严格的数据质量标准,并倡导数据隐私,我们可以为 AI 应用铺平道路,使其既服务于商业利益,也造福社会。AI 的未来依赖于我们集体的承诺,塑造一个数据成为进步力量、可及性为核心原则、可靠性为 AI 驱动洞察标志的世界。
Jeff White**** 是 Gravy Analytics 的创始人兼首席执行官。他热衷于构建具有颠覆性技术的公司,这些技术有潜力改变整个行业。在创办 Gravy Analytics 之前,他创办了几家科技公司并带领它们成功退出。
了解更多相关话题
超越肤浅:有实质内容的数据科学 MOOCs
原文:
www.kdnuggets.com/2020/08/beyond-superficial-data-science-moocs-substance.html
评论
由 Mathieu Plourde(Flickr 上的 Mathplourde)- https://www.flickr.com/photos/mathplourde/8620174342/sizes/o/in/photostream/ ,CC BY 2.0,https://commons.wikimedia.org/w/index.php?curid=75937656
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 工作
Benjamin Obi Tayo 在他最近的文章中"数据科学 MOOCs 过于肤浅"写道:
大多数数据科学 MOOC 是入门级课程。这些课程适合那些已经在相关学科(物理学、计算机科学、数学、工程、会计)有坚实背景的人,他们想进入数据科学领域。
他是对的。确实有很多入门级 MOOCs,彼此竞争以吸引入门级学习者。如果这是你所寻找的,那么这很好。但如果你是一个更高级的学习者呢?那你的选择是什么?是否存在有效的高级 MOOC 课程?
正如 Tayo 所指出的,学习数据科学有很多替代 MOOCs 的方法。确实没有理由将 MOOCs 视为唯一的选择。然而,除了入门级课程的相对占优势之外,还有一种趋势直接否定 MOOCs 在更高级别的有效性,这主要有两个原因。
首先,有一种普遍的假设认为,所有参加数据科学课程的人都完全没有相关的经验或教育,相关的假设是大家都相信他们可以在一个四周的课程之后成为数据科学家。
其次,有一种观点认为,很多人参加 MOOCs 只是为了获得相关证书,相关的假设是大家都认为获取这些证书必然会导致成功的数据科学职业。
如果你忽略这些假设,你可以将 MOOC 简单地视为一种潜在的学习和技能获取工具,适合不同程度的学生。鉴于许多 MOOC 是由世界级的讲师和教育机构组织的,因此从这些课程中学到有价值的东西的机会似乎很大。
鉴于此,本文将探讨一些适合那些已经掌握了一些数据科学基础技能的高级数据科学课程。什么是高级的呢?这显然是主观的,但我会尽力整理出自我分类为高级的相关课程。什么是数据科学基础技能?这也是主观的,在这个案例中,它们会有所不同,取决于所考虑的具体高级课程。
为了缩小庞大的 MOOC 课程范围,我不得不制定一个筛选标准。就我们的目的而言,有效的 MOOC 是指:
-
依托于一个 MOOC 平台,该平台允许免费访问课程材料,并可以选择付费获得证书
-
由大学或学习机构提供或附属(而不是由任何人组织)
-
实际上是将若干独立课程集合成某种多课程组合
第一条明显忽略了 Udacity 等相关的付费平台。第二条忽略了像 Udemy 这样的开放课程平台。第三条理论上允许课程的逻辑链条随着时间的推移构建深入相关的学习概念。
这个标准或多或少——就主要的 MOOC 平台而言——将我们限制在 Coursera 和 edx。请注意,我们本可以在这个标准的基础上进一步扩展定义,或考虑 MOOC 平台,但这个汇编列表旨在提供一些关于高级课程的想法,而不是全面的整理。
如果你已经掌握了数据科学的基础知识,并且希望通过优质的高级 MOOC 进一步提升自己的知识,看看这 4 个推荐课程吧。
高级机器学习专项课程 是由国立研究大学高等经济学院在 Coursera 提供的一系列 7 门机器学习相关课程。
这个专项课程介绍了深度学习、强化学习、自然语言理解、计算机视觉和贝叶斯方法。顶级 Kaggle 机器学习从业者和 CERN 科学家将分享他们解决实际问题的经验,并帮助你弥合理论与实践之间的差距。完成 7 门课程后,你将能够在企业中应用现代机器学习方法,并理解实际数据和设置中的注意事项。
这个专项课程包括:
-
深度学习导论
-
如何赢得数据科学竞赛:向顶级 Kagglers 学习
-
贝叶斯方法在机器学习中
-
实用强化学习
-
计算机视觉中的深度学习
-
自然语言处理
-
通过机器学习解决大型强子对撞机挑战
概率图模型专门化 是斯坦福大学 Daphne Koller 主办的 Coursera 上的 3 门课程的集合。
概率图模型 (PGMs) 是一种丰富的框架,用于在复杂领域中编码概率分布:大量随机变量之间的联合(多元)分布。这些表示位于统计学和计算机科学的交汇处,依赖于概率理论、图算法、机器学习等概念。它们是广泛应用中的最先进方法的基础,如医学诊断、图像理解、语音识别、自然语言处理等。它们也是制定许多机器学习问题的基础工具。
该专门化课程包括以下课程:
-
概率图模型 1:表示
-
概率图模型 2:推理
-
概率图模型 3:学习
哥伦比亚大学和 edX 的人工智能 MicroMasters®项目由 4 门课程组成,深入探讨了人工智能。
通过一个创新的在线项目,在人工智能及其应用领域的迷人而引人入胜的话题中,获得计算机科学最迷人和发展最快的领域之一的专业知识。哥伦比亚大学的这个 MicroMasters 项目将为你提供一个严格的、先进的、专业的研究生级别的人工智能基础。该项目代表了哥伦比亚大学计算机科学硕士学位课程的 25%。
组成 MicroMasters 项目的 4 门课程是:
-
人工智能 (AI)
-
机器学习
-
机器人技术
-
动画和 CGI 运动
强化学习专门化 是阿尔伯塔大学在 Coursera 上提供的 4 门课程的集合,涵盖了使用强化学习解决实际问题。你将学到以下内容:
发挥人工智能的全部潜力需要适应性学习系统。了解强化学习 (RL) 解决方案如何通过试错互动解决实际问题,方法是从头到尾实施完整的 RL 解决方案。
在完成这一专业课程后,学习者将理解现代概率人工智能(AI)的大部分基础,并为学习更高级的课程或将 AI 工具和思想应用于实际问题做好准备。本内容将重点关注“规模较小”的问题,以理解强化学习的基础,由阿尔伯塔大学科学学院的世界知名专家授课。
涉及的课程包括:
-
强化学习基础
-
基于样本的学习方法
-
使用函数逼近进行预测和控制
-
完整的强化学习系统(综合项目)
相关:
-
数据科学 MOOCs 太肤浅了
-
数据科学与机器学习的免费数学课程
-
绝佳的机器学习和人工智能课程
更多相关内容
超越 Word2Vec 仅限于词汇的使用
评论
作者:Stanko Kuveljic,SmartCat

构建一个机器学习模型通常需要经历大量的哭泣、痛苦、特征工程、折磨、训练、调试、验证、绝望、测试以及因无尽的痛苦而带来的一点点痛苦。经历了这些之后,我们部署模型并使用它来对未来的数据进行预测。我们可以根据情况和用例每小时、每天、每周、每月或者即时运行一次我们的“小恶魔”模型。
让我们看看一个与在线体育博彩推荐引擎相关的例子。该引擎的目标是预测用户是否会在某场比赛中选择特定的选项(例如,最终得分 - 主队获胜,进球 - 3 个或更多进球等)。这些预测基于用户历史记录,这些预测用于构建一个推荐给用户的投注单。
为了实现实时快速推荐,我们可以在用户出现之前就计算所有内容。这种用例允许我们对特征提取进行幻想,我们可以尽情玩弄特征,以便构建一个更准确的模型,而不会影响应用程序的性能。下图展示了一些玩具管道和预测。因此,基本上,我们的应用程序将快速提供预测,而我们的“撒旦仪式”可以安全地在后台运行。

哇哦,图片中甚至还有独角兽。但是,考虑到我们没有预定义的数据集,所有工作都需要即时处理,那怎么办呢?我们的独角兽可不会开心的 😦 让我们回到那个老生常谈的在线体育博彩例子。我们可以为尚未开始的比赛准备预测,但对于那些在比赛进行中下注的用户,也就是所谓的实时投注呢?我们的复杂特征工程和模型评分流程可能在实时为成千上万的用户提供服务时会遇到困难。一场体育比赛每隔几秒钟就可能发生变化,因此实时预测确实是我们所期待的。更糟糕的是,我们可能会对一场比赛的信息有限,从而无法提取所需的特征。可以尝试优化一个在尚未开始的比赛中表现非常好的模型,并尝试用更少的特征构建一个新模型。但是,我们总可以尝试一些新方法,从不同的角度看待问题。我们曾经处理过类似的问题,并尝试了 word2vector,但在我们的情况下是 bet2vector。有关 word2vector 的一般解释,请访问我们最新的博客之一 one。
Everything2Vector
所以 everything2vector 就是乐趣开始的地方。可以仅基于用户 ID 和过去模板的 IDs 为每个用户创建向量表示。我们来看以下数据样本:
从数据中我们可以看到,达斯·维德喜欢投注网球比赛,但他的儿子卢克则喜欢投注英超足球比赛。那么如何通过仅仅依靠 IDs 来实现魔法并进行学习呢?首先,我们需要进一步压缩关于比赛的信息,以便获取模板。这些模板可以根据一些相似特征对数据进行分组。在这种情况下,模板的创建方式是将相似的比赛——来自同一联赛的足球比赛、相同的比赛类型和类似的配额——分组到同一模板中。例如:
-
模板 1 - 网球 : 美国公开赛 : 赢得破发 : 1 : 配额范围 (1.5 - 2.1)
-
模板 2 - 网球 : 美国公开赛 : 决赛得分 : 2 : 配额范围 (1.8 - 2.6)
-
模板 3 - 足球 : 英超 : 进球数 : 0-2 : 配额范围 (1.5 - 2.0)
-
模板 4 - 足球 : 西甲 1 : 决赛得分 : 1 : 配额范围 (1.8 - 2.4)
-
………………..
-
模板 1000 - 篮球 : NBA : 总分 : >200 : 配额范围 (1.5 - 2.0)
确定模板的这些规则可以从数据统计中计算出来,也可以通过一些领域知识来定义。但最重要的是,这些规则在确定模板 ID 时运行非常快。这就是我们在特征工程任务中所需的一切。当我们将之前的数据转换为模板时,我们得到:

请注意,skip-gram 使用诸如“卢克,我是你父亲”这样的句子来确定哪些词是相似的。要实现类似的功能,我们需要将所有历史数据按会话分组。通过这种方式,我们可以获得表示用户历史的句子,并且用户 ID 现在接近他过去玩过的模板,如下所示:

结果
让我们看看向量表示在训练过程中是如何学习的。当一个算法看到一个用户玩了某个比赛模板时,它会将用户的向量表示和已玩模板的向量表示在向量空间中推得很近。同时(使用负采样技术),它将玩家向量和未玩的比赛模板向量在向量空间中推得远离彼此。在下图中,我们可以看到我们的“向量”在空间中的分布。图像中再次出现了一只快乐的独角兽,因为它喜欢这个解决方案。

我们看到达斯·维达接近那些代表网球比赛的模板,因为他喜欢打网球。卢克远离他的父亲,因为他不喜欢网球,但他喜欢足球,他会更接近那些代表足球比赛的向量。还有尤达,他也踢足球,但在不同的联赛中。但他比达斯更接近卢克,因为足球模板比足球和网球模板更相似。
算法的输出是用户 ID 和模板 ID 的向量,可以存储在某处。在预测时,数据每几秒钟变化一次,我们可以实时计算预测结果。我们只需要查找当前可用的模板向量,并与用户向量计算余弦相似度,以获取用户和模板之间的相似度分数。除了尝试有趣之外,这种技术在数据集上取得了良好的结果,并且实现了对大量用户和模板的快速预测,这些用户和模板经常发生变化。最重要的是,这种技术可以应用到任何地方,并且效果很好。例如,如果我们有关于历史交易的信息[user ID - 购买 - item ID],我们可以仅使用用户 ID 和物品 ID 来训练向量。基于训练得到的向量,我们可以向每个用户推荐最相似的物品。所谓最相似的,是指那些经常一起出现的物品。
圣诞快乐,愿力量向量与你同在。
原文。经许可转载。
相关内容
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启你的网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
机器学习中的偏差全都不好吗?
评论
Tom M. Mitchell 在 1980 年发表了一篇论文:学习归纳中的偏差需求中指出:
学习涉及从过去的经验中归纳,以应对与这些经验“相关”的新情况。处理新情况所需的归纳飞跃似乎只能在选择某种归纳而非另一种的特定偏差下才可能实现。本文准确地定义了归纳问题中的偏差概念,并表明偏差对于归纳飞跃是必要的。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在我们多年的预测模型构建过程中,我们被教导偏差会损害我们的模型。偏差控制需要由能够区分正确和错误偏差的人来掌握。
他的论文指出,某些偏差有助于我们为手头的问题创建适当的模型:
- 领域的事实知识
-
在为特定目的学习归纳时,可能会出现以下情况
通过参考关于任务领域的知识来限制考虑的归纳。比如在一个学习棒球规则的程序中(Soloway & Riseman 1978),关于竞争性游戏的一般知识限制了考虑的归纳数量。这种先验知识可以为所考虑的归纳提供强有力、合理的约束。在这种情况下,归纳系统的目标变为“确定与训练实例及任务领域中的其他已知事实一致的归纳”。
- 学习到的归纳的预期用途
- 对学习到的泛化的预期用途的知识可以为学习提供强大的偏差。举个简单的例子,如果学习到的泛化的预期用途涉及到错误的正类比错误的负类分类更高的成本,那么学习程序应该更倾向于选择更具体的泛化,而不是选择那些与相同训练数据一致的更一般的替代方案。
- 关于训练数据来源的知识
-
关于训练实例来源的知识也可以为学习提供有用的约束。例如,在从人类教师那里学习时,我们似乎利用了关于存在一个有组织课程的许多假设来约束我们对合适泛化的搜索。在有组织的课程中,我们的注意力会集中在实例的特定特征上,这种方式
消除关于哪个可能的泛化最合适的模糊性。
-
倾向于简单性和普遍性
- 人类似乎使用的一种偏差是倾向于简单、一般的解释。可解释性使我们能够向外行观众传达我们的模型,而黑箱模型可能会使模型构建者陷入困境。
-
与之前学到的概念的类比
-
如果一个系统正在学习一系列相关的概念或泛化,那么对这些概念的泛化可能会受到其他概念成功泛化的制约。例如,考虑学习块世界对象的结构描述任务,如“拱门”、“塔”等。学习了几个概念后,学到的描述可能会揭示某些特征在描述这一类概念时比其他特征更为重要。例如,如果泛化语言包含了结构中每个块的“形状”、“颜色”和“年龄”等特征,系统可能会注意到“年龄”很少是一个相关特征。
用于描述结构类别的偏差,可能会产生对其他特征的偏好。这种学习到的偏差的理由必须基于对所学习概念预期用途的某种相似性。
尽管这篇论文的时间是 1980 年,但其背后的逻辑确实让我们思考如何区分模型中的必要偏差和不必要的偏差。显然,我们必须消除那些会成为障碍的偏差,但随着我们不断实践并深入挖掘数据,我们可能会意识到一些偏差实际上可以使我们的模型更接近我们真正想要的效果。
在后续文章中,我将讨论在机器学习中应该避免的偏差类型。
相关:
-
大数据的三个主要问题及解决方法
-
设计伦理算法
-
算法并非偏见,我们才是
更多相关话题
偏差-方差权衡

编辑图片
你可能以前听说过偏差-方差权衡,觉得“嗯?”或者你可能从未听说过这个概念,正想着“这到底是什么?”
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
无论如何,偏差-方差权衡是监督式机器学习和预测建模中的一个重要概念。当你想训练一个预测模型时,可以选择各种监督式机器学习模型。每种模型都有其独特之处,但最大的区别在于它们的偏差和方差水平。
在模型预测中,你会关注预测误差。偏差和方差是预测误差的两种类型,被广泛应用于许多行业。在预测建模中,模型的偏差和方差之间存在权衡。
理解这些预测误差的工作原理以及如何利用它们将帮助你建立既准确又表现良好的模型,同时避免过拟合和欠拟合。
让我们从这两个概念的定义开始。
什么是偏差?
偏差是由于模型从数据集中学习信号的灵活性有限而导致的结果偏差。它是模型的平均预测值与我们尝试预测的正确值之间的差异。
当你遇到一个具有高偏差的模型时,这意味着模型在训练数据上学习得不好。这进一步导致在训练数据和测试数据上的误差较高,因为模型由于没有学习数据特征等而变得过于简化。
什么是方差?
方差是指模型在使用不同的训练数据集时的变化。它告诉我们数据的分布情况以及在使用不同数据集时的敏感度。
当你遇到一个具有高方差的模型时,这意味着模型在训练数据上学习得很好,但在未见过或测试数据上无法很好地推广。因此,这会导致测试数据上的误差率较高,造成过拟合。
那么,什么是权衡呢?
在机器学习模型中,也需要找到那个平衡点。
如果一个模型过于简单——这可能导致高偏差和低方差。如果一个模型过于复杂,参数过多——这可能导致高方差和低偏差。因此,我们的目标是找到那个完美的点,以避免过拟合或欠拟合的发生。
低方差模型通常较为简单,结构也较为简单——但存在高偏差的风险。这些模型的例子有朴素贝叶斯、回归等。这会导致欠拟合,因为模型无法识别数据中的信号,从而无法对未见过的数据进行预测。
低偏差模型通常较为复杂,结构也较为灵活——但存在高方差的风险。这些模型的例子有决策树、最近邻等。当模型过于复杂时,这会导致过拟合,因为模型记住了数据中的噪音,而不是信号。
如果你想了解更多关于如何避免过拟合、信号和噪音的信息,可以点击这个链接。
这就是权衡发挥作用的地方。我们需要找到偏差和方差之间的平衡点,以最小化总误差。让我们深入了解总误差。
背后的数学
让我们从一个简单的公式开始,假设我们要预测的是‘Y’,其他协变量是‘X’。两者之间的关系可以定义为:
‘e’ 代表误差项。
在点 x 处的期望平方误差可以定义为:
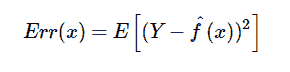
这将产生:
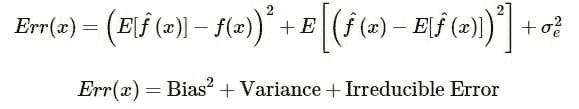
这可以更好地定义为:
总误差 = 偏差² + 方差 + 不可减少的误差
不可减少的误差指的是建模中无法减少的“噪音”——减少它的一种方法是通过数据清理。
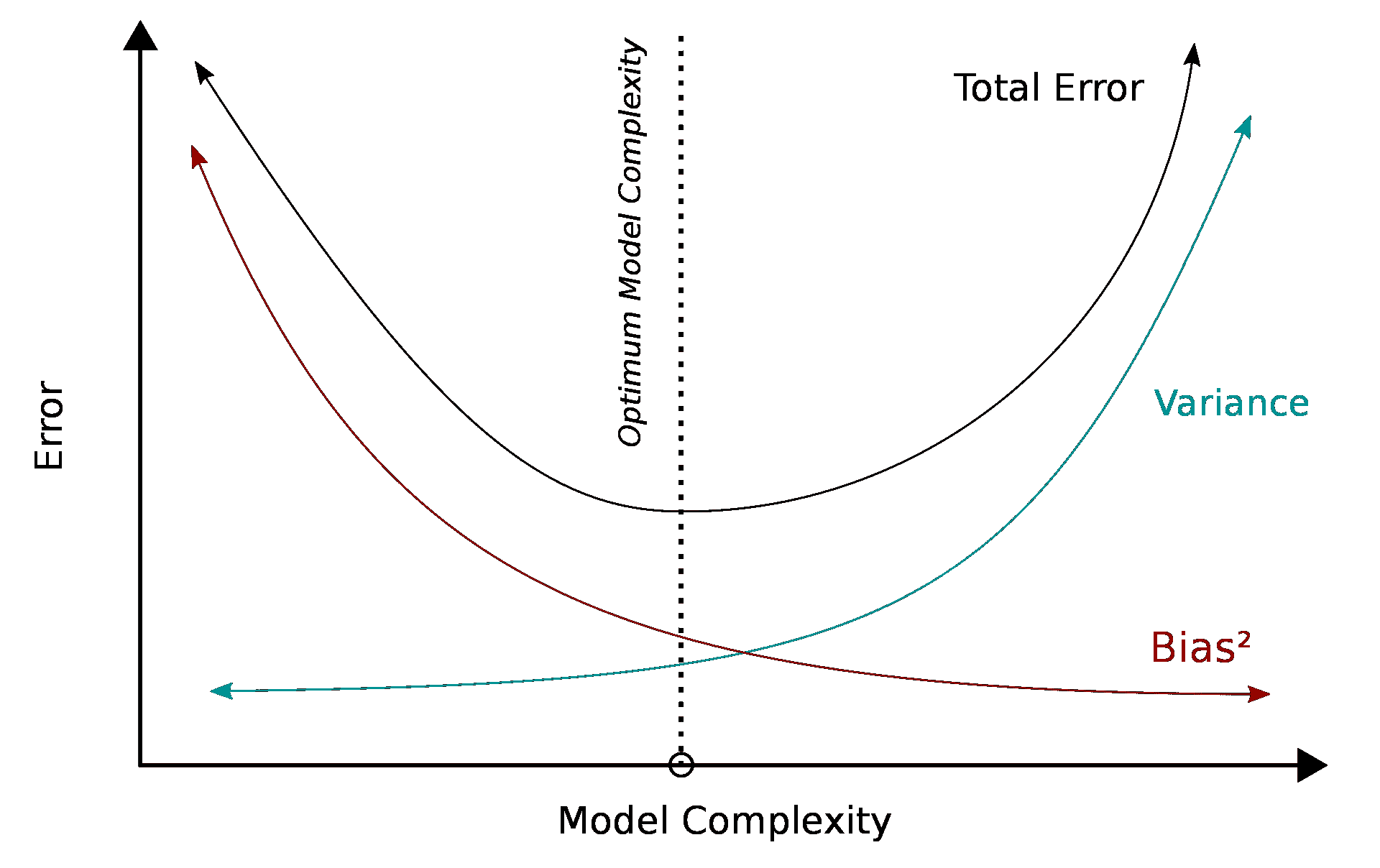
来源: 维基百科
然而,重要的是要注意,无论你的模型多么出色,数据总会有一个不可减少的误差元素,这无法被去除。当你找到偏差和方差之间的最佳平衡点时,你的模型将不会出现过拟合或欠拟合的情况。
结论
希望通过这篇文章,你能更好地理解什么是偏差,什么是方差以及它们如何影响预测建模。你还会了解到这两者之间的权衡是什么,为什么找到那个平衡点以产生最佳性能的模型是重要的,以避免过拟合或欠拟合——这背后有一点数学原理。
Nisha Arya 是一位数据科学家和自由技术作家。她特别关注提供数据科学职业建议、教程以及数据科学理论知识。她还希望探索人工智能如何有助于延长人类寿命的不同方式。作为一个热衷学习的人,她希望在拓宽技术知识和写作技能的同时,帮助指导他人。
大数据分析:为什么它对商业智能如此关键?
原文:
www.kdnuggets.com/2023/06/big-data-analytics-crucial-business-intelligence.html

编辑图像
人们常常误解大数据与商业智能之间的关系。在大多数情况下,你的商业智能解决方案已经在某种程度上使用了大数据分析。如果没有,那么这是你必须解决的一个巨大盲点。
但为什么大数据分析对现代企业如此重要?为什么你应该将其作为你的商业智能流程或技术栈的一部分?本指南将回答这两个问题及更多问题。但首先,让我们了解这些术语的含义,以便你能更好地理解它们如何以及在哪里适用。
什么是大数据分析?
随着越来越多的公司和行业开始拥抱技术,数字化转型支出预计到 2026 年将达到$3.4 万亿。我们已经看到对技术的依赖不断增加,没有哪个行业能够免于这种变化。例如,根据GetWeave进行的一项最新研究,98%的医疗服务提供者一致认为技术在提供卓越客户体验方面发挥了至关重要的作用。
所有这些技术和数字化转型开辟了数据收集的新途径。截至 2023 年,全球每天生成的至少有3.5 quintillion 字节的数据。这种大量收集的原始数据被称为大数据。
这些数据并非所有对企业都有用,通常,数据量太大,无法由传统的数据处理软件处理。在大多数大数据可以以有意义的方式使用之前,它必须经过排序、过滤甚至标记。这些过程构成了大数据分析的重要部分。
一些最常用的大数据技术和工具包括:
-
数据存储和处理(Hadoop)
-
数据供应和分发(Cassandra)
-
流分析工具
-
预测分析软件
-
数据湖
-
知识发现
-
数据挖掘工具
-
内存数据布置解决方案
-
数据虚拟化
-
数据清洗
-
集群计算框架
正如你所见,许多这些工具也被用于商业智能中。
什么是商业智能?
商业智能(BI)描述了使用技术从商业数据中提取可操作见解的过程。这些见解随后被可视化并呈现给公司高管,使他们能够基于实证数据做出明智的决策。
商业智能(BI)常常与商业分析(business analytics)混淆,这也是大数据分析被误解为 BI 的原因之一。然而,商业智能旨在通过利用旧数据和新数据来获得当下的成功,而商业分析则关注于当前数据与过去数据之间的联系,以预测未来数据(即业务的未来)。
这两种方法都可以利用大数据分析来实现目标,但让我们重点关注商业智能。它涉及到一系列分析流程和解决方案,例如(但不限于):
-
数据挖掘
-
预测分析
-
统计分析
-
大数据分析
-
数据可视化软件
-
关键绩效指标(KPI)
-
性能基准软件
-
查询软件
-
实时分析软件
通过实施有效的 BI 战略,公司可以提升访问和利用关键数据的能力。最终,BI 可以通过确保所有商业决策都以事实数据为基础,来提高公司整体盈利能力。它还可以帮助公司改善内部流程,从而使其运营更加优化。
你可以利用商业智能来揭示市场趋势,发现新的收入来源,识别被忽视的业务问题。大数据分析可以成为你组织 BI 战略的一个基本组成部分。

照片来源:Pexels
大数据分析在商业智能中的应用案例
大数据分析可以作为你商业智能战略的一部分,以下是几种应用方式:
产品开发和改进
新产品开发描述了一个产品的生命周期,从其创意到市场推广。你对产品开发的处理方式将取决于你使用的模型。例如,数据分析是 Roozenburg 和 Eekels 简单的 3 阶段新产品设计(NPD)模型中的第一步。
无论你选择哪种模型,基础步骤都需要进行严格的研究。这适用于产品改进或引入现有产品变体。
如今,大多数企业都有全球化的愿景,因为这为它们提供了更多的财务机会和激励。然而,这也需要更深入的市场研究,包括从调查、网站跟踪数据(cookies)、信用报告统计等获取的数据。
消费者的态度和需求不断演变,有些需求可能是季节性的。因此,你的数据池会不断增长和更新,实际上变成了大数据。你需要一个能够排序、处理和发现模式的大数据分析系统,其速度几乎与数据生成的速度相当。
商业智能软件可以以更可管理的方式呈现所有模式和统计数据。组织可以利用这些数据制定提案、蓝图和新产品设计和改进计划。他们还可以利用这些信息来确定运营和材料需求,并做出更精确的开发成本估算。
价格优化
如果公司能够在早期阶段计算开发成本,他们可以更准确地定价产品;这对于已建立的产品也是如此。
你的大数据应该包含指示当前全球经济气候与购物趋势之间联系的模式。例如,为了在 2022 年和 2023 年保持竞争力,公司们开始减少包装产品的总单位和质量。例如,一袋 500 克的薯片会被减少到 450 克但以相同的价格出售。这被称为缩水通货膨胀。

图片来源:Brett Jordan
大数据分析与商业智能相结合,可以帮助公司判断是提高价格还是通过其他方式弥补增长的成本会更有利。此外,它还将帮助你确定现有的产品线是否值得继续保留。
流媒体和电视制作也可以从大数据分析中受益。通过结合当前的时代精神、流媒体行为和民意调查,这些公司可以在决定取消哪些节目和保留哪些节目时做出更有效的决策。
例如,我们看到整批 Netflix 订阅者因为某个节目被取消而离开了这个流媒体巨头。Parrot Analytics 进行的一项研究发现,《青少年正义联盟》是 2023 年最受欢迎的系列之一。然而,HBO Max 在 2022 年底取消了它。
这告诉我们许多决策并没有完全基于信息。大数据分析和商业智能可以防止你的公司犯同样的错误。
供应链管理

2021 年和 2022 年经历了巨大的供应链中断,这也是当前通货膨胀的许多因素之一。许多零售商使用即时库存管理解决方案,尽管它可能很高效,但对供应链中断几乎没有保护。
大数据分析和商业智能可以帮助公司部署更灵活的库存和供应链管理。它们可以提供实时数据,然后由机器学习驱动的 BI 解决方案进行解释,以提供预测分析。
这可以帮助公司保护自己免受供应链中断的影响,因为这些供应链数据不仅限于可用的原材料或制造能力。它还考虑了天气、自然灾害导致的运输延误、购物趋势、定价、经济气候等。
你还可以利用这些信息在需求减少时减少库存,避免浪费。因此,它可以使你的 JIT 库存管理系统更为优化。
渠道分析
我们已经涵盖了大数据分析和商业智能如何结合来自各种渠道的信息,帮助企业改善其新产品设计和开发、价格优化和供应链管理。
但你如何确定每个渠道的质量和信息的完整性呢?渠道有很多种,而且不仅限于网络渠道。其他渠道可能包括客户支持电话、邮寄邮件、商店或分支机构位置等。
企业可以利用大数据分析和商业智能进行渠道发现。它们还可以揭示渠道的完整性、质量和效率,以及这些渠道如何与系统集成。最终,你可以把它看作是大元数据,因为它是关于你大数据的数据。通过确认你收集数据的渠道,你实际上是在确认你大数据的质量。
结论
大数据分析市场预计到 2029 年将达到超过 6500 亿美元。这并不令人惊讶,因为本指南已经展示了大数据分析如何用于丰富商业智能的多种方式。更多公司应该志在成为数据优先型企业,凭借如 Datapine 等公司提供的大数据分析商业智能解决方案,这应该比以往任何时候都更容易。
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任 Inc. 5,000 经验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
相关阅读
数据科学与大数据,解释
原文:
www.kdnuggets.com/2016/11/big-data-data-science-explained.html
介绍
什么是数据科学?什么是大数据?这些术语是什么意思,为什么弄清楚它们很重要?这些确实是热门话题,但经常被误解。此外,涉及的行业对这两个术语没有普遍一致的定义。
这些是极其重要的领域和概念,正变得越来越关键。世界上从未像今天这样收集或存储如此多的数据,而且速度如此之快。此外,数据的多样性和量也在以惊人的速度增长。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
为什么你应该关注数据科学和大数据?数据在许多方面类似于黄金。它非常宝贵,有很多用途,但你通常需要挖掘才能实现其价值。

这些是新领域吗?关于数据科学是否为新领域存在很多争议。许多人认为,类似的实践已被称为统计学、分析、商业智能等。无论如何,数据科学是一个非常流行且突出的术语,用于描述许多不同的数据相关过程和技术,接下来将进行讨论。另一方面,大数据相对较新,因为收集的数据量以及相关挑战继续需要新的创新硬件和处理技术。
本文旨在为非数据科学家提供数据科学和大数据背后许多概念和术语的全面概述。虽然相关术语会在很高的层次上提及,但鼓励读者探索参考资料和其他资源以获取更多细节。另有一篇文章将深入探讨相关技术、算法和方法。
有鉴于此,让我们开始吧!
数据科学定义
数据科学是复杂的,涉及许多特定领域和技能,但一般定义是,数据科学包括从数据中提取信息和知识的所有方式。
数据无处不在,并且以巨大的、指数增长的数量存在。数据科学整体上反映了无论数据的大小如何,数据被发现、条件化、提取、汇编、处理、分析、解释、建模、可视化、报告和呈现的方式。大数据(如即将定义的)是数据科学的一个特殊应用。
数据科学是一个非常复杂的领域,这主要是由于它所涉及的学术学科和技术的多样性和数量。数据科学包括数学、统计学、计算机科学与编程、统计建模、数据库技术、信号处理、数据建模、人工智能与学习、自然语言处理、可视化、预测分析等。
数据科学在许多领域都具有高度的应用性,包括社交媒体、医学、安全、医疗保健、社会科学、生物科学、工程、国防、商业、经济学、金融、营销、地理定位等。
大数据定义
大数据本质上是数据科学的一个特殊应用,其中数据集庞大,需要克服后勤挑战以处理这些数据。主要关注点是有效地捕获、存储、提取、处理和分析这些庞大数据集中的信息。
由于物理和/或计算限制,这些巨大的数据集的处理和分析通常不可行或难以实现。因此,需要特殊的技术和工具(例如,软件、算法、并行编程等)。
大数据是用来涵盖这些大型数据集、专业技术和定制工具的术语。它通常应用于大型数据集,以进行一般数据分析、发现趋势或创建预测模型。

你可能会想,为什么“大数据”这个术语如此引人注目。我们已经长期在各种数据存储机制上收集了大量不同类型的数据,对吗?是的,但我们从未像今天这样享有如此廉价的数据收集、存储能力和计算能力。此外,我们以前也没有如此轻松地获取到廉价而强大的原始数据传感技术、仪器等,这些都导致了今天巨大的数据集的产生。
那么这些数据到底来自哪里呢?大量数据是从移动设备、遥感、地理位置、软件应用、多媒体设备、射频识别读卡器、无线传感网络等处收集的。
大数据的一个主要组成部分是所谓的三大 V(3Vs)模型。该模型将大数据的特征和挑战表示为处理体积、种类和速度。IBM 等公司还包括了第四个“V”,即真实性,而维基百科也提到了可变性。
大数据本质上旨在解决处理大量不同类型、不同质量的数据的问题,这些数据有时以巨大的(实时)速度被捕获和处理。可以说这是一个不小的挑战!
总结来说,大数据可以被视为一个相对术语,适用于需要实体(个人、公司等)利用专门的硬件、软件、处理技术、可视化和数据库技术来解决与3Vs及类似特征模型相关的问题的大型数据集。
数据类型和数据集
数据以许多不同的方式收集,如前所述。可用数据的生命周期通常包括捕获、预处理、存储、检索、后处理、分析、可视化等。
一旦捕获,数据通常被称为结构化、半结构化或非结构化。这些区分很重要,因为它们直接关系到所需的数据库技术和存储、查询和处理数据的软件和方法以及处理数据的复杂性。
结构化数据是指存储在关系数据库或电子表格中的数据(或由结构或模式定义的数据)。由于数据的“结构”是已知的,通常可以使用 SQL(结构化查询语言)轻松查询。例如,销售订单记录就是一个很好的例子。每个销售订单都有购买日期、购买的商品、购买者、总费用等。
非结构化数据是指没有任何模式、模型或结构定义的数据,也没有以特定方式组织的。换句话说,它只是原始数据。想象一下地震仪(顺便说一下,地震是我很担心的一个问题!)。你可能见过这种设备捕捉到的弯曲线条,这些线条本质上表示在每个地震仪位置记录的能量数据。记录的信号(即数据)表示随时间变化的能量量。在这种情况下没有结构,它只是由信号表示的能量变化。
自然地,半结构化数据是两者的结合。它基本上是附加了结构化数据(即元数据)的非结构化数据。每次你用智能手机拍照时,快门捕捉光反射信息作为一堆二进制数据(即 1 和 0)。这些数据没有结构,但相机还附加了额外的数据,包括照片拍摄的日期和时间、上次修改时间、图像大小等。这就是结构化部分。数据格式如 XML 和 JSON 也被视为半结构化数据。
数据挖掘、描述、建模和可视化
为了使数据以有意义的方式使用,它们首先被捕获、预处理和存储。在此过程之后,数据可以被挖掘、处理、描述、分析,并用于构建既具描述性又具预测性的模型。

描述性统计 是一个术语,用于描述应用统计学于数据集,以便描述和总结数据包含的信息。基本上,它包括在一个具有均值、中位数、众数、方差、标准差等的分布背景下描述数据。描述性统计 还描述了其他形式的分析和可视化。
推断统计 和数据建模则是非常强大的工具,可以用来深入理解数据,并推断(即预测)数据收集之外的条件的意义和结果。通过使用某些技术,可以创建模型,并根据涉及的数据动态做出决策。
除了描述性统计 和推断统计,另一个领域叫做计算统计(计算科学的一个子集),在数据科学和大数据应用中通常扮演重要角色。计算统计 涉及利用计算机科学、统计学和算法,使计算机能够实现统计方法。这些方法在预测分析或预测建模等领域中被大量使用。机器学习可以被视为在预测建模背景下应用某些算法的一个例子。
数据通常也会被挖掘以便进行可视化分析。通过战略性地使用合适的图形、图表、图示和表格,许多人能够更快、更深入、更自然地理解数据。这些信息展示方法可用于显示类别数据和定量数据。将这些展示类型应用于数据表示的过程称为数据可视化。
这些技术、方法论、统计学和可视化主题将在即将发布的帖子中得到更详细的讲解。
数据管理与行业工具
处理数据科学和大数据所需的软件和数据库技术有很多。许多数据库设计旨在遵循 ACID 原则,即原子性、一致性、隔离性和持久性。

我们首先讨论数据库技术。自 1980 年代以来,数据库管理系统(DBMS)及其关系型数据库(RDBMS)是最广泛使用的数据库系统。它们通常非常适合基于事务的操作,并且通常遵循 ACID 原则。
关系型系统的缺点是这些数据库相对静态,且严重偏向结构化数据,以非直观和非自然的方式表示数据,并且产生显著的处理开销,因此性能较差。另一个缺点是基于表的数据通常无法很好地表示实际数据(即领域/业务对象)。这被称为对象关系阻抗不匹配,因此需要在基于表的数据和实际问题领域对象之间进行映射。描述的数据库管理系统包括 Microsoft SQL Server、Oracle、MySql 等。
NoSql 数据库技术近年来变得非常流行,这也是有充分理由的。NoSql 是一个用于描述非关系型、具有高度可扩展性、允许动态模式并且能够处理大量数据访问的高频率的数据库系统的术语。它们还以更自然的方式表示数据,能够轻松处理之前提到的三种类型的数据,并且性能优越。
因此,NoSql 数据库主要用于高规模交易。NoSql 数据库系统包括 MongoDB、Redis、Cassandra 和 CouchDb 等。请注意,NoSql 数据库有多种类型,包括文档型、图形型、键值型和宽列型。
NewSQL 是一种相对较新的数据库管理系统。这些系统试图将关系型数据库管理系统的最佳特性(例如,ACID)和查询语言(即 SQL)与 NoSQL 数据库的高度可扩展性能结合起来。对于 NewSQL 是否能获得足够的流行度以便像关系型和 NoSQL 数据库一样获得采用和发展,尚无定论。
大数据的从业者已经见证了高规模数据存储、处理能力和分析所需的特定技术的创建和普及。最受欢迎的系统包括 Apache Hadoop、Cloudera、Hortonworks 和 MapR。还有许多其他系统也在这一领域进行竞争。
对于基于统计和算法的数据处理与可视化,R、python 和 Matlab 是一些受欢迎的选择。
总结
我们从未像今天这样收集如此多样的数据,也没有像现在一样需要如此快速地处理这些数据。通过多种不同的机制收集的数据的种类和数量正在以指数级增长。这种增长要求我们采用新的策略和技术来捕获、存储、处理、分析和可视化数据。
数据科学是一个总括性术语,涵盖了在有用数据生命周期阶段使用的所有技术和工具。另一方面,大数据通常指的是需要专门且常常创新的技术和方法来高效“使用”这些数据的极大数据集。
这两个领域都会随着时间的推移变得更加重要。对这两个领域合格从业者的需求正在迅速增长,它们也成为了最热门、最有利可图的工作领域之一。
希望这篇文章对数据科学和大数据涉及的主要概念提供了相对简单的解释。掌握这些知识后,你应该能更好地理解最新的行业头条新闻,或者至少在讨论这两个话题时不至于完全陌生。
亚历克斯·卡斯特罗尼斯是Why of AI的创始人兼首席执行官,并且是《AI for People and Business》的作者。他还担任了西北大学凯洛格商学院/麦考密克工程学院 MBAi 项目的兼职讲师。
原文。经许可转载。
相关:
-
人工智能、深度学习和神经网络的解释
-
机器学习:完整详细概述
-
数据科学难题的解释
更多相关话题
旅行时需要了解的大数据工程热潮中的事项
原文:
www.kdnuggets.com/2018/10/big-data-engineering-hype-train.html
评论
由Wojciech Pituła,高级软件开发工程师

为什么?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
半年前,我在从事了三年的各种数据管道创建工作后离开了大数据领域。现在,我希望在这些知识变得完全过时之前分享我在这段时间积累的知识。本文尝试指出一些如果你要成为我的同事你需要了解的事情。这些也是我在前公司面试大数据工程师职位时询问候选人的问题。
我会尽量不仅指出相关问题,还简要回答其中一些问题。重要的是要记住,这些答案距离全面理解还有很大距离,要真正理解这个主题,你需要自己研究。
如果你对这些问题中的某些问题不了解,不要害怕。对这些主题的完全理解是高级开发人员的要求。对于中级或初级职位,掌握子集即可。
分析 vs 科学 vs 工程
这是一个非常热门的问题:数据科学、数据分析和数据工程之间有什么区别。这也是一个相当难以回答的问题。以下是我的理解:
-
数据分析师 - 指查看数据并尝试基于数据回答一些业务问题的人。他通常使用商业智能工具或只是 MS Excel。
-
数据科学家 - 指处理原始数据,结合各种数据源,进行基本数据处理,将数据输入机器学习模型,调整这些模型,并总体上尽可能从原始数据中获取最大价值的人。他通常使用 Python、R、Matlab、tensorflow 等工具。
-
数据工程师 - 一种专注于数据转换的软件开发人员。他的工作是获取数据并使其对业务有用,同时也要确保其长期可维护。这一广泛的描述涵盖了从各种来源(ELK、Splunk、Hadoop、Kafka、Rest APIs、对象存储等)提取数据、转换数据并提供以满足业务需求。他通常与数据科学家密切合作,以了解数据管道应如何构建、使用哪个 ML 模型等等。
有关更详细的比较以及“机器学习工程师”的介绍,你可以查看 这篇精彩的文章。
以下段落描述了数据工程师所需的知识,但这也与数据科学家相关,因为他们使用类似的工具集,但方式不同。
编程语言
为了高效地开发数据管道,你需要熟练掌握以下至少一种语言:Scala、Java、Python。
选择真的取决于你之前的经验和你的工作场所偏好。如果你现在在考虑学习哪一个,我会推荐Scala。它是 Spark 开发的主要语言,具有最多的示例,并且最具表现力。由于它具有函数式和强类型的特性,它也是最安全的。
无论你选择哪种语言,你都需要对 JVM 有基本的了解,因为它是最流行的数据处理平台。你需要能够诊断和调试 JVM 上发生的问题。这里有几个需要了解的事项:
-
你会如何处理抛出的
OutOfMemoryException? -
什么是垃圾收集器?有哪些垃圾收集器可用,它们之间有什么区别?
-
如何使用性能分析器找出性能瓶颈?
-
如何将调试器连接到远程 JVM?
Hadoop 生态系统
Apache Hadoop 是大数据工程师的最基本工具集。你不需要了解每个工具的所有细节,但了解它们的基本工作原理很重要,这样你才能有效沟通,并在需要时知道该学习什么。
-
什么是 Apache Hadoop? - 它是一组不同的工具,而不是一个单一的工具。这个生态系统中最流行的部分是 HDFS、Yarn、Hive、HBase 和 Oozie。
-
什么是 HDFS? - 它是一个分布式文件系统,用于在集群中存储数据。
-
什么是 namenode 和 datanode?
-
什么是复制因子?
-
什么是块大小?它如何影响性能和应用开发?
-
我们可以使用哪些安全机制来限制对集群上数据的访问?什么是 Kerberos?
-
-
什么是 Yarn? - 它是一个资源管理器,负责为计算作业分配内存和核心。
-
什么是调度程序,默认情况下有哪些调度程序?
-
什么是队列?
-
-
什么是 Hive? - 它是 HDFS 上的一层 SQL。
-
Hive、hiveserver2、metastore 和 beeline 之间有什么联系?
-
Hive、Pig 和 Impala 之间有什么区别?
-
什么是 UDFs?
-
-
什么是 HBase? - 它是一个构建在 HDFS 之上的 NoSQL 数据库。
-
它与 Cassandra 的比较如何?
-
它如何适应 CAP 定理?
-
-
什么是 Oozie? - 它是一个工作流管理器,用于创建数据管道。
- 有哪些替代方案?
-
你知道哪些序列化格式? - 最流行的有 Avro、orc、parquet、json 以及 Hadoop 对象和文本文件。
- 什么是基于列的格式?它与基于行的格式有何不同?
Apache Spark
Apache Spark 已成为处理数据时的首选工具。拥有一些经验是好的,但并不是关键。对我来说,这只是另一个暴露了一些 API 的工具,你需要学习它。一个有经验的开发者已经学会了数百个 API,不应对学习另一个 API 感到困扰。不过,即便没有实际经验,有一些事情值得了解。
-
什么是操作和转换?
-
有哪些部署模式?
-
跨越 JVM 边界时如何处理序列化和反序列化?RDD、Dataframe 和 Dataset API 之间有何不同?
-
什么是洗牌?它们什么时候发生,以及它们如何影响性能?
-
你如何进行有状态处理?无论是批处理还是流处理。
-
什么是 Spark 的替代方案? - 这是可能最重要的问题。你应该对 MapReduce、Flink、Kafka Streams、Cascading/Scalding 以及不集群的数据处理工具如 bash 或一些简单的库(例如 fs2 或 Akka Streams)有基本了解。
非 Hadoop 工具
有时,了解那些与大数据没有直接关联的工具更为重要。数据工程师的一个关键技能是知道何时不使用大数据,而选择更简单的工具。
-
什么是 Apache Kafka?
-
Kafka 已成为首选的数据流解决方案。迟早你会接触到它。
-
什么是主题?
-
什么是偏移量?
-
-
什么是 Redis?
- 至少要了解一种内存数据库。创建最终数据集后,你需要知道如何使用它,并且在许多情况下,你需要快速服务它。
-
什么是 ELK 堆栈?
- 总迟早你会需要某种搜索引擎或仪表盘解决方案。Elasticsearch 和 Kibana 是一个很好的开始。
-
你有多少 bash 经验?
-
在许多情况下,你需要一个可以以最灵活、最省时的方式处理数据集的工具。你应该熟练使用如 grep、cat、jq 或 awk 等工具,这些工具可以让你在没有任何开销的情况下过滤、修改和聚合数据。它们不适合生产环境,但非常适合实验和快速寻找答案。
-
创建 bash 脚本时你知道哪些最佳实践?
-
这些专业领域可以通过掌握其他脚本技术如 python、ruby 或 ammonite 来提升。
-
-
什么是概率数据结构?
- 当数据量超过某些阈值时,使用精确计算变得不再可行。在这种情况下,你应该了解一些基本的概率数据结构,例如布隆过滤器或 HyperLogLog,这些结构可以以受控的误差率计算诸如基数或集合成员资格等内容。
-
你知道哪些 SQL 数据库?它们有哪些限制?
- 熟悉至少一个成熟的 SQL 数据库是有好处的。我敢打赌,至少 30%的大数据项目可以仅使用 Postgres,并抛弃所有的 Spark/Hadoop 代码。
摘要
这个列表并不全面,但可能不可能创建一个全面的列表。你潜在雇主的具体要求可能与此列表有很大不同,但能够回答这些问题将为你未来的发展奠定良好的基础。
如果有人希望通过回答这些问题或添加更多主题(内联或通过链接)来完善本文,请随时通过GitHub repo提交 PR。
简介: Wojciech Pituła 是索尼的高级软件开发工程师。
原文。已获授权转载。
相关:
-
构建数据科学团队的成功计划
-
你应该了解的 10 大大数据趋势
-
机器学习会超越大数据吗?
更多相关话题
大数据游戏板™
评论
我最初在 2013 年 1 月发布了大数据故事图,以创造性地传达成功的大数据项目的关键因素(见图 1)。
图 1: 大数据故事图
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织的 IT
今天我唯一会做的重大改变就是将河流(它代表了大数据的深度、多样性和高速度)改为数据湖。
大数据故事图突出了 6 个对大数据项目成功至关重要的“里程碑”(看看您能否在图 1 中找到它们):
-
里程碑 #1: 激烈的市场动态。市场动态因大数据而变化。数据像水一样强大。海量的结构化和非结构化数据、广泛的内部和外部数据、以及高速数据可以推动组织变革和业务创新。确保您的#BigData 之旅不会陷入经济价值存疑的数据沼泽。
-
里程碑 #2: 业务与 IT 挑战。大数据促进了业务转型,从利用部分数据的“后视镜”视角监控业务表现,转变为利用所有可用数据的实时预测型企业,以优化业务表现。然而,组织在利用大数据来转型其业务时面临重大挑战。
-
里程碑 #3: 大数据业务转型。组织在利用大数据分析来推动价值创造过程方面的愿景是什么?一些组织难以理解大数据的业务潜力。他们不清楚业务成熟的不同阶段。我们的“大数据成熟度”模型对组织的大数据业务愿景进行基准评估,并提供了一种识别所需数据货币化机会的复杂程度的方法。
-
地标 #4: 大数据之旅。大数据之旅需要业务和 IT 利益相关者之间的合作,以识别正确的业务机会和必要的大数据架构。大数据之旅需要 1) 专注于为组织的关键业务举措提供支持,同时 2) 确保大数据业务机会能够由 IT 实施。
-
地标 #5: 运营大数据。成功的组织定义了一个持续发现和发布有关业务的新见解的过程。组织需要一个明确的过程,将分析见解提取并整合回到运营系统中。该过程应清晰地定义业务用户、BI/DW 团队和数据科学家之间的角色和责任,以使大数据能够投入运营。
-
地标 #6: 价值创造城市。大数据有潜力转变或重新构建你的价值创造过程,从而创造竞争差异。组织需要一个将其愿景与组织的关键业务举措联系起来的大数据战略。设想研讨会和分析实验室可以识别出大数据如何为组织的价值创造过程提供动力。
更多大数据故事图地标的详细信息,请参见博客“大数据故事图”。
介绍大数据游戏板™
虽然大数据故事图最近获得了很多关注,但它已经显得陈旧乏味,需要更新。因此,在我的朋友弗雷德里克·拉尔达罗(Twitter 账号 @FLardaro)的推动下,我创建了“大数据游戏板™”!所以,让“垄断”,“风险”,和“蜗牛赛跑”让开吧!是时候向全球的年轻人教授一个重要的职业发展游戏:如何利用数据和分析来改变你的生活!
介绍一下“大数据游戏板™”!

图 2: 大数据游戏板™
旋转转盘,看看你能否避免以下大数据(以及数据科学和 AI)陷阱:
陷阱 #1: 你是“陷入分析鸿沟”还是成功地“利用数据的经济价值”?
许多公司陷入了“分析鸿沟”。他们不理解如何利用“大数据经济学”从描述性的回顾报告和仪表板过渡到预测性分析见解和处方性行动。这一鸿沟阻碍了组织充分利用数据和分析的潜力,以推动组织的商业模式(见图 3)。

图 3: 跨越分析鸿沟
更多详情请参见“跨越大数据/数据科学分析鸿沟”博客。
陷阱 #2: 你是“陷入数据沼泽”还是在创建一个“协作价值创造平台”?
摆脱数据湖 2.0,其中数据被随机存储以待确定用途,而是开发数据湖 3.0,使其成为组织关键数字资产——数据和分析的终极存储库。数据湖 3.0 成为组织的协作价值创造平台,促进业务相关者与数据科学团队之间的合作,利用数据和分析发现新的客户、产品、服务、渠道和运营价值(见图 4)。
图 4: 数据湖 3.0: 协作价值创造平台
查看博客 “数据货币化?看看首席数据货币化官” 了解有关数据湖 3.0——协作价值创造平台的更多细节。
陷阱 #3: 你是在追求“技术追逐尾巴”,还是“专注于业务结果”?
组织在大数据方面失败,并不是因为缺乏用例,而是因为用例过多。组织需要一个正式的、协作的过程来识别、验证、审查、评估和优先排序用例,并确保信息技术与业务在追求这些用例时保持一致,找到高业务价值与高实施可行性的最佳组合(想想“低垂的果实”)。在启动大数据和数据科学计划时,前期投入时间详细了解构成用例的财务、客户和运营驱动因素,并标记任何潜在的抑制因素和实施风险。以睁大眼睛的状态进入这场游戏(见图 5)!
图 5: 文档使用案例的财务、客户和运营驱动因素
查看博客 “用例识别、验证和优先级排序” 获取指导组织的业务和运营用例识别、验证、评估和优先级排序的流程。
陷阱 #4: 你是在“沉浸于夸大承诺”中漂浮,还是采取“务实的价值工程”方法?
过度炒作的技术创新提供了最终的“梦想田野”时刻,让非科学家在进行科学实验。虽然组织对新技术的熟悉有其价值,但技术概念验证不应强加给业务相关者,并带有过度夸大的宏伟期望。商业用户早已停止相信技术的“银弹”解决方案——即一个看似神奇的简单解决方案来解决复杂问题(见图 6)。
图 6: 过度炒作的技术创新的经济成本
更多细节请参阅博客“为什么接受炒作?是时候转变我们对新兴技术的处理方式了”。
陷阱 #5: 你是否在“CLM 平原:职业限制性举措”中失败了,还是成功攀登了“构建业务支持的愿景”这座山?
成功的大数据之旅的一个关键挑战是获得业务和 IT 利益相关者之间的共识和一致,以识别初步的大数据业务用例,这些用例 1) 能够为业务带来足够的价值,同时 2) 具有较高的成功概率。 可以找到多个业务用例,其中大数据和先进分析能够提供有说服力的业务价值;对大数据和数据科学的采用至关重要的是,业务利益相关者有机会表达他们的意见,并主动帮助制定大数据和数据科学议程。
我们找到了一种工具,用于推动业务和 IT 的协作与一致,以确定你的大数据和数据科学之旅中“正确”的初步用例——优先级矩阵(见图 X)。
图 7: 优先级矩阵
请参阅博客“优先级矩阵:在大数据旅程中对齐业务和 IT”了解如何使用优先级矩阵推动组织对齐的机制。
所以现在我就坐下来等待 Hasbro 和 Ravensburger 来敲我的门,向我提供无尽的财富来大规模生产和推广我的“Big Data Game Board™”。 实际上,我可能会满足于几张 Chipotle、True Food 和 Starbucks 的礼品卡……
相关内容:
-
使用混淆矩阵量化错误成本
-
构建数据科学团队的成功游戏计划
-
伟大的数据科学家不仅仅是跳出思维框框,他们还重新定义了框框
更多相关主题
大数据科学:期望与现实
原文:
www.kdnuggets.com/2016/10/big-data-science-expectation-reality.html
comments
由 Stepan Pushkarev, Hydrosphere.io 的 CTO 提供。
过去几年对于从事分析和大数据工作的人来说就像梦想成真一样。平台工程师有了学习 Hadoop、Scala 和 Spark 的新职业道路。Java 和 Python 程序员有机会进入大数据领域。在那里,他们发现了更高的薪资、新的挑战,并能够扩展到分布式系统。但最近,我开始听到一些工程师对在那里工作感到失望和希望破灭的抱怨。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求

他们的期望并不总是实现。大数据工程师将大部分时间花在 ETL 上,为分析师准备数据集,并将数据科学家开发的模型编码成脚本。因此,他们在数据科学家和大数据之间成为了齿轮。
我从数据科学家那里听到相同的反馈。真正的大数据项目与 Kaggle 竞赛不同。即便是小任务也需要 Python 和 Scala 技能,还需与大数据工程师和运维团队多次互动和设计会议。
DevOps 工程师仅能使用基本工具并完成教程。他们对仅仅通过 Cloudera 向导和半自动化的 Ansible 脚本部署下一个 Hadoop 集群感到厌倦。
在这种环境下,大数据工程师永远无法从事可扩展性和存储优化的工作。数据科学家也不会发明新的算法。DevOps 工程师也不会将整个平台置于自动化状态。团队的风险在于,他们的想法可能无法超越概念验证。
我们如何改变这种情况?有 3 个关键点:
-
工具演变——Apache Spark/Hadoop 生态系统很棒。但它不够稳定和用户友好,不能让人完全忽视。工程师和数据科学家应贡献于现有的开源项目,并创建新工具来填补日常操作中的空白。
-
教育和跨领域技能——当数据科学家编写代码时,他们不仅需要考虑抽象问题,还需要考虑实际可行性和合理性。例如,他们需要思考查询运行的时间以及提取的数据是否适合他们使用的存储机制。
-
改进流程——DevOps 可能是解决方案。在这里,DevOps 不仅仅意味着编写 Ansible 脚本和安装 Jenkins。我们需要 DevOps 以最佳方式运作,以减少交接并发明新工具,为每个人提供自助服务,使他们尽可能高效。
数据科学家、大数据工程师和业务用户的持续分析环境
通过持续分析和自助服务,数据科学家可以从最初的构想到生产全过程中掌控数据项目。他们越是自主,就能投入更多时间来产生实际的见解。
数据科学家从最初的业务想法开始,经过数据探索和数据准备,然后进入模型开发。接下来是部署和验证环境,最后推动到生产阶段。拥有合适的工具后,他或她可以在一天内多次完成这个完整的迭代,而无需依赖大数据工程师。
大数据工程师则负责可扩展性和存储优化,开发并贡献于像 Spark 这样的工具,支持流处理架构等。他提供给数据科学家一个 API 和 DSL。
产品工程师应当获得数据科学家开发的整洁打包的分析模型。然后,他们可以为业务用户构建智能应用程序,使他们能够以自助服务的方式使用这些模型。
这样工作,没有人会因为等待下一个人而被困住。每个人都在使用自己的抽象进行工作。
这听起来可能像是一个乌托邦。但我相信这可以激励大数据团队改善他们现有的大数据平台和流程,额外的好处是让每个人都感到满意。
简介: Stepan Pushkarev 是 的首席技术官。Stepan 共同创办并领导了电子商务、物联网和广告技术公司的工程团队。负责从数学模型、基础设施与运营到网络和移动应用程序的完整产品栈,同时负责招聘、建立工程文化和交付流程,他结合了强大的技术、管理和企业家背景。
相关内容:
-
连接数据系统和 DevOps
-
成功的数据科学团队的三个基本组成部分
-
健康综合:大数据 DevOps 工程师
更多相关内容
学习数据科学的三大错误
原文:
www.kdnuggets.com/2019/05/biggest-mistakes-learning-data-science.html
评论 图片来源 Héizel Vázquez
图片来源 Héizel Vázquez
你好!又是我。我在其他文章中讨论过一些我将在这里提到的内容,但现在我想给出一些关于什么不是数据科学以及如何不学习数据科学的方向。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
所以让我们从基础开始。
什么是数据科学?
 由 memes_and_science 更新
由 memes_and_science 更新
数据科学不仅仅是掌握一些编程语言、数学、统计学和“领域知识”。
时代已经来临。我们创造了一个新领域,或者说是类似的东西。在这个领域有很多东西需要讲解和研究。名称无所谓,也许数据科学只是一个暂时的名称,但对数据的科学研究,从中获取洞察,然后能够预测某些事情是世界的现在和未来。
我将重点讨论与商业相关的数据科学定义和建议,这些建议可能适用于整个领域,但本文的观点主要是针对商业的数据科学。
我将提出三点建议:
-
数据科学是一门科学
-
学习数据科学有一些糟糕的方法
-
使用制作良好的备忘单可以帮助你系统地进行数据科学
数据科学是一门科学
我知道这可能对一些人来说是有争议的,但请坚持听我说。我想表达的是,数据科学当然与商业相关,但它终究是一门科学,或者说是在成为一门科学的过程中。
我曾经定义数据科学 如前所述:
[…] 通过 数学、编程 和 科学方法 来解决商业/组织问题,其中包括创建 假设、实验 和 测试 ,通过 数据分析 和 生成预测模型 来完成。它负责将这些 问题转化为明确的问题 ,并以 创造性 的方式回应初步假设。还必须包括 有效沟通 所获得的结果以及解决方案如何为商业/组织 创造价值。
我在这里陈述了数据科学作为一种科学的描述和定义。我认为将数据科学描述为科学非常有用,因为如果是这样的话,这一领域的每个项目至少应具备以下特点:
-
可重复:为了便于测试他人的工作和分析,这是必要的。
-
易出错:数据科学和科学并不追求真理,而是追求知识,因此每个项目都可以在未来被替代或改进,没有解决方案是终极的解决方案。
-
协作:数据科学家并非独立存在,他们需要一个团队,这个团队会使开发智能解决方案成为可能。协作是科学的重要组成部分,数据科学也应如此。
-
创造性:数据科学家所做的大多数工作都是新的研究、新的方法或对不同解决方案的尝试,因此他们的工作环境应当非常有创意且易于操作。创造力在科学中至关重要,这是我们找到复杂问题解决方案的唯一途径。
-
符合规定:目前科学领域有很多规定,虽然数据科学方面的规定不多,但未来会有更多。重要的是我们正在建设的项目要意识到这些不同类型的规定,以便我们能够为问题创造一个干净且可接受的解决方案。
如果我们不遵循这些基本原则,将很难进行正确的数据科学实践。数据科学应以能够使决策制定遵循系统化流程的方式实施。稍后会详细讲解。
如何避免错误学习数据科学。三大禁忌。
 memes_and_science
memes_and_science
如果你在这里,可能意味着你正在学习数据科学,或者你参加了一些 MOOCs 或相关课程。我不会在这里谈论平台或课程的好坏,我认为即使在最糟糕的课程中我们也能学到一些东西。
1. 只看而不实践

如果你正在上与数据科学相关的课程,如数学、统计学、编程或类似课程,而你只是听课。
如果你这样做,你是在浪费时间。数据科学需要实践。无论你学到什么,即使教授没有告诉你,也要实践并尝试。这对真正理解事物至关重要,当你在实际工作中时,你会做很多不同的实际操作。
对统计学、数学和 Python 的良好知识不会使你成为一个成功的数据科学家。你需要更多,你需要精通你的技能。能够使用这些工具解决业务问题。因此,如果你在学习新的东西,并且想真正理解它,找到一个你可以应用它或玩弄它的场景。
2. 以疯狂的方式创建模型

我们从“外部世界”获取数据,我们的身体和大脑分析我们得到的原始数据,然后我们“解释”这些信息。

towardsdatascience.com/going-beyond-with-agile-data-science-fcff5aaa9f0c
什么是“解释”?这就是我们从获得的信息中学到的如何反应、思考、感受和理解。当我们理解时,我们是在解码形成这个复杂事物的部分,并将我们一开始获得的原始数据转化为有用且简单的东西。
我们通过建模来做到这一点。这是理解“现实”的过程,即我们周围的世界,但创建一个更高级的原型,这个原型描述了我们所见、所听、所感的事物,但它是一个代表性的东西,而不是“实际的”或“真实的”东西。
所以在做之前请考虑:
model_i_created_i_5_seconds.fit(X,y)
建模在机器学习和数据科学领域非常重要,但它们必须有一个目的。你需要在使用之前理解它们。现在要了解它们在训练数据之前的假设,理解它们用于学习的不同指标,如何评估它们等等。
对此我可以告诉你,阅读像 Scikit-Learn 这样的库的文档是没有害处的:
关于科学数据处理的统计学习教程 - scikit-learn 0.20.3…
机器学习是一种越来越重要的技术,因为实验科学所面临的数据集的规模……scikit-learn.org
Apache Spark:
由于运行时专有二进制文件的许可问题,我们默认不包括 netlib-java 的本地代理……spark.apache.org
Tensorflow:
TensorFlow 指南 | TensorFlow 核心 | TensorFlow
会话是 TensorFlow 的机制,用于在一个或多个本地或远程设备上运行数据流图。如果……www.tensorflow.org
还有更多。它们将引导你到文章、论文和更多博客帖子,且大多数都包含如何在机器学习和统计学习中进行建模的实际示例。
此外,还有一些很棒的视频可以将你从零基础带到高手,比如我朋友Brandon Rohrer的作品:
3. “是的,我是个孤狼。我可以自己学习和做一切”

记住我之前提出的一个特点是,数据科学是一个合作性领域。那么,学习它也应该如此!
我不是说你需要和你的好朋友一起开始一个课程,而是利用今天在线平台所提供的资源。我们有论坛、聊天、讨论板等等,你可以在那里遇到学习相同内容的人。和更多人一起学习会更容易,不要害怕提问。
提出你需要理解的尽可能多的问题,直到你明白为止。也不要骚扰他人,但如果你礼貌地提问,大多数人都会很乐意帮助你。
这里有很棒的资源(除了 MOOCs 和课程内部提供的资源)可以找到学习相同内容的人:
Stack Overflow - 开发者学习、分享与职业发展的平台
Stack Overflow 是开发者学习、分享其编程经验的最大、最受信任的在线社区…… stackoverflow.com
Quora 是一个获取和分享知识的地方。它是一个提问和与人连接的平台…… www.quora.com
一个活跃的社区共同推动 AI 领域的增长和创新。 community.deepcognition.ai
r/datascience:一个供数据科学从业者和专业人士讨论和辩论数据科学职业的地方…… www.reddit.com
系统化的数据科学与备忘单
medium.com/personal-growth/all-strength-comes-from-repetition-1a95157e2c7c
备忘单通过提供有关语言、概念或库的不同片段的知识来节省时间。有些备忘单还包含指向文档和 R、Python、Scala 等重要包的包级备忘单的超链接。
去年年底,我创建了一个关于可以用于数据科学的各种备忘单的病毒式传播的仓库。
数据科学备忘单列表 - FavioVazquez/ds-cheatsheets github.com
在这个仓库中,你会找到关于以下主题的备忘单:
在那里你会找到每个备忘单的 PDF 和 PNG 版本。随意下载该存储库的 zip 文件以获取所有信息,如果你发现或创建了一个新的有用备忘单,请提交拉取请求。
感谢阅读,希望这些内容能帮助你找到在数据世界中成为成功专业人士的路径。更多内容敬请期待 😃
简介: Favio Vazquez 是一位物理学家和计算机工程师,专注于数据科学和计算宇宙学。他对科学、哲学、编程和音乐充满热情。他是 Ciencia y Datos 的创始人,这是一份西班牙语的数据科学出版物。他热爱新挑战,喜欢与优秀团队合作,解决有趣的问题。他参与了 Apache Spark 的协作,帮助 MLlib、Core 和文档方面的工作。他喜欢运用自己的知识和专业技能在科学、数据分析、可视化和自动学习方面,帮助世界变得更美好。
原文。已获授权转载。
相关内容:
-
学习数据科学硕士是否值得?
-
数据科学中最受欢迎的技能
-
如何辨别好数据科学职位与差数据科学职位
更多相关内容
机器学习的苦涩教训
原文:
www.kdnuggets.com/2020/07/bitter-lesson-machine-learning.html
评论
由理查德·萨顿,DeepMind 和阿尔伯塔大学。

我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
从 70 年的人工智能研究中可以得出的最大教训是,利用计算的一般方法最终是最有效的,并且差距很大。最终原因是摩尔定律,或者更准确地说,是其对计算单位成本持续指数下降的普遍化。大多数人工智能研究都假设代理可用的计算是恒定的(在这种情况下,利用人类知识将是提高性能的唯一途径之一),但在比典型研究项目稍长的时间内,大量更多的计算不可避免地变得可用。为了在短期内寻求有意义的改进,研究人员试图利用他们对领域的知识,但从长远来看,唯一重要的事情是利用计算。这两者并不一定相互矛盾,但在实践中往往会。投入到一种方法上的时间就是没有投入到另一种方法上的时间。对一种方法的心理投入往往会影响另一种方法。而人类知识的方法往往使方法复杂化,从而使其不太适合利用计算的通用方法。许多人工智能研究人员在之后才认识到这一苦涩的教训,回顾一些最突出的例子是很有启发性的。
从 70 年的人工智能研究中可以得出的最大教训是,利用计算的一般方法最终是最有效的,并且差距很大。
在计算机国际象棋中,1997 年击败世界冠军卡斯帕罗夫的方法是基于大规模、深度搜索的。当时,大多数计算机国际象棋研究人员对这种方法感到失望,他们曾追求那些利用人类对国际象棋特殊结构理解的方法。当一种更简单、基于搜索的方法配合特殊硬件和软件证明了更有效时,这些依赖人类知识的国际象棋研究人员并不善于接受失败。他们说,“蛮力”搜索可能这次获胜,但这不是一种通用策略,而且反正这也不是人们下棋的方式。这些研究人员希望基于人类输入的方法获胜,当他们未能实现这一点时感到失望。
计算机围棋中的研究进展模式与此类似,只是延迟了 20 年。最初的大量努力旨在通过利用人类知识或游戏的特殊特性来避免搜索,但一旦有效地大规模应用搜索,这些努力都证明了无关紧要,甚至更糟。自我对弈学习以学习价值函数也非常重要(正如在许多其他游戏中一样,甚至在国际象棋中也是如此,尽管在 1997 年首次击败世界冠军的程序中,学习并没有发挥重要作用)。自我对弈学习和学习一般来说与搜索类似,因为它能使大量计算得以运用。搜索和学习是人工智能研究中利用大量计算的两个最重要的技术类别。在计算机围棋中,与计算机国际象棋类似,研究人员最初的努力是集中在利用人类理解(以减少搜索需求),而只有在很晚的时候,通过采用搜索和学习才取得了更大的成功。
在语音识别领域,1970 年代有过一次由 DARPA 赞助的早期竞赛。参赛者包括大量利用人类知识的特殊方法——词汇知识、音素知识、人体发音道知识等。另一方面是基于隐藏马尔可夫模型(HMMs)的统计性方法,这些方法计算量大得多。统计方法再次战胜了基于人类知识的方法。这导致了自然语言处理领域的重大变化,逐渐经历了数十年,统计和计算成为主导。最近语音识别领域深度学习的崛起是这一一致方向的最新一步。深度学习方法甚至更少依赖于人类知识,使用更多的计算和在巨大训练集上进行学习,以产生更出色的语音识别系统。正如在游戏中一样,研究人员总是试图使系统按照他们认为自己思维运作的方式工作——他们试图将这种知识放入他们的系统中——但最终证明这是适得其反的,并且是对研究人员时间的巨大浪费,当摩尔定律下,大规模计算成为可能,并找到了有效利用它的方法时。
在计算机视觉领域,也出现了类似的模式。早期的方法将视觉视为寻找边缘、或通用的圆柱体,或以 SIFT 特征来进行处理。但今天,所有这些都被抛弃了。现代的深度学习神经网络仅使用卷积和某些类型的不变性,表现得更好。
这是一个重要的教训。作为一个领域,我们仍未彻底领会这一点,因为我们继续犯同样的错误。为了看清这一点并有效抵制它,我们必须理解这些错误的吸引力。我们必须吸取苦涩的教训,即在我们认为自己思考的方式中构建知识在长期内是行不通的。这个苦涩的教训基于以下历史观察:1)人工智能研究人员常常试图将知识构建到他们的代理中,2)这在短期内总是有帮助,并且对研究人员来说是个人上令人满意的,但 3)从长远来看,这会停滞不前,甚至抑制进一步的进展,4)突破性的进展最终通过一种基于计算规模化的搜索和学习的对立方法到来。最终的成功带有苦涩,常常因为是对一种偏爱的、人本中心方法的胜利而未被完全消化。
从这个苦涩的教训中应该学到的一点是,通用方法的巨大力量,那些即使在计算量非常大的情况下也能持续扩展的方法。似乎能够以这种方式无限扩展的两种方法是搜索和学习。
从这个痛苦的教训中学习到的第二个一般性观点是,心智的实际内容极其复杂、无法挽回;我们应停止寻找关于心智内容的简单思维方式,如关于空间、物体、多个代理或对称性的简单思维方式。所有这些都是任意的、内在复杂的外部世界的一部分。它们不应该被内建,因为它们的复杂性是无穷的;相反,我们应该只内建能够发现和捕捉这种任意复杂性的元方法。这些方法的关键是它们能找到好的近似值,但寻找这些近似值的过程应该由我们的方法完成,而不是由我们自己完成。我们希望 AI 代理能够像我们一样发现,而不是包含我们已经发现的内容。内建我们的发现只会让我们更难看到发现过程是如何进行的。
原文。经许可转载。
简介:理查德·S·萨顿是DeepMind的杰出研究科学家,并且是加拿大阿尔伯塔大学计算机科学的教授。萨顿被广泛认为是现代强化学习的奠基人之一,对该领域做出了若干重要贡献,包括时序差分学习和策略梯度方法。
相关:
更多相关主题
区块链在 7 个 Python 函数中的解释
原文:
www.kdnuggets.com/2018/04/blockchain-explained-7-python-functions.html
评论
由Tom Cusack,银行业数据科学家
我认为对于很多人来说,区块链是一种很难理解的现象。我开始观看视频和阅读文章,但对我来说,直到我编写了自己简单的区块链,我才真正理解它是什么及其潜在的应用。
我对区块链的理解是,它是一个公开的加密数据库。如果你是亚马逊,想用这项技术来跟踪你的库存水平,那么使用区块链有意义吗?可能没有,因为你的客户不会想花费资源来验证你的区块链,因为他们在网站上已经标明“仅剩 1 件”。
我将留给你们思考未来的应用。那么,事不宜迟,让我们设置我们的 7 个函数吧!
def hash_function(k):
*"""Hashes our transaction."""* if type(k) is not str:
k = json.dumps(k, sort_keys=True)
return hashlib.sha256(k).hexdigest()
区块链的核心是哈希函数。如果没有加密,区块链将很容易被操控,交易也可能被欺诈性地插入。
def update_state(transaction, state):
state = state.copy()
for key in transaction:
if key in state.keys():
state[key] += transaction[key]
else:
state[key] = transaction[key]
return state
‘状态’是记录谁拥有什么的。例如,我有 10 个硬币,我给 Medium 1 个,那么状态将是下面字典的值。
{‘transaction’: {‘Tom’: 9, ‘Medium’: 1}}
重要的是要注意,透支是不允许的。如果存在的硬币只有 10 个,那么我不能给某人 11 个硬币。下面的函数验证了我们尝试进行的交易是否确实有效。此外,交易必须平衡。我不能给出 5 个硬币而让接收者收到 4 个硬币,因为这会导致硬币的销毁和创建。
def valid_transaction(transaction, state):
*"""A valid transaction must sum to 0."""* if sum(transaction.values()) is not 0:
return False
for key in transaction.keys():
if key in state.keys():
account_balance = state[key]
else:
account_balance = 0
if account_balance + transaction[key] < 0:
return False
return True
现在,我们可以创建我们的区块。从之前的区块中读取信息,并用来将其链接到新区块。这一点也是区块链概念的核心。看似有效的交易可能会被尝试以欺诈方式插入区块链,但解密所有之前的区块在计算上(几乎)是不可能的,这保持了区块链的完整性。
def make_block(transactions, chain):
*"""Make a block to go into the chain."""* parent_hash = chain[-1]['hash']
block_number = chain[-1]['contents']['block_number'] + 1
block_contents = {
'block_number': block_number,
'parent_hash': parent_hash,
'transaction_count': block_number + 1,
'transaction': transactions
}
return {'hash': hash_function(block_contents), 'contents': block_contents}
以下是一个小助手函数,用于检查前一个区块的哈希值:
def check_block_hash(block):
expected_hash = hash_function(block['contents'])
if block['hash'] is not expected_hash:
raise
return
一旦我们把所有东西都组合在一起,就该创建我们的区块了。我们现在将更新区块链。
def check_block_validity(block, parent, state):
parent_number = parent['contents']['block_number']
parent_hash = parent['hash']
block_number = block['contents']['block_number']
for transaction in block['contents']['transaction']:
if valid_transaction(transaction, state):
state = update_state(transaction, state)
else:
raise
check_block_hash(block) # Check hash integrity
if block_number is not parent_number + 1:
raise
if block['contents']['parent_hash'] is not parent_hash:
raise
return state
在我们完成之前,链必须经过验证:
def check_chain(chain):
*"""Check the chain is valid."""* if type(chain) is str:
try:
chain = json.loads(chain)
assert (type(chain) == list)
except ValueError:
# String passed in was not valid JSON
return False
elif type(chain) is not list:
return False
state = {}
for transaction in chain[0]['contents']['transaction']:
state = update_state(transaction, state)
check_block_hash(chain[0])
parent = chain[0]
for block in chain[1:]:
state = check_block_validity(block, parent, state)
parent = block
return state
最后,需要一个交易函数,将以上所有内容连接在一起:
def add_transaction_to_chain(transaction, state, chain):
if valid_transaction(transaction, state):
state = update_state(transaction, state)
else:
raise Exception('Invalid transaction.')
my_block = make_block(state, chain)
chain.append(my_block)
for transaction in chain:
check_chain(transaction)
return state, chain
所以,现在我们有了我们的 7 个函数。我们怎么与之互动呢?首先,我们需要用一个创世区块来启动我们的链。这是我们新硬币(或库存等)的起点。为了本文的目的,我将说我,Tom,将以 10 个硬币开始。
genesis_block = {
'hash': hash_function({
'block_number': 0,
'parent_hash': None,
'transaction_count': 1,
'transaction': [{'Tom': 10}]
}),
'contents': {
'block_number': 0,
'parent_hash': None,
'transaction_count': 1,
'transaction': [{'Tom': 10}]
},
}
block_chain = [genesis_block]
chain_state = {'Tom': 10}
现在,看看当我给 Medium 一些硬币时会发生什么:
chain_state, block_chain = add_transaction_to_chain(transaction={'Tom': -1, 'Medium': 1}, state=chain_state, chain=block_chain)
状态会更新,以显示谁拥有什么:
{'Medium': 1, 'Tom': 9}
区块链是这样的:
[{'contents': {'block_number': 0,
'parent_hash': None,
'transaction': [{'Tom': 10}],
'transaction_count': 1},
'hash': '064d0b480b3b92761f31831d30ae9f01954efaa62371b4b44f11465ec22abe93'},
{'contents': {'block_number': 1,
'parent_hash': '064d0b480b3b92761f31831d30ae9f01954efaa62371b4b44f11465ec22abe93',
'transaction': {'Medium': 1, 'Tom': 9},
'transaction_count': 2},
'hash': 'b4ae25f0cc0ee0b0caa66b9a3473e9a108652d53b1dc22a40962fef5c8c0f08c'}]
我们的第一个新交易已经创建并插入到堆栈顶部。现在,我希望我已经引起了你的好奇心,并且你有兴趣复制代码并进行尝试。在我看来,这就是学习新技术的最佳方式——深入其中。
玩玩代码,制作你自己的币。如果你尝试给出超过存在的币会发生什么?如果你不断创建新的支付者,状态会发生什么?
你能想到区块链的未来应用吗?请随时在评论中问我任何问题,我会尽力帮助你。
简介:汤姆·库萨克 是银行业的数据科学家。
原文。经许可转载。
相关:
-
区块链和 API
-
人工智能与区块链的融合:这是怎么回事?
-
Swiftapply – 自动高效的 pandas 应用操作
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
更多相关话题
90 个关于分析、大数据、数据挖掘、数据科学、机器学习的活跃博客(更新中)
原文:
www.kdnuggets.com/2017/01/blogs-analytics-big-data-mining-data-science-machine-learning.html/2
中等活跃的群体:
-
Anil Batra 的网页分析(分析),在线广告和行为定向博客。
-
Annalyzin,为外行提供的分析,包含教程和实验,由 Annalyn Ng 撰写。
-
Ari Lamstein 博客,涵盖开放数据、制图、R 等。
-
商业。统计。技术,由印度商业学院统计学教授 Galit Shmueli 撰写。
-
商业分析(实用分析)博客由 Ravi Kalakota 撰写。
-
Clustify 博客,涵盖电子发现、预测编码、文档聚类、技术和软件开发。
-
Dr. Pham 和 Dr. Nguyen 的数据驱动论坛,大数据、物联网和数据科学:新闻和学术阅读。
-
数据挖掘研究博客由 Sandro Saitta 撰写,内容涉及数据挖掘研究问题、近期应用、重要事件、领先人物访谈、当前趋势、书评。
-
数据科学 Renee,由 Renee M. P. Teate 撰写,内容关于成为数据科学家的过程。
-
EMC 大数据博客,Dell EMC 的大数据博客。
-
Facebook 数据科学博客,由 Facebook 数据科学家呈现的有趣见解的官方博客。
-
FastML,涵盖机器学习和数据科学的实际应用。
-
![new]() Forrester 大数据博客 从公司贡献者那里汇聚的博客,专注于大数据话题。商业数据。
Forrester 大数据博客 从公司贡献者那里汇聚的博客,专注于大数据话题。商业数据。 -
Insight 数据科学博客由 Insight Data Science Fellows Program 校友撰写,关于数据科学的最新趋势和话题。您通往数据科学和数据工程职业的桥梁。
-
信息是美丽的,由独立数据记者和信息设计师 David McCandless 撰写,他也是其书《信息是美丽的》的作者。
-
Jeff Jonas 博客,关于隐私和信息时代的思考和资源。
-
学习爱好者关于编程、算法及一些学习用的记忆卡片。
-
Bickson.blogspot 大规模机器学习及其他动物,由 Danny Bickson 撰写,他创办了获奖的大规模开源项目 GraphLab。
-
永恒之谜由 Prateek Joshi 撰写,一位计算机视觉爱好者,通过问题风格的引人入胜的故事讲述机器学习。
-
随机沉思由 Yisong Yue 撰写,内容涉及人工智能、机器学习和统计学。
-
Steve Miller BI 博客,来自信息管理。
-
The Geomblog由 Suresh 撰写。
-
随机漫步由 Mike Croucher 撰写。

其他
-
超越得分 一个使用统计学分析棒球比赛的博客。
-
从大数据到大利润,由 Russell Walker 教授撰写,来自西北大学。
-
计算风险,金融与经济学
-
FiveThirtyEight,由 Nate Silver 及其团队提供,通过图表和饼图对从政治到科学再到体育的各种事物进行统计分析。
-
怪诞经济学博客,由 Steven Levitt 和 Stephen J. Dubner 撰写。
-
非官方 Google Analytics 博客来自 ROI Revolution。
-
The Guardian 数据博客,对新闻中的话题进行数据新闻报道。
-
网络分析与联盟营销,Dennis R. Mortensen 关于如何通过分析增加出版商收入的博客。
相关:
-
回顾过去一年,KDnuggets 博客的前 10 名帖子
-
公司和初创企业最佳数据科学、机器学习博客
-
关于分析、大数据、数据挖掘、数据科学和机器学习的 100 个活跃博客
更多相关话题
-
每个机器学习工程师都应该掌握的 5 种机器学习技能
大学担任若干统计课程的教学助理。
-
Revolution Analytics,关于使用开源 R 进行大数据分析、预测建模、数据科学和可视化的新闻。
-
Sabermetric 研究 由菲尔·伯恩鲍姆(Phil Burnbaum)撰写,讨论棒球统计学、股市、体育预测及各种主题。
-
Statisfaction 由巴黎(Université Paris-Dauphine, CREST)的博士生和博士后共同撰写的博客。主要提供日常工作中的技巧和窍门,链接到各种有趣的页面、文章、研讨会等。
-
数据的形状,由杰西·约翰逊(Jesse Johnson)撰写,从几何学的角度介绍数据分析算法。
-
简单统计 由三位生物统计学教授(杰夫·利克(Jeff Leek)、罗杰·彭(Roger Peng)和拉法·伊里扎里(Rafa Irizarry))撰写,他们对数据丰富的新时代以及统计学家作为科学家充满热情。
-
统计建模、因果推断与社会科学 由安德鲁·盖尔曼(Andrew Gelman)撰写。
-
猫咪统计,由查理·库夫斯(Charlie Kufs)撰写,他已经从事数据分析工作超过三十年。
-
分析因子 由凯伦·格雷斯·马丁(Karen Grace Martin)撰写。
-
汤姆·H·C·安德森个人博客,专注于数据和文本挖掘的市场研究。同时也有 OdinText 博客。
-
文森特·格兰维尔博客。文森特,AnalyticBridge 和 Data Science Central 的创始人,定期发布有关数据科学和数据挖掘的有趣话题。
-
Big Data 是什么。吉尔·普雷斯(Gil Press)覆盖大数据领域,并在《福布斯》上撰写有关大数据和商业的专栏。
-
西安的博客,由巴黎第九大学的统计学教授撰写,主要围绕计算和贝叶斯主题。
博客聚合器:
-
Analytics Vidhya 博客 关注分析技能的发展、分析行业的最佳实践等。
-
![new]() Hadoop360 是一个完全致力于所有 Hadoop 相关内容的数据科学中心社区频道。
Hadoop360 是一个完全致力于所有 Hadoop 相关内容的数据科学中心社区频道。 -
IBM 大数据中心博客,来自 IBM 思想领袖的博客。
-
KDnuggets,一个领先的大数据、数据科学、数据挖掘和预测分析网站/博客(包括这个网站,以便完整)。
-
O’Reilly 雷达,涵盖广泛的研究主题和书籍。雷达现已移至 oreilly.com/topics/data-science。
-
![new]() Planet Big Data 是一个聚合有关大数据、Hadoop 和相关主题的博客的平台。我们包括来自全球博主的文章。
Planet Big Data 是一个聚合有关大数据、Hadoop 和相关主题的博客的平台。我们包括来自全球博主的文章。 -
R-bloggers ,来自 R 领域丰富社区的最佳博客,包含代码、示例和可视化。
-
SAS 博客主页,连接到来自 SAS 的人、产品和理念。
-
Smart Data Collective,来自许多有趣的数据科学人物的博客聚合。
-
StatsBlog,一个聚焦于统计学相关内容的博客聚合器,并通过 RSS 提要从贡献博客中汇总文章。
-
![new]() 数据仓库内幕 来自 Oracle 团队的技术细节、理念和有关数据仓库和大数据的新闻。
数据仓库内幕 来自 Oracle 团队的技术细节、理念和有关数据仓库和大数据的新闻。
更多相关主题
Bokeh 速查表:Python 中的数据可视化
作者:Karlijn Willems,数据科学记者 & DataCamp 贡献者。
使用 Bokeh 进行 Python 数据可视化
数据可视化和讲故事是数据科学工作流程中的一个步骤,但常常被忽视。相反,这也可能是你数据科学学习中最困难的步骤之一,因为以一种能够让你的信息呈现出你分析所带来的信息的方式来可视化数据或讲述数据故事可能特别具有挑战性。当你开始考虑这些话题时,你会经常听到matplotlib是数据可视化的首选包,它确实如此,但有时你需要提升技能,如果你要在 Web 浏览器中交互式地可视化大型数据集。
这就是Bokeh包的用武之地:一个 Python 数据可视化库,能够在现代 Web 浏览器中高性能地展示大型数据集。这个包提供了许多将数据以引人注目的方式可视化的可能性,但它也非常灵活且庞大,以至于当你想要开始使用时,可能会被其可能性所压倒。这就是为什么 DataCamp 与Bryan Van de Ven,Bokeh 核心贡献者,合作开发了一门使用 Bokeh 进行交互式数据可视化课程,该课程最近上线,逐步且互动地指导你了解这个包所提供的可能性。
此外,DataCamp 还确保你可以免费下载一份Bokeh 速查表,以便在你遇到疑问时有一个方便的参考表可以依赖!
Bokeh 速查表

Bokeh 包为用户提供了很多可视化的灵活性:那些通常用于快速制作图表和统计图的工具是 Bokeh 的中级通用bokeh.plotting接口和高级bokeh.charts接口。
还有 bokeh.models接口,它为应用开发者提供了最大的灵活性,但没有包含在这份 Bokeh 速查表中。
现在,当你使用 bokeh.plotting 时,你会看到有两个主要组件,你需要了解如何高效地使用这个接口:数据和图形,这些组成了你的图表。
制作图表的基本步骤总共有五步:你需要你的数据来创建新的图表,你可以在其中添加字形和其他视觉自定义。你还需要指定你希望生成输出的位置,然后展示或保存结果,如左侧图片所示。
看起来很简单,对吧?让我们更详细地看看这些步骤。
数据

你可以传递各种类型的数据,如 Python 列表或元组、NumPy 数组或 Pandas DataFrame 来生成你的图表。
然而,在幕后,所有数据都被转换为 ColumnDataSource 对象。你也可以选择直接从字典和 Pandas DataFrame 创建 ColumnDataSource 对象,使用 ColumnDataSource() 函数,可以在从 bokeh.models 导入之后使用。如果你不确定如何创建和使用 DataFrames 和数组,可以考虑学习 DataCamp 的 Pandas 教程 和 NumPy 教程,以及 Pandas 备忘单 和 NumPy 备忘单。
绘图

就像在使用 Matplotlib 时一样,你可以通过初始化图形来开始使用 Bokeh 绘图。为此,你需要先从 bokeh.plotting 导入 figure。你可以使用这个函数创建一个新的绘图图形;当你创建新图形时,有一些额外的参数可以指定,以确保你根据自己的喜好修改图形:使用 plot_width 和 plot_height 你可以调整图形的宽度和高度,使用 tools 参数,你可以向图形中添加某些工具,例如平移或框选缩放。
此外,像 x_range 或 y_range 这样的参数用于设置 x 轴和 y 轴的范围也很有用。当然,你也可以选择不传递任何参数,直接创建一个图形。
渲染器和视觉自定义
字形
当你创建了一个要绘制的图形后,真正的工作开始了:为你的数据添加渲染器和视觉自定义(如果需要)。你不可能跟得上 Bokeh 为你准备的所有字形,因此备忘单仅列出最重要的字形:散点标记和线形字形。你可以使用第二步创建的图形,通过应用 circle() 或 square() 方法,确保在图表上将数据点散布为圆形和方形。line() 和 multi_line() 方法也一样,你可以使用它们来绘制折线图。然后你的数据点通过线连接起来。
当然,这些并不是 Bokeh 库提供的所有字形。前往此页面以查看更多字形!
自定义字形
你在上一部分看到的字形并不是非常自定义,对吗?Bokeh 确实允许你添加高度自定义的字形,这将使用户在使用你的图表时体验完全不同。
你对选择和非选择字形有什么看法?它们允许你突出显示数据中的某些数据点或区域;或者悬停字形,当你将鼠标悬停在图表上时突出显示你的数据?
很酷,对吧?
但可能会非常有用的是颜色映射:你可以用与数据所属类别相对应的颜色来显示数据点;查看备忘单以获取代码示例!
行和列布局
另一个在制作自定义可视化时非常有用的功能是 Bokeh 中的布局模块。它包含 row()和 column()函数,分别允许你创建行和列的图表。这意味着你的图表将水平或垂直显示。然而,这并不意味着你不能带来一些变化:你可以通过嵌套它们来结合两者。
这已经是自定义图表呈现的第一步了。
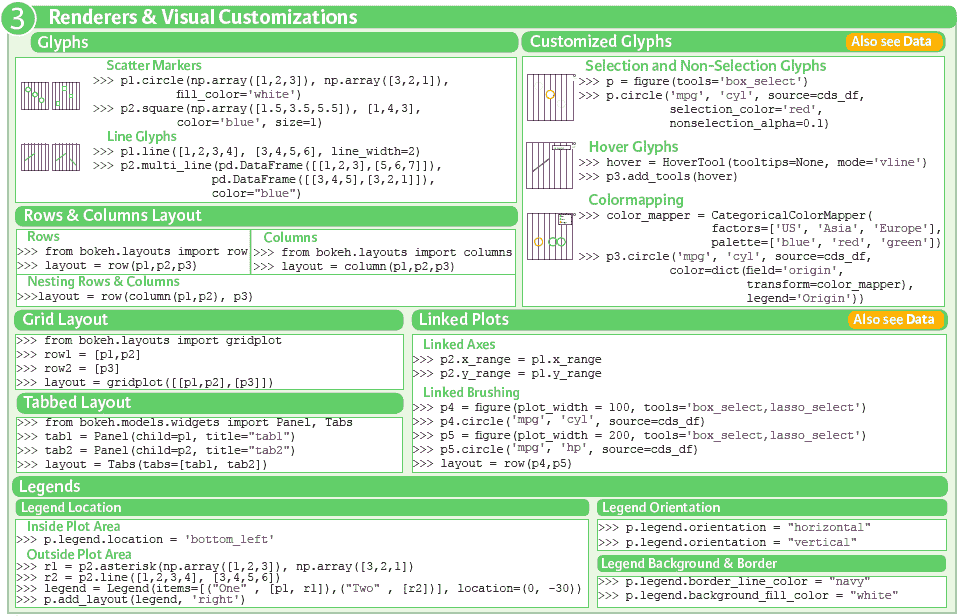
网格布局
当然,在某些情况下,仅创建行和列可能不足以满足你的布局需求。这就是为什么 Bokeh 还提供了网格布局:通过 gridplot()函数,你可以创建一个网格图,该网格图渲染在独立的画布上。在这种情况下,值得知道的是,该函数为网格中包含的所有图表构建了一个单一的工具栏,而这在使用 row()和 column()函数时是做不到的。
标签布局
除了行和列布局以及网格布局,还有标签布局。标签面板允许多个图表或布局显示在标签中;你可以从这些标签中选择你想要查看的图表。在备忘单中包含的代码中,你会看到你之前创建的两个图表现在被包含在面板中,这些面板构成了你布局中的标签。
关联图表
你会发现,将图表链接起来常常是有用的,这样可以在图表之间添加互联互动。链接图表的两种示例是链接坐标轴或链接刷选,这意味着数据源在图形渲染器之间共享。你对一个图形所做的所有选择也会传递到所有共享相同数据源的其他图形。为了更具体一点,假设在选择和未选择的图形中,你选择了一个包含数据点的区域。如果你的图表具有链接刷选,这也意味着其他图表中的相同数据点也会被选中。这是一种特别关注引起你注意的数据某些部分的好方法。
当你链接图表的坐标轴时,你会发现一旦你将图表拖动到左边、右边、上面或下面,其他图表的 x 轴和 y 轴也会跟随(或者只有两个轴中的一个会跟随,这当然取决于你如何具体指定链接)。在上面的代码示例中,图表的两个坐标轴都被链接。
图例
最后,除了图形、布局和链接外,非常重要的一点是,你添加到图表中的图例对你的观众理解图表的真实含义至关重要。你可以将图表做得尽可能美观和有意义,但图例将进一步帮助你的观众理解数据可视化想要传达的信息。这也是图例在此速查表中的位置原因:你可以看到如何指定图例的位置、方向、背景和边框。
当涉及到图例位置时,你可以将其清楚地放置在绘图区域内或外部。在第一种情况下,放置图例就像将字符串分配给绘图的属性一样简单。在第二种情况下,你需要多写一些代码来进行固定:你传递一个元组列表来组成图例,并且还添加一个位置。然后,你将布局添加到图表中,并指定你希望使用刚刚创建的变量中的图例值,并且将其添加到图表的右侧。
对于图例的方向,你不需要太担心;它可以是垂直的或水平的。再说一次,这就像调整绘图属性一样简单。至于背景和边框的规格,你只需要调整绘图属性即可。
如果你想查看更详细的代码示例,请访问此页面。
输出
输出你的 Bokeh 可视化的最显著方式是将其输出到 HTML 文件中或在 Jupyter notebook 中显示。你可以使用 output_file() 和 output_notebook() 函数来完成这些操作。前者函数允许你添加额外的参数来指定模式或如何包含 BokehJS;你可以在这里找到有关所有模式及其含义的更多信息。

当然,当你开始使用 Bokeh 并且觉得缺少输出选项时,请务必查看此页面获取更多信息。
展示或保存图表
就像在使用 Matplotlib 时一样,当你完成所有这些步骤后,终于到了展示或保存图表的时候!使用 show()和 save()函数来实现这一点!

Bokeh 的统计图表
中级通用的 bokeh.plotting 接口非常适合当你有时间逐行逐步设置图表自定义时。这非常适合制作演示文稿或最终报告中的图像。然而,对于数据探索的目的,你可能考虑使用高级的 bokeh.charts 接口,这是一种快速便捷的方式,以最少的代码生成图表。

备忘单包括了你在快速探索数据时最常用的图表,或者当你不想输入多余代码时使用的图表:条形图、箱线图、直方图和散点图。正如你可能已经猜到的那样,使用 Bar()、Boxplot()、Histogram()和 Scatter()函数来构建这些图表是非常简单的。
当然,使用最少的代码快速生成图表并不意味着你不能进行任何特定的自定义:你仍然可以添加各种参数以确保你的图表独一无二☺ 你可以在这里找到更多相关信息。
开始吧!
现在你已经准备好开始使用 Bokeh 库进行实验了!如果你觉得需要一些灵感,或者你有某种可视化想法但代码无法实现你的需求,考虑查看一下Bokeh 画廊。里面有很多美丽的例子,会让你陶醉!
PS. 当然,不要忘记随身携带你的备忘单。
DataCamp是一个在线互动教育平台,专注于为数据科学构建最佳学习体验。我们的课程包括R、Python和数据科学,围绕特定主题构建,结合视频讲解和浏览器内编码挑战,让你通过实践学习。你可以随时免费开始每门课程,无论何时何地。
Karlijn Willems 是一位数据科学记者,为DataCamp 社区撰稿,专注于数据科学教育、最新新闻和最热门的趋势。她拥有文学、语言学和信息管理学位。
相关:
-
Pandas 备忘单:Python 中的数据科学和数据清理
-
全面学习 Python 数据分析和数据科学指南
-
最佳数据科学在线课程
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关内容
《主算法》——由顶级机器学习研究员佩德罗·多明戈斯的新书
原文:
www.kdnuggets.com/2015/09/book-master-algorithm-pedro-domingos.html
我第一次见到佩德罗·多明戈斯是在 1995 年的第一次 KDD 会议上。他当时还是一位年轻而严肃的学生,但已经给我留下了深刻的印象,作为一位杰出的年轻研究员。他通过赢得多个奖项来证明了这些期望,包括 2014 年 KDD 数据挖掘/数据科学创新奖,这是该领域的最高奖项,他还是人工智能促进协会(AAAI)的研究员。
佩德罗在 2014 年的 KDnuggets 采访中描述了这本书的一些想法。
我对他即将出版的书籍非常感兴趣,并在最近的一次飞行中有机会阅读了它。
《主算法》博学、幽默且易读,它带你踏上探索机器学习专家的 5 个部落(规则、进化算法、贝叶斯、神经网络和类比)之旅,寻找主算法。
多明戈斯结合了不同的想法来构建一个潜在的主算法,并在此过程中甚至提出了对“42”的终极答案的一个问题,做出如此有趣的观察——“时间是记忆的主要成分”,并提出了一个可能比谷歌更有价值的公司构想——一个为你保存和分享数据的公司。
这里是一本书摘录。
算法越来越多地主导我们的生活。它们为我们寻找书籍、电影、工作和约会,管理我们的投资,发现新药物。越来越多,这些算法通过学习我们在数字化世界中留下的数据痕迹来运作。像好奇的孩子一样,它们观察我们、模仿和实验。在世界顶级研究实验室和大学中,发明终极学习算法的竞赛正在进行:一种能够从数据中发现任何知识,并在我们提出之前做任何我们想要的事情的算法。
机器学习是发现的自动化——科学方法的加强版——使智能机器人和计算机能够自我编程。今天,没有哪个科学领域比这更重要却又更神秘。佩德罗·多明戈斯,领域的领军人物之一,首次揭开面纱,让我们一窥驱动 Google、亚马逊和智能手机的学习机器内部。他展示了机器学习的五大主要学派,展示了如何将神经科学、进化论、心理学、物理学和统计学的理念转化为为你服务的算法。他一步步地构建了未来普遍学习者——大师算法——的蓝图,并讨论了它对你以及对商业、科学和社会未来的意义。
如果数据主义是当今崛起的哲学,那么这本书将是其圣经。对普遍学习的探索是所有时间里最重要、最迷人和最具革命性的智力发展之一。这本开创性的书籍,《大师算法》,是任何希望理解不仅仅是革命将如何发生,而是如何站在前沿的人的必备指南。
相关:
-
访谈:佩德罗·多明戈斯,KDD 2014 数据挖掘/数据科学创新奖获得者
-
数据挖掘/数据科学“诺贝尔奖”:ACM SIGKDD 2014 创新奖授予佩德罗·多明戈斯
-
顶级 KDnuggets 推文,9 月 15-21:顶级机器学习研究员佩德罗·多明戈斯的新书:《大师算法》
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
启动机器学习的书籍
原文:
www.kdnuggets.com/2020/01/book-start-machine-learning.html
评论
由 Jaime Zornoza,马德里理工大学

书籍封面。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
许多机器学习从业者经常被问到一个问题:“我该如何开始实际构建机器学习项目和解决方案?”
这里有太多的信息——既有好的也有不好的——让人很难知道从哪里开始。此外,人们的背景差异很大,因此起点可能差异很大。例如,对我而言,我通过观看计算机科学频道关于神经网络的理论视频进入了机器学习世界,随着兴趣的增加,我开始阅读有关该主题的文章、新闻和博客。
然而,通过这样做,我只是对机器学习最表面部分有了模糊的理解,离能够独立处理一个项目还远着呢。了解到这一点后,我决定参加一些实惠的 Udemy 机器学习课程。这些课程对我有帮助,因为它们稍微丰富和改善了我的知识,也涵盖了一些不同算法和模型的 Python 实现。
尽管如此,这些课程并没有让我对我所知道的感到满意,我想深入了解,理解每个对话,了解算法的核心内容,并自己构建一个端到端的机器学习项目。我希望能够有一个想法,构建或下载数据集,并执行它。
这就是我要谈论的书籍的作用。
— 提醒:本文包含附属链接,您可以通过这些链接舒适地购买任何书籍,而无需额外费用,同时支持更多类似文章的创作 —
我之前读过这本书,但随着新版的出版,我觉得分享一下我的想法是个好主意。

旧版书籍。
本书是“《动手学深度学习》”。这是一本最初于 2017 年出版的书籍,在我看来,每次修订后都变成了更好的版本,是学习机器学习的最佳深入资源之一。
这本书适合谁?
本书为机器学习的初学者设计,适合那些希望通过构建项目和在特定背景下学习不同机器学习算法来获得实践经验的人。在完成整本书后,你应该能够独立面对一个项目,并对这个过程中的不同步骤感到自如。
尽管这是一本相当基础的书籍,它也会为中级机器学习从业者提供一些工具。
这本书假设你有一定的 Python 编程经验,并且知道如何使用主要的科学库:Numpy、Pandas 和 Matplotlib。
此外,如果你想从中获得最大的收益,建议具备一些基础的数学、代数和统计知识。除此之外,即使你对机器学习几乎没有或完全没有初步理解,只要愿意付出努力,也可以轻松完成本书。
一切都讲解得非常清楚,配有代码片段、注释和示例。
包含哪些内容?
正如我之前提到的,这本书非常实用,早在第二章就让你开始动手编码一个项目。在此之前,它描述了什么是机器学习,什么不是,它的基本原理,以及它的主要应用和优势。
书中展示了如何实现不同的机器学习算法,并涵盖了你需要了解的理论,而不是深入复杂的方程式。最新的版本由 19 章组成,这些章节分为两个部分:
-
第一部分,解释了分类、回归、降维和无监督学习技术的主要概念,以及传统的机器学习算法,如线性回归、逻辑回归、支持向量机、决策树或集成模型。
-
第二部分,专注于使用 Tensorflow 和 Keras 进行人工神经网络和深度学习。解释了卷积神经网络和递归神经网络,以及自编码器,并且还有一章关于强化学习。
每章都进一步分解成更详细的结构,逐步讲解,书中还包含了各种附录。
章节如下:
-
第一部分:1. 机器学习概况,2. 从头到尾的机器学习项目,3. 分类,4. 训练模型,5. 支持向量机,6. 决策树,7. 集成学习和随机森林,8. 降维,9. 无监督学习技术。
-
第二部分:10. 使用 Keras 介绍人工神经网络,11. 训练深度神经网络,12. 使用 Tensorflow 自定义模型和训练,13. 使用 Tensorflow 加载和预处理数据,14. 使用卷积神经网络进行深度计算机视觉,15. 使用 RNN 和 CNN 处理序列,16. 使用 RNN 和注意力机制进行自然语言处理,17. 使用自编码器和 GAN 进行表示学习和生成学习,18. 强化学习,19. 训练和部署大规模 Tensorflow 模型。
正如我之前提到的,每章都有代码片段和附注来补充解释,并配有图形、图片和图表,每章末尾还有一组问题和练习,这些问题和练习在附录中得到了解答。
此外,非常有用的补充是一个逐步完成常见机器学习项目的检查清单。
如何阅读这本书?
每个人都不同,但对我来说,最有效的方法是边阅读纸质书边做笔记。同时,我会尝试阅读代码,每章末尾花时间回答问题和完成迷你练习。如果遇到困惑或不知道如何做某事,我会重读章节的某些部分或在线查找信息。
这本书会对我产生什么影响?
如果你刚刚开始学习机器学习,这本书将提升你现有的理论知识,并将其应用于一些实际项目中。很多时候,直到我们尝试将理论付诸实践,我们才会测试自己对某一事物的了解程度。通过阅读这本书,你将完全准备好在你感兴趣的项目中工作。
如果你已经了解机器学习并且参与过一些项目,这本书将完善你的理论知识,教你一些你可能不知道的实用技巧,并建议你如何以最佳方式构建项目。这是一本在日常工作中回答特定问题的极好参考书。
接下来做什么?
在你读完这本书后,我鼓励你考虑几个你希望用机器学习完成的项目,拿着这本书尝试执行它们。这将让你在现实世界问题上进行测试,面对一些机器学习项目的难题,并且你将建立一个解决问题的作品集,这在你的学习和未来作为机器学习工程师或数据科学家时将具有很高的价值。

我书库中的其他机器学习书籍
一旦你觉得自己可以舒适地处理这些项目,如果你想进一步接近专家,你可以尝试用同样的方法阅读一本更高级的书,例如以下之一:
或者,如果你对不那么技术性的书籍感兴趣,并想探讨人工智能的好奇心、危险和影响,你可以阅读以下描述的书籍之一:
三本令人惊叹的人工智能书籍,让你的思维翱翔,思想蓬勃发展。
同样,如果你希望专注于机器学习的特定领域,你可以寻找相关书籍,甚至是更专业的在线课程。
结束语
一如既往,希望你喜欢这篇帖子,并且我已经说服你阅读这本书。
这里你可以找到最新版本的链接:
如果你喜欢这篇帖子,请随时关注我在Twitter 上的 @jaimezorno。此外,你还可以查看我在数据科学和机器学习方面的其他帖子在这里。祝你阅读愉快!
如果你想深入了解机器学习和人工智能,请关注我在 Medium 的文章,并关注我的下一篇帖子!
在那之前,保重,享受人工智能!
简介:Jaime Zornoza 是一位工业工程师,拥有电子学本科学位和计算机科学硕士学位。
原文。经许可转载。
相关:
-
10 本免费必读的人工智能书籍
-
贝叶斯背后的数学
-
NLP 深度学习:ANNs、RNNs 和 LSTMs 解析!
相关话题
使用 O'Reilly 学习生成性人工智能的书籍、课程和现场活动
原文:
www.kdnuggets.com/books-courses-and-live-events-to-learn-generative-ai-with-oreilly

图片由编辑提供
生成性人工智能正在增长,越来越多的人对如何转入 AI 领域感兴趣。当前非常热门,如果你点击了这个链接,你也在想如何学习更多关于生成性人工智能的知识。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在这篇博客中,我将介绍使用O'Reilly学习生成性人工智能的书籍、课程和现场活动。
使用 Python 进行机器学习、数据科学和生成性人工智能
链接:课程 - 使用 Python 进行机器学习、数据科学和生成性人工智能
级别:初学者
对于那些希望通过更实际的学习途径的用户,O'Reilly 的这门课程《使用 Python 进行机器学习、数据科学和生成性人工智能》从 Python 速成课程开始,设置你的计算机,然后涉及机器学习、人工智能和数据挖掘技术的各个方面,包括深度学习和神经网络。
课程还将深入探讨变换器架构及其在 AI 中的作用,以及 GPT 应用,你将能够练习为电影评论分析等任务微调变换器。
初学者的生成性人工智能应用:关于扩散模型、ChatGPT 和其他大型语言模型的实用知识
级别:初学者
另一个适合初学者的资源,可以让你深入生成性人工智能的世界,你将学习神经网络的基础知识到像 ChatGPT 和 Google Bard 这样的高级语言模型。如果你对生成性人工智能感兴趣并希望从头开始学习 - 这本书是一个一站式的资源,可以做到这一点!
如果你是一位希望了解更高级模型的数据科学家,或是一位希望利用 AI 促进企业增长的商业人士,这本书将是你掌握生成性人工智能的指南 - 包含理论知识和实际见解。
企业中的生成性人工智能
链接: 报告 - 企业中的生成式 AI
级别: 初级/中级
如果你正在寻找一本新的读物,专注于生成式 AI,特别是在企业中的应用——这份报告适合你。O'Reilly 创建了一份报告,解读了来自成千上万用户的数据,以探索有多少组织正在使用生成式 AI 工具。
不仅仅是多少人正在使用它,还有他们如何使用它以充分利用它并改善他们的工作流程。在本报告中,你将发现最受欢迎的生成式 AI 模型、它们的应用案例,以及生成式 AI 工具相关的风险,这些风险让早期采用者犹豫不决。
为每个人提供生成式 AI
级别: 中级
在 2 月 12 日,O'Reilly 将举行一场公开活动,让公众了解和理解生成式 AI 的应用、好处和风险。
在这场 2 小时的实时活动中,你将学习生成式 AI 应用及其对你组织的潜在影响。你将深入了解什么是提示工程,为什么你应该掌握它,以及如何通过创建个性化内容和自动化繁琐任务来从生成式 AI 中受益。
AWS 上的生成式 AI
级别: 中级/专家
尽管有些人对采用生成式 AI 持犹豫态度,但另一方面,许多公司正迅速将生成式 AI 集成到他们的产品和服务中。然而,生成式 AI 如何真正影响和改善公司仍然存在灰色地带。
本书的作者来自 AWS,他们旨在指导 CTO、从业者、应用开发者、业务分析师等找到实用的方法来使用这一激动人心的新技术。你将深入了解生成式 AI 项目的生命周期,同时探索不同类型的模型,如大型语言模型(LLMs)和多模态模型。
生成式 AI 提示工程
链接: 书籍 - 生成式 AI 提示工程
级别: 中级/专家
提示工程是生成式 AI 工具背后的美妙之处。我们看到 AI 提示工程师年薪 30 万美元,所以你可以想象在这个时代学习这项技能是多么重要。在本书中,你将学习如何将生成式 AI 模型应用于实践,并克服通过提示工程获得可靠输出的挑战。
在本书中,你将学习提示的五个原则的概述,LLMs 的文本生成介绍,标准实践,先进技术,图像生成等。了解程序 AI 模型的交互链结构和自然语言处理、文本和图像生成、代码的关键原则。
总结
在这篇博客中,我旨在提供不同类型的资源,因为我理解人们以独特的方式学习。O’Reilly 提供了许多优秀的资源来帮助你提升职业生涯、提高技能,并确保持续的学习之旅。无论是个人还是团队,通过点击 这里 开始你的学习旅程吧。
Nisha Arya 是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的主题,并希望探索人工智能如何有益于人类生命的持久性。作为一个热衷学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
提升你的数据科学技能。学习线性代数。
原文:
www.kdnuggets.com/2018/05/boost-data-science-skills-learn-linear-algebra.html
评论
由 Hadrien Jean 提供,机器学习科学家

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
我想介绍一系列博客文章及其对应的 Python Notebooks,这些笔记汇总了 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville(2016)所著的《深度学习书籍》中的内容。这些 Notebooks 的目的是帮助初学者/高级初学者掌握深度学习和机器学习所涉及的线性代数概念。掌握这些技能可以提高你理解和应用各种数据科学算法的能力。在我看来,这些概念是机器学习、深度学习和数据科学的基础之一。
这些笔记涵盖了线性代数的第二章。我喜欢这一章,因为它给出了在机器学习和深度学习领域中最常用的知识。因此,它是任何想要深入了解深度学习并掌握有助于更好理解深度学习算法的线性代数概念的人的绝佳大纲。
你可以在Github上找到所有的笔记,以及这个帖子在我的博客上的版本。
开始学习线性代数
本系列的目标是为初学者提供足够的线性代数知识,以便能够掌握机器学习和深度学习。然而,我认为深度学习书籍中的线性代数章节对初学者来说有点困难。因此,我决定为本章的每个部分制作代码、示例和图示,以增加可能对初学者不明显的步骤。我还认为,通过示例传达的信息和知识与通过一般定义一样多。插图是了解一个思想大局的方式。最后,我认为编码是具体实验这些抽象数学概念的绝佳工具。与纸笔一起,它为你可以尝试推动理解的新领域添加了一层。
编码是具体实验抽象数学概念的绝佳工具
图形表示对于理解线性代数也非常有帮助。我尝试将概念与图表(以及生成这些图表的代码)结合起来。我在制作这系列时最喜欢的表示方式是你可以将任何矩阵视为空间的线性变换。在几个章节中,我们将扩展这一思想,看看它如何有助于理解特征分解、奇异值分解(SVD)或主成分分析(PCA)。
Python/Numpy 的使用
此外,我发现创建和阅读示例对理解理论非常有帮助。这就是为什么我构建了 Python 笔记本。目标有两个方面:
-
提供一个使用 Python/Numpy 应用线性代数概念的起点。由于最终目标是将线性代数概念应用于数据科学,因此在理论和代码之间不断切换是很自然的。你只需一个包含主要数学库如 Numpy/Scipy/Matplotlib 的工作 Python 环境。
-
提供一个更具体的基础概念视角。我发现通过在这些笔记本中玩耍和实验对建立对某些复杂理论概念或符号的理解非常有用。我希望阅读它们同样有用。
课程大纲
课程大纲严格遵循 深度学习书籍,因此如果你在阅读时无法理解某个具体点,可以找到更多细节。这里是内容的简要描述:
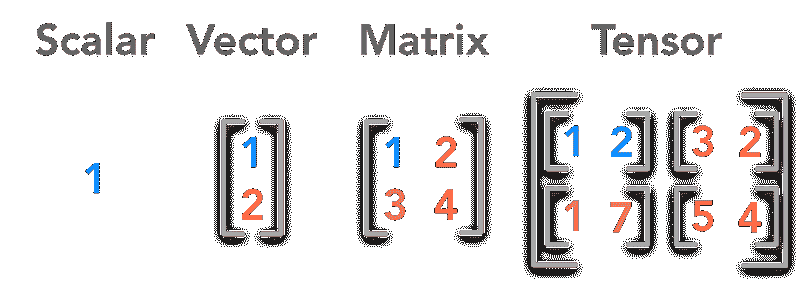
对向量、矩阵、转置和基本操作(向量或矩阵的加法)进行轻量介绍。还介绍了 Numpy 函数,最后提到广播。
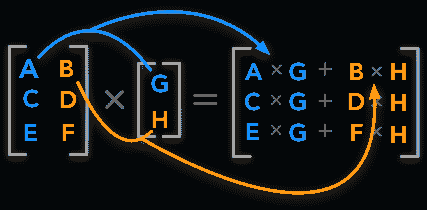
本章主要讨论点积(向量和/或矩阵乘法)。我们还将看到一些相关属性。然后,我们将了解如何使用矩阵表示法综合线性方程组。这是接下来章节的主要过程。
3. 单位矩阵和逆矩阵
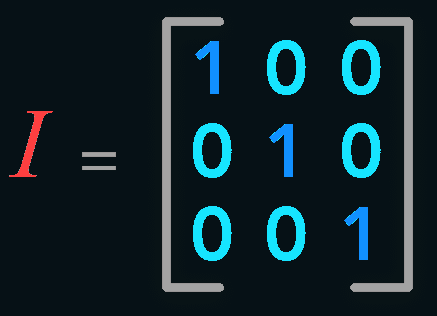
我们将讨论两个重要的矩阵:单位矩阵和逆矩阵。我们将探讨它们在线性代数中的重要性以及如何使用 Numpy 来操作它们。最后,我们将看到如何用逆矩阵解决线性方程组的例子。
4. 线性依赖与张成
在本章中,我们将继续研究线性方程组。我们将看到这样的系统不能有多于一个解,也不能少于无限多个解。我们将探讨这种说法的直观感受、图形表示和证明。然后,我们将回到系统的矩阵形式,并考虑 Gilbert Strang 所说的行图(即查看行,也就是多个方程)和列图(即查看列,也就是系数的线性组合)。我们还将了解什么是线性组合。最后,我们将看到过定方程组和欠定方程组的示例。
5. 范数
向量的范数是一个函数,它接受一个向量作为输入并输出一个正值。它可以被看作是向量的长度。例如,它被用来评估模型预测值与实际值之间的距离。我们将看到不同种类的范数(L⁰、L¹、L²…)及其示例。
6. 特殊类型的矩阵和向量
我们在 2.3 中见过一些非常有趣的特殊矩阵。在本章中,我们将看到其他类型的向量和矩阵。虽然这一章不长,但理解它对接下来的章节很重要。
7. 特征分解
本章将介绍线性代数的一些主要概念。我们将从了解特征向量和特征值开始。我们将看到矩阵可以被视为线性变换,并且对其特征向量应用矩阵会得到方向相同的新向量。接着我们将了解如何将二次方程表达为矩阵形式。我们将看到对应于二次方程的矩阵的特征分解可以用来找到其最小值和最大值。作为额外内容,我们还将看到如何在 Python 中可视化线性变换!
我们将看到另一种矩阵分解的方法:奇异值分解(SVD)。从本系列开始,我就强调了矩阵可以看作是空间中的线性变换。通过 SVD,你将一个矩阵分解为另外三个矩阵。我们将看到这些新矩阵可以被视为空间的子变换。而不是一次性完成变换,我们将其分解为三个步骤。作为额外内容,我们还将把 SVD 应用于图像处理。我们将看到 SVD 对一张卢西鹅的示例图像的效果,所以请继续阅读!
我们已经看到并不是所有的矩阵都有逆矩阵。这很遗憾,因为逆矩阵用于解决方程组。在某些情况下,方程组没有解,因此逆矩阵不存在。然而,找到一个接近解的值(在最小化误差方面)可能很有用。这可以通过伪逆来实现!我们将看到如何使用伪逆找到数据点集合的最佳拟合线。
我们将了解矩阵的迹。它将在关于主成分分析(PCA)的最后一章中用到。
本章讲解的是矩阵的行列式。这个特殊的数字可以告诉我们关于矩阵的很多信息!
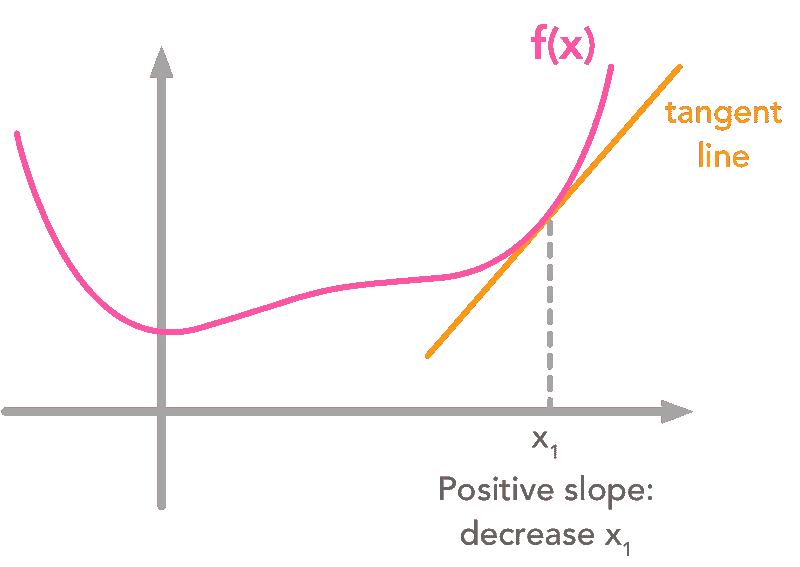
这是本系列关于线性代数的最后一章!它讲解的是主成分分析(PCA)。我们将使用在前几章中获得的一些知识来理解这一重要的数据分析工具!
要求
这些内容面向初学者,但对于至少有一些数学经验的人来说应该会更容易理解。
享受
希望你能在这一系列内容中找到一些有趣的东西。我尽力做到准确。如果你发现错误/误解/打字错误… 请报告!你可以发送电子邮件或在 notebooks 的 Github 上打开问题和拉取请求。
参考资料
Goodfellow, I., Bengio, Y., & Courville, A. (2016). 深度学习。MIT 出版社。
简介:Hadrien Jean 是一位机器学习科学家。他拥有巴黎高等师范学校的认知科学博士学位,在那里他通过行为和电生理数据研究听觉感知。他曾在行业中工作,构建了用于语音处理的深度学习管道。在数据科学与环境交汇处,他从事使用深度学习应用于音频录音的生物多样性评估项目。他还定期在 Le Wagon(数据科学训练营)创建内容和教学,并在他的博客(hadrienj.github.io)上撰写文章。
原文。已获许可转载。
相关内容:
-
掌握数据科学和机器学习数学基础的 7 本书
-
15 个数据科学数学 MOOCs
-
实际数据科学家需要的实用技能
更多相关话题
提升你的数据科学技能:必备的 SQL 认证
原文:
www.kdnuggets.com/boost-your-data-science-skills-the-essential-sql-certifications-you-need

编辑者图片
SQL,即结构化查询语言,通常发音为 s-q-l 或 sequel,是一种用于访问和操作数据库的编程语言。在处理大型数据集时,一个问题可能是从中提取确切需要的信息。
我们的 3 个最佳课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
SQL 可以帮助解决这个问题。专业人士可以通过清理、排序、提取和处理大型数据集与关系数据库系统进行沟通。由于大数据的宝贵资产以及需要处理、评估和分析数据的专业人士,SQL 专家的需求仍在上升。
SQL 认证有不同类型,针对特定平台。根据你感兴趣的数据库技术来确定最适合你的认证。
Microsoft 认证:Azure 数据基础
这个课程针对初学者,可以在 1 个月内完成,每周投入 10 小时。
在这个 5 门课程系列中,学习云环境中数据库概念的基础知识。你将获得云数据服务的基本技能,并建立对 Microsoft Azure 中云数据服务的基础知识。
这 5 门课程包括:
-
探索 Microsoft Azure 中的核心数据概念
-
Microsoft Azure SQL
-
Microsoft Azure Cosmos DB
-
Microsoft Azure 中的现代数据仓库分析
-
为 DP-900:Microsoft Azure 数据基础考试做准备
Oracle SQL 数据库
这个课程针对初学者,可以在 1 个月内完成,每周投入 10 小时。
Oracle SQL 数据库专业化认证包括 4 门课程,你将学习如何创建 Oracle SQL 数据库,并了解如何在 Oracle SQL 数据库中插入、修改和删除数据。
这 4 门课程包括:
-
Oracle 数据库基础
-
Oracle 数据库平台
-
Oracle SQL 基础
-
Oracle SQL 熟练度
IBM 数据仓库工程师
链接: IBM 数据仓库工程师
该课程面向初学者,预计可以在 3 个月内完成,每周投入 10 小时。
IBM 数据仓库工程师认证由 8 门课程组成,您将学习数据仓库工程师使用的最新实践技能和知识,如何部署、管理、安全、监控和优化 MySQL 和 PostgreSQL 等关系型数据库系统。您还将了解各种 SQL 类型和查询,以访问和操作数据库中的数据。
8 门课程包括:
-
数据工程简介
-
关系型数据库(RDBMS)简介
-
SQL:查询数据库的实用入门
-
Linux 命令和 Shell 脚本的实操介绍
-
关系型数据库管理(DBA)
-
使用 Shell、Airflow 和 Kafka 进行 ETL 和数据管道
-
数据仓库与商业智能分析入门
-
数据仓库顶点项目
IBM 商业智能(BI)分析师
该课程面向初学者,预计可以在 4 个月内完成。
获得 IBM 商业智能分析师认证后,您可以在不到 4 个月的时间内启动您的商业智能职业生涯。
该认证包含 10 门课程,您将学习 SQL 查询、关系型数据库、数据仓库、数据分析以及报告技术。您将学习如何应用统计分析方法来识别趋势、创建可视化并生成有价值的洞察,从而促进明智决策和过程改进。
10 门课程包括:
-
商业智能(BI)基础
-
数据分析的 Excel 基础
-
使用 Excel 和 Cognos 进行数据可视化和仪表板制作
-
关系型数据库(RDBMS)简介
-
SQL:查询数据库的实用入门
-
数据仓库与商业智能分析入门
-
使用 Excel 的统计基础
-
入门 Tableau
-
高级数据可视化与 Tableau
-
BI 分析师顶点项目
面向所有人的 PostgreSQL
该课程面向中级水平,预计可以在 1 个月内完成,每周投入 10 小时。
面向所有人的 PostgreSQL 认证包含 4 门课程。在这些课程中,您将学习 SQL 的基础知识到高级内容。您将深入了解如何有效使用 PostgreSQL 数据库,探索数据库设计原则、数据库架构和部署策略,并能够比较和对比 SQL 和 NoSQL 数据库设计方法。
4 门课程包括:
-
PostgreSQL 数据库设计与基础 SQL
-
中级 PostgreSQL
-
PostgreSQL 中的 JSON 和自然语言处理
-
数据库架构、规模与 NoSQL(使用 Elasticsearch)
总结
虽然知识和经验比认证更为重要,但招聘经理确实倾向于优先考虑有认证的申请者。在选择合适的 SQL 认证时,确保考虑到你所希望的工作的特定供应商或平台。
Nisha Arya是一名数据科学家、自由技术作家、KDnuggets 的编辑及社区经理。她特别关注提供数据科学职业建议、教程和理论知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷学习的人,Nisha 寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
提升您的图像分类模型
原文:
www.kdnuggets.com/2019/05/boost-your-image-classification-model.html
评论
由 Aditya Mishra,来自 difference-engine.ai 的机器学习工程师
图像分类被认为是一个几乎解决的问题。有趣的部分是当你必须发挥全部聪明才智来获得额外的 1% 准确度时。我遇到了这样的情况,当我参加了Intel 场景分类挑战赛(由 Analytics Vidhya 主办)。我非常享受这次比赛,因为我尽力从我的深度学习模型中提取所有精华。下面的技术通常可以应用于任何图像分类问题。
问题
问题是将给定的图像分类为 6 个类别

数据类别
我们获得了约 25K 张来自全球各地自然场景的图像
渐进式调整图像大小
这是一个在训练 CNN 时按顺序调整所有图像大小的技术。渐进式调整图像大小在他出色的fastai 课程“实用深度学习课程”中简要描述了。使用这种技术的一个很好的方法是用较小的图像大小(如 64x64)训练模型,然后使用该模型的权重来训练另一个图像大小为 128x128 的模型,依此类推。每个更大规模的模型都在其架构中包含了之前较小规模模型的层和权重。

渐进式调整图像大小
FastAI
fastai 库是一个强大的深度学习库。如果 FastAI 团队发现一篇特别有趣的论文,他们会在不同的数据集上进行测试,并研究如何调整它。一旦成功,它就会被纳入他们的库中,用户可以方便地使用。该库包含了许多最先进(SOTA)的技术。基于 PyTorch 类型,fastai 为大多数(如果不是全部的话)任务提供了出色的默认参数。以下是一些技术:
-
循环学习率
-
一周期学习
-
结构化数据上的深度学习
合理的权重初始化
在查看可用的标准数据集时,我偶然发现了 Places365 数据集。Places365 数据集包含了来自 365 个场景类别的 180 万张图像。挑战中提供的数据集与这个数据集非常相似,因此在这个数据集上训练的模型已经学到了与我们分类问题相关的特征。由于我们问题中的类别是 Places365 数据集的一个子集,我使用了一个用 Places365 权重初始化的 ResNet50 模型。
模型权重可以通过 pytorch weights 获得。下面的实用函数帮助我们将数据正确加载到 fastai 的 CNN Learner 中。
Mixup 数据增强
Mixup 数据增强是一种数据增强类型,通过对两个现有图像进行加权线性插值来形成新的图像。我们取两个图像并对它们进行张量的线性组合。

Mixup 数据增强
λ 是从贝塔分布中随机采样的。尽管论文的作者建议使用 λ=0.4,但 fastai 库中的默认值设置为 0.1

fastai中的 Mixup 数据增强
学习率调整
学习率是训练神经网络最重要的超参数之一。fastai 提供了一种方法来找到适当的初始学习率。这种技术叫做循环学习率,我们通过较低的学习率进行试验并以指数方式增加,记录过程中损失值。然后我们将损失值与学习率绘制成图,并选择损失最陡的学习率。

学习率查找器在 fastai 中 
损失在 1e-06 时最陡
该库还自动处理了带重启的随机梯度下降(SGDR)。在 SGDR 中,学习率在每个纪元开始时被重置为原始选择值,该值会随着纪元的进行而降低,类似于余弦退火。这样做的主要好处是,由于学习率在每个纪元开始时都会重置,学习者能够跳出可能卡住的局部最小值或鞍点。

fastai中的 SGDR
生成对抗网络
GANs 是由 Ian Goodfellow 在 2014 年引入的。GANs 是由两个网络组成的深度神经网络架构,相互对抗。GANs 可以模拟任何数据分布。它们可以学习生成与原始数据相似的数据,适用于任何领域——图像、语音、文本等。我们使用了 fast.ai 的 Wasserstein GAN 实现来生成更多的训练图像。
GANs 涉及训练两个神经网络,一个称为生成器,生成新的数据实例,而另一个称为判别器,评估这些实例的真实性,它决定每个数据实例是否属于实际的训练数据集。你可以在 这里 找到更多信息。

GAN 生成的样本图像
移除混淆图像
训练神经网络的第一步是不接触任何神经网络代码,而是开始彻底检查你的数据。这一步是至关重要的。我喜欢花费大量时间(以小时为单位)浏览成千上万的样本,理解它们的分布并寻找模式。
- Andrej Karpathy
正如 Andrej Karpathy 所说,“数据调查”是一个重要的步骤。在数据调查中,我发现有一些图像包含了两个或更多类别。
方法 1
使用之前训练的模型,我对整个训练数据进行了预测。然后丢弃了那些预测结果不正确但概率分数大于 0.9 的图像。这些是模型明显错误分类的图像。深入分析后,我发现这些图像被标注者错误标记了。

令人困惑的图像
我还从训练集中删除了那些预测概率在 0.5 到 0.6 范围内的图像,理论是图像中可能存在多个类别,因此模型对每个类别分配了大致相等的概率。查看这些图像后,理论最终被证明是正确的。
方法 2
fast.ai 提供了一个方便的小工具“图像清理小工具”,允许你清理和准备数据以供模型使用。ImageCleaner 用于清理不属于你的数据集的图像。它以一行的形式渲染图像,并给你机会从文件系统中删除文件。

测试时间增强
测试时间增强涉及对原始图像进行一系列不同版本的处理,并将它们通过模型。然后计算这些不同版本的平均输出,并将其作为图像的最终输出。

在 fastai 中的测试时间增强
之前使用过一种类似的技术叫做 10-crop 测试。我第一次在ResNet论文中了解到 10-crop 技术。10-crop 技术涉及将原始图像裁剪到四个角落,并在中心裁剪一次,总共得到 5 张图像。对其反向操作重复相同的步骤,再得到另外 5 张图像,总共 10 张图像。然而,测试时间增强的速度比 10-crop 技术要快。
集成学习
在机器学习中,集成学习是一种使用多种学习算法来获得比单一算法更好的预测性能的技术。集成学习效果最佳
-
组成模型具有不同的性质。例如,将 ResNet50 和 InceptionNet 进行集成比将 ResNet50 和 ResNet34 进行组合要有用得多,因为它们的性质不同。
-
组成模型之间的相关性较低
-
为每个模型更改训练集,以增加变化性。
在这种情况下,我通过选择出现次数最多的类别来集成所有模型的预测。如果有多个类别出现次数相同,我会随机选择其中一个类别。
结果
公共排行榜 — 第 29 名 (0.962)
私有排行榜 — 第 22 名 (0.9499)
结论
-
渐进式调整大小是一个很好的入门主意。
-
花时间理解和可视化你的数据是必要的。
-
像 fastai 这样的优秀深度学习库,具有合理初始化的参数,绝对是有帮助的。
-
在任何可能的地方和情况下使用迁移学习,因为它通常会给出良好的结果。最近,深度学习和迁移学习甚至已应用于结构化数据,因此迁移学习绝对应该是首选尝试的方案。
-
先进的技术如 Mixup 数据增强、TTA、循环学习率一定能帮助你将准确率提高额外的 1%或 2%。
-
始终寻找与你的问题相关的数据集,并尽可能将其包含在训练数据中。如果存在针对这些数据集训练的深度学习模型,使用它们的权重作为你的模型的初始权重。
简介: Aditya Mishra 是 difference-engine.ai 的机器学习工程师。
原文。经许可转载。
相关:
-
大规模图像分类器演变
-
通过迁移学习和弱监督廉价构建 NLP 分类器
-
如何在计算机视觉中做一切
更多相关话题
提升机器学习算法:概述
原文:
www.kdnuggets.com/2022/07/boosting-machine-learning-algorithms-overview.html

在解决问题时,结合各种机器学习算法通常会得到更好的结果。这些单独的算法被称为弱学习器。它们的组合形成了一个强学习器。弱学习器是指在分类问题中比随机预测或回归问题中的均值更有效的模型。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
这些算法的最终结果通过在训练数据上拟合它们并结合它们的预测来获得。在分类中,结合是通过投票完成的,而在回归中则是通过平均来完成的。
几个机器学习算法的组合被称为集成学习。集成学习有多种技术。在本文中,我们将重点介绍提升。
让我们开始学习——玩笑话!
什么是提升?
提升是一种集成学习技术,它依次将较弱的学习器拟合到数据集中。每个后续的弱学习器都旨在减少前一个学习器产生的错误。
提升(Boosting)是如何工作的?
一般来说,提升的工作原理如下:
-
创建初始的弱学习器。
-
使用弱学习器对整个数据集进行预测。
-
计算预测误差。
-
错误预测会被赋予更多的权重。
-
构建另一个弱学习器,旨在修正前一个学习器的错误。
-
使用新的学习器对整个数据集进行预测。
-
重复这个过程直到获得最佳结果。
-
最终模型通过加权所有弱学习器的均值来获得。
提升算法
让我们来看看一些基于刚才讨论的提升框架的算法。
AdaBoost
AdaBoost 通过逐个拟合弱学习器来工作。在随后的拟合中,它对错误预测给予更多权重,对正确预测给予较少权重。通过这种方式,模型学会了对难分类的样本进行预测。最终的预测是通过对多数类进行加权或求和得到的。学习率控制每个弱学习器对最终预测的贡献。AdaBoost 可以用于 分类 和 回归 问题。
Scikit-learn 提供了一个 AdaBoost 实现,你可以立即开始使用。默认情况下,算法使用 决策树 作为基础估计器。在这种情况下,将首先在整个数据集上拟合一个 DecisionTreeClassifier。在随后的迭代中,将对错误预测的实例给予更多权重进行拟合。
from sklearn.ensemble import DecisionTreeClassifier, AdaBoostClassifier
model = AdaBoostClassifier(
DecisionTreeClassifier(),
n_estimators=100,
learning_rate=1.0)
model.fit(X_train, y_train)
predictions = rad.predict(X_test)
为了提高模型的性能,应调整估计器的数量、基础估计器的参数以及学习率。例如,可以调整决策树分类器的最大深度。
一旦训练完成,通过 feature_importances_ 属性可以获得基于不纯度的特征重要性。
梯度树提升
梯度树提升是一种加法集成学习方法,它使用决策树作为弱学习器。加法意味着树一个接一个地添加。之前的树保持不变。在添加后续树时,使用 梯度下降 来最小化损失。
构建梯度提升模型的最快方法是使用 Scikit-learn。
from sklearn.ensemble import GradientBoostingClassifier
model = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
model.fit(X_train, y_train)
model.score(X_test,y_test)
极端梯度提升 - XGBoost
XGBoost 是一种流行的梯度提升算法。它使用弱回归树作为弱学习器。该算法还进行交叉验证并计算特征重要性。此外,它接受稀疏输入数据。
XGBoost 提供了 DMatrix数据结构,提高了其性能和效率。XGBoost 可用于R、Java、C++和Julia。
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1, max_depth = 5, alpha = 10, n_estimators = 10)
xg_reg.fit(X_train,y_train)
preds = xg_reg.predict(X_test)<
XGBoost 通过plot_importance()函数提供特征重要性。
import matplotlib.pyplot as plt
xgb.plot_importance(xg_reg)
plt.rcParams['figure.figsize'] = [5, 5]
plt.show()
LightGBM
LightGBM 是基于树的梯度提升算法,采用叶子-wise 树生长,而非深度-wise 生长。
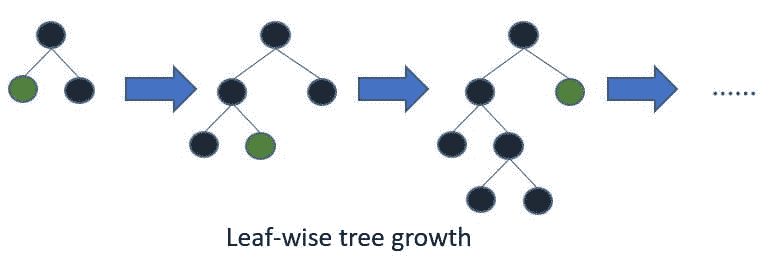
该算法可用于分类和回归问题。LightGBM 通过categorical_feature参数支持分类特征。指定分类列后,无需进行独热编码。
LightGBM 算法也能处理空值。通过设置use_missing=false可以禁用此功能。它使用 NA 表示空值。要使用零值,请设置zero_as_missing=true。
目标参数用于决定问题的类型。例如,binary用于二分类问题,regression用于回归问题,multiclass用于多分类问题。
使用 LightGBM 时,你通常会先将数据转换为LightGBM Dataset格式。
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
LightGBM 还允许你指定提升类型。可用选项包括随机森林和传统的梯度提升决策树。
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_leaves': 40,
'learning_rate': 0.1,
'feature_fraction': 0.9
}
gbm = lgb.train(params,
lgb_train,
num_boost_round=200,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train','valid'],
)
CatBoost
CatBoost是由 Yandex开发的深度梯度提升库。在 CatBoost 中,使用不可知树生长平衡树。在这些类型的树中,进行左右分裂时使用相同的特征。
与 LightGBM 类似,CatBoost 支持分类特征、GPU 训练和处理空值。CatBoost 可用于回归和分类问题。
在训练时设置plot=true可以可视化训练过程。
from catboost import CatBoostRegressor
cat = CatBoostRegressor()
cat.fit(X_train,y_train,verbose=False, plot=True)
最终思考
在这篇文章中,我们涵盖了提升算法以及如何在机器学习中应用它们。具体来说,我们讨论了:
-
什么是提升?
-
提升是如何工作的。
-
不同的提升算法。
-
不同的提升算法是如何工作的。
祝你提升愉快!
资源
Derrick Mwiti 在数据科学、机器学习和深度学习方面经验丰富,并且对构建机器学习社区有着敏锐的洞察力。
更多相关主题
作为机器学习工程师,你为什么需要掌握 Python 技能
原文:
www.kdnuggets.com/2021/10/bootcamp-python-skills-machine-learning-engineer.html
赞助文章。
Python 是机器学习领域中最受欢迎的编程语言之一。根据 Kaggle 对机器学习工程师的年度调查,大约 90% 的受访者 报告称在 2020 年使用了 Python。
像 Spotify、Amazon 等科技巨头 大量依赖 Python 来驱动其机器学习操作并构建更有效的产品。Netflix 使用 Python 来创建和管理推荐算法、个性化算法和营销算法。从机器人技术到机器学习,谷歌的许多 AI 投资也依赖于 Python。
如果你想学习如何在 AI 应用程序的背景下应用 Python 编程技能,UC San Diego Extension 机器学习工程师训练营 可以提供帮助。通过实践项目学习,你将探索构成机器学习工程堆栈的关键 Python 工具和库,并使用它们将机器学习系统部署到生产环境中。
继续阅读,了解机器学习工程师如何使用 Python,以及为何该语言在当今的机器学习领域中占据主导地位。
Python 基础
Python 是一种面向对象的编程语言,具有简单、简洁的语法,优先考虑可读性。实际上,Python 的语法 基于英语语言,这意味着讲英语的人可能会发现 Python 比其他编程语言更简单易懂。
Python 的简洁性使得开发者能够快速对程序进行修改。由于该语言不需要重新编译源代码,Python 程序员享有快速的编辑-测试-调试周期,可以迅速评估他们工作的结果。
Python 是一款开源软件,免费下载和使用。Python 文档、教育资源以及一般支持在 Python 社区中也广泛提供,包括初学者和专家。Python 还是一种高度可扩展的语言,既可用于编写小型项目,也适用于大型项目,包括机器学习算法。
机器学习工程师如何使用 Python
Python 用于实现机器学习模型和系统。在 AI 开发的背景下,Python 的简洁性是一个主要优点。其清晰和简洁的结构使机器学习工程师能够专注于 ML 问题的内容,而不是编写代码,从而加快了开发速度。使用 Python,机器学习工程师可以在部署之前快速测试算法。
机器学习工程师还使用各种 Python 框架和库,包括:
-
Matplotlib 和 Seaborn. 机器学习工程师经常需要执行探索性数据分析,以评估将哪种算法应用于数据集。这些 Python 库帮助机器学习工程师可视化数据并识别趋势。
-
Pandas. 机器学习工程师使用这个库进行数据操作和分析。数据推动机器学习,每个机器学习工程师都必须清理、处理和转换数据,以便产生高质量的见解。
-
Scikit-learn. 这个 Python 包帮助机器学习工程师实现监督和无监督算法。Scikit-learn 包括分类、聚类和回归算法。机器学习工程师还使用这个工具来评估算法的功能性,并将建模数据划分为测试集和训练集。
-
Keras 和 TensorFlow. 机器学习工程师使用 Keras 和 TensorFlow 来构建、训练和部署机器学习模型和深度神经网络。
机器学习工程师依靠 Python 广泛的库生态系统来管理和理解他们的数据——并在生产环境中部署 AI 解决方案。
机器学习工程师的就业前景
各行业对机器学习和 Python 编程技能的需求不断上升。在过去的一年中,LinkedIn 上评级最高的公司员工将这些技能分别提高了 23%和 25%。在其2021 年就业增长报告中,LinkedIn 还将 Python 列为 AI 从业者的关键技能。
从医疗保健到电子商务和金融,机器学习正在推动各个领域的增长——以至于 Indeed 将人工智能排名为2021 年第二大最需技能。
公司依赖机器学习工程师来利用大数据的力量,以优化运营、减少开支和解决复杂的商业问题。在冠状病毒大流行期间,企业转向人工智能以应对不断增长的消费者需求,并保护自己免受未来的干扰——这导致了从 2019 年到 2020 年AI 招聘增加了 32%。
目前,在LinkedIn上列出了超过 44,000 个入门级机器学习工程师职位。根据 Indeed 的数据,机器学习工程师的平均基础工资为$140,278,常见福利包括股票期权、灵活的工作时间、通勤补助和无限的带薪休假。
准备好启动你的机器学习工程师职业生涯了吗?
如果你有软件工程/数据科学的经验或高级 Python 知识,并希望转向机器学习工程,UC 圣地亚哥扩展学院机器学习工程师训练营可以帮助你。
通过 100%在线、导师主导的学习,你将掌握获得就业所需的应用技能。作为 UC 圣地亚哥扩展学院机器学习工程师训练营的学员,你将通过 15+个迷你项目获得实际经验,这些项目旨在巩固技术概念——此外还有一个毕业项目,可以在你的专业作品集中展示。
完成训练营后,你将能够部署机器学习算法并构建完整的机器学习应用程序。
迈出你机器学习工程师职业生涯的第一步,今天就探索UC 圣地亚哥扩展学院机器学习工程师训练营。有软件工程或数据科学经验者优先申请。
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
构建一个回答常见问题的机器人:预测文本相似度
原文:
www.kdnuggets.com/2017/03/bot-answer-faqs-predicting-text-similarity.html
由 Amanda Sivaraj 撰写,indico。
在我们关于客户支持机器人的前一个教程中,我们使用自定义集合 API 训练了一个机器人,以将客户引导到最适合解决他们问题或查询的团队成员。这个机器人提高了我们团队的响应速度,因为我们不再需要依赖一个人类协调者(他在公司里还扮演许多其他角色 #startuplife)来完成这项工作。然而,我们通常只能在东部时间上午 11 点到下午 7 点的办公时间内响应,因此在这个时间段之外的询问仍然会有延迟。我们如何改进这一点?构建一个回答常见问题的机器人,以减少对更多客户的延迟,并确保我们的工程师不需要花费过多时间远离我们为你构建的产品 😃.

任务
我们将进行 Python 中的最近邻搜索,将用户输入的问题与常见问题列表进行比较。为此,我们将使用 indico 的文本特征 API 来查找文本数据的所有特征向量,并计算这些向量与用户输入问题的向量在 300 维空间中的距离。然后,我们将根据用户的问题与哪个常见问题最相似(如果它符合某个置信度阈值)返回相应的答案。
入门指南
首先,从我们的 SuperCell GitHub 仓库获取骨架代码。
如果你没有所需的所有包,你需要安装它们——texttable 和当然还有indicoio。
如果你还没有设置 indico 账户,请按照我们的快速入门指南操作。它将引导你完成获取 API 密钥和安装indicoio Python 库的过程。如果遇到任何问题,请查看文档中的安装部分。如果问题依然存在,你也可以通过那个小聊天气泡联系我们。假设你的账户已设置完毕,并且一切都已安装好,我们就开始吧!
首先,前往文件的顶部并导入indicoio。不要忘记设置你的 API 密钥。有多种方法可以做到这一点;我喜欢把我的 API 密钥放在配置文件中。
import indicoio
indicoio.config.api_key = 'YOUR_API_KEY'
使用 indico 的文本特征 API
你需要将常见问题及其答案存储在一个字典中。为了简便起见,我在脚本中创建了一个包含五个问题和答案的字典faqs。这将是我们的初始数据集。我们只需要提取问题的文本特征,而不是答案,因此我们提取faqs.keys(),然后将这些数据传递给我们的make_feats()函数。
接下来,让我们更新run()函数。将feats保存到 Pickle 文件中,这样每次你想将用户的问题与静态的 FAQ 列表进行比较时,就不需要每次都重新运行文本特征 API。
比较常见问题与用户输入
现在我们已经获得了 FAQ 文本数据的特征表示,让我们进入下一阶段:收集和比较用户问题与我们的 FAQ。为了使每个人都可以在本地运行这个脚本,无论你打算将它连接到什么客户支持聊天服务,我们将使用raw_input()。你需要根据你的消息应用程序的文档设置自己的 webhook。
首先,让我们获取一个输入,将其添加到 FAQ 列表中,并为输入找到文本特征,然后将其添加到主要的feats列表中。这将简化我们在以后计算所有特征表示的距离时的操作。更新input_question()函数:
现在是时候再次更新run()函数了。这一次,你可以直接加载之前找到的 FAQ 特征的 Pickle 文件。
现在我们已经为所有 FAQ 和用户的问题获得了特征向量列表!这将如何帮助我们找出输入最相似的 FAQ?文本之间的相似性是通过它们对应的特征向量之间的相似性来衡量的。我们在calculate_distances函数中预测它们的相似性,该函数计算这些向量在余弦空间中的距离。余弦通常是处理高维空间中点时的比较指标。calculate_distances生成一个m乘n的矩阵,该矩阵存储文档m和文档n之间的距离,位置为distance_matrix[m][n]。
再次更新run()函数:
最后,让我们看看我们的最近邻搜索表现如何!similarity_text()函数将遍历distance_matrix,根据相似度级别对每一段文本进行排序,然后以表格形式打印出来。我们不希望机器人在不确定找到 FAQ 匹配的情况下给出答案,因此我们需要设置一个信心阈值。将以下代码添加到similarity_text()中,紧接在print t.draw()之后:
如果机器人的信心水平达到阈值,它应该返回相应的 FAQ 答案。否则,它应该通知你的客户支持经理(你需要根据你的消息应用程序的文档来配置):
最后一次更新run()函数,然后运行代码!
它的表现如何?这里有一个示例:

哇!它的表现相当不错,尽管输入问题的用词与 FAQ 匹配时有所不同且更加简洁,我们的丰富文本功能仍然能够捕捉其含义。那么,这里发生了什么——为什么会这样呢?
indico 的文本特征 API 为给定的文本输入创建了数十万个丰富的特征向量表示,这些特征是使用深度学习技术学习到的。这些特征向量——在多维空间中的数值表示——是计算机为一个词赋予意义的一种方式。
当我们将 FAQ 列表输入文本特征算法时,它本质上识别了每个问题中的某些词为“重要”,并确定了它们在多维空间中的位置。文本特征然后将这些词的表示组合起来,生成整个“文档”的表示(在这种情况下是 FAQ——你也可以传入整篇文章来找到其特征表示)。当我们展示给它我们的新输入问题时,它做了同样的事情。然后我们使用这些文档表示来计算它们之间的距离,以确定两个“文档”在概念上的相似性。多维空间中的特征越接近,它们的意义就越相近。
下一步
从本质上讲,这是一个预测文本相似性的练习。你能想象这个任务的其他应用吗?如果你用我们的 API 创建了什么酷东西,一定要告诉我们,邮箱是 contact@indico.io!
简介:Amanda Sivaraj 是一位内容创作者、数字营销专家以及数据与技术爱好者。她为indico开发内容和教程,该公司提供用于自动化文本和图像分析的机器学习工具。
原文。经许可转载。
相关:
-
增强版聊天机器人:推动聊天机器人的 10 项关键机器学习能力
-
人工智能与聊天机器人的语音识别:入门
-
近期聊天机器人技术进展的简要概述
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关主题
边界框深度学习:视频注释的未来
原文:
www.kdnuggets.com/2022/07/bounding-box-deep-learning-future-video-annotation.html

边界框是一种计算机视觉中的注释类型,指的是在图像或视频中的对象周围绘制的框。边界框的坐标可以用来表示对象的位置、大小和方向。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织中的 IT
计算边界框的方法有多种,但最常见的方法是使用滑动窗口,即在图像上覆盖一个网格,并将每个网格单元分类为包含对象或不包含对象。如果分类器预测在给定的单元格中存在物体,则在该单元格周围绘制一个框。
边界框通常用于目标检测算法中,其目标是识别图像中的所有对象并为每个对象绘制一个框。它们还可以用于在视频数据中跟踪对象的变化。
如何使用边界框深度学习?
要理解边界框深度学习如何工作,首先需要了解深度学习的基础。深度学习是一种机器学习方法,利用人工神经网络从数据中学习。
神经网络类似于大脑,由一系列层组成,每层包含一组节点(或神经元)。网络的第一层节点接收来自数据的输入,后续层的节点接收来自前一层节点的信息。最终层的输出用于对数据进行预测。
为了训练深度学习模型,我们需要指定网络的结构(即层数和每层的节点数),然后在数据集上训练模型。训练过程会调整节点之间连接的权重,以使最终层的输出尽可能接近数据的实际标签。
一旦深度学习模型经过训练,就可以用来对新数据进行预测。为此,我们将新数据通过网络,并使用最终层的输出进行预测。
现在我们了解了深度学习的工作原理,让我们看看它如何用于边界框检测。
边界框深度学习模型通常由一个物体检测器和一个回归器组成。物体检测器负责识别图像中哪些像素属于物体,而回归器则负责预测围绕该物体的边界框坐标。
训练这些模型的最常见方法是先在包含许多不同物体的大型图像数据集上对物体检测器进行预训练。这可以通过使用深度学习模型,如卷积神经网络(CNN)来完成。一旦物体检测器经过训练,就可以用来识别新图像中的物体。
物体检测器的输出通常是一组围绕检测到的物体的边界框,以及每个边界框的置信度分数。
然后,回归器会在这些边界框上进行训练,以学习如何预测围绕物体的最紧密边界框的坐标。在物体检测器和回归器都经过训练后,它们可以结合成一个单一的模型,用于在新图像中检测和定位物体。
到目前为止,我们已经了解了边界框深度学习模型如何用于检测图像中的物体。然而,这些模型也可以检测视频序列中的物体。在这种情况下,模型将被训练以预测视频序列中每一帧的边界框坐标。
如你所见,边界框深度学习是检测和定位图像及视频中物体的强大工具。然而,像其他类型的深度学习一样,它也有其局限性。例如,这些模型通常受限于可用的训练数据,并且在大型数据集上训练它们可能需要很长时间。
此外,它们只能用于包含以前标记过的物体的图像或视频。这意味着如果你想使用这些模型来检测图像中的物体,你需要首先标记图像中的所有物体。
边界框深度学习的好处
实时物体检测:边界框深度学习的一个重要好处是它可以用于实时检测物体。这是因为物体检测器可以作为 CNN 实现,CNN 可以在 GPU 上运行以实现高效推理。但是,这种推理过程不足以实现实时物体检测。
提高准确性: 边界框深度学习模型可以比传统物体检测方法实现更高的准确性。这是因为回归器可以从许多边界框中学习,并产生更准确的预测。
更快的训练: 边界框深度学习模型的训练速度比传统的物体检测模型更快。这是因为 CNN 可以在许多图像上并行训练,从而加快训练过程。
这可以用比传统物体检测模型少得多的计算能力来完成。
数据较少: 边界框深度学习模型比传统物体检测模型需要更少的训练数据。这是因为卷积神经网络可以从许多图像中学习,从而减少了训练模型所需的数据量。
边界框深度学习的缺点
需要标注数据:边界框深度学习的一个重大缺点是它需要大量标注数据来训练模型。这可能非常昂贵且耗时,特别是如果目标是识别具有各种形状、大小和颜色的真实世界物体。
限于矩形形状:边界框深度学习的另一个缺点是局限于矩形形状。这意味着它可能无法准确检测到非矩形的物体。
可能遗漏小物体: 边界框深度学习的另一个潜在缺点是它可能会遗漏小物体。这是因为模型在固定大小和纵横比的图像上进行训练,因此可能无法准确检测到离相机较近或超出画框的小物体。
可能难以处理遮挡: 边界框深度学习也可能在处理遮挡或被其他物体部分遮挡的物体时遇到困难。这是因为模型在所有物体可见且未遮挡的图像上进行训练,因此可能无法准确检测到被其他物体覆盖的物体。
结论
边界框深度学习是视频标注的未来吗?
边界框深度学习具有多个优点,使其非常适合视频标注。特别是它在实时检测物体和用更少的数据提高准确性方面的能力,使其成为许多视频标注任务的有吸引力的选项。
然而,在使用这种方法之前应考虑一些缺点。
Gaurav Sharma 在人工智能和机器学习领域工作了六年以上。Gaurav 是一名自由技术作家,为 Cogito Tech LLC、Anolytics.ai 和其他提供训练数据的知名数据标注公司工作。
进一步了解此主题
使用 Hugging Face 从零开始训练 BPE、WordPiece 和 Unigram 分词器
原文:
www.kdnuggets.com/2021/10/bpe-wordpiece-unigram-tokenizers-using-hugging-face.html
评论
由 Harshit Tyagi,数据科学讲师 | 导师 | YouTuber
在深入探讨 NLP 的海洋时,这篇文章全部关于通过利用 Hugging Face 的 tokenizers 包 从零开始训练分词器。
分词通常被视为自然语言处理(NLP)的一个子领域,但它有其自身的 演变故事 以及如何发展到目前的阶段,支撑了最先进的 NLP 模型。
在我们进入训练和比较不同分词器的有趣部分之前,我想简要总结一下这些算法之间的主要区别。
主要区别在于 字符对的选择 和 每种算法使用的合并策略,这些算法用于生成最终的令牌集合。
BPE - 基于频率的模型
-
字节对编码(Byte Pair Encoding)利用子词模式的频率来筛选它们进行合并。
-
使用频率作为驱动因素的缺点是,最终编码可能会产生模糊的结果,这对新输入文本可能没有用处。
-
在生成明确的令牌方面仍有改进的空间。
Unigram - 基于概率的模型
-
作为 Unigram 模型的一部分,它通过计算每个子词组合的可能性来解决合并问题,而不是选择最频繁的模式。
-
它计算每个子词令牌的概率,然后根据在 这篇研究论文中解释的损失函数来舍弃。
-
根据损失值的某个阈值,你可以触发模型丢弃底部 20-30% 的子词令牌。
-
Unigram 是一种完全基于概率的算法,它在每次迭代中基于概率选择字符对和最终的合并决定(或不合并)。
WordPiece
-
随着 2018 年 BERT 的发布,出现了一种新的子词分词算法,称为 WordPiece,它可以被视为 BPE 和 Unigram 算法之间的中介。
-
WordPiece 也是一种贪婪算法,它利用似然而不是计数频率来在每次迭代中合并最佳的对,但字符配对的选择基于计数频率。
-
因此,它在选择配对字符方面类似于 BPE,在选择最佳配对进行合并方面类似于 Unigram。
介绍完算法差异后,我尝试实现每种算法(不是从零开始),以比较它们生成的输出。
训练 BPE、Unigram 和 WordPiece 算法
现在,为了对输出进行无偏比较,我不想使用预训练算法,因为那样会将模型的大小、质量和数据集的内容考虑在内。
一种方法是从头编写这些算法,使用研究论文,然后进行测试,这是一种真正理解每种算法工作原理的好方法,但你可能会花费数周的时间来完成这个过程。
我则使用了Hugging Face 的 tokenizers包,它提供了今天最常用的所有分词器的实现。它还允许我在选择的数据集上从头开始训练这些模型,然后对我们选择的输入字符串进行分词。
训练数据集
我选择了两个不同的数据集来训练这些模型,一个是来自 Gutenberg 的免费书籍,作为一个小数据集,另一个是wikitext-103,它包含 516M 的文本。
在 Colab 中,你可以先下载数据集并解压(如果需要的话),
!wget http://www.gutenberg.org/cache/epub/16457/pg16457.txt
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip
!unzip wikitext-103-raw-v1.zip
导入所需的模型和训练器
通过文档,你会发现包的主要 API 是Tokenizer类。
然后,你可以用你选择的模型(BPE/Unigram/WordPiece)实例化任何分词器。
在这里,我导入了主类、所有我想要测试的模型以及它们的训练器,因为我希望从头开始训练这些模型。
## importing the tokenizer and subword BPE trainer
from tokenizers import Tokenizer
from tokenizers.models import BPE, Unigram, WordLevel, WordPiece
from tokenizers.trainers import BpeTrainer, WordLevelTrainer, \
WordPieceTrainer, UnigramTrainer
## a pretokenizer to segment the text into words
from tokenizers.pre_tokenizers import Whitespace
自动化训练和分词的 3 步过程
由于我需要对三种不同的模型执行类似的过程,我将这些过程分解为 3 个函数。我只需要为每个模型调用这些函数,我的工作就完成了。
那么,这些函数是什么样的呢?
第 1 步 - 准备分词器
准备分词器要求我们用我们选择的模型实例化Tokenizer类,但由于我们有四个模型(还添加了一个简单的词级算法)需要测试,我们将编写 if/else 语句来用正确的模型实例化分词器。
为了在小数据集和大数据集上训练实例化的分词器,我们还需要实例化一个训练器,在我们的案例中,这些将是BpeTrainer、WordLevelTrainer、WordPieceTrainer 和 UnigramTrainer。
实例化和训练将需要我们指定一些特殊的标记。这些标记用于未知词汇以及我们以后需要添加到词汇表中的其他特殊标记。
你也可以在这里指定其他训练参数,如词汇表大小或最小频率。
unk_token = "<UNK>" # token for unknown words
spl_tokens = ["<UNK>", "<SEP>", "<MASK>", "<CLS>"] # special tokens
def prepare_tokenizer_trainer(alg):
"""
Prepares the tokenizer and trainer with unknown & special tokens.
"""
if alg == 'BPE':
tokenizer = Tokenizer(BPE(unk_token = unk_token))
trainer = BpeTrainer(special_tokens = spl_tokens)
elif alg == 'UNI':
tokenizer = Tokenizer(Unigram())
trainer = UnigramTrainer(unk_token= unk_token, special_tokens = spl_tokens)
elif alg == 'WPC':
tokenizer = Tokenizer(WordPiece(unk_token = unk_token))
trainer = WordPieceTrainer(special_tokens = spl_tokens)
else:
tokenizer = Tokenizer(WordLevel(unk_token = unk_token))
trainer = WordLevelTrainer(special_tokens = spl_tokens)
tokenizer.pre_tokenizer = Whitespace()
return tokenizer, trainer
我们还需要添加一个预分词器,以将输入拆分为单词,因为没有预分词器,我们可能会得到重叠多个单词的标记:例如,我们可能会得到"there is"标记,因为这两个词经常出现在一起。
使用预分词器将确保没有标记比预分词器返回的单词更长。
该函数将返回分词器及其训练器对象,这些对象可以用于在数据集上训练模型。
在这里,我们对所有模型使用相同的预分词器(Whitespace)。你可以选择用 其他 进行测试。
步骤 2 - 训练分词器
准备好分词器和训练器后,我们可以开始训练过程。
这是一个函数,将接受我们打算训练分词器的文件(们)以及算法标识符。
-
‘WLV’- Word Level Algorithm -
‘WPC’- WordPiece Algorithm -
‘BPE’- Byte Pair Encoding -
‘UNI’- Unigram
def train_tokenizer(files, alg='WLV'):
"""
Takes the files and trains the tokenizer.
"""
tokenizer, trainer = prepare_tokenizer_trainer(alg)
tokenizer.train(files, trainer) # training the tokenzier
tokenizer.save("./tokenizer-trained.json")
tokenizer = Tokenizer.from_file("./tokenizer-trained.json")
return tokenizer
这是我们需要调用的主要函数,用于训练分词器,它将首先准备分词器和训练器,然后开始使用提供的文件训练分词器。
训练后,它将模型保存在 JSON 文件中,从文件中加载模型,并返回训练好的分词器以开始对新输入进行编码。
步骤 3 - 对输入字符串进行分词
最后一步是开始对新输入字符串进行编码,并比较每种算法生成的标记。
在这里,我们将编写一个嵌套的 for 循环,先在较小的数据集上训练每个模型,然后在较大的数据集上训练,并对输入字符串进行分词。
**输入字符串 - **“这是一个深度学习分词教程。分词是深度学习 NLP 流程中的第一步。我们将比较各个分词模型生成的标记。很兴奋吗?!????”
small_file = ['pg16457.txt']
large_files = [f"./wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
for files in [small_file, large_files]:
print(f"========Using vocabulary from {files}=======")
for alg in ['WLV', 'BPE', 'UNI', 'WPC']:
trained_tokenizer = train_tokenizer(files, alg)
input_string = "This is a deep learning tokenization tutorial. Tokenization is the first step in a deep learning NLP pipeline. We will be comparing the tokens generated by each tokenization model. Excited much?!????"
output = tokenize(input_string, trained_tokenizer)
tokens_dict[alg] = output.tokens
print("----", alg, "----")
print(output.tokens, "->", len(output.tokens))
##输出:

输出分析:
查看输出,你将看到标记生成方式的差异,这反过来导致生成的标记数量不同。
-
一个简单的 word-level algorithm 无论在什么数据集上训练都会生成 35 个标记。
-
BPE 算法在较小的数据集上生成了 55 个标记,在较大的数据集上生成了 47 个标记。这表明在较大的数据集上,它能够合并更多的字符对。
-
Unigram 模型 在两个数据集上生成了相似(68 和 67)的标记。但你可以看到生成的标记之间的差异:

使用较大的数据集时,合并更接近生成更适合编码我们常用的真实世界英语的标记。

-
WordPiece在较小的数据集上生成了 52 个令牌,在较大的数据集上生成了 48 个令牌。生成的令牌有双##以表示将令牌用作前缀/后缀。
-
所有三种算法在较大的数据集上生成了更少的子词令牌和更好的子词令牌。
比较令牌
为了比较令牌,我将每种算法的输出存储在一个字典中,并将其转化为数据框,以更好地查看令牌之间的差异。
由于每个模型生成的令牌数量不同,我已添加了一个
import pandas as pd
max_len = max(len(tokens_dict['UNI']), len(tokens_dict['WPC']), len(tokens_dict['BPE']))
diff_bpe = max_len - len(tokens_dict['BPE'])
diff_wpc = max_len - len(tokens_dict['WPC'])
tokens_dict['BPE'] = tokens_dict['BPE'] + ['<PAD>']*diff_bpe
tokens_dict['WPC'] = tokens_dict['WPC'] + ['<PAD>']*diff_wpc
del tokens_dict['WLV']
df = pd.DataFrame(tokens_dict)
df.head(10)
##输出:

你还可以使用集合查看令牌的差异:

所有代码可以在这个Colab 笔记本中找到。
结束思考和下一步!
基于生成的令牌类型,WPC 确实似乎生成了更常见于英语中的子词令牌,但不要对这一观察结果负责。
这些算法彼此略有不同,并且在开发一个不错的 NLP 模型时做了些类似的工作。但性能在很大程度上取决于语言模型的使用场景、词汇量、速度以及其他因素。
对这些算法的进一步改进是 SentencePiece 算法,它是对整个分词问题的全面方法,但 HuggingFace 已经缓解了大部分问题,更棒的是,他们在一个 GitHub 仓库中实现了所有这些算法。
这部分介绍了分词算法,下一步是理解什么是嵌入,分词在创建这些嵌入中的关键作用,以及它们如何影响模型的性能。
参考文献和注释
如果你不同意我的分析或本文中的任何工作,我强烈鼓励你查看这些资源,以准确理解每个算法的工作原理:
-
子词正则化:通过多个子词候选改善神经网络翻译模型 由 Taku Kudo 发表
-
用子词单元的稀有词神经机器翻译 - 研究论文讨论了基于 BPE 压缩算法的不同分割技术。
如果你想开始数据科学或机器学习领域的学习,可以查看我关于 数据科学与机器学习基础 的课程。
如果你希望查看更多类似内容而又不是订阅者,可以通过下面的按钮订阅我的通讯。
有什么要补充或建议的,可以回复此邮件或在 Substack 上的帖子中评论。
个人简介: Harshit Tyagi 是一名在网络技术和数据科学(即全栈数据科学)方面具有丰富经验的工程师。他指导了超过 1000 名人工智能/网络/数据科学的学员,并正在设计数据科学和机器学习工程学习路径。此前,Harshit 曾与耶鲁大学、麻省理工学院和加州大学洛杉矶分校的研究科学家共同开发数据处理算法。
原始。经许可转载。
相关:
-
使用 HuggingFace 管道的简单问答网络应用
-
分词的演变 – 自然语言处理中的字节对编码
-
深度学习的文本预处理方法
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 方面的组织
更多相关主题
解构 AutoGPT

图片来源:作者
ChatGPT 在 AI 世界中引起了很大的关注。我们看到许多其他模型进行渐进改进。但其中没有一个专注于改善人类与 AI 之间的互动。你仍然需要给出一个优秀的提示才能获得所需的结果。这就是 AutoGPT 的突出之处。它可以“自我提示”并对其工作进行批判性审查。你想了解更多吗?它是如何工作的,是什么使它与众不同?也许最重要的是,它有哪些局限性?别担心,我们会为你解答。让我们一起深入探讨这个话题。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求。
什么是 AutoGPT?
AutoGPT 是一个由 Toran Bruce Richards(游戏开发者及 Significant Gravitas 创始人)开发的开源应用程序。它利用 GPT-3.5 或 GPT-4 API 创建完全自主的 AI 代理。它的亮点在于你不需要根据理解来操控模型。你只需提供任务和目标列表,其余由它处理。与 ChatGPT 不同,它还可以访问外部资源来做出决策。你知道吗?在发布几周内,它获得的星数比 Pytorch(一个著名的开源机器学习库)还多。这里有一张显示其星数历史的图表。
图片由 Star-History 生成
AutoGPT 如何工作?
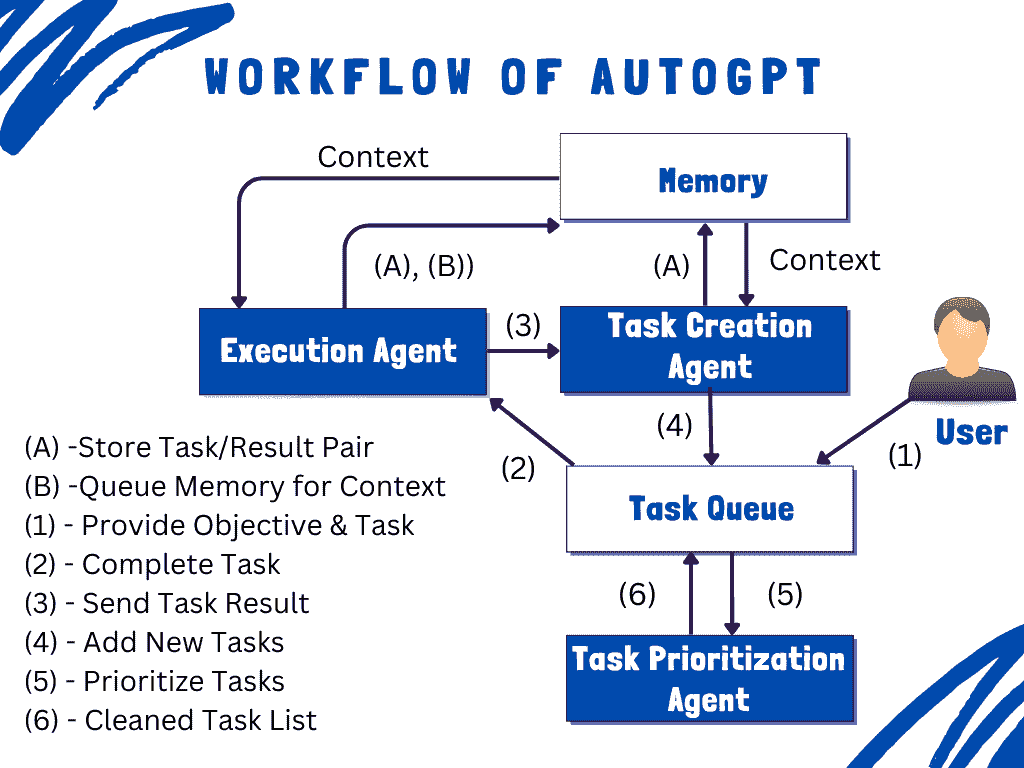
图片来源:作者
AutoGPT 结合了 GPT-4 的强大功能和个人助理的能力,以自主生成、执行和优先排序任务。作为一个自主系统,它创建 AI 代理来执行特定任务。这些代理也相互沟通。以下是描述 AutoGPT 工作原理的步骤:
步骤 01:用户输入
首先,用户需要输入以下三个内容:AI 名称、AI 角色和最多 5 个目标。例如,我可以创建一个名为 MarketResearchGPT 的 AI,它的角色是进行不同项目的市场分析。我可以设定目标,例如对不同手机进行市场调研、获取前 5 名及其优缺点、按价格升序排列、总结用户评论,并在完成时终止过程。
步骤 02:任务创建代理
一旦用户输入了信息,任务创建代理将理解目标,生成任务列表,并提及实现这些目标的步骤。然后,将结果任务集传递给任务优先级代理。
步骤 03:任务优先级代理
任务优先级代理审查任务的顺序,以确保逻辑上的合理性。因为我们不希望进入死锁情况,即当前任务依赖于尚未执行的任务结果。
步骤 04:任务执行代理
任务执行代理顾名思义,利用 GPT-4、互联网和其他资源来执行这些任务。
步骤 05:代理之间的通信
代理之间可以相互沟通以实现用户定义的目标。例如,如果生成了不满意的结果,它可以与任务创建代理沟通以生成新的任务列表。因此,它成为一个迭代过程。
步骤 06:最终结果
这些代理的操作在用户端以以下形式可见:
思考: AI 代理在完成操作后分享他们的想法
推理: 解释其选择的原因,即为什么选择特定的行动方案
计划: 计划包括新的任务集
批评: 通过识别局限性或关注点来批判性地审查选择
它还使用外部内存来跟踪历史记录并从过去的经验中学习,以生成更精确的结果。
它与 ChatGPT 有何不同?
尽管 AutoGPT 和 ChatGPT 都建立在相同的 GPT API 技术之上,但我们可以指出一些关键差异如下:
访问实时数据
ChatGPT 使用的是最新的 GPT-4 模型,该模型的训练截止至 2021 年 9 月,这意味着我们无法提取实时洞见。AutoGPT 具有访问外部资源的能力,并将最新趋势融入其响应中。
自主功能
与需要用户持续提示的 ChatGPT 不同,AutoGPT 在这方面是自主的,不需要不断提示。这对创意生成非常有帮助。
内存管理
ChatGPT 在 LLMs(如 GPT-4)的上下文窗口中存在内存限制,而 AutoGPT 使用向量数据库,适合短期和长期的内存管理。
图像和语音功能
ChatGPT 仅限于文本数据,而使用 AutoGPT 可以生成图像并将文本转换为语音。
如何使用 AutoGPT?
你将需要一个 OpenAI API 密钥,因为 AutoGPT 是建立在 GPT 之上的。如果你没有,可以注册一个免费账户以获得一些免费积分。按照下面的步骤在本地计算机上设置 AutoGPT。
要求
设置方法
使用以下命令在本地目录中克隆 GitHub 存储库:
git clone https://github.com/Significant-Gravitas/Auto-GPT.git
使用以下命令导航到项目目录:
cd Auto-GPT
运行以下命令以下载所需的依赖项:
pip install -r requirements.txt
在你的 Auto-GPT 文件夹中找到“.env.template”文件。如果找不到,请检查隐藏文件。使用以下命令创建此文件的副本:
cp .env.template .env
打开 .env 文件,将 OPENAI_API_KEY 替换为你从账户中生成的密钥。保存并关闭 .env 文件。
运行以下命令以启动 AutoGPT:
python -m autogpt
如果你使用的是 GPT-3.5,可以运行:
python -m autogpt --gpt3only
你现在可以开始了。如果有任何问题,请参考官方文档:Auto-GPT 设置
限制
虽然 AutoGPT 可以在最小化人工干预的情况下生成内容,但它有一些主要缺点,如高成本、功能有限、对上下文的理解不足、数据偏差、创意有限和安全风险。由于数据质量、泛化和解释性问题,它尚未能够实现 AGI(通用人工智能)。尽管存在这些不足,但它有巨大的潜力来彻底改变我们的日常生活和工作方式。希望你喜欢阅读这篇文章,也请在评论区告诉我你对 AutoGPT 的看法。
Kanwal Mehreen 是一位有抱负的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的 Google Generation Scholar。Kanwal 喜欢通过撰写有关趋势话题的文章分享技术知识,并且对提高女性在科技行业中的代表性充满热情。
更多相关话题
打破数据障碍:零样本学习、单样本学习和少样本学习如何改变机器学习

图片来源:Allison Saeng via Unsplash
介绍
在当今快速变化的世界中,技术每天都在进步,机器学习和人工智能利用过程自动化和提高效率的力量彻底改变了各种行业。然而,人类仍然在传统机器学习算法面前具有明显优势,因为这些算法需要数千个样本来响应潜在的关联和识别对象。
想象一下,在解锁你的智能手机时,需要通过进行 100 次扫描才让算法工作,这种挫败感。如果这种功能被推出市场,它绝不会成功。
然而,自 2005 年以来,机器学习专家们开发出了可能彻底改变游戏规则的新算法。在过去近二十年中取得的改进,产生了可以从最少(零、单或少量)样本中学习的算法。
在这篇文章中,我们深入探讨了这些算法背后的概念,并提供了对这些学习技术如何运作的全面理解,同时揭示了在实现它们时面临的一些挑战。
零样本学习是如何工作的?
零样本学习的核心概念是训练一个模型来分类它从未见过的对象。核心思想是利用另一个模型的现有知识,获得新类别的有意义表示。
它利用语义嵌入或基于属性的学习,以有意义的方式利用先验知识,从而提供对已知和未知类别之间关系的高层次理解。这两者可以一起使用,也可以单独使用。
语义嵌入是单词、短语或文档的向量表示,捕捉它们在连续向量空间中的基本意义和关系。这些嵌入通常使用无监督学习算法生成,例如 Word2Vec、GloVe 或BERT。目标是创建语言信息的紧凑表示,其中相似的意义通过相似的向量进行编码。通过这种方式,语义嵌入允许对文本数据进行高效准确的比较和操作,并通过将实例投影到一个连续的、共享的语义空间来对未见类别进行概括。
基于属性的学习使得在没有任何这些类别标记示例的情况下对未见类别的对象进行分类成为可能。它将对象分解为其有意义和显著的属性,这些属性作为中间表示,使模型能够建立已见类别和未见类别之间的对应关系。这个过程通常包括属性提取、属性预测和标签推断。
-
属性提取涉及为每个对象类别导出有意义和区分性的属性,以弥合低级特征与高级概念之间的差距。
-
属性预测涉及学习实例的低级特征与高级属性之间的对应关系,利用机器学习技术识别特征之间的模式和关系,从而对新类别进行概括。
-
标签推断涉及使用预测的属性和属性与未见类别标签之间的关系来预测新实例的类别标签,而无需依赖标记示例。
尽管零-shot 学习具有令人鼓舞的潜力,但仍然存在一些挑战,例如:
- 领域适应:目标领域中的实例分布可能与源领域中的分布显著不同,从而导致对已见类别和未见类别的语义嵌入之间的差异。这种领域偏移可能会损害性能,因为模型可能无法在领域之间建立实例和属性之间的有意义的对应关系。为克服这一挑战,提出了各种领域适应技术,例如对抗学习、特征解缠结和自监督学习,旨在对齐源领域和目标领域中实例和属性的分布。
一次性学习如何工作?
在开发传统神经网络的过程中,例如识别汽车,模型需要数千个样本,这些样本从不同角度和对比度拍摄,以有效地区分它们。单样本学习采取了不同的方法。该方法不是识别问题中的汽车,而是确定图像 A 是否等同于图像 B。这是通过概括模型从先前任务中获得的经验信息来实现的。单样本学习主要用于 计算机视觉。
实现这一点的技术包括 记忆增强型神经网络 (MANNs) 和 Siamese 网络。通过独立利用这些技术,单样本学习模型可以迅速适应新任务,即使在数据非常有限的情况下也能表现良好,使其适合在获取标注数据可能昂贵或耗时的实际场景中使用。
记忆增强型 神经网络 (MANNs) 是一种高级神经网络,旨在从极少的样本中学习,类似于人类如何从一个新对象的实例中学习。MANNs 通过具备额外的记忆组件来实现这一点,该组件可以存储和访问信息。
想象 MANN 是一个聪明的机器人,手里拿着一本笔记本。机器人可以使用它的笔记本记住之前见过的事物,并利用这些信息理解它遇到的新事物。这帮助机器人比普通的 AI 模型学习得更快。
Siamese 网络 则旨在通过使用两个或更多具有共享权重的相同子网络来比较数据样本。这些网络学习一种特征表示,捕捉数据样本之间的关键差异和相似性。
想象 Siamese 网络是成对的侦探,他们总是一起工作。他们共享相同的知识和技能,任务是比较两个项目并决定它们是否相同或不同。这些侦探查看每个项目的重要特征,然后比较他们的发现以做出决定。
Siamese 网络的训练分为两个阶段:验证阶段和泛化阶段。
-
在验证阶段,网络确定两个输入图像或数据点是否属于同一类别。网络通过使用双胞胎子网络分别处理两个输入。
-
在泛化阶段,模型通过有效学习特征表示来概括对输入数据的理解,从而区分不同类别。
一旦两个阶段完成,模型就能够确定图像 A 是否对应于图像 B。
单样本学习非常有前景,因为它不需要重新训练来检测新类别。然而,它面临挑战,例如高内存需求和巨大的计算能力需求,因为学习需要进行两倍的操作。
少样本学习是如何工作的?
需要介绍的最后一种学习方法是少样本学习,这是元学习的一个子领域,旨在开发能够从少量标记样本中学习的算法。
在这种情况下,原型网络和模型无关元学习(MAML)是两种突出的替代技术,已在少样本学习场景中取得了成功。
原型网络
原型网络是一类设计用于少样本分类任务的神经网络。核心思想是在特征空间中为每个类别学习一个原型或代表性示例。原型通过比较新输入与学习到的原型之间的距离来作为分类的基础。
主要涉及三个步骤:
-
嵌入:网络使用神经网络编码器(如卷积神经网络(CNN)或递归神经网络(RNN))计算每个输入的嵌入。嵌入是捕捉输入数据显著特征的高维表示。
-
原型计算:对于每个类别,网络通过计算支持集(这是每个类别的一小部分标记样本)的嵌入均值来计算原型。原型表示特征空间中类别的“中心”。
-
分类:给定一个新输入,网络计算其嵌入并计算输入嵌入与原型之间的距离(例如欧氏距离)。然后将输入分配给最近原型的类别。
学习过程涉及最小化一个损失函数,该函数鼓励原型与其各自类别的嵌入更接近,并与其他类别的嵌入距离更远。
模型无关元学习(MAML)
MAML 是一个元学习算法,旨在为模型的参数找到最佳初始化,使其能够通过少量梯度步骤快速适应新任务。MAML 是模型无关的,这意味着它可以应用于任何使用梯度下降进行训练的模型。
MAML 包括以下步骤:
-
任务采样:在元训练过程中,从任务的分布中采样任务,每个任务是一个少样本学习问题,具有少量标记样本。
-
任务特定学习:对于每个任务,模型的参数使用任务的训练数据(支持集)通过几步梯度更新进行微调。这会生成具有更新参数的任务特定模型。
-
元学习:元目标是最小化所有任务在验证数据(查询集)上的任务特定损失的总和。模型的初始参数通过 梯度下降 进行更新,以实现这一目标。
-
元测试:在元训练后,模型可以通过少量的梯度步骤迅速在新任务上进行微调,利用已学习的初始化。
MAML 需要大量的计算资源,因为它涉及多次嵌套的梯度更新,这带来了挑战。其中一个挑战是任务多样性。在许多少样本学习场景中,模型必须适应广泛的任务或类别,每个类别只有少量示例。这种多样性使得开发一个能够有效处理不同任务或类别的单一模型或方法变得具有挑战性,而无需大量的微调或适应。
结论
机器学习的奇妙世界为我们带来了开创性的技术,如零样本、单样本和少样本学习。这些方法允许人工智能模型仅通过少量示例来学习和识别对象或模式,类似于人类的学习方式。这为医疗保健、零售和制造等各个行业开辟了广阔的可能性,因为在这些行业中,获得大量标记数据并非总是一种奢侈。
Christophe Atten 领导着一个充满活力的数据科学团队,并自 2022 年起成为中等人工智能作者,专注于将原始数据转化为有洞察力的解决方案。
原文。转载授权。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关话题
逐步解析 DENSE_RANK():SQL 爱好者的指南
原文:
www.kdnuggets.com/breaking-down-denserank-a-step-by-step-guide-for-sql-enthusiasts

图片由编辑提供
在当今数据驱动的世界中,SQL(结构化查询语言)是管理和操作数据库系统的基石。SQL 的强大和灵活性的核心组成部分之一是其窗口函数,这是一类在与当前行相关的行集上执行计算的函数。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
想象一下你通过一个滑动窗口查看数据,并根据这个窗口的位置和大小,对数据进行计算或转换。这本质上就是 SQL 窗口函数的功能。它们处理如计算运行总计、平均值或排名等任务,这些任务使用标准 SQL 命令很难完成。
在窗口函数工具箱中,最强大的工具之一是排名函数,特别是 DENSE_RANK() 函数。这个函数对数据分析师来说是一个福音,它允许我们对不同的行进行排名而不产生任何间隙。无论你是在分析销售数据、网站流量数据,还是一个简单的学生考试分数列表,DENSE_RANK() 都是不可或缺的。
在这篇文章中,我们将深入探讨 DENSE_RANK() 的内部工作原理,将其与紧密相关的 RANK() 和 ROW_NUMBER() 进行对比,并展示如何避免在 SQL 旅程中可能遇到的常见陷阱。准备好提升你的数据分析技能了吗?那就开始吧。
理解 SQL 中排名函数的作用
SQL 中的排名函数是窗口函数的一个子集,为结果集中的每一行分配一个唯一的排名。这些排名值对应于通过函数中的 ORDER BY 子句确定的特定顺序。排名函数是 SQL 的主要组成部分,在数据分析中被广泛使用,用于各种任务,如查找最佳销售员、识别表现最好的网页,或确定特定年份的最高票房电影。
SQL 中有三种主要的排名函数,即 RANK()、ROW_NUMBER() 和 DENSE_RANK()。这些函数的操作方式略有不同,但它们的共同目的都是根据指定的条件对数据进行排名。RANK() 和 DENSE_RANK() 函数的行为类似,即对相同值的行分配相同的排名。关键的区别在于它们处理随后的排名方式。RANK() 跳过下一个排名,而 DENSE_RANK() 不会。
另一方面,ROW_NUMBER() 函数为每一行分配唯一的行号,无论排序列的值是否相同。虽然 RANK()、DENSE_RANK() 和 ROW_NUMBER() 从表面上看可能似乎可以互换使用,但理解它们的细微差别对 SQL 中的数据分析至关重要。这些函数之间的选择可以显著影响结果和从数据中获得的洞察。
SQL 中的 DENSE_RANK() 是什么?
DENSE_RANK() 是 SQL 中一种强大的排名函数,它在指定的分区内分配唯一的排名值。简而言之,DENSE_RANK() 为数据提供无间隔的排名,这意味着每个唯一的值都会获得一个独特的排名,相同的值会获得相同的排名。与其对等函数 RANK() 不同,DENSE_RANK() 在值出现相同的情况下不会跳过任何排名。
举个例子,假设你有一个学生成绩的数据集,其中三名学生获得了相同的分数,比如 85 分。使用 RANK() 时,所有三名学生都将获得 1 的排名,但下一个最佳分数将被排名为 4,跳过了排名 2 和 3。然而,DENSE_RANK() 处理方式不同。它会将所有三名学生的排名都定为 1,接下来的最佳分数将获得 2 的排名,确保排名中没有间隔。
那么,什么时候应该使用 DENSE_RANK() 呢?它特别适用于需要连续排名且没有任何间隔的场景。考虑一个需要奖励前三名表现者的用例。如果你的数据中存在并列情况,使用 RANK() 可能会导致遗漏应得的候选人。这时 DENSE_RANK() 就会派上用场,确保所有的顶尖得分者都得到应有的认可,并且排名不会被跳过。
SQL 中的 DENSE_RANK() 与 RANK() 和 ROW_NUMBER() 对比
理解 DENSE_RANK()、RANK() 和 ROW_NUMBER() 之间的差异对于高效的数据分析非常重要。这三种函数各有强大之处,但它们的细微差别可能会显著影响数据分析的结果。
让我们从RANK()开始。这个函数会给数据集中的每个不同值分配一个唯一的排名,对于相同的值分配相同的排名。然而,当RANK()遇到相同的值时,它会跳过序列中的下一个排名。例如,如果你有三种产品的销售数据相同,RANK()会为这些产品分配相同的排名,但随后会跳过下一个排名。这意味着如果这三种产品是最畅销的,它们都会被分配排名 1,但下一个最畅销的产品将被分配排名 4,而不是排名 2。
接下来,让我们考虑DENSE_RANK()。与RANK()类似,DENSE_RANK()会给相同的值分配相同的排名,但不会跳过任何排名。使用之前的例子,使用DENSE_RANK()时,这三种最畅销的产品仍会被分配排名 1,但下一个最畅销的产品会被分配排名 2,而不是排名 4。
最后,ROW_NUMBER()采取了不同的方法。它会给每一行分配一个唯一的排名,不论这些值是否相同。这意味着即使三种产品的销售数据相同,ROW_NUMBER()也会为每种产品分配一个唯一的编号,这使得它非常适合需要为每一行分配唯一标识符的情况。
解密 SQL 中 DENSE_RANK() 的语法和使用方法
DENSE_RANK()的语法很简单。它与OVER()子句一起使用,在分配排名之前对数据进行分区。语法如下:DENSE_RANK() OVER (ORDER BY column)。这里的column指的是你希望用来排名的数据列。假设我们有一个名为Sales的表,包含SalesPerson和SalesFigures列。为了根据销售数据对销售人员进行排名,我们可以使用DENSE_RANK()函数,如下所示:DENSE_RANK() OVER (ORDER BY SalesFigures DESC)。这个 SQL 查询会根据销售数据从高到低对销售人员进行排名。
将DENSE_RANK()与PARTITION BY结合使用可以特别有洞察力。例如,如果你想在每个地区内对销售人员进行排名,你可以通过Region对数据进行分区,然后在每个分区内进行排名。语法如下:DENSE_RANK() OVER (PARTITION BY Region ORDER BY SalesFigures DESC)。通过这种方式,你不仅能获得全面的排名,还能对每个地区的表现有更细致的了解。
SQL DENSE_RANK() 函数的实际示例
Apple SQL 问题:找出每个销售日期的最佳销售表现者
表格:sales_data
+------------+-----------+------------+
|employee_id | sales_date| total_sales|
+------------+-----------+------------+
|101 |2024-01-01 |500 |
|102 |2024-01-01 |700 |
|103 |2024-01-01 |600 |
|101 |2024-01-02 |800 |
|102 |2024-01-02 |750 |
|103 |2024-01-02 |900 |
|101 |2024-01-03 |600 |
|102 |2024-01-03 |850 |
|103 |2024-01-03 |700 |
+------------+-----------+------------+
输出
+------------+-----------+------------+
|employee_id | sales_date| total_sales|
+------------+-----------+------------+
|101 |2024-01-01 |800 |
|103 |2024-01-02 |900 |
|102 |2024-01-03 |850 |
+------------+-----------+------------+
Apple 顶级销售表现者解决方案
第 1 步:了解数据
首先,让我们了解sales_data表中的数据。该表有三列:employee_id、sales_date 和 total_sales。这个表代表了销售数据,包含有关员工、销售日期和总销售额的信息。
第 2 步:分析 DENSE_RANK() 函数
该查询使用 DENSE_RANK() 窗口函数根据每个销售日期分区内的 total_sales 对员工进行排名。DENSE_RANK() 用于在 sales_date 的分区内为每行分配一个排名,排序基于 total_sales 降序排列。
第 3 步:分析查询结构
现在,让我们来分析查询的结构:
SELECT
employee_id,
sales_date,
total_sales
FROM
(
SELECT
employee_id,
sales_date,
total_sales,
DENSE_RANK() OVER (
PARTITION BY sales_date
ORDER BY
total_sales DESC
) AS sales_rank
FROM
sales_data
) ranked_sales
WHERE
sales_rank = 1;
-
SELECT 子句:这指定了将在最终结果中包含的列。在这种情况下,它是 employee_id、sales_date 和 total_sales。
-
FROM 子句:这是实际数据来源的地方。它包括一个子查询(用括号括起来),该子查询从 sales_data 表中选择列,并使用 DENSE_RANK() 添加一个计算列。
-
DENSE_RANK() 函数:此函数在子查询中用于根据 total_sales 列为每行分配一个排名,并按 sales_date 进行分区。这意味着排名是针对每个销售日期单独进行的。
-
WHERE 子句:此子句筛选结果,只包括 sales_rank 等于 1 的行。这确保了每个销售日期的 top sales performer 只被包含在最终结果中。
第 4 步:执行查询
当你执行此查询时,它将生成一个结果集,其中包括每个销售日期的 top sales performer 的 employee_id、sales_date 和 total_sales。
第 5 步:查看输出
最终输出表格,名为 top_performers,将包含所需的信息:根据 DENSE_RANK() 计算的每个销售日期的 top sales performer。
Google SQL 问题:找出每个产品中提供最高评分的客户
表格:product_reviews
+------------+-----------+-------------+-------------------------------+
|customer_id | product_id| review_date | review_score | helpful_votes |
+------------+-----------+-------------+--------------+----------------+
|301 |101 |2024-04-01 |4.5 | 12 |
|302 |102 |2024-04-01 |3.8 | 8 |
|303 |103 |2024-04-01 |4.2 | 10 |
|301 |101 |2024-04-02 |4.8 | 15 |
|302 |102 |2024-04-02 |3.5 | 7 |
|303 |103 |2024-04-02 |4.0 | 11 |
|301 |101 |2024-04-03 |4.2 | 13 |
|302 |102 |2024-04-03 |4.0 | 10 |
|303 |103 |2024-04-03 |4.5 | 14 |
+------------+-----------+-------------+--------------+----------------+
输出
+------------+-----------+-------------+--------------+----------------+
|customer_id | product_id| review_date | review_score | helpful_votes |
+------------+-----------+-------------+--------------+----------------+
|301 |101 |2024-04-01 |4.5 | 12 |
|301 |101 |2024-04-02 |4.8 | 15 |
|303 |103 |2024-04-03 |4.5 | 14 |
+------------+-----------+-------------+--------------+----------------+
Google 最高评分解决方案
第 1 步:了解数据
product_reviews 表格包含有关各种产品的客户评价信息。它包括 customer_id、product_id、review_date、review_score 和 helpful_votes 等列。此表格表示与客户评价相关的数据,包含有关客户、被评价的产品、评价日期、评价分数以及获得的 helpful votes 数量。
第 2 步:分析 DENSE_RANK() 函数
在此查询中,DENSE_RANK() 窗口函数用于在 product_id 和 review_date 定义的每个分区内对行进行排名。排名是基于两个标准:review_score 降序排列和 helpful_votes 降序排列。这意味着评分较高且有更多 helpful votes 的行将被分配更低的排名。
第 3 步:分析查询结构
现在,让我们来分析查询的结构:
SELECT
customer_id,
product_id,
review_date,
review_score,
helpful_votes
FROM
(
SELECT
customer_id,
product_id,
review_date,
review_score,
helpful_votes,
DENSE_RANK() OVER (
PARTITION BY product_id,
review_date
ORDER BY
review_score DESC,
helpful_votes DESC
) AS rank_within_product
FROM
product_reviews
) ranked_reviews
WHERE
rank_within_product = 1;
-
SELECT 子句:指定将在最终结果中包含的列。它包括 customer_id、product_id、review_date、review_score 和 helpful_votes。
-
FROM 子句:这一部分包括一个子查询(括号内)选择 product_reviews 表中的列,并使用
DENSE_RANK()添加一个计算列。计算是在由 product_id 和 review_date 定义的分区上进行的,排名基于 review_score 和 helpful_votes 的降序。 -
DENSE_RANK()函数:此函数在子查询中应用,根据指定的标准为每一行分配一个排名。排名是根据每个 product_id 和 review_date 的组合单独进行的。 -
WHERE 子句:筛选结果以仅包括 rank_within_product 等于 1 的行。这确保了最终结果中只包含每个产品在每个评论日期的排名最高的行。
步骤 4:执行查询
执行此查询将生成包含所需信息的结果集:每个产品和评论日期组合中基于评论分数和有用票数的排名最高评论的 customer_id、product_id、review_date、review_score 和 helpful_votes。
步骤 5:检查输出
最终输出表,名为 top_reviewers,将显示每个产品在每个评论日期的排名最高的评论,同时考虑评论分数和有用票数。
避免 SQL 中使用DENSE_RANK()的常见错误
虽然DENSE_RANK()是一个非常有用的 SQL 函数,但分析师,特别是那些刚接触 SQL 的人,使用时出错并不少见。让我们更详细地探讨一些常见的错误及其避免方法。
一个常见的错误是误解DENSE_RANK()如何处理 NULL 值。与某些 SQL 函数不同,DENSE_RANK()将所有 NULL 视为相同。这意味着,如果你在排名数据中有 NULL 值,DENSE_RANK()会将所有 NULL 值赋予相同的排名。在处理包含 NULL 值的数据集时,请注意这一点,并考虑用在你的上下文中代表其含义的值替代 NULL,或根据具体要求将其排除。
另一个常见的错误是忽视在使用DENSE_RANK()时分区的重要性。PARTITION BY子句允许你将数据分为不同的段,并在这些分区内进行排名。不使用PARTITION BY可能会导致错误的结果,特别是当你希望对不同的类别或组重新开始排名时。
与此相关的是ORDER BY子句在DENSE_RANK()中的不当使用。DENSE_RANK()默认按升序分配排名,意味着最小值获得排名 1。如果你需要排名按降序进行,你必须在ORDER BY子句中包含DESC关键字。不这样做将产生可能与你的期望不符的排名。
最后,一些分析师错误地使用 DENSE_RANK() 而应使用 ROW_NUMBER() 或 RANK(),反之亦然。正如我们讨论的,这三种函数都有独特的行为。理解这些细微差别并根据你的特定用例选择正确的函数,对于进行准确和有效的数据分析至关重要。
掌握 DENSE_RANK() 如何提升 SQL 数据分析的效率
掌握 DENSE_RANK() 的使用可以显著提升 SQL 数据分析的效率,特别是在涉及排名和比较的情况下。这个函数提供了一种细致的排名方法,通过对相同的值分配相同的排名而不跳过任何排名数字,保持了排名尺度的连续性。
这在分析大型数据集时特别有用,因为数据点经常可能有相同的值。例如,在一个销售数据集中,多个销售人员可能达到了相同的销售额。DENSE_RANK() 使得排名公平,每个销售人员都分配相同的排名。此外,DENSE_RANK() 与 PARTITION BY 结合使用时,可以进行针对特定类别的分析。
这个函数的应用在处理空值时变得更加有效。DENSE_RANK() 不会将这些空值排除在排名过程之外,而是将所有空值视为相同并分配相同的排名。这确保了即使确切的值可能缺失,数据点也不会被忽略,从而提供了更全面的分析。
常见问题
我可以在哪里练习SQL 面试题,包括 DENSE_RANK()?
为了提升你的 SQL 技能,我们推荐在 BigTechInterviews、Leetcode 或类似的平台上进行在线练习。
DENSE_RANK() 在 SQL 中的作用是什么?
DENSE_RANK() 是一个 SQL 窗口函数,根据指定的列给数据行分配排名。它通过给相同的排名来处理并列情况,而不会在排名序列中留下任何空隙。
RANK()、ROW_NUMBER() 和 DENSE_RANK() 在 SQL 中有什么区别?
RANK() 和 ROW_NUMBER() 为数据分配排名,但处理并列情况的方式不同。RANK() 对于并列数据留有排名空隙,而 ROW_NUMBER() 为每一行分配一个唯一的编号,不考虑并列情况。另一方面,DENSE_RANK() 给并列数据点分配相同的排名,没有任何空隙。
如何在 SQL 中的 WHERE 子句中使用 DENSE_RANK()?
DENSE_RANK() 是一个窗口函数,不能直接在 WHERE 子句中使用。相反,它可以与其他函数如 ROW_NUMBER() 或 RANK() 结合使用,这些函数可以在 WHERE 子句中用来根据排名过滤数据。
DENSE_RANK() 可以在没有 PARTITION BY 的情况下使用吗?
不,指定 PARTITION BY 对于 DENSE_RANK() 的正常运行至关重要。如果没有它,所有数据将被视为一个组,从而导致不准确和无意义的排名。掌握 DENSE_RANK() 在 SQL 中的使用可以显著提升你的数据分析技能。
RANK() 和 DENSE_RANK() 之间的区别是什么?
RANK() 和 DENSE_RANK() 主要的区别在于它们处理平局的方式。RANK() 会在排名中留下空缺,而 DENSE_RANK() 会为平局的数据点分配相同的排名,没有空缺。此外,RANK() 总是为每一行的新数据递增排名,而 DENSE_RANK() 维持连续的排名。
约翰·休斯**** 曾是 Uber 的数据分析师,后来创办了名为 BigTechInterviews (BTI) 的 SQL 学习平台。他对学习新编程语言充满热情,并帮助候选人获得通过技术面试的信心和技能。他的家在科罗拉多州丹佛市。
更多相关内容
解读量子计算:对数据科学和 AI 的影响
原文:
www.kdnuggets.com/breaking-down-quantum-computing-implications-for-data-science-and-ai

编辑提供的图片
量子计算对数据科学和 AI 产生了深远的影响,在这篇文章中,我们将深入探讨超越基础知识的内容。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
我们将探索量子算法的前沿进展及其解决复杂问题的潜力,这些问题目前用现有技术是无法想象的。此外,我们还将讨论量子计算面临的挑战以及如何克服这些挑战。
这是对一个未来的迷人一瞥,在这个未来,技术的边界被推向新的前沿,大大加速了 AI 和数据科学的能力。
什么是量子计算?
量子计算涉及专门的计算机,这些计算机解决数学问题并运行量子模型,这些模型基于量子理论原则。这项强大的技术使数据科学家能够构建与复杂过程相关的模型,例如分子形成、光合作用和超导性。
信息处理方式不同于常规计算机,使用量子比特(量子位)而非二进制形式传输数据。量子比特在量子计算中至关重要,因为它们可以保持在叠加态 - 我们将在下一部分中详细解释这一点。
通过使用广泛的算法,量子计算机可以测量和观察大量数据。用户输入必要的算法后,量子计算机将创建一个多维环境,以解读各种数据点,从而发现模式和联系。
量子计算:重要术语
为了更好地理解计算,重要的是要掌握四个关键术语:量子比特、叠加态、纠缠和量子干涉。
量子比特
量子位(Qubits)是量子计算中的标准信息单元,类似于传统计算中使用的二进制位。量子位利用一种称为叠加(superposition)的原理,使其可以同时处于多种状态。二进制位只能是 0 或 1,而量子位可以是 0 或 1、0 或 1 的部分,或者是 0 和 1 的同时存在。
虽然二进制位通常是基于硅的微芯片,但量子位可以由光子、受困离子以及真实或人工的原子或准粒子组成。因此,大多数量子计算机需要极其复杂的冷却设备以在非常低的温度下工作。
叠加(Superposition)
叠加(Superposition)指的是量子粒子是所有可能状态的组合,这些粒子可以在量子计算机观察和单独测量时发生变化和移动。解释叠加的一个好比喻是掷硬币时,硬币在空中的不同瞬间。
这使得量子计算机可以以多种方式评估每个粒子,从而找到不同的结果。与传统的顺序处理不同,量子计算可以利用叠加一次运行大量的并行计算。
纠缠(Entanglement)
量子粒子可以在其测量方面相互关联,形成一种称为纠缠(entanglement)的网络。在这种纠缠过程中,一个量子位的测量可以被用于其他量子位的计算。因此,量子计算能够解决极其复杂的问题,并处理大量数据。
量子干涉(Quantum Interference)
在叠加过程中,量子位有时可能会经历量子干涉,导致量子位变得不可用。量子计算机设有措施以减少这种干涉,以确保结果尽可能准确。量子干涉越多,结果的准确性就越低。
量子计算如何在人工智能和数据科学中发挥作用?
量子机器学习(QML)和量子人工智能(QAI)是数据科学中两个被低估但快速增长的领域。这是因为机器学习算法正变得过于复杂,传统计算机无法有效处理,需要量子计算的能力。最终,这预计将推动人工智能的重大进展。
量子计算机可以像神经网络一样有效地进行训练,调整物理控制参数来解决问题,例如电磁场的强度或激光脉冲的频率。
一个容易理解的用例是可以训练的机器学习模型,用于对文档内容进行分类,通过将文档编码为设备的物理状态进行测量。借助量子计算和 AI,数据科学工作流将在毫秒级别内进行测量,因为量子 AI 模型能够处理 PB 级数据,并在语义上比较文档,为用户提供超出其想象的可操作见解。
量子机器学习研究
像谷歌、IBM 和英特尔这样的主要参与者在量子计算上投入了大量资金,但目前该技术在商业层面仍未被认为是可行的解决方案。然而,该领域的研究正在加速,涉及量子计算的技术挑战肯定会被通过机器学习解决,不会太久。
IBM 和麻省理工学院(MIT)可以被归功于揭示了 2019 年结合机器学习和量子计算的实验研究。在一项研究中,使用了一个两比特量子计算机来演示量子计算如何利用实验室生成的数据集提升分类监督学习。这为进一步研究铺平了道路,以勾勒出这种技术合作的全部潜力。
量子机器学习实践
在本节中,我们将详细介绍谷歌和 IBM 启动的量子计算项目,并洞察这项技术的巨大潜力。
-
谷歌的 TensorFlow Quantum (TFQ) - 在这个项目中,谷歌旨在克服将现有机器模型转移到量子架构的挑战。为了加速这一进程,TensorFlow Quantum 现在是开源的,允许开发人员使用 Python 和谷歌的量子计算框架来构建量子机器学习模型。这意味着量子算法和机器学习应用的研究拥有一个更活跃、更具备条件的社区,从而促进进一步的创新。
-
IBM 的量子挑战 - 连接传统软件开发与量子计算应用开发之间的差距,IBM 的量子挑战是一个年度多日活动,专注于量子编程。活动吸引了近 2000 名参与者,旨在教育开发者和研究人员,以确保他们为量子计算革命做好准备。
-
剑桥量子计算(CQC)和 IBM - CQC 和 IBM 于 2021 年 9 月推出了一款基于云的量子随机数生成器(QRNG)。这一开创性的应用能够生成可测量的熵(完全随机性)。这不仅是数据加密领域的一个宝贵突破,也可能在开发能够应对意外情况的高级人工智能系统中发挥作用。
多亏了持续的研究和教育,量子计算有可能推动机器学习模型的应用,这些模型可以用于各种现实世界场景。例如,在金融领域,股票投资和 利用 AI 信号进行期权交易 等活动将因量子 AI 的预测能力而得到极大增强。同样,物理量子计算机的出现将引发在 使用核方法 进行复杂数据线性分类方面的革命。
结论 - 量子机器学习的未来
在量子机器学习能够进入主流之前,还有许多重要步骤需要完成。幸运的是,像 Google 和 IBM 这样的科技巨头正在提供开源软件和 数据科学教育资源,以便访问它们的量子计算架构,为该领域培养新的专家铺平道路。
通过加速量子计算的采用,人工智能和机器学习预计将取得巨大的进展,解决传统计算无法解决的问题。甚至可能是全球性问题,如气候变化。
尽管这一研究仍处于非常早期的阶段,但技术的潜力正迅速显现,人工智能的新篇章即将开启。
纳赫拉·戴维斯 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾管理——包括其他有趣的事情——担任一家 Inc. 5,000 体验式品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关信息
进入数据科学领域:必要技能及其学习方法
原文:
www.kdnuggets.com/breaking-into-data-science-essential-skills-and-how-to-learn-them

来源:Canva
数据科学已经需求了相当长一段时间。幸运的是,教育的民主化使得建立学习必要技术技能的路线图变得相对容易。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
通常,学习路径包括建立线性代数、数学、概率、统计等基础,并掌握至少一种编程语言,如 Python。
技术细节
具备这些基础知识后,学习者对机器学习基础知识变得更加熟悉,理解关键算法——决策树、随机森林、集成方法和时间序列,并最终掌握复杂的深度学习算法。
在这个过程中,你还需要很好地掌握涉及偏差-方差权衡、泛化能力、算法假设等概念。这份清单绝非完整(也永远不会完整),因为数据科学领域涉及持续学习——这通常通过实际操作或学习行业专家的做法来实现。
在这种情况下,像 Kaggle 这样的平台为理解构建高性能模型的复杂细节提供了良好的练习场。此外,接触 Kaggle 上的获胜解决方案不仅增加了知识储备,还使学习者能够培养开发稳健模型的思维方式。
超越技术技能
到目前为止,一切顺利。但是,你注意到一件事了吗?
我所概述的技能和路径没有秘密;它们大多公开可得。每个人都在学习相同的方法,以建立技能,争取在数据科学领域获得理想的角色。
这时,现实检查是必要的。
不仅仅是关于可用的 AI 人才,还有市场对这些技能的需求。AI 进展迅速,尤其是自生成 AI 时代开始以来,这促使许多组织减少了员工。即使是 Nvidia 的首席执行官黄仁勋也分享了他对未来劳动力和技能的看法,他强调“AI 将接管编码,使学习变得可选。AI 将使编码对每个人都变得可及,重新塑造我们学习编程的方式。”

来源:Immigration & Jobs Talk Show YT 频道
你能做什么?
行业格局的变化突显了一个真理——变化的时代需要变化的措施。
鉴于行业技能期望的变化,以下是你应该关注的,以建立出色的数据科学职业:
-
打磨那些经常被忽视的决策技能,这对构建可扩展的机器学习系统中的权衡至关重要。
-
即使在缺乏完整信息的情况下,也要具备做出明智决策的能力,展示快速思维和适应能力。
-
构建 ML 模型需要广泛的利益相关者管理,这意味着可能会出现摩擦。掌握利益相关者管理的艺术,以应对潜在的冲突,并以有说服力的理由推动决策。

来源:Canva
-
与跨职能团队合作也意味着你的受众可能来自不同的背景,因此建立量身定制的沟通方式是一个很大的优势。
-
大多数 AI 项目在概念验证(PoC)阶段失败,甚至无法进入生产阶段,而在生产中的项目也难以展示结果。简而言之,组织在等待 AI 投资的回报。因此,成为那个人,做好事情并展示结果,同时取得进展。
-
确保业务问题与统计 ML 解决方案的对齐,以引导给定的 AI 项目成功。如果这一步骤出现问题,后续的任何东西都不会有用。
-
创新是必须的——不仅对企业,对我们所有人也是如此。跳出框框思考,设计创新解决方案。这是建立你作为专家数据科学家声誉的可靠途径。
软技能
随机解决问题是一门艺术,课堂上很少教授。然而,关键的问题仍然是——如何学习这些技能?
没有单一的精通路径,但这里有一些起点来培养这种视角:
-
不要害怕失败,而是将挑战视为学习新事物的机会。将每一个问题陈述视为在 AI 中学习新事物的入口。这类似于在大学学习,唯一的不同是你是被付费去学习以实现创新,而不是支付学费。数据科学涉及“科学”,即实验性,涉及多个迭代以提供有意义的结果(有时甚至没有成功,只是学习)。这些学习随着时间的推移积累,帮助你建立知识库,随着经验的增加,这成为你的差异化优势。
-
克服恐惧也意味着提出问题。例如,始终“从为什么开始?”我们为什么要构建这个?我们的客户/利益相关者为什么关心?为什么是现在?
-
一旦问题陈述背后的“为什么”明确了,“什么”和“如何”自然会随之而来,从而简化创建卓越 AI 产品的过程。
-
简而言之,在这个“构建 AI 产品只是调用 API”的新世界中,选择正确的问题,或者说,发明正确的问题,可以为你开辟一条极具回报的职业道路。

来源:builder.io
掌握这些技能可以在面试过程中脱颖而出,并构建出世界期待的卓越 ML 产品。
Vidhi Chugh**** 是一位 AI 策略师和数字化转型领导者,在产品、科学和工程的交汇处工作,致力于构建可扩展的机器学习系统。她是一位获奖的创新领导者、作者和国际演讲者。她的使命是让机器学习普及化,并将行业术语打破,使每个人都能参与这场变革。
相关阅读
经典机器学习:简约的二元分类树
原文:
www.kdnuggets.com/2016/06/breiman-stone-parsimonious-binary-classification-trees.html
作者:Leo Breiman 和 Charles J. Stone。
提出了一种三步法构建多分类问题的二叉决策树。首先,定义了一个基于吉尼指数广义化的划分规则。接下来,找到相对于惩罚错误分类和复杂树(即,具有许多终端节点的树)的标准的最优终止规则。最终获得的树依赖于一个复杂度参数,在最后一步通过数据划分或交叉验证来选择该参数。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
酿造特定领域的 LLM 魔药
原文:
www.kdnuggets.com/2023/08/brewing-domainspecific-llm-potion.html

图片来自 Unsplash
亚瑟·克拉克曾名言:“任何足够先进的技术都与魔法无异。” 人工智能通过引入视觉和语言(V&L)模型以及大语言模型(LLMs)已越过了这条界限。像Promptbase这样的项目本质上是将正确的词汇以正确的顺序编织起来,以召唤看似自发的结果。如果“提示工程”不符合施法的标准,那么很难说什么符合。而且,提示的质量很重要。更好的“咒语”能带来更好的结果!
几乎每家公司都热衷于利用这股 LLM 魔力。但只有当你能够将 LLM 与特定业务需求对接时,它才是魔力,比如从你的知识库中总结信息。
让我们开始一场冒险,揭示制作强效魔药的秘诀——一个具有领域特定专业知识的 LLM。作为一个有趣的例子,我们将开发一个擅长《文明 6》的 LLM,这个概念足够极客,能引起我们的兴趣,拥有一个出色的WikiFandom并且许可证为 CC-BY-SA,并且不复杂,以至于即使是非粉丝也能跟随我们的例子。
第 1 步:解读文档
语言模型(LLM)可能已经具备一些特定领域的知识,使用正确的提示词即可访问这些知识。然而,你可能已有现存的文档存储了你想要利用的知识。找到这些文档并继续下一步。
第 2 步:分割你的咒语
为了让你的领域特定知识对 LLM 可访问,将你的文档分割成更小、更易消化的部分。这种分割可以提高理解度,并使相关信息的检索变得更加容易。对我们来说,这涉及到将 Fandom Wiki 的 Markdown 文件分割成若干部分。不同的 LLM 可以处理不同长度的提示。将文档拆分成长度显著小于(例如,10%或更少)最大 LLM 输入长度的部分是合理的。
第 3 步:创建知识精华并构建你的向量数据库
使用相应的嵌入向量对每个分割后的文本进行编码,例如使用Sentence Transformers。
将生成的嵌入向量及其对应的文本存储在向量数据库中。你可以使用 Numpy 和 SKlearn 的 KNN 自行完成,但经验丰富的从业者通常推荐使用向量数据库。
第 4 步:打造引人入胜的提示词
当用户询问 LLM 关于《文明 6》的问题时,你可以在向量数据库中搜索与问题嵌入相似的元素。你可以在你制作的提示中使用这些文本。
第 5 步:管理背景的药剂锅
让我们认真对待魔法吧!你可以在提示中添加数据库元素,直到达到为提示设置的最大上下文长度。密切注意第 2 步中你的文本部分的大小。通常,嵌入文档的大小和你在提示中包含的数量之间存在显著的权衡。
第 6 步:选择你的魔法成分
无论你为最终解决方案选择了哪个 LLM,这些步骤都是适用的。LLM 的格局正在迅速变化,因此,一旦你的流程准备好后,选择你的成功指标,并对不同模型进行并行比较。例如,我们可以比较Vicuna-13b和 GPT-3.5-turbo。
第 7 步:测试你的药剂
测试我们的“药剂”是否有效是下一步。说起来容易做起来难,因为目前尚无科学共识来评估 LLM。一些研究人员开发了新的基准,如HELM或BIG-bench,而其他人则提倡人类在环评估,或通过一个更高级的模型来评估领域特定 LLM 的输出。每种方法都有优缺点。对于涉及领域特定知识的问题,你需要建立一个与你的业务需求相关的评估流程。不幸的是,这通常需要从零开始。
第 8 步:揭示神谕并施展答案和评估
首先,收集一组问题来评估领域特定 LLM 的表现。这可能是一项繁琐的任务,但在我们的《文明》示例中,我们利用了 Google Suggest。我们使用了像“文明 6 如何……”这样的搜索查询,并将 Google 的建议作为评估我们解决方案的问题。然后,使用一组与领域相关的问题,运行你的问答流程。为每个问题形成提示并生成答案。
第 9 步:通过预言者的视角评估质量
一旦你拥有了答案和原始查询,你必须评估它们的一致性。根据你期望的精确度,你可以将你的 LLM 答案与优越模型进行比较,或使用Toloka 上的并排比较。第二种选择的优势在于直接的人类评估,如果做得正确,可以防止优越 LLM 可能存在的隐性偏见(例如,GPT-4往往会将自己的回答评分更高)。这对实际业务实施可能至关重要,因为这种隐性偏见可能对你的产品产生负面影响。由于我们处理的是一个玩具示例,我们可以遵循第一条路径:将 Vicuna-13b 和 GPT-3.5-turbo 的回答与 GPT-4 进行比较。
第 10 步:提炼质量评估
LLMs 通常在开放设置中使用,因此理想情况下,你希望一个 LLM 能够区分你的向量数据库中有答案的问题与没有答案的问题。以下是由人类在Toloka(即 Tolokers)和 GPT 上对 Vicuna-13b 和 GPT-3.5 的并排比较。
| 方法 | Tolokers | GPT-4 |
|---|---|---|
| 模型 | vicuna-13b | GPT-3.5 |
| 可回答,正确答案 | 46.3% | 60.3% |
| 无法回答,AI 没有给出答案 | 20.9% | 11.8% |
| 可回答,错误答案 | 20.9% | 20.6% |
| 无法回答,AI 给出了一些答案 | 11.9% | 7.3% |
如果我们检查 Tolokers 对 Vicuna-13b 的评估,就如第一列所示,我们可以看到优越模型与人工评估之间的差异。从这次比较中可以得出几个关键点。首先,GPT-4 与 Tolokers 之间的差异值得注意。这些不一致主要发生在领域特定的 LLM 适当地不作回应时,但 GPT-4 却将这些无回应的情况评分为可回答问题的正确答案。这突显了当 LLM 的评估未与人工评估对比时,可能会出现的评估偏差。
其次,GPT-4 和人工评估者在评估整体表现时显示出一致性。这是通过比较前两行的数字总和与后两行的总和来计算的。因此,将两个领域特定的 LLM 与优越模型进行比较可以成为一种有效的 DIY 初步模型评估方法。
这就是结果!你已经掌握了迷人的技巧,你的领域特定 LLM 管道已全面运行。
伊万·亚姆什奇科夫 是应用科学大学维尔茨堡-施韦因富特人工智能与机器人中心的语义数据处理与认知计算教授。他还领导 Toloka AI 的数据倡导者团队。他的研究兴趣包括计算创造力、语义数据处理和生成模型。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
人工智能简史
原文:
www.kdnuggets.com/2017/04/brief-history-artificial-intelligence.html

I. 起源
尽管目前的炒作很多,人工智能并不是一个新兴领域,而是起源于五十年代。如果排除从古希腊到霍布斯、莱布尼茨和帕斯卡的纯哲学推理路径,人工智能作为我们所知的领域在1956 年于达特茅斯学院正式开始,最杰出的专家们聚集在一起进行智能模拟的头脑风暴。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
这发生在阿西莫夫设定他自己三大机器人定律的几年之后,但更相关的是在图灵(1950)发布的著名论文之后,在该论文中他首次提出了思维机器的概念以及更受欢迎的图灵测试来评估这样的机器是否确实表现出智能。
达特茅斯的研究小组公开发布了那次夏季会议的内容和想法后,政府资金流向了创建非生物智能的研究。
II. 幽灵威胁
那时,人工智能看似触手可及,但事实并非如此。在六十年代末,研究人员意识到人工智能确实是一个难以管理的领域,最初带来资金的火花开始消散。
这一现象贯穿了人工智能的整个历史,通常被称为人工智能效应,由两个部分组成:
-
不断承诺在未来十年内实现真正的人工智能;
-
人工智能在掌握某个问题后的表现被低估,不断重新定义什么是智能。
在美国,DARPA 资助人工智能研究的原因主要是为了创造一个完美的机器翻译器,但两个连续事件破坏了这个提案,开启了后来被称为第一次人工智能寒冬的时期。
实际上,美国自动语言处理咨询委员会(ALPAC)于 1966 年发布的报告,随后是“莱特希尔报告(1973)”,评估了人工智能在当前发展下的可行性,并对创建能够学习或被认为是智能的机器的可能性作出了否定结论。
这两份报告,加上有限的数据供给算法使用,以及那个时期计算能力的匮乏,使得这一领域崩溃,人工智能在整个十年中陷入了耻辱。
III. (专家)克隆的攻击
然而,在八十年代,英国和日本的新一轮资助是由于引入了“专家系统”,这些系统基本上是窄人工智能的例子,如前面文章所定义。
这些程序实际上能够模拟特定领域的专家技能,但这已经足以刺激新的资助趋势。在这些年里,最活跃的参与者是日本政府,其急于创建第五代计算机间接迫使美国和英国重新恢复对人工智能研究的资助。
然而,这一黄金时代并没有持续太久,当资助目标未能实现时,新的危机开始了。在 1987 年,个人计算机变得比Lisp Machine更强大,而Lisp Machine是多年来人工智能研究的成果。这标志着第二次人工智能寒冬的开始,DARPA 明确反对人工智能和进一步资助。
IV. Jed(AI)的回归
幸运的是,1993 年这一时期以MIT Cog 项目的结束告终,该项目旨在构建一个类人机器人,还有动态分析和重规划工具(DART)——这一工具为美国政府自 1950 年以来的全部资助支付了回报——当 1997 年 DeepBlue 在国际象棋中击败了卡斯帕罗夫时,人工智能显然重回巅峰。
在过去二十年中,学术研究取得了很多进展,但人工智能直到最近才被公认为一种范式转变。当然,有一系列原因可以帮助我们理解为什么我们现在在人工智能方面投入如此之多,但我们认为有一个特定事件对过去五年的趋势负有责任。
如果我们查看下面的图表,会注意到尽管取得了所有这些进展,人工智能直到 2012 年底才被广泛认可。该图表确实是使用 CBInsights Trends 创建的,它基本上绘制了特定词汇或主题(在这种情况下是人工智能和机器学习)的趋势。
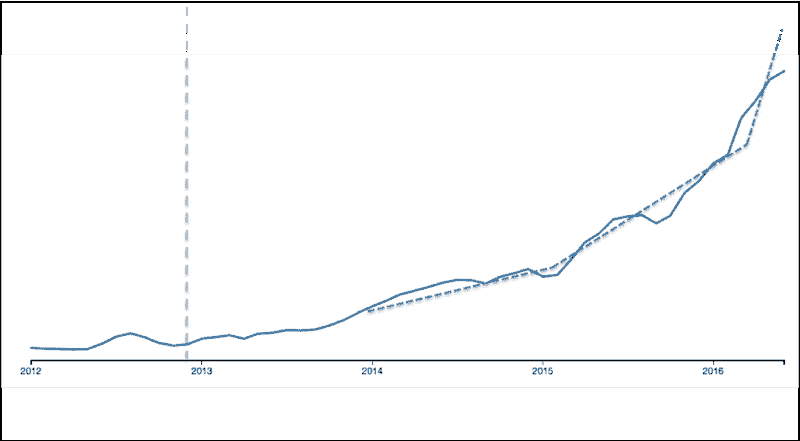
2012–2016 年的人工智能趋势。
更详细地说,我在一个特定的日期上划了一条线,我认为这是这股新人工智能乐观潮流的真正触发点,即2012 年 12 月 4 日。在那天星期二,一组研究人员在神经信息处理系统(NIPS)会议上展示了他们的卷积神经网络的详细信息,这使他们在几周前的ImageNet 分类竞赛中获得了第一名(Krizhevsky et al., 2012)。他们的工作将分类算法从 72%提高到 85%,并将神经网络的使用确立为人工智能的基础。
在不到两年的时间里,该领域的进展使得 ImageNet 竞赛中的分类达到了96%的准确率,略高于人类的约 95%。
图片还展示了 AI 发展的三大主要增长趋势(断裂的虚线),由三大事件概述:
-
3 岁的DeepMind于 2014 年 1 月被谷歌收购;
-
生命未来研究所的公开信由超过 8,000 人签署,及 Deepmind 于 2015 年 2 月发布的强化学习研究(Mnih et al., 2015);
-
2016 年 1 月 DeepMind 科学家在《自然》上发表的关于神经网络的论文(Silver et al., 2016),以及 2016 年 3 月 AlphaGo 战胜李世石的令人印象深刻的胜利(后续还有一系列其他令人印象深刻的成就——查看Ed Newton-Rex的文章)。
V. 新的希望
AI 本质上高度依赖资金,因为它是一个长期研究领域,需要耗费大量的努力和资源才能彻底开发。
然而,也有人担忧我们可能正处于下一个高峰阶段(Dhar, 2016),但这种兴奋注定很快就会消失。
然而,与许多人一样,我认为这一新时代有三个主要原因与众不同:
-
(大)数据,因为我们最终拥有了喂养算法所需的大量数据;
-
技术进步,因为存储能力、计算能力、算法理解、更高更大的带宽和更低的技术成本使我们能够实际让模型处理所需的信息;
-
Uber 和 Airbnb 商业模型引入的资源民主化和高效配置,这在云服务(即亚马逊网络服务)和由 GPU 进行的并行计算中得以体现。
参考文献
-
Dhar, V. (2016). “人工智能的未来”。《大数据》,4(1): 5–9。
-
Krizhevsky, A., Sutskever, I., Hinton, G.E. (2012). “使用深度卷积神经网络进行 Imagenet 分类”。《神经信息处理系统进展》,1097–1105。
-
Lighthill, J. (1973). “人工智能:概述”。在《人工智能:论文研讨会》,科学研究委员会。
-
Mnih, V., et al. (2015). “通过深度强化学习实现人类水平的控制”。《自然》,518: 529–533。
-
Silver, D., et al. (2016). “通过深度神经网络和树搜索掌握围棋游戏”。《自然》,529: 484–489。
-
Turing, A. M. (1950). “计算机械与智能”。《思维》,49: 433–460。
披露:本文最初是较长文章‘人工智能解释’的一部分,我现在基于一些读者对文章可读性的反馈将其拆分。希望这有所帮助。
简介:Francesco Corea 是一位决策科学家和数据策略师,现居伦敦,英国。
原创。经许可转载。
相关内容:
-
50 家引领 AI 革命的公司,详细介绍
-
数据挖掘的历史
-
为何要在人工智能上长线投资?
更多相关主题
数据概念简介
原文:
www.kdnuggets.com/2021/07/brief-introduction-concept-data.html
评论
由 Angelica Lo Duca 提供,国家研究委员会信息学与电信研究所
根据剑桥词典[1],数据是信息,特别是收集以供检查和考虑的信息或帮助决策的数字,或以电子形式存储并由计算机使用的信息。换句话说,数据是一组变量,可以是定量的或定性的[2,3]。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
数据类型
数据可以是定量的也可以是定性的。理解定量数据和定性数据之间的区别非常重要,因为它们的处理和分析方式不同:例如,您不能对定性数据计算统计数据,或无法对定量数据应用自然语言处理技术。
定量数据
定量数据包括可以用数字表示的数据,因此它们可以被测量、计数并通过统计计算进行分析。定量数据可以用来描述和分析现象,以发现趋势、比较差异并进行预测。通常,定量数据已经是结构化的,因此进一步分析相对容易。
定量数据包括:
1. 连续数据,它可以取任何数值。
连续数据的例子包括:
-
多年的平均温度(例如 35°C 或 84.2 °F)
-
一个月内的产品价格(例如 $ 23.50 或 45.00 €)
通常,连续数据分布在一个区间内,该区间可以包含负值和正值(区间数据)。
2. 离散数据,它只能取某些特定的数值。
离散数据的例子包括:
-
考试成绩,例如 18 或 30
-
鞋码,例如 42 EU
通常,离散数据是等距且非负的(比率数据)。
定性数据
定性数据无法通过标准计算技术进行测量,因为它们表达的是感受、感觉和经验。定性数据可以用于理解给定现象周围的背景和发现新方面。通常,定性数据是非结构化的,因此需要额外的技术来提取有意义的信息。
定量数据包括:
1. 名义数据,用于标记无法测量的数量,而不按照特定顺序排列。通常,名义数据将相似的对象分组。
名义数据的示例包括:
-
个人所讲的语言(例如,英语,意大利语,法语)
-
色彩调色板(例如,红色,绿色)
2. 顺序数据,与名义数据不同的是,它们可以被排序。
名义数据的示例包括:
-
对于给定产品的意见(例如,低质量,中等质量,高质量)
-
一天中的时间(例如,早晨,下午,夜晚)
数据分析类型
数据分析的目标是发现数据中隐藏的趋势、模式和关系。
根据数据类型,可以执行不同的分析:定量数据和定性数据的定量和定性分析。

定量分析
定量分析[4]指的是定量数据,包括经典的统计技术:
1. 描述性统计
描述性统计[5]分析过去,通过描述数据的基本特征。
描述性统计基于一些测量的计算:
-
频率(计数,百分比)
-
中央趋势(均值,中位数,众数)
-
变异性(最大值,最小值,范围,四分位数,方差)
2. 推论统计
推论统计旨在建立预测模型以理解给定现象的趋势。
推论统计包括以下类型的分析:
-
假设检验(ANOVA,t 检验,Box-Cox,…)
-
置信区间估计
定性分析
定性分析[6]利用定性数据并尝试理解数据背景。由于无法测量数据,因此可以采用以下策略来分析定性数据:
1. 演绎分析
在演绎分析中,研究人员制定一些先验结构或问题来调查数据。当研究者对数据有至少一个基本的概述时,可以使用这种方法。
2. 归纳分析
归纳分析开始时查看数据,希望提取一些有用的信息。这种分析相当耗时,因为它需要对数据进行深入调查。归纳分析用于当研究者对数据一无所知时。
结论
这篇文章介绍了数据的基本概念,包括定量数据和定性数据。定量分析关注数字,而定性分析关注类别。两种类型的分析都做了大量工作,但研究仍在进行中。
参考资料
[1] 剑桥词典:数据的定义:
dictionary.cambridge.org/dictionary/english/data
[2] 定性与定量数据:定义、分析、示例:
www.intellspot.com/qualitative-vs-quantitative-data/
[3] 如何理解您业务中的定量和定性数据:
laconteconsulting.com/2020/02/14/quantitative-qualitative-data/
[4] 定量数据:定义、类型、分析和示例:
www.questionpro.com/blog/quantitative-data/
[5] 直观介绍描述性分析:
medium.com/analytics-vidhya/a-gentle-introduction-to-descriptive-analytics-8b4e8e1ad238
[6] 定性数据 – 定义、类型、分析和示例:
www.questionpro.com/blog/qualitative-data/
简介:Angelica Lo Duca(Medium)在意大利比萨的国家研究委员会(IIT-CNR)信息学与远程通信研究所担任博士后研究员。她是比萨大学数字人文学科硕士课程中“数据新闻学”教授。她的研究兴趣包括数据科学、数据分析、文本分析、开放数据、网络应用程序和数据新闻学,应用于社会、旅游和文化遗产领域。她曾从事数据安全、语义网和关联数据的工作。Angelica 也是一位热情的技术写作者。
相关:
-
数据科学的残酷真相
-
你为什么以及如何学习“高效数据科学”?
-
初学者的前 10 个数据科学项目
更多相关内容
卡尔曼滤波器简要介绍
原文:
www.kdnuggets.com/2022/12/brief-introduction-kalman-filters.html
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
你能测量核反应堆核心内部的温度以确保核反应受控吗?这肯定对任何目前制造的温度计来说都过于炎热。那么我们最好的选择是什么?最接近的是测量靠近核心的表面温度,并估算内部温度。

让我们考虑另一个例子来内化这一概念:如果无法直接测量一个现象——例如,使用雷达技术测量飞行物体的确切位置时,考虑到空气密度、风向和风速的变化,你能做到吗?如果风向发生变化呢?与雷达设备相关的经验误差是否被考虑在内?
环境影响这些测量的准确性——如果环境没有控制,你会得到噪声较大的读数。因此,你需要一种能够滤除这些测量噪声并提供接近准确估计的方法,答案就在于卡尔曼滤波器。
为什么需要卡尔曼滤波器?
你可能在想,你的工作与上述示例和应用并不直接相关。那么,为什么你需要理解和学习卡尔曼滤波器呢?
好吧,也许你不直接处理核反应堆或雷达,但如果你想测量你车在一条长直路上向东移动的位置呢?当然,人们使用 GPS 技术来测量地球上任何物体的位置。然而,GPS 信号会受到卫星位置微小变化、热噪声、云层、尘土等影响。
里程表怎么样?它可以代替 GPS 吗?将里程表读数添加到最后已知的位置是一种简单的方法来了解当前位置。但事实证明,里程表读数受到车轮大小、轮胎气压等因素的影响。因此,里程表的读数对找到确切位置帮助不大。
你也可以使用 IMU(惯性测量单元)测量汽车的加速度,并通过双重积分得到距离,但这伴随有设备和数学误差。
因此,需要使用来自所有这些来源的读数来获得近乎完美的位置估计的卡尔曼滤波器。
理解卡尔曼滤波器算法
理解卡尔曼滤波器算法的内部需要对状态和观测等概念有深入了解。所以,让我们首先定义什么是状态。
系统状态 “描述了足够的信息来确定系统在没有任何外部力量影响系统的情况下的未来行为”。例如,汽车的实际位置是一个状态,它始终是隐藏的。因此,观测值,即里程表读数,用于估计这个状态。
考虑到这一点,让我们通过一个在直线中以恒定速度移动的汽车的例子来直观理解卡尔曼滤波器。注意,我们只能通过速度计观察到速度,而速度计可能会有噪声。假设速度是 10x+10y,这意味着在 x 方向上 10m/s,在 y 方向上 10m/s。假设有高斯噪声添加到其中,卡尔曼滤波器不知道这一点。
两步过程
卡尔曼滤波器的估计通常涉及两个步骤:
-
预测: 它涉及预测下一步的数量(汽车的位置)和误差协方差。
-
修正: 修正步骤涉及使用先前的预测计算卡尔曼增益,并结合预测和观测之间的误差来更新估计值和误差协方差。
上述过程的概述在此图示中以数学方式描述:
两步过程由 balzer82 / Kalman
这两个步骤对所有测量进行重复,直到卡尔曼增益稳定,如下所示:
图片来源于 ResearchGate
估计
解决估计问题的第一步是对问题进行建模,即定义卡尔曼滤波器将要估计的状态向量。请注意,我们需要估计位置和速度,因此状态向量(xk)将包括这两个部分。由于行进距离等于方向上的速度和经过的时间,因此时间 k+1(xk+1)的状态定义如下。
状态转移矩阵 A(在卡尔曼术语中称为动态矩阵)将对象的当前状态转换为下一个状态,即它定义了状态如何转移。第二个组成部分是观察,由一个称为观察矩阵的矩阵 H 定义。因为你只观察恒定速度而不是位置,所以矩阵中只有 (1,3) 和 (2,4) 单元格的值为非零。
降低噪声
卡尔曼试图最小化噪声项,这些项在两步过程中由 P0、Q 和 R 表示。矩阵 P0 捕获与位置和速度相关的初始不确定性。矩阵 Q 捕获与环境因素如风或颠簸道路等相关的系统噪声。矩阵 R 吸收测量噪声或测量误差。
基于预测和校正过程的迭代更新,卡尔曼滤波器从恒定速度模型中去除噪声(上图),并呈现出右下图所示的效果。值得注意的是,输出速度估计的方差随时间减少。
这描绘了卡尔曼滤波器如何从只有一个观察源,即速度的恒定速度模型中去除噪声。如果有多个噪声观察源,它的效果会更好。例如,如果你有噪声的里程计读数和速度读数,结果会更好。
总结
卡尔曼滤波器突出了估计的必要性,并用于一些噪声通过各种来源引入的应用中。文章通过一个二维运动的例子解释了卡尔曼滤波器的内部工作原理,以过滤这些噪声。
Vidhi Chugh 是一位人工智能战略家和数字化转型领导者,致力于在产品、科学和工程的交汇点上构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作者和国际演讲者。她的使命是使机器学习民主化,并打破术语,使每个人都能参与这一变革。
相关主题
《带代码的论文》简要介绍
原文:
www.kdnuggets.com/2022/04/brief-introduction-papers-code.html

作者提供的图片
这个名称说明了一切。带代码的论文是一个包含作者或社区提供的代码实现的研究论文的平台。最近,《带代码的论文》在流行度和提供机器学习研究完整生态系统方面都得到了增长。
你可以通过使用代码、检查所有先前的实现与模型性能指标、查看数据集、模型和研究论文中使用的方法来再现结果。这是一个下一代知识共享平台,由社区驱动,开放编辑,类似于维基百科,采用 CC-BY-SA 许可证。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
除了机器学习,该平台还有针对天文学、物理学、计算机科学、数学和统计学的专业门户。你还可以查看关于热门论文、框架和代码覆盖率的所有统计数据。
图片来自 带代码的论文
任何人都可以通过点击编辑按钮进行贡献。如果你想向论文、评估表、任务或数据集添加代码,可以在特定页面找到编辑按钮进行修改。用户界面非常友好,因此找到论文或添加资源都很容易。所有提交的代码和结果都在免费的CC BY-SA许可证下。
最新技术
最新技术部分包含 6434 个基准机器学习模型,2735 个任务和子任务(知识蒸馏,少样本图像分类),65,649 篇带代码的论文。这些机器学习模型按照计算机视觉、自然语言处理和时间序列等不同研究领域进行子分类。
选择一个研究领域后,你可以探索各种子领域和结果。例如,计算机视觉子类别图像分类使用CoAtNet-7模型达到最佳准确率 90.88%。你可以查看代码实现、阅读论文、查看神经网络中使用的参数,以及类似数据集的详细比较结果。

图片来自ImageNet 基准
数据集
数据集部分包含 5,628 个机器学习数据集,你可以直接搜索数据集或根据模态、任务和语言进行筛选。你不仅能访问数据集,还能获得基于基准结果和研究论文的热门数据集的完整统计信息。
每个数据集都包含指向原始数据集论文或网站的链接。数据页面易于导航,几分钟内你可以了解模态、许可证信息、发表的论文和基于子类别的基准。例如,自监督图像分类在ImageNet上的基准是iBOT,其准确率为 82.3%。
要与 ML 社区分享你的数据集,你需要填写表单添加数据集,并提供数据集的链接和详细信息。
图片来源于机器学习数据集。
方法
该平台结构良好,组织有序,将各个部分划分为较小的子部分。最先进的模型按各种机器学习领域(计算机视觉、语音)组织,每个研究领域包含任务(目标检测、图像生成)和子任务(无监督图像分类、细粒度图像分类)。最后,这些子任务是使用各种方法(随机优化、卷积神经网络)构建的。
方法部分按类型划分,每种类型包含各种方法。例如,通用类型包括注意力机制和激活函数。每种方法都有某种变体,用于创建模型或处理数据。如果你想改善当前的机器学习系统,那么方法部分是寻找解决方案的最佳地方。
示例
让我们来发现 CoAtNet 页面上获取了哪些信息。该页面包含完整的研究论文名称和作者姓名以及社交媒体链接。你可以阅读摘要或从 arxiv 或一般出版物下载完整论文。如果你喜欢这篇研究论文并想了解代码实现和结果,请开始向下滚动页面,以发现多个 GitHub 存储库链接、任务、数据集、结果和方法。该平台通过连接机器学习生态系统的各种组件来提升研究人员的体验。

Gif 来自 CoAtNet
结论
Papers with Code 拥有多个功能,使机器学习从业者和研究人员能够学习和贡献前沿技术。该平台还提供了与 Hugging Face Spaces 的链接,并附有 GitHub 存储库,以便你体验模型的工作方式。除此之外,你还可以 镜像结果 到 Papers with Code。例如,你可以将结果添加到 Hugging Face 模型中,它将显示在 Papers with Code 上,包括数据集、模型和模型指标。
在这篇博客中,我们探索了平台的各个部分以及它如何帮助全球研究人员了解顶级研究论文。我们了解到,最先进的模型、数据集、任务、子任务和方法是如何互相连接以改善阅读体验的。由于集成和通用包容性,这是机器学习社区中最受欢迎的平台。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个人工智能产品,以帮助那些正在与心理健康问题作斗争的学生。
更多相关内容
让你的 Pandas Dataframes 变得生动活泼,使用 D-Tale
原文:
www.kdnuggets.com/2020/08/bring-pandas-dataframes-life-d-tale.html
评论
作者 Andrew Schonfeld,全栈开发者 & D-Tale 创始人
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
厌倦了在你的 dataframes 上运行 df.head()?在本教程中,我们将探索开源 Pandas 数据框可视化工具 D-Tale。我们将涉及的功能包括安装、启动、导航网格、查看列统计数据、构建图表和代码导出。
这是什么?
D-Tale 是一个结合了 Flask 后端和 React 前端的工具,为你提供了一种简单的方式来查看和分析 Pandas 数据结构。它与 ipython notebooks 和 python/ipython 终端无缝集成。目前,该工具支持 DataFrame、Series、MultiIndex、DatetimeIndex 和 RangeIndex 等 Pandas 对象。
第 1 步:安装
安装可以通过 pip 或 conda 完成
# conda
conda install dtale -c conda-forge
# pip
pip install -U dtale
源代码可以在 这里 获取
第 2 步:打开网格
在你的 Python 控制台或 jupyter notebook 中执行以下代码
import pandas as pd
import dtale
df = pd.DataFrame(dict(a=[1,1,2,2,3,3], b=[1,2,3,4,5,6]))
dtale.show(df)
你将看到以下之一:
-
Python 控制台:一个链接,根据你的终端设置,你可以点击或复制到浏览器中,这将带你到 D-Tale 网格。
-
jupyter notebook:一个包含 D-Tale 网格的输出单元格
示例
| PyCharm | jupyter |
|---|---|
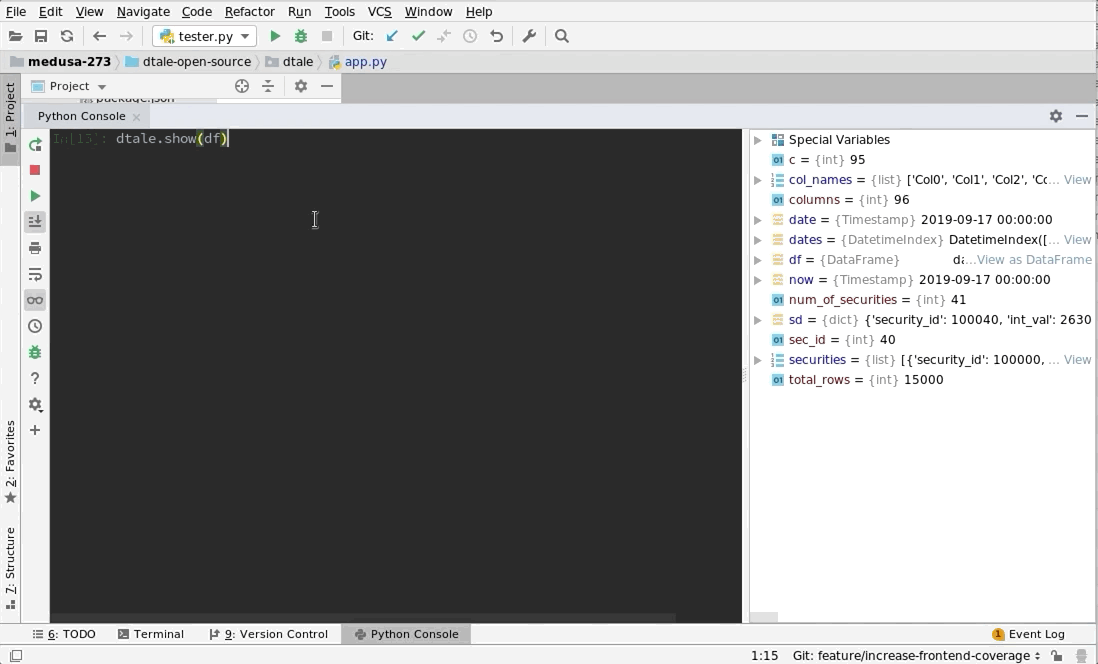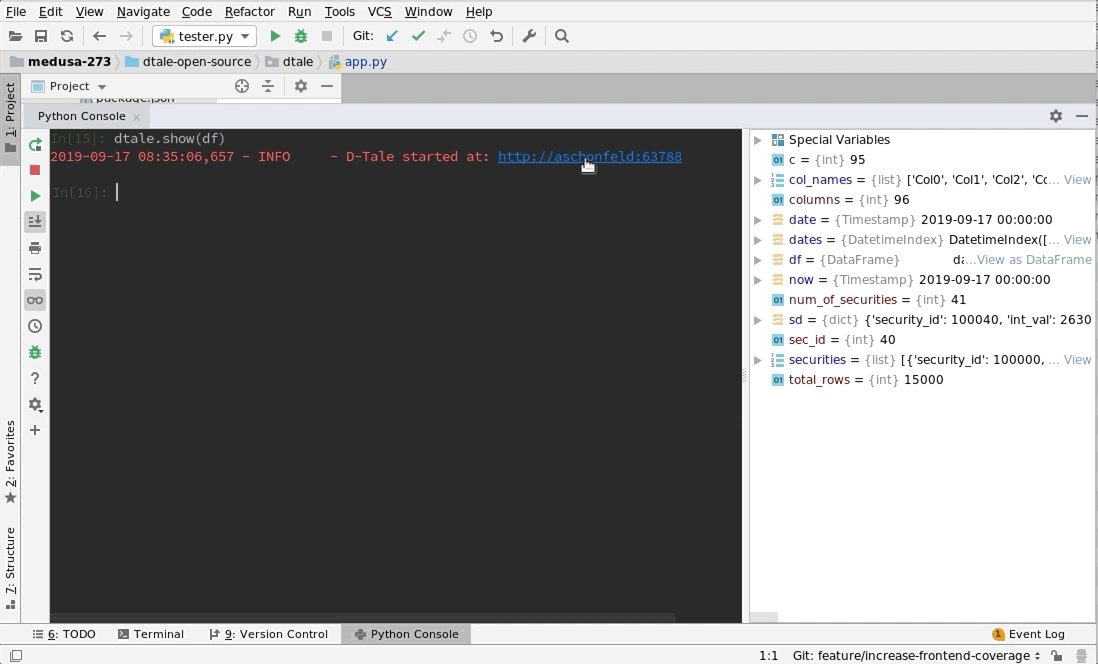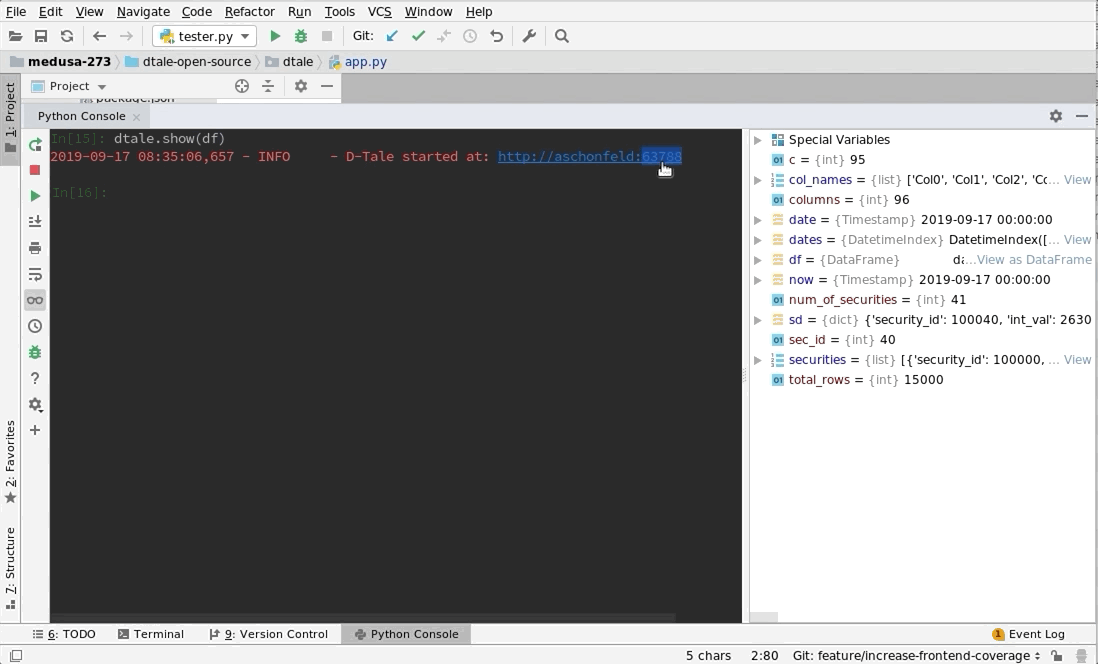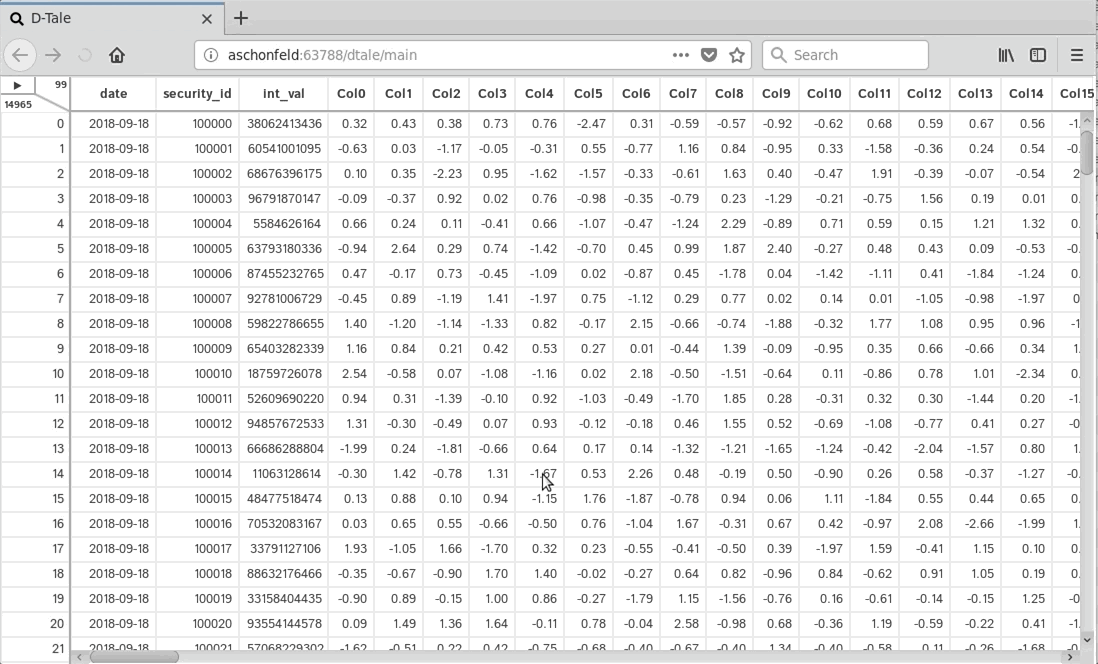 |
 |
第 3 步:导航网格
一旦进入网格,你可以通过点击列标题来使用所有标准网格功能。如果你还在 jupyter notebook 的输出单元格中,可以点击左上角的三角形,打开主菜单,然后点击“在新标签页中打开”,以便获得更大的工作空间。
|
-
排序
-
重命名
-
过滤
-
将列锁定在左侧(如果你的 dataframe 很宽,这非常方便)
 |
|---|
步骤 4:构建列
如果你通过点击左上角的三角形打开主菜单,你会看到许多选项,其中之一是“构建列”。点击该选项,你会看到许多基于现有数据构建新列的不同方法。以下是一些例子:
| 构建器 | 主菜单 | 列构建菜单 | 输出 |
|---|---|---|---|
| 转换(按组均值) | 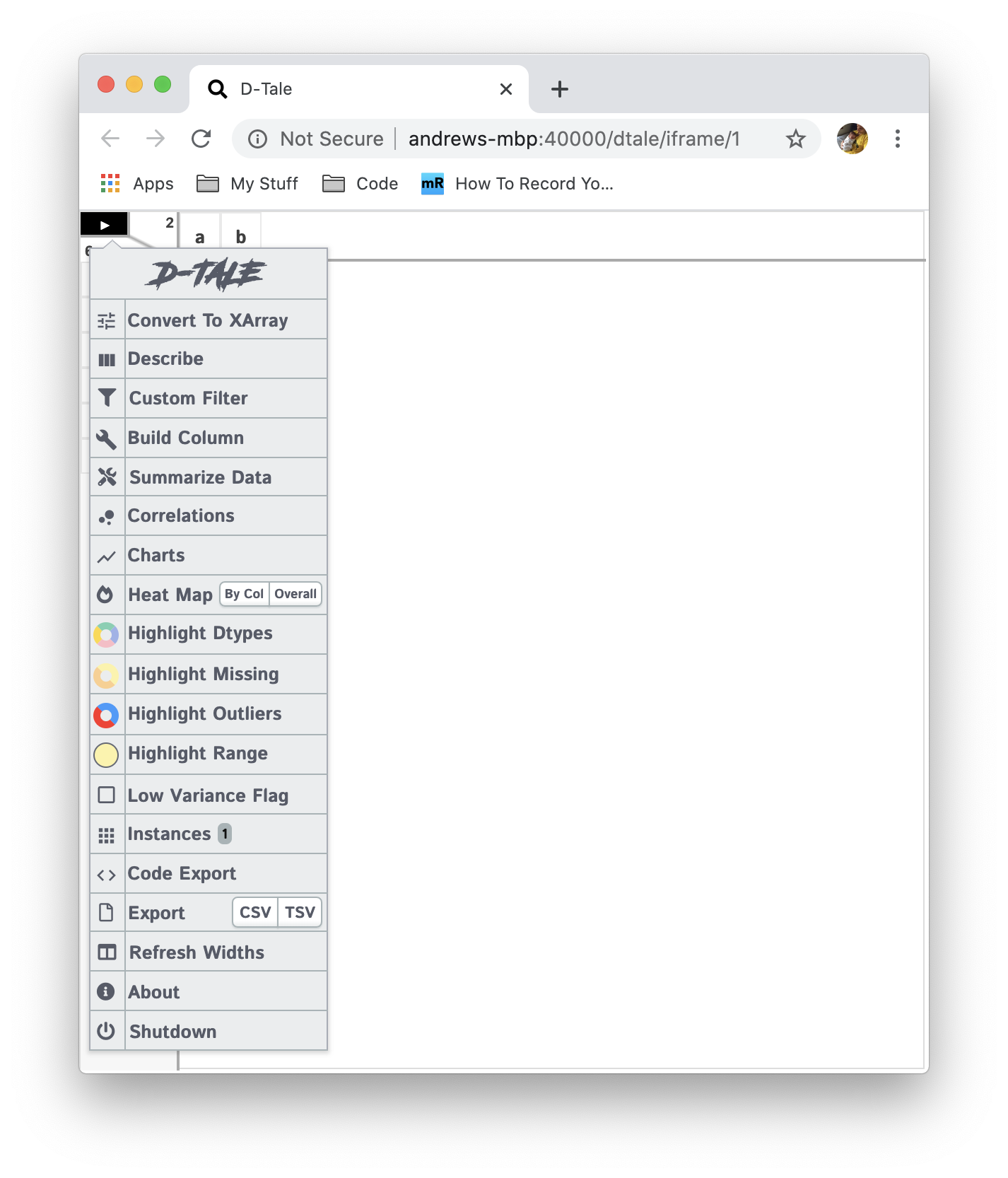 |
||
| 均值调整(减去列) | 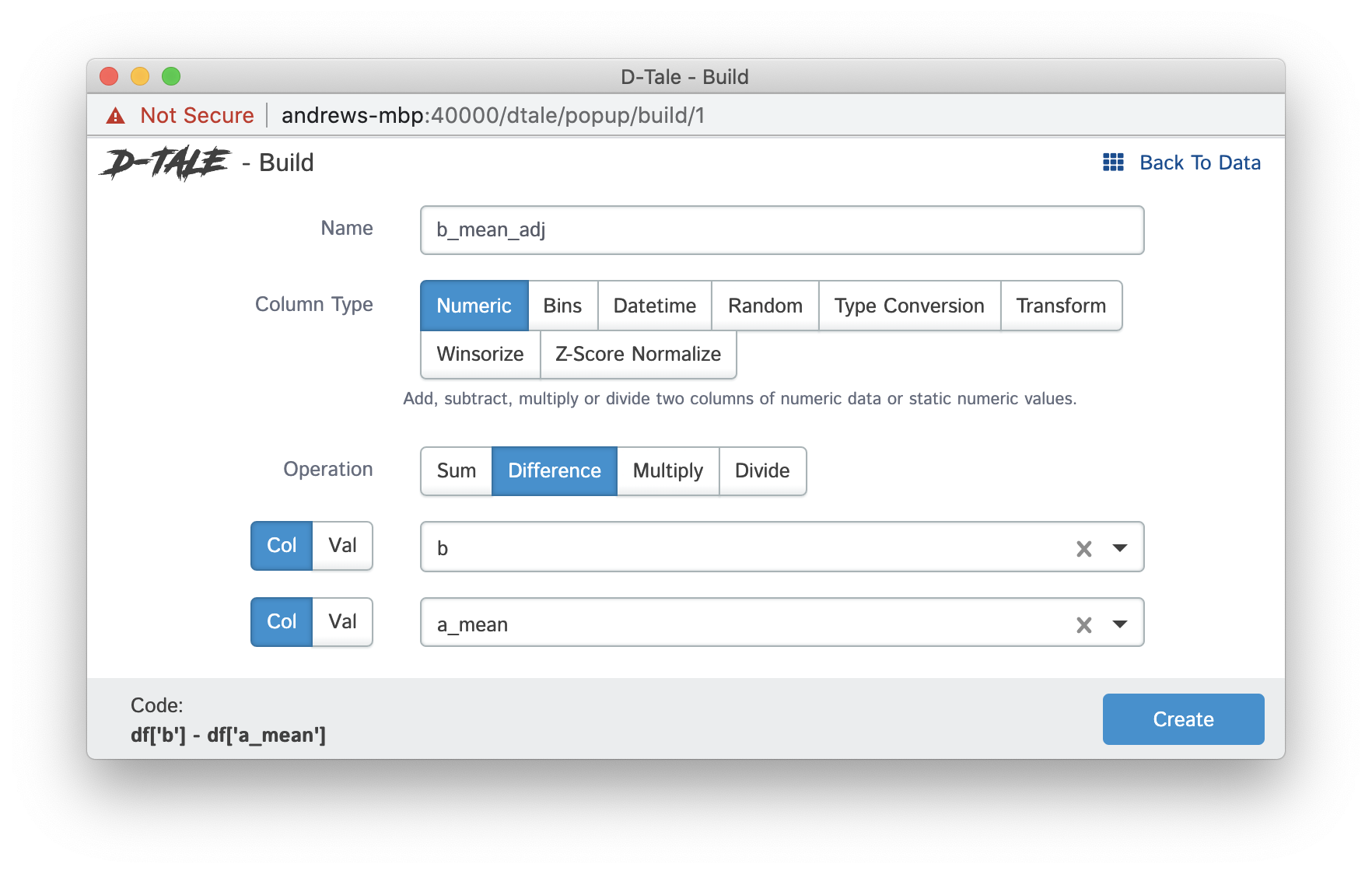 |
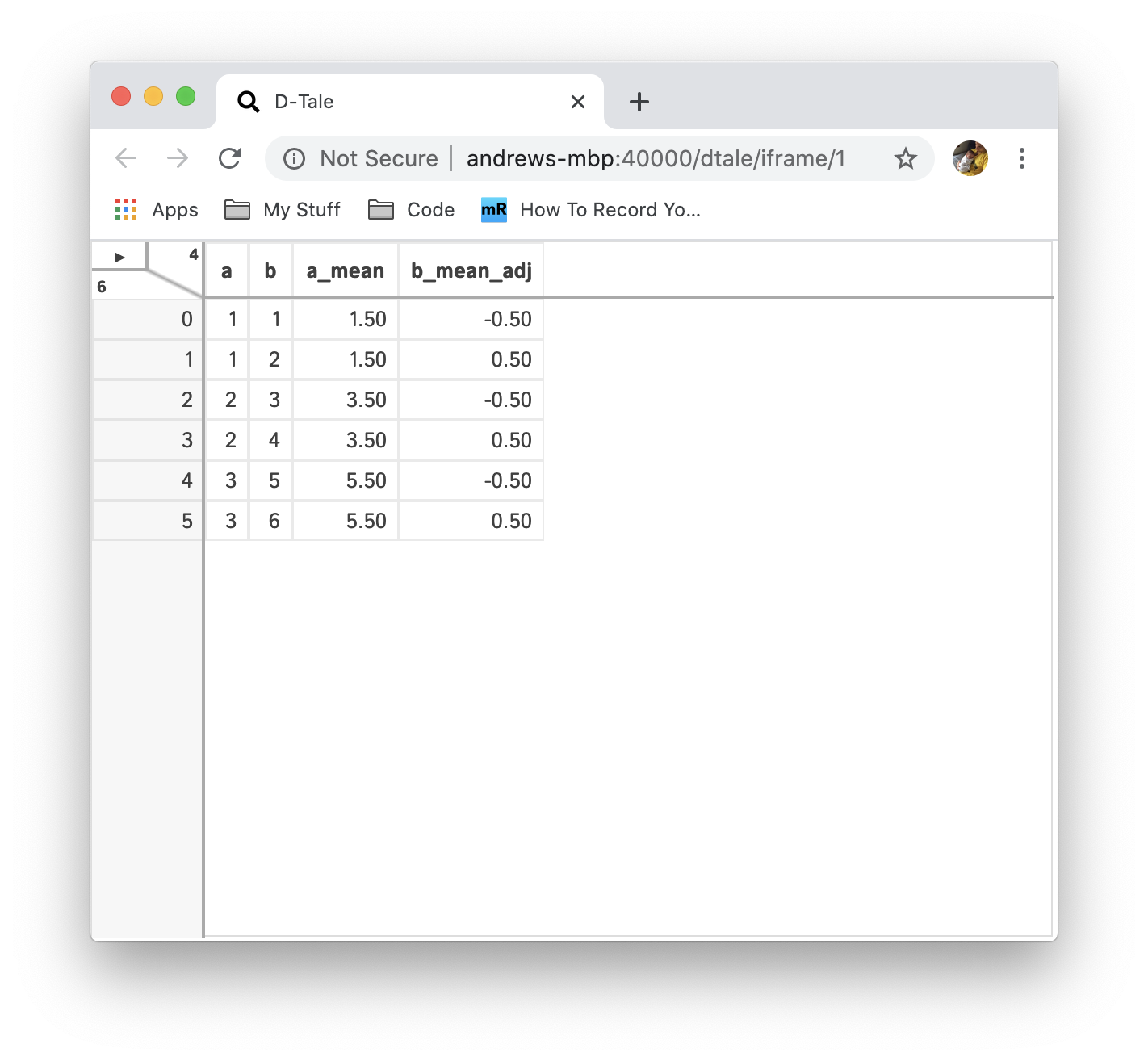 |
|
| 威布尔化 | 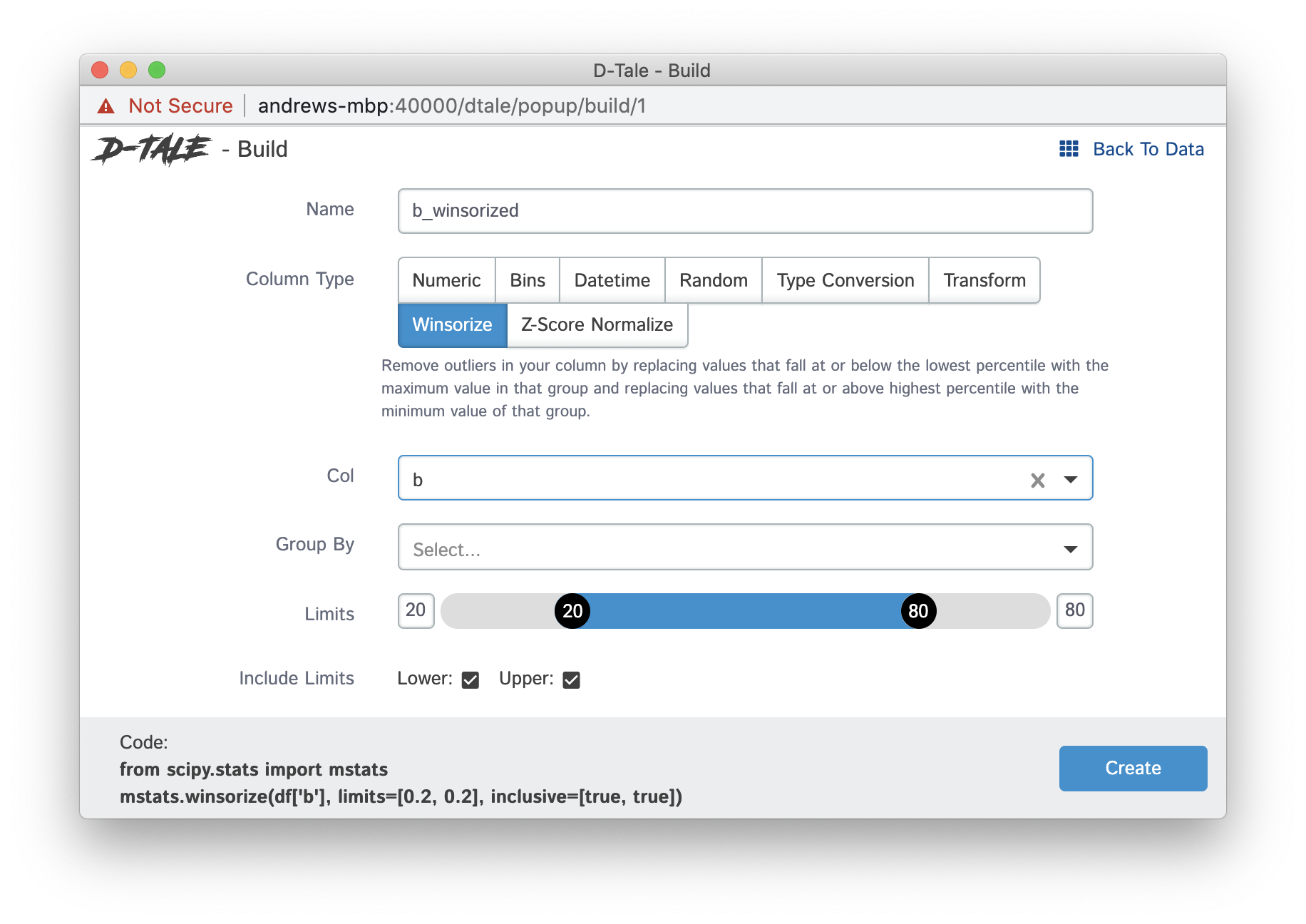 |
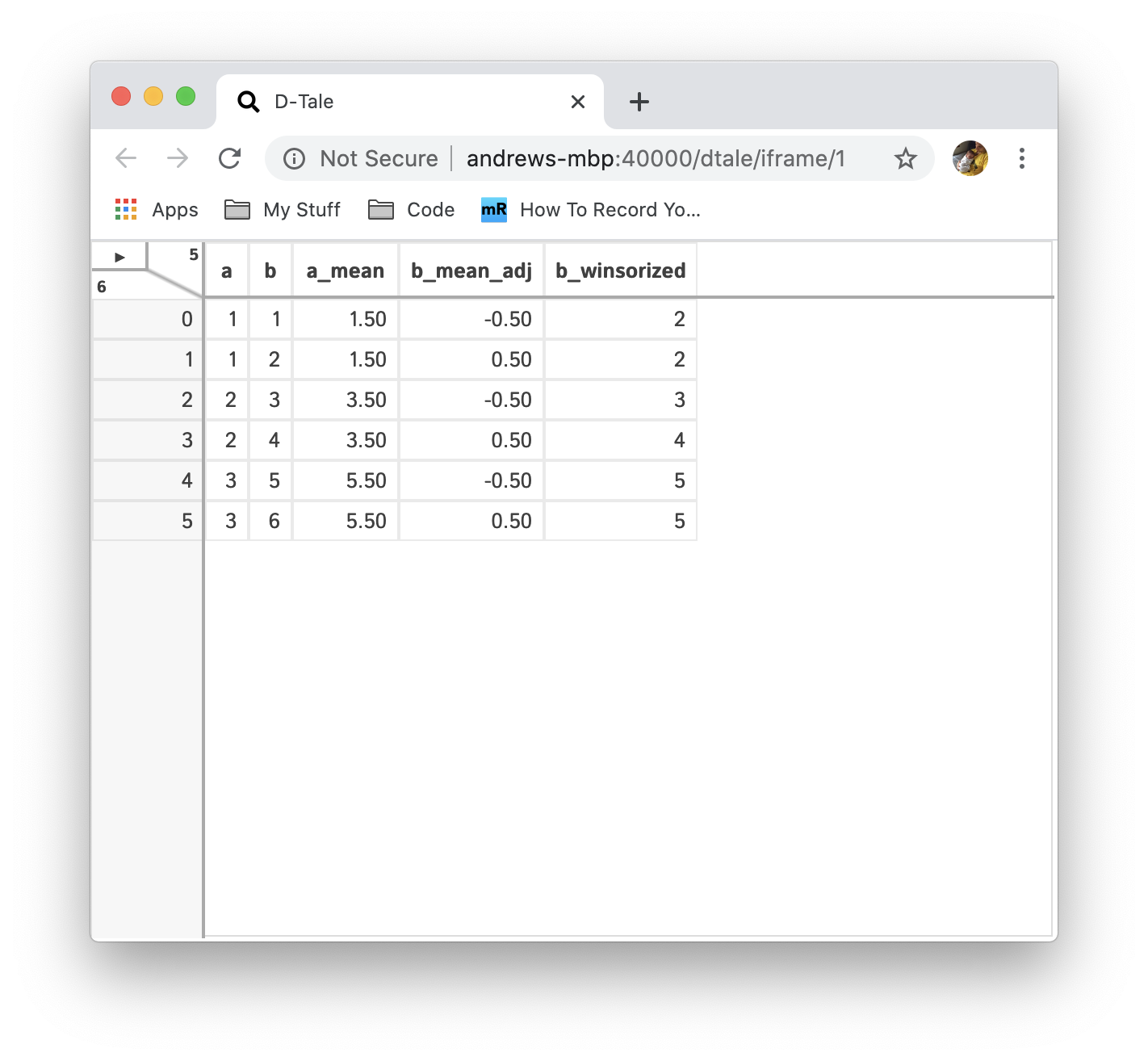 |
步骤 5:查看列统计信息
许多时候,你可能希望快速查看数据框的内容概述。一个方法是运行df.describe()。我们通过“描述”菜单选项实现了这个功能。你可以通过打开主菜单或点击列标题然后点击“描述”按钮来查看(从列标题点击将为你预选该列)。
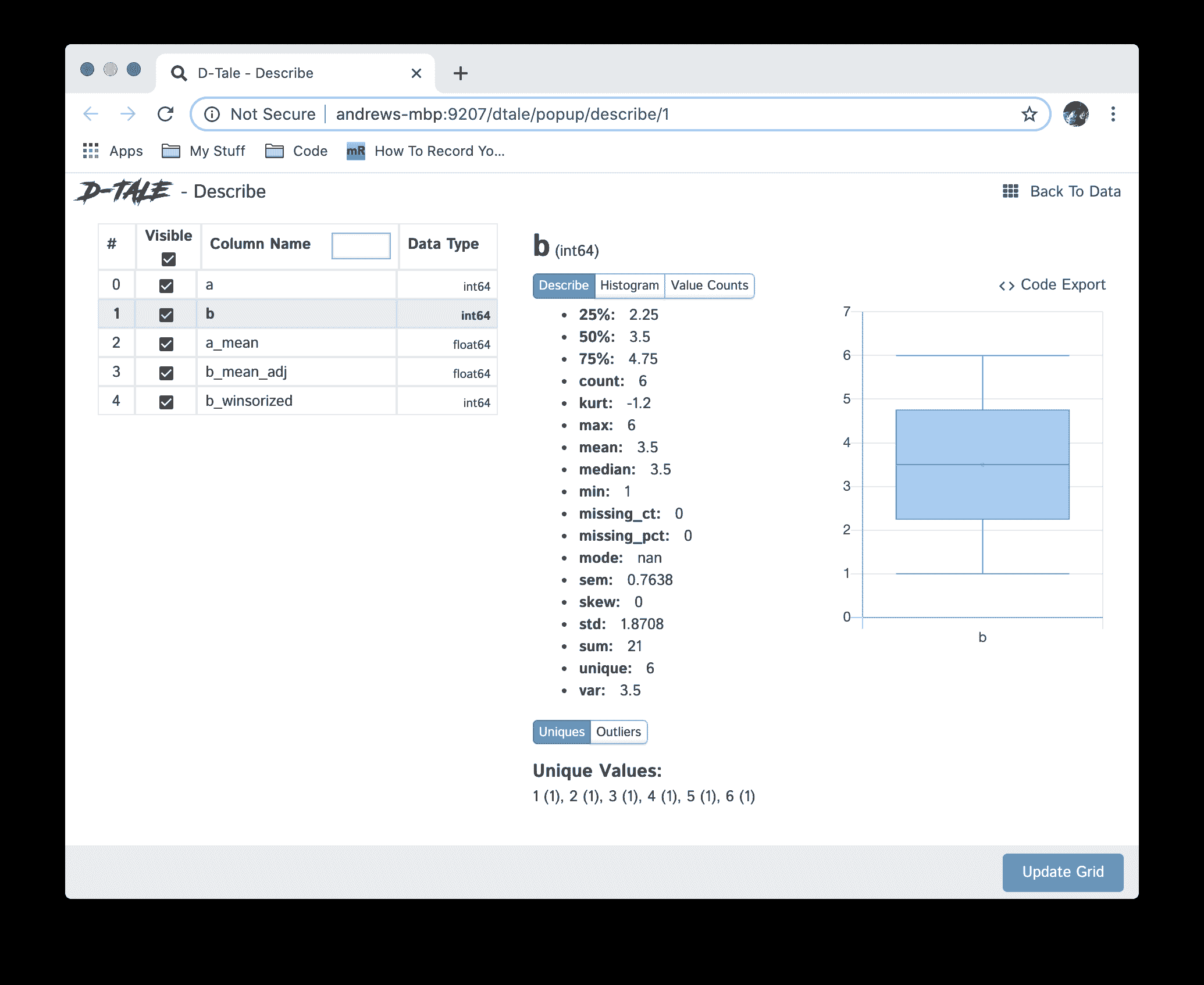
如果你查看一下,你会注意到不同统计信息的列表(这些统计信息将根据所选列的数据类型而变化)。这些统计信息是调用df.describe()对该列进行处理的结果,以及一些其他有用的统计数据,比如缺失值的百分比和峰度。你还可以查看其他有用的信息:
-
最小值、q1、 медиан、均值、q3、最大值的箱线图
-
列值的直方图
-
唯一值的计数
-
使用左侧网格切换列的可见性
步骤 6:使用你的数据构建图表
通过再次打开主菜单并点击“图表”按钮,你将进入一个新标签页,在那里你可以使用 Plotly Dash 构建以下图表:
-
线图
-
条形图
-
散点图
-
饼图
-
词云(这是一个特定于 D-Tale 的自定义插件,因此一些功能如导出可能无法使用)
-
热力图
-
3D 散点图
-
表面图
-
地图(Choropleth、Scattergeo 和 Mapbox)
这是一个示例,展示了比较原始值(a)与其分组均值(b_mean)的条形图。
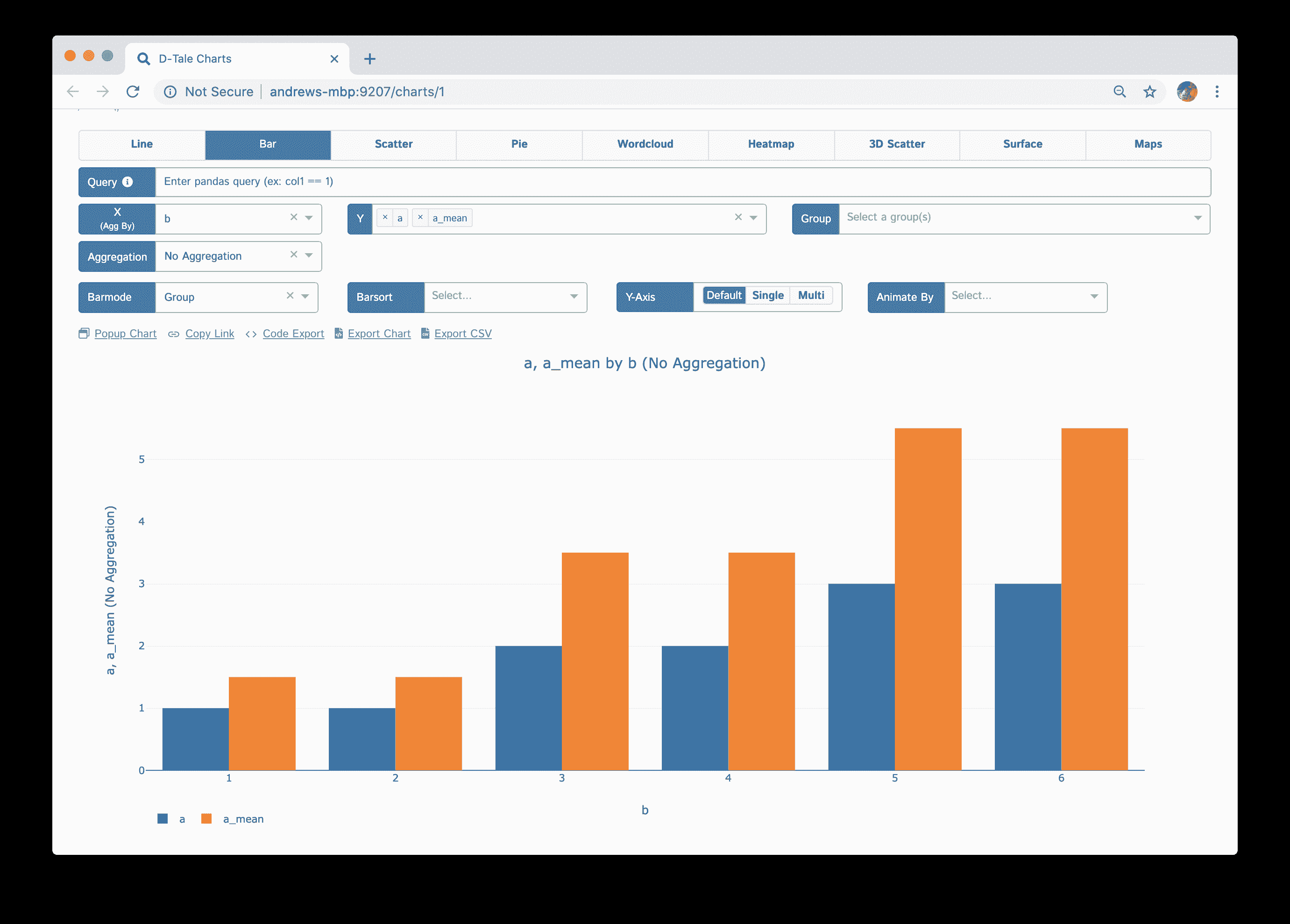
现在你还会注意到图表顶部的一些链接:
-
弹出图表:在新标签页中打开图表,以便构建另一个图表并进行比较。
-
复制链接:将图表的链接复制到剪贴板,以便与他人分享。
-
导出图表:将图表导出为静态 HTML,并以附件形式发送到电子邮件中。
-
导出 CSV:将图表的底层数据导出为 CSV。
-
代码导出:导出构建图表的底层代码,以便进行自定义或了解其构建方式。
第 7 步:代码导出
让我们看看点击图表中“代码导出”链接后的输出结果,该图表是在第 6 步中构建的。
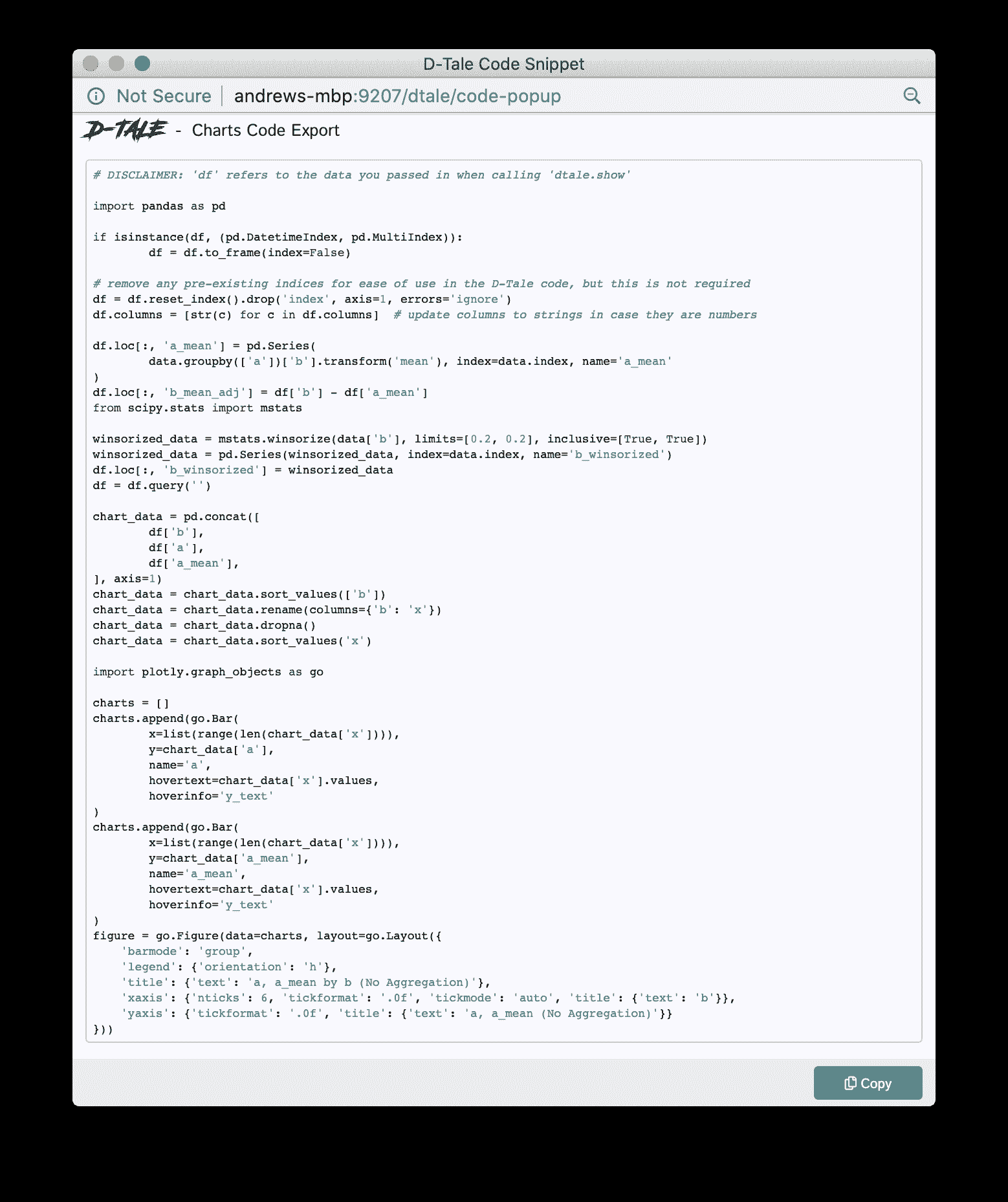
目前代码导出的目标是帮助用户了解生成图表所运行的代码,但这绝不是绝对的标准。因此,欢迎在问题页面提交建议或报告错误。
这里是一些与 D-Tale 竞争的其他工具:
感谢阅读本教程,希望它对你的数据探索有所帮助。这里还有许多其他功能我没有涉及,所以我鼓励你查看README,特别是不同的 UI 功能。如果你喜欢这个,请支持开源并给仓库点赞。😃
个人简介: 安德鲁·肖恩费尔德 作为全栈开发人员已有 14 年以上的经验。直到大约 3 个月前,他一直在波士顿从事金融工作。与数据科学团队合作并完全沉浸在 Python 中,他开始利用 Flask、Pandas 和 React 在前端构建工具套件。最终,寻找可视化 Pandas 数据框的方法成为了问题,结果便是 D-Tale。在当时公司支持下,他能够开源这个软件,并且它在数据科学社区中获得了大量关注。在过去的 15 个月里,他主要在空闲时间继续开发 D-Tale,并在波士顿和圣地亚哥的 Python 用户组以及今年 7 月的 FlaskCon 上做了演讲。
相关内容:
-
数据科学中的 Pandas 介绍
-
强化的探索性数据分析
-
使用 NumExpr 包加速你的 Numpy 和 Pandas
更多相关内容
将机器学习研究带入产品商业化
原文:
www.kdnuggets.com/2018/11/bringing-machine-learning-research-product-commercialization.html
评论
作者:Rasmus Rothe, Merantix 联合创始人
动机
上个周末,我在家与家人待了一段时间,开始反思过去几年自大学以来的经历,包括在职业不同阶段的所有兴奋和挑战。在深度学习的背景下观察到学术研究和行业研究,我发现日常生活和应用的方法之间有不少差异。
因此,在这篇博客文章中,我想分享一些关于在实际问题中应用深度学习时学术界与行业之间的差异的见解,这些差异是我们在Merantix经历的。在这些方面,我将详细探讨工作流程、一般期望以及性能、模型设计和数据需求等方面的差异。
自 2016 年我们创办了Merantix以来,我们在高度有趣但又充满挑战的行业中孵化了多个成长中的人工智能项目。这包括医疗保健,专注于乳腺 X 光自动图像诊断,或汽车领域,为全自动驾驶软件提供基于场景的测试环境。除了这些项目外,Merantix 还于 2018 年成立了一个新部门,MX Labs,该部门利用所有其他项目的能力和技术,探索新的用例,并与我们在许多行业的合作伙伴一起开发客户特定的解决方案。
可以说,我们在过去两年中在研究界建立了一个公认的品牌,并与行业专家和政治家建立了稳固的关系。在此期间,我们有机会吸取了一些非常重要的教训,因此现在觉得可以与您分享一些我们最相关的见解。
小小声明:
-
我将涵盖一系列挑战和经验,这些内容虽然不是详尽无遗,但提供了我们在各个行业面临的主要话题的结构化概述。
-
以下描述的学术界和行业的不同工作流程是实际流程的简化版。
-
尽管我们主要进行的是监督式深度学习,但许多挑战和经验对于其他类型的机器学习同样适用。
-
也许并非所有内容对您来说都是新的,但希望您至少能汲取到一些要点。
学术界与行业
当尝试将深度学习从研究转化为应用时,可以大致区分商业和技术挑战。商业挑战包括获得足够的训练数据、优化产品市场契合度、处理法律法规问题,以及最终成功进入市场。然而,这篇博客主要关注技术方面,接下来我会尽量引用行业特定的经验。
最重要的是,需要了解学术界与行业的工作差异,即两者的不同要求及其背后的原因,以及这两者本身的工作流程。

图片:学术界与行业的工作流程。
在学术界,研究人员通常从一个固定的训练数据集开始,比如 MNIST 或 ImageNet,她想在其上训练一个特定的模型。终极目标是开发新方法或调整现有方法,以在某些百分比点上提高模型性能,超越当前的最先进技术。通过这样做,研究人员在学术界建立了新的最先进技术,并可能将其结果发表在论文中。虽然这是一个具有挑战性和繁琐的过程,但这个工作流程相对直接。
然而,行业的工作流程通常是相反的。你从一个固定的性能要求开始,比如在乳腺 X 光筛查中达到 90% - 95%的癌症检测率(在灵敏度和特异性之间存在权衡),或者在每 10 亿英里内只发生一次严重事故或脱离情况。然后,你才开始考虑部署特定的模型以及所需的训练数据,以充分训练该模型以满足性能要求。实际上,关于模型和数据有很多灵活性,只要它们满足用例的要求,就不需要最先进的技术。然而,可能会有其他限制条件,比如可解释性或快速干预,我将在下面详细解释。
总的来说,区分学术界与行业是至关重要的,尤其要记住两者的工作流程是相反的,如上图所示。这反过来对如何成功地将研究成果转化为应用有很多影响。因此,我将讨论我们在 Merantix 过去两年中获得的一些见解,这些见解涵盖了 1) 性能,2) 模型 和 3) 数据这三章。
1. 性能
满足二元成功标准
在机器学习驱动的产品开发和商业化中,理解成功标准相对“二元”而非学术界的统计指标非常重要,后者定义了与当前研究最前沿相比的持续成功。虽然在学术界,特定机器学习任务的 70%表现可能是一个显著的成功(只要它比其他人更好),但商业应用要求最高的功能性和可靠性。事实上,这导致了对人工智能系统的部分扭曲、偏见和不理性的认知。因此,2018 年 3 月一辆自动驾驶 Uber 车辆的单次致命碰撞似乎在媒体中引起了比每年由人类司机造成的 130 万人道路交通死亡更多的关注。这意味着,即使机器学习算法在驾驶汽车或检测癌症方面平均优于人类,一次致命碰撞或假阴性仍可能被视为更糟。因此,为生产设定正确的范围以及理解和塑造公众认知非常重要。

图片:期望与现实。
定义(并限制)产品范围
关于上述提到的二元成功标准,许多机器学习应用具有非常严格的错误阈值,低于该阈值无法实现商业成功。这意味着,没有公司会销售偶尔会发生碰撞的自动驾驶汽车,也没有放射科医生会购买偶尔无法检测出癌症的软件——即使算法在平均水平上超越了人类,这一点仍然成立。
因此,设定正确的范围,从而将性能限制在特定环境或用例中,是机器学习产品开发中最关键的步骤之一。一般来说,期望模型的总体性能达到完美是不太现实或极为雄心勃勃的。然而,商业成功至少与设定产品范围一样依赖于实际神经网络性能。通常,如果机器的表现与人类相当或更好,它将开始变得具有商业吸引力。然而,即使在性能尚未足够好的情况下,也有两种方式可以增加商业价值:
-
限制环境: 领先的科技公司和汽车行业的 OEM 通过为自动驾驶定义所谓的操作设计领域(ODD)来执行这一策略。ODD 描述了在特定的驾驶自动化系统或其功能被专门设计以正常运行的操作条件,包括但不限于环境、地理和时间限制,以及/或某些交通或道路特征的必要存在或缺失。换句话说,通过声明自动驾驶车辆最初将被限制在特定的城市区域、公交线路或高速公路上,他们限制了产品的范围,从而能够保证一定的性能和可靠性。
-
将模型视为支持系统: 如果性能还不足以成为完全独立和普遍适用的产品,可以选择将模型作为决策支持系统出售,这在医疗领域相当常见。所谓的计算机辅助检测系统(CAD)充当“第二视角”,确保放射科医生不会遗漏图像中的任何可疑区域。它们不提供诊断,但能够分析模式,识别和标记可能含有异常的可疑区域。在第二步中,这些标记将由专业人员彻底检查和分类。另一个我们观察到机器学习模型作为支持系统的行业是增强客户服务和支持。尽管性能不足以完全取代人类,但可以采取一些过渡步骤,并且系统可以帮助简化流程以提高整体效率(例如增强消息传递、改进电话沟通、组织电子邮件查询)。
预测不确定性
在实际应用中部署的深度学习模型无论输入如何总会返回一个预测。然而,对于许多应用来说,接收与预测相关的不确定性也是有用的。在医学影像的情况下,算法能够对任何类型的输入图像做出预测,而基于不确定性可以决定是否需要医生再次检查结果。有人可能认为可以用 softmax 概率作为不确定性的度量。然而,这是一种严重的误解,如下图所示,对于二分类问题:将函数均值的点估计传入 softmax 将会产生一个高度自信的预测。当将分布(阴影区域)传入 softmax 时,输出的平均值要低得多(更接近 0.5)。
在传统的机器学习中,当不确定性发挥作用时,通常使用贝叶斯技术。新兴的贝叶斯深度学习领域正在尝试将这两个世界结合起来。尽管大多数提出的方法到目前为止结果有限,并且通常带有较大的计算开销,但该领域仍然充满希望,需要密切关注。
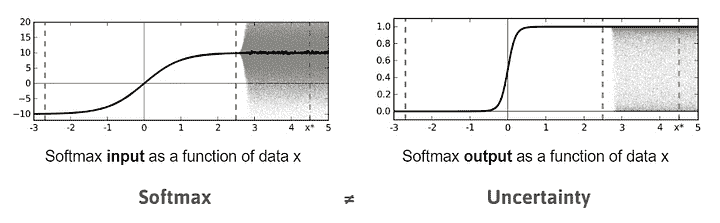
图像:Softmax 概率并没有表达不确定性。这可以通过查看数据点的分布而不是均值来理解。Gal & Ghahramani (2015).
了解你的目标环境
为了成功部署一个机器学习系统,必须确保它不仅在训练集上有效,而且在现实世界中也能正常工作。在机器学习中,为了衡量模型的性能,你通常会先在一个不同的训练数据集上训练它,然后使用一个单独的测试数据集进行评估。对于后者,数据尽可能与现实世界相似至关重要,希望模型在测试集上成功后也能在实践中有效。然而,这个过程,特别是测试数据集的设计,可能非常困难,因为需要非常了解目标环境,即了解相关的背景、动态元素以及对环境本身的影响。为了详细说明这个问题,我们来考虑几个行业类别的例子:
-
相关背景: 理解相关背景意味着了解所有可能的元素、条件及其结果。在自动驾驶的背景下,这包括在设计实际测试集之前详细了解城市、天气、代理以及所有其他重要因素。对于医疗视觉,这意味着理解技术和图像质量的差异以及筛查和诊断设置之间的差异。
-
动态元素: 更进一步,理解目标环境包括所有自然的、不可避免的时间变化,因此不仅限于特定的日期或时间点。想象一下,在一个只包含马车的环境中训练和测试一个模型。当你想要部署系统时,街道上已经开满了汽车。虽然这是一个过于简单化和夸张的例子,但很明显,OEM 和科技公司迟早需要包含自动驾驶车辆的训练数据。另一方面,医疗视觉公司则需要根据技术设备的变化调整测试集。
-
对环境的影响: 部署模型对目标环境本身的影响是理解目标环境中最具挑战性的方面,因为在测试时无法轻易测量和预见。例如,行人对环境中自动驾驶车辆日益增加的存在的反应就是一个例子。可以想象,一些行人看到没有驾驶员的完全装备的自动驾驶车辆时,可能会感到焦虑,不愿在过街道时横穿马路。关于医疗保健和乳腺 X 光检查,当部署的软件对使用它的放射科医生产生偏见时,也可能出现这些困难。或者,由于这种解决方案提供了更大的可行性和可及性,整体人口和分布可能随时间而异。
总结上述例子表明,由于数据和目标环境的变化,即使软件已经部署并投入使用,继续构建新的、更准确的测试集是至关重要的。
不要在你的测试集上过拟合
关于性能的最后一个见解再次与测试集的使用有关。Recht 等人(2018)的研究表明,最佳模型的令人印象深刻的准确性可能是由于多年来重复使用相同、不变的测试集。当收集一组新的未见图像以测试模型时,这些图像在数据分布上与原始图像非常相似,准确性下降了 4 - 10%。这表明这些模型的卓越性能在许多情况下是基于所谓的过拟合——在这种情况下是对测试数据集的过拟合。

图像:新收集的测试集准确性下降。
回到将机器学习研究应用于实际的情况,上述结果意味着:即使在一个非常好的测试集中,该测试集在前一章中足够代表现实世界,也必须始终考虑在先前评估模型性能时可能间接过拟合到特定测试集的可能性 - 可能还会有多次。如果要最小化这种风险,建议尽量少在“真实测试集”上评估,甚至仅评估一次。如果必要,仍然可以在不同的验证集上进行测试,通常建议定期更新测试集。
2. 模型
将损失函数对齐到业务目标
在设计模型时,优化正确的方面并将性能指标与正确的学习任务或业务目标对齐非常重要,即将损失函数尽可能接近用户的效用。例如,在交易的背景下,与其优化市场行为的完美预测,不如将损失函数设计与盈利能力相关。此外,在医疗保健中,与其追求最佳的整体检测准确性,优化少数假阴性可能更具影响力。在乳腺癌筛查的情况下,97%的检查结果是正常的。这就是为什么我们将神经网络对齐,以自动区分可疑的与正常的检查,提供无需人工干预的正常检查的结构化报告,筛选并将复杂病例转发给子专业的专家,同时提供基于风险的决策支持。这个过程就是我们所称的智能筛查。
考虑不平等的误分类成本
虽然在研究模型中将一张狗的照片误分类为猫不会产生实际成本,但在实际应用中,这种负面后果可能是巨大的。这一点在医疗保健中尤其相关,因为成本不仅仅是金钱方面的,还会影响到一个人的健康。乳腺 X 光检查的目标是检测无症状女性的癌症。乳腺 X 光检查的潜在结果是女性健康状况(健康/生病)和相应诊断(阳性/阴性)的组合。当健康的患者得到阴性诊断而生病的患者得到阳性诊断时,分类是有效的。然而,分类可能会由于不平等的负面后果而失败。如果健康的人被错误地诊断为癌症(即假阳性),她将不必要地接受活检,这可能导致心理压力和生理副作用。虽然这些后果已经很严重,但错误地将生病的患者诊断为健康(即假阴性)则更加严重,因为这会显著增加死亡率。
让你的模型可解释
与学术界的关注点在于性能和准确性不同,工业界非常重视可解释性和透明性。换句话说,工业界和监管机构都不喜欢神经网络黑箱,即输入和输出系统而不知道其内部工作原理的系统。在许多情况下,很难理解算法对一组数据输入给出特定响应的原因。

图片:黑箱问题。Sidney Harris 的漫画。
此外,在某些机器学习应用中,实际上关注的并不是模型本身,而是理解底层系统。例如,一家公司可能更感兴趣的是从业务角度理解客户流失的动态和原因,而不是通过机器学习应用程序进行逐步优化。
然而,在神经网络的复杂性和可解释性方面存在巨大矛盾:深度学习之所以被使用,是因为现实世界无法用简单规则来捕捉。换句话说,复杂的使用案例需要复杂的模型。因此,提出一个简单的规则来解释深度学习系统本身将非常困难。由于模型复杂性通常与其可解释性呈反比,我们常常会在各种使用案例中看到权衡取舍。
图片:复杂性-可解释性权衡。
不过,值得注意的是,这个领域的研究正在不断增长。深度神经网络的可视化变得越来越相关。使用这些方法,可以检查模型是否实际上是基于相关对象而不是相关联对象来分类图片。例如,我们将能够判断模型是否基于船本身而不是环绕船只的海洋来识别船只。然而,使用这些方法时必须小心。正如Adebayo et al. (2018)最近的论文中所示,他们描述了一系列随机实验来验证这些方法,一些方法可能在人类眼中看起来令人愉悦,但并未提供关于模型参数如何与输入数据相关或输入数据与其标签之间关系的解释能力。
在 Merantix,我们去年开源了一款名为 Picasso 的深度学习可视化工具箱(Medium Post,Github)。由于我们处理各种神经网络架构,我们开发了 Picasso,使其能够方便地查看不同工业应用中的模型标准可视化。
演示:Picasso可视化工具。
规模至关重要
在为工业应用设计神经网络时,模型的大小是另一个非常重要的方面,因为它会影响性能。在工业界,我们面临计算和连接的限制,如内存、带宽或执行速度的限制。考虑到这一点,很明显,复杂深度神经网络面临的一个关键挑战是使它们在不牺牲显著准确性的情况下,在较低质量的硬件上运行更快。以自动驾驶为例:如果你的目标是在实时识别行人、预测他们的动作并调整汽车行驶,那么简化和加速模型成为了安全部署的最重要任务之一。这一点在受到只能放置在单车上的硬件限制时尤为重要。因此,目前在模型压缩领域有大量研究,旨在加速推理过程,例如Cheng et al. (2017)。
最先进的模型通常不是必需的
与前面提到的模型大小和压缩紧密相关的是,我们在 Merantix 经常发现,当涉及到模型设计时,最新的最先进的方法可能并不总是最佳选择。事实上,许多模型和应用过度设计,以逐步提高其性能,但在实际应用中,这种改进可能不值得为实现它所需的时间和资源。此外,许多看起来极具前景的新方法只在非常简单的数据集(如 MNIST)上进行测试,未能在更困难和多样的实际数据上有效工作。在如此小而简单的数据集上测试不仅存在过拟合的风险,还不能保证对较大数据集的计算可扩展性。在实际生活和工业应用中,我们关注的是能够在多种情况和场景中工作的通用模型,以提供稳健和抵抗力强的系统。因此,尝试实施最先进的模型和研究论文并不总是有用的。
3. 数据
考虑数据获取或标记的成本效益权衡
一旦确定了业务目标、期望性能和模型设计,接下来的问题就是如何组装训练数据。一般来说,可以区分三种数据:1)现有且标记的数据,2)现有但未标记的数据,以及 3)缺失的数据。
关于第一种类型,即已经标记的数据,需要确定要执行哪些采样策略,以及模型应训练于哪个特定数据集。关于第二种类型,需要决定现有数据的哪部分需要标记,例如用于训练。在标记数据昂贵但未标记数据丰富的情况下,可以使用“主动学习”等技术,即尝试找出哪些未标记数据在标记后能为模型提供最大的 信息增益并使其改善。实际上,随着人们意识到在一些行业如自动驾驶中可能有几乎无限的数据,这一特定研究领域在过去两年里获得了很多关注,因此确定哪些数据最相关仍然是最大的挑战之一。因此,通过集成主动学习技术,可以减少训练数据获取的成本,而不影响模型性能和准确性。最后,关于缺失数据,需要评估收集更多数据的成本和收益,同时最终尝试覆盖大多数盲点和角落案例。
关注稀有样本
尤其在现实世界中,处理数据意味着处理类别不平衡。这意味着在现实世界的数据集中,一些事件极为稀少——所谓的边缘或角落案例。这些稀有示例很难收集,这导致了高昂的数据获取成本。然而,它们在解决最后 1%的最困难的机器学习任务时至关重要,例如自动驾驶或癌症检测(参见我们的相关Medium Post)。

图片:自动驾驶车辆应该为所有种类的(不)可能场景做好准备。
如前所述,将机器学习应用引入产品开发时存在二元成功标准。例如,为了推出完全自动驾驶的车辆,算法必须能够处理所有可想象的场景和风险,因此也必须覆盖长尾边缘案例。然而,这些案例在现实世界中非常难以收集或记录,使得测试和验证成为一个非常具有挑战性、缓慢且昂贵的过程。我们在 Merantix 使用的一种方法来缓解这些困难是基于场景的测试。它描述了一种在数千个非常短的驾驶场景目录上离线测试端到端自动驾驶软件堆栈的方法。这些场景可以基于现实世界的日志或模拟数据,并且被非常仔细地定义和组织。这个想法是以人类驾驶能力,如执行无保护左转或超车骑自行车的人为起点,随后非常具体地策划测试这些能力的场景。许多行业领导者如 Waymo 或 Uber 都在使用基于场景的测试。它独特的作用在于加速开发、优化资源使用,并且真正可扩展到大量的测试案例、车辆和工程师。
获取高质量注释
我想强调的最后一个关于数据的重要方面是注释的质量。由于标签可能会有噪声,特别是当由人类创建时,因此在标记数据时以及从一开始就定期监控其质量是非常必要的。这些努力和关注的原因是噪声对整体模型性能的巨大影响。如下面的图表所示,仅少量的标签污染就会导致相当显著的测试误差率。
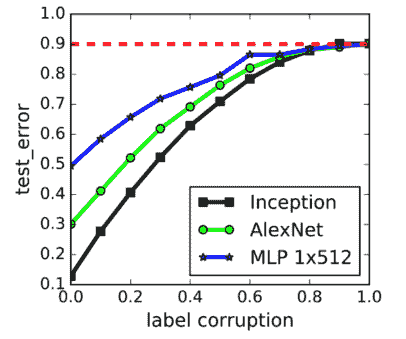
图像:标签污染的错误效应。Zhang et al. (2017)。
虽然标签污染对于那些有基础真相的简单任务来说可以很容易地缓解,即那些可以证明的客观数据(可与医学和统计中的黄金标准比较),但对于复杂任务如医学图像解读,它变得越来越困难。当进行乳腺 X 光检查时,乳房在 X 射线的帮助下被投影到一个二维的黑白图像上,该图像包含的信息远少于现实本身。因此,恶性病例的基础真相在乳腺 X 光图像中无法轻易定义,只能通过活检提取的组织检查提供。不幸的是,经过活检确认的研究非常稀少,难以获取,并且并不存在于所有类型的使用案例中。此外,乳腺 X 光图像本身的读取难度可能导致放射科医生的解读变异性很大以及高水平的标签噪声。
图像:不同放射科医生对相同图像的读者变异性。
在 Merantix,我们实施了众多流程和检查,以帮助我们减少读者的变异性和标签噪声。放射科医生会接受个别培训,学习全面的注释指南。一旦培训完成,每位放射科医生需要通过样本数据集测试才能开始为我们公司进行注释。此外,我们开发了一个自动基准系统,持续监测和比较注释者与其同行的质量。最后,我们创建了一个脚本,如果注释与回顾性放射学报告中的结果不同,该脚本会标记这些研究以供控制。
结论
在这篇博客文章中,我分享了展示学术界和工业界在机器学习中的差异的各种经验教训,以及我们在 Merantix 应用深度学习于现实世界问题时获得的一些见解。我希望你从这篇博客文章中获得的主要信息是,学术界和工业界的工作流程实际上是相互对立的,这导致了对整体性能、模型设计和数据集的不同影响和要求。我强烈希望上述提到的一些想法和方法对计划在业务中使用深度学习的其他人有所帮助和适用。如果你有任何意见或问题,请随时与我联系!如果你对将深度学习应用于现实世界问题感到兴奋,可以考虑加入我们在柏林。我们正在招聘!
致谢
-
感谢塞巴斯蒂安·斯皮特勒在撰写本文时的协助。
-
感谢 Robert、Florian、Maximilian 和 Thijs 提供的宝贵意见。
-
感谢 Clemens 和 John 对本文的审阅和反馈。
简介:拉斯穆斯·罗瑟 是欧洲领先的深度学习专家之一,也是Merantix的联合创始人。他在 ETH Zurich、牛津大学和普林斯顿大学学习计算机科学,专注于深度学习。此前,他在博士研究期间推出了howhot.io,发起了欧洲最大的黑客马拉松 HackZurich,并曾在 Google 和 BCG 工作。
原文。经许可转载。
相关:
-
将深度学习应用于现实世界问题
-
创建智能的 3 个阶段
-
如何让人工智能更易获取
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
更多相关内容
数据科学初学者 1: 数据科学回答的 5 个问题
原文:
www.kdnuggets.com/2016/07/brohrer-data-science-beginners-1-5-questions.html
从 数据科学初学者 中快速了解数据科学,通过五个简短的视频。这个视频系列对于你有兴趣从事数据科学工作或与从事数据科学的人合作,并且想从一些基础概念开始的人非常有用。
这个第一个视频是关于数据科学可以回答的各种问题。数据科学通过数字或类别来预测问题的答案。为了充分利用这个系列,按顺序观看它们。 查看视频列表
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
字幕:数据科学回答的 5 个问题
嗨!欢迎来到视频系列 数据科学初学者。
数据科学可能令人畏惧,因此我将在这里介绍基础知识,而不涉及任何方程式或计算机编程术语。
在这个第一个视频中,我们将讨论“数据科学回答的 5 个问题”。
数据科学使用数字和名称(也称为类别或标签)来预测问题的答案。
可能让你惊讶的是,数据科学回答的只有五个问题:
-
这是 A 还是 B?
-
这很奇怪吗?
-
多少 – 或者 – 多少个?
-
这是如何组织的?
-
我接下来该做什么?
这些问题中的每一个都由一组独立的机器学习方法,即算法来回答。
将算法视为食谱,将数据视为原料是很有帮助的。算法说明了如何组合和混合数据以得到答案。计算机就像搅拌机一样。它们为你完成了大部分算法的繁重工作,而且速度非常快。
问题 1: 这是 A 还是 B?使用分类算法
让我们从这个问题开始:这是 A 还是 B?

这类算法被称为二类分类。
对于任何只有两个可能答案的问题,它都很有用。
例如:
-
这个轮胎在接下来的 1000 英里内会失败吗:是还是不是?
-
哪种促销方式能带来更多客户:5 美元的优惠券还是 25%的折扣?
这个问题也可以重新表述为包含两个以上的选项:这是 A 还是 B 还是 C 还是 D,等等?这被称为多类分类,它在你有几个或几千个可能的答案时非常有用。多类分类会选择最可能的一个。
问题 2:这是否奇怪?使用异常检测算法。
数据科学可以回答的下一个问题是:这是否奇怪?这个问题由一组称为异常检测的算法来回答。

如果你有信用卡,你已经从异常检测中受益。你的信用卡公司会分析你的购买模式,以便在可能发生欺诈时提醒你。那些“奇怪”的费用可能是在你不常去的商店购物或购买异常昂贵的商品。
这个问题在很多方面都可能有用。例如:
-
如果你有一个带有压力表的汽车,你可能想知道:这个压力表的读数正常吗?
-
如果你在监控互联网,你会想知道:这条互联网信息是否典型?
异常检测标记意外或不寻常的事件或行为。它提供了寻找问题的线索。
问题 3:“多少?”或“多少个?”使用回归算法。
机器学习也可以预测“多少?”或“多少个?”的问题。回答这个问题的算法家族称为回归。

回归算法进行数值预测,例如:
-
下周二的温度会是多少?
-
我的第四季度销售额将是多少?
它们帮助回答任何要求数字的问题。
问题 4:这是如何组织的?使用聚类算法。
现在最后两个问题稍微复杂一点。
有时你想了解数据集的结构 - 这是如何组织的?对于这个问题,你没有已经知道结果的示例。
有很多方法可以揭示数据的结构。一种方法是聚类。它将数据分成自然的“簇”,以便于解释。使用聚类没有一个唯一正确的答案。

聚类问题的常见示例包括:
-
哪些观众喜欢相同类型的电影?
-
哪些打印机型号的故障方式相同?
通过理解数据的组织方式,你可以更好地理解 - 并预测 - 行为和事件。
问题 5:我现在应该做什么?使用强化学习算法。
最后一个问题 - 我现在应该做什么? - 使用一组称为强化学习的算法。
强化学习的灵感来自于老鼠和人类的大脑如何对惩罚和奖励做出反应。这些算法通过结果进行学习,并决定下一步行动。
通常,强化学习非常适合需要在没有人工指导的情况下做出大量小决策的自动化系统。

这些问题总是关于应该采取什么行动——通常是由机器或机器人执行的。示例如下:
-
如果我是一套房子的温控系统:调整温度还是保持现状?
-
如果我是一辆自动驾驶汽车:在黄灯时,刹车还是加速?
-
对于机器人吸尘器:继续吸尘,还是返回充电站?
强化学习算法在过程中收集数据,通过试错进行学习。
所以就这样了——数据科学可以回答的 5 个问题。
下一步
原文。转载已获许可。
相关:
-
Azure 机器学习工作室指南
-
构建数据科学组合:机器学习项目第一部分
-
构建数据科学组合:机器学习项目第二部分
更多相关内容
数据科学的残酷真相
评论
由 Prad Upadrashta,首席数据科学家

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
大多数数据科学家和雇佣他们的组织似乎不理解数据科学是如何实际完成的,也不完全理解它是什么。他们有点跟风——没有真正理解它,也不知道为什么它对他们如此重要。
许多组织将数据科学视为一种营销工具——将他们已经做的事情重新标记为“数据科学”,因为它涉及到数据的使用。这不是真正的数据科学,它完全错过了从事数据科学的重点。这就像是将孩子们在沙箱里玩耍与石油公司勘探油田的操作相提并论。数据科学的核心价值被忽视了,那就是科学。
科学不仅仅是预测——它的核心是解释和诊断。科学引领工程——一种系统的数学方法,用于创建基于对某些自然现象的利用的技术解决方案。
赢得 Kaggle 竞赛不是数据科学;尽管它是一个合理的开始,我想——即使 Kaggle 上最好的模型实际上是由运行遗传算法的机器构建的,自然选择驱动结果。尽管有其局限性,Kaggle 当然是一个很好的训练场,可以让人们初步涉足。
数据科学是关于理解生成数据的潜在过程或机制。它是关于利用这种知识来推导出统计上显著的价值点,推动企业的运营变革,从而创造可衡量的 ROI。它是关于以一种可重复、可扩展和迭代的方式系统地推动决策过程。
当你能将商业巫术转化为经过工程化的收入流时——那时你可以声称你已经做了真正的数据科学——这意味着你从根本上理解你的业务如何在非常细微的层面上运作。
是的,“数据科学家的 80%以上工作是清理数据”,这一说法常被重复——但这不仅仅是某种低级的无脑工作——智能清理需要你在迭代改进解决方案时,仔细关注以下几点:+ 重要的是什么 + 为什么重要 + 如何重要。应当用“策划”一词来取代“清理”。
如果你不理解最终目标,你将不可避免地搞砸起步阶段——然后疑惑为何你付出了那么多努力却看不到任何成果。你正在构建一个精心策划的数据集,以符合某种质量标准,以确保你的模型反映出你试图揭示、捕捉和/或复制的简单真理。这需要对你正在建模的内容及其固有的复杂、可能分层的结构有一些直觉。仅仅进行曲线拟合并声称“你有一个模型”几乎只是入门水平,当然也无法提供对竞争对手的可持续竞争优势。真正的问题是你是否理解你的业务科学。
你需要知道何时在“去掉脏水”的同时“扔掉婴儿”。特征工程和数据清洗之间有一条微妙的界限——你可能只是清除了那些告诉你真正发生了什么的重要内容!所以,不,任何随机的新毕业生不太可能做对这一点——这并不简单。实际上,许多我采访的数据科学家不理解数据清洗在某种程度上也是建模——因为要识别噪音,你必须有一个信号的模型!这就是为什么公司仍然愿意为那 0.1%的人才支付高价的原因。
要阅读博客的下一部分,点击这里。
简介: Prad Upadrashta 是一位高级分析执行官和经验丰富的数据科学从业者,在企业规模的 AI 思想领导、战略和创新方面拥有卓越的业绩记录。他的关注领域包括人工智能、机器/深度学习、区块链、工业物联网/物联网以及工业 4.0。
原文. 经许可转载。
相关内容:
-
为什么以及如何学习“高效的数据科学”?
-
顶级 Python 数据科学面试问题
-
何时重新训练机器学习模型?进行这 5 项检查以决定计划
更多相关内容
一种能让你成为数据科学英雄的错误
原文:
www.kdnuggets.com/2022/03/bug-make-data-science-hero.html
一种有用的错误?!?
“Bug”(错误)通常不是一个积极的词,我们通常会避免它。问问软件开发者,他们会对错误感到害怕。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT

来源:Web vector created by storyset - www.freepik.com
但如果我告诉你,有一种错误可以带你进入数据科学的世界呢?是的,如果你有好奇心这种“错误”,那你就是数据科学职业的最佳人选。
如果你不接受现状,且对了解当前一切的做法有敏锐的兴趣,你可能会最终构建出比现在更好的东西。
不是每个人都有询问“什么、为什么和怎么做”的好奇心,而不担心被评判。我们都被这种假设所塑造,认为每个人都已经考虑过我在思考的内容。
“如果我提出问题,却被贴上不合格、无能、缺乏经验和竞争力的标签怎么办?如果我没有足够的技能来提供合适的数据科学解决方案怎么办?”
这些感觉有一个名字:冒名顶替综合症。
这种情况在每个领域都存在,但在数据科学界更为普遍。考虑到机器学习概念和算法的广度和深度,冒名顶替者有其自身存在的理由。
你被期望戴上魔术师的帽子,挥动魔杖,创造出始终忠实于开发者的模型,即那个赋予它生命的人。
但这从未发生过。与人们对数据科学家的想法相反,魔法(如果存在的话)来自于数据本身。你不能随便拿任何数据集开始构建模型。
说“天下没有免费的午餐”的人并不是在开玩笑。这是真的——每一个商业问题都是不同的,它的目标、数据、特征和生命周期也是如此。
回到我们最初关于好奇心的讨论,嗅探的数据科学家对这种虚假的感觉免疫,不会被“如果我不行怎么办”的思想困扰。
好奇的数据科学家会抓住每一个机会,通过解决给定的问题留下足迹。
这并不容易
拥有天生的好奇心听起来像是一个容易培养的特质,但相信我,这并非如此。
像其他力量一样,若使用不当,会产生低效回报,同样在这里也适用。你不能忽视论坛中大多数人讨论的内容,也不能反复提问。
为了挑战现状,即当前解决方案的状态,你需要展示范围并执行差距分析。这被称为机会评估。
你不能仅仅靠直觉开始工作。首先,它需要有进一步改进的空间。
触手可及的成果
从 0 到 70%的进展相对容易,通过从零开始并获得巨大的回报。但一旦生成了基线,在此基础上进行边际改进并不容易。
来源:作者
你可以列出若干具有潜在改进空间的事项,但这完全不在你控制之中。业务必须采纳你的建议,并决定哪个问题有更高的时间和资源回报率,可以被视作快速胜利。
由于你无法一次性处理所有业务问题,你需要与业务部门商讨优先级,确定哪些更能增值。
在承诺之前请注意
数据科学的核心是发现业务问题并构建数据驱动的解决方案。首先,数据需要到位,并且必须有可学习的模式。
模式识别,根据定义,包括利用机器学习,借助大数据的日益普及和新的计算能力。
请注意,一旦你加入,事情并非一成不变。你可能会发现自己在从事自动化工作,设计简单的启发式方法以获得早期业务收益,尽管没人会明确告诉你这是工作的一部分。
因此,准备好接受这样的事实:并非所有数据科学家都会一直从事所有‘优质’建模工作。
现实检查时间
来源:背景矢量由 redgreystock 创建 - www.freepik.com
私下里说,他们负责所有与数据相关的事务,以实现业务目标。
一般来说,业务对使用哪种算法和如何解决问题并不特别关注。他们期望你理解他们的痛点,并利用数据来克服这些问题。你有责任向高管和利益相关者展示机器学习可以解决哪些问题,哪些仅是装饰。
提出问题以理解你的解决方案如何增值。识别并解释使用机器学习解决问题的利弊。
简而言之,如果你专注于提升业务数字的最终目标,那么所有使用的工具和技术都会成为你的盟友。
保持那份孩子般的好奇心
儿童在提问时没有任何偏见——无论相关与否。尽管我们专业人士不能在公开场合提出不相关的问题,但谁知道什么是相关的,什么不是?如果你需要这些信息来交付解决方案——就问吧。数据科学是一个迭代过程,需要频繁地发现“为什么”。
没有一个人能够完全掌握所有知识并单独完成所有任务,因此需要强大的团队合作。如果大家能共同头脑风暴并识别行动项,旅程将变得更加轻松。
但你不能等待其他人与你达成共识,因此,你有责任保持好奇心,成为你数据科学解决方案的英雄。
Vidhi Chugh 是一位获奖的 AI/ML 创新领导者和 AI 伦理学家。她在数据科学、产品和研究的交叉点工作,以提供业务价值和洞察。她是数据驱动科学的倡导者,并且在数据治理领域是领先的专家,致力于构建值得信赖的 AI 解决方案。
更多相关内容
用 Python 轻松构建命令行应用程序的 7 个步骤
原文:
www.kdnuggets.com/build-a-command-line-app-with-python-in-7-easy-steps

作者提供的图片
构建简单项目是学习 Python 和任何编程语言的绝佳方式。你可以学习写 for 循环的语法、使用内置函数、读取文件等等。但是,只有当你开始构建某些东西时,你才会真正“学习”。
采用“通过构建学习”的方法,让我们编码一个可以在命令行中运行的简单待办事项应用程序。在此过程中,我们将探索诸如解析命令行参数、处理文件和文件路径等概念。我们还将重新审视定义自定义函数等基础知识。
所以让我们开始吧!
你将构建的内容
通过跟随本教程进行编码,你将能够构建一个可以在命令行中运行的待办事项应用程序。好吧,那么你希望这个应用程序具备什么功能呢?
像纸上的待办事项列表一样,你需要能够添加任务、查看所有任务,并在完成后删除任务(是的,在纸上划掉或标记完成)。所以我们将构建一个可以实现以下功能的应用程序。
将任务添加到列表中:
作者提供的图片
获取列表中所有任务的清单:
作者提供的图片
以及在完成后使用索引删除任务:
作者提供的图片
现在让我们开始编码吧!
第 1 步:开始
首先,为你的项目创建一个目录。在项目目录中,创建一个 Python 脚本文件。这将是我们的待办事项列表应用程序的主要文件。我们称之为 todo.py。
这个项目不需要任何第三方库。因此,只需确保你使用的是最新版本的 Python。本教程使用 Python 3.11。
第 2 步:导入必要的模块
在 todo.py 文件中,首先导入所需的模块。对于我们的简单待办事项列表应用程序,我们需要以下模块:
所以让我们导入这两个模块:
import argparse
import os
第 3 步:设置参数解析器
请记住,我们将使用命令行标志来添加、列出和删除任务。对于每个参数,我们可以使用短选项和长选项。对于我们的应用程序,使用如下选项:
-
-a或--add用于添加任务 -
-l或--list用于列出所有任务 -
-r或--remove用于通过索引删除任务
这里我们将使用 argparse 模块来解析在命令行提供的参数。我们定义了create_parser()函数,完成以下操作:
-
初始化一个
ArgumentParser对象(我们称之为parser)。 -
为添加、列出和删除任务添加参数,通过在解析器对象上调用
add_argument()方法。
添加参数时,我们添加了短选项和长选项以及相应的帮助信息。所以这是create_parser()函数:
def create_parser():
parser = argparse.ArgumentParser(description="Command-line Todo List App")
parser.add_argument("-a", "--add", metavar="", help="Add a new task")
parser.add_argument("-l", "--list", action="store_true", help="List all tasks")
parser.add_argument("-r", "--remove", metavar="", help="Remove a task by index")
return parser
第 4 步:添加任务管理函数
我们现在需要定义函数来执行以下任务管理操作:
-
添加任务
-
列出所有任务
-
根据索引移除任务
以下函数add_task与一个简单的文本文件交互,以管理 TO-DO 列表中的项目。它以‘追加’模式打开文件,并将任务添加到列表末尾:
def add_task(task):
with open("tasks.txt", "a") as file:
file.write(task + "\n")
注意我们如何使用with语句来管理文件。这样可以确保文件在操作后关闭——即使发生错误——从而最小化资源泄漏。
要了解更多信息,请阅读本教程中的上下文管理器章节,以高效处理资源。
list_tasks函数通过检查文件是否存在来列出所有任务。文件仅在你添加第一个任务时创建。我们首先检查文件是否存在,然后读取并打印任务。如果当前没有任务,我们会得到一条有用的信息:
def list_tasks():
if os.path.exists("tasks.txt"):
with open("tasks.txt", "r") as file:
tasks = file.readlines()
for index, task in enumerate(tasks, start=1):
print(f"{index}. {task.strip()}")
else:
print("No tasks found.")
我们还实现了一个remove_task函数来根据索引删除任务。以‘写入’模式打开文件会覆盖现有文件。所以我们删除对应索引的任务,并将更新后的 TO-DO 列表写入文件:
def remove_task(index):
if os.path.exists("tasks.txt"):
with open("tasks.txt", "r") as file:
tasks = file.readlines()
with open("tasks.txt", "w") as file:
for i, task in enumerate(tasks, start=1):
if i != index:
file.write(task)
print("Task removed successfully.")
else:
print("No tasks found.")
第 5 步:解析命令行参数
我们已经设置了解析器来解析命令行参数。同时,我们也定义了执行添加、列出和删除任务的函数。那么接下来是什么?
你可能已经猜到了。我们只需根据接收到的命令行参数调用正确的函数。让我们定义一个main()函数,使用我们在第 3 步创建的ArgumentParser对象来解析命令行参数。
根据提供的参数,调用相应的任务管理函数。这可以通过一个简单的 if-elif-else 梯形结构来完成,如下所示:
def main():
parser = create_parser()
args = parser.parse_args()
if args.add:
add_task(args.add)
elif args.list:
list_tasks()
elif args.remove:
remove_task(int(args.remove))
else:
parser.print_help()
if __name__ == "__main__":
main()
第 6 步:运行应用程序
你现在可以从命令行运行 TO-DO 列表应用程序。使用短选项h或长选项help来获取使用信息:
$ python3 todo.py --help
usage: todo.py [-h] [-a] [-l] [-r]
Command-line Todo List App
options:
-h, --help show this help message and exit
-a , --add Add a new task
-l, --list List all tasks
-r , --remove Remove a task by index
起初,列表中没有任务,因此使用--list列出所有任务时会打印“未找到任务。”:
$ python3 todo.py --list
No tasks found.
现在我们可以这样向 TO-DO 列表中添加一项:
$ python3 todo.py -a "Walk 2 miles"
当你现在列出项目时,你应该能看到添加的任务:
$ python3 todo.py --list
1\. Walk 2 miles
由于我们添加了第一个项目,tasks.txt 文件已被创建(请参阅第 4 步中list_tasks函数的定义):
$ ls
tasks.txt todo.py
让我们在列表中再添加一个任务:
$ python3 todo.py -a "Grab evening coffee!"
还有一个:
$ python3 todo.py -a "Buy groceries"
现在让我们获取所有任务的列表:
$ python3 todo.py -l
1\. Walk 2 miles
2\. Grab evening coffee!
3\. Buy groceries
现在让我们按索引删除一个任务。假设我们完成了晚间咖啡(希望今天就此结束),所以按如下方式将其删除:
$ python3 todo.py -r 2
Task removed successfully.
修改后的待办事项列表如下:
$ python3 todo.py --list
1\. Walk 2 miles
2\. Buy groceries
第 7 步:测试、改进和重复
好的,我们的应用程序的最简单版本已经准备好了。那么如何进一步发展呢?这里有几个你可以尝试的事项:
-
当你使用无效的命令行选项(比如
-w或--wrong)时会发生什么?默认行为(如果你记得 if-elif-else 结构)是打印帮助信息,但也会有异常。尝试使用 try-except 块实现错误处理。 -
通过定义包括边界情况的测试用例来测试你的应用程序。你可以首先使用内置的 unittest 模块。
-
通过添加一个选项来指定每个任务的优先级来改进现有版本。还可以尝试按优先级对任务进行排序和检索。
▶️ 本教程的代码在 GitHub 上。
总结
在本教程中,我们构建了一个简单的命令行待办事项列表应用程序。在此过程中,我们学会了如何使用内置的 argparse 模块解析命令行参数。我们还使用命令行输入在后台对简单的文本文件执行相应操作。
那么,我们接下来该做什么呢?好吧,像 Typer 这样的 Python 库使构建命令行应用程序变得轻而易举。我们将在即将到来的 Python 教程中使用 Typer 构建一个。在此之前,继续编程吧!
Bala Priya C**** 是来自印度的开发者和技术写作者。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编程和喝咖啡!目前,她正在通过编写教程、操作指南、评论文章等与开发者社区分享她的知识。Bala 还创建引人入胜的资源概述和编码教程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
用 Hugging Face 和 Gradio 在 5 分钟内构建 AI 聊天机器人
原文:
www.kdnuggets.com/2023/06/build-ai-chatbot-5-minutes-hugging-face-gradio.html
作者提供的图片
本短教程将使用 Microsoft DialoGPT 模型、Hugging Face Space 和 Gradio 界面构建一个简单的聊天机器人。你将能够使用类似的技术在 5 分钟内开发和自定义自己的应用程序。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
1. 创建一个新 Space
-
访问 hf.co 并创建一个免费账户。之后,点击右上角的 显示图像 并选择“新建 Space”选项。
-
填写表单,包括应用程序名称、许可证、Space 硬件和可见性。
图片来源于 Space
-
点击“创建 Space”来初始化应用程序。
-
你可以克隆仓库并从本地系统推送文件,或者使用浏览器在 Hugging Face 上创建和编辑文件。
图片来源于 AI ChatBot
2. 创建 ChatBot 应用程序文件
我们将点击“文件”选项卡 > + 添加文件 > 创建新文件。
图片来源于 kingabzpro/AI-ChatBot
创建一个 Gradio 界面。你可以复制我的代码。
图片来源于 app.py
我已经加载了“microsoft/DialoGPT-large”分词器和模型,并创建了一个 predict 函数来获取响应和创建历史记录。
from transformers import AutoModelForCausalLM, AutoTokenizer
import gradio as gr
import torch
title = "????AI ChatBot"
description = "A State-of-the-Art Large-scale Pretrained Response generation model (DialoGPT)"
examples = [["How are you?"]]
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-large")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-large")
def predict(input, history=[]):
# tokenize the new input sentence
new_user_input_ids = tokenizer.encode(
input + tokenizer.eos_token, return_tensors="pt"
)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([torch.LongTensor(history), new_user_input_ids], dim=-1)
# generate a response
history = model.generate(
bot_input_ids, max_length=4000, pad_token_id=tokenizer.eos_token_id
).tolist()
# convert the tokens to text, and then split the responses into lines
response = tokenizer.decode(history[0]).split("<|endoftext|>")
# print('decoded_response-->>'+str(response))
response = [
(response[i], response[i + 1]) for i in range(0, len(response) - 1, 2)
] # convert to tuples of list
# print('response-->>'+str(response))
return response, history
gr.Interface(
fn=predict,
title=title,
description=description,
examples=examples,
inputs=["text", "state"],
outputs=["chatbot", "state"],
theme="finlaymacklon/boxy_violet",
).launch()
此外,我为我的应用程序提供了一个自定义主题:boxy_violet。你可以浏览 Gradio 的 主题画廊来根据你的喜好选择主题。
3. 创建需求文件
现在,我们需要创建一个 requirement.txt 文件,并添加所需的 Python 包。
来自requirements.txt的图片
transformers
torch
之后,你的应用将开始构建,几分钟内,它会下载模型并加载模型推断。
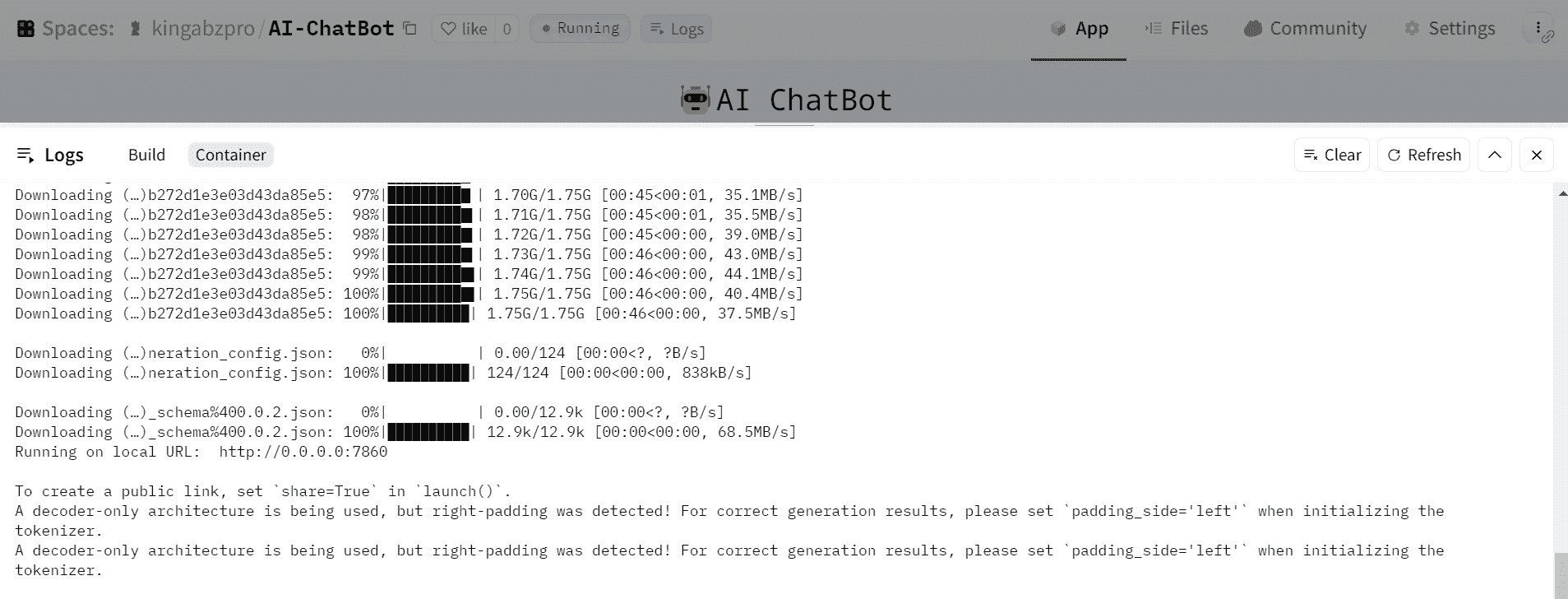
4. Gradio 演示
Gradio 应用看起来很棒。我们只需为每种不同的模型架构创建一个 predict 函数,以获取响应并维护历史记录。
你现在可以在kingabzpro/AI-ChatBot上聊天和互动,或者使用 https://kingabzpro-ai-chatbot.hf.space 将你的应用嵌入到你的网站上。
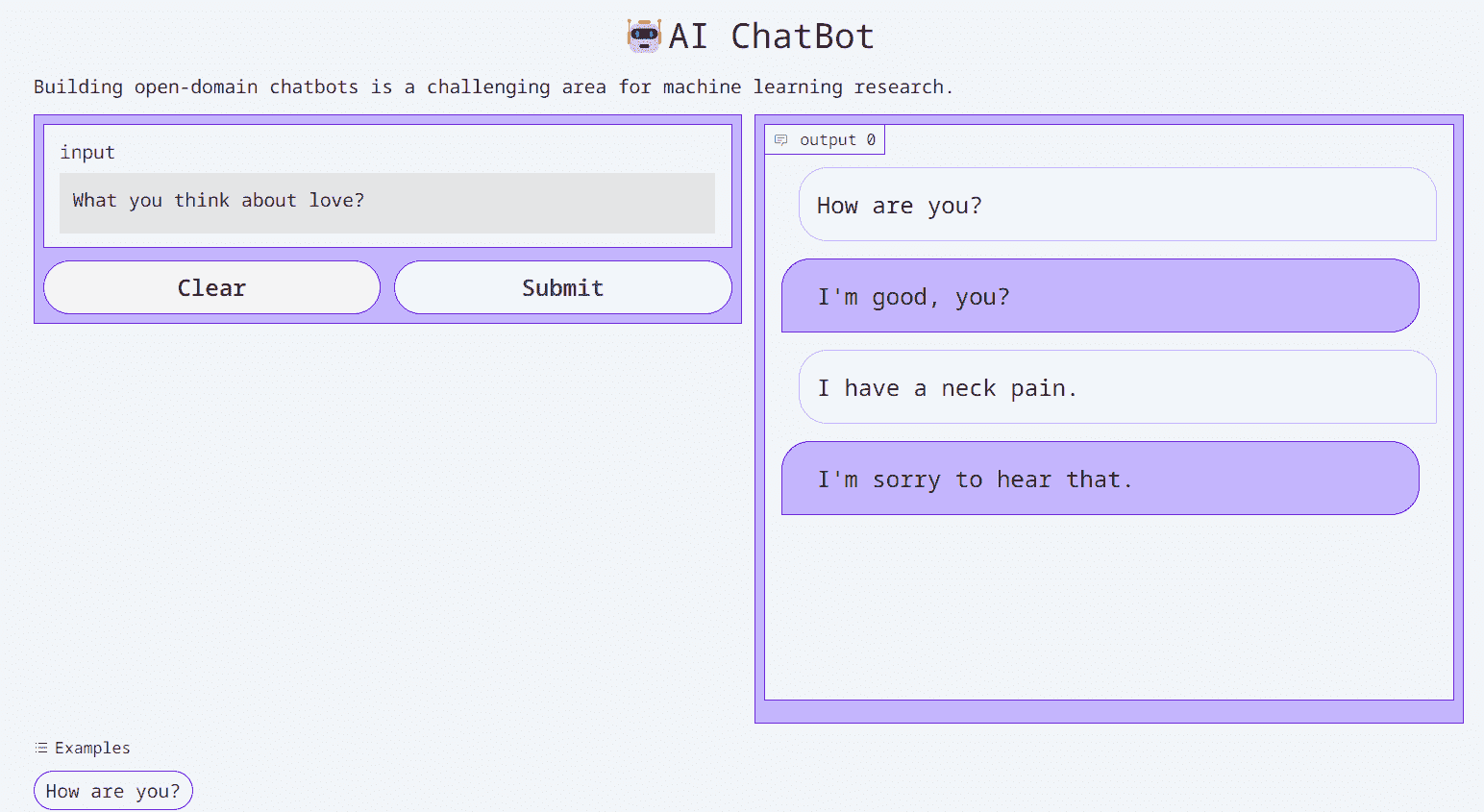
你还感到困惑吗?在Spaces上查找数百个聊天机器人应用,以获取灵感并了解模型推断。
例如,如果你有一个经过“LLaMA-7B”微调的模型,搜索模型并向下滚动查看模型的各种实现。

来自decapoda-research/llama-7b-hf的图片
结论
总之,这篇博客提供了一个快速而简单的教程,教你如何在 5 分钟内使用 Hugging Face 和 Gradio 创建 AI 聊天机器人。通过一步步的说明和可定制的选项,任何人都可以轻松创建自己的聊天机器人。
很有趣,希望你学到了些东西。请在评论区分享你的 Gradio 演示。如果你在寻找更简单的解决方案,查看一下 OpenChat: The Free & Simple Platform for Building Custom Chatbots in Minutes。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康困扰的学生开发 AI 产品。
相关话题
用 Python 构建 AI 应用的 10 个简单步骤
原文:
www.kdnuggets.com/build-an-ai-application-with-python-in-10-easy-steps

机器学习之所以如此受欢迎,有其充分的理由。许多企业选择利用这一机会来创建产品。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
你必须遵循一些步骤,以使你的应用程序不同于普通的应用,并选择最适合你项目的选项。
本文将探讨创建成功的 AI 应用程序的基本步骤和选项,使用 Python 和其他工具。

步骤 1:定义目标
首先,定义你希望用 AI 模型解决的问题。这可以是预测客户行为,也可以是自动化某项日常任务。如果你难以找到一个创意,可以使用 ChatGPT 或 Bard,输入以下提示。
Generate 5 ideas about AI Applications that I'll build with Python.
现在,让我们看看 ChatGPT 的回答。

步骤 2:收集数据
现在我们有了选项。下一步是收集数据。这一步包括从不同的仓库获取数据集或使用不同的 API 或网页抓取来寻找数据。如果你考虑使用干净且处理过的数据集,可以使用以下资源来收集数据集:
-
GitHub 仓库: 它是一个开发者平台,数百万开发者在这里协作完成项目。
-
Kaggle 数据集: 一个机器学习和数据科学的网站,提供数据集、竞赛和学习资源。
-
UCL Irvine 数据集: 这是一个用于机器学习研究的数据集集合。
-
谷歌数据集搜索: 它是一个数据集搜索引擎,可以按关键词或位置搜索。这里是链接。
-
AWS 开放数据: 这个计划提供对 AWS 上开放数据的访问。
步骤 3:数据准备
现在你已经有了目标,数据也准备好了。是时候进行实际操作了。接下来的步骤是准备数据以应用你想要的模型。这个模型可以是机器学习模型或深度学习模型。无论是哪种,数据需要具备特定的特征:
-
清理:如果你通过网络爬取或使用 API 收集数据,这一步会更加复杂。你应该删除重复项、无关条目、纠正类型、处理缺失值等,使用的方法可以包括填补或删除。
www.stratascratch.com/blog/data-cleaning-101-avoid-these-5-traps-in-your-data/ -
正确格式化:现在,为了应用你的模型,特征应该是一致和适当的。如果你有分类数据,它们需要被编码以应用机器学习。你的数值特征应该被缩放和标准化,以便获得更好的模型。
-
平衡:机器学习需要迭代,这要求你采取一些步骤,比如[这个]( https://towardsdatascience.com/how-to-balance-a-dataset-in-python-36dff9d12704#:~:text=A balanced dataset is a ,class%20weight)。你的数据集应该是平衡的,这意味着你必须确保数据集不会偏向某一类,以确保你的预测不会有偏差。
-
特征工程:有时,你需要调整特征以提高模型的性能。你可能会移除一些影响模型性能的特征,或者将它们组合起来以改善性能。
www.linkedin.com/posts/stratascratch_feature-selection-for-machine-learning-in-activity-7082376269958418432-iZWb -
拆分:如果你对机器学习不熟悉,并且你的模型表现得特别好,要小心。在机器学习中,一些模型可能表现得过于完美,这可能表示过拟合问题。为了解决这个问题,一种方法是将数据拆分为训练集、测试集,有时甚至是验证集。
platform.stratascratch.com/technical/2246-overfitting-problem
步骤 4: 选择模型。
好了,在这一步,一切都准备就绪。现在,你将应用哪个模型?你能猜出哪个模型最好吗?还是你应该考虑一下?当然,你应该有一个初步的建议,但你需要做的事情之一是测试不同的模型。
你可以从以下 Python 库中选择一个模型:
-
Scikit-learn: 这对于初学者来说非常理想。你可以用最少的代码实现机器学习代码。这里是官方文档:
scikit-learn.org/stable/ -
Tensorflow:Tensorflow 非常适合于扩展性和深度学习。它允许你开发复杂的模型。以下是官方文档:
www.tensorflow.org/ -
Keras:它在 TensorFlow 之上运行,使深度学习变得更加简单。以下是官方文档:
keras.io/ -
PyTorch:它通常更适合用于研究和开发,因为它可以轻松地动态修改模型。以下是官方文档:
pytorch.org/
步骤 5:训练你的模型
现在是训练你的模型的时候了。这涉及将数据输入模型,从而使我们能够从模式中学习,并随后调整其参数。这一步骤非常直接。
步骤 6:评估模型性能
你已经训练了你的模型,但如何判断它是好是坏呢?当然,有多种方法来评估不同的模型。让我们探索一系列模型评估指标。
-
回归 - MAE 衡量的是预测值和实际值之间的误差的平均大小,而不考虑其方向。此外,还可以使用 R2 分数。
-
分类 - 精确度、召回率和 F1 分数用于评估分类模型的性能。
-
聚类: 评估指标在这里不那么直接,因为我们通常需要真实标签进行比较。然而,像轮廓系数、戴维斯-鲍丁指数和卡林斯基-哈拉巴斯指数等指标被常用来评估。
步骤 7:迭代和优化
根据第 6 步收集的结果,你可以采取多种措施。这些措施可能会影响你模型的性能。让我们来看看。
-
调整超参数: 调整模型的超参数可以显著改变其性能。它控制着模型的学习过程和结构。
-
选择不同的算法:有时候,可能会有比你初始模型更好的选择。这就是为什么即使你已经进行到一半,探索不同的算法可能也是一个更好的主意。
-
增加数据量:更多的数据通常能导致更好的模型。因此,如果你需要提高模型的性能并且有数据收集的预算,增加数据量将是一个明智的选择。
-
特征工程: 有时候,解决问题的方案可能就在外面,等待你去发现。特征工程可能是最具成本效益的解决方案。
步骤 8:网络应用
你的模型已经准备好了,但它需要一个接口。目前它在 Jupyter Notebook 或 PyCharm 上,但缺少一个用户友好的前端。为此,你需要开发一个网络应用程序,这里有几个选项。
-
Django:它功能全面且可扩展,但对于初学者来说不够友好。
-
Flask:Flask 是一个适合初学者的微型网络框架。
-
FastAPI:这是一种现代且快速的构建网络应用的方法。
步骤 9:云部署
你的模型可能是有史以来开发的最佳模型。然而,如果它仅停留在你的本地驱动器上,你无法确定它是否有效。与世界分享你的模型并上线将是获取反馈、观察实际影响以及更高效地发展的好选择。
为了实现这一点,以下是你的选项。
-
AWS:AWS 提供更大规模的应用程序,并且为每个操作提供多种选项。例如,在数据库方面,他们提供了可以选择和扩展的选项。
-
Heroku:Heroku 是一个平台即服务(PaaS),允许开发者在云端完全构建、运行和操作应用程序。
-
Pythonanywhere.com:Pythonanywhere 是一个针对 Python 特定应用的云服务,非常适合初学者。
第 10 步:分享你的 AI 模型
分享你的 AI 模型的方式有很多,但如果你喜欢写作,我们来讨论一种著名且简单的方法。
-
内容营销:内容营销包括创建有价值的内容,如博客文章或视频,以展示你的 AI 模型的能力并吸引潜在用户。要了解更多关于有效内容营销策略的信息,请查看 此处。
-
社区参与:像 Reddit 这样的在线社区允许你分享关于你的 AI 模型的见解,建立信誉,并与潜在用户建立联系。
-
合作与协作:与该领域的其他专业人士合作可以帮助扩大你的 AI 模型的影响力并进入新市场。如果你在 Medium 上撰写关于你的应用程序的文章,可以尝试与那些在相同领域撰写文章的作者进行合作。
-
付费广告和推广:付费广告渠道,如 Google Ads 或其他社交媒体广告,可以帮助增加可见性并吸引用户关注你的 AI 模型。
结论
完成上述所有十个步骤后,是时候保持一致性并维护你开发的应用程序了。
在这篇文章中,我们介绍了构建和部署 AI 应用程序的十个终极步骤。
Nate Rosidi 是一名数据科学家和产品策略专家。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备面试,提供来自顶级公司的真实面试问题。Nate 关注职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖 SQL 相关内容。
更多相关主题
如何在 5 分钟内使用 Flask 为机器学习模型构建 API
原文:
www.kdnuggets.com/2019/01/build-api-machine-learning-model-using-flask.html
评论
作者 Tim Elfrink,Vantage AI 的数据科学家
作为一名数据科学家顾问,我希望通过我的机器学习模型产生影响。然而,这说起来容易做起来难。在开始一个新项目时,首先需要在 Jupyter Notebook 中对数据进行探索。一旦你对所处理的数据有了全面的理解,并与客户达成了下一步的计划,那么一个可能的结果是创建一个预测模型。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
你会感到兴奋,然后回到你的笔记本中尽可能创建最好的模型。模型和结果呈现出来,大家都很满意。客户希望在他们的基础设施中运行模型,以测试是否能真正产生预期的影响。此外,当人们能够使用模型时,你会得到必要的反馈,以便逐步改进它。但鉴于客户有一些你可能不熟悉的复杂基础设施,我们该如何迅速做到这一点呢?
为此,你需要一个能够适应他们复杂基础设施的工具,最好是你熟悉的语言。这就是你可以使用 Flask 的地方。Flask 是一个用 Python 编写的微型 Web 框架。它可以创建一个 REST API,允许你发送数据,并接收预测作为响应。
创建你的模型
让我向你展示 这是如何工作的。为了演示的目的,我将使用一个示例数据集来训练一个简单的 DecisionTreeClassifier 模型,该数据集可以从 scikit-learn 包 中加载。
我如何在 Jupyter Notebook 中创建我的模型
一旦客户对你创建的模型满意,你可以将其保存为 pickle 文件。然后你可以在之后打开这个 pickle 文件,并调用函数 predict 来对新的输入数据进行预测。这正是我们将在 Flask 中做的事情。
运行 Flask
Flask 运行在服务器上。根据客户端的要求,这可以是客户端环境或不同的服务器。当运行python app.py时,它首先加载创建的 pickle 文件。一旦加载完成,你就可以开始进行预测。
所有你需要的简单 API 代码都在 Flask 中!
请求预测
通过将 POST JSON 请求传递给创建的 Flask 网络服务器(默认在 5000 端口)来进行预测。在app.py中,这个请求被接收,并根据我们模型中已加载的预测函数做出预测。它以 JSON 格式返回预测结果。
测试我们的 API
现在,你只需使用正确的数据点语法调用网络服务器。这与原始数据集的格式相对应,以获取预测的 JSON 响应。例如:
python request.py -> <Response[200]> “[1.]"
对于我们发送的数据,我们得到了模型的类 1 预测结果。实际上,你所做的只是将数据以数组的形式发送到一个端点,该端点将其转换为 JSON 格式。端点读取 JSON POST 并将其转换回原始数组。
通过这些简单的步骤,你可以轻松让其他人使用你的机器学习模型,并迅速产生重大影响。
注意
在这篇文章中,我没有考虑数据中的任何错误或其他异常。本文展示了如何简单地启动并从模型输出中学习,但在准备投入生产之前还需要进行大量改进。当创建一个包含 API 的 Docker 文件并将其托管到 Kubernetes 上时,这个解决方案可以变得可扩展,从而可以在不同的机器之间平衡负载。但这些都是从概念验证到生产环境的过程中需要采取的步骤。
感谢 Ruurtjan Pul 和 Jasper Makkinje。
简介:Tim Elfrink 是 Vantage AI 的数据科学家,这是一家位于荷兰的数据科学咨询公司。如果你需要帮助创建适用于你的数据的机器学习模型,请随时通过 info@vantage-ai.com 联系我们。
原文。已获得许可转发。
相关:
-
为深度学习应用程序连接点
-
使用 TensorFlow 和 Flask RESTful Python API 构建 ConvNet HTTP 基础应用程序的完整指南
-
更多 Google Colab 环境管理技巧
更多相关主题
从头开始构建人工神经网络:第一部分
原文:
www.kdnuggets.com/2019/11/build-artificial-neural-network-scratch-part-1.html
评论
在我之前的文章人工神经网络(ANN)简介中,我们学习了与 ANN 相关的各种概念,因此我建议在继续之前先阅读它,因为在这里我将只关注实现部分。在这个系列文章中,我们将仅使用numpy Python 库从头开始构建 ANN。
在第一部分中,我们将构建一个相当简单的 ANN,只包含 1 个输入层和 1 个输出层,没有隐藏层。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
在第二部分中,我们将构建一个具有 1 个输入层、1 个隐藏层和 1 个输出层的 ANN。
为什么从头开始?
好吧,市面上有许多深度学习库(Keras、TensorFlow、PyTorch等),可以用几行代码创建一个神经网络。然而,如果你真的想深入理解神经网络的工作原理,我建议你学习如何使用 Python 或其他编程语言从头开始编写代码。让我们开始吧。
我们来创建一些随机数据集:
为了简化起见,使用二进制值的随机数据集
在上面的表格中,我们有五列:Person, X1, X2, X3 和 Y。其中 1 表示真,0 表示假。我们的任务是创建一个能够根据X1, X2 和 X3的值预测Y值的人工神经网络。
我们将创建一个只有一个输入层和一个输出层,没有隐藏层的人工神经网络。在开始编码之前,让我们首先看看我们的神经网络在理论上是如何运行的:
人工神经网络理论
人工神经网络是一种监督学习算法,这意味着我们提供给它包含自变量的输入数据和包含因变量的输出数据。例如,在我们的例子中,自变量是X1, X2 和 X3。因变量是Y。
一开始,人工神经网络(ANN)会做一些随机预测,这些预测与正确输出进行比较,计算误差(预测值与实际值之间的差异)。找到实际值与传播值之间差异的函数称为成本函数。这里的成本指的是误差。我们的目标是最小化成本函数。训练神经网络基本上就是指最小化成本函数。我们将看到如何执行这一任务。
神经网络分为两个阶段执行:前向传播阶段和反向传播阶段。让我们详细讨论这两个步骤。
前向传播
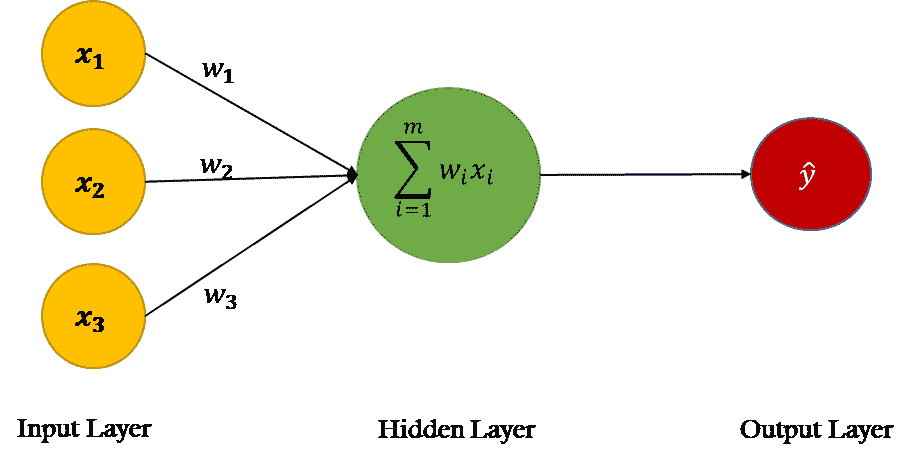
在 ANN 的前向传播阶段,基于输入节点的值和权重进行预测。如果你查看上图中的神经网络,你会看到数据集中有三个特征:X1、X2 和 X3,因此在第一层,也称为输入层,有三个节点。
神经网络的权重基本上是我们必须调整的参数,以便能够正确预测输出。目前只需记住,对于每个输入特征,我们有一个权重。
以下是 ANN 前向传播阶段执行的步骤:
步骤 1:计算输入与权重之间的点积
输入层的节点通过三个权重参数与输出层相连。在输出层,输入节点中的值与其对应的权重相乘后相加。最后,将偏置项b添加到总和中。
我们为什么需要偏置项?
假设我们有一个输入值为 (0,0,0) 的人,输入节点和权重的乘积之和将为零。在这种情况下,无论我们如何训练算法,输出将始终为零。因此,为了能够进行预测,即使我们对该人的信息没有任何非零值,我们也需要一个偏置项。偏置项对于构建一个稳健的神经网络是必要的。
数学上,点积的总和:
X.W=x1.w1 + x2.w2 + x3.w3 + b
步骤 2:将点积的总和 (X.W) 通过激活函数
点积 XW 可以产生任何一组值。然而,在我们的输出中,我们有 1 和 0 的形式。我们希望输出也以相同格式呈现。为此,我们需要一个[Activation Function],它将输入值限制在 0 和 1 之间。所以我们当然会选择 Sigmoid 激活函数。
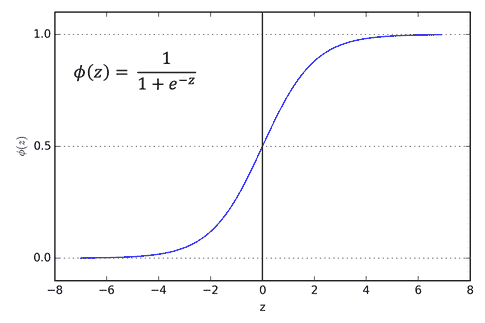
当输入为 0 时,sigmoid 函数返回 0.5。如果输入是一个大的正数,它返回接近 1 的值。在负输入的情况下,sigmoid 函数输出接近零的值。
因此,它特别用于需要预测概率作为输出的模型。由于概率值仅在0 和 1之间,sigmoid 是解决我们问题的正确选择。
在上图中,z 是点积 X.W 的总和。
从数学上讲,sigmoid 激活函数是:
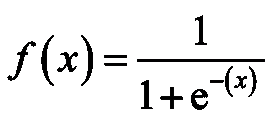
让我们总结一下到目前为止的工作。首先,我们需要计算输入特征(自变量矩阵)与权重的点积。接下来,将点积的总和通过激活函数。激活函数的结果基本上是输入特征的预测输出。
反向传播
在开始时,在进行任何训练之前,神经网络会做出随机的预测,这些预测显然是错误的。
我们开始时让网络进行随机输出预测。然后,我们将神经网络的预测输出与实际输出进行比较。接下来,我们以使预测输出更接近实际输出的方式更新权重和偏置。在这个阶段,我们训练我们的算法。让我们看看反向传播阶段涉及的步骤。
第 1 步:计算成本
此阶段的第一步是计算预测的成本。预测成本可以通过计算预测输出值和实际输出值之间的差异来得到。如果差异很大,则成本也会很高。
我们将使用均方误差或 MSE 成本函数。成本函数是一个计算给定输出预测成本的函数。
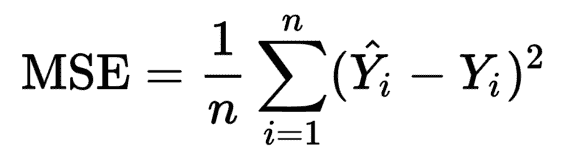
这里,*Yi 是实际输出值** 和 *Ŷi 是预测输出值* 以及 **n 是观察数量。*
第 2 步:最小化成本
我们的终极目标是调整神经网络的权重,以使成本达到最低。如果你仔细观察,你会发现我们只能控制权重和偏置。其他一切都超出了我们的控制范围。我们不能控制输入,不能控制点积,也不能操控 sigmoid 函数。
为了最小化成本,我们需要找到使成本函数返回最小值的权重和偏置值。成本越小,我们的预测就越准确。
要找到一个函数的极小值,我们可以使用 梯度下降 算法。梯度下降可以用数学公式表示为:
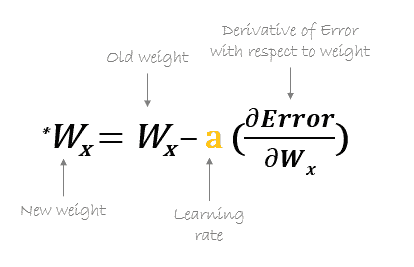
????错误 是成本函数。上述方程告诉我们要计算成本函数相对于每个权重和偏置的偏导数,并将结果从现有权重中减去,以获得新的权重。
函数的导数给我们在任何给定点的斜率。为了找到成本是否增加或减少,给定权重值,我们可以在该特定权重值处找到函数的导数。如果成本随着权重的增加而增加,导数将返回一个正值,然后从现有值中减去。
另一方面,如果成本随着权重的增加而减少,则会返回一个负值,该负值会被添加到现有的权重值中,因为负数加负数是正数。
在上述方程中 **a** 被称为学习率,它与导数相乘。学习率决定了我们的算法学习的速度。
我们需要对所有的权重和偏置重复执行梯度下降,直到成本最小化,并且成本函数返回的值接近零。
现在是时候实现我们到目前为止学习的内容了。我们将在 Python 中创建一个简单的神经网络,包含一个输入层和一个输出层。
使用 numpy 实现人工神经网络
图片来源:hackernoon.com
**要遵循的步骤:
1. 定义自变量和因变量
2. 定义超参数
3. 定义激活函数及其导数
4. 训练模型
5. 进行预测**
步骤-1:首先创建我们的自变量或输入特征集以及对应的因变量或标签。
#Independent variables
input_set = np.array([[0,1,0],
[0,0,1],
[1,0,0],
[1,1,0],
[1,1,1],
[0,1,1],
[0,1,0]])#Dependent variable
labels = np.array([[1,
0,
0,
1,
1,
0,
1]])
labels = labels.reshape(7,1) #to convert labels to vector
我们的输入集包含七条记录。类似地,我们还创建了一个 labels 集,其中包含输入集中每条记录的对应标签。这些标签是我们希望 ANN 预测的值。
步骤-2:定义超参数
我们将使用 random.seed 函数,以便每次执行下面的代码时都能获得相同的随机值。
接下来,我们用正态分布的随机数初始化权重。由于输入中有三个特征,我们有一个包含三个权重的向量。然后,我们用另一个随机数初始化偏置值。最后,我们将学习率设置为 0.05。
np.random.seed(42)
weights = np.random.rand(3,1)
bias = np.random.rand(1)
lr = 0.05 #learning rate
步骤-3:定义激活函数及其导数:我们的激活函数是 sigmoid 函数。
def sigmoid(x):
return 1/(1+np.exp(-x))
现在定义一个计算 sigmoid 函数导数的函数。
def sigmoid_derivative(x):
return sigmoid(x)*(1-sigmoid(x))
步骤-4:是时候训练我们的 ANN 模型了
我们将从定义 epoch 数量开始。一个 epoch 是我们希望在数据集上训练算法的次数。我们将对数据训练 25,000 次,因此我们的 epoch 将是 25000。你可以尝试不同的数量以进一步降低成本。
for epoch in range(25000):
inputs = input_set
XW = np.dot(inputs, weights)+ bias
z = sigmoid(XW)
error = z - labels
print(error.sum())
dcost = error
dpred = sigmoid_derivative(z)
z_del = dcost * dpred
inputs = input_set.T
weights = weights - lr*np.dot(inputs, z_del)
for num in z_del:
bias = bias - lr*num
让我们一步一步地理解每一个步骤,然后我们将进入最后一步:做预测。
我们将从输入 input_set 中存储的值保存在 inputs 变量中,以确保 input_set 的值在每次迭代中保持不变,所有的修改都必须应用到 inputs 变量中。
inputs = input_set
接下来,我们找到输入和权重的点积并加上偏置。 (前向传播阶段的步骤-1)
XW = np.dot(inputs, weights)+ bias
接下来,我们将点积通过 sigmoid 激活函数。 (前向传播阶段的步骤-2)
z = sigmoid(XW)
这完成了我们算法的前向传播部分,现在是开始反向传播的时候了。
变量z包含了预测输出。反向传播的第一步是找到误差。
error = z - labels
print(error.sum())
我们知道我们的成本函数是:
我们需要对这个函数进行关于每个权重的导数,这可以通过使用 链式法则 来轻松完成。我会跳过推导部分,但如果有人感兴趣,请告诉我,我会在评论区发布。
所以我们对任何权重的成本函数的最终导数是:
slope = input x dcost x dpred
现在,斜率可以简化为:
dcost = error
dpred = sigmoid_derivative(z)
z_del = dcost * dpred
inputs = input_set.T
weights = weight-lr*np.dot(inputs, z_del)
我们有 z_del 变量,它包含 dcost 和 dpred 的乘积。我们不是对每条记录进行循环,将输入与对应的 z_del 相乘,而是取输入特征矩阵的转置,并将其与 z_del 相乘。
最后,我们将学习率变量 lr 与导数相乘,以提高学习速度。
除了更新权重,我们还需要更新偏置项。
for num in z_del:
bias = bias - lr*num
一旦循环开始,你会看到总误差开始减少,并且在训练结束时,误差会剩下一个非常小的值。
-0.001415035616137969
-0.0014150128584959256
-0.0014149901015685952
-0.0014149673453557714
-0.0014149445898578358
-0.00141492183507419
-0.0014148990810050437
-0.0014148763276499686
-0.0014148535750089977
-0.0014148308230825385
-0.0014148080718707524
-0.0014147853213728624
-0.0014147625715897338
-0.0014147398225201734
-0.0014147170741648386
-0.001414694326523502
-0.001414671579597255
-0.0014146488333842064
-0.0014146260878853782
-0.0014146033431002465
-0.001414580599029179
-0.0014145578556723406
-0.0014145351130293877
-0.0014145123710998
-0.0014144896298846701
-0.0014144668893831067
-0.001414444149595611
-0.0014144214105213174
-0.0014143986721605849
-0.0014143759345140276
-0.0014143531975805163
-0.001414330461361444
-0.0014143077258557749
-0.0014142849910631708
-0.00141426225698401
-0.0014142395236186895
-0.0014142167909661323
-0.001414194059027955
-0.001414171327803089
-0.001414148597290995
-0.0014141258674925626
-0.0014141031384067547
-0.0014140804100348098
-0.0014140576823759854
-0.0014140349554301636
-0.0014140122291978665
-0.001413989503678362
-0.001413966778871751
-0.001413944054778446
-0.0014139213313983257
-0.0014138986087308195
-0.0014138758867765552
-0.0014138531655347973
-0.001413830445006264
-0.0014138077251906606
-0.001413785006087985
-0.0014137622876977014
-0.0014137395700206355
-0.0014137168530558228
-0.0014136941368045382
-0.0014136714212651114
-0.0014136487064390219
-0.0014136259923249635
-0.001413603278923519
-0.0014135805662344007
-0.0014135578542581566
-0.0014135351429944293
-0.0014135124324428719
-0.0014134897226037203
-0.0014134670134771238
-0.0014134443050626295
-0.0014134215973605428
-0.0014133988903706311
步骤-5:做预测
现在是做一些预测的时候了。让我们试试 [1,0,0]
single_pt = np.array([1,0,0])
result = sigmoid(np.dot(single_pt, weights) + bias)
print(result)
输出 : [0.01031463]
如你所见,输出值更接近 0 而不是 1,因此它被分类为 0。
让我们再试一次 [0,1,0]
single_pt = np.array([0,1,0])
result = sigmoid(np.dot(single_pt, weights) + bias)
print(result)
输出 : [0.99440207]
如你所见,输出值更接近 1 而不是 0,因此它被分类为 1。
结论
在这篇文章中,我们学习了如何使用 numpy python 库从零开始创建一个非常简单的人工神经网络,它包含一个输入层和一个输出层。这个人工神经网络能够对线性可分的数据进行分类。
如果我们有非线性分隔的数据,我们的人工神经网络将无法对这种数据进行分类。这是我们将在本系列文章的第二部分中构建的内容。
好了,就这些。我希望你们喜欢阅读这篇文章。请在评论区分享你的想法或疑问。
如有任何问题,可以通过LinkedIn联系我。

感谢阅读!!!
简介:Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发者。他在电信、分析、销售和数据科学等多个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原文。经许可转载。
相关内容:
-
人工神经网络简介
-
支持向量机友好介绍
-
使用 K-Nearest Neighbors 分类心脏病
了解更多相关主题
从头构建人工神经网络:第二部分
原文:
www.kdnuggets.com/2020/03/build-artificial-neural-network-scratch-part-2.html
评论
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
在我之前的文章中,从头构建人工神经网络(ANN):第一部分,我们开始讨论什么是人工神经网络;我们看到如何用 Python 从头创建一个简单的神经网络,具有一个输入层和一个输出层。这样的神经网络被称为感知器。然而,现实世界的神经网络能够执行复杂任务,如图像分类和股票市场分析,除了输入层和输出层,还包含多个隐藏层。
在上一篇文章中,我们总结了感知器能够找到线性决策边界。我们使用感知器预测一个人是否患糖尿病,使用的是一个虚拟数据集。然而,感知器无法找到非线性决策边界。
在本文中,我们将开发一个具有一个输入层、一个隐藏层和一个输出层的神经网络。我们将看到我们开发的神经网络将能够找到非线性边界。
生成数据集
让我们开始生成一个可以玩耍的数据集。幸运的是,scikit-learn 提供了一些有用的数据集生成器,因此我们不需要自己编写代码。我们将使用 make_moons 函数。
from sklearn import datasets
np.random.seed(0)
feature_set, labels = datasets.make_moons(300, noise=0.20)
plt.figure(figsize=(10,7))
plt.scatter(feature_set[:,0], feature_set[:,1], c=labels, cmap=plt.cm.Spectral)
我们生成的数据集有两个类别,以红色和蓝色点绘制。你可以将蓝色点视为男性患者,红色点视为女性患者,x 轴和 y 轴表示医疗测量。
我们的目标是训练一个机器学习分类器,该分类器根据 x 和 y 坐标预测正确的类别(男性或女性)。请注意,数据是非线性可分的,我们无法绘制一条直线将两个类别分开。这意味着线性分类器,例如没有隐藏层的 ANN 或者逻辑回归,将无法拟合数据,除非你手动工程化对给定数据集有效的非线性特征(例如多项式)。
单隐藏层神经网络
这是我们的简单网络:
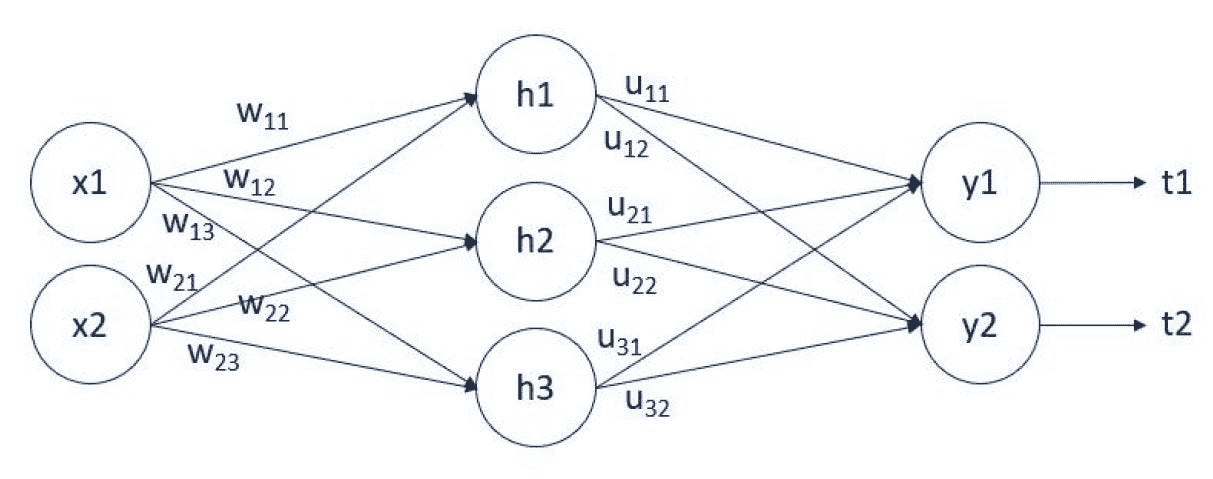
我们有两个输入:x1 和 x2。有一个隐藏层,包含 3 个单元(节点):h1, h2 和 h3。最后,有两个输出:y1 和 y2。连接它们的箭头是权重。共有两个权重矩阵:w 和 u。w 权重连接输入层和隐藏层。u 权重连接隐藏层和输出层。我们使用了字母 w 和 u,以便更容易跟踪计算。你还可以看到,我们将输出 y1 和 y2 与目标 t1 和 t2 进行比较。
在进行计算之前,我们需要引入最后一个字母。让 a 代表激活之前的线性组合。因此,我们有:
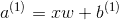
和
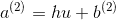
由于我们无法穷举所有激活函数和所有损失函数,我们将专注于两种最常见的:sigmoid 激活函数和 L2-norm 损失。有了这些新信息和新符号,输出 y 等于激活的线性组合。
因此,对于输出层,我们有:
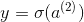
而对于隐藏层:
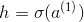
我们将分别考察输出层和隐藏层的反向传播,因为方法有所不同。
我想提醒你:
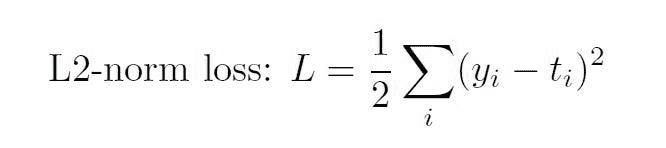
sigmoid 函数是:
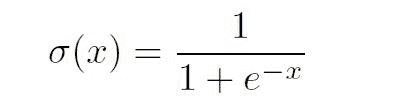
其导数是:
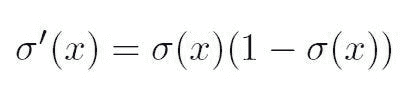
输出层的反向传播
为了得到更新规则:
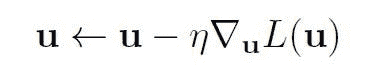
我们必须计算
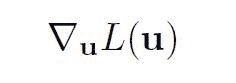
让我们考虑单个权重 uij。损失函数关于 uij 的偏导数等于:
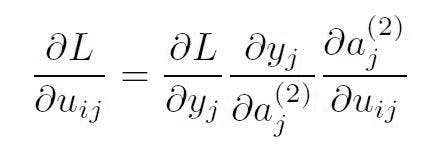
其中 i 对应于前一层(本次变换的输入层),j 对应于下一层(变换的输出层)。偏导数的计算是简单地按照链式法则进行的。
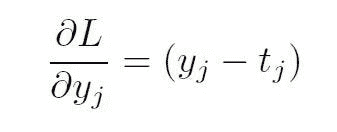
按照 L2-norm 损失的导数。
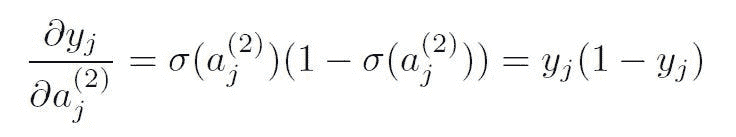
按照 sigmoid 导数进行。
最后,第三个偏导数只是以下的导数:
所以,

替换上述表达式中的偏导数,我们得到:
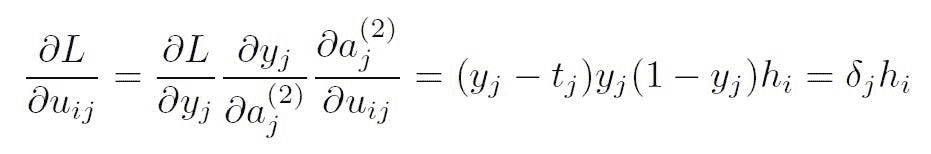
因此,输出层单个权重的更新规则为:
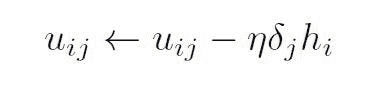
5. 隐藏层的反向传播
类似于输出层的反向传播,单个权重的更新规则,wij 将依赖于:
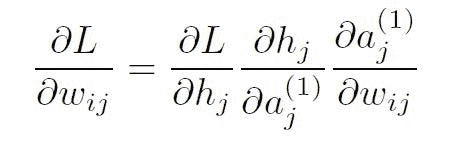
按照链式法则。利用目前我们为使用 sigmoid 激活函数和线性模型变换得到的结果,我们得到:
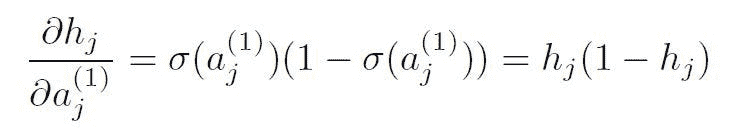
和
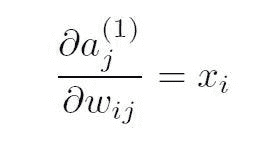
反向传播的实际问题来源于术语
这是因为没有“隐藏”的目标。你可以参考下面对权重 w11 的解决方案。在进行计算时,建议查看上面显示的神经网络图。
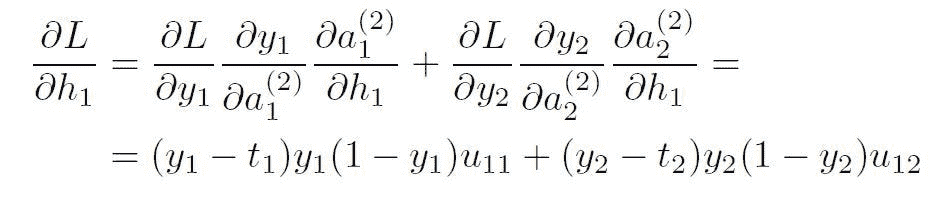
从这里,我们可以计算
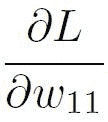
这正是我们想要的。最终的表达式是:
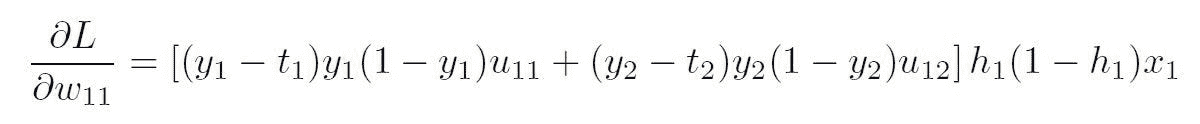
这个方程的广义形式是:
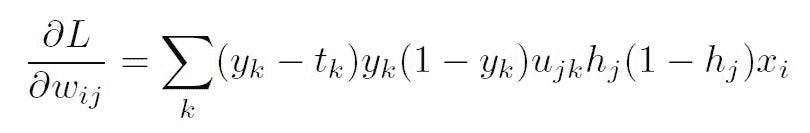
反向传播的广义化
使用输出层和隐藏层的反向传播结果,我们可以将它们合并为一个公式,总结反向传播,考虑 L2 范数损失和 sigmoid 激活。
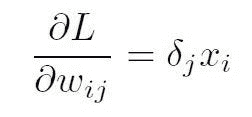
对于隐藏层
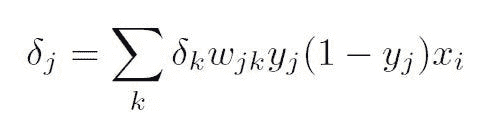
带有一个隐藏层的神经网络代码
现在让我们从头开始在 Python 中实现刚才讨论的神经网络。我们将再次尝试分类我们上面创建的非线性数据。
我们从定义一些用于梯度下降的有用变量和参数开始,比如训练数据集的大小、输入层和输出层的维度。
num_examples = len(X) # training set size
nn_input_dim = 2 # input layer dimensionality
nn_output_dim = 2 # output layer dimensionality
同时定义梯度下降的参数。
epsilon = 0.01 # learning rate for gradient descent
reg_lambda = 0.01 # regularization strength
首先,让我们实现上述定义的损失函数。我们用它来评估模型的表现:
# Helper function to evaluate the total loss on the dataset
def calculate_loss(model, X, y):
num_examples = len(X) # training set size
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation to calculate our predictions
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Calculating the loss
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# Add regulatization term to loss (optional)
data_loss += Config.reg_lambda / 2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1\. / num_examples * data_loss
我们还实现了一个辅助函数来计算网络的输出。它执行前向传播并返回概率最高的类别。
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
最后,这里是训练我们神经网络的函数。它实现了使用上述反向传播导数的批量梯度下降。
这个函数学习神经网络的参数并返回模型。
nn_hdim: 隐藏层中节点的数量
num_passes: 梯度下降训练数据的遍历次数
print_loss: 如果为 True,每 1000 次迭代打印一次损失
def build_model(X, y, nn_hdim, num_passes=20000, print_loss=False):
# Initialize the parameters to random values. We need to learn these.
num_examples = len(X)
np.random.seed(0)
W1 = np.random.randn(Config.nn_input_dim, nn_hdim) / np.sqrt(Config.nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, Config.nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, Config.nn_output_dim))# This is what we return at the end
model = {}# Gradient descent. For each batch...
for i in range(0, num_passes):# Forward propagation
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)# Backpropagation
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += Config.reg_lambda * W2
dW1 += Config.reg_lambda * W1# Gradient descent parameter update
W1 += -Config.epsilon * dW1
b1 += -Config.epsilon * db1
W2 += -Config.epsilon * dW2
b2 += -Config.epsilon * db2# Assign new parameters to the model
model = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don't want to do it too often.
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" % (i, calculate_loss(model, X, y)))return model
最后是主要方法:
def main():
X, y = generate_data()
model = build_model(X, y, 3, print_loss=True)
visualize(X, y, model)
每 1000 次迭代后打印损失:

当隐藏层节点数量为 3 时的分类
现在让我们了解一下隐藏层大小的变化如何影响结果。
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = build_model(X, y,nn_hdim, 20000, print_loss=False)
plot_decision_boundary(lambda x:predict(model,x), X, y)
plt.show()

我们可以看到,低维度的隐藏层很好地捕捉了数据的一般趋势。较高的维度容易导致过拟合。它们是在“记忆”数据,而不是拟合一般的形状。
如果我们在单独的测试集上评估我们的模型,较小隐藏层大小的模型由于更好的泛化能力可能会表现得更好。我们可以通过更强的正则化来对抗过拟合,但选择合适的隐藏层大小是更“经济”的解决方案。
你可以在这个 GitHub 仓库中获取完整的代码。
nageshsinghc4/人工神经网络从零开始-python
结论
所以在这篇文章中,我们看到如何从数学上推导出一个具有一个隐藏层的神经网络,并且我们还用 NumPy 从零开始创建了一个具有 1 个隐藏层的神经网络。
好了,这就结束了关于从零开始构建人工神经网络的两篇文章系列。 希望你们喜欢阅读,欢迎在评论区分享你的评论/想法/反馈。
简介:Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等各个领域拥有超过 4 年的工作经验,并在各种大数据组件方面具有专业知识。
原文。 经授权转载。
相关:
-
从零开始构建人工神经网络:第一部分
-
只有 NumPy:从头理解和创建神经网络的计算图
-
如何将图片转换为数字
更多相关主题
使用 PyCaret 2.0 构建你自己的 AutoML
评论
由 Moez Ali,PyCaret 的创始人和作者
PyCaret — 一个开源的低代码 Python 机器学习库
PyCaret 2.0
上周我们宣布了 PyCaret 2.0,这是一个开源的低代码 Python 机器学习库,自动化机器学习工作流。它是一个端到端的机器学习和模型管理工具,加快了机器学习实验周期,并帮助数据科学家提高效率和生产力。
在这篇文章中,我们展示了一个逐步教程,讲解如何在 Power BI 中使用 PyCaret 构建自动化机器学习解决方案,从而让数据科学家和分析师可以在他们的仪表板上添加机器学习层,而无需额外的许可或软件成本。PyCaret 是一个开源的免费使用的 Python 库,提供了多种在 Power BI 中工作的功能。
在本文结束时,你将学会如何在 Power BI 中实现以下内容:
-
设置 Python conda 环境并安装 pycaret==2.0。
-
将新创建的 conda 环境与 Power BI 连接起来。
-
在 Power BI 中构建你的第一个 AutoML 解决方案,并在仪表板上展示性能指标。
-
在 Power BI 中生产化/部署你的 AutoML 解决方案。
Microsoft Power BI
Power BI 是一个商业分析解决方案,让你能够可视化数据并在组织内部共享见解,或将其嵌入到应用程序或网站中。在本教程中,我们将通过将 PyCaret 库导入 Power BI 来使用 Power BI Desktop 进行机器学习。
什么是自动化机器学习?
自动化机器学习(AutoML)是自动化机器学习中耗时的迭代任务的过程。它允许数据科学家和分析师高效地构建机器学习模型,同时保持模型质量。任何 AutoML 解决方案的最终目标是根据某些性能标准确定最佳模型。
传统的机器学习模型开发过程资源消耗大,需要大量领域知识和时间来生成和比较多个模型。使用自动化机器学习,你可以更轻松、高效地加快获得生产就绪的机器学习模型的时间。
PyCaret 是如何工作的?
PyCaret 是一个用于监督学习和无监督学习的工作流自动化工具。它分为六个模块,每个模块都有一组函数,用于执行特定操作。每个函数接收输入并返回输出,在大多数情况下是一个训练好的机器学习模型。第二版发布时可用的模块有:
PyCaret 中的所有模块支持数据准备(超过 25 种基本预处理技术,配有大量未训练的模型以及对自定义模型的支持,自动超参数调优,模型分析和可解释性,自动模型选择,实验记录和简单的云部署选项)。
要了解更多关于 PyCaret 的信息,点击这里 阅读我们的官方发布公告。
如果你想开始学习 Python,点击这里 查看示例笔记本的图库。
“PyCaret 通过提供免费的开源低代码机器学习解决方案,正在推动机器学习和高级分析的普及,适用于业务分析师、领域专家、普通数据科学家以及经验丰富的数据科学家。”
开始之前
如果你是第一次使用 Python,安装 Anaconda Distribution 是开始的最简单方式。 点击这里 下载包含 Python 3.7 或更高版本的 Anaconda Distribution。

www.anaconda.com/products/individual
设置环境
在我们开始使用 PyCaret 在 Power BI 中的机器学习功能之前,需要创建一个虚拟环境并安装 pycaret。这是一个三步过程:
✅ 步骤 1 — 创建 anaconda 环境
从开始菜单中打开 Anaconda Prompt 并执行以下代码:
conda create --name **myenv** python=3.7
Anaconda Prompt — 创建环境
✅ 步骤 2 — 安装 PyCaret
在 Anaconda Prompt 中执行以下代码:
pip install **pycaret==2.0**
安装可能需要 15–20 分钟。如果你遇到安装问题,请查看我们的 GitHub 页面以获取已知问题和解决方案。
✅步骤 3 — 在 Power BI 中设置 Python 目录
创建的虚拟环境必须与 Power BI 关联。这可以通过 Power BI Desktop 中的全局设置完成(文件 → 选项 → 全局 → Python 脚本)。Anaconda 环境默认安装在:
C:\Users\***username***\AppData\Local\Continuum\anaconda3\envs\myenv
文件 → 选项 → 全局 → Python 脚本
???? 开始吧
设定业务背景
一家保险公司希望通过更好地预测患者费用来改善现金流预测,使用住院时的基本人口统计数据和患者健康风险指标。
(数据源)
目标
训练和选择最佳性能的回归模型,该模型根据数据集中其他变量(即年龄、性别、BMI、子女数、吸烟者和地区)预测患者费用。
???? 步骤 1 — 加载数据集
你可以直接从我们的 GitHub 上加载数据集,方法是:Power BI Desktop → 获取数据 → Web
数据集链接:raw.githubusercontent.com/pycaret/pycaret/master/datasets/insurance.csv
Power BI Desktop → 获取数据 → Web
在 Power Query 中创建一个重复的数据集:
Power Query → 创建一个重复的数据集
???? 步骤 2— 运行 AutoML 作为 Python 脚本
在 Power Query 中运行以下代码(转换 → 运行 Python 脚本):
**# import regression module**
from pycaret.regression import ***# init setup**
reg1 = setup(data=dataset, target = 'charges', silent = True, html = False)**# compare models**
best_model = compare_models()**# finalize best model** best = finalize_model(best_model)**# save best model**
save_model(best, 'c:/users/moezs/best-model-power')**# return the performance metrics df** dataset = pull()

Power Query 中的脚本
前两行代码用于导入相关模块并初始化设置函数。设置函数执行机器学习中所需的几个重要步骤,例如清理缺失值(如果有)、将数据拆分为训练集和测试集、设置交叉验证策略、定义指标、执行特定算法的转换等。
训练多个模型、比较和评估性能指标的魔法函数是compare_models。它根据可以在 compare_models 中定义的‘sort’参数返回最佳模型。默认情况下,它对回归用例使用‘R2’,对分类用例使用‘Accuracy’。
剩下的几行代码用于最终确定通过 compare_models 返回的最佳模型,并将其保存为本地目录中的 pickle 文件。最后一行返回包含训练模型及其性能指标详细信息的数据框。
输出:
Python 脚本的输出
仅用几行代码我们就训练了超过 20 个模型,表格展示了基于 10 折交叉验证的性能指标。
表现最佳的模型梯度提升回归器将与整个转换管道一起作为 pickle 文件保存在你的本地目录中。此文件稍后可以用来对新的数据集生成预测(见下方步骤 3)。
转换管道和模型保存为 pickle 文件
PyCaret 基于模块化自动化的理念。因此,如果你有更多的资源和时间用于训练,你可以扩展脚本以进行超参数调整、集成和其他可用建模技术。请参见以下示例:
**# import regression module**
from pycaret.regression import ***# init setup**
reg1 = setup(data=dataset, target = 'charges', silent = True, html = False)**# compare models**
top5 = compare_models(n_select = 5)
results = pull()**# tune top5 models** tuned_top5 = [tune_model(i) for i in top5]**# select best model** best = automl()**# save best model**
save_model(best, 'c:/users/moezs/best-model-power')**# return the performance metrics df** dataset = results
我们现在返回了前 5 个模型,而不是仅返回表现最好的一个模型。然后,我们创建了一个列表推导(循环)来调整前候选模型的超参数,最后automl 函数选择了表现最好的单一模型,该模型然后被保存为 pickle 文件(注意,我们这次没有使用finalize_model,因为 automl 函数返回的是最终模型)。
示例仪表板
示例仪表板已创建。PBIX 文件已上传到这里。
使用 PyCaret AutoML 结果创建的仪表板
???? 步骤 3 — 部署模型以生成预测
一旦我们将最终模型保存为 pickle 文件,我们可以使用它对新的数据集进行费用预测。
加载新数据集
为了演示目的,我们将再次加载相同的数据集并从数据集中删除‘charges’列。请在 Power Query 中执行以下 Python 脚本以获取预测:
**# load functions from regression module**
from pycaret.regression import load_model, predict_model**# load model in a variable** model = load_model(‘c:/users/moezs/best-model-powerbi’)**# predict charges** dataset = predict_model(model, data=dataset)
输出:
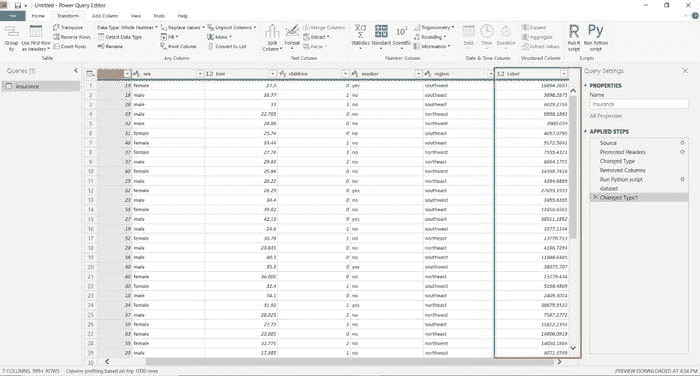
predict_model 函数在 Power Query 中的输出
在 Power BI 服务上部署
当你将包含 Python 脚本的 Power BI 报告发布到服务时,这些脚本也会在通过本地数据网关刷新数据时执行。
为了实现这一点,你必须确保安装了包含依赖 Python 包的 Python 运行时在托管个人网关的机器上。请注意,共享的本地数据网关不支持 Python 脚本执行。点击这里以了解更多信息。
本教程中使用的 PBIX 文件已上传到这个 GitHub 仓库:github.com/pycaret/pycaret-powerbi-automl
如果你想了解更多关于 PyCaret 2.0 的信息,请阅读这个公告。
如果你之前使用过 PyCaret,你可能会对当前版本的发行说明感兴趣。
使用这个轻量级的工作流自动化库在 Python 中,你可以实现无数目标。如果你觉得这个很有用,请不要忘记在我们的 GitHub 仓库上给我们⭐️。
想了解更多 PyCaret 信息,请关注我们的LinkedIn和Youtube。
你可能也感兴趣:
在 Power BI 中使用 PyCaret 构建你的第一个异常检测器
重要链接
想了解特定模块?
点击下面的链接查看文档和工作示例。
简介: Moez Ali 是一名数据科学家,同时也是 PyCaret 的创始人和作者。
原文。经许可转载。
相关:
-
Github 是你将来需要的最佳 AutoML
-
你不知道的 PyCaret 的 5 件事
-
使用 Docker 容器将机器学习管道部署到云端
我们的前 3 门课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
如何在数据科学领域建立职业生涯

图片来源:Lukas from Pexels
成功的职业生涯带来了许多好处和改变生活的机会。不幸的是,我们生活在一个由金钱和社会地位驱动的社会中。提升职业阶梯被认为能改善生活质量。它提供了安全感和成就感。人们能够将自己的生活从零起点转变为辉煌的职业生涯。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
如果你是一名数据科学家,并且将 2022 年的目标设定为提升和发展你的职业生涯,你来对地方了。
什么是数据科学家?
数据科学家是被雇佣来分析和解读复杂数据的人。他们是数学家、计算机科学家和擅长发现趋势的人的结合体。能够解读大数据集、分析和解释这些分析,允许公司将这些结果应用于其短期和长期业务目标。
成为数据科学家需要哪些技能?
软技能非常重要,对职业发展至关重要。然而,要成为数据科学家,你需要具备硬技能,如分析、数据可视化、机器学习、统计学等。与解决问题、积极自我驱动的学习者以及批判性思维者等软技能结合,将帮助你在成为成功的数据科学家方面脱颖而出。
科技世界发展如此迅速,阻碍你在这一领域发展的唯一因素就是证明你具备这些硬技能的资格证书。
数据科学角色
在你匆忙选择任何资格或课程之前,了解数据科学行业中有各种角色,而不仅仅是数据科学家,是很有必要的。以下是数据科学中最常见的职业列表。
1. 数据科学家
让我们先解决最明显的一个,以免混淆。数据科学家从各种来源提取、分析和解释大量数据。他们将理解业务的需求,并利用数据来提出假设、分析数据并探索不同的模式,以符合业务议程。
他们还使用算法方法、人工智能、机器学习和统计工具进一步分析数据,使其对业务有用。商业分析也在数据科学家的角色中得以实施,向公司展示数据如何在未来证明对公司产生影响或带来好处。
2. 高级数据科学家
高级数据科学家利用数据来指导和塑造公司,以便预测业务的未来需求。这可能包括指导、建议并雇佣初级员工,以将他们引导到公司目标的方向。除了管理数据团队,他们还分析数据以解决复杂的业务问题,并推动新标准的开发,从原型设计到生产。
高级数据科学家所需的硬技能类似于数据科学家,但在每个方面,如机器学习、SQL 和不同的编程语言上有更多的经验。他们还将具备卓越的人际交往和沟通技能,因为他们的角色涉及管理和指导高技能员工。对于依赖数据的公司来说,高级数据科学家就像船长一样。没有他们的专业知识、经验和知识,团队其他成员难以满足业务的当前和未来需求。
3. 商业智能分析师
商业智能分析师的角色是识别潜在的改进机会,发现趋势,并通过利用数据帮助业务增长。他们可以识别潜在的问题并提出解决方案,帮助公司更清晰地了解自身情况。他们的角色完全旨在提高效率、生产力、推动销售以及实现业务的短期和长期目标。
4. 数据挖掘工程师
数据挖掘是从大型数据集中提取、筛选和识别模式的过程,这些模式可以改善业务系统和操作。数据挖掘工程师建立和管理存储和分析数据的基础设施。他们的工作可能包括构建数据仓库和组织数据,使其对其他团队成员可访问。数据挖掘工程师任务的关键缩写是 ETL:提取、转换和加载。
他们将具备硬技能,如机器学习、统计学、数据库系统,以及他们列表中的首要技能 SQL,这在存储和访问数据方面被广泛使用。
5. 数据架构师
数据架构师创建蓝图,这些蓝图用于数据管理系统以集中、整合、管理、维护和保护数据源,无论是内部的还是外部的。数据架构师与用户、开发人员和系统设计师紧密合作,使员工能够在指定的位置访问特定和关键的信息。
职业市场
随着技术的不断提升和科技与大数据领域的职位空缺达到数百万,根据[glassdoor]( https://www.glassdoor.com/List/Best-Jobs-in-America-LST_KQ0 ,20.htm),数据科学家是美国第二最佳的职业。来自各个行业的公司,如时尚、社交媒体和金融,正在利用数据科学家的技能来保持领先地位,降低成本和公司面临的潜在威胁。企业在做出明智决策和有效规划时严重依赖数据,因此数据科学家的需求将始终存在。
成为数据科学家之前你应该知道的
成为数据科学家具有挑战性,这包括繁重的工作量、持续的学习,以及一些日子里无法理解数据为何出错或代码为何无法按预期工作。任何具有巨大好处的事物都很少会轻松获得。
成为数据科学家的要求很高,但一旦你完成了适当的教育,你将能够获得这些好处。随着数据成为各个领域的重要元素,数据科学技能在这些领域之间变得更加可转移。通过适当的培训和资格认证,你可以在职业生涯开始时为政治公司担任数据科学家,而几年后为大型金融科技公司工作。
成为数据科学家使你能够在工作中转移,同时带上你的硬技能,并学习新的技能。
Nisha Arya 是一名数据科学家和自由职业技术写作人员。她特别感兴趣于提供数据科学职业建议或教程和理论知识。她也希望探索人工智能如何或能够对人类寿命产生益处。她是一位热心的学习者,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
使用 Python 和 NLTK 构建你的第一个聊天机器人
评论 来源:
来源:octodev.net/most-advanced-chatbot-apps-powered-by-artificial-intellect/
“聊天机器人(也称为对话机器人、闲聊机器人、机器人、IM 机器人、互动代理或人工对话实体)是一个计算机程序或一个人工智能,通过听觉或文本方法进行对话。这些程序通常被设计为模拟人类在对话中的行为,从而通过图灵测试。聊天机器人通常用于对话系统中,具有多种实际用途,包括客户服务或信息获取。一些聊天机器人使用复杂的自然语言处理系统,但许多简单的系统则扫描输入中的关键词,然后从数据库中提取具有最匹配关键词或最相似措辞模式的回复。”
— 来源 维基百科
聊天机器人并不是很新,其中之一是 ELIZA,它在 1960 年代初期创建,值得探索。为了成功构建一个对话引擎,它应当考虑以下事项:
-
了解目标受众
-
了解交流的自然语言。
-
了解用户的意图或愿望
-
提供可以回答用户的问题的响应
今天我们将学习如何使用 Python 的 NLTK 库创建一个简单的聊天助手或聊天机器人。
NLTK 有一个模块,nltk.chat,它通过提供一个通用框架来简化这些引擎的构建。
在这个博客中,我使用了来自 nltk.chat.util 的两个导入:
聊天:这是一个包含聊天机器人所使用的所有逻辑的类。
反射:这是一个包含一组输入值及其对应输出值的词典。它是一个可选的词典,你可以使用它。你也可以创建自己的词典,格式如下,并在代码中使用。如果你查看 nltk.chat.util,你会看到它的值如下:
reflections = {
"i am" : "you are",
"i was" : "you were",
"i" : "you",
"i'm" : "you are",
"i'd" : "you would",
"i've" : "you have",
"i'll" : "you will",
"my" : "your",
"you are" : "I am",
"you were" : "I was",
"you've" : "I have",
"you'll" : "I will",
"your" : "my",
"yours" : "mine",
"you" : "me",
"me" : "you"
}
你也可以创建你自己的反射词典,格式与上面相同,并在代码中使用它。以下是一个示例:
my_dummy_reflections= {
"go" : "gone",
"hello" : "hey there"
}
并将其用作:
chat = Chat(pairs, my_dummy_reflections)
使用上述 Python 的 NLTK 库概念,让我们构建一个简单的聊天机器人,而不使用任何机器学习或深度学习算法。因此,显然我们的聊天机器人将是一个体面的,但不是智能的。
源代码:
from nltk.chat.util import Chat, reflections
pairs = [
[
r"my name is (.*)",
["Hello %1, How are you today ?",]
],
[
r"what is your name ?",
["My name is Chatty and I'm a chatbot ?",]
],
[
r"how are you ?",
["I'm doing good\nHow about You ?",]
],
[
r"sorry (.*)",
["Its alright","Its OK, never mind",]
],
[
r"i'm (.*) doing good",
["Nice to hear that","Alright :)",]
],
[
r"hi|hey|hello",
["Hello", "Hey there",]
],
[
r"(.*) age?",
["I'm a computer program dude\nSeriously you are asking me this?",]
],
[
r"what (.*) want ?",
["Make me an offer I can't refuse",]
],
[
r"(.*) created ?",
["Nagesh created me using Python's NLTK library ","top secret ;)",]
],
[
r"(.*) (location|city) ?",
['Chennai, Tamil Nadu',]
],
[
r"how is weather in (.*)?",
["Weather in %1 is awesome like always","Too hot man here in %1","Too cold man here in %1","Never even heard about %1"]
],
[
r"i work in (.*)?",
["%1 is an Amazing company, I have heard about it. But they are in huge loss these days.",]
]
[
r"(.*)raining in (.*)",
["No rain since last week here in %2","Damn its raining too much here in %2"]
],
[
r"how (.*) health(.*)",
["I'm a computer program, so I'm always healthy ",]
],
[
r"(.*) (sports|game) ?",
["I'm a very big fan of Football",]
],
[
r"who (.*) sportsperson ?",
["Messy","Ronaldo","Roony"]
],
[
r"who (.*) (moviestar|actor)?",
["Brad Pitt"]
],
[
r"quit",
["BBye take care. See you soon :) ","It was nice talking to you. See you soon :)"]
],
]
def chatty():
print("Hi, I'm Chatty and I chat alot ;)\nPlease type lowercase English language to start a conversation. Type quit to leave ") #default message at the start
chat = Chat(pairs, reflections)
chat.converse()
if __name__ == "__main__":
chatty()
代码非常简单,但我们还是来理解一下。
一旦调用函数 chatty(),将显示默认消息:

接下来,我创建了一个包含pairs(包含问题和答案集合的元组列表)和reflections(如上所述)的 Chat 类实例。
下一步是触发对话:
chat.converse()
一个简单的对话:
 与 Chatty 的简单对话
与 Chatty 的简单对话
正如你所见,我们只是将可能的问题和答案硬编码到列表 pairs 中。
让我们更多地与 Chatty 互动:
 与 Chatty 的简单对话
与 Chatty 的简单对话
nltk.chat 聊天机器人基于问题中存在的关键字的正则表达式工作。所以你可以添加任何数量的按正确格式编写的问题,以避免你的聊天机器人在确定正则表达式时感到困惑。
在这篇博客中,我用简单的步骤解释了如何使用 NLTK 构建自己的聊天机器人,当然它不是一个智能聊天机器人。
希望大家喜欢阅读。
快乐学习!!!
如有疑问/建议,请通过LinkedIn与我联系。
简介: 纳吉什·辛格·乔汉是 CirrusLabs 的一名大数据开发人员。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,并在各种大数据组件方面有专长。
原文。已获得许可重新发布。
相关:
-
如果聊天机器人要成功,它们需要这个
-
认识 Lucy:创建聊天机器人原型
-
机器如何理解我们的语言:自然语言处理简介
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
使用这些课程构建一个类似 ChatGPT 的聊天机器人
原文:
www.kdnuggets.com/2023/05/build-chatgptlike-chatbot-courses.html

图片由firmufilms提供,来自Freepik
新的技术进步总是引人注目。数据科学及其应用多年来一直是关注的焦点。2023 年开始时,随着OpenAI发布基于 AI 的聊天机器人 ChatGPT,开局强劲。ChatGPT 的发布引起了轰动,每个人以不同的方式使用它,挑战 AI 和聊天机器人的极限。它甚至促使其他公司,如 Notion,构建更好的聊天机器人,以挑战和超越 ChatGPT。
不仅仅是公司,许多数据科学家,无论是新手还是专家,也尝试构建自己的 ChatGPT 版本,以获得更多关于构建基于 AI 的聊天机器人的知识和经验,或挑战并提升他们的技能。你阅读这篇文章意味着你也考虑过制作一个类似 ChatGPT 的聊天机器人,或者只是对构建这样的工具所需的条件感到好奇。
本文将回顾构建你自己版本的 ChatGPT 所需的知识。但在我们深入讨论开发聊天机器人所需的技术知识之前,让我们简单谈谈构建聊天机器人所需的条件。
由于我们考虑构建一个类似 ChatGPT 的聊天机器人,即一个基于网页的聊天机器人,我们在设计和构建聊天机器人时需要考虑两个部分。前端(聊天机器人的外观),即用户将与之互动的部分,以及聊天机器人的核心(后端),即我们所称的聊天机器人的“大脑”。
让我们深入探讨一些能够提供构建外观良好且功能强大的 AI 聊天机器人所需知识的课程。然后,我们为每个元素建议一个课程,以便为你构建 ChatGPT 提供所有必要的工具。
外观
首先,我们将从构建聊天机器人外观所需的内容开始;你的聊天机器人外观越具有创意,用户体验就会越好。那么,你需要知道什么才能为聊天机器人设计一个好的界面呢?
UI 设计
一个网页的外观有两个方面:总体美学和设计的直观性。在我们的案例中,网页(聊天机器人)的感觉就是 UI(用户界面)设计。
当你构建聊天机器人时,了解用户界面设计的基本原理是至关重要的。这门课程由加州艺术学院提供,将帮助你理解 UI 设计的基础。
UX 设计
美观的设计和色彩很好,但如果导航困难,那么外观就显得无关紧要。这时候了解用户体验(UX)的基础知识就显得非常重要。UX 是设计易于导航和使用的应用程序的艺术,从而为使用该应用程序的任何人提供更好的体验。例如,如果我们想构建一个好的聊天机器人,它必须既美观又易于使用且直观。CalArts 还提供了一个课程,帮助你获得制作具有良好 UX 的聊天机器人所需的知识。
HTML & CSS
由于我们尝试构建一个基于网络的聊天机器人,我们需要了解如何构建网页应用程序。这意味着我们需要知道一些 HTML 和 CSS。当然,如今,我们可以使用许多服务来帮助开发网页,而无需编写 HTML 或 CSS。
但了解这些知识将让你对你构建的内容和细节有更多的控制。这个来自CodeAcademy的课程将帮助你学习 HTML 和 CSS 的基础知识。或者你可以查看这个来自 Coursera 的指导项目,你可以在 2 小时内完成。

作者提供的图像
大脑
既然我们设计好了聊天机器人的外观,接下来就让我们来构建它的“大脑”。我们想要建立一个基于人工智能的聊天机器人,因此必须掌握数据科学、编程和人工智能的基础知识。我们可以将 ChatGPT 的“大脑”分为两个部分:数据科学基础和聊天机器人的核心。现在让我们详细了解一下这两个部分。
数据科学基础
编程与数学
数据科学及其所有应用基于一些数学知识(概率论和线性代数)和编程。然而,如果你已经知道数据科学的基础知识,你可以跳过这一步,直接进入聊天机器人的核心部分。
如果 ChatGPT 让你对开始数据科学应用之旅感到好奇,这门由哈佛大学提供的课程将帮助你通过提供所需的数学和编程知识,帮助你入门构建聊天机器人!
机器学习
一旦你对编写代码感到舒适,并且掌握了一些数学知识,我们就可以进入任何数据科学应用程序的基础构建模块之一:机器学习。机器学习是一系列算法和技术,用于使计算机更智能。你可以使用这门来自斯坦福大学的课程来学习机器学习的基础知识。
聊天机器人的核心
聊天机器人是一类数据科学,特别是自然语言处理,旨在创建一个供用户对话的系统。我们可以根据其主要功能将聊天机器人分类为三类:
-
简单的 NLP 聊天机器人。
-
基于影响的聊天机器人
-
基于智能的聊天机器人
第一种类型是与用户进行简单对话的基础聊天机器人;第二种类型通常用于处理用户的问题,这些通常是大多数网站上的支持机器人。最后,第三种类型则模拟和预测用户可能如何与用户界面互动。仔细观察 ChatGPT,我们会发现它是这三种类型的混合体。要构建一个基于 AI 的聊天机器人,我们需要了解自然语言处理(NLP)、AI 的基础知识以及构建聊天机器人的基本原理。
图片由 macrovector 提供,来源于 Freepik
自然语言处理
这门 Udemy 的课程将帮助你掌握 NLP,它的含义、基本原理及其各种应用,包括聊天机器人。
聊天机器人基础
掌握 NLP 的基础知识是构建聊天机器人的第一步。一旦你了解了基础知识,我们就可以深入探讨如何设计和构建聊天机器人,主要使用这门课程。
人工智能
为了让你的聊天机器人显得真实并与用户进行引人入胜的对话,聊天机器人需要具备智能或类似人类智能。为此,我们将使用 AI。因此,我们需要学习如何将 AI 技术应用于我们的聊天机器人。这门来自 DeepLearning.AI 的课程涵盖了 AI 的基础知识以及如何利用它来构建聊天机器人。
结论
ChatGPT 最近成为了媒体关注的焦点,原因非常充分。它清楚地证明了技术的强大潜力。它证明了我们可以设计出优秀的工具,使我们的生活更轻松,同时也激励我们变得更好。
ChatGPT 激发了许多人,无论是技术领域还是其他领域的好奇心,想要了解这样的工具是如何构建的。虽然有些人可能觉得开发这样的工具很复杂,但构建聊天机器人的核心要素比看起来更简单。
本文讨论了构建类似 ChatGPT 的聊天机器人所需了解的内容。因此,下次你有一个空闲的周末时,可以尝试构建一个聊天机器人;也许你的聊天机器人将成为与 ChatGPT 竞争的成果!
Sara Metwalli 是庆应大学的博士候选人,研究测试和调试量子电路的方法。我是 IBM 的研究实习生和 Qiskit 促进者,致力于构建更具量子前景的未来。我还在 Medium、Built-in、She Can Code 和 KDN 撰写有关编程、数据科学和技术话题的文章。我也是 Woman Who Code Python 国际章节的负责人,一个铁路迷、旅行者和摄影爱好者。
更多相关话题
如何在 Airflow 上构建 DAG 工厂
评论
由Axel Furlan,数据工程师
图片由Chris Ried提供,来自Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 在 IT 领域支持你的组织
为什么选择 DAG 工厂?
让我们看一个有 2 个任务的简单 DAG……
在 Airflow 中执行 2 个简单的 Python 脚本需要这么多的样板代码,难道不奇怪吗?无论你编写多少 DAG,你几乎都会发现自己在不同的 DAG 中编写几乎相同的变量,只是有细微的变化。
请记住,在编码中,通常编写一段可以后续调用的代码,而不是每次需要该过程时都编写相同的代码是更好的。这被称为DRY。
如果你许多 DAG 共享相似的值,例如电子邮件地址、开始日期、调度间隔、重试次数等,那么拥有一段代码来完成这些值可能更好。这就是我们尝试通过工厂类实现的目标。
使用 Airflow 上的 DAG 工厂,我们可以将创建 DAG 所需的行数减少一半。
让我们看一下以下示例
在这里,我们需要一个简单的 DAG,它会先打印今天的日期,然后打印“hi”。
这就是它在 Airflow 上的样子:

注意我们减少了多少冗余。我们没有指定使用了什么操作符、任务的 ID、调度间隔、DAG 的创建者或创建时间。
我们还可以看到,我们使用字典指定了任务和依赖关系,这最终转化为正确的任务依赖关系 ????
让我们看一个稍微复杂的示例:
在这个 DAG 中,我指定了 2 个我希望覆盖默认值的参数。它们是 DAG 的所有者及其重试次数。我还在get_airflow_dag()方法中指定了希望调度为每日执行。
这个 DAG 有 3 个任务。say_bye() 和 print_date() 都依赖于 say_hi()。让我们看看在 Airflow 中是如何表现的。
现在,让我们来看看如何构建 DAG 工厂 ????
如何编码?
说实话,这很简单。我们首先创建一个类,该类将包含我们创建 DAG 及其任务所需的所有方法。
以下是 DAG 工厂的完整代码。
我们将要调用的主要方法以获取一个完全可用的 DAG 是 get_airflow_dag()。
该方法将接收 2 个必填参数:DAG 的名称和它应该运行的任务。其余参数是可选的,因为我们可以在函数的实现中设置默认值。在实现时,可以根据你的用例将任何这些可选参数设置为必填参数,例如,可能会有用将 cron (schedule_interval) 设置为必填参数,或者甚至是 DAG 的所有者。
default_args 参数将是一个字典,用于保存任何你可能想要覆盖的键值对。如果未指定,将使用默认的 default_args。
在我们的例子中,默认值为:
DEFAULT_ARGS = {
'owner': 'Data Engineer',
'depends_on_past': False,
'start_date': datetime(2021, 1, 1),
'email': ['data_engineers@company.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
另外 3 个参数是用于描述 DAG 的主要参数。还有更多选项,可以自由指定更多。
get_airflow_dag() 将运行 create_dag() 以创建 DAG 对象并返回它。add_tasks_to_dag() 稍微复杂一些,因为我们希望让用户容易指定创建任务依赖关系的方式,而无需编写 Operators。
在我们的例子中,我们总是为任务使用 PythonOperator,因此我们认为将其作为规范是合理的。
这个实现旨在简化数据工程师的工作,因此我们避免设置额外的内容,比如任务的名称,我们仅假设它与函数名称相同——因此我们使用了一点 反射 来搞清楚。
for func in tasks:
task_id = func.__name__
task = PythonOperator(
task_id=task_id,
python_callable=func,
dag=dag
)
aux_dict[task_id] = taskfor func, dependencies in tasks.items():
task_id = func.__name__
for dep in dependencies:
aux_dict[dep.__name__] >> aux_dict[task_id]
该函数首先创建一个辅助字典,以保存任务名称:任务对象的键值对。这是为了只拥有一组任务对象,并在以后用于设置依赖关系。然后,对于原始提供的任务字典中的每个键,使用辅助字典设置依赖关系。
在此操作完成后,DAG 对象准备好被返回并供团队使用 ????。
懂了!
文件中有一个小技巧,以便 Airflow 能够识别我们返回的是一个有效的 DAG。
当 Airflow 启动时,所谓的 DagBag 过程会解析所有文件以寻找 DAG。当前实现的工作方式大致如下:
-
DagBag 生成不同的进程,这些进程会检查 dag 文件夹中的文件。
-
名为
process_file的函数 这里 会为每个文件运行,以确定是否存在 DAG。 -
代码运行
might_contain_dag,根据文件中是否同时包含 “dag” 和 “airflow” 来返回 True。实现 见这里。
这就是为什么 get_airflow_dag 函数是这样命名的,以便在文件中包含两个关键字,从而确保文件被正确解析。
这是一件很难找到的事情,我花了很多小时试图弄清楚为什么我的 DAG 工厂不工作。关于如何以非传统方式创建 DAG 的文档不多,因此这是你在做类似事情时必须考虑的一个大坑。
结论
这篇简单的文章旨在解释如何通过在 Airflow 上利用 工厂模式 来简化数据工程师的工作。
希望你喜欢!可以点击我的个人资料,查看其他有用的 Airflow 和数据工程文章!
简历: Axel Furlan 是来自阿根廷的数据工程师和软件工程专业的学生。Axel 起初是数据科学家,然后将软件工程与数据结合起来,爱上了这个角色的多样性。他写作的目的是为了让其他数据工程师的生活更轻松。
原文。经允许转载。
相关:
-
2021 年数据科学学习路线图
-
成为数据工程师所需的 9 项技能
-
使用 NumPy 和 Pandas 在更大的图上加速机器学习
更多相关话题
如何构建数据科学赋能团队:完整指南
原文:
www.kdnuggets.com/2022/10/build-data-science-enablement-team-complete-guide.html
数据科学赋能团队(DSET)促进开发者和数据科学家的协作。在这篇博客中,我们将讨论什么是数据科学赋能团队,如何建立 DSET,以及如何与数据科学家合作。
数据科学家是具有卓越跨学科知识的专家。他们坚持为机器智能确定最佳培训方法。最近,成功的商业巨头们讨论了开发团队和数据科学家之间的有效协作。这确保了数据科学模型在应用中的可行性。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
成立数据科学赋能团队(DSET)的公司能够获得更快的开发周期的竞争优势。

让我们深入了解数据科学赋能团队(DSET)是什么。
关于数据科学赋能团队(DSET)你需要知道的
一般而言,赋能团队是一个卓越中心,旨在鼓励团队间的协作。就数据科学赋能团队而言,它特别旨在提高开发团队和数据科学团队之间的沟通。
两个团队在工作环境中的差异导致了更长的开发周期。然而,在 DSET 设置中,数据科学团队成员能够意识到他们的模型是如何被使用的。这使他们在未来的项目中能够更加高效,同时保持开发的视角。
数据科学赋能团队(DSET)让每个人都能从彼此的学习中受益,包括优化工作流程的新方法和获得更高效率。
如何建立数据科学赋能团队(DSET)
下一步是在你的组织中建立 DSET。别担心,这不需要你安排或投资额外的资源,只需在开发人员和数据科学家之间架起一座桥梁即可。

如果你是开发人员,你不必担心建立数据科学赋能团队,因为开发是所有项目的核心。你需要做的就是支持数据科学家并将他们的模型付诸实践。
此外,与 DSET 合作可以让你向数据科学家展示数据开发项目的范围,并增加他们的知识,例如教他们使用点对点编码、GitHub 等。因此,开发团队和数据科学家可以通过遵循敏捷和安全的开发流程,顺畅地共同构建模型和应用。
开发团队与数据科学家之间的有效合作
数据科学赋能团队是组织从他们拥有的数据中获取更多价值的一种方式。数据科学是一个不断发展的领域,具有很大的增长潜力。数据科学赋能团队负责确保数据科学家配备了完成工作的必要工具和资源。
DSET 主要是一组人员,大多是开发人员,他们与数据科学家合作,从数据中提取洞察,然后帮助他们基于这些洞察做出决策。
数据科学家需要帮助以便能够有效地完成工作。数据科学赋能团队可以通过从数据中提取洞察,然后基于这些洞察提供建议来提供这种帮助。

那么,数据科学家为什么需要帮助呢?一位数据科学家是拥有统计学、机器学习和其他定量领域专业知识的人。他们利用这些技能分析大量数据,并找到公司可以使用的洞察。
数据科学赋能团队由来自市场营销、销售、产品开发等各个部门的人组成。他们负责提供必要的工具和资源,以帮助数据科学家更高效地完成工作。
在与数据科学家合作时需要考虑几个关键点:
-
与数据科学家频繁合作,打破信息孤岛
-
在每一步都寻求帮助,以确保模型的准确性
-
将进展分阶段展示给你的合作科学家,并保持项目无误
你是否对建立数据科学赋能团队感到兴奋?
不再等待,用创新的方法展示数据科学和机器学习的力量。通过高效的合作优化模型部署,在现代商业世界中竞争。
Ayesha Saleem 是 Data Science Dojo 的数字内容作家。Ayesha 热衷于通过有意义的内容写作、文案写作、电子邮件营销、SEO 写作、社交媒体营销和创意写作来重新塑造品牌。
了解更多信息
如何建立数据科学投资组合
原文:
www.kdnuggets.com/2018/07/build-data-science-portfolio.html
评论
作者:Michael Galarnyk,数据科学家

投资组合是一种展示你是数据科学领域独角兽的方式。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
如何在数据科学领域找到工作? 知道足够的统计学、机器学习、编程等技能以获得工作是困难的。最近我发现,很多人可能 具备了获得工作的必要技能,但没有投资组合。尽管简历很重要,但拥有数据科学技能的公开证据的投资组合可以对你的求职前景产生奇妙的影响。即使你有推荐,能够展示你的能力而不仅仅是告诉潜在雇主你能做些什么也是重要的。本文将包含链接,介绍各种数据科学专业人士(数据科学经理、数据科学家、社交媒体达人或这些的组合)及其他人谈论投资组合应包含的内容以及如何引起注意。好了,我们开始吧!
投资组合的重要性
除了通过制作投资组合来学习的好处外,投资组合还很重要,因为它可以帮助你获得就业机会。本文的目的在于将投资组合定义为你数据科学技能的公开证据。这个定义来源于David Robinson,他是 DataCamp 的首席数据科学家,在接受Marissa Gemma采访时提到的,他被问到如何找到第一份行业工作时说,
对我来说,最有效的策略是进行公开工作。我在博士后期写博客和做了大量的开源开发,这些工作帮助提供了我数据科学技能的公开证据。但我获得的第一个行业职位的方式是公开工作的一个特别值得注意的例子。在我的博士期间,我是编程网站 Stack Overflow 的活跃回答者,公司的一位工程师看到我的一个回答(一个解释贝塔分布直观的回答)。他对这个回答印象深刻,于是通过[Twitter]联系了我,经过几次面试后,我被录用了。
你可能会认为这是一种偶然事件,但你会发现你越活跃,发生这种事情的机会就越大。从David 的博客文章中,
你做的公开工作越多,发生这种意外事件的机会就越高:有人注意到你的工作并将你引向一个工作机会,或者有人在面试你时听说了你做过的工作。
人们常常忘记,软件工程师和数据科学家也会在谷歌上搜索他们的问题。如果这些人通过阅读你的公开工作来解决了他们的问题,他们可能会对你有更好的看法并联系你。
应对经验要求的作品集
即使是入门级职位,大多数公司也希望拥有至少有一点实际经验的人。你可能见过如下的表情包。

问题是,如果你需要经验才能获得第一份工作,那么你怎么获得经验?如果有答案,那就是项目。项目可能是工作经验的最佳替代品,或者正如Will Stanton所说,
如果你没有数据科学家的任何经验,那么你绝对必须做独立项目。
事实上,当Jonathan Nolis面试候选人时,他希望听到你最近遇到的一个问题/项目的描述。
我想了解他们最近做的一个项目。我会问他们项目是如何开始的,如何确定值得投入时间和精力,他们的过程以及他们的结果。我还会问他们从项目中学到了什么。我从这个问题的回答中获益良多:如果他们能讲述一个故事,问题如何与更大的背景相关,以及他们如何解决困难的工作。
如果你没有一些与数据科学相关的工作经验,最佳选择是谈论你曾经做过的数据科学项目。
应包括在作品集中的项目类型
数据科学是一个非常广泛的领域,很难知道招聘经理希望看到什么样的项目。 William Chen,Quora 的数据科学经理,在 Kaggle 的 CareerCon 2018 上分享了他的想法(视频)。
我喜欢那些展示出他们对数据有深入兴趣的项目,超越了家庭作业的范围。任何探索有趣数据集并找到有趣结果的课程期末项目……投入精力在撰写报告上……我真的很喜欢看到那些很好的报告,其中人们发现了有趣且新颖的东西……有一些可视化并分享他们的工作。
很多人认识到创建项目的价值,但许多人会想知道从哪里获得有趣的数据集以及如何处理这些数据。 Jason Goodman,Airbnb 的数据科学家,写了一篇文章 关于构建数据作品集项目的建议,在文章中他讨论了许多不同的项目想法,并给出了关于应该使用哪些数据集的好建议。他还赞同了威廉(William)的一个观点,即处理有趣的数据。
我发现最好的作品集项目更多地涉及处理有趣的数据,而不是做复杂的建模。很多人使用财务信息或 Twitter 数据进行项目;这些数据可以工作,但本身并不特别有趣,因此你面临的挑战更大。
文章中的另一个观点是,网络爬取是获取有趣数据的好方法。如果你有兴趣学习如何通过 Python 进行网络爬取以构建自己的数据集,你可以查看我的文章 这里。如果你来自学术界,重要的是要注意你的论文可以作为一个项目(一个非常大的项目)。你可以在 这里 听到 William Chen 谈论这个话题。
Traffic Cruising Data Science for Social Good Project (github.com/uwescience/TrafficCruising-DSSG2017)。这是一个我个人觉得有趣的项目示例,但外面还有很多有趣的项目。致谢 (Orysya Stus, Brett Bejcek, Michael Vlah, Anamol Pundle)
不应包括在作品集中的项目类型
我发现一个非常常见的建议(在这篇博客文章中出现了多次)是你的作品集中不要包含常见的项目。
杰雷米·哈里斯在《成为数据科学家最容易失败的四种方式》中说,
很难想到比在你的个人项目中展示你在琐碎的概念验证数据集上做的工作更快地让你的简历被放入“绝对不行”堆的方式。
当你感到困惑时,这里有一些项目,它们对你造成的伤害大于帮助:
使用Titanic 数据集进行生存分类。
手写数字分类使用了MNIST 数据集。
使用鸢尾花数据集进行花卉种类分类。
下图展示了泰坦尼克号 (A)、MNIST (B) 和鸢尾花 (C) 数据集的部分分类示例。没有很多方法可以利用这些数据集让你在其他申请者中脱颖而出。确保列出新颖的项目。
泰坦尼克号 (A)、MNIST (B) 和鸢尾花 (C) 分类
作品集是迭代的
法维奥·瓦兹克斯有一篇优秀的文章,讲述了他如何获得数据科学家的工作。当然,他的一个建议是拥有一个作品集。
拥有一个作品集。如果你在寻找一个严肃的付费数据科学工作,做一些实际数据的项目。如果可以的话,把它们发布到 GitHub 上。除了 Kaggle 比赛外,找到你喜欢的东西或你想解决的问题,并利用你的知识来做这些事情。
另一个有趣的发现是,在求职过程中,你必须不断改进。
我申请了差不多 125 个工作(真的,也许你申请了更多),只收到大约 25 到 30 个回复。有些回复只是:谢谢,但不行。我得到过将近 15 次面试。我从每一次中学到了很多。变得更好。我不得不面对许多拒绝,这实际上是我没准备好的。但我喜欢接受面试的过程(老实说,并不是所有的面试)。我学习了很多,每天编程,阅读了许多文章和帖子。这些都帮助了我很多。
随着你学习的深入和自我提升,你的作品集也应该进行更新。这种观点在许多其他建议文章中都有提到。正如杰森·古德曼所说,
当你公开发布一个项目时,它并没有完成。不要害怕在项目发布后继续添加或编辑它们!
这条建议在你寻找工作时尤其重要。很多成功人士的故事,例如 凯利·彭,她是 Airbnb 的数据科学家,她真的坚持不懈,不断工作和提升自己。在 她的一篇博客文章中,她详细介绍了她申请和面试过的很多地方。
申请数量:475
电话面试次数:50
完成的数据科学家庭挑战:9
现场面试次数:8
录用:2
花费时间:6 个月
她显然申请了很多工作并坚持不懈。在她的文章中,她甚至提到你需要从面试经验中不断学习。
记下你被问到的所有面试问题,特别是那些你未能回答的问题。你可以再次失败,但不要在同一个地方失败。你应该始终学习和提升自己。
如果你还没有获得面试机会,请申请更多的工作并继续寻找学习和提升的方法。
将作品集整合到 1 页简历中
人们找到你作品集的一个方式通常是通过你的简历,因此值得一提。数据科学简历是专注于你的技术技能的地方。你的简历是一个简洁展示你的资格和适合特定角色的机会。招聘人员和招聘经理会非常快速地浏览简历,你只有短时间来留下印象。改善简历可以增加获得面试的机会。你必须确保简历中的每一行和每一部分都很重要。
威廉·陈,来自 Quora 的数据科学经理,提供了9 个制作数据科学简历的技巧。请注意下面简要总结中的要点,项目和作品集是第 6、7、8 点,甚至可以说是第 9 点。
1. 长度:保持简洁,最多一页。这可以让你在快速浏览时产生最大影响。建议使用简单的单列简历,因为它容易浏览。

视频中使用的简历示例(latex: github.com/sb2nov/resume)
2. 目标:不要包含一个。它们不能帮助你与其他人区分开来。它们占用了更重要的内容(技能、项目、经验等)的空间。求职信非常可选,除非你真的个性化它。

目标陈述不能帮助你与其他人区分开来。许多目标陈述说的非常相似。
3. 课程:列出相关课程,这些课程与职位描述相关。

各种简历中展示的相关课程示例。
4. 技能:不要对你的技能给出数值评级。如果你想对自己的技能进行评分,请使用“熟练”或“了解”等词汇。你甚至可以完全省略评估。
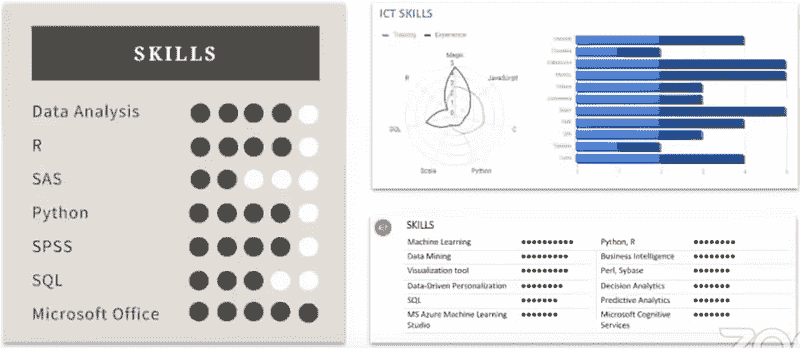
不要对你的技能给出数值评级。
5. 技能:列出职位描述中提到的技术技能。你列出技能的顺序可以暗示你最擅长的领域。

如何在简历上列出你的技能的示例
6. 项目:不要列出常见的项目或作业。它们在区分你和其他申请者方面帮助不大。列出新颖的项目。

7. 项目:展示结果并包含链接。如果你参与了 Kaggle 竞赛,请标明百分位排名,因为这有助于阅读你简历的人了解你在竞赛中的位置。在项目部分,总是可以加入写作和论文的链接,这样可以让招聘经理或招聘人员深入了解(偏向真实世界中的复杂问题,你可以从中学到新东西)。

好的项目部分示例
注意在上述一个项目部分中,有一个额外的博客链接,让招聘人员或招聘经理了解更多。这是从简历中链接到你作品集各个部分的一种方式。
8. 作品集:完善你的在线存在。最基本的是 LinkedIn 个人资料。这有点像一个扩展的简历。GitHub 和 Kaggle 个人资料可以帮助展示你的工作。填写每个个人资料,并包括其他网站的链接。填写你的 GitHub 仓库的描述。包括你知识分享个人资料/博客的链接(Medium、Quora)。数据科学特别注重知识分享和向他人传达数据的意义。你不必全部完成,但选择几个去做(稍后会详细说明)。
9. 经验:根据工作量身定制你的经验。经验是你简历的核心,但如果你没有工作经验该怎么办?专注于独立项目,如毕业设计、独立研究、论文工作或 Kaggle 竞赛。如果你没有工作经验,这些可以作为替代。避免在简历上放置不相关的经验。

如果你想了解数据科学经理如何审查作品集和简历,这里有 Kaggle’s CareerCon 2018 的链接(视频,审查的简历)。
社交媒体的重要性
这与“投资组合的重要性”部分非常相似,只是分成了子部分。拥有 Github 页面、Kaggle 个人资料、Stack Overflow 等可以支持你的简历。拥有完善的在线个人资料对招聘经理来说是一个良好的信号。
正如 David Robinson 所说,
通常,当我评估候选人时,我很高兴看到他们公开分享的内容,即使它不是完善或完成的。分享任何东西几乎总是比什么都不分享要好。
数据科学家喜欢查看公开工作的原因是正如 Will Stanton 所说,
数据科学家使用这些工具来分享他们的工作并找到问题的答案。如果你使用这些工具,那么你就是在向数据科学家表明你是他们中的一员,即使你从未作为数据科学家工作过。
数据科学很大程度上是关于沟通和呈现数据,因此拥有这些在线个人资料是很好的。除了这些平台帮助提供宝贵的经验之外,它们还可以帮助你被注意到并引导人们找到你的简历。人们可以通过各种渠道(LinkedIn、GitHub、Twitter、Kaggle、Medium、Stack Overflow、Tableau Public、Quora、YouTube 等)在线找到你的简历。你还会发现不同类型的社交媒体相互关联。
Github

Jennifer Bryan 和 Yuan (Terry) Tang 的 Github 个人资料
Github 个人资料是你作为一个合格数据科学家的强有力信号。在简历的项目部分,人们通常会留下指向他们 GitHub 的链接,那里存储了他们项目的代码。你也可以在上面添加写作和 Markdown。GitHub 让人们看到你构建了什么以及如何构建它。在一些公司中,招聘经理会查看申请者的 GitHub。这是向雇主展示你不是假冒伪劣的一种方式。如果你花时间完善你的 GitHub 个人资料,你将比其他人更容易被评估。
值得一提的是,你需要有某种 README.md 文件,其中包含对你项目的描述,因为数据科学很大程度上是关于沟通结果。确保 README.md 文件清楚地描述了你的项目是什么、做了什么以及如何运行你的代码。
Kaggle
参与 Kaggle 比赛、创建内核和参与讨论是展示数据科学家能力的一些方式。重要的是要强调 Kaggle 不像行业项目,正如科琳·法雷利在这个quora 问题中提到的那样。Kaggle 比赛负责提出任务,为你获取数据,并将其清理成某种可用的形式。它的作用是给你提供分析数据和提出模型的练习。瑞莎玛·谢赫有一篇文章参加 Kaggle 还是不参加,在文章中她谈到了 Kaggle 比赛的价值。她的文章中提到,
的确,参加一次 Kaggle 比赛并不足以使一个人成为数据科学家。也不是上一次课程、参加一次会议教程、分析一个数据集或阅读一本数据科学书籍就能成为数据科学家。参与比赛可以增加你的经验,并丰富你的作品集。这只是对其他项目的补充,而不是检验一个人数据科学技能的唯一标准。
同样,有充分的理由说明Kaggle 大师继续参与 Kaggle 比赛。
与简历不同的是,简历受长度限制,而 LinkedIn 个人资料允许你更详细地描述你的项目和工作经验。Udacity 提供了一份制作良好 LinkedIn 个人资料的指南。LinkedIn 的一个重要部分是他们的搜索工具,为了让你出现在搜索结果中,你必须在个人资料中包含相关关键词。招聘人员经常在 LinkedIn 上搜索人才。LinkedIn 允许你查看哪些公司搜索了你以及谁查看了你的个人资料。
检查你的搜索者工作在哪里以及有多少人查看了你的个人资料。
除了公司找到你并向你发送关于你可用性的消息外,LinkedIn 还有许多功能,例如请求推荐信。杰森·古德曼在他的文章申请数据科学职位的建议中利用 LinkedIn 间接请求推荐信。
我从未、从未、从未在没有介绍的情况下申请过任何公司……一旦我对某家公司感兴趣,我会使用 LinkedIn 寻找该公司的第一度或第二度关系。我会联系那个关系,询问他们关于在公司的经历,如果可能的话,是否能把我引荐给数据科学团队的某个人。我总是尽可能进行面对面的会谈(喝咖啡或吃午餐),而不是打电话。顺便说一下,Trey Causey 最近写了 一篇很棒的文章 ,介绍了如何请求这种类型的会谈。我从不直接要求工作,但他们通常会要求我的简历,并提出将我作为内部推荐人,或者把我介绍给招聘经理。如果他们似乎不愿意这样做……我会感谢他们的时间,然后继续前进。
注意他并没有立即要求推荐。虽然申请公司时常见的建议是获取推荐,但非常重要的一点是,你仍然需要一个作品集、经验或某种证明你能胜任工作的证据。Jason 甚至在那篇文章和 他写的其他文章 中提到作品集的重要性。
Aman Dalmia 通过 在多家 AI 公司和初创企业面试中学到的东西 学到了类似的东西。
网络不是向人们发送信息让他们为你推荐工作。当我刚开始的时候,我经常犯这个错误,直到我偶然发现了 这篇文章 ,作者是 Mark Meloon,在这篇文章中,他谈到了通过首先提供帮助来建立真正的*人际关系的重要性。
他说的另一个观点是 LinkedIn 对于发布你的内容/作品集非常有用。
网络中的另一个重要步骤是发布你的内容。例如,如果你擅长某件事,写博客并在 Facebook 和 LinkedIn 上分享这些博客。这不仅能帮助别人,也能帮助你。
Medium 和/或其他博客平台
拥有某种形式的博客可能非常有利。很多数据科学工作涉及沟通和展示数据。写博客是练习这项技能的方式,并展示你可以做到这一点。写关于项目或数据科学主题的文章,让你与社区分享,同时鼓励你写出你的工作过程和想法。这在面试时是一项有用的技能。
正如 David Robinson 所说,
博客是你练习相关技能的机会。
-
数据清理:与各种数据集一起工作的一个好处是,你会学会接受数据“原封不动”,无论它是以期刊文章的补充文件还是*电影剧本的形式出现。
-
统计:处理不熟悉的数据让你能够将统计方法付诸实践,而写作传达和教授概念有助于构建你自己的理解*
-
机器学习:使用预测算法一次和在各种问题上使用它之间有很大的区别,同时了解你为什么会选择一个而不是另一个*
-
可视化:拥有观众对你的图表有鼓励作用,这会促使你开始打磨图表并建立个人风格*
-
沟通:你在写作中获得经验,并练习构建数据驱动的论点。这可能是博客最相关的技能,因为在其他地方很难实践,而这是任何数据科学职业的核心部分*
通过写博客,你可以练习将发现传达给他人。这也是一种自我宣传的方式。关于使用 Scrapy 构建你自己的数据集的博客,以及具有讽刺意味的使用 Conda 管理 Python 环境博客,教会了我很多,也给我带来了许多我通常无法获得的机会。我发现的一个主要好处是,通过别人对我的项目提出批评和改进建议(通过博客的评论区),使得面试官不会成为第一个指出这些缺陷的人。更明显的好处是,通过写博客,你倾向于阅读更多的数据科学/机器学习博客帖子,从而学到更多。
至于选择哪个平台来写博客,我推荐使用 Medium。Manali Shinde在她的博客文章如何从零开始构建数据科学作品集中指出了她选择 Medium 的原因。
我曾考虑在 WordPress 或 Squarespace 等平台上创建自己的网站。虽然这些平台非常适合托管自己的作品集,但我想要一个可以获得一些曝光的地方,并且有一个很好的标签系统以接触更广泛的受众。幸运的是,Medium 如我们所知,提供了这些选项(而且它也是免费的)。
如果你不知道写什么,我建议你查看David Robinson 的建议。
在 Twitter 上活跃是识别和与领域内人士互动的绝佳方式。你还可以在 Twitter 上推广你的博客,让你的作品集更加显眼。在 Twitter 上有很多互动机会。正如Reshama Shaikh在她著名的博客文章“如何获得我的第一份数据科学工作?”中所说,
大卫·罗宾逊慷慨地提供转发你的第一篇数据科学帖子。拥有 20K+粉丝,这个提议是无法拒绝的。
Twitter 不仅仅可以用于自我推广。Data Science Renee有一篇帖子“如何利用 Twitter 学习数据科学(或其他任何东西)”,其中对如何利用 Twitter 学习技能非常有见地。她文章中的另一个收获是,Twitter 上的存在如何帮助她建立网络并获得机会。
我曾被邀请参加播客和博客的采访(其中一些很快就会出现),提供合同工作,并提供了一个我不幸无法参加但很高兴被考虑的会议的免费入场券。行业中的“名人”现在也来找我合作。
Tableau Public
并非所有的数据科学工作都使用 Tableau 或其他 BI 工具。然而,如果你申请的是使用这些工具的工作,重要的是要知道有些网站可以让你公开展示仪表板。例如,如果你说你在学习或掌握 Tableau,可以在Tableau Public上放几个仪表板。虽然很多公司可能会允许你在工作中学习 Tableau,但有公开的 Tableau 技能证据会有所帮助。如果你想查看 Tableau Public 档案的好例子,请查看Orysya Stus’和Brit Cava’s档案。

结论
记住,作品集是一个过程。继续改进。
拥有一份强大的简历一直以来都是求职者向潜在雇主展示技能的主要工具。如今,有多种方式来展示你的技能并找到工作。公开证据的作品集是一种获取通常无法获得的机会的方法。重要的是要强调作品集是一个迭代的过程。随着知识的增长,作品集应随着时间的推移进行更新。永远不要停止学习或成长。即使是这篇博客文章也会随着反馈和知识的增加而更新。如果你需要面试建议/指南,可以查看Brandon Rohrer 的数据科学面试生存建议、Sadat 的面试指南或Springboard 的建议。如果你对教程有任何问题或想法,可以在下面的评论区或通过Twitter联系我。
个人简介: Michael Galarnyk 是一名数据科学家和企业培训师。他目前在 Scripps 转化研究所工作。你可以在 Twitter (twitter.com/GalarnykMichael)、Medium (medium.com/@GalarnykMichael) 和 GitHub (github.com/mGalarnyk)上找到他。
原文。经许可转载。
相关:
-
大数据和数据科学中的 5 条职业路径解析
-
2018 年能让你被聘用的 5 个数据科学项目
-
解释正态分布的 68-95-99.7 规则
更多相关话题
如何从零开始构建数据科学项目
原文:
www.kdnuggets.com/2018/12/build-data-science-project-from-scratch.html
评论
由 Jekaterina Kokatjuhha 提供,Zalando 的研究工程师。
有许多关于数据科学和机器学习的在线课程,将指导你学习理论,并提供一些代码示例和非常干净的数据分析。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
然而,为了开始实践数据科学,最好还是挑战一个现实中的问题。深入挖掘数据以获得更深刻的见解。利用额外的数据源进行特征工程,并构建独立的机器学习管道。
本博客文章将指导你从零开始构建数据科学项目的主要步骤。它基于一个真实的问题——柏林租房价格的主要驱动因素是什么?它将提供对此情况的分析,并突出新手在机器学习中常犯的错误。
下面是将详细讨论的步骤:
-
寻找一个主题
-
从网络中提取数据并清理
-
获取更深入的见解
-
使用外部 API 进行特征工程

寻找一个主题
通过分析数据可以解决许多问题,但最好还是找到一个你感兴趣并能激励你的问题。在寻找主题时,你应该重点关注你的偏好和兴趣。
例如,如果你对医疗系统感兴趣,可以从多个角度挑战相关数据。“探索 ChestXray14 数据集:问题” 是如何质疑医疗数据质量的一个例子。另一个例子——如果你对音乐感兴趣,可以尝试 根据音频预测歌曲的风格。
然而,我建议不仅要专注于自己的兴趣,还要听听你周围的人在谈论什么。他们有什么困扰?他们在抱怨什么?这可能是数据科学项目的另一个好来源。如果人们仍在抱怨,这可能意味着第一次没有妥善解决问题。因此,如果你用数据来挑战它,你可以提供更好的解决方案,并对这个话题的认知产生影响。
这可能听起来有点抽象,因此让我们来看看我是如何产生分析柏林租金价格的想法的。
“如果我知道这里的租金如此高,我会争取更高的薪水。”
这是我从最近搬到柏林工作的人员那里听到的事情之一。大多数新来者抱怨说,他们没想到柏林会如此昂贵,而且没有关于公寓可能价格范围的统计数据。如果他们事先知道这些,他们本可以在求职过程中要求更高的薪水,或者考虑其他选项。
我在谷歌上搜索,检查了几个租赁公寓网站,并询问了几个人,但找不到任何可信的当前市场价格统计数据或可视化图表。这就是我产生这个分析想法的原因。
我想收集数据,构建一个互动仪表板,你可以选择不同的选项,比如在柏林米特区的一间带阳台和配备厨房的 40 平方米的公寓,它会显示价格范围。仅此一项就能帮助人们了解柏林的公寓价格。此外,通过应用机器学习,我将能够识别租金价格的驱动因素,并实践不同的机器学习算法。
从网上提取数据并进行清理
获取数据
现在你对数据科学项目有了一个想法,你可以开始寻找数据。有很多令人惊叹的数据仓库,如Kaggle,UCI ML Repository或dataset search engine和包含数据集的网站。或者,你可以使用网页抓取。
但要小心——旧数据无处不在。当我搜索柏林租金价格信息时,我发现了许多可视化图表但它们要么是过时的,要么没有指定年份。
对于一些统计数据,他们甚至注明这个价格只适用于 50 平方米的两居室公寓,没有家具。但如果我在寻找一间带家具厨房的小公寓呢?
旧数据无处不在。
由于我只能找到旧数据,我决定网页抓取提供租赁公寓的网站。网页抓取是一种通过自动化过程从网站提取数据的技术。
我的网页抓取博客文章详细讲解了网页抓取的陷阱和设计模式。
主要发现如下:
-
在抓取之前,检查是否有公开的 API 可用
-
要善良!不要通过每秒发送数百个请求来过载网站
-
保存提取发生的日期。将解释为什么这很重要。
数据清理
一旦开始获取数据,非常重要的一点是尽早查看数据,以便发现任何可能的问题。
在网页抓取租赁数据时,我包括了一些小检查,比如所有特征的缺失值数量。网站管理员可能会更改网站的 HTML,这可能会导致我的程序无法再获取数据。
一旦我确保了网页抓取的所有技术方面都得到覆盖,我认为数据几乎是理想的。然而,由于一些不太明显的重复数据,我最终花了大约一周的时间来清理数据。
一旦开始获取数据,非常重要的一点是尽早查看数据,以便发现任何可能的问题。例如,如果你进行网页抓取,可能会遗漏一些重要字段。如果在将数据保存到文件时使用逗号分隔符,而某个字段也包含逗号,你可能会得到分隔不好的文件。

幻觉 vs 现实
重复数据的来源有几个:
-
因为在线时间较长而重复的公寓
-
中介输入了错误的信息,例如租金或公寓的楼层。他们会在一段时间后纠正这些错误,或者发布一则完全新的广告,其中包含修正后的值和额外的描述修改
-
同一公寓的价格在一个月后有所变化(上涨或下降)
虽然第一种情况的重复项可以通过其 ID 轻松识别,但第二种情况的重复项则非常复杂。原因是中介可能会稍微更改描述,修改错误的价格,并将其作为新广告发布,这样 ID 也会变为新的。
我不得不提出许多基于逻辑的规则来筛选广告的旧版本。一旦我能够识别出这些公寓是实际的重复项但有些许修改,我可以按提取日期排序,将最新的一个视为最近的。
此外,一些中介在一个月后会对同一公寓的价格进行调整。我被告知,如果没有人想要这个公寓,价格会下降。相反,如果有很多人申请,中介会提高价格。这些听起来是合理的解释。
获取更深层次的见解
现在一切准备就绪,我们可以开始分析数据。我知道数据科学家们喜欢使用 seaborn 和 ggplot2,以及许多静态可视化图,从中可以得出一些见解。
然而,互动仪表板可以帮助你和其他利益相关者发现有用的见解。许多很棒的易用工具可以实现这一点,比如Tableau和Microstrategy。
我花了不到 30 分钟创建了一个互动仪表板,可以选择所有重要的组件,并查看价格如何变化。
柏林租赁价格的互动仪表板:可以选择所有可能的配置并查看相应的价格分布。(数据日期:2017/18 冬季)
一个相当简单的仪表板已经可以为新来者提供有关柏林价格的见解,并可能成为租赁公寓网站的良好用户驱动。
从这些数据可视化中,你可以看到 2.5 房间的价格分布落在 2 房间公寓的分布范围内。原因在于大多数 2.5 房间的公寓不位于市中心,这当然会降低价格。
柏林的价格分布和公寓数量。
这些数据是在 2017/18 冬季收集的,未来也会变得过时。然而,我的观点是,租赁网站可以频繁更新他们的统计数据和可视化,以提供更多的透明度。
使用外部 APIs 进行特征工程
可视化有助于识别重要的属性或“特征”,这些特征可以被机器学习算法使用。如果你使用的特征非常无信息,任何算法都会产生糟糕的预测。拥有非常强的特征,即使是一个非常简单的算法也可以产生相当不错的结果。
在租赁价格项目中,价格是一个连续变量,因此这是一个典型的回归问题。根据所有提取的信息,我收集了以下特征,以便能够预测租赁价格。

这些是用于预测租赁公寓价格的主要特征。
然而,有一个特征是有问题的,即地址。共有 6.6K 个公寓和大约 4.4K 个不同粒度的唯一地址。大约有 200 个唯一邮政编码可以转换为虚拟变量,但这样会丢失特定位置的非常宝贵的信息。

地址的不同粒度:街道和门牌号,街道和隐藏的门牌号,以及仅有邮政编码。
当你收到一个新地址时,你会怎么做?
你可以用谷歌查找它的位置或如何到达那里。
通过使用外部 API,并结合给定的四个附加特性,可以计算出公寓的地址:
-
从 S-Bahn Friedrichstrasse(中央车站)乘火车的时间
-
驾车到 U-Bahn Stadtmitte(市中心)的距离
-
步行到最近地铁站的时间
-
公寓周围一公里内的地铁站数量
这四个特性显著提升了性能。
个人简介:Jekaterina Kokatjuhha是 Zalando 的研究工程师,专注于可扩展的机器学习用于欺诈预测。
原文。经许可转载。
资源:
相关:
相关话题更多
学习构建一个端到端的数据科学项目
原文:
www.kdnuggets.com/2020/11/build-data-science-project.html
评论
由 Mathang Peddi,数据科学和机器学习爱好者。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT 需求
数据科学家是所有统计学家中最优秀的程序员,也是所有程序员中最优秀的统计学家。
每个数据科学家都需要一个有效的策略来解决数据科学问题。
数据科学职位在全国范围内是独特的,因此我们可以尝试根据职位名称、公司和地理位置等预测数据科学职位的薪资。这里我构建了一个项目,任何用户都可以输入信息,它会将薪资范围拆分开来,因此,如果有人在谈判薪资时,这将是一个相当不错的工具。
数据科学工作流程
业务理解
这个阶段很重要,因为它有助于明确客户的目标。任何项目的成功取决于提问的质量。如果你正确理解了业务需求,那么这将帮助你收集正确的数据。提出正确的问题将帮助你缩小数据获取的范围。
分析方法
在这个阶段,一旦业务问题被明确陈述,数据科学家可以定义解决问题的分析方法。此步骤包括从统计和机器学习技术的角度解释问题,这一点很重要,因为它有助于确定解决问题所需的趋势类型,以最有效的方式解决问题。如果问题是确定某事的概率,则可能需要使用预测模型;如果问题是展示关系,则可能需要描述性方法;如果我们的目标是计数,那么统计分析是解决它的最佳方法。对于每种方法,我们可以使用不同的算法。
数据要求
我们找出初始数据收集所需的数据内容、格式和来源,并在我们选择的方法的算法中使用这些数据。
数据揭示影响,通过数据,你可以为你的决策带来更多的科学性。
数据收集
我们识别与问题领域相关的可用数据资源。为了获取数据,我们可以对相关网站进行网页抓取,或者使用包含现成数据集的存储库。如果你想从任何网站或存储库收集数据,可以使用 Pandas 库,这是一个非常有用的工具,用于下载、转换和修改数据集。
为此,我已经调整了网络爬虫,以从 glassdoor.com 上抓取 1000 条职位发布信息。每个职位的信息包括:职位名称、薪资估算、职位描述、评分、公司、地点、公司总部、公司规模、公司成立日期、所有权类型、行业、部门、收入、竞争对手。这些都是确定数据科学领域从业人员薪资的各种属性。
要查看 Web Scraper 文章,请点击这里。
要查看 Web Scraper 的 Github 代码,请点击这里。
你可以没有信息的数据,但你不能没有数据的信息。
数据理解
数据科学家会尝试更多地了解以前收集的数据。我们需要检查每个数据的类型,并学习更多关于属性及其名称的知识。
有些薪资数据包含 -1,因此这些值对我们不太重要,可以将其移除。由于薪资估算列目前是字符串格式,所以我们需要将 -1 以字符串格式呈现。
现在我们可以看到,行数已经减少到 742。我们观察到大多数变量是分类变量而非数值变量。这个数据集包含 2 个数值变量和 12 个分类变量。但实际上,我们的依赖变量,薪资估算,必须是数值型的。因此,我们需要将其转换为数值变量。
数据准备
数据可以是任何格式。为了进行分析,你需要将数据转换为特定的格式。数据科学家必须为建模准备数据,这是最关键的步骤之一,因为模型必须干净且不包含任何错误或空值。
在现实世界中,数据科学家花费 80% 的时间清理数据,只花费 20% 的时间提供见解和结论。
这是一个相当繁琐的过程,所以你应该做好准备。
在抓取数据后,我需要清理数据,以便它可以用于我们的模型。我进行了一些更改并创建了新的变量。
当我们在左括号处分割时,发生的情况是,所有行的‘(’左侧和右侧部分进入两个不同的列表。这就是为什么我们需要包括 [0] 来获取薪资。获得薪资后,将‘K’,‘$’替换为空字符串。在一些条目中,薪资被标记为‘雇主提供’和‘按小时计算’,这些是不一致的,需要处理。
现在我们不应使用雇主提供的或按小时计算的薪资。所以我们返回包含每个条目最小和最大薪资的两个列表。这成为我们最终的因变量(用于预测一个人的平均薪资)。
探索性数据分析
EDA 在这一阶段扮演着非常重要的角色,因为清理数据的总结有助于识别数据的结构、异常值、异常现象和模式。这些见解可以帮助我们构建模型。然而,我将详细讨论 EDA 并在我的 Medium 个人资料中找到它。
模型构建
数据科学家有机会了解他的工作是否准备好提交,或是否需要审查。建模专注于开发描述性或预测性的模型。所以在这里,我们执行预测建模,这是一个利用数据挖掘和概率来预测结果的过程。对于预测建模,数据科学家使用一个训练集,这是一组已知结果的历史数据。这一步可以重复多次,直到模型理解问题和答案。
如果我们有分类数据,则需要创建虚拟变量,所以我将分类变量转换为虚拟变量。我还将数据分成训练集和测试集,测试集大小为 20%。我尝试了三种不同的模型,并使用平均绝对误差进行了评估。我选择 MAE,因为它相对容易解释,而且异常值对这种类型的模型没有特别大的影响。
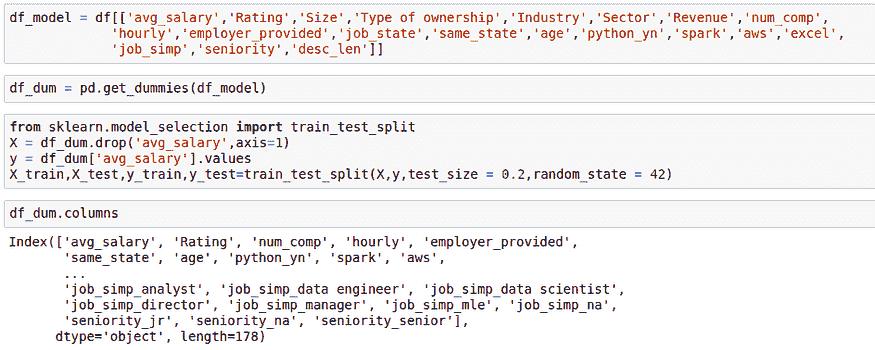
转换后,我们的数据集的列数从 14 增加到了 178!!
我已经实现了三种不同的模型:
-
多重线性回归——模型的基准
-
Lasso 回归——由于来自许多分类变量的数据稀疏,我认为像 lasso 这样的正规化回归会有效。
-
随机森林——同样,由于数据的稀疏性,我认为这会是一个很好的选择。

现在开始时,它稍微有点差。所以我们尝试找到 alpha 的最佳值,使得误差最小。
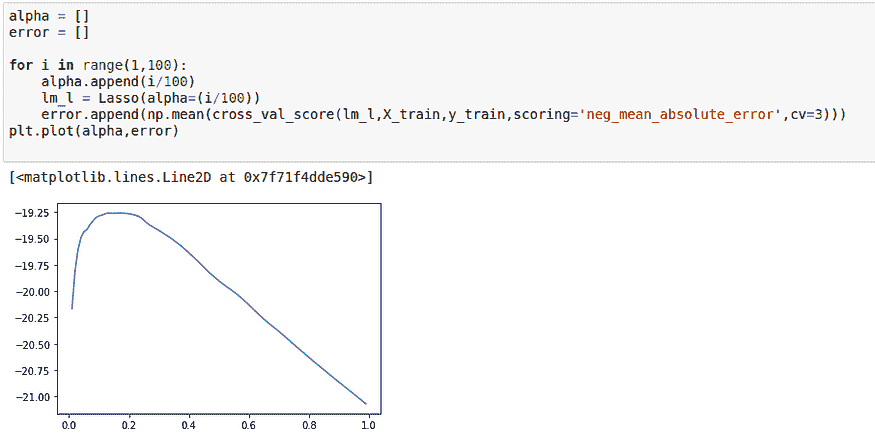
在这里我也选择了 i/10,但误差仍然很高,所以我减少了 alpha 的值。
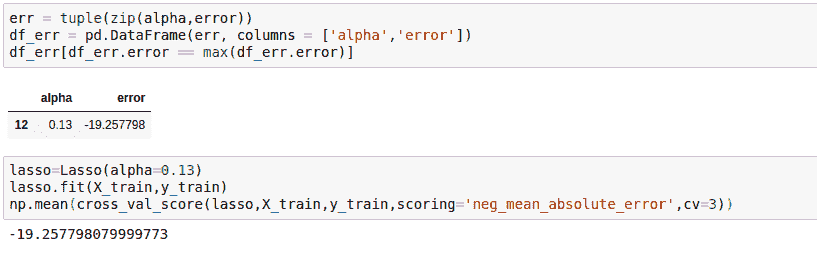
在绘制图表并检查 alpha 值后,我们发现 alpha 值为 0.13 可以得到最佳的误差项。现在我们的误差从 21.09 降低到 19.25(这意味着 19.25K 美元)。我们还可以通过调整 GridSearch 来改进模型。
GridSearch 是进行超参数调优的过程,以确定给定模型的最佳值。GridSearchCV 基本上就是将所有你想要的参数输入,然后它会运行所有模型,并筛选出结果最佳的模型。
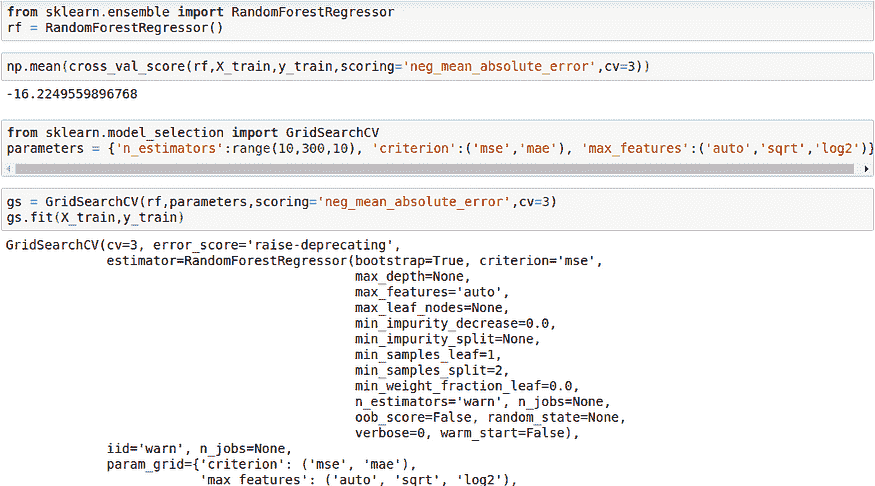
我们还可以使用支持向量回归、XGBoost 或其他任何模型。
随机森林回归是一种基于树的决策过程,并且我们的数据集中有很多 0 和 1,所以我们期望它是一个更好的模型。这就是为什么我在这里选择了随机森林回归。
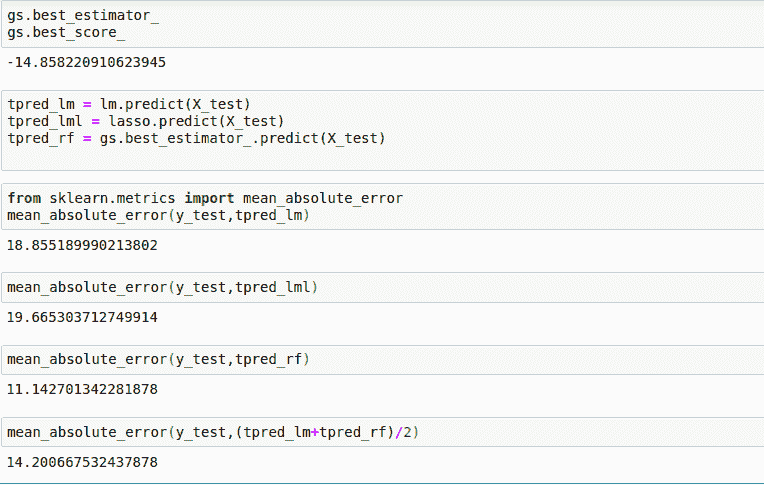
因此,我们现在获得的误差值比之前的更小,所以随机森林模型比之前的模型更好。我将随机森林模型与线性回归模型结合起来进行预测。所以我取了两者的平均值,即对每个模型给予了 50% 的权重。
大多数情况下,结合不同的模型进行预测更为有效,因为这样可以提高我们的准确性。这些类型的模型被称为集成模型,并且被广泛使用。误差可能会增加也可能不会,因为某一个模型可能会过拟合。
调优后的随机森林模型在这里表现最佳,因为与 Lasso 和线性回归相比,它的误差最小。因此,我们不仅可以取两者的平均值,还可以将 90% 的随机森林模型与 10% 的其他模型合并,测试准确性/性能。通常,这些类型的集成模型对于分类问题更好。
项目不应仅仅是尝试所有模型,而应选择最有效的模型,并能够讲述为什么选择这些特定模型的理由。通常,Lasso 回归应比线性回归效果更好,因为它具有归一化效果,而我们有稀疏矩阵,但在这里 Lasso 的表现却不如线性回归。因此,这取决于具体的模型,我们不能一概而论。
模型评估
数据科学家可以通过两种方式评估模型:Hold-Out 和交叉验证。在 Hold-Out 方法中,数据集被分为三个子集:训练集、用于评估训练阶段模型表现的验证集和用于测试模型未来可能表现的测试集。在大多数情况下,训练:验证:测试集的比例为 3:1:1,这意味着 60% 的数据用于训练集,20% 的数据用于验证集,20% 的数据用于测试集。
模型部署
所以我创建了一个基础网页,使其易于理解。给定员工和公司信息,该模型可以预测员工的预期薪资。
我已使用 flask 在 Heroku 部署了我的机器学习模型。我使用线性回归训练了模型(因为它易于理解),但你也可以使用任何其他机器学习模型,甚至可以使用集成模型,因为它们提供了良好的准确性。
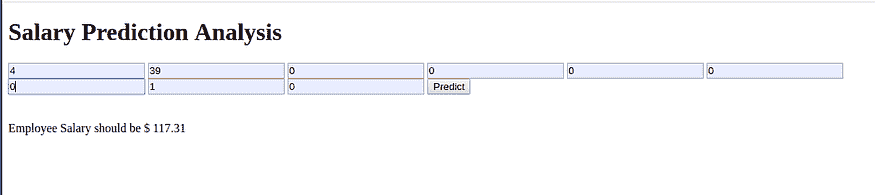
在部署模型后,我尝试预测一位机器学习工程师的薪资,其中公司的评级为 4,公司成立 39 年前。根据我的模型,员工的预期薪资为 117.31K 美元。
在本文中,我没有详细讨论所有内容。但你可以随时参考我的GitHub 仓库来获取整个项目。我的结论是,你不应期待一个完美的模型,而是期望一个你今天可以在自己的公司/项目中使用的工具!
对于Ken Jee在数据科学领域的出色贡献和项目,表示由衷的感谢。
“目标是将数据转化为信息,再将信息转化为洞察。”–Carly Fiorina
原文。已获许可转载。
相关:
更多相关话题
如何使用 Python 构建数据库
原文:
www.kdnuggets.com/2021/09/build-database-using-python.html
评论
作者 Irfan Alghani Khalid,计算机科学学生

由 Taylor Vick 摄影,刊登于 Unsplash
介绍
SQLAlchemy 是一个 Python 库,用于在不使用 SQL 语言本身的情况下实现 SQL 数据库。换句话说,你只需使用 Python 语言来实现你的数据库。
Flask-SQLAlchemy 是一个用于在 Flask 项目中连接 SQLAlchemy 库的库,它使得你的数据库实现比以往任何时候都要容易。本文将向你展示如何使用 Flask-SQLAlchemy 库构建你的数据库。
不再赘述,我们开始吧!
数据库
在进入实现之前,让我先解释一下什么是数据库。数据库是一个数据集合,这些数据彼此集成,我们可以通过计算机来访问它。
在数据科学中,你可能会以类似电子表格的形式插入和分析数据。在软件开发领域,这略有不同。我们来看看这个电子表格。
这张图片由作者拍摄。
在电子表格中,我们可以看到有两列。分别是书籍标题和作者姓名。如果你查看作者列,你会发现一些值重复了几次。这种情况我们称为冗余。
将整个数据集作为一个表格使用并不是最佳实践,特别是对于那些想要建立网站或应用程序的人来说。相反,我们需要将表格分开,这个过程叫做规范化。
总结来说,规范化过程将把数据集分成几个表格,每个表格都有其唯一的标识符,我们将这些标识符称为主键。如果我们分开上述数据集,它将会像这样:
这张图片由作者拍摄。
从上面可以看出,数据集已经分成了两个表格。分别是书籍表和作者表。作者的姓名在作者表中。因此,我们不能像在电子表格中那样直接访问姓名。
要检索作者的姓名,我们必须通过从作者表中获取 id 来连接书籍表和作者表。我们将作者的 id 视为书籍表的外键。
这可能很复杂,但如果你开始为应用程序实现数据库,它将提高你应用程序的性能。
实现
安装库
在我们进入实现之前,首先需要做的是在计算机上安装库。为此,我们可以使用 pip。下面是安装库的语法:
要加载库,我们可以调用以下语法:
正如你从库的名称中知道的那样,我们还需要加载 Flask 库。
启动数据库引擎
加载库后,下一步是设置我们的 SQLAlchemy 对象和数据库路径。默认情况下,SQLAlchemy 附带 SQLite 软件。
SQLite 是一种数据库管理系统,我们可以在其中构建和分析我们建立的数据库。你可以使用其他 DBMS,如 MySQL、PostgreSQL 或任何你喜欢的 DBMS。要设置我们的数据库,请添加以下代码行:
这段代码将初始化 Flask 和 SQLAlchemy 对象,并设置一个包含数据库路径的参数。在这种情况下,数据库路径是 sqlite:///C:\sqlite\library.db。
实现数据库
在我们设置好对象和参数之后,我们可以开始实现数据库。让我们回顾一下我们之前的数据库表:
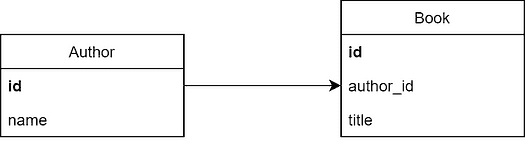
这张图片由作者拍摄。
从上面可以看出,有两个表。每个表将有它的类,我们可以在其中初始化列名和表之间的关系。我们将继承一个名为 Model 的类来实现我们的表。根据上面的图示,代码如下:
插入值
创建类之后,我们可以构建我们的数据库。要构建数据库,你可以访问终端并运行以下命令:
现在让我们尝试在表中插入值。以这个示例为例,让我们输入之前电子表格中的数据。你可以按照以下代码插入值:
查询表格
在你向表中插入值之后,现在让我们运行查询以查看数据是否存在。以下是执行此操作的代码:
正如你从上面看到的,我们的提交成功了。虽然这仍然是一个介绍,但我希望你能掌握这个概念并在更大的项目中实现它。
附加内容:SQL 查询
除了 Flask-SQLAlchemy 库外,我还将演示如何使用原生 SQLite 访问数据库。我们这样做是为了确保我们的数据库已经创建。要访问 SQLite,你可以打开终端并编写以下脚本:
**sqlite3**
之后,它将显示类似这样的 SQLite 界面:
这张图片由作者拍摄。
在下一步中,你可以使用 .open 命令打开数据库,并像这样添加数据库路径:
**.open absolute//path//to//your//database.db**
为了确保我们已打开数据库,请在终端中输入 .tables,如下所示:
**.tables**
它将生成如下结果:
这张图片由作者拍摄。
很好,成功了。现在让我们尝试使用 SQL 语言查询我们的数据库:
**SELECT * FROM books**
这是结果:

图片由作者拍摄。
现在让我们尝试将两个表合并为一个。你可以在终端中输入这行代码:
**SELECT Book.title, Author.name FROM Book
INNER JOIN Author ON Book.author_id = Author.id;**
结果如下:
图片由作者拍摄。
最后的评论
做得好!现在你已经使用 Flask-SQLAlchemy 库实现了你的数据库。我希望这篇文章对你在项目中实现数据库有所帮助,特别是当你想使用 Flask 构建网页应用时。
如果你对我的文章感兴趣,可以在 Medium 上关注我,也可以订阅我的通讯。如果你有任何问题或只是想打个招呼,也可以在 LinkedIn 上关注我。
感谢阅读我的文章!
简介: Irfan Alghani Khalid 是 IPB 大学的计算机科学学生,感兴趣于数据科学、机器学习和开源。
原文。转载已获许可。
相关内容:
-
如何用几行代码和 Flash 构建图像分类器
-
原生 Python 中的简单 SQL
-
如何查询你的 Pandas 数据框
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 方面支持你的组织
更多相关主题
构建和部署你的第一个机器学习 web 应用
原文:
www.kdnuggets.com/2020/05/build-deploy-machine-learning-web-app.html
评论
由 Moez Ali 贡献,PyCaret 的创始人和作者

在我们的 上一篇文章 中,我们展示了如何使用 PyCaret 在 Power BI 中训练和部署机器学习模型。如果你之前没有听说过 PyCaret,请阅读我们的 公告 以快速入门。
在本教程中,我们将使用 PyCaret 开发一个 机器学习管道,包括预处理转换和回归模型,以根据年龄、BMI、吸烟状态等人口统计数据和基本患者健康风险指标预测住院费用。
???? 在本教程中你将学到什么
-
什么是部署,我们为什么要部署机器学习模型。
-
使用 PyCaret 开发机器学习管道并训练模型。
-
使用一个名为‘Flask’的 Python 框架构建一个简单的 web 应用。
-
在‘Heroku’上部署 web 应用,并查看你的模型运行效果。
???? 本教程中我们将使用哪些工具?
PyCaret
PyCaret 是一个开源、低代码的 Python 机器学习库,用于训练和部署生产中的机器学习管道和模型。PyCaret 可以通过 pip 轻松安装。
# for Jupyter notebook on your local computer
pip install **pycaret**# for azure notebooks and google colab
!pip install **pycaret**
Flask
Flask 是一个允许你构建 web 应用的框架。一个 web 应用可以是商业网站、博客、电子商务系统,或是一个使用训练模型从实时数据中生成预测的应用。如果你还没有安装 Flask,可以使用 pip 进行安装。
# install flask
pip install **Flask**
GitHub
GitHub 是一个基于云的服务,用于托管、管理和控制代码。想象一下你在一个大型团队中工作,多人(有时是数百人)在进行更改。PyCaret 本身就是一个开源项目的例子,数百名社区开发者持续为源代码做出贡献。如果你以前没有使用过 GitHub,你可以 注册 一个免费的账户。
Heroku
Heroku 是一个平台即服务(PaaS),它基于托管容器系统提供 Web 应用程序的部署,集成了数据服务和强大的生态系统。简单来说,这将允许你将应用程序从本地计算机转移到云端,以便任何人都可以通过 Web URL 访问。在本教程中,我们选择 Heroku 进行部署,因为它提供免费资源小时,当你注册新账户时可以获得。
机器学习工作流程(从训练到 PaaS 部署)
为什么要部署机器学习模型?
机器学习模型的部署是将模型投入生产的过程,在此过程中,Web 应用程序、企业软件和 API 可以通过提供新数据点并生成预测来使用已训练的模型。
通常,机器学习模型的建立是为了预测结果(例如,分类中的二元值,即 1 或 0,回归中的连续值,聚类中的标签等)。生成预测的方式有两种: (i) 批量预测;和 (ii) 实时预测。在我们的上一教程中,我们展示了如何在 Power BI 中部署机器学习模型并进行批量预测。在本教程中,我们将学习如何部署机器学习模型以进行实时预测。
商业问题
一家保险公司希望通过在住院时使用人口统计和基本患者健康风险指标来更好地预测患者费用,从而改善其现金流预测。
(数据源)
目标
建立一个 Web 应用程序,在其中输入患者的人口统计和健康信息,以预测费用。
任务
-
训练和验证模型,并开发一个机器学习管道用于部署。
-
使用输入表单构建一个基本的 HTML 前端,输入独立变量(年龄、性别、BMI、子女数量、吸烟者、地区)。
-
使用 Flask 框架构建 Web 应用程序的后端。
-
在 Heroku 上部署 Web 应用程序。部署完成后,它将变得公开可用,并可以通过 Web URL 进行访问。
???? 任务 1 — 模型训练和验证
训练和模型验证在集成开发环境(IDE)或 Notebook 中进行,可以是在本地计算机上或在云端。在本教程中,我们将使用 Jupyter Notebook 中的 PyCaret 来开发机器学习管道并训练回归模型。如果你之前没有使用过 PyCaret,请点击这里 了解更多关于 PyCaret 的信息,或查看我们网站上的入门教程。
在本教程中,我们进行了两个实验。第一个实验使用 PyCaret 中的默认预处理设置(缺失值填补、分类编码等)。第二个实验有一些额外的预处理任务,如缩放和标准化、自动特征工程以及将连续数据分箱。请参阅第二个实验的设置示例:
# Experiment No. 2from **pycaret.regression** import *****r2 = **setup**(data, target = 'charges', session_id = 123,
normalize = True,
polynomial_features = True, trigonometry_features = True,
feature_interaction=True,
bin_numeric_features= ['age', 'bmi'])
两个实验的信息网格比较
只需几行代码,神奇就会发生。注意在实验 2中,变换后的数据集具有 62 个用于训练的特征,而这些特征仅源于原始数据集中的 7 个特征。所有的新特征都是 PyCaret 中变换和自动特征工程的结果。

数据集在变换后的列
模型训练和验证的示例代码在 PyCaret 中:
# Model Training and Validation
lr = **create_model**('lr')
线性回归模型的 10 折交叉验证
注意变换和自动特征工程的影响。R2 增加了 10%,且付出了很小的努力。我们可以比较两个实验的残差图,观察变换和特征工程对模型异方差性的影响。
# plot residuals of trained model **plot_model**(lr, plot = 'residuals')
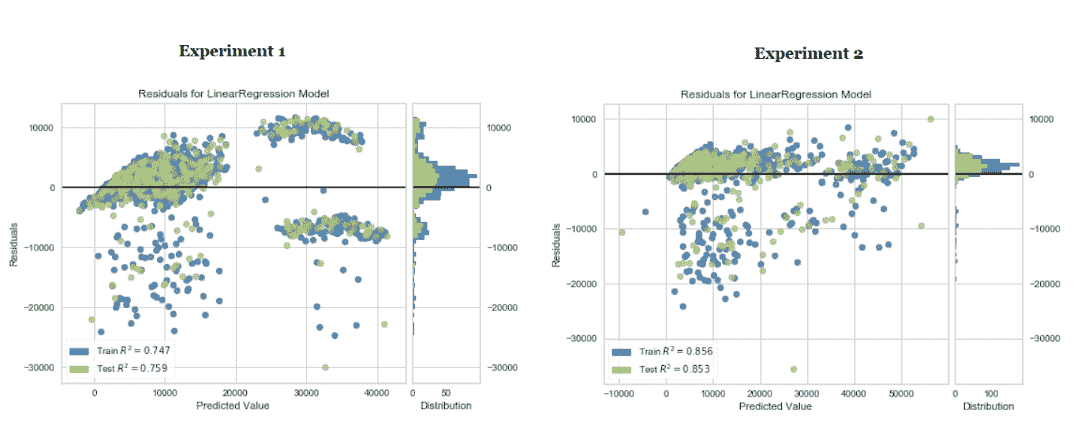
线性回归模型的残差图
机器学习是一个迭代过程。迭代次数和使用的技术取决于任务的关键程度以及预测错误的影响。机器学习模型在医院 ICU 中实时预测患者结果的严重性和影响远大于预测客户流失的模型。
在本教程中,我们仅进行了两次迭代,第二次实验中的线性回归模型将用于部署。然而,在这一阶段,模型仍然只是 Notebook 中的一个对象。要将其保存为可以转移到其他应用程序并被其使用的文件,请运行以下代码:
# save transformation pipeline and model
**save_model**(lr, model_name = 'c:/*username*/ins/deployment_28042020')
当你在 PyCaret 中保存模型时,会创建基于 setup() 函数中定义的配置的整个转换管道。所有的相互依赖关系都会自动协调。请参见存储在 ‘deployment_28042020’ 变量中的管道和模型:

使用 PyCaret 创建的管道
我们已经完成了训练和选择用于部署的模型的第一个任务。最终的机器学习管道和线性回归模型现在保存在本地驱动器中,位置由 save_model() 函数定义。(在此示例中:c:/username/ins/deployment_28042020.pkl)。
???? 任务 2 — 构建网页应用程序
现在我们的机器学习管道和模型已经准备好,我们将开始构建一个可以连接到这些管道并实时生成新数据预测的网页应用程序。该应用程序有两个部分:
-
前端(使用 HTML 设计)
-
后端(使用 Flask 在 Python 中开发)
网页应用程序的前端
通常,网页应用程序的前端是使用 HTML 构建的,这不是本文的重点。我们使用了一个简单的 HTML 模板和一个 CSS 样式表来设计输入表单。下面是我们网页应用程序前端页面的 HTML 代码片段。

home.html 文件中的代码片段
你不需要成为 HTML 专家来构建简单的应用程序。有许多免费的平台提供 HTML 和 CSS 模板,并且可以通过拖放界面快速构建美观的 HTML 页面。
CSS 样式表
CSS(也称为层叠样式表)描述了 HTML 元素如何在屏幕上显示。它是一种有效控制应用程序布局的方式。样式表包含背景颜色、字体大小和颜色、边距等信息。它们被保存在外部的 .css 文件中,并通过包含 1 行代码与 HTML 关联。
home.html 文件中的代码片段
网页应用程序的后端
网页应用程序的后端是使用 Flask 框架开发的。对于初学者来说,可以直观地将 Flask 视为一个可以像其他 Python 库一样导入的库。请参见我们用 Flask 框架在 Python 中编写的后端示例代码片段。
app.py 文件中的代码片段
如果你还记得上面第 1 步,我们已经完成了线性回归模型的确定,该模型在 62 个特征上进行了训练,这些特征由 PyCaret 自动工程化。然而,我们的网页应用程序的前端有一个输入表单,只收集六个特征,即年龄、性别、bmi、孩子数量、吸烟者、区域。
我们如何在实时中将新数据点的 6 个特征转换为模型训练时的 62 个特征?随着模型训练过程中应用的转换序列,编码变得越来越复杂且耗时。
在 PyCaret 中,所有的转换,如类别编码、缩放、缺失值填充、特征工程甚至特征选择,都会在生成预测之前实时自动执行。
想象一下你为了将所有转换严格按顺序应用到模型预测之前需要写多少代码。在实践中,当你想到机器学习时,你应该考虑整个 ML 管道,而不仅仅是模型。
Testing App
在我们将应用程序发布到 Heroku 之前的最后一步是本地测试 Web 应用程序。打开 Anaconda Prompt,导航到你计算机上保存 'app.py' 的文件夹。使用以下代码运行 Python 文件:
python **app.py**
执行 app.py 时 Anaconda Prompt 中的输出
执行后,将 URL 复制到浏览器中,它应该会打开一个托管在你本地机器 (127.0.0.1) 上的 Web 应用程序。尝试输入测试值,查看预测功能是否正常工作。在下面的示例中,预期的账单金额为 19 岁女性吸烟者且无子女的西南部地区为 $20,900。
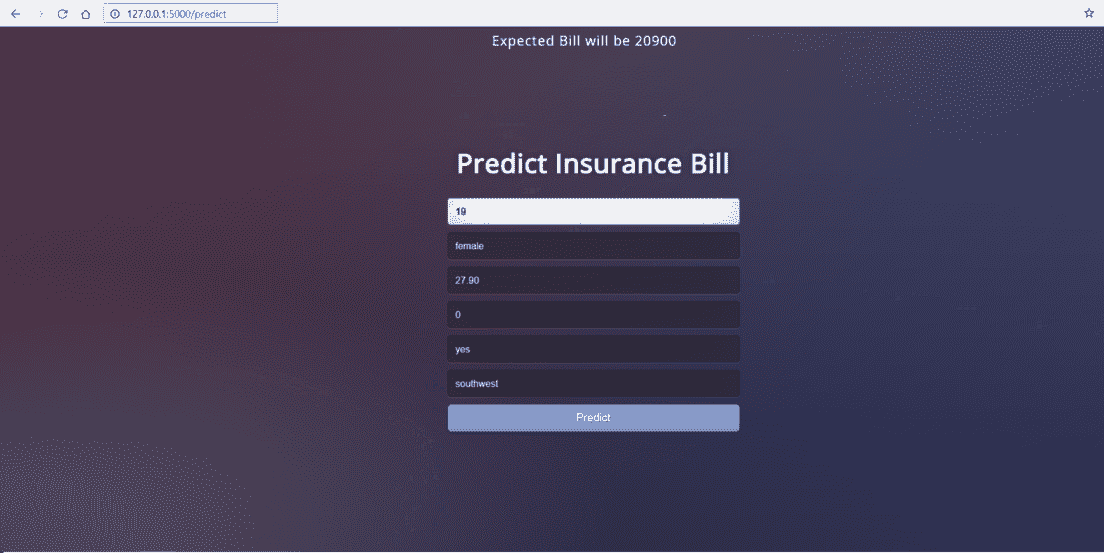
在本地机器上打开的 Web 应用程序
恭喜!你现在已经构建了你的第一个机器学习应用程序。现在是时候将这个应用程序从本地机器迁移到云端,以便其他人可以通过 Web URL 使用它。
???? 任务 3 — 在 Heroku 上部署 Web 应用
现在模型已经训练完成,机器学习管道也准备好了,应用程序已经在本地机器上测试过,我们准备开始在 Heroku 上部署。将应用程序源代码上传到 Heroku 有几种方法。最简单的方法是将 GitHub 仓库链接到你的 Heroku 账户。
如果你想跟着操作,可以从 GitHub 上叉取这个 仓库。如果你不知道如何叉取仓库,请 阅读这个 官方 GitHub 教程。
www.github.com/pycaret/deployment-heroku
现在你对上面展示的仓库中的所有文件都很熟悉了,除了两个文件,即 'requirements.txt' 和 'Procfile'。

requirements.txt
'requirements.txt' 文件是一个文本文件,包含执行应用程序所需的 Python 包的名称。如果这些包在应用程序运行的环境中没有安装,应用程序将会失败。

Procfile
Procfile 只是提供启动指令的代码行,告诉 web 服务器在有人登录应用程序时应该首先执行哪个文件。在这个例子中,我们的应用程序文件名是 ‘app.py’,应用程序的名称也是 ‘app’。(因此是 app:app)
一旦所有文件上传到 GitHub 仓库,我们现在可以开始在 Heroku 上进行部署。请按照以下步骤操作:
步骤 1 — 在 heroku.com 上注册并点击 ‘创建新应用程序’
Heroku 仪表盘
步骤 2 — 输入应用程序名称和区域
Heroku — 创建新应用程序
步骤 3 — 连接到托管代码的 GitHub 仓库
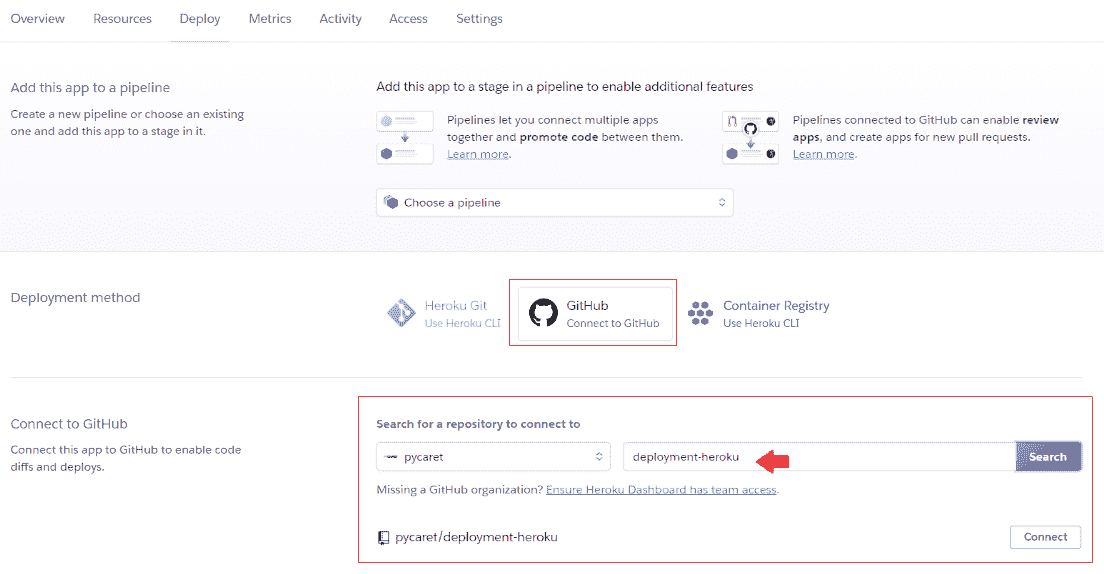
Heroku — 连接到 GitHub
步骤 4 — 部署分支
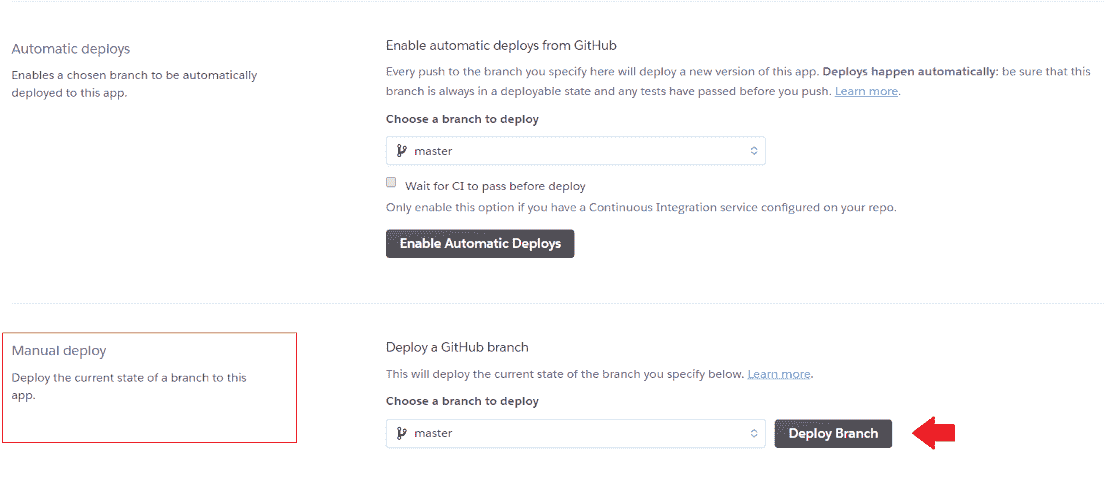
Heroku — 部署分支
步骤 5 — 等待 5–10 分钟,成功
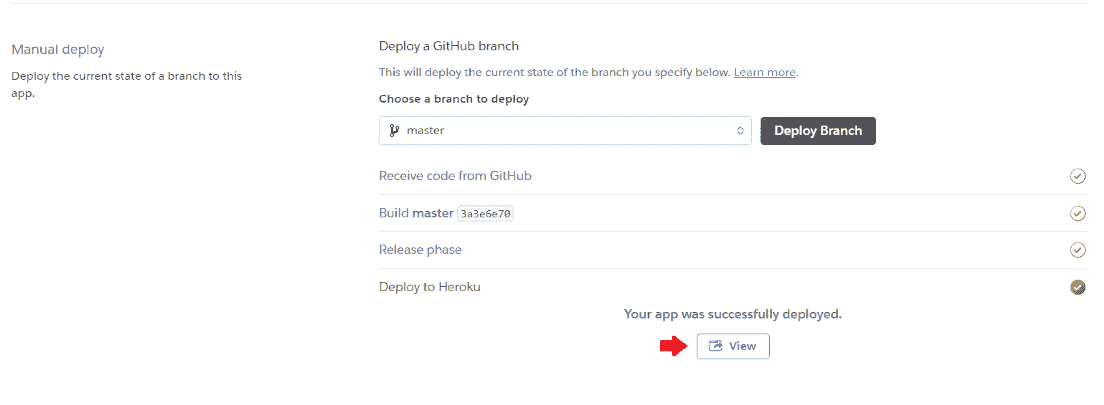
Heroku — 成功部署
应用程序已发布到网址:pycaret-insurance.herokuapp.com/
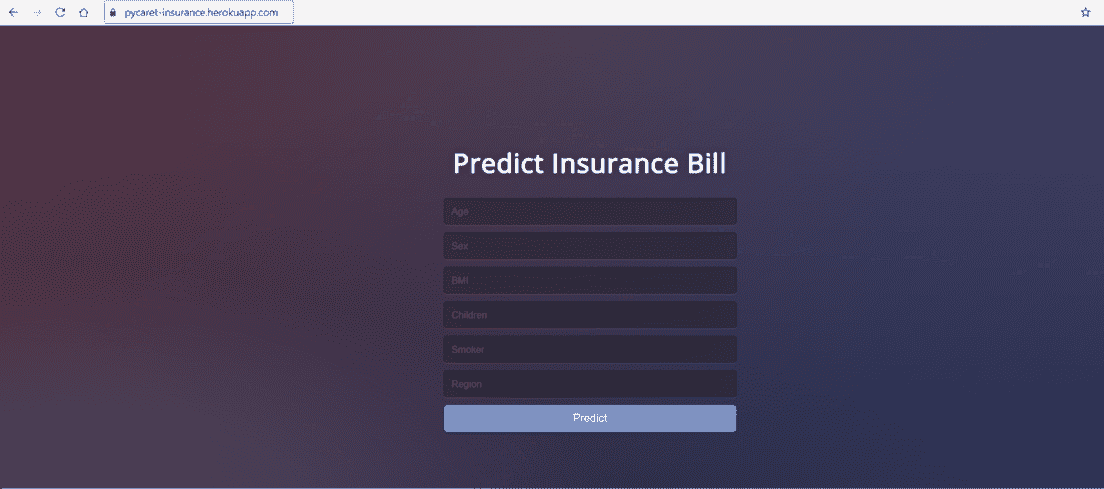
pycaret-insurance.herokuapp.com/
在结束教程之前还有最后一件事要查看。
到目前为止,我们已经构建并部署了一个与我们的机器学习管道配合使用的 web 应用程序。现在,假设你已经有了一个企业应用程序,你希望将模型的预测集成进去。你需要的是一个可以通过 API 调用输入数据点并返回预测的 web 服务。为此,我们在我们的 ‘app.py’ 文件中创建了 predict_api 函数。请查看代码片段:
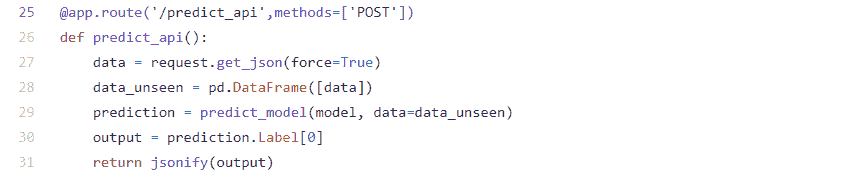
app.py 文件中的代码片段(web 应用程序的后端)
以下是如何使用 requests 库在 Python 中使用此网络服务:
import **requests**url = 'https://pycaret-insurance.herokuapp.com/predict_api'pred = **requests.post(**url,json={'age':55, 'sex':'male', 'bmi':59, 'children':1, 'smoker':'male', 'region':'northwest'})**print**(pred.json())

向发布的网络服务发送请求以在笔记本中生成预测
下一个教程
在下一个教程中,我们将深入探讨如何使用 Docker 容器部署机器学习管道。我们将演示如何在 Linux 上轻松部署和运行容器化的机器学习应用程序。
关注我们的 LinkedIn 并订阅我们的 YouTube 频道以了解更多有关 PyCaret 的信息。
重要链接
想了解特定模块的内容?
自 1.0.0 版首次发布以来,PyCaret 提供了以下可用模块。点击下面的链接查看文档和 Python 中的工作示例。
另见:
PyCaret 入门教程(Notebook 版):
开发管道中有哪些?
我们正在积极改进 PyCaret。未来的发展计划包括一个新的时间序列预测模块,与TensorFlow的集成,以及 PyCaret 可扩展性的重大改进。如果您想分享反馈并帮助我们进一步改进,可以在网站上填写此表单或在我们的GitHub或LinkedIn页面留言。
您想要贡献吗?
PyCaret 是一个开源项目。欢迎大家贡献。如果您想贡献,请随时处理开放问题。我们接受带有单元测试的开发分支上的拉取请求。
如果您喜欢 PyCaret,请在我们的GitHub 仓库上给我们⭐️。
Medium: medium.com/@moez_62905/
LinkedIn: www.linkedin.com/in/profile-moez/
Twitter: twitter.com/moezpycaretorg1
个人简介: Moez Ali 是数据科学家,也是 PyCaret 的创始人和作者。
原文。经许可转载。
相关:
-
宣布 PyCaret 1.0.0
-
在 Power BI 中使用 PyCaret 进行机器学习
-
使用 pdpipe 构建 Pandas 管道
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
更多相关话题
建立有效的数据分析团队和项目生态系统以实现成功
原文:
www.kdnuggets.com/2021/04/build-effective-data-analytics-team-project-ecosystem-success.html
评论
作者:兰迪·伦奇,数据分析师
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在长期的软件开发、信息安全和数据分析职业生涯中,我观察到大型、复杂且令人不知所措的项目,如果管理不善,很可能无法满足利益相关者的需求。相比之下,我参与的大多数成功的数据分析项目规模、团队人数和时间线都很小。它们通常在几天、几周或几个月内完成,而不是花费数年时间,通常能够满足最终用户的需求。
良好的管理、敏捷实践、熟练的从业人员、强大的工具、标准和指南可以结合起来,创建一个数据分析生态系统,从而实现短期项目周期和有用的解决方案。以下部分描述了我团队开发和利用的一些组织、项目和数据分析属性与技术。虽然我们在大型企业的风险管理和内部审计职能中建立了我们的数据分析程序,但你也许可以将其中许多技术应用于你的工作环境。
良好的管理和领导力
在我 34 年的软件开发和数据分析工作中,我观察到了许多管理和领导风格,无论好坏。最近,我在与一位创建框架并指导我们团队在大型企业中建立成功的部门数据分析程序的经理合作时取得了成功。根据经验和观察,以下是他和其他杰出领导者帮助个人、团队和程序成功的一些属性和行动:
-
为程序设定目标,并管理程序及团队以实现这些目标。
-
确定所需的能力,招聘并培训员工以满足这些能力。
-
与内部和外部组织合作,分享和学习最佳实践。
-
提供适合需求的强大软件工具。
-
作为与高层管理层沟通的桥梁。
-
与团队及其成员合作,并关心他们,但不要过于强势。
-
确保实施和遵循基本但足够的标准、指南和程序。
-
建立成长和成就的节奏。
-
尊重每个团队成员的时间和专注需求。
招聘并发展技能和知识
几年前,我参加了一次数据分析会议,讲者描述了她作为数据科学家所需的一些技能。她说,履行她的工作需要超过 200 种技能。确实,创建成功的数据分析解决方案需要分析师具备多种才能。为了招聘和发展具备所需技能和知识的分析师,您和您的管理层可以考虑这些步骤:
-
编写引人注目的职位描述和招聘广告— 制定职位描述和招聘广告,描述成功候选人必须具备的技能和知识。同时列出员工在职期间必须发展的技能和知识。
-
招聘具有专业知识和良好潜力的数据分析师— 应用职位描述和招聘广告来招聘具备所需技能和知识的分析师,并具备发展额外所需技能的潜力。
-
识别学习资源— 创建课程和教程清单,以帮助数据分析师发展所需的技能和知识,以在其职位上取得成功。
-
评估技能— 测量团队及其成员的优缺点,并识别发展和成长需求,评估每个数据分析师的技能和知识,以确保与职位描述和详细的能力清单相符。
-
培训分析师— 确保工作单位的预算和计划允许数据分析师有足够的资金和时间完成培训,以发展所需的技能和知识。根据技能评估结果,确保分析师按照学习资源清单中的要求进行培训。
保持项目团队小型化
复杂的项目如果团队过大可能会陷入困境,除非进行专业管理。尝试将每个项目的规模和范围保持较小,并将团队规模限制在一到三名最终用户和一名首席数据分析师,这可能有助于项目的成功。团队可以为复杂项目添加数据分析师,这些项目将受益于劳动分工或互补技能。对于大型或复杂项目,您可能希望指定项目经理与团队合作,识别和管理任务、时间表、风险和问题。最后,在需要时寻求项目业务领域的主题专家(SMEs)。
采用敏捷实践
项目团队,尤其是在软件开发中,通常会应用敏捷开发方法,例如 Scrum 或 Kanban,以组织任务并迅速推进。我的团队有效地使用了在 Microsoft OneNote 中开发的 Kanban Board,以跟踪和沟通团队和经理之间的任务,定期在站立会议中更新。它由一个页面上的三个列组成。每个任务从“准备工作”开始,到“进行中”时移动,并在完成时从“进行中”移到“完成”。

简单的看板可以用来管理项目任务。图像由作者提供。
定义简明的范围、目标和时间表
在整个项目生命周期中,与最终用户、团队成员和经理的对话对于建立和坚持其达成一致的、简明的范围、目标和时间表至关重要。通过保持项目简洁,我在一周到三个月长的项目中都取得了成功。
如果一个项目大而复杂,可以考虑将其拆分成更小的子项目,每个子项目都有有限的范围、目标和时间表。
为数据分析师分配合理的竞争项目和任务
一些研究人员发现,当进行multitasking时,人类的表现会下降。给个人分配大量的项目或任务可能适得其反。此外,虽然技能和任务多样性是可以提升个人满意度和表现的工作组成部分(见job characteristics theory),但分配给工人的项目或任务数量应当合理,以使工人能够成功并完成所有任务。
平衡团队合作与自主性
在一个高效运作的团队中工作可以带来许多好处,例如:
-
团队成员可以互补技能。
-
团队成员可以相互鼓励和推动。
-
团队成员可以分享想法并进行头脑风暴,以找出解决方案。
-
团队的生产力可能超过其部分的总和。
对于有效的团队合作的好处毋庸置疑。另一方面,一些工作类型,如数据分析、编程和写作,通常最好由半自主的个人完成,通常需要团队成员的输入。他们的工作需要集中注意力和有限的干扰。
采用并掌握强大而多功能的工具和语言
数据分析师应当配备强大而多功能的数据分析工具,以满足他们的需求。通过这种方法,分析师可以利用每个工具的特点,并开发技能和最佳实践。以下部分描述了我当前团队在数据分析项目中使用的每个软件包。
Alteryx Designer — 根据 Alteryx 的网站,Designer 可用于“自动化每一步分析,包括数据准备、混合、报告、预测分析和数据科学。”虽然单用户许可证费用高达数千美元,但它是一个强大的数据分析和数据科学工具。我的团队使用它创建和运行输入数据、转换和准备数据以及以多种格式输出数据的工作流。分析师使用它快速轻松地创建强大且运行迅速的工作流。
Tableau — Tableau 软件创建了一个强大且可能是最流行的商业智能和数据可视化平台。我的团队使用 Tableau Desktop 连接到数据源并开发可视化工作表和仪表板。然后,我们将可视化内容发布到 Tableau Server,最终用户可以在此查看和互动。
Python — Python 是一种用户友好且功能强大的编程语言,在数据分析师和数据科学家中很受欢迎。与同样受数据科学家欢迎的以统计为中心的 R 语言不同,Python 是一种通用语言。它是免费的,且易于学习。分析师可以通过自由获取的库扩展 Python 的功能,例如 NumPy 和 TensorFlow。

Python 编程语言代码示例。图片由作者提供。
SQL — 结构化查询语言(SQL)是用于实现、操作和查询存储在关系数据库管理系统(RDBMS)中的结构化数据的标准语言。它包括多个子语言。通过其数据查询语言(DQL),分析师可以查询和检索数据库表中的数据。RDBMS 数据库在全球企业中存储着大量数据集。
SQL(结构化查询语言)代码示例。图片由作者提供。
Microsoft SQL Server Management Studio (SSMS) — SSMS 是 Microsoft 的集成开发环境(IDE),用于管理和查询在其 SQL Server RDBMS 中实现的数据库。它免费且易于学习,我使用 SSMS 创建和运行 SQL 代码,以查询包含所需数据的数据库。
SQL Server Management Studio (SSMS) 用于管理 Microsoft SQL Server 数据库和 SQL 代码。图片由作者提供。
Rapid SQL — Rapid SQL 是一个类似于 SSMS 的 IDE,用于开发 SQL 查询,以访问存储在 Oracle、SQL Server、DB2 和 SAP Sybase 数据库中的数据。我使用 Rapid SQL 从 DB2 或 Oracle 数据库中获取数据。
Microsoft Visual Studio — Visual Studio 是微软的旗舰集成开发环境(IDE)。我使用 Visual Studio Professional 来创建用 Python 和其他编程语言编写的应用程序。它的编辑器功能强大,具有颜色编码的语法。Visual Studio Community 2019 是一个免费的 IDE 版本,可能满足你的需求。微软的 Visual Studio Code (VS Code) 是另一个免费的 IDE,在程序员和数据分析师中也非常受欢迎。
Microsoft Visual Studio Professional 是一个集成开发环境(IDE),用于编写程序和开发应用程序。图片由作者提供。
Microsoft Excel — Excel 当然是一个无处不在、有用、强大且有时不可或缺的工具。我使用 Excel 工作簿作为项目数据源和输出,用于创建小数据集、执行基本的数据清洗和计算等。像 Excel 这样的电子表格应用程序是任何数据分析或数据科学工作中的关键工具。
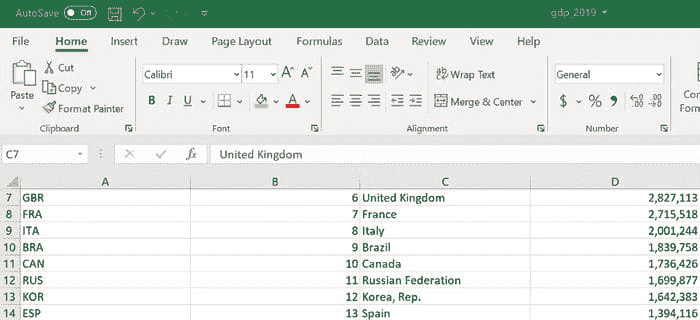
电子表格应用程序,如 Microsoft Excel,是多功能的数据分析工具。图片由作者提供。
制定基本标准、指南和程序
对数据分析项目应用简明的标准和指南可以提高生产力、以及工作成果的维护和共享。以下是指导我工作的标准和指南类型。
命名标准 — 标准化项目如文件夹、文件、数据库表、列和字段的命名方式,可以使它们的命名一致,并在大量产品中轻松找到工作成果。
文件夹结构标准和模板 — 对所有项目使用标准化的文件夹结构,可以方便地设置新项目并查找文件夹和文件。我的团队使用以下文件夹结构模板来组织和存储所有数据分析项目的工作成果:
-
项目名称(将此值更改为项目的名称)
-
alteryx_workflows
-
data
-
documentation
-
python_programs
-
sql_scripts
-
tableau_workbooks
文件夹结构根据每个项目的需要进行展开和收缩。
编码标准 — 编码标准就像语法对于英语散文一样重要。它们帮助我们组织和清晰、一致地传达思想。我曾参与的那些数据分析和软件开发团队都从文档化的编码规范中受益。在各个项目中应用这些标准可以使每个代码模块更容易为原作者编写,并且让团队的任何成员更容易阅读、理解、改进和维护。以下是我的团队用来指导工作的部分编码标准的描述。
-
类、变量和函数命名约定— 为了提高可读性,我们决定将所有类、函数和变量名称都用小写字母,每个单词或缩写由下划线(“_”)分隔。每个类和变量名称描述其存储的值的类型,而每个函数名称描述该函数对哪些值或对象执行了什么操作。例如,存储一个人姓名的变量可以命名为 person_name 或 person_nm。一个从数据库中检索人名列表的函数可以命名为 get_person_names()。
-
代码模块前言— 我们在每个模块的开头添加文本以描述其目的。为了帮助其他可能维护该模块的编码人员,我们会添加额外的信息,如作者姓名、数据库连接字符串、文件位置以及更改日志。
-
注释— 虽然有人说代码自解释,但我相信恰当的注释可以帮助编码人员整理思路,并帮助其他需要维护或增强代码的人更快地理解它。例如,在函数开始时,我描述它处理什么数据。我还会在每个执行任务的代码逻辑分组前添加简短的注释。
-
空白行— 为了使代码更易读,我在每个函数、每组变量定义以及每个执行特定任务的代码块之间插入空白行。
-
简洁的函数范围和可见大小— 和空白行一样,我限制每个函数的内容,使其更易于编写、理解、维护和增强。我努力保持每个函数简单,并尽量让其内容在编辑器中可见(如宽度不超过 80 字符,高度不超过 40 行)。
可视化风格指南— 虽然编码标准可以帮助程序员理解、编写和维护代码,但可视化风格指南可以帮助数据分析师开发一致、有用和有意义的视觉效果。它们也能通过提供一致、设计良好、易于理解和用户友好的视觉效果来惠及数据分析项目中的最终用户。以下是我的团队采纳的一些视觉风格指南。
-
品牌标准— 我们公司的品牌管理部门已确定了一组一致的字体、颜色和视觉设计风格及组件。我们已将这些纳入我们的可视化指南中,以增加专业性和一致性,并帮助为最终用户提供熟悉的用户界面风格。
-
字体— 我们公司设计了一款字体,我们会在可用时使用。如果不可用,我们的数据分析产品将默认使用 Arial 字体。
-
颜色— 我们公司的品牌标准包括一个小的颜色调色板。我们会在可能的情况下将这些颜色应用于图表、图形和仪表盘。我们还尝试将任何图表、图形或仪表盘上使用的颜色数量限制在视觉上令人愉悦的范围内。
-
标题、头部和标签——我们的指南描述了文本元素的标准位置、字体、大小和颜色,例如仪表板标题、图表和图形头部、列、过滤器和图例。
-
视觉组件的摆放——与文本一样,我们的指南描述了仪表板上元素的位置标准,例如图表和图形、过滤器和图例。
摘要
构建一个高效的数据分析团队,定期开发和交付能够为最终用户提供洞察并帮助他们做决策的数据分析解决方案并不容易。不过,应用一些我在软件开发和数据分析长时间职业生涯中学到、采纳并发展起来的经验和有效实践,可能会帮助你取得成功。
个人简介:兰迪·伦奇 是一名数据分析师、软件开发人员、作家、摄影师、骑行者和冒险者。他和妻子住在美国明尼苏达州东南部。请关注兰迪即将发布的文章,内容涉及公共数据集推动数据分析解决方案、编程、数据分析、骑行旅游、啤酒等。
原文。已获得许可转载。
相关:
-
数据科学团队的模型:国际象棋与跳棋
-
在小公司构建数据科学团队的六个建议
-
数据科学家的缺失团队
更多相关内容
制作你的第一个数据科学应用
原文:
www.kdnuggets.com/2021/02/build-first-data-science-application.html
评论
由 Naser Tamimi,壳牌的数据科学家

由 Kelly Sikkema 在 Unsplash 上拍摄
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
我需要学习什么才能制作我的第一个数据科学应用?关于网页部署呢?我是否需要学习 Flask 或 Django 来开发网页应用?我是否需要学习 TensorFlow 来制作深度学习应用?我应该如何设计我的用户界面?我还需要学习 HTML、CSS 和 JS 吗?
当我开始学习数据科学时,这些问题总是萦绕在我脑海中。我学习数据科学的目的不仅是为了开发模型或清理数据。我想要制作人们可以使用的应用。我在寻找一种快速制作 MVP(最小可行产品)以测试我的想法的方法。
如果你是一名数据科学家,想要制作你的第一个数据科学应用,在这篇文章中,我会展示你需要学习的 7 个 Python 库。我相信你已经知道其中的一些,但我在这里提到它们是为了那些不熟悉的人。

由 Med Badr Chemmaoui 在 Unsplash 上拍摄
Pandas
数据科学和机器学习应用都涉及数据。大多数数据集都不干净,需要进行某种清理和处理。Pandas 是一个可以加载、清理和处理数据的库。你可以使用像 SQL 这样的替代方案来进行数据处理和数据库管理,但 Pandas 更加简单,对希望成为开发者(或至少是 MVP 开发者)的数据科学家来说更为实用。
安装并了解更多关于 Pandas 的信息 这里。
Numpy
在许多数据科学项目中,包括计算机视觉,数组是最重要的数据类型。Numpy 是一个强大的 Python 库,允许你处理数组、操作它们并高效地应用算法。学习 Numpy 是使用我稍后提到的其他库的必要条件。
安装并了解更多关于 Numpy 这里 的信息。
SciKitLearn
这个库是许多类型的机器学习模型和预处理工具的工具包。如果你在做机器学习项目,几乎没有可能不需要 SciKitLearn。
安装并了解更多关于 SciKit-Learn 这里 的信息。
Keras 或 PyTorch
神经网络,特别是深度神经网络模型,是数据科学和机器学习中非常流行的模型。许多计算机视觉和自然语言处理方法都依赖于这些方法。一些 Python 库提供了访问神经网络工具的功能。TensorFlow 是最著名的,但我认为初学者使用 TensorFlow 较为困难。相反,我建议你学习 Keras,它是 TensorFlow 的一个接口(API)。Keras 使你作为人类能够轻松测试不同的神经网络架构,甚至构建自己的网络。另一个最近变得流行的选择是 PyTorch。
安装并了解更多关于 Keras 和 PyTorch 的信息。
请求
如今,许多数据科学应用程序都在使用 APIs(应用程序编程接口)。简单来说,通过 API,你可以请求服务器应用程序给你访问数据库或为你执行特定任务。例如,Google Map API 可以获取你提供的两个位置,并返回它们之间的旅行时间。没有 API,你必须重新发明轮子。Requests 是一个与 API 交互的库。现在,成为一名数据科学家几乎离不开使用 API。
安装并了解更多关于 Requests 这里 的信息。
Plotly
绘制不同类型的图表是数据科学项目的一个重要部分。虽然 Python 中最受欢迎的绘图库是 matplotlib,但我发现 Plotly 更专业、易于使用且灵活。Plotly 中的图表类型和绘图工具种类繁多。Plotly 的另一个优点是其设计。与具有科学外观的 matplotlib 图表相比,Plotly 看起来更友好。
安装并了解更多关于 Plotly 这里 的信息。
ipywidgets
在用户界面方面,你必须在传统外观的用户界面和基于网页的用户界面之间进行选择。你可以使用像 PyQT 或 TkInter 这样的库来构建传统外观的用户界面。但我的建议是,尽可能制作能够在浏览器上运行的网页应用程序。为了实现这一点,你需要使用一个提供浏览器小部件的库。ipywidgets 提供了一组丰富的 Jupyter Notebook 小部件。
安装并了解更多关于 ipywidgets 的信息,请点击 这里。
Jupyter Notebook 和 Voila
你需要学习的最后几个工具是最简单的。首先,ipywidgets 在 Jupyter Notebook 中工作,你需要使用 Jupyter 来制作你的应用。我相信很多人已经在模型构建和探索性分析中使用 Jupyter Notebook。现在,将 Jupyter Notebook 视为前端开发工具。此外,你需要使用 Voila,一个第三方工具,它可以隐藏 Jupyter Notebook 中的所有代码部分。当你通过 Voila 启动 Jupyter Notebook 应用时,它就像一个网页应用。你甚至可以在 AWS EC2 机器上运行 Voila 和 Jupyter Notebook,并通过互联网访问你的简单应用。
安装并了解更多关于 Voila 的信息,请点击 这里。
摘要
使用我在本文中提到的 7 个库,你可以构建出人们使用的数据科学应用。通过精通这些工具,你可以在几小时内构建 MVP,并用真实用户测试你的想法。之后,如果你决定扩展应用程序,你可以使用 Flask 和 Django 等更专业的工具,除了 HTML、CSS 和 JS 代码。
在 Medium 和 Twitter 上关注我,获取最新故事。
个人简介: Naser Tamimi 是一名为 Shell 工作的数据科学家。他的使命是教会读者他通过艰难的方式学到的东西。
原文。经许可转载。
相关内容:
-
使用 Pipes 进行更清晰的数据分析
-
使用 5 个必备的自然语言处理库入门
-
机器学习项目失败的五大原因
更多相关话题
如何通过网络抓取构建足球数据集
原文:
www.kdnuggets.com/2020/11/build-football-dataset-web-scraping.html
评论
由 Otávio Simões Silveira,经济学家,志向成为数据科学家

由 Bermix Studio 在 Unsplash 上提供的照片
当使用 Python 的库如 BeautifulSoup、requests 或 urllib 抓取网站时,常常会遇到无法访问网站某些部分的问题。这是因为这些部分是在客户端生成的,使用 JavaScript,而这些库无法处理。
为了解决这个问题,使用 Selenium 可以是一个有趣的选择。Selenium 通过打开一个自动化浏览器来工作,然后它能够访问整个内容并与页面交互。
本文将涵盖使用 Selenium 抓取 JavaScript 渲染内容的过程,以英超联赛网站为例,并抓取 2019/20 赛季每场比赛的统计数据。
了解网站
英超联赛网站通过其非常直接的 URL 使得抓取多个比赛变得非常简单。比赛的 URL 基本上由“ https://www.premierleague.com/match/ ”后跟一个唯一的比赛 ID 组成。
每个 ID 由一个数字组成,每个赛季的所有比赛 ID 都是按顺序排列的。例如,整个 2019/20 赛季的 ID 从 46605 到 46984。然后我们需要做的就是遍历这个区间并收集每场比赛的数据。
在本文中,我们将使用利物浦 5 比 3 战胜切尔西作为例子。这场比赛的 ID 是 46968。你可以在“premierleague.com/match/”后输入这个 ID 以访问页面,这样你可以跟随文章中描述的抓取过程。必要时请随时参考该页面。
正在抓取…
为了开始编写代码,我们将进行导入并初始化两个空列表,一个用于处理错误,稍后将在文章中解释,另一个用于存储我们抓取的每场比赛的数据。
在循环中,将使用比赛 ID 创建 URL,将实例化 driver 对象,并设置 Selenium。这里不会使用高级配置。option.headless = True 行表示我们不希望实际看到浏览器打开并访问网站以收集数据。完成这些操作后,我们将使用 driver 对象来获取页面。
现在我们准备开始抓取数据。我们将首先收集比赛的日期和涉及的团队。我们还将使用 Datetime 将日期格式从“Wed 22 Jul 2020”转换为 07/22/2020。
每个元素是通过其 Xpath 查找的,但也可以通过名称、类、标签等查找。请查看所有选择器这里。
请注意,我们在收集比赛日期时不得不使用WebDriverWait和expected_conditions。这是因为这是页面中通过 JavaScript 生成的部分,因此我们需要等待元素渲染完毕,以避免引发错误。
如果我们尝试仅使用requests和BeautifulSoup来收集比赛日期,我们将无法访问这些信息,因为BeautifulSoup无法解析 JavaScript 渲染的内容。
为了抓取最终比分,我们首先需要从我称之为比分框的区域中获取文本,该文本返回“5–3”,然后分配主队得分和客队得分。
下一步是获取比赛的统计数据。这些数据是页面上统计标签下的一个表格。我们可以简单地使用 Pandas 的read_html函数读取页面源代码,但页面的这一部分仅在我们点击选项卡后才会渲染。
那么,首先要做的是找到选项卡元素,并用 Selenium 单击它。之后,我们可以使用read_html函数。此函数返回一个包含页面上所有表格的列表,存储为 DataFrame。然后我们选择列表中的最后一个元素,即我们所需的元素。抓取完成后,我们可以退出驱动程序。
错误处理
有时 Selenium 可能会不太稳定,加载页面所需的时间可能会很长。这可能会引发一些错误,因为我们在抓取数百个页面。
为了处理这个问题,我们需要使用 try 和 except 子句。如果在收集数据时发生错误,代码将把比赛 ID 添加到错误列表中,并在不崩溃的情况下继续处理下一场比赛。当所有抓取完成后,你可以轻松查看这个列表,以便仅抓取缺失的比赛。这是所有这些的代码:
操作统计数据
目前统计数据的 DataFrame 看起来是这样的:
Liverpool Unnamed: 1 Chelsea
0 50 Possession % 50
1 7 Shots on target 5
2 10 Shots 10
3 749 Touches 752
4 584 Passes 575
5 19 Tackles 9
6 14 Clearances 15
7 6 Corners 0
8 0 Offsides 3
9 1 Yellow cards 0
10 8 Fouls conceded 11
由于我们需要将所有这些数据存储在 DataFrame 的一行中,这种格式并不好。为了解决这个问题,我们将创建两个字典,每个字典对应一个球队,其中每个键都代表一个统计数据。整个过程如下:
使数据一致
请注意,我们在统计数据 DataFrame 中没有红牌统计数据。这是因为这场比赛中没有红牌。当没有统计数据出现时,网站不会显示这些统计数据。
如果这没有修复,一些行将比其他行长,数据将不一致。为了解决这个问题,我们将使用一个包含所有预期统计数据的列表,如果该列表中的任何值不是统计数据字典的键(我们只需检查其中一个字典),那么该统计数据将作为键添加到两个字典中,值为零。
现在剩下的工作是创建一个新的列表,包含为这场比赛抓取的所有内容,并将这个列表附加到包含所有比赛的赛季列表中。
当我们完成对赛季所有比赛的抓取后,我们可以将赛季的列表列表转换为 DataFrame,并将数据导出为 .csv 文件。stats_check 列表被用来创建一个列表,用于命名 DataFrames 的列。
你可以在 这里 查看完整的代码。
总结
最后,这就是抓取的数据:

图片由作者提供
380 场比赛。这是整个英超 2019/20 赛季的数据集!你还可以做更多的事情:如果使用 ID 1,你可以回到 1992/93 赛季。但 ID 从 1992 年到今天并不是线性的,因为在某个时点,ID 开始涵盖杯赛、青少年比赛和女子比赛等。
不过,如果你想要一个包含数千场比赛的数据集,可以在 这里 找到几乎所有自 2011/12 赛季以来的英超比赛 ID。
如果你打算这样做,确保在代码中插入更多的暂停,使用 WebDriverWait 或甚至 sleep 函数,以避免因对网站发起过多请求而被封锁 IP。另一个可能的解决方案是联系代理服务提供商,如 Infatica,他们能够提供更好的 IP 地址基础设施,以保持你的代码正常运行。
如果想更进一步,你总是可以抓取更多关于每场比赛的数据。只需再增加几行代码,你的数据集中就可以包含裁判、比赛场地和城市、观众人数、半场比分、进球者、首发阵容等信息,甚至更多!
继续抓取数据!
希望你喜欢这篇文章,并且它能在某种程度上对你有所帮助。如果你有任何问题、建议,或只是想保持联系,请随时通过 Twitter、GitHub 或 Linkedin 联系我。
个人简介: Otávio Simões Silveira 是一名经济学家和有抱负的数据科学家。
原文。经授权转载。
相关内容:
-
Python, Selenium & Google 用于地理编码自动化: 免费与付费
-
用任务调度程序自动化你的 Python 脚本: 使用 Windows 任务调度程序抓取替代数据
-
创建真实数据科学项目组合的逐步指南
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关主题
如何构建令人印象深刻的数据科学简历
原文:
www.kdnuggets.com/2021/04/build-impressive-data-science-resume.html
评论
由 Sharan Kumar Ravindran,数据科学专家及作者

照片由 Glenn Carstens-Peters 拍摄,来源于 Unsplash
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
我们每个人都需要一份简历来展示我们的技能和经验,但我们为此付出了多少努力以使其具有影响力。不可否认,简历在我们的求职过程中扮演着关键角色。本文将探讨一些简单的策略,以显著改善数据科学简历的展示和内容。
首先,为什么专注于简历很重要?
数据科学职位变得非常竞争激烈,尽管机会的数量历史性地高,但申请这些职位的人数也极其庞大。
例如,下面是来自 LinkedIn 的职位发布截图,该职位发布总共有 1200+次查看,如果我们考虑大约十分之一的人申请这个职位,那么总共就是 120+个申请,这只是申请该职位的一种方式,还有通过其他来源、推荐以及直接申请的人,因此总申请人数可能接近 200+。同样的逻辑适用于任何数据科学职位,因此简历在筛选中起着关键作用。
来自 LinkedIn的截图
在本文中,我将指导您如何构建一个高影响力的简历,以帮助您在职位申请中获得筛选。本文涵盖的主题包括,
-
简历准备的基本规则
-
定制您的简历和求职信
-
谷歌的 X-Y-Z 公式,用于撰写有影响力的陈述
-
帮助构建出色简历的工具
如果你偏好视频格式,请点击这里。
简历准备的基本规则
简历格式
大多数职位申请接受 pdf 和 word 格式的简历。但我建议你坚持使用 pdf 版本,因为这可以确保格式的保留,即招聘人员看到的简历与你看到的是一样的。
个人简介
个人简介是简历的关键,视作电梯推介。它应该有说服力,并涵盖诸如你是谁、你的技能和优势等信息。简历的这一部分将是首要印象的主要推动力,并影响招聘人员的决定,因此要花足够的时间确保包括关于你的关键细节。
我个人认为简历开头应包括职业目标。我建议从简历中去除职业目标,而将空间用于更好的个人简介。因为大多数招聘基于你的成就、优势和技能,而不是你的愿望。所以做出明智的决定,合理利用简历的空间,尤其是开头部分。
使用要点
确保简历中包含的细节以要点形式呈现,无论是个人简介还是专业/项目经验。长段落很难集中注意力,因此将其保持简洁并以要点形式展示可以提高可读性,正如以下截图所示。

简历的个人简介应为一长段落。

个人简介以要点形式呈现
尝试将每个要点限制在 2-3 行,并将关键短语加粗,以帮助快速扫描。
格式一致性
简历的内容应保持一致的格式,包括标题、副标题、要点以及其他文本。以下是一些确保一致性的方法,
-
选择一种字体并在整个简历中使用它
-
简历中用于突出“工作经验”和“教育背景”的标题应保持一致格式。你可以选择使用较大的字体,但要在整个简历中保持一致。
-
如果你的简历超过一页,确保所有页面的边距、对齐和间距一致。
-
你可以选择将标题中的首字母大写,但要在整个简历中保持一致。
避免拼写错误
始终检查拼写和语法错误,因为这些错误可能会让招聘人员失去兴趣。虽然拼写和语法错误可能被忽视,但一旦被发现,会发出错误的信号,例如,
-
你没有足够的细节来发现这些错误。
-
作为数据科学家,沟通是关键方面,拼写或语法错误绝对不容忽视。
-
企业越来越多地使用自动化工具来筛选简历,这些工具很可能会拒绝包含排版错误的简历。
包括联系方式。
你的联系方式对招聘人员联系你非常重要,因此请确保仔细检查你的详细信息。许多人在编辑简历时会参考同事或朋友的简历,在这种情况下,确保在编辑文本时也修改超链接。例如,当你编辑电子邮件地址时,请确保超链接中的电子邮件地址也被修改。
包括你个人资料和作品集的链接。
确保你的简历中有指向 LinkedIn 个人资料、git 库以及其他你希望招聘人员注意的网页或个人资料的链接。
定制你的简历和求职信。
当你与许多人竞争一个职位申请时,像定制这样的简单事情可以成为一个差异化因素,并帮助你获得招聘人员的即时关注。当我说将简历定制到职位发布时,并不是完全重新编写你的简历,而只是做一些小的调整,以确保你的个人资料突出显示职位要求和期望。
定制你的简历有助于你在
-
确保你的简历针对职位发布进行了定制。
-
确保你的简历能够通过自动关键词筛选。
-
向招聘人员传达积极的信号,因为你已经做好了准备。
简历中有一些组件你可以定制,它们是
-
简历和求职信中的目标职位名称应与职位发布匹配。
-
确保简历中突出显示的技能包括职位描述中要求的一些技能。
-
对你的个人资料总结进行简单的修改,以确保符合职位发布中提到的期望。
-
如果你申请的职位远离你当前的城市,或申请的工作需要出差,则在简历或求职信中明确提及你愿意搬迁或旅行。
谷歌 X-Y-Z 公式来制作有影响力的陈述。
这是一个出色的公式,有助于将你的成就转化为高影响力的陈述。这个公式最早由 Laszlo Bock 在他的文章中介绍,点击这里。这是一个非常有效的技术,可以用来撰写有影响力的简历。这个公式的意思是,
以“X”作为“Y”的衡量标准,通过做“Z”实现的成就
我将用一些简单的例子来准确解释这个公式如何应用到你的数据科学简历中。
示例 1:
“建立了一个推荐系统”
这是一个简单的陈述,完全没有吸引力,因为它没有确切提到用例的影响。我们可以尝试通过使用以下陈述来改进它,
“建立了一个推荐系统,使收入增加了 10%”
现在,这比之前的陈述要好得多,但可以通过使用 Google X-Y-Z 公式进一步改进,如下所示(公式中的 X、Y 和 Z 在下面突出显示)
“构建了一个推荐系统 (X),通过使用协同过滤算法 (Z),帮助平台提高了 10%的收入 (Y)并改善了客户互动”
示例 2:
“参与了一个 Kaggle 比赛”
这又是一个简单的陈述,仅仅说你参与了一个 Kaggle 比赛,但没有提到你的表现,因此可以通过添加一些细节来改进,如下所示,
“在 Kaggle 比赛中获得第 20 名”
现在已经好多了,但我们可以通过使用 Google X-Y-Z 公式使其更有影响力,例如,
“参与了一个Kaggle 比赛 (X)并在1250 个团队中获得第 20 名 (Y),通过与 3 位同事一起构建一个集成预测模型 (Z)”
现在,使用这个公式将你的成就转化为更有力的陈述。
帮助构建出色简历的工具
有很多优秀的工具可以帮助你打造一份出色的简历。以下是我最喜欢的两个,
Resume.io
-
这是一个付费平台来构建简历和求职信,尽管使用平台和构建简历不需要支付任何费用,但下载简历时需要付款。
-
他们有许多针对不同职位类别的简历模板,帮助你开始。
-
虽然这个平台支持多种模板并提供许多选项进行修改,但模板的一些部分仍然比较僵化。不过我个人觉得这样更好,因为它能让你专注于需要关注的部分,并且确保你的简历保持一致性。
Flowcv.io
-
这是一个免费构建简历和求职信的平台,如果你希望拥有多个版本的简历,则需要一次性付款。
-
这个平台提供了多种配置选项来定义事物的外观。我觉得选项越多,决策就越多,因此耗时较长,可能导致一些不一致性。
这些工具在创建出色简历方面非常有帮助。
保持联系
-
如果你喜欢这篇文章并对类似内容感兴趣,请在 Medium 上关注我。
-
我在我的 YouTube 频道上教授和讨论各种数据科学话题。点击这里订阅我的频道。
-
订阅我的邮件列表,获取更多数据科学技巧并与我的工作保持联系。
个人简介:Sharan Kumar Ravindran (LinkedIn, GitHub) 是一名拥有超过 10 年经验的数据科学专业人士,并且撰写了两本数据科学相关书籍。
原文。已获许可转载。
相关内容:
-
数据职业并非一刀切!揭示你在数据领域理想角色的技巧
-
使用 NLP 提升你的简历
-
数据专业人士如何为简历增添更多变化
更多相关内容
让我们构建一个智能聊天机器人
评论
在文章 使用 Python NLTK 构建你的第一个聊天机器人中,我们编写了一个简单的 Python 代码并构建了一个聊天机器人。问题和答案被松散地硬编码,这意味着聊天机器人无法对代码中没有的问题给出令人满意的答案。因此,我们的聊天机器人被认为不是一个智能机器人。
在这篇文章中,我们将构建一个基于文档或信息的聊天机器人,它将深入分析你的查询,并根据这些查询进行回应。
我们的三大课程推荐
1. 谷歌网络安全证书 - 加入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
介绍
一个聊天机器人(也称为谈话机器人、聊天机器人、Bot、IM 机器人、互动代理或人工对话实体)是一个计算机程序或一个人工智能,通过听觉或文本方法进行对话。这些程序通常被设计成能够可信地模拟人类作为对话伙伴的行为,从而通过Turing 测试。聊天机器人通常用于对话系统,用于各种实际目的,包括客户服务或信息获取。—— 维基百科
聊天机器人在今天非常热门。谁不知道它们?聊天机器人被视为与客户、员工以及所有其他希望交流的人互动的未来方式。其精髓在于这种交流是一种对话。与仅仅发布信息不同,使用聊天机器人的人可以通过提问更直接地获取他们想要的信息。

来源: outgrow.co
聊天机器人能做什么?
聊天机器人相关的原因如下:
-
它们能在正确的时间、正确的地点提供给人们正确的信息,而且最重要的是,只在他们需要的时候。
-
我们在移动设备上约 90%的时间都花在电子邮件和消息平台上。因此,使用聊天机器人与客户互动比将他们引导到网站或移动应用程序更有意义。
借助聊天机器人,公司可以全天候提供服务。现在,销售和客服团队可以专注于更复杂的任务,而聊天机器人则引导用户完成流程。

来源:edureka.co
现代聊天机器人不仅仅依赖文本,通常还会显示有用的卡片、图像、链接和表单,提供类似应用程序的体验。
根据机器人编程的方式,我们可以将它们分为两种类型的聊天机器人:基于规则的(笨拙的机器人)和自学习的(智能机器人)。
自学习聊天机器人进一步分为检索型和生成型。
检索型
检索型机器人基于指向流或图的原理。机器人被训练从有限的预定义响应中排名出最佳回应。这里的响应是手动输入的,或者基于现有信息的知识库。
例如: 你们的营业时间是什么?
回答: 下午 9 点到 5 点
这些系统还可以扩展以集成第三方系统。
例如: 我的订单在哪里?
回答: 它正在路上,应该会在 10 分钟内到达你那里。
检索型机器人是你今天看到的最常见的聊天机器人类型。它们允许机器人开发者和用户体验团队控制体验,并使其符合客户的期望。它们最适合用于目标导向的客户支持、潜在客户生成和反馈。我们可以决定机器人的语气,并设计体验,同时考虑到客户的品牌和声誉。
生成型
另一种构建聊天机器人的方法是使用生成模型。这些聊天机器人不是通过预定义的响应来构建的。相反,它们是通过大量的先前对话进行训练的,根据这些对话生成对用户的响应。它们需要大量的对话数据进行训练。
生成模型适合用于用户仅仅想交换闲聊的对话型聊天机器人。这些模型几乎总是会有一个准备好的回答。然而,在许多情况下,回答可能是随意的,对你来说并不太有意义。聊天机器人也容易生成语法和句法不正确的回答。
聊天机器人构建
在继续之前,有几点需要了解。使用 NLTK 进行自然语言处理(NLP)、TF-IDF 和余弦相似度。
使用 NLTK 进行自然语言处理(NLP)
自然语言处理(NLP)是计算机程序理解人类语言的能力。NLP 是人工智能(AI)的一个组成部分。
NLP 应用的开发具有挑战性,因为计算机传统上需要人类用精确、明确和高度结构化的编程语言与其“对话”,或者通过有限数量的明确语音命令。然而,人类语言往往是不精确的,通常是模糊的,语言结构可能取决于许多复杂的变量,包括俚语、地方方言和社会背景。
自然语言工具包(NLTK)
NLTK 是一个领先的平台,用于构建 Python 程序以处理人类语言数据。它提供了超过 50 种语料库和词汇资源(如 WordNet)的易用接口,以及一套用于分类、分词、词干提取、标注、解析和语义推理的文本处理库、工业级 NLP 库的封装和一个活跃的讨论论坛。
TF-IDF
我们将计算每个文档的词频-逆文档频率(TF-IDF)向量。这将给你一个矩阵,其中每一列代表概述词汇表中的一个词(所有至少在一个文档中出现的词)。
TF-IDF 是一种统计方法,用于评估一个词在给定文档中的重要性。
TF — 词频(tf)指的是一个术语在文档中出现的次数。
IDF — 逆文档频率(idf)衡量词在文档中的权重,即该词在整个文档中是常见的还是稀有的。
TF-IDF 的直觉是,频繁出现的术语在文档中的重要性低于那些很少出现的术语。
幸运的是,scikit-learn 提供了一个内置的[TfIdfVectorizer](https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html)类,可以很容易地生成 TF-IDF 矩阵。
余弦相似度
现在我们有了这个矩阵,我们可以很容易地计算相似度得分。有几种选择可以做到这一点,例如欧氏距离、皮尔逊相关系数和余弦相似度。再次强调,没有绝对正确的得分方式。
我们将使用余弦相似度来计算表示两个单词相似度的数值量。使用余弦相似度评分因为它独立于大小,并且相对容易和快速计算(特别是与 TF-IDF 评分结合使用时)。从数学上讲,它定义如下:
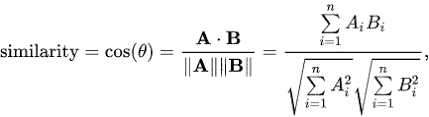
来源: 余弦相似度
由于我们使用了 TF-IDF 向量化器,计算点积将直接给出余弦相似度评分。因此,我们将使用sklearn的linear_kernel()而不是cosine_similarities(),因为它更快。
开始编码…
因此,我们将从这个网站复制数据。数据集包含了与人力资源管理相关的所有内容。将整个数据复制并粘贴为文本格式。我们将基于这些数据训练我们的模型,然后检查模型的表现。此外,我还包含了Wikipedia python 库,以便你可以询问任何问题。
导入所有必需的库。
import nltk
import random
import string
import re, string, unicodedata
from nltk.corpus import wordnet as wn
from nltk.stem.wordnet import WordNetLemmatizer
import wikipedia as wk
from collections import defaultdict
import warnings
warnings.filterwarnings("ignore")
nltk.download('punkt')
nltk.download('wordnet')
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity, linear_kernel
加载数据集并将所有文本转换为小写。
data = open('/../../chatbot/HR.txt','r',errors = 'ignore')
raw = data.read()
raw = raw.lower()
让我们查看一下我们的数据是什么样的。
raw[:1000]
'human resource management is the process of recruiting, selecting, inducting employees, providing orientation, imparting training and development, appraising the performance of employees, deciding compensation and providing benefits, motivating employees, maintaining proper relations with employees and their trade unions, ensuring employees safety, welfare and healthy measures in compliance with labour laws of the land.\nhuman resource management involves management functions like planning, organizing, directing and controlling\nit involves procurement, development, maintenance of human resource\nit helps to achieve individual, organizational and social objectives\nhuman resource management is a multidisciplinary subject. it includes the study of management, psychology, communication, economics and sociology.\nit involves team spirit and team work.\nit is a continuous process.\nhuman resource management as a department in an organisation handles all aspects of employees and has various functi'
数据预处理
现在让我们开始数据清理和预处理,将整个数据转换为句子列表。
sent_tokens = nltk.sent_tokenize(raw)
我们的下一步是对这些句子进行标准化。标准化是一个将单词列表转换为更统一序列的过程。这在为后续处理准备文本时非常有用。通过将单词转换为标准格式,其他操作能够处理数据,而无需处理可能影响过程的问题。
这一步包括词汇标记化、去除 ASCII 值、去除各种标签、词性标注和词形还原。
def Normalize(text):
remove_punct_dict = dict((ord(punct), None) for punct in string.punctuation)
#word tokenization
word_token = nltk.word_tokenize(text.lower().translate(remove_punct_dict))
#remove ascii
new_words = []
for word in word_token:
new_word = unicodedata.normalize('NFKD', word).encode('ascii', 'ignore').decode('utf-8', 'ignore')
new_words.append(new_word)
#Remove tags
rmv = []
for w in new_words:
text=re.sub("</?.*?>","<>",w)
rmv.append(text)
#pos tagging and lemmatization
tag_map = defaultdict(lambda : wn.NOUN)
tag_map['J'] = wn.ADJ
tag_map['V'] = wn.VERB
tag_map['R'] = wn.ADV
lmtzr = WordNetLemmatizer()
lemma_list = []
rmv = [i for i in rmv if i]
for token, tag in nltk.pos_tag(rmv):
lemma = lmtzr.lemmatize(token, tag_map[tag[0]])
lemma_list.append(lemma)
return lemma_list
所以数据预处理部分完成了,现在让我们定义欢迎词或问候语,这意味着如果用户提供的是问候消息,聊天机器人将根据关键字匹配以问候的方式回应。
welcome_input = ("hello", "hi", "greetings", "sup", "what's up","hey",)
welcome_response = ["hi", "hey", "*nods*", "hi there", "hello", "I am glad! You are talking to me"]
def welcome(user_response):
for word in user_response.split():
if word.lower() in welcome_input:
return random.choice(welcome_response)
生成聊天机器人响应
为了从我们的聊天机器人生成响应,将使用文档相似度的概念。正如我已经讨论过的,TFidf 向量化器用于将一系列原始文档转换为 TF-IDF 特征矩阵,而要查找用户输入的单词与数据集中单词之间的相似度,我们将使用余弦相似度。
我们定义了一个函数generateResponse(),它会搜索用户的输入词,并返回几种可能的回应之一。如果函数没有找到匹配任何关键词的输入,那么你可以让你的聊天机器人帮你搜索维基百科。只需输入“tell me about any_keyword”。如果在维基百科中没有找到任何内容,聊天机器人会生成一条消息“No content has been found”。
def generateResponse(user_response):
robo_response=''
sent_tokens.append(user_response)
TfidfVec = TfidfVectorizer(tokenizer=Normalize, stop_words='english')
tfidf = TfidfVec.fit_transform(sent_tokens)
#vals = cosine_similarity(tfidf[-1], tfidf)
vals = linear_kernel(tfidf[-1], tfidf)
idx=vals.argsort()[0][-2]
flat = vals.flatten()
flat.sort()
req_tfidf = flat[-2]
if(req_tfidf==0) or "tell me about" in user_response:
print("Checking Wikipedia")
if user_response:
robo_response = wikipedia_data(user_response)
return robo_response
else:
robo_response = robo_response+sent_tokens[idx]
return robo_response#wikipedia search
def wikipedia_data(input):
reg_ex = re.search('tell me about (.*)', input)
try:
if reg_ex:
topic = reg_ex.group(1)
wiki = wk.summary(topic, sentences = 3)
return wiki
except Exception as e:
print("No content has been found")
最终定义聊天机器人用户对话处理程序。
注意:如果你输入 Bye、shutdown、exit 或 quit,程序将退出。
flag=True
print("My name is Chatterbot and I'm a chatbot. If you want to exit, type Bye!")
while(flag==True):
user_response = input()
user_response=user_response.lower()
if(user_response not in ['bye','shutdown','exit', 'quit']):
if(user_response=='thanks' or user_response=='thank you' ):
flag=False
print("Chatterbot : You are welcome..")
else:
if(welcome(user_response)!=None):
print("Chatterbot : "+welcome(user_response))
else:
print("Chatterbot : ",end="")
print(generateResponse(user_response))
sent_tokens.remove(user_response)
else:
flag=False
print("Chatterbot : Bye!!! ")
现在,让我们测试一下聊天机器人,看看它的反应如何。
与 Chatterbot 对话的截图:


如果你希望你的聊天机器人搜索维基百科,只需输入
**“tell me about **”
这真是太酷了,不是吗?尽管结果不够准确,但至少我们达成了一个里程碑 😃
结论:聊天机器人的未来
聊天机器人的未来非常光明。随着人工智能领域的快速发展,聊天机器人毫无疑问是未来。我们刚刚构建的当前聊天机器人显然不是我所说的未来,这只是聊天机器人建设中的一个垫脚石。
未来的聊天机器人不仅仅是一个客户支持代理,它将成为一个为企业和消费者提供高级帮助的助手。
我们人类不喜欢做重复的乏味任务。因此,在未来,公司将雇佣 AI 聊天机器人来处理那些重复且不需要创造力的任务。通过让 AI 聊天机器人接管这些重复的乏味任务,公司将利用人力资源从事更具创造性的工作。这样,我们可以期待未来会有更多惊人的事物出现。
此外,人类不喜欢将内容(死记硬背)储存在脑海中。如今,借助互联网,他们可以利用这一点。因此,需要储存信息(数据)的任务可以转移到 AI 聊天机器人上。
好了,这篇文章就到这里,希望大家喜欢阅读,欢迎在评论区分享你的评论/想法/反馈。
如有任何疑问,请通过LinkedIn与我联系。

来源:gfycat.com
感谢阅读!!!
个人简介:Nagesh Singh Chauhan 是 CirrusLabs 的一个大数据开发者。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,并在各种大数据组件方面具有专长。
原文。经授权转载。
相关内容:
-
用于 NLP 的深度学习:用 Keras 创建一个聊天机器人!
-
BERT 正在改变 NLP 格局
-
自动化文本摘要入门
更多相关内容
如何在 Python 中构建自己的逻辑回归模型
原文:
www.kdnuggets.com/2019/10/build-logistic-regression-model-python.html
评论
这个算法的名称可能会有些混淆,因为逻辑回归机器学习算法用于分类任务而非回归问题。这里的“回归”名称意味着将线性模型拟合到特征空间中。该算法将逻辑函数应用于特征的线性组合,以预测基于预测变量的分类因变量的结果。逻辑回归算法有助于估计基于给定预测变量的分类因变量的特定水平的概率。
假设你想预测明天在多伦多是否会下雨。这里的预测结果不是一个连续的数字,因为要么会下雨,要么不会下雨,因此线性回归不能应用。这里的结果变量是多个类别之一,使用逻辑回归会有所帮助。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 事务
逻辑回归的应用
-
逻辑回归算法在流行病学领域中用于识别疾病的风险因素,并据此规划预防措施。
-
用于预测候选人是否会赢得政治选举,或预测选民是否会投票给某位候选人。
-
用于天气预报,以预测降雨的概率。
-
用于信用评分系统中的风险管理,以预测账户的违约情况。
环境和工具
代码在哪里?
话不多说,让我们开始代码吧。完整项目可以在 这里 找到。
让我们从加载库和依赖项开始。
import numpy as np
import matplotlib.pyplot as plt
第一个函数用于定义 sigmoid 激活函数。sigmoid 函数的图像如下所示:
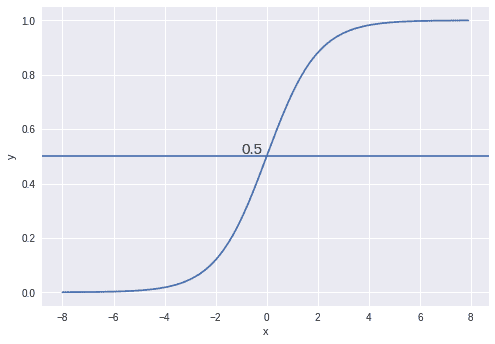
sigmoid 函数
def sigmoid(scores):
return 1 / (1 + np.exp(-scores))
sigmoid 函数表示如下:
Sigmoid 函数也称为逻辑函数,给出一个“S”形曲线,可以将任何实值数映射到 0 和 1 之间。如果曲线趋向于正无穷大,预测的 y 将变为 1,如果曲线趋向于负无穷大,预测的 y 将变为 0。如果 sigmoid 函数的输出大于 0.5,我们可以将结果分类为 1 或 yes;如果小于 0.5,我们可以将其分类为 0 或 no。
下一个函数用于返回对数似然度值。与此函数相关的参数包括特征向量、目标值和模型的权重。
对数似然度顾名思义是似然度的自然对数。反过来,给定一个样本和一个参数化的分布族(即,按参数索引的分布集合),似然度是一个将每个参数与观察到给定样本的概率关联的函数。
def log_likelihood(features, target, weights):
scores = np.dot(features, weights)
ll = np.sum(target * scores - np.log(1 + np.exp(scores)))
return ll
下一个函数用于创建逻辑回归模型。与该函数相关的参数包括特征向量、目标值、训练步骤数、学习率以及一个默认设置为 false 的添加截距的参数。
首先使用特征向量分配权重。接下来使用特征向量和权重向量的点积计算分数。通过对分数应用 sigmoid 函数来找到预测值。现在可以计算误差,即目标值与预测值之间的差异。这个误差用于找出梯度,梯度是转置特征向量和误差的点积。可以通过将学习率乘以梯度并加到旧权重上来计算新的权重。
def logistic_regression(features, target, num_steps, learning_rate, add_intercept=False):
if add_intercept:
intercept = np.ones((features.shape[0], 1))
features = np.hstack((intercept, features)) weights = np.zeros(features.shape[1])
for step in range(num_steps):
scores = np.dot(features, weights)
predictions = sigmoid(scores)
output_error_signal = target - predictions
gradient = np.dot(features.T, output_error_signal)
weights += learning_rate * gradient
if step % 10000 == 0:
print(log_likelihood(features, target, weights))
return weights
**random()** 函数用于在 Python 中生成随机数。Seed 函数用于保存随机函数的状态,以便在相同机器或不同机器上的多次执行代码时生成相同的随机数。选择的 seed 值为 10,数据点为 10000。
多元正态分布是将一维正态分布推广到更高维度的概念。这样的分布由其均值和协方差矩阵指定。
np.random.seed(10)
num_observations = 10000 x1 = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 1]], num_observations)
x2 = np.random.multivariate_normal([1, 4], [[1, 0.5], [0.5, 1]], num_observations)
hstack 用于水平附加数据,而 vstack 用于垂直附加数据。首先使用 vstack 来根据特征分隔数据点,然后使用 hstack 来根据标签分隔数据点。
simulated_separableish_features = np.vstack((x1, x2)).astype(np.float32)simulated_labels = np.hstack((np.zeros(num_observations), np.ones(num_observations)))
通过使用 scatter 函数绘制分隔的数据点来可视化结果,其中 alpha blending 值选择为 0.3。混合值范围从 0(透明)到 1(不透明)。
plt.figure(figsize=(10, 8))plt.scatter(simulated_separableish_features[:, 0], simulated_separableish_features[:, 1], c=simulated_labels, alpha=0.3,)
plt.show()
结果
样本数据点的分类
结论
总结一下,我展示了如何从零开始用 Python 构建一个逻辑回归模型。逻辑回归是一种广泛使用的监督学习技术。它是统计学家、研究人员和数据科学家在预测分析中的最佳工具之一。它具有几个优点,比如它是一个稳健的算法,因为自变量不需要具有相等的方差或正态分布,不假设因变量和自变量之间的线性关系,因此也可以处理非线性效应,并且它们也更易于检查且复杂度较低。
参考文献/进一步阅读
[逻辑回归 — 详细概述]
逻辑回归在二十世纪初被用于生物科学中。后来它被用于许多社会…](https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc?source=post_page-----de8d2d8feae5----------------------)
[提高你的逻辑回归模型的技巧 | Zopa 博客]
当我们在 Zopa 创建信用风险评估或欺诈预防机器学习模型时,我们使用各种…](https://blog.zopa.com/2017/07/20/tips-honing-logistic-regression-models/?source=post_page-----de8d2d8feae5----------------------)
[逻辑回归:概念与应用 | 博客 | 无量纲]
通过这篇文章,我们尝试理解逻辑回归的概念及其应用。我们将…](https://dimensionless.in/logistic-regression-concept-application/?source=post_page-----de8d2d8feae5----------------------)
在离开之前
相应的源代码可以在这里找到。
[abhinavsagar/机器学习教程]
目前你无法执行该操作。你已在另一个标签页或窗口中登录。你在另一个标签页或…](https://github.com/abhinavsagar/Machine-learning-tutorials/blob/master/logistic regression/logistic_regression.py?source=post_page-----de8d2d8feae5----------------------)
联系方式
如果你想及时了解我的最新文章和项目,请在 Medium 上关注我。以下是我的一些联系信息:
祝阅读愉快,学习愉快,编码愉快。
个人简介:Abhinav Sagar 是 VIT Vellore 的大四本科生。他对数据科学、机器学习及其在现实问题中的应用感兴趣。
原文。转载已获许可。
相关内容:
-
逻辑回归:简明技术概述
-
用于乳腺癌分类的卷积神经网络
-
如何使用 Flask 轻松部署机器学习模型
相关主题
在 5 分钟内构建机器学习网页应用
原文:
www.kdnuggets.com/2022/03/build-machine-learning-web-app-5-minutes.html
介绍
过去一年见证了数据相关职位范围的巨大增长。大多数有志于数据专业人士往往将大量精力放在模型构建上,而对数据科学生命周期中的其他元素关注较少。
由于这一点,许多数据科学家无法在 Jupyter Notebook 之外的环境中工作。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
他们无法将模型交到最终用户手中,而依赖于外部团队来完成这些工作。在没有数据管道的小公司中,这些模型往往永远不会被使用。由于公司忽视了招聘具有部署和监控模型所需技能的人才,这些模型没有创造任何商业价值。
在本文中,你将学会如何导出模型并在 Jupyter Notebook 环境之外使用它们。你将构建一个简单的网页应用,能够将用户输入传递到机器学习模型中,并向用户显示预测结果。
到本教程结束时,你将学会以下内容:
-
构建并调整机器学习模型以解决分类问题。
-
序列化并保存机器学习模型。
-
将这些模型加载到不同的环境中,使你能够超越 Jupyter Notebook 的局限。
-
使用 Streamlit 从机器学习模型构建网页应用。
这个网页应用将接受用户的人口统计数据和健康指标作为输入,并生成一个预测,判断他们在未来十年是否会发展成心脏病:
步骤 1:背景
Framingham 心脏研究是对马萨诸塞州 Framingham 居民进行的长期心血管研究。一系列临床试验在一组患者中进行,记录了如 BMI、血压和胆固醇水平等风险因素。
这些患者每隔几年会报告到一个检测中心,以提供更新的健康信息。
在本教程中,我们将使用来自 Framingham Heart Study 的 数据集,预测研究中的患者在十年内是否会发展心脏病。可以从 BioLincc 网站 请求获得,数据集包含约 3600 名患者的风险因素。
第 2 步:前提条件
你需要在设备上安装一个 Python IDE。如果你通常在 Jupyter Notebook 中工作,请确保安装其他 IDE 或文本编辑器。我们将使用 Streamlit 创建一个 Web 应用程序,而使用 notebook 无法运行它。
我建议在 Jupyter 中编写代码以构建和保存模型(第 3 步和第 4 步)。然后,切换到其他 IDE 加载模型并运行应用程序(第 5 步)。
如果你尚未安装,请选择以下一些选项: Visual Studio Code, Pycharm, Atom, Eclipse。
第 3 步:模型构建
确保下载 这个 数据集。然后,导入 Pandas 库并加载数据框。
import pandas as pd
framingham = pd.read_csv('framingham.csv')# Dropping null values
framingham = framingham.dropna()
framingham.head()

查看数据框的前几行,可以看到有 15 个风险因素。这些是我们的自变量,我们将使用它们来预测十年内心脏病的发生(TenYearCHD)。
现在,让我们看看我们的目标变量:
framingham['TenYearCHD'].value_counts()
注意,这一列中只有两个值——0 和 1。值为 0 表示患者在十年内未发展 CHD,值为 1 表示他们发展了 CHD。
该数据集也相当不平衡。结果为 0 的患者有 3101 名,而结果为 1 的患者仅有 557 名。
为了确保我们的模型不会在不平衡的数据集上训练并且始终预测多数类,我们将对训练数据进行随机过采样。然后,我们将为数据框中的所有变量拟合一个随机森林分类器。
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_scoreX = framingham.drop('TenYearCHD',axis=1)
y = framingham['TenYearCHD']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.20)oversample = RandomOverSampler(sampling_strategy='minority')
X_over, y_over = oversample.fit_resample(X_train,y_train)rf = RandomForestClassifier()
rf.fit(X_over,y_over)
现在,让我们评估模型在测试集上的表现:
preds = rf.predict(X_test)
print(accuracy_score(y_test,preds))
我们模型的最终准确率大约为 0.85。
第 4 步:保存模型
让我们保存刚刚构建的随机森林分类器。我们将使用 Joblib 库来完成此操作,因此请确保已安装该库。
import joblib
joblib.dump(rf, 'fhs_rf_model.pkl')
这个模型可以在不同的环境中轻松访问,并可以用于对外部数据进行预测。
第 5 步:构建 Web 应用程序
a) 创建用户界面
最后,我们可以开始使用上述创建的模型构建 Web 应用程序。开始之前,请确保安装了 Streamlit 库。
如果你之前使用的是 Jupyter Notebook 来构建分类器,你现在需要转到不同的 Python IDE。创建一个名为streamlit_fhs.py的文件。
你的目录应包含以下文件:

然后,在你的 *.py *文件中导入以下库:
import streamlit as st
import joblib
import pandas as pd
让我们为我们的网页应用创建一个标题,并运行它以检查一切是否正常:
st.write("# 10 Year Heart Disease Prediction")
要运行 Streamlit 应用,请在终端中输入以下命令:
streamlit run streamlit_fhs.py
现在,导航到 localhost:8501 你可以看到你的应用所在的页面。你应该会看到如下页面:

太棒了!这意味着一切正常。
现在,让我们为用户创建输入框,以便他们输入他们的数据(年龄、性别、血压等)。
这是如何在 Streamlit 中创建一个多选下拉框,让用户选择他们的性别的示例代码(这是示例代码。运行后请删除这一行,完整示例请见下方):
gender = st.selectbox("Enter your gender",["Male", "Female"])
再次导航到你的 Streamlit 应用并刷新页面。你会看到屏幕上出现这个下拉框:

记住,我们需要从用户那里收集 15 个独立变量。
运行以下代码行以创建输入框,供用户输入数据。我们将页面分成三列,以使应用更具视觉吸引力。
col1, col2, col3 = st.columns(3)
# getting user inputgender = col1.selectbox("Enter your gender",["Male", "Female"])
age = col2.number_input("Enter your age")
education = col3.selectbox("Highest academic qualification",["High school diploma", "Undergraduate degree", "Postgraduate degree", "PhD"])
isSmoker = col1.selectbox("Are you currently a smoker?",["Yes","No"])
yearsSmoking = col2.number_input("Number of daily cigarettes")
BPMeds = col3.selectbox("Are you currently on BP medication?",["Yes","No"])
stroke = col1.selectbox("Have you ever experienced a stroke?",["Yes","No"])
hyp = col2.selectbox("Do you have hypertension?",["Yes","No"])
diabetes = col3.selectbox("Do you have diabetes?",["Yes","No"])
chol = col1.number_input("Enter your cholesterol level")
sys_bp = col2.number_input("Enter your systolic blood pressure")
dia_bp = col3.number_input("Enter your diastolic blood pressure")
bmi = col1.number_input("Enter your BMI")
heart_rate = col2.number_input("Enter your resting heart rate")
glucose = col3.number_input("Enter your glucose level")
再次刷新应用以查看更改:
最后,我们需要在页面底部添加一个‘预测’按钮。用户点击这个按钮后,将显示输出结果。
st.button('Predict')
太棒了!刷新页面后你会看到这个按钮。
b) 进行预测
应用界面已准备好。现在,我们只需在每次系统接收到用户输入时收集这些数据。我们需要将这些数据传递给分类器,以得出预测结果。
用户输入现在存储在我们之前创建的变量中——年龄、性别、教育背景等。
然而,这些输入的格式并不容易被分类器处理。我们正在收集是/否问题形式的字符串,这需要以与训练数据相同的方式进行编码。
运行以下代码行以转换用户输入的数据:
df_pred = pd.DataFrame([[gender,age,education,isSmoker,yearsSmoking,BPMeds,stroke,hyp,diabetes,chol,sys_bp,dia_bp,bmi,heart_rate,glucose]],
columns= ['gender','age','education','currentSmoker','cigsPerDay','BPMeds','prevalentStroke','prevalentHyp','diabetes','totChol','sysBP','diaBP','BMI','heartRate','glucose'])
df_pred['gender'] = df_pred['gender'].apply(lambda x: 1 if x == 'Male' else 0)
df_pred['prevalentHyp'] = df_pred['prevalentHyp'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['prevalentStroke'] = df_pred['prevalentStroke'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['diabetes'] = df_pred['diabetes'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['BPMeds'] = df_pred['BPMeds'].apply(lambda x: 1 if x == 'Yes' else 0)
df_pred['currentSmoker'] = df_pred['currentSmoker'].apply(lambda x: 1 if x == 'Yes' else 0)def transform(data):
result = 3
if(data=='High school diploma'):
result = 0
elif(data=='Undergraduate degree'):
result = 1
elif(data=='Postgraduate degree'):
result = 2
return(result)df_pred['education'] = df_pred['education'].apply(transform)
我们可以直接加载之前保存的模型,并用它对用户输入的值进行预测:
model = joblib.load('fhs_rf_model.pkl')
prediction = model.predict(df_pred)
最后,我们需要在屏幕上显示这些预测结果。
导航到你之前创建预测按钮的代码行,并按如下所示修改它:
if st.button('Predict'):
if(prediction[0]==0):
st.write('<p class="big-font">You likely will not develop heart disease in 10 years.</p>',unsafe_allow_html=True)
else:
st.write('<p class="big-font">You are likely to develop heart disease in 10 years.</p>',unsafe_allow_html=True)
这些更改已被添加,以便只有当用户点击“预测”按钮后才显示输出结果。同时,我们希望向用户显示文本,而不仅仅是显示预测值(0 和 1)。
保存你所有的代码并刷新页面,你将看到屏幕上的完整应用程序。输入随机数字并点击预测按钮,确保一切正常:
如果你完成了整个教程,恭喜你!你已经成功构建了一个能够与终端用户交互的 Streamlit ML Web 应用。
下一步,你可以考虑部署应用程序,使其能够被互联网用户访问。可以使用像Heroku、GCP和AWS这样的工具来完成这项工作。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以在LinkedIn上与她联系。
更多相关信息
使用 pdpipe 构建 Pandas 管道
原文:
www.kdnuggets.com/2019/12/build-pipelines-pandas-pdpipe.html
评论
引言
Pandas 是 Python 生态系统中一个了不起的数据分析和机器学习库。它们在数据世界(如 Excel/CSV 文件和 SQL 表)与建模世界(如 Scikit-learn 或 TensorFlow 的魔力)之间架起了完美的桥梁。
数据科学流程通常是一系列步骤——数据集必须经过清洗、缩放和验证,然后才能被强大的机器学习算法使用。
这些任务当然可以通过 Pandas 等包提供的许多单步函数/方法完成,但更优雅的方式是使用管道。在几乎所有情况下,管道通过自动化重复任务来减少错误的机会并节省时间。
在数据科学领域,具有管道功能的优秀包示例包括——R 语言中的 dplyr,以及Python 生态系统中的 Scikit-learn。
数据科学流程通常是一系列步骤——数据集必须经过清洗、缩放和验证,然后才能准备好使用。
以下是一篇关于在机器学习工作流程中使用管道的精彩文章。
使用 Scikit-learn Pipelines 管理机器学习工作流程 第一部分:温和入门
你对 Scikit-learn Pipelines 熟悉吗?它们是管理机器学习的极简而非常有用的工具...
Pandas 还提供了一个**.pipe**方法,可以用于类似的目的与用户定义的函数。然而,在本文中,我们将讨论一个叫做pdpipe的绝妙小库,它专门解决了 Pandas DataFrame 的管道化问题。
在几乎所有情况下,管道通过自动化重复任务来减少错误的机会并节省时间。
使用 Pandas 进行管道化
示例Jupyter notebook 可以在我的 GitHub 仓库中找到。让我们看看如何利用这个库构建有用的管道。
数据集
为了演示,我们将使用一个美国住房价格数据集(从 Kaggle 下载)。我们可以在 Pandas 中加载数据集,并显示其摘要统计信息如下,
然而,数据集中也有一个包含文本数据的“Address”字段。
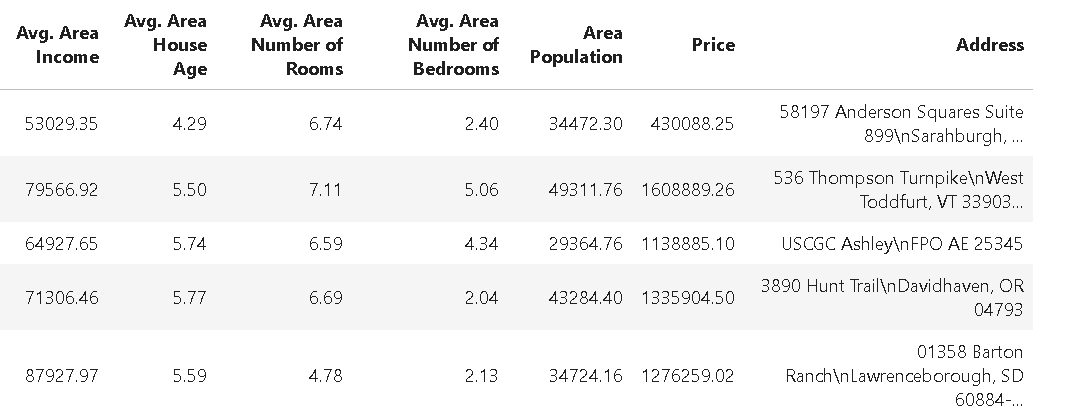
添加大小限定符列
为了演示,我们向数据集添加了一列来标示房子的大小,代码如下,

数据集在处理后如下所示,
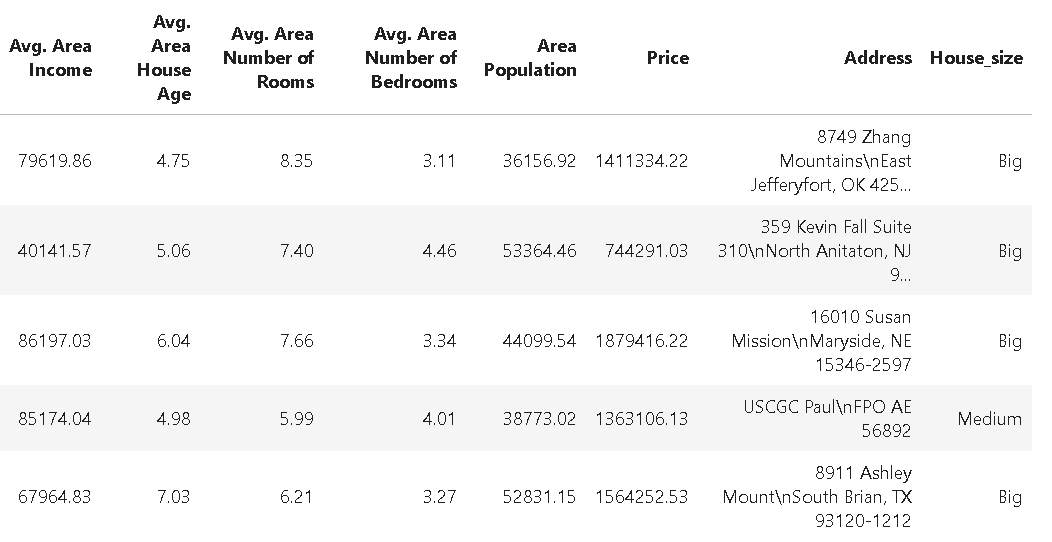
最简单的管道 — 一个操作
我们从最简单的管道开始,仅包含一个操作(别担心,我们很快会增加复杂性)。
假设机器学习团队和领域专家认为我们可以安全地忽略 Avg. Area House Age 数据用于建模。因此,我们将从数据集中删除此列。
对于此任务,我们创建了一个管道对象 drop_age,使用来自 pdpipe 的 ColDrop 方法,并将 DataFrame 传递给该管道。
import pdpipe as pdp
drop_age = pdp.ColDrop(‘Avg. Area House Age’)
df2 = drop_age(df)
结果 DataFrame,如预期的那样,如下所示,
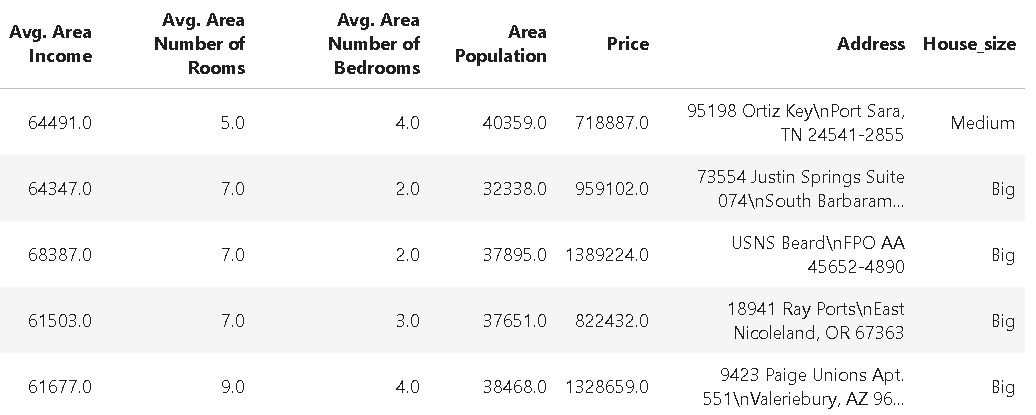
通过添加来链式链接管道的各个阶段
管道只有在我们能够进行多个阶段时才有用和实用。你可以使用多种方法在 pdpipe 中实现这一点。然而,最简单且直观的方法是使用 + 运算符。这就像是手动连接管道!
假设,除了删除年龄列,我们还希望对 House_size 列进行一热编码,以便可以轻松地在数据集上运行分类或回归算法。
pipeline = pdp.ColDrop(‘Avg. Area House Age’)
pipeline+= pdp.OneHotEncode(‘House_size’)
df3 = pipeline(df)
所以,我们首先创建了一个管道对象,使用 ColDrop 方法删除 Avg. Area House Age 列。然后,我们简单地将 OneHotEncode 方法添加到该管道对象中,使用通常的 Python += 语法。
结果 DataFrame 如下所示。注意由一热编码过程创建的附加指示器列 House_size_Medium 和 House_size_Small。
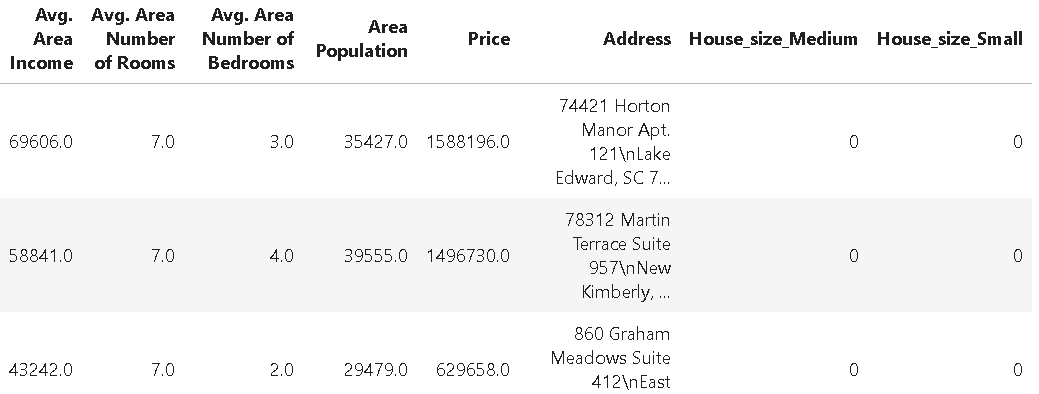
根据其值删除某些行
接下来,我们可能希望根据其值删除数据行。具体来说,我们可能希望删除所有房价低于 250,000 的数据。我们有 ApplybyCol 方法可以将任何用户定义的函数应用到 DataFrame,还有一个方法 ValDrop 用于根据特定值删除行。我们可以轻松地将这些方法链接到我们的管道中,以选择性地删除行(我们仍在向现有的 pipeline 对象添加内容,该对象已经完成了列删除和一热编码的其他工作)。
def price_tag(x):
if x>250000:
return 'keep'
else:
return 'drop'
pipeline+=pdp.ApplyByCols('Price',price_tag,'Price_tag',drop=False)
pipeline+=pdp.ValDrop(['drop'],'Price_tag')
pipeline+= pdp.ColDrop('Price_tag')
第一种方法通过应用用户定义的函数 price_tag(),根据 Price 列中的值标记行,
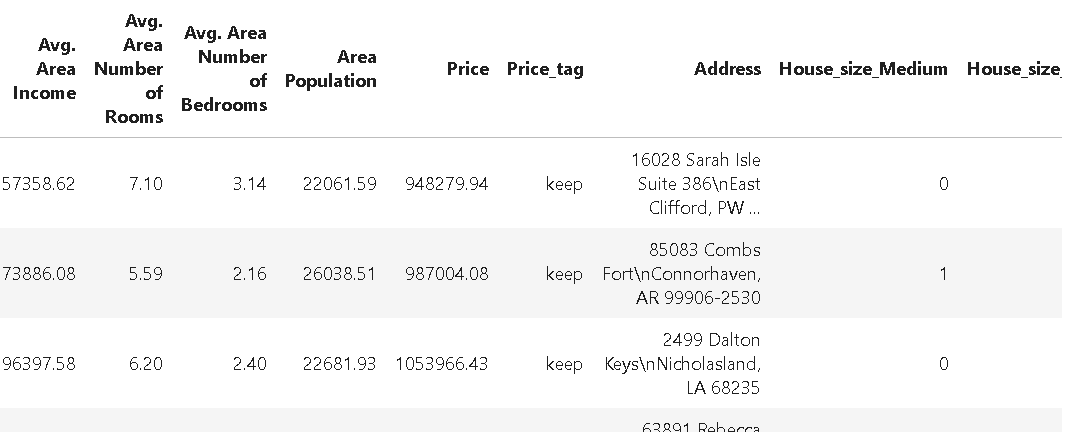
第二种方法查找 Price_tag 列中的字符串 drop,并删除匹配的行。最后,第三种方法删除 Price_tag 列,清理 DataFrame。毕竟,这个 Price_tag 列只是暂时需要的,用于标记特定的行,并在完成其用途后应被删除。
所有这些都是通过简单地链接同一管道上的操作阶段完成的!
此时,我们可以回顾一下我们的管道从一开始对数据框做了什么,
-
删除特定列
-
对类别数据列进行独热编码以进行建模
-
基于用户定义的函数标记数据
-
基于标签删除行
-
删除临时标记列
所有这些 — 使用以下五行代码,
pipeline = pdp.ColDrop('Avg. Area House Age')
pipeline+= pdp.OneHotEncode('House_size')
pipeline+= pdp.ApplyByCols('Price',price_tag,'Price_tag',drop=False)
pipeline+= pdp.ValDrop(['drop'],'Price_tag')
pipeline+= pdp.ColDrop('Price_tag')
df5 = pipeline(df)
Scikit-learn 和 NLTK 阶段
还有许多更多有用且直观的数据框操作方法可供使用。然而,我们只是想展示即使是来自 Scikit-learn 和 NLTK 包的一些操作也被包含在 pdpipe 中,以便创建出色的管道。
Scikit-learn 的缩放估算器
构建机器学习模型的最常见任务之一是数据缩放。Scikit-learn 提供了几种不同类型的缩放,例如 Min-Max 缩放或基于标准化的缩放(其中从数据集中减去均值,然后除以标准差)。
我们可以直接在管道中链接这样的缩放操作。以下代码演示了这种用法,
pipeline_scale = pdp.Scale('StandardScaler',exclude_columns=['House_size_Medium','House_size_Small'])
df6 = pipeline_scale(df5)
在这里,我们应用了来自 Scikit-learn 包的 [StandardScaler] 估算器 来转换数据以进行聚类或神经网络拟合。我们可以选择性地排除不需要此类缩放的列,如我们在这里对指标列 House_size_Medium 和 House_size_Small 所做的那样。
哇!我们得到了缩放后的数据框,

NLTK 的分词器
我们注意到,目前我们数据框中的地址字段几乎没有用处。然而,如果我们能够从这些字符串中提取邮政编码或州名,它们可能对某种可视化或机器学习任务有用。
我们可以使用一个 词汇分词器 来实现这个目的。NLTK 是一个流行且强大的 Python 库,用于文本挖掘和自然语言处理(NLP),并提供了一系列分词器方法。在这里,我们可以使用其中一个分词器来拆分地址字段中的文本,并从中提取州名。我们认识到,州名是地址字符串中的倒数第二个单词。因此,以下链式管道将为我们完成这项工作,
def extract_state(token):
return str(token[-2])
pipeline_tokenize=pdp.TokenizeWords('Address')
pipeline_state = pdp.ApplyByCols('Address',extract_state,result_columns='State')
pipeline_state_extract = pipeline_tokenize + pipeline_state
df7 = pipeline_state_extract(df6)
结果数据框如下所示,
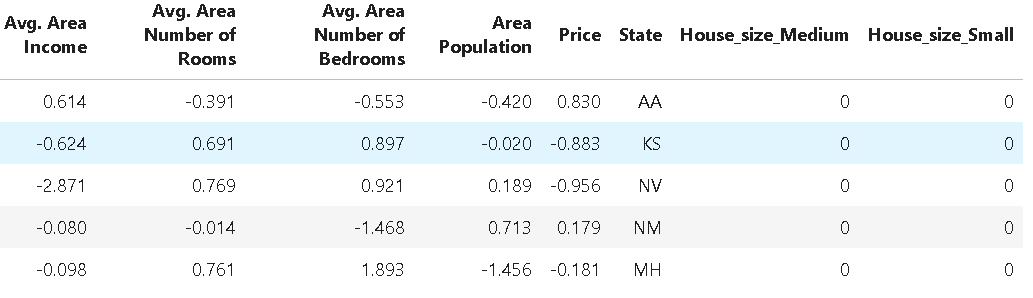
总结
如果我们总结一下演示中展示的所有操作,它看起来像以下内容,
所有这些操作可能会在类似类型的数据集上频繁使用,拥有一组简单的顺序代码块来执行数据集预处理操作将会非常棒,以便在数据集准备好进行下一阶段建模之前进行处理。
管道化是实现那一组统一的顺序代码块的关键。Pandas 是机器学习/数据科学团队中用于数据预处理任务的最广泛使用的 Python 库,pdpipe提供了一种简单而强大的方式来构建管道,使用类似 Pandas 的操作,这些操作可以直接应用于 Pandas DataFrame 对象。
自行探索此库并为你的特定数据科学任务构建更强大的管道。
如果你有任何问题或想法分享,请通过tirthajyoti[AT]gmail.com联系作者。此外,你还可以查看作者的GitHub** 代码库**,了解有关机器学习和数据科学的代码、想法和资源。如果你像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
原文。已获得许可转载。
相关:
-
如何用一行代码将 Pandas 加速 4 倍
-
最新 Scikit-learn 版本中的 5 个重要新特性
-
数据管道、Luigi、Airflow:你需要了解的一切
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
如何使用图数据库构建实时推荐引擎
原文:
www.kdnuggets.com/2023/08/build-realtime-recommendation-engine-graph-databases.html
“这是为您推荐的”、“为您推荐”或“您可能还喜欢”等短语已成为大多数数字业务,特别是电子商务或流媒体平台中的必备内容。
尽管它们可能看起来是一个简单的概念,但它们意味着企业与客户互动和连接的新时代:推荐时代。
坦白说,我们大多数人,甚至所有人,在寻找观看内容时,都会被 Netflix 的推荐所吸引,或者直接去 Amazon 的推荐部分查看下一个购买的东西。
在这篇文章中,我将解释如何使用图数据库构建实时推荐引擎。
什么是推荐引擎?
推荐引擎是一种工具包,利用高级数据过滤和预测分析来预测和预判客户的需求和愿望,即客户可能会消费或参与的内容、产品或服务。
为了获得这些推荐,引擎使用以下信息的组合:
-
客户的过去行为和历史,例如购买的产品或观看的系列。
-
客户当前的行为和与其他客户的关系。
-
产品的客户排名。
-
商业的畅销商品。
-
类似或相关客户的行为和历史。
什么是图数据库?
图数据库是一种 NoSQL 数据库,其中数据以图形结构存储,而不是表或文档。图数据结构由节点组成,这些节点可以通过关系连接。节点和关系都可以具有自己的属性(键值对),这些属性进一步描述它们。
以下图像介绍了图数据结构的基本概念:
图数据结构示例
流媒体平台的实时推荐引擎
现在我们知道了什么是推荐引擎和图数据库,我们已经准备好了解如何为流媒体平台使用图数据库构建推荐引擎。
下面的图展示了两个客户观看过的电影及这两个客户之间的关系。
流媒体平台的图示例。
将这些信息以图的形式存储后,我们现在可以考虑电影推荐,以影响下一个要观看的电影。最简单的策略是显示整个平台上观看次数最多的电影。这可以通过使用 Cypher 查询语言轻松实现:
MATCH (:Customer)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
然而,这个查询非常通用,没有考虑客户的上下文,因此没有针对特定客户进行优化。我们可以通过使用客户的社交网络,查询朋友和朋友的朋友关系来做得更好。使用 Cypher 是非常直接的:
MATCH (customer:Customer {name:'Marie'})
<-[:IS_FRIEND_OF*1..2]-(friend:Customer)
WHERE customer <> friend
WITH DISTINCT friend
MATCH (friend)-[:HAS_SEEN]->(movie:Movie)
RETURN movie, count(movie)
ORDER BY count(movie) DESC LIMIT 5
该查询分为两个部分,通过 WITH 子句将第一部分的结果传递到第二部分。
在查询的第一部分中,我们找到当前客户({name: 'Marie'})并遍历图形,匹配 Marie 的直接朋友或他们的朋友(她的朋友的朋友),使用灵活的路径长度表示法-[:IS_FRIEND_OF*1..2]->,这意味着一个或两个IS_FRIEND_OF关系深度。
我们注意不要在结果中包括 Marie 本人(WHERE子句)并且避免获取直接的重复朋友(DISTINCT子句)。
查询的第二部分与最简单的查询相同,但现在不再考虑平台上的所有客户,而是考虑 Marie 的朋友和朋友的朋友。
就这样,我们已经为流媒体平台建立了我们的实时推荐引擎。
总结
在这篇文章中,已涉及以下主题:
-
什么是推荐引擎以及它使用的信息量来进行推荐。
-
什么是图数据库以及数据如何作为图而不是表或文档进行存储。
-
一个如何使用图数据库为流媒体平台构建实时推荐引擎的示例。
José María Sánchez Salas 现居挪威。他是来自西班牙穆尔西亚的自由数据工程师。在商业和开发领域之间,他还写了一份数据工程时事通讯。
更多相关主题
如何使用 Apache Kafka 构建可扩展的数据架构
原文:
www.kdnuggets.com/2023/04/build-scalable-data-architecture-apache-kafka.html

图片由作者提供
Apache Kafka 是一个分布式消息传递系统,采用发布-订阅模型。它由 Apache 软件基金会开发,使用 Java 和 Scala 编写。Kafka 的创建旨在克服传统消息传递系统在分发和扩展性方面面临的问题。它可以以最小的延迟和高吞吐量处理和存储大量数据。由于这些优点,它适用于实时数据处理应用程序和流媒体服务。它目前是开源的,被许多组织如 Netflix、沃尔玛和 LinkedIn 使用。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
消息传递系统使多个应用程序可以相互发送或接收数据,而无需担心数据传输和共享问题。点对点和发布-订阅是两种广泛使用的消息传递系统。在点对点系统中,发送方将数据推送到队列中,接收方从队列中弹出数据,就像一个标准的队列系统,遵循 FIFO(先进先出)原则。此外,数据在被读取后会被删除,并且每次只允许一个接收方。接收方读取消息没有时间依赖。

图 1 点对点消息系统 | 图片由作者提供
在发布-订阅模型中,发送方称为发布者,接收方称为订阅者。在这种模型下,多个发送方和接收方可以同时读取或写入数据。但是,它存在时间依赖性。消费者必须在一定时间内消费消息,因为超过该时间消息将被删除,即使未被读取。根据用户的配置,这个时间限制可以是一天、一周或一个月。
图 2 发布-订阅消息系统 | 图片由作者提供
Kafka 架构
Kafka 架构由几个关键组件组成:
-
主题
-
分区
-
代理
-
生产者
-
消费者
-
Kafka 集群
-
Zookeeper
图 3 Kafka 架构 | 图片来源:ibm-cloud-architecture
让我们简要了解每个组件。
Kafka 将消息存储在不同的主题中。主题是包含特定类别消息的组。它类似于数据库中的表。一个主题可以通过其名称唯一标识。我们不能创建两个名称相同的主题。
主题进一步被分类为分区。这些分区的每条记录都与一个称为偏移量的唯一标识符相关联,这个标识符表示记录在该分区中的位置。
除此之外,系统中还有生产者和消费者。生产者使用生产 API 在主题中写入或发布数据。这些生产者可以在主题或分区级别写入数据。
消费者使用消费者 API 从主题中读取或消费数据。他们也可以在主题或分区级别读取数据。执行类似任务的消费者将组成一个称为消费者组的群体。
还有其他系统,如代理和Zookeeper,它们在 Kafka 服务器的后台运行。代理是维护和记录已发布消息的软件。它还负责使用偏移量将正确的消息传递给正确的消费者,并按照正确的顺序传递。集体相互通信的代理组可以称为Kafka 集群。代理可以动态添加或从 Kafka 集群中移除,而不会导致系统停机。Kafka 集群中的一个代理被称为控制器。它管理集群内的状态和副本,并执行管理任务。
另一方面,Zookeeper 负责维护 Kafka 集群的健康状态,并与集群中的每个代理协调。它以键值对的形式维护每个集群的元数据。
本教程主要集中在 Apache Kafka 的实际实现上。如果你想了解更多关于其架构的内容,可以阅读[这篇]( https://www.upsolver.com/blog/apache-kafka-architecture-what-you-need-to-know#:~:text=Its core architectural concept is ,maintain%20a%20consistent%20system%20state.)由 Upsolver 撰写的文章。
出租车预订应用程序:一个实际的用例
考虑一个像 Uber 这样的出租车预订服务的用例。这个应用程序使用 Apache Kafka 通过各种服务(如事务、电子邮件、分析等)发送和接收消息。
图 4 出租车应用程序的架构 | 图片来源:作者
架构包括几个服务。Rides服务接收来自客户的乘车请求,并将乘车详细信息写入 Kafka 消息系统。
然后这些订单详细信息被Transaction服务读取,该服务确认订单和支付状态。确认该乘车后,Transaction服务将确认的乘车再次写入消息系统,并附加一些额外的详细信息。最后,确认的乘车详细信息会被其他服务(如电子邮件或数据分析)读取,以向客户发送确认邮件并进行一些分析。
我们可以以非常高的吞吐量和最小的延迟实时执行所有这些过程。此外,由于 Apache Kafka 的水平扩展能力,我们可以扩展此应用程序以处理数百万用户。
上述用例的实际实现
本节包含了在我们的应用程序中实现 Kafka 消息系统的快速教程。它包括下载 Kafka、配置它以及创建生产者-消费者函数的步骤。
注意: 本教程基于 Python 编程语言,并使用 Windows 机器。
Apache Kafka 下载步骤
从该链接下载最新版本的 Apache Kafka。Kafka 基于 JVM 语言,因此必须在系统中安装 Java 7 或更高版本。
-
从计算机(C:)驱动器中提取下载的 zip 文件,并将文件夹重命名为
/apache-kafka。 -
上级目录包含两个子目录,
/bin和/config,其中包含 Zookeeper 和 Kafka 服务器的可执行文件和配置文件。
配置步骤
首先,我们需要为 Kafka 和 Zookeeper 服务器创建日志目录。这些目录将存储这些集群的所有元数据以及主题和分区的消息。
注意: 默认情况下,这些日志目录会创建在/tmp目录中,这是一个易失性目录,当系统关闭或重新启动时,所有数据都会消失。我们需要为日志目录设置永久路径以解决此问题。让我们看看如何操作。
导航到apache-kafka >> config并打开server.properties文件。在这里,你可以配置 Kafka 的许多属性,例如日志目录路径、日志保留时间、分区数量等。
在server.properties文件中,我们需要将日志目录文件的路径从临时的/tmp目录更改为永久目录。日志目录包含 Kafka 服务器中生成或写入的数据。要更改路径,请将log.dirs变量从/tmp/kafka-logs更新为c:/apache-kafka/kafka-logs。这将使日志永久存储。
log.dirs=c:/apache-kafka/kafka-logs
Zookeeper 服务器还包含一些日志文件,用于存储 Kafka 服务器的元数据。要更改路径,请重复上述步骤,即打开zookeeper.properties文件并按如下方式替换路径。
dataDir=c:/apache-kafka/zookeeper-logs
这个 Zookeeper 服务器将作为我们 Kafka 服务器的资源管理器。
运行 Kafka 和 Zookeeper 服务器
要运行 Zookeeper 服务器,请在父目录下打开一个新的 cmd 提示符,并运行以下命令。
$ .\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
作者提供的图片
保持 Zookeeper 实例运行。
要运行 Kafka 服务器,请打开一个独立的 cmd 提示符,并执行以下代码。
$ .\bin\windows\kafka-server-start.bat .\config\server.properties
保持 Kafka 和 Zookeeper 服务器运行,在下一节中,我们将创建生产者和消费者函数,它们将读取和写入 Kafka 服务器中的数据。
创建生产者和消费者函数
为了创建生产者和消费者函数,我们将以之前讨论的电子商务应用为例。Orders 服务将作为生产者,将订单详情写入 Kafka 服务器,而 Email 和 Analytics 服务将作为消费者,从服务器读取数据。Transaction 服务将既作为消费者又作为生产者工作。它读取订单详情,并在确认交易后将其重新写回。
但首先,我们需要安装 Kafka 的 Python 库,它包含用于生产者和消费者的内置函数。
$ pip install kafka-python
现在,创建一个名为 kafka-tutorial 的新目录。我们将在该目录中创建包含所需函数的 Python 文件。
$ mkdir kafka-tutorial
$ cd .\kafka-tutorial\
生产者函数:
现在,创建一个名为 rides.py 的 Python 文件,并将以下代码粘贴到其中。
rides.py
import kafka
import json
import time
import random
topicName = "ride_details"
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092")
for i in range(1, 10):
ride = {
"id": i,
"customer_id": f"user_{i}",
"location": f"Lat: {random.randint(-90, 90)}, Long: {random.randint(-90, 90)}",
}
producer.send(topicName, json.dumps(ride).encode("utf-8"))
print(f"Ride Details Send Succesfully!")
time.sleep(5)
解释:
首先,我们导入了所有必要的库,包括 kafka。然后,定义了主题名称和各种项目的列表。请记住,主题是一个包含类似类型消息的组。在这个例子中,这个主题将包含所有的订单。
然后,我们创建一个 KafkaProducer 实例,并将其连接到运行在 localhost:9092 的 Kafka 服务器。如果您的 Kafka 服务器运行在其他地址和端口上,则必须在此处指定服务器的 IP 和端口号。
然后,我们将生成一些 JSON 格式的订单,并将它们写入定义的主题名称的 Kafka 服务器。使用 Sleep 函数在后续订单之间生成间隔。
消费者函数:
transaction.py
import json
import kafka
import random
RIDE_DETAILS_KAFKA_TOPIC = "ride_details"
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
consumer = kafka.KafkaConsumer(
RIDE_DETAILS_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092")
print("Listening Ride Details")
while True:
for data in consumer:
print("Loading Transaction..")
message = json.loads(data.value.decode())
customer_id = message["customer_id"]
location = message["location"]
confirmed_ride = {
"customer_id": customer_id,
"customer_email": f"{customer_id}@xyz.com",
"location": location,
"alloted_driver": f"driver_{customer_id}",
"pickup_time": f"{random.randint(1, 20)}mins",
}
print(f"Transaction Completed..({customer_id})")
producer.send(
RIDES_CONFIRMED_KAFKA_TOPIC, json.dumps(confirmed_ride).encode("utf-8")
)
解释:
transaction.py 文件用于确认用户所做的过渡,并分配给他们一个司机和预计的接送时间。它从 Kafka 服务器读取行程详情,并在确认行程后将其重新写入 Kafka 服务器。
现在,创建两个名为 email.py 和 analytics.py 的 Python 文件,这些文件分别用于向客户发送行程确认邮件和进行一些分析。这些文件的创建只是为了演示即使是多个消费者也可以同时从 Kafka 服务器读取数据。
email.py
import kafka
import json
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
consumer = kafka.KafkaConsumer(
RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
print("Listening Confirmed Rides!")
while True:
for data in consumer:
message = json.loads(data.value.decode())
email = message["customer_email"]
print(f"Email sent to {email}!")
analysis.py
import kafka
import json
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
consumer = kafka.KafkaConsumer(
RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
print("Listening Confirmed Rides!")
while True:
for data in consumer:
message = json.loads(data.value.decode())
id = message["customer_id"]
driver_details = message["alloted_driver"]
pickup_time = message["pickup_time"]
print(f"Data sent to ML Model for analysis ({id})!")
现在,我们已经完成了应用程序,在下一部分,我们将同时运行所有服务并检查性能。
测试应用程序
在四个不同的命令提示符中逐一运行每个文件。
$ python transaction.py
$ python email.py
$ python analysis.py
$ python ride.py
作者提供的图片
当行程详情被推送到服务器时,您可以同时从所有文件中接收输出。您还可以通过删除rides.py文件中的延迟函数来提高处理速度。rides.py文件将数据推送到 kafka 服务器,其他三个文件则同时从 kafka 服务器读取数据并相应地执行功能。
希望您对 Apache Kafka 及其实现有一个基本的了解。
结论
在这篇文章中,我们了解了 Apache Kafka、它的工作原理以及如何使用出租车预订应用的案例来实际应用它。设计一个可扩展的 Kafka 管道需要精心规划和实施。您可以增加代理和分区的数量,以使这些应用程序更具可扩展性。每个分区是独立处理的,以便将负载分配到各个分区。同时,您可以通过设置缓存大小、缓冲区大小或线程数量来优化 kafka 配置。
GitHub 链接,获取文章中使用的完整代码。
感谢阅读本文。如果您有任何评论或建议,请随时通过Linkedin与我联系。
Aryan Garg 是一名电气工程学士学位学生,目前在本科的最后一年。他的兴趣领域是网页开发和机器学习。他已追求这一兴趣,并渴望在这些方向上进一步工作。
更多相关主题
使用 ML 在 AWS 云上构建一个无服务器新闻数据管道
原文:
www.kdnuggets.com/2021/11/build-serverless-news-data-pipeline-ml-aws-cloud.html
评论
由Maria Zentsova,Wood Mackenzie 高级数据分析师
作为一名分析师,我花费了很多时间跟踪新闻和行业动态。在产假期间思考这个问题后,我决定构建一个简单的应用程序来追踪绿色技术和可再生能源的新闻。使用 AWS Lambda 及其他 AWS 服务,如 EventBridge、SNS、DynamoDB 和 Sagemaker,可以非常轻松地入门,并在几天内构建一个原型。
这个应用程序由一系列无服务器的 Lambda 函数和一个作为 SageMaker 端点部署的文本总结机器学习模型提供支持。每 24 小时,AWS EventBridge 规则触发 Lambda 函数,从 DynamoDB 数据库中获取信息流。
这些信息流随后作为 SNS 主题发送,触发多个 Lambda 函数以解析信息流并提取新闻 URL。每个网站每天更新其 RSS 信息流,最多只有几篇文章,因此这样我们不会发送大量流量,避免消耗某个新闻出版物的过多资源。
然而,大问题在于提取文章的全文,因为每个网站都不同。幸运的是,像 goose3 这样的库通过应用 ML 方法来提取页面主体,从而解决了这个问题。由于版权问题,我不能存储文章的全文,这就是为什么我应用一个 HuggingFace 文本总结变换器模型来生成简短的摘要。
这里是一个详细的指南,介绍如何构建由 ML 驱动的新闻聚合管道。
1. 设置具有必要权限的 IAM 角色。
尽管这个数据管道非常简单,但它连接了多个 AWS 资源。为了授予我们的函数访问所有所需资源的权限,我们需要设置IAM 角色。该角色为我们的函数分配了使用云中其他资源的权限,例如 DynamoDB、Sagemaker、CloudWatch 和 SNS。出于安全考虑,最好不要给予 IAM 角色完全的 AWS 管理访问权限,仅允许它使用所需的资源。

2. 从 DynamoDB 中获取 RSS 信息流到 RSS 分发 Lambda
使用 AWS Lambda 几乎可以做任何事情,它是一个非常强大的无服务器计算服务,非常适合短期任务。对我来说,主要的优势是它可以非常方便地访问 AWS 生态系统中的其他服务。
我将所有 RSS 源存储在 DynamoDB 表中,并且从 Lambda 使用 boto3 库访问它非常容易。一旦我从数据库中获取了所有源,我将它们作为 SNS 消息发送,以触发 feed 解析的 Lambda 函数。
import boto3
import json
def lambda_handler(event, context):
# Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('rss_feeds')
# Get all records from the table
data = table.scan()['Items']
rss = [y['rss'] for y in data]
# Connect to SNS
client = boto3.client('sns')
# Send messages to the queue
for item in rss:
client.publish(TopicArn="arn:aws:sns:eu-west-1:802099603194:rss_to-parse", Message = item)
3. 创建带有必要库的 Layers
要在 AWS Lambdas 中使用一些特定的库,你需要将它们作为 Layer 导入。为了准备库进行导入,它需要打包成一个 python.zip 文件,我们可以将其上传到 AWS 并在函数中使用。要创建一个 Layer,只需进入 python 文件夹,运行 pip install 命令,打包成 zip 文件,然后就可以上传了。
pip install feedparser -t .
然而,我在将 goose3 库部署为 Layer 时遇到了一些困难。经过简短的调查,结果发现像 LXML 这样的库需要在类似 Lambda 的环境中编译,即 Linux。因此,如果库是在 Windows 上编译的,然后再导入到函数中,就会出现错误。为了解决这个问题,在创建归档之前,我们需要在 Linux 上安装库。
有两种方法可以做到这一点。首先,可以在 模拟的 Lambda 环境 中使用 docker 进行安装。对我来说,最简单的方法是使用 AWS sam build 命令。一旦函数构建完成,我只需从构建文件夹中复制所需的包,然后将它们作为 Layer 上传。
sam build --use-container
4. 启动 Lambda 函数以解析 feed
一旦我们将新闻 URL 发送到 SNS 作为主题,我们可以触发多个 Lambda 函数去从 RSS 源中获取新闻文章。一些 RSS 源有所不同,但 feed 解析库允许我们处理不同的格式。我们的 URL 是事件对象的一部分,因此我们需要通过键提取它。
import boto3
import feedparser
from datetime import datetime
def lambda_handler(event, context):
#Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('news')
# Get a url from from event
url = event['Records'][0]['Sns']['Message']
# Parse the rss feed
feed = feedparser.parse(url)
for item in feed['entries']:
result = {
"news_url": item['link'],
"title": item['title'],
"created_at": datetime.now().strftime('%Y-%m-%d') # so that dynamodb will be ok with our date
}
# Save the result to dynamodb
table.put_item(Item=result, ConditionExpression='attribute_not_exists(news_url)') # store only unique urls
5. 在 Sagemaker 上创建和部署文本摘要模型
Sagemaker 是一个服务,它使在 AWS 上编写、训练和部署 ML 模型变得更加容易。HuggingFace 已与 AWS 合作 以使在云中部署其模型变得更加容易。
在 Jupiter notebook 中,我编写了一个简单的文本摘要模型,并使用 deploy() 命令部署它。
from sagemaker.huggingface import HuggingFaceModel
import sagemaker
role = sagemaker.get_execution_role()
hub = {
'HF_MODEL_ID':'facebook/bart-large-cnn',
'HF_TASK':'summarization'
}
# Hugging Face Model Class
huggingface_model = HuggingFaceModel(
transformers_version='4.6.1',
pytorch_version='1.7.1',
py_version='py36',
env=hub,
role=role,
)
# deploy model to SageMaker Inference
predictor = huggingface_model.deploy(
initial_instance_count=1, # number of instances
instance_type='ml.m5.xlarge' # ec2 instance type
)
部署完成后,我们可以从 Sagemaker -> 推理 -> 端点配置中获取端点信息,并在我们的 Lambda 中使用它。
6. 获取文章的完整文本,总结它并将结果存储在 DynamoDB 中
-
我们不应存储完整的文本,因为这涉及版权问题,因此所有处理工作都在一个 lambda 函数中完成。我在 URL 进入 DynamoDB 表后启动文本处理 lambda 函数。为此,我设置了一个 DynamoDB 项目创建作为触发器来启动 lambda 函数。我设置了批处理大小为 1,以便 lambda 只处理一篇文章。
-
![图片]()
import json
import boto3
from goose3 import Goose
from datetime import datetime
def lambda_handler(event, context):
# Get url from DynamoDB record creation event
url = event['Records'][0]['dynamodb']['Keys']['news_url']['S']
# fetch article full text
g = Goose()
article = g.extract(url=url)
body = article.cleaned_text # clean article text
published_date = article.publish_date # from meta desc
# Create a summary using our HuggingFace text summary model
ENDPOINT_NAME = "your_model_endpoint"
runtime= boto3.client('runtime.sagemaker')
response = runtime.invoke_endpoint(EndpointName=ENDPOINT_NAME, ContentType='application/json', Body=json.dumps(data))
#extract a summary
summary = json.loads(response['Body'].read().decode())
#Connect to DynamoDB
dynamodb = boto3.resource('dynamodb')
# Get table
table = dynamodb.Table('news')
# Update item stored in dynamoDB
update = table.update_item(
Key = { "news_url": url }
,
ConditionExpression= 'attribute_exists(news_url) ',
UpdateExpression='SET summary = :val1, published_date = :val2'
ExpressionAttributeValues={
':val1': summary,
':val2': published_date
}
)
-
这是使用 AWS 工具构建和部署的一个简单无服务器数据管道,用于读取最新新闻。如果你有任何改进建议或问题,请随时联系我。
-
简介:Maria Zentsova 是 Wood Mackenzie 的高级数据分析师。她从事数据收集和分析、ETL 管道以及数据探索工具的工作。
-
相关:
-
我如何将 100 多个 ETL 重新设计为 ELT 数据管道
-
2022 年数据专业人士推广 AWS 技能的最佳方法
-
Prefect:如何使用 Python 编写和安排你的第一个 ETL 管道
- 更多相关主题
如何在 Snowflake 上构建流式半结构化分析平台
原文:
www.kdnuggets.com/2023/07/build-streaming-semistructured-analytics-platform-snowflake.html

编辑者图片
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
Snowflake 是一种 SaaS,即软件即服务,特别适合对大量数据进行分析。该平台极其易于使用,非常适合业务用户、分析团队等从不断增长的数据集中获得价值。本文将深入探讨在 Snowflake 上为医疗数据创建流式半结构化分析平台的组件。我们还将讨论此阶段的一些关键考虑因素。
背景
医疗行业支持多种不同的数据格式,但我们将考虑最新的半结构化格式,即 FHIR(快速医疗互操作资源)来构建我们的分析平台。这种格式通常将所有以患者为中心的信息嵌入到一个 JSON 文档中。该格式包含大量信息,如所有医院接触、实验室结果等。当分析团队拥有一个可查询的数据湖时,可以提取有价值的信息,例如有多少患者被诊断为癌症等。假设所有这些 JSON 文件每 15 分钟通过不同的 AWS 服务或端 API 端点推送到 AWS S3(或其他公共云存储)。
架构设计
架构组件
-
AWS S3 到 Snowflake RAW 区域:
-
数据需要不断地从 AWS S3 流式传输到 Snowflake 的 RAW 区域。
-
Snowflake 提供 Snowpipe 管理服务,可以以连续流式方式读取 S3 中的 JSON 文件。
-
在 Snowflake RAW 区域中需要创建一个具有变体列的表,以保存原生格式的 JSON 数据。
-
Snowflake RAW 区域到流:
-
Streams 是一种管理更改数据捕获服务,能够捕获所有新到达的 JSON 文档到 Snowflake RAW 区域
-
Streams 应指向 Snowflake RAW Zone 表,并应设置为 append=true
-
Streams 就像任何表一样,易于查询。
-
Snowflake 任务 1:
-
Snowflake 任务类似于调度程序。查询或存储过程可以使用 cron 作业符号安排运行。
-
在此架构中,我们创建任务 1 来从 Streams 中获取数据,并将其导入临时表。此层将被截断并重新加载。
-
这样做是为了确保每 15 分钟处理一次新的 JSON 文档。
-
Snowflake 任务 2:
-
此层将原始 JSON 文档转换为分析团队可以轻松查询的报告表。
-
要将 JSON 文档转换为结构化格式,可以使用 Snowflake 的 lateral flatten 功能。
-
Lateral flatten 是一个易于使用的功能,可以展开嵌套的数组元素,并可以使用‘:’符号轻松提取。
关键考虑事项
-
推荐使用 Snowpipe 处理少量大文件。如果小文件在外部存储中未合并,成本可能会很高。
-
在生产环境中,确保创建自动化进程以监控 streams,因为一旦它们变得陈旧,数据将无法从中恢复。
-
单个 JSON 文档允许的最大大小为 16MB 压缩,能够加载到 Snowflake 中。如果您有超出这些大小限制的大型 JSON 文档,请确保在将其导入 Snowflake 之前有一个拆分的过程。
结论
由于 JSON 文档中嵌入的元素的嵌套结构,管理半结构化数据始终具有挑战性。在设计最终报告层之前,请考虑即将到来的数据量的逐步和指数增长。本文旨在展示如何轻松构建半结构化数据的流管道。
Milind Chaudhari 是一位经验丰富的数据工程师/数据架构师,拥有十年的工作经验,使用各种传统和现代工具构建数据湖/湖仓。他对数据流架构充满热情,并且还是 Packt 和 O'Reilly 的技术审稿人。
更多相关主题
使用 Gretel 和 Apache Airflow 构建合成数据管道
原文:
www.kdnuggets.com/2021/09/build-synthetic-data-pipeline-gretel-apache-airflow.html
评论
作者:Drew Newberry,Gretel.ai 的软件工程师

大家好,我是 Drew,我是 Gretel 的一名软件工程师。我最近一直在思考如何将 Gretel API 集成到现有工具中的模式,以便轻松构建安全性和客户隐私为首要特性的数据管道,而不仅仅是事后的考虑或需要打勾的选项。
在 Gretel 的工程师和客户中,Apache Airflow 是一个很受欢迎的数据工程工具。它也与 Gretel 配合得很好。在这篇博客文章中,我们将展示如何使用 Airflow、Gretel 和 PostgreSQL 构建一个合成数据管道。让我们开始吧!
什么是 Airflow
Airflow 是一个常用于构建数据管道的工作流自动化工具。它使数据工程师或数据科学家能够使用 Python 和其他熟悉的构造程序化地定义和部署这些管道。Airflow 的核心概念是 DAG,即有向无环图。Airflow DAG 提供了一个模型和一组 API,用于定义管道组件、它们的依赖关系和执行顺序。
你可能会发现 Airflow 管道将数据从产品数据库复制到数据仓库。其他管道可能会执行将规范化数据连接到一个适合分析或建模的单一数据集的查询。还有的管道可能会发布每日报告,汇总关键业务指标。这些用例的共同主题是:协调跨系统的数据流动。这正是 Airflow 擅长的地方。
利用 Airflow 及其丰富的 集成 生态系统,数据工程师和科学家可以将任意数量的异构工具或服务编排成一个易于维护和操作的统一管道。了解这些集成功能后,我们将开始讨论 Gretel 如何集成到 Airflow 管道中,以改进常见的数据操作工作流程。
Gretel 如何融入其中?
在 Gretel,我们的使命是让数据处理变得更加简单和安全。在与客户交流时,我们经常听到的一个痛点是,获取敏感数据所需的时间和精力。通过使用 Gretel Synthetics,我们可以通过生成数据集的合成副本来减少处理敏感数据的风险。通过将 Gretel 与 Airflow 集成,可以创建自助服务管道,使数据科学家能够快速获取所需的数据,而不需要每个新数据请求都依赖数据工程师。
为了演示这些功能,我们将构建一个 ETL 管道,该管道从数据库中提取用户活动特征,生成数据集的合成版本,并将数据集保存到 S3。将合成数据集保存到 S3 后,它可以被数据科学家用于下游建模或分析,而不会影响客户隐私。
首先,让我们从鸟瞰图开始了解管道。图中的每个节点代表一个管道步骤,或 Airflow 术语中的“任务”。

示例 Gretel 合成管道在 Airflow 上。
我们可以将管道分为三个阶段,这类似于你在 ETL 管道中可能遇到的情况:
-
提取 - extract_features 任务将查询数据库,并将数据转换为数据科学家可以用来构建模型的特征集。
-
合成 - generate_synthetic_features 将提取的特征作为输入,训练一个合成模型,然后使用 Gretel API 和云服务生成合成特征集。
-
加载 - upload_synthetic_features 将合成特征集保存到 S3 中,在那里可以被下游模型或分析程序使用。
在接下来的几个部分,我们将更详细地探讨这三个步骤。如果你希望跟随每个代码示例,你可以前往 gretelai/gretel-airflow-pipelines 下载本博客文章中使用的所有代码。该仓库还包含启动 Airflow 实例和运行整个管道的说明。
此外,在我们剖析每个组件之前,查看整个 Airflow 管道可能会很有帮助,dags/airbnb_user_bookings.py。以下部分的代码片段是从链接的用户预订管道中提取的。
提取特征
第一个任务,extract_features 负责从源数据库中提取原始数据并将其转换为特征集。这是任何机器学习或分析管道中可能遇到的常见特征工程问题。
在我们的示例管道中,我们将配置一个 PostgreSQL 数据库,并从 Airbnb Kaggle 竞赛 中加载预订数据。
这个数据集包含两个表格,Users 和 Sessions。Sessions 包含一个外键引用,user_id。利用这种关系,我们将创建一个特征集,包含按用户聚合的各种预订指标。下图展示了用于构建这些特征的 SQL 查询。
py` WITH session_features_by_user AS ( SELECT user_id, count() AS number_of_actions_taken, count(DISTINCT action_type) AS number_of_unique_actions, round(avg(secs_elapsed)) AS avg_session_time_seconds, round(max(secs_elapsed)) AS max_session_time_seconds, round(min(secs_elapsed)) AS min_session_time_seconds, ( SELECT count() FROM sessions s WHERE s.user_id = user_id AND s.action_type = 'booking_request') AS total_bookings FROM sessions GROUP BY user_id ) SELECT u.id AS user_id, u.gender, u.age, u.language, u.signup_method, u.date_account_created, s.number_of_actions_taken, s.number_of_unique_actions, s.avg_session_time_seconds, s.min_session_time_seconds, s.max_session_time_seconds FROM session_features_by_user s LEFT JOIN users u ON u.id = s.user_id LIMIT 5000 py The SQL query is then executed from our Airflow pipeline and written to an intermediate S3 location using the following task definition. @task() def extract_features(sql_file: str) -> str: context = get_current_context() sql_query = Path(sql_file).read_text() key = f"{context['dag_run'].run_id}_booking_features.csv" with NamedTemporaryFile(mode="r+", suffix=".csv") as tmp_csv: postgres.copy_expert( f"copy ({sql_query}) to stdout with csv header", tmp_csv.name ) s3.load_file( filename=tmp_csv.name, key=key, ) return key py The input to the task, sql_file, determines what query to run on the database. This query will be read-in to the task and then executed against the database. The results of the query will then be written to S3 and the remote file key will be returned as an output of the task. The screenshot below shows a sample result set of the extraction query from above. We will describe how to create a synthetic version of this dataset in the next section.  *Query result preview.* ## Synthesize Features using Gretel APIs To generate a synthetic version of each feature, we must first train a synthetic model, and then run the model to generate synthetic records. Gretel has a set of Python SDKs that make it easy to integrate into Airflow tasks. In addition to the Python Client SDKs, we’ve created a [Gretel Airflow Hook](https://github.com/gretelai/gretel-airflow-pipelines/blob/main/plugins/hooks/gretel.py) that manages Gretel API connections and secrets. After setting up a Gretel Airflow Connection, connecting to the Gretel API is as easy as from hooks.gretel import GretelHook gretel = GretelHook() project = gretel.get_project() py For more information about how to configure Airflow connections, please refer to our Github repository [README](https://github.com/gretelai/gretel-airflow-pipelines#2-configure-airflow-connections). The project variable in the example above can be used as the main entrypoint for training and running synthetic models using Gretel’s API. For more details, you can check out our [Python API docs](https://python.docs.gretel.ai/en/stable/projects/projects.html). Referring back to the booking pipeline, we’ll now review the generate_synthetic_features task. This step is responsible for training the synthetic model using the features extracted in the previous task. @task() def generate_synthetic_features(data_source: str) -> str: project = gretel.get_project() model = project.create_model_obj( model_config="synthetics/default", data_source=s3.download_file(data_source) ) model.submit_cloud() poll(model) return model.get_artifact_link("data_preview") py Looking at the method signature, you will see it takes a path, data_source. This value points to the S3 features extracted in the previous step. In a later section we’ll walk through how all these inputs and outputs are wired together. When creating the model using project.create_model_obj, the model_config param represents the synthetic model configuration used to generate the model. In this pipeline, we’re using our [default model config](https://github.com/gretelai/gretel-blueprints/blob/main/config_templates/gretel/synthetics/default.yml), but many other [configuration options](https://docs.gretel.ai/synthetics/synthetics-model-configuration) are available. After the model has been configured, we call model.submit_cloud(). This will submit the model for training and record generation using Gretel Cloud. Calling poll(model) will block the task until the model has completed training. Now that the model has been trained, we’ll use get_artifact_link to return a link to download the generated synthetic features.  *Data preview of the synthetic set of features.* This artifact link will be used as an input to the final upload_synthetic_features step. ## Load Synthetic Features The original features have been extracted, and a synthetic version has been created. Now it’s time to upload the synthetic features so they can be accessed by downstream consumers. In this example, we’re going to use an S3 bucket as the final destination for the dataset. @task() def upload_synthetic_features(data_set: str): context = get_current_context() with open(data_set, "rb") as synth_features: s3.load_file_obj( file_obj=synth_features, key=f"{..._booking_features_synthetic.csv", ) py This task is pretty straightforward. The data_set input value contains a signed HTTP link to download the synthetic dataset from Gretel’s API. The task will read that file into the Airflow worker, and then use the already configured S3 hook to upload the synthetic feature file to an S3 bucket where downstream consumers or models can access it. ## Orchestrating the Pipeline Over the last three sections we’ve walked through all the code required to extract, synthesize and load a dataset. The last step is to tie each of these tasks together into a single Airflow pipeline. If you’ll recall back to the beginning of this post, we briefly mentioned the concept of a DAG. Using Airflow’s TaskFlow API we can compose these three Python methods into a DAG that defines the inputs, outputs and order each step will be run. feature_path = extract_features( "/opt/airflow/dags/sql/session_rollups__by_user.sql" ) synthetic_data = generate_synthetic_features(feature_path) upload_synthetic_features(synthetic_data) py If you follow the path of these method calls, you will eventually get a graph that looks like our original feature pipeline.  *Gretel synthetics pipeline on Airflow.* If you want to run this pipeline, and see it in action, head over to the [accompanying Github repository](https://github.com/gretelai/gretel-airflow-pipelines). There you will find instructions on how to start an Airflow instance and run the pipeline end to end. ## Wrapping things up If you’ve made it this far, you’ve seen how Gretel can be integrated into a data pipeline built on Airflow. By combining Gretel’s developer friendly APIs, and Airflow’s powerful system of hooks and operators it’s easy to build ETL pipelines that make data more accessible and safer to use. We also talked about a common feature engineering use case where sensitive data may not be readily accessible. By generating a synthetic version of the dataset, we reduce the risk of exposing any sensitive data, but still retain the utility of the dataset while making it quickly available to those who need it. Thinking about the feature pipeline in more abstract terms, we now have a pattern that can be repurposed for any number of new SQL queries. By deploying a new version of the pipeline, and swapping out the initial SQL query, we can front any potentially sensitive query with a synthetic dataset that preserves customer privacy. The only line of code that needs to change is the path to the sql file. No complex data engineering required. ## Thanks for reading Send us an email at [hi@gretel.ai](https://gretel.ai/blog/running-gretel-on-apache-airflow#) or come join us in [Slack](https://gretel.ai/slackinvite) if you have any questions or comments. We’d love to hear how you’re using Airflow and how we can best integrate with your existing data pipelines. **Bio: [Drew Newberry](https://www.linkedin.com/in/drew-newberry/)** is a Software Engineer at Gretel.ai. [Original](https://gretel.ai/blog/running-gretel-on-apache-airflow). Reposted with permission. **Related:** * Prefect: How to Write and Schedule Your First ETL Pipeline with Python * 15 Python Snippets to Optimize your Data Science Pipeline * How to Query Your Pandas Dataframe * * * ## Our Top 3 Course Recommendations  1\. [Google Cybersecurity Certificate](https://www.kdnuggets.com/google-cybersecurity) - Get on the fast track to a career in cybersecurity.  2\. [Google Data Analytics Professional Certificate](https://www.kdnuggets.com/google-data-analytics) - Up your data analytics game  3\. [Google IT Support Professional Certificate](https://www.kdnuggets.com/google-itsupport) - Support your organization in IT * * * ### More On This Topic * [5 Airflow Alternatives for Data Orchestration](https://www.kdnuggets.com/5-airflow-alternatives-for-data-orchestration) * [6 Data Science Technologies You Need to Build Your Supply Chain Pipeline](https://www.kdnuggets.com/2022/01/6-data-science-technologies-need-build-supply-chain-pipeline.html) * [How to Build a Scalable Data Architecture with Apache Kafka](https://www.kdnuggets.com/2023/04/build-scalable-data-architecture-apache-kafka.html) * [High-Fidelity Synthetic Data for Data Engineers and Data Scientists Alike](https://www.kdnuggets.com/2022/tonic-high-fidelity-synthetic-data-engineers-scientists-alike.html) * [How to Democratize AI/ML and Data Science with AI-generated Synthetic Data](https://www.kdnuggets.com/2022/11/mostly-ai-democratize-aiml-data-science-aigenerated-synthetic-data.html) * [Data access is severely lacking in most companies, and 71% believe…](https://www.kdnuggets.com/2023/07/mostly-data-access-severely-lacking-synthetic-data-help.html)
用 Python 在 5 分钟内构建文本转语音转换器
原文:
www.kdnuggets.com/2022/09/build-texttospeech-converter-python-5-minutes.html

对于你的早期编程技能,最好的事情就是项目。你可能拥有知识,但将其应用到实际中才是真正的挑战,并保持你的竞争力。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
最近几个月我采访了一些前辈,他们提到的新人常见问题是缺乏将技能应用到项目或现实问题中的经验。所以,我觉得创建这个快速 5 分钟的项目来帮助应用和提升你的技能会很有趣。
我选择了展示如何在 Python 中构建一个文本转语音转换器,这不仅简单,而且有趣且互动。我将向你展示两种用 Python 实现的方法。
那么,让我们开始吧。
使用 pyttsx3
要求
对于这个快速简单的构建,你需要以下模块:pyttsx3。这个模块是一个文本转语音转换库,兼容 Python 2 和 3。
要安装这个模块,请输入以下内容:
pip install pyttsx3
导入
现在你需要将库导入到你的环境中:
import pyttsx3
引擎实例
我们现在将初始化‘init’函数以获得引擎实例
engine = pyttsx3.init()
告诉我们的引擎要说什么
使用引擎上的‘say’方法,我们输入希望被朗读的文本
engine.say('Oh my. I can't believe I did this in less than 5 minutes')
现在听听吧
我们现在使用“运行并等待”方法来处理语音命令
engine.runAndWait()
就这样。现在另一个..
使用 gTTS API
要求
对于这个文本转语音转换器,我们需要 Google 文本转语音 API。它可以轻松将输入的文本转换为音频,然后保存为 mp3 文件。
这可以用于多种语言,如英语、印地语、泰米尔语、法语、德语等。
要安装 API,请输入以下内容:
pip install gTTS
导入
现在你需要将库导入到你的环境中:
from gtts import gTTS
你还需要导入 os 以播放音频:
import os
输入你的文本
text = 'Learn how to build something with Python in 5 minutes'
选择你的语言
选择你喜欢的语言。你可以通过点击这个 链接 查找语言列表。
language = 'en'
将文本传递给引擎
你还可以选择音频播放速度是快还是慢。
myobj = gTTS(text=mytext, lang=language, slow=False)
将你的音频保存为 .mp3
myobj.save("mytext2speech.mp3")
该听听了
mpg123 是一个免费的开源音频播放器,我们将添加它来指定我们希望 .mp3 文件在哪个程序中播放。
os.system("mpg321 mytext2speech.mp3")
哒哒!你选择的媒体播放器应该已经说了:
“学习如何在 5 分钟内用 Python 构建东西”
总结一下
这篇文章完全是为了让你探索你的 Python 技能,然后构建更好更酷的项目。& 为了一点乐趣!
妮莎·阿里亚 是一位数据科学家和自由技术写作人。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何有益于人类寿命的不同方式。她是一位热衷于学习、寻求拓展技术知识和写作技能的热心者,同时帮助引导他人。
更多相关话题
用 Python 在 5 分钟内构建网络爬虫
原文:
www.kdnuggets.com/2022/02/build-web-scraper-python-5-minutes.html
数据科学家通常需要收集大量数据,以便在组织中提取业务价值。不幸的是,这是一项经常被忽视的技能,因为大多数数据科学课程并不教授如何收集外部数据。相反,大多注重于模型构建和训练。
在本文中,我将向你展示如何从头开始创建一个网络爬虫。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
如果你还不熟悉这个术语,网络爬虫是一个自动化工具,可以从网站中提取大量数据。借助网络抓取,你可以在几分钟内收集多达数十万条数据点。
在本教程中,我们将抓取一个名为 “Quotes to Scrape” 的网站。这个网站是专门为练习网络抓取而建立的。
在本文结束时,你将熟悉以下内容:
-
从网站提取原始 HTML
-
使用 BeautifulSoup 库来解析这些 HTML 并从网站中提取有用的信息
-
同时从多个网页收集数据
-
将这些数据存储到 Pandas 数据框中
在我们开始构建爬虫之前,请确保已安装以下库 — Pandas,BeautifulSoup,requests。
完成后,让我们查看一下我们想要抓取的网站,并决定要从中提取的数据点。
这个网站包含了名人名言的列表。页面上显示了三项主要信息——名言、作者及其相关的几个标签。
该网站有十页,我们将抓取其中的所有信息。
让我们首先导入以下库:
import pandas as pd
from bs4 import BeautifulSoup
import requests
然后,使用 requests 库,我们将获取我们想抓取的页面并提取其 HTML:
f = requests.get('[`quotes.toscrape.com/'`](http://quotes.toscrape.com/'))
接下来,我们将把网站的 HTML 文本传递给 BeautifulSoup,它将解析这些原始数据,以便轻松进行抓取:
soup = BeautifulSoup(f.text)
现在,网站的所有数据都存储在 soup 对象中。我们可以很容易地在这个对象上运行 BeautifulSoup 的内置函数,以提取我们想要的数据。
例如,如果我们想提取网页上所有的文本,可以通过以下代码轻松完成:
print(soup.get_text())
你应该能看到网站上的所有文本出现在你的屏幕上。
现在,让我们开始抓取网站上列出的引用。右键点击任何一个引用,选择 "检查元素"。Chrome 开发者工具将会出现在你的屏幕上:
BeautifulSoup 具有像 find() 和 findAll() 这样的函数,你可以用它们从网页中提取特定的 HTML 标签。
在这种情况下,请注意名为 text 的 <span> 类被高亮显示。这是因为你右键点击了页面上的一个引用,所有引用都属于这个 text 类。
我们需要提取这个类中的所有数据:
for i in soup.findAll("div",{"class":"quote"}):
print((i.find("span",{"class":"text"})).text)
一旦你运行上述代码,将会生成以下输出:

网页上有十个引用,我们的抓取器已经成功地收集了所有这些引用。太棒了!
现在,我们将使用相同的方法抓取作者名字。
如果你右键点击网页上的任何一个作者名字并选择检查,你会看到它们都包含在 <small> 标签内,且类名为 author。
我们将使用 find() 和 findAll() 函数来提取这个标签内的所有作者名字。
for i in soup.findAll("div",{"class":"quote"}):
print((i.find("small",{"class":"author"})).text)
以下输出将被渲染:

再次,我们成功地抓取了页面上列出的所有作者。我们快完成了!
最后,我们将抓取网站上列出的标签。
如果你右键点击任何一个标签并选择检查元素,你会看到它们都包含在 <meta> 标签内,并用逗号分隔:

同时,请注意 <meta> 标签被一个父 <div> 标签包裹,且类名为 tags。
要提取页面上的所有标签,请运行以下代码:
for i in soup.findAll("div",{"class":"tags"}):
print((i.find("meta"))['content'])
屏幕上的输出将如下所示:

我们现在已经成功地抓取了网站单页上的所有数据。
但我们还没有完成!记住,网站有十页,我们需要从所有页面中收集相同的数据。
在我们做这些之前,让我们创建三个空数组,以便存储收集到的数据。
quotes = []
authors = []
tags = []
现在,我们将创建一个范围从 1 到 10 的循环,并遍历网站上的每一页。我们将运行之前创建的完全相同的代码行。唯一的区别是,我们现在将其附加到数组中,而不是打印输出。
for pages in range(1,10): f = requests.get('[`quotes.toscrape.com/page/'+str(pages))`](http://quotes.toscrape.com/page/'+str(pages)))
soup = BeautifulSoup(f.text) for i in soup.findAll("div",{"class":"quote"}):
quotes.append((i.find("span",{"class":"text"})).text)
for j in soup.findAll("div",{"class":"quote"}):
authors.append((j.find("small",{"class":"author"})).text) for k in soup.findAll("div",{"class":"tags"}):
tags.append((k.find("meta"))['content'])
完成!
最后,让我们将所有收集到的数据汇总到一个 Pandas 数据框中:
finaldf = pd.DataFrame(
{'Quotes':quotes,
'Authors':authors,
'Tags':tags
})
查看最终数据框的开头,我们可以看到所有抓取到的数据都已被整理到三列中:

这就是本教程的全部内容!
我们已经成功使用 Python 库抓取了一个网站,并将提取的数据存储到数据框中。
这些数据可以用于进一步分析——你可以构建一个聚类模型来将相似的引用聚集在一起,或者训练一个模型,根据输入的引用自动生成标签。
如果你想练习上述学到的技能, 这里 是另一个相对简单的网站可以抓取。
网页抓取不仅仅是本文中提到的技术。现实中的网站通常有机器人保护机制,这使得从数百个页面中收集数据变得困难。当你想从像上述那样的静态 HTML 网页中提取数据时,使用 requests 和 BeautifulSoup 就足够了。
如果你从需要认证的网站抓取数据,或有验证码等验证机制,或者在页面加载时有 JavaScript 运行,你将需要使用像 Selenium 这样的浏览器自动化工具来帮助抓取。
如果你想学习用于网页抓取的 Selenium,我建议你从 this 初学者友好的教程开始。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以在 LinkedIn 上与她联系。
更多相关内容
创建你的第一个语音助手
原文:
www.kdnuggets.com/2019/09/build-your-first-voice-assistant.html
评论
来源:giphy
现在,听到有人跟不存在的人说话已不再令人惊讶。我们问 Alexa 天气情况和调低恒温器的温度。然后,我们询问 Siri 我们今天的日程安排并拨打电话。现在我们通过声音和语音界面技术连接得比以往任何时候都更多。我无法再想象手动完成任务的情景!这真是未来的科技。
— 福布斯
介绍
谁不想拥有一个总是听到你呼唤、预见你每个需求并在必要时采取行动的助手呢?得益于基于人工智能的语音助手,这种奢侈现在已经可以实现。
语音助手体积较小,能够在听到你的命令后执行各种操作。它们可以开灯、回答问题、播放音乐、下在线订单,并做各种基于 AI 的事情。
语音助手不应与虚拟助手混淆,后者是远程工作的人,因此可以处理各种任务。语音助手则是基于技术的。随着语音助手变得越来越强大,它们在个人和商业领域的实用性也会增加。

什么是语音助手?
一个语音助手或智能个人助手是一个可以根据口头命令执行任务或服务的软件代理,即通过解读人类语言并通过合成声音回应。用户可以通过语音提问、控制家庭自动化设备和媒体播放,以及通过口头命令管理其他基本任务,如电子邮件、待办事项列表、打开或关闭应用程序等。
让我给你一个例子,Braina (Brain Artificial) 是一个智能个人助手、人类语言界面、自动化和语音识别软件,用于 Windows PC。Braina 是一个多功能的 AI 软件,它允许你使用语音命令与计算机互动,支持世界上大多数语言。Braina 还允许你在世界上 100 多种不同语言中准确地将语音转换为文本。
语音助手的历史
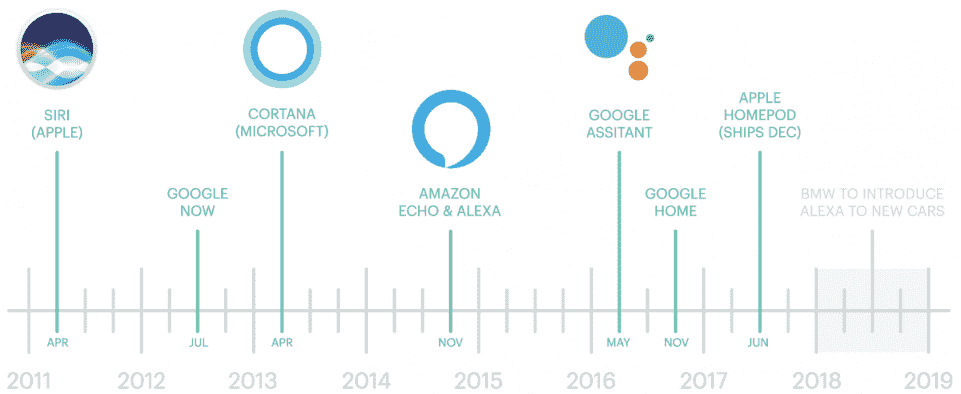
近年来,语音助手在苹果公司整合了令人惊叹的虚拟助手 Siri 后获得了主要平台。真正的演变时间线开始于 1962 年的西雅图世博会,IBM 展示了一种名为 Shoebox 的独特装置。它的实际大小是一个鞋盒,可以执行科学功能,能够识别 16 个单词,并用人类可识别的声音发音,包含 0 到 9 的数字。
在 1970 年代,匹兹堡的卡内基梅隆大学的研究人员——在美国国防部及其国防高级研究计划局 (DARPA) 的巨大帮助下——制作了 Harpy。它能够理解大约 1,000 个单词,相当于三岁小孩的词汇量。
像苹果和 IBM 这样的大组织在 90 年代初开始制作利用语音识别的产品。1993 年,Macintosh 开始在其 Macintosh 电脑上通过 PlainTalk 构建语音识别技术。
1997 年 4 月,Dragon NaturallySpeaking 是第一个能够理解约 100 个单词并将其转换为可读内容的持续听写产品。

话虽如此,构建一个简单的基于语音的桌面/笔记本助手,具备以下功能会有多酷呢:
-
在浏览器中打开子版块。
-
在浏览器中打开任何网站。
-
给你的联系人发送一封电子邮件。
-
启动任何系统应用程序。
-
告诉你几乎任何城市的当前天气和温度
-
告诉你当前的时间。
-
问候
-
在 VLC 媒体播放器上播放一首歌曲(当然,你需要在你的笔记本/台式机上安装 VLC 媒体播放器)
-
更改桌面壁纸。
-
告诉你最新的新闻动态。
-
告诉你几乎任何你问的问题。
所以在这篇文章中,我们将构建一个基于语音的应用程序,它可以完成上述所有任务。但首先,查看下面我在与桌面语音助手互动时录制的视频,我称她为 Sofia。
与 Sofia 的互动
我希望你们喜欢我与 Sofia 互动的上面的视频。现在让我们开始构建这个酷炫的东西……
依赖关系和要求:
系统要求:Python 2.7,Spyder IDE,MacOS Mojave(版本 10.14)
安装所有这些 Python 库:
pip install SpeechRecognition
pip install beautifulsoup4
pip install vlc
pip install youtube-dl
pip install pyowm
pip install wikipedia
让我们开始使用 Python 构建我们的桌面语音助手
首先导入所有所需的库:
py` import speech_recognition as sr import os import sys import re import webbrowser import smtplib import requests import subprocess from pyowm import OWM import youtube_dl import vlc import urllib import urllib2 import json from bs4 import BeautifulSoup as soup from urllib2 import urlopen import wikipedia import random from time import strftime ```py ````
为了让我们的语音助手执行上述所有功能,我们必须在一个方法中编写每个功能的逻辑。
所以我们的第一步是创建一个方法来解释用户的语音响应。
py` def myCommand(): r = sr.Recognizer() with sr.Microphone() as source: print('说点什么...') r.pause_threshold = 1 r.adjust_for_ambient_noise(source, duration=1) audio = r.listen(source) try: command = r.recognize_google(audio).lower() print('你说了: ' + command + '\n') # 如果收到无法识别的语音则循环继续监听命令 except sr.UnknownValueError: print('....') command = myCommand(); return command ```py ````
接下来,创建一个方法,将文本转换为语音。
py` def sofiaResponse(audio): print(audio) for line in audio.splitlines(): os.system("say " + audio) ```py ````
现在创建一个循环以继续执行多个命令。在方法 assistant() 中传递用户命令(myCommand()) 作为参数。
py` while True: assistant(myCommand()) ```py ````
我们的下一步是为每个功能创建多个 if 语句。因此,让我们看看如何在 if 语句中为每个命令创建这些小模块。
1. 在浏览器中打开 Reddit 子版块。
用户将给出任何命令以打开 Reddit 的子版块,命令应为 “Hey Sofia! Can you please open Reddit subreddit_name”。 只有斜体粗体短语需要按原样使用。你可以使用任何前缀,只要注意斜体粗体短语。
工作原理 : 如果你在命令中说了短语open reddit,那么它将使用 re.search() 在用户命令中搜索子版块名称。子版块将通过www.reddit.com进行搜索,并使用 Python 的 Webbrowser 模块在浏览器中打开。Webbrowser模块提供了一个高级接口,允许用户显示基于 Web 的文档。
py` if 'open reddit' in command: reg_ex = re.search('open reddit (.*)', command) url = 'https://www.reddit.com/' if reg_ex: subreddit = reg_ex.group(1) url = url + 'r/' + subreddit webbrowser.open(url) sofiaResponse('Reddit 内容已经为您打开。') ```py ````
所以,上面的代码将在默认浏览器中打开你所期望的 Reddit。
2. 在浏览器中打开任意网站。
你可以通过说“打开 website.com”或“打开 website.org”来打开任何网站。
例如:“请打开 facebook.com”或“嘿,你能打开 linkedin.com 吗”,你可以像这样让苏菲亚为你打开任何网站。
如何运作:如果你在指令中说了打开这个词,它将使用 re.search() 在用户的指令中搜索网站名称。接着,它将把网站名称附加到
www.上,并通过webbrowser模块在浏览器中打开完整的 URL。
py` elif 'open' in command: reg_ex = re.search('open (.+)', command) if reg_ex: domain = reg_ex.group(1) print(domain) url = 'https://www.' + domain webbrowser.open(url) sofiaResponse('您请求的网站已为您打开。') else: pass ```py ````
3. 发送邮件。
你也可以让桌面助手发送邮件。
如何运作:如果你在指令中说了邮件这个词,那么机器人会询问收件人。如果我的回复是 rajat,机器人将使用 Python 的 smtplib 库。 smtplib 模块定义了一个 SMTP 客户端会话对象,可以用来向任何具有 SMTP 或 ESMTP 监听守护进程的互联网机器发送邮件。发送邮件使用 Python 的 smtplib 和 SMTP 服务器。首先,它会使用smtplib.SMTP() 初始化 Gmail SMTP,然后使用ehlo() 函数识别服务器,然后加密会话starttls(),接着使用login() 登录到你的邮箱,然后使用sendmail() 发送消息。
py` elif 'email' in command: sofiaResponse('收件人是谁?') recipient = myCommand()if 'rajat' in recipient: sofiaResponse('我应该对他说什么?') content = myCommand() mail = smtplib.SMTP('smtp.gmail.com', 587) mail.ehlo() mail.starttls() mail.login('your_email_address', 'your_password') mail.sendmail('sender_email', 'receiver_email', content) mail.close() sofiaResponse('邮件已成功发送。你可以查看你的收件箱。')else: sofiaResponse('我不知道你说的是什么意思!') ```py ````
4. 启动任何系统应用程序。
说“启动日历”或“你能启动 Skype 吗”或“苏菲亚启动查找器”等,苏菲亚将为你启动该系统应用程序。
它是如何工作的:如果你在命令中提到launch这个词,它将使用 re.search() 搜索应用程序名称(如果它存在于你的系统中)。然后,它会将后缀“.app”附加到应用程序名称上。例如,你的应用程序名称可能是 calender.app(在 macOS 中,执行文件以 .app 结尾,而在 Windows 中则以 .exe 结尾)。所以执行应用程序名称将通过 python subprocess 的 Popen() 函数启动。subprocess 模块使你能够从 Python 程序中启动新应用程序。
py` elif 'launch' in command: reg_ex = re.search('launch (.*)', command) if reg_ex: appname = reg_ex.group(1) appname1 = appname+".app" subprocess.Popen(["open", "-n", "/Applications/" + appname1], stdout=subprocess.PIPE)sofiaResponse('我已经启动了所需的应用程序') ```py ````
5. 告诉你几乎任何城市的当前天气和温度。
Sofia 还可以告诉你世界上任何城市的天气、最高温度和最低温度。用户只需说类似“伦敦当前的天气如何”或“告诉我德里的当前天气”这样的句子。
它是如何工作的:如果你在命令中提到current weather这个短语,它将使用 re.search() 搜索城市名称。我使用了 Python 的 pyowm 库来获取任何城市的天气。get_status() 会告诉你天气状况,如雾霾、阴天、雨天等,而 get_temperature() 会告诉你城市的最高和最低温度。
py` elif 'current weather' in command: reg_ex = re.search('current weather in (.*)', command) if reg_ex: city = reg_ex.group(1) owm = OWM(API_key='ab0d5e80e8dafb2cb81fa9e82431c1fa') obs = owm.weather_at_place(city) w = obs.get_weather() k = w.get_status() x = w.get_temperature(unit='celsius') sofiaResponse('%s 的当前天气是 %s。最高温度是 %0.2f 度,最低温度是 %0.2f 度' % (city, k, x['temp_max'], x['temp_min'])) ```py ````
6. 告诉你当前时间。
“Sofia,你能告诉我当前时间吗?”或者“现在几点了?”Sofia 将告诉你你所在时区的当前时间。
它是如何工作的:非常简单
py` elif 'time' in command: import datetime now = datetime.datetime.now() sofiaResponse('当前时间是 %d 小时 %d 分钟' % (now.hour, now.minute)) ```py ````
7. 问候/离开
说“hello Sofia”来打招呼,或者当你想让程序终止时,可以说类似“shutdown Sofia”或“Sofia 请关闭”等。
工作原理:如果你在指令中提到了hello这个词,那么根据一天中的时间,机器人会向用户打招呼。如果时间超过中午 12 点,机器人会回应“Hello Sir. Good afternoon”,同样,如果时间超过下午 6 点,机器人会回应“Hello Sir. Good evening”。当你给出关闭命令时,sys.exit() 将被调用以终止程序。
py` #问候索非亚 elif 'hello' in command: day_time = int(strftime('%H')) if day_time < 12: sofiaResponse('Hello Sir. Good morning') elif 12 <= day_time < 18: sofiaResponse('Hello Sir. Good afternoon') else: sofiaResponse('Hello Sir. Good evening')#终止程序 elif 'shutdown' in command: sofiaResponse('Bye bye Sir. Have a nice day') sys.exit() ```py ````
8. 在 VLC 媒体播放器中播放歌曲
该功能允许你的语音机器人在 VLC 媒体播放器中播放你想要的歌曲。用户会说“索非亚,给我放一首歌”,机器人会问“Sir,我该播放什么歌?”只需说出歌曲的名称,索非亚会从 YouTube 下载这首歌到你的本地驱动器中,在 VLC 媒体播放器中播放该歌曲,如果你再次要求播放歌曲,之前下载的歌曲将会自动删除。
工作原理:如果你在指令中提到了play me a song这个短语,那么它会询问你要播放什么视频歌曲。你要求的歌曲将在 youtube.com 上进行搜索,如果找到,歌曲将使用 Python 的 youtube_dl 库下载到你的本地目录中。 youtube-dl 是一个用于从 YouTube.com 及其他一些网站下载视频的命令行程序。下载完成后,歌曲会使用 Python 的 VLC 库 播放,play(path_to__videosong) 模块会实际播放这首歌。
如果下次你要求播放任何其他歌曲,本地目录将被清空,并且在该目录中会下载一首新的歌曲。
py` elif 'play me a song' in command: path = '/Users/nageshsinghchauhan/Documents/videos/' folder = path for the_file in os.listdir(folder): file_path = os.path.join(folder, the_file) try: if os.path.isfile(file_path): os.unlink(file_path) except Exception as e: print(e)sofiaResponse('我该播放什么歌曲,先生?')mysong = myCommand() if mysong: flag = 0 url = "https://www.youtube.com/results?search_query=" + mysong.replace(' ', '+') response = urllib2.urlopen(url) html = response.read() soup1 = soup(html,"lxml") url_list = [] for vid in soup1.findAll(attrs={'class':'yt-uix-tile-link'}): if ('https://www.youtube.com' + vid['href']).startswith("https://www.youtube.com/watch?v="): flag = 1 final_url = 'https://www.youtube.com' + vid['href'] url_list.append(final_url)url = url_list[0] ydl_opts = {}os.chdir(path) with youtube_dl.YoutubeDL(ydl_opts) as ydl: ydl.download([url]) vlc.play(path)if flag == 0: sofiaResponse('我在 Youtube 上没有找到任何东西 ') py
9. 更换桌面壁纸。
你们也可以使用此功能更换桌面壁纸。当你说“更换壁纸”或“索非亚,请更换壁纸”时,机器人会从unsplash.com下载随机壁纸,并将其设置为你的桌面背景。
工作原理: 如果你在命令中说了更换壁纸这句话,程序将从 unsplash.com 下载一张随机壁纸,将其存储在本地目录中,并通过 subprocess.call()将其设置为桌面壁纸。我使用了 unsplash API 来访问其内容。
如果下次你要求再次更换壁纸,本地目录将被清空,并且会在该目录下下载新的壁纸。
py` elif '更改壁纸' 在命令中: folder = '/Users/nageshsinghchauhan/Documents/wallpaper/' 对于文件夹中的每个文件: file_path = os.path.join(folder, the_file) 尝试: 如果 os.path.isfile(file_path): os.unlink(file_path) except Exception as e: print(e) api_key = 'fd66364c0ad9e0f8aabe54ec3cfbed0a947f3f4014ce3b841bf2ff6e20948795' url = 'https://api.unsplash.com/photos/random?client_id=' + api_key # 来自 unspalsh.com 的图片 f = urllib2.urlopen(url) json_string = f.read() f.close() parsed_json = json.loads(json_string) photo = parsed_json['urls']['full'] urllib.urlretrieve(photo, "/Users/nageshsinghchauhan/Documents/wallpaper/a") # 我们下载图片的位置 subprocess.call(["killall Dock"], shell=True) sofiaResponse('壁纸更改成功') ```py ````
10. 告诉你最新的新闻动态。
Sofia 还可以告诉你最新的新闻更新。用户只需说 “Sofia,今天的头条新闻是什么?” 或 “告诉我今天的新闻”。
工作原理: 如果你在命令中说了 今天的新闻,那么它会使用 Beautiful Soup 从 Google News RSS() 中抓取数据并为你朗读。为了方便起见,我已将新闻数量限制设置为 15 条。
py` elif '今天的新闻' 在命令中: 尝试: news_url="https://news.google.com/news/rss" Client=urlopen(news_url) xml_page=Client.read() Client.close() soup_page=soup(xml_page,"xml") news_list=soup_page.findAll("item") 对于前 15 条新闻: sofiaResponse(news.title.text.encode('utf-8')) except Exception as e: print(e) ```py ````
11. 告诉你几乎任何你询问的内容。
你的机器人可以获取几乎任何你询问的详细信息。例如 “Sofia,告诉我关于 Google 的事” 或 “请告诉我关于超级计算机的事” 或 “请告诉我关于互联网的事”。所以你可以看到,你几乎可以询问任何内容。
工作原理: 如果你在命令中说了 告诉我关于,那么它会使用 re.search() 在用户命令中搜索关键字。使用 Python 的 Wikipedia 库,它会搜索该主题并提取前 500 个字符(如果你不指定限制,机器人将为你读取整个页面)。 Wikipedia 是一个 Python 库,使得访问和解析 Wikipedia 数据变得简单。
py` elif 'tell me about' in command: reg_ex = re.search('tell me about (.*)', command) try: if reg_ex: topic = reg_ex.group(1) ny = wikipedia.page(topic) sofiaResponse(ny.content[:500].encode('utf-8')) except Exception as e: sofiaResponse(e) ```py ````
让我们把一切放在一起
py` 导入 speech_recognition 作为 sr 导入 os 导入 sys 导入 re 导入 webbrowser 导入 smtplib 导入 requests 导入 subprocess 从 pyowm 导入 OWM 导入 youtube_dl 导入 vlc 导入 urllib 导入 urllib2 导入 json 从 bs4 导入 BeautifulSoup 作为 soup 从 urllib2 导入 urlopen 导入 wikipedia 导入 random 从 time 导入 strftime def sofiaResponse(audio): "说出传递的音频" print(audio) for line in audio.splitlines(): os.system("say " + audio) def myCommand(): "监听命令" r = sr.Recognizer() with sr.Microphone() as source: print('说点什么...') r.pause_threshold = 1 r.adjust_for_ambient_noise(source, duration=1) audio = r.listen(source) try: command = r.recognize_google(audio).lower() print('你说: ' + command + '\n') #loop back to continue to listen for commands if unrecognizable speech is received except sr.UnknownValueError: print('....') command = myCommand(); return command def assistant(command): "执行命令的 if 语句" #打开 subreddit Reddit if 'open reddit' in command: reg_ex = re.search('open reddit (.)', command) url = 'https://www.reddit.com/' if reg_ex: subreddit = reg_ex.group(1) url = url + 'r/' + subreddit webbrowser.open(url) sofiaResponse('Reddit 内容已为您打开。') elif 'shutdown' in command: sofiaResponse('再见。祝您有美好的一天') sys.exit() #打开网站 elif 'open' in command: reg_ex = re.search('open (.+)', command) if reg_ex: domain = reg_ex.group(1) print(domain) url = 'https://www.' + domain webbrowser.open(url) sofiaResponse('您请求的网站已为您打开。') else: pass #问候 elif 'hello' in command: day_time = int(strftime('%H')) if day_time < 12: sofiaResponse('您好。早上好') elif 12 <= day_time < 18: sofiaResponse('您好。下午好') else: sofiaResponse('您好。晚上好') elif 'help me' in command: sofiaResponse(""" 您可以使用这些命令,我会帮助您: 1. 打开 reddit subreddit : 在默认浏览器中打开 subreddit。 2. 打开 xyz.com : 将 xyz 替换为任何网站名称 3. 发送电子邮件/email : 会依次询问收件人姓名、内容等问题。 4. {cityname} 当前天气 : 告诉您当前的天气情况和温度 5. 你好 6. 播放视频 : 在 VLC 媒体播放器中播放歌曲 7. 更改壁纸 : 更改桌面壁纸 8. 今日新闻 : 阅读今日的头条新闻 9. 时间 : 当前系统时间 10. Google 新闻的头条故事 (RSS feeds) 11. 告诉我关于 xyz 的信息 : 告诉您关于 xyz 的信息 """) #笑话 elif 'joke' in command: res = requests.get( 'https://icanhazdadjoke.com/', headers={"Accept":"application/json"}) if res.status_code == requests.codes.ok: sofiaResponse(str(res.json()['joke'])) else: sofiaResponse('哎呀!笑话讲完了') #Google 新闻的头条故事 elif 'news for today' in command: try: news_url="https://news.google.com/news/rss" Client=urlopen(news_url) xml_page=Client.read() Client.close() soup_page=soup(xml_page,"xml") news_list=soup_page.findAll("item") for news in news_list[:15]: sofiaResponse(news.title.text.encode('utf-8')) except Exception as e: print(e) #当前天气 elif 'current weather' in command: reg_ex = re.search('current weather in (.)', command) if reg_ex: city = reg_ex.group(1) owm = OWM(API_key='ab0d5e80e8dafb2cb81fa9e82431c1fa') obs = owm.weather_at_place(city) w = obs.get_weather() k = w.get_status() x = w.get_temperature(unit='celsius') sofiaResponse('当前 %s 的天气是 %s。最高温度是 %0.2f 度,最低温度是 %0.2f 度' % (city, k, x['temp_max'], x['temp_min'])) #时间 elif 'time' in command: import datetime now = datetime.datetime.now() sofiaResponse('当前时间是 %d 小时 %d 分钟' % (now.hour, now.minute)) elif 'email' in command: sofiaResponse('收件人是谁?') recipient = myCommand() if 'rajat' in recipient: sofiaResponse('我应该对他说些什么?') content = myCommand() mail = smtplib.SMTP('smtp.gmail.com', 587) mail.ehlo() mail.starttls() mail.login('your_email_address', 'your_password') mail.sendmail('sender_email', 'receiver_email', content) mail.close() sofiaResponse('电子邮件已成功发送。您可以查看收件箱。') else: sofiaResponse('我不明白您的意思!') #启动任何应用程序 elif 'launch' in command: reg_ex = re.search('launch (.)', command) if reg_ex: appname = reg_ex.group(1) appname1 = appname+".app" subprocess.Popen(["open", "-n", "/Applications/" + appname1], stdout=subprocess.PIPE) sofiaResponse('我已启动所需的应用程序') #播放 YouTube 歌曲 elif 'play me a song' in command: path = '/Users/nageshsinghchauhan/Documents/videos/' folder = path for the_file in os.listdir(folder): file_path = os.path.join(folder, the_file) try: if os.path.isfile(file_path): os.unlink(file_path) except Exception as e: print(e) sofiaResponse('我应该播放什么歌曲?') mysong = myCommand() if mysong: flag = 0 url = "https://www.youtube.com/results?search_query=" + mysong.replace(' ', '+') response = urllib2.urlopen(url) html = response.read() soup1 = soup(html,"lxml") url_list = [] for vid in soup1.findAll(attrs={'class':'yt-uix-tile-link'}): if ('https://www.youtube.com' + vid['href']).startswith("https://www.youtube.com/watch?v="): flag = 1 final_url = 'https://www.youtube.com' + vid['href'] url_list.append(final_url) url = url_list[0] ydl_opts = {} os.chdir(path) with youtube_dl.YoutubeDL(ydl_opts) as ydl: ydl.download([url]) vlc.play(path) if flag == 0: sofiaResponse('我在 YouTube 上没有找到任何内容') #更改壁纸 elif 'change wallpaper' in command: folder = '/Users/nageshsinghchauhan/Documents/wallpaper/' for the_file in os.listdir(folder): file_path = os.path.join(folder, the_file) try: if os.path.isfile(file_path): os.unlink(file_path) except Exception as e: print(e) api_key = 'fd66364c0ad9e0f8aabe54ec3cfbed0a947f3f4014ce3b841bf2ff6e20948795' url = 'https://api.unsplash.com/photos/random?client_id=' + api_key #从 unspalsh.com 获取图片 f = urllib2.urlopen(url) json_string = f.read() f.close() parsed_json = json.loads(json_string) photo = parsed_json['urls']['full'] urllib.urlretrieve(photo, "/Users/nageshsinghchauhan/Documents/wallpaper/a") # 下载图片的位置 subprocess.call(["killall Dock"], shell=True) sofiaResponse('壁纸已成功更换') #问我任何事 elif 'tell me about' in command: reg_ex = re.search('tell me about (.)', command) try: if reg_ex: topic = reg_ex.group(1) ny = wikipedia.page(topic) sofiaResponse(ny.content[:500].encode('utf-8')) except Exception as e: print(e) sofiaResponse(e) sofiaResponse('您好用户,我是 Sofia,您的个人语音助手,请给出命令或说 "help me" 我将告诉您我能做什么。') #循环以继续执行多个命令 while True: assistant(myCommand()) py
所以你已经看到,仅通过编写简单的 Python 代码,我们就可以创建一个非常酷的语音助手。除了这些功能,你还可以在你的语音助手中添加许多不同的功能。
请注意,一旦你开始执行程序时,在与语音助手互动时要大声清晰,因为如果你的声音不清晰,语音助手可能无法正确解读你。
结论:未来会带来什么
在计算机历史中,用户界面变得越来越自然。屏幕和键盘是这方面的一步。鼠标和图形用户界面是另一种。触摸屏是最新的发展。下一步很可能会是增强现实、手势和语音命令的结合。毕竟,提问或对话往往比输入内容或在在线表单中填写多个详细信息更容易。
人们与语音激活设备的互动越多,系统基于收到的信息识别的趋势和模式就越多。然后,这些数据可以用来确定用户的偏好和口味,这对使家居智能化是一个长期卖点。谷歌和亚马逊正致力于整合能够分析和回应人类情感的语音启用人工智能。
我希望你们喜欢阅读这篇文章。在评论区分享你的想法/评论/疑虑。你可以通过 LinkedIn 联系我。
简历: Nagesh Singh Chauhan 是 CirrusLabs 的大数据开发工程师。他在电信、分析、销售、数据科学等多个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原文。经许可转载。
相关:
-
实用的 Python 语音识别基础
-
顶级语音处理 API 比较
-
TensorFlow 与 PyTorch 与 Keras 的 NLP 比较
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
使用 LlamaIndex 构建自己的 PandasAI
原文:
www.kdnuggets.com/build-your-own-pandasai-with-llamaindex

图片作者
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您所在的组织的 IT 工作
Pandas AI 是一个 Python 库,利用生成 AI 的力量来增强 Pandas——这一流行的数据分析库。只需一个简单的提示,Pandas AI 就能执行复杂的数据清理、分析和可视化,这些以前需要许多行代码。
除了处理数据外,Pandas AI 还理解自然语言。你可以用简单的英语提问数据,它会用日常语言提供总结和见解,免去你解读复杂图表和表格的麻烦。
在下面的示例中,我们提供了一个 Pandas 数据框,并要求生成 AI 创建一个条形图。结果令人印象深刻。
pandas_ai.run(df, prompt='Plot the bar chart of type of media for each year release, using different colors.')
注意: 代码示例来自 Pandas AI: 生成 AI 驱动的数据分析指南 教程。
在这篇文章中,我们将使用 LlamaIndex 创建类似的工具,这些工具可以理解 Pandas 数据框并生成复杂的结果,如上所示。
LlamaIndex 使得通过聊天和代理自然语言查询数据成为可能。它允许大型语言模型在不重新训练新数据的情况下大规模解释私有数据。它将大型语言模型与各种数据源和工具集成在一起。LlamaIndex 是一个数据框架,只需几行代码即可轻松创建带有 PDF 的聊天应用程序。
设置
您可以通过使用 pip 命令安装 Python 库。
pip install llama-index
默认情况下,LlamaIndex 使用 OpenAI 的 gpt-3.5-turbo 模型进行文本生成,使用 text-embedding-ada-002 进行检索和嵌入。为了无障碍运行代码,我们必须设置 OPENAI_API_KEY。我们可以在 新的 API 令牌 页面免费注册并获取 API 密钥。
import os
os.environ["OPENAI_API_KEY"] = "sk-xxxxxx"
他们还支持 Anthropic、Hugging Face、PaLM 等模型的集成。你可以通过阅读 模块的 文档了解有关它的一切。
Pandas 查询引擎
让我们进入创建自己的 PandasAI 的主要话题。在安装库和设置 API 密钥后,我们将创建一个简单的城市数据框,列包括城市名称和人口。
import pandas as pd
from llama_index.query_engine.pandas_query_engine import PandasQueryEngine
df = pd.DataFrame(
{"city": ["New York", "Islamabad", "Mumbai"], "population": [8804190, 1009832, 12478447]}
)
使用 PandasQueryEngine,我们将创建一个查询引擎以加载数据框并对其进行索引。
之后,我们将编写查询并显示响应。
query_engine = PandasQueryEngine(df=df)
response = query_engine.query(
"What is the city with the lowest population?",
)
如我们所见,它已经开发了用于显示数据框中最少人口城市的 Python 代码。
> Pandas Instructions:
eval("df.loc[df['population'].idxmin()]['city']")
eval("df.loc[df['population'].idxmin()]['city']")
> Pandas Output: Islamabad
如果你打印响应,你将得到“伊斯兰堡”。这很简单但令人印象深刻。你不必自己想出逻辑或实验代码。只需输入问题,你将得到答案。
print(response)
Islamabad
你还可以使用响应元数据打印结果背后的代码。
print(response.metadata["pandas_instruction_str"])
eval("df.loc[df['population'].idxmin()]['city']")
全球 YouTube 统计分析
在第二个示例中,我们将从 Kaggle 加载全球 YouTube 统计数据 2023 数据集,并进行一些基本分析。这比简单示例要更复杂。
我们将使用 read_csv 将数据集加载到查询引擎中。然后我们将编写提示以仅显示缺失值的列和缺失值的数量。
df_yt = pd.read_csv("Global YouTube Statistics.csv")
query_engine = PandasQueryEngine(df=df_yt, verbose=True)
response = query_engine.query(
"List the columns with missing values and the number of missing values. Only show missing values columns.",
)
> Pandas Instructions:
df.isnull().sum()[df.isnull().sum() > 0]
df.isnull().sum()[df.isnull().sum() > 0]
> Pandas Output: category 46
Country 122
Abbreviation 122
channel_type 30
video_views_rank 1
country_rank 116
channel_type_rank 33
video_views_for_the_last_30_days 56
subscribers_for_last_30_days 337
created_year 5
created_month 5
created_date 5
Gross tertiary education enrollment (%) 123
Population 123
Unemployment rate 123
Urban_population 123
Latitude 123
Longitude 123
dtype: int64
现在,我们将直接询问有关流行频道类型的问题。在我看来,LlamdaIndex 查询引擎非常准确,尚未产生任何幻觉。
response = query_engine.query(
"Which channel type have the most views.",
)
> Pandas Instructions:
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
eval("df.groupby('channel_type')['video views'].sum().idxmax()")
> Pandas Output: Entertainment
Entertainment
最终,我们会要求它可视化条形图,结果非常惊人。
response = query_engine.query(
"Visualize barchat of top ten youtube channels based on subscribers and add the title.",
)
> Pandas Instructions:
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='基于订阅者数量的十大 YouTube 频道')")
eval("df.nlargest(10, 'subscribers')[['Youtuber', 'subscribers']].plot(kind='bar', x='Youtuber', y='subscribers', title='Top Ten YouTube Channels Based on Subscribers')")
> Pandas Output: AxesSubplot(0.125,0.11;0.775x0.77)
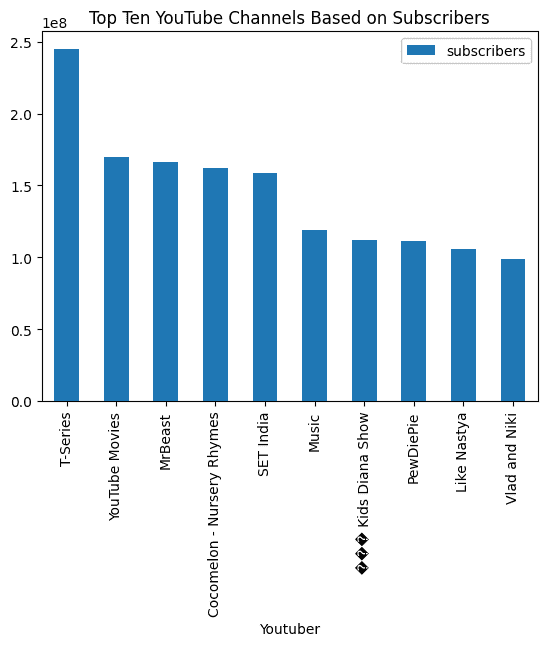
通过简单的提示和查询引擎,我们可以自动化数据分析并执行复杂任务。LamaIndex 还有更多功能。我强烈建议你阅读 官方文档 并尝试构建一些惊人的东西。
结论
总结一下,LlamaIndex 是一个令人兴奋的新工具,它允许开发者创建自己的 PandasAI——利用大型语言模型的力量进行直观的数据分析和对话。通过使用 LlamaIndex 对你的数据集进行索引和嵌入,你可以在不妥协安全性或重新训练模型的情况下,为你的私人数据启用高级自然语言能力。
这只是一个开始,通过 LlamaIndex,你可以构建文档问答系统、聊天机器人、自动化 AI、知识图谱、AI SQL 查询引擎、全栈 Web 应用程序,并构建私人生成式 AI 应用程序。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络构建一个 AI 产品,帮助那些在精神健康方面挣扎的学生。
更多相关话题
在人工智能领域建立职业生涯:从学生到专业人士
原文:
www.kdnuggets.com/building-a-career-in-ai-from-student-to-professional

图片来源:编辑 | Midjourney
人工智能是当前的热门话题。它被应用于各个领域来解决实际问题。让我们讨论一下在人工智能领域建立职业生涯的步骤。
第一步:建立教育基础
选择与你的人工智能职业规划相匹配的学位。你可以选择计算机科学、数学或工程学的学位。如果你选择计算机科学课程,你将学习编程语言和算法。数学和统计课程包括概率、线性代数和微积分等主题。工程学学位通常集中于信号处理和机器人技术。还有许多在线课程涵盖了人工智能的不同领域。这些课程包括有教程和作业的子部分。课程可以是自定进度的,也可以有固定的时间表。你可以在 edX、Coursera 和 Udemy 等热门平台上找到这些课程。
第二步:动手学习
参与项目和竞赛
项目和竞赛提供了使用人工智能解决实际问题的动手经验。它们能增强我们的人工智能概念并提高问题解决能力。你应该先实现基本项目,然后参加挑战。一些常见的人工智能项目包括图像分类任务,如数字识别或目标检测。自然语言处理项目通常涉及情感分析或聊天机器人。一些受欢迎的人工智能竞赛包括 ImageNet 大规模视觉识别挑战(ILSVRC)、社会公益人工智能挑战赛和 NeurIPS 挑战赛。你还应该参加黑客马拉松来探索不同的项目。
确保实习机会
实习能为你提供实践经验,并可能带来全职工作。以下是如何获得实习的方法:首先,识别那些涉及实习生的人工智能公司。在线和离线与人工智能专业人士建立联系。确保你的简历在技能部分和教育背景中包含与人工智能相关的信息。创建一个人工智能项目和研究的作品集。确保你的申请与公司和职位匹配。在面试中讨论与实习角色相关的项目和经验也很重要。最后但同样重要的是,不要忘记联系招聘人员。
第三步:建立作品集和网络
强大的作品集对于展示你的人工智能技能至关重要。作品集应以专业的方式制作。你应该在学术期刊和网站上发布你的工作。此外,你还应该撰写文章并参与开源项目。例如,你可以使用 GitHub 分享你的代码并与同行合作。建立人际网络有助于在人工智能领域的职业发展和知识交流。通过 LinkedIn 与专家互动,以保持在人工智能社区中的联系。关注技术领域的意见领袖,如 Elon Musk 和 Andrew Ng,并参与他们的讨论。参加本地的人工智能聚会,以跟上最新的人工智能趋势。此外,加入 Reddit 的 r/MachineLearning 论坛,讨论人工智能话题。
步骤 4:准备求职市场
制作简历和求职信
你应该确保简历的格式正确。因此,在提交简历前要进行修订。你应该根据申请的职位修改每一份求职信。最佳方法是了解公司的文化,以符合其关键要求。你应该在求职信中解释你为何对该职位感兴趣。求职信的内容应简要总结你最相关的经验。
研究公司和职位
你应该提前研究你感兴趣的雇主和职位。了解公司的目标和近期动态。你还应该研究公司的文化和价值观。这将帮助你全面了解公司的运作方式,并帮助你回答面试问题。
目前流行的人工智能职业包括:
-
数据科学家:分析数据以发现有价值的见解和模式
-
机器学习工程师:创建和实施使用机器学习的系统
-
人工智能研究科学家:进行研究以开发新的和改进的人工智能技术
练习面试技巧
商业行为面试问题通常比较笼统,并不涉及具体职业。你可以使用结构、任务、行动、结果技巧来回答这些问题。麻省理工学院职业咨询与发展部以讲故事的方式解释了 STAR 方法。
来源: https://capd.mit.edu/resources/the-star-method-for-behavioral-interviews/
应进行模拟面试,以模拟真实面试并获取关于表现的反馈。此外,你还应该在 Leetcode 等平台上做更多的编码问题。
总结
通过遵循本文中的步骤,你可以在人工智能领域获得成功的职业。每一步都同等重要,按顺序执行。如果你掌握了人工智能所需的技能,那么你就准备好进入人工智能领域了。
Jayita Gulati 是一位对构建机器学习模型充满热情的机器学习爱好者和技术作家。她拥有利物浦大学的计算机科学硕士学位。
这个话题的更多信息
使用 PyTorch 构建卷积神经网络
原文:
www.kdnuggets.com/building-a-convolutional-neural-network-with-pytorch
作者提供的图像
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
卷积神经网络(CNN 或 ConvNet)是一种深度学习算法,专门用于对象识别至关重要的任务——如图像分类、检测和分割。CNN 能够在复杂的视觉任务上达到最先进的准确率,推动许多实际应用,如监控系统、仓库管理等。
作为人类,我们可以通过分析模式、形状和颜色轻松识别图像中的对象。CNN 也可以通过学习哪些模式对于区分很重要来进行这种识别。例如,当尝试区分猫和狗的照片时,我们的大脑会关注独特的形状、纹理和面部特征。CNN 学会捕捉这些相同类型的区分特征。即使是非常细致的分类任务,CNN 也能直接从像素中学习复杂的特征表示。
在这篇博客文章中,我们将学习卷积神经网络以及如何使用它们与 PyTorch 构建图像分类器。
卷积神经网络是如何工作的?
卷积神经网络(CNNs)通常用于图像分类任务。从高层次看,CNN 包含三种主要类型的层:
-
卷积层。 对输入应用卷积滤波器以提取特征。这些层中的神经元称为滤波器,捕捉输入中的空间模式。
-
池化层。 对卷积层的特征图进行降采样,以整合信息。最大池化和平均池化是常用的策略。
-
全连接层。 将来自卷积层和池化层的高级特征作为分类的输入。可以堆叠多个全连接层。
卷积滤波器作为特征检测器,当它们看到输入图像中的特定类型模式或形状时会激活。随着这些滤波器在图像上的应用,它们生成的特征图会突出显示某些特征的存在位置。
例如,当一个过滤器看到垂直线时,它可能会激活,产生一个特征图,显示图像中的垂直线。应用于相同输入的多个过滤器会产生一系列特征图,捕捉图像的不同方面。
Gif 来源于 IceCream Labs
通过堆叠多个卷积层,CNN 可以学习特征的层次结构——从简单的边缘和模式构建到更复杂的形状和物体。池化层有助于巩固特征表示并提供平移不变性。
最终的全连接层将这些学到的特征表示用于分类。对于图像分类任务,输出层通常使用 softmax 激活函数来生成类别的概率分布。
在 PyTorch 中,我们可以定义卷积层、池化层和全连接层来构建 CNN 架构。以下是一些示例代码:
# Conv layers
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size)
# Pooling layer
self.pool = nn.MaxPool2d(kernel_size)
# Fully-connected layers
self.fc1 = nn.Linear(in_features, out_features)
self.fc2 = nn.Linear(in_features, out_features)
然后我们可以在图像数据上训练 CNN,使用反向传播和优化。卷积层和池化层将自动学习有效的特征表示,使网络在视觉任务上表现出色。
入门 CNN
在这一部分,我们将加载 CIFAR10 数据集,并使用 PyTorch 构建和训练一个基于 CNN 的分类模型。CIFAR10 数据集提供了十个类别的 32x32 RGB 图像,非常适合测试图像分类模型。共有十个类别,标记为整数 0 到 9。
注意: 示例代码是来自 MachineLearningMastery.com 博客的修改版本。
首先,我们将使用 torchvision 下载和加载 CIFAR10 数据集。我们还将使用 torchvision 将测试集和训练集转换为张量。
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
transform = torchvision.transforms.Compose(
[torchvision.transforms.ToTensor()]
)
train = torchvision.datasets.CIFAR10(
root="data", train=True, download=True, transform=transform
)
test = torchvision.datasets.CIFAR10(
root="data", train=False, download=True, transform=transform
)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to data/cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [00:10<00:00, 15853600.54it/s]
Extracting data/cifar-10-python.tar.gz to data
Files already downloaded and verified
之后,我们将使用数据加载器将图像分成批次。
batch_size = 32
trainloader = torch.utils.data.DataLoader(
train, batch_size=batch_size, shuffle=True
)
testloader = torch.utils.data.DataLoader(
test, batch_size=batch_size, shuffle=True
)
为了在图像的一批中可视化图像,我们将使用 matplotlib 和 torchvision 实用函数。
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
def show_batch(dl):
for images, labels in dl:
fig, ax = plt.subplots(figsize=(12, 12))
ax.set_xticks([]); ax.set_yticks([])
ax.imshow(make_grid(images[:64], nrow=8).permute(1, 2, 0))
break
show_batch(trainloader)
正如我们所见,我们有汽车、动物、飞机和船只的图像。

接下来,我们将构建我们的 CNN 模型。为此,我们需要创建一个 Python 类并初始化卷积层、最大池化层和全连接层。我们的架构包含 2 个卷积层以及池化和线性层。
初始化后,我们不会在前向函数中按顺序连接所有层。如果你是 PyTorch 新手,你应该阅读 可解释的 PyTorch 神经网络 来详细了解每个组件。
class CNNModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=(3,3), stride=1, padding=1)
self.act1 = nn.ReLU()
self.drop1 = nn.Dropout(0.3)
self.conv2 = nn.Conv2d(32, 32, kernel_size=(3,3), stride=1, padding=1)
self.act2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=(2, 2))
self.flat = nn.Flatten()
self.fc3 = nn.Linear(8192, 512)
self.act3 = nn.ReLU()
self.drop3 = nn.Dropout(0.5)
self.fc4 = nn.Linear(512, 10)
def forward(self, x):
# input 3x32x32, output 32x32x32
x = self.act1(self.conv1(x))
x = self.drop1(x)
# input 32x32x32, output 32x32x32
x = self.act2(self.conv2(x))
# input 32x32x32, output 32x16x16
x = self.pool2(x)
# input 32x16x16, output 8192
x = self.flat(x)
# input 8192, output 512
x = self.act3(self.fc3(x))
x = self.drop3(x)
# input 512, output 10
x = self.fc4(x)
return x
我们现在将初始化我们的模型,设置损失函数和优化器。
model = CNNModel()
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
在训练阶段,我们将训练我们的模型 10 个 epoch。
-
我们使用模型的前向函数进行前向传播,然后使用损失函数进行反向传播,最后更新权重。这一步骤在所有类型的神经网络模型中几乎是相似的。
-
之后,我们使用测试数据加载器在每个训练轮次结束时评估模型性能。
-
计算模型的准确性并打印结果。
n_epochs = 10
for epoch in range(n_epochs):
for i, (images, labels) in enumerate(trainloader):
# Forward pass
outputs = model(images)
loss = loss_fn(outputs, labels)
# Backward pass and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
correct = 0
total = 0
with torch.no_grad():
for images, labels in testloader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Epoch %d: Accuracy: %d %%' % (epoch,(100 * correct / total)))
我们的简单模型达到了 57% 的准确率,这个结果并不好。但是,你可以通过添加更多层、增加训练轮次以及优化超参数来提高模型性能。
Epoch 0: Accuracy: 41 %
Epoch 1: Accuracy: 46 %
Epoch 2: Accuracy: 48 %
Epoch 3: Accuracy: 50 %
Epoch 4: Accuracy: 52 %
Epoch 5: Accuracy: 53 %
Epoch 6: Accuracy: 53 %
Epoch 7: Accuracy: 56 %
Epoch 8: Accuracy: 56 %
Epoch 9: Accuracy: 57 %
使用 PyTorch,你不必从头创建卷积神经网络的所有组件,因为这些组件已经存在。如果使用 torch.nn.Sequential,事情会变得更加简单。PyTorch 被设计为模块化,并在构建、训练和评估神经网络方面提供了更大的灵活性。
结论
在这篇文章中,我们探讨了如何使用 PyTorch 构建和训练一个卷积神经网络进行图像分类。我们涵盖了 CNN 架构的核心组件——用于特征提取的卷积层、用于降采样的池化层和用于预测的全连接层。
我希望这篇文章提供了一个有用的概述,介绍了如何使用 PyTorch 实现卷积神经网络。卷积神经网络(CNN)是深度学习中计算机视觉的基础架构,而 PyTorch 使我们能够灵活地快速构建、训练和评估这些模型。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些面临心理健康问题的学生开发一个 AI 产品。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号