KDNuggets-博客中文翻译-二十五-
KDNuggets 博客中文翻译(二十五)
原文:KDNuggets
数学 2.0:机器学习的基本重要性
原文:
www.kdnuggets.com/2021/09/math-fundamental-importance-machine-learning.html
评论
由 Dr. Claus Horn,人工智能研究员和讲师

一些人,特别是在当前数据科学的热潮中,将机器学习视为仅仅是另一种算法。它是数字化的一部分,帮助我们自动化事务,仅此而已。不幸的是,这种解释完全忽略了主要的观点。机器学习不仅仅是编程计算机的另一种方式;它代表了我们理解世界方式的根本转变。它是数学 2.0。
科学理论通过建立世界的模型来帮助我们理解世界。它们的有用性在于它们允许我们对未来做出预测。直到历史上的这一点,我们对世界的最复杂模型都是用数学语言(数学 1.0)编写的。现在这一点正在发生变化。即将到来的科学模型将是机器学习模型(可能是神经网络):数学 2.0。
原因在于机器学习模型允许我们描述更高复杂度的现象。我们在数学理论中能够描述的功能关系非常有限,相比之下,例如现代深度学习能够很好地将一万像素值映射到狗或猫的概念。
回到 2003 年,在我攻读物理学博士学位期间,我们在扫描几拍字节的数据时,寻找新型基本粒子的迹象,这些数据记录在德国高能物理中心 DESY(当时是世界上最大的数据库之一,谷歌成立才五年)。
我们发现,对观测变量应用独立选择的常规过程有些乏味,因为在改变一个变量的切割之后,我们必须重新检查所有其他变量。因此我们想:我们能否自动化这个过程?事实上,我们想到的一个简单算法允许我们自动优化选择。后来我们发现,计算机科学家有一个术语来形容我们所做的事情:他们称之为机器学习。
很快,这种新方法显然意味着我们需要调整我们的科学工作流程。与其利用所有物理学知识来增加信号与背景的比率,不如仅做最小限度的清理切割,让算法来完成工作。后来,随着深度学习的出现,CERN 的研究人员意识到,即使是物理量的重建也是适得其反的。仅凭原始测量数据,深度学习能够超越任何人工选择的物理学家(见下图)。因此,数学 2.0 让我们能看到基于数学 1.0 的模型无法看到的粒子。

图 1: 基于低级特征(黑色)和物理学家通常使用的高级特征(红色)的深度学习算法性能比较。 (图取自参考文献 1 的 2014 年《自然》论文。)
人们一直在疑惑为何大多数物理模型非常简单,大多数情况下仅涉及三次或更低次的多项式。也许原因在于我们只能看到我们能够用语言表达的内容。
物理学中发生的事情现在也发生在其他领域:一段给定的氨基酸序列总是以相同的方式折叠。在这里有很多规律性!实际上,是蛋白质的结构决定了它的功能。然而,我们无法产生一个数学函数来描述这种关系。但我们可以构建一个能够做到这一点的机器学习模型。 构建这样一个模型是一个重要的里程碑,因此有关于 AlphaFold(这个模型的名称)是否值得诺贝尔奖的猜测。
由于 Math 2.0 让我们描述比 Math 1.0 更复杂的关系,未来十年可能会看到生物学的转变。数字生物学将用 Math 2.0 的语言书写。其他科学领域中也会有许多机会,特别是那些关系更复杂的领域,如社会科学。
因此,掌握 Math 2.0 的语言应该是每个学术课程的核心组成部分,也是每位学生,尤其是在科学领域的学生,的基本能力。
当然,科学理论不仅仅是数学。主要的困难在于找到合适的概念和量来描述给定范围的现象。这一点不会改变。但数学不仅帮助我们建立模型和推导预测。它还允许我们通过代数计算和推导新的简化洞察,并通过微积分回答关于系统动态的问题。
我们仍处于 Math 2.0 革新的起始阶段,但我预测,与数学的发展类似,我们将会看到一个新领域的出现,这个领域将研究机器学习模型的系统及其构建方式、自动优化自身的方式,以及如何利用这些模型获得新的洞察,使我们以新的视角看待世界。
这些发展将带来科学计算的下一层次,并为我们提供一种新的科学方法,这要归功于 Math 2.0。
参考文献:
- Baldi, P., Sadowski, P. & Whiteson, D. 利用深度学习在高能物理中寻找奇异粒子。Nat Commun 5, **4308 (2014)。 https://doi.org/10.1038/ncomms5308
个人简介: Dr. Claus Horn 是一位人工智能领域的研究员和讲师,他相信 21 世纪人类条件进步的最高潜力存在于人工智能与生命科学的交汇点。
原文。经许可转载。
相关:
-
机器学习如何利用线性代数解决数据问题
-
反脆弱性与机器学习
-
自然语言处理中的线性代数
我们的三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业生涯。
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
更多相关话题
机器学习数学:免费电子书
原文:
www.kdnuggets.com/2020/04/mathematics-machine-learning-book.html

图片来源于 Freepik
数学是机器学习的基础,对理解该领域的根基至关重要。要成功成为一名机器学习从业者,掌握相关的数学基础是绝对必要的。你可以转向哪里来复习机器学习数学,或通过扩展基础来加深理解?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
机器学习数学 是由 Marc Peter Deisenroth、A Aldo Faisal 和 Cheng Soon Ong 合著的一本书,旨在激励人们学习数学概念,由剑桥大学出版社出版。根据作者的说法,该书的目标是提供必要的数学技能,以便后续阅读更高级的机器学习主题书籍。
直接来自书中的页面:
虽然机器学习取得了许多成功故事,并且有丰富的可用软件来设计和训练灵活的机器学习系统,但我们认为机器学习的数学基础对于理解更复杂的机器学习系统所建立的基本原则是重要的。理解这些原则可以促进创造新的机器学习解决方案,理解和调试现有的方法,并了解我们所使用方法的固有假设和限制。
《机器学习数学》分为两个部分:
-
数学基础
-
使用数学基础的机器学习算法示例
目录内容如下:
第一部分:数学基础
-
引言和动机
-
线性代数
-
解析几何
-
矩阵分解
-
向量微积分
-
概率与分布
-
连续优化
第二部分:核心机器学习问题
-
当模型遇见数据
-
线性回归
-
使用主成分分析的降维
-
使用高斯混合模型的密度估计
-
使用支持向量机的分类
显然,书的第一部分涵盖了纯数学概念,没有涉及机器学习。第二部分则将注意力转向将这些新获得的数学技能应用于机器学习问题。根据你的需求,你可以选择自上而下或自下而上的方式来学习机器学习及其基础数学,或者选择其中一部分作为重点。

图片来自机器学习数学
你可以在这里下载该书的 PDF。该书已经出版并可以购买纸质版,作者们还将继续提供免费可下载的 PDF 版本。
该书旨在提供一本简短而精炼的书籍,并通过练习和 Jupyter 笔记本进行补充。要了解更多信息,你可以在这里找到配套网站。
担心这本书是否值得你的时间?不要只听我的话;看看这些重量级人物怎么说:
这本书很好地覆盖了机器学习所需的所有基本数学概念。我期待与学生、同事以及任何有兴趣建立扎实基础的人分享它。”
—乔厄尔·皮诺,麦吉尔大学和 Facebook
“近年来,机器学习领域得到了极大的发展,成功应用的范围也越来越广。这本综合性的教材涵盖了现代机器学习的关键数学概念,重点关注线性代数、微积分和概率论。无论是作为新手教程还是机器学习研究人员和工程师的参考书,它都将非常有价值。”
—克里斯托弗·比晓普,微软研究院剑桥
“这本书提供了对现代机器学习背后的数学的精彩阐述。强烈推荐给任何想要深入了解机器学习基础的人。”
—皮特·阿贝尔,加州大学伯克利分校
我希望你觉得这本书和其他人一样有用。
马修·梅奥 (@mattmayo13)是一名数据科学家,同时也是 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和机器学习的自动化方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关主题
一个 IT 工程师需要学习多少数学才能进入数据科学领域?
原文:
www.kdnuggets.com/2017/12/mathematics-needed-learn-data-science-machine-learning.html
 评论
评论

免责声明和前言
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
首先,免责声明,我不是 IT 工程师 😃 我在半导体领域工作,专注于高功率半导体,作为技术开发工程师,我的日常工作主要涉及半导体物理、硅制造过程的有限元模拟或电子电路理论。当然,这项工作中确实涉及一些数学,但无论好坏,我并不需要涉及数据科学家所需的那种数学。
然而,我有许多 IT 行业的朋友,并且观察到许多传统的 IT 工程师对学习/贡献于数据科学和机器学习/人工智能这个激动人心的领域充满热情。我自己也在涉足这个领域,学习一些可以应用于半导体器件或工艺设计领域的技巧。但当我开始深入研究这些激动人心的主题(通过自学)时,我很快发现自己不知道/只对/大多忘记了本科时学习的一些基本数学知识。在这篇 LinkedIn 文章中,我聊了聊这个话题...
现在,我拥有一所美国知名大学的电气工程博士学位,但仍然觉得自己在准备扎实掌握机器学习或数据科学技术时感到不够全面,因为没有对一些必要的数学知识进行复习。我并无意冒犯 IT 工程师,但我必须说,他/她的工作性质和长期的培训通常使他/她与应用数学的世界保持距离。他/她可能每天处理大量数据和信息,但可能不会强调对这些数据的严格建模。通常情况下,时间压力很大,重点放在“用数据满足你即时的需求然后继续前进”而不是对数据进行深入探究和科学探索。不幸的是,数据科学应该始终关于科学(而非数据),按照这个思路, 某些工具和技术变得不可或缺。
这些工具和技术——通过探查潜在动态建模一个过程(物理或信息),严格估计数据源的质量,训练识别信息流中隐藏模式的能力,或明确理解模型的局限性——是健全科学过程的标志。
这些内容通常在应用科学/工程学科的高级研究生课程中教授。或者,通过类似领域的高质量研究生级别的研究工作也可以掌握。不幸的是,即便在传统 IT(开发运维、数据库或质量保证/测试)领域拥有十年的职业生涯,也不足以严格传授这类培训。简单来说,这没有必要。
时代在变迁
直到现在。
你看,在大多数情况下,拥有无可挑剔的 SQL 查询知识、清晰的整体业务需求感和对相应关系型数据库管理系统的一般结构的了解,对于执行提取-转换-加载周期并为公司创造价值来说,已经足够了。但如果有人突然出现,开始问一些奇怪的问题,比如“你的人工合成测试数据集足够随机吗”或“你如何知道下一个数据点是否在你数据的底层分布的 3-sigma 范围内”?或者,甚至是隔壁计算机科学毕业生/极客偶尔的调侃,即“与数据表(即矩阵)相关的任何有意义的数学操作的计算负荷随着表的大小(即行和列的数量)的增加呈非线性增长”,可能会让人感到沮丧和困惑。
而且,这些类型的问题正在越来越频繁和紧迫地出现,仅仅因为数据是新的货币。
高管、技术经理、决策者已经不满足于仅仅通过传统 ETL 工具获得的干巴巴的表格描述。他们想要看到隐藏的模式,渴望感受到列之间的微妙互动,希望获取完整的描述性和推断性统计数据,这些数据可能有助于预测建模并将数据集的投影能力扩展到超出其包含的值的即时范围之外。
今天的数据必须讲述一个故事,或者,如果你愿意,可以唱一首歌。然而,要听到它美妙的旋律,人们必须掌握音乐的基本音符,并且
那些是数学真理。
不再赘述,让我们来探讨核心问题。一个普通的 IT 工程师如果想进入商业分析/数据科学/数据挖掘领域,必须学习/复习哪些基本数学主题/子主题?我将在下面的图表中展示我的想法。

基础代数、函数、集合论、绘图、几何学

从根本开始总是一个好主意。现代数学的建筑基于一些关键基础——集合论、泛函分析、数论等。从应用数学学习的角度来看,我们可以通过一些简明的模块(没有特定顺序)来简化这些主题的学习:

a) 集合论基础,b) 实数和复数及其基本性质,c) 多项式函数、指数、对数、三角恒等式,d) 线性和二次方程,e) 不等式、无穷级数、二项式定理,f) 排列和组合,g) 图形绘制和绘图,笛卡尔坐标系和极坐标系,圆锥曲线,h) 基本几何学和定理,三角形性质。
微积分
艾萨克·牛顿想要解释天体的运动。然而,他没有足够好的数学工具来描述他的物理概念。因此,他在隐藏在乡村农场避开城市英国的瘟疫爆发时发明了这一分支数学(或某种现代形式的数学)。从那时起,它被认为是任何分析研究——无论是纯科学还是应用科学、工程学、社会科学、经济学等领域高级学习的入口。

因此,微积分的概念和应用出现在数据科学或机器学习领域的许多地方也就不足为奇了。需要覆盖的最重要主题如下 -
a) 单变量函数、极限、连续性和可微性;b) 平均值定理、不确定形式和 L'Hospital 法则;c) 极值和最小值;d) 积分和链式法则;e) 泰勒级数;f) 积分学的基本和平均值定理;g) 定积分和不定积分的计算;h) 贝塔函数和伽马函数;i) 二变量函数、极限、连续性、偏导数;j) 常微分方程和偏微分方程的基础知识。
线性代数
在 Facebook 上收到新的朋友建议?一个久未联系的专业联系人突然在 LinkedIn 上添加了你?Amazon 突然为你的下次假期阅读推荐了一本绝佳的浪漫惊悚小说?或者 Netflix 挖掘出一部你正好合口味的小众纪录片?

知道如果你学习线性代数的基础知识,你将掌握关于技术行业那些高人一等的人所利用的基本数学对象的知识,这不是很棒吗?
至少,你将了解控制你在 Target 上购物、使用 Google Map 驾驶、在 Pandora 上听的歌曲,或在 Airbnb 上租房的数学结构的基本属性。
需要学习的基本主题包括(这不是一个有序或详尽的列表):
a) 矩阵和向量的基本属性——标量乘法、线性变换、转置、共轭、秩、行列式;b) 内积和外积;c) 矩阵乘法规则和各种算法;d) 矩阵的逆;e) 特殊矩阵——方阵、单位矩阵、三角矩阵、稀疏矩阵和密集矩阵的概念、单位向量、对称矩阵、厄米矩阵、反厄米矩阵和单位矩阵;f) 矩阵分解概念/LU 分解、高斯/Gauss-Jordan 消去法、解 Ax=b 线性方程组;g) 向量空间、基、张成、正交性、正交归一性、线性最小二乘法;h) 奇异值分解;i) 特征值、特征向量和对角化。
这里有一篇很好的 Medium 文章,讲述了你可以用线性代数完成的事情。
统计学与概率
死亡和税收是唯一确定的,其余的都遵循正态分布。

在讨论数据科学时,掌握统计学和概率学基本概念的重要性不容低估。许多从业者实际上称机器学习不过是统计学习。我在做我的第一个机器学习 MOOC 时,跟随了广为人知的“统计学习导论”,并立即意识到自己在这个主题上的概念缺口。为了弥补这些缺口,我开始参加其他关注基础统计学和概率学的 MOOC,并阅读/观看相关主题的视频。这个领域广泛而无尽,因此有针对性的规划对于覆盖最重要的概念至关重要。我尽力列出这些内容,但我担心这是我最可能短缺的领域。
a) 数据摘要和描述统计、集中趋势、方差、协方差、相关性,b) 概率:基本概念、期望、概率计算、贝叶斯定理、条件概率,c) 概率分布函数——均匀分布、正态分布、二项分布、卡方分布、学生 t 分布、中心极限定理,d) 抽样、测量、误差、随机数,e) 假设检验、A/B 测试、置信区间、p 值,f) 方差分析,g) 线性回归,h) 效能、效应量、均值检验,i) 研究研究和实验设计。
这里有一篇关于数据科学家统计知识必要性的不错文章。
专题:优化理论,算法分析
这些主题与传统的应用数学讨论略有不同,因为它们主要与理论计算机科学、控制理论或运筹学等专业领域相关且广泛使用。然而,基本理解这些强大技术的能力在机器学习实践中非常有用,因此值得在这里提及。

例如,几乎每种机器学习算法/技术都旨在最小化某种估计误差,并受各种约束条件的限制。这本身就是一个优化问题,通常通过线性规划或类似技术来解决。另一方面,理解计算机算法的时间复杂度总是一种令人满足和洞察力深刻的体验,因为当算法应用于大数据集时,时间复杂度变得极其重要。在这个大数据时代,数据科学家通常需要提取、转换和分析数十亿条记录,他/她必须非常小心选择合适的算法,因为这可能意味着从惊人的表现到彻底失败的差异。算法的一般理论和属性最好在正式的计算机科学课程中学习,但要理解它们的时间复杂度(即,算法在给定数据大小下运行所需的时间)如何分析和计算,一个必须具备对数学概念如动态规划或递归方程的基础了解。对数学归纳法证明的熟悉也可能非常有帮助。
后记
感到害怕?学习这些作为前提的主题让你感到困惑?不要担心,你会边学边用。目标是保持你的思维窗户和大门开放,欢迎新知识。
甚至有一个简明的MOOC 课程来帮助你入门。请注意,这是一个针对高中或大一水平知识的初学者课程。这里还有一篇关于数据科学的 15 个最佳数学课程的总结文章在 kdnuggets 网站上。
但你可以放心,在复习这些话题后,许多你可能在本科时学过的,或者即使是学习新概念,你会感到如此充满力量,以至于你肯定会开始听到数据所唱的隐秘音乐。这就意味着你向成为数据科学家的目标迈出了重要的一步……
#数据科学, #机器学习, #信息, #技术, #数学
如果你有任何问题或想法,请联系作者,邮箱地址是tirthajyoti[AT]gmail.com。你也可以查看作者的GitHub 库获取其他有趣的 Python、R 或 MATLAB 代码片段和机器学习资源。你也可以在 LinkedIn 上关注我。
简介:Tirthajyoti Sarkar 是一位半导体技术专家、机器学习/数据科学爱好者、电子工程博士、博客作者和作家。
原文。经许可转载。
相关:
-
为什么你应该忘记数据科学代码中的‘for-loop’,而应该拥抱向量化
-
15 门用于数据科学的数学 MOOC 课程
-
回归分析真的属于机器学习吗?
更多相关话题
通过反复试验建立机器学习模型
原文:
www.kdnuggets.com/2018/09/mathworks-building-machine-learning-model-through-trial-error.html
赞助文章。
由 Seth DeLand, 产品营销经理, 数据分析,MathWorks
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
机器学习的路线图充满了反复试验。对于概念新手的工程师和科学家来说,他们将不断调整和改变他们的算法和模型。在这个过程中,挑战将会出现,特别是在处理数据和确定正确模型时。
在构建机器学习模型时,了解现实世界的数据是不完美的,不同类型的数据需要不同的方法和工具,并且在确定正确模型时总会有权衡。
以下系统化工作流程描述了如何开发一个用于手机健康监测应用的训练模型,该应用跟踪用户一天中的活动。输入由手机的传感器数据组成。输出将是执行的活动:行走、站立、坐着、跑步或跳舞。由于目标是分类,这个示例将涉及 监督学习。
获取和加载数据
用户将坐下并持有手机,记录传感器数据,并将其存储在标记为“sitting”的文本文件中。然后,他们应站立持手机,记录传感器数据,并将其存储在标记为“standing”的文本文件中。对于跑步、行走和跳舞也如此操作。
预处理数据
由于机器学习算法无法区分噪声和有价值的信息,因此必须在训练前清理数据。数据可以通过数据分析工具进行预处理,如 MATLAB。为了清理数据,用户可以导入和绘制数据,并去除异常值。在此示例中,异常值可能是由于在加载数据时不小心移动了手机。用户还必须检查缺失的数据,这些数据可以通过近似值或来自另一个样本的可比数据来替换。
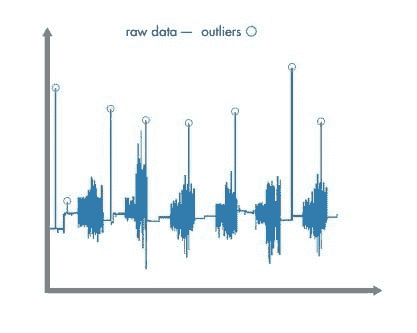 图 1:数据预处理包括移除任何异常值,即那些位于数据其余部分之外的数据点。清理后,将数据分成两部分。一半用于训练模型,另一半用于测试和交叉验证。
图 1:数据预处理包括移除任何异常值,即那些位于数据其余部分之外的数据点。清理后,将数据分成两部分。一半用于训练模型,另一半用于测试和交叉验证。
使用预处理数据提取特征
原始数据必须转化为机器学习算法可以使用的信息。为此,用户必须提取能够对电话数据内容进行分类的特征。
在这个例子中,工程师和科学家必须区分特征,以帮助算法在步行(低频率)和跑步(高频率)之间进行分类。
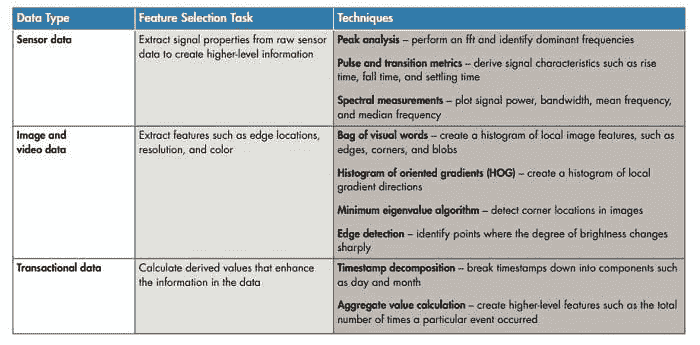 图 2:从数据类型中提取特征将原始数据转化为可以用于机器学习模型的高级信息。构建和训练模型
图 2:从数据类型中提取特征将原始数据转化为可以用于机器学习模型的高级信息。构建和训练模型
从一个简单的决策树开始。
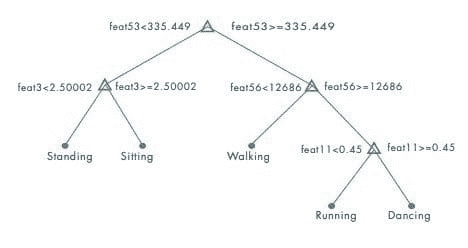 图 3:决策树根据特征特性建立分类参数。绘制混淆矩阵以观察其性能。
图 3:决策树根据特征特性建立分类参数。绘制混淆矩阵以观察其性能。 图 4:这个矩阵展示了一个在区分跑步和跳舞方面有困难的模型。根据上述混淆矩阵,这表明要么决策树不适用于这种数据,要么应使用不同的算法。
图 4:这个矩阵展示了一个在区分跑步和跳舞方面有困难的模型。根据上述混淆矩阵,这表明要么决策树不适用于这种数据,要么应使用不同的算法。
K 最近邻(KNN)算法存储所有训练数据,将新点与训练数据进行比较,并返回“K”个最近点中最频繁的类别。这显示出更高的准确性。
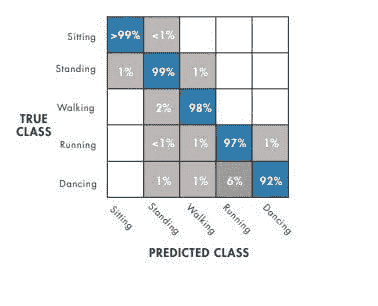 图 5:将 KNN 算法进行更改可以提高准确性——尽管仍有进一步改进的空间。另一种选择是多类支持向量机(SVM)。
图 5:将 KNN 算法进行更改可以提高准确性——尽管仍有进一步改进的空间。另一种选择是多类支持向量机(SVM)。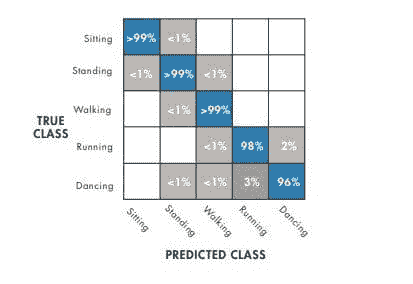 图 6:SVM 表现很好,几乎所有活动的准确率都达到了 99%。这被证明效果更好,并展示了通过反复试验达成目标的过程。
图 6:SVM 表现很好,几乎所有活动的准确率都达到了 99%。这被证明效果更好,并展示了通过反复试验达成目标的过程。
改进模型
如果模型不能可靠地区分跳舞和跑步,则需要进行改进。可以通过使模型更复杂(以更好地适应数据)或更简单(以减少过拟合的可能性)来改进模型。
为了简化模型,可以通过以下方法减少特征数量:相关矩阵,以便可以移除相关性不高的特征;主成分分析(PCA)以消除冗余;或顺序特征减少,重复减少特征直到没有进一步改进。为了使模型更复杂,工程师和科学家可以将多个简单模型合并为一个更大的模型或添加更多数据源。
一旦训练和调整完成,可以使用在预处理期间预留的“留出”数据集来验证模型。如果模型能够可靠地分类活动,那么它就准备好用于手机应用程序了。
对于第一次训练机器学习模型的工程师和科学家来说,会遇到挑战,但应该意识到试错是过程的一部分。上述工作流程提供了构建机器学习模型的路线图,这些模型还可以用于预测维护、自然语言处理和自动驾驶等各种应用。
探索这些其他资源,深入了解机器学习方法和示例。
-
监督学习工作流程和算法:了解监督学习过程中的工作流程和步骤。
-
MATLAB 机器学习示例:通过探索示例、文章和教程开始机器学习之旅。
-
MATLAB 中的机器学习:下载这本电子书,提供机器学习基础知识的逐步指南以及高级技术和算法。
更多相关主题
常见的机器学习障碍
原文:
www.kdnuggets.com/2019/09/mathworks-common-machine-learning-obstacles.html
赞助文章。
作者:Seth DeLand,MathWorks 数据分析产品营销经理
从事机器学习建模的工程师和科学家在处理数据时常常面临挑战。两个最常见的障碍与选择合适的分类模型和消除数据过拟合有关。
分类模型根据特定特征集将项目分配到离散组或类别。由于每个数据集的独特性和期望结果,确定最佳分类模型通常会遇到困难。过拟合发生在模型与可能包含噪声或错误的有限训练数据过于贴合时。过拟合的模型无法很好地推广到训练集之外的数据,限制了其在生产系统中的实用性。

图 1:分类学习器应用程序用于训练和比较各种分类器。© 1984–2019 The MathWorks, Inc.
通过整合可扩展的软件工具和机器学习技术,工程师和科学家可以识别最佳模型并防止过拟合。
选择分类模型
分类模型类型可能具有挑战性,因为每种模型类型都有其自身的特点,这可能是根据问题的不同而成为优势或劣势。
首先,你必须回答一些关于数据类型和用途的问题:
-
这个模型的目的是什么?
-
数据有多少?是什么类型的数据?
-
需要多少细节?存储是否是限制因素?
回答这些问题可以帮助缩小选择范围并选择正确的分类模型。工程师和科学家可以使用交叉验证来测试模型评估数据的准确性。经过交叉验证后,你可以选择最合适的分类模型。
分类模型有很多种类型,这里列出了五种常见类型:
-
逻辑回归:由于其简单性,这个模型通常被用作基准。它用于数据可以被分类为两个可能类别的问题。逻辑回归模型返回每个数据点属于各个类别的概率。
-
k-最近邻 (kNN):这种简单而有效的分类方法根据数据点与训练数据集中其他点的距离来对数据点进行分类。kNN 的训练时间较短,但除非对数据应用权重,否则该模型可能会将无关属性误认为重要属性,特别是在数据点数量增加时。
-
决策树:这些模型通过视觉方式预测响应,从根到叶的决策路径相对容易跟随。当展示结论如何得出时,这种类型的模型特别有用。
-
支持向量机(SVM):该模型使用超平面将数据分为两个或更多类别。它准确,不容易过拟合,并且相对容易解释,但对于较大的数据集,训练时间可能较长。
-
人工神经网络(ANNs):这些网络可以配置和训练以解决各种不同的问题,包括分类和时间序列预测。然而,训练后的模型通常难以解释。
工程师和科学家可以通过使用可扩展的软件工具来简化决策过程,以确定哪个模型最适合一组特征,评估分类器性能,比较和提高模型准确性,并最终导出最佳模型。这些工具还帮助用户探索数据,选择特征,指定验证方案,并训练多个模型。

图 2:深度神经网络的训练进度,显示训练集和验证集的准确性和损失。© 1984–2019 The MathWorks, Inc.
消除数据过拟合
过拟合发生在模型适应特定数据集但对新数据的泛化能力较差时。过拟合通常难以避免,因为它通常是训练数据不足的结果,特别是当负责模型的人没有收集数据时。避免过拟合的最佳方法是使用足够的训练数据来准确反映模型的多样性和复杂性。
数据正则化和泛化是工程师和科学家可以应用的两种额外方法来检查过拟合。正则化是一种防止模型过度依赖个别数据点的技术。正则化算法向模型引入额外信息,并通过使模型更简洁和准确来处理多重共线性和冗余预测变量。这些算法通常通过对复杂度施加惩罚来工作,例如将模型的系数添加到最小化中或包括粗糙度惩罚。
泛化将可用数据分成三个子集。第一个是训练集,第二个是验证集。在训练过程中监控验证集上的误差,并对模型进行微调直到准确。第三个子集是测试集,用于在训练和交叉验证阶段后对完全训练的分类器进行测试,以检验模型是否未过拟合训练和验证数据。
有六种交叉验证方法可以帮助防止过拟合:
-
k-fold: 将数据划分为 k 个随机选择的子集(或折叠),每个子集大小大致相等,其中一个子集用于验证用其余子集训练的模型。这个过程重复 k 次,因为每个子集在验证中使用一次。
-
Holdout: 将数据分为指定比例的两个子集,用于训练和验证。
-
Leave one out: 使用 k-fold 方法对数据进行分割,其中 k 等于数据中的总观察数。
-
Repeated random subsampling: 执行蒙特卡罗重复实验,随机分隔数据并汇总所有运行的结果。
-
Stratify: 将数据分割,使得训练集和测试集在响应或目标的类别比例上大致相同。
-
Resubstitution: 使用训练数据进行验证而不进行分离。这种方法往往会产生过于乐观的性能估计,如果数据量足够,应避免使用。
机器学习的老手和初学者在分类和过拟合方面都可能遇到问题。尽管机器学习中的挑战可能显得令人生畏,但利用正确的工具和使用本文介绍的验证方法将帮助工程师和科学家更轻松地将机器学习应用于现实世界的项目中。
要了解更多关于分类建模和过拟合的信息,以及 MATLAB 如何帮助克服这一机器学习挑战,请参见下面的链接或通过电子邮件联系我 sdeland@mathworks.com。
-
试用分类学习器应用程序: 通过在浏览器中运行 MATLAB 来创建和训练机器学习模型。
-
分类示例: 查看这些 25 个分类示例,包括判别分析和朴素贝叶斯。
-
提高浅层神经网络的泛化能力并避免过拟合: 这是一个过拟合的示例。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面的工作
更多相关话题
将预测性维护从理论转向实践
原文:
www.kdnuggets.com/2019/12/mathworks-predictive-maintenance-theory-practice.html
赞助文章。
由 Philipp H. F. Wallner,工业自动化与机械行业经理,MathWorks
如今你经常听到预测性维护及其价值。它是一个理想的状态,设备操作员可以预测即将发生的故障,预先安排维修,最小化对工厂操作的干扰,最重要的是,保护设备免受灾难性故障。我们都能欣然接受预测性维护的价值,或者我应该说预测性维护的预期价值?
当谈到在现场设备上实施预测性维护时,我们的明亮眼睛很快失去了光泽。事实证明,少数公司实际实施了预测性维护,这引发了一个问题,为什么会这样?
在与行业领袖的对话中,存在一个一致的主题,即设备制造商和操作员必须克服的四个关键挑战,以便成功地与数据科学界合作并在操作中实施预测性维护解决方案:
1. 促进合作以利用现有领域知识,同时设计算法。 公司如何帮助促进数据科学家与领域专家之间的合作,以便设计出基于统计方法结合领域知识的强大预测性维护算法?数据科学家和领域专家如何紧密合作,以确保每个强大预测性维护应用的关键组成部分——数据分析方法和领域知识——都得到充分利用?
成功的预测性维护应用程序结合了:基于统计的数据分析方法,如机器学习,以及研发工程师对设备的领域专业知识(在许多情况下,已经在仿真模型中捕获)。仅用数据分析方法来处理预测性维护将会遗漏工程和运营团队中持有的重要信息,这些团队负责构建和支持设备。
2. 在缺乏故障数据的情况下训练算法。 机器学习的一个关键方面是使用来自现场的数据来训练算法。这包括来自正常生产使用的“好”数据以及捕获的故障数据,用于各种操作设备时可能出现的错误场景。但是,当目标是避免设备首先出现故障时,你从哪里获得故障数据呢?
对于将预测性维护应用于从风力涡轮机到空气压缩机等工业系统的组织来说,这成为了一个日益重要的难题。作为解决这一困境的途径,可以使用模拟模型生成合成故障数据,以在缺乏现场测量故障数据的情况下训练算法。

图 1. 一个用于训练故障分类机器学习算法以克服缺乏测量故障数据的三重泵模拟模型,位于 Simulink 和 Simscape 中。© 1984–2019 The MathWorks, Inc.
3. 部署用于运行中的算法。 一旦预测性维护算法在桌面上完成设计和训练,就需要将其部署到设备上。此步骤的工作量高度依赖于现有的 IT 和 OT 基础设施。虽然有些算法在实时硬件平台上实现(例如,嵌入式控制器、工业 PC 或 PLC),但其他算法将被集成到现有的非实时基础设施中(例如,运行 Windows 或 Linux 的边缘设备)或在云中。越来越多的公司选择使用能够自动生成 C 或 IEC 61131-3 代码、.NET 组件或独立可执行文件的工具链,例如这家国际包装和纸品制造商,它使用预测性维护软件来减少塑料制造厂的废料和机器停机时间。

图 2. 一个基于 MATLAB 的人机界面(HMI),使设备操作员在故障发生之前能够接收潜在故障的警告。© 1984–2019 The MathWorks, Inc.
4. 制定预测性维护的商业案例。 每个公司在开始实施预测性维护之前必须能够回答的主要问题是,我将如何通过此方法产生收入?
如果你无法回答这个“关键问题”,你为建立复杂的预测性维护解决方案所做的所有努力将很快陷入停滞。了解你的商业案例并制定预测性维护的货币化策略,将有助于说服公司管理层为实施预测性维护应用程序的投资提供正当理由。
对于设备操作员来说,设备在运行过程中不易出现故障通常足以证明投资的合理性,但对设备制造商来说,这一案例则稍显挑战。我见到的一些有希望的想法,用于帮助建立实施预测性维护的案例包括
-
将服务费用与操作员(即他们的客户)运行的设备的预测性维护挂钩;
-
使用知识产权保护销售已部署的预测维护算法;以及
-
转向一种完全新的基于使用的商业模式(例如,销售压缩空气的立方米而不是压缩机,或电梯使用小时而不是整个电梯)。
要了解更多有关本文博客帖子中涵盖的主题的信息,请发送电子邮件至 pwallner@mathworks.com 的工业自动化与机械行业经理 Philipp H. F. Wallner,或查看以下链接:
-
预测维护(视频系列):了解更多关于预测维护的概念和工作流程。
-
使用 Simulink 生成故障数据(示例):此示例展示了如何使用仿真模型生成故障和健康数据。它使用一个传动系统,并对齿轮齿故障、传感器漂移故障和轴磨损故障进行建模。
-
Mondi 实施基于统计的健康监测和机器学习预测维护以优化制造过程(客户参考):查看 Mondi Gronau 如何减少工厂中的废料和机器停机时间,每年节省超过 50,000 欧元。
-
MATLAB 中的预测维护简介(电子书):学习如何开发你的预测维护、状态监测和异常检测算法。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
矩阵分解解读
原文:
www.kdnuggets.com/2020/12/matrix-decomposition-decoded.html
评论
由 Tanveer Sayyed, 数据科学爱好者
要理解矩阵分解,我们首先需要理解特征值(从现在开始称为 lambda)和特征向量。在理解 lambda 和特征向量的直觉之前,我们首先需要揭示在线性代数中使用矩阵和向量的目的。
那么矩阵和向量在线性代数中的目的是什么呢?
在机器学习中,我们通常关注的矩阵的列是特征。因此,我们在心中天然地将矩阵视为神圣的。现在这可能会让你感到惊讶,因为—矩阵的 目的是“作用于”(输入)向量,以给出(输出)向量! 记住线性回归的线性代数方程:
(X^T . X)^-1 . X^T **.** y **------>** coefficients
***[---m-a-t-r-i-x----] . [input vector]* ------> *[output vector]***
正确的阅读方式是——我们“应用”矩阵到一个向量(y)上,以得到输出向量(系数)。换句话说——矩阵“转换/扭曲”输入向量以成为输出向量。一个向量输入,通过矩阵变换/扭曲,输出另一个向量。这就像是微积分中的函数:一个数字 x(比如 3)输入,得到一个数字 f(x)(例如 27,如果 f(x) = x³)。
关于 lambda 和特征向量的直觉
既然矩阵的目的已经明确,那么定义特征向量就会变得容易。如果我们发现输入向量和输出向量仍然彼此平行,那么这个向量就是特征向量。这意味着它们保持了变形或未受到影响。“平行”指的是以下两种情况之一:
------------**>** ------------**>**
------------**>** **<**------------
1\. 2.
在学校里,我们被教导力是一个向量。它具有方向以及magnitude。同样,特征向量可以被看作是变形的方向,而 lambda 则是在该方向上的变形幅度。因此,矩阵被分解/因式分解(就像 6= 3*2 一样)为一个向量及其幅度,可以表示为两者的乘积:
A.x = λ x
where,
…… A is a **square** matrix,
…… x is eigenvector of A
…… λ is the scalar eigenvalue
这称为特征分解。但是我们如何找到特征向量呢?从 λs 中找! 这里是方法:
A.x - λx = 0 …. (rearranging above equation)
(A - λI) . x = 0 …. (eq.1)Now x is a non-zero vector.
In matrices, if we want the product to be equal to zero,
then the term (A - λI) must be singular! That is,
the determinant of this whole term must be = 0\.
Hence,
|A - λI| = 0 ….. (eq.2) Solve eq.2 and
substitute ‘each’ value of λ in eq.1 to get
the corresponding eigenvector for that λ.
重要的是了解和理解这些步骤,因此我们将不会手动执行这些操作,因为在numpy库中已经存在一个函数。(我们将使用这段代码来展示和重新缩放特征向量)。例如:

特征向量 e1 = [-1, 0.5] 和 e2 = [-1, -1] 是粉色的,而输出向量是绿色的。
注意 λ 的效果 [-1, 5]。λ 负责特征向量的缩放(大小的变化)。λ1 是 负的,因此我们观察到负向变换——输出向量相对于 e1 移动 相反,并且缩放为 e1 长度的 1 倍。而 λ2 是 正的,因此我们观察到正向变换——输出向量与 e2 在 相同 方向上移动,并且缩放为 e2 长度的 5 倍。
现在,在我们转向特征向量和 λ 的应用之前,让我们先了解它们的属性:
-
我们只能找到 方形 矩阵的特征向量和 λ。
-
如果 A 的形状是(n,n),则最多会有 n 个 独立的 λ 及其对应的特征向量。
--------------**>**--------------**>**--------------------------**>**------
(2,2) (4,4) (8,8)
Take the line above. We can observe 3 eigenvectors, but they are not
independent as they are just multiples of each other and are part of the **same** line x = y.
-
λ 的 和 = 矩阵的迹(对角线之和)。
-
λ 的 积 = 矩阵 A 的行列式。
-
对于 三角形 矩阵,λ 是对角线值。
-
重复的 λ 是问题的根源。每重复一个 λ,我们将减少一个独立的特征向量。
-
矩阵的 对称性 越好越好。对称矩阵意味着 A = transpose(A)。对称矩阵产生“实数” λ。随着我们从对称矩阵转向非对称矩阵,λ 开始变成复数(a + i b),因此特征向量开始映射到虚拟空间而不是实空间。尽管矩阵 A 的每个元素都是实数,但如代码所示,这种情况仍然发生。
特征向量和 λ 的应用
首先,我们需要明确特征值(λ)不是线性的。这意味着如果 x, α 和 y, β 分别是矩阵 A, B 的特征值和 λ,则:
A . B ≠ αβ (x . y),而且,A + B ≠ αx + βy。
但是当涉及到计算矩阵的幂时,即寻找 A²⁰ 或 B⁵⁰⁰ 时,它们确实很有用。如果 A, B 是小矩阵,可能可以在我们的机器上计算结果。但是想象一下一个巨大的矩阵,列数众多,那时是否可行?我们是否会重复输入 B 500 次或循环 500 次?不,因为矩阵乘法是计算密集型的。所以让我们通过讨论同一矩阵的第二种因式分解/分解方式来理解“特征量”如何提供帮助。这是从以下方程推导出的:
**S^-1 . A . S = Λ** …. (eq.3)
where,
S***** is eigenvector matrix (each eigenvector of A is a column in matrix-S)
A is our square matrix
Λ (capital lambda) is a diagonal matrix of all lambda values*****[For S to be invertible, all eigenvectors *must* be independent (the above stated property-2 must be satisfied). And by the way, **very few** matrices fulfill it].
**Now, let's get our matrix from eq.3:**
1\. Left multiplication by S --> (S.S^-1).A.S = S.Λ
--> A.S = S.Λ
2\. Right multiplication by S^-1 --> A.S.(S^-1) = S.Λ.(S^-1)
**--> A = S.Λ.S^-1
*The matrix A has thus been factorized into three terms: S and Λ and S^-1.***
Now 12² can also be calculated as squares of its prime factors viz 3² * 2² * 2².
Similarly lets also do for A²:
A² = A . A
= (S . Λ . S^-1).(S . Λ . S^-1)
= S . Λ . (S^-1 . S) . Λ . S^-1
= S . Λ . Λ . S^-1
A² = S . Λ**²**. S^-1
Generalizing as:
**A^K = S . Λ^K. S^-1**
现在看看通过因式分解计算大幂是多么方便。
现在让我们更深入地探讨一下为什么会这样。再举一个例子:
观察 F¹ 和 F⁵ 的特征向量。它们保持不变并始终指向相同的方向。因此,矩阵的幂对特征向量完全没有影响!但是观察 λ,当指数从 1 改变为 5 时;λ1 增加(1.618 到 11.09)的速度远远快于 λ2 减少(-0.618 到 -0.09)。因此 λ2 的影响几乎可以忽略不计。这表明矩阵总体上是递增的,这可以从 F⁵[5,3,3,2] 的值中验证。
由于我们知道矩阵乘法在计算上是耗时的,因此对于任何方阵,如果它的每个 |λ| < 0,则我们知道矩阵是一个稳定的矩阵;如果每个 |λ| > 0,则矩阵在膨胀,是一个不稳定的矩阵,所以最好不要继续前进。
上面的例子实际上是斐波那契矩阵,其中矩阵 F 每次自乘时会增加/扩展约1.6180399倍!我们来验证一下:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34.... is the Fibonacci Series
5 * 1.6180399 **≈** 8
8 * 1.6180399 **≈** 13
13 * 1.6180399 **≈** 21
而这个数字就是 λ 的值……这难道不是令人惊讶吗!!!
特征值(eigenvalues)的美妙之处在于,尽管它们数量非常少,但它们可以揭示矩阵/变换f函数的属性的隐藏秘密。
“特征值”的另一个应用当然是主成分分析——PCA!
为什么选择 PCA?
PCA 用于特征提取/维度减少,这指的是通过投影将数据的已知变量减少到较少的变量中,同时保留“几乎”相同数量的信息。有两种等价的方式来解释 PCA:
(i) 最小化投影误差,
(ii) 最大化投影的方差。
在这里,极其重要的一点是,上述两个陈述实际上是同一个事物的两个方面,因此最小化一个就等同于最大化另一个。

投影的必要性是什么?
我们需要它,因为当有 1000 个特征时,我们有 1000 个未知变量。结果是,我们需要 1000 个同时方程来解所有变量!但是“如果”没有解决方案呢?例如,考虑一下 2 个变量的情况:
a + b = 2
a + 2b = 2 ….?
PCA 的作用是,它找到最接近当前问题的近似,以便保留初始数据的某些属性(换句话说,噪声被减少)。因此,投影有助于将噪声与数据分离(代码示例见下文)。这是通过最小化最小二乘投影误差来完成的,这给出了最佳可能的解决方案。
最小化投影误差是否与线性回归中的最小二乘误差最小化相同?
不。以下是原因:

贡献者:Andrew Ng
这个图示也暗示了为什么 PCA 也可以用于无监督学习!
那么“特征值”在哪些方面有所贡献?
为此,我们需要了解 PCA 的步骤:
-
由于 PCA 对缩放非常敏感,因此我们首先需要对矩阵 A 进行标准化/归一化。M = mean(A),然后 C = A − M。
-
下一步是记住,为了获得最佳结果,即利用“特征值”,我们需要一个方阵,并且它是对称的(属性-7)。那么,哪个矩阵满足这两个条件呢?嗯……啊哈!——协方差矩阵!所以我们得到:V = cov(C)
-
既然我们已经得到我们想要的东西,就快速分解一下。
特征值, 特征向量 = np.linalg.eig(V)
-
然后将特征值按降序排列。它们对应的特征向量现在代表了降维子空间的组件。在降维子空间中,这些组件(特征向量)现在已经成为我们的新坐标轴,我们知道坐标轴总是正交的。(这只有在 PCA 中的每个组件都是独立的特征向量时才会发生)。这些坐标轴的组合产生了投影数据。(点击这里链接以获得更好的理解。让每个组件直接指向你。你会看到第一个组件捕获了最高的方差,其次是第二个,然后是第三个)
-
选择 k 个特征值以保留最大解释方差。k 个特征值捕获的方差量称为解释方差。
重要的是了解这些步骤,所以我们将不会手动执行这些操作,因为sklearn库中已经存在一个函数。为了简单起见,我们将把二维数据降到一维数据,同时观察噪声在过程中产生的效果。以下是代码:

注意投影与主成分完全平行。红点和绿点的接近度(相对于黑点和绿点)表明噪声已经在很大程度上减少。
(如果你发现任何错误/不正确的地方,请回复。欢迎批评。)
参考文献:
[www.youtube.com/playlist?list=PLE7DDD91010BC51F8(Prof.](https://www.youtube.com/playlist?list=PLE7DDD91010BC51F8(Prof.) 吉尔伯特·斯特朗,斯坦福大学。我的大部分内容都来自这里。)
www.youtube.com/watch?v=vs2sRvSzA3o(可能是对特征值和特征向量的最佳可视化表示)
hadrienj.github.io/posts/Deep-Learning-Book-Series-Introduction/(可视化向量的代码)
en.wikipedia.org/wiki/Singular_value_decomposition
你对 PCA 了解的与不了解的一切 · Its Neuronal
medium.com/@zhang_yang/python-code-examples-of-pca-v-s-svd-4e9861db0a71
个人简介:Tanveer Sayyed 是数据科学爱好者。热情的读者。艺术爱好者。异议爱好者……其余时间则在土星的环上摇摆。
原文。经许可转载。
相关:
-
机器学习数学:免费电子书
-
数据科学的基础数学:积分与曲线下的面积
-
数据科学和机器学习的免费数学课程
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 部门
更多相关话题
数据科学(或机器学习)的矩阵乘法
原文:
www.kdnuggets.com/2022/11/matrix-multiplication-data-science-machine-learning.html

作者提供的图片
主要收获
-
矩阵乘法在数据科学和机器学习中扮演着重要角色
-
要使两个矩阵之间的乘法定义明确,这两个矩阵必须兼容,即矩阵 A 的列数必须等于矩阵 B 的行数。
-
矩阵乘法不满足交换律,即 AB ≠ BA。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
矩阵乘法在数据科学和机器学习中扮演着重要角色。考虑一个具有 m 个特征和 n 个观测值的数据集,如下所示:

基本的回归模型可以表示如下:

其中 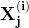 是 n×m 特征矩阵,而 w 是 m×1 权重系数或回归系数矩阵。这里我们观察到
是 n×m 特征矩阵,而 w 是 m×1 权重系数或回归系数矩阵。这里我们观察到 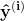 的计算涉及特征矩阵 X 和回归系数矩阵 w 之间的矩阵乘法。由于 X 是一个 n × m 矩阵,而 w 是一个 m × 1 矩阵,因此 X 和 w 之间的矩阵乘法是明确的。在矩阵形式中,上述方程可以简化为
的计算涉及特征矩阵 X 和回归系数矩阵 w 之间的矩阵乘法。由于 X 是一个 n × m 矩阵,而 w 是一个 m × 1 矩阵,因此 X 和 w 之间的矩阵乘法是明确的。在矩阵形式中,上述方程可以简化为

其中 Xw 代表矩阵 X 和 w 之间的乘法。**
矩阵乘法的定义
设 A 为一个 n×p 矩阵,B 为一个 p×m 矩阵,

乘积矩阵 C = AB 是一个 n×m 矩阵,其元素为

矩阵乘法的性质
矩阵乘法不具有交换性,也就是说
AB≠BA
Python 中的矩阵乘法实现
使用 for 循环
import numpy as np
A = np.array([[1,2,3],[4,5,6]]) # create (2 x 3) matrix
B = np.array([[7,8],[9,10],[11,12]]) # create (3 x 2) matrix
A.shape[1] == B.shape[0] # ensures two matrices are compatible
C = np.zeros((2,2)) # (2 x 2) matrix
for i in range(2):
for k in range(2):
for j in range(3):
C[i,k]= C[i,k] + A[i,j]*B[j,k]
print(C)
[[ 58, 64]
[139, 154]]
使用 Numpy 库
C = np.dot(A, B)
print(C)
[[ 58, 64]
[139, 154]]
请注意,np.dot(B, A)会产生以下输出:
print(np.dot(B, A))
[[ 39 54 69]
[ 49 68 87]
[ 59 82 105]]
很明显,我们看到 np.dot(A, B) ≠ np.dot(B, A)。
总结来说,我们讨论了矩阵乘法的数学基础。我们还演示了如何使用简短的 python 代码执行矩阵乘法,以及使用 numpy 中内置的矩阵乘法方法。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,也是 DataScienceHub 的所有者。之前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程和物理学。
更多相关话题
建立成熟的机器学习团队
原文:
www.kdnuggets.com/2020/03/mature-machine-learning-team.html
评论
由张纪超,Georgian Partners 的软件工程总监撰写。
虽然新员工的知识和技能可以推动单个项目的成功,但良好的流程才能推动整个项目组合和团队的成功。在创建流程时,与团队合作,专注于采取小步骤和快速迭代想法,而不是重大突破。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你们组织的 IT 工作
你还需要选择最适合你们目标的技术栈。技术不应替代良好的流程和合适的团队。相反,在你实施流程时,寻找能够提高效率的技术。
在创建流程时,与团队合作,专注于采取小步骤和快速迭代想法,而不是重大突破。
成熟度框架是如何工作的?
建立机器学习团队并非易事。我们的 ML 框架模型展示了构建团队的演变过程,并提供了在成熟过程中应关注的重点指导。
共有五个级别。
在每个级别,你的组织都将面临一套独特的挑战,无论是制定战略、增加新员工,还是实施更成熟的流程。


入门
首先,为你们组织内的机器学习(ML)制定战略和应用重点。在此阶段,与你的领导团队讨论以下问题:
-
你的解决方案能够支持哪些业务流程?
-
你的关键客户和受众是谁?
-
你如何解决他们的日常痛点或改进
他们的工作流程?
-
他们寻找哪些关键见解?
-
他们目前在哪些方面遇到困难?
-
自动化如何改善流程和工作角色?你的用户是否定期基于数据做出决策?
与产品管理、客户成功、支持、销售以及客户本身沟通,以收集回答这些问题所需的信息。
利用收集到的信息进行头脑风暴,寻找业务自动化的机会,始终牢记最终目标是改善客户的生活。考虑如何利用你独特的数据为客户提供最有价值的见解。你可以使用价值/成本框架来优先考虑这些机会,如下面的机会矩阵所示。这使你在招聘之前能够建立优先级列表,并明确招聘的原因。
接下来,进行数据审计,以了解你的数据如何支持已识别的机会。考虑如何收集任何缺失的数据,或重新调整你的流程以收集未来使用的额外数据。请记住,一些关键的机器学习项目在所需数据到位之前无法开始。
有了愿景和策略,你就准备好进行第一次招聘,将这些计划付诸实践。


探索
让你的第一次招聘发挥作用!在这个早期阶段,将你的机器学习团队视为一个创业中的创业公司通常是更好的。通常,寻找具有广泛技能并习惯于跨机器学习开发过程工作的通才候选人更为理想。你的理想候选人应该在类似的创业环境中工作过——那些能在有限资源下创造性解决问题的人。这是因为在企业中,角色更加专业化,团队有更多资源来解决问题。你的早期招聘人员需要做一切工作,直到你准备好扩展团队。
首先,聘请或指派一名产品经理,帮助验证市场问题、制定产品需求并管理路线图。如果你招聘 PM,必须具备第一手的机器学习经验。你也可能找到一位高级科学家,可以暂时担任 PM 角色。
内部分配有其优缺点。它们可以帮助团队快速了解领域和背景,但可能需要外部导师或培训资源来指导他们完成第一个机器学习项目。
接下来需要招聘的角色包括一名用于实验的机器学习科学家和一名能够支持实验、建立数据管道并将预测和模型集成到核心应用中的机器学习工程师。聘请最资深的科学家,以为你的团队设立长期成功的基础。
一名高级招聘人员可以:
-
帮助建立和吸引一支一流的数据科学团队。
-
通过选择最可行的途径来加速研发。
-
推动知识产权的创建,并开发接近生产就绪的机器学习模型。
-
高效设置工具和处理流程,并考虑规模问题。
理想情况下,你聘用的科学家还应具备数据工程技能,并能在团队扩展之前承担部分这方面的工作。以至少两名技术成员开始团队能推动更有效的头脑风暴,并平衡研究与实施之间的权衡。
利用组织中其他领域的专业知识来指导团队。科学家和工程师可以在此期间学习你的行业以及他们要解决的问题。
选择好的沟通者会带来结果。他们能够提出正确的问题,以了解你的业务,并清晰地向领导团队汇报他们的发现。一旦你的招聘到位,向包括产品、工程、营销和客户成功在内的跨职能团队提供期望的简要说明。
完成第一个项目
根据我们的经验,对于第一个项目,不必过于担心流程和工具。让团队找到解决方案并做他们需要做的事情以使第一个产品顺利推出。确保机器学习团队有灵活性选择所需的计算资源。与软件工程相比,计算需求(核心数、内存、GPU 等)变化更快,这使得预订所需的机器变得具有挑战性。云平台通常在时间和成本上更高效。
在第一个项目中,你想要建立动力,并迅速展示投资于机器学习(ML)的回报率。
寻找以下类型的项目:
-
专注于一个使用案例
-
可以在较高的成功率下完成
-
可以在相对较短的时间框架内完成
这种方法还为你的团队提供了一些额外的喘息空间,以便在处理更复杂的项目之前了解业务。
尽管选择一个可能提供更高回报的项目很有诱惑,但这也是有风险的。过于雄心勃勃的项目可能需要更长的时间才能推向市场,甚至可能失败。造成延迟的原因有很多:你的数据可能比预期的更混乱,你可能会发现额外的需求,或者你可能没有部署的流程。延迟会随着时间的推移导致信心和支持的丧失,并可能对初创的机器学习团队造成致命打击。

构建
完成机器学习产品开发的完整周期后,你的下一步优先事项是建立市场推广的能力和其他机会的可重复流程。
重新审视你的优先事项,确保路线图仍然合理。验证你是否正在解决市场问题,就像你对待任何其他产品一样。早期采用者或顾问委员会可以提供帮助。然后,制定你的市场推广计划,保持对解决买家问题的关注。为所有参与购买决策的人创建买家角色。考虑他们需要看到什么才能继续前进。建立一个销售支持和营销计划,以在买家旅程中传达正确的信息。
当你开始迭代并将更多模型投入生产时,到了扩展规模并在团队中招聘更多专业角色的时候。例如,你可以引入:
-
一位专职产品经理,如果之前是兼职角色,以制定完整的产品战略和长期路线图。
-
一名数据工程师负责构建所有可用数据的目录,以及架构和构建数据管道。
-
更多的数据科学家用于提升模型构建的吞吐量。
-
一名机器学习架构师负责监督整体技术愿景和实施。
-
一名 QA 工程师。
随着团队的成长,集中精力优化流程,以减少摩擦、提高可预测性,并促进跨功能协作。可以使用敏捷方法作为起点,但需要根据机器学习进行调整。请记住,数据科学工作不像软件开发那样可预测,需要更快的迭代。
如果整个团队一次只处理一个项目,Kanban 可以加速迭代,而不需要冗长的规划周期。可以通过团队深度探讨来鼓励知识共享,克服技术挑战。
现在是确定机器学习技术栈的时候了。生态系统发展迅速,新产品不断涌现。主要的选择包括语言(Python 或 R)、框架(Tensorflow 或 PyTorch)、云服务提供商、ETL 和部署解决方案。

我们的应用人工智能原则提供了一个务实的框架,以协助在你的软件解决方案中采用机器学习及其他人工智能构件。
白皮书:
-
为你提供了一个启动框架,帮助避免常见错误。
-
提供成熟度模型,以便你可以衡量自己的进展。

扩展
随着团队的成熟和数据差距的弥补,新的机会将会出现。其他产品线或业务部门可能希望利用机器学习。为了把握这一势头,你需要组建新的机器学习团队。
不过,首先考虑一下组织结构。通常会组建由几个科学家、一两名工程师和一名产品人员组成的小团队。这些团队负责一个产品线或内部业务职能。尽可能寻找具备匹配这些领域的专业技能的人选。询问团队瓶颈所在,并进行调整,以在科学家和工程师之间创建良好的平衡。
对于大型数据科学组织,有三种常见模型。
-
分散式模型:在分散式模型中,个别数据科学团队向相应的产品或业务部门汇报。这种模式允许数据科学团队与其业务相关者密切合作,但也有将数据科学团队孤立的风险。
-
集中式模型:在集中式模型中,所有数据科学团队都向 CTO 或数据科学负责人汇报。这种方法促进了同行之间的合作,有助于招聘和知识共享。如果采用这种模型,请特别关注与业务目标的对齐。
-
混合模型:第三种方法,已经在许多案例中成功采用,是一种混合模式,其中数据科学团队与业务伙伴紧密合作,但仍集中汇报。
查看这篇文章以深入讨论这个话题。
每个成长中的团队都会面临效率问题。随着团队的发展,抽出一些时间,远离日常的繁忙事务,专注于长期项目。例如,通过完善注释的数据目录、数据仓库和 ETL 解决方案来实现数据访问的民主化。寻求系统化地自动化工作流程中的手动步骤,提高其他工具的可用性,如管道编排和数据/模型质量监控。
随着你将越来越多的模型投入生产,你需要监控每个模型的版本并比较性能。
有关如何跟踪机器学习产品性能的一些考虑,请参阅我们《应用人工智能原则》第 5 条,了解性能目标和《信任原则》第 9 条,使信任可衡量。

高级
在高级阶段,你是一个成熟的 ML 组织,拥有一个与产品和工程团队紧密对齐的 ML 团队。你的流程和工具使你能够管理生产中的多个 ML 模型。你的团队和公司被认为是你领域的思想领袖,你能够利用这一点明确区分你的竞争对手。
在此时添加一名首席工程师和一名首席产品经理,以推动由科学家领导的子团队的最佳实践。考虑任命一位数据科学负责人,以推动子团队之间的最佳实践和一致性。
作为一个高级团队,根据你的行业和使用案例,考虑以下新兴角色。
-
随着团队和产品组合的扩展,添加更多工具以保持生产力:
-
使用一个集中且可搜索的笔记本库来实现知识发现。
-
添加一个可发现的功能/模型存储,以便重用。
-
使用基于元数据的编排来跟踪数据/模型依赖关系并管理变更。
-
构建统一的 ETL 和训练基础设施管理,以降低计算成本。
处于前沿的公司可能正在开发自己的 ML 框架,以填补开源和商业工具的空白,并可能将最新的 ML 研究部署到生产中,以建立强大而独特的产品。
为什么使用成熟度框架?
我们的成熟度框架允许处于 AI/ML 成熟路径上的公司对当前状况进行诚实评估,并了解达到下一个阶段所需的措施。
原文。经许可转载。
简介: 季超是我们的软件工程总监,并且是 Georgian Impact 团队的成员。在这个角色中,他领导我们的内部软件工程工作,并支持投资组合参与。在加入 Georgian Partners 之前,季超是亚马逊的软件开发工程师,他在设计和开发数据平台、商业分析和机器学习系统方面工作,以支持供应链优化和履行。在亚马逊之前,季超是 Bloomberg 的高级软件开发人员,他设计并实施了 Bloomberg Tradebook 股票交易系统的软件组件,并倡导 OOD/OOP/C++的最佳实践。他还曾是 IBM 的高级软件开发人员,致力于编译器技术、编程语言实现和测试失败调查的专家系统。
相关:
更多相关内容
通过组织来最大化你的数据科学家生产力
原文:
www.kdnuggets.com/2022/03/maximize-productivity-data-scientist-organizing.html

Kaleidico 来自 Unsplash
有时感觉一天的时间不够用。当你正在完成一个任务时,另一个请求可能会出现。如果你处理数据,原本希望用几个小时完成的任务可能会变成几天。
你的 8 小时工作日可能会变成 9 小时、10 小时,有时甚至更多。你开始花费如此多的时间在工作上,以至于忽视了个人生活。
有很多文章解释了如何提高你的工作生产力;然而,数据科学家的生活却是不同的。组织自己将为你节省大量时间和精力,使你的工作日更加顺畅;让你能按时完成工作。
我们都会遇到这种情况;大多数时候我们做得很好,但有时工作太多导致我们偏离了规律,组织工作也就无从谈起。我总是对人们说,关于组织自己;如果花费不到 10 分钟,马上去做。
当涉及到在数据导向环境中组织自己时,可能会感到不堪重负。文件、笔记本和文档繁多,容易变得混乱。以下是一些帮助你在处理数据时进行组织的提示。
给文件起具有描述性的名称
当你在浏览成千上万的数据集时,这将为你节省大量时间。很多时候文件会丢失,因为团队成员不记得文件名;然而,如果你给文件起具有描述性的名称,Mac 或 Windows 上的快速搜索可以解决这个问题,节省你的时间。
以下是给文件命名时需要考虑的一些要点,无论是在项目开始前还是思考新系统时。
文件名称需要:
-
一致性
-
对你和你的同事有意义
-
容易访问
在开始一个新项目或重新考虑现有系统之前,如果你的团队能就以下几个方面达成一致,将会很有帮助:
-
词汇 – 确保大家使用统一的语言
-
标点符号 – 需要仔细考虑标点符号,如大写字母、连字符和空格,以及它们的使用效果。
-
日期 – 这将帮助你区分项目,使你能够回顾旧项目。例如:YYYY-MM-DD
-
顺序 - 讨论并达成共识,确定哪个元素应该优先,以便文件可以轻松找到。例如,按日期、项目代码和客户排序文件名。
创建文件夹
将所有的数据集、笔记本和输出集中在一个地方会很快变得混乱。为特定项目创建文件夹,并包含子文件夹,将帮助您区分不同的内容,也能更容易找到文件等。向团队其他成员解释这一过程,并确保每个人使用相同的系统,将解决缺失数据集、笔记本等问题。
如果团队成员想回顾一个旧项目,他们将能够舒适地做到这一点,因为项目将被划分,并附有描述性文件名。如果每个人都遵守程序,他们将不需要咨询其他团队成员这些文件的位置。
文档
作为数据科学家,您每天会处理大量的数据集,这些数据集可能彼此不同。您可能在进行一个项目时遇到与以前的项目类似的问题;然而,您不记得问题是否相同或解决方案是什么。
文档,文档,文档。我们的脑袋很棒,但我们不能保证记住所有事情。然而,如果我们记得把所有东西写下来;至少我们有可以参考的东西。
在每个项目开始时记录数据是一个好的实践;这可能包括研究或可能影响项目的问题。随着项目的进展,继续添加信息对理解问题和解决方案非常重要,同时也能了解下次应该避免的事项。这是改善组织工作流程的重要因素。
有几种方法可以将文档添加到您的数据中:
-
嵌入文档 - 这是指一个文档,通常结构为文本文件或二进制文件,嵌入到另一个文档中。
-
支持文档 - 这是附带数据的独立文件。它提供了背景、解释或关于如何使用数据的说明。

Sigmund 通过 Unsplash
一旦这些数据科学项目工作流程的元素被修正并且所有团队成员遵守,您将开始看到生产力的变化;这将使您能够专注于其他紧迫的问题。这些可以是数据整理、修复错误等。
Nisha Arya 是一位数据科学家和自由职业技术写作员。她特别感兴趣于提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何能够促进人类寿命的不同方式。她是一个热衷学习者,寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关主题
利用 ChatGPT 最大化数据分析效率
原文:
www.kdnuggets.com/maximizing-efficiency-in-data-analysis-with-chatgpt

编辑提供的图像
随着数据成为最有价值的商业资产,数据分析在组织决策中扮演着至关重要的角色。公司需要全面检查、转化和建模数据,以发现有用的信息并帮助决策。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
随着组织必须处理越来越多的数据,分析数据变得越来越具挑战性。在这种情况下,ChatGPT 能够参与数据分析过程是一项宝贵的资产。
ChatGPT 能够理解和生成类似人类的文本,帮助你查询数据集、生成代码片段以及解释结果。因此,当组织将这个先进的语言模型整合到数据分析过程中时,它简化了工作流程并提高了效率。
本文探讨了将 ChatGPT 无缝融入数据分析工作流的过程、挑战和案例研究。让我们简要了解 ChatGPT 的定义和功能。
什么是 ChatGPT 以及它能做什么?
在过去一年中,ChatGPT 已经成为科技界及其他领域的家喻户晓的名字。它是基于 OpenAI 的 GPT-3.5 架构开发的语言模型。在这里,GPT 代表“生成预训练变换器”。基本上,这是一个人工智能模型,可以理解人类提供的输入,并生成类似人类的文本作为回应。
ChatGPT 可以执行多种任务。其中一些包括:
-
理解人类使用的自然语言
-
理解讨论的上下文
-
生成连贯而多样的响应以应对各种提示
-
从一种语言翻译成另一种语言
-
基于其训练知识资源回答问题
-
生成代码片段和解释
-
基于提示写故事和诗歌
几乎所有职业的人都可以利用 ChatGPT 的这些功能来简化个人和职业生活。
数据分析的效率重要性
实时决策
在任何需要即时决策的商业环境中,高效的数据分析是必需的。它使组织能够快速提取有意义的数据洞察,从而确保及时和明智的决策。
资源优化
所有商业资源都很宝贵,包括人力和时间。高效的数据分析可以简化分析过程,从而明智地利用你的宝贵资源。
超越竞争对手
通过分析数据,公司可以获得可操作的洞察,从而帮助他们在竞争中保持领先。
提高生产力
如果数据分析过程变得高效,它减少了分析师生成洞察所需的时间和精力。这不仅提高了他们的生产力,还使他们能够专注于更复杂和战略性的任务。
提高准确性
高效的数据分析方法对于数据验证和质量检查非常有用。因此,你可以获得准确的结果,减少由于分析过程效率低下而可能出现的错误。
ChatGPT 在数据分析中的相关特性
高级数据分析
这是 ChatGPT-4 的独特功能。这允许用户直接将数据上传到平台以编写和测试代码。如果你没有访问权限,这里是如何免费获取付费 ChatGPT 计划的方法。
解决问题
如果你在数据分析过程中遇到障碍,ChatGPT 可以为与数据、算法或分析方法相关的问题建议故障排除解决方案。
理解自然语言
由于 ChatGPT 能理解自然语言文本,用户可以使用普通语言与这个模型互动。实际上,这是最受欢迎的 ChatGPT 特性之一。
解释概念
ChatGPT 可以用易于理解的语言解释数据分析概念、统计方法和机器学习技术。希望学习数据分析基础的用户可以利用它。
头脑风暴创意
即使是在数据分析策略的头脑风暴会议中,ChatGPT 也可以协助制定假设、实验设计或处理复杂数据问题的方法。
协助工具使用
ChatGPT 还可以指导你使用不同的数据分析工具或平台。它是解释工具功能的有用资源。
帮助文档编写
ChatGPT 可以帮助解释方法、记录代码以及撰写数据分析项目的文档。
数据解释
ChatGPT 能够解释分析数据的结果。它可以告诉你统计发现和机器学习预测的含义。
使用 AI 和 NLP 在数据分析中的优势
-
从非结构化数据源自动提取洞察
-
增强的自然语言交互用于查询和报告
-
提高数据处理和分析的效率和速度
-
情感分析和基于上下文的数据解释
-
多语言数据分析的语言翻译
-
通过 AI 建议强化决策过程
-
支持大数据集的自动文档处理
-
趋势分析和模式识别
如何将 ChatGPT 集成到数据分析工作流中
以下是如何将 ChatGPT 融入你的数据分析工作流。这可能涉及也可能不涉及将其集成到数据分析工具中。
确定具体的使用案例
根据你的行业和组织需求,你需要定义你希望使用 ChatGPT 的情况。这可能是自然语言查询、代码辅助、数据解释或协作沟通。仅选择 ChatGPT 能够增值的领域。
选择集成点
如果你想将 ChatGPT 融入你的数据分析工作流,请确定它最有益的地方。你可以在数据探索阶段、编写代码时或输出数据解释时纳入它。
选择互动方式
然后,你需要选择用户如何与 ChatGPT 互动。你可以选择将其集成到数据分析工具中,或通过网页界面使用它。此外,你还可以通过 ChatGPT API 来使用它。实现 API 可以通过进行 API 调用来完成。关于如何发起 API 请求和处理响应的详细 OpenAI 文档是可用的。
用户培训和指南
完成这些后,你必须教会用户如何与 ChatGPT 互动,以进行有效的数据分析。创建一个指南,说明其局限性和获取准确响应的最佳实践。处理敏感数据时还应有严格的安全和隐私规定。这将确保与 ChatGPT 的互动符合数据隐私法规。
评估与改进
你应定期评估 ChatGPT 在数据分析工作流中的表现。始终寻找优化其效果的方法,以最大限度地发挥它的作用。你还可以收集用户反馈,以了解用户可能面临的任何挑战。
ChatGPT 在数据分析中的使用案例
代码辅助
你可以使用 ChatGPT 来获得编码任务的帮助。例如,你可以要求它生成一个特定数据分析任务的代码片段,ChatGPT 会做到这一点。

自然语言查询
ChatGPT 可以用来处理数据分析中的自然语言查询。你可以要求它总结数据集或根据标准筛选数据。
结果解释
ChatGPT 的一个关键使用案例是结果解释。要求 ChatGPT 进行统计分析或将见解转化为模式将节省你的时间和精力。
探索性数据分析(EDA)
使用 ChatGPT 进行探索性数据分析意味着获得理解数据和制定假设的帮助。它可以为你提供有关数据转换和关键变量检查的指导。
情感分析
你可以让 ChatGPT 分析数据集中客户的情感。例如,你可以提供用户反馈,它会告诉你反馈是积极的、消极的还是中立的。

如何克服将 ChatGPT 集成到数据分析中的挑战
如果你计划将 ChatGPT 集成到数据分析中,明智的做法是了解可能遇到的挑战及其解决方法。
可靠性
ChatGPT 不能保证提供 100%准确的数据。这是将该语言模型应用于数据分析过程中的最大挑战。为避免这一点,你需要通过与已知数据交叉验证 ChatGPT 提供的信息的准确性,或通过用户反馈循环来验证信息。
理解上下文
如果你向 ChatGPT 提供复杂或高度专业化的上下文进行数据分析,它可能会难以理解。因此,在与 ChatGPT 互动时,你必须提供尽可能多的上下文,并且使用更简单、更明确的语言。
管理模糊性
在数据分析过程中,ChatGPT 可能需要处理模糊的查询或复杂的要求。用户可以通过使查询更加具体或添加更多细节来解决这个问题。
数据隐私和安全
如果你希望 ChatGPT 分析数据,可能需要与模型分享敏感和私密的原始数据。为了克服这一点,你必须使用数据匿名化技术来掩盖敏感数据。
最终想法
可以理解的是,人工智能(AI)通过自动化复杂任务和从大量数据集中提取有价值的见解来提高数据分析效率。随着这项技术的不断发展,ChatGPT 可以对数据分析产生突破性的影响。
该模型的自然语言处理功能可以生成代码片段、与数据互动并提供上下文见解。未来,预计 ChatGPT 将拥有领域特定的知识,使其能够与各种行业的数据进行更细致的互动。
对于数据分析,它能够提供针对特定分析任务的定制解决方案。用户可以与数据分析平台协作,促进更具动态性的问题解决方法。可以肯定的是,ChatGPT 将发挥其在数据分析普及化方面的作用,使更多用户能够访问和使用数据分析。
Vijay Singh Khatri**** 计算机科学学士,专注于编程和市场营销。我非常喜欢撰写技术文章和创造新产品。
更多主题
掌握季节性和提升业务成果的终极指南

图片由 upklyak 提供,来自 Freepik
企业每年在广告上花费数十亿以提高产品的知名度和消费者的兴趣,从而推动更多的购买。为了接触更广泛的受众,企业会推出有针对性的广告或活动,以吸引新客户。广告通过多种媒体进行广播,包括电视、广播、杂志、在线、社交媒体,甚至在商店中进行,以覆盖广泛的受众。由于选择众多以及必须最大化投资回报(ROI)的压力,有效分配广告资源成为一个重大挑战。在这种情况下,媒体组合建模对企业优化广告支出和最大化 ROI 变得至关重要。通过估算在某些媒体渠道上应该花费多少资金以实现特定目标(如增加销售额或品牌知名度),媒体组合建模成为企业的有用工具。这使得企业能够比较各种渠道的表现,识别改进的机会,并合理分配资源。数据驱动的洞察使企业能够调整其营销方法,提高支出的价值,并加速实现业务目标的过程。媒体组合建模是一种统计分析技术,通过分析历史广告数据(包括支出、广告展示量或点击量、产品销售、新客户获得等)来理解不同媒体渠道对业务结果的影响。这使得企业能够优化广告预算组合,提升其 ROI。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 部门
除了媒体渠道的影响,媒体混合建模还考虑了外部因素,例如业务是否进行过任何促销活动、假期或任何可能影响销售的特殊事件。这是为了避免对媒体渠道绩效的影响进行任何形式的高估。
但企业需要解决并纳入其媒体混合模型中的一个关键因素是季节性。
什么是季节性,为什么它对媒体广告如此重要
简单来说,我们可以将季节性定义为时间序列数据的一种特征,其中我们可以观察到每年都会重复的可预测且规律的行为。因此,我们可以说任何可预测并且每年都会重复的行为就是季节性行为。
那么,季节性与周期性效应有何不同?周期性效应是指可以跨越不同时间段的效应。它们可能持续时间长于或短于一年,例如由于水管故障导致某地区水过滤设备销售的增加。这种效应并不规律或可预测,也可能不会每年重复。而流感季节导致流感药物销售的增加可以被称为季节性,因为它每年从 12 月到 2 月重复,并且可以预测。
那么季节性为何对媒体广告如此重要?季节性主要在两个方面影响媒体混合建模。首先,观察到媒体消费模式的变化;其次,广告效果的变化。正如我们上面讨论的,媒体混合建模如何帮助营销人员了解各种媒体渠道对销售或其他关键绩效指标(如新客户获取)的影响。将季节性纳入这些模型使广告主能够更准确地反映全年广告绩效的变化。例如,在节假日期间,各种媒体渠道可能会观察到观众增加或参与度提高,这使得它们在接触各自目标受众时更加成功。当广告主认识到并考虑季节性时,他们能够最大化媒体分配计划的效果。他们能够调整广告预算、活动和渠道选择,以便与季节性趋势和消费者需求保持一致。这确保了营销工作在最有可能产生最大影响的时间集中,从而优化广告投资回报。
时间序列数据中的季节性表现是什么样的?
我们可以通过使用季节性因素或虚拟变量将季节性纳入媒体组合模型中,以表示特定的季节性事件,例如节假日。这些因素捕捉了不同时间段对媒体响应的影响,并帮助调整模型的预测。这些变量捕捉了不同时间段对媒体响应的影响,并有助于模型的预测。
在 Python 中,我们有一个名为seasonal_decompose的 Statsmodel 库,它可以帮助我们生成季节性变量。该库将时间序列分为三个组成部分,即趋势、季节性和残差。季节性可以用两种模型表示:加法模型或乘法模型。
为了简化,我们假设我们使用的是加法模型。当时间序列的方差在不同值之间没有变化时,可以使用加法模型。在数学上,我们可以将加法模型表示为趋势、季节性和残差的各个组成部分相加。


图 1:8 个月的收入季节性分解
趋势因素
趋势成分描述了时间序列在较长时间内发生的变化,并且更具系统性。它反映了序列的根本增加或减少,并提供了对长期收集的数据的整体趋势及其幅度的指示。这有助于确定数据的基本模式以及数据的方向性。在图 1 中,我们可以看到 8 个月的收入季节性分解,如果我们查看趋势,会发现每年的夏季收入有所下降。这一见解对广告商至关重要,因为他们可以据此调整策略或支出模式。
季节性因素
季节性因素指的是在较短时间内(通常是一年内)发生的重复模式。这是外部影响如天气、节假日或其他文化事件所导致的频繁波动的表现。季节性特征的反复出现的峰值和谷值反映了数据中可以预期的规律。在上图的图 1 中,我们可以看到每隔一个月就有一个峰值,这可以帮助企业识别对收入产生影响的外部因素。
残差因素
随机和无法解释的变化无法归因于趋势或季节性,称为残差成分,也称为误差或噪声成分。它考虑了在趋势和季节性成分考虑后仍然存在的任何波动或异常。残差成分表示数据中不可预测且缺乏系统性模式的部分。
季节性分析面临的挑战
-
多重季节性:在某些时间序列数据中,可以观察到每日、每周以及每月的多重季节性模式,这些模式用简单的季节分解方法难以捕捉,可能需要更复杂的处理过程。
-
数据稀疏:如果我们在一段时间内没有均匀分布的数据,即采样频率较低或数据点非常少,则可能影响季节性估计。因此,建议至少有 2 年的每日或每周数据集,以获得更高质量的季节性估计。
-
非平稳性:如果时间序列数据具有变化的方差,这将影响季节性估计。
特定季节中的数据点有限或稀疏可能会妨碍季节效应的准确估计,特别是在处理较短的时间序列或采样频率较低的数据时。
-
不规则性:数据中常常由于一些外部因素存在异常值,这可能会扭曲季节性分析。建议在进行季节性分析之前进行数据筛选,例如异常值检测和去除。
最后,我们看到季节性如何影响媒体组合建模,并推动战略业务决策。通过在媒体组合模型中纳入季节性,营销人员可以根据消费者行为和市场动态的波动来优化他们的广告策略和预算分配。了解季节性模式使公司能够瞄准正确的受众,选择最佳的媒体渠道,并在最佳时机进行广告活动以达到最大的效果。通过利用季节性分析信息,公司可以提高广告活动的效率和效果,增加客户参与度,创造销售机会,并最终提高投资回报率。季节性使公司能够调整和量身定制其营销策略,以适应不断变化的消费者需求和偏好,从而在动荡的环境中获得竞争优势。
Mayukh Maitra 是沃尔玛的数据科学家,专注于媒体组合建模领域,拥有超过 5 年的行业经验。从构建基于马尔科夫过程的医疗结果研究模型到执行基于遗传算法的媒体组合建模,我不仅在改善人们的生活方面有所贡献,还通过有意义的洞察力将企业提升到一个新的水平。在加入沃尔玛之前,我曾在 GroupM 担任数据科学经理,专注于广告技术领域,在 Axtria 担任决策科学高级助理,工作于健康经济学和结果研究领域,并在 ZS Associates 担任技术分析师。除了我的专业角色,我还参与了多个同行评审会议的评审和技术委员会,并有机会评审多个技术奖项和黑客马拉松。
更多相关话题
了解 Gorilla:UC 伯克利和微软的 API 增强 LLM 超越 GPT-4、Chat-GPT 和 Claude

图片来自 Adobe Firefly
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
我最近开始了一份专注于 AI 的教育新闻通讯,目前已有超过 160,000 名订阅者。TheSequence 是一份没有废话(即没有炒作、新闻等)的 ML 取向新闻通讯,阅读时间为 5 分钟。其目标是让您了解最新的机器学习项目、研究论文和概念。请通过下面的链接订阅尝试一下:
大型语言模型(LLMs)的最新进展彻底改变了该领域,使其具备了自然对话、数学推理和程序合成等新能力。然而,LLMs 仍面临固有的局限性。它们的信息存储能力受到固定权重的限制,其计算能力也受限于静态图和狭窄的上下文。此外,随着世界的发展,LLMs 需要重新训练以更新其知识和推理能力。为了克服这些限制,研究人员已开始赋予 LLMs 工具。通过访问广泛而动态的知识库和支持复杂计算任务,LLMs 可以利用搜索技术、数据库和计算工具。领先的 LLM 提供商已开始集成插件,允许 LLMs 通过 API 调用外部工具。从有限的手动编码工具转向访问大量云 API,这一过渡有可能将 LLMs 转变为计算基础设施和网络的主要接口。像预订假期或举办会议这样的任务,可能像与一个可以访问航班、租车、酒店、餐饮和娱乐网络 API 的 LLM 对话一样简单。
最近,UC Berkeley 和 Microsoft 的研究人员揭示了Gorilla,这是一个专门为 API 调用设计的 LLaMA-7B 模型。Gorilla 依靠自我指导微调和检索技术,使 LLM 能够从一个大规模且不断发展的工具集合中准确选择,这些工具通过其 API 和文档表达出来。作者通过从主要模型库如 TorchHub、TensorHub 和 HuggingFace 中抓取机器学习 API,构建了一个名为 APIBench 的大型 API 语料库。使用自我指导,他们生成了指令和相应 API 的配对。微调过程涉及将数据转换为用户代理聊天风格的对话格式,并对基础 LLaMA-7B 模型进行标准指令微调。

图片来源:UC Berkeley
API 调用通常带有约束,这增加了 LLM 理解和分类调用的复杂性。例如,一个提示可能要求调用具有特定参数大小和精度约束的图像分类模型。这些挑战突显了 LLM 不仅需要理解 API 调用的功能描述,还需要对嵌入的约束进行推理。
数据集
当前的技术数据集涵盖了三个不同的领域:Torch Hub、Tensor Hub 和 HuggingFace。每个领域提供了大量的信息,揭示了数据集的多样性。例如,Torch Hub 提供了 95 个 API,奠定了坚实的基础。相比之下,Tensor Hub 更进一步,拥有多达 696 个 API。最后,HuggingFace 以惊人的 925 个 API 领先,使其成为最全面的领域。
为了提升数据集的价值和可用性,进行了额外的努力。数据集中的每个 API 都附带了一组 10 个精心设计且独特定制的指令。这些指令作为训练和评估的不可或缺的指南。此举确保每个 API 超越了单纯的表示,实现了更强的利用和分析能力。
架构
Gorilla 引入了检索感知训练的概念,其中指令调优的数据集包含一个额外的字段,用于参考检索到的 API 文档。这种方法旨在教会 LLM 根据提供的文档解析和回答问题。作者展示了这种技术使 LLM 能够适应 API 文档的变化,提升了性能,减少了幻觉错误。
在推理过程中,用户以自然语言提供提示。猩猩可以在两种模式下操作:零样本和检索。在零样本模式下,提示直接输入到猩猩 LLM 模型中,该模型返回推荐的 API 调用以完成任务或目标。在检索模式下,检索器(BM25 或 GPT-Index)从 API 数据库中检索最新的 API 文档。这些文档与用户提示一起连接,并附有指示 API 文档参考的消息。然后将连接的输入传递给猩猩,猩猩输出要调用的 API。在此系统中,除了连接步骤外,不会进行提示调整。

图片来源:UC 伯克利
归纳程序合成在多个领域取得了成功,通过合成满足特定测试用例的程序。然而,当涉及评估 API 调用时,仅依靠测试用例是不够的,因为验证代码的语义正确性变得困难。以图像分类为例,该任务有超过 40 个不同的模型可用。即使将其缩小到特定的模型系列,如 Densenet,也有四种可能的配置。因此,存在多种正确答案,使得通过单元测试确定所用 API 是否在功能上等同于参考 API 变得困难。为了评估模型的性能,使用收集的数据集对其功能等价性进行比较。为了识别 LLM 在数据集中调用的 API,采用 AST(抽象语法树)树匹配策略。通过检查候选 API 调用的 AST 是否为参考 API 调用的子树,可以追踪使用的是哪个 API。
识别和定义幻觉是一个重大挑战。AST 匹配过程被利用来直接识别幻觉。在这种情况下,幻觉指的是调用一个不在任何数据库中的 API,本质上是调用一个完全虚构的工具。值得注意的是,这种幻觉的定义不同于错误地调用 API,后者被定义为一种错误。
AST 子树匹配在识别数据集中被调用的具体 API 中扮演了至关重要的角色。由于 API 调用可能具有多个参数,因此每个参数都需要进行匹配。此外,考虑到 Python 允许默认参数,需要定义在数据库中每个 API 应匹配的参数。

图片来源:UC 伯克利
《行动中的猩猩》
研究人员与论文一起,开源了 Gorilla 的一个版本。该版本包括一个包含多个示例的笔记本。此外,以下视频清晰地展示了 Gorillas 的一些魔力。
Gorilla 是工具增强 LLM 领域中最有趣的方法之一。希望我们能在一些主要的 ML 中心看到该模型的分发。
Jesus Rodriguez 目前是 Intotheblock 的首席技术官。他是一位技术专家、执行投资者和创业顾问。Jesus 创立了 Tellago,这是一家获奖的软件开发公司,专注于通过利用新兴企业软件趋势帮助公司成为卓越的软件组织。
原文。已获得许可转载。
相关话题
认识 MetaGPT:由 ChatGPT 提供支持的 AI 助手,将文本转换为 Web 应用
原文:
www.kdnuggets.com/meet-metagpt-the-chatgptpowered-ai-assistant-that-turns-text-into-web-apps

图片由作者提供
作为白天的数据科学家和晚上的自由职业者,我的日程安排非常紧张。
当 ChatGPT 去年首次发布时,它对我的日常生活来说简直是天赐之物。我用它来更快地学习数据科学概念,编写编程教程,创建数据可视化,甚至起草电子邮件。
GPT-4 和 代码解释器 的发布让我大开眼界,并为我的工作流程带来了无与伦比的效率提升。
就在我以为情况再也不会更好时,我发现了一个更具突破性的东西:MetaGPT。
什么是 MetaGPT?
MetaGPT 由 Pico 提供,允许用户利用自然语言的力量构建他们设想的任何类型的应用程序。
你只需输入一个文本提示,MetaGPT 就会自动将你的输入转换为一个功能完整的 Web 应用程序。
该工具在后台使用 GPT-4,这使其能够理解复杂的提示,并为 Web 应用程序构建底层逻辑。
尽管 MetaGPT 当前的功能可能看起来很令人印象深刻,但这只是生成 AI 领域未来发展的冰山一角。随着我们不断完善 AI 模型,无代码平台能够提供的功能将不断扩展,从而让技术开发的领域更加民主化。
我们正在开创一个未来,在这个未来中,任何人都可以将他们的应用程序想法变为现实,而无需大量投资或花费多年学习编程语言。
如何使用 MetaGPT 构建自己的 Web 应用程序?
这里有 6 个步骤,你可以用来在几分钟内构建自己的 ChatGPT 驱动的 Web 应用程序:
步骤 1:访问 MetaGPT
要访问 MetaGPT,请导航到 Pico 网站并创建一个免费账户。然后你将看到一个类似这样的界面:

你可以在文本框中输入任何应用程序想法,然后选择“创建”。
步骤 2:创建提示
由于我对了解不同的 MBTI 人格类型及其如何影响我们日常互动产生了新的兴趣,我向 MetaGPT 提出了以下应用程序想法:
Build me a ChatGPT-powered app that…
“Can predict my MBTI personality type based on a sentence”
在将这个提示输入到 MetaGPT 并点击“创建”后,将会出现以下界面:

步骤 3:向 MetaGPT 输入用户详细信息
工具正在询问我们需要从用户那里获取什么信息以构建这个应用程序。
它还根据我们输入的提示提出了一些 AI 生成的建议:

我决定使用第三个提示 - 让我们构建一个基于用户解决问题的方法预测其个性类型的应用程序。
第四步:自定义你的 MetaGPT 应用程序
MetaGPT 还允许你创建一个定制的 ChatGPT 提示,让你指定你希望应用程序如何创建。
你还可以选择一种美学(你希望应用程序的外观),甚至可以输入你的网站链接,这将被包含在应用程序的底部。

现在,让我们点击“构建我的应用程序”来看看 MetaGPT 会生成什么。
仅需几秒钟,MetaGPT 就会生成一个符合我们要求的应用程序:

在屏幕的右侧是工具生成的应用程序的视觉表示。你可以在左侧调整应用程序的界面,通过输入提示来指定你希望反映的任何设计更改。
例如,你可以要求 MetaGPT“将按钮颜色更改为蓝色”,它将生成相应的代码。这使得非程序员可以指定设计更改,而无需编写一行代码。
第五步:编辑 MetaGPT 生成的代码
该平台还允许你查看和修改用于构建 Web 应用程序的代码。
你可以点击“编辑代码”按钮,这让你查看并修改界面中的代码:

第六步:分享你的 MetaGPT Web 应用程序
最后,MetaGPT 创建一个可共享的 URL,并将你的 Web 应用程序托管在一个临时域名上,让你可以部署你的 Web 应用并与他人分享。
你可以点击这个链接来访问我刚刚通过 MetaGPT 构建的 MBTI 个性预测应用程序。
你只需输入一个解释你解决问题方法的提示,应用程序就会生成一个基于你的句子的个性类型预测。
这是我的结果:

这个应用程序几乎准确地猜测了我的个性类型!我是一名 INFP,它将我的类型辨识为 INFJ,这相当接近。
由于 MetaGPT 由 ChatGPT 驱动,基础语言模型的自然语言和推理能力在推动如此细致的预测中发挥了关键作用。
MetaGPT 为 ChatGPT 驱动的网页应用程序 - 下一步
MetaGPT 是一个强大的无代码应用程序,可以将文本输入转换为网页应用程序。
以下是一些你可以用来进行数据科学和分析的工具:
1. 模型部署
你可以使用 MetaGPT 构建机器学习应用程序的原型,以查看它在真实环境中的表现。
过去,这些原型需要创建者具备 HTML、CSS 和 JavaScript 等网页开发框架的知识,而数据科学家往往不具备这些知识。
像 MetaGPT 这样的工具帮助消除了这种入门障碍,使你能够加快从创意到构建功能原型的过渡。
2. 简化的数据库交互
我见过的 MetaGPT 最具创新性的应用之一就是这个 SQL 查询生成器 工具。
当我作为数据科学实习生加入我的第一家公司时,我不知道如何编写 SQL 查询,并且必须经历一个陡峭的学习曲线才能成功访问和操作数据库中的数据。
像这样的查询生成器应用程序对像我这样的数据专业人员来说是福音,即使我们可能对 SQL 不太精通,但仍需要在日常工作中使用它。
你只需上传现有的数据库模式,并指定你想使用的表。
然后,在纯文本中输入你希望查询执行的内容,点击“生成查询”。
只需几秒钟,网页应用程序就会编写出执行预期操作的 SQL 查询。
3. 跨团队协作
如果你是数据科学家,可以使用像 MetaGPT 这样的平台构建数据科学应用程序,并在组织内部的不同团队之间共享它们。
这使数据科学和分析能力得以民主化,使其他部门更容易获取这些能力。
例如,如果营销团队有数据分析需求,他们可以简单地将数据集上传到应用程序中,获得所需的输出,而不是每次都找数据科学团队。
这样,作为数据科学家,你可以将精力集中在更复杂的任务上,比如优化模型性能和研究新算法,而不是执行重复的分析任务。
本文就到此为止,感谢阅读。我很想听听你对 MetaGPT 的评论,以及你计划如何利用这个平台将你的应用程序创意变为现实!
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以通过 LinkedIn 与她联系。
更多相关主题
变压器的内存复杂度
原文:
www.kdnuggets.com/2022/12/memory-complexity-transformers.html
变压器模型的关键创新是引入了自注意力机制,它为输入序列中的所有位置对计算相似度分数,并且可以并行评估每个标记,避免了递归神经网络的顺序依赖,从而使变压器能够大大超越以前的序列模型如 LSTM。
其他地方有很多深度解释,因此在这里我想分享一些面试设置中的示例问题。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在一个有 100 万标记的书籍上运行变压器模型的问题是什么?解决这个问题的办法是什么?


以下是供读者参考的一些提示:
简而言之,
如果你尝试在长序列上运行大型变压器模型,你会发现内存不够用。
根据谷歌研究博客(2021 年):
现有变压器模型及其衍生模型的一个限制是,完整的self-attention mechanism的计算和内存需求与输入序列长度的平方成正比。使用当前常见的硬件和模型尺寸,这通常将输入序列限制在大约 512 个标记左右,并且阻止变压器直接应用于需要更大上下文的任务,如问答、文档摘要或基因组片段分类。
查看Dr.Younes Bensouda Mourri来自Deeplearning.ai的解释:
解决变压器模型的内存复杂度问题。
对变换器进行的两个“改革”使其在内存和计算方面更高效:可逆层减少内存,局部敏感哈希(LSH)减少大输入大小下点积注意力的成本。
当然,还有其他解决方案,如 扩展变换器构建 (ETC)等。我们将在后续文章中深入探讨更多细节!
快乐练习!
注意:回答面试问题有不同的角度。此新闻通讯的作者并未尝试找到一个详尽回答问题的参考,而是希望分享一些快速见解,帮助读者思考、练习并在必要时进行进一步研究。
图片来源/好读物: 论文。通过 Deepmind 改进语言模型,通过数万亿个标记进行检索(2022) 博客。通过 Google(2021)使用稀疏注意力方法构建更长序列的变换器
视频/答案来源: 自然语言处理中的注意力模型由Dr.Younes Bensouda Mourri 提供,来自Deeplearning.ai
Angelina Yang 是一位数据和机器学习高级执行官,拥有超过 15 年的经验,致力于提供先进的机器学习解决方案和能力,以提高金融服务和金融科技行业的业务价值。专长包括在客户体验、监控、对话式 AI、风险与合规、营销、运营、定价和数据服务领域的 AI/ML/NLP/DL 模型开发和部署。
原文。经授权转载。
更多相关主题
你的机器学习代码消耗了多少内存?
原文:
www.kdnuggets.com/2021/07/memory-machine-learning-code-consuming.html
评论

图片来源:Pixabay
为什么要分析内存使用情况?
假设你写了一个很酷的机器学习(ML)应用程序或创建了一个全新的神经网络模型。现在你想通过某个网络服务或 REST API 部署这个模型。
或者,你可能是基于来自制造厂的工业传感器的数据流开发了这个模型,现在你需要将模型部署到工业控制 PC 之一,以便基于持续输入的数据做出决策。

“兴奋地开发了一个全新的 ML 模型”。图片来源:Pixabay
作为数据科学家,你可能会收到工程/平台团队非常常见的问题:“你的模型/代码占用了多少内存?”或者“在给定的数据负载下,代码的内存峰值是多少?”
这很自然,因为硬件资源可能有限,单个 ML 模块不应占用系统的全部内存。这在边缘计算场景中尤其如此,即 ML 应用可能在边缘运行,例如在工业 PC 上的虚拟化容器内。
此外,你的模型可能是运行在那块硬件上的数百个模型之一,你必须对内存使用的峰值有一定了解,因为如果大量模型在同一时间内达到内存峰值,可能会导致系统崩溃。
现在,你开始好奇了,不是吗?

图片来源:Pixabay
… 硬件资源可能有限,单个 ML 模块不应占用系统的全部内存。这在边缘计算场景中尤其如此…
不要犯这个根本错误
注意,我们讨论的是你整个代码的运行时内存剖面(一个动态量)。这与 ML 模型的大小或压缩无关(你可能将其保存为磁盘上的特殊对象,如Scikit-learn Joblib dump、一个简单的 Python Pickle dump、TensorFlow HFD5等)。
Scalene:一个整洁的内存/CPU/GPU 分析工具
这里有一篇关于一些旧的内存分析工具的文章,用于 Python。
在本文中,我们将讨论Scalene——你的终极工具,用于解答你的工程团队提出的问题。
根据其GitHub 页面,“Scalene 是一个高性能的 CPU、GPU 和内存分析工具,提供其他 Python 分析工具无法做到的功能。它的运行速度比其他分析工具快几个数量级,同时提供更详细的信息。”
它是在麻省大学开发的。查看这个视频以获取全面的介绍。
安装
毕竟,它是一个 Python 包。因此,通常按照常规安装即可,
**pip install scalene**
目前仅适用于 Linux 操作系统。我没有在 Windows 10 上进行测试。
在 CLI 或 Jupyter Notebook 中使用
使用 Scalene 非常简单直接,
**scalene <yourapp.py>**
另外,你可以通过使用这个魔法命令在 Jupyter Notebook 中使用它,
**%load_ext scalene**
示例输出
这是一个示例输出。我们将很快深入探讨这个话题。

特性
以下是 Scalene 的一些酷炫功能。大多数功能都是不言而喻的,可以从上面的截图中了解,
-
行或函数:报告整个函数和每个独立代码行的信息
-
线程:支持 Python 线程。
-
多进程:支持使用
multiprocessing库 -
Python 与 C 的时间:Scalene 区分了在 Python 与原生代码(例如库)中的时间
-
系统时间:它区分系统时间(例如,休眠或执行 I/O 操作)
-
GPU:它还可以报告在 NVIDIA GPU 上花费的时间(如果存在)
-
拷贝量:报告每秒拷贝的数据量(以 MB 为单位)
-
检测泄漏:Scalene 可以自动定位可能导致内存泄漏的代码行!
一个具体的机器学习代码示例
让我们开始将 Scalene 用于内存分析标准机器学习代码的实际操作。我们将查看两种不同类型的机器学习模型——原因很快会得到澄清。我们将使用 Scikit-learn 库来创建所有三个模型,并利用其合成数据生成函数来创建我们的数据集。
-
一个多重线性回归模型
-
使用相同数据集的深度神经网络模型
建模代码对于所有三个模型遵循完全相同的结构。外部 I/O 操作也在下图中标出,我们将看到它们可能会或不会主导内存分析,具体取决于模型类型。

图片来源:作者制作(拥有版权)
线性回归模型
代码文件在我的 GitHub 仓库中。
我们使用标准导入和两个变量NUM_FEATURES和NUM_SMPLES来进行一些后续实验。

我们没有展示数据生成和模型拟合代码。它们很标准,可以在这里查看。我们将拟合的模型保存为 pickle 格式,并与测试 CSV 文件一起加载以进行推理。

我们在main循环下运行所有内容,以便清晰地进行 Scalene 执行和报告(你很快会明白的)。

当我们运行命令时,
$ scalene linearmodel.py --html >> linearmodel-scalene.html
我们得到这些结果作为输出。注意,这里我使用了**--html**标志并将输出管道到一个 HTML 文件中以便于报告**。


那么,这个结果中有什么引人注目的地方?
内存占用几乎完全由外部 I/O 主导,比如 Pandas 和 Scikit-learn 估算器的加载,以及少量内存用于将测试数据写入磁盘上的 CSV 文件。
实际的机器学习建模、Numpy 或 Pandas 操作和推理完全不影响内存!
随着模型和数据的规模扩大会发生什么?
我们可以扩大数据集大小(行数)和模型复杂性(特征数),并运行相同的内存分析,以记录各种操作在内存消耗方面的表现。结果如下。
这里的X 轴表示特征数/数据点数的配对。请注意,这个图展示的是百分比而不是绝对值,以展示各种操作的相对重要性。

图片来源:作者提供(拥有版权)
所以,对于线性回归模型……
从这些实验中,我们得出结论,Scikit-learn 的线性回归估算器相当高效,实际模型拟合或推理并不消耗大量内存。
但是,它确实有一个固定的内存占用量,这在加载时会被消耗。然而,随着数据大小和模型复杂性的增加,该代码占用的比例会减少。
因此,如果你在处理这样的小型线性模型时,可能需要关注数据文件 I/O 以优化你的代码以获得更好的内存性能。
深度神经网络会发生什么?
如果我们用一个 2 隐层的神经网络(每个隐层 50 个神经元)运行类似的实验,那么结果如下。代码文件在这里。

图片来源:作者提供(拥有版权)
很明显,神经网络模型在训练/拟合步骤中消耗大量内存,这与线性回归模型不同。然而,对于特征数量少且数据量大的情况,拟合所需的内存量较少。
你也可以尝试各种架构和超参数,并记录内存使用情况,以找到适合你情况的设置。
遵循实验方法
如果你用相同的 代码文件 反复进行实验,结果会因硬件、磁盘/CPU/GPU/内存类型而大相径庭。本文的目的是提供一种内存分析实验的方法,而不是关注实际值或趋势。我希望你能带走对你自己代码进行内存分析实验的方法。
一些关键建议
-
最好在代码中编写小函数,专注于单一任务
-
保留一些自由变量,如特征数量和数据点数量,以便可以用最小的修改运行相同的代码文件,检查数据/模型扩展时的内存使用情况。
-
如果你在比较一个机器学习算法与另一个算法,尽量保持整体代码结构和流程尽可能一致,以减少混淆。最好只是更改估算器类,并比较内存使用情况。
-
数据和模型输入/输出(导入语句、磁盘上的模型持久化)在内存占用方面可能会出乎意料地占据主导地位,具体取决于你的建模场景。在进行优化时,千万不要忽视它们。
-
基于上述原因,考虑比较来自多个实现/包的相同算法的内存使用情况(例如 Keras 与 PyTorch 与 Scikit-learn)。如果内存优化是你的主要目标,你可能需要寻找内存占用最小但仍能满意完成工作的实现,即使它在特性或性能方面不是绝对最佳的。
-
如果数据输入/输出成为瓶颈,可以探索更快的选项或其他存储类型,例如将 Pandas CSV 替换为 parquet 文件和 Apache Arrow 存储。请查看这篇文章,
读取 Parquet 文件(使用 Arrow)与使用 Pandas 读取 CSV 的速度有多快?
你还可以使用 Scalene 做其他事情
在这篇文章中,我们只讨论了关注于经典机器学习建模代码的最基本内存分析。Scalene CLI 还有其他选项,你可以利用这些选项,
-
仅分析 CPU 时间而不分析内存使用情况
-
仅分析非零内存占用的情况
-
指定 CPU 和内存分配的最低阈值
-
设置 CPU 采样率
-
多线程并检查差异
有时需要最终验证
对于资源有限的情况,最好能托管一个验证环境/服务器,该环境将接受给定的建模代码(开发完成后)并通过这样的内存分析器运行,以生成运行时统计数据。如果它满足预定的内存占用标准,建模代码才会被接受用于进一步部署。

图片来源:作者制作(拥有版权)
如果内存优化是您的主要目标,您可能需要寻找一种内存占用最小但能够令人满意地完成工作的实现方案。
总结
在这篇文章中,我们讨论了内存分析在与平台/工程团队顺畅对接、将代码部署到服务/机器上的重要性。内存分析也可以揭示一些基于特定数据和算法优化代码的惊人方法。
我们展示了一个典型的 ML 建模代码示例,使用强大而轻量的 Python 库 Scalene 进行分析。我们展示了一些线性回归和神经网络模型的代表性结果,并提供了一些一般性的建议。
希望这些工具和技术能帮助您在将 ML 代码实施并部署到生产环境中获得更多成功。
您可以查看作者的GitHub** 代码库**,获取机器学习和数据科学方面的代码、想法和资源。如果您像我一样,对 AI/机器学习/数据科学充满热情,请随时在 LinkedIn 上添加我或在 Twitter 上关注我。
原文。经许可转载。
相关:
-
作为数据科学家的可重用 Python 代码管理
-
5 个 Python 数据处理技巧与代码片段
-
GitHub Copilot:您的 AI 编程伙伴 – 到底有什么大惊小怪的?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关内容
如何合并 Pandas DataFrames

图片由catalyststuff在Freepik上提供
在数据处理过程中,两个或更多数据集之间的数据合并是典型的。在本博客中,我们将学习如何使用 Pandas 进行数据合并以及各种提升数据合并技能的技巧。让我们深入探讨数据合并技术。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您组织的 IT
合并 Pandas DataFrame
首先,我们需要导入 Pandas Python 包。
import pandas as pd
合并两个 Pandas DataFrames 需要使用 Pandas 包中的 merge 方法。这个函数会根据我们意图连接的变量或列合并两个 DataFrame。让我们通过一个示例 DataFrame 来尝试 Pandas 的合并方法。
# Create Population DataFrame
df1 = pd.DataFrame({
'Country': ['America', 'Indonesia', 'France'],
'Location': ['New York', 'Jakarta', 'Paris'],
'Population': [731800, 575030, 183305]
})
# Create Income DataFrame
df2 = pd.DataFrame({
'Country': ['America', 'America', 'Indonesia', 'India', 'France', 'Greece'],
'Location': ['New York', 'Chicago', 'Jakarta', 'Mumbai', 'Paris', 'Yunani'],
'Income': [1000, 1500, 1400, 1100, 900, 1200]
})
# Merge Dataframe
merged_df = pd.merge(df1, df2, on='Country')
merged_df

图片由作者提供
在上面的示例中,我们创建了两个具有稍微不同列的 DataFrame,并在‘Country’列上合并它们。结果是两个 DataFrame 中具有相似值的行被合并在一起。我们通过一行代码成功合并了两个不同的 DataFrame。
应用可选参数
Pandas 的.merge 方法有各种可选参数可以利用。让我们看一下其中一些有用的参数。
重命名合并的同名列
在上面的示例中,我们可以看到一个名为‘Location’的列,在合并后该列带有后缀 _x 和 _y。如果我们想在合并时更改列名,可以使用以下代码来实现。
merged_df = pd.merge(df1, df2, on='Country', suffixes = ('_Population', '_Income'))
merged_df

图片由作者提供
在这段代码中,我们传递了带有两个值的元组作为 suffixes 参数;第一个和第二个 DataFrame 的名称。在我的示例中,我们将第一个 DataFrame 命名为 Population,将第二个命名为 Income。
基于不同列名进行合并
如果我们有两个 DataFrame,其列名不同但指代相同的定义,我们仍然可以合并它们,但需要指定要合并的 DataFrame 和列。
df2 = pd.DataFrame({
'Index': ['America', 'America', 'Indonesia', 'India', 'France', 'Greece'],
'Location': ['New York', 'Chicago', 'Jakarta', 'Mumbai', 'Paris', 'Yunani'],
'Income': [1000, 1500, 1400, 1100, 900, 1200]
})
merged_df = pd.merge(df1, df2, left_on='Country', right_on = 'Index')
merged_df

图片由作者提供
在上述示例中,我们将第二个 DataFrame 的‘Country’列更改为‘Index’,然后通过在每个 DataFrame 中指定列名来合并数据集。Left_on 参数用于第一个 DataFrame,right_on 用于第二个 DataFrame。
更改合并类型
Pandas 合并方法中有五种不同的合并类型。默认情况下,合并是内连接,只包括在两个列中都有匹配值的行。然而,我们可以通过将值传递给 how 参数来更改合并类型:
- 左连接
左连接仅使用第一个 DataFrame 的值。
merged_df = pd.merge(df1, df2, on='Country', how = 'left')
merged_df
图片由作者提供
- 右连接
右连接仅使用第二个 DataFrame 的值。
merged_df = pd.merge(df1, df2, on='Country', how = 'right')
merged_df

图片由作者提供
- 外连接
通过使用两个 DataFrame 键的并集来包含两个 DataFrame 中的所有行。

图片由作者提供
- 交叉连接
从两个 DataFrame 创建一个笛卡尔积
merged_df = pd.merge(df1, df2, how = 'cross')
merged_df

图片由作者提供
通过两个或更多不同的列进行合并
使用 Pandas 合并可以将两个 DataFrame 与两个或更多不同的列连接在一起。我们需要在 on 参数中指定要合并的列列表。
merged_df = pd.merge(df1, df2, on = ['Country', 'Location'])
merged_df

图片由作者提供
结论
在数据处理过程中,合并两个不同的 DataFrame 是一种常见的活动。为此,我们可以使用 Pandas 的 merge 方法。在 Pandas merge 中,我们可以访问各种可选参数以执行特定任务,包括更改合并列的名称、基于不同列名称合并 DataFrame、更改合并类型以及通过两个或更多列进行合并。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。尽管全职工作于 Allianz Indonesia,他仍喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关主题
在 Python 中合并 Pandas DataFrames
原文:
www.kdnuggets.com/2020/12/merging-pandas-dataframes-python.html
评论
作者 Dean McGrath, 渴望成为数据分析师

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
介绍
作为数据科学家,我们经常需要同时分析来自多个数据源的数据。要成功实现这一目标,我们需要能够高效地使用各种方法合并不同的数据源。今天我们将探讨使用 Pandas 内置的 .merge() 函数来通过几种不同的连接方法合并两个数据源。
入门
对于那些刚接触数据科学或尚未接触 Python Pandas 的人,我们建议首先阅读 Pandas 系列 & DataFrame 解析 或 Python Pandas 迭代 DataFrame。这两篇文章将为你提供安装说明和今天文章的背景知识。
Pandas 合并
Pandas 内置的 .merge() 函数提供了一种强大的方法,通过数据库风格的连接来合并两个 DataFrames。
语法
上述 Python 代码片段显示了 Pandas .merge() 函数的语法。
参数
-
right— 这将是你要连接的 DataFrame。 -
how— 在这里,你可以指定你希望两个 DataFrame 如何连接。默认值是inner,但是你可以传递left进行左外连接,right进行右外连接,outer进行完全外连接。 -
on— 如果两个 DataFrame 都包含一个共享的列或一组列,你可以将这些列传递给on作为合并的键。 -
left_on— 在这里,你可以指定一个列或标签列表,用于连接左侧 DataFrame。当你希望在两个 DataFrame 中连接的列名不同的时候,这个参数非常有用。 -
right_on— 条件与left_on相同,只是针对右侧 DataFrame。 -
left_index— 如果你希望使用索引来连接左侧 DataFrame,那么传入True。 -
right_index— 如果你希望使用索引来连接右侧 DataFrame,那么传入True。 -
sort— 如果你希望连接的键按字母顺序排序,可以传入True。 -
suffixes— 如果两个 DataFrame 共享列标签名称,则可以指定应用于重叠部分的后缀类型。默认的是左侧使用_x,右侧使用_y。 -
indicator— 如果你希望标记行的来源,可以将此参数设置为True。此标记将指示行的键是否仅出现在左侧 DataFrame、右侧 DataFrame,或两者都出现。 -
validate— 在这里,你可以检查 DataFrame 是如何连接的以及键之间的关系。你可以传入以下参数来检查:1:1检查键是否在左侧和右侧 DataFrame 中唯一,1:m检查合并的键是否仅在左侧 DataFrame 中唯一,m:1检查合并的键是否仅在右侧 DataFrame 中唯一。
实际应用
接下来,我们将通过几个示例来演示如何自己使用 merge 函数。下面提供的代码片段将帮助你创建两个我们将在后续故事中使用的 DataFrame。
上面的 Python 代码片段创建了两个 DataFrame,你可以使用它们来继续以下示例。

上面的控制台输出显示了执行 Python 代码片段以创建两个 DataFrame 的结果。
内连接
内连接方法是 Pandas merge 的默认方法。当你传入 how='inner' 时,返回的 DataFrame 只会包含两个 DataFrame 中共享的列的值。
上面的 Python 代码片段演示了如何使用内连接来连接两个 DataFrame。

上面的图片显示了内连接两个 DataFrame 后的控制台输出。
从上面的控制台输出截图中,我们可以看到内连接对两个 DataFrame 的影响。由于值 a、c、e 和 f 在两个 DataFrame 中不共享,它们不会出现在控制台输出中。输出还演示了处理两个 DataFrame 之间共享列标签时默认的后缀应用。
左连接
Pandas 的左连接函数类似于 SQL 中的左外连接。返回的 DataFrame 将包含左侧 DataFrame 中的所有值,以及在合并过程中与右侧 DataFrame 中的连接键匹配的任何值。
上面的 Python 代码片段展示了使用左连接来合并两个 DataFrame 的语法。

上面的截图显示了使用左连接合并两个 DataFrame 的控制台输出。
如果右侧 DataFrame 中的值与合并列不匹配,则在返回的 DataFrame 中将插入 NaN,不是数字。
右连接
Pandas 右连接执行的功能类似于左连接,但连接方法应用于右侧 DataFrame。
上面的 Python 代码片段展示了使用 Pandas 右连接合并两个 DataFrame 的语法。

上面的截图显示了使用右连接合并两个 DataFrame 的结果。
如上所示,右侧 DataFrame 中不存在的任何键,在左侧 DataFrame 中将插入一个 NaN 值。
外连接
Pandas 外连接合并两个 DataFrame,并本质上反映了左外连接和右外连接的结果。外连接将返回左侧和右侧 DataFrame 的所有值。如果 Pandas 无法在合并的 DataFrame 中找到一个值,将使用 NaN 代替。
上面的 Python 代码片段展示了使用外连接连接两个 DataFrame 的语法。

上面的截图显示了使用外连接合并两个 DataFrame 的结果。
在使用外连接合并两个 DataFrame 时,有时了解新 DataFrame 中记录的来源是有用的信息。你可以通过将 indicator=True 作为参数传递给 .merge() 函数来查看记录的来源,这将创建一个标题为 _merge 的新列。
总结
要成为成功的数据科学家,你需要具备处理来自多个数据源的数据的技能,并且经常是同时进行的。我们常常需要结合数据源来丰富数据集或在当前数据中合并历史快照。Pandas 提供了一个强大的方法来通过内置的 .merge() 函数连接数据集。Pandas .merge() 函数提供了创建不同类型连接的灵活性,以实现所需的输出。
感谢你抽出时间阅读我们的故事——希望你觉得它有价值!
个人简介:Dean McGrath (@DeanMcGrath8) 是一名有志的数据分析师,并且是 Towards Data Science 的贡献者。
原文。经许可转载。
相关内容:
-
Pandas 升级版:使用 Dask 完成端到端的数据科学
-
每个复杂的 DataFrame 操作,直观解释与可视化
-
10 个被低估的 Python 技能
更多相关话题
元数据如何改善安全性、质量和透明度
原文:
www.kdnuggets.com/2022/04/metadata-improves-security-quality-transparency.html
Spotify 如何与像 Apple 这样的巨头抗衡?一个字:数据。通过机器学习和 AI,Spotify 通过提供更个性化和定制化的体验为用户创造价值。让我们快速了解一下用于增强其平台的聚合信息层:
-
Spotify 使用自然语言处理(NLP)扫描关于你正在听的音乐的讨论论坛,然后将你的偏好与其他讨论相似的音乐匹配;
-
音乐的组成被分析以了解音调、声音、响度、音质(即大调或小调)以及其他用于推荐类似歌曲和艺术家的因素;
-
当然,Spotify 会在听音乐时测量行为,追踪重复播放或跳过歌曲,建立偏好,从而改进推荐。
这里的核心数据是音乐——歌曲的基本组成部分,如标题、艺术家和时长。选择一首歌来听定下了基线(也许你喜欢它的低音线)。其他一切都可以视为元数据:关于如何听歌、歌曲的构成以及其他类似的音乐的附加元素。
我们的前 3 名课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路。
2. Google Data Analytics Professional Certificate - 提升你的数据分析技能
3. Google IT Support Professional Certificate - 支持组织的 IT 需求
在这里,元数据是 Spotify 算法的驱动力,它被不断收集和应用,以提供智能推荐,保持你不断听歌。
什么是元数据?
简单来说,在技术行业中,“meta”指的是底层定义或描述。更直接地说,元数据提供了关于数据的上下文,超出你在行和列中看到的内容。
这个定义相当广泛,但主要是因为它几乎可以用于任何目的——它可以详细告诉你每一列标题的含义,谁上传了数据及何时,整个数据集的列数和行数,原始数据来源,甚至仓储和居留要求。
元数据如何组织?
有 3 种主要的元数据类型相互作用:行政性、描述性和结构性。每种类型在解释相应数据方面发挥不同的作用。
结构化元数据 – 提供数据元素组织方式的见解。这便于快速和轻松的导航,如目录或页码。结构化元数据允许将类似数据分组,记录唯一数据集之间的关系。
管理性元数据 – 提供有关数据的技术信息。它涵盖数据的来源、数据类型和访问或使用许可等方面。
描述性元数据 – 添加有关所有者、数据创建/发布时间以及数据包含内容的信息。其基本目的是简化识别,并提供数据的快照。
这些类型的元数据的组合使组织能够高效地在大量数据中导航,使其在需要时容易找到所需的信息。

元数据为何重要?
53%的分析消费者在定位和访问数据内容时遇到困难。随着数据量的增加,组织了解其拥有的数据、数据位置和使用方式变得越来越重要。
元数据的作用不仅限于描述数据。元数据可以使数据发现变得更加容易,并帮助增加对数据集的理解。例如,以图书馆书籍为例。如果文本是主要数据,则书籍封面可能包含书籍的简要总结和其他人的评论。重要的是,图书馆还可能附加数据,为书籍提供类别、类型和唯一标识符,以便于组织和检索。
元数据还可以通过确保组织在数据集级别跟踪使用情况、共享和许可权限,来协助遵守监管要求。通过附加使数据使用方式、目的以及可以或不可以共享对象的元数据,您可以将安全性和合规性内建于数据本身。
数据目录平台中的元数据管理
通过管理您的元数据,您实际上是在创建数据资产的百科全书。元数据管理是数据管理的一个子集,而数据管理本身属于数据治理的范畴。
因此,关注元数据管理的主要原因与实施数据治理策略的原因相同:提高数据安全性、数据质量和整体透明度。

提高数据安全性:
-
元数据将使用限制和许可直接与数据绑定
-
揭示数据所有权和维护者,以便明确角色
-
将与数据集相关的信息整合和编纂,以确保不会丢失
提高数据质量:
-
设计/实施组织范围的本体论
-
实体解析/记录关联变得更加简单
-
对于随时间变化的洞察
提高透明度:
-
增加了组织内部和跨团队的可发现性
-
创建可审计的使用、访问和更新记录
-
分享信息而不泄露敏感数据
精细的元数据管理不仅是将这些丰富信息与数据集本身连接起来,而是以一种易于访问、执行和管理的方式来处理。
元数据在数据目录中的好处是什么?
使用 ThinkData Works 的特定工具和功能,你可以解锁源于元数据的宝贵收益:
自定义元数据 – 向数据集添加任何元数据的能力,包括关联/相关的数据集、上传使用协议、成本与许可以及数据字典
可配置的属性定义 – 数据目录允许你在数据集中输入模式描述,将元数据绑定到属性
数据集版本控制/修订 – 每个数据集结构随着模式的变化而产生的版本,以及每次数据更新时跟踪的修订。这样,用户可以在更新其模型和仪表板时跟踪数据的稳定版本
数据健康监控 – 一个用于报告和警报配置的仪表板,根据数据随时间变化的情况,包括“宏观”信息(如行和列计数)或“微观”信息(如值类型或值范围)
访问审计 – 具体的使用统计信息和描述用户行为、API 调用及对数据进行或进行的数据操作的信息。
灵活管理,严格治理
元数据管理是健全数据治理的关键部分 – 是有效数据战略中最重要的部分之一。我们知道每个组织都有独特的需求,因此一个好的元数据解决方案应当强大且可执行,同时足够灵活以便按照每家公司量身定制的数据管理方式。
通过提供全面的元数据管理,ThinkData Works 使我们的客户能够在强大、安全的基础上构建数据驱动的解决方案。
你认为你的业务是否需要一个数据目录来查找、理解和使用可信的数据以推动业务成果? 联系我们 以解锁数据的价值。
Tim Lysecki 是 ThinkData Works 的产品营销经理,他负责塑造公司的市场战略,指导媒体报道公司和产品,并扩展客户名单。在业余时间,他还是一位热衷于创作歌曲、表演和摄影的人。
更多相关内容
介绍 MetaGPT 的数据解释器:SOTA 开源 LLM 基于的数据解决方案
原文:
www.kdnuggets.com/metagpt-data-interpreter-open-source-llm-based-data-solutions

图像由作者使用 Midjourney 创建
MetaGPT 是一个多智能体框架,用于将角色分配给各种智能体,形成协作实体,这些实体能够协调工作以执行复杂指令。MetaGPT 自称为“作为多智能体系统的软件公司”,为你提供这些协作实体的预期用途的想法。MetaGPT 可作为独立应用程序从命令行使用,也可作为库在你自己的 Python 脚本中使用,提供了所需的灵活性和控制。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
该项目始于 2023 年 4 月,利用 ChatGPT,目前在撰写时 GitHub 上已有近 40K 星标。其 GitHub 仓库进一步描述如下:
MetaGPT 接收一行要求作为输入,并输出用户故事/竞争分析/需求/数据结构/API/文档等。
在内部,MetaGPT 包括产品经理/架构师/项目经理/工程师。它提供了一个软件公司的整个过程以及精心编排的标准操作程序(SOP)。

MetaGPT 的软件公司多智能体示意图(逐步实施)(来自 MetaGPT 的 GitHub)
MetaGPT 可用于代码生成、原型设计、项目规划等。它被认可为 杰出的开源成就,并且持续成为 GitHub 上的热门仓库。
这就是 MetaGPT。现在让我们深入讨论 数据解释器、Deep Wisdom's 最新 MetaGPT 改进和成就。
介绍 MetaGPT 数据解释器的完整视频
展示如何通过动态规划、工具利用、增强推理和基于经验的验证来应对电力负荷预测挑战。
案例:
t.co/GhNH54Ahhi… pic.twitter.com/Xc5aam1TXz— MetaGPT (@MetaGPT_) 2024 年 3 月 19 日
数据解释器是 MetaGPT 框架中的另一个成员代理,专注于评估和解决数据相关任务。从论文中:
在这项研究中,我们介绍了数据解释器,这是一种通过代码解决问题的解决方案,强调三项关键技术以增强数据科学中的问题解决能力:1) 使用分层图结构进行动态规划,以实现实时数据适应性;2) 动态工具集成,以提高执行期间的代码熟练度,丰富所需的专业知识;3) 反馈中的逻辑不一致性识别,通过经验记录提高效率。[...] 与开源基准相比,它展示了优越的性能,在机器学习任务中表现出显著改进,从 0.86 提高到 0.95。此外,它在 MATH 数据集上表现出 26%的提升,在开放性任务上则取得了 112%的显著改善。
这些发现确实令人印象深刻。而且无需盲目相信这些结果,因为他们已经发布了这些结果。Deep Wisdom 还提供了大量示例,以展示他们的数据解释器代理如何与现有的 MetaGPT 框架一起使用。
这个示例展示了它如何用于 NVIDIA 股票趋势分析。要查看 MetaGPT 数据解释器提示的样子,我将在下面重复一遍:
从 Yahoo Finance 获取 NVIDIA Corporation (NVDA)的股票价格数据,重点关注过去 5 年的历史收盘价。总结统计数据(均值、中位数、标准差等)以了解收盘价的集中趋势和离散程度。分析数据以发现任何明显的趋势、模式或异常情况,可能使用滚动平均或百分比变化。创建一个图表来可视化所有的数据分析。保留 20%的数据集用于验证。对训练集训练预测模型。报告模型的验证准确率,并可视化预测结果。
你可以查看上面链接的示例笔记本,以跟随 MetaGPT 的过程并查看结果。剧透:Deep Wisdom 没有分享这些结果,因为它们并不令人印象深刻 😃
阅读完整论文以获取所有相关信息。有关安装和使用的更多信息,请查看项目的GitHub 仓库。根据我的经验,我可以证明 MetaGPT 是一个值得查看的项目,并且随着数据解释器代理的加入,这一点比以前更加真实。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为KDnuggets与Statology的执行编辑,以及Machine Learning Mastery的特约编辑,马修致力于使复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、语言模型、机器学习算法以及探索新兴的人工智能。他的使命是让数据科学社区中的知识变得更加民主化。马修从 6 岁起就开始编程。
更多相关主题
Meta 的新数据分析师专业认证已发布!
原文:
www.kdnuggets.com/metas-new-data-analyst-professional-certification-has-dropped

图片由作者提供
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
Coursera 平台上推出了一个新的专业认证 - Meta 数据分析师专业证书。
如果你曾考虑进入数据分析市场,现在是个绝佳机会。目前美国数据分析师的中位年薪为$82,000+,该领域有超过 90,000+个职位空缺。
让我们直接进入课程…
Meta 数据分析师认证
链接: Meta 数据分析师专业证书
本课程面向希望从数据分析师角度进入技术行业的初学者。你可以根据自己的时间和节奏进行学习。如果每周投入 10 小时,整个课程需要 5 个月完成,但如果你能投入更多时间,则可以更快完成!
该认证由 5 门课程组成:
-
数据分析入门
-
使用电子表格和 SQL 进行数据分析
-
Python 数据分析
-
市场营销统计学
-
数据管理入门
我将学到什么?
在这 5 门课程中,你将学习到:
-
如何收集、清理、排序、评估和可视化数据
-
学习如何应用 OSEMN 框架来指导数据分析过程
-
确保你采取的方法能提供可操作的见解
-
使用统计分析,如假设检验和回归分析,做出数据驱动的决策
-
理解有效数据管理的基础原则
-
理解数据资产在组织中的可用性
我将从此认证中获得什么?
如果你计划参加此认证,这里是一些特点和附带的好处:
-
从 Meta 获得专业级培训
-
展示你在准备好项目上的能力
-
符合热门职位要求:数据分析师、助理数据分析师和业务分析师
-
简历和 LinkedIn 评审,提供个性化反馈
-
使用互动工具和模拟面试来实践你的技能
-
借助 Coursera 的求职指南获得职业支持
总结
在 5 个月内,你可能准备好开始新的职业生涯,获得所需的支持和指导。随着数据价值的提升,对数据分析师的需求持续增长。
祝学习愉快!
Nisha Arya是一名数据科学家、自由技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及理论基础知识。Nisha 涉及广泛的话题,并希望探索人工智能如何有益于人类寿命的不同方式。作为一个热衷的学习者,Nisha 寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
我该使用哪个指标?准确度与 AUC

准确度和 AUC(曲线下面积)是评估模型性能优劣的指标。两者都对根据你试图解决的业务问题来评估模型性能有所帮助。那么你应该在何时使用哪一个呢?简短的回答是 - 这要看情况!
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在这篇文章中,我们将首先描述这两个指标,然后详细了解每个指标,并理解何时使用它们。
什么是准确度?
准确度是最受欢迎的指标,用来确定模型做出正确预测的百分比。
它是通过将正确预测的数量与数据集中样本总数的比率来计算的。结果以百分比形式表示,例如,如果模型正确预测了数据集中 90%的项目,则准确度为 90%。
从数学上讲,它写作:

公式中的四个成分基于实际值和下述对应的模型预测:
-
真阳性(TP) - 模型正确识别为正类的实例数量。
-
真阴性(TN) - 模型正确识别为负类的实例数量。
-
假阳性(FP) - 模型错误识别为负类的实例数量。
-
假阴性(FN) - 模型错误识别为正类的实例数量。
这些指标通过对模型预测的概率得分应用适当的截止值来得出。关于每个术语及其与混淆矩阵的关系的详细解释在这篇文章中有所说明。
什么是 AUC?
AUC 代表“曲线下面积”,全称为“接收者操作特征曲线下的面积”。它捕捉 ROC(接收者操作特征)曲线下的面积,并比较不同阈值下真实正例率(TPR)与假正例率(FPR)之间的关系。
但在深入了解 AUC 之前,让我们首先了解这些新术语的含义。
TPR 或真实正例率
这是所有正样本中被正确预测为正实例的比例。例如,如果模型的任务是识别欺诈交易,那么 TPR 被定义为所有欺诈交易中被正确预测的欺诈交易的比例。
FPR 或假正例率
这是被错误预测为负例的负样本的百分比。继续以欺诈检测模型为例,FPR 被定义为所有合法交易中被错误预测为欺诈警报的比例。
从数学上讲,TPR 和 FPR 的表达式如下:

现在我们理解了 TPR 和 FPR 的定义,让我们了解它们如何与 AUC 指标相关。

编辑提供的图片
从上面的图片中可以看出,左上角,即高 TPs 和低 FPs,是理想状态。因此,紫色曲线代表了 AUC 为 1 的完美分类器,即该曲线下的矩形区域为 1。
但在现实应用中,构建这样的理想分类器实际上是不可实现的。因此,了解分类器的下界是重要的,红色对角线表示这一点。它被标注为随机分类器,AUC 为 0.5,即红色虚线下的三角形面积。这被称为随机分类器,因为其预测效果与随机抛硬币一样好。
总之,机器学习模型的表现介于随机分类器和完美分类器之间,这表明期望的 AUC 在 0.5(随机状态)和 1(完美状态)之间。
本质上,数据科学家旨在最大化 AUC,即曲线下面积更大。这表示模型在生成正确预测方面的好坏,即力求最高的 TPR,同时保持最低的 FPR。
何时使用准确率?
准确率用于平衡的数据集,即类别分布均等时。
现实生活中的一个例子是欺诈检测,它必须正确识别并区分欺诈交易(关注类别)与常规交易。通常,欺诈交易很少,即它们在训练数据集中出现的频率低于~1%。
在这种情况下,准确率会偏袒模型的表现,即使模型将每笔交易都识别为非欺诈性交易,也会宣称模型良好。这样的模型虽然准确率高,但未能预测任何欺诈交易,违背了构建模型的目的。
何时使用 AUC?
AUC 非常适合处理不平衡的数据集。例如,欺诈检测模型必须正确识别欺诈,即使这意味着将一些(少量的)非欺诈交易标记为欺诈。
在专注于正确识别目标类别(欺诈交易)即 TP 时,模型很可能会犯一些错误,即 FP(将非欺诈交易标记为欺诈)。因此,查看一个比较 TPR 和 FPR 的度量是重要的,这就是 AUC 的作用。
你应该选择哪个指标以及何时选择?
准确率和 AUC 都用于分类模型。然而,在决定使用哪一个时,有一些事项需要注意。
高准确率的模型表明预测错误很少。然而,这并没有考虑这些错误预测的商业成本。在这些业务问题中使用准确率度量忽略了诸如 TP 和 FP 的细节,并给模型预测带来了夸大的信心,这对业务目标有害。
在这种情况下,AUC 是首选指标,因为它在最佳选择的阈值下校准了敏感性和特异性之间的权衡。
此外,准确率衡量单个模型的表现,而 AUC 则比较两个模型,并评估同一模型在不同阈值下的表现。
总结
选择适当的指标对于获得期望的结果至关重要。准确率和 AUC 是两个常用的评估指标,用于客观地衡量模型性能。它们都有助于评估模型的表现,并将一个模型与另一个模型进行比较。文章解释了为什么准确率对平衡数据来说是足够的,但 AUC 适合衡量模型在不平衡数据集上的表现。
Vidhi Chugh是一位获奖的 AI/ML 创新领袖和 AI 伦理学家。她在数据科学、产品和研究的交叉点上工作,以提供商业价值和见解。她提倡以数据为中心的科学,并在数据治理领域是一位领先专家,致力于构建值得信赖的 AI 解决方案。
更多相关话题
评估深度学习对象检测器的指标
原文:
www.kdnuggets.com/2020/08/metrics-evaluate-deep-learning-object-detectors.html
评论
由 Venkatesh Wadawadagi, Sahaj Software Solutions
已经采用了不同的方法来解决对准确对象检测模型日益增长的需求。最近,随着卷积神经网络(CNN)和 GPU 加速深度学习框架的普及,对象检测算法开始从新的角度进行开发。R-CNN、Fast R-CNN、Faster R-CNN、R-FCN、SSD 和 Yolo 等 CNN 显著提高了该领域的性能标准。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
一旦你训练了第一个对象检测器,下一步就是了解其性能。确实,你可以看到模型找到了你提供的图片中的所有对象。很好!但你如何量化这一点?我们应该如何决定哪个模型更好?
由于分类任务仅评估对象在图像中出现的概率,对于分类器来说,从正确预测和错误预测中识别正确预测是一个直接的任务。然而,对象检测任务进一步通过与相应置信度得分关联的边界框来定位对象,以报告对象类别的边界框被检测到的确定程度。
检测器的结果通常由边界框列表、置信度水平和类别组成,如下图所示:

对象检测指标作为评估模型在对象检测任务中表现的衡量标准。它还使我们能够客观地比较多个检测系统或将它们与基准进行比较。在大多数竞赛中,平均精度(AP)及其衍生指标是用于评估检测结果并排名的指标。
理解各种指标:
IoU:
所有先进指标中的指导原则是所谓的交并比(IoU)重叠度量。它字面上定义为检测边界框与真实边界框的交集与并集的比值。
将预测边界框和真实标签之间的重叠面积除以它们的联合面积,得到交并比。
交并比(IoU)分数 > 0.5 通常被认为是“好”的预测。

IoU 指标确定了正确检测到的物体数量以及产生的假阳性数量(将稍后讨论)。
真正例 [TP]
检测数(IoU>0.5)
假阳性 [FP]
检测数(IoU<=0.5)或检测到多次
假阴性 [FN]
未检测到或检测到的物体数(IoU<=0.5)
精确度
精确度衡量你的预测准确性,即预测正确的百分比。
精确度 = 真正例 / (真正例 + 假阳性)
召回率
召回率衡量你找到所有正例的能力。
召回率 = 真正例 / (真正例 + 假阴性)
F1 分数
F1 分数是精确度和召回率的调和均值(HM)。

AP
平均精确度(AP)的通用定义是找到精确度-召回曲线下的面积。
mAP
物体检测的 mAP 是计算所有类的 AP 的平均值。mAP@0.5 表示在 IOU 阈值 0.5 处计算的 mAP。

mAP 与其他指标
mAP 是衡量神经网络灵敏度的良好指标。因此,较高的 mAP 表明模型在不同置信度阈值下的稳定性和一致性。精确度、召回率和 F1 分数是在给定置信度阈值下计算的。
如果“模型 A”的精确度、召回率和 F1 分数优于“模型 B”,但“模型 B”的 mAP 优于“模型 A”,这种情况表明“模型 B”在较高置信度阈值下的召回率很差,或在较低置信度阈值下的精确度很差。因此,“模型 A”在该置信度阈值下的较高精确度、召回率和 F1 分数表明,它在所有三个指标方面都优于“模型 B”。

哪个指标更重要?
通常为了分析表现更好的模型,建议使用验证集(用于调整超参数的数据集)和测试集(用于评估完全训练好的模型性能的数据集)。
在验证集上
-
使用 mAP 从所有训练权重中选择表现最好的模型(更稳定且一致的模型)。使用 mAP 来了解模型是否需要进一步训练/调整。
-
检查类级 AP 值以确保模型在各类中的稳定性和优良性。
-
根据用例/应用,如果你对假阴性完全宽容而对假阳性高度不容忍,则应使用精确度来训练/调整模型。
-
根据使用案例/应用,如果你对假阳性完全容忍且对假阴性高度不容忍,那么相应地训练/调整模型时使用召回率。
在测试集上
-
如果你对假阳性(FPs)和假阴性(FNs)都持中立态度,那么使用 F1 分数来评估表现最佳的模型。
-
如果你不接受假阳性(FPs),而对假阴性(FNs)不太关心,那么选择具有更高精准度的模型。
-
如果你不接受假阴性(FNs),而对假阳性(FPs)不太关心,那么选择具有更高召回率的模型。
-
一旦决定了要使用的指标,尝试对给定模型使用多个置信度阈值(例如 0.25、0.35 和 0.5),以了解哪个置信度阈值下所选指标对你更有利,并且了解可接受的权衡范围(例如,你希望精准度至少为 80% 并有一定的召回率)。一旦决定了置信度阈值,就可以在不同模型中使用它,以找出表现最佳的模型。
参考文献
个人简介:Venkatesh Wadawadagi 是 Sahaj Software Solutions 的解决方案顾问。他帮助企业使用 AI 驱动的解决方案解决复杂问题。他专注于深度学习、计算机视觉、机器学习、自然语言处理(NLP)、嵌入式 AI、商业智能和数据分析。
相关:
-
机器学习中的模型评估指标
-
零售中的图像识别和目标检测
-
你应该知道的更多分类问题性能评估指标
相关主题
数据科学备忘单
原文:
www.kdnuggets.com/2018/09/meverick-lin-data-science-cheat-sheet.html
评论
目前有很多备忘单,质量参差不齐,涵盖了各种不同的话题,这些话题都被视为“数据科学”范畴。一些非常好,一些还不错,但许多并不值得你的时间。偶尔可以发现一些宝石,涵盖了某些特定领域,并达到一定的理解水平。
这就是最近由 Maverick Lin 发布的 "数据科学备忘单" 的用武之地。这是一个相对广泛的初级理解深度的工作,但它做得非常好。这份 9 页的资料简明扼要地涵盖了数据科学的诸多方面:
-
统计与概率
-
数据准备
-
特征工程
-
建模
-
机器学习
-
深度学习
-
SQL
-
…还有更多
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面


值得强调的是,这对数据科学的资深专家可能没有立即的价值,但鼓励初学者查看一下,也适合那些准备面试或只是寻找轻松复习材料的人。
您可以访问 Github 仓库 获取更多信息,或从这个 直接下载链接 下载备忘单。
感谢 Maverick Lin 制作这个备忘单,它是一个不断发展的进行中的工作。
相关:
-
Docker 备忘单
-
数据可视化备忘单
-
SQL 备忘单
更多相关话题
F1 分数的微观、宏观和加权平均值,清晰解释
原文:
www.kdnuggets.com/2023/01/micro-macro-weighted-averages-f1-score-clearly-explained.html

作者图片和Freepik
F1 分数(也称 F 度量)是评估分类模型性能的常用指标。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
在多类别分类的情况下,我们采用平均方法来计算 F1 分数,从而在分类报告中得到一组不同的平均分数(宏观、加权、微观)。
本文讨论了这些平均值的含义,如何计算它们,以及选择哪个来进行报告。
(1)基础知识回顾(可选)
注意:如果你已经对精确率、召回率和 F1 分数的概念很熟悉,可以跳过这一部分。
精确率
通俗定义: 在我做出的所有正例预测中,有多少是真正的正例?
计算: 真正例数(TP)除以真正例数(TP)和假阳性(FP)的总数。

精确率的公式 | 作者图片
召回率
通俗定义: 在所有实际的正例中,我正确预测为正例的有多少?
计算: 真正例数(TP)除以真正例数(TP)和假阴性(FN)的总数。

召回率的公式 | 作者图片
如果你比较精确率和召回率的公式,你会发现它们看起来很相似。唯一的不同是分母的第二项,对于精确率是假阳性,对于召回率是假阴性。
F1 分数
为了全面评估模型性能,我们应该检查精确率和召回率。F1 分数作为一个有用的指标,考虑了这两者。
定义:精确率和召回率的调和均值,用于更平衡地总结模型性能。
计算:

F1 分数的方程 | 图片由作者提供
如果我们用真正例(TP)、假正例(FP)和假负例(FN)来表示,我们会得到这个方程:

F1 分数的另一种方程 | 图片由作者提供
(2) 设置动机示例
为了说明 F1 分数的平均概念,我们将在本教程中使用以下示例。
想象一下,我们已经在一个包含三类图像的多类数据集上训练了一个图像分类模型:飞机、船和汽车。

图片由 macrovector 提供 — freepik.com
我们使用这个模型来预测****十个测试集图像的类别。以下是原始预测:

我们的演示分类器的样本预测 | 图片由作者提供
运行sklearn.metrics.classification_report后,我们得到以下分类报告:

分类报告来自 scikit-learn 包 | 图片由作者提供
讨论的重点是带有每类分数(即每个类别的分数)和平均分数的列(橙色)。
从上面可以看出,数据集是不平衡的(十个测试集实例中只有一个是“船”)。因此,正确匹配的比例(即准确率)在评估模型性能时将无效。
相反,让我们查看混淆矩阵以全面理解模型预测。

混淆矩阵 | 图片由作者提供
上面的混淆矩阵使我们能够计算真正例(TP)、假正例(FP)和假负例(FN)的关键值,如下所示。

从混淆矩阵中计算的 TP、FP 和 FN 值 | 图片由作者提供
上表为我们计算每个三类中的每类的精确度、召回率和 F1 分数奠定了基础。
重要的是要记住,在多类分类中,我们计算每个类别的 F1 分数,采用一对其余(OvR)的方法,而不是像二分类那样计算一个整体的 F1 分数。
在这种OvR方法中,我们分别为每个类别确定指标,就好像每个类别都有一个不同的分类器。以下是每个类别的指标(显示了 F1 分数的计算):

然而,与其有多个每类 F1 分数,不如平均它们以获得一个单一数字来描述总体性能。
现在,让我们讨论平均方法,这些方法导致了分类报告中的三种不同的平均 F1 分数。
(3) 宏观平均
宏观平均可能是所有平均方法中最简单的。
宏观平均 F1 分数(或宏观 F1 分数)是通过所有每个类别 F1 分数的算术平均(即未加权平均)计算得出的。
此方法对所有类别一视同仁,无论其支持度值如何。

宏观 F1 分数计算 | 图片来源于作者
我们计算得到的0.58与我们的分类报告中的宏观平均 F1 分数相匹配。

(4) 加权平均
加权平均 F1 分数是通过计算所有类别的 F1 分数的平均值来得到的,同时考虑每个类别的支持度。
支持度指的是数据集中该类别的实际出现次数。例如,船的支持度值为 1 意味着只有一个实际标签为船的观察。
“权重”本质上是指每个类别的支持度相对于所有支持度值总和的比例。

加权 F1 分数计算 | 图片来源于作者
使用加权平均,输出的平均值将考虑到每个类别按该类别示例数加权的贡献。
计算得到的0.64与我们分类报告中的加权平均 F1 分数一致。

(5) 微观平均
微观平均通过计算真实正例(TP)、假阴性(FN)和假正例(FP)的总和来计算全局平均F1 分数。
我们首先将所有类别的 TP、FP 和 FN 值相加,然后将这些值代入 F1 方程,得到我们的微观 F1 分数。

微观 F1 分数计算 | 图片来源于作者
在分类报告中,你可能会想知道为什么我们的微观 F1 分数0.60显示为“准确率”,以及为什么没有‘微观平均’的行。

这是因为微观平均本质上计算的是正确分类观察结果在所有观察结果中的比例。如果我们考虑这一点,这一定义就是我们用来计算整体准确率的标准。
此外,如果我们对精确率和召回率进行微观平均,我们将得到相同的0.60值。

所有微观平均指标的计算 | 作者提供的图像
这些结果意味着,在每个观察结果只有单一标签的多类别分类情况下,微观-F1、微观精确率、微观召回率和准确率共享相同的值(即,本示例中的0.60)。
这也解释了为什么分类报告只需要显示一个准确率值,因为微观-F1、微观精确率和微观召回率也有相同的值。
微观-F1 = 准确率 = 微观精确率 = 微观召回率
(6) 我应该选择哪种平均方式?
一般而言,如果你在处理一个类别不平衡的数据集,其中所有类别同样重要,使用宏观平均将是一个不错的选择,因为它对所有类别一视同仁。
这意味着,对于我们涉及飞机、船只和汽车分类的示例,我们将使用宏观-F1 分数。
如果你有一个不平衡的数据集,但希望对数据集中样本更多的类别赋予更大的贡献,那么加权平均是首选。
这是因为,在加权平均中,每个类别对 F1 平均值的贡献是根据其大小加权的。
假设你有一个平衡的数据集,并且希望得到一个易于理解的整体性能指标,不论类别如何,那么你可以选择准确率,这本质上是我们的微观F1 分数。
在你离开之前
我欢迎你加入我的数据科学学习之旅! 关注我的Medium页面,并查看我的GitHub以获取更多令人兴奋的数据科学内容。同时,祝你在解释 F1 分数时玩得愉快!
Kenneth Leung 是波士顿咨询集团(BCG)的数据科学家、技术作者和药剂师。
原文。经允许转载。
更多相关内容
如何在 SQL Server 中执行 R 和 Python 使用机器学习服务
原文:
www.kdnuggets.com/2018/06/microsoft-azure-machine-learning-r-python-sql-server.html
评论
作者 Kyle Weller,Microsoft Azure 机器学习
你知道吗?你可以在 T-SQL 语句中编写 R 和 Python 代码。 机器学习服务 在 SQL Server 中消除了数据移动的需求。你无需通过网络传输大量和敏感的数据,或通过示例 csv 文件丢失准确性,你可以让 R/Python 代码在你的数据库中执行。轻松通过 SQL 存储过程部署你的 R/Python 代码,使其在你的 ETL 过程中或任何应用程序中可用。在数据库中训练和存储机器学习模型,将智能带到数据所在的位置。

你可以安装并运行任何最新的开源 R/Python 包,以在 SQL Server 上处理大量数据构建深度学习和 AI 应用程序。我们还提供了 Microsoft 的 前沿 高性能算法,包含在 RevoScaleR 和 RevoScalePy APIs 中。使用这些与开源世界中的最新创新结合,能够为你的应用程序带来无与伦比的选择、性能和规模。
如果你对尝试 SQL Server 机器学习服务感到兴奋,请查看下面的动手教程。如果你没有在 SQL Server 中安装机器学习服务,你首先需要按照我在这里发布的入门教程进行操作:
使用教程
在本教程中,我将介绍如何在 T-SQL 语句中执行 R 和 Python 的基础知识。如果你更喜欢通过视频学习,我也在 YouTube 上发布了教程:
基础知识
打开 SQL Server Management Studio 并连接到你的服务器。打开一个新的查询窗口并粘贴以下基本示例:(虽然我在这些示例中使用的是 Python,但你也可以用 R 完成所有操作)
EXEC sp_execute_external_script @language = N'Python', @script = N'print(3+4)'
sp_execute_external_script 是一个特殊的系统存储过程,它使 R 和 Python 在 SQL Server 中的执行成为可能。这里有一个“language”参数,允许我们在 Python 和 R 之间进行选择。还有一个“script”参数,我们可以在其中粘贴 R 或 Python 代码。如果你没有看到输出打印 7,请返回并查看 这篇文章 中的设置步骤。
参数介绍
现在我们讨论了一个基本示例,让我们开始添加更多内容:
EXEC sp_execute_external_script @language = N'Python', @script = N' OutputDataSet = InputDataSet; ', @input_data_1 = N'SELECT 1 AS Col1';
机器学习服务提供了 SQL 和 R/Python 之间更自然的通信,通过一个接受任何 SQL 查询的输入数据参数。输入参数名为“input_data_1”。
你可以在 Python 代码中看到,定义了一些默认变量来在 Python 和 SQL 之间传递数据。默认变量名是“OutputDataSet”和“InputDataSet”。你可以像下面这个示例一样更改这些默认名称:
EXEC sp_execute_external_script @language = N'Python', @script = N' MyOutput = MyInput; ', @input_data_1_name = N'MyInput', @input_data_1 = N'SELECT 1 AS foo', @output_data_1_name = N'MyOutput';
当你执行这些示例时,你可能会注意到它们每个都返回一个带有“(No column name)”的结果?你可以通过在语句末尾添加 WITH RESULT SETS 子句来指定返回列的名称,该子句是列名和其数据类型的逗号分隔列表。
EXEC sp_execute_external_script @language = N'Python', @script = N' MyOutput = MyInput; ', @input_data_1_name = N'MyInput', @input_data_1 = N' SELECT 1 AS foo, 2 AS bar ', @output_data_1_name = N'MyOutput' WITH RESULT SETS ((MyColName int, MyColName2 int));
输入/输出数据类型
好的,我们来多讨论一下 SQL 和 Python 之间使用的输入/输出数据类型。你的输入 SQL SELECT 语句通过 Python Pandas 包 将一个“Dataframe”传递给 Python。你从 Python 返回 SQL 的输出也需要是 Pandas Dataframe 对象。如果你需要将标量值转换为数据框,这里有一个示例:
EXEC sp_execute_external_script @language = N'Python', @script = N' import pandas as pd c = 1/2 d = 1*2 s = pd.Series([c,d]) df = pd.DataFrame(s) OutputDataSet = df '
变量 c 和 d 都是标量值,你可以将它们添加到 pandas Series 中,然后转换为 pandas 数据框。这一个示例稍微复杂一点,详细信息和示例请参考 python pandas 包文档:
EXEC sp_execute_external_script @language = N'Python', @script = N' import pandas as pd s = {"col1": [1, 2], "col2": [3, 4]} df = pd.DataFrame(s) OutputDataSet = df '
你现在知道如何在 T-SQL 中执行 Python 的基础知识了!
你知道你也可以在你喜欢的 IDE(如 RStudio 和 Jupyter Notebooks)中编写 R 和 Python 代码,然后将这些代码的执行结果远程发送到 SQL Server 吗?查看这些文档链接以了解更多信息:aka.ms/R-RemoteSQLExecution https://aka.ms/PythonRemoteSQLExecution
查看 SQL Server 机器学习服务 文档页面获取更多文档、示例和解决方案。也可以查看这些 E2E tutorials on github。
我们期待你的反馈!在下方留言提问或开始讨论!
个人简介: Kyle Weller 是微软 Azure 机器学习团队的项目经理。曾在几家初创公司担任软件开发人员后,他加入了微软,并在 Office 和 Bing 中从事可扩展数据仪表板、平台和 API 解决方案的构建。他曾在 Cortana 数据与分析团队中主导测量策略、研究用户行为模式、标准化 KPI,并识别产品增长机会。他现在专注于 Azure 机器学习产品,致力于将智能带入数据存储的位置。这包括 SQL Server 的新机器学习服务,允许在 SQL 中执行 R + Python。
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
为什么 Azure ML 是机器学习的下一大亮点?
原文:
www.kdnuggets.com/2014/11/microsoft-azure-machine-learning.html
 在 Hadoop 基础的 Azure HDInsight 和 Office 365 的 PowerBI 成功之后,微软通过公开预览版 Azure Machine Learning(也称为“Azure ML”)迈出了在大数据市场中取得领导地位的又一步。将预测分析引入公共云似乎是机器学习大规模消费化的下一个逻辑步骤。Azure ML 就是这样做的,同时大大简化了开发者的工作。该服务运行在 Azure 公共云上,这意味着用户无需购买任何硬件或软件,也不需要担心部署和维护。
在 Hadoop 基础的 Azure HDInsight 和 Office 365 的 PowerBI 成功之后,微软通过公开预览版 Azure Machine Learning(也称为“Azure ML”)迈出了在大数据市场中取得领导地位的又一步。将预测分析引入公共云似乎是机器学习大规模消费化的下一个逻辑步骤。Azure ML 就是这样做的,同时大大简化了开发者的工作。该服务运行在 Azure 公共云上,这意味着用户无需购买任何硬件或软件,也不需要担心部署和维护。
通过一个名为 ML Studio 的集成开发环境,没有数据科学背景的人也可以通过拖放手势和简单的数据流图构建数据模型。这不仅最小化了编码,还通过 ML Studio 的实验样本库节省了大量时间。另一方面,有经验的数据科学家将会高兴地发现 Azure ML 强烈支持 R。你可以直接将现有的 R 代码拖放到 Azure ML 中,或使用 ML Studio 支持的 350 多个 R 包来开发自己的代码。  Azure ML 建立在多个微软产品和服务的机器学习能力之上。它共享了 Windows Phone 中新的个人助手 Cortana 的许多实时预测分析功能。Azure ML 还利用了来自 Xbox 和 Bing 的成熟解决方案。超越了 Nate Silver 备受赞誉的 FiveThirtyEight 博客,Bing Predicts 最近通过 准确预测了超过 95% 的美国中期选举结果 让许多人感到惊讶。因此,值得一试 Azure ML,以看看其强大的基于云的预测分析能为你带来什么。
Azure ML 建立在多个微软产品和服务的机器学习能力之上。它共享了 Windows Phone 中新的个人助手 Cortana 的许多实时预测分析功能。Azure ML 还利用了来自 Xbox 和 Bing 的成熟解决方案。超越了 Nate Silver 备受赞誉的 FiveThirtyEight 博客,Bing Predicts 最近通过 准确预测了超过 95% 的美国中期选举结果 让许多人感到惊讶。因此,值得一试 Azure ML,以看看其强大的基于云的预测分析能为你带来什么。
在一个月前的纽约 Strata+Hadoop 世界大会上,Azure ML 被拿来与 IBM 的 Watson 相比较。在他的主题演讲中,Joseph Sirosh,微软机器学习的 CVP,宣布了 Azure Marketplace 的新机器学习功能,这些功能在过去几年(自 2010 年 10 月推出以来)得到了显著发展。Azure Marketplace 提供了许多令人兴奋的使用 ML 的 API,包括 Bing 语音识别控制、Microsoft 翻译器、Bing 同义词 API 和 Bing 搜索 API。截至今天,Azure Marketplace 上已有 25 个以上的机器学习 API。
 该市场是数据科学家构建自定义网络服务、发布 API 并对其使用收费的便捷平台。Azure ML 用户可以搜索这些 API 并订阅它们。因此,除了其他分析市场,Azure 市场也是数据科学家将其专业知识和创造力货币化的另一个良好平台,这与开发者在 iOS 或 Android 应用商店中的操作非常相似。
该市场是数据科学家构建自定义网络服务、发布 API 并对其使用收费的便捷平台。Azure ML 用户可以搜索这些 API 并订阅它们。因此,除了其他分析市场,Azure 市场也是数据科学家将其专业知识和创造力货币化的另一个良好平台,这与开发者在 iOS 或 Android 应用商店中的操作非常相似。 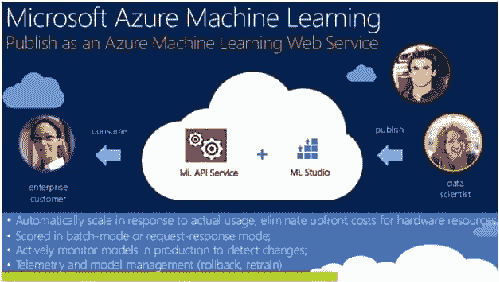 为了推动仍然较新的 Azure ML 服务的采用,微软采取了一些措施来让更多人尝试。最近,微软高管在西雅图的 PASS 峰会上宣布了 Azure ML 的免费访问层(即现在您可以在不提供任何信用卡信息的情况下尝试 Azure ML)。这鼓励了 DBA、开发者、BI 专业人士和业余数据科学家尝试 Azure ML 以构建可集成到应用中的模型。此外,微软还启动了微软 Azure 研究奖计划,向资深研究人员和学生提供研究资助,以尝试 Azure ML。
为了推动仍然较新的 Azure ML 服务的采用,微软采取了一些措施来让更多人尝试。最近,微软高管在西雅图的 PASS 峰会上宣布了 Azure ML 的免费访问层(即现在您可以在不提供任何信用卡信息的情况下尝试 Azure ML)。这鼓励了 DBA、开发者、BI 专业人士和业余数据科学家尝试 Azure ML 以构建可集成到应用中的模型。此外,微软还启动了微软 Azure 研究奖计划,向资深研究人员和学生提供研究资助,以尝试 Azure ML。
这里有一个简短的视频,展示了 Azure ML 如何解决开发和部署预测分析项目中的常见挑战:
如果您有兴趣尝试 Azure ML,您可以在机器学习中心找到大量资源以帮助您入门。
自 2014 年 6 月推出以来,微软 Azure 机器学习服务已经取得了长足的进步,而且微软显然正在投资于其长期成功。
相关:
-
访谈:Joseph Sirosh,微软谈 Azure ML 如何简化预测分析
-
访谈:Joseph Sirosh,微软谈 Azure ML 与新兴的数据科学经济
-
机器学习夏季学校 2015,悉尼,澳大利亚
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 领域
更多相关内容
微软正在变成 M(ai)crosoft
原文:
www.kdnuggets.com/2016/04/microsoft-becoming-m-ai-crosoft.html
由彼得·热金(Peter Zhegin),Flint Capital,以及丹尼尔·科尔涅夫(Daniel Kornev),Zet Universe, Inc。
科技巨头们在认知技术领域扮演着积极的角色。字母表和 Facebook 证明了自己是积极的收购者和投资者 在认知技术方面。超级计算机、机器人和无人机是互联网巨头们关注的主题之一。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 事务
然而,微软似乎走了一条不同的道路:它将认知技术集成到传统产品中,使其更加智能。
比尔·盖茨创造了“数字神经系统(DNS)”的概念……它……[提供]一个在正确时间将信息流整合到组织的正确部分的系统。这一知识系统继承了其生物学原型的一些重要特征,例如,它“……屏蔽不重要的信息……”。[1] 该系统作为代理,预见用户的意图并自主做出一些决策。
最近微软在认知技术方面的努力遵循了 DNS 概念曾经突出的路径。例如,在最近的 Build 大会上,微软强调了“对话”界面,旨在缓解用户面临的信息过载问题[2]。
 Cortana,一款数字助手,已经更深入地融入公司的传统产品,并获得了更多独立于用户的自由。例如,这位助手可以查找并发送文档,也可以代表用户预订酒店[3]。比尔·盖茨已经退休了,专注于“个人助手”项目,表明了 DNS 方法对公司未来的重要性[4]。
Cortana,一款数字助手,已经更深入地融入公司的传统产品,并获得了更多独立于用户的自由。例如,这位助手可以查找并发送文档,也可以代表用户预订酒店[3]。比尔·盖茨已经退休了,专注于“个人助手”项目,表明了 DNS 方法对公司未来的重要性[4]。
通过内部研发以及收购和投资,微软使其软件更加智能。至少探索并集成了五种认知技术到微软的产品中,即:
-
机器学习是优先级和通知平台以及自适应界面的关键元素;
-
语音识别自 90 年代以来就已开创,作为操作系统的一部分自 Windows XP 起出货,然后依靠云计算,目前作为 Cognitive Services(Project Oxford)的一部分提供;
-
自然语言处理(NLP)在拼写、语法和其他领域的努力,使得在 Office 中形成了自己的 NLP 平台,并开发了 Bing/Cognitive Services APIs;
-
自 2007 年以来,微软一直在研究 知识图谱,并于 2008 年初建立了日常事物的本体;
-
计算机视觉的努力导致了 Bing 的 Lenses、Windows Phone 和 iOS 上的 Office Lenses,以及 Kinect 和最近推出的 AR 头戴设备 HoloLens。计算机视觉也可能成为数字助理的一部分,使其能够描述周围的世界[5]。
微软在认知技术方面的广泛兴趣体现在其投资和收购中。Pitchbook 的数据库显示,微软至少进行了十七笔与购买或投资认知技术资产相关的交易(见表 1)。
点击放大。
也许,第一笔旨在将 AI 组件添加到公司软件中的收购发生在 1993 年,当时购买了 Knowledge Industries。其 CEO Eric Horvitz 领导了微软研究院的 Adaptive Systems 和 Interactions(ASI)组。收购的技术被应用于‘Clippy’(一个办公助手)、Notification Platform[6] 的原型以及 MS Office[7] 的自适应界面等。
微软通过收购 Tellme Networks 和 Powerset,分别花费5.91 亿欧元和6300 万欧元,改善了在语音识别、自然语言处理和知识图谱方面的地位。Tellme 的产品使语音搜索查询成为可能[8],而 Powerset 带来了额外的自然语言搜索能力,并帮助改进了 Bing[9]。
此后,公司收购了 Equivio,该公司允许用户“……探索大量的非结构化数据集,并快速找到相关内容”[10]。最近,预测键盘软件 Swiftkey 被以2.25 亿欧元收购。
计算机视觉对微软也至关重要。发生了四笔计算机视觉相关的交易,包括收购具有视频搜索能力的 VideoSurf。
为了改善数字代理生态系统,公司投入了约3.8 亿欧元购买生产力解决方案,如 Acompli(Outlook)或 Wunderkinder(Wunderlist 的制造商)(见表 2)。

点击放大。
除了开发认知技术资产外,微软还推动了处理其关键元素——数据所需的基础设施建设。公司积累了能够从多种类型的来源和存储中收集数据的资产(见表 3)。
例如,€761M 收购 Fast Search & Transfer 使微软获得了一个‘…灵活且可扩展的集成技术平台和个性化门户 [这] 将用户连接起来,无论媒介如何,获取所需的信息[11]。
除了开发基础设施外,微软还让开发者受益于此。公司通过 Cortana Intelligence Suit[12] 开放了 22 个 API,并推出了 Power BI Embedded,这是一种用于应用内数据可视化的工具[13]。

点击放大。
反思微软的努力,可以得出几个结论。
-
将技术应用于优质产品对领先的科技公司来说似乎也具有挑战性。在 Clippy 的有限成功之后,Windows Longhorn 和 WinFS 的 Notifications Management Platform[14] 微软对其认知科技研究变得沉寂。仅在微软研究峰会和 PDC 会议上展示了少量原型(例如 MyLifeBits[15]、LifeBrowser[16]、Situated Interaction — MSR Receptionist[17] 和 Microsoft Semantic Engine[18]);
-
认知科技基础设施的关键元素可能几乎对公众隐藏。例如,Microsoft Semantic Engine 并未受到媒体的广泛关注。然而,它允许用户通过自然语言请求搜索私人和公共数据,例如‘展示我去年在希腊拍的照片’或‘告诉我关于汤姆·克鲁斯的事’[19];
-
长期愿景允许将研发与投资活动相结合。微软在认知科技领域进行了开创性研究,并成为这一新兴领域最早的收购者之一;
-
微软似乎对数字代理和智能软件非常认真。这些可能成为公司发展的下一个章节,以及 AI 发展的一个重要里程碑。
参考文献:
[1] 比尔·盖茨,《思维的速度:在数字经济中成功》,1999 年。
[2] http://thenextweb.com/microsoft/2016/03/31/everything-microsoft-announced-build-2016-day-2/
[3] http://www.theverge.com/2016/3/30/11317924/microsoft-event-news-recap-hololens-windows-10-build-2016
[4] http://www.theverge.com/2015/1/28/7932751/bill-gates-microsoft-personal-agent
[5] 例如 https://www.captionbot.ai/
[6] http://www.nytimes.com/library/tech/00/07/biztech/articles/17lab.html
[7] http://www.eecs.harvard.edu/~kgajos/papers/2008/kgajos-chi08-predictability.pdf
[8] http://www.cnet.com/news/microsoft-buys-speech-recognition-company-tellme/
[9] http://venturebeat.com/2007/02/08/powersets-search-technology-scoop-may-scare-google/
[11] https://news.microsoft.com/2008/01/08/microsoft-announces-offer-to-acquire-fast-search-transfer/
[12] http://www.theverge.com/2016/3/30/11317924/microsoft-event-news-recap-hololens-windows-10-build-2016
[13] http://thenextweb.com/microsoft/2016/03/31/everything-microsoft-announced-build-2016-day-2/
[14] http://www.zdnet.com/article/bill-gates-biggest-microsoft-product-regret-winfs/
[15] http://research.microsoft.com/en-us/projects/mylifebits/mylifebitsdemo.aspx
[16] http://research.microsoft.com/apps/video/default.aspx?id=159531
[17] https://blogs.msdn.microsoft.com/semantics/2009/02/25/msr-techfest-2009/
[18] http://sqlblog.com/blogs/jamie_thomson/archive/2009/10/19/microsoft-semantic-engine.aspx
[19] 基于:丹尼尔·科尔涅夫,《21 世纪的搜索与语义革命》。
简介:
彼得·泽金 是 Flint Capital 的副总裁,这是一个在美国、以色列和欧洲投资的国际风险投资基金。彼得负责 B2B 软件和金融科技领域的投资。在加入该基金之前,彼得曾在 CIS 领先的互联网零售商之一 Ozon.ru 的总部工作。
丹尼尔·科尔涅夫 是 Zet Universe, Inc.的首席执行官,这是一家为企业提供认知平台的公司。他曾在微软、谷歌和微软研究院工作。
原文。经许可转载。
相关:
-
数据科学工具——专有供应商仍然相关吗?
-
微软深度学习带来创新功能——CNTK 展现前景
-
AI 超级计算机:微软牛津、IBM Watson、谷歌 DeepMind、百度敏华
更多相关话题
微软的 DoWhy 是一个酷炫的因果推断框架
原文:
www.kdnuggets.com/2020/08/microsoft-dowhy-framework-causal-inference.html
评论
来源: www.microsoft.com/en-us/research/blog/dowhy-a-library-for-causal-inference/
我最近开始了一份新的关注人工智能教育的通讯。TheSequence 是一份无废话(即无炒作、无新闻等)的 AI 专注通讯,阅读时间为 5 分钟。目标是让你了解机器学习项目、研究论文和概念。请通过下面的订阅尝试一下:
人类大脑具有将原因与特定事件关联的卓越能力。从选举结果到物体掉落在地板上,我们不断地将事件链联系起来,以产生特定的效果。神经心理学将这种认知能力称为因果推理。计算机科学和经济学研究一种特定形式的因果推理,称为因果推断,它专注于探索两个观察变量之间的关系。多年来,机器学习已经产生了许多因果推断的方法,但它们在主流应用中仍然大多难以使用。最近,微软研究院开源了 DoWhy,这是一个用于因果思维和分析的框架。
因果推断面临的挑战不是它是一门新学科,恰恰相反,而是当前的方法仅代表因果推理的一个非常小且简单的版本。大多数试图连接原因的模型,如线性回归,依赖于对数据进行某些假设的经验分析。纯粹的因果推断依赖于反事实分析,这更接近于人类做决定的方式。想象一个场景,你和家人一起去一个未知的目的地度假。在度假前后,你正与一些反事实问题进行挣扎:

回答这些问题是因果推断的重点。与监督学习不同,因果推断依赖于对未观察量的估计。这通常被称为因果推断的“根本问题”,意味着模型永远不能通过留出的测试集进行纯粹客观的评估。在我们的假期例子中,你可以观察到度假与不度假的效果,但永远不能同时观察到。这一挑战迫使因果推断对数据生成过程做出关键假设。传统的因果推断机器学习框架试图绕过“根本问题”,这导致数据科学家和开发人员感到非常沮丧。
介绍 DoWhy
Microsoft 的 DoWhy* 是一个基于 Python 的因果推断和分析库,旨在简化因果推理在机器学习应用中的采用。受 Judea Pearl 的因果推断 do-calculus 启发,DoWhy 将几种因果推断方法结合在一个简单的编程模型中,从而去除了许多传统方法的复杂性。与其前辈相比,DoWhy 对因果推断模型的实现做出了三项关键贡献。*
-
提供了一种有原则的方法,将给定问题建模为因果图,以便所有假设都明确。
-
提供了一个统一的接口,支持许多流行的因果推断方法,结合了图模型和潜在结果这两个主要框架。
-
自动测试假设的有效性(如果可能)并评估估计对违反假设的鲁棒性。
从概念上讲,DoWhy 的创建遵循了两个指导原则:明确因果假设和测试估计对这些假设违反的鲁棒性。换句话说,DoWhy 将因果效应的识别与其相关性的估计分开,这使得推断非常复杂的因果关系成为可能。
为了实现其目标,DoWhy 将任何因果推断问题建模为一个包含四个基本步骤的工作流程:建模、识别、估计和反驳。

-
建模: DoWhy 使用因果关系图来建模每个问题。当前版本的 DoWhy 支持两种图输入格式:gml(推荐)和 dot。图中可能包含变量之间因果关系的先验知识,但 DoWhy 不做任何直接假设。
-
识别: 使用输入图,DoWhy 基于图模型找到识别所需因果效应的所有可能方法。它使用基于图的标准和 do-calculus 来找到潜在的方法,从而找到可以识别因果效应的表达式。
-
估计: DoWhy 使用匹配或工具变量等统计方法来估计因果效应。当前版本的 DoWhy 支持基于倾向评分分层或倾向评分匹配的估计方法,这些方法专注于估计治疗分配,以及专注于估计响应面回归技术。
-
验证: 最后,DoWhy 使用不同的稳健性方法来验证因果效应的有效性。
使用 DoWhy
开发人员可以通过以下命令安装 Python 模块来开始使用 DoWhy:
python setup.py install
像其他机器学习程序一样,DoWhy 应用的第一步是加载数据集。在这个例子中,假设我们试图推断不同医疗治疗与结果之间的相关性,如下数据集所示。
Treatment Outcome w0
0 2.964978 5.858518 -3.173399
1 3.696709 7.945649 -1.936995
2 2.125228 4.076005 -3.975566
3 6.635687 13.471594 0.772480
4 9.600072 19.577649 3.922406
DoWhy 依赖 pandas 数据框来捕获输入数据:
rvar **=** 1 **if** np**.**random**.**uniform() **>**0.5 **else** 0
data_dict **=** dowhy**.**datasets**.**xy_dataset(10000, effect**=**rvar, sd_error**=**0.2)
df **=** data_dict['df']
print(df[["Treatment", "Outcome", "w0"]]**.**head())
此时,我们仅需大约四个步骤来推断变量之间的因果关系。这四个步骤对应 DoWhy 的四个操作:建模、估计、推断和反驳。我们可以从将问题建模为因果图开始:
model**=** CausalModel(
data**=**df,
treatment**=**data_dict["treatment_name"],
outcome**=**data_dict["outcome_name"],
common_causes**=**data_dict["common_causes_names"],
instruments**=**data_dict["instrument_names"])
model**.**view_model(layout**=**"dot")
**from** IPython.display **import** Image, display
display(Image(filename**=**"causal_model.png"))

下一步是识别图中的因果关系:
identified_estimand **=** model**.**identify_effect()
现在我们可以估计因果效应,并确定估计是否正确。这个例子使用线性回归来简化说明:
estimate **=** model**.**estimate_effect(identified_estimand,
method_name**=**"backdoor.linear_regression")
*# Plot Slope of line between treamtent and outcome =causal effect*
dowhy**.**plotter**.**plot_causal_effect(estimate, df[data_dict["treatment_name"]], df[data_dict["outcome_name"]])

最后,我们可以使用不同的技术来反驳因果估计器:
res_random**=**model**.**refute_estimate(identified_estimand, estimate, method_name**=**"random_common_cause")
DoWhy 是一个非常简单且有用的框架,用于实现因果推断模型。当前版本可以作为独立库使用,也可以集成到流行的深度学习框架中,如 TensorFlow 或 PyTorch。将多种因果推断方法结合在一个框架下,再加上四步简单编程模型,使得 DoWhy 对于处理因果推断问题的数据科学家来说极其简单易用。
原文。转载已获许可。
相关:
-
Facebook 使用贝叶斯优化在机器学习模型中进行更好的实验
-
通过遗忘学习:深度神经网络与詹妮弗·安妮斯顿神经元
-
Netflix 的 Polynote 是一个新的开源框架,用于构建更好的数据科学笔记本
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
更多相关话题
微软探索集成学习的三大关键谜团
原文:
www.kdnuggets.com/2021/02/microsoft-explores-three-key-mysteries-ensemble-learning.html
评论
来源: www.quora.com/What-is-ensemble-learning
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 维护
我最近启动了一个新的新闻通讯,专注于人工智能教育,已经有超过 50,000 名订阅者。TheSequence 是一个没有废话(即没有炒作、没有新闻等)的 AI 专注型新闻通讯,阅读时间为 5 分钟。目标是让你及时了解机器学习项目、研究论文和概念。请通过下面的订阅尝试一下:
集成学习 是提升深度学习模型性能的最古老且较少被理解的技术之一。集成学习的理论非常简单:独立训练的神经网络组的性能应该在长期内超越组中的最佳者。此外,我们还知道,通过一种称为知识蒸馏的技术,可以将模型集成的性能转移到单一模型上。集成学习的世界非常令人兴奋,只是我们还没有完全理解。最近,微软研究院发布了一篇开创性的论文,试图通过理解该领域的三大根本谜团来揭示集成的魔力。
微软研究院致力于理解以下两个关于集成学习的理论问题:
-
1) 当我们简单地对几个独立训练的神经网络进行平均时,集成如何提升深度学习的测试性能?
-
2) 如何将如此优越的集成测试性能,通过训练单个模型以匹配集成输出在相同的训练数据集上,之后“提炼”成具有相同架构的单一神经网络?
对这些理论问题的答案涉及到微软研究院有点戏剧性地称之为集成学习三大谜团的内容:
谜团 1: 集成
集成学习的第一个神秘问题与性能提升有关。给定一组神经网络 N1, N2…NM,一个简单地对输出进行平均的集成很可能会产生显著的性能提升。然而,当训练 (N1 + N2 +…Nm)/M 时,这种性能却没有实现。令人困惑……

神秘 2: 知识蒸馏
集成模型性能高,但运行成本极高且速度慢。知识蒸馏是一种可以训练单个模型以匹配集成性能的技术。知识蒸馏方法的成功引出了集成的第二个神秘问题。为什么匹配集成的输出会比匹配真实标签产生更好的测试准确率?
神秘 3: 自我蒸馏
集成的第三个神秘问题与第二个密切相关,但更加扑朔迷离。知识蒸馏表明,一个较小的模型可以匹配较大集成的性能。一个称为自我蒸馏的现象更加令人困惑。自我蒸馏基于对单个模型进行知识蒸馏,这也能提高性能!基本上,自我蒸馏是基于使用自身作为教师来训练相同的模型。为什么这种方法会产生性能提升仍然是一个谜。

一些答案
微软研究院进行了各种实验,以理解上述集成学习的一些神秘现象。初步工作产生了一些有趣的结果。
1) 深度学习集成与特征映射
最著名的集成学习形式是所谓的随机特征映射,其中模型在随机特征数量下进行训练。这种技术在线性模型中效果很好,并且被很好地理解,因此可以作为分析深度学习集成性能的基准。微软研究院的初步实验结果显示,深度学习集成的行为与特征映射非常相似。然而,知识蒸馏的效果却不完全相同。

2) 多视角数据集对集成模型的有效性至关重要
微软研究的一项最具启发性的结果是基于数据的性质。多视角数据集是基于一个结构,其中数据的每个类别都有多个视角特征。例如,通过查看车灯、车轮或窗户,可以将汽车图像分类为汽车。微软研究显示,具有多视角结构的数据集更有可能提升集成模型的性能,而没有这种结构的数据集则没有相同的效果。

微软研究院的论文是近年来深度学习集成领域最先进的工作之一。论文涵盖了许多其他发现,但这个总结应该能给你一个关于主要贡献的非常具体的概念。
原文。经许可转载。
相关:
-
XGBoost:它是什么,以及何时使用它
-
微软利用 Transformer 网络回答有关图像的问题,训练最小化
-
从头实现 AdaBoost 算法
更多相关话题
微软推出 Icebreaker,以应对机器学习中的著名冰启动挑战
原文:
www.kdnuggets.com/2019/12/microsoft-introduces-icebreaker-ice-start-challenge-machine-learning.html
评论

训练数据的获取和标记仍然是主流机器学习解决方案面临的主要挑战之一。在机器学习研究社区内,已经出现了若干努力,例如弱监督学习或单次学习,以解决这个问题。微软研究院最近孵化了一个名为 Minimum Data AI 的团队,致力于开发无需大量训练数据集即可运行的机器学习模型的不同解决方案。最近,该团队发布了一篇论文,揭示了 Icebreaker,这是一个“明智的训练数据获取”框架,允许部署能够在少量或没有训练数据的情况下运行的机器学习模型。
当前机器学习研究和技术的演变优先考虑了监督模型,这些模型需要在生成任何相关知识之前对世界有相当多的了解。在现实世界中,高质量训练数据集的获取和维护相当具有挑战性,有时甚至是不可能的。在机器学习理论中,我们将这种困境称为冰(冷)启动问题。
了解你不知道的:机器学习中的冰启动挑战
冰启动问题/困境指的是使机器学习模型有效所需的训练数据量。从技术上讲,大多数机器学习代理需要从大量训练数据集开始,并在随后的训练过程中定期减少其规模,直到模型达到所需的准确度水平。冰启动挑战指的是模型在没有训练数据集的情况下有效运行的能力。
解决冰启动问题的办法可以用流行的短语“知道你不知道什么”来描述。在生活中的许多情况下,理解当前上下文中的缺失知识被证明与现有知识同样重要或更为重要。统计学爱好者常常引用二战的一个著名轶事来说明这一困境。
第二次世界大战期间,五角大楼召集了国家最著名的数学家团队,以开发能够协助盟军的统计模型。人才真是惊人。后来将创立哈佛统计系的弗雷德里克·莫斯特勒也在其中。决策理论的先驱、后来的贝叶斯统计大力倡导者莱昂纳德·吉米·萨维奇也在其中。麻省理工学院的数学家、控制论创始人诺伯特·维纳以及未来诺贝尔经济学奖得主米尔顿·弗里德曼也是小组成员之一。小组的第一个任务之一是估算应为美国飞机增加多少额外的保护,以便在与德国空军的战斗中幸存下来。作为优秀的统计学家,该小组收集了返回基地的飞机所遭受的损伤数据。
对于每架飞机,数学家们计算了不同部位(如门、机翼、引擎等)的弹孔数量。随后,小组提出了关于哪些区域需要额外保护的建议。不出所料,大多数建议集中在弹孔较多的区域,假设这些区域是德国飞机攻击的重点。然而,小组中有一个例外,一位名叫亚伯拉罕·瓦尔德的年轻统计学家建议将额外的保护集中在未显示任何损伤的区域。为什么?非常简单,这位年轻的数学家认为,输入数据集(飞机)只包括那些在与德国人作战中幸存下来的飞机。虽然这些飞机的损伤很严重,但并不足以使它们无法返回基地。因此,他得出结论,未返回的飞机可能在其他区域受到了影响。非常聪明,对吧?

本课教会我们的一个重要观点是,在给定的背景中,理解缺失的数据与理解现有数据同样重要。将这一点推广到机器学习模型中,解决冰山问题的关键在于拥有一个可扩展的模型,该模型知道自己不知道什么,即量化认知不确定性。这些知识可以用于指导训练数据的获取。从直观上讲,不熟悉但信息量大的特征对模型训练更为有用。
冰山问题
Microsoft Icebreaker 是一种新颖的解决方案,用于应对冰启动挑战的一部分。从概念上讲,Icebreaker 依赖于深度生成模型,减少训练机器学习模型所需的数据量和成本。从架构的角度来看,Icebreaker 采用了两个组件。第一个组件是深度生成模型(PA-BELGAM),如上图的上半部分所示,它具有一种新颖的推理算法,可以明确量化认识上的不确定性。第二个组件是一组新的逐元素训练数据选择目标,用于数据采集,如下图所示。

Icebreaker 的核心是 PA-BELGAM 模型。该模型基于一种变分自编码器版本,能够处理缺失的元素和解码器权重。与使用标准深度神经网络作为解码器以将数据从潜在表示映射出来不同,Icebreaker 使用贝叶斯神经网络,并在解码器权重上设置了先验分布。

Microsoft 在不同大小的数据集上评估了 Icebreaker。该模型相比于最先进的模型表现出相关的改进,如下图所示。左侧的图表显示 Icebreaker 比几个基准模型表现更好,在训练数据较少的情况下取得了更好的测试准确率。右侧的图表显示了随着数据集总大小的增长,八个特征的数据点数量。

Microsoft Icebreaker 是一个创新的模型,可以实现低数据或无数据的机器学习模型部署。通过利用新颖的统计方法,Icebreaker 能够在不需要大型数据集的情况下选择适合给定模型的特征。微软研究院开源了 Icebreaker 的早期版本,该版本与研究论文相辅相成。
原文。经许可转载。
相关:
-
用户生成数据标记的崛起
-
这个微软神经网络可以用最少的训练回答关于风景图片的问题
-
Facebook 静悄悄地开源了一些令人惊叹的 PyTorch 深度学习能力
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
介绍 MIDAS:图中异常检测的新基线
原文:
www.kdnuggets.com/2020/04/midas-new-baseline-anomaly-detection-graphs.html
评论

在机器学习中,自动驾驶汽车、生成对抗网络(GAN)和面部识别等热门话题常常占据媒体焦点。然而,数据科学家们正在解决的另一个同样重要的问题是异常检测。从网络安全到金融欺诈,异常检测帮助保护企业、个人和在线社区。为改善异常检测,研究人员开发了一种名为 MIDAS 的新方法。
什么是 MIDAS?
在新加坡国立大学,博士候选人 Siddharth Bhatia 和他的团队开发了 MIDAS,这是一种新的异常检测方法,其速度和准确性超越了基线方法。

新加坡国立大学的 Siddharth Bhatia
MIDAS 代表基于微簇的边流异常检测器。顾名思义,MIDAS 检测图中的微簇异常或突然出现的可疑相似边群。MIDAS 的主要优势之一是能够实时检测这些异常,速度远超现有的最先进模型。
图中异常检测的实际应用案例
简而言之,异常检测是寻找与数据集中预期模式或异常值偏离的实践。这可以帮助我们发现并消除有害内容。Siddharth 说:“图中的异常检测是发现无数系统中可疑行为的关键问题。” “这些系统包括入侵检测、虚假评分和金融欺诈。”

这项技术可以帮助社交网络如 Twitter 和 Facebook 发现用于垃圾邮件和网络钓鱼的虚假账户。它甚至可以帮助调查人员识别在线性侵者。Siddharth 说:“使用 MIDAS,我们可以在动态(时间演变)图中找到异常的边和节点。” “在 Twitter 和 Facebook 中,推文和消息网络可以被视为时间演变图,我们可以通过在这些图中找到异常的边和节点来发现恶意消息和虚假账户。”
异常检测的其他常见应用包括:
-
垃圾邮件过滤器
-
信用卡欺诈检测
-
数据集预处理
-
网络安全
-
社交媒体内容审核
MIDAS 超越了最先进的方法
Siddharth 说:“异常检测是一个研究较多的问题,大多数提出的方法集中在静态图上。 然而,许多现实世界的图具有动态特性,基于静态连接的方法可能会错过图的时间特征和异常。”
MIDAS 解决了实时检测异常的需求,以便尽快开始恢复,并减少恶意活动(如信用卡欺诈购买)的影响。
Siddharth 解释说:“此外,由于随着我们处理边流,顶点数量可能会增加,我们需要一个在图的大小上使用恒定内存的算法。 而且,许多应用中的欺诈或异常事件发生在微集群中或突然出现的类似边的组中,例如网络流量数据中的拒绝服务攻击和同步行为。”
Siddharth 说:“通过使用有原则的假设检验框架,MIDAS 提供了关于假阳性概率的理论界限,而早期的方法则没有提供。”
Midas 是如何被测试的?
Siddharth 和他的同事展示了 MIDAS 在社交网络安全和入侵检测任务中的潜力。他们使用了以下数据集进行异常检测:
-
Darpa 入侵检测(450 万个 IP-IP 通信)
-
Twitter 安全数据集(2014 年与安全事件相关的 260 万条推文)
-
Twitter 世界杯数据集(2014 年足球世界杯期间的 170 万条推文)
为了比较 MIDAS 的性能,团队查看了以下基线:
-
RHSS
-
SEDANSPOT
然而,由于 RHSS 在 Darpa 数据集上的 AUC 测量 为 0.17,因此团队通过与 SEDANSPOT 进行比较来测量准确性、运行时间和现实世界的有效性。
结果
MIDAS 检测微集群异常的准确率提高了多达 48%,并且比当前基线方法快了多达 644 倍。
Siddharth 说:“我们的实验结果表明,MIDAS 在准确性(以 AUC 为标准)上超越了基线方法 42%-48%。此外,MIDAS 处理数据的速度比基线方法快 162−644 倍。”
改进 MIDAS:未来的工作
Siddharth 说:“我们将 MIDAS 扩展到了 M-Stream:快速流式多方面组异常检测。 在 M-Stream 中,我们在具有类别和数值属性的多方面数据上检测异常。”
Siddharth 和他的团队表示,M-Stream 在准确性和运行时间方面也超越了包括 Isolation Forest 和 Local Outlier Factor 等流行的 Sklearn 算法的多个基线。然而,他们的 M-Stream 工作目前正在审查中。
Siddharth 说:“考虑到 MIDAS 的性能,我们认为它将成为一种新的基线方法,并且对于异常检测非常有用。 此外,探索 MIDAS 如何在其他应用中做出贡献将是非常有趣的。”
如果你有兴趣了解更多关于 MIDAS 的内容,可以查看Siddharth 的完整论文。你还可以在Github下载代码和数据集。
欲了解更多机器学习访谈、指南和新闻,请查看以下相关资源,并不要忘记订阅我们的新闻通讯。
简介:Limarc Ambalina 是一位驻东京的作家,专注于人工智能、科技和流行文化。他曾为包括 Hacker Noon、日本今日、以及 Towards Data Science 在内的多个出版物撰稿。
原文。经授权转载。
相关:
-
图神经网络模型校准以获得可信预测
-
异常检测,AI 和机器学习的关键任务,解释
-
什么是本福德定律,它对数据科学为何重要?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
MiniGPT-4:一种轻量级的 GPT-4 替代方案,增强视觉-语言理解

作者提供的图片
我们看到 ChatGPT 的 开源替代品 发展迅速,但没有人专注于提供多模态能力的 GPT-4 替代品。GPT-4 是一种先进且强大的多模态模型,能够接受图像和文本输入并输出文本响应。它可以更准确地解决复杂问题并从错误中学习。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业之路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我们将了解 MiniGPT-4,这是一种开源替代品,旨在提供轻量级的视觉和文本理解能力,与 OpenAI 的 GPT-4 类似。
什么是 MiniGPT-4?
与 GPT-4 类似,MiniGPT-4 能够生成详细的图像描述、使用图像编写故事,以及利用手绘用户界面创建网站。它通过使用更先进的大型语言模型(LLM)来实现这一点。
你可以通过尝试演示来亲身体验:MiniGPT-4 - 由 Vision-CAIR 提供的 Hugging Face 空间。

作者提供的图片 | MiniGPT-4 演示
MiniGPT-4:利用先进的大型语言模型增强视觉-语言理解 的作者发现,直接在原始图像-文本对上进行预训练可能会产生缺乏连贯性的较差结果,包括重复和断裂的句子。为了解决这个问题,他们策划了一个高质量、良好对齐的数据集,并使用对话模板对模型进行了微调。
MiniGPT-4 模型在计算上非常高效,因为他们仅训练了一个投影层,利用了大约 500 万对对齐的图像-文本对。
MiniGPT-4 如何工作?
MiniGPT-4 将一个冻结的视觉编码器与一个名为 Vicuna 的冻结 LLM 对齐,使用的只是一个投影层。视觉编码器由预训练的 ViT 和 Q-Former 模型组成,这些模型通过一个线性投影层与先进的 Vicuna 大型语言模型连接。

作者提供的图片 | MiniGPT-4 的架构。
MiniGPT-4 仅需训练线性层即可将视觉特征与 Vicuna 对齐。因此,它体积小、所需计算资源少,并且产生的结果与 GPT-4 相似。
结果
如果你查看 [minigpt-4.github.io]( https://minigpt-4.github.io/##Results:~:text=of MiniGPT-4.- ,Results,-Acknowledgement) 的官方结果,你会看到作者通过上传手绘 UI 并要求其生成 HTML/JS 网站创建了一个网站。MiniGPT-4 理解了上下文,并生成了 HTML、CSS 和 JS 代码。这真是令人惊叹。


图片来源于 [minigpt-4.github.io]( https://minigpt-4.github.io/##Results:~:text=of MiniGPT-4.- ,Results,-Acknowledgement)
他们还展示了如何通过提供食物图像生成食谱、为产品编写广告、描述复杂图像、解释画作等。
让我们通过访问 MiniGPT-4 演示自行尝试。正如我们所见,我提供了 Bing AI 生成的图像,并要求 MiniGPT-4 使用它编写一个故事。结果令人惊叹。
故事是连贯的。

作者提供的图片 | MiniGPT-4 演示
我想了解更多,因此我让它继续写作,就像一个 AI 聊天机器人一样,它不断编写情节。

作者提供的图片 | MiniGPT-4 演示
在第二个例子中,我让它帮助我改进图像设计,然后要求它为博客生成图像字幕。

作者提供的图片 | MiniGPT-4 演示
MiniGPT-4 真是太棒了。它从错误中学习,并生成高质量的回应。
局限性
MiniGPT-4 具有许多先进的视觉-语言能力,但仍然面临一些局限性。
-
目前,即使使用高端 GPU,模型推断仍然很慢,这可能导致结果延迟。
-
该模型基于大型语言模型(LLMs),因此继承了它们的一些局限性,例如推理能力不可靠和产生虚假知识。
-
该模型的视觉感知有限,可能难以识别图像中的详细文本信息。
开始使用
该项目包括源代码的训练、微调和推理。还包括公开的模型权重、数据集、研究论文、演示视频以及 Hugging Face 演示的链接。
你可以开始编程,开始在你的数据集上微调模型,或者通过官方页面上的各种演示实例体验模型。
-
官方网站: minigpt-4.github.io
-
研究论文: MiniGPT-4/MiniGPT_4.pdf
-
GitHub: Vision-CAIR/MiniGPT-4
-
Gradio 演示: MiniGPT-4 演示
-
模型权重: Vision-CAIR/MiniGPT-4
这是模型的第一个版本。你将在接下来的日子里看到一个更改进的版本,敬请关注。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为那些挣扎于心理疾病的学生打造一个 AI 产品。
相关内容
什么是最小可行(数据)产品?
原文:
www.kdnuggets.com/2018/07/minimum-viable-data-product.html
评论
由 Dat Tran, Idealo。

几个月前,我离开了 Pivotal,加入了 idealo.de(欧洲领先的价格比较网站之一,也是德国电子商务市场最大的门户之一),帮助他们将机器学习(ML)整合到他们的产品中。除了像建立数据科学团队、搭建基础设施和处理许多行政事务这样的常规任务,我还需要定义 ML 驱动的产品路线图。与此相关的是为机器学习产品定义一个最小可行产品(MVP)。然而,我在 idealo 工作时以及在 Pivotal 时常常面临的问题是,究竟什么才是一个好的 MVP?在这篇文章中,我将深入探讨一个优秀的机器学习产品 MVP 的不同维度,并分享我迄今为止获得的经验。
什么是 MVP?
在 Pivotal Labs,我接触到了由 Eric Ries 推广的精益创业思维。精益创业本质上是当前产品开发的最前沿方法论。其核心理念是通过不断整合客户反馈迭代地构建产品或服务,从而降低产品/服务失败的风险(build-measure-learn)。

构建-测量-学习概念的一个重要组成部分是 MVP,它本质上是“一种新产品的版本,允许团队以最少的努力收集关于客户的最大量的验证学习”。一个众所周知的例子是验证移动性是否会成功(见下图)。

我们基本上从最小的努力开始测试想法。在这种情况下,我们只需用两个轮子和一个板子。然后我们将它推向市场,通过反馈不断改进我们的产品,逐渐增加更多复杂性。最终,我们得到了一个整合了消费者反馈的汽车。一个著名的例子是 Airbnb。2007 年,布赖恩·切斯基(Brian Chesky)和乔·盖比亚(Joe Gebbia)想要创业,但也负担不起旧金山的租金。与此同时,一个设计会议将要在他们的城市举办。他们决定将自己的地方租给找不到附近酒店的会议参与者。他们所做的是拍摄他们公寓的照片,将其在线发布在一个简单的网站上(见下图),很快他们就有了三个支付住宿费的客人。这次小测试给了他们宝贵的见解,让他们知道人们愿意付费住在别人家里而不是酒店,而且不仅仅是最近的大学毕业生愿意报名。之后他们创办了 Airbnb,后来的故事大家都知道了(如果你想阅读更多成功的 MVP 故事,请查看这个链接)。

相对而言,另一种方法是从轮子到车架逐步构建汽车,而不进行一次发货。然而,这种方法成本非常高。最终,我们可能会推出一个客户不需要的产品。例如,以 Juicero 为例。他们从投资者那里筹集了 1.2 亿美元,用于创建一个设计精良的榨汁机,并在经过一段时间的开发后以非常高的价格发布(最初定价为$699,随后降至$399)。除了机器,你还可以购买价格为$5-$7 的装满原料水果和蔬菜的果汁包。也许你们中的一些人知道,这家公司已经关闭,因为他们没有意识到并不需要一个高价的榨汁机来挤出果汁包。他们没有真正理解客户。一次简单的用户研究会让他们意识到,挤出果汁包并不需要昂贵的机器,两只健康的手就足够了。

MVP 概念如何与机器学习产品相关?
MVP 概念也可以应用于机器学习,因为最终机器学习也是整体产品或最终产品的一部分。在这方面,我认为有三个重要维度:
- 最小可行模型

机器学习产品的重要部分是建模本身。假设我们有一个分类问题,我们希望将一些数据分类到预定义的类别中,比如热狗与非热狗!

解决这个分类问题的一个可能方法是使用一个具有隐藏层的神经网络。接下来,我们将训练和评估模型。然后根据结果,我们可能希望继续改进模型。接着我们会添加另一个隐藏层,然后再进行相同的建模操作。根据结果,我们可能会添加更多的隐藏层。这种方法比较直接,实际上是解决热狗与非热狗问题的最佳方案,因为不需要特征工程(我们可以直接使用原始图像作为输入数据)。然而,对于大多数分类问题,除非它们是像计算机视觉或自然语言理解中那样的专业问题,否则这并不是解决此类问题的最佳方法。深度学习的主要缺点通常是其可解释性。根据你使用的网络类型,通常很难解释神经网络的结果。此外,你可能花费大量时间来调整神经网络的参数,而模型性能的提升往往微乎其微。
从简单开始,建立基准…
对于大多数分类问题,更合理的方法是从像逻辑回归这样的线性模型开始。虽然在许多实际应用中,线性假设是不现实的,但逻辑回归表现得相当不错,并且作为一个好的基准模型也很有用。它的主要优点还包括可解释性,并且你可以免费获得条件概率,这在许多情况下非常方便。
然后,为了改进模型并放宽线性假设,你可以使用基于树的模型。在这种情况下,有两大类方法:袋装和提升。在内部,两者都使用决策树,但训练方式不同。最后,当所有选项都用尽且你希望继续改进模型时,我们可以利用深度学习技术。
- 最低可行平台

在我在 Pivotal Labs 工作期间,我参与了很多项目,帮助财富 500 强公司启动他们的数据之旅。他们共有的一个特点是,很多这些项目都开始于对基础设施的巨大投资。他们花费大量资金购买大数据平台,即所谓的“数据湖”。然后在购买之后,他们开始将数据加载到数据湖中,却没有考虑潜在的使用案例。之后,他们听说了 Apache Spark,并将其添加到这一层中。现在,由于人工智能成为了下一个热门领域,他们也开始购买 GPU,并在其上部署深度学习框架,如 TensorFlow。拥有所有(酷)工具在一个地方听起来不错,对吧?然而,最大的问题是,在将所有数据放入数据湖后,这些数据往往不适合特定的使用案例。他们要么没有收集到正确的数据,要么数据本身并不存在,无法支持潜在的使用案例。
利用云计算来启动你的“数据”计划……
更合理的方法是首先解决问题,而不是考虑硬件/软件。通过这种方法,他们可以尽早了解到解决问题所需的数据,并且能够对数据错误进行补救。此外,我见过的很多机器学习问题仍然可以在本地机器上现实地解决。他们并不一定需要对基础设施进行如此巨大的投资。如果数据确实很大,他们可以使用 AWS 或 Google Cloud 等云服务提供商,这样可以很容易地启动 Spark 集群。如果他们遇到深度学习问题,也有很多选项。他们可以使用已经提到的云服务提供商,或者像 FloydHub 这样的服务,它为云上的深度学习模型训练和部署提供了平台即服务(PaaS)。
- 最小可行(数据)产品
我想讨论的最后一点是数据产品本身。基本上,数据产品有很多例子,例如聊天机器人、垃圾邮件检测器等——这个列表很长(查看 Neal Lathia的精彩文章,了解更多机器学习产品的例子)。但在这种情况下,我将专注于推荐服务,因为我现在在电子商务领域工作。

启动推荐服务的一种方式是使用简单的相似度算法,然后继续使用矩阵分解技术。最后,我们也可以尝试更复杂的模型,如深度学习方法(例如,深度结构语义模型)。然而,这种方法并不真正推荐。推荐可以有多种形式。例如,你朋友给出的推荐也是推荐,或者最受欢迎的前 100 个产品也是推荐。并不是所有我们使用的复杂算法都会带来成功,但必须进行测试。事实上,不要害怕在没有机器学习的情况下启动你的推荐服务。
做正确的事情…

所以正确的方法是首先建立 A/B 测试框架和评估指标(例如,跳出率或点击率),然后从简单的方法开始,如顶级产品。然后,在测试用户是否真的倾向于点击这些推荐(有时他们需要先适应,尤其是如果这是一个新产品功能),以及最终可能也会购买这些推荐的商品之后,我们可以尝试更复杂的方法,如协同过滤技术。例如,我们可以基于购买了此项商品的用户也对那些商品感兴趣,或查看了此项商品的用户也对那些商品感兴趣来创建推荐。对于“用户谁…此商品也对那些商品感兴趣”的选项,种类繁多。
总结
在本文中,我表达了我对机器学习产品中 MVP 的个人观点。本质上,这就是从小做起,然后迭代。此外,为了更清晰地理解我所说的机器学习产品 MVP,我讨论了我认为对好的 MVP 数据产品至关重要的三个主要维度:
-
最小可行模型,
-
最小可行平台,
-
和最小可行(数据)产品。
希望在你下一个机器学习项目中,你也能记住这三个维度。如果你觉得这篇文章有用,请与朋友分享。关注我在 Medium 上的账号(Dat Tran)或在 Twitter 上的账号(@datitran),以便了解我的最新工作。感谢阅读!
原文。已获授权转载。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT
更多相关话题
《使用 Python 矿工 Twitter 数据 第一部分:数据收集》
原文:
www.kdnuggets.com/2016/06/mining-twitter-data-python-part-1.html
作者:Marco Bonzanini,独立数据科学顾问。
Twitter 是一个流行的社交网络,用户可以分享短消息,称为 推文。用户在 Twitter 上分享思想、链接和图片,记者评论实时事件,公司推广产品并与客户互动。使用 Twitter 的方式可以非常多样,每天有 5 亿条推文,有大量数据供分析和使用。
我们的前三个课程推荐
1. Google 网络安全证书 - 加速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
这是一个系列文章的第一篇,专注于使用 Python 挖掘 Twitter 数据。在这一部分,我们将探讨从 Twitter 收集数据的不同选项。一旦我们建立了数据集,在接下来的文章中我们将讨论一些有趣的数据应用。

注册你的应用程序
为了以编程方式访问 Twitter 数据,我们需要创建一个与 Twitter API 互动的应用程序。
第一步是注册你的应用程序。具体来说,你需要将浏览器指向 apps.twitter.com,登录 Twitter(如果尚未登录)并注册一个新应用程序。你现在可以为你的应用程序选择一个名称和描述(例如“矿工演示”或类似名称)。你将收到一个 consumer key 和一个 consumer secret:这些是应用程序设置,应该始终保密。你还可以从应用程序的配置页面申请一个访问令牌和一个访问令牌秘密。与 consumer keys 类似,这些字符串也必须保密:它们提供应用程序代表你的账户访问 Twitter。默认权限是只读,这正是我们所需的,但如果你决定更改权限以提供写入功能,你必须协商一个新的访问令牌。
重要说明:使用 Twitter API 有速率限制,并且如果你想提供可下载的数据集也有限制,请参见:
访问数据
Twitter 提供了 REST APIs 供我们与他们的服务交互。也有 一堆基于 Python 的客户端 可供使用,我们无需重新发明轮子。特别是,Tweepy 是一个最有趣且易于使用的库,所以我们来安装它:
pip install tweepy==3.3.0
更新:Tweepy 的 3.4.0 版本引入了 Python 3 的问题,目前在 github 上已修复,但通过 pip 仍不可用,因此我们使用版本 3.3.0 直到新版本发布。
更多更新:Tweepy 的 3.5.0 版本,已通过 pip 提供,似乎解决了上述提到的 Python 3 问题。
为了授权我们的应用程序代表我们访问 Twitter,我们需要使用 OAuth 接口:
import tweepy
from tweepy import OAuthHandler
consumer_key = 'YOUR-CONSUMER-KEY'
consumer_secret = 'YOUR-CONSUMER-SECRET'
access_token = 'YOUR-ACCESS-TOKEN'
access_secret = 'YOUR-ACCESS-SECRET'
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth)
api 变量现在是我们可以执行的大多数 Twitter 操作的入口点。
例如,我们可以通过以下方式读取自己的时间线(即我们的 Twitter 首页):
for status in tweepy.Cursor(api.home_timeline).items(10):
# Process a single status
print(status.text)
Tweepy 提供了方便的 Cursor 接口,用于迭代不同类型的对象。在上面的示例中,我们使用 10 来限制我们读取的推文数量,但我们当然可以访问更多。status 变量是 Status() 类的一个实例,这是一个很好的封装,用于访问数据。来自 Twitter API 的 JSON 响应在属性 _json 中(以一个下划线开头),这不是原始的 JSON 字符串,而是一个字典。
所以上面的代码可以重写为处理/存储 JSON:
for status in tweepy.Cursor(api.home_timeline).items(10):
# Process a single status
process_or_store(status._json)
如果我们想要一个包含所有关注者的列表?这就来了:
for friend in tweepy.Cursor(api.friends).items():
process_or_store(friend._json)
那么,所有推文的列表呢?很简单:
for tweet in tweepy.Cursor(api.user_timeline).items():
process_or_store(tweet._json)
通过这种方式,我们可以轻松收集推文(以及更多)并以原始 JSON 格式存储,转换成不同的数据模型相当容易,具体取决于我们的存储(许多 NoSQL 技术提供一些批量导入功能)。
函数 process_or_store() 是你自定义实现的占位符。在最简单的形式下,你可以将 JSON 打印出来,每条推文占一行:
def process_or_store(tweet):
print(json.dumps(tweet))
流式
如果我们想要“保持连接打开”,并收集关于特定事件的所有即将到来的推文,流式 API 是我们需要的。我们需要扩展 StreamListener() 以自定义处理传入数据的方式。一个工作示例,收集带有 #python 标签的所有新推文:
from tweepy import Stream
from tweepy.streaming import StreamListener
class MyListener(StreamListener):
def on_data(self, data):
try:
with open('python.json', 'a') as f:
f.write(data)
return True
except BaseException as e:
print("Error on_data: %s" % str(e))
return True
def on_error(self, status):
print(status)
return True
twitter_stream = Stream(auth, MyListener())
twitter_stream.filter(track=['#python'])
根据搜索词,我们可以在几分钟内收集大量推文。尤其是对于具有全球覆盖范围的实时事件(世界杯、超级碗、奥斯卡奖等),请关注 JSON 文件以了解其增长速度,并考虑你可能需要多少推文用于测试。上述脚本将每条推文保存在新的一行中,因此你可以使用命令wc -l python.json从 Unix shell 中知道你收集了多少条推文。
你可以在以下 Gist 中看到 Twitter Stream API 的一个最小工作示例:
摘要
我们介绍了tweepy作为一种用 Python 轻松访问 Twitter 数据的工具。我们可以收集不同类型的数据,显然重点是“推文”对象。
一旦我们收集了一些数据,在分析应用方面的可能性是无穷无尽的。在接下来的章节中,我们将讨论一些选项。
简介: Marco Bonzanini 是一位驻伦敦的数据科学家。活跃于 PyData 社区,他喜欢从事文本分析和数据挖掘应用。他是《"用 Python 掌握社交媒体挖掘"》(Packt Publishing, 2016 年 7 月)的作者。
原文。经授权转载。
相关:
-
数据觉醒:星球大战情感分析
-
教程:构建 Twitter 情感分析过程
-
通过大数据视角剖析大数据 Twitter 社区
更多相关话题
用 Python 挖掘 Twitter 数据 第四部分:橄榄球和术语共现
原文:
www.kdnuggets.com/2016/06/mining-twitter-data-python-part-4.html
作者:Marco Bonzanini,独立数据科学顾问。
上周六(编者注:已经过去一段时间)是六国锦标赛的闭幕日,这是一个年度国际橄榄球比赛。在打开电视观看意大利被威尔士击败之前,我决定利用这个事件从 Twitter 收集一些数据,并对比我的小列表的推文进行一些更有趣的探索性文本分析。
本文继续 Twitter 数据挖掘教程,重用我们在之前文章中讨论的内容,并引入更具现实的数据。它还通过引入术语共现的概念来扩展分析。
应用领域
正如名称所示,比赛涉及六支队伍:英格兰、爱尔兰、威尔士、苏格兰、法国和意大利。这意味着我们可以预计比赛会用多种语言(英语、法语、意大利语、威尔士语、盖尔语,可能还有其他语言)进行推文,其中英语是主要语言。假设队伍名称会被频繁提及,我们可以决定也查找它们的昵称,例如法国的Les Bleus或意大利的Azzurri。在比赛的最后一天,三场比赛依次进行。特别是三支队伍有机会争夺冠军:英格兰、爱尔兰和威尔士。最后,爱尔兰赢得了比赛,但一切都悬而未决直到最后一刻。
设置
我使用了流式 API 下载了当天包含字符串#rbs6nations的所有推文。显然,并非所有关于此事件的推文都包含该标签,但这是一个很好的基准。下载时间范围是从大约 12:15PM 到 7:15PM GMT,即从第一场比赛前大约 15 分钟,到最后一场比赛结束后大约 15 分钟。最后,下载了超过 18,000 条推文,JSON 格式,总数据约为 75Mb。这应该足够小以便在内存中快速处理,同时又足够大以观察到一些可能有趣的内容。
推文的文本内容已经通过使用教程第二部分中介绍的preprocess()函数进行了分词和小写处理。
有趣的术语和标签
根据我们在第三部分(术语频率)中讨论的内容,我们希望观察一天中使用的最常见的术语和标签。如果你已经跟随了关于创建不同词项列表的讨论,以捕捉没有标签的术语、仅标签、去除停用词等,你可以在不同列表中进行实验。
这是数据集中最常见的前 10 个术语(terms_only在第三部分)列表,这一点并不令人惊讶。
[('ireland', 3163), ('england', 2584), ('wales', 2271),
('', 2068), ('day', 1479), ('france', 1380), ('win', 1338),
('rugby', 1253), ('points', 1221), ('title', 1180)]
前三个术语对应于争夺冠军的球队。频率也尊重最终表中的顺序。第四个术语则是一个我们遗漏的标点符号,未包含在停用词列表中。这是因为string.punctuation只包含 ASCII 符号,而这里涉及的是一个 unicode 字符。如果我们深入数据,将会有更多类似的例子,但目前我们不需要担心这个问题。
在将省略号符号添加到停用词列表后,我们在列表末尾有了一个新的条目:
[('ireland', 3163), ('england', 2584), ('wales', 2271),
('day', 1479), ('france', 1380), ('win', 1338), ('rugby', 1253),
('points', 1221), ('title', 1180), ('__SHAMROCK_SYMBOL__', 1154)]
有趣的是,我们没有考虑到的新词项是一个表情符号(在这种情况下是爱尔兰三叶草)。
如果我们查看最常见的标签,我们需要考虑到#rbs6nations将是最常见的词项(这是我们下载推文的搜索词),因此我们可以将其从列表中排除。这给我们留下了:
[('#engvfra', 1701), ('#itavwal', 927), ('#rugby', 880),
('#scovire', 692), ('#ireland', 686), ('#angfra', 554),
('#xvdefrance', 508), ('#crunch', 500), ('#wales', 446),
('#england', 406)]
我们可以观察到,除了#rugby之外,最常见的标签与个别比赛相关。特别是英格兰对法国的比赛收到了最多的提及,可能是因为这是当天最后一场比赛,结局非常戏剧化。值得注意的是,相当多的推文还包含了法语术语:#angfra的计数实际上应该添加到#engvfra中。对橄榄球不太熟悉的人可能不会意识到#crunch也应该与#EngvFra比赛一起包含,因为Le Crunch是该事件的传统名称。因此,到目前为止,最后一场比赛吸引了大量关注。
术语共现
有时我们对同时出现的术语感兴趣。这主要是因为上下文能让我们更好地理解术语的含义,支持诸如词义消歧或语义相似性等应用。我们讨论了使用bigrams的选项在上一篇文章中,但我们想将术语的上下文扩展到整个推文中。
我们可以重构来自上一篇文章的代码,以捕捉共现情况。我们构建了一个共现矩阵com,使得com[x][y]包含术语x在同一推文中出现与术语y的次数:
from collections import defaultdict
# remember to include the other import from the previous post
com = defaultdict(lambda : defaultdict(int))
# f is the file pointer to the JSON data set
for line in f:
tweet = json.loads(line)
terms_only = [term for term in preprocess(tweet['text'])
if term not in stop
and not term.startswith(('#', '@'))]
# Build co-occurrence matrix
for i in range(len(terms_only)-1):
for j in range(i+1, len(terms_only)):
w1, w2 = sorted([terms_only[i], terms_only[j]])
if w1 != w2:
com[w1][w2] += 1
在构建共现矩阵时,我们不想重复计算相同的术语对,例如 com[A][B] == com[B][A],因此内层循环从 i+1 开始,以构建一个三角矩阵,而 sorted 会保持术语的字母顺序。
对于每个术语,我们提取 5 个最频繁的共现术语,创建一个形式为 ((term1, term2), count) 的元组列表:
com_max = []
# For each term, look for the most common co-occurrent terms
for t1 in com:
t1_max_terms = sorted(com[t1].items(), key=operator.itemgetter(1), reverse=True)[:5]
for t2, t2_count in t1_max_terms:
com_max.append(((t1, t2), t2_count))
# Get the most frequent co-occurrences
terms_max = sorted(com_max, key=operator.itemgetter(1), reverse=True)
print(terms_max[:5])
结果:
[(('6', 'nations'), 845), (('champions', 'ireland'), 760),
(('nations', 'rbs'), 742), (('day', 'ireland'), 731),
(('ireland', 'wales'), 674)]
这个实现方法相当直接,但根据数据集和矩阵的使用情况,可能需要考虑使用像 scipy.sparse 这样的工具来构建稀疏矩阵。
我们还可以寻找特定术语,并提取其最频繁的共现术语。我们只需在主循环中添加一个额外的计数器,例如:
search_word = sys.argv[1] # pass a term as a command-line argument
count_search = Counter()
for line in f:
tweet = json.loads(line)
terms_only = [term for term in preprocess(tweet['text'])
if term not in stop
and not term.startswith(('#', '@'))]
if search_word in terms_only:
count_search.update(terms_only)
print("Co-occurrence for %s:" % search_word)
print(count_search.most_common(20))
“ireland”的结果:
[('champions', 756), ('day', 727), ('nations', 659), ('wales', 654), ('2015', 638),
('6', 613), ('rbs', 585), ('http://t.co/y0nvsvayln', 559), ('__SHAMROCK_SYMBOL__', 526), ('10', 522),
('win', 377), ('england', 377), ('twickenham', 361), ('40', 360), ('points', 356),
('sco', 355), ('ire', 355), ('title', 346), ('scotland', 301), ('turn', 295)]
“rugby”的结果:
[('day', 476), ('game', 160), ('ireland', 143), ('england', 132), ('great', 105),
('today', 104), ('best', 97), ('well', 90), ('ever', 89), ('incredible', 87),
('amazing', 84), ('done', 82), ('amp', 71), ('games', 66), ('points', 64),
('monumental', 58), ('strap', 56), ('world', 55), ('team', 55), ('http://t.co/bhmeorr19i', 53)]
总体来说,非常有趣。
总结
这篇文章讨论了一个关于 Twitter 上文本挖掘的示例,使用了一些在体育赛事中收集的现实数据。运用我们在之前的章节中学到的知识,我们通过流媒体 API 下载了一些数据,处理成 JSON 格式,并从推文中提取了一些有趣的术语和标签。文章还介绍了术语共现的概念,展示了如何构建共现矩阵,并讨论了如何使用它来发现一些有趣的洞察。
简介: Marco Bonzanini 是一名驻伦敦的 数据科学家。活跃于 PyData 社区,他喜欢从事文本分析和数据挖掘应用。他是《用 Python 精通社交媒体挖掘》(Packt Publishing,2016 年 7 月)的作者。
原文。经许可转载。
相关:
-
用 Python 挖掘 Twitter 数据 第一部分:数据收集
-
用 Python 挖掘 Twitter 数据 第二部分:文本预处理
-
用 Python 挖掘 Twitter 数据 第三部分:术语频率
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
使用 Python 挖掘 Twitter 数据 第五部分:数据可视化基础
原文:
www.kdnuggets.com/2016/06/mining-twitter-data-python-part-5.html
作者:Marco Bonzanini,自由数据科学顾问。
一图胜千言:设计一个好的可视化表现可以帮助我们理解数据并突出有趣的见解。收集和分析 Twitter 数据后,本教程将继续介绍使用 Python 进行数据可视化的一些概念。
从 Python 到 JavaScript 使用 Vincent
尽管使用如 matplotlib 或 ggplot 等库在 Python 中创建图表有一些选项,但可能最酷的数据可视化库是D3.js,顾名思义,它是基于 JavaScript 的。D3 与 CSS 和 SVG 等 Web 标准兼容,并允许创建一些精彩的互动可视化效果。
Vincent弥合了 Python 后端和支持 D3.js 可视化的前端之间的差距,让我们能够受益于两者。Vincent 的口号实际上是“Python 的数据能力。JavaScript 的可视化能力”。Vincent 作为一个 Python 库,将我们的数据转换成Vega,一种基于 JSON 的可视化语法,该语法将在 D3 上使用。听起来可能很复杂,但实际上很简单且符合 Python 风格。如果你不想的话,你不需要写一行 JavaScript/D3 代码。
首先,让我们安装 Vincent:
sudo pip install vincent
其次,让我们创建我们的第一个图表。使用我们的rugby data set中的最常见术语列表(不包括标签),我们想要绘制它们的频率:
import vincent
word_freq = count_terms_only.most_common(20)
labels, freq = zip(*word_freq)
data = {'data': freq, 'x': labels}
bar = vincent.Bar(data, iter_idx='x')
bar.to_json('term_freq.json')
此时,term_freq.json 文件将包含一个描述图表的内容,可以交给 D3.js 和 Vega。一个简单的模板(取自 Vincent 资源)用于可视化图表:
<html>
<head>
<title>Vega Scaffold</title>
<script src="http://d3js.org/d3.v3.min.js" charset="utf-8"></script>
<script src="http://d3js.org/topojson.v1.min.js"></script>
<script src="http://d3js.org/d3.geo.projection.v0.min.js" charset="utf-8"></script>
<script src="http://trifacta.github.com/vega/vega.js"></script>
</head>
<body>
<div id="vis"></div>
</body>
<script type="text/javascript">
// parse a spec and create a visualization view
function parse(spec) {
vg.parse.spec(spec, function(chart) { chart({el:"#vis"}).update(); });
}
parse("term_freq.json");
</script>
</html>
将上述 HTML 页面保存为chart.html,然后运行简单的 Python Web 服务器:
python -m http.server 8888 # Python 3
python -m SimpleHTTPServer 8888 # Python 2
现在你可以打开浏览器访问http://localhost:8888/chart.html,观察结果:
点击放大。
注意:你可以直接从 Python 保存 HTML 模板,使用:
bar.to_json('term_freq.json', html_out=True, html_path='chart.html')
但至少在 Python 3 中,输出的 HTML 并不完整,你需要手动去除一些字符。
使用这个过程,我们可以用 Vincent 绘制多种类型的图表。让我们花点时间browse the docs查看其功能。
时间序列可视化
分析 Twitter 数据的另一个有趣方面是观察推文随时间的分布。换句话说,如果我们将频率组织成时间段,我们可以观察 Twitter 用户对实时事件的反应。
我最喜欢的 Python 数据分析工具之一是Pandas,它对时间序列也有相当不错的支持。作为示例,让我们跟踪标签#ITAvWAL以观察第一场比赛期间发生了什么。
首先,如果我们还没有这样做,我们需要安装 Pandas:
sudo pip install pandas
在读取所有推文的主循环中,我们只需跟踪标签的出现次数,即我们可以将代码重构为类似于之前的几集的形式:
import pandas
import json
dates_ITAvWAL = []
# f is the file pointer to the JSON data set
for line in f:
tweet = json.loads(line)
# let's focus on hashtags only at the moment
terms_hash = [term for term in preprocess(tweet['text']) if term.startswith('#')]
# track when the hashtag is mentioned
if '#itavwal' in terms_hash:
dates_ITAvWAL.append(tweet['created_at'])
# a list of "1" to count the hashtags
ones = [1]*len(dates_ITAvWAL)
# the index of the series
idx = pandas.DatetimeIndex(dates_ITAvWAL)
# the actual series (at series of 1s for the moment)
ITAvWAL = pandas.Series(ones, index=idx)
# Resampling / bucketing
per_minute = ITAvWAL.resample('1Min', how='sum').fillna(0)
最后一行使我们能够跟踪频率的变化。序列以 1 分钟的间隔重新采样。这意味着所有在特定一分钟内的推文将被汇总,更准确地说,它们将被求和,给定how='sum'。时间索引将不再跟踪秒数。如果在特定的一分钟内没有推文,fillna()函数将用零填充空白。
要将时间序列绘制到图表中,使用 Vincent:
time_chart = vincent.Line(ITAvWAL)
time_chart.axis_titles(x='Time', y='Freq')
time_chart.to_json('time_chart.json')
一旦将time_chart.json文件嵌入到上面讨论的 HTML 模板中,你将看到以下输出:

点击放大。
比赛的有趣时刻可以通过序列中的峰值观察到。第一次峰值发生在下午 1 点前,对应于第一次意大利尝试。1:30 和 2:30 之间的其他所有峰值对应于威尔士的尝试,显示了威尔士在下半场的主导地位。比赛在 2:30 结束,所以之后 Twitter 变得安静。
与其一次观察一个序列,不如比较不同的序列以观察匹配情况如何演变。因此,让我们重构时间序列的代码,将三个不同的标签#ITAvWAL、#SCOvIRE和#ENGvFRA跟踪到相应的pandas.Series中。
# all the data together
match_data = dict(ITAvWAL=per_minute_i, SCOvIRE=per_minute_s, ENGvFRA=per_minute_e)
# we need a DataFrame, to accommodate multiple series
all_matches = pandas.DataFrame(data=match_data,
index=per_minute_i.index)
# Resampling as above
all_matches = all_matches.resample('1Min', how='sum').fillna(0)
# and now the plotting
time_chart = vincent.Line(all_matches[['ITAvWAL', 'SCOvIRE', 'ENGvFRA']])
time_chart.axis_titles(x='Time', y='Freq')
time_chart.legend(title='Matches')
time_chart.to_json('time_chart.json')
以及输出:

点击放大。
我们可以立即观察到不同比赛的发生时间(大约 12:30-2:30、2:30-4:30 和 5-7),并且可以看到最后一场比赛吸引了所有的关注,特别是在赢家揭晓时。
概述
数据可视化是数据分析中一个重要的学科。通过支持数据的可视化表示,我们可以提供有趣的见解。我们讨论了一个相对简单的选项,使用 Python 和 Vincent 支持数据可视化。特别是,我们看到如何轻松地弥合 Python 与 Javascript 这样一个提供了 D3.js 这样重要工具的语言之间的差距。总体而言,我们仅仅触及了数据可视化的表面,但作为一个起点,这应该足以激发一些好的想法。Twitter 作为一种媒介的性质也促使我们快速了解时间序列分析,使我们提到pandas作为一个出色的 Python 工具。
简历:Marco Bonzanini 是一位总部位于英国伦敦的数据科学家。他活跃于 PyData 社区,喜欢从事文本分析和数据挖掘应用。他是《用 Python 掌握社交媒体挖掘》(Packt Publishing,2016 年 7 月)的作者。
原文。经许可转载。
相关:
-
用 Python 挖掘 Twitter 数据 第二部分:文本预处理
-
用 Python 挖掘 Twitter 数据 第三部分:术语频率
-
用 Python 挖掘 Twitter 数据 第四部分:橄榄球和术语共现
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
更多相关主题
使用 Python 矿掘 Twitter 数据 第六部分:情感分析基础
原文:
www.kdnuggets.com/2016/07/mining-twitter-data-python-part-6.html
作者:Marco Bonzanini,独立数据科学顾问。
情感分析 是文本分析的一个有趣应用。虽然这个术语通常与 文档情感分类 相关联,但广义上讲,它指的是将文本分析方法应用于识别和提取文本源中主观材料的一系列问题。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
本文继续讲解使用 Python 矿掘 Twitter 数据的系列,描述了一种简单的情感分析方法,并将其应用于橄榄球数据集(见 第四部分)。
一种简单的情感分析方法
我们在本文讨论的技术是从 Peter Turney 在其论文 “赞成还是反对?语义取向应用于无监督的评论分类” 中提出的传统方法发展而来的。从那时起,情感分析领域做了大量工作,但这种方法仍然具有有趣的教育价值。特别是,它直观、易于理解和测试,而且最重要的是 无监督,因此不需要任何标注数据进行训练。
首先,我们将一个词的 语义取向 (SO) 定义为其与积极和消极词汇关联的差异。实际上,我们想要计算一个词与 好 和 坏 等术语的“接近程度”。所选择的“接近度”度量是 点互信息 (PMI),计算方法如下(t1 和 t2 是术语):
 = \log\Bigl(\frac{P(t_1 \wedge t_2)}{P(t_1) \cdot P(t_2)}\Bigr)")
在 Turney 的论文中,词汇的 SO 是通过与excellent和poor进行比较计算的,但当然我们可以扩展正面和负面术语的词汇表。使用 和正面词汇的词汇表以及
和正面词汇的词汇表以及 用于负面词汇,术语 t 的语义取向定义如下:
用于负面词汇,术语 t 的语义取向定义如下:
 = \sum_{t' \in V^{+}}\mbox{PMI}(t, t') - \sum_{t' \in V^{-}}\mbox{PMI}(t, t')")
我们可以建立自己的一组正面和负面术语,或者使用在线提供的众多资源之一,例如Bing Liu 的意见词典。
计算术语概率
为了计算") (观察到术语t的概率)和")(观察到术语t1和t2同时出现的概率),我们可以重用一些之前的代码来计算术语频率和术语共现。给定文档集(推文)D,我们将术语的文档频率(DF)定义为术语出现的文档数量。相同的定义可以应用于共现术语。因此,我们可以定义我们的概率为:
(观察到术语t的概率)和")(观察到术语t1和t2同时出现的概率),我们可以重用一些之前的代码来计算术语频率和术语共现。给定文档集(推文)D,我们将术语的文档频率(DF)定义为术语出现的文档数量。相同的定义可以应用于共现术语。因此,我们可以定义我们的概率为:
 = \frac{\mbox{DF}(t)}{|D|}\ P(t_1 \wedge t_2) = \frac{\mbox{DF}(t_1 \wedge t_2)}{|D|}")
在之前的文章中,单一术语的文档频率存储在字典count_single和count_stop_single中(后者不存储停用词),而共现的文档频率存储在共现矩阵com中。
这就是我们计算概率的方法:
# n_docs is the total n. of tweets
p_t = {}
p_t_com = defaultdict(lambda : defaultdict(int))
for term, n in count_stop_single.items():
p_t[term] = n / n_docs
for t2 in com[term]:
p_t_com[term][t2] = com[term][t2] / n_docs
计算语义取向
给定两个正面和负面术语的词汇表:
positive_vocab = [
'good', 'nice', 'great', 'awesome', 'outstanding',
'fantastic', 'terrific', ':)', ':-)', 'like', 'love',
# shall we also include game-specific terms?
# 'triumph', 'triumphal', 'triumphant', 'victory', etc.
]
negative_vocab = [
'bad', 'terrible', 'crap', 'useless', 'hate', ':(', ':-(',
# 'defeat', etc.
]
我们可以计算每对术语的 PMI,然后计算如上所述的语义取向:
pmi = defaultdict(lambda : defaultdict(int))
for t1 in p_t:
for t2 in com[t1]:
denom = p_t[t1] * p_t[t2]
pmi[t1][t2] = math.log2(p_t_com[t1][t2] / denom)
semantic_orientation = {}
for term, n in p_t.items():
positive_assoc = sum(pmi[term][tx] for tx in positive_vocab)
negative_assoc = sum(pmi[term][tx] for tx in negative_vocab)
semantic_orientation[term] = positive_assoc - negative_assoc
如果术语经常与正面(负面)词汇中的术语相关联,则该术语的语义取向将为正(负)值。对于中性术语,值将为零,例如正面和负面 PMI 平衡,或更有可能的是,术语从未与正面/负面词汇中的其他术语一起出现。
我们可以打印出一些术语的语义取向:
semantic_sorted = sorted(semantic_orientation.items(),
key=operator.itemgetter(1),
reverse=True)
top_pos = semantic_sorted[:10]
top_neg = semantic_sorted[-10:]
print(top_pos)
print(top_neg)
print("ITA v WAL: %f" % semantic_orientation['#itavwal'])
print("SCO v IRE: %f" % semantic_orientation['#scovire'])
print("ENG v FRA: %f" % semantic_orientation['#engvfra'])
print("#ITA: %f" % semantic_orientation['#ita'])
print("#FRA: %f" % semantic_orientation['#fra'])
print("#SCO: %f" % semantic_orientation['#sco'])
print("#ENG: %f" % semantic_orientation['#eng'])
print("#WAL: %f" % semantic_orientation['#wal'])
print("#IRE: %f" % semantic_orientation['#ire'])
不同的词汇表会产生不同的分数。使用来自 Bing Liu 的意见词典,我们可以观察到在 Rugby 数据集上的结果:
# the top positive terms
[('fantastic', 91.39950482011552), ('@dai_bach', 90.48767241244532), ('hoping', 80.50247748725415), ('#it', 71.28333427277785), ('days', 67.4394844955977), ('@nigelrefowens', 64.86112716005566), ('afternoon', 64.05064208341855), ('breathtaking', 62.86591435212975), ('#wal', 60.07283361352875), ('annual', 58.95378954406133)]
# the top negative terms
[('#england', -74.83306534609066), ('6', -76.0687215594536), ('#itavwal', -78.4558633116863), ('@rbs_6_nations', -80.89363516601993), ("can't", -81.75379628180468), ('like', -83.9319149443813), ('10', -85.93073078165587), ('italy', -86.94465165178258), ('#engvfra', -113.26188957010228), ('ball', -161.82146824640125)]
# Matches
ITA v WAL: -78.455863
SCO v IRE: -73.487661
ENG v FRA: -113.261890
# Individual team
#ITA: 53.033824
#FRA: 14.099372
#SCO: 4.426723
#ENG: -0.462845
#WAL: 60.072834
#IRE: 19.231722
一些局限性
基于 PMI 的方法被介绍为简单而直观,但当然也有一些局限性。语义分数是基于术语计算的,这意味着没有“实体”或“概念”或“事件”的概念。例如,将所有对球队名称的引用进行聚合和归一化,例如#ita、Italy和Italia,应该都对同一实体的语义倾向产生贡献。此外,单个球队的意见是否也会影响对一场比赛的整体意见?
一些自然语言的方面也未被此方法捕捉,尤其是修饰语和否定词:我们如何处理像not bad(这与bad正好相反)或very good(这比good更强烈)的短语?
摘要
本文继续介绍使用 Python 挖掘 Twitter 数据的教程,引入了一种简单的情感分析方法,基于计算语义倾向分数,该分数告诉我们一个术语更接近于正面还是负面词汇。这种方法的直觉非常简单,可以使用点对点互信息作为关联度量来实现。这种方法当然有一些局限性,但它是熟悉情感分析的良好起点。
简介: Marco Bonzanini 是一名驻伦敦的数据科学家。他活跃于 PyData 社区,喜欢从事文本分析和数据挖掘应用。他是《Mastering Social Media Mining with Python》(Packt Publishing, 2016 年 7 月)的作者。
原文。经许可转载。
相关:
-
使用 Python 挖掘 Twitter 数据第三部分:术语频率
-
使用 Python 挖掘 Twitter 数据第四部分:橄榄球和术语共现
-
使用 Python 挖掘 Twitter 数据第五部分:数据可视化基础
相关主题
使用 Python 进行 Twitter 数据挖掘 第七部分:地理位置和交互式地图
原文:
www.kdnuggets.com/2016/07/mining-twitter-data-python-part-7.html
作者:Marco Bonzanini,独立数据科学顾问。
地理定位是识别对象地理位置的过程,例如移动电话或计算机。Twitter 允许用户在发布推文时提供他们的位置,形式为纬度和经度坐标。有了这些信息,我们准备好为我们的数据创建一些不错的交互式地图可视化。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的组织
本文简要介绍了GeoJSON格式和Leaflet.js,这是一个用于交互式地图的优秀 Javascript 库,并讨论了它与我们在本教程前面部分收集的 Twitter 数据的集成(详细信息请参见第四部分)。
GeoJSON
GeoJSON 是一种用于编码地理数据结构的格式。该格式支持各种几何类型,这些类型可以用于将所需的形状可视化到地图上。对于我们的示例,我们只需要最简单的结构,即Point。点通过其坐标(纬度和经度)来识别。
在 GeoJSON 中,我们还可以表示如Feature或FeatureCollection这样的对象。第一个基本上是一个带有附加属性的几何体,而第二个是特征列表。
我们的 Twitter 数据集可以表示为 GeoJSON 中的一个FeatureCollection,其中每条推文将是一个包含单个几何体(即前面提到的Point)的独立Feature。
这就是 JSON 结构的样子:
{
"type": "FeatureCollection",
"features": [
{
"type": "Feature",
"geometry": {
"type": "Point",
"coordinates": [some_latitude, some_longitude]
},
"properties": {
"text": "This is sample a tweet",
"created_at": "Sat Mar 21 12:30:00 +0000 2015"
}
},
/* more tweets ... */
]
}
从推文到 GeoJSON
假设数据存储在单个文件中,如本教程第一章所述,我们只需遍历所有推文,查找可能存在的coordinates字段。请记住,你需要使用coordinates,因为geo字段已被弃用(请参见API)。
这段代码将读取数据集,查找坐标明确给出的推文。一旦创建了 GeoJSON 数据结构(以 Python 字典形式),数据将被转储到名为 geo_data.json 的文件中:
# Tweets are stored in "fname"
with open(fname, 'r') as f:
geo_data = {
"type": "FeatureCollection",
"features": []
}
for line in f:
tweet = json.loads(line)
if tweet['coordinates']:
geo_json_feature = {
"type": "Feature",
"geometry": tweet['coordinates'],
"properties": {
"text": tweet['text'],
"created_at": tweet['created_at']
}
}
geo_data['features'].append(geo_json_feature)
# Save geo data
with open('geo_data.json', 'w') as fout:
fout.write(json.dumps(geo_data, indent=4))
使用 Leaflet.js 的互动地图
Leaflet.js 是一个开源的 Javascript 库,用于创建互动地图。你可以创建包含你选择的瓦片(例如来自 OpenStreetMap 或 MapBox)的地图,并叠加互动组件。
为了准备一个可以托管地图的网页,你只需在文档的头部部分包含库及其 CSS,添加以下几行代码:
<link rel="stylesheet" href="http://cdnjs.cloudflare.com/ajax/libs/leaflet/0.7.3/leaflet.css" />
<script src="http://cdnjs.cloudflare.com/ajax/libs/leaflet/0.7.3/leaflet.js"></script>
此外,我们将所有的 GeoJSON 数据放在一个单独的文件中,因此我们希望动态加载数据,而不是手动将所有点放在地图上。为此,我们可以轻松地使用jQuery,这也是我们需要包括的:
<script src="http://code.jquery.com/jquery-2.1.0.min.js"></script>
地图本身将放置在一个 div 元素中:
<script src="http://code.jquery.com/jquery-2.1.0.min.js"></script><!-- this goes in the <head> -->
<style>
#map {
height: 600px;
}
</style>
<!-- this goes in the <body> -->
<div id="map"></div>
我们现在准备使用 Leaflet 创建地图:
// Load the tile images from OpenStreetMap
var mytiles = L.tileLayer('http://{s}.tile.osm.org/{z}/{x}/{y}.png', {
attribution: '© <a href="http://osm.org/copyright">OpenStreetMap</a> contributors'
});
// Initialise an empty map
var map = L.map('map');
// Read the GeoJSON data with jQuery, and create a circleMarker element for each tweet
// Each tweet will be represented by a nice red dot
$.getJSON("./geo_data.json", function(data) {
var myStyle = {
radius: 2,
fillColor: "red",
color: "red",
weight: 1,
opacity: 1,
fillOpacity: 1
};
var geojson = L.geoJson(data, {
pointToLayer: function (feature, latlng) {
return L.circleMarker(latlng, myStyle);
}
});
geojson.addTo(map)
});
// Add the tiles to the map, and initialise the view in the middle of Europe
map.addLayer(mytiles).setView([50.5, 5.0], 5);
结果的截图:
上面的例子使用了 OpenStreetMap 的瓦片图像,但 Leaflet 允许你选择其他服务。例如,在下面的截图中,瓦片图像来自 MapBox。
你可以在这里看到互动地图的实际效果:
总结
一般来说,Python 有许多数据可视化的选项,但在基于浏览器的交互方面,Javascript 也是一个有趣的选择,两种语言可以很好地配合使用。本文展示了构建简单互动地图是一个相当直接的过程。
几行 Python 代码就能将数据转换为可以传递给 Javascript 进行可视化的通用格式(GeoJSON)。Leaflet.js 是一个很棒的 Javascript 库,几乎开箱即用,让我们创建一些不错的互动地图。
个人简介:Marco Bonzanini 是一位常驻伦敦的 数据科学家。他活跃于 PyData 社区,喜欢从事文本分析和数据挖掘应用。他是《用 Python 掌握社交媒体挖掘》(Packt Publishing,2016 年 7 月)的作者。
原文。转载已获许可。
相关内容:
-
用 Python 挖掘 Twitter 数据 第四部分:橄榄球和术语共现
-
用 Python 矿工 Twitter 数据 第五部分:数据可视化基础
-
用 Python 矿工 Twitter 数据 第六部分:情感分析基础
更多相关主题
关于语义分割注释的误解
原文:
www.kdnuggets.com/2022/01/misconceptions-semantic-segmentation-annotation.html

语义分割是一个计算机视觉问题,涉及将图像中相关的元素归入同一类别。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
语义分割涉及三个步骤:
分类: 识别并分类图片中的特定对象。
定位: 查找物体并围绕其绘制边界框。
分割: 使用分割掩码将局部图片中的像素进行分组的过程。
语义分割有几种子类型,但它们都源于从两个类别中选择一对参数:数据的维度和输出注释的粒度。
维度
数据源中的维度数量称为此。普通相机照片是 2D 对象的一个例子,因为它只有两个维度:高度和宽度。3D 数据是 2D 数据的一种变体,增加了一个“深度”组件。Lidar 和雷达扫描是两种传感器数据。当多个连续的 3D 对象沿时间轴层叠时,会创建一个 4D 表示,通常称为电影。
我们根据数据的维度使用不同形式的语义分割来创建分割掩码。在 2D 分割的情况下,使用两种方法之一:基于像素或基于多边形的着色。由于像素是此模型中最小的基本组成部分,每个像素都被分配到一个注释类别中。这导致在 3D 中进行基于点的分割,每个 3D 点都会被标记。如果提供了足够的点,可以从单个物体中提取分割网格。
粒度
结果标注的精确度称为粒度。基于类别和实例感知分割是最常见的两种类型。在第一个例子中,特定类别的分割掩模涵盖了所有表示该类别成员的区域。在第二种情况下,为每个选择类别的独特物体构建了不同的分割掩模,从而能够区分不同的实例(例如分开两辆不同的车)。
在机器学习中,哪种语义分割更有用?
为了最大限度地发挥语义分割的效果,应该使用实例感知子类型。以下是一些原因。
格式非常灵活
有了分割的数据,你可以训练和实验各种机器学习模型,包括分类、检测、定位、图像生成、前景/背景分离、手写识别、内容修改等。因此,它被广泛应用于各种行业,包括自动驾驶、时尚、电影制作和后期制作、农业等。
精确度无与伦比
分割掩模最为精确,因为它们只覆盖真实物体的位置。另一方面,边界框经常包括或与邻近区域连接。这是因为非刚性物体在其他非刚性物体内或上面。
一个标注两个标注
尽管分割掩模更为精确,许多程序仍然使用边界框。幸运的是,可以始终通过分割掩模来估计周围的边界框。这就是你如何全面覆盖所有基础!
尽管有这些优点,使用语义分割作为标注类型也有显著的缺点。
第一部分是最困难的
1. 手动标注既困难又耗时
手动制作语义掩模是一项耗时且困难的任务。当面对不规则形状或物体边界不易察觉的区域时,标注者必须准确跟随每个物体的轮廓(见下图)。没有专业工具的情况下标注单帧容易出错、不一致,且可能需要超过 30 分钟。
2. 完全自动化的方法无法提供高质量的结果
如果我们可以只训练一个神经网络进行语义分割,然后获得所有标注而无需做任何事情,那不是很好吗?
原因在于我们对质量的认知与准确度的评估之间存在不一致。分割掩模是通过物体轮廓生成的,质量由正确检测到的区域百分比来确定。
3. 纠正错误需要很长时间
上述每种方式中的错误可能都很昂贵。修正一个不完美的分割掩膜需要修正 N 个额外的掩膜,其中 N 是邻近掩膜的数量(稍后我们会回到这个问题)。调整掩膜所需的时间与从头创建掩膜的时间相同。因此,完全自动化的分割输出也无法通过人工调整来完成。唯一防止这个问题的方法是使用专门的标注软件和经过充分培训的标注员。
4. 语义分割标注成本
正如你可能看到的,创建分割掩膜需要使用特定的标注员、设备和自动化技术。这大大提高了价格,通常是标注基本边界框成本的几倍,并迅速耗尽预算。
Gaurav Sharma 在人工智能和机器学习领域工作了超过六年。Gaurav 是一名自由技术作家,为 Cogito Tech LLC、Anolytics.ai 及其他提供训练数据给 AI 业务的著名数据标注公司工作。
更多相关话题
机器学习栈中缺失的关键部分
原文:
www.kdnuggets.com/2020/04/missing-part-machine-learning-stack.html
评论
作者:Malo Marrec,cloudnative.fr 独立从业者。

几年前,大多数机器学习(ML)和数据科学平台的计划集中在解决计算编排问题上。许多公司认为,管理和共享 GPU 是一个重大问题,Kubernetes 将成为基石,围绕它构建工具是正确的选择。因此,像 Rise ML、我共同创办的公司 Clusterone,或者像 Kubeflow 这样的开源项目应运而生。一些项目失败了,一些成功了,大多数仍处于早期阶段(Kubeflow 最近宣布了 1.0 版本候选)。
在我看来,那时大多数关注点都在于训练模型,但没有一个框架涵盖机器学习的所有环节。那些声称涵盖完整故事的框架专注于训练和部署。数据管理、特征提取、特征选择被主要平台忽视了,数据科学家和数据工程师之间的沟通鸿沟也是如此。大多数平台公司忽略了这一痛点,“我们不想重新构建 ETL”是他们的理由。
现在的情况发生了变化。机器学习团队意识到,他们在模型开发的第一步:特征定义和提取上浪费了大量时间。随着机器学习实验和管道开发受到软件工程最佳实践(版本化、标准化、隔离或容器化)的影响,特征工程需要变得更加结构化和可靠。代码管理中适用的严谨性在数据和特征管理中缺失,但这正在改变。
在过去的一年里,我们看到围绕一个新趋势(但其实是旧观念)的热潮:特征存储。
我们还看到像 Logical Clocks 和 Kaskada 这样的公司,以及开源项目如 Feast 的重大公告和融资,逐渐获得关注。
为什么选择特征存储
让我们从一个例子开始。假设我在一家酒店预订平台公司的数据科学团队工作。我负责构建一个酒店容量预测系统。我有一个记录客户入住时间的数据表和一个记录客户退房时间的数据表。我想预测一个特定的酒店是否会有空闲房间。第一步是尝试定义有用的数据观察方式。在我们的例子中,通过比较每位客户的入住日期和退房日期,我们可以判断酒店的某个房间是否空闲。我可以在酒店层面汇总这些数据,并知道某一时间点有多少房间是可用的/空闲的。从这个特性中,我可以尝试预测在给定的容量下是否会有空闲房间。
为了达到这个目的,我已经探索了数据,编写了提取潜在有用特性的代码——包括查询、清理、过滤和汇总来自酒店预订数据库的数据的代码。只有在完成这些工作后,我才开始着手我的模型。
结果是,这个特性(酒店中的空闲房间数量)对公司内其他数据科学团队的许多人可能都很有用:比如预测高层财务结果的团队,构建帮助酒店预测清洁需求的产品的团队等。但这些团队每一个都在重新实现相同的特性计算管道,以便在他们的算法中使用相同的特性。
更糟糕的是,为了将模型投入生产,数据科学团队通常将模型交给数据工程团队,由他们将其调整为生产环境所需的状态(可扩展、运行更快等)。该团队通常会重写特性计算代码(例如,添加更高效的实时表格比较方式,以便在添加新预订时进行处理)。
到一天结束时,你可能会发现定义一个特性(比如酒店的空闲房间数量)的方法有很多种。
“作为数据科学家,你和我会以不同的方式看待事物,比如以不同的方式总结数据。这会产生很大的影响。每次我们都必须在进入生产环境时重新编译每个特性。” Swedbank 的首席数据科学家 Davit Bzhalava 说道。
这里有几个问题:
-
这没有单一的真实来源,这意味着模型在生产环境和训练环境中可能表现不同。
-
大量的返工是由于多个团队重写内容,无论是因为缺乏集中定义特性的方式,还是因为没有意识到特性已经在其他地方定义过。
-
团队最终大量复制数据,特别是在“一个有很多遗留系统的大组织中,你必须从很多地方查询数据。人们最终会复制大量数据来整合这些数据”,Davit Bzhalava 补充道。
这就是特性存储的作用所在。
特性存储是一个集中管理数据特性的地方,特性在这里被定义、整理、一致提供和共享。它提供了从数据源到模型的追溯性。
从架构上讲,Logical Clocks 的首席执行官 Dr. Jim Dowling 表示,“这是一个双数据库。”他说:“你有一个低延迟数据库,用于在在线应用中快速访问特征数据。然后,你有一个可扩展的数据库,可以存储大量的特征数据,用于训练更大更好的模型。”
此外,特征存储重新定义了团队的工作方式,位于数据科学工作流的核心,这可能就是它们市场出现花费了一段时间的原因:它们是复杂的产品。
获得势头
项目构建特征存储正在获得势头。一切始于 2017 年,当时 Uber 工程部门推出了其内部的Michelangelo 平台。从那时起,我们看到了一些开源项目获得了势头,例如Feast,这是一个由 Gojek 维护的开源特征存储,Gojek 是一款南亚地区的按需预订应用。
与任何技术一样,一些公司更倾向于采用开源技术,这通常需要将多个组件集成到一个平台中。一些公司则倾向于选择商业产品。
首批向市场宣布其产品的两家公司是 Logical Clocks 和 Kaskada。Logical Clocks 在 2019 年 1 月发布了一个开源特征存储及其商业支持版本。根据公司网站,Kaskada 目前处于Beta阶段。这两家公司的想法是提供一个端到端的、集成的平台,突出显示特征存储。
“我们在 2018 年底发布了第一个开源特征存储,现在我们在 AWS 云上发布了第一个托管特征存储。当我们在 2018 年开始构建特征存储时,我几乎觉得已经太晚了。2017 年底,Uber 曾写过关于特征存储的文章。但由于从头到尾都需要相当多的工程工作,直到现在,实施它们的人并不多。” Logical Clocks 的 Dr. Dowling 如是说。
我从总部位于西雅图的初创公司 Kaskada 那里听到了类似的观点,该公司最近筹集了 800 万美元。Kaskada 的首席执行官 Davor Bonaci 表示:“我们正在构建一个端到端的特征工程平台。我们不仅仅是一个特征存储。我们使你能够构建和可视化特征。然后,所有这些都可以生产并监控生产中的数据。我怀疑这将是最大的差异点,特别是与开源软件相比。”
采纳触发因素
我总是想知道是什么触发了平台软件的采用。确实,它会提供下一层次的能力,或者像 Davor Bonaci 所说的“使公司具备类似亚马逊、谷歌的数据基础设施”。但另一方面,它会要求流程和思维方式的改变。数据科学家将需要更多地考虑定义特征和计算问题的最佳实践。数据工程师将更早地参与到过程中,而不仅仅是接手模型。
似乎特征存储现在获得采用的原因是,经过几年的实验,公司现在开始在生产中运行模型。他们看到这样做的复杂性,并感到需要更稳健的工程(这让我很想起 DevOps:一旦你达到一定规模,你就会重新架构、自动化,并确保你不依赖于那个知道如何运行事情的团队成员)。
我询问了什么样的特征存储是好的,以及何时是采用的最佳时机。
Swedebank 的 Davit Bzhalava 表示,采用的触发因素是看到团队成员进出并感到需要将 DevOps 原则应用于 ML。“你需要达到部署点才会意识到这是一个问题。然后你有生产中的模型,人员进出,你意识到需要让事情更稳健。我们经历了这一点,然后运行了特征存储的 POC 来解决这个问题。我们现在正在考虑如何在组织层面推广它。” 我在听这个特征存储真实案例的集合时,也听到了类似的想法。
Kaskada 公司的首席执行官 Davor Bonaci 同意这个观点。“如果我们回顾几年前的市场,只有少数几家公司拥有有意义的 ML 用例。今天,我们看到公司正在过渡到生产中的实际工作负载。他们开始意识到,通过松散的特征定义实践,他们浪费了多少时间。” 他还给出了选择特征存储的看法。“有些特征存储是实际的引擎,存储公式并按需计算。有些只是数据库。那么,它是数据库,还是有表达和计算特征的方法的存储?”
逻辑时钟公司的首席执行官 Dr. Dowling 总结道:“特征存储可以通过整合公司范围内的特征工程工作,减少开发成本和市场推出时间,并改善数据工程和数据科学团队之间的协作。尽管特征存储的能力可能有所不同——我们的特征存储版本特征和特征数据,但总体来说,声称特征存储将通过将单一的端到端 ML 管道分解为更可管理和可测试的特征工程和模型训练管道来帮助改善 ML 模型工程,这并不不合理。”
近年来,许多公司将机器学习从实验阶段发展到生产阶段。这催生了对更强大、高效的模型开发方法的需求,特别是在被大多数人忽视的特征计算和管理领域。特征库的兴起引发了新一波的机器学习平台。虽然采用仍处于初期阶段,但我们可能会在未来几年看到大玩家的崛起和重大举措。
相关内容:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关主题
数据科学家缺失的团队
原文:
www.kdnuggets.com/2020/11/missing-teams-data-scientists.html
评论
由 Jesse Anderson,大数据学院常务董事。
当公司相信他们仅需数据科学家来完成大数据项目时,数据科学团队受到的影响最大。数据科学家们感受到了其他两个缺失团队的压力。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
让我们讨论一下数据科学家如何受到影响,其他缺失的团队,以及数据科学家如何开始为这些缺失的团队发声。
对数据科学家的影响
当数据科学团队是唯一的数据团队时,数据科学家们被期望能兼任多种角色,并且在每个角色上都做到精通。过多的工作意味着数据科学家们将花费大量时间在边缘工作,而在实际的数据科学上投入的时间很少。
问题的根源在于公司及数据科学团队对数据团队的误解。他们已经认为只需要数据科学家。
对数据科学家本身的影响是有害的。我观察到数据科学家在花费大量时间处理除数据科学外的其他事务后,会在 3-6 个月内辞职。离职会造成双输的局面,数据科学家需要寻找新职位,公司则需要从招聘和培训流程重新开始。这种情况本可以通过所有数据团队的共同存在来完全避免。
什么是数据团队?

成功完成大数据项目更多的是一种团队运动。这需要具备多种技能的人,这些技能并不局限于单个人或单一团队。成功需要三个数据团队的共同努力。这些团队分别是数据工程、运维和数据科学。
每一个团队对项目的成功或失败都同样重要。各团队之间应该有高带宽的连接。这应是一个共生关系,而非对抗关系。
正确的数据工程
有时候,公司名义上拥有所有的数据团队,但实际上仅仅是名义上的团队。这些名义上的团队产生了数据工程师不真正需要的错觉。让我们讨论一下何时会发生这种情况。
错误的数据工程师
数据工程师的头衔可以包含两种非常不同的技能集。公司可能没有意识到这种差异,仍然聘用错误的数据工程师。
数据工程师的一个定义是一个专注于 SQL 的人。这个人通常来自 GUI 基础的 ETL 程序、DBA 或数据仓库背景。另一种数据工程师的定义,即我所指的,是专注于大数据的软件工程师。这类人拥有扎实的软件工程背景。
如你所见,这两种定义的技能集非常不同。这是 HR 或管理层可能没有理解的区别。由完全专注于 SQL 的数据工程师组成的团队对数据科学家几乎没有价值,甚至可能妨碍他们。由拥有软件工程背景的数据工程师组成的团队将大有裨益,并能够承担数据科学家缺乏的复杂软件工程任务。
糟糕的数据工程业绩记录
数据工程和数据科学之间的另一个常见问题可能是糟糕业绩记录的认知。数据工程或 IT 部门是好项目夭折的地方。结果,数据科学家会尽一切力量把他们的项目从数据工程师手中保护出来。
数据科学家经常抱怨数据工程师的过度工程化解决方案。在数据科学家看来,数据工程师在实施过多的流程或做法。数据工程师应该在过多的流程和不足的进展之间找到一个平衡点,与数据科学家协同工作。
糟糕的业绩记录可以归因于数据工程团队由原始的数据工程师组成。这些数据工程师缺乏做出正确技术决策和推动进展的经验和知识。双方可能都有一些成长上的不足需要修复。
提倡
我们往往专注于数据科学的技术方面,比如选择正确的模型或技术。我们较少关注可能导致我们表现不佳或完全失败的组织问题。在只有数据科学家的组织中,他们有责任倡导组织变革,以获得数据工程和运营团队。
我们可能需要对自己和团队保持一定的诚实,承认我们并不是适合做所有事情的最佳团队。从这种诚实的自我审视开始,我们可以逐渐看到我们最需要帮助的地方。这可能是意识到我们选择了错误的工具,或者我们的处理时间过长。我们可能会发现自己厌倦了 24/7 随时待命,或者模型的可靠性低到企业无法再使用。整体的认识是,我们缺乏改善和解决这些问题的核心能力。这并不是我们不聪明的体现,而是一个人或团队不能被期望做到所有事情。
在我们的诚实审视之后,我们可以向管理层提出有力的论证,说明为何我们需要其他团队。我们将能够提供具体的例子,说明投资将带来怎样的回报。例如,我发现数据科学家在软件工程任务上的效率比数据工程师低 80%。通过仅仅增加数据工程师,整个数据科学团队可能会变得更加高效。
数据科学家的工作并不会在管理层相信他们需要数据工程和运营后就结束,因为还会有增长期和更多工作。你将遇到未知的未知问题和新团队开始揭示的技术债务。各方的努力是必需的,以沟通并形成共生关系。这些努力是值得的,投资将带来丰厚的回报。
如果你希望避免成为刻板印象,组建一个新团队或修复现有团队,我邀请你阅读我最新的书籍数据团队。这本书涵盖了管理数据团队的正确方法。
个人简介:杰西·安德森 是一名数据工程师、创意工程师和大数据研究所的董事总经理。他与从初创公司到财富 100 强公司等各类公司合作,涉及大数据领域。这包括对 Apache Kafka、Apache Hadoop 和 Apache Spark 等前沿技术的培训。他已经教授了超过 30,000 人掌握成为数据工程师的技能。
他被广泛认为是该领域的专家,并因其创新的教学方法而受到认可。杰西的作品已在 Apress、O’Reilly 和 Pragmatic Programmers 上发表,并被《华尔街日报》、CNN、BBC、NPR、Engadget 和 Wired 等权威媒体报道。
相关内容:
更多相关主题
缺失值填补 – 综述
原文:
www.kdnuggets.com/2020/09/missing-value-imputation-review.html
评论
由 Kathrin Melcher,KNIME 数据科学家,和 Rosaria Silipo,KNIME 首席数据科学家
缺失值出现在从工业到学术的各种数据集中。它们可以以不同的方式表示 - 有时用问号,或 -999,有时用“n/a”,或用其他专用的数字或字符。正确检测和处理缺失值很重要,因为它们会影响分析结果,并且有些算法无法处理它们。那么正确的方法是什么?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
如何选择正确的策略
填补缺失值的两种常见方法是用固定值(例如零)或所有可用值的均值替代所有缺失值。哪种方法更好?
我们来看两个不同案例研究的效果:
-
案例研究 1:传感器数据中的基于阈值的异常检测
-
案例研究 2:客户聚合数据报告
案例研究 1:基于阈值的异常检测中的缺失值填补
在经典的基于阈值的异常检测解决方案中,从原始数据的均值和方差计算出的阈值会应用于传感器数据以生成警报。如果缺失值用固定值(例如零)填补,这将影响用于阈值定义的均值和方差的计算。这可能会导致警报阈值的错误估计以及一些昂贵的停机时间。
在这里,用可用值的均值填补缺失值是正确的做法。
案例研究 2:聚合客户数据中的缺失值填补
在经典的客户数据报告中,需要对每个地理区域的客户数量和总收入进行汇总和可视化,例如通过条形图。客户数据集在业务尚未开始或尚未发展时,有些区域的数据缺失,没有记录客户和业务。在这种情况下,使用可用数字的平均值来填补缺失值,将生成客户和收入的记录,但实际上客户和收入并不存在。
这里正确的做法是用固定值零来填补缺失值。
在这两种情况下,我们对过程的了解可以指导我们填补缺失值的正确方法。在传感器数据的情况下,缺失值是由于测量设备故障,实际数值没有被记录。在客户数据集的情况下,缺失值出现的地方还没有需要测量的内容。
从这两个例子中你已经可以看出,没有一种万能的解决方案来处理所有的缺失值填补问题,我们显然无法回答经典问题:“我的数据集缺失值填补的正确策略是什么?”答案过于依赖于领域和业务知识。
然而,我们可以提供对最常用技术的回顾,以:
-
检测数据集中是否包含缺失值及其类型,
-
填补缺失值。
检测缺失值及其类型
在尝试理解缺失值的来源和原因之前,我们需要检测它们。缺失值的常见编码包括 n/a、NA、-99、-999、?、空字符串或任何其他占位符。当你打开一个新的数据集时,没有说明书,你需要识别是否使用了任何这样的占位符来表示缺失值。
直方图是查找占位符字符(如果有的话)的好工具。
-
对于数值型数据,许多数据集使用远离数据分布的值来表示缺失值。经典的例子是正值范围中的-999。在图 1 中,直方图显示大多数数据在[3900-6600]范围内呈现出良好的高斯分布。左侧的-99 附近的小条形与其余数据相比显得很不自然,可能是用来指示缺失值的占位符号码。
-
通常,对于名义数据,识别缺失值的占位符更容易,因为字符串格式允许我们写出某些缺失值的参考,例如“未知”或“N/A”。直方图也可以在这里提供帮助。对于名义数据,具有不匹配值的区间可能是缺失值占位符的一个指示。

图 1:直方图是检测缺失值占位符字符的好工具。在这个例子中,我们看到大多数值落在 3900 和 6600 之间。值-99 看起来相当偏离,在这种情况下,可能是缺失值的占位符。
这一步骤,即检测表示缺失值的占位符字符/数字,属于数据探索阶段,在分析开始之前。在检测到这个缺失值的占位符字符后,在真正的分析之前,必须根据所使用的数据工具对缺失值进行适当的格式化。
一个有趣的学术练习是对缺失值的类型进行定性分析。缺失值通常被分类为三种不同类型[1][2]。
-
完全随机缺失 (MCAR)
定义: 实例缺失的概率不依赖于已知值或缺失值本身。
示例: 一张数据表被打印出来,没有缺失值,但有人不小心在上面滴了一些墨水,导致一些单元格变得不可读[2]。在这种情况下,我们可以假设缺失值遵循与已知值相同的分布。
-
随机缺失 (MAR)
定义: 实例缺失的概率可能依赖于已知值,但不依赖于缺失值本身。
传感器示例: 在温度传感器的情况下,值的缺失并不依赖于温度,但可能依赖于其他因素,例如温度计的电池电量。
调查示例: 无论某人是否回答一个问题——例如年龄——在调查中并不取决于答案本身,但可能依赖于另一个问题的答案,即女性性别。
-
非随机缺失 (NMAR)
定义: 实例缺失的概率可能依赖于变量本身的值。
传感器示例: 在温度传感器的情况下,当温度低于 5°C 时,传感器无法正常工作。
调查示例: 无论某人是否回答了一个问题——例如病假天数——在调查中确实取决于答案本身——因为对一些超重的人来说可能会有所不同。
只有数据收集过程的知识和业务经验才能告诉我们发现的缺失值是 MAR、MCAR 还是 NMAR 类型。
在本文中,我们将仅关注 MAR 或 MCAR 类型的缺失值。填补 NMAR 缺失值更加复杂,因为需要考虑比统计分布和统计参数更多的额外因素。
处理缺失值的不同方法
多年来提出的处理缺失值的多种方法可以分为两个主要组:删除和填补。
删除方法
有三种常见的删除方法:列表删除、成对删除和删除特征。
-
列表删除: 删除所有存在一个或多个缺失值的行。
-
配对删除: 仅删除在用于分析的列中具有缺失值的行。如果缺失数据是 MCAR,则仅推荐使用此方法。
-
特征删除: 删除缺失值超过给定阈值(例如 60%)的整个列。

图 2:左侧是一个包含缺失值的表格,其中只有 F1、F2 和 F3 被用于分析。右侧是应用不同删除方法后的结果表格。
插补方法
插补方法的核心思想是用其他合理的值替代缺失值。由于使用删除方法时会丢失信息(无论是删除样本(行)还是整个特征(列)),插补通常是首选方法。
多种插补技术可以分为两类:单次插补或多次插补。
在单次插补中,为每个缺失的观察值生成一个单一的插补值。插补值被视为真实值,忽略了没有插补方法可以提供确切值这一事实。因此,单次插补不能反映缺失值的不确定性。
在多次插补中,为每个缺失的观察值生成多个插补值。这意味着创建了多个具有不同插补值的完整数据集。对每个数据集进行分析(例如,训练线性回归以预测目标列),然后汇总结果。创建多次插补,相对于单次插补,更能考虑插补中的统计不确定性[3][4]。
单次插补
大多数插补方法是单次插补方法,主要有三种策略:用现有值替代、用统计值替代和用预测值替代。根据这些策略中使用的值,我们最终得到只适用于数值型数据的方法和同时适用于数值型和名义型列的方法。这些方法在表格 1 中进行了总结,并在下面进行了详细说明。
| 替代方法: | 仅数值特征 | 数值和名义特征 |
|---|---|---|
| 现有值 | 最小值 / 最大值 | 先前 / 后续 / 固定 |
| 统计值 | (四舍五入的)均值 / 中位数 / 移动平均,线性 / 平均插值 | 最频繁值 |
| 预测值 | 回归算法 | 回归和分类算法,k 最近邻 |
表 1:仅对数值特征和对数值及名义特征的单次插补方法,基于现有值、统计测量和预测值。
固定值
固定值填补是一种适用于所有数据类型的一般方法,包含将缺失值替代为固定值。我们在本文开头提到的聚合客户示例中使用了固定值填补来处理数值。作为在名义特征上使用固定值填补的示例,你可以在调查中用“未回答”填补缺失值。
最小 / 最大值
如果你知道数据必须符合给定范围[最小值,最大值],并且从数据收集过程中知道测量系统在超出这些边界之一时停止记录且信号饱和,你可以使用范围的最小值或最大值作为缺失值的替代值。例如,如果在货币兑换中已达到最低价格且兑换过程已停止,则可以用法律兑换边界的最小值替代缺失的货币兑换价格。
(四舍五入的)均值 / 中位数 / 移动平均
其他常见的数值特征填补方法包括均值、四舍五入均值或中位数填补。在这种情况下,该方法使用整个数据集中该特征计算出的均值、四舍五入均值或中位数值来替代缺失值。在数据集中异常值数量较多的情况下,建议使用中位数而不是均值。
最频繁值
另一种适用于数值和名义特征的常见方法是使用列中最频繁的值来替代缺失值。
前一个 / 下一个值
有专门针对时间序列或有序数据的填补方法。这些方法考虑了数据集的排序特性,其中接近的值可能比远离的值更相似。时间序列中填补缺失值的一种常见方法是用时间序列中的下一个或上一个值替代缺失值。这种方法适用于数值和名义值。
线性 / 平均插值
类似于前一个/下一个值填补,但仅适用于数值,是线性或平均插值,该方法计算前一个和下一个可用值之间的插值,并替代缺失值。当然,对于有序数据的所有操作,提前正确排序数据是重要的,例如在时间序列数据中根据时间戳排序。
K 最近邻
这里的想法是寻找数据集中 k 个最近的样本,其中相应特征的值不缺失,并将该组中最常出现的特征值作为缺失值的替代。
缺失值预测
另一种常见的单次插补选项是训练机器学习模型,根据其他特征预测特征 x 的插补值。特征 x 中没有缺失值的行用作训练集,模型根据其他列的值进行训练。这里可以使用任何分类或回归模型,具体取决于特征的数据类型。训练后,将模型应用于所有缺失值的样本,以预测其最可能的值。
如果有多个特征列存在缺失值,所有缺失值首先用基本插补方法临时填补,例如均值。然后将一列的值重新设为缺失。然后训练模型并应用于填补缺失值。通过这种方式,为每个有缺失值的特征训练一个模型,直到所有缺失值都通过模型插补完毕。
多重插补
多重插补是一种源自统计学的插补方法。单次插补方法的缺点是没有考虑插补值的不确定性。这意味着它们将插补值视为实际值,而没有考虑标准误差,这会导致结果偏差[3][4]。
解决此问题的一种方法是多重插补,即为每个缺失值创建多个插补,而不是一个。这意味着多次填补缺失值,创建多个“完整”的数据集[3][4]。
已经开发出多种算法用于多重插补。其中一个著名的算法是链式方程的多重插补(MICE)。
链式方程的多重插补(MICE)
多重插补(Multiple Imputation by Chained Equations,简称 MICE)是一种处理数据集中缺失值的强大而信息丰富的方法。MICE 基于缺失数据是随机缺失(Missing At Random,MAR)或完全随机缺失(Missing Completely At Random,MCAR)的假设[3]。
该过程是“缺失值预测”单次插补过程的扩展(见上文):这就是第 1 步。然而,MICE 程序中还有两个额外的步骤。
第 1 步:这是在原始数据子集上进行“缺失值预测”插补过程的步骤。训练一个模型来预测一个特征中的缺失值,使用数据行中的其他特征作为模型的自变量。这一步为所有特征重复进行。这是一个循环或迭代。
第 2 步:重复第 1 步 k 次,每次使用最新的插补值作为自变量,直到收敛为止。通常情况下,k=10 次循环已经足够。
第 3 步:整个过程在 N 个不同的随机子集上重复 N 次。得到的 N 个模型会略有不同,并为每个缺失值产生 N 个略有不同的预测值。
分析,例如,为目标变量训练线性回归,现在在每一个最终的数据集上进行。最后,结果被合并,这通常也称为汇总。
这比单一填补提供了更稳健的结果。当然,这种稳健性的缺点是计算复杂度的增加。
比较填补技术
许多填补技术。选择哪一种?
有时候我们应该已经知道最佳的填补方法是什么,基于我们对业务和数据收集过程的了解。然而,有时候我们没有线索,只能尝试几种不同的选项,看看哪种效果最好。
要定义“最佳”,我们需要一个任务。对我们指定任务表现最佳的程序就是“最佳”程序。这正是我们在这篇文章中尝试做的:定义一个任务,为任务定义一个成功的度量,尝试几种不同的缺失值填补程序,并比较结果以找到最合适的方案。
让我们将研究范围限定在分类任务上。成功的度量标准将是模型预测的准确度和 Cohen’s Kappa。准确度是平衡类数据集中任务成功的明确度量。然而,Cohen’s Kappa,尽管不易读解,但对于不平衡类数据集来说,代表了更好的成功度量。
我们实施了两个分类任务,每个任务在一个专用的数据集上:
-
在客户流失预测数据集上进行流失预测(3333 行,21 列)
-
在Census 收入数据集上进行收入预测(32561 行,15 列)
对于这两个分类任务,我们选择了一个简单的决策树,训练数据使用原始数据的 80%,测试数据使用剩余的 20%。这里的重点是通过观察在使用某一种填补方法而非另一种时模型性能的可能改善来比较不同填补方法的效果。
我们重复了每个分类任务四次:在原始数据集上,以及在引入 10%、20%和 25% MCAR 类型缺失值后。这意味着我们随机删除数据集中的值,并将其转换为缺失值。
每次,我们都尝试了四种不同的缺失值填补技术(见图 3)。
-
删除:逐行删除(蓝色)
-
0 填补:用零进行固定值填补(橙色)
-
均值 - 最频繁:对数值进行均值填补,对名义值进行最频繁值填补(绿色)
-
线性回归 - kNN:用线性回归预测数值的缺失值,用 kNN 预测名义值的缺失值(红色)
图 3 比较了在对原始数据集和人工插入缺失值版本应用四种选择的插补方法后的决策树的准确性和 Cohen's Kappa 值。

图 3:应用四种选择的插补方法到原始数据集及其随机插入缺失值的变体后,决策树模型在两个不同分类任务上的准确性(左侧)和 Cohen's Kappa 值(右侧)。
对于四种插补方法中的三种,我们可以看到一个普遍趋势,即缺失值比例越高,准确性和 Cohen's Kappa 值通常越低。唯一的例外是删除方法(蓝线)。
此外,我们无法看到明确的最佳方法。这支持了我们关于最佳插补方法取决于使用案例和数据的观点。
流失数据集是一个类别流失不平衡的数据集,其中类别 0(未流失)远多于类别 1(流失)。列表删除在这里导致非常小的数据集,使得无法训练出有意义的模型。在这个例子中,我们在测试集中只剩下一行数据,正好被预测正确(蓝线)。这解释了 100%的准确率和缺失的 Cohen's Kappa 值。
所有其他插补技术在所有数据集变体上的决策树性能在准确性和 Cohen's Kappa 值方面都差不多。然而,最好的结果是通过缺失值预测方法获得的,使用线性回归和 kNN。
人口普查收入数据集相较于流失预测数据集更大,其中两个收入类别<=50K 和>50K 也是不平衡的。图 3 中的图示显示,均值和最频繁插补方法在准确性和 Cohen's Kappa 值方面优于缺失值预测方法以及 0 插补方法。在删除方法的情况下,人口普查数据集的结果不稳定,并且依赖于由列表删除产生的子集。在这里使用的设置中,删除(蓝线)对于小比例缺失值的性能有所提升,但对于 25%或更多缺失值的性能较差。
比较应用程序
用于比较所有描述的技术并生成图 3 中的图表的应用程序是使用KNIME Analytics Platform开发的(见图 4)。
在这里,一个循环遍历数据集的四个变体:0%、10%、20%和 25%缺失值。在每次迭代中,循环中的两个分支之一实现两个分类任务之一:流失预测或收入预测。特别是每个分支:
-
读取数据集并在此循环迭代设置的百分比上撒入缺失数据。
-
随机将数据划分为 80%-20%的比例,分别用于训练和测试所选任务的决策树
-
根据四种选定的方法填充缺失值,并训练和测试决策树
-
计算不同模型的准确性和 Cohen 的 Kappa 系数。
之后,两个循环分支被合并,Loop End 节点收集不同迭代的性能结果,然后通过“可视化结果”组件进行可视化

图 4:该工作流使用循环随机替换 10%、20%和 25%的值为缺失值。在每次迭代中,使用四种不同的方法对缺失值进行填充。之后,训练并应用决策树于每个数据集变体,最后对不同迭代的性能进行可视化。
这里关注的组件是“填充缺失值并训练和应用模型”。其内容如图 5 所示:四个分支,每个分支对应一种填充技术。
前三条分支实现了逐列表删除(“删除”)、用零填充值(“0 填充”)、使用均值填充数值特征和使用最频繁值填充名义特征的统计度量(“均值 - 最频繁”)。
最后一条分支实现了缺失值预测填充,使用线性回归处理数值特征,kNN 处理名义特征(“线性回归 - kNN”)。

图 5:“填充缺失值并训练和应用模型”组件内部,使用强大的缺失值节点进行填充,同时包括线性回归、kNN 和 MICE。
让我们用几句话来描述一下缺失值节点,简单而有效。缺失值节点提供了大部分介绍的单一填充技术(仅 kNN 和预测模型方法不可用)。在这里,你可以根据选定的策略对所有数据集或逐列(特征)填充缺失值。

图 6:缺失值节点的配置窗口。在第一个标签页中,可以为整个数据集定义每种数据类型的默认填充方法,在第二个标签页中可以为每一列定义。
KNIME Analytics Platform 中的多重填充
在上述工作流中,比较缺失值处理方法,我们看到了如何在 KNIME Analytics Platform 中应用不同的单次插补方法。而且明显可以建立一个循环来实现使用 MICE 算法的多重插补方法。KNIME Analytics Platform 的一个优势是我们不必重新发明轮子,可以轻松集成 Python 和 R 中可用的算法。
R 中的“mice”包允许你插补混合的连续、二元、无序分类和有序分类数据,并从许多不同的算法中进行选择,创建多个完整的数据集。[5]
在 Python 中,“IterativeImputar”函数受到了 MICE 算法的启发。它以相同的轮回方式多次迭代不同的列,但只创建一个插补数据集。通过使用不同的随机种子,可以创建多个完整的数据集。[6]
总体而言,在用户不关心因缺失值导致的不确定性的情况下,单次插补与多重插补在预测和分类中的有效性仍然是一个未解问题。
图 7 中的工作流,缺失值的多重插补,展示了如何使用 R 的“mice”包进行多重插补,创建五个完整的数据集。

图 7.**这个工作流使用 R 的“mice”包来执行多重插补。然后在每个完整的数据集上使用 KNIME Analytics Platform 进行分析。
工作流读取了输入特征的 25% 值被替换为缺失值后的普查数据集。在 R 片段节点中,加载并应用了 R 的“mice”包以创建五个完整的数据集。此外,为每一行添加了一个索引,用于标识不同的完整数据集。
在下一步骤中,一个循环处理不同的完整数据集,通过在每次迭代中训练和应用决策树。在工作流的最后部分,通过统计每个类别被预测的频率来汇总预测结果,并提取最多数预测的类别。最后,使用 Scorer 节点评估结果。在 Iris “mice”插补的数据集上,模型达到了 83.867% 的准确率。相比之下,单次插补方法在缺失值为 25% 的数据集上达到了 77% 到 80% 的准确率。
总结
所有数据集都有缺失值。需要知道如何处理这些缺失值。我们是应该完全删除数据行,还是用某个合理的值来替代缺失值?
在这篇博客文章中,我们描述了一些常见的删除和插补缺失值的技术。我们随后实现了四种最具代表性的技术,并在两个不同的分类问题上比较了它们在处理逐渐增加的缺失值时的表现效果。
总结一下,我们可以得出以下结论。
使用全列表删除(“删除”)时需谨慎,特别是在小数据集上。删除数据时,你是在删除信息。并非所有数据集都有多余的信息可以舍弃!我们在流失预测任务中见证了这种显著的效果。
使用固定值插补时,你需要了解该固定值在数据领域和业务问题中的含义。在这里,你将任意信息注入到数据中,这可能会影响最终模型的预测。
如果你想在没有先验知识的情况下插补缺失值,很难说哪种插补方法效果最佳,因为这高度依赖于数据本身。
最后需要说明的一点是,所有结果仅适用于这两个简单任务、相对简单的决策树和小数据集。对于更复杂的情况,相同的结果可能不适用。
最终,没有什么比对任务和数据收集过程的先验知识更重要!
参考文献:
[1] Peter Schmitt, Jonas Mandel 和 Mickael Guedj,“六种缺失数据插补方法的比较”,《生物统计与生物测定学》
[2] M.R. Berthold, C. Borgelt, F. Höppner, F. Klawonn, R. Silipo,“智能数据科学指南”,Springer,2020
[3] lissa J. Azur, Elizabeth A. Stuart, Constantine Frangakis 和 Philip J. Leaf 1,“链式方程的多重插补:它是什么,它是如何工作的?”链接:www.ncbi.nlm.nih.gov/pmc/articles/PMC3074241/
[4] Shahidul Islam Khan, Abu Sayed Md Latiful Hoque,“SICE:一种改进的缺失数据插补技术”,链接:link.springer.com/content/pdf/10.1186/s40537-020-00313-w.pdf
[5] Python 文档。链接:scikit-learn.org/stable/modules/impute.html
[6] 人口普查收入数据集:archive.ics.uci.edu/ml/datasets/Census+Income
相关:
-
Python 中的数据预处理简易指南
-
自动化机器学习:究竟有多大?
-
如何处理数据集中的缺失值
更多相关主题
如何处理数据集中的缺失值
评论
作者 Yogita Kinha,顾问和博客作者

我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
在上一篇博客中,我们讨论了数据清理过程在数据科学项目中的重要性以及将原始数据集转换为可用形式的方法。在这里,我们将一步一步讲解如何识别和处理数据中的缺失值。
现实世界的数据中肯定会有缺失值。这可能是由于数据输入错误或数据收集问题等多种原因。无论原因是什么,处理缺失数据是重要的,因为任何基于具有非随机缺失值的数据集的统计结果可能会有偏差。此外,许多机器学习算法不支持缺失值的数据。
如何识别缺失值?
我们可以使用 pandas 函数检查数据集中的空值,如下所示:


但是,有时识别缺失值可能并不那么简单。需要使用领域知识并查看数据描述来理解变量。例如,在下面的数据集中,isnull() 不显示任何空值。

在这个例子中,有些列的最小值为零。在某些列中,零值没有意义,并表示无效或缺失的值。
经过仔细分析特征,发现以下列具有无效的零最小值:
-
血浆葡萄糖浓度
-
舒张血压
-
三头肌皮肤褶皱厚度
-
2 小时血清胰岛素
-
体重指数
通过检查这些列中的零值数量,可以明显看出第 1、2 和 5 列有少量零值,而第 3 和 4 列有更多零值。

每列中的缺失值可能需要不同的策略。我们可以将这些零值标记为 NaN,以突出缺失值,以便进一步处理。
缺失数据的快速分类
缺失数据有三种类型:
MCAR: 完全随机缺失。它是随机性的最高级别。这意味着任何特征中的缺失值不依赖于任何其他特征的值。这是处理缺失数据时最理想的情况。
MAR: 随机缺失。这意味着任何特征中的缺失值依赖于其他特征的值。
MNAR: 非随机缺失。非随机缺失的数据是一个更严重的问题,在这种情况下,可能需要进一步检查数据收集过程,并尝试了解信息缺失的原因。例如,如果调查中大多数人没有回答某个问题,他们为什么会这样?问题是否不清楚?
如何处理缺失值?
现在我们已经识别了数据中的缺失值,接下来我们应检查缺失值的程度,以决定进一步的处理措施。
忽略缺失值
-
个别案例或观察中的缺失数据低于 10% 通常可以忽略,除非缺失数据是 MAR 或 MNAR。
-
完整案例的数量,即没有缺失数据的观察值,必须足够用于所选的分析技术,如果不考虑不完整的案例。
删除缺失值
删除变量
-
如果数据是 MCAR 或 MAR,并且某个特征的缺失值数量非常高,那么该特征应排除在分析之外。如果某个特征或样本的缺失数据超过 5%,则最好将该特征或样本排除在外。
-
如果案例或观察值的目标变量存在缺失值,建议删除依赖变量,以避免与独立变量之间关系的任何人为增加。
案例删除
在这种方法中,删除一个或多个特征存在缺失值的案例。如果存在缺失值的案例数量较少,最好将其删除。尽管这是一种简单的方法,但可能会导致样本量显著减少。此外,数据可能并不总是完全随机缺失,这可能导致参数估计的偏差。
插补
插补是通过一些统计方法替代缺失数据的过程。插补的好处在于它通过用基于其他可用信息的估计值替代缺失数据,从而保留所有案例。但应谨慎使用插补方法,因为大多数方法会引入大量偏差并减少数据集的方差。
均值/众数/中位数插补
如果某列或特征中的缺失值是数值型的,可以用该变量完整情况的均值来插补。如果特征被怀疑有异常值,均值可以用中位数替代。对于分类特征,缺失值可以用列中的众数替代。该方法的主要缺点是减少了插补变量的方差。该方法还减少了插补变量与其他变量之间的相关性,因为插补值只是估计值,不会与其他值自然相关。
回归方法
缺失值的变量被视为因变量,而具有完整案例的变量被作为预测变量或自变量。自变量用于拟合因变量观察值的线性方程。然后使用这个方程来预测缺失数据点的值。
该方法的缺点是,通过选择,识别出的自变量与因变量之间会有较高的相关性。这会导致对缺失值的拟合过于准确,从而减少对该值的预测不确定性。此外,这假设关系是线性的,而现实中可能并非如此。
K-最近邻插补 (KNN)
该方法使用 k-最近邻算法来估计并替代缺失数据。k-邻居是通过某种距离度量选择的,它们的平均值被用作插补估计。这可以用于估计定性属性(k 最近邻中的最频繁值)和定量属性(k 最近邻的均值)。
应尝试不同的 k 值以及不同的距离度量来找到最佳匹配。距离度量可以根据数据的属性进行选择。例如,如果输入变量在类型上相似(例如,所有测量的宽度和高度),则欧几里得距离是一个很好的距离度量。如果输入变量在类型上不相似(如年龄、性别、身高等),则曼哈顿距离是一个很好的度量。
使用 KNN 的优点在于它实现简单。但它受制于维度诅咒。它在变量较少时表现良好,但当变量数量较多时,计算效率变低。
多重插补
多重插补是一种迭代方法,其中通过使用观察数据的分布来估计缺失数据点的多个值。该方法的优点在于它反映了对真实值的不确定性,并返回无偏估计。
MI 包括以下三个基本步骤:
-
插补:缺失的数据用估计值填补,创建一个完整的数据集。这个插补过程重复 m 次,生成 m 个数据集。
-
分析:每个m完整的数据集都使用感兴趣的统计方法(例如线性回归)进行分析。
-
汇总:从每个分析的数据集中获得的参数估计(例如系数和标准误差)然后被平均以得到一个单一的点估计。
Python 的 Scikit-learn 提供了方法——impute.SimpleImputer 用于单变量插补,impute.IterativeImputer 用于多变量插补。
R 中的 MICE 包支持多重插补功能。Python 虽然不直接支持多重插补,但可以通过在样本后验为 True 时,使用不同随机种子重复应用 IterativeImputer 来进行多重插补。
总之,处理缺失数据对于数据科学项目至关重要。然而,在处理缺失数据时,数据分布不应改变。任何缺失数据处理方法应满足以下规则:
-
无偏估计——任何缺失数据处理方法不应改变数据分布。
-
属性之间的关系应保留。
希望您喜欢阅读这篇博客!!
请分享您的反馈和您希望了解的话题。
参考文献:
-
machinelearningmastery.com/handle-missing-data-python/en.wikipedia.org/wiki/Imputation_(statistics)stats.idre.ucla.edu/stata/seminars/mi_in_stata_pt1_new/ -
pdfs.semanticscholar.org/e4f8/1aa5b67132ccf875cfb61946892024996413.pdf
原文发表在https://www.edvancer.in上,日期为 2019 年 7 月 2 日。
简介:Yogita Kinha 是一位熟练的专业人士,拥有 R、Python、机器学习和统计计算及图形的程序环境经验,具备 Hadoop 生态系统的实操经验,以及在软件测试领域的测试和报告经验。
原文。经许可转载。
相关内容:
-
数据转换:标准化与归一化
-
在 Scikit-Learn 中简化混合特征类型预处理的管道
-
Scikit-learn 0.23 中的 5 个重要新特性
更多相关内容
每个数据科学家至少犯过一次的错误
原文:
www.kdnuggets.com/2022/09/mistake-every-data-scientist-made-least.html
如果你使用一个工具,而这个工具没有被验证为安全,那么你制造的任何混乱都是你的错…… AI 是一种工具,就像其他工具一样,因此同样的规则适用。绝不要盲目相信它。
相反,让 机器学习和 AI 系统通过赢得你的信任。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 在 IT 领域支持你的组织
如果你想通过例子来教学,例子必须要好。如果你想信任学生的能力,测试必须要好。
始终牢记,你对系统在你检查过的条件之外的安全性一无所知,因此要仔细检查!这里有一份实用的提醒清单,不仅适用于ML/AI,还适用于每个基于data的解决方案。
-
如果你没有测试它,就不要信任它。
-
如果你没有在你的环境中进行测试,就不要在你的环境中信任它。
-
如果你没有用你的用户群体进行测试,就不要用你的用户群体来信任它。
-
如果你没有用你的数据集进行测试,就不要用你的数据集来信任它。
设计良好的测试是保护我们所有人的安全。
数据新手和data science专家之间的一个区别是专家有一些巨大的信任问题……并且乐于接受这些问题。

来源:Pixabay
专家犯的错误
在我们的上一篇文章中,我们讨论了初学者犯的测试错误及如何避免它。现在是时候看一个即便是专家也会犯的更隐蔽的错误了。
对于那些还没读过上一篇文章的人,让我们来回顾一下背景(在一个我们没有犯新手错误的平行宇宙中):

我们用 70,000 张输入图像(你在上面图片中看到的每一张图像都是一个代表 10,000 张类似照片的占位符,标签为香蕉、赫胥黎或特斯拉;其中一种是我的早餐,另外两种是我的猫,你猜哪个是哪个)训练了一个相当不错的模型,然后在 40,000 张原始图像上进行了测试。

然后我们得到了……完美的结果!哇。

当你观察到machine learning任务上的完美表现时,你应该非常担心。正如上一篇文章警告你对 0%有错误态度一样,每当你看到完美结果时,保持警惕是一种好习惯。一位专家的第一个想法是测试可能过于简单,或者标签泄露了,或者数据不像我们希望的那样原始。正如一位经验丰富的大学教授发现每个学生完美回答每个问题时的想法一样。他们会疯狂调试,而不是自满于良好的教学。
由于 100%在真实场景中不切实际,我们来设想得到一个其他高但不是过高的分数,比如 98%。

很棒的表现,对吧?听起来像是在原始数据上也表现得很棒。而且所有的统计假设检验的繁杂细节都处理好了!我们已经建立了一个很棒的特斯拉/赫胥黎检测器,赶紧启动吧!!!
小心点。
你会被诱惑去迅速得出结论。即使它在测试中给出了很好的结果,这可能根本不是一个特斯拉/赫胥黎检测器。
专家犯的错误与技术方面关系不大,更与人的思维有关:屈服于愿望思维。
专家也不是对愿望思维错误免疫的。
不要认为这些结果意味着系统实际上检测到了什么。我们没有证据表明它已经学会了——更糟糕的是,“它理解”——如何区分赫胥黎和特斯拉。再看仔细一点……

你注意到所有特斯拉照片背景中的那个小细节了吗?哎呀,结果我们不小心建立了一个散热器/非散热器分类器!
过度关注对我们有趣的问题和数据的部分,例如两只猫的身份,而忽视其他部分,如大多数 Tes 照片中散热器的存在,因为她喜欢待在那里,因此也最可能被拍到。不幸的是,她太喜欢散热器,以至于相同的问题出现在训练数据和测试数据中,因此你不会通过在与训练数据相同的数据集上进行测试来发现这个问题。

只要你(以及你的利益相关者和用户)具备如下的严格自律,所有这些(或多或少)都是可以接受的:
-
不要将结果解读成有趣的故事,比如“这是一个 Hux/Tes 分类器。”这种语言暗示了比我们拥有的证据要一般得多的东西。如果你对机器学习系统实际正在做的事情的理解可以简化成一个简洁的报纸标题… 那你很可能做错了。它至少应该以其细节让你感到乏味。
-
始终清楚地意识到,如果你测试系统的设置与训练系统的设置之间存在差异,你没有保证你的解决方案会有效。
这种自律是罕见的,因此在我们拥有更好的数据素养之前,我唯一能做的就是梦想大,尽我所能地为教育人们做出贡献。
这个系统只能在与测试和训练数据集拍摄方式相同的照片上工作——冬季同一个公寓的照片,因为那时 Tesla 倾向于待在散热器旁,而 Huxley 则不。在相同的方式拍摄大量照片的情况下,如果你得到了正确的标签,不管你的系统如何完成标记任务也无所谓。如果它利用散热器来赢得标记游戏,那也没关系…… 只要你不期望它在任何其他背景下工作(它不会)。为此,你需要更好、更广泛的训练和测试数据集。如果你将系统移到另一个公寓,即使你认为你理解了系统的工作原理,也要重新测试以确保它仍然有效。
由你的数据所代表的世界是你唯一能够成功的世界。
记住,由你的数据所代表的世界是你唯一能够成功的世界。所以你需要仔细考虑你正在使用的数据。
避免专家错误
永远不要假设你理解 AI 系统正在做什么。相信你对复杂事物的简单理解是万无一失的,这是一种极端的傲慢。你会为此受到惩罚。
永远不要假设你理解 AI 系统正在做什么。相信你对复杂事物的简单理解是万无一失的,这是一种极端的傲慢。你会为此受到惩罚。
在你的数据中很容易忽视现实世界的细微差别。不管你有多么有才华,只要你在数据科学领域工作够久,你几乎肯定会至少一次犯这个充满幻想的错误,直到你通过艰苦的经验学会严重限制你的结论——你能建立的最佳习惯就是在你彻底检查证据之前避免在事物中读取额外的含义。当你发现自己对结果的内心独白听起来不再像 TED 演讲,而更像是世界上最无聊合同的细则时,你就知道你达到了下一个水平。这是件好事。如果你坚持的话,你可以稍后用你的快语来惊艳众人,只要别让数据素养因为相信你自己的夸张言辞而尴尬。
从良好的测试结果中你唯一能学到的就是系统在与测试条件相似的环境、情况、数据集和人群中表现良好。任何你可能对其在这些条件之外的表现做出的猜测都是虚构的。要仔细测试,不要草率得出结论!
感谢阅读!要不要来看看一个 YouTube 课程?
如果你在这里感到有趣,并且正在寻找一个为初学者和专家都设计的有趣应用 AI 课程,这里有一个我为你的娱乐而制作的:
在这里享受整个课程播放列表:bit.ly/machinefriend
Cassie Kozyrkov 是谷歌的数据科学家和领导者,她的使命是使决策智能和安全、可靠的 AI 普及。
原文。经许可转载。
了解更多相关主题
新手数据科学家应避免的错误
原文:
www.kdnuggets.com/2022/06/mistakes-newbie-data-scientists-avoid.html

照片由 Andrea Piacquadio 提供
我们都知道数据科学领域目前有多么苛刻。越来越多来自各种背景的人进入这一领域。有些人拥有计算机科学学位,有些人则完全没有技术背景。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
这使得那些技术背景较少的候选人进入这个领域并避免常见错误变得更加困难。以下是这些常见错误的列表,以帮助你在求职过程中知道应该避免什么。
不要低估正式教育
如果你搜索数据科学学位,大多数学位都要求有一定的教育背景。虽然有很多补充简历的 BootCamps 和课程,但许多招聘人员还是在寻找拥有某种技术学位和/或硕士学位的候选人。
好的一面是,越来越多的大学提供数据科学课程和在线课程,以使你掌握申请数据科学职位所需的知识水平。当然,也有可能自学,但这需要更多的独立努力和决心。这是一条更艰难的路,但它是可以实现的。
如果你想查看一些免费的大学资源,可以看看这个:免费大学数据科学资源
专注于理论而不是项目
对于新进入一个行业的新人来说,通常会过度关注理论工作;他们希望对理论有深入了解,以备有人提问。然而,尽量不要过于深入理论,而是应开始专注于展示你技能和实际应用的项目。
这些将测试你的理论水平,并让你更好地理解在哪里应用理论,哪里不应用。理论学习与实际应用相结合将提高你在该领域成功和掌握这两者的可能性。
有这么多免费的数据集,你可以在其中玩耍和测试你的知识。你完全没有限制,只需要勇敢尝试。
如果你想了解一些你可以参与的潜在项目,可以查看这个:提升技能的顶级数据科学项目
尝试跃升至顶尖职位
许多人进入数据科学领域时希望能从事自动驾驶汽车或医学相关的工作。这需要大量的深度学习知识,而这些知识不是一夜之间就能掌握的;它需要时间。甚至需要几年。你需要有处理简单数据集、构建机器学习算法等方面的经验。
这是一个不能急于求成的过程;因此,你不能自动进入你的兴趣领域,你需要为此努力。
接受你可能需要做一两年的初级职位,然后在接下来的 5 年中从事机器学习项目的现实检查,这是你实现最终目标的一个很好的现实检查。
简历
简历总是很难准备,因为你想推销自己,但有时这可能导致你的简历看起来过于混乱。在Ladders 2018 年眼动追踪研究中,他们揭示了招聘者平均在每份简历上扫描 7.4 秒。
你可以想象有多少人正在申请数据科学职位,以及招聘者在遇到充满大量信息的简历时可能会感到多么不知所措。与其这样,不如通过要点和良好的结构向招聘者展示一个清晰的画面。
这会自动提高你进入下一阶段的机会。
为面试做好准备
许多数据科学毕业生不断申请一个又一个工作,但当有人回电时,他们已经花费了大量的时间和精力申请职位,以至于没有真正为面试阶段做好准备。简单的部分是申请,最难的是赢得招聘者的青睐。
每个科技公司可能会以不同的方式进行招聘阶段,但它们通常是相似的。它可以从一个初步电话开始,然后进入编码评估,这些评估可能要求在远程或办公室完成。
在这里,你的技能将真正受到考验,你要确保你为此做好了准备。你将被测试你的硬技能和软技能,所以尽量不要忽视其中任何一项。
如果你想要更多的信息来帮助你,可以阅读这个:
-
数据科学面试指南 – 第一部分:结构
-
数据科学面试指南 – 第二部分:面试资源
有效地寻找工作
-
不要仅仅通过职位名称申请;使用你的技能来帮助你的搜索。虽然数据科学家职位有很多,但你可能没有他们所要求的技能。为了做到这一点,你需要确保你阅读职位描述和要求,以查看自己是否匹配。
-
使用你已经拥有的技能进行搜索,将缩小你的搜索范围,节省大量时间和精力,避免申请成千上万可能不会回复的职位。你可以按职位责任(如预测建模)或技能(如 SQL)进行搜索。
了解你所进入的行业
-
数据科学家在几乎所有行业中都受到高度需求;从金融到时尚。申请职位时;你必须了解所在的行业。你不想在对银行如何运作以及相关术语一无所知的情况下开始在银行担任数据科学家的职业生涯。
-
如果你这样做的话,你实际上是在把自己扔到深渊中,可能很难摆脱。你最终会讨厌你的工作和职业选择;因此,确保你进入你希望的领域时拥有足够的知识。
结论
- 这些是帮助你有效进入数据科学领域的基础知识。这些是非常常见的错误,可以轻松解决。如果你想了解更多关于正在招聘的数据科学家的行业,可以阅读:2022 年招聘数据科学家的顶级行业和雇主
Nisha Arya 是一位数据科学家和自由技术作家。她特别感兴趣于提供数据科学职业建议或教程以及有关数据科学的理论知识。她还希望探索人工智能如何能有益于人类寿命的不同方式。作为一个积极学习者,她寻求拓宽技术知识和写作技能,同时帮助引导他人。
相关主题
Mistral 7B-V0.2: 用 Hugging Face 微调 Mistral 的新开源 LLM
原文:
www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face

图片来源:作者
Mistral AI,全球领先的 AI 研究公司之一,最近发布了Mistral 7B v0.2的基础模型。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织的 IT
这个开源语言模型在 2024 年 3 月 23 日的公司黑客松活动中首次揭晓。
Mistral 7B 模型具有 73 亿个参数,使其极为强大。它们在几乎所有基准测试中都优于 Llama 2 13B 和 Llama 1 34B。 最新的 V0.2 模型引入了 32k 上下文窗口等改进,增强了处理和生成文本的能力。
此外,最近公布的版本是指令调优变体的基础模型,“Mistral-7B-Instruct-V0.2”,该版本早在去年发布。
在本教程中,我将展示如何在 Hugging Face 上访问和微调这个语言模型。
理解 Hugging Face 的 AutoTrain 功能
我们将使用 Hugging Face 的 AutoTrain 功能对 Mistral 7B-v0.2 基础模型进行微调。
Hugging Face 以使机器学习模型的使用变得更加民主化而闻名,让普通用户能够开发先进的 AI 解决方案。
AutoTrain 是 Hugging Face 的一项功能,它自动化了模型训练过程,使其变得易于访问和高效。
它帮助用户选择最佳参数和训练技术进行模型微调,这一任务通常令人畏惧且耗时。
用 AutoTrain 微调 Mistral-7B 模型
以下是微调你的 Mistral-7B 模型的 5 个步骤:
1. 设置环境
你必须首先创建一个 Hugging Face 帐户,然后创建一个模型库。
为了实现这一点,只需按照此链接中提供的步骤操作,然后返回本教程。
我们将在 Python 中训练模型。选择一个笔记本环境进行训练时,你可以使用 Kaggle Notebooks 或 Google Colab,这两者都提供免费的 GPU 访问。
如果训练过程花费的时间过长,你可能需要切换到像 AWS Sagemaker 或 Azure ML 这样的云平台。
最后,在开始跟随本教程编写代码之前,请执行以下 pip 安装:
!pip install -U autotrain-advanced
!pip install datasets transformers
2. 准备你的数据集
在本教程中,我们将使用 Hugging Face 上的 Alpaca 数据集,其样例如下:

我们将对模型进行微调,使用指令和输出对,并在评估过程中评估其对给定指令的响应能力。
要访问和准备此数据集,请运行以下代码行:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")
第一个函数将使用“datasets”库加载 Alpaca 数据集,并对其进行清理,以确保不包含任何空指令。第二个函数将你的数据结构化为 AutoTrain 可以理解的格式。
在运行上述代码后,数据集将被加载、格式化并保存在指定路径。当你打开格式化后的数据集时,你应该会看到一个标记为“formatted_text”的单列。
3. 设置你的训练环境
现在你已经成功准备了数据集,我们来设置你的模型训练环境。
为此,你必须定义以下参数:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'
下面是上述规格的详细说明:
-
你可以指定任何 project_name。这将是你所有项目和训练文件存储的地方。
-
model_name 参数是你希望微调的模型。在这种情况下,我指定了 Hugging Face 上的 Mistral-7B v0.2 基础模型 的路径。
-
hf_token 变量必须设置为你的 Hugging Face 令牌,该令牌可以通过访问 此链接 获得。
-
你的 repo_id 必须设置为你在本教程第一步中创建的 Hugging Face 模型库。例如,我的仓库 ID 是 NatasshaS/Model2。
4. 配置模型参数
在微调我们的模型之前,我们必须定义训练参数,这些参数控制模型行为的各个方面,如训练时长和正则化。
这些参数影响关键方面,比如模型训练的时间长度、如何从数据中学习,以及如何避免过拟合。
你可以为你的模型设置以下参数:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.01
5. 设置环境变量
现在我们通过设置一些环境变量来准备我们的训练环境。
这一步骤确保 AutoTrain 功能使用期望的设置来微调模型,例如我们的项目名称和训练偏好:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)
6. 启动模型训练
最后,让我们使用autotrain命令开始训练模型。此步骤包括指定你的模型、数据集和训练配置,如下所示:
!autotrain llm \
--train \
--model "${MODEL_NAME}" \
--project-name "${PROJECT_NAME}" \
--data-path "formatted_data/training_dataset/" \
--text-column "formatted_text" \
--lr "${LEARNING_RATE}" \
--batch-size "${BATCH_SIZE}" \
--epochs "${NUM_EPOCHS}" \
--block-size "${BLOCK_SIZE}" \
--warmup-ratio "${WARMUP_RATIO}" \
--lora-r "${LORA_R}" \
--lora-alpha "${LORA_ALPHA}" \
--lora-dropout "${LORA_DROPOUT}" \
--weight-decay "${WEIGHT_DECAY}" \
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" ) \
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" ) \
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" ) \
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )
确保将data-path更改为你的训练数据集所在的位置。
7. 评估模型
一旦你的模型完成训练,你应该会在你的目录中看到一个与项目名称相同的文件夹出现。
对我来说,这个文件夹被命名为“mistralai,” 如下图所示:

在这个文件夹中,你可以找到包含模型权重、超参数和架构细节的文件。
现在我们来检查这个微调后的模型是否能够准确回答数据集中的问题。为此,我们首先需要运行以下代码行,从数据集中生成 5 个样本输入和输出:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}\n---")
你应该看到一个类似于以下内容的响应,展示了 5 个样本数据点:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2\. Exercise regularly to keep your body active and strong.
3\. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.
我们将把上述指令之一输入到模型中,检查它是否生成准确的输出。以下是一个向模型提供指令并从中获取响应的函数:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer
最后,按照下面的显示,输入一个问题到这个函数中:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)
你的模型应生成与训练数据集中相应输出完全一致的响应,如下所示:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business and
请注意,由于我们指定的令牌数量,响应可能看起来不完整或被截断。请随意调整“max_length”值,以允许更长的响应。
微调 Mistral-7B V0.2 - 下一步
如果你已经走到这一步,恭喜你!
你已经成功微调了一个最先进的语言模型,利用了 Mistral 7B v-0.2 的强大功能以及 Hugging Face 的能力。
但旅程并不会就此结束。
作为下一步,我建议尝试不同的数据集或调整某些训练参数以优化模型性能。对更大规模的模型进行微调将提升其效用,因此可以尝试使用更大的数据集或不同格式的文件,如 PDF 和文本文件。
在处理组织中的真实数据时,这种经验变得极为宝贵,因为这些数据通常是混乱且无结构的。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。Natassha 写作内容涉及所有数据科学相关主题,真正是所有数据话题的专家。你可以通过LinkedIn与她联系,或查看她的YouTube 频道。
更多相关话题
使用米切尔范式对学习算法的简明解释
原文:
www.kdnuggets.com/2018/10/mitchell-paradigm-concise-explanation-learning-algorithms.html
评论
如果一个计算机程序在一些任务类别T和性能测量P方面,随着经验E的增加,其在T中任务的性能(由P衡量)有所提升,则称该程序从经验E中学习。
- Tom Mitchell, "机器学习"¹
Tom Mitchell 的引言在机器学习界广为人知并经过时间考验,首次出现在他 1997 年的书中。这个句子对我个人产生了很大的影响,我在多年来多次引用了它,并在我的硕士论文中提到过。这个引言在 Goodfellow, Bengio & Courville 的《深度学习》第五章中也占据了重要位置,为书中对学习算法的解释提供了起点。
尽管本质上抽象,但变量E、T和P可以映射到机器学习算法及其学习过程中,以帮助加深对学习算法的抽象理解,甚至更具体地理解。让我们看看如何从这些简洁的几个词中获得大量的信息。
图 1. 视觉化的米切尔范式。
机器学习任务通常是根据机器学习系统应如何处理一个示例来描述的。
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "深度学习"²
首先,让我们记住我们这里关注的是机器学习算法和学习过程。这意味着我们必须区分我们的任务和学习过程,并理解它们之间的关系。
比如,如果我们想对图像进行分类,那么区分执行我们的任务(图像分类)和学习如何执行我们的任务非常重要,这可以被描述为“我们获得执行任务能力的方法”²。单张图像就是我们机器学习系统将处理的示例,回到上面的引用。
其他任务的示例包括回归、翻译、异常检测和密度估计。
为了评估机器学习算法的能力,我们必须设计一个定量的性能衡量标准。
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "深度学习"²
在学习过程中,我们必须确定我们的示例是否使我们更接近最终的任务目标;我们需要衡量其性能。换句话说,在我们的示例中,我们从之前处理的示例中学到的知识是否使我们能够更好地分类图像?
幸运的是,我们在这种情况下想要了解的可以量化和轻松测量:在分类的情况下是准确性或反向的错误率。有时,知道要测量什么很困难;知道要测量什么但无法测量也是一个潜在的问题。
为了最佳地测量性能,我们通常感兴趣的是评估那些之前未被我们的学习算法看到的数据,这就是训练数据集和测试数据集概念发挥作用的地方。
机器学习算法可以大致分为无监督或监督,这取决于它们在学习过程中允许拥有何种经验。
- Ian Goodfellow, Yoshua Bengio & Aaron Courville, "深度学习"²
经验的概念比其他概念稍微抽象一些,很难指向某个具体的东西(例如,某个实现模型中的特定代码行)来体现它。
广义上,经验与学习算法如何从中学习的数据有关。我们可以从数据是否被标记(监督学习)或未标记(无监督学习)的角度来描述这种经验。在这个意义上,经验就是关于学习过程如何进行的,比如:这是自我学习的形式,还是一个有指导的过程?
我们还可以将数据集作为经验的一部分更全面地描述。通常,数据被打包成矩阵,这些矩阵是示例的集合。示例则是特征的集合,这些特征描述了一个特定的示例。这个特征集可能会被标签(或目标)补充,具体取决于它是否用于监督学习或无监督学习。

图 2. 使用 Mitchell 模式来解释图像分类任务。
关于这个主题的更多信息,你可以在下面找到的参考书籍中自由获取。
参考文献:
-
机器学习,Tom Mitchell,麦 Graw-Hill,1997 年。
-
深度学习,Ian Goodfellow, Yoshua Bengio & Aaron Courville,MIT 出版社,2016 年。
相关:
-
Keras 4 步工作流
-
接近机器学习过程的框架
-
接近文本数据科学任务的框架
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
解锁选择完美机器学习算法的秘密!
在解决数据科学问题时,您需要做出的关键决策之一是选择使用哪种machine learning算法。
机器学习算法有数百种可供选择,每种算法都有其优缺点。有些算法在特定类型的问题或数据集上可能比其他算法更有效。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 工作
“无免费午餐” (NFL) 定理 认为,没有一种算法对每个问题都最好,换句话说,所有算法的表现都在所有可能问题的平均表现中相同。

不同的机器学习模型
在这篇文章中,我们将讨论在为您的问题选择模型时需要考虑的主要点以及如何比较不同的机器学习算法。
关键算法方面
以下列表包含了您在考虑特定机器学习算法时可以问自己的 10 个问题:
-
该算法可以解决哪类型的问题?它能仅解决回归或分类问题,还是两者皆能?它能处理多类/多标签问题还是仅二分类问题?
-
该算法是否对数据集有任何假设?例如,一些算法假设数据是线性可分的(如感知机或线性 SVM),而其他算法假设数据是正态分布的(如高斯混合模型)。
-
关于算法的性能是否有任何保证?例如,如果算法尝试解决优化问题(如逻辑回归或神经网络),它是否保证找到全局最优解或仅局部最优解?
-
训练模型有效需要多少数据?有些算法,如深度神经网络,比其他算法更能处理大量数据。
-
该算法是否容易过拟合?如果是,它是否提供处理过拟合的方法?
-
该算法在训练和预测过程中需要多少运行时间和内存?
-
为了准备数据以供算法使用,需要哪些数据预处理步骤?
-
算法有多少个超参数?超参数较多的算法在训练和调整时需要更多的时间。
-
算法的结果是否容易解释?在许多问题领域(如医学诊断),我们希望能够用人类的语言解释模型的预测。一些模型可以被轻松可视化(例如决策树),而其他模型则表现得更像一个黑箱(例如神经网络)。
-
算法是否支持在线(增量)学习,即我们是否可以在不从头开始重建模型的情况下对其进行额外样本的训练?
算法比较示例
例如,假设我们比较两个最流行的算法:决策树和神经网络,并根据上述标准进行比较。
决策树
-
决策树可以处理分类和回归问题。它们也可以轻松处理多类别和多标签问题。
-
决策树算法对数据集没有任何特定的假设。
-
决策树是使用贪婪算法构建的,这种算法并不能保证找到最优树(即最小化分类所有训练样本所需测试次数的树)。然而,如果我们不断扩展其节点直到所有叶节点中的样本都属于同一类,决策树可以在训练集上达到 100%的准确率。这种树通常不是好的预测器,因为它们会过拟合训练集中的噪声。
-
决策树即使在小型或中型数据集上也能表现良好。
-
决策树容易过拟合。然而,我们可以通过使用树剪枝来减少过拟合。我们还可以使用集成方法,例如随机森林,这些方法结合了多个决策树的输出。这些方法在过拟合方面表现较好。
-
构建决策树的时间为O(n²p),其中 n 是训练样本的数量,p 是特征的数量。决策树中的预测时间取决于树的高度,通常与n的对数成正比,因为大多数决策树都相当平衡。
-
决策树不需要任何数据预处理。它们可以无缝处理不同类型的特征,包括数值特征和分类特征。它们也不需要对数据进行归一化。
-
决策树有几个关键的超参数需要调整,特别是如果你使用了剪枝方法,比如树的最大深度以及用来决定如何分裂节点的纯度度量。
-
决策树易于理解和解释,我们可以轻松地对其进行可视化(除非树非常大)。
-
决策树不能轻易修改以考虑新的训练样本,因为数据集的细微变化可能会导致树的拓扑结构发生重大变化。
神经网络
-
神经网络是现存最通用和灵活的机器学习模型之一。它们几乎可以解决任何类型的问题,包括分类、回归、时间序列分析、自动内容生成等。
-
神经网络对数据集没有假设,但数据需要被规范化。
-
神经网络使用梯度下降法进行训练。因此,它们只能找到局部最优解。然而,有多种技术可以用来避免陷入局部最小值,例如动量和自适应学习率。
-
深度神经网络需要大量数据进行训练,通常在数百万个样本点的数量级。一般来说,网络越大(层数和神经元越多),所需的数据量也越多。
-
过大的网络可能会记住所有训练样本而无法很好地泛化。对于许多问题,你可以从一个小型网络(例如,只有一两层隐藏层)开始,逐渐增加其规模,直到出现过拟合。你还可以添加 正则化 以应对过拟合。
-
神经网络的训练时间取决于许多因素(网络的大小、训练所需的梯度下降迭代次数等)。然而,预测时间非常快,因为我们只需对网络进行一次前向传播即可获得标签。
-
神经网络要求所有特征都为数值型并进行规范化。
-
神经网络有许多超参数需要调整,如层数、每层的神经元数量、使用哪个激活函数、学习率等。
-
神经网络的预测结果难以解释,因为它们基于大量神经元的计算,每个神经元对最终预测的贡献都很小。
-
神经网络可以轻松适应包括额外的训练样本,因为它们使用增量学习算法(随机梯度下降)。
时间复杂度
下表比较了一些流行算法的训练和预测时间(n 是训练样本的数量,p 是特征的数量)。

Kaggle 竞赛中最成功的算法
根据 2016 年进行的一项调查,Kaggle 竞赛获胜者最常用的算法是梯度提升算法(XGBoost)和神经网络(参见 这篇文章)。
在 2015 年的 29 名 Kaggle 竞赛获胜者中,有 8 人使用了 XGBoost,9 人使用了深度神经网络,11 人则使用了两者的集成。
XGBoost 主要用于处理结构化数据(例如关系表格)的问题,而神经网络在处理非结构化问题(例如涉及图像、声音或文本的问题)方面更为成功。
查看这种情况是否仍然存在或者趋势是否已经改变会很有趣(有人愿意接受这个挑战吗?)
感谢阅读!
Roi Yehoshua 博士 是波士顿东北大学的教授,教授数据科学硕士课程。他在多机器人系统和强化学习方面的研究已经在人工智能领域的顶级期刊和会议上发表。他还是 Medium 社交平台的顶级作者,经常发布有关数据科学和机器学习的文章。
原文。经许可转载。
更多相关主题
机器学习模型解释性如何加速金融服务的 AI 采用之旅
金融服务公司越来越多地使用人工智能来改进其运营操作,以及业务相关任务,包括分配信用评分、识别欺诈、优化投资组合和支持创新。AI 提高了这些操作中人类工作的速度、精确度和效率,并且可以自动化目前由人工完成的数据管理任务。然而,随着 AI 的进步,新挑战也随之而来。
真实的问题是透明度:当人们不理解或只有少数人理解 AI 模型背后的推理时,AI 算法可能会无意中引入偏见或失败。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
现今,分析领导者常常目睹领导层在部署黑箱 AI 驱动解决方案时的犹豫。这加快了对行业中机器学习模型解释性的需求。事实上,根据 Gartner 的数据,到 2025 年,30% 的政府和大型企业 AI 产品及服务采购合同将要求使用可解释和道德的 AI。
尽管当前金融服务中的 AI 仅限于流程自动化和营销等任务,但未来它可能会变得复杂并不断发展,使得黑箱模型方法具有风险。黑箱 AI 无法提供解释性和透明度,使得利益相关者对模型失败的原因或如何做出特定决策感到困惑。为应对这一挑战,银行和金融机构正在探索各种应用中的 AI 模型解释性。
什么是可解释的 AI?
可解释的人工智能模型允许利益相关者理解模型驱动决策的主要驱动因素,并解释人工智能和机器学习模型做出的决策。事实上,欧洲 GDPR 规定,自动化决策的存在应提供关于涉及逻辑的有意义信息。可解释的模型必须能够解释其理由,描述其优缺点,并传达对未来行为的理解,从而克服无法解释为何以及如何达到特定决策点的黑箱人工智能的挑战。
可解释的人工智能克服了信任问题和由于设计者偏见、错误的训练数据或缺乏适当的业务背景而可能出现的偏见。它使机器学习算法变得透明、稳健和负责任。通过为决策分配理由代码并使其对用户可见,解决这些问题。利益相关者可以审查这些代码,以解释决策并验证结果。好的可解释人工智能必须具有高度的可扩展性、易于理解、高度个性化,并根据用例和国家遵守监管和隐私要求。

图:黑箱人工智能与可解释人工智能模型的工作原理
为什么可解释的人工智能对金融机构至关重要?
金融机构遵循严格的监管政策,任何不正确的决定都可能花费数百万美元并损害消费者信任。因此,金融公司必须对人工智能模型进行严格、动态的模型风险管理和验证。银行必须确保所提出的人工智能解决方案可以根据用例提供所需的透明度。
拥有一个扎实且实际的可解释治理框架可以帮助金融机构理解其关于人工智能可解释性的义务以及如何将其付诸实践。下面我们讨论了几个金融服务领域广泛使用人工智能的应用案例,以及为什么在每种场景中可解释模型都是至关重要的。
消费者信用: 在银行业中,人工智能的一个常见应用是决定贷款标准。银行必须理解人工智能为何做出贷款批准或拒绝的决定。人工智能的可解释性确保决策是公平的,不会因性别或种族而产生偏见。
反洗钱(AML): 反洗钱广泛使用人工智能,并要求其可解释性,以理解模型输出是否建议交易中的异常行为或可疑活动。
客户入驻: 金融机构因客户入驻流程不足而损失数百万美元,而人工智能确保流程顺畅,损失最小。可解释的人工智能提供了一个进行资格检查和风险管理的系统,同时保持透明度。
风险管理: 使用历史结构化和非结构化数据,AI 帮助银行和金融机构跟踪欺诈和潜在风险的迹象。模型的可解释性必须说明为何将某项活动识别为风险,以便能够管理风险并保持更好的客户体验。
预测: AI 预测模型帮助实时监控和预测金融交易参数。可解释性确保了自动预测的准确性和动态特性。
如何确保 AI 模型的可解释性?
人工智能技术越强大,其推理过程的解释就越具挑战性,因为它涉及复杂的神经网络架构来执行 AI。此外,不同的利益相关者需要不同层次的解释。他们必须能够为每个决策提供理由。例如,在贷款审批的 AI 系统中,如果系统拒绝了一份贷款申请,它应该能够解释为何拒绝申请,并且建议结果是否正确。模型应该能够回答以下问题,以了解模型是否正常工作。
-
使用了什么算法?
-
模型是如何工作的?
-
模型在确定输出时考虑了哪些数据?
-
哪些变量对模型决策产生了影响?
-
模型的决策是否符合监管指导?
-
模型是否有可能对某些群体/性别/种族产生歧视?
虽然可解释的 AI 模型是理想的情形,但随着模型复杂性和精确度的增加,创建这些模型可能变得越来越具有挑战性。此外,还存在竞争对手逆向工程专有机器学习模型和算法的担忧。还有可能面临敌对攻击导致故障的风险。为了克服这些挑战,许多金融机构开始利用最先进的算法,同时保持可解释性。对数据和过程的深入理解可以帮助数据科学家构建定制架构,并通过以下方式确保 AI 模型的可解释性
-
在选择算法时,要仔细考虑可解释性
-
在不影响准确性的情况下控制模型的跨度
-
在模型训练中构建经济和监管假设
-
构建 MLOps 管道
-
确保强大的模型监控框架

图:确保 AI 模型可解释性需要注意的要点
结论
解释性和良好的模型治理可以降低风险,并为金融服务中的道德和透明 AI 创建框架,消除偏见。随着 AI 用例的增长,创建透明且可解释的 AI 模型以解释关键决策将变得至关重要。将 AI 和机器学习模型的解释性整合到流程中,将为未来铺平道路。
金融机构可以选择具有丰富经验的 AI 合作伙伴,以确保 AI 模型的解释性和透明度,同时满足全球合规要求。合作伙伴应能够为 AI 系统的设计、开发、部署和运营制定道德保护措施。一个透明的机器学习框架将为模型带来问责制,并增强对复杂 AI 解决方案的依赖。
Yuktesh Kashyap,Sigmoid 数据科学副总裁。他在金融服务领域实施基于机器学习的决策和监控解决方案方面有近十年的经验。
更多相关话题
比较机器学习即服务:Amazon、Microsoft Azure、Google Cloud AI
原文:
www.kdnuggets.com/2018/01/mlaas-amazon-microsoft-azure-google-cloud-ai.html/2
语音和文本处理 API: Google Cloud Services
尽管这组 API 主要与 Amazon 和 Microsoft Azure 的建议交集,但它有一些有趣且独特的功能值得关注。
Dialogflow。 随着各种聊天机器人成为今日的趋势,Google 也有相关的产品。Dialogflow 基于自然语言处理技术,旨在定义文本中的意图,并解释一个人想要什么。该 API 可以通过 Java、Node.js 和 Python 进行调整和定制,以满足所需的意图。
云自然语言 API。 这个 API 在核心功能上几乎与 Amazon 的 Comprehend 和 Microsoft 的 Language 相同。
-
定义文本中的实体
-
识别情感
-
分析句法结构
-
分类话题(例如:食品、新闻、电子产品等)
云语音 API。 该服务可以识别自然语音,其相较于类似 API 的主要优势可能是 Google 支持的语言种类丰富。目前,它的词汇支持超过 110 种全球语言及其变体。它还具有一些附加功能:
-
词汇提示允许将识别定制到特定的上下文和可说的词汇(例如,更好地理解地方或行业术语)
-
过滤不适当的内容
-
处理嘈杂的音频
云翻译 API。 基本上,你可以使用这个 API 在你的产品中集成 Google 翻译。它支持超过一百种语言和自动语言检测。
除了文本和语音,Amazon、Microsoft 和 Google 还提供了相当多功能的图像和视频分析 API。

尽管图像分析与视频 API 密切交集,但许多视频分析工具仍在开发或测试版本中。例如,Google 提供对各种图像处理任务的丰富支持,但在视频分析功能上明显落后于 Microsoft 和 Amazon。

图像和视频处理 API: Amazon Rekognition
不,我们没有拼错这个词。 Rekognition API 被用于图像和最近的视频识别任务。这些任务包括:
-
物体检测和分类(在图像中找到并检测不同的物体,并定义它们是什么)
-
在视频中,它可以检测如“跳舞”这样的活动或“灭火”这样的复杂动作
-
面部识别(用于检测面孔和查找匹配的面孔)和面部分析(这一点非常有趣,因为它检测微笑、分析眼睛,甚至定义视频中的情感)
-
检测不当视频
-
识别图像和视频中的名人(无论出于何种目的)
图像和视频处理 API:Microsoft Azure 认知服务
微软的 Vision 包结合了六个 API,专注于不同类型的图像、视频和文本分析。
-
计算机视觉能够识别图像中的对象、动作(例如,行走),并定义主导颜色
-
内容审核员检测图像、文本和视频中的不当内容
-
面部 API 检测面孔、对其进行分组、定义年龄、情感、性别、姿势、微笑和面部毛发
-
情感 API 是另一个面部识别工具,用于描述面部表情
-
自定义视觉服务支持使用自己的数据构建自定义图像识别模型
-
视频索引器是一个工具,用于在视频中查找人物、定义语音情感和标记关键字
图像和视频处理 API:Google 云服务
云视觉 API. 该工具用于图像识别任务,对于查找特定图像属性非常强大:
-
标记对象
-
识别面孔并分析表情
-
查找地标并描述场景(例如,度假、婚礼等)
-
查找图像中的文本并识别语言
-
主导颜色
云视频智能. Google 的视频识别 API 仍在开发初期,因此缺少 Amazon Rekognition 和 Microsoft Cognitive Services 提供的许多功能。目前,该 API 提供以下工具集:
-
标记对象和定义动作
-
识别显式内容
-
转录语音
尽管在功能列表级别上 Google AI 服务可能缺少一些能力,但 Google API 的力量在于 Google 可访问的庞大数据集。
特定 API 和工具
在这里,我们将讨论来自微软和 Google 的具体 API 提供和工具。我们没有包含 Amazon,因为他们的 API 集仅仅匹配上述提到的文本分析和图像+视频分析类别。然而,这些特定 API 的一些功能也存在于 Amazon 产品中。
Azure 服务机器人框架。 微软在提供灵活的 机器人开发工具集 方面投入了大量精力。该服务基本上包含了一个完整的环境,用于使用不同的编程语言构建、测试和部署机器人。
有趣的是,Bot 服务不一定需要机器学习方法。由于微软提供了五种机器人模板(基本、表单、语言理解、主动和问答),只有语言理解类型需要先进的 AI 技术。
目前,你可以使用 .NET 和 Node.js 技术来构建 Azure 机器人,并将它们部署到以下平台和服务:
-
Bing
-
Cortana
-
Skype
-
Web Chat
-
Office 365 邮箱
-
GroupMe
-
Facebook Messenger
-
Slack
-
Kik
-
Telegram
-
Twilio
微软的 Bing 搜索。 微软提供了七个与核心 Bing 搜索功能连接的 API,包括自动建议、新闻、图片和视频搜索
微软的知识。 这个 API 组结合了文本分析和广泛的独特任务:
-
Recommendations API 允许构建用于购买 个性化 的推荐系统
-
Knowledge Exploration Service 允许你输入自然语言查询以从数据库中检索数据,进行数据可视化,并自动补全查询
-
Entity Linking Intelligence API 旨在突出显示表示实体的名称和短语(例如,探索时代),并确保消歧
-
Academic Knowledge API 进行词汇自动补全,找到文档中词汇和概念的相似性,并在文档中搜索图谱模式
-
QnA Maker API 可用于匹配问题的各种变体与答案,以构建客户服务聊天机器人和应用程序
-
Custom Decision Service 是一种强化学习工具,用于根据用户的偏好个性化和排名不同类型的内容(例如,链接、广告等)
Google Cloud Job Discovery。 该 API 仍在早期开发阶段,但很快可能会重新定义我们今天拥有的职位搜索能力。与依赖精确关键词匹配的传统职位搜索引擎不同,Google 利用机器学习在高度变化的职位描述之间找到相关连接,并避免歧义。例如,它努力减少无关或过于宽泛的返回,例如将所有包含“助理”关键词的职位返回为“销售助理”查询。该 API 的主要功能是什么?
-
修正职位搜索查询中的拼写错误
-
匹配所需的资历水平
-
查找可能涉及变化表达和行业术语的相关职位(例如,将“服务器”查询返回为“咖啡师”,而不是“网络专家”;或将“业务发展”查询返回为“参与专家”)
-
处理缩写(例如,将“HR”查询返回为“人力资源助理”)
-
匹配变化的地点描述
IBM Watson 和其他
前述的所有三个平台提供了相当详尽的文档,以便启动机器学习实验并在企业基础设施中部署训练好的模型。此外,还有一些来自初创企业的 ML-as-a-service 解决方案,受到数据科学家的尊敬,例如 PredicSis 和 BigML。
那么,IBM Watson Analytics 呢?
IBM Watson Analytics 目前还不是一个完全成熟的用于商业预测的机器学习平台。目前,Watson 的优势在于数据可视化和描述数据中不同值之间的交互。它还提供了类似于Google 提供的 视觉识别服务 和一 系列其他认知服务(APIs)。当前 Watson 的问题在于该系统执行的是狭窄且相对简单的任务,非专业人员易于操作。在涉及定制机器学习或预测任务时,IBM Watson 的发展还不够成熟。
数据存储
寻找适合存储数据并用机器学习进一步处理的数据存储不再是一个重大挑战,只要你的数据科学家具备足够的知识来操作流行的存储解决方案。
在大多数情况下,机器学习需要 SQL 和 NoSQL 数据库方案,许多成熟且可靠的解决方案如 Hadoop 分布式文件系统(HDFS)、Cassandra、Amazon S3 和 Redshift 都支持这些方案。对于已经使用过强大存储系统的组织而言,这不会构成障碍。如果你计划使用某些 ML-as-a-service 系统,最直接的方法是选择相同的提供商进行存储和机器学习,因为这将减少配置数据源所花费的时间。
然而,这些平台中的一些可以轻松地与其他存储进行集成。例如,Azure ML 主要与其他 Microsoft 产品(Azure SQL、Azure Table、Azure Blob)集成,但也支持 Hadoop 和一些其他数据源选项。这些选项包括从桌面或本地服务器直接上传数据。如果你的机器学习工作流是多样化的且数据来自多个来源,可能会遇到挑战。
建模与计算
我们讨论了主要提供计算能力的 ML-as-a-service 解决方案。但如果学习工作流是在内部执行的,那么计算挑战迟早会到来。机器学习在大多数情况下需要大量的计算能力。数据抽样(制作经过精心筛选的子集)仍然是一个相关的实践,尽管大数据时代已经来临。虽然模型原型可以在笔记本电脑上完成,但使用大数据集训练复杂模型需要投资更强大的硬件。数据预处理也是如此,在普通办公机器上可能需要几天时间。在对截止日期非常敏感的环境中——有时模型需要每周或每天修改和重新训练——这显然不是一个选项。处理性能高的三种可行方法如下:
-
加速硬件。 如果你进行的是相对简单的任务,并且没有对大数据应用你的模型,可以使用固态硬盘(SSDs)来处理数据准备或使用分析软件等任务。计算密集型操作可以通过一个或多个图形处理单元(GPUs)来解决。有许多库可以使 GPUs 处理甚至用像 Python 这样的高级语言编写的模型。
-
考虑分布式计算。 分布式计算意味着拥有多台机器,任务在这些机器之间分配。然而,这种方法并不适用于所有的机器学习技术。
-
使用云计算以实现可扩展性。 如果你的模型处理客户相关数据并且有高峰期,云计算服务将允许快速扩展。对于那些仅要求数据在本地存储的公司,值得考虑私有云基础设施。
下一步
在众多解决方案中很容易迷失。它们在算法上有所不同,所需技能集也不同,最终任务也有所差异。这种情况在这个年轻的市场中相当普遍,即使是我们讨论的三种主要解决方案也并未完全互相竞争。更重要的是,变化的速度令人印象深刻。你很可能会坚持使用一个供应商,而突然间另一个供应商会推出符合你业务需求的新产品。
正确的做法是尽早明确你打算通过机器学习实现的目标。这并不容易。如果你缺乏数据科学或领域专长,在数据科学与商业价值之间架起一座桥梁是很棘手的。我们在 AltexSoft 经常遇到这个问题,尤其是在与客户讨论机器学习应用时。通常,这涉及将一般问题简化为单一属性。不论是价格预测还是其他数值、对象的类别或将对象划分为多个组,一旦你找到这个属性,决定供应商并选择所提议的方案将变得更简单。
Bradford Cross,DCVC 的创始合伙人,认为机器学习即服务并非一个可行的商业模式。他认为,它处于那些使用开源产品的数据科学家和那些购买解决高层次任务工具的高管之间的空白地带。然而,似乎行业目前正在克服初期问题,最终我们将看到更多公司转向机器学习即服务,以避免昂贵的人才招募,同时仍然拥有多功能的数据工具。
原文。经许可转载。
相关
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关话题
MLDB:机器学习数据库
原文:
www.kdnuggets.com/2016/10/mldb-machine-learning-database.html
由 François Maillet,MLDB.ai。
在这篇文章中,我们将展示使用 MLDB 构建自己的实时图像分类服务有多么简单。我们将在这个示例中使用不同品牌的汽车,但你可以根据我们展示的内容来训练任何图像数据集上的模型。我们将使用一个 TensorFlow 深度卷积神经网络、迁移学习,所有这些都将由 MLDB 运行。
使用 Inception 模型的迁移学习
从高层次来看,迁移学习允许我们使用在一个任务上训练的模型,将其学到的知识应用到另一个任务上。我们使用了Inception-v3 模型,这是一个深度卷积神经网络,已经在ImageNet大规模视觉识别挑战数据集上进行了训练。该挑战的任务是将图像分类为多达 1000 个类别,如獾、货车或汉堡包。
Inception 模型作为训练好的 TensorFlow 图形公开发布。TensorFlow是 Google 去年开源的深度学习库,MLDB 有一个内置的集成。正如你将看到的,MLDB 使得直接在 SQL 中运行 TensorFlow 模型变得极其简单。
在解决任何机器学习问题时,一个关键步骤是选择和设计特征提取器。它们用于将我们想要分类的对象——无论是图像、歌曲还是新闻文章——转换为可以提供给分类器的数值表示,称为特征向量。传统上,特征提取器的选择是手动完成的。深度神经网络一个真正令人兴奋的方面是它们能够自我学习特征提取器。
以下是 Inception 模型的架构,图像从左侧输入,预测从右侧输出。最后一层的大小将是 1000,并为每个类别提供一个概率。然而,之前的层是网络对原始图像的变换,因为这些层在解决图像分类任务时最有用。例如,一些层是边缘检测器。
所以我们的想法是将图像传递到网络中,但不是获取最后一层的输出,而是获取倒数第二层,这将给我们一个图像的概念性数值表示。我们可以将该表示作为特征,提供给一个新的分类器,并在我们自己的任务上进行训练。因此,你可以将 Inception 模型视为从图像到特征向量的方式,新分类器可以高效地对其进行操作。我们利用了数百小时的 GPU 计算时间来训练 Inception 模型,但将其应用于完全新的任务。
MLDB 上的 Inception
让我们开始吧!下面的代码使用了我们的 pymldb 库。你可以在MLDB 文档中了解更多信息。
我们在这里做了什么?我们使用 pymldb 进行了一个简单的 PUT 调用,创建了类型为tensorflow.graph的inception函数。它使用 JSON blob 进行参数化。该函数加载了一个训练好的 Inception 模型实例(请注意,MLDB 可以透明地加载远程资源,以及压缩档案中的文件;更多内容在这里)。我们指定模型的输入将是位于url的远程资源,输出将是模型的pool_3 层,即倒数第二层。使用pool_3 层将提供高级特征,而最后一层softmax是专门用于 ImageNet 任务的。
现在创建了 inception 函数后,它可以在 SQL 中使用,也可以作为 REST 端点。然后,我们可以通过简单的 SQL 查询将图像传递到网络中。这里我们将 Inception 应用于 KDNuggets 徽标,得到的是该图像的数值表示。这 2048 个数字是我们可以用作特征向量的内容。
使用 SQL 准备训练数据集
现在我们可以导入训练数据。我们有一个包含大约 200 个汽车图像链接的 CSV 文件,这些图像来自 3 个流行品牌:奥迪、宝马和特斯拉。重要的是要记住,尽管我们使用的是汽车数据集,但你可以用任何你想要的图像替代它。
我们可以通过运行一个import.text 程序来将 CSV 文件导入数据集。
我们可以使用 SQL 生成一些快速统计数据:

我们现在可以使用一种类型为transform的过程来对所有图像应用Inception模型,并将结果存储在另一个数据集中。转换过程只是执行一个 SQL 查询,并将结果保存到一个新数据集中。运行下面的代码本质上就是进行特征提取。
对我们的图像数据集进行处理。
训练一个专用模型
既然我们已经为所有图像准备了特征,我们就使用一种类型为classifier.experiment的过程来训练和测试随机森林分类器。默认情况下,数据集会在训练和测试之间 50/50 地拆分。
注意inputData键的内容,它指定了用于训练和测试的数据是 SQL 格式。{* EXCLUDING(label)}是 MLDB 行表达式语法的一个好例子,旨在处理具有数百万列的稀疏数据集。
从测试集的表现来看,这个模型的表现相当不错:
![MLDB Out[10]](../Images/abd4814eadc1bdcae9850bd76368b649.png)
![MLDB Out[11]](../Images/859c33d6a895df6860ea564c1e4483e5.png)
实时预测
现在我们有了一个训练好的模型,我们如何用它来对新图像进行评分呢?我们需要做两件事:从图像中提取特征,然后将这些特征输入到我们新训练的分类器中。这本质上就是我们的评分管道。
我们所做的是创建一个名为brand_predictor的函数,类型为sql.expression。这允许我们将 SQL 表达式持久化为一个可以多次调用的函数。当我们上面训练分类器时,训练过程会自动创建一个car_brand_cls_scorer_0,可以在常规 SQL/Rest 中使用,该函数会运行模型。它会期望一个名为features的输入列。
就这样,我们现在已经准备好从互联网中对新图像进行评分了:
py` { "output": { "scores": [ [ ""audi"", [ -8, "2016-05-05T04:18:03Z" ] ], [ ""bmw"", [ -7.333333492279053, "2016-05-05T04:18:03Z" ] ], [ ""tesla"", [ 0.2666666805744171, "2016-05-05T04:18:03Z" ] ] ] } } ```py The image we gave it represented a Tesla, and that is the label that got the highest score. ### Conclusion The Machine Learning Database solves machine learning problems end-to-end, from data collection to production deployment, and offers world-class performance yielding potentially dramatic increases in ROI when compared to other machine learning platforms. In this post, we only scratched the surface of what you can do with MLDB. We have a white-paper that goes over all of our design decisions in details. If we’ve peaked your interest, here are a few links that may interest you: * try MLDB for free in 5 minutes by launching a hosted instance * run a trial version of MLDB on your own hardware using Docker or Virtualbox * Check out our demos and tutorials, especially DeepTeach which uses the same techniques as shown in this post, and MLPaint, a whitebox realtime handwritten digit recogniser * MLDB Github repository Don’t hesitate to get in touch! You can find us on Gitter, or follow us on Twitter. All the code from this article is available in the MLDB repository as a Jupyter notebook, and is also shipped with MLDB. Boot up an instance, go the the demos folder and you can run a live version. Happy MLDBing! Bio: François Maillet is a computer scientist specialising in machine learning and data science. He leads the machine learning team at MLDB.ai, a Montréal startup building the Machine Learning Database (MLDB). François has been applying machine learning for almost 10 years to solve varied problems, like real-time bidding algorithms and behavioral modelling for the adtech industry, automatic bully detection on web forums, audio similarity and fingerprinting, steerable music recommendation and playlist generation. Related: * Recycling Deep Learning Models with Transfer Learning * Spark for Scale: Machine Learning for Big Data * The Deception of Supervised Learning * * * ## Our Top 3 Course Recommendations 1. Google Cybersecurity Certificate - Get on the fast track to a career in cybersecurity. 2. Google Data Analytics Professional Certificate - Up your data analytics game 3. Google IT Support Professional Certificate - Support your organization in IT * * * ### More On This Topic * KDnuggets News, September 21: 7 Machine Learning Portfolio Projects… * Vector Database for LLMs, Generative AI, and Deep Learning * Database Key Terms, Explained * Free SQL and Database Course * In-Database Analytics: Leveraging SQL's Analytic Functions * Database Optimization: Exploring Indexes in SQL ````
MLOps:最佳实践及如何应用
原文:
www.kdnuggets.com/2022/04/mlops-best-practices-apply.html

编辑封面
你可能已经对机器学习及其在当今世界的应用非常熟悉。人工智能(AI)和机器学习(ML)促进了智能软件的开发,这些软件能够准确预测结果并自动化通常由人类执行的各种工作。将机器学习纳入应用程序至关重要,但确保其平稳运行对组织而言更为关键。
公司利用一套被称为“机器学习操作”或 MLOps 的最佳实践来实现这一目的。MLOps 对任何企业的未来繁荣至关重要。
根据德勤的说法,市场可能在2025 年扩大$40 亿,这意味着自 2019 年以来增长了近 12 倍。
尽管机器学习为各种业务流程带来了众多优势,但公司在实施 ML 方法以提高生产力方面仍面临困难。
最佳 MLOps 实践及如何应用
你不能仅仅注册一个新的 SaaS 供应商或创建新的云计算实例,然后期望 MLOps 能正常运作。这需要细致的准备和团队及部门之间的统一方法,无论你是启动 DAO还是注册了 LLC。以下是成功实施 MLOps 的一些最佳实践。
跨多个市场细分验证模型
模型可以被重复使用,但软件不能。模型的有效性会随着时间的推移而减少,需要重新训练过程。每种新情况都需要调整模型。你需要一个训练管道来完成这一任务。
虽然实验监控可以帮助我们管理模型版本和可重复性,但在使用模型之前验证它们也是至关重要的。
离线或在线验证是企业可以根据优先级选择的选项。使用测试数据集评估模型是否适合实现业务目标,重点关注精度、准确性等指标。在做出推广决策之前,应该将这些指标与当前的生产/基准模型进行比较。
如果你的实验得到良好跟踪并在元数据方面得到管理,那么进行推广或回滚是可能的。在这篇文章中,我们将探讨如何使用 A/B 测试验证在线模型,以查看其在真实数据上的表现。
机器学习系统越来越意识到它们可能从数据中获取的偏差。例如,Twitter 的图像裁剪工具对某些用户无效。可以通过将模型的表现与不同用户群体进行比较来发现和修复这种不准确性。还应该在各种数据集上测试模型的表现,以确认它符合要求。
尝试新事物,并跟踪结果
超参数搜索和特征工程是不断发展的领域。ML 团队的目标是根据当前的技术状态和数据中变化的模式,生产出最佳的系统。
然而,这需要跟上最新的趋势和标准。同时,测试这些概念,以确定它们是否可以帮助你的机器学习 (ML) 系统表现得更好。
数据、代码和超参数都可以用于实验。每种可能的变量组合都会产生可与其他实验结果比较的指标。调查发生的环境也可能会改变结果。
你可能还想部署时间追踪软件来确保结果的及时性,并跟踪每个项目所花费的时间。
了解你的 MLOps 的成熟度
像 Microsoft 和 Google 等领先的云服务提供商使用 MLOps 采用的成熟度模型。
实施 MLOps 需要组织变革和新的工作实践。这会随着组织的系统和程序逐渐发展而发生。
成功的 MLOps 实施要求对组织的 MLOps 成熟度进展进行诚实的评估。在进行有效的成熟度评估后,公司可以学习如何提高到更高的成熟度级别。部署过程的变化,如实施 DevOps 或引入新团队成员,都是其中的一部分。
有多种方法可以存储机器学习的数据,如特征存储。特征存储对数据基础设施相对成熟的组织非常有帮助。他们需要确保不同的数据团队使用相同的特征,并减少重复劳动。如果组织只有少数几个数据科学家或分析师,特征存储可能不值得投入。
组织可以通过利用 MLOps 成熟度模型,让其技术、流程和团队一起成熟。这确保了在实施之前可以进行迭代和测试工具的可能性。
进行成本效益分析
确保你了解 MLOps 能为你的组织做什么。如果你按照策略进行另一次购买,你可以高效地处理每一个交易。假设你是一个寻找最佳汽车的买家。当然,你会有广泛的选择——例如,跑车、SUV、紧凑型车、豪华轿车等等。你必须首先选择最符合你需求的类别,以进行成本效益购买,然后根据你的预算分析不同的型号和类别。
选择最适合你公司的 MLOps 技术时也适用相同的原则。例如,运动型车辆和 SUV 有不同的优缺点。同样,你可以分析几种 MLOps 工具的优缺点。
要做出一个明智的战略决策,你必须考虑多个变量,包括公司预算和目标、你计划进行的 MLOps 活动、你打算处理的数据集的来源和格式以及你团队的能力。
保持开放的沟通渠道
产品经理和用户体验设计师可以影响支持你系统的产品如何与客户互动。机器学习工程师、DevOps 工程师、数据科学家、数据可视化专家和软件开发人员共同合作,以实施和管理长期的机器学习系统。
员工绩效由经理和企业主进行评估和认可,而合规专业人员则验证活动是否符合公司的政策和监管标准。
如果机器学习系统在面对不断变化的用户和数据模式及期望时继续实现商业目标,它们需要进行沟通。
将自动化融入你的工作流程
公司的 MLOps 成熟度可能通过广泛和先进的自动化得到提升。在缺乏 MLOps 的环境中,许多机器学习任务必须手动完成。这包括特征工程、数据清洗和转换、将训练和测试数据分成较小的块、构建模型训练代码等。
数据科学家通过手动执行这些程序,给错误留下空间,并浪费本可以用于探索的时间。
持续再培训是自动化应用的一个完美示例,其中数据分析师可以建立验证、数据摄取、特征工程、实验和模型测试的管道。持续再培训可以防止模型漂移,并通常被视为自动化机器学习的早期步骤。
结论
总的来说,机器学习很复杂,但如果你运用 MLOps 来改善参与开发和实施的团队之间的沟通,还是可以实现的。它不仅详细高效,而且还可能节省公司建立新机器学习系统的时间和成本。
Nahla Davies 是一位软件开发者和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5,000 的体验品牌组织担任首席程序员,服务的客户包括三星、时代华纳、Netflix 和索尼等。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关主题
你应该了解的 MLOps 最佳实践

照片由 Arian Darvishi 提供,来源于 Unsplash
MLOps,即机器学习运维,是用于模型部署到生产环境的一系列技术和工具。近年来,DevOps 在缩短软件发布之间的时间和减少差距方面的成功,对任何公司的生命周期都至关重要。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
由于成功的历史,开发人员进入了机器学习领域,应用 DevOps 原则,这催生了 MLOps。通过将 CI/CD 原则与机器学习模型结合,数据领域能够及时整合和交付模型。MLOps 引入了新的原则,如持续训练 (CT) 和持续监控,使生产环境更加适合任何机器学习模型。
随着 MLOps 的进步,我们应该遵循一些最佳实践,以实现最佳工作流程。这些实践是什么呢?让我们深入了解一下。
MLOps 最佳实践
在继续之前,本文假设读者已具备 MLOps、机器学习和编程的基础知识。考虑到这一点,让我们继续探讨最佳实践。
1. 建立清晰的项目结构
通过清晰的结构来评估 MLOps 更加容易。没有适用于每一个点的确切 MLOps 流水线和工具,因此我们需要为我们的项目建立清晰的结构。一个组织良好的项目结构使得我们未来的项目更易于导航、维护和扩展。
项目结构意味着我们需要从头到尾了解,从业务问题到生产和监控,都需要精确。一些改进我们项目结构的建议包括:
-
根据环境和功能组织我们的代码和数据。同时,保持代码和数据的命名规范整洁,以避免意外。
-
使用版本控制,如 GIT 或 DVC 来跟踪更改,
-
拥有一致风格的文档,
-
与团队沟通你所做的任何更改。
建立清晰的项目结构是一个麻烦的过程,但从长远来看,它肯定会对我们的项目有帮助。
2. 了解你的工具栈
MLOps 不仅仅是一个概念,它也涉及到工具。你的 MLOps 活动中有很多工具可以选择。然而,选择取决于你的项目和公司要求。
例如,如果公司的合规要求数据分析必须在本公司创建的工具中完成,我们必须遵守。这就是为什么了解你在 MLOps 管道中想使用的工具栈在开发能力时至关重要。
为了帮助你了解项目所需的工具,这里有MLOps Stack Template由Valohai提供,你可以参考。

图片来源:Valohai
另外,尽量将工具限制在三到五个之间。使用的工具越多,情况就会变得越复杂。
3. 追踪你的开支
在我们的管道中使用 MLOps 的目标是最小化技术债务。这是一个很好的目标,因为我们不希望技术债务让项目变得复杂。然而,不要因为我们想要最小化技术债务而让开支变得过高。
许多用于 MLOps 的工具是基于订阅或按使用收费的,这取决于工具本身。与其从头开发或使用开源工具,许多付费工具提供了更好的集成 MLOps 体验的服务。
但有时我们需要记住,服务是需要收费的,而我们又稀疏使用这些服务,这也是我在早期采用 MLOps 时遇到的情况。记得好好追踪开支,我们不希望 MLOps 带来的价值被金钱削减。
使用像 AWS 这样的云服务,计算器和警报会提醒你开支。如果没有,可以尝试使用各种工具来跟踪。即使是简单的 Excel 也能奏效。
4. 对所有事物设立标准
我们不仅需要一个简洁的项目结构,还需要MLOps 管道每个部分的标准。最小化技术债务意味着我们希望一切正常运作,常常问题出在团队缺乏标准。
想象一下,如果工具、变量、脚本、数据等的命名是随机的,并且团队成员之间没有一致性。开发者需要理解发生了什么,过程会变得更长,并且会产生技术债务。
标准化不仅适用于命名约定,还可以应用于与 MLOps 管道相关的所有方面。数据分析过程、使用的环境、管道结构、部署过程等等。制定所有标准,MLOps 的效果会更好。
5. 定期评估你的 MLOps 成熟度
我们的 MLOps 准备情况有多远是一个我们需要经常问的问题。我们希望充分发挥 MLOps 的好处,这只有在成熟度达到时才会出现。遗憾的是,这不是一天或一个月可以实现的。
这可能需要一些时间,但这就是为什么在实施 MLOps 时不要等待一个完美的管道。相反,从可以首先处理的事项开始,并持续评估我们的 MLOps 准备情况。
作为参考,我喜欢使用 Microsoft Azure 提供的 MLOps 成熟度金字塔来评估准备情况。共有五个级别,每个级别为我们的生态系统提供价值。

图片来源于 Microsoft Azure
结论
MLOps 或机器学习操作对公司生命周期至关重要。这就是为什么你可以遵循一些最佳实践:
-
建立一个清晰的项目结构
-
了解你的工具栈
-
跟踪你的开支
-
为一切设定标准
-
定期评估你的 MLOps 成熟度
希望这有所帮助。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关主题
MLOps 最佳实践
评论
**Siddharth (Sid) Kashiramka,(高级经理,平台,Capital One),
Anshuman Guha,(首席数据科学家,Card DS,Capital One),
DeCarlos Taylor,(主任,Card DS,Capital One)**。
现在在多个行业中,人们普遍认识到预测建模和机器学习可能为那些将这些技术作为其商业模式核心部分的组织提供巨大的价值。许多跨越公共和私营部门的组织已经采用了数据驱动的商业战略,利用从全面的数据分析或高度复杂的机器学习算法中得出的洞察来影响关键的业务或运营决策。虽然有许多组织在大规模应用机器学习,并且各种使用案例层出不穷,但整体机器学习生命周期在所有组织中具有相似的结构,无论具体的使用案例或应用是什么。具体来说,对于任何大规模利用数据科学的组织,机器学习生命周期由四个关键组成部分定义:模型开发、模型部署、模型监控和模型治理(见图 1)。

图 1 - 机器学习生命周期的四个关键步骤。
大多数数据科学家对机器学习生命周期中的模型开发部分非常熟悉,并且对复杂的数据查询(例如 SQL)、数据处理、特征工程和算法训练有很高的熟练度。此外,生命周期中的模型监控部分在某种程度上与数据科学家的职能相关。模型在时间推移中对数据分布变化或新应用领域的性能可以使用相关的统计指标(例如均方误差、精确度-召回率等)来监控,这些都是许多数据科学家熟悉的。此外,根据行业不同,模型治理的要求通常定义明确(尽管执行情况未必理想!),并且在组织政策文件和由监管机构发布的一般性法规中常有详细阐述。
尽管机器学习生命周期的模型开发、监控和治理组件复杂且充满挑战,但模型部署 (或称“生产化”) 组件是许多组织似乎最难应对的部分。一份最新报告 [1] 表示 87%的数据科学项目最终未能进入生产,原因包括:
-
组织内缺乏必要的部署专业知识[2]。
-
部署过程需要多个利益相关者之间的紧密合作,包括数据科学家、软件工程师和平台工程师,这可能会带来有效管理的挑战。
-
关键利益相关者之间可能缺乏透明度,一个小组采用的设计选择可能与其他关键利益相关者的基本要求或实践不完全兼容。
-
大规模生产化模型可能需要一个具有弹性且设计良好的模型部署平台,以支持各种机器学习应用程序并提供任何额外的支持功能。
-
部署平台服务水平协议(例如,最大模型响应时间)可能很难遵守,除非进行大量的软件工程和代码优化。
这绝不是组织在部署和生产化模型时可能面临的挑战的详尽清单。虽然对于上述每一项内容都有很多需要讨论的地方,但在本文中,我们专注于最后两项内容,即构建良好架构的部署平台和在打包机器学习模型时需要考虑的技术。基于我们在管理、维护和提升重要模型部署平台的经验,以及在打包和性能调优生产化机器学习模型方面的丰富经验,我们在下文中分享了一些我们在过程中识别出的高级考虑因素和最佳实践。我们希望这些知识分享能够帮助其他团队和组织更快速地实现机器学习目标,避免可能导致失败的陷阱。
机器学习部署平台设计
构建满足组织需求的模型部署平台始于定义潜在最终用户可能需要的总体需求[3]。这些条件可能涵盖执行、治理、监控或维护需求,并且在设计一个稳健的平台时,你可能需要包括的一些功能包括:
-
实时/批处理 - 机器学习平台可以支持实时或批处理,或者两者兼有,具体取决于业务需求。在做出决策时,必须考虑组织的数据质量需求和系统响应/延迟。批处理流程对数据质量问题更具耐受性,因为大多数批处理流程有足够的时间在处理后检测问题并在执行客户决策前修复这些问题。相反,对于实时评分,决策是在几秒钟内做出的。数据质量检查、从外部源提取数据、流数据输出等,可能会增加模型响应延迟的要求。
-
模型注册/清单 - 在构建平台时,制定关于遗留/旧版本模型的计划(例如,它们是否会被退役或是否有监管要求这些模型保留一定时间等)。拥有一个一致且自动化的路径将所有模型投入生产,并了解模型更新的频率,将有助于减少遗留模型带来的技术债务。
-
模型治理和风险管理 - 在受监管的环境中,系统审计的能力至关重要。不幸的是,模型治理有时可能被忽视作为一个关键能力。然而,构建强大的跟踪和管理控制对于模型在机器学习系统中的整个生命周期是必要的。这里的一些考虑因素包括收集和持久化详细的模型元数据、记录数据血统、建立控制措施,以及对文件和模型进行版本管理。
-
并发模型执行 - 了解被调用模型的需求/量以及模型是否需要并发执行。在大多数情况下,多个模型在后台同时运行。机器学习平台应确保能够适应不断增长的需求,同时保持最小的执行延迟。
-
模型监控 - 为了使模型有效和有价值,它们需要在整个生命周期内进行监控,从投入生产时开始,直到退役。有效的机器学习模型通过减少将偏差模型投入生产环境的风险来创造价值,同时也通过更快地识别瓶颈来提高数据科学团队的生产力。
启用所有这些功能是耗时的(有时甚至需要多年的努力)并且需要复杂的设计和基础设施设置。你的平台架构应该有助于实现这些功能。最终确定的架构应受到扎实工程最佳实践的支持。对于机器学习系统,几个最相关的最佳实践是:
-
可重复性 - 每个组件的输出必须在任何版本的时间点上都可以复制。
-
可扩展性 - 系统应能够适应动态变化的容量,并保持最小的响应时间。
-
自动化 - 尽可能消除手动步骤,以减少错误发生的机会。
将模型部署到平台
平台的另一个关键设计选择是用于模型部署的工具和技术[4]。模型部署的一个常见标准是使用容器,这实际上是针对给定应用程序的完整打包和可移植的计算环境。(有关容器化的更多详细信息,请参见链接 [5])。从平台的角度来看,容器化模型提供了几个好处[6],包括:
-
由于容器与宿主操作系统的抽象,实现了灵活性和可移植性
-
由于能够部署新版本的模型而不会干扰生产中的模型,因此可更好地进行管理
-
更高的效率和更快的模型部署
尽管使用模型容器提供了几个好处,但在打包和部署容器化模型时会出现一些技术挑战。确保容器化模型返回正确的输出分数至关重要,特别是在高度受监管的行业中,模型评分错误可能会对组织或其客户基础产生负面后果。因此,必须拥有一个稳健的测试框架,包括在多个场景下(包括在范围内、范围外、缺失和边界值)的输入数据(也许是模拟数据)上测试容器化模型。
另一个关键考虑因素是容器化模型部署的整体响应时间(“延迟”)。高延迟模型可能会导致许多负面后果,包括平台成本的增加(主要是在云服务提供商托管平台时)或由于平台响应缓慢而导致潜在客户未能完成申请或交易,从而失去机会。因此,容器化模型的性能调优以减少响应延迟是部署过程中的重要部分。
使用 cProfiler 改善延迟
根据应用程序或组织施加的基准阈值,模型容器可能需要在 200-300 毫秒(或更短时间)内返回输出。根据我们的经验,通常需要进行显著的代码优化以满足这一要求。传统上,代码优化过程包括对单独的代码块进行计时,识别限制速率的函数,然后对这些代码块进行性能调整。一个流行的开源工具是cProfiler [7],它跟踪各种方法和过程被调用的频率,并监控整体执行时间。举个例子,考虑下面图 2 中表示的调用图。这个调用图表明函数‘plustwo’被调用了 10 次,并消耗了 88%+的评分时间。因此,任何减少对这个限制步骤的函数调用次数的修改,或优化‘plustwo’函数以减少其运行时间的措施,都将减少模型的整体评分时间。

图 2 - 使用 Cprofiler 的代码性能分析。
负载测试
对于许多组织而言,机器学习模型最终可能会部署到面向客户的平台上,例如,由推荐系统支持的零售网站或用于实时决定申请者的金融服务网站。平台必须处理的请求数量可能高度变化,组织可能会经历低活动期(对模型容器的调用较少),随后是极高负载期,在这些期间,平台和模型可能需要处理大量请求,这些请求源于高客户需求。因此,在高负载下测试模型容器的鲁棒性(和准确性!)也是一个关键考虑因素。一个有价值的工具是Locust [8],这是一个开源负载测试工具,具有分布式和可扩展性,拥有基于 Web 的用户界面,并可以处理用 Python 编写的测试场景。

图 3 - 使用 Locust 的完整延迟测试。
图 3 展示了 Locust 的一个样本输出,这个输出来自于一个测试场景,其中每秒向模型发送十个请求,持续了 10 分钟。输出显示了请求的总数,并报告了几个百分位的响应时间。在这个例子中,95 百分位和 99 百分位的延迟分别为 170 毫秒和 270 毫秒,根据平台的阈值,这些延迟可能被接受,也可能表明需要进行额外的性能优化。
结论
总结一下,以下是本文的主要要点:
-
在构建你的机器学习系统/平台时,需要考虑所有利益相关者的需求,包括模型合规团队、业务部门和最终客户。
-
对于能够解锁组织中所需功能的机器学习系统,确保在架构方法上达成一致。
-
选择合适的工具进行模型部署;模型容器化是最常见的机器学习模型部署方法。
-
对部署容器和包进行彻底的模型验证测试。
-
复制整个数据处理和部署评分流程的独立代码库可以作为基准真相。
-
针对上下游过程进行充分记录的质量控制措施、生产问题时的应急计划以及日志记录都可能是有帮助的。
参考文献
[1] VB Staff. “为何 87%的数据科学项目从未进入生产?” venturebeat.com venturebeat.com/2019/07/19/why-do-87-of-data-science-projects-never-make-it-into-production/(访问日期:2021 年 7 月 5 日)
[2] Chris. “机器学习变得越来越简单,软件工程仍然困难” towardsdatascience.com towardsdatascience.com/machine-learning-is-getting-easier-software-engineering-is-still-hard-d4e8320bc046(访问日期:2021 年 7 月 5 日)
[3] Mckinsey Podcast. “公司在整个组织中采用人工智能的投资与对人员和流程的投资一样多。” mckinsey.com www.mckinsey.com/business-functions/mckinsey-digital/our-insights/getting-to-scale-with-artificial-intelligence(访问日期:2021 年 7 月 5 日)
[4] Assaf Pinhasi. “将机器学习模型部署到生产环境 — 推理服务架构模式” medium.com
medium.com/data-for-ai/deploying-machine-learning-models-to-production-inference-service-architecture-patterns-bc8051f70080(访问日期:2021 年 7 月 5 日)
[5] Citrix. “什么是容器化以及它是如何工作的?” citrix.com
www.citrix.com/solutions/application-delivery-controller/what-is-containerization.html(访问日期:2021 年 7 月 5 日)
[6] Christopher. G.S.“如何部署机器学习模型” christopherergs.com
christophergs.com/machine%20learning/2019/03/17/how-to-deploy-machine-learning-models/(访问日期:2021 年 7 月 5 日)
[7] docs.python.org/3/library/profile.html
[8] locust.io
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
MLOps 正在改变机器学习模型的开发方式
原文:
www.kdnuggets.com/2020/12/mlops-changing-machine-learning-developed.html
评论
由 Henrik Skogstrom,Valohai 增长负责人。

照片由 Kelly Sikkema 提供,来自 Unsplash。
MLOps 指的是 机器学习操作。它是一种旨在使生产中的机器学习变得高效且无缝的实践。尽管 MLOps 这一术语相对新兴,但它与 DevOps 有相似之处,即它不是单一的技术,而是如何以正确的方式做事的共享理解。
MLOps 引入的共享原则 鼓励数据科学家将机器学习视为一个持续的过程,而不是单独的科学实验,用于开发、启动和维护现实世界中的机器学习能力。机器学习应当是协作的、可再现的、持续的,并经过测试。
MLOps 的实际实施涉及采纳某些最佳实践,并建立支持这些最佳实践的基础设施。让我们来看三种 MLOps 改变机器学习开发方式的方式:对版本控制的影响、如何建立保护措施,以及对机器学习管道的关注。
1. 版本控制不仅仅是代码
在组织中利用机器学习时,版本控制应是首要任务。然而,这一概念不仅仅适用于驱动模型的代码。
机器学习版本控制应涵盖训练算法时使用的代码、底层数据和参数。这个过程对于确保可扩展性和 再现性 至关重要。

机器学习的版本控制不仅限于传统软件中的代码。再现性检查表 是 MLOps 设置应该能够记录的一个良好起点。
首先,让我们讨论代码中的版本控制,因为大多数数据科学家对此比较熟悉。无论是用于系统集成的实现代码,还是允许您开发机器学习算法的建模代码,都应有清晰的更改文档。这一领域通常由 Git 等工具很好地覆盖。
版本控制也应该应用于用于训练模型的数据。场景和用户不断变化和适应,因此你的数据也不可能总是相同。
这种持续变化意味着我们必须不断重新训练模型,并验证它们是否仍能与新数据保持准确。因此,需要适当的版本控制以维持可复现性。
我们用来构建模型的数据不仅会不断演变,元数据也会如此。元数据指的是关于基础数据和模型训练的信息——它告诉我们模型训练过程的情况。数据是否按预期使用?模型达到了什么样的准确度?
即使基础数据没有变化,元数据也可能会发生变化。元数据需要严格的版本控制,因为你需要有一个基准,以便在之后训练模型时参考。
最后,模型本身必须有适当的版本控制。作为数据科学家,你的目标是不断提高机器学习模型的准确性和可靠性,因此,演变中的算法需要有自己的版本控制。这通常被称为模型注册。
MLOps 实践鼓励对上述所有组件进行版本控制作为标准实践,大多数 MLOps 平台使其易于实现。通过适当的版本控制,你可以确保随时可复现,这对于治理和知识共享至关重要。
2. 将保护措施构建到代码中
在将保护措施构建到机器学习过程时,它们应该在代码中——而不是在你的脑海中!
力求避免手动或不一致的过程。所有收集数据、数据测试和模型部署的程序都应该写入代码中——而不是过程文档——以便你可以确信模型的每次迭代都将遵循所需的标准。
例如,训练机器学习模型的方式很重要——非常重要。因此,模型训练中的任何小变化都可能导致预测结果中的问题和不一致。这种风险就是为什么将这些保护措施直接构建到代码中至关重要的原因。

数据测试通常以临时的方式进行,但它应该是程序化的。
应该在机器学习管道中编写代码,以保护训练数据应该是什么样的(训练前测试)和训练后的模型应该如何表现(训练后测试)。这包括设置预期预测的参数——这将让你安心,确保生产模型遵循你制定的所有规则。
实施 MLOps 平台的一个好处是所有这些步骤都是自文档化和可重用的——至少在代码自文档化的程度上。保护措施可以很容易地用于其他机器学习用例,并且可以应用相同的标准,例如模型准确性。
3. 管道是产品——而不是模型
应该认识到的第三个 MLOps 概念是,机器学习管道是产品——而不是模型本身。这个认识通常由一个成熟度模型来表征,即组织从手动过程过渡到自动化管道。

机器学习管道的最终目标是实现一个自愈的机器学习系统。
机器学习模型对克服业务挑战和满足组织的即时需求很重要。然而,有必要认识到模型只是暂时的,和生产它的系统不同。
支持模型的基础数据将快速变化,模型也会漂移。这意味着,最终模型将不得不被重新训练和调整,以便在新环境中提供准确的结果。
结果是,产生准确有效的机器学习模型的管道应该是数据科学家专注于创建的产品。那么,机器学习管道到底是什么?
没有 MLOps 和建立好的机器学习管道,更新模型将会非常耗时且困难。与其临时完成这些任务并只在问题出现时解决,不如建立一个管道来解决这个问题。它为模型的更新和更改提供了清晰的框架和治理。
机器学习管道包括收集和预处理数据、训练机器学习模型、将其投入生产以及不断监控,以便在准确性下降时重新触发训练。一个构建良好的管道帮助你在组织内扩展这一过程,从而最大化生产模型的使用,并确保这些能力始终保持最佳状态。
一个完善的机器学习管道还允许你对模型在业务中的实现和使用进行控制。它还改善了部门间的沟通,并使其他人能够审查管道——而不是手动工作流程——以确定是否需要进行更改。同样,它减少了生产瓶颈,使你能够充分利用你的数据科学能力。
总结来说,有三个基本的 MLOps 概念是每个人都应该理解的。
-
版本控制在整个机器学习过程中都是必要的。这不仅包括代码,还包括数据、参数和元数据。
-
应设置自动工作的保护措施——不要通过依赖手动或不一致的过程来冒险影响机器学习模型的结果。
-
最后,管道是产品,而不是机器学习模型。一个成熟的管道是支持生产 ML 长期运行的唯一方式。
个人简介:亨里克·斯科格斯特罗姆 领导Valohai MLOps 平台的采用,并广泛撰写有关生产中机器学习最佳实践的文章。在加入 Valohai 之前,亨里克曾在 Quest Analytics 担任产品经理,致力于改善美国的医疗保健可及性。Valohai 于 2017 年推出,是 MLOps 的先驱,帮助 Twitter、LEGO 集团和 JFrog 等公司更快地将模型投入生产。
相关内容:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
MLOps 是一门工程学科:初学者概述
原文:
www.kdnuggets.com/2021/07/mlops-engineering-discipline.html
评论
由 Angad Gupta 提供,数据科学学生
介绍
MLOps 是 ML + DEV + OPS 的结合。MLOps 基本上通过增加自动化来提高生产可扩展性和生产模型的质量。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
MLOps 是将长期存在的 DevOps 实践与新兴的机器学习领域结合起来的理念。它是创建一个自动化环境,集成模型开发、模型再训练、漂移监控、管道自动化、质量控制和模型治理于一个平台中。

图片来源:techinnocens
MLOps 团队包括策划数据集和设计 AI 模型的数据科学家,以及以自动化方式运行这些模型和数据集的机器学习工程师。
为什么 MLOps 很重要
MLOps 团队将帮助你解决以下问题:
部署问题:
-
使用多种语言构建机器学习
-
模型在开发和生产环境中的部署
-
解决模型部署中出现的问题
-
准备具有不同语言的部署包
监控问题:
-
模型性能监控
-
一致的方式来监控在整个组织中部署的模型
模型生命周期管理问题:
-
需要数据科学家参与更新生产模型和维护活动
-
追踪初始部署后的模型衰退
模型治理:
-
生产访问控制
-
可追溯的模型结果
-
模型审核记录
-
模型升级审批工作流程
MLOps 的目标
MLOps 的目标包括:
-
部署和自动化
-
模型训练与升级
-
操作诊断与修复
-
数据治理和业务合规性
-
生产可扩展性
-
团队协作
-
监控和管理
主要好处
创建可重复的工作流管道和 ML 模型: 管道是机器学习工作流基础设施的骨干。管道帮助从源系统获取数据,处理和验证数据。它还跟踪所有活动,如模型版本、用于训练模型的数据集等。
-
创建机器学习流水线以设计、部署和重现模型部署。
-
提供跟踪代码版本、数据、各种矩阵以及执行日志的机制。
在任何生产环境中轻松部署模型: 机器学习模型本质上是复杂的,每次部署都需要资源以高效运行模型。机器学习模型的部署需要自动化系统来提供和管理所需资源并进行正确的执行。
-
快速且完美地部署机器学习模型。
-
自动控制云资源的使用。
-
在部署之前进行模型验证和各种测试。
-
预定义专用系统,以将模型从部署迁移到生产系统。
机器学习生命周期管理: 最终的机器学习模型可能嵌入许多相关的微服务和辅助服务。需要跟踪机器学习模型中使用的所有相关资源,以便进一步改进和验证。
-
使用有效的集成工具跟踪模型开发及其组件,并通过专用工具集成所有组件。
-
进行高级偏差数据分析,以跨时间段验证模型性能。
机器学习资源控制和管理: 机器学习模型需要不断使用不同的数据集进行训练,因此必须跟踪模型版本、代码版本、数据集版本以及相关所需资源。
-
跟踪模型版本历史以备审计目的。
-
评估特征的重要性,并使用均匀分布指标创建具有最小偏差的更高级模型。
-
设置资源配额并建立适当的政策,以根据需求增加/减少这些资源,从而高效地运行模型。
-
创建审计记录,以满足监管要求,并自动追踪实验。
最佳实践
ML 流水线: 设置各种 ML 流水线,例如数据流水线,以定义依赖关系及其执行顺序,并生成用于监控特定流水线资源的矩阵。
混合团队: MLOps 包含数据科学家、机器学习工程师、DevOps 工程师和数据工程师的工作;这样的混合团队希望通过设计能快速高效地处理问题。
模型和数据版本控制: 除了维护代码版本外,我们还需要维护机器学习模型版本、用于训练模型的数据、模型的超参数和模型的元数据等;模型版本控制不仅仅是处理最终模型本身。
模型验证: 需要设置统计测试以进行模型验证,因为模型验证不能仅仅通过合格/不合格或真/假来衡量;它更加复杂,详细的统计测试可以提供有价值的教训。
数据验证: 在对提供的数据进行模型训练之前,必须验证输入数据,以避免模型插入不确定性和偏差
监控: 随着训练和部署模型占用越来越多的资源,通过可视化模型使用的各种资源矩阵来监控模型性能变得更加重要
辅助 MLOps 的平台和工具
如上所述,以下类型的平台和工具可以辅助 MLOps:
-
专门用于模型跟踪、模型历史和模型注册信息的工具
-
旨在进行模型版本控制以及版本控制模型的各种单独方面(代码、数据集等)的工具
-
执行模型实验以及模型和 ML 管道部署的云服务平台
结论
MLOps 是工程学科的一个新分支。它是由机器学习工程师、DevOps 和数据科学家组成的混合团队,帮助检索数据、验证数据、部署机器学习模型,并用适当的数据集进行训练。MLOps 还帮助监控模型输出,以优化模型,运行并无缝产生所需的输出。MLOps 对于部署和训练模型以及跟踪模型和相关数据集非常有帮助。
个人简介:Angad Gupta 目前在 AutoGrid India Pvt Ltd 担任客户交付工程师,并在 Bits Pilani 攻读数据科学硕士学位。你可以在LinkedIn上关注他。
相关:
-
释放 MLOps 和 DataOps 在数据科学中的力量
-
使用 PyCaret + MLflow 轻松实现 MLOps
-
将 Docker 化的 FastAPI 应用部署到 Google Cloud Platform
更多相关主题
MLOps: 将 AI 推向主流的关键
原文:
www.kdnuggets.com/2022/07/mlops-key-pushing-ai-mainstream.html

图片由 Miguel Á. Padriñán 提供
根据报告,MLOps 解决方案的市场预计到 2025 年将增长到 40 亿美元。感谢对 AI 业务技术不断扩大的需求,这些技术不断改善外部和内部各行业的操作。
尽管如此,AI 解决方案在业务中的突然扩张对机器学习(ML)和类似 DevOps 的先进实践产生了很大的影响。由于不产生价值的 AI 部署可能会变成非常昂贵的实验,MLOps 推动了创新的步伐,以增强 AI 执行。
换句话说,将 MLOps 集成到 AI 开发过程中可以帮助简化从部署到监控和生产的各个环节,并带来附加的投资回报。因此,将 AI 集成到业务中可能会成为一个巨大的技术成就。
然而,阻碍商业组织将 AI 转化为操作行动的最重要障碍之一是推动整个开发过程到培训和生产中的成功。更重要的是,AI 的渐进实施涉及在现有业务环境中实现必要的速度和可扩展性,这通常是一个艰巨的任务。
因此,对更高稳定性和成功的需求促使 DevOps 介入 AI 部署。此外,更具前瞻性的企业已经开始在传统的 DevOps 模型中依赖机器学习,为 MLOps 腾出了空间。从简化 AI 实施到自动化智能应用程序开发过程,MLOps 展示了持续从部署中驱动价值的潜力。
在本博客中,我们将讨论使 MLOps 成为推动 AI 主流的关键因素。此外,我们还将突出 MLOps 作为 AI 实施催化剂的能力。
MLOps 作为 AI 实施的催化剂
由于 MLOps 将机器学习和 DevOps 的最佳实践带入 AI 实施,有很多方法可以使 MLOps 为企业的 AI 计划带来更多价值。其中一些可以列举为:
改进部署
MLOps 对 AI 实施的主要优势是改进的部署。不论是适应多个团队还是构建中使用的语言,它都帮助减少模型积压,优化部署。此外,MLOps 有助于标准化模型,涵盖从开发到生产的所有环节,减少缺陷并缩短故障排除时间。
机器学习和 DevOps 能力结合时,可以降低 AI 生产的复杂性,同时加快多个系统上的关键更新。
CI/CD 集成
MLOps 对 AI 实施的另一个重要原因是它为 CI/CD 集成过程带来的优势。每次更新代码或数据时,该过程都会重新运行机器学习管道。换句话说,MLOps 使得在新模型发布之前实现早期集成,允许验证新数据和代码。
高级监控
在 AI 实施过程中,MLOps 补充的下一个重要因素是监控方面,这通常在生产中被忽略。MLOps 允许以非常一致的方式对跨组织部署的不同模型进行持续检查。
更重要的是,它允许刷新在生产中停留较长时间的所有模型,同时通过 ML 技术本身评估模型性能,将数据科学家的压力转移开。简而言之,MLOps 的监控提供了一种更集中化的方式来查看 AI 实施中的模型性能,促进了更大的问责制。
生命周期管理
企业中的 AI 系统遇到的另一个重要问题是无法评估模型衰退。然而,MLOps 能够满足生命周期管理过程的资源密集型需求,使得在生产中更新模型并在初始部署后不断检查模型衰退成为可能。
MLOps 能够消除潜在的停机时间,减少数据科学家在生产模型更新中的参与。此外,MLOps 甚至有助于满足 AI 系统现有和即将推出模型的高维护需求。
模型治理
由于企业涉及高成本审计以确保与部署、建模语言相关的合规要求相一致,MLOps 的集中化过程使事情变得简单。从生产访问控制到可追溯的模型结果、模型审计跟踪以及模型升级工作流程。
MLOps 如何推动 AI 向前发展?
MLOps 作为一种数字化实践帮助企业解决与智能应用构建、部署和管理相关的多个问题。尤其是当 AI 企业实施中有大量不断扩展的训练数据集时,MLOps 可以补充监控、调整和重新训练 AI 模型。因此,ML 在生产 AI 模型的资源消耗方面使过程变得更加经济。以下是 MLOps 如何推动企业 AI 建模的方式:
改善环境
使 MLOps 成为业务中 AI 实施必要性的重要原因之一是改善环境。从数据准确性检查例程到响应模型代码变更的 DevOps 过程。
此外,MLOps 在 AI 部署中的实施允许通过创建可重用资产的窗口来节省时间。无论是动态可扩展基础设施的设置,还是诸如创建封装 REST API、数据漂移分析或通过多因素认证进行安全保障的服务自动化。
满足 MLOps 要求
有效实施 MLOps 能够访问各种功能,如全生命周期跟踪、元数据优化、超参数日志记录,最重要的是,提供最佳的 AI 基础设施,包括网络、存储和服务器。
此外,该过程还需要能够帮助快速迭代 ML 模型的软件技术。该过程还需要围绕两种 MLOps 形式进行构建,包括预测性和规范性。前者基于过去的数据预测未来结果,而后者则旨在为决策提供建议。
这一过程在将 AI 推广到每一个组织中,大小组织均应如此,都是极为重要的。大多数情况下,传统部署实践下的 ML 项目失败阻碍了 AI 系统的发展。
如果你能够很好地与 MLOps 的要求对齐,它具有将所有失败转化为成功的潜力。最重要的是,这一过程可以帮助消除所有障碍,使 AI 的实施与企业的主流数据操作相辅相成。
更加可预测的成功
尽管机器学习(ML)的概念非常年轻,MLOps 这一术语也是如此,但在实施过程中,它已经证明远不只是一个流行词。因此,以适当的方式设计和针对 MLOps 需要对 MLOps 环境中各个组件之间的有效协调。
这包括 CI/CD 管道、数据监控、模型服务和版本控制,同时保持对安全性和治理机制的检查。这种方法不仅可以最小化 ML 活动相关的风险,还能减少任何泄露的可能性。
有时,虽然自主性元素可能会超过人类,但有报告证明,没有能够实施和指挥系统的团队,AI 无法扩展。
简言之,MLOps 是技术多样化中一个极其重要的组成部分。从 AI 项目的开发、部署到进步管理,致力于 MLOps 并与 AI 系统对齐需要广泛的人力密集技能,这些技能有助于创造未来的企业商业模式。
要点
即使是最先进的数字化举措,如果在从实验室到实时实施的过渡过程中存在任何阶段的妥协,也可能无法产生价值。而且,由于人工智能(AI)是最具动态性的技术创新之一,可能会改变人类的未来,因此必须确保围绕 AI 的每一项创新都能产生实际价值。
考虑到围绕 AI 和 ML 技术的广泛误解和复杂性,完全押注于 MLOps 可能涉及意外结果。然而,一次成功的行动或任何可以通过 ML 优势促进 AI 最佳实践的行动计划,都可能改变整个企业世界。
更重要的是,朝着正确方向付出的努力可能在减少实验成本和克服失败风险方面具有巨大的价值。此外,将技术交到更多能够找到有效 AI 和 ML 实施方法的人手中,可以帮助创造一个更具生产力的数字世界。
总之,MLOps 允许企业通过每次模型部署实现 AI 计划的全部好处。此外,利用机器学习和 DevOps 可以帮助企业在 AI 目标上提前取得进展,绕过模型开发过程中遇到的任何干扰。从提供部署目标的速度到与可扩展性要求的对齐,MLOps 作为 AI 商业解决方案开发的催化剂。总的来说,它实际上可能是管理和治理 AI 的下一个重大步骤。
Kanika Vatsyayan 是BugRaptors的副总裁,负责交付和运营,该公司是一家认证的软件测试和质量保证公司。她是一位 QA 专业人士,掌握多个领导职位,如测试程序规划、创新和过程转型。从质量控制到测试领导、测试实践和保证策略,Vatsyayan 是一位经验丰富的专家,拥有影响力的技术技能。此外,她还擅长写作,因此发表了无数篇文章和博客,教育软件测试行业的受众。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 相关工作
相关阅读
如何像老板一样进行 MLOps: 无泪的机器学习指南
原文:
www.kdnuggets.com/2023/06/mlops-like-boss-guide-machine-learning-without-tears.html

编辑图片
MLOps 市场在 2019 年的估计规模为 232 亿美元,预计到 2025 年将达到 1260 亿美元,这得益于其迅速的普及。
介绍
许多数据科学项目无法看到光明。MLOps 是一个从数据阶段到部署阶段的过程,确保机器学习模型的成功。在这篇文章中,你将学习到 MLOps 的关键阶段(从数据科学家的角度)以及一些常见的陷阱。
MLOps 的动机
MLOps 是一个专注于将数据科学模型运作化的实践。通常,在大多数企业中,数据科学家负责创建建模数据集、数据预处理、特征工程,最后构建模型。然后,模型被“抛”给工程团队以进行 API/端点的部署。科学和工程往往在各自的孤岛中进行,这导致了部署延迟或最坏情况下的错误部署。
MLOps 解决了 准确且快速 地 部署 企业级 ML 模型的挑战。
数据科学领域的“说起来容易做起来难”的对应说法可能是“建起来容易,部署难”。
MLOps 可以是解决企业在将机器学习模型投入生产过程中面临困难的灵丹妙药。对于我们数据科学家来说,发现 ~90% 的 ML 模型未能投入生产并不令人惊讶。MLOps 为数据科学和工程团队带来了规范和流程,以确保他们紧密且持续地合作。 这种合作对确保成功的模型部署至关重要。
MLOps 概述
对于熟悉 DevOps 的人来说,MLOps 对机器学习应用的作用类似于 DevOps 对软件应用的作用。
MLOps 根据询问对象的不同有多种形式。然而,有五个关键阶段对于成功的 MLOps 策略至关重要。附带说明的是,每个阶段中都需要一个重要的元素,那就是与利益相关者的沟通。
问题框架
彻底了解业务问题。这是成功部署和使用模型的关键步骤之一。在这个阶段,与所有利益相关者进行沟通,以获得项目的支持。这可能包括工程、产品、合规等。
解决方案框架
只有在明确了问题陈述之后,才考虑“如何”。是否需要机器学习来解决这个业务问题?起初,作为数据科学家,我建议远离机器学习可能会让人感到奇怪。这仅仅是因为“权力越大,责任越大”。在这种情况下,责任是确保机器学习模型被谨慎地构建、部署和监控,以确保它满足并持续满足业务需求。这个阶段还应与利益相关者讨论时间表和资源。
数据准备
一旦你决定走机器学习的路线,就开始考虑“数据”。这个阶段包括数据收集、数据清理、数据转换、特征工程和标记(对于监督学习)。这里需要记住的格言是“垃圾进,垃圾出”。这个步骤通常是过程中最繁琐的,也是确保模型成功的关键。确保验证数据和特征多次,以确保它们与业务问题对齐。记录你在创建数据集时做出的所有假设。例如:一个特征的离群值真的是离群值吗?
模型构建和分析
在这个阶段,建立并评估多个模型,选择最能解决当前问题的模型架构。选择的优化指标应反映业务需求。如今,有众多机器学习库可以加速这一过程。记得记录和跟踪你的实验,以确保你的机器学习流程的可重复性。
模型服务和监控
一旦我们从上一阶段获得了模型对象,就需要考虑如何让它对最终用户“可用”。需要最小化响应延迟,同时最大化吞吐量。 服务模型的一些流行选项包括 - REST API 端点、作为云上的 Docker 容器或边缘设备上的容器。一旦我们部署了模型对象,我们还不能庆祝,因为它们本质上非常动态。例如,生产中的数据可能会漂移导致模型衰退,或者模型可能会遭受对抗性攻击。我们需要为机器学习应用程序建立一个强大的监控基础设施。这里需要监控两件事:
-
部署环境的健康状况(例如:负载、使用情况、延迟)
-
模型本身的健康状况(例如:性能指标、输出分布)。
在这个阶段,还需要确定监控过程的频率。你打算每天、每周还是每月监控你的机器学习应用程序?
现在,你已经构建、部署并监控了一个强大的机器学习应用程序。但遗憾的是,进程不会停止,因为上述步骤需要不断迭代。

成功数据科学项目的 MLOps 周期 | 图片由作者提供
金融科技案例研究
为了将上述五个阶段付诸实践,我们假设在本节中你是一个在金融科技公司负责部署欺诈模型以检测欺诈交易的数据科学家。
在这种情况下,从深入了解你尝试检测的欺诈类型(第一方还是第三方?)开始。如何将交易识别为欺诈或非欺诈?它们是由最终用户报告的,还是你需要使用启发式方法来识别欺诈?谁会使用这个模型?它会被实时使用还是以批处理模式使用?上述问题的答案对于解决这个业务问题至关重要。
接下来,考虑一下什么解决方案最能解决这个问题。你是否需要机器学习来处理这个问题,还是可以从一个简单的启发式方法开始解决欺诈?所有的欺诈行为是否都来自一小部分 IP 地址?
如果你决定构建一个机器学习模型(假设为监督学习),你将需要标签和特征。你将如何处理缺失的变量?那异常值呢?欺诈标签的观察窗口是多久?即用户报告欺诈交易需要多长时间?是否有数据仓库可以用来构建特征?确保在继续之前验证数据和特征。 这也是与利益相关者讨论项目方向的好时机。
一旦你拥有了所需的数据,构建模型并进行必要的分析。确保模型指标与业务使用对齐。(例如:这个用例可能是前十分位的召回率)。所选择的模型算法是否满足延迟要求?
最后,与工程团队协调,部署和服务模型。由于欺诈检测是一个非常动态的环境,欺诈者努力超越系统,监控非常关键。对数据和模型有监控计划。像 PSI(人口稳定性指数)这样的措施常用于跟踪数据漂移。你将多久重新训练一次模型?
现在,你可以通过机器学习成功地减少欺诈交易,从而创造业务价值(如有需要!)。
结论
希望在阅读完这篇文章后,你能看到在你的公司实施 MLOps 的好处。总结来说,MLOps 确保数据科学团队:
-
解决正确的业务问题
-
使用正确的工具来解决问题
-
利用代表问题的数据集
-
构建最优的机器学习模型
-
最后,部署和监控模型以确保持续成功
然而,要注意常见的陷阱,以确保你的数据科学项目不会成为数据科学墓地中的一块墓碑! 应记住,数据科学应用是一个活的、呼吸的事物。 数据和模型需要持续监控。 AI 治理应从一开始就考虑,而不是事后的想法。
牢记这些原则,我相信你可以利用机器学习真正创造商业价值(如果需要的话!)。
MLOps 参考文献
Natesh Babu Arunachalam 是 Mastercard 的数据科学领导者,目前专注于使用开放银行数据构建创新的 AI 应用程序。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。
了解更多关于这个话题的信息
MLOps 和机器学习路线图
原文:
www.kdnuggets.com/2021/08/mlops-machine-learning-roadmap.html
评论
由 Ben Rogojan,数据科学和数据工程解决方案架构师
图片由作者创建 — PDF 来源
每当我学习一个新主题时,我都会制定某种形式的学习计划。现在有如此多的内容,现代时代学习起来可能很困难。
这几乎是滑稽的。我们有如此丰富的知识资源,但许多人却因为不知道去哪里找而难以学习。
这就是为什么我整理了路线图和学习计划。
以下是我在接下来的几个月内将要进行的 MLOps 学习计划。
重点将首先是快速复习机器学习,并且参加一个高级 Kubernetes 课程。
从那里,我将专注于 Kubeflow、Azure ML 和 DataRobot。
MLOps 背景
2014 年,一组 Google 研究人员发布了一篇题为 机器学习:技术债务的高利息信用卡 的论文。这篇论文指出了许多公司可能忽视的一个日益严重的问题。
使用技术债务框架,我们注意到在应用机器学习时,在系统层面产生巨大的持续维护成本是非常容易的。[D. Sculley, Gary Holt 等]
研究人员在后续演讲中将这个问题表述为,发射火箭很容易,但之后的持续操作却很困难。那时,DevOps 的概念仍在逐步形成,但这些工程师和研究人员意识到,相比于部署代码,部署机器学习模型涉及更多复杂的情况。
这时,机器学习平台的普及开始上升。最终,许多这些平台采用了 MLOps 这个术语来解释他们提供的服务。
这就引出了一个问题。什么是 MLOps?
什么是 MLOps?
机器学习运维(MLOps)帮助简化了机器学习模型在运维团队和机器学习研究人员之间的管理、物流和部署。
从一个幼稚的角度来看,这只是将 DevOps 应用到机器学习领域。
但 MLOps 实际上需要管理比 DevOps 通常管理的内容多得多。
像 DevOps 一样,MLOps 也管理自动化部署、配置、监控、资源管理以及测试和调试。
可能的机器学习管道如下图所示。
图片由作者创建
与 DevOps 不同,MLOps 还可能需要考虑数据验证、模型分析和重新验证、元数据管理、特征工程以及机器学习代码本身。
但归根结底,MLOps 的目标非常相似。MLOps 的目标是创建机器学习模型的持续开发流水线。
一个能迅速让数据科学家和机器学习工程师部署、测试和监控其模型的流水线,以确保他们的模型继续按预期运行。
MLOps 路线图
为了更好地了解 MLOps 市场中存在的各种工具,让我们制定一个快速学习计划,看看我们应该复习哪些内容。
1. 数据科学数学复习
我们无法绕过这个问题。
数学是机器学习和数据科学的重要部分。由于我个人已经很久没有接触,同时也考虑到可能对我的读者感兴趣,以下是一些很棒的资源,供那些希望刷新自己的数据科学数学技能和机器学习的朋友们使用。
有一个课程引起了我的注意,那就是约翰·霍普金斯大学的数据科学统计学课程。特别是,我对统计推断感兴趣,因为它是比较有趣的课程。
接下来,许多人可能更喜欢阅读数学书籍而不是参加课程。这时《数据科学家的实用统计学》就派上用场了。某一天我可能应该订阅 O'Reilly,但现在我打算购买这本实用统计学书籍。
特别是,O'Reilly 的书籍通常由专业人士撰写。因此,我期待能看到应用数据科学数学的实际案例。
数据科学家的实用统计学:使用 R 和 Python 的 50 多个基本概念
2. 复习机器学习和手动部署模型
在深入研究MLOps之前,让我们复习一下机器学习以及如何使用 Docker 部署机器学习模型。
这将帮助我们在后续步骤中比较一些未来的课程,因为我们可以看到多种部署机器学习模型的方法。
我特别发现了一个叫做“使用 Docker 部署机器学习和 NLP 模型”的课程。由于这是部署机器学习模型的一种方式,它将作为一个很好的基础。
使用 Docker(DevOps)部署机器学习和 NLP 模型
3. Kubernetes
Kubernetes 是一个开源的 容器编排 平台。使用 Kubernetes 允许开发者自动化手动部署、管理和扩展应用程序的过程。
换句话说,你可以将运行 Linux 容器的主机组集成在一起,而 Kubernetes 使你能够轻松高效地管理这些集群。
所以为了深入学习 Kubernetes,我打算钻研 freeCodeCamp 提供的三小时课程。一方面,这将提供一份很棒的内容。另一方面,freeCodeCamp 通常能将你需要了解的内容浓缩成一个简短的几小时课程。
在 3 小时内学习 Kubernetes:容器编排的详细指南
一旦你完成了 freeCodeCamp 的三小时 Kubernetes 课程,你现在可以深入学习高级 Kubernetes。此课程将涵盖 日志记录 使用 ElasticSearch、Kibana、Fluentd 和 LogTrail,打包 使用 Helm,部署 使用 Spinnaker 等内容。
4. Kubeflow
Kubeflow 是一个机器学习平台,负责管理 Kubernetes 上 ML 工作流的部署。Kubeflow 的最佳部分是它提供了一个可扩展和可移植的解决方案。
该平台最适合那些希望构建和实验数据管道的数据科学家。Kubeflow 也很适合将机器学习系统部署到不同环境中,以进行测试、开发和生产级服务。
Kubeflow 由 Google 发起,作为一个运行 TensorFlow 的开源平台。它最初是通过 Kubernetes 运行 TensorFlow 作业的方式,但现在已经扩展为一个多云、多架构的框架,能够运行整个 ML 管道。使用 Kubeflow,数据科学家不需要学习新的平台或概念来部署他们的应用程序或处理网络证书等问题。他们可以像在 TensorBoard 上一样简单地部署他们的应用程序。
了解更多关于 Kubeflow 的信息
为了开始学习 Kubeflow,让我们从 Google 的课程开始,该课程专注于部署机器学习模型。现在这个课程只有一个部分专门讲解 Kubeflow,但希望它足够。
如果 Google 的课程不适合,那么Amina A关于如何开始使用 Kubeflow 的文章应该有助于补充。文章中讲述了几个值得深入研究的其他资源。因此,我期待着解析这些内容。
想象一下在任何地方、任何设备上运行机器学习训练和推理堆栈,几乎无需配置……
amina-alsherif.medium.com)
5.Azure ML
Azure Machine Learning (Azure ML) 是一个用于创建和管理机器学习解决方案的云服务。它结合了 SDK 和提供了一个 Azure Machine Learning 的网页门户,支持低代码和无代码的模型训练、部署和资产管理选项。
现在,够了营销。我对 Azure ML 提供的一些低代码解决方案方法很感兴趣。
我学到的第一个工具是 SSIS,它有类似的感觉。这是一个拖放自动化解决方案。显然,重点更多在于 ETL 和数据管道。那么我应该从哪里开始呢?
首先,我总是尝试寻找由实际公司支持或开发的课程。
微软有一个课程,旨在帮助准备名为 AI-900: Microsoft Azure AI Fundamentals 的认证。
本课程的目的是教授在 AI 基础考试领域中评估的核心概念和技能。它们似乎涵盖了 Azure 提供的自动化机器学习,以及回归、分类和聚类。
最后,看看他们如何部署这些模型将会很有趣。
最后,我通常喜欢挑选一些文章,看看其他人和创作者在做什么。在这种情况下,我打算查看 Toptal 如何使用 Azure ML 预测燃气价格。
Azure 教程:使用 Azure 机器学习工作室预测燃气价格
6.DataRobot
DataRobot 是一个 AI 自动化工具,允许数据科学家自动化部署、维护或构建 AI 的端到端过程。这个框架由开源算法驱动,这些算法不仅在云上可用,也可以在本地使用。DataRobot 允许用户在短短十个步骤中轻松快速地提升他们的 AI 应用程序。这个平台包括关注于提供价值的赋能模型。
DataRobot 不仅适用于数据科学家,还适用于希望在不学习传统数据科学方法的情况下维护 AI 的非技术人员。因此,数据科学家现在可以使用 DataRobot 自动化整个过程,而不必花费大量时间开发或测试机器学习模型。
这个平台最棒的部分是它的普及性。你可以通过多种方式在任何设备上随时访问 DataRobot,以满足你的业务需求。
MLOps 入门任务
在这个课程中,重点将是提供使用 MLOps 的基础。但在这一点上,我假设我已经知道这些了。因此,我真的希望 DataRobot 能提供比仅仅了解 MLOps 基础更多的内容。
特别是,我希望它能涵盖如何实际使用 DataRobot。
这似乎在第二个课程中得到了更多的涵盖,该课程介绍了如何使用 MLOps 部署 DataRobot AutoML 模型。你将学习不同的部署选项,以及如何使用 MLOps 中的不同组件来部署、监控、管理和治理模型。
我会告知你!
DataRobot 白皮书
DataRobot 还整理了一份很有视觉吸引力的 PDF,似乎涵盖了如何最好地利用 DataRobot 的相当多内容。
此外,我还可以将其精简成一页有趣的文档。
7. 下一步——机器学习与 MLOps
我预见 MLOps 在未来 2-3 年内会真正兴起。
是的,如果你在数据领域工作,你可能已经对这个概念有所了解。然而,我觉得在大公司开始大量采用之前,还需要一段时间。
我遇到过一些公司在关注这些工具。总体而言,大多数公司仍在尝试管理他们的数据管道。这就是为什么你可能会更倾向于学习更多关于数据工程的内容而非 MLOps。
祝你好运!
阅读/观看接下来内容
-
121 个资源帮助你找到数据科学的梦想工作
-
如何成为数据工程师——以及如何知道这是否适合你
-
获取你的第一个客户
关于我
我在职业生涯中专注于各种形式的数据。我致力于开发算法以检测欺诈、减少患者再入院率以及重新设计保险公司政策,以帮助降低整体医疗成本。我还帮助开发了营销和 IT 运营的分析,以优化员工和预算等有限资源。我在数据科学和工程问题上提供私人咨询,既可以单独工作,也可以与名为 Acheron Analytics 的公司合作。我有处理技术问题的实践经验,同时也帮助领导团队制定战略,以最大化他们的数据。
在社交网络上与我联系
✅ YouTube: www.youtube.com/channel/SeattleDataGuy
✅ 网站: www.theseattledataguy.com/
✅ LinkedIn: www.linkedin.com/company/18129251
✅ 个人 LinkedIn: www.linkedin.com/in/benjaminrogojan/
✅ FaceBook: www.facebook.com/SeattleDataGuy
简介: Ben Rogojan 是一位数据科学和数据工程解决方案架构师,专注于数据架构和统计学。他专注于开发端到端的数据解决方案,帮助将数据从原始格式转化为数据产品和分析。他曾为医疗保健、金融、SaaS 和技术领域的客户提供项目服务,并在大型科技公司工作过。他在网络上保持强大的存在,为数据工程师和那些对进入数据工程职业路径感兴趣的人创建内容,并在线上被称为“Seattle Data Guy”。
原文。经许可转载。
相关内容:
-
何时重新训练机器学习模型?运行这 5 个检查来决定计划
-
将 ModelOps 纳入您的 AI 战略
-
MLOps 最佳实践
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
MLOps Is a Mess But That’s to be Expected

这听起来熟悉吗?你读到一篇文章说,做机器学习是 2022 年最好的工作,不仅需求狂热,而且薪水在行业中名列前茅。
听起来不错:工作安全和钱。这有什么不好?
你决定去学习,掌握成为机器学习工程师的技能,做一些项目来丰富你的简历,并争取到那份工作。你感觉很好。我是说,这可能有多难呢?
你记得在 Twitter 上看到有伯克利的全栈深度学习课程似乎非常好。你做了几节课,然后看到这个现代 ML 生态系统所需工具的图表:
哇。这真是要学很多东西。你用过一些这些技术,但什么是 Airflow?dBt?Weights & Biases?Streamlit?Ray?
你有点沮丧。经过一天的课程材料审查后,你决定从专家那里获得一些激励。
风险投资家总是善于考虑大局,描绘美好的前景,让人们感到兴奋。
你记得那位风险投资人Matt Turck总是会做一些关于当前 AI 热门的年度回顾。
新兴的炫酷技术。那总能让你比波士顿动力的演示视频更兴奋。
所以你查看了他 2021 年的回顾讨论机器学习和数据领域的情况。
这是你看到的第一张图片:

这究竟是什么鬼?
你关闭浏览器,倒上一杯苏格兰威士忌,思索生活的无常。
今天,机器学习仍然是最受关注和推崇的技术浪潮之一,承诺将彻底改变社会的每一个角落。
尽管如此,这个生态系统依然处于狂热的状态。
每周都有新的基础科学进展。初创公司和企业将新的开发工具投入市场,试图捕捉被许多人猜测为 2025 年市场价值在$40-120 billion之间的份额。
事情发展迅猛而激烈。
然而,如果你刚刚进入这个讨论,你如何理解这一切呢?
在这篇文章中,我想重点讨论今天机器学习操作(MLOps)的现状,我们现在的位置,以及未来的方向。
作为在像 Amazon Alexa 这样的 AI 先进组织工作过的从业者,同时还经营着一个 机器学习咨询公司,我亲身经历了将机器学习应用于现实世界中的种种考验与磨难。
我真的相信机器学习有很多值得乐观的地方,但这条路并非没有一些小障碍。
因为 Google Analytics 告诉我约 87% 的读者会在这个引言后离开,这里是给忙碌读者的 TLDR。
TLDR: 目前 MLOps 在工具、实践和标准方面处于非常混乱的状态。然而,考虑到我们仍处于更广泛企业机器学习采纳的早期阶段,这种状态是可以预期的。随着这一转型在未来几年继续发展,预计混乱将会平息,同时基于 ML 的价值将变得更加普遍。
我们开始吧。
名称背后的意义
让我们先从一些定义开始。
MLOps 指的是一套将机器学习系统部署并可靠维护于生产环境中的实践和工具。简而言之,MLOps 是机器学习进入和存在于现实世界的媒介。
这是一门存在于 devops、数据科学和软件工程交汇处的多学科领域。
尽管 AI 研究中仍有令人兴奋的新进展,但今天我们正处于机器学习的部署阶段。
在 Gartner 的炒作周期范式中,我们正逐渐进入启蒙坡度,我们已经超过了 AGI 的恐慌宣传和 Her 的承诺,组织现在开始提出关于如何最大化机器学习投资的严肃操作问题。
目前的状态
目前 MLOps 的状态非常混乱,工具的种类繁多,犹如亚马逊雨林中的珍稀物种。
举个例子,大多数从业者都会同意,在生产环境中监控你的机器学习模型是维护一个稳健、高效架构的关键部分。
然而,当你开始选择供应商时,我可以在不费吹灰之力的情况下列出 6 个不同的选项:Fiddler、Arize、Evidently、Whylabs、Gantry、Arthur 等。我们甚至还没提到那些纯数据监控工具。
不要误解我:有选项是好的。但这些监控工具是否真的如此有区别,以至于我们需要 6 个以上的工具?即使你选择了一个监控工具,你仍然需要知道跟踪哪些指标,这通常高度依赖于上下文。
这进一步引出了一个问题,监控市场是否真的如此庞大,以至于这些都是十亿美元的公司?
至少在监控方面,人们通常对这些公司试图掌控机器学习生命周期的确切部分有一个普遍的共识。堆栈的其他部分则没有那么明确地被理解和接受。
为了说明这一点,许多公司现在倾向于将他们为 MLOps 堆栈构建的每一个新工具称为某种商店。我们从模型商店开始。接着,特征商店出现了。现在我们还有度量商店。哦,还有评估商店。
我的一般看法是,机器学习社区在为数据库创造同义词方面特别有创造力。
更严肃的看法是,整个领域仍在标准化全面构建 ML 管道的最佳方式。围绕最佳实践达成共识将是一个 5-10 年以上的转型过程。
在MLOps 社区的从业者之间进行的一次特别引人入胜的讨论中,Lina提出了一个观点,即ML 堆栈大致上和后端编程开发堆栈一样普遍。
那种观察非常敏锐,认为经典的ML 堆栈仍然没有明确定义。
从这个角度来看,当我们考虑 MLOps 管道的阶段时,与其像famous Sculley paper中的清晰架构图,不如说我们现在有了我称之为 MLOps Amoeba™的东西。
我们对很多正确的部分有一个大致的认识,但真正的关注点分离仍在发展中。
因此,MLOps 工具公司往往进入市场时解决某个特定的细分市场,然后不可避免地开始像变形虫一样扩展到周围的架构职责。
我相信,这种不断变化的工具景观和新的界限对于领域中的新手尤其困难。现在是进入 MLOps 领域的艰难时期。
我把今天的 MLOps 比作现代网页开发的状态,新工具不断进入市场,你可以使用大约 300 种不同的框架组合来构建一个简单的Hello World网页应用。
在这种情况下,我对新手的建议是:
-
寻求更有经验的个人来帮助你考虑选择,思考不同的技术,并成为“愚蠢”问题的倾听者。
-
仔细考虑你要解决的问题和解决问题所需的基本方法论,而不是过于分心于炫目的工具或平台。
-
花大量时间构建真实系统,以便你可以亲身体验不同工具解决的问题。
并且要认识到没有人拥有所有答案。我们仍在摸索正确的做法。
你可以从合理规模的机器学习开始。
另一点值得注意的是,很容易给人一种企业中的机器学习成熟度非常先进的印象。
根据我的经验以及与我交谈的其他从业者的经验,企业机器学习成熟度的现实远比我们根据工具和资金环境所认为的要温和得多。
事实上,只有少数几个超级先进的 AI 首创企业拥有强大的机器学习基础设施来处理其 PB 级的数据。
尽管大多数公司没有那种规模的数据,因此没有那些类型的机器学习需求,但以 AI 为首的企业最终会定义工具和标准的叙事。
实际上,仍有大量杰出的公司在摸索自己的机器学习战略。
这些“合理规模的机器学习”公司(使用Jacopo 的术语),本身就是出色的企业(涉及自动化、时尚等不同领域),拥有良好的专有数据集(数百 GB 到 TB),但在机器学习应用上仍处于早期阶段。
这些公司有望通过机器学习获得首次成功,通常有相对容易获得的成果来实现这些成功。它们甚至不一定需要这些超级先进的亚毫秒延迟的超实时基础设施来开始提升其机器学习水平。
我相信,在未来 10 年中,MLOps 面临的一个大挑战将是帮助这些类型的企业上手。
这需要构建适合机器学习稀缺的工程团队的友好工具,改善尚未准备好进行高级数据工作的内部基础设施,并获得关键业务利益相关者的文化认同。
MLOps 可以从 DevOps 的经验中学到什么
为了帮助我们理解 MLOps 的进展阶段以及未来的方向,考虑 DevOps 运动的类比是有帮助的。
企业对 DevOps 实践的采纳是一个历时数十年的转型。在 DevOps 引入之前,软件工程和 IT(或运维)团队作为功能上独立的实体运作。这种孤立的组织造成了产品发布和更新的巨大低效。
谷歌是最早认识到这种低效的组织之一,在 2003 年引入了站点可靠性工程师的角色,以帮助弥合开发人员和运维人员之间的差距。
DevOps 的原则在 2009 年由 John Allspaw 和 Paul Hammond 在一场重要演讲中进一步确立,演讲中主张企业应雇佣“像开发者一样思考的运维人员”和“像运维人员一样思考的开发者”。
随着 DevOps 的成熟,我们引入了诸如持续集成(和部署)等概念,以及一些已经成为全球开发团队常用的工具。
好的,历史课讲完了,我们怎么把这些联系起来呢?
DevOps 是理解 MLOps 的一个有趣案例,原因有很多:
-
这突显了企业采纳所需的漫长转型过程。
-
这显示了该运动既包括工具的进步,也包括组织文化心态的变化。两者必须携手前进。
-
这突显了对具备cross-functional skills and expertise的从业者的迫切需求。孤立无用。
目前的 MLOps 处于一种混乱状态,但这是意料之中的。如何最好地定义关于基础设施、开发和数据问题的清晰抽象仍不清楚。
我们将采用新的实践和方法论。工具会不断变化。存在很多问题,作为一个社区,我们正在积极地假设答案。这个运动仍处于初期阶段。
强预测,弱持有
现在我们已经讨论了现状,我想花些时间描述一下未来值得期待的事物。
这些未来的趋势是许多与 ML 从业者讨论的轶事性组合,以及我最兴奋的内容的适度添加。
从技术和架构的角度来看,有几个方面我们将继续看到投资:
-
闭环机器学习系统。现在许多机器学习系统仍然主要遵循从数据源到预测的单向信息流。但这会导致过时和根本破碎的流程。我们需要关闭这些环路,以使流程变得更智能和灵活。实现这一目标的第一步是拥有一个好的监控系统。虽然我在本文的早期部分批评了监控,但我确实认为我们应该继续考虑对系统的监控,包括预测建模层以及更上游的数据层。这是Shreya在这方面做了大量优秀写作的内容。
-
机器学习的声明式系统。近年来,我们已经看到机器学习建模工具随着像PyTorch这样的软件以及像HF Transformers这样的高层库的出现而逐渐商品化。这对该领域来说是一个受欢迎的步骤,但我相信我们还能做得更多。使某事物民主化涉及开发隐藏不必要实现细节的抽象,以便下游用户使用。声明式机器学习系统是这一建模演变中最令人兴奋的下一个阶段之一。让全新一代领域专家将机器学习应用于他们的问题需要一些工具,这些工具类似于Webflow 和其他工具对网页开发所做的工作。
-
实时机器学习。机器学习系统本质上是数据驱动的,因此对于大多数应用来说,拥有最新的数据可以提供更准确的预测。实时机器学习可以有很多含义,但一般来说,拥有更新的模型更好。这是我们在接下来的几年中将继续看到投资的领域,因为构建实时系统是一个困难的基础设施挑战。我还要补充一点,我不认为许多公司(特别是那些在上面提到的“合理规模”的公司)需要实时机器学习才能获得初步胜利。但最终我们会达到这样的阶段,从第一天起集成这些类型的系统将不再是一个巨大的负担。Chip在这方面做得非常好。
-
更好的数据管理。数据是每个机器学习系统的命脉,在一个机器学习驱动大多数企业功能的未来世界中,数据是每个组织的命脉。然而,我认为我们在开发工具来管理数据生命周期,从来源和策划到标记和分析,方面还有很长的路要走。不要误解我的意思:我和其他人一样喜欢 Snowflake。但我相信我们可以做得比组织 VPN 中的少数几个孤立表更好。我们如何才能让数据从业者更容易回答关于他们拥有什么数据、他们可以用数据做什么以及他们还需要什么的问题?数据发现工具 是解决这些问题的初步步骤。在我看来,当我们考虑到非结构化数据时,工具的不足尤为明显。
-
将商业洞察工具与数据科学/机器学习工作流程融合。围绕商业洞察的工具一直比数据科学的工具更为成熟,更多成熟的原因之一在于,数据分析师的产出往往更容易被商业领袖看到,因此商业智能工具的投资被认为对组织的底线更为关键。随着数据科学产出越来越直接地为组织创造价值,我相信我们将看到这两个领域之间的协同作用不断增加。归根结底,机器学习是一种能够实现更高效操作、改善指标和更好产品的工具。从这个角度来看,它的目标与商业智能的目标并没有太大区别。
现在,从技术层面退一步,以下是我们未来将看到的一些元趋势:
-
人才短缺仍然严重。对许多组织来说,如今很难吸引优质的机器学习人才。当大型科技公司为 AI 人才开出中位数年薪$330K/year时,你可以想象招聘领域的竞争有多激烈。供给要多年才能最终与需求平衡。在此期间,这种短缺将继续证明公司对 MLOps 工具的投资是合理的:如果你无法雇佣机器学习工程师,就尝试用工具替代他们!
-
围绕端到端平台的整合越来越紧密。三大云服务提供商(AWS、GCP、Azure)以及其他专门的公司(DataRobot、Databricks、Dataiku)都在积极尝试掌控从头到尾的机器学习工作流。虽然我认为目前没有任何端到端解决方案已经准备好进入主流市场,但这些公司有几个优势:1)大量资本用于吞并(抱歉,收购)较小的公司,2)使用方便,但灵活性不足且成本较高,3)品牌惯性(即“买 IBM 不会被解雇”症候群)。
-
机器学习思维的文化采纳。随着我们获得越来越先进的工具,组织将围绕其产品和团队采纳机器学习的思维方式。在许多方面,这也呼应了DevOps 原则被采纳时发生的文化转变。我们可以期待看到一些变化,包括更全面的系统思维(打破孤岛)、增强产品中的反馈循环,以及培养持续实验和学习的心态。
哇,这篇文章很长。如果你还在阅读,谢谢你。
虽然今天的 MLOps 仍然混乱,但我对机器学习为社会带来的价值仍然充满乐观。在许多领域,数据驱动的技术能够带来效率提升、洞察和改善结果。
所有的要素都在逐步到位:不断发展的工具链来构建系统,使其不断改进,教育 资源 帮助培训下一波从业者,以及越来越广泛地认识到对机器学习的有意识投资对组织的重要性。
未来光明。
感谢 Goku Mohandas、Shreya Shankar、Eugene Yan、Demetrios Brinkmann 和 Sarah Catanzaro 对本帖早期版本提供的深刻和周到的反馈。好的内容归他们所有,任何糟糕的笑话都是我的。
Mihail Eric 是一名机器学习研究员以及 Confetti 的创始人。
原文。经允许转载。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
MLOps 思维方式:始终保持生产就绪
原文:
www.kdnuggets.com/2023/07/mlops-mindset-always-productionready.html
机器学习(ML)在许多领域的成功带来了新的挑战——特别是需要持续训练和评估模型,并不断检查训练数据的漂移。持续集成和部署(CI/CD)是任何成功软件工程项目的核心,通常被称为 DevOps。DevOps 帮助简化代码演变,支持各种测试框架,并提供灵活性以实现对不同部署服务器(开发、预发布、生产等)的选择性部署。
与机器学习相关的新挑战扩展了传统的 CI/CD 范畴,还包括现在常被称为持续训练(CT)的内容,这一术语最早由谷歌提出。持续训练要求机器学习模型在新的数据集上进行持续训练,并在部署到生产环境之前进行评估,以满足预期,还需支持更多机器学习特定功能。如今,在机器学习背景下,DevOps 正逐渐被称为 MLOps,包括 CI、CT 和 CD。
MLOps 原则
所有产品开发都基于一定的原则,MLOps 也不例外。以下是三个最重要的 MLOps 原则。
-
持续 X: MLOps 的重点应放在演变上,无论是持续训练、持续开发、持续集成还是任何持续演变/变化的内容。
-
跟踪一切: 由于机器学习的探索性特征,需要像科学实验一样跟踪和收集所有发生的事情。
-
拼图方法: 任何 MLOps 框架都应支持可插拔组件。然而,重要的是要找到正确的平衡:过多的可插拔性会导致兼容性问题,而过少则限制了使用。
牢记这些原则,让我们确定治理良好 MLOps 框架的关键要求。
MLOps 要求
如前所述,机器学习驱动了 Ops 的一系列独特要求。
-
可重复性: 使机器学习实验能够重复相同的结果,以验证性能。
-
版本控制: 从各个方向维护版本控制,包括:数据、代码、模型和配置。一种执行“数据-模型-代码”版本控制的方法是使用如 GitHub 之类的版本控制工具。
-
管道化: 尽管基于有向无环图(DAG)的管道在非 ML 场景(如 Airflow)中经常使用,ML 带来了自己的管道需求以实现持续训练。管道组件的可重用性对于训练和预测确保特征提取的一致性,并减少数据处理错误。
-
编排与部署: ML 模型训练需要一个涉及 GPU 的分布式机器框架,因此,在云中执行管道是 ML 训练周期的固有部分。基于各种条件(指标、环境等)的模型部署在机器学习中带来了独特的挑战。
-
灵活性: 使选择数据源、选择云服务提供商和决定不同工具(数据分析、监控、ML 框架等)变得灵活。灵活性可以通过提供外部工具插件选项和/或提供定义自定义组件的能力来实现。一个灵活的编排与部署组件可以确保云中立的管道执行和 ML 服务。
-
实验跟踪: 对于 ML 而言,实验是任何项目的隐性组成部分。经过多轮实验(即对架构或架构中的超参数进行实验)后,ML 模型会成熟。记录每次实验以供将来参考对于 ML 是至关重要的。可以使用实验跟踪工具来确保代码和模型版本控制,而类似 DVC 的工具则确保代码-数据版本控制。
实际考虑
在创建 ML 模型的兴奋中,通常会忽略一些特定的 ML 卫生问题:如初步数据分析、超参数调整或预处理/后处理。在许多情况下,项目开始时缺乏 ML 生产思维,这会导致项目后期出现意外情况(内存问题、预算超支等),特别是在生产阶段,导致重新建模和市场发布时间的延迟。但从 ML 项目开始就使用 MLOps 框架可以及早解决生产考虑问题,并强制实施系统化的方法来解决机器学习问题,如数据分析、实验跟踪等。
MLOps 还使得在任何给定时刻都能准备好生产变得可能。这对于需要更短市场发布时间的初创企业尤其重要。通过提供编排与部署方面的灵活性,MLOps 使得通过预定义编排器(如 github action)或部署器(如 MLflow、KServe 等)来实现生产就绪成为可能,这些都是 MLOps 管道的一部分。
现有的 MLOps 框架
云服务提供商如 Google、Amazon、Azure 提供了自己的 MLOps 框架,可以在其平台上使用,或作为现有机器学习框架(如 Tensorflow 框架中的 TFX 管道)的一部分。这些 MLOps 框架易于使用,功能全面。
使用来自云服务提供商的 MLOps 框架会限制组织在其环境中使用 MLOps。对于许多组织来说,这成为了一个大限制,因为云服务的使用取决于客户的需求。在许多情况下,需要一个在选择云提供商方面具有灵活性,并且拥有 MLOps 大部分功能的框架。
开源 MLOps 框架在这种情况下非常有用。ZenML、MLRun、Kedro、Metaflow 是一些广泛使用的知名开源 MLOps 框架,它们各有其优缺点。这些框架在选择云提供商、编排/部署和机器学习工具方面都提供了良好的灵活性。选择任何一个开源框架取决于特定的 MLOps 需求。然而,所有这些框架都足够通用,可以满足各种需求。
根据对这些开源 MLOps 框架当前状态的经验,我推荐如下:

早期采用 MLOps
MLOps 是 DevOps 的下一次演变,汇集了来自不同领域的人:数据工程师、机器学习工程师、基础设施工程师等。未来我们可以期待 MLOps 变得低代码,类似于我们今天在 DevOps 中看到的情况。尤其是初创公司应该在开发早期就采纳 MLOps,以确保更快的市场时间,以及它带来的其他好处。
Abhishek Gupta 是 Talentica Software 的首席数据科学家。在他目前的角色中,他与许多公司紧密合作,帮助他们在产品线中应用 AI/ML。Abhishek 是印度科学学院(IISc Bangalore)的校友,已有超过 7 年的 AI/ML 和大数据领域的工作经验。他在通信网络和机器学习等多个领域拥有许多专利和论文。
我们的三大课程推荐
1. Google 网络安全证书 - 加入网络安全职业的快速通道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关话题
MLOps:模型监控 101
原文:
www.kdnuggets.com/2021/01/mlops-model-monitoring-101.html
评论
作者 Pronojit Saha 和 Dr. Arnab Bose,Abzooba

图 1:机器学习工作流(图片来源于 martinfowler.com,2019)
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
背景
机器学习模型正在驱动一些对企业至关重要的决策。因此,这些模型在部署到生产环境中后,必须确保它们在最新数据的背景下仍然具有相关性。如果数据发生偏差,例如生产中的数据分布可能与训练时的数据不同,模型可能会失去上下文。此外,生产数据中的某个特征可能变得不可用,或者模型可能不再相关,因为现实世界环境可能发生了变化(例如 Covid19),或者更简单地说,用户行为可能发生了变化。因此,监控模型行为的变化以及推理中使用的最新数据的特征至关重要。这确保了模型在训练阶段承诺的性能保持相关和/或真实。
如下图 2 所示,这是一个模型监控框架的实例。其目标是跟踪模型在各种指标上的表现,详细内容将在接下来的部分中讨论。但首先,让我们理解模型监控框架的动机。


图 2:模型监控框架示意图(图片由作者提供)
动机
反馈循环在生活和商业的各个方面都扮演着重要角色。反馈循环很简单易懂:你生产一些东西,测量生产信息,并利用这些信息来改善生产。这是一个持续的监控和改进的循环。任何具有可测量信息和改进空间的事物都可以纳入反馈循环,机器学习模型自然也能从中受益。
一个典型的机器学习工作流包括数据摄取、预处理、模型构建与评估,最后是部署。然而,这个过程缺少一个关键方面,即反馈。因此,“模型监控”框架的主要动机是创建一个在部署后返回模型构建阶段的重要反馈循环(如图 1 所示)。这有助于机器学习模型不断自我改进,通过决定是更新模型还是继续使用现有模型。为了做出这个决定,框架应该在下面描述的两种可能场景下跟踪和报告各种模型指标(详情见“指标”部分)。
-
场景 I: 训练数据可用,框架在训练数据和生产(推理)数据上计算所述模型指标,并进行比较以做出决定。
-
场景 II: 训练数据不可用,框架仅基于部署后可用的数据计算所述模型指标。
下表列出了模型监控框架在两种场景下生成所述指标所需的输入。

根据适用的场景,下一节中突出显示的指标被计算出来,以决定生产中的模型是否需要更新或其他干预。
指标
如下图 3 所示,提出了一种模型监控指标堆栈。它根据指标对数据和/或机器学习模型的依赖性定义了三种广泛的指标类型。一个理想的监控框架应包含所有三个类别中的一到两个指标,但如果存在权衡,则可以从基础开始构建,即从操作指标开始,然后随着模型的成熟逐步增加。此外,操作指标应实时监控,或至少每天监控,而稳定性和性能指标可以在每周或更长时间框架内进行监控,具体取决于领域和业务场景。

图 3:模型监控指标堆栈(作者提供)
1. 稳定性指标 — 这些指标帮助我们捕捉两种类型的数据分布变化:
a) 先验概率变化 — 捕捉预测输出和/或因变量在训练数据和生产数据(场景 I)之间,或生产数据的不同时间段(场景 II)之间的分布变化。这些指标的示例包括人口稳定性指数(PSI)、发散指数(概念漂移)、错误统计(详细信息和定义将在本系列下一篇文章中跟进)
b) 协变量漂移 — 捕捉训练数据和生产数据(情景 I)或生产数据的不同时间段(情景 II)之间的每个自变量的分布漂移,如适用。这些指标的示例包括特征稳定性指数(CSI)和新颖性指数(详细信息和定义将在本系列的下一篇文章中介绍)
2. 性能指标— 这些指标帮助我们检测数据中的概念漂移,即识别自变量与因变量之间的关系是否发生了变化(例如,COVID 之后用户在节日期间的购买方式可能发生了变化)。它们通过检查现有部署模型在与训练时(情景 I)或在部署后的先前时间段(情景 II)相比时的表现好坏来实现。因此,可以决定是否重新调整部署模型。这些指标的示例包括,
a) 项目指标 如 RMSE、R-Square 等用于回归,准确率、AUC-ROC 等用于分类。
b) Gini 和 KS - 统计量:衡量预测概率/类别分离程度的统计度量(仅适用于分类模型)
3. 操作指标— 这些指标帮助我们从使用的角度判断部署模型的表现。它们独立于模型类型、数据,并且不需要像上述两个指标那样的输入。这些指标的示例包括,
a. 过去调用 ML API 端点的次数
b. 调用 ML API 端点的延迟
c. 预测时的 IO/内存/CPU 使用
d. 系统正常运行时间
e. 磁盘利用率
结论
在 MLOps 领域,模型监控已成为成熟 ML 系统的必备部分。实施这样的框架对于确保 ML 系统的一致性和稳健性至关重要,因为没有它,ML 系统可能会失去终端用户的“信任”,这可能是致命的。因此,在任何 ML 用例实施的整体解决方案架构中包含和规划这一点是极其重要的。
在系列博客的下一篇中,我们将详细介绍两个最重要的模型监控指标,即稳定性和性能指标,并将讨论如何利用这些指标构建我们的模型监控框架。
参考文献
-
D. Sato, A. Wider, C. Windheuser, 机器学习的持续交付 (2019), martinflower.com
-
M. Stewart, 理解数据集漂移 (2019), towardsdatascience.com
Pronojit Saha 是一位 AI 从业者,拥有丰富的商业问题解决经验,擅长架构设计并构建端到端的机器学习驱动的产品和解决方案,通过领导和促进跨职能团队来实现。他目前是 Abzooba 的高级分析实践负责人,除了项目执行外,他还通过培养人才、建立思想领导力和推动可扩展的流程来领导和发展实践。Pronojit 曾在零售、医疗保健和工业 4.0 领域工作。他的专长是时间序列分析和自然语言处理,并将这些技能与其他 AI 方法应用于价格优化、再入院预测、预测性维护、基于方面的情感分析、实体识别、主题建模等用例。
Dr. Arnab Bose 是 Abzooba 的首席科学官,同时也是芝加哥大学的兼职教员,教授机器学习和预测分析、机器学习操作、时间序列分析与预测以及健康分析等课程,属于分析学硕士项目。他是具有 20 年预测分析行业经验的资深人士,喜欢利用结构化和非结构化数据来预测和影响医疗保健、零售、金融和运输领域的行为结果。他当前的关注领域包括利用机器学习进行健康风险分层和慢性疾病管理,以及机器学习模型的生产部署和监控。
相关:
-
MLOps – “为什么需要它?”和“它是什么”?
-
使用 MLflow 在 Databricks 上进行模型实验、跟踪和注册
-
数据科学与 Devops 相遇:使用 Jupyter、Git 和 Kubernetes 进行 MLOps
更多相关内容
MLOps 和 ModelOps:区别是什么,为什么重要
评论
作者:Stu Bailey,ModelOp 联合创始人及首席企业 AI 架构师。
你知道吗,约有一半开发的 AI 模型实际上并没有投入生产?如果你想了解原因,并防止数据科学家的时间和其他资源在你的组织中被浪费,那么了解 MLOps 和 ModelOps 之间的区别是很重要的。这两个术语并不相同,但常常被互换使用。对 MLOps 和 ModelOps 特定角色和价值的不了解削弱了企业 AI 项目的价值。了解 MLOps 和 ModelOps 之间的区别很重要,因为它们各有其独特的作用,并不能相互替代。


本博客解决以下问题:
-
MLOps 和 ModelOps 有什么区别
-
各自的用途是什么?
-
谁在使用它们?
-
你的组织需要哪个?(这是个伪问题,你可能需要两者。)
-
使用 MLOps 和 ModelOps 的价值是什么?
理解和重视 ModelOps 和 MLOps 之间的区别很重要,因为虽然两者都需要,但只有其中之一能完全解决拖慢近三分之二企业 AI 项目的运营和治理过程问题(2021 年 ModelOps 状态报告)。
MLOps 和 ModelOps 之间的主要区别
MLOps 帮助数据科学家在数据科学过程中快速实验和部署 ML 模型。它是像 Amazon Sagemaker、Domino Data Lab 和 DataRobot 这样的成熟和不断成熟的数据科学平台的一个特性。
ModelOps 是针对所有生产中的 AI 和分析模型的企业操作和治理,确保所有模型的独立验证和问责,以便无论这些模型如何创建,都能进行对业务产生影响的决策。ModelOp Center 等 ModelOps 平台自动化了模型操作的各个方面,无论模型的类型、开发方式或模型的运行位置如何。

各自的用途及使用者
MLOps 工具和功能用于开发机器学习(ML)模型。包括 ML 模型的实际编码、测试、训练、验证和重新训练。数据科学家负责模型开发,与 DataOps 和数据分析团队紧密合作,以识别模型所需的适当数据和数据集。数据科学家通常与业务线对齐,并专注于特定业务单元或项目的目标。
ModelOps 平台和功能用于确保生产中的任何和所有模型的可靠和最佳结果。包括管理生产中的所有模型方面,例如盘点生产中的模型,确保生产模型提供可靠的决策,并遵守所有监管、合规和风险要求及控制。CIO 和 IT 运营部门与业务线合作,负责建立和实施满足企业需求的 ModelOps 平台。
MLOps 和 ModelOps 的价值
MLOps 和 ModelOps 是互补的解决方案,而非竞争关系。ModelOps 解决方案无法构建模型,而 MLOps 无法在整个企业生命周期中管理和治理生产模型。
一些 MLOps 解决方案提供有限的管理能力,但当企业开始扩大 AI 工作并统一执行风险和合规控制时,这些限制往往变得明显。此外,“经过验证”的做法是开发和生产操作之间要有检查和制衡,这适用于每个开发并投入生产的模型。历史已经证明,“学生自己评分”或“狐狸看守鸡舍”是不行的。
ModelOps 平台自动化模型的风险、监管和操作方面,并确保模型可以被审计和评估其技术合规性、商业价值及业务和操作风险。通过将这些企业能力与 MLOps 工具的效率结合,企业可以利用其 MLOps 工具的投资,建立一个加速、扩展和治理企业 AI 的基础平台。
简介: Stu Bailey 是 ModelOp 的首席企业 AI 架构师。他是一位技术专家和企业家,专注于分析和数据密集型分布式系统已有二十多年,帮助大型非数字化企业扩大和管理其 AI 计划。Stu 是 Infoblox (NYSE:BLOX) 的创始人和最近的首席科学家。在多年的成功产品市场推广过程中,Stu 获得了多项专利和奖项,并帮助推动了分析和分布式系统控制的新兴标准。在担任国家数据挖掘中心技术负责人期间,Stu 首先开创了一些使用模型交换格式的分析应用。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
MLOps - “为何需要?” 和 “它是什么?”
原文:
www.kdnuggets.com/2020/12/mlops-why-required-what-is.html
评论
由 Arnab Bose(首席科学官)和 Aditya Aggarwal(高级分析实践负责人,Abzooba)
MLOps 动机
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
数据科学家构建的机器学习(ML)模型仅占企业生产部署工作流中的一小部分,如下图 1 所示 [1]。为了将 ML 模型投入运营,数据科学家需要与多个其他团队紧密合作,如业务、工程和运营团队。这在组织层面上代表了沟通、协作和协调方面的挑战。MLOps 的目标是通过成熟的实践来简化这些挑战。此外,MLOps 带来了敏捷性和速度,这在当今数字世界中是基石。

图 1: 现实世界的机器学习系统仅有一小部分由 ML 代码组成,如图中间的小框所示。所需的外围基础设施广泛且复杂。
MLOps 挑战与 DevOps 类似
机器学习模型运营化的挑战与软件生产化有很多共同之处,而 DevOps 已经证明了自己在这方面的有效性。
因此,采纳 DevOps 的最佳实践 是帮助数据科学家克服软件生产化常见挑战的明智方法。例如,DevOps 提倡的敏捷方法论相比于瀑布方法论,能显著提升效率。表 1 中列出了 MLOps 中使用的额外 DevOps 实践。
表 1: MLOps 利用 DevOps。
| 机器学习模型运营化挑战 | 来自 DevOps 的解决方案 |
|---|---|
| 1) 持续集成和持续交付(CI/CD): 设置一个流水线,以便更新能够准确、安全、无缝地持续构建并准备好生产。 | 使用 CI/CD 框架 来构建、测试和部署软件。它提供了可重复性、安全性和代码版本控制的好处。 |
| 2) 更长的开发到部署生命周期:数据科学家开发模型/算法并将其交给运营部门部署到生产环境中。缺乏协调和不当的交接导致了延迟和错误。3) 团队之间沟通不畅导致最终解决方案的延迟: 机器学习解决方案的评估通常在项目生命周期的末期进行。由于开发团队通常各自为政,解决方案对其他利益相关者来说变成了黑箱。缺乏中间反馈使情况更糟。这些都在时间、精力和资源方面带来了重大挑战。 | 敏捷方法 通过在初始阶段就强制执行端到端的管道设置来解决这个协调问题。敏捷方法将项目划分为若干个冲刺。在每个冲刺中,开发者交付准备好部署的增量特性。每个冲刺的输出(通过管道制作)从项目的早期阶段开始对每个成员可见。因此,最后一分钟惊喜的风险减少,而早期反馈成为一种常见做法。在行业术语中,这对协调问题做了“左移”。 |
MLOps 挑战与 DevOps 的不同
根据行业术语,MLOps 是机器学习的 DevOps。虽然在某种程度上是正确的,但 MLOps 平台需要解决典型的机器学习挑战。
这种挑战的一个例子是数据的角色。在传统的软件工程(即软件 1.0)中,开发者编写逻辑和规则(作为代码),这些逻辑和规则在程序空间中定义明确,如图 2 所示 [2]。然而,在机器学习(即软件 2.0)中,数据科学家编写代码来定义如何使用参数解决业务问题。参数值是通过数据(如梯度下降技术)找到的。这些值可能会随着数据的不同版本而改变,从而改变代码的行为。换句话说,数据在定义输出时与编写的代码同样重要,并且二者可以独立变化。这为软件中需要定义和跟踪的模型代码增加了一层数据复杂性。

图 2:软件 1.0 与软件 2.0。
需要由 MLOps 平台处理的各种挑战列在表 2 中。
表 2:机器学习特定挑战。
| 机器学习特定挑战 | 描述 |
|---|---|
| 1) 数据和超参数版本管理 | 在传统的软件应用中,代码版本管理工具用于跟踪更改。版本控制是任何持续集成(CI)解决方案的前提条件,因为它使得完全自动化的重现成为可能。源代码中的任何更改都会触发 CI/CD 流水线来构建、测试并交付生产就绪的代码。在机器学习中,如果算法代码、超参数或数据发生变化,输出模型也可能会发生变化。虽然代码和超参数由开发人员控制,但数据的变化可能无法控制。这就需要数据和超参数版本管理的概念,除了算法代码之外。请注意,数据版本管理对于图像和音频等非结构化数据是一个挑战,而 MLOps 平台采用独特的方法来应对这一挑战。 |
| 2) 迭代开发和实验 | 机器学习算法和模型开发是迭代和实验性的。它需要大量的参数调优和特征工程。机器学习流水线与数据版本、算法代码版本和/或超参数一起工作。这些工件中的任何变化(独立)都会触发新的可部署模型版本,从而需要进行实验和度量计算。MLOps 平台跟踪这些工件的完整谱系。 |
| 3) 测试 | 机器学习需要数据和模型测试,以便尽早发现问题。a) 数据验证 - 检查数据是否干净且没有异常,新数据是否符合先前的分布。b) 数据预处理 - 检查数据是否高效且可扩展地进行预处理,避免任何训练-服务偏差 [3]。c) 算法验证 - 根据业务问题跟踪分类/回归指标,并确保算法公平性。 |
| 4) 安全性 | 生产中的机器学习模型通常是一个更大系统的一部分,其输出被应用程序消费,这些应用程序可能是已知的也可能是未知的。这带来了多种安全风险。MLOps 需要提供安全性和访问控制,以确保机器学习模型的输出仅被已知用户使用。 |
| 5) 生产监控 | 生产中的模型需要持续监控,以确保模型在处理新数据时的表现符合预期。监控的维度包括协变量偏移、先验偏移等 |
| 6) 基础设施要求 | 机器学习应用需要规模和计算能力,这转化为复杂的基础设施。例如,实验过程中可能需要 GPU,生产扩展可能需要动态进行。 |
MLOps 组件
根据 MLOps 的背景及其与 DevOps 的相似性和差异,以下描述了 MLOps 框架的不同组件,如图 3 所示。其底层工作流程通过敏捷方法论,如第二部分所示。

图 3:MLOps 框架。
-
用例发现: 这一阶段涉及业务和数据科学家之间的协作,以定义业务问题,并将其转化为通过 ML 解决的问题陈述和目标,以及相关的 KPI(关键绩效指标)。
-
数据工程: 这一阶段涉及数据工程师和数据科学家之间的合作,以从各种来源获取数据,并为建模准备数据(处理/验证)。
-
机器学习管道: 这一阶段设计和部署一个与 CI/CD 集成的管道。数据科学家使用管道进行多次实验和测试。平台跟踪数据和模型的谱系以及实验中的相关 KPI。
-
生产部署: 这一阶段涉及将系统安全无缝地部署到选择的生产服务器中,无论是公共云、本地服务器还是混合模式。
-
生产监控: 这一阶段包括模型和基础设施的监控。使用配置的 KPI(如输入数据分布的变化或模型性能的变化)对模型进行持续监控。为更多的实验设置触发器,涉及新算法、新数据和超参数,这些会生成新版本的 ML 管道。基础设施根据内存和计算需求进行监控,并在需要时进行扩展。
参考文献
-
Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V. Chaudhary, M. Young, J. Crespo, 和 D. Dennison, “机器学习系统中的隐性技术债务”,在《神经信息处理系统进展 28:神经信息处理系统年会 2015》,2015 年 12 月 7-12 日,加拿大蒙特利尔,2015 年,页 2503–2511。 [在线] 可用:
papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems -
Karpathy, "软件 2.0", 2017 年 11 月 12 日 [在线] 可用:
medium.com/@karpathy/software-2-0-a64152b37c35 -
Breck, M. Zinkevich, N. Polyzotis, S. Whang 和 S. Roy, "机器学习的数据验证",在《第 2 届 SysML 会议论文集》,美国加州帕洛阿尔托,2019 年。可用:
mlsys.org/Conferences/2019/doc/2019/167.pdf
简历: Dr. Arnab Bose 是 Abzooba 的首席科学官,并且是芝加哥大学的兼职教授,教授机器学习与预测分析、机器学习操作、时间序列分析与预测以及健康分析。他是一位拥有 20 年预测分析行业经验的资深专家,喜欢利用结构化和非结构化数据预测和影响医疗保健、零售、金融和交通领域的行为结果。他目前的关注领域包括使用机器学习进行健康风险分层和慢性病管理,以及机器学习模型的生产部署和监控。
Aditya Aggarwal 担任 Abzooba Inc. 的数据科学实践负责人。Aditya 拥有超过 12 年通过数据驱动解决方案推动业务目标的经验,专注于预测分析、机器学习、商业智能和业务战略,涉及多个行业。
相关内容:
更多相关话题
SQL、Python 和 R 一个平台
原文:
www.kdnuggets.com/2018/10/mode-analytics-sql-python-r-platform.html
赞助文章。
| 不再需要在应用程序之间跳转。Mode Studio 将 SQL 编辑器、Python 和 R 笔记本以及可视化构建器集成到一个平台中。从 SQL 查询到 Python 或 R 笔记本 将数据连接到 Mode,在我们的 SQL 编辑器中进行探索,并将结果传递给集成的 Python 或 R 笔记本,以便进行更深入的探索和可视化。创建自定义可视化,或使用我们内置的图表
使用最舒适的工具添加可视化。使用 D3、ggplot、matplotlib 或 Mode 的拖放图表工具来探索数据并传达你所发现的内容。一键分享分析结果
当你完成分析(或者即使没有完成)时,只需获取 URL 并发送给协作者和观众。你的分析将永远存在于 URL 上,观众可以在不打扰你的情况下刷新。注册 Mode Studio |
| Mode Analytics 208 Utah Street, Suite 400
旧金山,加州 94103
|
更多相关话题
最新文章
|
顶级文章
|
© 2024 Guiding Tech Media | 关于 | 联系 | 广告 | 隐私 | 服务条款
发表日期:2018 年 10 月 26 日,作者
机器学习中的模型漂移 – 如何在大数据中处理它
原文:
www.kdnuggets.com/2021/08/model-drift-machine-learning-big-data.html
评论
由 Sai Geetha 编写,她是大数据工程和数据科学领域的专家。

我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
Ted Dunning 和 Ellen Friedman 在他们的《机器学习物流》一书中提出的 Rendezvous 架构 是我在处理一个特定架构问题时找到的一个绝妙解决方案。我在寻找一种经过验证的设计模式或架构模式,帮助我以可维护和可支持的方式运行 Challenger 和 Champion 模型。在大数据世界中,rendezvous 架构显著更有用,因为你处理的是大量数据和大型数据管道。
在机器学习中,同时运行 Challenger 模型和 Champion 模型的能力是一个非常真实的需求,因为模型性能可能随着时间漂移,而你希望不断改进模型的性能,使其始终变得更好。
在我深入探讨这种架构之前,我想澄清一些我在上文中使用的术语。什么是 Champion 模型?什么是 Challenger 模型?什么是模型漂移,为什么会发生?然后,我们可以看看 rendezvous 架构本身以及它解决了哪些问题。
模型漂移
一旦你将模型投入生产,假设它会始终表现良好是一个错误。事实上,有人说 - "当你把模型投入生产的那一刻起,它就开始退化。" (注意,ML 中的“性能”通常指的是统计性能——无论是准确度、精确度、召回率、敏感性、特异性还是适用于你用例的其他指标)。
为什么会发生这种情况?模型是在一些过去的数据上训练的。它对具有相同特征的数据表现出色。然而,随着时间的推移,实际数据的特征可能不断变化,而模型对此毫无察觉。这会导致模型漂移,即模型性能退化。
例如,你训练了一个模型来检测垃圾邮件与正常邮件。模型部署后表现良好。随着时间的推移,垃圾邮件的类型不断变化,因此预测的准确性下降。这被称为模型漂移。
模型漂移可能是由于概念漂移或数据漂移。今天不讨论这些,了解模型性能不会保持恒定就足够了。因此,我们需要持续监控模型的性能。通常情况下,最好是更频繁地用更新的数据重新训练模型,或者根据性能下降的阈值进行训练。
有时,即使重新训练模型也不能进一步提高性能。这意味着你可能需要理解问题特征的变化,并用更合适的模型经历整个数据分析、特征创建和模型构建过程。
如果你可以使用挑战者模型,即使我们当前有一个模型在生产中,这个周期可以缩短。这是一个机器学习的持续改进过程,并且是非常必要的。
冠军-挑战者模型
通常,生产中的模型称为冠军模型。任何在较小试验中表现良好并准备投入生产的其他模型称为挑战者模型。这些挑战者模型被提出是因为我们假设它们有可能比冠军模型表现更好。但是我们如何证明这一点呢?
冠军模型通常会在所有输入数据上运行以提供预测。然而,挑战者模型在什么数据上运行呢?
挑战者模型可以通过两种方式进行测试。理想情况下,是在所有数据上与冠军模型并行运行挑战者模型,并比较结果。这将真正证明挑战者模型是否能够表现得更好。然而,这在大数据世界中似乎是不可行的,因此挑战者模型总是会在输入数据的一个子集上进行试验。一旦表现良好,它会逐渐推广到更多的数据上,几乎像是 alpha-beta 测试。
正如你可能知道的,在 alpha-beta 测试中,一小部分用户或输入数据(在这种情况下)会通过新的测试或挑战者流程,而其余的全部通过原始冠军流程。这种 alpha-beta 测试对某些应用程序是有效的,但在机器学习的世界中并不特别令人印象深刻。你无法在相同的数据上比较模型,因此很难自信地说哪个模型在所有数据上更好。一旦推广到所有数据上,可能会出现意外情况,模型漂移可能会比预期更早发生。
一个典型的 alpha-beta 流程如下:

数据根据某些标准(如产品类别)在两个管道之间分配。随着对 Challenger 模型性能的信心增加,这种数据分配会不断增加,逐渐倾向于 Challenger。
从数据科学家的角度来看,这并不理想。理想的是能够与 Champion 模型并行运行所有数据的 Challenger 模型。正如我之前所说,这非常昂贵。
考虑最坏的情况。如果你希望它们并行运行,你必须设置两个数据管道,这两个管道独立地运行所有步骤。
它可能看起来是这样的:

这具有巨大的工程意义,因此也会影响市场时间。随着时间推移,这种成本可能变得非常高。
主要影响之一是不断重复建立这些管道所需的时间和精力,而不确定 Challenger 模型是否会按预期表现。CI/CD 过程、部署、监控、认证机制等,都是需要考虑的一部分。此外,另一个成本是必须双倍配置的基础设施。
如果这些管道是大数据管道,这一点就更为重要。很快,你会意识到这不是一个可扩展的模型。我们确实需要看看如何摆脱并行管道,甚至摆脱 alpha-beta 测试方法。
作为推论,最佳情况是能够重复使用大量的数据管道。这个想法是最小化开发和重新部署到生产环境中的工作量。这也将确保基础设施使用的优化。这是一种思考如何优化的方式。
更理想的是能够直接插入 Challenger 模型,其余的管道就像什么都没有改变一样运行。难道这不是很棒吗?这正是Rendezvous 架构所实现的。
Rendezvous 架构
书中所描述的 Rendezvous 架构倾向于处理小规模数据的 ML。我已经对其进行了调整,以满足大数据世界及相关管道的需求,如下图所示:(书籍和另一篇文章的引用见参考部分)

现在让我逐部分解释这个架构。
第一部分:
这包括接收传入数据、清洗数据、准备数据和创建所需特征的标准数据管道。每个要部署的模型应该只有一个管道。准备好的数据应该保持一个标准接口,该接口具有该领域可能需要的所有特征,而与手头的模型无关。(我理解这并非总是可能,可能需要随着时间的推移进行逐步调整。但我们可以在需要时单独处理这一部分。)
第二部分:
这是一个类似 Kafka 的消息基础设施,通过引入异步性发挥作用。作为特征准备好的数据会被发布到消息总线上。现在,每个模型都监听这个消息总线并触发自身,用准备好的数据执行。这个消息总线使得这里的即插即用架构成为可能。
第三部分:
这是所有模型逐一部署的部分。可以部署一个新的 Challenger 模型并使其监听消息总线,随着数据流入,它可以执行。可以在这里部署任意数量的模型,而不仅仅是一个 Challenger 模型!此外,基础设施要求仅仅是额外模型的运行。无论是预模型管道还是后模型管道都不需要单独开发或部署。
如图所示,只要数据科学家认为这些 Challenger 模型足够成熟以便与真实数据进行测试,就可以有多个 Challenger 模型。
还有一个特殊的模型叫做诱饵模型。为了确保每个模型过程不被持久化负担所困扰,准备好的数据还会被所谓的诱饵模型读取,该模型的唯一任务是读取准备好的数据并进行持久化。这有助于审计目的、追踪和调试。
第四部分:
所有这些模型再次将它们的预测或分数输出到另一个消息总线上,从而避免了彼此之间的依赖。此外,这在确保模型的可插拔性而不干扰管道中的其他部分方面也发挥了重要作用。
从那里,Rendezvous 过程会获取分数并决定需要做什么,如第五部分所述。
第五部分:
这里引入了Rendezvous 过程的新概念,它有两个重要的子过程。一个即时子过程负责从接收到的众多分数中为消费者提供正确的输出,另一个过程则是将所有模型的输出持久化,以便进行进一步的比较和分析。
所以,我们在这里实现了两件事:
-
最佳输出提供给消费者。
-
所有数据都经过了所有模型,因此它们在相似情况下的性能是完全可比的。
它如何决定发送哪个模型的输出?这可以基于多个标准,比如数据的一个子集应始终来自 Challenger,另一个子集应始终来自 Champion。这几乎像是实现 alpha-beta 测试。然而,优势在于,尽管对消费者来说这听起来像是 alpha-beta 测试,但对于数据科学家而言,所有数据都经过了两个模型,因此他们可以比较两个输出,了解哪个表现更好。
另一种标准可能是输出应基于模型性能。在这种情况下,汇合过程会等待所有模型完成并发布到消息总线。然后,它会寻找最佳性能指标,并将其作为结果发送出去。
是的,另一个标准可以是时间或延迟。如果我们需要在例如 5 秒内获得结果,过程会等待模型返回的所有结果,最多 5 秒,只比较这些结果,并返回最佳数据。即使另一个模型在第 6 秒返回,可能表现更好,但也会被忽略,因为它不符合延迟标准。
但这个过程如何知道遵循哪些标准来处理哪些数据或模型呢?这可以作为第二部分输入数据的一部分传入消息总线。请注意,汇合过程也在监听这些消息,并了解如何处理与输入对应的输出。也可能有其他聪明的方式,但这是提出的其中一种方法。
结论
通过引入异步性和消息总线,引入了一种解耦的层次,带来了将模型插入到原本僵化的数据管道中的能力。
通过引入汇合过程,选择不同模型输出、持久化这些输出、比较它们的能力都被引入了。因此,现在引入或支持任何数量的新模型来处理相同的数据集似乎不再是艰巨的任务。
总结
汇合架构在各个层面提供了极大的灵活性。
-
可以使用多种标准来决定从预测过程中发送什么评分、输出或预测。这些标准可能基于延迟、模型性能或简单的时间。
-
它提供了通过汇合过程动态定义和更改这些标准的能力。你可以通过在这里引入规则引擎将其提升到另一个层次。
-
它提供了使所有数据通过所有管道或仅选择一个子集通过多个管道的能力。例如,如果你有需要预测的杂货和一般商品,杂货可以通过它们自己的冠军和挑战者模型,而一般商品,通常是销售较慢的,可以有自己的管道。
-
它还提供了同时运行多个模型的能力,而不需要重新开发或重新部署大部分的大数据管道。除了节省工作量和时间外,还优化了基础设施成本。
参考文献
-
机器学习物流 by Ted Dunning; Ellen Friedman - 第三章“机器学习的汇合架构”
-
一篇来自 towardsdatascience.com 的文章,标题为"生产中的数据科学约会架构",作者:Jan Teichmann
原文。经授权转载。
简介: Sai Geetha (@saigeethamn) 是一名建筑师,具有制定战略路线图和基于企业需求及领先技术进行创新的经验。她是一位大数据专家,具备数据科学知识,能够弥合这两个领域之间的差距,并为您企业中的任何大型数据项目带来成功。
相关:
更多相关内容
机器学习中的模型评估指标
原文:
www.kdnuggets.com/2020/05/model-evaluation-metrics-machine-learning.html
评论
预测模型已成为许多企业值得信赖的顾问,原因很充分。这些模型能够“预见未来”,而且有许多不同的方法可供选择,这意味着任何行业都能找到适合其特定挑战的方法。
当我们谈论预测模型时,我们讨论的要么是回归模型(连续输出),要么是分类模型(名义或二进制输出)。在分类问题中,我们使用两种类型的算法(依赖于生成的输出类型):
-
类别输出:像 SVM 和 KNN 这样的算法会生成类别输出。例如,在一个二分类问题中,输出将是 0 或 1。然而,如今我们有能够将这些类别输出转换为概率的算法。
-
概率输出:像逻辑回归、随机森林、梯度提升、Adaboost 等算法提供概率输出。将概率输出转换为类别输出只需创建一个阈值概率。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
介绍
数据准备和训练机器学习模型是机器学习流程中的关键步骤,但同样重要的是评估已训练模型的性能。模型在未见数据上的泛化能力是定义自适应与非自适应机器学习模型的标准。
通过使用不同的性能评估指标,我们应该能够在将模型投入生产之前提高其整体预测能力,特别是在未见数据上。
如果没有使用不同的指标对机器学习模型进行适当的评估,仅依赖准确性可能会导致模型在未见数据上部署时出现问题,进而产生较差的预测结果。
这发生是因为在这些情况下,我们的模型不是学习,而是记忆;因此,它们不能在未见数据上很好地泛化。
模型评估指标
现在让我们定义评估机器学习模型性能的评估指标,这是任何数据科学项目的重要组成部分。它旨在估计模型在未来(未见/样本外)数据上的泛化准确性。
混淆矩阵
混淆矩阵是任何二元测试的预测结果的矩阵表示,通常用于描述分类模型(或“分类器”)在一组已知真实值的测试数据上的性能。
混淆矩阵本身相对简单易懂,但相关术语可能会令人困惑。

带有 2 个类别标签的混淆矩阵。
每个预测结果可以是四种结果中的一种,具体取决于它与实际值的匹配情况:
-
真正正例(TP): 预测为真,现实中也为真。
-
真正负例(TN): 预测为假,而现实中也为假。
-
假正例(FP): 预测为真,现实中为假。
-
假负例(FN): 预测为假,现实中为真。
现在让我们通过假设检验来理解这个概念。
假设 是基于不充分证据的推测或理论,需要进一步的测试和实验。通过进一步测试,假设通常可以被证明为真或假。
零假设 是一种假设,表示假设中的两个变量之间没有统计学意义。它是研究者试图证伪的假设。
当零假设为假时,我们总是会拒绝它;当零假设确实为真时,我们会接受它。
尽管假设检验旨在提供可靠结果,但可能会发生两种类型的错误。
这些错误被称为第一类和第二类错误。
例如,当检查药物的有效性时,零假设将是药物对疾病没有影响。
第一类错误: 等同于假正例(FP)。
第一类错误涉及拒绝一个真实的零假设。
让我们回到药物用于治疗疾病的例子。如果在这种情况下我们拒绝了零假设,那么我们声称药物确实对疾病有一些效果。但如果零假设为真,那么实际上药物根本没有对抗疾病。药物被错误地宣称对疾病有积极效果。
第二类错误: 等同于假负例(FN)。
另一种错误发生在我们接受了一个错误的零假设时。这种错误被称为第二类错误,也被称为第二类错误。
如果我们回到测试药物的情景,第二类错误会是什么样的?第二类错误会发生在我们接受药物对疾病没有效果的结论,但实际上药物确实有效的情况下。
混淆矩阵的一个 Python 实现示例。

带有 3 个类别标签的混淆矩阵。
对角线上的元素表示预测标签与真实标签相等的点的数量,而对角线之外的任何内容都被分类器误标记了。因此,混淆矩阵的对角线值越高越好,表示预测正确的数量多。
在我们的案例中,分类器准确地预测了所有 13 个山鸢尾和 18 个维吉尼亚鸢尾植物。然而,它错误地将 4 个变色鸢尾植物分类为维吉尼亚鸢尾。
还有一个通常从混淆矩阵中计算出的二分类器指标列表:
1. 准确率
总体上,分类器的正确率是多少?
准确率 = (TP+TN)/总数
当我们的类别大致相等时,我们可以使用准确率,它将给出正确分类的值。
准确率是分类问题的常见评估指标。它是正确预测的数量与所有预测数量的比率。
误分类率(错误率): 总体上,它出错的频率。由于准确率是我们正确分类的百分比(成功率),因此我们的错误率(错误的百分比)可以通过以下公式计算:
误分类率 = (FP+FN)/总数
我们使用 sklearn 模块来计算分类任务的准确率,如下所示。
验证集上的分类准确率为88%。
2. 精确率
当预测为正时,模型的准确率是多少?
精确率 = TP/预测为正
当我们面对类别不平衡时,准确率可能成为评估性能的不可靠指标。例如,如果我们在两个类别 A 和 B 之间有 99/1 的分割,其中稀有事件 B 是我们的正类,我们可以构建一个通过仅仅说所有数据属于 A 类的模型来获得 99% 的准确率。显然,如果模型没有任何用于识别 B 类的功能,我们就不应该花时间去构建这个模型;因此,我们需要其他指标来避免这种情况。为此,我们使用精确率和召回率来代替准确率。
3. 召回率或灵敏度
当实际为正时,模型预测为正的频率是多少?
真阳性率 = TP/实际为正
召回率给我们提供了真实正例率 (TPR),即真实正例与所有正例的比率。
在 A 类和 B 类之间 99/1 的情况下,所有数据都被分类为 A 的模型会导致正类 B 的召回率为 0%(精确率将未定义 — 0/0)。精确率和召回率提供了一种在面对类别不平衡时评估模型性能的更好方法。它们能正确地告诉我们模型对我们的使用案例几乎没有价值。
就像准确率一样,精确率和召回率也很容易计算和理解,但需要阈值。此外,精确率和召回率仅考虑混淆矩阵的一半:

4. F1 分数
F1 分数是调和均值与精确度和召回率的调和均值,F1 分数在 1(完美的精确度和召回率)时达到最佳值,在 0 时最差。

为什么选择调和均值? 因为调和均值对列表中最小的元素有很强的偏斜,相较于算术均值,它倾向于减轻大异常值的影响,而加剧小异常值的影响。
F1 分数对极端值的惩罚更大。理想情况下,F1 分数可以在以下分类场景中作为有效的评估指标:
-
当 FP 和 FN 的成本相等时——即它们错过真正的阳性或找到假阳性——两者对模型的影响几乎相同,如我们的癌症检测分类示例中所示
-
增加更多数据不会有效地改变结果
-
TN 很高(例如洪水预测、癌症预测等)
一个 F1 分数的 Python 示例实现。

5. 特异性
当预测为否时,它有多频繁预测为否?
真负率=TN/实际否
它是真负率或真实负例与所有应被分类为负例的比例。
请注意,特异性和敏感性一起考虑了完整的混淆矩阵:

6. 接收者操作特性(ROC)曲线
测量 ROC 曲线下的面积也是评估模型的一个非常有用的方法。通过绘制真正阳性率(敏感性)与假阳性率(1 — 特异性)的关系,我们得到接收者操作特性(ROC)曲线。该曲线使我们能够可视化真正阳性率与假阳性率之间的权衡。
以下是一些好的 ROC 曲线的例子。虚线表示随机猜测(没有预测价值),作为基准;低于该线的则被认为比猜测更差。我们希望接近左上角:

一个 ROC 曲线的 Python 示例实现。

在上面的例子中,AUC 相对接近 1 且大于 0.5。完美的分类器将使 ROC 曲线沿 Y 轴,然后沿 X 轴延展。
对数损失
对数损失是基于概率的最重要的分类指标。

随着预测概率接近真实类别的零,损失呈指数增加
它衡量分类模型的性能,其中预测输入是介于 0 和 1 之间的概率值。Log loss 随着预测概率与实际标签的偏离而增加。任何机器学习模型的目标是最小化这个值。因此,较小的 log loss 更好,完美模型的 log loss 为 0。
Log Loss 的 Python 实现示例。
Logloss: 8.02
Jaccard 指数
Jaccard 指数是计算和评估分类 ML 模型准确性的一种最简单的方法之一。让我们通过一个例子来理解它。假设我们有一个标记的测试集,标签为 –
y = [0,0,0,0,0,1,1,1,1,1]
我们的模型预测的标签为 –
y1 = [1,1,0,0,0,1,1,1,1,1]

上面的维恩图展示了测试集的标签、预测标签及它们的交集和并集。
Jaccard 指数或 Jaccard 相似度系数是一种用于理解样本集之间相似性的统计量。该测量方法强调有限样本集之间的相似性,正式定义为交集的大小除以两个标记集的并集的大小,公式如下 –


因此,在我们的例子中,我们可以看到两个集合的交集等于 8(因为有八个值被正确预测),并且并集为 10 + 10–8 = 12。所以,Jaccard 指数给出的准确率为 –

因此,根据 Jaccard 指数,我们的模型的准确率为 0.66,即 66%。
Jaccard 指数越高,分类器的准确率越高。
Jaccard 指数的 Python 实现示例。
Jaccard Similarity Score : 0.375
Kolmogorov Smirnov 图表
K-S 或 Kolmogorov-Smirnov 图表衡量分类模型的性能。更准确地说,K-S 是衡量正负分布之间分离程度的指标。

观察到的和假设的分布的累计频率与有序频率绘制在一起。垂直双箭头表示最大垂直差异。
K-S 为 100,如果分数将总体划分为两个独立的组,其中一个组包含所有正样本,另一个组包含所有负样本。另一方面,如果模型无法区分正负样本,那么就像模型从总体中随机选择案例一样。K-S 将为 0。
在大多数分类模型中,K-S 值会在 0 和 100 之间,且值越高,模型在分离正负样本的能力越强。
K-S 检验也可以用于测试两个一维概率分布是否不同。这是一种非常有效的方式来确定两个样本是否显著不同。
Kolmogorov-Smirnov 的一个 Python 实现示例。

这里使用的零假设假定数据遵循正态分布。它返回统计量和 p 值。如果p 值 < alpha,我们将拒绝零假设。
Alpha 定义为在零假设(H0)为真的情况下拒绝零假设的概率。对于大多数实际应用,alpha 选择为 0.05。
增益和提升图表
增益或提升是分类模型效果的度量,计算为使用模型和不使用模型之间的结果比率。增益和提升图表是评估分类模型性能的可视化工具。然而,与评估整个数据集的混淆矩阵不同,增益或提升图表评估模型在数据部分的表现。
提升越高(即离基线越远),模型越好。
以下的增益图表,在验证集上运行,显示了使用 50%的数据时,模型包含了 90%的目标,增加更多的数据对模型中包含的目标百分比的增加几乎没有影响。

提升图表通常显示为累积提升图表,也称为增益图表。因此,增益图表有时(可能会令人困惑地)称为“提升图表”,但它们更准确地被称为cumulative提升图表。
它们最常见的用途之一是在营销中,用来决定一个潜在客户是否值得联系。
基尼系数
基尼系数或基尼指数是一个用于处理不平衡类别值的流行指标。该系数的范围从 0 到 1,其中 0 表示完全平等,1 表示完全不平等。在这里,如果一个指标的值更高,则数据将更加分散。
基尼系数可以通过以下公式从 ROC 曲线下的面积计算得出:
基尼系数 = (2 * ROC_curve) — 1
结论
理解机器学习模型在未见数据上的表现如何是使用这些评估指标的最终目的。像准确率、精确率、召回率这样的指标适用于评估平衡数据集的分类模型,但如果数据不平衡且存在类别差异,则其他方法如 ROC/AUC、基尼系数在评估模型性能方面表现更好。
好的,这就结束了这篇文章。希望大家喜欢阅读这篇文章,欢迎在评论区分享你的评论/想法/反馈。
感谢阅读!!!
简历:纳戈什·辛格·乔汉 是 CirrusLabs 的大数据开发人员。他在电信、分析、销售、数据科学等各个领域拥有超过 4 年的工作经验,专注于各种大数据组件。
原文。已获授权转载。
相关:
-
主成分分析(PCA)降维
-
机器学习模型的超参数优化
-
DBSCAN 聚类算法在机器学习中的应用
更多相关话题
使用 MLflow 在 Databricks 上进行模型实验、跟踪和注册
原文:
www.kdnuggets.com/2021/01/model-experiments-tracking-registration-mlflow-databricks.html
评论
作者 Dash Desai,StreamSets 平台和技术推广总监
了解 StreamSets 这一个现代数据集成平台如何帮助加快机器学习生命周期和 MLOps 一些关键阶段的操作。
我们的三大课程推荐
1. Google 网络安全证书 - 快速迈入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织 IT
数据获取和准备
机器学习模型的质量仅与用于训练模型的数据质量和数据集大小有关。数据表明数据科学家约花费 80% 的时间用于准备和管理分析数据,57% 的数据科学家认为清理和组织数据是工作中最不愉快的部分。这进一步验证了 MLOps 的理念以及数据科学家与数据工程师之间需要合作的必要性。
在数据获取和准备的关键阶段,数据科学家识别出需要哪些类型的(受信任的)数据集来训练模型,并与数据工程师密切合作,从可行的数据源中获取数据。
StreamSets 如何提供帮助
一些常见的数据源用于获取数据科学项目的数据集,包括:Amazon S3、Microsoft Azure Blob 存储、Google Cloud 存储、Kafka、Hadoop、本地和云数据仓库。StreamSets DataOps 平台提供易于使用的图形界面,用于构建智能数据管道,支持流数据和批处理数据流,从分布式系统中快速摄取大量数据——包括上述所有常见来源。
数据摄取过程的另一个方面是存储——在某些情况下,公司可能已经拥有数据湖或数据仓库,而在某些情况下,他们可能需要建立一个。StreamSets DataOps 平台能够连接到现有的数据湖和数据仓库(无论是本地的还是云端的),还具有创建新数据湖和数据仓库的内置功能。

在构建这些数据管道的过程中,数据工程师还可以执行数据科学家所需的一些关键转换。数据准备过程中一些常见的转换包括:字段/列/特征的数据类型转换、重命名字段/列/特征、连接数据集、合并数据集、重新分区、数据集数据格式转换(例如,将 JSON 转换为 Parquet,以便在 Apache Spark 中进行高效的下游分析)等。所有这些转换及更多转换均由 StreamSets DataOps 平台提供支持。
重要说明:广泛而彻底的特征工程任务及对特征、其与目标变量的相关性、特征重要性等的深入分析,最适合使用交互式工具进行,如 Databricks Notebook、Jupyter、RStudio 和 ML 平台。
模型实验、跟踪和注册
实验是模型开发的重要前置步骤,其中数据科学家会从可信数据集中取出足够的子集,并以快速、迭代的方式创建多个模型。
在没有适当行业标准的情况下,数据科学家不得不依靠手动跟踪模型、输入、超参数、输出及其他类似工件,这导致模型部署/发布周期非常长,实际上阻碍了组织适应动态变化、获得竞争优势,并在某些情况下无法遵守不断变化的治理和法规。
StreamSets 如何提供帮助
使用 StreamSets Transformer,一个 Spark ETL 引擎,很容易通过其 PySpark 或 Scala API 与MLflow集成。
-
这种 MLflow 集成允许跟踪和版本化模型训练代码、数据、配置、超参数,并且可以从 Transformer 在 MLflow 的中央存储库中注册和管理模型。这对于重新训练模型和/或重现实验至关重要。
-
使用MLflow on Databricks时,它创建了一个强大而无缝的解决方案,因为Transformer can run on Databricks集群,而 Databricks 自带 MLflow 服务器。
端到端用例
让我们通过一个端到端的场景进行演练,我们将从云对象存储(例如,Amazon S3)中获取数据,执行必要的转换,并训练一个回归模型。数据集包含一组房屋,其特征包括卧室数量、浴室数量、平方英尺等,以及其出售价格。
除了跟踪、版本控制和在 MLflow 中注册模型之外,我们还希望管道在满足特定条件时自动将模型从“staging”提升到“production”。例如,如果r2 >= ${r2Threshold} 或 rmse <= ${rmseThreshold}, 则该模型需要在 Databricks 上的 MLflow 服务器上提升到“生产”状态。这可以作为数据科学家向负责部署模型的数据工程团队提供的要求和规范的一部分。
管道概述
下面展示的 StreamSets Transformer 管道旨在从Amazon S3加载训练数据,执行像删除行 ID、将目标列“mdev”重命名为“label”(这是 SparkMLlib 所需的),使用PySpark处理器训练梯度提升回归模型,并将训练数据存档到Amazon S3中。
更重要的是,管道还与Databricks 上的 MLflow集成,以跟踪和版本化模型训练代码,包括超参数、模型评估指标,并注册模型。

模型训练与实验
这里是PySpark 处理器的代码片段——这是管道的一部分,它训练梯度提升回归模型,并在 MLflow 中跟踪一切,包括根据某些条件将模型从“staging”提升到“production”。
# Import required libraries
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.linalg import Vectors
from pyspark.ml import Pipeline, PipelineModel
from pyspark.sql.functions import *
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import MulticlassClassificationEvaluator, RegressionEvaluator
from pyspark.ml.regression import GBTRegressor
from pyspark.sql.types import FloatType
import mlflow
import mlflow.spark
import mlflow.tracking
mlflow.set_experiment('/Users/dash@streamsets.com/transformer-experiments')
mlflow_client = mlflow.tracking.MlflowClient()
# Setup variables for convenience and readability
trainSplit = ${trainSplit}
testSplit = ${testSplit}
maxIter = ${maxIter}
numberOfCVFolds = ${numberOfCVFolds}
r2 = 0
rmse = 0
stage = "Staging"
# The input dataframe is accessbile via inputs[0]
df = inputs[0]
features = ['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax', 'ptratio', 'black', 'lstat']
# MUST for Spark features
vectorAssembler = VectorAssembler(inputCols = features, outputCol = 'features')
df = vectorAssembler.transform(df)
# Split dataset into "train" and "test" sets
(train, test) = df.randomSplit([trainSplit, testSplit], 42)
# Setup evaluator -- default is F1 score
classEvaluator = MulticlassClassificationEvaluator(metricName="accuracy")
with mlflow.start_run():
# Gradient-boosted tree regression
gbt = GBTRegressor(maxIter=maxIter)
# Setup pipeline
pipeline = Pipeline(stages=[gbt])
# Setup hyperparams grid
paramGrid = ParamGridBuilder().build()
# Setup model evaluators
rmseevaluator = RegressionEvaluator() #Note: By default, it will show how many units off in the same scale as the target -- RMSE
r2evaluator = RegressionEvaluator(metricName="r2") #Select R2 as our main scoring metric
# Setup cross validator
cv = CrossValidator(estimator=pipeline, estimatorParamMaps=paramGrid, evaluator=r2evaluator, numFolds=numberOfCVFolds)
# Fit model on "train" set
cvModel = cv.fit(train)
# Get the best model based on CrossValidator
model = cvModel.bestModel
# Run inference on "test" set
predictions = model.transform(test)
rmse = rmseevaluator.evaluate(predictions)
r2 = r2evaluator.evaluate(predictions)
mlflow.log_param("transformer-pipeline-id","${pipeline:id()}")
mlflow.log_param("features", features)
mlflow.log_param("maxIter_hyperparam", maxIter)
mlflow.log_param("numberOfCVFolds_hyperparam", numberOfCVFolds)
mlflow.log_metric("rmse_metric_param", rmse)
mlflow.log_metric("r2_metric_param", r2)
# Log and register the model
mlflow.spark.log_model(spark_model=model, artifact_path="SparkML-GBTRegressor-model", registered_model_name="SparkML-GBTRegressor-model")
mlflow.end_run()
# Transition the current model to 'Staging' or 'Production'
current_version = mlflow_client.search_model_versions('name="SparkML-GBTRegressor-model"')[0].version
while mlflow_client.search_model_versions('name="SparkML-GBTRegressor-model"')[0].status != 'READY':
current_version = current_version
if (r2 >= ${r2Threshold} or rmse <= ${rmseThreshold}):
stage = "Production"
mlflow_client.transition_model_version_stage(name="SparkML-GBTRegressor-model",stage=stage,version=current_version)
output = inputs[0]
显示全部 ▼
Databricks 上的模型跟踪
这里是 MLflow 中跟踪的来自 Transformer 管道的模型训练运行。

Databricks 上的模型版本控制
这里是从 Transformer 管道注册的模型版本。

Databricks 上的模型比较
这是从 Transformer 管道创建的两个选定模型的并排比较。

模型重新训练
现在,一个非常常见的需求是自动化重新训练模型的过程,当更多数据变得可用时——特别是当模型尚未满足评估标准时。例如,准确率可以是评估特定模型的指标之一。这种类型的自动化可以通过设置 编排管道 实现,如下所示。
编排管道被设计为持续运行并“等待”训练数据集文件上传到 Amazon S3。 一旦训练数据集上传,此管道会触发/启动前面描述的模型(重新)训练任务。

还需注意,管道中传递了两个超参数 maxIter 和 numberOfCVFolds,因此无需硬编码它们,并且可以在模型重新训练和实验过程中动态传递到管道中。 StreamSets DataOps 平台还提供检查当前运行的作业状态的方法,以便根据管道中所示的状态采取行动。
示例管道
如果你对额外的技术细节和示例管道感兴趣,请联系我:dash at streamsets dot com 或 @iamontheinet。
开始你自己的模型实验
StreamSets DataOps 平台不是一个机器学习平台,但它提供了重要的功能和扩展性,能够帮助并加快机器学习生命周期和 MLOps 中一些最关键阶段的操作。
了解更多关于 StreamSets For Databricks 在 AWS Marketplace 和 Microsoft Azure Marketplace 上的信息。
个人简介: Dash Desai 是 StreamSets 的平台和技术布道总监,拥有超过 18 年的软件和数据工程实践经验。凭借在大数据、数据科学和机器学习方面的最新经验,Dash 运用他的技术技能帮助构建解决方案,解决商业问题,并揭示以新方式塑造市场的趋势。Dash 曾在全球企业和技术初创公司担任工程师和解决方案架构师。作为平台和技术布道者,他对评估新想法充满热情,以帮助阐明技术如何解决特定的商业问题。他还喜欢撰写技术博客、动手教程和主持技术研讨会。
原文。经许可转载。
相关:
-
MLOps 正在改变机器学习模型的开发方式
-
生产机器学习监控:异常值、漂移、解释器与统计性能
-
管理机器学习周期:从比较数据科学实验/协作工具中获得的五个经验教训
更多相关话题
以下是你在模型服务器中构建 ML 驱动服务时需要关注的要素
原文:
www.kdnuggets.com/2020/09/model-server-build-ml-powered-services.html
评论
由Ben Lorica(协助组织Ray Summit)和Ion Stoica(伯克利,Anyscale)

机器学习正被嵌入到涉及多种数据类型和数据源的应用程序中。这意味着来自不同背景的软件开发者需要在涉及机器学习的项目上进行合作。在我们上一篇文章中,我们列出了机器学习平台需要具备的关键特性,以满足当前和未来的工作负载。我们还描述了 MLOps,这是一套专注于机器学习生命周期生产化的实践。

在这篇文章中,我们专注于模型服务器,这些软件是实时或离线机器学习服务的核心。用于服务机器学习模型有两种常见的方法。第一种方法是将模型评估嵌入到一个网页服务器(例如,Flask)中,作为一个专门用于预测服务的 API 服务端点。
第二种方法将模型评估任务转移到一个独立的服务上。这是初创公司活跃的领域,相关选项越来越多。提供的服务包括来自云服务提供商的服务(SageMaker,Azure,Google Cloud),模型服务的开源项目(Ray Serve,Seldon,TorchServe,TensorFlow Serving 等),专有软件(SAS,Datatron,ModelOp 等),以及通常用一些通用框架编写的定制解决方案。
虽然机器学习可以用于一次性项目,但大多数开发者希望将机器学习嵌入到他们的产品和服务中。模型服务器是生产化机器学习的软件基础设施的重要组成部分,因此,公司需要仔细评估他们的选项。本文重点介绍了公司在选择模型服务器时应该关注的关键特性。
支持流行工具包
您的模型服务器可能与模型训练系统是分开的。选择一个能够使用多种流行工具生成的训练模型工件的模型服务器。开发者和机器学习工程师使用许多不同的库来构建模型,包括深度学习库(PyTorch、TensorFlow)、机器学习和统计学库(scikit-learn、XGBoost、SAS、statsmodel)。模型构建者还继续使用各种编程语言。虽然 Python 已成为机器学习的主流语言,但其他语言如 R、Java、Scala、Julia、SAS 也仍然有许多用户。最近,许多公司实现了像 Databricks、Cloudera、Dataiku、Domino Data Lab 等的数据科学工作台。
模型部署及更多功能的图形用户界面
开发者可能会使用命令行界面,但企业用户将需要一个图形用户界面,该界面引导他们完成模型部署过程,并突出显示机器学习生命周期的不同阶段。随着部署过程的成熟,它们可能更多地转向脚本和自动化。具有用户界面的模型服务器包括Seldon Deploy、SAS Model Manager、Datatron等,针对企业用户。
操作简便,部署快捷,但性能高且可扩展性强
随着机器学习被嵌入到关键应用程序中,公司将需要低延迟的模型服务器来支持大规模的预测服务。像 Facebook 和 Google 这样的公司拥有提供实时响应的机器学习服务,每天数十亿次。虽然这些可能是极端案例,但许多公司也部署了像推荐和个性化系统这样的应用程序,每天与许多用户互动。借助 Ray Serve 等开源软件,公司现在可以访问可扩展到多台机器的低延迟模型服务器。
大多数模型服务器使用微服务架构,并可以通过 REST 或 gRPC API 访问。这使得将机器学习(“推荐系统”)与其他服务(“购物车”)集成更为容易。根据您的设置,您可能需要一个允许您在云端、本地或两者兼有的模型服务器。您的模型服务器必须参与自动扩展、资源管理和硬件配置等基础设施功能。
一些模型服务器增加了最近的创新,这些创新减少了复杂性,提高了性能,并提供了与其他服务集成的灵活选项。随着新 Tensor 数据类型的引入,RedisAI 支持数据本地性——这一功能使用户能够从他们喜欢的客户端获取和设置 Tensors,并“在数据所在的位置运行他们的 AI 模型。”Ray Serve 将模型评估逻辑更接近业务逻辑,通过给开发人员从 API 端点到模型评估再到 API 端点的端到端控制。此外,Ray Serve 易于操作,部署起来就像简单的 web 服务器一样简单。
包括测试、部署和推出的工具
一旦模型训练完成,它必须经过审查和测试,然后才能部署。Seldon Deploy、Datatron 和其他模型服务器具有一些有趣的功能,允许你通过单次预测或负载测试来测试模型。为了便于错误识别和测试,这些模型服务器还允许你上传测试数据并可视化测试预测。
一旦你的模型经过审查和测试,你的模型服务器应该能让你安全地提升或降级模型。其他流行的推出模式包括:
理想情况下,推出工具应该是完全自动化的,这样你的部署工具就可以与 CI/CD 或 MLOps 过程集成。
支持复杂的部署模式
随着你对机器学习的使用增加,你的模型服务器应该能够支持许多生产中的模型。你的模型服务器还应支持复杂的部署模式,包括同时部署多个模型。它应该支持各种模式,包括:
-
A/B 测试:一部分预测使用一个模型,其余的则使用另一个模型。
-
集成模型:将多个模型结合起来形成一个更强大的预测模型。
-
级联:如果基线模型产生低置信度的预测,流量将被路由到替代模型。另一个用例是细化:检测图片中是否有车,如果有,则将图片发送到一个读取车牌的模型。
-
多臂老丨虎丨机:一种强化学习形式,老丨虎丨机将流量分配到多个竞争的模型中。
开箱即用的度量和监控
机器学习模型可能会随着时间的推移而退化,因此重要的是要有系统来指示模型何时变得不准确或开始表现出偏差和其他意外行为。你的模型服务器应该生成性能、使用情况和其他自定义指标,这些指标可以被可视化和实时监控工具使用。一些模型服务器开始提供高级功能,包括异常检测和警报。甚至有初创公司(Superwise,Arize)专注于使用“机器学习来监控机器学习”。虽然这些目前是与模型服务器分开的专用工具,需要与模型服务器集成,但很可能一些模型服务器将把高级监控和可观测能力内置到他们的产品中。
与模型管理工具集成
随着你将更多模型部署到生产环境,你的模型服务器将需要与模型管理工具进行集成。这些工具有许多不同的标签——访问控制、模型目录、模型注册、模型治理仪表板——但本质上,它们为你提供了对过去和当前模型的 360 度全景视图。
因为模型需要定期检查,你的模型服务器应该与审计和重现模型的服务对接。模型版本控制现在已经成为标准,并且大多数我们检查过的模型服务器都具备这个功能。Datatron 提供了一个模型治理仪表板,用于审计表现不佳的模型。许多模型服务器提供数据血缘服务,记录请求的发送时间及模型输入和输出。调试和审计模型还需要对其关键驱动因素有深入的理解。Seldon Deploy 集成了一个用于模型检查和解释的开源工具。
统一批量和在线评分
假设你更新了模型,或者你收到了一大量的新记录。在这两种情况下,你可能需要将模型应用于大型数据集。你将需要一个能够有效地以小批量处理大型数据集的模型服务器,并且提供低延迟的在线评分(例如,Ray Serve 支持批量和在线评分)。
总结
随着机器学习嵌入更多的软件应用程序,公司需要仔细选择他们的模型服务器。虽然Ray Serve 是一个相对较新的开源模型服务器,但它已经具备了我们在这篇文章中列出的许多功能。Ray Serve 是一个可扩展、简单且灵活的工具,用于部署、操作和监控机器学习模型。正如我们在上一篇文章中提到的,我们相信 Ray 和 Ray Serve 将成为未来许多 ML 平台的基础。
原文。转载许可。
简介: Ben Lorica 组织了 #SparkAISummit 和 #raysummit,并曾担任 Strataconf 和 OReillyAI 的程序主席。
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
使用正则化线性模型和 XGBoost 建模价格
原文:
www.kdnuggets.com/2019/05/modeling-price-regularized-linear-model-xgboost.html
评论
由 Susan Li,高级数据科学家
我们想要对房价进行建模,我们知道价格取决于房子的地点、房子的面积、建造年份、翻修年份、卧室数量、车库数量等。因此,这些因素会影响价格的模式——优质位置通常会导致更高的价格。然而,同一区域内具有相同面积的所有房子并不具有完全相同的价格。价格的变动是噪声。我们在价格建模中的目标是建模模式并忽略噪声。相同的概念也适用于酒店房间价格建模。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
因此,首先我们将对房价数据实施正则化技术。
数据
可以在 这里 找到一个优秀的房价数据集。
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from scipy.stats import norm, skew
from sklearn import preprocessing
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNetCV, ElasticNet
from xgboost import XGBRegressor, plot_importance
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import StratifiedKFold
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x))
df = pd.read_csv('house_train.csv')
df.shape

图 1
(df.isnull().sum() / len(df)).sort_values(ascending=False)[:20]

图 2
好消息是我们有很多特征可以使用(81 个),坏消息是 19 个特征有缺失值,其中 4 个特征缺失值超过 80%。对于任何特征,如果缺失 80% 的值,那么它可能并不重要,因此,我决定移除这 4 个特征。
df.drop(['PoolQC', 'MiscFeature', 'Alley', 'Fence', 'Id'], axis=1, inplace=True)
探索功能
目标特征分布
sns.distplot(df['SalePrice'] , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(df['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('Sale Price distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(df['SalePrice'], plot=plt)
plt.show();

图 3
目标特征 - SalePrice 是右偏的。由于线性模型喜欢正态分布的数据,我们将对 SalePrice 进行转换,使其更接近正态分布。
sns.distplot(np.log1p(df['SalePrice']) , fit=norm);
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(np.log1p(df['SalePrice']))
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('log(Sale Price+1) distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(np.log1p(df['SalePrice']), plot=plt)
plt.show();

图 4
数值特征之间的相关性
pd.set_option('precision',2)
plt.figure(figsize=(10, 8))
sns.heatmap(df.drop(['SalePrice'],axis=1).corr(), square=True)
plt.suptitle("Pearson Correlation Heatmap")
plt.show();

图 5
一些特征之间存在强相关性。例如,GarageYrBlt 和 YearBuilt,TotRmsAbvGrd 和 GrLivArea,GarageArea 和 GarageCars 之间存在强相关性。它们实际上表达的东西多多少少是一样的。我将让 ElasticNetCV 帮助减少冗余。
SalePrice 与其他数值特征之间的相关性
corr_with_sale_price = df.corr()["SalePrice"].sort_values(ascending=False)
plt.figure(figsize=(14,6))
corr_with_sale_price.drop("SalePrice").plot.bar()
plt.show();

图 6
SalePrice 与 OverallQual 的相关性最大(约 0.8)。GrLivArea 的相关性超过 0.7,GarageCars 的相关性超过 0.6。让我们更详细地了解这 4 个特征。
sns.pairplot(df[['SalePrice', 'OverallQual', 'GrLivArea', 'GarageCars']])
plt.show();

图 7
特征工程
-
对分布高度偏斜(偏斜度 > 0.75)的特征进行对数变换
-
哑编码分类特征
-
用列的均值填充 NaN。
-
训练集和测试集分割。
feature_engineering_price.py
ElasticNet
-
Ridge 和 Lasso 回归是正则化线性回归模型。
-
ElasticNet 本质上是 Lasso/Ridge 的混合体,涉及最小化一个包含 L1(Lasso)和 L2(Ridge)范数的目标函数。
-
ElasticNet 在多个特征彼此相关时很有用。
-
类 ElasticNetCV 可以通过交叉验证设置参数
alpha(α) 和l1_ratio(ρ)。 -
ElasticNetCV:通过交叉验证选择最佳模型的 ElasticNet 模型。
让我们看看 ElasticNetCV 将为我们选择什么。
ElasticNetCV.py

图 8
0 < 最优 l1_ratio < 1,表示惩罚是 L1 和 L2 的组合,即 Lasso 和 Ridge 的组合。
模型评估
ElasticNetCV_evaluation.py

图 9
这里的 RMSE 实际上是 RMSLE(均方根对数误差)。因为我们对实际值进行了对数变换。这里有一个 很好的文章解释 RMSE 和 RMSLE 之间的区别。
特征重要性
feature_importance = pd.Series(index = X_train.columns, data = np.abs(cv_model.coef_))
n_selected_features = (feature_importance>0).sum()
print('{0:d} features, reduction of {1:2.2f}%'.format(
n_selected_features,(1-n_selected_features/len(feature_importance))*100))
feature_importance.sort_values().tail(30).plot(kind = 'bar', figsize = (12,5));

图 10
减少 58.91% 的特征看起来很有成效。ElasticNetCV 选择的前 4 个重要特征是 Condition2_PosN、MSZoning_C(all)、Exterior1st_BrkComm 和 GrLivArea。我们将看看这些特征与 Xgboost 选择的特征的比较。
Xgboost
第一个 Xgboost 模型,我们从默认参数开始。
xgb_model1.py

图 11
它已经远远好于 ElasticNetCV 选择的模型!
第二个 Xgboost 模型,我们逐渐添加一些参数,以期提高模型的准确性。
xgb_model2.py

图 12
又有了改进!
第三个 Xgboost 模型中,我们加入了学习率,希望能得到更准确的模型。
xgb_model3.py

图 13
不幸的是,没有改进。我得出结论 xgb_model2 是最佳模型。
特征重要性
from collections import OrderedDict
OrderedDict(sorted(xgb_model2.get_booster().get_fscore().items(), key=lambda t: t[1], reverse=True))

图 14
Xgboost 选出的前 4 个最重要特征是LotArea、GrLivArea、OverallQual和TotalBsmtSF。
只有一个特征GrLivArea被 ElasticNetCV 和 Xgboost 都选中了。
现在我们将选择一些相关特征,再次拟合 Xgboost。
xgb_model5.py

图 15
又有了小改进!
Jupyter notebook 可以在Github上找到。祝你一周愉快!
简介: Susan Li 正在通过一篇文章一次性改变世界。她是位于加拿大多伦多的高级数据科学家。
原始文章。经许可转载。
相关:
-
使用 Scikit-Learn 进行多分类文本分类
-
简单神经网络和 LSTM 的时间序列预测介绍
更多相关内容
模型:从实验室到工厂
作者:Mauricio Vacas,硅谷数据科学。
在我们的行业中,很多关注点放在开发分析模型以回答关键业务问题和预测客户行为上。然而,当数据科学家完成模型开发并需要将其部署到更大的组织中时会发生什么?
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
在没有严格流程的情况下部署模型是有后果的——请看一下金融服务中的以下示例。
由于其高频交易算法,Knight 是美国股票市场上最大的交易商,在纽约证券交易所的市场份额为 17.3%,在纳斯达克的市场份额为 16.9%。由于2012 年的计算机交易“故障”,公司在不到一小时的时间内损失了 4.4 亿美元。该公司在年底被收购。这说明了将未经充分测试的模型部署到生产环境中的风险以及可能出现的错误的影响。
在这篇文章中,我们将探讨通过模型管理和部署过程来避免这些情况的技术。以下是我们在部署模型到生产环境时需要解决的一些问题:
-
模型结果如何到达受益于这些分析的决策者或应用程序手中?
-
模型能否自动运行而没有问题?它如何从故障中恢复?
-
如果模型由于基于不再相关的历史数据进行训练而变得过时,会发生什么?
-
如何在不破坏下游用户的情况下部署和管理模型的新版本?
将数据科学开发和部署视为更大模型生命周期工作流中的两个独立过程是有帮助的。下面的示例图说明了这个过程是什么样的。

-
我们有终端用户与应用程序交互,生成的数据会存储在应用程序的在线生产数据存储库中。
-
这些数据随后会被送入离线历史数据存储库(如 Hadoop 或 S3),以便数据科学家可以分析这些数据,了解用户如何与应用程序互动。例如,它还可以用于构建一个模型,将用户根据他们在应用程序中的行为进行聚类,以便我们可以利用这些信息进行市场推广。
-
一旦模型开发完成,我们需要将其注册到模型注册库中,以便进行治理流程,在该流程中,模型将被审查和批准用于生产,并且可以评估部署的需求。
-
一旦模型获得生产使用批准,我们需要将其部署。为此,我们需要了解模型在组织中的使用方式,并进行相应的更改以支持这一点,确保模型可以在指定的性能约束内端到端自动运行,并且需要有测试以确保部署的模型与开发的模型相同。一旦这些步骤完成,模型将被再次审查和批准,然后才能上线。
-
最后,一旦模型部署完成,来自该模型的预测将提供给应用程序,根据用户互动收集预测的指标。这些信息可以用于改进模型或提出新的业务问题,这会使我们回到(2)。
为了使生命周期成功,了解数据科学开发和部署有不同的需求是重要的。这就是为什么你需要一个实验室和一个工厂。
实验室
数据实验室是一个供数据科学家探索的环境,与应用程序的生产关注点分离。我们的最终目标可能是能够利用数据驱动组织内的决策,但在达到这一目标之前,我们需要理解哪些假设对我们的组织有意义并验证其价值。因此,我们主要关注创建一个环境——“实验室”——让数据科学家可以提出问题、构建模型和实验数据。
该过程主要是迭代的,如下图所示,基于CRISP-DM 模型。

我们不会在这篇文章中深入探讨太多细节,但我们确实有一个教程可以深入了解这个主题。如果你想下载该教程的幻灯片,可以在我们的Enterprise Data World 2017 页面上进行下载。
我们在这里关注的是,我们需要一个实验室来支持模型的探索和开发,但当我们需要将该模型部署以自动应用于实时数据、在定义的约束内向适当的用户提供结果并监控过程中的失败或异常时,我们也需要一个工厂。
工厂
在工厂中,我们希望优化价值创造和降低成本,重视稳定性和结构而非灵活性,以确保在定义的约束条件下将结果交付给正确的消费者,并监控和管理失败。我们需要为模型提供结构,以便对其在生产中的行为有预期。
为了理解工厂,我们将探讨如何通过模型注册表管理模型,以及在部署过程中需要考虑的事项。
模型注册表
为了为模型提供结构,我们根据其组件——数据依赖关系、脚本、配置和文档——来定义模型。此外,我们捕获模型及其版本的元数据,以提供额外的业务背景和模型特定信息。通过为模型提供结构,我们可以在模型注册表中保持模型库存,包括不同的模型版本和由执行过程提供的相关结果。下图说明了这一概念。

从注册表中,我们可以:
-
了解和控制生产中使用的模型版本。
-
审查解释特定版本中发生变化的发行说明。
-
审查与模型相关的资产和文档,这在需要创建现有模型的新版本或进行维护时非常有用。
-
监控模型执行的性能指标及其消耗的进程。这些信息由模型执行过程提供,该过程将指标发送回注册表。
你还可以选择在模型版本中包含一个Jupyter Notebook。这使得审查者或开发人员可以了解原开发者在模型版本中所做的思考过程和假设。这有助于支持模型的维护和组织的发现。
这里是一个矩阵,分解了我们在实际工作中模型的不同元素:

注册表需要捕获数据、脚本、训练模型对象和特定模型版本的文档之间的关联,如图所示。
实际上这给我们带来了什么?
-
通过收集运行模型所需的资产和元数据,我们可以驱动执行工作流,将特定版本的模型应用于实时数据,以向最终用户生成预测。如果这是批处理过程的一部分,我们可以利用这些信息创建短暂的执行环境,以便模型拉取数据、拉取脚本、运行模型、将结果存储在对象存储中,并在过程完成时关闭环境,从而最大化资源利用并最小化成本。
-
从治理的角度来看,我们可以支持业务工作流来决定何时将模型推送到生产环境,并允许进行持续的模型监控,例如,当我们发现预测结果不再与实际情况相符时,决定是否需要重新训练模型。如果有审计要求,你可能需要解释如何为客户产生特定的结果。为此,你需要能够追踪在特定时间运行的模型的具体版本,以及使用了哪些数据,以便能够重现结果。
-
如果我们在现有模型中发现了一个错误,我们可以将该版本标记为“不可使用”,并发布一个修复后的新版本。通过通知所有使用了有缺陷模型的用户,他们可以过渡到使用修复后的模型版本。
如果没有这些步骤,我们面临的风险是模型维护变成一个试图理解原开发者意图的挑战性过程,生产环境中的模型可能与开发环境中的模型不匹配,从而产生不正确的结果,并且在更新现有模型时会干扰下游消费者。
模型部署
一旦模型被批准部署,我们需要经过一些步骤以确保模型可以顺利部署。应该有测试措施来验证模型的正确性,提取原始数据、特征生成和模型评分的管道应被分析,以确保模型执行可以自动运行、以消费者所需的方式暴露结果,并满足业务定义的性能要求。同时,确保模型执行得到监控,以防出现错误或模型变得过时,不再产生准确的结果。
在部署之前,我们需要确保测试以下内容:
-
部署的模型是否符合原始模型开发者的期望。通过使用在开发过程中识别的测试输入集,这些输入集会生成经过验证的结果,我们可以验证部署的代码是否与开发过程中预期的结果匹配。我们在之前的博客文章中说明了这一需求。
-
模型在部署时是否能够适应各种不同的输入,测试这些输出的极端情况以及由于数据质量问题可能缺失的值。模型应具备防止这些输入使模型崩溃的控制措施,从而避免影响下游消费者。
我们通过以下方式最小化部署的模型与开发模型不匹配的风险:1)在将模型部署到生产环境之前进行测试,2)捕捉环境的具体细节,如模型的特定语言版本和库依赖(例如 Python 的 requirements.txt 文件)。
一旦部署到生产环境中,我们希望将模型的预测结果暴露给消费者。有多少用户会使用这个模型预测?在对模型进行评分时,特征数据必须多快才能可用?例如,在欺诈检测的情况下,如果特征每 24 小时生成一次,则可能会存在事件发生和欺诈检测模型检测到事件之间的延迟。这些是需要回答的一些可扩展性和性能问题。
在应用的情况下,理想的做法是通过网络服务暴露模型的结果,无论是通过模型的实时评分还是通过批处理过程生成的离线评分。或者,模型可能需要支持业务流程,我们需要将模型的结果放置在一个可以创建报告的位置,以便决策者根据这些结果采取行动。在任何情况下,没有模型注册表,可能很难理解在哪里找到和使用当前生产中的模型结果。
另一个用例是希望了解模型在实时数据上的表现,以判断模型是否已经过时,或者新开发的模型是否优于旧模型。一个简单的例子是回归模型,我们可以比较预测值和实际值。如果我们不监控模型随时间的表现,可能会根据不再适用于当前情况的历史数据做出决策。
结论
在这篇文章中,我们讨论了模型生命周期,并讨论了实验室和工厂的需求,目的是减少部署可能影响业务决策(并可能产生巨大成本)的“坏”模型的风险。此外,注册表提供了组织中模型的透明度和可发现性。这通过暴露组织中用于解决类似问题的现有技术,促进了新模型的开发,并通过明确当前生产中的模型版本、相关资产以及发布新模型版本的过程,促进了现有模型的维护或改进。
在 SVDS,我们正在开发一种架构,支持将模型及其版本注册到注册表中,并管理这些模型版本如何部署到执行引擎。如果你想了解更多关于这项工作的内容,请联系我们。
简介: Mauricio Vacas 在云计算和分布式数据架构方面有多年的经验。Mauricio 热衷于利用技术创造价值,并且是业内公认的云托管数据解决方案技术架构领导者。
原文。经许可转载。
相关内容:
-
Jupyter 生态系统导航简短指南
-
深度学习入门指南
-
开源语音识别工具包
更多相关内容
modelStudio 和 交互式解释性模型分析的语法
原文:
www.kdnuggets.com/2020/06/modelstudio-grammar-interactive-explanatory-model-analysis.html
评论
由 Przemyslaw Biecek,Model Oriented
新版本的 modelStudio 最近在 CRAN 上发布。
modelStudio 是一个 R 包,它自动化了 ML 模型的探索并允许进行互动检查。它以模型无关的方式工作,因此与大多数 ML 框架兼容(例如 mlr/mlr3, xgboost, caret, h2o, scikit-learn, lightGBM, keras/tensorflow)。
最近,我们在 arXiv 上上传了一篇介绍该工具主要原理的文章:交互式解释性模型分析的语法。以下是一些亮点。

第一代模型解释旨在探索模型行为的个别方面。第二代模型解释则旨在将个别方面整合成一个生动且多线程的定制化故事,满足不同利益相关者的需求。
局部和全局层级的模型解释相互补充。 随着越来越多的声音认为单一的模型探索方法无法满足不同利益相关者的所有需求(参见例如 Arya et al 2019 或 Sokol et al 2020)。在 这篇 文章中,我们展示了如何将常见的 XAI 方法结合成更大的模块,彼此互补。这些结构可以满足更广泛的用户需求。下图展示了这种方面的并列如何从不同的角度展示模型,并帮助更好地理解模型的行为。

来源:www.theblindelephant.com/the_blind_elephant_fable.html
正如盲人与大象的故事所示,我们无法仅用单一的方法解释复杂的模型,因为这种方法只能提供一种视角。
单独的解释容易导致误解,这不可避免地会导致错误的推理。如果没有多方面的互动解释,就不会有对模型的理解和信任。

互动模型解释分析的语法。它展示了模型探索的各种方法如何相互丰富。流行技术的名称列在单元格中。列和行覆盖了分类法。图中的边缘指示哪些方法可以互补。
预测模型的解释是一个过程,而不是一张图表。 我们还认为,每一个解释都会引发新的问题。因此,一个好的 XAI 系统应该允许对模型不同方面进行交互式探索。为了实现这一点,我们引入了解释的分类法,并提出了生成复杂模型探索过程的语法。
modelStudio 实现了 IEMA 的原则。 modelStudio 框架的创建旨在允许这种迭代探索,并提供快速反馈,因为模型调试通常要求高且繁琐。

基于 FIFA 数据集预测玩家价值的 gbm 模型示例探索。更多信息请访问 pbiecek.github.io/explainFIFA20/
eXplainable 人工智能(XAI)的主题最近引起了广泛关注。然而,文献中主要集中于列出其更好采用的要求或仅解释模型单一方面的非常技术性贡献。在本文中,我们提出了第三种方式。首先,我们认为解释模型的单一方面是不完整的。其次,我们提出了一种解释方法的分类法,重点关注机器学习模型生命周期中不同利益相关者的需求。第三,我们描述了交互式 XAI 是一个将解释与互补模型方面的分析序列相关联的过程。
这无疑只是朝着更好地理解模型探索过程迈出的第一步。如果你对这个过程有任何建议和意见,我们将非常乐意听取。
感谢 Hubert Baniecki。
个人简介: Przemyslaw Biecek 对预测建模中的创新非常感兴趣。涉及 eXplainable AI、IML、AutoML、AutoEDA 和基于证据的机器学习的帖子。是 r-bloggers.com 的一部分。
原文。已获许可转载。
相关:
-
解释“黑箱”机器学习模型:SHAP 的实际应用
-
用于解释大数据上的预测模型的证据反事实
-
用于二元分类器的简单且可解释的性能度量
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT
相关主题
现代数据科学技能: 8 类,核心技能,热门技能
原文:
www.kdnuggets.com/2020/09/modern-data-science-skills.html
评论最新的 KDnuggets 调查是对去年非常受欢迎的数据科学技能调查的后续,提出了相同的两个问题:
1. 你当前具备哪些技能/知识领域(达到可以在工作或研究中使用的水平)?和
- 你希望增加或改进哪些技能?
Drew Conway 在 2013 年提出的经典数据科学 Venn 图有 3 个主要领域:黑客(编程),数学与统计,以及商业/领域知识。然而,数据科学领域的发展如此迅速,这 3 个领域已不再足够。现在,数据科学包括额外的领域,如深度学习算法和云计算平台。深度学习需要更多的数学知识(特别是代数和微积分)。COVID 大流行增加了对生存分析和流行病学的需求。部署数据科学需要理解软件开发、DevOps,以及使用 GitHub、Docker 等工具。
我们回顾了许多关于数据科学技能的博客和文章,并将技能/知识领域从去年的 30 项更新扩展到本次调查中的 50 项。为了更好地组织此列表,我们将其分为 8 个类别,并在 Conway Venn 图的基础上增加了 5 个类别:
-
编程语言: Python,R,Java,Java,C++,MATLAB,SAS,Scala,Julia
-
数学与统计: 代数与微积分,概率与统计,生存分析,流行病学
-
商业与沟通: 商业理解,批判性思维,沟通技巧,Excel,数据可视化,Tableau,PowerBI
-
数据科学/机器学习工具/方法: 数据清理/准备,ML 算法,Scikit-learn,文本处理,XGBoost,非结构化数据,Kaggle,强化学习
-
软件开发: Github,软件工程,Docker,DevOps,Kubernetes
-
SQL / 数据库: SQL/数据库编码,No-SQL 数据库,图数据库
-
大数据/云计算: AWS,Apache Spark,Dask,Microsoft Azure,Google Cloud,Hadoop,其他大数据工具,其他云计算平台
-
深度学习: DL 算法,Keras,自然语言处理,TensorFlow,计算机视觉,PyTorch,其他 DL 框架
上述列表和分类并不完整或完美,但它们是了解数据科学家当前技能状态的有用方式,如调查结果所示。
本次调查共收到近 1000 个投票。平均受访者拥有 16 项技能(相比 2019 年的 10 项),并希望增加或改进 18 项技能(相比 2019 年的 6.5 项)。
下面的图 1 显示了按类别划分的技能雷达图,蓝线表示受访者已拥有的技能,橙线表示所需技能。由于每个类别中有许多条目,我们使用最大百分比(最受欢迎的条目)来代表该类别。

图 1: 现代数据科学相关技能的 8 个类别,拥有与需求对比
我们注意到,典型的数据科学家在前 6 个类别中表现良好:编程、数学与统计、业务与沟通、数据科学/机器学习工具、软件开发和 SQL/数据库,% 拥有的范围从 79% 到 69%。只有 54% 具备软件开发技能。两个最现代的领域显示出当前技能的差距,% 需求超出 % 拥有的技能 - 大数据与云计算和深度学习。
表 1: 各类别的 % 拥有 vs % 需求
| 类别 | 最大 % 拥有 | 最大 % 需求 |
|---|---|---|
| 编程语言 | 79% | 43% |
| 数学与统计 | 73% | 39% |
| 业务与沟通 | 72% | 38% |
| 数据科学与机器学习工具/方法 | 70% | 52% |
| 软件开发 | 54% | 45% |
| SQL/数据库 | 69% | 43% |
| 大数据与云计算 | 20% | 49% |
| 深度学习 | 34% | 51% |
现代数据科学不是由拥有所有必要技能的独角兽完成的,而是由团队完成的,研究不同职位的技能(如研究员、数据科学家、数据分析师、机器学习工程师、业务分析师等)会很有用。我们将这部分内容留到未来讨论。
接下来,我们将深入分析在这次调查中单独的数据科学技能的受欢迎程度。

图 2: 现代数据科学相关技能,拥有与需求对比
X 轴显示 % 拥有技能 - 第一个调查问题的答案,Y 轴显示 % 需求技能 - 第二个调查问题的答案。
形状代表类别 - 见下文。形状的大小与拥有该技能的选民比例成正比。颜色取决于需求/拥有的比率:红色表示高 - 大于 1.2,灰色表示 1.2 到 0.8 之间,蓝色表示低 - 小于 0.8。

与 去年数据科学技能调查 相同,我们可以看到两个主要的集群。
集群 1 位于图表右侧的蓝色虚线矩形中,包括所有超过 50% 受访者拥有的技能。此集群中所有形状的颜色为蓝色,表明需求/拥有的比率小于 0.8。与去年一样,我们将这组技能称为 核心数据科学技能。它们列在表 2 中。
表 2: 13 个核心数据科学技能,按 %拥有 的降序排列
| 技能 | 类别 | %拥有 | %需求 | %需求/ %拥有 |
|---|---|---|---|---|
| Python | 编程语言 | 78.8% | 43.1% | 0.55 |
| 概率与统计 | 数学与统计 | 73.4% | 38.7% | 0.53 |
| 数据可视化 | 业务与沟通 | 71.6% | 37.7% | 0.53 |
| 数学(代数与微积分) | 数学与统计 | 70.7% | 28.6% | 0.40 |
| 批判性思维 | 商业与沟通 | 70.3% | 28.8% | 0.41 |
| 数据清洗/数据准备/ETL | 数据科学与机器学习工具 | 70.1% | 31.9% | 0.45 |
| 沟通技能 | 商业与沟通 | 69.4% | 33.4% | 0.48 |
| Excel | 商业与沟通 | 69.4% | 15.0% | 0.22 |
| SQL | SQL/数据库 | 69.2% | 29.1% | 0.42 |
| 机器学习技术 | 数据科学与机器学习工具 | 61.9% | 42.2% | 0.68 |
| 商业理解 | 商业与沟通 | 60.9% | 34.9% | 0.57 |
| Github | 软件开发 | 54.2% | 41.1% | 0.76 |
| Scikit-learn | 数据科学与机器学习工具 | 52.3% | 37.6% | 0.72 |
核心技能几乎与 2019 年调查相同,唯一的两个例外是:R 的受欢迎程度从 45%下降到 40%,因此未包含在核心技能中。新增了一个技能:Github(2019 年调查中没有)。
核心技能中最常见的类别是商业与沟通(5 项)和数据科学与机器学习工具(3 项)。
调查还允许人们选择“拥有”和“希望增加或改进”该技能(这解释了为什么某些技能的%拥有 + %希望 > 100%)。在核心技能中,人们最希望改进的是
-
Python,有 33%的人希望提升它。
-
机器学习技术,33%
-
概率与统计,31%
-
数据可视化,30%
-
Scikit-learn,29%
改进意愿最低的技能是
-
Excel,11%
-
SQL,18%
第二个集群,在图 2 的左侧,用红色边框标记,包括了目前较少人掌握(%拥有 < 30%)但更多人希望增加的技能,其中%希望/%拥有 > 1.2,并且至少 15%的受访者希望掌握这些技能。
我们称这些为热门/新兴数据科学技能,它们列在表 3 中。我们可以看到,最热门的技能,拥有最高的学习愿望百分比,分别是强化学习、TensorFlow、深度学习算法和 PyTorch。
表 3:现代数据科学技能的热门/新兴技能,按%希望降序排列
| 技能 | 类别 | %希望 | %拥有 | %希望/ %拥有 |
|---|---|---|---|---|
| 强化学习 | 数据科学与机器学习工具 | 51.9% | 13.8% | 3.8 |
| TensorFlow | 深度学习 | 51.2% | 26.0% | 2.0 |
| 深度学习算法 | 深度学习 | 50.8% | 34.0% | 1.5 |
| PyTorch | 深度学习 | 50.1% | 12.5% | 4.0 |
| AWS(亚马逊网络服务) | 大数据与云计算 | 48.8% | 20.1% | 2.4 |
| 自然语言处理 | 深度学习 | 48.7% | 27.3% | 1.8 |
| Apache Spark | 大数据与云计算 | 45.3% | 17.8% | 2.5 |
| Docker | 软件开发 | 44.9% | 17.0% | 2.6 |
| No-SQL 数据库 | SQL/数据库 | 43.0% | 25.5% | 1.7 |
| 计算机视觉 | 深度学习 | 42.7% | 20.7% | 2.1 |
| Kubernetes | 软件开发 | 41.3% | 5.8% | 7.2 |
| Keras | 深度学习 | 41.1% | 28.2% | 1.5 |
| 非结构化数据 | 数据科学与机器学习工具 | 40.8% | 29.4% | 1.4 |
| 图数据库 | SQL/数据库 | 39.4% | 14.2% | 2.8 |
| 生存分析 | 数学与统计 | 37.7% | 19.8% | 1.9 |
| Google 云计算 | 大数据与云计算 | 37.4% | 14.7% | 2.5 |
| Microsoft Azure | 大数据与云计算 | 37.3% | 15.3% | 2.4 |
| DevOps | 软件开发 | 36.2% | 14.9% | 2.4 |
| Kaggle | 数据科学与机器学习工具 | 36.0% | 25.9% | 1.4 |
| PowerBI | 商务与沟通 | 33.6% | 25.1% | 1.3 |
| Hadoop 或 Spark 以外的大数据工具 | 大数据与云计算 | 32.6% | 9.5% | 3.4 |
| Hadoop | 大数据与云计算 | 32.5% | 13.1% | 2.5 |
| 其他深度学习框架 | 深度学习 | 30.0% | 6.0% | 5.0 |
| Julia | 编程语言 | 29.1% | 2.0% | 14.9 |
| Scala | 编程语言 | 28.4% | 5.9% | 4.8 |
| 流行病学 | 数学与统计 | 27.4% | 8.2% | 3.3 |
| Dask | 大数据与云计算 | 21.2% | 3.4% | 6.2 |
| 其他云计算平台 | 大数据与云计算 | 18.4% | 4.4% | 4.2 |
| SAS | 编程语言 | 17.6% | 11.6% | 1.5 |
新兴数据科学技能中最常见的类别包括:
-
大数据与云计算, 8
-
深度学习, 7
-
数据科学与机器学习工具, 3
-
编程语言, 3
-
软件开发, 3
剩余的技能是那些需求增长不强劲的技能,期望/拥有比率小于 1.2,并且当前流行度低于 50%。这些技能在许多领域仍然非常有用。该组技能在表 4 中列出。
表 4:有用/其他数据科学技能,按%拥有降序排列
| 技能 | 类别 | %拥有 | %期望 | %期望/ %拥有 |
|---|---|---|---|---|
| R 语言 | 编程语言 | 40.6% | 34.8% | 0.86 |
| 文本处理 | 数据科学与机器学习工具 | 37.5% | 39.9% | 1.1 |
| 软件工程 | 软件开发 | 33.9% | 31.8% | 0.94 |
| Tableau | 商务与沟通 | 31.8% | 35.5% | 1.1 |
| XGBoost | 数据科学与机器学习工具 | 29.5% | 34.6% | 1.2 |
| Java | 编程语言 | 22.2% | 22.3% | 1.0 |
| C++ | 编程语言 | 21.0% | 24.9% | 1.2 |
| MATLAB | 编程语言 | 18.8% | 16.1% | 0.86 |
告诉我们我们遗漏了什么以及你的想法 - 请在下面评论!
相关内容:
-
哪些数据科学技能是核心的,哪些是热门/新兴的?, 2019 KDnuggets 调查
-
Python 领先的 11 大数据科学、机器学习平台:趋势与分析
-
Python 蚕食 R:2018 年分析、数据科学、机器学习的顶级软件:趋势与分析
-
成为顶级数据科学家的前 13 项技能
-
数据科学家最需的技能
-
我没有被聘为数据科学家。因此,我寻找了关于谁被聘用的数据。
了解更多相关内容
现代数据栈是否把你甩在了后头?
原文:
www.kdnuggets.com/2021/11/modern-data-stack-leaving-behind.html
评论
由 Josh Benamram,Databand 的联合创始人兼 CEO

图片由 Andy Beales 提供,来源于 Unsplash
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
“现代数据栈”最近在数据博客圈内获得了大量关注。理由很充分——它是识别构建有效数据组织所需工具的有用模型。
假设你刚刚在全新的工具上投入了大量时间和金钱来运行你的数据基础设施。但你的工具与所描述的现代栈不匹配。你正在使用一堆其他工具,并且不认识所有这些标志。被“现代栈”排除在外,你可能会认为数据操作会因其不可动摇的衰退而逐渐停止。或者你永远无法找到和聘用愿意容忍你过时的数据平台的新工程师。
这些都不太可能是真的。事实是,“现代栈”的定义过于狭窄,只适用于某种特定类型的数据组织。对于许多数据团队来说,你需要以不同的方式思考你的栈。
现代数据栈:当前定义
现代数据栈的当前定义是一个自助服务的数据平台,包含以下层次:
-
管理的数据集成工具(Fivetran)
-
基于云的数据仓库(Bigquery)
-
工作流协调器(DBT)
-
商业智能平台(Looker)
独立来看,这些都是很棒的工具。将它们结合起来,就能提供许多组织所需的组合。但如果你不符合这种模式,这是否意味着你的团队不“现代”?当然不是!虽然这些工具满足了许多人的需求,但它们并未讲述全部故事。它缺少了许多团队无法缺少的核心数据平台服务的关键层。
现代数据栈:重新定义
事实是现代数据堆栈有不同的偏差。你需要什么样的“现代数据堆栈”取决于你公司的战略和数据产品的性质。你选择的堆栈类型将影响你数据平台中的压力源(失败源)和你对数据质量的定义。
目前,现代堆栈正与分析工程的兴起混为一谈。DBT Labs 在这里对这一角色提供了很好的描述。如果你更全面地看待数据行业,你会发现围绕“现代数据堆栈”有两个分化的趋势。
其中之一,你猜对了,就是现代数据堆栈(MDS)用于分析工程。这个版本的 MDS 针对可访问性、易用性和工作(“T”)在数据仓库中的集中进行了优化。它通常被认为是一种“无代码”构建的方法。
我们看到的另一种版本是优化工程的现代数据堆栈。这一版本的 MDS 旨在实现灵活性、控制和可扩展性。
现代分析工程堆栈
这是围绕这个话题讨论最多的现代数据堆栈类型。这一类别的数据平台通常是低代码和 SQL 导向的。因此,数据团队通常由数据分析师和分析工程师组成,数据工程师较少(根据组织规模,可能没有数据工程师)。
在这种范式下工作的团队对数据工程师的依赖较少,以便摄取和准备他们的数据。他们有较少的常用数据源,这些数据源可以被 Fivetran 和 Stitch 等平台完全摄取。如果存在数据工程师,他们将负责维护整个数据平台,并偶尔进行自定义集成。数据仓库左侧的所有内容都更简单,不需要深度的工程关注。

当出现复杂性时,它会来自数据流的内部内容,但更多地来自用户如何查询和分析数据。因此,许多数据问题和失败将是由于 SQL 和仪表板错误。分析师将主要与负责在数据仓库中聚合数据并提供文档以改善最终用户可访问性的分析工程师对接。
这个平台灵活,能够快速启动。管理它所需的技能更容易学习(SQL,基于 GUI 的工具),因此这是一个快速、精简的方式来启动一个分析程序。例如,当业务利益相关者希望对 Salesforce 数据进行持续和临时分析,以便能够快速做出决策时,这种模型非常适合。
现代数据工程堆栈

现代数据栈的重点是为数据工程师提供构建更复杂数据产品所需的工具,以便以一种可维护、可靠和可扩展的方式进行构建。
现代数据栈包括:
-
基于云的数据湖(S3, Delta Lake, BigQuery 或 GCS)
-
云转型工具(Spark, Google Dataflow)
-
工作流编排工具(Airflow, Argo, Dagster)
-
流处理系统(Kafka, Beam, Flink)
使用这种架构的组织需要来自广泛来源的大量数据来构建他们的数据产品。这些团队在如何处理和从独特数据集中生成洞察或模型方面积累了大量的知识产权。他们处理更多独特和多样的数据源(csv, parquest, json),并对数据进行更重的处理以使其适配。
这些团队需要比分析工程更多的专业技能,将所有数据转化为分析就绪的形式。数据工程师对于控制、灵活性和数据摄取、准备及交付给分析师和科学家的能力至关重要。为了提供这些灵活性和控制,这些团队使用面向代码的架构;Python 和定制的管道构建。由于这种复杂性和数据源的多样性,我们将在数据仓库左侧的摄取和预处理层看到一个扩展架构,这引入了更多的故障点,并需要专业工具来确保跨大量数据源和可能的故障原因的数据可靠性。
现代数据栈 2.0
现代数据栈运动使得以分析工程为导向的团队实现了更高的可访问性和速度,同时也使得以数据工程为导向的团队能够大规模地交付高质量的数据。
现在,我们已经开始看到这一运动的下一次迭代成形:数据可观测性。
随着数据平台变得越来越可扩展和灵活,团队需要让这些系统更可靠和可信。数据可观测性工具应运而生。既有像Re-data这样的解决方案,主要面向分析工程师,也有像我们在Databand这样更专注于数据工程的解决方案。
无论你选择何种数据栈,有一点是明确的:数据可观测性平台将塑造现代数据栈的未来。通过对数据质量的更大控制,团队将能够自动化和加速他们的数据平台开发,并更快地将高质量的数据产品推向市场。
简介: Josh Benamram 拥有丰富的背景,以对数据的痴迷为共同特点。他最初在金融领域开始,曾在一家量化投资公司担任分析师,随后在 Bessemer Venture Partners 专注于投资数据和机器学习公司。在创办 Databand.ai 之前,他在 Sisense 担任产品经理,这是一家快速增长的分析公司,他在这里构建了针对数据工程团队的产品功能。他与两位共同创始人一起创立了 Databand.ai,以帮助数据工程师提供更可靠的数据产品。他拥有康奈尔大学的理学学士学位。
相关:
-
数据工程技术 2021
-
没有数据工程技能的数据科学家将面临严峻的现实
-
数据工程师最重要的工具
更多相关话题
-
[ChatGPT 的工作原理:机器人背后的模型]( https://www.kdnuggets.com/2023/04/chatgpt-works-model-behind-bot.html )
-
[稳定扩散:生成 AI 的基本直觉]( https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html )
-
[开始使用 LLMOps:无缝互动背后的秘密武器]( https://www.kdnuggets.com/getting-started-with-llmops-the-secret-sauce-behind-seamless-interactions )
-
[LLM 基础的自主代理背后的增长]( https://www.kdnuggets.com/the-growth-behind-llmbased-autonomous-agents )
-
[如何在预算内建立你的数据科学技术栈]( https://www.kdnuggets.com/2022/01/data-science-stack-budget.html )
-
[全栈一切?数据科学、开发和技术之间的组织交集]( https://www.kdnuggets.com/2022/08/full-stack-everything-organizational-intersections-data-science-dev-tech.html )
现代图形查询语言 – GSQL
原文:
www.kdnuggets.com/2018/06/modern-graph-query-language-gsql.html
评论
作者:余旭博士,TigerGraph CEO

根据咨询公司DB-Engines.com,图形数据库技术是所有数据管理类别中增长最快的。最近的Forrester调查显示,全球超过一半的数据和分析技术决策者现在使用图形数据库。
目前,企业使用图形技术作为客户分析、欺诈检测、风险评估和其他复杂数据挑战的竞争优势。这项技术提供了快速高效地探索、发现和预测关系的能力,以揭示关键模式和洞察,支持业务目标。
是时候使用现代图形查询语言了
随着图形数据库的广泛采用,现在正是制定标准图形查询语言的时候。企业今天成功地使用各种查询语言,如 Neo4j 的 Cypher、Apache TinkerPop Gremlin,但这些也有其自身的局限性。
尽管 Cypher 是高级且用户友好的,但它不是图灵完备的。有许多图形算法和业务逻辑规则无法使用 Cypher 实现。例如,PageRank/Label Propagation 风格的算法,其中变异对电力流计算和优化、风险分析等垂直领域很重要。
Gremlin 是图灵完备的,但层次较低。该语言适用于非常简单的查询,但在实际业务问题中,需要高级编程技能,生成的查询可能难以理解和维护。有关图形查询语言的技术比较可以在这里找到。
随着数据和用例的增长和复杂化,显然组织需要具备向上和向外扩展的能力,以及为大数据、复杂分析(如机器学习和 AI)和实时操作生成所需的物质性能影响的能力。
国际标准还将有助于解决图市场中普遍存在的挑战,包括难以找到熟练的图开发人员和加快企业采纳的需求。通过高级图查询语言降低学习和实施图应用的门槛,使更多开发人员能够更轻松地从提出高层次的现实生活问题过渡到轻松构建基于图的解决方案。
现代图查询语言,以及支持它的超高速和可扩展系统,对于帮助企业大规模实现数字化转型也至关重要。
现代图查询语言应该是什么样的?
让我们退一步,理解为何用户选择图数据库而不是关系型数据库、键值存储、文档存储和其他类型的数据库。通常是因为他们希望以令人满意的性能解决复杂问题。非图数据库有以下缺点:
-
表达现实世界商业问题极其困难。例如,像账户或人员这样的实体如何以各种通常未知的方式(特别是对已知的恶意行为者)连接起来?
-
在访问数千万到数亿个实体及其关系时,实时性能极差。对于实时个性化推荐、欺诈检测等应用,速度至关重要。
图数据库提供了解决这些问题的平台,但用户仍然需要适当的查询语言:以定义图模式来建模复杂的实体和关系,以轻松将各种数据源映射到图中,以快速将数据加载到图中,并且具有足够的表达能力(图灵完备),以建模和解决各类行业的现实商业问题。这些都是使图技术能够跨越鸿沟,实现更广泛企业采纳的关键。
鉴于此,专家指出了现代图查询语言的重要八个关键特征:1)基于模式并具有动态模式更改的能力,2)图遍历的高级表达,3)图遍历的精细控制,4)内置并行语义以保证高性能,5)高度表达的加载语言,6)数据安全和隐私,7)支持查询调用查询(递归)和 8)SQL 用户友好。关于这些要求的更多细节可以在这里找到。
介绍 GSQL
GSQL 是一种用户友好、高度表达和图灵完备的图查询语言。与其他选项不同,GSQL 支持组织已经遇到的现实商业需求,并从头开始设计以满足上述标准。
实际上,GSQL 的开发是在寻找一种能够充分满足实际业务需求的现代图查询语言失败之后开始的。当 TigerGraph 六年前成立时,我们决定花费数年时间创建 GSQL,以缓解这一痛点。我们从头开始设计,支持并行加载、查询和实时交易的更新,以及超快的分析。
自去年年底 TigerGraph 公开发布以来,客户反馈极为积极。我们不断听到客户获得了之前认为不可能的数据洞察。换句话说,GSQL 使得不可能变为可能。GSQL 被包括支付宝在内的一些大型公司使用,支付宝是全球最大的图形部署,每天有超过二十亿的实时交易。
用户们还报告说,GSQL 在处理大数据查询时使用方便。速度也是一个好处,因为 GSQL 查询在几秒钟内就能返回结果,而使用 Cypher 或 Gremlin 等解决方案可能需要几个小时——当然,前提是查询能够实现。简而言之,GSQL 满足了图查询语言最重要的需求:性能、表达能力和易用性。要了解更多关于 Tigergraph 和 GSQL 的信息,请访问 www.tigergraph.com。
我鼓励业界推动制定国际标准,以最大化他们的图数据库投资。这将对所有人都有利。然而,在选择设计用于满足现代业务需求的语言时,需要考虑关键因素。
示例 GSQL 查询 1:PageRank 计算节点的相对权威性,对于许多应用程序(如社区聚类、影响分析、电力流收敛、预测分析中的标签传播等)至关重要。能够在高级图查询语言中纯粹实现和 定制 PageRank 风格(迭代、对迭代次数和终止条件的完全控制等)的图算法对于这些用例至关重要。相反,硬编码 的 PageRank 算法无法提供解决现实问题的表达能力。
创建查询 pageRank (FLOAT diffLimit, INT maxIter, FLOAT damping) FOR GRAPH G { # @@ = 全局累加器; @ = 每个顶点的累加器
MaxAccum
SumAccum
SumAccum
Vertices = {ANY};
当 @@maxDiff > diffLimit 时,LIMIT maxIter DO
@@maxDiff = 0;
Vertices = SELECT s FROM Vertices:s-(:e)->:t
ACCUM t.@rcvd_score += s.@score/(s.outdegree())
POST-ACCUM s.@score = (1-damping) + damping * t.@rcvd_score,
s.@rcvd_score = 0,
@@maxDiff += abs(s.@score - s.@score');
结束;
打印 Vertices;
}
个人简介: 余旭博士是 TigerGraph 的创始人兼首席执行官,TigerGraph 是世界上首个原生并行图数据库。余博士在加州大学圣地亚哥分校获得计算机科学与工程博士学位。他是大数据、并行数据库系统以及图数据库方面的专家,并拥有 26 项并行数据管理和优化的专利。在创办 TigerGraph 之前,余博士曾在 Twitter 负责大规模数据分析的数据基础设施工作。在此之前,他曾担任 Teradata 的 Hadoop 架构师,领导公司的大数据项目。
相关内容:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
相关话题
Mojo Lang:新编程语言
原文:
www.kdnuggets.com/2023/05/mojo-lang-new-programming-language.html

图片由作者提供
就在我们以为科技行业无法再出现更多震荡时,欢迎这门作为 Python 编程语言的超集设计的新编程语言。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
Python 仍然是最受欢迎的编程语言之一,因为它能够使用简单易读的语法创建复杂的应用程序。然而,如果你使用 Python,你就会知道它最大的问题是速度。速度是编程的重要元素,那么 Python 在简单语法下创造复杂应用的强大能力是否会忽略它的速度不足呢?不幸的是,不会。
还有其他编程语言,如 C 或 C++,它们的速度惊人,相比 Python 性能更高。虽然 Python 是最广泛使用的 AI 编程语言,但如果你追求速度,大多数人会选择 C、Rust 或 C++。
但这一切可能会改变,欢迎新编程语言 Mojo Lang。
Mojo Lang 是什么?
Mojo Lang 的创始人 Chris Latner,是 Swift 编程语言和 LLVM 编译器基础设施 的创始人,他将 Python 的易用性与 C 编程语言的性能相结合。这为所有 AI 开发人员解锁了新的编程层次,具有无与伦比的 AI 硬件可编程性和 AI 模型的扩展性。
相比 Python,PyPy 快 ??22 倍,Scalar C++ 快 5000 倍,而 Mojo Lang 快 35000 倍。
Mojo Lang 是一种为 AI 硬件(如运行 CUDA 的 GPU)编程而设计的语言。它通过使用多级中间表示(MLIR)来扩展硬件类型,而不增加复杂性。
Mojo Lang 是 Python 的超集,这意味着它不需要你学习一种新的编程语言。方便吧?基础语言与 Python 完全兼容,允许你与 Python 生态系统互动,并利用诸如 NumPy 的库。
Mojo Lang 的其他特点包括:
-
利用类型以获得更好的性能和错误检查。
-
通过将值内联分配到结构中,零成本抽象来控制存储。
-
所有权和借用检查器,通过利用内存安全性而不留粗糙边缘。
-
自动调优,允许你自动找到参数的最佳值。
Mojo Lang 和 Python 的区别
Mojo Lang 和 Python 非常相似,但一定还是有一些区别,对吧?
是的,我们已经指出两者之间最大的区别是速度。但还有一些其他的区别。
添加类型
Mojo Lang 有一个内置的 struct 关键字,类似于 Python 的类。区别在于 struct 是静态的,而 class 是动态的。
在 struct 中,Mojo Lang 有像 var 这样的关键字,它是可变的,还有 let,它是不可变的。我们在 Python 中知道的 def 定义了一个函数,在 Mojo Lang 中,def 被替换为更严格的 fn。
它还可以包括 SIMD,即单指令多数据,这是一种内置类型,表示一个向量,在底层硬件上可以对多个元素同时执行单个指令。
将 struct 作为一种类型,并在 Python 实现中使用它,可以将性能提高 500 倍。
并行计算
Mojo Lang 具有内置的并行化功能,可以使你的代码支持多线程,从而提高速度 2000 倍。Python 中没有并行处理,并且实现起来可能非常复杂。
瓷砖优化
Mojo 具有内置的瓷砖优化工具,允许你更有效地缓存和重用数据。你可以在同一时间使用接近的内存,并进行重用。
自动调整
Mojo Lang 允许你自动调优代码,帮助你自动找到目标硬件的最佳参数。
Mojo Lang 还有更多功能,要了解其工作原理,请观看这个由 Jeremy Howard 演示的 Mojo 演示:
我现在可以使用 Mojo Lang 吗?
不幸的是,Mojo Lang 目前还不对公众开放,它仍处于早期开发阶段。然而,未来它会开源,你可以在 等待名单中尝试 Mojo Lang。
总结一下
你已经对新的 Mojo Lang 编程语言及其特点有所了解。Mojo Lang 是不是只是 Python++,还是说它会完全取代所有 Python 用户?
妮莎·阿里亚 是一名数据科学家、自由技术作家以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于人类寿命的延续。她是一位热衷学习的个人,寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关主题
什么是矩生成函数?
原文:
www.kdnuggets.com/2022/12/momentgenerating-functions.html
数据科学是一个多学科领域。因此,它通常更倾向于多语种和多才多艺的人。它需要对计算和应用数学的理解,这可能会让纯编码背景的数据科学家感到望而却步。然而,掌握数学统计学是重要的,特别是如果你计划为预测结果创建算法和数据模型的话。
在大多数情况下,学习任何东西的最佳方法是将其分解成概念。这也适用于概率与统计中的概念。矩生成函数(MGF)就是所有数据科学家都应了解的概念之一。以下指南将回答它们是什么以及如何在编程中实现它们。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在概率和统计中,什么是矩?
如果你字面理解矩生成函数,你会发现 MGF 是生成矩的函数。但什么是矩?在统计学中,我们使用所谓的分布来说明值在一个领域中的分布情况,即哪些值是常见的,哪些是稀有的。
数据科学家和统计学家使用矩来测量分布。从根本上说,矩是分布的参数,它们可以用来确定或描述其形状,允许你提取有关数据的信息(元数据)。我们将下文介绍四种最常见的矩。
均值 E(X)
均值是第一矩。它描述了分布的中心位置/位置/倾向。此外,它是初始期望值,也称为(数学)期望或平均值。在结果具有联合发生概率的情况下,我们使用算术平均公式:

简而言之,所有变量值的总和可以除以值的数量 [(值的总和)÷(值的总数)]。
然而,如果结果的发生概率不同,你必须计算每个概率的结果,将这些值加总,然后乘以相应的结果/概率。
均值公式是最受欢迎的方法之一来测量平均值或中心趋势。它也可以表示为中位数(中间值)或众数(最可能的值)。
方差 E(X²)
方差是第二个矩。它表示分布的宽度或扩散程度——值与平均值或标准的偏离程度。这个矩最终用于说明或查找分布或数据集中的任何偏差。我们通常使用标准差,它由方差的平方根表示[E(X³)]。
偏度 E(X³)
偏度是第三个矩。它表示分布的非对称性或相对于分布均值的偏斜程度。偏度影响均值、中位数和众数之间的关系。一个分布的偏度可以分为三类:
-
对称分布: 分布的两侧/尾部对称。在这个类别中,偏度的值为 0。在一个完全对称(单峰)分布中,均值、中位数和众数是相同的。
-
正偏:分布的右侧/尾部比左侧长。这用于识别和表示异常值,这些值大于均值。这个类别也可以称为右偏、右尾或右偏分布。通常,均值大于中位数,中位数大于众数(众数 < 中位数 < 均值)。
-
负偏:分布的左侧/尾部比右侧长。我们用它来识别和表示值小于均值的异常值。这个类别也可以称为左偏、左尾或左偏分布。通常,众数大于中位数,中位数大于均值(众数 > 中位数 > 均值)。
你还可以使用以下简单公式来找出偏度:

或


峰度 E(X⁴)
峰度是第四个矩。我们用它来通过分布的“尾部”来测量和指示异常值的出现。因此,峰度最关注分布的尾部。它帮助我们确定分布是否正常或充满极端值。
通常,正态分布的峰度值为 3 或超额峰度为 0。具有这种类型峰度的分布称为中峰度型。具有较轻尾部和峰度值小于三(K < 3)的分布称为负峰度。在这些情况下,分布通常较宽且较平坦,称为平峰型。
另一方面,具有较重尾部和峰度值大于三(K > 3)的分布称为具有正峰度。在这些情况下,分布较窄,具有尖锐或高峰,称为尖峰型。高峰度表明分布包含异常值。

现在我们已经涵盖了什么是矩,我们可以讨论矩生成函数(MGF)。
什么是矩生成函数(MGF)?
矩生成函数最终是允许你生成矩的函数。在 X 是一个具有累积分布函数 Fx 的随机变量且 t 的期望值接近于零的某个邻域的情况下,X 的 MGF 定义为:

其中 X 是离散的,pi 代表概率质量函数(PMF),其定义为:

其中 X 是连续的,f(X) 代表概率密度函数(PDF),其定义如下:

在我们尝试找到原矩的情况下,我们必须找到 E[xn] 的值。这涉及使用 E[etx] 的 nth 导数。我们还通过将 t (t = 0) 作为值来简化它:

因此,使用 MGF 找到第一阶原矩(均值)时,将 t 设为 0 看起来如下:


你可以使用相同的方法找到第二阶原矩:


你可以使用泰勒展开式(ex=1+x1!+x22!+x33!+…,-∞
为什么矩生成函数是必要的?
MGF 提供了一种替代方案,用于在连续概率分布中积分 PDF 以找到其矩。在编程中,寻找正确的积分使算法变得更加复杂,需要更多的计算资源,增加了程序的负载或运行时间。MGF 和其衍生方法在找到矩时更为高效。
结论
在不使用 MGF 的情况下找到分布的矩是可能的,但计算高阶矩而不使用 MGF 会变得复杂。Python 的内置统计模块提供了一系列足够的函数,可用于从数据集中计算矩。然而,这并不是在 Python 中使用统计函数的唯一选项。
上述指南提供了对矩和矩生成函数的基本探讨。作为程序员或数据科学家,你可能从未需要手动计算原始矩或尝试手动推导中心矩。很可能,有多种模块和库可以为你完成这些任务。然而,了解后台发生的过程始终是重要的。
Nahla Davies 是一名软件开发者和技术作家。在全职从事技术写作之前,她管理了——除了其他有趣的工作——担任过 Inc. 5,000 实验性品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关主题
Mongo DB 基础
评论
由 Jyoti Reddy 提供,Krones 数据工程师

Mongo DB 是一种面向文档的 NO SQL 数据库,不同于具有宽列存储的 HBASE。面向文档的数据库相较于关系型数据库的优势在于,可以根据需要为每个情况更改列名,而不是所有行使用相同的列名。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
在 Mongo DB 中操作的方法
1. 创建数据库
使用命令 — use

2. 列出 Mongo DB 系统中的数据库
使用命令 — show dbs
该命令将显示默认数据库以及客户端创建的数据库。然而,如果在创建的数据库中没有集合,则它不会出现在列表中。此外,要检查当前选定的数据库,请使用命令- db。下图显示了数据库
当前正在操作中。

3. 删除数据库
使用命令 — db.dropDatabase()。按照以下命令,显示了在删除选定数据库前后的情况。我们无法指定选定的数据库名称。当前选定的数据库将被自动删除。此外,我们在 sampledb 中插入了一些数据,这就是它出现在列表中的原因。如果 sampledb 中没有数据,则在输入命令 — show dbs 后将不会出现。

4. 创建集合
以下过程展示了如何在数据库中创建一个集合。集合中包含文档。使用命令 — db.collectionname.insert({})。下图仅显示了在集合‘Country’中创建的一个文档。我们可以在同一集合中创建多个文档。这个集合相当于 HBase 中的表或关系型数据库管理系统中的表。

以下示例展示了一个包含多个文档的集合。注意两个文档中的字段数量。第一个文档没有 suburb 字段,这意味着我们只需插入我们拥有的信息。

5. 查找集合中的文档
使用命令- db.collectionname.find()。对象 ID 会附加到每个文档中,使每个文档唯一。

我们还可以使用 AND 和 OR 操作符在集合中查找特定的文档。例如,要查找包含城市 Mumbai 的文档,请使用以下命令:
db.country.find({city:’Mumbai’});
6. 更新集合中的文档
要更新特定字段,请使用命令-
db.collectionname.update({field:’old name’},{$set:{field:’new name’}})
更新前

更新后

7. 删除文档
要删除文档,请使用以下命令-
db.collectioname.remove({field:’Value’})

我们还可以使用命令 db.collectionname.remove({}) 来清空整个集合,这已在版本 2.6 中添加。以前命令 db.collectionname.remove() 也可以使用。这相当于 SQL 中的 truncate 命令。
8. 行的投影
要选择所需的字段,我们可以使用下面给出的命令。我们需要在命令中将‘1’或‘0’附加到字段上。如果给‘1’,则该字段的所有行都会出现,‘0’则相反。如果命令中没有指定字段名,则默认为 Object ID 字段取‘1’,这种情况不适用于列表中的其他字段。这里的字段对应于关系型数据库中的列。
db.collectionname.find({},field:1})

9. 限制行数
这是投影行的高级版本。在投影技术中,所有行都会出现,导致获取不需要的数据。在这里,我们可以限制列数并跳过一些行。使用命令 - db.collectionname.find({},{field:1 or 0,field:1 or 0…}).limit(1).skip(1)。该方法将只检索一行。跳过的数量决定了从结果中移除的行数。

10. 排序行
在这种方法中,我们可以以升序或降序排列行。选择所需的字段,然后将 1 或 -1 附加到排序命令中。默认值为 1,因此在这种情况下,排序命令不需要指定。升序或降序将基于排序命令中选择的列。
Command: db.country.find({},{state:1}).sort({state:-1})

这些是操作 Mongo DB 的一些方法。语法友好且易于理解。这个数据库的另一个优点是,我们不需要在同一集合中的所有文档中包含所有字段。例如,如果一个文档有一个名为 city 的字段,而另一个文档不需要这个字段,那么我们可以不包括它。这有助于节省大量空间。请参阅下面的示例

简介: Jyoti Reddy 是 Krones 的数据工程师。
原文。经授权转载。
相关:
-
理解 NoSQL 数据库的 7 个步骤
-
数据工程初学者指南 – 第一部分
-
数据工程初学者指南 – 第二部分
更多相关内容
如何实时监控机器学习模型
原文:
www.kdnuggets.com/2019/01/monitor-machine-learning-real-time.html
评论
由 Ted Dunning,MapR 首席应用架构师
介绍
信不信由你,在机器学习课程中学到的东西并不是你需要知道的内容来将机器学习付诸实践。学术机器学习几乎完全涉及对机器学习模型的离线评估。这种理想化的观点也由 Kaggle^([1]) 或 Netflix 挑战赛^([2]) 等广泛宣传的竞赛所助长。在现实世界中,这种方法令人惊讶地通常仅能作为一个粗略的初步筛选,用于剔除真正糟糕的模型。对于严肃的生产工作,在线评估通常是确定多个最终候选模型中哪个可能被选择用于进一步使用的唯一选择。正如爱因斯坦所传言的那样,理论与实践在理论上是一样的。在实践中,它们是不同的。模型也是如此。部分问题与其他模型和系统的互动有关。另一个问题则涉及现实世界的变异性,可能是对手的作用。甚至可能是太阳黑子。一个特别的问题是,当模型选择自己的训练数据时,它们会表现出自我强化的行为。
除了这些困难,生产模型几乎总是有服务水平协议,这些协议涉及它们必须多快产生结果以及它们允许失败的频率。这些操作性考虑因素可能与模型的准确性一样重要……返回的正确结果迟到比及时返回的基本正确结果要糟糕得多。
本文将重点讨论如何实时或近实时地监控机器学习系统。由于这个重点,我们不会多谈论如何确定一个模型是否产生了正确答案,因为你通常很难在很长时间内确认这一点。例如,如果一个欺诈模型说某个账户已被接管,你可能要几个月才能得知真相。然而,即便如此,我们通常可以在此之前很早就发现模型是否在某些重要方面表现异常。
这里描述的技术将包括使用粗略功能监控器、非线性延迟直方图、如何规范化用户响应数据以及如何将得分分布与参考分布和金丝雀模型进行比较。这些技术听起来可能很神秘,但在华丽的名称背后,每一种都有一个简单的核心,不需要高级数学就能理解、实施或解释。
这是一个充满挑战的世界
让我们谈谈除了在课堂上学到的内容之外你需要关注的方面。如果一切像在课堂和比赛中那样简单,那将绝对是一个更简单的世界,但实际情况远非如此。不仅正确提取训练数据是一项巨大的工程工作,而且在实际运行的模型必须处理一些非常复杂的现实世界问题。如果你在构建一个欺诈模型,欺诈者会调整他们的方法以避开你的模型。如果你在做市场营销,你的竞争对手将总是寻找超越你努力的方法。即使是那些不依赖于人类行为的系统,如飞机引擎或工厂,也会发生意外。这些意外可能是像双引擎鸟击、铣床的意外升级,甚至是市场条件或天气等上下文问题。
即使数据环境没有变化,也可能会发生设备故障,导致世界看起来奇怪和令人惊讶。
无论你构建的是哪种类型的机器学习系统,你都需要监控你的模型,以确保它们仍然按照你认为的方式工作。让我们看看一些帮助发现问题的具体技术。
关注基础知识
模型性能的最基本方面是它是否接收到请求以及它产生结果的速度。如果你不提出请求,模型不会给出好的结果。而且,结果的质量也取决于你是否能及时获得这些结果。
要监控请求是否到达,你需要记录每一个传入请求的到达时间、请求所到达的机器名称以及准确的时间戳。通常,将这些数据记录到分布式平台上的持久流中会更好,因为如果机器宕机,日志文件可能会消失。将请求到达和完成记录为单独的事件也更好,这样你可以区分响应失败与请求缺失。你可以构建的最简单的监控方法是测量请求之间的时间。更进一步的是基于最近的请求速率构建当前请求速率的简单预测器,并使用预测速率与上次请求之间的时间的乘积。即使是简单的线性模型通常也会在一个小时前预测请求速率,误差小于 10%,这将允许你在请求停止时发出警报。图 1 展示了通过绘制“圣诞节”维基百科页面的预测流量,预测的准确性如何。

图 1. 实际流量(深色线)与针对 11 月流量训练的流量预测模型预测流量(灰色线)进行对比。尽管圣诞节期间的流量与训练期间的流量大相径庭,但预测仍然足够准确,能够非常快速地检测到系统故障。
用于此预测的模型是一个线性回归模型,使用了最近 4 小时、24 小时前和 48 小时前的流量对流量的对数进行预测。这个预测可以用于检测请求率异常,如图 2 所示。

图 2. 请求率异常检测器的架构。使用阈值来确定何时请求率下降到预测值以下,因为事件之间的时间将上升到一个高水平。预测率用于对这个时间进行归一化。
一旦我们确认请求正在到达,我们可以查看我们的模型是否及时产生结果。为此,我们需要记录每个请求响应的时间。这些日志条目应指定原始请求的唯一 ID、当前时间、计算请求所用的模型和硬件的详细信息以及经过的时间。作为初步工作,我们可以计算报告的经过时间的分布。对于延迟,最佳方法是使用 非均匀直方图。我们可以为每个,例如,每五分钟的时间间隔计算这样的直方图。为了监控性能,我们可以在相当长的一段时间内积累背景,并将最近的结果与该背景分布进行对比。图 3 显示了我们可能看到的情况。

图 3. 以毫秒为单位的正常响应时间(黑线)与大约 1% 的响应显著延迟的响应时间进行对比。由于纵轴上的对数刻度和非均匀的区间大小,99%延迟的变化非常明显。
这些直方图也可以使用基于比较对应区间计数的更高级的自动化技术进行比较。一种很好的方法是使用被称为 G-检验 的统计方法。这种测试可以将每个直方图转换为一个单一的得分,描述其与长期背景相比的异常程度。如果进入直方图的延迟测量有标签,那么可以比较单个直方图中的慢速和快速部分,以找出在慢速部分更常见的标签。如果这些标签代表硬件 ID 或型号版本,则可以用来定向诊断工作。
但这是否正确?!
到目前为止提到的所有方法都适用于模型应执行的任务。但这种普遍性也意味着这些技术不能告诉我们模型实际产生的响应情况。结果是否良好?是否正确?我们没有真正的了解。目前我们只知道请求正在到达,结果也在以历史上合理的水平和速度产生。速度和处理量很好,但我们还需要了解事情不仅仅是在运行,还要了解它们是否运行正确。
在一些情况下,特别是在处理营销模型时,我们可以在几分钟内获得有关我们模型是否表现良好的初步反馈。然而,在进行比较时,我们必须非常小心。特别是,我们不能仅仅比较每个模型的转化数量,因为随着时间的推移,广告或优惠呈现给用户后,转化数量会不断增加,这给较老的印象带来了优势。图 4 显示了发生了什么。

图 4. 转化需要相对于原始印象的时间和印象的数量进行归一化。比较还必须在印象后经过足够长的时间以获得可靠的比较,但等待过长时间并没有帮助。在这里,绿色轨迹起初似乎最好,但在印象后 2 秒,当只有 60%的转化被接收时,明显是黑色最佳,红色最差。选择适当的延迟可以实现模型的最快准确评估。
问题在于,每次广告或优惠的印象都是独立于其他印象的。如果接收印象的人会做出反应,他们可能会在看到印象后的相对较短时间内做出回应。然而,有些人可能需要更长时间,有些人可能会在很长时间后才做出反应。这意味着,随着时间的推移,任何优惠的转化率都会逐渐上升。因此,首先要做的就是相对于相应印象的时间来调整每个转化率。同样,有些优惠会获得更多的印象,因此你也需要按印象的数量进行纵向缩放。
当你这样做时,你会发现,由于统计变异,你必须等待一段时间才能确定哪个优惠效果最好,但通常不需要等到超过最终响应数的 60%。这非常重要,因为等待 95%的所有印象可能比等待 50-60%的印象要长 10 倍。这个技巧也很重要,因为它允许我们近乎实时地测量响应率。
事实可能需要很长时间
尽管实时的真实反馈可能很有用,但在许多情况下这是不可能的。例如,我们可能几天或几周内都无法确定检测到的欺诈行为是否确实存在。然而,我们仍然可以采取一些措施快速检测问题。
许多模型会产生某种分数或一组分数。这些分数通常代表某种概率估计。我们可以用来监控的最简单的方法之一是查看模型产生的分数分布。如果该分布发生意外变化,则很可能是模型输入发生了重要变化,反映了外部世界的变化,或者模型依赖的系统,例如特征提取系统,发生了某种变化。无论哪种情况,发现变化是了解发生了什么的第一步。
检测这种变化的最佳方法之一是使用称为t-digest 的系统。你不能真正使用我们讨论过的用于延迟分布的 logHistogram,因为分数没有延迟那样明确的特征。t-digest 的使用成本稍高,但它几乎可以处理任何情况。方法是每分钟存储一次分数分布的摘要,并标记模型版本等。要检查分数分布,你可以从过去积累这些存储的摘要,以获得参考分布,并将该参考分布与最新的摘要进行比较。
比较分布有两种常用方法。其一是使用参考分布的十分位数作为区间边界,然后使用最新的摘要来估计每个区间中的样本数量。如果分布相同,那么最近数据中每个区间中的样本数量应该是一样的。可以像以前一样使用 G 检验来测试,以获得当分布有趣地不同的时候分数较大的结果。
另一种方法是使用称为 Kolmogorov-Smirnov 统计量的值直接检测参考分布与最近分布之间的差异。在即将发布的t-digest 版本中有计算此统计量的代码,但重要的因素是,当分布显著不同的时候统计量较大,当它们不同时则较小。
没有什么能像金丝雀那样唱歌。
通常来说,我们对模型应执行的任务了解得越多,并且在与参考行为比较时越具体,我们就能更快、可靠地检测到变化。这就是使用金丝雀模型的动机。这个想法是我们像往常一样将每个请求发送给当前的生产模型,同时保留一个较旧版本的模型,并将每个(或几乎每个)请求也发送给那个较旧版本。这个较旧的模型被称为金丝雀。
因为我们向两个模型发送的是完全相同的请求,并且金丝雀模型几乎做的是我们希望当前模型做的事情,我们可以逐请求比较这两个模型的输出,从而非常具体地了解新模型是否按预期运行。金丝雀模型与当前冠军模型之间的平均偏差是当前模型故障的非常敏感指标,特别是如果我们选择金丝雀时考虑到获得一个非常稳定(即使不那么准确)的模型。
当我们面对潜在的新挑战者要取代当前的冠军时,金丝雀模型也非常有用。如果我们试图量化推出这个新挑战者以替代当前冠军的风险,我们可以比较挑战者与冠军之间的差异,以及挑战者与金丝雀之间的差异。特别是,一旦我们拥有了相当好的模型并进行渐进改进时,任何新的挑战者都不应与当前的冠军或金丝雀有显著差异。差异存在的地方既是我们面临低准确度风险的地方,也是挑战者有机会表现出色的地方。专注于这些特定实例进行人工检查通常能给我们提供重要的见解,帮助判断挑战者是否准备好迎接冠军。
总结一下
本文介绍了一系列近实时监控机器学习模型的技术,首先是查看请求率和响应时间等总体操作特性的监控器。这些监控器通常对于检测评估请求时的系统级问题非常有效。接下来,我们讨论了如何对搜索结果或营销印象等情况的响应进行归一化,以便能够干净地进行比较,并在近实时中估计准确性。在不知道模型应该输出什么的情况下,我们讨论了通过比较过去模型的表现或比较金丝雀模型来寻找分数分布变化的方法。
你可能不需要实现所有这些监控方法,但你可能需要实现其中的几个。你永远不知道隐藏着什么,直到你去查看,而你肯定需要了解清楚。
^([1]) 参见 www.kaggle.com/c/GiveMeSomeCredit
^([2]) 参见 en.wikipedia.org/wiki/Netflix_Prize
简介: Ted Dunning 是 MapR 的首席应用架构师,同时也是 Apache 软件基金会的董事会成员。他在建立成功的创业公司方面有着丰富的经验,其中机器学习在公司价值上发挥了重要作用。他在数十项专利中被列为发明人,并继续开发新的算法和架构。
资源:
相关:
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
了解更多相关话题
在 MLOps 管道中使用 Python 监控模型性能
原文:
www.kdnuggets.com/2023/05/monitor-model-performance-mlops-pipeline-python.html

图片来源于 rawpixel.com 在 Freepik
机器学习模型只有在生产中用于解决业务问题时才有用。然而,业务问题和机器学习模型在不断发展。这就是为什么我们需要维护机器学习,以便性能能够跟上业务 KPI。这就是 MLOps 概念的来源。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
MLOps,或机器学习运维,是用于生产环境中机器学习的一系列技术和工具。从机器学习的自动化、版本控制、交付到监控都是 MLOps 处理的内容。本文将重点介绍监控以及如何使用 Python 包来设置生产环境中的模型性能监控。让我们深入了解一下。
监控模型性能
当我们谈论 MLOps 中的监控时,它可能指很多方面,因为 MLOps 的原则之一就是监控。例如:
-
监控数据分布随时间的变化
-
监控开发与生产中使用的特征
-
监控模型衰退
-
监控模型性能
-
监控系统的陈旧性
在 MLOps 中仍有许多元素需要监控,但在本文中,我们将重点关注监控模型性能。模型性能,在我们的案例中,指的是模型从未见过的数据中进行可靠预测的能力,通过特定的指标如准确率、精确率、召回率等来衡量。
为什么我们需要监控模型性能?是为了保持模型预测的可靠性,以解决业务问题。在生产之前,我们通常会计算模型的性能及其对 KPI 的影响;例如,基准是 70%的准确率,如果我们希望模型仍然符合业务需求,低于这个值就是不可接受的。这就是为什么监控性能可以使模型始终满足业务需求。
使用 Python,我们将学习如何进行模型监控。让我们从安装包开始。虽然有许多模型监控的选择,但在这个示例中,我们将使用名为 evidently 的开源监控包。
使用 Python 设置模型监控
首先,我们需要使用以下代码安装evidently 包。
pip install evidently
安装包之后,我们将下载数据示例,即来自 Kaggle 的保险索赔数据。同时,我们会在进一步使用数据之前对其进行清理。
import pandas as pd
df = pd.read_csv("insurance_claims.csv")
# Sort the data based on the Incident Data
df = df.sort_values(by="incident_date").reset_index(drop=True)
# Variable Selection
df = df[
[
"incident_date",
"months_as_customer",
"age",
"policy_deductable",
"policy_annual_premium",
"umbrella_limit",
"insured_sex",
"insured_relationship",
"capital-gains",
"capital-loss",
"incident_type",
"collision_type",
"total_claim_amount",
"injury_claim",
"property_claim",
"vehicle_claim",
"incident_severity",
"fraud_reported",
]
]
# Data Cleaning and One-Hot Encoding
df = pd.get_dummies(
df,
columns=[
"insured_sex",
"insured_relationship",
"incident_type",
"collision_type",
"incident_severity",
],
drop_first=True,
)
df["fraud_reported"] = df["fraud_reported"].apply(lambda x: 1 if x == "Y" else 0)
df = df.rename(columns={"incident_date": "timestamp", "fraud_reported": "target"})
for i in df.select_dtypes("number").columns:
df[i] = df[i].apply(float)
data = df[df["timestamp"] < "2015-02-20"].copy()
val = df[df["timestamp"] >= "2015-02-20"].copy()
在上面的代码中,我们选择了一些列用于模型训练,将它们转换为数值表示,并将数据拆分为参考数据(data)和当前数据(val)。
我们在 MLOps 流水线中需要参考数据或基准数据来监控模型性能。它通常是从训练数据中分离出来的数据(例如测试数据)。此外,我们还需要当前数据或模型未见过的数据(新数据)。
我们需要使用evidently来监控数据和模型性能。由于数据漂移会影响模型性能,所以监控数据漂移也是必要的。
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(current_data=val, reference_data=data, column_mapping=None)
data_drift_report.show(mode='inline')

evidently 包会自动显示数据集发生了什么情况的报告。报告信息包括数据集漂移和列漂移。在上述示例中,我们没有数据集漂移的发生,但有两个列发生了漂移。

报告显示‘property_claim’和‘timestamp’列确实检测到了漂移。这些信息可以在 MLOps 流水线中用于重新训练模型,或者我们仍需进一步的数据探索。
如果需要,我们还可以在日志字典对象中获取上述数据报告。
data_drift_report.as_dict()
接下来,让我们尝试从数据中训练一个分类模型,并尝试使用evidently来监控模型的性能。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(data.drop(['target', 'timestamp'], axis = 1), data['target'])
evidently 需要在参考数据集和当前数据集中都有目标列和预测列。让我们将模型预测添加到数据集中,并使用evidently来监控性能。
data['prediction'] = rf.predict(data.drop(['target', 'timestamp'], axis = 1))
val['prediction'] = rf.predict(val.drop(['target', 'timestamp'], axis = 1))
作为备注,最好有一些不包含在训练数据中的参考数据来监控模型性能。让我们使用以下代码设置模型性能监控。
from evidently.metric_preset import ClassificationPreset
classification_performance_report = Report(metrics=[
ClassificationPreset(),
])
classification_performance_report.run(reference_data=data, current_data=val)
classification_performance_report.show(mode='inline')

结果显示,我们当前模型的质量指标低于参考值(由于我们使用了训练数据作为参考,因此这是预期的)。根据业务需求,上述指标可以成为我们需要采取的下一步的指示。让我们查看从 evidently 报告中获得的其他信息。
类别表示报告显示了实际的类别分布。
混淆矩阵展示了预测值与实际数据在参考数据集和当前数据集中的对比。

按类别的质量指标展示了每个类别的性能。
如前所述,我们可以将分类性能报告转换为字典日志,使用以下代码。
classification_performance_report.as_dict()
目前就是这些。你可以在你现有的任何 MLOps 管道中使用 evidently 设置模型性能监控,它仍然会表现出色。
结论
模型性能监控是 MLOps 管道中的一个重要任务,因为它帮助维护模型如何满足业务需求。通过一个名为 evidently 的 Python 包,我们可以轻松设置模型性能监控,这可以集成到任何现有的 MLOps 管道中。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。在全职工作于 Allianz Indonesia 期间,他喜欢通过社交媒体和写作分享 Python 和数据技巧。
更多相关话题

获取免费的电子书《伟大的自然语言处理指南》和《数据科学备忘单完整合集》,以及关于数据科学、机器学习、AI 和分析的领先新闻通讯,直送到你的收件箱。
订阅即表示您接受 KDnuggets 的 隐私政策
最新文章
|
热门文章
|
© 2024 Guiding Tech Media | 关于 | 联系 | [广告]( https://mailchi.mp/kdnuggets/media-kit ) | 隐私 | 服务条款
发表时间:2023 年 5 月 9 日 作者:Cornellius Yudha Wijaya
使用 Python 的监控程序监控你的文件系统
原文:
www.kdnuggets.com/monitor-your-file-system-with-pythons-watchdog

图片由作者提供 | DALLE-3 & Canva
Python 的监控程序库使得监控你的文件系统并自动响应这些变化变得容易。监控程序是一个跨平台的 API,允许你在监控的文件系统中发生任何变化时运行命令。我们可以对文件创建、修改、删除和移动等多个事件设置触发器,然后用自定义脚本响应这些变化。
我们的 top 3 课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
监控程序设置
开始时你需要两个模块:
-
监控程序: 在终端中运行以下命令以安装监控程序。
pip install watchdog -
日志记录: 这是一个内置的 Python 模块,因此无需外部安装。
基本使用
让我们创建一个简单的脚本 ‘main.py’,它监控一个目录,并在文件被创建、修改或删除时打印一条消息。
步骤 1:导入所需模块
首先,从监控程序库中导入必要的模块:
import time
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
步骤 2:定义事件处理程序类
我们定义了一个 MyHandler 类,继承自 FileSystemEventHandler。这个类重写了 on_modified、on_created 和 on_deleted 等方法,以指定这些事件发生时的操作。事件处理程序对象将在文件系统发生任何变化时被通知。
class MyHandler(FileSystemEventHandler):
def on_modified(self, event):
print(f'File {event.src_path} has been modified')
def on_created(self, event):
print(f'File {event.src_path} has been created')
def on_deleted(self, event):
print(f'File {event.src_path} has been deleted')
FileSystemEventHandler 的一些有用方法如下所示。
-
on_any_event: 对任何事件执行。
-
on_created: 在创建新文件或目录时执行。
-
on_modified: 在文件被修改或目录被重命名时执行。
-
on_deleted: 在文件或目录被删除时触发。
-
on_moved: 当文件或目录被重新定位时触发。
步骤 3:初始化并运行 Observer
Observer 类负责跟踪文件系统中的任何变化,并随后通知事件处理程序。它持续跟踪文件系统活动,以检测任何更新。
if __name__ == "__main__":
event_handler = MyHandler()
observer = Observer()
observer.schedule(event_handler, path='.', recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
我们启动观察者并使用循环使其持续运行。当你想停止它时,可以通过键盘信号 (Ctrl+C) 中断。
步骤 4:运行脚本
最后,使用以下命令运行脚本。
python main.py
输出:
File .\File1.txt has been modified
File .\New Text Document (2).txt has been created
File .\New Text Document (2).txt has been deleted
File .\New Text Document.txt has been deleted
上述代码会在终端记录目录中所有的更改,如果有任何文件/文件夹被创建、修改或删除。
高级用法
在以下示例中,我们将探讨如何设置一个系统,以检测 Python 文件中的任何更改并自动运行测试。我们需要使用以下命令安装 pytest。
pip install pytest
第一步:创建一个简单的 Python 项目及测试
首先,设置项目的基本结构:
my_project/
│
├── src/
│ ├── __init__.py
│ └── example.py
│
├── tests/
│ ├── __init__.py
│ └── test_example.py
│
└── watchdog_test_runner.py
第二步:在示例 Python 文件中编写代码
在 src/example.py 中创建一个简单的 Python 模块:
def add(a, b):
return a + b
def subtract(a, b):
return a - b
第三步:编写测试用例
接下来,为 tests/test_example.py 中的函数编写测试用例:
import pytest
from src.example import add, subtract
def test_add():
assert add(1, 2) == 3
assert add(-1, 1) == 0
assert add(-1, -1) == -2
def test_subtract():
assert subtract(2, 1) == 1
assert subtract(1, 1) == 0
assert subtract(1, -1) == 2
第四步:编写 Watchdog 脚本
现在,创建 watchdog_test_runner.py 脚本以监控 Python 文件中的更改并自动运行测试:
import time
import subprocess
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
class TestRunnerHandler(FileSystemEventHandler):
def on_modified(self, event):
if event.src_path.endswith('.py'):
self.run_tests()
def run_tests(self):
try:
result = subprocess.run(['pytest'], check=False, capture_output=True, text=True)
print(result.stdout)
print(result.stderr)
if result.returncode == 0:
print("Tests passed successfully.")
else:
print("Some tests failed.")
except subprocess.CalledProcessError as e:
print(f"Error running tests: {e}")
if __name__ == "__main__":
path = "." # Directory to watch
event_handler = TestRunnerHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
print(f"Watching for changes in {path}...")
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
第五步:运行 Watchdog 脚本
最后,打开终端,导航到项目目录(my_project),并运行 watchdog 脚本:
python watchdog_test_runner.py
输出:
Watching for changes in ....
========================= test session starts =============================
platform win32 -- Python 3.9.13, pytest-8.2.1, pluggy-1.5.0
rootdir: F:\Web Dev\watchdog
plugins: anyio-3.7.1
collected 2 items
tests\test_example.py .. [100%]
========================== 2 passed in 0.04s ==============================
Tests passed successfully.
该输出显示在对 example.py 文件进行更改后,所有测试用例均已通过。
总结
Python 的 watchdog 库是监控文件系统的强大工具。无论你是在自动化任务、同步文件,还是构建更响应的应用程序,watchdog 使实时响应文件系统更改变得容易。只需几行代码,你就可以开始监控目录和处理事件,从而简化工作流程。
Kanwal Mehreen**** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及 AI 与医学的交集有深厚的热情。她共同撰写了电子书《利用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation 学者,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,创立了 FEMCodes,旨在赋能 STEM 领域的女性。
更多内容
Python 中的蒙特卡洛积分
原文:
www.kdnuggets.com/2020/12/monte-carlo-integration-python.html
评论
图片来源:维基百科(免费)及作者制作的拼贴图
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 工作
免责声明:本文的灵感来源于 乔治亚理工学院的在线分析硕士(OMSA) 项目的学习资料。我为追求这一优秀的在线硕士项目而感到自豪。你也可以 在这里查看详细信息。
什么是蒙特卡洛积分?
蒙特卡洛实际上是位于摩纳哥(这个城市-国家,也称为公国)同名区的世界著名赌场的名字,位于世界闻名的法国里维埃拉。
事实证明,这个赌场激发了著名科学家们发明一种有趣的数学技术,用于解决统计学、数值计算和系统模拟中的复杂问题。

图片来源:维基百科
这种技术的最早和最著名的用途之一是在曼哈顿计划期间,当时,高度浓缩铀的链式反应动力学给科学家们带来了极其复杂的理论计算。即使是像约翰·冯·诺依曼、斯坦尼斯瓦夫·乌拉姆、尼古拉斯·美特罗波利斯这样的天才也无法用传统的方法解决。因此,他们转向了随机数的奇妙世界,让这些概率量驯服了原本难以处理的计算。

三位一体试验:(图片来源:维基百科)
令人惊讶的是,这些随机变量能够解决计算问题,这个问题困扰了确定性方法。实际上,不确定性的元素赢得了胜利。
正如不确定性和随机性主导了蒙特卡洛游戏的世界。这就是这个名字的灵感来源。

图像来源:Pixabay
今天,它是一种在广泛领域中使用的技术——
尽管取得了许多成功和声誉,但基本思想却非常简单且易于演示。我们在本文中用一组简单的 Python 代码进行演示。
这种技术最早和最著名的用途之一是在曼哈顿计划期间
这个想法
一个棘手的积分
尽管一般的蒙特卡洛模拟技术范围更广,但我们在这里特别关注蒙特卡洛积分技术。
这只是计算复杂定积分的数值方法,这些积分缺乏闭式解析解。
比如,我们想要计算,

对于这个不定积分,获得闭式解既不容易也几乎不可能。但数值近似总是可以给我们一个作为总和的定积分。
这是函数的图像。

黎曼和
在黎曼和的广泛类别下,有许多这样的技术。这个想法就是将曲线下的区域划分为小的矩形或梯形,通过简单的几何计算来近似这些区域,并将这些部分相加。
为了简单说明,我展示了一个只有 5 个等距区间的方案。

对于程序员朋友们,实际上,Scipy 包中有一个现成的函数可以快速准确地完成这个计算。
如果我选择随机呢?
如果我告诉你,我不需要均匀选择区间,实际上,我可以完全采用概率方法,随机选择 100%的区间来计算相同的积分呢?
疯狂的说法?我的样本选择可能是这样的……

或者,这个……

我们没有时间或范围来证明背后的理论,但可以表明 通过合理数量的随机抽样,我们实际上可以以足够高的准确度计算积分!
我们只需选择随机数(在限制范围内),在这些点上评估函数,将它们加起来,并按已知因子进行缩放。这样就完成了。
好的。我们在等什么呢?让我们用一些简单的 Python 代码来演示这个说法。
尽管取得了许多成功和声誉,但基本思想却 deceptively simple,容易演示。
Python 代码
用简单的平均值替代复杂的数学
如果我们尝试计算下面这种形式的积分——任何积分,

我们只是用以下平均值替代积分的‘估算’,

其中 U 代表介于 0 和 1 之间的均匀随机数。注意,我们是如何 通过简单地将一堆数字相加并取其平均值来替代复杂的积分过程!
在任何现代计算系统、编程语言,甚至是像 Excel 这样的商业软件包中,你都可以访问这个统一的随机数生成器。查看我关于这个主题的文章,
我们使用一个简单的伪随机生成器算法,并展示如何使用它生成重要的随机数……
我们只需选择随机数(在限制范围内),在这些点上评估函数,将它们加起来,并按已知因子进行缩放。这样就完成了。
函数
这是一个 Python 函数,它接受另一个函数作为第一个参数,两个积分限制,以及一个可选的整数来计算由参数函数表示的定积分。

代码可能看起来与上面的方程(或你可能在教科书中见到的另一个版本)略有不同。这是因为 我通过将随机样本分布在 10 个区间上来提高计算的准确性。
对于我们具体的例子,参数函数看起来像这样,

我们可以通过将其传递给 monte_carlo_uniform() 函数来计算该积分,

在这里,如你所见,我们在积分限制 a = 0 和 b = 4 之间取了 100 个随机样本。
那计算效果到底如何?
这个积分无法用解析方法计算。因此,我们需要将蒙特卡洛方法的准确性与另一种数值积分技术进行基准比较。为此我们选择了 Scipy 的 integrate.quad() 函数。
现在,你可能还在想——当采样密度变化时,准确度会发生什么。这个选择显然影响了计算速度——如果选择减少采样密度,我们需要添加更少的量。
因此,我们对不同采样密度范围内的相同积分进行了模拟,并将结果绘制在金标准——下图中的水平线代表的 Scipy 函数之上。

因此,我们在低样本密度阶段观察到一些小的扰动,但随着样本密度的增加,它们平滑地消失。无论如何,与 Scipy 函数返回的值相比,绝对误差非常小——约为 0.02%。
蒙特卡洛技巧表现得非常棒!

图像来源:Pixabay
速度怎么样?
但它的速度是否与 Scipy 方法一样快?更快?更慢?
我们尝试通过运行 100 次循环,每次 100 次运行(总共 10,000 次运行)来找出答案,并获取总结统计数据。

在这个特定的例子中,蒙特卡洛计算的速度是 Scipy 积分方法的两倍快!
虽然这种速度优势依赖于许多因素,但我们可以确信蒙特卡洛技术在计算效率方面并不逊色。
我们观察到在低样本密度阶段存在一些小的扰动,但随着样本密度的增加,它们平滑地消失。
冲洗,重复,冲洗,再重复……
对于像蒙特卡洛积分这样的概率技术,数学家和科学家几乎总是不满足于一次运行,而是重复计算多次并取平均值。
这是一个来自 10,000 次实验的分布图。

如你所见,图表几乎类似于高斯正态分布,这一事实可以利用不仅得到平均值,还可以在该结果周围构建置信区间。
4 加减 2 的区间置信区间是一个我们相当确定真实值所在范围的值……
特别适用于高维积分
虽然为了简单说明(并出于教学目的),我们坚持使用单变量积分,但同样的思路可以很容易地扩展到具有多个变量的高维积分。
在更高维度中,蒙特卡洛方法相较于基于黎曼和的方法特别突出。对于蒙特卡洛方法而言,样本密度可以以更有利的方式进行优化,使其在不影响准确性的情况下大大加快速度。
从数学角度看,该方法的收敛速度与维度数量无关。用机器学习的术语来说,蒙特卡洛方法是你在复杂积分计算中战胜维度诅咒的最佳朋友。
阅读这篇文章以获得一个很好的介绍,
实践中的蒙特卡洛方法 如果你了解并掌握了概率的最重要概念和…
在更高维度中,蒙特卡洛方法相较于基于黎曼和的方法特别突出。
总结
我们介绍了蒙特卡洛积分的概念,并展示了它如何与传统的数值积分方法不同。我们还展示了一组简单的 Python 代码,以评估一维函数,并评估这些技术的准确性和速度。
更广泛的蒙特卡洛模拟技术更令人兴奋,并在人工智能、数据科学和统计建模等领域得到普遍应用。
例如,DeepMind 的著名 Alpha Go 程序使用了蒙特卡洛搜索技术,在围棋这一高维空间中实现了计算效率。实践中可以找到许多类似的例子。
蒙特卡洛树搜索简介:深度学习 AlphaGo 背后的游戏改变算法
五局三胜制,总奖金 100 万美元——一场高风险的对决。2016 年 3 月 9 日至 15 日…
如果你喜欢它…
如果你喜欢这篇文章,你可能还会喜欢我关于类似主题的其他文章,
我们介绍了一个简单的伪随机生成器算法,并展示了如何使用它生成重要的随机…
我们展示了迈向数学编程习惯的一个小步骤,这在新兴数据科学家的技能库中是一个关键技能…
我们展示了如何模拟布朗运动,这是一种在广泛应用中使用的最著名的随机过程,使用…
此外,你还可以查看作者的 GitHub** 代码库**,获取机器学习和数据科学方面的代码、想法和资源。如果你和我一样,对 AI/机器学习/数据科学充满热情,请随时 在 LinkedIn 上添加我 或 在 Twitter 上关注我。
原文。经许可转载。
相关:
-
使用 Pomegranate 进行快速直观的统计建模
-
被遗忘的算法
-
实用的马尔可夫链蒙特卡罗方法
更多相关话题
更多数据还是更好的算法:最佳平衡点
原文:
www.kdnuggets.com/2017/01/more-data-better-algorithms.html
评论
作者:Erik Bernhardsson,CTO(首席巨魔官)betterdotcom
这篇博客文章数据集是新的服务器房间指出,一些公司筹集大量资金去获取真正专有的优秀数据作为竞争壁垒。因为一旦你拥有数据,你就能构建更好的产品,而没有人可以轻易复制(至少不便宜)。理想情况下,你会进入一个良性循环,即系统使用一旦开始,就会提供更多的数据,这使得系统更好,从而吸引更多用户……
随着数据量增加,机器学习模型的行为很有趣。如果你正在建立一个基于机器学习的公司,首先,你要确保更多的数据能带来更好的算法。
但这只是必要条件,而非充分条件。你还需要找到一个最佳平衡点。
-
收集足够的数据并不太容易,因为那样数据的价值就会很小。
-
收集足够的数据并不太难,因为那样你将花费过多的钱来解决问题(如果有解决办法的话)。
-
数据的价值随着数据量的增加而不断增长。
在推荐系统领域(我在那里待了 5 年),算法在 100M 或 1B 数据点后基本会收敛,这并不罕见。这当然取决于你拥有多少项目。一些模型类在它们甚至尚未有用之前就会收敛,这种情况下显然更多的数据没有价值。如果你想了解更多,Xavier Amatriain 在Quora 上的一个优秀回答值得你查看。
无论如何,让我们简化这个问题。考虑一下某些算法的行为:

-
蓝色模型代表了在相对便宜的成本下能够获得良好数据的问题。例如,猫与狗的分类器不是一个有用的技术,因为获取这些训练数据的价值大约是$0。对于任何构建通用图像分类器的公司,我会对此感到担忧。或者,如果你正在构建一个包含 10k 项的推荐系统,可能用 10M 个评分已经足够。拥有 100B 个评分未必更有价值。
-
红色模型可能出现在你的数据来自不同分布或你的损失函数不符合产品需求的情况下。在这些情况下,更多的数据在某些时候会变得无用。如果你通过抓取网络文本来构建一个电影推荐系统,它可能会收敛到一个还不错但不够好的模型。(这里还有一个假设:也许收集被动数据来学习如何主动驾驶汽车是不够的?)
-
绿色模型是当你的问题可能需要如此巨大的数据量以至于不切实际。例如,构建一个可以解决世界上所有问题的通用问答服务,从机器学习的角度来看,如果你有无限的数据问题和答案,这并不难。但如果输入数据少于数 TB 或 PB,可能就会变得无用。如果我尝试构建一个虚拟助手,这将是我最大的担忧。
这里是一些我认为你可以建立数据集的甜蜜点,但这很难。困难是好的,因为这意味着一旦你完成,你就有了一道护城河:
-
从交易数据中检测欺诈
-
预测哪些贷款将会违约
-
从安全监控中检测犯罪
难以记住?这里有一个我制作的实用表格

我认为这个总体思路是相当有效的。但它 100%正确吗?可能不是。是否过于简化?哦,是的,极端地简化了。
原始帖子。经许可转载。
个人简介: Erik Bernhardsson (@fulhack),是 betterdotcom 的首席怪才官(CTO)。
前 Spotify,纽约机器学习聚会共同组织者,有时开源(Luigi,Annoy),博主,爸爸。
相关内容:
-
数据就是新一切
-
Python 中的随机森林
-
机器学习和数据科学中最流行的语言是……
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关内容
更多数据科学备忘单
原文:
www.kdnuggets.com/2021/03/more-data-science-cheatsheets.html
我们最近意识到已经有一段时间没有给你带来任何数据科学备忘单了。这并不是因为备忘单的缺乏;数据科学备忘单无处不在,从入门到高级,涵盖从算法、统计到面试技巧等各种主题。
那么,什么使得一个备忘单优秀呢?是什么使得一个备忘单值得被特别指出?虽然很难准确指出什么使得一个备忘单好,但显然,能够简洁地传达基本信息的备忘单——无论这些信息是具体的还是一般性的——无疑是一个好的开始。这也是我们今天的候选备忘单值得关注的原因。所以,继续阅读以获取四个精心挑选的备忘单,帮助你进行数据科学学习或复习。
我们的三大课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全领域的职业生涯。
2. Google Data Analytics Professional Certificate - 提升你的数据分析能力
3. Google IT Support Professional Certificate - 支持你所在组织的 IT 工作
首先是Aaron Wang's Data Science Cheatsheet 2.0,这是一个四页的统计抽象、基本机器学习算法和深度学习主题及概念的汇编。它并不是详尽无遗的,而是作为一种快速参考,适用于面试准备、考试复习及其他需要类似审查深度的情况。作者提到,尽管对统计学和线性代数有基本了解的人会从中受益最多,但初学者也应该能够从中获取有用的信息。

截图来源于 Aaron Wang 的Data Science Cheatsheet 2.0
我们今天的下一个备忘单是基于Maverick Lin 的数据科学备忘单的资源,这也是 Aaron Wang 参考的对象(Wang 将自己的备忘单称为 2.0,是对 Lin“原版”的直接致敬)。我们可以认为 Lin 的备忘单比 Wang 的更为深入(尽管 Wang 决定让他的备忘单不那么深入似乎是有意为之,并且是一个有用的替代方案),涵盖了更多基本的数据科学概念,如数据清洗、建模的理念、使用 Hadoop 处理“大数据”、SQL,甚至是 Python 的基础知识。
显然,这将吸引那些更加坚定的“初学者”阵营,并且很好地激发了兴趣,让读者了解数据科学的广泛领域以及其包含的许多不同概念。这绝对是另一个值得推荐的资源,尤其是对于数据科学的初学者。

Maverick Lin 的数据科学备忘单的截屏
随着我们向过去追溯——寻找 Lin 备忘单的灵感——我们发现了William Chen 的概率备忘单 2.0。Chen 的备忘单在这些年里获得了很多关注和赞誉,你可能在某个时候见过它。显然,由于其名称,Chen 的备忘单重点介绍了概率概念的速成课程或深度回顾,包括各种分布、协方差和变换、条件期望、Markov 链、各种重要公式等。
10 页的长度,你应该可以想象这里涵盖了概率主题的广度。但不要因此却步;Chen 将概念提炼成本质要点并用简单的英语解释,同时不牺牲要点的能力值得注意。它还丰富了说明性可视化,在空间有限且需要简洁表达时,这一点尤其有用。
Chen 的汇编不仅质量上乘、值得你花时间阅读,作为初学者或有兴趣进行全面回顾的人,我会按照这些资源呈现的相反顺序使用——从 Chen 的备忘单到 Lin 的,最后到 Wang 的,逐步构建概念。

William Chen 的概率备忘单 2.0的截屏
最后一个我在这里包含的资源,虽然不完全是备忘单,是Rishabh Anand 的机器学习精华。它自称为“关于常见机器学习概念、最佳实践、定义和理论的面试指南”,Anand 汇编了范围广泛的知识“片段”,其用处确实超越了最初的面试准备。涵盖的主题包括:
-
模型评分指标
-
参数共享
-
k 折交叉验证
-
Python 数据类型
-
改善模型性能
-
计算机视觉模型
-
注意力及其变体
-
处理类别不平衡
-
计算机视觉词汇表
-
基础反向传播
-
正则化
-
参考资料

来自机器学习精华的截图
虽然“概念、最佳实践、定义和理论”在资源的描述中有所提及,但这些“片段”无疑更倾向于实际应用,这使得该网站对之前提到的三个备忘单中的许多内容形成了补充。如果我想覆盖这篇帖子中所有四个资源的所有材料,我肯定会在看完其他三个之后查看这个。
所以你有四个备忘单(或者三个备忘单和一个相关资源)可以用来学习或复习。希望这里有些对你有用的内容,我邀请大家在下方评论中分享他们找到的有用备忘单。
关于这个主题的更多内容
3 个额外的 Google Colab 环境管理技巧
原文:
www.kdnuggets.com/2019/01/more-google-colab-environment-management-tips.html
评论
Google 的 Colab 在 2018 年初首次公开发布时受到了各种宣传。最初对它非常兴奋之后,我写了一篇简短的帖子,给新用户提供了一些提示,其中包括利用免费的 GPU 运行时、安装额外的第三方 Python 库,以及上传和使用数据文件到你的 Colab 环境。

像每一种新事物一样,Colab 的兴奋感在初期的狂热之后有所减退。然而,在重新翻阅书籍并需要一个可以在我的笔记本、工作站和 Chromebook 之间无缝访问和共享的稳定笔记本环境后,我决定再看一眼 Colab。事实证明这是一个好决定;在过去几个月里,我一直定期使用 Colab 进行所有与学习相关的编码。
本文是短小但希望有用的 Google Colab 环境管理技巧系列的第二篇,包括了我在管理自己的 Colab 编码环境过程中学到的另外 3 件事。我强调这是我用于学习的内容,没有关键任务项目,我主要使用 Colab,因为我可以在不同的机器之间无缝切换,同时仍然可以访问用于训练的 GPU(甚至 TPU)。
注意,某些这些只是普通的 Jupyter 技巧,所以别@我。
0. 从浏览器中退出 Colab
好吧,这实际上不算是 Colab 的技巧,但首先要将 Colab 从浏览器中移出。如果你像我一样,你的标签页情况不太理想。再添加 Colab 管理界面和一堆笔记本不会有所帮助,所以将 Colab 作为独立应用运行。这依赖于操作系统,但涉及到在你的 Chrome 浏览器中安装 Colab "应用",并从应用上下文菜单中选择“以窗口打开”和“创建快捷方式...”,然后你需要找到该快捷方式并用它在自己的窗口中打开应用。

就这样;现在你可以从自己的图标中在独立窗口中打开 Colab,就像在帖子头图中一样。我知道,这其实不是重点,但仍然很有用。
1. 将文件下载到本地计算机
这是另一个简单的技巧,但足够重要以至于值得一提。用例:你创建了一个 Keras 模型并想要可视化该模型。你调用 plot_model 来创建一个 PNG 文件,但由于 Colab 虚拟机中的文件存储没有持久性,你想下载该图像。以下摘录可以完成这个操作:
# plot model
plot_model(model, to_file='rnn-mnist.png', show_shapes=True)
# download model image file
from google.colab import files
files.download('rnn-mnist.png')
执行单元格,弹出对话框提示你选择下载位置。这将引导我们到……
1(b). 内联显示图像
是的,这很基础,但我花了几次才记住我在用的基本上是一个普通的 Jupyter 环境在 Colab 中。所以,要将上述图像内联显示,使用:
# display model image file inline
from IPython.display import Image, display
Image('rnn-mnist.png')
一个快速的直观修改将允许你像预期的那样内联各种其他文件。课程:记住你在使用的基本上是一个普通的 Jupyter notebook。好,继续讲 Colab 的内容。
2. 访问你的 Google Drive 文件系统
假设我想将那个模型图像文件保存到我的 Google Drive,而不是本地计算机。有各种方法可以将文件进出 Google Drive。我发现这是将 CSV 数据从 Google Drive 中取出的最直接的方法。
# save model image file to Google Drive
from google.colab import drive
drive.mount('/content/gdrive')

点击链接并输入授权代码后,你可以按照如下方式访问你的驱动器:
!ls -la /content/gdrive/My\ Drive/Colab\ Notebooks/

当然,它不是永久性的,但也不费多少事,而且在我看来,比使用其他任何选项都更直接(并且也不那么不永久)。如果你使用像AutoKey这样的桌面自动化和文本扩展工具,那么常用的代码片段和命令会变得更加简单。
回到正题:现在你可以将文件保存到(或从)Google Drive。只要你对终端操作感到舒适,这很简单……反正你应该已经习惯了。你可以在文件所在位置处理数据文件,或者将其移动或复制到 Colab VM 根目录的上几级目录。不过,由于在丢弃实例后文件会从这里消失,我认为直接从文件系统中的 CSV 文件读取数据更有意义:
# import pandas as pd
titanic_train = pd.read_csv('/content/gdrive/My Drive/Colab Notebooks/datasets/titanic/train_clean.csv')
3. 使用存储在 Google Drive 中的自定义库和模块
那么,如果你有自定义的 Python 库或模块想要导入到 Colab 项目中怎么办呢?
例如,我在 Colab 目录下有一个名为 'my_modules' 的文件夹,我将常用的 .py 文件存储在其中,以便在 Colab 中访问。我不想将它们存储在 GitHub 上,它们也不是我想要整理干净并与他人共享的文件。假设它们只是一些我自己习惯使用的辅助模块的集合,比如数据加载函数、数据清理函数等。
我将此类文件存储在一个与 Google Drive 版本同步的 Dropbox 文件夹中,这个文件夹名称相同。这样,我可以在 Colab 内部和外部都使用该文件。我可以直接在 Chrome 上访问 Google Drive 内容,也可以通过ocamlfuse在 Ubuntu 上访问,并且可以利用上述 Google Drive 文件系统访问技巧。
这个代码片段很有用。假设我在 my_modules 目录下有一个名为 naive_sharding.py 的模块。由于它在多个目录级别下,这是我在 Colab 中将文件保持原位并导入的最简单方法:
import sys
sys.path.insert(0, '/content/gdrive/My Drive/Colab Notebooks/my_modules')
import naive_sharding
就这样;naive_sharding.py 模块已经被导入,并且可以使用。
修改上述一些代码片段,你可以看到如何轻松地将模型权重进出 Colab 环境。因此,凭借上述简短的说明和发散性思维,你可以在 Google Colab 上完成相当多的工作,尽管许多反对者可能会让你相信不可能。鉴于无需设置,并且 Chromebook 访问也非常简单,我最近发现 Colab 是一个理想的编码工具。
别忘了阅读这里找到的前三个提示和技巧。
相关内容:
-
3 个必备的 Google Colaboratory 提示与技巧
-
数据科学笔记本使用最佳实践
-
如何在 Google Cloud 上设置免费的数据科学环境
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
更多相关内容
更多成功导航初级数据科学职位面试的技巧
原文:
www.kdnuggets.com/more-tips-for-successfully-navigating-beginner-data-science-job-interviews

之前的九条建议涵盖了对初级数据科学家较为明显的建议。
我们的前三大课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
接下来的面试技巧涉及到将自己塑造成最佳候选人的更细微方面。
基于我之前的文章,这些额外的技巧将进一步提升你在初级数据科学职位面试中的成功机会。
1. 准备一个作品集
创建一个数据科学项目作品集是展示你作为数据科学家能力的最佳方式之一。
对于初学者来说,选择适合的项目来构建作品集可能会很困难。这里有一些数据科学项目创意作为开始。你也可以参考Datacamp 的建议或StrataScratch 上的数据项目。

2. 使用领域知识练习编码
领域知识意味着你对特定行业、部门或主题领域有深入了解。这些知识包括该领域的复杂性、挑战、术语、流程和细微差别。

这必须在你的编码技能中体现出来,因为你将使用这些技能来解决特定公司在特定行业中的问题。
当你练习编码时,最好是在你面试的公司提供的实际问题上进行。我在第一篇文章中提到了StrataScratch和LeetCode。
当然,你可以在不直接来自面试的问题上进行练习。但是当你选择时,尽量找到数据科学面试问题和相关行业的数据集。比如,你正在面试 Meta(科技行业)和 Pfizer(制药行业)。这些公司处理的数据完全不同,数据行为也不同。自然,问题也会不同。所以,对 Meta 使用科技/社交媒体数据,对 Pfizer 使用制药数据。
通过这种方式,你也在确保你在提升领域知识。你可能会遇到一些你不熟悉的特定数据,因此你需要学习它以及它在行业中的重要性。
现在,你正在将编码与领域知识相结合!
3. 展示你的数据讲故事技能
数据讲故事意味着你可以清晰易懂地传达你数据项目的见解。考虑一下你为什么开始了某个项目以及你取得了什么成果;其中总有一个故事。
通过为你的项目创建一个故事,你会让数据对非技术人员更易于理解。作为回报,你将在决策过程中拥有更多的影响力。
这里有一些展示这一技能的技巧。
创建叙事: 任何好的故事都有一个弧线:引言、问题、上升动作、高潮、跌行动作和解决方案。在讲述你的数据故事时,包含这些元素。
你可以从业务背景开始,例如:“公司在过去三年推出了五款新产品。”然后是问题。你注意到销售在增长,但客户留存率却没有。现在,你需要深入数据,尝试找到留存问题的原因。在这里,你的故事应该深入探讨项目的技术方面:你做了什么和为什么。高潮是当你发现一款产品的销售额很高,但退货率也很高。跌行动作是你讨论高退货的潜在原因。在解决方案中,你提出了产品改进的建议。在解决方案中,直接关联你的项目做了什么,并量化其成就。不要让你的故事以你给出产品改进建议结束,而是讲述那款产品的销售增长,给公司带来了多少钱等。
使用清晰的可视化图表: 使用支持你故事的可视化图表。
在你关于过去几年销售趋势的项目中,不要只是展示一个包含每月销售数据的表格。相反,使用折线图来直观地表示销售的波动。这样,观众将能够把握趋势。对于销售的显著峰值,使用柱状图将销售按产品或产品类别分解,突出显示哪些产品推动了峰值。
避免使用行话并简化复杂概念: 只有在必要时才使用技术术语。重点是要向商业人士“推销”你的想法和项目,因此需要简化复杂概念。不要说,“残差中的异方差性表明我们的线性回归模型可能不适合。”相反,应该说,“我们数据中的模式表明我们的初始模型可能未能有效捕捉所有信息。”这样会更好!
4. 讨论失败和学习
我们都会犯错。错误是学习过程中的必要部分。面试官并不寻求完美的候选人;他们在寻找愿意并能够学习的人。
让面试官了解你这一方面。如果你诚实地分享你的失败以及从中学到的东西,会建立信任,并展示你的挫折恢复能力。
以下是一些如何谈论这个话题的建议。
避免责备他人: 避免将错误归咎于他人和一切事物。当然,要说明超出你控制范围的情况,但不要表现出受害者。对你自己部分的责任负责,展示你从这些情况中学到的东西,并谈谈你本该如何做得更好。
强调学习,而不是失败: 谈论失败的目的应仅仅是展示你从中学到了什么,因此要集中讲述这一点。
谈论经验: 从你之前的工作中找一个真实的例子。即使它不是数据科学相关的,如果它展示了你对学习和自我意识的关注,也可能适用。如果你没有工作经验,可以谈谈你在数据项目中犯的错误以及学到的东西。
谈论你采取的步骤: 这与您纠正错误或减少其影响的做法有关,例如,改变数据、调整算法,或完全放弃该项目并开始一个新项目。
这里是你(Y)和面试官(I)之间对话的可能样子。
I: “你能告诉我一个项目或任务没有按计划进行的例子,以及你是如何处理的吗?”
Y: 当然!在我之前担任数据科学家的角色时,我负责一个旨在预测客户流失的项目。我根据最初的理解选择了 k 最近邻算法并使用了它。然而,结果并不像我期望的那样准确。
I: 为什么?你意识到时做了什么?
Y: 有一些数据不一致,截止日期非常紧迫,所以我的 EDA 不够详细。尽管如此,我现在意识到我应该做得更详细。发现不一致后,我与数据质量团队合作,进一步了解这些问题。我还探索了其他算法并进行了评估。最后,我切换到了 XGBoost 算法,这显著提高了模型的预测准确性。我学到了不要低估 EDA 的重要性。我也很高兴我敢于承认错误,并从头开始,明白一个我们无法信任的模型是没有用的。
结论
数据科学不仅仅是无脑的数据处理和代码编写。这涉及到能够通过数据讲故事和可视化将你的工作转化为普通人的语言。
你需要在面试中展示这一点。你必须确保你能说得出,但也能证明你能做得出。做到这一点的最佳方法是拥有一个扎实的数据项目组合,你的编码、讲故事和可视化技能将显而易见。
在项目过程中,你会犯错误。不要隐瞒这些错误。公开谈论它们,并从你的面试官那里寻求反馈。
这归结为两件简单的事情:要有能力,并且诚实地讲述你是如何达到这个能力的。说起来容易,做起来难!
但是,通过我在这篇文章中给出的提示,我相信你会在下次数据科学面试中表现出色!
内特·罗斯迪是一名数据科学家,专注于产品策略。他也是一名兼职教授,教授分析课程,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过来自顶尖公司的真实面试问题准备面试。内特撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 内容。
更多相关话题
数据科学家的 PyTorch 最完整指南
原文:
www.kdnuggets.com/2020/09/most-complete-guide-pytorch-data-scientists.html
评论
PyTorch 已经成为创建神经网络的事实标准之一,我非常喜欢它的接口。然而,对于初学者来说,掌握它还是有点困难的。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
我记得几年前在经过一番广泛的实验之后才开始接触 PyTorch。说实话,花了我很长时间才掌握它,但我很高兴从 Keras 转到 PyTorch。凭借其高度的自定义性和 Python 风格的语法,PyTorch 使用起来非常愉快,我会推荐给任何想在深度学习中做些重型工作的朋友。
因此,在这本 PyTorch 指南中,我将尝试缓解初学者在使用 PyTorch 时的一些困难,并逐步讲解在使用 PyTorch 创建任何神经网络时所需的一些最重要的类和模块。
不过,这并不意味着这仅仅针对初学者,因为我还将讨论 PyTorch 提供的高度自定义性,并将讨论自定义层、数据集、数据加载器和损失函数。
那么,让我们喝杯咖啡 ☕ ️ 开始吧。
张量
张量 是 PyTorch 中的基本构建块,简单来说,它们是 GPU 上的 NumPy 数组。在这一部分,我将列出一些我们在处理张量时最常用的操作。这绝不是张量操作的详尽列表,但了解张量是什么是非常有帮助的,然后再进入更激动人心的部分。
1. 创建张量
我们可以通过多种方式创建 PyTorch 张量。这包括从 NumPy 数组转换为张量。下面只是一些示例的小概要,你可以像在 NumPy 数组中做的那样,使用张量做很多其他事情,更多内容请参考 这里。

2. 张量操作
再次强调,这些张量上可以执行很多操作。完整的函数列表可以在这里找到。

注意: PyTorch 变量是什么?在之前的 PyTorch 版本中,Tensor 和 Variables 是不同的,并提供不同的功能,但现在变量 API 已弃用,所有变量的方法都与张量一起工作。因此,如果你不了解它们也没关系,因为它们不再需要;如果你了解它们,可以忘记它们。
nn.Module
 照片由Fernand De Canne在Unsplash提供
照片由Fernand De Canne在Unsplash提供
这里来到了有趣的部分,我们将讨论一些在创建深度学习项目时最常用的构造。nn.Module 允许你将深度学习模型创建为类。你可以从nn.Module继承,以类的形式定义任何模型。每个模型类必然包含一个__init__过程块和一个forward传递块。
-
在
__init__部分,用户可以定义网络将要拥有的所有层,但尚未定义这些层如何相互连接。 -
在
forward传递块中,用户定义了数据如何在网络中的一个层流向另一个层。
简单来说,我们定义的任何网络都将如下所示:
在这里,我们定义了一个非常简单的网络,它接受大小为 784 的输入,并将其按顺序通过两个线性层。但需要注意的是,在定义前向传播时,我们可以定义任何类型的计算,这使得 PyTorch 在研究中具有极高的自定义性。例如,在我们的疯狂实验模式中,我们可能会使用以下网络,其中我们任意地附加层。在这里,我们将第二个线性层的输出再返回到第一个线性层,并在将输入加到其中后(跳跃连接)再次返回(老实说,我不知道这会有什么效果)。
我们还可以检查神经网络前向传播是否有效。我通常通过首先创建一些随机输入,并将其传递到我创建的网络中来做到这一点。
x = torch.randn((100,784))
model = myCrazyNeuralNet()
model(x).size()
--------------------------
torch.Size([100, 10])
关于层的说明
PyTorch 非常强大,你实际上可以使用nn.Module自己创建任何新的实验层。例如,与上面使用的预定义线性层nn.Linear相比,我们可以创建我们自定义的线性层。
你可以看到我们如何将权重张量包装在nn.Parameter.中。这是为了使张量被视为模型参数。来自 PyTorch 的文档:
参数是
[*Tensor*](https://pytorch.org/docs/stable/tensors.html#torch.Tensor)子类,这些子类在与*Module*一起使用时具有非常特殊的属性——当它们被分配为模块属性时,会自动添加到其参数列表中,并会出现在*parameters()*迭代器中。
正如你稍后会看到的,model.parameters() 迭代器将作为优化器的输入。不过,稍后会详细讲解。
现在,我们可以像使用其他层一样在任何 PyTorch 网络中使用这个自定义层。
不过,如果 Pytorch 没有提供许多常用的现成层,它也不会被如此广泛使用。这里有一些例子:[nn.Linear](https://pytorch.org/docs/stable/generated/torch.nn.Linear.html#torch.nn.Linear)、[nn.Conv2d](https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d)、[nn.MaxPool2d](https://pytorch.org/docs/stable/generated/torch.nn.MaxPool2d.html#torch.nn.MaxPool2d)、[nn.ReLU](https://pytorch.org/docs/stable/generated/torch.nn.ReLU.html#torch.nn.ReLU)、[nn.BatchNorm2d](https://pytorch.org/docs/stable/generated/torch.nn.BatchNorm2d.html#torch.nn.BatchNorm2d)、[nn.Dropout](https://pytorch.org/docs/stable/generated/torch.nn.Dropout.html#torch.nn.Dropout)、[nn.Embedding](https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html#torch.nn.Embedding)、[nn.GRU](https://pytorch.org/docs/stable/generated/torch.nn.GRU.html#torch.nn.GRU)/[nn.LSTM](https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html#torch.nn.LSTM)、[nn.Softmax](https://pytorch.org/docs/stable/generated/torch.nn.Softmax.html#torch.nn.Softmax)、[nn.LogSoftmax](https://pytorch.org/docs/stable/generated/torch.nn.LogSoftmax.html#torch.nn.LogSoftmax)、[nn.MultiheadAttention](https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html#torch.nn.MultiheadAttention)、[nn.TransformerEncoder](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoder.html#torch.nn.TransformerEncoder)、[nn.TransformerDecoder](https://pytorch.org/docs/stable/generated/torch.nn.TransformerDecoder.html#torch.nn.TransformerDecoder)
我已经链接了所有层的来源,你可以阅读所有相关内容,但为了展示我通常如何尝试理解一层并阅读文档,我将尝试查看一个非常简单的卷积层。

因此,一个 Conv2d 层需要输入一个高度为 H、宽度为 W、具有 Cin 通道的图像。现在,对于卷积网络中的第一层,in_channels 的数量将为 3(RGB),out_channels 的数量可以由用户定义。常用的 kernel_size 是 3x3,通常使用的 stride 是 1。
要检查我不太了解的新层,我通常会尝试查看该层的输入和输出,如下所示,其中我会先初始化该层:
conv_layer = nn.Conv2d(in_channels = 3, out_channels = 64, kernel_size = (3,3), stride = 1, padding=1)
然后通过它传递一些随机输入。这里的 100 是批次大小。
x = torch.randn((100,3,24,24))
conv_layer(x).size()
--------------------------------
torch.Size([100, 64, 24, 24])
所以,我们按要求从卷积操作中获得输出,并且我对如何在我设计的任何神经网络中使用这一层有足够的信息。
数据集和数据加载器
在训练或测试期间,我们如何将数据传递给神经网络?我们当然可以像上面那样传递张量,但 Pytorch 还提供了预构建的数据集,以便更方便地将数据传递给神经网络。你可以查看在torchvision.datasets和torchtext.datasets提供的完整数据集列表。但是,为了给出一个具体的数据集示例,假设我们需要使用一个包含图像的文件夹将图像传递给图像神经网络,这些图像的结构如下:
data
train
sailboat
kayak
.
.
我们可以使用torchvision.datasets.ImageFolder数据集来获取一个示例图像,如下所示:

这个数据集有 847 张图像,我们可以使用索引来获取图像及其标签。现在我们可以通过 for 循环将图像一个一个地传递给任何图像神经网络:
for i in range(0,len(train_dataset)):
image ,label = train_dataset[i]
pred = model(image)
但这不是最优的。我们希望进行批量处理。 我们实际上可以编写一些代码来将图像和标签追加到一个批次中,然后将其传递给神经网络。但是 Pytorch 提供了一个实用的迭代器torch.utils.data.DataLoader来精确完成这项工作。现在我们可以简单地将我们的train_dataset包装在 Dataloader 中,这样我们将获得批次而不是单个样本。
train_dataloader = **DataLoader**(train_dataset,batch_size = 64, shuffle=True, num_workers=10)
我们可以简单地使用批次进行迭代,如下所示:
for image_batch, label_batch in train_dataloader:
print(image_batch.size(),label_batch.size())
break
------------------------------------------------------------------
torch.Size([64, 3, 224, 224]) torch.Size([64])
所以实际上,使用数据集和数据加载器的整个过程变成了:
你可以在我之前关于使用深度学习进行图像分类的博客文章中查看这个特定示例:这里。
这很好,Pytorch 确实提供了大量开箱即用的功能。但 Pytorch 的主要优势在于其巨大的自定义能力。如果 Pytorch 提供的数据集不符合我们的使用情况,我们还可以创建自己的自定义数据集。
理解自定义数据集
要编写我们的自定义数据集,我们可以利用 Pytorch 提供的抽象类torch.utils.data.Dataset。我们需要继承这个Dataset类,并定义两个方法来创建自定义数据集。
-
__len__:一个函数,返回数据集的大小。这个在大多数情况下都比较简单。 -
__getitem__:一个函数,输入一个索引i,并返回索引i处的样本。
例如,我们可以创建一个简单的自定义数据集,它从一个文件夹中返回图像和标签。请注意,大多数任务都发生在__init__部分,我们使用glob.glob来获取图像名称并进行一些常规预处理。
此外,请注意,我们在__getitem__方法中逐个打开图像,而不是在初始化时。这么做是因为我们不想将所有图像加载到内存中,只需加载所需的图像即可。
我们现在可以像以前一样使用这个数据集和Dataloader工具。它的工作原理与 PyTorch 提供的以前的数据集相同,但没有一些实用函数。
理解自定义 DataLoaders
这一部分有点复杂,可以在浏览此帖时跳过,因为在很多情况下并不需要。 但我在这里添加它以便完整。
假设你想为一个处理文本输入的网络提供批次,而该网络可以处理任意序列大小的输入,只要批次内的大小保持不变。例如,我们可以有一个 BiLSTM 网络,可以处理任何长度的序列。如果你现在还不理解其中使用的层没关系;只要知道它可以处理变长序列即可。
这个网络期望其输入形状为(batch_size, seq_length),并且可以处理任何seq_length。我们可以通过将两个具有不同序列长度(10 和 25)的随机批次传递给模型来检查这一点。
model = BiLSTM()
input_batch_1 = torch.randint(low = 0,high = 10000, size = (100,**10**))
input_batch_2 = torch.randint(low = 0,high = 10000, size = (100,**25**))
print(model(input_batch_1).size())
print(model(input_batch_2).size())
------------------------------------------------------------------
torch.Size([100, 1])
torch.Size([100, 1])
现在,我们希望将这个模型提供紧凑的批次,使得每个批次的序列长度根据批次中的最大序列长度来保持一致,以最小化填充。这还有一个附加的好处,就是使神经网络运行更快。事实上,这正是 Kaggle Quora Insincere 挑战赛获胜提交中使用的一种方法,因为运行时间至关重要。
那么,我们该怎么做呢?首先,让我们写一个非常简单的自定义数据集类。
此外,让我们生成一些随机数据,用于这个自定义数据集。
 随机序列和标签的示例。序列中的每个整数对应于句子中的一个单词。
随机序列和标签的示例。序列中的每个整数对应于句子中的一个单词。
现在我们可以使用自定义数据集:
train_dataset = CustomTextDataset(X,y)
如果我们现在尝试在这个数据集上使用batch_size>1 的 Dataloader,我们将遇到一个错误。这是为什么呢?
train_dataloader = DataLoader(train_dataset,batch_size = 64, shuffle=False, num_workers=10)
for xb,yb in train_dataloader:
print(xb.size(),yb.size())

这是因为序列长度不同,而我们的数据加载器期望所有序列具有相同的长度。请记住,在之前的图像示例中,我们使用转换将所有图像调整为 224 的大小,因此我们没有遇到这个错误。
那么,我们该如何迭代这个数据集,以便每个批次具有相同长度的序列,但不同批次可能有不同的序列长度呢?
我们可以在 DataLoader 中使用collate_fn参数,定义如何在特定批次中堆叠序列。要使用它,我们需要定义一个函数,该函数以批次为输入,并根据批次中的max_sequence_length返回(x_batch,y_batch)与填充后的序列长度。下面函数中使用的函数是简单的 NumPy 操作。此外,函数中有适当的注释,以便你理解发生了什么。
现在我们可以将这个collate_fn与我们的数据加载器一起使用:
train_dataloader = DataLoader(train_dataset,batch_size = 64, shuffle=False, num_workers=10,**collate_fn** **=** **collate_text**)for xb,yb in train_dataloader:
print(xb.size(),yb.size())
 现在可以看到批次的序列长度不同了
现在可以看到批次的序列长度不同了
由于我们提供了自定义的collate_fn,这次它会起作用。现在我们看到批次的序列长度不同。因此,我们可以使用可变输入大小来训练我们的 BiLSTM,正如我们希望的那样。
训练神经网络
我们知道如何使用nn.Module创建神经网络。那么如何训练它呢?任何需要训练的神经网络都会有一个训练循环,其形式如下:
在上面的代码中,我们运行了五个周期,在每个周期中:
-
我们使用数据加载器迭代数据集。
-
在每次迭代中,我们使用
model(x_batch)进行前向传播。 -
我们使用
loss_criterion计算损失。 -
我们使用
loss.backward()调用反向传播损失。我们不需要担心梯度的计算,因为这个简单的调用会为我们完成所有工作。 -
采取优化器步骤来通过
optimizer.step()更改整个网络中的权重。这时,网络的权重会使用在loss.backward()调用中计算的梯度进行修改。 -
我们通过验证数据加载器检查验证得分/指标。在进行验证之前,我们使用
model.eval()将模型设置为评估模式。请注意,在评估模式下我们不会进行损失的反向传播。
到目前为止,我们已经讨论了如何使用nn.Module创建网络以及如何在 Pytorch 中使用自定义数据集和数据加载器。接下来我们来讨论损失函数和优化器的各种选项。
损失函数
Pytorch 为我们提供了各种损失函数,用于处理最常见的任务,如分类和回归。一些常用的例子有[nn.CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss)、[nn.NLLLoss](https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html#torch.nn.NLLLoss)、[nn.KLDivLoss](https://pytorch.org/docs/stable/generated/torch.nn.KLDivLoss.html#torch.nn.KLDivLoss)和[nn.MSELoss](https://pytorch.org/docs/stable/generated/torch.nn.MSELoss.html#torch.nn.MSELoss)。你可以阅读每个损失函数的文档,但为了说明如何使用这些损失函数,我将通过[nn.NLLLoss](https://pytorch.org/docs/stable/generated/torch.nn.NLLLoss.html#torch.nn.NLLLoss)的例子来讲解。

NLLLoss 的文档相当简洁。即,这个损失函数用于多类别分类,根据文档:
-
预期的输入需要是 (
batch_sizexNum_Classes) 的大小 —— 这些是我们创建的神经网络的预测结果。 -
我们需要输入中每个类别的对数概率 —— 为了从神经网络中获取对数概率,我们可以在网络的最后一层添加一个
LogSoftmax层。 -
目标需要是一个类的张量,类编号在范围(0, C-1) 内,其中 C 是类别的数量。
因此,我们可以尝试在一个简单的分类网络中使用这个损失函数。请注意在最终线性层后面的 LogSoftmax 层。如果不想使用 LogSoftmax 层,你可以直接使用 [nn.CrossEntropyLoss](https://pytorch.org/docs/stable/generated/torch.nn.CrossEntropyLoss.html#torch.nn.CrossEntropyLoss)
让我们定义一个随机输入来测试我们的网络:
# some random input:X = torch.randn(100,784)
y = torch.randint(low = 0,high = 10,size = (100,))
然后将其通过模型以获取预测结果:
model = myClassificationNet()
preds = model(X)
现在我们可以得到损失值为:
criterion = nn.NLLLoss()
loss = criterion(preds,y)
loss
------------------------------------------
tensor(2.4852, grad_fn=<NllLossBackward>)
自定义损失函数
定义自定义损失函数再次是件简单的事,只要你在损失函数中使用张量操作就可以了。例如,这里是 customMseLoss
def customMseLoss(output,target):
loss = torch.mean((output - target)**2)
**return** loss
你可以像以前一样使用这个自定义损失。但请注意,这次我们不使用 criterion 实例化损失,因为我们将其定义为一个函数。
output = model(x)
loss = customMseLoss(output, target)
loss.backward()
如果需要,我们也可以将其编写为一个使用 nn.Module 的类,然后将其作为对象使用。这里是一个 NLLLoss 自定义示例:
优化器
一旦通过 loss.backward() 调用获取梯度,我们需要进行一次优化器步骤以改变整个网络中的权重。Pytorch 提供了多种现成的优化器,使用 torch.optim 模块。例如:[torch.optim.Adadelta](https://pytorch.org/docs/stable/optim.html#torch.optim.Adadelta)、[torch.optim.Adagrad](https://pytorch.org/docs/stable/optim.html#torch.optim.Adagrad)、[torch.optim.RMSprop](https://pytorch.org/docs/stable/optim.html#torch.optim.RMSprop) 和最广泛使用的 [torch.optim.Adam](https://pytorch.org/docs/stable/optim.html#torch.optim.Adam)。要使用 Pytorch 最常用的 Adam 优化器,我们可以简单地实例化它:
optimizer **=** torch.optim.Adam(model.parameters(), lr=0.01, betas=(0.9, 0.999))
然后在训练模型时使用 optimizer**.**zero_grad() 和 optimizer.step()。
我没有讨论如何编写自定义优化器,因为这是一个不常见的用例,但如果你想要更多优化器,可以查看pytorch-optimizer库,它提供了许多在研究论文中使用的其他优化器。此外,如果你确实想创建自己的优化器,可以参考PyTorch或pytorch-optimizers中实现的优化器的源代码。
 来自pytorch-optimizer库的其他优化器
来自pytorch-optimizer库的其他优化器
使用 GPU/多个 GPU
到目前为止,我们所做的都是在 CPU 上。如果你想使用 GPU,可以使用model.to('cuda')将模型放到 GPU 上。或者,如果你想使用多个 GPU,可以使用nn.DataParallel。以下是一个检查机器中 GPU 数量并在需要时自动使用DataParallel进行并行训练的实用函数。
我们唯一需要改变的就是在训练时将数据加载到 GPU 中,如果我们有 GPU 的话。这就像在训练循环中添加几行代码一样简单。
结论
PyTorch 提供了极大的可定制性,且代码量很少。虽然一开始可能很难理解整个生态系统如何通过类来构建,但最终它就是简单的 Python。在这篇文章中,我尝试拆解了你使用 PyTorch 时可能需要的大部分部分,希望阅读后能让你多一些理解。
你可以在我的GitHub仓库中找到这篇文章的代码,我在这里保存了我所有博客的代码。
如果你想通过课程结构深入学习 Pytorch,可以查看 IBM 在 Coursera 上提供的使用 PyTorch 的深度神经网络课程。此外,如果你想了解更多关于深度学习的内容,我推荐这个在计算机视觉中的深度学习方面的优秀课程,它是高级机器学习专项课程的一部分。
感谢阅读。我将来还会写更多适合初学者的文章。请关注我的 Medium 或订阅我的 博客 以获取更新。像往常一样,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系我。
此外,小小的免责声明——本文可能包含一些与相关资源相关的附属链接,因为分享知识从来不是坏事。
简介:Rahul Agarwal 是 WalmartLabs 的高级统计分析师。关注他的 Twitter @mlwhiz。
原文。经许可转载。
相关内容:
-
数据科学家的 6 条建议
-
特征提取指南
-
每个数据科学家必须知道的 5 种分类评估指标
更多相关内容
2021 年数据工程师最需求的技能
原文:
www.kdnuggets.com/2021/05/most-demand-skills-data-engineers-2021.html
评论

在撰写了2021 年数据科学家最需求技能之后,我想对数据工程师进行相同的分析,因为该领域的需求正快速增长。根据Interview Query 的数据显示科学面试报告,2019 年到 2020 年之间,数据科学面试的数量仅增长了 10%,而在同一时期内,数据工程面试的数量增长了 40%!
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
再次说明,我想预先声明,这受到 Jeff Hale 在 2018/2019 年所写文章的启发。我撰写这篇文章只是因为我想获取更符合当下的技能需求分析,并且我分享这篇文章是因为我假设也有其他人希望看到 2021 年数据工程师最需求技能的更新版本。
从这项分析中获取你想要的内容——显然,通过抓取招聘广告获得的见解并不能完美地与实际最受需求的数据科学技能相关联。然而,我认为这可以很好地指示出你应该更多关注哪些通用技能,同时避免哪些技能。
话虽如此,希望你喜欢这份分析,让我们开始吧!
方法论
在这项分析中,我从 Indeed、Monster 和 SimplyHired 上抓取并累计了超过 17,000 个招聘广告。我没有抓取 LinkedIn,因为我在尝试抓取时遇到了验证码问题。
我接着检查了每个我搜索的术语在招聘广告中出现的频率。我搜索的术语列表如下:
-
Python, SQL, R, Java, Git, C, MATLAB, Excel, C++, JavaScript, C#, Julia, Scala, SAS
-
Scikit-learn, Pandas, NumPy, SciPy
-
Matplotlib, Looker, Tableau
-
TensorFlow, PyTorch, Keras
-
Spark, Hadoop, AWS, GCP, Hive, Azure, Google Cloud, MongoDB, BigQuery
-
Docker, Kubernetes, Airflow
-
NoSQL, MySQL, PostgreSQL
-
Caffe, Alteryx, Perl, Cassandra, Linux
在获取每个来源的数据后,我将它们相加,然后除以数据工程师职位总数以获得百分比。例如,Python 的值为 0.76 表示 76% 的职位中要求掌握 Python。
最后,我将数据工程师分析的结果与数据科学家分析的结果进行了比较,以查看这两个角色之间的差异。
结果
数据工程师的前 25 项技能
以下是 2021 年最受欢迎的数据工程师技能前 25 名,从高到低排名:

数据工程师的顶级编程语言
为了获得更详细的视图,下图显示了数据工程师的顶级编程语言:

数据工程师与数据科学家在顶级编程语言上的两个主要区别:首先,要求 SQL 的职位百分比对于数据工程师来说要高得多——这是合理的,因为 SQL 是构建数据管道、表视图等所必需的。其次,要求 R 的职位百分比对于数据工程师则要小得多。因此,如果你想同时保持数据工程师和数据科学家的职业选择,那么我建议学习 Python 而不是 R。
数据工程师和数据科学家之间正差异最大的前 10 项技能
下图显示了数据工程师和数据科学家之间在技能百分比上的最大差异:

不出所料,云计算技能和 Apache 的大数据产品如 Spark、Hive 和 Hadoop 对数据工程师而言比数据科学家更为重要,这很合理,因为数据工程师的工作重点是构建和维护组织的数据基础设施。Airflow 对数据工程师来说也更为重要,因为它正逐渐成为工作流调度的首选技术。
数据工程师和数据科学家之间负差异最大的前 10 项技能

同样,上图也不令人惊讶,因为这些技能大多集中在数据建模和数据分析上,这更符合数据科学家的领域而非数据工程师。
总体
总体而言,所有分析技能的差异在下图中提供:

希望你发现这项分析有用。我不会仅凭这一资源完全决定学习某项技能而非另一项技能,但正如我之前所说的,我认为这能很好地展示出哪些技能在重要性上有所上升或下降。
相关:
更多相关主题
2021 年数据科学家最需要的技能
原文:
www.kdnuggets.com/2021/04/most-demand-skills-data-scientists.html
评论

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
作者创建的图片。
我想首先说明,这些内容深受 Jeff Hale 的文章启发,他在 2018/2019 年写的。我写这篇文章是为了获得对当前需求技能的更新分析,并分享给大家,因为我假设还有人也希望看到 2021 年数据科学家最需要技能的更新版本。
从这项分析中提取你所需要的内容——显然,从网页抓取的职位发布中获取的见解并不完全与实际需求的技能完美匹配。然而,我认为这给出了一个良好的指示,说明你应该更多地关注哪些通用技能,同时,避免哪些技能。
说完这些,希望你喜欢这篇文章,让我们深入了解吧!
方法论
对于这项分析,我从 Indeed、Monster 和 SimplyHired 抓取并积累了超过 15,000 个职位发布。我没有抓取 LinkedIn,因为在尝试抓取时遇到了验证码问题。
我接着检查了有多少职位发布包含了我搜索的每个术语。我搜索的术语列表如下(如果你想看到其他技能,请在评论中提及,我会在明年的分析中添加!):
-
Python, SQL, R, Java, Git, C, MATLAB, Excel, C++, JavaScript, C#, Julia, Scala, SAS
-
Scikit-learn, Pandas, NumPy, SciPy
-
Matplotlib, Looker, Tableau
-
TensorFlow, PyTorch, Keras
-
Spark, Hadoop, AWS, GCP, Hive, Azure, Google Cloud, MongoDB, BigQuery
-
Docker, Kubernetes, Airflow
-
NoSQL, MySQL, PostgreSQL
-
Caffe, Alteryx, Perl, Cassandra, Linux
在获取每个来源的计数后,我将它们相加,然后除以数据科学家职位发布的总数,以获取百分比。例如,Python 的值为 0.77,意味着 77%的职位发布中包含了 Python。
最后,我将结果与 Jeff Hale 在 2019 年进行的分析进行了比较,以获取 2019 年至 2021 年的百分比变化。
结果
顶级技能
以下是 2021 年最受欢迎的 25 项数据科学技能,按需求量从高到低排名:

图片由作者创建。
顶级编程语言
为了更详细地了解情况,下图显示了数据科学家使用的顶级编程语言:

图片由作者创建。
不足为奇的是,Python、SQL 和 R 是前三大编程语言。
就个人而言,我也认为你应该掌握 Python 或 R 以及 SQL。我从 Python 开始,可能会在余生中继续使用 Python。它在开源贡献方面遥遥领先,并且学习起来相对简单。SQL 无疑是学习任何数据相关职业中最重要的技能,无论你是数据科学家、数据工程师、数据分析师、业务分析师等等。
顶级 Python 库
类似地,下图显示了数据科学家最常用的 Python 库:

图片由作者创建。
TensorFlow 排名第一,因为它是 Python 中最受欢迎的深度学习库之一。PyTorch 是一个强有力的替代品,因此其排名紧随其后。
Scikit-learn 可以说是 Python 中最重要的机器学习库。在使用 Pandas 和/或 NumPy 清洗和处理数据之后,scikit-learn 用于构建机器学习模型,因为它拥有大量用于预测建模和分析的工具。
在我看来,尽管上面未能体现,Pandas、NumPy 和 SciPy 对数据科学家来说也是至关重要的。
增长最快和下降最快的技能
以下图表显示了 2019 年至 2021 年期间增长最快和下降最快的技能:

图片由作者创建。

图片由作者创建。
以下是上述两张图表的一些要点:
-
与云相关的技能,如 AWS 和 GCP,出现了大幅增长。
-
类似地,深度学习相关技能,如 PyTorch 和 TensorFlow,也有大幅增长。
-
SQL 和 Python 继续增长重要性,而 R 保持不变。
-
Apache 产品,如 Hadoop、Hive 和 Spark,重要性持续下降。
原文。已获许可转载。
相关:
-
数据科学家最需要的技能,作者:Jeff Hale,2018 年 11 月。
更多相关内容
数据科学家最需要的技术技能
原文:
www.kdnuggets.com/2019/12/most-demand-tech-skills-data-scientists.html
评论
作者:Jeff Hale,数据科学家、作者、电商首席运营官
在 2018 年秋季,我分析了数据科学家最需要的技能和技术。那篇文章引起了大家的共鸣。它在 Medium 上获得了超过 11,000 次点赞,被翻译成了几种语言,并且在 2018 年 11 月成为 KD Nuggets 上最受欢迎的故事。
一年多的时间已经过去了。让我们看看有什么新变化。????
到文章的最后,你将知道哪些技术在雇主中变得越来越受欢迎,哪些技术则变得不那么受欢迎。

在我2018 年的原始文章中,我考察了对统计学和沟通等通用技能的需求。我还考察了对 Python 和 R 等技术的需求。软件技术的变化速度远远快于对通用技能的需求,因此在这次更新的分析中我只包含了技术方面的内容。
我搜索了SimplyHired、Indeed、Monster和LinkedIn,查看“数据科学家”职位的招聘信息中出现了哪些关键词。这次我决定编写代码来抓取职位列表,而不是手动搜索。这项工作对 SimplyHired、Indeed 和 Monster 都取得了良好的结果。我使用了Requests和Beautiful Soup这两个 Python 库。你可以在我的 GitHub 仓库中查看抓取和分析的代码 Jupyter 笔记本。
抓取 LinkedIn 的过程远比预期的要困难得多。需要身份验证才能查看职位列表的准确数量。我决定使用 Selenium 进行无头浏览。在 2019 年 9 月,关于 LinkedIn 的一个美国最高法院案件作出了对 LinkedIn 不利的裁决,允许抓取 LinkedIn 的数据。尽管如此,在几次抓取尝试后,我仍无法访问我的账户。这个问题可能是由于速率限制造成的。???? 更新:我现在已经可以访问了,但担心如果再次尝试抓取会被锁定。
顺便提一下,微软拥有 LinkedIn,Randstad Holding 拥有 Monster,Recruit Holdings 拥有 Indeed 和 SimplyHired。
LinkedIn 的数据可能没有提供从去年到今年的逐一对比。这个夏天,我注意到 LinkedIn 对一些技术职位搜索词的波动变得非常大。我推测他们可能在通过使用自然语言处理来评估意图,来测试他们的搜索结果算法。相比之下,‘数据科学家’的职位列表在其他三个搜索网站上的数量在两年间变化相对较小。
因此,我在本文中排除了 LinkedIn 在 2019 年和 2018 年的分析。



对于每个职位搜索网站,我计算了该网站上每个关键词出现在数据科学家职位列表中的总百分比。然后我计算了这些百分比在三个网站上的平均值。
我手动调查了新的搜索词,并筛选了那些看起来有前途的词汇。没有新的词汇在 2019 年达到 5%的职位列表平均比例,这是我用于结果包含的截止值。
让我们看看我们发现了什么! ????
结果
对于每个关键词,有至少四种方法来查看结果:
-
对于每个招聘网站,每一年,将包含该关键词的职位数量除以包括数据科学家的所有搜索词的总数。然后计算这三个招聘网站的平均值。这就是上述所描述的过程。
-
在完成上述第 1 步之后,计算 2018 年到 2019 年职位列表平均百分比的变化。
-
在完成上述第 1 步之后,计算 2018 年到 2019 年职位列表平均百分比的变化。
-
在完成上述第 1 步之后,计算每个关键词相对于当年其他关键词的排名。然后计算从一年到下一年的排名变化。
我们来看前面三个选项的条形图。然后我会展示一个包含数据的表格,并讨论结果。
这是上述第 1 步的 2019 年图表,显示了 Python 出现在近 75%的职位列表中。

这是上述第 2 步的图表,显示了 2018 年和 2019 年职位列表平均百分比的增减变化。AWS 显示出 5 个百分点的增长。它在 2019 年的职位列表中出现的平均比例为 19.4%,而在 2018 年的职位列表中为 14.6%。

这是上述第 3 步的图表,显示了年际之间的百分比变化。PyTorch 相比于 2018 年出现的职位列表平均百分比增长了 108.1%。

所有图表均使用了 Plotly 制作。如果你想学习如何使用 Plotly 制作互动可视化,请查看 我的指南。如果你想查看互动图表,请查看 我的 GitHub 仓库 中的 HTML 文件。Jupyter Notebook 用于抓取、分析和可视化也在那里。
下面是上述图表中的信息,只是以表格格式呈现,并按 2018 年至 2019 年的平均职位百分比变化排序。

我知道这些不同的指标可能会让人感到困惑,所以这里是对上面图表中内容的指导。
-
2018 平均值 是指 2018 年 10 月 10 日的职位列表在 SimplyHired、Indeed 和 Monster 上的百分比平均值。
-
2019 平均值 与 2018 平均值 相同,只是针对 2019 年 12 月 4 日的数据。这个数据在上述三张图表的第一张中显示。
-
平均变化 是 2019 列减去 2018 列。它显示在上述三张图表的第二张中。
-
% 变化 是指从 2018 到 2019 的百分比变化。它显示在上述三张图表的最后一张中。
-
2018 排名 是指 2018 年相对于其他关键词的排名。
-
2019 排名 是指 2019 年相对于其他关键词的排名。
-
排名变化 是指从 2019 年到 2018 年的排名上升或下降。
重点总结
在不到 14 个月的时间里发生了相当大的变化!
胜出者
Python 仍然居于榜首。它是出现频率最高的关键词,占近四分之三的职位列表。Python 从 2018 年开始有了显著的增长。

SQL 处于上升趋势。它几乎超越了 R,成为第二高的平均分数。如果趋势继续,它很快将成为第二名。

最显著的 深度学习框架 变得越来越受欢迎。 PyTorch 是所有关键词中增长百分比最大的一项。 Keras 和 TensorFlow 也有了大幅度的增长。Keras 和 PyTorch 在排名中分别上升了四位,TensorFlow 上升了三位。需要注意的是,PyTorch 的起始平均值较低——TensorFlow 的平均值仍然是 PyTorch 的两倍。



云平台技能 在数据科学家中变得越来越受欢迎。AWS 出现在近 20%的职位列表中,而 Azure 出现在大约 10%的职位列表中。Azure 在排名中上升了四位。


这些是最具活力的技术! ????
败出者
R的整体平均下降幅度最大。鉴于其他调查的结果,这一发现并不令人惊讶。Python 显然已经超越了 R,成为数据科学的首选语言。不过,R 仍然非常受欢迎,在大约 55%的职位列表中出现。如果你知道 R,不必气馁,但如果你想拥有更受欢迎的技能,也可以考虑学习 Python。
许多Apache产品的受欢迎程度下降,包括Pig、Hive、Hadoop和Spark。Pig 在排名中下降了五个位次,比任何其他技术都多。Spark 和 Hadoop 仍然是常见的技能,但我的发现显示出从它们向其他大数据技术的转变趋势。
专有统计软件包MATLAB和SAS经历了显著的下降。MATLAB 在排名中下降了四个位次,而 SAS 从第六位降至第八位。与 2018 年的平均水平相比,这两种语言都经历了大幅度的百分比下降。
建议
这个列表上有很多技术。???? 你肯定不需要了解它们所有的。所谓的神话数据科学家被称为独角兽是有原因的。????

我建议,如果你刚刚开始数据科学的学习,集中精力在那些需求量大且正在增长的技术上。
专注于学习一种。
技术。
在。
A.
时间。
(这是一条非常好的建议,尽管我并不总是遵循它。????)
以下是我推荐的学习路径,顺序如下:

- 学习 Python 进行通用编程。查看我的书,Memorable Python,以学习基础知识。

- 学习 pandas 进行数据处理。我认为招聘 Python 数据科学家角色的组织会期待申请者熟悉 pandas 和 Scikit-learn 库。Scikit-learn 出现在列表上,而 Pandas 刚好没有进入名单。你在学习 pandas 的同时也会学习一些 Matplotlib 可视化和 NumPy。我正在完成一本关于 pandas 的书。订阅我的邮件列表以确保你不会错过它。

-
使用 Scikit-learn 库学习机器学习。我推荐 Müller & Guido 的书Introduction to Machine Learning with Python。
-
高效查询关系型数据库需要学习 SQL。我也正在完成一本关于 SQL 的书。订阅我的邮件列表以确保你不会错过它。
-
学习 Tableau 进行数据可视化。这可能是列表中最有趣且最容易上手的技术。 ???? 查看我的 Medium 文章,了解六分钟的基础知识介绍,点击这里。
-
适应云平台。由于市场份额,AWS 是一个不错的选择。微软 Azure 是一个稳健的第二选择。虽然它的受欢迎程度较低,但我个人偏爱 Google Cloud,因为我喜欢它的用户体验和机器学习关注点。如果你想熟悉 Google Cloud 的数据摄取、转换和存储选项,请参阅我关于成为 Google Cloud 认证专业数据工程师的文章。
-
学习一个深度学习框架。TensorFlow 是最受欢迎的。Chollet 的书Deep Learning with Python 是学习 Keras 和深度学习原理的绝佳资源。Keras 现在与 TensorFlow 紧密集成,因此是一个很好的起点。PyTorch 也在快速增长。有关不同深度学习框架的受欢迎程度,请查看我这里的分析。
这就是我的一般学习路径建议。根据你的需要调整或忽略它,做你想做的事情吧! ????
总结
我希望你发现这份关于数据科学家最受欢迎技术的指南有用。如果你觉得有用,请在你喜欢的社交媒体上分享,以便其他人也能找到它。 ????
我撰写关于 Python、Docker、数据科学以及其他技术话题的文章。如果你对这些感兴趣,请关注我,并在这里阅读更多内容。


祝学习愉快! ????????
简历:Jeff Hale 是一名数据科学家,《Memorable Python ????》和《Memorable Docker ????》的作者,以及电子商务首席运营官。
原文. 经许可转载。
相关:
-
数据科学家最受欢迎的技能
-
哪个深度学习框架增长最快?
-
哪些数据科学技能是核心的,哪些是热门/新兴的?
更多相关主题
数据科学中最受欢迎的技能
原文:
www.kdnuggets.com/2019/04/most-desired-skill-data-science.html
评论
凯瑟尔·冯,创始人,Principal Analytics Prep
这一技能差距通常被描述为缺乏“批判性思维”。
很难想象一个拥有 STEM 学位的人缺乏批判性思维,我们来解析一下这意味着什么。
数据科学中的批判性思维可以分为两个方面。首先是提出问题的能力。在实践中,这涉及到与数据科学或分析结果的用户进行广泛的采访,以真正理解需要解决的问题。许多从业者,包括我最近参加的一次会议上的几位发言人,都指出用户经常无法准确表达问题。

我并不完全同意这种描述。提出问题的过程需要数据科学家(他们对数据和分析工具了解很多)与业务负责人(他们对业务目标和指标了解很多)之间的合作。这种合作促成了知识的共享和共生的解决问题方法。
批判性思维的第二个方面是质疑数据的能力。有经验的分析师绝不会直接将原始数据投入软件中看会得到什么。经验告诉我们需要进行哪些调整,以去除数据中可能分散注意力或具有误导性的特征。
STEM 培训特别缺乏这两方面的批判性思维。数学、科学或工程课程中的典型问题包括(a)一个明确定义的问题,和(b)整洁的数据,学生的挑战是找出哪个公式或方法可以利用提供的数据来回答指定的问题。没有必要进一步发展问题;实际上,任何试图改变问题的学生都会受到惩罚!也不需要质疑数据。如果数据应该被质疑,那么问题将没有单一正确答案,这与传统的学术 STEM 培训不太符合。(相比之下,社会科学毕业生在处理复杂性和不完整数据方面训练得更好。)
在最近的博客文章中,我展示了数据分析师如何利用批判性思维来质疑数据,并避免得出令人尴尬的错误结论。国家公路交通安全管理局(NHTSA)的分析师未能注意到特斯拉提交的数据中的巨大漏洞,当他们支持特斯拉的说法,即自动驾驶功能将降低 40%的碰撞率时。一位独立顾问成功地使数据得以公开,并发现了大量的空白条目。当使用标准方法(均值插补)对缺失值进行插补时,报告的自动驾驶功能的好处完全消失了。

弥合这个技能差距是我启动 Principal Analytics Prep 时的一个关键目标。我们通过与具有多年实际工作经验的从业人员在课堂内进行动手学习,并寻找具有多样背景的学生,以考虑科学和社会科学的方法来解决问题,来实现这一目标。
在第二部分中,我提供了帮助你准备招聘经理用来测试批判性思维的案例面试材料。
本文最初发布在 Kaiser Fung 的博客上(www.principalanalyticsprep.com/news/critical-thinking-the-most-desired-skill-in-data-science),并经过了略微修改。
简历:Kaiser Fung 是 Principal Analytics Prep 的创始人,这是一个领先的数据分析训练营;畅销书《Numbers Rule Your World》的作者;以及 Junk Charts 的作者(www.junkcharts.com),这是一个受欢迎的数据可视化博客。
Twitter: @junkcharts
Youtube: bitly.com/fungwithdata-1
资源:
相关内容:
更多相关主题
机器学习项目中最重要的步骤是什么?
原文:
www.kdnuggets.com/2017/08/most-important-step-machine-learning-project.html
评论
作者:Shahar Cohen,YellowRoad。

CRISP-DM 是机器学习项目的常见标准。业务理解、数据理解、数据准备、建模、评估和部署。这六个步骤对机器学习项目至关重要。每个步骤中的质量问题都会直接影响整个结果的质量。它们都很重要。
然而,在向许多组织提供机器学习建议,并自己运行更多此类项目后,我们(在 YellowRoad)得出结论,流程中投资最少的步骤是业务理解。我们看到许多公司在理解他们要解决的任务的业务方面之前,讨论算法和技术。这显然不是一个好的起点。
我们编制了一系列问题,用于任何我们参与的机器学习项目,在得到这些问题的良好答案之前,我们不会在后续步骤上投入过多精力。我们发现这种做法非常有帮助。
这些是问题:
-
我们试图实现什么目标,从业务角度来看?这有多重要?
-
我们正在尝试解决的任务的输入和输出是什么?
-
给定一个假设的解决方案,它将如何影响我们的操作?(另一种问法是:假设我有一个完美的解决方案,你将如何使用它?)
-
我们是否已经具备根据这种解决方案行动的能力,还是我们还需要开发这种能力?(如果能力已经具备,仔细学习。如果没有,保持与负责开发该能力的团队的紧密联系)
-
我们将如何衡量建议的解决方案?(关键绩效指标)
-
什么会使它成功?
-
我们是否有可用的输入数据?提取这些数据有多难?我们是否被允许使用这些数据?
-
我们是否有构建类似解决方案的经验?我们是否了解需要什么?
-
我们是否面临严格的预算和时间限制?
-
谁将开发解决方案?我们是否具备所需的内部技能?
原文。经许可转载。
简历: Shahar Cohen 是 YellowRoad 的联合创始人,同时也是一位经验丰富的数据科学家和研究员,拥有超过 10 年的经验。
相关:
-
数据科学家如何提高生产力
-
数据版本控制:迭代机器学习
-
解决 CRISP-DM 中的部署和迭代问题
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
数据工程师最重要的工具
原文:
www.kdnuggets.com/2021/08/most-important-tool-data-engineers.html
评论
由Leo Godin,高级数据工程师

图片来源于Emily Morter 在Unsplash
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
最优秀的技术专家如果解决错误的问题,就注定会遭遇挫折和失败。然而,我们常常看到优秀的 Python 开发者和 SQL 专家创造了极好的技术,却对业务几乎没有价值。在某些情况下,更糟糕的是,这些解决方案不仅没有争议的价值,反而消耗资源并混乱业务流程。作为数据工程师,我们有责任充分理解我们解决方案所支持的业务流程。
作为高级数据工程师,我们应该对业务有深刻的理解,以至于能够推荐工作中的效率和改进。这是一个大胆的声明,但我将坚定地坚持这一点,并与任何不同意见的人作斗争。当然是比喻的,因为我没有剑,更偏爱和平而非战斗。重点是,我们需要理解业务,有一个关键工具可以帮助我们做到这一点。
在此之前,请阅读这句来自 Julien Kervizic 的精彩引用, 简明扼要地指出了问题:
“通过对底层数据及其相关业务过程的理解来塑造数据,如今似乎不如能够移动数据那样重要。”
他在这里说的是,我们如此专注于将数据从那里移动到这里,以及我们可以用来完成这项工作的酷工具,以至于我们忘记了最初为什么要这样做。数据工程师从多个来源收集原始数据,创建可供人类和机器有效使用的可消费包。介于两者之间的一切对我们的消费者来说都是一个黑箱。为什么我们把大部分时间和精力花在黑箱上,而不是可消费包上?
犀利的看法会说这是因为黑箱是有趣的部分。虽然这可能是一个因素,但我相信我们中的许多人只是对业务流程了解得不够深入,无法有效地花时间改善可消耗的包裹。让我明确一点。这是你的工作和责任,更好地理解业务。这并不容易。在一个完美的世界里,我们会有很好的文档可以依赖,但……好吧,你知道的。这就是我们进入数据工程工具箱中最重要工具的地方。
这是什么重要工具?
问题。就是这样。问题。很多问题。好的问题。坏的问题。尴尬的问题。所有的问题!这样强调够了吗?你想从好到优秀吗?提出问题,充分理解你支持的业务流程。我无法强调与只关心技术的数据工程师交谈的挫败感,我自己也是数据工程师。想象一下,作为财务分析师、人力资源负责人或销售人员。他们需要可消耗的数据包,但可能不了解技术术语。他们对技术的理解可能仅限于他们使用的具体工具。
因此,仅仅提问是不够的。相反,我们需要用业务能理解的语言提出正确的问题。忘掉表格、数据源和主键。这些东西会在后面出现,通常还要通过更多的问题向更多的人确定。相反,询问人们在日常工作中做什么。问业务目标是什么。工作如何在各种系统中流动。问到你完全理解公司使用的业务流程。然后记录下来。
编写业务文档。当然,编写文档是他们的工作,但你是那个需要这些文档的人。创建包括业务所用工具的流程图。包括人们与流程互动的地方。然后与业务一起审查,并提出更多问题。你会发现没有一个人能理解所有内容,所以你会与几个人交谈,最终统一业务流程。你编写的文档将成为业务的宝贵资料。砰!你刚刚变得对公司不可或缺。我敢说,你刚刚成为了高级数据工程师?
赶紧总结一下
作为数据工程师,我们有责任理解我们的解决方案支持的业务流程。如果没有完全理解这些流程,我们注定会面临挫折和失败。我们生活的这个不完美的世界通常文档记录不佳,而我们数据工程师是需要搞清楚所有这些的那个人。通过提出大量问题,我们可以更好地理解我们的解决方案支持的业务流程,这使我们能够不断提升工作影响力。所以,开始吧。质疑一切!
要了解这些问题如何引导到业务文档,请阅读 Sue 在 Krispy Krabcakes 的冒险故事。她玩得很开心,并提供了关于业务分析和架构的精彩入门介绍。
简介: Leo Godin 目前在 Capital Markets Gateway 担任高级数据工程师,喜欢谈论数据和职业发展。
原文. 经授权转载。
相关内容:
-
2021 年数据工程师最需要的技能
-
数据科学家、数据工程师及其他数据职业解析
-
分析工程无处不在
更多相关话题
机器学习和数据科学中最受欢迎的语言是…
原文:
www.kdnuggets.com/2017/01/most-popular-language-machine-learning-data-science.html
评论
由Jean-Francois Puget,IBM。
应该学习什么编程语言才能获得机器学习或数据科学职位?这是一个至关重要的问题。它在许多论坛中被讨论。我可以在这里提供我自己的答案并解释原因,但我更愿意先看一些数据。毕竟,这就是机器学习者和数据科学家应该做的:看数据,而不是意见。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
那么,让我们来看看一些数据。我将使用 indeed.com 上的趋势搜索功能。它查看在职位招聘中所选术语的时间发生频率。这能提供雇主正在寻找哪些技能的指示。然而,请注意,这不是关于哪些技能实际在使用的调查。这更像是技能受欢迎程度如何演变的高级指示器(更正式地说,它可能接近于受欢迎程度的一阶导数,因为后者是招聘技能加上再培训技能减去退休和离职技能的差值)。
说够了,让我们来看数据。我搜索了与“机器学习”和“数据科学”相关联的技能,其中技能包括主要编程语言 Java、C、C++ 和 Javascript。我还包括了 Python 和 R,我们知道这两者在机器学习和数据科学中非常受欢迎,以及 Scala 因为它与 Spark 的关联,还有 Julia,一些人认为它是下一个重要的语言。运行这个查询我们得到我们所需的数据:

当我们专注于机器学习时,数据类似:

我们可以从这些数据中得出什么?
首先,我们看到一种方式并不适合所有情况。在这个背景下,一些语言相当受欢迎。
第二,所有这些语言的受欢迎程度都急剧上升,反映了近年来对机器学习和数据科学的兴趣增加。
第三,Python 是明确的领导者,其次是 Java,然后是 R,再是 C++。Python 对 Java 的领先优势在增加,而 Java 对 R 的领先优势在减少。我必须承认看到 Java 排在第二位让我感到惊讶,我本以为是 R。
第四,Scala 的增长令人印象深刻。三年前几乎不存在,而现在与更成熟的语言相当。这在我们切换到 indeed.com 上的数据的相对视角时更容易发现:

第五,Julia 的受欢迎程度远不及其他语言,但最近几个月确实有所上升。Julia 会成为机器学习和数据科学中的流行语言之一吗?未来会告诉我们答案。
如果我们忽略 Scala 和 Julia 以便放大其他语言的增长,那么我们确认 Python 和 R 的增长速度快于通用语言。

鉴于增长率的差异,R 的受欢迎程度可能很快会超过 Java。
当我们专注于深度学习 通过这个查询时,数据是相当不同的:

在那里,Python 仍然是领先者,但 C++ 现在排第二,其次是 Java,C 排在第四位。R 仅排在第五。这里明显强调了高性能计算语言。虽然 Java 增长很快,可能很快会达到第二位,就像一般的机器学习一样。R 不会在短期内接近前列。让我感到惊讶的是 Lua 的缺席,尽管它被用于一个主要的深度学习框架(Torch)。Julia 也不在其中。
对于原始问题的答案现在应该很清楚了。Python、Java 和 R 是与机器学习和数据科学工作相关的最受欢迎的技能。如果你想专注于深度学习而不是一般的机器学习,那么 C++,以及程度稍低的 C,也值得考虑。然而请记住,这只是看待问题的一个方式。如果你在寻找学术界的职位,或者只是想在闲暇时间学习机器学习和数据科学,你可能会得到不同的答案。
那我个人的回答呢?我在这个博客中早些时候回答了这个问题。除了得到许多顶级机器学习框架的支持,Python 适合我,因为我有计算机科学背景。我也会对用 C++ 开发新算法感到舒适,因为我在这个语言中编程的时间占据了我职业生涯的大部分。但这只是我,背景不同的人可能会对其他语言感到更合适。一个编程技能有限的统计学家肯定会更喜欢 R。一个强大的 Java 开发者可以继续使用他最喜欢的语言,因为有很多开源项目提供 Java API。对这些图表中的任何语言都可以做出合理的论证。
因此,我的建议是,在投入大量时间学习一种语言之前,阅读其他讨论相同问题的博客。
更新于 2016 年 12 月 23 日。 该帖子在HackerNews上讨论过。
原始帖子。经授权重新发布。
简介:Jean-François Puget (@JFPuget),博士,是 IBM 杰出工程师,专注于机器学习和优化。他驻法国圣拉斐尔。
相关:
-
数据科学 101:如何提高 R 语言技能
-
Dataiku DSS 3.1 – 现在支持 5 种机器学习后端和 Scala!
-
在 Python 中整理数据
更多关于此主题
以下是最受欢迎的 Python IDE / 编辑器
原文:
www.kdnuggets.com/2018/12/most-popular-python-ide-editor.html
评论我们最新的调查受到最近 KDnuggets 博客 最适合数据科学的 Python IDE 是什么? 的启发,该博客获得了大量的浏览量和评论,就像我在 LinkedIn 的帖子 一样。
为了帮助解决关于哪些是最受欢迎的 Python IDE 或编辑器的争论,我们询问了
你在 2018 年使用最多的 Python 编辑器或 IDE 是什么?
 你在 2018 年使用最多的 Python 编辑器或 IDE 是什么?
你在 2018 年使用最多的 Python 编辑器或 IDE 是什么?超过 1900 人参与了这项调查,结果见下方的图 1。前 5 名选择是
-
Jupyter,57%
-
PyCharm,35%
-
Spyder,27%
-
Visual Studio Code,21%
-
Sublime Text,12%
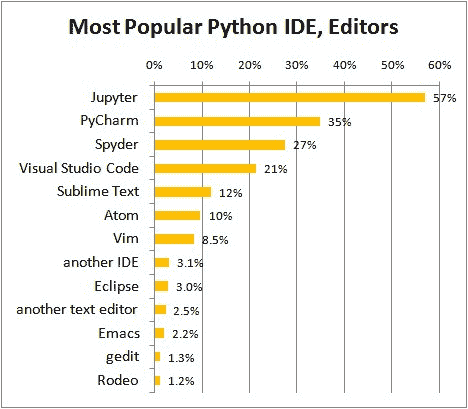 图 1:最受欢迎的 Python IDE,编辑器
图 1:最受欢迎的 Python IDE,编辑器
结果加起来超过 100%,因为我们允许最多选择 3 项。大约 43%的受访者只选择了一个选项,30%选择了 2 项,27%选择了 3 项。
我们还询问了雇佣情况,结果如下
-
公司或自雇,63.4%
-
学生,16.1%
-
学术界/大学,10.9%
-
政府/非营利组织,3.7%
-
其他/未知,5.9%
IDE/编辑器的分布是否因雇佣情况而异?
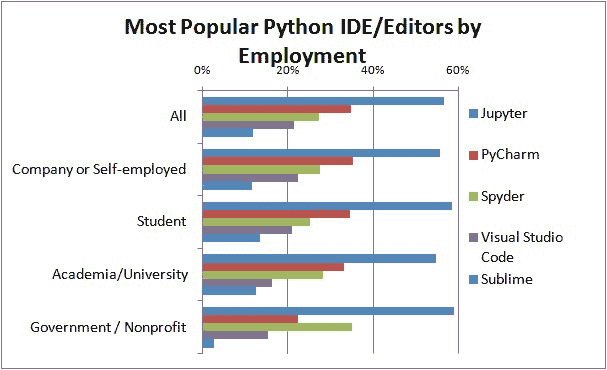 图 2:按雇佣情况最受欢迎的 Python IDE,编辑器
图 2:按雇佣情况最受欢迎的 Python IDE,编辑器
图 2 显示了按雇佣情况的前 5 名选择,相对比例在公司/自雇、学生和学术界中惊人地相似。Jupyter 作为一个大神,在所有雇佣类型中都是明确的领导者,份额在每种情况下都惊人地均匀——在 56%到 59%之间。
我们看到的唯一主要区别是政府/非营利组织的第二选择是 Spyder,而不是其他人选择的 PyCharm。
数据科学 Python 的偏好似乎在全球范围内都是普遍的——这可能是 Python 和数据科学快速全球传播的一个良好迹象。
接下来,我们查看了按地区划分的选民情况
-
美国/加拿大,36%
-
欧洲,35%
-
亚洲,16%
-
拉丁美洲,6.9%
-
非洲/中东,3.9%
-
澳大利亚/新西兰,3.0%
各地区的偏好是否相同?
 图 3:按地区最受欢迎的 Python IDE,编辑器
图 3:按地区最受欢迎的 Python IDE,编辑器
Jupyter 在所有地方都是无可争议的领导者。主要区域如美国/加拿大、欧洲、亚洲以及澳大利亚/新西兰的偏好顺序都是相同的:Jupyter > PyCharm > Spyder > VS Code > Sublime。
两个较小的(按参与者数量,不是地理位置)地区有所不同。拉丁美洲的第二受欢迎 Python 编辑器是 VS Code,而非洲/中东的第二选择是 Spyder。
最后,不同的 Python IDE/编辑器之间是否存在显著的关联?
在这次调查中,大约 43% 的受访者仅选择了一项,30% 选择了两项,27% 选择了三项。
我使用了与我的博客新兴生态系统:数据科学和机器学习软件分析中相同的关联提升方法。
 图 4:各地区最受欢迎的 Python IDE 和编辑器
图 4:各地区最受欢迎的 Python IDE 和编辑器
绿色 - 正相关,红色 - 负相关。
仅显示大于 10% 或小于 -10% 的提升。
除了 Jupyter 和 Atom 之间没有明显的正相关性外,我们没有看到其他明显的正相关性。Spyder、PyCharm 和 Visual Studio Code 在添加到 Jupyter 时彼此“排斥”。
相关:
-
新兴生态系统:数据科学和机器学习软件分析
-
什么是数据科学的最佳 Python IDE?
-
前 10 个 Python 数据科学库
我们的前三大课程推荐
1. Google 网络安全证书 - 快速通道进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
这里是最受欢迎的 Python IDE/编辑器
原文:
www.kdnuggets.com/2020/10/most-popular-python-ides-editors.html
评论最新的 KDnuggets 调查问道:
你在 2020 年使用最多的 Python IDE / 编辑器是什么?
这次调查收到了超过 2,500 个回应。我们允许最多选择 3 个选项,因此份额之和超过 100%。平均每位受访者使用 1.7 个 IDE。
我们还将每个 IDE 的份额与类似的 2018 年调查 最受欢迎的 Python IDE / 编辑器 进行比较(该调查获得了超过 1900 个回应)。
这里列出了今年份额超过 2% 的前几名 IDE。由于 2018 年我们没有单独列出 JupyterLab 选项,因此为了进行准确比较,我们将 Jupyter Notebook(42%)和 JupyterLab(14%)的答案合并为一个条目 - Jupyter,其份额为 51%。不是 56%,因为 5% 的受访者同时使用了这两者。

图 1:最受欢迎的 Python IDE,2020 年使用份额与 2018 年比较
其他 IDE 由于份额 < 2%,未在图 1 中显示,分别为
-
其他 IDE,1.9%
-
其他文本编辑器,1.9%
-
IntelliJ Idea 1.8%
-
Eclipse,1.2%
-
gedit,0.2%
与 2018 年的调查相比,我们看到 VS Code 的份额显著增长,从 21% 增长到 32%,而几乎所有其他 IDE 的份额都在下降。
因此,如果你只使用 Jupyter Notebook,请也检查一下 VS Code!
我们还询问了就业类型,结果如下
-
公司/自雇,60.8%(2018 年为 63.4%)
-
学生,16.4%(16.1%)
-
学术界,10.2%(10.9%)
-
政府/非营利组织,5.5%(3.7%)
-
其他/未知,2.7%(5.9%)
-
失业者,4.2%(2018 年未询问)
按就业类型的分布与 2018 年的调查类似。
我们还查看了是否前三类中流行的 IDE 根据就业类型有所不同 - 请参见图 2。

图 2:按就业类型最受欢迎的 Python IDE
我们看到 Jupyter Notebook 在所有就业类型中都是领导者。VSCode 在公司/自雇群体中排名第二,而 PyCharm 刚好超过 VSCode 在学生中排名第二。Spyder 在学术界排名第二。JupyterLab 在学术界和工业界的份额大约为 15%,在学生中仅为 10%。
最后,我们还按地区分析了回应。整体地区分布如下:
-
欧洲,35%
-
美国/加拿大,31%
-
亚洲,17%
-
拉丁美洲,8.6%
-
非洲/中东,5.0%
-
澳大利亚/新西兰,3.2%
下图 Fig. 3 显示了前四个地区的最受欢迎 Python IDE 的地区分布。 
图 3:按地区最受欢迎的 Python IDE
我们看到 Jupyter Notebook 在所有地方都是领先者,VSCode 强势排名第二。PyCharm 在所有地方都排名第三,除了拉丁美洲,那里 Spyder 排在 PyCharm 之前,位列第三。
相关内容:
-
这里是最受欢迎的 Python IDE / 编辑器,2018 年 KDnuggets 民意调查
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
最受欢迎的 Slideshare 数据挖掘演示文稿
原文:
www.kdnuggets.com/2014/11/most-popular-slideshare-presentations-data-mining.html
作者:Grant Marshall,2014 年 11 月
Slideshare 是一个上传、注释、分享和评论基于幻灯片的演示文稿的平台。该平台已经存在一段时间,并积累了大量关于数据挖掘等技术主题的演示文稿。
 图 1:与演示文稿相关的标签词云
图 1:与演示文稿相关的标签词云
今天,我们将深入探讨一些在 Slideshare 上找到的顶级数据挖掘演示文稿。这些演示文稿是通过 Python 脚本和Slideshare search_slideshow API 检索的,然后经过精心筛选以选择最佳和最相关的演示文稿。以下是幻灯片及其相关指标:
| 标题 | 日期 | 浏览量 | 下载量 | 收藏量 |
|---|---|---|---|---|
| 数据挖掘:概念与技术 | 2010-05-10 | 60288 | 932 |
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的捷径。 2. 谷歌数据分析专业证书 - 提升你的数据分析技能! 3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
8 |
| 机器学习与数据挖掘:11 棵决策树 | 2007-04-02 | 52487 | 0 | 71 |
|---|---|---|---|---|
| 大数据[抱歉]与数据科学:数据科学家在做什么? | 2013-01-26 | 51793 | 0 | 138 |
| 挖掘社交数据的乐趣与洞察 | 2007-11-05 | 40434 | 1903 | 91 |
| 构建工具以通过机器学习 API 挖掘非结构化文本 | 2012-02-14 | 32812 | 98 | 16 |
| 机器学习与数据挖掘:19 种挖掘文本和网络数据的方法 | 2007-06-03 | 33329 | 2003 | 43 |
| Mahout 与机器学习简介 | 2013-07-27 | 29261 | 575 | 49 |
| 日志挖掘:超越日志分析 | 2007-09-27 | 27497 | 0 | 28 |
| 社交数据挖掘 | 2013-11-02 | 28944 | 0 | 4 |
| 机器学习与数据挖掘:04 关联规则挖掘 | 2007-03-18 | 26448 | 0 | 42 |
| 数据挖掘:分类与预测 | 2010-08-19 | 27776 | 0 | 6 |
| 第十一章:数据挖掘中的应用与趋势 | 2010-05-10 | 26285 | 1024 | 10 |
| 使用 R 进行文本挖掘 | 2012-02-23 | 25380 | 4 | 63 |
| 机器学习与数据挖掘:01 数据挖掘 | 2007-03-14 | 25407 | 0 | 123 |
| 数据挖掘概念 | 2007-05-18 | 26125 | 2166 | 24 |
| 统计学家对大数据和数据科学的看法(第 1 版) | 2013-11-25 | 22832 | 0 | 60 |
| 讲座 01 数据挖掘 | 2008-03-11 | 22405 | 1474 | 18 |
| 网页挖掘教程 | 2010-05-10 | 21408 | 1319 | 35 |
| 机器学习与数据挖掘:12 个分类规则 | 2007-04-11 | 20386 | 0 | 23 |
| 分析与数据挖掘行业概述 | 2011-11-18 | 20604 | 1007 | 29 |
| 使用 Excel 2007 和 SQL Server 2008 的数据挖掘 | 2008-12-06 | 19718 | 824 | 9 |
| 数据仓库与数据挖掘在支持斯里兰卡高等教育系统规划中的应用 | 2009-07-25 | 20225 | 417 | 5 |
| 数据挖掘 - 使用决策树归纳法对乳腺癌数据集进行分类 - Sunil Nair 健康信息学 达尔豪斯大学 | 2008-12-04 | 19715 | 608 | 6 |
| 大数据与数据挖掘 | 2013-01-31 | 19266 | 559 | 20 |
关于表中这 24 个幻灯片的一些快速统计数据:每个幻灯片平均约有 29,000 次观看,621 次下载,5 条评论和 38 个收藏。然而,这些总数可能具有误导性。
在评论方面,例如,大量评论来自于机器学习与数据挖掘:11 个决策树和使用 R 进行文本挖掘。在第一个案例中,大多数评论是请求幻灯片(作者选择禁用下载),而在第二个案例中,大多数评论是请求演示文稿中摘录的代码。类似地,由于某些演示文稿禁用了下载功能,因此平均下载次数可能会产生误导。调整这些评论和一些下载禁用情况后,实际的平均值大约为每个演示文稿 994 次下载和 3 条评论。
尽管如此,社交功能似乎得到了应用,以分析与数据挖掘行业概述为例,作者可以看到回复评论。这显示了这种格式为人们与数据挖掘专家互动提供了有趣的潜力。
 图 2:SlideShare 收藏与次数
图 2:SlideShare 收藏与次数
在这张图表中,我们可以看到这些不同幻灯片所吸引的观众的多样性。尽管与观看次数相比,收藏数量总体上呈上升趋势,但也存在一些例外。我的假设是,像数据挖掘:概念与技术这样的通用讲座可能会吸引更多的普通观众,但观众更不容易收藏这些幻灯片。另一方面,像挖掘社交数据以获取乐趣和洞见这样的更具特定性的幻灯片可能不会吸引那么多普通观众,但观众可能更倾向于收藏它。
相关:
-
马萨诸塞州的文本挖掘与选举分析
-
审视 GoodData 开放分析平台
-
解读公共数据 – 处理 Jeopardy
更多相关话题
最受欢迎的数据科学 SlideShare 演示文稿
原文:
www.kdnuggets.com/2014/11/most-popular-slideshare-presentations-data-science.html
由 Grant Marshall,2014 年 11 月。
SlideShare 是一个用于上传、注释、共享和评论基于幻灯片的演示文稿的平台。该平台已经存在了一段时间,并且积累了大量关于技术主题如数据科学的演示文稿。

图 1:SlideShare 上的数据科学相关标签
这张展示了与 SlideShare 上“数据科学”标签相关的标签的可视化图,说明了数据科学、大数据和开放数据集之间的基本互动。
今天,我们将查看一些在 SlideShare 上发现的顶级“数据科学”演示文稿。类似于我们为之前的帖子收集数据的方式,这些演示文稿是通过使用 Python 脚本和Slideshare search_slideshow API 检索的,然后手动挑选出最好的、最相关的演示文稿。下面展示了这些幻灯片及其相关指标:
| 标题 | 作者 | 日期 | 浏览次数 | 下载次数 | 收藏次数 |
|---|---|---|---|---|---|
| 管理数据科学家的科学 | katemats | 2013-02-26 | 58219 | 189 | 29 |
| 大数据[抱歉]与数据科学:数据科学家做什么? | datasciencelondon | 2013-01-26 | 54778 | 0 | 158 |
| 数据科学家的迷思与数学超能力 | davidpittman1 | 2012-11-14 | 29485 | 297 | 21 |
| 统计学家对大数据和数据科学的看法(第 1 版) | kuonen | 2013-11-25 | 25277 | 0 | 67 |
| 关于 Dunkin’和 Starbucks 饮品消费者的 25 个见解 | TrueLens | 2013-08-05 | 21573 | 0 | 34 |
| 企业大数据的数据科学简介 | pacoid | 2012-08-20 | 19807 | 969 | 70 |
| 数据战术分析随便聊(2013 年 8 月 22 日) | rheimann04 | 2013-08-22 | 29651 | 5 | 0 |
| Google 的创新:数据的物理学[PARC 论坛] | PARCInc | 2010-05-04 | 20550 | 0 | 34 |
| 分析与大数据 | Idiro | 2012-10-01 | 16057 | 14 | 2 |
| 由人民创造,为人民服务的数据 | dtunkelang | 2012-11-02 | 14377 | 101 | 13 |
| 以用户为中心的数字身份,计算机科学和电信委员会讲座,国家科学院 | Kaliya | 2010-09-24 | 14841 | 141 | 5 |
| 数据科学:不仅仅是大数据 | RevolutionAnalytics | 2013-11-15 | 13772 | 110 | 7 |
| MSR 2013 预览 | tom.zimmermann | 2013-04-02 | 14390 | 0 | 1 |
| 开放数据社区如何消亡——来自未来的警告 | countculture | 2011-10-21 | 13849 | 65 | 22 |
| OSCON 2013:使用 Cascalog 构建 Palo Alto 市开放数据应用 | pacoid | 2013-07-29 | 14911 | 14 | 3 |
| Web2.0 科学好奇心的展示柜 | IanMulvany | 2009-09-22 | 14380 | 343 | 22 |
| 社会科学定量数据分析简单指南 | paulbourne01 | 2010-01-10 | 14264 | 375 | 1 |
| Dataiku——数据极客巴黎@Criteo——闭环数据 | Dataiku | 2013-11-29 | 12601 | 9 | 0 |
| 如何成为数据科学家 | ryanorban | 2014-07-02 | 12312 | 23 | 87 |
| 地理分析教程——Where 2.0 2011 | pskomoroch | 2011-04-19 | 12163 | 454 | 29 |
| 用于数据挖掘和数据分析的 NumPy 和 SciPy,包括 iPython、SciKits 和 matplotlib | bytemining | 2011-09-11 | 12618 | 234 | 18 |
| 开放获取,开放数据。开放研究? | CameronNeylon | 2009-01-27 | 12174 | 291 | 18 |
一些快速统计数据:这一类别幻灯片的平均浏览量、下载量、收藏数和评论数分别约为 20000、165、29 和 2。与数据科学幻灯片的数据相比,这些数字普遍较低。这部分是因为许多带有数据科学标签的大型幻灯片实际上更偏向数据挖掘,因此被从此列表中过滤掉了。通过这样做,许多最受欢迎的幻灯片被排除了。
从这些演示文稿的发布日期来看,有趣的是 2013 年是最常见的日期。考虑到 SlideShare 自八年前推出以来一直存在,这表明近年来数据科学的受欢迎程度不断上升,使得新的演示文稿更受欢迎。

图 2:数据科学演示文稿下载次数与查看次数
请注意,大多数下载次数为 0 的演示文稿已禁用下载功能。有趣的是,特定演示文稿的查看次数与下载次数之间几乎没有相关性。似乎某些类型的演示文稿会引发下载,但这些下载数量并不一定比其他演示文稿更多或更少。例如,看起来像是讲解性的演示文稿, 企业大数据数据科学简介 似乎会鼓励下载,可能是为了离线学习。
相关:
-
最受欢迎的 Slideshare 数据挖掘演示文稿
-
Top KDnuggets 推文,9 月 29-30 日:机器学习 #cheatsheet;你能比电脑更快找到麦当劳吗?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
SQL 中最被低估的函数
原文:
www.kdnuggets.com/2017/03/most-underutilized-function-sql.html
Tristan Handy, Fishtown Analytics 的创始人和总裁。
在过去的九个月里,我与十几家风险投资资助的初创公司合作,构建了他们的内部分析。在这个过程中,有一个 SQL 函数我意外地使用得非常频繁。起初我并不清楚为什么我要使用这个函数,但随着时间的推移,我发现它的用途越来越多。
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

这是什么? md5()。如果你不熟悉,这里有一个来自 Redshift 文档的示例代码片段:
select md5('Amazon Redshift');
md5
----------------------------------
f7415e33f972c03abd4f3fed36748f7a
(1 row)
给 md5() 一个 varchar,它会返回其 MD5 哈希。简单……但看似无用。我为什么要使用这个?!
很好的问题。在这篇文章中,我将向你展示 md5() 的两个用法,使其成为我 SQL 工具包中最强大的工具之一。
#1:构建唯一的 ID
我将做一个非常强烈的声明,但我真的相信这一点:你仓库中的每一个 数据模型 都应该有一个坚如磐石的唯一 ID。
这种情况非常常见。一种原因是你的源数据没有唯一键——如果你通过 Stitch 或 Fivetran 同步 Facebook Ads 的广告表现数据,你的 ad_insights 表中的源数据没有可以依赖的唯一键。相反,你有一个组合字段(在这种情况下是日期和 ad_id),它是可靠唯一的。利用这些信息,你可以使用 md5() 构建一个唯一 id。
select
md5(date_start::varchar || ad_id::varchar) as insight_id
from
stitch_fb_ads.facebook_ads_insights
limit 5;
insight_id
----------------------------------
6d475ea96f23b097b51ed500116d8c5e 822c9429eabb28ccbcd7286836d7cd60 8b7fcd2aff879772ccac4f0f8bcb6a45 8a2cfd7eb1a723c49db47232e73ca29c 10338719dfadb3d4c9d44c608063998a
(5 rows)
结果哈希是一个无意义的字母数字字符串,作为记录的唯一标识符。当然,你可以创建一个单独的连接 varchar 字段来执行相同的功能,但 实际上隐藏哈希背后的底层逻辑是重要的:如果字段看起来像一个 ID 而不是像一堆人类可读的文本,你会本能地以不同的方式对待它。
创建唯一 ID 是一个重要实践的原因有几个:
-
最常见的错误原因之一是分析师期望唯一的键中存在重复值。在该字段上的联接会以意想不到的方式“扩展”结果集,并可能导致难以排查的显著错误。为避免这种情况,只在你已经验证了基数并在必要时构建了唯一键的字段上进行联接。
-
一些 BI 工具要求你必须有一个唯一键才能提供某些功能。例如,Looker 的对称聚合需要一个唯一键才能正常工作。
我们为每个表创建唯一键,然后使用dbt schema 测试测试该键的唯一性。我们每天多次在Sinter上运行这些测试,并对任何失败情况进行通知。这使我们对在这些数据模型上实施的分析充满信心。
#2:简化复杂的联接
这个案例在执行上类似于 #1,但解决了一个完全不同的问题。假设你有与之前提到的相同的 Facebook Ads 数据集,但这次你面临一个新的挑战:将该数据与网页分析会话表中的数据进行联接,以便计算 Facebook 的ROAS。
在这种情况下,你可以使用的联接键是日期和你的UTM 参数(utm_medium、source、campaign 等)。看起来很简单,对吧?只需在所有 6 个字段上进行联接,然后就完成了。
不幸的是,这行不通,原因非常简单:这些字段中的某些子集为空是极其常见的,而空值无法与另一个空值联接。所以,那 6 个字段的联接是一条死胡同。你可以用大量的条件逻辑拼凑出一些非常复杂的东西,但那段代码非常丑陋且性能极差(我试过)。
相反,使用 md5()。在这两个数据集中,你可以将我们提到的 6 个字段连接成一个字符串,然后对整个字符串调用 md5()。下面是我们在一个客户项目中确切执行此操作的代码片段:
你可以看到这段代码实际上是在更多字段上构建 ID:在这个例子中,我们实际上是将来自 7 个不同广告渠道的广告支出数据进行联合,而 Bing 和 Adwords 的数据通过 ad_group_id 和 keyword_id 而不是 UTM 参数进行标识。这种方法干净地扩展。
在会话表中,你接着创建完全相同的哈希 ID 字段。结果联接简单、可读,并且易于用于下游分析:
资源
有兴趣自己实现类似的功能吗?以下是一些资源:
-
(我们构建和使用的开源工具,用于进行所有数据建模)
-
(我们的开源 Facebook 广告 dbt 包)
感谢阅读!我非常好奇是否有人对md5()有其他巧妙的用法。
个人简介:Tristan Handy 是 Fishtown Analytics 的创始人兼总裁。他为高级分析构建开源工具。
原文。经许可转载。
相关内容:
-
掌握数据科学 SQL 的 7 个步骤
-
让 Python 用 pandasql 说 SQL
-
用 SQL 做统计
更多相关主题
2020 年最有用的机器学习工具
原文:
www.kdnuggets.com/2020/03/most-useful-machine-learning-tools-2020.html
评论
作者 Ian Xiao,Dessa 的互动负责人

由 Creatv Eight 提供的照片,来自 Unsplash
TD; DR — 构建优秀的机器学习应用就像制作米其林风格的菜肴。拥有一个组织良好且管理得当的厨房至关重要,但有太多的选择。在这篇文章中,我将重点介绍我在交付专业项目时发现有用的工具,分享一些想法和替代方案,并进行一次实时调查(你可以在参与后查看社区的想法)。
像所有工具讨论一样,列表并不详尽;但我尝试专注于最有用和最简单的工具。欢迎在评论区提供反馈,或者告诉我是否有其他更好的替代方案我应该提到。
免责声明:此帖子未获得认可或赞助。我交替使用“数据科学”和“机器学习”这两个术语。
喜欢你所读到的内容? 关注我 Medium,LinkedIn,或 Twitter。你想学会如何沟通并成为一名有影响力的数据科学家吗?查看我的“影响力与机器学习”指南。
常见问题
“我如何构建优秀的机器学习应用?”
这个问题在与学校中的有抱负的数据科学家、寻求转行的专业人士和团队经理的交流中多次出现,并且以各种形式呈现。
交付一个专业的数据科学项目有许多方面。像许多人一样,我喜欢用厨房的类比:有原料(数据)、食谱(设计)、烹饪过程(你独特的方法),以及最终的厨房(工具)。
所以,这篇文章带你了解我的 厨房。它突出展示了 最有用的工具 用于设计、开发和部署 全栈机器学习 应用程序——这些解决方案可以与系统集成或在生产环境中服务于用户。
如果你想了解更多关于交付 ML 的其他方面,请查看我的文章 这里。
令人眼花缭乱的可能性
我们生活在一个黄金时代。如果你在谷歌中搜索“ML 工具”或询问顾问,你可能会得到类似这样的内容:

数据与人工智能领域 2019,图像来源
现在有(太多)工具,可能的组合是无限的。这可能会让人感到困惑和不知所措。所以,让我帮助你缩小范围。也就是说,没有完美的设置,一切都取决于你的需求和限制。因此,请根据实际情况选择。
我的列表优先考虑以下几点(不按顺序):
-
免费 ????
-
易于学习和设置 ????
-
未来证明(采纳 & 工具成熟度) ♻️
-
工程优于研究 ????
-
适用于初创公司或大型企业的大型或小型项目 ????
-
只需完成工作 ????
警告:我99%的时间使用 Python。所使用的工具都与 Python 原生兼容或是用 Python 构建的。我没有用其他编程语言(如 R 或 Java)测试过它们。
1. 冰箱:数据库
PostgreSQL
一个免费的开源关系数据库管理系统(RDBMS),强调可扩展性和技术标准遵循。它旨在处理从单台机器到数据仓库或具有多个并发用户的 Web 服务的一系列工作负载。

替代方案:MySQL、SAS、IBM DB2、Oracle、MongoDB、Cloudera、GCP、AWS、Azure*
2. 台面:部署管道工具
管道工具对于开发的速度和质量至关重要。我们应该能够以最少的人工处理快速迭代。这里有一个效果良好的设置,详情请参见我的 12 小时机器学习挑战 文章。每个懒惰的数据科学家都应该在项目初期尝试这种方法。

作者的工作,12 小时机器学习挑战
Github
它提供 Git 的分布式版本控制和源代码管理(SCM)功能,并且具有自己的特性。它提供访问控制和多个协作功能,如错误跟踪、功能请求、任务管理和每个项目的维基。
PyCharm** 社区版**
一种用于计算机编程的集成开发环境(IDE),专为 Python 语言设计。由捷克公司 JetBrains 开发。它提供代码分析、图形调试器、集成单元测试器、与版本控制系统(VCS)的集成,并支持使用 Django 进行 web 开发以及使用 Anaconda 进行数据科学。
Pytest
框架使得编写小型测试变得容易,同时能够扩展以支持复杂的应用和库的功能测试。它节省了大量的手动测试时间。如果你需要每次修改代码时进行测试,可以使用 Pytest 来自动化这一过程。
替代方案:Unittest
CircleCi
CircleCI 是一个持续集成和部署工具。它使用远程 Docker 创建自动化测试工作流程,当你提交到 Github 时,Circle CI 会拒绝任何未通过 PyTest 测试用例的提交。这确保了代码质量,尤其是当你与较大的团队合作时。
替代方案:Jenkins*, Travis CI, *Github Action
Heroku (仅在需要 web 托管时)
一种平台即服务(PaaS),使开发者能够完全在云中构建、运行和操作应用程序。你可以与 CircleCI 和 Github 集成,实现自动部署。
替代方案:Google App Engine,AWS Elastic Compute Cloud*, *其他
Streamlit (仅当你需要一个互动 UI 时)
Streamlit 是一个开源应用框架,专为机器学习和数据科学团队设计。近年来,它已经成为我最喜欢的工具之一。查看我如何使用它以及本节中的其他工具创建一个 电影** 和 模拟 应用**。
3. iPad: 探索工具
Streamlit (再次提及)
忘记 Jupyter Notebook 吧。对,就是这样。
Jupyter 曾经是 我探索数据、进行分析和试验不同数据和建模过程的首选工具。但我记不清有多少次:
-
我花了很多时间调试(并抓狂),但最终意识到我忘记从头运行代码;Streamlit 修复了这个问题。
-
即使对小代码更改,我也不得不等待数据管道重新运行;Streamlit 缓存修复了这个问题。
-
我不得不重写或将代码从 Jupyter 转换为可执行文件——而且花费了时间重新测试;Streamlit 提供了捷径。
这很让人沮丧???????。所以,我使用 Streamlit 进行早期探索,并提供最终的前端——一箭双雕。以下是我的典型屏幕设置。左侧是 PyCharm IDE,右侧是结果可视化。试试看吧。

IDE(左侧)+ Streamlit 实时更新(右侧),作者作品来自 被遗忘的算法
替代方案:Jupyter Notebook, Spyder from Anaconda, Microsoft Excel (认真地说)
4. 刀具:ML 框架
就像使用实际的刀子一样,你应该根据食物和切割方式选择合适的刀子。有通用型刀和专用刀。
要小心。 使用寿司专用刀切骨头会花费很长时间,尽管寿司刀更光亮。选择合适的工具完成工作。
Sklearn (常见的 ML 用例)
在 Python 中进行一般机器学习的首选框架。无需多言。

Sklearn 的使用案例,来源
替代方案:没有,完毕。
PyTorch (深度学习用例)
基于 Torch 库的开源机器学习库。鉴于其深度学习的重点,它主要用于计算机视觉和自然语言处理等应用。主要由 Facebook 的 AI 研究实验室(FAIR)开发。最近,许多知名的 AI 研究机构,如 Open AI,都将 PyTorch 作为其标准工具。
替代方案:Tensorflow*, Keras, *Fast.ai
Open AI Gym (强化学习用例)
用于开发和比较强化学习算法的工具包。它提供 API 和可视化环境。这是一个社区正在构建工具的活跃领域。现在还没有很多打包良好的工具。
替代方案:许多小项目,但没有多少像 Gym 那样维护良好的。
5. 炉子:实验管理
Atlas
一个免费工具,允许数据科学家通过几个代码片段设置实验,并将结果显示在基于网页的仪表板上。

Atlas 过程,来源
免责声明:我曾在 Dessa 工作,该公司创建了 Altas。
替代方案:ML Flow、SageMaker、Comet、Weights & Biases、Data Robot、Domino
一项调查
出于好奇,在寻找合适工具时,什么困扰你最多? 我很想听听你的想法。它是一个实时调查,所以你可以在参与后看到社区的看法。
替代视角
正如我提到的,没有完美的设置。这一切都取决于你的需求和限制。这里是另一个视角,展示了有哪些工具以及它们如何协同工作。

Sergey Karayev在全栈深度学习上的演讲,2019 年
一个迷你挑战
如果你想了解更多关于如何使用这些工具,最好的方法是找到一个项目来实践。你可以将这些工具融入到当前的项目中,或进行一个12 小时机器学习挑战。不确定怎么做?查看我如何用讨论过的工具和流程创建用户赋能推荐应用。
我期待看到你能创造出的成果。请与社区分享,并在Twitter上标记我????。
喜欢你所读的内容?* 在Medium、LinkedIn或Twitter上关注我。此外,你想学习作为数据科学家的商业思维和沟通技巧吗?查看我的“机器学习影响力”指南。*
这里是一些你可能喜欢的文章:
使用 Streamlit 探索蒙特卡罗模拟
我如何应对机器学习部署中的枯燥日子
如何用 Streamlit 和 DevOps 工具构建和部署机器学习应用
如何不将敏捷方法应用于机器学习项目
如何促进人类与人工智能之间的信任
如何部署更多的机器学习解决方案 — 五种策略
简介:Ian Xiao 是 Dessa 的参与主管,负责在企业中部署机器学习。他领导商业和技术团队部署机器学习解决方案,并改善 F100 企业的营销和销售。
原文。经许可转载。
相关:
-
12 小时机器学习挑战:使用 Streamlit 和 DevOps 工具构建和部署应用
-
数据科学无聊(第一部分)
-
抵御另一场 AI 寒冬的最后防线
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
最受欢迎的数据挖掘讲座
原文:
www.kdnuggets.com/2014/09/most-viewed-data-mining-talks-videolectures.html
由 Grant Marshall 提供,2014 年 9 月
今天,我们来看看videolectures.net上观看次数最多的前 25 个数据挖掘讲座
这些视频取自于videolectures.net 上最受欢迎的数据挖掘视频。这些视频按照观看次数排序,包括作者、时长和场馆:
-
大数据教程,Marko Grobelnik,11250 次观看,1:09:51(2012 年 7 月 4 日,ESWC 夏季学校,Kalamaki 2012)
-
用于欺诈检测、预防和评估的统计技术,David J. Hand,7836 次观看,1:43:27(2007 年 12 月 3 日,北约高级研究所关于挖掘大规模数据集以保障安全,Gazzada 2007)
-
挖掘大规模 RFID、轨迹和交通数据集,Jiawei Han,Jae-Gil Lee,Hector Gonzalez,Xiaolei Li,4912 次观看,2:23:41(2008 年 9 月 26 日,第 14 届 ACM SIGKDD 国际知识发现与数据挖掘大会 (KDD),拉斯维加斯 2008)
-
数据挖掘和机器学习算法,Jose L. Balcazar,4635 次观看,2:15:01(2011 年 2 月 18 日,2011 年 AI 训练营 @ AITI-KACE,加纳阿克拉)
-
从树到森林和规则集——集成方法的统一概述,John Elder,Giovanni Seni,4451 次观看,2:44:39(2007 年 8 月 14 日,第 13 届 ACM SIGKDD 国际知识发现与数据挖掘大会 (KDD),圣荷西 2007)
-
开源情报,Clive Best,4407 次观看,1:29:46(2007 年 12 月 3 日,北约高级研究所关于挖掘大规模数据集以保障安全)
-
异常检测的数据挖掘,Aleksandar Lazarevic,Jaideep Srivastava,Vipin Kumar,Arindam Banerjee,Varun Chandola,4172 次观看,2:23:20(2008 年 10 月 10 日,欧洲机器学习与数据库知识发现原则与实践会议 (ECML PKDD),安特卫普 2008)
-
时间序列分析,Riccardo Bellazzi,4145 次观看,1:32:51(2007 年 2 月 25 日,高级人工智能课程(ACAI),卢布尔雅那 2005)
-
数据挖掘者的故事 - 了解重大挑战,Usama Fayyad,4058 次观看,0:48:33(2007 年 8 月 14 日,第 13 届 ACM SIGKDD 国际知识发现与数据挖掘大会(KDD),圣荷西 2007)
-
大规模数据挖掘:MapReduce 及其扩展,Spiros Papadimitriou,Jimeng Sun,Rong Yan,3751 次观看,2:46:59(2010 年 10 月 1 日,第 16 届 ACM SIGKDD 国际知识发现与数据挖掘大会(KDD),华盛顿 2010)
-
其他机器学习/数据挖掘软件(R,Weka,Yale),Lluis Belanche,3417 次观看,0:56:57(2007 年 7 月 5 日,PASCAL 机器学习训练营,维拉诺瓦 2007)
-
数据挖掘,Rao Kotagiri,2720 次观看,3:06:58(2009 年 4 月 1 日,逻辑与学习夏季学校,堪培拉 2009)
-
数据挖掘的图形模型简介,Arindam Banerjee,2068 次观看,2:35:45(2010 年 10 月 1 日,第 16 届 ACM SIGKDD 国际知识发现与数据挖掘大会(KDD),华盛顿 2010)
-
广告的量化及基于大规模数据挖掘构建业务的经验,Konrad Feldman,2067 次观看,0:59:35(2010 年 10 月 1 日,第 16 届 ACM SIGKDD 国际知识发现与数据挖掘大会(KDD),华盛顿 2010)
-
网络,斯坦福和硅谷,Jure Leskovec,1600 次观看,1:27:58(2013 年 1 月 7 日,为VideoLectures.NET - 单讲座系列录制)
-
社会推荐中的迁移学习,Qiang Yang,1468 次观看,0:42:14(2011 年 8 月 4 日,社会网络挖掘国际研讨会,巴塞罗那 2011)
-
金融领域的 Twitter 情感分析,Miha Grcar,1257 次观看,0:16:55(2012 年 4 月 11 日,FIRST 工业研讨会,米兰 2012)
-
超越 MapReduce 的规模扩展,Raghu Ramakrishnan,1203 次观看,0:51:49(2013 年 9 月 27 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
ORANGE:数据挖掘的丰硕与乐趣,Janez Demsar,1195 次观看,0:15:14(2012 年 11 月 16 日,艾伦·图灵 100 周年暨 SLAIS 20 周年会议)
-
数据科学家的创业盈利指南,Geoff Webb, Foster Provost, Ron Bekkerman, Oren Etzioni, Usama Fayyad, Claudia Perlich,1169 次观看,1:07:58(2013 年 9 月 27 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
学习与数据分析中的优化,Stephen J. Wright,861 次观看,1:01:24(2013 年 9 月 27 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
信息扩散在社交网络演变中的作用,Filippo Menczer,547 次观看,0:19:06(2013 年 9 月 27 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
挖掘异质信息网络,Jiawei Han,490 次观看,0:30:30(2013 年 9 月 27 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
在线革命:全民教育,Andrew Ng,381 次观看,1:13:21(2013 年 9 月 20 日,第 19 届 ACM SIGKDD 知识发现与数据挖掘会议(KDD),芝加哥 2013)
-
级联可以预测吗?,Jure Leskovec,251 次观看,1:03:49(2014 年 6 月 2 日,Solomon 研讨会)
查看这些最受欢迎的视频标题内容,我们可能会发现关于 videolectures.net 数据挖掘观众最受欢迎话题的线索。  基于这种可视化,MapReduce 和 Web Mining 的讲座似乎与数据挖掘讲座观众产生了共鸣。
基于这种可视化,MapReduce 和 Web Mining 的讲座似乎与数据挖掘讲座观众产生了共鸣。
数据中一个有趣的方面是视频的长度与视频观看次数的比较。下面是一个散点图,展示了视频的排名与其长度之间的关系。

视频长度与其观看排名之间存在轻微的负相关关系。这一普遍趋势的三个主要异常值是 大规模数据挖掘:MapReduce 及其扩展 (10)、数据挖掘 (12)、和 数据挖掘图形模型介绍 (13)。这意味着,在数据挖掘讲座中,即使内容更深入且开发时间较长,讲座也可以非常受欢迎。

请注意,这仅适用于按观看次数排序的情况。如果我们按照 videolectures.net 的受欢迎度指标对视频进行排序,长度与受欢迎程度之间没有明确的关联。这是因为 videolectures.net 对“受欢迎”视频的定义考虑了比观看次数更多的因素,可能包括投票和发布日期等特征。
相关:
-
2014 年 9 月 – 2015 年 3 月:分析、大数据、数据挖掘与数据科学会议
-
KDD 2013 视频讲座:观看数据挖掘和知识发现领域的顶尖研究者
-
小组报告:数据科学家指南:如何启动初创公司
更多相关主题
最受欢迎的机器学习讲座
原文:
www.kdnuggets.com/2014/09/most-viewed-machine-learning-talks-videolectures.html
由 Grant Marshall 撰写,2014 年 9 月
今天,我们查看 videolectures.net 上观看次数最多的前 25 个数据挖掘讲座
流行度的确定方法是通过查看机器学习视频列表上的“热门”排序。这些视频,包括作者、时长和场地,按照观看次数排序:
-
贝叶斯推断简介,Christopher Bishop,43045 次观看,2:51:04(2009 年 11 月 2 日,在 机器学习暑期学校(MLSS),剑桥 2009)
-
机器学习、概率与图形模型,Sam Roweis,41039 次观看,1:02:45(2007 年 2 月 25 日,在 机器学习暑期学校(MLSS),台北 2006)
-
马尔可夫链蒙特卡罗,Iain Murray,37223 次观看,2:27:56(2009 年 11 月 2 日,在 机器学习暑期学校(MLSS),剑桥 2009)
-
高斯过程基础,David MacKay,35956 次观看,1:00:47(2007 年 2 月 25 日,在 高斯过程实践研讨会,布莱切利公园 2006)
-
支持向量机,Chih-Jen Lin,32530 次观看,1:17:15(2007 年 2 月 25 日,在 机器学习暑期学校(MLSS),台北 2006)
-
主题模型,David Blei,26666 次观看,2:57:01(2009 年 11 月 2 日,在 机器学习暑期学校(MLSS),剑桥 2009)
-
蒙特卡罗模拟用于统计推断、模型选择和决策制定,Nando de Freitas,26596 次观看,5:22:55(2008 年 3 月 13 日,在 机器学习暑期学校(MLSS),基奥洛亚 2008)
-
狄利克雷过程:教程与实践课程,Yee Whye The,23579 次观看,0:58:40(2007 年 8 月 27 日,在 机器学习暑期学校(MLSS),图宾根 2007)
-
深度学习教程,Geoffrey E. Hinton,23489 次观看,1:34:53(2009 年 9 月 15 日,在 VideoLectures.NET - 单场讲座系列)
-
支持向量机简介,Colin Campbell,21925 次观看,0:51:54(2008 年 2 月 5 日,EPSRC 数据建模数学冬季学校,谢菲尔德 2008)
-
随机微分方程教程介绍:连续时间高斯马尔可夫过程,Chris Williams,19482 次观看,0:42:43(2007 年 2 月 25 日,NIPS 动态系统、随机过程和贝叶斯推断研讨会,惠斯勒 2006)
-
概率图模型,Sam Roweis,18860 次观看,0:52:06(2007 年 2 月 25 日,机器学习夏季学校(MLSS),堪培拉 2005)
-
统计学习理论,John Shawe-Taylor,15659 次观看,0:48:52(2007 年 2 月 25 日,机器学习夏季学校(MLSS),贝尔德岛 2004)
-
贝叶斯还是频率派,你是哪种?,Michael I. Jordan,15612 次观看,2:57:10(2009 年 11 月 2 日,机器学习夏季学校(MLSS),剑桥 2009)
-
讲座 1:信息理论简介,David MacKay,13931 次观看,1:01:50(2012 年 11 月 5 日,信息理论、模式识别与神经网络课程)
-
信息理论,David MacKay,13694 次观看,1:26:35(2009 年 11 月 2 日,机器学习夏季学校(MLSS),剑桥 2009)
-
机器学习简介,Iain Murray,12498 次观看,0:49:14(2010 年 8 月 5 日,PASCAL 机器学习暑期培训班,马赛 2010)
-
压缩感知与稀疏信号恢复概述,Emmanuel Candes,11723 次观看,0:58:36(2009 年 7 月 30 日,机器学习夏季学校(MLSS),芝加哥 2009)
-
深度信念网络,Geoffrey E. Hinton,11024 次观看,1:27:00(2009 年 11 月 2 日,机器学习夏季学校(MLSS),剑桥 2009)
-
粒子滤波器,Simon Godsill,10744 次观看,1:21:00(2009 年 11 月 2 日,机器学习夏季学校(MLSS),剑桥 2009)
-
如何培养思维:统计、结构与抽象,乔舒亚·B·特嫩鲍姆,4949 次观看,1:09:08(2012 年 8 月 17 日,在第 26 届人工智能协会年会(AAAI),多伦多 2012)
-
量子信息与大脑,斯科特·阿龙森,4283 次观看,0:53:11(2013 年 1 月 16 日,在第 26 届神经信息处理系统年会(NIPS),太浩湖 2012)
-
Dropout:一种简单有效的改进神经网络的方法,杰弗里·E·辛顿,3851 次观看,0:25:19(2013 年 1 月 16 日,在第 26 届神经信息处理系统年会(NIPS),太浩湖 2012)
-
学习表示:学习理论中的挑战,扬·勒库恩,2916 次观看,0:54:32(2013 年 8 月 9 日,在第 26 届学习理论年会(COLT),普林斯顿 2013)
-
计算与统计界面及“BIG DATA”,迈克尔·I·乔丹,421 次观看,0:56:26(2014 年 7 月 15 日,在第 27 届学习理论年会(COLT),巴塞罗那 2014)
你会立即注意到,这个列表中有许多讲座来自机器学习暑期学校。总体来看,视频讲座网中最受欢迎的二十五个机器学习讲座中有超过一半(十三个)来自这里,占据了前四名。
现在我们将查看视频标题,以确定什么因素使得机器学习视频受欢迎。

这幅可视化图表清晰地集中于理论、建模和统计等主题——显示了视频讲座的观众对机器学习的理论方面的亲和力,而非应用方面。
现在,我们来看一下讲座的长度如何影响视频的观看次数。

与视频讲座上的其他类别视频类似,较长的视频长度与更多的观看次数相关,表明深入的内容在视频讲座的观众中更受欢迎。
相关内容:
-
视频讲座中观看次数最多的大数据讲座
-
视频讲座中观看次数最多的数据挖掘讲座
我们的前三大课程推荐
1. Google 网络安全认证 - 快速进入网络安全职业领域
2. Google 数据分析职业认证 - 提升你的数据分析技能
3. Google IT 支持专业认证 - 支持你组织的 IT 需求
更多相关内容
从数据科学到机器学习工程
原文:
www.kdnuggets.com/2020/11/moving-data-science-machine-learning-engineering.html
评论
Caleb Kaiser,Cortex Labs
在过去的 20 年里,机器学习一直在回答一个问题:我们能否训练一个模型来做某些事情?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
某些事情 当然可以是任何任务。预测句子中的下一个单词,识别照片中的人脸,生成某种声音。目标是查看机器学习是否有效,如果我们能做出准确的预测。
感谢数据科学家们几十年的努力,我们现在拥有了很多可以做很多事情的模型:
-
OpenAI 的 GPT-2(现在还有 GPT-3)可以生成勉强像人类的文本。
-
像 YOLOv5 这样的目标检测模型(官方版本的争论暂且不提)每秒可以解析 140 帧视频中的物体。
-
文本到语音模型如 Tacotron 2 可以生成类似人类的语音。
数据科学家和机器学习研究人员所做的工作是令人难以置信的,因此,一个第二个问题自然出现了:
我们可以用这些模型做些什么,怎么做呢?
这显然是不是 数据科学问题。这是一个工程问题。为了解答这个问题,一门新的学科——机器学习工程应运而生。
机器学习工程就是如何将机器学习应用于现实世界的问题
数据科学和机器学习工程之间的差异起初可能感觉有些无形,因此查看一些例子是很有帮助的。
1. 从图像分类到机器学习生成的目录
图像分类和关键词提取分别是计算机视觉和自然语言处理的经典问题。
Glisten.ai 使用训练有素的模型集来创建一个 API,从产品图像中提取结构化信息:

来源: TechCrunch
这些模型本身是数据科学的令人惊叹的成果。然而,Glisten API 是机器学习工程的杰作。
从目标检测到打击盗猎
Wildlife Protection Solutions 是一个小型非营利组织,利用技术保护濒危物种。最近,他们升级了视频监控系统,纳入了一个经过训练的目标检测模型,以识别偷猎者。该模型的检测率已经翻倍:

来源:Silverpond
像 YOLOv4 这样的目标检测模型是数据科学的成功案例,而 Highlighter——WPS 用于训练其模型的平台——是一个令人印象深刻的数据科学工具。然而,WPS 的偷猎者检测系统则是机器学习工程的一项壮举。
3. 从机器翻译到 COVID19 的重大挑战
机器翻译指的是使用机器学习将数据从一种形式“翻译”成另一种形式——有时是在人类语言之间,有时是完全不同的格式之间。
PostEra 是一个药物化学平台,利用机器翻译将化合物“翻译”为工程蓝图。目前,化学家们正在利用这个平台进行一个开源项目,寻找 COVID19 的治疗方法:

来源:PostEra
开发一个能够将分子转化为一系列“路线”(从一个分子转变为另一个分子的变换)的模型是数据科学的一项壮举。构建 PostEra 平台则是机器学习工程的一项壮举。
4. 从文本生成到机器学习地下城主
OpenAI 的 GPT-2 在发布时是历史上最强大的文本生成模型。拥有惊人的 15 亿参数,它代表了变换器模型的一个重大进步。
AI Dungeon 是一个经典的地下城探险游戏,带有一个小变化:它的地下城主实际上是经过文本微调的 GPT-2,用于选择你自己的冒险故事:
Reddit 今日发现 ???? 有没有其他人有幸为你的龙车买保险?pic.twitter.com/TGQh3Tju89
— AI Dungeon (@AiDungeon) 2020 年 6 月 28 日
训练 GPT-2 是一项历史性的 数据科学 成就。将其构建成地下城探险游戏则是机器学习工程的一项壮举。
所有这些平台都建立在数据科学的基础之上。如果不能为其任务训练模型,它们是无法工作的。但为了将这些模型应用于现实世界的问题,它们需要被工程化成应用程序。
换句话说,机器学习工程是数据科学的创新在机器学习研究之外的体现。
然而,机器学习工程带来的核心挑战是它引入了一种全新的工程问题类别——这些问题我们目前还没有简单的答案。
机器学习工程的内容
从高层次来看,我们可以说机器学习工程指的是所有需要将训练好的模型转化为生产应用程序的任务:

为了让这些更具体,我们可以用一个简单的例子。
让我们回到 AI Dungeon,这个由 ML 驱动的地下城爬行游戏。游戏的架构很简单。玩家输入一些文本,游戏调用模型,模型生成响应,然后游戏显示出来。显而易见的构建方法是将模型部署为微服务。
理论上,这应该类似于部署任何其他 Web 服务。将模型封装在类似 FastAPI 的 API 中,用 Docker 容器化它,部署到 Kubernetes 集群中,并通过负载均衡器暴露它。

来源:Cortex 推理架构
实际上,GPT-2 使事情变得复杂:
-
GPT-2 非常庞大。完全训练好的模型超过 5 GB。为了服务它,你需要一个配备了大实例类型的集群。
-
GPT-2 资源密集。单次预测可能会长时间占用一个 GPU。低延迟很难实现,而且单个实例无法同时处理多个请求。
-
GPT-2 成本高。由于上述事实,将 GPT-2 部署到生产环境意味着——假设你有相当多的流量——你将运行许多大型 GPU 实例,这会很昂贵。
当你考虑到游戏在发布后很快就拥有了超过 100 万名玩家,这些问题变得更加严重。
编写高性能 API、配置带 GPU 实例的集群、使用抢占实例来优化成本、为推理工作负载配置自动扩展、实施滚动更新以便每次更新模型时 API 不会崩溃——这是大量的工程工作,而这只是一个 简单 的 ML 应用程序。
有许多常见的功能——重新训练、监控、多模型端点、批量预测等——对于许多 ML 应用程序来说都是必要的,每个功能都会显著提高复杂性。
解决这些问题是机器学习工程师(根据组织情况,可能还需与 ML 平台团队合作)的工作,他们的工作因大多数机器学习工具是为数据科学而非工程设计的而变得更加困难。
幸运的是,这种情况正在改变。
我们正在构建一个用于机器学习工程的平台——而不是数据科学。
几年前,我们中的一些人从软件工程转向了 MLE。在花了几周时间破解数据科学工作流和编写粘合代码以使 ML 应用程序正常工作后,我们开始思考如何将软件工程原则应用于机器学习工程。
例如,看看 AI Dungeon。如果他们在构建一个普通的 API——一个不涉及 GPT-2 的 API——他们会使用类似 Lambda 的工具在 15 分钟内启动 API。然而,由于服务 GPT-2 的机器学习特定挑战,软件工程的编排工具将不起作用。
但,为什么这些原则不能继续适用呢?
所以,我们开始开发适用于机器学习工程的工具,这些工具应用了这些原则。Cortex,我们的开源 API 平台使机器学习工程师尽可能容易地将模型部署为 API,使用的界面对任何软件工程师来说都很熟悉:

来源:Cortex repo
API 平台实际上是 AI Dungeon 以及上述所有其他机器学习初创公司用来部署其模型的工具。其设计哲学非常简单:
我们将机器学习工程的挑战视为工程问题,而非数据科学问题。
对于 API 平台来说,这意味着我们使用 YAML 和 Python 文件,而不是难以版本化、依赖隐性状态并允许任意执行顺序的笔记本。我们构建了一个 CLI,而不是带有“部署”按钮的 GUI,通过 CLI,你可以实际管理部署。
你可以将这种哲学应用于生产环境中使用机器学习的许多挑战。
可重复性,例如,不仅仅是机器学习中的挑战。这也是软件工程中的问题——但我们使用版本控制来解决它。而虽然传统的版本控制软件如 Git 不适用于机器学习,你仍然可以应用这些原则。DVC(数据版本控制),将类似 Git 的版本控制应用于训练数据、代码及其结果模型,就实现了这一点。

来源:DVC
那么,所有用于初始化模型和生成预测的样板代码和胶水代码呢?在软件工程中,我们会设计一个框架来处理这些问题。
最终,我们也看到这种情况发生在机器学习工程中。例如,Hugging Face 的 Transformers 库提供了大多数流行变换模型的简易接口:

来源:Hugging Face
使用那六行 Python 代码,你可以下载、初始化并提供 GPT-2 的预测,这是一个强大的文本生成模型。这六行 Python 代码完成了即使是成熟、资金充足的团队三年前也无法做到的事情。
我们对这个生态系统如此兴奋——不仅仅因为我们是其中的一部分——是因为它代表了机器学习几十年的研究与人们每天面临的问题之间的桥梁。每当这些项目消除了机器学习工程的障碍时,新团队就更容易用机器学习解决问题。
在未来,机器学习将成为每位工程师工具栈的一部分。几乎没有问题是机器学习无法触及的。这一进程的速度完全取决于我们能够多快开发出像 Cortex 这样的平台,并加速机器学习工程的普及。
如果这也让你兴奋,我们随时欢迎新的贡献者。
个人简介:Caleb Kaiser (@KaiserFrose) 是 Cortex Labs 的创始团队成员,帮助维护 Cortex。
原文。经许可转载。
相关内容:
-
如何将 PyTorch Lightning 模型部署到生产环境
-
机器学习工程师与数据科学家(数据科学结束了吗?)
-
你不必再使用 Docker 了
更多相关话题
从实践到生产中迁移机器学习时需要问的问题
原文:
www.kdnuggets.com/2016/11/moving-machine-learning-practice-production.html
评论
作者:Ramanan Balakrishnan,Semantics3
随着对神经网络和深度学习的兴趣不断增长,个人和公司声称将人工智能越来越多地融入到他们的日常工作流程和产品提供中。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
再加上人工智能研究的飞速发展,新一波的热潮显示了在解决一些难题方面的巨大潜力。
尽管如此,我感觉这个领域在欣赏这些发展和随后部署它们以解决“现实世界”任务之间存在差距。
许多框架、教程和指南已经出现,以普及机器学习,但它们规定的步骤往往与需要解决的模糊问题不一致。
这篇文章是一些值得思考的问题(以及一些(可能甚至是错误的)答案)的集合,在将机器学习应用于生产环境时值得考虑。
垃圾进,垃圾出
我是否有可靠的数据来源?我从哪里获得我的数据集?
在开始时,大多数教程通常包含定义良好的数据集。无论是MNIST、维基百科语料库还是来自UCI 机器学习库的任何优秀选项,这些数据集通常无法代表你希望解决的问题。
对于你的具体使用案例,可能根本不存在合适的数据集,构建数据集可能比你预期的要花费更长的时间。
例如,在 Semantics3,我们处理了许多电子商务特定的问题,从产品分类到产品匹配再到搜索相关性。针对这些问题,我们不得不内部审视并付出相当的努力来生成高保真的产品数据集。
在许多情况下,即使你拥有所需的数据,仍可能需要大量(且昂贵)的人工劳动来对数据进行分类、注释和标记以供训练使用。
数据转换为输入
需要哪些预处理步骤?在使用算法之前,我如何对数据进行归一化?
这是另一个步骤,通常与实际模型无关,在大多数教程中被忽略。特别是在探索深度神经网络时,这种遗漏显得更加明显,因为将数据转化为可用的“输入”至关重要。
虽然存在一些图像的标准技术,如裁剪、缩放、零中心化和白化——但最终的决定仍然取决于个人对每个任务所需归一化水平的判断。
在处理文本时,领域变得更加混乱。大写字母重要吗?我应该使用分词器吗?词嵌入呢?我的词汇量和维度应该有多大?我应该使用预训练向量,还是从头开始或叠加它们?
没有适用于所有情况的正确答案,但了解可用的选项通常是战斗的一半。最近,来自spaCy创建者的帖子详细介绍了一种标准化文本深度学习的有趣策略。
现在,我们开始吧?
我应该使用哪种语言/框架?Python、R、Java、C++?Caffe、Torch、Theano、Tensorflow、DL4J?
这可能是拥有最多意见的问提。我将此部分包含在此仅为完整性,并乐于指出各种 其他 资源 可用的。
虽然每个人可能有不同的评估标准,但我主要关注的是自定义、原型设计和测试的便利性。在这一方面,我倾向于在可能的情况下从scikit-learn开始,并使用Keras进行我的深度学习项目。
进一步的问题如我应该使用哪种技术?我应该使用深度模型还是浅层模型,CNN/RNN/LSTM 呢? 再次,有许多资源可以帮助做出决策,这可能是人们谈论“使用”机器学习时讨论最多的方面。
训练模型
我如何训练我的模型?我应该购买 GPUs、定制硬件,还是使用 ec2(spot?)实例?我可以为提高速度进行并行化吗?
随着模型复杂性的不断上升以及对处理能力的需求增加,这在迁移到生产环境时是一个不可避免的问题。
一个亿级参数的网络可能会承诺在其数据集达到 TB 级时表现出色,但大多数人无法承受训练仍在进行中时等待数周的情况。
即使是较简单的模型,构建、训练、汇总和拆除任务所需的基础设施和工具也可能让人感到相当艰巨。
花时间规划你的infrastructure、标准化setup并尽早定义工作流程,可以在你构建每个新模型时节省宝贵的时间。
没有哪个系统是孤立存在的
我需要进行批处理还是实时预测?嵌入式模型还是接口?RPC 还是 REST?
你的99%-验证准确率模型除非与生产系统的其他部分接口,否则用处不大.这个决策至少部分取决于你的使用案例。
执行简单任务的模型可能可以将其权重直接打包到应用程序中,而更复杂的模型可能需要与集中式的重型服务器进行通信。
在我们的案例中,大多数生产系统离线批处理任务,而少数通过 HTTP 上的 JSON-RPC 提供实时预测。
知道这些问题的答案也可能会限制你在构建模型时应该考虑的架构类型。构建一个复杂的模型,结果发现它无法在你的移动应用中部署,是一个可以轻松避免的灾难。
监控性能
我如何跟踪我的预测?我是否将结果记录到数据库中?在线学习怎么办?
在构建、训练并将模型部署到生产环境后,任务仍未完成,除非你有监控系统到位。确保模型成功的一个关键组件是能够衡量和量化其性能。在这方面值得回答很多问题。
我的模型如何影响整体系统性能?我应该测量哪些数据?模型是否正确处理了所有可能的输入和场景?
由于曾在过去使用过 Postgres,我倾向于用它来监控我的模型。定期保存生产统计数据(数据样本、预测结果、异常数据细节)在执行分析(和错误追踪)时证明了其无价之宝。
另一个需要考虑的重要方面是模型的在线学习要求。你的模型是否应该即时学习新特性?当滑板成为现实,产品分类器应该将其归入车辆、玩具还是保持未分类?这些都是在构建系统时值得讨论的重要问题。
总结一下

这不仅仅是秘密调料
本文提出了更多问题而非答案,但这正是其真正的目的。随着新技术、细胞、层 和网络架构的诸多进展,比以往更容易因关注细节而忽视整体。
从业者之间需要更多关于端到端部署的讨论,以推动这一领域向前发展,并真正使机器学习普及到大众。
简历: 拉马南·巴拉克里希南 是 Semantics3 的数据科学家。当他不在深度学习、信息理论或现代物理领域钻研时,他也会参与偶尔的开锁挑战。
原文。经许可转载。
相关:
-
机器学习:完整而详细的概述
-
深度学习研究综述:生成对抗网络
-
将更智能的决策深嵌入运营 IT 结构
更多相关话题
从 R 迁移到 Python:你需要了解的库
这篇文章最初出现在 Yhat 博客 上。Yhat 是一家位于布鲁克林的公司,旨在让数据科学对开发者、数据科学家和企业都适用。Yhat 提供了一个用于部署和管理预测算法的 REST API 的软件平台,同时消除了与生产环境相关的痛苦的工程障碍,如测试、版本控制、扩展和安全。
为什么要切换?
我在 Python 中最喜欢的机器学习部分之一是它受益于观察 R 社区,然后模仿其最佳部分。我坚信语言的有用性在于其库。因此,在这篇文章中,我将介绍一些我在使用 R 时几乎每次都会用到的重要包,以及它们在 Python 中的对应包。

glm, knn, randomForest, e1071 -> scikit-learn
在 R 中,一个既是福音又是诅咒的特点是机器学习算法通常由不同的包进行划分。这意味着不是拥有一个(或一组)实现一些常见算法的 ML 库,而是每个算法都有自己的包。这有点好,因为你可以找到非常小众、前沿的算法实现,但在日常使用中切换算法可能会很麻烦。这个麻烦是 Python 的 scikit-learn 很好地解决了的。scikit-learn 提供了一套共同的 ML 算法,全部在相同的 API 下。这使得在 LogisticRegression 和 GradientBoostingMachines 之间切换变成了一行代码。
reshape/reshape2, plyr/dplyr -> pandas
实际上,这也是 我们第一篇文章之一 的主题。pandas 采用了 R 中数据处理的最佳部分,并将其转化为一个 Python 包。这包括其自己的数据框架实现以及修改和重构的方式。基本上,它采纳了 reshape/reshape2 和 plyr/dplyr 的最佳部分,并将其 Python 化!
ggplot2 -> ggplot + seaborn + bokeh
R 仍然在绘图方面做得比 Python 更好。毫无疑问,R 在几乎所有的 方面 都更好。即便如此,Python 的绘图也已经成熟,尽管社区是碎片化的。如果你喜欢 ggplot 风格的语法,可以看看 Yhat 的 ggplot。如果你需要超级统计和技术图表,那么可以尝试 seaborn。如果你想要一些超酷、好看的交互式图表,那就试试 bokeh。
stringr -> nothing
在 “base R” 中,字符串操作几乎同样不直观且傻乎乎的。每次我在 R 中处理字符串时,我会做两件事(按顺序):
-
对新西兰生产 Hadley Wickham 简单表示感谢
-
导入
stringr

非常感谢,新西兰
stringr 是一个绝对的救星。它编写良好,性能优异(至少我认为如此),且易于安装(不要忽视最后这一点。如果人们无法安装你的软件,那就没有意义了)。
好了,所以 stringr 赞美独白完成。好消息是,Python 在字符串操作方面非常出色,你实际上不需要一个字符串库!它有一个出色的内置正则表达式库 re,以及一个恰当地称为 string 的内置字符串元库。所以幸运的是,Python 带有所有与字符串相关的电池!
RStudio -> Rodeo
对许多用户来说,RStudio 是 R 的代名词。为什么不呢?它是一个出色的 R 数据分析 IDE。从历史上看,Python 没有很多类似的选项。当然,现在情况已经不一样了。我们在一年前发布了 Rodeo 的第一个版本,并在一个月前发布了适用于 Windows、OSX 和 Linux 的 2.0 版本。
“自从我们使用 RStudio 以来,我们一直在寻找一个类似的 Python IDE。我们尝试了如 Sublime Text 和 Spyder 等 IDE,但没有一个符合我们的喜好。我们搜索并找到了 Rodeo,对这个 IDE 非常满意。” - Stephen Hsu,加州大学伯克利分校
Knitr -> Jupyter
Knitr 是一个使用 R 创建可重复和高度视觉化分析的绝佳工具。它在 RStudio 中已经使用了一段时间。在 Python 世界中,最类似的包是 Jupyter。Jupyter 笔记本提供了一个用于 Python(以及其他语言)编程的交互环境,专注于可重复性和可视化——它甚至有一个 R 插件!
sqldf -> pandasql
sqldf 是 SQL 用户在 R 中舒适操作数据的好方法。我自己在刚开始学习 R 时也使用过它。早在那时,Yhat 实际上为 Python 开发了一个类似的包,叫做 pandasql。概念相同:对数据框写 SQL 查询,获取数据框!快进三年,pandasql 在 GitHub 上已经有超过 256 个星标了 😃。对于一个只有 358 行代码的库来说,这不算差!
原文。经许可转载。
相关:
-
R 用户在学习 Python 时会遇到的八大挫折
-
R 与 Python 在数据科学中的对决:赢家是...
-
R 与 Python:面对面的数据分析
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
了解更多相关信息
为什么你不应该使用 MS MARCO 来评估语义搜索
原文:
www.kdnuggets.com/2020/04/ms-marco-evaluate-semantic-search.html
评论
作者:Thiago Guerrera Martins,Verizon Media 首席数据科学家

图片来源:Free To Use Sounds 在 Unsplash
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
MS MARCO是微软发布的大规模数据集,旨在帮助推进与搜索相关的深度学习研究。当我们决定创建一个展示如何使用Vespa设置文本搜索应用的tutorial时,它是我们的首选。这在社区中引起了很大关注,主要由于排行榜上的激烈竞争。此外,作为一个大型且具有挑战性的标注文档语料库,它在当时满足了所有要求。
我们在第一个基础搜索教程之后,跟进了一个博客文章和一个tutorial,介绍了如何在 Vespa 中使用 ML 来改进文本搜索应用。到目前为止,一切顺利。当我们撰写第三个教程时,讨论如何使用(预训练的)语义嵌入和近似最近邻搜索来改进应用时,我们开始意识到,可能完整文本排名的 MS MARCO 数据集并不是最佳选择。
在更仔细地查看数据后,我们开始意识到数据集对术语匹配信号的偏见非常严重。这比我们预期的要多得多。
但我们知道它有偏见……
在讨论数据之前,我们必须说明我们预期数据集中会有偏见。根据MS MARCO 数据集论文,他们通过以下方式构建数据集:
-
从 Bing 的搜索日志中抽样查询。
-
过滤掉非问题查询。
-
使用 Bing 从其大规模网络索引中检索每个问题的相关文档。
-
自动提取这些文档中的相关段落
-
人工编辑随后对包含有用和必要信息以回答问题的段落进行标注。
查看步骤 3 和 4(可能还有 5),发现数据集中的偏差并不令人惊讶。公平地说,我认为文献中已经认识到偏差是一个问题。令人惊讶的是我们观察到的偏差程度以及这可能如何影响涉及语义搜索的实验。
语义嵌入设置
我们的主要目标是展示如何通过使用术语匹配和语义信号来创建开箱即用的语义感知文本搜索应用程序。结合 Vespa 执行近似最近邻搜索的能力,用户可以在大规模下构建此类应用程序。
在接下来的结果中,我们使用了BM25 分数作为我们的术语匹配信号,并使用sentence BERT 模型生成嵌入以表示语义信号。使用更简单的术语匹配信号和其他语义模型如 Universal Sentence Encoder 也获得了类似的结果。更多细节和代码可以在教程中找到。
结合信号
我们从仅涉及术语匹配信号的合理基准开始。接下来,当我们仅在应用中使用语义信号时,获得了令人鼓舞的结果,这只是为了检查设置的合理性并确认嵌入中确实包含相关信息。之后,显然的后续步骤是结合这两种信号。
Vespa 在这里提供了很多可能性,因为我们可以在匹配阶段和排名阶段结合术语匹配和语义信号。在匹配阶段,我们可以使用nearestNeighbor操作符来处理语义向量,并使用通常用于术语匹配的多种操作符,如常见的AND和OR语法来组合查询标记,或使用有用的近似如weakAND。在排名阶段,我们可以使用众所周知的排名特征如 BM25 和Vespa 张量评估框架来对输入信号如语义嵌入进行各种操作。
当我们开始尝试所有这些可能性时,我们开始怀疑 MS MARCO 数据集在这种实验中的有用性。主要的问题是,尽管语义信号在单独使用时表现尚可,但当考虑术语匹配信号时,这些改进会消失。
我们原本期望术语匹配和语义信号之间会有显著的交集,因为两者都应包含关于查询文档相关性的信息。然而,语义信号需要补充术语匹配信号才能发挥价值,因为它们存储和计算的成本更高。这意味着它们应该匹配那些术语匹配信号无法匹配的相关文档。
然而,就我们所见,这并不是情况。因此,我们决定更仔细地查看数据。
术语匹配偏差
为了更好地调查发生了什么,我们从 Vespa 收集了关于相关和随机文档的查询-文档数据。例如,下图显示了查询与标题嵌入之间和查询与正文嵌入之间点积和的经验分布。蓝色直方图显示了随机(因此可能与查询不相关)文档的分布。红色直方图显示了相同的信息,但现在以文档对查询的相关性为条件。

嵌入点积分数的经验分布。给定一组查询,蓝色代表随机(非相关)文档,红色代表相关文档。
正如预期的那样,我们在相关文档上平均得分更高。很好。现在,让我们看看 BM25 分数的类似图表。结果类似,但在这种情况下更为极端。相关文档的 BM25 分数要高得多,以至于几乎没有相关文档的信号足够低而被术语匹配信号排除。这意味着,在考虑术语匹配后,几乎没有相关文档留给语义信号进行匹配。即使语义嵌入信息丰富,这一点也是真实的。

BM25 分数的经验分布。给定一组查询,蓝色代表随机(非相关)文档,红色代表相关文档。
在这种情况下,我们所能期望的最好情况是相关文档的两个信号都呈正相关,显示出两者都携带了关于查询-文档相关性的信息。下面的散点图确实显示了,相关文档(红色)的 BM25 分数与嵌入分数之间的相关性远强于一般人群(黑色)的分数之间的相关性。

嵌入的点积得分与 BM25 得分的散点图。给定一组查询,黑色代表随机(不相关)文档,红色代表相关文档。
备注和结论
在这一点上,合理的观察是我们讨论的是预训练的嵌入,如果我们将嵌入微调到具体应用中,可能会获得更好的结果。这可能确实是这样,但需要考虑至少两个重要因素:成本和过拟合。资源/成本的考虑很重要,但更容易被识别。你要么有足够的资金来追求它,要么没有。如果有,你还需要检查所获得的改进是否值得成本。
在这种情况下,主要问题与过拟合有关。当使用诸如通用句子编码器和句子 BERT 等大型复杂模型时,避免过拟合并不容易。即使我们使用整个 MS MARCO 数据集,该数据集被认为是帮助推进 NLP 任务研究的重要发展之一,我们也只有大约 300 万个文档和 30 万个标记查询。这相对于如此大规模的模型并不算大。
另一个重要观察是,BERT 相关的架构在 MSMARCO 排行榜 上占据了主导地位已有一段时间。安娜·罗杰斯 写了一篇很好的文章 讨论了当前使用排行榜来衡量 NLP 任务模型性能的一些挑战。主要的收获是,我们在解读这些结果时要小心,因为很难理解性能是来源于架构创新还是部署了过多资源(即过拟合)来解决任务。
尽管有这些评论,这里最重要的一点是,如果我们想要调查语义向量(无论是预训练的还是未训练的)的力量和局限性,我们理想的优先考虑数据集应该是那些对术语匹配信号的偏见较少的数据集。这可能是一个显而易见的结论,但目前我们不明显的是如何找到这些数据集,因为报告中的偏见可能存在于许多其他数据集中,由于类似的数据收集设计。
感谢 Lester Solbakken 和 Jon Bratseth。
简介:Thiago Guerrera Martins(@Thiagogm)是 Verizon Media 的首席数据科学家,并在开源搜索引擎 vespa.ai 上工作。他拥有统计学博士学位。
原文。经许可转载。
相关信息:
-
如何构建自己的反馈分析解决方案
-
一种简单且可解释的二分类器性能度量
-
使用 TensorFlow 和 Keras 进行分词和文本数据准备
更多相关话题
一个(更好)的评估机器学习模型的方法
原文:
www.kdnuggets.com/2022/01/much-better-approach-evaluate-machine-learning-model.html
数据科学家像我一样评估机器学习模型使用经典性能指标时,困难重重。
即使有多种指标和评分方法,理解哪些指标适合我——以及可能许多其他人——面临的问题仍然具有挑战性。这正是我使用 Snitch AI 来评估大多数机器学习模型质量的原因。PS——过去两年我一直积极参与 Snitch AI 的开发。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
让我通过一个例子来解释为什么选择正确的指标如此重要:生成一个可以使用集中在 UC Irvine 机器学习库中的数据来预测公司破产的模型。数据集被称为Taiwanese Bankruptcy Prediction(在 CC BY 4.0 许可下),利用了 1999 年至 2009 年台湾经济期刊中的破产数据。
问题:不平衡的数据集
你将遇到的第一个问题是数据集的不平衡。这既是好消息也是坏消息。好消息是只有 3.3%的公司破产了!但另一方面,坏消息是数据集的不平衡使得预测“稀有类别”(3.3%)变得更加困难,因为我们的懒惰模型可以通过简单地预测没有破产来为 96.7%的公司预测正确的结果。

作者的目标不平衡评估
你可以看到这也是一个性能评估问题,因为大多数指标对最大类有偏见,最终使它们不准确。为什么?预测没有破产使我们的模型理论上准确度达到 96.7%。这里是 Snitch AI 中第一个建立并评估的模型的示例。该工具默认计算多个相关的性能指标。如下所示,我们的第一个模型准确度为 96%。然而,当你查看 F1 分数时,一个更适合不平衡类的指标,我的分数勉强达到 26%...

作者提供的初步质量分析图像
那么这是什么情况?
不平衡数据集的解决方案
处理不平衡数据时,一个好的做法是在第二步尝试让训练数据集更加平衡。你可以通过以下方式来实现:对多数类(无破产)进行欠采样,通过移除随机观察值,或者对少数类(破产)进行过采样。
对于过采样,你可以选择随机复制观察值或使用经过验证的算法来创建合成观察值,例如 合成少数类过采样技术(SMOTE)。SMOTE 通过选择相近的示例,绘制这些示例之间的连线,并在连线上的某一点绘制新样本来工作。
如你所见,我可以使用许多技术来增强我的模型。
使用 Snitch,我可以查看我各种实验的清晰历史记录:

作者提供的多种质量分析图像
这里是我从上述实验中得出的一些结论:
-
欠采样和过采样技术显著提升了 F1 分数。这是件好事!
-
然而,这种性能提升是以我们模型的整体质量为代价的。
-
我们的模型 4(使用欠采样的梯度提升)是最好的模型,因为它的性能几乎与模型 2 一样,但总体质量更佳。
等等!这“质量评分”是什么?
Snitch 使用约十几种自动化质量分析来生成这个质量评分。
质量分析产生了:
-
特征贡献评分: 检查你的模型预测是否对输入变量的分布有偏或公平。
-
随机噪声鲁棒性评分: 检查你的模型是否对噪声数据的引入具有鲁棒性。
-
极端噪声鲁棒性评分: 检查你的模型是否对最糟糕情况下的噪声数据引入具有鲁棒性。

来自 Snitch AI 质量分析方法 的图像,2021 年。经许可转载
性能评估很困难
没有什么好的东西是容易得到的,性能评估也不例外。虽然很难做到正确,性能评估在开发模型时需要认真对待。仅仅因为你的模型有好的准确率,并不意味着它就是一个好的模型。
事实是,准确率可能甚至不是一个相关的性能指标。在我们的案例中,由于数据集不平衡,F1 分数显然更好。这里的教训很简单。确保你验证所选指标是否能准确衡量你想要实现的目标。
尽管性能指标很重要(毕竟是衡量模型预测结果的好坏),但这些指标不能验证数据偏差或模型的整体稳健性。一个好的做法是专门测试其他特性,如偏差和稳健性。
我们看到一些模型在理论上比其他模型表现更好,但实际上质量较差。我们也看到一些表现不佳但质量更好的模型。最终目标是能够比较这些信号,以选择最佳方法。
记住,更好的方法不仅应集中于估计模型的性能,它实际上还需要深入测试,以确保你的系统在实际生产中新数据上能够稳健工作……这就是魔法发生的地方!
奥利维耶·布莱斯 是 Moov AI 的联合创始人和决策科学部负责人。他还是加拿大标准委员会的成员,负责定义人工智能解决方案的 ISO 标准,并领导人工智能系统质量评估指南的倡议。
原文。已获许可转载。
更多相关主题
2022 年数据科学家的薪资是多少?
原文:
www.kdnuggets.com/2022/02/much-data-scientists-make-2022.html

数据科学家在 2021 年仍然需求旺盛。过去几年中世界的重塑,使我们明显变得依赖数据,这是数据科学受欢迎的主要原因。
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 系统
为了吸引顶尖数据科学家,公司们正在激烈竞争,因此使数据科学成为一个高薪职业。薪资有多高,这是我将在这篇文章中尝试回答的问题。
为此,我将向你展示一些关于数据科学家薪资的数据。我不会讲太多,或者说,在这种情况下,是写得太多。我将让数据和图表做大部分讲解。
方法论
我相信你已经知道,回答作为数据科学家你能赚多少并不容易。你的薪资依赖于许多因素,如教育水平、职级、技术知识、行业、公司规模、地点和谈判技巧。
在这次分析中,我关注了三个主要因素:
-
职级
-
行业
-
公司规模
所有图表和表格中展示的数据均来自[Glassdoor]( https://www.glassdoor.com/Salaries/data-scientist-salary-SRCH_KO0 ,14.htm),截至 2022 年 2 月 3 日。
分析将集中在数据科学这一职位上。当然,还有更多属于数据科学范畴的职位。这些职位包括数据分析师、数据工程师、机器学习工程师等。我将简要概述所有这些职位的一般数据。
但根据职级、行业和公司规模的薪资分析将仅限于数据科学职位。
显示的薪资将是一个平均基本工资。这意味着实际的总补偿会稍高一些。为了了解这有多少,我还准备了一个图表,显示了 Glassdoor 上 20 家最受欢迎公司的平均总补偿。在这里,受欢迎程度意味着提交到网站上的数据科学薪资数量。
所有数据均为美国的数据。
数据科学家薪资
根据 Glassdoor 的数据,数据科学家的平均基本薪资为 117,000 美元。让我们看看这个平均薪资如何根据一些因素而变化。
数据科学家薪资按经验和行业分类
正如你可能预期的那样,不管行业如何,薪资通常随着数据科学家的经验增加而上升。

薪资最高的自然是在科技行业。数据科学家在这里的薪资在前三年的经验中几乎没有变化。但这些起薪点显著高于其他行业。在每个经验类别中,科技行业的薪资都是最高的。唯一的例外是 15 年及以上的数据。数据显示,这可能是因为科技公司对最有经验的员工的需求远低于其数据科学职位的总数。他们对拥有 0-1 年和 1-3 年经验的数据科学家的需求最高。
银行与金融服务、生物技术与制药、以及媒体与营销排名第二、第三和第四。有趣的是,在所有三个行业中,拥有 10-14 年经验的数据科学员工的薪资下降(数据也支持这一点)显示,这些行业对这些专业人士的需求最少。随后,对经验最丰富的数据科学家的需求显著上升,尤其是在生物技术与制药和媒体与营销领域。如果你是数据科学高管,你将在这些行业中赚取最多。
咨询行业的薪资最低,尤其是对于拥有 0-1 年和 1-3 年经验的人。考虑到薪资上涨,如果你的经验在中间阶段,咨询行业的工作最具优势。但相比其他行业,它的薪资还是最低的。
数据科学家薪资按经验和公司规模分类

薪资最高的公司也是规模最大的公司,这一点并不令人惊讶。与其他公司相比,最适合在这类公司工作的时期是你拥有三年或七年以上的经验。如果你在这两个阶段之间,那么在员工较少的其他公司工作,你的薪资会更高。
拥有 501 到 1,000 名员工的公司是经验最少者的第二佳选择。接下来是最小的公司和拥有 1,001 到 5,000 名员工的公司。对于经验最少者而言,最差的选择是拥有 51 到 500 名员工的公司。
如果你有 4-9 年的经验,拥有 1,001 到 5,000 名员工的公司成为最佳选择。经验更丰富时也不差,但对于经验最丰富的员工而言,相对较差。
所有其他公司规模也是如此,只有两个例外:最大型公司和拥有 51-200 名员工的公司。如果你处于高管层,这些公司薪资最高。
数据科学家薪资排名前 20 家公司
前两个图表显示,最有经验的数据科学家的最高平均基本工资约为$140k。为了更好地了解你的薪资,这里提供了平均总薪资的概览,这包括基本薪资之外的所有奖金。

在最受欢迎的数据科学公司中,薪资最高的是 Airbnb,平均总薪资为$190k。其次是最受欢迎的公司 Meta,薪资为$168k。第三高薪公司是 Cisco($164k),而 Apple 排名第四,为$163k。
Uber 和 Google 并列第五;它们的平均薪资都是$152k。
虽然这些公司并非仅因为薪资高而受欢迎,但这无疑助长了它们的受欢迎程度。与我上面提到的$140k 相比,这六家公司支付的薪资要高得多。如果你考虑到美国数据科学家的平均薪资是$117k,难怪这些公司如此受欢迎。
未来会带来什么?
我提供的数据展示了数据科学家迄今为止的收入。
虽然预测准确的数字是不可能的,但我可以说,只要 2022 年的薪资至少保持不变,这就是一个确定的赌注。
这也可能是一个过于保守的预测。除了 2016 年和 2021 年,Glassdoor 的数据表明,数据科学职位的数量一直在不断上升。2022 年,相比 2021 年已经增长了 70%,而这一年才刚刚开始。

这如何反映在数据科学家的薪资上?如果你查看这篇 Dice 上的文章,它还链接了数据科学薪资研究,你可以感受到 2022 年薪资将会增长。2021 年数据科学家的平均基本薪资增长了 20%。
根据当前平均基本薪资$117k,它可能增加到$140k。对于经验最少的科学家来说,2022 年在薪资最低的行业中,薪资可能为$120k,而在薪资最高的行业中可达$148k。最有经验的科学家的薪资可能从$151k 到$166k 不等。
请注意,这只是基本薪资。看到职位空缺的增加,我认为这甚至是一个保守的预测。
数据科学家的薪资增长需要努力争取。这适用于每个经验水平,尤其是那些 0-3 年经验的人。数据科学的吸引力也会随着时间的推移增加竞争力。在这个领域,像 StrataScratch 这样的平台可能会变得越来越重要,对于那些希望为求职面试做准备并提高获得数据科学职位的机会的人来说尤为如此。
我还推荐查看这篇文章“数据科学家赚多少钱?”,了解数据科学领域的薪资以及其受各种因素的影响。
概览
下面的概览展示了属于数据科学领域的 14 个职位的平均基础工资。通过这些数据,你可以更全面地了解数据科学中不同职位的薪资水平。
| 无 | 职位名称 | 平均基础薪资($USD) |
|---|---|---|
| 1 | 数据分析师 | $70k |
| 2 | 数据库管理员 | $84k |
| 3 | 数据建模师 | $94k |
| 4 | 软件工程师 | $108k |
| 5 | 数据工程师 | $112k |
| 6 | 数据架构师 | $119k |
| 7 | 统计学家 | $89k |
| 8 | 商业智能(BI)开发者 | $92k |
| 9 | 营销科学家 | $94k |
| 10 | 商业分析师 | $77k |
| 11 | 定量分析师 | $112k |
| 12 | 数据科学家 | $117k |
| 13 | 计算机与信息研究科学家 | $142k |
| 14 | 机器学习工程师 | $131k |
Nate Rosidi 是一位数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过真实的面试问题准备面试。他可以通过 Twitter: StrataScratch 或 LinkedIn 联系。
更多相关话题
使用 Doc2Vec 和逻辑回归进行多类文本分类
原文:
www.kdnuggets.com/2018/11/multi-class-text-classification-doc2vec-logistic-regression.html
评论
作者 Susan Li, 高级数据科学家

图片来源:Pexels
Doc2vec 是一种NLP工具,用于将文档表示为向量,是word2vec方法的推广。
为了理解 doc2vec,建议先了解 word2vec 方法。然而,完整的数学细节超出了本文的范围。如果你对 word2vec 和 doc2vec 不熟悉,以下资源可以帮助你入门:
使用相同的数据集进行使用 Scikit-Learn 进行多类文本分类,在本文中,我们将使用 doc2vec 技术通过Gensim按产品对投诉叙述进行分类。让我们开始吧!
数据
目标是将消费者金融投诉分类到 12 个预定义的类别中。数据可以从data.gov下载。
import pandas as pd
import numpy as np
from tqdm import tqdm
tqdm.pandas(desc="progress-bar")
from gensim.models import Doc2Vec
from sklearn import utils
from sklearn.model_selection import train_test_split
import gensim
from sklearn.linear_model import LogisticRegression
from gensim.models.doc2vec import TaggedDocument
import re
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('Consumer_Complaints.csv')
df = df[['Consumer complaint narrative','Product']]
df = df[pd.notnull(df['Consumer complaint narrative'])]
df.rename(columns = {'Consumer complaint narrative':'narrative'}, inplace = True)
df.head(10)

图 1
在移除叙述列中的空值之后,我们需要重新索引数据框。
df.shape
(318718, 2)
df.index = range(318718)
df['narrative'].apply(lambda x: len(x.split(' '))).sum()
63420212
我们拥有超过 6300 万字的数据集,这相对来说是一个比较大的数据集。
探索
cnt_pro = df['Product'].value_counts()
plt.figure(figsize=(12,4))
sns.barplot(cnt_pro.index, cnt_pro.values, alpha=0.8)
plt.ylabel('Number of Occurrences', fontsize=12)
plt.xlabel('Product', fontsize=12)
plt.xticks(rotation=90)
plt.show();

图 2
类别不平衡,然而,一个将所有预测都为“债务催收”的简单分类器只能达到超过 20%的准确率。
让我们看看一些投诉叙述及其相关的产品。
def print_complaint(index):
example = df[df.index == index][['narrative', 'Product']].values[0]
if len(example) > 0:
print(example[0])
print('Product:', example[1])
print_complaint(12)

图 3
print_complaint(20)

图 4
文本预处理
下面我们定义一个函数,将文本转换为小写,并去除标点符号/符号等。
from bs4 import BeautifulSoup
def cleanText(text):
text = BeautifulSoup(text, "lxml").text
text = re.sub(r'\|\|\|', r' ', text)
text = re.sub(r'http\S+', r'<URL>', text)
text = text.lower()
text = text.replace('x', '')
return text
df['narrative'] = df['narrative'].apply(cleanText)
以下步骤包括 70/30 的训练/测试拆分,移除停用词,并使用 NLTK tokenizer 对文本进行分词。首次尝试时,我们为每个投诉叙述标记其产品。
train, test = train_test_split(df, test_size=0.3, random_state=42)
import nltk
from nltk.corpus import stopwords
def tokenize_text(text):
tokens = []
for sent in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sent):
if len(word) < 2:
continue
tokens.append(word.lower())
return tokens
train_tagged = train.apply(
lambda r: TaggedDocument(words=tokenize_text(r['narrative']), tags=[r.Product]), axis=1)
test_tagged = test.apply(
lambda r: TaggedDocument(words=tokenize_text(r['narrative']), tags=[r.Product]), axis=1)
这就是一个训练条目的样子——一个被标记为“信用报告”的示例投诉叙述。
train_tagged.values[30]

图 5
设置 Doc2Vec 训练与评估模型
首先,我们实例化一个 doc2vec 模型——分布式词袋(DBOW)。在 word2vec 架构中,两个算法名称是“连续词袋”(CBOW)和“跳字”(SG);在 doc2vec 架构中,相应的算法是“分布式记忆”(DM)和“分布式词袋”(DBOW)。
分布式词袋(DBOW)
DBOW 是 doc2vec 模型,相当于 word2vec 中的 Skip-gram 模型。段落向量是通过在预测段落中词汇概率分布的任务上训练神经网络获得的,给定一个从段落中随机抽样的词。
我们将调整以下参数:
-
如果
dm=0,使用分布式词袋(PV-DBOW);如果dm=1,使用“分布式记忆”(PV-DM)。 -
300 维特征向量。
-
min_count=2,忽略所有总频率低于该值的词汇。 -
negative=5,指定应该抽取多少个“噪声词”。 -
hs=0,且负采样非零时,将使用负采样。 -
sample=0,配置随机下采样的高频词汇的阈值。 -
workers=cores,使用这些工作线程来训练模型(=使用多核机器加速训练)。
import multiprocessing
cores = multiprocessing.cpu_count()
构建词汇表
model_dbow = Doc2Vec(dm=0, vector_size=300, negative=5, hs=0, min_count=2, sample = 0, workers=cores)
model_dbow.build_vocab([x for x in tqdm(train_tagged.values)])

图 6
在 Gensim 中训练 doc2vec 模型非常简单,我们初始化模型并训练 30 个周期。
%%time
for epoch in range(30):
model_dbow.train(utils.shuffle([x for x in tqdm(train_tagged.values)]), total_examples=len(train_tagged.values), epochs=1)
model_dbow.alpha -= 0.002
model_dbow.min_alpha = model_dbow.alpha

图 7
为分类器构建最终向量特征
def vec_for_learning(model, tagged_docs):
sents = tagged_docs.values
targets, regressors = zip(*[(doc.tags[0], model.infer_vector(doc.words, steps=20)) for doc in sents])
return targets, regressorsdef vec_for_learning(model, tagged_docs):
sents = tagged_docs.values
targets, regressors = zip(*[(doc.tags[0], model.infer_vector(doc.words, steps=20)) for doc in sents])
return targets, regressors
训练逻辑回归分类器。
y_train, X_train = vec_for_learning(model_dbow, train_tagged)
y_test, X_test = vec_for_learning(model_dbow, test_tagged)
logreg = LogisticRegression(n_jobs=1, C=1e5)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
from sklearn.metrics import accuracy_score, f1_score
print('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))
测试准确率 0.6683609437751004
测试 F1 分数:0.651646431211616
分布式记忆(DM)
分布式记忆(DM)作为一个记忆,记住当前上下文中缺少的内容——或作为段落的主题。虽然词向量表示的是词汇的概念,但文档向量旨在表示文档的概念。我们再次实例化一个 Doc2Vec 模型,词向量大小为 300,并对训练语料库进行 30 次迭代。
model_dmm = Doc2Vec(dm=1, dm_mean=1, vector_size=300, window=10, negative=5, min_count=1, workers=5, alpha=0.065, min_alpha=0.065)
model_dmm.build_vocab([x for x in tqdm(train_tagged.values)])

图 8
%%time
for epoch in range(30):
model_dmm.train(utils.shuffle([x for x in tqdm(train_tagged.values)]), total_examples=len(train_tagged.values), epochs=1)
model_dmm.alpha -= 0.002
model_dmm.min_alpha = model_dmm.alpha

图 9
训练逻辑回归分类器
y_train, X_train = vec_for_learning(model_dmm, train_tagged)
y_test, X_test = vec_for_learning(model_dmm, test_tagged)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))
测试准确率 0.47498326639892907
测试 F1 分数:0.4445833078167434
模型配对
根据Gensim doc2vec IMDB 情感数据集教程,将分布式词袋模型(DBOW)和分布式记忆(DM)的段落向量结合起来可以提高性能。我们将按照这个方法,将模型进行配对进行评估。
首先,我们删除临时训练数据以释放 RAM。
model_dbow.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)
model_dmm.delete_temporary_training_data(keep_doctags_vectors=True, keep_inference=True)
连接两个模型。
from gensim.test.test_doc2vec import ConcatenatedDoc2Vec
new_model = ConcatenatedDoc2Vec([model_dbow, model_dmm])
构建特征向量。
def get_vectors(model, tagged_docs):
sents = tagged_docs.values
targets, regressors = zip(*[(doc.tags[0], model.infer_vector(doc.words, steps=20)) for doc in sents])
return targets, regressors
训练逻辑回归模型
y_train, X_train = get_vectors(new_model, train_tagged)
y_test, X_test = get_vectors(new_model, test_tagged)
logreg.fit(X_train, y_train)
y_pred = logreg.predict(X_test)
print('Testing accuracy %s' % accuracy_score(y_test, y_pred))
print('Testing F1 score: {}'.format(f1_score(y_test, y_pred, average='weighted')))
测试准确率 0.6778572623828648
测试 F1 得分: 0.664561533967402
结果提高了 1%。
对于这篇文章,我使用训练集来训练 doc2vec。然而,在Gensim 的教程中,使用了整个数据集进行训练。我尝试了这种方法,使用整个数据集训练 doc2vec 分类器,用于我们的消费者投诉分类,我能够获得 70%的准确率。你可以在这里找到那个笔记本,它是一种稍有不同的方法。
上述分析的Jupyter 笔记本可以在Github上找到。我期待听到任何问题。
简介: Susan Li 正在通过一篇文章改变世界。她是位于加拿大多伦多的高级数据科学家。
原文。转载已获许可。
相关内容:
-
使用 SpaCy 进行文本分类的机器学习
-
使用 LSA、PLSA、LDA 和 lda2Vec 进行主题建模
-
使用 Scikit-Learn 进行多类别文本分类
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
多类别文本分类模型比较与选择
原文:
www.kdnuggets.com/2018/11/multi-class-text-classification-model-comparison-selection.html/2
评论
Word2vec 与逻辑回归
Word2vec像doc2vec一样,属于文本预处理阶段。具体来说,是将文本转换为一排数字的部分。Word2vec 是一种映射方式,可以使意义相似的词具有相似的向量表示。
Word2vec 背后的想法相当简单:我们希望使用周围的词来表示目标词,通过一个神经网络,其隐藏层编码词表示。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在 IT 领域的工作
首先我们加载一个 word2vec 模型。该模型由 Google 在1000 亿字的 Google 新闻语料库上进行预训练。
from gensim.models import Word2Vec
wv = gensim.models.KeyedVectors.load_word2vec_format("GoogleNews-vectors-negative300.bin.gz", binary=True)
wv.init_sims(replace=True)
我们可能想要探索一些词汇。
from itertools import islice
list(islice(wv.vocab, 13030, 13050))

图 9
基于 BOW 的方法包括平均、求和、加权相加。常见的方法是对两个词向量取平均。因此,我们将遵循最常见的方法。
我们将对文本进行分词,并将分词应用于“post”列,然后对分词后的文本应用词向量平均。
现在是时候看看逻辑回归分类器在这些词平均文档特征上的表现了。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(n_jobs=1, C=1e5)
logreg = logreg.fit(X_train_word_average, train['tags'])
y_pred = logreg.predict(X_test_word_average)
print('accuracy %s' % accuracy_score(y_pred, test.tags))
print(classification_report(test.tags, y_pred,target_names=my_tags))

图 10
这让人失望,是我们迄今为止见过的最糟糕的。
Doc2vec 与逻辑回归
word2vec的相同思想可以扩展到文档中,在这里我们学习的是句子或文档的特征表示,而不是词。要对word2vec有一个大致了解,可以将其视为文档中所有词向量表示的数学平均值。Doc2Vec扩展了word2vec的思想,然而词语只能捕捉到一定程度,有时我们需要的是文档之间的关系,而不仅仅是词。
对于我们的 Stack Overflow 问题和标签数据,训练 doc2vec 模型的方法与训练多类别文本分类与 Doc2vec 和逻辑回归时非常相似。
首先,我们对句子进行标记。Gensim 的 Doc2Vec实现要求每个文档/段落都必须有一个相关联的标签,我们通过使用TaggedDocument方法来实现。格式将为“TRAIN_i”或“TEST_i”,其中“i”是帖子的虚拟索引。
根据Gensim doc2vec 教程,其 doc2vec 类是在整个数据集上训练的,我们也将进行相同的操作。让我们看看标记文档的样子:
all_data[:2]

图 11
在训练 doc2vec 时,我们将调整以下参数:
-
dm=0,使用分布式词袋(DBOW)。 -
vector_size=300,300 维的特征向量。 -
negative=5,指定应该抽取多少个“噪声词”。 -
min_count=1,忽略所有总频率低于此的词。 -
alpha=0.065,初始学习率。
我们初始化模型并训练 30 个 epoch。
接下来,我们从训练好的 doc2vec 模型中获取向量。
最后,我们得到一个由 doc2vec 特征训练的逻辑回归模型。
logreg = LogisticRegression(n_jobs=1, C=1e5)
logreg.fit(train_vectors_dbow, y_train)
logreg = logreg.fit(train_vectors_dbow, y_train)
y_pred = logreg.predict(test_vectors_dbow)
print('accuracy %s' % accuracy_score(y_pred, y_test))
print(classification_report(y_test, y_pred,target_names=my_tags))

图 12
我们获得了 80%的准确率,比 SVM 高出 1%。
使用 Keras 的 BOW
最后,我们将使用Keras进行文本分类,Keras 是一个 Python 深度学习库。
以下代码大部分来自于Google 工作坊。过程如下:
-
将数据分成训练集和测试集。
-
使用
tokenizer方法来计算我们词汇中的唯一词,并将每个词分配到索引。 -
调用
fit_on_texts()会自动创建我们的词汇的词索引查找。 -
我们通过向分词器传递
num_words参数来限制我们的词汇为前几个词。 -
使用我们的分词器,我们现在可以使用
texts_to_matrix方法来创建训练数据,然后传递给我们的模型。 -
我们向模型输入一个 one-hot 向量。
-
在我们将特征和标签转换为 Keras 可以读取的格式后,我们就准备好构建文本分类模型了。
-
当我们构建模型时,我们只需要告诉 Keras 输入数据的形状、输出数据的形状和每层的类型。Keras 会处理其余的部分。
-
在训练模型时,我们会调用
fit()方法,传入训练数据和标签、批量大小和训练轮数。

图 13
准确率是:
score = model.evaluate(x_test, y_test,
batch_size=batch_size, verbose=1)
print('Test accuracy:', score[1])

图 14
那么,哪个模型最适合这个特定的数据集呢?我会留给你去决定。
Jupyter notebook 可以在 Github 上找到。祝您一天愉快!
参考文献:
-
github.com/tensorflow/workshops/blob/master/extras/keras-bag-of-words/keras-bow-model.ipynb -
datascience.stackexchange.com/questions/20076/word2vec-vs-sentence2vec-vs-doc2vec
简介:Susan Li 正在以一篇文章改变世界。她是一位高级数据科学家,工作地点在加拿大多伦多。
原文。经许可转载。
相关内容:
-
使用 SpaCy 进行文本分类的机器学习
-
使用 Scikit-Learn 的多分类文本分类
-
使用 Scikit-Learn 进行命名实体识别和分类
更多相关话题
使用 Scikit-Learn 的多类别文本分类
原文:
www.kdnuggets.com/2018/08/multi-class-text-classification-scikit-learn.html
评论
由 Susan Li, 高级数据科学家

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
文本分类在商业世界中有许多应用。例如,新闻报道通常按主题组织;内容或产品通常按类别标记;用户可以根据他们在线谈论产品或品牌的方式被分类到不同的群体中...
然而,互联网上绝大多数的文本分类文章和教程都是二分类文本分类,例如电子邮件垃圾过滤(垃圾邮件与正常邮件)、情感分析(积极与消极)。在大多数情况下,我们现实中的问题要复杂得多。因此,这就是我们今天要做的事情:将消费者金融投诉分类为 12 个预定义类别。数据可以从data.gov下载。
我们使用 Python 和 Jupyter Notebook 来开发我们的系统,依靠 Scikit-Learn 进行机器学习组件。如果你想查看 PySpark的实现,可以阅读 下一篇文章。
问题制定
这个问题是监督文本分类问题,我们的目标是研究哪些监督机器学习方法最适合解决这个问题。
假设有一个新的投诉进来,我们希望将其分配到 12 个类别中的一个。分类器假设每个新的投诉被分配到一个且只有一个类别。这是一个多类别文本分类问题。我迫不及待想看看我们能取得什么成果!
数据探索
在深入训练机器学习模型之前,我们应该先查看一些示例以及每个类别中的投诉数量:
import pandas as pd
df = pd.read_csv('Consumer_Complaints.csv')
df.head()

图 1
对于这个项目,我们只需要两列——“产品”和“消费者投诉叙述”。
输入:Consumer_complaint_narrative
示例:“我在我的信用报告上有过时的信息,我之前已提出异议,这些信息尚未被删除,这些信息超过七年且不符合信用报告要求”
输出:产品
示例:信用报告
我们将删除“消费者投诉叙述”列中的缺失值,并添加一个将产品编码为整数的列,因为分类变量通常用整数比用字符串表示更好。
我们还创建了几个字典以备将来使用。
清理之后,这是我们将要处理的数据的前五行:
from io import StringIO
col = ['Product', 'Consumer complaint narrative']
df = df[col]
df = df[pd.notnull(df['Consumer complaint narrative'])]
df.columns = ['Product', 'Consumer_complaint_narrative']
df['category_id'] = df['Product'].factorize()[0]
category_id_df = df[['Product', 'category_id']].drop_duplicates().sort_values('category_id')
category_to_id = dict(category_id_df.values)
id_to_category = dict(category_id_df[['category_id', 'Product']].values)
df.head()

图 2
不平衡类
我们看到每个产品的投诉数量不平衡。消费者的投诉更倾向于债务催收、信用报告和抵押贷款。
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
df.groupby('Product').Consumer_complaint_narrative.count().plot.bar(ylim=0)
plt.show()

图 3
当我们遇到这种问题时,使用标准算法往往会有困难。传统算法往往偏向于主要类别,而不考虑数据分布。在最坏的情况下,少数类别会被视为异常值并被忽略。对于一些情况,如欺诈检测或癌症预测,我们需要仔细配置模型或人工平衡数据集,例如通过欠采样或过采样每个类别。
然而,在我们学习不平衡数据的情况下,主要类别可能是我们非常感兴趣的。希望有一个分类器能够对主要类别提供高预测准确度,同时对少数类别保持合理的准确度。因此,我们将保持原样。
文本表示
分类器和学习算法不能直接处理原始文本文档,因为它们大多数期望固定大小的数值特征向量,而不是具有可变长度的原始文本文档。因此,在预处理步骤中,文本会被转换为更易于处理的表示。
从文本中提取特征的一种常见方法是使用词袋模型:在该模型中,对于每个文档(在我们这里是投诉叙述),考虑的是词的出现(通常还有频率),但忽略它们出现的顺序。
具体来说,对于数据集中每个术语,我们将计算一个叫做词频-逆文档频率的度量,简称 tf-idf。我们将使用sklearn.feature_extraction.text.TfidfVectorizer为每个消费者投诉叙述计算tf-idf向量:
-
sublinear_df设置为True以使用频率的对数形式。 -
min_df是词必须出现在的最小文档数量,以便保留。 -
norm设置为l2,以确保我们所有的特征向量都有一个欧几里得范数为 1。 -
ngram_range设置为(1, 2)以表示我们希望同时考虑单词和双词组合。 -
stop_words设置为"english"以去除所有常见代词("a"、"the"等),以减少噪声特征的数量。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(sublinear_tf=True, min_df=5, norm='l2', encoding='latin-1', ngram_range=(1, 2), stop_words='english')
features = tfidf.fit_transform(df.Consumer_complaint_narrative).toarray()
labels = df.category_id
features.shape
(4569, 12633)
现在,每个 4569 个消费者投诉叙述由 12633 个特征表示,表示不同单词和双词组合的 tf-idf 分数。
我们可以使用 sklearn.feature_selection.chi2 来找到与每个产品最相关的术语:
from sklearn.feature_selection import chi2
import numpy as np
N = 2
for Product, category_id in sorted(category_to_id.items()):
features_chi2 = chi2(features, labels == category_id)
indices = np.argsort(features_chi2[0])
feature_names = np.array(tfidf.get_feature_names())[indices]
unigrams = [v for v in feature_names if len(v.split(' ')) == 1]
bigrams = [v for v in feature_names if len(v.split(' ')) == 2]
print("# '{}':".format(Product))
print(" . Most correlated unigrams:\n. {}".format('\n. '.join(unigrams[-N:])))
print(" . Most correlated bigrams:\n. {}".format('\n. '.join(bigrams[-N:])))
'银行账户或服务':
最相关的单词:
-
银行
-
透支
最相关的双词组合:
-
透支费用
-
活期账户
'消费贷款':
最相关的单词:
-
汽车
-
车辆
最相关的双词组合:
-
车辆 xxxx
-
丰田金融
'信用卡':
最相关的单词:
-
花旗
-
卡
最相关的双词组合:
-
年费
-
信用卡
'信用报告':
最相关的单词:
-
Experian
-
Equifax
最相关的双词组合:
-
TransUnion
-
信用报告
'债务催收':
最相关的单词:
-
讨债
-
债务
最相关的双词组合:
-
收债
-
讨债机构
'汇款':
最相关的单词:
-
吴
-
PayPal
最相关的双词组合:
-
西联汇款
-
汇款
'按揭':
最相关的单词:
-
修改
-
抵押贷款
最相关的双词组合:
-
抵押贷款公司
-
贷款修改
'其他金融服务':
最相关的单词:
-
牙科
-
护照
最相关的双词组合:
-
帮助支付
-
声明支付
'发薪日贷款':
最相关的单词:
-
借款
-
发薪日
最相关的双词组合:
-
大致情况
-
发薪日贷款
'预付卡':
最相关的单词:
-
服务
-
预付
最相关的双词组合:
-
获取资金
-
预付卡
'学生贷款':
最相关的单词:
-
学生
-
Navient
最相关的双词组合:
-
学生贷款
-
学生贷款
'虚拟货币':
最相关的单词:
-
处理
-
https
最相关的双词组合:
-
xxxx 服务提供商
-
资金需求
这些都很有道理,不是吗?
多类别分类器:特征与设计
-
为了训练监督分类器,我们首先将“消费者投诉叙述”转换为数字向量。我们探索了诸如 TF-IDF 加权向量等向量表示。
-
在获得文本的向量表示后,我们可以训练监督分类器,以训练未见的“消费者投诉叙述”并预测它们属于哪个“产品”。
在完成上述所有数据转换后,现在我们已经拥有了所有特征和标签,是时候训练分类器了。对于这种类型的问题,我们可以使用多种算法。
朴素贝叶斯分类器:最适合词频统计的是多项式变体:
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.naive_bayes import MultinomialNB
X_train, X_test, y_train, y_test = train_test_split(df['Consumer_complaint_narrative'], df['Product'], random_state = 0)
count_vect = CountVectorizer()
X_train_counts = count_vect.fit_transform(X_train)
tfidf_transformer = TfidfTransformer()
X_train_tfidf = tfidf_transformer.fit_transform(X_train_counts)
clf = MultinomialNB().fit(X_train_tfidf, y_train)
在拟合训练集之后,让我们做一些预测。
print(clf.predict(count_vect.transform(["This company refuses to provide me verification and validation of debt per my right under the FDCPA. I do not believe this debt is mine."])))
[‘债务催收’]
df[df['Consumer_complaint_narrative'] == "This company refuses to provide me verification and validation of debt per my right under the FDCPA. I do not believe this debt is mine."]

图 4
print(clf.predict(count_vect.transform(["I am disputing the inaccurate information the Chex-Systems has on my credit report. I initially submitted a police report on XXXX/XXXX/16 and Chex Systems only deleted the items that I mentioned in the letter and not all the items that were actually listed on the police report. In other words they wanted me to say word for word to them what items were fraudulent. The total disregard of the police report and what accounts that it states that are fraudulent. If they just had paid a little closer attention to the police report I would not been in this position now and they would n't have to research once again. I would like the reported information to be removed : XXXX XXXX XXXX"])))
[‘信用报告’]
df[df['Consumer_complaint_narrative'] == "I am disputing the inaccurate information the Chex-Systems has on my credit report. I initially submitted a police report on XXXX/XXXX/16 and Chex Systems only deleted the items that I mentioned in the letter and not all the items that were actually listed on the police report. In other words they wanted me to say word for word to them what items were fraudulent. The total disregard of the police report and what accounts that it states that are fraudulent. If they just had paid a little closer attention to the police report I would not been in this position now and they would n't have to research once again. I would like the reported information to be removed : XXXX XXXX XXXX"]

图 5
不错哦!
模型选择
我们现在准备实验不同的机器学习模型,评估它们的准确性,并找到潜在问题的来源。
我们将对以下四个模型进行基准测试:
-
Logistic Regression
-
(Multinomial)朴素贝叶斯
-
线性支持向量机
-
随机森林
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.model_selection import cross_val_score
models = [
RandomForestClassifier(n_estimators=200, max_depth=3, random_state=0),
LinearSVC(),
MultinomialNB(),
LogisticRegression(random_state=0),
]
CV = 5
cv_df = pd.DataFrame(index=range(CV * len(models)))
entries = []
for model in models:
model_name = model.__class__.__name__
accuracies = cross_val_score(model, features, labels, scoring='accuracy', cv=CV)
for fold_idx, accuracy in enumerate(accuracies):
entries.append((model_name, fold_idx, accuracy))
cv_df = pd.DataFrame(entries, columns=['model_name', 'fold_idx', 'accuracy'])
import seaborn as sns
sns.boxplot(x='model_name', y='accuracy', data=cv_df)
sns.stripplot(x='model_name', y='accuracy', data=cv_df,
size=8, jitter=True, edgecolor="gray", linewidth=2)
plt.show()

图 6
cv_df.groupby('model_name').accuracy.mean()
model_name
LinearSVC: 0.822890
LogisticRegression: 0.792927
MultinomialNB: 0.688519
RandomForestClassifier: 0.443826
名称:accuracy,dtype:float64
LinearSVC 和 Logistic Regression 比其他两个分类器表现更好,其中 LinearSVC 具有略微的优势,中位数准确率约为 82%。
模型评估
继续使用我们最好的模型(LinearSVC),我们将查看混淆矩阵,并展示预测标签与实际标签之间的差异。
model = LinearSVC()
X_train, X_test, y_train, y_test, indices_train, indices_test = train_test_split(features, labels, df.index, test_size=0.33, random_state=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import confusion_matrix
conf_mat = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(conf_mat, annot=True, fmt='d',
xticklabels=category_id_df.Product.values, yticklabels=category_id_df.Product.values)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show()

图 7
大多数预测结果都落在对角线(预测标签 = 实际标签)上,这是我们期望的。然而,也存在一些误分类,了解这些误分类的原因可能会很有趣:
from IPython.display import display
for predicted in category_id_df.category_id:
for actual in category_id_df.category_id:
if predicted != actual and conf_mat[actual, predicted] >= 10:
print("'{}' predicted as '{}' : {} examples.".format(id_to_category[actual], id_to_category[predicted], conf_mat[actual, predicted]))
display(df.loc[indices_test[(y_test == actual) & (y_pred == predicted)]][['Product', 'Consumer_complaint_narrative']])
print('')

图 8 
图 9
如你所见,一些误分类的投诉涉及多个主题(例如,涉及信用卡和信用报告的投诉)。这种错误将始终发生。
我们再次使用卡方检验来找出与各类别相关性最高的术语:
model.fit(features, labels)
N = 2
for Product, category_id in sorted(category_to_id.items()):
indices = np.argsort(model.coef_[category_id])
feature_names = np.array(tfidf.get_feature_names())[indices]
unigrams = [v for v in reversed(feature_names) if len(v.split(' ')) == 1][:N]
bigrams = [v for v in reversed(feature_names) if len(v.split(' ')) == 2][:N]
print("# '{}':".format(Product))
print(" . Top unigrams:\n . {}".format('\n . '.join(unigrams)))
print(" . Top bigrams:\n . {}".format('\n . '.join(bigrams)))
‘银行账户或服务’:
顶级单词组:
-
bank
-
account
顶级双词组:
-
debit card
-
overdraft fees
‘消费者贷款’:
顶级单词组:
-
vehicle
-
car
顶级双词组:
-
personal loan
-
history xxxx
‘信用卡’:
顶级单词组:
-
card
-
discover
顶级双词组:
-
credit card
-
discover card
‘信用报告’:
顶级单词组:
-
equifax
-
transunion
顶级双词组:
-
xxxx account
-
trans union
‘债务催收’:
顶级单词组:
-
debt
-
collection
顶级双词组:
-
account credit
-
time provided
‘资金转移’:
顶级单词组:
-
paypal
-
transfer
顶级双词组:
-
money transfer
-
send money
‘按揭’:
顶级单词组:
-
mortgage
-
escrow
顶级双词组:
-
loan modification
-
mortgage company
‘其他金融服务’:
顶级单词组:
-
passport
-
dental
顶级双词组:
-
stated pay
-
help pay
‘发薪日贷款’:
顶级单词组:
-
payday
-
loan
顶级双词组:
-
payday loan
-
pay day
‘预付卡’:
顶级单词组:
-
prepaid
-
serve
顶级双词组:
-
预付卡
-
use card
‘学生贷款’:
顶级单词组:
-
navient
-
loans
顶级双词组:
-
student loan
-
sallie mae
‘虚拟货币’:
顶级单词组:
-
https
-
tx
顶级双词组:
-
money want
-
xxxx provider
它们在我们的预期范围内保持一致。
最后,我们打印出每个类别的分类报告:
from sklearn import metrics
print(metrics.classification_report(y_test, y_pred, target_names=df['Product'].unique()))

图 9
源代码可以在Github找到。期待收到您的反馈或问题。
简介:Susan Li 正在通过一篇文章改变世界。她是一位位于加拿大多伦多的高级数据科学家。
原文。已获得许可重新发布。
相关:
-
使用 LSTMs、CNNs 和预训练词向量进行文本分类与嵌入可视化
-
TF-IDF 是什么?
-
自然语言处理要点:入门 NLP
更多相关话题
Tensorflow 中的多任务学习:第一部分
原文:
www.kdnuggets.com/2016/07/multi-task-learning-tensorflow-part-1.html/2
交替训练
第一个解决方案特别适合于你会有一批任务 1 的数据,然后是一批任务 2 的数据的情况。
记住,Tensorflow 会自动确定操作所需的计算,并仅进行这些计算。这意味着如果我们只在一个任务上定义优化器,它只会训练计算该任务所需的参数——并且不会动其他参数。由于任务 1 仅依赖于任务 1 和共享层,任务 2 层将不会被触及。让我们画另一个图示,显示每个任务末尾的期望优化器。

# GRAPH CODE
# ============
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 20], name="Y1")
Y2 = tf.placeholder("float", [10, 20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights, name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights, name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights, name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
# optimisers
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
我们可以通过交替调用每个任务的优化器来进行多任务学习,这意味着我们可以不断将一些信息从一个任务转移到另一个任务。从宽泛的意义上讲,我们正在发现任务之间的“共性”。以下代码实现了这一点,如果你在跟随教程,请将其粘贴到之前代码的底部:
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
for iters in range(10):
if np.random.rand() < 0.5:
_, Y1_loss = session.run([Y1_op, Y1_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y1_loss)
else:
_, Y2_loss = session.run([Y2_op, Y2_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Y2_loss)
提示:何时交替训练效果较好?
当你为不同任务有两个不同的数据集时(例如,从英语翻译成法语和英语翻译成德语),交替训练是个好主意。通过这种方式设计网络,你可以在不需要找到更多任务特定训练数据的情况下提高每个任务的性能。
交替训练是你最常遇到的情况,因为没有多少数据集有两个或更多的输出。我们会讲一个例子,但最清晰的例子是你想在任务中建立层次结构。例如,在视觉任务中,你可能希望一个任务预测物体的旋转,另一个任务预测如果你改变相机角度物体会是什么样子。这两个任务显然是相关的——实际上,旋转可能发生在图像生成之前。
提示:何时交替训练效果不佳?
交替训练容易对特定任务产生偏差。第一种方式很明显——如果你的一个任务的数据集比另一个任务大得多,那么如果你按数据集大小的比例进行训练,你的共享层将包含关于更重要任务的更多信息。
第二种情况则不然。如果你交替训练,模型中的最终任务将对参数产生偏差。没有明显的方法可以克服这个问题,但这确实意味着在你不需要交替训练的情况下,你不应该这样做。
同时训练 - 联合训练
当你有一个包含多个标签的数据集时,你真正需要的是同时训练这些任务。问题是,如何保持任务特定函数的独立性?答案出奇简单 - 你只需将各个任务的损失函数相加,并在此基础上进行优化。下面是一个展示可以联合训练的网络的图示,附有相应的代码:

# GRAPH CODE
# ============
# Import Tensorflow and Numpy
import Tensorflow as tf
import numpy as np
# ======================
# Define the Graph
# ======================
# Define the Placeholders
X = tf.placeholder("float", [10, 10], name="X")
Y1 = tf.placeholder("float", [10, 20], name="Y1")
Y2 = tf.placeholder("float", [10, 20], name="Y2")
# Define the weights for the layers
initial_shared_layer_weights = np.random.rand(10,20)
initial_Y1_layer_weights = np.random.rand(20,20)
initial_Y2_layer_weights = np.random.rand(20,20)
shared_layer_weights = tf.Variable(initial_shared_layer_weights, name="share_W", dtype="float32")
Y1_layer_weights = tf.Variable(initial_Y1_layer_weights, name="share_Y1", dtype="float32")
Y2_layer_weights = tf.Variable(initial_Y2_layer_weights, name="share_Y2", dtype="float32")
# Construct the Layers with RELU Activations
shared_layer = tf.nn.relu(tf.matmul(X,shared_layer_weights))
Y1_layer = tf.nn.relu(tf.matmul(shared_layer,Y1_layer_weights))
Y2_layer = tf.nn.relu(tf.matmul(shared_layer,Y2_layer_weights))
# Calculate Loss
Y1_Loss = tf.nn.l2_loss(Y1-Y1_layer)
Y2_Loss = tf.nn.l2_loss(Y2-Y2_layer)
Joint_Loss = Y1_Loss + Y2_Loss
# optimisers
Optimiser = tf.train.AdamOptimizer().minimize(Joint_Loss)
Y1_op = tf.train.AdamOptimizer().minimize(Y1_Loss)
Y2_op = tf.train.AdamOptimizer().minimize(Y2_Loss)
# Joint Training
# Calculation (Session) Code
# ==========================
# open the session
with tf.Session() as session:
session.run(tf.initialize_all_variables())
_, Joint_Loss = session.run([Optimiser, Joint_Loss],
{
X: np.random.rand(10,10)*10,
Y1: np.random.rand(10,20)*10,
Y2: np.random.rand(10,20)*10
})
print(Joint_Loss)
结论和下一步
在这篇文章中,我们已经探讨了深度神经网络中多任务学习的基本原理。如果你之前使用过 Tensorflow,并且有自己的项目,希望这能为你提供足够的启示来开始。
对于那些想要更详细、具体的示例来展示如何提高多任务性能的人,请关注教程的第二部分,我们将深入探讨自然语言处理,构建一个用于浅层解析和词性标注的多任务模型。
个人简介:Jonathan Godwin 目前在 UCL 学习机器学习硕士,专攻深度多任务学习和自然语言处理。他将于九月完成学业,并寻求可以在有趣问题上运用这一技能的工作或研究岗位。
原文。经授权转载。
相关:
-
TensorFlow 中的递归网络介绍
-
TensorFlow 的优缺点
-
Scikit Flow:使用 TensorFlow 和 Scikit-learn 轻松深度学习
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多此主题
多维多传感器时间序列数据分析框架
原文:
www.kdnuggets.com/2021/02/multidimensional-multi-sensor-time-series-data-analysis-framework.html
评论
由 Ajay Arunachalam,厄勒布大学
你好,朋友们。在这篇博客文章中,我将向你介绍我的包“msda”,它对时间序列传感器数据分析非常有用。还提供了关于时间序列数据的简要介绍。演示笔记本可以在这里找到。
使用该包进行“无监督特征选择”的特定应用案例可以在博客文章这里中找到。
什么是时间序列数据?
时间序列数据是指在特定时间段内收集的信息。例如,一组在特定等间隔下观察到的传感器数据,每个传感器都可以被归类为时间序列。如果数据是无时间顺序或一次性收集的,那就不是时间序列数据。
时间序列数据有两种类型:
1- 存货系列(在特定时间点的属性度量)
2- 流量系列(在时间间隔内的活动度量)
时间序列数据的组成部分
要分析时间序列数据,我们需要了解不同的模式类型。这些模式将共同创建时间序列上的观察集合。
1) 趋势: 时间序列中存在的长期模式。它表示从时间序列中过滤出的低、中、高频率的变化。
如果时间序列数据中没有上升或下降模式,则视为平稳的均值。
有两种趋势模式:
-
确定性: 在这种情况下,时间序列中的冲击效应被消除。
-
随机: 这是一个过程,在其中,冲击效应永远不会被消除,因为它们永久改变了时间序列的水平。
2) 循环: 模式表现为围绕指定趋势的上下波动。时间周期不固定,通常由至少 2 个月的时间组成。
3) 季节性: 反映规律性波动的模式。这些短期波动由于季节性和个人习惯因素而发生。数据面临定期和可预测的变化,这些变化发生在日历的规律间隔上。它总是包含固定且已知的周期。
季节性主要来源:
-
气候
-
机构
-
社会习惯和实践
-
日历等。
模型用于在时间序列中创建季节性成分:
-
加法模型——这是一个将季节性成分与趋势成分相加的模型。
-
乘法 模型— 在此模型中,如果时间序列中没有趋势成分,则季节成分与截距相乘。
4) 不规则: 这是时间序列中不可预测的成分。
时间序列数据 vs 横截面数据
时间序列数据由在特定时间间隔收集的单一变量的数据组成。另一方面,横截面数据由在特定时间间隔从不同来源收集的多个变量的数据组成。公司股票市场数据在一年中的定期收集是时间序列数据的一个例子。但当公司销售收入、销售量在过去三个月内收集时,则作为横截面数据的例子。时间序列数据主要用于在较长时间内获取结果,而横截面数据则集中在特定时间点从调查中获得的信息。
什么是时间序列分析?
分析的目的是理解时间序列产生的结构和功能。
用于分析时间序列数据的两种方法是 -
-
在时域中
-
在频域中
时间序列分析主要用于 -
-
分解时间序列
-
识别和建模基于时间的依赖关系
-
预测
-
识别和建模系统变异
时间序列分析的需求
为了成功建模,时间序列在机器学习和深度学习中非常重要。时间序列分析用于理解用于生成观察结果的内部结构和功能。时间序列分析用于 -
-
**描述 — **识别相关数据中的模式。换句话说,识别时间序列中的趋势和季节性的变化。
-
**解释 — **进行数据的理解和建模。
-
**预测 — **对短期趋势进行从先前观察中得出的预测。
-
**发明分析 — **分析时间序列数据中任何事件产生的效果。
-
**质量控制 — **当特定尺寸偏离时,会提供警报。
时间序列分析的应用

时间序列应用领域示例
现在,我们已经了解了时间序列的基础知识,让我们深入探讨 MSDA 包及其详细信息。
什么是 MDSA?
MSDA 是一个开源低代码的多传感器数据分析库,旨在减少时间序列多传感器数据分析与实验中的假设到洞察的周期时间。它使用户能够快速有效地执行端到端的概念验证实验。该模块通过捕捉变异和趋势来识别多维时间序列中的事件,从而建立关系,旨在识别相关特征,有助于从原始传感器信号中进行特征选择。
包括内容:-
-
时间序列分析。
-
每个传感器列随时间变化(增加、减少、相等)。
-
每列值相对于其他列的变化,以及每列与其他列之间的最大变化比率。
-
与趋势数组建立关系,以识别最合适的传感器。
-
用户可以选择窗口长度,然后检查每个窗口中的平均值和每个传感器列的标准差。
-
它提供了每个传感器列值超过或低于阈值的增长/衰退值的计数。
-
特征工程
a) 涉及各种聚合窗口中值的趋势的特征:窗口中的平均值、标准差的变化及变化率。
b) 变化率、增长率与标准差的比率。
c) 随时间的变化。
d) 随时间变化的速率。
e) 增长或衰退。
f) 增长或衰退的速率。
g) 超过或低于阈值的值计数。
概述:-
从多维异质/同质时间序列多传感器数据中进行特征/传感器选择的原型。框架的直观表示如下所示。

多维时间序列数据特征选择的图示表示
功能包括:-

MSDA 的核心功能
MSDA 工作流程:-

MSDA 算法工作流程
终端安装:-
安装 msda 最简单的方法是使用 pip。
pip install msda
或
$ git clone https://github.com/ajayarunachalam/msda
$ cd msda
$ python setup.py install
在 Jupyter Notebook 中安装:-
!pip install msda
请按照演示示例中的其余部分操作 [这里] — github.com/ajayarunachalam/msda/tree/master/demo.ipynb
谁应该使用 MSDA?
MSDA 是一个开源库,任何人都可以使用。在我看来,MSDA 的理想目标受众是:
-
学生。
-
进行快速 POC 测试的研究人员。
-
有经验的数据科学家,希望提高生产力。
-
喜欢低代码解决方案的公民数据科学家。
-
从事概念验证项目的 数据科学专业人员和顾问。
联系
你可以通过 ajay.arunachalam08@gmail.com 联系我
感谢阅读。祝学习愉快 😃
参考资料
时间序列是一系列按时间顺序编排(或列出或绘制)的数据点。最常见的是,时间序列是……
大家好,非常感谢你们阅读我的博客并激励我继续写作。你可以在这里阅读我所有的博客。
个人简介: Ajay Arunachalam (个人网站) 是瑞典厄勒布鲁大学应用自主传感器系统中心的人工智能博士后研究员。在此之前,他在 True Corporation 担任数据科学家,处理 PB 级数据,构建和部署深度模型。他真正相信,AI 系统的透明性是当下的需求,才能完全接受 AI 的力量。基于这一点,他一直致力于让 AI 更加普及,并更倾向于构建可解释的模型。他的兴趣包括应用人工智能、机器学习、深度学习、深度强化学习和自然语言处理,特别是学习良好的表示。通过在现实问题中的经验,他完全认识到,找到良好的表示是设计能够解决超越人类智能的有趣挑战性现实问题的系统的关键,并最终解释我们无法理解的复杂数据。为实现这一目标,他设想了一种可以从未标记和标记数据中学习特征表示的学习算法,无论是否有人的互动进行指导,并且在不同的抽象层次上,以弥合低级数据和高级抽象概念之间的差距。
原文。经授权转载。
相关:
-
为高频流数据构建 AI 模型
-
R 中的简单直观集成学习
-
用于比较、绘制和评估回归模型的简单 Python 包
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
更多相关主题
多标签分类:使用 Python 的 Scikit-Learn 入门
原文:
www.kdnuggets.com/2023/08/multilabel-classification-introduction-python-scikitlearn.html

图片来源:Freepik
在机器学习任务中,分类是一种监督学习方法,用于根据输入数据预测标签。例如,我们希望根据某人的历史特征预测他们是否对销售产品感兴趣。通过使用可用的训练数据训练机器学习模型,我们可以对传入的数据执行分类任务。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
我们经常遇到经典的分类任务,例如二分类(两个标签)和多分类(多个标签)。在这种情况下,我们会训练分类器,模型将尝试从所有可用标签中预测一个标签。用于分类的数据集类似于下图所示的图像。

上图显示,目标(销售产品)在二分类中包含两个标签,而在多分类中包含三个标签。模型将从可用特征中进行训练,然后仅输出一个标签。
多标签分类不同于二分类或多分类。在多标签分类中,我们不会仅预测一个输出标签。相反,多标签分类会尝试预测尽可能多的适用于输入数据的标签。输出可以是没有标签到最大数量的可用标签。
多标签分类通常用于文本数据分类任务。例如,以下是多标签分类的示例数据集。

在上面的示例中,假设 Text 1 到 Text 5 是可以分类到四个类别中的句子:事件、体育、流行文化和自然。通过上面的训练数据,多标签分类任务预测哪个标签适用于给定的句子。每个类别彼此独立,因为它们不是互斥的;每个标签可以被视为独立的。
更详细的信息可以看到,Text 1 标记了体育和流行文化,而 Text 2 标记了流行文化和自然。这表明每个标签是相互独立的,多标签分类可以同时输出没有标签或所有标签的预测结果。
介绍完毕,让我们尝试用 Scikit-Learn 构建多分类器。
使用 Scikit-Learn 进行多标签分类
本教程将使用 Kaggle 上公开提供的生物医学 PubMed 多标签分类数据集。数据集包含各种特征,但我们只使用 abstractText 特征及其 MeSH 分类(A: 解剖学,B: 生物体,C: 疾病等)。样本数据如下图所示。

上述数据集显示每篇论文可以被分类到多个类别中,这就是多标签分类的情况。利用这个数据集,我们可以用 Scikit-Learn 构建多标签分类器。在训练模型之前,让我们准备数据集。
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
df = pd.read_csv('PubMed Multi Label Text Classification Dataset Processed.csv')
df = df.drop(['Title', 'meshMajor', 'pmid', 'meshid', 'meshroot'], axis =1)
X = df["abstractText"]
y = np.asarray(df[df.columns[1:]])
vectorizer = TfidfVectorizer(max_features=2500, max_df=0.9)
vectorizer.fit(X)
在上面的代码中,我们将文本数据转换为TF-IDF表示形式,以便我们的 Scikit-Learn 模型可以接受训练数据。此外,我跳过了预处理数据的步骤,如停用词去除,以简化教程。
数据转换后,我们将数据集拆分为训练数据集和测试数据集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=101)
X_train_tfidf = vectorizer.transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
在所有准备工作完成后,我们将开始训练我们的多标签分类器。在 Scikit-Learn 中,我们将使用MultiOutputClassifier对象来训练多标签分类器模型。该模型的策略是为每个标签训练一个分类器。基本上,每个标签都有其自己的分类器。
在这个示例中,我们将使用逻辑回归,而 MultiOutputClassifier 将它们扩展到所有标签。
from sklearn.multioutput import MultiOutputClassifier
from sklearn.linear_model import LogisticRegression
clf = MultiOutputClassifier(LogisticRegression()).fit(X_train_tfidf, y_train)
我们可以更改模型并调整传递给 MultiOutputClassifier 的模型参数,因此根据您的需求进行管理。训练后,让我们使用模型来预测测试数据。
prediction = clf.predict(X_test_tfidf)
prediction

预测结果是每个 MeSH 类别的标签数组。每一行代表一个句子,每一列代表一个标签。
最后,我们需要评估我们的多标签分类器。我们可以使用准确率指标来评估模型。
from sklearn.metrics import accuracy_score
print('Accuracy Score: ', accuracy_score(y_test, prediction))
准确率得分: 0.145
准确率得分结果为 0.145,这表明模型仅能在不到 14.5% 的时间内预测正确的标签组合。然而,准确率得分在多标签预测评估中存在不足。准确率得分要求每个句子中所有标签都必须出现在准确的位置,否则将被视为错误。
例如,第一行预测与测试数据之间只差一个标签。

如果标签组合不同,则会被视为错误预测。因此,我们的模型得分较低。
为了缓解这个问题,我们必须评估标签预测而不是它们的标签组合。在这种情况下,我们可以依赖 汉明损失 评估指标。汉明损失通过将错误预测的数量与标签总数的比例来计算。由于汉明损失是一个损失函数,分数越低越好(0 表示没有错误预测,1 表示所有预测都错误)。
from sklearn.metrics import hamming_loss
print('Hamming Loss: ', round(hamming_loss(y_test, prediction),2))
汉明损失: 0.13
我们的多标签分类器汉明损失模型为 0.13,这意味着我们的模型在 13% 的时间内会有错误预测。这意味着每个标签预测可能有 13% 的错误。
结论
多标签分类是一种机器学习任务,其中输出可能没有标签或根据输入数据所有可能的标签。这与二分类或多分类不同,在二分类或多分类中,标签输出是互斥的。
使用 Scikit-Learn MultiOutputClassifier,我们可以开发多标签分类器,其中我们为每个标签训练一个分类器。对于模型评估,最好使用汉明损失指标,因为准确率可能不能完全准确地反映情况。
Cornellius Yudha Wijaya 是一名数据科学助理经理和数据撰稿人。他在全职工作于 Allianz Indonesia 的同时,喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
更多相关话题
多标签自然语言处理:类别不平衡和损失函数方法的分析
原文:
www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html
多标签自然语言处理(NLP)指的是将多个标签分配给给定的文本输入,而不仅仅是一个标签。在传统的 NLP 任务中,例如文本分类或情感分析,每个输入通常根据其内容分配一个标签。然而,在许多实际场景中,一段文本可能同时属于多个类别或表达多种情感。
多标签自然语言处理很重要,因为它允许我们从文本数据中捕捉更细致和复杂的信息。例如,在客户反馈分析领域,一条客户评论可能同时表达积极和消极的情感,或者可能涉及产品或服务的多个方面。通过为这些输入分配多个标签,我们可以更全面地理解客户的反馈,并采取更有针对性的措施来解决他们的关切。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
本文深入探讨了 Provectus 使用多标签 NLP 的一个值得注意的案例。
背景:
一位客户找到我们,请求帮助自动标记某种类型的文档。乍一看,这个任务似乎简单易解。然而,当我们处理这个案例时,遇到了一个注释不一致的数据集。尽管我们的客户面临了类数变化和审查团队随时间变化的挑战,他们仍然投入了大量精力来创建一个具有多种注释的多样化数据集。虽然标签中存在一些不平衡和不确定性,但这个数据集为分析和进一步探索提供了宝贵的机会。
让我们更详细地查看数据集,探讨指标和我们的方法,并回顾 Provectus 如何解决多标签文本分类的问题。
数据集概述
数据集包含 14,354 个观测值,124 个独特的类别(标签)。我们的任务是为每个观测值分配一个或多个类别。
表 1 提供了数据集的描述统计信息。
平均而言,我们每个观察值大约有两个类别,每个类别有大约 261 个不同的文本描述。

表 1:数据集统计
在图 1 中,我们看到顶部图中的类别分布,我们在数据集中有一定数量的 HEAD 标签,其出现频率最高。还需注意,大多数类别的出现频率较低。

在底部图中,我们看到在数据集中,最佳表示的类别与低显著性类别之间存在频繁的重叠。
我们改变了将数据集拆分为训练/验证/测试集的过程。我们没有使用传统方法,而是采用了迭代分层抽样,以提供标签关系的良好平衡分布。为此,我们使用了 Scikit Multi-learn。
from skmultilearn.model_selection import iterative_train_test_split
mlb = MultiLabelBinarizer()
def balanced_split(df, mlb, test_size=0.5):
ind = np.expand_dims(np.arange(len(df)), axis=1)
mlb.fit_transform(df["tag"])
labels = mlb.transform(df["tag"])
ind_train, _, ind_test, _ = iterative_train_test_split(
ind, labels, test_size
)
return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]]
df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
我们获得了以下分布:
-
训练数据集包含 60% 的数据,并涵盖所有 124 个标签。
-
验证数据集包含 20% 的数据,并涵盖所有 124 个标签。
-
测试数据集包含 20% 的数据,并涵盖所有 124 个标签。
应用的指标
多标签分类是一种监督机器学习算法,它允许我们为单个数据样本分配多个标签。它不同于二分类,后者模型仅预测两个类别,也不同于多类别分类,后者模型仅预测一个样本的多个类别之一。
多标签分类性能的评估指标与多类别(或二分类)分类中的指标本质上不同,因为分类问题的固有差异。更多详细信息可以在维基百科上找到。
我们选择了最适合我们的指标:
-
精确度 衡量模型所做的所有正预测中真实正预测的比例。
-
召回率 衡量所有实际正样本中真实正预测的比例。
-
F1 分数 是精确度和召回率的调和平均数,有助于恢复两者之间的平衡。
-
汉明损失 是预测错误的标签的比例。
我们还跟踪预测标签的数量,在集合 {定义为标签的计数,F1 分数 > 0 的标签}。
K. I. S. S. 方法
多标签分类是一种监督学习问题,其中单个实例或示例可以与多个标签或分类相关联,与传统的单标签分类不同,在单标签分类中,每个实例仅与单一类别标签相关联。
解决多标签分类问题的主要技术有两个类别:
-
问题转换方法
-
算法适应方法
问题转换方法使我们能够将多标签分类任务转化为多个单标签分类任务。例如,二进制相关(BR)基线方法将每个标签视为一个独立的二进制分类问题。在这种情况下,多标签问题被转化为多个单标签问题。
算法适应方法修改算法本身,以本地处理多标签数据,而不是将任务转化为多个单标签分类任务。这种方法的一个例子是 BERT 模型,它是一个预训练的基于变换器的语言模型,可以针对各种 NLP 任务进行微调,包括多标签文本分类。BERT 设计用来直接处理多标签数据,无需问题转换。
在使用 BERT 进行多标签文本分类的背景下,标准方法是使用二进制交叉熵(BCE)损失作为损失函数。BCE 损失是二进制分类问题中常用的损失函数,可以通过独立计算每个标签的损失,然后将损失总和来轻松扩展到处理多标签分类问题。在这种情况下,BCE 损失函数测量预测概率和真实标签之间的误差,其中预测概率来自 BERT 模型中的最终 sigmoid 激活层。
现在,让我们更深入地查看下图中的图 2。

图 2. 基线模型指标
左侧图表展示了“基线:BERT”和“基线:ML”指标的对比。因此,可以看出,对于“基线:BERT”,F1 和召回率分数约高出 1.5 倍,而“基线:ML”的精准率是模型 1 的 2 倍。通过分析右侧显示的预测类别的整体百分比,我们看到“基线:BERT”预测的类别是“基线:ML”的 10 倍以上。
由于“基线:BERT”的最大结果不到所有类别的 50%,结果相当令人沮丧。让我们想办法改善这些结果。
方法的黄金比例
根据杰出文章“具有长尾类别分布的多标签文本分类平衡方法”,我们了解到分布平衡损失可能是最适合我们的方案。
分布平衡损失
分布平衡损失是一种用于多标签文本分类问题的技术,用于解决类别分布中的不平衡问题。在这些问题中,一些类别的出现频率远高于其他类别,导致模型偏向于这些更频繁的类别。
为了解决这个问题,分布平衡损失旨在平衡每个样本在损失函数中的贡献。这是通过根据样本在数据集中的出现频率的倒数重新加权每个样本的损失来实现的。通过这样做,较少出现类别的贡献增加,较多出现类别的贡献减少,从而平衡整体类别分布。
这种技术已被证明在改善长尾类别分布问题的模型性能方面有效。通过减少频繁类别的影响和增加不频繁类别的影响,模型能够更好地捕捉数据中的模式,并产生更平衡的预测。

重采样类的实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class ResampleLoss(nn.Module):
def __init__(
self,
use_sigmoid=True,
partial=False,
loss_weight=1.0,
reduction="mean",
reweight_func=None,
weight_norm=None,
focal=dict(focal=True, alpha=0.5, gamma=2),
map_param=dict(alpha=10.0, beta=0.2, gamma=0.1),
CB_loss=dict(CB_beta=0.9, CB_mode="average_w"),
logit_reg=dict(neg_scale=5.0, init_bias=0.1),
class_freq=None,
train_num=None,
):
super(ResampleLoss, self).__init__()
assert (use_sigmoid is True) or (partial is False)
self.use_sigmoid = use_sigmoid
self.partial = partial
self.loss_weight = loss_weight
self.reduction = reduction
if self.use_sigmoid:
if self.partial:
self.cls_criterion = partial_cross_entropy
else:
self.cls_criterion = binary_cross_entropy
else:
self.cls_criterion = cross_entropy
# reweighting function
self.reweight_func = reweight_func
# normalization (optional)
self.weight_norm = weight_norm
# focal loss params
self.focal = focal["focal"]
self.gamma = focal["gamma"]
self.alpha = focal["alpha"]
# mapping function params
self.map_alpha = map_param["alpha"]
self.map_beta = map_param["beta"]
self.map_gamma = map_param["gamma"]
# CB loss params (optional)
self.CB_beta = CB_loss["CB_beta"]
self.CB_mode = CB_loss["CB_mode"]
self.class_freq = (
torch.from_numpy(np.asarray(class_freq)).float().cuda()
)
self.num_classes = self.class_freq.shape[0]
self.train_num = train_num # only used to be divided by class_freq
# regularization params
self.logit_reg = logit_reg
self.neg_scale = (
logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0
)
init_bias = (
logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0
)
self.init_bias = (
-torch.log(self.train_num / self.class_freq - 1) * init_bias
)
self.freq_inv = (
torch.ones(self.class_freq.shape).cuda() / self.class_freq
)
self.propotion_inv = self.train_num / self.class_freq
def forward(
self,
cls_score,
label,
weight=None,
avg_factor=None,
reduction_override=None,
**kwargs
):
assert reduction_override in (None, "none", "mean", "sum")
reduction = (
reduction_override if reduction_override else self.reduction
)
weight = self.reweight_functions(label)
cls_score, weight = self.logit_reg_functions(
label.float(), cls_score, weight
)
if self.focal:
logpt = self.cls_criterion(
cls_score.clone(),
label,
weight=None,
reduction="none",
avg_factor=avg_factor,
)
# pt is sigmoid(logit) for pos or sigmoid(-logit) for neg
pt = torch.exp(-logpt)
wtloss = self.cls_criterion(
cls_score, label.float(), weight=weight, reduction="none"
)
alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha)
loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss
loss = reduce_loss(loss, reduction)
else:
loss = self.cls_criterion(
cls_score, label.float(), weight, reduction=reduction
)
loss = self.loss_weight * loss
return loss
def reweight_functions(self, label):
if self.reweight_func is None:
return None
elif self.reweight_func in ["inv", "sqrt_inv"]:
weight = self.RW_weight(label.float())
elif self.reweight_func in "rebalance":
weight = self.rebalance_weight(label.float())
elif self.reweight_func in "CB":
weight = self.CB_weight(label.float())
else:
return None
if self.weight_norm is not None:
if "by_instance" in self.weight_norm:
max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True)
weight = weight / max_by_instance
elif "by_batch" in self.weight_norm:
weight = weight / torch.max(weight)
return weight
def logit_reg_functions(self, labels, logits, weight=None):
if not self.logit_reg:
return logits, weight
if "init_bias" in self.logit_reg:
logits += self.init_bias
if "neg_scale" in self.logit_reg:
logits = logits * (1 - labels) * self.neg_scale + logits * labels
if weight is not None:
weight = (
weight / self.neg_scale * (1 - labels) + weight * labels
)
return logits, weight
def rebalance_weight(self, gt_labels):
repeat_rate = torch.sum(
gt_labels.float() * self.freq_inv, dim=1, keepdim=True
)
pos_weight = (
self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate
)
# pos and neg are equally treated
weight = (
torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma))
+ self.map_alpha
)
return weight
def CB_weight(self, gt_labels):
if "by_class" in self.CB_mode:
weight = (
torch.tensor((1 - self.CB_beta)).cuda()
/ (1 - torch.pow(self.CB_beta, self.class_freq)).cuda()
)
elif "average_n" in self.CB_mode:
avg_n = torch.sum(
gt_labels * self.class_freq, dim=1, keepdim=True
) / torch.sum(gt_labels, dim=1, keepdim=True)
weight = (
torch.tensor((1 - self.CB_beta)).cuda()
/ (1 - torch.pow(self.CB_beta, avg_n)).cuda()
)
elif "average_w" in self.CB_mode:
weight_ = (
torch.tensor((1 - self.CB_beta)).cuda()
/ (1 - torch.pow(self.CB_beta, self.class_freq)).cuda()
)
weight = torch.sum(
gt_labels * weight_, dim=1, keepdim=True
) / torch.sum(gt_labels, dim=1, keepdim=True)
elif "min_n" in self.CB_mode:
min_n, _ = torch.min(
gt_labels * self.class_freq + (1 - gt_labels) * 100000,
dim=1,
keepdim=True,
)
weight = (
torch.tensor((1 - self.CB_beta)).cuda()
/ (1 - torch.pow(self.CB_beta, min_n)).cuda()
)
else:
raise NameError
return weight
def RW_weight(self, gt_labels, by_class=True):
if "sqrt" in self.reweight_func:
weight = torch.sqrt(self.propotion_inv)
else:
weight = self.propotion_inv
if not by_class:
sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True)
weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True)
return weight
def reduce_loss(loss, reduction):
"""Reduce loss as specified.
Args:
loss (Tensor): Elementwise loss tensor.
reduction (str): Options are "none", "mean" and "sum".
Return:
Tensor: Reduced loss tensor.
"""
reduction_enum = F._Reduction.get_enum(reduction)
# none: 0, elementwise_mean:1, sum: 2
if reduction_enum == 0:
return loss
elif reduction_enum == 1:
return loss.mean()
elif reduction_enum == 2:
return loss.sum()
def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None):
"""Apply element-wise weight and reduce loss.
Args:
loss (Tensor): Element-wise loss.
weight (Tensor): Element-wise weights.
reduction (str): Same as built-in losses of PyTorch.
avg_factor (float): Avarage factor when computing the mean of losses.
Returns:
Tensor: Processed loss values.
"""
# if weight is specified, apply element-wise weight
if weight is not None:
loss = loss * weight
# if avg_factor is not specified, just reduce the loss
if avg_factor is None:
loss = reduce_loss(loss, reduction)
else:
# if reduction is mean, then average the loss by avg_factor
if reduction == "mean":
loss = loss.sum() / avg_factor
# if reduction is 'none', then do nothing, otherwise raise an error
elif reduction != "none":
raise ValueError(
'avg_factor can not be used with reduction="sum"'
)
return loss
def binary_cross_entropy(
pred, label, weight=None, reduction="mean", avg_factor=None
):
# weighted element-wise losses
if weight is not None:
weight = weight.float()
loss = F.binary_cross_entropy_with_logits(
pred, label.float(), weight, reduction="none"
)
loss = weight_reduce_loss(
loss, reduction=reduction, avg_factor=avg_factor
)
return loss
DBLoss
loss_func = ResampleLoss(
reweight_func="rebalance",
loss_weight=1.0,
focal=dict(focal=True, alpha=0.5, gamma=2),
logit_reg=dict(init_bias=0.05, neg_scale=2.0),
map_param=dict(alpha=0.1, beta=10.0, gamma=0.405),
class_freq=class_freq,
train_num=train_num,
)
"""
class_freq - list of frequencies for each class,
train_num - size of train dataset
"""
通过深入调查数据集,我们得出参数  = 0.405。
= 0.405。
阈值调整
改进模型的另一个步骤是调整阈值的过程,包括在训练阶段、验证阶段和测试阶段。我们计算了诸如 F1 分数、精确度和召回率等指标对阈值水平的依赖关系,并根据最高的指标分数选择了阈值。下面可以看到这一过程的函数实现。
通过调整阈值优化 F1 分数:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray):
best_med_th = 0.5
true_bools = [tl == 1 for tl in true_labels]
micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th
f1_results, pre_results, recall_results = [], [], []
for th in micro_thresholds:
pred_bools = [pl > th for pl in pred_labels]
test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0)
test_precision = precision_score(
true_bools, pred_bools, average="micro", zero_division=0
)
test_recall = recall_score(
true_bools, pred_bools, average="micro", zero_division=0
)
f1_results.append(test_f1)
prec_results.append(test_precision)
recall_results.append(test_recall)
best_f1_idx = np.argmax(f1_results)
return micro_thresholds[best_f1_idx]
基准线的评估和比较
这些方法使我们能够训练一个新模型,并获得以下结果,与基准线比较:下图中的 BERT。

图 3. 基准线和新方法的比较指标。
通过比较与分类相关的指标,我们发现性能指标几乎提高了 5-6 倍:
F1 分数从 12% 提升至 55%,而精确度从 9% 提升至 59%,召回率从 15% 提升至 51%。
根据图 3 右侧图中的变化,我们现在可以预测 80% 的类别。
类别切片
我们将标签分为四组:HEAD、MEDIUM、TAIL 和 ZERO。每组包含具有相似数量的支持数据观测值的标签。
如图 4 所示,各组的分布是不同的。玫瑰盒(HEAD)具有负偏态分布,中间盒(MEDIUM)具有正偏态分布,绿色盒子(TAIL)似乎具有正态分布。
所有组中也有离群值,它们是箱形图中胡须外的点。HEAD 组对 MAJOR 类有重大影响。
此外,我们还识别出一个名为“ZERO”的单独组,其中包含模型无法学习且由于数据集中出现次数极少(少于 3% 的所有观察值)而无法识别的标签。

图 4. 标签数量与组
表 2 提供了每个标签组在测试子集数据中的指标信息。

表 2. 各组指标。
-
HEAD 组包含 21 个标签,每个标签的平均支持观察值为 112。由于其在数据集中的高表示度,该组受到离群值的影响,其指标较高:F1 - 73%,精准度 - 71%,召回率 - 75%。
-
MEDIUM 组由 44 个标签组成,每个标签的平均支持观察值为 67,大约是 HEAD 组的一半。该组的指标预计会下降 50%:F1 - 52%,精准度 - 56%,召回率 - 51%。
-
TAIL 组拥有最多的类别,但所有类别在数据集中表现都很差,每个标签的平均支持观察值为 40。因此,指标显著下降:F1 - 21%,精准度 - 32%,召回率 - 16%。
-
ZERO 组包括模型无法识别的类别,这可能是由于这些类别在数据集中出现频率较低。该组中的 24 个标签每个平均有 7 个支持观察值。
图 5 可视化了表 2 中的信息,提供了每个标签组指标的视觉表现。

图 5. 指标与标签组。所有 ZERO 值 = 0。
结论
在这篇综合文章中,我们展示了在应用传统方法时,表面上看似简单的多标签文本分类任务可能具有挑战性。我们提出了使用分布平衡损失函数来解决类别不平衡问题。
我们将提出的方法与经典方法进行了比较,并使用实际业务指标进行了评估。结果表明,利用损失函数来解决类别不平衡和标签共现问题为多标签文本分类提供了一种可行的解决方案。
提出的使用案例突显了在处理多标签文本分类时考虑不同方法和技术的重要性,以及分布平衡损失函数在解决类别不平衡问题上的潜在好处。
如果你面临类似问题并寻求 优化文档处理操作 在你的组织中,请联系我或 Provectus 团队。我们将乐意帮助你寻找更高效的自动化方法。
奥列克西·巴比奇 是 Provectus 的机器学习工程师。凭借物理学背景,他具备出色的分析和数学技能,并通过科学研究和国际会议演讲(包括 SPIE Photonics West)获得了宝贵的经验。奥列克西专注于为医疗保健和金融科技行业创建端到端的大规模 AI/ML 解决方案。他参与机器学习开发生命周期的每个阶段,从识别业务问题到部署和运行生产 ML 模型。
里纳特·阿赫梅托夫 是 Provectus 的机器学习解决方案架构师。凭借扎实的机器学习(尤其是计算机视觉)实践背景,里纳特是一个极客、数据爱好者、软件工程师和工作狂,他的第二大激情是编程。在 Provectus,里纳特负责发现和概念验证阶段,并领导复杂 AI 项目的执行。
更多相关话题
多模态基础学习与视觉和语言
原文:
www.kdnuggets.com/2022/11/multimodal-grounded-learning-vision-language.html

图片由编辑提供
大家好!我叫博格丹·波诺马尔,我是 AI HOUSE 的首席执行官——一个将人才聚集在一起的乌克兰 AI 社区,涵盖了几十个以教育为主的计划。我们是 Roosh 技术生态系统的一部分。
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
在 2022 年 8 月,我们推出了一个新的教育项目 “AI for Ukraine”——由国际人工智能专家举办的一系列研讨会和讲座,以支持乌克兰科技社区的发展。领先的国际 AI/ML 专家参与了这个慈善项目,我们决定分享一些最具洞察力和引人入胜的 AI for Ukraine 会议的摘要。
系列中的第一个摘要是关于乔书亚·本吉奥的讲座,主题是“弥合当前深度学习与人类高级认知能力之间的差距”。你可以在 这里 阅读。
接下来的主题是“具有视觉和语言的多模态基础学习”,由 UC 伯克利的研究科学家安娜·罗尔巴赫(Anna Rohrbach)讲授。
让我们首先承认,人类使用各种感知方式,最显著的是视觉和语言,来感知他们的环境和相互交流。描述我们观察到的事物是人类的一项基本能力。我们有一个共享的现实,这对于理解彼此至关重要,因为我们将概念与我们周围的世界相结合。
在大多数情况下,人类也使用语言来传递关于新事物的知识。
因此,我们可以仅通过语言进行学习。在她的讲座中,加州大学伯克利分校的研究科学家安娜·罗赫巴赫讨论了如何为人工智能模型提供类似的能力,如沟通、基础建立和从语言中学习。尽管在经典的视觉和语言任务中取得了显著进展,尤其是在视觉标注方面,人工智能模型有时仍然面临困难。多模态学习中最具挑战性的方面之一正是基础建立,即——准确地将语言概念映射到视觉观察上。缺乏适当的基础建立可能会通过产生偏见或幻觉对模型产生负面影响。
此外,即使是能够进行交流和基础建立的模型,仍可能需要人类的“建议”,或者学习如何更像人类。语言越来越多地被用来通过实现零-shot 能力、改善泛化、最小化偏见等方式来提升视觉模型。安娜·罗赫巴赫特别感兴趣于开发可能使用语言建议来改善其行为的模型。在讲座中,安娜介绍了她和其他领域研究人员如何实现上述能力以及面临的挑战和即将到来的令人兴奋的机遇。
人工智能已经无处不在,影响着我们生活的各个方面,从医疗保健和辅助技术到自动驾驶和智能家居。此外,更类似人类的人工智能互动将会建立。我们将与人工智能进行更多的交流并建立信任。
在我们的多模态世界中,主要的互动方式有视觉和语言。人与人之间的互动形式包括:
-
关于你看到的内容的沟通(例如,看,一个蓝松鸦正坐在树枝上)
-
将概念基础建立到共同现实中
-
从语言中学习(例如,你知道吗,蓝松鸦喜欢吃橡果?)
这三点是人类与人工智能互动的关键优先事项。研究人员通过视觉标注来实现这一目标,包括协助视力受限用户和生成解释(例如,蓝松鸦——是一种上部蓝色、下部白色、带有大冠和黑色项链的鸟)。这些解释应该是忠实和自省的。
基础建立
视觉基础建立的任务包括名词或短语的定位(例如,一个黑色的喙,一个蓝色的翅膀)。最近,对将其规模化的兴趣增加了。
我们期望 AI 训练模型在模态之间的对齐问题经常出现。我们希望它们将正确的词汇与图像相关联。然而,实际上情况并非总是如此。例如,系统可能会说“鸟儿正坐在树枝上”,但我们在图像中看不到树枝。这是基础建立失败的一个例子。缺乏基础建立有时甚至可能伤害用户。
安娜建议将语言作为人工智能模型的知识来源,就像我们人类一样。我们可以利用语言进行零样本学习。这种方法已经被使用过。例如,当你被要求列出需要了解的新物种的属性时。最近,随着大型模型的出现,这种方法得到了进一步的发展。
实现基础的另一种方法是使用建议性学习。我们不仅仅通过经验或做事来学习,我们还可以通过阅读和听其他人来学习。同样,人工智能也可以通过纠正不良模型行为来进行训练。例如,如果有一张鸟在水面上飞翔的照片,机器可能会对鸟的类型感到困惑,因此我们可以告诉它关注鸟而不是水面。因此,机器不会将其与鸭子混淆。
因此,我们需要构建能够交流、具有基础并从语言中学习的人工智能模型。
安娜·罗尔巴赫将讲座概述为以下几个方面:
-
交流需要有基础。
-
有建议性的基础交流。
-
从语言中学习以提高视觉鲁棒性和迁移能力。
交流需要有基础。
如果有一张人骑滑雪板的照片。机器很可能将其识别为“他”。描述模型即使在人类不会提及性别的情况下也会谈论性别。模型不仅捕捉到不平等(男性的数据更多),还夸大了这种不平衡。例如,在一张女人坐在桌前使用笔记本电脑的照片中,机器仍然将此人识别为“男人”。模型甚至没有看到这个人,它看到的是一个显示器,并基于一些相关性假设这是一个男人。在一个男人拿着网球拍的例子中,模型正确地识别了性别,但不是通过看人,而是通过看网球拍。因此,在讨论性别时,模型并没有关注到这个人。
安娜和其他研究人员正在通过将注意力转移到正确的对象上来克服这个问题。为此,他们将描述正确性损失应用于性别。他们引入了置信度损失和外观混淆损失。这提供了更加公平的模型行为:对男性和女性的错误率相似。
在 Baseline-FT 和 UpWeight 中,模型识别了“一个男人和一只狗在雪地里”。
在模型无法清晰识别图片中的性别时,均衡器更关心性别错误,并将其识别为“一个人牵着狗散步”。
缺乏基础可能会导致的问题包括:不适当、有害和冒犯性的内容。
有建议性的基础交流。
当你自驾时,汽车在减速时可以与你沟通,因为它即将左转。有一个描述(汽车减速)和一个行动解释(因为它即将左转)。安娜和她的同事们在伯克利大学进行了 DeepDrive eXplanation (BDD-X) 数据集实验。模型试图预测车辆的未来自我运动。
他们引入了一种解释生成器,用于生成驾驶模型背后的合理性解释的自然语言。在注意力对齐过程中,关键思想是将车辆控制器和文本解释器对齐,使它们关注相同的输入区域。他们得到的关键结果是最弱对齐的注意力,“作为额外损失的解释”可解释且不影响性能。问题在于系统没有关注行人,也没有对其存在作出反应。
可建议的驾驶模型
如何通过建议让模型识别行人?观察到的行动,而不是相反。这样,模型学习将其视觉观察总结成自然语言,并预测适当的行动响应。在 CARLA 模拟器中,研究人员研究了一个不可解释的模型、一个可解释的模型和一个建议的模型。人们对建议模型的信任度最高。
因此,将语言建议纳入深度模型可以导致性能更好、更具可解释性的模型,从而获得更高的人类信任。
从语言中学习以提高视觉鲁棒性
大规模视觉语言模型
CLIP——一个预训练模型,学习将图像与说明匹配。它可以识别和定位许多高层次的概念,但不能识别细粒度的类别,如犬种。
研究人员发现了许多存在于将概念与上下文分离的情境偏差。他们引入了 GALS:通过语言规范引导视觉注意力。这通过提示(如鸟的照片)改善了模型学习。他们将高层次语言任务规范转化为空间注意力,从而引导 CNN 远离偏差。
从语言中学习以提高视觉迁移能力
大规模的视觉+语言模型在高层次概念上表现良好,但在细粒度概念上效果不佳。其理念是大量的通用知识被捕捉在外部资源中。
Zero-Shot Learning
传统的类别级迁移旨在将知识泛化到未见过的对象类别。新的任务级迁移旨在将知识泛化到未见过的数据集或任务。然而,建模外部知识尚未被探索。相比之下,传统的类别级迁移建模外部知识探讨了如何通过一些辅助信息,如嵌入或属性,将已见类别与未见类别关联起来。
在外部知识中,我们可以使用解释。人类利用先前(结构化的)知识。AI 能否做到这一点?研究人员使用了 K-Lite:知识增强语言图像训练和评估。知识有助于提升对细粒度概念的表现,比如 sashimi——一种日本特色菜,由新鲜的生鱼或肉切成薄片,通常配以酱油食用。然而,当知识覆盖范围低且包含虚假信息时,性能会受到影响。研究人员发现,我们可以通过从外部语言中学习进一步提升语言学习。
下一步是什么?
AI 模型可以从语言中学习。然而,可能的限制是难以扩展的人类监督。安娜预测,将会引入具有开放式场景、任意概念、复杂关系和世界知识的大规模预训练模型。她的长期愿景是基础的、有根有据的模型将是可组合的和结构化的,这样 AI 将能够进行沟通,更加扎实,并能够从语言中学习。它们还将具有更高的样本效率,减少对人类监督的依赖。
Bohdan Ponomar 是 AI HOUSE 社区的首席执行官。他正在为乌克兰的学生和专家创建一个领先的 AI 生态系统,以便建立世界级的 AI 企业。
更多相关话题
多模态模型解释
原文:
www.kdnuggets.com/2023/03/multimodal-models-explained.html

图片来源:作者
深度学习是一种智能类型,旨在模仿人脑中的系统和神经元,这些系统和神经元在人的思维过程中扮演了至关重要的角色。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织在 IT 方面
这项技术利用深度神经网络,这些网络由多层人工神经元组成,可以分析和处理大量数据,使其能够随着时间的推移学习和改进。
我们人类依赖五感来解读周围的世界。我们利用视、听、触、味、嗅等感官来收集环境信息并理解这些信息。
同样,多模态学习是一个令人兴奋的人工智能新领域,试图通过结合来自多个模型的信息来复制这种能力。通过整合来自文本、图像、音频和视频等多种来源的信息,多模态模型可以建立对基础数据更丰富、更完整的理解,揭示新的洞察,并支持广泛的应用。
多模态学习中使用的技术包括基于融合的方法、基于对齐的方法以及后期融合。
在本文中,我们将探讨多模态学习的基本原理,包括融合不同来源信息的各种技术,以及其从语音识别到自动驾驶等众多令人兴奋的应用。
什么是多模态学习?

图片来源:作者
多模态学习是人工智能的一个子领域,旨在有效处理和分析来自多种模态的数据。
简单来说,这意味着将来自不同来源的信息如文本、图像、音频和视频结合起来,以建立对基础数据更完整、更准确的理解。
多模态学习的概念已经在包括语音识别、自动驾驶和情感识别等广泛领域找到了应用。我们将在接下来的部分中讨论这些内容。
多模态学习技术使模型能够有效地处理和分析来自多种模态的数据,从而提供对底层数据更全面和准确的理解。
在下一节中,我们将提到这些技术,但在此之前,让我们先讨论组合模型。
这两个概念可能看起来相似,但你很快会发现它们并不相同。
组合模型
组合模型是一种机器学习技术,涉及使用多个模型来提高单个模型的性能。
组合模型的理念在于,一个模型的优势可以弥补另一个模型的不足,从而产生更准确和更稳健的预测。集成模型、堆叠和装袋是用于组合模型的技术。

作者提供的图片
集成模型

作者提供的图片
集成模型涉及将多个基础模型的输出进行组合,以产生一个更好的整体模型。
一个集成模型的例子是随机森林。随机森林是一种决策树算法,通过结合多棵决策树来提高模型的准确性。每棵决策树都在数据的不同子集上进行训练,最终的预测是通过对所有树的预测结果进行平均来得出的。
你可以在 这里 查看如何在 scikit-learn 库中使用随机森林算法。
堆叠

作者提供的图片
堆叠涉及将多个模型的输出作为另一个模型的输入。
堆叠的一个现实生活中的例子是自然语言处理中的情感分析。
例如,斯坦福情感树库数据集包含了情感标签从非常负面到非常正面的电影评论。在这种情况下,可以训练多个模型,如 随机森林、支持向量机(SVM) 和朴素贝叶斯来预测评论的情感。
这些模型的预测结果可以通过使用元模型(如逻辑回归或神经网络)进行组合,该元模型在基础模型的输出上进行训练,以得出最终预测结果。
堆叠可以提高情感预测的准确性,并使情感分析更为稳健。
装袋

作者提供的图片
集成学习是另一种创建模型集成的方法,其中多个基础模型在不同的数据子集上进行训练,并将它们的预测结果平均以作出最终决策。
集成学习的一个例子是自助聚合方法,其中多个模型在训练数据的不同子集上进行训练。最终预测通过对所有模型的预测结果进行平均得出。
现实生活中的一个集成学习示例是金融领域。S&P 500 数据集包含 2012 年至 2018 年间美国 500 家最大上市公司的股票价格历史数据。
可以通过在 scikit-learn 中训练多个模型(如 随机森林 和 梯度提升)来使用集成学习预测公司的股票价格。
每个模型在训练数据的不同子集上进行训练,然后将它们的预测结果平均,以得到最终预测。使用集成学习可以提高股票价格预测的准确性,使财务分析更具鲁棒性。
结合模型与多模态学习的区别
在结合模型中,模型是独立训练的,最终预测通过使用集成模型、堆叠或集成学习等技术将这些模型的输出结合起来。
当单个模型具有互补的优缺点时,结合模型特别有用,因为这种结合可以导致更准确和更稳健的预测。
在多模态学习中,目标是结合来自不同模态的信息以执行预测任务。这可能涉及使用融合方法、对齐方法或晚期融合等技术,创建捕捉每种模态数据语义信息的高维表示。
多模态学习在不同模态提供互补信息、能提高预测准确性时特别有用。
结合模型和多模态学习的主要区别在于,结合模型涉及使用多个模型来提高单个模型的性能。相比之下,多模态学习涉及从多个模态(如图像、文本和音频)中学习并结合信息,以进行预测测试。
现在,让我们深入了解多模态学习技术。
多模态学习技术

作者提供的图片
基于融合的方法
基于融合的方法涉及将不同的模态编码到一个共同的表示空间中,在这个空间中,这些表示被融合以创建一个单一的模态不变表示,捕捉来自所有模态的语义信息。
这种方法可以进一步分为早期融合和中期融合技术,具体取决于融合发生的时间。
文本标题生成
一个典型的基于融合的方法是图像和文本标题生成。
这是一种基于融合的方法,因为图像的视觉特征和文本的语义信息被编码到一个公共表示空间中,然后融合生成一个单一的模态不变表示,从而捕捉两个模态的语义信息。
具体来说,图像的视觉特征是通过卷积神经网络(CNN)提取的,而文本的语义信息则是通过递归神经网络(RNN)捕捉的。
这两种模态然后被编码到一个公共表示空间中。视觉和文本特征通过连接或逐元素乘法技术融合,以创建一个单一的模态不变表示。
这个最终表示可以用来为图像生成标题。
一个可以用于图像和文本标题生成的开源数据集是Flickr30k 数据集,该数据集包含 31,000 张图像,每张图像配有五个标题。该数据集包含各种日常场景的图像,每张图像由多个标注者注释,以提供多样化的标题。

来源: paperswithcode.com/dataset/flickr30k-cna
Flickr30k 数据集可以通过从预训练 CNN 中提取视觉特征,并使用诸如词嵌入或词袋表示等技术来应用基于融合的方法进行图像和文本标题生成。生成的融合表示可以用来生成更准确和信息量更大的标题。
基于对齐的方法
这种方法涉及对齐不同的模态,以便它们可以直接进行比较。
目标是创建可以跨模态比较的模态不变表示。当模态之间有直接关系时,如音频-视觉语音识别,这种方法是有利的。
手语识别

作者提供的图像
对齐方法的一个例子是在手语识别任务中。
这种使用涉及基于对齐的方法,因为它要求模型对视觉(视频帧)和音频(音频波形)两种模态的时间信息进行对齐。
任务是让模型识别手语手势并将其翻译成文本。手势通过视频摄像机捕捉,音频和两种模态必须对齐,以准确识别手势。这涉及识别视频帧和音频波形之间的时间对齐,以识别手势和相应的语音。
一个用于手语识别的开源数据集是 RWTH-PHOENIX-Weather 2014T 数据集,它包含了各种手语使用者的德国语手语(DGS)视频录制。该数据集包括视觉和音频模态,适合需要对齐方法的多模态学习任务。
晚期融合
这种方法涉及结合分别在每种模态上训练的模型的预测结果。然后将各个预测结果结合以生成最终预测。这种方法在模态之间没有直接关系,或单个模态提供互补信息时特别有用。
情感识别

图片来源:作者
晚期融合的一个现实生活中的例子是音乐中的情感识别。在这个任务中,模型必须使用音频特征和歌词来识别一首音乐的情感内容。
在这个例子中应用了晚期融合方法,因为它结合了分别在不同模态(音频特征和歌词)上训练的模型的预测结果,以创建最终预测。
各个模型分别在每种模态上训练,预测结果随后被结合。因此,使用晚期融合。
音频特征可以使用梅尔频率倒谱系数(MFCCs)等技术提取,而歌词可以使用词袋模型或词嵌入技术进行编码。可以在每种模态上分别训练模型,然后通过晚期融合将预测结果结合起来生成最终预测。
DEAM 数据集旨在支持音乐情感识别和分析的研究,它包括了超过 2000 首歌曲的音频特征和歌词。音频特征包括 MFCCs、谱对比度和节奏特征等各种描述符,而歌词则使用词袋模型和词嵌入技术表示。
通过将分别在每种模态(音频和歌词)上训练的模型的预测结果结合起来,可以将晚期融合方法应用于 DEAM 数据集。

例如,你可以训练一个单独的机器学习模型,使用音频特征,如 MFCCs 和谱对比度,来预测每首歌的情感内容。
另一个模型可以使用歌词来预测每首歌的情感内容,歌词通过词袋模型或词嵌入等技术表示。
训练各个单独模型后,可以使用后期融合方法将每个模型的预测结果结合起来,以生成最终预测。
多模态学习挑战

图片由作者提供
表示
多模态数据可以来自不同的模态,如文本和音频。将它们以保留其个性特征同时捕捉它们之间关系的方式结合起来是具有挑战性的。
这可能导致模型无法很好地泛化、对某一模态有偏见,或者不能有效地捕捉联合信息等问题。
为了解决多模态学习中的表示问题,可以采用几种策略:
联合表示:如前所述,这种方法涉及将两个模态编码到一个共享的高维空间中。可以使用基于深度学习的融合方法来学习最佳的联合表示。
协调表示:这种方法不是直接融合模态,而是保持每个模态的独立编码,但确保它们的表示是相关的并传达相同的意义。可以使用对齐或注意力机制来实现这种协调。
图像-标题对
MS COCO 数据集在计算机视觉和自然语言处理研究中被广泛使用,包含了许多具有各种背景的对象图像,以及描述图像内容的多个文本标题。
在处理 MS COCO 数据集时,处理表示挑战的两种主要策略是联合表示和协调表示。
联合表示:通过结合两个模态的信息,模型可以理解它们的综合意义。例如,你可以使用一个深度学习模型,设计处理和合并图像和文本数据特征的层。这会产生一个捕捉图像和标题之间关系的联合表示。
协调表示:在这种方法中,图像和标题是分开编码的,但它们的表示是相关的,并传达相同的意义。模型不直接融合模态,而是保持每个模态的独立编码,同时确保它们在意义上的关联。
在处理 MS COCO 数据集时,可以使用联合表示和协调表示策略,以有效应对多模态学习的挑战,并创建能够处理和理解视觉与文本信息之间关系的模型。
融合
融合是一种在多模态学习中使用的技术,用于将来自不同数据模态的信息(如文本、图像和音频)结合起来,以创建对特定情况或背景的更全面理解。融合过程帮助模型基于综合信息做出更好的预测和决策,而不是依赖单一模态。
多模态学习中的一个挑战是确定最佳的融合方式。不同的融合技术可能对特定任务或情况更有效,找到合适的方法可能会很困难。
电影评分

作者提供的图片
在多模态学习中的一个实际例子是电影推荐系统。在这种情况下,系统可能会使用文本数据(电影描述、评论或用户档案)、音频数据(原声带、对话)和视觉数据(电影海报、视频片段)来生成个性化的推荐。
融合过程将这些不同来源的信息结合起来,以创建对用户偏好和兴趣的更准确和有意义的理解,从而提供更好的电影推荐。
适合开发融合电影推荐系统的一个实际数据集是 MovieLens 数据集。MovieLens 是由明尼苏达大学 GroupLens 研究项目收集的一组电影评分和元数据,包括用户生成的标签。数据集中包含关于电影的信息,如标题、类型、用户评分和用户档案。
为了使用 MovieLens 数据集创建一个多模态电影推荐系统,你可以将文本信息(电影标题、类型和标签)与额外的视觉数据(电影海报)和音频数据(原声带、对话)结合起来。你可以从其他来源(如 IMDB 或 TMDB)获取电影海报和音频数据。
融合可能会面临什么挑战?
在将多模态学习应用于此数据集时,融合可能会面临挑战,因为你需要确定最有效的方式来结合不同的模态。
例如,你需要找到文本数据(类型、标签)、视觉数据(海报)和音频数据(原声带、对话)在推荐任务中的重要性之间的正确平衡。
此外,一些电影可能会缺少或不完整的数据,比如缺少海报或音频样本。
在这种情况下,推荐系统应该足够强大,能够处理缺失的数据,并且根据可用的信息提供准确的推荐。
总结来说,使用 MovieLens 数据集,以及额外的视觉和音频数据,你可以开发一个多模态电影推荐系统,利用融合技术。
然而,在确定最有效的融合方法和处理缺失或不完整的数据时可能会遇到挑战。
对齐
对齐在如视听语音识别等应用中是一个关键任务。在这个任务中,音频和视觉模态必须对齐,以准确识别语音。
研究人员使用隐马尔可夫模型和动态时间规整等对齐方法来实现这一同步。
例如,隐马尔可夫模型可以用来建模音频和视觉模态之间的关系,并估计音频波形与视频帧之间的对齐。动态时间规整可以通过在时间上拉伸或压缩数据序列来对齐它们,从而使它们更紧密地匹配。
视听语音识别

图片来源:作者
通过对齐 GRID Corpus 数据集中的音频和视觉数据,研究人员可以创建协调的表示,这些表示捕捉了模态之间的关系,然后使用这些表示来准确地使用这两种模态识别语音。
GRID Corpus 数据集包含了讲英语的说话者发音句子的视听录音。每个录音包括音频波形和说话者面部的视频,这些视频捕捉了嘴唇和其他面部特征的运动。该数据集在视听语音识别研究中被广泛使用,其目标是利用音频和视觉模态准确识别语音。
翻译
翻译是一个常见的多模态挑战,其中不同的数据模态,如文本和图像,必须对齐以创建一致的表示。例如,图像描述任务就是这样一个挑战,其中需要用自然语言描述图像。
在这个任务中,模型需要能够识别图像中的对象和背景,并生成准确传达图像意义的自然语言描述。
这需要对齐视觉和文本模态,以创建协调的表示,捕捉它们之间的关系。
Dall-E
一幅油画,画中熊猫在西藏冥想

参考:Dall-E
最近的一个多模态翻译模型的例子是 DALL-E2。DALL-E2 是由 OpenAI 开发的神经网络模型,它可以根据文本描述生成高质量的图像。它也可以根据图像生成文本描述,从而有效地在视觉和文本模态之间进行翻译。
DALL-E2 通过学习一个联合表示空间来实现这一点,该空间捕捉了视觉模态和文本模态之间的关系。
模型在一个大规模的图像-标题对数据集上进行训练,学习将图像与其对应的标题关联。然后,它可以通过从学习的表示空间中采样来生成图像,也可以通过解码学习的表示从图像生成文本描述。
总体而言,多模态翻译是一个重大挑战,需要对不同的数据模态进行对齐以创建协调的表示。像 DALL-E2 这样的模型可以通过学习联合表示空间来捕捉视觉和文本模态之间的关系,并应用于图像描述和视觉问答等任务。
共学习
多模态共学习旨在将通过一个或多个模态学到的知识转移到涉及其他任务中。
共学习在低资源目标任务中,完全/部分缺失或噪声模态尤其重要。
然而,找到有效的知识转移方法以保持语义含义是在多模态学习中的一个重大挑战。
在医学诊断中,不同的医学成像模态,如 CT 扫描和 MRI 扫描,提供了对诊断的互补信息。多模态共学习可以用来结合这些模态,以提高诊断的准确性。
多模态肿瘤分割

来源:www.med.upenn.edu/sbia/brats2018.html
例如,在脑肿瘤的情况下,MRI 扫描提供了高分辨率的软组织图像,而 CT 扫描提供了骨结构的详细图像。结合这些模态可以提供患者病情的完整图像,并指导治疗决策。
包括脑肿瘤的 MRI 和 CT 扫描的多模态脑肿瘤分割(BraTS)数据集用于多模态共学习。该数据集包含脑肿瘤的 MRI 和 CT 扫描以及肿瘤区域分割的注释。
为了实施包含脑肿瘤的 MRI 和 CT 扫描的共学习,我们需要开发一种将两种模态的信息结合起来以提高诊断准确性的方式。一种可能的方法是使用在 MRI 和 CT 扫描上训练的多模态深度学习模型。
多模态学习的流行应用
我们将提到多模态学习的其他几个应用,如语音识别和自动驾驶汽车。
语音识别

图片来源:作者
多模态学习可以通过结合音频和视觉数据来提高语音识别的准确性。
例如,多模态模型可以同时分析语音的音频信号和对应的唇部运动,以提高语音识别的准确性。通过结合音频和视觉模态,多模态模型可以减少噪音和语音信号变异的影响,从而提高语音识别性能。

来源: CMU-MOSEI 数据集
一个可以用于语音识别的多模态数据集例子是CMU-MOSEI 数据集。这个数据集包含了 1,000 名 YouTube 讲者发音的 23,500 个句子,并包括讲者的音频和视觉数据。
该数据集可以用于开发用于情感识别、情绪分析和说话人识别的多模态模型。
通过将语音的音频信号与说话者的视觉特征结合起来,多模态模型可以提高语音识别和其他相关任务的准确性。
自动驾驶汽车

多模态学习可以通过整合来自多个传感器的信息来增强机器人的能力。
例如,在开发自动驾驶汽车时,这一点至关重要,因为这些汽车依赖于来自多个传感器的信息,如摄像头、激光雷达和雷达,以进行导航和决策。
多模态学习可以帮助整合这些传感器的信息,使汽车能够更准确、高效地感知和反应环境。
一个自动驾驶汽车数据集的例子是Waymo 开放数据集,它包括 Waymo 自动驾驶汽车的高分辨率传感器数据,以及车辆、行人和骑自行车者等物体的标签。Waymo 是谷歌的自动驾驶汽车公司。
该数据集可以用于开发和评估用于自动驾驶汽车相关任务的多模态模型,如物体检测、跟踪和预测。
语音录音分析

作者提供的图片
语音录音分析项目是在 Sandvik 的数据科学职位面试过程中提出的。它是多模态学习应用的一个优秀例子,因为它试图基于音频数据中的语音特征预测一个人的性别。
在这种情况下,问题涉及分析和处理来自两个不同模态的信息:音频信号和文本特征。这些模态提供了宝贵的信息,可以提高预测模型的准确性和有效性。
扩展该项目的多模态特性:
音频信号

作者提供的图像
本项目的主要数据来源是英语男性和女性声音的音频录音。这些音频信号包含了关于说话者声音特征的丰富而复杂的信息。通过提取这些音频信号中的相关特征,如音高、频率和谱熵,模型可以识别与性别特定声音属性相关的模式和趋势。
文本特征

作者提供的图像
每个音频录音都附带一个文本文件,该文件提供有关样本的重要信息,如说话者的性别、所说语言以及说话者所说的短语。这个文本文件不仅为训练和评估机器学习模型提供了真实标签(性别标签),还可以与音频数据结合创建额外的特征。通过利用文本文件中的信息,模型可以更好地理解每个音频样本的上下文和内容,从而可能提高其整体预测性能。
因此,语音录音分析项目通过利用来自多种模态的数据、音频信号和文本特征来预测一个人的性别,从而体现了多模态学习应用的实例。
这种方法强调在开发机器学习模型时考虑不同数据类型的重要性,因为这有助于发现隐藏的模式和关系,这些模式和关系在单独分析每种模态时可能不会显现出来。
结论
总之,多模态学习已成为整合多样数据以提高机器学习算法精度的强大工具。结合不同的数据类型,包括文本、音频和视觉信息,可以产生更稳健和准确的预测。这在语音识别、文本与图像融合以及自动驾驶汽车行业尤为重要。
然而,多模态学习确实存在若干挑战,如表示、融合、对齐、翻译和共同学习等问题。这需要谨慎考虑和关注。
尽管如此,随着机器学习技术和计算能力的不断发展,我们可以预见未来几年会出现更先进的多模态技术。
内特·罗西迪 是一名数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,这个平台帮助数据科学家准备来自顶级公司的真实面试问题。可以在 Twitter: StrataScratch 或 LinkedIn 上与他联系。
更多相关主题
使用 PyCaret 进行多时间序列预测
原文:
www.kdnuggets.com/2021/04/multiple-time-series-forecasting-pycaret.html
评论
由 Moez Ali,PyCaret 创始人及作者

PyCaret — 一个开源、低代码的 Python 机器学习库
PyCaret
PyCaret 是一个开源、低代码的机器学习库和端到端模型管理工具,内置于 Python 中,用于自动化机器学习工作流程。它因易用性、简洁性和快速高效地构建和部署端到端机器学习原型的能力而极受欢迎。
PyCaret 是一个替代的低代码库,可以用少量代码替代数百行代码。这使得实验周期变得指数级加快和高效。
PyCaret 是简单和易用的。在 PyCaret 中执行的所有操作都按顺序存储在一个管道中,该管道完全自动化以部署。无论是填补缺失值、一键编码、转换分类数据、特征工程,还是超参数调优,PyCaret 都会自动化处理。
本教程假设你已有一定的 PyCaret 知识和经验。如果你以前没用过,也没关系——你可以通过以下教程快速入门:
回顾
在我之前的 教程 中,我演示了如何通过 PyCaret 回归模块 使用 PyCaret 进行时间序列数据预测。如果你还没读过,可以先阅读 使用 PyCaret 回归模块进行时间序列预测 这篇教程,因为本教程建立在之前教程的一些重要概念之上。
安装 PyCaret
安装 PyCaret 非常简单,只需几分钟。我们强烈建议使用虚拟环境,以避免与其他库的潜在冲突。
PyCaret 的默认安装是 PyCaret 的精简版,只安装了硬性依赖项,详细信息请见 这里。
**# install slim version (default)** pip install pycaret**# install the full version**
pip install pycaret[full]
当你安装 PyCaret 的完整版时,所有可选的依赖项也会被安装,详细信息请见 这里。
???? PyCaret 回归模块
PyCaret 回归模块 是一个监督机器学习模块,用于估计因变量(通常称为“结果变量”或“目标”)与一个或多个自变量(通常称为“特征”或“预测变量”)之间的关系。
回归的目标是预测连续值,例如销售金额、数量、温度、客户数量等。PyCaret 中的所有模块提供了许多预处理功能,通过setup函数准备数据以进行建模。它拥有超过 25 种现成的算法和若干图表来分析训练模型的性能。
???? 数据集
在本教程中,我将展示多时间序列数据预测的端到端实现,包括训练过程以及预测未来值。
我使用了来自 Kaggle 的商店商品需求预测挑战数据集。该数据集包含 10 个不同的商店,每个商店有 50 个项目,即总共有 500 个日常时间序列数据,跨度为五年(2013–2017)。

示例数据集
???? 加载和准备数据
**# read the csv file** import pandas as pd
data = pd.read_csv('train.csv')
data['date'] = pd.to_datetime(data['date'])**# combine store and item column as time_series**
data['store'] = ['store_' + str(i) for i in data['store']]
data['item'] = ['item_' + str(i) for i in data['item']]
data['time_series'] = data[['store', 'item']].apply(lambda x: '_'.join(x), axis=1)
data.drop(['store', 'item'], axis=1, inplace=True)**# extract features from date**
data['month'] = [i.month for i in data['date']]
data['year'] = [i.year for i in data['date']]
data['day_of_week'] = [i.dayofweek for i in data['date']]
data['day_of_year'] = [i.dayofyear for i in data['date']]data.head()

从数据中采样行
**# check the unique time_series**
data['time_series'].nunique()
>>> 500
???? 可视化时间序列
**# plot multiple time series with moving avgs in a loop**import plotly.express as pxfor i in data['time_series'].unique():
subset = data[data['time_series'] == i]
subset['moving_average'] = subset['sales'].rolling(30).mean()
fig = px.line(subset, x="date", y=["sales","moving_average"], title = i, template = 'plotly_dark')
fig.show()

store_1_item_1 时间序列和 30 天移动平均

store_2_item_1 时间序列和 30 天移动平均
???? 开始训练过程
现在我们已经准备好数据,让我们开始训练循环。注意在所有函数中使用verbose = False,以避免在训练过程中在控制台打印结果。
以下代码是对我们在数据准备步骤中创建的time_series列进行循环。总共有 150 个时间序列(10 个商店 x 50 个项目)。
下方第 10 行是对time_series变量进行数据过滤。循环的第一部分初始化了setup函数,然后使用compare_models查找最佳模型。第 24–26 行捕获结果,并将最佳模型的性能指标附加到名为all_results的列表中。代码的最后部分使用finalize_model函数在整个数据集上重新训练最佳模型,包括测试集中剩余的 5%,并将整个管道(包括模型)保存为一个 pickle 文件。
gist.github.com/moezali1/f258195ba1c677654abffb0d1acb2cc0
我们现在可以从all_results列表创建一个数据框。它将显示每个时间序列选择的最佳模型。
concat_results = pd.concat(all_results,axis=0)
concat_results.head()

从 concat_results 中采样行
训练过程 ????

训练过程
???? 使用训练模型生成预测
现在我们已经训练了模型,让我们用它们来生成预测,但首先,我们需要创建评分的数据集(X 变量)。
**# create a date range from 2013 to 2019**
all_dates = pd.date_range(start='2013-01-01', end = '2019-12-31', freq = 'D')**# create empty dataframe**
score_df = pd.DataFrame()**# add columns to dataset**
score_df['date'] = all_dates
score_df['month'] = [i.month for i in score_df['date']]
score_df['year'] = [i.year for i in score_df['date']]
score_df['day_of_week'] = [i.dayofweek for i in score_df['date']]
score_df['day_of_year'] = [i.dayofyear for i in score_df['date']]score_df.head()

从 score_df 数据集提取样本行
现在让我们创建一个循环来加载训练好的管道,并使用 predict_model 函数生成预测标签。
from pycaret.regression import load_model, predict_modelall_score_df = []for i in tqdm(data['time_series'].unique()):
l = load_model('trained_models/' + str(i), verbose=False)
p = predict_model(l, data=score_df)
p['time_series'] = i
all_score_df.append(p)concat_df = pd.concat(all_score_df, axis=0)
concat_df.head()

从 concat_df 中提取样本行
我们现在将 data 和 concat_df 合并。
final_df = pd.merge(concat_df, data, how = 'left', left_on=['date', 'time_series'], right_on = ['date', 'time_series'])
final_df.head()

从 final_df 中提取样本行
我们现在可以创建一个循环来查看所有图表。
for i in final_df['time_series'].unique()[:5]:
sub_df = final_df[final_df['time_series'] == i]
import plotly.express as px
fig = px.line(sub_df, x="date", y=['sales', 'Label'], title=i, template = 'plotly_dark')
fig.show()

store_1_item_1 实际销售和预测标签

store_2_item_1 实际销售和预测标签
我希望你会欣赏 PyCaret 的易用性和简洁性。通过不到 50 行代码和一小时的实验,我已经训练了超过 10,000 个模型(25 个估计器 x 500 个时间序列),并将 500 个最佳模型投入生产以生成预测。
敬请期待!
下周我将写一篇关于使用 PyCaret 异常检测模块 进行无监督时间序列异常检测的教程。请关注我的 Medium、LinkedIn 和 Twitter 以获取更多更新。
使用这个轻量级的 Python 工作流自动化库,你可以实现无限的目标。如果你觉得这有用,请不要忘记在我们的 GitHub 仓库上给我们 ⭐️。
想了解更多关于 PyCaret 的信息,请关注我们的 LinkedIn 和 Youtube。
加入我们的 Slack 频道。邀请链接 在此。
你可能还对以下内容感兴趣:
使用 PyCaret 2.0 在 Power BI 中构建你自己的 AutoML
在 Google Kubernetes Engine 上部署机器学习管道
使用 AWS Fargate 无服务器部署 PyCaret 和 Streamlit 应用
使用 PyCaret 和 Streamlit 构建并部署机器学习 web 应用
在 GKE 上部署使用 Streamlit 和 PyCaret 构建的机器学习应用
重要链接
想了解特定模块?
点击下面的链接查看文档和工作示例。
个人简介:Moez Ali 是数据科学家,同时是 PyCaret 的创始人和作者。
原文。经授权转载。
相关:
-
使用 PyCaret 回归模块进行时间序列预测
-
使用 PyCaret 进行自动化异常检测
-
使用 Docker 容器将机器学习管道部署到云端
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
多尺度方法与机器学习
原文:
www.kdnuggets.com/2018/03/multiscale-methods-machine-learning.html
评论
多尺度方法,即在不同尺度下查看和分析数据集,近年来在机器学习中变得越来越普遍,并且被证明是有价值的工具。它们的核心是捕捉由一系列点之间的距离或最近邻的集合定义的邻域的局部几何形状。这有点像通过一系列显微镜分辨率来观察幻灯片的一部分。在高分辨率下,非常小的特征会在样本的一个小空间内被捕捉。在低分辨率下,更多的幻灯片区域可见,人们可以研究更大的特征。多尺度方法的主要优点包括相对于最先进的方法性能的提升,以及实现这些结果所需样本量的显著减少。
举一个简单的例子,考虑在数轴或二维空间中取最近邻的均值。当 k 增加时,数轴上点集的均值变得更加分散,较远的邻居对均值的影响大于较近的邻居。在数轴示例中,假设点位于 1、2、4、5、9、11 和 14。考虑最左边点(在 1)及其 3 个最近邻:2、4 和 5。该集合的均值是 3,其中有 2 个点的值较高,2 个点的值较低。当 9 作为点 1 的第 4 个最近邻加入集合时,均值跳到 4.2,这个均值偏向于点 9,而不是那 4 个值接近的点。检查点 1 的 3 个最近邻的均值揭示了一个具有相似值和方差的点集。然而,检查点 1 的 4 个最近邻则捕捉到了一个离群点。具有单一 k 值的 KNN 均值函数无法捕捉这些在不同尺度下出现的重要局部属性,从而导致重要信息的丢失。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持

并非所有的多尺度方法都依赖于 KNN 定义的尺度,但它们确实使用了类似的原理,使得方法可以在数据集中学习多尺度特征。将点在一系列距离内分组、提供不同尺度的卷积序列以及采用集群层次结构是多尺度方法中的常见选择。Pelt 和 Sethian(2017)的一篇基于多尺度方法的深度学习论文能够在多达 6 张图像的小训练集上以高精度(>90%)进行图像分割和图像分类;该算法显著减少了深度学习框架的调参需求。另一篇深度学习论文(Xiao 等,2018)将全局图像特征与一系列局部提取(在卷积层中,见下图)结合起来,以捕捉单一深度学习框架中的多种图像特征尺度。该算法在多个基准数据集上 consistently 优于最新的深度学习算法,表明多尺度方法可以进一步改进最先进的卷积网络。

最近关于 k-近邻(KNN)回归和分类集成方法在使用不同邻域大小时显示出了显著的改进,不仅比单一 k 值的 KNN 算法表现更好,还超越了其他机器学习方法。拓扑数据分析(TDA)的多尺度工具,包括持久同调,帮助分析了小型数据集、图像、视频和其他类型的数据,为数据科学家和机器学习研究人员提供了一个强大且通用的无监督学习工具。最近添加的 TDA 工具 Mapper 上的多尺度组件改善了算法的理论稳定性,并产生了一致的结果。
存在多尺度方法的替代方案,但它们通常伴随一定的成本。与使用小样本训练样本来提高性能和计算时间相比,许多方法要么提供了改进的性能,要么减少了所需的样本量。贝叶斯方法,近年来多尺度方法的主要竞争者,已减少了深度学习算法良好性能所需的样本量,但其计算成本很高,这可能不适合在线算法使用或在工业中快速分析。这些方法还需要高水平的统计专业知识,而许多实践者可能没有。近年来,深度学习已成为一种普遍的通用工具,但其力量似乎在于渐近性质。深度学习算法在样本量足够大时不会停滞不前,而是随着样本量的进一步增加而不断提高。这在数据量充足时是令人期望的,但许多工业用例和研究问题涉及的是小数据集或有限的类别样本。
看起来局部几何结构很重要。对一个邻域而言相关和重要的内容,可能对围绕原始邻域的更大邻域来说并不相关或重要,检查多个尺度可以帮助捕捉所有重要特征,而不是仅仅依赖于邻域所提供的最佳特征子集。鉴于多尺度方法在各种学习任务中的成功及其对多种算法的增强,预计未来几年机器学习将会出现更多结合多尺度子集的算法。
参考文献
Dey, T. K., Mémoli, F., & Wang, Y. (2016). 多尺度映射器:通过余域覆盖的拓扑总结。在第二十七届 ACM-SIAM 离散算法年会论文集(第 997-1013 页)。工业与应用数学学会。
Farrelly, C. M. (2017). KNN 集成方法用于 Tweedie 回归:多尺度邻域的力量。arXiv 预印本 arXiv:1708.02122。
Pelt, D. M., & Sethian, J. A. (2017). 一种用于图像分析的混合尺度密集卷积神经网络。美国国家科学院院刊, 201715832。
Xia, K., & Wei, G. W. (2014). 蛋白质结构、灵活性和折叠的持久同调分析。生物医学工程数值方法国际期刊, 30(8), 814-844。
Xiao, F., Deng, W., Peng, L., Cao, C., Hu, K., & Gao, X. (2018). MSDNN:用于显著目标检测的多尺度深度神经网络。arXiv 预印本 arXiv:1801.04187。
简介:Colleen M. Farrelly 是一位数据科学家,拥有涉及医疗保健、教育、生物技术、营销和金融的行业经验。她的研究领域包括拓扑/拓扑数据分析、集成学习、非参数统计、流形学习以及向普通观众解释数学( https://www.quora.com/profile/Colleen-Farrelly-1 )。当她不从事数据科学时,她是一位诗人和作者( https://www.amazon.com/Colleen-Farrelly/e/B07832WQG7 )。
相关内容:
更多相关话题
多变量时间序列预测与 BQML
原文:
www.kdnuggets.com/2023/07/multivariate-timeseries-prediction-bqml.html

图片来源于 Pexels
去年冬天,我在乌兹别克斯坦首都塔什干的GDG DevFest Tashkent 2022上做了一个关于‘使用 BQML 进行更可预测的时间序列模型’的演讲。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
我本打算分享一些我在 DevFest 上使用的材料和代码,但时间已经过去,BQML 中已发布一些新功能,这些功能与一些内容重叠。
因此,我将简要提及一些新功能和一些仍然有效的内容。
时间序列模型与 BQML
时间序列数据被许多组织用于各种目的,需要注意的是,“预测分析”关注的是时间上的“未来”。时间序列预测分析已经在短期、中期和长期中使用,虽然它有许多不准确性和风险,但也在稳步改进。
由于“预测”似乎非常有用,如果你有时间序列数据,你可能会被诱导去应用时间序列预测模型。但时间序列预测模型通常计算密集,如果数据量很大,它会更加计算密集。因此,这很繁琐,处理、加载到分析环境并进行分析都很困难。
如果你使用Google BigQuery进行数据管理,可以使用BQML(BigQuery ML)以简单、便捷、快速的方式将机器学习算法应用于你的数据。许多人使用 BigQuery 处理大量数据,其中许多数据通常是时间序列数据。而BQML 也支持时间序列模型。
目前 BQML 支持的时间序列模型的基础是 自回归积分滑动平均(ARIMA) 模型。ARIMA 模型仅利用现有时间序列数据进行预测,已知其短期预测性能良好,并且由于它结合了 AR 和 MA,因此是一个能够覆盖广泛时间序列模型的流行模型。
然而,这个模型整体上计算密集,并且由于它仅利用正常的时间序列数据,因此在存在趋势或季节性情况下使用起来很困难。因此,ARIMA_PLUS 在 BQML 中包含了几个附加特性作为选项。你可以将时间序列分解、季节性因素、波动和下跌、系数变化等添加到模型中,或者可以分别处理它们并手动调整模型。我个人也喜欢可以通过自动包含假期选项来调整周期性,这也是使用一个不需要你手动添加日期相关信息的平台的好处之一。

ARIMA_PLUS 的结构(来自 BQML 手册)
你可以参考这个 页面 以获取更多信息。
然而,当涉及到实际应用时,时间序列预测并不像这样简单。当然,我们已经能够利用 ARIMA_PLUS 识别多个周期并对多个时间序列进行干预,但时间序列数据中存在许多外部因素,并且很少有事件是孤立发生的。时间序列数据中的平稳性可能很难找到。
在原始演示中,我研究了如何处理这些实际时间序列数据以建立预测模型——分解这些时间序列,清理分解后的数据,将其导入 Python,然后与其他变量结合创建多变量时间序列函数,估计因果关系并将其纳入预测模型中,评估事件变化对效果的影响程度。
新特性:ARIMA_PLUS_XREG
而在仅仅过去几个月里,用于创建带有外部变量的多变量时间序列函数(ARIMA_PLUS_XREG, XREG )的新特性已经成为 BQML 的一项显著功能。
你可以在 这里 阅读全部内容(截至 2023 年 7 月仍处于预览阶段,但我猜它会在今年晚些时候推出)。
我应用了官方教程,以查看它与传统的单变量时间序列模型的比较情况,并了解其工作原理。
步骤与教程中的相同,因此我不再重复,但这是我创建的两个模型。首先,我创建了一个传统的 ARIMA_PLUS 模型,然后使用相同的数据创建了一个 XREG 模型,同时加入了当时的温度和风速。
ARIMA_PLUS
# ARIMA_PLUS
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_plus_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
#ARIMA_PLUS_XREG
CREATE OR REPLACE MODEL test_dt_us.seattle_pm25_xreg_model
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25') AS
SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date BETWEEN DATE('2012-01-01') AND DATE('2020-12-31')
使用这些多数据的模型可能如下所示

结构 ARIMA_PLUS_XREG(来自 BQML 手册)
两个模型通过 ML.Evaluate 进行比较。
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_plus_model,
( SELECT date, pm25
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ))
SELECT *
FROM ML.EVALUATE
( MODEL test_dt_us.seattle_pm25_xreg_model,
( SELECT date, pm25, temperature, wind_speed
FROM test_dt_us.seattle_air_quality_daily
WHERE date > DATE('2020-12-31') ),
STRUCT( TRUE AS perform_aggregation, 30 AS horizon))
结果如下。
ARIMA_PLUS

ARIMA_PLUS_XREG

你可以看到XREG 模型在 MAE、MSE 和 MAPE 等基本性能指标上表现更好。(显然,这不是一个完美的解决方案,依赖于数据,我们只能说这是一个有用的工具。)
多元时间序列分析在许多情况下是一个非常需要的选项,但由于各种原因,往往难以应用。现在,只要原因存在于数据和分析步骤中,我们就可以使用它。看起来我们有一个不错的选择,所以了解它是很好的,希望在许多情况下它会有用。
权政敏 是一名拥有超过 10 年实际操作经验的自由职业高级数据科学家,擅长利用机器学习模型和数据挖掘。
更多相关内容
必知:如何评估二分类器
原文:
www.kdnuggets.com/2017/04/must-know-evaluate-binary-classifier.html编辑注释: 本文最初作为我们 17 个必须知道的数据科学面试问题及答案系列中的一个问题的回答进行发布。由于答案足够详尽,故认为应有独立的帖子。
二分类涉及将数据分为两组,例如,基于性别、年龄、位置等独立变量,判断客户是否购买特定产品(是/否)。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面

玩具二分类数据集 (source)。
由于目标变量不是连续的,二分类模型预测目标变量为是/否的概率。为了评估这样的模型,使用一种叫做混淆矩阵的指标,也称为分类矩阵或偶然矩阵。借助混淆矩阵,我们可以计算重要的性能指标。
-
真阳性率(TPR)或命中率或召回率或灵敏度 = TP / (TP + FN)
-
假阳性率 (FPR) 或假警报率 = 1 - 特异性 = 1 - (TN / (TN + FP))
-
准确率 = (TP + TN) / (TP + TN + FP + FN)
-
错误率 = 1 – 准确率 或 (FP + FN) / (TP + TN + FP + FN)
-
精确度 = TP / (TP + FP)
-
F-measure: 2 / ( (1 / 精确度) + (1 / 召回率) )
-
ROC(接收者操作特征)= FPR 与 TPR 的图示
-
AUC(曲线下面积)
-
Kappa 统计量
你可以在这里找到关于这些指标的更多细节:衡量分类模型准确性的最佳指标。
所有这些指标都应结合领域技能和综合考虑,例如,如果你仅在预测没有癌症的患者时获得更高的 TPR,这对癌症诊断毫无帮助。
在癌症诊断数据的相同示例中,如果只有 2%或更少的患者有癌症,那么这就是一个类别不平衡的情况,因为癌症患者的比例相比其他人群非常小。处理这一问题主要有两种方法:
- 使用成本函数:在这种方法中,通过成本矩阵(类似于混淆矩阵,但更关注假阳性和假阴性)评估与数据分类错误相关的成本。主要目的是减少分类错误的成本。假阴性的成本总是高于假阳性的成本。例如,将癌症患者错误预测为无癌症比将无癌症患者错误预测为癌症更危险。
Total Cost = Cost of FN * Count of FN + Cost of FP * Count of FP
- 使用不同的采样方法:在这种方法中,你可以使用过采样、欠采样或混合采样。在过采样中,通过复制少数类观测值来平衡数据。观测值的复制会导致过拟合,从而在训练中表现良好但在未见数据中的准确性较低。在欠采样中,删除多数类观测值会导致信息丢失。这有助于减少处理时间和存储,但仅在你拥有大量数据集时才有用。
有关类别不平衡的更多信息,请点击这里。
如果目标变量中有多个类别,则会形成一个维度等于类别数的混淆矩阵,并可以为每个类别计算所有性能指标。这称为多类别混淆矩阵。例如,如果响应变量中有 3 个类别 X、Y、Z,则每个类别的召回率将按以下方式计算:
Recall_X = TP_X/(TP_X+FN_X)
Recall_Y = TP_Y/(TP_Y+FN_Y)
Recall_Z = TP_Z/(TP_Z+FN_Z)
相关:
-
17 个必须知道的数据科学面试问题及答案
-
21 个必须知道的数据科学面试问题及答案
-
必须知道:为什么在机器学习模型中使用更少的预测变量可能更好?
更多相关话题
必知:为什么在机器学习模型中使用较少的预测变量可能更好?
原文:
www.kdnuggets.com/2017/04/must-know-fewer-predictors-machine-learning-models.html编辑注: 本文最初作为对我们 17 个必知的数据科学面试问题与答案系列中一个问题的回答而发布。由于回答内容足够详尽,因此决定将其独立成文。
以下是为什么使用较少的预测变量可能比使用更多预测变量更好的几个原因:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT
冗余/无关性:
如果你处理的预测变量很多,那么很可能它们之间存在隐藏的关系,从而导致冗余。除非你在数据分析的早期阶段识别并处理这些冗余(通过仅选择非冗余的预测变量),否则这可能会对你后续的步骤造成很大阻碍。
同样,也有可能并不是所有的预测变量对因变量有显著影响。你应该确保你选择的预测变量集合中没有任何无关的变量——即使你知道数据模型会通过赋予它们较低的重要性来处理它们。
注意:冗余和无关性是两个不同的概念——一个相关的特征可能由于存在其他相关特征而变得冗余。
过拟合:
即使你有大量的预测变量,且它们之间没有任何关系,通常还是建议使用较少的预测变量。具有大量预测变量的数据模型(也称为复杂模型)常常会遇到过拟合的问题,在这种情况下,数据模型在训练数据上表现很好,但在测试数据上表现较差。
生产力:
假设你有一个项目,其中有大量的预测变量,并且所有这些变量都是相关的(即对因变量有可测量的影响)。因此,你显然希望使用所有变量,以获得一个成功率非常高的数据模型。尽管这种方法听起来非常诱人,但实际考虑因素(如可用数据量、存储和计算资源、完成所需时间等)使得这种方法几乎不可能实现。
因此,即使你有大量相关的预测变量,使用较少的预测变量(通过特征选择筛选或通过特征提取开发)也是一个好主意。这本质上类似于帕累托原则,即许多事件中,大约 80%的效果来自 20%的原因。
专注于这 20%最重要的预测变量,将大大有助于在合理时间内建立成功率可观的数据模型,而不需要大量不切实际的数据或其他资源。

训练误差与测试误差对模型复杂度的关系(来源:Quora由Sergul Aydore发布)
可理解性:
具有较少预测变量的模型更容易理解和解释。由于数据科学步骤将由人类执行,结果也将由人类展示(并希望被使用),因此考虑到人脑的全面能力非常重要。这实际上是一种权衡——你放弃了一些可能带来数据模型成功率的潜在好处,同时使你的数据模型更易于理解和优化。
如果在项目结束时你需要向某人展示结果,而他们不仅对高成功率感兴趣,还希望了解“幕后”的情况,这个因素就尤为重要。
相关:
-
17 个必须了解的数据科学面试问题及答案
-
接近(几乎)任何机器学习问题
-
识别可能更好预测的变量
更多相关内容
过去 12 个月必读的 NLP 论文
原文:
www.kdnuggets.com/2023/03/must-read-nlp-papers-last-12-months.html

由Anil Sharma 拍摄的照片,发布于Pexels
自从 2018 年 10 月突破性发布的BERT以来,通过巧妙的优化和增强计算,机器学习达到了更高的高度。BERT,即双向编码器表示变换器,引入了神经网络架构的新范式。变换器在机器学习能力方面起到了重要的解锁作用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
自然语言处理(NLP)领域的进一步进展改善了外语翻译,增强了无代码应用程序,提高了聊天机器人的流利度,并迅速为一系列最先进的基准设定了新的标准。
除了这些显著成就,大型语言模型(LLMs)的发展也不乏争议。在 2021 年发表的"随机鹦鹉"论文中,包括机器学习工程师和伦理学家 Timnit Gebru 在内的研究团队批评了这些模型:
-
施加了一个令人谴责的环境成本
-
排除边缘化声音 通过不优雅的数据集策划
-
剽窃 互联网内容和盗用人类创作者的作品
Gebru 被迅速解雇了谷歌伦理人工智能团队的职位。
在这篇文章中
我们探讨了过去一年中发表的四篇 NLP 论文,它们代表了最新的进展。理解这些发展将提高你作为数据科学家的能力,并使你处于这个动态研究领域的前沿。
1. 训练计算最优的大型语言模型
本文探讨了使用变换器架构的语言模型的理想模型大小和标记数。它旨在回答在预定计算预算下,模型的理想参数数量和数据集大小是什么。
研究人员发现,在以往的案例中,大型语言模型(LLMs)似乎严重训练不足。作者批评这些团队过于强调计算资源的扩展,而忽视了训练数据量的重要性。
作者总结认为,为了实现计算最优化训练,模型规模和训练标记的数量应该等比例扩展。换句话说,
每当模型规模翻倍时,训练标记的数量也应翻倍。
研究表明,一个相对较小的模型(70B 参数)在训练数据量增加 4 倍的情况下,能够在最先进的基准测试(如多任务语言理解(MMLU)中 consistently 超越较大的模型(最高可达 530B 参数)。
增强的训练数据使得较小的模型在推理和微调时可以使用显著更少的计算资源。这对下游应用具有良好的前景。
总结 — 本文表明,之前对扩展规律的理解是错误的。实际上,当使用足够广泛的标记数量进行训练时,较小的网络可以显著优于较大的网络。
2. 通过人类反馈训练语言模型以遵循指令
增强 LLMs 的计算能力并不会自动提升它们解读用户意图的能力。作为这个事实的一个令人担忧的结果,LLMs 可能会提供不真实或有害的结果。
本文强调了一种使用人类反馈来微调语言模型的新方法,以便在各种任务中更好地使输出与用户意图对齐。
研究人员从 OpenAI API 提示集合开始,收集了一个数据集。他们利用这些数据通过监督学习对 GPT-3 进行微调。随后,基于用户输入的强化学习生成了一个新的数据集,用于对模型输出进行排名。研究人员然后使用这些数据进一步微调监督模型,最终得到一个他们称之为 InstructGPT 的模型。
与原始的 GPT-3 相比,InstructGPT 的参数少了 100 倍,但它在人工评估中却能够超越 GPT-3。
在测试数据上,InstructGPT 模型更有可能诚实回应,且不太可能生成有害内容。尽管 InstructGPT 仍偶尔会犯基本错误,这些发现表明,通过人机互动的微调是使语言模型与人类意图匹配的一条可行路线。
总结 — 本文表明,进行人类反馈强化学习是一种极其有用的低资源方式,可以使现有模型更具实用性。
3. 通用智能体
本文探讨了改进后的模型,这些模型能够进行 Atari 游戏、图像描述、文本生成、利用机器人手臂堆叠物理块等更多任务。
模型 Gato 由一个单一的神经网络组成,在各种任务中权重保持不变。
Gato 源于放大的行为克隆,这是一种序列建模挑战。将多个模态编码到一个单一的标记向量空间中构成了研究人员在努力过程中面临的最大障碍。研究在标准视觉和语言数据集的标记化方面取得了一些进展。此外,研究人员还寻求了新的解决方案,以应对典型序列模型问题中的上下文窗口长度确定问题。
总结 — 这篇论文展示了多模态模型表现良好,并且很可能是建模范式的未来。与以前只能在狭窄领域表现的最先进模型相比,Gato 执行了能够处理各种任务和多种模态的通用策略。
4. 大型语言模型是零样本推理者
大型语言模型(LLMs)在使用狭窄、特定任务的示例进行少样本学习方面非常出色。这篇研究论文表明,LLMs 也是合格的零样本推理者,特别是当用“我们逐步思考”这个短语进行提示时。
是的,你没读错。
指示 LLM“逐步思考”实际上能显著改善结果,足以为其撰写论文。
作者 Kojima 等人创建的模型在推理任务上超越了现有的基准,例如算术(如 MultiArith、GSM8K、AQUA-RAT、SVAMP)、符号推理(如 Last Letter、Coin Flip)和逻辑推理(如 Date Understanding、Tracking Shuffled Objects)。
这一单一提示“逐步思考”的适应性表明,零样本技能此前被显著低估了。通过采用要求更高认知负荷的语言框架来提出问题,可能会显著恢复非常高水平的多任务能力。
我的脑袋被震撼了。
总结 — 这篇论文表明,LLM 回答的质量在很大程度上依赖于提示的措辞。
摘要
过去四年间,机器学习取得了显著进展。只有时间才能证明这种发展速度是否能够持续下去。
这些论文讨论了 NLP 的最新改进,揭示了在训练过程中涉及更大数据集和人类反馈强化学习方面还有相当大的改进空间。
最近的研究还探讨了通过对模型输入提示进行简单的调整,来创建多模态范式和增强零样本推理能力。
Nicole Janeway Bills 是数据战略专业人员的社区组织者。她在培训数据从业者以快速有效地通过 CDMP 考试方面有着验证的成功记录。在她作为数据战略顾问的工作中,Nicole 帮助建立了数据收集、数据存储和数据分析功能。她运用最佳实践来解决客户最紧迫的挑战。此外,她还曾在联邦和商业咨询团队中担任数据科学家和项目经理。她的业务经验包括自然语言处理、云计算、统计测试、定价分析、ETL 过程以及网页和应用程序开发。
原文。经许可转载。
更多相关话题
数据科学简历必备项
原文:
www.kdnuggets.com/2022/06/musthaves-data-science-resume.html

João Ferrão via Unsplash
写简历本身就是一项任务,但对于数据科学专业人员来说,这可能是获得你想要的工作的关键。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
根据 Ladders: 眼动追踪研究;招聘人员在决定候选人之前会查看简历 7.4 秒。这意味着你基本上只有不到 10 秒的时间来留下良好的印象。10 秒钟的时间不多,尤其是当你非常想要这份工作时。
那么,你可以做些什么来用简历打动技术招聘人员呢?以下是一些你应考虑的要点。
格式和结构
作为数据科学家,你知道格式和结构的重要性。
你简历的最佳格式是倒序排列。这意味着你最新的工作、经历等会被列在最前面。这有助于招聘人员看到你当前的技能以及你能为他们带来的价值。
简历的结构非常重要。你不希望简历显得杂乱无章,让招聘人员感到沮丧并立即关闭它。市面上有许多简历模板,你可以简单地在 Google 上搜索并筛选出你喜欢的结构。我个人使用过 Zety,相信它对应届生来说是一个很好的工具。
数据科学家简历中应包含的内容
招聘人员寻找的主要元素是:
-
联系信息
-
简历摘要/目标
-
工作经历
-
技能
-
教育背景
使你的数据科学简历出类拔萃的其他方面
-
项目
-
奖项与认证
-
兴趣与爱好
但了解你为每一部分写什么以及如何写是你应考虑的事项。我们从联系信息开始吧。
联系信息
将这一部分作为单独的板块可能听起来有些滑稽,但这决定了招聘人员是否能够联系到你,因此非常重要。
这一部分应包括:
*** 全名
-
标题 - 例如,“数据科学家”
-
联系电话 - 确保检查是否有错误
-
电子邮箱 - 专业的电子邮箱始终是唯一的选择,例如 firstname.lastname@gmail.com
-
地点 - 这能让招聘人员更好地了解你的所在位置。你也可以说明你是否愿意迁移。
简历总结/目标
如上所述,招聘人员不会花太多时间浏览每份简历。一些招聘人员寻找与他们要求相符的流行词,例如‘Python’,‘Pipeline’,‘机器学习’等。
简历总结概述了你的职业经历和成就,通常在 2-4 句话中完成。简历目标则概述了你希望在职业生涯中实现的潜在兴趣/目标,通常也在 2-4 句话中完成。
在一小段文字中,你能够告诉招聘人员很多关于你自己的信息,你带来了什么,以及你如何计划提升你的职业生涯。
工作经历
如前所述,逆时间顺序始终是最佳的方法。招聘人员希望了解你最近的工作以及如何将其应用于公司。你应该提到
-
你在公司的职位
-
公司名称
-
你在公司工作的时间范围/日期
-
你的职责和成就
在提及你的职责和成就时,总是要进一步解释。例如,与其说“提高数据准确性”,不如说“将预测数据的准确性提高了 22%”。这不仅向招聘人员展示了你在提高准确性方面的技能,还展示了提升的程度。
一个格式化你的工作经历的例子可能如下所示:
| 数据科学家 公司 X 01/2019 - 01/2022
-
开发了端到端的机器学习原型,并提高了 20%的效率
-
提出了并实施了一个新的目标模型,产生了 75 万美元的销售额
-
制定行动计划,通过使用数据科学来改善决策过程
|
如果你刚刚进入数据科学领域,你可能没有任何工作经验。然而,你可能在大学、在线课程、训练营等地方做过一些项目工作。这是一个很好的地方来说明这些经历。
另一种展示你作为新手经验的方法是
-
开始做一些自由职业工作
-
从事一些开源项目
-
在个人项目上工作,使用平台如 Kaggle。
技能
有硬技能,也有软技能。尽管许多数据科学职位以技术技能为主,但软技能仍然非常重要。
数据科学家的典型硬技能包括
-
数据整理/清洗
-
数据分析
-
数据可视化
-
统计学
-
数学
-
概率
-
机器学习
-
建模
数据科学家的典型软技能包括:
-
沟通能力
-
问题解决者
-
商业头脑
-
研究
-
时间管理
-
团队合作
-
独立
-
批判性思维者
教育
教育是简历中的重要元素。它让招聘人员了解你所学习的内容以及你如何走到现在的位置。特别是在数据科学领域,有许多 BootCamps 和课程可以选择,这些都应该列出,因为它们都是你教育的一部分。
你的教育需要包括:
-
教育类型;学位、硕士、Bootcamp 等
-
主要领域:计算机科学、数据科学等
-
大学/机构名称
-
学习年限
-
GPA、荣誉等
格式应如下所示:
| 计算机科学学士 - 哥伦比亚大学 2016 - 2020
- 课程包括:线性代数、统计学、应用建模、SQL、机器学习、计算机科学和生产部署
|
数据科学简历中的其他重要方面
普通简历和技术数据相关简历的区别在于项目、成就和证书。
证书/成就
这个领域是一个你永远不会停止学习的领域,因此你会发现自己参加额外的课程。这些课程将向招聘人员证明你已经主动发展了自己的学习;这点会受到高度关注。
这个结构可能如下所示:
| 奖项和证书:
-
100 Python 问题 – Udemy
-
IBM 数据科学 - Coursera 证书
-
自动化无聊的事情 – Udemy
|
项目
如果你在该领域没有任何工作经验,你的项目应该解释你掌握的技能以及你如何将这些技能应用于你的项目,例如端到端的机器学习。如果是这种情况,你可能会发现你的简历大部分内容会集中在项目领域。
兴趣和爱好
虽然这些可能与技术无关,但陈述你的兴趣和爱好将让招聘人员更多地了解你。这也让数据团队经理知道你是否容易融入团队,以及你的兴趣和爱好是否有益。
结论
如果你正在积极寻找数据科学岗位,考虑调整和优化你当前的简历,以确保它能引起技术招聘人员的注意。
记住,招聘人员每份简历的查看时间是 7.4 秒,所以要确保它有价值。
尼莎·阿亚 是一名数据科学家和自由职业技术作家。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何有助于延长人类寿命。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
MXNet 张量基础和简单自动微分的速成课程
原文:
www.kdnuggets.com/2018/08/mxnet-tensor-basics-simple-derivatives.html
评论
我原本打算很早之前就玩弄 MXNet,大约在 Gluon 公共发布的时候。事情变得忙碌了,我被分散了注意力。
我最近终于开始使用 MXNet。为了了解我的工作方式,我认为覆盖一些基础知识,比如张量和导数的处理,可能是一个好的开始(就像我在 这里 和 这里与 PyTorch 所做的那样)。
这不会一步步重复之前的 PyTorch 文章中的内容,所以如果你想要进一步的背景,可以查看那些文章。下面的内容应该相对简单明了。

MXNet 是一个开源神经网络框架,一个“灵活且高效的深度学习库。” Gluon 是 MXNet 的命令式高级 API,它提供了额外的灵活性和易用性。你可以把 MXNet 和 Gluon 之间的关系看作类似于 TensorFlow 和 Keras。我们在这里不会进一步介绍 Gluon,但会在未来的文章中探索它。
MXNet 的张量实现以 [ndarray](https://mxnet.apache.org/api/python/ndarray/ndarray.html) 包的形式存在。在这里,你将找到构建多维(n维)数组所需的内容,并执行一些实现神经网络所需的操作,以及 autograd 包。我们将在下面利用这个包。
ndarray(非常)基础
首先,让我们从库中导入我们需要的内容,以简化 API 调用:
import mxnet as mx
from mxnet import autograd as ag
from mxnet import nd
现在,让我们在 CPU 上创建一个基本的 ndarray:
# Create CPU array
a = nd.ones((3, 2))
print(a)
[[1\. 1.]
[1\. 1.]
[1\. 1.]]
<NDArray 3x2 @cpu(0)>
注意,打印 ndarray 也会打印出对象的类型(再次是 NDArray),以及其大小和附加的设备(在这个例子中是 CPU)。
如果我们想用 GPU 创建一个 ndarray 对象 上下文(注意上下文是指用于在对象上执行操作的设备类型和 ID)怎么办?首先,让我们确定是否有 GPU 可供 MXNet 使用:
# Test if GPU is recognized
def gpu_device(gpu_number=0):
try:
_ = mx.nd.array([1, 2, 3], ctx=mx.gpu(gpu_number))
except mx.MXNetError:
return None
return mx.gpu(gpu_number)
gpu_device()
gpu(0)
这个响应表示存在一个 GPU 设备,其 ID 为 0。
让我们在这个设备上创建一个 ndarray:
# Create GPU array
b = nd.zeros((2, 2), ctx=mx.gpu(0))
print(b)
[[0\. 0.]
[0\. 0.]]
<NDArray 2 x 2 @gpu(0)>
这里的输出确认创建了一个大小为 2 x 2 的全零 ndarray,并且上下文为 GPU。
要获取一个返回的转置ndarray(而不仅仅是原始的转置视图):
# Transpose
T = c.T
print(T)
[[1\. 2\. 3.]
[4\. 5\. 6.]]
<NDArray 2x3 @cpu(0)>
重新塑造一个ndarray为视图,而不改变原始数据:
# Reshape
r = T.reshape(3,2)
print(r)
[[1\. 2.]
[3\. 4.]
[5\. 6.]]
<NDArray 3x2 @cpu(0)>
一些 ndarray 信息:
# ndarray info
print('ndarray shape:', r.shape)
print('Number of dimensions:', r.ndim)
print('ndarray type:', r.dtype)
ndarray shape: (3, 2)
Number of dimensions: 2
ndarray type: <class 'numpy.float32'>
MXNet ndarray与 Numpy ndarray之间的转换
从 Numpy ndarrays到 MXNet ndarrays以及反向的转换很简单。
import numpy as np
# To numpy ndarray
n = c.asnumpy()
print(n)
print(type(n))
[[1\. 4.]
[2\. 5.]
[3\. 6.]]
<class 'numpy.ndarray'>
# From numpy ndarray
a = np.array([[1, 10], [2, 20], [3, 30]])
b = nd.array(a)
print(b)
print(type(b))
[[ 1\. 10.]
[ 2\. 20.]
[ 3\. 30.]]
<class 'mxnet.ndarray.ndarray.NDArray'>
矩阵-矩阵乘法
这是计算矩阵-矩阵点积的方法:
# Compute dot product
t1 = nd.random.normal(-1, 1, shape=(3, 2))
t2 = nd.random.normal(-1, 1, shape=(2, 3))
t3 = nd.dot(t1, t2)
print(t3)
[[1.8671514 2.0258508 1.1915313]
[9.009048 8.481084 6.7323728]
[5.0241795 4.346245 4.0459785]]
<NDArray 3x3 @cpu(0)>
使用 autograd 查找和解决导数
继续使用 MXNet 的[autograd](http://mxnet.apache.org/api/python/autograd/autograd.html)包来解决导数的自动微分。
首先,我们需要一个用于计算导数的函数。随意选择这个:
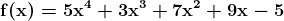
要查看我们如何手动计算这个函数的一阶导数,并找到给定x值的导数函数的值,请参阅这篇文章。
出于显而易见的原因,我们必须以这样的方式在 Python 中表示我们的函数:
y = 5*x**4 + 3*x**3 + 7*x**2 + 9*x - 5
现在让我们为给定的x值找到导数函数的值。我们随意使用 2:
x = nd.array([2])
x.attach_grad()
with ag.record():
y = 5*x**4 + 3*x**3 + 7*x**2 + 9*x - 5
y.backward()
x.grad
一行一行地,以上代码:
-
将我们想要计算导数的值(2)定义为一个 MXNet ndarray 对象
-
使用
**attach_grad()**来为计算梯度分配空间 -
用
**ag.record()**标记的代码块包含了计算和跟踪梯度所需执行的计算 -
定义我们想要计算导数的函数
-
使用 autograd 的backward()来计算梯度的总和,使用链式法则
-
输出存储在x
ndarray的grad属性中的值,如下所示
tensor([ 233.])
这个值 233 与我们手动计算的结果相匹配,请参见这篇文章。
这只是对 MXNet 中简单ndarray操作和导数的一个非常基础的概述。由于这些是构建神经网络的两个基本要素,这应该能让你对库的这些基本构建块有一些熟悉,并为深入研究更复杂的代码做好准备。下次我们将使用 MXNet 和 Gluon 创建一些简单的神经网络,进一步探索这些库。
要了解更多(现在!)关于 MXNet、Gluon 以及深度学习的内容,那本由这些库的开发和推广人员编写的免费书籍深度学习 - 直接真相绝对值得一看。
相关:
-
PyTorch 张量基础
-
用 PyTorch 做简单导数
-
Tensor 究竟是什么?!?
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 服务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号