KDNuggets-博客中文翻译-二十四-
KDNuggets 博客中文翻译(二十四)
原文:KDNuggets
机器学习与网络安全资源
原文:
www.kdnuggets.com/2017/01/machine-learning-cyber-security.html
评论
作者:Faizan Ahmad,Fsecurify

机器学习与网络安全的数据:
我们的前三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业轨道。
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
机器学习在网络安全中的一个重要数据来源是 SecRepo。这个网站包含了各种你可以使用的数据。我没有找到比这个网站更好的网络安全数据来源。
论文:
让我们看看一些很好的论文,这些论文展示了机器学习在网络安全中的应用。
-
快速、精简且准确:使用神经网络建模密码猜测能力。 这是篇很棒的论文,作者使用神经网络破解密码。我已经阅读了这篇论文,真的很棒。
-
超越封闭世界:使用机器学习进行网络入侵检测。这篇论文讨论了使用机器学习进行网络入侵检测。这是另一篇很好的论文。
-
基于异常载荷的网络入侵检测。另一篇被大量引用的论文。
-
基于元数据和结构特征的恶意 PDF 检测。数据科学在网络安全中的独特应用。
-
利用机器学习破坏你的垃圾邮件过滤器。另一本值得阅读的好书。
以下论文来自于 covert.io。你可以查看他们的网站,那里有大量的论文,但数量太多,并且并非所有的论文都很易读和新颖。
书籍:
关于数据科学和机器学习在网络安全中的应用,市面上并没有很多书籍,但我找到了一些看起来相当有前途的书。我将在即将到来的假期中阅读这些书籍。
演讲:
关于这一主题有一些精彩的演讲。我也收集了它们。
-
5 分钟内构建一个杀毒软件 – 新鲜的机器学习 #7。一个有趣的视频。
这些是我找到的不错的内容。我还没全部观看,但它们似乎都很不错。如果你找到更多的讲座,请在评论中告诉我。
教程:
我找到了一些与这个话题相关的很棒的教程。
-
点击安全数据黑客项目。该项目包含许多带有笔记本和代码的教程。这是每个对 ML 在信息安全中应用感兴趣的人必读的内容。
-
大数据和数据科学用于安全与欺诈检测。 很不错的一篇。
-
使用深度学习破解验证码系统。 值得一读。
课程:
关于这个话题也有一些课程。不过这里是我找到的几个。
- 斯坦福大学的网络安全数据挖掘。 这是使用数据进行网络安全的最佳课程之一。讲师在幻灯片中提供了很多应用和技术。课程页面上还有很多学生使用机器学习进行安全的项目。
杂项:
-
系统通过人类专家的输入预测 85%的网络攻击。 必读文章。
-
在mlsecproject上发布了一份使用机器学习的网络安全开源项目列表。
就这些了。这些是我能找到的一些与此主题相关的非常好的资源。如果你知道其他资源,请在下方评论,我会添加进去。
简介: Faizan Ahmad 是一名富布赖特本科生,目前在 NUCES FAST 学习,同时担任巴基斯坦拉合尔管理科学大学的研究助理。
相关:
-
使用机器学习检测恶意网址
-
数据科学家如何缓解敏感数据暴露的脆弱性?
-
大数据安全的 5 个最佳实践
更多相关话题
Dask 中的机器学习
评论
在个人电脑上处理几 GB 的数据通常是一个艰巨的任务,除非该电脑具有高 RAM 和大量计算能力。
尽管如此,数据科学家仍然需要寻找替代方案来处理这个问题。一些解决方法包括调整 Pandas 以使其能够处理大型数据集,购买 GPU 机器或在云端购买计算资源。在本文中,我们将看到如何使用Dask在本地机器上处理大数据集。
我们的前三个课程推荐
1. Google Cybersecurity Certificate - 快速进入网络安全职业道路
2. Google Data Analytics Professional Certificate - 提升您的数据分析技能
3. Google IT Support Professional Certificate - 支持您的组织的 IT
Dask 和 Python
Dask 是一个用于 Python 的灵活并行计算库。它被构建为能够很好地与其他开源项目(如 NumPy、Pandas 和 scikit-learn)集成。在 Dask 中,Dask 数组 相当于 NumPy 数组,Dask DataFrames 相当于 Pandas DataFrames,而 Dask-ML 相当于 scikit-learn。
这些相似性使得将 Dask 轻松地融入您的工作流程。使用 Dask 的优势在于您可以将计算扩展到计算机上的多个核心。这使得您能够处理内存无法容纳的大型数据集。它还帮助加快通常需要很长时间的计算。
Dask DataFrames
当加载大量数据时,Dask 通常会读取数据的一个样本以推断数据类型。如果某一列的数据类型不同,这通常会导致问题。为了避免类型错误,通常的好做法是事先声明数据类型。Dask 通过将数据切分成块(由 blocksize 参数定义)来加载大型文件。
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )

Dask DataFrame 中的命令与 Pandas 中的命令大致相同。例如,获取 head 和 tail 是类似的:
df.head()
df.tail()
DataFrame 上的函数是懒惰执行的。这意味着它们不会被计算,直到调用 compute 函数。
df.isnull().sum().compute()
由于数据是分区加载的,一些 Pandas 函数如 sort_values() 可能会失败。解决方法是使用 nlargest() 函数。
Dask 集群
并行计算是 Dask 的关键,因为它允许在多个核心上运行计算。Dask 提供了一个在单台计算机上工作的机器调度器。它不具备扩展性。它还提供了一个可以扩展到多台计算机的分布式调度器。
使用 dask.distributed 需要你设置一个 Client。如果你打算在分析中使用 dask.distributed,这应该是你首先做的事情。它提供了低延迟、数据本地性、工作节点之间的数据共享,并且易于设置。
from dask.distributed import Client
client = Client()

即使在单台机器上使用 dask.distributed 也是有利的,因为它通过仪表板提供了一些诊断功能。
如果未声明 Client,默认将使用单机调度器。它通过使用进程或线程在单台计算机上提供并行性。
Dask ML
Dask 还使你能够以并行方式进行机器学习训练和预测。dask-ml 的目标是提供可扩展的机器学习。当你在 scikit-learn 中声明 n_jobs = -1 时,你可以并行运行计算。Dask 利用这一能力来使你能够在集群中分配计算。这是通过 joblib 实现的,该包允许 Python 中的并行处理和管道化。使用 Dask ML,你可以实现 scikit-learn 模型以及其他库,如 XGboost。
这就是简单实现的样子。
首先像往常一样导入 train_test_split,用于将数据分成训练集和测试集。
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
接下来,导入你想使用的模型并实例化它。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)
然后你需要导入 joblib 以启用并行计算。
import joblib
接下来,使用并行后端运行你的训练和预测。
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)
机器学习正迅速接近数据采集地点——边缘设备。订阅 Fritz AI 新闻通讯以了解更多关于这一过渡以及如何帮助扩展你的业务。
限制和内存使用
Dask 中的单个任务不能并行运行。工作节点是继承了 Python 计算的所有优缺点的 Python 进程。在分布式环境中工作时,还应注意确保数据安全和隐私。
Dask 有一个中央调度器,用于跟踪工作节点和集群上的数据。这个调度器还控制从集群中释放数据。一旦任务完成,它会从内存中清除数据,以释放内存供其他任务使用。如果某个 client 需要某些数据,或者它对正在进行的计算很重要,它会保留在内存中。
另一个 Dask 的限制是它没有实现 Pandas 中的所有函数。Pandas 接口很庞大,因此 Dask 并未完全实现它。这意味着在 Dask 上尝试一些操作可能会比较困难。此外,Pandas 上慢的操作在 Dask 上也同样慢。
当你不需要 Dask DataFrame 时
在以下情况下,你可能不需要 Dask:
-
当有一些 Pandas 函数尚未在 Dask 中实现时。
-
当你的数据完全适合计算机的内存时。
-
当你的数据不是表格形式时。在这种情况下,可以尝试 dask.bag 或 dask.array。
最后的思考
在这篇文章中,我们看到我们如何使用 Dask 在本地机器或以分布式方式处理巨大数据集。我们了解到,由于 Dask 的熟悉语法和扩展能力,我们可以使用 Dask。它能够扩展到数千个核心。
我们还看到我们可以在机器学习中使用它来训练和运行预测。你可以通过查看这些官方文档中的演示文稿来了解更多信息:
简历: 德里克·穆伊提 是一位数据分析师、作家和导师。他致力于在每项任务中取得卓越成果,并且是 Lapid Leaders Africa 的导师。
原文。已获许可转载。
相关:
-
为什么以及如何在大数据中使用 Dask
-
五个有趣的数据工程项目
-
Python 中的自动化机器学习
相关阅读
50 个有用的机器学习与预测 API
原文:
www.kdnuggets.com/2015/12/machine-learning-data-science-apis.html/2
面部和图像识别
-
Animetrics Face Recognition:这个 API 可以用于检测照片中的人脸,并与一组已知面孔进行匹配。该 API 还可以将主题添加或移除到可搜索的画廊中,并将面孔添加或移除到主题中。
-
Betaface:一个面部识别和检测的网络服务。功能包括多面孔检测、面孔裁剪、123 个面部点检测(22 个基础点,101 个高级点)、面孔验证、识别、在非常大的数据库中进行相似性搜索等。
-
Eyedea Recognition:一个识别服务,提供眼睛面孔、车辆、版权和车牌检测。该 API 的主要价值在于可以即时了解对象、用户和行为。
-
Face++:一个提供检测、识别和分析的面部识别和检测服务,供应用程序使用。用户可以调用程序进行训练、检测面孔、识别面孔、分组面孔、操控人员、创建面孔集合、创建组和获取信息。
-
FaceMark:FaceMark 是一个能够在正面面孔照片上检测 68 个点,在侧面面孔照片上检测 35 个点的 API。
-
Google Cloud Vision API:帮助你快速大规模地找到你喜欢的图片,并获得丰富的注释。它将图像分类到数千个类别(例如,“船”,“狮子”,“埃菲尔铁塔”),检测带有相关情感的面孔,并识别多种语言中的打印文字。
-
Microsoft Project Oxford Vision:允许开发者访问和集成 Microsoft Project Oxford 的视觉功能。一些示例 API 方法包括处理图像、检测图像和返回缩略图。
-
Rekognition:提供优化用于社交照片应用的面部和场景图像识别。利用眼睛、嘴巴、面部和鼻子以及情绪识别和性别相关特征,Rekognition API 可以预测性别、年龄和情绪。
-
FaceRect:一个能够在图像中检测面孔的 API。该 API 可以在给定的图像中检测多个面孔,包括正面和侧面面孔,并搜索每个检测到的面孔中的面部特征(眼睛、鼻子、嘴巴)。
-
Kairos: 一个面部识别 API,允许用户将先进的安全功能集成到他们的应用程序和服务中。
-
Skybiometry Face Detection and Recognition: 提供面部检测和识别服务,可作为 discontinued face.com API 的替代品。
文本分析、自然语言处理、情感分析
-
AlchemyAPI: AlchemyAPI 提供人工智能作为服务。目前可用的文本分析功能包括实体提取、情感分析、关键词提取、概念标记、关系提取、文本分类、作者提取、语言检测、文本提取、微格式解析和 RSS/ATOM 订阅源检测。
-
AlchemyAPI Keyword Extraction: 从文本、HTML 或发布的网页内容中提取主题关键词。此 API 会对目标文本进行规范化,去除广告、导航链接和其他不必要的内容,然后提取主题关键词。
-
Bitext Sentiment Analysis: 一套多语言语义服务。目前提供四种语义服务:实体和概念提取、情感分析和文本分类。
-
Calais: 使用自然语言处理、机器学习和其他方法,Calais 将文档中的实体(人、地点、组织等)、事实(某人“x”在公司“y”工作)和事件(某人“z”在日期“x”被任命为公司“y”的主席)进行分类和链接。
-
Semantic Biomedical Tagger: 具有内置能力识别 133 种生物医学实体类型,并将它们语义链接到知识库系统中。
-
Free Natural Language Processing Service: 情感分析、内容提取和语言检测。
-
nlpTools: 解码在线新闻来源进行情感分析和文本分类。为了分析一行文本的情感或分类,开发者可以使用此 API 来返回一个类别标签以及该文本的情感条件,范围从积极、中性到消极。
-
Diffbot Analyze: 提供开发者工具,可以识别、分析并提取任何网页的主要内容和部分。
-
Skyttle: Market Sentinel 的文本挖掘引擎,分析文本中的主题关键词和短语级情感。支持的语言包括英语、法语、德语、俄语。
-
Speech2Topics:分析音频和视频,以外推大数据,使用自然语言处理和语音识别。
-
TweetSentiments:使用支持向量机算法对推文进行语义分析,从而确定推文是积极的、消极的还是中性的。
-
Text Processing: 提供包括总结文档、标记文档、词干化、去除停用词、标记词性(POS)、从印尼语翻译成英语和检索词汇定义等功能。
-
MeaningCloud 文本分类:文本分类 API 执行预分类任务,如:提取文本、分词、去除停用词和词形还原。使用基于规则的过滤和统计文档分类,该 API 可以在广泛的环境中进行准确的分类。
翻译
-
Google Translate:目前为第二版,Google Translate 为自动机器翻译领域的研究人员提供工具,以帮助比较、对比,并在 Google 的统计机器翻译系统基础上进行构建。
-
LangId:快速检索有关任何语言的信息,而无需指定语言。
-
MotaWord:提供 70 多种语言的翻译。该 API 还允许开发者获取每个翻译的报价,提交翻译项目及文档和风格指南,跟踪翻译项目的进度,并实时获取活动动态。
-
WritePath 翻译:API 允许开发者访问并将 WritePath 的功能与其他应用程序集成。一些示例 API 方法包括检索字数、提交翻译文档以及获取翻译后的文档和文本。
-
IBM Watson 语言翻译:使用统计机器翻译技术提供特定领域的翻译。他们目前提供三个领域(对话、专利和新闻),可以在总共七种语言之间进行翻译。
参考资料:Mashape 博客 & Programmable Web
我们是否遗漏了您最喜欢的 API?我们将继续更新列表!在评论中告诉我们您的想法。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
相关:
-
5 个最佳机器学习 API 用于数据科学
-
预测和机器学习的 API:投票结果和分析
-
预测分析培训资源热榜
相关内容
免费高质量机器学习与数据科学书籍与课程:隔离版
原文:
www.kdnuggets.com/2020/04/machine-learning-data-science-books-courses-quarantine.html
评论
你现在有机会待在家里吗?由于 COVID-19,许多人被限制在家中隔离、居家避难或类似的情况。如果你发现自己处于这种情况,并且正在寻找免费的学习材料,比如书籍和课程,以便充分利用并提升你的数据科学和机器学习技能,这些我之前编写的文章将对你有帮助。总的来说,你会找到链接到这些材料的小型合集,总计超过 100 本高质量的书籍和课程。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
我们也借此机会向那些当前无法享受这种奢侈的关键工作者致敬。KDnuggets 想向所有在这次疫情期间奋战在一线的工作者表示感谢:医生、护士、医学研究人员、邮递员、警察、消防员、急救人员、药店工作人员、超市店员、餐饮服务提供者、卡车司机、供应链上的每一个人,以及所有提供关键服务以保护脆弱群体、前线医疗工作者,并让我们其他人能够在家工作的人。谢谢你们!
10 本机器学习和数据科学必读书籍

10 本更多免费的必读书籍,涵盖机器学习和数据科学

另外 10 本免费的必读书籍,涵盖机器学习和数据科学

10 本免费的必看机器学习和数据科学课程

10 本更多的必看免费课程,涵盖机器学习和数据科学

另有 10 本免费的必看课程,涵盖机器学习和数据科学

10 本免费的顶级机器学习课程

10 个免费顶级自然语言处理课程

免费数学课程用于数据科学与机器学习

相关:
-
2020 年每个数据科学家必读的 50 本免费书籍
-
理解机器学习的 24 本最佳(免费)书籍
-
数据科学家的最佳免费流行病学课程
更多相关内容
7 个做机器学习时常见的错误
原文:
www.kdnuggets.com/2015/03/machine-learning-data-science-common-mistakes.html
作者:程涛(@chengtao_chu)。
统计建模很像工程学。
 在工程学中,有多种方法可以构建键值存储,每种设计对使用模式做出不同的假设。在统计建模中,有各种算法可以构建分类器,每种算法对数据做出不同的假设。
在工程学中,有多种方法可以构建键值存储,每种设计对使用模式做出不同的假设。在统计建模中,有各种算法可以构建分类器,每种算法对数据做出不同的假设。
当处理少量数据时,尝试尽可能多的算法并选择最佳算法是合理的,因为实验成本较低。但当面对“大数据”时,提前分析数据并据此设计建模流程(预处理、建模、优化算法、评估、生产化)是值得的。
正如我在之前的帖子中指出的,有许多方法可以解决给定的建模问题。每种模型假设的情况不同,如何判断这些假设是否合理并不明显。在行业中,大多数从业者选择他们最熟悉的建模算法,而不是选择最适合数据的算法。在这篇文章中,我想分享一些常见的错误(即“不要做”的事)。一些最佳实践(即“要做”的事)我会在未来的文章中分享。
1. 以为默认损失函数是正确的
许多从业者使用默认的损失函数(例如,平方误差)训练并选择最佳模型。实际上,现成的损失函数很少与业务目标一致。以欺诈检测为例。当尝试检测欺诈交易时,业务目标是最小化欺诈损失。现成的二分类器损失函数对假阳性和假阴性给予相同的权重。为了与业务目标对齐,损失函数不仅应对假阴性施加比假阳性更大的惩罚,还应根据金额对每个假阴性施加惩罚。此外,欺诈检测中的数据集通常包含高度不平衡的标签。在这些情况下,应通过上采样/下采样来倾斜损失函数,偏向于稀有情况。
2. 对非线性交互使用简单线性模型
在构建二元分类器时,许多从业者会立刻选择逻辑回归,因为它简单。然而,许多人也会忘记逻辑回归是线性模型,并且预测变量之间的非线性交互需要手动编码。回到欺诈检测,高阶交互特征如“账单地址 = 送货地址且交易金额 < $50”对模型性能至关重要。因此,应优先选择像带有核的 SVM 或树基分类器等非线性模型,它们可以内置高阶交互特征。
3. 忘记异常值
异常值很有趣。根据上下文,它们可能值得特别关注,或者应该完全忽略。例如,在收入预测中,如果观察到收入的异常峰值,可能应该额外关注一下,找出峰值的原因。但如果异常值是由于机械故障、测量误差或其他无法普遍化的原因造成的,那么在将数据输入建模算法之前,最好过滤掉这些异常值。
 一些模型对异常值比其他模型更敏感。例如,AdaBoost 可能会将这些异常值视为“困难”案例,并对异常值施加巨大权重,而决策树可能只是将每个异常值计为一个错误分类。如果数据集中包含大量异常值,那么要么使用对异常值具有鲁棒性的建模算法,要么在建模之前过滤掉异常值。
一些模型对异常值比其他模型更敏感。例如,AdaBoost 可能会将这些异常值视为“困难”案例,并对异常值施加巨大权重,而决策树可能只是将每个异常值计为一个错误分类。如果数据集中包含大量异常值,那么要么使用对异常值具有鲁棒性的建模算法,要么在建模之前过滤掉异常值。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
更多相关话题
最佳机器学习语言、数据可视化工具、深度学习框架和大数据工具
原文:
www.kdnuggets.com/2018/12/machine-learning-data-visualization-deep-learning-tools.html
 评论
评论
由 Altexsoft。
原文。经许可转载。
最训练有素的士兵不能空手完成任务。数据科学家有自己的武器——机器学习(ML)软件。已经有大量文章列出了可靠的机器学习工具,并深入描述了它们的功能。然而,我们的目标是获取行业专家的反馈。
这就是为什么我们采访了数据科学实践者——真正的专家——关于他们为自己的项目选择的有用工具。我们联系的专家有不同的专长,分别在 Facebook 和三星等公司工作。其中一些代表了 AI 初创公司(Objection Co、NEAR.AI 和 Respeecher);一些在大学(哈尔科夫国立无线电电子大学)教授。AltexSoft 的数据科学团队也参与了讨论。
如果你在寻找特定类型的机器学习工具,只需跳到你感兴趣的领域:
最受欢迎的机器学习语言
你在一家民族餐馆用餐,对文化不太熟悉。你可能会先询问服务员菜单上的词语是什么含义,甚至在了解你将使用什么餐具之前。所以,在讨论数据科学家最喜欢的工具之前,我们先来了解一下他们使用哪些编程语言。
Python:一种流行的语言,拥有高质量的机器学习和数据分析库。
Python 是一种通用语言,因其可读性、良好的结构和相对平缓的学习曲线而受到青睐,并继续获得越来越高的受欢迎度。根据 Stack Overflow 年度开发者调查 的数据,Python 可以称得上是增长最快的主要编程语言。它排名第七,受欢迎程度为 38.8%,现已超过 C#(34.4%)。
Respeecher 的研究负责人 Grant Reaber,专注于应用于语音识别的深度学习,将 Python 作为“几乎所有人目前都将其用于深度学习。 Swift 用于 TensorFlow 听起来是一个很酷的项目,但我们会等到它更加成熟再考虑使用它,” Grant 总结道。
NEAR.AI 初创公司的联合创始人 Illia Polosukhin ,曾在 Google Research 负责 NLU 的深度学习团队,也继续使用 Python:“Python 一直以来都是数据分析的语言,并且随着时间的推移,成为了深度学习的事实标准语言,所有现代库都是为其构建的。”
Python 机器学习的一个应用场景是模型开发,特别是原型设计。
AltexSoft 的数据科学能力负责人 Alexander Konduforov 说他主要将 Python 用作构建机器学习模型的语言。
Vitaliy Bulygin,三星乌克兰的首席工程师,认为 Python 是快速原型设计的最佳语言之一。“在原型设计过程中,我找到最佳解决方案并将其重写为项目所需的语言,例如 C++,” 这位专家解释道。
Facebook AI 研究员 Denis Yarats 指出,这种语言有着惊人的深度学习工具集,如 PyTorch 框架或 NumPy 库(我们将在文章后面讨论)。
C++:一种用于 CUDA 上并行计算的中级语言
C++ 是一种灵活的、面向对象的、静态类型的语言,基于 C 编程语言。由于其可靠性、性能以及支持大量应用领域,该语言在开发者中仍然非常受欢迎。C++ 具有高级和低级语言的特点,因此被认为是一种中级编程语言。该语言的另一应用是开发能够在实时约束下直接与硬件交互的驱动程序和软件。由于 C++ 足够简洁以解释基本概念,因此也用于研究和教学。
数据科学家使用这种语言处理多种但具体的任务。 Andrii Babii 是哈尔科夫国立无线电电子大学(NURE)的高级讲师,他使用 C++ 在 CUDA 平台上并行实现算法,以加速基于这些算法的应用程序。
“当我为 CUDA 编写自定义内核时,我需要 C++,” Denis Yarats 补充道。
R:用于统计计算和图形的语言
R,作为一种统计、可视化和数据分析的语言和环境,是数据科学家的首选。它是 S 编程语言 的另一种实现。
R 及其编写的库提供了众多图形和统计技术,如经典统计测试、线性和非线性建模、时间序列分析、分类、聚类等。你可以轻松地通过 R 机器学习包扩展语言。该语言允许创建高质量的图表,包括公式和数学符号。
Alexander Konduforov 指出,使用 R 进行机器学习能够快速进行数据分析和可视化。
数据分析和可视化工具
pandas:增强分析和建模的 Python 数据分析库
现在是时候稍微谈谈 Python 的 pandas,一个名字非常可爱的免费库。数据科学爱好者 Wes McKinney 开发了这个库,以便在 Python 中方便地进行数据分析和建模。在 pandas 之前,这种编程语言 仅适用于数据准备和处理。
pandas 通过将 CSV、JSON 和 TSV 数据文件或 SQL 数据库转换为数据框(一个看起来像 Excel 或 SPSS 表格的 Python 对象,具有行和列)来简化分析。更重要的是,pandas 与 IPython 工具包和其他库结合,以提高性能并支持协作工作。
matplotlib:用于高质量可视化的 Python 机器学习库
matplotlib 是一个 Python 2D 绘图库。绘图是机器学习数据的可视化。matplotlib 源自 MATLAB:其开发者 John D. Hunter 模拟了 Mathworks 的 MATLAB 软件中的绘图命令。
虽然主要用 Python 编写,但该库通过 NumPy 和其他代码进行了扩展,因此即使在处理大数组时也表现良好。
matplotlib 允许用几行代码生成生产质量的可视化。库的开发者 强调 了使用的简便性:“如果你想看到数据的直方图,你不应该需要实例化对象、调用方法、设置属性等等,它应该直接工作。”
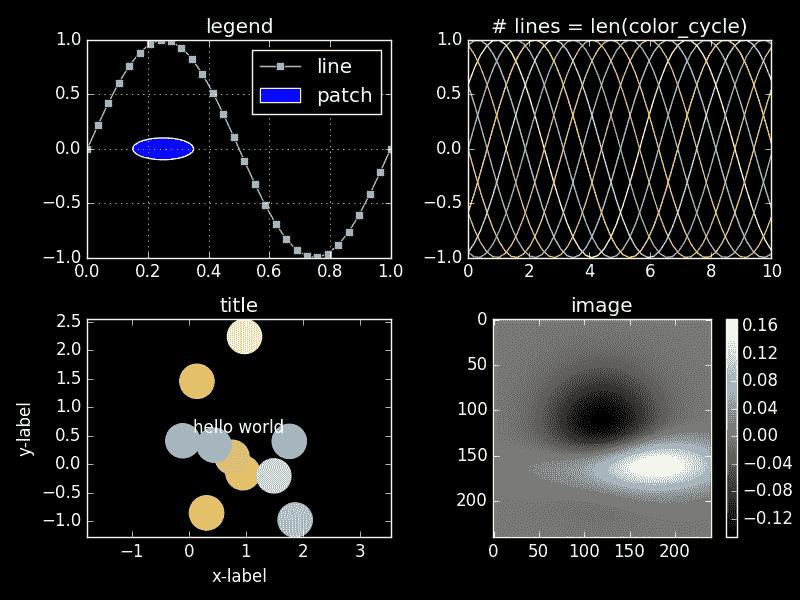
matplotlib 可视化演示。图像来源:matplotlib Style Gallery
该库的功能可以通过第三方可视化包扩展,如 seaborn、ggplot 和 HoloViews。专家们还可以使用 Basemap 和 cartopy 投影和制图工具包添加额外功能。
数据科学从业者注意到 matplotlib 的灵活性和集成能力。例如,Andrii Babii 更倾向于将 matplotlib 与 seaborn 和 ggplot2 一起使用。
Denis Yarats(Facebook AI Research)表示,他选择 matplotlib 主要是因为它很好地集成到 Python 工具集,并且可以与 NumPy 库或 PyTorch 机器学习框架一起使用。
Alexander Konduforov 和他的 AltexSoft 团队也使用 matplotlib。除了众多的 Python 机器学习库如 pandas,以及支持 R 和 Python 的 Plotly,团队还选择 dplyr、ggplot2、 tidyr 和 Shiny R 库。“这些工具是免费的,但你必须至少了解一些编程才能使用它们,有时还需要额外的时间。”
Jupyter notebook:协作工作能力
Jupyter Notebook 是一款免费的互动计算网页应用程序。用户可以创建和共享包含实时代码的文档,开发和执行代码,以及展示和讨论任务结果。文档可以通过 Dropbox、电子邮件、GitHub 和 Jupyter Notebook Viewer 共享,并可以包含图形和叙述性文本。
Notebook 功能丰富,并提供多种使用场景。
它可以与许多工具集成,如 Apache Spark、pandas 和 TensorFlow。它支持 40 多种语言,包括 R、Scala、Python 和 Julia。除此之外,Jupyter Notebook 还支持容器平台——Docker 和 Kubernetes。
NEAR.AI 的 Illia Polosukhin 分享了他主要用于自定义临时分析的 Jupyter Notebook:“这个应用程序允许快速进行任何数据或模型分析,并能够连接到远程服务器上的内核。你还可以与同事分享结果笔记本。”
Tableau:强大的数据探索能力和互动可视化
Tableau 是一款用于数据科学和商业智能的数据可视化工具。许多具体功能使这款软件在各种行业和数据环境中解决问题时非常高效。
通过数据探索和发现,Tableau 软件可以快速从数据中提取见解并以易于理解的格式展示出来。它不需要出色的编程技能,并且可以轻松安装在各种设备上。虽然需要编写少量脚本,但大多数操作都是通过拖放完成的。
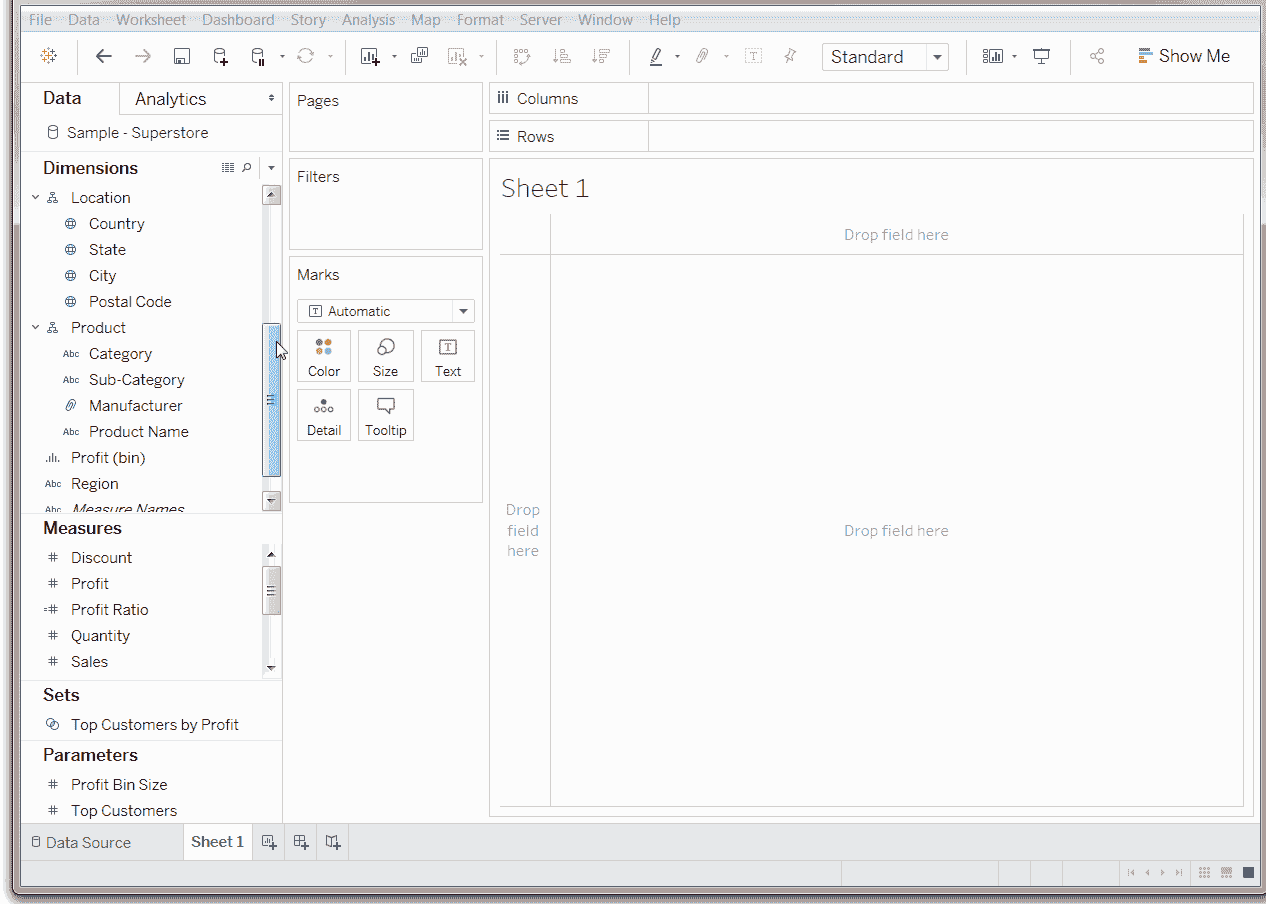
Tableau 拖放菜单的工作原理
Tableau 支持实时分析和云集成(例如与 AWS、Salesforce 或 SAP),允许结合不同的数据集和集中数据管理。
易用性和一整套功能是数据科学家选择这个工具的原因。 “Tableau 具有许多内置功能,不需要编码。你可以在 UI 中进行大量数据预处理、分析和可视化,这节省了大量精力。不过,由于它不是免费的产品,你需要购买许可证,” Alexander Konduforov 说。
一般机器学习框架
NumPy:一个用于 Python 科学计算的扩展包
前面提到的 NumPy 是一个用于 Python 数值计算的扩展包,它取代了 NumArray 和 Numeric。它支持多维数组(表格)和矩阵。机器学习数据以数组的形式表示,而矩阵是一个二维的数字数组。NumPy 包含广播功能,作为与 C/C++ 和 Fortran 代码集成的工具。它的功能还包括傅里叶变换、线性代数和随机数能力。
数据科学从业者可以使用 NumPy 作为存储多维通用数据的有效容器。通过定义任意数据类型的能力,NumPy 可以轻松快捷地与多种数据库集成。
scikit-learn:一个易于使用的机器学习框架,适用于众多行业
scikit-learn 是一个开源 Python 机器学习库,建立在 SciPy(科学 Python)、NumPy 和 matplotlib 之上。
scikit-learn 最初由 David Cournapeau 于 2007 年作为 Google Summer of Code 项目开始,目前由志愿者维护。截至今天,共有 1,092 人为其做出贡献。
该库设计用于生产使用。简单性、优质的代码、协作选项、性能以及用通俗语言编写的广泛文档都促进了它在各种专业人士中的受欢迎程度。
scikit-learn 为用户提供了许多成熟的监督学习和无监督学习算法。来自 Machine Learning Mastery 的数据科学从业者 Jason Brownlee 指出,该库专注于数据建模,而不是数据加载、处理和总结。他建议使用 NumPy 和 pandas 来处理这三项功能。
Denis Yarats 使用 NumPy、pandas 和 scikit-learn 进行一般机器学习:“我喜欢它们的简洁和透明。这些工具被广泛采用,经过多年的使用,经过了许多人的考验,这也很好。”
Aleksander 观察到:“AltexSoft 数据科学团队主要使用像 scikit-learn 和 xgboost 这样的 Python 库来进行分类和回归任务。”
Andrii Babii 更喜欢将 scikit-learn 与 R 语言库和包 一起使用。“我使用这个组合是因为它开源,功能丰富且互补,”数据科学家解释道。
NLTK:基于 Python 的人类语言数据处理平台
NLTK 是一个用于开发处理人类语言的 Python 程序的平台。
Aleksander Konduforov 更喜欢这个工具用于 NLP 任务。“NLTK 是 Python 中处理文本的标准库,具有许多有用的功能。例如,不同类型的文本、句子和单词处理、词性标注、句子结构分析、命名实体识别、文本分类、情感分析等。所有这些库都是免费的,提供了足够的功能来解决我们大多数任务,” 专家指出。
神经网络建模的 ML 框架
TensorFlow:大规模机器学习的灵活框架
TensorFlow 是一个开源的软件库,用于机器学习和深度神经网络研究,由 Google AI 组织中的 Google Brain Team 开发并于 2015 年发布。
这个库的一个显著特点是,数值计算通过由节点和边组成的数据流图来完成。节点代表数学运算,而边是多维数据数组或 张量,这些操作在其上执行。
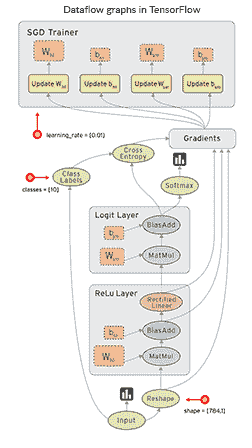 TensorFlow 中操作间数据流的可视化
TensorFlow 中操作间数据流的可视化
TensorFlow 灵活,可以在各种计算平台(CPU、GPU 和 TPU)和设备上使用,从桌面到服务器集群,再到移动设备和边缘系统。它支持 Mac、Windows 和 Linux。
这个框架的另一个优势是,它既适用于研究,也适用于重复的机器学习任务。
TensorFlow 开发工具丰富,特别是对于 Android。三星乌克兰的首席工程师 Vitaliy Bulygin 建议:“如果你需要在 Android 上实现某些功能,使用 TensorFlow。”
Curtis Boyd,Objection Co 的首席执行官,他的公司提供自动化差评移除策略,他表示他的团队选择使用 TensorFlow 进行机器学习,因为它是开源的且非常容易集成。
TensorBoard:一个用于模型训练可视化的好工具
TensorBoard 是一个工具套件,用于图形化表示 TensorFlow 中机器学习的不同方面和阶段。
TensorBoard 读取 TensorFlow 事件文件,这些文件包含在 TensorFlow 运行时生成的总结数据(关于模型特定操作的观察)。
通过图示展示的模型结构可以让研究人员确保模型组件的位置和连接都正确。

TensorBoard 中的模型图形表示
使用图形可视化工具,用户可以探索模型抽象的不同层次,放大或缩小图示的任何部分。TensorBoard 可视化的另一个重要好处是,相同类型和相似结构的节点会用相同的颜色显示。用户还可以按设备(CPU、GPU 或两者的组合)查看颜色,使用“追踪输入”功能高亮特定节点,并一次性可视化一个或多个图表。
这种可视化方法使 TensorBoard 成为模型性能评估的热门工具,特别是对于深度神经网络等复杂结构的模型。
Grant Reaber 指出 TensorBoard 使得模型训练的监控变得简单。Grant 和他的团队也使用这个工具进行自定义可视化。
Illia Polosukhin 也选择了 TensorBoard。“TensorBoard 在模型开发过程中显示指标,并允许做出有关模型的决策。例如,在调整超参数并选择表现最佳的参数时,监控模型性能非常方便,”Illia 总结道。
除了显示性能指标外,TensorBoard 还可以展示许多其他信息,如直方图、音频、文本和图像数据、分布、嵌入和标量。
PyTorch:易于使用的研究工具
PyTorch 是一个开源机器学习框架,支持深度神经网络并加速 GPU。由 Facebook 团队与 Twitter、SalesForce、NRIA、ENS、ParisTech、Nvidia、Digital Reasoning 和 INRIA 的工程师们共同开发,首次发布于 2016 年 10 月。PyTorch 基于 Torch 框架,但与前身 Lua 编写的框架不同,它支持常用的 Python。
PyTorch 的开发理念是提供尽可能快速和灵活的建模体验。值得一提的是,PyTorch 的工作流程类似于NumPy,这是一个基于 Python 的科学计算库。
动态计算图是使该库受欢迎的特性之一。在大多数框架如 TensorFlow、Theano、CNTK 和 Caffe 中,模型是以 静态 的方式构建的。数据科学家必须更改整个神经网络的结构 —— 从头重建 —— 才能改变其行为。PyTorch 使这一过程更简单、更快。该框架允许随意更改网络行为,而不会出现延迟或开销。
Denis Yarats 来自 Facebook AI Research 认为,构建模型 动态(在运行时)的能力是使用 PyTorch 的一个重要因素。“我使用 PyTorch——它是最好的。我曾尝试过许多深度学习框架,包括 TensorFlow、Torch、Keras 和 Theano。没有一个比 PyTorch 更简单、更强大。由于我从事深度学习研究,我重视快速修改和调试模型的能力。”
伊利亚·波洛苏金和维塔利·布柳金也强调了通过使用动态计算图实现的研究的便利性和灵活性,这也是他们选择 PyTorch 作为深度学习工具的原因。
Keras:轻量级、易于使用的快速原型设计库
Keras 是一个 Python 深度学习库,可以在 Theano、TensorFlow 或 CNTK 之上运行。Google Brain 团队成员弗朗索瓦·肖莱开发了它,以便数据科学家能够快速进行机器学习实验。
该库可以在 GPU 和 CPU 上运行,并支持递归网络和卷积网络及其组合。
利用该库的高级、易于理解的接口、将网络划分为易于创建和添加的独立模块的序列,可以实现快速原型设计。
数据科学家表示,建模速度是该库的一个优势。来自三星的维塔利·布柳金指出,Keras 与 TensorFlow 结合可以实现非常快速的神经网络实施。他建议,如果工具集足够完成特定任务,则应继续使用 Keras。如果不够,最好用 PyTorch 进行研究。
Caffe2:具有移动部署支持的深度学习库
Caffe2,是 Caffe 的改进版,是 Facebook 为简化和灵活处理复杂模型并支持移动部署而构建的开放机器学习框架。
用户可以通过多种方式组织计算,该库可以在桌面、云端或数据中心安装和运行。
该库具有本地 Python 和 C++ API,允许开发人员交替使用,便于快速原型设计和后期优化。
部署的模型可以通过与 Xcode、Visual Studio 和 Android Studio IDE 的集成,在移动设备上快速运行。该框架还允许快速扩展或缩减,无需重新设计。
快速原型设计、研究和开发是使用 Caffe2 的优势。“我使用它是因为它有清晰的代码结构,并且容易扩展以研究新方法,” NURE 的高级讲师 Andrii Babii 总结道。
大数据工具
Apache Spark: 分布式计算工具
使用 Apache Spark 进行大数据处理就像驾驶一辆法拉利:它更快、更便捷,并且在相同时间内可以探索更多内容,相比普通汽车。
Apache Spark 是一个分布式开源集群计算框架,通常配备有内存数据处理引擎。该引擎的功能包括 ETL(提取、转换和加载)、机器学习、数据分析、批处理和数据流处理。
Apache Spark 的流处理能力是 Facebook AI 的研究员 Denis Yarats 使用它的原因之一:“这个工具使用数据流/流处理概念进行分布式计算,并且允许将解决方案扩展到大型集群。”
尽管主要使用 Scala 编写,但引擎提供了 Java、Python、Clojure 和 R 的高级开发者 API。
Apache Spark 的其他有益特性包括多种运行选项(本地、集群、云或本地部署)和从任何数据源访问数据的能力。
MemSQL: 一个为实时应用设计的数据库
MemSQL 是用于实时分析的分布式内存 SQL 数据库平台。它处理和分析流数据,并执行 PB 级查询,以支持即时通讯、在线游戏或社区存储解决方案等实时应用。MemSQL 支持 关系 SQL、地理空间 或 JSON 数据的查询。
简而言之,该平台可以同时提供数据库、实时数据处理和数据仓库服务,帮助用户实现数据效率。
“MemSQL 让你不必担心数据的大小,并且可以像使用普通 SQL 数据库一样操作,” NEAR.AI 的 Illia Polosukhin 强调道。
结论
我们通过比较 机器学习工具 和 库,明确了它们的使用场景和需求。在准备过程中,这对我们帮助很大。我们计划下个月写一篇关于 航空公司如何使用人工智能解决方案 的文章。如果你是一个活跃的机器学习从业者,请随时在评论区或直接联系我们,分享你偏好的工具。我们也乐意分享你的评论。
简介: Altexsoft 是一家旅行与酒店科技咨询公司。他们与在线旅行社、旅行管理解决方案提供商以及旅行科技初创公司合作,开发定制软件。
资源:
相关:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT。
更多相关话题
为什么机器学习部署很困难?
原文:
www.kdnuggets.com/2019/10/machine-learning-deployment-hard.html
评论
作者 亚历山大·贡法洛涅里,AI 顾问。
经过几个 AI 项目,我意识到,在大规模部署机器学习(ML)模型是那些希望通过 AI 创造价值的公司面临的最重要挑战之一,随着模型变得越来越复杂,这一挑战也在不断增加。
根据我的顾问经验,只有极少数的机器学习项目能够投入生产。AI 项目可能因为很多原因失败,其中之一就是部署。每个决策者都需要完全理解部署的工作原理,以及在这一关键步骤中如何降低失败的风险。
一个已部署的模型可以定义为任何无缝集成到生产环境中的代码单元,能够接收输入并返回输出。
我发现,为了将工作投入生产,数据科学家通常必须将其数据模型移交给工程团队进行实施。而在这个步骤中,一些最常见的数据科学问题出现了。
挑战
机器学习具有一些独特的特点,使得在大规模部署时更具挑战性。这些是我们正在处理的一些问题(其他问题也存在):
管理数据科学语言
如你所知,机器学习应用通常由不同的编程语言编写的元素组成,这些元素之间并不总是能够良好互动。我多次看到过一个机器学习管道,从 R 开始,继续在 Python 中,然后在另一种语言中结束。
通常,Python 和 R 是目前最受欢迎的机器学习应用语言,但我注意到,由于速度等各种原因,生产模型很少使用这些语言。将 Python 或 R 模型移植到 C++ 或 Java 等生产语言中是复杂的,并且通常会导致原始模型的性能(速度、准确性等)下降。
R 包在软件新版本发布时可能会出错。此外,R 的速度较慢,无法高效处理大数据。
这是一个很好的原型设计语言,因为它允许轻松的互动和问题解决,但它需要被转换为 Python、C++ 或 Java 以用于生产。
容器化技术,如 Docker,可以解决由各种工具引入的不兼容性和可移植性问题。然而,自动依赖检查、错误检查、测试和构建工具无法跨越语言障碍解决问题。
可重现性也是一个挑战。确实,数据科学家可能会构建多个模型版本,每个版本使用不同的编程语言、库或相同库的不同版本。手动跟踪这些依赖项非常困难。为了解决这些挑战,需要一个 ML 生命周期工具,能够在训练阶段自动跟踪和记录这些依赖项,并将它们与训练后的模型一起打包成一个可以部署的工件。
我建议你依赖一个可以即时将代码从一种语言翻译成另一种语言的工具或平台,或者允许你的数据科学团队将模型部署到 API 后面,以便可以在任何地方集成。
计算能力和 GPU
神经网络通常非常深,这意味着训练和使用它们进行推断需要大量的计算能力。通常,我们希望我们的算法能为许多用户快速运行,这可能成为一个障碍。
此外,许多生产中的 ML 今天依赖于 GPU。然而,它们稀缺且昂贵,这容易为扩展 ML 任务增加另一层复杂性。
可移植性
模型部署的另一个有趣挑战是缺乏可移植性。我注意到这通常是遗留分析系统中的一个问题。由于缺乏将软件组件轻松迁移到另一个主机环境并在那里运行的能力,组织可能会被锁定在特定平台上。这可能为数据科学家在创建和部署模型时带来障碍。
可扩展性
可扩展性是许多 AI 项目中的一个真实问题。确实,你需要确保你的模型能够扩展并满足生产中性能和应用需求的增加。在项目开始时,我们通常依赖于相对静态的数据,规模也较易管理。随着模型进入生产阶段,它通常会暴露于更大体积的数据和数据传输模式。你的团队将需要多个工具来监控和解决随着时间推移而出现的性能和可扩展性挑战。
我相信,通过采用一致的、基于微服务的生产分析方法,可以解决可扩展性问题。团队应该能够通过简单的配置更改,快速将模型从批处理迁移到按需处理或流处理。类似地,团队应该有选项来扩展计算和内存的使用,以支持更复杂的工作负载。
机器学习计算工作呈峰值状态
一旦你的算法被训练完成,它们并不总是会被使用——你的用户只会在需要时调用它们。
这可能意味着你在早上 8:00 仅支持 100 次 API 调用,但在早上 8:30 支持 10,000 次。
根据经验,我可以告诉你,扩展和缩减同时确保不为不需要的服务器付费是一个挑战。
由于所有这些原因,只有少数数据科学项目最终会投入生产系统。
强化以实现操作化
我们总是花费大量时间使我们的模型准备就绪。增强模型的鲁棒性包括将原型准备好,以便它能够实际服务于所需的用户数量,这通常需要大量工作。
在许多情况下,整个模型需要用适合当前架构的语言重新编码。仅这一点就往往是大规模且痛苦的工作源,导致部署延迟数月。完成后,它必须集成到公司的 IT 架构中,并处理之前讨论的所有库问题。此外,访问生产中的数据通常是一项艰巨的任务,往往受到技术和/或组织数据孤岛的困扰。
更多挑战
在我的项目中,我还注意到以下问题:
-
如果我们改变了输入特征,那么其余特征的重要性、权重或使用方式可能会发生变化,也可能不会。机器学习系统必须设计得使特征工程和选择的变化能够轻松追踪。
-
当模型不断迭代和微调时,跟踪配置更新,同时保持配置的清晰性和灵活性,变成了额外的负担。
-
一些数据输入可能会随着时间变化。我们需要一种方法来理解和跟踪这些变化,以便能全面理解我们的系统。
-
机器学习应用中可能出现多种问题,这些问题不会被传统的单元/集成测试识别。部署错误版本的模型、遗漏特征以及在过时的数据集上训练只是一些例子。
测试与验证问题
正如你可能已经知道的那样,模型由于数据变化、新方法等而不断演变。因此,每次发生这样的变化时,我们必须重新验证模型性能。这些验证步骤带来了几个挑战:

除了离线测试中的模型验证外,评估生产中模型的性能非常重要。通常,我们在部署策略和监控部分进行规划。
机器学习模型需要比普通软件应用程序更频繁地更新。
自动化机器学习平台
你们中的一些人可能听说过自动化机器学习平台。这可能是更快生成模型的好解决方案。此外,该平台可以支持多个模型的开发和比较,以便业务可以选择最符合其预测准确性、延迟和计算资源要求的模型。
多达 90%的企业机器学习模型可以自动开发。数据科学家可以与业务人员合作,开发目前自动化无法达到的小部分模型。
许多模型会经历漂移(性能随时间下降)。因此,已部署的模型需要被监控。每个已部署的模型应记录所有输入、输出和异常。模型部署平台需要提供日志存储和模型性能可视化功能。密切关注模型性能是有效管理机器学习模型生命周期的关键。

需要通过部署平台监控的关键要素。
发布策略
探索多种部署软件的方法(这是一个很棒的长篇文章),其中“影子模式”和“金丝雀”部署对于机器学习应用特别有用。在“影子模式”中,你可以捕捉新模型在生产环境中的输入和预测,而不实际提供这些预测。相反,你可以自由分析结果,如果发现错误,不会有重大后果。
随着架构的成熟,考虑启用渐进式或“金丝雀”发布。这种做法是将发布范围限制在少数客户中,而不是“全有或全无”。这需要更成熟的工具,但当发生错误时,它可以最小化影响。
结论
机器学习仍处于早期阶段。实际上,软件和硬件组件都在不断发展,以满足当前机器学习的需求。
Docker/Kubernetes 和微服务架构可以用来解决异质性和基础设施挑战。现有工具可以在某些方面大大解决问题。我相信,将所有这些工具结合起来实现机器学习的运作是今天面临的最大挑战。
部署机器学习是且将继续是一个困难的过程,这是组织必须面对的现实。不过,值得庆幸的是,一些新架构和产品正在帮助数据科学家。此外,随着越来越多的公司扩展数据科学操作,他们也在实施使模型部署更容易的工具。
原文。转载自许可。
个人简介:亚历山大·贡法隆内里是一位人工智能顾问,并广泛撰写有关人工智能的文章。
相关内容:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关话题
使用机器学习检测恶意 URL
原文:
www.kdnuggets.com/2016/10/machine-learning-detect-malicious-urls.html
评论
作者:Faizan Ahmad,Fsecurify CEO。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
随着过去几年机器学习的增长,许多任务都借助机器学习算法来完成。不幸或幸运的是,关于机器学习算法在安全方面的工作很少。因此,我想在Fsecurify上展示一些内容。
几天前,我有了一个想法:如果我们可以使用某种机器学习算法从非恶意 URL 中检测恶意 URL 会怎样。对此主题已经有一些研究,所以我认为应该尝试一下,从零开始实现一些东西。让我们开始吧。
数据收集
第一个任务是收集数据。我做了一些搜索,发现了一些提供恶意链接的网站。我设置了一个小爬虫,爬取了许多来自不同网站的恶意链接。接下来的任务是寻找清晰的 URL。幸运的是,我不需要爬取任何数据。已经有一个数据集可用。如果我没有提及数据来源,请不要担心。你将在本文末尾获得数据。
所以,我收集了大约 400,000 个 URL,其中大约 80,000 个是恶意的,其他的是干净的。这就是我们的数据集。接下来我们继续。
分析
我们将使用逻辑回归,因为它速度很快。第一步是对 URL 进行标记化。我为此编写了自己的标记化函数,因为 URL 与其他文档文本有所不同。

下一步是加载数据并将其存储到列表中。

既然我们已经将数据放入列表中,我们需要对 URL 进行向量化。我使用了tf-idf 分数,而不是使用词袋分类,因为 URL 中的某些词比其他词更重要,例如 ‘virus’, ‘.exe’, ‘.dat’ 等。让我们将 URL 转换为向量形式。

我们有了向量。现在让我们将其转换为测试和训练数据,并进行逻辑回归分析。

就是这样。看,它简单却有效。我们获得了 98%的准确率。这是一个非常高的值,能让机器有效检测恶意网址。想测试一些链接看看模型的预测是否准确吗?当然。我们来试试。

结果非常惊人。
-
wikipedia.com (好网址)
-
google.com/search=faizanahmad (好网址)
-
pakistanifacebookforever.com/getpassword.php/ (坏网址)
-
www.radsport-voggel.de/wp-admin/includes/log.exe (坏网址)
-
ahrenhei.without-transfer.ru/nethost.exe (坏网址)
-
www.itidea.it/centroesteticosothys/img/_notes/gum.exe (坏网址)
这正是一个人类可能预测的结果。不是吗?
数据和代码可在Github获取。
简历: Faizan Ahmad 是一名富布赖特计算机科学本科生,同时也是 Fsecurify 的首席执行官。
相关:
-
大数据安全的 5 个最佳实践
-
数据科学家如何缓解敏感数据暴露的漏洞?
-
大数据与数据科学在安全和欺诈检测中的应用
更多相关内容
进行机器学习时的 7 个常见错误
www.kdnuggets.com/2015/03/machine-learning-data-science-common-mistakes.html/2
4. 当 n<<p 时使用高方差模型
支持向量机(SVM)是最流行的现成建模算法之一,其最强大的特性之一是能够使用不同的核函数来拟合模型。SVM 的核函数可以看作是自动组合现有特征以形成更丰富特征空间的一种方式。由于这种强大的功能几乎是免费的,因此大多数从业者在训练 SVM 模型时默认使用核函数。然而,当数据的 n<<p(样本数量 << 特征数量)——在医疗数据等行业中很常见——时,更丰富的特征空间意味着更高的过拟合风险。实际上,当 n<<p 时,高方差模型应该完全避免。
5. 没有标准化的 L1/L2/... 正则化
对线性或逻辑回归施加 L1 或 L2 惩罚大系数是一种常见的正则化方法。然而,许多从业者没有意识到在应用这些正则化之前标准化特征的重要性。
回到欺诈检测的例子,假设有一个具有交易金额特征的线性回归模型。如果没有正则化,当交易金额的单位是美元时,拟合的系数将比单位为美分时的拟合系数大约大 100 倍。使用正则化时,由于 L1 / L2 对较大系数的惩罚更多,因此如果单位是美元,交易金额会受到更多的惩罚。因此,正则化存在偏倚,倾向于惩罚较小规模的特征。为了解决这个问题,作为预处理步骤,标准化所有特征并使其具有相同的基础。
6. 使用线性模型而不考虑多重共线性预测变量
想象构建一个包含两个变量 X1 和 X2 的线性模型,假设真实模型是 Y=X1+X2。理想情况下,如果数据观察时噪声很小,线性回归解决方案将恢复真实模型。然而,如果 X1 和 X2 存在共线性,则对大多数优化算法而言,Y=2X1、Y=3X1-X2 或 Y=100X1-99X2 都是同样有效的。这个问题可能不会对估计造成偏差,但确实使问题变得条件不良,并使系数权重无法解释。
7. 从线性或逻辑回归中解读系数的绝对值作为特征重要性
由于许多现成的线性回归模型返回每个系数的 p 值,许多从业者认为,对于线性模型来说,系数的绝对值越大,对应的特征就越重要。这种情况很少发生,因为(a)改变变量的尺度会改变系数的绝对值,(b)如果特征之间存在多重共线性,系数可能会从一个特征转移到其他特征。此外,数据集中的特征越多,特征之间存在多重共线性的可能性就越大,通过系数解释特征重要性也就越不可靠。
那么,这里是:实际应用机器学习时的 7 个常见错误。这个列表并不是详尽无遗的,而只是为了促使读者考虑可能不适用于当前数据的建模假设。为了获得最佳的模型性能,选择最适合假设的建模算法非常重要——而不仅仅是你最熟悉的算法。
原文:机器学习中的常见错误
是 Codecademy 的分析总监。专长:数据工程和机器学习。曾任职于:Google、LinkedIn 和 Square。
相关:
-
11 种聪明的过拟合方法及如何避免它们
-
大数据是否加速了医学研究?还是没有?
-
统计学教会我们关于大数据分析的 10 件事
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
更多相关话题
机器学习驱动的防火墙
原文:
www.kdnuggets.com/2017/02/machine-learning-driven-firewall.html
评论
作者:Faizan Ahmad,Fsecurify CEO。
最近,我一直在思考将机器学习应用于我可以做的安全项目并与大家分享的方法。几天前,我偶然发现了一个叫做ZENEDGE的网站,提供AI 驱动的网络应用防火墙。我喜欢这个概念,想做一些类似的东西并与社区分享。所以,让我们做一个吧。
fWaf – 机器学习驱动的网络应用防火墙
数据集:
首先需要做的是找到标记的数据,但我找到的数据相当旧(2010 年)。有一个网站叫做SecRepo,提供了很多安全相关的数据集。其中之一是包含数百万个查询的 http 日志。这是我想要的数据集,但它没有标记。我使用了一些启发式方法和我以前的安全知识,通过编写几个脚本来标记数据集。
在修剪数据之后,我想收集更多的恶意查询。因此,我去找了payloads,并找到了一些包含 Xss、SQL 及其他攻击负载的著名 GitHub 仓库,并将它们全部用于我的恶意查询数据集。
现在,我们有两个文件;一个包含干净的网络查询(1000000),另一个包含恶意的网络查询(50000)。这就是我们训练分类器所需的所有数据。
训练:
对于训练,我使用了逻辑回归,因为它速度快,我需要快速的东西。我们可以使用 SVM 或神经网络,但它们比逻辑回归稍慢。我们的问题是二分类问题,因为我们需要预测一个查询是否恶意。我们将使用ngrams作为我们的标记。我阅读了一些研究论文,使用 ngrams 对于这种项目来说是一个好主意。对于这个项目,我使用了n=3。
让我们直接进入代码部分。
让我们定义我们的分词器函数,它将提供 3 个 grams。
def getNGrams(query):
tempQuery = str(query)
ngrams = []
for i in range(0,len(tempQuery)-3):
ngrams.append(tempQuery[i:i+3])
return ngrams
让我们加载查询数据集。
filename = 'badqueries.txt'
directory = str(os.getcwd())
filepath = directory + "/" + filename
data = open(filepath,'r').readlines()
data = list(set(data))
badQueries = []
validQueries = []
count = 0
for d in data:
d = str(urllib.unquote(d).decode('utf8'))
badQueries.append(d)
filename = 'goodqueries.txt'
directory = str(os.getcwd())
filepath = directory + "/" + filename
data = open(filepath,'r').readlines()
data = list(set(data))
for d in data:
d = str(urllib.unquote(d).decode('utf8'))
validQueries.append(d)
现在我们已经将数据集加载到好的查询和坏的查询中。让我们尝试可视化它们。我使用了主成分分析来可视化数据集。红色的是坏查询的 ngrams,蓝色的是好查询的 ngrams。
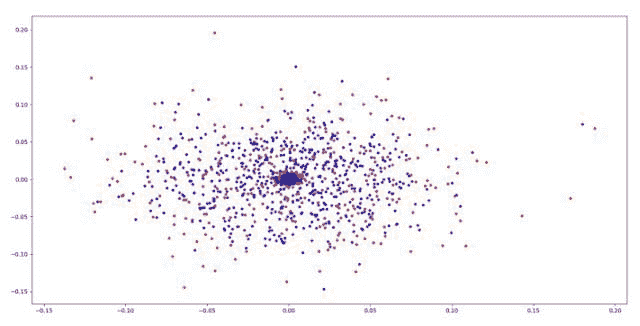
我们可以看到,坏点和好点确实在不同的位置出现。让我们继续深入。
badQueries = list(set(badQueries))
tempvalidQueries = list(set(validQueries]))
tempAllQueries = badQueries + tempvalidQueries
bady = [1 for i in range(0,len(tempXssQueries))]
goody = [0 for i in range(0,len(tempvalidQueries))]
y = bady+goody
queries = tempAllQueries
现在让我们使用 Tfidvectorizer 将数据转换为 tfidf 值,然后使用我们的分类器。我们使用 tfidf 值是因为我们想给我们的 ngrams 赋予权重,例如 ngram ‘<img’ 应该有较大的权重,因为包含此 ngram 的查询很可能是恶意的。你可以在这个 链接 中了解更多关于 tfidf 的信息。
vectorizer = TfidfVectorizer(tokenizer=getNGrams)
X = vectorizer.fit_transform(queries)
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42)
现在我们一切准备就绪,让我们应用逻辑回归。
lgs = LogisticRegression()
lgs.fit(X_train, y_train)
print(lgs.score(X_test, y_test))
就这些了。
这是大家都期待的部分,你一定想看到准确度,对吧?准确度达到 99%。这非常惊人,对吧?但你不会相信,直到你看到一些证据。所以,让我们检查一些查询,看看模型是否将其检测为恶意的。这是结果。
wp-content/wp-plugins (CLEAN)
<script>alert(1)</script> (MALICIOUS)
SELECT password from admin (MALICIOUS)
"> (MALICIOUS)
/example/test.php (CLEAN)
google/images (CLEAN)
q=../etc/passwd (MALICIOUS)
javascript:confirm(1) (MALICIOUS)
"> (MALICIOUS)
foo/bar (CLEAN)
foooooooooooooooooooooo (CLEAN)
example/test/q=<script>alert(1)</script> (MALICIOUS)
example/test/q= (MALICIOUS)
fsecurify/q= (MALICIOUS)
example/test/q= (MALICIOUS)
看起来不错,不是吗?它能很好地检测恶意查询。
接下来呢? 这是一个周末项目,还有很多可以做或添加的东西。我们可以进行多类分类,以检测恶意查询是 SQL 注入还是跨站脚本攻击或其他任何注入。我们可以拥有一个更大的数据集,包含所有类型的恶意查询,并在其上训练模型,从而扩展其检测的恶意查询类型。还可以将此模型保存并与 Web 服务器一起使用。如果你做了上述任何操作,请告诉我。
数据和脚本: github.com/faizann24/F<wbr>waf-Machine-Learning-driven-We<wbr>b-Application-Firewall
希望你喜欢这篇文章。我们致力于向社区免费提供安全资源。欢迎提出你的意见和批评。
Fsecurify
简介:Faizan Ahmad 是现任 Fulbright 本科生,正在拉合尔的 NUCES FAST 学习。
相关:
-
机器学习与网络安全资源
-
使用机器学习检测恶意 URL
-
通过 Databricks 实现 Apache Spark 的端到端安全
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
边缘上的机器学习

照片由 Alessandro Oliverio 提供
在过去的十年里,许多公司已经转向云端来存储、管理和处理数据。这似乎是一个更有前景的机器学习解决方案领域。通过在云端部署 ML 模型,你可以使用大量由第三方维护的强大服务器。你可以在最新的图形处理单元(GPUs)、张量处理单元(TPUs)和视觉处理单元(VPUs)上生成预测,而不必担心初始设置成本、可扩展性或硬件维护。此外,云解决方案提供了强大的服务器,这些服务器可以比本地服务器更快地进行推断(生成预测的过程)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
可能有人会认为在云端部署 ML 模型更便宜。毕竟,你不需要构建基础设施或维护所有内部系统。你只需为服务器使用的时间付费。然而,这种看法远非真实。云成本逐年上涨,大多数组织很难控制这些成本。Gartner 最近的报告预测,到 2022 年,终端用户在公共云服务上的支出将接近 5000 亿美元 [1]。
像 Netflix、Snapchat、Tik Tok 和 Pinterest 这样的巨大公司每年在云端账单上的支出已经达到数亿美元 [2, 3]。即便是小型和中型企业(SMBs),这笔费用也平均在一百万左右。机器学习工作负载需要大量计算,这在云端的成本很高。尽管云解决方案提供了管理 ML 应用程序的简便方法,但边缘 ML 最近也开始迅速发展。
从云端 ML 到边缘 ML
为了控制运行成本,公司开始寻找将尽可能多的计算推送到终端用户设备上的方法。这意味着将机器学习模型放在消费者设备上,这些设备可以独立进行推断,无需互联网连接,实时进行,而且没有额外成本。例如,亚马逊的 Alexa 和 Echo 是一个语音控制的虚拟助手,使用机器学习为你执行各种任务。在 2020 年 9 月,亚马逊发布了 AZ1 Neural Edge 处理器,使 Alexa 能够在设备上进行推断,而不是与云端交互。通过将计算移到边缘设备,Echo 能够以两倍的速度运行,同时由于数据在本地处理,也提供了隐私保护[4]。
性能
你可以构建一个精确度最高的最先进的机器学习模型,但如果响应时间多了几毫秒,用户可能会离开。尽管将机器学习模型部署到云端可以访问高性能的硬件,但这并不一定意味着你的应用程序的延迟会减少。通过网络传输数据通常比用特殊硬件加速模型性能的开销要大。你可以将深度学习模型的性能提高几毫秒,但网络传输的数据可能需要几秒钟。
离线推断
云计算要求你的应用程序有稳定的互联网连接,以进行持续的数据传输。而边缘计算允许你的应用程序在没有互联网连接的情况下运行。这在网络连接不可靠但应用程序严重依赖计算的区域尤为有益。例如,一款心脏监测应用可能需要实时推断以预测患者心脏的健康状况。即使互联网连接中断,模型也应在边缘设备上生成推断。
数据隐私
边缘计算提供了数据隐私的好处。用户的个人数据在靠近用户的地方处理,而不是在公司数据中心积累。这也使得数据更不容易被网络拦截。事实上,对于许多使用场景来说,边缘计算是遵守隐私合规的唯一途径。智能手机制造商越来越多地将面部识别系统集成到用户的手机解锁功能中。用户不希望他们深度个人化的数据被转移或存储在云端。
成本
可能最吸引人转向边缘机器学习的理由是你不需要支付云端计算的重复成本。如果你的模型保留在用户的设备上,所有计算都由该设备承担。模型利用消费者设备的处理能力,而不是支付云端计算费用。
边缘机器学习的当前局限性
到目前为止,你已经看到边缘机器学习如何让你获得竞争优势。然而,当前机器学习基础设施的现状表明,还需要大量的工作来有效利用这种优势。最先进的深度学习模型 notoriously 大,而在边缘设备上部署这些模型是另一个挑战。边缘设备涵盖了从智能手机到嵌入式处理器和物联网设备等各种任意硬件。真正的挑战在于如何将机器学习模型编译以优化的方式在异构硬件平台上运行。这是一个不断增长的研究领域,公司正在投入数十亿美元以领先于机器学习硬件竞赛[5]。包括 NVIDIA、苹果和特斯拉在内的大公司已经在开发自己的 AI 芯片,以优化运行特定的机器学习模型。
参考资料
-
“Gartner 预测 2022 年全球公共云终端用户支出将接近 5000 亿美元,”2022 年 4 月 19 日,Gartner,
www.gartner.com/en/newsroom/press-releases/2022-04-19-gartner-forecasts-wordwide-public-cloud-end-user-spending-to-reach-nearly-500-billion-in-2022 -
马修·古丁(Matthew Gooding),“三分之一的云计算支出浪费掉了,”2022 年 3 月 21 日,Tech Monitor
techmonitor.ai/technology/cloud/cloud-spending-wasted-oracle-computing-aws-azure -
阿米尔·埃夫拉提(Amir Efrati),凯文·麦克劳克林(Kevin McLaughlin),“随着 AWS 使用量的激增,公司对云账单感到惊讶,”2019 年 2 月 25 日,《信息报》(The Information)
www.theinformation.com/articles/as-aws-use-soars-companies-surprised-by-cloud-bills -
拉里·迪根(Larry Dignan),“亚马逊的 Alexa 在 Echo 上获得了新大脑,通过人工智能变得更聪明并旨在营造氛围,”2020 年 9 月 25 日,ZDNet,
www.zdnet.com/article/amazons-alexa-gets-a-new-brain-on-echo-becomes-smarter-via-ai-and-aims-for-ambience/ -
奇普·惠恩(Chip Huyen),“机器学习编译器和优化器的友好介绍,”2021 年 9 月 7 日,
huyenchip.com/2021/09/07/a-friendly-introduction-to-machine-learning-compilers-and-optimizers.html
Najia Gul 是 IBM 的数据科学家,专注于构建、建模、部署和维护机器学习模型。她还是数据和人工智能公司的开发者倡导者,帮助他们制作面向技术受众的内容。可以在她的个人网站找到她。
更多相关内容
如何高效进行机器学习
原文:
www.kdnuggets.com/2018/03/machine-learning-efficiently.html
评论
Radek Osmulski,自学开发者
我刚刚完成一个项目,在项目进行到 80%时,我觉得几乎没有任何进展。我投入了大量时间,但最后完全失败了。
我知道或不知道的数学,我编写代码的能力——这些都是次要的。我处理项目的方式才是问题所在。
我现在相信,构建机器学习工作的结构是有艺术性的,或说是工艺性的,而我曾经喜欢的数学重的书籍似乎都没有提到这一点。
我做了一些自我反思,回到了Jeremy Howard在Practical Deep Learning for Coders MOOC中提到的内容,这就是这篇文章的来源。
10 秒规则
我们坐在电脑前做事。对宇宙产生影响。降低预测成本或减少模型运行时间。
这里的关键词是做。这包括移动代码。重命名变量。可视化数据。疯狂地敲击键盘。
但盯着计算机屏幕空白地看两分钟,让它进行计算,以便我们可以一次次地运行它们,尽管参数稍作修改,这并不是在做事。
这也使我们面临机器学习工作的最大祸根——额外浏览器标签的诅咒。按下 ctrl+t 是如此容易,跟踪我们在做什么也变得如此困难。
这个解决方案可能听起来很荒谬,但它有效。不要让计算超过 10 秒钟,当你在处理一个问题时。
那我怎么调整我的参数呢?我怎么能对问题有任何有意义的了解?
所需的只是以一种能创建代表性样本的方式来子集你的数据。这可以用于任何领域,在大多数情况下,只需随机选择一些示例进行处理即可。
一旦你对数据进行子集划分,工作就变得互动起来。你进入了一个专注的流状态。你不断进行实验,找出什么有效,什么无效。你的手指从键盘上永远不会离开。
时间被拉长了,你所做的工作时间与如果你让自己分心时所做的工作时间不相等,甚至不如你所做的 5 小时工作。
如何构建代码以促进这种工作流程?使其非常简单地切换到在完整数据集上运行。
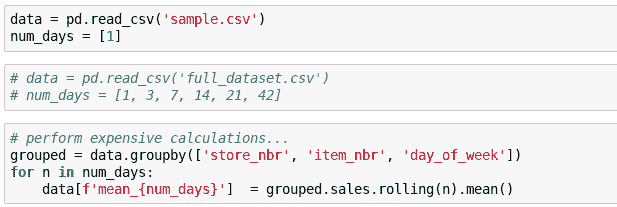
当你快要结束编码会话时,取消注释该单元格并运行所有代码。
成为时间浪费者
这补充了上述内容。但它还远不止这些。
根据你如何结构化代码,性能的提升可以有几个数量级的差距。了解某个操作的运行时间以及如果你做了某些更改它将运行多长时间是很有益的。你可以尝试弄清楚差异的原因,这会立即让你成为一个更好的程序员。

更重要的是,这与承诺不运行任何超过 10 秒钟的代码是密切相关的。
测试自己
一旦你在数据处理管道中犯了错误且未被发现,几乎是不可能恢复的。在很大程度上,这同样适用于模型构建(尤其是当你开发自己的组件如层等时)。
关键是随着进展不断检查数据。在转换前后查看数据。总结它。如果你知道合并后不应该有 NAs,就检查确实没有。
测试一切。
长期保持理智的唯一方法是短期内保持警惕。
急于成功
在解决问题时你应该关注的第二件事是什么(我会马上谈到第一件事)?创建一个比随机机会更好的模型,任何端到端的数据处理管道。
这可以且应该是你能想到的最简单的模型。通常这意味着线性组合。但你需要开始感受问题的本质。你需要开始建立一个可能性的基准。
比如你花了 3 天时间构建一个非常复杂的模型,但它完全没有效果,或者效果远不如你预期的那样好。你会怎么做?
在这个阶段,你一无所知。你不知道是否在处理数据时犯了错误,也不知道数据是否无用。你没有线索是否模型中可能存在问题。祝你好运,希望在没有可靠组件的情况下解开这些混乱。
此外,建立一个简单的模型可以让你从整体上看待情况。也许有缺失数据?也许类别不平衡?也许数据标签不正确?
在开始处理更复杂的模型之前,了解这些信息是很有用的。否则,你可能会构建出一个非常复杂的模型,虽然客观上可能很棒,但却完全不适合当前的问题。
不要调整参数,调整架构
“哦,如果我再加一层线性层,我相信模型会表现得更好”
“也许再增加 0.00000001 的 dropout 会有帮助,看起来我们对训练集的拟合有点过度了”
尤其是在早期,调整超参数是绝对适得其反的。但这确实非常诱人。
这几乎不需要任何工作,而且很有趣。你可以看到计算机屏幕上的数字变化,感觉像是你在学习一些东西并取得进展。
这只是一种幻象。更糟糕的是,你可能会过拟合你的验证集。每次你运行模型并根据验证损失进行更改时,你都会使模型的泛化能力受到惩罚。
你更好地投资时间于探索架构。你会学到更多。突然间,集成变得可能。
解放小鼠
你计划使用电脑多长时间?即使我偶然变得富有到不再需要工作一天,我仍会每天使用电脑。
如果你打网球,你会练习每一个动作。你甚至可能会花钱请人告诉你如何在特定击球时调整手腕的位置!
但现实是,你最多只会打这么多小时的网球。为什么不对使用电脑也同样认真呢?
使用鼠标是不自然的。它很慢。需要复杂且精确的动作。从任何上下文中,你只能访问有限的操作集合。
使用键盘让你感到自由。老实说,我也不知道为什么它会有如此大的差别。但确实如此。

一个人在用电脑时没有使用鼠标。
最后但同样重要的是
除非你有一个好的验证集,否则你做的任何事情都没有意义。
我可以推荐给你最终的资源。这是一篇直言不讳且基于实践的文章。
如何(以及为什么)创建一个好的验证集 由 Rachel Thomas 撰写。
如果你觉得这篇文章有趣并且想保持联系,你可以在 Twitter 上 这里 找到我。
简介: Radek Osmulski 是一位自学成才的开发者,对机器学习充满热情。他是 Fast.ai 国际研究员,并且是该领域的积极学生。你可以在 Twitter 上 这里 与他联系。
原文。经许可转载。
相关:
-
关于机器学习你需要知道的 5 件事
-
机器学习新手的十大算法导览
-
用 Python 精通机器学习的 7 个步骤
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 需求
更多相关内容
在加密数据上进行机器学习
原文:
www.kdnuggets.com/2022/08/machine-learning-encrypted-data.html

本博客介绍了一种隐私保护机器学习(PPML)解决方案,用于 Kaggle 上的泰坦尼克挑战,使用Concrete-ML开源工具包。其主要目标是展示全同态加密(FHE)如何用于保护数据,同时使用机器学习模型进行预测而不降低其性能。在这个例子中,将考虑XGBoost分类器模型,因为它实现了接近最先进的准确度。
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织中的 IT 工作
竞赛
Kaggle是一个在线社区,让任何人都可以围绕机器学习和数据科学构建和分享项目。它提供数据集、课程、示例和竞赛,任何愿意发现或提升自己领域知识的数据科学家都可以免费使用。其简易性使其成为 ML 社区中最受欢迎的平台之一。
此外,Kaggle 提供了几个难度不同的教程,供新手开始在真实例子中操作基本数据科学工具。在这些教程中可以找到Titanic 竞赛。它通过使用一组简单的乘客数据来介绍一个二分类问题,这些乘客在悲惨的泰坦尼克号船难中旅行。
Concrete-ML 团队为本次竞赛发送的 Jupyter Notebook 可以在此处找到。它是借助几个其他公开可用的笔记本创建的,以提供清晰的指南和高效的结果。
准备工作
在能够构建模型之前,需要进行一些准备步骤。
包要求
Concrete-ML 是一个 Python 包,因此代码使用这种编程语言编写。还需要一些额外的包,包括用于数据预处理的 Pandas 框架以及一些 scikit-learn 交叉验证工具。
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV, ShuffleSplit
from xgboost import XGBClassifier
from concrete.ml.sklearn import XGBClassifier as ConcreteXGBClassifier
清洗数据
Kaggle 平台提供了训练数据集和测试数据集。完成这些后,让我们加载数据并提取目标 ID。
train_data = pd.read_csv("./local_datasets/titanic/train.csv")
test_data = pd.read_csv("./local_datasets/titanic/test.csv")
datasets = [train_data, test_data]
test_ids = test_data["PassengerId"]
数据的样子如下:
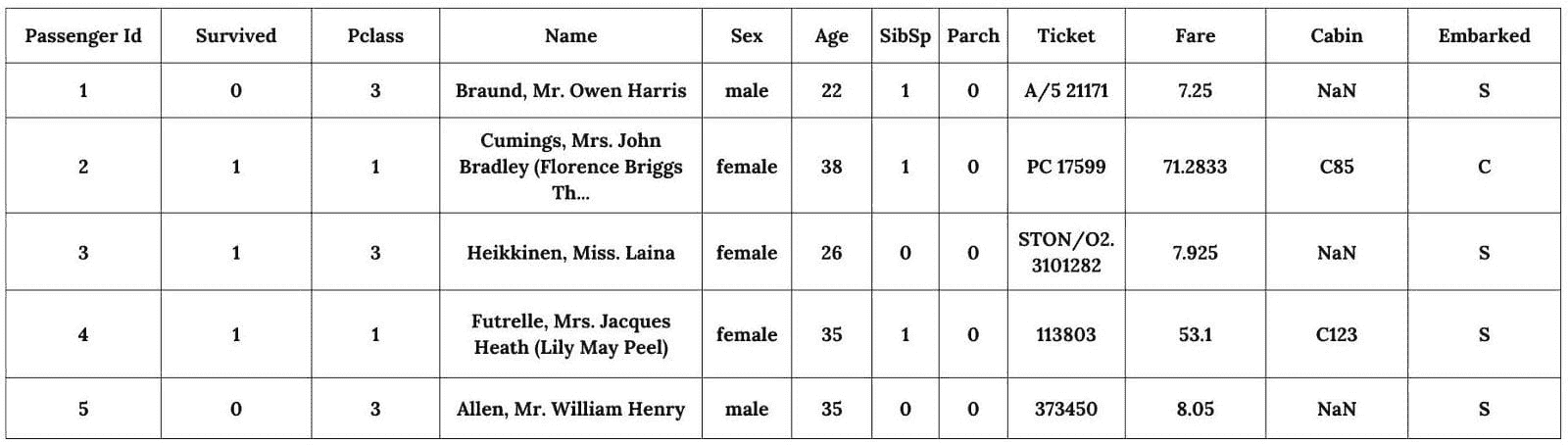
可以做出以下几项陈述:
-
目标变量是 Survived 变量。
-
一些变量是数值型的,如 PassengerID、Pclass、SbSp、Parch 或 Fare。
-
一些变量是类别型的(非数值型的),如 Name、Sex、Ticket、Cabin 或 Embarked。
第一步预处理是删除 PassengerId 和 Ticket 变量,因为它们似乎是随机标识符,对生存没有影响。此外,我们注意到 Cabin 变量中有些值缺失。因此,我们必须通过打印每个变量缺失值的总数来进一步调查这一观察结果。
print(train_data.isnull().sum())
print(test_data.isnull().sum())
这将输出以下结果。
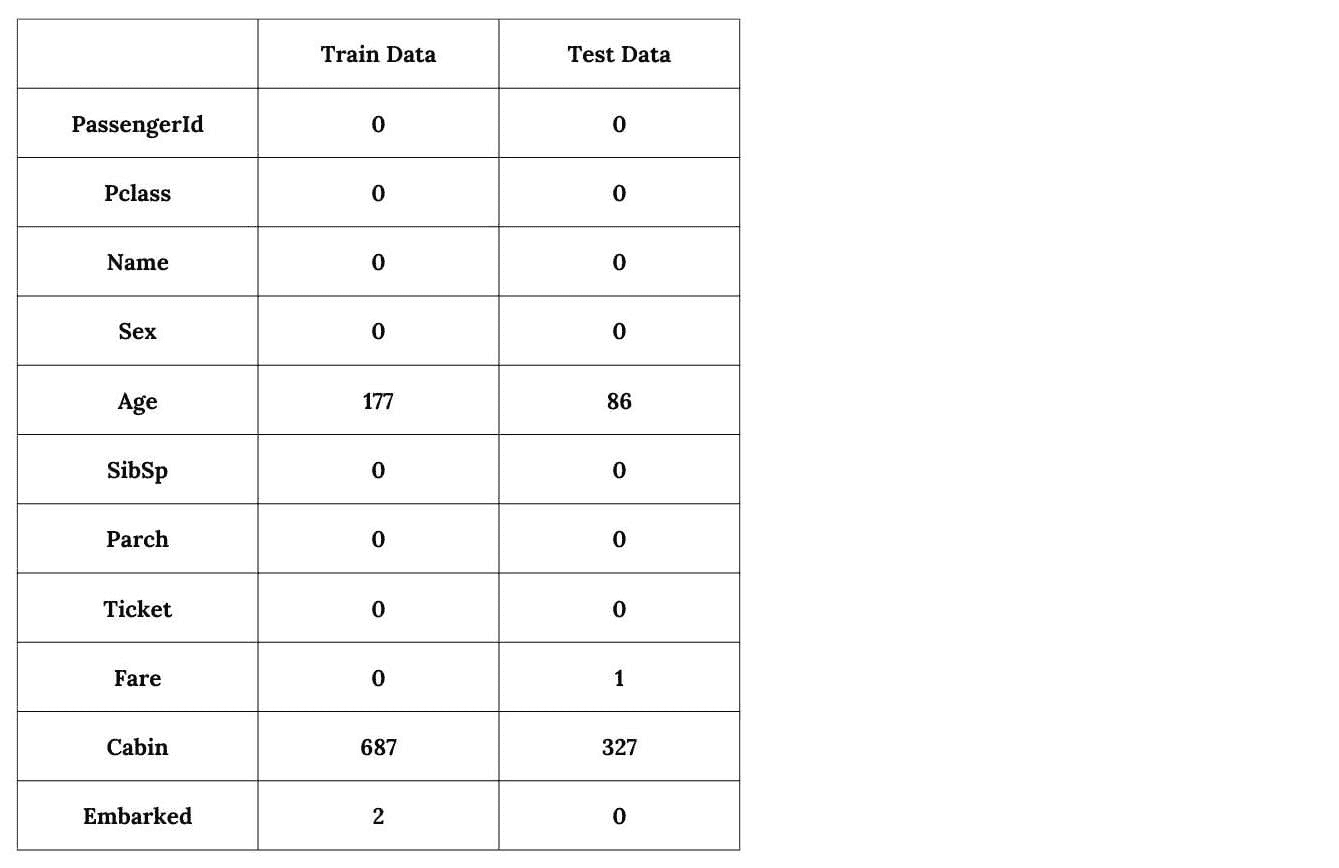
似乎有四个变量是不完整的,即 Cabin、Age、Embarked 和 Fare。然而,Cabin 变量似乎缺失的数据最多:
for incomp_var in train_data.columns:
missing_val = pd.concat(datasets)[incomp_var].isnull().sum()
if missing_val > 0 and incomp_var != "Survived":
total_val = pd.concat(datasets).shape[0]
print(
f"Percentage of missing values in {incomp_var}: "
f"{missing_val/total_val*100:.1f}%"
)
Percentage of missing values in Cabin: 77.5%
Percentage of missing values in Age: 20.1%
Percentage of missing values in Embarked: 0.2%
Percentage of missing values in Fare: 0.1%
由于 Cabin 变量缺失了超过 2/3 的值,因此保留它也可能不合适。因此,我们从两个数据集中删除这些变量。
drop_column = ["PassengerId", "Ticket", “Cabin”]
for dataset in datasets:
dataset.drop(drop_column, axis=1, inplace=True)
关于其他三个存在缺失值的变量,删除它们可能会丢失大量可能帮助模型预测乘客生存的相关信息。对于年龄变量尤其如此,因为其值中有超过 20% 缺失。因此,可以使用其他技术来填补这些不完整的变量。由于年龄和票价都是数值型的,缺失值可以用现有数据的中位数来替代。对于类别变量 Embarked,我们使用最常见的值作为替代。
for dataset in datasets:
dataset.Age.fillna(dataset.Age.median(), inplace=True)
dataset.Embarked.fillna(dataset.Embarked.mode()[0], inplace=True)
dataset.Fare.fillna(dataset.Fare.median(), inplace=True)
工程新特征
此外,我们还可以从已有的变量中手动创建新变量,以帮助模型更好地解释一些行为,从而提高预测准确性。在所有可用的选项中,选择了四个新特征:
-
家庭规模:个人旅行时所陪伴的家庭成员数,1 表示单独旅行。
-
IsAlone:一个布尔变量,表示个人是否单独旅行(1)或非单独旅行(0)。这可能帮助模型强调旅行时是否与亲属同行。
-
标题:个人的称谓(如先生、女士等),通常表示某种社会地位。
-
Farebin 和 AgeBin:Fare 和 Age 变量的分箱版本。它将值分组在一起,通常减少了轻微观察误差的影响。
我们为两个数据集创建这些新变量。
# Function that helps generating proper bin names
def get_bin_labels(bin_name, number_of_bins):
labels = []
for i in range(number_of_bins):
labels.append(bin_name + f"_{i}")
return labels
for dataset in datasets:
dataset["FamilySize"] = dataset.SibSp + dataset.Parch + 1
dataset["IsAlone"] = 1
dataset.IsAlone[dataset.FamilySize > 1] = 0
dataset["Title"] = dataset.Name.str.extract(
r" ([A-Za-z]+)\.", expand=False
)
dataset["FareBin"] = pd.qcut(
dataset.Fare, 4, labels=get_bin_labels("FareBin", 4)
)
dataset["AgeBin"] = pd.cut(
dataset.Age.astype(int), 5, labels=get_bin_labels("AgeBin", 5)
)
# Removing outdated variables
drop_column = ["Name", "SibSp", "Parch", "Fare", "Age"]
dataset.drop(drop_column, axis=1, inplace=True)
此外,打印数据集中的不同标题显示,只有少数几个标题代表了大多数个体。
data = pd.concat(datasets)
titles = data.Title.value_counts()
print(titles)
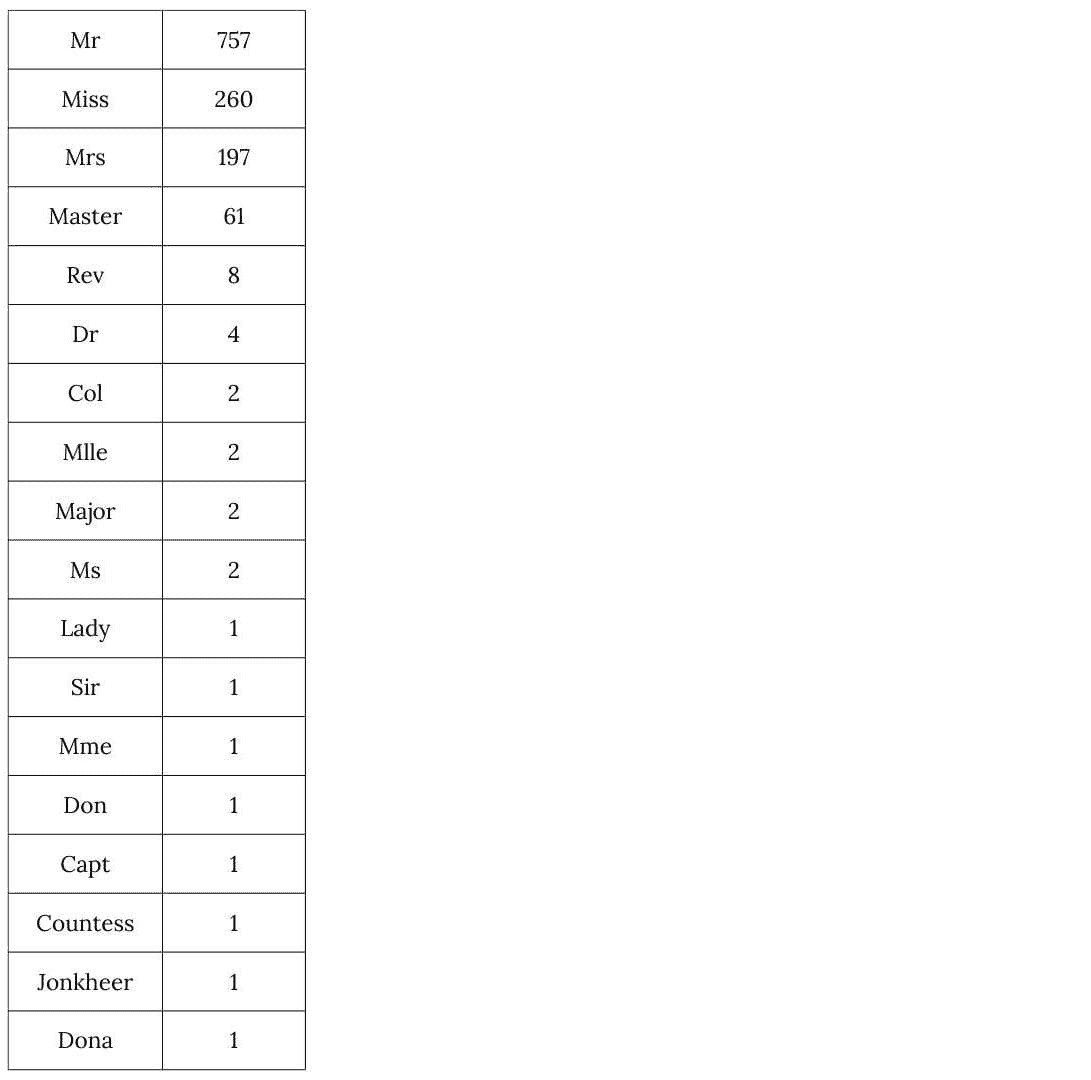
为了防止模型变得过于特定,将所有“少见”的标题归为一个新的“Rare”变量。
uncommon_titles = titles[titles < 10].index
for dataset in datasets:
dataset.Title.replace(uncommon_titles, "Rare", inplace=True)
应用虚拟化
最后,我们可以对剩余的分类变量进行“虚拟化”。虚拟化是一种将分类(非数值)数据转换为数值数据的常见技术,无需映射值或考虑它们之间的任何顺序。其思想是提取变量中所有不同的值,并创建一个新的相关的二进制变量。
例如,“Embarked”变量有三个分类值,“S”、“C”和“Q”。虚拟化数据将创建三个新变量,“Embarked_S”、“Embarked_C”和“Embarked_Q”。然后,“Embarked_S”(或“Embarked_C”和“Embarked_Q”)的值对于在“Embarked”变量中最初标记为“S”(或“C”和“Q”)的每个数据点设置为 1,否则设置为 0。
categorical_features = train_data.select_dtypes(exclude=np.number).columns
x_train = pd.get_dummies(train_data, prefix=categorical_features)
x_test = pd.get_dummies(test_data, prefix=categorical_features)
x_test = x_test.to_numpy()
然后,我们将目标变量与其他变量分开,这是训练之前的必要步骤。
target = "Survived"
x_train = x_train.drop(columns=[target])
x_train = x_train.to_numpy()
y_train = train_data[target].to_numpy()
构建模型
使用 XGBoost 进行训练
首先,使用 XGBoost 构建一个分类模型。由于需要事先固定几个参数,我们使用 scikit-learn 的 GridSearchCV 方法进行交叉验证,以最大化找到最佳参数的机会。给定的范围故意较小,以保持每次推理的 FHE 执行时间相对较低(低于 10 秒)。实际上,我们发现,在这个特定的 Titanic 示例中,具有更多估算器或最大深度的模型并没有显著提高准确率。然后,我们使用训练集来拟合这个模型。
cv = ShuffleSplit(n_splits=5, test_size=0.3, random_state=0)
param_grid = {
"max_depth": list(range(1, 5)),
"n_estimators": list(range(1, 5)),
"learning_rate": [0.01, 0.1, 1],
}
model = GridSearchCV(
XGBClassifier(), param_grid, cv=cv, scoring="roc_auc"
)
model.fit(x_train, y_train)
使用 Concrete-ML 进行训练
现在,让我们使用 Concrete-ML 的 XGBClassifier 方法进行相同的操作。
为了做到这一点,我们需要指定输入、输出和权重将被量化的位数。这个值会影响模型的精度及其推理运行时间,因此可能导致网格搜索交叉验证找到不同的参数集。在我们的例子中,将该值设置为 2 位可以在更快的运行速度下获得出色的准确度评分。
param_grid["n_bits"] = [2]
x_train = x_train.astype(np.float32)
concrete_model = GridSearchCV(
ConcreteXGBClassifier(), param_grid, cv=cv, scoring="roc_auc"
)
concrete_model.fit(x_train, y_train)
Concrete-ML API 设计得尽可能接近最常见的机器学习和深度学习 Python 库,以使其使用尽可能简单。此外,它使任何数据科学家可以在没有加密知识的情况下使用 Zama 的技术。因此,构建和拟合 FHE 兼容的模型对任何习惯于使用 scikit-learn 工具等常见数据科学工作流程的人来说,都变得非常直观和方便。实际上,这些观察对于预测过程仍然有效,只需考虑几个额外的步骤。
预测结果
首先,我们使用 XGBoost 模型在清晰的环境中计算预测结果。
clear_predictions = model.predict(x_test)
此外,也可以使用 Concrete-ML 模型在清晰的环境中计算预测。这将本质上执行库的 XGBoost 版本的模型,并考虑量化过程。这里不涉及任何 FHE 相关的计算。
clear_quantized_predictions = concrete_model.predict(x_test)
为了使用 FHE 实现相同的功能,需要额外的编译步骤。通过提供一个用于表示可达值范围的输入数据子集,编译方法构建一个适当的 FHE 电路,该电路将在预测过程中执行。请注意,execute_in_fhe 参数也需要设置为 True。
fhe_circuit = concrete_model.best_estimator_.compile(x_train[:100])
fhe_predictions = concrete_model.best_estimator_.predict(
x_test, execute_in_fhe=True
)
使用配备 8 个 11 代 Intel® Core™ i5-1135G7 处理器(2.40GHz,4 核心,每个核心 2 线程)的机器,每次推理的平均执行时间在 2 到 3 秒之间。这不包括密钥生成时间,密钥生成仅在所有预测之前发生一次,时间不超过 12 秒。
此外,FHE 计算预计是准确的。这意味着 FHE 中执行的模型会产生与 Concrete-ML 模型相同的预测,后者在清晰的环境中执行并仅考虑量化。
number_of_equal_preds = np.sum(
fhe_predictions == clear_quantized_predictions
)
pred_similarity = number_of_equal_preds / len(clear_predictions) * 100
print(
"Prediction similarity between both Concrete-ML models"
f"(quantized clear and FHE): {pred_similarity:.2f}%"
)
Concrete-ML 模型(量化清晰和 FHE)之间的预测相似度:100.00%
然而,正如之前所见,网格搜索交叉验证是在 XGBoost 模型和 Concrete-ML 模型之间分别进行的。因此,这两个模型没有共享相同的超参数集合,使它们的决策边界不同。
因此,逐一比较它们的预测结果的相似性是不相关的,应该仅考虑 Kaggle 平台给出的最终准确性分数来评估它们的表现。
因此,我们将 XGBoost 和 Concrete-ML 模型的预测结果保存为 csv 文件。然后,可以使用这个 链接 在 Kaggle 平台上提交这些文件。FHE 模型的准确率约为 78%,可在公开的 排行榜 上查看。相比之下,XGBoost 清晰模型的得分为 77%。
实际上,使用给定的数据集,大多数提交的笔记本似乎都没有超过 79% 的准确率。因此,额外的预处理和特征工程可能有助于提高我们当前的分数,但可能不会提高太多。
submission = pd.DataFrame(
{
"PassengerId": test_ids,
"Survived": fhe_predictions,
}
)
submission.to_csv("titanic_submission_fhe.csv", index=False)
submission = pd.DataFrame(
{
"PassengerId": test_ids,
"Survived": clear_predictions,
}
)
submission.to_csv("titanic_submission_xgb_clear.csv", index=False)
感谢阅读!我们的主要目标不仅是建立一个预测模型来回答“哪些人更可能生存?”这个问题,还要在加密数据上实现这一点。
这一切得益于我们的 Python 包:Concrete-ML,旨在简化数据科学家对全同态加密(FHE)的使用。
Roman Bredehoft 是 Zama 的机器学习工程师。
更多相关信息
机器学习评估指标:理论与概述
原文:
www.kdnuggets.com/machine-learning-evaluation-metrics-theory-and-overview
作者插图
构建一个在新数据上表现良好的机器学习模型是非常具有挑战性的。需要对其进行评估,以了解模型是否足够好,或者是否需要一些修改来提高性能。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
如果模型没有从训练集中学习到足够的模式,它将在训练集和测试集上表现不佳。这就是所谓的欠拟合问题。
对训练数据的模式,包括噪声,过度学习会导致模型在训练集上表现非常好,但在测试集上表现不佳。这种情况称为过拟合。如果训练集和测试集上的表现相似,可以获得模型的泛化能力。
在本文中,我们将探讨分类和回归问题中最重要的评估指标,这些指标将帮助验证模型是否能够很好地捕捉训练样本中的模式,并在未知数据上表现良好。让我们开始吧!
分类
当我们的目标是分类时,我们就面对一个分类问题。最合适的指标选择取决于不同的方面,比如数据集的特征、是否不平衡以及分析的目标。
在展示评估指标之前,有一个重要的表格需要解释,叫做混淆矩阵,它很好地总结了分类模型的表现。
假设我们想训练一个模型来从超声图像中检测乳腺癌。我们只有两类:恶性和良性。
-
真正例:预测为恶性癌症的终末期病人数量
-
真负例:预测为良性癌症的健康人数量
-
假正例:预测为恶性癌症的健康人数量
-
假负例:预测为良性癌症的终末期病人数量
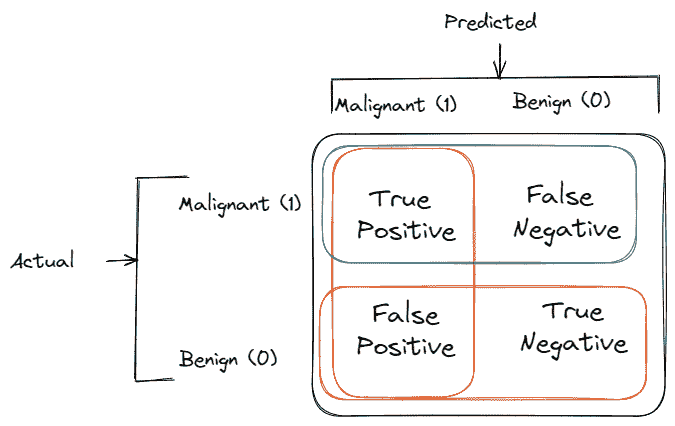
混淆矩阵示例。作者插图。
准确度

准确度是评估分类模型最著名和最受欢迎的指标之一。它是正确预测的分数除以样本数量。
当我们知道数据集是平衡的时,使用准确度。因此,输出变量的每个类别有相同数量的观察值。
使用准确度,我们可以回答问题:“模型是否正确预测了所有类别?”因此,我们有正类(恶性癌症)和负类(良性癌症)的正确预测。
精确度

与准确度不同,精确度是用于类别不平衡时的分类评估指标。
精确度回答以下问题:“恶性癌症识别的比例实际上是正确的吗?”它是通过真正阳性和正预测之间的比率计算的。
如果我们担心假阳性并希望将其最小化,我们会使用精确度。最好避免因恶性癌症的虚假信息而影响健康人的生活。
假阳性数量越少,精确度越高。
召回率

召回率与精确度一起,是应用于输出变量类别观察数量不同的另一种指标。召回率回答以下问题:“我能识别出多少比例的恶性癌症患者?”。
如果我们的关注点集中在假阴性上,我们就关心召回率。假阴性指的是患者实际患有恶性癌症,但我们未能识别出来。然后,应该监控召回率和精确度,以在未知数据上获得理想的表现。
F1-分数
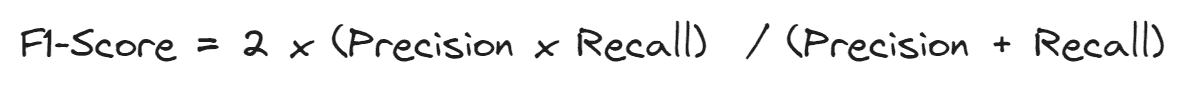
同时监控精确度和召回率可能会很麻烦,因此最好有一个可以总结这两个指标的度量。这可以通过 F1-分数来实现,F1-分数定义为精确度和召回率的调和平均数。
高 F1-分数是因为精确度和召回率都具有高值。如果召回率或精确度值较低,F1-分数将受到惩罚,结果也会较低。
回归
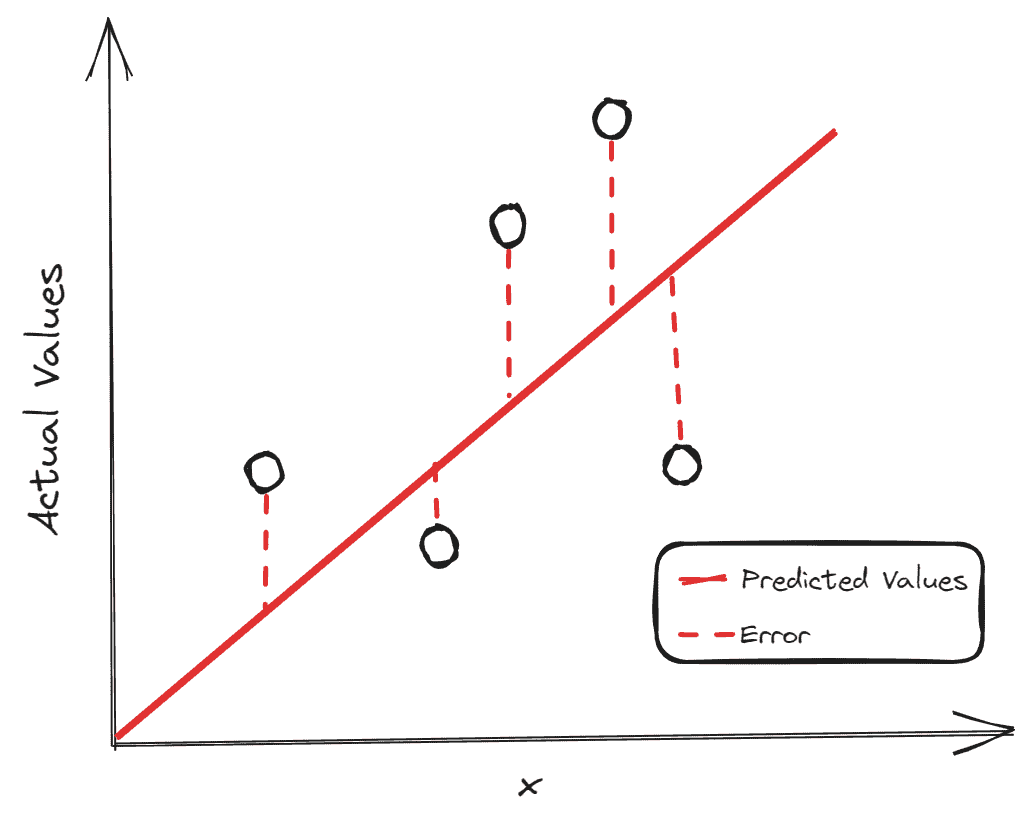
作者插图
当输出变量是数值时,我们处理的是回归问题。与分类问题一样,根据分析的目的选择评估回归模型的指标至关重要。
回归问题最常见的例子是房价预测。我们是否关注准确预测房价?还是只关心最小化总体误差?
在所有这些指标中,构建块是残差,即预测值与实际值之间的差异。
MAE
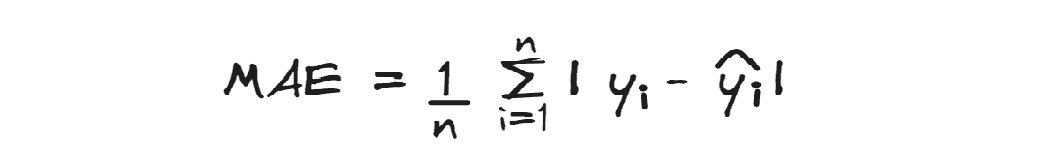
均绝对误差计算的是平均绝对残差。
它没有像其他评估指标那样对高误差进行惩罚。每个误差都被同等对待,即使是异常值的误差,所以这个指标对异常值具有鲁棒性。此外,差异的绝对值忽略了误差的方向。
MSE
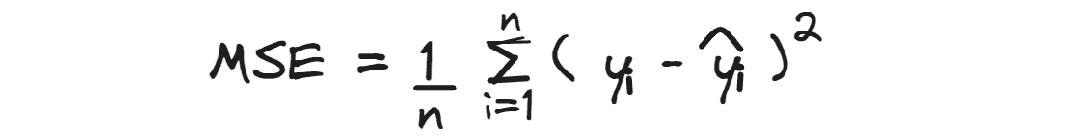
均方误差计算的是平均平方残差。
由于预测值与实际值之间的差异被平方,它对较大的误差赋予了更多的权重,
因此,当大的误差不可接受时,它可能比最小化总体误差更有用。
RMSE
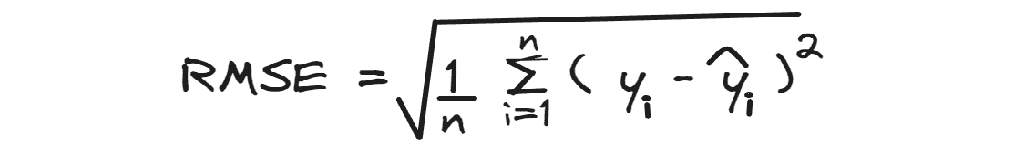
均方根误差计算的是 平方根 的平均平方残差。
当你理解了 MSE 后,稍作停留即可掌握均方根误差,它只是 MSE 的平方根。
RMSE 的优点在于它更容易解释,因为该指标的尺度与目标变量的尺度一致。除了形状外,它与 MSE 非常相似:它总是对较大的差异赋予更多的权重。
MAPE
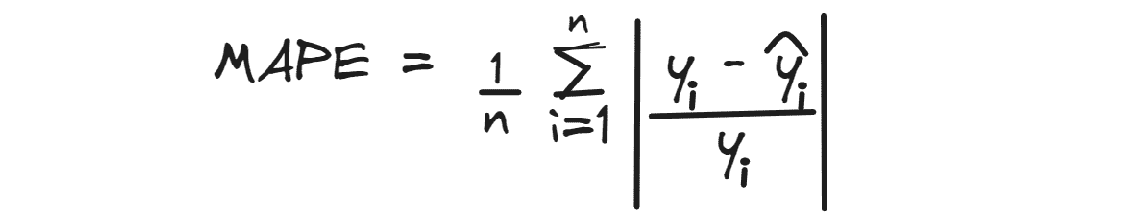
均绝对百分比误差计算的是预测值与实际值之间的平均绝对百分比差异。
像 MAE 一样,它忽略了误差的方向,理想的最佳值是 0。
例如,如果我们在预测房价时得到一个 MAPE 值为 0.3,这意味着平均而言,预测值低于实际值 30%。
结束语
我希望你喜欢这次评估指标的概述。我只涵盖了评估分类和回归模型性能的最重要的度量标准。如果你发现了其他对解决问题非常有帮助但没有在此提及的关键指标,请在评论中告诉我。
尤金尼亚·安内洛 目前是意大利帕多瓦大学信息工程系的研究员。她的研究项目集中在持续学习与异常检测的结合上。
更多相关主题
机器学习适合每个人!
原文:
www.kdnuggets.com/2022/10/machine-learning-everybody.html

机器学习适合每个人的截屏
现在是 2022 年。机器学习适合谁呢?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术
机器学习适合每个人!
或者,至少,这就是feeCodeCamp 的新视频课程的名称,由讲师凯莉·英编排。该课程旨在向完全的初学者介绍机器学习的基础知识。
来自课程视频的 YouTube 页面:
以一种对绝对初学者友好的方式学习机器学习。你将学习机器学习的基本知识,并了解如何使用 TensorFlow 实现许多不同的概念。
该课程不仅向新手介绍概念,还让你立即用代码实现这些概念。因此,虽然这是针对机器学习初学者的课程,但并不适合编程初学者。
首先,这门课程从最基础的内容开始,比如入门级的 Google Colab、机器学习的基本概念、特征是什么、分类和回归是什么、数据准备和模型训练的意义等。接着,你将深入机器学习领域,学习如 K-近邻、朴素贝叶斯、逻辑回归和支持向量机等算法的理论和实现。
课程的其余部分将关注神经网络和 TensorFlow。你将学习如何在 TensorFlow 中实现分类器,了解带有神经元的线性回归,使用 TensorFlow 实现回归神经网络,以及 K-均值聚类。课程最后将介绍主成分分析及 K-均值和 PCA 的实现。
你可以在这里找到这门课程,也可以在下面找到。
凯莉做得很好,确保机器学习适合每个人。你的任务是享受将其变得适合你的过程。
马修·梅约 (@mattmayo13) 是一名数据科学家,并且是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络和自动化机器学习方法。马修拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关话题
《Python 中的机器学习练习:入门教程系列》
原文:
www.kdnuggets.com/2017/07/machine-learning-exercises-python-introductory-tutorial-series.html
作者:John Wittenauer,数据科学家。
编辑说明: 本教程系列于 2014 年 9 月开始,8 期教程在 2 年内发布。我提及这一点是为了将约翰的第一段话置于背景中,并向读者保证,这个包括所有代码的系列教程在今天仍然与写作时一样相关和最新。这些资料非常棒,无论是对于参加 Andrew Ng 的 MOOC 课程的人,还是作为独立资源。
今年我职业发展中的一个关键时刻是发现了 Coursera。我听说过“MOOC”现象,但一直没时间深入学习课程。今年早些时候,我终于下定决心报名参加 Andrew Ng 的机器学习课程。我完成了整个课程,包括所有编程练习。这段经历让我认识到了这种教育平台的力量,从此我就迷上了它。
本博客文章将是系列中的第一篇,涵盖 Andrew 课程中的编程练习。我不太喜欢课程中使用 Octave 做作业的一个方面。虽然 Octave/Matlab 是一个很好的平台,但大多数现实世界的“数据科学”都是用 R 或 Python 完成的(当然还有其他语言和工具在使用,但这两种毫无疑问位列前茅)。由于我正在努力提高我的 Python 技能,所以我决定从头开始用 Python 做这些练习。完整的源代码可以在我的 IPython Github 仓库找到。如果你感兴趣,你还会在根目录的子文件夹中找到这些练习所用的数据和原始练习 PDF。
在我关于 Python 机器学习系列的第一部分中,我们介绍了安德鲁·恩的机器学习课程第一部分的内容。在这篇文章中,我们将通过完成第二部分的练习来总结第一部分。如果你还记得,在第一部分中,我们实现了线性回归来预测新食品卡车的利润,这些卡车将被放置在某个城市中。第二部分的任务是预测房屋的销售价格。这次的不同之处在于我们有多个因变量。我们得到的输入包括房屋的平方英尺数以及卧室的数量。我们能否轻松扩展之前的代码来处理多元线性回归?让我们来看看吧!
在系列的第二部分中,我们总结了使用梯度下降法实现多元线性回归,并将其应用于一个简单的房价数据集。在这篇文章中,我们将目标从预测一个连续值(回归)转变为将结果分类为两个或更多离散类别(分类),并将其应用于学生录取问题。假设你是一个大学部门的管理员,你想根据申请人在两个考试中的成绩来确定每个申请人的录取机会。你有来自先前申请人的历史数据,可以用作训练集。对于每个训练样本,你都有申请人在两个考试中的得分以及录取决策。为此,我们将构建一个分类模型,该模型使用一种名为逻辑回归的稍微让人困惑的技术,根据考试成绩估计录取概率。
在本系列的第三部分中,我们实现了简单和正则化逻辑回归,完成了安德鲁·恩机器学习课程第二个练习的 Python 实现。然而,我们的解决方案有一个限制——它仅适用于二分类问题。在这篇文章中,我们将扩展之前练习的解决方案,以处理多类分类问题。在此过程中,我们将涵盖第三部分的前半部分,并为下一个重要话题——神经网络做好准备。
在第四部分中,我们通过扩展解决方案来处理多类分类,并在手写数字数据集上进行测试,从而完成了逻辑回归的实现。仅使用逻辑回归,我们就能够达到约 97.5% 的分类准确率,这相当不错,但几乎达到了线性模型的极限。在这篇博客文章中,我们将再次处理手写数字数据集,但这次使用带有反向传播的前馈神经网络。我们将实现未正则化和正则化的神经网络成本函数版本,并通过反向传播算法计算梯度。最后,我们将通过优化器运行算法,并评估网络在手写数字数据集上的表现。
我们现在正接近课程内容和这系列博客文章的最后阶段。在这个练习中,我们将使用支持向量机(SVM)来构建一个垃圾邮件分类器。我们将从一些简单的二维数据集开始使用 SVM 以了解其工作原理。然后我们将查看一组电子邮件数据,并利用 SVM 在处理过的邮件上构建分类器,以确定它们是否是垃圾邮件。
我们现在只剩下这系列中的最后两篇文章了!在这一部分中,我们将讨论两个引人入胜的主题:K 均值聚类和主成分分析(PCA)。K 均值和 PCA 都是无监督学习技术的例子。无监督学习问题没有任何标签或目标供我们学习以进行预测,因此无监督算法试图从数据本身中学习一些有趣的结构。我们将首先实现 K 均值,并看看它如何用于压缩图像。我们还将实验 PCA,以找到人脸图像的低维表示。
我们现在已经到达这一系列的最后一篇文章!这是一次有趣的旅程。安德鲁的课程做得非常出色,将其全部翻译成 Python 是一次有趣的经历。在这最后一部分中,我们将覆盖课程中的最后两个主题——异常检测和推荐系统。我们将使用高斯模型实现异常检测算法,并将其应用于检测网络上的故障服务器。我们还将看到如何使用协同过滤构建推荐系统,并将其应用于电影推荐数据集。
简介: 约翰·维滕瑙尔 (@jdwittenauer) 是一名数据科学家、工程师、企业家和技术爱好者。
相关内容:
-
掌握 Python 机器学习的 7 个步骤
-
数据科学新手: 软件工程师入门教程系列
-
机器学习: 完整详细概述
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
机器学习实验跟踪
原文:
www.kdnuggets.com/2020/06/machine-learning-experiment-tracking.html
评论
由 Lukas Biewald,Weights and Biases 的创始人/首席执行官。
初看,构建和部署机器学习模型看起来很像编写代码。但有一些关键的区别使得机器学习更具挑战性:
-
机器学习项目有比典型软件项目更多的分支和实验。
-
机器学习代码通常不会抛出错误,只会表现不佳,使得调试变得格外困难和耗时。
-
训练数据、训练代码或超参数中的一个小变化可能会极大地改变模型的性能,因此重现早期工作通常需要完全匹配之前的设置。
-
运行机器学习实验可能非常耗时,仅计算成本也可能变得昂贵。
以有组织的方式跟踪实验有助于解决这些核心问题。Weights and Biases(wandb)是一个简单的工具,帮助个人跟踪他们的实验——我与几位不同规模团队的机器学习领导者讨论了他们如何使用 wandb 来跟踪实验。
开始使用 wandb 进行实验跟踪
查看 实时仪表板
在 ML 项目中,进展的基本单元是实验,因此大多数人会以某种方式跟踪他们的工作——通常我看到从业者开始使用电子表格或文本文件来记录他们的工作。
电子表格和文档非常灵活——这种方法有什么问题?
这是我几年前用于一个项目的 Google 文档:
我确定这些笔记在当时很重要,但现在我不知道这些笔记的含义。
Weights and Biases 使得自动记录所有超参数(输入)和指标(输出)变得非常简单。
在 wandb 中的一个典型项目。
这就是你如何在 pytorch 中设置 wandb(你可以在 文档 中找到其他常见的 ML 框架)。
**import wandb****wandb.init(config=args)** # track hyperparameters
**wandb.watch(model)** # track model metricsmodel.train()
for batch_idx, (data, target) in enumerate(train_loader):
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step() **wandb.log({“loss”: loss})** # track a specific metric
一旦设置完成,Weights and Biases 默认会监控很多内容。任何命令行参数都会变成保存的超参数。任何由 pytorch 提供的值都会成为一个指标。实验可以自动链接到最新的 git 提交或训练代码的确切状态。被动收集信息真的很重要,因为几乎不可能始终如一地记录你可能关心的所有事项。

实验概述 在 Weights & Biases 中
记录关于你构建的模型的定性笔记也极为重要,以便以后参考。在 Weights and Biases 中,你可以创建报告来跟踪笔记和模型指标,并与团队分享你的发现和进展。
在后台收集系统指标是一个很好的例子。Wandb 在后台收集系统使用指标——例如 GPU 内存分配、网络流量和磁盘使用情况。大多数时候你不需要查看所有这些信息,但当你不再使用大部分 GPU 内存并且很难追踪到这个变化时,情况会变得复杂。如果你 用 wandb 监控你的训练代码 一次,你将能够回顾所有实验并查看使用情况的变化。
在 实时仪表盘查看
使用实验跟踪来比较实验结果
典型的机器学习工作流程涉及运行大量实验。我们发现,将结果 放在其他结果的背景下查看,比单独查看某个实验要有意义得多。
同时查看大量实验会迅速变得混乱。有很多输入变化和不同的可能输出。一些运行不可避免地会提前失败。
不同的实验风格会导致不同的工作流程,但我们发现,记录你可能关注的每一个指标,并用几个对你有意义的标签标记实验,可以使后续工作更加有序。
在 实时仪表盘查看。
一旦你记录了大量模型,你就有了更多的维度可以检查,而这些维度无法一眼看完。我们发现的一个强大的可视化工具是平行坐标图。
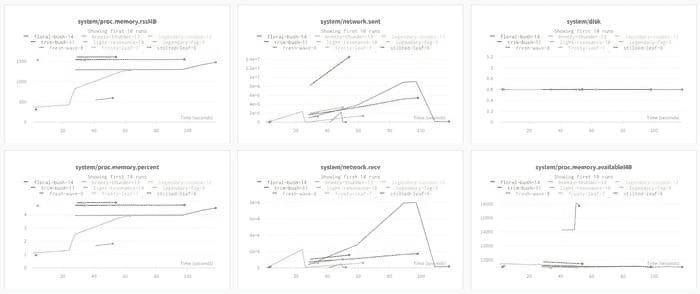
在 实时仪表盘查看
在这里,每一行是一个独立的实验,每一列是一个输入超参数或输出指标。我已经突出了准确率最高的运行,结果很清楚地显示,在我选择的所有实验中,高准确率来自低 dropout 值。
跨实验查看如此重要,以至于 wandb 允许你构建工作区,你可以选择图形分组进行可视化,如散点图,然后立即查看所选运行的比较。
查看具体示例
聚合指标很重要,但查看具体的示例也至关重要。函数 wandb.log() 可以处理各种数据类型并自动可视化它们。
查看 实时报告
记录图像
记录图像 对于许多应用非常重要,并且可以跨多个运行查看图像。这些是构建 GAN 的不同方法及其在各种尺度和时间步长下的结果。
记录 Matplotlib 图表
通常代码已经在 matplotlib 中跟踪了内容——如果你 记录图表,它将被永久保存,并且容易检索。实际上,你可以为训练代码的每个步骤记录一个独特的图表。
使用实验跟踪来管理分布式训练
在进行 分布式训练 时,甚至只是可视化结果也变得更加困难。
在多台机器上的分布式运行中,每个实例都可以调用 wandb init 并像这样设置 group 和 job_type:
wandb.init(group=”first-run”, job_type=”train”)

查看 实时仪表盘
Wandb 会显示组内所有运行的指标汇总,但也可以进入并查看单个过程,了解它们的表现如何。
使用实验跟踪报告来管理团队协作
随着团队的发展,跟踪一切变得越来越重要。Wandb 允许你构建 静态报告,准确展示你运行的实验、汇总统计数据以及深入挖掘的能力。
在 OpenAI 机器人团队中,wandb 报告是机器学习从业人员记录他们所做工作的地方,并与同事分享。这对于可视化何时更改可能会无意中阻碍进展至关重要。
在 Latent Space,每个团队项目会议都以审查最新的 wandb 实验报告开始,并讨论当前方法的有效性以及下一步应尝试的实验。
查看 实时报告
使用实验跟踪作为模型的记录系统
随着团队的扩展和模型的投入生产,记录发生的一切变得越来越重要。在丰田研究所,wandb 实验链接被用作每个构建的机器学习模型的官方记录。如果模型构建后发生了问题,他们可以追溯到 wandb 训练运行。通过一组实验生成报告意味着有一个永久记录工作的文档,团队可以轻松地回顾发生了什么。
简介:Lukas Biewald 是 Weights & Biases 的创始人,之前是 Figure Eight(前身为 CrowdFlower)的创始人。
原文。经许可转载。
相关内容:
-
为什么机器学习项目如此难以管理?
-
互动式机器学习实验
-
机器学习中的模型评估指标
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织中的 IT 事务
更多相关话题
机器学习可解释性与可理解性:两个概念可能有助于恢复对 AI 的信任
原文:
www.kdnuggets.com/2018/12/machine-learning-explainability-interpretability-ai.html
评论
由 Richard Gall,Packt

不需要数据科学家来发现,内置于自动化和人工智能系统中的机器和深度学习算法缺乏透明性。也不需要太多侦探工作就能看到,这些系统中包含了开发这些系统的工程师无意识偏见的印记。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
可以说,在《经济学人》所称的技术反弹的背景下,这种不透明性(具有讽刺意味地)变得更加明显。尽管许多导致技术反弹的事件既是公司自身利益与令人担忧的治理和问责缺失的混合问题,但不可否认的是,数据科学和机器学习工程的实践自然地与今年最大的一些商业和政治故事紧密相关。
在这种背景下,可解释性和可理解性的概念变得更加紧迫。由于对人工智能伦理的讨论持续进行,它们在 2019 年可能会变得更加重要。
但是,什么是可解释性和可理解性?它们对我们这些从事数据挖掘、分析、科学的人在 2019 年究竟意味着什么?
机器学习可解释性与可理解性之间的区别
在机器学习和人工智能的背景下,可解释性和可理解性通常被交替使用。虽然它们非常密切相关,但值得探讨它们之间的区别,至少可以看到深入了解机器学习系统后事情可能会变得多么复杂。
可解释性是指在系统中观察因果关系的程度。换句话说,就是在输入或算法参数发生变化时,你能够预测会发生什么的程度。它就是能够看着一个算法,嗯,我可以看到这里发生了什么。
同时,可解释性是指机器或深度学习系统的内部机制可以用人类术语解释的程度。理解这个细微的差别可能很困难,但可以这样考虑:可解释性是能够辨别机制而不一定知道原因。可解释性则是能够字面上解释发生了什么。
可以这样理解:假设你在学校做科学实验。实验可能在你看到自己在做什么时是可以解释的,但只有当你深入了解你所看到的化学反应时,它才真正具备可解释性。
这可能有点粗略,但它仍然是思考这两个概念之间关系的一个很好的起点。
为什么在人工智能和机器学习中,可解释性和可理解性如此重要?
如果 2018 年的技术反弹教会了我们什么,那就是尽管技术确实可以被用于可疑的用途,但它也有很多方式可能产生不良 - 歧视性 - 结果,而这些结果并非有意造成伤害。
随着医疗保健等领域希望部署人工智能和深度学习系统,其中问责制和透明度的问题尤其重要,如果我们无法在算法中妥善提升可解释性,最终实现可解释性,我们将严重限制人工智能的潜在影响。这将是非常可惜的。
除了需要考虑的法律和专业问题外,还有一个论点认为,在更平凡的商业场景中,提高可解释性和可理解性同样重要。了解算法的实际工作方式可以帮助更好地将数据科学家和分析师的活动与他们组织的关键问题和需求对齐。
提高机器学习可解释性的方法和技巧
尽管透明性和伦理的问题对实际工作中的数据科学家来说可能显得抽象,但实际上有许多实用的方法可以用来提高算法的可解释性和可理解性。
算法的泛化
第一点是提高泛化能力。这听起来简单,但实际上并不容易。当你认为大多数机器学习工程是在以非常具体的方式应用算法以揭示某个期望结果时,模型本身可能会显得是一个次要元素——它只是实现目标的手段。然而,通过转变这种态度,考虑算法的整体健康状况及其运行的数据,你可以开始为改善可解释性奠定坚实的基础。
注意特征的重要性
这应该是显而易见的,但很容易被忽视。仔细查看算法中各种特征的设置方式,是实际解决从业务对齐到伦理等各种问题的有效方法。对每个特征如何设置进行辩论和讨论可能会有些耗时,但尽管如此,意识到不同特征以某种方式被设置仍然是朝着可解释性和透明性迈出的重要一步。
LIME:局部可解释模型无关解释
虽然上述技术提供了数据科学家可以采取的实际步骤,但 LIME 是由研究人员开发的一种实际方法,用于获得对算法内部发生的事情的更大透明度。研究人员解释说,LIME 可以以“可解释且忠实的方式解释任何分类器的预测,通过在预测周围局部学习一个可解释的模型”。
实际上,这意味着 LIME 模型通过测试来开发模型的近似值,以查看当模型中的某些方面发生变化时会发生什么。本质上,这就是通过实验过程尝试从相同的输入重现输出。
DeepLIFT(深度学习重要特征)
DeepLIFT 是一个在深度学习领域特别棘手的情况中非常有用的模型。它通过一种反向传播形式工作:它获取输出,然后尝试通过“读取”形成该原始输出的各种神经元来分解它。
实质上,这是一种深入挖掘算法内部特征选择的方法(正如名称所示)。
层级相关传播
层级相关传播类似于 DeepLIFT,它从输出向后工作,识别神经网络中的最相关神经元,直到你回到输入(例如,一张图片)。如果你想了解更多关于这一概念背后的数学知识,Dan Shiebler 的这篇文章是一个很好的起点。
增加复杂性以应对复杂性:这能提高透明度吗?
可解释性和透明性的核心问题在于,你在开发过程中增加了一个额外的步骤。实际上,你可能还添加了多个步骤。从某种角度看,这就像是试图用更大的复杂性来应对复杂性。
在某种程度上,这确实是对的。实际上,这意味着如果我们要真正认真对待解释性和可解释性,就需要在数据科学和工程的方式,以及人们相信它应该如何进行的文化上,进行更广泛的变革。
这或许才是最具挑战性的部分。
个人简介: 理查德·加尔 是 Packt 的编辑内容产品经理。通过优质的信息传递,专注于 Packt 帮助的社区和客户的需求,理查德致力于推动直接和入站收入的增长,并提高 Packt 品牌在当今技术领域的影响力和相关性。
资源:
相关:
更多相关话题
机器学习以 88%的准确率发现“虚假新闻”
原文:
www.kdnuggets.com/2017/04/machine-learning-fake-news-accuracy.html
乔治·麦金泰尔,贡献数据科学撰稿人,ODSC

“谎言在真相来得及穿上裤子之前,就已经传遍了半个世界。”
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
– 温斯顿·丘吉尔
自 2016 年总统选举以来,一个主导政治讨论的话题是“虚假新闻”问题。许多政治评论员声称,显著偏见和/或虚假的新闻影响了选举,尽管斯坦福大学和纽约大学的研究得出了不同的结论。尽管如此,虚假新闻帖子已经利用 Facebook 用户的信息流在互联网中传播。
“什么是虚假新闻?”
显然,一个故意误导的故事就是“虚假新闻”,但最近喧闹的社交媒体讨论正在改变它的定义。一些人现在使用这个术语来拒绝与他们偏好的观点相悖的事实,最突出的例子是特朗普总统。这样的模糊定义的术语很容易被玩弄。
数据科学社区已经做出回应,采取行动来解决这个问题。有一个类似 Kaggle 的比赛,称为“虚假新闻挑战”,而Facebook 正在使用 AI来过滤用户信息流中的虚假新闻。打击虚假新闻是一个经典的文本分类项目,提出了一个直接的问题:你能建立一个区分“真实”新闻和“虚假”新闻的模型吗?
这正是我为这个项目所尝试做的。我组建了一个包含虚假新闻和真实新闻的数据集,并使用了一个朴素贝叶斯分类器,以便创建一个模型,根据文章中的词汇和短语将其分类为虚假或真实。
数据收集/整理
数据获取过程分为两个部分:获取“假新闻”和获取真实新闻。第一部分很快,Kaggle 发布了一个fake news dataset,包含了在 2016 年选举周期内发布的 13,000 篇文章。
第二部分要困难得多。为了获取数据集中真实新闻的部分,我转向了All Sides,这是一个致力于汇集政治光谱各方新闻和观点文章的网站。该网站上的文章按主题(环境、经济、堕胎等)和政治倾向(左派、中立、右派)进行分类。我使用 All Sides,因为这是从众多媒体渠道中抓取成千上万篇文章的最佳方式。此外,它还允许我下载文章的完整文本,这一点是《纽约时报》和 NPR API 所不具备的。经过漫长而艰辛的过程,我最终抓取了5279 篇文章。我的真实新闻数据集中的文章来自于《纽约时报》、华尔街日报、彭博社、NPR 和《卫报》,并且这些文章发表于 2015 年或 2016 年。
我决定将我的完整数据集构建为假新闻和真实新闻各占一半,从而使模型的空白准确率为 50%。我随机选择了 5279 篇假新闻文章用于我的完整数据集,其余的文章则留作测试集,以便在我的模型完成时使用。
我最终的数据集包含了 10558 篇文章,包括它们的标题、完整正文和标签(真实与假)。数据存放在这个github repo中。
目的与期望
当我刚开始这个项目时,我承认这不会是一个完美的项目。这个项目的目的是看看我能在创建假新闻分类器上走多远,并从中获得什么见解,然后用于改进模型。我的计划是将这个项目视为一个常规的垃圾邮件检测项目。
基于计数向量化器(使用词频统计)或 tfidf 矩阵(词频相对于它们在数据集中其他文章中的使用频率)来构建模型只能取得一定的效果。这些方法没有考虑重要的特质,比如词序和上下文。两个在词频上类似的文章,其含义可能完全不同。我并没有期望我的模型能够熟练处理那些词语和短语重叠的假新闻和真实新闻。然而,我期待这个项目能够提供一些有价值的见解。
建模
由于这是一个文本分类项目,我只使用了朴素贝叶斯分类器,这是文本数据科学项目中的标准做法。
制定模型的真正工作是文本转换(计数向量器与tfidf 向量器)和选择使用哪种类型的文本(标题与全文)。这给了我四对重新配置的数据集来进行操作。
下一步是确定计数向量器或tfidf 向量器的最优参数。对于那些不熟悉文本机器学习的人来说,这意味着使用 n 个最常见的词,使用词和/或短语,是否小写,去除停用词(如 the、when 和 there)以及仅使用在文本语料库中出现至少指定次数的词(文本数据集或文本集合的术语)。
为了测试多个参数及其众多组合的性能,我利用了 Sci-kit Learn 的 GridSearch 功能来高效地执行此任务。要了解如何优化算法参数,请查看这个教程。
在网格搜索交叉验证过程之后,我发现我的模型在使用计数向量器而不是tfidf时效果最佳,并且在用文章的全文训练时比训练在标题上产生了更高的分数。计数向量器的最佳参数是不进行小写转换、使用两词短语而非单个词,并且仅使用在语料库中出现至少三次的词。
鉴于我在帖子中之前概述的期望,我对模型产生的高分感到惊讶甚至有些困惑。我的模型的交叉验证准确率为 91.7%,召回率(真正率)为 92.6%,AUC 分数为 95%。
这是我模型的 ROC 曲线。

如果我基于此图决定模型的阈值,我会选择一个在 0.08 左右产生假阳性率(FPR)和在 0.90 左右产生真正率(TPR)的阈值,因为在图中此点假阳性与真正率之间的权衡是平衡的。
结果与结论
我的模型质量的真正考验是看它能多准确地分类测试集中(未用于模型创建的假新闻文章)假新闻文章。
在 5234 篇其他假新闻数据集中,我的模型能够正确识别 88.2%的假新闻。 这比我的交叉验证准确率低了 3.5 个百分点,但在我看来,这是对我的模型的相当不错的评估。
事实证明,我预测模型在分类新闻文章时会遇到困难的假设是相当错误的。我原本认为 60 多或 70 多的准确率是优秀的,但我设法显著超越了这个预期。
尽管我创建了一个看似相当不错的模型,但考虑到任务的复杂性,我并不完全相信它的表现如同表面上看起来的那样,这就是原因所在。
为了更好地理解为什么会发生这种情况,我们来看看数据中的“最虚假”和“最真实”词汇——我会解释我的意思。
使用我从数据学校的 Kevin Markham 那里借用的技术,这里是我如何得出语料库中“最虚假”和“最真实”词汇的方法。我首先使用了一个宽两列、长 10558 行的表格(这就是语料库中的词汇数量)。第一列表示一个词在被分类为“虚假”的文章中出现的次数,第二列表示一个词在“真实”文章中出现的次数。然后,我将虚假列的数值除以我模型分类的虚假文章总数,真实列也做了同样的处理。接着,我在数据的每个值上加了一,因为我创建了一个新的“虚假:真实”比率列,不想因为除以零而产生错误。这个“虚假:真实”是衡量某个词汇“虚假”或“真实”的一个相当不错但并不完美的指标。逻辑很简单,如果一个词在“虚假”文章中频繁出现而在“真实”文章中很少出现,那么它的虚假与真实比率分数将会很高。
这里是我数据集中前 20 个“最虚假”和“最真实”的词汇。


这两个图表展示了一些令人困惑的结果。“虚假”图表中的词汇种类繁杂,包括一些典型的互联网术语,如 PLEASE、Share、Posted、html 和 Widget,以及一些甚至不是真正的词汇,如 tzrwu。然而,看到 infowars 被提及以及“羊群”和“UFO”等词汇进入前 20 个“最虚假”词汇并不令人惊讶。Infowars 是由 Alex Jones 领导的一个右翼阴谋论媒体,推广关于化学轨迹和 9/11 的阴谋理论。
“真实”的图表主要由名字、政治家以及在政治文章中经常使用的词汇构成,占据了图表中 60%的条形图。二十个词汇中有七个,包括前六名中的四个,是政治家名字。这引发了一个问题,即关于政治家的文章是否更有可能是真实的?当然不是,如果有什么的话,你会预期有大量的虚假新闻传播关于政治家的虚假信息。如果我得出提到政治家的文章更有可能真实的结论,那将是一个巨大的错误。
这个项目的一个重要假设是,各类文章所涵盖的主题有相当大的重叠。正如我们上面所见,仅仅因为某个词在“真实”新闻中出现得比在“虚假”新闻中多,并不意味着包含这些词的文章一定是“真实”的,而只是这些词可能在真实新闻数据集中更常见,而虚假新闻数据集中则反之。
我和另一方对塑造这个数据集有相当大的影响。我决定了哪些文章用于“真实”数据集。“虚假”数据集中的文章是由一个名为“BS Detector”的 Chrome 扩展程序确定的,该程序由 Daniel Sieradski 制作。确定什么是“虚假新闻”、什么不是“虚假新闻”时存在显著的主观性。政治人物的名字被高评级为“真实”的原因,很可能是因为这部分语料库不成比例地来自政治新闻。此外,我确实发现了一些我认为来自可靠新闻来源的文章。其中一篇文章来自 The Intercept,一个具有高新闻标准的新闻组织。是的,我的模型确实将这篇所谓的“虚假新闻”文章标记为真实。
使事情变得更加复杂的是,我们必须决定如何为我们的模型设置阈值概率。如果我是一名在 Facebook 的数据科学家,负责实现一个筛选用户动态中真实与虚假新闻的模型,我将面临选择一个屏蔽所有或大部分虚假新闻和一些真实新闻的模型,还是一个允许所有或大部分真实新闻和一些虚假新闻的模型的困境。但在做出决定之前,我需要弄清楚未能阻止虚假新闻与阻挡真实新闻的成本是什么?如何尝试回答这样一个抽象的问题?除非我们能训练一个 100%真阳性率和 0%假阳性率的模型,否则我们将被困在这个困境中。
总之,虽然我认为标准的朴素贝叶斯文本分类模型可以提供一些解决这个问题的见解,但在专业环境中,应使用更强大的深度学习工具来对抗虚假新闻。
对“虚假新闻”的分类为数据科学界提供了一个新挑战。在许多机器学习项目中,你想要预测的不同类别之间的区别是明确的,而在这种情况下则要模糊得多。这个项目验证了数据科学中的一种观点,即对数据的直觉和熟悉程度与任何模型或工具一样重要,甚至更为重要。
简介:乔治·麦金泰尔 是一位转行的数据科学家/记者混合型人才。寻找数据科学和/或新闻学方面的机会。对新事物充满好奇和热情。在完成 Metis 数据科学训练营之前,他曾在旧金山为 Vice、Salon、SF Weekly、San Francisco Magazine 等媒体担任自由记者。
原文。已获授权转载。
相关内容:
-
这里越来越热:数据科学与假新闻
-
昨晚瑞典发生了什么:数据科学与假新闻
-
警惕两种数据混淆策略
更多相关内容
亚马逊免费入门机器学习课程
原文:
www.kdnuggets.com/2020/10/machine-learning-free-course-amazon.html
评论
我们最近分享了亚马逊新推出的机器学习大学计划的入门课程,这些课程集中在计算机视觉(CV)和自然语言处理(NLP)上。这些课程假设你对这些主题没有任何先验知识,并基于短视频讲座和相应的 Python 笔记本。
但如果你对计算机视觉(CV)或自然语言处理(NLP)的专业路径不感兴趣呢?如果你希望了解将机器学习应用于更传统的数据集怎么办?如果这些描述符合你,加速表格数据 可能是一个不错的起点。
这门课程由亚马逊的技术培训专家Paula Grajdeanu教授,涵盖以下材料:

课程讲座可以在课程的YouTube 播放列表中找到,而附带材料——包括幻灯片、笔记本和数据集——可以在课程的GitHub 仓库中找到。最终项目与课程的实际技能目标一致,基于奥斯汀动物中心的宠物领养数据。
为什么提到“表格数据”?这是因为这门课程并不旨在教授最新深度学习的理论,而是加速表格数据将介绍使用各种技术在表格数据上实现机器学习解决方案——即以行和列存储的字母数字数据,其中行代表观察值,列代表这些观察值的特征。这与其他类型数据的技术形成对比,即计算机视觉和自然语言处理,亚马逊 MLU 的补充课程可以在这些技术的学习上提供支持。
这门课程并不是旨在详尽无遗,而是为了激发你对实际机器学习的兴趣。请查看课程主题,并将其视为对现有内容的一个样本,以及你之后可能选择专注的内容。
通过这门入门课程,你不会立即工程化生产就绪的机器学习系统,但它应当为你提供关于机器学习在实际中可以实现什么的概述,给你必要的工具来完成一些这些任务,并帮助你在课程结束后指引到更深入的学习方向。总体来看,这门课程是一个值得考虑开始机器学习之路的好地方。
相关:
-
加速计算机视觉:亚马逊的免费课程
-
加速自然语言处理:亚马逊的免费课程
-
超越肤浅:具有实质内容的数据科学 MOOC
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多此主题
《从头开始的机器学习:免费在线教材》
原文:
www.kdnuggets.com/2020/09/machine-learning-from-scratch-free-online-textbook.html
评论
由丹尼尔·弗里德曼编写,他是哈佛大学统计学的高级学生。
本书涵盖的内容
本书涵盖了机器学习中最常见方法的基础知识。这套方法就像是机器学习工程师的工具箱。那些进入机器学习领域的人应该对这个工具箱感到熟悉,这样他们才能在各种任务中使用合适的工具。本书的每一章都对应一个单独的机器学习方法或方法组。换句话说,每一章都集中于 ML 工具箱中的一个单独工具。
根据我的经验,熟悉这些方法的最佳方式是从头开始理解它们,无论是理论上还是代码实现上。本书的目的是提供这些推导。每章分为三个部分。概念 部分从概念上介绍这些方法,并在数学上推导其结果。构建 部分展示了如何使用 Python 从头构建这些方法。实现 部分演示了如何使用 Python 中的包,如 scikit-learn、statsmodels 和 tensorflow 来应用这些方法。
为什么选择这本书
许多关于机器学习的优秀书籍由更有经验的作者编写,涵盖了更广泛的主题。特别是,我建议阅读统计学习导论、统计学习的元素和模式识别与机器学习,这些书籍都可以在网上免费获取。
虽然这些书籍提供了机器学习的概念概述及其方法背后的理论,但本书专注于机器学习算法的基本内容。其主要目的是使读者能够独立构建这些算法。继续使用工具箱的比喻,本书旨在作为用户指南:它并不旨在教用户广泛的领域实践,而是如何在微观层面上使用每个工具。
本书适合谁
本书适合那些希望学习新的机器学习算法或深入理解算法的读者。特别是,它旨在帮助读者看到从头到尾推导出的机器学习算法。这些推导可能帮助之前不熟悉常见算法的读者直观地理解它们的工作原理。或者,这些推导可能帮助有建模经验的读者理解不同算法如何创建它们的模型以及每种算法的优缺点。
本书对那些有基本建模实践的读者最为有用。它不回顾最佳实践——如特征工程或响应变量平衡——也不深入讨论在何种情况下某些模型比其他模型更合适。相反,它关注这些模型的要素。
读者应了解的内容
本书的概念章节主要需要微积分知识。然而,有些章节需要理解概率(例如最大似然估计和贝叶斯规则)以及基础线性代数(例如矩阵运算和点积)。附录回顾了理解本书所需的数学和概率。概念章节还参考了一些常见的机器学习方法,这些方法在附录中也有介绍。概念章节不需要编程知识。
本书的构造和代码章节使用了一些基本的 Python。构造章节需要理解相关内容章节,并且熟悉 Python 中的函数和类的创建。代码章节则不需要这些知识。
提问或反馈的方式
你可以通过提出问题或发送电子邮件至 dafrdman@gmail.com 来联系我。你也可以通过Twitter或LinkedIn与我联系。
目录
1. 普通线性回归
**2. 线性回归扩展
**3. 判别式分类器(逻辑回归)
**4. 生成式分类器(朴素贝叶斯)
**5. 决策树
**6. 树集成方法
**7. 神经网络
**附录
**开放教材
相关内容:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力。
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持。
更多相关内容
-
学习数据科学统计的顶级资源****************
机器学习在网络安全中是否有未来角色?
原文:
www.kdnuggets.com/2017/06/machine-learning-future-role-cyber-security.html
评论
作者:保罗·奥尼尔,数据分析师,来自Black Duck Software。

我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 工作
根据谷歌趋势,机器学习自 2015 年以来的兴趣稳步增长(几乎增长了三倍)。Coursera 和 Udacity 的机器学习课程都位列前十相关主题。看来许多人希望了解更多关于它的信息。
如果你曾经使用过谷歌、Netflix、亚马逊、Gmail,那么你已经与机器学习(ML)互动过了。它已成为在线零售、推荐系统、欺诈检测等领域的重要组成部分。开源的机器学习和数据科学工具,如Python 的 Scikit-learn 包,是免费的,非常强大,常用于构建这些工具。
机器学习的早期尝试
过去,机器学习在网络安全领域的成功不如在其他领域。许多早期尝试面临生成过多假阳性的难题,导致对其态度不一。例如,Bromium 的首席技术官 Simon Crosby 认为,尽管机器学习在发现相似性方面表现很好,但在发现异常方面却不如人意,因此不适用于网络安全。前 Symantec 首席技术官 Amit Mital 声称,网络安全“基本上破碎”,而机器学习是为数不多的‘希望之光’之一。我不同意第一个观点,它在事实上的确不正确。无监督机器学习能够区分异常值和正常活动。
演算法应用
机器学习算法有很多种,通常分为有监督学习和无监督学习。有监督学习需要标记的训练数据集,对于网络安全来说不太适用。无监督学习不需要标记的训练数据,更适合发现可疑活动,包括检测以前从未见过的攻击的能力。
Amit Mital的观点更为有趣。网络安全是否已经崩溃?我不是安全专家,所以无法对安全的技术方面发表评论,但我可以查看事实。每天,大型公司和组织都遭受攻击,其中一些攻击是成功的。网络安全是一个‘零容忍领域’,我的意思是,任何成功的攻击都是安全失败。对我来说,如果机器学习有任何帮助的可能性,我们应该加以调查。
大数据能力
最近几个月,一些主要公司已经获得了机器学习能力。例如,Sophos 收购了 Invincia,Radware 购买了 Seculert,而惠普则收购了 Niara。这可能是一个迹象,表明至少一些大型组织将机器学习和大数据能力视为未来的重要资产。
机器学习可能很快在网络安全中将不再是可选的。物联网将严峻地挑战现有的网络安全方法。一旦那些潜在不安全的‘智能’马桶、电烤箱等开始联网,它将显著增加产生和分发的数据量。这可能会显著增加可被利用的弱点数量,这是一种挑战,机器学习或许可以帮助解决。
机器学习提供 24/7 的监控,并处理比人类能够处理的更大的数据负荷。它仍然需要人工干预。机器学习并不是真正的‘即插即用’技术;它需要调优,以帮助筛选真正的攻击与看似可疑但实际上是良性活动的区别,而这种调优需要人类专家。我认为即使是最支持机器学习的人也不会声称它可以替代防火墙、杀毒软件或人工安全专家,但它将补充这些更传统的防御措施,创造出更为多层次的防御体系。
最近的进展
近年来,网络安全机器学习的一些重要进展和改进包括麻省理工学院计算机科学与人工智能实验室(CSAIL)与一家名为 PatternEx 的机器学习初创公司之间的合作。这项合作的成果是 AI2,一个提供 85%检测率的系统,并且减少了五倍的误报率。
深度学习也是未来值得关注的领域。这种形式的人工智能不同于机器学习,因为它基于模仿大脑中神经元行为的算法。深度学习的目标与无监督学习的目标类似:能够识别已知和未知的攻击类型。然而,深度学习可能更好地处理不完整、混乱和复杂的数据——这正是我们在现实世界中看到的数据。
简介: 保罗·奥尼尔 (LinkedIn) 拥有物理学,特别是天体物理学的背景。现在他是一名数据分析师。不仅仅是他的职位,保罗对数据充满了热情。他的兴趣包括数据可视化、自然语言处理、机器学习以及与数据相关的技术方面。但保罗最感兴趣的是数据革命对人类的影响。
原文. 经许可转载。
相关:
-
机器学习与网络安全资源
-
人工“人工智能”泡沫与网络安全的未来
-
使用机器学习检测恶意网址
更多相关话题
机器学习与深度链接图分析:强大的组合
原文:
www.kdnuggets.com/2019/04/machine-learning-graph-analytics.html
评论
作者:Yu Xu(TigerGraph 创始人兼 CEO)和 Gaurav Deshpande(TigerGraph 市场副总裁)
机器学习(ML)——人工智能(AI)的一个方面,使软件能够准确识别模式和预测结果——已经成为一个热门的行业话题。近年来,随着数据分析、存储和计算能力的不断进步,机器学习在企业应用中,如防欺诈、个性化推荐、预测分析等,扮演着越来越重要的角色。
将图形数据库功能应用于机器学习和人工智能应用相对较新。然而,这一点令人惊讶,因为 Google 的知识图谱首次普及了在数据中寻找关系以获得更相关、更精确的信息的概念,早在 2012 年就已出现。此外,这种应用自然契合:图形非常适合存储、连接和从复杂数据中进行推理。
图形在机器学习中未能发挥重要作用的主要原因是,传统的图形数据库无法提供机器学习真正需要的深度链接图分析,用于大数据集。
让我们深入探讨图形如何帮助机器学习以及它们如何与大数据的深度链接图分析相关。
无监督的原生图形基础机器学习算法
首先,图形分析直接提供了一组独特的无监督机器学习方法。许多图算法——社区检测、PageRank、标签传播、介数中心性、接近中心性和邻域相似度——识别出具有广泛应用的有意义的图形导向模式。这些应用包括识别欺诈模式、寻找用户群体、计算影响力用户或社区,并报告操作或供应链中的薄弱环节或瓶颈。
这些原生图算法共有的一个特点是它们都需要进行深度链接图分析——在图中遍历多个连接层级以收集数据并进行分析。这种遍历,尤其是像社区检测这样的全图分析,要求强大的图计算能力。只有原生并行图数据库才能提供这种能力。
用于训练监督式机器学习算法的图形特征
深度链接图分析帮助机器学习的第二种方式是通过丰富用于监督机器学习的数据特征集。考虑中国移动的例子,它是全球最大的移动服务提供商,拥有超过 9 亿用户。中国移动的网络每周有超过 20 亿次语音通话,他们的主要挑战是找到使用预付费 SIM 卡的电话诈骗者,这些 SIM 卡几乎没有用户详细信息。因此,很难将属于正常用户的好电话与属于诈骗者的差电话区分开来。像通话时长或拒接电话百分比这样的简单特征会导致很多误报。
中国移动利用基于图的机器学习特征,如稳定的群体和内部连接,提高了欺诈检测的机器学习准确性。一个好电话还会定期拨打一组其他电话——例如,每周或每月——而且这组电话在一段时间内相当稳定(“稳定群体”)。
另一个表明好电话行为的特征是当一个电话拨打了一个已经在网络中存在了多个月或多年的电话,并且收到回电时。我们还看到在好电话、长期电话联系人和网络中的其他电话之间有大量的通话,这些电话频繁地拨打这两个号码。这表明好电话有很多“内部连接”。中国移动通过为每个电话生成 118 个基于图的特征,将数十亿的新训练数据记录输入到其机器学习解决方案中,从而改进了其欺诈检测过程。
可解释的机器学习/人工智能模型
可解释的模型在机器学习应用日益增长的背景下成为了一个广泛讨论的话题。像神经网络及其衍生物深度学习网络等方法常被批评,因为它们生成的预测模型通常无法提供任何因果因素的洞见。它们无法给出为什么会预测结果的简单答案。另一方面,可解释模型往往会突出导致决策的关键变量。一个传统的例子是决策树。考虑一个用于评估你癌症风险的决策树:你是否定期吸烟?如果是,你的风险高于平均水平。如果不是,就问下一个问题……请注意,决策树是一种专门的图。
类似地,当图算法或图特征作为 AI 模型的一部分使用时,图关系的自然语义,例如“客户 --(购买)--> 产品”,容易被解读。
可解释的人工智能模型有很多好处。例如,消费者已经习惯了个性化推荐。如果推荐附带一些解释或证据,用户更有可能采取行动。图形分析非常适合计算并展示这些个性化推荐背后的证据,并根据需要通过图形可视化进行解释。例如,图形分析可能会显示你两到三度关系中的一部分朋友喜欢这个产品或服务,或者与你兴趣相似的其他用户喜欢它,或者该产品类似于你之前的购买。
基于图的机器学习和分析不仅对消费者有帮助,也对企业用户有用。以欺诈检测为例。许多企业雇佣大量训练有素的调查员来判断交易是否可能是欺诈性的。图形擅长将多个数据源结合起来,连接点,允许调查员直观且互动地看到该交易如何与之前标记为欺诈的交易相关联。这比仅仅收到一些机器学习模型给出的模糊 0.7 欺诈评分要有帮助。
另一个例子:实时电话诈骗防护。每天,数以亿计的电话被拨打,但其中只有极小的一部分是恶意诈骗。图形技术可以快速探索拨打者、电话号码和接收者之间的关系,并结合机器学习开发训练模型,以检测哪些是虚假的。
此外,当涉及到监管机构或其他审计方时,可解释的机器学习成为一种必要条件。银行被要求拥有高质量的方法来检测可能的洗钱行为。越来越多的银行使用机器学习来提高检测准确性,但同时,他们必须能够向审计员展示他们的系统如何以及为何有效。使用基于图的特征的机器学习模型提供了所需的透明度。
本地并行图数据库
机器学习一直计算需求很高,基于图的机器学习也不例外。每一次跳跃或连接数据的级别,搜索的数据量呈指数级扩展,要求进行大规模的并行计算来遍历数据。这对需要过多单独查找的键值数据库或在处理过多慢速连接时困难的关系数据库管理系统来说计算开销太大。即使是标准的图数据库也可能无法处理大型图上的深度链接分析。需要一个具有大规模并行和分布式处理能力的本地图数据库。
为了计算和解释个性化推荐和欺诈检测背后的原因,图形数据库需要一个强大的查询语言,它不仅能够遍历图中的连接,还能支持诸如过滤和聚合的计算以及复杂的数据结构来记住证据。
深层图形分析推动了机器学习的下一次进步,通过无监督学习图形模式、为监督学习提供特征增强,并提供可解释的模型和结果。结合 AI 和 ML,这是一种强大的组合,将在未来几年内为企业提供良好的服务。
BioYu Xu 是 Tigergraph 的创始人兼首席执行官,专长包括并行计算、数据库管理、Hadoop、MapReduce、大规模数据分析、数据仓库、半结构化数据的信息检索、XML 文档中的关键词搜索、空间数据库、可扩展的网络系统开发、搜索引擎优化、XML 语言和查询引擎、PigLatin、Cassadra、HBase 和 HIVE。
Gaurav Deshpande 是一位经验丰富的技术高管,专注于组建获胜团队,创造新产品和行业解决方案,建立新市场并主导市场。
资源:
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
机器学习正在发生:组织采纳、实施和投资的调查
评论
由 Asir Disbudak,企业家兼营销顾问
编辑注:这是完整报告的摘录。你可以在这里阅读完整的调查报告。
执行摘要。
-
机器学习(ML)正在发生。 大多数受访者(54%)已经实施了机器学习策略,近 28%的人认为自己处于扩展/转型阶段。
-
组织正在投资于机器学习。 在现有的机器学习实施者中,我们看到当公司在人工智能成熟度曲线上提升时,数据科学家的数量大幅增加。
-
机器学习提供了更快的行动和决策。 根据受访者的反馈,机器学习的一个主要好处是能够做出更快的有依据的决策,50% 的现有机器学习实施者认为他们已经实现了这一目标。算法和机器学习技术可以提供有价值的管理指导和支持。
-
大多数机器学习实施者和规划者希望通过扩展数据分析工作和增加数据洞察来获益。 约 35%的早期和成熟阶段的用户表示,他们的机器学习工作已导致更好的客户支持,从而在营销和销售方面带来了可观的投资回报。
-
机器学习实施者正在追求广泛的项目。 当前机器学习实施者中最常见的项目包括信息处理(26%);自然语言处理(19%),规划与探索(17%),机器视觉(16%)以及处理与控制(11%)。
-
初创公司正在意识到机器学习的最大潜在好处。
调查于 2019 年 4 月在 LinkedIn 上进行,作为 A.Disbudak 准备的大学论文的一部分。该调查旨在评估机器学习在当今操作中的相关性,评估机器学习采纳的当前状态,并识别用于机器学习的工具。140 位合格的受访者代表了从非常小型(一人初创公司)到非常大型(员工超过 10,000 人的跨国公司)的各种公司规模。
引言:机器学习正在发生。
数据革命的下一个阶段已经到来。计算机科学的一个分支——机器学习,是推动商业世界的下一个重大进展(Raconteur, 2015)。各类企业正在制定技术采纳战略,并已经实现了真正的投资回报(ROI)(Insights, 2017)。
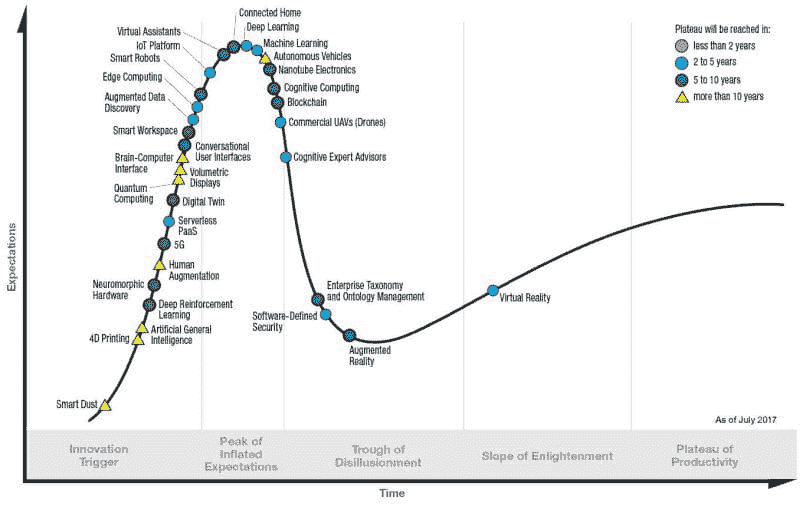
图 1. Gartner 新兴技术的炒作周期,2017
来源:Gartner,Gartner-新兴技术炒作周期,2017。
国际企业对机器学习(ML)的关注可能看起来像是突如其来的发展,但对这一技术的热议自 2005 年大数据兴起以来一直在稳步增长。ML 系统用于帮助计算机从大数据集中识别模式,使其能够执行任务,如预测消费者行为和预测人们对不同营销策略的反应(Raconteur, 2015)。这项技术是解锁大数据价值的关键。创新思维的商业领袖们将 ML 视为“下一个大事物”,并已经制定了 ML 战略和计划,这些计划承诺带来实际收益和投资回报率(Pettey & Meulen, 2018)。
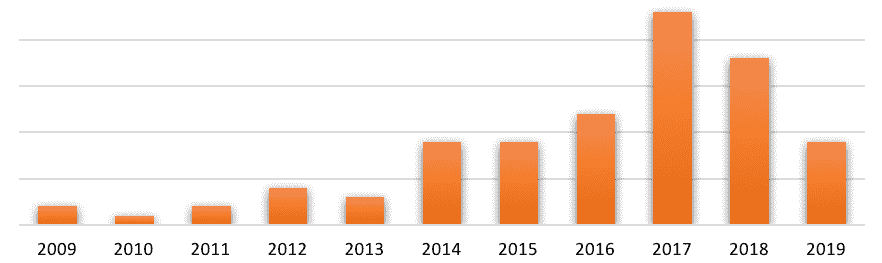
图 2. 机器学习采纳
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
机器学习在今天运营中的相关性。
美国科技和互联网巨头,即所谓的 GAFA 公司(Google、Apple、Facebook、Amazon)通过获得大量关于客户及其在线行为的数据来建立他们的业务(Raconteur, 2015)。此外,NATU 公司(Netflix、Airbnb、Tesla、Uber)或 BATX 公司(百度、阿里巴巴、腾讯、小米)也都开发了强大的机器学习能力,通过内部平台和模型来实现。他们获取的数据越多,机器学习的效果就越好。然而,这些机器学习能力并不容易被大多数公司获取。他们需要获得不同的方法来访问机器学习能力,以便将自己独特而有价值的数据资产发挥作用。新一代机器学习平台的出现将使各种规模和行业的企业能够更容易地使用机器学习。
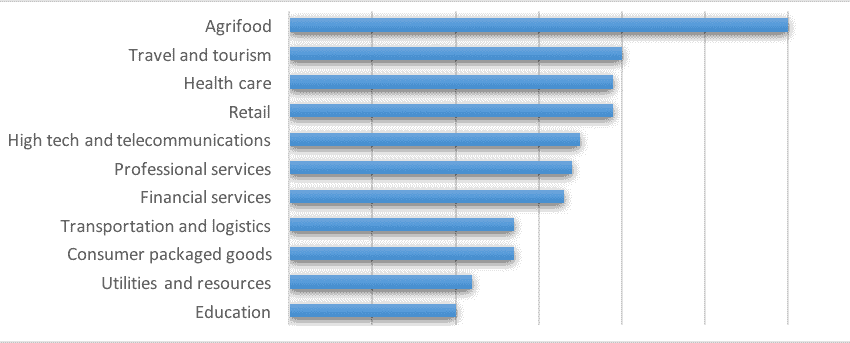
图 3. 机器学习成熟度与行业
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
计算能力的进步和大数据现象将 AI、机器学习和深度学习技术推向了一个新领域。Forrester 预测,2017 年 AI 将吸引三倍于以往的企业投资(Press, 2016)。同时,较小的公司声称由于从一开始就将 AI 作为业务核心,其 AI 发展更为先进。
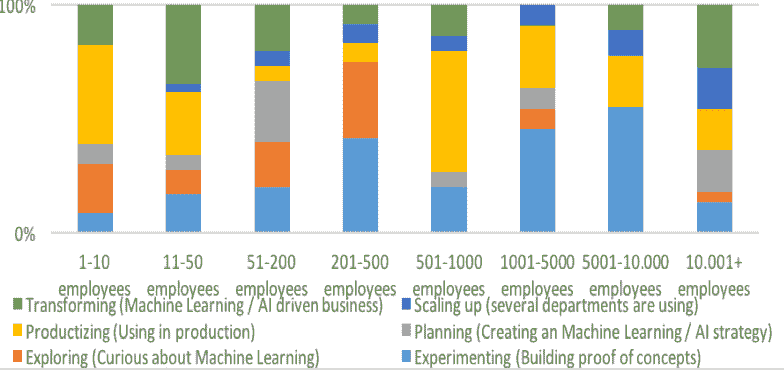
图 4. 组织规模与机器学习成熟度
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
机器学习正在帮助公司优化各种业务流程,以实现其战略数字化转型目标。如果组织继续犹豫,它将错失机器学习技术为企业今天提供的宝贵机会。根据埃森哲的报告,管理者如果理解智能系统的工作原理,更愿意信任它(埃森哲,《人工智能的承诺》报告,2016 年)。
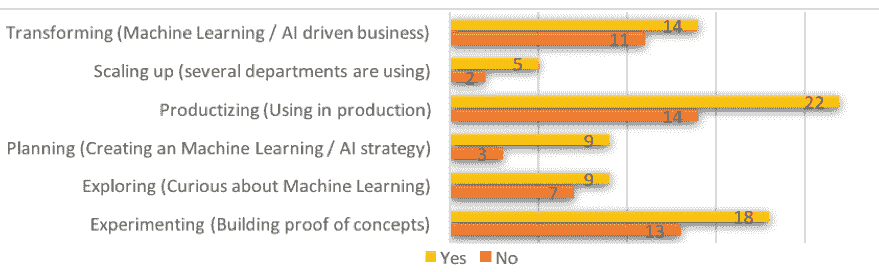
图 5. 机器学习成熟度对培训的需求
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
2019 年,公司被认为处于机器学习的“增长”阶段。这意味着最佳实践仍在建立中。机器学习主要被视为研发工作,生产化模型所需的基础设施尚不可用。由于数据访问、研发预算和机器学习案例的多样性,大公司相比于小公司具有优势。谷歌是首个向市场提供大量数据清理和模型训练解决方案的公司,称为 Hadoop。
图 6. 产品生命周期
我们预计在 2020 年机器学习生产化将取得重大突破。数据科学家正在获得更多用于 AI 实验的工具,使他们能够更轻松地管理和部署模型。
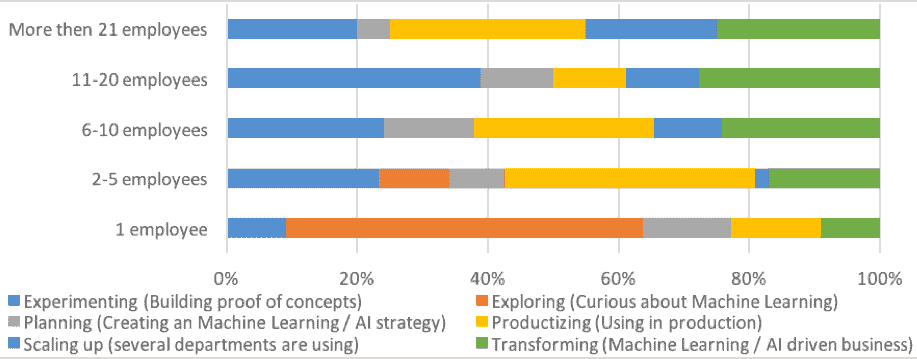
图 7. 机器学习成熟度与数据科学部门规模
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
商业竞争不仅仅由产品质量或交付物流定义,还由独特的数据资产及其利用能力定义。因此,随着公司在 AI 战略和执行上投入巨资,数据科学家面临着巨大的需求(AI 战略,《福布斯》,2019 年)。
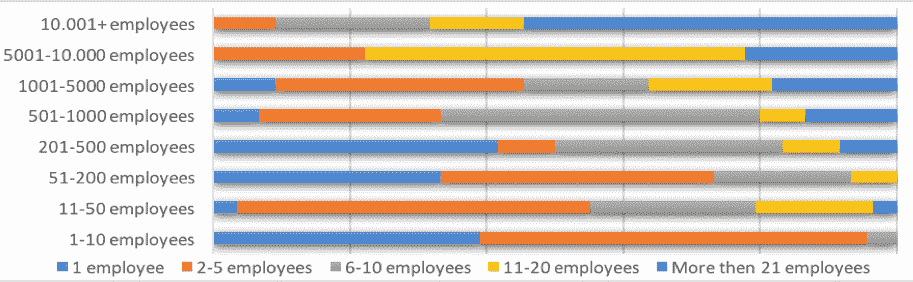
图 8. 公司规模与数据科学家数量
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
关于业务相关性的数据显示并转化为需要内部销售的产品和服务创新。将业务需求与机器学习任务连接起来成为数据科学家的核心技能,并为所有参与者带来价值。
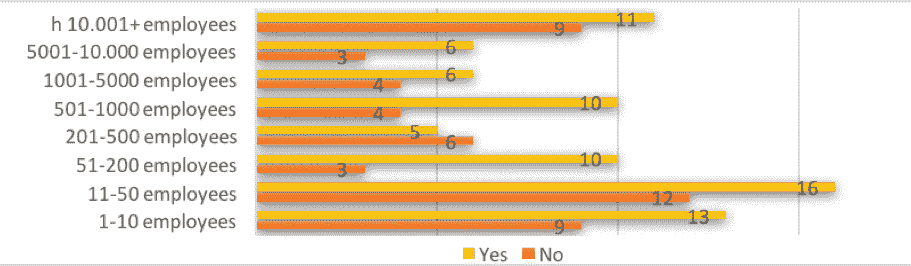
图 9. 组织规模对培训的需求
来源:A.Disbudak 进行的学生调查(机器学习调查,2019 年 4 月)。
简介:Asir Disbudak 是一位企业家和营销顾问。他是阿姆斯特丹国际商学院的国际商务学生,充满激情和激励。在这段学习期间,他发展了作为企业家的远见。
相关:
-
Python 引领 11 大数据科学、机器学习平台:趋势与分析
-
打开黑箱:如何利用可解释的机器学习
-
你需要了解的:现代开源数据科学/机器学习生态系统
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
做到不可能的事?少于一个示例的机器学习
原文:
www.kdnuggets.com/2020/11/machine-learning-less-than-one-example.html
评论

“少于一个示例学习”使机器学习算法能够用少于 N 个训练示例来分类 N 个标签。
如果我让你想象一种介于马和鸟之间的生物——比如一匹会飞的马——你是否需要看到一个具体的例子?这样的生物并不存在,但这并不妨碍我们用想象力创造一个:飞马。

人类的思维具备各种机制,可以通过结合其对现实世界的抽象和具体知识来创造新概念。我们可以想象出我们可能从未见过的现有事物(如长脖子的马——长颈鹿),以及在现实生活中不存在的事物(如喷火的有翅蛇——龙)。这种认知灵活性使我们能够用很少甚至没有新的示例来学习新事物。
相比之下,机器学习和深度学习,作为当前人工智能领域的领先技术,通常需要许多示例才能学习新任务,即使这些任务与它们已经知道的内容相关。
克服这一挑战促成了大量的研究工作和机器学习领域的创新。尽管我们仍然远未创造出能够复制大脑理解能力的人工智能,但这一领域的进展是显著的。
例如,迁移学习是一种技术,它使开发人员能够对人工神经网络进行微调,以适应新任务,而不需要大量的训练示例。少样本学习和单样本学习使得一个在某一任务上训练的机器学习模型可以通过一个或很少的新示例来执行相关任务。例如,如果你有一个图像分类器已经训练来检测排球和足球,你可以使用单样本学习将篮球加入它可以检测的类别中。
一种名为“少于一个示例学习”(或 LO-shot 学习)的新技术,最近由滑铁卢大学的 AI 科学家开发,将单次学习提升到了一个新水平。LO-shot 学习的理念是,要训练一个机器学习模型以检测 M 个类别,你需要每个类别少于一个样本。这项技术在 arXiv 预印本 中介绍,由 Ilia Sucholutsky 和 Matthias Schonlau 提供,仍处于早期阶段,但显示出潜力,可以在数据不足或类别过多的各种场景中发挥作用。
k-NN 分类器
k-NN 机器学习算法通过寻找最接近的实例来对数据进行分类。
研究人员提出的 LO-shot 学习技术适用于“k-最近邻”机器学习算法。k-NN 可用于分类(确定输入的类别)或回归(预测输入的结果)任务。但为了讨论的方便,我们将重点讨论分类。
正如名字所示,k-NN 通过将输入数据与其 k 个最近邻进行比较来进行分类(k 是一个可调整的参数)。假设你想创建一个 k-NN 机器学习模型来分类手写数字。首先,你需要提供一组标记的数字图像。然后,当你给模型提供一张新的、未标记的图像时,它将通过查看其最近邻来确定其类别。
例如,如果你将 k 设置为 5,机器学习模型将为每个新输入找到五张最相似的数字照片。如果说,其中三张属于类别“7”,那么它将把图像分类为数字七。
k-NN 是一种“基于实例”的机器学习算法。当你提供更多每个类别的标记样本时,它的准确性会提高,但其性能会下降,因为每个新样本都会增加新的比较操作。
在他们的 LO-shot 学习论文中,研究人员展示了你可以在提供比类别少的示例时使用 k-NN 实现准确的结果。“我们提出了‘少于一个’-shot 学习(LO-shot 学习),这是一个模型必须在只有 M < N 个示例的情况下学习 N 个新类别的设置,”AI 研究人员写道。“乍一看,这似乎是不可能的任务,但我们从理论和实证上都展示了其可行性。”
每个类别少于一个示例的机器学习
经典的 k-NN 算法提供“硬标签”,这意味着对于每个输入,它提供了一个确切的类别。另一方面,软标签则提供输入属于每个输出类别的概率(例如,有 20% 的概率是“2”,70% 的概率是“5”,以及 10% 的概率是“3”)。
在他们的工作中,滑铁卢大学的 AI 研究人员探索了是否可以使用软标签来概括 k-NN 算法的能力。LO-shot 学习的提议是,软标签原型应该允许机器学习模型使用少于 N 个标记实例来分类 N 个类别。
该技术建立在研究人员之前关于软标签和数据蒸馏的工作基础上。论文的共同作者 Ilia Sucholutsky 告诉TechTalks:“数据集蒸馏是生成小型合成数据集的过程,这些数据集可以训练模型达到与使用完整训练集相同的准确度。在软标签之前,数据集蒸馏能够使用每个类别仅一个示例来表示像 MNIST 这样的数据集。我意识到,添加软标签意味着我实际上可以使用每个类别少于一个示例来表示 MNIST。”
MNIST 是一个手写数字图像数据库,通常用于训练和测试机器学习模型。Sucholutsky 和他的同事 Matthias Schonlau 仅使用五个合成示例,在卷积神经网络LeNet 上实现了超过 90% 的准确度。
“这个结果真的让我很惊讶,这也是让我更广泛地思考 LO-shot 学习设置的原因,”Sucholutsky 说。
基本上,LO-shot 通过在现有类别之间划分空间来使用软标签创建新类别。
LO-shot 学习使用软标签来划分现有类别之间的空间。
在上面的示例中,有两个实例来调整机器学习模型(用黑点表示)。经典的 k-NN 算法会将两个点之间的空间分割为两个类别之间的空间。但是,被称为 OL-shot 学习模型的“软标签原型 k-NN”(SLaPkNN)算法,在两个类别之间创建了一个新的空间(绿色区域),该区域表示一个新标签(想象一下有翅膀的马)。在这里,我们已经实现了 N 个类别,具有 N-1 个样本。
在论文中,研究人员展示了 LO-shot 学习可以扩展到使用 N 个标签甚至更多的 3N-2 类别。
LO-shot 学习可以扩展以每个实例获得多个类别。左侧:从四个实例获得的 10 个类别。右侧:从五个实例获得的 13 个类别。
在他们的实验中,Sucholutsky 和 Schonlau 发现,通过正确配置软标签,LO-shot 机器学习即使在数据嘈杂的情况下也能提供可靠的结果。
“我认为 LO-shot 学习也可以从其他信息来源中获得成功——类似于许多零-shot 学习方法的做法——但软标签是最直接的方法,”Sucholutsky 说,并补充道,目前已经有几种方法可以为 LO-shot 机器学习找到合适的软标签。
虽然论文展示了 LO-shot 学习在 k-NN 分类器中的威力,但 Sucholutsky 表示,这种技术也适用于其他机器学习算法。“论文中的分析专门集中在 k-NN 上,因为它更容易分析,但它应该适用于任何可以利用软标签的分类模型,”Sucholutsky 说。研究人员很快将发布一篇更全面的论文,展示 LO-shot 学习在深度学习模型中的应用。
机器学习研究的新领域
“对于像 k-NN 这样的基于实例的算法,LO-shot 学习的效率提升是相当显著的,特别是对于具有大量类别的数据集,”Susholutsky 说。“更广泛地说,LO-shot 学习在任何将分类算法应用于具有大量类别的数据集的场景中都很有用,特别是如果某些类别的样本很少,甚至没有样本。基本上,大多数零-shot 学习或少-shot 学习有用的场景中,LO-shot 学习也可能有用。”
例如,一个必须从图像和视频帧中识别数千个对象的 计算机视觉 系统可以从这种机器学习技术中受益,特别是当某些对象没有示例时。另一个应用是那些自然具有软标签信息的任务,例如 自然语言处理 系统进行情感分析(例如,一句话可以同时是悲伤和愤怒的)。
在他们的论文中,研究人员将“少于一次”学习描述为“机器学习研究中的一种可行的新方向”。
“我们相信,创建一个专门优化 LO-shot 学习原型的软标签原型生成算法是探索这一领域的重要下一步,”他们写道。
“软标签在以前的几种设置中已经被探索过。这里的新颖之处在于我们探索它们的极端设置,”Susholutsky 说。“我认为在一次学习和零-shot 学习之间还有另一种状态,这一点并不明显。”
原文。经许可转载。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
更多相关话题
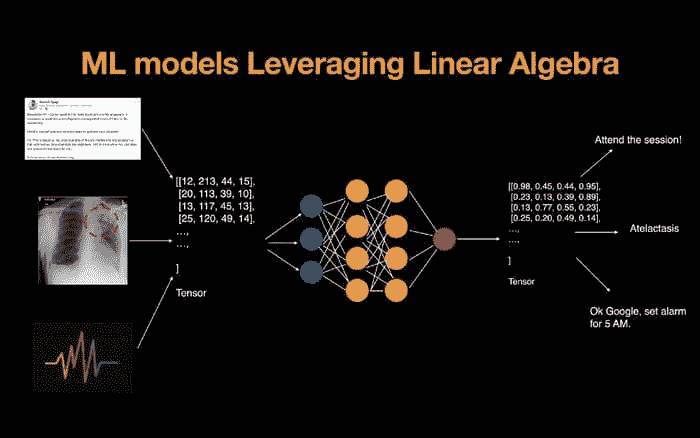
机器学习如何利用线性代数来解决数据问题
原文:
www.kdnuggets.com/2021/09/machine-learning-leverages-linear-algebra-solve-data-problems.html
评论
来源: www.wiplane.com/p/foundations-for-data-science-ml
机器或计算机只能理解数字,这些数字需要以一种方式表示和处理,使这些机器能够通过从数据中学习而不是像编程那样依赖预定义指令来解决问题。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
所有类型的编程在某种程度上都使用数学,机器学习是对数据进行编程,以学习最能描述数据的函数。
使用数据找到函数最佳参数的问题(或过程)在机器学习中称为模型训练。
因此,总而言之,机器学习就是编程以优化最佳解决方案,我们需要数学来理解问题是如何解决的。
学习机器学习数学的第一步是线性代数。
线性代数是解决表示数据和计算在机器学习模型中问题的数学基础。
这是数组的数学 — 技术上称为向量、矩阵和张量。
应用的常见领域 — 线性代数的实际应用

来源: www.wiplane.com/p/foundations-for-data-science-ml
在机器学习的背景下,开发模型的所有主要阶段背后都运行着线性代数。
由线性代数使能的重要应用领域包括:
-
数据与学习模型的表示
-
词嵌入
-
降维
数据表示 — 机器学习模型的燃料,也就是数据,需要在输入模型之前转换成数组,这些数组上执行的计算包括矩阵乘法(点积)等操作,这些操作进一步返回的结果也被表示为转化后的矩阵/张量。
词嵌入 — 不用担心术语,这只是关于用较小维度的向量表示大维数据(想象一下你数据中的大量变量)。
自然语言处理(NLP)处理文本数据。处理文本意味着理解大量单词的含义,每个单词代表不同的意义,这些意义可能与另一个单词相似,线性代数中的向量嵌入使我们能够更有效地表示这些单词。
特征向量(SVD) — 最后,像特征向量这样的概念使我们能够在保持所有数据本质的同时,减少数据的特征或维度,使用一种叫做主成分分析的技术。
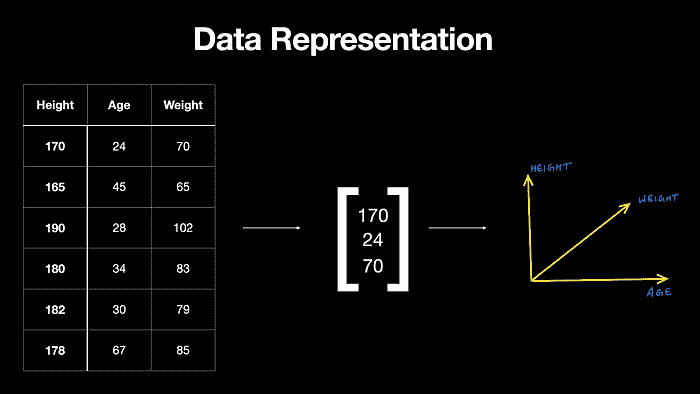
从数据到向量
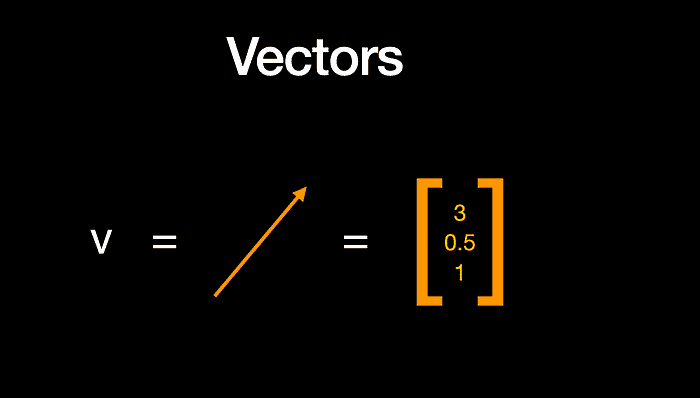
来源:www.wiplane.com/p/foundations-for-data-science-ml
线性代数基本上处理向量和矩阵(不同形状的数组)及这些数组上的操作。在 NumPy 中,向量基本上是一个一维的数字数组,但在几何上,它具有大小和方向。
来源:www.wiplane.com/p/foundations-for-data-science-ml
我们的数据可以用向量表示。在上图中,这些数据中的一行由一个特征向量表示,该特征向量有 3 个元素或成分,表示 3 个不同的维度。向量中的 N 个条目使其成为 n 维向量空间,在这种情况下,我们可以看到 3 个维度。
深度学习 — 张量在神经网络中流动
线性代数在今天所有主要应用中都可以看到,无论是在 LinkedIn 或 Twitter 帖子上的情感分析(嵌入),还是从 X 射线图像中检测肺部感染类型(计算机视觉),或者任何语音到文本的机器人(NLP)。
所有这些数据类型都通过张量中的数字表示,我们运行向量化操作以使用神经网络从中学习模式,然后输出处理过的张量,这些张量反过来被解码以生成模型的最终推断结果。
降维 — 向量空间变换

来源:www.wiplane.com/p/foundations-for-data-science-ml
说到嵌入,您可以基本上将一个 n 维向量想象成被替换成另一个属于较低维空间的向量,这个较低维空间更具意义,并且克服了计算复杂性。
例如,这里是一个被替换为二维空间的三维向量,但你可以将其推断到一个现实世界的场景中,在那里你有大量的维度。
降维并不是从数据中丢弃特征,而是找到新的特征,这些特征是原始特征的线性函数,并且保留了原始特征的方差。
找到这些新变量(特征)意味着找到主成分(PCs),这些主成分收敛于解决特征值和特征向量问题。
推荐引擎 — 利用嵌入
你可以将嵌入(Embedding)视为一个 2D 平面嵌入在 3D 空间中,这就是这个术语的来源。你可以把你站立的地面想象成一个嵌入在我们生活的空间中的 2D 平面。
只是为了给你一个现实世界的用例,让你与向量嵌入的讨论相关联,所有给你个性化推荐的应用程序都以某种形式使用了向量嵌入。

例如,这里是 Google 推荐系统课程中的一张图,我们获得了关于不同用户及其偏好电影的数据。一些用户是孩子,另一些是成年人,一些电影是永恒的经典,而另一些则更具艺术性。一些电影是针对年轻观众的,而像《记忆碎片》这样的电影则更受成年人欢迎。
现在,我们不仅需要将这些信息表示为数字,还需要找到新的、更小维度的向量表示,以便很好地捕捉所有这些特征。
来源:Google 的推荐系统机器学习课程
了解我们如何执行这项任务的一种非常快速的方法是理解矩阵分解(Matrix Factorization),它允许我们将一个大矩阵分解为较小的矩阵。
现在忽略这些数字和颜色,只需尝试理解我们如何将一个大矩阵分解成两个较小的矩阵。
例如,这里一个 4X5 的矩阵,4 行 5 特征,被分解成两个矩阵,一个形状为 4X2,另一个形状为 2X5。我们基本上得到了用户和电影的新较小维度的向量。
这使我们可以在 2D 向量空间中绘制图形,在这里你会看到用户 #1 和电影《哈利·波特》更接近,而用户 #3 和电影《怪物史瑞克》更接近。
点积(矩阵乘法)的概念告诉我们两个向量的相似性更多的信息。它在相关性/协方差计算、线性回归、逻辑回归、PCA、卷积、PageRank 和许多其他算法中都有应用。
线性代数被广泛使用的行业
到现在为止,我希望你已经相信线性代数在当今多个领域的机器学习(ML)倡议中发挥了重要作用。如果没有,以下是一些例子:
-
统计学
-
化学物理学
-
基因组学
-
单词嵌入 — 神经网络/深度学习
-
机器人技术
-
图像处理
-
量子物理学
你应该了解多少才能开始学习 ML / DL
现在,重要的问题是如何学习编程这些线性代数概念。因此,答案是你不需要重新发明轮子,你只需计算机上理解向量代数的基础,然后学习使用 NumPy 编程这些概念。
NumPy 是一个科学计算包,提供了线性代数所有基础概念的访问。它运行编译的 C 代码,速度快,并且有大量的数学和科学函数可供使用。
推荐资源
-
3Blue1Brown 的线性代数播放列表 — 非常吸引人的可视化,解释了线性代数的本质及其应用。对初学者来说可能有点困难。
-
Ian Goodfellow 和 Yoshua Bengio 的深度学习书籍** —** 一本学习 ML 和应用数学的绝佳资源。值得一读,刚开始时可能会觉得过于技术性和符号繁重。
-
数据科学与 ML 基础 — 我创建了一个课程,让你对编程、数学(基础代数、线性代数和微积分)和统计学有足够的理解。一个完整的学习 DS/ML 的起步包。了解更多这里。
???? 你可以使用代码TDS10获得 10%的折扣。
查看课程大纲:
简历:Harshit Tyagi 是一位在网络技术和数据科学(即全栈数据科学)方面具有丰富经验的工程师。他指导了超过 1000 名 AI/Web/数据科学的 aspirants,并设计了数据科学和 ML 工程学习路径。之前,Harshit 与耶鲁、麻省理工学院和 UCLA 的研究科学家一起开发数据处理算法。
原文。经许可转载。
相关:
-
2021 年数据科学学习路线图
-
自然语言处理的线性代数
-
抗脆弱性与机器学习
更多相关内容
机器学习与大脑的不同 第三部分:基本架构
原文:
www.kdnuggets.com/2022/06/machine-learning-like-brain-part-3-fundamental-architecture.html

今天的人工智能(AI)能够做一些非凡的事情。然而,它的功能与人类大脑完成相同任务的方式几乎没有关系。为了使 AI 克服其固有的局限性并发展到人工通用智能,我们必须认识到大脑与其人工对应物之间的差异。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 需求
考虑到这一点,本系列的九部分将探讨生物神经元的能力和局限性,以及这些与机器学习(ML)的关系。在本系列的前两部分中,我们考察了神经元的缓慢如何使 ML 学习方法在神经元中显得不切实际,以及感知器的基本算法如何与涉及尖峰的生物神经元模型不同。第三部分探讨了 ML 和大脑的基本架构。
我们都见过 ML 神经网络中有序层次的示意图,其中每一层的神经元都与下一层的神经元完全连接。相反,大脑似乎包含了许多看似无序的连接。由于很难追踪大脑中的单个连接,我们不知道大脑的分层结构到底是什么。尽管如此,显然它不是 ML 的有序分层结构。
这种基本差异严重影响了在机器学习(ML)中可以使用的算法。虽然我们不太关注感知器和 ML 算法如何依赖有序的分层结构,但如果我们允许感知器与网络中的任何任意神经元建立突触,就会出现问题。
突触数量
在每一层都与下一层完全连接的神经网络中,突触的数量随着每一层神经元数量的平方增加(假设所有层大小相同以便于计算)。如果允许网络中的任何神经元与其他任何神经元连接,突触的数量会随着网络中神经元总数的平方增加。一个每层有 1000 个神经元的 10 层网络总共有 900 万个突触(输出层不需要突触)。如果任何神经元可以连接到任何其他神经元,理论上可能有 1 亿个突触,这可能会导致 11 倍的性能损失。
在大脑中,大多数这样的突触并不存在。新皮层具有 160 亿(16x10⁹)个神经元,每个神经元都有可能与其他任何神经元连接,即 256x10¹⁸ 个可能的突触——如果每个突触占用 1 字节,则总共有 256 艾字节,这个数字极其庞大。然而,实际的突触数量估计为每个神经元 104 个,总共仅为 16x10¹³,这只是一个惊人的大数字(160 太字节)。
这些突触中的很大一部分必须具有接近零的权重。这些“待用突触”用来存储记忆,通过快速改变权重来应对需要。然而,我们最终会得到一个“稀疏数组”,其中大多数条目为零。虽然很容易设计一个只表示非零突触的结构,但如果这样做,今天的 GPU 惊人的性能提升可能会被浪费。
感知器算法
感知器的基本算法对来自上一层的输入值进行求和。如果允许来自后续层的连接,则需要区分已经从前一层计算过的神经元内容和那些尚未计算的内容。如果算法不包括这个扩展,则感知器的值将依赖于神经元的处理顺序。在多线程实现中,这会使得感知器的值变得不可确定。
为了解决这个问题,感知器算法需要两个阶段和两个内部值:PreviousValue 和 CurrentValue。在第一个阶段,算法基于输入神经元的 PreviousValues 计算其 CurrentValue。在第二个阶段,它将当前值转移到前一个值。通过这种方式,所有在计算中使用的 PreviousValues 在第一个阶段的计算期间都是稳定的。这个算法的变化解决了这个问题,但代价是性能下降。
这个两阶段算法的实现可以在开源的 Brain Simulator II 中找到,文件为 NeuronBase.cpp(github.com/FutureAIGuru/BrainSimII)。为了恢复这种性能,我们可以构建定制硬件或利用脉冲模型的优势,其中只有在神经元发射时才需要处理。在一台 16 核桌面计算机上,上述算法的处理速度达到了每秒 25 亿个突触。
数据结构
由于人类新皮层的 160 亿个神经元不可能完全连接到所有其他神经元,我们可以转向一种更接近生物结构的数据结构。通过这种方式,每个神经元只表示有用的突触,通过维护一个仅包含这些突触的列表或数组。这在内存使用上更高效,且可能更快,因为无需处理所有这些零条目。然而,这确实削弱了 GPU 处理的优势,因为今天的 GPU 在处理支持这种结构的小数组、循环和条件语句方面表现不佳。
反向传播
将更随机的神经元/突触结构适应到机器学习中的实际问题在于反向传播算法对这种结构的适应性较差。反向传播的梯度下降依赖于稳定的误差面。一旦我们允许循环连接,这个面就不再是时间上的常量。
在本系列的第四部分,将讨论神经元在表示机器学习所依赖的精确值方面的局限性。
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做准备》的作者,并且是 AGI 研究软件平台 Brain Simulator II 的开发者。欲了解更多信息,请访问这里。
更多相关话题
机器学习不像你的大脑 第四部分:神经元表示精确值的能力有限

图片来源:camilo jimenez 通过 Unsplash
机器学习算法依赖于它们以高分辨率和准确性表示数字的能力。这在生物神经元中很困难或不可能实现。此外,所需的准确性越高,基于神经元的系统运行速度就会越慢。任何生物大脑要实现机器学习所需的数值精度都会太慢,无法发挥作用。
在计算机或你的大脑中,神经元和晶体管都以数字方式表示信息——神经元通过发射脉冲,晶体管通过接受两种定义的电压状态之一来表示。鉴于这些数字组件,有多种方式来编码数值:
-
单个串行信号中的脉冲频率(位数);
-
单个信号中的脉冲时序;
-
一些并行信号的编码;
-
一些更复杂的编码方案,如二进制整数、浮点数或 Unicode。虽然从理论上讲,神经脉冲流可能编码二进制数字或 Unicode 字符串,但这种可能性极其微小。
前三种方法确实出现在你的神经系统中,它们在计算机系统中也存在。
方法 1
在大脑中,数值可以通过在给定时间段内的神经脉冲数量来表示。但要记住,神经元的速度非常慢,脉冲的最大频率约为 250Hz 或 4 毫秒。如果我们想表示 0-10,我们可以分配一个 40 毫秒的时间段。如果在该时间段内出现 10 个脉冲,这可以表示 10,而没有脉冲可以表示零,等等。
这种方法的一些问题:
-
你不能有分数脉冲,因此在 40 毫秒内,你永远无法表示超过 11 个不同的值;
-
如果你想表示 100 个不同的值,你必须等待 400 毫秒(将近半秒钟)来知道你表示了哪个值——这太慢,无法有效使用,因为任何复杂的神经过程都需要多个处理层级;
-
要处理更大的值数量,你需要逐渐更小的突触权重,且大脑内部的电子噪声水平会成为一个问题;
-
对于一个波动的值,你只能在时间段结束时知道新的值。换句话说,一个大部分时间为零而 20ms 为 10 的信号将被记录为 5,因为在 40ms 的时间段内只会有 5 次脉冲。
方法 2
在这种方法中,我们不再计数给定时间段内的脉冲数量,而是检查相邻脉冲之间的时间。许多外周神经在更大的刺激下发射速度更快。例如,一些视网膜神经在更亮的光线下发射速度更快。由于最快的发射速率是每 4ms,我们可以让它代表 10,每 5ms 发射可以代表 9,等等。现在我们可以在 14ms 内表示相同的 11 个值,而不是 40ms。神经元实际上在这种区分上非常出色。例如,大脑以亚毫秒精度检测声音方向的能力依赖于信号到达时间差的精确区分。
你可能会认为可以说4ms代表一个值,而4.01ms(例如)代表另一个值,并且可以获得任何期望的精度。不幸的是,这并不起作用,因为老问题——噪音。大脑是一个电气噪声环境,神经信号可能会在毫秒级别上抖动。
让我们看看这种信号的接收端。通过调整神经元模型的各种参数,单个神经元可以响应任何特定的发射时机。这意味着要区分 10 种不同的信号时机,你需要 10 个神经元。然而,神经元对信号的相对速度差异检测具有相当高的准确性。这意味着,虽然这种信号对于检测两个不同亮度级别之间的边界等相对值非常有用,但不能用于检测绝对信号值。
另一个问题是,尽管个别大脑神经元可以检测这种类型的信号,但没有办法生成这种信号。神经元生成6ms与7ms脉冲间隙的唯一方法是接收这种输入信号。这使得对这种类型的信号进行大脑计算变得极其复杂。
方法 3
考虑一个神经元簇来表示一个信号。发射的神经元数量越多,值越高。有趣的是,人类触觉敏感性使用了这种机制。因此,你的指尖按压得越用力,感觉神经的发射数量就越多。这有利于在一个发射时间内表示任何数量的值,但实际的限制是它使用了大量神经元。要表示一个 1000x1000 的视觉数组,其中每个可能是 1000 种颜色之一,这将需要十亿个神经元。由于人类视觉皮层中只有 1.4 亿个神经元,这种机制的实用性有限。
结论
神经元放电所能表示的最大值数量在 10 到 100 个独特值之间。机器学习算法需要比这更高的精度,因为梯度下降的基本概念假设存在连续的梯度面。你需要在大脑中表示的信息值越多,运行速度就越慢。
在本系列的第五部分中,我们将探讨为什么神经元无法执行机器学习所需的最简单求和操作。
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,同时也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做准备》的作者,并且是 Brain Simulator II 的开发者,这是一个 AGI 研究软件平台。欲了解更多信息,请访问这里。
主题更多内容
机器学习不像你的大脑 第五部分:生物神经元无法对输入进行求和
所有机器学习系统的基本思想是人工神经元,即感知器,对来自各种输入突触的加权信号进行求和。诚然,在生物神经元模型中确实有少数情况看起来能工作。然而,在大多数情况下,它不能。
生物神经元具有一个膜电位或电压,我称之为“电荷”。神经元从其输入突触中积累电荷,各个突触具有对应于它们贡献电荷量的“权重”。突触权重可以是正的也可以是负的。当电荷超过阈值时,神经元会发射神经冲动,向所有连接的神经元发送信号,并重置内部电荷。为了方便起见,我们将静息电荷称为 0,阈值水平称为 1。
生物神经元有三个特征,使得信号求和变得困难或不可能:
-
在神经元发射信号后,它在约 4 毫秒内不能再次发射,这段时间称为“绝对不应期”。在绝对不应期内,所有输入信号都被忽略。
-
无论输入信号的水平如何,神经元的发射速度都不能超过其最大速率。
-
内部电荷不能低于 0。如果内部电荷为 0,负权重的输入信号将被忽略。你可以看到,忽略任何输入信号都会扰乱求和的准确性。
-
内部电荷不能超过 1。如果电荷达到了 1,神经元将发射信号,因此在绝对不应期内,额外的输入信号(无论是正的还是负的)都将被忽略。这一点加上前面提到的内容意味着,如果任何部分和低于 0 或高于 1,总体求和将无法正确进行。
以一个简单的例子来说明。假设我们的神经元在 40 毫秒的时间段内表示一个 0 到 1 之间的值,这个值由该时间段内发射的神经冲动数量表示。为了表示 0.6,我们需要 6 个冲动,这些冲动可能均匀分布,但更可能是在 40 毫秒的时间段内随机分布。我们将图中的信号值 0.6 分配给“In1”,将另一个值 0.1 分配给“In2”。为了确保总和的准确性,我们希望“Out”在该时间段内发射 7 次冲动。
仅从 6 的值来看,在 40 毫秒的时间段内,Out 会处于其不应期 24 毫秒,因此我们的信号从 In2 到达不应期并被忽略的概率为 60%。如果 6 个脉冲均匀分布,它们每隔 6.7 毫秒发生一次,因此如果我们的 in2 脉冲恰好在此期间到达,来自 In1 的下一个脉冲将到达不应期并被忽略。因此,如果脉冲均匀分布,6 个脉冲+1 个脉冲永远不会等于除 6 个脉冲之外的任何值。
如果脉冲是随机分布的,神经元有可能计算出 6+1=7,但概率较小,并且与脉冲的分布有关。如果信号值相对于时间段总是较小,你可能会通过神经元获得更好的加总。要做到这一点,你需要进一步减少允许的值的数量和/或延长时间段。使用 400 毫秒的时间段,你可以获得类似 6+1 的小值的合理加总,但这对于机器学习来说速度太慢且限制太多。
考虑到以上第 3 和第 4 点,感知机有类似的限制,这就是为什么会有一个函数,通常是 sigmoid,将加总的输入映射回 0-1 范围(或-1,1)。问题在于生物神经元会在加总完成之前“剪裁”输入信号,因此没有办法用等效的 sigmoid 函数来清理。
尽管神经元无法执行最基本的机器学习功能,但它们在识别多个信号中哪个先到达方面要好得多。这就是你如何通过在两只耳朵之间仅相差毫秒的信号来识别声音的方向。神经元在确定两个输入信号中哪个脉冲更快方面也非常擅长。这种功能被用于识别视觉领域中的边界,其中边界一侧的神经元的发放速率与另一侧的不同。机器学习算法通常忽略了生物神经元的这些能力。
就像之前文章中讨论的神经元具有有限的值范围一样,突触的限制更大。这也是我们九部分系列文章中下一个主题——为什么机器学习不像你的大脑。
6+1=6,表明脉冲神经元并不像人工感知器那样执行求和操作。神经元的“时序”只是每 40 毫秒发射一次标记。“In1”稍微随机化,在每个时间段内产生 6 个脉冲,而“In2”每个周期仅发射一次。两者都通过权重为 1 的突触连接到“Out”。通过观察 Out,你可以看到哪个脉冲落在 Out 的不应期中并被丢失。在左侧情况下,In2 的脉冲在不应期内到达。在右侧情况下,In2 的脉冲导致 Out 发射,但 In1 的下一个脉冲在不应期内到达。在任何情况下,求和显然都不能正常工作。
你可以在这个视频中了解更多关于这个话题。
查尔斯·西蒙 是一位全国认可的企业家和软件开发者,未来人工智能公司的首席执行官。西蒙是《计算机会叛变吗?:为人工智能的未来做准备》的作者,也是脑模拟器 II 的开发者,这是一个 AGI 研究软件平台。更多信息,请访问这里。
更多相关内容
机器学习不像你的大脑 第一部分:神经元很慢、很慢、很慢
原文:
www.kdnuggets.com/2022/04/machine-learning-like-brain-part-one-neurons-slow-slow-slow.html
生物学的大脑理解物理对象存在于一个受各种物理属性影响的三维环境中。它会将所有事物放在之前学到的其他事物的背景下进行解释。相比之下,人工智能——尤其是机器学习(ML)——在没有理解任何处理数据的情况下,分析大量数据集以寻找模式和相关性。一个需要成千上万标记样本的 ML 系统与一个只需通过少量未标记数据经验就能学习的儿童的大脑在本质上是不同的。即使是最近的“类脑”芯片也依赖于生物学中不存在的能力。
这只是冰山一角。机器学习和生物大脑之间的差异要深得多,因此为了使今天的人工智能克服其固有的局限性并发展到下一个阶段——人工通用智能(AGI)——我们应该考察一下已经实现了通用智能的大脑与人工智能之间的差异。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
有了这些背景知识,这个九部分系列将逐步详细解释生物神经元的能力和局限性,以及这些如何与机器学习相关。这样做将揭示出最终需要什么来复制人脑的情境理解,从而使人工智能获得真正的智能和理解。
要理解为什么机器学习和你的大脑不太相似,你需要了解一下大脑的工作原理及其主要组成部分——神经元。神经元细胞是复杂的电化学装置,这个简短的描述只是表面上的介绍。我会尽量简洁明了,请耐心阅读,然后我们会回到机器学习上。
神经元有一个细胞体和一个长轴突(平均长度约为 10 毫米),通过突触与其他神经元连接。每个神经元积累一个内部电荷(“膜电位”),这个电荷可以发生变化。如果电荷达到阈值,神经元将“放电”。
神经元的内部电荷可以通过增加神经递质离子来修改,这些离子可以增加或减少内部电荷(取决于神经递质离子的电荷)。这些神经递质来自突触,当连接的神经元发射时,我们称之为每个突触的“权重”。随着权重的变化,突触向目标神经元的内部电荷贡献更多或更少的离子。当神经元发射时,它沿着轴突发射神经脉冲,并通过每个突触向每个连接的神经元传递神经递质。发射后,电压恢复到静息状态,神经递质回到其初始位置以供再利用。
这与大多数机器学习系统所基于的理论感知器的过程有显著不同。(我会在随后的文章中深入探讨这些差异。)感知器在某些计算上表现出色,而神经元在其他计算上更具优势。
(左) 神经元示意图显示“输入”和“输出”,这些是突触,数量可能达到数千个。轴突上的髓鞘仅存在于长轴突上,在新皮质中可能长达 100mm,因此此图并非按比例绘制。大脑中的短轴突没有髓鞘,使其速度较慢,但更加密集,通常仍然比细胞体直径长数百倍。图示由英文维基百科的 Egm4313.s12 绘制 / CC BY-S
(右) 感知器示意图显示许多加权输入和一个连接到许多其他类似单元的单一输出。由于它是一个数学构造,感知器的性能仅受实现它的硬件的限制。图示由维基共享资源提供,CC BY-SA-3.0。
神经元的速度非常慢,最大发射频率约为 250 Hz。(不是 KHz、MHz 或 GHz;是 Hz!)即每 4ms 最多一个脉冲。相比之下,晶体管的速度快上百万倍。神经脉冲约为 1ms 长,但在脉冲后的 3ms 期间,神经元处于重置状态,无法再次发射,接收到的神经脉冲被忽略。这在考虑神经元和感知器之间的一个主要区别时显得重要:信号到达感知器的时间并不重要,而生物神经元中的信号时间则至关重要。
神经元之所以如此缓慢,是因为它们不是电子的,而是电化学的。它们依赖于离子分子的运输或重新定向,这比电子信号要慢得多。神经元的脉冲信号沿轴突从一个神经元传输到下一个神经元的速度非常缓慢,约为 1-2m/s,比电子信号的速度(接近光速)慢得多。
回到机器学习上,如果我们假设需要 10 次神经脉冲来建立一个发射频率(下一篇文章会详细介绍),那么现在需要 40 毫秒来表示一个值。一个有 10 层的网络需要将近半秒钟的时间才能让信号从第一层传播到最后一层。考虑到用于视觉基础如边界检测的附加层,大脑必须限制在不到 10 个处理阶段。
神经元的慢速也意味着通过多次展示数千个训练样本的学习方法是不切实际的。如果一个生物大脑每秒可以处理 1 张图片,那么 MNIST 手写数字数据集中的 60,000 张图片将需要 1,000 分钟或 16 小时的专注时间。你需要多长时间才能学习这些符号?十分钟?显然,这里发生的事情确实非常不同。
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,也是 FutureAI 的首席执行官。西蒙是《计算机会叛变吗?:为人工智能的未来做准备》的作者,也是 Brain Simulator II 的开发者,这是一款 AGI 研究软件平台。欲了解更多信息,请访问这里。
更多相关话题
机器学习不像你的大脑 第七部分:神经元擅长的东西
原文:
www.kdnuggets.com/2022/08/machine-learning-like-brain-part-seven-neurons-good.html
在我的本科时期,电话交换从电机继电器过渡到晶体管,因此有很多被淘汰的电话继电器可用。我和一些电气工程专业的同学一起,用电话继电器制作了一台计算机。我们使用的继电器具有 12 毫秒的切换延迟——也就是说,当你给继电器通电时,触点会在 12 毫秒后闭合。有趣的是,这个时间范围与神经元的最大 4 毫秒发放速率相同。
我们还获得了一台使用串行连接的电传打字机,运行速率为 110 波特或大约每 9 毫秒 1 位。这引发了一个问题:如何让 12 毫秒的继电器每 9 毫秒输出一个串行位?答案揭示了你大脑的工作原理,它与机器学习的不同之处,以及为什么 65%的大脑用于肌肉协调而不到 20%用于思考。
答案是,你可以让几乎任何设备(电子设备或神经设备)运行得比其最大速度更慢。通过选择性地减慢继电器速度,我们可以以任何我们选择的速率生成信号,仅受系统噪声水平的限制。例如,你可以让一个继电器(神经元)开始一个数据位,而一个稍慢的继电器结束它。但这需要大量的继电器或神经元。
很容易看出,一个能够让你的身体尽可能快速执行的心理控制系统具有的进化优势。我们的脑部包含一个庞大的小脑,正是为了完成这个任务。因此,许多神经元专门用于肌肉协调,因为它们实际上不够快,需要大量神经元来补偿。
以下是神经元擅长的一些其他功能:
-
作为频率分频器;
-
精确检测两个脉冲哪个先到达;
-
检测两个脉冲神经元中哪个发放得更快;
-
作为频率检测器;以及
-
作为短期记忆装置。
频率分频器
通过将源神经元通过 0.5 的突触权重连接到目标,目标神经元的发放速度将是源神经元的一半。实际上,它会在 0.5 到 1 之间进行二分,因此精确的突触权重并不是关键。对于 0.2 的权重,它是一个五分之一的系统。尽管神经元在频率分频方面表现出色,但在频率倍增方面则不那么擅长。一个每次发放时发射 2 次脉冲的神经元类似于一个两倍的倍增器,但没有简单的方法将每 20 毫秒一次的信号转换为每 10 毫秒一次的信号。
初到检测器
这对于方向听觉非常重要。如果声源直接在你面前(或背后),声音会同时到达你的两个耳朵。如果它直接在你旁边,声音会比另一只耳朵早到达大约 0.5 毫秒。研究表明,你可以通过到达时间差识别声音方向,时间差低至 10 微秒。怎么做?假设一个目标神经元连接到两个源,一个权重为 1,另一个权重为-1。如果 1 先到达,目标就会发火。如果-1 先到达,即使只是稍微早一点,它也不会发火。现在,耳朵与探测器之间的轴突长度小差异可以造成微小的延迟,这可以用来非常准确地检测声音方向。
哪个更快
一般来说,光感神经元在光线更亮时发火更快。为了检测光亮区域和暗区之间的边界,你的神经元需要检测冲动频率的微小差异。通过类似于前述的电路,可以设置一对神经元进行发火,如果边界的一侧更亮则发火,反之亦然。事实证明,你可以比感知绝对亮度或颜色强度更精确地检测边界,这也是许多视觉错觉和计算机视觉困难的来源。
频率传感器
我还没有详细讨论过,但如果我们加入电荷泄漏,神经元模型会更生物学上准确。当突触向目标神经元施加电荷时,它不会永远停留在那里,而是会泄漏。这种效应可以以多种方式使用。如果你有一个源连接到一个权重为 0.9 的目标,目标需要两个传入的冲动才能发火,但前提是第二个冲动在电荷泄漏到 0.1 或更少之前到达。通过这种方式,任何神经元都可以作为频率传感器,只要源的冲动频率达到或超过由泄漏率和突触权重决定的特定频率。由单一信号驱动的一群神经元可以以相当高的精度检测入射信号的频率,但每个要检测的频率级别需要一个单独的神经元。
短期记忆
上述效果可以用于短期记忆,在神经元中存储单个信息位,但必须在信息泄漏之前读取。我们将神经元的记忆内容定义为当电荷为 0.1 或更大时为 1。我们以 0.9 的权重写入记忆位,并可以在电荷降到 0.1 以下之前随时读取它。图中所示的电路将在每次读取记忆位时刷新记忆内容,因此它可以潜在地无限期存储。这使用了与动态 RAM 非常相似的机制,动态 RAM 也必须定期刷新以防止记忆内容泄漏。
本文涵盖了一些神经元能够完成的任务,这些任务在很大程度上超出了机器学习的范围。在下一篇文章中,将探讨神经元在机器学习中的最大优势——其惊人的效率。
演示本文中示例的视频在这里: https://youtu.be/gq9H6APDgRM
这个神经回路在短期记忆中存储一个信息位,该信息可能会逐渐消失。它使用一个标记为“Bit”的神经元在其电荷水平中存储数据位。激活“Set”神经元会在 Bit 神经元中设置电荷,该电荷可以通过“Reset”神经元清除。当“Read”激活时,Bit 神经元会根据其电荷水平决定是否发放。如果它发放,它也会激活 Set 以重新存储 Bit 中的值。每个位都需要一个 Set 和 Bit 神经元,而 Read 和 Reset 神经元可以共享于任意数量的位。
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,同时也是 FutureAI 的首席执行官。西蒙是《计算机会反叛吗?:为人工智能的未来做准备》的作者,也是 Brain Simulator II 的开发者,这是一款 AGI 研究软件平台。欲了解更多信息,请访问这里。
更多相关话题
机器学习并不像你的大脑 第二部分:感知机与神经元
原文:
www.kdnuggets.com/2022/05/machine-learning-like-brain-part-two-perceptrons-neurons.html
虽然今天的人工智能(AI)能够完成一些非凡的任务,但其功能与人脑实现相同任务的方式几乎没有关系。AI——特别是机器学习(ML)——通过分析大量数据集,寻找模式和相关性,而不理解其处理的数据。因此,需要数千个标记样本的 ML 系统与一个可以通过少量未标记数据经验学习的儿童的大脑在本质上是不同的。
为了使今天的人工智能克服这些固有的限制,并进化到下一阶段(人工通用智能),我们应当检查大脑(已经实现了通用智能)与其人工对应物之间的差异。
鉴于此,这个九部分系列将逐步深入探讨生物神经元的能力和局限性,以及这些如何与机器学习(ML)相关联。在第一部分,我们探讨了神经元的慢速如何使得通过数千个训练样本的学习方法显得不切实际。在第二部分,我们将审视感知机的基本算法及其与涉及脉冲的生物神经元模型的不同之处。
大多数机器学习算法所依赖的感知机在本质上与任何生物神经元模型都不同。感知机的值是通过突触传递的信号总和的函数计算得出的,每个突触的值是突触权重和感知机值的乘积。相比之下,生物神经元随着时间的推移累积电荷,直到达到一个阈值,这赋予了它一定的记忆。
同样,虽然感知机有一个模拟值,神经元则简单地发出脉冲。感知机没有内在的记忆,而神经元有。而且,虽然许多人认为感知机的值类似于神经元的脉冲频率,但这种类比是有缺陷的,因为感知机忽略了脉冲的相对时序或传入信号的相位,仅考虑频率。因此,生物神经元可以根据脉冲到达的顺序作出不同的反应,而感知机则不能。
举例来说,具有正权重的突触会对神经元的内部电荷产生贡献,并在累积电荷超过阈值水平(定义为 1)时刺激神经元发放脉冲,而负权重的突触则抑制发放。如果一个神经元由两个权重分别为.5 和-.5 的输入刺激。如果输入序列为.5, -.5, .5, -.5,该神经元将永远不会发放脉冲,因为每个正输入后面都有一个负输入,导致累积电荷归零。如果输入按.5, .5, -.5, -.5 的顺序发放,神经元将在第二个正权重脉冲之后发放脉冲。
展示了一个以.25 权重刺激的神经元如何累积电荷,并在每第四个输入脉冲(来自输入神经元 In)的脉冲后发放。
当 In1 和 In2 分别以.5 和-.5 的权重刺激时,Out 将永远不会发放脉冲。
但改变进入脉冲的时序可以使 Out 发放。感知器模型不支持这个功能,因为它忽略了进入信号的时序/相位。
在这两种情况下,平均输入频率为.5(最大发放率的一半)。感知器模型将给出相同的输出 0,因为加权输入的总和或.5.5 + .5-.5 始终等于 0,无论输入的时序如何。这意味着感知器模型无法在生物神经元中可靠实现,反之亦然。
这是神经网络与生物神经元之间如此根本的区别,我将撰写一篇单独的文章来深入探讨它,以及其他生物因素,使得今天的人工智能在一个非常基础的层面上与大脑的功能有所不同。
生物神经元模型允许单个脉冲具有意义。大多数大脑神经元很少发放脉冲,因此许多神经元确实具有特定的意义。例如,由于你理解什么是球,因此你的大脑中可能包含一个“球神经元”(或多个)当你看到球或听到这个词时会发放脉冲。在生物模型中,这个神经元可能在识别到球时只发放一次脉冲。然而,感知器模型的发放率并不允许这种情况,因为单个脉冲的发放率没有定义。
在下一篇文章中,我将讨论大脑中的连接是如何不像机器学习中的有序层次那样组织的,以及这如何需要对基本感知机算法进行一些修改,这可能会导致反向传播完全不起作用。
接下来:基本架构
查尔斯·西蒙 是一位全国知名的企业家和软件开发者,也是 FutureAI 的首席执行官。西蒙是《计算机会叛乱吗?:为人工智能的未来做准备》的作者,也是 Brain Simulator II 的开发者,这是一个 AGI 研究软件平台。欲了解更多信息,请访问这里。
更多相关话题
利用 BigQuery ML 为数据分析师简化机器学习
原文:
www.kdnuggets.com/machine-learning-made-simple-for-data-analysts-with-bigquery-ml

图片由 freepik 提供
数据分析正经历一场革命。机器学习 (ML),曾经是数据科学家的专属领域,现在对像你这样的数据分析师也变得触手可及。借助像 BigQuery ML 这样的工具,你可以利用机器学习的强大功能,而不需要计算机科学学位。让我们来探讨一下如何开始。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
什么是 BigQuery?
BigQuery 是一个完全托管的企业数据仓库,帮助你管理和分析数据,内置机器学习、地理空间分析和商业智能等功能。BigQuery 的无服务器架构允许你使用 SQL 查询来回答组织中最重要的问题,无需管理基础设施。
什么是 BigQuery ML?
BigQuery ML (BQML) 是 BigQuery 中的一项功能,允许你使用标准 SQL 查询来构建和执行机器学习模型。这意味着你可以利用现有的 SQL 技能来执行以下任务:
-
预测分析: 预测销售、客户流失或其他趋势。
-
分类: 对客户、产品或内容进行分类。
-
推荐引擎: 基于用户行为推荐产品或服务。
-
异常检测: 识别数据中的异常模式。
为什么选择 BigQuery ML?
接受 BigQuery ML 有几个令人信服的理由:
-
无需 Python 或 R 编码: 告别 Python 或 R。BigQuery ML 允许你使用熟悉的 SQL 语法来创建模型。
-
可扩展: BigQuery 的基础设施设计用于处理海量数据集。你可以在数 TB 的数据上训练模型,而不必担心资源限制。
-
集成: 你的模型与数据所在的位置相同。这简化了模型管理和部署,使得将预测直接纳入现有报告和仪表板变得轻而易举。
-
速度: BigQuery ML 利用 Google 强大的计算基础设施,实现更快的模型训练和执行。
-
成本效益: 仅为训练和预测过程中使用的资源付费。
谁能从 BigQuery ML 中受益?
如果你是一个希望在分析中增加预测能力的数据分析师,BigQuery ML 是一个很好的选择。无论你是在预测销售趋势、识别客户细分,还是检测异常,BigQuery ML 都可以帮助你获得有价值的洞察,而无需深入的机器学习专业知识。
你的第一步
1. 数据准备: 确保你的数据是干净的、有组织的,并且在 BigQuery 表中。这对任何机器学习项目都至关重要。
2. 选择模型: BQML 提供各种模型类型:
-
线性回归: 预测数值(例如销售预测)。
-
逻辑回归: 预测类别(例如客户流失——是或否)。
-
聚类: 将相似的项目归为一类(例如客户细分)。
-
更多功能: 时间序列模型、推荐系统的矩阵分解,甚至是用于高级情况的 TensorFlow 集成。
3. 构建和训练: 使用简单的 SQL 语句创建和训练你的模型。 BQML 处理背后的复杂算法。
这是一个基于面积预测房价的基本示例:
CREATE OR REPLACE MODEL `mydataset.housing_price_model`
OPTIONS(model_type='linear_reg') AS
SELECT price, square_footage FROM `mydataset.housing_data`;
SELECT * FROM ML.TRAIN('mydataset.housing_price_model');
4. 评估: 检查你的模型表现如何。 BQML 提供如准确率、精确率、召回率等指标,具体取决于你的模型类型。
SELECT * FROM ML.EVALUATE('mydataset.housing_price_model');
5. 预测: 进入有趣的部分!使用你的模型对新数据进行预测。
SELECT * FROM ML.PREDICT('mydataset.housing_price_model',
(SELECT 1500 AS square_footage));
高级功能和注意事项
-
超参数调整: BigQuery ML 允许你调整超参数来微调模型的性能。
-
[可解释的 AI]( https://cloud.google.com/bigquery/docs/xai-overview#:~:text=Explainable AI helps you understand ,contributed%20to%20the%20predicted%20result.): 使用类似于可解释的 AI 的工具来理解影响模型预测的因素。
-
监控: 持续监控你的模型表现,并在新数据可用时根据需要重新训练模型。
成功的小贴士
-
从简单开始: 从一个简单的模型和数据集入手,以了解整个过程。
-
实验: 尝试不同的模型类型和设置,以找到最适合的。
-
学习: Google Cloud 提供了关于 BigQuery ML 的优秀文档和教程。
-
社区: 加入论坛和在线小组,与其他 BQML 用户交流。
BigQuery ML:你的机器学习入门门户
BigQuery ML 是一个强大的工具,为数据分析师普及了机器学习。凭借其易用性、可扩展性和与现有工作流的集成,利用机器学习的力量来从数据中获取更深入的见解从未如此简单。
BigQuery ML 使你能够使用标准 SQL 查询来开发和执行机器学习模型。此外,它还允许你利用Vertex AI 模型和Cloud AI API 进行各种 AI 任务,例如生成文本或翻译语言。此外,Google Cloud 的 Gemini 通过 AI 驱动的功能增强了 BigQuery,简化了你的任务。有关 BigQuery 中这些 AI 能力的全面概述,请参阅BigQuery 中的 Gemini。
开始尝试,今天就为你的分析解锁新的可能性!
Nivedita Kumari 是一位经验丰富的数据分析和人工智能专业人士,拥有超过 8 年的经验。在她目前的角色中,作为 Google 的数据分析客户工程师,她与高管不断互动,帮助他们设计数据解决方案,并指导他们在 Google Cloud 上构建数据和机器学习解决方案的最佳实践。Nivedita 在伊利诺伊大学厄本那-香槟分校获得了数据分析方向的技术管理硕士学位。她希望普及机器学习和人工智能,打破技术障碍,让每个人都能参与这项变革性技术。她通过创建教程、指南、观点文章和编码演示,与开发者社区分享她的知识和经验。在 LinkedIn 上与 Nivedita 连接。
更多相关主题
将机器学习应用于三月的疯狂
原文:
www.kdnuggets.com/2017/03/machine-learning-march-madness.html

介绍
三月的疯狂。
这两个词能让全国的每一个大学篮球迷都感到鸡皮疙瘩。这是每位球迷都会填写表格的月份,每个人都认为自己选对了 12 号对 5 号种子的冷门,或是他们是唯一选中了进入精英 8 强的灰姑娘球队的人。这个月里,人们会花几个小时观看常规赛,仔细研究数据和专家分析,试图准确预测最有可能获胜的球队,却发现自己的选择在第一轮就输了(谢谢密歇根州立大学)。这个月里,你的妹妹因为选择了“更酷”的吉祥物的球队,最终拥有了比你更好的表格(悲伤,但确实是这样)。三月的疯狂是一种引发焦虑、遗憾、兴奋和其他各种情感的体育现象。它将在4 天后开始。
编辑:在阅读完这个概述后,不要忘记查看 KDnuggets 的漫画:当人工智能掌握三月的疯狂时
从未听说过?
三月的疯狂指的是年度大学男子篮球锦标赛。比赛由 64 支大学球队组成,采用单场淘汰制。为了赢得冠军,一支球队必须赢得 6 场连续的比赛。
比赛被划分为 4 个区域。每个区域有 16 支球队,按 1 到 16 进行排名。这个排名由 NCAA 委员会确定,基于每支球队的常规赛表现。NCAA 安排比赛的方式是,区域中排名最高的球队对阵排名最低的球队,第 2 高的对第 2 低的,以此类推。
那么,问题在哪里?
1/9.2 quintillion。
这些是你在整个锦标赛中正确预测所有 63 场比赛获胜者的几率。从数学角度讲,你可以填充这个表格的方式有 2⁶³(约 9.2 quintillion)。2014 年,沃伦·巴菲特著名地提出了 10 亿美元的奖励给任何能填出完美表格的人(不用说,实际上没有人接近过)。
作为体育迷,预测比赛结果是我们的天性。我们想相信我们的母校能进入甜蜜的 16 强。我们想要有权 bragging 说我们知道第 11 种子 VCU 会进入四强(2011 年非常疯狂)。三月疯狂的魅力在于如此大型单场淘汰赛的不可预测性。虽然选择所有 1 号种子晋级(这被称为“挑选标记”)可能很容易,但比赛历史表明,肯定会有一些惊喜。
在接下来的 2 周中,球迷们将会在课堂上(个人经验)或工作时观看比赛,欣赏令人惊叹的绝杀、令人瞠目的冷门,最重要的是,希望他们的预测不会在第一天就被打破。

预测问题
在深入机器学习之前,让我们退一步思考体育比赛预测的概念。这不是一个很复杂的主题,对吧?想象一下这个情境。

让我们在这里停下来。体育预测中的根本问题是:作为预测者,你使用哪些因素来确定未来体育赛事的结果? 想象一下你可能会得到的回答。
A 个人:“爱国者队在 NFL 中防守最好,根据每场比赛失分来看,他们在允许的冲球码数上排名第 4,且在联赛中在失误差异上排名第 3。他们将轻松获胜。”
B 个人:“100 名 NFL ESPN 分析师中有 72 人选择了爱国者队,所以我也选择他们。”
C 个人:“爱国者队有汤姆·布雷迪,我喜欢汤姆·布雷迪。”
D 个人:“我的前女友喜欢猎鹰队,所以支持爱国者队!”
当你查看这些回应时,你会发现每个回应对某个特定的统计数据/感觉/情绪(在机器学习术语中称为“特征”)赋予了不同的重要性(在机器学习术语中称为“权重”)。A 个人在做出预测时非常依赖常规赛统计数据。B 个人选择考虑 ESPN 的 NFL 分析师的意见。C 个人对汤姆·布雷迪有个人偏好,这使他/她选择了爱国者队。最后,D 个人可能从未看过一场橄榄球比赛,但由于对某个人的负面情绪,选择了爱国者队。

关键是我们都有不同的预测方式。我们考虑的输入特征不同,我们对这些特征赋予的权重不同,因此我们对未来的体育赛事有不同的解读方式。
对预测有这么多不同的观点是很好的。这使我们能够在比赛前进行激烈的争论,也让我们能够在赢得夸耀权时尽情享受,或促使我们重新考虑我们的预测思维过程。
我们所有观点的一个共同点是我们都有偏见。没有两种方式。我们每个人在处理体育预测时都有偏见。我们有偏见,因为“什么构成一个好的预测”这个问题没有明确的答案。我们应该关注统计数据吗?我们应该关注无形因素吗?我们应该忘掉这些,简单地根据个人感觉做预测吗?没有简单的解决方案。
这就是机器学习的用武之地。
机器学习能否帮助预测?
好了,通过上一段,我们已经确定了问题空间。我们想看看是否可以构建一个能够查看训练数据(过去的 NCAA 篮球比赛)、找到球队成功与他们的属性(统计数据)之间关系的机器学习模型,并对未来的比赛做出预测。
那么,为什么机器学习可以成为这个预测问题的一个可能用例呢?首先,数据在这里。我们有大量的数据。在过去 25 年中,进行了超过 100,000 场 NCAA 常规赛比赛,我们通常有每个赛季球队的大量统计数据。由于我们拥有所有这些数据,我们可以尝试使用机器学习找出哪些特定统计数据与球队赢得特定比赛最相关。如果一个球队每场比赛允许的得分少于 60 分,他们赢得比赛的可能性更大吗?如果一个球队失误超过 15 次,这是否是他们输给一个重视控球的球队的致命迹象?这些都是我们希望数据分析和机器学习能够提供见解的问题。
所有这些数据分析的代码可以在 这个 iPython Notebook中找到。一定要跟着做!
基本模型结构
我们的机器学习模型将接收有关两个球队(球队 1 和球队 2)的信息作为输入,然后输出球队 1 赢得比赛的概率。

现在,立即想到的问题是,机器学习算法通常以单一矩阵或向量的形式接受输入。我们需要想到一种方法,将关于两个球队的信息封装在一个单一的向量中。让我们首先看看是否可以将每个球队表示为一个向量。
以 2016 年的堪萨斯大学 Jayhawks 为例。

Jayhawks 度过了一个伟大的赛季,赢得了他们第 12 次连续获得的 Big 12 冠军,并在锦标赛中获得了#1 种子。让我们思考一下如何用一个单一的向量来表示他们的赛季。在机器学习术语中,我们希望表示哪些特征?让我们从常见的统计指标开始。
-
常规赛胜场数:29
-
每场比赛平均得分:80.30
-
每场比赛平均失分:67.61
-
每场比赛平均三分球命中数:9.21
-
每场比赛平均失误数:14.39
-
每场比赛平均助攻数:18.30
-
每场比赛平均篮板数:43.73
-
每场比赛平均抢断数:7.66
然后,我们可以考虑与他们所参加的会议相关的其他因素。
-
“Power 6”会议(Big 12、Big 10、SEC、ACC、Pac-12、Big East):1 - 二进制标签
-
常规赛会议冠军:1 - 二进制标签
-
会议锦标赛冠军:1 - 二进制标签
我们可以考虑其他更高级的指标。
-
简单评级系统(对手强度和平均得分差的函数):23.87
-
对手强度:11.22
最后,我们还会查看一些历史因素。
-
自 1985 年以来的锦标赛参赛次数:31
-
自 1985 年以来的全国冠军数量:2
最后,我们有一个描述位置的三元标签。
- 位置(如果团队 1 在客场为-1,中立场地为 0,主场为 1):1
为 2016 年的堪萨斯 Jayhawks 创建我们的表示形式,我们可以将所有特征连接成一个 16 维向量。
现在,让我们对 2016 赛季的另一支球队,俄克拉荷马州 Sooners,做同样的分析。

由 NBA 首轮选秀球员 Buddy Hield 领导的 Sooners 度过了一个令人难以置信的赛季,常规赛赢得了 25 场比赛,并在锦标赛中获得了#2 种子。我们可以在下面看到俄克拉荷马州的向量。
我们可以把创建团队向量的过程想象成类似于在 NLP 深度学习方法中使用词向量的想法。在将输入喂入 RNN 或 LSTM 之前,我们首先必须将句子或短语转换成可用的表示形式。
看一下体育比赛预测的任务,让我们思考一下我们希望模型做什么。由于 ML 模型通常接收单一输入,我们可以将每场比赛表示为两队向量之间的差异(团队 1 向量 - 团队 2 向量)。这是一种表示比赛的方法。虽然有些人可能选择将两个向量连接起来,但取差异有助于强调两支球队之间的不同,这可能有助于确定对比赛结果有影响的统计数据类型。
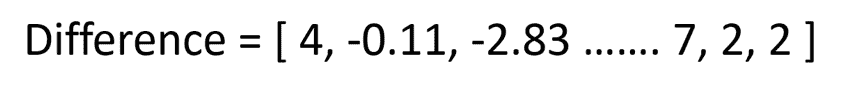
我们的模型将接收这个差异向量,并输出团队 1 赢得比赛的概率。
我们训练这个模型的方法是通过查看过去常规赛比赛的结果,并查看两支竞争球队的向量。让我们看一个实际的训练示例来使其更清晰。
俄克拉荷马州和堪萨斯在 2016 年常规赛中交手两次。第一次在堪萨斯著名的 Allen Fieldhouse 举行,成为了历史上最伟大的大学篮球常规赛比赛之一。

1 对 #2. 三次加时。是的,那场比赛真是激烈。这将是我们训练数据中的众多比赛之一。这场比赛的情况会是怎样的?
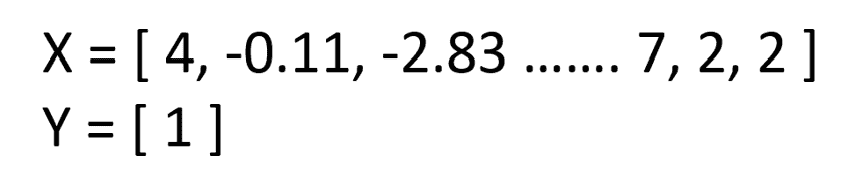
明白了吗?每个训练样本的 X 组件将是该赛季两个球队向量之间的差异。训练样本的 Y 组件将是 [1] 或 [0],分别表示球队 1 获胜或球队 2 获胜。
Kaggle 数据集和来自 Sports-Reference 的统计数据包含了从 1993 赛季开始的常规赛和锦标赛数据。从 1993 年到 2016 年,共进行了超过 115,000 场比赛。我们的 xTrain 维度将是 115113 x 16,yTrain 为 115113 x 1。
应用机器学习算法
现在我们有了训练集,我们需要选择一个 ML 算法。从简单的逻辑回归到随机森林再到复杂的集成方法,有很多模型可以适应我们的任务。
每当你刚开始处理一个数据集和预测任务时,始终尝试使用一个非常简单的模型(例如线性/逻辑回归、决策树或 KNN),然后再尝试更复杂的神经网络和集成方法。在将训练数据分成训练集和测试集后,我们训练模型(使用 Scikit-Learn 函数),并在测试集上进行评估。
下面,你可以看到我们的一些模型表现如何的表格。为了确保模型不是仅仅因为分类容易的游戏而运气好,我们对模型进行了 100 次不同训练/测试拆分的评估,并取了平均值。

梯度提升树
这个模型在测试集上取得了最佳性能。这个模型基本上是一种集成网络,其中包含多个浅层回归或分类树,这些树根据前面树的错误重新加权训练样本(如果你想了解更多信息,请查看 Peter Prettenhofer 的 精彩演讲)。梯度提升树在异质数据(不同尺度的数据)上表现非常好,并且能够检测非线性特征交互,这在我们的任务中极为有用。这个模型的一个有趣属性是我们可以分析每个特征对整体分类的重要性。通过查看每个特征在回归树上的位置,我们可以检查哪些特征对游戏的正确分类贡献最大。
正如你所见,常规赛胜场数对一个球队是否赢得比赛有很大影响。直观上,这是有道理的。并不需要高级的机器学习模型或专家分析师来预测胜场数更多的球队更有可能获胜。
然而,有趣的是查看列表中的后续特征。接下来的两个特征是 SOS(赛程强度)和位置。如果你考虑一下,SOS 也很直观。即使一个球队的胜场数不高,它们仍然有可能是一个强队,只是整个赛季中遇到的对手更强。位置也是一个影响比赛的知名因素,这就是“主场优势”一词的来源。
下一步行动
76.37%的准确率很棒,但我们可以做些什么来真正将其提升到 80%或 85%呢?这就是成为机器学习从业者的艰难之处。实际上并没有明确的指导方针来改进模型。对于决策树,你可以尝试增加树的深度。对于神经网络,你也可以尝试新的架构或经典的“再加一层”思路。有无数的超参数可以尝试调整。
然而,我将更关注数据的表现形式以及模型本身。以下是一些可能会为明年的锦标赛带来更好结果的调整。
-
除了依赖常见的统计特征(PPG、APG 等),还可以尝试量化专家意见、粉丝投票或博彩赔率。
-
使用 SVD 或 PCA 来降低维度,让模型从具有更简单特征的数据集中学习预测。
-
纳入关于锦标赛结果的历史信息(例如,第 12 种子在首轮比赛中战胜第 5 种子的次数)
-
尝试不同的方式将两个团队向量合并为一个(例如,连接、平均等)
-
考虑使用 RNN 类型的模型来分析时间序列数据。与其将一个赛季表示为单一向量,不如尝试将球队的进展建模为时间序列。这样,我们就能找出哪些球队在进入锦标赛时表现特别好。
机器学习模型中的偏差讨论
我现在想花一点时间来讨论一个我认为对所有机器学习从业者来说都非常重要的问题。这就是训练集偏差的概念。正如我在文章开头提到的,我们作为人类在预测时都存在偏见。在体育预测中,我们对某些球队有个人情感,对可用统计数据的视角不完整,有时也有不一致的评判标准。使用机器学习可以让我们利用与预测任务相关的大量数据。然而,它仍然会受到类似的偏见问题的影响。
偏差影响机器学习模型的方式是通过我们使用的训练集和我们的表示(在这种情况下,是我们的球队向量)。作为机器学习从业者,我们需要对使用哪些训练数据做出有意识的决定。对于这个特定的模型,我决定使用自 1993 年以来的所有常规赛和锦标赛比赛数据。我本可以决定只包含最近几年的数据,或者可以寻找包含 1993 年以前比赛信息的数据集。
与我选择的特征相同。我本可以添加像罚球命中率或主场胜利次数等特征,但我没有。我创建了这些特征,因为我认为这些特征最有可能与球队的成功相关联。
对数据集和特征选择的这种控制意味着我们对模型输出的责任比我们想象的要大。
关键点在于,机器学习模型不仅仅是从无处提取预测。它们在某种程度上是黑箱,但我们仍然需要决定我们输入的数据以及如何表示这些数据。虽然体育预测只是一个有趣和无害的任务,但许多领域(如医疗保健、法律、保险等)中,机器学习模型的结果至关重要。我们需要花时间确保我们使用的训练数据能够代表整体人群、不对某一群体存在歧视,并且模型能够很好地适应训练集和测试集中的大多数示例。
机器学习模型 2017 年锦标预测
对于今年比赛的预测,我对每场首轮比赛运行了一个训练好的梯度提升分类器模型,并让概率更高的队伍晋级到下一轮。我然后对所有后续轮次重复了这一过程。

所以,你准备好你的赛程表了吗?
向我的好朋友Arvind Sankar致敬,感谢他在特征创建方面的有益讨论以及一些数据抓取脚本。
简介:Adit Deshpande 目前是 UCLA 计算机科学专业的二年级本科生,并辅修生物信息学。他热衷于将他的机器学习和计算机视觉知识应用于医疗保健领域,以为医生和患者工程出更好的解决方案。
原文。经许可转载。
相关内容:
-
漫画:当人工智能掌握三月疯狂时会发生什么
-
数据科学游戏,面向学生的机器学习比赛
-
掌握 Python 机器学习的 7 个额外步骤
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关话题
机器学习元数据存储
原文:
www.kdnuggets.com/2022/08/machine-learning-metadata-store.html

图片由 Manuel Geissinger 提供
机器学习主要是数据驱动的,涉及大量的原始和中间数据。目标通常是在生产环境中创建并部署一个模型,以供他人使用以实现更大的利益。要理解模型,必须在不同阶段检索和分析我们机器学习模型的输出及其创建所用的数据集。关于这些数据的数据称为元数据。元数据就是关于数据的数据。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
在本文中,我们将学习:
-
元数据存储,
-
元数据存储的组成部分,
-
元数据存储的需求
-
元数据存储的选择标准
-
元数据管理,
-
元数据管理的架构和组件
-
声明式元数据管理
-
流行的元数据存储及其特点
-
文章末尾有这些存储的 TL;DR 对比表。
为什么我们需要一个元数据存储?
构建机器学习模型的过程与从理论上进行科学实验有些相似。你从一个假设开始,设计一个模型来测试你的假设,测试并改进你的设计以适应你的假设,然后根据你的数据选择最佳方法。在机器学习中,你从一个关于哪些输入数据可能产生期望结果的假设开始,训练模型,并调整超参数,直到你构建出产生所需结果的模型。
图:机器学习开发生命周期。 [来源]
存储这些实验数据有助于可比性和可重复性。如果实验模型的参数不可比,那么迭代的模型构建过程将是徒劳的。如果需要重现之前的结果,可重复性也是至关重要的。鉴于机器学习实验的动态和随机性质,实现可重复性是复杂的。
存储元数据将有助于重新训练相同的模型并获得相同的结果。由于大量实验数据在管道中流动,必须将每个实验模型的元数据与输入数据分开。因此,需要有一个元数据存储库,即一个包含元数据的数据库。
元数据类型
既然我们已经讨论了存储元数据的重要性,那么让我们来看一下不同类型的元数据。
数据
用于模型训练和评估的数据在可比性和可重复性方面起着主导作用。除了数据外,你还可以存储以下内容:
-
数据位置的指针
-
数据集的名称和版本
-
列名和数据类型
-
数据集的统计信息
模型
实验通常是为了锁定一个适合我们业务需求的模型。在实验结束之前,很难确定选择哪个模型。因此,如果所有实验模型都是可重复的,这将非常有用并节省大量时间。需要注意的是,我们关注的是模型的可重复性,而不是可检索性。为了检索一个模型,必须存储所有模型,这会占用太多空间。这是可以避免的,因为以下参数有助于在需要时重复模型。
特征预处理步骤
原始数据已经被记录并保存以便检索。但这些原始数据并不总是被喂给模型进行训练。在大多数情况下,模型所需的关键数据,即特征,是从原始数据中提取的,并成为模型的输入。
由于我们追求可重复性,因此需要保证所选特征处理方式的一致性,因此特征预处理步骤需要被保存。一些预处理步骤的示例包括特征增强、处理缺失值、将其转换为模型所需的不同格式等。
模型类型
为了重建模型,存储使用的模型类型,如 AlexNet、YoloV4、Random Forest、SVM、等,及其版本和框架,如 PyTorch、Tensorflow、Scikit-learn。这确保了在重复模型时没有选择上的模糊性。
超参数
机器学习模型通常有一个损失函数或成本函数。为了创建一个强健且高效的模型,我们的目标是最小化损失函数。损失函数最小化时模型的权重和偏差是需要保存的超参数,以便重复之前创建的高效模型。这可以节省寻找正确超参数的处理时间,并加快模型选择过程。
评价指标
模型评估的结果对理解你如何构建模型非常重要。它们有助于找出:
-
如果模型对训练集过拟合,
-
不同的超参数如何影响输出,以及评估指标或
-
进行全面的错误分析。
存储这些数据有助于在任何给定时间进行模型评估。
上下文
模型上下文是关于机器学习实验环境的信息,这可能会或不会影响实验的结果,但可能是结果变化的因素。
模型上下文包括:
-
源代码
-
依赖项,如任何包及其版本
-
编程语言及其版本
-
主机信息,如环境变量、系统包等。
元数据存储的用例
现在,我们了解了元数据、其需求以及元数据存储的组成部分。让我们看看元数据存储的一些用例以及如何在机器学习工作流中使用它们:
-
搜索和发现。 数据搜索和数据发现涉及从各种来源收集和评估数据。它通常用于了解元数据中的趋势和模式。你可以获取有关数据架构、字段、标签和使用情况的信息。
-
访问控制 确保所有团队成员可以访问相同的元数据,并在团队协作中发挥重要作用。它确保元数据由控制组访问,并遵循组织的政策。
-
数据溯源 是数据旅程的地图,包括数据的来源、沿途的每一站,以及数据随时间移动的原因和解释。它有助于跟踪管道执行、查询、API 日志和 API 架构。
-
数据合规性 是确保组织遵循一套法规以保护 敏感数据 防止滥用的实践。它规定了应保护的数据类型、保护方式以及未能达标的处罚。将元数据整理、存储和管理在一个地方,有助于根据这些法规管理数据。
-
数据管理。 元数据存储有助于配置数据源、数据摄取和数据保留。它有助于遵循数据清理政策和数据导出政策。
-
机器学习的可解释性和可重复性。 理想的元数据存储包含重现机器学习模型所需的所有信息。这些信息可以用来证明模型的用途是否符合业务需求。
-
数据运营。 数据运营是一种为端到端数据管道(从收集到交付)带来速度和灵活性的实践。由于元数据存储包含有关数据流动的所有必要信息,它在实践数据运营时发挥了重要作用。
-
数据质量。 顾名思义,拥有所有数据的元数据有助于评估数据质量,并确保数据质量,这对任何成功的机器学习模型开发至关重要。
我们为什么需要元数据管理?
仅存储元数据而没有任何管理就像把成千上万本书随意堆放。我们存储这些数据是为了提升模型构建。如果没有管理,检索数据变得更加困难,并且影响其可复现性。元数据管理确保数据治理。
以下是元数据管理必要性的全面列表:
-
统一和管理来自不同模型和系统的数据。
-
关于整个机器学习工作流程的管理信息在调试和根本原因分析中非常有帮助。
-
大规模的数据治理需要一定程度的自动化,尤其是在使用不同工具时。
-
数据发现对生产力至关重要。及时找到所需的数据可以节省大量时间。
元数据管理架构
Assaf Araki 和 Ben Lorica 在元数据管理的崛起播客中精彩地解释了元数据管理系统的三个构建块。
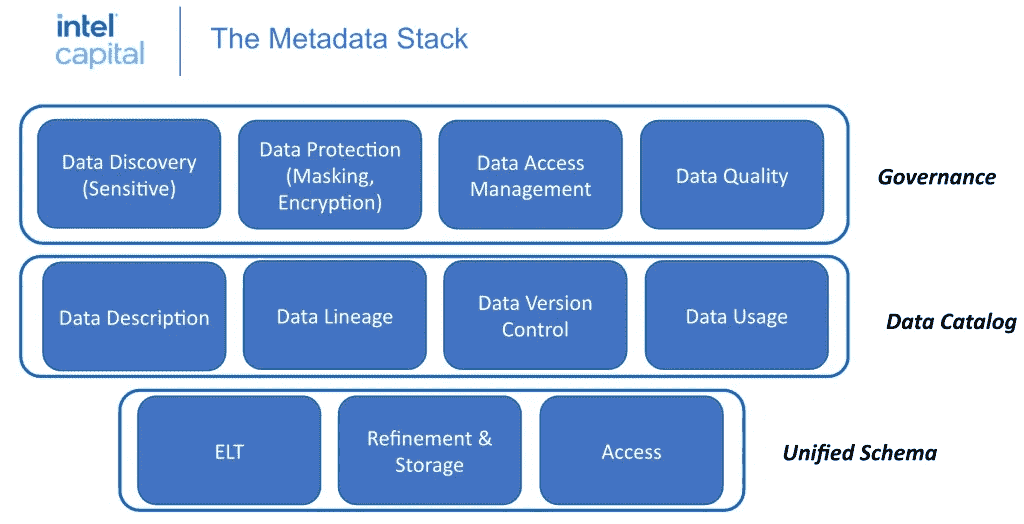
图:元数据堆栈。 [来源]
统一模式
需要从所有系统中收集元数据。这一层中的三个组件完成这项工作:
- 提取、加载、转换 - ELT 是从一个或多个来源提取数据并将其加载到数据仓库中的过程。它是传统 ETL(提取、转换、加载)的替代方案。
由于它利用了数据存储基础设施中已经构建的处理能力,ELT 减少了数据在传输中的时间,并提高了效率。
-
精炼和存储 - 精炼和以一种格式存储有助于数据的轻松检索。
-
访问 - 用于从元数据系统中提取数据的 API 或特定领域语言,用于构建后续层。
数据目录
现在我们已经在上一层收集了数据,数据需要被分类到目录中,以使其具有信息性和可靠性。它的四个组件有助于完成这一任务:
-
数据描述 - 对所有数据元素的详细描述和总结。
-
数据血缘 - 数据从创建到经过时间的转化的全过程记录。这是理解、记录和可视化数据流动的过程。
图:数据血缘过程 [来源]
-
版本控制 - 数据版本控制确保跟踪数据集随时间变化的情况。
-
数据使用 跟踪用户或应用程序、系统的数据消耗。这有助于观察数据流并帮助构建成本管理解决方案。
治理
正如其名称所示,这一层共同工作以治理数据,确保数据的一致性和安全性。这是组织用于管理、利用和保护企业系统中的数据的过程。

图:数据治理的支柱。[来源]
了解更多关于数据治理指南的信息。
关于确保数据治理的组件:
-
数据发现 检测所有平台上的敏感数据,节省时间并减少手动错误的风险。
-
数据保护 减少敏感数据的暴露和不必要的传播,同时保持可用性。
-
数据访问管理 确保数据符合组织的政策和法规。
-
数据质量 帮助评估数据的质量,确保准确性、完整性、一致性和相关性。
声明式元数据管理
声明式元数据管理是一个轻量级系统,跟踪在机器学习工作流中生成的工件的血统。它自动提取诸如模型的超参数、数据集的模式和深度神经网络的架构等元数据。
声明式元数据系统可用于实现各种功能,例如:
-
定期自动比较 模型与旧版本的差异,
-
量化准确性改进 团队在特定目标上随着时间的推移所取得的进展,例如,通过存储和比较模型的输出,并且
-
显示排行榜中的差异。
在这里,实验元数据和机器学习管道,构成了一种定义复杂特征转换链的方式,会自动提取,从而简化其元数据跟踪系统。这通过一个模式实现,该模式旨在存储血统信息和机器学习特定属性。下图展示了声明式元数据管理的重要原则。

图:声明式元数据管理的重要原则。来源:DMM 中讨论的原则的图形表示 - 图片由作者创建
系统采用三层架构来使用上述讨论的原则。
-
第 1 层 是一个文档数据库存储,存储实际的实验数据。
-
第 2 层 是一个集中式数据存储,向外界开放,允许用户显式地存储特定工件的元数据并查询现有数据。
-
第 3 层: 这一最上层,也称为高级客户端,旨在与流行的 ML 库(如 SparkML、scikit-learn、MXNet)兼容。
第三层的高级客户端可以自动化元数据提取,从流行 ML 框架的内部数据结构中提取元数据。
让我们通过一些这些框架的例子来获得更清晰的理解。
-
SparkML: SparkML 中的 ML 工作负载包含 DataFrames。SparkML 管道的架构允许 DMM 系统自动跟踪所有模式转换(如读取、添加、删除列)以及运算符的参数化。
-
MXNet: MXNet 框架提供了细粒度的抽象,通过将数学运算符(如卷积、激活函数)组合到网络布局中进行声明性定义。第 3 层提取并存储结果计算图、参数化以及运算符的维度和相应的超参数。
声明式元数据管理的有用性
现在我们对声明式元数据管理有了一个初步的了解,让我们看看这些属性如何改善你的机器学习工作流程:
-
自动回归测试: DMM 不存储任意的键值标签、ML 代码或实际数据,而是存储指向实际数据的指针。这严格解耦了参数和工作流程。此外,它还赋予我们自动化查询、解释和分析元数据及其来源的特权。这种自动化分析使模型的回归测试成为可能。
-
自动化元数据提取: DMM 架构强制存储工件和指向 ML 特定属性及其来源信息的指针。由于它严格关注元数据,因此查询或元数据提取支持过程的自动化。
-
加速实验: 在实验过程中自动比较模型与其他模型,使团队能够轻松量化改进,从而加快实验过程。
-
增加自动化: 整个模型构建的目标是使其可扩展并准备投入生产。工作流程中许多步骤的自动化简化了操作并有助于避免大规模的错误。测试和元数据提取的自动化减少了人工劳动,并减轻了团队的负担。
如果有人希望将声明式元数据管理提升到一个新的水平,而不是自动提取元数据,那么可以启用元学习,它将推荐特征、算法或新数据集的超参数设置。这再次需要实现元特征的自动计算,并进行相似性查询,以根据这些元特征找到与新数据最相似的数据集。
元数据存储的选择标准
在更详细地讨论元数据存储之前,让我们先看看一些有助于你选择合适的元数据存储的重要特性。
*** 易于集成 - 由于你使用它来简化和加速你的机器学习开发,你应该考虑它与当前流程和工具的集成难易程度。
-
数据追溯管理 - 数据追溯跟踪数据流动。如果你处理实验中流动的各种数据,你应该考虑数据追溯管理的能力。
-
允许数据整理 - 如果你期望数据类型有很大的多样性,那么数据整理将清理和结构化元数据,以便于访问和分析。这确保了数据的质量。另一个需要记住的方面是它还允许直观的查询界面。
-
跟踪特性 - 如果平台允许数据跟踪、代码版本控制、笔记本版本控制和环境版本控制,它将使你可以访问更广泛的元数据,并确保易于重现。
-
可扩展性 - 如果你正在构建你的机器学习模型以投入生产,那么元数据存储的可扩展性成为需要考虑的一个因素。
-
团队协作 - 如果你将与一个大型团队合作,拥有这个功能将变得必要。
-
用户界面 - 最后,拥有一个用户友好的界面确保实验管理的清晰,并被所有团队成员无缝采纳。
元数据存储列表
元数据需要存储以确保实验机器学习模型的可比性和可重复性。常见的元数据包括超参数、特征预处理步骤、模型信息和模型上下文。数据也需要管理。
之前,我们还考虑了选择合适元数据存储时可能考虑的品质。考虑到这些,让我们看看一些广泛使用的元数据存储。
层数据目录
Layer提供了一个集中存储数据集和特征的库,便于系统化构建、监控和评估。Layer 与其他元数据存储的不同之处在于它是一个声明式工具,赋予它提供自动化实体提取和自动化管道的能力。此外,它还提供数据管理、监控和搜索工具等功能。
它的一些功能包括:
数据发现
Layer 提供了强大的搜索功能,方便在遵守授权和治理规则的同时发现数据。它有两个主要的存储库,一个用于数据,另一个用于模型。数据目录管理和版本化数据及功能。
模型目录将所有 ML 模型组织和版本化在集中存储空间中,使得在实验中使用的模型容易回忆。
自动版本控制
随着数据集、模式的变化、文件的删除和管道的中断,自动版本控制帮助创建可重现的 ML 管道。这种实体之间的自动化血统跟踪简化了 ML 工作流,有助于重现实验。
特性存储
特性存储是 Layer 的独特功能。特性被分组到 featuresets 中,使特性更易于访问。这些 featuresets 可以被动态创建、删除、作为值传递或存储。你可以简单地构建特性,Layer 赋予你在线或离线服务它们的权限。
数据质量测试
Layer 通过执行自动化测试确保数据质量。它帮助你创建响应式或自动化管道,使用声明性元数据管理(如前所述)来自动构建、测试和部署数据及 ML 模型。这不仅确保了数据的质量测试,还实现了持续交付和部署。
数据血统
数据由 Layer 严格跟踪和管理。跟踪在版本化和不可变的实体(数据、模型、特性等)之间自动进行。任何时候,都可以重现实验。Layer 还提供了对以前实验的更好理解。
可扩展性
Layer 数据目录的大多数属性与自动化紧密配合。数据集、特性集和 ML 模型也是一流实体,使其在大规模管理生命周期变得容易。Layer 还具有与基础设施无关的管道,支持资源的可扩展性。
简单协作
除了在实验期间通过其功能增强数据团队的能力外,它还可以用于监控实体在生产后的生命周期。其广泛的用户界面支持跟踪漂移、监控变化、版本对比等。
Amundsen
Amundsen 是一个元数据和数据发现引擎。它的一些功能包括:
-
发现可信的数据 - 在组织内部搜索数据非常简单。
-
自动化和策划的元数据 - 通过自动化和策划的元数据建立对数据的信任。也允许预览数据。
-
简单集成和元数据自动化。
-
通过链接生成数据的 ETL 作业和代码,进行简易分类。
-
团队协作 - 你可以轻松与同事分享上下文,并查看他们经常关注的数据或拥有的数据或查找常见查询。
Tensorflow Extended ML Metadata
ML Metadata或 MLMD 是一个库,其唯一目的就是作为元数据存储。它存储并记录元数据,并在需要时通过 API 从存储后端检索。
其一些特性包括:
-
数据沿袭管理 - 与管道组件相关的沿袭信息被存储,并在需要时可以追踪。
-
除了通常存储管道生成的工件的元数据外,它还存储管道执行的元数据。
-
它可以轻松地集成到你的机器学习工作流中。
Kubeflow
Kubeflow不仅提供了元数据存储,还提供了整个企业机器学习工作流的解决方案。
我们现在感兴趣的是 KubeFlow Metadata。它的一些特性包括:
-
易于扩展 - 作为企业机器学习解决方案的 Kubeflow,扩展性扮演了重要角色。
-
版本控制 - 所有元数据和其他工件都受到版本控制。
-
它内置了 Jupyter notebook 服务器,帮助进行数据清理。
-
它可以轻松集成到你的机器学习工作流中。
-
可以在笔记本上记录元数据并进行沿袭跟踪。
Apache Atlas
Apache Atlas的元数据存储提供了一些功能,允许组织管理和治理元数据。它的一些特性包括:
-
数据发现 - 通过类型、分类、属性值或纯文本在直观的用户界面中搜索实体。
-
查看数据沿袭 - 在数据流经管道组件的过程中查看其沿袭信息。
-
你可以动态创建分类,如 SENSITIVE_DATA、EXPIRES_ON 等,并通过沿袭传播这些分类。它会自动确保分类在数据流经组件时保持一致。
-
细粒度元数据安全访问,允许对实体实例进行控制。
Sagemaker
Amazon SageMaker特征存储是一个完全托管的仓库,用于存储、更新、检索和共享机器学习特征。它跟踪存储特征的元数据。
所以如果你希望存储特征的元数据而不是整个管道的元数据,Sagemaker 特征存储是适合你的选择。它的一些其他特性包括:
-
从多个来源摄取数据 - 你可以使用像Amazon SageMaker Data Wrangler这样的数据准备工具创建数据,或者使用像Amazon Kinesis Data Firehose这样的流数据源。
-
数据发现 - 它通过在 SageMaker Studio的可视化界面对元数据进行标记和索引,方便发现。它还允许浏览数据目录。
-
确保功能一致性 - 它允许模型访问相同的元数据和特性集,无论是离线批量训练还是实时推理。
-
标准化 通过将元数据定义存储在一个单一的存储库中消除团队之间的混淆,使每个元数据的定义更加明确。拥有明确定义的数据使得在不同应用中重用元数据变得更容易。
MLflow
MLflow中的元数据存储被称为MLflow Tracking。它记录和查询来自实验的代码、数据、配置和结果。
MLflow 在运行机器学习代码时记录参数、代码版本、指标、键值输入参数等,之后 API 和 UI 也帮助可视化结果。它的一些功能包括:
-
输出文件可以以任何格式保存。例如,你可以将图像(PNG)、模型(Pickled sci-kit-learn 模型)和数据文件(Parquet 文件)记录为工件。
-
它可以将运行组织和记录到实验中,这些实验将特定任务的运行分组在一起。
-
你可以选择记录运行的位置。它可以被记录在本地(默认)、数据库或 HTTP 服务器。
-
MLflow 提供自动记录功能。这个特性通过不依赖显式的记录语句来简化记录指标、参数和模型等元数据。
最后的思考
不可否认的是,数据在机器学习领域的重要性。一个拥有所有必要数据的元数据存储无疑是重要的。根据不同的业务需求,合适的元数据存储可能因组织而异。
我已经总结了我们之前讨论的七个元数据存储。我希望这能给你一个关于一些著名元数据存储的概述,并促使你找到合适的存储。这个结论纯粹基于元数据存储文档中的信息。
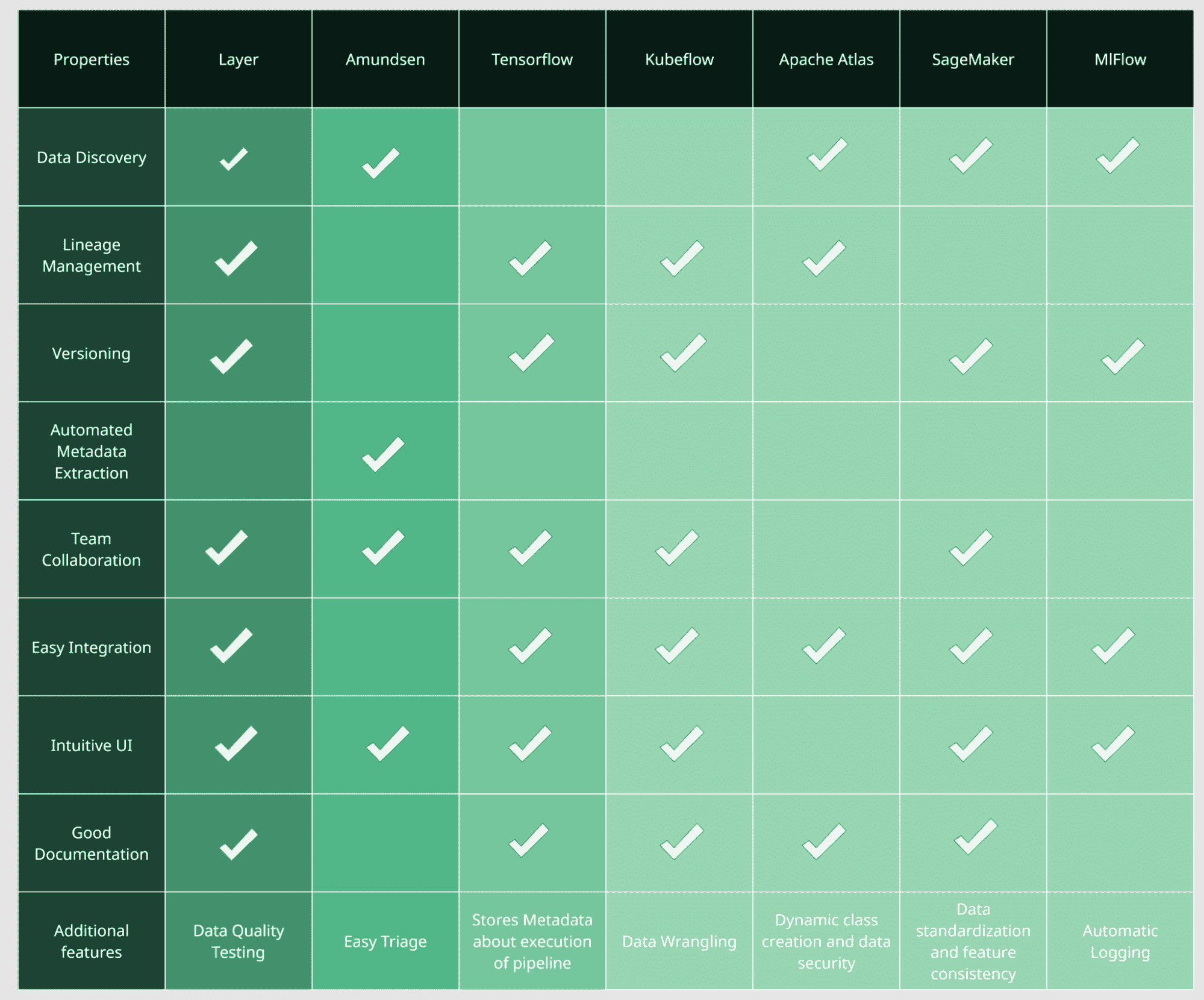
进一步阅读
Akruti Acharya 是伯明翰大学的技术内容撰稿人和研究生
更多相关话题
机器学习模型部署
原文:
www.kdnuggets.com/2020/09/machine-learning-model-deployment.html
评论
由 Asha Ganesh,数据科学家

机器学习模型无服务器部署
什么是无服务器部署
无服务器计算是云计算的下一步。这意味着服务器在画面中被隐藏了。在无服务器计算中,服务器和应用程序的分离是通过使用平台来管理的。平台或无服务器提供者的责任是管理应用程序的所有需求和配置。这些平台在幕后管理服务器的配置。这就是在无服务器计算中,用户可以简单地专注于构建或部署的应用程序或代码本身的方式。
机器学习模型部署与软件开发不完全相同。在机器学习模型中,需要不断输入新数据以保持模型的良好性能。模型需要在现实世界中进行调整,因为有各种原因,如添加新类别、新级别等。部署模型只是开始,因为模型往往需要重新训练并检查其性能。因此,使用无服务器部署可以节省时间和精力,并且每次重新训练模型,这很酷!
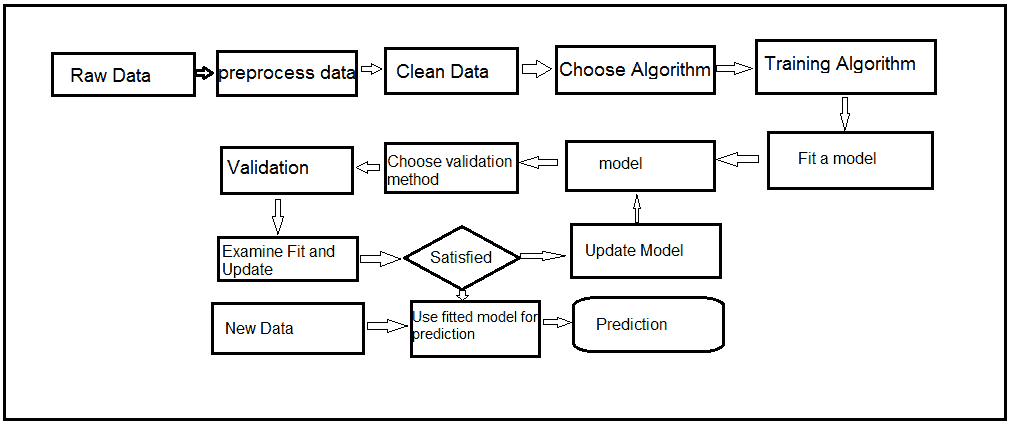
机器学习工作流
模型在生产环境中的表现比在开发环境中差,需要在部署中寻找解决方案。因此,通过无服务器部署部署机器学习模型是很简单的。
理解无服务器部署的先决条件
-
对云计算的基本理解
-
对云函数的基本理解
-
机器学习
预测的部署模型
我们可以通过三种方式部署我们的机器学习模型:
-
像 Flask 和 Django 这样的网页托管框架等
-
无服务器计算 AWS Lambda、Google Cloud Functions、Azure Functions
-
特定于云平台的框架,如 AWS Sagemaker、Google AI Platform、Azure Functions
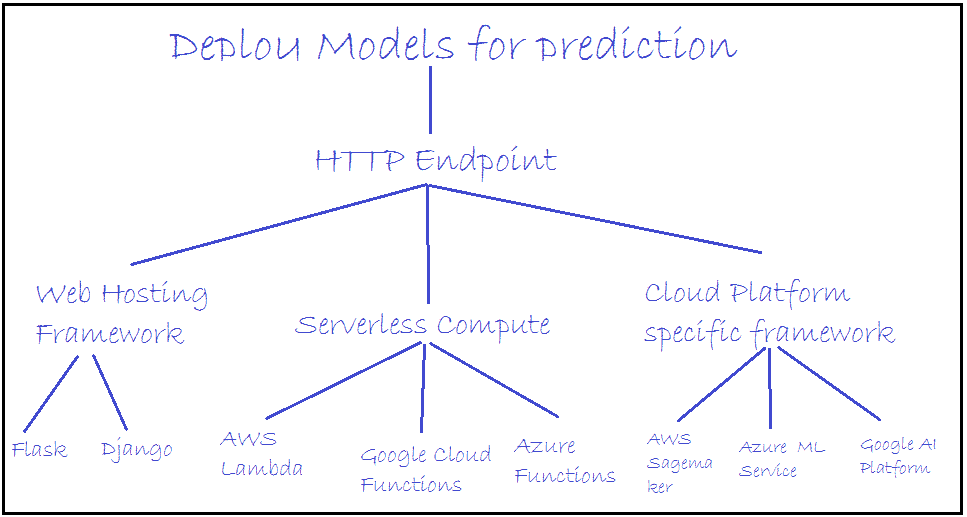
以各种方式部署模型
无服务器部署架构概述
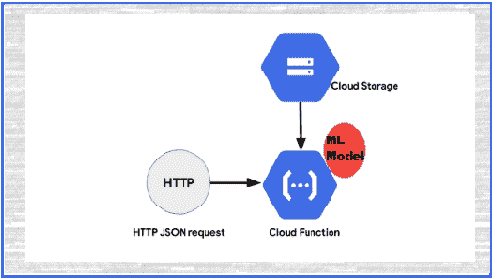
图片来源并修改自 Google Cloud
将模型存储在 Google Cloud Storage 存储桶中,然后编写 Google Cloud Functions。使用 Python 从存储桶中检索模型,通过 HTTP JSON 请求,我们可以在 Google Cloud Function 的帮助下获得给定输入的预测值。
开始模型部署的步骤
1. 关于数据、代码和模型
以电影评论数据集进行情感分析,解决方案见这里在我的 GitHub 代码库中,数据也可以在同一代码库中找到。
2. 创建存储桶
通过执行“ServerlessDeployment.ipynb”文件,你将获得 3 个 ML 模型:DecisionClassifier、LinearSVC 和 Logistic Regression。
点击 Storage 选项中的浏览器,创建新桶,如图所示:
创建存储桶
3. 创建新函数
创建一个新桶,然后创建一个文件夹,并通过创建 3 个子文件夹将 3 个模型上传到该文件夹中,如图所示。
这里models是我的主文件夹名,我的子文件夹有:
-
decision_tree_model
-
linear_svc_model
-
logistic_regression_model
在 Google 存储中将模型存储在 3 个文件夹中
4. 创建函数
然后前往 Google Cloud Functions 并创建一个函数,选择触发器类型为 HTTP,选择语言为 Python(你可以选择任何语言):
创建云函数
5. 在编辑器中编写云函数
在我的代码库中检查云函数。在这里,我已经导入了从 Google Cloud Bucket 调用模型所需的库,以及用于 HTTP 请求的其他库。
-
GET 方法用于测试 URL 响应,POST 方法
-
删除默认模板并粘贴我们的代码,然后pickle用于反序列化我们的模型
-
google.cloud — 访问我们的云存储功能。
-
如果传入请求是GET,我们仅返回“欢迎使用分类器”
-
如果传入请求是POST,则访问请求体中的 JSON 数据
-
GET JSON 实例化存储客户端对象并从存储桶中访问模型;在这里,我们的存储桶中有 3 个分类模型
-
如果用户指定“DecisionClassifier”,我们会从相应的文件夹中访问该模型,与其他模型类似
-
如果用户未指定任何模型,默认模型为 Logistic Regression
-
blob 变量包含对 model.pkl 文件的引用,以获取正确的模型
-
我们将 .pkl 文件下载到运行该云函数的本地机器上。现在每次调用可能在不同的虚拟机上运行,我们只能访问虚拟机上的 /temp 文件夹,这就是我们保存 model.pkl 文件的原因
-
我们通过调用 pkl.load 反序列化模型,以访问传入请求中的预测实例,并在预测数据上调用 model.predict
-
从无服务器函数返回的响应是原始文本,即我们要分类的评论和我们的预测类
-
在 main.py 后编写 requirement.txt,包含所需的库和版本
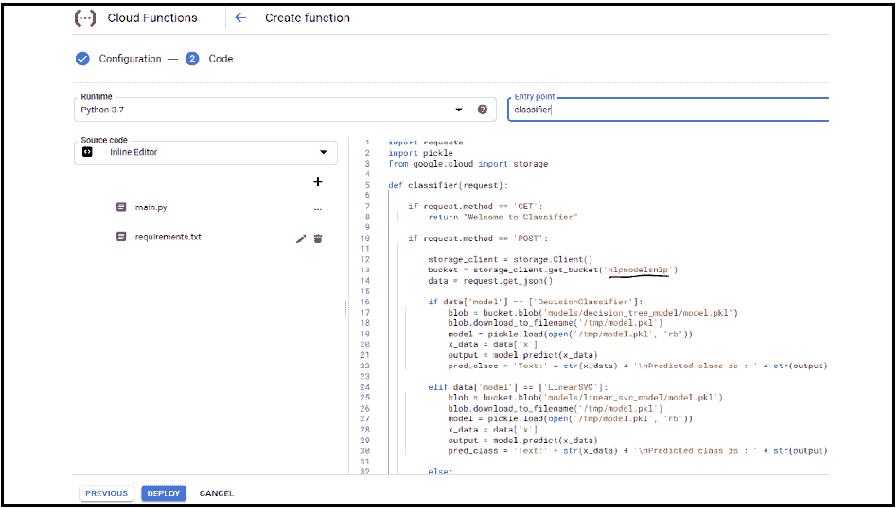
谷歌云函数(图像不清晰,但为了理解目的在此提及)
6. 部署模型

绿色勾选表示模型部署成功
7. 测试模型
提供模型名称和测试的评价
用其他模型测试功能。
将为你提供该模型部署的完整 UI 细节。
代码参考:
我的 GitHub 仓库:github.com/Asha-ai/ServerlessDeployment
不要犹豫,尽情点赞 😃
简介:Asha Ganesh 是一名数据科学家。
原文。经授权转载。
相关:
-
使用 Python 和 Heroku 创建并部署你的第一个 Flask 应用
-
为什么要将 Scikit-learn 放入浏览器?
-
停止训练更多模型,开始部署它们
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
更多相关话题
机器学习模型开发与模型操作:原则与实践
原文:
www.kdnuggets.com/2021/10/machine-learning-model-development-operations-principles-practice.html
评论
由 Suresh Yaram, DXC Technology 首席解决方案架构师
1. 引言
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
机器学习(ML)的使用在企业数据分析场景中显著增加,以从业务数据中提取有价值的洞见。因此,在生产环境中建立、测试、部署和维护企业级机器学习模型的生态系统非常重要。ML 模型开发涉及从多个可信来源获取数据、处理数据以适合构建模型、选择算法构建模型、建立模型、计算性能指标并选择最佳性能模型。一旦模型部署到生产中,模型维护扮演了关键角色。机器学习模型的维护包括使模型保持最新,并与源数据变化保持相关,因为模型有过时的风险。此外,随着模型数量的增加,ML 模型的配置管理在模型管理中也发挥着重要作用。本文重点介绍原则和行业标准实践,包括在企业环境中用于 ML 模型开发、部署和维护的工具和技术。
2. 模型开发
机器学习(ML)模型生命周期 指的是从源数据识别到模型开发、模型部署和模型维护的整个过程。从高层次看,所有活动大致分为两个主要类别,如 ML 模型开发和 ML 模型操作。
机器学习(ML)模型开发 包括图 1 中提到的一系列步骤。
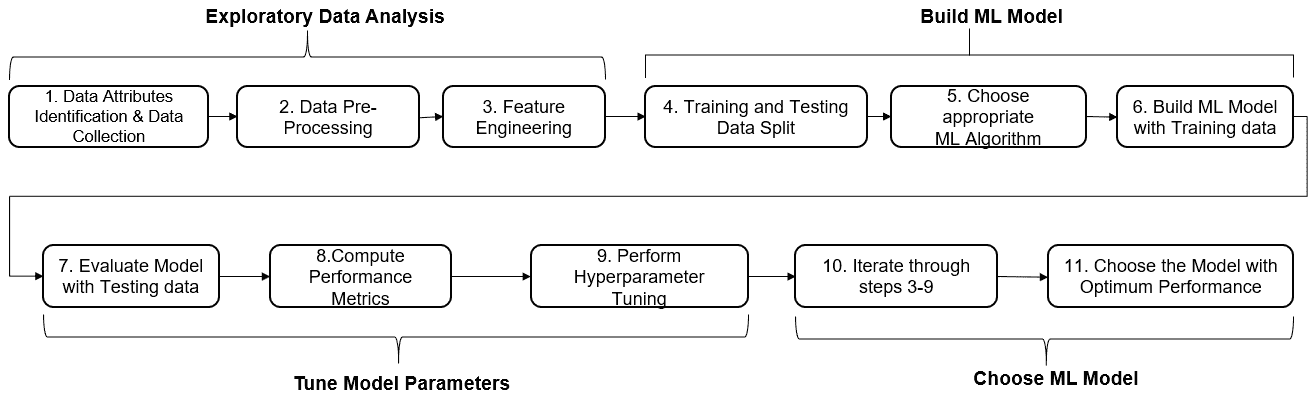
图 1: 机器学习(ML)模型开发生命周期
ML 模型开发生命周期步骤大致可以分为:数据探索、模型构建、模型超参数调整和性能最优的模型选择。
探索性数据分析是一个重要的步骤,它在商业假设准备好后开始。这个步骤占据了整个项目时间的 40-50%,因为模型的结果依赖于输入数据的质量。探索性数据分析涉及数据属性识别、数据预处理和特征工程。属性识别包括预测变量/特征变量(输入)和目标/分类变量(输出)的识别,以及其数据类型(字符串、数值或日期时间),并将特征分类为类别变量和连续变量,这有助于在构建模型时算法对变量进行适当的处理。数据预处理包括识别缺失值和异常值,并通过计算定量属性的均值或中位数以及定性属性的众数来填补这些空缺,以提高模型的预测能力。异常值会导致均值和标准差的增加,通过取自然对数值可以消除这些异常值,从而减少极端值引起的变异。
特征工程是探索性数据分析中的下一个重要步骤,在此过程中,原始数据集被处理以将字符串、日期时间或数值类型的数据转换为数值向量,以便机器学习算法理解并构建高效的预测模型。此外,带标签的类别数据(例如,颜色:红色、绿色、蓝色;表现:差、一般、好、非常好、优秀;风险:低、中、高;状态:已开始、进行中、暂停、已关闭;性别:男性/女性;是否批准贷款/是否欺诈索赔:是/否)在机器学习算法中不能被正确理解,因此需要转换为数值数据。特征编码是将类别数据转换为连续(数值)值的广泛使用的技术,例如,将颜色编码为 1、2、3;表现编码为 1、2、3、4、5;风险编码为 1、2、3;状态编码为 1、2、3、4;性别/是否批准贷款/是否欺诈索赔编码为 0/1 等。推荐在类别变量没有顺序关系的情况下使用标签编码(例如,颜色和状态),在类别变量有顺序关系的情况下使用有序编码(例如,表现、风险),在类别变量数据是二元性质的情况下使用独热编码(例如,性别、是否批准贷款、是否欺诈索赔)。在 R 或 Python 中有一系列库可用于实现这些编码方法。在某些情况下,尤其是在处理“日期”数据类型时,会创建一组虚拟变量或派生变量。一旦将类别文本数据转换为数值数据,数据就可以输入到模型中;最后一步是选择适当的特征,以帮助提高模型的准确性,使用的方法包括单变量选择(统计度量)、特征重要性(模型属性)和相关矩阵(识别哪些特征与目标变量最相关)。这些方法检测两个变量之间的共线性,即它们高度相关并包含关于给定数据集中的方差的相似信息。可以使用方差膨胀因子(VIF)来检测多重共线性,其中三个或更多高度相关的变量被纳入模型中。探索性数据分析中的关键点在下图(图 2)中表示。
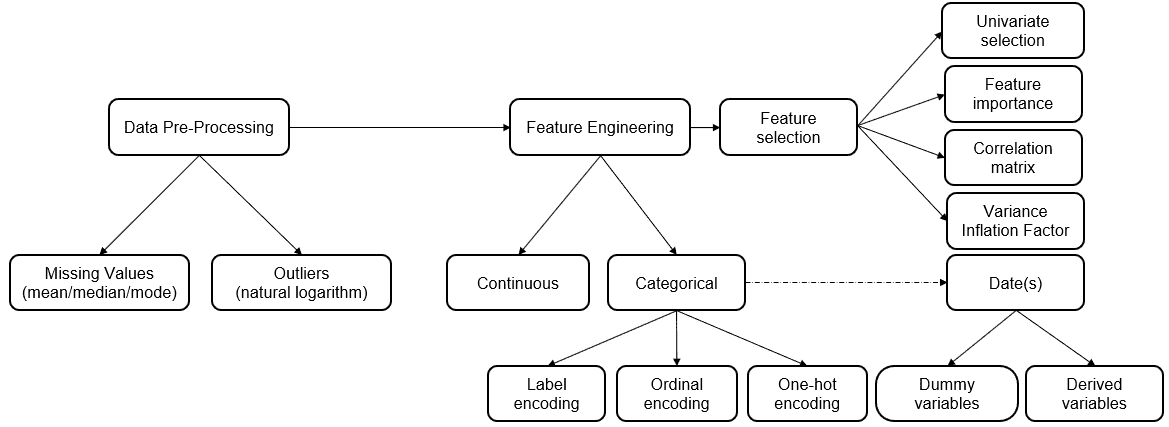
图 2: 探索性数据分析
构建机器学习模型 需要将数据分为两组,例如按 80:20 或 70:30 的比例分为“训练集”和“测试集”;根据输入数据的性质和业务结果的预测,可以选择一组监督(用于有标签数据)和无监督(用于无标签数据)算法。如果是有标签数据,如果预测的结果是二元(0/1)性质,建议选择逻辑回归算法;如果预测的结果是多类(1/2/3/...)性质,则选择决策树分类器(或)随机森林®分类器(或)KNN;如果预测的结果是连续性数据,则选择线性回归算法(例如,决策树回归器、随机森林回归器)。对于无标签/非结构化(文本)数据,建议使用聚类(无监督)算法(例如,k-means 聚类)。建议使用人工神经网络(ANN)算法来分析其他非结构化(图像/语音)数据类型,例如用于图像识别的卷积神经网络(CNN)和用于语音识别及自然语言处理(NLP)的递归神经网络(RNN)。模型使用训练数据集进行构建,并使用测试数据集进行预测。相比回归模型(机器学习模型),推荐使用深度学习(神经网络)模型来获得更好的性能,因为这些模型通过引入激活函数(AF)增加了额外的非线性层。不同场景下的算法选择在图 3 中表示,如下所示。
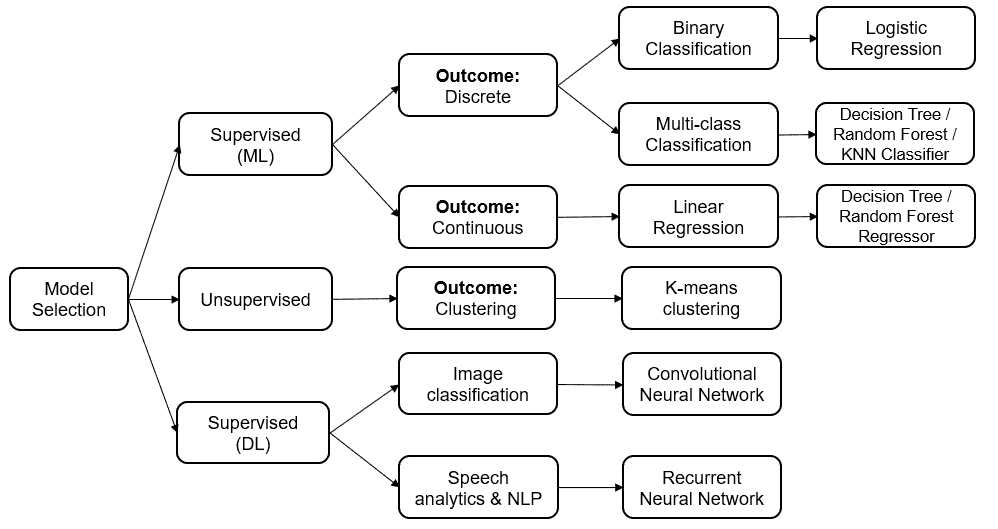
图 3: 选择正确的算法
模型性能计算 是选择正确模型的下一个逻辑步骤。模型性能指标将决定最终模型选择,包括计算准确性、精确度、召回率、F1 分数(精确度和召回率的加权平均),以及分类模型的混淆矩阵和回归模型的决定系数。对于用不平衡/偏斜数据集训练的分类模型,不建议使用准确性作为衡量标准,而是建议计算精确度和召回率,以选择正确的分类模型。
模型超参数调优 是流程中非常推荐的步骤,持续进行直到模型性能达到大约 80%-85%。例如,随机森林算法使用最大深度、最大特征数、树的数量等作为超参数,这些可以直观地调整以提高模型准确性。类似地,神经网络算法使用层数、批量大小、训练轮数、样本数量等。建议使用网格搜索方法来寻找模型的最佳超参数,以获得最‘准确’的预测。此外,还推荐进行交叉验证,因为模型准确性的提升有时可能由于过拟合(模型过于敏感,无法泛化)或欠拟合(模型过于泛化),使用 k 折交叉验证技术可以解决这一问题。为了避免过拟合,可以增加训练数据样本量以引入更多模式,或减少特征数量以避免复杂性,或使用岭回归和套索回归方法进行数据正则化以减少误差/惩罚。同样,为了避免欠拟合,可以增加模型复杂性,例如从线性模型转为非线性模型,或为神经网络添加更多隐藏层(训练轮次),或添加更多特征以引入隐藏模式。然而,增加数据量并不能解决欠拟合问题,反而会影响模型性能。
最后,选择性能最佳的模型。
机器学习模型开发最佳实践: 推荐的机器学习模型开发最佳实践包括:(1)在属性识别之前,针对已识别的业务问题制定明确的假设;(2)首先使用基础算法构建模型,例如逻辑回归或决策树,并编译性能指标,这可以在使用更复杂的算法(如神经网络)之前,提供足够的数据相关性信心;(3)在构建模型过程中保持中间检查点,以跟踪模型超参数及其相关性能指标,这可以使模型逐步训练,并在性能与训练时间之间做出良好判断;(4)使用真实生产数据进行模型训练,以提高预测的正确性。
模型操作
机器学习 (ML) 模型操作 指的是实施过程以维护生产环境中的 ML 模型。在典型企业场景中,常见的挑战是实验室环境中的 ML 模型在很多情况下停留在概念验证阶段。如果模型被推出到生产环境中,它会因为频繁的数据源变化变得过时,这需要重新构建模型。由于模型会被多次重新训练,需要跟踪模型性能及用于重新训练模型的相应特征和超参数。为了执行所有这些操作,应当有一个定义明确的可重复过程来实现端到端的机器学习操作 (MLOps),以保持模型在生产环境中的最新和准确。ML 模型操作生命周期过程如图 4 所示,涵盖了从模型开发到模型部署,再到模型性能监控的整个过程,确保其无缝衔接。
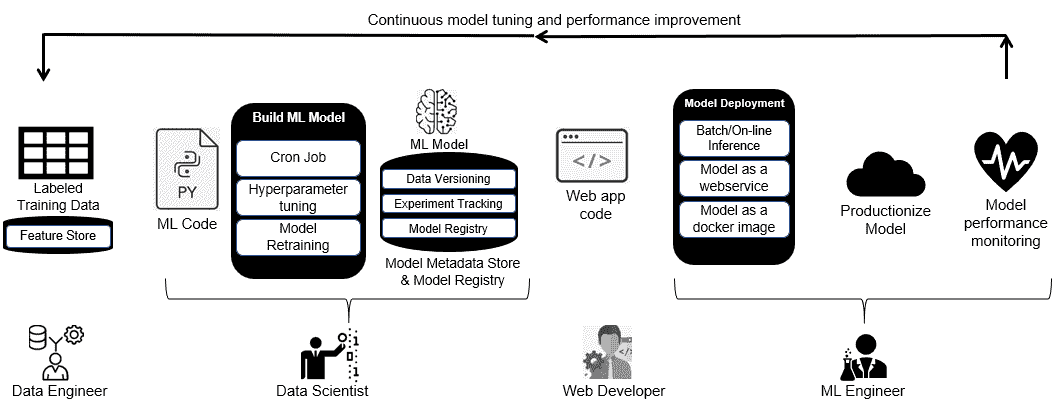
图 4: 机器学习 (ML) 模型操作生命周期
定期重新训练模型非常重要,例如每两周、每月、每季度或按需进行,因为在实际场景中,底层数据源很可能会随着时间发生变化。可以通过定时任务在预定的间隔时间内重新训练模型,或者在数据源变化时,或在模型性能下降时重新训练模型。模型代码可能会因超参数调整而有所变化,因此需要通过自动化模型管道来自动化这些模型操作。
在企业生产环境中,典型的自动化模型管道包括 3 种类型的存储,例如特征存储、元数据存储和模型注册中心。特征存储包含从各种源系统提取的数据,并转换为模型所需的特征。机器学习管道从特征存储中批量获取数据以训练模型。元数据存储是一个集中式模型跟踪(记录)系统,在企业级维护,包含管道每个阶段的模型元数据。模型元数据存储促进模型阶段的过渡,例如从暂存到生产到归档。模型训练在一个环境中进行,而部署在另一个环境中进行,只需指定远程模型文件路径即可执行模型推断。模型元数据存储用于跟踪模型实验并根据其性能比较模型实验。模型元数据包括训练数据集版本、训练运行和实验的链接。模型注册中心包含所有训练模型的数据,如训练模型版本、模型训练日期、模型训练指标、用于训练模型的超参数、预测结果和诊断图表(混淆矩阵、ROC 曲线)。将根据目标用户的需求从模型注册中心中选择适当的模型。模型元数据存储和模型注册中心可以使用轻量级数据库(如 SQLite)和一组 python 函数,或一组开源/专有产品(如 MLflow(社区版/Databricks 提供的托管服务))来实现。该工具提供了通过 GUI 或一组 API 管理模型的功能。
模型部署: 模型可以在生产环境中进行部署,以执行批量推断模式或在线推断模式。批量推断可以通过安排任务在特定时间间隔运行,并通过电子邮件将结果发送给目标用户来实现。在线推断可以通过将模型公开为网络服务来实现,使用如 python flask 库或 streamlit 库来开发交互式 Web 应用程序,并通过 HTTP 端点调用模型。
模型打包/分发: 训练好的机器学习模型被序列化成各种格式,以便将模型分发到 TEST/PROD 环境中进行部署。最常见的格式有 pickle(用于在 python 中开发的机器学习或深度学习模型)、ONNX(开放神经网络交换格式,用于深度学习模型)和 PMML(预测模型标记语言基于 XML 的格式,专门用于使用逻辑回归和神经网络开发的模型)。模型可以打包为 .jar 文件或 docker 容器镜像,并作为预测服务部署到生产环境中。
模型容器化可以通过构建一个包含训练和推理代码的 Docker 镜像来实现,并且将必要的训练和测试数据以及模型文件一起打包以用于未来的预测。一旦创建了包含必要机器学习模型的 Docker 文件,就可以使用诸如 Jenkins 之类的工具构建 CI/CD 流水线。这个 Docker 容器镜像可以作为 REST API 进行暴露,以便任何外部利益相关者都可以从本地或公共云(在构建深度学习模型时计算需求较高的情况下)访问这个机器学习模型。在包装和管理多个 Docker 容器的情况下,可以使用 Kubeflow,这是一个适用于 Kubernetes 的机器学习工具包。
模型性能监控是一项重要活动,其中预测结果(例如,项目的预测销售价格)与实际值(实际销售价格)会持续进行监控。同时建议了解最终预测的最终用户反应。在某些场景下,建议保持旧模型和新模型并行运行,以了解两种模型的性能变化(模型验证)。必须解决由于“数据漂移”(由于季节性和趋势导致的底层源数据模式变化,例如年终销售数据(或)新增类别(或)某个属性未由上游系统生成)和“模型漂移”(目标变量的统计属性变化,例如欺诈交易的定义本身发生变化)而导致的性能下降。测量模型漂移的最准确方法是通过测量 F1 分数,该分数将分类器的精确度和召回率结合成一个单一指标,并取其调和均值。模型会在模型漂移(F1 分数)低于某个阈值时,或在定期间隔(批处理模式)时,或一旦数据可用时(在线训练)进行重新训练。使用流行的日志记录工具如 elasticstack 和 fluentd 来收集模型日志和预测日志是非常重要的。
模型版本管理是机器学习模型管理中的一项强制性活动,因为模型会由于底层源数据的变化或审计和合规要求定期进行重新训练。源数据、模型训练脚本、模型实验和训练好的模型都在代码仓库中进行版本管理。现在有一些开源工具可用,如数据版本控制(Data Version Control,DVC)或 AWS CodeCommit,它们使用 Git 作为底层代码仓库来进行模型版本管理。
ML 项目开发角色: 在实现 ML 模型开发和操作过程中涉及各种角色。数据工程师分析来自不同来源的业务数据,确保以成本有效的方式访问正确且最新的数据,且数据具有所需的粒度和质量。数据科学家查看数据,进行数据预处理和特征工程、模型构建,并选择最符合业务预测/处方要求的模型。通常,数据科学家采用基于假设的方法选择适合要求的模型。ML 工程师确保构建的模型可靠地提供结果,并通过监控结果来评估是否需要重新训练模型。Web 应用开发人员构建所需的展示层组件,以调用和向相关利益相关者展示结果。ML 项目还需要 DevOps 工程师以实现持续交付,并需要数据可视化专家以生成精美的仪表板。
ML 模型部署最佳实践: 推荐的模型部署最佳实践是 (1) 自动化 ML 模型开发和部署所需的步骤,通过利用 DevOps 工具为模型重新训练提供额外的时间;(2) 在生产部署后执行持续的模型测试、性能监控和重新训练,以保持模型的相关性/当前性,因为源数据的变化可能会影响预测结果;(3) 在将 ML 模型暴露为 API 时实现日志记录,包括捕获输入特征/模型输出(以跟踪模型漂移)、应用上下文(用于调试生产错误)、模型版本(如果生产中部署了多个重新训练的模型);(4) 在单一存储库中管理所有模型元数据。
简介: 苏雷什·亚拉姆 在一家 IT 公司(DXC Technology,前身为 CSC India Limited)担任首席解决方案架构师。苏雷什拥有 20 多年的 IT 经验,专注于数据架构、大数据分析、人工智能和机器学习。他参与了为客户在银行、金融和保险等多个领域构建数据与分析解决方案,包括针对保险行业场景的 AI/ML,并在 DXC 的各种技术论坛上进行了展示。苏雷什还在印度举行的 IEEE 数据科学会议上发表了一篇 论文。
相关:
-
部署机器学习模型到生产环境的不同方法概述
-
MLOps 概述
-
MLOps 是一门工程学科:初学者概述
更多相关内容
如何轻松检查您的机器学习模型是否公平?
原文:
www.kdnuggets.com/2020/12/machine-learning-model-fair.html
评论
由Jakub Wiśniewski撰写,数据科学学生及 MI2 DataLab 的研究软件工程师。

我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
照片由Eric Krull拍摄,刊登于Unsplash。
我们生活在一个日益分裂的世界中。在世界的某些地方,种族、民族以及有时性别之间的差异和不平等正在加剧。我们用于建模的数据在很大程度上反映了其来源的世界。而这个世界可能存在偏见,因此数据和模型也可能反映这种偏见。我们提出了一种方法,ML 工程师可以轻松检查他们的模型是否存在偏见。我们的公平性工具目前仅适用于分类模型。
案例研究
为了展示dalex 公平性模块的功能,我们将使用著名的[德国信用数据集](https://archive.ics.uci.edu/ml/datasets/statlog+(german+credit+data)为每个信用申请者分配风险。这一简单任务可能需要使用可解释的决策树分类器。
一旦我们有了dx.Explainer,我们需要执行方法model_fairness(),以便它可以计算protected向量中子组的所有必要指标,该向量是一个包含性别、种族、国籍等敏感属性的数组或列表,适用于每个观察(个体)。除此之外,我们还需要指出哪个子组(即protected中的唯一元素)是最有特权的,这可以通过privileged参数来完成,在我们的案例中,将是年长男性。
这个对象有很多属性,我们不会逐一介绍它们。更详细的概述可以在这个tutorial中找到。相反,我们将重点关注一种方法和两个图表。
那么,我们的模型是否存在偏见?
这个问题很简单,但由于偏差的性质,回答是:这要看情况。但这种方法从不同的角度来衡量偏差,以确保没有偏差模型可以通过。要检查公平性,必须使用fairness_check()方法。
fobject.fairness_check(epsilon = 0.8) # default epsilon
以下部分是上述代码的控制台输出。
Bias detected in 1 metric: FPR
Conclusion: your model cannot be called fair because 1 metric score exceeded acceptable limits set by epsilon.
It does not mean that your model is unfair but it cannot be automatically approved based on these metrics.
Ratios of metrics, based on 'male_old'. Parameter 'epsilon' was set to 0.8 and therefore metrics should be within (0.8, 1.25)
TPR ACC PPV FPR STP
female_old 1.006508 1.027559 1.000000 0.765051 0.927739
female_young 0.971800 0.937008 0.879594 0.775330 0.860140
male_young 1.030369 0.929134 0.875792 0.998532 0.986014
在指标 FPR(假正率)中发现了偏差。上面的输出表明,该模型不能被自动批准(如上所述)。所以决定权在用户手中。在我看来,这不是一个公平的模型。较低的 FPR 表明特权子群体比不利子群体更频繁地出现假正例。
更多关于fairness_check()的内容
我们获得了有关偏差、结论和指标比率的原始 DataFrame 数据。这里有指标 TPR(真正率)、ACC(准确率)、PPV(正预测值)、FPR(假正率)、STP(统计公平性)。这些指标来源于每个不利子群体的混淆矩阵,然后将其除以基于特权子群体的指标值。可能的结论有 3 种类型:
# not fair
Conclusion: your model is not fair because 2 or more metric scores exceeded acceptable limits set by epsilon.
# neither fair or not
Conclusion: your model cannot be called fair because 1 metric score exceeded acceptable limits set by epsilon.It does not mean that your model is unfair but it cannot be automatically approved based on these metrics.
# fair
Conclusion: your model is fair in terms of checked fairness metrics.
一个真正公平的模型不会超过任何指标,但当真实值(目标)依赖于敏感属性时,情况就变得复杂,并超出了本博客的范围。简而言之,一些指标可能不会相等,但它们不一定会超过用户的阈值。如果你想了解更多,我强烈建议查阅公平性与机器学习这本书,特别是第二章。
但有人可能会问,为什么我们的模型不公平,我们依据什么做出判断?
这个问题的答案很棘手,但判断公平性的方法似乎是目前最好的。通常,每个子群体的分数应该接近特权子群体的分数。用更数学的角度来看,特权指标和不利指标分数之间的比率应该接近 1。越接近 1,模型越公平。但为了稍微放宽这一标准,可以更有思考地表述:
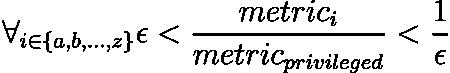
其中,epsilon 是一个介于 0 和 1 之间的值,应该是比率的最小可接受值。默认情况下,它是 0.8,这符合在招聘中常用的four-fifths规则(80% 规则)。很难找到一个非任意的公平与歧视差异之间的界限,并且检查指标的比率是否恰好为 1 是没有意义的,因为如果比率是 0.99 呢?这就是为什么我们决定选择 0.8 作为默认值epsilon,因为它是唯一已知的可作为可接受歧视量的具体阈值。当然,用户可以根据需要更改此值。
偏差也可以被绘制出来。
提供了两种偏见检测图(不过,包中还有更多可视化偏见的方法)
-
fairness_check— fairness_check() 方法的可视化
-
metric_scores— metric_scores 属性的可视化,它是度量的原始分数。
类型只需传递给plot方法的type参数。
fobject.plot()
上图显示了与公平检查输出类似的内容。度量名称已更改为更标准的公平等价物,但公式指明了我们所指的度量。查看上图,直观上很简单——如果条形图进入了红色区域,则意味着度量超过了基于 epsilon 的范围。条形图的长度等同于|1-M|,其中 M 是特权度量分数除以非特权度量分数(就像在之前的公平检查中一样)。
fobject.plot(type=’metric_scores’)
度量分数图与公平检查图相结合,可以很好地理解度量和它们的比率。这里的点是原始(未划分)度量分数。垂直线象征着特权度量分数。离那条线越近,越好。
多个模型可以放入一个图中,以便它们可以彼此轻松比较。让我们添加一些模型并可视化metric_scores:
上述代码的输出。
现在让我们检查基于fairness_check的图:
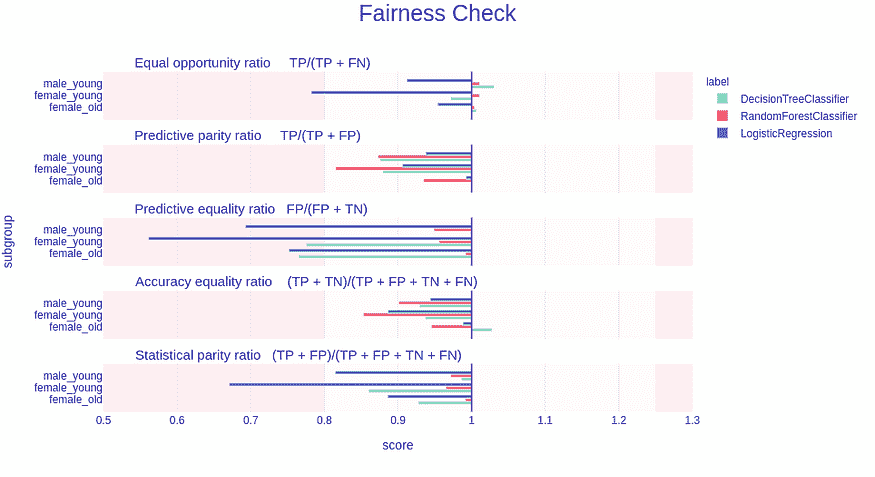
我们可以看到RandomForestClassifier在绿色区域内,因此在这些度量方面是公平的。另一方面,LogisticRegression在三个度量中进入红色区域,因此不能被称为公平。
每个图都是交互式的,使用 Python 可视化包plotly制作。
总结
dalex中的公平性模块是一种统一和可访问的方法,以确保模型的公平性。还有其他可视化模型偏见的方法,务必查看一下!未来将添加偏见缓解方法。长期计划是添加对个体公平性和回归公平性的支持。
一定要查看一下。你可以通过以下命令安装 dalex:
pip install dalex -U
如果你想了解更多关于公平性的信息,我强烈推荐:
-
关于R 包更新的博客
-
关于使用dalex 公平性模块的教程
原文。转载经许可。
相关:
了解更多相关话题
机器学习模型解释
原文:
www.kdnuggets.com/2021/06/machine-learning-model-interpretation.html
评论
Himanshu Sharma,生物信息学数据分析师
树(来源: 作者)
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
解释机器学习模型是一项困难的任务,因为我们需要了解模型在后台如何工作、模型使用了哪些参数以及模型是如何生成预测的。有不同的 Python 库可以用来创建机器学习模型的可视化并分析模型的工作情况。
创建仪表板以解释机器学习模型
Skater 是一个开源 Python 库,能够对不同类型的黑箱模型进行机器学习模型解释。它帮助我们创建不同类型的可视化,使我们更容易理解模型的工作原理。
在这篇文章中,我们将探索 Skater 及其不同的功能。让我们开始吧……
安装所需的库
我们将开始使用 pip 安装 Skater。以下命令将使用 pip 安装 Skater。
!pip install -U skater
导入所需库
下一步将是导入所需的库。要使用 Skater 解释模型,我们首先需要创建一个模型。
%matplotlib inline
import matplotlib.pyplot
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection
import train_test_split from sklearn.ensemble
import RandomForestClassifier
from sklearn import datasets
from sklearn import svm
from skater.core.explanations import Interpretation
from skater.model import InMemoryModel
from skater.core.global_interpretation.tree_surrogate
import TreeSurrogate
from skater.util.dataops import show_in_notebook
创建模型
我们将创建一个随机森林分类器并使用 IRIS 数据集。
iris = datasets.load_iris()
digits = datasets.load_digits()
X = iris.data
y = iris.target
clf = RandomForestClassifier(random_state=0, n_jobs=-1)
xtrain, xtest, ytrain, ytest = train_test_split(X,y,test_size=0.2, random_state=0)
clf = clf.fit(xtrain, ytrain)
y_pred=clf.predict(xtest)
prob=clf.predict_proba(xtest)
from skater.core.explanations import Interpretation
from skater.model import InMemoryModel
from skater.core.global_interpretation.tree_surrogate import TreeSurrogate
from skater.util.dataops import show_in_notebook
interpreter = Interpretation(
training_data=xtrain, training_labels=ytrain, feature_names=iris.feature_names
)
pyint_model = InMemoryModel(
clf.predict_proba,
examples=xtrain,
target_names=iris.target_names,
unique_values=np.unique(ytrain).tolist(),
feature_names=iris.feature_names,
)
创建可视化
我们将开始创建不同的可视化图,以帮助我们分析我们创建的模型的工作情况。
1. 部分依赖图
该图显示了某个特征如何影响模型的预测。
interpreter.partial_dependence.plot_partial_dependence(
['sepal length (cm)'] , pyint_model, n_jobs=-1, progressbar=**False**, grid_resolution=30, with_variance=**True**,figsize = (10, 5)
)
PDP 图(来源: 作者)
2. 特征重要性
在这个图中,我们将分析我们创建的模型中各个特征的重要性。
plots = interpreter.feature_importance.plot_feature_importance(pyint_model, ascending=True, progressbar=True,
n_jobs=-1)
特征重要性(来源:作者)
3. 替代树
这是我们创建的随机森林模型的图示表示。在每一步中,它显示了基尼指数值、类别等。
surrogate_explainer = interpreter.tree_surrogate(oracle=pyint_model, seed=5)
surrogate_explainer.fit(xtrain, ytrain)
surrogate_explainer.plot_global_decisions(show_img=True)
替代树(来源: 作者)
这是我们如何使用 Skater 创建不同图表的示例,这些图表帮助我们分析模型的表现。请尝试使用不同的数据集,并在评论区告诉我你的反馈。
本文与 Piyush Ingale 合作完成
在你离开之前
感谢你阅读!如果你想与我联系,可以随时通过 hmix13@gmail.com 或我的LinkedIn 个人主页与我取得联系。你还可以查看我的Github个人主页,了解不同的数据科学项目和包教程。同时,欢迎你浏览我的个人主页,阅读我撰写的与数据科学相关的不同文章。*
个人简介: Himanshu Sharma 是 MEDGENOME 的生物信息学数据分析师。Himanshu 是数据科学爱好者,拥有分析数据集、创建机器学习和深度学习模型的实际经验。他曾为不同组织创建各种数据科学项目和概念验证。他在创建用于图像识别和物体检测的 CNN 模型以及用于时间序列预测的 RNN 模型方面拥有丰富的经验。Himanshu 是一名活跃的博主,已在数据科学领域发表了约 100 篇文章。
原文。已获得许可重新发布。
相关:
-
自动化机器学习模型优化
-
可解释增强机器
-
可解释性、解释性与机器学习——数据科学家需要了解的内容
更多相关话题
机器学习模型管理
原文:
www.kdnuggets.com/2022/07/machine-learning-model-management.html

Alvaro Reyes via Unsplash
当你想到机器学习时,你会想到模型。这些模型需要有效的管理,以确保它们产生解决特定问题或任务所需的输出。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织进行 IT
机器学习模型管理用于帮助数据科学家、机器学习工程师等跟踪和管理他们的所有实验及模型生成的结果。机器学习模型管理的唯一职责是确保 ML 模型的开发、训练、版本管理和部署在有效水平上进行。
用于机器学习开发周期和模型管理的工具需要 MLOps - 机器学习操作。
以便总结并对那些可能不确定的人,MLOps 是机器学习工程的核心功能。它通过使用团队之间的协作和沟通等实践,帮助组织通过自动化和可扩展性更好地管理机器学习生命周期。
MLOps 改善:
-
数据团队成员之间的协作
-
自动化重复任务,减少对人工输入的需求
-
通过输入新数据来改进模型
-
利用客户知识并识别模式以改善整体体验
这些实践改善了整体机器学习生命周期、管理过程以及可扩展性。
ML 模型管理的层级
在管理模型之前,生命周期包括准备数据、特征工程,然后训练、构建和测试模型,直到最优模型进行部署。此时,使用 ML 模型管理。这是对模型进行评估、比较、重建和监控的阶段。
ML 模型管理可以分为两个部分。第一个是实验跟踪,另一个是模型的版本管理和部署。
实验跟踪
这包括训练模型、评估模型,然后一遍又一遍地回顾模型的架构。
模型版本管理与部署
版本控制是当你基本上创建一个带有实施更改的新版本的模型时,随后该模型会被部署。
直到最佳表现的模型进入部署阶段,这一过程将持续进行,并与之前的工程特征、数据标注和数据版本控制阶段相结合。
数据科学家使用机器学习模型管理来监督:
-
模型的打包 - 这是将最终模型以特定格式导出的过程。
-
模型历史 - 这是与模型创建相关的所有内容,例如使用的数据、参数、训练等。
-
模型部署 - 这个过程帮助数据科学家在决策过程中
-
监控模型 - 在这一过程中,数据科学家将跟踪和监控模型的性能和准确性。
-
再训练 - 这是一个重要步骤,通过使用新数据等来继续提升模型的性能。
我们为什么需要机器学习模型管理?
对数据科学家来说,持续构建、跟踪、比较、重建和部署模型将需要大量的时间和金钱。这以前已经做过,这就是机器学习模型管理存在的原因。
机器学习模型管理使得通过实验和更好地理解模型来管理模型生命周期变得更加容易。它帮助团队提高了效率,并引导他们找到需要改进的方向,从而实现更好的研究和整体生产性发展。
协作是 MLOps 管道中的一个重要元素,它允许团队中的不同成员在生命周期的任何步骤开始之前理解当前问题,进行评论,使用以前的实验作为基准,以及整体审查整个生命周期。这可以涉及数据科学家、研究人员和机器学习工程师协作工作,并改善整个生命周期。
如何实现机器学习模型管理
因此,我们可以理解我们的机器学习模型管理将包括数据标注、数据版本控制、模型实验跟踪、模型版本控制和模型部署。
实验跟踪是一个需要实施的重要元素,以确保整体机器学习模型管理有效运作。它包括收集、组织和跟踪模型,提供更多信息,如模型的大小、使用的参数等。以下是如何在您的机器学习模型管理中实施实验跟踪的三种主要方法。
日志记录
正如我们所提到的,跟踪实验及其产生的结果是非常无序和耗时的 - 尤其是当你有很多人同时在同一个项目上工作时。这就是日志记录的重要性,它也可以复制用于未来的使用;这同样节省了大量的时间和金钱。需要记录的重要参数包括:
-
模型的名称
-
模型的版本号
-
训练过程中每次迭代使用的参数
-
训练过程中的每次迭代的训练准确率
-
训练时间
-
测试准确率
-
混淆矩阵
-
内存消耗
-
每个模型基于输入数据的概率
-
代码
-
环境配置
-
问题及潜在解决方案
-
解决方案评估
版本控制
在机器学习模型生命周期中将会有大量的版本控制,因此追踪和管理所有这些变化是重要的,以便更好地理解哪个模型表现最佳。
仪表盘
仪表盘是协作的最大推动力。数据科学家和研究人员可以利用它更好地理解模型和实验,进行调查,更好地审查,并与其他协作者分享他们的发现以供进一步审查。
仪表盘将包含所有与实验、元数据等相关的信息。它帮助你通过图表可视化所有记录和版本控制的数据,以便更好地比较和发现差异。
总结
机器学习模型管理使得许多数据科学家和研究人员的生活更轻松。这是 MLOps 工作流程中的一个重要元素;它允许更好的团队协作、更深入的洞察、团队审查的机会、提高生产力、节省时间以及改善整体生命周期。
Nisha Arya 是一位数据科学家和自由职业技术作家。她特别感兴趣于提供数据科学职业建议或教程以及数据科学的理论知识。她还希望探索人工智能如何/可以促进人类寿命的不同方式。作为一个热衷学习的人,她寻求拓宽技术知识和写作技能,同时帮助指导他人。
更多相关话题
机器学习模型监控检查清单:需要跟踪的 7 件事
原文:
www.kdnuggets.com/2021/03/machine-learning-model-monitoring-checklist.html
评论
由 Emeli Dral,Evidently AI 的首席技术官兼联合创始人 & Elena Samuylova,Evidently AI 的首席执行官兼联合创始人
建立一个机器学习模型并不容易。将服务部署到生产环境中则更为困难。但即使您成功将所有管道拼接在一起,事情也不会止步于此。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 工作
一旦模型投入使用,我们立即必须考虑如何平稳运行。毕竟,它现在在提供业务价值!任何对模型性能的干扰都会直接转化为实际的业务损失。
我们需要确保模型的表现不仅仅是一个返回 API 响应的软件,而是一个我们可以信任以做出决策的机器学习系统。
这意味着我们需要监控我们的模型。而且还有更多的事情需要注意!
如果生产中的 ML 让您感到措手不及,这里有一个检查清单,供您关注。
1. 服务健康
机器学习服务仍然是一种服务。您的公司可能已经有一些建立好的软件监控流程可以重用。如果模型是实时运行的,它需要适当的警报和负责任的人员值班。
即使您只处理批处理模型,也不要例外!我们仍然需要跟踪标准的健康指标,如内存利用率、CPU 负载等等。
我们的目标是确保服务正常运作,并遵守必要的约束,如响应速度。
一个开源工具供检查:Grafana.
2. 数据质量与完整性
机器学习模型出现问题了吗?在绝大多数情况下,数据是罪魁祸首。
上游管道和模型可能会出现故障。用户可能会进行未通知的模式更改。数据可能在源头消失,物理传感器可能会失败。问题不胜枚举。
因此,验证输入数据是否符合我们的预期至关重要。检查可能包括范围合规性、数据分布、特征统计、相关性或我们认为“正常”的任何行为。
我们的目标是确认我们输入的数据是模型能够处理的。在模型返回不可靠的响应之前。
开源工具检查:Great Expectations。
3. 数据与目标漂移
事物总在变化。即使我们处理的是非常稳定的过程。几乎每个机器学习模型都有一个不便的特性:它会随着时间的推移而退化。
我们可能会遇到数据漂移,当模型接收到它在训练中未见过的数据时。想象一下用户来自不同的年龄组、营销渠道或地理区域。
如果现实世界的模式发生变化,概念漂移就会发生。想想像全球大流行这种影响所有客户行为的常见情况。或者市场上出现了一款提供慷慨免费层的新竞争产品。它改变了用户对你营销活动的响应。
这两种漂移的最终衡量标准是模型质量的退化。但有时,实际值尚未知道,我们不能直接计算。在这种情况下,有一些领先指标可以跟踪。我们可以监测输入数据或目标函数的属性是否发生变化。
例如,你可以跟踪关键模型特征和模型预测的分布。如果它们与过去的时间段显著不同,则触发警报。
我们的目标是获得数据或世界发生变化的早期信号,及时更新我们的模型。
开源工具检查:Evidently。
4. 模型性能
了解模型是否表现良好的最直接方法是将预测结果与实际值进行对比。你可以使用与模型训练阶段相同的指标,无论是分类的精准度/召回率,回归的 RMSE,等等。如果数据质量或现实世界的模式发生变化,我们将看到这些指标逐渐下降。
这里有一些警告。
首先,真实标签或实际标签往往会有延迟。 例如,如果你为较长时间范围做预测,或者数据传递有延迟。有时你需要额外的努力来标记新数据以检查预测是否正确。在这种情况下,首先追踪数据和目标漂移作为早期警告是有意义的。
其次,需要追踪的不仅仅是模型质量,还要关注相关的业务 KPI。 ROC AUC 的下降并不能直接说明它对营销转化率的影响有多大。将模型质量与业务指标连接起来或找到一些可解释的代理指标是至关重要的。
第三,你的质量度量标准应适合使用场景。 例如,如果你有不平衡的类别,准确度指标远非理想。在回归问题中,你可能会关注误差的符号。因此,你不仅应追踪绝对值,还应追踪误差分布。区分偶发异常值和实际退化也是至关重要的。
所以选择你的度量标准要明智!

我们的目标是追踪模型的实际效果以及在出现问题时如何进行调试。
一个开源工具进行检查:Evidently。
5. 按段性能
对于许多模型,上述监控设置将足够。但如果你处理的是更关键的使用场景,还有更多的检查项。
例如,模型在哪些方面错误更多,在哪些方面表现最好?
你可能已经知道一些特定的段需要跟踪:比如针对你的高端客户与整体基础的模型准确性。这需要计算仅针对你定义的段内对象的自定义质量指标。
在其他情况下,主动搜索低性能段可能更有意义。比如说,你的房地产定价模型在某个特定地理区域始终建议高于实际的报价。这是你想要注意的!
根据使用场景,我们可以通过在模型输出上添加后处理或业务逻辑来解决问题。或者通过重建模型以考虑低性能段。
我们的目标是超越整体性能,了解模型在特定数据切片上的质量。
6. 偏差/公平性
在金融、医疗保健、教育以及其他模型决策可能具有严重影响的领域,我们需要更加仔细地审视我们的模型。
例如,模型性能可能因不同人口统计群体在训练数据中的代表性而有所不同。模型创建者需要意识到这种影响,并与监管者和利益相关者一起使用工具来减轻不公平现象。
为此,我们需要跟踪适当的度量标准,如准确率的公平性。这适用于模型验证和持续生产监控。因此,仪表盘上再添加几个指标!
我们的目标是确保所有子群体的公平对待并追踪合规性。
一个开源工具进行检查:Fairlearn。
7. 异常值
我们知道模型会出错。在一些使用场景中,比如广告定向,我们可能不在乎个别输入是否显得奇怪或不寻常。只要它们不构成模型失败的有意义的段落即可!
在其他应用中,我们可能希望了解每一个这样的案例。为了最小化错误,我们可以设计一套规则来处理异常值。例如,将它们送去人工审核,而不是做出自动决策。在这种情况下,我们需要一种方法来检测和标记这些异常。
我们的目标是标记异常数据输入,其中模型预测可能不可靠。
一个开源工具供检查:Seldon Alibi-Detect
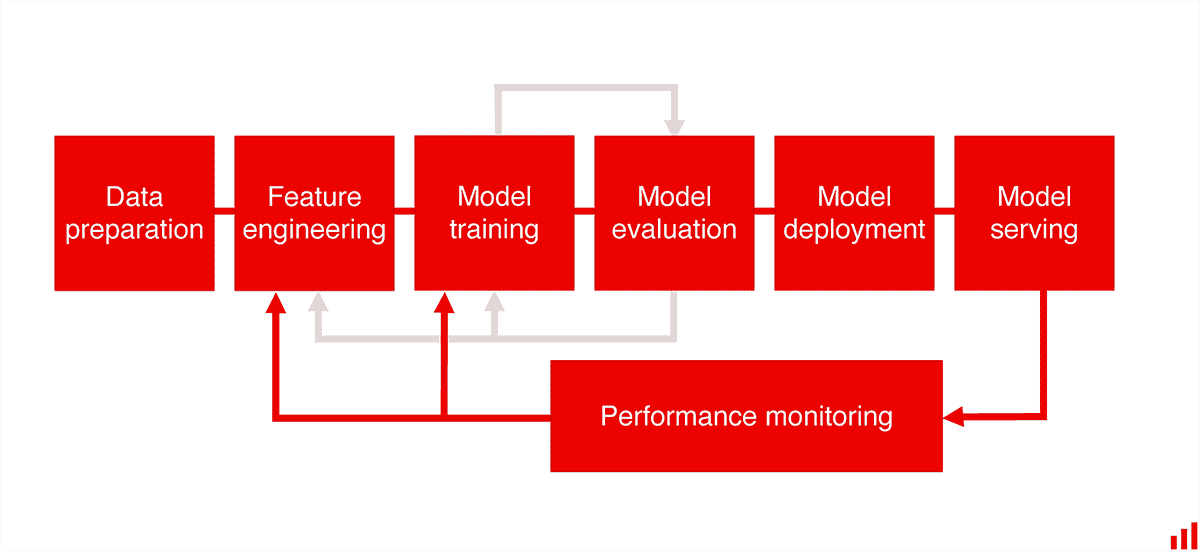
监控可能听起来很无聊。但它对机器学习在现实世界中的应用至关重要。不要等到模型失败才去创建你的第一个仪表板!
Emeli Dral 是 Evidently AI 的联合创始人兼首席技术官,她在这里创建了用于分析和监控机器学习模型的工具。此前,她共同创立了一家工业 AI 初创公司,并担任 Yandex Data Factory 的首席数据科学家。她是 Coursera 上机器学习和数据分析课程的共同作者,拥有超过 100,000 名学生。
Elena Samuylova 是 Evidently AI 的联合创始人兼首席执行官。此前,她共同创立了一家工业 AI 初创公司,并在 Yandex Data Factory 领导业务发展。自 2014 年以来,她与从制造业到零售业的公司合作,提供基于机器学习的解决方案。在 2018 年,Elena 被 Product Management Festival 评选为欧洲 50 位女性产品经理之一。
相关:
-
机器学习系统设计:斯坦福大学免费课程
-
MLOps:模型监控 101
-
如何使用 MLOps 制定有效的 AI 策略
更多相关话题
我的机器学习模型无法学习。我该怎么办?
原文:
www.kdnuggets.com/2021/02/machine-learning-model-not-learn.html
comments
由 Rosaria Silipo、KNIME 和 Diego Arenas、圣安德鲁斯大学,英国

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
如果你一般处理数据,特别是机器学习算法,你可能会对模型真的不愿意学习当前任务感到沮丧。你已经尝试了所有方法,但准确性指标就是无法提高。接下来怎么办?问题出在哪里?这是一个无法解决的任务还是有你未意识到的解决方案?
首先,不要担心。这种迷茫和不知道如何继续的感觉曾经发生过——并且仍然会发生——在所有人身上,即使是最有经验的机器学习专家也是如此。人工智能(AI)、数据科学或预测分析——无论名称如何——都比一系列预定义的步骤要复杂得多。选择合适的模型、成功的架构、最佳的超参数,强烈依赖于任务、数据领域和可用数据集。获得一个可行的 AI 模型仍然需要大量的手工调整,这部分解释了为什么一些数据科学家对许多宣称能够训练成功数据科学模型的自动化应用感到反感。
现在我们希望让你冷静下来,让我们看看你可以做些什么来解决这个困境。我们在这里提出了一些我们在模型训练似乎失控时使用的技巧。
在释放你的创造力之前,请进行一些尽职调查,确保你的训练过程没有明显的错误。这里有一个你可以使用的检查清单,以确保:
-
项目的目标清晰且定义明确,并与所有相关方一致。这意味着你的项目将回答一个明确的问题。
-
你的数据质量足够。
-
训练集的规模适合你尝试训练的模型架构。
-
你的训练过程并不太慢。如果你的训练集太大,你可以提取一个较小的样本进行训练
-
对于分类问题:所有类别在训练集中都有充分的描述。如果你有几个类别的表现非常低,你可以将它们合并为“其他”。如果你有太多类别,你可以尝试通过先进行聚类来减少它们的数量。
-
训练集和测试集之间没有数据泄露。
-
数据集中没有噪声/空属性、过多的缺失值或过多的异常值。
-
如果模型需要标准化,则数据已被标准化。
-
所有超参数已正确设置和优化,这意味着你了解算法。在使用技术之前总是要学习基础知识,你需要能够向利益相关者解释过程和结果。
-
评估指标对当前问题具有意义。
-
模型已经训练得足够长时间,以避免欠拟合。
-
模型不会对数据进行过拟合。
-
性能不好。对那些准确率为 100%或误差为 0%的模型要保持怀疑:这可能是模型存在问题的红旗,很可能数据集中包含了与你试图预测的目标变量同义的变量。
-
最后,你确定自己真的卡住了吗?有时,模型表现得很好,或者至少表现得相当好,而我们缺少的只是下一步。
如果出现了之前的任何错误,应迅速识别问题并实施解决方案。我们在这里提供了一些想法,以帮助你完成尽职调查列表,并在当前实现看似无望时提供创意灵感。
检查与业务目的的一致性。
大家都说这一点,我们也重复了。在继续进行之前,像推土机一样编写代码,确保你了解业务项目是什么。不同部门之间的语言不同。确保我们在开始之前了解所需内容。
例如,确保我们没有计划构建一个交通预测应用程序,而利益相关者期望的是一个自动驾驶汽车。显然,根据分配的时间和预算,交通预测应用程序更可能实现,而不是自动驾驶汽车。但正如我们所说,我们说着不同的语言。确保我们的目标一致。
一旦开始,我们就要定期寻求对中间里程碑的反馈。在未完成的应用程序中加入更改比在展示最终产品时看到利益相关者失望的表情要少得多。这种情况发生的频率比你想象的要高。
对原型的首个版本进行快速迭代,并尽早展示结果以获得及时反馈。
检查数据质量
如果你确信自己正在实施正确的应用程序,符合利益相关者的期望要求,那么问题可能出在数据上。因此,下一步是检查数据质量。对于任何数据科学任务,你需要足够的数据。
首先,数据必须具有代表性。如果是分类问题,则所有类别必须在其所有细微差别中得到充分表示。如果是数值预测问题,则数据集必须足够通用,以涵盖所有可预见的情况。如果数据质量不足(数据集太小或不够通用),以至于无法训练你正在尝试的模型,那么只有两个选项:你可以修订业务规格或收集更多、更通用的数据。
其次,数据领域的所有维度必须得到表示。所有必要的信息必须出现在某些输入属性中。确保你导入并预处理了所有属性。
探索使用特征工程技术添加特征。评估特征的有用性,并集中精力在这些特征上。你能否创建对模型影响更大的新特征?
接下来,确保删除错误过多、噪声过多或缺失值过多的列。这些列有可能影响算法并产生不令人满意的结果。在大数据时代,有一种观点认为数据越多越好,但这并不总是正确的。
还要确保训练集中的数据不会泄漏到评估集中。寻找重复记录;对时间序列分析执行严格的时间划分;确保数据收集的逻辑得到遵守。有些字段通常在目标变量之后记录。包括这些字段会泄露目标变量的值,从而导致对性能的度量不现实,并使部署应用不可行。我们记得有一个关于预测车祸死亡率的项目,其中“种族”字段仅在一些种族中填写,并且仅在死亡发生后填写。算法开始将较高的死亡可能性仅与某些种族相关联。嗯……确保你在数据收集过程的限制范围内操作。
探索模型大小和超参数
数据很好。业务目标很明确。我的算法仍然没有表现好。哪里出错了?现在是时候深入研究算法并调整一些超参数了。
-
机器学习模型的大小是一个重要的超参数。模型过小会导致欠拟合,但模型过大会导致过拟合。我们如何找到正确的中间点?为了自动完成这项任务,你可以使用正则化项、剪枝、丢弃技术和/或仅使用经典的验证集来监控进展。
-
如果你在项目中采用了深度学习神经网络,那么可以使用多种不同的单元,每种单元在处理特定类型的问题时都有所专长。如果你处理的是时间序列,并且需要算法记住过去的信息,那么递归神经单元、LSTM 单元或 GRU 可能比经典的前馈单元更合适。如果你处理的是图像,那么一系列卷积层可能有助于神经网络处理更好提取的图像特征。如果你处理的是异常情况,那么自编码器架构可能是一个有趣的替代方案,等等。
-
对于深度学习神经网络,激活函数的数量至少与神经单元的数量一样多。明智地选择。一些激活函数在某些情况下表现良好,而一些则不然。例如,我们通过实践了解到,虽然 ReLU 激活函数在深度学习社区中很受欢迎,但在自编码器中表现并不好。自编码器似乎更倾向于传统的 sigmoid 函数。
-
脱离神经网络,决策树和随机森林中的信息/熵度量是一个有趣的超参数,值得探索。
-
聚类算法中的簇的数量可以发现数据中的不同组。
还有许多其他机器学习算法也是如此。当然,调优模型的超参数的能力假设我们对算法及其控制参数有充分的了解。这就引出了下一个问题:我们是否理解我们正在使用的算法?
理解算法
随着易于使用的数据科学工具界面的普及,滥用算法也变得更容易了。然而,不要被迷惑!简单的图形用户界面并没有减少其背后的算法复杂性。我们已经看到在不够理解的算法中设置参数时出现了大量随机选择。有时候,最好的做法是坐下来深入学习核心算法或其变体背后的数学知识。
互联网充满了学习资料,包括课程、视频和博客文章。尽量利用这些资源!不时停下来,花些时间深入了解,个人或团队都可以。
从项目的规划阶段开始,考虑测试或尝试新的事物(例如软件、技术、算法等)。利用项目的空间来获得一些额外的经验。通过这种方式,组织内部的知识可以得到扩展,并推动创新。这将是对未来的投资。保留一个想法的待办清单,记录下如果有更多时间你会做什么。当项目顺利时,这个待办清单可以帮助你在利益相关者希望了解更多实施细节时,或者当项目效果不佳时,你需要一个潜在活动的清单以便在之后开展。
这里有一个提示。在进行项目的同时,要关注组织文化。项目中的相关因素往往是参与人员,而这些人创造了公司的内部文化。因此,请确保你为组织创建了正确的文化,并在项目中找到了合适的人。
搜索现有解决方案
要成功训练机器学习模型,你需要理解算法,这当然很重要。你还需要应用所有那些选择的算法所需或避免的技巧和技巧:规范化、洗牌、编码和其他类似操作。其他数据科学家可能已经实现了类似的解决方案,因此:
不要重新发明轮子!搜索现有的类似任务解决方案并将其适应于你的项目。搜索不仅限于书籍和科学文章,还要查阅博客和代码库,并与同事交流。确保你采用和重用先前项目中的成功想法。特别是同事们是获取材料、提示和想法的极佳来源。愿意回报并分享你的工作,接受有意义的反馈。甚至可以组织审查会议,让你的同事利用他们的经验和创造力来帮助你。
不要将自己局限于相同领域中类似任务的解决方案。跨领域的知识交流具有很大优势。实际上,机械引擎中的异常检测和信用卡交易中的欺诈检测往往共享相同的技术。阅读不同领域的成果。如果你在进行欺诈检测,不要害怕参加化学领域的网络研讨会。你永远不知道你会从中获得什么灵感。
接下来做什么?
数据科学项目不仅仅是训练一个算法。确保所有部分能够组合成成功的解决方案,还有更多工作。在训练算法之前,我们需要适当地准备数据。即使在训练和测试算法之后,我们也需要根据算法的响应触发一些操作。项目往往在获得结果后不知道该怎么办而陷入困境。
如果我们建立一个流失预测器,我们需要实施行动,例如对高风险流失客户的活动或呼叫中心的回应。如果我们分析社交媒体上的影响者及其帖子,我们需要制定策略来接触他们。如果我们构建一个聊天机器人,我们需要知道将其集成到最终应用程序中的位置。如果我们建立一个自动翻译器,我们需要在对话中的另一方听到之前插入它。如果我们建立一个异常检测器,我们需要安排它定期运行,以及时发现机械链中的问题。
当我们达到这一部分时,需要做好准备。我们需要考虑基于项目洞察的行动和决策,并为采取下一步做好准备。
停下来,深呼吸
如果你尝试了所有这些方法,模型仍然无法学习到可接受的错误水平,那么就停下来,休息一天,与工作保持一定距离,然后以清新的心态重新回到工作中。这在许多情况下对我们有效。
不要放弃!
机器学习模型在工作时很出色,但使它们工作并不是一项简单的任务。与机器学习问题本身类似,找出具体问题所在并改进是一个多维的问题。我们希望我们为你提供了一些想法,以帮助你摆脱模型无法改进的困境。
然而,如果你确定模型架构已正确实施,训练集足够通用,评估指标合适,模型训练时间充足且没有过拟合数据,如果你已经对应用进行了尽职调查并未发现任何问题,那么问题可能更为普遍。也许模型不合适,也许预处理不适合那种数据,或者其他基本缺陷影响了你的过程。是时候深入阅读和探索了!
我们给你的总体建议是不断尝试,不要因为模型第一次不工作就放弃。在实施几个模型和经过几次试验与错误后,你将成为专家,届时我们也希望听到你的经验。
相关:
-
生产机器学习监控:异常值、漂移、解释器和统计性能
-
2021 年你应该了解的所有机器学习算法
-
MLOps:模型监控基础
更多主题
机器学习模型的可理解性有多重要?我们分析了调查结果
原文:
www.kdnuggets.com/2018/11/machine-learning-model-understandable-poll-results.html
评论之前的 KDnuggets 调查问卷询问了
在 2018 年构建机器学习/数据科学模型时,模型可被人类理解/解释的重要性有多大?
基于超过 500 票的总体结果显示,对于约 37%的投票者来说,这一点始终重要,另有 48%的人表示它“频繁”重要,因此大约 85%的受访者认为这点始终或频繁重要。仅有 2%的人表示这点从未重要。

图 1:机器学习模型可理解性的重要性
调查还询问了就业类型,整体分布如下
-
公司或自雇,69%
-
政府/非营利组织,5%
-
学生,15%
-
学术界/大学,9%
-
其他,2%
根据就业类型,理解机器学习结果的重要性是否有所不同?图 2 展示了按就业类型的结果,排除了其他类别。

图 2:按就业类型划分机器学习模型可理解性的重要性
颜色表示重要性:橙色:“始终”,绿色:“频繁”,浅灰色:“偶尔”,深灰色:“从不”。
我们注意到,来自公司或自雇的受访者给出的“频繁”回答的比例最高——51.6%,而学生的比例最低——仅为 36.7%。
学术研究人员表示“始终”重要的比例高于其他任何群体,这表明机器学习的理解是一个活跃的研究领域。
然而,总体而言,所有群体中理解性始终或频繁重要的比例都超过 80%。不出所料,唯一的例外是学生,其重要性稍低——仅为 76%。
按地区划分的整体分布如下
-
美国/加拿大,36%
-
欧洲,34%
-
亚洲,18%
-
拉丁美洲,6.0%
-
非洲/中东,3.7%
-
澳大利亚/新西兰,2.8%
我们接下来查看四个回答最多的地区的答案分布。
鉴于GDPR于 2018 年 5 月 25 日在欧洲生效,理解机器学习在欧洲是否尤为重要?

图 3:按地区划分机器学习模型可理解性的重要性
出人意料的是,对可理解性最担忧的地区不是欧洲,而是美国/加拿大。将“总是”和“经常”两种回答合并,我们看到美国/加拿大的受访者最为担忧,达到 88.5%,其次是欧洲:81.9%,亚洲:81.0%,拉丁美洲:78.2%。其他两个地区的受访者数量太少,无法进行统计分析。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
为什么机器学习模型在沉默中消亡?
原文:
www.kdnuggets.com/2022/01/machine-learning-models-die-silence.html生命的意义因人而异,因日而异,因时而异。
— 维克多·E·弗兰克尔,《人类寻求意义》
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
弗兰克尔不仅对生命的意义有正确的看法。他关于生产中机器学习模型的说法也是正确的。
机器学习模型在生产环境中表现良好。然而,它们的性能会随着时间的推移而下降。预测质量逐渐衰退,变得不再有价值。
这是软件部署和机器学习部署之间的主要区别。软件程序每次都以相同的方式执行任务。即使在创建数十年后,它们仍然保持有用,除非新技术取代它们或最初创建的目的已经过时。
大多数公司尝试但未能在业务操作中使用机器学习而不了解这一差异。他们在未能从这项技术中获得价值之前就很快放弃了。
使用机器学习和人工智能来推动业务操作的公司越来越少。— 图片由作者提供。
根据美国人口普查局对 2018 年 583,000 家美国公司的调查,只有 2.8%使用机器学习来提升他们的业务操作。约有8.9%的受访者使用某种形式的 AI,例如语音识别。
为什么机器学习模型在生产中表现会下降?
你花了几周甚至几个月训练一个机器学习模型,最终,它被投入生产。现在,你应该看到你辛勤工作的成果。
但相反,你会注意到模型的性能随着时间的推移缓慢下降。这可能是什么原因?
如果不进行持续监控和充分评估预测质量的衰退,概念漂移可能会在预期的退役日期之前就使机器学习模型失效。
什么是概念漂移?
概念漂移发生在训练集示例的分布发生变化时。
在最基本的层面上,概念漂移会导致曾经被认为是一个概念的的数据点随着时间的推移被视为完全不同的概念。
例如,当欺诈的概念不断变化时,欺诈检测模型面临概念漂移的风险。
这可能导致模型性能退化,特别是在概念漂移持续发生且未被监控系统检测到的长时间段内。
什么是概念漂移?
概念漂移发生的主要原因是应用中的基础数据分布不断变化。
当数据分布发生变化时,旧的机器学习模型可能无法做出准确的预测,必须重新定义或完全重新训练以适应这些变化。
尽管这听起来像是你绝对不希望在应用程序中发生的事情,但许多机器学习模型的目标是尽可能频繁地更新。
这是因为从生产环境中收集的新数据包含有价值的信息,有助于提高模型预测的准确性。
输入数据的分布可能会因为外部原因或由于预测本身而发生变化。例如,客户的购买行为受宏观经济趋势的影响。然而,他们在你的平台上的行为也可能是你推荐系统的直接结果。
如何解决生产中模型的概念漂移?
尽管概念漂移看起来非常令人畏惧,但有办法解决它。这是所有机器学习开发人员迟早都会面对的一个普遍问题。
概念漂移随着时间推移而变化,数据从用于训练模型的数据中发生了变化。如果你没有监控这种漂移的方法,你的准确性将会逐渐下降,直到最终没有人再信任你的预测。
随时间监控模型的输入和输出。
通过监控输入和输出数据的分布,我们可以识别性能泄漏是否是数据问题或模型问题。
如果这是数据问题,你可以查看是什么变化导致了这种转变。这可能是数据收集方法的改变或趋势的真正变化。
如果这是模型问题,你应该检查模型的哪个特征可能导致这种分布变化。这可能是由于模型中出现了偏差,或者是环境变化导致训练集与实际数据不匹配。
随时间跟踪模型预测质量
随时间监控不同的性能指标至关重要,因为我们可以通过仔细查看这些指标来发现任何漂移。一些关键的模型性能指标包括精度、召回率、F-measure 和 ROC。
精确度 是当真正的正例被所有预测结果除时,预测的准确度。如果你查看精确度随时间的变化,这表明我们的模型从实际数据分布到当前预测的漂移程度。
召回率 告诉我们是否捕获了足够的正例。
如果召回率随时间下降,这表明我们的模型从真正的正例漂移到了假阴例,这对于业务决策是不适用的。
F-度量 通过使用它们值的调和平均数将精确度和召回率结合成一个单一的数字。如果 F-度量随着准确性变化,那么这也表明模型漂移。
ROC 使我们能够查看一个真正的正例与所有其他预测结果的对比,这有助于识别任何分类器偏差问题或导致假阳性的特征变化。它可以被视为精确度和召回率的扩展,但信息更多。
定期使用新数据重新训练你的模型,以保持准确性
虽然跟踪性能指标可以尽早识别概念漂移,但定期重新训练主动尝试消除这种情况。
不断重新训练你的模型可能需要大量的时间和资源,但这是一个长期投资的回报。
重新训练的频率在很大程度上取决于领域。在电子商务中,每周重新训练模型可能是合理的。但对于欺诈检测系统,其中欺诈用户的行为不断变化,你可能需要每天重新训练你的模型。
使用模型集成
这些都是防止或解决生产中机器学习漂移的优秀策略。然而,解决这个问题的另一种方法是使用集成模型。
集成模型同时使用多个算法,并将它们的预测结果结合成一个最终预测,这比任何单个算法的预测更准确。
这可以是提高准确性和防止时间推移过程中出现漂移的好方法。
最后的思考
概念漂移导致生产中的机器学习模型表现不同于训练期间的表现。这是一个大问题,如果漂移没有被正确预测,可能会导致糟糕的用户体验甚至模型失败。
概念漂移在生产中最常见的方式是当你的数据随时间变化(例如,添加了新特征,移除了某些现有特征)。监控你的数据并尽早检测漂移是至关重要的。
你还应该使用如定期重新训练或集成的方法来防止漂移的发生。
你必须在用户开始报告产品体验不佳之前解决机器学习漂移。如果发生这种情况,它将迅速导致信任丧失和后续修复成本的显著增加。要有前瞻性!
Thuwarakesh Murallie (@Thuwarakesh) 是 Stax, Inc.的首席数据科学家,也是 Medium 上的分析领域顶尖作者。Murallie 分享了他在数据科学领域每天的探索。
更多相关话题
机器学习中,哪个更好:更多数据还是更好的算法?
原文:
www.kdnuggets.com/2015/06/machine-learning-more-data-better-algorithms.html
评论
由 Xavier Amatriain(Quora 的工程副总裁)。
“在机器学习中,更多数据是否总是比更好的算法更好?” 不一定。更多数据有时会有帮助,有时则没有。
可能最著名的支持数据力量的名言是 Google 的研究总监 Peter Norvig 宣称的 “我们没有更好的算法。我们只是有更多的数据。”。这句话通常与 Norvig 本人合著的《数据的非理性有效性》一文有关(你可能可以在网上找到 pdf,虽然 原文 被 IEEE 付费墙挡住了)。当 Norvig 被误引为说 “所有模型都是错误的,你根本不需要它们” 时,关于更好模型的最后一根钉子就被钉上了(阅读 这里 了解作者对如何被误引的澄清)。

Norvig 等人在他们的文章中提到的效果,早在微软研究员 Banko 和 Brill 的著名论文《Scaling to Very Very Large Corpora for Natural Language Disambiguation》[2001] 中就已经被捕捉到了。在那篇论文中,作者展示了下面的图表。

该图显示,对于给定的问题,非常不同的算法几乎表现相同。然而,向训练集添加更多示例(词汇)会单调地提高模型的准确性。
所以,你可能会认为案子已经结案了。实际上,情况并非如此。现实是,Norvig 的论断和 Banko 与 Brill 的论文在某种背景下都是正确的。但它们有时会被引用在与原始背景完全不同的上下文中。不过,为了理解为什么如此,我们需要稍微深入一些技术细节。(我不打算在这篇文章中提供完整的机器学习教程。如果你不理解我下面解释的内容,请阅读我对 如何学习机器学习? 的回答。)
方差还是偏差?
基本的想法是,模型表现不佳可能有两个可能(且几乎相反)的原因。
在第一种情况下,我们可能会有一个模型对我们拥有的数据量过于复杂。这种情况被称为高方差,导致模型过拟合。我们知道当训练误差远低于测试误差时,我们面临的是高方差问题。高方差问题可以通过减少特性数量来解决,并且…是的,通过增加数据点的数量来解决。那么,Banko & Brill 和 Norvig 处理的是哪种模型?是的,你猜对了:高方差。在这两种情况下,作者们都在处理语言模型,其中词汇表中的每个词大致都会成为一个特性。这些模型与训练示例相比,特性数量非常多。因此,它们很可能会过拟合。是的,在这种情况下,添加更多示例将有帮助。
但是,相反的情况是,我们可能会有一个模型过于简单,无法解释我们拥有的数据。在这种情况下,被称为高偏差,添加更多的数据是没有帮助的。下面是 Netflix 的真实生产系统的一个图示,以及随着我们添加更多训练示例时的性能。

所以,不,更多数据并不总是有帮助。正如我们刚刚看到的,有许多情况添加更多示例到我们的训练集中不会改善模型的性能。
更多特性来救援
如果你到目前为止跟上了我的思路,并且你已经做了功课理解了高方差和高偏差问题,你可能会认为我故意遗漏了某些讨论内容。是的,高偏差模型不会从更多的训练示例中受益,但它们可能会非常受益于更多的特性。所以,最终,这一切都是关于添加“更多”数据,对吗?嗯,再次,这要视情况而定。
以 Netflix 奖为例。在游戏初期,有一篇博客文章由连续创业者和斯坦福大学教授Anand Rajaraman评论使用额外特性来解决问题。文章解释了一个学生团队通过添加来自 IMDb 的内容特性来提高预测准确率。

从 retrospect 来看,很容易批评这篇文章因为从一个数据点做了过度概括。更重要的是,后续文章提到了 SVD 作为一种“复杂”的算法,不值得尝试,因为它限制了扩展到更多特性的能力。显然,Anand 的学生没有赢得 Netflix 奖,他们现在可能意识到 SVD 确实在获胜条目中扮演了重要角色。
事实上,许多团队后来展示了,将来自 IMDB 或类似来源的内容特征添加到优化算法中几乎没有任何改善。重力团队,作为奖项的顶级竞争者之一,发布了一篇详细的论文,展示了这些基于内容的特征如何对高度优化的协同过滤矩阵分解方法没有任何改善。该论文题为推荐新电影:即使是少量评分也比元数据更有价值。

公平地说,论文的标题也是一种过度概括。基于内容的特征(或一般的不同特征)在许多情况下可能能够提高准确性。但你明白我的观点:更多的数据并不总是有帮助的。
更好的数据 != 更多的数据(新增此部分 以回应一个评论)
需要指出的是,在我看来,更好的数据总是更好。这一点没有争论。所以你可以投入任何精力去“改善”你的数据,总是值得的。问题是,更好的数据并不意味着更多的数据。事实上,有时这可能意味着更少!
以数据清洗或异常值移除作为我观点的一个简单例子。但,还有许多其他更微妙的例子。例如,我见过有人花费大量精力实施分布式矩阵分解,而实际上他们可能只需对数据进行采样就能得到非常相似的结果。事实上,对你的人群进行某种形式的智能采样(例如,使用分层抽样)可以比使用完整的未过滤数据集得到更好的结果。
科学方法的终结?
当然,每当关于可能的范式变化进行激烈辩论时,总会有像马尔科姆·格拉德威尔或克里斯·安德森这样的人通过加剧讨论来谋生(不要误解我的意思,我是他们的粉丝,并且读过他们的大部分书籍)。在这种情况下,安德森挑剔了一些诺维格的评论,并在一篇题为理论的终结:数据洪流使科学方法过时的文章中对其进行了误引。

- 文章解释了数据丰富如何帮助个人和公司做出决策,即使不理解数据本身的意义。如 Norvig 在他的反驳中指出,Anderson 有些观点是正确的,但为了证明这些观点却走得太远。结果是一系列错误的陈述,从标题开始:数据洪流并没有使科学方法过时。我认为恰恰相反。
没有良好方法的数据 = 噪声
所以,我是否在试图表明大数据革命只是炒作?绝对不是。拥有更多数据,无论是更多的样本还是更多的特征,都是一种福祉。数据的可用性带来了更多更好的洞察和应用。更多的数据确实使方法更好。更重要的是,它要求更好的方法。

-
总之,我们应该摒弃那些简单化的声音,它们宣称理论或模型毫无用处,或者数据战胜了这些。数据固然重要,但同样需要好的模型和解释它们的理论。总体来说,我们需要的是有效的方法,帮助我们理解如何解读数据、模型以及两者的局限性,从而产生最佳的输出。
-
换句话说,数据很重要。但没有良好方法的数据就成了噪声。
原文。已获得许可转载。
简介: Xavier Amatriain,是 Quora 的工程副总裁,因其在推荐系统和机器学习方面的工作而闻名。他建立了团队和算法,以解决具有商业影响的难题。此前,他曾是 Netflix 的研究/工程总监。
相关
-
揭穿大数据神话,再次
-
采访:Josh Hemann,Activision 谈为什么对模糊性的容忍至关重要
-
深度学习会取代机器学习,使其他算法过时吗?
- 我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
更多相关话题
机器学习的最大遗漏:业务领导力
原文:
www.kdnuggets.com/2020/10/machine-learning-omission-business-leadership.html
赞助帖子。
在这篇文章中,我识别了我面向商业的机器学习课程解决的非常特别的学习者需求,该课程提供对技术人员和商业领导者都至关重要的材料。如果你或你团队的成员会从中受益,请查看更多信息并在这里报名。
机器学习。你的团队需要它,你的老板要求它,而你的职业也喜欢它。毕竟,LinkedIn 将其列为“公司最需要的技能”中的前几名,以及美国最顶尖的新兴职位。
但如今的数字分析热潮往往悲剧性地忽视了一个关键点:在所有对机器学习成功至关重要的因素中,最常缺失的并不是技术或数据,而是领导力。许多商业领导者知道机器学习在没有经过验证的管理流程指导下无法成功优化运营——但数据科学家往往只关注一件事,那就是:实际操作分析。
现在,确实是通过实践来学习最好——但数字分析只是需要完成的一半。还有一个对机器学习的价值驱动部署至关重要的业务领导流程,数据科学家必须与商业领导者一样深入学习。无论你是参与机器学习项目的业务还是技术方面,机器学习的业务技能都是必不可少的相关知识。它们是确保核心技术在业务运营中正常运行并成功创造价值的必要条件。
我的课程的一个主要部分,机器学习领导力与实践——全程精通,正是解决这一需求。首先,让我介绍一下整体课程:它将指导你和你的团队领导或参与机器学习的全程实施。这是一门适合商业层面学习者但对技术人员也至关重要的广泛课程。它涵盖了最新的技术和业务方面的最佳实践。
与大多数机器学习课程不同,通过覆盖业务方面的要求,“机器学习领导力与实践——全程精通”课程将帮助你避免使机器学习项目偏离轨道的最常见管理错误:在建立和规划操作部署路径之前直接进入数字分析阶段。
本课程的三个子课程中的第二个,名为“启动机器学习:通过黄金标准的机器学习领导力实现操作成功”,完全侧重于业务方面。完成本课程后,你将能够:
-
领导机器学习: 管理机器学习项目,从生成预测模型到其发布。
-
应用机器学习: 确定机器学习能够提升市场营销、销售、财务信用评分、保险、欺诈检测等领域的机会。
-
规划机器学习: 确定机器学习的操作集成和部署方式,以及实现这些目标所需的人员和数据要求。
-
批准机器学习: 预测机器学习项目的有效性,然后在内部进行销售,获得同事的认可。
-
准备机器学习数据: 监督数据准备工作,这直接受业务优先级的影响。
-
评估机器学习: 从业务术语如利润和投资回报率(ROI)报告预测模型的表现。
-
规范机器学习: 管理伦理陷阱,如预测模型揭示个人敏感信息,包括是否怀孕、是否会辞职或可能被逮捕。
本课程的第一个模块深入探讨机器学习在营销、金融服务、欺诈检测等领域的商业应用。我们将通过案例研究和详细示例展示这些领域所带来的价值。同时,我们将精确测量预测模型本身的表现,重点关注模型提升,这是一个告诉你模型改进情况的预测乘数。
本课程的第二个模块涵盖了机器学习计划、批准和管理。启动机器学习既是一个管理任务,也是一项技术任务——其成功依赖于非常特定的业务领导力实践。这个模块将展示这种实践,指导你领导机器学习的端到端实施。以下是其主题大纲:
领导过程:如何管理机器学习项目
-
项目管理概述
-
运行机器学习项目的六个步骤
-
运行和迭代过程步骤
-
一个机器学习项目的时间长度
-
完善预测目标
项目范围和批准
-
从哪里开始 – 选择第一个机器学习项目
-
战略目标和关键绩效指标
-
人员配置 – 配置你的机器学习团队
-
为机器学习项目寻找合适的人员
-
批准:内部销售机器学习项目
-
获得批准的更多技巧
最后,这第二门课程的第三模块涵盖了数据需求——这些需求需要受到商业方面的考虑影响——而第四个也是最后一个模块则涵盖了更多的商业指标——包括一个在互联网上传播虚假信息的有趣谬论——并且涉及一些机器学习伦理中的关键和令人担忧的话题。
那些更偏向于实践技术量化而非商业领袖的人会发现这个课程是一个难得的机会,可以在商业方面提升自己,因为技术机器学习培训通常不会涉及这些内容。但数据迷们必须知道:软技能往往是最难掌握的。
想了解更多,请查看我的机器学习课程的详细大纲。
 埃里克·西格尔(Eric Siegel),博士,是一位领先的顾问和前哥伦比亚大学教授,他让机器学习变得易于理解和引人入胜。他是长期举办的预测分析世界和深度学习世界会议系列的创始人,自 2009 年以来已服务于超过 17,000 名与会者,同时也是备受推崇的在线课程机器领导力与实践——端到端精通的讲师,一位受欢迎的演讲者,他已被委托进行超过 110 次主题演讲,并且是机器学习时代的执行编辑。他著有畅销书预测分析:预测谁会点击、购买、说谎或死亡,该书在 35 多所大学的课程中被使用过,他在哥伦比亚大学教授时曾获教学奖,并且为学生演唱过教育歌曲。埃里克还发布了关于分析和社会正义的专栏文章。关注他@predictanalytic。
埃里克·西格尔(Eric Siegel),博士,是一位领先的顾问和前哥伦比亚大学教授,他让机器学习变得易于理解和引人入胜。他是长期举办的预测分析世界和深度学习世界会议系列的创始人,自 2009 年以来已服务于超过 17,000 名与会者,同时也是备受推崇的在线课程机器领导力与实践——端到端精通的讲师,一位受欢迎的演讲者,他已被委托进行超过 110 次主题演讲,并且是机器学习时代的执行编辑。他著有畅销书预测分析:预测谁会点击、购买、说谎或死亡,该书在 35 多所大学的课程中被使用过,他在哥伦比亚大学教授时曾获教学奖,并且为学生演唱过教育歌曲。埃里克还发布了关于分析和社会正义的专栏文章。关注他@predictanalytic。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求。
相关阅读
机器学习超越大数据了吗?
原文:
www.kdnuggets.com/2017/05/machine-learning-overtaking-big-data.html
评论 大数据在 2011 年左右作为一个领域和流行词汇突然流行起来。
然而,最近它的光彩有所减退,Gartner 在 2015 年将大数据从其炒作周期中移除,并将其替换为机器学习。
我们注意到,2012 年的 KDnuggets 投票曾询问大数据何时会过时,中位预测为 2015 年,因此 KDnuggets 的读者预测是准确的(尽管他们预计智能数据将取代大数据,而不是机器学习)。
“机器学习”现在比“大数据”更受欢迎了吗?
我们使用 Google Trends 进行调查。
看过去五年的数据(2012 年 5 月 - 2017 年 4 月),[全球范围内的大数据与机器学习]( https://trends.google.com/trends/explore?date=2012-05-01 2017-04-30&q=Machine Learning ,Big%20Data)在 Google Trends 上显示,“机器学习”的受欢迎程度增长更快,而就在本周(2017 年 4 月 30 日 - 5 月 6 日),机器学习的搜索量首次与大数据的搜索量持平!
 图 1:Google Trends,2012 年 5 月 - 2017 年 4 月,全球范围
图 1:Google Trends,2012 年 5 月 - 2017 年 4 月,全球范围
“大数据”与“机器学习”搜索词全球对比
搜索量的下降对应着圣诞节/新年假期。
如果我们仅限于[美国]( https://trends.google.com/trends/explore?date=2012-05-01 2017-04-30&geo=US&q=Machine Learning ,Big%20Data)进行比较,我们会看到“机器学习”在 2016 年 10 月左右已经超过了“大数据”。
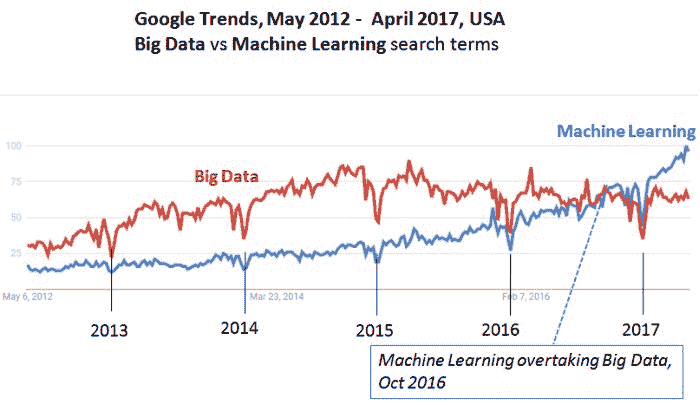 图 2:Google Trends,2012 年 5 月 - 2017 年 4 月,美国
图 2:Google Trends,2012 年 5 月 - 2017 年 4 月,美国
“大数据”与“机器学习”搜索词对比
最后,我们还加入了其他三个热门搜索词:“人工智能”(Artificial Intelligence)、“数据科学”(Data Science)和“深度学习”(Deep Learning),并检查了[全球范围内的大数据、机器学习、人工智能、数据科学和深度学习的 Google Trends]( https://trends.google.com/trends/explore?date=2012-05-01 2017-04-30&q=Machine Learning ,Big%20Data,Artificial%20Intelligence,Data%20Science,Deep%20Learning),从 2012 年 5 月 1 日到 2017 年 4 月 30 日。
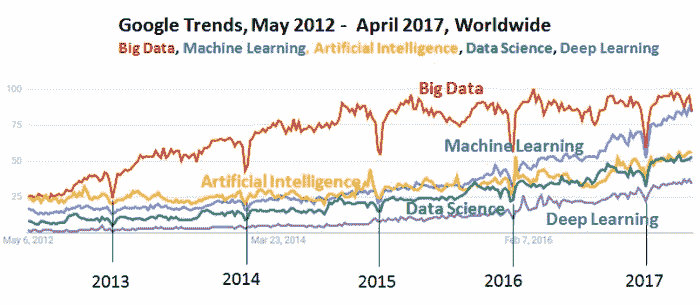 图 3:Google Trends,2012 年 5 月 - 2017 年 4 月,全球范围
图 3:Google Trends,2012 年 5 月 - 2017 年 4 月,全球范围
“大数据”(Big Data)与“机器学习”(Machine Learning)与“人工智能”(Artificial Intelligence)与“数据科学”(Data Science)与“深度学习”(Deep Learning)搜索词对比。
我们注意到,尽管深度学习(Deep Learning)增长速度较快,但仍然不如其他四个术语受欢迎。
在 2012 年、2013 年和 2014 年,前四名术语的排名是
-
大数据
-
人工智能(Artificial Intelligence)
-
机器学习
-
数据科学
2015 年,机器学习超越了“人工智能”,位居第二,而 2016 年“数据科学”追赶上人工智能,排名第 3-4 位。
告诉我你的想法!
相关内容:
-
什么将取代大数据以及何时会发生
-
大数据过于庞大而无法消亡
-
Gartner 2015 炒作周期:大数据已过时,机器学习为主流
-
KDnuggets 顶级推文,8 月 18-19 日:大数据在 Gartner 炒作周期中进入“失望低谷”
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关内容
通过多样性增强机器学习个性化
原文:
www.kdnuggets.com/2021/08/machine-learning-personalization-variety.html
评论
作者:Raghavan Kirthivasan,Epsilon India 数据科学总监,以及 Anuj Chaturvedi,Epsilon India 领先数据科学家。

企业通常会运行持续 8 到 10 周的营销活动,每周向可达的客户群发送电子邮件。由于客户的购买模式取决于产品目录中的产品性质,到下一次购买的时间通常为一个月或更长,具体取决于类别。因此,对于大多数客户来说,每周活动中发送的内容通常是相同的,因为基于历史数据的模型推荐不会每周变化。因此,3 到 4 周的推荐停滞可能导致糟糕的客户体验。
另一方面,基于购买频率,发送内容类似的电子邮件也可以作为提醒,以防客户错过了之前的邮件。因此,发送重复的电子邮件并提供相同的推荐也可能导致收入增加。
本文探讨了通过电子邮件发送的内容个性化,例如 SKU、产品、类别等的优惠,并概述了如何利用多样性的概念。
期望状态和限制
理想的情况是,我们可以在每周级别而非每月级别向客户展示更多选项,通过机器学习模型的推荐来改善整体客户体验,而不牺牲投资回报率。我们还将讨论在活动中引入这种策略的理想阶段。
这个想法是设计一种策略,在可能的情况下引入推荐的多样性,以便模型推荐不变,活动提升不会受到影响。
如前所述,由于机器学习模型的推荐通常不会频繁变化,想法是识别出机器学习模型推荐的前 3 或 4 个类别之外的类别,这些类别客户最有可能购买,同时不牺牲投资回报率。
提议解决方案
假设有 50 个类别被指定用于活动。这些类别是客户希望向他们的客户发送电子邮件并告知他们有关这些类别的折扣的类别。我们称这组类别为“选择池”。
数据科学团队的期望是识别出客户最有可能在“选择池”中购买的前 3 或 4 个类别。在构建模型时,模型将对选择池中的所有类别进行排序,从中选择前 3 或 4 个类别,我们将通过电子邮件发送这些类别。
多样性不是针对客户即将购买的商品进行优化,而是建议客户可能购买的额外产品。
引入多样性
根据我们在解决问题的阶段,关于引入多样性可以采取各种行动。将问题进一步拆解成以下问题更为合理:
-
何处引入多样性?
-
何时引入多样性?
-
如何引入多样性?
我们将尝试单独讨论并找出这些问题的潜在答案。
何处引入多样性?
这将帮助我们识别哪些客户可能需要在推荐中提供多样性。根据模型生命周期的不同阶段,回答这个问题的策略可能会有所变化。
部署前
在模型投入生产之前,有一系列维度可以帮助我们识别在推荐中混合多样性的良好策略。
-
选择推荐的模型强度: 这可以通过分析模型对池中不同选择的概率差异来理解。差异越大,模型在识别客户相关选择集时越自信。
-
客户的历史选择池: 客户已购买的选择集合或客户的历史记录
下表结合了这两个方面,并尝试基于不同组合识别一系列行动:

上述策略可以在模型投入生产前进行探索。但在此之后,我们需要关注模型上线后如何做出决策。
部署后
一旦模型投入生产,我们将拥有一个重要的额外信息,即客户的实际选择如何与模型推荐相比。这些新信息在进一步细化哪些客户更可能通过多样性推荐受到积极影响时可能非常重要。
可能有不同的方法来使用这些信息和做出决策。以下是一种利用客户实际购买行为识别可能从多样性推荐中受益的客户集的方法。
何时引入多样性?
由于将多样性融入推荐在所有场景中可能不起作用,我们尝试寻找引入多样性似乎合乎逻辑的活动标准。
-
广告长度: 在处理长时间的广告时,引入推荐的多样性似乎很合适,因为客户会多次接触广告,从而有机会在多个邮件中看到相同的推荐。
-
广告运行时间在引入多样性之前: 在引入推荐的多样性之前,需要给广告一些时间成熟,因为初始结果可能无法提供准确的反馈。大约 2 到 3 周的时间似乎是一个好的选择,这样可以让广告成熟后再引入多样性,并使我们能做出更明智的决策。
-
选择池大小: 选择池中的选择数量在多样性相关决策中扮演着重要角色。在选择池非常小的情况下,多样性的决策变得不重要,因为可以尝试的选项很少。选择池有 20 个选项似乎是一个不错的起点。我们也可以从剩余选项的百分比来考虑,例如,我们需要从 20 个选项池中推荐 4 个选项,这样在第一次推荐周期后,我们还剩下 80%的选项。
如何引入多样性?
在模型推荐由于某些原因未随时间变化的情况下,有许多方法可以将多样性融入推荐中。我们将探讨一些技术和基于启发式的方法。
市场篮子分析
这是引入多样性的技术方法之一,基于关联规则挖掘。关联规则挖掘是一种识别一起购买的产品对之间关联强度的技术,并识别共现模式。共现是指两个或更多事物同时发生。关联规则不是提取个人偏好,而是寻找每个独立交易中元素集之间的关系。
通俗来说,市场篮子分析(MBA)识别通常一起购买的产品组合。
一种方法是利用模型找到购买概率最高的选择,然后使用 MBA 识别与模型推荐选择关联度最高的产品组合,并将这些选择作为推荐选择。
我们现在将看一些基于启发式的方法来增加推荐的多样性。
基于价格的多样性
一种基于规则的方法是将价格作为将选择分组的基础。这种分类方法使我们能够从整个价格范围内向客户提供推荐。
我们可以选择每个价格组中模型购买概率最高的选项,并提供尚未呈现给相应客户的选项,从而提供多样性。这种方法还可以帮助理解提供不同价格选项的多样性是否与客户群体相契合。
基于产品类别的多样性
另一种可以遵循的基于规则的方法是使用业务定义的选择类别作为选择的基础,并在不同类别之间提供多样性。类似于最后的策略,我们可以从尚未呈现给相应客户的每个选择类别中展示模型预测概率最高的选项。
结论与未来展望
通过本文,我们尝试探讨了目前推荐模型中遇到的一个非常实际的问题。
可以在个性化推荐由于各种原因在每次发送时不会变化的情况下引入多样性。我们已经讨论了在不牺牲广告效果的情况下引入多样性的方法。
上述讨论的策略是基于分析和启发式方法的混合,应该作为企业在个性化推荐时遇到的任何类似问题的起点。下一步可能因项目而异,具体取决于在利用这一方法后所获得的初步结果。
参考文献
市场篮子模型的解释,信息构建者。
个人简介: 拉贾凡·基尔提瓦桑 是 Epsilon India 的数据科学总监。他在数据科学/分析方面拥有 18 年的经验,具备市场营销/风险管理和欺诈分析的职能专长,涵盖多个地区(美国、英国、亚太地区)。在他之前的 WNS、AIG 和 Epsilon Agency 的职位中,拉贾凡培养了数据科学团队。
阿努杰·查图尔维迪 是 Epsilon India 的首席数据科学家。他在数据科学领域拥有近 9 年的经验,利用各种数据资产支持包括数字体验、客户、营销和定价在内的不同业务领域。他目前在 Epsilon 担任首席数据科学家,开发旨在提升数字空间客户体验的机器学习解决方案。
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
了解更多此话题
机器学习管道优化与 TPOT
原文:
www.kdnuggets.com/2021/05/machine-learning-pipeline-optimization-tpot.html

图片来源:Erik Mclean于Unsplash
AutoML 与 TPOT
我已经有一段时间没查看TPOT了,这是一种基于树的管道优化工具。TPOT 是一个 Python 自动化机器学习(AutoML)工具,通过遗传编程来优化机器学习管道。作者告诉我们要将其视为我们的“数据科学助手”。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
AutoML 的理由来源于这个想法:如果需要构建多个机器学习模型,使用各种算法和不同的超参数配置,那么可以自动化这一模型构建过程,模型性能和准确性的比较也可以自动化。
我希望重新审视 TPOT,看看我们是否能完善一个真正完全自动化的数据科学助手。假如我们可以扩展 TPOT 的功能,构建一个端到端的预测管道,将其指向数据集并得到预测结果,中间没有干预,那会怎样?当然,其他类似的工具也存在,但没有比自己动手构建机器学习管道和决策更好的方式来理解这一过程及其结果单一构建管道。
目标不一定是完全排除数据科学家,但提供一个基准或多个可能的解决方案,以便与手工制作的机器学习管道进行比较。在助手在后台默默工作时,专家可以提出更聪明的尝试方法。至少,结果预测管道可以作为数据科学家手动调整和干预的良好起点,大部分繁琐工作已经由其代劳。
一个 AutoML“解决方案”可能包括数据预处理、特征工程、算法选择、算法架构搜索和超参数调优的任务,或者这些不同任务的某个子集或变体。因此,自动化机器学习现在可以被认为是从仅执行单一任务(如自动特征工程)到完全自动化的管道(从数据预处理到特征工程,再到算法选择等等)的一切。那么,为什么不构建一个能完成所有这些的东西呢?
不管怎样,这个计划的第一步是重新熟悉 TPOT,这个项目最终将成为我们完全自动化预测管道优化器的核心。TPOT 是一个 Python 工具,它“通过遗传编程自动创建和优化机器学习管道。”TPOT 与 Scikit-learn 配合使用,自称为 Scikit-learn 的包装器。TPOT 是开源的,使用 Python 编写,旨在通过基于遗传编程的 AutoML 方法简化机器学习过程。最终结果是自动化超参数选择、使用多种算法建模,以及探索各种特征表示,所有这些都导致了迭代模型构建和模型评估。
TPOT 自动化的机器学习管道的各个方面 (source)
管道优化
我们将查看一个比TPOT 仓库中的简单但非常有用的示例脚本更复杂的内容。代码应该比较直接且相对容易跟随,因此我不会对其进行详细审查。
这里是运行我们优化脚本后的一个示例输出:
Optimizing prediction pipeline for the iris dataset with stratified k-fold cross-validation using the accuracy scoring metric
Pipeline optimization iteration: 0
>>> elapsed time: 135.48434898200503 seconds
>>> pipeline score on test data: 1.0
Pipeline optimization iteration: 1
>>> elapsed time: 132.3554882509925 seconds
>>> pipeline score on test data: 1.0
Pipeline optimization iteration: 2
>>> elapsed time: 133.29390010499628 seconds
>>> pipeline score on test data: 1.0
All best pipelines were the same:
Pipeline(memory=None,
steps=[('stackingestimator',
StackingEstimator(estimator=KNeighborsClassifier(algorithm='auto',
leaf_size=30,
metric='minkowski',
metric_params=None,
n_jobs=None,
n_neighbors=11,
p=1,
weights='uniform'))),
('extratreesclassifier',
ExtraTreesClassifier(bootstrap=True, ccp_alpha=0.0,
class_weight=None, criterion='gini',
max_depth=None,
max_features=0.9000000000000001,
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=18, min_samples_split=14,
min_weight_fraction_leaf=0.0,
n_estimators=100, n_jobs=None,
oob_score=False, random_state=42,
verbose=0, warm_start=False))],
verbose=False)
输出提供了一些关于管道迭代的基本信息。如果你从脚本和输出的组合中无法看出,我们已经总共运行了 3 次优化过程;每次都使用了分层 10 折交叉验证;每次迭代的遗传优化过程都运行了 5 代,每代的种群规模为 50。你能计算出在这个过程中测试了多少个管道吗?这是我们在未来需要考虑的一个问题,尤其是与计算时间相关的实际原因。
正如你可能记得的,TPOT 会将最佳管道(或经过多次迭代后的管道)输出到文件中,然后可以用来重现相同的实验,或在新数据上使用相同的管道。我们将在创建我们完全自动化的端到端预测管道时利用这一点。
在我们的情况下,我们的脚本注意到每个生成的管道都是相同的,因此只输出了其中一个。在如此小的数据集上这是一个合理的结果,但由于遗传优化的性质,最佳管道在较大、复杂的数据集上可能会有所不同。
摘要
我们这次在脚本中尝试的一些方法,是我们过去没有做过的:
-
用于模型评估的交叉验证
-
对建模进行多次迭代——在如此小的数据集上可能没有用,但随着进展可能会有所帮助
-
比较这些多次迭代中产生的管道——它们都相同吗?
-
你知道 TPOT 现在在后台使用 PyTorch 来构建预测神经网络吗?
也许你已经看到了我们可以在上述内容上改进的一些方法。以下是我们未来实现中可能不希望做的一些具体事项:
-
我们希望考虑数据集拆分比例,以便获得理想的训练、验证和测试数据量
-
由于我们使用交叉验证进行训练和验证(与上述要点相关),我们希望保留测试数据,仅用于我们表现最佳的模型,而不是每一个模型上
-
由于特征选择/工程/构建是通过 TPOT 处理的,我们将希望在输入之前自动将类别变量转换为数值形式
-
我们希望能够处理更广泛的数据集 😃
-
还有更多内容!
这些要点虽然对实际建模很重要,但目前并不是问题,因为我们的重点只是建立结构,以便迭代地构建和评估机器学习管道。我们可以在未来进展时解决这些合理的担忧。
我鼓励你查看一下TPOT 文档,看看它能为我们提供什么,因为我们利用它来帮助构建端到端的预测管道。
Matthew Mayo (@mattmayo13) 是数据科学家和 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计和优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关主题
在 Power BI 中使用 PyCaret 进行机器学习
原文:
www.kdnuggets.com/2020/05/machine-learning-power-bi-pycaret.html
评论
由 Moez Ali, PyCaret 的创始人兼作者

机器学习与商业智能相结合
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
PyCaret 1.0.0
上周我们宣布了PyCaret,这是一个开源的 Python 机器学习库,用于在低代码环境中训练和部署机器学习模型。在我们的上一篇文章中,我们演示了如何在 Jupyter Notebook 中使用 PyCaret 来训练和部署 Python 中的机器学习模型。
在这篇文章中,我们展示了如何在Power BI中集成逐步教程,从而使分析师和数据科学家能够在其仪表板和报告中添加机器学习层,而无需额外的许可证或软件费用。PyCaret 是一个开源的免费使用的 Python 库,提供了广泛的功能,专门用于在 Power BI 中使用。
在本文结束时,您将学习如何在 Power BI 中实现以下内容:
-
聚类— 将具有相似特征的数据点分组。
-
异常检测— 识别数据中的稀有观察值/异常值。
-
自然语言处理— 通过主题建模分析文本数据。
-
关联规则挖掘— 发现数据中的有趣关系。
-
分类— 预测二元(1 或 0)的类别标签。
-
回归— 预测连续值,如销售额、价格等
“PyCaret 通过提供免费、开源和低代码的机器学习解决方案,正在使机器学习和高级分析变得更加普及,适用于业务分析师、领域专家、普通数据科学家和经验丰富的数据科学家。”
Microsoft Power BI
Power BI 是一个业务分析解决方案,可以让你可视化数据并在组织内分享洞察,或将其嵌入到你的应用或网站中。在本教程中,我们将使用 Power BI Desktop 通过将 PyCaret 库导入 Power BI 来进行机器学习。
在开始之前
如果你以前使用过 Python,那么你可能已经在电脑上安装了 Anaconda Distribution。如果没有,点击这里下载带有 Python 3.7 或更高版本的 Anaconda Distribution。
www.anaconda.com/distribution/
环境设置
在我们开始使用 PyCaret 的机器学习功能之前,我们必须创建一个虚拟环境并安装 pycaret。这是一个三步过程:
✅ 步骤 1 — 创建一个 anaconda 环境
从开始菜单打开Anaconda 提示符并运行以下代码:
conda create --name **myenv** python=3.6
Anaconda 提示符 — 创建环境
✅ 步骤 2 — 安装 PyCaret
在 Anaconda 提示符中运行以下代码:
conda activate **myenv**
pip install pycaret
安装可能需要 10 – 15 分钟。
✅ 步骤 3 — 在 Power BI 中设置 Python 目录
创建的虚拟环境必须与 Power BI 关联。这可以通过 Power BI Desktop 中的全局设置完成(文件 → 选项 → 全局 → Python 脚本)。Anaconda 环境默认安装在:
C:\Users*username*\AppData\Local\Continuum\anaconda3\envs\myenv
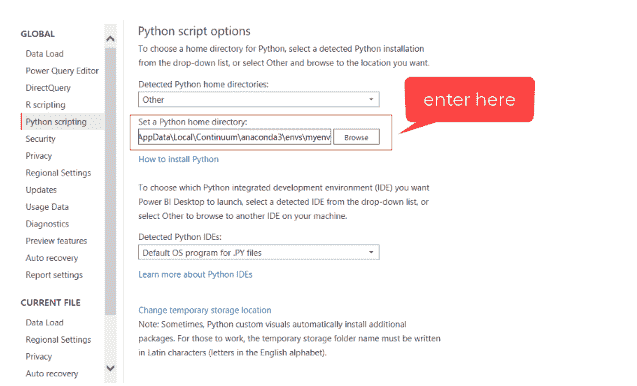
文件 → 选项 → 全局 → Python 脚本
???? 示例 1 — Power BI 中的聚类
聚类是一种机器学习技术,它将具有相似特征的数据点分组。这些分组对于探索数据、识别模式和分析数据子集非常有用。聚类的一些常见商业应用包括:
✔ 客户细分用于市场营销。
✔ 客户购买行为分析用于促销和折扣。
✔ 确定流行病爆发(如 COVID-19)中的地理聚类。
在本教程中,我们将使用‘jewellery.csv’文件,该文件可在 PyCaret 的 github 仓库中找到。你可以使用 Web 连接器加载数据。(Power BI Desktop → 获取数据 → 从 Web)。
CSV 文件链接:raw.githubusercontent.com/pycaret/pycaret/master/datasets/jewellery.csv
Power BI Desktop → 获取数据 → 其他 → 网络
来自 jewellery.csv 的样本数据点
K-Means 聚类
为了训练一个聚类模型,我们将在 Power Query 编辑器中执行 Python 脚本(Power Query 编辑器 → 转换 → 运行 Python 脚本)。

Power Query 编辑器中的功能区
运行以下代码作为 Python 脚本:
from **pycaret.clustering** import *****
dataset = **get_clusters**(data = dataset)
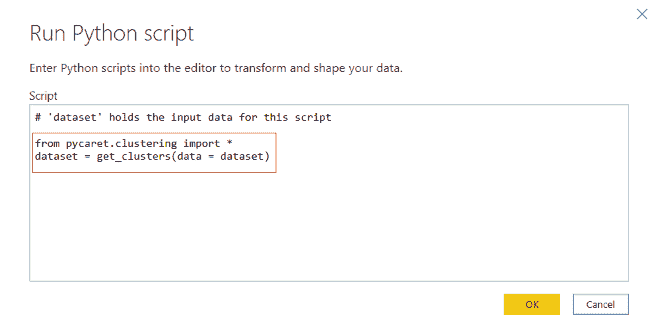
Power Query 编辑器(转换 → 运行 Python 脚本)
输出:
集群结果(代码执行后)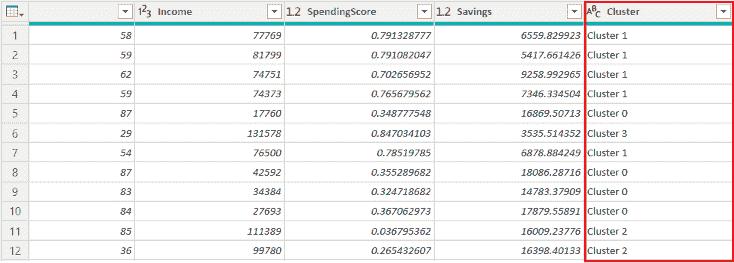
最终输出(点击表格后)
一个新的列‘Cluster’包含标签,并附加到原始表格中。
一旦应用查询(Power Query 编辑器 → 首页 → 关闭并应用),你可以在 Power BI 中可视化集群,如下所示:

默认情况下,PyCaret 训练一个K-Means集群模型,设置为 4 个集群(即表格中的所有数据点被分类为 4 组)。默认值可以轻松更改:
-
要更改集群数量,可以在get_clusters( )函数中使用num_clusters参数。
-
要更改模型类型,请在get_clusters( )中使用model参数。
查看以下训练 K-Modes 模型并设置 6 个集群的示例代码:
from **pycaret.clustering** import *
dataset = **get_clusters**(dataset, model = 'kmodes', num_clusters = 6)
PyCaret 提供了 9 种现成的集群算法:
所有训练集群模型所需的预处理任务,如缺失值填补(如果表格中有任何缺失或空值)、归一化或独热编码,这些任务都会在训练集群模型之前自动完成。点击这里了解更多关于 PyCaret 预处理功能的信息。
???? 在此示例中,我们使用了get_clusters( )函数来为原始表格分配集群标签。每次查询刷新时,集群都会重新计算。另一种实现方法是使用predict_model( )函数来使用预训练模型在 Python 或 Power BI 中预测集群标签(见下面的示例 5,了解如何在 Power BI 环境中训练机器学习模型)。
???? 如果你想学习如何使用 Jupyter Notebook 在 Python 中训练集群模型,请参见我们的Clustering 101 初学者教程。(无需编码背景)
???? 示例 2 — Power BI 中的异常检测
异常检测是一种用于识别稀有项、事件或观察的机器学习技术,通过检查表格中与大多数行显著不同的行来实现。通常,异常项会转化为某种问题,如银行欺诈、结构缺陷、医疗问题或错误。异常检测的一些常见业务用例包括:
✔ 使用金融数据进行欺诈检测(信用卡、保险等)。
✔ 入侵检测(系统安全,恶意软件)或监控网络流量的激增和下降。
✔ 识别数据集中的多变量异常值。
在本教程中,我们将使用 PyCaret 的 github 仓库 上提供的 ‘anomaly.csv’ 文件。您可以使用 Web 连接器加载数据。(Power BI Desktop → 获取数据 → 从 Web)。
链接到 csv 文件: raw.githubusercontent.com/pycaret/pycaret/master/datasets/anomaly.csv
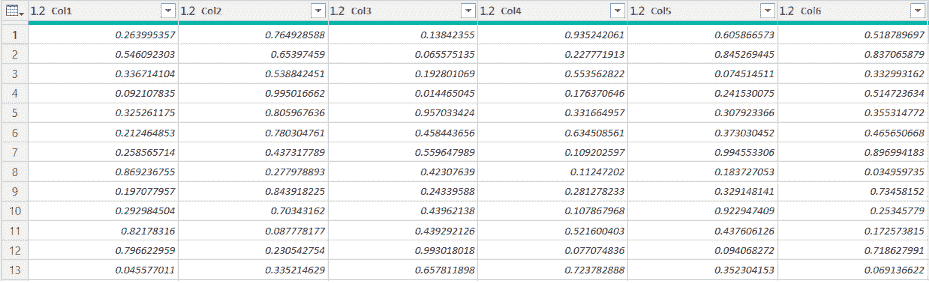
来自 anomaly.csv 的示例数据点
K-最近邻异常检测器
类似于聚类,我们将从 Power Query 编辑器(转换 → 运行 Python 脚本)运行 Python 脚本来训练异常检测模型。运行以下代码作为 Python 脚本:
from **pycaret.anomaly** import *****
dataset = **get_outliers**(data = dataset)
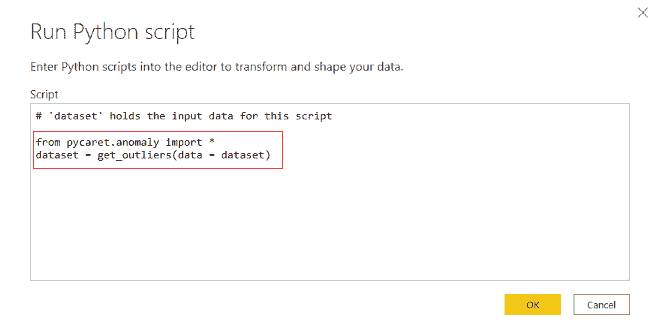
Power Query 编辑器(转换 → 运行 Python 脚本)
输出:
异常检测结果(代码执行后)
最终输出(点击表格后)
原始表格附加了两个新列。标签(1 = 异常,0 = 正常)和分数(高分的数据点被归类为异常)。
一旦应用查询,您可以在 Power BI 中以以下方式可视化异常检测结果:
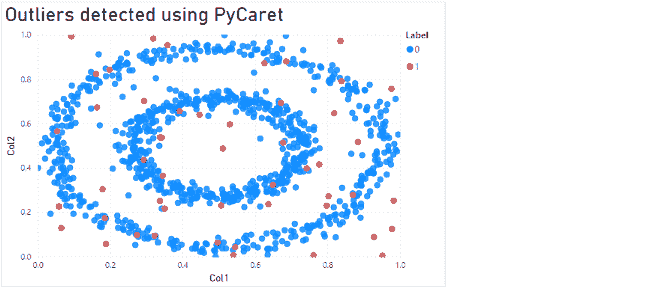
默认情况下,PyCaret 使用 5% 的分数(即表格中总行数的 5% 将被标记为异常)训练 K-最近邻异常检测器。默认值可以很容易地更改:
-
要更改分数值,您可以使用 fraction 参数在 get_outliers() 函数中。
-
要更改模型类型,请使用 model 参数在 get_outliers() 中。
请参阅以下代码以训练 Isolation Forest 模型,分数值为 0.1:
from **pycaret.anomaly** import *
dataset = **get_outliers**(dataset, model = 'iforest', fraction = 0.1)
PyCaret 中有超过 10 种现成的异常检测算法:
所有必要的预处理任务,如 缺失值填补(如果表格中有缺失或 空 值),或 归一化,或 独热编码,都将在训练异常检测模型之前自动执行。 点击这里 了解更多关于 PyCaret 的预处理功能。
???? 在这个示例中,我们使用了get_outliers()函数为分析分配异常值标签和分数。每次刷新查询时,异常值会被重新计算。另一种实现方式是使用predict_model()函数,通过 Python 或 Power BI 中的预训练模型预测异常值(请参见下面示例 5,了解如何在 Power BI 环境中训练机器学习模型)。
???? 如果你想学习如何使用 Jupyter Notebook 在 Python 中训练异常检测器,请参见我们的异常检测 101 初学者教程。(无需编码背景)
???? 示例 3 — 自然语言处理
分析文本数据的技术有很多,其中主题建模是一种流行的方法。主题模型是一种统计模型,用于发现文档集合中的抽象主题。主题建模是一种常用的文本挖掘工具,用于发现文本数据中的隐藏语义结构。
在本教程中,我们将使用 PyCaret 的‘kiva.csv’文件,该文件可以在github 存储库中找到。你可以通过 Web 连接器加载数据。(Power BI Desktop → 获取数据 → 来自 Web)。
CSV 文件链接:raw.githubusercontent.com/pycaret/pycaret/master/datasets/kiva.csv
潜在狄利克雷分配
在 Power Query 编辑器中作为 Python 脚本运行以下代码:
from **pycaret.nlp** import *****
dataset = **get_topics**(data = dataset, text = 'en')
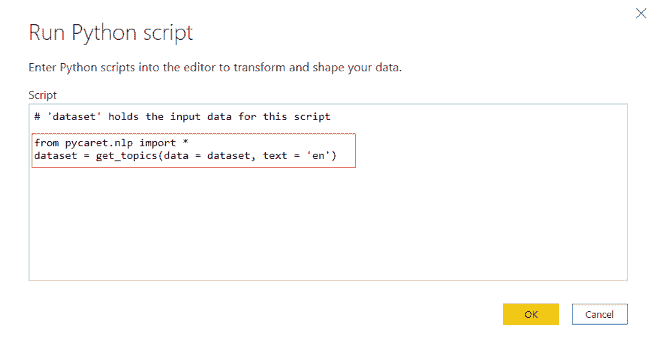
Power Query 编辑器(转换 → 运行 Python 脚本)
‘en’是表‘kiva’中包含文本的列名。
输出:
主题建模结果(代码执行后)
最终输出(点击表格后)
一旦代码执行完成,新列会附加到原始表格中,包括主题的权重和主导主题。在 Power BI 中,有多种方法可视化主题模型的输出。请参见下面的示例:
默认情况下,PyCaret 训练一个包含 4 个主题的潜在狄利克雷分配模型。默认值可以轻松更改:
-
要更改主题数量,可以在get_topics()函数中使用num_topics参数。
-
要更改模型类型,请使用model参数,在get_topics()中。
请参见示例代码以训练一个非负矩阵分解模型,主题数量为 10:
from **pycaret.nlp** import *
dataset = **get_topics**(dataset, 'en', model = 'nmf', num_topics = 10)
PyCaret 提供了用于主题建模的现成算法:

???? 示例 4— Power BI 中的关联规则挖掘
关联规则挖掘是一种基于规则的机器学习技术,用于发现数据库中变量之间的有趣关系。它旨在使用有趣度的度量来识别强规则。一些常见的关联规则挖掘业务用例包括:
✔ 市场篮子分析以了解经常一起购买的商品。
✔ 医疗诊断以帮助医生确定根据因素和症状的疾病发生概率。
在本教程中,我们将使用 PyCaret 的‘france.csv’文件,该文件可在 github 仓库 上找到。你可以使用网络连接器加载数据。(Power BI Desktop → 获取数据 → 从 Web)。
csv 文件链接:raw.githubusercontent.com/pycaret/pycaret/master/datasets/france.csv

来自 france.csv 的示例数据点
Apriori 算法
到目前为止,所有 PyCaret 功能都在 Power Query 编辑器(转换 → 运行 Python 脚本)中作为 Python 脚本执行。运行以下代码以使用 Apriori 算法训练关联规则模型:
from **pycaret.arules** import *
dataset = **get_rules**(dataset, transaction_id = 'InvoiceNo', item_id = 'Description')
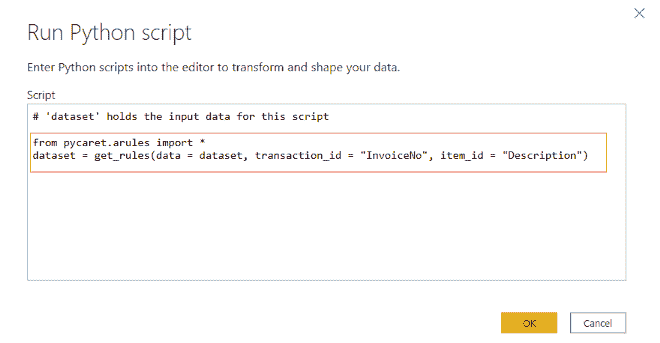
Power Query 编辑器(转换 → 运行 Python 脚本)
‘InvoiceNo’ 是包含交易 ID 的列,‘Description’ 包含感兴趣的变量,即产品名称。
输出:
关联规则挖掘结果(代码执行后)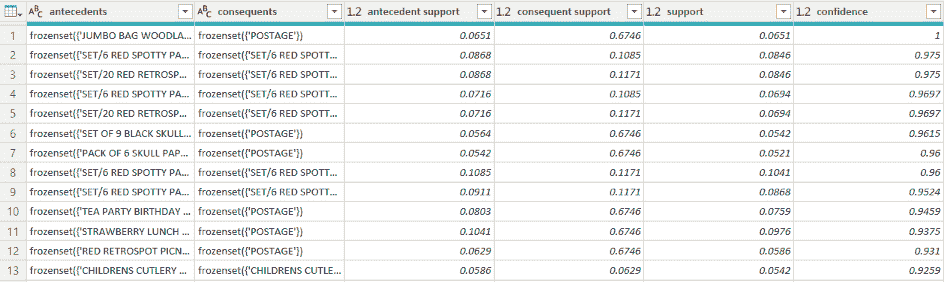
最终输出(点击表格后)
它返回一个包含前提和结论的表格,并附有相关指标,如支持度、置信度、提升度等。点击这里 了解更多关于 PyCaret 中的关联规则挖掘的信息。
???? 示例 5 — Power BI 中的分类
分类是一种监督学习技术,用于预测类别分类标签(也称为二元变量)。分类的一些常见业务用例包括:
✔ 预测客户贷款/信用卡违约。
✔ 预测客户流失(客户是否会留下或离开)
✔ 预测患者结果(患者是否有疾病)
在本教程中,我们将使用 PyCaret 的‘employee.csv’文件,该文件可在 github 仓库 上找到。你可以使用网络连接器加载数据。(Power BI Desktop → 获取数据 → 从 Web)。
csv 文件链接:raw.githubusercontent.com/pycaret/pycaret/master/datasets/employee.csv
目标:表‘employee’包含了公司中 15,000 名在职员工的信息,例如在公司的工作时间、平均每月工作小时、晋升历史、部门等。基于这些列(也称为机器学习术语中的特征),目标是预测员工是否会离开公司,由‘left’列表示(1 表示离开,0 表示不离开)。
与聚类、异常检测和 NLP 示例不同,它们属于无监督机器学习的范畴,分类是一种有监督技术,因此它被分为两个部分:
第一部分:在 Power BI 中训练分类模型
第一步是创建一个 Power Query 编辑器中的表‘employee’的副本,用于训练模型。
Power Query 编辑器 → 右键点击‘employee’ → 复制
在新创建的副本表‘employee (model training)’中运行以下代码以训练分类模型:
# import classification module and setup environmentfrom **pycaret.classification** import *****
clf1 = **setup**(dataset, target = 'left', silent = True)# train and save xgboost modelxgboost = **create_model**('xgboost', verbose = False)
final_xgboost = **finalize_model**(xgboost)
**save_model**(final_xgboost, 'C:/Users/*username*/xgboost_powerbi')

Power Query 编辑器(转换 → 运行 Python 脚本)
输出:
该脚本的输出将是一个pickle 文件,保存于定义的位置。pickle 文件包含了整个数据转换管道以及训练好的模型对象。
???? 另一个选择是在 Jupyter Notebook 中训练模型,而不是 Power BI。在这种情况下,Power BI 将仅用于在前端生成预测,使用的是在 Jupyter Notebook 中预训练的模型,该模型将作为 pickle 文件导入 Power BI(请参见下面的第二部分)。要了解有关在 Python 中使用 PyCaret 的更多信息,点击这里。
???? 如果你想学习如何在 Jupyter Notebook 中使用 Python 训练分类模型,请参见我们的二分类 101 初学者教程。(无需编程背景)。
PyCaret 提供了 18 种现成的分类算法:
第二部分:使用训练好的模型生成预测
现在我们可以使用训练好的模型对原始‘employee’表进行预测,判断员工是否会离开公司(1 或 0)以及概率百分比。运行以下代码作为 Python 脚本以生成预测结果:
from **pycaret.classification** import *****
xgboost = **load_model**('c:/users/*username*/xgboost_powerbi')
dataset = **predict_model**(xgboost, data = dataset)
输出:
分类预测(代码执行后)
最终输出(点击表格后)
原始表中附加了两个新列。‘Label’ 列表示预测结果,‘Score’ 列表示结果的概率。
在此示例中,我们对用于训练模型的相同数据进行了预测,仅用于演示目的。在实际情况下,‘Left’ 列是实际结果,在预测时是未知的。
在本教程中,我们训练了极端梯度提升(‘xgboost’)模型并用其生成了预测。我们这样做只是为了简化。实际上,你可以使用 PyCaret 来预测任何类型的模型或模型链。
PyCaret 的predict_model( )函数可以与使用 PyCaret 创建的 pickle 文件无缝协作,因为它包含了整个转换管道以及训练好的模型对象。 点击这里了解更多关于predict_model函数的信息。
???? 所有训练分类模型所需的预处理任务,例如缺失值填补(如果表格中有任何缺失或空值),或独热编码,或目标编码,这些任务都会在训练模型之前自动执行。 点击这里了解更多关于 PyCaret 的预处理功能。
???? 示例 6——Power BI 中的回归
回归是一种监督机器学习技术,用于根据过去的数据及其相应的过去结果,以最佳方式预测连续结果。与用于预测二元结果如是或否(1 或 0)的分类不同,回归用于预测连续值如销售、价格、数量等。
在本教程中,我们将使用‘boston.csv’文件,该文件可以在 PyCaret 的github 存储库中找到。你可以使用 Web 连接器加载数据。(Power BI Desktop → 获取数据 → 从 Web)。
CSV 文件链接: raw.githubusercontent.com/pycaret/pycaret/master/datasets/boston.csv
目标: 表‘boston’包含了 506 栋波士顿房屋的信息,如平均房间数、财产税率、人口等。根据这些列(在机器学习术语中也称为特征),目标是预测房屋的中位数值,由列‘medv’表示。
第一部分:在 Power BI 中训练回归模型
第一步是创建‘boston’表的副本,在 Power Query 编辑器中用于训练模型。
在新的重复表中运行以下代码作为 Python 脚本:
# import regression module and setup environmentfrom **pycaret.regression** import *****
clf1 = **setup**(dataset, target = 'medv', silent = True)# train and save catboost modelcatboost = **create_model**('catboost', verbose = False)
final_catboost = **finalize_model**(catboost)
**save_model**(final_catboost, 'C:/Users/*username*/catboost_powerbi')
输出:
此脚本的输出将是保存在指定位置的pickle 文件。pickle 文件包含整个数据转换管道以及训练好的模型对象。
PyCaret 中有 20 多种现成的回归算法:
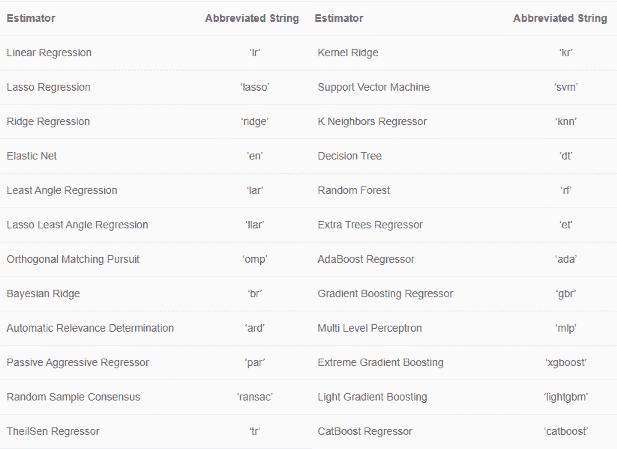
第二部分:使用训练好的模型生成预测
现在我们可以使用训练好的模型来预测房屋的中位数值。在原始表‘boston’中运行以下代码作为 Python 脚本:
from **pycaret.classification** import *****
xgboost = **load_model**('c:/users/*username*/xgboost_powerbi')
dataset = **predict_model**(xgboost, data = dataset)
输出:
回归预测(代码执行后)
最终输出(点击表格后)
新添加了一个包含预测结果的列‘Label’到原始表格中。
在这个示例中,我们在同一数据上进行了预测,这些数据用于训练模型仅为演示目的。在实际应用中,‘medv’列是实际结果,在预测时是未知的。
???? 所有训练回归模型所需的预处理任务,如缺失值插补(如果表格中有任何缺失或空值)、独热编码、或目标变换,在训练模型之前都会自动完成。点击这里了解更多关于 PyCaret 预处理功能的信息。
下一个教程
在使用 PyCaret 进行 Power BI 中的机器学习系列的下一个教程中,我们将深入探讨 PyCaret 中的高级预处理功能。我们还将了解如何在 Power BI 中实现机器学习解决方案,并利用PyCaret在 Power BI 前端的强大功能。
如果你想了解更多,请保持关注。
在我们的Linkedin页面关注我们,并订阅我们的Youtube频道。
另见:
初级 Python 笔记本:
开发计划中有什么?
我们正在积极改进 PyCaret。我们未来的开发计划包括一个新的时间序列预测模块,与TensorFlow的集成,以及 PyCaret 可扩展性的重大改进。如果你愿意分享你的反馈并帮助我们进一步改进,你可以在网站上填写此表格或在我们的Github或LinkedIn页面留言。
想了解特定模块吗?
从 1.0.0 首次发布开始,PyCaret 提供以下模块供使用。点击下面的链接查看文档和 Python 中的示例。
重要链接
如果你喜欢 PyCaret,请在我们的 github 仓库 上给我们 ⭐️。
在 Medium 上关注我:medium.com/@moez_62905/
简介:Moez Ali 是一名数据科学家,同时是 PyCaret 的创始人和作者。
原文。已获许可转载。
相关:
-
宣布 PyCaret 1.0.0
-
机器学习堆栈中的关键缺失部分
-
通过公共 API 共享你的机器学习模型
更多相关主题
使用机器学习预测和解释员工流失
原文:
www.kdnuggets.com/2017/10/machine-learning-predict-employee-attrition.html
作者:Matt Dancho,BusinessScience.io
员工流失(attrition)是组织面临的主要成本之一,预测流失是许多组织人力资源(HR)的迫切需求。直到现在,主流的方法是使用逻辑回归或生存曲线来建模员工流失。然而,随着机器学习(ML)的进步,我们现在可以获得更好的预测性能和对关键特征与员工流失之间关联的更好解释。在这篇文章中,我们将解释如何使用 H2O 的自动化机器学习功能来开发一个预测模型,该模型在机器学习准确度方面与商业产品相当;我们还将解释如何应用新的 LIME 包,该包能够将复杂的黑箱机器学习模型分解为变量重要性图。
问题:员工流失
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 需求
组织面临着因员工流失而产生的巨大成本。其中一些成本是可见的,比如培训费用和从员工开始工作到成为生产力成员所需的时间。然而,最重要的成本是无形的。考虑到当一名高效的员工离职时所失去的:新产品创意、出色的项目管理或客户关系。随着机器学习和数据科学的发展,现在不仅可以预测员工流失,还可以理解影响流失的关键变量。
我们使用了来自IBM Watson 网站的 HR 员工流失数据集来测试几种高级机器学习技术。该数据集包括 1470 名员工(行)和 35 个特征(列),其中一部分员工已离开组织(Attrition = “Yes”)。请注意,根据 IBM 的说法,“这是由 IBM 数据科学家创建的虚构数据集”。
解决方案:H2O 和 LIME
我们实施的解决方案同时使用了 H2O 进行自动化机器学习和 LIME 用于理解和分解复杂的黑箱模型。我们将概述分析的亮点,但感兴趣的读者可以查看包含代码的完整解决方案。
使用h2o包中的h2o.automl()进行机器学习:这个函数通过测试许多高级算法(如随机森林、集成方法和深度学习)以及更传统的算法(如逻辑回归),将自动化机器学习提升到了一个新的水平。主要的收获是,我们现在可以轻松实现与商业算法和 ML/AI 软件相当(在某些情况下甚至更好)的预测性能。
领导者模型(在验证集上产生的最准确模型)在一个未在建模过程中出现的测试集上达到了惊人的 88%准确率。此外,二分类分析的召回率(算法预测离职 = “是”而实际离职的次数)为 62%,这意味着人力资源专业人员可以准确地识别出 100 名被认为有风险的员工中的 62 名。在人力资源背景下,召回率非常重要,因为我们不想错过有风险的员工,而 62%的表现相当不错。
使用lime包的特征(变量)重要性:像深度学习这样的高级机器学习算法的问题在于,由于其复杂性,几乎无法理解算法。lime包的出现改变了这一切。lime的主要进展在于,通过局部递归分析模型,它可以提取出全球重复的特征重要性。这对我们来说意味着,lime为理解机器学习模型打开了大门,无论其复杂性如何。现在,最好的(通常非常复杂的)模型也可以被调查并潜在地理解其变量或特征如何影响模型。
我们投入使用 LIME 的回报是这个特征重要性图。展示了前十个案例(观察)的前四个特征。绿色条表示特征支持模型结论,红色条则相反。LIME 检测到加班、职位角色和培训时间是与模型预测相关的特征。

我们随后分析了关键特征,以了解这些特征是否与员工流失相关。对于像加班和职位这样的特征,方差似乎有关联。我们可以看到,流失=“否”的组有更低的加班员工比例。此外,销售代表、实验室技术员和人力资源等职位的流失百分比较高。
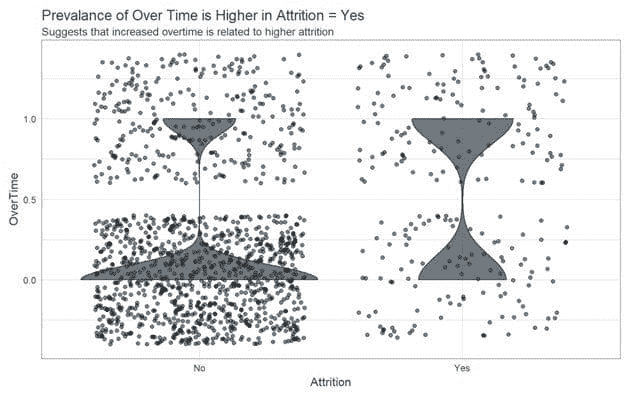
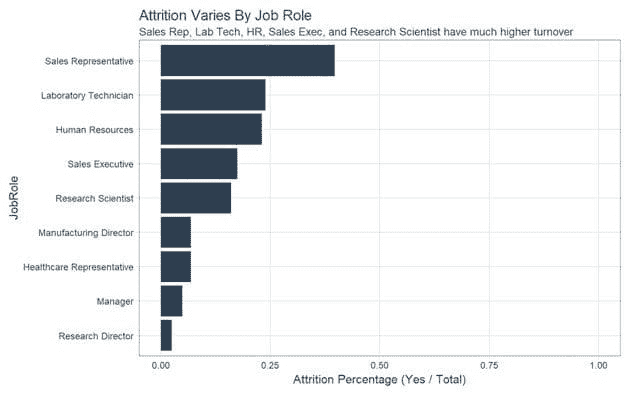
结论
新的机器学习技术可以应用于业务应用,特别是预测分析。在这种情况下,我们使用了 H2O 和 LIME 来开发和解释非常准确地检测员工流失风险的复杂模型。H2O 的h2o.autoML函数在对未见/未建模数据进行分类时表现良好,准确率约为 88%。LIME 帮助将 H2O 返回的复杂集成模型分解成与流失相关的关键特征。
个人简介:Matt Dancho 是 Business Science 的创始人,这是一家帮助组织将数据科学应用于业务应用的咨询公司。他是 R 包tidyquant和timetk的创作者,并且在业务和金融分析的数据科学领域工作了六年。Matt 拥有商业和工程硕士学位,并在商业智能、数据挖掘、时间序列分析、统计和机器学习方面拥有丰富的经验。
相关:
-
HR 经理如何利用数据科学来管理公司人才
-
每位员工的收入:黄金比例还是红鲱鱼?
-
构建预测流失模型的挑战
主题更多
机器学习没有为我的业务创造价值。为什么?
原文:
www.kdnuggets.com/2021/12/machine-learning-produce-value-business.html
由Necati Demir,datagran.io 的联合创始人兼首席技术官

Anton Grabolle / Better Images of AI / Classification Cupboard / Licenced by CC-BY 4.0
关键词“机器学习”一直在被提及。你不断听到它,人们把它说成是解决一切问题的魔法,作为领导者,你希望在业务中解决你的问题。你开始招聘数据科学家,并要求他们做 X,你不断听到他们在测试数据集中“有很好的准确性结果”,你喜欢你听到的;你听说这是一件好事。一段时间后,你想在日常操作中使用它,它却开始失败。那么,发生了什么?发生了什么事?
当然,可能有多个需要关注的原因,但在这篇文章中,我将重点关注三个非技术点:
-
无法区分问题和解决方案
-
不使用正确的指标
-
不进行迭代
区分问题和解决方案
上一段有以下句子:
你开始招聘数据科学家,并要求他们做 X……
你是怎么想到 X 的?数据科学团队还有其他可以帮助的 X 吗?可能,X 是你认为最适合你问题的解决方案,但你是否考虑过其他解决方案?在继续之前,让我们非常简短地解释一下什么是问题,什么是解决方案。
-
问题是你想要实现的目标
-
解决方案是你想要如何实现
让我们用这个例子来说明问题-解决方案的关系:
我希望通过开发一个推荐系统来提高我的电子商务网站的转化率。
你的业务问题(你想要实现的目标)是提高转化率,而你认为最好的解决方案是开发一个推荐系统。
对同一个问题可能有多种解决方案,你可以
-
构建一个基于机器学习的推荐系统,或者
-
提高你网站搜索引擎的质量。
可能有多种方法来解决你的问题。数据科学团队可能倾向于跳到他们脑海中的第一个解决方案,或者业务领导者可能倾向于要求数据科学团队实施她听说过的大公司的解决方案。那么,应该怎么做呢?
实际上,解决方案非常简单;作为领导者,你需要解释你想要实现的目标,然后与团队一起进行头脑风暴。 当然,可能会有挑战,这里的挑战可能是;
-
数据科学团队需要更多地考虑业务,而不仅仅是技术,
-
业务领导者需要更加开放,清楚地解释业务情况并理解机器学习过程。
使用正确的指标
让我们继续使用相同的“提高转化率 + 构建推荐系统”示例。如果你只是想出一个“构建推荐系统”的想法,并通过测量转化率来评估数据科学家团队的表现,那可能是错误的。
这个示例的边缘情况是:将公司的收入作为评估数据科学家团队表现的指标。你可以很容易地想象,收入不仅仅与推荐系统的结果相关。那该怎么办呢?
构建中间指标并进行测量。
指标 1 -> 指标 2 -> 指标 3 ->… -> 最终指标
在推荐系统的示例中;数据科学家团队可以立即衡量的指标是点击率(CTR),它测量了推荐项目被点击的次数。下一个层级的指标可以是加入购物车率,用来衡量推荐项目被加入购物车的次数。就这样继续下去…
CTR -> 加入购物车率 -> 指标 x -> 指标 y -> 转化率
你只需知道,越往右滑,数据科学家团队的信心就越少。作为领导者,你需要在业务目标和数据科学家团队有信心且有影响力的指标之间找到正确的平衡。
迭代
我很少看到一个想法在第一次尝试时就能成功。机器学习项目也不例外。开发机器学习项目是一个高度迭代的过程,期望第一次尝试就取得成功是一个错误。数据科学家团队在测试数据集上可能有很好的准确率,但在现实世界中情况会有所不同。
在实际应用机器学习时,可能会出现许多问题和解决方案选项;
-
如果这是一个推荐系统,可以开发一个流程,将点击数据输入推荐引擎,以便推荐引擎可以进行自我调整,
-
如果这是一个计算机视觉应用,可能是工厂的光照条件不够好,输入到视觉系统中的图像非常黑暗,
-
也许用户行为发生了变化,数据科学家团队用来开发机器学习系统的数据分布不再有效;这正是 COVID 爆发时信用卡欺诈检测系统发生的情况,因为每个人开始在网站上使用信用卡购物,造成了急剧的变化。
那该怎么办呢?
接受开发机器学习项目是一个高度迭代的过程。构建一个数据科学家团队可以从生产系统中获得反馈的过程。不要将机器学习项目视为技术问题,机器学习带来了组织变革,可能需要公司内部多个部门的协作。
结论
在这篇简短的文章中,我尝试解释了可能导致机器学习项目未能产生价值的三个非技术性问题,并提到了可能的挑战。
-
分离问题与解决方案 是找到正确的机器学习项目来实施的关键。这可以通过头脑风暴来实现,但面临的挑战是数据科学家团队和商业领导者需要理解对方的立场。
-
使用正确的指标 是衡量项目和团队的关键。这可以通过找到中间指标来实现,但面临的挑战是如果指标对数据科学家团队变得模糊,他们可能会缺乏信心。
-
迭代 是在现实世界与数据科学家团队所处理的数据集之间建立桥梁的关键。这可以通过构建一个将生产/现实世界数据提供给数据科学家团队的过程来实现,但这面临着一个挑战,即商业领导者可能不会将其视为组织变革,而只是将其视为技术问题。
简历: Necati Demir 是 datagran.io 的联合创始人兼首席技术官。Necati 是一位计算机工程师,拥有机器学习博士学位,并在私营行业有 15 年的软件开发经验。
原文。经许可转载。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织 IT
更多相关内容
机器学习项目检查清单
原文:
www.kdnuggets.com/2018/12/machine-learning-project-checklist.html
评论
我认为将各种对特定过程的解释进行编纂和比较,以加强自己对该过程的解释是一项值得的活动。我以前曾对我们可以称之为机器学习过程的替代解释进行过类似的操作(这些过程可以在一定程度上与数据科学或数据挖掘过程密切相关),你可以在这里、这里 和这里找到例子。

我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你在 IT 方面的组织
之前的帖子讨论了经典的 CRISP-DM 模型、KDD 过程、Francois Chollet 的 4 步模型(虽然针对 Keras,但可以推广)、Yufeng Guo 的 7 步机器学习方法,甚至还包括专门针对更窄学科的修改,例如基于文本的数据科学任务框架。为了进一步完善我们的内部模型,本文将概述 Aurélien Géron 的《机器学习项目检查清单》,如他畅销书《动手学机器学习:Scikit-Learn 和 TensorFlow》中所见。它类似于 Guo 的 7 步过程,但在细微的更高层次上呈现;它被展示为一个处理项目的检查清单,因此感觉更具描述性而非规定性,提醒你在做的过程中该做什么,而不是一些宏大的解释说明你为何这样做。这是一个没有判断的观察。
以下是 Géron 检查清单的简要概述。我谦逊地建议尚未阅读 Géron 书籍的任何人查看一下,以获取更多针对初学者和从业者的有用信息。
1. 确定问题
这第一步是定义目标的地方。Géron 用商业术语来描述目标,但这并不是严格必要的。然而,理解机器学习系统解决方案最终将如何使用是很重要的。这一步也是讨论可比场景和当前问题的权宜之计的地方,同时还要考虑假设,并确定对人类专业知识的需求程度。在这一阶段需要框定的其他关键技术项目包括确定适用的机器学习问题类型(有监督、无监督等),以及采用适当的性能指标。
2. 获取数据
这一步以数据为中心:确定需要多少数据,什么类型的数据,数据从哪里获取,评估获取数据的法律义务……然后获取数据。一旦你获得了数据,确保它经过适当的匿名化,确保你知道它实际是什么类型的数据(时间序列、观察、图像等),将数据转换为你所需的格式,并根据需要创建训练集、验证集和测试集。
3. 探索数据
检查清单中的这一步类似于通常所说的探索性数据分析(EDA)。目标是尝试在建模之前从数据中获得洞察。回想一下,在第一步中需要识别和探索关于数据的假设;这是更深入调查这些假设的好时机。在这一步中,人类专家可以特别有用,他们可以回答关于相关性的问题,这些问题可能对于机器学习从业者来说并不明显。在这里进行特征及其特征的研究,同时也进行特征及其值的总体可视化(例如,通过箱线图比通过数值查询更容易快速识别异常值)。记录你探索的发现以备后用是一种良好的做法。
4. 准备数据
现在是应用你在上一步中识别出的值得进行的数据转换的时候了。这一步还包括你将执行的任何数据清理,以及特征选择和工程。任何用于值标准化和/或归一化的特征缩放也将在此进行。
5. 建模数据
是时候对数据建模,并将初始模型集缩减到看似最有前景的那一批。(这类似于 Chollet 过程中的第一个建模步骤:好的模型→“过于优秀”的模型,你可以在这里阅读更多)这些尝试可能涉及使用完整数据集的样本来促进初步模型的训练,这些模型应涵盖广泛的类别(树模型、神经网络、线性模型等)。应构建、测量和比较模型,调查每个模型所犯的错误类型,以及每种算法使用的最重要特征。应将表现最佳的模型入围,然后可以进行进一步微调。
6. 微调模型
入围的模型现在应该对其超参数进行微调,并且在此阶段应调查集成方法。如果在前一建模阶段使用了数据集样本,则在此步骤中应使用完整数据集;没有经过全部训练数据或与其他同样经过全部训练数据的模型比较的微调模型不应被选为“优胜者”。另外,你没有过度拟合,对吧?
7. 提出解决方案
现在是展示的时候了,因此希望你的可视化技能(或实施团队中某个人的技能)达到标准!这是一个技术含量较低的步骤,但此时确保系统技术方面的适当文档记录也很重要。回答相关方的问题:相关方是否理解整体情况?解决方案是否达到了目标?你是否传达了假设和局限性? 这本质上是一个销售推介,因此要确保其收获是对系统的信心。如果结果不被理解和采纳,那为什么要做这些工作呢?
8. 启动机器学习系统
使机器学习系统准备好投入生产;它需要被接入某个更广泛的生产系统或战略中。作为一个软件解决方案,它在投入运行前需要进行单元测试,并且一旦启动后应该得到适当的监控。在这个过程中,基于新数据或更新数据对模型进行再训练也是其中的一部分,即使在早期步骤中已经考虑过这一点,也应予以重视。
相关:
-
接近机器学习过程的框架
-
Keras 四步工作流程
-
数据科学过程的重新发现
更多相关话题
为什么机器学习项目如此难以管理?
原文:
www.kdnuggets.com/2020/02/machine-learning-projects-manage.html
评论
由Lukas Biewald——Weights and Biases 的创始人/首席执行官。
我看过很多公司尝试部署机器学习——有些取得了巨大的成功,有些则失败得非常惨烈。一个共同点是,机器学习团队在设定目标和期望方面遇到困难。这是为什么呢?

1. 很难事先判断什么是困难的,什么是简单的。
是击败卡斯帕罗夫下棋更难,还是拿起并移动棋子更难?计算机早在二十多年前就击败了世界冠军棋手,但可靠地抓取和移动物体仍然是一个未解决的研究问题。人类不擅长评估什么对 AI 来说会很难,什么会很容易。即使在同一个领域,性能也可能有很大差异。预测情感的准确度是什么?在电影评论中,有很多文本,作者往往对自己的观点非常明确,如今期望的准确率是 90%到 95%。在 Twitter 上,两个人可能仅在 80%的时间内就某条推文的情感达成一致。对于关于某些航空公司的推文,通过始终预测情感为负面,可能能够达到 95%的准确率。
在项目的早期阶段,指标也可能会迅速增加,然后突然碰到瓶颈。我曾经举办过一个 Kaggle 比赛,成千上万的人在全球范围内竞争我的数据。在第一周,准确率从 35%上升到 65%,但在接下来的几个月中,它从未超过 68%。68%的准确率显然是数据在最好的、最新的机器学习技术下的极限。那些参加 Kaggle 比赛的人为了达到 68%的准确率付出了极大的努力,我相信他们觉得这是一个巨大的成就。但对于大多数用例来说,65%与 68%之间的差异是完全无法区分的。如果那是一个内部项目,我肯定会对结果感到失望。
我的朋友 Pete Skomoroch 最近告诉我,作为一名从事机器学习的数据科学家,进行工程立会是多么令人沮丧。工程项目通常会有进展,但机器学习项目可能会完全停滞。花一周时间进行数据建模可能完全没有任何改进,这种情况是可能的,甚至很常见。
2. 机器学习容易以意想不到的方式失败。
只要你有大量的训练数据并且生产环境中的数据与训练数据非常相似,机器学习通常能表现良好。人类在从训练数据中泛化方面非常出色,但我们对这一点的直觉非常糟糕。我用一个相机和一个基于 ImageNet 数百万张图像训练的视觉模型构建了一个小机器人,这些图像是从网上获取的。我在机器人相机上预处理了图像,使其看起来像来自网上的图像,但准确性远低于我预期的水平。为什么?网上的图像往往会把目标框起来。我的机器人可能不会像人类摄影师那样直接看着物体。人类可能甚至不会注意到这种差异,但现代深度学习网络却受到了很大的影响。有办法处理这种现象,但我只是因为性能下降非常明显,花了很多时间调试。
更棘手的是那些微妙的差异,这些差异导致性能下降且难以察觉。训练在《纽约时报》上的语言模型不适合社交媒体文本。这是我们可以预期的。然而,显然,训练于 2017 年文本的模型在处理 2018 年写的文本时性能下降。上游分布随着时间以多种方式发生变化。欺诈模型在对手适应模型行为时完全崩溃。
3. 机器学习需要大量相关的训练数据。
每个人都知道这一点,然而这依然是一个巨大的障碍。计算机视觉可以做出惊人的事情,只要你能够收集和标注大量的训练数据。对于某些使用案例,数据是某些业务过程的免费副产品。这是机器学习往往表现非常好的地方。对于许多其他使用案例,训练数据是极其昂贵且难以收集的。很多医疗使用案例看起来非常适合机器学习——做出关键决策时有许多微弱信号和明确结果——但由于重要的隐私问题,数据被锁定或最初没有被一致地收集。
很多公司不知道从哪里开始投资于收集训练数据。这是一个重大工作,而且很难预先预测模型的表现如何。
处理这些问题的最佳实践是什么?
1. 非常注意你的训练数据。
查看算法错误分类了它曾训练过的数据的情况。这些几乎总是标签错误或奇怪的边缘案例。不管怎样,你真的需要了解这些情况。让所有从事模型构建的人员查看训练数据,并自己标注一些训练数据。对于许多使用案例,模型的表现很可能不会超过两个独立的人的一致率。
2. 立即使某些东西从头到尾正常工作,然后一次改进一件事。
从可能有效的最简单方案开始并将其部署。你将从中学到很多。在过程中的任何阶段添加的复杂性通常在研究论文中会改善模型,但在现实世界中却很少见效。为每一项额外的复杂性提供合理的理由。
将产品交到最终用户手中可以帮助你早期了解模型的表现如何,并可能暴露出一些关键问题,例如模型优化的目标与最终用户需求之间的矛盾。这也可能促使你重新评估你所收集的训练数据。快速发现这些问题要好得多。
3. 寻找优雅的方式来处理算法不可避免的失败情况。
几乎所有的机器学习模型都有一定的失败率,如何处理这些失败至关重要。模型通常有一个可靠的置信度评分可以使用。通过批处理流程,你可以建立人工干预系统,将低置信度的预测发送给操作员,从而使系统在端到端的工作中保持可靠,并收集高质量的训练数据。在其他用例中,你可能能够以某种方式展示低置信度的预测,从而标记潜在的错误或减少对最终用户的困扰。
这是一个未能优雅处理的失败示例。微软未能预测到他们的 Tay 机器人会多快从 Twitter 上的恶意用户那里学到不良行为。
下一步?
机器学习最初的目标主要是智能决策,但我们越来越多地将机器学习应用于我们使用的产品中。随着我们越来越依赖机器学习算法,机器学习不仅仅是一个研究主题,它也成为了一个工程学科。我对能够构建全新类型的产品感到非常兴奋,但对缺乏工具和最佳实践感到担忧。因此,我创办了一家名为Weights and Biases的公司来帮助解决这个问题。如果你对了解更多感兴趣,可以查看我们正在做的事情。
感谢Yan-David Erlich、James Cham、Noga Leviner以及Carey Phelps阅读早期版本,并感谢Peter Skomoroch让我开始思考这个话题。
原文。已获许可转载。
个人简介: 卢卡斯·比沃尔德 是 Weights & Biases 的创始人,曾是 Figure Eight(前身为 CrowdFlower)的创始人。
相关内容:
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
机器学习难题,解释
原文:
www.kdnuggets.com/2019/06/machine-learning-puzzle-explained.html
评论
之前我写过关于 数据科学难题 的文章,概述了与数据科学相关的多个关键概念,并尝试解释这些概念之间的关系及其如何结合在一起。这次我们将以类似的方式探讨机器学习模型。
请记住,我们将从监督学习的角度来探讨机器学习,所有概念都围绕分类作为我们的目标进行讨论(虽然回归也是类似的)。重要的是,这种难题视角不会涵盖其他机器学习范式,如无监督学习和强化学习,因此在揭示这些部分时要记住这一点。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
说到这里,请继续阅读,了解机器学习难题如何组合在一起。

机器学习是数据科学的主要技术驱动因素之一。数据科学的目标是从数据中提取洞察,而机器学习是使这一过程得以自动化的引擎。机器学习算法不断促进计算机程序从经验中自动改进,这些算法在各种不同领域中变得越来越重要。
数据是当今世界运转的基础。数据是输入机器学习算法以进行“学习”的内容。特定的数据集是静态的、有限的实例— 或观察值 — 及其对应的特征;如果我们考虑用于训练和测试模型的数据,还会存在一个类别标签 — 或目标 — 以定义观察值所属于的分类组。简单来说,可以将数据视为一个表格(尽管不一定非如此),在这种情况下,表格中的行是实例,而列是特征。数据不必以简单的表格形式排列;然而,我们尽力将数据整理成多维数组 — 具有不同维度 — 这些数组足够稳健,能够捕捉到我们能想到的各种数据表示,前提是我们有时使用一些独创性的办法。
机器学习算法是用于学习如何最好地建模数据的特定方法和步骤序列。算法使用不同的方法来尝试最佳预测数据实例的标签,基于该实例的特征值。在数据实例足够多的情况下,机器学习算法的目的是能够以某种程度的成功(无论你如何定义成功)来近似给定实例所属的类别,因此有了“分类”这一术语。超参数是可以调整的旋钮,用于微调算法的“学习”。
简单来说,算法 + 数据集 = 模型。模型是数据和算法在训练阶段后的结果,此时生成的模型已经“学会”了如何理解数据,即如何从实例的特征集得出类别预测。模型是一个数学函数(作为训练的结果创建;见下文),能够接受数据集中的实例并预测其类别成员资格。
算法如何利用数据创建模型?这通过训练来实现,这一过程将部分可用数据,即训练集,输入算法中,算法经过其步骤并生成一个训练好的模型。然后,可以将这个训练好的模型应用于未见过的持出数据,作为验证集,以检查它在对从未见过的数据进行分类时的表现如何。最后,可以使用测试集来区分不同模型的质量,这是一组未见过的数据,仅在模型经过优化以达到最佳性能后,才会呈现给最终产品。
损失函数是通过对训练数据实例的类别预测和实际类别标签进行比较的机制。机器学习算法的目标是通过迭代最小化这个损失——损失函数输出的值代表预测和现实之间的距离——因此,这个值越低,模型对类别标签的预测学习得越好。
还有什么用来确定模型表现的好坏?有许多指标可用于模型评估。对于分类,最简单的形式是准确率,即正确预测的比例。精确率和召回率是另一对有用的分类指标,还有其他指标。回归,这一分类的连续变体,使用一组不同的指标来确定预测值与实际值之间的距离。
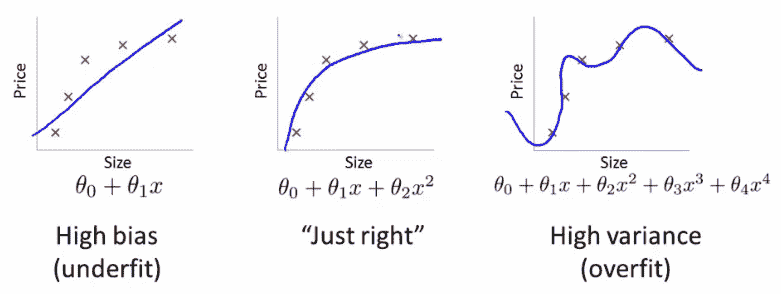
来源:斯坦福大学 Andrew Ng 的机器学习课程
你的模型在预测训练数据的类别方面做得很好,但对保留数据集的泛化效果不好吗?你可能陷入了过拟合的困境,这是一种模型对问题的内部理解紧密依赖于训练集中的特定实例的情况。过拟合是未能区分信号和噪声,而是将所有数据视为信号。
解决过拟合的一个方法是正则化,这是一种对特定模型参数施加惩罚的方法,以强制学习一个较少灵活、较少复杂的模型。这种缺乏复杂性的模型应当不会很好地捕捉训练数据的细微差别,并且应该对未见过的数据有更好的泛化能力。
以上是一些核心概念的简要介绍,这些概念适合对机器学习领域感兴趣的新手。理解这些基本概念可以帮助建立一个坚实的基础,以构建你内部的机器学习框架。
相关:
-
数据科学难题,再探讨
-
机器学习的本质
-
机器学习项目检查清单
更多相关话题
机器学习正在走向实时
原文:
www.kdnuggets.com/2021/01/machine-learning-real-time.html
评论
由Chip Huyen撰写,Snorkel AI 的 ML 生产,斯坦福大学讲师。

在与来自美国、欧洲和中国主要互联网公司的机器学习和基础设施工程师交流后,我注意到两个公司群体。一个群体在基础设施上投入了大量资金(数亿美元),以实现实时机器学习,并且已经看到了投资回报。另一个群体仍在怀疑实时机器学习是否有价值。
对于实时机器学习的定义似乎没有一致的看法,也没有很多关于它在行业中如何实现的深入讨论。在这篇文章中,我想分享一下在与大约十家公司交流后,我学到的东西。
本文将介绍两个实时机器学习的级别。
-
Level 1:你的机器学习系统实时进行预测(在线预测)。
-
Level 2:你的系统可以实时地(在线学习)纳入新数据并更新模型。
我使用“模型”来指代机器学习模型,使用“系统”来指代围绕它的基础设施,包括数据管道和监控系统。
Level 1:在线预测——你的系统可以实时进行预测
实时在这里定义为在毫秒到秒的范围内。
用例
延迟很重要,特别是对于用户面向的应用程序。在 2009 年,谷歌的实验表明,将网页搜索延迟增加 100 到 400 毫秒会使用户每天的搜索次数减少 0.2%到 0.6%。在 2019 年,Booking.com 发现延迟增加 30%大约会导致 0.5%的转化率下降——“这是对我们业务的一个相关成本。”
无论你的机器学习模型多么出色,如果它们在预测时仅仅多花费了几毫秒,用户就会去点击其他东西。
批量预测的问题
一种非解决方案是避免在线进行预测。你可以离线批量生成预测,存储它们(例如,存储在 SQL 表中),并在需要时提取预先计算好的预测结果。
当输入空间是有限的时,这种方法可以奏效——你确切知道有多少个可能的输入需要进行预测。一个例子是当你需要为用户生成电影推荐时——你确切知道有多少用户。因此,你可以定期(例如每几小时)为每个用户预测一组推荐结果。
为了使用户输入空间有限,许多应用程序要求用户从类别中选择,而不是输入任意查询。例如,如果你访问 TripAdvisor,你首先必须选择一个预定义的大都市区域,而不能直接输入任何位置。
这种方法有许多限制。TripAdvisor 的结果在其预定义类别中还不错,如“餐厅”在“旧金山”,但当你尝试输入诸如“海斯谷高评分泰国餐厅”这样的任意查询时,效果就很差。
批量预测所造成的限制即使在像 Netflix 这样的技术进步公司中也存在。比如你最近看了很多恐怖片,所以当你第一次登录 Netflix 时,恐怖片占据了推荐列表。但今天你心情不错,于是你搜索“喜剧”并开始浏览喜剧分类。Netflix 应该学习并在你的推荐列表中显示更多喜剧内容,对吗?但它不能在下一次生成批量推荐之前更新列表。
在上述两个例子中,批量预测导致用户体验下降(这与用户参与度/保留度密切相关),而非灾难性失败。其他例子包括广告排名、Twitter 的热门话题排名、Facebook 的新闻动态排名、到达时间估算等。
还有许多应用程序如果没有在线预测,将导致灾难性的失败或根本无法正常工作。例如,高频交易、自动驾驶汽车、语音助手、使用面部/指纹解锁手机、老年人跌倒检测、欺诈检测等。能够检测到三小时前发生的欺诈交易总比根本无法检测到要好,但能够实时检测到可以防止欺诈交易的发生。
从批量预测切换到实时预测可以让你使用动态特征来做出更相关的预测。静态特征是变化缓慢或很少变化的信息——如年龄、性别、职业、邻里等。动态特征是基于当前发生的事情——如你正在观看的内容、你刚刚点赞的内容等。了解用户现在的兴趣将使你的系统能够做出更相关的推荐。
解决方案
为了使你的系统能够进行在线预测,它必须具备两个组件:
-
快速推断:一个能够以毫秒级别做出预测的模型。
-
实时管道:一个可以实时处理数据、输入模型并返回预测结果的管道。
- 快速推断
当一个模型过于庞大并且预测时间过长时,有三种方法可以解决:
- 加快模型速度(推断优化)
例如,融合操作、分布计算、内存占用优化、编写针对特定硬件的高性能内核等。
- 使模型更小(模型压缩)
起初,这一系列技术旨在使模型更小,以便适应边缘设备。使模型更小通常会使其运行更快。模型压缩的最常见通用技术是量化,例如,使用 16 位浮点数(半精度)或 8 位整数(定点)代替 32 位浮点数(全精度)来表示模型权重。在极端情况下,有些人尝试了 1 位表示(二进制权重神经网络),例如,BinaryConnect和Xnor-Net。Xnor-Net 的作者创办了 Xnor.ai,这是一家专注于模型压缩的初创公司,该公司已被苹果以 2 亿美元的价格收购。
另一种流行的技术是知识蒸馏——一个小模型(学生)被训练以模仿一个较大的模型或模型集合(教师)。尽管学生通常是通过预训练的教师进行训练,但两者也可以同时训练。一个在生产中使用的蒸馏网络的例子是DistilBERT,它将 BERT 模型的大小减少了 40%,同时保留了 97%的语言理解能力,并且运行速度快了 60%。
其他技术包括剪枝(找出对预测最不重要的参数并将其设置为 0)和低秩分解(用紧凑的块替换过度参数化的卷积滤波器,以减少参数数量并提高速度)。详见A Survey of Model Compression and Acceleration for Deep Neural Networks(Cheng et al. 2017)。
关于模型压缩的研究论文数量正在增长。现成的工具也在不断增加。Awesome Open Source 有一个列表,前 40 名模型压缩开源项目。
- 使硬件更快
这是另一个蓬勃发展的研究领域。大型公司和初创公司都在竞相开发硬件,以使大型机器学习模型在云端以及尤其在设备上更快地进行推理,甚至训练。IDC 预测,到 2020 年,边缘和移动设备进行推理的总量将达到 37 亿台,而进一步有 1.16 亿台进行训练。
- 实时管道
假设你有一个共享打车应用,并且想要检测欺诈交易,例如使用被盗信用卡进行的支付。当真正的信用卡持有者发现未经授权的支付时,他们会与银行争议,你需要退款。为了最大化利润,欺诈者可能会连续打车或者使用多个账户进行打车。2019 年,商家估计欺诈交易占其年度在线销售的平均27%。你检测到被盗信用卡的时间越长,损失的钱就越多。
要检测交易是否欺诈,仅仅查看该交易是不够的。你需要至少查看涉及该交易的用户的近期历史、他们在应用内的最近行程和活动、信用卡的近期交易以及其他同时发生的交易。
为了快速访问这些信息,你需要尽可能将它们保存在内存中。每当发生你关心的事件——用户选择位置、预订行程、联系司机、取消行程、添加信用卡、删除信用卡等——这些事件的信息会进入你的内存存储。信息会保留在内存中直到它们仍然有用(通常为几天),然后要么进入永久存储(例如 S3),要么被丢弃。最常用的工具是Apache Kafka,还有如 Amazon Kinesis 这样的替代品。Kafka 是一个流存储:它存储数据的同时流入。
流数据与静态数据不同——静态数据是指已经存在于某个地方的完整数据,如 CSV 文件。当读取 CSV 文件时,你知道何时任务完成。而数据流是不会结束的。
一旦你有了处理流数据的方法,你就需要提取特征以输入到你的机器学习模型中。在流数据的特征基础上,你可能还需要静态数据的特征(例如账户创建时间、用户评分等)。你需要一个工具,能够处理流数据和静态数据,并将它们从各种数据源中整合在一起。
流处理与批处理
人们通常使用“批处理”来指代静态数据处理,因为你可以将数据分批处理。这与“流处理”相对,后者处理每个到达的事件。批处理是高效的——你可以利用 MapReduce 等工具处理大量数据。流处理是快速的,因为你可以在数据到达时立即处理。Apache Flink 的 PMC 成员 Robert Metzger 争辩说流处理的效率可以和批处理一样高,因为批处理是流处理的一个特殊情况。
处理流数据更为困难,因为数据量是不受限的,而且数据以不同的速率和速度到达。让流处理器进行批处理要比让批处理器进行流处理容易。
Apache Kafka 具备一定的流处理能力,一些公司在其 Kafka 流存储之上利用这一能力,但 Kafka 的流处理在处理各种数据源方面能力有限。已有努力将 SQL 这一流行的用于静态数据表的查询语言扩展以处理数据流[1, 2]。然而,最流行的流处理工具是Apache Flink,它原生支持批处理。
在机器学习生产的早期阶段,许多公司在其现有的 MapReduce/Spark/Hadoop 数据管道上构建了 ML 系统。当这些公司需要进行实时推断时,他们需要为流数据建立一个独立的管道。
拥有两个不同的数据处理管道是机器学习生产中常见的错误原因,例如,一个管道中的变化没有在另一个管道中正确复制,导致两个管道提取出不同的特征集。如果两个管道由两个不同的团队维护,这种情况尤其常见,例如,开发团队维护用于训练的批处理管道,而部署团队维护用于推断的流处理管道。包括Uber和微博在内的公司已经进行了重大基础设施改革,以通过 Flink 统一他们的批处理和流处理管道。
事件驱动 vs. 请求驱动
过去十年,软件世界已经转向了微服务架构。这个理念是将业务逻辑拆分成小组件——每个组件都是一个独立的服务——以便于独立维护。每个组件的拥有者可以快速更新和测试该组件,而无需咨询系统的其余部分。
微服务通常与 REST 密切相关,REST 是一组让这些微服务进行通信的方法。REST API 是请求驱动的。客户端(服务)通过 POST 和 GET 等方法发送请求,以告诉服务器确切要做什么,服务器则以结果回应。服务器必须监听请求才能使请求注册。
因为在请求驱动的世界里,数据通过对不同服务的请求来处理,没有人能够概览数据如何在整个系统中流动。考虑一个简单的有 3 个服务的系统:
-
A 管理司机的可用性
-
B 管理乘车需求
-
C 预测每次客户请求乘车时显示的最佳可能价格
由于价格依赖于可用性和需求,服务 C 的输出依赖于服务 A 和 B 的输出。首先,该系统需要服务间通信:C 需要向 A 和 B 请求预测,A 需要向 B 请求以了解是否需要调动更多司机,并向 C 请求以知道给他们什么价格激励。其次,没有简单的方法来监控 A 或 B 的逻辑变化如何影响服务 C 的性能,或映射数据流以调试如果服务 C 的性能突然下降。
仅有 3 个服务的情况下,事情已经变得复杂。试想一下,如果有像主要互联网公司那样的数百甚至上千个服务,服务间的通信将会变得非常庞大。通过 HTTP 发送 JSON 数据块——这是常见的 REST 请求方式——速度也很慢。服务间的数据传输可能成为瓶颈,减慢整个系统的速度。
与其让 20 个服务向服务 A 请求数据,不如在服务 A 内部发生事件时,将该事件广播到一个流中,任何需要 A 数据的服务可以订阅这个流并挑选所需的数据?如果有一个流,所有服务都可以广播它们的事件并进行订阅呢?这个模型称为 pub/sub:发布与订阅。这是像 Kafka 这样的解决方案所允许的。由于所有数据都流经一个流,你可以设置一个仪表板来监控数据及其在系统中的转换。因为它基于服务广播的事件,这种架构是事件驱动的。
超越微服务:流、状态与可扩展性 (Gwen Shapira, QCon 2019).
请求驱动架构适用于依赖逻辑而非数据的系统。事件驱动架构则更适合数据密集型系统。
挑战
许多公司正在从批处理转向流处理,从请求驱动架构转向事件驱动架构。我从与美国和中国主要互联网公司的交谈中得到的印象是,这一变化在美国仍然很慢,但在中国则要快得多。流式架构的采用与 Kafka 和 Flink 的普及有关。Robert Metzger 告诉我,他观察到在亚洲,使用 Flink 进行机器学习工作负载的情况比在美国更多。关于“Apache Flink”的 Google 趋势数据与这一观察结果一致。
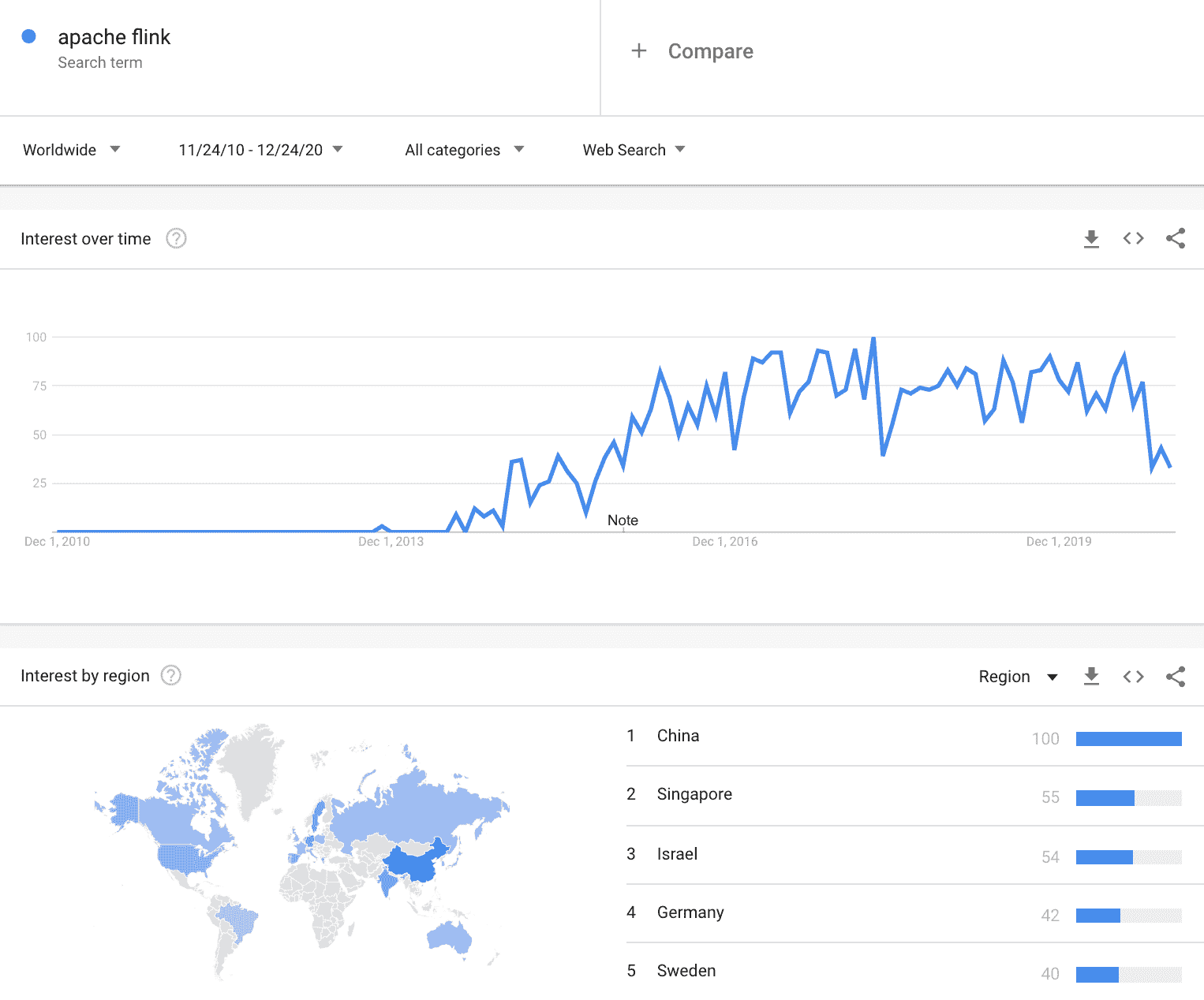
流处理不够普及有很多原因。
-
公司看不到流处理的好处
-
他们的系统规模还没有达到服务间通信成为瓶颈的程度。
-
他们没有从在线预测中受益的应用程序。
-
他们可能有应用程序可以从在线预测中受益,但由于他们从未进行过在线预测,所以还未意识到这一点。
-
-
基础设施的高初始投资
基础设施的更新费用昂贵,并可能危及现有应用。管理者可能不愿意投资于升级基础设施以支持在线预测。
-
思维方式的转变
从批处理转向流处理需要一种思维方式的转变。使用批处理时,你知道何时完成任务。使用流处理时,任务永远不会完成。你可以制定规则,比如获取过去 2 分钟内所有数据点的平均值,但如果一个发生在 2 分钟前的事件被延迟了,还没有进入流中怎么办?在批处理下,你可以有明确定义的表并进行联接,但在流处理下没有表可以联接,那么在两个流上进行联接操作意味着什么呢?
-
Python 不兼容
Python 是机器学习的通用语言,而 Kafka 和 Flink 运行在 Java 和 Scala 上。引入流处理可能会在工作流程中造成语言不兼容。Apache Beam 在 Flink 之上提供了一个 Python 接口用于与流进行通信,但你仍然需要能够使用 Java/Scala 的人。
-
更高的处理成本
批处理意味着你可以更高效地利用计算资源。如果你的硬件能够一次处理 1000 个数据点,那么一次只处理 1 个数据点就显得非常浪费。
级别 2:在线学习 - 你的系统可以实时地整合新数据并进行更新
实时 在这里被定义为分钟级别
定义“在线学习”
我使用“在线学习”而不是“在线训练”,因为后者的定义有争议。按照定义,在线训练意味着从每一个进入的数据点中学习。实际上,很少有公司真正这样做,因为:
-
这种方法存在灾难性遗忘的问题——神经网络在学习新信息时会突然忘记之前学到的信息。
-
在只有一个数据点的情况下运行学习步骤可能比在批量数据上运行要昂贵(这可以通过拥有刚好足够处理一个数据点的硬件来缓解)。
即使一个模型在每个数据点到来时都在学习,这也并不意味着新的权重在每个数据点后都会被部署。由于我们对机器学习算法学习方式的理解仍然有限,更新的模型需要先进行评估,以查看其表现如何。
对于大多数所谓的在线培训公司,它们的模型在微批次中学习,并在一段时间后进行评估。只有在性能被评估为令人满意之后,模型才会被更广泛地部署。对于微博来说,他们从学习到部署模型更新的迭代周期是 10 分钟。
微博中的 Flink 机器学习(钱宇,Flink Forward 2020)。
用例
TikTok 非常令人上瘾。其秘密在于其 推荐系统,这些系统可以快速学习你的偏好,并建议你可能会观看的视频,为用户提供了令人难以置信的滚动体验。这得益于 TikTok 背后的公司 ByteDance 建立了一个成熟的基础设施,使他们的推荐系统能够实时学习用户偏好(他们术语中的“用户档案”)。
推荐系统是在线学习的完美候选者。它们有自然的标签——如果用户点击了推荐,这是一个正确的预测。并不是所有的推荐系统都需要在线学习。用户对房子、汽车、航班、酒店等物品的偏好不太可能在一分钟内发生变化,因此系统不断学习意义不大。然而,用户对在线内容——视频、文章、新闻、推文、帖子、表情包——的偏好可以迅速变化(“我刚刚读到章鱼有时会无缘无故地打鱼,现在我想看一段相关视频”)。随着在线内容偏好的实时变化,广告系统也需要实时更新以显示相关广告。
在线学习对于系统适应罕见事件至关重要。考虑一下黑色星期五的在线购物。由于黑色星期五一年只有一次,亚马逊或其他电子商务网站无法获得足够的历史数据来了解用户当天的行为,因此它们的系统需要在当天不断学习以适应变化。
或者考虑一下当某位名人发了一条愚蠢的推文时在 Twitter 上的搜索。例如,当“四季园艺”新闻上线时,许多人会去搜索“总园艺”。如果你的系统没有立即学会“总园艺”在这里指的是新闻发布会,你的用户就会收到很多园艺推荐。
在线学习也可以帮助解决冷启动问题。当用户刚加入你的应用时,你对他们一无所知。如果你没有进行任何形式的在线学习的能力,你将不得不为用户提供通用的推荐,直到下次你的模型离线训练时。
解决方案
由于在线学习仍然相对较新,并且大多数进行在线学习的公司尚未公开详细信息,因此没有标准解决方案。
在线学习并不意味着“没有批量训练。”那些最成功使用在线学习的公司通常也会并行进行离线训练,然后将在线版本与离线版本结合起来。
挑战
在线学习面临许多挑战,包括理论上的和实际的。
- 理论上的
在线学习颠覆了我们对机器学习的许多认知。在入门级的机器学习课程中,学生可能会学习到“用足够多的周期训练你的模型直到收敛”的不同版本。在在线学习中,没有周期——你的模型每次只见到一个数据点。也不存在收敛的概念。你的基础数据分布不断变化,没有固定的目标可以收敛。
在线学习的另一个理论挑战是模型评估。在传统的批量训练中,你会在固定的保留测试集上评估模型。如果一个新模型在相同的测试集上表现优于现有模型,我们会说新模型更好。然而,在线学习的目标是使你的模型适应不断变化的数据。如果你的更新模型已经适应了现在的数据,而我们知道现在的数据与过去的数据不同,那么用旧数据测试你的更新模型就没有意义了。
那么我们如何知道在过去 10 分钟的数据上训练的模型是否优于在 20 分钟前的数据上训练的模型呢?我们必须在当前数据上比较这两个模型。在线训练要求在线评估,但使用未经用户测试的模型似乎是灾难的开端。
许多公司仍然在进行在线学习。新模型首先会接受离线测试以确保它们不会造成灾难,然后通过复杂的 A/B 测试系统与现有模型进行在线评估。只有当一个模型在公司关心的某些指标上表现优于现有模型时,才会被更广泛地部署。(别让我谈论选择在线评估指标的问题。)
- 实用性
目前尚无标准化的在线训练基础设施。一些公司已经趋向于流式架构和参数服务器,但除此之外,我所接触到的进行在线训练的公司需要在内部构建很多基础设施。我不愿意在线讨论这个问题,因为一些公司要求我保密这些信息,因为他们正在为他们构建解决方案——这是他们的竞争优势。
美国和中国的 MLOps 竞赛
我读了很多关于美国和中国在人工智能竞赛中的对比,但大多数比较似乎关注于研究论文、专利、引用和资助。只有在我开始与美国和中国公司讨论实时机器学习后,我才注意到他们的 MLOps 基础设施存在惊人的差异。
很少有美国互联网公司尝试在线学习,即使在这些公司中,在线学习也仅用于简单的模型,如逻辑回归。我从直接与中国公司交流和与在两个国家工作过的人的交流中得到的印象是,在线学习在中国更为普遍,中国工程师更渴望进行尝试。你可以在这里和这里看到一些对话。

结论
机器学习正在变得实时,无论你是否准备好。虽然大多数公司仍在争论在线推断和在线学习是否有价值,但那些正确实施这些技术的公司已经看到了投资回报,他们的实时算法可能是帮助他们领先于竞争对手的主要因素。
我对实时机器学习还有很多想法,但这篇文章已经很长了。如果你对讨论这个话题感兴趣,可以给我发封邮件。
致谢
这篇文章综合了许多与以下优秀工程师和学者的对话。我要感谢 Robert Metzger、Neil Lawrence、Savin Goyal、Zhenzhong Xu、Ville Tuulos、Dat Tran、Han Xiao、Hien Luu、Ledio Ago、Peter Skomoroch、Piero Molino、Daniel Yao、Jason Sleight、Becket Qin、Tien Le、Abraham Starosta、Will Deaderick、Caleb Kaiser、Miguel Ramos。
原文。经许可转载。
个人简介: Chip Huyen 是一位作家和计算机科学家。她致力于将最佳的工程实践应用于机器学习研究和生产。她写作关于文化、人和技术。
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 加速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关话题
机器学习推荐系统的简单介绍
原文:
www.kdnuggets.com/2019/09/machine-learning-recommender-systems.html
评论

YouTube 如何知道你会观看哪些视频?Google 如何总是能知道你会阅读哪些新闻?它们使用一种叫做推荐系统的机器学习技术。
实际上,推荐系统包括一类能够向用户建议“相关”项目的技术和算法。理想情况下,建议的项目对用户越相关越好,以便用户能够参与这些项目:YouTube 视频、新闻文章、在线产品等等。
项目根据其相关性进行排名,最相关的项目会显示给用户。相关性是推荐系统必须确定的,主要基于历史数据。如果你最近观看了很多关于大象的 YouTube 视频,那么 YouTube 会开始向你推荐许多标题和主题相似的大象视频!
推荐系统一般分为两大类:协同过滤和基于内容的系统。
图 1:不同类型推荐系统的分类树。
协同过滤系统
协同过滤方法是仅基于用户与目标项目之间过去的互动。因此,协同过滤系统的输入将是所有用户与目标项目互动的历史数据。这些数据通常存储在一个矩阵中,其中行表示用户,列表示项目。
这种系统的核心思想是用户的历史数据应该足以做出预测。即我们不需要比这些历史数据更多的东西,不需要额外的用户推动,也不需要当前的趋势信息等。

图 2:展示了协同过滤如何预测用户对四个事物的评分:一张图片、一册书、一段视频和一个视频游戏。根据用户的历史数据,每个项目的喜欢和不喜欢,系统试图预测用户对一个他们还没有评分的新项目的评分。预测本身基于其他用户的过去评分,这些用户的评分和因此假设的偏好与当前用户相似。在这种情况下,系统做出了预测/推荐,即当前用户可能不会喜欢这个视频。来源由Moshanin
除此之外,协同过滤方法进一步分为两个子组:基于记忆的方法和基于模型的方法。
基于记忆的方法最为简单,因为它们完全不使用模型。它们假设可以基于对过去数据的纯粹“记忆”进行预测,通常只使用简单的距离度量方法,比如最近邻方法。
另一方面,基于模型的方法总是假设某种潜在的模型,并基本上试图确保所有预测结果都能很好地适应模型。
举个例子,假设我们有一个用户到首选午餐项目的矩阵,其中所有用户都是喜欢芝士汉堡的美国人(它们非常棒)。基于记忆的方法只会查看用户在过去一个月中吃过什么,而不会考虑他们是喜欢芝士汉堡的美国人的这个小事实。另一方面,基于模型的方法将确保预测结果总是稍微倾向于芝士汉堡,因为潜在的模型假设是数据集中的大多数人应该喜欢芝士汉堡!
代码
我们可以使用Graph Lab轻松创建一个协同过滤推荐系统!我们将采取以下步骤:
-
使用 pandas 加载数据
-
将 pandas 数据框转换为 graph lab SFrames
-
训练模型
-
提供推荐
import graphlab
import pandas as pd
# Load up the data with pandas
r_cols = ['user_id', 'food_item', 'rating']
train_data_df = pd.read_csv('train_data.csv', sep='\t', names=r_cols)
test_data_df = pd.read_csv('test_data.csv', sep='\t', names=r_cols)
# Convert the pandas dataframes to graph lab SFrames
train_data = graphlab.SFrame(train_data_df)
test_data = graphlab.SFrame(test_data_df)
# Train the model
collab_filter_model = graphlab.item_similarity_recommender.create(train_data,
user_id='user_id',
item_id='food_item',
target='rating',
similarity_type='cosine')
# Make recommendations
which_user_ids = [1, 2, 3, 4]
how_many_recommendations = 5
item_recomendation = collab_filter_model.recommend(users=which_user_ids,
k=how_many_recommendations)
基于内容的系统
与协同过滤相比,基于内容的方法会使用关于用户和/或项目的额外信息来进行预测。
例如,在上面的动图中,基于内容的系统在进行预测时可能会考虑年龄、性别、职业和其他个人用户因素。如果我们知道视频是关于滑板的,但用户的年龄是 87 岁,那么预测这个人不会喜欢这个视频会容易得多!
这就是为什么当你注册许多在线网站和服务时,它们会要求你(可选)提供你的出生日期、性别和种族!这只是为他们的系统提供更多数据,以便进行更好的预测。
因此,基于内容的方法在某种程度上更类似于经典的机器学习,因为我们将根据用户和项目数据构建特征,并利用这些特征来帮助我们进行预测。我们的系统输入是用户的特征和项目的特征。我们的系统输出是预测用户是否喜欢或不喜欢该项目。
代码
我们可以使用Graph Lab轻松创建一个协同过滤推荐系统!我们将采取以下步骤:
-
使用 pandas 加载数据
-
将 pandas 数据框转换为 graph lab SFrames
-
训练模型
-
提供推荐
import graphlab
import pandas as pd
# Load up the data with pandas
r_cols = ['user_id', 'food_item', 'rating']
train_data_df = pd.read_csv('train_data.csv', sep='\t', names=r_cols)
test_data_df = pd.read_csv('test_data.csv', sep='\t', names=r_cols)
# Convert the pandas dataframes to graph lab SFrames
train_data = graphlab.SFrame(train_data_df)
test_data = graphlab.SFrame(test_data_df)
# Train the model
cotent_filter_model = graphlab.item_content_recommender.create(train_data,
user_id='user_id',
item_id='food_item',
target='rating')
# Make recommendations
which_user_ids = [1, 2, 3, 4]
how_many_recommendations = 5
item_recomendation = cotent_filter_model.recommend(users=which_user_ids,
k=how_many_recommendations)
喜欢学习吗?
关注我在twitter上,我会发布最新最棒的人工智能、技术和科学内容!也可以在LinkedIn上与我联系!
相关内容:
我们的前三个课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 部门
更多相关主题
从零开始的机器学习:决策树
原文:
www.kdnuggets.com/2022/11/machine-learning-scratch-decision-trees.html

图片来源于 Pexel
决策树是机器学习世界中最简单的非线性监督算法之一。顾名思义,它们用于在 ML 术语中进行决策,我们称之为分类(尽管它们也可以用于回归)。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT 需求
决策树具有单向树结构,即在每个节点上,算法根据某些停止标准做出决策以分裂成子节点。决策树通常使用熵、信息增益、基尼指数等。
决策树中有一些已知的算法,如 ID3、C4.5、CART、C5.0、CHAID、QUEST、CRUISE。在这篇文章中,我们将讨论最简单且最古老的一个:ID3。
ID3,即 Iterative Dichotomiser,是 Ross Quinlan 开发的三种决策树实现中的第一个。
算法以自上而下的方式构建树,从一组行/对象和特征规范开始。在树的每个节点上,根据最小化熵或最大化信息增益来测试一个特征以分裂对象集。这个过程会持续进行,直到某个节点中的集合是同质的(即节点包含相同类别的对象)。该算法使用贪婪搜索。它使用信息增益标准选择测试,然后从不探索替代选择的可能性。
缺点:
-
模型可能存在过拟合的情况。
-
仅适用于分类特征
-
不处理缺失值
-
低速
-
不支持剪枝
-
不支持提升
既然一个算法有这么多缺点,我们为什么还要讨论它呢?
答:这很简单,非常适合培养对树算法的直觉。
让我们通过一个例子来理解
今天的示例是最受欢迎的童谣之一,其中雨决定 Johny/Arthur 是否会在外面玩。唯一的变化是不仅仅是雨,任何恶劣天气都会影响孩子的玩耍,我们将使用决策树来预测他是否会在外面。

来源:维基百科
数据如下所示:
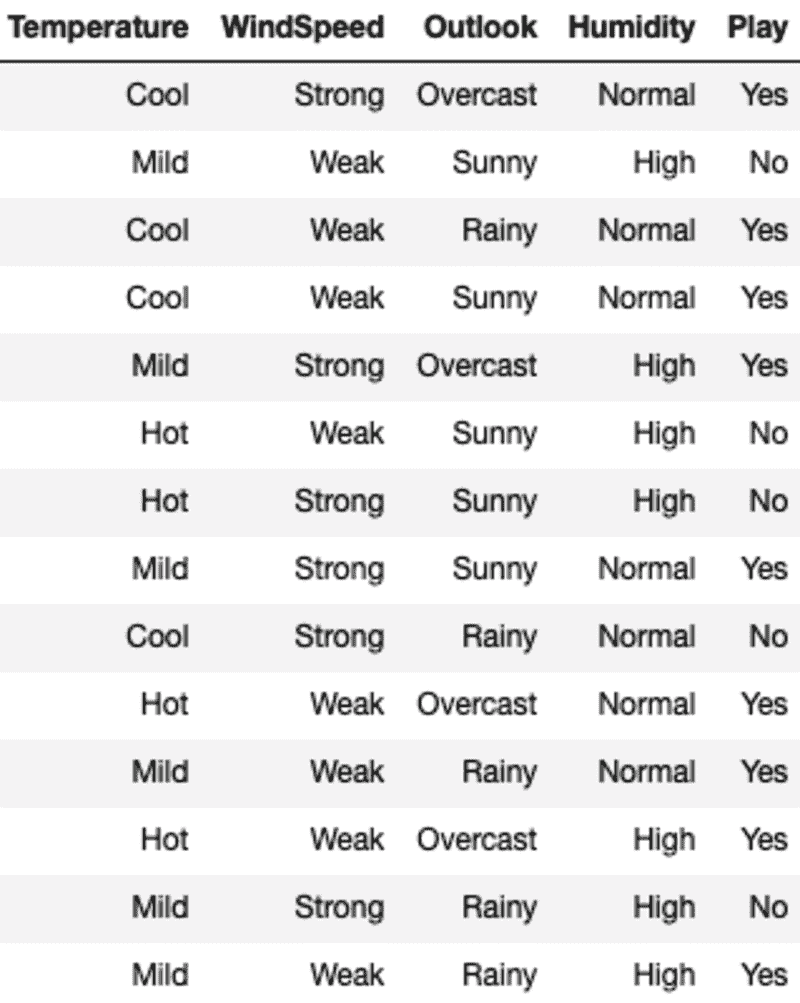
‘Temperature’,‘WindSpeed’,‘Outlook’和‘Humidity’是特征,而‘Play’是目标变量。只有分类数据且没有缺失值意味着我们可以使用 ID3。
在深入算法之前,我们先了解一下划分标准。为了简化起见,我们将仅讨论二分类情况的每个标准。
熵: 这用于计算样本的异质性,其值在 0 和 1 之间。如果样本是同质的,则熵为 0,如果样本中所有类别的比例相同,则熵为 1。
S = -(p * log₂p + q * log₂q)
p和q是样本中两个类别的各自比例。
这也可以写作:S = -(p * log₂p + (1-p)* log₂(1-p))
信息增益: 它是节点的熵与子节点所有值的平均熵之间的差异。选择信息增益最大的特征进行拆分。
让我们通过示例来理解这一点
根节点的熵:(9 — Yes 和 5 — No)
S = -(9/14)*log(9/14) — (5/14) * log(5/14) = 0.94
根节点有 4 种可能的拆分方式。(‘Temperature’,‘WindSpeed’,‘Outlook’,和‘Humidity’)。因此,如果选择上述任意一个,我们将计算子节点的加权平均熵。
I(Temperature) = Hot*E(Temperature=Hot) + Mild*E(Temperature=Mild) + Cool*E(Temperature=Cool)
其中,Hot,Mild 和 Cool 代表数据中三个值的比例。
I(Temperature) = (4/14)*1 + (6/14)*0.918 + (4/14)*0.811 = 0.911
这里,每个值的熵通过使用特征的值过滤样本,然后使用熵的公式来计算。例如,E(Temperature=Hot) 是通过过滤原始样本中温度为 Hot 的样本来计算的(在这种情况下,我们有相等数量的 Yes 和 No,这意味着熵等于 1)。
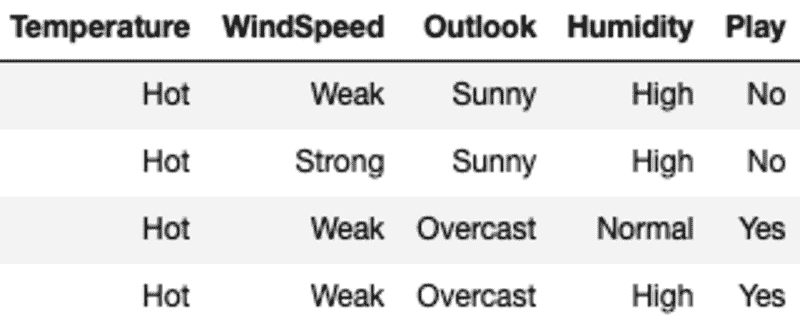
我们通过从根节点的熵中减去温度的平均熵来计算温度划分的信息增益。
G(Temperature) = S — I(Temperature) = 0.94–0.911 = 0.029
同样,我们计算所有四个特征的增益,并选择增益最大的一项。
G(WindSpeed) = S — I(WindSpeed) = 0.94–0.892 =0.048
G(Outlook) = S — I(Outlook) = 0.94–0.693 =0.247
G(Humidity) = S — I(Humidity) = 0.94–0.788 =0.152
Outlook 具有最大的 信息增益,因此我们将在 Outlook 上拆分根节点,每个子节点代表按 Outlook 的某个值(即 Sunny,Overcast 和 Rainy)过滤的样本。
现在,我们将重复相同的过程,将新形成的节点视为根节点,使用过滤样本计算每个节点的熵,并通过计算每个进一步拆分的平均熵并从当前节点熵中减去来获得 信息增益。请注意,ID3 不允许使用已使用的特征来拆分子节点。因此,每个特征在树中只能用于一次拆分。
这是通过所有拆分形成的最终树:
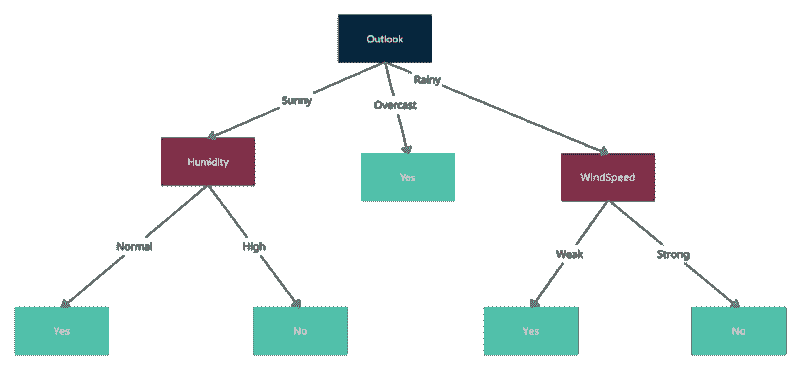
使用 Python 代码的简单实现可以在这里找到
结论
我尽力解释了 ID3 的工作原理,但我知道你可能还有问题。请在评论中告诉我,我会很高兴回答。
谢谢阅读!
安基特·马利克 正在多个领域(如市场营销、供应链、零售、广告和流程自动化)构建可扩展的 AI/ML 解决方案。他曾在财富 500 强公司领导数据科学项目,也曾是多个初创公司数据科学孵化器的创始成员。他开创了各种创新产品和服务,并且相信服务型领导。
原文。经授权转载。
更多相关内容
机器学习安全
评论
作者:Zak Jost,亚马逊网络服务研究科学家。
介绍
随着越来越多的系统在其决策过程中利用机器学习模型,考虑恶意行为者如何利用这些模型以及如何设计防御措施将变得越来越重要。本文的目的是分享我在这一主题上的一些最新学习。
机器学习无处不在
可用数据、处理能力和机器学习领域创新的爆炸性增长导致了机器学习的普及。由于开源框架和数据的广泛存在,构建这些模型实际上相当简单(这个教程可以将一个零机器学习/编程知识的人带到 6 个机器学习模型中,时间约为 5-10 分钟)。此外,云服务提供商持续推出机器学习服务,使客户能够构建解决方案而无需编写代码或了解其底层工作原理。
Alexa 可以通过语音命令代我们进行购买。模型可以识别色情内容,并帮助使互联网平台对我们的孩子更安全。它们正在我们的道路上驾驶汽车,并保护我们免受诈骗和恶意软件的侵害。它们监控我们的信用卡交易和互联网使用,以寻找可疑的异常。
“Alexa,给我的猫买鳄梨酱”
机器学习的好处是显而易见的——不可能让人类手动审查每一笔信用卡交易、每一张 Facebook 图片、每一个 YouTube 视频……等等。那么风险呢?
理解机器学习算法在自动驾驶汽车中出现错误可能带来的潜在危害并不需要过多的想象。常见的论点是,“只要它比人类犯的错误少,就是一种净收益”。
但当恶意行为者主动试图欺骗模型时情况又如何?来自 MIT 的学生小组 Labsix 3D 打印了一个在任何摄像角度下都被 Google 的 InceptionV3 图像分类器可靠地分类为“步枪”的乌龟^(1)。对于语音转文本系统,Carlini 和 Wagner 发现^(2):
给定任何音频波形,我们可以生成另一种与之 99.9%相似的波形,但可以转录成我们选择的任何短语……我们的攻击成功率为 100%,无论所需的转录内容或初始音频样本是什么。
Papernot 等人表明,有针对性地向恶意软件添加一行代码可能会使最先进的恶意软件检测模型在超过 60%的情况下受到欺骗^(3)。*
通过使用相当简单的技术,一个坏演员可以让即使是最具性能和令人印象深刻的模型也以几乎任何他们想要的方式出错。例如,这张图片使谷歌模型几乎以 100%的置信度判断它是一张鳄梨酱的图片^(1):
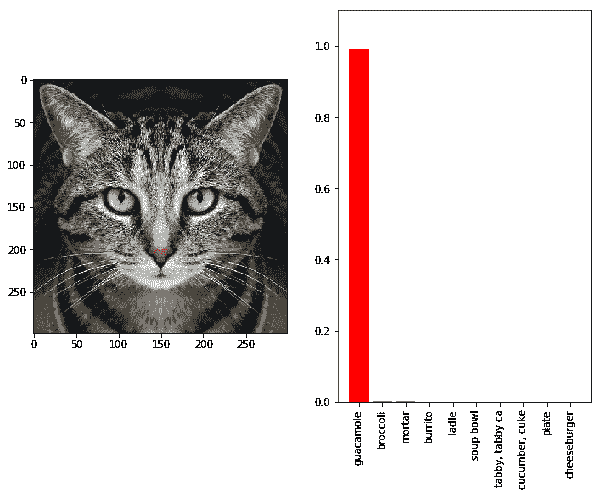
这是一张真实世界中交通标志的图片,该标志被操控,以致于在经过实验中计算机视觉模型被 100%地欺骗,误以为这是一个“限速 45 英里/小时”的标志^(4):

怎么这么好,却这么糟?
在所有这些例子中,基本的思想是以最大化模型输出变化的方式来扰动输入。这些被称为“对抗性示例”。利用这个框架,你可以找出如何最有效地调整猫的图像,使得模型认为它是鳄梨酱。这有点像让所有的小错误排列成一行并指向相同的方向,从而使雪花变成雪崩。从技术上讲,这等同于找到输出对输入的梯度——这是机器学习从业者很擅长的事情!
值得强调的是,这些变化大多是难以察觉的。例如,听听 这些音频样本。尽管听起来对我来说是相同的,但一个翻译为“没有数据集这篇文章就没用”,另一个翻译为“好的谷歌,浏览到 evil.com”。更值得强调的是,真正的恶意用户并不总是受限于做出难以察觉的变化,因此我们应该假设这是对安全漏洞的一个下限估计。
那么我需要担心吗?
好吧,所以这些模型的鲁棒性存在问题,使得它们相对容易被利用。但是除非你是谷歌或脸书,你可能不会在生产系统中构建大型神经网络,所以你不必担心……对吧? 对吧!?
错了。这个问题并不是神经网络所独有的。实际上,发现能欺骗一种模型的对抗性示例往往也能欺骗其他模型,即使它们使用了不同的架构、数据集,甚至算法。这意味着即使你组合了不同类型的模型,你仍然不安全(5)。如果你将模型暴露给世界,即使是间接地,让别人能向它发送输入并得到响应,你就有风险。这个领域的历史从暴露*线性模型*的脆弱性开始,后来才在深度网络的背景下重新点燃(6)。
我们怎么阻止它?
攻击和防御之间存在持续的军备竞赛。最近的 ICML 2018 的“最佳论文” “击破”了同年会议论文中提出的 9 种防御中的 7 种。这个趋势不太可能在短期内停止。
那么,普通的机器学习从业者该怎么办呢?他们可能没有时间跟进最新的机器学习安全文献,更不用说不断地将新防御措施整合到所有面向外部的生产模型中。在我看来,唯一理智的办法是设计多个信息来源的系统,以便单点故障不会破坏整个系统的效能。这意味着你假设单一模型可能会被攻破,并设计你的系统以抵御这种情况。
例如,完全由计算机视觉机器学习系统导航的无人驾驶汽车可能是一个非常危险的想法(原因不仅仅是安全问题)。使用激光雷达、GPS 和历史记录等正交信息的环境冗余测量可能有助于反驳对抗性视觉结果。这自然假设系统被设计成整合这些信号以做出最终判断。
更大的问题是,我们需要认识到模型安全是一个重大的、普遍存在的风险,随着机器学习越来越多地融入我们的生活,这一风险只会随着时间的推移而增加。因此,我们需要作为机器学习从业者培养思考这些风险和设计抗风险系统的能力。正如我们在网络应用中采取预防措施以保护系统免受恶意用户的攻击一样,我们也应该对模型安全风险采取积极措施。正如机构有应用安全审查小组进行例如渗透测试,我们也需要建立类似功能的模型安全审查小组。可以肯定的是:这个问题不会很快消失,而且可能会变得越来越重要。
如果你想了解更多关于这个话题的信息,Biggio 和 Roli 的论文提供了对该领域的精彩回顾和历史,包括一些这里未提及的完全不同的攻击方法(例如数据中毒)。^(6)
参考文献
*1. “在物理世界中欺骗神经网络。” Labsix,2017 年 10 月 31 日,www.labsix.org/physical-objects-that-fool-neural-nets。
-
N. Carlini, D. Wagner. “音频对抗样本:对语音转文本的有针对性攻击。” arXiv 预印本 arXiv:1801.01944,2018。
-
K. Grosse, N. Papernot, P. Manoharan, M. Backes, P. McDaniel (2017) 恶意软件检测中的对抗样本。在:Foley S., Gollmann D., Snekkenes E.(编辑)《计算机安全 – ESORICS 2017》。ESORICS 2017。计算机科学讲义,卷 10493。Springer,Cham。
-
K. Eykhold, I. Evtimov 等。“对深度学习视觉分类的稳健物理世界攻击”。arXiv 预印本 arXiv:1707.08945,2017。
-
N. Papernot, P. McDaniel, I.J. Goodfellow. “Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples”. arXiv 预印本 arXiv:1605.07277, 2016.
-
B. Biggio, F. Roli. “Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning.” arXiv 预印本 arXiv:1712.03141, 2018.
原文。经许可转载。
个人简介: Zak Jost 是一名构建者和机器学习科学家。
资源:
相关:
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升您的数据分析水平
3. Google IT 支持专业证书 - 支持您的组织的 IT
更多相关话题
机器学习如何用于社会公益
原文:
www.kdnuggets.com/2020/11/machine-learning-social-good.html
评论

就像企业利用机器学习的价值一样,慈善和非营利组织也可以这样做。人们正在以多种方式将机器学习应用于社会公益。
机器学习的社会公益应用分为三类:
-
保护。 确定最脆弱或高风险的对象以进行干预。
-
筹款。 针对直接邮寄请求捐款——适用于任何类型的慈善组织。
-
审批。 预测哪些项目提案最可能成功,以分配资助和其他类型的援助。
1) 保护
预测对齐预防应用机器学习来识别面临虐待风险的儿童。在美国,每年有 1500 到 3000 名婴儿和儿童因虐待和忽视而死亡。0-3 岁的儿童面临最大风险。最脆弱的儿童通常不被专业人士看到。模型提高了早期检测和干预能力,该组织进行战略规划以优化预防资源的空间分配。
这说明了一个绝妙的趋势:就像典型的商业应用标记不良结果——例如违约、取消和欺诈——并作出相应的干预,类似的概念也适用于利他主义地干预可能发生在个人身上的不良事件。这是模型基本上用来分配有限资源的另一种方式。公司只有有限的资源来留住高风险客户,就像儿童福利组织有有限的资源来保护高风险儿童一样。优先和针对资源可以提高固定资源的效力。这是相同的商业价值主张,现在被应用于社会公益。
另一个例子是,美国平等就业机会委员会预测歧视,标记特定行业中哪些特定群体更容易受到歧视。
芝加哥市模型预测哪些住宅更有可能发生铅中毒事件。这作为一个早期预警系统,以主动标记,改进了传统的在检测到中毒后采取的被动措施。风险评分用于确定需要检查的住宅和需要检测的儿童,并帮助人们决定迁移到更安全的住宅。
扩展这一概念,机器学习被应用于标记所有类型的潜在不良事件风险,以便进行干预,包括:
-
营养不良的儿童
-
人口贩卖
-
自杀
-
警察不当行为
-
每个求职者的失业持续时间
-
空气质量差
-
洪水
-
饥荒
-
非法雨林砍伐——基于声学监测
2) 筹款
应用机器学习来针对募捐请求的做法更为普遍——毕竟,大多数非营利或慈善组织都在筹款。大学也通常会对其筹款进行有针对性的工作。
这与营销中的响应建模具有相同的价值主张,只是“订单履行”实际上并非必要——你不需要履行任何购买。但在这两种情况下,你都会以相同的方式计算净回报,基于活动的成本和产生的收入。
这里有几个例子。Charlotte Rescue Mission 通过预测建模将筹款活动的捐赠额增加了近 50%。
自然保护协会通过仅向其捐赠者名单中预测最有可能贡献的 10%人群邮寄,从而获得了 669,000 美元的利润。
3) 绿灯
预测性地针对受益者是一种日益增长的做法。在这种情况下,模型的目标是决定将钱给谁,而不是决定向谁索要钱!例如,一些慈善组织通过预测项目成功来决定哪个开发项目可以获得批准。这样,组织就能更有效地执行其使命。
在一个项目中,我帮助一个助力低收入、准备上大学的学生的项目将其宣传活动针对最具响应性和符合条件的申请者。在另一个案例中,我为美洲开发银行——拉丁美洲和加勒比地区最大的开发融资来源——进行了一次为期五天的培训项目,帮助他们研究项目结果成功的建模。
类似地,向那些有需求但通常不符合传统银行贷款条件的人提供小额贷款的公司——他们通常被传统金融机构标记为高风险——开发了自己的专门风险模型,以适应这些借款人。通过降低向无银行账户或贫困人群提供贷款的财务风险,像 Mimoni 和 Kiva 这样的组织能够实现其使命。
如果你希望拓宽你或你所在组织应用机器学习的方式,我强烈建议你参与这些社会公益应用。机器学习的伦理审视通常会问某些应用是否弊大于利——但如果你是专门为了社会公益而应用它,那么答案就很明确,社区也会热情地欢迎你。
要开始,可以查看一些完全致力于将预测建模应用于社会公益的机器学习公司,例如 Predict Align Prevent、Data Science for Social Good Foundation 或 DrivenData。
相关内容:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 方面的工作
更多相关内容
机器学习系统设计:一个免费的斯坦福课程
原文:
www.kdnuggets.com/2021/02/machine-learning-systems-design-free-stanford-course.html
comments
你是否已经浏览了所有的入门机器学习教程?是否阅读了你能处理的所有算法理论?对机器学习数据的所有问题都很熟悉?但仍然不知道如何设计一个现实世界的机器学习系统?不确定哪种软件架构是有用的?即便知道了,你是否仍然对如何部署和维护它感到毫无头绪?
不用担心!机器学习系统设计 是斯坦福大学提供的一个免费课程,由Chip Huyen教授,旨在为你提供设计、部署和管理实用机器学习系统的工具包。以下是课程网站对机器学习系统设计的简要描述:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
机器学习系统设计是定义机器学习系统的软件架构、基础设施、算法和数据的过程,以满足特定要求。
课程的初步提供目前正在进行中,课程网站上提供了最新资源,包括详细的课堂笔记、幻灯片,以及在某些情况下的代码和视频。目前无法访问视频、讨论或其他课程材料,且应注意,公开的材料仅供审计目的;无法通过此过程获得课程完成认证。然而,与我们曾经介绍的斯坦福免费课程一样,这些精选资源对部分读者的学习仍然有明显的好处。
机器学习系统设计课程究竟涵盖了什么内容?
课程涵盖了从项目范围定义、数据管理、模型开发、部署、基础设施、团队结构到业务分析的所有步骤。在每一步中,它会讨论不同解决方案的动机、挑战和局限性(如果有的话)。课程最后讨论了机器学习生产生态系统的未来。
更具体地说,课程大纲列出了以下主题:
-
理解机器学习生产
-
理解机器学习系统设计
-
数据工程
-
模型开发
-
模型评估
-
实验追踪
-
部署
-
模型扩展
-
系统监控
-
机器学习系统的未来
…以及更多。
如果上述主题让你觉得这不像是入门级的机器学习或编程课程,那是因为它确实不是。在准备深入这些材料之前,应该已经具备(从课程网站获得):
-
计算机科学基本原理和技能的知识
-
对机器学习算法的良好理解
-
熟悉至少一个框架,如 TensorFlow、PyTorch、JAX
-
熟悉基础概率理论
除了网站上的课程材料外,Chip 还编写了这些相关的机器学习系统设计笔记可在她的网站上查阅;由于我没有进行彻底比较,课程网站上的材料可能会与这些材料有重叠。
虽然课程由 Chip Huyen 主讲,但课程助教包括 Karan Goel、Michael Cooper 和 Xi Yan,课程顾问则为 Michele Catasta 和 Christopher Ré。客座讲座由包括 Lavanya Shukla、Christopher Ré、Daniel Bourke、Piero Molino、Saam Motamedi、Neil Lawrence 等多位贡献者主讲。
由于机器学习系统设计的深入优质材料稀缺,这门课程正在成为任何希望将所有这些部分整合在一起,并希望拥有自己坚实的 ML 设计工具包的人的首选。
相关:
-
最好的深度学习 NLP 课程是免费的
-
通过 Yann LeCun 的免费课程学习深度学习
-
亚马逊的免费入门机器学习课程
相关主题更多
解码机器学习元素表
原文:
www.kdnuggets.com/2015/03/machine-learning-table-elements.html
来自MLN.io的机器学习周期表列出了针对像 Python 和 Java 这样的语言以及像 NLP 和计算机视觉这样的任务的机器学习包。以下是表格本身。
以下是按“组”列出的表格元素。
Python 中的机器学习包(浅蓝色):
Java 中的机器学习包(绿色):
大数据中的机器学习包(深蓝色):
Lua/JS/Clojure 中的机器学习包(红色):
Scala 中的机器学习包(黄色):
C/C++中的机器学习包(深橙色):
计算机视觉和自然语言处理的机器学习包(Orange):
R/Julia 中的机器学习包(Grey):
原文链接: www.mln.io/resources/periodic-table/
相关:
-
分析、数据挖掘、数据科学的四种主要语言
-
机器学习的开源工具
-
最受欢迎的数据科学和数据挖掘技能
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
更多相关话题
使用 Python 中的 SpaCy 进行文本分类的机器学习
原文:
www.kdnuggets.com/2018/09/machine-learning-text-classification-using-spacy-python.html
评论
由苏珊·李,高级数据科学家

图片来源: Pixabay
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
spaCy 是一个流行且易于使用的 Python 自然语言处理库。它提供了当前最先进的准确性和速度水平,并且拥有一个活跃的开源社区。然而,由于 SpaCy 是一个相对较新的 NLP 库,它的采用程度还不及NLTK,目前还没有足够的教程可用。
在这篇文章中,我们将演示如何使用spaCy实现文本分类,而无需具备深度学习经验。
数据
对于年轻研究者来说,寻找和选择合适的学术会议以提交学术论文通常是耗时且令人沮丧的经历。我们定义的“合适会议”是指会议与研究者的工作相一致,并且具有良好的学术排名。
使用会议论文集数据集,我们将按会议对研究论文进行分类。让我们开始吧。数据集可以在这里找到。
探索
快速浏览一下:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import base64
import string
import re
from collections import Counter
from nltk.corpus import stopwords
stopwords = stopwords.words('english')
df = pd.read_csv('research_paper.csv')
df.head()

图 1
没有缺失值。
df.isnull().sum()
***标题 0
会议 0
dtype: int64***
将数据分割为训练集和测试集:
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.33, random_state=42)
print('Research title sample:', train['Title'].iloc[0])
print('Conference of this paper:', train['Conference'].iloc[0])
print('Training Data Shape:', train.shape)
print('Testing Data Shape:', test.shape)
***研究标题示例:与智能合作:在自组织网络中使用异构智能天线。
这篇论文的会议: INFOCOM
训练数据形状: (1679, 2)
测试数据形状: (828, 2)***
数据集包含 2507 个短篇研究论文标题,这些标题被分类为 5 个类别(按会议)。下图总结了不同会议的研究论文分布。
fig = plt.figure(figsize=(8,4))
sns.barplot(x = train['Conference'].unique(), y=train['Conference'].value_counts())
plt.show()
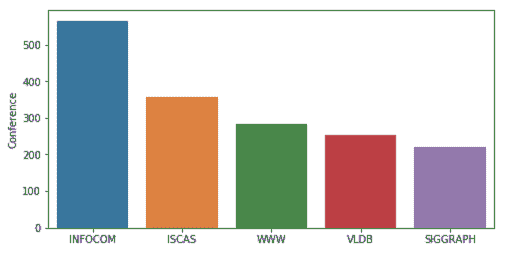
图 2
以下是使用 SpaCy 进行文本预处理的一种方法。之后,我们尝试找出提交至第一类和第二类(会议)INFOCOM 和 ISCAS 的论文中使用的最常见词汇。
import spacy
nlp = spacy.load('en_core_web_sm')
punctuations = string.punctuation
def cleanup_text(docs, logging=False):
texts = []
counter = 1
for doc in docs:
if counter % 1000 == 0 and logging:
print("Processed %d out of %d documents." % (counter, len(docs)))
counter += 1
doc = nlp(doc, disable=['parser', 'ner'])
tokens = [tok.lemma_.lower().strip() for tok in doc if tok.lemma_ != '-PRON-']
tokens = [tok for tok in tokens if tok not in stopwords and tok not in punctuations]
tokens = ' '.join(tokens)
texts.append(tokens)
return pd.Series(texts)
INFO_text = [text for text in train[train['Conference'] == 'INFOCOM']['Title']]
IS_text = [text for text in train[train['Conference'] == 'ISCAS']['Title']]
INFO_clean = cleanup_text(INFO_text)
INFO_clean = ' '.join(INFO_clean).split()
IS_clean = cleanup_text(IS_text)
IS_clean = ' '.join(IS_clean).split()
INFO_counts = Counter(INFO_clean)
IS_counts = Counter(IS_clean)
INFO_common_words = [word[0] for word in INFO_counts.most_common(20)]
INFO_common_counts = [word[1] for word in INFO_counts.most_common(20)]
fig = plt.figure(figsize=(18,6))
sns.barplot(x=INFO_common_words, y=INFO_common_counts)
plt.title('Most Common Words used in the research papers for conference INFOCOM')
plt.show()
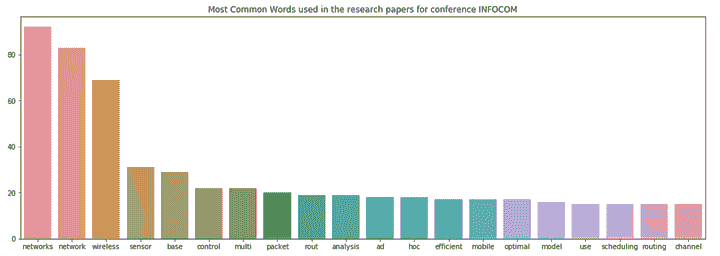
图 3
IS_common_words = [word[0] for word in IS_counts.most_common(20)]
IS_common_counts = [word[1] for word in IS_counts.most_common(20)]
fig = plt.figure(figsize=(18,6))
sns.barplot(x=IS_common_words, y=IS_common_counts)
plt.title('Most Common Words used in the research papers for conference ISCAS')
plt.show()
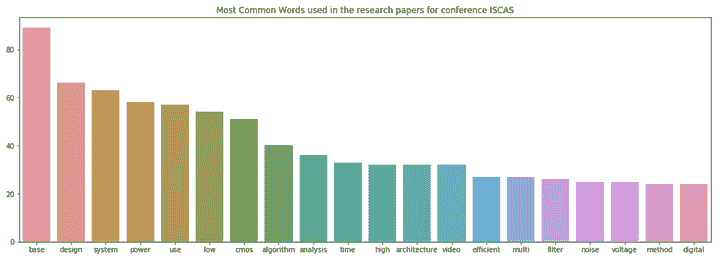
图 4
INFOCOM 中的最常见词是“networks”和“network”。显然,INFOCOM 是一个网络及相关领域的会议。
ISCAS 中的最常见词是“base”和“design”。这表明 ISCAS 是一个关于数据库、系统设计及相关主题的会议。
使用 spaCy 的机器学习
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.base import TransformerMixin
from sklearn.pipeline import Pipeline
from sklearn.svm import LinearSVC
from sklearn.feature_extraction.stop_words import ENGLISH_STOP_WORDS
from sklearn.metrics import accuracy_score
from nltk.corpus import stopwords
import string
import re
import spacy
spacy.load('en')
from spacy.lang.en import English
parser = English()
以下是使用 spaCy 清理文本的另一种方法:
STOPLIST = set(stopwords.words('english') + list(ENGLISH_STOP_WORDS))
SYMBOLS = " ".join(string.punctuation).split(" ") + ["-", "...", "”", "”"]
class CleanTextTransformer(TransformerMixin):
def transform(self, X, **transform_params):
return [cleanText(text) for text in X]
def fit(self, X, y=None, **fit_params):
return self
def get_params(self, deep=True):
return {}
def cleanText(text):
text = text.strip().replace("\n", " ").replace("\r", " ")
text = text.lower()
def tokenizeText(sample):
tokens = parser(sample)
lemmas = []
for tok in tokens:
lemmas.append(tok.lemma_.lower().strip() if tok.lemma_ != "-PRON-" else tok.lower_)
tokens = lemmas
tokens = [tok for tok in tokens if tok not in STOPLIST]
tokens = [tok for tok in tokens if tok not in SYMBOLS]
return tokens
定义一个函数来打印出最重要的特征,即具有最高系数的特征:
def printNMostInformative(vectorizer, clf, N):
feature_names = vectorizer.get_feature_names()
coefs_with_fns = sorted(zip(clf.coef_[0], feature_names))
topClass1 = coefs_with_fns[:N]
topClass2 = coefs_with_fns[:-(N + 1):-1]
print("Class 1 best: ")
for feat in topClass1:
print(feat)
print("Class 2 best: ")
for feat in topClass2:
print(feat)
vectorizer = CountVectorizer(tokenizer=tokenizeText, ngram_range=(1,1))
clf = LinearSVC()
pipe = Pipeline([('cleanText', CleanTextTransformer()), ('vectorizer', vectorizer), ('clf', clf)])
# data
train1 = train['Title'].tolist()
labelsTrain1 = train['Conference'].tolist()
test1 = test['Title'].tolist()
labelsTest1 = test['Conference'].tolist()
# train
pipe.fit(train1, labelsTrain1)
# test
preds = pipe.predict(test1)
print("accuracy:", accuracy_score(labelsTest1, preds))
print("Top 10 features used to predict: ")
printNMostInformative(vectorizer, clf, 10)
pipe = Pipeline([('cleanText', CleanTextTransformer()), ('vectorizer', vectorizer)])
transform = pipe.fit_transform(train1, labelsTrain1)
vocab = vectorizer.get_feature_names()
for i in range(len(train1)):
s = ""
indexIntoVocab = transform.indices[transform.indptr[i]:transform.indptr[i+1]]
numOccurences = transform.data[transform.indptr[i]:transform.indptr[i+1]]
for idx, num in zip(indexIntoVocab, numOccurences):
s += str((vocab[idx], num))
***准确率:0.7463768115942029
用于预测的前 10 个特征:
第 1 类最佳:
(-0.9286024231429632, ‘database’)
(-0.8479561292796286, ‘chip’)
(-0.7675978546440636, ‘wimax’)
(-0.6933516302055982, ‘object’)
(-0.6728543084136545, ‘functional’)
(-0.6625144315722268, ‘multihop’)
(-0.6410217867606485, ‘amplifier’)
(-0.6396374843938725, ‘chaotic’)
(-0.6175855765947755, ‘receiver’)
(-0.6016682542232492, ‘web’)
第 2 类最佳:
(1.1835964521070819, ‘speccast’)
(1.0752051052570133, ‘manets’)
(0.9490176624004726, ‘gossip’)
(0.8468395015456092, ‘node’)
(0.8433107444740003, ‘packet’)
(0.8370516260734557, ‘schedule’)
(0.8344139814680707, ‘multicast’)
(0.8332232077559836, ‘queue’)
(0.8255429594734555, ‘qos’)
(0.8182435133796081, ‘location’)***
from sklearn import metrics
print(metrics.classification_report(labelsTest1, preds,
target_names=df['Conference'].unique()))
precision recall f1-score support
VLDB 0.75 0.77 0.76 159
ISCAS 0.90 0.84 0.87 299
SIGGRAPH 0.67 0.66 0.66 106
INFOCOM 0.62 0.69 0.65 139
WWW 0.62 0.62 0.62 125
avg / total 0.75 0.75 0.75 828
这就是了。我们现在已经在 SpaCy 的帮助下完成了文本分类的机器学习。
源代码可以在 Github 上找到。祝你学习愉快!
参考资料:Kaggle
个人简介:Susan Li 正在通过一篇文章改变世界。她是一位资深数据科学家,位于加拿大多伦多。
原文。已获许可转载。
相关内容:
-
使用 Scikit-Learn 的多分类文本分类
-
LSA、PLSA、LDA 和 lda2Vec 的主题建模
-
自然语言处理技巧:开始使用 NLP
更多相关主题
文本的机器学习
赞助广告。

文本的机器学习,Springer,2018 年 3 月
Charu C. Aggarwal。
关于文本的综合教材: ** 目录**
PDF 下载链接 (仅对连接到订阅机构的计算机免费)
购买硬封面或 PDF (供普通读者使用)
使用右侧目的页链接购买低价平装本 (链接仅对连接到订阅机构的计算机显示,平装本折扣价为$25)
本书涵盖了使用词袋和以序列为中心的两种方法的文本机器学习技术。覆盖范围广泛,包括传统的信息检索方法以及来自神经网络和深度学习的最新方法。书中的章节可以分为三个类别:
经典机器学习方法: 这些章节讨论了经典的机器学习方法,如矩阵分解、主题建模、降维、聚类、分类、线性模型和评估。所有这些技术将文本视为词袋。还涵盖了将不同类型的文本和异构数据类型相结合的上下文学习方法。
经典信息检索和搜索引擎: 虽然本书重点是文本挖掘,但在挖掘应用中检索和排序方法的重要性非常显著。因此,本书涵盖了信息检索的关键方面,如数据结构、网页排名、爬虫和搜索引擎设计。重点介绍了不同类型的信息检索评分模型和学习排序技术。
以序列为中心的深度学习和语言学方法: 虽然词袋表示对传统应用如分类和聚类很有用,但更高级的应用如机器翻译、图像描述、情感分析、信息提取和文本分割要求将文本视为序列。这些章节讨论了以序列为中心的挖掘方法,如深度学习技术、word2vec、递归神经网络、LSTM、最大熵马尔可夫模型和条件随机场。还讨论了文本摘要、情感分析和事件检测等应用的自定义方法。
这本书既可以用作教科书,也包含大量练习。然而,它也旨在对研究人员和工业从业者有所帮助。因此,它包含了大量的文献参考资料供研究人员使用,文献部分还包含了供从业者使用的软件参考资料。书中提供了大量的示例和练习。
获取电子版和硬拷贝版本
这本书有硬拷贝(精装版)和电子版两种形式。精装版可以通过所有常见渠道(如 Amazon、Barnes and Noble 等)购买,也可以以 Kindle 格式购买,或直接从 Springer 以硬拷贝和 PDF 格式购买。电子版可通过以下 Springerlink 链接 获取。对于订阅机构,请从直接连接到您机构网络的计算机上点击下载免费书籍。 Springer 使用计算机的域名来管理访问权限。要符合条件,您的机构必须订阅“e-book package english (Computer Science)”或“e-book package english (full collection)”。除了从订阅机构免费下载 PDF 版本外,在格式方面,它优于付费 Kindle 版本。电子 PDF 包含嵌入链接,您也可以在 Kindle 阅读器上加载。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的 IT 组织
相关话题
如何(不)使用机器学习进行时间序列预测:续集
原文:
www.kdnuggets.com/2020/03/machine-learning-time-series-forecasting-sequel.html
评论
由 Vegard Flovik,数据科学家,Axbit AS。
时间序列预测是机器学习的一个重要领域。之所以重要,是因为有许多预测问题涉及时间因素。然而,尽管时间因素增加了额外的信息,但它也使时间序列问题比许多其他预测任务更难处理。时间序列数据,顾名思义,与其他类型的数据不同,因为时间方面是重要的。好的一面是,这为我们在构建机器学习模型时提供了额外的信息——不仅输入特征包含有用的信息,还有输入/输出随时间的变化。
我之前关于同一主题的文章,如何(不)使用机器学习进行时间序列预测,收到了很多反馈。基于此,我认为时间序列预测和机器学习对人们非常感兴趣,许多人也认识到我在文章中讨论的潜在陷阱。由于对这个主题的极大兴趣,我选择撰写了一篇后续文章,讨论一些与 时间序列预测和机器学习相关的问题,并且如何避免一些常见的陷阱。
通过一个具体的例子,我将演示如何看似拥有一个良好的模型并决定将其投入生产,而实际上,该模型可能完全没有预测能力。重要的是,我会详细讨论一些这些问题,并说明如何在为时已晚之前发现它们。
示例案例:时间序列数据的预测
本案例中使用的示例数据如下面的图所示。我们稍后会更详细地回到数据,但现在假设这些数据代表,例如,股票指数的年度演变、产品的销售/需求、某些传感器数据或设备状态,或者其他与您的情况最相关的内容。现在的基本思路是,数据实际代表的内容并不会真正影响以下的分析和讨论。
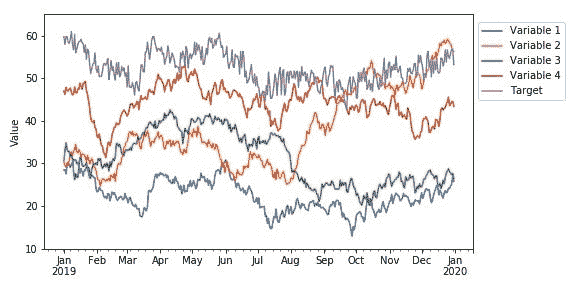
从图中可以看到,我们共有 4 个“输入特征”或“输入变量”以及一个目标变量,即我们尝试预测的内容。类似情况下的基本假设是,我们模型的输入变量包含一些有用的信息,这些信息可以基于这些特征来预测目标变量(这可能是对的,也可能不是)。
相关性和因果性
在 统计学 中,相关性或依赖性是任何统计关系,无论是否 因果。相关性很有用,因为它们可以指示一种可以在实践中利用的预测关系。例如,电力公司可能会根据电力需求与天气的相关性在温和的日子里减少发电。在这个例子中,存在一个 因果关系,因为极端天气导致人们使用更多的电力来取暖或制冷。然而,通常情况下,相关性的存在不足以推断因果关系的存在(即,相关性不意味着因果性)。这是一个非常重要的区别,我们稍后会更详细地探讨这个问题。
为了检查我们的数据,我们可以计算相关矩阵,它表示数据集中所有变量之间的相关系数。在 统计学 中,皮尔逊相关系数是衡量两个变量之间线性 相关性 的一种度量。根据 柯西-施瓦茨不等式,它的值介于 +1 和 −1 之间,其中 1 表示完全正线性相关,0 表示没有线性相关,−1 表示完全负线性相关。
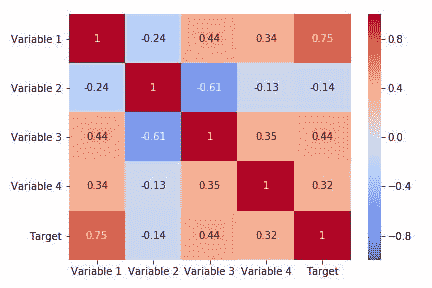
然而,虽然 相关性 是一回事,我们通常感兴趣的却是 因果性。传统格言 "相关性不意味着因果性" 意味着相关性不能单独用来推断变量之间的因果关系(无论哪个方向)。
儿童的年龄与身高之间的相关性是相当因果透明的,但人们的情绪与健康之间的相关性则较少如此。改善情绪是否会导致健康改善,还是良好的健康会带来良好的情绪,或两者都有?或者是否有其他因素在两个方面都起作用?换句话说,相关性可以作为潜在因果关系的证据,但不能指示如果存在的话,因果关系可能是什么。
(来源: xkcd.com/925/)
相关性和因果性的重大区别是构建基于机器学习的预测模型时面临的主要挑战之一。模型是基于我们希望能够代表我们试图预测的过程的数据进行训练的。模型利用输入变量与目标之间的任何特征模式/相关性来建立一种关系,从而进行新的预测。
在我们的情况下,从相关矩阵中,我们看到我们的目标变量确实与一些输入变量相关。然而,在我们的数据上训练模型时,这种明显的相关性可能仅仅是统计上的偶然,并且它们之间可能根本没有因果关系。不过,现在我们先忽略这一点,尝试建立我们的预测模型。我们稍后会更详细地讨论这些潜在的陷阱。
用于时间序列预测的机器学习模型
用于时间序列预测的模型有几种类型。在我之前的文章中,我使用了一种长短期记忆网络,简称 LSTM 网络。这是一种特殊的神经网络,根据之前的时间数据进行预测,即,它在模型结构中明确地内置了“记忆”概念。
然而,根据我的经验,在许多情况下,更简单类型的模型实际上能够提供同样准确的预测。因此,在这个例子中,我实现了一个基于 前馈神经网络 的预测模型(如下所示),而不是 递归神经网络。我还将预测结果与 随机森林 模型进行比较(这是我常用的模型之一,基于其简单性和通常良好的开箱即用性能)。
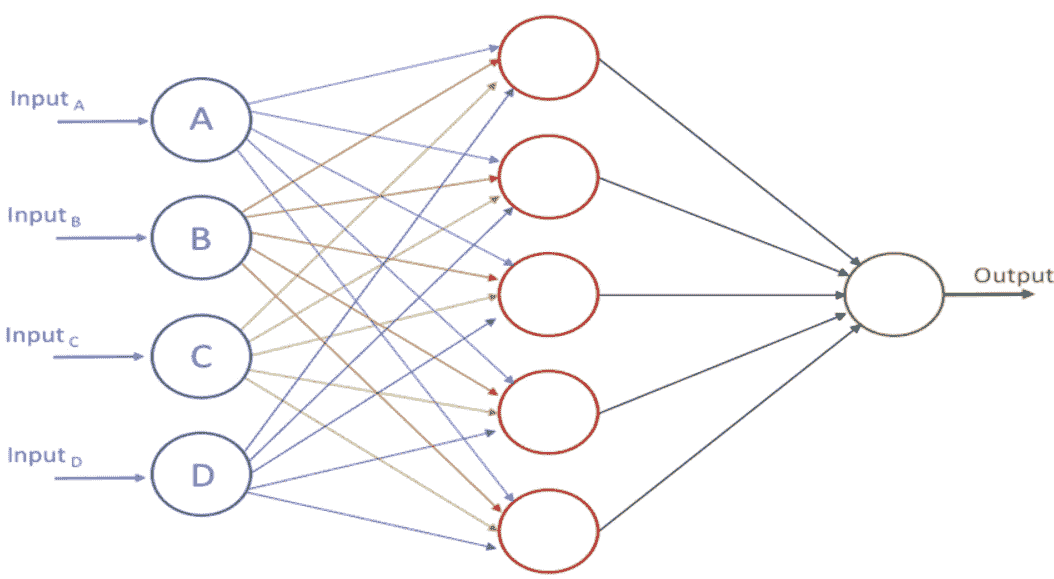
使用开源软件库实现模型
我通常使用 Keras 定义我的神经网络模型,Keras 是一个高级神经网络 API,使用 Python 编写,能够在 TensorFlow、 CNTK 或 Theano 之上运行。对于其他类型的模型(比如这次的随机森林模型),我通常使用 Scikit-Learn,这是一个免费的机器学习库。它提供了各种 分类、 回归 和 聚类 算法,并且设计为与 Python 数值和科学库 NumPy 和 SciPy 互操作。
本文的主要主题并不涉及如何实现时间序列预测模型的细节,而是如何评估预测结果。因此,我不会详细讨论模型构建等内容,因为还有很多其他博客文章和文章涉及这些主题。(不过,如果你对本例中使用的代码感兴趣,请在下面的评论中告诉我,我会与您分享代码)。
训练模型
在使用 Keras 设置神经网络模型后,我们将数据分为训练集和测试集。前 6 个月的数据用于训练,其余数据用作持出测试集。在模型训练过程中,10% 的数据用于验证,以跟踪模型的表现。然后可以从下面的训练曲线中可视化训练过程,其中绘制了训练损失和验证损失与周期的关系。从训练曲线来看,模型确实从数据中学到了一些有用的信息。训练损失和验证损失随着训练进度而减少,然后在大约 50 个周期后开始趋于平稳(没有明显的过拟合/欠拟合迹象)。到目前为止,一切顺利。
评估结果
现在让我们可视化模型预测与持出测试集中的真实数据的对比,以查看我们是否得到了一个良好的匹配。我们还可以在散点图中绘制真实值与预测值,并可视化误差分布,如右侧下方的图所示。
从上面的图中可以清楚地看到,我们的模型在比较真实值和预测值时并没有得到一个很好的匹配。我们的模型明明看似能够学习到有用的信息,但在持出测试集上的表现却如此糟糕,这可能是什么原因呢?
为了获得更好的比较,我们还将在相同的数据上实现一个random forest model,以查看是否能获得更好的结果。从左侧下方的图中可以看到,随机森林模型的表现并没有比神经网络模型好太多。然而,随机森林模型的一个有用特性是它还可以在训练过程中输出“特征重要性”,指示最重要的变量(根据模型)。这种特征重要性在许多情况下可以为我们提供有用的信息,这也是我们稍后会详细讨论的内容。
虚假相关性和因果关系
有趣的是,从上图中我们注意到,根据随机森林模型,变量 4 显然是最重要的输入变量。然而,从下方的相关矩阵和图表中,我们注意到与目标最强相关的变量是“变量 1”(其特征重要性排名第二)。实际上,如果你仔细查看下面绘制的变量,你可能会发现变量 1 和目标完全遵循相同的趋势。这是有意义的,正如我们在接下来的数据讨论中将显而易见的。
本例中数据的来源
随着我们接近完成文章,现在是揭示一些关于所用数据来源的额外细节的时候了。如果你阅读了我之前关于时间序列预测中机器学习的陷阱的文章,你可能已经意识到我对随机游走过程(以及随机过程)非常感兴趣。在本文中,我确实选择了类似的方法来处理虚假相关性和因果关系。
实际上,数据集中所有的变量(4 个输入变量和一个“目标”)都是通过随机游走过程生成的。我最初生成了 4 个随机游走者,为了得到目标变量,我只是对“变量 1”实施了 1 周的时间偏移(加上了一些随机噪声,以使其不易被一眼发现)。
因此,变量与目标之间当然没有因果关系。至于第一个变量,由于目标时间上比变量 1 提前了一周,目标变量的任何变化都会发生在变量 1 的相应变化之前。因此,唯一与目标变量的耦合是通过随机游走过程本身的固有自相关。
如果我们计算变量 1 与目标之间的互相关,可以很容易发现这种时间偏移,如下图左侧所示。在互相关中,7 天的时间偏移有一个明显的峰值。然而,从上面的相关矩阵和下面的图中,我们注意到,即使在零天的滞后下,目标与变量 1 之间也存在显著的相关性(精确地说,相关系数为 0.75)。然而,这种相关性仅仅是由于目标变量有一个缓慢衰减的自相关(比一周的时间偏移显著更长),如下图右侧所示。
Granger 因果关系检验
如前所述,我们模型的输入变量与目标变量相关,但这并不意味着它们之间有因果关系。这些变量在尝试估计目标变量的后期阶段时实际上可能没有预测能力。然而,在建立数据驱动的预测模型时,混淆相关性和因果关系是一个容易陷入的陷阱。这就引出了一个重要的问题:我们可以做些什么来避免这种情况?
格兰杰因果检验是一种用于确定一个时间序列是否对预测另一个时间序列有用的统计假设检验。通常,回归分析反映的是“仅仅是”相关性,但克莱夫·格兰杰认为可以通过测量使用另一个时间序列的先前值来预测时间序列的未来值,从而检验因果关系。如果能通过一系列的t 检验和F 检验(包括Y的滞后值)显示那些X值提供了关于Y未来值的统计显著信息,那么一个时间序列X就被称为格兰杰导致Y。
格兰杰基于两个原则定义了因果关系:
-
原因发生在结果之前。
-
原因对其结果的未来值有独特的信息。
当时间序列X对时间序列Y有格兰杰因果关系(如下所示),X中的模式会在经过一定时间滞后后大致重复出现在Y中(两个示例用箭头标出)。因此,X的过去值可以用于预测Y的未来值。
来源.
格兰杰因果关系的原始定义没有考虑到潜在的混淆效应,也未能捕捉瞬时和非线性的因果关系。因此,进行格兰杰因果检验无法给出你输入变量和你尝试预测的目标之间是否存在因果关系的确切答案。然而,它确实值得关注,并且比仅仅依赖(可能虚假的)相关性提供了额外的信息。
非平稳时间序列的“危险”
大多数统计预测方法基于这样一种假设:通过数学变换,时间序列可以被近似地变为平稳(即,“平稳化”)。一个平稳时间序列是一个其统计特性,如均值、方差、自相关等,都在时间上保持不变的序列。一个基本的变换是对数据进行时间差分。
这种变换的作用是,相较于直接考虑数值,我们计算的是连续时间步骤之间的difference。定义模型来预测时间步骤之间的difference,而不是数值本身,是对模型预测能力的更强测试。在这种情况下,它不能仅仅利用数据的强自相关性,使用时间“t”的值作为“t+1”的预测。因此,它提供了对模型的更好测试,以及模型是否从训练阶段中学到了有用的东西,历史数据分析是否能实际帮助模型预测未来的变化。
总结
我希望通过这篇文章强调的主要点是,在处理时间序列数据时要非常小心。如上例所示,人们很容易被误导(在我之前的一篇关于AI 和大数据的隐藏风险的文章中也讨论过)。仅仅定义一个模型,做出一些预测,并计算常见的准确度指标,人们似乎就有了一个好的模型,并决定将其投入生产。然而,实际上,该模型可能根本没有预测能力。
随着高质量且易于使用的机器学习库和工具箱的出现,构建模型的实际编码部分变得相当简单。这一进展是好消息。它节省了我们大量的时间和精力,并且在实现过程中限制了编码错误的风险。在模型构建过程中节省下来的时间应该用来专注于提出正确的问题。在我看来,这是数据科学中最重要的方面之一。你如何正确验证模型预测?你的数据中是否存在任何隐藏的偏差可能会扭曲你的预测,或者是否有任何微妙的反馈循环可能会导致意外结果?
我想强调的最重要一点是,始终对数据告诉你的信息保持怀疑。提出关键问题,绝不要仓促下结论。科学方法应在数据科学中应用,就像在其他科学领域一样。
原文。经许可转载。
简介: Vegard Flovik 是 Axbit AS 机器学习和高级分析领域的首席数据科学家。
相关:
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT
更多相关话题
如何(不)使用机器学习进行时间序列预测:避免陷阱
原文:
www.kdnuggets.com/2019/05/machine-learning-time-series-forecasting.html
评论
在我的其他文章中,我已经涉及了诸如:如何结合机器学习和物理学以及机器学习如何用于生产优化和异常检测与状态监测。但在这篇文章中,我将讨论机器学习在时间序列预测中的一些常见陷阱。

时间序列预测是机器学习的一个重要领域。这一点非常重要,因为有许多预测问题涉及时间因素。然而,虽然时间因素增加了额外的信息,但也使得时间序列问题比许多其他预测任务更难处理。
本文将探讨使用机器学习进行时间序列预测的任务,以及如何避免一些常见的陷阱。通过一个具体的例子,我将展示如何看似拥有一个良好的模型并决定将其投入生产,而实际上,该模型可能根本没有预测能力。更具体地说,我将重点关注如何评估模型的准确性,并展示如何仅依赖常见的错误指标,如平均百分比误差、R2 分数等,如果不加以小心应用,这些指标可能会非常误导。
时间序列预测的机器学习模型
有几种类型的模型可以用于时间序列预测。在这个具体的例子中,我使用了长短期记忆网络,简称LSTM 网络,这是一种特殊类型的神经网络,根据之前的时间数据进行预测。它在语言识别、时间序列分析等方面非常流行。然而,根据我的经验,简单类型的模型在许多情况下实际上能提供同样准确的预测。使用例如random forest、gradient boosting regressor和time delay neural networks这样的模型,可以通过一系列延迟添加到输入中来包含时间信息,使得数据在不同的时间点上被表示。由于其序列特性,TDNN 被实现为一个前馈神经网络而非递归神经网络。
如何使用开源软件库实现这些模型
我通常使用Keras来定义我的神经网络类型模型,它是一个高级神经网络 API,使用 Python 编写,并且可以在TensorFlow、CNTK或Theano上运行。对于其他类型的模型,我通常使用Scikit-Learn,这是一个免费的机器学习库,提供各种classification、regression和clustering算法,包括support vector machines、random forests、gradient boosting、k-means和DBSCAN,并设计为与 Python 的数值和科学库NumPy和SciPy兼容。
然而,本文的主要主题不是如何实现时间序列预测模型,而是如何评估模型预测。因此,我不会详细讨论模型构建等内容,因为有很多其他博客文章和文章涵盖了这些主题。
示例案例:时间序列数据的预测
本案例中使用的示例数据如下面的图所示。我稍后会更详细地介绍这些数据,但目前,让我们假设这些数据代表了例如股票指数的年度演变。数据被分为训练集和测试集,其中前 250 天的数据用于模型训练,然后我们尝试预测数据集的最后部分的股票指数。
由于本文不关注模型实现,让我们直接进入模型准确性评估的过程。仅通过视觉检查上述图形,模型预测似乎与实际指数紧密跟随,表明准确性较高。然而,为了更精确一些,我们可以通过绘制实际值与预测值的散点图来评估模型准确性,如下所示,同时计算常见的误差指标 R2 score。
从模型预测中,我们获得了 0.89 的 R2 分数,实际值与预测值之间似乎匹配良好。然而,正如我将详细讨论的那样,这个指标和模型评估可能非常具有误导性。
这完全是错误的……
从上述图形和计算的误差指标来看,模型显然给出了准确的预测。然而,事实并非如此,这只是一个如何选择错误的准确性指标可能在评估模型性能时非常具有误导性的例子。在这个示例中,为了说明问题,数据被明确选择为实际上无法预测的数据。更具体地说,我所称的“股票指数”数据,实际上是使用 random walk process进行建模的。正如名称所示,随机游走是一个完全的 stochastic process。因此,使用历史数据作为训练集以学习行为和预测未来结果的想法根本不可行。鉴于此,模型为何看似给出了如此准确的预测?正如我将详细回顾的,这都归结于(错误的)准确性指标选择。
时间延迟预测和自相关
时间序列数据,顾名思义,与其他类型的数据不同,因为时间方面是重要的。积极的一面是,这为我们提供了在构建机器学习模型时可以使用的额外信息,不仅输入特征包含有用的信息,而且输入/输出随时间的变化也是有用的。然而,尽管时间因素增加了额外的信息,它也使时间序列问题比许多其他预测任务更难处理。
在这个具体的例子中,我使用了一个LSTM 网络,它根据之前的数据进行预测。然而,当稍微放大模型预测的细节时,如下图所示,我们开始看到模型实际上在做什么。
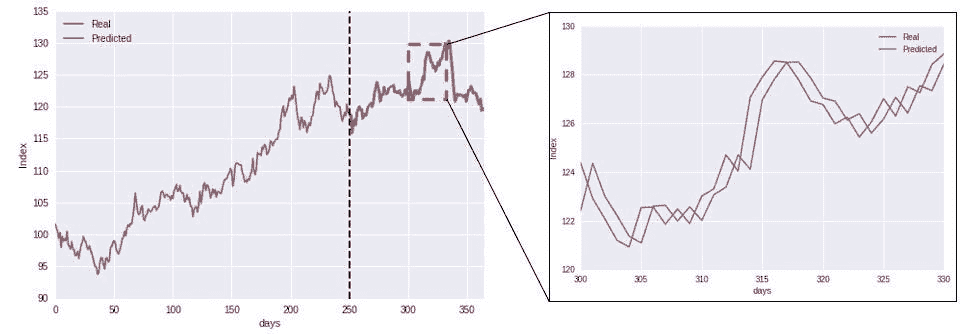
时间序列数据往往在时间上具有相关性,并显示出显著的自相关。在这种情况下,这意味着时间“t+1”的指数很可能接近时间“t”的指数。如右侧的图示所示,模型实际在做的是,当预测时间“t+1”的值时,它简单地使用时间“t”的值作为预测(通常称为persistence model)。绘制预测值和真实值之间的cross-correlation(下图),我们看到在 1 天的时间滞后处有一个明显的峰值,表明模型只是将前一个值作为未来的预测。
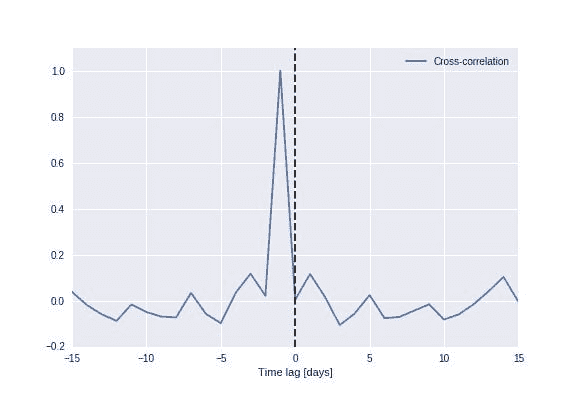
当不正确使用时,准确度指标可能会非常具有误导性。
这意味着在评估模型直接预测值的能力时,常见的误差指标,如均值百分比误差和R2 分数,都显示出高预测准确性。然而,由于示例数据是通过随机游走过程生成的,模型不可能预测未来的结果。这突显了一个重要事实,即仅通过直接计算常见误差指标来评估模型的预测能力可能非常具有误导性,人们很容易对模型的准确性感到过于自信。
平稳性和差分时间序列数据
一个平稳时间序列是指其统计属性,如均值、方差、自相关等,都在时间上保持不变。大多数统计预测方法基于这样一个假设:时间序列可以通过数学变换大致“平稳化”。一种基本的变换是时间差分数据,如下面的图所示。
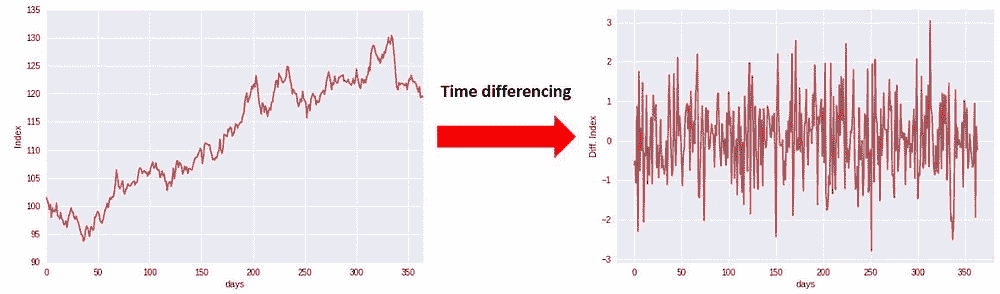
这种变换的作用是,我们不直接考虑指数,而是计算连续时间步之间的difference。
将模型定义为预测时间步之间的差异而不是值本身,是对模型预测能力的更强测试。在这种情况下,它不能简单地使用数据具有强自相关性,并将时间“t”的值作为“t+1”的预测。因此,它提供了对模型的更好测试,检验其是否从训练阶段学到有用的东西,以及分析历史数据是否确实能帮助模型预测未来变化。
时间差分数据的预测模型
由于能够预测时间差分数据,而不是直接预测数据,能更强地指示模型的预测能力,因此我们用我们的模型进行尝试。该测试的结果在下图中展示,显示了实际值与预测值的散点图。
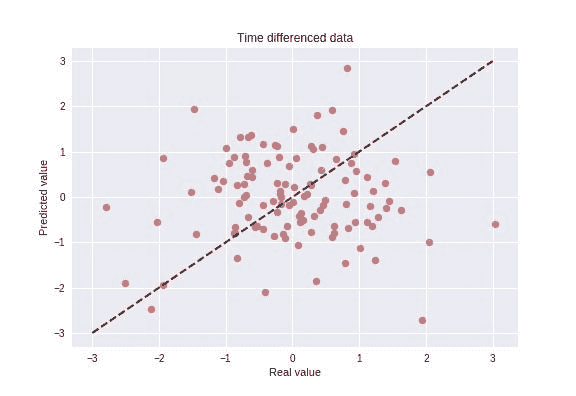
这个图表表明模型不能根据历史事件预测未来变化,这在这种情况下是预期结果,因为数据是通过完全随机的 随机游走过程生成的。根据定义,预测 随机过程 的未来结果是不可能的,如果有人声称可以做到这一点,应该有点怀疑……
你的时间序列是随机游走吗?
你的时间序列实际上可能是随机游走,以下是一些检查方法:
-
时间序列显示出强烈的时间依赖性(自相关性),其衰减呈线性或类似模式。
-
时间序列是非平稳的,将其平稳化后显示数据中没有明显的可学习结构。
-
持久性模型(使用上一个时间步的观察值作为下一个时间步的预测)提供了最可靠的预测来源。
这一点对于时间序列预测至关重要。基线预测使用 持久性模型 可以迅速指示你是否能够显著改进。如果不能,你可能在处理随机游走(或接近随机游走)。人类的大脑被固有地编程去寻找模式,我们必须警惕不要自欺欺人,浪费时间开发复杂的模型用于随机游走过程。
作者注:在发布文章后,我意识到 Jason Brownlee 在相同主题上有一篇很好的文章,处理了随机游走和时间序列: 使用 Python 进行时间序列预测的随机游走温和介绍。
摘要
我希望通过这篇文章强调的主要观点是,在评估模型预测准确性时要非常小心。正如上述例子所示,即使是完全随机的过程,其中预测未来结果在定义上是不可能的,也很容易被欺骗。通过简单地定义一个模型,进行一些预测,并计算常见的准确性指标,似乎可以有一个好的模型并决定将其投入生产。然而,实际上,该模型可能根本没有预测能力。
如果你正在进行时间序列预测,且可能认为自己是数据科学家,我建议你同样重视科学家的角色。始终对数据告诉你的内容持怀疑态度,提出关键问题,绝不要匆忙下结论。科学方法应在数据科学中应用,就像在任何其他科学领域一样。
原文. 经授权转载。
简介:Vegard Flovik 是一名首席数据科学家,负责 Axbit AS 的机器学习和高级分析工作。
资源:
相关:
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持组织的 IT 工作
更多相关话题
机器学习翻译与谷歌翻译算法
原文:
www.kdnuggets.com/2017/09/machine-learning-translation-google-translate-algorithm.html
作者:达尼尔·科尔布特,Statsbot。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
每天我们使用不同的技术,却不知道它们具体是如何工作的。事实上,了解由机器学习驱动的引擎并不容易。 Statsbot团队希望通过在这篇博客中讲述数据故事来使机器学习变得清晰。今天,我们决定探讨机器翻译器,并解释谷歌翻译算法的工作原理。
多年前,将文本从未知语言翻译过来非常耗时。使用简单的词汇逐字翻译存在两个困难:1) 读者必须了解语法规则;2) 翻译整个句子时需要记住所有语言版本。
现在,我们不需要再费那么多劲了——我们可以通过将短语、句子甚至大型文本放入谷歌翻译来进行翻译。但大多数人实际上并不关心机器学习翻译引擎是如何工作的。这篇文章是给那些关心的人准备的。
深度学习翻译问题
如果谷歌翻译引擎试图保持对即使是短句的翻译,这将不起作用,因为可能的变体数量巨大。最好的办法可能是教计算机一组语法规则,并根据这些规则翻译句子。只可惜这并不像听起来那么简单。
如果你曾经尝试学习一门外语,你就会知道总是有很多规则的例外。当我们试图在程序中捕捉所有这些规则、例外以及例外的例外时,翻译的质量会下降。
现代机器翻译系统使用不同的方法:通过分析大量文档来从文本中提取规则。
创建你自己的简单机器翻译器将是任何数据科学简历中的一个伟大项目。
让我们试着深入探究我们称之为机器翻译器的“黑箱”中隐藏的内容。深度神经网络能够在非常复杂的任务(语音/视觉对象识别)中取得优异的结果,但尽管它们具有灵活性,它们只能应用于输入和目标具有固定维度的任务。
递归神经网络
这时,长短期记忆网络(LSTMs)发挥作用,帮助我们处理长度无法先验确定的序列。
LSTMs 是一种特殊的递归神经网络(RNN),能够学习长期依赖关系。所有 RNN 看起来像是一个重复模块的链条。
因此,LSTM 将数据从一个模块传递到另一个模块,例如,为了生成 Ht,我们不仅使用 Xt,还使用所有之前的输入值 X。要了解有关 LSTM 结构和数学模型的更多信息,可以阅读这篇精彩的文章“理解 LSTM 网络”。
双向 RNNs
我们的下一步是双向递归神经网络(BRNNs)。BRNN 的作用是将常规 RNN 的神经元分为两个方向。一个方向用于正时间,或前向状态。另一个方向用于负时间,或后向状态。这两个状态的输出与相反方向状态的输入不相连。
为了理解为什么 BRNNs 比简单 RNN 效果更好,想象一下我们有一个 9 个单词的句子,我们想预测第 5 个单词。我们可以让它知道前 4 个单词,或者前 4 个单词和最后 4 个单词。当然,第二种情况的质量会更好。
序列到序列
现在我们准备转向序列到序列模型(也称为 seq2seq)。基本的 seq2seq 模型由两个 RNN 组成:一个编码器网络处理输入,一个解码器网络生成输出。

最终,我们可以制作我们的第一个机器翻译器!
不过,让我们考虑一个技巧。Google 翻译目前支持 103 种语言,因此我们应该有 103x102 个不同的模型来处理每对语言。显然,这些模型的质量会根据语言的流行程度和训练网络所需的文档量而有所不同。我们能做的最好的是制作一个神经网络,接受任何语言作为输入并翻译成任何语言。
Google 翻译
这个想法在 2016 年底由 Google 工程师 实现。NN 的架构基于 seq2seq 模型,这是我们已经研究过的。
唯一的例外是,在编码器和解码器之间有 8 层 LSTM-RNN,这些层之间有残差连接,并进行了一些调整以提高准确性和速度。如果你想深入了解,可以查看文章 Google 的神经机器翻译系统。
这个方法的主要优点是,现在 Google 翻译算法只使用一个系统,而不是每对语言使用一整套系统。
系统需要在输入句子的开头指定一个“标记”,以说明你尝试将短语翻译成的语言。
这提高了翻译质量,并使得即使在系统尚未见过的两种语言之间进行翻译也成为可能,这种方法被称为“零样本翻译”。
什么是更好的翻译?
当我们谈论 Google 翻译算法的改进和更好的结果时,我们如何正确评估第一个候选翻译是否优于第二个?
这不是一个简单的问题,因为对于一些常用的句子,我们拥有来自专业翻译人员的参考翻译集,这些翻译集之间自然会有一些差异。
有很多方法部分解决了这个问题,但最流行和有效的指标是 BLEU (双语评价理解)。想象一下,我们有两个来自机器翻译的候选翻译:
候选 1:Statsbot 使公司可以通过自然语言轻松地紧密监控来自各种分析平台的数据。
候选 2:Statsbot 使用自然语言准确分析来自不同分析平台的业务指标。

尽管它们具有相同的含义,但在质量和结构上存在差异。
让我们看看两个人工翻译:
参考文献 1:Statsbot 帮助公司通过自然语言紧密监控来自不同分析平台的数据。
参考文献 2:Statsbot 允许公司通过自然语言仔细监控来自各种分析平台的数据。
显然,候选 1 更好,相比候选 2 分享了更多的单词和短语。这是简单 BLEU 方法的关键思想。我们可以比较候选翻译与参考翻译的n-grams,并计算匹配的数量(与它们的位置无关)。我们只使用 n-gram 精确度,因为计算召回率在有多个参考的情况下很困难,结果是 n-gram 分数的几何平均值。
现在你可以评估复杂的机器学习翻译引擎。下次当你用 Google 翻译翻译某些内容时,想象一下它分析了多少百万份文档才为你提供了最佳的语言版本。
简介:丹尼尔·科尔布特 是Statsbot的初级数据科学家。
原文。经许可转载。
相关:
-
深度学习和 NLP 中的注意力与记忆
-
Top /r/MachineLearning 帖子,5 月:深度图像类比;风格化面部动画;Google 开源 Sketch-RNN
-
5 个免费的自然语言处理深度学习入门资源
更多相关主题
机器学习趋势与人工智能的未来
原文:
www.kdnuggets.com/2016/06/machine-learning-trends-future-ai.html
评论
由 Matt Kiser, Algorithmia。

由于三种机器学习趋势:数据飞轮、算法经济 和 云托管智能,每家公司现在都是数据公司,能够利用云中的机器学习大规模部署智能应用。
这是上个月在西雅图举行的首届机器学习/人工智能峰会的结论,此次峰会由Madrona Venture Group主办,超过 100 位专家、研究人员和记者汇聚一堂,讨论人工智能的未来、机器学习趋势以及如何构建更智能的应用。
通过托管的机器学习模型,公司现在可以快速分析大量复杂数据,并提供更快、更准确的见解,而无需承担高昂的机器学习系统部署和维护成本。
“今天构建的每个成功的新应用都将是一个智能应用,” Madrona Venture Group 的风险投资合伙人索玛·索马塞加说。“智能构建模块和学习服务将是应用程序的核心。”
以下是三种机器学习趋势的概述,这些趋势引领了一个新的范式,在这个范式中,每个应用都有可能成为智能应用。
数据飞轮
数字数据和云存储遵循摩尔定律:世界数据每两年翻一番,而存储数据的成本大致以相同的速度下降。这种数据的丰富性使得更多特性和更好的机器学习模型得以创建。
“在智能应用的世界中,数据将是王者,能够生成最高质量数据的服务将因其数据飞轮——更多的数据带来更好的模型,进而带来更好的用户体验,吸引更多用户,从而产生更多数据——而获得不公平的优势,” 索马塞加说。
例如,特斯拉已收集了 7.8 亿英里的驾驶数据,并且每 10 小时增加一百万英里。
这些数据被输入到自动驾驶仪中,这是他们的辅助驾驶程序,使用超声波传感器、雷达和摄像头来操控方向盘、更换车道,并在很少有人为干预的情况下避免碰撞。最终,这些数据将成为他们计划在 2018 年发布的自主自动驾驶汽车的基础。计划在 2018 年发布。
与 Google 的自动驾驶项目相比,该项目已经积累了超过 150 万英里的驾驶数据。特斯拉的数据飞轮正在全面运作。
算法经济
如果你不能利用数据,那么全世界的数据也不是很有用。算法是你高效扩展手动管理业务流程的方式。
“这个世界上所有的大规模事务都将由算法和数据管理,”微软数据集团和机器学习的 CVP Joseph Sirosh 说。在不久的将来,“每个企业都是一个算法驱动的企业。”
这创造了一个算法经济,其中算法市场作为全球研究人员、工程师和组织创建、共享和重混算法智能的聚集地。作为可组合的构建块,算法可以组合在一起操作数据,并提取关键洞察。

在算法经济中,最先进的研究被转化为功能性、可运行的代码,并提供给其他人使用。智能应用堆栈展示了形成智能应用所需的抽象层次。
“算法市场类似于创建了‘应用经济’的移动应用商店,”Gartner 的研究总监亚历山大·林登说。 “应用经济的本质是允许各种个人在全球范围内分发和销售软件,而不需要向投资者推销他们的想法或建立自己的销售、营销和分销渠道。”
云托管智能
对于一家公司来说,发现业务洞察的唯一可扩展方法是使用算法机器智能从数据中反复学习。这在历史上是一个昂贵的前期投资,没有显著回报的保证。
“今天的分析和数据科学就像 40 年前的裁缝,”Sirosh 说。 “这需要很长时间和巨大的努力。”
例如,一个组织需要首先收集自定义数据,聘请一组数据科学家,持续开发模型,并优化它们以跟上快速变化和增长的数据量——这只是开始而已。
随着更多数据变得可用以及存储成本的降低,机器学习开始转向云端,在那里,扩展性网络服务只需一个 API 调用即可。数据科学家将不再需要管理基础设施或实现自定义代码。这些系统将自动扩展,为他们生成新的模型,并提供更快速、更准确的结果。
“当构建和部署机器学习模型的工作量大大减少——当你可以‘大规模生产’它时——那么用于实现这一点的数据在云中变得广泛可用,”Sirosh 说。
新兴的机器智能平台提供预训练的机器学习模型即服务,将使公司轻松开始使用机器学习,使他们能够快速将应用程序从原型阶段推进到生产阶段。
“随着公司采纳微服务开发范式,将不同的机器学习模型和服务插拔式地集成以提供特定功能变得越来越有趣,”Somasegar 说。
当开源机器学习和深度学习框架在云中运行时,例如Scikit-Learn、NLTK、Numpy、Caffe、TensorFlow、Theano 或 Torch,公司将能够轻松利用预训练的托管模型来标记图像、推荐产品以及执行一般自然语言处理任务。
机器学习趋势回顾
“我们的世界观是今天的每家公司都是数据公司,每个应用程序都是智能应用程序,”Somasegar 说。 “公司如何从大量数据中获得洞察并从中学习?这是需要在全球每个组织中讨论的事情。”
随着数据飞轮的启动,获取、存储和计算这些数据的成本将继续降低。
这创造了一个算法经济体,其中机器智能的构建模块存在于云端。这些预训练的托管机器学习模型使每个应用程序能够大规模地利用算法智能。
数据飞轮、算法经济和云托管智能的汇聚意味着:
-
现在每个公司都可以成为数据公司
-
现在每个公司都可以访问算法智能
-
现在每个应用程序都可以是智能应用
“我们已经走了很远,” Madrona Venture Group 的管理合伙人 Matt McIlwain 说。“但我们仍然有很长的路要走。”
披露: Madrona Venture Group 是 Algorithmia 的投资者
简介: Matt Kiser 是 Algorithmia 的产品营销经理,在那里他帮助开发者为他们的应用程序提供超能力。
原文。经许可转载。
相关:
-
算法经济和容器如何改变应用程序
-
变量选择的数据科学:综述
-
机器智能与机器学习、深度学习及人工智能(AI)的区别是什么?
更多相关内容
机器学习与统计学
原文:
www.kdnuggets.com/2016/11/machine-learning-vs-statistics.html
Edvancer Eduventures 的首席执行官 Aatash Shah。

许多人对统计学和机器学习之间的区别感到疑惑。机器学习与统计学之间真的存在差异吗?
从传统的数据分析角度来看,以上问题的答案很简单。
-
机器学习是 一种能够从数据中学习的算法,无需依赖基于规则的编程。
-
统计建模是 一种通过数学方程形式来形式化数据中变量之间关系的方法。
机器学习主要涉及预测、监督学习、无监督学习等。
统计学涉及样本、总体、假设等。
两种不同的生物,对吧?那么,让我们看看它们是否真的那么不同!
机器学习和统计学有相同的目标
根据拉里·瓦瑟曼的说法:
它们都关注同一个问题:我们如何从数据中学习?
在他的博客中,他指出在这两个领域中,相同的概念有不同的名称:
| 统计学 | 机器学习 |
|---|---|
| 估计 | 学习 |
| 分类器 | 假设 |
| 数据点 | 示例/实例 |
| 回归 | 监督学习 |
| 分类 | 监督学习 |
| 协变量 | 特征 |
| 响应 | 标签 |
统计学家及斯坦福大学的机器学习专家罗伯特·提布希拉尼称机器学习为“被美化的统计学。”
现在,无论是机器学习还是统计学技术都用于模式识别、知识发现和数据挖掘。尽管下图可能将它们显示为几乎互不相交,但这两个领域正越来越趋于融合。
来源: SAS Institute - 一个展示机器学习和统计学关系的维恩图
机器学习和统计学的共同目标是从数据中学习。这两种方法都专注于从数据中提取知识或洞见,但它们的方法受其固有文化差异的影响。
它们确实相关,但它们的“父母”不同。
机器学习 是计算机科学和人工智能的一个子领域。它涉及构建能够从数据中学习的系统,而不是明确编程指令。
一个 统计模型,另一方面,是数学的一个子领域。
机器学习是一个相对较新的领域。
便宜的计算能力和大量数据的可用性使数据科学家能够通过分析数据来训练计算机学习。但统计建模早在计算机发明之前就已存在。
机器学习与统计学之间的方法论差异
两者之间的区别在于,机器学习强调优化和性能,而统计学则关注推断。
这就是统计学家和机器学习从业者对同一模型结果的描述方式:
-
机器学习专业人士:“在给定 a、b 和 c 的情况下,模型预测 Y 的准确率为 85%。”
-
统计学家:“在给定 a、b 和 c 的情况下,模型预测 Y 的准确率为 85%;我有 90%的把握你会得到相同的结果。”
机器学习不需要对变量之间的基本关系做出先验假设。你只需将所有数据输入,算法会处理数据并发现模式,利用这些模式可以对新数据集进行预测。机器学习将算法视为一个黑匣子,只要它有效。它通常应用于 高维数据集,数据越多,预测越准确。
相比之下,统计学家必须理解数据的收集方式、估计量的统计性质(p 值、无偏估计量)、他们研究的总体的基本分布以及如果多次进行实验你会期望得到的属性。你需要准确知道自己在做什么,并制定出提供预测能力的参数。统计建模技术通常应用于低维数据集。
结论
机器学习和统计建模可能看起来像是预测建模的两个不同分支。过去十年这两者之间的差异已经显著减少。这两个领域相互学习了很多,并将继续在未来更加接近。
但理解关联和了解它们之间的差异使机器学习者和统计学家能够扩展他们的知识,甚至将方法应用到他们专业领域之外。这就是“数据科学”的概念,旨在弥合差距。两个数据驱动领域之间的合作和沟通使我们能够做出更好的决策,最终将积极影响我们的生活方式。
在我们的 认证商业分析专业课程 中,你可以学习一些基于统计学的机器学习技术。
简介:Aatash Shah 是 Edvancer Eduventures 的联合创始人兼首席执行官。在创办 Edvancer 之前,他在投资银行行业有超过 6 年的经验。
原文。转载经许可。
相关:
-
数据科学基础:数据挖掘与统计学
-
数据科学基础:初学者的 3 个见解
-
数据科学与大数据,解释
我们的 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
机器学习大战:Amazon 对抗 Google 对抗 BigML 对抗 PredicSis
原文:
www.kdnuggets.com/2015/05/machine-learning-wars-amazon-google-bigml-predicsis.html/2
Kaggle 竞赛中的大致排名
-
Amazon 排名 #60
-
PredicSis 排名 #570
-
BigML 排名 #770
-
Google 排名 #810
重要的是要注意,根据你的应用需求,这三种性能指标中的某些可能比其他指标更为关键。这个 Kaggle 挑战的排行榜并没有考虑时间,但在某些需要高频预测的应用中(例如当你需要预测用户是否会点击广告时,对于每个访问高流量网站的用户),预测时间将变得极其重要。
摘要
免责声明:此比较使用了真实世界的数据集,但使用其他数据集可能会得到不同的结果。你应该用自己的数据试用这些 API 以找出最适合你的!
-
PredicSis 提供了精度和速度之间的最佳折衷,成为第二快和第二准确的。
-
BigML 在训练和预测中都最快,但精度较低。
-
Amazon 最准确,但代价是训练速度最慢,预测也非常慢。
-
Google 在精度和预测时间上都排在最后。
关于实际基准测试
这次比较非常简单,但仍然距离实际基准测试有些差距。我希望改善的一件事是让其他人更容易复制(和验证)这些结果。我使用了这些服务的网页接口来获取 AUC 值,最好能有能在本地计算 AUC 的代码。目前,你可以查看这个 评估 ML/预测 API 的库。欢迎提交拉取请求!(例如新的 API、新的评估指标等。)
在未来的基准测试中,尝试回归问题以及各种类型的数据集:小型、大型、不平衡等,将会很有趣。
了解更多
-
如果你想了解更多关于 PredicSis 和 BigML 的信息,它们将在 5 月 21 日于巴黎的 PAPIs Connect 会议上出现——欢迎来加入我们!
-
BigML 也将在 APIdays Mediterranea 参加会议,日期是 5 月 7 日,地点是巴塞罗那,他们的首席技术官将就 ML API 的未来进行精彩演讲。
-
我正在赠送两个会议的免费票! 在此注册 PAPIs Connect 和 在此注册 APIdays Mediterranea。
-
通过这些新的机器学习/预测 API,我正在考虑更新我的书籍,Bootstrapping Machine Learning,书中已经涵盖了 Google 预测和 BigML…但在那之前,你可能会对在我的机器学习入门套件中查看当前版本的摘录感兴趣!
在此获取机器学习入门套件
个人简介:路易斯·多拉德,@louisdorard 是一名独立顾问及PAPIs.io国际会议的总主席,专注于预测 API 和应用。他还是《Bootstrapping Machine Learning》一书的作者。路易斯拥有伦敦大学学院的机器学习博士学位。
原文。
相关内容:
-
云机器学习大战:亚马逊 vs IBM Watson vs 微软 Azure
-
BigML 机器学习平台 2015 年冬季发布,2 月 11 日
-
Google BigQuery 公共数据集
我们的前三大课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
机器学习 101:权重的定义、目的和方法
原文:
www.kdnuggets.com/2019/11/machine-learning-what-why-how-weighting.html
评论
作者 Eric Hart,Altair。
介绍
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
我经常被问到关于权重的事情。它是什么?我怎么做?我需要注意什么?根据大家的需求,我最近在公司举办了一次午餐学习活动,旨在解答这些问题。目标是适用于广大受众(例如,进行温和的介绍),同时也提供一些良好的技术建议/细节以帮助从业者。这个博客是从那次演讲中改编而来的。
模型基础
在讨论权重之前,我们需要对模型是什么、它们的用途以及建模过程中常见的一些问题有一个共同的认识。模型基本上是人类用来以严谨的方式(过度)简化现实世界的工具。通常,它们表现为方程式或规则集,通常尝试捕捉数据中的模式。人们通常将模型分为两个高层次的类别(是的,也可能有重叠):推断和预测。推断意味着尝试使用模型来帮助理解世界。想象一下科学家从数据中揭示物理真相。预测则意味着尝试对未来发生的事情进行猜测。在接下来的讨论中,我们将重点关注以预测为目的构建的模型。
如果你正在建立一个模型来进行预测,你需要一种衡量该模型预测效果的方法。一个好的起点是准确率。模型的准确率只是它的预测结果中正确的百分比。这可以是一个有用的指标,实际上它也是许多自动训练模型工具的默认指标,但它确实有一些缺点。例如,准确率不关心模型认为每个预测的可能性(与猜测相关的概率)。准确率也不关心模型做出的预测(例如,如果它在决定正面事件或负面事件,准确率不会优先考虑其中一个)。准确率也不关心准确率测量的记录集与模型应该适用的实际人群之间的差异。这些可能是重要的。
让我们来看一个例子。最近,2019 年世界大赛结束了。我将对比一些关于那个世界大赛的预测。剧透警告:我将告诉你谁赢得了世界大赛。
2019 年世界大赛是在华盛顿国民队和休斯顿太空人队之间进行的

我们来调查一些模型。我脑海中有一个内部模型,我不会解释。它给出了该系列赛 7 场比赛的这些预测:

显然,我对国民队的期望很高。与此同时,我最喜欢的网站之一,FiveThirtyEight,有一个先进的统计模型,用于预测比赛。它给出了这些预测:

值得注意的是:这些是单场比赛的预测,提前做出,如果比赛真的会发生;这些预测不是针对整个系列赛的。由于系列赛是七场四胜制,一旦一个队赢得 4 场比赛,将不再进行更多比赛,因此显然上述两组预测都不会完全如预期发生。
这些预测是基于团队实力、主场优势和每场比赛首发投手的具体情况。FiveThirtyEight 的模型预测主队会赢得每场比赛,除了第 5 场比赛,当时休斯顿最好的投手,杰里特·科尔,正在华盛顿投球。
无论如何,让我们揭示系列赛的结果,看看发生了什么,并比较准确率。这里是实际结果:

系列赛进行了 7 场比赛,华盛顿赢得了前两场和最后两场。(顺便提一下,在这个系列赛中,客队赢得了每一场比赛,这在这个或其他任何主要的北美职业运动中从未发生过。)
那么,我们来看看我们每个人的表现:
我的结果:
我正确预测了 7 场比赛中的 5 场,准确率为 0.71
FiveThirtyEight 的结果:
FiveThirtyEight 只预测对了 1 场比赛,准确率为 0.14。
因此,你可能会被诱导认为我的模型比 FiveThirtyEight 的更好,或者至少在这种情况下表现更好。但预测并不是全部。FiveThirtyEight 的模型不仅有预测,还有有用的概率,建议 FiveThirtyEight 认为每个队伍赢的可能性。在这种情况下,这些概率是这样的:

同时,我是那个总是确信自己对一切都正确的讨厌鬼。你们都知道这种人。我的概率看起来是这样的。

记住这一点,尽管我的准确率更高,你可能需要重新考虑你更喜欢哪个模型。
讨论这一点很重要,因为我们将很快再次谈论准确性,同时解决某些模型的缺陷。重要的是要记住,准确性可以是一个有用的指标,但它并不总是提供完整的情况。还有其他工具可以衡量模型的质量,这些工具关注诸如概率等更微妙的概念,而不仅仅是预测。我喜欢使用的一些例子是提升图、ROC 曲线和精准度-召回曲线。这些都是选择好模型的好工具,但单独使用任何一个都不是万无一失的。此外,这些工具更具可视化性质,通常,机器学习算法需要一个单一的数值,因此准确性常常被作为许多算法的默认选择,即使这对某些外部目标有害。
权重的意义
请考虑以下数据表:
假设你想建立一个只用年龄和性别来预测‘DV’的模型。因为只有一个例子 DV=1,你可能会很难预测这个值。如果这是一个关于信用贷款的数据集,而 DV 是某人是否会违约(1 表示违约),你可能更关心 DV=1 的案例,而不是 DV=0 的案例。花一点时间看看你是否能提出一个好的模型(例如一些规则)来预测这个数据集中的 DV=1。(剧透,你不可能得到 100%的准确率)。
这里是一些可能的例子:
-
仅拦截模型
-
总是预测 0
-
准确率 = 0.9
-
-
27 岁
-
对 27 岁的人预测 DV=1,其余预测 0
-
准确率 = 0.9
-
-
年轻女性
-
对于 30 岁以下的女性预测 DV=1,其余预测 0
-
准确率 = 0.9
-
所有这些模型的准确率相同,但其中一些在某些用例中可能更有用。如果你要求决策树或逻辑回归算法在这些数据集上建立模型,它们默认都会给你模型#1。这些模型不知道你可能更关心 DV=1 的案例。那么,我们如何让 DV=1 的案例对模型更重要呢?
想法 #1:过采样:复制现有的稀有事件记录,保持常见事件记录不变。
想法 #2:欠采样:移除一些常见事件记录,保留所有稀有事件记录。
在这两种情况下,我们都使用了与自然数据不同的人群来训练模型,目的在于影响我们将要构建的模型。
权重类似于这样,但不是复制或删除记录,而是将不同的权重分配给每条记录作为单独的列。例如,不是这样做:
我们可以这样做:
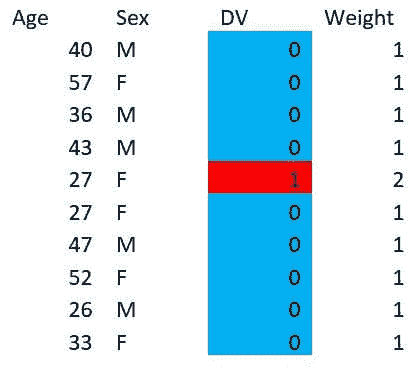
你可能会合理地问,机器学习算法是否可以以这种方式处理加权数据,但一个合理的回答是:“是的,没问题,不用担心。”
实际上,我们甚至不需要给出整数权重。你可以像这样做:
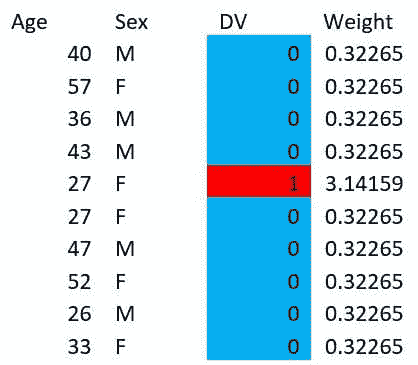
但现在,让我们坚持使用整数权重。假设你想在上述加权数据集上构建你的模型:
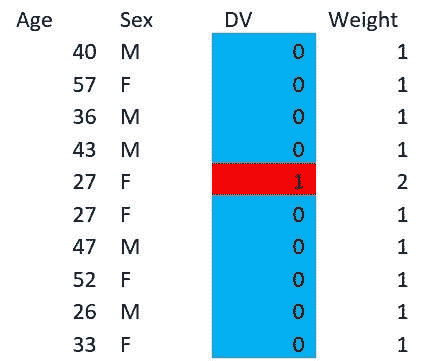
然后如果我们回顾之前讨论的可能模型,我们会看到:
-
仅拦截模型
-
加权准确率(用于训练模型):0.82
-
实际准确率 = 0.9
-
-
27 岁
-
加权准确率(用于训练模型):0.91
-
实际准确率 = 0.9
-
-
年轻女性
-
加权准确率(用于训练模型):0.91
-
实际准确率 = 0.9
-
通过加权,虽然我们没有改变实际准确率,但我们改变了加权准确率,这会使得在训练时,第一个选项不如后两个选项理想。实际上,如果你在这个加权表上构建模型,决策树自然会找到第二个模型,而逻辑回归自然会找到第三个模型。
关于加权,我常常遇到一个问题:在模型训练之后你如何处理这些权重?你是否需要在验证或部署过程中应用这些权重?答案是否定的!加权的目的是影响你的模型,而不是影响现实世界。一旦你的模型训练完成,权重就不再需要(或有用)。
加权的原因
在上一节中,我们对为什么可能想使用加权来影响模型选择有了一个模糊的了解,但让我们更深入地探讨一下。
你可能想使用加权的一个原因是如果你的训练数据不是你计划应用模型的数据的代表性样本。民意测验者经常遇到这个问题。有趣的事实是:用一个真正随机的 2500 人样本,民意测验者可以在+/- 1%范围内预测选举结果。问题是如何获得一个真正的随机样本。这很困难,因此民意测验者通常对不同的投票者应用权重,使样本人口统计更接近预期的投票人口统计。2016 年有一个很棒的故事,讲述了一个人如何强烈地扭曲了整个民意测验。你可以在这里阅读。
这是我听到的另一个你可能想使用加权的常见理由:
-
欺诈很少见
-
需要增加稀有案例的权重
-
这样模型整体表现会更好
这个常见的论点被证明是错误的。一般来说,加权会使模型整体表现更差,但在某些人群中表现更好。在欺诈的情况下,上述论点的遗漏之处在于,未能捕捉到欺诈通常比错误标记非欺诈交易的成本更高。
我们真正想讨论的作为加权的一个好理由是成本敏感分类。一些例子:
-
在欺诈检测中,假阴性往往比假阳性更昂贵
-
在信用贷款中,违约往往比被拒绝的不会违约的贷款更昂贵
-
在预防性维护中,部件故障通常比过早维护更昂贵
所有这些仅在合理范围内才成立。你不能走到极端,因为将每个交易标记为欺诈、拒绝所有贷款申请或花费所有时间维修系统而不是使用它们显然都是糟糕的商业决策。但关键是,某些类型的错误分类比其他类型的错误分类更昂贵,因此我们可能希望影响我们的模型,使其做出更多错误的决定,但整体上仍然更便宜。使用加权是一种合理的工具来解决这个问题。
加权的方法
提前说明:本节的许多有用信息来自同一篇论文。
这引出了一个重要的问题:你如何加权?使用大多数现代数据科学软件,你只需使用计算机魔法,权重就会被处理好。
但当然,还有重要的决策要做。你应该过采样还是欠采样,还是仅仅使用加权?你应该使用像 SMOTE 或 ROSE 这样的高级包吗?你应该选择什么权重?
好消息是:我要告诉你最优的做法。但当然,由于我是数据科学家,我会先给你很多警告:
-
这种方法仅对成本敏感的分类问题(例如,你对预测结果有不同的成本)是“最佳”的。我不会在这里帮助民调机构(抱歉)。
-
这种方法假设你知道与你的问题相关的成本,并且这些成本是固定的。如果真实成本未知或可变,这会变得更加困难。
在我们深入公式之前,先谈谈你可能会陷入的基准/参考错误的一个小陷阱。这是来自Statlog 项目的德国信用数据集的一个典型成本矩阵示例。
| 实际坏 | 实际好 | |
|---|---|---|
| 预测坏 | 0 | 1 |
| 预测好 | 5 | 0 |
如果你看几分钟,这个来源的理由就会变得清晰。这意味着如果你错误分类了一个会违约的人并给他们贷款,你会损失$5,但如果你错误分类了一个不会违约的人而不给他们信用,你会失去赚取$1 的机会,这本身也是一种成本。
但这里似乎有些问题。如果目的是当你预测坏时不延长某人的信用,那么预测坏所关联的成本应当是相同的,无论实际情况如何。事实上,这个成本矩阵可能应该是这样的:
| 实际坏 | 实际好 | |
|---|---|---|
| 预测坏 | 0 | 0 |
| 预测好 | 5 | -1 |
其中对一个实际会偿还贷款的人预测好会有负成本(或收益)。虽然这两个成本矩阵类似,但不能互换。如果你想象一下每种类型一个客户的情况,第一个矩阵建议你的总成本是$6,而第二个矩阵建议你的总成本是$4。第二个显然是这里的意图。因此,将矩阵以收益而非成本的形式呈现通常是有益的。尽管如此,我还是将以成本的形式给出公式,留给读者自己将其转化为收益公式。
所以,假设你有一个看起来像这样的成本矩阵:
| 实际负面 | 实际正面 | |
|---|---|---|
| 预测负 | C[00] | C[01] |
| 预测积极 | C[10] | C[11] |
首先,我们将陈述两个合理性标准:
-
C[10] > C[00]
-
C[01] > C[11]
这些标准基本上表明,如果你错误分类某个事物的成本会高于你不分类的成本。合理,对吧?
现在定义:
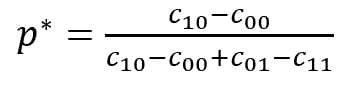
那么你应该通过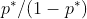 加重你的负面样本的权重(并保持你的正面样本不变)。
加重你的负面样本的权重(并保持你的正面样本不变)。
实际上,我们甚至可以更进一步。许多机器学习模型生成的是概率(而不是仅仅预测),然后使用阈值将该概率转换为预测。换句话说,你有一些规则,比如:如果正例的概率大于 0.5,则预测为正例,否则预测为负例。但你可以有另一种规则,例如,如果正例的概率大于 0.75,则预测为正例,否则预测为负例。这里的数字(上面例子中的 0.5 或 0.75)称为“阈值”。稍后会有更多相关内容,但现在,我们可以写下一个公式,说明如何让具有阈值 p[0] 的模型表现得像具有阈值 p^* 一样,我们可以通过上调负例的权重来实现:

注意,在 p[0] 为 0.5 的特殊情况下(这很典型),这将简化为之前的公式。
再次值得注意的是,变动成本的情况要困难得多。如果你使用决策树,一些平滑处理是个好主意,但一般来说,这里不便详细讨论。你可以查看这篇论文以获取一些想法。
权重调整的理由
权重调整有点像是为了更好地决策而假装生活在幻想世界中。你可以直接做出更好的决策,而不需要假装部分。
让我们回到上一节讨论阈值的内容。与其使用权重让一个具有某一阈值的机器学习模型表现得像具有不同阈值一样,你可以直接更改该模型的阈值。这可能(假设)会导致模型校准不佳,但它仍可能是一个好的商业决策,因为它可能减少成本。
实际上,如果你回到之前考虑的成本矩阵,
| 实际负例 | 实际正例 | |
|---|---|---|
| 预测为负例 | C[00] | C[01] |
| 预测为正例 | C[10] | C[11] |
为了最小化成本,做出决策的最佳阈值恰好是 p^*
这通常更简单,实证证据表明,直接调整阈值比权重调整在实践中效果稍好。
所以,总的来说,经过这些关于权重的讨论,我的建议是,如果可能的话,尽量不要使用权重,而是调整你的阈值!但当然,许多想法是重叠的,所以希望这次讨论仍然有用。
另外,最后一个提示:如果你不担心成本敏感的分类问题(例如,你有不同的预测和 DV 情况相关的不同成本),你可能不应该考虑使用权重作为工具。除非你是一个民意调查员。
个人简介: 埃里克·哈特博士 是 Altair 服务团队的高级数据科学家。他拥有工程和数学背景,喜欢运用自己的问题解决技巧来应对有趣的数据挑战。他还是 Blokus 世界冠军。
相关:
更多相关内容
从头开始的 Python 机器学习工作流程 第一部分:数据准备
原文:
www.kdnuggets.com/2017/05/machine-learning-workflows-python-scratch-part-1.html
现在,机器学习的认知似乎常常被简化为将一系列参数传递给越来越多的库和 API,期望得到魔法般的结果并等待输出。也许你对这些库的内部运作非常了解——从数据准备到模型构建,再到结果解释、可视化等——但你仍然依赖这些各种工具来完成任务。

从头开始的 Python 机器学习工作流程。
这没问题。使用经过良好测试和验证的工具实现常规任务是有意义的,有很多原因。重新发明不高效的轮子并不是最佳实践……这会限制你,而且花费时间不必要地长。无论你是使用开源工具还是专有工具来完成工作,这些实现都经过团队的精心打磨,确保你能获得最优质的工具来实现你的目标。
然而,自己动手做这些“肮脏的工作”往往是有价值的,即使只是作为一种教育尝试。我不会建议你从头开始编写自己的分布式深度学习训练框架——至少,通常情况下不建议这样做——但经历一次自己从头实现算法和支持工具的过程是一个好主意。我可能错了,但我不认为今天学习机器学习、数据科学、人工智能或<< 插入相关流行词 >>的绝大多数人实际上是在这样做的。
所以让我们从头开始构建一些 Python 机器学习工作流程。
我们所说的“从头开始”是什么意思?
首先,让我们澄清一下:当我说“从头开始”时,我的意思是尽可能少地借助帮助。这个定义是相对的,但为了我们的目的,我会在编写我们自己的矩阵、数据框和/或绘图库这方面画出界限,因此我们将分别依赖 numpy、pandas 和 matplotlib。在某些情况下,我们甚至不会使用这些库的所有可用功能,正如我们将很快看到的那样,我们会绕过它们以更好地理解。标准 Python 库中的任何东西也是可以使用的。然而,除此之外,我们将独立完成。
我们需要从某个地方开始,因此这篇文章将从一些简单的数据准备任务开始。我们将慢慢开始,但在对我们正在做的事情有了感觉之后,接下来的几篇文章中会迅速推进。除了数据准备之外,我们还需要额外的数据转换、结果解释和可视化工具——更不用说机器学习算法——来完成我们的旅程,我们会逐一讲解这些内容。
这个想法是手动拼凑出完成机器学习任务所需的任何非平凡功能。随着系列的展开,我们可以添加新的工具和算法,以及重新考虑我们之前的一些假设,使整个过程既具有迭代性又具有进步性。一步一步地,我们将关注我们的目标是什么,制定实现目标的策略,在 Python 中实现这些策略,然后测试它们是否有效。
最终结果,如目前设想,将是一组简单的 Python 模块,组织成我们自己的简单机器学习库。对于未接触过的人来说,我相信这将是理解机器学习过程、工作流和算法如何工作的宝贵经验。
我们所说的工作流是什么意思?
工作流对不同的人可能意味着不同的东西,但我们通常谈论的是被视为机器学习项目一部分的整个过程。有许多过程框架可以帮助我们跟踪我们正在做的事情,但现在我们简化为包括以下内容:
-
获取一些数据
-
处理和/或准备数据
-
构建模型
-
解释结果
我们可以随着进展对这些进行扩展,但这就是我们目前的简单机器学习过程框架。此外,“管道”意味着能够将工作流功能链在一起,因此我们在前进时也会记住这一点。
非常简单的机器学习过程框架。
获取我们的数据
在我们开始构建模型之前,我们需要一些数据,并确保这些数据符合一些合理的预期。为了测试目的(不是训练/测试的意义上,而是测试我们的基础设施),我们将使用鸢尾花数据集,你可以在这里下载。考虑到数据集的各种版本可以在网上找到,我建议我们都从相同的原始数据开始,以确保我们的所有准备步骤都能正常工作。
让我们来看看:
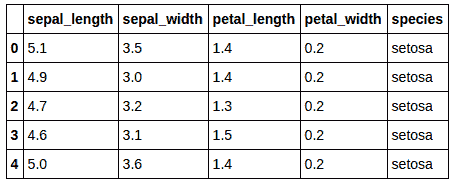
鉴于我们对这样一个简单数据集及其文件的了解,让我们首先考虑一下从原始数据到结果我们需要做什么:
-
数据存储在 CSV 文件中
-
实例主要由数值属性值组成
-
类别是分类文本
现在,上述内容并不适用于所有数据集,但也不特定于这个数据集。这使我们有机会编写可以在以后重复使用的代码。我们将在此关注的良好编码实践将包括重用性和模块化。
一些简单的探索性数据分析如下所示。

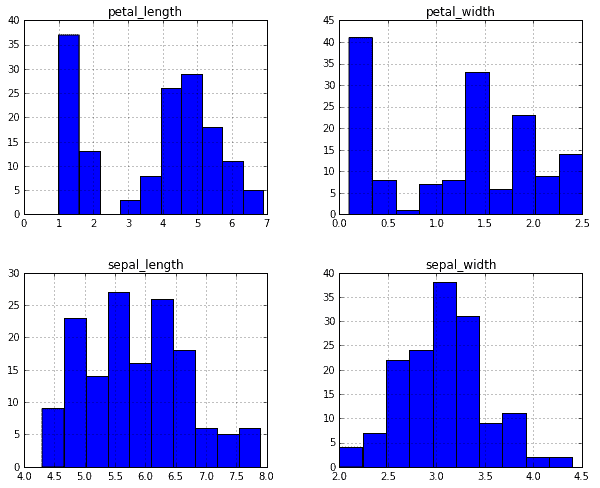
对鸢尾花数据集的非常简单的探索性数据分析:数据集描述(上),默认属性分布直方图(下)。
准备我们的数据
虽然在这个特定场景中我们所需的数据准备是最小的,但仍然是必需的。具体而言,我们需要确保考虑到标题行,移除 pandas 自动执行的任何索引,并将我们的类值从名义值转换为数值。由于我们将用于建模的特征中没有名义值,因此不需要更复杂的转换——至少目前不需要。
最终,我们还需要为我们的算法提供更好的数据表示方式,因此我们在继续之前将确保得到一个矩阵——或 numpy ndarray。我们的数据准备工作流程应该如下:
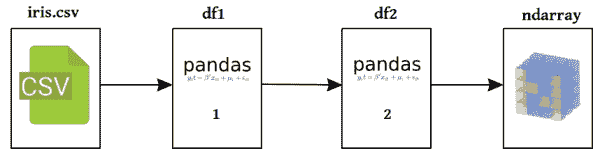
非常简单的数据准备过程。
另外,请注意,并非所有有趣的数据都存储在逗号分隔的文件中。我们可能会在某个时候从 SQL 数据库或直接从网络获取数据,届时我们会再次处理这个问题。
首先,让我们编写一个简单的函数,将 CSV 文件加载到 DataFrame 中;当然,这样做很简单,但考虑到未来,我们可能想要向数据集加载函数中添加一些额外的步骤。相信我。
这段代码非常简单。逐行读取数据文件可以轻松进行一些额外的预处理,比如忽略非数据行(我们暂时假设数据文件中的注释以‘#’开头,尽管这很荒谬)。我们可以指定数据集文件是否包括标题,并且支持 CSV 和 TSV 文件,默认是 CSV。
存在一些错误检查,但目前还不够健壮,因此我们可能想在以后再回来处理。此外,逐行读取文件并逐个决策这些行的处理方式会比使用内置功能直接将符合条件的 CSV 文件读取到 DataFrame 中要慢,但为了更多的灵活性,这个权衡在这个阶段是值得的(但在处理较大的文件时可能会花费相当长的时间)。不要忘记,如果这些内部操作似乎不是最佳方法,我们可以在以后随时进行更改。
在我们尝试运行代码之前,我们需要首先编写一个函数,将名义类值转换为数值。为了使函数更加通用,我们应该允许它用于数据集中任何属性,而不仅仅是类属性。我们还应跟踪属性名称与最终变为整数的映射。鉴于我们之前将 CSV 或 TSV 数据文件加载到 pandas DataFrame 中的步骤,这个函数应该接受 pandas DataFrame 以及要转换为数值的属性名称。
另请注意,我们暂时跳过了关于使用独热编码处理类别非类属性的讨论,但我怀疑我们会在之后回到这个话题。
上述函数虽然简单,但能完成我们想要的功能。我们本可以通过多种不同的方法来完成这项任务,包括使用 pandas 的内置功能,但从实际操作开始正是我们所要做的。
目前,我们可以从文件中加载数据集,并将类别属性值替换为数值(我们还会保留这些映射的字典以备后用)。如前所述,我们希望最终将数据集转换为 numpy ndarray,以便最方便地与我们的算法一起使用。再次,这是一项简单的任务,但将其做成函数会使我们在将来需要时能够继续扩展。
即使之前的函数看起来并不过于复杂,这个函数可能会显得有些过头。但请耐心等待;我们实际上是在遵循合理的 —— 尽管过于谨慎 —— 编程原则。随着我们前进,可能会对目前构建的函数进行更改或添加新的功能。在一个地方实施这些更改,并对其进行良好的文档记录,从长远来看是明智的。
测试我们的数据准备工作流程
我们目前的工作流程可能仍处于构建块形式,但让我们给代码做个测试。
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5 3.6 1.4 0.2 setosa
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 0
1 4.9 3 1.4 0.2 0
2 4.7 3.2 1.3 0.2 0
3 4.6 3.1 1.5 0.2 0
4 5 3.6 1.4 0.2 0
{'setosa': 0, 'versicolor': 1, 'virginica': 2}
[['5.1' '3.5' '1.4' '0.2' 0]
['4.9' '3' '1.4' '0.2' 0]
['4.7' '3.2' '1.3' '0.2' 0]
['4.6' '3.1' '1.5' '0.2' 0]
['5' '3.6' '1.4' '0.2' 0]
['5.4' '3.9' '1.7' '0.4' 0]
['4.6' '3.4' '1.4' '0.3' 0]
['5' '3.4' '1.5' '0.2' 0]
['4.4' '2.9' '1.4' '0.2' 0]
['4.9' '3.1' '1.5' '0.1' 0]]
既然我们的代码按预期工作,让我们做一些快速的清理工作。我们会在后续工作中为我们的代码制定更全面的组织结构,但现在我们应该将所有这些函数添加到一个文件中,并将其保存为dataset.py。这将使重用更加方便,下一次我们会看到这一点。
展望未来
接下来,我们将关注更重要的内容,即 k-means 聚类算法的实现。然后我们将看看一个简单的分类算法,k-最近邻算法。我们将了解如何在简单的工作流程中构建分类和聚类模型。这无疑需要编写一些额外的工具来帮助我们的项目,并且我相信我们之前做的内容会需要进行一些修改。
但这没关系;练习机器学习是理解机器学习的最佳方法。实施我们工作流所需的算法和支持工具最终应当证明有用。希望你觉得这些内容足够有帮助,以至于去查看下一期。
相关内容:
-
数据准备技巧、窍门和工具:与业内人士的访谈
-
Pandas 备忘单:Python 中的数据科学与数据处理
-
通过 Python 和 Scikit-learn 简化决策树解释
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
更多相关话题
从零开始的 Python 机器学习工作流 第二部分:k-均值聚类
原文:
www.kdnuggets.com/2017/06/machine-learning-workflows-python-scratch-part-2.html
在这一系列的第一部分,我们起步较慢但稳健。上一篇文章列出了我们的目标,并从一些机器学习工作流和管道的基本构建块开始。如果你还没有阅读这一系列的第一部分,建议你在继续之前先阅读它。
这一次我们加速前进,将通过实现 k-均值聚类算法来完成。我们将在编码过程中讨论 k-均值的具体方面,但如果你对该算法的概述以及它与其他聚类方法的关系感兴趣,你可以 查看这个。

Python 中的 k-均值聚类算法。从零开始。
继续前进的唯一真实先决条件是我们在第一篇文章中创建的 dataset.py 模块,以及原始的 iris.csv 文件,因此请确保你手头有这两者。
k-均值聚类算法
k-均值是一种简单但常常有效的聚类方法。k 个点被随机选择作为簇中心或质心,所有训练实例被绘制并添加到最近的簇中。在所有实例都被添加到簇中之后,代表每个簇实例均值的质心被重新计算,这些重新计算的质心成为各自簇的新中心。
此时,所有的簇成员资格被重置,所有训练集实例被重新绘制并添加到它们最接近的、可能重新中心化的簇中。这个迭代过程会继续,直到质心或其成员资格没有变化为止,簇被认为已稳定。
就聚类方法而言,k-均值算法是最简单的之一——其概念上的简单性优雅得几乎如诗一般。它也是一个经过验证的有效工具,具有持久的表现力,常常能够产生有用的结果。
我们要做的,简而言之,就是编码一个简单的 k-均值实现,这将把相似的东西分到一起,把不相似的东西分开,至少在理论上是这样。足够简单。请记住,这里的“相似”被简化为“在欧几里得空间中相对接近”,或者类似这样非常非哲学的东西。
我们在这里需要几个函数。考虑算法中的步骤可以帮助我们确定这些函数的内容:
-
设置初始质心
-
测量数据实例与质心之间的距离
-
将数据实例添加为最近质心的成员
-
重新计算质心
-
如有必要,重新测量,重新聚类,重新计算
这就是算法的核心。但在我们到达那之前,先做一步(暂时的)后退。
数据准备……再次
在撰写这篇文章时,我突然意识到我们的数据准备工作流程中缺少了一个重要部分。在将我们的 pandas DataFrame 转换为 numpy ndarray(矩阵)之前,我们需要确保我们的数值确实是数字,而不是伪装成数字的字符串。由于我们上次从 CSV 文件中读取数据,即使是我们的数值也被存储为字符串(在之前的帖子底部明显可见,因为数字被单引号包围——例如 '5.7')。
因此,处理此问题的最佳方法是创建另一个函数并将其添加到我们的 dataset.py 文件中,该函数将字符串转换为其数值表示(我们已经有一个函数用于将类名转换为数值,并跟踪这些更改)。该函数经历了 3 次具体的迭代,我在操作过程中即接受了:1)一个数据集和一个单一属性的名称,该属性对应的列中的所有值应从字符串转换为浮点数;2)一个数据集和属性名称列表……;以及 3)一个数据集和一个单一属性作为字符串,或一个属性列表作为哎呀列表。
最终的迭代(第三种,更灵活的选项)就是下面显示的那个。让我们将其添加到上次的 dataset.py 模块中。
好的,既然这些问题解决了,我们将能够加载数据集、清理数据,并创建一个(完全数值化的)矩阵表示,然后可以将其输入到我们的 k-means 聚类算法中,一旦我们有了算法。说到这一点……
初始化质心
我们的算法需要做的第一件事是创建一组 k 个初始质心。这里有多种方法可以实现,但我们将从最基本的开始:随机初始化。我们需要一个接受数据集和整数 k 的函数,并返回一个包含该数量随机生成质心的 ndarray。
你可能已经想象到随机初始化可能会出错。举个简单的例子,考虑在二维空间中有 5 个不同的、紧密聚集的类别,配有初始化不良的质心,如下所示。
显然是不理想的质心初始化。
即使没有数学支持直观感受,很明显这些质心的位置并不最优。然而,k-means 的一个强大特点是它能够从这种初始化中恢复,随着聚类的轮次逐步趋向最优位置,通过最小化簇实例成员与簇质心之间的均值距离。
虽然这可能发生得非常快,但在高维数据量大的情况下,较差的初始化可能会导致更多的聚类迭代。随机放置的初始数据空间调查本身也可能变得漫长。因此,存在替代的质心初始化方法,其中一些我们可能在未来会研究。
关于测试代码的简要说明:在我们进行的过程中用高度构造的场景进行测试似乎麻烦不堪,因此我们会等到最后再看看我们的整体表现。
测量距离
拥有数据集和一组初始化质心后,我们最终必须进行大量的测量计算。实际上,对于每次聚类迭代,我们需要测量每个数据点到每个质心的距离,以确定实例属于哪个簇(也许是暂时的)。因此,让我们为欧几里得空间编写一个测量函数。我们将使用 Scipy 来完成繁重的工作;虽然编写一个距离测量函数并不难,Scipy 包含一个函数 来优化这种向量计算,方便的是,这正是我们要做的。
让我们将这个功能封装在我们自己的函数中,以便以后我们可以改变或实验距离计算的方法。
凭借初始化质心和进行测量的能力,我们现在可以编写一个函数来控制我们聚类算法的逻辑,并执行几个额外的必要步骤。
聚类实例
在查看代码之前,以下是我们的算法将遵循的过程的简单概述,考虑到上述和以下的几个函数。
我们的 k-means 聚类算法过程。
以下代码有很好的注释,但让我们逐步查看几个主要点。
首先,我们的函数接受一个作为 numpy ndarray 的数据集,以及我们希望在聚类过程中使用的簇数量。它返回几个东西:
-
聚类完成后的结果质心
-
聚类后的簇分配
-
聚类算法所需的迭代次数
-
原始质心
创建一个 ndarray 来存储实例簇分配及其误差,然后初始化质心,并保留一份副本以便稍后返回。
接下来,while 循环将继续运行,直到聚类分配没有发生变化,意味着已经达到了收敛——请注意,此时并不存在限制迭代次数的额外机制。计算实例到质心的距离,跟踪最小距离,并用其来确定聚类分配。然后记录最近的质心及两个实体之间的实际距离(误差),并检查特定实例的聚类分配是否发生变化。
在对每个实例执行完上述操作后,质心位置会被更新,仅仅是通过使用成员实例的均值作为质心坐标。同时记录迭代次数。当适当时,检查是否已经收敛,将控制权转出 while 循环,并返回上述项。
我想指出,部分代码以及额外的灵感来源于 Peter Harrington 的书籍《机器学习实战》(MLIA)。我在这本书首次发布时购买了它,并且它在许多方面证明了其无价之处,尽管这本书常常受到批评,大部分批评集中在理论不足和/或代码问题上。然而,在我看来,这些恰恰是它的优势。如果你像我一样,在阅读这本书时有理论基础,并且愿意并能够调整需要优化的代码,或者可以自行修改代码,MLIA 对于任何希望初次涉足机器学习算法编码的人来说,都可以是一个有用的资源。
测试我们的 k-means 聚类算法
有一些典型任务我们将在这篇文章中跳过,稍后会再讨论,但我想在这里指出这些任务。
首先,在进行聚类时,特别是对于尺度不同的属性,通常最好至少考虑数据的缩放或归一化,以确保某个单一属性(或属性集合)的尺度远大于其他属性时,不会过多地影响结果。如果我们有 3 个属性,其中前两个在 [0, 1] 范围内,而第三个在 [0, 100] 范围内,那么很容易看出第三个变量将主导测量结果及后续的聚类成员分配。
其次,在聚类(就像许多机器学习任务一样)时,我们可以将数据集拆分为训练集和测试集,从而在一个数据子集上训练模型,然后在另一个(独立的)数据集上测试模型。虽然这并不总是特定聚类任务的目标,因为我们可能只是想构建一个聚类模型,而不关心用它来分类后续实例,但它通常是可行的。我们将在下面继续测试代码,而不考虑这些因素,但可能会在后续的文章中回顾。
在继续之前,确保你已经将上面提到的数据集相关函数添加到现有的 dataset.py 模块中,并创建了一个 kmeans.py 模块来存放所有相关函数。
让我们尝试一下我们的代码:
Number of iterations: 5
Final centroids:
[[ 6.62244898 2.98367347 5.57346939 2.03265306 2\. ]
[ 5.006 3.418 1.464 0.244 0\. ]
[ 5.91568627 2.76470588 4.26470588 1.33333333 1.01960784]]
Cluster membership and error of first 10 instances:
[[ 1\. 0.021592]
[ 1\. 0.191992]
[ 1\. 0.169992]
[ 1\. 0.269192]
[ 1\. 0.039192]
[ 1\. 0.467592]
[ 1\. 0.172392]
[ 1\. 0.003592]
[ 1\. 0.641592]
[ 1\. 0.134392]]
Original centroids:
[[ 4.38924071 3.94546253 5.49200482 0.40216215 1.95277771]
[ 5.43873792 3.58653594 2.73064731 0.79820023 0.97661014]
[ 4.62570586 2.46497863 3.14311939 2.4121321 0.43495676]]
看起来不错!我们代码的这次测试结果如上,但你会发现后续迭代会返回不同的结果——至少是不同的迭代次数和原始质心的集合。
展望未来
尽管我们尚未评估我们的聚类结果,但现在就到这里……不过,话说回来,我敢打赌你可以猜到下一篇文章的内容。下次我们将专注于更多的聚类相关活动。我们有一个算法可以用来构建模型,但还需要一些机制来评估和可视化它们的结果。这就是我们接下来要做的。
深入思考之后,我计划将我们的注意力转向使用 k 最近邻算法进行分类,以及一些与分类相关的任务。希望你发现这些内容足够有用,以便查看下一篇文章。
相关:
-
从头开始的 Python 机器学习工作流 第一部分:数据准备
-
提高 k-means 聚类效率的朴素分片质心初始化方法
-
K-Means 和其他聚类算法:Python 快速入门
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
更多相关主题
机器学习模型的三种主要方法
原文:
www.kdnuggets.com/2019/06/main-approaches-machine-learning-models.html
评论
在 2018 年 9 月,我发布了一篇关于我的即将出版的《数据科学的数学基础》一书的博客。我们讨论的核心问题是:我们如何弥合人工智能(深度学习和机器学习)所需的数学与高中所教授的数学(至 17/18 岁)之间的差距?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 为你的组织提供 IT 支持
在这篇文章中,我们介绍了这本书中的一章,名为“机器学习模型的分类”。这本书现在已经发布,并以章节形式提供早鸟折扣。如果你有兴趣获得早期折扣版,请联系 ajit.jaokar at feynlabs.ai。
1. 机器学习模型的分类
没有简单的方法来分类机器学习算法。在这一部分,我们呈现了从彼得·弗拉赫的《机器学习》一书中改编的机器学习模型分类法。虽然分类算法的结构基于该书,但下面的解释是我们创建的。
对于给定问题,所有可能结果的集合表示样本空间或实例空间。
创建算法分类法的基本理念是通过以下三种方式之一划分实例空间:
-
使用逻辑表达式。
-
使用实例空间的几何。
-
使用概率来分类实例空间。
使用上述技术转换实例空间的机器学习算法的结果应该是详尽的(涵盖所有可能的结果)和互斥的(不重叠)。
2. 逻辑模型
2.1 逻辑模型 - 树模型和规则模型
逻辑模型使用逻辑表达式将实例空间划分为多个段,从而构建分组模型。逻辑表达式是返回布尔值的表达式,即 True 或 False 结果。一旦使用逻辑表达式对数据进行分组,数据将被划分为解决问题的同质分组。例如,对于分类问题,组中的所有实例都属于同一类。
逻辑模型主要有两种类型:树模型和规则模型。
规则模型由一组蕴涵或 IF-THEN 规则组成。对于树模型,“if 部分”定义了一个段,“then 部分”定义了该段的模型行为。规则模型遵循相同的推理。
树模型可以看作是规则模型的一种特殊类型,其中规则的 if 部分以树结构组织。树模型和规则模型都采用相同的监督学习方法。该方法可以总结为两种策略:我们可以首先找到覆盖足够同质实例的规则主体(概念),然后找到代表该主体的标签。或者,我们可以从另一个方向入手,即首先选择一个我们想要学习的类别,然后找到覆盖该类别实例的规则。
下图展示了一个简单的树模型。树模型显示了泰坦尼克号乘客的生存数量(“sibsp”是船上配偶或兄弟姐妹的数量)。叶子下的值显示了生存的概率以及叶子的观察百分比。该模型可以总结为:如果你是(i)女性,或(ii)年龄小于 9.5 岁且兄弟姐妹少于 2.5 个的男性,那么你的生存机会很好。
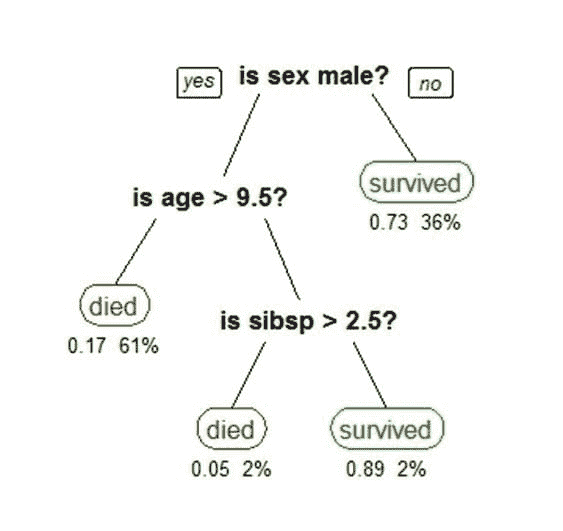
(图片来源.)
2.2 逻辑模型与概念学习
要进一步理解逻辑模型,我们需要了解概念学习的概念。概念学习涉及从实例中学习逻辑表达式或概念。概念学习的思想与机器学习的理念非常契合,即从具体的训练实例中推断出一般函数。概念学习是树模型和规则模型的基础。更正式地说,概念学习包括从给定的一组正负训练实例中获得一般类别的定义。概念学习的正式定义是“从输入和输出的训练实例中推断一个布尔值函数。”在概念学习中,我们仅为正类学习描述,并将所有不满足该描述的标记为负类。
以下示例详细解释了这一思想。
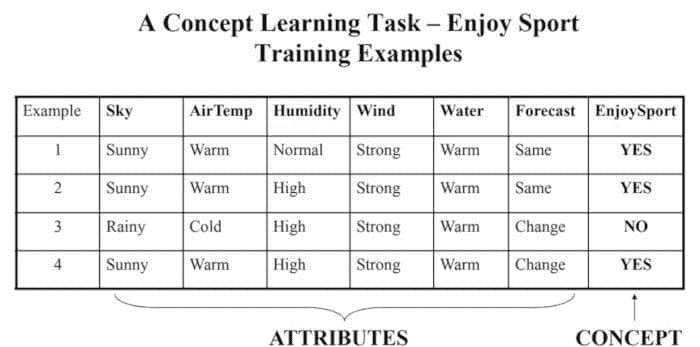
一个 概念学习 任务,称为“享受运动”,如上所示,由一些示例日期的数据集定义。每个数据由六个属性描述。任务是学习基于属性值预测“享受运动”的值。问题可以用 一系列假设 来表示。每个假设由对属性的约束的结合描述。训练数据代表目标函数的正例和负例。在上面的例子中,每个假设是一个包含六个约束的向量,指定了六个属性的值——天空、空气温度、湿度、风、水和预报。训练阶段涉及学习一组日期(作为属性的结合),其中“享受运动”= 是。
因此,问题可以表述为:
-
给定实例 X,表示所有可能的日期集合,每个日期由以下属性描述:
-
天空 – (值:晴天,多云,雨天),
-
空气温度 – (值:温暖,寒冷),
-
湿度 – (值:正常,高),
-
风 – (值:强,弱),
-
水 – (值:温暖,寒冷),
-
预报 – (值:相同,变化)。
-
尝试识别一个可以预测目标变量“享受运动”是“是”/“否”,即 1 或 0 的函数。
2.3 概念学习作为搜索问题和归纳学习
我们也可以将概念学习表述为 搜索问题。我们可以将概念学习看作是在预定义的潜在假设空间中搜索,以识别最符合训练示例的假设。概念学习也是 归纳学习 的一个例子。归纳学习,也称为发现学习,是一种通过观察示例发现规则的过程。归纳学习不同于演绎学习,演绎学习是学生获得规则后需要应用的。归纳学习基于 归纳学习假设。归纳学习假设认为:任何在足够大的训练示例集上能很好近似目标函数的假设,预计在其他未观察到的示例上也能很好近似目标函数。这一思想是归纳学习的基本假设。
总结一下,在本节中,我们看到了第一类算法,在这些算法中,我们基于逻辑表达式划分了实例空间。我们还讨论了逻辑模型如何基于概念学习理论——而概念学习理论又可以表述为归纳学习或搜索问题。
3. 几何模型
在前一节中,我们看到使用逻辑模型,如决策树,使用逻辑表达式来划分实例空间。当两个实例最终落在相同的逻辑片段中时,它们是相似的。在本节中,我们考虑通过考虑实例空间的几何来定义相似性的模型。在几何模型中,特征可以描述为二维(x- 和 y 轴)或三维空间(x、y 和 z)。即使特征本质上不是几何的,也可以以几何方式建模(例如,时间函数的温度可以在两个轴上建模)。在几何模型中,我们可以通过两种方式强加相似性。
-
我们可以使用几何概念,如直线或平面进行分割(分类)实例空间。这些称为线性模型。
-
或者,我们可以使用几何上的距离概念来表示相似性。在这种情况下,如果两个点接近,它们在特征上具有相似的值,因此可以被归类为相似。我们称这种模型为基于距离的模型。
3.1 线性模型
线性模型相对简单。在这种情况下,函数被表示为其输入的线性组合。因此,如果 x[1] 和 x[2] 是两个相同维度的标量或向量,a 和 b 是任意标量,那么 ax[1] + bx[2] 表示 x[1] 和 x[2] 的线性组合。在最简单的情况下,当 f(x) 表示一条直线时,我们有一个形式为 f(x) = mx + c 的方程,其中 c 代表截距,m 代表斜率。
(图片来源.)
线性模型是参数化的,这意味着它们有一个固定的形式,具有少量需要从数据中学习的数值参数。例如,在 f (x) = mx + c 中,m 和 c 是我们试图从数据中学习的参数。这种技术不同于树或规则模型,其中模型的结构(例如,树中使用哪些特征以及位置)不是预先固定的。
线性模型是稳定的,即训练数据的微小变化对学习到的模型的影响有限。相比之下,树模型通常会随着训练数据的变化而变化更多,因为树的根部选择不同的分割通常意味着树的其余部分也会不同。 由于参数相对较少,线性模型具有低方差和高偏差。这意味着线性模型比其他一些模型更不容易过拟合训练数据。然而,它们更容易欠拟合。例如,如果我们想根据标记数据学习国家之间的边界,那么线性模型可能不会给出一个好的近似。
在这一部分,我们还可以使用包括核方法的算法,例如支持向量机(SVM)。核方法使用核函数将数据转换到另一个维度,在该维度上可以更容易地进行数据分离,例如使用超平面进行 SVM。
3.2 基于距离的模型
基于距离的模型是几何模型的第二类。与线性模型一样,基于距离的模型基于数据的几何。顾名思义,基于距离的模型依赖于距离的概念。在机器学习的背景下,距离的概念不仅仅是两点之间的物理距离。我们可以考虑两点之间的运输方式。通过飞机旅行的城市之间的距离在物理上比火车旅行的距离要少,因为飞机没有限制。类似地,在国际象棋中,距离的概念依赖于使用的棋子——例如,象可以对角移动。因此,根据实体和旅行方式,距离的概念可以有不同的体验。常用的距离度量包括欧几里得、闵可夫斯基、曼哈顿和马氏。
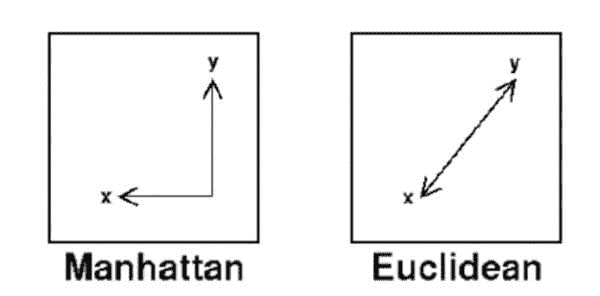
(图片来源.)
距离通过邻居和样本的概念应用。邻居是相对于通过样本表示的距离度量的邻近点。样本是找到根据所选距离度量的质量中心的中心点或找到最中央数据点的代表元。最常用的中心点是算术均值,它最小化了与所有其他点的平方欧几里得距离。
备注:
-
中心点代表平面图形的几何中心,即图形中所有点相对于中心点的算术平均位置。这个定义扩展到任意n维空间中的对象:其中心点是所有点的平均位置。
-
代表元在概念上类似于均值或中心点。代表元通常用于无法定义均值或中心点的数据场景。它们在中心点无法代表数据集的情况下使用,例如在图像数据中。
基于距离的模型的例子包括最近邻模型,它们使用训练数据作为样本,例如在分类中。K 均值聚类算法也使用样本来创建相似数据点的簇。
4. 概率模型
机器学习算法的第三类是概率模型。我们之前已经看到,k-近邻算法使用距离(例如,欧几里得距离)的理念来分类实体,而逻辑模型使用逻辑表达式来划分实例空间。在本节中,我们将看到概率模型如何使用概率的概念来分类新实体。
概率模型将特征和目标变量视为随机变量。建模过程表示和操控这些变量的不确定性。概率模型有两种类型:预测型和生成型。预测型概率模型使用条件概率分布 P (Y |X) 从中可以从 X 预测 Y。生成型模型估计联合分布 P (Y, X)。一旦我们知道生成模型的联合分布,我们可以推导出涉及相同变量的任何条件或边际分布。因此,生成模型能够创建新的数据点及其标签,知道联合概率分布。联合分布寻找两个变量之间的关系。一旦推断出这种关系,就可以推断出新的数据点。
朴素贝叶斯 是一种概率分类器的例子。
任何概率分类器的目标是,给定一组特征(x_0 到 x_n)和一组类别(c_0 到 c_k),我们旨在确定特征在每个类别中出现的概率,并返回最可能的类别。因此,对于每个类别,我们需要计算 P(c_i | x_0, …, x_n)。
我们可以使用贝叶斯规则来实现这一点
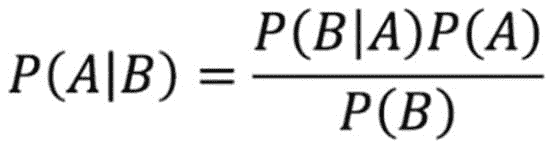
朴素贝叶斯算法基于条件概率的理念。条件概率是基于找到某事发生的概率,前提是其他事情 已经发生。算法的任务是查看证据并确定特定类别的可能性,并相应地为每个实体分配标签。
结论
上述讨论提供了一种基于数学基础的分类算法的方法。虽然讨论简化了,但它提供了一种从基本原理深入探讨算法的全面方式。如果你对获得早期折扣副本感兴趣,请联系 ajit.jaokar at feynlabs.ai。
相关:
更多相关主题
自然语言处理任务的主要方法
原文:
www.kdnuggets.com/2018/10/main-approaches-natural-language-processing-tasks.html
评论
来源:2017 年值得关注的 5 大语义技术趋势(ontotext)。
我们之前讨论了若干个自然语言处理(NLP)入门话题,我原计划在此时继续介绍一些有用的实际应用。然后我注意到我忽略了一些在继续之前可能需要的重要入门讨论。其中第一个话题将在这里讨论,更多的是对目前常见的自然语言处理任务方法的一般讨论。这也引出了一个问题:具体来说,有哪些类型的 NLP 任务呢?
另一个被指出的被忽视的基础话题将在下周讨论,那将涉及“我们如何为机器学习系统表示文本?”这个常见问题。
不过,首先回到今天的话题。让我们看看我们可以使用的 NLP 任务的主要方法。然后我们将查看我们可以用这些方法处理的具体 NLP 任务。
NLP 任务的方法
虽然并非绝对明确,但解决 NLP 任务的主要方法有 3 个大类。

图 1. 使用 spaCy 的依存解析树。
1. 基于规则
基于规则的方法是最早的 NLP 方法。你可能会问,为什么它们仍然被使用?这是因为它们经过验证且效果良好。应用于文本的规则可以提供很多洞察:想想通过找出哪些词是名词,哪些动词以-ing 结尾,或者是否可以识别出一个可识别的 Python 代码模式,我们可以学到什么。正则表达式 和 上下文无关文法 是基于规则的 NLP 方法的经典例子。
基于规则的方法:
-
倾向于关注模式匹配或解析。
-
通常可以被认为是“填空”方法。
-
精度较低,召回率高,意味着它们在特定应用场景中表现优异,但通常在泛化时会出现性能下降。
2. “传统”机器学习
“传统”的机器学习方法包括概率建模、似然最大化和线性分类器。值得注意的是,这些不是神经网络模型(见下文)。
传统的机器学习方法的特点是:
-
训练数据 - 在这种情况下,是带标记的语料库
-
特征工程 - 词类型、周围词汇、大写、复数等
-
在参数上训练模型,然后在测试数据上拟合(这是机器学习系统的一般特点)
-
推理(将模型应用于测试数据)以找到最可能的词汇、下一个词、最佳类别等为特征
-
“语义槽填充”
3. 神经网络
这类似于“传统”机器学习,但有一些不同之处:
-
特征工程通常被跳过,因为网络会“学习”重要特征(这通常是使用神经网络进行 NLP 的一个主要好处)
-
相反,输入神经网络的是原始参数流(“词汇”-- 实际上是词汇的向量表示),而不是经过工程化的特征
-
非常大的训练语料库
在 NLP 中有用的特定神经网络包括递归神经网络(RNNs)和卷积神经网络(CNNs)。
为什么对 NLP 使用“传统”机器学习(或基于规则)方法?
-
对于序列标注仍然有效(使用概率建模)
-
神经网络中的一些想法与早期方法非常相似(word2vec 在概念上类似于分布语义方法)
-
使用传统方法中的方法来改进神经网络方法(例如,词对齐和注意机制是相似的)
为什么深度学习胜过“传统”机器学习?
-
许多应用中的 SOTA(例如,机器翻译)
-
目前在 NLP 领域有大量研究(大多数?)
重要的是,神经网络和非神经网络方法本身都可以对现代 NLP 有用;它们也可以一起使用或研究,以获得最大潜在利益
NLP 任务是什么?
我们有了方法,但任务本身呢?
这些任务类型之间没有明确的界限;然而,目前许多任务已经相当明确。给定的宏观 NLP 任务可能包括各种子任务。
我们首先概述了主要的方法,因为这些技术通常对初学者很重要,但了解 NLP 任务的类型是有好处的。以下是 NLP 任务的主要类别。
1. 文本分类任务
-
表示:词袋模型(不保留词序)
-
目标:预测标签、类别、情感
-
应用:过滤垃圾邮件,根据主要内容对文档进行分类
2. 词序列任务
-
表示:序列(保留词序)
-
目标:语言建模 - 预测下一个/之前的词汇,文本生成
-
应用:翻译、聊天机器人、序列标注(预测序列中每个词的 POS 标签)、命名实体识别
3. 文本意义任务
-
表示:词向量,即将词汇映射到向量(n维数值向量),也称为嵌入
-
目标:我们如何表示意义?
-
应用:寻找相似词(相似向量)、句子嵌入(相对于词嵌入)、主题建模、搜索、问答

图 2. 使用 spaCy 的命名实体识别(NER)(文本摘自这里)。
4. 序列到序列任务
-
NLP 中的许多任务可以这样表述
-
示例包括机器翻译、总结、简化、问答系统
-
此类系统的特点是编码器和解码器,这些编码器和解码器互补工作以找到文本的隐藏表示,并使用该隐藏表示
5. 对话系统
-
对话系统的 2 个主要类别,按其使用范围分类
-
目标导向对话系统专注于在特定、受限的领域中发挥作用;精确度更高,但可泛化性较差
-
对话式对话系统关注于在更广泛的背景下提供帮助或娱乐;精确度较低,但泛化性更强
无论是对话系统还是规则基础与更复杂方法在解决 NLP 任务中的实际差异,请注意精确度与泛化性之间的权衡;通常你会在一个方面做出牺牲以提高另一个方面。
在下一篇文章中覆盖文本数据表示后,我们将深入探讨一些更高级的 NLP 主题,并进行一些有用 NLP 任务的实际探索。
参考文献:
-
从语言到信息,斯坦福大学
-
自然语言处理,国立研究大学高等经济学院(Coursera)
-
自然语言处理中的神经网络方法,Yoav Goldberg
相关:
-
预处理文本数据的一般方法
-
处理文本数据科学任务的框架
-
文本数据预处理:Python 实操指南
我们的前三大课程推荐
1. 谷歌网络安全证书 - 加速你的网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
我如何通过数据科学每月赚取$3,500
原文:
www.kdnuggets.com/2023/01/make-3500-online-every-month-data-science.html

图片由 Vlada Karpovich 提供
我从 2020 年 1 月开始自学数据科学。那时,我的唯一目标是找到一份全职工作。
然而,尽管数据科学家的薪酬非常丰厚,但在 9 到 5 的工作中攀登职场阶梯并积累财富需要很长时间。
因此,我开始寻找在公司工作之外应用数据科学技能的不同方法。由于我的全职工作灵活并允许远程工作,我每天有大约 3 到 4 小时的自由时间来赚取副收入。
现在,我已经成功地在全职工作之外建立了多个收入来源,每月大约能提供$3,000-$3,500。
其中许多收入来源是被动的,这意味着我可以在不需要主动投入时间和精力的情况下赚取收入。
在这篇文章中,我将展示我是如何做到的。如果你是数据科学家或渴望成为数据科学家,你可以利用这些想法来实现技能变现。
1. 在线写作
我的一大部分收入来自于在线写作。这包括创建数据科学教程、技巧和建议。我在 2020 年 5 月开始在 Medium 上写博客。
在平台上建立了观众群体后,雇主们开始联系我,为他们的品牌撰写自由职业文章。在过去的两年里,我为六家公司创建了各种博客文章、教程、白皮书和 SEO 内容。
要点:
a) 只需开始写作
你不必成为某个领域的专家就能开始分享你所知道的。事实上,根据 Fast.AI 的共同创始人 Rachel Thomas 的说法,你最能帮助那些比你稍微落后的人。
这意味着如果你刚刚学习了一个概念,它仍然在你的脑海中十分清晰。你可以轻松简化这个概念并向另一个初学者解释——你会比那些已经忘记了初学者感觉的专家做得更好。
b) 自我营销
要作为内容创作者成长,你需要进行自我营销。创建一个引人注目的 LinkedIn 个人资料,并在平台上分享你的文章。定期发布,加入数据科学小组,与该领域的其他专业人士建立联系。
扩展你在数据领域的联系将增加你的博客访问量,提高你获得付费写作机会的可能性。
2. 联盟营销
在自学数据科学时,我在 Udemy、Coursera 和 Datacamp 上参加了许多在线课程。我会向那些想成为数据科学家的同事和同行推荐这些课程。
一段时间后,我意识到我可以通过与他人分享我的学习路径来获得报酬。附属营销允许发布者通过附属链接与其他人分享课程。如果有人通过他们的链接购买了程序,发布者将获得一小部分佣金。
收获:
为你已经做的事情获得报酬
即使在我的内容中添加附属链接之前,我几乎在每篇博客文章中都会分享学习材料。唯一的区别是我现在为此获得报酬。实际上,根据 Affise 的一项调查,超过 25%的附属人员每年赚取$81,000 到$200,000 之间的收入。
虽然我从附属营销中赚取的只是其中的一小部分(每次发布时大约$100-$200),但对许多博客作者来说,它是一个巨大的收入来源,绝对是你应该考虑添加到你内容中的东西。
然而,请记住要保持道德,只推广你已消费并从中受益的产品。你还必须保持透明,清楚地向读者披露附属链接的使用。
3. 执行市场研究
这可能听起来像是一个不寻常的赚钱方式,但请听我说完。
我的第一份全职数据科学工作是在营销分析领域。在这个角色中,我学会了应用数据科学技术来创建个性化的客户定位策略并推动营销成功。
我写了一篇关于在营销领域应用数据科学技术的文章,这引起了一位雇主的注意,他正在寻找具有我相同技能的自由职业者。他通过 LinkedIn 联系了我,现在我以合同形式与公司合作。
收获:
a) 选择一个领域
由于我在营销分析领域工作了很长时间,我熟悉行业中的一些主要挑战。我也知道如何利用数据来解决这些问题。
这是我的领域。找到与我具备相同技能组合的人很难,这使我成为这份自由职业工作的有力竞争者。
如果你是一个有抱负的数据科学家,我建议你在开始时选择一个专长领域。这可以是金融、营销、医疗保健、保险或任何你喜欢做的事情。
数据科学家的价值在于他们解决问题的能力。如果你能在特定行业做到这一点,你将比其他数据科学家更具竞争优势。
我可以自信地说,即使是拥有数据科学硕士学位或博士学位的人,没有领域经验也无法胜任我获得的这份工作。
b) 建立在线存在感
我能获得这个角色只是因为雇主在浏览平台时找到了我的 Medium 个人资料。我曾与其他营销数据科学家合作过,其中许多人比我经验更丰富,对该领域的了解更深入。
尽管如此,我能得到这份工作是因为雇主首先找到了我——这要归功于我的博客文章和社交媒体存在。
如果你没有时间撰写关于你工作的文章,我建议你至少创建一个包含技能概述的个人作品集网站。在 LinkedIn 和其他社交媒体平台上包含该网站的链接,以便潜在的雇主在招聘时可以轻松找到你。
如果你还没有,阅读这个指南以获取有关如何创建个人作品集网站的建议。
4. 创建课程和研讨会
我曾举办过关于数据收集和分析等主题的研讨会,以教导非技术学生如何处理数据。这涉及了大量的准备工作,因为我需要熟悉我教授的每一个概念,并确保不犯错误。
成为讲师的最大好处是教学加深了我对主题的理解,并显著提高了我将复杂概念拆解给初学者的能力。
收获:
教授你所知道的
我大约在两到三年前开始学习数据科学,目前还不是这个领域的专家。然而,在这段时间里,我学到了很多,并且可以将这些知识教给一群能从中受益的人。
例如,作为一个在数据科学和营销领域都有经验的人,我很适合教导营销人员数据素养技能。我还可以教数据科学家关于营销分析的知识,以便他们能够获得领域知识,并有可能在该行业找到工作。
即使你是一个正在学习阶段的有志数据科学家,你也可以通过与他人分享你所知道的来赚取额外收入。通常,当你结合一些少有人拥有的独特技能时,这种方式效果最佳。
例如,“Python 入门”课程可能不会引起学生的兴趣,因为类似的课程在互联网上随处可见。然而,“金融 Python 入门”课程更具专业性,可能会吸引一群对预测股市感兴趣的观众。
YouTube、Udemy、Pluralsight 和 Thinkific 是一些可以用来创建和分享在线课程的平台。
5. 其他自由职业任务
此外,我还为客户从事过自由职业的数据科学任务,如数据收集、模型构建和仪表板创建。虽然大多数自由职业者都推崇 Upwork 和 Fiverr 等平台,但我大多数的工作机会都是通过 Medium、LinkedIn 和我的网站获得的。
以下是一些为我带来自由职业机会的文章:
使用 Python 进行客户细分:我最终为客户构建了一个 K-Means 聚类模型,并在一个幻灯片演示中展示了我的结果。
如何使用 Python 收集 Twitter 数据:我指导客户使用 Python API 收集 Twitter 数据。
使用 Python 进行完整的数据分析项目:我为客户的产品进行了类似的竞争分析。
收获:
构建项目: 当雇主寻找自由职业者时,他们通常会在互联网上搜寻从事类似项目的人。频繁地构建项目并发布相关信息将提高你被注意到并获得工作的几率。
结论
无论你在数据科学旅程中的哪一阶段,你都可以从今天开始建立多种在线收入来源。
从在线写作和教授你所知道的开始。这可以在像 Medium 这样的发布平台上完成。你甚至可以利用 Wix 和 WordPress 等网站开发服务创建自己的博客网站。
然后,选择数据科学中的一个专业领域。我建议你在该领域获得全职工作,因为这将为你提供其他地方无法获得的行业特定经验。
最后,利用你的领域经验和数据科学技能,扩展到自由职业和课程创作。你还可以在本地提供咨询服务和举办数据科学研讨会。
“成功的秘诀在于开始行动。”—— 马克·吐温
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
原文。已获得许可转载。
相关话题
用 Python 图表画廊制作惊人的可视化
原文:
www.kdnuggets.com/2022/12/make-amazing-visualizations-python-graph-gallery.html

截图来自 Python 图表画廊
如果你希望让你的数据更具视觉效果,Python 图表画廊 提供了约 400 个图表,分为 40 个不同类别。所有类别都有多个示例和可重复的代码以及一些解释。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
前提条件
要充分利用这个免费资源,掌握以下工具的基本知识将非常有用:
-
Matplotlib
-
Seaborn
-
Plotly
如果你对这些工具的了解不是最全面的,下面是它们的官方文档和教程,可以帮助你:
如果你需要进一步的资源,可以尝试以下内容:
-
Matplotlib 教程 - YouTube
-
Seaborn 教程 - YouTube
-
Plotly 教程 - YouTube
一旦你掌握了这些工具,你可以应用它们来创建美丽的可视化,如下所示。
示例可视化
动态气泡图
基本圆形条形图
和弦图
雷达图
结论
数据可视化是展示你工作的最佳方式。解释数据可能是一个挑战。然而,大多数人可以欣赏可视化内容。可视化易于解释和理解。能够创建惊人的可视化是每个数据科学家应该掌握的技能,而 Python 图表库对此提供了帮助。
妮莎·阿里亚 是一名数据科学家和自由技术写作人。她特别感兴趣于提供数据科学职业建议或教程以及关于数据科学的理论知识。她还希望探索人工智能如何能促进人类寿命的不同方式。作为一个热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
如何简化代码文档
原文:
www.kdnuggets.com/2022/12/make-documenting-code-easier.html

图片由编辑提供
文档是程序员最讨厌的任务之一。我的意思是,我们是程序员而不是作家。众所周知,程序员在编写代码方面很出色,但在解释他们的思维过程方面可能还需改进。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
这就是为什么我们如此厌恶编写文档的原因。我们需要用文字解释我们的思维过程,以便他人理解。这总是一个具有挑战性的任务。
无论如何,所有程序员都知道良好文档的重要性以及它对任何编码项目成功的重要性,无论是用于开源还是作为团队内部的项目。
记录编写代码的步骤和一些设计决策的理由,对使用代码的人和编写代码的人在添加/删除新功能时都是有益的。
在软件工程中,编写文档通常指的是主要代码开发者编写脚本,详细说明代码的功能、目标以及如何实现这一目标。程序员讨厌编写文档的主要原因是,作为程序员,你更愿意编写代码而不是解释它。
在开始编码之前制定一份路线图
这可能需要读者注意,但在你开始编写代码之前,先起草文档的路线图。这将帮助你两方面,一方面它将让你更容易知道需要在文档中添加什么,另一方面在你开始编写代码时,它将成为你的指南。
我这里所说的“路线图”是你文档的骨架,即你将要解释的不同部分。例如,如果你查看 Matplotlib 的文档,它有四个主要部分:安装、学习材料、第三方包,以及如何贡献源代码。在这些部分中,还有更详细的子部分。
边做边草拟
一旦你完成了文档框架并开始编写代码,尝试同时编写代码和文档草稿。我知道我们大多数数据科学家会说,“我会在完成代码后再写完整的文档”,虽然我理解这种想法(即专注于代码编写),但我认为这会使编写文档变得更加麻烦。
在编写代码时起草文档将帮助你理解你在过程中做出的决策,什么有效,什么无效。最后,当你编辑和调整文档时,你可以选择保留那些不起作用的部分,作为展示你如何达到最终产品的方式,或者跳过那些部分,专注于有效的部分。就个人而言,我喜欢保留那些无效的部分,因为它们和有效的部分一样重要。
将你的评论作为进一步解释的提示
评论对不同的原因至关重要,但它们不能替代完整的文档。我喜欢将代码中的评论或文档字符串看作是文档中将解释代码不同功能部分的标题。评论将为用户提供他们使用不同函数和/或类所需的最少信息。与此同时,文档将进一步阐述函数的工作原理以及该函数的一些用例。
编写更具可读性的代码
你是否厌烦编写详细的长文档?我有一个解决方案,如果你的代码组织良好、清晰且编写规范,你不需要详细的文档来解释它是如何工作的;几个示例和教程可能就能达到目的。
在上一篇文章中,我们深入讨论了如何使你的代码更具可读性。幸运的是,编写可读代码是一种可以通过练习直到掌握的技能。
因此,更具可读性的代码会导致更简短的文档。
阅读更多优秀的文档
如果你想学习如何编写清晰、简洁且切中要点的优秀文档,就要多阅读优秀的文档。在这里,我指的是带着学习编写优秀文档的风格和过程的意图去阅读,而不是收集如何使用代码的信息。
我读过的一些最佳文档是 Matplotlib、Pandas 和 Numpy 的文档。这些文档都清晰、简洁且组织良好。作为数据科学家,我们必须使用不同的包来处理不同的算法和应用。我相信你一定觉得某些文档比其他的更好,可能有各种原因。思考一下为什么你认为某些包的文档比其他的更好。这将帮助你了解在编写自己文档时应该避免哪些问题。
寻求反馈、重新阅读并修订
产生更好文档的一个好方法是向他人寻求反馈。这可以帮助你了解用户需要/想要更准确的信息、缺少了什么,以及你的文档如何整体改善。
最后的想法
现在,仅仅编写稳健的代码已经不够;为了证明你的能力以及你对项目和领域的熟悉程度,你需要提供撰写良好的文档,并突出显示你的代码如何工作以及如何使用。
不幸的是,我们中的大多数人宁愿花更多的时间编写实际代码,而不是处理文档。在这篇文章中,我们探讨了一些可以使编写代码文档过程更容易的步骤,并帮助你生产出更高质量的文档。
Sara Metwalli 是庆应义塾大学的博士候选人,研究测试和调试量子电路的方法。我是 IBM 的研究实习生和 Qiskit 倡导者,致力于建设一个更加量子化的未来。我还是 Medium、Built-in、She Can Code 和 KDN 的作者,撰写关于编程、数据科学和技术主题的文章。我还是“Woman Who Code Python”国际章节的负责人,火车爱好者,旅行者和摄影爱好者。
相关话题
如何使你的机器学习模型对离群值具有鲁棒性
原文:
www.kdnuggets.com/2018/08/make-machine-learning-models-robust-outliers.html
评论
由 Alvira Swalin,旧金山大学
“这个漏洞的出现如此出乎意料,以至于数年间分析臭氧数据的计算机系统性地抛弃了本应指向臭氧增长的读数。” — 《新科学家》1988 年 3 月 31 日
我们的前三名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

根据维基百科,离群值是指与其他观测值相距较远的观测点。这个定义模糊,因为它没有量化“远离”这个词。在本博客中,我们将尝试理解这个“远离”概念的不同解释。我们还将探讨离群值检测和处理技术,同时观察它们对不同类型的机器学习模型的影响。
离群值的产生可能是由于系统行为的变化、欺诈行为、人为错误、仪器误差,或仅仅是自然偏差。样本可能被外部因素污染。
许多机器学习模型,如线性回归和逻辑回归,容易受到训练数据中离群值的影响。像 AdaBoost 这样的模型在每次迭代中增加被误分类点的权重,因此可能对这些离群值施加较高的权重,因为它们通常被误分类。如果这些离群值是某种错误,或者如果我们希望模型具有良好的泛化能力而不关注极端值,这可能会成为一个问题。
为了克服这个问题,我们可以更改模型或度量标准,或者对数据进行一些修改并使用相同的模型。在分析中,我们将查看 House Prices Kaggle Data。所有绘图和实施的代码可以在这个 Github 仓库中找到。
我们所说的离群值是什么意思?
极端值可能出现在依赖变量和自变量中,特别是在监督学习方法的情况下。
这些极端值不一定会影响模型的性能或准确性,但当它们确实会影响时,它们被称为“影响点”。
自变量中的极端值
这些被称为“高杠杆点”。对于单一预测变量,极端值只是特别高或低的值。对于多个预测变量,极端值可能是一个或多个预测变量特别高或低的值(单变量分析——逐一分析变量),也可能是预测变量值的“异常”组合(多变量分析)。
在下图中,所有在橙色线右侧的点都是杠杆点。
因变量中的极端值
回归——这些极端值被称为“异常值”。它们可能是也可能不是影响点,我们稍后会看到。在下图中,所有在橙色线以上的点都可以被归类为异常值。
分类:这里我们有两种类型的极端值:
1. 异常值:例如,在一个图像分类问题中,我们试图识别狗/猫,但训练集中有一张错误地包含猩猩(或其他不属于问题目标类别的类别)的图像。在这里,猩猩图像显然是噪声。在这里检测异常值没有意义,因为我们已经知道要关注哪些类别以及要丢弃哪些类别。
2. 新颖性:很多时候我们处理的是新颖性,这个问题通常被称为监督异常检测。在这种情况下,目标不是去除异常值或减少其影响,而是我们关注的是检测新观察中的异常。因此我们不会在此帖子中讨论它。它特别用于信用卡交易中的欺诈检测、虚假电话等。
我们之前讨论的所有点,包括影响点,一旦我们可视化以下图形,就会变得非常清晰。
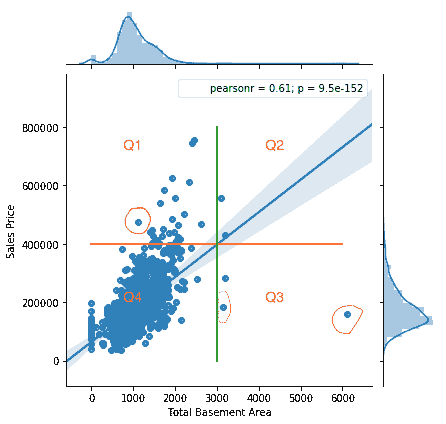
推断
*- Q1 中的点:异常值
Q3 中的点:杠杆点
Q2 中的点:既是异常值也是杠杆点,但不是影响点
圈出的点:影响点的示例。可能还有更多,但这些是显著的*
我们的主要关注点将是异常值(因变量中的极端值,以进一步调查和处理)。我们将看到这些极端值对模型性能的影响。
检测异常值的常用方法
在检测离群值时,我们要么进行单变量分析,要么进行多变量分析。当你的线性模型只有一个预测变量时,你可以使用单变量分析。然而,如果你对多个预测变量使用它,它可能会给出误导性的结果。执行离群值检测的一种常见方法是假设常规数据来自已知分布(例如,数据呈高斯分布)。这一假设在下面的 Z-Score 方法部分进行了讨论。
箱形图
识别离群值最快最简单的方法是通过可视化图形。如果你的数据集不是很庞大(大约最多 10k 个观察值和 100 个特征),我强烈推荐你绘制变量的散点图和箱形图。如果没有离群值,你仍然可以获得其他见解,比如相关性、变异性,或如世界大战/经济衰退对经济因素的影响等外部因素。然而,这种方法不适用于高维数据,因为可视化的效果会减弱。
箱形图使用四分位距来检测离群值。在这里,我们首先确定四分位数 Q1 和 Q3。
四分位距由以下公式给出:IQR = Q3 — Q1
上限 = Q3 + 1.5 * IQR
下限 = Q1 – 1.5 * IQR
低于下限和高于上限的任何值都被认为是离群值
库克距离
这是一种用于寻找影响点的多变量方法。这些点可能是也可能不是离群值,如上所述,但它们有能力影响回归模型。我们将在博客的后面部分看到它们的影响。
该方法仅用于线性回归,因此应用有限。库克距离 衡量删除某个观察值的效果。它表示当观察值“i” 从回归模型中移除时,模型中所有变化的总和。
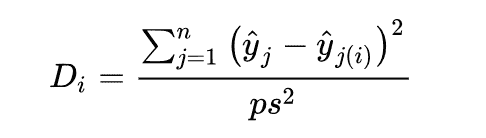
这里,p 是预测变量的数量,s² 是回归模型的均方误差。关于用来识别高度影响点的截断值有不同的观点。经验法则是 D(i) > 4/n,可以作为影响点的良好截断值。
R 有一个 car(应用回归的伴侣)包,你可以直接使用库克距离来查找离群值。实现可以在这个 R-Tutorial 中找到。另一种类似的方法是DFFITS,你可以在 这里 查看详细信息。
Z-Score
该方法假设变量具有高斯分布。它表示一个观察值离均值的标准差数:
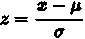
在这里,我们通常将离群点定义为 z-score 的模值大于某个阈值的点。这个阈值通常大于 2(3 是一个常见值)。
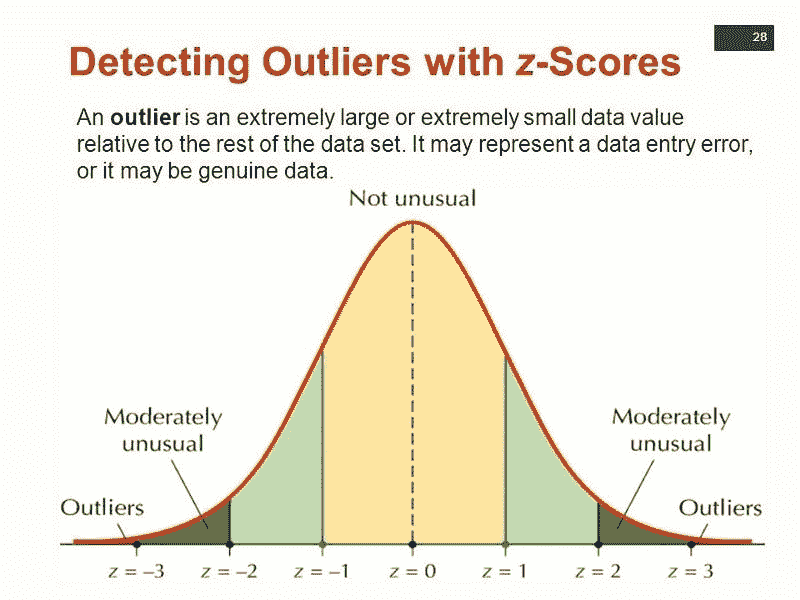
参考: slideplayer.com/slide/6394283/
上述所有方法适用于数据的初步分析,但在多变量设置或高维数据中它们的价值有限。对于这样的数据集,我们需要使用像主成分分析(PCA)、局部离群因子(LOF)和 HiCS: 高对比度子空间用于基于密度的离群点排序等高级方法。
我们不会在这篇博客中讨论这些方法,因为它们超出了博客的范围。我们在这里的重点是看看各种离群点处理技术如何影响模型的性能。有关这些方法的详细信息,你可以阅读这篇博客。
离群点的影响与处理
离群点的影响不仅可以在预测建模中看到,还可以在统计测试中看到,它会降低测试的效能。大多数参数统计,如均值、标准差和相关性,以及基于这些的每个统计量,都对离群点高度敏感。但在这篇文章中,我们只关注离群点在预测建模中的影响。
是否删除
我认为删除数据始终是一个严厉的步骤,只应在极端条件下进行,当我们非常确定离群点是测量误差时,这种情况我们通常并不了解。数据收集过程很少提供。当我们删除数据时,我们会失去关于数据变异性的的信息。当观察值过多且离群点较少时,我们可以考虑删除这些观察值。
在以下示例中,我们可以看到回归线的斜率在顶部的极端值存在时变化很大。因此,删除这些极端值以获得更好的拟合和更通用的解决方案是合理的。
来源: www.r-bloggers.com/outlier-detection-and-treatment-with-r/
其他基于数据的方法
-
Winsorizing(温索化): 这种方法涉及将属性的极端值设置为某个指定的值。例如,对于 90% 的 Winsorization,底部 5% 的值被设置为第 5 百分位的最小值,而顶部 5% 的值被设置为第 95 百分位的最大值。这比仅仅排除极端值的修剪方法要更高级。
-
对数尺度变换: 这种方法通常用于减少包括离群观察在内的数据的变异性。在这里,y 值被更改为 log(y)。当响应变量遵循指数分布或右偏分布时,这种方法通常更受欢迎。
-
然而,这是一种有争议的步骤,并不一定减少方差。例如,这个答案很好地捕捉了所有这些情况。
-
变换的糟糕示例 -
初始左偏的分布在对数变换后变得更加偏斜
- 分箱: 这指的是将一组连续变量划分为多个组。我们这样做是为了发现连续变量中的模式集合,这些模式在其他情况下难以分析。然而,它也会导致信息丢失和能力损失。
基于模型的方法
-
使用不同的模型:与线性模型不同,我们可以使用像随机森林和梯度提升技术这样的树基方法,这些方法不容易受到异常值的影响。这个答案清楚地解释了为什么树基方法对异常值具有鲁棒性。
-
指标:使用 MAE 代替 RMSE 作为损失函数。我们还可以使用截断损失:

来源:eranraviv.com/outliers-and-loss-functions/
案例研究比较
在这个比较中,我仅选择了四个重要预测变量(总体质量、MSubClass、总地下室面积、地面生活面积),从总共 80 个预测变量中进行预测。目的是看看异常值如何影响线性和树基方法。
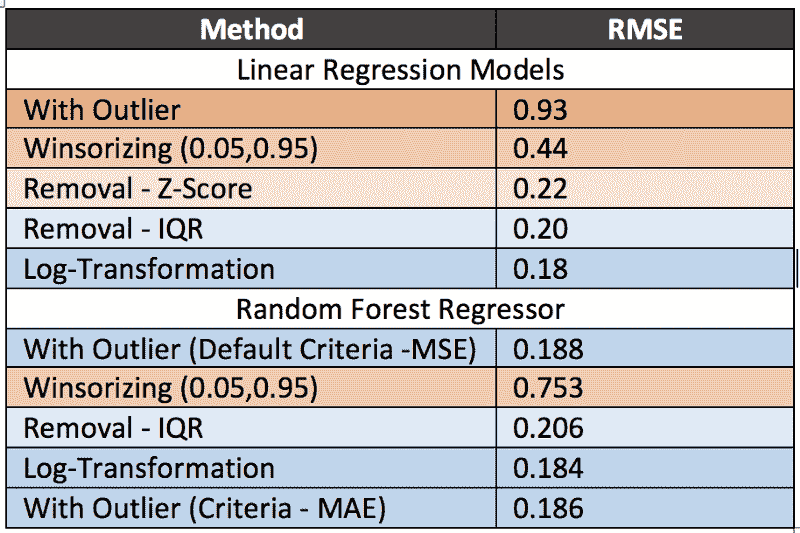
结束注释
-
由于数据集中只有 1400 个观察值,异常值对线性回归模型的影响相当大,正如我们从“有异常值”(0.93)和“无异常值”(0.18)的 RMSE 分数中可以看到——显著下降。
-
对于这个数据集,目标变量右偏。因此,对数变换比去除异常值效果更好。因此,我们应始终尝试先转换数据而不是去除它。然而,温莎化效果不如去除异常值。这可能是因为通过硬性替换,我们在数据中引入了某些不准确性。
-
显然,随机森林不受异常值影响,因为在去除异常值后,RMSE 增加了。这可能是将标准从 MSE 更改为 MAE 并没有太大帮助的原因(从 0.188 到 0.186)。即使在这种情况下,对数变换也被证明是赢家:原因在于目标变量的偏斜特性。经过变换后,数据变得更均匀,随机森林中的分裂也变得更好。
从以上结果可以得出结论,变换技术通常比丢弃技术更有效于提高线性模型和基于树的模型的预测准确性。如果你使用的是线性回归模型,处理异常值(无论是丢弃还是变换)都非常重要。
如果我遗漏了任何关于异常值处理的重要技术,欢迎在评论中告诉我。感谢阅读。
关于我: 研究生毕业于 USF 的数据科学专业。对与跨职能团队合作以从数据中提取见解以及将机器学习知识应用于解决复杂的数据科学问题感兴趣。 alviraswalin.wixsite.com/alvira
查看我的其他博客 这里!
**LinkedIn: **www.linkedin.com/in/alvira-swalin
参考资料:
在 Hacker News 上讨论此帖子。
个人简介:阿尔维拉·斯瓦林(Alvira Swalin) (Medium) 目前在 USF 攻读数据科学硕士学位,特别关注机器学习与预测建模。她是 Price (Fx) 的数据科学实习生。
原文。已获许可转载。
相关:
-
CatBoost vs. Light GBM vs. XGBoost
-
选择正确的度量标准评估机器学习模型 – 第一部分
-
选择正确的度量标准评估机器学习模型 – 第二部分
相关话题
谁将从生成性 AI 黄金热潮中获利?
原文:
www.kdnuggets.com/2023/08/make-money-generative-ai-gold-rush.html
生成性 AI 黄金热潮已经真正展开。生成性 AI(GenAI)现在正在创造内容——文字、图像、视频和音频——这些内容往往与人类生产的内容难以区分。写作、视觉设计、编码、市场营销、游戏制作、音乐创作和产品设计只是受到 GenAI 影响的几个领域。随着创意服务被整合进如 Microsoft Office 365、Slack、Discord、Salesforce Cloud 和 Gmail 等产品中,GenAI 将在不久的将来提升数十亿人的生产力。我们都将很快使用 GenAI 来创建我们的一切初稿。
那么谁将从 GenAI 中获利?我问了 OpenAI 的 Dall-E-2 文本到图像服务这个问题,它生成了下面的图像。不赖。

Dall-E-2 提示 “谁将从生成性 AI 中获利?”
2018 年,我写了一篇关于 谁将从 AI 中获利 的热门博客文章。这是我关于在成千上万的新用例中投资于 GenAI 的后续文章。从本质上讲,这场黄金热潮有五层潜在的价值捕获:
-
基础设施 – 提供运行庞大 GenAI 计算模型的芯片和云基础设施的公司。
-
基础 模型 — 构建巨大的文本、图像、音频及其他生成创造性输出的模型的公司。
-
应用程序 — 大小公司正在开发应用程序,这些应用程序将被消费者、企业和政府用于创造性任务。
-
行业和组织 — 作为其创意活动的一部分,从 GenAI 应用程序、工具和平台中提取价值。
-
国家 — 将在国内和跨国界创建、出口和部署 GenAI 技术。
© 生成性 AI 的五层价值捕获
在这些层次中,谁将成为赢家?
1. GenAI 基础设施
大型科技公司已经在 GenAI 基础设施中占据主导地位,凭借其云服务和硬件芯片。

提供 GenAI 基础设施的大型科技和芯片公司示例
微软和谷歌在美国云市场中处于有利位置,而百度和阿里巴巴在中国市场中处于有利位置。他们的大型超级计算机云基础设施旨在运行生成型 AI(GenAI)的复杂、昂贵、大型文本、视觉和音频基础模型。目前已经有许多开发者在使用他们的云 AI API 服务和工具来构建应用程序,预计随着企业家们急于解决几乎无限的 GenAI 应用案例,这一趋势将加速。亚马逊在基础模型方面保持沉默,因此一个大问题是他们将如何应对。
生成型 AI 使用大量计算能力来生成创意输出。OpenAI 的首席执行官 Sam Altman 表示:
我们将不得不在某个时候对其进行盈利 [ChatGPT 和 Dall-E-e],计算机成本令人瞠目结舌。
有传闻称,Open AI 的 GPT-3 训练成本仅1200 万美元的电费。毫不奇怪,OpenAI 在 2023 年初从微软获得了额外的100 亿美元,其中大部分将以访问微软 Azure 超级计算基础设施的积分形式提供。
芯片制造商对超级计算机的需求垂涎欲滴。拥有超过半万亿美元市值的NVIDIA(纳斯达克股票代码:NVDA)股票价格从 2018 年的 60 美元上涨至 2023 年初的 240 美元。大型科技公司也在投资自己的 AI 优化芯片。最近的美国对中国高级 AI 芯片的出口禁令将加速中国政府援助和国内对半导体行业的投资(同时也提高了地缘政治紧张局势)。鉴于所需的投资金额,这一领域的赢家将是那些由大型企业支持或本身就是大型企业的公司。
2. 基础模型
大型科技公司的规模和范围使他们在开发生成型 AI 基础模型方面具有竞争优势。这些模型在大量数据上进行训练,利用大型科技公司的广泛计算资源。例如,OpenAI 的 GPT-3文本模型,称为大型语言模型(LLM),在约 45TB 的文本数据上进行训练,这些数据代表了半万亿个词汇,这些词汇从大部分英语互联网中“吸取”而来。同样,OpenAI 的Dall-E-2文本到图像模型在6.5 亿对图像-标题上进行训练。
大型科技公司不希望因未能抓住未来这些基础模型数十亿最终用户所产生的巨额收入而失去在云服务领域的领导地位。微软已与 OpenAI 合作,Google最近推出了其Bard语言聊天机器人,它与其Imagen模型相辅相成,用于从输入文本创建逼真的图像。
中国的大型科技公司也不甘示弱。阿里巴巴正在测试一项内部聊天服务。百度已经提供了ERNIE-ViLG,一个文本到图像的参数模型,并且目前正在测试一项新的聊天服务。大型科技公司的规模给予了它们一些初创公司难以复制的优势。

基础模型提供商的示例,包括文本、图像、视频和音频,以及工具和服务
大型科技公司具有规模优势,以解决基础模型中的真实性、偏见和毒性问题
大型科技公司可能是唯一能够处理生成式人工智能(GenAI)阴暗面的问题的玩家。尽管 GenAI 仍处于起步阶段,但基础模型的问题已变得明显。这些问题包括真实性(GenAI 生成的内容完全错误)、偏见(对特定群体的偏见)和毒性(例如种族主义、厌女或仇恨言论)。2023 年初,Alphabet市值蒸发了 1000 亿美元,因金融市场对 Google 的Bard聊天机器人服务提供的错误和冒犯性回答感到恐慌。微软的有限发布的Bing聊天机器人也展示了令人不安(甚至是种族主义)的回应,用户破解了保护措施,尽管其股价并未急剧下跌。还有一种新的提示注入网络攻击类型,可以通过注入恶意指令绕过保护措施。
开发这些基础模型的挑战在于确保其输出既负责任又准确。基础模型不能仅仅复述从互联网偏远角落抓取的有偏见和有毒的内容。这些模型也有幻觉的特性。这意味着它们可能会自信地提供结构良好且雄辩的回答,但这些回答可能在事实上的准确性上存在问题。正如Character.AI的联合创始人 Noam Shazeer 在《纽约时报》中所述:
“…这些系统并不是为了真相而设计的。它们是为了可信的对话而设计的。”
换句话说,它们是自信的胡说八道艺术家。
大型科技公司无法承受模型失败可能带来的声誉、财务和战略风险。他们正在建立包括保护措施和模型调优的监督系统。为了赢得用户的信任并满足可能的监管要求,大型科技公司需要设计解决方案以确保模型的透明度、可解释性和来源引用。来自人类反馈的强化学习(RLFH)将需要大量人员来审查和评估模型对问题的回答。这些问题在大规模解决时并不简单。再次强调,大型科技公司因其资本、工程人才、数据集以及拥有数十亿用户带来的庞大人类反馈循环而处于有利位置。
大型科技公司的模型并不适合所有情况。
尽管大型科技公司规模庞大,它们仍无法控制整个基础模型的淘金热。它们的模型广泛水平化,适合回答任何可想象的消费者问题,虽然未必总是准确。然而,它们并不总是很适合企业的垂直任务。为什么?大型科技公司的水平模型(1)在专业任务上表现不总是理想,(2)经常无法保护企业专有数据,(3)没有对非英语语言进行训练,(4)缺乏透明度和可解释性,(5)不太适合在边缘设备和本地使用,(6)在云端运行可能昂贵,以及(7)会使公司对大型科技公司产生依赖。
一些资金极为充足的初创公司正在提供替代大型科技公司基础模型的方案。
大型科技公司基础模型并不适合所有人。这为那些获得数亿甚至数十亿美元资金支持的少数初创公司留出了空间。
-
Anthropic成立于 2021 年,专注于更可靠、可解释和可操控的 LLM,并已筹集超过10 亿美元,最近的一轮投资3 亿美元来自谷歌。
-
AI21labs 已经筹集了 1.19 亿美元 用于其 Jurassic-1 文本模型。Jurassic-1 的参数超过 1780 亿,规模与 GPT-3 相当。
-
BLOOM 是一个私营和公共研究的 LLM 项目,由私营部门 Hugging Face 和欧洲研究机构支持,旨在创建一个具有 1760 亿参数的开源 LLM。它已经在 46 种人类语言上进行了训练,包括在大多数 LLM 中未被充分代表的二十种非洲语言。
-
总部位于英国的 Stability AI 最近筹集了惊人的 1 亿美元 以获得超过 10 亿美元 的估值,用于其开源图像生成服务 Stable Diffusion。
大科技公司意识到它们模型的局限性,尤其是微软,最近宣布 企业将能够“微调” 它们的模型,而不必担心专有数据被泄露,从而为所有人建立更好的模型。
然而,这些步骤并不能满足所有人。 Adelph Alpha,一家德国初创公司,已经筹集了 3100 万美元,它正通过自身的“欧洲”中心模型来解决企业对大科技基础模型的担忧。但尚不清楚它们是否能够在规模上竞争。
大科技公司将在水平基础模型的竞争中获胜,留给一些资本雄厚的初创公司空间。也许像 BLOOM 和 Stable Diffusion 这样的开源模型将实现规模化,或至少找到一个利基存在。像往常一样,将会有工具和服务提供商从使这些基础模型更易于使用中获利。但总体而言:
大科技公司的市场主导地位将通过它们有效地免费提供基础模型的能力得到放大,因为它们将主要通过其底层云服务赚取收入。
生成式 AI 应用
虽然大科技公司将在生成 AI 淘金热中赢得工具和服务,但应用层则是一个更公平的竞争场。现有的企业软件公司、“全栈”初创公司以及成千上万受这些基础模型启发的初创公司将提供新的生成 AI 应用。
传统的企业软件公司,如 Salesforce 和 Microsoft,将通过内部开发或收购的方式将 GenAI 功能带给数十亿用户。微软还将其 GenAI 聊天服务集成到其 Bing 搜索应用中,直接挑战谷歌的搜索霸权。
少数获得良好资助的初创公司将提供专门的“全栈”应用程序。 在具有专门数据、序列和计算要求的领域,这些公司将开发自己的基础模型。例如,GenAI 可能通过构建应用程序的专有模型来彻底改变药物发现和材料科学。投资者将被这些初创公司吸引,因为它们可能提供丰厚的财务回报以及强大的竞争防御能力。
Adept AI例如,已经筹集了6500 万美元来开发基于大型语言模型(LLMs)的下一代机器人流程自动化(RPA)自然语言接口。在隐身模式下,Inflection.ai也在做类似的事情。Character.AI,一个采用角色声音和知识的聊天机器人,筹集了2 亿到 2.5 亿美元的资金,以大约10 亿美元的估值全栈实施专门的 LLMs 以支持实时代理企业应用。
GenAI 的采用速度将极其迅速。 如果比如说,AI 生成的营销文案初稿不完美,那么修改起来非常简单。ChatGPT 是历史上增长最快的消费者应用,在发布后仅两个月多一点就拥有了超过1 亿的月活跃用户。这意味着对于几乎无限数量的 GenAI 创意应用的竞争将会非常激烈且迅速。

主要是初创公司提供的应用程序示例,用于解决主要的 GenAI 用例
每个可以想象的用例都会有一个“副驾驶”GenAI 应用程序
将 GenAI 投入使用将使全球的消费者、企业和组织使用由基于这些基础模型的初创公司构建的应用程序。许多 GenAI 初创公司将使用“X 的副驾驶”商业模式来协助用户完成“创意”任务,如写作或编码,以及重复性任务,如数据输入或表单填写。以下是一些在各种垂直用例中竞争赚钱的初创公司。
-
通用文本写作 初创公司正在实时协助用户处理日常写作任务,如电子邮件撰写、文档创建和文本表单填写。AI21labs 的 Wordtune 将“把你的文本改写成专业文案的风格。” 写作助手中的佼佼者是 Grammarly,它已筹集超过 4 亿美元。写作初创公司名单很长,包括 Lex、HyperWrite、Compose AI 和 Rytr。
-
销售和营销 初创公司包括巨头 Jasper.ai,它已筹集 1.45 亿美元。Anyword 已筹集超过 4500 万美元,以提供“高转化率的销售文本内容”。Persado 为语言生成筹集了超过 6600 万美元,并且“在 96% 的时间里超越你的最佳文案。” 初创公司越来越专注于如产品营销描述等特定任务。
-
图像生成 初创公司 正在借助 Open AI 的 DALL-E-2、Stability AI 的 Stable Diffusion 和 Midjourney的文本到图像基础模型获得支持。初创公司包括 Art Breeder,它帮助用户创建拼贴画。
-
消费者面部和头像 初创公司包括 Lightricks 的 Facetune 应用程序,帮助创建“完美”的 Instagram 图像。Lightricks 已筹集了 3.5 亿美元。非常受欢迎的 Lensa AI 应用的用户可以创建个性化的“魔法头像”。 Reface, 让用户将他们的面孔换到不同的场景中,已筹集了 550 万美元。
-
产品设计 初创公司包括 Botika,它通过超现实主义的模特图像,重新定义了时尚拍摄,Maket 协助“从文本提示中生成建筑计划,时间从几个月缩短为几分钟。” Tailorbird 加速了为希望翻新的房主创建平面图的过程。Swapp 已筹集了 700 万美元 来帮助自动化项目的施工文档。TestFit 已筹集了 2200 万美元,以帮助进行房地产设计。
-
视频 领域的初创公司提供视频创意、生成、编辑和团队协作工具。Runway 是资金最多的,银行存款接近 $100 million。Magnifi 已为视频编辑筹集了超过 $60 million,而 InVideo 已筹集超过 $53 million。包括 Hour One 在内的几家初创公司提供文本转视频服务,后者已筹集 $26 million。总部位于伦敦的 Synthesia 为其头像视频创建平台筹集了超过 $67 million。总体来看,NFX 正在跟踪 54 家已筹集总计 $0.5 billion 的生成视频初创公司。
-
音频 GenAI 初创公司包括音乐创作公司 Soundraw、Boomy 和 Aiva。Splash 已筹集 $23 million,允许用户创作原创音乐并为任何旋律演唱歌词。DupDub 已筹集超过 $250 million 用于语音覆盖服务,并声称拥有一百万用户。Descript 已筹集超过 $100 million,并提供音频转录、播客、屏幕录制、音频和视频编辑的语音克隆服务。Deepgram的语音转文本服务与大科技公司和 OpenAI 的 Whisper 竞争,并获得了超过 $87 million 的融资。
-
游戏生成 初创公司希望节省制作工作室数百万美元的生产成本。Masterpiece Studio 已筹集 $6 million 用于创建 2D 到 3D 模型。Replica 已筹集 $5 million 专注于为游戏、电影和元宇宙提供 AI 配音演员。Latitude/AI Dungeon 是一家游戏工作室,已筹集 $4 million 用于基于文本的游戏生成。VoiceMod 已筹集超过 $7 million 用于在 Fortnite 等游戏和 Skype 等应用中提供实时语音变换。Ponzu 是一个用于创建 3D 表面纹理的初创公司,Charisma AI 是一个用于创建非玩家角色(NPC)虚拟角色的初创公司。Inworld 已为其 AI 开发平台筹集了 $70 million,用于“创建沉浸式现实、虚拟角色和元宇宙空间”。总体来看,A16Z 目前跟踪游戏行业中的 50 多家初创公司。
-
聊天机器人和对话式 AI 初创公司包括垂直健康症状检查器 ada, 其融资额为 $190 million,以及总部位于英国的 Healthily, 其融资额约为 **\(70**](https://www.crunchbase.com/organization/your-md)** million**。鉴于 AI 可以 [每年为呼叫中心业务节省 **\)** million。鉴于 AI 可以 每年为呼叫中心业务节省 **\(80B**](https://techmonitor.ai/technology/ai-and-automation/call-centre-ai),初创公司正在筹集巨额资金。 [**Cresta**](https://cresta.com/)** AI** 已筹集超过 [**\),初创公司正在筹集巨额资金。 Cresta AI** 已筹集超过 **\(150**](https://www.crunchbase.com/organization/cresta)** million**,而总部位于伦敦的 [**PolyAI**](https://poly.ai/) 已筹集 **\)** million**,而总部位于伦敦的 PolyAI 已筹集 $68 million 以支持其“超人类语音助手”。
-
编码副驾 初创公司正跟随微软的 GitHub Copilot, 该工具声称可以自动生成多达 40% 的代码。 Warp,一家将自然语言转换为计算机命令的公司,已筹集 $70 million。 Tabnine 已筹集 $30 million。
-
知识管理、总结和企业搜索 初创公司包括 Primer AI, 其融资额为 $168 million,以及 Otter 其融资额为 $63 million。 Sana Labs,一家总部位于斯德哥尔摩的初创公司,已筹集 $54.6 million 以促进信息在组织内部的发现、共享和重新利用。
那么,哪些初创公司将会成功?
流入生成 AI 应用初创公司的资本并不缺乏。 全栈初创公司 将在药物发现等垂直领域筹集大量资金,在这些领域中,他们将创建高度专业化的模型和应用。在更广泛的 B2B 领域,竞争将是 横向 和 纵向的,副驾 业务模型将处于中心。一方面,横向 初创公司将提供跨行业的服务,例如 Jasper 的销售和营销助手。另一方面,初创公司越来越多地 纵向 聚焦于行业、职能和任务。
成功者将通过实施以下措施实现规模和防御性:
-
强大的投资回报率 — 针对其用例,以及快速验证价值。
-
专有和定制化基础模型 — 针对特定受众进行“微调”,使用本地化、专业化和公司专有的数据。
-
工作流程 — 证明其可用性并深入集成到客户流程中,使其一旦安装就难以移除。
-
反馈循环 — 例如,通过人类反馈的强化学习(RLFH)来提高模型与用户意图的一致性。
-
飞轮动态 — 增加 RLFH 和其他反馈越多,通过“微调”模型表现越好,使用频率越高,因此动量也会增长。
-
投资的规模和速度 —由于大部分知识产权属于基础模型,利润率较低,这场竞争完全依赖于规模。那些能够迅速建立品牌并吸引大量用户和客户以推动飞轮运转的人将会成为类别领导者。
在 B2C 生成式 AI 消费领域,拥有速度和大规模消费者获取预算的横向玩家可能会赢得竞争。
AutogenAI,总部位于英国,是一个B2B初创公司,处于其招标管理助手类别的有利位置。他们花费了过去两年开发了一款帮助企业节省时间、金钱,同时提高投标、招标和提案质量的应用程序。他们已经使用公司网站内容、成功和失败的销售投标、营销文案和年度报告的示例“微调”了 OpenAI的 LLM。他们还提供了一个监督用户界面来协助审查生成内容和事实的来源及准确性。这还提供了一个重要的人机强化学习循环,随着使用的增加而增强。客户越来越多地将他们的应用程序用作下一代知识管理和搜索工具,使其更具黏性。
一些生成式 AI 初创公司将被收购并成为更大企业和消费者应用程序中的功能。例如,拥有数百万用户的大型社交媒体公司将收购最新的面孔和头像创建初创公司。现有的图形设计软件公司将收购最有前景的图像和视频编辑初创公司。例如,微软现在在其 CRM 和 ERP 应用程序中原生提供生成式 AI“Microsoft Dynamics 365 Copilot”。
简而言之,如果一些幸运而勇敢的初创公司能够迅速建立规模并为其助手用例建立飞轮,他们将会获得丰厚的回报。同样,一些全栈初创公司将在药物发现等专业用例中繁荣发展。由于其大规模融资、统一市场以及美国企业、政府和个人对创新的快速采用,美国初创公司将主导市场。但大多数初创公司将空手而归,为这一淘金热的“挑选和铲子”提供商——主要是美国大型科技公司——贡献利润。
这是关于谁将从生成式 AI 中赚钱的系列文章中的第一篇。在随后的文章中,我将讨论哪些组织将从生成式 AI 中获得最多利益,以及哪些国家和公民将从这一技术中受益最多。
我欢迎您的反馈。
Simon Greenman 是人工智能和技术创新的先驱。作为 MapQuest 的联合创始人,他帮助推出了第一个互联网和 AI 品牌之一。目前,他是 Best Practice AI 的合伙人,负责 AI 战略、技术和治理的咨询工作,他最近曾在世界经济论坛的全球 AI 委员会任职,为其董事会和高管 AI 工具包做出贡献。Simon 在担任首席数字官期间,领导了目录公司数字化转型工作,并曾担任 HomeAdvisor Europe 的首席执行官,该公司提供领先的交易市场。他曾与 Bowers & Wilkins、AOL 和埃森哲等知名公司合作。他活跃于英国初创企业生态系统,并拥有哈佛商学院的 MBA 学位和苏塞克斯大学的计算机与人工智能学士学位。他还是皇家地理学会的会员。
原文。转载自许可。
相关话题
如何让 Python 代码运行得极快
原文:
www.kdnuggets.com/2021/06/make-python-code-run-incredibly-fast.html

由 brgfx 制作的图片 在 Freepik 上
Python 是开发者中最受欢迎的编程语言之一。无论是网页开发还是机器学习,它都无处不在。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你组织的 IT
其流行有很多原因,例如社区支持、惊人的库、在机器学习和大数据中的广泛使用以及简易的语法。
尽管有这些优点,Python 仍然有一个缺点,就是其 速度较慢。作为一种解释型语言,Python 比其他编程语言要慢。不过,我们可以通过一些技巧来克服这个问题。
在本文中,我将分享一些 Python 技巧,利用这些技巧,我们可以让 Python 代码运行得比平时更快。让我们开始吧!
1. 合适的算法和数据结构
每种数据结构对运行时间都有显著影响。Python 中有许多内置数据结构,如列表、元组、集合和字典。大多数人使用列表数据结构来处理所有情况。
在 Python 中,集合和字典具有 O(1) 的查找性能,因为它们使用哈希表。你可以在以下情况下使用集合和字典代替列表:
-
你在集合中没有重复项。
-
你需要在集合中重复搜索项目。
-
该集合包含大量项目。
你可以在这里查看不同数据结构的时间复杂度:
本页面记录了当前 CPython 中各种操作的时间复杂度(又称“Big O”或“Big Oh”)...
2. 使用内置函数和库
Python 的内置函数是加速代码的最佳方法之一。你必须在需要时使用内置 Python 函数。这些内置函数经过良好测试和优化。
这些内置函数之所以快,是因为 Python 的内置函数,如 min、max、all、map 等,是用 C 语言实现的。
你应该使用这些内置函数,而不是编写手动函数,这将帮助你更快地执行代码。
示例:
newlist = []
for word in wordlist:
newlist.append(word.upper())
更好的代码写法是:
newlist = map(str.upper, wordlist)
这里我们使用了内置的 map 函数,它是用 C 编写的。因此,它比使用循环要快得多。
3. 使用多重赋值
如果你想赋值多个变量,那么不要逐行赋值。Python 有一种优雅且更好的方式来赋值多个变量。
示例:
firstName = "John"
lastName = "Henry"
city = "Manchester"
更好的变量赋值方式是:
firstName, lastName, city = "John", "Henry", "Manchester"
这种变量赋值方式比上述方法更简洁优雅。
4. 优先使用列表推导而非循环
列表推导是一种优雅且更好的方式,可以基于现有列表的元素在一行代码中创建新列表。
列表推导被认为是一种比定义空列表并向其添加元素更具 Python 风格的创建新列表的方式。
列表推导的另一个优点是比使用追加方法向 Python 列表添加元素更快。
示例:
使用列表追加方法:
newlist = []
for i in range(1, 100):
if i % 2 == 0:
newlist.append(i**2)
使用列表推导的更好方式:
newlist = [i**2 for i in range(1, 100) if i%2==0]
使用列表推导时代码更简洁。
5. 正确导入
应避免在不需要时导入不必要的模块和库。你可以指定模块名,而不是导入整个库。
导入不必要的库会导致代码性能下降。
示例:
假设你需要计算一个数的平方根。代替这样:
import math
value = math.sqrt(50)
使用这个:
from math import sqrt
value = sqrt(50)
6. 字符串连接
在 Python 中,我们使用‘+’运算符连接字符串。但在 Python 中连接字符串的另一种方式是使用 join 方法。
Join 方法是一种更具 Python 风格的字符串连接方式,并且比使用‘+’运算符连接字符串更快。
join() 方法更快的原因是‘+’运算符每一步都会创建一个新字符串并复制旧字符串,而 join() 方法并不会这样工作。
示例:
output = "Programming" + "is" + "fun
使用 join 方法:
output = " ".join(["Programming" , "is", "fun"])
两种方法的输出结果是相同的。唯一的区别是 join() 方法比‘+’运算符更快。
结论
这篇文章到此为止。在这篇文章中,我们讨论了一些可以使代码运行更快的技巧。这些技巧特别适用于竞争编程,其中时间限制至关重要。
希望你喜欢这篇文章。感谢阅读!
Pralabh Saxena 是一名拥有 1 年经验的软件开发人员。Pralabh 撰写文章 涉及 Python、机器学习、数据科学和 SQL 等主题。
更多相关内容
在数据科学旅程中实现量子飞跃
原文:
www.kdnuggets.com/2023/02/make-quantum-leaps-data-science-journey.html

来自 Unsplash 的图片
主要收获
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
-
数据科学是一个不断发展的领域
-
在数据科学领域,学习是终身的。
-
数据科学专业人员必须不断提升领域知识,以跟上新的技术发展和软件应用。
介绍
我还记得大约 6 年前开始我的数据科学旅程时的喜悦和兴奋。对我来说,由于在高级数学和计算物理方面的强大背景,向数据科学的过渡相当顺利。
然而,随着我在数据科学旅程中的深入,我意识到在学习高级概念方面进展不大。我只是专注于基础概念的学习。与其将已有的基础知识应用到实际的数据科学项目中,我却不停地在 DataCamp、Udemy、YouTube、edX 和 Coursera 等平台上参加各种数据科学课程和专业化课程。
一度,这几乎成了一种瘾,我不断寻找免费的数据科学课程来注册。这些平台上的大多数课程仅覆盖基础概念,尽管引入了高级概念,但大多只是表面上的。
回顾我的数据科学旅程,如果可以重来,我会更加注重基于项目的学习。在我看来,基于项目的学习是学习数据科学的最可靠方式,因为它让你在实践中学习,并有机会将知识应用到实际数据科学项目中。
虽然获得尽可能多的基础知识令人兴奋,但重点应是从基础概念逐步进阶到更高级的概念。数据科学领域的初学者必须在从入门级到高级数据科学专业人士的过渡过程中不断实现量子飞跃。
在接下来的内容中,我们讨论数据科学的一些基本级别。
一级数据科学
一级数据科学也可以称为基础级。在一级水平,数据科学学习者应能够掌握以下技能:
-
能够处理以 CSV(逗号分隔值)文件格式呈现的数据
-
能够清理和组织非结构化数据
-
能够处理数据框
-
能够使用不同类型的可视化工具来可视化数据,如折线图、散点图、QQ 图、密度图、直方图、饼图、散点对图、热图等
-
能够进行简单和多重回归分析
-
熟练掌握数据科学所需的基本 Python 库,如 numpy、pandas、scikit-learn、seaborn 和 matplotlib
二级数据科学
二级数据科学也可以称为中级。在二级水平,数据科学学习者应掌握以下内容:
-
能够使用机器学习分类算法,如逻辑回归、KNN(K-最近邻)、SVM(支持向量机)、决策树等
-
能够构建、测试和评估机器学习模型
-
能够进行超参数优化
-
熟悉高级概念,如 k 折交叉验证、网格搜索和集成方法
-
应该在使用 scikit-learn 库进行机器学习应用方面成为专家
三级数据科学
三级数据科学可以称为高级。在三级水平,数据科学学生应获得以下能力:
-
能够处理以高级格式呈现的数据,如文本、图像、语音或视频
-
熟悉高级机器学习技术,如聚类
-
熟悉深度学习和神经网络
-
熟悉深度学习库,如 TensorFlow 和 PyTorch
-
熟悉用于机器学习部署的云平台,如 AWS 和 Azure
结论
上述三个数据科学级别可以在下图中总结。

数据科学的三个级别 | 作者提供的图像。
虽然一级和二级的能力可以通过在线课程获得,但学习三级(高级)概念需要大量的自学。一项重要的资源是以下教科书:《使用 PyTorch 和 Scikit-Learn 进行机器学习》。

书籍封面
该教科书的 GitHub 仓库可以在这里找到。
总结来说,我们讨论了数据科学的三个层次。由于数据科学是一个不断发展的领域,每个数据科学爱好者都应该继续努力,以实现向下一个层次的飞跃。
本杰明·O·泰约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的创始人。之前,本杰明在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
更多相关主题
使用 ChatGPT 的 GPTs 创建你自己的 GPTs!
Sam Altman 抓住机会推特推广 GPTs,同时批评 Elon 的 Grok
GPTs 概述
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
它们来了!
上周刚刚宣布的 OpenAI,现在推出了其雄心勃勃的新 ChatGPT 附加功能:恰如其分命名的 GPTs。
任何人都可以轻松构建自己的 GPT——无需编码。你可以为自己、仅供公司内部使用或为所有人创建它们。创建一个就像开始对话一样简单,给它指令和额外知识,并选择它可以做的事情,比如搜索网络、制作图像或分析数据。
这一举措背后的理由是什么?
自从 ChatGPT 推出以来,人们一直在寻求定制 ChatGPT 以适应他们使用方式的方法。我们在 7 月推出了自定义指令,允许你设置一些偏好,但对更多控制的请求不断增加。许多高级用户维护一份精心制作的提示和指令集,手动将它们复制到 ChatGPT 中。GPTs 现在为你完成所有这些工作。
这是否可以替代经过微调的语言模型,如 GPT-3.5 Turbo 或开源替代品?嗯,不能。这更像是结合了上述的自定义指令、自定义提示词以及对你上传文档的检索增强生成。GPTs 类似于使用一个普通的 LLM 与LangChain、一系列提示模板、像文本生成 Web UI这样的用户界面,以及一个RAG实施方案用于知识检索。
GPT 的目标是使这些操作的组合和配置快速且简单,不过,我们可以试一试。
在 5 分钟内创建一个 GPT
我想看看创建我自己的 GPT 是否像 Sam Altman 的 Open AI Dev Days 演示 那样快捷无痛,因此我进行了这个过程。注意,这是一时兴起的决定,一旦我发现可以使用 GPT Builder,所以并未经过精心策划。让我们看看我们能多快且顺利地完成这项工作。
我的 5 分钟 GPT 创建:乔治代理
我通过一系列……嗯,实际上什么也没有,决定创建一个房地产咨询聊天机器人。并且它将具有乔治·科斯坦扎的声音和个性。
为此,我开始了 GPT Builder 过程。首先,我需要让它知道 GPT 的高级描述是什么。
创建一个顾问,为希望购买或了解更多房地产及房地产市场的用户提供见解和建议。
接下来,我被问及如何为 GPT 设定回应框架以及其他与 GPT 个性相关的重要事项。我首先说明了回应应基于事实,并且 GPT 应在必要时提出澄清问题。为了赋予其个性,我下载了一个 《塞恩菲尔德》剧本数据集,解压后将原始内容作为知识上传,以便检索,并指导 GPT 学习和模仿乔治·科斯坦扎的“声音”和互动。以下是 GPT Builder 从这些指令中学到的内容。
乔治代理将把乔治·科斯坦扎独特的语调和反应融入他的互动中。他会用神经质的幽默和过度思考的倾向来表达观点,经常转入个人轶事或夸张的情景。乔治代理会使用修辞性问题、自嘲,以及带有些许偏执的建议,完全符合乔治·科斯坦扎的风格。他的建议会以简短、有力的言辞呈现,充满紧迫感和偶尔的激动语调。他将富有人情味、引人入胜,并为房地产咨询带来独特的喜剧视角,同时避免详细的财务或法律建议。
经过几次与 GPT Builder 的配置互动(例如,它创建了一个头像,但我不喜欢,因此上传了自己的头像),我添加了一个指令,在每次用户互动结束时附上一个与情境相关的《塞恩菲尔德》引用。就是这样。乔治代理 准备就绪,整个过程大约花了 5 分钟。
OpenAI 的 GPTs 创建、配置和共享都如承诺般简单。我认为这是一个聪明的举措,以应对未知的局面,即谷歌神秘的 Gemini,这个项目可能很快会出现,也可能会不符合其炒作。 然而,我心中的问题仍然是 OpenAI 的 GPTs 是否会像 OpenAI 期望的那样有用。我想时间会告诉我们答案。
与此同时,去问 George 关于房地产市场。
现在保持宁静!
Matthew Mayo (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 和 Statology 的执行编辑,以及 Machine Learning Mastery 的特邀编辑,Matthew 旨在使复杂的数据科学概念变得易于理解。他的职业兴趣包括自然语言处理、语言模型、机器学习算法,以及探索新兴的人工智能。他致力于使数据科学社区的知识民主化。Matthew 从 6 岁开始编程。
更多相关话题
什么使 Python 成为初创企业理想的编程语言
原文:
www.kdnuggets.com/2021/12/makes-python-ideal-programming-language-startups.html
由Nikita Bajaj撰写,数字营销负责人
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
在市场上有多种编程语言表现出色的情况下,选择合适的编程语言在你初创企业的早期阶段总是一个艰巨的任务。无论你是希望构建一个最小可行产品(MVP)以获得对你概念的关注,还是希望尽快将完成的产品推向市场,编程语言的选择都应该是明智的,并且基于充分的理由。并非所有编程语言都适合你的业务需求。
初创企业在选择编程语言时必须仔细考虑语言的受欢迎程度、预算、开发速度、库、集成、可扩展性、稳定性、软件安全性和开发者成本。正因如此,Python 通常被认为是最适合初创企业的编程语言之一,因为它满足了所有这些要求。
在这篇博客中,我们将探讨是什么让 Python 如此受欢迎,它的特点是什么,以及为什么你应该将 Python 作为你的初创企业的编程语言进行考虑。
Python 的受欢迎程度
Python 已经在市场上存在了 30 年,吸引了全球开发者社区越来越多的追随者。Python 是一种强大且高级的面向对象编程语言,以其构建可扩展和强健应用程序的能力而闻名。Python 使公司能够开发各种各样的应用程序,包括网页应用程序、软件和游戏开发、网络编程、图形用户界面(GUI)、科学和数值应用等。
TIOBE 编程社区指数将Python 排为全球最受欢迎的编程语言第一(截至 2021 年 11 月)。
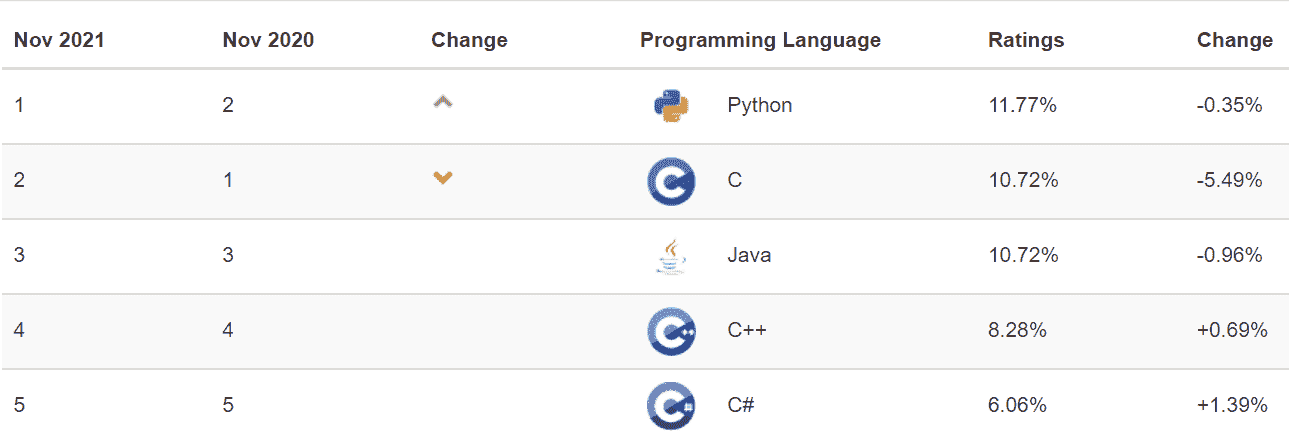
Python 在 2021 年 6 月被 RedMonk 语言排名评为第二名,仅次于 JavaScript。 RedMonk 排名根据考察 Stack Overflow 和 GitHub 的公式评估语言的使用情况。全球科技巨头如 Google、Facebook、Spotify、Netflix、IBM 和 Dropbox 都在很大程度上依赖于 Python。
报告、研究和使用情况清楚地显示,Python 仍然受到需求,并且是世界上大多数公司和企业家在开发项目中首选的顶级编程语言之一。现在,让我们看看为什么如此多人认为 Python 是创业公司最佳编程语言。
选择 Python 作为你创业公司的 8 个理由
让我们更深入地探讨一下是什么使得 Python 成为你创业公司的绝佳选择。
高度可扩展
创业公司需要灵活性来成长,而 Python 提供了扩展业务应用程序的灵活性。由于 Python 是一种面向对象的语言,它支持多种编程范式。通过使用 Django,这个流行的 Python 框架,企业可以轻松创建易于维护的高度可扩展的应用程序。Django 框架由一系列组件组成,这些组件可以解耦,这意味着这些组件可以根据项目需求轻松地进行更改、移除甚至替换。
受欢迎
Python 是增长最快的编程语言,并且已经获得了相当大的受欢迎程度。像 Google、Quora 和 Instagram 等主要公司都依赖于用 Python 编写的代码。到现在为止,你应该已经理解了 Python 的受欢迎程度及其庞大的追随者。
简单且用户友好
与 C++ 或 Java 等其他编程语言相比,Python 简单且相对容易学习。它具有干净且结构化的代码库,这使得开发人员能够轻松更新和维护应用程序。因此,它成为开发者社区中最用户友好的语言之一。
多才多艺
Python 支持所有主要的操作系统和架构。它是一种多用途的语言,可以用于各种项目,从网页开发到数据科学。它可以在包括 Windows、Linux、UNIX 和 Macintosh 在内的多种平台上运行。Python 可以用于开发各种各样的应用程序,从网页应用到科学计算、机器学习(ML)和其他大数据计算系统。数据科学和机器学习的兴起是推动 Python 作为编程语言发展的主要驱动因素。
开源
Python 是一种开源编程语言,这意味着任何人都可以在社区中改进它。这也意味着 Python 可以用于任何你需要的项目,并且可以根据你的项目范围进行修改。
庞大且支持性强的社区
对于一种编程语言来说,拥有一个强大的社区支持是很重要的,这样的社区能为用户提供广泛的支持。Python 社区不断致力于改善语言的核心功能和特性。在开发过程中,你将始终获得快速支持和解决方案。
构建 MVP 和原型
作为一个初创公司,你可能想要迅速测试项目的想法或吸引投资者。由于其强大而快速的开发能力,Python 是构建最小可行产品(MVP)的好选择,这有助于初创公司进行快速迭代。它配备了内置的包和模块,帮助加快产品完成过程。使用 Python,你可以用更少的代码行实现相同的功能,这对初创公司来说是相当节省时间的。Python 帮助你在几周内构建一个完全功能的原型,而不是几个月。因此,它是创建 MVP 的完美选择。
非常适合人工智能(AI)、机器学习(ML)和大数据
如果你的初创公司希望在 AI、ML 和数据科学领域进行创新,Python 是一个很好的选择。Python 拥有丰富而成熟的库集合、扩展性、易用性,并且在科学社区中得到广泛采用。它是与大数据、机器学习和人工智能相关的所有开发类型的完美选择。这是因为它具有针对这些任务的强大包和通过 API 进行数据可视化的广泛可能性。
总结
那么,你应该为你的初创公司选择 Python 吗?
Python 非常适合初创公司,在所有这些领域表现出色,并以效率、速度和质量超越任何其他语言。Python 的特性使其成为大型企业和初创公司都极好的选择。
个人简介: Nikita Bajaj 曾在 SaaS、IT、旅游、软件、电商和数字营销公司工作过。她在开发数据驱动的营销活动和策略方面有着丰富的经验。她领导营销团队,并通过内容营销策略和社交媒体渠道成功吸引潜在客户。
更多相关话题
让智能文档处理更智能:第一部分
原文:
www.kdnuggets.com/2023/02/making-intelligent-document-processing-smarter-part-1.html
作者:阿克谢·库马尔与维坚德拉·贾因
1. 引言
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
迄今为止,大量的组织流程仍依赖纸质文档。比如发票处理和保险公司的客户入职流程。数据科学和数据工程的进步促成了智能文档处理(IDP)解决方案的发展。这些解决方案允许组织利用人工智能技术自动提取、分析和处理纸质文档,从而最小化人工干预。实际上,光学字符识别(OCR)领域有两个主要参与者:亚马逊的 API Textract 和谷歌的 Vision API,以及开源 API Tesseract。
根据 Forrester 的报告,80% 的组织数据是非结构化的,包括 PDF、图片等。这是 IDP 解决方案的真正考验。我们的假设是,由于扫描文档中存在的各种噪声,如模糊、水印、褪色的文字、变形等,这些 OCR API 的准确性可能会受到影响。本文旨在测量这些噪声对各种 API 性能的影响,以确定“是否有可能使智能文档处理更智能?”
2. 文档中的噪声类型
文档中存在各种噪声,这些噪声可能导致 OCR 准确性下降。这些
噪声可以分为两类:
由于文档质量引起的噪声:
-
纸张变形 - 纸张皱褶、纸张起皱、纸张撕裂
-
污点 - 咖啡渍、液体溢出、墨水溢出
-
水印、印章
-
背景文本
-
特殊字体
图 2.1 由于文档质量引起的噪声
图像捕捉过程中产生的噪声:
-
偏斜 - 变形、非平行相机
-
模糊 - 焦点模糊、运动模糊
-
光照条件 - 低光(曝光不足)、强光(曝光过度)、部分阴影

图 2.2 与图像捕捉过程相关的噪声
由于存在这些噪声,图像在输入到 IDP/OCR 流程之前需要预处理/清理。一些 OCR 引擎具有内置的预处理工具,可以处理大多数这些噪声。我们的目标是用各种噪声测试 API,以确定 OCR API 能处理哪些噪声。
3. 衡量 API 性能的指标
为了衡量 OCR 引擎的性能,需要将真实文本或实际文本与 OCR 输出或 API 检测到的文本进行比较。如果 API 检测到的文本与真实文本完全相同,则表示该文档的准确率为 100%。但这是一种非常理想的情况。在现实世界中,由于文档中存在噪声,检测到的文本会与真实文本有所不同。这种真实文本与检测到的文本之间的差异通过各种指标进行衡量。
下表列出了我们考虑用来衡量 API 性能的指标。除了第一个指标(平均置信度得分)外,其余所有指标都将检测到的文本与真实文本进行比较。
| 序号 | 指标 | 类型 | 简要描述 |
|---|---|---|---|
| 1 | 平均置信度得分 | 由 API 提供 | 置信度得分表示 OCR API 对识别文本组件正确性的确定程度。平均置信度得分是所有单词级别置信度得分的平均值。 |
| 2 | 字符错误率 (CER) | 错误率 | CER 比较真实文本中的字符总数(包括空格),与 OCR 输出中获得真实结果所需的最小插入、删除和替换字符的数量。CER = (替换 + 插入 + 删除) 在 OCR 输出中的字符数 / 真实文本中的字符数 |
| 3 | 字词错误率 (WER) | 错误率 | 它类似于 CER,但唯一的区别是 WER 在词级别操作,而不是字符级别。WER = (替换 + 插入 + 删除) 在 OCR 输出中的词数 / 真实文本中的词数 |
| 4 | 余弦相似度 | 相似度 | 如果 x 是真实文本的数学向量表示,y 是 OCR 输出的数学向量表示,则余弦相似度定义如下:Cos(x, y) = x . y / ||x|| * ||y|| |
| 5 | Jaccard 指数 | 相似度 | 如果 A 是真实文本中的所有词的集合,B 是 OCR 输出中的所有词的集合,则 Jaccard 指数定义如下: ????= |????∩????|/|????∪????| |
请注意,WER 和 CER 会受到文本顺序的影响,而余弦相似性、Jaccard 指数和平均置信度分数则不受文本顺序的影响。考虑这样一种情况:如果 OCR API 正确检测了所有单词,但检测到的单词顺序与真实顺序不同,则 WER/CER 将非常差(高错误即性能差),而余弦相似性将非常好(高相似性,即性能好)。因此,查看所有指标一起以获得 OCR API 性能的清晰概念是很重要的。
4. 探索的数据集
我们探索了一些文献中提供的标准数据集,并且还创建了一些使用真实发票和虚拟发票的自定义数据集。在探索了约 5900 个文档,包括发票、账单、收据、文本文档和在各种噪声条件下扫描的虚拟发票后,这些噪声包括咖啡渍、折叠、皱纹、小字体、倾斜、模糊、水印等。

图 4.1 – 来自各种数据集的示例图像。左侧框:嘈杂办公室;中间框:智能文档问答;右上框:SROIE 数据集;右下框:自定义数据集。
5. 结果总结
如前所述,我们在提到的数据集上测试了三种 API:Vision、Textract 和 Tesseract,并计算了性能指标。我们观察到,在几乎所有情况下,Tesseract 的表现明显逊色于 Vision 和 Textract,因此在结果总结中排除了 Tesseract。我们的结果总结分为两部分,一部分基于数据集,另一部分基于噪声类型。
结果总结(基于数据集)
我们将指标分为两组,第一组包括错误率(WER & CER),第二组包括相似性指标(余弦相似性 & Jaccard 指数)。使用这些指标的均值来比较 API 的性能。这个评分系统的范围从 1 到 10。这里,评分 1 表示该数据集的平均性能指标在 0-10% 之间(最差表现),而评分 10 表示在 91-100% 之间(最佳表现)。
| 序号 | 数据集 | API 性能较差的主要噪声 | API 性能相对评分(1: 最差, 10: 最佳) |
|---|---|---|---|
| 基于错误率 | 基于相似性指标 | ||
| 视觉 | Textract | 视觉 | Textract |
| 1 | 嘈杂办公室 2007 | 两个 API 在嘈杂办公室数据集的所有噪声中表现良好 | 10 |
| 2 | 智能文档问答 2015 | 运动模糊、失焦模糊、发票类型文档 | 7 |
| 3 | SROIE 2019 | 点阵打印机字体、印章 | 6 |
| 4 | 自定义数据集 1 | 模糊和水印 | 6 |
| 5 | 自定义数据集 2(Alpha Foods) | 两个 API 在所有噪声中表现良好 | 5 |
| 6 | 自定义数据集 3 | 无实心背景(当两侧都有文本时) | 3 |
这里一个重要的点是,Vision 的 CER 和 WER 错误率通常高于 Textract。但是,两者的余弦相似度和 Jaccard 指数相似。这是因为 API 使用的单词顺序或排序方法不同。我们的发现是,尽管 Vision 和 Textract 检测文本的性能几乎相同,但由于 Vision 输出中的不同排序,其错误率高于 Textract。因此,Vision 基于错误率表现较差。
结果总结(基于噪声)
在这里,我们根据观察到的性能提供对 API 的主观评估。右勾 (✓) 表示 API 一般能处理该特定噪声,叉号 (X) 表示 API 在该特定噪声下表现较差。例如,我们观察到 Textract 无法检测文档中的垂直文本。
| 序号 | 噪声/变化 | Google Vision API | Amazon Textract API | 观察 |
|---|---|---|---|---|
| 1 | 光线变化(白天光、夜晚光、局部阴影、网格阴影、低光) | ✓ | ✓ | Vision 和 Textract API 可以处理这些噪声 |
| 2 | 非平行相机 (x, y, x-y) | ✓ | ✓ | |
| 3 | 不平整表面 | ✓ | ✓ | |
| 4 | 2x 放大 | ✓ | ✓ | |
| 5 | 垂直文本 | ✓ | X | 亚马逊 API 的限制 |
| 6 | 无实心背景 | X | X | Vision 和 Textract API 在这些噪声下表现较差 |
| 7 | 水印 | X | X | |
| 8 | 模糊(失焦) | X | X | |
| 9 | 模糊(运动模糊) | X | X | |
| 10 | 点阵打印机字体 | X | X |
下面是一些示例:

图 5.2 (a): SmartDocQA - 焦点模糊:Vision 和 Textract 文本输出比较。左侧图像是输入,中间图像是 Vision 输出,黄色框为单词级别的边界框,右侧图像是 Textract 输出,蓝色框为单词级别的边界框。红框表示没有边界框的单词,即 API 没有检测到的单词。
图 5.2 (b): SmartDocQA - 2D 运动模糊:Vision 和 Textract 文本输出比较。红框表示 API 未识别的文本。
图 5.2 (c): SmartDocQA - 垂直文本:Vision 和 Textract 文本输出比较。红圈表示 Textract API 无法检测图像中的垂直文本。
6. 文档去噪
现在已经确定,一些噪声确实会影响 API 的文本识别能力。
因此,我们尝试了多种方法来清理图像,然后输入 API,并检查了 API 的性能是否有所改善。我们在参考部分提供了这些方法的链接。以下是观察结果的总结:
| 序号 | 噪声 / 变异 | 清理方法 | 总样本数 | 观察结果 |
|---|---|---|---|---|
| 视觉 | Textract | |||
| 1 | 模糊(焦点外) | 内核锐化 | 1 | 退化 |
| 自定义预处理 | 3 | 1: 改进 1: 稍微改进 1: 稍微退化 | 1: 改进 2: 无效 | |
| 2 | 模糊(2D 运动模糊) | 模糊(平均/中位数) | 2 | 2: 改进 |
| 内核锐化 | 2 | 1: 无效 1: 退化 | 1: 退化 1: 改进 | |
| 自定义预处理 | 1 | 无效 | 1: 无效 | |
| 3 | 水平运动模糊 | 模糊(平均/中位数) | 2 | 1: 退化 1: 改进 |
| 自定义预处理 | 1 | 稍微改进 | 无效 | |
| 4 | 水印 | 形态学过滤 | 2 | 1: 改进 1: 退化 |
从表中可以看出,这些清理方法并不适用于所有图像,实际上,应用这些清理方法后,API 的性能有时会下降。因此,需要一种统一的解决方案,能够应对各种噪声。
结论
在测试了包括 Noisy Office、Smart Doc QA、SROIE 和自定义数据集在内的各种数据集,以比较和评估 Tesseract、Vision 和 Textract 的性能后,我们可以得出结论:OCR 输出受文档中噪声的影响。内置去噪器或预处理器不足以处理大多数噪声,包括运动模糊、水印等。如果对文档图像进行去噪,OCR 输出可以显著改善。文档中的噪声种类繁多,我们尝试了各种非模型方法来清理图像。不同的方法对不同种类的噪声有效。目前,还没有一种统一的选项能够处理所有种类的噪声,或者至少是主要噪声。因此,有必要使智能文档处理更加智能。需要一种统一的(“一个模型适用所有”)解决方案,在输入 OCR API 之前对文档进行去噪,以提高性能。在本博客系列的第二部分中,我们将探讨去噪方法以提升 API 的性能。
参考文献
-
F. Zamora-Martinez, S. España-Boquera 和 M. J. Castro-Bleda,基于行为的神经网络聚类应用于文档增强,见:计算与环境智能,第 144-151 页,Springer,2007 年。
UCI 机器学习库 [https://archive.ics.uci.edu/ml/datasets/NoisyOffice]
-
Castro-Bleda, MJ.; España Boquera, S.; Pastor Pellicer, J.; Zamora Martínez, FJ. (2020). The NoisyOffice 数据库:用于训练监督式机器学习滤镜的语料库。计算机杂志。63(11):1658-1667。 https://doi.org/10.1093/comjnl/bxz098
-
尼巴尔·纳耶夫、穆罕默德·穆扎米尔·卢克曼、索菲亚·普鲁姆、塞巴斯蒂安·埃斯克纳齐、约瑟夫·查扎隆、让-马克·奥吉耶:“SmartDoc-QA:用于智能手机捕获文档图像的质量评估数据集——单一和多重失真”,第六届基于相机的文档分析与识别国际研讨会(CBDAR)论文集,2015 年。
-
郑黄、凯陈、简华赫、项白、迪莫斯特尼斯·卡拉察斯、舒简·卢、C.V.贾瓦哈尔,《ICDAR2019 扫描收据 OCR 和信息提取竞赛(SROIE)》,2021 [arXiv:2103.10213v1]
-
scikit-image.org/docs/stable/auto_examples/applications/plot_morphology.html -
pyimagesearch.com/2014/09/01/build-kick-ass-mobile-document-scanner-just-5-minutes/
阿克谢·库马尔 是 Sigmoid 的首席数据科学家,拥有 12 年数据科学经验,专长于市场分析、推荐系统、时间序列预测、欺诈风险建模、图像处理和自然语言处理。他构建可扩展的数据科学解决方案和系统,以解决复杂的业务问题,同时以用户体验为核心。
维坚德拉·贾恩 目前在 Sigmoid 担任副首席数据科学家。拥有 7 年以上的数据科学经验,他主要从事市场混合建模、图像分类和分割以及推荐系统等领域的工作。
更多相关主题
预测:Python 中线性回归的初学者指南
原文:
www.kdnuggets.com/2023/06/making-predictions-beginner-guide-linear-regression-python.html

图片由作者提供
线性回归是数据科学家在开始数据科学职业生涯时学习的最受欢迎且最早的机器学习算法。它是最重要的监督学习算法,因为它为所有其他高级机器学习算法奠定了基础。这就是为什么我们需要非常清楚地学习和理解这个算法的原因。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
在这篇文章中,我们将从头开始介绍线性回归、其数学和几何直觉,以及其 Python 实现。唯一的前提是你有学习的愿望和基本的 Python 语法知识。让我们开始吧。
什么是线性回归?
线性回归是一种监督式机器学习算法,用于解决回归问题。回归模型用于根据一些其他因素预测连续输出。例如,通过考虑利润率、总市值、年度增长等来预测下个月的股票价格。线性回归还可以用于预测天气、股票价格、销售目标等应用。
顾名思义,线性回归,它在两个变量之间建立了线性关系。该算法找到最佳的直线(y=mx+c),可以根据自变量(x)预测因变量(y)。被预测的变量称为因变量或目标变量,而用于预测的变量称为自变量或特征。如果只使用一个自变量,则称为单变量线性回归。否则,称为多变量线性回归。
为了简化本文,我们将仅考虑一个自变量(x),以便我们可以在二维平面上轻松可视化。在接下来的部分,我们将讨论它的数学直觉。
数学直觉
现在我们将深入理解线性回归的几何和数学。如果我们有一组 X 和 Y 值的样本对,
我们必须使用这些值来学习一个函数,以便如果我们给它一个未知的 (x),它可以根据学习结果预测一个 (y)。在回归中,可以使用许多函数进行预测,但线性函数是所有函数中最简单的。
图 1 样本数据点 | 作者提供的图片
该算法的主要目的是在这些数据点中找到最佳拟合线,如上图所示,从而得到最小的残差误差。残差误差是预测值与实际值之间的差异。
线性回归的假设
在继续之前,我们需要讨论线性回归的一些假设,以确保得到准确的预测。
-
线性关系: 线性关系意味着独立变量和因变量必须遵循线性关系。否则,将难以获得一条直线。此外,数据点必须彼此独立,即一个观察的数据不依赖于另一个观察的数据。
-
同方差性: 这意味着残差误差的方差必须是恒定的。这意味着误差项的方差应该是恒定的,即使独立变量的值变化也不应改变。此外,模型中的误差必须遵循正态分布。
-
无多重共线性: 多重共线性意味着独立变量之间存在相关性。因此,在线性回归中,独立变量之间不能存在相关性。
假设函数
我们将假设因变量 (Y) 和独立变量 (X) 之间存在线性关系。我们可以如下表示线性关系。

我们可以观察到,直线依赖于参数 Θ0 和 Θ1。因此,为了得到最佳拟合线,我们需要调整这些参数。这些参数也称为模型的权重。为了计算这些值,我们将使用损失函数,也称为成本函数。它计算预测值与实际值之间的均方误差。我们的目标是最小化这个成本函数。Θ0 和 Θ1 的值,使得成本函数最小化,将形成我们的最佳拟合线。成本函数用 (J) 表示。
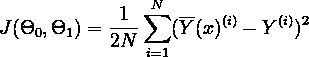
其中,
N 是样本的总数
选择平方误差函数来处理负值(即预测值低于实际值)。此外,将函数除以 2 以简化微分过程。
优化器(梯度下降)
[优化器]( https://www.datarobot.com/blog/introduction-to-optimizers/#:~:text=In simpler terms%2C optimizers shape ,component%20of%20AI%2FML%20governance.) 是一种通过迭代更新模型的属性(如权重或学习率)来最小化均方误差的算法,以实现最佳拟合线。在线性回归中,使用梯度下降算法来通过更新 Θ0 和 Θ1 的值来最小化成本函数。
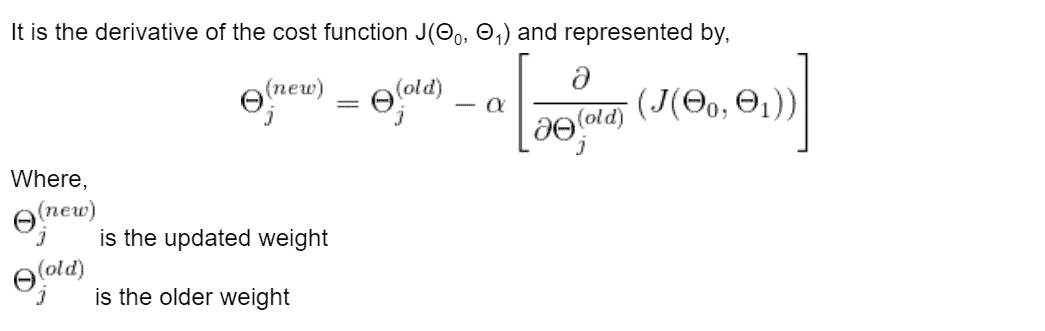
是一个超参数,称为学习率。它决定了我们的权重相对于梯度损失的调整幅度。学习率的值应当是最佳的,不应过高或过低。如果过高,模型难以收敛到全局最小值;如果过小,则收敛速度较慢。
我们将绘制成本函数与权重之间的图表,以找到最佳的 Θ0 和 Θ1。
图 2 梯度下降曲线 | 图片由 GeeksForGeeks 提供
初始时,我们将随机赋值给 Θ0 和 Θ1,然后计算成本函数和梯度。对于负梯度(即成本函数的导数),我们需要朝着增加 Θ1 的方向移动以达到最小值。而对于正梯度,我们必须向回移动以达到全局最小值。我们的目标是找到梯度几乎等于零的点。在这个点上,成本函数的值是最小的。
到目前为止,你已经理解了线性回归的工作原理和数学基础。接下来的部分将展示如何在 Python 中使用样本数据集从头开始实现它。
线性回归 Python 实现
在这一部分,我们将学习如何从头开始实现线性回归算法,仅使用 Numpy、Pandas 和 Matplotlib 等基础库。我们将实现单变量线性回归,其中包含一个因变量和一个自变量。
我们将使用的数据集包含大约 700 对 (X, Y),其中 X 是自变量,Y 是因变量。此数据集由 Ashish Jangra 提供,你可以从 这里 下载。
导入库
# Importing Necessary Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.axes as ax
from IPython.display import clear_output
Pandas 读取 CSV 文件并获取数据框,而 Numpy 执行基本的数学和统计操作。Matplotlib 负责绘制图表和曲线。
加载数据集
# Dataset Link:
# https://github.com/AshishJangra27/Machine-Learning-with-Python-GFG/tree/main/Linear%20Regression
df = pd.read_csv("lr_dataset.csv")
df.head()
# Drop null values
df = df.dropna()
# Train-Test Split
N = len(df)
x_train, y_train = np.array(df.X[0:500]).reshape(500, 1), np.array(df.Y[0:500]).reshape(
500, 1
)
x_test, y_test = np.array(df.X[500:N]).reshape(N - 500, 1), np.array(
df.Y[500:N]
).reshape(N - 500, 1)
首先,我们将获取数据框 df,然后删除空值。之后,我们将数据拆分为训练集和测试集 x_train、y_train、x_test 和 y_test。
构建模型
class LinearRegression:
def __init__(self):
self.Q0 = np.random.uniform(0, 1) * -1 # Intercept
self.Q1 = np.random.uniform(0, 1) * -1 # Coefficient of X
self.losses = [] # Storing the loss of each iteration
def forward_propogation(self, training_input):
predicted_values = np.multiply(self.Q1, training_input) + self.Q0 # y = mx + c
return predicted_values
def cost(self, predictions, training_output):
return np.mean((predictions - training_output) ** 2) # Calculating the cost
def finding_derivatives(self, cost, predictions, training_input, training_output):
diff = predictions - training_output
dQ0 = np.mean(diff) # d(J(Q0, Q1))/d(Q0)
dQ1 = np.mean(np.multiply(diff, training_input)) # d(J(Q0, Q1))/d(Q1)
return dQ0, dQ1
def train(self, x_train, y_train, lr, itrs):
for i in range(itrs):
# Finding the predicted values (Using the linear equation y=mx+c)
predicted_values = self.forward_propogation(x_train)
# Calculating the Loss
loss = self.cost(predicted_values, y_train)
self.losses.append(loss)
# Back Propagation (Finding Derivatives of Weights)
dQ0, dQ1 = self.finding_derivatives(
loss, predicted_values, x_train, y_train
)
# Updating the Weights
self.Q0 = self.Q0 - lr * (dQ0)
self.Q1 = self.Q1 - lr * (dQ1)
# It will dynamically update the plot of the straight line
line = self.Q0 + x_train * self.Q1
clear_output(wait=True)
plt.plot(x_train, y_train, "+", label="Actual values")
plt.plot(x_train, line, label="Linear Equation")
plt.xlabel("Train-X")
plt.ylabel("Train-Y")
plt.legend()
plt.show()
return (
self.Q0,
self.Q1,
self.losses,
) # Returning the final model weights and the losses
我们创建了一个名为LinearRegression()的类,其中包含了所有必要的函数。
__init__ : 这是一个构造函数,当创建这个类的对象时,它会用随机值初始化权重。
forward_propogation(): 这个函数将使用直线的方程找到预测的输出。
cost(): 这个函数将计算与预测值相关的残差误差。
finding_derivatives(): 这个函数计算权重的导数,导数可以用于之后更新权重以减少误差。
train(): 该函数将接受训练数据、学习率和总迭代次数作为输入。它将使用反向传播来更新权重,直到达到指定的迭代次数。最后,它将返回最佳拟合线的权重。
模型训练
lr = 0.0001 # Learning Rate
itrs = 30 # No. of iterations
model = LinearRegression()
Q0, Q1, losses = model.train(x_train, y_train, lr, itrs)
# Output No. of Iteration vs Loss
for itr in range(len(losses)):
print(f"Iteration = {itr+1}, Loss = {losses[itr]}")
输出:
Iteration = 1, Loss = 6547.547538061649
Iteration = 2, Loss = 3016.791083711492
Iteration = 3, Loss = 1392.3048668536044
Iteration = 4, Loss = 644.8855797373262
Iteration = 5, Loss = 301.0011032250385
Iteration = 6, Loss = 142.78129818453215
.
.
.
.
Iteration = 27, Loss = 7.949420840198964
Iteration = 28, Loss = 7.949411555664398
Iteration = 29, Loss = 7.949405538972356
Iteration = 30, Loss = 7.949401025888949
你可以观察到在第一次迭代中,损失最大,而在随后的迭代中,这个损失逐渐减少,并在第 30 次迭代结束时达到最小值。
图 3 最佳拟合线的寻找 | 图片作者
上面的 gif 显示了直线如何在完成第 30 次迭代后达到最佳拟合线。
最终预测
# Prediction on test data
y_pred = Q0 + x_test * Q1
print(f"Best-fit Line: (Y = {Q1}*X + {Q0})")
# Plot the regression line with actual data pointa
plt.plot(x_test, y_test, "+", label="Data Points")
plt.plot(x_test, y_pred, label="Predited Values")
plt.xlabel("X-Test")
plt.ylabel("Y-Test")
plt.legend()
plt.show()
这是最佳拟合线的最终方程。
Best-fit Line: (Y = 1.0068007107347927*X + -0.653638673779529)
图 4 实际值与预测值的对比 | 图片作者
上面的图展示了最佳拟合线(橙色)和测试集的实际值(蓝色 +)。你还可以调整超参数,例如学习率或迭代次数,以提高准确性和精确度。
线性回归(使用 Sklearn 库)
在上一节中,我们已经学习了如何从头实现单变量线性回归。但是,sklearn 也提供了一个可以直接用来实现线性回归的内置库。我们来简要讨论一下如何实现。
我们将使用相同的数据集,但如果你愿意,也可以使用不同的数据集。你需要额外导入两个库,如下所示。
# Importing Extra Libraries
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
加载数据集
df = pd.read_csv("lr_dataset.csv")
# Drop null values
df = df.dropna()
# Train-Test Split
Y = df.Y
X = df.drop("Y", axis=1)
x_train, x_test, y_train, y_test = train_test_split(
X, Y, test_size=0.25, random_state=42
)
之前,我们需要使用 numpy 库手动执行训练集和测试集的划分。但现在我们可以使用 sklearn 的 train_test_split() 直接通过指定测试集大小来划分数据。
模型训练与预测
model = LinearRegression()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
# Plot the regression line with actual data points
plt.plot(x_test, y_test, "+", label="Actual values")
plt.plot(x_test, y_pred, label="Predicted values")
plt.xlabel("X")
plt.ylabel("Y")
plt.legend()
plt.show()
现在,我们不需要为前向传播、反向传播、成本函数等编写代码。我们可以直接使用LinearRegression()类并在输入数据上训练模型。下面是从训练模型的测试数据中获得的图。结果与我们自己实现算法时类似。
图 5 Sklearn 模型输出 | 作者提供的图片
参考文献
- GeeksForGeeks: ML 线性回归
总结
完整代码的 Google Colab 链接 - 线性回归教程代码
在本文中,我们详细讨论了什么是线性回归,它的数学直觉以及它的 Python 实现,包括从零开始的实现和使用 sklearn 库的实现。这个算法直观且易于理解,因此有助于初学者奠定坚实的基础,并帮助获得实际的编码技能,以使用 Python 做出准确的预测。
感谢阅读。
Aryan Garg 是一名电气工程专业的 B.Tech.学生,目前在本科最后一年。他对网页开发和机器学习领域充满兴趣。他已经追求了这一兴趣,并渴望在这些方向上继续工作。
主题更多内容
让 Python 程序闪电般快速
原文:
www.kdnuggets.com/2020/09/making-python-programs-blazingly-fast.html
评论
由 Martin Heinz,IBM 的 DevOps 工程师
Python 反对者总是说,他们不想使用它的原因之一是它慢。好吧,是否特定程序——无论使用何种编程语言——快还是慢,很大程度上取决于编写它的开发人员及其编写优化和快速程序的技能和能力。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 在 IT 方面支持你的组织
那么,让我们证明一些人的观点是错误的,看看如何提高我们Python 程序的性能,让它们真正变快!

by @veri_ivanova 在 unsplash
计时和剖析
在我们开始优化任何东西之前,我们首先需要找出代码中哪些部分实际上拖慢了整个程序。有时程序的瓶颈可能很明显,但如果你不知道它在哪里,那么你可以尝试以下选项来找出:
注意:这是我将用于演示目的的程序,它计算 *e* 的 *X* 次方(取自 Python 文档):
最懒的“剖析”
首先,最简单的、老实说非常懒的解决方案——Unix time 命令:
如果你只是想计时整个程序,这可能会有效,但通常这还不够……
最详细的剖析
另一端的选择是 cProfile,它会给你过多的信息:
在这里,我们使用了 cProfile 模块和 time 参数来运行测试脚本,因此行按内部时间(cumtime)排序。这给我们提供了大量的信息,您上面看到的行只是实际输出的约 10%。从中,我们可以看到 exp 函数是罪魁祸首(惊讶,惊讶),现在我们可以更具体地进行计时和剖析……
计时特定函数
现在我们知道了要关注的地方,我们可能想要对慢函数进行计时,而不测量其余的代码。为此,我们可以使用简单的装饰器:
这个装饰器可以像这样应用于被测试的函数:
这会给我们如下输出:
一件需要考虑的事情是我们实际上(想要)测量的时间类型。time包提供了time.perf_counter和time.process_time。它们的区别在于,perf_counter返回的是绝对值,包括你 Python 程序未运行时的时间,因此可能会受到机器负载的影响。另一方面,process_time仅返回用户时间(不包括系统时间),这是你程序的运行时间。
加速
现在,来点有趣的。让我们让你的 Python 程序运行得更快。我(主要)不会给你展示一些黑客技巧、窍门和代码片段,这些东西能神奇地解决你的性能问题。这更多是关于一般的想法和策略,这些想法和策略在使用时可以对性能产生巨大影响,在某些情况下甚至可以提高 30%的速度。
使用内置数据类型
这一点很明显。内置数据类型非常快,尤其是与我们的自定义类型如树或链表相比。主要是因为内置类型是用C实现的,而我们在用 Python 编写代码时无法匹敌这种速度。
使用 lru_cache 进行缓存/记忆化
我已经在之前的博客文章中这里展示过这个内容,但我认为用简单的例子重复一遍是值得的:
上面的函数使用time.sleep模拟了重计算。当第一次用参数1调用时,它会等待 2 秒钟,然后才返回结果。当再次调用时,结果已经被缓存,所以它跳过了函数体,立即返回结果。更多的实际生活例子请参见之前的博客文章这里。
使用局部变量
这与每个作用域中变量查找的速度有关。我说每个作用域是因为这不仅仅是关于局部变量与全局变量的使用。实际上,即使是在函数内部的局部变量(最快)、类级属性(例如self.name - 较慢)和全局变量(例如导入的函数如time.time - 最慢)之间,查找速度也存在差异。
你可以通过使用看似不必要(完全没用的)赋值来提高性能,例如:
使用函数
这可能看起来有些反直觉,因为调用函数会将更多的东西放到栈上,并且创建函数返回的开销,但这与前一点相关。如果你把整个代码放在一个文件里而不放入函数中,它会因为全局变量而变得更慢。因此,你可以通过将整个代码包裹在main函数中,并一次调用它来加快你的代码,如下所示:
不要访问属性
另一个可能会减慢程序速度的因素是点操作符(.),它在访问对象属性时使用。这个操作符触发了使用__getattribute__的字典查找,这会在你的代码中创建额外的开销。那么,我们如何实际避免(限制)使用它呢?
注意字符串
当在循环中使用 取模 (%s) 或 .format() 时,字符串操作可能变得非常慢。我们还有什么更好的选择?根据最近的 Raymond Hettinger 推文,我们应该使用的唯一方法是 f-string,它最具可读性、简洁且最快。因此,根据该推文,这是你可以使用的方法列表——从最快到最慢:
生成器本身并不比其他方法快,因为它们是为了实现惰性计算而设计的,从而节省内存而非时间。然而,节省的内存可以使你的程序实际运行得更快。如何做到这一点?如果你有一个大型数据集且不使用生成器(迭代器),数据可能会溢出 CPU 的 L1 缓存,这会显著减慢内存中的值查找速度。
说到性能,CPU 能将其处理的数据尽可能接近地保存在缓存中是非常重要的。你可以观看Raymond Hettinger 的讲座,他在其中提到了这些问题。
结论
优化的首要原则是 不要优化。但如果你真的必须这样做,希望这些小贴士能帮助你。然而,优化代码时要谨慎,因为它可能使代码难以阅读,从而难以维护,这可能会抵消优化的好处。
注:这最初发布在 martinheinz.dev
简历: 马丁·海因茨 是 IBM 的 DevOps 工程师。作为一名软件开发人员,马丁对计算机安全、隐私和加密充满热情,专注于云计算和无服务器计算,并始终准备迎接新的挑战。
原文。经授权转载。
相关:
-
自动化你的 Python 项目的每个方面
-
MIT 免费课程:Python 计算机科学与编程导论
-
用一行代码进行统计和可视化探索数据分析
更多相关主题
机器学习生命周期
原文:
www.kdnuggets.com/2022/06/making-sense-crispmlq-machine-learning-lifecycle-process.html
构建和管理机器学习(ML)应用程序没有标准实践。因此,机器学习项目往往组织不善,缺乏可重复性,并且长期内容易完全失败。我们需要一个模型来帮助我们在整个机器学习生命周期中维持质量、可持续性、鲁棒性和成本管理。
作者提供的图像 | 机器学习开发生命周期过程
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT
机器学习应用程序的跨行业标准过程与质量保证方法论(CRISP-ML(Q))是CRISP-DM的升级版,以确保高质量的机器学习产品。
CRISP-ML(Q) 包含六个独立的阶段:
-
业务和数据理解
-
数据准备
-
模型工程
-
模型评估
-
模型部署
-
监控与维护
这些阶段需要不断的迭代和探索,以构建更好的解决方案。尽管框架中有一个顺序,但后期阶段的输出可以决定我们是否需要重新审视前期阶段。
作者提供的图像 | 各阶段的质量保证
质量保证方法论被引入到框架的每个阶段。该方法论包含性能指标、数据质量要求和鲁棒性等要求和限制。它有助于减轻影响机器学习应用成功的风险。这可以通过持续监控和维护整体系统来实现。
例如: 在电子商务业务中,数据和概念漂移会导致模型退化,如果我们没有系统来监控这些变化,公司将会因失去客户而遭受损失。
业务和数据理解
在开发过程开始时,我们需要确定项目的范围、成功标准和 ML 应用的可行性。之后,我们开始数据收集和质量验证的过程。这一过程漫长且具有挑战性。
范围: 我们希望通过机器学习过程实现什么?是保留客户还是通过自动化减少运营成本。
成功标准:我们必须定义清晰且可衡量的业务、机器学习(统计指标)和经济(KPI)成功指标。
可行性:我们需要确保数据的可用性、ML 应用的适用性、法律约束、稳健性、可扩展性、可解释性和资源需求。
数据收集: 收集数据,为可重复性进行版本控制,并确保不断获得真实和生成的数据。
数据质量验证: 通过维护数据描述、要求和验证来确保数据质量。
为了确保质量和可重复性,我们需要记录数据的统计属性和数据生成过程。
数据准备
第二阶段相当简单。我们将为建模阶段准备数据,包括数据选择、数据清理、特征工程、数据增强和标准化。
-
我们从特征选择、数据选择开始,并通过过采样或欠采样处理不平衡的类别。
-
然后,专注于减少噪声和处理缺失值。为了质量保证,我们将添加数据单元测试,以降低错误值的风险。
-
根据你的模型,我们执行特征工程和数据增强,例如,一热编码和聚类。
-
标准化和缩放数据。这将降低特征偏差的风险。
为确保可重复性,我们创建数据建模、转换和特征工程管道。
模型工程
业务和数据理解阶段的约束和要求将决定建模阶段。我们需要理解业务问题以及我们将如何开发机器学习模型来解决这些问题。我们将重点关注模型选择、优化和训练,确保模型性能指标、稳健性、可扩展性、可解释性,并优化存储和计算资源。
-
研究模型架构和类似的业务问题
-
定义模型性能指标
-
模型选择
-
通过引入专家来理解领域知识。
-
模型训练
-
模型压缩和集成
为了确保质量和可重复性,我们将存储和版本化模型元数据,如模型架构、训练和验证数据、超参数和环境描述。
最后,我们将跟踪 ML 实验并创建 ML 管道,以建立可重复的训练过程。
模型评估
这是我们测试并确保模型准备好部署的阶段。
-
我们将测试模型在测试数据集上的表现。
-
通过提供随机或虚假数据来评估模型的稳健性。
-
提高模型解释性以满足监管要求。
-
将结果与初始成功指标进行比较,自动或由领域专家进行。
为了保证质量,评估阶段的每一步都会被记录。
模型部署
模型部署是一个将机器学习模型集成到现有系统中的阶段。模型可以部署在服务器、浏览器、软件和边缘设备上。模型的预测结果可以用于 BI 仪表板、API、Web 应用程序和插件中。
模型部署流程:
-
硬件推理定义
-
生产中的模型评估
-
确保用户接受度和可用性
-
提供备选计划并最小化损失
-
部署策略。
监控与维护
生产中的模型需要持续监控和维护。我们将监控模型的陈旧性、硬件性能和软件性能。
持续监控是过程的第一部分,如果性能低于阈值,将自动决定在新数据上重新训练模型。此外,维护部分不仅限于模型再训练。它涉及决策以获取新数据、更新硬件和软件,并根据业务用例改进机器学习过程。
简而言之,这是机器学习模型的持续集成、训练和部署。
结论
训练和验证模型只是机器学习应用的一小部分。将初始想法转化为现实涉及多个过程。在这篇文章中,我们了解了 CRISP-ML(Q)及其如何强调风险评估和质量保证。
我们首先定义业务目标,收集和清理数据,构建模型,在测试数据集上进行验证,然后将其部署到生产环境中。
这个框架的关键组成部分是持续监控和维护。我们将监控数据、软件和硬件指标,以决定是否需要重新训练模型或升级系统。
图片作者
如果你对机器学习运维不太熟悉,想了解更多,可以阅读 DataTalks.Club 的免费 MLOps 课程的评论。你将获得所有 6 个阶段的实践经验,并了解 CRISP-ML 的实际应用。
参考
Abid Ali Awan (@1abidaliawan) 是一名认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作,并撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络开发一种人工智能产品,帮助面临心理健康问题的学生。
更多相关话题
理解集成学习技术
原文:
www.kdnuggets.com/2020/03/making-sense-ensemble-learning-techniques.html
评论
作者:Ido Zehori,Bigabid的数据科学团队负责人
图片来源:Packt
我们的三大课程推荐
1. Google 网络安全证书 - 快速开启网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
对于许多专注于机器学习(ML)的公司/数据科学家来说,集成学习方法已经成为首选工具。由于集成学习方法结合了多个基础模型,因此它们能够生成更为准确的 ML 模型。例如,在 Bigabid,我们通过集成学习成功解决了从优化 LTV(客户终身价值)到欺诈检测的各种问题。
难以过分强调集成学习在整体 ML 过程中的重要性,包括偏差-方差权衡以及三种主要的集成技术:装袋、提升和堆叠。这些强大的技术应成为任何数据科学家工具包的一部分,因为它们是普遍存在的概念。此外,理解它们的基本机制是机器学习领域的核心。
集成学习方法概述
集成学习是一种 ML 范式,其中多个基础模型(通常被称为“弱学习者”)被组合和训练以解决同一问题。这种方法基于这样的理论:通过正确地组合多个基础模型,这些弱学习者可以作为设计更复杂 ML 模型的构建块。这些集成模型(恰如其分地称为“强学习者”)能够实现更好、更准确的结果。
换句话说,弱学习者只是一个单独表现较差的基础模型。实际上,它的准确性水平仅略高于偶然情况,这意味着它的预测结果仅比随机猜测稍好。这些弱学习者通常也会很简单。通常,基础模型之所以自身表现不佳,是因为它们要么有高偏差,要么方差过大,使它们变得薄弱。
这就是集成学习的作用。该方法试图通过将多个弱学习者组合在一起,来减少总体误差。可以将集成模型视为“两个脑袋总比一个好”的数据科学版本。如果一个模型表现良好,那么多个模型共同工作可以做得更好。
关于偏差-方差权衡的一点说明
理解弱学习者的概念以及为什么它会得到这个名字非常重要,因为其原因归结为偏差或方差。更具体地说,机器学习模型的预测错误,即训练模型与真实值之间的差异,可以分解为以下两部分:偏差和方差。例如:
-
偏差导致的错误: 这是模型的预期预测与我们希望预测的精确值之间的差异。
-
方差导致的错误: 这是模型对特定数据点预测的方差。
如果一个模型过于简单且没有很多参数,那么它可能有高偏差和低方差。相比之下,如果一个模型有很多参数,那么它可能有高方差和低偏差。因此,有必要找到适当的平衡,避免对数据的欠拟合或过拟合,因为这种复杂性权衡是存在偏差和方差之间权衡的原因。简单来说,一个算法不能同时变得更复杂和更简单。
集成学习技术 - 结合弱学习者
集成学习有三种主要技术:自助法、提升法和堆叠法。它们的定义如下:
自助法(Bagging):
自助法试图在小样本群体上结合相似的学习者,并计算所有预测的平均值。通常,自助法允许你在不同的样本群体中使用不同的学习者。通过这样做,这种方法有助于减少方差错误。
提升法(Boosting)
提升是一种迭代方法,它根据最新的分类结果微调观察的权重。如果一个观察被错误分类,该方法将在下一轮(即训练下一个模型的轮次)增加该观察的权重,并减少误分类的倾向。类似地,如果一个观察被正确分类,那么它将在下一个分类器中减少其权重。权重表示特定数据点正确分类的重要性,这使得顺序分类器可以集中关注之前被误分类的例子。通常,提升方法能减少偏差错误,形成强大的预测模型,但有时可能会在训练数据上过拟合。
堆叠
堆叠是一种巧妙的方法,通过组合不同模型提供的信息。使用这种方法,可以将任何类型的学习者用于结合不同学习者的输出。结果可能是通过使用哪些组合模型来减少偏差或方差。
集成学习的承诺
集成学习涉及将多个基础模型结合,以实现更有效、更准确的集成模型,这种模型具有更强大的特性,因此表现更佳。集成学习方法在挑战性数据集上成功创下了记录,并且经常成为 Kaggle 竞赛获胜提交的一部分。
值得注意的是,即使是三种主要的集成技术——装袋、提升和堆叠——也可以有变体,这些变体可以更好地设计以更有效地适应特定问题,如分类、回归、时间序列分析等。这首先需要了解当前的问题,并在解决问题时保持创造性!
使用集成学习方法是一种很好的、有前景的解决问题的方法。
简介:Ido Zehori 是 Bigabid 的数据科学团队负责人,该公司开发了针对应用内广告用户获取和重新参与优化的第二代 DSP,提供了一级 DSP 的规模和尖端 DMP 的精准度。
相关内容:
-
集成学习方法:AdaBoost
-
随机森林® — 强大的集成学习算法
-
解释黑箱模型:使用 LIME 和 SHAP 的集成学习和深度学习
更多相关主题
理解机器学习
原文:
www.kdnuggets.com/2017/06/making-sense-machine-learning.html
来源:Sebastian Raschka (sebastianraschka.com/Articles/2014_intro_supervised_learning.html)
机器学习如今备受关注,通常与大数据和人工智能(AI)相关联。但到底是什么呢?广义上讲,机器学习算法是用于模式识别、曲线拟合、分类和聚类的计算机算法。术语中的学习一词源于从数据中学习的能力。机器学习也广泛应用于数据挖掘和预测分析,一些评论者将其称为大数据。它还用于消费者调查分析,并不限于高容量、高速度数据或非结构化数据,也不一定与 AI 相关联。
实际上,许多营销研究人员熟悉的方法,例如回归分析和 k 均值聚类,也常被称为机器学习算法。例如,可以参考 Apache Spark 的机器学习库或本文最后一节中引用的书籍。为了简单起见,我将把回归分析和因子分析等知名统计技术称为较旧的机器学习算法,而将人工神经网络等方法称为较新的机器学习算法,因为它们通常对营销研究人员来说较不熟悉。
机器学习被用于许多领域,如地震学、医学研究、计算机网络安全和人力资源管理。以下是一些更常见的机器学习在营销中的应用方式:
-
预测客户购买某个产品的可能性;
-
估计客户在某个产品类别中的消费金额;
-
识别相对同质的消费者群体——消费者细分;
-
找出关键驱动因素(哪些服务元素最能预测客户满意度?);
-
在营销组合建模中(识别回报最大的营销活动);
-
用于推荐系统(例如,购买 John Grisham 的人也购买了 Scott Turow);
-
用于个性化定向广告;以及
-
在社交媒体分析中。
机器学习算法类型
目前有数百种机器学习算法,许多算法用于多种目的。有些机器学习算法非常复杂,而另一些则巧妙简单,可以以多种方式进行分类。以下是一些例子:
-
有监督的方法用于存在依赖变量的情况。回归分析和判别分析是有监督的方法。依赖变量通常被数据科学家称为标签。
-
有监督方法进一步按标签类型进行细分,标签可以是类别,例如购买者/非购买者,或数量,例如花费金额。在第一种情况下,判别分析是合适的,这在统计学中称为分类问题;在第二种情况下,回归分析是合适的,称为回归问题。
-
当没有依赖变量时,例如在聚类和因子分析中,使用无监督方法。
-
当数据在多个时间点收集时,例如每周或每日的销售数据,需要使用时间序列方法,如 ARMAX 和 GARCH。市场营销研究人员通常更熟悉横截面研究,例如一次性消费者调查。回归分析、判别分析和因子分析是分析横截面数据时常用的技术。
-
关联模式挖掘用于优化货架摆放和推荐系统。
-
还有许多专门的方法用于文本分析、社交网络分析、网站分析、流数据挖掘和异常检测(例如,检测信用卡欺诈)。
流行的机器学习方法
让我们快速了解四种较新的机器学习方法。请记住,关于机器学习已有许多详细的书籍,我在这里的目的是让你对一些较为流行的方法有一个初步的了解。
人工神经网络(ANN)是用于广泛用途的复杂且多才多艺的学习方法。虽然难以简单描述,但 ANN 的灵感来源于对人脑功能的认识。它们有多种类型,并用于分类、回归、聚类、文本挖掘以及各种实时分析。ANN 也经常是人工智能和深度学习的核心部分。缺点包括较长的运行时间、过拟合(对新数据预测不准确)的倾向,以及由于复杂性难以解释。神经网络和人工智能有时被交替使用,这具有误导性,因为其他机器学习方法也被用于人工智能软件中。
支持向量机(SVM)最初在 1960 年代初期的苏联被提出。尽管最初是为二元(两组)分类问题开发的,这些机器学习算法已经扩展到多组分类和定量因变量,现在被用于各种应用。像 ANN 一样,SVM 是复杂的,但基本思想——如这张图片所示——是构建一个或一组超平面,用于分类、回归和其他任务。运行时间可能非常长,特别是对于非常大的数据文件,建模者所做的选择对结果有很大影响(ANN 和许多其他工具也一样)。SVM 在机器学习社区中引起了相当大的兴趣,最近在这一领域有很多进展。
随机森林和 AdaBoost —— 自适应增强的简称——在数据科学家中非常受欢迎。它们最常见的实现方法使用了一个愚蠢委员会策略。随机森林速度快且适合并行计算。它易于使用,并且在预测组成员或数量方面表现良好。随机选择的样本(例如消费者)和变量用于构建数百或有时数千个弱学习器——这些小模型预测效果差但比随机预测要好——然后使用众数或中位数结果作为每个样本的预测结果。随机森林通常基于决策树,但也可以使用其他方法作为基础学习器。一个缺点是,随机森林可能过于简单,经验不足的建模者可能会倾向于选择它而不是其他表现更好的方法。
同样,AdaBoost 也是多用途的,并且不仅限于决策树作为基础学习器,尽管决策树运行速度快且通常足够好。与随机森林的主要区别在于,所有样本都会被使用,并根据预测难度进行加权,困难样本会在算法遍历数据时获得更多权重。对于非常嘈杂的数据,AdaBoost 可能会因为追逐离群点而表现不佳。和随机森林一样,提升方法有多种变体,其中一种,随机梯度提升,近年来变得特别受欢迎。
记住的关键点
有大量的机器学习算法在许多领域的各种分析中都很有用。有些算法仅在过去几年出现,而有些则是在几十年前开发的,正如我所指出的,机器学习本身的意义并不明确。最好的做法是当你不确定术语的使用时,询问具体细节。
没有单一的机器学习算法在所有情况下都能表现最好,因此通常会将多种算法结合起来。我所称之为较新方法的主要优点在于,它们在某些情况下可能更快、更易于使用或更准确。例如:
-
当变量数量非常庞大时;
-
当数据中存在强烈的曲线关系或交互作用时;
-
当较旧方法的统计假设严重违背时。
在这些情况下,较旧的方法仍然可以有效使用,但模型构建有时可能变得非常耗时。此外,一些较新的软件已针对特定用途——如文本分析——进行了设计,并且在这些用途上通常是更好的选择。
较新方法的一个缺点是,它们通常对理解产生数据的机制(例如,为什么某些类型的消费者会有这样的行为)帮助较小。大多数较新的机器学习算法不使用非专业人士可以容易理解的方程式或用简单的语言表达。另一方面,较旧的方法通常更具信息性。不过,并不是总是非此即彼,在一些项目中,我们可以通过使用较新的机器学习算法进行预测建模,而利用较旧的方法来阐明为什么和如何,从而兼得两者的优点。
较旧机器学习方法的另一个优点是,它们通常需要较小的训练样本就能在新数据上达到相同的准确度。大多数是在数据收集和处理成本高昂的时代开发的。这对于大多数市场研究人员分析小数据集时可能是一个很大的优势。
无论使用哪种方法或方法组合,我必须强调,机器学习不仅仅是按下 ENTER 键这么简单。定义项目的目标和目的,并拥有具备正确技能和经验的团队仍然至关重要。同样,机器学习算法只是整个过程的一部分,数据的设置和清理通常占用分析师相当一部分时间。 “数据、数据、数据:理解预测分析的作用” 提供了这一过程的快照以及一些应做和应避免的事项的提示。
额外资源
如果你有兴趣进一步了解这个主题,有很多资源可以参考,包括一些大学提供的大规模开放在线课程和正式的数据科学学位项目。对统计学有扎实的基础(按照通常的定义)也将非常宝贵——在我看来,这确实是一个很好的起点。
两个受欢迎的数据科学网站是 KDnuggets 和 Data Science Central。许多优秀的教科书也已出版。以下是我觉得有用的一些书籍:数据挖掘技术(Linoff 和 Berry);应用预测建模(Kuhn 和 Johnson);统计学习的元素(Hastie 等);数据挖掘:教科书(Aggarwal);以及 模式识别与机器学习(Bishop)。概率图模型(Koller 和 Friedman)和 人工智能(Russell 和 Norvig)是重要的卷册,也是机器学习和人工智能的权威参考书籍。
个人简介: Kevin Gray 是 Cannon Gray 的总裁,Cannon Gray 是一家市场科学和分析咨询公司。
原文。经许可转载。
相关:
-
统计建模:入门
-
文本分析:入门
-
数据科学家的神经科学:理解人类行为
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
端到端机器学习:从图像制作视频
评论
你可以将图像拼接成电影
ffmpeg -pattern_type glob -i '*.png' -y -c:v libx264 movie_name.mp4
或将电影的帧分解为图像
ffmpeg -i movie_name.mp4 img_%05d.png
视频是我们理解三维和时间变化信息的自然方式。这是我们导航世界的方式。将图像转换为视频是提升数据科学结果的好方法。它帮助你更清晰地沟通,并在过程中提供引人注目的 GIF。
你也可以反向操作,将视频转换为一系列图像。如果你想对视频进行逐帧分析,这会很有帮助,尤其是在机器学习应用中。
前提条件
-
安装 FFmpeg。这是一个强大的开源音视频处理工具。它有一系列令人眼花缭乱的神秘命令行选项,因此当你找到满足需求的选项时,这确实是一个 Wingardium Leviosa 时刻。它在 Linux、MacOS 和 Windows 上都可用。
-
确保所有图像的大小相同 - 即具有相同数量的像素行和列。
-
将所有你想用作视频帧的
.png图像放入一个目录中。
图像按文件名的字母顺序排列,并拼接成你的视频。
对于喜欢冒险的人,你可以对这个过程的每一步进行绝对控制。想要改变帧率?使用不同的视频文件类型?添加音乐?只需阅读 FFmpeg 文档。
你可以帮助保持开源的开放性
如果这个解决方案对你有效,考虑 向 FFmpeg 项目捐款。也许够买一杯咖啡。或者一台咖啡机。它用于维持他们的服务器运行。所有的人工工作都是捐赠的。
祝你视频制作顺利!
原文。经许可转载。
相关:
-
深度学习的预处理:从协方差矩阵到图像白化
-
使用 Numpy 和 OpenCV 进行基础图像数据分析 – 第一部分
-
掌握 Python 数据准备的 7 个步骤
我们的前 3 名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
更多相关主题
如何通过 AIOps 管理复杂的 IT 环境
原文:
www.kdnuggets.com/2022/05/manage-complex-landscape-aiops.html
我们能否通过机器学习和人工智能来管理 IT 运维,通过预测重大干扰事件并在服务中断发生之前解决这些问题?还是说用算法来运行 IT 运维过于复杂?答案是谨慎的肯定,我们可以用算法来运行 IT 运维并做出预测。这是因为随着 AI 和机器学习(ML)技术在这一特定领域的进步,IT 复杂性增加了管理各种业务应用程序和 IT 基础设施的需求和压力。因此,解决这一需求的答案当然是人工智能结合机器学习,换句话说,就是人工智能驱动的 IT 运维(AIOps)。
在这篇关于 AIOps 的首篇博客中,我们将深入探讨 AIOps 是什么,它如何提供无缝的企业 IT 服务以保持系统正常运转,以及人工智能、机器学习和数据科学原理如何被运用来实现这些目标。本文仅是对 AIOps 的初步概述,接下来的博客文章将详细阐述这一方法背后的技术背景和细节。
AIOps 的主要支柱
TOIL 正在消耗 IT 团队的精力
我们称之为 TOIL 的工作是指那些与运行生产服务相关的、手动的、重复的、可自动化的、战术性的、没有持久价值的工作,并且随着服务的增长而线性扩展 1。TOIL 会消耗 IT 团队的精力和时间,因为他们需要处理大量的数据、警报和任务。企业每天可能会有多达 1000 万个事件 2。因此,大量数据、流程和监控对业务的影响之间日益扩大的脱节,呼唤一种新的 IT 基础设施和服务管理与监控的方法。AIOps 就在这里发挥作用。
可观察性:对您的应用程序和服务进行深度可视化
在深入讨论 AIOps 之前,必须指出,对 IT 基础设施和系统状态进行良好的可观察性是必要的。能够将正确的数据输入到你的 AI 和机器学习模型中非常重要。可能需要一些基本的 IT 基础设施。我们将在下一篇关于领域专属和领域无关的 AIOps 平台的博客文章中详细讨论。这里的主要信息是:AIOps 需要对 IT 基础设施的每个方面以及所有连接的应用程序具有良好的可观察性和可视性,以捕获和监控整个 IT 环境中 IT 服务和应用程序之间的复杂互动。一旦某个组件缺失且未被监控或观察,当它停止正常工作时,找到根本原因将变得极其困难,因为你在那个部分没有“眼睛”和“耳朵”。话虽如此,让我们看看 AIOps 是如何工作的。

智能预测性 IT 运维管理
我们可以将 AIOps 定义为在 IT 运维中使用人工智能、机器学习和自动化,从而通过最小化人工操作干预来改变 IT 运维的管理方式。目标并不是将人类排除在外,相反,它是为了帮助人类操作员管理不断增加的 IT 运维复杂性。IT 复杂性有三个维度:
-
体量:IT 基础设施和业务应用程序生成的数据呈指数级增长。
-
多样性:不同类型的数据,如指标、日志、事件、跟踪、文档。
-
速度:数据生成的速度正在迅速增长。
为了在重大事件和大量警报面前保持领先,需要预测性、自动化的统计工具来应对 IT 复杂性三大维度所带来的挑战。仅凭人类能力无法提供合适的解决方案。
AIOps 解决方案旨在实现这些目标。我们可以将不同平台/供应商的 AIOps 解决方案概括为四项原则:
-
高级数据处理和分析:对大数据进行实时流分析和历史数据分析,以训练 AI 和机器学习模型。
-
拓扑数据分析:绘制和发现 IT 环境中的所有 IT 资产和应用程序。
-
事件和其他相关数据的关联:将时间和 IT 网络拓扑映射到集群相关事件。此外,通过不断学习数据的行为来发现模式和预测事件或事故。关联分析对于自动化有效、精准的根本原因分析在 IT 服务问题和事故中至关重要。
-
自动修复: 在通过 AI 和 ML 持续监控 IT 环境的同时,如果发生异常行为和 IT 问题,AIOps 会推荐人类操作员采取某些措施,或者在启用的情况下,触发自动修复以即时解决问题。
异常检测作为 AIOps 的核心
AIOps 的基本动态是,机器学习算法可以检测和预测可能导致 IT 服务问题的异常,如服务中断或重大干扰事件。此外,根据预测和高级数据处理,可以创建更准确的动态阈值、规则、统计基线、事件和警报。在后续的一系列博客文章中,我们将深入探讨这些先进复杂的过程是如何实现的。
总结我们对 AIOps 的全景视角
在这篇博客文章中,我简要概述了如何利用 AI 和机器学习算法管理 IT 运营。即将到来的博客系列将深入探讨我们在这里讨论的每一个概念,并提供更技术性的概述。请继续关注,加入我们的 AIOps 之旅!
Akif Baser 是一位多学科工程师,对人工智能和计量经济学的研究与开发充满热情。
更多相关话题
如何管理 Python 中的多重继承
原文:
www.kdnuggets.com/2022/03/manage-multiple-inheritance-python.html

图片由 Hitesh Choudhary 在 Unsplash 提供
高级 面向对象编程语言 如 C# 和 Java 不支持多重继承。这也是有原因的。它避免了模糊性,促进了强类型和封装。这最终导致了更清晰的代码和更少令人困惑的类/对象模型结构。然而,多重继承允许更多灵活的设计模式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
它也可以非常方便,让程序员编写更少的代码,更快地推向生产。然而,当你处理大型、复杂的应用程序(特别是与机器学习相关的应用程序)时,多重继承可能会很难管理和维护。在本指南中,我们将学习如何使用多重继承并使其可持续。
Python 中的多重继承
与 C++ 类似,Python 中的类可以从多个类派生(而不仅仅是一个)。派生类继承所有父类的特性(变量和方法/函数)。实际上,定义一个具有多重继承的类与定义一个具有单一继承的类没有什么不同。以下是一个示例来帮助说明这一点:
单一继承
class Parent:
pass
class Child(Parent):
pass
多重继承
class Parent1:
pass
class Parent2:
pass
class Child(Parent1, Parent2):
pass
由于子类从两个类派生,它继承了这两个类的特性。当然,你可以从多个类继承。从理论上讲,构建子类时可以使用的类数没有限制。
多级继承
与大多数面向对象编程语言一样,Python 具有多级继承。如果你的子类是从一个继承了另一个类特性的类派生的,它将继承两个类的所有特性。
图 1
从上面的图示可以看出,类层次结构中最低的类继承了两个上层类的所有函数/方法和变量。结合多重继承,多层继承可以为开发者提供灵活的设计选项。它们还可以增加代码的重用性。然而,它们也可能使类结构变得更复杂。
例如,如果你使用一个与超类或基类中的方法具有相同名称和结构的特性(方法或变量),那么从子类中将首先调用哪个方法?你的类层次结构中可能有相同名称和签名的函数和变量。Python 是如何处理这种情况的?
方法解析顺序
再次说明,与大多数面向对象(OO)编程语言一样,所有类都派生自一个单一的类。在 Python 中,这被称为对象类。因此,默认情况下,你创建的每一个类都是 Object 类的子类/派生类/子类。在尝试理解 Python 中方法和变量的调用顺序时,你必须始终记住这些信息,以便绘制程序的方法调用顺序图。
由于 Python 特性包括多重和多层继承,它需要一个系统来解决继承冲突,其中相同的属性在多个基类/超类中具有不同的定义。理解这一点的最佳方式是查看一个编码示例:
class A:
num = 10
class B(A):
pass
class C(A):
num = 1
class D(B,C):
pass
类 A 继承自 Object 类(正如 Python 中的所有类一样)。类 B 使用类 A 作为基类。它没有自己的特性。然而,它确实从类 A 继承了 num 类对象属性(以及来自对象类的其他特性)。
类 C 也是类 A 的子类,并定义了一个类对象属性,该属性与类 A 中定义的一个属性同名。类 D 从 D 和 C 继承,但没有定义自己的属性。关系看起来像这样:
图 2
上面的图示说明了所谓的钻石问题(或致命的钻石问题)。方法解析顺序(MRO)是一种解决这个问题的规则。它使用 MRO 来组织方法和属性的调用。
注意:图 2 不是严格的依赖图。它展示了继承的流程。
让我们添加一个引用 D 类继承的 num 属性的方法。这个方法应该在所有类之外被调用。
print(D.num)
如果我们将其与之前的代码一起运行,它应该返回数字 1 作为输出。你可能会发现它是类 C 中 num 属性的值。但为什么会返回这个特定的属性和值呢?
MRO 从当前类开始进行属性搜索,然后移动到父类。如果有多个父类,MRO 将从左到右进行搜索。因此,在我们的示例中,搜索将按照以下顺序进行:D -> B -> C -> A -> object 类。
虽然像构建商业计划那样详细构建一个依赖图或类图会很有帮助,但这并非必要。你可以简单地使用 Python 内置的mro()方法来查找解析顺序。
如果我们对 D 类运行 mro() 方法并打印输出(即 print(D.mro())),控制台应显示以下结果:
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
再次翻译为:D -> B -> C -> A -> object 类。然而,对于如上所述的简单钻石问题,这很容易理解。然而,如果你得到:
图 3(来源:维基媒体公用领域 (CC) 许可)
MRO 使用称为深度优先搜索的算法来解析所有方法和属性调用。Python 的最新版本修订了 MRO 的工作方式。目前还不确定 Python 的类路径规则和 MRO 是否会在未来的版本中得到完善。因此,许多开发者(包括我自己)建议你避免构建过多的多重和多层次继承的程序或算法。
如果你编写的代码具有类似于上述图示的依赖结构,可以认为你写了坏代码。实际上,这个指南中的示例几乎没有类之间的真实功能代码。然而,这些结构仍然令人困惑。现在,假设你定义了具有相同结构的方法和属性并开始调用它们……
结论
虽然 MRO 存在并且每个 Python 开发者都应该理解它,但你的代码不应该像图 3 那样结构化。然而,作为开发者(特别是从事机器学习的开发者),你很可能会遇到具有复杂依赖关系的类结构。使用mro()方法应有助于你调试、解开和理解你可能没有编写的代码。
Python 相对于其他面向对象编程语言的主要优势在于其灵活性和自由度。然而,这种流动性也可能被视为一个劣势。错误和低效代码的空间过大。因此,程序员,特别是那些从事机器学习和深度学习的程序员,应学习和应用最优化的设计模式。尽管如此,为了安全起见,你可以选择完全避免在代码中使用多重继承。然而,如果你决定实现它,请谨慎且节俭地使用。
Nahla Davies 是一位软件开发者和技术写作专家。在全职投入技术写作之前,她曾担任一家 Inc. 5000 体验品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
管理机器学习周期:从比较数据科学实验/协作工具中获得的五个经验
原文:
www.kdnuggets.com/2020/01/managing-machine-learning-cycles.html
评论
由 Dr. Michael Eble 提供,hlthfwd 的联合创始人及总经理。
机器学习项目需要处理不同版本的输入数据、源代码、超参数、环境配置等。通常,在机器学习模型可以投入生产之前,需要计算许多模型迭代。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
在实验过程中,其工件及其相互依赖关系会增加数据科学项目的复杂性。为了管理这种复杂性,我们需要适当的结构和流程以及涵盖机器学习周期的足够软件工具。
如果你遇到类似的挑战,从比较这些工具中获得的经验可能对你有帮助。你可以在文章末尾找到我们原始数据的链接。
问题陈述和用例
对我们来说,相应的工具需要涵盖以下用例,并且适应典型的机器学习工作流:
-
在机器学习周期中,我们需要跟踪输入数据、源代码、环境配置、超参数和性能指标的来源及其变化。
-
此外,我们还需要比较工件的差异,以分析不同方法的效果。
-
此外,我们需要能够内部和外部解释最终投入生产的模型是如何构建的。
-
最终,能够协作和复现迭代是重要的(即使或特别是当团队成员离开项目/公司时)。
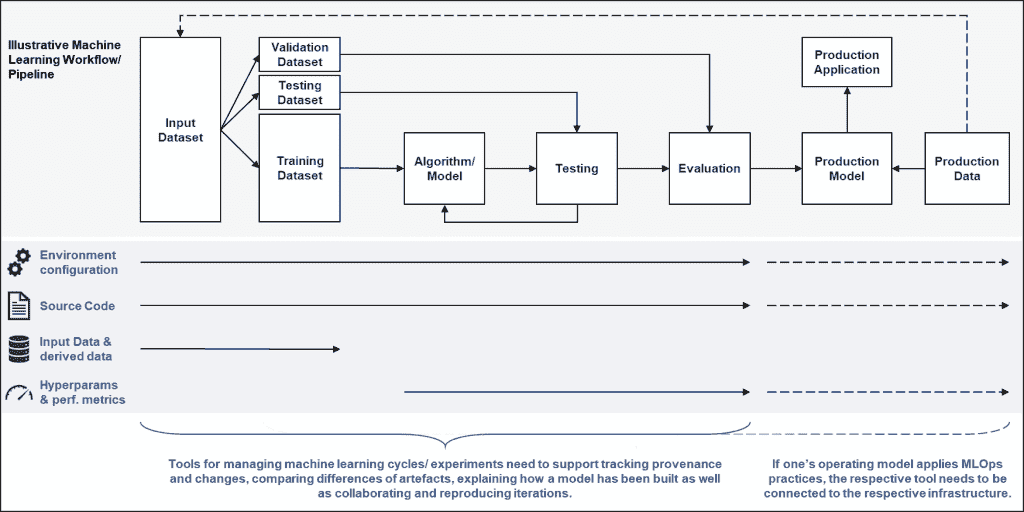
考虑或排除的工具

我们发现,AI、dotscience、MLFlow 和 Polyaxon 针对大型企业,而 Comet.ml、Neptune.ml 以及 Weights and Biases 面向较小的组织/初创公司。
选择标准
-
支持的库和框架:该工具与哪些机器学习/深度学习框架和库(在 Python 生态系统内)兼容?到目前为止,我们主要使用 TensorFlow 和 Keras。然而,切换到 Caffe2 和 PyTorch 是可能的。
-
与基础设施的集成:该工具支持哪些类型的基础设施?这对于将模型投入生产以及例如从 Google 迁移到 Amazon 等迁移路径的实现是相关的。
-
指标和参数的跟踪:该工具记录了哪些性能指标(例如准确率)?它跟踪了哪些附加元数据?该标准涵盖超参数(例如批量大小)、环境配置等。
-
额外功能:该工具是否跟踪输入数据、代码等的变化?它提供了哪些自动化超参数优化的方法?关于在团队内导出和共享实验数据的功能如何?
-
商业模型/社区:工具可作为开源版本和/或商业版本提供。关于开源,相关 GitHub 仓库的维护活跃程度如何?在商业提供方面,业务模型是什么样的?
选择过程中的收获
-
支持的库和框架:所有考虑支持 TensorFlow 和 Keras 的工具。在大多数情况下(10 个中的 8 个),scikit-learn 也得到支持。至于 Caffe2 和 PyTorch,只有 Comet.ml 和 Polyaxon 似乎支持这些工具。一些工具还附带对 MXNet、Chainer、Theano 等的额外支持。
-
与基础设施的集成:几乎所有工具覆盖了广泛的基础设施组件——从 AWS、AML 和 GCP 到 Docker 和 Kubernetes。特别是 MLFlow、Neptune.ml 和 Polyaxon 满足了各种需求。然而,似乎没有工具支持 CNTK。工具允许在本地或 PaaS/SaaS 上部署,有些工具提供了这两种选项。
-
指标和参数的跟踪:所有工具跟踪常见的性能指标(准确率、损失、训练时间等)和超参数(批量大小、层数、优化器名称、学习率等)。例如,MLFlow 还允许用户定义指标。模型图形等的可视化在几个工具中都是可能的。
-
额外功能:查看代码和数据源差异是常见的——Comet.ml、dotscience、Guild 和 MLFlow 提供了这种功能,仅举几例。在至少四种情况下,这包括与 GitHub 仓库的集成。五种工具提供基于网格、随机、贝叶斯、自适应和/或 Hyperband 搜索方法的超参数优化。关于共享和协作,Jupyter 和专有数据空间是首选接口。
-
商业模型/社区:Comet.ml、Determined AI、dotscience、Neptune.ml,以及 Weights and Biases,均提供专有许可证和相应的支付方案。Guild、MLFlow、Sacred 和 StudioML 是开源的——要么是 Apache 2.0 许可证,要么是 MIT 许可证。从贡献者、分支、观察者和 GitHub 上的星标数量来看,MLFlow 似乎拥有最活跃的社区。Polyaxon 提供其软件的商业版本和开源版本。
数据收集和数据来源/参考
关于这些工具的信息是在 2019 年第三季度和第四季度收集的,并逐步更新。我们尚未完全完成对所有入围工具的动手测试,但审查了相关网站、GitHub 仓库和文档。进一步的调查涉及数据可视化、服务器位置(在 PaaS/SaaS 的情况下)等方面。
你可以从 GitHub 下载包含更详细数据的完整 电子表格。
简介: 迈克尔·艾布尔博士 是德国一家数字健康初创公司的联合创始人,负责其数据驱动的商业模型。在当前职位之前,迈克尔曾是 管理咨询公司 mm1 的首席顾问,并负责该咨询公司的“数据思维”实践。他领导了在电信和移动等行业的项目团队,重点是新产品开发。迈克尔拥有经济学和管理学硕士学位,以及计算语言学和媒体研究硕士学位。他在波恩大学获得博士学位,同时在 弗劳恩霍夫 IAIS 研究所 执行数据分析项目。迈克尔目前正在完成计算机科学的学习,并撰写关于医疗领域机器学习的硕士论文。
相关:
更多相关内容
使用 Scikit-learn Pipelines 管理机器学习工作流 第一部分:温和的介绍
原文:
www.kdnuggets.com/2017/12/managing-machine-learning-workflows-scikit-learn-pipelines-part-1.html
评论

你熟悉 Scikit-learn Pipelines 吗?
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
它们是管理机器学习工作流的极其简单但非常有用的工具。
一个典型的机器学习任务通常涉及不同程度的数据准备。我们不会在这里深入探讨数据准备的各种活动,但有很多。这些任务以占用大量机器学习任务时间而闻名。
在数据集从潜在的初始大混乱状态中清理干净之后,仍然有几个较不密集但同样重要的变换数据预处理步骤,如 特征提取、特征缩放 和 降维,仅举几例。
也许你的预处理只需要其中一种转换,比如某种形式的缩放。但也许你需要将多个转换串联起来,并最终用某种估算器完成。这就是 Scikit-learn Pipelines 可以提供帮助的地方。
Scikit-learn 的 Pipeline 类 旨在以可管理的方式应用一系列 数据转换,然后应用 估算器。事实上,这就是它的全部功能:
转换管道与最终估算器。
就是这样。最终,这个简单的工具对以下内容非常有用:
-
创建连贯且易于理解的工作流的便利性
-
强制执行工作流实施和步骤应用的期望顺序
-
可重复性
-
持久化整个管道对象的价值(涉及到可重复性和便利性)
那么让我们快速了解管道。具体来说,我们将做以下事情。
构建 3 个管道,每个使用不同的估计器(分类算法),采用默认超参数:
为了演示管道转换,将进行:
-
特征缩放
-
降维,使用 PCA 将数据投影到二维空间
然后我们将以拟合我们的最终估计器来结束。
之后,几乎完全不相关,为了让它更像一个完整的工作流(虽然还不是,但更接近),我们将:
-
跟进评分测试数据
-
比较管道模型的准确性
-
确定“最佳”模型,即在我们的测试数据上准确度最高的模型
-
持久化(保存到文件)“最佳”模型的整个管道
当然,由于我们将使用默认超参数,这可能不会产生最准确的模型,但它会提供如何使用简单管道的感觉。我们将在之后回到更复杂的建模、超参数调整和模型评估的问题上。
哦,为了额外的简便,我们使用了鸢尾花数据集。代码注释完善,应该很容易跟随。
让我们运行我们的脚本,看看会发生什么。
$ python3 pipelines.py
Logistic Regression pipeline test accuracy: 0.933
Support Vector Machine pipeline test accuracy: 0.900
Decision Tree pipeline test accuracy: 0.867
Classifier with best accuracy: Logistic Regression
Saved Logistic Regression pipeline to file
所以,这就是它;一个简单的 Scikit-learn 管道实现。在这个特定的案例中,我们基于逻辑回归的管道使用默认参数取得了最高准确率。
如上所述,这些结果可能并不代表我们的最佳努力。如果我们想测试一系列不同的超参数怎么办?我们可以使用网格搜索吗?我们可以引入自动化方法来调整这些超参数吗?AutoML 可以融入这个过程吗?使用交叉验证怎么样?
在接下来的几篇文章中,我们将关注这些额外的问题,并看看这些简单的部分如何组合在一起,使管道比初始示例看起来更强大。
相关:
-
掌握 Python 数据准备的 7 个步骤
-
从零开始的 Python 机器学习工作流第一部分:数据准备
-
从零开始的 Python 机器学习工作流第二部分:k-means 聚类
主题更多
使用 Scikit-learn 管道管理机器学习工作流第二部分:集成网格搜索
原文:
www.kdnuggets.com/2018/01/managing-machine-learning-workflows-scikit-learn-pipelines-part-2.html
评论

在我们上一篇文章中,我们讨论了 Scikit-learn 管道作为简化机器学习工作流的方法。管道设计为一种可管理的方式,先进行一系列数据转换,然后应用估计器,管道被认为是一个简单的工具,主要用于:
-
创建连贯且易于理解的工作流的便利性
-
强制执行工作流实施和所需步骤应用的顺序
-
可复现性
-
完整管道对象的持久性价值(涉及可复现性和便利性)
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持组织的 IT
另一个可以与管道配对以提高性能的简单但强大的技术是网格搜索,它尝试优化模型超参数组合。详尽的网格搜索——与随机优化等替代超参数组合优化方案不同——测试和比较所有可能的期望超参数值组合,这是一个指数增长的过程。在可能最终导致高昂运行时间的权衡中,所期望的是尽可能优化的模型。
来自官方文档:
GridSearchCV 提供的网格搜索会根据 param_grid 参数指定的参数值网格生成候选项。例如,以下 param_grid:
param_grid = [ {'C': [1, 10, 100, 1000], 'kernel': ['linear']}, {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}, ]指定应该探索两个网格:一个是线性核和 C 值在 [1, 10, 100, 1000] 之间,另一个是 RBF 核,C 值的交叉乘积范围在 [1, 10, 100, 1000] 之间,gamma 值在 [0.001, 0.0001] 之间。
首先回顾一下上一篇文章中的代码,并运行修改后的摘录。由于这次练习中我们将使用一个单独的管道,所以不需要像上一篇文章那样使用完整的集合。我们将再次使用鸢尾花数据集。
让我们将这个非常简单的管道实现起来。
$ python3 pipelines-2a.py
以及模型返回的准确性和超参数:
Test accuracy: 0.867
Model hyperparameters:
{'min_impurity_decrease': 0.0, 'min_weight_fraction_leaf': 0.0, 'max_leaf_nodes': None, 'max_depth': None,
'min_impurity_split': None, 'random_state': 42, 'class_weight': None, 'min_samples_leaf': 1, 'splitter': 'best',
'max_features': None, 'presort': False, 'min_samples_split': 2, 'criterion': 'gini'}
再次注意,我们正在应用特征缩放、降维(使用 PCA 将数据投影到二维空间),最后应用我们的最终估算器。
现在让我们将网格搜索添加到我们的管道中,希望能够优化模型的超参数并提高其准确性。默认模型参数是否是最佳选择?让我们来找出答案。
由于我们的模型使用决策树估算器,我们将使用网格搜索来优化以下超参数:
-
criterion - 这是用于评估分割质量的函数;我们将使用 Scikit-learn 中的两个选项:基尼不纯度和信息增益(熵)
-
min_samples_leaf - 这是构成有效叶节点所需的最小样本数;我们将使用整数范围 1 到 5
-
max_depth - 这是树的最大深度;我们将使用整数范围 1 到 5
-
min_samples_split - 这是拆分非叶节点所需的最小样本数;我们将使用整数范围 1 到 5
-
presort - 这指示是否预排序数据以加速在拟合过程中找到最佳分割;这不会影响最终模型的准确性(仅影响训练时间),但为了在网格搜索模型中使用 True/False 超参数而被包含在内(有趣吧?!?)
这是在我们调整的管道示例中使用详尽的网格搜索的代码。
重要的是,请注意我们的管道是网格搜索对象中的估算器,且模型是在网格搜索对象的层级中拟合的。还要注意我们的网格参数空间在一个字典中定义,然后传递给我们的网格搜索对象。
在网格搜索对象创建过程中还发生了什么?为了对结果模型进行评分(潜在有 2 * 5 * 5 * 5 * 2 = 500 种),我们将引导网格搜索通过在测试集上的准确性来评估它们。我们还指定了 10 折的交叉验证拆分策略。请注意有关 GridSearchCV 的以下内容:
用于应用这些方法的估算器的参数通过对参数网格进行交叉验证网格搜索来优化。
最终,当然,我们的模型已拟合。
你可以查看官方的 GridSearchCV 模块文档,以获取所有其他有用配置的信息,包括但不限于并行处理。
让我们试试看。
$ python3 pipelines-2b.py
这是结果:
Best accuracy: 0.925
Best params:
{'clf__min_samples_split': 2, 'clf__criterion': 'gini', 'clf__max_depth': 2,
'clf__min_samples_leaf': 1, 'clf__presort': True}
脚本报告了最高的准确度(0.925),这显然比默认的 0.867 要好,并且额外的计算量并不多,至少在我们的玩具数据集上是这样。我们包括 500 个模型的详尽方法在强大的数据集上可能会有更严重的计算影响,正如你所想象的那样。
脚本还报告了具有最高准确度的模型的最佳超参数配置,如上所示。在我们的简单示例中,这种差异应该足以表明,不应盲目跟随 Scikit-learn 的默认设置。
这一切看起来过于简单。确实是。Scikit-learn 使用起来几乎过于简单,只要你知道有哪些选项。我们使用玩具数据集也没有让它看起来更复杂。
不妨这样看:管道和网格搜索就像巧克力和花生酱一样相互配合,现在我们已经了解了它们如何一起工作,接下来我们可以挑战一些更复杂的问题。更复杂的数据?当然可以。比较各种估算器和每个估算器的大量参数搜索空间,以找到“真正的”最优化模型?为什么不呢?将管道转换组合起来,既有趣又有利?是的!
下次加入我们,我们将超越配置和玩具数据集的基础知识。
相关:
-
使用 Scikit-learn 管道管理机器学习工作流 第一部分:温和的介绍
-
掌握 Python 数据准备的 7 个步骤
-
从零开始的 Python 机器学习工作流 第一部分:数据准备
了解更多相关主题
管理机器学习工作流程与 Scikit-learn 管道 第三部分:多个模型、管道和网格搜索
原文:
www.kdnuggets.com/2018/01/managing-machine-learning-workflows-scikit-learn-pipelines-part-3.html
评论
首先,我知道我在上篇文章中承诺我们会结束玩具数据集,但为了比较目的,我们将继续使用鸢尾花数据集。我认为我们应该在整个过程中保持一致,进行“苹果对苹果”的比较。

到目前为止,在前两篇文章中,我们已经:
-
介绍了 Scikit-learn 管道
-
通过创建和比较一些管道,展示了它们的基本用法。
-
介绍了网格搜索
-
通过使用网格搜索来寻找优化的超参数,并将其应用到嵌入式管道中,展示了管道和网格搜索如何协同工作。
下面是我们计划继续的内容:
-
在这篇文章中,我们将使用网格搜索来优化由多种不同类型的估算器构建的模型,然后对这些模型进行比较。
-
在后续文章中,我们将转向使用自动化机器学习技术来协助优化模型超参数,最终结果将是一个自动生成的、优化的 Scikit-learn 管道脚本文件,由TPOT提供。
这次不会有太多需要重新解释的内容;我建议你阅读本系列的第一篇文章以获得 Scikit-learn 管道的入门介绍,并阅读本系列的第二篇文章以了解如何将网格搜索集成到管道中。我们现在要做的是构建一系列不同估算器的管道,使用网格搜索进行超参数优化,然后比较这些不同的“苹果与橙子”以确定最准确的(“最佳”)模型。
下面的代码注释良好,如果你已经阅读了前两篇文章,应该容易跟随。
请注意,这里有很多重构的机会。例如,每个管道都被显式地定义,而可以使用一个简单的函数作为生成器;网格搜索对象也是如此。长形式的代码希望在下一篇文章中提供更好的“苹果对苹果”比较。
让我们试试看。
$ python3 pipelines-3.py
下面是输出结果:
Performing model optimizations...
Estimator: Logistic Regression
Best params: {'clf__penalty': 'l1', 'clf__C': 1.0, 'clf__solver': 'liblinear'}
Best training accuracy: 0.917
Test set accuracy score for best params: 0.967
Estimator: Logistic Regression w/PCA
Best params: {'clf__penalty': 'l1', 'clf__C': 0.5, 'clf__solver': 'liblinear'}
Best training accuracy: 0.858
Test set accuracy score for best params: 0.933
Estimator: Random Forest
Best params: {'clf__criterion': 'gini', 'clf__min_samples_split': 2, 'clf__max_depth': 3, 'clf__min_samples_leaf': 2}
Best training accuracy: 0.942
Test set accuracy score for best params: 1.000
Estimator: Random Forest w/PCA
Best params: {'clf__criterion': 'entropy', 'clf__min_samples_split': 3, 'clf__max_depth': 5, 'clf__min_samples_leaf': 1}
Best training accuracy: 0.917
Test set accuracy score for best params: 0.900
Estimator: Support Vector Machine
Best params: {'clf__kernel': 'linear', 'clf__C': 3}
Best training accuracy: 0.967
Test set accuracy score for best params: 0.967
Estimator: Support Vector Machine w/PCA
Best params: {'clf__kernel': 'rbf', 'clf__C': 4}
Best training accuracy: 0.925
Test set accuracy score for best params: 0.900
Classifier with best test set accuracy: Random Forest
Saved Random Forest grid search pipeline to file: best_gs_pipeline.pkl
重要的是,在我们拟合估计器后,我们测试了每个网格搜索的最佳参数在测试数据集上的效果。这是我们在上一篇文章中没有做的,尽管我们在比较不同模型,但鉴于引入了其他概念,之前关键的步骤——在之前未见的测试数据上比较不同模型——直到现在才被忽略。我们的例子证明了这一步骤的必要性。
如上所示,在我们的训练数据中表现“最佳”的模型是支持向量机(不使用 PCA),使用线性核和 C 值为 3(控制正则化量),它能够准确分类 96.7% 的训练实例。然而,在测试数据中表现最佳的模型(我们数据集中 20%在训练后对所有模型都是未见过的数据)是随机森林(不使用 PCA),使用基尼标准,最小样本分裂数为 2,最大深度为 3,叶节点的最小样本数为 2,能够准确分类 100% 的未见数据实例。请注意,该模型的训练准确率较低,为 94.2%。
因此,除了观察我们如何混合和匹配各种不同的估计器类型、网格搜索参数组合和数据转换,以及如何准确比较训练后的模型外,显然评估不同模型时应始终包括在之前未见的保留数据上进行测试。
对管道感到厌倦了吗?下次我们将探讨一种替代的方法来自动化它们的构建。
相关:
-
使用 Scikit-learn 管理机器学习工作流第一部分:简要介绍
-
使用 Scikit-learn 管理机器学习工作流第二部分:整合网格搜索
-
使用遗传算法优化递归神经网络
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT 工作
相关主题
使用 AutoML 生成带 TPOT 的机器学习管道
原文:
www.kdnuggets.com/2018/01/managing-machine-learning-workflows-scikit-learn-pipelines-part-4.html
评论
到目前为止,在这一系列文章中,我们已经:
-
介绍了 Scikit-learn 的管道
-
展示了如何将网格搜索和管道结合起来,成为一个强大的工具进行超参数优化
-
演示了众多模型、管道和网格搜索的组合,以及它们的评估和选择
这篇文章将采用一种不同的方法来构建管道。显然,标题揭示了这种不同:我们将不再亲自手动构建管道和进行超参数优化,也不再亲自进行模型选择,而是将自动化这些过程。我们将使用自动化机器学习工具 TPOT 来完成一些繁重的工作。

但首先,什么是自动化机器学习(AutoML)?
数据科学家及自动化机器学习的主要倡导者 Randy Olson 表示,有效的机器学习设计要求我们:
- 始终调整我们模型的超参数
- 始终尝试许多不同的模型
- 始终探索我们数据的多种特征表示
因此,从根本上说,我们可以认为 AutoML 是算法选择、超参数调整、迭代建模和模型评估的任务。
为了了解为什么会这样,可以参考人工智能研究员和斯坦福大学博士生 S. Zayd Enam 在其精彩博客文章《为什么机器学习“难”?》中写到的内容:
难点在于,机器学习是一个根本上难以调试的问题。机器学习的调试发生在两种情况:1)你的算法不起作用,或者 2)你的算法效果不够好。[...] 极少有算法第一次就能成功,因此这成为了构建算法时花费大部分时间的地方。
基本上,如果一个算法不起作用,或者效果不够好,而选择和优化的过程变得迭代,这就暴露了自动化的机会,因此自动化机器学习应运而生。
我曾尝试捕捉AutoML 的本质,如下所示:
如果,正如Sebastian Raschka 所描述的,计算机编程是关于自动化的,而机器学习是“关于自动化自动化的”,那么自动化机器学习就是“自动化自动化的自动化”。跟随我,在这里:编程通过管理机械任务来减轻我们的负担;机器学习允许计算机学习如何最好地执行这些机械任务;自动化机器学习允许计算机学习如何优化学习如何执行这些机械操作的结果。
这是一个非常强大的想法;虽然我们以前必须担心调整参数和超参数,但自动化机器学习系统可以通过多种不同的方法学习调整这些参数以获得最佳结果。
AutoML 的基本原理来自这个想法:如果必须构建众多机器学习模型,使用各种算法和不同的超参数配置,那么这个模型构建过程可以自动化,模型性能和准确性的比较也可以自动化。
那么我们实际如何做到这一点?TPOT是一个 Python 工具,它“自动创建和优化机器学习管道,使用遗传编程。” TPOT 与 Scikit-learn 协同工作,自我描述为 Scikit-learn 的包装器。TPOT 是开源的,用 Python 编写,旨在通过基于遗传编程的 AutoML 方法简化机器学习过程。最终结果是自动化超参数选择、使用各种算法建模以及探索众多特征表示,所有这些都导致了迭代模型构建和模型评估。
你可以在这里阅读关于使用 TPOT 的更多信息,并且可以在这里阅读与项目(前)首席开发者的访谈。
现在回到我们讨论的话题。我们有兴趣使用 TPOT 为我们生成优化的机器学习管道。你可能会对这样做的简单性感到惊讶。
代码:
请注意,我们几乎需要的一切都可以通过这一行完成:
tpot = TPOTClassifier(generations=10, verbosity=2)
这开始了基于遗传编程的超参数选择、使用各种算法建模以及特征表示探索。结果应该是一个优化的模型。
完成后,TPOT 将显示“最佳”模型(基于测试数据准确性)的超参数,并将管道输出为一个可以执行的 Python 脚本文件,以便于后续使用和进一步调查。
让我们用这个代码运行一下:
$ python3 tpot_test.py
事情是这样的:
Generation 1 - Current best internal CV score: 0.9833333333333332
Generation 2 - Current best internal CV score: 0.9833333333333332
Generation 3 - Current best internal CV score: 0.9833333333333332
Generation 4 - Current best internal CV score: 0.9833333333333332
Generation 5 - Current best internal CV score: 0.9833333333333332
Generation 6 - Current best internal CV score: 0.9833333333333332
Generation 7 - Current best internal CV score: 0.9833333333333332
Generation 8 - Current best internal CV score: 0.9833333333333332
Generation 9 - Current best internal CV score: 0.9833333333333334
Generation 10 - Current best internal CV score: 0.9833333333333334
Best pipeline: XGBClassifier(RobustScaler(PolynomialFeatures(XGBClassifier(LogisticRegression(input_matrix, C=10.0, dual=False, penalty=l2), learning_rate=0.001, max_depth=6, min_child_weight=9, n_estimators=100, nthread=1, subsample=0.9000000000000001), degree=2, include_bias=False, interaction_only=False)), learning_rate=0.01, max_depth=4, min_child_weight=13, n_estimators=100, nthread=1, subsample=0.9000000000000001)
TPOT classifier finished in 409.84891986846924 seconds
Best pipeline test accuracy: 1.000
就这样。这个过程花费了不到 7 分钟,结果基于 XGBoost 的管道能够准确分类 100%的测试数据实例。这显然是一个玩具数据集,遗传过程中的交叉验证分数几乎没有改变,但既然我们已经使用鸢尾花数据进行了一系列管道构建(包括使用 TPOT),我们绝对准备好向其他数据迈进了。
上述执行生成了这个 Python 管道脚本并将其保存为 tpot_iris_pipeline.py:
记住 TPOT 使用遗传算法进行优化,因此后续执行会产生不同的结果。不要怪我,怪进化。
这个过程可能引发了更多的问题而非答案,特别是如果你对模型优化的自动化方法感到陌生的话。我们将在未来的文章中重新审视这些概念。目前只需记住,AutoML 从一个例子来看,可能似乎是一个强大的模型优化工具。
你可能想通过阅读 自动化机器学习的当前状态 来跟进,这是一篇我一年前写的文章,但仍然相关。
相关:
-
使用 Scikit-learn 管道管理机器学习工作流第一部分:温和的介绍
-
使用 Scikit-learn 管道管理机器学习工作流第二部分:集成网格搜索
-
使用 Scikit-learn 管道管理机器学习工作流第三部分:多个模型、管道和网格搜索
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
更多相关主题
在生产中管理模型漂移与 MLOps
原文:
www.kdnuggets.com/2023/05/managing-model-drift-production-mlops.html
机器学习模型是强大的工具,可以帮助企业做出更明智的决策并优化运营。然而,随着这些模型的部署和运行,它们会受到称为模型漂移的现象的影响。
模型漂移发生在机器学习模型的性能因底层数据的变化而随着时间下降,导致不准确的预测,并可能对企业产生重大影响。为了解决这一挑战,组织正在转向 MLOps,这是一套帮助管理生产机器学习生命周期的实践和工具。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在这篇文章中,我们将深入探讨模型漂移、不同类型的模型漂移、如何检测模型漂移以及最重要的,如何在生产中使用 MLOps 来处理模型漂移。通过理解和管理模型漂移,企业可以确保其机器学习模型随时间保持准确和有效,提供他们所需的洞察和结果以蓬勃发展。

图片由 Nicolas Peyrol 提供,来源于 Unsplash
什么是模型漂移?
模型漂移,也称为模型衰退,是一种机器学习现象,指模型性能随着时间的推移而降低。这意味着模型会逐渐开始给出不准确的预测,从而导致准确性随时间降低。
模型漂移的原因有很多,例如数据收集的变化或变量之间的基本关系变化。因此,模型无法捕捉这些变化,随着变化的增加,性能会下降。
发现和解决模型漂移是 MLOps 解决的基本任务之一。技术如模型监控被用来检测模型漂移的存在,而模型重新训练是克服模型漂移的主要技术之一。
漂移的类型
理解模型漂移的类型对于根据数据变化更新模型至关重要。模型漂移主要有三种类型:
概念漂移
概念漂移发生在目标与输入之间的关系发生变化时。因此,机器学习算法将无法提供准确的预测。概念漂移主要有四种类型:
-
突发漂移:如果自变量与因变量之间的关系突然发生变化,就会发生突发概念漂移。一个非常著名的例子是新冠疫情的突然爆发。疫情的发生突然改变了目标变量与不同领域特征之间的关系,因此,基于预训练数据的预测模型将无法在疫情期间提供准确的预测。
-
渐进漂移:在渐进概念漂移中,输入与目标之间的关系可能会缓慢而微妙地变化。这会导致机器学习模型的性能缓慢下降,因为模型随着时间推移变得不那么准确。渐进概念漂移的一个例子是欺诈行为。欺诈者往往会了解欺诈检测系统的工作原理,并随着时间的推移调整自己的行为以逃避系统。因此,基于历史欺诈交易数据训练的机器学习模型将无法准确预测欺诈者行为的渐进变化。例如,考虑一个用于预测股票价格的机器学习模型,该模型以过去五年的数据进行训练,并在当前年份的新数据上评估其性能。然而,随着时间的推移,市场动态可能会发生变化,影响股票价格的变量之间的关系可能会逐渐演变。这可能导致渐进漂移,即模型的准确性随着时间的推移逐渐恶化,因为它变得越来越难以捕捉变量之间不断变化的关系。
-
增量漂移:增量漂移发生在目标变量与输入之间的关系随时间逐渐变化时,这通常是由于数据生成过程的变化。
-
重复漂移:这也称为季节性漂移。一个典型的例子是圣诞节或黑色星期五期间销售的增加。如果机器学习模型未能准确考虑这些季节性变化,将最终提供不准确的预测。
下面的图中展示了这四种概念漂移类型。
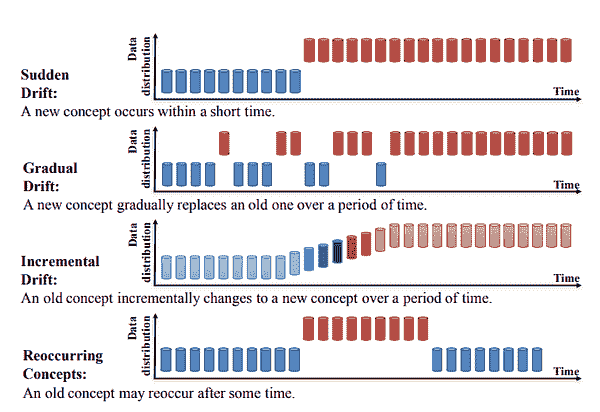
概念漂移类型 | 图片来源于在概念漂移下学习:综述。
数据漂移
数据漂移发生在输入数据的统计属性发生变化时。一个例子是某个应用程序用户的年龄分布随时间变化,因此,训练时基于特定年龄分布的模型将需要调整,因为年龄变化会影响营销策略。
上游数据变化
第三种类型的漂移是上游数据变化。这指的是数据管道中的操作数据变化。一个典型的例子是某个特征不再生成,导致缺失值。另一个例子是测量单位的变化,例如某个传感器原本用摄氏度测量数量,然后改为华氏度。
检测模型漂移
检测模型漂移并不简单,并且没有通用的方法来检测它。然而,我们将讨论一些流行的方法来检测它:
-
Kolmogorov-Smirnov 检验(K-S 检验): K-S 检验是一种非参数检验,用于检测数据分布的变化。它用于比较训练数据和训练后数据之间的分布变化。该检验的零假设是两个数据集的分布相同,因此如果零假设被拒绝,则说明存在模型漂移。
-
人口稳定性指数(PSI): PSI 是一种统计度量,用于测量两个不同数据集中类别变量分布的相似性。因此,它可以用来测量训练数据集和训练后数据集类别变量特征的变化。
-
Page-Hinkley 方法: Page-Hinkley 方法也是一种统计方法,用于观察数据均值随时间的变化。它通常用于检测数据中不明显的小变化。
-
性能监控: 监控机器学习模型在生产环境中的性能并观察其变化是检测概念漂移的重要方法之一。如果性能变化超过某个阈值,我们可以触发某种动作来纠正这种概念漂移。
处理生产环境中的漂移

处理生产环境中的漂移 | 图片由 ijeab 提供,来自 Freepik。
最后,让我们来看看如何处理生产环境中检测到的模型漂移。处理模型漂移的策略有广泛的范围,取决于漂移类型、我们所处理的数据以及生产中的项目。以下是处理生产环境中模型漂移的几种流行方法的总结:
-
在线学习: 由于大多数现实世界应用运行在流数据上,在线学习是处理漂移的常见方法之一。在在线学习中,模型在处理一个样本时会实时更新。
-
定期重新训练模型: 一旦模型性能下降到某个阈值以下或观察到数据漂移,可以设置触发器,用最新数据重新训练模型。
-
在代表性子样本上定期重新训练: 处理概念漂移的一个更有效的方法是选择一个具有代表性的子样本,并使用人工专家标注它们,然后在这些样本上重新训练模型。
-
特征丢弃: 这是一种简单但有效的方法,用于处理概念漂移。使用此方法,我们将训练多个模型,每个模型使用一个特征,并监控每个模型的 AUC-ROC 响应,如果 AUC-ROC 值超出特定阈值,则可以丢弃该特征,因为它可能参与了漂移。
参考文献
在本文中,我们讨论了模型漂移,这是指机器学习中由于基础数据的变化导致模型性能随着时间恶化的现象。为了克服这些挑战,企业正在转向 MLOps,一套管理生产中机器学习模型生命周期的实践和工具。
我们概述了可能发生的不同类型的漂移,包括概念漂移、数据漂移和上游数据变化,以及如何使用 Kolmogorov-Smirnov 检验、人口稳定性指数和 Page-Hinkley 方法检测模型漂移。最后,我们讨论了处理生产中模型漂移的流行技术,包括在线学习、定期模型重新训练、在代表性子样本上定期重新训练和特征丢弃。
Youssef Rafaat 是一名计算机视觉研究员和数据科学家。他的研究集中在为医疗保健应用开发实时计算机视觉算法。他还在市场营销、金融和医疗保健领域担任数据科学家超过 3 年。
更多相关话题
管理 Python 依赖项与 Poetry 对比 Conda 和 Pip
原文:
www.kdnuggets.com/managing-python-dependencies-with-poetry-vs-conda-pip

有效地管理依赖项,包括对项目功能至关重要的库、函数和包,可以通过使用包管理器来实现。Pip 是一种被广泛采用的经典工具,为许多开发者提供了从 Python 包索引 (PyPI) 无缝安装 Python 包的能力。Conda 不仅作为包管理器被认可,还作为环境管理器,扩展了处理 Python 和非 Python 依赖项的能力,使其成为一个多功能的工具。就我们的目的而言,我们将主要关注用于纯 Python 环境。
Pip 和 Conda 是值得信赖的工具,在开发者社区中被广泛使用和信任。然而,随着项目的扩展,在不断增加的依赖项中保持组织变得具有挑战性。在这种背景下,Poetry 作为一种现代化和有序的依赖管理解决方案应运而生。
Poetry 基于 Pip 构建,提出了一种现代化的依赖管理方法。它不仅仅是 Pip 和虚拟环境的简单结合,而是一个涵盖依赖管理、项目打包和构建过程的全面工具。与 Conda 的比较则更为细致;Poetry 旨在简化 Python 项目的打包和分发,提供了一套独特的功能。
Pip 和 Conda 仍然是管理依赖项的宝贵选择,Conda 在处理多样化依赖项方面具有灵活性。另一方面,Poetry 提供了一种现代化且全面的解决方案,简化了 Python 项目及其依赖项的管理。选择合适的工具取决于项目的具体需求和开发者的偏好。
包管理
Poetry 使用 pyproject.toml 文件来指定项目的配置,并附带一个自动生成的锁定文件。pyproject.toml 文件的样子如下:
[tool.poetry.dependencies]
python = "³.8"
pandas = "¹.5"
numpy = "¹.24.3"
[tool.poetry.dev.dependencies]
pytest = "⁷.3.2"
precomit = "³.3.3"
和其他依赖管理工具一样,Poetry 通过锁定文件认真跟踪当前环境中的包版本。这个锁定文件包含项目元数据、包版本参数等,确保在不同环境中的一致性。开发者可以在 toml 文件中智能地将依赖项分为 dev 和 prod 类别,从而简化部署环境并减少冲突的风险,尤其是在不同的操作系统上。
Poetry 的 pyproject.toml 文件旨在解决 Pip 的 requirement.txt 和 Conda 的 environment.yaml 文件中发现的某些限制。与常常生成冗长依赖列表而没有单独文件中的元数据的 Pip 和 Conda 不同,Poetry 追求更有组织且简洁的表现形式。
虽然 Pip 和 Conda 默认缺乏锁定功能,但需要注意的是,最近版本提供了通过像 pip-tools 和 conda-lock 这样的已安装库生成锁文件的选项。这种功能确保不同用户可以安装 requirements.txt 文件中指定的目标库版本,从而促进了可重复性。
Poetry 作为一个现代且有组织的 Python 依赖管理解决方案,相比于传统工具如 Pip 和 Conda,提供了改进的组织、版本控制和灵活性。
更新、安装和移除依赖
使用 Poetry 更新库非常简单,并会考虑其他依赖以确保它们也相应更新。Poetry 有一个批量更新命令,会根据你的 toml 文件更新依赖,同时保持所有依赖之间的兼容性,并维护锁文件中的包版本参数。这将同时更新你的锁文件。
至于安装,操作简单至极。要使用 Poetry 安装依赖,你可以使用 poetry add 函数,你可以指定版本,使用逻辑指定版本参数(大于、小于),或使用类似 @latest 的标志,它将从 PyPI 安装该包的最新版本。你甚至可以在同一个添加函数中组合多个包。任何新安装的包都会自动解决以维持正确的依赖关系。
$poetry add requests pandas@latest
至于经典的依赖管理工具,我们来测试一下当尝试安装一个较旧的不兼容版本时会发生什么。Pip 安装的包将输出错误和冲突,但最终仍会安装该包,这可能导致开发情况不理想。Conda 确实有一个解决器来处理兼容性错误并会通知用户,但在找不到解决方案时会立即进入搜索模式,输出次级错误。
(test-env) user:~$ pip install "numpy<1.18.5"
Collecting numpy<1.18.5
Downloading numpy-1.18.4-cp38-cp38-manylinux1_x86_64.whl (20.7 MB)
|████████████████████████████████| 20.7 MB 10.9 MB/s
Installing collected packages: numpy
Attempting uninstall: numpy
Found existing installation: numpy 1.22.3
Uninstalling numpy-1.22.3:
Successfully uninstalled numpy-1.22.3
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
pandas 1.4.2 requires numpy>=1.18.5; platform_machine != "aarch64" and platform_machine != "arm64" and python_version < "3.10", but you have numpy 1.18.4 which is incompatible.
Successfully installed numpy-1.18.4
(test-env) user:~$ pip list
Package Version
--------------- -------
numpy 1.18.4
pandas 1.4.2
pip 21.1.1
python-dateutil 2.8.2
pytz 2022.1
six 1.16.0
Poetry 对依赖兼容性错误有即时响应,能快速并早期通知冲突。它拒绝继续安装,因此用户需要负责寻找不同版本的新包或现有包。我们认为这比 Conda 的即时行动提供了更多控制。
user:~$ poetry add "numpy<1.18.5"
Updating dependencies
Resolving dependencies... (53.1s)
SolverProblemError
Because pandas (1.4.2) depends on numpy (>=1.18.5)
and no versions of pandas match >1.4.2,<2.0.0, pandas (>=1.4.2,<2.0.0) requires numpy (>=1.18.5).
So, because dependency-manager-test depends on both pandas (¹.4.2) and numpy (<1.18.5), version solving failed.
...
user:~$ poetry show
numpy 1.22.3 NumPy is the fundamental package for array computing with Python.
pandas 1.4.2 Powerful data structures for data analysis, time series, and statistics
python-dateutil 2.8.2 Extensions to the standard Python datetime module
pytz 2022.1 World timezone definitions, modern and historical
six 1.16.0 Python 2 and 3 compatibility utilities
最后但同样重要的是 Poetry 的包卸载。一些包需要更多的依赖项。对于 Pip,它的包卸载只会卸载定义的包,而不会影响其他包。Conda 会删除一些包,但不是所有的依赖项。另一方面,Poetry 会删除包及其所有依赖项,以保持依赖项列表的整洁。
Poetry 是否兼容现有的 Pip 或 Conda 项目?
是的,Poetry 兼容现有的由 Pip 或 Conda 管理的项目。只需使用 Poetry 的 Poetry.toml 格式初始化你的代码并运行它,即可获取包库及其依赖项,实现无缝过渡。
如果你有一个使用 Pip 或 Conda 的现有项目,你可以毫不费力地将其迁移到 Poetry。Poetry 使用自己的 pyproject.toml 文件来管理项目的依赖项和设置。要在你的项目中开始使用 Poetry,你可以按照以下步骤进行:
1. 通过 curl 和管道或者使用 Pip 安装 Poetry
curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | python -
2. 导航到你现有项目的根目录。
3. 在你的项目目录中初始化 Poetry:
poetry init
这个命令将引导你通过一系列提示来设置你项目的初始配置。
4. 初始化完成后,Poetry 会在你的项目目录中创建 pyproject.toml 文件。打开这个 toml 文件以添加或修改你的项目依赖项。
5. 安装项目中的现有依赖项到
poetry install
这将创建一个虚拟环境,并在其中安装项目的依赖项。
6. 现在你可以使用 Poetry 的 run 命令来执行你项目的脚本,类似于你使用 Python 或 Conda 命令的方式。
poetry run python my_script.py
Poetry 管理你的项目的虚拟环境和依赖项解析,使其兼容现有的 Pip 或 Conda 项目。它简化了依赖项管理,并允许在不同环境中进行一致的包安装。
注意:在对项目的配置或依赖项管理工具进行任何重大更改之前,备份项目始终是一个好习惯。
结束语
确保包的正确版本在你的代码环境中是至关重要的,以便每次都能获得正确的结果。代码后端的轻微变化可能会改变结果。同时,保持这些包和库的更新同样重要,以利用每个补丁提供的创新。
对于处理更多复杂和多样化项目、依赖项较多的情况,Poetry 是一个很好的工具来管理这些依赖项。虽然 Pip 和 Conda 仍然是可行的选项,但它们更适合较小的、不那么复杂的环境。不是每个人都可能使用 Poetry,但由于 Pip 存在已久,使用 Pip 的便利性可能值得考虑。
但如果你的项目和工作负载重视组织的重要性,并愿意探索新工具以改善你的流程,Poetry 是你应该考虑的工具。从 Pip 到 Poetry 的扩展功能确实带来了变化。我们鼓励你亲自试用 Poetry。
原文。经许可转载。
Kevin Vu 管理着 Exxact Corp 博客,并与许多才华横溢的作者合作,他们撰写关于深度学习不同方面的内容。
更多相关内容
作为数据科学家管理可重用的 Python 代码
原文:
www.kdnuggets.com/2021/06/managing-reusable-python-code-data-scientist.html

图片由 Chris Ried 提供,出处 Unsplash
管理自己代码的方法有很多,这些方法会根据你的需求、个性、技术水平、角色和其他许多因素有所不同。虽然一位经验丰富的开发者可能会有一种极其规范的代码组织方法,适用于多种语言、项目和用例,但一位很少编写代码的数据分析师可能会因为没有必要而采用更加临时和随意的方法。实际上,没有对错之分,这只是看什么对你来说有效——并且合适。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 支持
具体来说,我所说的“管理代码”是指你如何组织、存储和回忆你自己编写并作为长期补充添加到编程工具箱中的不同代码。编程的核心在于自动化,因此,如果你作为代码编写者发现自己重复执行相似任务,那么自动化回忆与该任务相关的代码是很有意义的。
这就是你为什么已经在使用第三方库的原因。每次想使用时都不需要从头实现一个支持向量机代码库;相反,你可以利用一个库——比如 Scikit-learn——并利用众多专家对某些代码的不断完善。
将这一思想扩展到个人编程领域也是合情合理的。你可能已经在这样做了(我希望你在做),但如果没有,这里有一些我为管理自己可重用的 Python 代码所确定的方法,按代码使用的从最一般到最具体的顺序呈现。
完整的库
这是一种最通用的方法,也可以说是最“专业”的方法;然而,这本身并不意味着它总是最合适的选择。
如果你发现自己在多个使用场景中频繁使用相同的功能,并且经常这样做,那么这就是最佳方法。如果你想重用的功能容易参数化,即可以通过编写并调用一个带有每次调用时可以定义的变量的通用函数来反复处理任务,那么这也很合理。
例如,我经常发现需要查找字符串中某个子串的第 n 次出现,而 Python 标准库中没有这样的函数。因此,我有一段简单的代码,它接受一个字符串、一个子串和我要查找的第 n 次出现作为输入,并返回字符串中第 n 次出现的起始位置(很久以前从这里借鉴的)。
def find_nth(haystack, needle, n):
start = haystack.find(needle)
while start >= 0 and n > 1:
start = haystack.find(needle, start+len(needle))
n -= 1
return start
由于我处理大量文本处理工作,我收集了许多我经常使用的文本处理函数,并创建了一个库,就像其他 Python 库一样存在于我的计算机上,我能够像使用其他库一样导入它。创建库的步骤虽然有点长,但很简单,因此我不会在这里详细说明,但这篇文章是众多讲解得很好的文章之一。
现在我有了一个textproc库,我可以轻松地导入并使用我的find_nth函数,而且可以随意使用,而不必将函数复制并粘贴到每个使用它的程序中。
from textproc import find_nth
segment = line[:find_nth(line, ',', 4)].strip()
如果我想扩展库以添加更多功能,或更改现有的find_nth代码,我可以在一个地方进行修改,然后重新导入。
项目特定的共享脚本
也许你不需要一个全面的库,因为你要重用的代码似乎只在你当前工作的项目中有用,但你确实需要在特定项目中重用它。在这种情况下,你可以将这些函数放在一个脚本中,然后按名称导入该脚本。这是简易版的库,但通常正是所需的。
在我的研究生工作中,我需要编写大量与无监督学习相关的代码,特别是 k 均值聚类。我编写了一些函数,用于初始化质心、计算数据点与质心之间的距离、重新计算质心等,并使用不同的算法执行这些任务。我很快发现将这些算法函数的副本保存在单独的脚本中并不是最优的,因此将它们移到自己的脚本中以供导入。它的工作方式几乎与库相同,但过程是特定路径的,仅用于该项目。
很快,我有了不同的质心初始化函数和距离计算函数的脚本,还有数据加载和处理函数的脚本。随着这些代码变得越来越参数化和普遍有用,最终这些代码被整合进了一个真正的库中。
这似乎是事物通常的进展方式,至少在我的经验中是这样:你在脚本中编写一个现在需要使用的函数,并且你使用它。项目扩展,或者你转到一个类似的项目,你意识到那个函数现在会很有用。因此,这个函数会被放到一个自己的脚本中,然后你导入它以使用。如果这种有用性在短期内持续,并且你发现这个函数有更普遍和长期的用途,那么这个函数现在会被添加到现有的库中,或者成为新库的基础。
然而,导入简单脚本的另一个具体有用的方面是使用 Jupyter notebooks。鉴于 Jupyter notebooks 中许多操作的临时性、探索性和实验性,我不太喜欢将 notebooks 导入到其他 notebooks 作为模块。如果我发现多个 notebooks 定期使用某些代码片段,那么这些代码会被放入存储在同一文件夹中的脚本中,然后导入到 notebook(s) 中。我觉得这种方法更为合理,并且通过知道一个 notebook 所依赖的另一个 notebook 没有被以有害的方式编辑,提供了更多的稳定性。
任务特定的模板
我发现我经常重复执行一些相同的任务,这些任务不适合被参数化,或者是可以参数化的任务,但所需的努力超过了实际的价值。在这种情况下,我采用代码模板或样板代码。这比我在本文开头想要避免的所有情况下的代码复制和粘贴要多,但有时这是正确的选择。
例如,我经常需要将 Pandas DataFrame 的内容“转化为列表”(缺乏更好的词汇),虽然编写一个能够确定列数的函数,能够接受作为输入的列等,通常输出也需要调整,这些都表明编写一个函数是非常耗时的。
在这种情况下,我只需编写一个可以轻松更改的脚本模板,并将其保存在类似模板的文件夹中。以下是 listify_df 的一个片段,它将 CSV 文件转换为 Pandas DataFrame,然后转换为所需的 HTML 输出。
import pandas as pd
# Read CSV file into dataframe
csv_file = 'data.csv'
df = pd.read_csv(csv_file)
# Iterate over df, creating numbered list entries
i = 1
for index, row in df.iterrows():
entry = '<b>' + str(i) + \
'. <a href="' + \
row['url'] + \
'">' + \
row['title'] + \
'</a> + \
'\n\n<blockquote>\n' + \
row['description'] + \
'\n</blockquote>\n'
i += 1
print(entry)
在这种情况下,清晰的文件名和文件夹组织有助于管理这些常用的代码片段。
短小的单行代码和块
最后,有很多你可能经常输入的重复代码片段。那么你为什么要这样做呢?
你应该利用文本扩展工具在需要时插入短小的“短语”。我使用AutoKey来管理这些短语,它们与触发关键词关联,当输入这些关键词时就会插入这些短语。
例如,你是否在所有特定类型的项目中导入大量相同的库?我会。举个例子,你可以通过输入,例如,#nlpimport 来设置完成特定任务所需的所有导入,一旦输入,这将被识别为触发关键词并替换为以下内容:
import sys, requests
import numpy as np
import pandas as pd
import texthero
import scattertext as st
import spacy
from spacy.lang.en.stop_words import STOP_WORDS
from datasets import load_metric, list_metrics
from transformers import pipeline
from fastapi import FastAPI
需要注意的是,一些 IDE 具备这些功能。我自己通常使用升级版文本编辑器进行编码,因此 AutoKey 对我来说是必需的(且极其有用)。如果你有一个处理这方面的 IDE,那很好。关键是,你不应该需要不断重复输入这些内容。
这已经是关于作为数据科学家管理可重用 Python 代码的概述。我希望你觉得它有用。
Matthew Mayo (@mattmayo13) 是数据科学家及 KDnuggets 主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣在于自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关内容
五行代码
赞助广告。
在小说作家中有一个规则:第一稿总是很糟糕。你会发现,真正的好作品往往是在第二稿、第三稿甚至第四稿中完成的。同样的原则也适用于编写代码!与其花费所有时间在第一次尝试时力求完美,不如先编写出不完美的代码,然后再进行改进。无论你的架构、面向对象语言选择还是作为程序员的技能如何,你都会发现,适当的重构会使你的代码更简单、更易读,并且不易出错。
如果你想学习简单且实用的重构最佳实践规则,五行代码是你的最佳指南。由敏捷教练克里斯蒂安·克劳森编写,出版方是 Manning Publications——所以你可以放心其质量。与那些需要多年开发经验才能掌握的复杂“代码异味”或其他技巧不同,它教授的是任何人都能学习的具体重构原则,不论其经验水平如何。
不需要行话或复杂的自动化测试技能,只需简单的指南和通过详细代码示例说明的模式。逐章你将通过重构一个完整的 2D 拼图游戏来实践这些技术,不久之后,你将会对你的代码库进行显著且实际的改进。
直到 7 月 24 日,你可以节省 50%购买《五行代码》以及所有其他 Manning 书籍和视频!
购买时在 manning.com 结账时输入代码nlfive40。
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你所在组织的 IT
更多相关内容
关于图形驱动机器学习、图形数据库、搜索深度学习的书籍——享受 50%折扣
原文:
www.kdnuggets.com/2019/05/manning-books-graph-machine-learning-databases.html
由 Manning 出版社出版。 赞助文章。

在现实世界中,数据很少像行和列那样简单。数据模式更像是一个网络,存在着大量的链接、连接和不同数据点之间的关系。作为机器学习工程师,我们如何建模这种复杂的互联性,以改善我们的机器学习应用?这正是基于图形的机器学习的优势所在。
基于图形的机器学习是处理大数据集中的模式匹配任务的一个极其强大的工具。通过将数据组织和分析为图形,你的应用程序能够更流畅地发现连接和识别关系。这可能是你提升搜索结果优化、推荐引擎或社交网络等常见机器学习任务性能的关键。
Manning 出版社有三本书能帮助你充分利用图形驱动的数据库。更棒的是,限时优惠,使用代码kdngraph,你可以在manning.com上享受半价优惠!以下是每本书的简要介绍。
《Graph-Powered Machine Learning》教你如何使用基于图形的算法和策略来开发优越的机器学习应用。基于作者与真实客户合作的三个端到端应用实例,让主题生动有趣!
在《Graph Databases in Action》中,你将学习如何为你的任务选择合适的数据库解决方案,以及如何利用新知识构建敏捷、灵活和高性能的图形驱动应用程序!
《Deep Learning for Search》将所有内容结合在一起,教你如何利用神经网络、自然语言处理和深度学习技术来提升搜索性能,并每次都给客户提供正确的结果。
无论你是希望帮助客户找到更好的搜索结果,还是希望在你的工具包中增加更多技能,这三本书都是实现目标的完美选择。
今天任何一本书都可以享受 50%折扣! 只需在 manning.com 结账时使用代码kdngraph。此优惠适用于电子书和印刷版。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
更多相关内容
《程序员的数学》!
赞助文章。
数学是程序员的基本工具,在游戏开发、计算机图形学和动画、图像和信号处理、定价引擎,甚至股票市场分析中都扮演着不可或缺的角色。当你拥有了专业的数学技能,你就拥有了完成工作的工具。
《程序员的数学》是你解决各种数学问题的指南。
本书由硅谷初创公司 Tachyus 的首席执行官 Paul Orland 编写,你将学会像程序员一样享受数学思考。通过易于理解的示例、场景和练习,适合在职开发人员,你将从探索 2D 和 3D 中的函数和几何开始。掌握这些基础知识后,你将进入机器学习和游戏编程的核心数学,包括矩阵和线性变换、导数和积分、微分方程、概率、分类算法等。如果这听起来令人生畏,或者更糟,感觉无聊!Paul 的写作风格使一切变得生动,因此学习这些重要概念是轻松、相关且有趣的。
本实用教程中的实际示例包括构建和渲染 3D 模型、利用矩阵变换制作动画、操作图像和声音波形,以及为视频游戏构建物理引擎。在学习过程中,你将通过大量练习来测试自己,确保你对这些概念有牢固的掌握。贯穿整个教程的动手小项目将巩固你所学到的知识。如果你希望掌握今天最流行的技术趋势中必不可少的数学技能,那么这本书就是你需要拥有的!
你可以在 1 月 31 日之前享受《程序员的数学》50%的折扣!
只需在从manning.com购买时输入代码kdmath50即可享受折扣。
如果你点击下面的链接,电子书版本将自动添加到你的购物车,并且会应用折扣。
| 立即订购! |
|---|
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域的职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织中的 IT 工作
更多相关话题
Python 锻炼 / Python 高手实践 / 经典计算机科学问题 Python 版
赞助文章。

Python 是新手自学编程者在行业中起步的热门选择。尽管它因其简单性和可访问性而受到青睐,但 Python 语言仍能被推向令人惊叹的结果。无论你是初学者还是专家,总有新的方法可以提升你的 Python 编码技能。
通过计算机科学课堂的正式技术,你可以将你的计算机科学技能提升到专业水平。书籍 经典计算机科学问题 Python 版 旨在做到这一点。由 Champlain College 的计算机科学与创新助理教授 David Kopec 编写,通过设置你在计算机科学课程和许多求职面试中可能遇到的挑战,来磨练你的 Python 技能。
目前提高你 Python 技能的最佳方法是实践。这就是为什么书籍 Python 锻炼 充满了 50 道精心挑选的练习,邀请你灵活运用你的编程能力。每个新挑战都会让你练习一种新技能,并学习如何将其应用于日常编码任务。
你是否在以专业水平设计你的 Python 代码和应用程序? Python 高手实践 教你设计和编写易于理解、维护和扩展的软件。它充满了行业标准的最佳实践,涵盖了编码风格、应用设计和开发过程,所有内容均使用 Python 代码。
今天你可以享受 经典计算机科学问题 Python 版、Python 锻炼 和 Python 高手实践 的 40% 折扣!在 manning.com 购买时,只需输入代码 nlpropython40 即可。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关内容
《软件错误与权衡》:托马什·莱莱克和 StackOverflow 大师乔恩·斯基特的新书
原文:
www.kdnuggets.com/2021/12/manning-software-mistakes-tradeoffs-book.html
赞助文章。
性能与简洁的权衡。交付速度与重复的权衡。灵活性与可维护性的权衡——软件工程中的每个决策都涉及权衡。
但软件系统存在的时间越长,早期决策更难以更改。你在开发中的每一个选择都会留下遗产,限制你未来的方向,并将你固定在特定的路径上。通常,你会在截止日期、成本考虑和其他挑战的压力下做出这些决策,而这时明智的权衡可能变成错误。
《软件错误与权衡》帮助你优化那些将定义你代码的重要决策。这本有趣友好的指南直接来自资深开发者托马什·莱莱克和业界英雄乔恩·斯基特,他是世界上最伟大的现役程序员之一。书中,作者们揭示了他们长期职业生涯中的真实场景,探讨了错误的权衡决策以及本可以如何做得更好。你将开始注意到你每天做出的设计决策,以及如何更加深思熟虑地做出这些决策。
“我可以自信地说,100% 的软件开发者都会问自己至少一个本书中提到的问题。”
—内尔森·冈萨雷斯
你会发现代码重复在分布式架构中并不总是坏事,如何在 API 灵活性和减少维护量之间取得平衡,甚至如何决定何时将代码更新到新的趋势和范式。发现如何根据 80/20 帕累托原则有效地缩小优化范围,并确保分布式系统的一致性。你将能够将作者的宝贵经验应用到自己的项目中,预防错误并采取更深思熟虑的决策方法。
《软件错误与权衡》在其出版商 Manning 处可提前访问。现在预购并立即开始阅读,作为 Manning 早期访问计划(MEAP)的部分内容。
查看这些额外的 Manning 促销码,专为 KDnuggets 读者准备:
《软件错误与权衡》的一个免费电子书代码:softkd-AEC0
我们 35%的折扣码(适用于所有格式的所有产品):nlkdnuggets21
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关主题
程序员的数学!
赞助帖子。
数学是程序员的重要工具,在游戏开发、计算机图形学和动画、图像和信号处理、定价引擎,甚至股市分析中扮演着不可或缺的角色。当你拥有了专业的数学技能,你就拥有了完成任务所需的工具。
《程序员的数学》是你解决各种数学问题的指南。
由硅谷初创公司 Tachyus 的首席执行官 Paul Orland 编写,你将学会像程序员一样享受思考数学。通过适合工作开发者的易于理解的示例、场景和练习,你将从探索 2D 和 3D 的函数和几何开始。掌握了这些基本构建块后,你将进入机器学习和游戏编程的核心数学,包括矩阵和线性变换、导数和积分、微分方程、概率、分类算法等。即使这些听起来令人生畏,或者更糟的是无聊!Paul 的写作风格让一切变得生动,学习这些重要概念变得轻松、相关且有趣。
本实用教程中的真实案例包括构建和渲染 3D 模型、使用矩阵变换制作动画、操控图像和声波,以及为视频游戏构建物理引擎。在此过程中,你将通过大量练习测试自己,以确保对概念有牢固的掌握。课程中的动手迷你项目将巩固你所学到的一切。如果你希望掌握当今最流行技术趋势中必不可少的数学技能,那么这是你需要拥有的书籍!
你可以在 8 月 29 日之前节省 50%的《程序员的数学》费用!
只需在maning.com购买时输入kdmath50折扣码即可。
如果你点击下面的链接,电子书版本将会自动添加到你的购物车,并应用折扣。
| 立即订购! |
|---|
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全领域的职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
手动编码还是自动化数据集成 – 何者为最佳的数据集成方式?
原文:
www.kdnuggets.com/2019/08/manual-coding-automated-data-integration-best-way.html
评论
作者 Tehreem Naeem,Astera

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织进行 IT 管理
数据到洞察的旅程对每个组织在做出决策和获得盈利结果方面都非常重要。集成是这一旅程中的关键步骤,它简化了数据处理流程,使决策者能够获取信息。
Gartner 估计到 2020 年,构建数字平台的成本和时间中有 50%将用于集成。这意味着通过简化集成,您可以消除数据管道中的瓶颈。
所有这些挑战使得企业必须将数据集成作为一种策略进行适应;这种策略应符合您的企业需求和目标。选择合适的数据集成策略时,数据的类型、量和质量都会影响决定。根据这些因素和其他一些因素,组织会决定是采用手动还是自动化的集成方式。
设计数据集成策略 – 需要考虑的因素
设计一个良好的数据集成策略时,必须评估您的企业数据的范围及其对初始集成项目之外的计划的影响。关键在于,随着公司增长,您的数据量也会增加。设计一个考虑到这种增长的集成策略将有助于您建立作为数据驱动型组织的声誉。
这三大因素将帮助您规划一个强大的数据集成策略:
长期计划
在大多数组织中,数据集成是迈向更大目标的第一步,比如迁移或数据仓库。例如,一个最初希望整合其市场营销和销售数据的组织,可能最终目标是创建一个具有详细客户记录的主数据管理系统。因此,在做出选择时,应该考虑项目的最终目标。
成本
无论是手动还是自动化的数据集成方案都会产生成本。这包括设计、维护和扩展持续流项目所需的资源,如果你希望建立数据驱动的组织声誉。同时,这可能还需要在公司范围内对组织功能进行变更,除了技术方面。如果你希望修改公司的数据环境,请确保与那些了解这些变化如何影响业务和数据工作的 IT 用户的利益相关者合作。
可扩展性
将新技术与现有系统集成的能力为你的组织带来了显著的改善。然而,如果你倾向于手动方法,你将无法在数据生态系统中纳入这些技术,而不需要投入大量的开发时间和开发人员资源。一个足够可扩展的集成策略,能够适应如云应用和基础设施等新技术进展,能够为组织带来显著的改善。
手动与自动化的困境——找到正确的方法
手动与自动化的方法一直是数据专业人士讨论的焦点。倾向于手动方法的组织认为这是一个成本效益高的选项,而使用 ETL 工具的用户则看重其自动化功能。
根据数据管理专家里克·谢尔曼的说法,一些组织仍然倾向于手动集成方法。这在中小型企业中是一种普遍的做法。即使一些大型企业也会使用 SQL 编码和存储过程来提取和集成数据,以进行报告和分析。
对于其他组织来说,可能合适的选择,对你来说也许是一个错误的方向。为了使这一点更加透明,我们根据常见的决定因素讨论了这两种方法:
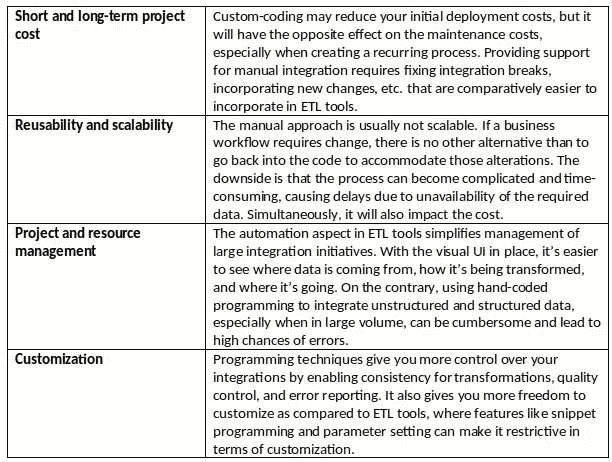
两种方法都有其优点,但主要问题是,如何找到适合你组织的方法。考虑以下问题,这将帮助你做出决定:
你是否有足够的开发人员资源来完成集成任务?
找到优秀的开发人员很难,尤其是使用新技术(如云平台或 Hadoop)的专家。如果业务用户和编码新手可以使用 ETL 工具完成相同的任务,而且所需时间更少,您不会更愿意将他们的专业技能用于更复杂的任务吗?
这是一次性的任务还是定期任务,或者您是否计划扩展项目的范围?
如果您正在进行使用大数据或分析的集成工作,那么它可能是一个定期任务。在这种情况下,修改代码或寻找专家以维护任务以维持集成流可能会很耗时。而对于一次性任务,您可能更适合使用手动编码。
您是否能够在不同的技术平台上重用代码?
在规划项目成本和时间表时,考虑到如果您决定将其纳入数据管道,可能需要额外的努力来重新开发代码以适应任何新平台。大多数 ETL 工具允许数据从一个处理平台轻松转移到另一个平台。
谁将负责集成项目的维护?
如果您在编写手动代码,您的开发人员不仅需要负责编写代码,还需要维护代码。后者可能是一个耗时的任务,使他们难以兼顾其他项目。
该项目是否涉及多个用户?
可视化界面、自动化、易于重用;这些只是使 ETL 工具成为涉及多个用户的集成项目的首选选项的一些因素。
收获
在当今世界,数据集成是获取商业关键洞察和获得竞争优势的最快方法之一。因此,选择正确的策略和工具来实现预期的商业目标对于组织来说至关重要。手动编码的简单性使其成为一个有吸引力的选择,但从长远来看,ETL 的自动化、直接体验效果更佳。哪种集成策略适合您的组织?
简历:Tehreem Naeem 是 Astera 的技术内容策略师,Astera 是一家数据管理解决方案提供商,她在这里创建以产品为重点的内容。她拥有来自知名机构的电子工程学位,并在该领域有超过 7 年的经验。
相关:
-
数据工程师的角色正在发生变化
-
ETL 与 ELT:考虑数据仓库的进展
-
数据集成与数据工程有什么区别?
更多相关话题
为什么这么多数据科学家辞职?
原文:
www.kdnuggets.com/2022/03/many-data-scientists-quitting-jobs.html

图片来源:Anete Lusina,来自 Pexels
当我刚开始学习数据科学时,我以为找到一份相关工作就意味着困难的部分已经结束。然而,经过几年的行业工作,我意识到我错得离谱。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您组织的 IT 需求
我认识的许多数据科学家在获得职位后的几个月内就离职了。我在加入数据科学实习工作一周后辞职,因为我觉得我被分配的任务与我辛苦学习的所有技能毫无关系。
与数据行业中的同事交谈后,他们像我一样在职业生涯的早期离开了工作,我意识到数据科学领域员工流失率高的主要原因有两个:
原因 #1:雇主期望的错配
想象一下:
您花费了数千小时学习统计学和不同机器学习算法的细微差别。然后,您申请了几十个数据科学职位列表,经历了漫长的面试过程,最终被一家中型公司录用。
您很高兴终于可以开始处理实际的机器学习问题,并将这些年来获得的所有技能付诸实践。然而,在您的第一天上班时,您意识到公司有大量未经过格式化或处理的非结构化数据进入系统。
您的雇主将您视为“数据专家”,并让您负责利用他们每天收集的大量数据来帮助他增加销售。
到头来,您不再像想象中的那样构建复杂的算法和预测模型。您现在花费所有时间来提高 SQL 和数据准备技能,将数据从系统中提取成不同的格式,并将这些数据展示给利益相关者,以便他们用于做出业务决策。
尽管你的职位名称中包含“数据科学”一词,但你并不在你一直想象的角色中。你对成为公司的数据清洁工感到不满,想要参与真正利用你所花费大量时间获得的技能的项目。
最终,你只有两个选择——留在公司几年的时间,继续做你不喜欢的工作,或者离开并寻找一个与你目标更匹配的组织。
问题在于:
上述情景可能对你来说不太可能,但这是我从周围的数据科学家那里听到的最大抱怨之一。他们中的许多人对职位范围的期望与实际工作内容差异很大,结果每天都在进行数据报告和分析任务。
在这些公司待了一段时间后,许多数据科学家最终失去了对机器学习技能的掌握,因为他们已经多年没有参与实际的机器学习项目。
在寻找其他工作时,他们无法申请中级或高级数据科学职位,因为他们缺乏必要的专业知识。这些人通常最终会转行,成为数据或报告分析师。
原因 #2:无法增加业务价值
大多数数据科学家挫败感的另一个常见原因是无法通过他们的机器学习模型增加业务价值。
在我看来,这个问题发生的频率甚至比前一个问题还要高——因为它同样困扰着那些有明确职位范围和适当数据管道的组织。
以下是一些数据科学家未能为组织创造价值的原因:
技术和业务之间的古老差距:
利益相关者和高层管理者相当非技术化,通常不了解机器学习建模的可能性。由于这个领域的炒作非常多,作为数据科学家,你会听到一些相当雄心勃勃的要求。
你需要向他们解释一个项目是否能够成功完成,以及它是否真的会带来他们期望的结果。确保期望与潜在结果一致,以免以后出现太多失望。
在开始任何机器学习项目之前,创建一份成本效益报告可能也很有用,这样公司可以集体决定是否值得分配时间和资源。
没有提出正确的问题:
作为数据科学家,你需要知道你构建的模型是否会为业务增加价值。
我见过的大多数数据科学家很快就会根据他们得到的指示开始一个项目。他们不提出正确的问题,也不尝试理解经理的思路。
当你只是因为别人告诉你要做某事而去做时,你就没有对你所带来的价值有任何洞察。如果你被要求解释你的工作为何有用,你将无法做到这一点。
如果你不知道为什么要构建一个产品,你怎么能说服别人你的产品有效呢?
缺乏领域知识:
为了提出正确的问题,你需要了解业务是如何运作的。
你构建的模型应该针对特定领域的问题进行定制,并且你需要理解它对最终用户的影响。
例如,如果你在为一家服装公司构建模型,你需要记住季节性等因素会对你向消费者提供的推荐产生影响。
我从事市场营销工作,这些领域知识大多数是通过与业务团队直接合作获得的。部分知识来自在线课程。当然,还有很多知识是基于我日常与人互动和对他们行为的基本理解。
根据你工作的领域,明智的做法是花些时间获取行业特定知识。这将应用于你数据科学工作流程的每一个步骤——预处理、特征选择、特征加权,以及模型部署后的偶尔调整。
那么……如何成为一个不讨厌自己工作的数据科学家呢?
首先,选择一家公司时,重要的是要选择一家允许你从事你喜欢工作的公司。远离那些在招聘描述中列出所有工具栈的公司。在申请之前,通过 LinkedIn 查找这些公司,并查看他们是否曾经招聘过数据科学职位。如果没有,你可能要远离这些公司,因为这意味着你可能需要完成所有与数据相关的任务。
如果他们有招聘数据科学家,查看这些数据科学家的个人资料,并检查他们为该职位填写的描述。看看是否符合你的期望。
确保你的面试过程不是单方面的。尽可能多地向面试官询问关于职位范围和内容的问题。如果这些内容与你的期望不符,那么你可能需要考虑其他机会。
最后,确保花些时间获取你所在领域的领域知识。利用这些知识向你的经理提出正确的问题,并确保他们的期望与你的项目结果相一致。
Natassha Selvaraj 是一位自学成才的数据科学家,对写作充满热情。你可以在 LinkedIn 上与她联系。
相关话题
Markdown 备忘单
我们为什么需要 Markdown?
Markdown?我们为什么要讨论 Markdown?
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT。
Markdown 是一种轻量级标记语言,用于使用纯文本编辑器创建格式化文本。你可以把它看作是比普通未格式化文本更进一步的一步,而不需要过多涉及 HTML 标签。
但仍然,我们为什么要讨论 Markdown?!?
在处理数据科学项目时,Markdown 是一个重要的相关技能,这里有一些原因:
-
Markdown 在博客、文档、协作中被广泛使用。
-
在 R 编程语言生态系统中,Markdown 被广泛依赖来创建可重复的文档,提供笔记本界面,以及格式化输出。
-
GitHub 和其他代码共享及协作服务已经使 Markdown 成为其创作平台的重要组成部分。
-
Markdown 提供了一个比 HTML 更轻便的替代方案。
所以,虽然 Markdown 可能在执行数据科学任务中不是必需的,但它已成为传播和展示结果、文档以及协作信息的有用工具。
这就是为什么我们为你准备了一个 Markdown 备忘单作为便捷参考。
你可以在这里下载备忘单。
Markdown 备忘单
在这个便捷的资源中,你将找到创建 Markdown 文档所需的一切,包括:
-
格式化常规文本
-
嵌入代码
-
使用 LaTeX
-
创建不同类型的列表
-
添加图片
-
创建表格
-
还有更多
我们希望你能发现这个备忘单对你的 Markdown 相关需求有用!
现在就查看它,并请及时回来获取更多信息。
更多相关话题
市场篮子分析:教程
评论
来源:oracle.com
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的快车道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 领域
零售业务的命脉一直是销售。零售商不能假设他的客户知道所有的产品。他必须努力以增加客户参与度和销售额的方式展示所有相关选项。
关联规则挖掘
关联规则挖掘用于寻找集合中不同对象之间的关联,发现交易数据库、关系数据库或任何其他信息库中的频繁模式。关联规则挖掘的应用包括市场营销、零售中的篮子数据分析(或市场篮子分析)、聚类和分类。
寻找这些模式的最常见方法是市场篮子分析,这是一种由大型零售商如 Amazon、Flipkart 等使用的关键技术,通过发现顾客在“购物篮”中放置的不同商品之间的关联来分析顾客的购买习惯。发现这些关联可以帮助零售商通过洞察哪些商品经常一起购买来制定营销策略。这些策略可能包括:
-
根据趋势更改商店布局
-
客户行为分析
-
目录设计
-
在线商店的交叉营销
-
顾客购买的热门商品是什么
-
定制的电子邮件加上销售等
在线零售商和出版商可以使用这种分析来:
-
通知内容项在其媒体网站上的位置或产品在其目录中的位置
-
提供有针对性的营销(例如,向购买了特定产品的顾客发送有关其他产品及相关优惠的电子邮件,这些产品可能对他们感兴趣。)
关联与推荐的区别
关联规则并不提取个人的偏好,而是寻找每个独立交易中元素集合之间的关系。这使得它们不同于用于推荐系统的协同过滤。
为了更好地理解,请查看下方来自 amazon.com 的快照,你会在每个产品的信息页面上看到两个标题:“常一起购买的商品”和“购买了此商品的顾客还购买了”。
“常一起购买的商品” → 关联
“购买了此商品的顾客还购买了” → 推荐
现在说实话,市场篮子分析是非常简单的。确实如此:你实际上只是在查看不同元素一起出现的可能性。虽然不仅仅是这样,但这就是这个技术的基础。我们真正感兴趣的是了解事物发生在一起的频率以及如何预测何时它们会一起发生。
Apriori 算法
Apriori 算法假设任何频繁项集的子集也必须是频繁的。它是市场篮子分析背后的算法。
比如,一个包含 {葡萄,苹果,芒果} 的交易也包含 {葡萄,芒果}。因此,根据 Apriori 原则,如果 {葡萄,苹果,芒果} 是频繁的,那么 {葡萄,芒果} 也必须是频繁的。
这里是一个包含六个交易的数据集。每个交易是由 0 和 1 组合而成,其中 0 表示项的缺失,1 表示项的存在。
数据集
为了从这个小型商业场景中找出有趣的规则,我们将使用以下矩阵:
1. 支持度: 这是项的默认流行度。从数学角度看,项A 的支持度就是涉及到A 的交易数与总交易数的比率。
支持度(葡萄) = (涉及到葡萄的交易数) / (总交易数)
支持度(葡萄) = 0.666
2. 置信度: 顾客购买A 和 B 的可能性。它是涉及到A 和 B 的交易数与涉及到B 的交易数之比。
置信度(A => B) = (同时涉及 A 和 B 的交易数) / (仅涉及 A 的交易数)
置信度({葡萄,苹果} => {芒果}) = 支持度(葡萄,苹果,芒果) / 支持度(葡萄,苹果)
= 2/6 / 3/6
= 0.667
3. 提升度: 当你销售B时,A的销售量增加。
提升度(A => B) = 置信度(A, B) / 支持度(B)
提升度 ({葡萄,苹果} => {芒果}) = 1
因此,顾客同时购买A 和 B 的可能性是单独购买的‘提升度’倍数。
-
提升度 (A => B) = 1 表示项集内没有相关性。
-
提升度 (A => B) > 1 表示项集内存在正相关,即项集中的产品A 和 B 更有可能被一起购买。
-
提升度 (A => B) < 1 表示项集内存在负相关,即项集中的产品A 和 B 不太可能被一起购买。
关联规则基础的算法被视为两步法:
-
频繁项集生成: 查找所有支持度 >= 预设最小支持度的频繁项集
-
规则生成: 列出所有从频繁项集中生成的关联规则。计算所有规则的支持度和置信度。修剪未通过最小支持度和最小置信度阈值的规则。
Apriori 算法的限制
频繁项集生成是计算最耗时的步骤,因为算法扫描数据库的次数过多,从而降低了整体性能。因此,算法假设数据库是常驻内存的。
此外,该算法的时间和空间复杂度非常高:O(2^{|D|}),因此是指数级的,其中 |D| 是数据库中存在的水平宽度(项的总数)。
优化 Apriori 算法
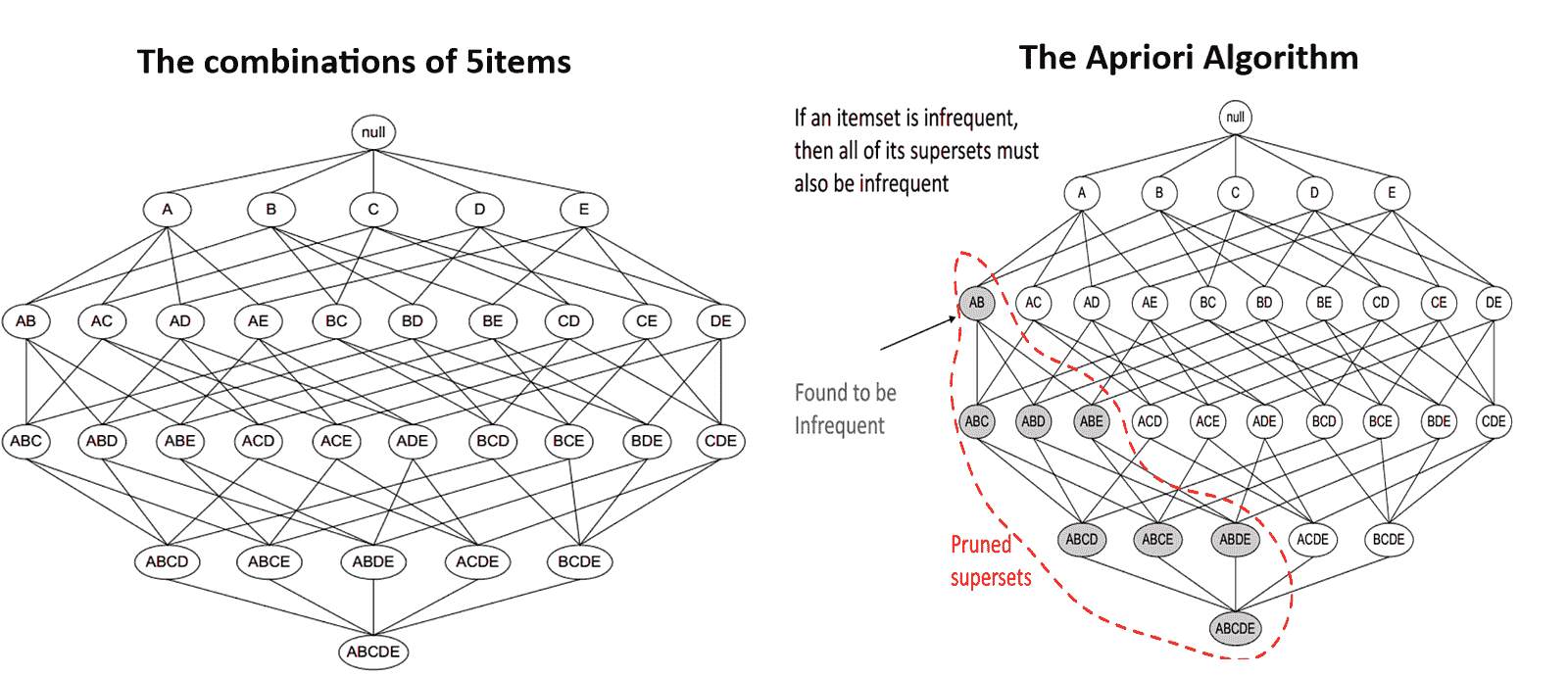
交易减少
我们可以通过以下方法优化现有的 Apriori 算法,从而减少时间消耗并且使用更少的内存:
-
基于哈希的项集计数: 其对应哈希桶计数低于阈值的 k-项集不能是频繁的。
-
交易减少: 不包含任何频繁 k-项集的交易在后续扫描中是无用的。
-
划分: 数据库中潜在频繁的项集必须在数据库的至少一个划分中是频繁的。
-
抽样: 在给定数据的子集上进行挖掘,较低的支持度阈值 + 确定完整性的方法。
-
动态项集计数: 仅当所有子集被估计为频繁时才添加新的候选项集。
Apriori 算法的实现 — 使用 Python 进行市场篮子分析
一家零售商试图找出 20 件商品之间的关联规则,以确定哪些商品更常一起购买,从而可以将这些商品放在一起以增加销售。
你可以从 这里 下载数据集。
环境设置: Python 3.x
pip install apyori
加载所有所需的库和数据集。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from apyori import aprioridataset = pd.read_csv('/Users/.../.../Market_Basket_Optimisation.csv', header = None)
数据集
现在,将 Pandas DataFrame 转换为列表列表。
transactions = []
for i in range(0, 7501):
transactions.append([str(dataset.values[i,j]) for j in range(0, 20)])
构建 Apriori 模型。
rules = apriori(transactions, min_support = 0.003, min_confidence = 0.2, min_lift = 3, min_length = 2)
打印规则:
print(list(rules))
让我们来看一个规则:
RelationRecord(items=frozenset({'avocado', 'spaghetti', 'milk'}), support=0.003332888948140248, ordered_statistics=[OrderedStatistic(items_base=frozenset({'avocado', 'spaghetti'}), items_add=frozenset({'milk'}), confidence=0.41666666666666663, lift=3.215449245541838)]),
第一条规则的支持值为 0.003。这个数字是通过将包含‘牛油果’、‘意大利面’和‘牛奶’的交易数量除以总交易数量计算得出的。
该规则的置信度为 0.416,这表明在所有包含‘牛油果’和‘意大利面’的交易中,41.6% 的交易也包含‘牛奶’。
1.241 的提升度告诉我们,与‘牛奶’的默认销售概率相比,购买‘牛油果’和‘意大利面’的客户购买‘牛奶’的可能性高出 1.241 倍。
结论
除了作为零售商技术的流行性外,市场篮子分析还适用于许多其他领域:
-
在制造业中进行设备故障的预测性分析。
-
在制药/生物信息学中发现诊断和不同患者群体所用药物之间的共现关系。
-
在银行/犯罪学中基于信用卡使用数据进行欺诈检测。
-
通过将购买行为与人口统计和社会经济数据关联来分析客户行为。
越来越多的组织正在发现如何利用市场篮分析来获得对关联和隐藏关系的有用洞察。随着行业领导者继续探索这一技术的价值,市场篮分析的预测版本正在许多领域取得进展,以识别顺序购买行为。
恭喜你!你已经学习了 Apriori 算法,它是数据挖掘中最常用的算法之一。你已经了解了关联规则挖掘及其应用,以及在零售领域称为市场篮分析的应用。
好了,这篇文章就是这些内容了。希望你们喜欢阅读,请在评论区分享你的建议/观点/问题。
感谢阅读 !!!
个人简介:纳格什·辛格·乔汉 是一位数据科学爱好者。对大数据、Python 和机器学习感兴趣。
原文。经许可转载。
相关:
-
频繁模式挖掘与 Apriori 算法:简明技术概述
-
初学者的十大机器学习算法
-
友好的支持向量机介绍
相关话题
市场数据与新闻:时间序列分析
原文:
www.kdnuggets.com/2022/06/market-data-news-time-series-analysis.html
作者:Parsa Ghaffari 和 Chris Hokamp
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 工作
总结 - 在本文中,我们介绍了一些用于研究股市与新闻之间关系的工具和技术。我们探讨了时间序列处理、异常检测和基于事件的新闻视角。我们还生成了直观的图表来演示这些概念,并在笔记本中分享了所有代码。
你可以在这个笔记本中查看代码。
介绍
新闻对市场的影响一直是许多年来备受关注的领域,随着定量分析的出现,从学术界到量化分析师,许多人使用统计方法更好地理解新闻与市场数据(如股价或交易量)之间的关系。
在本文中,我们旨在提供一个简单的实用指南,用于探索新闻数据与市场之间的统计关系,为更深入和更有针对性的分析奠定基础。我们的目标是为读者提供一套工具,帮助他们探索和交叉参考金融及新闻数据。我们的目标不是预测股市或发现特定的相关性或因果关系。
将市场数据与新闻对齐
为了研究新闻与市场数据之间的关系,我们首先利用Aylien 的新闻 API,它允许用户使用全面的筛选器过滤全球新闻数据,包括实时和历史数据。我们使用这些筛选器创建与我们关注的证券(例如股票、ETF、加密货币等)相对应的新闻源。然后,我们使用 Yahoo! Finance 获取这些证券的市场数据(价格和成交量)。将两者结合起来,我们可以构建一个包含市场和新闻相关数据的联合数据集,适用于任何给定的证券,时间范围可选择。
下表总结了不同类型金融实体的News API筛选器:
| 证券/市场数据 | 对应的新闻 API 过滤器 | 过滤描述 |
|---|---|---|
| 股票 | 实体 | 根据公司、产品、人物等过滤新闻。支持公司代码 |
| ETF | 行业(使用智能标签器) | 根据 1,500 个行业和子行业过滤新闻 |
| 事件 | 主题与事件(使用智能标签器) | 根据 2,900 个主题和事件的分类法过滤新闻 |
我们还可以利用新闻 API中提供的其他筛选选项,如来源和地区,来进一步细化我们的新闻源,这在具体任务中可能会很有用。
虽然我们在本文中主要使用市场的价格和交易量数据,但值得一提的是,我们在此文中探讨的许多技术可以扩展到其他类型的金融或经济数据。例如,为了研究裁员与新闻之间的关系,我们可以从统计局获取历史裁员数据,并使用新闻 API的事件过滤器将其与新闻对齐(例如,检索明确涉及裁员和劳动力相关公告的新闻文章)。
一些基本示例
为了更好地展示对齐的概念,让我们看几个基本示例。我们将研究两家科技公司,苹果和特斯拉,技术行业 ETF XLK,以及最后的标准普尔指数 (GSPC)。对于每个实体,我们将从 2021 年 4 月 1 日到 2022 年 4 月 1 日的 1 年期间内获取并绘制新闻和市场数据在一个图表上。我们可以使用多种参数来获取市场和新闻数据,例如:
| 市场数据参数 | 新闻数据参数 |
|---|---|
| 价格(调整后的收盘价)和衍生物(例如每日收益率) | 文章数量 - 使用时间序列端点检索 |
| 量 | 文章的平均情绪 - 作为时间序列数据检索,针对正面和负面标题的文章,然后取平均值 |
示例 1. 苹果公司 (AAPL) 新闻量、情绪、股票价格和交易量
示例 2. 特斯拉公司 (TSLA) 新闻量、情绪、股票价格和交易量
示例 3. 技术行业 ETF (XLK) 新闻量、情绪、股票价格和交易量
这是一种快速简便的方式,通过可视化比较各种时间序列之间的变化。在接下来的部分,我们将具体研究如何找到并比较这些时间序列上的有趣点,作为研究因果关系和相关关系的步骤。
深入研究关系
时间序列分析
到目前为止,我们已经以对齐的方式检索了反映新闻(文章数量、情感)和市场(股票价格、交易量)属性的时间序列数据。为了进一步分解和理解这些时间序列,我们将采用一些时间序列分析技术。我们将使用 Meta 的 Kats 库,它提供了一系列时间序列分析工具。
1. 预处理
我们首先将对时间序列进行分解,以识别和标准化时间序列中的趋势和季节性。
我们将把 Kats 的分解工具以“加性”模式应用到我们的每个时间序列中。
示例 4. 苹果公司 (AAPL) 的新闻量时间序列分解为趋势、季节性和残差
2. 预测
Kats 包中的另一个有用工具是其预测模块。Kats 支持各种时间序列预测技术,包括 SARIMA、Prophet(Meta 的预测库)和 Holt-Winters,以及集成预测模型。每种技术都有优缺点,并需要调整参数以在给定时间序列中实现最佳效果。你可以在 这里 阅读有关 Kats 预测模块的更多信息。
请注意,我们在这里引入预测作为时间序列分析技术。我们的目标不是预测未来的新闻量或股票价格。
示例 5. 使用 Holt-Winters 对苹果公司 (AAPL) 新闻文章量进行的 1 个月预测
3. 变点检测
变点检测试图识别随机过程或时间序列概率分布发生变化的时间,例如时间序列均值的变化。它是时间序列分析中最受欢迎的检测任务之一。
与预测类似,Kats 支持多种变点检测模型,包括:
-
CUSUM 作为一种检测时间序列均值上升/下降的方法
-
贝叶斯在线变点检测 (BOCPD),作为检测时间序列中持续时间的突变的方法
-
RobustStatDetector,类似于 CUSUM,是一种变点检测算法,用于找到时间序列数据中的均值变化
为了更好地展示这个概念,我们将把 BOCPD 应用到苹果新闻量时间序列中,以识别有关苹果新闻覆盖的突然跳跃。
示例 6. 贝叶斯在线变点检测 (BOCPD) 应用于有关苹果公司 (AAPL) 新闻文章的量
4. 异常检测
异常是任何时间序列数据的重要方面,对于像苹果这样的大公司所撰写的新闻文章数量等相对稳定的活动,异常反映了基本输入的根本变化,而这些变化可能反映了诸如盈利公告或新产品发布等重要的现实世界变化。
我们实现了一个简单但强大的算法,通过在修正时间序列数据中的趋势和季节性之后,检测超出四分位数范围的点来识别异常。这个算法的输出是一系列一个或多个感兴趣的窗口。
一些Aylien的客户目前正在使用类似的算法,旨在通知他们的交易员市场中可能与新闻头条相关的有趣变动。
示例 7. 将异常检测应用于苹果公司(AAPL)的新闻量、新闻情绪、股票价格和交易量
每个异常的显著性通过从蓝色(弱)到红色(强)的颜色进行指示。对于情绪异常,我们使用绿色表示正面,红色表示负面。我们可以看到新闻量和新闻情绪中的一些异常之间有重叠。此外,正面情绪时间序列中的一些异常似乎先于异常的交易量。
5. 相关性(Beta 和 R 平方)
在观察股票价格或交易量的变动时,理解这些变动是否独立发生或与市场相关非常重要。直观上,当证券的变动独立于市场时,或者在变动对市场的依赖性较小时,我们或许会期望看到新闻与市场活动之间有更显著的相关性。
为了研究这一假设,我们可以利用两个知名的金融指标:Beta 值和 R 平方值。
Beta 是一个派生统计量,用于衡量股票相对于整体市场或基准股票/指数的方差或波动性。从理论上讲,高 Beta 股票在市场上涨时表现出超额的表现,在市场下跌时表现出超额的低迷。为了计算股票的 Beta 值,我们可以绘制其变化与基准股票/指数(例如 S&P 500)的变化对比,并找到最适合数据的线性回归线。这条线的斜率代表 Beta 值。
R 平方衡量证券的表现可以归因于所选基准指数表现的程度。换句话说,R 平方旨在确定资产的变动有多少可以通过市场的变动来解释。
示例 8. 新闻量/情绪,与苹果公司(AAPL)相对于 S&P 指数和科技部门 ETF(XLK)的 Beta 值和 R 平方值
6. 新闻事件
Aylien 新闻 API的一个强大功能是其根据主题、事件和行业对文章进行分类的能力(这一功能称为Smart Tagger)。Aylien使用高度详细的分类法和 NLP 模型来识别与特定商业事件(例如并购或分析师评论)或行业(例如技术或制药)相关的语言片段。
我们可以利用这一能力将新闻量时间序列拆分为针对关键业务事件的单独时间序列,例如:
-
新产品 - 关于新产品发布的新闻
-
裁员 - 关于裁员的新闻
-
分析师评论 - 关于股票的分析师评论、财报公告等
-
股票 - 与股市相关的文章
-
企业收益 - 企业收益公告
-
并购 - 关于并购事件的新闻
-
店铺开业 - 消费品业务的新店开业
示例 9. 新闻文章时间序列按事件类型划分,针对苹果公司 (AAPL)
值得关注的是,关于苹果公司财报公告的新闻文章在量和频率(按季度)上的一致性,以及苹果公司宣布新产品时标记为“新产品”的文章激增。
将之前的所有图表整合在一起,我们得到了一个相当丰富和全面的时间序列数据集,用于进一步分析:
结论
在本文中,我们探讨了一些基础和高级概念,用于研究市场数据和新闻数据之间的关系,并介绍了一些构建模块,可以用来进行更详细的分析。
-
我们演示了如何检索和对齐市场和新闻数据,针对感兴趣的股票或 ETF;
-
我们引入了一些时间序列数据和分析的预处理步骤;
-
我们探索了几种不同的技术来识别和对齐不同时间序列数据中的异常;并且
-
我们研究了如何根据新闻文章的语义属性(如情感或类别)对新闻时间序列数据进行细分。
未来工作
在这项工作之后,一些有趣的探索方向如下:
-
多变量异常检测:检测多个时间序列中的异常,识别在多个时间序列中持续存在的小异常,分析新闻和市场数据之间的关系。
-
时间序列之间的相似性搜索:使用模式识别识别不同时间序列之间的相似性。
-
探索因果关系模型,例如格兰杰因果关系,以识别一个时间序列中的信号,这些信号可以很好地预测另一个时间序列。
-
将此工作扩展到其他类型的证券(如加密货币或商品)和市场信号(如宏观经济指标)。
附录
1. 新闻量、新闻情感、股票价格和交易量图表:
-
苹果公司 (AAPL)
-
特斯拉公司 (TSLA)
-
XLF - 科技行业 ETF
-
辉瑞公司 (PFE)
-
Moderna 公司 (MRNA)
-
XPH - 制药行业 ETF
-
标准普尔指数

2. 新闻量、新闻情感、β值和 R 平方值:
-
苹果公司 (AAPL)
-
特斯拉公司 (TSLA)
-
辉瑞公司 (PFE)
-
Moderna 公司 (MRNA)
Parsa Ghaffari (@parsaghaffari) 是 AYLIEN 的首席执行官和创始人。AYLIEN 是一家市场和风险智能金融科技公司,主要客户包括 Wells Fargo、IHS Markit、Revolut 和 Fidelity,这些客户依赖 AYLIEN 的平台将全球新闻数据转换为识别风险和机会的丰富、可靠且实时的信息源。Parsa 的背景是人工智能研究和开发,特别关注基于文本数据和自然语言处理的定量风险建模。
更多相关内容
营销数据科学的未来在哪里?
原文:
www.kdnuggets.com/2021/01/marketing-data-science-headed.html
评论
许多人将“数据科学”与自动驾驶汽车、人工智能、智能城市和生物信息学联系在一起,尽管它越来越多地应用于营销。营销数据科学是多方面的,但其核心是个性化营销,这是直接营销的高科技扩展。个性化广告和推荐这两种表现形式现在如此普遍,以至于它们常常被我们忽视。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
《算法营销导论》(Katsov)和《数字营销分析》(Hartman)是两本提供数据科学如何在营销中应用的绝佳概述的书籍。数据与营销协会的网站也可能引起许多读者的兴趣,而 JM-MSI 特别期刊中的"从营销优先事项到研究议程"从学术角度提供了深入探讨。
就像任何事物一样,营销数据科学也受外部因素的影响,如经济衰退、技术创新,更不用说疫情。 隐私立法以及广告拦截器和不跟踪的搜索引擎的普及正在产生影响。一个"无 Cookies 的未来"已经成为博客和文章的主题。
另一个可能引发激烈讨论的话题是个性化营销的效果。一些人认为,从技术角度来看,它实际上并不起作用,也就是说,个性化广告和推荐并没有真正到达合适的人群或任何时间的适当人群。
部分原因在于数据问题。数字营销中使用的“巨大数据”中不少是拼凑和汇总的数据,这些数据被混合在一起。营销科学家和其他分析和建模数据的人知道,单一数据文件中的缺失数据甚至小错误都可能对我们的分析产生严重影响。
当然,这只是一个观点,许多人会争辩说个性化营销比大众营销或大多数市场研究人员熟悉的宏观细分更有效。
预测分析目前主要关注“做什么”(包括在哪里、如何、由谁以及多频繁)而不是“为什么”。理解消费者的行为动机可以帮助营销人员预测他们的未来行为,有效沟通,并设计他们喜欢的产品。从他们过去的行为推断出他们的动机并不总是简单的,因为不同的人可能出于不同的原因做相同的事情。他们也可能出于相同的原因做不同的事情。
一个简单的例子是家庭清洁剂。一个人可能因为其消毒特性而最常购买 Lysol Clean,而另一个人则因为它在他们通常购物的地方很容易找到。一个人可能使用 Goo Gone 因为他们喜欢它的香味,而另一个人则使用 Citrasolv 因为他们喜欢它的香味。
另一个有时被称为“多重自我”的概念也会发挥作用。这一观念反映了这样一个简单事实:消费者行为往往会根据场合或动机而有所不同——例如,为了烹饪而购买葡萄酒与为了庆祝晋升而购买葡萄酒就是一个例子。我们的行为也可能因个人情况的变化而有所不同,如婚姻、孩子出生、晋升或搬迁。我们的口味也可能发生变化。
结果是,忽视“为什么”会错过很多信息。
其他批评者认为,个性化营销经常补贴那些本来会做出的购买,并在此过程中增加了消费者的价格敏感度,随着时间的推移,可能会侵蚀品牌价值。聪明的营销人员确实应该避免鼓励“捡便宜货”的购物方式。Les Binet 和 Peter Field 在这些话题上有很多值得倾听的观点。
有人认为个性化营销通常有效,但并不总是成本效益高。市场营销的投资回报率(ROI)很难估算,因为一些成本是估算的,而且调整外部因素如经济衰退和竞争者活动是具有挑战性的——例如,竞争对手的营销如果帮助扩大市场份额,实际上可能对我们的品牌有利。
此外,如果忽略了对数据基础设施和分析团队的投资,可能会显得成本效益更高。即使在我们在一个较小的消费者群体中拥有更高的“命中”率时,目标营销的成本效益也可能具有误导性。即使营销 ROI 更高,总体销售可能仍会因目标营销而下降。
还有一些人,特别是拜伦·夏普及其在埃伦贝格-巴斯研究所的同事,认为定位作为一种规则是一种坏习惯和坏主意。品牌如何成长(Sharp)、品牌如何成长:第二部分(Romaniuk 和 Sharp)以及建立独特品牌资产(Romaniuk)在我看来是市场营销人员和营销研究人员的必读书籍。
还有广告欺诈(ad fraud)的问题,这不是微不足道的,现在越来越难以掩盖。Bob Hoffman 和 Augustine Fou 是这个敏感话题的好信息来源。
我没有提到与营销相关的 UX(用户体验)或 CX(客户体验),这两者从拥有更多数据、更丰富的数据和更复杂的分析工具中受益。我还应该指出,预测分析和其他个性化营销的方面可以通过传统的营销研究方法如焦点小组和消费者调查来增强。这不是非此即彼的关系。
这些不断发展的“老”方法,在阐明为什么方面可能非常有帮助。营销研究人员对这种协同效应的认识在增加,但数据科学家们通常专注于数据管理和编程。我一直觉得这是一个被忽视的营销研究机会。
虽然我在这篇文章中主要强调了对营销数据科学的威胁,但作为一个营销数据科学从业者,我自身的偏见大多是相反的。然而,作为一个商人,我不能相信万灵药或只相信我愿意相信的东西。即使在疫情之前,我也感受到商业界和投资者对人工智能和大数据价值的怀疑——可以参考大数据,大骗局(Few)和大数据的笑话(Jones)来了解我的意思。
总结来说,我对“营销数据科学的未来发展方向”这个问题没有明确的答案,我不确定是否有人有。我只是尽量避免做出假设和过度相信。
个人简介:Kevin Gray 是 Cannon Gray 的总裁,一家营销科学和分析咨询公司。他在 Nielsen、Kantar、McCann 和 TIAA-CREF 拥有超过 30 年的营销研究和数据科学经验。
原文。经许可转载。
相关:
-
因果关系一览
-
人工智能的伦理
-
社交媒体的自然语言处理
更多相关话题
Marshmallow: 最甜美的 Python 数据序列化与验证库
原文:
www.kdnuggets.com/marshmallow-the-sweetest-python-library-for-data-serialization-and-validation

图片由作者提供 | Leonardo AI & Canva
数据序列化是一个基础的编程概念,在日常程序中具有很大价值。它指的是将复杂的数据对象转换为中间格式,以便保存并可以轻松地转换回原始形式。然而,像 JSON 和 pickle 这样的常见数据序列化 Python 库功能非常有限。随着结构化程序和面向对象编程的发展,我们需要更强的支持来处理数据类。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 部门
Marshmallow 是最著名的数据处理库之一,广泛被 Python 开发者用于开发健壮的软件应用程序。它支持数据序列化,并提供了在面向对象范式中处理数据验证的强大抽象解决方案。
在本文中,我们将通过下面给出的示例来了解如何在现有项目中使用 Marshmallow。代码展示了三个表示简单电子商务模型的类:Product、Customer 和 Order。每个类都最小地定义了它的参数。我们将看到如何保存对象的实例并确保在代码中重新加载时其正确性。
from typing import List
class Product:
def __init__(self, _id: int, name: str, price: float):
self._id = _id
self.name = name
self.price = price
class Customer:
def __init__(self, _id: int, name: str):
self._id = _id
self.name = name
class Order:
def __init__(self, _id: int, customer: Customer, products: List[Product]):
self._id = _id
self.customer = customer
self.products = products
开始使用 Marshmallow
安装
Marshmallow 作为一个 Python 库可以在 PyPI 上找到,并且可以通过 pip 轻松安装。要安装或升级 Marshmallow 依赖项,请运行以下命令:
pip install -U marshmallow
这会在活动环境中安装最新稳定版本的 Marshmallow。如果你想要包含所有最新功能的开发版本,可以使用下面的命令安装:
pip install -U git+https://github.com/marshmallow-code/marshmallow.git@dev
创建 Schemas
让我们首先将 Marshmallow 功能添加到Product类中。我们需要创建一个新的类,表示Product类的实例必须遵循的 schema。可以把 schema 想象成一个蓝图,定义了Product类中的变量及其数据类型。
让我们分解并理解下面的基本代码:
from marshmallow import Schema, fields
class ProductSchema(Schema):
_id = fields.Int(required=True)
name = fields.Str(required=True)
price = fields.Float(required=True)
我们创建一个继承自 Marshmallow 中的Schema类的新类。然后,我们声明与Product类相同的变量名称并定义它们的字段类型。Marshmallow 中的字段类支持各种数据类型;在这里,我们使用原始类型 Int、String 和 Float。
序列化
既然我们已经为对象定义了模式,我们现在可以将 Python 类实例转换为 JSON 字符串或 Python 字典进行序列化。这里是基本实现:
product = Product(_id=4, name="Test Product", price=10.6)
schema = ProductSchema()
# For Python Dictionary object
result = schema.dump(product)
**# type(dict) -> {'_id': 4, 'name': 'Test Product', 'price': 10.6}**
# For JSON-serializable string
result = schema.dumps(product)
**# type(str) -> {"_id": 4, "name": "Test Product", "price": 10.6}**
我们创建一个ProductSchema对象,它将Product对象转换为可序列化的格式,如 JSON 或字典。
注意
dump和dumps函数结果之间的区别。一个返回一个可以使用 pickle 保存的 Python 字典对象,另一个返回一个遵循 JSON 格式的字符串对象。
反序列化
为了逆转序列化过程,我们使用反序列化。一个对象被保存,以便以后可以加载和访问,而 Marshmallow 可以帮助实现这一点。
Python 字典可以通过 load 函数进行验证,该函数验证变量及其相关的数据类型。下面的函数展示了它是如何工作的:
product_data = {
"_id": 4,
"name": "Test Product",
"price": 50.4,
}
result = schema.load(product_data)
print(result)
**# type(dict) -> {'_id': 4, 'name': 'Test Product', 'price': 50.4}**
faulty_data = {
"_id": 5,
"name": "Test Product",
"price": "ABCD" # Wrong input datatype
}
result = schema.load(faulty_data)
**# Raises validation error**
模式验证字典是否具有正确的参数和数据类型。如果验证失败,将引发ValidationError,因此将load function封装在 try-except 块中是必要的。如果验证成功,结果对象仍然是一个字典,当原始参数也是字典时,这并不是很有用,对吧?我们通常希望的是验证字典并将其转换回最初序列化的原始对象。
为了实现这一点,我们使用 Marshmallow 提供的post_load装饰器:
from marshmallow import Schema, fields, post_load
class ProductSchema(Schema):
_id = fields.Int(required=True)
name = fields.Str(required=True)
price = fields.Float(required=True)
@post_load
def create_product(self, data, **kwargs):
return Product(**data)
我们在模式类中创建一个带有post_load装饰器的函数。这个函数接收经过验证的字典并将其转换回Product对象。包括**kwargs非常重要,因为 Marshmallow 可能会通过装饰器传递其他必要的参数。
对 load 功能的这种修改确保在验证后,Python 字典被传递到post_load函数中,该函数从字典中创建Product对象。这使得使用 Marshmallow 进行对象反序列化成为可能。
验证
通常,我们需要针对我们的使用案例进行额外的验证。虽然数据类型验证是必不可少的,但它并不能涵盖我们可能需要的所有验证。即使在这个简单的示例中,我们的Product对象也需要额外的验证。我们需要确保价格不低于 0. 我们还可以定义更多规则,例如确保产品名称的长度在 3 到 128 个字符之间。这些规则有助于确保我们的代码库符合定义的数据库模式。
现在让我们看看如何使用 Marshmallow 实现这种验证:
from marshmallow import Schema, fields, validates, ValidationError, post_load
class ProductSchema(Schema):
_id = fields.Int(required=True)
name = fields.Str(required=True)
price = fields.Float(required=True)
@post_load
def create_product(self, data, **kwargs):
return Product(**data)
@validates('price')
def validate_price(self, value):
if value <= 0:
raise ValidationError('Price must be greater than zero.')
@validates('name')
def validate_name(self, value):
if len(value) < 3 or len(value) > 128:
raise ValidationError('Name of Product must be between 3 and 128 letters.')
我们修改了 ProductSchema 类,添加了两个新函数。一个用于验证价格参数,另一个用于验证名称参数。我们使用 validates 函数装饰器并标注函数要验证的变量名称。这些函数的实现很简单:如果值不正确,我们会引发 ValidationError。
嵌套模式
现在,随着基本的 Product 类验证,我们已经涵盖了 Marshmallow 库提供的所有基本功能。现在让我们增加复杂性,看看其他两个类如何进行验证。
Customer 类相当简单,因为它包含了基本属性和原始数据类型。
class CustomerSchema(Schema):
_id = fields.Int(required=True)
name = fields.Int(required=True)
然而,为 Order 类定义模式迫使我们学习一个新的必需概念——嵌套模式。一个订单将关联到一个特定的客户,而客户可以订购任意数量的产品。这在类定义中得以定义,当我们验证 Order 模式时,我们还需要验证传递给它的 Product 和 Customer 对象。
我们将避免在 OrderSchema 中重新定义一切,使用嵌套模式来避免重复。订单模式定义如下:
class OrderSchema(Schema):
_id = fields.Int(require=True)
customer = fields.Nested(CustomerSchema, required=True)
products = fields.List(fields.Nested(ProductSchema), required=True)
在 Order 模式中,我们包括了 ProductSchema 和 CustomerSchema 定义。这确保了这些模式的定义验证被自动应用,遵循编程中的 DRY(不要重复自己) 原则,从而实现现有代码的重用。
总结
在这篇文章中,我们介绍了 Marshmallow 库的快速入门和使用案例,这是 Python 中最受欢迎的序列化和数据验证库之一。虽然与 Pydantic 类似,但许多开发人员更喜欢 Marshmallow,因为它的模式定义方法类似于其他语言(如 JavaScript)中的验证库。
Marshmallow 易于与像 FastAPI 和 Flask 这样的 Python 后端框架集成,使其成为 Web 框架和数据验证任务的热门选择,同时也适用于像 SQLAlchemy 这样的 ORM。
Kanwal Mehreen** Kanwal 是一名机器学习工程师和技术作家,对数据科学以及人工智能与医学的交汇点充满热情。她共同撰写了电子书《用 ChatGPT 最大化生产力》。作为 2022 年 APAC 地区的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认可为 Teradata 多样性技术学者、Mitacs Globalink 研究学者和哈佛 WeCode 学者。Kanwal 是变革的积极倡导者,她创立了 FEMCodes 以赋能 STEM 领域的女性。
更多相关主题
NumPy 中处理缺失数据的掩码数组
原文:
www.kdnuggets.com/masked-arrays-in-numpy-to-handle-missing-data

作者提供的图像
想象一下试图解决一个缺少拼图块的谜题。这会很令人沮丧,对吧?这是处理不完整数据集时的常见情境。NumPy 中的掩码数组是专门的数组结构,允许你高效地处理缺失或无效的数据。在必须对包含不可靠条目的数据集进行计算的情境下,它们特别有用。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 为你的组织提供 IT 支持
掩码数组本质上是两个数组的组合:
-
数据数组:包含实际数据值的主要数组。
-
掩码数组:一个与数据数组形状相同的布尔数组,其中每个元素指示对应的数据元素是有效还是被掩码(无效/缺失)。
数据数组
数据数组是掩码数组的核心组件,保存了你想分析或处理的实际数据值。这个数组可以包含任何数值或分类数据,就像标准的 NumPy 数组一样。以下是一些重要的考虑点:
-
存储:数据数组存储了你需要处理的值,包括有效和无效的条目(如
NaN或代表缺失数据的特定值)。 -
操作:在执行操作时,NumPy 使用数据数组来计算结果,但会考虑掩码数组以确定包含或排除哪些元素。
-
兼容性:掩码数组中的数据数组支持所有标准的 NumPy 功能,使得在常规数组和掩码数组之间切换变得容易,而不会显著改变现有代码库。
示例:
import numpy as np
data = np.array([1.0, 2.0, np.nan, 4.0, 5.0])
masked_array = np.ma.array(data)
print(masked_array.data) # Output: [ 1\. 2\. nan 4\. 5.]
掩码数组
掩码数组是一个与数据数组形状相同的布尔数组。掩码数组中的每个元素对应于数据数组中的一个元素,并指示该元素是有效(False)还是被掩码(True)。以下是一些详细的点:
-
结构:掩码数组的创建形状与数据数组相同,以确保每个数据点都有一个对应的掩码值。
-
标识无效数据:掩码数组中的 True 值将相应的数据点标记为无效或缺失,而 False 值则表示有效数据。这允许 NumPy 在计算过程中忽略或排除无效数据点。
-
自动掩码:NumPy 提供了根据特定条件自动创建掩码数组的函数(例如,
np.ma.masked_invalid()用于掩盖 NaN 值)。
示例:
import numpy as np
data = np.array([1.0, 2.0, np.nan, 4.0, 5.0])
mask = np.isnan(data) # Create a mask where NaN values are True
masked_array = np.ma.array(data, mask=mask)
print(masked_array.mask) # Output: [False False True False False]
掩码数组的强大之处在于数据与掩码数组之间的关系。当你对掩码数组执行操作时,NumPy 会考虑这两个数组,确保计算仅基于有效数据。
掩码数组的好处
NumPy 中的掩码数组提供了多种优势,尤其是在处理包含缺失或无效数据的数据集时,其中包括:
-
缺失数据的高效处理:掩码数组允许你轻松标记无效或缺失的数据,例如 NaN,并在计算中自动处理它们。操作仅在有效数据上执行,确保缺失或无效的条目不会扭曲结果。
-
简化数据清理:像
numpy.ma.masked_invalid()这样的函数可以自动掩盖常见的无效值(例如 NaN 或无穷大),而无需额外的代码来手动识别和处理这些值。你可以根据特定标准定义自定义掩码,允许灵活的数据清理策略。 -
与 NumPy 函数的无缝集成:掩码数组与大多数标准 NumPy 函数和操作兼容。这意味着你可以使用熟悉的 NumPy 方法,而无需手动排除或预处理掩码值。
-
提高计算准确性:在执行计算(例如,均值、总和、标准差)时,掩码值会自动从计算中排除,从而得到更准确和有意义的结果。
-
增强数据可视化:在可视化数据时,掩码数组确保无效或缺失值不会被绘制,从而产生更清晰和准确的视觉表示。你可以仅绘制有效数据,避免杂乱,提高图表的可解释性。
使用掩码数组处理 NumPy 中的缺失数据
本节将演示如何使用掩码数组处理 NumPy 中的缺失数据。首先,让我们看一个简单的示例:
import numpy as np
# Data with some missing values represented by -999
data = np.array([10, 20, -999, 30, -999, 40])
# Create a mask where -999 is considered as missing data
mask = (data == -999)
# Create a masked array using the data and mask
masked_array = np.ma.array(data, mask=mask)
# Calculate the mean, ignoring masked values
mean_value = masked_array.mean()
print(mean_value)
输出:
25.0
说明:
-
数据创建:
data是一个整数数组,其中 -999 代表缺失值。 -
掩码创建:
mask是一个布尔数组,将 -999 位置标记为 True(表示缺失数据)。 -
掩码数组创建:
np.ma.array(data, mask=mask)创建一个掩码数组,将掩码应用于data。 -
计算:
masked_array.mean()。
计算平均值时忽略掩码值(即-999),结果是剩余有效值的平均值。
在此示例中,平均值仅从 [10, 20, 30, 40] 计算,不包括 -999 值。
让我们通过一个更全面的示例来探索使用掩码数组处理较大数据集中缺失数据的情况。我们将使用涉及多个传感器跨多个日期的温度读数数据集的场景。数据集中包含一些由于传感器故障而缺失的值。
用例:分析来自多个传感器的温度数据
场景:你有来自五个传感器的十天温度读数。由于传感器问题,一些读数缺失。我们需要计算平均每日温度,同时忽略缺失数据。
数据集:数据集表示为二维 NumPy 数组,行表示日期,列表示传感器。缺失值由np.nan表示。
步骤:
-
导入 NumPy:用于数组操作和处理掩码数组。
-
定义数据:创建一个包含一些缺失值的二维温度读数数组。
-
创建掩码:识别数据集中的缺失值(NaNs)。
-
创建掩码数组:应用掩码以处理缺失值。
-
计算每日平均温度:计算每一天的平均温度,忽略缺失值。
-
输出结果:显示分析结果。
代码:
import numpy as np
# Example temperature readings from 5 sensors over 10 days
# Rows: days, Columns: sensors
temperature_data = np.array([
[22.1, 21.5, np.nan, 23.0, 22.8], # Day 1
[20.3, np.nan, 22.0, 21.8, 23.1], # Day 2
[np.nan, 23.2, 21.7, 22.5, 22.0], # Day 3
[21.8, 22.0, np.nan, 21.5, np.nan], # Day 4
[22.5, 22.1, 21.9, 22.8, 23.0], # Day 5
[np.nan, 21.5, 22.0, np.nan, 22.7], # Day 6
[22.0, 22.5, 23.0, np.nan, 22.9], # Day 7
[21.7, np.nan, 22.3, 22.1, 21.8], # Day 8
[22.4, 21.9, np.nan, 22.6, 22.2], # Day 9
[23.0, 22.5, 21.8, np.nan, 22.0] # Day 10
])
# Create a mask for missing values (NaNs)
mask = np.isnan(temperature_data)
# Create a masked array
masked_data = np.ma.masked_array(temperature_data, mask=mask)
# Calculate the average temperature for each day, ignoring missing values
daily_averages = masked_data.mean(axis=1) # Axis 1 represents days
# Print the results
for day, avg_temp in enumerate(daily_averages, start=1):
print(f"Day {day}: Average Temperature = {avg_temp:.2f} °C")
输出:

解释:
-
导入 NumPy:导入NumPy库以利用其功能。
-
定义数据:创建一个二维数组
temperature_data,其中每行代表特定日期传感器的温度,且有些值缺失(np.nan)。 -
创建掩码:使用
np.isnan(temperature_data)生成布尔掩码,以识别缺失值(True表示值为np.nan)。 -
创建掩码数组:使用
np.ma.masked_array(temperature_data, mask=mask)创建masked_data。这个数组屏蔽掉缺失值,使操作忽略它们。 -
计算每日平均温度:使用
.mean(axis=1)计算每天的平均温度。这里,axis=1表示在每一天的传感器之间计算均值。 -
输出结果:打印每天的平均温度。掩码值被排除在计算之外,提供准确的每日平均值。
结论
在这篇文章中,我们探讨了掩码数组的概念以及如何利用它们处理缺失数据。我们讨论了掩码数组的两个关键组成部分:数据数组,它包含实际值,和掩码数组,它指示哪些值是有效的或缺失的。我们还考察了它们的好处,包括高效处理缺失数据、与 NumPy 函数的无缝集成以及提高计算准确性。
我们通过简单和复杂的示例演示了掩码数组的使用。初始示例展示了如何处理由特定标记如 -999 表示的缺失值,而更全面的示例则展示了如何分析来自多个传感器的温度数据,其中缺失值由 np.nan 表示。这两个示例都突出了掩码数组通过忽略无效数据来准确计算结果的能力。
进一步阅读请查看以下两个资源:
Shittu Olumide 是一位软件工程师和技术写作者,热衷于利用前沿技术来编写引人入胜的叙述,具有敏锐的细节观察力和简化复杂概念的天赋。你也可以在 Twitter 上找到 Shittu。
更多相关话题
在一年内掌握数据科学:终极指南,以负担得起的、自定进度的学习方式
原文:
www.kdnuggets.com/master-data-science-in-a-year-the-ultimate-guide-to-affordable-self-paced-learning

图片来源:编辑
开始新的学习旅程可能会很困难,特别是当你对所选路径几乎没有经验或理解时。你应该参加训练营吗?但也许你无法承诺时间限制。是否应该回到大学?但那费用不菲,很多人不愿意承担。如何选择在线课程,让你可以按自己的节奏学习,不会伤及财务?
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT
本博客面向那些希望转行进入数据科学领域的初学者。这个领域正变得越来越受欢迎。虽然这些课程已提供了基于你投入时间的完成时长细节——但我真的相信,你投入的时间越多,完成课程的速度就会越快。
如果你愿意投入时间,你可以在一年内完成所有这些课程!
数据分析
这是在数据科学领域非常受欢迎的课程。我个人也参加过这门课程,我相信这是任何初学者的最佳课程之一!如果你每周投入 10 小时,这门课程将需要 6 个月完成。我能够在一个月内完成,因为我有空闲时间,可以更快完成!
由 8 个部分组成,本课程将深入探讨数据的日常使用、最佳实践以及新数据分析工作的流程。你将学习如何清理和组织数据以进行分析,并使用电子表格、SQL 和 R 编程进行计算。课程不仅仅止步于此,你还将通过创建数据可视化和学习如 Tableau 等工具来进一步提升你的分析技能。
最终,你将获得证书,并且可以独享简历审查、面试准备和职业支持等职业资源。
数据科学
链接:IBM 数据科学专业证书
更进一步,通过 IBM 的数据科学专业证书提升你的分析技能。无需经验,如果每周投入 10 小时,你可以在 5 个月内完成该课程。记住,投入的时间越多,完成课程的速度就越快。
在课程中,你将学习数据科学家在日常任务中使用的最新实用技能和知识。深入了解 Python 和 SQL 等流行工具、语言和库。你不仅会学习数据清理、分析和可视化,还会学习如何构建机器学习模型和管道。
将你在这门课程中学到的技能应用于实际项目,并建立自己的数据项目组合,以便在面试时展示。
机器学习
链接: 机器学习专项课程
随着聊天机器人成为热门话题,掌握机器学习比以往任何时候都更为重要。这门由斯坦福大学和 DeepLearning.AI 提供的初学者友好课程旨在帮助人们进入 AI 领域。如果每周投入 10 小时,你可以在 2 个月内完成。
这门课程将帮助你掌握 AI 概念的基础知识,并具备实际的机器学习技能。学习如何使用 NumPy 和 scikit-learn 构建机器学习模型,如用于预测的监督模型。你还将学习如何使用 TensorFlow 构建和训练神经网络。决策树、集成方法、聚类、异常检测、深度强化学习——这门课程应有尽有!
深度学习
链接: 深度学习专项课程
另一门课程由 DeepLearning.AI 提供,在这里你将从机器学习初学者转变为专家。该课程不断更新前沿技术,帮助你进入 AI 领域,如果每周投入 10 小时,你将在 3 个月内完成。
学习如何构建和训练深度神经网络以及识别关键的架构参数。你还将学习如何使用标准技术和优化算法来训练/测试和分析深度学习应用。你将构建一个卷积神经网络(CNN)并将其应用于检测和识别任务,其中你可以使用神经风格迁移生成艺术内容——很酷吧?
总结
当我们学习新事物时,常常会发现自己把学习过程弄得过于复杂。通过这 4 门课程,你可以在年底前从初学者转变为专家。
但重要的是要提醒自己,数据科学领域总是关于学习的,因此确保你准备好在新知识出现时进行学习。如果你将生成性 AI 作为你的目标之一,可以查看一下掌握生成性 AI 的 Top 5 DataCamp 课程。
尼莎·阿雅 是一名数据科学家、自由职业技术写作者,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程以及基于理论的数据科学知识。尼莎涵盖了广泛的话题,并希望探索人工智能如何促进人类寿命的不同方式。作为一个热衷学习者,尼莎寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
更多相关话题
掌握数据分析的力量:分析数据的四种方法
原文:
www.kdnuggets.com/2023/03/master-power-data-analytics-four-approaches-analyzing-data.html

图片来源:Leeloo Thefirst
你是否曾希望拥有一个水晶球,能够告诉你业务的未来?虽然我们不能承诺你一个神秘的未来预见,但我们有下一个最佳选择:数据分析。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
在今天这个数据驱动的世界里,企业收集和生成大量数据变得轻而易举。然而,拥有数据仅仅是不够的。
作为一家企业,你需要能够理解数据并以能够做出更好决策的方式利用它。这就是数据分析的作用。数据分析指的是检查数据以提取见解并做出明智决策的过程。
根据统计数据,数据分析市场正在快速增长,预计到 2029 年将超过6500 亿美元。这显示了数据分析在企业和全球经济中的日益重要性。
未来是由数据驱动的。从预测客户行为到识别优化领域,数据分析可以帮助企业揭示数据中隐藏的秘密,并推动更好的结果。然而,面对众多工具和技术,确定从哪里开始可能会让人感到不知所措。
本文将带你了解数据分析,并探讨分析数据的四种方法。阅读完这篇文章后,你将掌握利用数据的力量所需的知识,做出明智的决策,从而将业务提升到新高度。
图片来源:hbs
描述性分析
描述性分析是一种数据分析类型,它专注于描述和总结数据,以获得对过去发生了什么的洞察。它通常用于回答诸如“发生了什么?”和“多少?”的问题。
描述性分析可以帮助企业和组织理解他们的数据,并识别可以为决策提供依据的模式和趋势。
以下是一些描述性分析的真实例子:
-
零售店可能会分析历史销售数据,以识别受欢迎的产品和趋势。例如,人们在二月份往往会买更多的糖果。
-
患者数据可以被总结以识别常见的健康问题。例如,大多数人从十月到六月期间会得流感。
-
学生的表现数据可以被分析以识别改进的领域。例如,大多数未能通过微积分考试的学生通常上课迟到。
要有效使用描述性分析,你需要确保你的数据准确且高质量。同样,使用清晰简明的可视化工具来有效传达洞见也至关重要。
预测性分析
预测性分析使用统计和机器学习技术来分析历史数据并预测未来事件。它通常用于回答诸如“什么可能会发生?”和“如果发生了什么?”的问题。
预测性分析非常有用,因为它可以帮助你提前规划。它可以帮助改善业务运营,降低成本,并增加收入。例如,你可以根据季节性和以往销售数据预测销售情况。如果你的预测分析告诉你冬季销售可能会减少,你可以利用这些信息为这个季节设计一个有效的营销活动。
以下是一些预测性分析实际应用的例子:
-
银行可能会使用预测性分析来评估信用风险,并决定是否向客户提供贷款。在开放银行业务中,预测性分析可以帮助建立高度个性化的行为模型,特定于每个客户,并以新的方式评估他们的信用 worthiness。对客户而言,这可能意味着更好且更便宜的访问银行账户、信用卡和抵押贷款。
-
在营销中,预测性分析可以帮助识别哪些客户最可能响应特定的优惠。
-
在医疗保健中,预测性分析可以用于识别有风险发展特定疾病的患者。
-
在制造业中,预测性分析可以用于预测需求和优化供应链管理。
然而,使用预测分析也存在一些挑战。一个挑战是高质量数据的可用性,这对于准确预测至关重要。另一个挑战是选择适当的建模技术来分析数据并做出准确预测。最后,将预测分析结果传达给决策者可能会很有挑战性,因为所使用的技术可能复杂且难以理解。
处方分析
处方分析是一种数据分析方法,它超越了描述性和预测性分析,为你应该采取的行动提供建议。换句话说,这种方法涉及使用优化技术来确定最佳行动方案,在一系列约束和目标的条件下。
它通常用于回答诸如“我们应该做什么?”和“我们如何改进?”的问题。
为了有效,处方分析需要对所分析的数据有深刻的理解,并能够建模和模拟不同的情景,以确定最佳行动方案。因此,这是一种四种方法中最复杂的方法。
处方分析可以帮助你解决各种问题,包括产品组合、劳动力规划、市场营销组合、资本预算和产能管理。

图片由Pixabay提供
处方分析的最佳例子是高峰时段使用谷歌地图获取方向。该软件考虑了所有交通工具和交通状况,以计算出最佳路线。交通公司可能会以这种方式使用处方分析来优化配送路线和最小化燃料成本。特别是当你考虑到燃料成本上升时,这一点尤为重要。例如,在加拿大,普通人每年在燃料上的支出约为 2,000 加元,而在美国,家庭在燃料上的支出占总年收入的近 2.24%。
然而,与预测分析一样,有效使用处方分析也面临一些挑战。第一个挑战是高质量数据的可用性,这是进行准确分析和优化所必需的。另一个挑战是所使用的优化算法的复杂性,这可能需要专业的技能和知识来有效实施。
诊断分析
诊断分析是一种数据分析类型,超越了描述性分析,以识别问题的根本原因。它回答诸如“为什么会发生?”和“是什么造成的?”的问题。例如,你可以使用诊断分析来确定为什么你的 1 月销售额下降了 50%。
诊断分析涉及探索和分析数据,以识别能够帮助解释问题或难题的关系和相关性。这可以通过回归分析、假设检验和因果分析等技术来完成。
现实生活中的例子包括:
-
你可以使用诊断分析来识别生产过程中质量问题的根本原因。
-
你还可以用它来识别客户投诉背后的原因,并提供有针对性的解决方案。
-
在网络威胁的情况下,你也可以用它来识别安全漏洞的来源,并防止未来的攻击。
使用诊断分析有许多好处,例如识别问题的根本原因并制定有针对性的解决方案。但与前两种数据分析方法一样,也存在一些挑战需要考虑。例如,获取高质量的数据和确保分析准确性可能比较困难。其次,分析技术可能相当复杂,可能需要专业的技能和知识才能有效实施。
| 方法 | 定义 | 回答的问题 |
|---|---|---|
| 描述性 | 描述和总结数据,以获得对过去发生了什么的洞察。 |
-
发生了什么?
-
多少?
|
| 诊断性 | 识别问题或难题的根本原因 |
|---|
-
为什么会发生?
-
是什么原因造成的?
|
| 预测性 | 分析历史数据并对未来事件进行预测。 |
|---|
-
可能发生什么?
-
如果发生什么情况?
|
| 处方性 | 根据分析提供应采取的行动建议。 |
|---|
-
我们应该怎么做?
-
我们如何改进?
|
如何有效使用四种方法
尽管四种数据分析方法各有优缺点,选择最合适的方法对于实现预期结果可能至关重要。选择方法时需要考虑的一些因素包括:
所解决问题的性质。不同的问题需要不同的方法。例如,你可以使用:
-
描述性分析总结客户反馈数据并识别客户需求模式
-
诊断分析用于识别驱动销售业绩变化的因素
-
预测性分析来预测产品的未来需求
-
处方分析用于优化制造设施中的生产计划
可用数据的类型和质量。确保数据准确、完整且相关也很重要。这可能涉及清理、转换或以其他方式准备数据,以确保其适合所选的方法。在许多情况下,数据准备可能是一个耗时且迭代的过程,可能需要专门的工具或专业知识。
分析所需的资源和技能是可用的。要进行有效的数据分析,还需要掌握正确的技能和工具。这可能包括统计分析软件、编程语言和可视化工具。一些常见的技能 可能对数据分析师有用,包括数据整理、数据可视化、机器学习和统计推断。
结论
从以上讨论中可以看出,数据分析是一个强大的工具,可以提供有价值的见解并推动业务增长。通过理解和利用数据分析的四种不同方法,企业可以更好地理解其数据,并做出更明智的决策。
然而,在选择分析方法时,仔细考虑业务的具体需求和目标以及了解每种方法的优缺点是非常重要的。
最终,通过选择正确的方法并有效实施,企业可以获得竞争优势并实现长期成功。因此,勇敢探索数据分析的激动人心的世界吧——可能性无穷无尽!
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾担任 Inc. 5000 实验性品牌组织的首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼等。
更多相关内容
掌握命令行艺术与此 GitHub 仓库
原文:
www.kdnuggets.com/master-the-art-of-command-line-with-this-github-repository

作者提供的图片
作为一名处理数据的专业人士,我理解在工作中高效和准确的重要性。这就是为什么我认为掌握命令行是简化数据分析任务和提高生产力的必备技能。对于希望优化操作系统使用和自动化各种任务的普通用户来说,这也同样重要。
我们的前三课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
在这篇博客中,我们将回顾一个在 GitHub 上广受欢迎的(144k ?)单页指南。该指南旨在为你提供可以提升工作流程的基本命令行技能。
什么是命令行?
命令行(CLI),也称为终端或控制台,是一种基于文本的界面,允许用户通过输入命令与计算机操作系统互动。它提供了图形用户界面(GUIs)的替代方案,并提供了一种更直接、更精确的方式来访问和操作文件、目录和系统资源。
作者提供的截图
用户可以在终端中输入命令,以精确和自动化的方式执行任务,例如脚本编写、软件开发、数据处理和系统管理。终端允许用户通过一个命令执行多个复杂操作。
为什么这个指南很重要?
掌握命令行艺术是一个可以显著提升你工作效率和计算机系统理解的过程。无论你是初学者还是有经验的用户,命令行都提供了一种强大的方式来导航、定制和自动化计算机上的任务。
对于数据科学家来说尤其有益。通过命令行,数据专业人士可以简化数据清洗、执行数据管道、自动化数据相关任务,并使用各种命令行工具进行测试和模型开发。
来自jlevy/the-art-of-command-line的截图
本指南旨在在一页内提供基本的命令行知识,重点是 Linux,但也包括适用于 macOS 和 Windows 用户的工具。它涵盖了基本命令、文件和数据处理、系统调试,以及仅在 Mac 和 Windows 上可用的命令。由于各种作者和翻译者的贡献,该指南提供了多种语言版本。
语言: Čeština ∙ Deutsch ∙ Ελληνικά ∙ English ∙ Español ∙ Français ∙ Indonesia ∙ Italiano ∙ 日本語 ∙ 한국어 ∙ polski ∙ Português ∙ Română ∙ Русский ∙ Slovenščina ∙ Українська ∙ 简体中文 ∙ 繁體中文
指南内容
本指南的范围广泛而简洁,旨在涵盖所有重要内容,提供具体示例,避免不必要的细节。它设计用于交互式 Bash 使用,但许多提示也适用于其他 Shell 和 Bash 脚本。
基础知识
学习基本的 Bash 命令,并理解它们的文档man <command>,以及至少精通一种基于文本的编辑器(如 Vim、Emacs、nano),以便进行高效的终端编辑。此外,还要了解文件和输出操作,包括重定向(>、<、|)和文件模式匹配。
日常使用
为了高效的命令补全和历史记录,分别使用 Tab 和 Ctrl-R。要导航和管理文件,了解使用 ls、cd、ln、chmod 和 chown 进行目录导航。
文件和数据处理
学习使用文本处理工具:grep、awk、sed、cut、sort、uniq 和 wc。对于文件搜索,学习使用 find 和 locate 来定位文件和目录。
系统调试
熟悉系统监控和调试工具,如 top、ps、netstat、dmesg 和 iotop。使用 strace、ltrace 和系统日志进行性能分析和问题诊断。
一行命令
一行命令是执行复杂任务的强大命令序列。示例包括排序和计数文本文件中的出现次数、批量重命名和系统监控。
批量重命名脚本,将目录中的所有.txt 文件更改为.md:
**for** file **in** *.txt; do mv "$file" "${file%.txt}.md"; done
既冷僻又有用
专用命令如 expr、cal、yes、env 和 printenv 在特定场景下提供有用的功能。
仅限 macOS
Mac 用户可以使用如 Homebrew 这样的独特工具进行软件包管理,pbcopy 和 pbpaste 用于剪贴板交互,以及特定的文件和系统实用程序(mdfind、mdls)。
仅限 Windows
Windows 用户可以转向 Cygwin、Windows Subsystem for Linux(WSL)或 MinGW,以获得类 Unix 命令行环境。工具如 wmic、ipconfig 和 PowerShell 脚本扩展了 Windows 上的命令行功能。
有趣的命令
使用诸如 curl、egrep、tr 和 cowsay 等工具,你可以创造性地获取、处理和显示信息,展示你手中的力量和灵活性。
结论
-
本指南是一个有用的速查表,帮助您了解新的 CLI 工具及其在各种场景中的应用。它在积极维护中,您甚至可以通过创建拉取请求来贡献您的力量。 Master The Art Of Command Line 指南由社区制作并服务于社区,因此如果您发现任何错误或学到了一些新的遗漏内容,请更新主要的 README.md 文件。
-
我希望您能从本指南中了解新的工具和实用程序,并将其应用于您的项目。根据我的经验,我在数据项目中使用了比实际 Python 代码更多的命令行工具,特别是如果您是数据工程师或 MLOps 工程师的话。
进一步阅读
-
5 个更多的数据科学命令行工具
-
如何在命令行中清理文本数据
-
数据科学命令行:免费电子书 (必读)
- Abid Ali Awan(@1abidaliawan)是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作和撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为在精神健康方面挣扎的学生开发 AI 产品。
相关话题
使用这门免费的斯坦福课程掌握变换器!
原文:
www.kdnuggets.com/2022/09/master-transformers-free-stanford-course.html

截图来自于 Transformers United: DL Models that have revolutionized NLP, CV, RL
最先进(SOTA)的自然语言处理(NLP)意味着变换器!
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织 IT
不是 擎天柱或大黄蜂(80 年代的小伙伴们站起来!),而是这种神经网络架构,在过去几年里彻底改变了 NLP 领域。
有很多资源可以学习变换器及其在 SOTA NLP 中的应用,但似乎只有这门课程采用了系统的、学术的方法来真正理解变换器的内在,而这门课程就是斯坦福大学的 CS25: Transformers United。
让我立刻说明:这不是一个你可以报名并获得学分的课程。这是第一门关于变换器的大学课程的免费内容(据我了解),由斯坦福大学的讲师提供,在著名自然语言处理(NLP)研究员和教职工克里斯·曼宁的指导下进行。但不要灰心;所有课程材料都可以获得,包括阅读资料、视频等。如果你真的对深入理解变换器感兴趣,这门课程就是为你准备的。
尽管变换器可能最常与 NLP 应用相关,但还有更多内容值得关注。
自 2017 年推出以来,变换器已经彻底改变了自然语言处理(NLP)。现在,变换器正在深度学习领域得到应用,无论是计算机视觉(CV)、强化学习(RL)、生成对抗网络(GANs)、语音还是生物学等。变换器不仅促进了强大语言模型如 GPT-3 的创建,还在 DeepMind 最近的 AlphaFold2 中发挥了重要作用,该模型解决了蛋白质折叠问题。
来自斯坦福大学的 CS25: Transformers United 课程主页
该课程内容全面,分为 10 周的讲座。你将首先学习注意力机制,这一概念催生了变换器,然后学习变换器本身,接着是它们在自然语言处理中的应用、视觉变换器、预训练变换器、开关变换器等等。课程包括 Geoff Hinton、Chris Olah、Aidan Gomez 及许多该领域的知识渊博的研究人员的讲座。课程讲师为 Div Garg、Chetanya Rastogi、Advay Pal,Chris Manning,如前所述,担任教师顾问。
你可以在下面找到讲座视频,也可以在 YouTube 上观看。
这似乎是目前任何地方可以获得的变换器课程中的巅峰之作,因此,如果你认真想要深入学习变换器,请访问 课程页面 并立即开始学习。
Matthew Mayo (@mattmayo13) 是数据科学家以及 KDnuggets 的主编,KDnuggets 是开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及机器学习的自动化方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系到。
更多相关内容
掌握数据讲故事的艺术:数据科学家的指南
原文:
www.kdnuggets.com/2023/06/mastering-art-data-storytelling-guide-data-scientists.html
图片由Isaac Smith提供,来源于 Unsplash
如果你想成为一名数据科学家,或者已经是数据科学家——你会读到或知道所需的技能。你需要掌握一种编程语言,了解数学统计,能够创建数据可视化等。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
如果你想成为数据科学专业人士并需要一些指导,可以查看这篇文章:五步成为数据科学专业人士。
尽管你大部分时间会花在数据准备阶段,试图找到和清理数据,但数据科学还有其他重要元素。
一旦你找到了有价值的见解,无论是趋势、模式还是可视化,你都需要能够解释这些。作为数据专业人士,非技术人员可能难以理解技术语言。
如果你是一个技术人员,将你的信息传达给非技术人员可能会很具挑战性。你不仅会遇到非技术人员,还可能要面对那些喜欢通过可视化或项目演示来进行解释的人。
因此,一旦你有了发现,你需要迎合各种各样的人——掌握如何做到这一点可能很困难,但这是可以实现的。
让我们开始吧……
非技术语言
作为一名数据科学家,我知道许多利益相关者或管理者并没有技术背景。因此,你日常团队中使用的一些术语对他们来说可能是陌生的。例如,F1 分数或交叉验证。
想想老师是如何向学生解释一个话题的,并在解释给观众时保持这个思路。将你的数据科学术语翻译成所有人都能理解的语言。如果没有办法替换特定的数据科学术语,解释它的含义也没有坏处。你会因为失去观众对技术术语的关注而带来更多的伤害。
数据可视化
不同的人有不同的学习方式。有些人只需读一遍教科书就能理解,有些人需要色彩编码,有些人需要可视化。当你展示你的发现时,不要限制自己,也不要陷入只能回答 1000 个问题的困境。可视化可以为你解答问题。
数据可视化将使你的观众对你采取的步骤和发现有直观的理解。当你在背景中谈论这些可视化时,他们的眼睛在学习并理解你所说的内容。
总结
在你的演示结束时,确保有一页总结所有重要点和数据可视化供观众查看。在这段时间里,你应该对问题保持开放,观众可以持续查看总结板提出新问题。
观众提问并不是坏事,这表明他们在听,他们感兴趣,并且想要学习和理解更多。
三幕式讲故事
以上几点是使你的讲故事有效的元素。然而,一个结构才会让你的数据讲故事成功。
三幕式故事讲述是叙事小说中一种流行的模型,它将故事分为三个部分:
设置
目标: 以最清晰的语言陈述你试图解决的问题。
这包括对你的项目进行介绍,说明项目的目的,你要解决的问题等等。在设置阶段,从数据科学的角度,你将更深入地探讨问题或议题,为项目的目标提供背景。你项目的目标将等同于你的第 1 点。
对抗
目标: 向你的观众解释解决这个问题的重要性以及你解决问题的不同路径。
在对抗部分,你可以继续谈论当前任务,以及公司为何会面临这个问题。你要保持观众的兴趣和好奇心,因此谈论公司面临的问题总是能吸引利益相关者。
一步一步向你的读者解释你所经过的不同路径以及每个路径的结果,以完成当前任务。你在数据科学项目中采取的不同步骤将反映不同的点,例如第 2 点、第 3 点,……
向听众提供你遇到的失败和障碍的背景以及原因,将有助于在你提供解决方案后建立你与听众之间的信任和理解。
解决方案
目标: 解释你可以提供的解决方案,并确保听众感到满意。
这是听众从担忧转为释然的地方。你的解决方案应说明它如何克服了之前的失败和障碍。为这一部分留出提问的机会,因为你的听众会希望对你的数据洞察充满信任,并相信这是正确的方向。
一旦听众感到安心,你可以开始总结并讨论需要采取的行动,以确保任务的成功。
金字塔原理
另一个非常有效的结构是金字塔原理。这是一种有效的沟通工具,用于向繁忙的高管清晰地传达复杂问题。其目的是确保书面中的思想始终在一个单一思想下形成金字塔结构。
让我再详细解释一下。当处理希望了解你的数据洞察但时间紧张或急于了解解决方案的繁忙高管时,金字塔原理是最佳选择。
它被分为三部分:
你的答案
在这种情况下,你的答案将是当前任务的解决方案。这是你希望你的听众记住的重点。这是关键的信息,你希望注意力集中在这一主要点上——解决方案。
支持性论据
一旦你陈述了解决方案,你的下一步是说服你的听众这是正确的方法。为此,你需要带领他们经历一段支持性论据的旅程,提供高层次的见解。在这一部分,听众可能会有一些悬而未决的问题。
支持性事实/数据
在这一部分,所有可能的问题将会得到解答。你所有的支持性论据需要有数据和事实的支持,以确保你的听众相信你做了功课,并且你的初步答案/解决方案不是凭空而来的。
总结
使用非技术性语言和可视化技能,无论是三幕剧故事结构还是金字塔原理,都将帮助你掌握数据讲述的艺术。
你选择的结构取决于你对听众的了解程度。你可以通过反复试验两种结构来查看哪一种最有效。衡量结构对你听众的有效性的一种好方法是注意哪种结构的问题更少。听众的问题越少,说明你的讲述越成功。
Nisha Arya 是一名数据科学家、自由技术写作人以及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。她还希望探索人工智能如何/可以有益于人类寿命的不同方式。作为一名热衷学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
主题更多内容
掌握具有细分问题的聚类
原文:
www.kdnuggets.com/2021/08/mastering-clustering-segmentation-problem.html
评论
由 Indraneel Dutta Baruah 提供,人工智能驱动的解决方案开发者
在当前时代,针对大量客户/产品的详细数据的可用性和处理 PB 级数据的技术能力正在迅速增长。因此,现在可以提出非常有战略意义和有效的目标群体集群。识别目标细分需要一个强大的细分过程。在这篇博客中,我们将讨论最流行的无监督聚类算法及其在 python 中的实现方法。
在这篇博客中,我们将使用来自在线商店的点击流 数据,该商店提供孕妇服装。数据包括产品类别、网页上照片的位置、IP 地址的来源国家和以美元计的产品价格。数据时间范围从 2008 年 4 月到 2008 年 8 月。
第一步是为细分准备数据。我建议你查看下面的文章,以获取有关数据准备的详细说明,然后再继续:
独热编码、标准化、PCA:Python 中细分的数据准备步骤
选择最佳聚类数是处理细分问题时应了解的另一个关键概念。如果你阅读下面的文章,将有助于理解选择聚类的全面指标列表:
在 Python 中实现选择最佳聚类数的 7 种方法的备忘单
在这篇博客中,我们将讨论 4 类模型:
-
K-means
-
凝聚层次聚类
-
基于密度的空间聚类(DBSCAN)
-
高斯混合模型(GMM)
K-means
K-means 算法是一个迭代过程,包括三个关键阶段:
1. 选择初始聚类中心
该算法首先选择初始 k 个聚类中心,即质心。确定最佳聚类数 k 以及正确选择初始聚类对模型性能至关重要。聚类数应始终依赖于数据集的性质,而初始聚类选择不当可能会导致局部收敛问题。幸运的是,我们有解决这两个问题的方法。
有关选择最佳聚类数的更多细节,请参阅这篇详细的博客。对于初始聚类的选择,我们可以通过运行多个不同初始化的模型迭代来选择最稳定的聚类,或者使用“k-means++”算法,其步骤如下:
-
从数据集中随机选择第一个质心
-
计算数据集中所有点与选择的质心之间的距离
-
选择具有最大概率的点作为新的质心,按距离的比例
-
重复步骤 2 和 3,直到采样到 k 个质心
该算法将质心初始化为彼此远离,从而比随机初始化更稳定。
2. 聚类分配
K-means 然后根据点到所有质心的欧几里得距离,将数据点分配到最近的聚类质心。
3. 移动质心
模型最终计算聚类中所有点的平均值,并将质心移动到该平均位置。
步骤 2 和 3 会重复,直到聚类没有变化或满足其他停止条件(如最大迭代次数)。
在 Python 中实现模型时,我们需要首先指定聚类数。我们使用了肘部法、Gap Statistic、轮廓系数、Calinski Harabasz 分数和 Davies Bouldin 分数。每种方法的最佳聚类数如下:
-
肘部法: 8
-
Gap statistic: 29
-
轮廓系数: 4
-
Calinski Harabasz 分数: 2
-
Davies Bouldin 分数: 4
如上所述,5 种方法中有 2 种建议使用 4 个聚类。如果每种模型建议不同数量的聚类,我们可以取其平均值或中位数。找到最佳 k 数的代码可以在这里找到,而每种方法的进一步细节可以在这篇博客中找到。
一旦我们有了最佳聚类数,就可以拟合模型,并使用轮廓系数、Calinski Harabasz 分数和 Davies Bouldin 分数来评估模型的性能。
# K meansfrom sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.metrics import calinski_harabasz_score
from sklearn.metrics import davies_bouldin_score# Fit K-Means
kmeans_1 = KMeans(n_clusters=4,random_state= 10)# Use fit_predict to cluster the dataset
predictions = kmeans_1.fit_predict(cluster_df)# Calculate cluster validation metricsscore_kemans_s = silhouette_score(cluster_df, kmeans_1.labels_, metric='euclidean')score_kemans_c = calinski_harabasz_score(cluster_df, kmeans_1.labels_)score_kemans_d = davies_bouldin_score(cluster_df, predictions)print('Silhouette Score: %.4f' % score_kemans_s)
print('Calinski Harabasz Score: %.4f' % score_kemans_c)
print('Davies Bouldin Score: %.4f' % score_kemans_d)

图 1: K-Means 聚类验证指标(作者提供的图像)
我们还可以使用聚类间距离图来检查聚类的相对大小和分布。
# Inter cluster distance map
from yellowbrick.cluster import InterclusterDistance# Instantiate the clustering model and visualizervisualizer = InterclusterDistance(kmeans_1)visualizer.fit(cluster_df) # Fit the data to the visualizer
visualizer.show() # Finalize and render the figure
图 2:聚类间距离图:K-Means(作者提供的图片)
如上图所示,两个聚类相较于其他聚类较大,并且它们之间似乎有良好的分隔。然而,如果两个聚类在二维空间中重叠,这并不意味着它们在原始特征空间中也重叠。有关模型的更多细节可以在这里找到。最后,像 Mini Batch K-means、K-Medoids 这样的 K-Means 变体将在另一篇博客中讨论。
聚合聚类
聚合聚类是一种通用的聚类算法家族,通过连续合并数据点来构建嵌套的聚类。这种层级的聚类可以表示为称为树状图的树形图。树的顶端是一个包含所有数据点的单一聚类,而底部包含单个点。有多种选项可以以连续的方式链接数据点:
-
单链式连接: 它最小化聚类对之间最近观察值的距离
-
完整或最大链式连接: 尝试最小化聚类对之间观察值的最大距离
-
平均链式连接: 它最小化所有聚类对之间观察值距离的平均值
-
Ward: 类似于 k-means,因为它最小化所有聚类内的平方差之和,但采用层级方法。我们将在练习中使用这个选项。
理想的选项可以通过检查哪种连接方法在聚类验证指标(轮廓系数、Calinski Harabasz 评分和 Davies Bouldin 评分)中表现最佳来选择。与 K-means 类似,我们还需要在此模型中指定聚类数,树状图可以帮助我们做到这一点。
# Dendrogram for Hierarchical Clustering
import scipy.cluster.hierarchy as shc
from matplotlib import pyplot
pyplot.figure(figsize=(10, 7))
pyplot.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(cluster_df, method='ward'))
图 3:树状图(作者提供的图片)
从图 3 中,我们可以选择 4 或 8 个聚类。我们还使用肘部法、轮廓系数和 Calinski Harabasz 评分来寻找最佳聚类数,得到以下结果:
-
肘部法:10
-
Davies Bouldin 评分:8
-
轮廓系数:3
-
Calinski Harabasz 评分:2
我们将选择 8,因为 Davies Bouldin 评分和树状图都建议这样做。如果指标给出不同的聚类数,我们可以选择树状图建议的数量(因为它基于这个特定模型)或取所有指标的平均值/中位数。寻找最佳聚类数的代码可以在这里找到,关于每种方法的更多细节可以在这个博客中找到。
与 K-means 类似,我们可以通过优化的聚类数量和连接类型来拟合模型,并使用 K-means 中使用的三种度量标准来测试其性能。
# Agglomerative clustering
from numpy import unique
from numpy import where
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot# define the model
model = AgglomerativeClustering(n_clusters=4)
# fit model and predict clusters
yhat = model.fit(cluster_df)
yhat_2 = model.fit_predict(cluster_df)
# retrieve unique clusters
clusters = unique(yhat)# Calculate cluster validation metricsscore_AGclustering_s = silhouette_score(cluster_df, yhat.labels_, metric='euclidean')score_AGclustering_c = calinski_harabasz_score(cluster_df, yhat.labels_)score_AGclustering_d = davies_bouldin_score(cluster_df, yhat_2)print('Silhouette Score: %.4f' % score_AGclustering_s)
print('Calinski Harabasz Score: %.4f' % score_AGclustering_c)
print('Davies Bouldin Score: %.4f' % score_AGclustering_d)

图 4:聚类验证指标:层次聚类(作者提供的图像)
比较图 1 和图 4,我们可以看到 K-means 在所有聚类验证指标上优于层次聚类。
基于密度的空间聚类 (DBSCAN)
DBSCAN 将紧密聚集在一起的点分组,而将那些孤立在低密度区域的点标记为离群点。模型中定义“密度”的两个关键参数是:形成密集区域所需的最小点数 min_samples 和定义邻域的距离 eps。较高的 min_samples 或较低的 eps 需要更高的密度来形成一个簇。
基于这些参数,DBSCAN 从一个任意点 x 开始,根据 eps 识别 x 的邻域内的点,并将 x 分类为以下之一:
-
核心点:如果邻域中的点数至少等于
min_samples参数,则称其为核心点,并且围绕 x 形成一个簇。 -
边界点:如果 x 是一个聚类的一部分,该聚类的核心点不同,但其邻域中的点数少于
min_samples参数,则 x 被认为是边界点。直观上,这些点位于聚类的边缘。 -
离群点或噪声:如果 x 不是核心点,并且与任何核心样本的距离至少等于或大于
eps,则它被认为是离群点或噪声。
为了调整模型参数,我们首先通过查找点邻域之间的距离并绘制最小距离来识别最佳的 eps 值。这会给我们一个肘部曲线来找出数据点的密度,最佳的 eps 值可以在拐点处找到。我们使用 NearestNeighbours 函数来获取最小距离,并使用 KneeLocator 函数来识别拐点。
# parameter tuning for eps
from sklearn.neighbors import NearestNeighbors
nearest_neighbors = NearestNeighbors(n_neighbors=11)
neighbors = nearest_neighbors.fit(cluster_df)
distances, indices = neighbors.kneighbors(cluster_df)
distances = np.sort(distances[:,10], axis=0)from kneed import KneeLocator
i = np.arange(len(distances))
knee = KneeLocator(i, distances, S=1, curve='convex', direction='increasing', interp_method='polynomial')
fig = plt.figure(figsize=(5, 5))
knee.plot_knee()
plt.xlabel("Points")
plt.ylabel("Distance")print(distances[knee.knee])
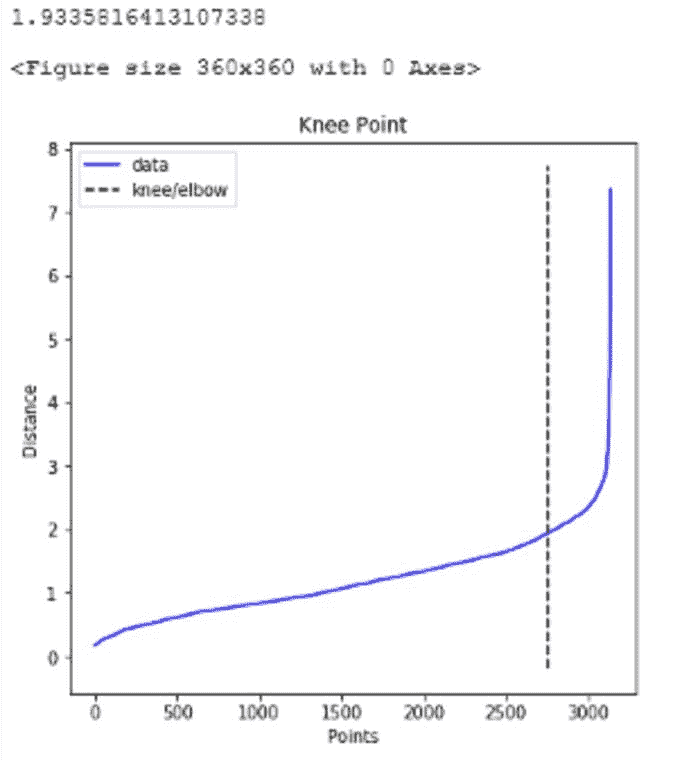
图 5:eps 的最佳值(作者提供的图像)
如上所示,最佳的 eps 值为 1.9335816413107338。我们将使用这个值作为参数,并根据轮廓系数、Calinski Harabasz 评分和 Davies Bouldin 评分来尝试找出最佳的 min_samples 参数值。对于这些方法,每种方法的最佳簇数量如下:
-
轮廓系数:18
-
Calinski Harabasz 评分:29
-
Davies Bouldin 评分:2
查找最优 min_samples 的代码可以在 这里 找到,每种方法的进一步细节可以在这个 博客 中找到。我们选择了 Silhouette 评分的中位数建议,即 18。如果没有时间对这些指标进行网格搜索,一条快速的经验法则是将 min_samples 参数设置为特征数的两倍。
# dbscan clustering
from numpy import unique
from numpy import where
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# define dataset
# define the model
model = DBSCAN(eps=1.9335816413107338, min_samples= 18)# rule of thumb for min_samples: 2*len(cluster_df.columns)# fit model and predict clusters
yhat = model.fit_predict(cluster_df)
# retrieve unique clusters
clusters = unique(yhat)# Calculate cluster validation metricsscore_dbsacn_s = silhouette_score(cluster_df, yhat, metric='euclidean')score_dbsacn_c = calinski_harabasz_score(cluster_df, yhat)score_dbsacn_d = davies_bouldin_score(cluster_df, yhat)print('Silhouette Score: %.4f' % score_dbsacn_s)
print('Calinski Harabasz Score: %.4f' % score_dbsacn_c)
print('Davies Bouldin Score: %.4f' % score_dbsacn_d)

图 6:聚类验证指标:DBSCAN(图片来源:作者)
比较图 1 和图 6,我们可以看到 DBSCAN 在 Silhouette 评分上优于 K-means。该模型在论文中进行了描述:
一种用于发现大型空间数据库中簇的基于密度的算法,1996 年。
在另一篇博客中,我们将讨论一种更高级的 DBSCAN 版本,称为层次密度聚类(HDBSCAN)。
高斯混合建模(GMM)
高斯混合模型是一种基于距离的概率模型,它假设所有数据点是从具有未知参数的多变量高斯分布的线性组合中生成的。与 K-means 一样,它考虑了潜在高斯分布的中心,但与 K-means 不同的是,还考虑了分布的协方差结构。该算法实现了期望最大化 (EM) 算法,通过迭代找到使模型质量度量(称为对数似然)最大的分布参数。该模型执行的关键步骤包括:
-
初始化 k 个高斯分布
-
计算每个点与每个分布的关联概率
-
根据每个点与分布的关联概率重新计算分布参数
-
重复过程直到对数似然最大化
GMM 中计算协方差有 4 种选项:
-
完全:每个分布具有自己的总体协方差矩阵
-
绑带:所有分布共享总体协方差矩阵
-
对角线:每个分布具有自己的对角协方差矩阵
-
球形:每个分布具有自己的单一方差
除了选择协方差类型,我们还需要选择模型中的最佳簇数。我们使用 BIC 评分、Silhouette 评分、Calinski Harabasz 评分和 Davies Bouldin 评分,通过网格搜索来选择这两个参数。对于每种方法,最佳簇数如下:
-
BIC 评分:协方差-‘完全’和簇数-26
-
Silhouette 评分:协方差-‘绑带’和簇数-2
-
Calinski Harabasz 评分:协方差-‘球形’和簇数-4
-
Davies Bouldin 评分:协方差-‘完全’和簇数-8
查找最佳参数值的代码可以在这里找到,关于每种方法的更多细节可以在这个博客中找到。我们选择了“full”协方差和 26 个聚类数,是基于特定模型的 BIC 得分。如果我们从多个指标中获得相似的配置,我们可以取所有指标的平均值/中位数/众数。现在我们可以拟合模型并检查模型性能。
# gaussian mixture clustering
from numpy import unique
from numpy import where
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# define the model
model = GaussianMixture(n_components= 26,covariance_type= "full", random_state = 10)
# fit the model
model.fit(cluster_df)
# assign a cluster to each example
yhat = model.predict(cluster_df)
# retrieve unique clusters
clusters = unique(yhat)# Calculate cluster validation scorescore_dbsacn_s = silhouette_score(cluster_df, yhat, metric='euclidean')score_dbsacn_c = calinski_harabasz_score(cluster_df, yhat)score_dbsacn_d = davies_bouldin_score(cluster_df, yhat)print('Silhouette Score: %.4f' % score_dbsacn_s)
print('Calinski Harabasz Score: %.4f' % score_dbsacn_c)
print('Davies Bouldin Score: %.4f' % score_dbsacn_d)

图 7: 聚类验证指标:GMM(图像由作者提供)
比较图 1 和图 7,我们可以看到 K-means 在所有聚类验证指标上优于 GMM。在另一个博客中,我们将讨论一种更先进的 GMM 版本,称为变分贝叶斯高斯混合模型。
结论
这个博客的目的是帮助读者理解 4 种流行的聚类模型的工作原理以及它们在 python 中的详细实现。如下面所示,每种模型都有其优缺点:
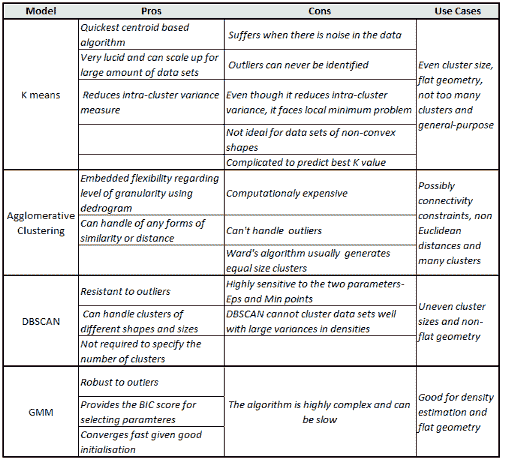
图 8: 聚类算法的优缺点(图像由作者提供)
最后,重要的是要理解这些模型只是找到逻辑性和易于理解的客户/产品细分的一种手段,可以有效地针对这些细分市场。因此,在大多数实际情况下,我们最终会尝试多个模型,并从每次迭代中创建客户/产品档案,直到找到最具商业意义的细分市场。因此,细分既是一门艺术,也是一门科学。
对这个博客有任何问题或建议吗?请随时留言。
感谢阅读!
如果你像我一样,对 AI、数据科学或经济学充满热情,请随时在LinkedIn、Github和Medium上添加/关注我。
参考文献
-
Ester, M, Kriegel, H P, Sander, J, 和 Xiaowei, Xu. 一种基于密度的算法,用于发现具有噪声的大型空间数据库中的聚类。美国:N. p., 1996。网络。
-
MacQueen, J. 一些用于分类和分析多变量观察的方法。第五届伯克利统计与概率研讨会论文集,第 1 卷:统计学, 281–297,加州大学出版社,伯克利,加州,1967。
projecteuclid.org/euclid.bsmsp/1200512992 -
Scikit-learn: Python 中的机器学习,Pedregosa 等人,JMLR 12,第 2825–2830 页,2011 年。
简介: Indraneel Dutta Baruah 正在努力通过 AI 解决商业问题,追求卓越!
原文。经许可转载。
相关内容:
-
k-means 聚类的质心初始化方法
-
关键数据科学算法解析:从 k-means 到 k-medoids 聚类
-
使用 K 均值聚类进行客户细分
我们的前三推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
更多相关话题
使用 ChatGPT 掌握数据科学工作流程
原文:
www.kdnuggets.com/mastering-data-science-workflows-with-chatgpt
图片由编辑提供
数据科学是一个不断发展的领域,数据的不断涌入使得它成为一个用创新解决方案解决复杂问题的引人注目的案例。最近引起关注的一个解决方案是 ChatGPT。这款由 OpenAI 开发的强大语言模型展现了出色的自然语言理解和生成能力。
我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的快车道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 工作
虽然 ChatGPT 主要用于对话和文本生成任务,但数据科学家可以在他们的工作流程中利用其潜力,以简化和增强他们的工作,使其过程更加高效和生产力。
本文突出了数据科学家可以学习的技能,以充分利用 ChatGPT 的能力。
ChatGPT 在数据科学工作流程中的应用
ChatGPT 可以作为一个多功能助手,生成代码、解释和见解。有效的 ChatGPT 提示对于数据科学工作流程和代码调试非常有帮助。此外,迭代和实验性提示技术可以从 ChatGPT 获得更准确和有见地的回答。
图片由作者提供
掌握提示技术
一些有效提示 ChatGPT 的常见方法如下。
-
迭代提示:涉及到制定基于之前回答的提示,从而促进对话的流畅性。
-
实验性提示:类似于机器学习模型的迭代和实验开发,数据科学家也可以通过不同层次的指导来进行提示实验。这是新兴数据科学家必备的技能,主要因为 ChatGPT 倾向于假设任何缺失的信息,而不是主动询问。一个典型的例子是让 ChatGPT 读取一个文件并对数据进行处理,这可能导致它假设输入文件是 CSV 格式。根据你的使用案例,这可能是对的也可能是不对的。因此,实验逐步的指导往往是一个最佳实践。
-
零样本学习和少样本学习:当模型没有看到任何示例但接收到响应指令时,这种直接提示被称为零样本学习,而少样本学习涉及在提示之前提供一些示例供模型学习。
有效的提示技术对于从 ChatGPT 中提取有意义的信息至关重要。我们可以探索各种方法来制定清晰准确的提示指令,以获得期望的结果。
-
理解使用定界符来有效地结构化指令和查询是至关重要的。
-
学习如何在提示中指定输入参数、所需步骤和数据科学工作流函数的返回数据结构。
图片由作者提供
提示 ChatGPT 进行编码和调试
精简代码审查工作流
高效的代码审查对数据科学项目的成功至关重要。作为数据科学家,我们可以提示 ChatGPT 改进代码审查工作流,遵守编码标准,并有效地调试代码。
连锁思维(CoT)提示可以用于提升代码质量。作为快速参考,CoT 是一种技术,通过提供少量示例来激发 LLM 的推理过程,明确描述推理过程。模型随后遵循类似的推理过程来回答提示,从而提高模型在需要复杂推理的任务中的表现。
代码解释与简化
数据科学代码有时可能变得复杂,对于技术不太熟悉的受众来说可能很难理解。ChatGPT 可以解释或简化复杂的代码,使其更易读、易懂。 CoT 提示对代码解释和简化非常有帮助。
图片由作者提供
代码优化
优化代码效率是数据科学工作流中的一个关键方面。ChatGPT 可用于编写高效的代码,并探索替代解决方案的可能性。
有效的 CoT 提示被用来提出高效的替代代码,并提供解释。数据科学家还可以学习开发提示,鼓励编写高效的代码,使用诸如“算法效率”这样的关键词或建议替代的数据结构。
代码测试与验证
数据科学家还使用 ChatGPT 设计实用的测试和断言,生成代码测试,并验证代码的正确性。
零样本提示在为 Python 中常用函数编写断言语句方面效果相当好。为生成单元测试以验证代码块开发提示也是 ChatGPT 的一个好用法。
数据分析的提示工程
SQL 数据分析
SQL 是数据分析中的基本工具,ChatGPT 可以协助生成各种任务的 SQL 查询。数据科学家可以探索撰写零样本 CoT 提示来生成用于查询特定数据条件的 SQL 语句。
此外,他们还可以设计用于数据聚合的 SQL 命令提示。
数据翻译与处理
在数据科学中,不同格式和语言之间的数据翻译和处理很常见。数据科学家可以利用 ChatGPT 学习设计少样本比较和条件提示,将复杂的 SQL 查询转换为相应的 Python 代码。
他们还可以应用零样本和少样本提示技术来计算不同字段的汇总值,并有效地操纵数据。
数据转换与重塑
ChatGPT 还可以被提示来协助数据转换和重塑任务,这在数据分析中非常常见。我们可以应用基于上下文的零样本提示技术来整合来自不同来源的数据。此外,少样本提示也可用于创建混淆矩阵或透视表,以根据需要重塑数据。
图片由作者提供
机器学习与讲故事的提示
数据预处理
我们可以使用 ChatGPT 来识别缺失字段并确定异常值。还可以设计有效的提示来使用均值和中位数填补缺失数据。
数据可视化
作为数据从业者,我们可以编写基于上下文的提示来生成用于创建各种图表、图形和图表的代码。通过提示 ChatGPT,我们还可以进行图表格式化和标注,添加相关标签、图例和标题,以改善数据表示。
图片由作者提供
特征工程
特征工程是数据科学家工具箱中最受欢迎的技能之一。ChatGPT 可以协助生成有意义的特征用于机器学习模型,例如创建基于时间的工程特征。来自日期时间列的常见时间特征包括星期几、月份和年份。
此外,ChatGPT 在通用特征工程方面也有帮助,如分箱、归一化和分类。
面向非技术观众的报告
ChatGPT 可以识别技术与非技术沟通风格之间的关键差异,并认识到根据特定受众量身定制沟通的重要性。基于上下文的迭代提示可以帮助使用适合非技术利益相关者的术语和 KPI 来解释数据科学见解。
通过这篇文章,我们总结了如何通过讨论各种提示技巧来有效利用 ChatGPT 在数据科学工作流中的作用。这份详尽的路线图涵盖了 ChatGPT 如何成为提升编码、数据分析、机器学习或讲故事等方面生产力和效率的宝贵工具。
Vidhi Chugh** 是一位人工智能战略家和数字化转型领导者,专注于产品、科学和工程的交汇点,以构建可扩展的机器学习系统。她是一位屡获殊荣的创新领导者、作者和国际演讲者。她的使命是使机器学习大众化,并打破术语,让每个人都能参与这一转型。**
更多相关内容
在 Google Colaboratory 上掌握快速梯度提升与免费 GPU
原文:
www.kdnuggets.com/2019/03/mastering-fast-gradient-boosting-google-colaboratory-free-gpu.html
评论
作者 Anna Veronika Dorogush,CatBoost 团队负责人

NVIDIA K80 GPU,www.nvidia.com/ru-ru/data-center/tesla-k80/
决策树上的梯度提升(GBDT)是一个最先进的机器学习工具,用于处理异构或结构化数据。在处理数据时,理想的算法高度依赖于数据的类型。对于同质数据,如图像、声音或文本,最佳解决方案是神经网络。而对于结构化数据,例如信用评分、推荐或其他表格数据,最佳解决方案是 GBDT。
因此,许多 Kaggle 竞赛的获胜解决方案都是基于 GBDT 的。GBDT 还被广泛用于各种推荐系统、搜索引擎和许多金融结构中。
许多人认为 GBDT 不能通过 GPU 高效加速,但实际上并非如此。在这篇文章中,我将解释如何利用 GPU 加速 GBDT。
对于 GBDT 实现,我将使用CatBoost,这是一个以支持分类特征和高效 GPU 实现而闻名的库。它不仅可以处理分类数据,还可以处理任何数据,在许多情况下,它的表现优于其他 GBDT 库。
该库是在领先的俄罗斯科技公司 Yandex 的生产需求下开发的,约一年半前以 Apache 2 许可证 开源。

我演示的测试环境将是Google Colaboratory。这是一个用于机器学习的研究工具,提供免费的 GPU 运行时访问。它是一个不需要设置的 Jupyter notebook 环境。
Google Colaboratory 免费提供相当老旧的 GPU——一块大约 11GB 内存的 Tesla K80 GPU。使用更新的 GPU,速度提升会更加显著。但即使使用这块旧 GPU,你也会看到显著的速度差异。如果谈到 CPU,它是每个实例 2x Intel Xeon E5-2600v3。
下面你将找到几个简单的步骤,以在 Colab 中设置 CatBoost,下载数据集,在 CPU 和 GPU 上训练模型,并比较执行时间。
创建 notebook
前往 Colaboratory 并创建一个新的 Python 3 notebook。
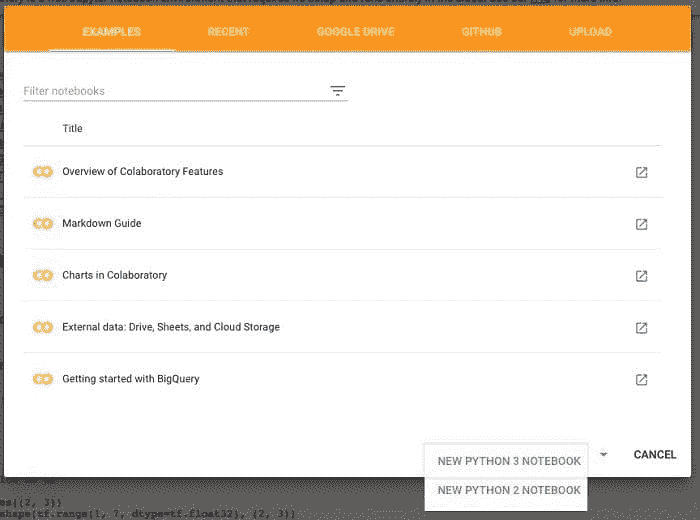
设置 GPU 作为硬件加速器
选择 GPU 作为硬件加速器有两个简单步骤:
第 1 步。导航到 “Runtime” 菜单并选择 “Change runtime type”
第 2 步。选择 “GPU” 作为硬件加速器。
导入 CatBoost
下一步是将 CatBoost 导入环境中。 Colaboratory 内置了库,大多数库可以通过简单的 !pip install 命令快速安装。
请忽略有关已导入 enum 包的警告信息。此外,请注意每次启动新的 Colab 会话时,你需要重新导入库。
!pip install catboost
从 pypi 安装的 CatBoost 库支持 GPU,因此你可以直接使用它。 你只需要在机器上安装 NVIDIA 驱动程序,其他一切都会开箱即用。 这对 Windows 也适用,使得希望在 GPU 上训练模型的 Windows 用户更加轻松。
下载并准备数据集
现在是编码的时候了! 一旦我们配置好环境,下一步是下载和准备数据集。 对于 GPU 训练,数据集越大,提速效果越明显。 使用 GPU 训练对于一千个或更少的对象没有太大意义,但从大约 10,000 开始,你将获得很好的加速效果。
我们需要一个大型数据集来展示 GPU 在 GBDT 任务中的强大能力。我们将使用 Epsilon,它有 500,000 个文档和 2,000 个特征,并且包含在 catboost.datasets 中。
下面的代码大约需要 10-15 分钟来完成这个任务。 请耐心等待。
在 CPU 上训练
为了打破 GBDT 在 GPU 上没有显著加速的迷思,我想比较 CPU 和 GPU 上的 GBDT 训练时间。 让我们从 CPU 开始。下面的代码创建了一个模型,训练它,并测量训练的执行时间。 它使用默认参数,因为在许多情况下,默认参数提供了相当好的基准。
我们将首先训练所有模型 100 次迭代(因为在 CPU 上训练需要很长时间)。
在运行此代码后,你可以将其更改为默认的 1000 次或更多迭代,以获得更好的质量结果。
CatBoost 在 CPU 上训练 100 次迭代需要大约 15 分钟。
你想展示可以加速的效果,对吗?
如果 feed = training,是的。
在 CPU 上拟合模型的时间:862 秒
在 GPU 上训练
所有之前的代码执行都在 CPU 上完成。 现在是使用 GPU 的时候了!
要启用 GPU 训练,你需要使用 task_type='GPU' 参数。
让我们在 GPU 上重新运行实验,看看结果时间是多少。
如果 Colab 显示警告“GPU 内存使用接近限制”,只需点击“忽略”。

在 GPU 上适配模型的时间:195 秒
GPU 相比于 CPU 的加速:4 倍
如你所见,GPU 的速度是 CPU 的 4 倍。在 GPU 上适配模型仅需 3-4 分钟,而在 CPU 上则需要 14-15 分钟。此外,学习过程在 GPU 上仅需 30 秒,而在 CPU 上则需要 12 分钟。
当我们训练 100 次迭代时,瓶颈在于预处理,而不是训练本身。但对于数千次迭代以获得大数据集上的最佳质量,这个瓶颈将不可见。你可以尝试在 CPU 和 GPU 上训练 5,000 次迭代,再次进行比较。
代码
你可以在 CatBoost 仓库的 教程 中找到上述所有代码。
替代 GBDT 库
公平地说,还有至少两个更受欢迎的开源 GBDT 库:
两者都作为预装库在 Colaboratory 上提供。我们在 CPU / GPU 上训练它们并比较时间。剧透:我们没有从中获得结果。详细信息如下。
XGBoost
开始时我们尝试 XGBoost 的 CPU 版本。需要强调的是,训练参数与 CatBoost 库相同。
代码相当简单,但一旦我们在 Epsilon 数据集上运行,Colaboratory 会话崩溃。

不幸的是,GPU 版本也出现了相同的错误。启动上述简单代码后,内核会崩溃。
LightGBM
LightGBM 的 CPU 版本出现相同的错误消息“您的会话在使用完所有可用 RAM 后崩溃。”
Colaboratory 预装的 LightGBM 版本不支持 GPU。并且 GPU 版本的安装指南 不幸地无法使用。详见下文。
!pip install -U lightgbm --install-option=--gpu

很遗憾,我们无法比较其他库的 CPU 与 GPU 执行时间,除了 CatBoost。可能在较小的数据集上会有效。
摘要
-
GBDT 算法在 GPU 上运行效率高。
-
CatBoost 是一个快速实现的 GBDT,开箱即用 GPU 支持。
-
XGBoost 和 LightGBM 在 Colaboratory 上处理大数据集时并不总是有效。
-
Google Colaboratory 是一个有用的工具,提供免费的 GPU 支持。
进一步阅读
[1] V. Ershov,CatBoost 通过 GPU 实现快速梯度提升,NVIDIA 博客文章
[2] R. Mitchell, 梯度提升、决策树与 CUDA 下的 XGBoost,NVIDIA 博客文章
[3] LightGBM GPU 教程
[4] CatBoost GitHub
简介: 安娜·维罗妮卡·多罗古什 是 Yandex 的机器学习系统负责人。
资源:
相关:
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织进行 IT 工作
更多相关主题
精通新一代梯度提升
原文:
www.kdnuggets.com/2018/11/mastering-new-generation-gradient-boosting.html
评论
作者:Tal Peretz,数据科学家

Catboost
梯度提升决策树和随机森林是我最喜欢的用于表格异构数据集的机器学习模型。这些模型在Kaggle 竞赛中表现突出,并在业界广泛使用。
Catboost,这个新兴的模型,已经存在了一年多,现在已经对XGBoost、LightGBM和H2O构成威胁。
为什么选择 Catboost?
更好的结果
Catboost 在基准测试中取得了最佳结果,这很棒,但我不确定是否仅凭一小部分对数损失的改善就替换一个正在运行的生产模型(尤其是当进行基准测试的公司明显偏向 Catboost 时????)。
然而,当你查看分类特征发挥重要作用的数据集时,如Amazon和Internet数据集,这一改进变得显著而不可否认。
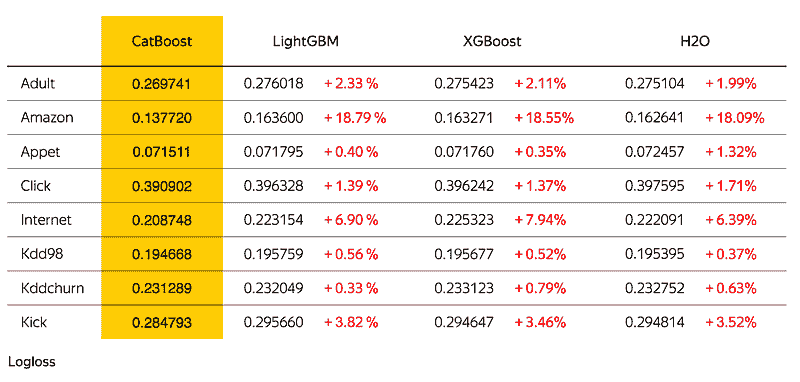
GBDT 算法基准测试
更快的预测
尽管训练时间可能比其他 GBDT 实现要长,但根据 Yandex 基准测试,预测时间比其他库快 13 到 16 倍。
左侧:CPU,右侧:GPU
功能齐全
Catboost 的默认参数是比其他 GBDT 算法更好的起点。这对希望快速上手体验树集成或参与 Kaggle 竞赛的初学者来说是好消息。
然而,还有一些非常重要的参数我们必须讨论,我们马上会谈到这些。
使用默认参数的 GBDT 算法基准测试
Catboost 的一些更值得注意的进展包括特征交互、对象重要性和快照支持。
除了分类和回归,Catboost 开箱即用地支持排名。
经过实战考验
Yandex 在排名、预测和推荐中严重依赖 Catboost。这个模型每月为超过 7000 万用户提供服务。
CatBoost 是一种基于决策树的梯度提升算法。由 Yandex 的研究人员和工程师开发,它是广泛应用于公司排名任务、预测和推荐的MatrixNet 算法的继任者。它具有通用性,可以应用于广泛的领域和各种问题。

算法
经典梯度提升

Wikipedia 上的梯度提升
Catboost 秘密配方
Catboost 引入了两个关键的算法进步——实现了 有序提升,这是一种基于排列的经典算法替代方案,以及一种用于 处理分类特征 的创新算法。
这两种技术都使用训练样本的随机排列来对抗所有现有梯度提升算法中存在的 预测偏移 造成的特殊类型的 目标泄漏。
分类特征处理
有序目标统计量
大多数 GBDT 算法和 Kaggle 竞争者已经熟悉目标统计量(或目标均值编码)的使用。
这是一种简单而有效的方法,我们对每个分类特征进行编码,编码值是根据类别条件计算的预期目标 y 的估计。
事实证明,不加小心地应用这种编码(同一类别训练样本的 y 平均值)会导致目标泄漏。
为了对抗这种 预测偏移,CatBoost 使用了一种更有效的策略。它依赖于排序原则,并受到在线学习算法的启发,这些算法按时间顺序获取训练样本。在这种设置下,每个样本的 TS 值仅依赖于观察到的历史。
为了将这一思想适应标准的离线设置,Catboost 引入了一个人工“时间”——训练样本的随机排列 σ1。
然后,对于每个样本,它使用所有可用的“历史”来计算其目标统计量。
注意,仅使用一个随机排列,会导致前面的样本在目标统计量中具有比后续样本更高的方差。为此,CatBoost 对梯度提升的不同步骤使用不同的排列。
One Hot 编码
Catboost 对所有具有至多 one_hot_max_size 唯一值的特征使用 one-hot 编码。默认值为 2。

Catboost 的秘密配方
有序提升
CatBoost 有两种选择树结构的模式,Ordered 和 Plain。 Plain 模式 对应于标准 GBDT 算法与有序目标统计量的结合。
在 Ordered 模式 提升中,我们对训练样本进行随机排列——σ2,并维持 n 个不同的支持模型——M1, ... , Mn,使得模型 Mi 仅使用排列中的前 i 个样本进行训练。
在每一步,为了获得 j -th 样本的残差,我们使用模型 Mj−1。
不幸的是,由于需要维护 n 个不同的模型,这个算法在大多数实际任务中不可行,这会使复杂性和内存需求增加 n 倍。Catboost 实现了该算法的一个修改版,基于梯度提升算法,使用所有模型共享的一个树结构来构建。

Catboost 有序提升与树构建
为了避免 预测偏移,Catboost 使用置换使得 σ1 = σ2。这确保了目标-yi 既不用于训练 Mi,也不用于目标统计计算或梯度估计。
实践操作
对于本节,我们将使用 Amazon 数据集,因为它干净且强调类别特征。
数据集简述
调整 Catboost
重要参数
-
cat_features — 这个参数对于利用 Catboost 对类别特征的预处理是必须的,如果你自己编码类别特征而不传递列索引作为cat_features,你就错过了 Catboost 的精髓。*
-
one_hot_max_size* — 如前所述,Catboost 对所有特征使用一热编码,前提是这些特征最多有 one_hot_max_size 个唯一值。在我们的案例中,类别特征有很多唯一值,因此我们不会使用一热编码,但根据数据集的不同,调整此参数可能是个好主意。
-
learning_rate & n_estimators — 学习率越小,需要的n_estimators就越多。通常的方法是从相对较高的learning_rate开始,调整其他参数,然后在增加n_estimators的同时减少learning_rate。
-
max_depth* — 基础树的深度,这个参数对训练时间有很大影响。
-
***subsample ****— 行的采样率,不能在 Bayesian 提升类型设置中使用。
-
***colsample_bylevel ****— 列的采样率。
-
***l2_leaf_reg ****— L2 正则化系数。
-
***random_strength ****— 每个分裂都会得到一个分数,而 random_strength 会给分数添加一些随机性,这有助于减少过拟合。
使用 Catboost 进行模型探索
除了特征重要性(这在 GBDT 模型中非常流行),Catboost 还提供了 特征交互和 对象(行)重要性
Catboost 的特征重要性
Catboost 的特征交互
Catboost 的对象重要性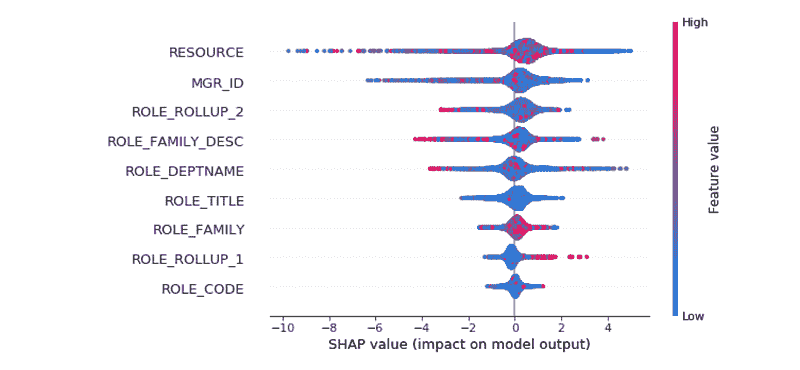
SHAP 值也可以用于其他集成方法
完整笔记本
查看一些有用的 Catboost 代码片段
Catboost Playground Notebook ### 结论

Catboost 与 XGBoost(默认、贪婪和全面的参数搜索)

要点
-
Catboost 的构建方法和特性类似于“较旧”一代的 GBDT 模型。
-
Catboost 的优势在于其类别特征预处理、预测时间和模型分析。
-
Catboost 的弱点在于其训练和优化时间。
-
不要忘记将cat_features 参数传递给分类器对象。如果没有它,你就没有真正利用 Catboost 的力量。
-
尽管 Catboost 在默认参数下表现良好,但还有几个参数在调优时会显著提高结果。
进一步阅读
非常感谢 Catboost 团队负责人 Anna Veronika Dorogush。
如果你喜欢这篇文章,随时点击掌声按钮 ????????,如果你对即将发布的文章感兴趣,确保关注我
**中等: **https://medium.com/@talperetz24 推特:https://twitter.com/talperetz24 领英:https://www.linkedin.com/in/tal-per/
每年,我都想提到 DataHack- 最好的数据驱动黑客马拉松。今年 דור פרץ 和我使用了 Catboost 进行我们的项目并赢得了第一名 ????。
个人简介: Tal Peretz 是数据科学家、软件工程师和持续学习者。他热衷于利用数据、代码和算法解决具有高价值潜力的复杂问题。他特别喜欢构建和改进模型,将一与零区分开来。0|1
原文。经许可转载。
相关:
-
TensorFlow 中的梯度提升与 XGBoost
-
CatBoost 与 Light GBM 与 XGBoost
-
直观的梯度提升集成学习指南
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
了解更多相关话题
掌握 Python:编写清晰、有组织和高效代码的 7 种策略
原文:
www.kdnuggets.com/mastering-python-7-strategies-for-writing-clear-organized-and-efficient-code
 作者提供的图片
作者提供的图片
您是否曾将自己的 Python 代码与经验丰富的开发者的代码进行比较,感到差异很大?尽管从在线资源中学习 Python,但初学者和专家级代码之间常常存在差距。这是因为经验丰富的开发者遵循了社区建立的最佳实践。这些实践在在线教程中经常被忽视,但对于大规模应用程序至关重要。在本文中,我将分享我在生产代码中使用的 7 个技巧,以编写更清晰、更有组织的代码。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯
2. Google 数据分析专业证书 - 提升您的数据分析能力
3. Google IT 支持专业证书 - 支持您的组织在 IT 方面
1. 类型提示和注解
Python 是一种动态类型编程语言,变量类型在运行时推断。虽然它允许灵活性,但在协作环境中会显著降低代码的可读性和理解度。
Python 在函数声明中提供了类型提示支持,作为函数参数类型和返回类型的注解。尽管Python 在运行时不会强制这些类型,但它仍然有助于使您的代码更容易被其他人(以及您自己!)理解。
从一个简单的例子开始,这里是一个带有类型提示的简单函数声明:
def sum(a: int, b: int) -> int:
return a + b
在这里,即使函数本身比较直观,我们仍然可以看到函数参数和返回值被标注为 int 类型。函数体可以是一行代码,如这里的例子,或者是数百行代码。然而,我们可以仅通过查看函数声明来理解前置条件和返回类型。
了解这些注释仅用于清晰和指导非常重要;它们在执行过程中并不会强制类型。 因此,即使你传入不同类型的值,如字符串而不是整数,函数仍然会运行。但要小心:如果你没有提供预期的类型,可能会导致运行时出现意外行为或错误。例如,在提供的示例中,函数sum()期望两个整数作为参数。但是,如果你尝试将字符串和整数相加,Python 会抛出运行时错误。为什么?因为它不知道如何将字符串和整数相加!这就像尝试将苹果和橙子相加——这根本没有意义。然而,如果两个参数都是字符串,它将毫无问题地连接它们。
下面是带有测试用例的澄清版本:
print(sum(2,5)) # 7
# print(sum('hello', 2)) # TypeError: can only concatenate str (not "int") to str
# print(sum(3,'world')) # TypeError: unsupported operand type(s) for +: 'int' and 'str'
print(sum('hello', 'world')) # helloworld
高级类型提示的类型库
对于高级注释,Python 包含了 typing 标准库。让我们以更有趣的方式来看看它的使用。
from typing import Union, Tuple, List
import numpy as np
def sum(variable: Union[np.ndarray, List]) -> float:
total = 0
# function body to calculate the sum of values in iterable
return total
在这里,我们修改了相同的求和函数,使其现在接受一个 numpy 数组或列表可迭代对象。它计算并返回它们的和作为浮点值。我们利用 typing 库中的 Union 注释来指定变量参数可以接受的可能类型。
让我们进一步修改函数声明,以显示列表成员也应该是 float 类型。
def sum(variable: Union[np.ndarray, List[float]]) -> float:
total = 0
# function body to calculate the sum of values in iterable
return total
这些只是一些初学者的示例,帮助理解 Python 中的类型提示。随着项目的增长,代码库变得更加模块化,类型注释显著提高了可读性和可维护性。typing 库提供了丰富的功能,包括 Optional、各种可迭代对象、Generics 和对自定义类型的支持,使开发人员能够以精确和清晰的方式表达复杂的数据结构和关系。
2. 编写防御性函数和输入验证
即使类型提示看起来很有帮助,它仍然容易出错,因为这些注释并没有被强制执行。这些只是额外的文档供开发人员参考,但如果使用了不同的参数类型,函数仍然会被执行。因此,需要强制执行函数的前置条件,并以防御性方式编写代码。因此,我们手动检查这些类型,并在条件违反时引发适当的错误。
下面的函数展示了如何使用输入参数计算利息。
def calculate_interest(principal, rate, years):
return principal * rate * years
这是一个简单的操作,但这个函数会适用于所有可能的解决方案吗?不,不适用于传递无效值作为输入的边界情况。我们需要确保输入值在函数正确执行所需的有效范围内。实质上,函数实现必须满足一些前置条件才能正确。
我们按照如下方式进行:
from typing import Union
def calculate_interest(
principal: Union[int, float],
rate: float,
years: int
) -> Union[int, float]:
if not isinstance(principal, (int, float)):
raise TypeError("Principal must be an integer or float")
if not isinstance(rate, float):
raise TypeError("Rate must be a float")
if not isinstance(years, int):
raise TypeError("Years must be an integer")
if principal <= 0:
raise ValueError("Principal must be positive")
if rate <= 0:
raise ValueError("Rate must be positive")
if years <= 0:
raise ValueError("Years must be positive")
interest = principal * rate * years
return interest
注意,我们使用条件语句进行输入验证。Python 还有断言语句,有时也用于此目的。然而,用于输入验证的断言不是最佳实践,因为它们可以很容易地被禁用,并且会导致生产环境中的意外行为。显式的 Python 条件表达式更适用于输入验证以及强制执行前置条件、后置条件和代码不变式。
3. 使用生成器和yield语句进行延迟加载
考虑这样一个场景,你被提供了一个大型文档数据集。你需要处理这些文档并对每个文档执行特定操作。然而,由于数据集的巨大规模,你不能将所有文档同时加载到内存中并进行预处理。
一种可能的解决方案是仅在需要时将文档加载到内存中,并且一次只处理一个文档,这也被称为延迟加载。即使我们知道需要哪些文档,我们也不会在需要之前加载资源。当文档在代码中不处于活动使用状态时,无需将大量文档保留在内存中。这正是生成器和yield语句处理问题的方式。
生成器允许延迟加载,从而提高了 Python 代码执行的内存效率。值在需要时动态生成,减少了内存占用并提高了执行速度。
import os
def load_documents(directory):
for document_path in os.listdir(directory):
with open(document_path) as _file:
yield _file
def preprocess_document(document):
filtered_document = None
# preprocessing code for the document stored in filtered_document
return filtered_document
directory = "docs/"
for doc in load_documents(directory):
preprocess_document(doc)
在上述函数中,load_documents函数使用了yield关键字。该方法返回一个类型为yield语句的位置继续执行。因此,单个文档被加载和处理,提高了 Python 代码的效率。
4. 使用上下文管理器防止内存泄漏
对于任何语言,资源的高效使用是最重要的。我们只在需要时将资源加载到内存中,如上文通过生成器的使用所述。然而,当程序不再需要某个资源时,关闭该资源同样重要。我们需要防止内存泄漏,并执行适当的资源拆解以节省内存。
上下文管理器简化了资源设置和拆解的常见用例。当资源不再需要时,释放资源是重要的,即使在出现异常和故障的情况下也是如此。上下文管理器通过自动清理减少了内存泄漏的风险,同时保持代码简洁和可读。
资源可以有多种变体,如数据库连接、锁、线程、网络连接、内存访问和文件句柄。我们先关注最简单的情况:文件句柄。挑战在于确保每个打开的文件只关闭一次。未能关闭文件可能导致内存泄漏,而尝试关闭文件句柄两次会导致运行时错误。为了解决这个问题,文件句柄应放在try-except-finally块中。这确保了文件被正确关闭,无论执行过程中是否发生错误。以下是实现的可能方式:
file_path = "example.txt"
file = None
try:
file = open(file_path, 'r')
contents = file.read()
print("File contents:", contents)
finally:
if file is not None:
file.close()
然而,Python 提供了一个更优雅的解决方案,即使用上下文管理器,它自动处理资源管理。下面是如何使用文件上下文管理器简化上述代码:
file_path = "example.txt"
with open(file_path, 'r') as file:
contents = file.read()
print("File contents:", contents)
在这个版本中,我们不需要显式地关闭文件。上下文管理器会处理这个问题,防止潜在的内存泄漏。
虽然 Python 提供了用于文件处理的内置上下文管理器,我们也可以为自定义类和函数创建自己的上下文管理器。对于基于类的实现,我们定义enter和exit双下划线方法。下面是一个基本示例:
class CustomContextManger:
def __enter__(self):
# Code to create instance of resource
return self
def __exit__(self, exc_type, exc_value, traceback):
# Teardown code to close resource
return None
现在,我们可以在‘with’块中使用这个自定义上下文管理器:
with CustomContextManger() as _cm:
print("Custom Context Manager Resource can be accessed here")
这种方法保持了上下文管理器的简洁语法,同时允许我们根据需要处理资源。
5. 使用装饰器分离关注点
我们经常看到多个函数具有相同的逻辑被显式实现。这是一种常见的代码异味,过多的代码重复使代码难以维护和不可扩展。装饰器用于将类似的功能封装在一个地方。当多个函数需要使用类似的功能时,我们可以通过在装饰器中实现公共功能来减少代码重复。这符合面向切面编程(AOP)和单一职责原则。
装饰器在 Python 网络框架中被广泛使用,如 Django、Flask 和 FastAPI。让我通过在 Python 中将装饰器作为日志记录中间件来解释装饰器的有效性。在生产环境中,我们需要知道服务请求所需的时间。这是一个常见的用例,并且会在所有端点之间共享。所以,让我们实现一个简单的基于装饰器的中间件,它将记录服务请求所需的时间。
下面的虚拟函数用于服务用户请求。
def service_request():
# Function body representing complex computation
return True
现在,我们需要记录这个函数执行所需的时间。一种方法是在这个函数中添加日志记录,如下所示:
import time
def service_request():
start_time = time.time()
# Function body representing complex computation
print(f"Time Taken: {time.time() - start_time}s")
return True
虽然这种方法有效,但会导致代码重复。如果我们添加更多的路由,就需要在每个函数中重复日志记录代码。这增加了代码重复,因为这个共享的日志记录功能需要在每个实现中添加。我们通过使用装饰器来解决这个问题。
日志记录中间件将如下实现:
def request_logger(func):
def wrapper(*args, **kwargs):
start_time = time.time()
res = func()
print(f"Time Taken: {time.time() - start_time}s")
return res
return wrapper
在这个实现中,外部函数是装饰器,它接受一个函数作为输入。内部函数实现日志记录功能,输入函数在包装器内部被调用。
现在,我们只需用我们的 request_logger 装饰器 装饰原始的 service_request 函数:
@request_logger
def service_request():
# Function body representing complex computation
return True
使用 @ 符号将 service_request 函数传递给 request_logger 装饰器。它记录所花费的时间,并在不修改其代码的情况下调用原始函数。这种关注点分离使我们可以以类似的方式轻松地将日志记录添加到其他服务方法中。
@request_logger
def service_request():
# Function body representing complex computation
return True
@request_logger
def service_another_request():
# Function body
return True
6. match case 语句
match 语句是在 Python3.10 中引入的,因此它是 Python 语法中相对较新的补充。它允许更简单、更可读的模式匹配,防止了典型的 if-elif-else 语句中过多的样板代码和分支。
对于模式匹配,match case 语句是更自然的写法,因为它们不需要像条件语句那样返回布尔值。以下来自 Python 文档的示例展示了 match case 语句如何相比条件语句提供更大的灵活性。
def make_point_3d(pt):
match pt:
case (x, y):
return Point3d(x, y, 0)
case (x, y, z):
return Point3d(x, y, z)
case Point2d(x, y):
return Point3d(x, y, 0)
case Point3d(_, _, _):
return pt
case _:
raise TypeError("not a point we support")
根据文档,没有模式匹配的情况下,这个函数的实现需要几个 isinstance() 检查,一两个 len() 调用,以及更复杂的控制流程。在内部,match 示例和传统的 Python 版本转化为类似的代码。然而,熟悉模式匹配后,match case 方法可能会更受欢迎,因为它提供了更清晰和自然的语法。
总体而言,match case 语句为模式匹配提供了一种改进的替代方案,这在较新的代码库中可能会变得更加普遍。
7. 外部配置文件
在生产环境中,我们的大部分代码依赖于外部配置参数,如 API 密钥、密码和各种设置。将这些值直接硬编码到代码中被认为是不利于可扩展性和安全性的做法。相反,将配置与代码本身分开是至关重要的。我们通常使用配置文件,如 JSON 或 YAML,来存储这些参数,确保它们对代码易于访问,而不是直接嵌入其中。
一个日常使用的场景是数据库连接,它有多个连接参数。我们可以将这些参数保存在一个单独的 YAML 文件中。
# config.yaml
database:
host: localhost
port: 5432
username: myuser
password: mypassword
dbname: mydatabase
为了处理这个配置,我们定义了一个名为DatabaseConfig的类:
class DatabaseConfig:
def __init__(self, host, port, username, password, dbname):
self.host = host
self.port = port
self.username = username
self.password = password
self.dbname = dbname
@classmethod
def from_dict(cls, config_dict):
return cls(**config_dict)
在这里,from_dict 类方法作为 DatabaseConfig 类的构建器方法,使我们能够从字典创建数据库配置实例。
在我们的主要代码中,我们可以使用参数注入和构建器方法来创建数据库配置。通过读取外部 YAML 文件,我们提取数据库字典并用它来实例化配置类:
import yaml
def load_config(filename):
with open(filename, "r") as file:
return yaml.safe_load(file)
config = load_config("config.yaml")
db_config = DatabaseConfig.from_dict(config["database"])
这种方法消除了将数据库配置参数硬编码到代码中的需要。它比使用参数解析器有所改进,因为我们不再需要每次运行代码时传递多个参数。此外,通过通过参数解析器访问配置文件路径,我们可以确保代码保持灵活,并且不依赖于硬编码的路径。这种方法简化了配置参数的管理,可以随时修改,而无需更改代码库。
结束语
在这篇文章中,我们讨论了用于生产就绪代码的一些最佳实践。这些是行业中的常见实践,可以缓解在现实情况下可能遇到的多种问题。
尽管有所有这些最佳实践,但值得注意的是,文档、文档字符串和测试驱动开发仍然是最重要的实践。考虑一个函数应该做什么,然后记录所有设计决策和实现对未来非常重要,因为随着时间的推移,参与代码库的人会发生变化。如果你有任何见解或坚持的实践,请随时在下面的评论区告知我们。
Kanwal Mehreen** Kanwal 是一位机器学习工程师和技术作家,对数据科学以及人工智能与医学的交汇处有着深厚的热情。她共同撰写了电子书《用 ChatGPT 最大化生产力》。作为 2022 年 APAC 的 Google Generation Scholar,她倡导多样性和学术卓越。她还被认定为 Teradata 多样性技术学者、Mitacs Globalink 研究学者以及哈佛 WeCode 学者。Kanwal 是变革的热心倡导者,创办了 FEMCodes,以赋能 STEM 领域的女性。
更多相关内容
掌握 Python 数据科学:超越基础
原文:
www.kdnuggets.com/mastering-python-for-data-science-beyond-the-basics

图片来源:Freepik
Python 在数据科学领域中无可匹敌,但许多有抱负的(甚至是经验丰富的)数据科学家仅仅触及了其真正能力的表面。要真正掌握 Python 的数据分析,你必须超越基础,使用高级技术来高效处理数据、并行处理以及利用专业库。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT
大型复杂的数据集和计算密集型任务要求的不仅仅是入门级的 Python 技能。
本文作为提升你的 Python 技能的详细指南。我们将深入探讨加速代码的技术,使用 Python 处理大数据集,以及将模型转化为 Web 服务。在整个过程中,我们将探索有效处理复杂数据问题的方法。
掌握数据科学的高级 Python 技术
在当前的就业市场上,掌握高级 Python 技术对于数据科学至关重要。大多数公司需要具备 Python 技能的数据科学家。Django 和 Flask。
这些组件简化了关键安全功能的集成,特别是在相邻领域,如运行PCI 合规托管、构建数字支付的 SaaS 产品或在网站上接受支付。
那么,实际步骤呢?以下是一些你现在可以开始掌握的技术:
高效的数据处理与 Pandas
高效的数据处理与 Pandas 相关,围绕着利用其强大的 DataFrame 和 Series 对象来处理和分析数据。
Pandas 在过滤、分组和 合并数据集 等任务中表现出色,使得可以用最少的代码进行复杂的数据操作。其索引功能,包括多级索引,能够快速检索和切片数据,使其非常适合处理大型数据集。
此外,Pandas 与其他数据分析 和可视化库(如 NumPy 和 Matplotlib)的集成,进一步提升了其高效数据分析的能力。
这些功能使得 Pandas 成为数据科学工具箱中不可或缺的工具。因此,即使 Python 是一种非常常见的语言,你也不应该把这视为一个缺陷。Python 既普遍又多才多艺——掌握 Python 可以让你从统计分析、数据清理和可视化,到一些更“专业”的任务,比如使用 vapt 工具 甚至 自然语言处理 应用。
使用 NumPy 进行高性能计算
NumPy 显著提升了 Python 的高性能计算能力,特别是通过对大型 多维数组 和矩阵的支持。它通过提供一整套旨在高效操作这些数据结构的数学函数来实现这一点。
NumPy 的关键特性之一 是其 C 实现,这允许使用矢量化操作快速执行复杂的数学计算。这与使用 Python 的本地数据结构和循环进行类似任务相比,显著提高了性能。例如,像矩阵乘法这样的任务,在许多科学计算中很常见,可以使用 np.dot() 函数 快速执行。
数据科学家可以利用 NumPy 对数组的高效处理和强大的计算能力,在 Python 代码中实现显著的加速,使其适用于需要高水平数值计算的应用。
通过多进程提升性能
通过 Python 中的多进程 提升性能涉及使用‘multiprocessing’模块在多个 CPU 核心上并行运行任务,而不是在单个核心上按顺序运行。
这对需要大量计算资源的 CPU 密集型任务特别有利,因为它允许任务的分割和并发执行,从而减少整体执行时间。基本用法包括创建‘Process’对象并指定要并行执行的目标函数。
此外,‘Pool’ 类可以用来管理多个工作进程并在它们之间分配任务,这可以抽象化许多手动的进程管理。进程间通信机制如 ‘Queue’ 和 ‘Pipe’ 促进了进程间的数据交换,而同步原语如 ‘Lock’ 和 ‘Semaphore’ 确保了进程在访问共享资源时不会互相干扰。
为了进一步提高代码执行效率,像 JIT 编译库 中的 Numba 这样的技术可以通过在运行时动态编译代码的部分来显著加速 Python 代码。
利用小众库提升数据分析水平
使用特定的 Python 库进行数据分析可以显著提升你的工作效率。例如,Pandas 非常适合用于组织和处理数据,而 PyTorch 提供了先进的深度学习功能,并支持 GPU 加速。
另一方面,Plotly 和 Seaborn 可以帮助你在创建可视化时使数据更易于理解和吸引人。对于计算要求较高的任务,像 LightGBM 和 XGBoost 这样的库 提供了高效的实现 的梯度提升算法,可以处理具有高维度的大型数据集。
这些库中的每一个都专注于数据分析和机器学习的不同方面,使它们成为任何数据科学家的宝贵工具。
数据可视化技术
Python 中的数据可视化已经有了显著进步,提供了多种技术来以有意义和吸引人的方式展示数据。
高级数据可视化不仅提升了数据的解释能力,还 帮助发现潜在的模式、趋势和相关性,这些可能通过传统方法并不明显。
掌握 Python 可以独立完成的工作是不可或缺的,但对 Python 平台如何在企业环境中充分利用 的概述将使你在其他数据科学家中脱颖而出。
这里有一些值得考虑的高级技术:
-
交互式可视化。 像 Bokeh 和 Plotly 这样的库允许创建用户可以交互的动态图表,例如放大特定区域或悬停在数据点上以查看更多信息。这种交互性可以使复杂的数据变得更易于理解和访问。
-
复杂图表类型。除了基本的折线图和柱状图,Python 支持高级图表类型,如热图、箱形图、小提琴图以及更专业的图表如雨云图。每种图表类型都有特定的用途,帮助突出数据的不同方面,从分布和相关性到组间比较。
-
使用 matplotlib 自定义。Matplotlib 提供广泛的自定义选项,允许对图表外观进行精确控制。通过使用 plt.getp 和 plt.setp 函数调整图表参数,或操作图表组件的属性,可以创建出版质量的图形,以最佳方式展示数据。
-
时间序列可视化。对于时间数据,时间序列图可以有效地显示随时间变化的值,帮助识别趋势、模式或不同时间段的异常。像 Seaborn 这样的库使创建和自定义时间序列图变得简单,提升了对时间数据的分析。
数据科学的可视化工具
通过 Python 中的多线程 来提升性能,可以实现并行代码执行,非常适合 CPU 密集型任务,而无需 IO 或用户交互。
不同的解决方案适用于不同的目的——从创建简单的折线图到复杂的互动仪表盘,以及介于两者之间的各种用途。以下是一些流行的工具:
-
Infogram 以其用户友好的界面和多样化的模板库而闻名,涵盖了媒体、营销、教育和政府等多个行业。它提供免费基础账户和各种高级功能的定价计划。
-
FusionCharts 允许创建超过 100 种不同类型的互动图表和地图,适用于网页和移动项目。它支持自定义,并提供各种导出选项。
-
Plotly 提供了简单的语法和多种交互选项,甚至对于没有技术背景的用户也适用,得益于其 GUI。不过,其社区版存在一些限制,如公共可视化和有限的美学选项。
-
RAWGraphs 是一个开源框架,强调无代码、拖放数据可视化,使复杂数据的视觉理解变得简单易懂。它特别适合填补电子表格应用程序与矢量图形编辑器之间的差距。
-
QlikView 受到经验丰富的数据科学家青睐,用于分析大规模数据。它与各种数据源集成,并且数据分析速度非常快。
结论
掌握高级 Python 技术对数据科学家至关重要,以释放这一强大语言的全部潜力。虽然基础 Python 技能非常宝贵,但掌握复杂的数据处理、性能优化和利用专门的库可以提升你的数据分析能力。
持续学习、迎接挑战并保持对最新 Python 发展动态的关注是成为熟练实践者的关键。
因此,投入时间掌握 Python 的高级特性,以增强自己解决复杂数据分析任务、推动创新并做出创造实际影响的数据驱动决策的能力。
Nahla Davies是软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家 Inc. 5,000 的体验品牌组织担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
更多相关话题
精通 Python 中的正则表达式
原文:
www.kdnuggets.com/2023/08/mastering-regular-expressions-python.html

图片由作者使用 Midjourney 创建
介绍
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在的组织 IT
正则表达式或称 regex,是操作文本和数据的强大工具。它们提供了一种简洁而灵活的方式来‘匹配’(指定和识别)文本字符串,例如特定字符、单词或字符模式。正则表达式在多种编程语言中使用,但在本文中,我们将重点讨论如何在 Python 中使用正则表达式。
Python 以其清晰、易读的语法,是学习和应用正则表达式的绝佳语言。Python 的re 模块提供了正则表达式操作的支持。该模块包含了根据指定模式搜索、替换和拆分文本的功能。通过掌握 Python 中的正则表达式,你可以高效地处理和分析文本数据。
本文将指导你从正则表达式的基础到更复杂的操作,为你提供应对任何文本处理挑战的工具。我们将从简单的字符匹配开始,然后探讨更复杂的模式匹配、分组和前瞻断言。让我们开始吧!
基本正则表达式模式
正则表达式的核心原理是对字符串中的模式进行匹配。这些模式最简单的形式是字面匹配,其中寻找的模式是字符的直接序列。但正则表达式模式可以比简单的字面匹配更为复杂和强大。
在 Python 中,re模块提供了一整套处理正则表达式的函数。例如,re.search()函数扫描给定的字符串,寻找正则表达式模式匹配的位置。我们用一个例子来说明:
import re
# Define a pattern
pattern = "Python"
# Define a text
text = "I love Python!"
# Search for the pattern
match = re.search(pattern, text)
print(match)
这段 Python 代码在变量text中搜索变量pattern定义的模式。如果在文本中找到该模式,re.search()函数返回一个 Match 对象,否则返回 None。
Match 对象包括关于匹配的信息,包括原始输入字符串、使用的正则表达式和匹配的位置。例如,使用 match.start() 和 match.end() 可以提供字符串中匹配的起始和结束位置。
然而,我们通常不仅仅是寻找精确的单词 - 我们希望匹配模式。这就是特殊字符发挥作用的地方。例如,点 (.) 匹配除换行符之外的任何字符。让我们看看实际应用:
# Define a pattern
pattern = "P.th.n"
# Define a text
text = "I love Python and Pithon!"
# Search for the pattern
matches = re.findall(pattern, text)
print(matches)
这段代码搜索字符串中任何一个以 "P" 开头、以 "n" 结尾并且中间包含 "th" 的五个字母单词。点代表任何字符,因此它匹配 "Python" 和 "Pithon"。如你所见,即使只有字面字符和点,正则表达式也提供了一个强大的模式匹配工具。
在后续章节中,我们将深入探讨正则表达式的更复杂模式和强大功能。通过理解这些基本构建块,你可以构建更复杂的模式,以匹配几乎任何文本处理和操作任务。
元字符
虽然字面字符构成了正则表达式的基础,但元字符通过提供灵活的模式定义来增强其功能。元字符是具有独特含义的特殊符号,决定了正则表达式引擎如何匹配模式。以下是一些常用元字符及其意义和用法:
-
. (点) - 点是一个通配符,匹配除换行符之外的任何字符。例如,模式 "a.b" 可以匹配 "acb"、"a+b"、"a2b" 等。
-
^ (脱字符) - 脱字符表示字符串的开头。"^a" 将匹配任何以 "a" 开头的字符串。
-
$ (美元符号) - 相反,美元符号对应于字符串的结尾。"a$" 将匹配任何以 "a" 结尾的字符串。
-
*** (星号)** - 星号表示前一个元素的零次或多次出现。例如,"a*" 匹配 ""、"a"、"aa"、"aaa" 等。
-
+ (加号) - 与星号类似,加号表示前一个元素的一次或多次出现。"a+" 匹配 "a"、"aa"、"aaa" 等,但不匹配空字符串。
-
? (问号) - 问号表示前一个元素的零次或一次出现。它使前一个元素变为可选。例如,"a?" 匹配 "" 或 "a"。
-
{ } (大括号) - 大括号量化出现的次数。"{n}" 表示恰好 n 次出现,"{n,}" 表示 n 次或更多次出现,"{n,m}" 表示 n 到 m 次之间的出现次数。
-
[ ] (方括号) - 方括号指定一个字符集,方括号内的任何单个字符都可以匹配。例如,"[abc]" 匹配 "a"、"b" 或 "c"。
-
\ (反斜杠) - 反斜杠用于转义特殊字符,实际上将特殊字符视为字面字符。"$" 将匹配字符串中的美元符号,而不是表示字符串的结尾。
-
| (管道符) - 管道符作为逻辑或使用。匹配管道符前的模式或管道符后的模式。例如,"a|b" 匹配 "a" 或 "b"。
-
( ) (圆括号) - 圆括号用于分组和捕获匹配。正则表达式引擎将括号内的所有内容视为一个单一的元素。
掌握这些元字符可以让你在文本处理任务中获得新的控制水平,使你能够创建更精确和灵活的模式。正则表达式的真正威力在于你学会将这些元素组合成复杂的表达式。在接下来的部分,我们将探索这些组合,以展示正则表达式的多样性。
字符集
正则表达式中的字符集是强大的工具,允许你指定你希望匹配的字符组。通过将字符放在方括号 "[]" 中,你可以创建一个字符集。例如,"[abc]" 匹配 "a"、"b" 或 "c"。
但字符集不仅仅是指定单个字符的工具 - 它们提供了定义字符范围和特殊组的灵活性。让我们来看一下:
字符范围: 你可以使用短横线 ("-") 指定一个字符范围。例如,"[a-z]" 匹配任何小写字母。你甚至可以在一个集合中定义多个范围,如 "[a-zA-Z0-9]" 匹配任何字母数字字符。
特殊组: 一些预定义的字符集代表常用的字符组。这些是方便的简写:
-
\d: 匹配任何十进制数字;等同于 [0-9]
-
\D: 匹配任何非数字字符;等同于 [⁰-9]
-
\w: 匹配任何字母数字单词字符(字母、数字、下划线);等同于 [a-zA-Z0-9_]
-
\W: 匹配任何非字母数字字符;等同于 [^a-zA-Z0-9_]
-
\s: 匹配任何空白字符(空格、制表符、换行符)
-
\S: 匹配任何非空白字符
否定字符集: 通过在方括号内将插入符号 "^" 作为第一个字符,你可以创建一个否定集合,它匹配集合中不存在的任何字符。例如,"[^abc]" 匹配任何不是 "a"、"b" 或 "c" 的字符。
让我们看看这些在实际中的应用:
import re
# Create a pattern for a phone number
pattern = "\d{3}-\d{3}-\d{4}"
# Define a text
text = "My phone number is 123-456-7890."
# Search for the pattern
match = re.search(pattern, text)
print(match)
这段代码在文本中搜索美国电话号码的模式。模式 "\d{3}-\d{3}-\d{4}" 匹配任何三个数字,后跟一个短横线,然后是任意三个数字,再跟一个短横线,最后是任意四个数字。它成功匹配了文本中的 "123-456-7890"。
字符集和相关的特殊序列大大增强了你的模式匹配能力,提供了一种灵活且高效的方式来指定你希望匹配的字符。通过掌握这些元素,你就能充分发挥正则表达式的潜力。
一些常见模式
虽然正则表达式可能看起来令人生畏,但你会发现许多任务只需要简单的模式。这里有五个常见的模式:
邮件
提取电子邮件是一个常见的任务,可以通过正则表达式完成。以下模式匹配大多数常见的电子邮件格式:
# Define a pattern
pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
# Search for the pattern
match = re.findall(pattern, text)
print(match)
电话号码
电话号码的格式可能会有所不同,但以下是匹配北美电话号码的模式:
# Define a pattern
pattern = r'\b\d{3}[-.\s]?\d{3}[-.\s]?\d{4}\b'
# Search for the pattern
...
IP 地址
要匹配 IP 地址,我们需要四个用句点分隔的数字(0-255):
# Define a pattern
pattern = r'\b(?:\d{1,3}\.){3}\d{1,3}\b'
# Search for the pattern
...
网络网址
网络网址遵循一致的格式,可以用以下模式匹配:
# Define a pattern
pattern = r'https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+'
# Search for the pattern
...
HTML 标签
HTML 标签可以使用以下模式进行匹配。要小心,因为这不会捕捉标签内的属性:
# Define a pattern
pattern = r'<[^>]+>'
# Search for the pattern
...
Python 正则表达式匹配工作流程
提示与建议
以下是一些实用技巧和最佳实践,帮助你有效使用正则表达式。
-
从简单开始:从简单模式开始,逐渐增加复杂性。一开始解决复杂问题可能会让人不知所措。
-
增量测试:每次更改后测试你的正则表达式。这使得定位和修复问题更加容易。
-
使用原始字符串:在 Python 中,使用原始字符串作为正则表达式模式(即 r"text")。这确保 Python 文字解释字符串,防止与 Python 的转义序列冲突。
-
具体明确:你的正则表达式越具体,就越不容易意外匹配到不需要的文本。例如,与其使用 .*,不如考虑使用 .+? 以非贪婪的方式匹配文本。
-
使用在线工具:在线正则表达式测试工具可以帮助你构建和测试你的正则表达式。这些工具可以实时显示匹配、分组,并提供正则表达式的解释。一些流行的工具有 regex101 和 regextester。
-
可读性优于简洁性:虽然正则表达式允许非常紧凑的代码,但它可能很快变得难以阅读。优先考虑可读性而非简洁性。在必要时使用空白和注释。
记住,掌握正则表达式是一个过程,实际上是一种组装构建块的练习。通过练习和坚持,你将能够处理任何文本处理任务。
结论
正则表达式,或称为 regex,确实是 Python 工具箱中的一个强大工具。它的复杂性可能会让人一开始感到困惑,但一旦你深入探讨它的细节,你会开始认识到它的真正潜力。它为处理、解析和操控文本数据提供了无与伦比的强大和多功能性,使其在数据科学、自然语言处理、网页抓取等众多领域中成为一个必不可少的工具。
正则表达式的主要优点之一在于它能够在大量文本中执行复杂的模式匹配和提取操作,代码量极少。把它想象成一个精密的搜索引擎,不仅能定位准确的文本字符串,还能识别模式、范围和特定的序列。这使得它能够从原始的非结构化文本数据中识别和提取关键信息,这在信息检索、数据清理和情感分析等任务中非常必要。
此外,尽管正则表达式的学习曲线看似陡峭,但不应让热情的学习者气馁。是的,正则表达式有其独特的语法和特殊字符,刚开始可能显得难以理解。然而,通过一些专注的学习和实践,你很快会欣赏到其逻辑结构和优雅。正则表达式在处理文本数据时的效率和节省的时间远远超过了初始学习的投资。因此,尽管掌握正则表达式具有挑战性,但其带来的宝贵回报使其成为任何数据科学家、程序员或处理文本数据的人员的重要技能。
我们讨论的概念和例子只是冰山一角。还有许多正则表达式的概念值得深入探讨,如量词、分组、环视断言等。因此,继续练习、实验并掌握 Python 中的正则表达式。祝你编码愉快!
Matthew Mayo (@mattmayo13) 是数据科学家,也是 KDnuggets 的主编,KDnuggets 是著名的数据科学和机器学习在线资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。他可以通过 editor1 at kdnuggets[dot]com 联系。
更多相关话题
通过 5 个简单步骤掌握 TensorFlow 张量
原文:
www.kdnuggets.com/2020/11/mastering-tensorflow-tensors-5-easy-steps.html
评论
作者 Orhan G. Yalçın,AI 研究员
如果你正在阅读这篇文章,我相信我们有相似的兴趣,并且在相似的行业中。那就通过 Linkedin 来联系吧!请不要犹豫发送联系请求! Orhan G. Yalçın — Linkedin
 照片由 Esther Jiao 提供,来自 Unsplash
照片由 Esther Jiao 提供,来自 Unsplash
在这篇文章中,我们将深入探讨 TensorFlow 张量 的细节。我们将通过这五个简单步骤涵盖所有与 TensorFlow 张量相关的主题:
-
**步骤 I:张量的定义 → ** 张量是什么?
-
**步骤 II:张量的创建 → ** 创建张量对象的函数
-
**步骤 III:张量的资格 → ** 张量对象的特征和属性
-
**步骤 IV:与张量的操作 → ** 索引、基本张量操作、形状调整和广播
-
**步骤 V:特殊类型的张量 → ** 除了常规张量的特殊张量类型
让我们开始吧!
张量的定义:张量是什么?
 图 1. 三阶张量的可视化(图由作者提供)
图 1. 三阶张量的可视化(图由作者提供)
张量是 TensorFlow 的多维数组,具有统一的数据类型。它们与 NumPy 数组非常相似,并且是不可变的,这意味着一旦创建后不能被更改。你只能创建一个新的副本并进行编辑。
让我们看看张量如何通过代码示例工作。但首先,为了处理 TensorFlow 对象,我们需要导入 TensorFlow 库。我们经常与 TensorFlow 一起使用 NumPy,所以也需要用以下几行导入 NumPy:
张量的创建:创建张量对象
创建 tf.Tensor 对象有几种方法。让我们从几个示例开始。你可以使用多个 TensorFlow 函数来创建张量对象,如下面的示例所示:
tf.constant、tf.ones、tf.zeros 和 tf.range 是你可以用来创建张量对象的一些函数
**Output:**
tf.Tensor([[1 2 3 4 5]], shape=(1, 5), dtype=int32)
tf.Tensor([[1\. 1\. 1\. 1\. 1.]], shape=(1, 5), dtype=float32)
tf.Tensor([[0\. 0\. 0\. 0\. 0.]], shape=(1, 5), dtype=float32)
tf.Tensor([1 2 3 4 5], shape=(5,), dtype=int32)
如你所见,我们使用三种不同的函数创建了形状为 (1, 5) 的张量对象,并使用 tf.range() 函数创建了一个形状为 (5,) 的第四个张量对象。请注意,tf.ones 和 tf.zeros 接受形状作为必需的参数,因为它们的元素值是预先确定的。
张量的资格:张量对象的特征和属性
TensorFlow 张量被创建为 tf.Tensor 对象,它们有几个特征。首先,它们的秩基于维度数量。其次,它们有一个形状,一个由所有维度长度组成的列表。所有张量都有一个大小,即张量内元素的总数。最后,它们的元素都记录在统一的数据类型中。让我们更详细地了解这些特征。
秩系统与维度
张量根据它们的维度数量进行分类:
-
秩-0(标量)张量: 一个包含单个值且没有轴(0 维)的张量;
-
秩-1 张量: 一个包含单个轴(1 维)中的值列表的张量;
-
秩-2 张量: 一个包含 2 个轴(2 维)的张量;以及
-
秩-N 张量: 一个包含 N 个轴(N 维)的张量。
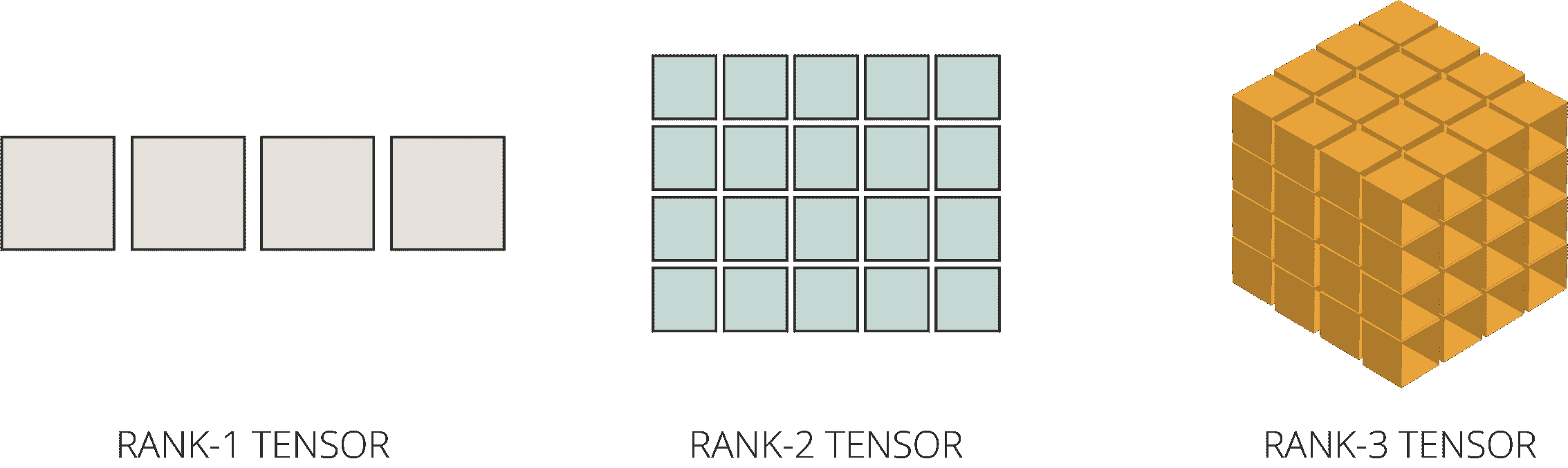 图 2. 秩-1 张量 | 秩-2 张量 | 秩-3 张量(作者提供的图)
图 2. 秩-1 张量 | 秩-2 张量 | 秩-3 张量(作者提供的图)
例如,我们可以通过将一个三层嵌套列表对象传递给 tf.constant 函数来创建一个秩-3 张量。对于这个例子,我们可以将数字分割成一个每层有三个元素的三层嵌套列表:
创建一个秩-3 张量对象的代码
**Output:** tf.Tensor( [[[ 0 1 2]
[ 3 4 5]]
[[ 6 7 8]
[ 9 10 11]]],
shape=(2, 2, 3), dtype=int32)
我们可以通过 .ndim 属性查看我们当前的 rank_3_tensor 对象的维度数量。
**Output:** The number of dimensions in our Tensor object is 3
形状
形状特征是每个张量都有的另一个属性。它以列表形式显示每个维度的大小。我们可以通过 .shape 属性查看我们创建的 rank_3_tensor 对象的形状,如下所示:
**Output:** The shape of our Tensor object is (2, 2, 3)
如你所见,我们的张量在第一层有 2 个元素,在第二层有 2 个元素,在第三层有 3 个元素。
大小
大小是张量的另一个特征,意味着张量中的元素总数。我们不能用张量对象的属性来测量大小。相反,我们需要使用 tf.size() 函数。最后,我们将输出转换为 NumPy,以通过实例函数 .numpy() 获取更可读的结果:
**Output:** The size of our Tensor object is 12
数据类型
张量通常包含数值数据类型,如浮点数和整数,但也可能包含许多其他数据类型,如复数和字符串。
然而,每个张量对象必须以单一的统一数据类型存储所有元素。因此,我们还可以通过 .dtype 属性查看特定张量对象所选择的数据类型,如下所示:
**Output:** The data type selected for this Tensor object is <dtype: 'int32'>
张量操作
索引
索引是项目在序列中的位置的数值表示。这个序列可以指代许多事物:一个列表、一个字符字符串或任何任意的值序列。
TensorFlow 还遵循标准的 Python 索引规则,这与列表索引或 NumPy 数组索引类似。
关于索引的一些规则:
-
索引从零(0)开始。
-
负索引(“ -n”)值表示从末尾向后计数。
-
冒号(“:”)用于切片:
start:stop:step。 -
逗号(“,”)用于达到更深的层次。
让我们用以下代码行创建一个 rank_1_tensor:
**Output:**
tf.Tensor([ 0 1 2 3 4 5 6 7 8 9 10 11],
shape=(12,), dtype=int32)
并测试我们的规则第 1 条、第 2 条和第 3 条:
**Output:**
First element is: 0
Last element is: 11
Elements in between the 1st and the last are: [ 1 2 3 4 5 6 7 8 9 10]
现在,让我们用以下代码创建我们的 rank_2_tensor 对象:
**Output:** tf.Tensor( [[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]], shape=(2, 6), dtype=int32)
并用几个示例测试第四条规则:
**Output:**
The first element of the first level is: [0 1 2 3 4 5]
The second element of the first level is: [ 6 7 8 9 10 11]
The first element of the second level is: 0
The third element of the second level is: 2
现在,我们已经覆盖了索引的基础知识,让我们来看看我们可以对 Tensor 执行的基本操作。
Tensor 的基本操作
你可以轻松地对 Tensor 执行基本数学操作,例如:
-
加法
-
元素级乘法
-
矩阵乘法
-
查找最大值或最小值
-
查找最大元素的索引
-
计算 Softmax 值
让我们看看这些操作的实际效果。我们将创建两个 Tensor 对象并应用这些操作。
我们可以从加法开始。
**Output:** tf.Tensor( [[ 3\. 7.]
[11\. 15.]], shape=(2, 2), dtype=float32)
让我们继续进行元素级乘法。
**Output:** tf.Tensor( [[ 2\. 12.]
[30\. 56.]], shape=(2, 2), dtype=float32)
我们还可以进行矩阵乘法:
**Output:** tf.Tensor( [[22\. 34.]
[46\. 74.]], shape=(2, 2), dtype=float32)
注意: Matmul 操作是深度学习算法的核心。因此,尽管你不会直接使用 matmul,但了解这些操作至关重要。
我们上面列出的其他操作示例:
**Output:**
The Max value of the tensor object b is: 7.0
The index position of the Max of the tensor object b is: [1 1]
The softmax computation result of the tensor object b is: [[0.11920291 0.880797 ] [0.11920291 0.880797 ]]
操作形状
就像在 NumPy 数组和 pandas DataFrames 中一样,你也可以重塑 Tensor 对象。
tf.reshape 操作非常快,因为底层数据不需要重复。对于重塑操作,我们可以使用tf.reshape() 函数。让我们在代码中使用 tf.reshape 函数:
**Output:** The shape of our initial Tensor object is: (1, 6)
The shape of our initial Tensor object is: (6, 1)
The shape of our initial Tensor object is: (3, 2)
The shape of our flattened Tensor object is: tf.Tensor([1 2 3 4 5 6], shape=(6,), dtype=int32)
正如你所见,我们可以轻松地重塑我们的 Tensor 对象。但要注意,在进行重塑操作时,开发人员必须合理操作。否则,Tensor 可能会混乱或甚至引发错误。因此,留意这一点 ????。
广播
当我们尝试使用多个 Tensor 对象进行组合操作时,较小的 Tensor 可以自动扩展以适应较大的 Tensor,就像 NumPy 数组一样。例如,当你尝试将标量 Tensor 与二阶 Tensor 相乘时,标量会被扩展以与每个二阶 Tensor 元素相乘。请参见下面的示例:
**Output:** tf.Tensor( [[ 5 10]
[15 20]], shape=(2, 2), dtype=int32)
由于广播,你在对 Tensor 进行数学操作时无需担心匹配尺寸的问题。
特殊类型的 Tensor
我们倾向于生成矩形形状的 Tensor 并将数值作为元素存储。然而,TensorFlow 也支持不规则或特殊类型的 Tensor,具体包括:
-
不规则 Tensor
-
字符串 Tensor
-
稀疏 Tensor
 图 3. 不规则 Tensor | 字符串 Tensor | 稀疏 Tensor(图由作者提供)
图 3. 不规则 Tensor | 字符串 Tensor | 稀疏 Tensor(图由作者提供)
让我们仔细看看它们每一个是什么。
不规则 Tensor
不规则 Tensor 是在大小轴上具有不同元素数量的 Tensor,如图 X 所示。
你可以构建一个不规则 Tensor,如下所示:
**Output:** <tf.RaggedTensor [[1, 2, 3],
[4, 5],
[6]]>
字符串 Tensor
字符串 Tensor 是存储字符串对象的 Tensor。我们可以像创建普通 Tensor 对象一样创建一个字符串 Tensor。但是,我们传递的是字符串对象作为元素,而不是数值对象,如下所示:
**Output:**
tf.Tensor([b'With this'
b'code, I am'
b'creating a String Tensor'],
shape=(3,), dtype=string)
稀疏 Tensor
最后,稀疏张量是用于稀疏数据的矩形张量。当数据中有空洞(即空值)时,稀疏张量是首选对象。创建一个稀疏张量有点耗时,并且应该更为普及。不过,以下是一个示例:
**Output:**
tf.Tensor( [[ 25 0 0 0 0]
[ 0 0 0 0 0]
[ 0 0 50 0 0]
[ 0 0 0 0 0]
[ 0 0 0 0 100]], shape=(5, 5), dtype=int32)
恭喜
我们已经成功覆盖了 TensorFlow 的 Tensor 对象基础知识。
给自己一个奖励吧!
这应该会让你更有信心,因为你现在对 TensorFlow 框架的构建块有了更多了解。
查看 本教程系列的第一部分:
了解 TensorFlow 平台及其对机器学习专家的提供
继续阅读 系列第三部分:
了解如何使用 TensorFlow 变量,它们与普通 Tensor 对象的区别,以及何时优于…
订阅邮件列表获取完整代码
如果你希望访问 Google Colab 上的完整代码和我最新的内容,请考虑订阅邮件列表:
滑动以订阅我的通讯
最后,如果你对应用深度学习教程感兴趣,可以查看我的一些文章:
使用卷积神经网络对手写数字进行分类,采用 TensorFlow 和 Keras | 监督深度学习
使用无监督深度学习生成手写数字,采用 TensorFlow 和深度卷积 GANs
使用深度卷积自编码器清洁(或去噪)噪声图像,借助 Fashion MNIST | 无监督…
如果你能够预测明天的比特币 (BTC) 价格,那不是太棒了吗?加密货币市场有…
简介:Orhan G. Yalçın 是法律领域的 AI 研究员。他是一位合格的律师,拥有商业发展和数据科学技能,曾在 Allen & Overy 担任法律实习生,处理资本市场、竞争和公司法事务。
原文。已获许可转载。
相关:
-
什么是张量?!?
-
TensorFlow 2 入门
-
你应该知道的 PyTorch 最重要基础知识
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
相关话题
在 5 个简单步骤中掌握 TensorFlow 变量
原文:
www.kdnuggets.com/2021/01/mastering-tensorflow-variables-5-easy-steps.html
评论
作者:Orhan G. Yalçın,AI 研究员
警告: 请勿将本文与“在 5 个简单步骤中掌握 TensorFlow 张量”混淆!
如果你正在阅读这篇文章,我相信我们有相似的兴趣,并且在相似的行业中工作/将会工作。所以让我们通过Linkedin联系吧!请随时发送联系请求!Orhan G. Yalçın — Linkedin*
 图 1。照片由Crissy Jarvis提供,发布在Unsplash
图 1。照片由Crissy Jarvis提供,发布在Unsplash
在本教程中,我们将重点关注TensorFlow 变量。教程结束后,你将能够有效地创建、更新和管理TensorFlow 变量。像往常一样,我们的教程将提供详细的代码示例以及概念解释。我们将在 5 个简单步骤中掌握TensorFlow 变量:
-
步骤 1:变量定义 → 简要介绍,与Tensors的比较
-
步骤 2:变量创建 → 实例化 tf.Variable 对象
-
步骤 3: 变量的资格 → 特征和属性
-
步骤 4:变量操作 → 基本张量操作、索引、形状操作和广播
-
步骤 5:变量的硬件选择 → GPUs,CPUs,TPUs
系好安全带,让我们开始吧!
变量定义
在这一步中,我们将简要介绍变量的概念,并理解普通 Tensor 对象和变量对象之间的区别。
简要介绍
TensorFlow 变量是表示共享和持久状态的首选对象类型,你可以通过任何操作(包括 TensorFlow 模型)来操控。操控指的是任何值或参数的更新。这一特性是变量与tf.Tensor对象最主要的区别。TensorFlow 变量被记录为tf.Variable对象。让我们简要比较一下tf.Tensor和tf.Variable对象,以理解它们的相似性和差异。
 图 2。变量值可以更新(图由作者提供)
图 2。变量值可以更新(图由作者提供)
与张量的比较
因此,变量和张量之间最重要的区别是可变性。与张量不同,变量对象中的值可以被更新(例如,通过*assign()*函数)。
“张量对象的值不能被更新,你只能用新的值创建一个新的张量对象。””
变量对象主要用于存储模型参数,由于这些值在训练过程中会不断更新,因此使用变量而不是张量是一种必需而非选择。
变量对象的形状可以使用reshape()实例函数更新,就像张量对象的形状一样。由于变量对象是基于张量对象构建的,因此它们具有.shape和.dtype等共同属性。但变量还具有张量所没有的唯一属性,如.trainable、.device和.name。
 图 3. TensorFlow 变量实际上是围绕 TensorFlow 张量的一个包装器,具有额外的功能(图由作者提供)
图 3. TensorFlow 变量实际上是围绕 TensorFlow 张量的一个包装器,具有额外的功能(图由作者提供)
让我们来看看如何创建
tf.Variable对象!
变量的创建
我们可以使用tf.Variable()函数实例化(即,创建)tf.Variable对象。tf.Variable()函数接受不同的数据类型作为参数,如整数、浮点数、字符串、列表和tf.Constant对象。
在展示不同数据类型的变量对象示例之前,我希望你能*“打开一个新的 Google Colab 笔记本”并使用以下代码导入 TensorFlow 库:*
现在,我们可以开始创建tf.Variable对象。
1 — 我们可以将一个tf.constant()对象作为initial_value传递:
2 — 我们可以将一个单独的整数作为initial_value传递:
3 — 我们可以将一个整数或浮点数列表作为initial_value传递:
4 — 我们可以将一个单独的字符串作为initial_value传递:
5 — 我们可以将一个字符串列表作为initial_value传递:
正如你所看到的,tf.Variable()函数接受作为initial_value参数的几种数据类型。现在让我们看看变量的特征和功能。
变量的资格
每个变量必须具有一些属性,如值、名称、统一数据类型、形状、秩、大小等。在这一部分,我们将看到这些属性是什么以及如何在 Colab 笔记本中查看这些属性。
值
每个变量必须指定一个initial_value。否则,TensorFlow 会引发错误,并提示Value Error: initial_value must be specified.因此,请确保在创建变量对象时传递initial_value参数。为了查看变量的值,我们可以使用.value()函数以及.numpy()函数。请参见下面的示例:
**Output:**
The values stored in the variables:
tf.Tensor( [[1\. 2.]
[1\. 2.]], shape=(2, 2), dtype=float32)The values stored in the variables:
[[1\. 2.]
[1\. 2.]]
名称
Name 是一个 Variable 属性,帮助开发者跟踪特定变量的更新。你可以在创建 Variable 对象时传递name参数。如果你没有指定名称,TensorFlow 会分配一个默认名称,如下所示:
**Output:**
The name of the variable: Variable:0
Dtype
每个 Variable 必须有统一的数据类型进行存储。由于每个 Variable 存储的是单一类型的数据,你也可以通过.dtype属性查看这个类型。见下方示例:
**Output:**
The selected datatype for the variable: <dtype: 'float32'>
形状、秩和大小
形状属性以列表形式显示每个维度的大小。我们可以使用.shape属性查看 Variable 对象的形状。然后,我们可以使用tf.size()函数查看一个 Variable 对象的维度数量。最后,大小对应于一个 Variable 拥有的元素总数。我们需要使用tf.size()函数来计算 Variable 中的元素数量。见下方代码了解所有三个属性:
**Output:**
The shape of the variable: (2, 2)
The number of dimensions in the variable: 2
The number of dimensions in the variable: 4
与变量的操作
使用数学运算符和 TensorFlow 函数,你可以轻松进行多种基本操作。除了我们在本教程系列第二部分中介绍的内容,你还可以使用以下数学运算符进行 Variable 操作。
基本 Tensor 操作
 图 4. 你可能会从基本数学运算符中受益(图示由作者提供)
图 4. 你可能会从基本数学运算符中受益(图示由作者提供)
加法和减法:我们可以使用+和—符号进行加法和减法运算。
Addition by 2:
tf.Tensor( [[3\. 4.] [3\. 4.]], shape=(2, 2), dtype=float32)Substraction by 2:
tf.Tensor( [[-1\. 0.] [-1\. 0.]], shape=(2, 2), dtype=float32)
乘法和除法:我们可以使用*和/符号进行乘法和除法运算。
Multiplication by 2:
tf.Tensor( [[2\. 4.] [2\. 4.]], shape=(2, 2), dtype=float32)Division by 2:
tf.Tensor( [[0.5 1\. ] [0.5 1\. ]], shape=(2, 2), dtype=float32)
矩阵乘法和取模操作:最后,你还可以使用@和%符号进行矩阵乘法和取模操作:
Matmul operation with itself:
tf.Tensor( [[3\. 6.] [3\. 6.]], shape=(2, 2), dtype=float32)Modulo operation by 2:
tf.Tensor( [[1\. 0.] [1\. 0.]], shape=(2, 2), dtype=float32)
这些是基础示例,但它们可以扩展为复杂计算,从而创建我们在深度学习应用中使用的算法。
**Note:** These operators also work on regular Tensor objects.
赋值、索引、广播和形状操作
赋值
使用tf.assign()函数,你可以在不创建新对象的情况下给一个 Variable 对象赋予新值。赋值是 Variables 的一个优点,特别是在需要重新赋值的情况下。以下是重新赋值的示例:
**Output:**
...array([[ 2., 100.],
[ 1., 10.]],...
索引
就像在 Tensors 中一样,你可以使用索引值轻松访问特定元素,如下所示:
**Output:**
The 1st element of the first level is: [1\. 2.]
The 2nd element of the first level is: [1\. 2.]
The 1st element of the second level is: 1.0
The 3rd element of the second level is: 2.0
广播
就像在 Tensor 对象中一样,当我们尝试使用多个 Variable 对象进行组合操作时,较小的 Variable 可以自动扩展以适应较大的 Variable,就像 NumPy 数组一样。例如,当你尝试将一个标量 Variable 与一个二维 Variable 相乘时,标量会被扩展以乘以每个二维 Variable 元素。见下方示例:
tf.Tensor([[ 5 10]
[15 20]], shape=(2, 2), dtype=int32)
形状操作
与 Tensor 对象一样,你也可以对 Variable 对象进行重塑操作。对于重塑操作,我们可以使用tf.reshape()函数。让我们在代码中使用tf.reshape()函数:
tf.Tensor( [[1.]
[2.]
[1.]
[2.]], shape=(4, 1), dtype=float32)
变量的硬件选择
正如你在接下来的部分中将看到的,我们将使用 GPU 和 TPU 加速模型训练。为了能够查看我们的变量是在哪种设备(即处理器)上处理的,我们可以使用 .device 属性:
The device which process the variable: /job:localhost/replica:0/task:0/device:GPU:0
我们还可以使用 tf.device() 函数,通过将设备名称作为参数传递来设置处理特定计算的设备。请参见下面的示例:
**Output:**
The device which processes the variable a: /job:localhost/replica:0/task:0/device:CPU:0The device which processes the variable b: /job:localhost/replica:0/task:0/device:CPU:0The device which processes the calculation: /job:localhost/replica:0/task:0/device:GPU:0
虽然在训练模型时你不需要手动设置,但在某些情况下,你可能需要为特定的计算或数据处理工作选择一个设备。所以,要注意这个选项。
恭喜你
我们已经成功覆盖了 TensorFlow 变量对象的基础知识。
给自己一个奖励吧!
这应该会给你很大的信心,因为你现在对 TensorFlow 中用于各种操作的主要可变变量对象类型有了更多了解。
如果这是你的第一篇文章,考虑从 本教程系列的第一部分 开始:
理解 TensorFlow 平台及其对机器学习专家的价值
或 查看第二部分:
了解 TensorFlow 的基本构件如何在底层工作,并学习如何充分利用 Tensor…
订阅邮件列表以获取完整代码
如果你想访问 Google Colab 上的完整代码以及我最新的内容,考虑订阅邮件列表:
滑动以订阅最后,如果你对更多高级的应用深度学习教程感兴趣,请查看我的其他文章:
使用卷积神经网络与 TensorFlow 和 Keras 对手写数字进行分类 | 监督深度学习
使用深度卷积自编码器清理(或去噪)带有噪声的图像,借助 Fashion MNIST | 无监督…
使用无监督深度学习生成手写数字,利用深度卷积 GAN 和 TensorFlow…
用 TensorFlow Hub 和 Magenta 在 5 分钟内快速神经风格迁移
将梵高的独特风格通过 Magenta 的任意图像风格化网络和深度学习转移到照片中
简历: Orhan G. Yalçın 是法律领域的 AI 研究员。他是一位合格的律师,具有商业发展和数据科学技能,并曾在 Allen & Overy 担任法律实习生,处理资本市场、竞争和公司法事务。
原始链接。经许可转载。
相关:
-
在 5 个简单步骤中掌握 TensorFlow 张量
-
使用 TensorFlow Serving 部署训练好的模型到生产环境
-
在 TensorFlow 中修剪机器学习模型
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的信息技术
更多相关话题
掌握 Python 数据清理的艺术
原文:
www.kdnuggets.com/mastering-the-art-of-data-cleaning-in-python

作者提供的图片
数据清理是任何数据分析过程中的关键部分。这一步骤中你会去除错误,处理缺失数据,并确保数据以可处理的格式存在。没有经过良好清理的数据集,任何后续分析都可能会产生偏差或错误。
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业的捷径
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 部门
本文介绍了几种在 Python 中进行数据清理的关键技术,使用了 pandas、numpy、seaborn 和 matplotlib 等强大库。
理解数据清理的重要性
在深入数据清理的机制之前,让我们了解其重要性。现实世界中的数据通常是混乱的。它可能包含重复条目、错误或不一致的数据类型、缺失值、无关特征和异常值。所有这些因素都可能导致分析数据时得出误导性结论。这使得数据清理成为数据科学生命周期中不可或缺的一部分。
我们将涵盖以下数据清理任务。
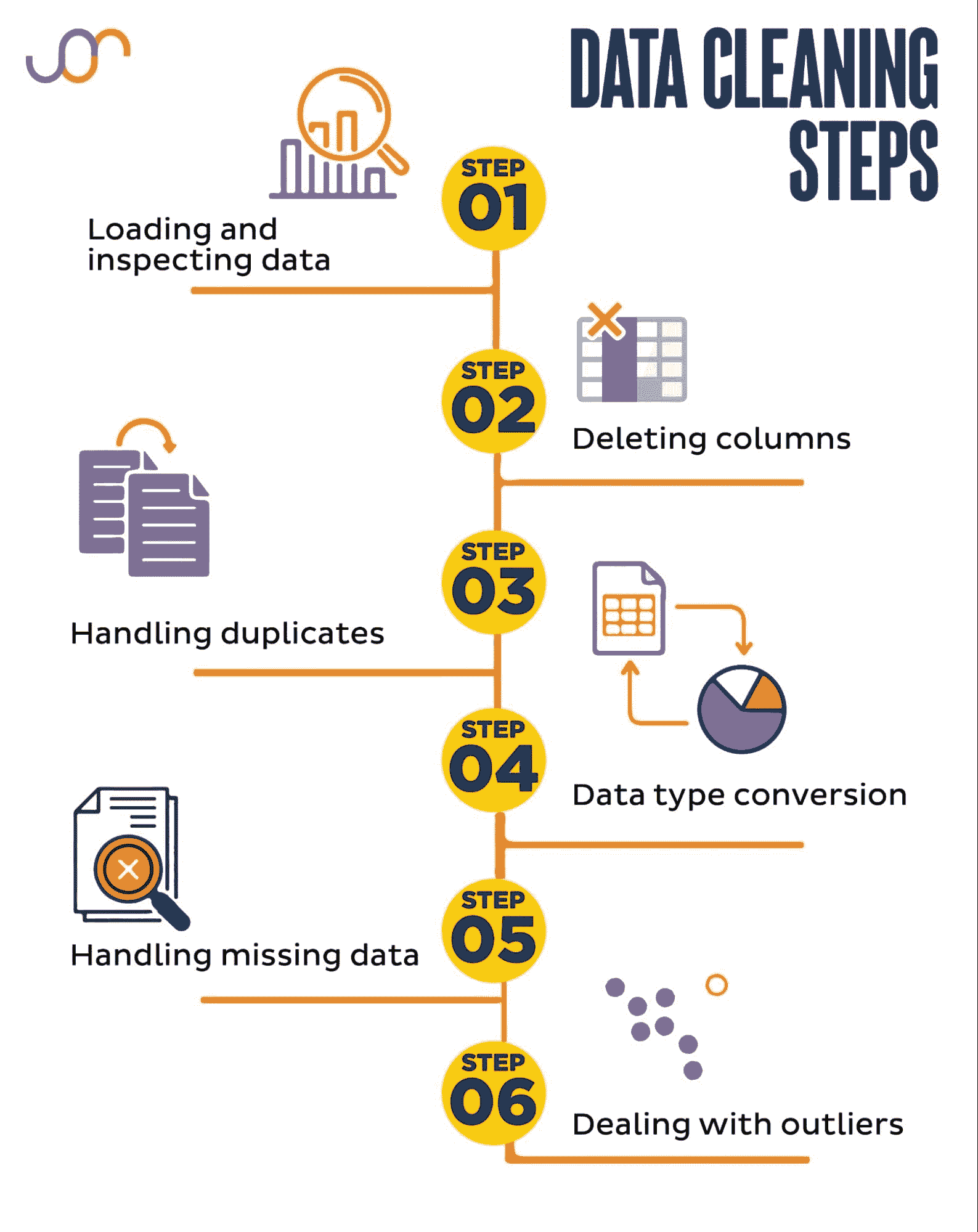
作者提供的图片
Python 数据清理的设置
在开始之前,让我们导入必要的库。我们将使用 pandas 进行数据处理,使用 seaborn 和 matplotlib 进行可视化。
我们还将导入 datetime Python 模块以便处理日期。
import pandas as pd
import seaborn as sns
import datetime as dt
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
加载和检查您的数据
首先,我们需要加载数据。在这个例子中,我们将使用 pandas 加载一个 CSV 文件。我们还添加了分隔符参数。
df = pd.read_csv('F:\\KDNuggets\\KDN Mastering the Art of Data Cleaning in Python\\property.csv', delimiter= ';')
接下来,检查数据以了解其结构、我们正在处理的变量类型以及是否有缺失值是很重要的。由于我们导入的数据量不大,让我们查看整个数据集。
# Look at all the rows of the dataframe
display(df)
数据集的样子如下。
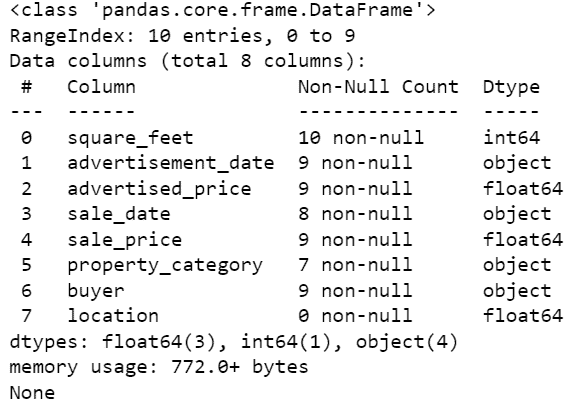
你可以立即看到有一些缺失值。此外,日期格式不一致。
现在,让我们使用 info() 方法查看 DataFrame 概况。
# Get a concise summary of the dataframe
print(df.info())
这是代码输出。
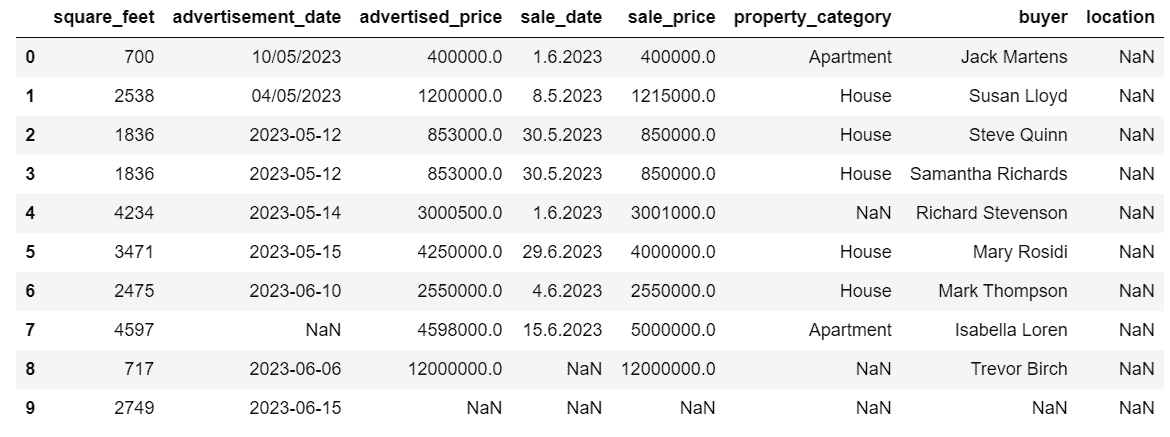
我们可以看到,只有列 square_feet 没有任何 NULL 值,因此我们需要处理这一点。此外,列 advertisement_date 和 sale_date 的数据类型是对象类型,尽管它们应该是日期。
列的位置完全为空。我们需要它吗?
我们将向你展示如何处理这些问题。我们首先学习如何删除不必要的列。
删除不必要的列
数据集中有两列在数据分析中不需要,因此我们将删除它们。
第一列是 buyer。我们不需要它,因为买方的名字不会影响分析。
我们使用了 drop() 方法,并指定了列名。我们将 axis 设置为 1,以指定要删除的是列。另外,将 inplace 参数设置为 True,以便我们修改现有的 DataFrame,而不是创建一个没有被删除列的新 DataFrame。
df.drop('buyer', axis = 1, inplace = True)
我们要删除的第二列是 location。虽然这些信息可能有用,但这是一列完全为空的列,所以我们直接删除它。
我们采用与第一列相同的方法。
df.drop('location', axis = 1, inplace = True)
当然,你可以同时删除这两列。
df = df.drop(['buyer', 'location'], axis=1)
这两种方法都返回了以下数据框。
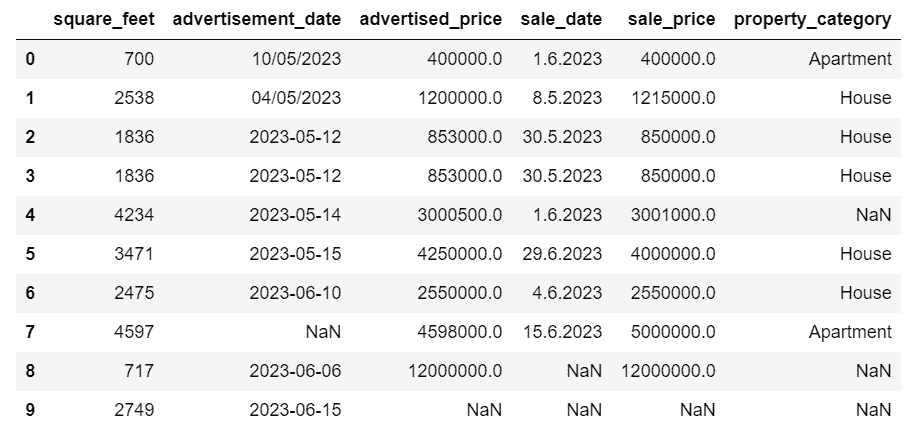
处理重复数据
数据集中的重复数据可能由于各种原因发生,并且可能会影响你的分析。
让我们检测数据集中的重复项。以下是如何操作。
以下代码使用了 duplicated() 方法来检查整个数据集中的重复项。默认情况下,它将值的第一次出现视为唯一,之后的出现视为重复。你可以使用 keep 参数来修改这一行为。例如,df.duplicated(keep=False) 会将所有重复项标记为 True,包括第一次出现。
# Detecting duplicates
duplicates = df[df.duplicated()]
duplicates
这是输出结果。

索引为 3 的行被标记为重复,因为值相同的第 2 行是它的第一次出现。
现在我们需要去除重复项,这里使用了以下代码。
# Detecting duplicates
duplicates = df[df.duplicated()]
duplicates
drop_duplicates() 函数在识别重复项时会考虑所有列。如果你只想考虑某些列,可以将它们作为列表传递给此函数,例如:df.drop_duplicates(subset=['column1', 'column2'])。
如你所见,重复的行已经被删除。然而,索引保持不变,索引 3 丢失了。我们将通过重置索引来整理这一点。
df = df.reset_index(drop=True)
这个任务是通过使用reset_index()函数来完成的。drop=True参数用于丢弃原始索引。如果不包括此参数,旧索引将作为新列添加到你的 DataFrame 中。通过设置drop=True,你告诉 pandas 忘记旧索引并将其重置为默认的整数索引。
练习一下,尝试从这个Microsoft 数据集中删除重复项。
数据类型转换
有时,数据类型可能设置不正确。例如,日期列可能被解释为字符串。你需要将其转换为适当的类型。
在我们的数据集中,我们将对advertisement_date和sale_date列进行此操作,因为它们显示为对象数据类型。此外,日期格式在各行之间不同。我们需要使其一致,同时转换为日期。
最简单的方法是使用to_datetime()方法。你可以像下面所示,一列一列地进行转换。
在这样做时,我们将dayfirst参数设置为 True,因为某些日期以天为首。
# Converting advertisement_date column to datetime
df['advertisement_date'] = pd.to_datetime(df['advertisement_date'], dayfirst = True)
# Converting sale_date column to datetime
df['sale_date'] = pd.to_datetime(df['sale_date'], dayfirst = True)
你也可以使用apply()方法结合to_datetime()同时转换两列。
# Converting advertisement_date and sale_date columns to datetime
df[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(pd.to_datetime, dayfirst = True)
两种方法都会给你相同的结果。
现在日期格式一致了。我们看到并非所有数据都已转换。advertisement_date中有一个 NaT 值,sale_date中有两个。这意味着日期缺失了。
让我们使用info()方法检查列是否已转换为日期。
# Get a concise summary of the dataframe
print(df.info())
正如你所见,两列都不是 datetime64[ns]格式。
现在,尝试在这个Airbnb 数据集中将数据从文本转换为数字。
处理缺失数据
现实世界的数据集通常会有缺失值。处理缺失数据是至关重要的,因为某些算法不能处理这些值。
我们的示例中也有一些缺失值,所以我们来看一下处理缺失数据的两种最常见的方法。
删除缺失值的行
如果缺失数据的行数与总观察数相比不重要,你可以考虑删除这些行。
在我们的示例中,最后一行除了平方英尺和广告日期外没有值。我们不能使用这些数据,所以我们来删除这一行。
这是我们指明行索引的代码。
df = df.drop(8)
DataFrame 现在看起来是这样的。
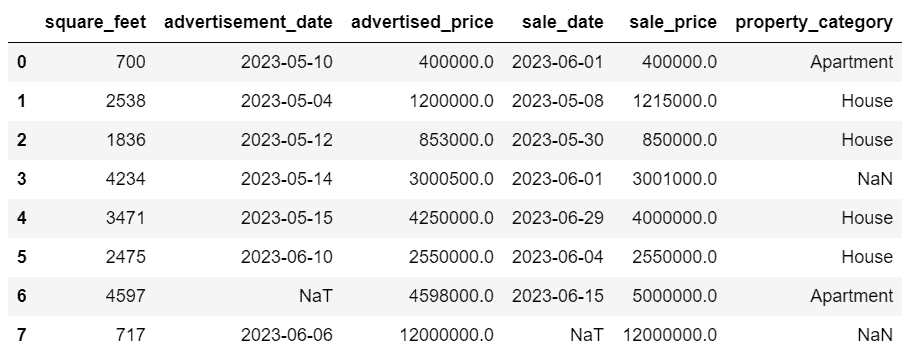
最后一行已经被删除,我们的 DataFrame 现在看起来更好了。不过,仍然有一些缺失的数据,我们将使用另一种方法处理这些数据。
插补缺失值
如果你有显著缺失的数据,除了删除,另一种更好的策略是插补。这个过程涉及根据其他数据填充缺失值。对于数值数据,常见的插补方法包括使用集中趋势的度量(均值、中位数、众数)。
在我们已经更改的 DataFrame 中,advertisement_date 和 sale_date 列中有 NaT(非时间)值。我们将使用mean()方法插补这些缺失值。
代码使用fillna()方法查找并用均值填充空值。
# Imputing values for numerical columns
df['advertisement_date'] = df['advertisement_date'].fillna(df['advertisement_date'].mean())
df['sale_date'] = df['sale_date'].fillna(df['sale_date'].mean())
你也可以用一行代码完成相同的操作。我们使用apply()来应用用lambda定义的函数。与上述相同,这个函数使用fillna()和mean()方法填充缺失值。
# Imputing values for multiple numerical columns
df[['advertisement_date', 'sale_date']] = df[['advertisement_date', 'sale_date']].apply(lambda x: x.fillna(x.mean()))
两种情况下的输出如下所示。
我们的 sale_date 列现在有一些我们不需要的时间。让我们把它们移除。
我们将使用strftime()方法,它将日期转换为其字符串表示形式和特定格式。
df['sale_date'] = df['sale_date'].dt.strftime('%Y-%m-%d')
现在日期看起来都很整齐了。
如果你需要在多个列上使用strftime(),你可以再次使用lambda,方法如下。
df[['date1_formatted', 'date2_formatted']] = df[['date1', 'date2']].apply(lambda x: x.dt.strftime('%Y-%m-%d'))
现在,让我们看看如何插补缺失的分类值。
分类数据是一种用于将信息分组的类型,每个组是一个类别。分类数据可以取数值(例如“1”表示“男”和“2”表示“女”),但这些数字没有数学意义。例如,你不能将它们相加。
分类数据通常分为两类:
-
名义数据: 这是指类别仅仅被标记,不能按特定顺序排列。例如性别(男、女)、血型(A、B、AB、O)或颜色(红、绿、蓝)。
-
顺序数据: 这是指类别可以被排序或排名。虽然类别之间的间隔不均等,但类别的顺序具有意义。例如评分尺度(电影的 1 到 5 评分)、教育水平(高中、本科、研究生)或癌症阶段(I 期、II 期、III 期)。
对于插补缺失的分类数据,通常使用众数。在我们的例子中,property_category 列是分类(名义)数据,并且有两个行数据缺失。
我们将用众数替换缺失值。
# For categorical columns
df['property_category'] = df['property_category'].fillna(df['property_category'].mode()[0])
这段代码使用fillna()函数来替换 property_category 列中的所有 NaN 值。它用众数替代这些值。
此外,[0] 部分用于从此系列中提取第一个值。如果存在多个众数,它将选择第一个。如果只有一个众数,它也会正常工作。
这是输出结果。
现在数据看起来相当不错。剩下的唯一任务是检查是否有异常值。
你可以在这个 Meta 面试问题 上练习处理空值,其中你需要将 NULL 替换为零。
处理异常值
异常值是数据集中明显不同于其他观察值的数据点。它们可能远离数据集中其他值,位于整体模式之外。由于其值显著高于或低于其他数据点,它们被认为是不寻常的。
异常值可能由于各种原因产生,例如:
-
测量或输入错误
-
数据损坏
-
真实的统计异常
异常值可能会显著影响数据分析和统计建模的结果。它们可能导致分布偏斜、偏差,或使基本的统计假设无效,扭曲估计的模型拟合,降低预测模型的预测准确性,并导致不正确的结论。
一些常用的检测异常值的方法包括 Z-score、IQR(四分位距)、箱线图、散点图和数据可视化技术。在一些高级情况下,也会使用机器学习方法。
数据可视化可以帮助识别异常值。Seaborn 的箱线图在这方面很有用。
plt.figure(figsize=(10, 6))
sns.boxplot(data=df[['advertised_price', 'sale_price']])
我们使用 plt.figure() 设置图形的宽度和高度(以英寸为单位)。
然后我们为广告价格和销售价格列创建箱线图,如下所示。
可以通过将此添加到上述代码来改进图表,以便更容易使用。
plt.xlabel('Prices')
plt.ylabel('USD')
plt.ticklabel_format(style='plain', axis='y')
formatter = ticker.FuncFormatter(lambda x, p: format(x, ',.2f'))
plt.gca().yaxis.set_major_formatter(formatter)
我们使用上述代码设置两个轴的标签。我们还注意到 y 轴上的值以科学记数法显示,而我们不能用这种方式显示价格值。因此,我们使用 plt.ticklabel_format() 函数将其更改为普通样式。
然后我们创建格式化器,将 y 轴上的值显示为用逗号分隔的千位数和小数点。最后一行代码将其应用到轴上。
现在输出结果如下。
那么,我们如何识别和去除异常值呢?
其中一种方法是使用 IQR 方法。
IQR,即四分位距,是一种统计方法,用于通过将数据集划分为四分位数来测量变异性。四分位数将按顺序排列的数据集分为四个相等的部分,第一个四分位数(25 百分位数)和第三个四分位数(75 百分位数)之间的值构成了四分位距。
四分位距用于识别数据中的异常值。其工作原理如下:
-
首先,计算第一个四分位数(Q1),第三个四分位数(Q3),然后确定 IQR。IQR 的计算公式是 Q3 - Q1。
-
任何低于 Q1 - 1.5IQR 或高于 Q3 + 1.5IQR 的值都被视为异常值。
在我们的箱线图上,箱体实际上代表了 IQR。箱体内的线是中位数(或第二四分位数)。箱线图的“胡须”表示距离 Q1 和 Q3 的 1.5*IQR 范围内的范围。
任何超出这些“胡须”的数据点都可以被视为异常值。在我们的案例中,就是$12,000,000 的值。如果你查看箱线图,你会清楚地看到这一点,这显示了数据可视化在检测异常值中的重要性。
现在,让我们通过使用 Python 代码中的 IQR 方法来去除异常值。首先,我们将去除 advertised price 的异常值。
Q1 = df['advertised_price'].quantile(0.25)
Q3 = df['advertised_price'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['advertised_price'] < (Q1 - 1.5 * IQR)) |(df['advertised_price'] > (Q3 + 1.5 * IQR)))]
我们首先使用quantile()函数计算第一个四分位数(即第 25 百分位数)。对第三个四分位数或第 75 百分位数也进行相同操作。
它们显示了 25%和 75%的数据分别落在的值。
然后我们计算四分位数之间的差异。到目前为止,一切都是将 IQR 步骤转化为 Python 代码。
最后一步,我们去除异常值。换句话说,去除所有小于 Q1 - 1.5 * IQR 或大于 Q3 + 1.5 * IQR 的数据。
'~'运算符否定条件,因此我们只保留不是异常值的数据。
然后我们可以对 sale price 做同样的处理。
Q1 = df['sale_price'].quantile(0.25)
Q3 = df['sale_price'].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df['sale_price'] < (Q1 - 1.5 * IQR)) |(df['sale_price'] > (Q3 + 1.5 * IQR)))]
当然,你可以使用for loop以更简洁的方式实现。
for column in ['advertised_price', 'sale_price']:
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
df = df[~((df[column] < (Q1 - 1.5 * IQR)) |(df[column] > (Q3 + 1.5 * IQR)))]
循环遍历两列。对于每一列,它计算 IQR,然后从数据框中删除相应的行。
请注意,这一操作是顺序进行的,首先处理 advertised_price,然后处理 sale_price。因此,数据框在每一列中都会就地修改,行可能会因为在任一列中是异常值而被删除。因此,这一操作可能导致行数少于分别去除 advertised_price 和 sale_price 中的异常值后再合并结果的行数。
在我们的例子中,两种情况的输出将是相同的。要查看箱线图的变化,我们需要使用之前相同的代码再次绘制。
plt.figure(figsize=(10, 6))
sns.boxplot(data=df[['advertised_price', 'sale_price']])
plt.xlabel('Prices')
plt.ylabel('USD')
plt.ticklabel_format(style='plain', axis='y')
formatter = ticker.FuncFormatter(lambda x, p: format(x, ',.2f'))
plt.gca().yaxis.set_major_formatter(formatter)
这是输出结果。
你可以通过解决General Assembly 面试题来练习在 Python 中计算百分位数。
结论
数据清理是数据分析过程中的一个关键步骤。尽管这可能很耗时,但确保发现的准确性至关重要。
幸运的是,Python 丰富的库生态系统使这一过程更加可控。我们学习了如何删除不必要的行和列,重新格式化数据,并处理缺失值和异常值。这些是对大多数数据必须执行的常规步骤。然而,有时你还需要将两列合并为一列、验证现有数据、给数据分配标签或去除空白字符。
这一切都是数据清理,因为它使你能够将混乱的现实世界数据转化为一个结构良好的数据集,从而可以自信地进行分析。只需比较我们开始时的数据集和最终的数据集。
如果你对这个结果不满意,干净的数据没有让你感到异常兴奋,那你在数据科学领域到底在做什么!?
内特·罗西迪 是一位数据科学家,专注于产品战略。他还是一名兼职教授,教授分析学,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司提供的真实面试问题准备面试。内特撰写有关职业市场的最新趋势,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题
掌握数据宇宙:成功数据科学职业的关键步骤
原文:
www.kdnuggets.com/mastering-the-data-universe-key-steps-to-a-thriving-data-science-career

图片作者
要在数据科学领域取得成功,你需要加强我认为的六大支柱:技术技能、建立作品集、网络建设、软技能,以及最后的发展专业领域。一旦具备了这些,你还需要在面试阶段表现出色。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 相关工作
太多想成为数据科学家的人认为只要有技能就足够了,而忽视了网络的重要性。或者你依赖于一个网络联系人来获得面试机会,但在压力下表现不佳,无法充分展示你的技能。
1. 教育和技能发展
这些部分没有真正的选项,但这可能是六个支柱中最重要的一项。如果你不知道对的人,或者你的作品集不完美,你可能会偶然找到一份工作,但如果你没有合适的技能,你将无法获得这份工作。更糟糕的是:你可能会得到这份工作,但最终会失败,并被解雇。
这里是你应该关注的内容:
学习基础知识
每个数据科学职位都需要扎实的数学、统计学和编程基础。掌握如 Python 或 R 等编程语言是必不可少的。几乎每个数据科学职位的描述中都会提到这两种语言之一。
我还建议你考虑将 学习 SQL 作为基本要求。SQL 数据库是数据科学家的现实需求,它是一种相对简单的语言。
图片来自 r/datascience
机器学习与数据处理
不仅仅是最近的 AI 兴起;数据科学家一直以来都需要掌握机器学习。你需要在机器学习算法、数据预处理、特征工程和模型评估方面获得专业知识。
数据可视化
数据科学家的发现毫无价值,除非她能将其传达给他人。这通常通过图表、图形和其他数据可视化形式实现。你需要掌握数据可视化工具和技术,以便有效地与公司内的重要利益相关者沟通数据中的见解。
当我谈到软技能时,我会进一步深入——沟通是一个至关重要的技能。
大数据技术
数据科学家处理的数据量不再是微不足道的,假如它曾经存在的话。如今,你需要对大数据及其相关工具非常熟悉。即使你的公司不处理真正的“大”数据,他们也会期望做到这一点。
熟悉处理大数据集的工具,如 Hadoop、Spark 和云平台。
2. 建立强大的作品集
进入第二个支柱:你的作品集。
你可能知道合格的数据科学家稀缺。训练营毕业生填补了这一空缺。这带来了新的问题:缺乏信任。公司知道学位不一定是做好工作的必要资格。然而,不良的训练营也给有抱负的数据科学家带来了坏名声,因为许多训练营生产出“毕业生”,他们连连接和子查询都分不清。因此,你的个人作品集是证明你具备专业知识的机会。(值得注意的是,训练营非常昂贵,尤其是相比于目前稍微不乐观的就业前景。)

图片来自 r/ProgrammerHumor
你需要的东西如下:
个人项目
从事个人项目来展示你的技能。这些项目可以是 Kaggle 比赛、开源贡献或你自己的数据分析项目。你可以维护一个组织良好的 GitHub 仓库,以展示你的项目、代码样本和贡献。
博客或网站
考虑创建一个博客或个人网站,在那里你可以分享与数据科学相关的见解、教程和案例研究。虽然可以通过作弊系统找人代劳,但费用高昂且耗时极长,因此很少有人尝试伪造。博客是展示你知识的绝佳平台。
准备好解释你的项目、方法论和解决问题的思路。复习常见的数据科学面试问题和编码挑战。
3. 网络建设
记住求职的黄金法则,无论哪个领域:潜在的多达 70% 的职位信息从未被公开。这是一个旧统计数据,但即使是 20%到 30%,也证明了人际关系的重要性。更不用说[三分之一]( https://compensationxl.com/study-finds-that-nearly-one-third-of-job-postings-are-fake/#:~:text=COMP NEWS – An alarming survey ,ad%20stays%20online%20for%20months.)的职位招聘实际上是假的,旨在让公司看起来比实际更成功。个人网络可以帮助你避免浪费时间。
你应该做的是:
加入专业网络
加入数据科学社区,参加聚会、会议和网络研讨会,以与该领域的其他专业人士建立联系。这种更正式的网络方式可以帮助你结识合适的人,提升你在行业中的影响力,并保持对时事的了解。
社交媒体
更随意地,你还应该在 LinkedIn、Twitter 和相关论坛上参与分享你的工作、见解,并从他人那里学习。
4. 软技能
记住,硬技能只是成功的一半。这就是为什么你需要确保软技能没有被忽视。我不是说软技能比硬技能更重要。硬技能与软技能的对立是错误的 – 它们都很重要。但人们招聘的不是数据科学机器,而是人。这里是我建议关注的领域:
沟通
记住那个数据可视化技能吗?数据科学家需要将复杂的技术发现有效地传达给非技术利益相关者。令人惊讶的是,数据科学家的工作中有多少是为了向市场部解释为什么他们应该理解那个漂亮的图表。
问题解决
这几乎是一个毫无意义的流行词,所以一定要真正理解“问题解决”是什么意思。在数据科学的背景下,解决问题不仅仅是调试。还包括知道何时与不同部门合作,何时重新调整项目的技术栈以满足新规格,或在测试数据集上遇到问题时回顾你的模型。

图片来源于 r/DataScienceMemes
批判性思维
另一个几乎成为流行词但值得深入考虑的概念是批判性思维。批判性思维意味着从多个角度分析数据、质疑假设,并创造性地思考以获得有意义的见解。
团队合作
数据科学家并非在真空中工作。你将与网页开发人员、数据分析师、业务分析师、营销人员、销售人员和高管合作。与跨职能团队合作,了解业务需求并协调数据驱动的解决方案。
5. 行业专业化
没听说过吗?我们正处于招聘的技术寒冬中。风险投资资金流动不如从前,公司正在收紧预算。现在不是做全能型人才的好时机。你需要专业化以求生存。
选择一个利基
数据科学涵盖了各个行业,如医疗保健、金融、电子商务等。专注于特定领域可以让你在该领域的雇主眼中更具吸引力。寻找你自然感兴趣的领域,或你可能已经具备额外知识的领域。
领域知识
获取与你想要从事的行业相关的领域特定知识。这有助于你理解数据的细微差别,并做出更明智的决策。例如,如果你想在谷歌工作,你需要了解搜索算法和用户行为的复杂性。
6. 面试
最后但同样重要的是:准备面试。即使你掌握了前五个支柱,仍然可能在最后关头出现失误。以下是我建议的准备方法:
解释
你可以了解一个概念,却不一定能够向他人解释它。为了面试,你需要准备好解释你的项目、方法论和解决问题的方法。
花时间确保你不仅对你所做的工作、为什么这么做以及它为何在所有项目中有效有一个完整的理解,而且你能够解释得足够清晰,让外行人也能理解。(这也是一个很好的练习“沟通”软技能的方法。)
编码准备
白板是编码面试中的一个著名支柱,但很多人在面对那面空白的白板时会感到恐慌。提前练习面试问题,你在面试当天的表现会更好。
如何在数据科学领域发展成功的职业
即使假装存在一个单一正确答案,或者它可以在一篇文章中解释也是有些自负的。希望这篇博客文章更像是一张路线图,而不是一个全面的解决方案。练习这六大数据科学工作的支柱,你将顺利走上数据科学职业发展的道路,直到你希望的时间。
内特·罗西迪是一位数据科学家和产品战略专家。他还担任分析学的兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家通过顶级公司的真实面试问题准备面试。内特撰写有关职业市场最新趋势的文章,提供面试建议,分享数据科学项目,并涵盖所有 SQL 相关内容。
更多相关话题
数据科学需要多少数学知识?
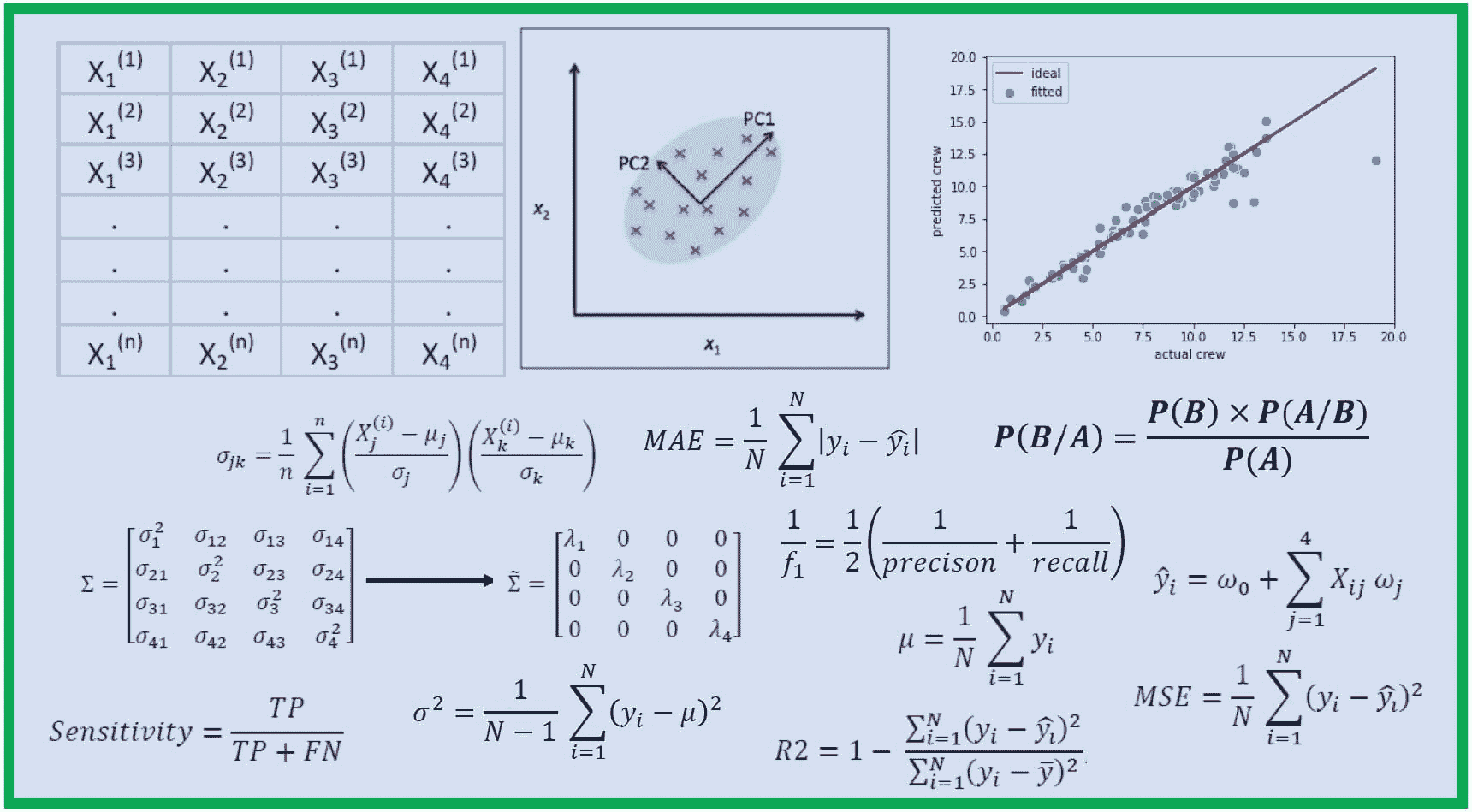
作者提供的图片
介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
如果你是数据科学的 aspirant,你无疑会有以下问题:
如果我数学基础很薄弱,是否可以成为数据科学家?
数据科学中哪些基本数学技能是重要的?
有很多优秀的软件包可以用来构建预测模型或生成数据可视化。一些最常用的描述性和预测性分析软件包包括:
-
Ggplot2
-
Matplotlib
-
Seaborn
-
Scikit-learn
-
Caret
-
TensorFlow
-
PyTorch
-
Keras
多亏了这些软件包,任何人都可以建立模型或生成数据可视化。然而,要对模型进行微调以生成可靠且性能最佳的模型,扎实的数学背景知识是必不可少的。构建模型是一回事,而解释模型并得出有意义的结论以用于数据驱动决策则是另一回事。在使用这些软件包之前,了解每个软件包的数学基础是很重要的,这样你就不会仅仅把这些软件包当作黑箱工具使用。
2. 案例研究:建立多重回归模型
假设我们要建立一个多重回归模型。在此之前,我们需要问自己以下问题:
我的数据集有多大?
我的特征变量和目标变量是什么?
哪些预测特征与目标变量的相关性最大?
哪些特征是重要的?
我应该对特征进行缩放吗?
我的数据集应该如何划分为训练集和测试集?
主成分分析(PCA)是什么?
我应该使用 PCA 来去除冗余特征吗?
我该如何评估我的模型?我应该使用 R2 分数、MSE 还是 MAE?
我该如何提高模型的预测能力?
我应该使用正则化回归模型吗?
回归系数是什么?
截距是什么?
我应该使用非参数回归模型,例如 KNeighbors 回归或支持向量回归吗?
我的模型中的超参数是什么?如何对其进行微调以获得最佳性能的模型?
如果没有扎实的数学背景,你将无法解决上述问题。关键是,在数据科学和机器学习中,数学技能与编程技能同样重要。因此,作为数据科学的追求者,你必须投入时间学习数据科学和机器学习的理论和数学基础。你构建可靠且高效模型的能力,取决于你的数学技能水平。要了解数学技能在构建机器学习回归模型中的应用,请参见这篇文章:机器学习过程教程。
现在让我们讨论数据科学和机器学习中所需的一些基本数学技能。
3. 数据科学和机器学习的基本数学技能
统计与概率
统计与概率用于特征可视化、数据预处理、特征变换、数据填补、降维、特征工程、模型评估等。
下面是你需要熟悉的主题:
均值、中位数、众数、标准差/方差、相关系数和协方差矩阵、概率分布(二项分布、泊松分布、正态分布)、p 值、贝叶斯定理(精确度、召回率、正预测值、负预测值、混淆矩阵、ROC 曲线)、中心极限定理、R_2 评分、均方误差(MSE)、A/B 测试、蒙特卡洛模拟
多变量微积分
大多数机器学习模型是用具有多个特征或预测变量的数据集构建的。因此,熟悉多变量微积分对于构建机器学习模型至关重要。
下面是你需要熟悉的主题:
多个变量的函数;导数和梯度;阶跃函数、Sigmoid 函数、Logit 函数、ReLU(修正线性单元)函数;成本函数;函数的绘制;函数的最小值和最大值
线性代数
线性代数是机器学习中最重要的数学技能。数据集被表示为矩阵。线性代数用于数据预处理、数据转换、降维和模型评估。
下面是你需要熟悉的主题:
向量;向量的范数;矩阵;矩阵的转置;矩阵的逆;矩阵的行列式;矩阵的迹;点积;特征值;特征向量
优化方法
大多数机器学习算法通过最小化目标函数来进行预测建模,从而学习必须应用于测试数据的权重,以获得预测标签。
下面是你需要熟悉的主题:
成本函数/目标函数;似然函数;误差函数;梯度下降算法及其变种(例如随机梯度下降算法)
总结与结论
总结来说,我们讨论了数据科学和机器学习中所需的基本数学和理论技能。有几个免费的在线课程可以教你在数据科学和机器学习中所需的数学技能。作为数据科学的追求者,重要的是要记住数据科学的理论基础对于构建高效可靠的模型至关重要。因此,你应该投入足够的时间来研究每种机器学习算法背后的数学理论。
参考文献
本杰明·奥比·塔约博士 是中欧大学的物理学教授,同时也是数据科学教育者和作家,研究领域包括数据科学、机器学习、人工智能、Python 和 R、预测分析、材料科学以及生物物理学。
原文。经许可转载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号