KDNuggets-博客中文翻译-二十七-
KDNuggets 博客中文翻译(二十七)
原文:KDNuggets
如何优化你的简历以适应数据科学家职业
原文:
www.kdnuggets.com/2020/08/optimize-cv-data-scientist-career.html
评论
由 Dorian Martin,技术作家。

我们的前三大课程推荐
 1. Google 网络安全证书 - 快速进入网络安全职业。
1. Google 网络安全证书 - 快速进入网络安全职业。
 2. Google 数据分析专业证书 - 提升你的数据分析技能
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
(图片来源.)
想让你的数据科学家简历更吸引雇主吗?
你来对地方了。
在这篇文章中,你将找到专家的建议、示例和要点,以制作出足够好的简历,帮助你获得真正想要的工作。
数据科学雇主在简历中寻找什么?
让我们暂时成为数据科学招聘人员。
要在众多简历中脱颖而出,吸引雇主的注意,我们需要了解他们在候选人中寻找什么。
根据 成为数据科学家所需的 9 个必备技能*,这些是吸引雇主的最重要技能:
-
教育(至少拥有计算机科学、社会科学或统计学的学士学位)
-
R 编程
-
Python 编码
-
Hadoop 平台
-
SQL 数据库/编码
-
Apache Spark
-
机器学习和人工智能
-
数据可视化
-
非结构化数据。
因此,作为一个有意招聘数据科学家的人,你更可能在简历中寻找这些技能。
这就引出了第一个建议……
1. 将需求技能放在首位
为了省去招聘经理寻找你技能的麻烦,把它们放在简历的最上面。务必将它们列在一个单独的部分,以引起注意。
不要使用单列的项目符号列表来列出技能。这可能会占用大量简历空间,因此尝试其他方式。如果你没有使用设计师已经处理过空间的模板,你可以简单地将技能列在一句话中。
另一种更有创意的方式是像 Upwork 那样通过视觉上区分每项技能,Upwork 在其用户资料中这样做。

你应该按什么顺序列出技能?最佳的做法是首先列出那些需求量大的技能,然后再列出“较不显著”的技能。此外,不要忘记提供对技能水平的评估,例如,“初学者”,“中级”或“专家”。
要点:将你的技能列在前面。这将有助于引起招聘经理的注意,并让他们知道你是否是适合这份工作的候选人。
2. 提供详细且简洁的成就概述
这是另一个关键部分,值得放在简历的前半部分。这是招聘经理想要的“展示,而非告诉”部分。在要求你在面试中披露你的缺陷之前,他们需要被你的优势所吸引。
你的主要目标是找出并列出你的主要专业成就。
正确的做法如下:
-
仅包含相关成就。像“为学生提供专家级论文帮助,以提高他们的学术写作技能”这样的成就听起来很棒,但请坚持数据科学相关的成就。
-
包含数字。量化的成就能更好地展示你的影响力,例如,“通过定制的机器学习算法分析市场营销过程,实现节省$2,000”通过数字显得更具说服力。
-
每项成就只用一句话。你的简历应该控制在一页之内,所以要小心,每项成就限制为一句话。
专业提示:对于每项成就使用“技能 - 活动 - 结果”公式。
这是“通过定制机器学习算法分析市场营销过程,实现节省$2,000”示例中的部分:
-
技能:使用定制机器学习算法
-
活动:市场营销过程分析
-
结果:节省$2,000。
通过这种方式在简历中组织成就,你会使它们简明扼要。
3. 解释,而不是列出你的非技术技能
许多数据科学家犯了一个错误,就是将他们的软技能以项目符号列表的形式呈现。虽然提及这些技能很重要,但不要仅仅以这种方式呈现。
我是说,“口头沟通”这类内容对阅读你简历的人到底说了什么呢?
这需要一些细节来展示你的能力,对吗?
以下是一些示例:
| 非技术技能 | 出色描述 |
|---|---|
| 口头沟通 | 管理每周与客户的会议,以更新项目进展并收集反馈 |
| 书面沟通与团队合作 | 与 10 多个营销团队成员合作,应用数据分析模型来识别客户数据中的模式 |
| 讲故事 | 创建数据可视化演示文稿,并向客户展示以解释数据分析结果 |
| 适应能力 | 同时进行机器学习和数据可视化项目,以帮助识别意外问题并将结果转换为可视化 |
现在,这听起来更有趣了,对吧?
阅读你简历的招聘经理也会同意。
沟通和团队合作是最重要的软技能之一,需要以这种方式呈现。
为什么?因为大多数数据科学专业人士——约 60%——在五人或更多人的团队中工作,正如2019 年数据科学现状报告所说。

来源:数据科学现状 2019
描述这些非技术技能时唯一需要记住的就是每个技能只写一句话(就像成就一样)。
4. 匹配职位描述中的关键词
不秘密的是,招聘经理在职位描述中使用关键词。在数据科学行业,他们包括技能、资格、认证和技术的名称。
让我们看一下这份来自 LinkedIn 的数据科学家职位发布。虽然有点长,但请耐心点,这就是你很快也要做的事情。
职位发布中大多数关键词已为你下划线,以便你快速找到。

你能找到多少个呢?
这份职位发布字面上填满了完美候选人简历上应该有的关键词(如果你申请,这也意味着你需要)。
如果你想申请这样的职位,简历中有以下内容是非常重要的:机器学习、书面和口头沟通技能、软件工程、快速原型制作。
这些是主要的关键词,但你可以用你真正的专业知识涵盖更多的关键词,这样会更好。
重要! 不要让简历充满关键词。这会让招聘人员觉得不自然和可疑。自然地包含这些关键词,以避免显得过于刻意。
此外,关键词堆砌也可能暗示候选人这样做只是为了通过面试,这反过来意味着他们可能不具备资格。
你的下一步
按照你刚刚阅读的提示,制作那份出色的简历,并发送出去!
现在,它应该更加吸引人、详细,并且对潜在雇主更具吸引力。
如果你想了解公司如何聘请数据科学家,可以查看下面的指南(它有一个问题库,包含雇主用来评估数据科学家技能的问题!)
简介: 多里安·马丁拥有七年的技术内容写作经验,并帮助众多技术博客制定内容营销策略。目前,他在Essaysupply.com担任主编,协助制作优质内容。除了写作之外,多里安最大的热情是打排球和观看音乐纪录片。
相关:
更多相关内容
如何优化你的 Jupyter Notebook
评论
由 Pier Paolo Ippolito 提供,南安普顿大学

(来源: gdcoder.com/how-to-create-and-add-a-conda-environment-as-jupyter-kernel/)
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 工作
介绍
Jupyter Notebook 现在可能是解决 Python 中机器学习/数据科学任务最常用的环境。
Jupyter Notebook 是一种客户端-服务器应用程序,用于在浏览器中运行 notebook 文档。Notebook 文档是能够包含代码和丰富文本元素(如段落、方程式等)的文档。
在这篇文章中,我将向你展示一些简单的技巧,帮助你提升 Jupyter Notebook 的使用体验。我们将从有用的快捷键开始,最后加入主题、自动生成的目录等内容。
快捷键
快捷键可以显著加快编写代码的速度。现在,我将向你介绍一些我发现的在 Jupyter 中最有用的快捷键。
与 Jupyter Notebook 互动的方式有两种:命令模式和编辑模式。一些快捷键只在一种模式下有效,而其他快捷键在两种模式下都适用。
一些在两种模式中都适用的快捷键包括:
-
Ctrl + Enter: 运行所有选定的单元格
-
Shift + Enter: 运行当前单元格并移动到下一个单元格
-
Ctrl + s: 保存 notebook
为了进入 Jupyter 命令模式,我们需要按 Esc 然后执行以下任一命令:
-
H: 显示 Jupyter Notebook 中所有可用的快捷键
-
Shift + 上/下箭头: 同时选择多个 notebook 单元格(选择多个单元格后按回车将使所有单元格运行!)
-
A: 在上方插入一个新单元格
-
B: 在下方插入一个新单元格
-
X: 剪切选定的单元格
-
Z: 撤销单元格的删除
-
Y: 将单元格类型更改为代码
-
M: 将单元格类型更改为 Markdown
-
Space: 向下滚动 notebook
-
Shift + 空格: 向上滚动 notebook
为了进入 Jupyter 编辑模式,我们需要按 Enter,然后依次执行以下任一命令:
-
Tab:代码竞赛建议
-
Ctrl + ]:增加代码缩进
-
**Ctrl + **:减少代码缩进
-
Ctrl + z:撤销
-
Ctrl + y:重做
-
Ctrl + a:全选
-
Ctrl + Home:将光标移动到单元格开头
-
Ctrl + End:将光标移动到单元格的末尾
-
Ctrl + Left:将光标向左移动一个单词
-
Ctrl + Right:将光标向右移动一个单词
Shell 命令和包安装
很少有用户知道这一点,但实际上可以通过在单元格开头添加感叹号来在 Jupyter notebook 单元格中运行 shell 命令。例如,运行一个包含 !ls 的单元格将返回当前工作目录中的所有项目。运行一个包含 !pwd 的单元格则会打印出当前目录的文件路径。
相同的技巧也可以用于在 Jupyter notebook 中安装 Python 包。
!pip install numpy
Jupyter 主题
如果你对改变 Jupyter notebook 的外观感兴趣,可以安装一个包含不同主题的包。默认的 Jupyter 主题如图 1 所示。在图 2 中你将看到我们如何能够个性化它的外观。

图 2:Solarized1 notebook 主题
如果你想随时恢复到原始的 Jupyter notebook 主题,只需运行以下命令并刷新页面即可。
!jt -r
Jupyter Notebook 扩展
Notebook 扩展可以用来增强用户体验,并提供各种个性化技巧。
在这个例子中,我将使用 nbextensions 库来安装所有必要的控件(这次我建议你先通过终端安装包,然后再打开 Jupyter notebook)。这个库利用不同的 Javascript 模型来丰富 notebook 的前端。
! pip install jupyter_contrib_nbextensions
! jupyter contrib nbextension install --system
一旦 nbextensions 被安装,你会注意到在 Jupyter notebook 主页上多了一个额外的标签(图 3)。

图 3:将 nbextensions 添加到 Jupyter notebook
通过点击 Nbextensions 标签,我们将看到可用的控件列表。在我的案例中,我决定启用图 4 中显示的控件。

图 4:nbextensions 控件选项
我的一些最喜欢的扩展是:
1. 目录
自动从 markdown 标题生成目录(图 5)。

图 5:目录
2. 代码片段
加载常用库和创建样本图的代码示例,你可以将其作为数据分析的起点(图 6)。

图 6:代码片段
3. Hinterland
Jupyter 笔记本的代码自动补全(图 7)。

图 7:代码自动补全
nbextensions 库提供了许多其他扩展,因此我鼓励你尝试和测试其他对你可能感兴趣的扩展!
Markdown 选项
默认情况下,Jupyter 笔记本单元格中的最后输出是唯一打印的内容。如果我们想要自动打印所有命令而不使用 print(),可以在笔记本开始时添加以下代码行。
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
此外,可以通过将文本包围在美元符号($)之间来在 Markdown 单元格中编写 LaTex。
笔记本幻灯片
通过进入 视图 -> 单元格工具栏 -> 幻灯片 并选择笔记本中每个单元格的幻灯片配置,可以创建 Jupyter 笔记本的幻灯片演示。
最后,通过进入终端并输入以下命令,将创建幻灯片放映。
pip install jupyter_contrib_nbextensions
# and successively:
jupyter nbconvert my_notebook_name.ipynb --to slides --post serve

魔法命令
魔法命令是可以用来执行特定操作的指令。举例来说:内联绘图、打印单元格的执行时间、打印运行单元格的内存消耗等。
以单个 % 开头的魔法命令只应用于单元格中的一行(命令所在的行)。而以两个 %% 开头的魔法命令则应用于整个单元格。
可以使用以下命令打印出所有可用的魔法命令:
%lsmagic
联系信息
如果你想保持对我最新文章和项目的更新, 关注我 并订阅我的 邮件列表。以下是我的一些联系方式:
简介:Pier Paolo Ippolito 是南安普顿大学人工智能硕士课程的最后一年学生。他是一名 AI 爱好者、数据科学家和 RPA 开发者。
原文。经授权转载。
相关内容:
-
笔记本反模式
-
GPU 加速的数据分析与机器学习
-
利用机器学习理解癌症
了解更多此主题
优化生产环境中机器学习 API 的响应时间
原文:
www.kdnuggets.com/2020/05/optimize-response-time-machine-learning-api-production.html
评论
由 Yannick Wolf,Sicara 领先数据科学家
本文展示了如何通过构建更智能的 API 服务深度学习模型来最小化响应时间。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

你的团队努力为特定任务(比如:通过计算机视觉检测商店中的购买产品)构建了一个深度学习模型。很好。
然后你开发并部署了一个集成此模型的 API(让我们继续这个例子:自助结账机会调用这个 API)。太棒了!
新产品运行良好,你感觉所有工作都已完成。
但由于经理决定安装更多自助结账机(我真的很喜欢这个例子),用户开始抱怨每次扫描商品时都会出现巨大的延迟。
你可以做什么?购买速度快十倍且昂贵十倍的 GPU?让数据科学家尝试在不降低准确性的情况下减少模型的深度?
更便宜、更简单的解决方案存在,如本文所示。
一个基础的 API 和一个大型虚拟模型
首先,我们需要一个具有长推理时间的模型。以下是我如何使用 TensorFlow 2's Keras API 来实现这一点(如果你不熟悉这个深度学习框架,可以跳过这段代码):
在我的 GeForce RTX 2080 GPU 上测试模型时,我测得推理时间为 303 毫秒。这就是我们可以称之为大模型的情况。
现在,我们需要一个非常简单的 API 来服务我们的模型,仅一个路由来请求预测。Python 中一个非常标准的 API 框架是 Flask。这是我选择的框架,还有一个叫做 Gunicorn 的 WSGI HTTP 服务器。
我们独特的路径解析请求中的输入,调用实例化的模型,并将输出发送回用户。
我们可以使用以下命令运行我们的深度学习 API:
gunicorn wsgi:app
好的,现在我可以向我的 API 发送一些随机数字,它会用其他随机数字回应我。问题是:有多快?
让我们对我们的 API 进行负载测试
我们确实想了解我们的 API 响应有多快,特别是当每秒请求数量增加时。这样的负载测试可以使用 Locust Python 库进行。
这个库与一个 locustfile.py 一起工作,指示要模拟的行为:
Locust 模拟多个用户同时执行不同的任务。在我们的案例中,我们只想定义一个任务,即使用随机输入调用 /predict 路由。
我们还可以参数化wait_time,这是一个模拟用户在接收到 API 响应后等待的时间,然后再发送下一个请求。为了模拟自助结账的用例,我将这个时间设置为 1 到 3 秒之间的随机值。
用户数量通过 Locust 的仪表盘选择,所有统计数据都会实时显示。可以通过调用以下命令来运行此仪表盘:
locust --host=[`localhost:8000`](http://localhost:8000/) # host of the API you want to load test
Locust 仪表盘
那么,当我们增加用户数量时,我们天真的 API 会有什么反应呢?正如我们所预期的,反应非常糟糕:
-
使用 1 个用户时,我测量的平均响应时间是 332 ms(略高于之前测量的孤立推理时间,没什么惊讶的)
-
使用 5 个用户时,这个平均时间稍微增加了一点:431 ms
-
使用 20 个用户时,它达到了 4.1 秒(比 1 个用户时多了 12 倍以上)

当我们考虑到 API 是如何处理请求的,这些结果并不那么令人惊讶。默认情况下,Gunicorn 启动 2 个进程:一个主进程监听传入的请求,将它们存储在一个 FIFO 队列中,并将它们依次发送到一个工作进程,每次工作进程可用时。后者会运行您的代码来计算每个请求的响应。
由于工作进程是单线程的,请求是逐一处理的。如果 5 个请求同时到达,第 5 个请求将在 5 x 300 ms = 1500 ms 后收到响应,这解释了 20 个用户时高的平均响应时间。
越多越快
幸运的是,Gunicorn 提供了两种通过增加以下内容来扩展 API 的方法:
-
处理请求的线程数量
-
工作进程的数量
多线程选项可能不是对我们帮助最大的一种,因为 TensorFlow 不允许一个线程访问在另一个线程中初始化的会话图。
另一方面,设置大于 1 的工作进程数量将创建多个进程,每个工作进程都初始化整个 Flask 应用程序。每个进程都会实例化自己的 TensorFlow 会话和模型。

让我们通过运行以下命令来尝试这种方法:
gunicorn wsgi:app --workers=5
这是我们在多工人 API 中获得的新性能:

你可以看到,使用 5 个工人而不是 1 个工人对响应时间的影响是巨大的:20 个用户的 4.1 秒平均时间几乎减少了一半。减少了两倍,而不是预期的五倍,因为请求之间的等待时间——如果模拟用户在收到响应后立即重新请求 API,响应时间将减少五倍。
你可能会想知道为什么我止步于 5 个工人:为什么不设置 20 个工人,以便能够处理 20 个用户在同一时间请求 API 的情况?原因是每个工人是一个独立的进程,在 GPU 内存中实例化其自己的模型版本。
因此,20 名工人仅仅在初始化权重时就会消耗 20 倍模型的大小,推理计算则需要更多的内存。对于一个 2GiB 的模型和一个 8GiB 的 GPU 来说,我们的资源有些有限。

每个工人消耗 2349MiB 的 GPU 内存
通过调整分配给每个工人的内存,可以最大化运行工人的数量,使用 TensorFlow 参数(TensorFlow 1.x 中的 per_process_gpu_memory_fraction 和 TensorFlow 2.x 中的 memory_limit——我只测试过第一个),将其设置为不会因内存不足错误而导致预测失败的最小值。
正如库所警告的那样,减少可用内存可能会通过禁用优化理论上增加推理时间。然而,我个人并没有注意到任何显著变化。
无论如何,这样做并不能让我们运行 20 个工人,即使使用我们的 2 个 GPU。那么,买 2 个更多的 GPU?别慌,你还有其他的解决方案。
欲速则不达
现在让我们回到单工人的情况。如果你考虑到当两个或更多请求几乎同时到达此 API 时发生的情况,会发现有一些优化不到位的地方:

3 个请求间隔 100 毫秒到达,平均响应时间为 1433 毫秒
API 将 3 个输入逐个通过模型。然而,由于深度学习模型的数学运算特性,大多数模型可以同时处理多个输入而不会增加推理时间——这就是我们所说的批处理,也就是我们在训练阶段通常做的。
那么,为什么不将这 3 个输入批量处理呢?这将意味着在接收到第一个请求后,API 会稍等片刻,以接收接下来的 2 个请求,然后一次性处理所有请求。这会增加第一个请求的响应时间,但在平均上会减少。

如果 API 在处理批量请求之前等待 300 毫秒,我们得到的平均响应时间是 600 毫秒
在实践中,我们不知道未来请求何时到达,而且决定等待潜在下一个请求的时间有点复杂。一条相当合理的规则是触发处理排队请求的时间是:
- 如果排队请求的数量达到最大值,通常对应于 GPU 内存限制或最大用户数(如果已知)
或者
- 如果队列中最旧的请求比超时时间值还要久。这一值需要通过经验调优以最小化平均响应时间。
这里有一种实现这种行为的方法,仍然使用 Gunicorn - Flask - TensorFlow 堆栈,使用 Python 队列和专门处理批量请求的线程。
这个新 API 必须以与我们希望能够处理的批处理请求最大数量相同的线程数运行:
gunicorn wsgi:app --threads=20
以下是我在对超时时间值进行快速微调后的非常满意的结果:

如你所见,当仅模拟 1 个用户时,这个新 API 设置的超时时间为 500 毫秒,会使响应时间增加 500 毫秒(超时时间值),当然是无用的。但对于 20 个用户,平均响应时间减少了 6 倍。
注意,为了获得更好的结果,这种批处理技术可以与上述的多工人技术并行使用。
难道我们没有重新发明轮子吗?
作为开发人员,从头开始编写一些可能已经由现有工具实现的东西是一种隐秘的快乐,这也是我们在这篇文章中一直做的事情。
确实存在一个用于在 API 中服务 TensorFlow 模型的工具。它由 TensorFlow 开发,名为... TensorFlow Serving。
它不仅允许为模型启动一个预测 API,而无需编写模型以外的任何其他代码,而且还提供了几种你可能会觉得有趣的优化,例如并行处理和请求批处理!
要使用 TF Serving 服务一个模型,你需要做的第一件事是将其导出到磁盘(使用 TensorFlow 格式,而不是 Keras 格式),可以使用以下代码实现:
然后,启动一个服务 API 的最简单方法之一是使用 TF Serving docker 镜像。
下面的命令将启动一个预测 API,你可以通过请求此端点来测试:localhost:8501/v1/models/my_model:predict
docker run -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
-e MODEL_NAME=my_model -it tensorflow/serving
注意,它默认不使用 GPU。你可以在 此文档 中找到如何使其工作。
关于批处理呢?你需要编写这样的批处理配置文件:
max_batch_size { value: 20 }
batch_timeout_micros { value: 500000 }
max_enqueued_batches { value: 100 }
num_batch_threads { value: 8 }
特别包括了我们自定义实现中使用的 2 个参数:max_batch_size 和 batch_timeout_micros 参数。后者是我们称之为超时的参数,必须以微秒为单位给出。
最后,运行启用了批处理的 TF Serving 的命令是:
docker run -p 8501:8501 \
--mount type=bind,source=/path/to/my_model/,target=/models/my_model \
--mount type=bind,source=/path/to/batching.cfg,target=/batching.cfg \
-e MODEL_NAME=my_model -it tensorflow/serving \
--enable_batching --batching_parameters_file=/batching.cfg
我进行了测试,感谢一些黑魔法,我得到了比自定义批处理 API 更好的结果:

我希望你能利用本文中提出的不同技巧来提升你自己的机器学习 API。我没有探索的很多领域,尤其是模型本身的优化(而不是 API),如模型剪枝或后训练量化。
简历:Yannick Wolf 是 Sicara 的首席数据科学家。
原文。经许可转载。
相关:
-
机器学习部署的软件接口
-
TensorFlow 2.0 教程:优化训练时间性能
-
如何在 3 个简单步骤中对任何 Python 脚本进行超参数调优
更多相关主题
如何优化 SQL 查询以加快数据检索速度
原文:
www.kdnuggets.com/2023/06/optimize-sql-queries-faster-data-retrieval.html

图片作者
SQL(结构化查询语言),如你所知,帮助你从数据库中收集数据。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT。
它是专门为此设计的。换句话说,它处理行和列,使你能够使用 SQL 查询操作数据库中的数据。
什么是 SQL 查询?
SQL 查询是一组你给数据库的指令,用以收集信息。
你可以通过使用这些查询来收集和操作数据库中的数据。
通过使用它们,你可以创建报告、进行数据分析等。
由于这些查询的形式和长度,执行时间可能会很长,特别是当你处理更大的数据表时。
为什么我们需要 SQL 查询优化?
SQL 查询优化的目的是确保你有效地使用资源。简单来说,它可以减少执行时间,节省成本,并提高性能。这是开发人员和数据分析师的重要技能。不仅仅是从数据库中返回正确的数据同样重要,你还需要知道你是多么高效地做到这一点。
你应该总是问自己:“有没有更好的方式来编写我的查询?”
让我们更深入地探讨一下原因。
资源效率: 未优化的 SQL 查询会消耗过多的系统资源,如 CPU 和内存。这可能导致整体系统性能降低。优化 SQL 查询可以确保这些资源的高效使用,从而带来更好的性能和可扩展性。
减少执行时间: 如果查询运行缓慢,这会对用户体验产生负面影响。或者如果你有一个运行中的应用程序,这也会影响应用程序性能。优化查询可以帮助减少执行时间,提供更快的响应时间和更好的用户体验。
成本节约: 优化的查询可以减少支持数据库系统所需的硬件和基础设施。这可以导致硬件、能源和维护成本的节省。
查看 “编写 SQL 查询的最佳实践” 以了解如何改善你的代码结构,即使它是正确的。
SQL 查询优化技术
这是我们将在本文中涵盖的 SQL 查询优化技术概述。

作者提供的图片
这是一个显示优化 SQL 查询时建议遵循的步骤的流程图。我们将在示例中采用相同的方法。值得注意的是,优化工具也可以帮助提高查询性能。因此,让我们从著名的 SQL 命令 SELECT 开始探索这些技术。

作者提供的图片
使用指定字段的 SELECT 代替 SELECT *
当你使用 SELECT * 时,它将返回表中的所有行和所有列。你需要问自己是否真的需要这样做。
使用特定字段替代扫描整个数据库。
在这个示例中,我们将用具体的列名替换 SELECT *。如你所见,这将减少检索的数据量。
结果是,查询运行得更快,因为数据库只需获取和提供请求的列,而不是表的所有列。
这可以最小化数据库的 I/O 负担,尤其是在表包含大量列或大量数据行时特别有用。
以下是优化前的代码。
SELECT * FROM customer;
这是输出。

总查询运行时间为 260 毫秒。这是可以改进的。
为了展示这一点,我将仅选择 3 个不同的列,而不是选择所有列。
你可以根据项目需求选择所需的列。
这是代码。
SELECT customer_id,
age,
country
FROM customer;
这是输出。

正如你所见,通过定义我们要选择的字段,我们不会强迫数据库扫描所有数据,因此运行时间从 260 毫秒减少到 79 毫秒。
想象一下,如果有数百万或数十亿行,或者数百列会是什么情况。
避免使用 SELECT DISTINCT
SELECT DISTINCT 用于返回指定列中的唯一值。为此,数据库引擎必须扫描整个表并删除重复值。在许多情况下,使用诸如 GROUP BY 之类的替代方法可以通过减少处理的数据量来提高性能。
这是代码。
SELECT DISTINCT segment
FROM customer;
这是输出。

我们的代码?? 从客户表中检索 segment 列中的唯一值。数据库引擎必须处理表中的所有记录,识别重复值,并仅返回唯一值。这可能在时间和资源上是昂贵的,特别是对于大型表。
在替代版本中,以下查询通过使用 GROUP BY 子句来检索 segment 列中的唯一值。GROUP BY 子句根据指定的列对记录进行分组,并为每个组返回一条记录。
这是代码。
SELECT segment
FROM customer
GROUP BY segment;
这是输出结果。

在这种情况下,GROUP BY 子句有效地根据 segment 列对记录进行分组,结果与 SELECT DISTINCT 查询相同。
通过避免使用 SELECT DISTINCT,而改用 GROUP BY,你可以优化 SQL 查询,将总查询时间从 198 毫秒减少到 62 毫秒,速度提高了三倍多。
避免使用循环
循环可能会导致查询变慢,因为它们强迫数据库逐条记录进行处理。
在可能的情况下,使用内置操作和 SQL 函数,这可以利用数据库引擎的优化并更高效地处理数据。
让我们定义一个带有循环的自定义函数。
CREATE OR REPLACE FUNCTION sum_ages_with_loop() RETURNS TABLE (country_name TEXT, sum_age INTEGER) AS $$
DECLARE
country_record RECORD;
age_sum INTEGER;
BEGIN
FOR country_record IN SELECT DISTINCT country FROM customer WHERE segment = 'Corporate'
LOOP
SELECT SUM(age) INTO age_sum FROM customer WHERE country = country_record.country AND segment = 'Corporate';
country_name := country_record.country;
sum_age := age_sum;
RETURN NEXT;
END LOOP;
END;
$$ LANGUAGE plpgsql;
上面的代码使用基于循环的方法来计算每个国家中客户 segment 为 'Corporate' 的年龄总和。
它首先检索一个唯一国家的列表,然后使用循环遍历每个国家,计算该国客户的年龄总和。这种方法可能会很慢且效率低,因为它逐行处理数据。
现在让我们运行这个函数。
SELECT *
FROM sum_ages_with_loop()
这是输出结果。

使用这种方法的运行时间为 198 毫秒。
让我们看看我们优化后的 SQL 代码。
SELECT country,
SUM(age) AS sum_age
FROM customer
WHERE segment = 'Corporate'
GROUP BY country;
这是它的输出结果。

一般来说,使用单个 SQL 查询的优化版本会表现得更好,因为它可以利用数据库引擎的优化能力。
为了在我们第一个代码中获得相同的结果,我们在 PL/pgSQL 函数中使用了循环,这通常比使用单个 SQL 查询更慢且效果较差。并且它强迫你编写更多的代码行!
正确使用通配符
适当地使用通配符对优化 SQL 查询至关重要,特别是在匹配字符串和模式时。
通配符是 SQL 查询中用于查找特定模式的特殊字符。
SQL 中最常用的通配符是“%”和“”,其中“%”代表任意字符序列,“”代表单个字符。
明智地使用通配符很重要,因为不当使用可能会导致性能问题,尤其是在大型数据库中。
然而,效率地使用它们可以大大提高字符串匹配和模式匹配查询的性能。
现在让我们查看我们的例子。
这个查询使用 RIGHT() 函数提取 customer_name 列的最后三个字符,然后检查它是否等于 'son'。
SELECT customer_name
FROM customer
WHERE RIGHT(customer_name, 3) = 'son';
这是输出结果。

尽管这个查询达到了预期的结果,但效率不是很高,因为 RIGHT() 函数必须应用到表中的每一行。
让我们通过使用通配符来优化我们的代码。
SELECT customer_name
FROM customer
WHERE customer_name LIKE '%son';
这是输出结果。

这个优化后的 SQL 查询使用 LIKE 运算符和通配符 “%” 来查找 customer_name 列以 'son' 结尾的记录。
这种方法更高效,因为它利用了数据库引擎的模式匹配能力,如果有索引的话,它能更好地利用索引。
如我们所见,总查询时间从 436 毫秒减少到 62 毫秒,几乎快了 7 倍。
使用 TOP 或 LIMIT 来限制样本结果的数量
使用 TOP 或 LIMIT 来限制样本结果对于优化 SQL 查询至关重要,尤其是处理大型表时。
这些子句允许你从表中检索指定数量的记录,而不是所有记录,这对性能是有益的。
现在,让我们从客户表中检索所有信息。
SELECT *
FROM customer
这是输出结果。
在处理大型表时,这个操作可能增加 I/O 和网络延迟,从而降低 SQL 查询性能。
现在让我们通过限制输出为 10 条来优化代码。
SELECT *
FROM customer
LIMIT 10;
这是输出结果。

通过限制输出,你将减少网络延迟和内存使用,改善响应时间,特别是在处理大型表时。在我们的例子中,SQL 查询优化后,总查询运行时间从 260 毫秒减少到 89 毫秒。
所以我们的查询速度变快了近 3 倍。
使用索引
这次,我们将识别并创建适当的索引,用于 WHERE、JOIN 和 ORDER BY 子句中的列,以提高查询性能。
通过对频繁访问的列建立索引,数据库可以更快地检索数据。
现在,让我们首先运行以下查询。
SELECT customer_id,
customer_name
FROM customer
WHERE segment = 'Corporate';
这是输出结果。

我们的查询运行时间为 259 毫秒。
让我们尝试通过创建索引来进一步改进。
CREATE INDEX idx_segment ON customer (segment);
很好,现在我们再次运行代码。
SELECT customer_id,
customer_name
FROM customer WITH (INDEX(idx_segment))
WHERE segment = 'Corporate';
这是输出结果。

通过在 INDEX() 中使用 idx_segment,数据库引擎能够基于 segment 列高效搜索客户表,使查询速度更快——将总查询时间从 259 毫秒减少到 75 毫秒。
奖励部分:使用 SQL 查询优化工具
由于长代码和高度复杂查询的复杂性,你可能考虑使用查询优化工具。
这些工具可以分析你的查询执行计划,识别缺失的索引,并建议替代查询结构,以帮助优化查询。一些流行的查询优化工具包括:
- SolarWinds 数据库性能分析器:该工具帮助你监控和提升数据库性能。它展示了查询中的问题及其运行方式。它兼容多种数据库系统,如 SQL Server、Oracle 和 MySQL。
你可以在这里找到它。
-
SQL Query Tuner for SQL Diagnostic Manager:该工具具有先进的功能来提升查询效果,如性能提示、索引检查以及展示查询的运行方式。它帮助你通过发现和修复问题来改进 SQL 查询。
-
SQL Server Management Studio (SSMS):SSMS 具有内置工具来检查性能和优化查询,如活动监视器、执行计划分析和索引调整向导。
-
EverSQL:EverSQL 是一个在线工具,通过查看数据库结构和查询运行方式自动优化你的查询。它提供建议并重写你的 SQL 查询以提高速度。
使用 SQL 查询优化工具和资源对于改进查询至关重要。通过这些工具,你可以了解查询的工作原理,发现问题,并采用最佳实践来加快数据获取速度,提升应用程序性能。
如果你想简化复杂的 SQL 查询,可以查看 “如何简化复杂 SQL 查询”。
最后的说明
通过优化 SQL 查询所做的更改可能由于其规模(毫秒)看起来微不足道。但随着你处理的数据量增长,这些毫秒将变为秒、分钟,甚至小时。到那时,你会意识到这些 SQL 查询优化技术是非常重要的。
如果你想了解更多,这里有30 个顶级 SQL 查询面试问题,这将帮助那些在学习时也想为面试做准备的人。
感谢阅读!
Nate Rosidi 是一名数据科学家及产品战略专家。他还是一名兼职教授,教授分析课程,并且是StrataScratch的创始人,这个平台帮助数据科学家通过顶级公司的真实面试问题准备面试。可以在Twitter: StrataScratch或LinkedIn上与他联系。
更多相关内容
优化数据分析:在 Databricks 中集成 GitHub Copilot
原文:
www.kdnuggets.com/optimizing-data-analytics-integrating-github-copilot-in-databricks
介绍
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
GitHub Copilot 是 GitHub 和 OpenAI 合作开发的人工智能驱动的代码补全助手,利用 ChatGPT 模型。它旨在帮助开发者加速编码过程,同时减少错误。该模型在 GitHub 自有代码库和公开可用代码的混合数据上进行训练,赋予其广泛的编程范式理解。
另一方面,Databricks 是一个由 Apache Spark 原始创建者创建的开源分析和云平台,帮助组织无缝构建数据分析和机器学习管道,从而加速创新。此外,它促进了用户之间的协作。
将 GitHub Copilot 与 Databricks 集成,使数据分析和机器学习工程师能够高效且及时地部署解决方案。此集成促进了更顺畅的代码开发,提高了代码质量和标准化,提升了跨语言效率,加快了原型开发,并有助于文档编写,从而提高了工程师的生产力和效率。
GitHub Copilot 和 Databricks 集成的前提条件:
Databricks 账户 设置。
设置 GitHub Copilot。
下载并安装 Visual Studio Code。
集成步骤
在 Visual Studio Code 市场中安装 Databricks 插件。

在 Visual Studio Code 中配置 Databricks 插件。如果你之前使用过 Databricks CLI,那么它已经在 databrickscfg 文件中为你本地配置好。如果没有,请在 ~/.databrickscfg 文件中创建以下内容。
[DEFAULT]
host = https://xxx
token = <token>
jobs-api-version = 2.0
点击“配置 Databricks”选项,然后从下拉菜单中选择第一个选项,该选项显示在上述步骤中配置的主机名,并继续使用“DEFAULT”配置文件。

配置完成后,Databricks 连接会与 Visual Studio Code 建立。点击 Databricks 插件时,可以查看工作区和集群配置详细信息。
用户完成 GitHub Copilot 账户设置后,确保您可以访问 GitHub Copilot。通过 Marketplace 在 VSCode 中安装 GitHub Copilot 和 GitHub Copilot Chat 插件。

一旦用户安装了 GitHub Copilot 和 Copilot Chat 插件,将提示通过 Visual Studio IDE 登录 GitHub Copilot。如果没有提示进行授权,请点击 Visual Studio 代码 IDE 底部面板中的铃铛图标。

现在,是时候使用 GitHub Copilot 开发了
开发数据工程管道
数据工程师可以利用 GitHub Copilot 快速编写数据工程管道,包括文档,几乎无需时间。以下是使用提示技术创建简单数据工程管道的步骤。
使用 Python 和 Spark 框架从 S3 存储桶中读取文件。

使用 Python 和 Spark 框架将数据框写入 S3 存储桶

通过主方法执行函数:在提示中表示相同,并通过代码执行步骤得到结果

在 Databricks 中使用 GitHub Copilot 进行数据工程和机器学习的好处
-
优秀的 AI 配对编程工具,可快速提供合理建议并生成模板代码。
-
顶级建议,以优化代码和运行时间。
-
更好的文档和逻辑步骤的 ASCII 表示。
-
更快的数据管道实现,错误最小。
-
详细解释现有的简单/复杂功能,并建议智能代码重构技术。
备忘单
-
打开一个 Co-pilot 文本/搜索栏,您可以在其中输入您的提示。
![优化数据分析:在 Databricks 中集成 GitHub Copilot]()
Windows: [Cltr] + [I]
Mac: Command + [I]
-
在右侧打开一个单独的窗口,显示前 10 个代码建议。
Windows: [Cltr] + [Enter]
Mac: [control] + [return]


-
在左侧打开一个单独的 Copilot 聊天窗口。
Windows: [Cltr] + [Alt] + [I]
Mac: [Control] + [Command] + [I]
-
驳回内联建议。
Windows/Mac: Esc
-
接受建议。
Windows/Mac: Tab
-
参考以前的建议。
Windows: [Alt] + [
Mac: [option] + [
-
检查下一个建议
Windows: [Alt] + ]
Mac: [option] + ]
结论
人工智能配对编程工具与集成开发环境的集成,帮助开发人员通过实时代码建议加速开发,减少查阅文档以获取模板代码和语法的时间,并使开发人员能够专注于创新和业务问题解决方案。
进一步资源
Naresh Vurukonda** 是一位首席架构师,在医疗保健、生命科学和媒体网络组织中拥有超过 10 年的数据工程和机器学习项目经验。
更多相关主题
优化数据存储:探索 SQL 中的数据类型和规范化
原文:
www.kdnuggets.com/optimizing-data-storage-exploring-data-types-and-normalization-in-sql

图片由作者提供
在当今世纪,数据是新的石油。优化数据存储对获取良好的性能始终至关重要。选择合适的数据类型并应用正确的规范化过程对于决定其性能至关重要。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
本文将研究最重要且常用的数据类型,并了解规范化过程。
SQL 中的数据类型
SQL 中主要有两种数据类型:字符串和数值。除此之外,还有布尔型、日期和时间、数组、区间、XML 等额外的数据类型。
字符串数据类型
这些数据类型用于存储字符字符串。字符串通常作为数组数据类型实现,包含一个元素序列,通常是字符。
- CHAR(n):
这是一个固定长度的字符串,可以包含字符、数字和特殊字符。n表示它可以容纳的字符串的最大长度。
它的最大范围是从 0 到 255 个字符,问题在于这种数据类型会占用指定的全部空间,即使字符串的实际长度少于指定长度。额外的字符串长度会用额外的内存空间填充。
- VARCHAR(n):
Varchar 类似于 Char,但可以支持可变大小的字符串,没有填充。该数据类型的存储大小等于字符串的实际长度。
它最多可以存储 65535 个字符。由于其可变长度特性,其性能不如 CHAR 数据类型。
- BINARY(n):
它类似于 CHAR 数据类型,但只接受二进制字符串或二进制数据。它可以用于存储图像、文件或任何序列化对象。还有一种数据类型VARBINARY(n),类似于 VARCHAR 数据类型,但也只接受二进制字符串或二进制数据。
- TEXT(n):
这种数据类型也用于存储字符串,但其最大尺寸为 65535 字节。
- BLOB(n): 代表二进制大型对象,存储数据最多可达 65535 字节。
除这些之外,还有其他数据类型,如 LONGTEXT 和 LONGBLOB,它们可以存储更多的字符。
数值数据类型
- INT():
它可以存储一个 4 字节(32 位)的数字整数。这里的 n 表示显示宽度,最大可以达到 255。它指定用于显示整数值的最小字符数。
范围:
-
a) -2147483648 <= 有符号 INT <= 2147483647
-
b) 0 <= 无符号 INT <= 4294967295
-
BIGINT():
它可以存储最大为 64 位的大整数。
范围:
-
a) -9223372036854775808 <= 有符号 BIGINT <= 9223372036854775807
-
b) 0 <= 无符号 BIGINT <= 18446744073709551615
-
FLOAT():
它可以存储带有小数位的浮点数,精度有一定的近似。它存在一些小的舍入误差,因此在需要精确度的情况下不适合使用。
- DOUBLE():
此数据类型表示双精度浮点数。与 FLOAT 数据类型相比,它可以存储更高精度的十进制值。
- DECIMAL(n, d):
此数据类型表示具有固定精度的确切十进制数字,精度由 d 表示。参数 d 指定小数点后的位数,参数 n 表示数字的大小。d 的最大值为 30,默认值为 0。
其他数据类型
- BOOLEAN:
该数据类型仅存储两个状态:真或假。它用于执行逻辑操作。
- ENUM:
它代表枚举类型。它允许你从预定义选项列表中选择一个值。它还确保存储的值仅来自指定的选项。
例如,考虑一个属性 color,它只能是 'Red'、'Green' 或 'Blue'。当我们将这些值放入 ENUM 时,color 的值只能是这些指定的颜色。
- XML:
XML 代表可扩展标记语言。此数据类型用于存储用于结构化数据表示的 XML 数据。
- 自动编号:
它是一个整数,每当添加记录时,值会自动递增。它用于生成唯一或顺序的数字。
- 超链接:
它可以存储文件和网页的超链接。
这完成了我们关于 SQL 数据类型的讨论。还有许多其他数据类型,但我们讨论的数据类型是最常用的。
SQL 中的归一化
归一化是从数据库中去除冗余、不一致和异常的过程。冗余指的是相同数据的重复值存在,而数据库中的不一致性指的是相同的数据在多个表中以不同格式存在。
数据库异常可以定义为数据库中任何突然出现或不应存在的变化或差异。这些变化可能由于各种原因,如数据损坏、硬件故障、软件漏洞等。异常可能导致严重后果,如数据丢失或不一致,因此尽快检测和修复异常至关重要。主要有三种类型的异常。我们将简要讨论每一种,但如果你想了解更多,请参考这篇文章。
- 插入异常:
当新插入的行在表中创建不一致时,会导致插入异常。例如,我们想将一个员工添加到组织中,但他的部门尚未分配给他。那么我们无法将该员工添加到表中,这就产生了插入异常。
- 删除异常:
删除异常发生在我们想从表中删除某些行时,需要从数据库中删除其他数据。
- 更新异常:
当我们想更新某些行时,会发生这种异常,这会导致数据库中的不一致。
规范化过程包含一系列准则,使数据库设计高效、优化且不含冗余和异常。存在多种类型的范式,如 1NF、2NF、3NF、BCNF 等。
1. 第一范式(1NF)
第一范式确保表中不包含复合属性或多值属性。这意味着单一属性中只能存在一个值。如果每个属性都是单值的,则关系处于第一范式。
例如

图片由GeeksForGeeks提供
在表 1 中,属性STUD_PHONE包含多个电话号码。但是在表 2 中,该属性被分解为第一范式。
2. 第二范式
表必须处于第一范式,并且关系中不得存在任何部分依赖。部分依赖意味着非主属性(即不属于候选键的属性)部分依赖于候选键的任何适当子集。为了使关系处于第二范式,非主属性必须完全依赖于整个候选键。
例如,考虑一个名为Employees的表,具有以下属性。
EmployeeID (Primary Key)
ProjectID (Primary Key)
EmployeeName
ProjectName
HoursWorked
在这里,EmployeeID 和 ProjectID 一起构成主键。然而,你可以注意到 EmployeeName 和 EmployeeID 之间存在部分依赖。这意味着 EmployeeName 仅依赖于主键的一部分(即 EmployeeID)。为了完全依赖,EmployeeName 必须依赖于 EmployeeID 和 ProjectID。因此,这违反了第二范式的原则。
要使该关系处于第二范式,我们必须将表拆分为两个独立的表。第一个表包含所有员工详细信息,第二个表包含所有项目详细信息。
因此,Employee 表具有以下属性,
EmployeeID (Primary Key)
EmployeeName
并且 Project 表具有以下属性,
Project ID (Primary Key)
Project Name
Hours Worked
现在你可以看到,通过创建两个独立的表,部分依赖关系被消除了。而两个表中的非主属性依赖于主键的完整集合。
3. 第三范式
在第二范式之后,关系仍可能存在更新异常。如果我们仅更新一个元组而不更新另一个,则可能导致数据库中的不一致。
第三范式的条件是表应处于第二范式(2NF),并且非主属性之间没有传递依赖关系。传递依赖关系发生在非主属性依赖于另一个非主属性时,而不是直接依赖于主属性。主属性是候选键的一部分。
考虑一个关系 R(A, B, C),其中 A 是主键,B 和 C 是非主属性。假设 A→B 和 B→C 是两个函数依赖,则 A→C 将是传递依赖关系。这意味着属性 C 并不是由 A 直接决定的。B 在它们之间充当中介。
如果一个表包含传递依赖关系,我们可以通过将表拆分成独立的关系来将其转换为第三范式(3NF)。
4. 博伊斯-科得范式
尽管第二范式(2NF)和第三范式(3NF)消除了大部分冗余,但冗余仍未完全消除。如果函数依赖关系的左侧不是候选键或超键,则可能会发生冗余。候选键 由主属性形成,而 超键 是候选键的超集。为了解决这个问题,还有另一种函数依赖关系类型,称为博伊斯-科得范式(BCNF)。
要使表处于 BCNF,函数依赖关系的左侧必须是候选键或超键。例如,对于函数依赖 X→Y,X 必须是候选键或超键。
考虑一个包含以下属性的员工表。
-
员工 ID(主键)
-
员工姓名
-
部门
-
部门主管

员工 ID 是唯一标识每一行的主键。部门属性表示特定员工的部门,部门主管属性表示该特定部门的主管员工的员工 ID。
现在我们将检查此表是否符合 BCNF。条件是函数依赖关系的左侧必须是超键。以下是该表的两个函数依赖关系。
函数依赖 1: 员工 ID → 员工姓名、部门、部门主管
函数依赖 2: 部门 → 部门主管
对于 FD1,EmployeeID 是主键,也是超键。但对于 FD2,Department 不是超键,因为多个员工可以在同一个部门。
因此,这个表违反了 BCNF 的条件。为了满足 BCNF 的属性,我们需要将该表拆分为两个独立的表:Employees 和 Departments。Employees 表包含 EmployeeID、EmployeeName 和 Department,而 Department 表将包含 Department 和 Department Head。


现在我们可以看到在两个表中,所有的功能依赖都依赖于主键,即没有非平凡的依赖。
我们已经涵盖了所有著名的标准化技术,但除此之外,还有两种标准范式,即 4NF 和 5NF。如果你想了解更多,可以参考这篇 文章。
总结
我们已经讨论了 SQL 中最常用的数据类型以及数据库管理系统中重要的标准化技术。在设计数据库系统时,我们的目标是使其可扩展,最小化冗余并确保数据完整性。
通过选择合适的数据类型,我们可以在存储、精度和内存消耗之间创建一个微妙的平衡。此外,标准化过程有助于消除数据异常,使模式更加有序。
今天就到这里。直到下次,继续阅读和学习吧。
Aryan Garg 是一名电气工程专业的 B.Tech. 学生,目前在本科最后一年。他的兴趣在于网页开发和机器学习,他已经追求了这一兴趣,并渴望在这些方向上进一步工作。
更多相关内容
使用遗传算法优化基因
原文:
www.kdnuggets.com/2022/04/optimizing-genes-genetic-algorithm.html

介绍
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 部门
遗传算法可以是解决优化问题的好方法,因为它们可以可靠地找到一个好的解决方案,即使在具有许多局部最优解的复杂适应度景观中。我正在使用这种技术来优化 DNA 序列,以准确生产大量有用的蛋白质。在这里,我们将查看实现遗传算法的关键步骤,而不是深入探讨其背后的理论,但在其他地方有许多更详细的描述,例如 这里 和 这里。
简单来说,遗传算法模拟一个种群,其中每个个体都是一个可能的“解决方案”,并让适者生存发挥作用。困难的部分,就像数据科学和机器学习中的许多问题一样,是如何为计算机构建问题。我们将看到如何通过更好地构建问题来改善您的解决方案。
所有代码均可在 github.com/DAWells/codon_path 获取
问题
DNA 代码用于氨基酸,蛋白质的构建块。三个位于一起的 DNA 字母(A、T、G 或 C)编码一个氨基酸,称为密码子。几个不同的密码子可以编码相同的氨基酸。例如,CAA 和 CAG 都编码氨基酸谷氨酰胺。给定一个已知的蛋白质,我们想要编码的序列应该是简单的。实际上,当蛋白质合成时,前一个密码子可能会影响添加下一个氨基酸的时间,可能需要更长时间或出现错误。尽管几个密码子可以完成相同的工作,但并非所有的配对都能很好地配合在一起。我的目标是优先使用这些配对良好的密码子。
那么,为什么这很重要?通过这种方式优化基因可以让你获得更多你想要的蛋白质。你可能需要一种蛋白质来催化化学反应,或者生产治疗药物。为什么这很困难?每个密码子是两个对中的一部分,这意味着你不能单独选择最佳对。相反,你必须同时考虑所有对。在下面的例子中,每个位置有两个密码子的选择,邻近密码子的配合效果由连接它们的颜色(绿色>黄色>红色)表示。一个好的密码子对可能会让你陷入下一个坏对,如下所示。

解决方案
遗传算法所需的第一件事是一个评分函数,一种衡量可能解决方案适应性的方式。这用于决定哪些解决方案可以“繁殖”。决定如何计算这个数字是任何优化问题的关键步骤,因为它必须在这个值中捕捉问题的所有复杂性。幸运的是,Coleman 等人(2008)为所有 3,721 对可能的密码子对计算了一个评分,我们使用这个评分作为在蛋白质合成过程中对一对密码子效果的衡量。因此,对于任何 DNA 序列,我可以将序列中每对连续密码子的值加起来,并计算一个分数;分数越高,解决方案对我的问题越好。
接下来,我们需要为遗传算法框定问题,即在算法优化过程中,每个可能的解决方案将采取何种形式?最明显的密码子表示方式是一个向量,其中每个元素是一个密码子,用 1-61 的数字表示(对应 61 个密码子中的每一个)。但这对于我们的算法来说自由度过大,因为它可以替换成产生错误氨基酸的密码子。
更好的表述是每个元素表示一个编码正确氨基酸的密码子。确定什么是“正确氨基酸”可以抽象到评分函数中,这意味着我们的遗传算法不会破坏任何东西。任何单一氨基酸可以由多达 6 种不同的密码子编码,因此我们的解决方案向量包含范围为 0-5 的整数值,编码 6 种密码子,并且长度与我们优化的氨基酸序列相同(或 DNA 基因长度的三分之一)。
另一个关键好处是将我们的解决方案向量从 1-6 而非 1-61,这大大减少了问题空间。如果 L 是我们向量的长度,那么要探索的可能解决方案数量是 6L 而非 61L。较小的问题空间意味着更快的答案,这在遗传算法中尤为重要。尽管它们能找到好的解决方案,但速度较慢。如果我没有重新格式化为较小的问题空间,我就没有时间优化基因。
使用 0-5 表示密码子存在一个问题,并不是所有氨基酸都有 6 个密码子,例如赖氨酸只有 2 个。遗传算法可能会使用第 5 个赖氨酸密码子(实际上不存在);那怎么办?你可以让评分函数在每次使用无效密码子时扣分,并希望这能促使你找到好的有效解决方案,但这并没有高效利用我们的问题空间。任何包含无效密码子的解决方案都绝对不是最佳解决方案。这意味着我们在 6L 空间中尝试的许多解决方案(尽管仍然很多)都是浪费的努力。
与其使用惩罚,更好的解决方案是使用模除余数。每当遗传算法请求一个不在真实密码子列表中的密码子时,我将其循环回列表的开头。因此,如果它请求第 5 个密码子而列表中只有 3 个,它将回到开始处并计算剩余的 2 个。这意味着遗传算法探索的任何解决方案都有可能是最佳解决方案。因此,我们应该能更快地得到更好的答案。在下面的图中,我们可以看到惩罚算法总是落后于模除算法,并且需要 30 代才能达到相同的起点。

幸运的是,这使我得到了一个非常好的解决方案,比自然发生的基因要好得多。下面我绘制了自然基因和优化基因在长度上的累积适应度;好的密码子对增加适应度,差的对减少适应度。自然基因的累积得分通常是增加的,因为好的密码子对通常是优选的,但差别不大。而在我们优化的基因中,斜率要陡得多且始终为正,表明密码子对的利用要好得多。总体而言,我们优化的基因比自然基因好 6 倍。

结论
为了最大限度地发挥你的遗传算法的效果,你需要将问题框架设计得尽可能小且高效地探索问题空间。你还需要一个准确捕捉你试图实现目标本质的适应度函数。数据科学中很大一部分就是将现实世界问题转化为数字,以便计算机可以帮助你。通过实践,你可以用多种方式来框定同一个问题。希望这篇文章展示了如何通过恰当框定同一问题来获得更好的答案。
参考文献
Coleman, J. R., Papamichail, D., Skiena, S., Futcher, B., Wimmer, E., & Mueller, S. (2008). 通过基因组规模的密码子对偏好变化进行病毒减毒。科学,320(5884),1784–1787。https://doi.org/10.1126/science.1155761
David Wells 是一位生物信息学家,他将机器学习应用于基因组学以开发疫苗。
更多关于此主题
优化 Python 代码性能:深入了解 Python 性能分析工具
原文:
www.kdnuggets.com/2023/02/optimizing-python-code-performance-deep-dive-python-profilers.html

图片由作者提供
介绍
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT 需求
尽管 Python 是最广泛使用的编程语言之一,但在处理大数据集时,它往往会遭遇较差的执行时间。性能分析是动态监控代码性能并识别缺陷的方法之一。这些缺陷可能表示存在错误或编写不当的代码,这些代码消耗了大量的系统资源。使用性能分析工具可以提供程序的详细统计信息,你可以利用这些信息来优化代码以提高性能。让我们来看看一些 Python 性能分析工具及其示例。
1. cProfile
cProfile 是 Python 内置的性能分析工具,它跟踪程序中的每个函数调用。它提供了有关函数被调用频率及其平均执行时间的详细信息。由于它是标准 Python 库的一部分,因此我们不需要显式安装。然而,它不适合用于实时数据分析,因为它会捕捉每一个函数调用,并默认生成大量统计信息。
示例
import cProfile
def sum_():
total_sum = 0
# sum of numbers till 10000
for i in range(0,10001):
total_sum += i
return total_sum
cProfile.run('sum_()')
输出
4 function calls in 0.002 seconds
Ordered by: standard name
| ncalls | tottime | percall | cumtime | percall | percall 文件名:行号(函数) |
|---|---|---|---|---|---|
| 1 | 0.000 | 0.000 | 0.002 | 0.002 | |
| 1 | 0.002 | 0.002 | 0.002 | 0.002 | cprofile.py:3(sum_) |
| 1 | 0.000 | 0.000 | 0.002 | 0.002 | |
| 1 | 0.000 | 0.000 | 0.000 | 0.000 |
从输出中可以看出,cProfile 模块提供了大量关于函数性能的信息。
-
ncalls = 函数被调用的次数
-
tottime = 函数中花费的总时间
-
percall = 每次调用中花费的总时间
-
cumtime = 在此函数及所有子函数中花费的累计时间
-
percall = 每次调用中花费的累计时间。
2. 行分析器
Line Profiler 是一个强大的 Python 模块,可逐行分析代码性能。有时,代码中的热点可能只是单行,直接从源代码中定位并不容易。Line Profiler 对于识别每行执行所花费的时间以及需要特别关注的优化区域非常有价值。然而,它不包含在标准 Python 库中,需要使用以下命令进行安装:
pip install line_profiler
示例
from line_profiler import LineProfiler
def sum_arrays():
# creating large arrays
arr1 = [3] * (5 ** 10)
arr2 = [4] * (3 ** 11)
return arr1 + arr2
lp = LineProfiler()
lp.add_function(sum_arrays)
lp.run('sum_arrays()')
lp.print_stats()
输出
Timer unit: 1e-07 s
Total time: 0.0562143 s
File: e:\KDnuggets\Python_Profilers\lineprofiler.py
Function: sum_arrays at line 2
| 行号 | 点击次数 | 时间 | 每次点击 | % 时间 | 行内容 |
|---|---|---|---|---|---|
| 2 | def sum_arrays(): | ||||
| 3 | # 创建大型数组 | ||||
| 4 | 1 | 168563.0 | 168563.0 | 30.0 | arr1 = [1] * (10 ** 6) |
| 5 | 1 | 3583.0 | 3583.0 | 0.6 | arr2 = [2] * (2 * 10 ** 7) |
| 6 | 1 | 389997.0 | 389997.0 | 69.4 | return arr1 + arr2 |
-
行号 = 代码文件中的行号
-
点击次数 = 执行的次数
-
时间 = 执行该行所花费的总时间
-
每次点击 = 每次点击的平均时间
-
% 时间 = 相对于函数总时间的每行时间占比
-
行内容 = 实际源代码
3. 内存分析器
内存分析器是一个 Python 分析器,跟踪代码的内存分配。它还可以生成火焰图,以帮助分析内存使用情况并识别代码中的内存泄漏。它还可以帮助识别导致大量分配的热点区域,因为 Python 应用程序通常容易出现内存管理问题。内存分析器逐行分析内存消耗的统计信息,需要使用以下命令进行安装:
pip install memory_profiler
示例
import memory_profiler
import random
def avg_marks():
# Genrating Random marks for 50 students for each section
sec_a = random.sample(range(0, 100), 50)
sec_b = random.sample(range(0, 100), 50)
# combined average marks of two sections
avg_a = sum(sec_a) / len(sec_a)
avg_b = sum(sec_b) / len(sec_b)
combined_avg = (avg_a + avg_b)/2
return combined_avg
memory_profiler.profile(avg_marks)()
输出
Filename: e:\KDnuggets\Python_Profilers\memoryprofiler.py
| 行号 | 内存使用 | 增量 | 出现次数 | 行内容 |
|---|---|---|---|---|
| 4 | 21.7 MiB | 21.7 MiB | 1 | def avg_marks(): |
| 5 | # 为每个部分生成 50 个随机分数 | |||
| 6 | 21.8 MiB | 0.0 MiB | 1 | sec_a = random.sample(range(0, 100), 50) |
| 7 | 21.8 MiB | 0.0 MiB | 1 | sec_b = random.sample(range(0, 100), 50) |
| 8 | ||||
| 9 | # 两个部分的综合平均分 | |||
| 10 | 21.8 MiB | 0.0 MiB | 1 | avg_a = sum(sec_a) / len(sec_a) |
| 11 | 21.8 MiB | 0.0 MiB | 1 | avg_b = sum(sec_b) / len(sec_b) |
| 12 | 21.8 MiB | 0.0 MiB | 1 | combined_avg = (avg_a + avg_b)/2 |
| 13 | 21.8 MiB | 0.0 MiB | 1 | return combined_avg |
-
行号 = 代码文件中的行号
-
内存使用 = Python 解释器的内存使用情况
-
增量 = 当前行与上一行的内存消耗差
-
出现次数 = 代码行执行的次数
-
行内容 = 实际源代码
4. Timeit
Timeit 是一个内置的 Python 库,专门用于评估小代码片段的性能。它是一个强大的工具,可以帮助你识别和优化代码中的性能瓶颈,使你的代码更快、更高效。虽然可以使用 timeit 模块比较算法的不同实现,但缺点是只能分析代码块的单独行。
示例
import timeit
code_to_test = """
# creating large arrays
arr1 = [3] * (5 ** 10)
arr2 = [4] * (3 ** 11)
arr1 + arr2
"""
elapsed_time = timeit.timeit(code_to_test, number=10)
print(f'Elapsed time: {elapsed_time}')
输出
Elapsed time: 1.3809973997995257
它的使用限制在于只评估较小的代码片段。需要注意的是,它每次运行代码片段时显示的时间不同。这是因为你的计算机上可能运行着其他进程,资源分配可能在不同的运行中有所变化,使得控制所有变量并实现相同的处理时间变得困难。
5. Yappi
Yappi 是一个 Python 性能分析器,允许你轻松识别性能瓶颈。它用 C 语言编写,是最有效的分析器之一。它拥有一个可定制的 API,允许你仅分析代码中需要关注的特定部分,从而对分析过程有更多控制。它能够分析并发协程,提供对代码运行情况的深入理解。
示例
import yappi
def sum_arrays():
# creating large arrays
arr1 = [3] * (5 ** 10)
arr2 = [4] * (3 ** 11)
return arr1 + arr2
with yappi.run(builtins=True):
final_arr = sum_arrays()
print("\n--------- Function Stats -----------")
yappi.get_func_stats().print_all()
print("\n--------- Thread Stats -----------")
yappi.get_thread_stats().print_all()
print("\nYappi Backend Types: ",yappi.BACKEND_TYPES)
print("Yappi Clock Types: ", yappi.CLOCK_TYPES)
注意: 使用以下命令安装 yappi:
pip install yappi
输出
--------- Function Stats -----------
Clock type: CPU
Ordered by: totaltime, desc
| name | ncall | tsub | ttot | tavg |
|---|---|---|---|---|
| ..lers\yappiProfiler.py:4 sum_arrays | 1 | 0.109375 | 0.109375 | 0.109375 |
| builtins. next | 1 | 0.000000 | 0.000000 | 0.000000 |
| .. _GeneratorContextManager.exit | 1 | 0.000000 | 0.000000 | 0.000000 |
--------- 线程统计 ---------
| name | id | tid | ttot | scnt |
|---|---|---|---|---|
| _MainThread | 0 | 15148 | 0.187500 | 1 |
Yappi Backend Types: {'NATIVE_THREAD': 0, 'GREENLET': 1}
Yappi Clock Types: {'WALL': 0, 'CPU': 1}
记得为内置模块起不同的名称。否则,导入将导入你的模块(即你的 Python 文件),而不是实际的内置模块。
结论
通过使用这些分析工具,开发者可以识别代码中的瓶颈,并决定哪种实现方式最佳。使用合适的工具和一点技巧,任何人都能将他们的 Python 代码性能提升到新的高度。所以,准备好优化你的 Python 性能,看看它如何腾飞到新高度吧!
我很高兴你决定阅读这篇文章,希望它对你是一次有价值的体验。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年亚太地区的 Google Generation Scholar。Kanwal 喜欢通过撰写关于热门话题的文章来分享技术知识,并热衷于改善女性在科技行业中的代表性。
更多相关内容
优化你的 LLM 以提高性能和可扩展性
原文:
www.kdnuggets.com/optimizing-your-llm-for-performance-and-scalability

图片来源:作者
大型语言模型或 LLM 已成为自然语言处理的推动力。它们的使用场景从聊天机器人和虚拟助手到内容生成和翻译服务。然而,它们已经成为科技界增长最快的领域之一——我们可以在各种场景中见到它们。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
随着对更强大语言模型需求的增长,对有效优化技术的需求也在增加。
然而,许多自然的问题出现了:
如何提升它们的知识?
如何提升它们的整体性能?
如何扩展这些模型?
OpenAI DevDay 上由 John Allard 和 Colin Jarvis 主讲的题为“最大化 LLM 性能的技术调查”的深刻演讲试图回答这些问题。如果你错过了这一活动,可以在YouTube上观看这场讲座。
这场演讲提供了各种技术和最佳实践的精彩概述,以提升 LLM 应用的性能。本文旨在总结改善我们 AI 驱动的解决方案性能和可扩展性的最佳技术。
理解基础知识
LLM 是精密的算法,旨在理解、分析和生成连贯且符合上下文的文本。它们通过对大量语言数据进行广泛训练,涵盖各种主题、方言和风格,从而实现这一目标。因此,它们能够理解人类语言的运作方式。
然而,在将这些模型集成到复杂应用中时,需要考虑一些关键挑战:
优化 LLM 面临的主要挑战
-
LLM 的准确性:确保 LLM 输出准确且可靠的信息,没有幻觉。
-
资源消耗:LLM 需要大量的计算资源,包括 GPU 能力、内存和大型基础设施。
-
延迟:实时应用要求低延迟,这可能由于 LLM 的规模和复杂性而具有挑战性。
-
可扩展性:随着用户需求的增长,确保模型能够处理增加的负载而不降低性能至关重要。
提升表现的策略
第一个问题是关于“如何提升其知识?”
创建一个部分功能的 LLM 演示相对简单,但将其完善以投入生产需要迭代改进。LLM 可能在需要深厚专业知识、系统和流程理解或精准行为的任务中遇到困难。
团队使用提示工程、检索增强和微调来应对这一问题。一个常见的错误是认为这个过程是线性的,应按特定顺序进行。相反,根据问题的性质,从两个轴来处理更为有效:
-
上下文优化:问题是否由于模型缺乏获取正确信息或知识?
-
LLM 优化:模型是否未能生成正确的输出,例如不准确或不符合期望的风格或格式?

作者提供的图像
为应对这些挑战,可以使用三种主要工具,每种工具在优化过程中都扮演着独特的角色:
提示工程
定制提示以引导模型的响应。例如,改进客服机器人提示,以确保其始终提供有用且礼貌的回答。
检索增强生成(RAG)
通过外部数据提升模型的上下文理解。例如,将医疗聊天机器人与最新研究论文数据库集成,以提供准确且最新的医疗建议。
微调
修改基础模型以更好地适应特定任务。就像使用法律文本数据集对法律文档分析工具进行微调,以提高其总结法律文档的准确性。
该过程高度迭代,并非所有技术都会对你的具体问题有效。然而,许多技术是可以叠加的。当你找到有效的解决方案时,可以将其与其他性能改进结合,以实现最佳结果。
优化性能的策略
第二个问题是关于“如何提升其整体性能?”
在拥有准确的模型后,第二个令人关切的问题是推理时间。推理是一个训练好的语言模型,如 GPT-3,在现实应用中生成对提示或问题的响应的过程(例如聊天机器人)。
这是一个关键阶段,在实际场景中对模型进行测试,生成预测和响应。对于像 GPT-3 这样的巨大 LLM,计算需求是巨大的,因此在推理期间进行优化至关重要。
考虑像 GPT-3 这样的模型,它有 1750 亿个参数,相当于 700GB 的 float32 数据。这个规模,加上激活需求,要求显著的 RAM。这就是为什么在没有优化的情况下运行 GPT-3 需要一个庞大的设置。
一些技术可以用来减少执行这些应用所需的资源量:
模型剪枝
这涉及修剪非关键参数,确保只有对性能至关重要的参数保留。这可以大幅减少模型的大小,而不会显著影响其准确性。
这意味着计算负载显著减少,同时保持相同的准确性。你可以在以下 GitHub 中找到易于实现的修剪代码。
量化
这是一种模型压缩技术,将 LLM 的权重从高精度变量转换为低精度变量。这意味着我们可以将 32 位浮点数减少到 16 位或 8 位等更节省内存的格式,这可以大幅减少内存占用并提高推理速度。
LLMs 可以通过 HuggingFace 和 bitsandbytes 以量化方式轻松加载。这使我们能够在低功耗资源上执行和微调 LLMs。
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import bitsandbytes as bnb
# Quantize the model using bitsandbytes
quantized_model = bnb.nn.quantization.Quantize(
model,
quantization_dtype=bnb.nn.quantization.quantization_dtype.int8
)
蒸馏
这是训练一个较小模型(学生)以模拟较大模型(也称为教师)性能的过程。这个过程涉及训练学生模型以模拟教师的预测,使用教师的输出 logits 和真实标签的组合。通过这样做,我们可以在资源需求的很小一部分中实现类似的性能。
这个想法是将较大模型的知识转移到具有更简单架构的较小模型上。最著名的例子之一是 Distilbert。
这个模型是模拟 Bert 性能的结果。它是 BERT 的一个较小版本,保留了 97%的语言理解能力,同时速度快 60%,体积小 40%。
可扩展性技术
第三个问题是关于“如何扩展这些模型?”
这一步通常至关重要。当一个系统被少量用户使用时,它的行为可能与在扩展以应对密集使用时大相径庭。以下是一些应对这一挑战的技术:
负载均衡
这种方法有效分配传入请求,确保计算资源的最佳利用和对需求波动的动态响应。例如,为了在不同国家提供像 ChatGPT 这样的广泛使用服务,最好部署多个相同模型的实例。
有效的负载均衡技术包括:
横向扩展:添加更多模型实例以应对增加的负载。使用像 Kubernetes 这样的容器编排平台来管理不同节点上的这些实例。
垂直扩展:升级现有机器资源,例如 CPU 和内存。
分片
模型分片将模型的片段分布在多个设备或节点上,实现并行处理并显著减少延迟。完全分片数据并行(FSDP)提供了利用各种硬件的关键优势,如 GPU、TPU 和其他在多个集群中的专用设备。
这种灵活性允许组织和个人根据他们的具体需求和预算来优化硬件资源。
缓存
实现缓存机制可以通过存储频繁访问的结果来减少对 LLM 的负载,这对于有重复查询的应用程序尤其有利。缓存这些频繁的查询可以通过消除重复处理相同请求的需要,从而显著节省计算资源。
此外,批处理可以通过将类似任务分组来优化资源使用。
结论
对于那些依赖 LLM 的应用程序来说,这里讨论的技术对于最大化这种变革性技术的潜力至关重要。掌握并有效应用策略以获得更准确的模型输出、优化其性能以及实现扩展,是从一个有前景的原型发展为一个强大的、生产就绪的模型的重要步骤。
要充分理解这些技术,我强烈推荐深入了解并开始在你的 LLM 应用程序中实验这些技术,以获得最佳结果。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他毕业于物理工程专业,目前在应用于人类流动的数据科学领域工作。他是一个兼职内容创作者,专注于数据科学和技术。Josep 撰写关于人工智能的文章,涵盖了该领域的持续爆炸性发展。
更多相关内容
从 Oracle 到 AI 数据库:数据存储的演变
原文:
www.kdnuggets.com/2022/02/oracle-databases-ai-evolution-data-storage.html

技术矢量图由 fullvector 创作 - www.freepik.com
尽管机器学习已经变得商品化,但它仍然是西部荒野。各个行业的 ML 团队正在开发自己的数据处理、模型训练和生产使用的技术。这显然不是一个可持续的机器学习方法。随着时间的推移,这些多样化的方法将会标准化。为了加快这一过程,行业需要专门为 AI 设计的开发者工具。在本文中,你将看到传统的数据存储解决方案与专为解决 AI 用例而构建的数据库之间的区别。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
任何与企业打过交道的人都见过一个具有行和列的界面,在那里你认真地添加与工作相关的信息。
Oracle 数据库在 40 多年前作为这种数据输入的目标被引入。尽管许多企业将其作为默认数据库使用,但它对于普通用户来说相当复杂。它也是专有的,因此对开发者不可访问。Oracle 甚至启动了 DeWitt 条款,禁止发布未经数据库创建者授权的数据库基准测试。
快进 15 年,我们见证了像 MySQL 和 PostgreSQL 这样的新一代数据库的出现。与 Oracle 的产品相比,主要的区别在于可访问性——这些新型数据库是开源产品,可以在本地计算机上运行,这使得开发者更容易进行设置和使用。它们在互联网泡沫期间得到了广泛采用也就不足为奇了。
Web 2.0 和开源数据库的崛起
随着时间的推移,我们见证了 2000 年代初“Web 2.0”的兴起。Google 的 Jeff Dean 和 Sanjay Ghemawat 提出了 MapReduce,一种根本性的新数据处理方法。该方法的逻辑是对数据集执行映射和归约操作。映射操作包括对数据行和列的过滤和排序。归约操作涉及对表格数据的汇总和聚合。该基础设施被设计为并行运行。这种 MapReduce 方法是 Hadoop 的核心,Hadoop 是 2000 年代最成功的开源项目之一。
2007-2012 年间,世界迎来了各种开源 NoSQL 数据库。最受欢迎的有:Apache Cassandra、Google 的 BigTable、MongoDB、Redis 和 Amazon 的 DynamoDB。
这些数据库的关键区分点在于它们水平扩展良好。许多机器可以并行启动并协作服务一个能够容纳真正大规模数据集的数据库。NoSQL 数据库不使用关系型的方法将数据建模为行和列,且可以轻松接受非结构化数据,而不需要复杂的数据模型。
还需要提到的是,有两种类型的数据库:事务型和分析型。事务型数据库是操作性的,存储关键数据,如用户日志、活动、IP 地址、采购订单等。它们被设计为能够快速接受新数据,并以最小的延迟响应数据请求。分析型数据库工作速度较慢,可以托管在更便宜的存储上,并允许对数据进行比在事务型数据库中更深入的分析。
大数据:分析与人工智能炒作周期的开端
“大数据”这一术语最初在 2005 年引入,但在应用程序变得更加复杂后才被广泛接受。当时,适当的分析涉及从不同地方提取大量数据。为了应对不断上升的挑战,市场上出现了新产品——Amazon RedShift、Snowflake、Google BigQuery、Clickhouse。这些数据仓库已经成为现代企业的主流。
2020 年引入了一种新的数据协调解决方案——‘湖屋’。湖屋帮助用户以低成本查询历史数据,但在分析和机器学习工作负载方面几乎没有性能下降。这转变成了Snowflake 和 Databricks 之间的一场军备竞赛。虽然它们在表格数据的世界中继续争斗,但一些重大变化正在深处酝酿。
在 2021 年,深度学习(DL)已经成为主流。这是非结构化数据的时代。与以行和列表示的表格数据不同,非结构化数据包括图像、视频流、音频和文本。这些数据无法以电子表格形式表示。
由于去年的封锁,Netflix、TikTok 以及其他社交媒体的消费量飙升至前所未有的水平。这些产品都处理和生成大量的非结构化数据。公司应该如何管理这些数据,尤其是当他们希望通过 AI 来挖掘深层次的见解时?AI 团队在处理这些数据时是否可以使用数据库解决方案?
你可能会感到惊讶,但我们讨论的技术没有一个能完全满足深度学习从业者的需求。像特斯拉这样的公司,处理大量非结构化数据,承认他们不得不构建自己的基础设施。
很少有企业拥有足够的内部带宽从头开始构建数据基础设施。AI 行业需要一个坚实的数据基础和专门为 AI 设计的数据库。
AI 数据库是深度学习创新的支柱
长期以来,行业一直需要一个简单的 API 来创建、存储和协作处理任何大小的 AI 数据集。更重要的是,这个工具应该专门为深度学习相关任务创建。
传统数据库将数据存储在内存中以快速执行查询,但内存存储对 ML 数据集而言极其昂贵,因为它们非常大。即便是使用像 AWS EBS 这样的附加磁盘也非常昂贵。最具成本效益的存储层是对象存储,例如 S3、Google Cloud Storage 和 MinIO,但这些工具在快速查询或计算方面较慢。
专门为深度学习构建的数据库应该支持在这些云存储系统上托管数据并以深度学习模型原生格式存储数据。这种功能将允许更快的计算,并且更具成本效益,因为从这种框架中访问数据不应产生任何额外的预处理成本。这样的框架将帮助现代的 AI 驱动企业节省多达 30%的基础设施成本。
该框架应优化数据从云存储传输到机器学习模型的过程,以尽量减少延迟。这将允许 AI 即时探索和可视化无法存放在其他地方的大规模数据集。
更重要的是,现代 AI 数据库应该非常易于使用,只需几行代码即可实现。根据 Kaggle 最近的调查,超过 20%的数据科学家在行业经验上少于 3 年,另有 14%的人经验不足一年。机器学习仍然是一个年轻的领域,简单性至关重要。
我们已经开始看到专门为 AI 使用案例构建的数据库的出现。在未来五年,我们将见证对 机器学习基础设施堆栈的标准化。更快采用 AI 数据库的组织将站在机器学习革命的前沿。
Davit Buniatyan (@DBuniatyan) 在 20 岁时开始了普林斯顿大学的博士学位。他的研究涉及在 Sebastian Seung 的指导下重建小鼠大脑的连接组。为了克服在神经科学实验室分析大型数据集时遇到的困难,David 成为 Activeloop 的创始首席执行官,该公司是 Y-Combinator 的毕业生初创企业。他还是戈登·吴奖学金和 AWS 机器学习研究奖的获得者。Davit 是 Activeloop 的创始人,这是一个为 AI 设计的数据库。
更多相关话题
Orca LLM: 模拟 ChatGPT 的推理过程
原文:
www.kdnuggets.com/2023/06/orca-llm-reasoning-processes-chatgpt.html

介绍
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业的捷径。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织进行 IT 管理
在大型语言模型(LLM)领域,始终在追求在不影响效率的情况下提升小型模型的能力。传统的方法是使用模仿学习,小型模型从大型基础模型(LFM)生成的输出中学习。然而,这种方法面临几个挑战,包括来自浅层 LFM 输出的有限模仿信号、小规模的同质训练数据以及缺乏严格评估。这常常导致小型模型模仿风格但无法模仿 LFM 的推理过程。
论文Orca: 从 GPT-4 的复杂解释踪迹中渐进学习介绍了 Orca,一个设计用来模仿大型基础模型(LFM)如 GPT-4 的推理过程的 13 亿参数模型。与传统的大型语言模型(LLM)不同,Orca 采用了一种独特的训练方法,将渐进学习和教师辅助相结合,以克服小型学生模型与其大型对应模型之间的能力差距。
训练方法
Orca 的训练过程包括两个阶段。
在第一阶段,Orca 在 FLAN-5M 上进行训练,该训练包括 ChatGPT 的增强技术。这一中级教师助手有助于弥合 Orca 与 GPT-4 之间的能力差距,后者具有显著更大的参数规模。通过利用 ChatGPT 的能力,Orca 受益于改进的模仿学习表现。
在第二阶段,Orca 接受 FLAN-1M 的训练,该训练融合了 GPT-4 的增强技术。这种渐进的学习方法遵循课程学习范式,其中学生模型从简单的例子学习,然后再处理更具挑战性的例子。通过逐步将 Orca 暴露于越来越复杂的推理和逐步解释中,该模型提升了其推理能力和模仿技能。
优势和贡献
Orca 的训练方法相比传统 LLM 具有多个优势。
首先,它通过利用中间教师模型解决了能力差距问题,使 Orca 能够从更有能力的来源学习。这种方法已被证明能够提高较小学生模型的模仿学习性能。
其次,Orca 训练的渐进学习方面使模型能够逐步积累知识。通过从简单的示例开始,逐渐引入更复杂的示例,Orca 为推理和生成解释打下了更坚实的基础。
此外,Orca 模仿像 GPT-4 这样的 LFMs 的推理过程的能力,为各种任务的增强性能打开了可能性。通过利用 GPT-4 的解释痕迹和逐步思维过程提供的丰富信号,Orca 获得了宝贵的见解,并提升了自身能力。
性能基准
Orca 在复杂的零-shot 推理基准测试中表现出色。在 Big-Bench Hard (BBH)等基准测试中,比传统的最先进的指令调整模型 Vicuna-13B 高出 100%以上,在 AGIEval 中高出 42%以上。此外,Orca 在 BBH 基准测试中取得了与 ChatGPT 相同的分数,并在 SAT、LSAT、GRE 和 GMAT 等专业和学术考试中表现具有竞争力。考虑到这些都是零-shot 设置且没有链式思维,Orca 仍表现出竞争力,但与 GPT-4 相比略逊一筹,这一点尤其令人印象深刻。
含义与未来方向
Orca 的发展代表了 LLMs 领域的重大进步。通过学习丰富的信号并模仿 LFMs 的推理过程,Orca 能够以高度准确性执行复杂的推理任务。这具有广泛的影响,尤其是在需要复杂推理和问题解决的领域。
此外,这项研究表明,从逐步 AI 模型解释中学习是一种有前景的方向,有助于提升模型能力。这为 LLMs 领域的研究和开发开辟了新的途径。
结论
Orca 提出了一种新的大规模语言模型训练方法,将渐进学习和教师辅助结合在一起,以增强模仿学习。通过利用中间教师模型,并逐渐将学生模型暴露于更复杂的示例中,Orca 克服了能力差距,提升了推理和生成解释的能力。该论文的发现有助于模仿学习技术的进步,并对未来语言模型的发展产生了影响。
有关 Orca 及其研究的更多细节,请参阅微软的介绍文章和相关研究论文。
更多相关话题
使用 Prefect 在 Python 中协调数据科学项目
原文:
www.kdnuggets.com/2022/02/orchestrate-data-science-project-python-prefect.html
动机
作为数据科学家,为什么你应该关心优化你的数据科学工作流程?让我们以一个基本的数据科学项目为例来开始。
想象一下你在处理一个 Iris 数据集。你开始编写函数来处理你的数据。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速入门网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
定义了函数后,你需要执行它们。
你的代码运行正常,你没有看到输出中的任何问题,所以你认为工作流程已经足够好了。然而,像上述这样的线性工作流程可能存在许多缺点。

作者提供的图片
缺点包括:
- 如果函数
get_classes出现错误,由函数encode_categorical_columns生成的输出将会丢失,工作流程将需要从头开始。这可能会很令人沮丧,特别是如果执行函数encode_categorical_columns需要很长时间的话。

作者提供的图片
- 由于函数
encode_categorical_columns和get_classes之间没有相互依赖,因此可以同时执行它们以节省时间:

作者提供的图片
以这种方式运行函数还可以防止在不工作的函数上浪费不必要的时间。如果函数get_classes出现错误,工作流程将立即重新启动,而无需等待函数encode_categorical_columns完成。

作者提供的图片
现在,你可能会同意我所说的,优化不同功能的工作流程是重要的。然而,手动管理工作流程可能需要大量的工作。
是否有一种方法可以通过仅添加几行代码来自动优化工作流程?这就是 Prefect 发挥作用的地方。
什么是 Prefect?
Prefect是一个开源框架,用于在 Python 中构建工作流。Prefect 使得构建、运行和监控大规模数据管道变得容易。
要安装 Prefect,请输入:
pip install prefect
使用 Prefect 构建你的工作流
要了解 Prefect 的工作原理,让我们用 Prefect 封装本文开头的工作流。
第一步 — 创建任务
一个Task是在 Prefect 流中的一个离散操作。首先,使用装饰器prefect.task将上述定义的函数转换为任务:
第二步 — 创建一个流
一个Flow表示通过管理任务之间的依赖关系来管理整个工作流。要创建一个流,只需将代码插入到with Flow(...)上下文管理器中运行你的函数即可。
请注意,上述代码运行时,这些任务都不会执行。Prefect 允许你立即运行流或安排以后执行。
让我们尝试立即使用flow.run()执行流:
运行上述代码将得到类似于以下内容的输出:
为了理解 Prefect 创建的工作流,让我们可视化整个工作流。
首先安装prefect[viz]:
pip install "prefect[viz]"
然后将visualize方法添加到代码中:
你应该能看到如下所示的data-engineer工作流的可视化效果!

作者提供的图像
请注意,Prefect 自动管理任务之间的执行顺序,以优化工作流。这对于增加几行代码来说相当酷!
第三步 — 添加参数
如果你发现自己经常尝试不同的变量值,最好将该变量转换为Parameter。
你可以将Parameter视为Task,只是它可以在每次运行流时接收用户输入。要将变量转换为参数,只需使用task.Parameter。
Parameter的第一个参数指定了参数的名称。default是一个可选参数,用于指定参数的默认值。
再次运行flow.visualize将得到如下输出:

作者提供的图像
你可以通过以下方式覆盖每次运行的默认参数:
-
将参数
parameters添加到flow.run()中: -
或使用 Prefect CLI:
-
或使用 JSON 文件:
你的 JSON 文件应类似于此:
你还可以使用 Prefect Cloud 更改每次运行的参数,下一节将介绍此功能。
监控你的工作流
概述
Prefect 还允许你在 Prefect Cloud 中监控工作流。请按照此说明安装 Prefect Cloud 所需的相关依赖项。
安装和设置所有依赖项后,首先通过运行以下命令创建 Prefect 项目:
$ prefect create project "Iris Project"
接下来,启动本地代理,将我们的流本地部署到单台计算机上:
$ prefect agent local start
然后添加:
...在文件的末尾。
运行文件后,您应该会看到类似以下的内容:
点击输出中的 URL,您将被重定向到概述页面。概述页面显示了您的流的版本、创建时间、流的运行历史和运行摘要。

作者提供的图片
您还可以查看其他运行的摘要、执行时间和配置。

作者提供的图片
这些重要信息能够自动跟踪,真是太酷了!
使用默认参数运行工作流
请注意,工作流已注册到 Prefect Cloud,但尚未执行。要使用默认参数执行工作流,请点击右上角的“快速运行”。

作者提供的图片
点击创建的运行。现在您将能够实时查看新流运行的活动!

作者提供的图片
使用自定义参数运行工作流
要使用自定义参数运行工作流,请点击“运行”标签,然后更改“输入”下的参数。

作者提供的图片
当您对参数满意时,只需点击“运行”按钮即可开始运行。
查看工作流图表
点击“示意图”将显示整个工作流的图表。

作者提供的图片
其他功能
除了上述提到的一些基本功能外,Prefect 还提供了一些其他酷炫的功能,这些功能将显著提高您的工作流效率。
输入缓存
记得我们在文章开头提到的问题吗?通常,如果函数 get_classes 失败,则函数 encode_categorical_columns 创建的数据将被丢弃,整个工作流需要从头开始。
然而,使用 Prefect 时,encode_categorical_columns 的输出会被存储。下次重新运行工作流时,encode_categorical_columns 的输出将被下一个任务无需重新运行 encode_categorical_columns 使用。

作者提供的图片
这可能会大幅减少运行工作流所需的时间。
持久化输出
有时,您可能希望将任务的数据导出到外部位置。这可以通过在任务函数中插入保存数据的代码来实现。
但是,这样做会使得测试函数变得困难。
Prefect 通过以下方式简化了每次运行任务的输出保存:
- 将检查点设置为
True
$ export PREFECT__FLOWS__CHECKPOINTING=true
- 并将
result = LocalResult(dir=...))添加到装饰器@task中。
现在任务 split_data 的输出将被保存到目录 data/processed 中!名称会类似于这样:
prefect-result-2021-11-06t15-37-29-605869-00-00
如果你想自定义文件名称,可以在 @task 中添加 target 参数:
Prefect 还提供了其他 Result 类,比如 GCSResult 和 S3Result。你可以在这里查看 API 文档。
在当前流中使用另一个流的输出
如果你正在处理多个流,例如 data-engineer 流和 data-science 流,你可能希望将 data-engineer 流的输出用于 data-science 流。

作者提供的图片
在将 data-engineer 流的输出保存为文件后,你可以使用 read 方法读取该文件:
连接相关流
想象这种情况:你创建了两个互相依赖的流。流 data-engineer 需要在流 data-science 之前执行。
有人查看了你的工作流但没有理解这两个流之间的关系。结果,他们同时执行了流 data-science 和流 data-engineer,并遇到了错误!

作者提供的图片
为了防止这种情况发生,我们应该指定流之间的关系。幸运的是,Prefect 使这变得更简单。
首先使用 StartFlowRun 获取两个不同的流。将 wait=True 添加到参数中,以确保下游流仅在上游流执行完毕后才执行。
接下来,在 with Flow(...) 上下文管理器下调用 data_science_flow。使用 upstream_tasks 指定将在 data-science 流执行前执行的任务/流。
现在两个流连接如下:

作者提供的图片
相当酷!
调度你的流
Prefect 也使得在特定时间或特定间隔执行流变得无缝。
例如,要每分钟运行一次流,你可以初始化 IntervalSchedule 类,并将 schedule 添加到 with Flow(...) 上下文管理器中:
现在你的流将每分钟重新运行一次!
了解更多关于调度流的不同方式,请访问这里。
日志记录
你可以通过简单地将 log_stdout=True 添加到 @task 中来记录任务中的打印语句:
执行任务时,你应该会看到如下输出:
[2021-11-06 11:41:16-0500] INFO - prefect.TaskRunner | Model accuracy on test set: 93.33
结论
恭喜!你刚刚了解了如何用几行 Python 代码优化你的数据科学工作流程。代码中的小优化在长远中可能会带来巨大的效率提升。
随意玩耍并 在这里 fork 这篇文章的源代码。
我喜欢写关于基本数据科学概念的文章,并玩各种数据科学工具。你可以在 LinkedIn 和 Twitter 上与我联系。
如果你想查看我撰写的所有文章的代码,请给this repo打星。关注我的 Medium,获取最新的数据科学文章:
Khuyen Tran 是一位多产的数据科学作家,她撰写了 一系列令人印象深刻的有用数据科学话题,包括代码和文章。她在 Data Science Simplified 分享了超过 400 个关于数据科学和 Python 的技巧。订阅她的新闻通讯,接收她的每日提示。
原文。转载已获许可。
更多相关话题
用 Rmd 文件在 Python 和 R 中编排动态报告
原文:
www.kdnuggets.com/2019/11/orchestrating-dynamic-reports-python-r-rmd-files.html
评论
由 Marija Ilic,数据分析师/科学家

Python 和 R 互相嵌套
几个用 Python 和 R 编写的支持包允许分析师将 Python 和 R 结合在一个 Python 或 R 脚本中。熟悉 R 的人可以使用 reticulate 包在 R 中调用 Python 代码。然后,一个 R 脚本可以在 Python 和 R 之间互操作(Python 对象被转换为 R 对象,反之亦然)。然而,如果你使用 Python 但希望使用 R 的一些功能,考虑使用用 Python 编写的 rpy2 包来启用嵌入的 R 代码。
R markdown,一个将代码和结果合并到一个输出中的流行框架,提供了优雅的 Python 和 R 集成。我们将创建一个动态报告,将两种语言结合在一个 Rmd 脚本中。我们将使用 外汇交易数据 来捕捉 15 分钟间隔的价格变动,然后绘制交易分析师在定价模型中使用的烛台图(OHLC 图表)。
在 R Markdown 文档中运行 R 和 Python 代码
R markdown,或 Rmd,是一个包含文本或评论(结合文本格式)和由 ```py. From a file, inside R or R Studio, you can create and render useful reports in output formats like HTML, pdf, or word. However, the primary benefit is that source code, outputs, and comments are contained in one file, facilitating easy collaboration among your team.
Even R lovers may not know that Rmd files can contain Python chunks. More conveniently, objects are shared between the environments, allowing programmers to call objects in Python and R in the opposing language.
R Markdown with Python
Let’s examine how to use Python in Rmd. First, ensure Python is installed on your computer and all Python libraries or modules you’re planning to use in Rmd are installed (pip works and virtual environments can be utilized, if preferable).
In Rmd files, Python code chunks are similar to R chunks: Python code is placed inside marks: {python} 和 py.
Here’s a simple R markdown with embedded Python code:

In the example above the csv is loaded with the help of the pandas library, a column is renamed, and the first rows are printed. In the file heading, the report is defined with ### and a single author comment is printed. Here’s the result when we run the Rmd:

Beside the code and output, the heading and author comment prints. Now that the data has been loaded using Python, it can be used inside R:
The R code starts with {r} 包围的 R 代码块的文本文件,文件以 结束。代码后面跟着一个 Python 代码块和在 R 代码中引用的对象。在我们的示例中,R 对象在 reticulate 包的帮助下从 Python 对象转换过来。命令 py$data 检索在 Python 中创建的对象并将其转换为 R 数据框。现在,当创建了 R 数据框后,它可以在 R 代码中进一步使用。
输出效果如下:

现在我们将继续使用 R 并创建一个交易者常用的可视化:烛台图。以下是使用 plotly 库编写的 Candlestick 图表的 R 代码:
这应该显示如下内容:

这个简单的例子演示了如何将 Python 和 R 用于报告创建。流行的 Python pandas 库用于加载和数据准备。然后,R 被用于可视化。
可以创建一个 R 数据对象,然后在 Python 环境中引用。以下是一个示例,其中使用 Python mpl_finance 模块创建了一个可视化:
就这些了!现在你可以选择使用哪种语言,或者让你的团队使用他们偏好的语言进行协作。
开始使用 Rmd
R 和 Python 课程在多个流行平台上均可用(例如:Coursera、Udemy、Vertabelo Academy、Data Camp)。许多课程也涵盖了数据可视化概念。R 和 Python 都是数据科学的优秀工具,可以同时使用。如果你有兴趣开始学习,可以考虑这些:
-
在 Coursera 上,有一个很棒的关于可重复研究和 R markdown 基础的课程:
www.coursera.org/lecture/reproducible-research/r-markdown-5NzHN -
如果你对 R 不太熟悉,Data Camp 提供了一个很好的入门课程:
-
作为 Vertabelo Academy 的作者,我个人推荐我们的 Python 和 R 课程。它们特别适合那些来自商业背景的人士:
-
Edx 提供了许多 Python 和 R 课程,包括来自哈佛、IBM、微软的课程。对于 Python 初学者,可以尝试这个 IBM 课程:
www.edx.org/course/python-basics-for-data-science-2
总结
Python 和 R 是当前最热门的数据科学语言。熟悉这两种语言是很有好处的,因为项目可能需要每种语言的不同方面。有许多包可以帮助将两者集成到使用场景中。一个是 R markdown,一种用于在 R 中创建动态文档的文件格式。Rmd 文件无缝集成了可执行代码和评论。在 reticulate 包的帮助下,可以轻松地在 Python 中访问 R 对象,反之亦然。分析师现在无需在 Python 和 R 之间做出选择——可以在一个文件中集成两者。
简介: Marija Ilic 是一名数据分析师/科学家。她喜欢分析大量数据。Marija 在银行业的 DWH/ETL 开发方面有着丰富的背景。
相关:
-
应用于 Pandas DataFrames 的集合操作
-
你可能不知道的 R 中的十个随机有用的东西
-
R 用户的客户细分
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全领域。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
主题拓展
为什么组织需要数据仓库
原文:
www.kdnuggets.com/2022/09/organizations-need-data-warehouses.html

Fabio 通过 Unsplash
无论你尝试构建什么,你都需要合适的工具。你可以在没有螺丝刀或电钻的情况下安装衣柜,对吧?你不能没有化妆刷来化妆,对吧?处理数据也是如此。数据被认为是新的石油 - 所以你可以想象你需要什么样的工具来处理这样高价值的东西。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
许多公司多年来认识到数据的价值,并决定开始构建机器学习模型,运用分析技能等,以帮助我们对这些数据进行更深入的洞察。但许多人忽视了存储和利用数据是策略中的一个重要方面。
那么你可以在哪里存储、利用和收集数据中的发现 - 在一个地方?这个正确的工具是什么?数据仓库
什么是数据仓库?
数据仓库,也可以称为企业数据仓库,是一个集中存储数据、信息等的仓库,这些数据可以被分析以做出更明智的决策。
它被认为是商业智能的核心组成部分,以及当今任何组织成功的关键。
团队中的业务和数据分析师可以通过以下方式利用数据仓库:
-
绩效测量 - 使用数据查看不同活动的表现,例如某个特定的销售工具。
-
获取验证 - 当使用不同的工具和方法时,你会想要更好地了解这些工具/方法如何改进你的组织目标。
存储的数据可以来自公司的操作数据库或外部来源。
数据仓库与操作数据库的不同之处
操作数据库是一个用于实时管理和存储数据的数据库 - 意味着它只处理当前数据。
然而,数据仓库的工作包括维护历史数据,并帮助知识工作者和组织内的其他方进一步分析,以帮助决策过程。
决策者、分析师和数据专家需要快速访问数据仓库,以帮助他们履行职责。
数据仓库的组成部分是什么?
为了理解数据仓库对业务的好处,我们需要了解数据仓库的实际运作方式。
存储在数据仓库中的数据需要包括报告、仪表板、分析应用程序和临时查询。
数据仓库由原始的原始数据或源数据组成,这些数据可以:
-
不仅处理实时数据,还可以利用更多数据
-
从多个来源收集数据,从而最大化数据质量
-
通过编码和描述不断提高数据的质量
-
能够纠正数据中的错误,如重复数据
-
格式化数据,以便它可以轻松使用并提高查询性能
-
拥有一致的数据历史记录,可以轻松维护
-
改善业务的其他领域,如客户关系管理、销售等
-
向决策者和利益相关者提供集中查看收集的不同类型数据及其关联的视图
为什么需要数据仓库?
组织到达一个点时,他们会意识到所有数据都分散在不同的地方,他们无法看到数据之间的关联,这使得分析师和其他人需要花费时间来找出这些关联,以便向决策者和利益相关者展示。
你希望将所有数据集中在一个地方,以便它可以:
作为单一真实来源
当你的所有数据都存储在一个集中式的存储库中,并且经过正确的维护和管理时,它可以消除数据质量问题、不一致的数据、不准确的数据报告和低查询性能。
一致性
当数据以统一的格式编排时,不仅在整个系统中保持一致,而且使决策者能够基于共享的数据洞察做出准确的决策。一旦数据格式标准化,无论其来源如何,都可以大幅减少风险并提高整体准确性。
更快做出更好的决策!
当你的所有数据、报告和分析都集中在一个地方时,你可以轻松地对大量数据集进行分析。数据仓库不仅提高了数据集访问的效率,还使团队成员能够基于得到的洞察做出更快的决策。
随着公司增长,复杂性也增长
对于任何变得更加创新和成功的公司来说,这都是自然的。这样会导致查询复杂性的增加,分析师、决策者和其他用户将需要更快的查询处理速度。
结论
数据仓库是组织需要的工具,以便拥有可靠和准确的存储数据。它不仅改善了跨组织的数据访问,还使组织能够监控其绩效、改善决策过程——这一切都因为他们知道自己的数据是可信的。
尼莎·阿里亚 是一位数据科学家和自由职业技术写作员。她特别关注提供数据科学职业建议或教程以及围绕数据科学的理论知识。她还希望探索人工智能如何/能够促进人类寿命的延续。作为一名热心学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关内容
使用 Python 的 Pathlib 组织、搜索和备份文件
原文:
www.kdnuggets.com/organize-search-and-back-up-files-with-pythons-pathlib

图片由作者提供
Python 内置的 pathlib 模块 使得处理文件系统路径变得非常简单。在 如何使用 Python 的 Pathlib 导航文件系统 中,我们了解了处理路径对象和导航文件系统的基础知识。现在是时候深入了解了。
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你在 IT 领域的组织
在本教程中,我们将使用 pathlib 模块的功能来处理三项具体的文件管理任务:
-
按扩展名组织文件
-
搜索特定文件
-
备份重要文件
在本教程结束时,你将学会如何使用 pathlib 进行文件管理任务。让我们开始吧!
1. 按扩展名组织文件
当你在为一个项目进行研究和工作时,你通常会创建临时文件并下载相关文档到工作目录中,直到它变得杂乱,你需要整理它。
让我们来看一个简单的例子,其中项目目录包含 requirements.txt、配置文件和 Python 脚本。我们希望将文件按扩展名分类到子目录中——每个扩展名对应一个子目录。为了方便起见,我们选择将扩展名作为子目录的名称。

按扩展名组织文件 | 图片由作者提供
这是一个 Python 脚本,它扫描一个目录,按文件扩展名识别文件,并将它们移动到相应的子目录中:
# organize.py
from pathlib import Path
def organize_files_by_extension(path_to_dir):
path = Path(path_to_dir).expanduser().resolve()
print(f"Resolved path: {path}")
if path.exists() and path.is_dir():
print(f"The directory {path} exists. Proceeding with file organization...")
for item in path.iterdir():
print(f"Found item: {item}")
if item.is_file():
extension = item.suffix.lower()
target_dir = path / extension[1:] # Remove the leading dot
# Ensure the target directory exists
target_dir.mkdir(exist_ok=True)
new_path = target_dir / item.name
# Move the file
item.rename(new_path)
# Check if the file has been moved
if new_path.exists():
print(f"Successfully moved {item} to {new_path}")
else:
print(f"Failed to move {item} to {new_path}")
else:
print(f"Error: {path} does not exist or is not a directory.")
organize_files_by_extension('new_project')
organize_files_by_extension() 函数接受一个目录路径作为输入,将其解析为绝对路径,并按文件扩展名在该目录内组织文件。它首先确保指定的路径存在且为目录。
然后,它遍历目录中的所有项目。对于每个文件,它获取文件扩展名,创建一个以扩展名命名的新目录(如果该目录尚不存在),并将文件移动到这个新目录中。
在移动每个文件后,它会通过检查文件在新位置的存在来确认操作是否成功。如果指定路径不存在或不是目录,它会打印错误信息。
下面是示例函数调用的输出(在 new_project 目录中整理文件):

现在在你的工作环境中的项目目录上尝试这个。我使用了 if-else 来处理错误。但你也可以使用 try-except 块来改进这个版本。
2. 查找特定文件
有时你可能不希望像前面的示例那样按扩展名将文件组织到不同的子目录中。但你可能只想找到所有具有特定扩展名的文件(如所有图像文件),为此你可以使用 globbing。
假设我们想找到 requirements.txt 文件来查看项目的依赖项。让我们使用相同的示例,但在按扩展名将文件分组到子目录之后。
如果你使用如上所示的 glob() 方法在路径对象上查找所有文本文件(由模式 '*.txt' 定义),你会发现它没有找到文本文件:
# search.py
from pathlib import Path
def search_and_process_text_files(directory):
path = Path(directory)
path = path.resolve()
for text_file in path.glob('*.txt'):
# process text files as needed
print(f'Processing {text_file}...')
print(text_file.read_text())
search_and_process_text_files('new_project')
这是因为 glob() 只搜索当前目录,而该目录不包含 requirements.txt 文件。requirements.txt 文件位于 txt 子目录中。因此,你必须使用 递归 globbing 和 rglob() 方法。
所以这里是找到文本文件并打印其内容的代码:
from pathlib import Path
def search_and_process_text_files(directory):
path = Path(directory)
path = path.resolve()
for text_file in path.rglob('*.txt'):
# process text files as needed
print(f'Processing {text_file}...')
print(text_file.read_text())
search_and_process_text_files('new_project')
search_and_process_text_files 函数接收一个目录路径作为输入,将其解析为绝对路径,并使用 rglob() 方法在该目录 及 其子目录中查找所有 .txt 文件。
对于找到的每个文本文件,它打印文件的路径,然后读取并打印出文件的内容。此函数对于递归地定位和处理指定目录中的所有文本文件非常有用。
由于 requirements.txt 是我们示例中唯一的文本文件,我们得到了以下输出:
Output >>>
Processing /home/balapriya/new_project/txt/requirements.txt...
psycopg2==2.9.0
scikit-learn==1.5.0
现在你知道如何使用 globbing 和递归 globbing,尝试重新做第一个任务——按扩展名整理文件——使用 globbing 查找并分组文件,然后将它们移动到目标子目录。
3. 备份重要文件
迄今为止我们看到的示例是按扩展名整理文件和查找特定文件。但如何备份某些重要文件呢?为什么不呢?
在这里,我们希望将文件从项目目录复制到备份目录,而不是将文件移动到另一个位置。除了 pathlib,我们还将使用 shutil 模块的 copy 函数。
让我们创建一个函数,将所有具有特定扩展名(所有 .py 文件)的文件复制到备份目录:
#back_up.py
import shutil
from pathlib import Path
def back_up_files(directory, backup_directory):
path = Path(directory)
backup_path = Path(backup_directory)
backup_path.mkdir(parents=True, exist_ok=True)
for important_file in path.rglob('*.py'):
shutil.copy(important_file, backup_path / important_file.name)
print(f'Backed up {important_file} to {backup_path}')
back_up_files('new_project', 'backup')
back_up_files() 函数接收一个现有的目录路径和一个备份目录路径函数,并将指定目录及其子目录中的所有 Python 文件备份到指定的备份目录。
它为源目录和备份目录创建路径对象,并通过创建备份目录及其任何必要的父目录(如果尚不存在)来确保备份目录的存在。
然后,函数使用 rglob() 方法迭代源目录中的所有 .py 文件。对于每个找到的 Python 文件,它将文件复制到备份目录,同时保留原始文件名。本质上,这个函数帮助在项目目录内创建所有 Python 文件的备份。
运行脚本并验证输出后,你可以随时检查备份目录的内容:

对于你的示例目录,你可以使用 back_up_files('/path/to/directory', '/path/to/backup/directory') 来备份感兴趣的文件。
总结
在本教程中,我们探讨了使用 Python 的 pathlib 模块来按扩展名组织文件、搜索特定文件和备份重要文件的实际示例。你可以在 GitHub 上找到本教程中使用的所有代码。
正如你所见,pathlib 模块使得处理文件路径和文件管理任务变得更加轻松和高效。现在,继续在你的项目中应用这些概念,以更好地处理文件管理任务。祝编程愉快!
Bala Priya C**** 是来自印度的开发者和技术作家。她喜欢在数学、编程、数据科学和内容创作的交汇处工作。她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。她喜欢阅读、写作、编码和喝咖啡!目前,她正在通过编写教程、操作指南、意见文章等方式学习并与开发者社区分享她的知识。Bala 还创建了有趣的资源概述和编码教程。
相关主题
疫情分析:应对新问题的数据科学策略
原文:
www.kdnuggets.com/2020/04/outbreak-analytics-data-science-novel-problem.html
评论
由 Susan Sivek 提供,Alteryx。

我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你组织的 IT
你走在超市的一条过道上,去拿你最喜欢的麦片。在乳制品过道上,有人因 COVID-19 咳嗽。
你在拿牛奶之前先拿麦片的决定是否可能让你保持健康?
在全球疫情期间,我们在做简单的日常决定时都会问这样的问题。但现在设想一下,你的工作是创建一个 COVID-19 传播模型,这个模型需要考虑人类不可预测的、近乎随机的选择。你的模型还可能包括政府的社交距离规定、医院护理的可用性、人口中的既有疾病等。
听起来复杂吗?确实如此,但来自各种领域的研究人员正在努力创建尽可能准确、有用的模型,以预测和解释 COVID-19 的传播。我不是流行病学家,但如果你也对迄今为止公布的数据可视化和建模感到印象深刻和好奇,这篇文章就是为你准备的。
我查阅了一些最近的研究,以了解这些研究人员如何进行所谓的 疫情分析。这里是对这一独特分析过程几个组成部分的初步介绍。我们也会发现一些其他分析应用的经验教训。
估算病毒传播
“一旦我们知道 R[0],我们就能够掌握疫情的规模。” - 电影《传染病》

再生数,或 R[0](读作“R 零”),指的是一个生病的人可能感染的人的数量。由于人口统计、气候、社会结构和社交距离措施等因素,R[0] 在疾病发生的每个时间和地点都会发生变化。研究人员通过确定第一次感染和第二次感染之间的时间(生成时间,当这种时间对许多对病人已知时,可以绘制为生成时间分布)来计算 R[0]。估计 R[0] 对于预测疾病传播至关重要。对于引起 COVID-19 的 SARS-CoV-2,目前R[0] 被认为在不同地方的范围为 1.5 到 3.5。
一个名为 R0 的 R 包(可以在这里获取)能够利用疫情数据计算当前的 R[0]。该包提供了五种不同的计算方法,还具有一个灵敏度分析选项,显示了哪种时间窗口或生成时间的选择最适合数据。
还有一个类似的 R 包,EpiEstim,由不同的研究小组开发,具有Excel 选项。EpiEstim 基于分支过程模型,并根据简单的时间序列数据估计 R[0]。该模型试图捕捉每个感染者将感染的人的数量,但带有随机性(或随机性)元素——就像在商店里与感染者随机相遇一样。下图(更大图的一部分)显示了该模型为过去五次疫情生成的 R[0] 估计。

病原体基因组测序
“它展示了新奇的特征……它是哥斯拉、金刚和弗兰肯斯坦的结合体。”
- Contagion

对来自不同地点和时间的病人的 SARS-CoV-2 样本进行基因分析可以帮助研究人员追踪病毒的传播和突变。这项分析还可以帮助快速识别可能的治疗方法。研究人员最近展示了一种新的机器学习方法,通过基因组识别未知病毒的类型及其不同的变种(即确定其分类,如“冠状病毒”的广泛类别)。
这种方法将 SARS-CoV-2 基因组序列转换为数值表示(详见 完整研究论文)。几乎 15,000 种其他病毒的序列也被用于训练数据中。研究人员训练了六种不同的机器学习模型(线性判别分析、线性支持向量机、二次支持向量机、细化的 KNN、子空间判别分析和子空间 KNN)。训练后的模型对 COVID-19 病毒株基因组的最高分类等级进行标签预测。研究人员随后将模型转向下一个更具体的分类等级,并重复这一过程。
下图展示了研究人员在最后两次测试中的结果,这些测试将 153 个病毒序列分类为四个亚属和 COVID-19,然后将 76 个病毒序列分类为其他 Sarbecovirus 类型或 COVID-19。

这一策略不仅帮助确认了 SARS-CoV-2 应正确归类于其他冠状病毒科和 β 冠状病毒病原体,而且还发现它与在蝙蝠中发现的其他病毒有重要的相似之处。研究人员认为,他们的方法更快(包括 10 倍交叉验证在内的 10 分钟内),且能够比较更多、更具多样性的样本,相比于以前的分析过程。虽然对当前疫情可能会有一些见解,但这种方法对未来的疫情爆发也可能有所帮助。
尽管存在不确定性,预测疾病传播
“基于我们的模型,根据 R[0] 为 3.2 … 这是我们预计在 48 小时后达到的情况。”
- 传染*

一种流行病学建模方法是创建一个“SIR 模型”,该模型将整体人群划分为“易感”、“感染”和“移除”(即从疾病中康复并被赋予一定程度免疫,或因死亡不再在人群中)这三个“隔间”。
然而,生成这样的模型从来都不容易。由于多种原因,包括制度性障碍、缺乏检测、未知或无症状病例等,疫情数据可能难以准确收集。而且,正如我们所见,各国政府在不同时间实施了不同的社交距离和隔离措施,这可能对“易感”隔间中的人数产生不可预测的影响。
为了处理所有不确定性来源,一组研究人员开发了他们所谓的“eSIR”模型——一个扩展模型,包括“一个时间变化的概率,表示易感者遇到感染者的概率或反之亦然”,以及一个新的区隔来包括选择自我隔离的易感者。这两个因素在特定地区会根据实施隔离协议的时间而有所变化。
为了进一步将不确定性纳入模型,研究人员使用了马尔可夫链蒙特卡罗(MCMC)算法。(这里有两个对 MCMC 的解释:一个较简单的,一个较复杂的)。MCMC 方法允许对那些不能直接知道的分布(如 SARS-CoV-2 感染的真实数量)或过于昂贵以至于难以计算的分布进行近似。eSIR 模型的预测旨在揭示疫情中的“转折点”。转折点包括每日新增病例停止增长的时候,以及感染病例达到最高点的时候。该模型还可以提供 R[0]的估计值。
研究人员正在发布一个名为 eSIR 的 R 包,该包生成模型、ggplot2 对象和总结统计数据。这种方法的有用之处在于,它可以帮助确定哪些隔离策略可能最有效以及何时实施。正如研究人员所说,“……过于严格的隔离可能会适得其反;人们可能会失去对隔离系统的信任和耐心,因此可能会尝试减少遵守或甚至避免隔离。”必须权衡实施严格隔离系统的风险与疾病预防的收益。该模型提供了一种重要计算的途径。

对所有建模的启示
从这些尚处于初步阶段的模型中,我们可以学到哪些超越疫情的教训?有几个关键点。
首先,这些模型展示了在应对极其复杂情况时的快速创新。(上述基因组和“eSIR”研究仍为“预印本”,即尚未经过同行评审,并已尽可能快速发布,以贡献于科学界应对疫情的努力。)尽管面临巨大的压力,看到研究人员如此迅速地将创造力应用于这场危机,实在令人印象深刻,也激励了我们在寻求应对众多新挑战的解决方案。
其次,另一个可能对数据人员来说熟悉的挑战是:让决策者采取行动 基于数据洞察。伟大的“扁平化曲线”可视化和相关的预测似乎对政策制定者和公众产生了强烈的影响。同样,数据专家需要能够清晰地沟通他们的分析和模型——例如,通过 有效的数据可视化——组织也应在各个领域建立数据素养。
最后,我审查的研究经常提到获取优质 COVID-19 数据以建立良好模型的挑战。即使在正常时期,获取我们需要的数据种类和质量也可能很困难。关于大流行的模型——或者任何其他现象——只有建立在高质量数据之上才有价值。数据无处不在,但并非所有数据都值得信赖、可用或相关。每个组织都需要建立稳固的数据收集、管理和分析结构(正如 这些流行病学家建议的用于爆发)。有了这些准备,如果出现任何危机,你的响应可以基于准确、相关、最新的数据。
原文。经许可转载。
个人简介: 苏珊·库里·西维克,博士,是一位作家和数据爱好者,喜欢以日常语言解释复杂的想法,有时以有趣的方式进行。她喜欢美食、科幻小说和狗。
相关内容:
更多相关话题
异常值检测方法的直观可视化
原文:
www.kdnuggets.com/2019/02/outlier-detection-methods-cheat-sheet.html
 评论
评论
异常值是指那些似乎无法很好适应剩余数据或模型的数据实例。虽然许多机器学习算法故意不考虑异常值,或者可以修改为明确地丢弃它们,但有时异常值本身可能就是关键。
在欺诈检测中,这种情况尤为明显,欺诈检测利用异常值来识别欺诈活动。如果你经常在纽约及其周边以及在线使用信用卡,主要用于一些微不足道的消费?今天早上在 Soho 的咖啡店用过,晚上在 Upper West Side 吃过晚饭,但在这期间在巴黎“亲自”花费几千美元购买电子设备?这就是你的异常值,这些会被用各种机器学习技术进行不懈追踪。
这个简单的例子实际上让这看起来过于简单了。实际上,没有普遍适用的异常值定义;你能想象试图定义一个具体规则来界定地理上“过远”而不适用的情况,并且这个规则适用于所有类似上述情况的欺诈检测场景吗?即使我们能达成共识什么是异常值,根据应用的不同,我们可能不希望去除它,只是对其存在保持警觉。
即使我们说我们希望在检测到异常值时收到通知,仍然有各种方法可以实现这一点。想要使用简单的描述性统计方法,比如识别在正态分布中偏离均值特定倍数的低维数据点?很好,如果这对你有效。但也有许多其他方法。
查看这个用于异常值检测方法的可视化,它来自于Python 异常值检测(PyOD)的创建者——我鼓励你点击查看以享受高清分辨率的效果:
点击放大
至少有 12 种异常值检测方法以非常直观的方式进行了可视化。他们在这方面做得非常出色。
当然,虽然这作为了解不同异常值检测方法如何工作的极好备忘单,但实际上这是来自于之前提到的 Python 项目:
PyOD 是一个全面且可扩展的 Python 工具包,用于检测多变量数据中的异常对象。这个既令人兴奋又具有挑战性的领域通常被称为异常值检测或异常检测。自 2017 年以来,PyOD 已成功应用于各种学术研究和商业产品中。
如果你正在学习异常值检测,PyOD 是一个简单的工具包,具有 Scikit-learn 风格的 API,包括许多检测算法的实现(它的 GitHub 仓库链接到算法的原始论文),且足够直观,可以几乎立即上手,只要你对当代 Python 机器学习生态系统的各个组件有一定了解。你可以在这里找到项目文档。
相关:
-
如何使你的机器学习模型对异常值具有鲁棒性
-
异常值检测的四种技术
-
数据科学基础:从数据中可以挖掘出哪些模式?
更多相关话题
使用 Great Expectations 解决您的数据质量问题
原文:
www.kdnuggets.com/2023/01/overcome-data-quality-issues-great-expectations.html
Gartner, Inc. 估计,不良数据的成本 每年给组织带来的平均损失为 1290 万美元。
我们每天处理 PB 级的数据,大规模的数据量中常常会出现数据质量问题。不良数据会给组织带来金钱、声誉和时间上的损失。因此,持续监控和验证数据质量非常重要。
我们的三大课程推荐
1. Google 网络安全证书 - 加速您的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您组织的 IT
什么是不良数据?
不良数据包括不准确的信息、缺失的数据、错误的信息、不符合规范的数据和重复的数据。不良数据会导致错误的数据分析,从而导致不良决策和无效的策略。
Experian 数据质量发现,平均公司因数据不足而损失了 12%的收入。除了金钱,公司还会遭受浪费时间的损失。
在处理数据之前识别异常将帮助组织更好地洞察客户行为并减少成本。
Great Expectations 库帮助组织通过 200 多种现成规则来验证和确认数据中的异常。
什么是 Great Expectations(GE)?
Great Expectations 是一个开源的 Python 库,帮助我们验证数据。Great expectations 提供了一组方法或函数来帮助数据工程师 快速验证给定的数据集。
在这篇文章中,我们将探讨如何通过 Great Expectations 库进行数据验证的步骤。
Great Expectations 如何工作
GE 就像是数据的单元测试。GE 提供了称为 Expectations 的断言,用来对测试数据应用一些规则。例如,保险单文件中的政策 ID/号码不应该为空。要设置和执行 GE,必须按照以下步骤进行。尽管有多种方法可以使用 GE(例如通过其 CLI),我将在本文中解释编程方式的设置。本文解释的所有源代码均可在这个 GitHub 仓库 中找到。
第一步:设置数据配置
GE 有一个存储的概念。存储就是它可以在磁盘上存储期望(规则/断言)、运行详情、检查点详情、验证结果和数据文档(验证结果的静态 HTML 版本)的物理位置。点击这里 了解更多关于存储的信息。
GE 支持多种存储后端。本文中,我们使用文件存储后端和默认设置。GE 还支持其他存储后端,如 AWS(亚马逊 Web 服务)S3、Azure Blob、PostgreSQL 等。请参阅 了解更多关于后端的信息。下面的代码片段展示了一个非常简单的数据配置:
STORE_FOLDER = "/Users/saisyam/work/github/great-expectations-sample/ge_data"
#Setup data config
data_context_config = DataContextConfig(
datasources = {},
store_backend_defaults = FilesystemStoreBackendDefaults(root_directory=STORE_FOLDER)
)
context = BaseDataContext(project_config = data_context_config)
上述配置使用了默认的文件存储后端。GE 将自动创建运行期望所需的文件夹。我们将在下一步中添加数据源。
第二步:设置数据源配置
GE 支持三种类型的数据源:
-
Pandas
-
Spark
-
SQLAlchemy
数据源配置告诉 GE 使用特定的执行引擎来处理提供的数据集。例如,如果你将数据源配置为使用 Pandas 执行引擎,你需要提供一个 Pandas 数据框给 GE 以运行期望。下面是一个使用 Pandas 作为数据源的示例:
datasource_config = {
"name": "sales_datasource",
"class_name": "Datasource",
"module_name": "great_expectations.datasource",
"execution_engine": {
"module_name": "great_expectations.execution_engine",
"class_name": "PandasExecutionEngine",
},
"data_connectors": {
"default_runtime_data_connector_name": {
"class_name": "RuntimeDataConnector",
"module_name": "great_expectations.datasource.data_connector",
"batch_identifiers": ["default_identifier_name"],
},
},
}
context.add_datasource(**datasource_config)
请参阅 这份文档 以获取有关数据源的更多信息。
第三步:创建期望套件并添加期望
这一步是关键部分。在这一步中,我们将创建一个套件并向套件中添加期望。你可以将套件视为一组将作为批次运行的期望。在这里创建的期望是为了验证一个示例销售报告。你可以下载 sales.csv 文件。
下面的代码片段展示了如何创建一个套件并添加期望。我们将向套件中添加两个期望。
# Create expectations suite and add expectations
suite = context.create_expectation_suite(expectation_suite_name="sales_suite", overwrite_existing=True)
expectation_config_1 = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_in_set",
kwargs={
"column": "product_group",
"value_set": ["PG1", "PG2", "PG3", "PG4", "PG5", "PG6"]
}
)
suite.add_expectation(expectation_configuration=expectation_config_1)
expectation_config_2 = ExpectationConfiguration(
expectation_type="expect_column_values_to_be_unique",
kwargs={
"column": "id"
}
)
suite.add_expectation(expectation_configuration=expectation_config_2)
context.save_expectation_suite(suite, "sales_suite")
第一个期望 “expect_column_values_to_be_in_set” 检查列(product_group)值是否等于给定 value_set 中的任何值。第二个期望检查 “id” 列的值是否唯一。
一旦期望被添加并保存后,我们现在可以在数据集上运行这些期望,这将在第四步中进行。
第四步:加载并验证数据
在这一步骤中,我们将 CSV 文件加载到 pandas.DataFrame 中,并创建一个检查点以运行我们之前创建的期望。
# load and validate data
df = pd.read_csv("./sales.csv")
batch_request = RuntimeBatchRequest(
datasource_name="sales_datasource",
data_connector_name="default_runtime_data_connector_name",
data_asset_name="product_sales",
runtime_parameters={"batch_data":df},
batch_identifiers={"default_identifier_name":"default_identifier"}
)
checkpoint_config = {
"name": "product_sales_checkpoint",
"config_version": 1,
"class_name":"SimpleCheckpoint",
"expectation_suite_name": "sales_suite"
}
context.add_checkpoint(**checkpoint_config)
results = context.run_checkpoint(
checkpoint_name="product_sales_checkpoint",
validations=[
{"batch_request": batch_request}
]
)
我们为数据创建了一个批量请求,提供数据源名称,这将告诉 GE 使用特定的执行引擎,在我们的例子中是 Pandas。我们创建一个检查点配置,然后将批量请求与检查点进行验证。如果期望适用于单个检查点中的批量数据,您可以添加多个批量请求。run_checkpoint方法以 JSON 格式返回结果,可以用于进一步处理或分析。
结果
一旦我们在数据集上运行了期望,GE 会创建一个静态 HTML 仪表板,显示检查点的结果。结果包括评估期望的数量、成功的期望、不成功的期望和成功百分比。任何与给定期望不匹配的记录将在页面上突出显示。以下是成功执行的示例:

来源:伟大期望
以下是一个失败期望的示例:

来源:伟大期望
结论
我们已通过四个步骤设置了 GE,并成功在给定数据集上运行了期望。GE 具有更高级的功能,如编写自定义期望,我们将在未来的文章中介绍。许多组织广泛使用 GE 来定制客户需求并编写自定义期望。
Saisyam Dampuri 拥有超过 18 年的软件开发经验,热衷于探索新技术和工具。他目前在美国德克萨斯州 Anblicks 担任高级云架构师。在不编程的时候,他会忙于摄影、烹饪和旅行。
更多相关内容
如何克服对数学的恐惧,并学习数据科学所需的数学
原文:
www.kdnuggets.com/2021/03/overcome-fear-learn-math-data-science.html

编辑器提供的图像
有一件事你需要首先关注:数据科学所需的数学量。使用这些文章作为参考,了解你需要学习什么:
-
一篇很好的博客文章来自 Sharp Sight Labs 的Josh Ebner。他解释了初级数据科学家与高级数据科学家之间的区别,数据科学基础技能所需的数学,数据科学理论与实践之间的区别等。
-
一篇博客文章来自Tim Hopper。他曾是数学专业学生,并在成为数据科学家之前是数学博士生一年。这里是他关于数据科学所需数学量的 YouTube 演讲。
-
Rebecca Vickery有一个数据科学所需学习的数学主题列表。这是我用作参考的内容。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
根据上述内容,这里是我学习数学的方式:
第一步:一种新的学习方法
学习统计学非常令人困惑。我无法将不同部分的主题联系起来。我参加了宾州州立大学的 STAT100 在线课程(一周),但仍然记不住任何东西。
然后是概率。我花了数天数夜和周末试图掌握贝叶斯定理,但它就像一个我永远无法解开的谜。我问自己:
在我个人生活中,我在过去几个月是如何娱乐自己的?我从哪里找到了快乐?
我喜欢观看 纸牌屋、金装律师、攻壳机动队、亿万 和 星球大战。我曾 沉迷观看 了这些剧集的许多季节/卷。我决定在一整周内沉迷于概率学习:从周一到周日。我制定了一个新计划:
我不会阅读数学教科书。我也不会参加任何 MOOC。原因是:这两者都源于为研究生学习(3+ 年)设计的学术标准。学术界的人已经是这些学科的专家,他们已经教授了这些内容多年,因此,关于这些内容的 MOOC/书籍至少是一个或两个学期的长度。那么,对于一个对这些学科一无所知且没有一两个学期时间学习的人来说呢?
我如何学习
-
如果我在一个地方没有理解某个内容,我就会离开,转到另一个地方。与其在同一篇文章、博客或视频上花费几个小时,不如专注于当前主题的学习,这样我能更灵活。我使用了一个又一个资源,直到我理解了概念。
-
我练习了问题。我们不能通过阅读和理解来学习数学。我们需要将其应用到问题中。mathsisfun.com 提供了带有答案的问题列表。
第 2 步:沉迷于*
我最终沉迷于学习、阅读和练习了许多概念:
-
Eddie Woo 的离散随机变量。总共 3 个视频(包括期望值)
-
来自 Eddie Woo 的排列与组合
-
来自 Mario’s Math Tutoring 的排列与组合
-
来自 Math is fun 的贝叶斯定理
-
来自 Investopedia 的条件概率、贝叶斯定理等内容
-
来自 zedstatistics 的概率分布(以梯度形式解释)
-
来自 Explained by Michael 的概率密度函数(以代数和图形形式解释)
-
来自 Explained by Michael 的累积分布函数
-
来自 Jason Gibson 和 mathtutordvd.com 的离散概率分布(这是关于离散概率分布的最佳视频)
-
一篇优秀的 StackExchange 文章 关于 PDF 与 PMF
-
来自我上面提到的 StackExchange 帖子的数学洞察链接关于 PDF 的想法
-
MIT OCW 的PDF 讲座(它在 StackExchange 帖子中提到)
现在我可以用费曼技巧解释关于 PDF 的一切 😃
我不是唯一一个理解这个学习原则的人。Ken Jee在他的 YouTube 视频中提出了一个类似的计划。
Ken Jee 在YouTube上的内容。
第 3 步:统计学和线性回归
最后,我狂看了统计学基础,由 StatQuest 的Josh Starmer主讲。
他现在正在观看的线性回归和线性模型播放列表。这位讲解者非常擅长解释内容。他不浪费时间,直奔主题,确保在继续之前进行复习,而且几乎没有代码。他追求清晰和基础,这才是学习任何东西的核心。Josh 的对数和线性回归介绍是我迄今为止见过的最佳。而且你一定会喜欢他的 BAMs、tiny bam 和 triple BAMs 😃
第 4 步:线性代数
我推荐你从这些地方学习线性代数,而不是使用传统的学习方法(拿起一本书,花几个月时间)。你可以在一周内完成。他们有你进行数据科学所需的所有线性代数:
-
来自Ritchie Ng的线性代数
-
来自Dive Into Deep Learning的线性代数
-
来自Pablo Caceres的线性代数(最全面。我做了 70%的内容,因为我想学习某些主题。它包含了很多理论,我认为它包含了足够的内容,即使是深度学习也需要了解)
-
来自Deep Learning Book的线性代数
第 5 步:克服对数学的恐惧
许多学习者对数学感到恐惧。这种数学恐惧让我们无法理解和掌握我们需要学习的任何主题。我们认为自己没有数学头脑。像乔治·坎托尔那样成为天才,创造数学实体,并能够理解和使用数学作为解决问题的工具或模型,这两者是截然不同的。前者是宇宙(或上帝)赐予的礼物,而后者是一种技能。此外,我们既不是天才,也不是哈佛或牛津的优秀毕业生。我们无法改变这一限制,但我们可以改变态度和能力,将数学作为技能来掌握。查看这些视频来改变你对数学的信念:
列表 A:
你喜欢的任何来自数学巫师的视频(我已经看了 30 多个)。从这些视频开始:
-
6 个鲜为人知的理由为什么自学是数学成功的关键
列表 B:
-
学习数学需要什么?生活需要什么? | Miroslav Lovric
-
任何人都可以成为数学达人一旦他们知道最佳学习技巧 | Po-Shen Loh
-
如何成为数学高手,以及学习的其他惊人事实 | Jo Boaler
-
我们教育系统的有趣故事 | Adhitya Iyer
最后一部视频是关于印度教育系统如何运作的。我在这里学习过,所以我有点偏见把它包括在内。顺便说一句,这是一个有趣的视频。
列表 C:
选择一个你一直想学的数学主题,去数学很有趣阅读并完成所有练习。通过这样做,你会立刻减少一半的恐惧。解释已经简单到让你看穿数学,无论你的年龄或背景如何。
第 6 步:如何不忘记你所学的内容
当你通过阅读、观看和解决问题来学习上述内容时,你很快会在一周左右的时间内忘记 80-90%的内容。让学习持久的唯一方法是:在你的工作中每天使用它。
成为数据科学家的自学诅咒是你不能使用你所学到的一切。因此,这里有一种不同的方法:
-
一旦你学会了一个主题,接下来使用费曼技巧
-
将主题的标题放在一个列表上
-
在一周结束时,检查你的列表,并使用费曼技巧来解释列表上的所有主题

这种方法的好处
这种Binge-* + 费曼技巧的方法有几个好处:
-
你节省了很多时间,因为你不需要阅读整本书或进行大规模在线课程,这些都需要几个月的时间。
-
你只学习你需要的内容。数据科学不是数学。不要忘记业务价值、作品集准备、利益相关者和使用数据讲故事。这些比“全面学习数学”更重要。
-
你的重点仍然放在实际工作上。
-
你学习如何解释。这是在工作场所中能够有效表达观点的一个非常有用的技能,同时尊重周围的每个人。它在面试中也很有帮助。
-
既然你已经掌握了某些数学主题的基本思想,你可以在就业后深入探索和学习。
Arnuld 是一位具有 5 年经验的工业软件开发人员,擅长 C、C++、Linux 和 UNIX。在转型进入数据科学并作为数据科学内容撰稿人工作了一年后,他目前担任自由职业数据科学家。
更多相关主题
克服多语言语音技术中的障碍:前 5 大挑战及创新解决方案
介绍
我们的前 3 个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业的轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力。
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求。
你多久会在用西班牙语(你的首选语言)向语音助手提问后不得不暂停一下,然后重新用语音助手能理解的语言(可能是英语)重复你的请求,因为语音助手没有理解你的西班牙语请求?或者你多久会在要求语音助手播放你最喜欢的艺术家 A. R. Rahman 的音乐时故意发错音,因为你知道如果你正确地说出他们的名字,语音助手根本听不懂,但如果你说 A. R. Ramen,语音助手就能明白?此外,你多久会在语音助手用它那安抚的、全知的声音把你最喜欢的音乐剧《悲惨世界》叫成“Les Miz-er-ables”时感到尴尬?
尽管语音助手在大约十年前已经成为主流,但它们在多语言环境中的用户请求理解方面仍然显得很简单。在多语言家庭日益增多、现有和潜在用户群体变得越来越全球化和多样化的世界中,语音助手在理解用户请求时必须做到无缝对接,无论是语言、方言、口音、语调、调制还是其他语音特征。然而,语音助手在与用户进行流畅对话方面依然大大滞后于人类之间的自然交流。本文将探讨使语音助手能够进行多语言操作的主要挑战,并讨论一些可能的解决策略。我们将在整篇文章中使用假设的语音助手Nova作为示例。
语音助手的工作原理
在深入探讨使语音助手用户体验多语言化的挑战和机遇之前,让我们先了解一下语音助手是如何工作的。以 Nova 为假设的语音助手,我们看看请求音乐曲目的端到端流程是什么样的(参考)。

图 1. 假设语音助手 Nova 的端到端概览
如图 1 所示,当用户请求 Nova 播放流行乐队 Coldplay 的原声音乐时,用户的声音信号首先被转换为一串文本令牌,这一步是人类与语音助手互动的第一步。这一阶段称为自动语音识别(ASR)或语音转文本(STT)。一旦文本令牌串生成,它将被传递到自然语言理解步骤,在这里语音助手尝试理解用户意图的语义和句法含义。在这种情况下,语音助手的 NLU 解释用户在寻找由乐队 Coldplay 演唱的歌曲(即解释 Coldplay 是一个乐队),这些歌曲的性质是原声的(即在该乐队的专辑中查找歌曲的元数据,只选择版本为原声的歌曲)。然后,这种用户意图理解被用来查询后端以找到用户所寻找的内容。最后,实际的用户查询内容以及任何其他需要呈现给用户的附加信息被转移到下一步骤。在这一步中,响应和任何其他可用信息被用来装饰用户体验,并令人满意地响应用户查询。在这种情况下,输出将是一个文本到语音(TTS)输出(“这是一些 Coldplay 的原声音乐”),接着播放为此用户查询所选择的实际歌曲。
构建多语言语音助手的挑战
多语言语音助手(VAs)意味着能够理解和回应多种语言的语音助手,无论这些语言是否由同一个人或不同的人说,或者如果它们在同一句话中混合着另一种语言(例如“Nova, arrêt! Play something else”)。以下是语音助手在多模态环境中无缝操作时面临的主要挑战。
语言资源的数量和质量不足
为了使语音助手能够很好地解析和理解查询,它需要在该语言的大量训练数据上进行训练。这些数据包括人类的语音数据、地面真实情况的注释、大量的文本语料库、用于改进 TTS(例如发音词典)的资源和语言模型。虽然这些资源在英语、西班牙语和德语等热门语言中很容易获得,但对于斯瓦希里语、普什图语或捷克语等语言,它们的可用性有限甚至不存在。尽管这些语言有足够多的使用者,但仍没有结构化的资源。为多种语言创建这些资源可能成本高昂、复杂且劳动密集,从而成为进步的障碍。
语言变化
语言有不同的方言、口音、变体和地区适应。处理这些变体对语音助手来说是一个挑战。除非语音助手适应这些语言细微差别,否则很难正确理解用户请求或以相同的语言语调作出回应,以提供自然且更像人类的体验。例如,仅英国就有超过 40 种英语口音。另一个例子是墨西哥讲的西班牙语与西班牙讲的西班牙语的区别。
语言识别和适应
多语言用户在与其他人互动时通常会切换语言,他们可能希望与语音助手的互动也能自然地进行。例如,“Hinglish”是一个常用术语,用于描述一个人在讲话时使用印地语和英语的单词。能够识别用户与语音助手互动时使用的语言并相应调整回应是一个困难的挑战,目前没有主流的语音助手能够做到这一点。
语言翻译
扩展语音助手到多种语言的一种方法可能是将来自像卢森堡语这样的非主流语言的 ASR 输出翻译成可以被 NLU 层更准确解释的语言,如英语。常用的翻译技术包括使用一种或多种技术,如神经机器翻译(NMT)、统计机器翻译(SMT)、基于规则的机器翻译(RBMT)等。然而,这些算法可能无法很好地扩展到多样化的语言集,并且可能还需要大量的训练数据。此外,语言特定的细微差别往往会丧失,翻译版本常常显得生硬和不自然。翻译的质量在扩展多语言语音助手方面仍然是一个持续的挑战。翻译步骤中的另一个挑战是它引入的延迟,降低了人类与语音助手互动的体验。
真实语言理解
语言通常具有独特的语法结构。例如,虽然英语有单数和复数的概念,但梵语有 3 种(单数、双数、复数)。还可能存在一些难以翻译的成语。最后,文化细微差别和文化参考可能会被翻译得不好,除非翻译技术具有高质量的语义理解。开发语言特定的 NLU 模型是昂贵的。
克服构建多语言语音助手的挑战
上述挑战是难以解决的问题。然而,有一些方法可以部分地(即使不能完全)缓解这些挑战。以下是一些可以解决上述一个或多个挑战的技术。
利用深度学习检测语言
解释句子意义的第一步是知道句子属于哪种语言。这时深度学习发挥作用。深度学习使用人工神经网络和大量数据来生成似乎人类般的输出。基于 Transformer 的架构(如 BERT)在语言检测中表现成功,即使在资源匮乏的语言中也不例外。一个替代的基于 RNN 的语言检测模型是递归神经网络(RNN)。这些模型的一个应用示例是,如果一个通常讲英语的用户某天突然用西班牙语与语音助手对话,语音助手可以正确检测并识别西班牙语。
使用上下文机器翻译来“理解”请求
一旦检测到语言,解释句子的下一步是将 ASR 阶段的输出,即一串标记,翻译成可以处理的语言,以生成回应。与可能无法始终了解语境和语音界面特性的翻译 API 不同,这些 API 还会因高延迟而引入次优的响应延迟,从而降低用户体验。然而,如果将上下文感知的机器翻译模型集成到语音助手中,翻译的质量和准确性会更高,因为这些模型是针对特定领域或会话上下文的。例如,如果语音助手主要用于娱乐,它可以利用上下文机器翻译来正确理解和回应关于音乐类型和子类型、乐器和音符、某些曲目的文化相关性等问题。
利用多语言预训练模型
由于每种语言都有独特的结构和语法、文化参考、短语、习语和表达方式等细微差别,因此处理多样的语言是具有挑战性的。考虑到特定语言的模型费用高昂,预训练的多语言模型可以帮助捕捉语言特有的细微差别。像 BERT 和 XLM-R 这样的模型是捕捉语言特有细微差别的预训练模型的良好示例。最后,这些模型可以进一步微调以适应特定领域,从而提高准确性。例如,训练于音乐领域的模型可能不仅能够理解查询,还可以通过语音助手返回丰富的响应。如果这个语音助手被问到一首歌歌词背后的意义,它将能够比简单的词汇解释提供更丰富的答案。
使用代码切换模型
实施代码切换模型以处理混合多种语言的语言输入可以帮助应对用户在与语音助手互动时使用多种语言的情况。例如,如果一个语音助手专门为加拿大的一个地区设计,而用户在该地区经常混合使用法语和英语,那么可以使用代码切换模型来理解对语音助手发出的混合语言句子,语音助手将能够处理这些情况。
利用迁移学习和零样本学习处理低资源语言
迁移学习是一种机器学习技术,其中一个模型在一个任务上进行训练,但作为第二个任务模型的起点。它利用第一个任务中的学习来提高第二个任务的性能,从而在一定程度上克服了冷启动问题。零样本学习是指使用预训练模型处理之前从未见过的数据。迁移学习和零样本学习都可以用来将知识从高资源语言转移到低资源语言。例如,如果一个语音助手已经在世界上最常用的前十种语言上进行了训练,那么它可以用于理解像斯瓦希里语这样的低资源语言中的查询。
结论
总结而言,在语音助手上构建和实施多语言体验是具有挑战性的,但也有办法减轻这些挑战。通过解决上述提到的挑战,语音助手将能够为用户提供无缝的体验,不论他们使用什么语言。
注意: 本文中所呈现的所有内容和观点仅代表撰写文章的个人,不代表其雇主的任何形式或形态。
Ashlesha Kadam 领导着 Amazon Music 的全球产品团队,负责为 45 多个国家的数百万客户构建 Alexa 和 Amazon Music 应用(网页、iOS、Android)上的音乐体验。她还是女性技术倡导者,担任 Grace Hopper Celebration(全球最大女性技术会议,参会者超过 3 万人,来自 115 个国家)的计算机人机交互(HCI)分会的共同主席。在闲暇时,Ashlesha 喜欢阅读小说,听商业技术播客(当前最爱 - Acquired),在美丽的太平洋西北地区徒步旅行,并与丈夫、儿子及 5 岁的金毛寻回犬共度时光。
更多相关内容
克服实际场景中的数据不平衡挑战
原文:
www.kdnuggets.com/2023/07/overcoming-imbalanced-data-challenges-realworld-scenarios.html
对流行 NLP 架构的性能进行基准测试是建立对可用选项的理解的重要步骤,尤其是在处理文本分类任务时。在这里,我们将深入探讨与分类相关的最常见挑战之一——数据不平衡。如果你曾经将机器学习应用于实际的分类数据集,你可能对此已经很熟悉了。
理解数据分类中的不平衡
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
在数据分类中,我们通常关心的是数据点在各个类别中的分布。一个平衡的数据集在所有类别中大致有相同数量的点,这使得处理起来更容易。然而,实际世界中的数据集往往是不平衡的。
数据不平衡可能会导致问题,因为模型可能会学习将所有内容标记为最频繁的类别,从而忽略实际输入。如果主导类别过于普遍,模型在对少数类别进行误分类时不会受到太大惩罚,这种情况可能会发生。此外,代表性不足的类别可能没有足够的数据让模型学习到有意义的模式。
不平衡是需要纠正的问题吗?不平衡是数据的一种特征,一个好的问题是我们是否真的想对其采取措施。有一些技巧可以让模型的训练过程更容易。我们可能会选择操控训练过程或数据本身,以便让模型知道哪些类别对我们特别重要,但这应该由业务需求或领域知识来证明。此外,我们将更详细地讨论这些技巧和操控。
为了说明不同技术处理数据不平衡的效果,我们将使用 sms-spam 数据集,该数据集包含 747 条垃圾短信和 4827 条正常短信。尽管只有两个类别,为了更好地进行泛化,我们将把任务视为多类别分类问题。我们将使用一个 roberta-base 模型。
请记住,这些技术在其他数据上可能会产生不同的结果。必须在特定的数据集上测试它们。
在没有任何调整的情况下训练分类模型,我们得到以下分类报告:

“安全”技巧
偏差初始化
我们的第一个技巧是让模型从一开始就了解数据分布。我们可以通过相应地初始化最终分类层的偏差来传播这一知识。这个技巧由 Andrej Karpathy 在他的[神经网络训练配方]( http://karpathy.github.io/2019/04/25/recipe/#2-set-up-the-end-to-end-trainingevaluation-skeleton--get-dumb-baselines:~:text=Huber losses%2C etc.- ,init%20well.,-Initialize%20the%20final)中分享,有助于模型以知情的视角开始。在我们的多类分类情况下,我们使用 softmax 作为最终激活函数,我们希望模型在初始化时的输出能反映数据分布。为此,我们解决以下问题:

提醒一下,

然后,

这里 b0 和 b1 分别是负类和正类的偏差,neg 和 pos 分别是负类和正类的元素数量。
通过这种初始化,所有指标都显著改善!

在贝叶斯术语中,这意味着手动设置先验,并允许模型在训练过程中学习后验。
下采样和上权重/上采样和下权重
这些技术也有效地解决了类别不平衡问题。它们有类似的概念但执行方式不同。下采样和上权重涉及减少主导类别的大小以平衡分布,同时在训练过程中给该类别的样本赋予更大的权重。上权重确保输出概率仍能代表观察到的数据分布。相反,上采样和下权重则涉及增加代表性不足类别的大小,并按比例减少它们的权重。
下采样和上权重结果:

上采样和下权重结果:

在这两种情况下,“spam”的召回率下降,可能是因为“ham”的权重是“spam”权重的两倍。
焦点损失
焦点损失,作者称之为“动态缩放交叉熵损失”,旨在解决数据不平衡的训练问题。它仅适用于二分类情况,幸运的是,我们的问题涉及的仅是两个类别。请查看下面的公式:

在公式中,p 是真实类别的概率,ɑ 是加权因子,???? 控制我们根据置信度(概率)惩罚损失的程度。
设计确保了概率较低的样本会获得指数级更大的权重,推动模型学习更具挑战性的示例。alpha 参数允许对类别示例进行不同的加权。
通过调整 alpha 和 gamma 的组合,你可以找到最佳配置。为了消除显式的类别偏好,将 alpha 设置为 0.5;然而,作者注意到这一平衡因子带来了轻微的改进。
这是我们使用焦点损失获得的最佳结果:

所有指标都优于基线,但这需要一些参数调整。请记住,它可能并不总是这样顺利地运行。
“非安全”技巧
存在一些已知的方法,故意改变输出概率分布,以使代表性不足的类别获得优势。通过使用这些技术,我们明确地向模型发出信号,某些类别至关重要,不应被忽视。这通常是由业务需求驱动的,例如检测金融欺诈或攻击性评论,这比错误标记良好示例更为重要。在目标是提高特定类别的召回率时,即使需要牺牲其他指标,也应应用这些技术。
权重调整
权重调整涉及为不同类别的样本分配独特的损失权重。这是一种有效且灵活的方法,因为它允许你向模型指示每个类别的重要性。以下是单个训练示例的多类别加权交叉熵损失公式:

,
其中 pytrue 代表真实类别的概率,wytrue 是该类别的权重。
确定权重的一个好的默认方法是逆类别频率:

其中 N 是数据集的总项数,c 是类别数,ni 是第 i 类的元素数量。
权重计算如下:{'ham': 0.576, 'spam': 3.784}
以下是使用这些权重获得的指标:

指标超越了基线场景。虽然这种情况可能发生,但并不总是如此。
但是,如果避免从特定类别中漏掉正例至关重要,请考虑增加类别权重,这可能会提高类别的召回率。让我们尝试权重{"ham": 0.576, "spam": 10.0}来查看结果。
结果如下:

正如预期的那样,“垃圾邮件”的召回率增加了,但精确率下降了。与使用逆类频率权重相比,F1 分数变差了。这表明基本损失加权的潜力。即使对于平衡的数据,加权也可能有利于召回关键类别。
上采样和下采样。
虽然与前面讨论的方法类似,但它们不包括加权步骤。下采样可能导致数据丢失,而上采样则可能导致对上采样类别的过拟合。尽管它们可以提供帮助,但加权通常是更高效、更透明的选项。
比较概率
我们将使用一个明显看起来像垃圾邮件的例子来评估各种模型版本的信心:“请致电索取您的奖品!”请查看下表以获取结果。

正如预期的那样,加权模型显示出过度自信,而“下采样 + 上加权”模型则表现出不足自信(由于上加权的“正常邮件”),与基线相比。值得注意的是,偏差初始化增加和焦点损失减少了模型在“垃圾邮件”类别中的信心。
摘要
总之,在必要时解决数据不平衡是可能的。请记住,一些技术会故意改变分布,仅在需要时应用。数据不平衡是一个特征,而不是一个错误!
尽管我们讨论了概率,但最终的性能指标是对业务最重要的。如果离线测试显示模型带来了价值,请继续在生产环境中测试它。
在我的实验中,我使用了Toloka ML平台。它提供了一系列现成的模型,可以为机器学习项目提供良好的开端。
总的来说,考虑数据分布对于训练机器学习模型至关重要。训练数据必须代表现实世界的分布,以使模型有效。如果数据本质上是不平衡的,模型应考虑这一点以在现实场景中表现良好。
谢尔盖·彼得罗夫 是一名数据科学家,专注于各种深度学习应用。他的兴趣在于构建高效且可扩展的机器学习解决方案,这些解决方案对企业和社会都大有裨益。
更多相关主题
AI 指数报告概览:衡量人工智能趋势
原文:
www.kdnuggets.com/2023/04/overview-ai-index-report-measuring-trends-artificial-intelligence.html

图片来源:作者
2023 年是充满精彩的一年,AI 应用的持续发布令人兴奋。我们迎来了 ChatGPT、Google Bard、Baby AGI 等诸多新应用。我们中的许多人都急于了解未来的趋势和潜力。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
什么是 AI 指数?
AI 指数是斯坦福大学人本人工智能研究所(HAI)发布的独立报告,由来自不同学术界和各行各业的专家组成。该年度报告的目的是跟踪、汇总和可视化与人工智能相关的数据。它被用于引导公司和决策者更好地推动 AI 的负责任和伦理的发展。
为了更好地理解 AI 的进展,HAI 委员会包括来自乔治敦大学安全与新兴技术中心、LinkedIn、麦肯锡等成员。
斯坦福大学每年发布 AI 指数报告,然而 2023 年的报告比以往更多地包含了自收集的数据和原创分析。特别是,该报告深入探讨了基础模型及其不同方面和影响。我们已经看到 Visual ChatGPT 中基础模型的应用。
今年,AI 指数还增加了对全球 AI 立法的追踪,从 2022 年的 25 个国家增加到 2023 年的 127 个国家。
AI 指数报告 2023
2023 年 AI 指数报告包括 8 个章节:
1. 研究与开发
研究与开发是 AI 的巅峰,因为它帮助 AI 在几十年里持续增长。本章节通过各种资源,如 AI 出版物、期刊文章、数据仓库等,深入探讨 AI 中的具体趋势。
它还通过数据探讨了如大型语言模型等机器学习系统。大型语言模型非常受欢迎,如 ChatGPT 所示。
当前,美国和中国主导了 AI 的研究和开发,然而,越来越多的国家也在地理上采用 AI。
2. 技术表现
技术表现涵盖了从 2022 年起 AI 的采用和使用情况以及其有效性。它进一步探讨了 AI 应用的进展,如计算机视觉、语言、语音、强化学习和硬件。
本章还分析了 AI 对环境的影响,例如它如何帮助特定行业以更快的速度增长,并提供了最近 AI 发展的最重要的时间线式概述。
3. 技术 AI 伦理
伦理是 AI 应用中一个重要的关注点,各国政府纷纷合作制定立法、框架和标准。由于这是围绕 AI 的一个重大话题,它成为了生成性 AI 系统(如 OpenAI Dall-E)创建和实施的技术障碍。
生成性 AI 系统非常受欢迎,这导致越来越多的公司加入竞争,部署和发布生成性 AI 模型的数量比以往更多。然而,围绕 AI 系统的伦理问题对公众变得更加明显。
4. 经济
我们看到比以往更多的公司、政府和组织实施 AI 应用。虽然一些人采用 AI 应用来提高生产力,但一些人看到 AI 的采用取代了工人。本章使用来自 LinkedIn、Deloitte 等的数据探讨了 AI 应用对经济的好坏影响。
5. 教育
随着 AI 的持续增长,对技术专业人员的需求巨大。自然地,基于供需关系,我们看到越来越多的人尝试进入技术领域。更多的人回到大学学习计算机科学,获得博士学位,以及广泛的在线课程和培训。
6. 政策和治理
有人可能会说 AI 的增长是因为它一直是一个开放的领域。然而,由于 AI 的不断增长,各国政府和组织被促使制定 AI 治理策略。为了将 AI 应用融入日常生活,这些组织被指示关注围绕 AI 的社会和伦理问题。
7. 多样性
尽管 AI 系统正在创建和部署,本章探讨了实际使用 AI 的人群。本章解释了北美的 AI 研究人员和从业者发现主要是白人男性在使用 AI。这可能导致现有社会不平等和偏见。
8. 公众舆论
如果没有公众的声音,这份报告将不够准确。本章探讨了全球、人口统计和伦理方面的 AI 公众意见。AI 已经融入我们的日常生活,监测公众对 AI 的态度对于识别伦理问题、趋势和整体社会影响至关重要。
人工智能指数报告的关键结论
以下是 2023 年人工智能指数报告的主要结论:
-
在生产机器学习模型方面,科技行业赢得了对学术界的竞赛。
-
AI 在帮助环境的同时,也带来了严重的环境影响。
-
AI 基准改进仍然很有限。
-
一些 AI 应用在科学领域表现出极高的性能和能力,以至于它们被认为是‘最佳新科学家’
-
自 2012 年以来,AI 的滥用增加了 26 倍,事件数量持续上升。
-
美国各行业对 AI 专业人才和技能的需求增加了
-
自 2021 年以来,对 AI 的私人投资已减少 26.7%。
-
为了满足 AI 应用的需求,AI 立法、法规、框架和标准正在增加。
-
中国公民对 AI 产品持有最积极的态度。
总结
在过去两个月里,我们接收了大量有关不同 AI 应用的新闻。我们预计会看到更多大型语言模型、多模态模型和自主 AI 应用。2024 年的报告将会很有趣。你认为明年的报告会有什么内容?请在评论中告诉我们。
Nisha Arya 是一位数据科学家、自由技术写作员及 KDnuggets 的社区经理。她特别关注提供数据科学职业建议或教程以及数据科学理论知识。她还希望探索人工智能如何或将如何促进人类寿命的延续。作为一个热心学习者,她寻求拓宽自己的技术知识和写作技能,同时帮助指导他人。
更多相关话题
Plotly 的 Dash Python 框架概述用于构建仪表板
原文:
www.kdnuggets.com/2018/05/overview-dash-python-framework-plotly-dashboards.html
评论
作者:Damian Rodziewicz,Appsilon。

Appsilon 技术讲座 - 每周三我们举行内部会议,讨论技术。通过与社区分享我们的技术讲座并贡献开源,我们激发了讨论和成长,让其他人从我们的成就中学习并与我们分享。
最近,我有机会做一个关于Dash Python 框架的技术演讲。Dash 是一个用于构建仪表板的反应式框架。它们类似于使用Shiny R 框架构建的仪表板。在 Appsilon,我们已经在 Shiny 中构建了复杂的仪表板。我们还为成千上万的用户进行了部署。
Python 社区正在赶上,我们很高兴探索这些机会。值得比较这两者。我们已经进行了若干内部测试。我们已经为最具创新性的客户交付了 Dash 项目。从今天开始,我们为更广泛的受众交付用 Dash 编写的业务项目。以下是我们经验教训的快速总结!
本次技术演讲涵盖了基础知识和更高级的主题。你将从简单的开始,逐步完成自定义组件的构建和扩展。
技术演讲中涵盖的主题广泛列表:
1. 什么是 Dash?
-
Dash 是一个用于构建 web 应用程序的高效 Python 框架。
-
由 Plotly 创建和维护。 https://plot.ly/products/dash/ 。
-
基于 Flask、Plotly.js 和 React.js 上层构建。
-
仪表板使用纯 Python 实现。
-
Dash 是一个开源库,发布在宽松的 MIT 许可证下。
2. 使用 Dash 可以获得什么
-
前端用 Python 生成
-
反应式计算抽象
-
每个 HTML 标签的组件类以及在 dash_html_components 包中实现的所有 HTML 参数的关键字参数
-
在 dash-core-components 中实现的交互式 HTML 元素
-
Dash-core-components 中实现的 Plotly python API,通过 Graph 类提供
3. Dash 演示应用程序及其源代码解释。
更深入地了解 Dash 的交互性以及重新计算的工作原理。
4. Dash 核心组件是什么?如何构建自定义组件?
你可以在 Dash 中实现自己的组件。有关如何做到这一点的信息,请访问 dash.plot.ly/plugins
我们已经开始实施自己的组件和助手:
-
Leaflet 地图
-
时间线(反应式水平时间线移植)
-
Mixpanel 钩子(允许使用 Mixpanel 的前端插件通过 cookie 识别用户)
-
IncludeScript(按需包含并运行外部脚本 - 如果应用在本地模式下运行则很有用)
5. 单线程 Dash
图形的重新计算是阻塞的且是单线程的。然而,我们可以提取生成的 Flask 服务器,并使用 Gunicorn 来使计算并发。
Gunicorn ‘Green Unicorn’ 是一个用于 UNIX 的 Python WSGI HTTP 服务器。它是一个预分叉工作模型。Gunicorn 服务器与各种网络框架广泛兼容,实现简单,占用服务器资源少,并且相当迅速。
似乎仍然对并发用户数量有一定限制。
6. Dash 的限制
-
我们仍在探索它在众多并发用户下的可扩展性。
-
在某些时候,你将需要比 Dash 默认提供的更复杂的组件。
-
你将不得不在 React.js 中编写自己的组件。
-
或者你将不得不将现有组件从 React.js 移植到 Dash。
-
你很快会发现一些快速解决方案仍在开发中(Mapbox 栅格示例)。
-
在反应图中没有中间值。
-
你必须添加一个隐藏的 div 以存放中间数据(如 plotly 所建议的)。
-
你必须为每一个输出编写单独的函数,这迫使你重构代码。
-
有一些问题我们可能无法解决,除非深入了解 Dash 的工作方式。
-
可能仍然存在一些我们不知道的 Dash 问题 - 我们必须为我们的工作留出余地。
7. 问答环节
-
状态是保留在服务器上还是客户端上?与 Shiny 和 Dash 比较。
-
使用记忆化作为一种变通方法。讨论带有记忆化的线程。
-
在 Dash 和 Shiny 之间指定反应性有什么不同?每种模型的优缺点。
希望你喜欢!请在评论中告诉我你想接下来探索什么!
资源:
简介: Damian 喜欢称自己为技术狂热者,这一点很贴切,因为他是我们的联合创始人和首席数据科学家。他拥有计算机科学硕士学位和管理法律研究生学位。在创办 Appsilon 之前,他曾在 Accenture、UBS、Microsoft 和 Domino Data Lab 工作。他是一名热衷于游泳和心理学的爱好者。

原文。经许可转载。
相关:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 需求
更多相关主题
逻辑回归概述
原文:
www.kdnuggets.com/2022/02/overview-logistic-regression.html
由 Arvind Thorat,Kavikulguru 工程技术学院
机器学习是编程计算机以便它们能够从数据中学习的科学(和艺术)。这是一个稍微更一般的定义:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 方面
机器学习是 赋予计算机在没有明确编程的情况下学习的领域。
—亚瑟·塞缪尔,1959
以及一个更面向工程的定义:
如果计算机程序在某个任务 T 上的表现随着经验 E 的增加而提升,并且这一表现通过性能度量 P 来衡量,那么这个程序就被认为是从经验 E 中学习了。
—汤姆·米切尔,1997
在本文中,我们将讨论逻辑回归这一术语,它是许多行业和机器学习应用中广泛使用的算法。
逻辑回归
逻辑回归是线性回归的扩展,用于解决分类问题。我们将看到如何使用基于梯度下降的优化方法来解决一个简单的逻辑回归问题,这也是最流行的优化方法之一。

假设
-
在二元逻辑回归中,依赖变量需要是二元的,而有序逻辑回归则要求依赖变量是有序的。观察值不应来自重复测量或匹配数据。逻辑回归排除了独立变量之间的多重共线性。它基于独立线性假设,要求独立变量与对数几率线性相关。
你们可能会问,逻辑回归是否可以用于多个独立变量呢?
答案是肯定的,逻辑回归可以用于任意数量的独立变量。然而,请注意,你将无法在三维以上的空间中可视化结果。
在讨论这些要点之前,让我们首先讨论逻辑函数,也就是 sigmoid 函数。
Sigmoid 函数(见图 1)
逻辑回归以方法核心使用的函数命名,即逻辑函数。它也被称为 sigmoid 函数。它用于描述生态学中种群增长的特性,快速上升并在环境承载能力达到最大值时趋于稳定。它是一个三段曲线,可以将任何数值映射到 0 和 1 之间,但从不完全到达这些极限。
我们可以推导出
Sigmoid Function = 1 / 1 + e^-value其中:
e = 自然对数的底当我们不能通过线性边界将数据分成类时,也会使用它。
从示例中:
p / 1 - p其中;
p = 事件的概率我们可以从中创建公式
log p / 1 - p它最初也用于生物科学,随后被广泛应用于许多社会科学领域。当因变量是分类变量时会使用它。
这是一个简单的模型:
Output = 0 或 1Hypothesis => Z = Wx + Bh(x) = Sigmoid(z)有两个条件:
Z = ∞ (无限)和
Y(predict) = 1如果
Z = -∞Y(predict) => 0在实现任何算法之前,我们必须为其准备数据。以下是逻辑回归的一些数据准备方法。
方法论
-
数据准备
-
二元输出变量
-
移除噪声
-
高斯分布
-
移除相关输入
使用示例
-
信用评分
-
医学
-
文本编辑
-
游戏
优点
逻辑回归是解决分类问题的最有效技术之一。使用逻辑回归的一些优点包括:
-
逻辑回归容易实现、解释,并且训练效率很高。它在对未知记录进行分类时非常迅速。
-
当数据集是线性可分时,它表现良好。
-
它可以将模型系数解释为特征重要性的指标。
缺点
-
它构造线性边界;逻辑回归需要自变量与几率线性相关。
-
逻辑回归的主要限制是对因变量和自变量之间线性关系的假设。
-
更强大且紧凑的算法,如神经网络,往往可以轻松超越该算法。
结论
逻辑回归是传统机器学习方法之一。它与线性回归、k-均值聚类、主成分分析等算法一起,形成了一套基础的机器学习方法。神经网络也在逻辑回归的基础上发展起来的。即使你不是机器学习专家,你也可以高效地使用逻辑回归,而很多其他算法则不然。相反,没有对逻辑回归的扎实理解,无法成为机器学习大师。
Arvind Thorat 是 NPPD 的数据科学实习生。
更多相关话题
-
Mercury 概述:创建数据科学作品集和基于 notebook 的网页应用

图片由作者提供
Mercury 是一个将你的 Python Jupyter notebooks 转换为互动式网页应用并部署到云端的工具。它适用于那些希望创建惊人仪表盘和使用少量 YAML 脚本制作机器学习演示的数据分析师和机器学习工程师。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你所在组织的 IT 工作
Mercury 的关键功能:
-
使用 YAML 头部添加互动小部件。
-
更改值,执行 notebook 并保存结果。
-
在 Jupyter 单元格中显示或隐藏代码的选项。
-
易于在云服务器上部署。
-
创建并将多个 notebooks 添加到服务器上。
-
作品集首页。
-
管理员控制和身份验证。
-
使用 iframe 嵌入互动网页应用。
-
AGPLv3 下的开源
Mercury 的开源版本包含了诸如多个网页应用、欢迎页面编辑和互动小部件等核心功能。Mercury Pro 版本则具有额外的功能,如团队支持、私人共享、管理员控制和身份验证,还提供专门的支持。
使用 pip install mljar-mercury 安装 Mercury 或在终端中使用 mercury run demo。要验证安装,请运行演示 mercury run demo,然后在浏览器中输入 http://127.0.0.1 地址。你也可以在 Mercury 文档中参加一个 迷你教程,以了解基本操作。
在本概述中,我们将了解 Mercury 的关键功能以及如何利用它。
YAML 参数
最重要的是为 Jupyter notebook 添加一个头部。你需要在顶部创建一个新单元格,并将其更改为 Raw NBConvert。然后,添加 YAML 代码以修改参数。

来自 Mercury 的 Gif
YAML 头部中使用的参数列表:
-
标题:是网络应用程序的名称。它显示在侧边栏和主页上。
-
作者:网络应用程序的创建者。
-
描述:添加网络应用程序的详细描述。
-
显示代码:隐藏或显示 python 代码。
-
显示提示:隐藏或显示 jupyter 单元格的提示信息。
-
共享:与公众、私有或特定组共享网络应用程序。
-
参数:添加、删除、修改小部件。这是控制应用程序输入和输出的最重要的参数。
小部件
小部件是你应用程序的交互式输入。你可以添加文本、整数、滑块、复选框、范围、多个选项,甚至上传文件用于你的机器学习演示。
下面的示例代码演示了如何将一个小部件(滑块)添加到 Python 变量(my_variable)中。
params:
my_variable:
input: slider
label: This is slider label
value: 5
min: 0
max: 10

图片由 Mercury 提供
欢迎页面
你可以使用 Markdown 创建自定义首页。如果问我,这是创建数据科学作品集的最简单方法,其中包括你的简历、成就和通过网络应用程序了解的项目。要创建首页,请添加welcome.md文件并使用 Markdown 添加信息。
要获取灵感,请查看由作者(Piotr Płoński)创建的数据科学作品集。

图片来自Mercury 文档
嵌入
你也可以通过使用 iframe 将你的网络应用程序添加到博客或 WordPress 网站中。只需复制你的网络应用程序的链接,并在 iframe 脚本中添加“/embed”,如下面所示。
<iframe src="https://mercury.mljar.com/app/5/embed" height="700px" width="1200px"/>
这个功能很特别,因为没有其他网络应用程序提供嵌入功能。

管理员和认证
如果你想限制谁可以查看你的笔记本,请将你的应用程序设置为私有。要访问 Mercury 网络应用程序,你需要提供用户名和密码。你可以在 YAML 头部的share参数中列出用户或组。你可以使用管理面板来管理笔记本、任务、用户和组。添加、删除和更新用户或组需要专业版。

Gif 由 Mercury 提供
Heroku 上的部署
对我来说,fork 一个仓库并将其部署到Heroku服务器上相当简单。你可以查看我的项目,了解我是如何在不写一行代码的情况下部署 GitHub 仓库的。要访问我部署的网络应用程序,请点击这里。同样,你也可以轻松地在 AWS 或 Google Cloud 上部署你的应用程序。确保你已经添加了环境变量:
-
NOTEBOOKS= *.ipynb
-
PORT= 8080
-
SERVE_STATIC= True
-
ALLOWED_HOST=
结论
Mercury 为 Python Web 应用的工作带来了不同的风味。你可以一次添加多个笔记本,甚至创建你的作品集页面,而不是仅仅创建一个。在这篇博客中,我们学习了如何使用 YAML 头文件创建仪表盘或机器学习演示。Mercury 非常简单,你可以通过 GitHub 集成部署你的应用。此外,你可以添加认证、管理用户、创建欢迎页面、添加多个小部件,并将输出保存为 HTML 文件。
-
GitHub: mljar/mercury
-
文档: Mercury 文档
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热衷于构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是使用图神经网络构建一个 AI 产品,帮助那些在心理健康方面挣扎的学生。
相关主题
PEFT 概述:最先进的参数高效微调
原文:
www.kdnuggets.com/overview-of-peft-stateoftheart-parameterefficient-finetuning

作者提供的图片
什么是 PEFT
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
随着 GPT-3.5、LLaMA2 和 PaLM2 等大型语言模型(LLMs)规模的不断扩大,在下游自然语言处理(NLP)任务中对它们进行微调变得越来越计算密集且内存占用巨大。
参数高效微调(PEFT)方法通过仅微调少量额外参数,同时冻结大部分预训练模型,来解决这些问题。这可以防止大型模型出现灾难性遗忘,并且使得在有限计算资源下也能进行微调。
PEFT 已被证明在图像分类和文本生成等任务中有效,同时只使用了参数的一小部分。小的调整权重可以简单地添加到原始预训练权重中。
你甚至可以在 Google Colab 的免费版本上使用 4 位量化和 PEFT 技术 QLoRA 来微调 LLMs。
PEFT 的模块化特性还允许通过添加少量任务特定的权重来将相同的预训练模型适应于多个任务,从而避免存储完整的副本。
PEFT 库集成了流行的 PEFT 技术,如 LoRA、前缀调整、AdaLoRA、提示调整、多任务提示调整和 LoHa,支持 Transformers 和 Accelerate。这提供了对前沿大型语言模型的简便访问,同时实现高效和可扩展的微调。
什么是 LoRA
在本教程中,我们将使用最流行的参数高效微调(PEFT)技术,称为 LoRA(大型语言模型的低秩适应)。LoRA 是一种显著加快大型语言模型微调过程,同时消耗更少内存的技术。
LoRA 的关键思想是通过低秩分解使用两个较小的矩阵表示权重更新。这些矩阵可以训练以适应新数据,同时最小化总体修改数量。原始权重矩阵保持不变,不会再进行任何调整。最终结果是通过结合原始权重和适应后的权重得到的。
使用 LoRA 有几个优势。首先,它通过减少可训练参数的数量大大提高了微调的效率。此外,LoRA 与各种其他高效参数方法兼容,并可以与它们结合使用。使用 LoRA 微调的模型表现出与完全微调模型相当的性能。重要的是,LoRA 不会引入额外的推理延迟,因为适配器权重可以与基础模型无缝合并。
使用案例
PEFT 有许多使用案例,从语言模型到图像分类器。你可以在官方 文档 中查看所有使用案例教程。
使用 PEFT 训练 LLMs
在本节中,我们将学习如何使用 bitsandbytes 和 peft 库加载和包装我们的 transformer 模型。我们还将涵盖加载已保存的微调 QLoRA 模型并使用它进行推理。
入门
首先,我们将安装所有必要的库。
%%capture
%pip install accelerate peft transformers datasets bitsandbytes
然后,我们将导入必要的模块,并命名基础模型(Llama-2-7b-chat-hf),以使用 mlabonne/guanaco-llama2-1k 数据集对其进行微调。
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import get_peft_model, LoraConfig
import torch
model_name = "NousResearch/Llama-2-7b-chat-hf"
dataset_name = "mlabonne/guanaco-llama2-1k"
PEFT 配置
创建 PEFT 配置,我们将用它来包装或训练我们的模型。
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
4 位量化
在消费者或 Colab GPU 上加载 LLMs 面临重大挑战。然而,我们可以通过使用 BitsAndBytes 实施 4 位量化技术和 NF4 类型配置来克服这个问题。通过这种方法,我们可以有效地加载模型,从而节省内存并防止机器崩溃。
compute_dtype = getattr(torch, "float16")
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)
包装基础 Transformers 模型
为了使我们的模型在参数上更高效,我们将使用 get_peft_model 来包装基础 transformer 模型。
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
我们的可训练参数少于基础模型的参数,这使我们能够使用更少的内存并更快地微调模型。
trainable params: 33,554,432 || all params: 6,771,970,048 || trainable%: 0.49548996469513035
下一步是训练模型。你可以按照 4 位量化和 QLoRA 指南进行操作。
保存模型
训练后,你可以选择将模型适配器保存到本地。
model.save_pretrained("llama-2-7b-chat-guanaco")
或者,将其推送到 Hugging Face Hub。
!huggingface-cli login --token $secret_value_0
model.push_to_hub("llama-2-7b-chat-guanaco")
如我们所见,模型适配器仅为 134MB,而基础的 LLaMA 2 7B 模型约为 13GB。

加载模型
要运行模型推理,我们首先需要使用 4 位精度量化加载模型,然后将训练好的 PEFT 权重与基础(LlaMA 2)模型合并。
from transformers import AutoModelForCausalLM
from peft import PeftModel, PeftConfig
import torch
peft_model = "kingabzpro/llama-2-7b-chat-guanaco"
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto"
)
model = PeftModel.from_pretrained(base_model, peft_model)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = model.to("cuda")
model.eval()
推理
在进行推理时,我们需要以 guanaco-llama2-1k 数据集风格编写提示(“[INST] {prompt} [/INST]”)。否则你将获得不同语言的响应。
prompt = "What is Hacktoberfest?"
inputs = tokenizer(f"<s>[INST] {prompt} [/INST]", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=100
)
print(
tokenizer.batch_decode(
outputs.detach().cpu().numpy(), skip_special_tokens=True
)[0]
)
输出似乎完美。
[INST] What is Hacktoberfest? [/INST] Hacktoberfest is an open-source software development event that takes place in October. It was created by the non-profit organization Open Source Software Institute (OSSI) in 2017\. The event aims to encourage people to contribute to open-source projects, with the goal of increasing the number of contributors and improving the quality of open-source software.
During Hacktoberfest, participants are encouraged to contribute to open-source
注意: 如果你在 Colab 中加载模型时遇到困难,可以查看我的笔记本:PEFT 概述。
结论
诸如 LoRA 这样的参数高效微调技术使得使用少量参数高效微调大型语言模型成为可能。这避免了昂贵的全量微调,并能在有限的计算资源下进行训练。PEFT 的模块化特性允许将模型适配于多个任务。像 4 位精度这样的量化方法可以进一步减少内存使用。总体而言,PEFT 将大型语言模型的能力拓展到更广泛的受众。
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,他喜欢构建机器学习模型。目前,他专注于内容创作和撰写关于机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为面临心理健康问题的学生开发 AI 产品。
更多相关话题
来自 PyOD 的异常检测方法概述 – 第一部分
原文:
www.kdnuggets.com/2019/06/overview-outlier-detection-methods-pyod.html
评论
Matthew Mayo 以前的一篇文章标题为:异常检测方法的直观可视化 概述了由 Yue Zhao 开发的 PyOD 包。
本文将从这里继续,形成一个多部分系列,概述包中提供的不同异常检测方法。我将使用 PyOD 文档中的信息,以避免因重叠技术而造成混淆。
1. PCA (主成分分析)
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
pyod.models.pca.PCA(n_components=None, n_selected_components=None, contamination=0.1, copy=True, whiten=False, svd_solver='auto', tol=0.0, iterated_power='auto', random_state=None, weighted=True, standardization=True)
PCA 是一种线性降维方法,通过对数据进行奇异值分解,将其投影到较低维空间。在此过程中,数据的协方差矩阵可以分解为与特征值相关的正交向量,称为特征向量。具有较高特征值的特征向量捕捉数据中的大部分方差。
因此,由 k 个特征向量构建的低维超平面可以捕捉数据中的大部分方差。然而,异常点与正常数据点不同,这在由特征值较小的特征向量构建的超平面上更为明显。因此,可以将样本在所有特征向量上的投影距离之和作为异常分数。
2. MCD (最小协方差行列式)
pyod.models.mcd.MCD(contamination=0.1, store_precision=True, assume_centered=False, support_fraction=None, random_state=None)
最小协方差行列式协方差估计器用于高斯分布的数据,但也可能对从单峰对称分布中提取的数据仍然相关。它不适用于多模态数据(在这种情况下,用于拟合 MinCovDet 对象的算法可能会失败)。应考虑使用投影追寻方法来处理多模态数据集。
3. OCSVM (一类支持向量机)
pyod.models.ocsvm.OCSVM(kernel='rbf', degree=3, gamma='auto', coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, contamination=0.1)
这是一种无监督学习的异常检测方法。OCSVM 算法将输入数据映射到高维特征空间(通过核函数),并迭代地寻找最佳的最大间隔超平面,以最有效地将训练数据与原点分离。
4. LOF(局部异常因子)
pyod.models.lof.LOF(n_neighbors=20, algorithm='auto', leaf_size=30, metric='minkowski', p=2, metric_params=None, contamination=0.1, n_jobs=1)
每个样本的异常评分称为局部异常因子。它衡量给定样本相对于其邻居的局部密度偏差。局部性在于异常评分依赖于对象与周围邻域的隔离程度。更准确地说,局部性由 k 近邻确定,其距离用于估计局部密度。通过将样本的局部密度与其邻居的局部密度进行比较,可以识别出那些密度明显低于其邻居的样本。这些样本被视为异常值。
相关内容:
-
异常检测方法的直观可视化
-
异常检测的四种技术
-
如何使你的机器学习模型对异常值具有鲁棒性
更多相关内容
Python 的 Datatable 包概述
原文:
www.kdnuggets.com/2019/08/overview-python-datatable-package.html
评论
 照片由Johannes Groll提供,来源于Unsplash
照片由Johannes Groll提供,来源于Unsplash
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
“在文明的曙光到 2003 年之间创建了 5 Exabytes 的信息,而现在每 2 天就会创建这么多信息”:Eric Schmidt
如果你是 R 用户,你可能已经在使用data.table包。[Data.table](https://cran.r-project.org/web/packages/data.table/data.table.pdf)是 R 中的[data.frame](https://www.rdocumentation.org/packages/base/versions/3.6.0/topics/data.frame)包的扩展。它也是 R 用户在快速聚合大型数据(包括 100GB 内存)时的首选包。
R 的data.table包因其易用性、便利性和编程速度而非常多功能且高性能。它在 R 社区中相当著名,每月下载量超过 40 万次,几乎有 650 个 CRAN 和 Bioconductor 包在使用它(source)。
那么,对于 Python 用户来说有什么好处呢?好消息是,data.table包在 Python 中也有一个对应的包叫做datatable,它明确关注大数据支持、高性能、内存和外存数据集,以及多线程算法。从某种程度上来说,它可以被称为data.table的“小弟弟”。
Datatable

现代机器学习应用需要处理大量数据并生成多个特征。这是为了构建更高准确性的模型。Python 的datatable模块就是为了解决这个问题而创建的。它是一个在单节点机器上以最大可能速度执行大数据(最多 100GB)操作的工具包。datatable 的开发得到了H2O.ai的赞助,datatable的首个用户是Driverless.ai。
这个工具包与pandas非常相似,但更注重速度和大数据支持。Python 的datatable也致力于实现良好的用户体验、实用的错误信息和强大的 API。在本文中,我们将探讨如何使用 datatable,以及在处理大型数据集时它相较于 pandas 的优势。
安装
在 MacOS 上,可以通过 pip 轻松安装 datatable:
pip install datatable
在 Linux 上,安装可以通过以下二进制发行版完成:
# If you have Python 3.5
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp35-cp35m-linux_x86_64.whl# If you have Python 3.6
pip install https://s3.amazonaws.com/h2o-release/datatable/stable/datatable-0.8.0/datatable-0.8.0-cp36-cp36m-linux_x86_64.whl
目前,datatable 在 Windows 上不可用,但正在进行工作以添加对 Windows 的支持。
欲了解更多信息,请参阅构建说明。
本文的代码可以从关联的Github 存储库访问,或通过点击下面的图像在我的 binder 上查看。

读取数据
使用的数据集来自 Kaggle,属于Lending Club Loan Data Dataset。数据集包含了 2007-2015 年间所有贷款的完整信息,包括当前的贷款状态(当前、逾期、已还清等)和最新的支付信息。文件包含226 万行和145 列。数据规模非常适合展示 datatable 库的能力。
# Importing necessary Librariesimport numpy as np
import pandas as pd
import datatable as dt
让我们将数据加载到Frame对象中。在 datatable 中,Frame是基本的分析单元。这与 pandas 的 DataFrame 或 SQL 表相同:数据以二维数组的形式排列,具有行和列。
使用 datatable
%%time
datatable_df = dt.fread("data.csv")
____________________________________________________________________CPU times: user 30 s, sys: 3.39 s, total: 33.4 s
Wall time: 23.6 s
上面的fread()函数既强大又极快。它可以自动检测和解析大多数文本文件的参数,从.zip 归档或 URL 加载数据,读取 Excel 文件,等等。
此外,datatable 解析器:
-
可以自动检测分隔符、标题、列类型、引号规则等。
-
可以从多个来源读取数据,包括文件、URL、shell、原始文本、归档和通配符。
-
提供多线程文件读取以实现最大速度
-
读取大型文件时包含进度指示器
-
可以读取RFC4180合规和不合规的文件。
使用 pandas
现在,让我们计算 pandas 读取相同文件所花费的时间。
%%time
pandas_df= pd.read_csv("data.csv")
___________________________________________________________CPU times: user 47.5 s, sys: 12.1 s, total: 59.6 s
Wall time: 1min 4s
结果显示,datatable 在读取大型数据集时明显优于 pandas。相比之下,pandas 需要超过一分钟,而 datatable 只需几秒钟。
数据框转换
现有数据框也可以转换为 numpy 或 pandas 数据框,如下所示:
numpy_df = datatable_df.to_numpy()
pandas_df = datatable_df.to_pandas()
让我们将现有数据框转换为 pandas 数据框对象,并比较所需的时间。
%%time
datatable_pandas = datatable_df.to_pandas()
___________________________________________________________________
CPU times: user 17.1 s, sys: 4 s, total: 21.1 s
Wall time: 21.4 s
似乎将文件作为 datatable 数据框读取,然后转换为 pandas 数据框所需的时间少于直接通过 pandas 数据框读取。 因此,将大型数据文件通过 datatable 导入,然后转换为 pandas 数据框可能是一个好主意。
type(datatable_pandas)
___________________________________________________________________
pandas.core.frame.DataFrame
基本数据框属性
让我们看看 datatable 数据框的一些基本属性,这些属性类似于 pandas 的属性:
print(datatable_df.shape) # (nrows, ncols)
print(datatable_df.names[:5]) # top 5 column names
print(datatable_df.stypes[:5]) # column types(top 5)
______________________________________________________________(2260668, 145)('id', 'member_id', 'loan_amnt', 'funded_amnt', 'funded_amnt_inv')(stype.bool8, stype.bool8, stype.int32, stype.int32, stype.float64)
我们还可以使用 head 命令输出前 'n' 行。
datatable_df.head(10)
 datatable 数据框前 10 行的快照
datatable 数据框前 10 行的快照
颜色表示数据类型,其中 红色 表示字符串,绿色 表示整数,蓝色 表示浮点数。
摘要统计量
在 pandas 中计算摘要统计量是一个内存消耗的过程,但使用 datatable 就不再如此。我们可以使用 datatable 计算每列的以下摘要统计量:
datatable_df.sum() datatable_df.nunique()
datatable_df.sd() datatable_df.max()
datatable_df.mode() datatable_df.min()
datatable_df.nmodal() datatable_df.mean()
让我们使用 datatable 和 pandas 计算列的 均值 以测量时间差异。
使用 datatable
%%time
datatable_df.mean()
_______________________________________________________________
CPU times: user 5.11 s, sys: 51.8 ms, total: 5.16 s
Wall time: 1.43 s
使用 pandas
pandas_df.mean()
__________________________________________________________________
Throws memory error.
上述命令在 pandas 中无法完成,因为它开始抛出内存错误。
数据操作
数据表(如数据框)是列式数据结构。在 datatable 中,所有这些操作的主要工具是 方括号符号,灵感来自传统的矩阵索引,但具有更多功能。
 datatable 的 方括号符号
datatable 的 方括号符号
相同的 DT[i, j] 符号在数学中用于索引矩阵,在 C/C++、R、pandas、numpy 等中也使用。让我们看看如何使用 datatable 执行常见的数据操作活动:
#选择行/列的子集
以下代码从数据集中选择所有行和 funded_amnt 列。
datatable_df[:,'funded_amnt']

以下是选择前 5 行和 3 列的方法
datatable_df[:5,:3]

#排序数据框
使用 datatable
通过 datatable 可以按照特定列对数据框进行排序,如下所示:
%%time
datatable_df.sort('funded_amnt_inv')
_________________________________________________________________
CPU times: user 534 ms, sys: 67.9 ms, total: 602 ms
Wall time: 179 ms
使用 pandas:
%%time
pandas_df.sort_values(by = 'funded_amnt_inv')
___________________________________________________________________
CPU times: user 8.76 s, sys: 2.87 s, total: 11.6 s
Wall time: 12.4 s
注意 datatable 和 pandas 之间的显著时间差异。
#删除行/列
以下是如何删除名为 member_id 的列:
del datatable_df[:, 'member_id']
#分组
与 pandas 类似,datatable 也具有 groupby 功能。让我们看看如何按 grade 列分组并获取 funded_amount 列的均值。
使用 datatable
%%time
for i in range(100):
datatable_df[:, dt.sum(dt.f.funded_amnt), dt.by(dt.f.grade)]
____________________________________________________________________
CPU times: user 6.41 s, sys: 1.34 s, total: 7.76 s
Wall time: 2.42 s
使用 pandas
%%time
for i in range(100):
pandas_df.groupby("grade")["funded_amnt"].sum()
____________________________________________________________________
CPU times: user 12.9 s, sys: 859 ms, total: 13.7 s
Wall time: 13.9 s
.f 代表什么?
f 代表 frame proxy,并提供了一种简单的方式来引用我们当前操作的 Frame。在我们的例子中,dt.f 仅代表 dt_df。
#筛选行
筛选行的语法与 GroupBy 非常相似。让我们筛选出 loan_amnt 中那些值大于 funded_amnt 的行。
datatable_df[dt.f.loan_amnt>dt.f.funded_amnt,"loan_amnt"]
保存 Frame
也可以将 Frame 的内容写入一个 csv 文件,以便将来使用。
datatable_df.to_csv('output.csv')
有关更多数据处理函数,请参阅 文档 页面。
结论
与默认的 pandas 相比,datatable 模块确实加快了执行速度,这在处理大数据集时无疑是一个福音。然而,datatable 在功能方面落后于 pandas。不过,由于 datatable 仍在积极开发中,我们可能会在未来看到一些重大更新。
参考文献
-
R 的 data.table
-
Python datatable 入门: 一篇关于 datatable 使用的精彩 Kaggle Kernel
简介: Parul Pandey 是一位数据科学爱好者,经常为数据科学出版物如 Towards Data Science 撰写文章。
原文。经许可转载。
相关内容:
-
25 个 Pandas 技巧
-
10 个简单技巧加速 Python 数据分析
-
成为 Pandas 专家,Python 的数据处理库
相关主题
Python 可视化工具概述
原文:
www.kdnuggets.com/2015/11/overview-python-visualization-tools.html
作者 Chris Moffitt。
介绍
在 Python 世界里,有多种选项可以用于数据可视化。由于这种多样性,确定何时使用哪个工具可能非常具有挑战性。本文包含了一些较为流行的工具示例,并演示了如何使用它们创建简单的条形图。我将使用以下工具来创建数据绘图示例:
在这些示例中,我将使用 pandas 来处理数据,并利用这些数据进行可视化。在大多数情况下,这些工具可以在没有 pandas 的情况下使用,但我认为 pandas 和可视化工具的组合非常常见,因此这是最好的起点。
那么 Matplotlib 呢?
Matplotlib 是 Python 可视化包的“祖父”。它非常强大,但这种强大也带来了复杂性。通常,你可以使用 matplotlib 做任何你需要的事情,但这并不总是容易弄清楚。我不会详细讲解一个纯粹的 Matplotlib 示例,因为许多工具(尤其是 Pandas 和 Seaborn)都是 matplotlib 的简化封装。如果你想了解更多,我在我的 简单绘图 文章中讲解了几个示例。
我对 Matplotlib 最大的不满是,获取合理外观的图表需要花费太多工作。在尝试一些这些示例时,我发现无需大量代码就能更容易地获得漂亮的可视化。举一个 matplotlib 冗长特性的例子,看看这个 ggplot 帖子中的分面示例。
方法论
对于本文的方法,我有一个快速说明。我确信一旦人们开始阅读,就会指出更好的使用这些工具的方法。我的目标不是在每个示例中创建完全相同的图表。我希望在每个示例中以大致相同的方式可视化数据,并花费大致相同的时间来研究解决方案。
在这个过程中,我面临的最大挑战是格式化 x 轴和 y 轴,并且在某些大标签的情况下让数据看起来合理。还花了一些时间搞清楚每个工具如何要求数据格式。一旦弄清楚了这些部分,其余的相对简单。
另一个需要考虑的点是,条形图可能是最简单的一种图表类型。这些工具允许你创建更多类型的图表。我的示例更侧重于格式化的简便性,而非创新的可视化示例。此外,由于标签的原因,一些图表占用了很多空间,因此我自行裁剪了一些图表——只是为了保持文章长度的可控性。最后,我调整了图像的大小,因此任何模糊现象都是缩放问题,而不是实际输出质量的问题。
最后,我从尝试使用另一种工具来代替 Excel 的思路来处理这个问题。我认为我的示例更适合在报告、演示文稿、电子邮件或静态网页上展示。如果你正在评估用于实时数据可视化或通过其他机制共享的工具,那么其中一些工具提供了更多的功能,这些我没有深入探讨。
数据集
上一篇文章 描述了我们将使用的数据。我将抓取示例深入了一层,并确定了每个类别中的详细支出项目。此数据集包含 125 个条目,但我选择只展示前 10 个,以保持简单。你可以在这里找到完整的数据集。
Pandas
我使用 pandas DataFrame 作为所有图表的起点。幸运的是,pandas 提供了一个内置的绘图功能,这是一层在 matplotlib 之上的工具。我将以此为基础。首先,导入我们的模块并将数据读入预算 DataFrame。我们还需要对数据进行排序,并将其限制为前 10 项。
budget = pd.read_csv("mn-budget-detail-2014.csv") budget = budget.sort('amount',ascending=False)[:10]
我们将使用相同的预算行进行所有示例。以下是前 5 项的样子:
| 类别 | 详细 | 金额 | |
|---|---|---|---|
| 46 | 行政部门 | 议会大厦翻修与恢复续篇 | 126300000 |
| 1 | 明尼苏达大学 | 明尼阿波利斯;泰特实验室翻修 | 56700000 |
| 78 | 人力服务 | 明尼苏达安全医院 – 圣彼得 | 56317000 |
| 0 | 明尼苏达大学 | 高等教育资产保护与更换… | 42500000 |
| 5 | 明尼苏达州立大学及大学 | 高等教育资产保护与更换… | 42500000 |
现在,设置我们的显示以使用更好的默认值并创建条形图:
pd.options.display.mpl_style = 'default' budget_plot = budget.plot(kind="bar",x=budget["detail"], title="MN 资本预算 - 2014", legend=False)
这将利用“详细”列创建图表,同时显示标题并移除图例。以下是保存图像为 png 格式所需的额外代码。
fig = budget_plot.get_figure() fig.savefig("2014-mn-capital-budget.png")
这里是其样子(截断以保持文章长度适中):

基本效果看起来非常好。理想情况下,我希望对 y 轴进行更多的格式化,但这需要进行一些 matplotlib 的操作。这是一个完全可以使用的可视化,但仅通过 pandas 很难进行更多的自定义。
Seaborn
Seaborn 是一个基于 matplotlib 的可视化库。它旨在使默认的数据可视化更加美观,并且目标是简化更复杂的图表的创建。它与 pandas 也有很好的集成。我的例子没有使 seaborn 显著地展现其优势。我喜欢 seaborn 的一个特点是其内置的各种样式,这使得你可以快速更改颜色调色板,使其看起来更加漂亮。否则,seaborn 在这个简单的图表中对我们帮助不大。标准导入和数据读取:
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
budget = pd.read_csv("mn-budget-detail-2014.csv") budget = budget.sort('amount',ascending=False)[:>10]
我发现一个问题是,我必须明确设置 x 轴上项目的顺序,使用 x_order。这段代码设置了顺序,并对图表和条形图的颜色进行了样式设置:
sns.set_style("darkgrid") bar_plot = sns.barplot(x=budget["detail"],y=budget["amount"], palette="muted", x_order=budget["detail"].tolist()) plt.xticks(rotation=>90) plt.show()

如你所见,我不得不使用 matplotlib 旋转 x 轴标题,以便能够实际读取它们。在视觉上,显示效果很好。理想情况下,我希望格式化 y 轴上的刻度,但我无法在不使用 matplotlib 的 plt.yticks 的情况下做到这一点。
ggplot
ggplot 与 Seaborn 类似,因为它也是基于 matplotlib 并且旨在以简单的方式改善 matplotlib 可视化的视觉效果。它与 seaborn 的不同之处在于,它是 R 的 ggplot2 的移植版。鉴于这一目标,部分 API 的设计不符合 Python 的习惯,但它是非常强大的。我没有在 R 中使用过 ggplot,因此有一定的学习曲线。然而,我开始看到 ggplot 的吸引力。这个库正在积极开发中,我希望它能继续成长和成熟,因为我认为它可能成为一个非常强大的选项。在学习过程中,我确实遇到过几次解决不了的问题。经过查看代码和一些谷歌搜索后,我能够解决大部分问题。继续导入并读取我们的数据:
import pandas as pd from ggplot import *
budget = pd.read_csv("mn-budget-detail-2014.csv") budget = budget.sort('amount',ascending=False)[:>10]
现在我们通过将多个 ggplot 命令串联在一起来构建图表:
p = ggplot(budget, aes(x="detail",y="amount")) + \ geom_bar(stat="bar", labels=budget["detail"].tolist()) +\ ggtitle("MN Capital Budget - 2014") + \ xlab("Spending Detail") + \ ylab("Amount") + scale_y_continuous(labels='millions') + \ theme(axis_text_x=element_text(angle=>90)) print p
这似乎有点奇怪——特别是使用print p来显示图表。然而,我发现弄清楚这点相对简单。确实花了一些时间弄明白如何将文本旋转 90 度,以及如何排列 x 轴上的标签。我发现的最酷的功能是scale_y_continous,它使标签显示得更加美观。如果你想保存图像,使用ggsave很简单:
ggsave(p, "mn-budget-capital-ggplot.png")
这是最终的图像。我知道这是一大片灰度。我本可以给它上色,但没有花时间去做。

我们的前三课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
Python 中基于潜在狄利克雷分配的主题提取概述
原文:
www.kdnuggets.com/2019/09/overview-topics-extraction-python-latent-dirichlet-allocation.html
comments
作者:Félix Revert,DataRobot 和 Velocity
自然语言处理中的一个反复出现的主题是通过主题提取来理解大量文本数据。无论是分析用户的在线评论、产品描述,还是搜索框中输入的文本,理解关键主题总是非常有用的。
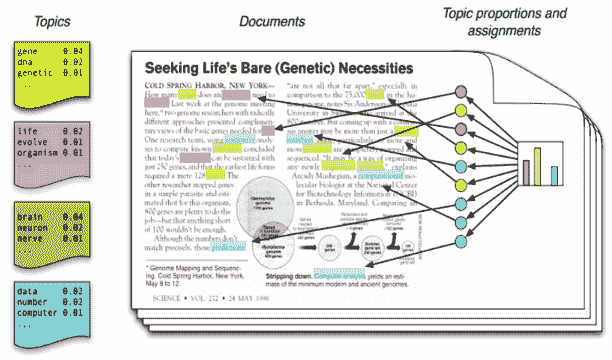 文献中常用的图示来解释 LDA
文献中常用的图示来解释 LDA
在介绍 LDA 方法之前,我想提醒你,通常避免重复发明轮子并选择快速解决方案是最佳的开始。许多提供商提供了很棒的主题提取 API(且在一定调用次数内是免费的):Google、Microsoft、MeaningCloud… 我试过这三者,它们都非常有效。
但是,如果你的数据非常具体,且没有通用的主题可以代表它,那么你将需要采用更个性化的方法。本文关注其中的一种方法:LDA。
理解 LDA
直观理解
LDA(潜在狄利克雷分配)是一个无监督的机器学习模型,它以文档作为输入,并以主题作为输出。该模型还会说明每个文档涉及每个主题的百分比。
一个主题被表示为一个加权的词列表。下面是一个主题的示例:
flower * 0,2 | rose * 0,15 | plant * 0,09 |…
 LDA 输入/输出工作流的示意图
LDA 输入/输出工作流的示意图
该模型有三个主要参数:
-
主题的数量
-
每个主题的单词数量
-
每个文档的主题数量
实际上,最后两个参数在算法中的设计并不完全是这样,但我更倾向于使用这些简化的版本,因为它们更容易理解。
实现
[专门的 Jupyter 笔记本在文末分享]
在这个例子中,我使用了从 BBC 网站获取的文章数据集。
要在 Python 中实现 LDA,我使用了gensim包。
LDA 的简单实现,我们要求模型创建 20 个主题
之前展示的参数是:
-
主题的数量等于num_topics
-
[每个主题的] 单词分布由eta处理
-
[每个文档的] 主题分布由alpha处理
要打印发现的主题,可以使用以下代码:
0: 0.024*"base" + 0.018*"data" + 0.015*"security" + 0.015*"show" + 0.015*"plan" + 0.011*"part" + 0.010*"activity" + 0.010*"road" + 0.008*"afghanistan" + 0.008*"track" + 0.007*"former" + 0.007*"add" + 0.007*"around_world" + 0.007*"university" + 0.007*"building" + 0.006*"mobile_phone" + 0.006*"point" + 0.006*"new" + 0.006*"exercise" + 0.006*"open"1: 0.014*"woman" + 0.010*"child" + 0.010*"tunnel" + 0.007*"law" + 0.007*"customer" + 0.007*"continue" + 0.006*"india" + 0.006*"hospital" + 0.006*"live" + 0.006*"public" + 0.006*"video" + 0.005*"couple" + 0.005*"place" + 0.005*"people" + 0.005*"another" + 0.005*"case" + 0.005*"government" + 0.005*"health" + 0.005*"part" + 0.005*"underground"2: 0.011*"government" + 0.008*"become" + 0.008*"call" + 0.007*"report" + 0.007*"northern_mali" + 0.007*"group" + 0.007*"ansar_dine" + 0.007*"tuareg" + 0.007*"could" + 0.007*"us" + 0.006*"journalist" + 0.006*"really" + 0.006*"story" + 0.006*"post" + 0.006*"islamist" + 0.005*"data" + 0.005*"news" + 0.005*"new" + 0.005*"local" + 0.005*"part"
[显示前 3 个主题及其前 20 个最相关的词] 主题 0 似乎与军事和战争有关。
关于印度健康的主题 1,涉及女性和儿童。
关于北马里的伊斯兰主义者的主题 2。
要打印文档涉及的主题百分比,请执行以下操作:
[(14, 0.9983065953654187)]
第一个文档关于主题 14 的比例为 99.8%。
对于未见过的文档进行主题预测也是可行的,如下所示:
[(1, 0.5173717951813482), (3, 0.43977106196150995)]
这份新文档讨论了 52%的主题 1,和 44%的主题 3。注意有 4%无法标记为现有主题。
探索
有一种很好的方式可以使用pyLDAvis包可视化你构建的 LDA 模型:
 pyLDAvis 的输出
pyLDAvis 的输出
这种可视化方法允许你在两个降维的维度上比较主题,并观察主题中词汇的分布。
另一个很好的可视化方法是按照主要主题以对角格式显示所有文档。
 文档中主题的比例可视化 (文档为行,主题为列)
文档中主题的比例可视化 (文档为行,主题为列)  主题 18 是文档中最主要的主题:25 个文档主要讨论它。
主题 18 是文档中最主要的主题:25 个文档主要讨论它。
如何成功实现 LDA
LDA 是一个复杂的算法,通常被认为难以微调和解释。确实,使用 LDA 获得相关结果需要对其工作原理有深入了解。
数据清理
使用 LDA 时你会遇到的一个常见问题是词汇出现在多个主题中。应对这种情况的一种方法是将这些词加入到停用词列表中。
另一个需要注意的是复数和单数形式。我建议进行词形还原——或者如果无法进行词形还原,则进行词干提取,但在主题中出现的词干不容易理解。
去除包含数字的词也会清理你的主题中的词。如果你认为年份(2006 年,1981 年)在你的主题中有意义,可以保留这些年份。
过滤出至少在 3 个(或更多)文档中出现的词是去除不相关稀有词的好方法。
数据准备
包括双词组和三词组,以获取更相关的信息。
另一个经典的准备步骤是仅使用名词和动词,使用词性标注(POS:词性)。
微调
-
主题数量:尝试几个不同的主题数量,以了解哪个数量是合理的。你实际上需要查看这些主题,才能知道你的模型是否合理。与 K-Means 相比,LDA 收敛且模型在数学层面上合理,但这并不意味着它在人的层面上也合理。
-
清理数据:添加在主题中出现过于频繁的停用词,并重新运行模型是一种常见步骤。仅保留名词和动词,去除文本中的模板,迭代测试不同的清理方法,将改善你的主题。准备花费一些时间在这里。
-
Alpha、Eta。如果你不懂技术细节,就忘了这些吧。否则,你可以调整 alpha 和 eta 来调整你的主题。从‘auto’开始,如果主题不相关,可以尝试其他值。我建议使用低值的 Alpha 和 Eta,以便每个文档中有较少的主题,每个主题中有较少的相关词汇。
-
增加 passes 的数量以获得更好的模型。3 到 4 次是一个不错的数字,但你可以尝试更多。
评估结果
-
你的主题是否可解释?
-
你的主题是否独特?(两个不同的主题是否有不同的词汇)
-
你的主题是否详尽?(这些主题是否很好地代表了你的所有文档?)
如果你的模型符合这 3 个标准,它看起来是一个好的模型 😃
LDA 的主要优点
速度快
使用 %time 命令在 Jupyter 中验证它。模型通常运行很快。当然,这取决于你的数据。有几个因素可能会拖慢模型的速度:
-
长文档
-
大量文档
-
大的词汇表大小(尤其是当你使用大 n 的 n-gram 时)
直观性
将主题建模为加权的词汇列表是一种简单的近似方法,但如果你需要解释,它是非常直观的方法。没有嵌入或隐藏维度,只有加权的词袋。
它可以预测新未见文档的主题
一旦模型运行完成,它就可以为任何文档分配主题。当然,如果你的训练数据集是英语的,而你想预测中文文档的主题,这将不起作用。但如果新文档具有相同的结构,并且应该有更多或更少相同的主题,它将有效。
LDA 的主要缺点
大量微调
如果 LDA 运行很快,但要得到好的结果却会遇到一些麻烦。这就是为什么提前了解如何微调它会真正帮助你。
需要人工解释
主题由机器发现。人类需要给它们标注,以便向非专家展示结果。
你无法影响主题
知道你的某些文档讨论了你熟悉的话题,但在 LDA 找到的主题中找不到它,肯定会让人感到沮丧。而且没有办法告诉模型某些词应该放在一起。你必须等待 LDA 给你想要的结果。
结论
LDA 仍然是我最喜欢的主题提取模型之一,我在许多项目中使用过它。然而,它需要一些练习才能掌握。这就是为什么我写了这篇文章,以便你可以轻松使用 LDA,跳过使用它的入门障碍。
代码: github.com/FelixChop/MediumArticles/blob/master/LDA-BBC.ipynb
个人简介:Félix Revert 是 DataRobot 和 Velocity 的客户数据科学家
原文。已获得许可转载。
相关:
-
使用 LSA、PLSA、LDA 和 lda2Vec 进行主题建模
-
从 PDF 文档中解锁并提取数据
-
领域特定语言处理从非结构化数据中挖掘价值
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织进行 IT 管理
更多相关主题
数据科学家解释的 P 值
原文:
www.kdnuggets.com/2019/07/p-values-explained-data-scientist.html
评论
作者 Admond Lee,美光科技 / AI Time Journal / Tech in Asia
我记得在我第一次在 CERN 的暑期实习时,大多数人还在谈论希格斯玻色子的发现,确认它达到了“五个西格玛”阈值(即 p 值为 0.0000003)。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在的组织的 IT
当时我对 p 值、假设检验甚至统计显著性一无所知。
你说得对。
我去谷歌搜索了“p 值”这个词,在维基百科上的内容让我更加困惑了……
在统计假设检验中,p-值 或 概率值 是对于给定的统计模型,当零假设为真时,统计摘要(如两个比较组之间样本均值差的绝对值)大于或等于实际观察结果的概率。
— 维基百科
干得好,维基百科。
好吧,我最终没能真正理解 p 值的含义。
直到现在,进入数据科学领域后,我才开始欣赏 p 值的意义以及它如何作为某些实验决策工具的一部分。
因此,我决定在本文中解释 p 值以及它们如何在假设检验中使用,希望能给你对 p 值有更好的直观理解。
虽然我们不能跳过其他概念的基础理解和 p 值的定义,但我保证我会以直观的方式解释,而不会用我所遇到的所有技术术语来轰炸你。
本文共有四个部分,为你提供从构建假设检验到理解 p 值以及使用这些来指导决策的完整图景。我强烈建议你通读所有部分,以详细理解 p 值:
-
假设检验
-
正态分布
-
什么是 p 值?
-
统计显著性
这将会很有趣。????
让我们开始吧!
1. 假设检验

假设检验
在讨论 p 值的含义之前,让我们先了解假设检验,其中p 值用于确定结果的统计显著性。
我们的终极目标是确定结果的统计显著性。
统计显著性建立在这 3 个简单的概念上:
-
假设检验
-
正态分布
-
p 值
假设检验用于检验关于总体的声明的有效性(零假设)。如果零假设被认为不成立,那么备择假设就是你会相信的。
换句话说,我们会提出一个声明(零假设),并使用样本数据来检验该声明是否有效。如果声明无效,我们将选择我们的备择假设。就是这么简单。
为了判断声明是否有效,我们会使用 p 值来衡量证据的强度,以查看其是否具有统计学意义。如果证据支持备择假设,那么我们将拒绝零假设并接受备择假设。这将在后续部分进一步解释。
让我们用一个例子来更清楚地说明这个概念,这个例子将在本文中用于其他概念。
???? ???? 示例:假设一个披萨店声称他们的送餐时间平均为 30 分钟或更少,但你认为超过了这个时间。因此你进行假设检验,并随机抽取一些送餐时间来检验这一声明:
-
零假设——平均送餐时间为 30 分钟或更少
-
备择假设——平均送餐时间超过 30 分钟
这里的目标是确定哪种声明——零假设还是备择假设——更有力地被样本数据支持。
在我们的案例中,我们将使用 单尾检验,因为我们 只关心均值交付时间是否大于 30 分钟。我们将忽略另一方向的可能性,因为均值交付时间低于或等于 30 分钟的后果更为可取。我们要测试的是均值交付时间是否有可能大于 30 分钟。换句话说,我们想看看比萨店是否以某种方式欺骗了我们。
常见的假设检验方法之一是使用 Z 检验。这里我们不会详细讲解,因为我们想在深入探讨之前对表面上的内容有一个高层次的了解。
2. 正态分布

正态分布是一个 概率密度函数,用于查看数据分布。
正态分布有两个参数 — 均值 (μ) 和 标准差,也称为 sigma (σ)。
均值 是分布的中心趋势。它定义了正态分布的峰值位置。标准差 是一个变异性的度量。它决定了数值偏离均值的远近程度。
正态分布通常与 [**68-95-99.7 规则**](https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule?source=post_page---------------------------)(见上图)相关联。
-
68% 的数据位于均值 (μ) 的 1 个标准差 (σ) 内。
-
95% 的数据位于均值 (μ) 的 2 个标准差 (σ) 内。
-
99.7% 的数据位于均值 (μ) 的 3 个标准差 (σ) 内。
还记得我一开始提到的用于发现希格斯玻色子的 “五西格玛”阈值 吗?5 sigma 是大约 99.9999426696856% 的数据必须达到的水平,科学家们才确认了希格斯玻色子的发现。这是为了避免任何潜在的假信号而设定的严格阈值。
很好。现在你可能在想,“正态分布如何应用于我们之前的假设检验?”
由于我们使用 Z 检验进行假设检验,我们需要计算Z 分数(用于我们的检验统计量),它是数据点与均值的标准差数量。在我们的例子中,每个数据点是我们收集的比萨配送时间。

计算 Z 分数的公式用于每个数据点
请注意,当我们计算了每个比萨配送时间的所有 Z 分数并绘制了如下的标准正态分布曲线时,X 轴上的单位将从分钟变为标准差单位,因为我们已经通过减去均值并除以标准差来标准化了变量(见上面的公式)。
查看标准正态分布曲线是有用的,因为我们可以将测试结果与标准化的标准差单位的“正常”人群进行比较,尤其是当我们有一个不同单位的变量时。

Z 分数可以告诉我们总体数据相对于平均人群的位置。
我喜欢Will Koehrsen这样描述——Z 分数越高或越低,结果发生的可能性越小,结果越有意义。
但是,什么程度的高(或低)被认为足够令人信服,以量化我们的结果有多么有意义?
????????重点
这就是我们需要最后一块拼图来解决难题的地方——p 值,并根据我们设定的显著性水平(也称为alpha)来检查我们的结果是否具有统计显著性,这些显著性水平是在我们开始实验之前设定的。
3. 什么是 P 值?
p 值由Cassie Kozyrkov精彩解释
最后……我们谈论的是 p 值!
所有前面的解释都是为了铺垫,引导我们到这个 p 值。我们需要这些前置的背景和步骤,以便理解这个神秘(实际上并不那么神秘的)p 值以及它如何影响我们对假设检验的决策。
如果你已经读到这里,继续阅读。因为这一部分是所有部分中最激动人心的!
与其用 Wikipedia(对不起 Wikipedia)给出的定义来解释 p 值,不如在我们的背景下——披萨配送时间来解释!
记住我们随机抽取了一些披萨配送时间,目标是检查平均配送时间是否超过 30 分钟。如果最终证据支持披萨店的说法(平均配送时间为 30 分钟或更少),那么我们将不拒绝原假设。否则,我们会拒绝原假设。
因此,p 值在这里的作用是回答这个问题:
如果我生活在一个披萨配送时间为 30 分钟或更少的世界里(原假设为真),我的证据在现实中有多令人惊讶?
p 值用一个数字来回答这个问题——概率。
p 值越低,证据越令人惊讶,我们的原假设看起来就越荒谬。
当我们觉得原假设荒谬时,我们该怎么办?我们拒绝它,选择我们的替代假设。
如果 p 值低于预定的显著性水平(人们称之为alpha,我称之为*荒谬的临界值 — 不要问我为什么,我只是觉得这样更容易理解),那么我们会拒绝原假设。
现在我们理解了 p 值的含义。让我们在我们的案例中应用它。
???? 披萨配送时间中的 p 值 ????
现在我们收集了一些抽样的配送时间,计算发现平均配送时间长了 10 分钟,p 值为 0.03。
这意味着在一个披萨配送时间为 30 分钟或更少的世界中(原假设为真),我们有3% 的机会看到平均配送时间因为随机噪声而至少长 10 分钟。
p 值越低,结果越有意义,因为它越不容易被噪声造成。
大多数人对 p 值有一个常见的误解:
p 值 0.03 意味着结果有 3%(百分比概率)是由于偶然——这不是真的。
人们通常希望得到明确的答案(包括我自己),这就是我长时间困惑于解释 p 值的原因。
p 值并不证明任何东西。它只是用惊讶作为做出合理决策的基础。
这是我们如何使用 p 值 0.03 帮助我们做出合理决策的方法(重要):
-
想象一下我们生活在一个平均配送时间始终为 30 分钟或更少的世界里——因为我们相信披萨店(我们的初始信念)!
-
在分析了收集到的样本交付时间后,p 值 0.03 低于显著性水平 0.05(假设我们在实验前设定了这个值),我们可以说结果是 统计上显著的。
-
因为我们一直相信披萨店能够履行其 30 分钟或更短时间内送达披萨的承诺,我们现在需要考虑这个信念是否仍然成立,因为结果告诉我们披萨店未能履行承诺,结果是 统计上显著的。
-
那么我们该怎么办?首先,我们尝试找出使我们初始信念(零假设)有效的每一种可能的方法。但是由于披萨店逐渐收到其他人的差评,并且经常提供不靠谱的借口导致迟到,即使我们自己也觉得难以再为披萨店辩解,因此,我们决定拒绝零假设。
-
最终,合理的决策是选择不再从该地点购买任何披萨。
现在您可能已经意识到一些事情……根据我们的背景,p 值并不是用来证明或证实任何事情的。
在我看来,p 值作为工具用于挑战我们初始的信念(零假设),当结果是 统计上显著的 时。当我们觉得自己的信念有些荒谬(前提是 p 值显示结果具有统计显著性),我们就会丢弃初始信念(拒绝零假设),并做出合理的决策。
4. 统计显著性
最后,这是最后阶段,我们将所有内容汇总并测试结果是否 统计上显著的。
仅有 p 值是不够的,我们需要设定一个阈值(即 显著性水平 — alpha)。alpha 应该在实验前设定,以避免偏见。如果观察到的 p 值低于 alpha,那么我们可以得出结果是 统计上显著的。
经验法则是将 alpha 设为 0.05 或 0.01(再次说明,值取决于您的具体问题)。
如前所述,假设我们在实验开始前将 alpha 设定为 0.05,得到的结果具有统计显著性,因为 p 值 0.03 低于 alpha。
供参考,以下是 整个实验的基本步骤:
-
陈述零假设
-
陈述替代假设
-
确定要使用的 alpha 值
-
找到与您的 alpha 水平相关的 Z 分数
-
使用此公式找到检验统计量
-
如果检验统计量的值低于 alpha 水平的 Z 分数(或 p 值低于 alpha 值),则拒绝零假设。否则,不拒绝零假设。

计算第 5 步的检验统计量的公式
如果你想了解更多关于统计显著性的信息,请随时查看这篇文章——统计显著性解析,由Will Koehrsen撰写。
最后想法

感谢你的阅读。
这里有很多内容需要消化,不是吗?
我不能否认,p 值对于很多人来说本质上是令人困惑的,我花了相当长的时间才真正理解和欣赏 p 值的含义及其在我们作为数据科学家的决策过程中如何应用。
但不要过于依赖 p 值,因为它们仅在整个决策过程中起到一小部分的辅助作用。
我希望你觉得 p 值的解释直观且有助于理解 p 值的真正含义及其在假设检验中的应用。
归根结底,p 值的计算是简单的。困难的部分在于我们想要解读假设检验中的 p 值。希望现在困难的部分对你来说至少稍微容易一点。
如果你想学习更多关于统计学的知识,我强烈推荐你阅读这本书(我现在正在读!)——数据科学家的实用统计学,专门为数据科学家编写,以帮助理解统计学的基本概念。
一如既往,如果你有任何问题或意见,请随时在下面留言,或者你可以通过LinkedIn联系我。期待在下一个帖子中见到你! ????
个人简介:Admond Lee被誉为帮助初创公司和各类公司解决数据问题的数据科学家和顾问中的佼佼者,他在数据科学咨询和行业知识方面拥有强大的专业能力。你可以通过LinkedIn、Medium、Twitter和Facebook与他联系,或者在这里预约与他通话,如果你正在寻找数据科学咨询服务。
原文。经许可转载。
相关内容:
-
你应该关注的十大数据科学领袖
-
如何进入数据科学领域:针对有志数据科学家的终极问答指南
-
简单而实用的数据清理代码
更多相关主题
如何使用 MLFlow 打包和分发机器学习模型
原文:
www.kdnuggets.com/2022/08/package-distribute-machine-learning-models-mlflow.html
在机器学习模型生命周期开发的每个阶段,协作是一个基本活动。将机器学习模型从构思到部署的过程需要不同角色之间的参与和互动。此外,机器学习模型开发的性质涉及实验、工件和指标的跟踪、模型版本等,这要求有效的组织来正确维护机器学习模型生命周期。
幸运的是,有一些工具用于开发和维护模型生命周期,比如 MLflow。在本文中,我们将解析 MLflow、它的主要组件及其特性。我们还将提供示例,展示 MLflow 在实际中的工作方式。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
什么是 MLflow?
MLflow 是一个开源工具,旨在支持机器学习模型生命周期的每个阶段的开发、维护和协作。此外,MLflow 是一个框架无关的工具,因此任何机器学习/深度学习框架都可以迅速适应 MLflow 提出的生态系统。
MLflow 是一个提供跟踪指标、工件和元数据工具的平台。它还提供了用于打包、分发和部署模型及项目的标准格式。
MLflow 还提供了管理模型版本的工具。这些工具被封装在其四个主要组件中:
-
MLflow 跟踪,
-
MLflow 项目,
-
MLflow 模型和
-
MLflow 注册表。
MLflow 跟踪
MLflow 跟踪 是一个基于 API 的工具,用于记录指标、参数、模型版本、代码版本和文件。MLflow 跟踪集成了一个用户界面,用于可视化和管理工件、模型、文件等。
每个 MLflow 跟踪会话都在运行的概念下组织和管理。运行指的是代码的执行,其中工件日志被显式记录。
MLflow Tracking 允许你通过 MLflow 的 Python、R、Java 和 REST APIs 生成运行记录。默认情况下,这些运行记录会存储在代码会话执行的目录中。不过,MLflow 也允许将工件存储在本地或远程服务器上。
MLflow 模型
MLflow Models 允许将机器学习模型打包为标准格式,以便通过 REST API、Microsoft Azure ML、Amazon SageMaker 或 Apache Spark 等不同服务直接使用。MLflow Models 规范的一个优点是打包支持多语言或多风味。
对于打包,MLflow 会生成一个包含两个文件的目录,一个是模型文件,另一个是指定模型打包和加载细节的文件。例如,下面的代码片段展示了一个 MLmodel 文件,其中指定了风味加载器以及定义环境的 conda.yaml 文件。
artifact_path: model
flavors:
python_function:
env: conda.yaml
loader_module: MLflow.sklearn
model_path: model.pkl
python_version: 3.8.2
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.24.2
run_id: 39c46969dc7b4154b8408a8f5d0a97e9
utc_time_created: '2021-05-29 23:24:21.753565'
MLflow 项目
MLflow Projects 提供了一个用于打包、共享和重用机器学习项目的标准格式。每个项目可以是一个远程仓库或本地目录。与 MLflow Models 不同,MLflow Projects 旨在实现机器学习项目的可移植性和分发。
一个 MLflow 项目由一个名为 MLProject 的 YAML 清单定义,其中公开了项目的规格。
模型实现的关键特性在 MLProject 文件中指定。这些特性包括:
-
模型接收的输入参数,
-
参数的数据类型,
-
执行模型的命令,以及
-
项目运行的环境。
下面的代码片段展示了一个 MLProject 文件的示例,其中实现的模型是一个决策树,其唯一参数是树的深度,默认值为 2。
name: example-decision-tree
conda_env: conda.yaml
entry_points:
main:
parameters:
tree_depth: {type: int, default: 2}
command: "python main.py {tree_depth}"
同样,MLflow 提供了一个 CLI 来运行位于本地服务器或远程仓库中的项目。下面的代码片段展示了如何从本地服务器或远程仓库运行项目的示例:
$ mlflow run model/example-decision-tree -P tree_depth=3
$ mlflow run git@github.com:FernandoLpz/MLflow-example.git -P tree_depth=3
在这两个示例中,环境将根据 MLProject file 规格生成。触发模型的命令将在命令行上传递的参数下执行。由于模型允许输入参数,这些参数通过 -P 标志进行分配。在这两个示例中,模型参数指的是决策树的最大深度。
默认情况下,如示例所示的运行将把工件存储在 .mlruns 目录中。
如何在 MLflow 服务器中存储工件?
实施 MLflow 时最常见的用例之一是使用 MLflow 服务器来记录指标和工件。MLflow 服务器负责管理由 MLflow 客户端生成的工件和文件。这些工件可以存储在不同的方案中,从文件目录到远程数据库。例如,要在本地运行 MLflow 服务器,我们输入:
$ mlflow server
上述命令将通过 IP 地址 http://127.0.0.1:5000/ 启动一个 MLflow 服务。为了存储工件和指标,服务器的跟踪 URI 在客户端会话中定义。
在下面的代码片段中,我们将看到在 MLflow 服务器中实施工件存储的基本实现:
import MLflow
remote_server_uri = "http://127.0.0.1:5000"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 1)
MLflow.log_metric("test-metric", 2)
MLflow.set_tracking_uri () 命令设置服务器的位置。
如何在 MLflow 服务器中运行身份验证?
暴露一个没有身份验证的服务器可能是有风险的。因此,添加身份验证是很方便的。身份验证将取决于你部署服务器的生态系统:
-
在本地服务器上,只需添加基于 用户 和 密码 的基本身份验证即可,
-
在远程服务器上,凭据必须与相应的代理一起调整。
为了说明,我们来看一个应用基本身份验证(用户名 和 密码)的 MLflow 服务器示例。我们还将看到如何配置客户端以使用该服务器。
示例:MLflow 服务器身份验证
在这个例子中,我们通过 Nginx 反向代理对 MLflow 服务器应用基本的用户名和密码身份验证。
让我们从安装 Nginx 开始,我们可以通过以下方式进行:
# For darwin based OS
$ brew install nginx
# For debian based OS
$ apt-get install nginx
# For redhat based OS
$ yum install nginx
对于 Windows 操作系统,你需要使用本机 Win32 API。请按照 这里 的详细说明操作。
安装完成后,我们将使用 htpasswd 命令生成一个具有相应密码的用户,如下所示:
sudo htpasswd -c /usr/local/etc/nginx/.htpasswd MLflow-user
上述命令为 .htpasswd 文件中的用户 mlflow-user 生成凭据。之后,为了在创建的用户凭据下定义代理,将修改配置文件 /usr/local/etc/nginx/nginx.conf,该文件默认内容如下:
server {
listen 8080;
server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
生成的凭据应如下所示:
server {
# listen 8080;
# server_name localhost;
# charset koi8-r;
# access_log logs/host.access.log main;
location / {
proxy_pass http://localhost:5000;
auth_basic "Restricted Content";
auth_basic_user_file /usr/local/etc/nginx/.htpasswd;
}
我们通过端口 5000 为 localhost 定义了一个身份验证代理。这是 MLflow 服务器默认部署的 IP 地址和端口号。当使用云提供商时,你必须配置实现所需的凭据和代理。现在按照以下代码片段初始化 MLflow 服务器:
$ MLflow server --host localhost
当尝试在浏览器中访问 http://localhost 时,将会要求通过创建的用户名和密码进行身份验证。

图 1. 登录
输入凭据后,你将被引导到 MLflow 服务器 UI。

图 2. MLflow 服务器 UI
要从客户端将数据存储到 MLflow 服务器,你需要:
-
定义将包含访问服务器凭证的环境变量,并
-
设置将存储工件的 URI。
因此,对于凭证,我们将导出以下环境变量:
$ export MLflow_TRACKING_USERNAME=MLflow-user
$ export MLflow_TRACKING_PASSWORD=MLflow-password
一旦定义了环境变量,你只需定义工件存储的服务器 URI。
import MLflow
# Define MLflow Server URI
remote_server_uri = "http://localhost"
MLflow.set_tracking_uri(remote_server_uri)
with MLflow.start_run():
MLflow.log_param("test-param", 2332)
MLflow.log_metric("test-metric", 1144)
执行上述代码片段时,我们可以看到测试指标和参数在服务器上的反映。

图 3. 从带有服务器身份验证的客户端服务中存储的指标和参数。
如何注册一个 MLflow 模型?
在开发机器学习模型时,一个日常需求是保持模型版本的有序性。为此,MLflow 提供了MLflow 注册表。
MLflow 注册表是一个扩展,有助于:
-
管理每个 MLModel 的版本并
-
记录每个模型在三个不同阶段的演变:归档、暂存和生产。它是 与 git 版本系统非常相似。
有四种注册模型的替代方案:
-
通过 UI,
-
作为
MLflow.<flavor>.log_model()的参数, -
使用
MLflow.register_model()方法或 -
使用
create_registered_model()客户端 API。
在以下示例中,使用MLflow.<flavor>.log_model()方法注册模型:
with MLflow.start_run():
model = DecisionTreeModel(max_depth=max_depth)
model.load_data()
model.train()
model.evaluate()
MLflow.log_param("tree_depth", max_depth)
MLflow.log_metric("precision", model.precision)
MLflow.log_metric("recall", model.recall)
MLflow.log_metric("accuracy", model.accuracy)
# Register the model
MLflow.sklearn.log_model(model.tree, "MyModel-dt", registered_model_name="Decision Tree")
如果这是一个新模型,MLFlow 会将其初始化为版本 1。如果模型已经有版本,它将被初始化为版本 2(或后续版本)。
默认情况下,注册模型时分配的状态为无。要为注册的模型分配状态,我们可以按以下方式进行:
client = MLflowClient()
client.transition_model_version_stage(
name="Decision Tree",
version=2,
stage="Staging"
)
在上述代码片段中,版本 2的决策树模型被分配到暂存状态。在服务器 UI 中,我们可以看到状态,如图 4 所示:

图 4. 注册的模型
为了服务模型,我们将使用 MLflow CLI,为此我们只需服务器 URI、模型名称和模型状态,如下所示:
$ export MLflow_TRACKING_URI=http://localhost
$ mlflow models serve -m "models:/MyModel-dt/Production"
模型的服务和 POST 请求
$ curl http://localhost/invocations -H 'Content-Type: application/json' -d '{"inputs": [[0.39797844703998664, 0.6739875109527594, 0.9455601866618499, 0.8668404460733665, 0.1589125298570211]}'
[1]%
在之前的代码片段中,向模型服务的地址发送了一个 POST 请求。请求中传递了一个包含五个元素的数组,这正是模型期望的推断输入数据。此情况下的预测结果为 1。
然而,需要提到的是,MLFlow 允许通过签名的实现定义MLmodel文件的推断数据结构。同样,请求中传递的数据可以是不同类型的,这些类型可以在这里查看。
上述示例的完整实现可以在此找到:github.com/FernandoLpz/MLFlow-example
MLflow 插件
由于 MLflow 的框架无关特性,MLflow 插件 应运而生。其主要功能是以适应不同框架的方式扩展 MLflow 的功能。
MLflow 插件允许对特定平台的部署和工件存储进行自定义和调整。
例如,针对平台特定部署有插件:
-
MLflow-redisai:允许将从 MLFlow 创建和管理的模型部署到 RedisAI。
-
MLflow-torchserve:使 PyTorch 模型能够直接部署到 TorchServe。
-
MLflow-algorithmia:允许将使用 MLFlow 创建和管理的模型部署到 Algorithmia 基础设施中。
-
MLflow-ray-serve:支持将 MLFlow 模型部署到 Ray 基础设施中。
另一方面,对于 MLflow 项目的管理,我们有 MLflow-yarn,一个用于在 Hadoop / Yarn 支持下管理 MLProjects 的插件。对于 MLflow Tracking 的自定义,我们有 MLflow-elasticsearchstore,它允许在 Elasticsearch 环境下管理 MLFlow Tracking 扩展。
同样,针对 AWS 和 Azure 的特定插件也可用。
需要提到的是,MLflow 提供了根据需求创建和 自定义插件 的功能。
MLflow 与 Kubeflow
由于对开发和维护机器学习模型生命周期工具的需求不断增加,像 MLflow 和 KubeFlow 这样的不同替代方案应运而生。
正如我们在本文中所见,MLflow 是一个允许在开发机器学习模型生命周期中协作的工具,主要集中在工件跟踪(MLflow Tracking)、协作、维护和项目版本控制上。
另一方面,还有 KubeFlow,它与 MLflow 类似,是一个用于开发机器学习模型的工具,但有一些具体的区别。
Kubeflow 是一个运行在 Kubernetes 集群上的平台;也就是说,KubeFlow 利用 Kubernetes 的容器化特性。此外,KubeFlow 提供了如 KubeFlow Pipelines 等工具,旨在通过 SDK 扩展生成和自动化管道(DAGs)。
KubeFlow 还提供了 Katib,这是一个用于大规模优化超参数的工具,并提供来自 Jupyter notebooks 的管理和协作服务。
SEO 链接:Kubernetes 和 Kubeflow 指南
具体来说,MLflow 是一个专注于机器学习项目开发管理和协作的工具。另一方面,Kubeflow 是一个专注于通过 Kubernetes 集群和容器使用开发、训练和部署模型的平台。
两个平台都提供了显著的优势,是开发、维护和部署机器学习模型的替代方案。然而,考虑到这些技术在开发团队中的使用、实施和集成的门槛是至关重要的。
由于 Kubeflow 与 Kubernetes 集群相关联用于实施和集成,因此建议有专家来管理这项技术。同样,开发和配置管道自动化也是一个挑战,可能在特定情况下对公司不利。
总结来说,MLflow 和 Kubeflow 是专注于机器学习模型生命周期特定阶段的平台。MLflow 是一个具有协作导向的工具,而 Kubeflow 更侧重于利用 Kubernetes 集群生成机器学习任务。然而,Kubeflow 需要 MLOps 部分的经验。需要了解 Kubernetes 中服务的部署,这可能是在尝试接触 Kubeflow 时需要考虑的问题。
Fernando López (GitHub) 是 Hitch 的数据科学负责人,领导一个数据科学团队,负责整个组织中人工智能模型的开发和部署,用于视频面试评估、候选人画像和评估管道。
更多相关话题
将你的 Python 项目打包并分发到 PyPI 以便通过 pip 安装
原文:
www.kdnuggets.com/2018/06/packaging-distributing-python-project-pypi-pip.html/2
评论
5. 准备包及其文件(init.py 和 setup.py)
第一步是结构化包及其文件。包的结构如图 7 所示。
图 7

目录的根目录包含了包的所有文件和目录。在根目录下,还有一个名为“printmsg”的目录,其中包含了实际的模块。该模块包含了我们的项目的 Python 代码,这些代码在安装后会被导入。
对于我们的简单示例,将使用所需的最小文件,即 init.py 和 setup.py,以及实际项目文件 print_msg_file.py。接下来是准备这些文件。
5.1 init.py
第一个需要准备的文件是 init.py 文件。这个文件的主要用途是允许 Python 将目录视为一个包。当包中有 init.py 文件时,包可以像普通库一样被导入,无论是通过哪个安装程序安装。即使文件为空,它的存在也足够。你可能会好奇为什么现在需要这个文件,而在第 3 步中手动安装库时不需要。答案是安装程序不会知道目录是一个包,如果没有 init.py 文件。因此,它不会提取库的 Python 文件(print_msg_file.py)。
在 Windows 上安装库时,使用 init.py 文件后,在 site-packages 目录中会生成两个文件夹(“printmsg-1.4.dist-info”和“printmsg”),如图 8 所示。“printmsg” 文件夹包含了待导入的 Python 文件。如果不使用 init.py 文件,那么将找不到“printmsg” 文件夹。结果,将无法使用 Python 代码,因为它将缺失。
图 8

除了告诉 Python 目录是一个 Python 包之外,init.py 文件是模块导入时第一个被加载的文件,因此可以进行初始化。
5.2 setup.py
在使用 init.py 文件将目录标记为包之后,接下来是添加有关包的更多详细信息。这就是 setup.py 文件的用途。setup.py 脚本提供了有关项目的详细信息,例如运行项目所需的依赖项。该脚本使用 setuptools 分发工具来构建分发文件,以便稍后上传到 PyPI。以下是用于分发项目的 setup.py 文件内容。
import setuptools
setuptools.setup(
name="printmsg",
version="1.6",
author="Ahmed Gad",
author_email="ahmed.f.gad@gmail.com",
description="Test Package for Printing a Message")
该文件包含多个字段,记录了如name(包名)、version(版本)、author(作者)、author_email(作者邮箱)、简短的description(描述)等细节,这些将在 PyPI 上显示,还有其他字段可以根据需要使用。
请注意,包名在当前有两个位置使用。一是模块目录,另一个是在 setup.py 文件中。它们必须相同吗?答案是否定的。每个名称有其自身的作用,但两者之间没有依赖关系。setup.py文件中使用的名称是安装包时使用的名称。目录的名称是导入模块时使用的名称。如果它们不同,则包将以一个名称安装,以另一个名称导入。为了避免混淆包用户,这两个名称之间应保持一致。
6. 分发包
准备好包后,我们可以分发它。在实际分发之前,我们应该确保所需的依赖项已经存在。要分发项目,需要安装setuptools和wheel项目。wheel项目用于生成wheel分发格式。确保它们已安装并更新,如图 9 所示,根据此命令:
ahmed-gad@ubuntu:~/Desktop/root $ pip install –upgrade setuptools wheel
Figure 9

然后我们可以通过运行setup.py文件来分发包,如图 10 所示。打开终端后,将包的根目录设置为当前目录,然后执行setup.py文件。
ahmed-gad@ubuntu:~/Desktop/root$ python3 setup.py sdist bdist_wheel
sdist用于生成源代码分发格式,而bdist_wheel生成轮子构建分发格式。这两种分发格式都为不同用户的兼容性提供支持。
Figure 10

执行setup.py文件后,预期在包的根目录下会生成一些新目录。根目录中的文件和目录如图 11 所示。
Figure 11

最重要的文件夹是dist文件夹,因为它包含将上传到 PyPI 的发行文件。其内容如图 12 所示。它包含.whl文件,即构建分发文件,还有源代码分发.tar.gz文件。
Figure 12

准备好发行文件后,接下来是将它们上传到 PyPI。
7. 将发行文件上传到测试 PyPI
有两个 Python 包仓库可供使用。其中一个用于测试和实验,即 Test PyPI (test.pypi.org),另一个用于真实索引,即 PyPI (pypi.org)。它们的使用类似,但我们可以先使用 Test PyPI。
在上传到 Test PyPI 之前,你应该注册以获得用于上传包的用户名和密码。只需通过你的有效电子邮件地址注册,确认邮件将被发送以激活你的账户。注册链接是test.pypi.org/account/register/。
注册完成后,我们可以使用twine工具将包分发上传到 Test PyPI。你应该确保按照以下命令安装和升级:
ahmed-gad@ubuntu:~/Desktop/root $ pip install –upgrade twine
一旦安装完成,你可以将包上传到 Test PyPI。打开终端,确保你当前在包的根目录,然后发出以下命令:
ahmed-gad@ubuntu:~/Desktop/root $ twine upload --repository-url https://test.pypi.org/legacy/ dist/*
系统会要求你输入 Test PyPI 的用户名和密码。一旦验证成功,上传将开始。结果如图 13 所示。
图 13

成功上传文件后,你可以打开 Test PyPI 的个人资料查看你上传的项目。图 14 显示了printmsg项目成功上线。请注意,setup.py文件中的描述字段值现在已出现在仓库中。
图 14

8. 从 Test PyPI 安装分发包
到这一步,你已成功打包和分发你的 Python 项目。现在任何连接到互联网的用户都可以下载它。要使用 pip 安装该项目,只需发出以下命令。结果如图 15 所示。
ahmed-gad@ubuntu:~/Desktop/root $ pip install --index-url https://test.pypi.org/simple/ printmsg
图 15

9. 导入和使用已安装的包
安装项目后,它可以被导入。之前输入的以下两行现在可以执行。不同之处在于使用从 Test PyPI 安装的包,而不是手动安装的包。结果与图 4 所示相同。
import printmsg.print_msg_file
printmsg.print_msg_file.print_msg_func()
10. 使用 PyPI 代替 Test PyPI
如果你决定将项目放入真实的 PyPI,你只需重复之前的步骤,稍作修改。首先,你需要在pypi.org/注册并获取用户名和密码。我不想说你必须再次注册,因为 Test PyPI 的注册与 PyPI 的注册不同。
第一个变化是不使用--repository-url选项与twine,因为 PyPI 是上传包的默认仓库。因此,所需的命令如下:
ahmed-gad@ubuntu:~/Desktop/root $ twine upload dist/*
类似地,第二个更改是出于相同原因省略--index-url选项和pip(PyPI 是安装包时的默认仓库)。
ahmed-gad@ubuntu:~/Desktop/root $ pip install printmsg
简介:Ahmed Gad 于 2015 年 7 月获得埃及门努非亚大学计算机与信息学院信息技术学士学位,成绩优异并获得荣誉。由于在学院中排名第一,他被推荐在 2015 年在一家埃及机构担任助教,并在 2016 年继续在学院担任助教和研究员。他目前的研究兴趣包括深度学习、机器学习、人工智能、数字信号处理和计算机视觉。
原文。经许可转载。
相关:
-
构建基于 HTTP 的 ConvNet 应用程序的完整指南,使用 TensorFlow 和 Flask RESTful Python API
-
使用 NumPy 从零开始构建卷积神经网络
-
遗传算法优化简介
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT
更多相关主题
免费电子书:用 Python 进行机器学习与实用数据分析
原文:
www.kdnuggets.com/2016/12/packt-free-ebooks-machine-learning-python-data-analysis.html
今年十二月,我们的朋友在 Packt 有一些我们认为你会喜欢的东西。简单来说,就是两个免费的电子书——这两本书将帮助你提升技能,并为你的新年决心开启学习新事物的一个良好开端。
在 用 Python 构建机器学习系统 中,你将学习如何将 Python 应用到各种分析问题中。290 页的内容,这不仅仅是一个快速入门——这是一本全面且实用的免费 Python 电子书,可能对你的数据科学技能集非常宝贵。
我们的前三大课程推荐
1. Google 网络安全证书 - 快速迈向网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
如果说一本免费的电子书还不够,Packt 还提供了另一本免费的电子书。
使用 ,你将直接进入数据分析的实际操作。你只需一些基本的编程和数值技能;这本 360 页的指南将帮助你将来自多种来源的数据转化为有价值的洞察。在数据驱动思维从未如此重要的时刻,这是一个提升分析技巧和锻炼思维的绝佳机会!
领取你的免费电子书所需做的就是用电子邮件地址和密码注册 Packt,并点击页面上的下载链接。电子书将立即添加到你的账户中;然后你可以将其下载为 PDF 格式。
要领取这两本电子书,请下载一本,然后使用你创建的账户登录以领取另一本!
如果您在索取免费电子书时遇到任何问题,请联系 customercare@packtpub.com
点击 这里下载《用 Python 构建机器学习系统》 立即免费下载!
点击 这里 立即免费下载《使用 Python 进行实用数据分析》!
更多相关话题
如何轻松分析你的时间序列
原文:
www.kdnuggets.com/2020/03/painlessly-analyze-time-series.html
评论
作者 Andrew Van Benschoten,Matrix Profile Foundation 联合创始人
我们周围充满了时间序列数据。从金融到物联网,再到营销,许多组织产生了数以千计的这些指标,并对其进行挖掘以揭示商业关键洞察。一个网站可靠性工程师可能会监控来自服务器农场的数十万条时间序列流,希望检测异常事件并防止灾难性故障。另一方面,一家实体零售商可能关心识别客户流量的模式,并利用这些模式来指导库存决策。
识别异常事件(或称“discords”)和重复模式(“motifs”)是两个基本的时间序列任务。那么,如何开始呢?针对这两个问题有数十种方法,每种方法都有其独特的优点和缺陷。
此外,时间序列数据分析 notoriously 困难,而数据科学社区的爆炸性增长带来了对更多“黑箱”自动化解决方案的需求,这些解决方案可以被具有广泛技术背景的开发人员所利用。

如何用一张图分析你的时间序列(图片来源:Matrix Profile Foundation)
我们在 Matrix Profile Foundation 相信,问题的答案其实很简单。虽然说没有免费的午餐,但 Matrix Profile(一个由 Keogh 研究组 在 UC-Riverside 开发的数据结构和相关算法集合)是一个强大的工具,可以帮助解决异常检测和模式发现这两个双重问题。Matrix Profile 具有稳健性、可扩展性,并且基本无需参数:我们已经看到它在包括网站用户数据、订单量和其他商业关键应用在内的广泛指标中发挥了作用。
如下文所述,Matrix Profile Foundation 已经在三种最常见的数据科学语言(Python、R 和 Golang)中实现了 Matrix Profile,作为一个易于使用的 API,适合时间序列的新手和专家。
那么,Matrix Profile 是什么呢?
Matrix Profile 的基本概念很简单:如果我拿一段数据并将其沿着时间序列滑动,那么它在每个新位置上的重叠程度如何?更具体地说,我们可以评估一个子序列与每个相同长度的时间序列段之间的欧几里得距离,从而构建所谓的片段“距离配置文件”。
如果数据中子序列重复,将至少有一个完美匹配,最小欧几里得距离将为零(或在噪声存在的情况下接近零)。相比之下,如果子序列非常独特(例如包含显著的异常值),匹配将很差,所有重叠分数都将很高。请注意,数据类型并不重要:我们只关心一般模式的保留。
然后,我们将每一个可能的片段滑过时间序列,建立起距离剖析的集合。通过取每个时间步长上所有距离剖析的最小值,我们可以建立最终的矩阵剖析。注意,矩阵剖析值谱的两个端点都是有用的。高值表示不常见的模式或异常事件;相反,低值突出可重复的模式,并为你的时间序列提供有价值的洞察。

图片来源:矩阵剖析基金会
对于感兴趣的读者,我们的一位联合创始人撰写的这篇文章提供了对矩阵剖析的更深入讨论。
尽管矩阵剖析(Matrix Profile)在时间序列分析中可以成为改变游戏规则的工具,但利用它生成洞察力是一个多步骤的计算过程,每一步都需要一定的领域经验。然而,我们相信,数据科学中最强大的突破发生在复杂的事物变得易于接触时。关于矩阵剖析,易于接触有三个方面:“开箱即用”的实现,温和的核心概念介绍,能够自然引导深入探索,以及多语言的可访问性。
今天,我们很自豪地推出矩阵剖析 API(MPA),这是一个用 R、Python 和 Golang 编写的通用代码库,实现了所有这三个目标。
MPA:它的工作原理
使用矩阵剖析包括三个步骤。
首先,你需要计算矩阵剖析本身。然而,这还不是终点:你需要利用你创建的矩阵剖析来发现一些东西。你是想寻找重复的模式?还是发现异常事件?最后,关键是你需要可视化你的发现,因为时间序列分析在一定程度上的可视化检查中获益匪浅。
通常,你需要阅读大量文档(包括学术和技术)来了解如何执行这三个步骤中的每一个。如果你是一个对矩阵剖析有先前知识的专家,这可能不是问题,但我们发现许多用户只是希望通过突破方法论来分析他们的数据,以获得一个基本的起点。代码是否可以简单地利用一些合理的默认值来生成合理的输出?
为了与这种自然的计算流程相并行,MPA 包含三个核心组件:
-
计算(计算矩阵剖析)
-
发现(评估 MP 以寻找模式、异异常等)
-
可视化(通过基本图表展示结果)
由于 Matrix Profile 仅有几年的历史,我们预期其会持续发展,并计划相应地更新该库;我们热忱欢迎社区反馈和开发协助!我们还希望通过不断增加的 Jupyter Notebook 教程来教育数据科学社区这一技术。开源工具构成了现代分析的基础,我们希望这一实现能像对我们一样有效地服务于其他用户。
这三种功能被封装成一个称为 Analyze 的高级功能。这是一个用户友好的界面,使得不了解 Matrix Profile 内部工作的用户也能快速利用它来处理自己的数据。随着用户对 MPA 的经验和直觉的增加,他们可以轻松深入了解这三个核心组件,以实现进一步的功能提升。
MPA:一个玩具示例
作为示例,我们将使用 MPA 的 Python 版本 来分析下面显示的合成时间序列:
py` from matplotlib import pyplot as plt import numpy as np import matrixprofile as mp %matplotlib inline data = pd.read_csv('rawdata.csv') vals = data.data.values fig,ax = plt.subplots(figsize=(20,10)) ax.plot(np.arange(len(vals)),vals, label = '测试数据') ```py ```` 
图片来源:Matrix Profile Foundation
视觉检查显示存在模式和不一致。然而,一个直接的问题是你选择的子序列长度将改变模式的数量和位置!在索引 0–500 之间只有两个正弦模式,还是每个周期都是该模式的一个实例?让我们看看 MPA 如何处理这个挑战:
py` profile, figures = mp.analyze(vals) ```py ````
图片来源:Matrix Profile Foundation
因为我们没有指定任何关于子序列长度的信息,analyze 通过利用一种称为全矩阵配置文件(或 PMP)的强大计算来生成帮助我们评估不同子序列长度的见解。我们将在后续文章中讨论 PMP 的细节(或者你可以阅读相关论文),但简而言之,它是将所有可能的子序列长度的全局计算浓缩成一个单一的视觉摘要。X 轴是矩阵配置文件的索引,Y 轴是对应的子序列长度。阴影越深,那个点的欧几里得距离越小。我们可以使用三角形的“峰值”来直观地找到合成时间序列中存在的 6 个“大”模式。
PMP 本身很不错,但我们承诺提供一种简单的方式来理解你的时间序列。为此,analyze 将结合 PMP 和底层算法,从所有可能的窗口大小中选择合适的模式和异常值。analyze 创建的附加图表展示了前三个模式和前三个异常值,以及对应的窗口大小和在 Matrix Profile 中的位置(并且,扩展到你的时间序列)。

图片来源:Matrix Profile Foundation
图片来源:Matrix Profile Foundation
图片来源:Matrix Profile Foundation
图片来源:Matrix Profile Foundation
图片来源:Matrix Profile Foundation
不出所料,默认设置下的信息量很大。我们的目标是让这个核心功能调用能够作为你未来许多分析的起点。例如,PMP 表明我们的时间序列中存在一个长度约为 175 的保守模式。尝试对该子序列长度调用 analyze,看看会发生什么!
py` profile, figures = mp.analyze(vals,windows=175) ```py ````
总结
我们希望 MPA 能使你更轻松地分析时间序列!欲了解更多信息,请访问我们的 网站、GitHub 仓库 或关注我们的 Twitter。如果你发现代码有用,请给我们的 GitHub 仓库加星!MPF 还运营一个 Discord 频道,你可以在这里与其他 Matrix Profile 用户互动并提问。祝你在时间序列分析中好运!
致谢
感谢 Tyler Marrs、Frankie Cancino、Francisco Bischoff、Austin Ouyang 和 Jack Green 对本文的审阅及创作协助。最重要的是,感谢 Eamonn Keogh、Abdullah Mueen 及他们众多的研究生,感谢他们创建了 Matrix Profile 并持续推动其发展。
补充信息
-
Matrix Profile 研究论文可以在 Eamonn Keogh 的 UCR 页面找到:
www.cs.ucr.edu/~eamonn/MatrixProfile.html -
Matrix Profile 算法的 Python 实现可以在这里找到:
github.com/matrix-profile-foundation/matrixprofile -
Matrix Profile 算法的 R 实现可以在这里找到:
github.com/matrix-profile-foundation/tsmp -
Matrix Profile 算法的 Golang 实现可以在这里找到:
github.com/matrix-profile-foundation/go-matrixprofile
简历:Andrew Van Benschoten 是一位数据科学领袖,拥有利用复杂信息生成有价值洞察的良好记录。擅长人员和项目管理,并且能够有效地向跨学科的利益相关者传达结果。
原文。经许可转载。
相关:
-
时间序列分类:合成与真实金融时间序列
-
利用 R、SQL 和 Tableau 进行地理时间序列预测介绍
-
预测故事:这是季节性还是其他?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您的组织的 IT。
更多相关内容
Pandas AI:生成型 AI Python 库
原文:
www.kdnuggets.com/2023/05/pandas-ai-generative-ai-python-library.html

图片由编辑提供
Python Pandas是一个开源工具包,为数据科学家和分析师提供了使用 Python 编程语言进行数据操作和分析的能力。Pandas 库在机器学习和深度学习的预处理阶段非常受欢迎。但现在你可以用它做更多的事情……
新的数据科学库 - Pandas AI即将推出。一个将生成型人工智能功能集成到 Pandas 中的 Python 库,使数据框能够进行对话。
什么是 Pandas AI?
让数据框能够对话是什么意思?
这正如它所说的那样 - 你可以与你的数据集对话。是的,你没听错,你可以与数据交谈并获得快速回应。作为数据科学家或分析师,你将不再需要盯着数据集看,反复浏览行列几个小时。Pandas AI 不会替代 Pandas,它只是给了它一个巨大的推动!
数据科学家和分析师花费大量时间清洗数据以进行分析阶段。他们现在将能够将数据分析提升到一个新的水平。数据专业人员寻找不同的方法和流程,以减少数据准备的时间,而现在他们可以使用 Pandas AI 实现这一目标。
PandasAI 与 Pandas 一起使用,而不是替代 Pandas。与其自己浏览并回答有关数据集的问题,不如向 PandasAI 提问,它将以 Pandas DataFrames 的形式返回答案。
话虽如此,这是否意味着人们不再需要精通 Python 才能使用诸如 Pandas 库这样的工具进行数据分析?
借助OpenAI API,Pandas AI 旨在实现与你的机器进行对话的目标,以输出你想要的结果,而不是你自己编程任务。机器将以它们的语言 - 机器可解释代码(DataFrame) - 输出结果。
我如何使用 Pandas AI?
使用 pip 安装 Pandas AI
pip install pandasai
使用 OpenAI 导入 PandasAI
为了使用新的 Pandas AI 库,你需要一个 OpenAI 密钥。一旦你开始使用你的笔记本,你需要导入以下内容:
import pandas as pd
from pandasai import PandasAI
from pandasai.llm.openai import OpenAI
llm = OpenAI(api_token=your_API_key)
如果你没有唯一的 OpenAI API 密钥,你可以在OpenAI 平台上创建一个帐户,并在这里创建一个 API 密钥。你将获得一个 5 美元的积分,可以用于探索和实验 API。
一旦你准备好,你就可以开始使用 Pandas AI 了。
在你的数据框上运行模型
首先,你需要将你的 OpenAI 模型运行到 Pandas AI 上:
pandas_ai = PandasAI(openAImodel)
然后你需要在数据框上运行模型,该数据框包含两个参数:你正在处理的数据框和你想要提问的问题:
pandas_ai.run(df, prompt='the question you would like to ask?')
例如,你可能在浏览数据集时对某列值大于 5 的行感兴趣。你可以通过使用 Pandas AI 来实现:
import pandas as pd
from pandasai import PandasAI
# Sample DataFrame
df = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"gdp": [19294482071552, 2891615567872, 2411255037952, 3435817336832, 1745433788416, 1181205135360, 1607402389504, 1490967855104, 4380756541440, 14631844184064],
"happiness_index": [6.94, 7.16, 6.66, 7.07, 6.38, 6.4, 7.23, 7.22, 5.87, 5.12]
})
# Instantiate a LLM
from pandasai.llm.openai import OpenAI
llm = OpenAI()
pandas_ai = PandasAI(llm)
pandas_ai.run(df, prompt='Which are the 5 happiest countries?')
它将返回一个 DataFrame 输出:
6 Canada
7 Australia
1 United Kingdom
3 Germany
0 United States
Name: country, dtype: object
它还具有执行更复杂查询的能力,如数学计算和数据可视化。
数据可视化示例:
pandas_ai.run(
df,
"Plot the histogram of countries showing for each the gpd, using different colors for each bar",
)
数据可视化输出:

图片由PandasAI提供
Pandas AI 非常新,团队仍在寻找改进库的方法。截至 5 月 10 日,他们的待办事项清单中还有以下内容:
-
添加对更多 LLMs 的支持
-
使 PandasAI 能够通过 CLI 访问
-
为 PandasAI 创建一个 Web 界面
-
添加单元测试
欢迎提出建议和贡献。如果你有兴趣为 Pandas AI 的成长做出贡献,请参考贡献指南。
如果你想查看使用 Pandas AI 的演示,查看这个视频:
总结一下
虽然 Pandas AI 并不取代 Pandas,但它是提升工作流程的好工具。尽管你可以向 Pandas AI 提问你的数据集,你仍需精通编程,以便在库出现错误时进行修正和指导。
如果你有机会使用 Pandas AI,欢迎在下方评论告诉我们你的看法!
Nisha Arya 是一名数据科学家,自由技术写作人员和 KDnuggets 的社区经理。她特别关注提供数据科学职业建议、教程和理论知识。她还希望探索人工智能如何有助于人类寿命的不同方式。她是一个热衷学习的人,寻求拓宽她的技术知识和写作技能,同时帮助指导他人。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织在 IT 方面
更多相关话题
Pandas 不够用?这里有几个处理更大、更快数据的 Python 替代方案。
原文:
www.kdnuggets.com/2021/07/pandas-alternatives-processing-larger-faster-data-python.html
评论
由 DaurEd 提供优质且负担得起的教育。

我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业道路。
2. Google 数据分析专业证书 - 提升你的数据分析技能。
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作。
数据以各种格式存在于各处,如 CSV、平面文件、JSON 等。当数据量较大时,很难读取到内存中,并且进行探索性数据分析(EDA)耗时较长。此博客围绕以 CSV 格式 处理表格数据,并使用 Pandas 以及 cuDF、dask、modin 和 datatable 等一些替代方案。
问题: 导入(读取)大型 CSV 文件会导致 内存不足 错误。RAM 不足以一次读取整个 CSV 文件,经常导致计算机崩溃。而且,使用单个 CPU 核心处理时速度较慢。
关于本次探索中使用的数据:一个包含 500 万行和 14 列的销售数据记录,如下所示。此数据集以 zip 格式提供,下载地址为:
数据的前 5 行:

Pandas 设计为 仅在单个核心上运行,因此无法利用系统上可用的多核。
然而,cuDF 库旨在在 GPU 上实现 Pandas API。Modin 和 Dask Dataframe 库提供了围绕 Pandas API 的 并行算法。
Modin 旨在对整个 pandas API 进行并行化,没有例外。这意味着所有 pandas 函数都可以在 Modin 上使用,只需更改一行代码:import modin.pandas as pd(查看下面的 Git 链接了解实现细节)。
Dask 目前缺少 Modin 已实现的多个 pandas API。
要了解如何通过参数 num_cpus 控制 Modin 使用的处理器数量,请查看:
github.com/Piyush-Kulkarni/ByeByePandas.git
在 Windows 平台上,您可以在任务管理器 > 性能中检查系统的核心数。

使用num_cpu超出系统可用核心数不会提升性能。实际上,它可能会降低性能。在我的案例中,超出系统提供的 6 个核心后,性能略有下降,如上述图表所示。
原文。已获许可转载。
相关:
更多相关话题
你还在用 Pandas 处理大数据吗?这里有两个更好的选择
原文:
www.kdnuggets.com/2021/03/pandas-big-data-better-options.html
评论
作者 Roman Orac,数据科学家。

我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
我最近写了两篇关于用 Dask 和 Vaex 处理大数据的入门文章——这些库用于处理超出内存的数据集。在写作过程中,我心里产生了一个问题:
这些库真的能处理超出内存的数据集吗,还是仅仅是销售口号?
这让我产生了用 Dask 和 Vaex 进行实际实验的兴趣,尝试处理一个超出内存的数据集。数据集大到连 Pandas 都无法打开。
我所说的大数据是什么意思?

大数据是一个松散定义的术语,其定义如同 Google 上的点击次数一样多。在本文中,我用这个术语来描述一个如此庞大的数据集,以至于我们需要专业的软件来处理它。这里的“大”指的是“超出单台机器的主内存”。
维基百科定义:
大数据是一个领域,处理分析、系统性提取信息或以其他方式处理数据集的方法,这些数据集太大或复杂,传统的数据处理应用程序软件无法处理。
Dask 和 Vaex 是什么?

照片由 JESHOOTS.COM 提供,来自 Unsplash。
Dask 提供了先进的并行处理分析能力,使你喜爱的工具在规模上表现优异。这包括 numpy、pandas 和 sklearn。它是开源的,并且免费提供。它使用现有的 Python API 和数据结构,方便你在 Dask 驱动的等效工具之间切换。
Vaex 是一个高性能的 Python 库,用于懒加载的 Out-of-Core DataFrames(类似于 Pandas),用于可视化和探索大型表格数据集。它可以每秒计算超过十亿行的基本统计数据。它支持多种可视化,允许对大数据进行交互式探索。
Dask 和 Vaex Dataframes 与 Pandas Dataframes 并不完全兼容,但一些最常见的“数据整理”操作都被这两种工具所支持。Dask 更专注于将代码扩展到计算集群,而 Vaex 则使在单台机器上处理大型数据集变得更加容易。
实验

由Louis Reed拍摄,发布在Unsplash上的照片。
我生成了两个包含 100 万行和 1000 列的 CSV 文件。每个文件的大小为 18.18 GB,两个文件合计 36.36 GB。文件中包含从 0 到 100 的均匀分布的随机数。

两个包含随机数据的 CSV 文件。作者拍摄的照片。
import pandas as pd
import numpy as np
from os import path
n_rows = 1_000_000
n_cols = 1000
for i in range(1, 3):
filename = 'analysis_%d.csv' % i
file_path = path.join('csv_files', filename)
df = pd.DataFrame(np.random.uniform(0, 100, size=(n_rows, n_cols)), columns=['col%d' % i for i in range(n_cols)])
print('Saving', file_path)
df.to_csv(file_path, index=False)
df.head()

文件头。作者拍摄的照片。
实验在一台具有 32 GB 主内存的 MacBook Pro 上运行——真是一个强大的机器。在测试 pandas Dataframe 的极限时,我惊讶地发现,在这样的机器上遇到内存错误是相当有挑战性的!
当内存接近其容量时,macOS 会开始将数据从主内存转储到 SSD 上。pandas Dataframe 的上限是机器上 100 GB 的自由磁盘空间。
当你的 Mac 需要内存时,它会将当前未使用的内容推送到交换文件中进行临时存储。当再次需要访问时,它会从交换文件中读取数据并恢复到内存中。
我花了一些时间思考如何解决这个问题,以确保实验的公平性。我想到的第一个想法是禁用交换空间,这样每个库只有主内存可用——在 macOS 上实现这一点真是困难重重。经过几个小时的努力,我无法禁用交换空间。
第二个想法是使用暴力破解的方法。我将 SSD 填满了它的全部容量,以至于操作系统无法使用交换空间,因为设备上没有剩余空间。

实验期间的“磁盘几乎已满”通知。作者拍摄的照片。
这有效!pandas 无法读取两个 18 GB 的文件,Jupyter 内核崩溃了。
如果我再次进行这个实验,我会创建一个内存较少的虚拟机。这样,更容易展示这些工具的限制。
Dask 或 Vaex 能否帮助我们处理这些大文件?哪个更快?让我们来找出答案。
Vaex 与 Dask

照片由 Frida Bredesen 在 Unsplash提供。
在设计实验时,我考虑了进行数据分析时的基本操作,如分组、过滤和数据可视化。我提出了以下操作:
-
计算一列的第 10 分位数,
-
添加新列,
-
按列过滤,
-
按列分组并聚合,
-
可视化一列。
上述所有操作都使用单列进行计算,例如:
# filtering with a single column
df[df.col2 > 10]
因此我对尝试一个需要处理所有数据的操作产生了兴趣:
- 计算所有列的总和。
通过将计算分解成更小的块可以实现这一点。例如,单独读取每一列并计算总和,最后一步计算整体总和。这类计算问题被称为 Embarrassingly parallel —— 不需要费力将问题分解成独立任务。
Vaex

照片由 Photos by Lanty 在 Unsplash提供。
让我们从 Vaex 开始。实验设计遵循了每个工具的最佳实践——这就是使用 Vaex 的二进制格式 HDF5。因此,我们需要将 CSV 文件转换为 HDF5 格式(层次数据格式第 5 版)。
import glob
import vaex
csv_files = glob.glob('csv_files/*.csv')
for i, csv_file in enumerate(csv_files, 1):
for j, dv in enumerate(vaex.from_csv(csv_file, chunk_size=5_000_000), 1):
print('Exporting %d %s to hdf5 part %d' % (i, csv_file, j))
dv.export_hdf5(f'hdf5_files/analysis_{i:02}_{j:02}.hdf5')
Vaex 需要 405 秒将两个 CSV 文件(36.36 GB)转换为两个 HDF5 文件(总共 16 GB)。从文本到二进制格式的转换减少了文件大小。
使用 Vaex 打开 HDF5 数据集:
dv = vaex.open('hdf5_files/*.hdf5')
Vaex 读取 HDF5 文件花费了 1218 秒。我原本期望它更快,因为 Vaex 声称可以瞬间打开二进制格式的文件。
打开此类数据是瞬时的,无论磁盘上的文件大小如何:Vaex 只会将数据映射到内存中,而不是读取到内存中。这是处理比可用 RAM 更大的数据集的最佳方式。
使用 Vaex 显示表头:
dv.head()
Vaex 显示表头花费了 1189 秒。我不确定为什么显示每列的前 5 行需要这么长时间。
使用 Vaex 计算第 10 分位数:
注意,Vaex 具有 percentile_approx 函数,用于计算分位数的近似值。
quantile = dv.percentile_approx('col1', 10)
Vaex 计算 col1 列第 10 分位数的近似值花费了 0 秒。
使用 Vaex 添加新列:
dv[‘col1_binary’] = dv.col1 > dv.percentile_approx(‘col1’, 10)
Vaex 有一个虚拟列的概念,它将表达式存储为列。它不占用任何内存,并在需要时动态计算。虚拟列与普通列一样对待。正如预期的那样,Vaex 执行上述命令所需的时间为 0 秒。
使用 Vaex 过滤数据:
Vaex 有一个 选择 的概念,我没有使用,因为 Dask 不支持选择,这会使实验不公平。下面的过滤器类似于用 pandas 进行的过滤,只不过 Vaex 不会复制数据。
dv = dv[dv.col2 > 10]
Vaex 执行上述过滤器所需的时间为 0 秒。
使用 Vaex 进行数据分组和聚合:
下面的命令与 pandas 稍有不同,因为它结合了分组和聚合。该命令按 col1_binary 对数据进行分组,并计算 col3 的均值:
group_res = dv.groupby(by=dv.col1_binary, agg={'col3_mean': vaex.agg.mean('col3')})

使用 Vaex 计算均值。照片由作者拍摄。
Vaex 执行上述命令所需的时间为 0 秒。
可视化直方图:
使用更大数据集进行可视化是有问题的,因为传统的数据分析工具未针对处理这些数据集进行优化。让我们尝试用 Vaex 制作 col3 的直方图。
plot = dv.plot1d(dv.col3, what='count(*)', limits=[0, 100])

使用 Vaex 可视化数据。照片由作者拍摄。
Vaex 显示图表所需的时间为 0 秒,这速度令人惊讶。
计算所有列的总和
在一次处理单列时,内存不是问题。让我们尝试用 Vaex 计算数据集中所有数字的总和。
suma = np.sum(dv.sum(dv.column_names))
Vaex 需要 40 秒计算所有列的总和。
Dask

照片由 Kelly Sikkema 贡献,来源于 Unsplash。
现在,让我们用 Dask 重复以上操作。Jupyter 内核在运行 Dask 命令之前已重新启动。
我们将 CSV 文件转换为 HDF5,以使实验公平,而不是直接使用 Dask 的 read_csv 函数读取 CSV 文件。
import dask.dataframe as dd
ds = dd.read_csv('csv_files/*.csv')
ds.to_hdf('hdf5_files_dask/analysis_01_01.hdf5', key='table')
Dask 需要 763 秒进行转换。如果你知道更快的转换方法,请在评论中告诉我。我尝试读取用 Vaex 转换的 HDF5 文件但没有成功。
HDF5 是 Pandas 用户在高性能需求下的热门选择。我们鼓励 Dask DataFrame 用户使用 Parquet 存储和加载数据。
用 Dask 打开 HDF5 数据集:
import dask.dataframe as dd
ds = dd.read_csv('csv_files/*.csv')
Dask 需要 0 秒打开 HDF5 文件。这是因为我没有明确运行计算命令,这实际上会读取文件。
用 Dask 显示头部:
ds.head()
Dask 需要 9 秒钟输出文件的前 5 行。
使用 Dask 计算第 10 个分位数:
Dask 有一个分位数函数,它计算实际分位数,而不是近似值。
quantile = ds.col1.quantile(0.1).compute()
Dask 无法计算分位数,因为 Jupyter Kernel 崩溃了。
使用 Dask 定义新列:
下面的函数使用分位数函数定义一个新的二进制列。Dask 无法计算,因为它使用了分位数。
ds['col1_binary'] = ds.col1 > ds.col1.quantile(0.1)
使用 Dask 过滤数据:
ds = ds[(ds.col2 > 10)]
上面的命令执行了 0 秒,因为 Dask 使用延迟执行范式。
使用 Dask 对数据进行分组和聚合:
group_res = ds.groupby('col1_binary').col3.mean().compute()
Dask 无法对数据进行分组和聚合。
可视化 col3 的直方图:
plot = ds.col3.compute().plot.hist(bins=64, ylim=(13900, 14400))
Dask 无法可视化数据。
计算所有列的总和:
suma = ds.sum().sum().compute()
Dask 无法对所有数据进行求和。
结果
下表显示了 Vaex 与 Dask 实验的执行时间。NA 表示该工具无法处理数据,Jupyter Kernel 崩溃。

实验中的执行时间总结。照片由作者提供。
结论

照片由 Joshua Golde 提供,来自 Unsplash。
Vaex 需要将 CSV 转换为 HDF5 格式,这对我来说没问题,因为你可以去吃午餐,回来时数据就会被转换。我也理解,在恶劣条件下(如实验中)主内存不足或没有主内存的情况下,读取数据将需要更长时间。
我不明白的是 Vaex 显示文件头部所需的时间(前 5 行需要 1189 秒!)。Vaex 中的其他操作经过了大量优化,使我们能够对大于主内存的数据集进行交互式数据分析。
我有点预期 Dask 会出现问题,因为它更优化用于计算集群而非单台机器。Dask 建立在 pandas 之上,这意味着在 pandas 中缓慢的操作在 Dask 中仍然缓慢。
实验的赢家已经明确。Vaex 能够处理大于主内存的文件,而 Dask 不能。这个实验是具体的,因为我是在单台机器上测试性能,而不是计算集群。
原文。经许可转载。
相关:
更多相关内容
Pandas 备忘单:Python 中的数据科学与数据处理
作者:Karlijn Willems,数据科学记者 & DataCamp 贡献者。
使用 Python 进行数据处理
数据科学工作流中一个非常重要的组件是数据处理。就像 matplotlib 是数据科学中数据可视化的首选工具一样,Pandas 库 是你在 Python 中进行数据操作和分析时的首选工具。这个库最初建立在 NumPy 上,NumPy 是 Python 中用于科学计算的基础库。Pandas 库提供的数据结构快速、灵活且表达力强,专门设计用于使现实世界的数据分析显著更容易。
我们的三大推荐课程
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织 IT 需求
然而,这种灵活性可能对初学者来说是有代价的;当你刚开始时,Pandas 库可能看起来非常复杂,可能很难找到一个统一的学习入口点:其他学习材料关注库的不同方面,你绝对可以使用备忘单来帮助你掌握它。
这就是 DataCamp 的 Pandas 教程 和 备忘单 发挥作用的地方。
Pandas 备忘单
使用这个库的第一件事是导入它。对于刚开始学习 Python 和/或编程的人来说,导入惯例可能显得不自然。然而,如果你看过第一张备忘单,你应该已经有了一些了解;在这种情况下,导入惯例规定你应该将 pandas 导入为 pd。然后在代码中使用 Pandas 模块时,你可以使用这个缩写。
这非常方便!

Pandas 数据结构
当你开始使用 Pandas 数据结构时,你将立即看到这种导入是如何工作的。但是,当你谈论“数据结构”时,究竟是什么意思?最简单的理解就是将它们看作是你数据的结构化容器。或者,如果你已经使用过 NumPy,这些数据结构基本上是带有索引的数组。
观看这个视频,如果你想了解更多关于 Pandas 数据结构如何与 NumPy 数组连接的信息。

无论如何,Pandas 库使用的基本结构是 Series 和 DataFrames。Series 基本上是带有索引的一维数组。要创建一个简单的 Series,可以使用pd.Series()。将一个列表传递给此函数,如果你愿意,还可以指定一些索引。结果可以在左侧的图片中看到。
请注意,Series 可以包含任何数据类型。
要创建 DataFrames,这些是具有不同数据类型列的二维结构,可以使用pd.DataFrame()。在这种情况下,你将一个字典传递给此函数,并传递一些额外的索引以指定列。
输入/输出
当你使用 Pandas 库进行数据处理时,你首先不会自己创建一个 DataFrame;而是从外部来源导入数据,然后将其放入 DataFrame 中,以便更容易处理。正如你在介绍中所读到的,Pandas 的终极目的是使现实世界的数据分析变得显著容易。

由于你的数据大多数不会仅来自文本文件,因此备忘单包括了三种将数据输入和输出到 DataFrames 或文件的方法,即 CSV、Excel 和 SQL 查询/数据库表。这三种方法被认为是数据到达你的三种最重要方式。你将看到 Pandas 有特定的函数来提取和推送数据:pd.read_csv()、pd.read_excel()和pd.read_sql()。但你也可以使用pd.read_sql_table()或pd.read_sql_query(),具体取决于你是从表格还是查询中读取。
请注意,to_sql()是对后两个函数的便捷封装。这意味着它只是调用另一个函数。类似地,如果你想将数据输出到文件中,可以使用pd.to_csv()、pd.to_excel()和pd.to_sql()。
想了解更多关于如何使用 Pandas 导入数据并用它来探索数据的信息吗?可以考虑参加 DataCamp 的Pandas Foundations课程。
帮助!
其中一个始终实用的工具是help()函数。使用此函数时,你不应忘记尽可能完整:如果你想获取更多关于 Pandas 库中某个函数或概念的信息,例如 Series,请调用pd.Series。

选择
当你最终获得了关于 Series 和 DataFrames 的所有信息,并且已经将数据导入这些结构中(或者你可能已经创建了自己的示例 Series 和 DataFrames,就像在备忘单中一样),你可能想要更仔细地检查数据结构。做到这一点的方法之一是选择元素。作为提示,备忘单指出你可能还会查看如何在 NumPy 数组中做到这一点。如果你已经了解 NumPy,你在这里显然会有优势!
如果你需要开始使用这个用于科学计算的 Python 库,可以考虑这个 NumPy 教程。

实际上,如果你已经使用过 NumPy,选择的过程非常相似。如果你还没有使用过,也不用担心,因为它很简单:要获取一个元素,你使用方括号 [] 并放入所需的索引。在这种情况下,你在方括号中放入 ‘b’,你会得到 -5。如果你回顾一下“Pandas 数据结构”,你会发现这是正确的。对于 2D DataFrame 结构,当你使用方括号结合冒号时,也有类似的情况。冒号前面放置的是表示行索引的数字;在第二个例子中 df[1:],你请求所有从索引 1 开始的行。这意味着具有比利时条目的行不会出现在结果中。
要根据 DataFrame 或 Series 中的位置选择值,你不仅需要使用方括号和索引,还可以使用 iloc() 或 iat()。然而,你也可以通过行和列标签来选择元素。正如你在 Pandas 数据结构的介绍中看到的那样,列有标签:“Country”、“Capital”和“Population”。借助 loc() 和 at(),你实际上可以根据这些标签选择元素。除了这四个函数,还有一个基于标签或位置的索引器:ix 主要是基于标签的,但当没有提供标签时,它将接受整数以指示 DataFrame 或 Series 中要检索值的位置。
布尔索引也包含在备忘单中;这是一个重要的机制,用于从原始 DataFrame 或 Series 中选择仅满足特定条件的值。条件可以使用逻辑运算符 & 或 | 与运算符 <、>、== 或组合(如 <= 或 >=)轻松指定。
最后,还有设置值的选项:在这种情况下,你将 Series 的索引 a 更改为值 6,而不是原始值 3。
你是否对如何操控你的 DataFrames 以充分利用它们感兴趣?可以考虑参加 DataCamp 的 使用 Pandas 操作 DataFrames 课程。
删除值
除了获取、选择、索引和设置 DataFrame 或 Series 的值,你还需要灵活地删除不再需要的值。利用 drop() 从列或行中删除值。此函数默认影响轴 0 或行。这意味着,如果你想从列中删除值,你不应忘记在代码中添加参数 axis=1!

排序与排名
操控 DataFrame 或 Series 的另一种方法是对数据结构中的值进行排序和/或排名。使用 sort_index() 按标签沿轴排序,或使用 sort_values() 按值沿轴排序。正如你所期待的,rank() 允许你对 DataFrame 或 Series 的条目进行排名。

检索 DataFrame/Series 信息
当你最终掌握了数据科学项目的数据时,了解一些关于 DataFrames 或 Series 的基本信息可能会很有用,特别是当这些信息可以告诉你更多关于数据的形状、索引、列和非 NA 值的数量时。此外,任何通过 info() 获得的其他信息都将是非常欢迎的,尤其是在处理不熟悉或新数据时。

除了左侧显示的属性和函数外,你还可以利用聚合函数来了解你的数据。你会发现它们中的大多数作为统计学中常用的函数(如 mean() 或 median())应该对你很熟悉。
应用函数
在某些情况下,你还可能需要对 DataFrames 或 Series 应用函数。除了 lambda 函数(你可能已经从 DataCamp 的 Python 数据科学工具箱 课程中了解过),你还可以使用 apply() 将函数应用于整个数据集,或者在希望逐元素应用函数时使用 applymap()。换句话说,你将对 DataFrame 或 Series 的每个元素应用函数。想看看这在实践中是如何工作的?试试 DataCamp 的 Pandas DataFrame 教程。

数据对齐
你需要了解的最后一件事是,当你的索引不同步时,数据是如何处理的。在示例中,你会看到 s3 的索引与 Series s 的索引不一致。
这可能经常发生!

在这种情况下,Pandas 会为你引入不重叠索引中的 NA 值。每当发生这种情况时,你可以将 fill_value 参数传递给你使用的算术函数,这样任何 NA 值都会被替换为有意义的替代值。
现在你已经了解了构成 Pandas 基础的各个组件,请点击下面的图片以访问完整的备忘单。
DataCamp 是一个在线互动教育平台,专注于为数据科学构建最佳学习体验。我们关于 R、Python 和 数据科学 的课程围绕特定主题展开,结合视频讲解和浏览器内编码挑战,让你通过实践学习。 你可以随时免费开始每门课程,无论何时何地。
简介: Karlijn Willems 是一名数据科学记者,为 DataCamp 社区 撰写文章,专注于数据科学教育、最新新闻和热门趋势。她拥有文学与语言学以及信息管理的学位。
相关内容:
-
为你的团队提供的 4 个在线数据科学培训选项
-
全面学习 Python 用于数据分析和数据科学指南
-
最佳数据科学在线课程
更多相关内容
Pandas DataFrame 索引
评论
使用 loc[] 按标签选择行和列。
使用 iloc[] 按位置选择行和列。
明确指定行和列,即使是使用“:”
我们的前 3 个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你组织的 IT
要观看视频、获取幻灯片和代码,请查看课程。它是免费的($ 和 CC0)。
长版:为不喜欢记忆的人的 Pandas DataFrame 索引
有很多方法可以从 DataFrame 中提取元素、行和列。(如果你有兴趣,可以查看 Ted Petrou 的 7(!)-部分系列 关于 pandas 索引。)一些索引方法看起来非常相似,但行为却非常不同。本文的目标是确定一种简单易懂并且结果可靠的 DataFrame 数据提取策略。只是提醒一下——这些仅仅是我个人的想法,并不保证权威或准确。
首先,我们使用维基百科上关于世界最高山峰的数据创建一个小数据框。对于每座山,我们都有其名称、高度(以米为单位)、首次登顶的年份以及所属的山脉。如果这是你第一次接触 pandas DataFrame,那么每座山及其相关信息就是一行,每条信息,例如名称或高度,是一列。

每一列都有一个名称,也称为标签。我们列的标签是 'name'、'height (m)'、'summitted' 和 'mountain range'。在 pandas 数据框中,每一行也有一个名称。默认情况下,这个标签就是行号。然而,你可以将其中一列设置为 DataFrame 的索引,这意味着它的值将用作行标签。我们将列 'name' 设置为我们的索引。

从 DataFrame 中挑选一个列进行操作是常见的操作。要通过标签选择列,我们使用 .loc[] 函数。为了使我们的命令易于解释,我们可以始终包括我们感兴趣的行索引和列索引。在这种情况下,我们对所有行感兴趣。为了表示这一点,我们使用冒号。然后,为了指示我们感兴趣的列,我们添加它的标签。命令 mountains.loc[:, 'summitted'] 获取的是 'summitted' 列。

值得注意的是,这个命令返回的是 Series,这是 pandas 用来表示列的数据结构。如果我们只想要 'summitted' 列中的数字数组,而不是 Series,那么我们在命令末尾添加 .values。这会返回一个包含 [1953, 1954, 1955, 和 1956] 的 numpy 数组。

如果我们只想获取单行,则再次使用 .loc[] 函数,这次指定行标签,并在列位置放置冒号。

如果我们只想要一个单一值,比如 K2 被征服的年份,那么我们可以同时指定行和列的标签。行标签总是先于列标签。

虽然你可以只使用一个参数来调用 .loc[] 函数,但如果你总是同时指定行和列,即使是用冒号,这样会更容易解释。
使用这种方法,我们不必仅限于单行或单列。在这里,在行位置,我们传递一个标签列表。这会返回一组行,而不是仅仅一行。

我们还可以通过指定起始列和结束列,并在其间放置冒号,来获取列的子集。在这种情况下,'height': 'summitted' 会给我们起点 'height' 和终点 'summitted' 之间(包括这两者)的所有列。请注意,这与 numpy 中的数字索引不同,在 numpy 中,端点是被省略的。此外,由于我们已经将名称列指定为索引,它也会在我们返回的数据框中出现。

此外,我们可以选择满足某个条件的行或列。在这种情况下,我们想要找到 'summitted' 列中值大于 1954 的行。在行位置,我们可以放置任何布尔表达式,该表达式的值数量与行数相同。如果我们愿意,也可以对列做同样的操作。

作为基于标签选择行和列的替代方法,我们也可以通过行和列的编号来选择它们。列的排序以及位置取决于数据框的初始化方式。索引列,即我们的“名称”列,不计入其中。

要通过位置选择数据,我们使用 .iloc[] 函数。再次,第一参数用于行,第二参数用于列。要选择零行中的所有列,我们写 .iloc[0, ;]

同样,我们可以通过位置选择列,将所需的列号放入 .iloc[] 函数的列位置中。

我们可以通过指定行和列的位置来提取单个值。

如果我们想挑选特定的行和/或列,可以传递位置列表。

我们还可以使用冒号范围操作符通过位置获取一组连续的行或列。注意,与使用标签的 .loc[] 函数不同,使用位置的 .iloc[] 函数不包括端点。在这种情况下,它仅返回列零和一,而不返回列二。

所有这些可以总结如下。
-
使用 .loc[] 进行基于标签的索引
-
使用 .iloc[] 进行基于位置的索引,并且
-
明确指定行和列,即使使用冒号也是如此。
这一组指南将为你提供一致且易于解读的方式,从 pandas DataFrame 中提取所需的数据。
祝你数据处理顺利!查看我的 端到端机器学习课程 获取更多数据处理技巧和机器学习教程。
原文。已获授权转载。
相关:
更多相关主题
使用 PyPolars 使 Pandas 的速度提升 3 倍
评论
由 Satyam Kumar,机器学习爱好者和程序员

Pandas 是数据科学家处理数据时最重要的 Python 包之一。Pandas 库主要用于数据探索和可视化,因为它提供了大量内置函数。由于 Pandas 无法处理大规模数据集,因为它无法扩展或将处理过程分配到 CPU 的所有核心。
为了加快计算速度,可以利用 CPU 的所有核心来提升工作流程的速度。包括 Dask、Vaex、Modin、Pandarallel、PyPolars 等在内的各种开源库可以将计算并行化到 CPU 的多个核心。在这篇文章中,我们将讨论 PyPolars 库的实现和使用,并将其性能与 Pandas 库进行比较。
PyPolars 是什么?
PyPolars 是一个开源的 Python 数据框架库,类似于 Pandas。PyPolars 利用 CPU 的所有可用核心,因此比 Pandas 更快地执行计算。PyPolars 的 API 与 Pandas 相似。它是用 Rust 编写的,并具有 Python 包装器。
理想情况下,当数据过大以至于无法使用 Pandas 处理,但又小到不需要使用 Spark 时,应使用 PyPolars。
PyPolars 如何工作?
PyPolars 库有两个 API,一个是 Eager API,另一个是 Lazy API。Eager API 非常类似于 Pandas,结果在执行完成后立即产生。Lazy API 则类似于 Spark,当执行查询时会形成一个映射或计划,然后在 CPU 的所有核心上并行执行。

(图片由作者提供),PyPolars API
PyPolars 基本上是 Polars 库的 Python 绑定。PyPolars 库的最佳部分是其与 Pandas 的 API 相似性,这使得开发者更容易上手。
安装:
可以使用以下命令从 PyPl 安装 PyPolars:
**pip install py-polars**
并使用以下命令导入库
**import pypolars as pl**
基准时间限制:
在演示中,我使用了一个大规模数据集(约 6.4GB),包含 2500 万个实例。

(图片由作者提供),Pandas 和 Py-Polars 基本操作的基准时间数量
对于使用 Pandas 和 PyPolars 库的一些基本操作的基准时间数据,我们可以观察到 PyPolars 的速度几乎比 Pandas 快 2 到 3 倍。
现在我们知道 PyPolars 的 API 非常类似于 Pandas,但仍然未覆盖 Pandas 的所有功能。例如,PyPolars 中没有 **.describe()** 函数,而是可以使用 **df_pypolars.to_pandas().describe()**
用法:
(作者提供的代码)
结论:
在本文中,我们简要介绍了 PyPolars 库,包括其实现、用法,并将其基准时间与 Pandas 进行了一些基本操作的比较。请注意,PyPolars 的工作方式与 Pandas 非常相似,且 PyPolars 是一个内存高效的库,因为它的内存是不可变的。
可以查看 文档 以详细了解该库。还有各种其他开源库可以并行化 Pandas 操作,加速过程。阅读 下文提到的文章 以了解 4 个这样的库:
通过使用这些框架来进行并行处理以分配 Python 工作负载
参考文献:
[1] Polars 文档和 GitHub 存储库:github.com/ritchie46/polars
感谢阅读
简介: Satyam Kumar 是一位机器学习爱好者和程序员。Satyam 撰写 关于数据科学的文章,并且是 AI 的顶级写手。他正在寻求一个具有挑战性的职业机会,以发挥他的技术技能和能力。
原文。经授权转载。
相关:
-
Vaex: Pandas 但快 1000 倍
-
如何用 Modin 加速 Pandas
-
如何处理机器学习中的分类数据
我们的 3 大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT
更多相关话题
10 个 Pandas 一行代码用于数据访问、处理和管理
原文:
www.kdnuggets.com/2023/01/pandas-one-liners-data-access-manipulation-management.html

Pandas 一行代码... 明白了吗?图片由 Midjourney 创建
Python 以易于阅读、编写和理解而闻名。它的语法也很有表现力和灵活,这意味着在其他语言中可能需要多行代码的操作在 Python 中可以更简洁地完成。大量功能可以浓缩在一行 Python 代码中。
我们的前三名课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业轨道。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
Pandas 是一个流行的开源 Python 库,用于数据分析、处理和清理。Pandas 提供了存储数据集的数据结构,以及处理它们的工具。这些工具范围广泛,使用该库可以完成各种数据处理任务。
这篇文章将分享 10 个简单的 Python 一行代码,用于 Pandas 库,以便让你立即开始访问、处理和管理数据。
1. 从 CSV 文件读取数据
这行代码用于从 CSV 文件中读取数据到 Pandas 数据框。
df = pd.read_csv('data.csv')
2. 删除包含空值的列
这行代码用于删除包含任何数量空值的列。
df.drop(df.columns[df.isnull().sum() > 0], axis=1, inplace=True)
3. 基于现有列创建新列
这行 Python 代码基于现有列创建一个新列。
df['new_col'] = df.apply(lambda x: x['col_1'] * x['col_2'], axis=1)
4. 分组并计算列的均值
这是一个用于分组和计算列均值的代码。
df.groupby('group_col').mean()
5. 根据特定值过滤行
这行代码用于根据特定值过滤行。
df.loc[df['col'] == 'value']
6. 按特定列排序数据框
这行 Python 代码用于按特定列排序数据框。
df.sort_values(by='col_name', ascending=False)
7. 填充所有空值
这将把数据框中所有的空值填充为 0。
df.fillna(0)
8. 删除重复行
这行代码将从数据框中删除重复的行。
df.drop_duplicates()
9. 创建数据透视表
这行代码用于创建数据透视表。
df.pivot_table(index='col_1', columns='col_2', values='col_3')
10. 保存为 CSV 文件
最后,这段 Python 代码将把处理过的数据框保存到一个新的 CSV 文件中。
df.to_csv('new_data.csv', index=False)
这篇文章介绍了 10 个简单的 Python 单行代码,用于使用 Pandas 库访问、处理和管理数据。我们是否遗漏了什么?请在下面的评论中分享一些有趣的 Pandas 单行代码。
Matthew Mayo (@mattmayo13) 是数据科学家,也是 KDnuggets 的主编,这是一个开创性的在线数据科学和机器学习资源。他的兴趣包括自然语言处理、算法设计与优化、无监督学习、神经网络以及自动化机器学习方法。Matthew 拥有计算机科学硕士学位和数据挖掘研究生文凭。你可以通过 editor1 at kdnuggets[dot]com 联系他。
更多相关话题
Pandas: 如何进行独热编码

图片来自 Pexels
什么是独热编码
我们的 Top 3 课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
独热编码是将类别值转换为兼容的数值表示形式的数据预处理步骤。
| categorical_column | bool_col | col_1 | col_2 | label |
|---|---|---|---|---|
| value_A | True | 9 | 4 | 0 |
| value_B | False | 7 | 2 | 0 |
| value_D | True | 9 | 5 | 0 |
| value_D | False | 8 | 3 | 1 |
| value_D | False | 9 | 0 | 1 |
| value_D | False | 5 | 4 | 1 |
| value_B | True | 8 | 1 | 1 |
| value_D | True | 6 | 6 | 1 |
| value_C | True | 0 | 5 | 0 |
例如,对于这个虚拟数据集,类别列具有多个字符串值。许多机器学习算法要求输入数据为数值形式。因此,我们需要将这些数据属性转换为适合这些算法的形式。因此,我们将类别列拆分为多个二值列。
如何使用 Pandas 库进行独热编码
首先,将 .csv 文件或任何其他关联文件读入 Pandas 数据框。
df = pd.read_csv("data.csv")
为了检查唯一值并更好地理解数据,我们可以使用以下 Panda 函数。
df['categorical_column'].nunique()
df['categorical_column'].unique()
对于这些虚拟数据,这些函数返回以下输出:
>>> 4
>>> array(['value_A', 'value_C', 'value_D', 'value_B'], dtype=object)
对于类别列,我们可以将其拆分为多个列。为此,我们使用 pandas.get_dummies() 方法。它接受以下参数:
| 参数 | |
|---|---|
| 数据: 类数组、Series 或 DataFrame | 原始的 pandas 数据框对象 |
| 列: 类似列表,默认为 None | 类别列的列表,用于进行独热编码 |
| drop_first: 布尔值,默认为 False | 移除类别标签的第一个级别 |
为了更好地理解该函数,让我们对虚拟数据集进行独热编码。
类别列的独热编码
我们使用 get_dummies 方法并将原始数据框作为 data 输入。在 columns 中,我们传递一个仅包含 categorical_column 头的列表。
df_encoded = pd.get_dummies(df, columns=['categorical_column', ])
以下命令删除了 categorical_column 并为每个唯一值创建了一个新列。因此,单个类别列被转换为 4 个新列,其中只有一个列的值为 1,其他 3 列的值均为 0。这就是为什么它被称为一热编码。
| categorical_column_value_A | categorical_column_value_B | categorical_column_value_C | categorical_column_value_D |
|---|---|---|---|
| 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 |
| 0 | 0 | 0 | 1 |
| 0 | 0 | 1 | 0 |
| 0 | 0 | 0 | 1 |
当我们想对布尔列进行一热编码时会出现问题。这也会创建两个新列。
热编码二进制列
df_encoded = pd.get_dummies(df, columns=[bool_col, ])
| bool_col_False | bool_col_True |
|---|---|
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
当我们可以仅使用一列将 True 编码为 1,False 编码为 0 时,不必要地增加了一列。为解决此问题,我们使用 drop_first 参数。
df_encoded = pd.get_dummies(df, columns=['bool_col'], drop_first=True)
| bool_col_True |
|---|
| 1 |
| 0 |
| 1 |
| 0 |
结论
虚拟数据集经过一热编码后,最终结果如下
| col_1 | col_2 | bool | A | B | C | D | label |
|---|---|---|---|---|---|---|---|
| 9 | 4 | 1 | 1 | 0 | 0 | 0 | 0 |
| 7 | 2 | 0 | 0 | 1 | 0 | 0 | 0 |
| 9 | 5 | 1 | 0 | 0 | 0 | 1 | 0 |
| 8 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 9 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 5 | 4 | 0 | 0 | 0 | 0 | 1 | 1 |
| 8 | 1 | 1 | 0 | 1 | 0 | 0 | 1 |
| 6 | 6 | 1 | 0 | 0 | 0 | 1 | 1 |
| 0 | 5 | 1 | 0 | 0 | 1 | 0 | 0 |
| 1 | 8 | 1 | 0 | 0 | 0 | 1 | 0 |
类别值和布尔值已经转换为可以作为机器学习算法输入的数值。
穆罕默德·阿赫姆 是一名深度学习工程师,专注于计算机视觉和自然语言处理。他曾参与多个生成式 AI 应用的部署和优化,这些应用在 Vyro.AI 全球排行榜上名列前茅。他对构建和优化智能系统的机器学习模型充满兴趣,并相信持续改进。
更多相关主题
Pandas Profiling:用于 EDA 的一行神奇代码
原文:
www.kdnuggets.com/2021/02/pandas-profiling-one-line-magical-code-eda.html
评论
由 Juhi Sharma 提供,产品分析师
使用 Pandas Profiling Python 库的自动化探索性数据分析
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT
探索性数据分析是一种探索/分析数据集以生成可视化形式洞察的方法。EDA 用于了解数据集的主要特征。
EDA 帮助我们了解缺失值、计数、均值、中位数、分位数、数据分布、变量间的相关性、数据类型、数据形状等。为了进行 EDA,我们需要编写大量代码,这需要很多时间。
为了使 EDA 更加简单快捷,我们可以编写一行神奇代码来进行 EDA。
EDA 可以通过一个名为 Pandas Profiling 的 Python 库进行自动化。这是一个出色的工具,可以创建交互式 HTML 格式的报告,易于理解和分析数据。让我们探索 Pandas Profiling,以便在非常短的时间内和仅用一行代码进行 EDA。
Pandas Profiling 的安装:
使用 pip 包安装
!pip install pandas-profiling
使用 conda 包安装
conda install -c conda-forge pandas-profiling
加载数据集
在这篇文章中,我使用了 Titanic 数据集。
import pandas as pd
df=pd.read_csv(“titanic2.csv”)
df.head()

Titanic 数据集
数据集属性的描述
survived — 生存(0 = 否;1 = 是)
Pclass — 乘客等级(1 = 1st;2 = 2nd;3 = 3rd)
name — 乘客姓名
sex — 性别(男/女)
age — 年龄
Sibsp — 登船的兄弟姐妹/配偶数量
Parch — 登船的父母/子女数量
Ticket — 票号
Fare — 乘客票价
Cabin — 舱位
Embarked — 登船港口(C = 切尔堡;Q = 皇后镇;S = 南安普敦)
运行 pandas_profiling 的代码在我们的数据框上,返回 Pandas Profiling 报告。
import pandas_profiling as pp
pp.ProfileReport(df) #to display the report

Pandas Profiling 报告
你可以看到,我们的 Pandas Profiling EDA 报告通过一行代码已经准备好了。
Pandas Profiling 报告包含以下部分:
-
概述
-
变量
-
交互
-
相关性
-
缺失值
-
示例
1. 概述部分:

报告的概述部分
本部分提供了整体数据集信息。** 数据集统计** 和 变量类型。
数据集统计 显示了列、行、缺失值等信息。
变量类型 显示了数据集中属性的数据类型。它还显示了 “警告”,指出哪些特征与其他特征高度相关。
2.变量部分

本部分详细提供了每个特征的信息。当我们点击上图所示的 切换详细信息 选项时,新部分会显示出来。

本部分展示了特征的统计信息、直方图、常见值和极端值。
3.相关性部分

相关性部分
本部分展示了特征之间的相关性,利用 Seaborn 的热图。我们可以轻松切换不同类型的相关性,如 Pearson, Spearman, Kendall 和 phik。
4.缺失值部分

缺失值部分

我们可以从上述的计数和矩阵图中看到“年龄”和“船舱”列的缺失值。
5.样本部分

前 10 行 
最后 10 行
本部分展示了数据集的前 10 行和最后 10 行。
我希望“Pandas Profiling”库能帮助更快、更轻松地分析数据。那么你对这个美丽的库有什么看法?试试看,并在回复部分提到你的经验。
在离开之前
感谢阅读!如果你想与我联系,请随时通过 jsc1534@gmail.com 或我的 LinkedIn 个人主页 联系我。
简介: Juhi Sharma (Medium) 热衷于通过数据驱动的方法解决业务问题,包括数据可视化、机器学习和深度学习。Juhi 正在攻读数据科学硕士学位,并拥有 2.2 年分析师工作经验。
原始 文章。经许可转载。
相关:
-
仅用两行代码进行强大的探索性数据分析
-
在 Python 中合并 Pandas 数据框
-
使用管道进行更清洁的数据分析
更多相关话题
强化学习中的 Pandas:使用 Dask 进行端到端数据科学
原文:
www.kdnuggets.com/2020/11/pandas-steroids-dask-python-data-science.html
评论
由 Ravi Shankar,数据科学家
 Dask - 拥有超级能力的 pandas
Dask - 拥有超级能力的 pandas
我们的三大推荐课程
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持组织的 IT 工作
正如俗话所说,数据科学家花费 90% 的时间在清理数据上,10% 的时间抱怨数据。他们的抱怨可能涉及数据大小、数据分布不准确、空值、数据随机性、数据捕捉中的系统性错误、训练集和测试集之间的差异等等。
一个常见的瓶颈主题是数据大小的庞大,数据无法适配内存或处理时间过长(以分钟为单位),导致内在模式分析难以进行。数据科学家本质上是好奇的,他们希望识别和解释那些通常在表面拖拽观察中隐藏的模式。他们需要戴上多顶帽子,通过反复的折磨(即多次迭代)让数据“坦白”。
在探索性数据分析中,他们戴上了多种帽子,从包含 6 列的纽约出租车费用数据集(www.kaggle.com/c/new-york-city-taxi-fare-prediction) - ID、费用、旅行时间、乘客和位置,他们的问题可能包括:
- 费用年复一年地变化情况如何?
- 年复一年,旅行次数是否增加了?
- 人们更喜欢单独旅行还是有同行?
- 随着人们变得更加懒惰,小距离的骑行是否增加了?
- 人们希望在一天中的什么时间和一周中的哪几天旅行?
- 最近城市中是否出现了新的热点区域,除了常规的机场接送?
- 人们是否在进行更多的城际旅行?
- 交通量是否增加,导致相同距离的费用/时间增加?
- 是否存在接送点的集群或高流量区域?
- 数据中是否存在异常值,如 0 距离和超过 $100 的费用等?
- 需求是否在节假日季节变化,机场接送是否增加?
- 是否有天气因素(如雨雪)与出租车需求的相关性?
即使回答了这些问题,仍然可能会出现多个子线程,例如我们能否预测新年受 Covid 影响的情况、年度纽约马拉松如何影响出租车需求、某个特定路线是否更容易有多个乘客(聚会中心)与单个乘客(机场到郊区)?
为了满足这些好奇心,时间至关重要。如果让数据科学家等待 5 分钟以上来读取一个 csv 文件(5500 万行)或进行列添加和后续聚合,那是犯罪行为。此外,由于大多数数据科学家是自学成才的,他们已经习惯了 pandas 数据框 API,不愿意用不同的 API,如 numba、Spark 或 datatable,重新开始学习过程。我曾尝试在 DPLYR(R)、Pandas(Python)和 pyspark(Spark)之间来回切换,这有点令人失望/不高效,因为需要一个统一的管道和代码语法。然而,对于好奇的人,我在这里写了一个 pyspark 入门指南:medium.com/@ravishankar_22148/billions-of-rows-milliseconds-of-time-pyspark-starter-guide-c1f984023bf2
在后续部分,我尝试提供一个 Dask 的实用指南,尽量减少与我们钟爱的 Pandas 的架构差异:
1. 数据读取和分析
Dask 与 Pandas 的速度对比
Dask 如何能够将数据处理速度提高 ~90 倍,即在 pandas 中从 1 秒以下到 91 秒。
 来源:
来源:Dask 之所以如此受欢迎,是因为它使 Python 中的分析具有可扩展性,并且不一定需要在 SQL、Scala 和 Python 之间来回切换。它的神奇之处在于这个工具需要最小的代码更改。它将计算分解为 pandas 数据框,从而并行操作以实现快速计算。
 来源:https://docs.dask.org/en/latest/
来源:https://docs.dask.org/en/latest/
2. 数据聚合
完全没有改变 Pandas API 的情况下,它能够在毫秒级别执行聚合和排序操作。请注意,compute() 函数在延迟计算结束时,将大数据的结果带到 Pandas 数据框中。
3. 机器学习
下面的代码片段提供了使用 XGBoost 在 Dask 中进行特征工程和 ML 模型构建的工作示例
特征工程和 Dask 的 ML 模型
结论:
Dask 是一个强大的工具,提供并行计算、大数据处理以及创建端到端的数据科学管道。它有一个陡峭的学习曲线,因为它的 API 与 pandas 几乎相似,而且可以轻松处理超出内存限制的计算(~10 倍 RAM)。
由于这是一个动态博客,我将继续编写 Dask 系列的后续部分,我们将通过并行处理来瞄准 Kaggle 排行榜。如果你在设置 Dask 或执行任何 Dask 操作时遇到问题,或者只是想聊聊,请在评论中告诉我。祝学习愉快!!!
资源:
-
www.kaggle.com/yuliagm/how-to-work-with-big-datasets-on-16g-ram-dask -
medium.com/better-programming/what-is-dask-and-how-can-it-help-you-as-a-data-scientist-72adec7cec57
简历:Ravi Shankar 是亚马逊定价部门的数据科学家-II。
原文。转载已获许可。
相关:
-
在 Dask 中进行机器学习
-
在云中使用 Dask 进行数据科学
-
为什么以及如何在大数据中使用 Dask
更多相关话题
Pandas 与 Polars:Python 数据框库的比较分析
原文:
www.kdnuggets.com/pandas-vs-polars-a-comparative-analysis-of-python-dataframe-libraries

作者提供的图片
Pandas 长期以来一直是处理数据的首选库。然而,我相当确定你们中的大多数人可能已经体验过在 Pandas 处理大型 DataFrame 时坐上几个小时的痛苦。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升您的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持您的组织的 IT 工作
对于那些关注 Python 最新发展的用户,很难忽视 Polars 的热度,这是一款专门开发用于处理大型数据集的强大数据框库。
所以今天我将尝试深入探讨这两个数据框库之间的关键技术差异,审视它们各自的优势和局限性。
语法与执行:Pandas 与 Polars
首先,为什么大家都这么执着于比较 Pandas 和 Polars 库呢?
与专为大型数据集设计的其他库(如 Spark 或 Ray)不同,Polars 是专门为单机使用而设计的,这使得它与 pandas 的比较非常频繁。
然而,Polars 和 pandas 在数据处理方法及其理想使用场景上存在显著差异。
Polars 出色性能的秘密在于四个主要原因:
1. Rust 提升了效率
与基于 Python 库如 NumPy 的 Pandas 形成鲜明对比,Polars 是使用 Rust 构建的。这个以快速性能著称的低级语言,可以编译成机器代码,而不需要使用解释器。

作者提供的图片
这样的基础为 Polars 提供了显著的优势,特别是在处理 Python 难以应对的数据类型时。
2. 急切和惰性执行选项
Pandas 遵循急切执行模型,按编码顺序处理操作,而 Polars 提供急切执行和惰性执行选项。
Polars 在其惰性执行中使用了查询优化器,以高效地规划并可能重新组织操作顺序,从而消除任何不必要的步骤。
这与 Pandas 可能在应用过滤器之前处理整个 DataFrame 相对。
例如,在计算某些类别的列均值时,Polars 会首先应用过滤器,然后进行分组操作,从而优化处理效率。
3. 进程的并行化
根据 Polars 用户指南,其主要目标是:
“提供一个 lightning-fast 的 DataFrame 库,利用你机器上所有可用的核心。”
Rust 设计的另一个好处是其对安全并发的支持,确保可预测和高效的并行处理。此功能使 Polars 能够充分利用机器的多个核心进行复杂操作。

作者提供的图片
因此,Polars 显著优于 Pandas,后者仅限于单核操作。
4. 富有表现力的 API
Polars 拥有高度灵活的 API,几乎可以使用其方法执行所有所需任务。相比之下,在 pandas 中执行复杂任务通常需要使用 apply 方法及其 apply 方法中的 lambda 表达式。
然而,这种方法有一个缺点:它逐行处理 DataFrame,每次执行操作时都是顺序进行的。
相反,Polars 利用固有方法在列级别上执行操作,利用一种被称为 SIMD(单指令、多数据)的不同并行性类型。
每个库的理想使用案例
Polars 是否优于 Pandas?它在未来是否可能取代 Pandas?
一如既往,这主要取决于具体的使用案例。
Polars 相对于 Pandas 的主要优势在于其速度,特别是在处理大型数据集时。对于处理大量数据的任务,强烈建议探索 Polars。
虽然 Polars 在数据转换效率方面表现出色,但在数据探索和集成到机器学习管道等领域仍不及 Pandas。
Polars 与大多数 Python 数据可视化和机器学习库(如 scikit-learn 和 PyTorch)的不兼容性限制了其在这些领域的适用性。
关于在这些软件包中集成 Python 数据帧交换协议以支持多样化数据帧库的讨论仍在进行中。
这一发展可能简化目前依赖于 Pandas 的数据科学和机器学习过程,但这是一个相对较新的概念,实施需要时间。
在数据科学工作流中同时使用这两种工具
Pandas 和 Polars 各有其独特的优势和局限性。Pandas 仍然是数据探索和机器学习集成的首选库,而 Polars 在大规模数据转换方面表现突出。
理解每个库的功能和最佳应用方式是有效应对不断发展的 Python 数据框架环境的关键。
拥有这些见解后,你可能迫不及待地想亲自尝试 Polars 了!
作为数据科学家和 Python 爱好者,拥抱这两种工具可以提升我们的工作流程,使我们能够在数据驱动的工作中利用两者的最佳特性。
随着这些库的持续发展,我们可以期待在 Python 中处理数据的方式会变得更加精细和高效。
Josep Ferrer**** 是一位来自巴塞罗那的分析工程师。他在物理工程方面毕业,目前在数据科学领域专注于人类流动性。他还兼职从事数据科学和技术方面的内容创作。Josep 涉及人工智能的各个方面,涵盖了这一领域的持续爆炸性发展。
更多相关话题
带代码的论文:机器学习的一个极好的 GitHub 资源
原文:
www.kdnuggets.com/2018/12/papers-with-code-fantastic-github-resource-machine-learning.html
评论

寻找带代码的论文吗?
如果是这样,这个GitHub 仓库,准确地称为“带代码的论文”,由Zaur Fataliyev创建,正是你所需要的。
带代码的论文。按星级排序。每周更新。
这可能很直接,但也相当准确。
基于首尔的机器学习工程师 Fataliyev,在贡献者的请求帮助下,整理了这一广泛的资源,并进一步描述了该仓库如下:
这项工作正在持续进展和更新。我们每天都在添加新的 PWC!在推特上关注我 @fvzaur
使用这个线程请求我们将你最喜欢的会议添加到我们的观察列表和 PWC 列表中。
除了按星级排序,论文还按年份排列,使得找到突出研究变得更加容易——当然,还有相应的代码。

如果这听起来对你感兴趣,务必查看一下这个仓库,并且向 Zaur 表示感谢,因为他为我们整理了这样一个有用的资源。
相关:
-
GitHub Python 数据科学亮点:AutoML、NLP、可视化、ML 工作流
-
前 10 大 Python 数据科学库
-
前 20 大 Python AI 和机器学习开源项目
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析水平
3. Google IT 支持专业证书 - 支持你的组织 IT
了解更多相关信息
人工智能和机器学习领域的最新进展——代码论文亮点
原文:
www.kdnuggets.com/2019/02/paperswithcode-ai-machine-learning-highlights.html
评论
正如任何机器学习、人工智能或计算机科学爱好者所知,找到感兴趣主题的资源和论文可能是一项麻烦的工作。通常,你需要注册一个网站,有些甚至会收取订阅费用来阅读他人的研究成果。
 这就是使* Papers with code*如此出色的原因;他们提供了大量免费的资源,涵盖了各种主题。他们的使命声明如下:
这就是使* Papers with code*如此出色的原因;他们提供了大量免费的资源,涵盖了各种主题。他们的使命声明如下:
Papers With Code 的使命是创建一个免费的开放资源,提供机器学习论文、代码和评估表格。
我们相信,这最好是与社区共同完成并通过自动化实现的。
我们已经自动化了代码与论文的链接,现在正致力于自动化从论文中提取评估指标。
在此基础上,他们有自己的slack 频道,并允许用户下载所有帮助运行网站的数据。他们欢迎贡献,所以可以随时参与进来,继续壮大社区!
为了庆祝这一伟大资源,我们尝试总结了网站上我们最喜欢的 6 个主题(网站称之为“任务”)及其提供的一些论文:
语义分割
语义分割的概念是识别和理解图像中的每一个像素。这是网站上内容最多的类别之一,共有 322 篇带代码的论文。其中最受欢迎的论文标题为带有 Atrous 可分离卷积的编码器-解码器用于语义图像分割。该论文旨在结合语义分割的两种方法的优势:空间金字塔池化模块和编码-解码结构。该论文附带了一个公开的 TensorFlow 模型实现。
其他顶级语义分割论文:
自然语言处理(NLP)
自然语言处理是站点上最大的一类任务集合之一,涵盖了机器翻译、语言建模、情感分析、文本分类等多个子领域。在这些子领域中,问答系统是最受欢迎的类别之一,相关论文超过 200 篇。该领域排名最高的论文由 Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova 撰写,题为BERT:用于语言理解的深度双向变换器预训练。该论文介绍了一种新的语言表示模型,称为 BERT,代表双向编码器表征来自变换器。与近期的语言表示模型不同,BERT 旨在通过在所有层中共同考虑左右上下文来进行深度双向表示的预训练。
其他顶级 NLP 论文:
迁移学习
迁移学习是一种方法论,其中从一个任务上训练的模型的权重被提取并用于:
-
构建一个固定的特征提取器
-
作为权重初始化和/或微调
关于迁移学习,最受欢迎的论文是半监督知识迁移:从私有训练数据中学习。这篇论文旨在解决一个影响使用私有数据的模型的问题,即模型可能会无意中和隐性地存储一些训练数据,因此对模型的后续仔细分析可能会揭示敏感信息。为了解决这个问题,论文展示了一种通用的提供敏感数据安全性的办法:教师集体的私有聚合(PATE)。这种方法以黑箱的方式结合了用不重叠的数据集训练的多个模型,例如来自不同用户子集的记录。该论文还包括一个指向 GitHub 仓库的链接,其中包含该项目的所有 TensorFlow 代码。
其他顶级迁移学习论文:
腾讯 ML-Images:一个用于视觉表示学习的大规模多标签图像数据库
多任务学习
多任务学习旨在同时学习多个不同的任务,同时最大化一个或所有任务的性能。目前星标最多的论文是:DRAGNN:一个基于转换的动态连接神经网络框架。这项工作提出了一个紧凑的模块化框架,用于构建新型的递归神经网络架构。再次提醒,这篇论文还提供了一个完整的 TensorFlow 工作代码示例。
关于多任务学习的其他顶级论文:
推荐系统
推荐系统的目标是为用户生成推荐列表。该领域的一个热门论文是【训练深度自编码器用于协同过滤](https://paperswithcode.com/paper/training-deep-autoencoders-for-collabora2),作者是 Oleksii Kuchaiev 和 Boris Ginsburg。这篇论文提出了一种新颖的模型用于推荐系统中的评分预测任务,该模型在时间切分的 Netflix 数据集上显著超越了以前的最先进模型。该模型基于 6 层的深度自编码器,并且是端到端训练的,没有任何逐层预训练。这是一个在 PyTorch 中进行的 NVIDIA 研究项目,所有使用的代码都可以公开使用。
关于推荐系统的其他顶级论文:
DeepFM:一个端到端的广泛与深度学习框架用于 CTR 预测
当然,我们只是触及了Papers with Code提供的表面。我们希望你像我们一样喜欢这个网站!
资源:
相关:
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业领域。
2. Google 数据分析专业证书 - 提升您的数据分析技能
3. Google IT 支持专业证书 - 支持您所在组织的 IT 工作
相关主题更多信息
数据科学的悖论
评论
由托马斯·鲍尔,分析专业人士。
 在当今的数据科学世界中存在许多悖论、讽刺和脱节:痛点、被忽视的事情、被掩盖的东西、被否认的东西,或者仅仅是口头上的承诺,而数据科学的强大势头仍在数字领域不断推进。例如,尽管 Hal Varian 广泛引用的观察是“未来 10 年最性感的工作将是统计学家”,但易于使用的点选式统计软件和分析工具的出现意味着实际上任何人都可以按下按钮得到答案。这是否像是把装满子弹的火箭筒交给一只大猩猩,让它出去玩得开心一样,这并不重要。未言明的现实是,统计分析已被贬低为一种次要的重要技能,与更紧迫的任务相比,这些任务需要真正管理数字信息流架构的技能。一个相关的假设是,任何具有计算机科学背景的人都具备必要的统计和分析技能,不管他们是否真正具备这些技能。
在当今的数据科学世界中存在许多悖论、讽刺和脱节:痛点、被忽视的事情、被掩盖的东西、被否认的东西,或者仅仅是口头上的承诺,而数据科学的强大势头仍在数字领域不断推进。例如,尽管 Hal Varian 广泛引用的观察是“未来 10 年最性感的工作将是统计学家”,但易于使用的点选式统计软件和分析工具的出现意味着实际上任何人都可以按下按钮得到答案。这是否像是把装满子弹的火箭筒交给一只大猩猩,让它出去玩得开心一样,这并不重要。未言明的现实是,统计分析已被贬低为一种次要的重要技能,与更紧迫的任务相比,这些任务需要真正管理数字信息流架构的技能。一个相关的假设是,任何具有计算机科学背景的人都具备必要的统计和分析技能,不管他们是否真正具备这些技能。
我们的前 3 名课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你的组织的 IT 需求
说时代具有颠覆性是一句陈词滥调,但正如麦克卢汉所指出的,文明正处于数字化、网络化变革的边缘,这一变革的重要性相当于古滕堡圣经的印刷。那一创新的影响花了几个世纪才在宗教和文化中逐渐显现,因为大规模生产的圣经传播到欧洲各地,减少了神职人员和天主教会的权威在与上帝关系中的调解作用,这在路德的理解中,印刷的圣经使每个人都成为了神学家,最终形成了新教改革。
在这个民主化的历史时刻,几乎没有人愿意给数字革命几百年的时间去展开。成千上万的声音在博客或 PLOS One 上涌现,每年出版数百万篇文章和书籍,共同传递着希望、炒作和虚伪的海啸。虚假药水供应商和大数据及数据科学的 PT Barnum 们与令人窒息的知识过剩一同涌现,且在混乱中没有明确的视线。以许多方式,无知已经成为我们时代的讽刺裁判——我们可以赞美愚蠢,但没有人愿意为此买单。
然而,穿越混乱的视线代理是可能的。其中一个代理是华尔街给予像谷歌、苹果、亚马逊和 FB 等实体的过高市场估值,与巨大的代理和媒体控股公司如 WPP、Publicis、Omnicom 和 Interpublic 形成对比——雅虎也可以被纳入这一组。无论现实与否,科技公司累积的市场总值大约是大型媒体公司估值的 20 倍(截至 2015 年 8 月 14 日星期五)。尽管这些差异看起来痛苦地明显,但背后的原因并不明确。

其中一个关键点是,科技实体是由技术精通的工程师和数学家创办和/或管理的,而那些最多只是半懂技术的控股公司则由传统的老派营销人员管理:那些凭借其卓越的沟通和人际交往能力上升到高层的高管们。
这强调了一个容易识别的界限,将技术精通、前瞻性的商业领域与不懂技术的传统主义者区分开来:传统主义者是那些被迎合的对象,是那些在面对即使是稍微具挑战性的演示时,眼神呆滞的技术文盲,要求信息被简化到可以立即理解和消化的水平。另一方面,这些人却完全能够流利地谈论数字时代,对这种不连续性视而不见,安慰自己任何有技术精通的下属都会因为“缺乏适配性”而被迫离开他们的组织。
这些传统主义者是巨大的惯性和趋同于“常识”做事方式和赚钱方式的源头:总是按照既定方式进行。他们围绕维护现状构建了商业模型:只需考虑从 Napster 开始到今天的音乐版权争夺战的证据。所有这些的讽刺和悖论在于,尽管许多人愿意将自己标榜为创新前卫者,但实际上却是老派或传统主义者。这就像行为经济学研究显示的 80%的人认为自己高于平均水平一样。如今每个人都是自封的前瞻性创新者,加入到最新“热点”中,以参与所有的兴奋、激动的热潮,使得区分优质内容和次要内容变得极其困难。
这对数据科学有重要影响,特别是在对预测分析、算法学习和人工智能的胃口、潜力和投资方面——这些高度技术化、最难理解的领域具有最显著的前景潜力。在数据科学家需求的所谓直观、创造性见解与能够使复杂想法“易于理解”的能力之间存在一种未被承认的分歧,这与推动不直观的黑箱算法答案的那些人形成对比。

不直观的技术精通者正在提供基础性的、算法驱动的创新,20 世纪科幻小说中的构想如无人驾驶汽车、虚拟现实、可穿戴技术、芯片上的研究实验室等正在变为现实。另一方面,媒体实体则保持犹豫和风险规避,远远落后于这些创新的潮流,以至于这个词几乎失去了意义。他们更倾向于“易于理解”的事物,这些事物已经广泛被认可,争议较少,例如在医疗保健领域,使用 CMS 批准的方法如医疗保险的 CDPS 进行慢性病费用分析和控制,而不是利用专注于快速高效、机器学习方法的动态诊断和治疗的新兴学术研究。毕竟,CDPS 方式是“经过验证”的,而另一种方法几乎没有真实依据,只是“凭空捏造”(这是数据科学分歧前线的直接引语)。
所有这些中的另一个巨大脱节是所谓的人才争夺战,即公司正在争夺技能资源短缺的神话。这个“短缺”人才的一个显著方面是许多数据科学职位描述的惊人不切实际,几乎是妄想。如果 HR 成本是公司损益表上的最大项目,在错误地尝试最小化这些成本时,公司寻找的候选人更像是史蒂夫·乔布斯——即使是初级职位——以便将计算机科学、IT 和实际分析等一系列技能浓缩到一个人身上,同时代表公司参加行业会议、推动创新、战略规划、团队领导、产品开发和客户管理。找到一个具备所有这些技能的资源并不容易,但有深口袋的公司愿意等待,像煮海一样等待完美的雇佣——那只传说中的紫色松鼠。
话虽如此,现实是人才洪流——花 2 秒钟在 Google Trends 上查看,几年来“数据科学家”关键词的指数增长便能提供有力证据。这意味着竞争并不是为了人才本身,而是为了优秀、富有创意、便宜的人才——愿意接受生存工资的员工。这里的重点是“便宜”,因为许多初创公司的薪资规模——即使对于高度技能的高级数据科学资源——不仅是生存水平,而且低得让人感觉对这个职业的蔑视。从 Y2K 以来,利用离岸资源的举措是这种制度化蔑视的另一个表现,伪装成成本节约。
这种变化使得对规范数据科学薪酬的预期被重新设置到了一个极低的基准:既然可以从次大陆以巨大的折扣获得“相同的东西”,为何还要为北美人才支付更高的薪水?这些是无情的、以 MBA 驱动的财务决策,像大多数削减成本的措施一样,影响了公司资产负债表的单变量维度。其他不易量化的指标,如交付工作的质量、开发的创新或获得的答案,可能在过程中受到阻碍,但由于不易量化,因此变得不重要。
理解这一点的一个方式是将其视为一种虚假的二分法,这种二分法源自制造业,将服务分为事实上的白领与蓝领技能集,以及相应的薪酬(性别也是这种划分中的一个隐含因素)。由于每个人都使用某种计算机,因此这种划分不仅由平台(例如,移动设备或平板电脑与固定工作站)定义,还由日常使用的软件定义。任何编写代码的人,按定义都是蓝领工人——程序员——在组织中具有二级或三级的商品化地位,他们只是按照白领思考者和战略家的创意、战术大纲来操作——并因此获得相应的报酬。
相关:
-
我爱数据和分析的 10 个原因
-
数据科学的历史信息图:5 条脉络
-
我被分析机器人取代了
-
采访:迈克尔·布罗迪谈行业经验、知识发现与未来趋势
相关主题
提示工程中的并行处理:Skeleton-of-Thought 技术
原文:
www.kdnuggets.com/parallel-processing-in-prompt-engineering-the-skeleton-of-thought-technique

图片由作者使用 Midjourney 创建
主要要点
-
Skeleton-of-Thought(SoT)是一种创新的提示工程技术,旨在最小化大型语言模型(LLMs)的生成延迟,提高其效率。
-
通过创建答案的骨架并平行地详细阐述每个要点,SoT 模拟人类思维,促进更可靠和准确的 AI 响应。
-
在项目中实施 SoT 可以显著加快问题解决和答案生成,特别是在需要 AI 结构化和高效输出的场景中。
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能。
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT。
SoT 是数据中心优化的初步尝试,揭示了推动 LLMs 更像人类思考的潜力,以提高答案质量。
简介
提示工程是利用生成 AI 潜力的起点。通过设计有效的提示和提示编写方法,我们可以引导 AI 理解用户的意图并有效地应对这些意图。在这个领域,一种值得注意的技术是 Chain-of-Thought(CoT)方法,它指示生成 AI 模型在处理任务或回应查询时逐步阐明其逻辑。在 CoT 的基础上,出现了一种新的有前景的技术 Skeleton-of-Thought(SoT),旨在改进 AI 处理和输出信息的方式,从而促进更可靠和准确的响应。
理解 Skeleton-of-Thought
思维骨架的起源来自于减少大型语言模型(LLMs)固有生成延迟的努力。与顺序解码方法不同,SoT 通过首先生成答案的骨架,然后平行填充细节来模拟人类思维,从而显著加快推理过程。与 CoT(链式思维)相比,SoT 不仅鼓励结构化的响应,还有效组织生成过程,以提高生成文本系统的性能。

图 1:思维骨架过程(来源:思维骨架:大型语言模型可以进行并行解码)
实施思维骨架
如上所述,实施 SoT(思维骨架)涉及引导 LLM(大型语言模型)创建问题解决或答案生成过程的骨架,然后对每一点进行平行详细阐述。这种方法在需要 AI 高效且结构化输出的场景中尤其有用。例如,在处理大规模数据集或回答复杂查询时,SoT 可以显著加快响应时间,提供一个简化的工作流程。通过将 SoT 融入现有的提示工程策略,提示工程师可以更有效、可靠和快速地利用生成文本的潜力。
也许展示 SoT 的最佳方式是通过示例提示。
示例 1
-
问题:描述光合作用的过程。
-
骨架:光合作用发生在植物中,涉及将光能转化为化学能,生成葡萄糖和氧气。
-
要点扩展:详细阐述光的吸收、叶绿素的作用、卡尔文循环和氧气释放。
示例 2
-
问题:解释大萧条的原因。
-
骨架:大萧条是由于股市崩盘、银行倒闭和消费者支出减少引起的。
-
要点扩展:深入探讨“黑色星期二”、1933 年的银行危机以及减少购买力的影响。
这些示例展示了 SoT 提示如何促进结构化的、逐步的回答复杂问题的方法。它还展示了工作流程:提出问题或定义目标,给 LLM 一个广泛或全面的答案作为阐述支持性推理的基础,然后明确地呈现这些支持性推理问题并特意提示其进行操作。

图 2:思维骨架简化过程(作者图片)
虽然 SoT 提供了一种结构化的问题解决方法,但它可能并不适用于所有场景。识别合适的应用案例和理解其实现是重要的。此外,从顺序处理到并行处理的过渡可能需要系统设计的调整或额外的资源。然而,克服这些障碍可以揭示 SoT 在提升生成文本任务的效率和可靠性方面的潜力。
结论
SoT 技术在 CoT 方法的基础上,提供了一种新的提示工程方法。它不仅加速了生成过程,还促进了结构化和可靠的输出。通过在项目中探索和整合 SoT,实践者可以显著提升生成文本的性能和可用性,推动更高效和更具洞察力的解决方案。
马修·梅奥 (@mattmayo13) 拥有计算机科学硕士学位和数据挖掘研究生文凭。作为 KDnuggets 的总编辑,马修的目标是让复杂的数据科学概念变得易于理解。他的专业兴趣包括自然语言处理、机器学习算法和探索新兴的人工智能。他致力于在数据科学社区中普及知识。马修从 6 岁起便开始编程。
了解更多信息
Python 中的大文件并行处理
原文:
www.kdnuggets.com/2022/07/parallel-processing-large-file-python.html

图片由作者提供
对于并行处理,我们将任务划分为子单元。这增加了程序处理的作业数量,并减少了总体处理时间。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的 IT 组织
例如,如果你正在处理一个大型 CSV 文件,并且想要修改单列。我们会将数据以数组的形式传递给函数,函数会根据可用的工作者的数量同时并行处理多个值。这些工作者的数量基于你处理器中的核心数。
注意: 在较小的数据集上使用并行处理不会提高处理速度。
在这篇博客中,我们将学习如何使用multiprocessing、joblib和tqdm Python 包来减少大型文件的处理时间。这是一个简单的教程,适用于任何文件、数据库、图像、视频和音频。
注意: 我们使用的是 Kaggle 笔记本进行实验。处理时间可能因机器而异。
入门
我们将使用来自 Kaggle 的美国事故数据集(2016 - 2021),该数据集包含 280 万条记录和 47 列。
我们将导入multiprocessing、joblib和tqdm用于并行处理,pandas用于数据引入,以及re、nltk和string用于文本处理。
*# Parallel Computing*
import multiprocessing as mp
from joblib import Parallel, delayed
from tqdm.notebook import tqdm
*# Data Ingestion*
import pandas as pd
*# Text Processing*
import re
from nltk.corpus import stopwords
import string
在我们开始之前,让我们将n_workers设置为cpu_count()的两倍。如你所见,我们有 8 个工作者。
n_workers = 2 * mp.cpu_count()
print(f"{n_workers} workers are available")
>>> 8 workers are available
在下一步中,我们将使用pandas的read_csv函数引入大型 CSV 文件。然后,打印出数据框的形状、列名和处理时间。
注意: Jupyter 的魔法函数
%%time可以在处理结束时显示CPU 时间和墙钟时间。
%%time
file_name="../input/us-accidents/US_Accidents_Dec21_updated.csv"
df = pd.read_csv(file_name)
print(f"Shape:{df.shape}\n\nColumn Names:\n{df.columns}\n")
输出
Shape:(2845342, 47)
Column Names:
Index(['ID', 'Severity', 'Start_Time', 'End_Time', 'Start_Lat', 'Start_Lng',
'End_Lat', 'End_Lng', 'Distance(mi)', 'Description', 'Number', 'Street',
'Side', 'City', 'County', 'State', 'Zipcode', 'Country', 'Timezone',
'Airport_Code', 'Weather_Timestamp', 'Temperature(F)', 'Wind_Chill(F)',
'Humidity(%)', 'Pressure(in)', 'Visibility(mi)', 'Wind_Direction',
'Wind_Speed(mph)', 'Precipitation(in)', 'Weather_Condition', 'Amenity',
'Bump', 'Crossing', 'Give_Way', 'Junction', 'No_Exit', 'Railway',
'Roundabout', 'Station', 'Stop', 'Traffic_Calming', 'Traffic_Signal',
'Turning_Loop', 'Sunrise_Sunset', 'Civil_Twilight', 'Nautical_Twilight',
'Astronomical_Twilight'],
dtype='object')
CPU times: user 33.9 s, sys: 3.93 s, total: 37.9 s
Wall time: 46.9 s
清理文本
clean_text是一个简单的文本处理和清理函数。我们将使用nltk.corpus获取英语stopwords,并用它来过滤文本中的停用词。之后,我们将从句子中移除特殊字符和多余的空格。这将成为确定serial、parallel和batch处理时间的基准函数。
def clean_text(text):
*# Remove stop words*
stops = stopwords.words("english")
text = " ".join([word for word in text.split() if word not in stops])
*# Remove Special Characters*
text = text.translate(str.maketrans('', '', string.punctuation))
*# removing the extra spaces*
text = re.sub(' +',' ', text)
return text
串行处理
对于串行处理,我们可以使用 pandas 的.apply()函数,但如果你想查看进度条,你需要激活tqdm以支持pandas,然后使用.progress_apply()函数。
我们将处理 280 万条记录,并将结果保存回“Description”列。
%%time
tqdm.pandas()
df['Description'] = df['Description'].progress_apply(clean_text)
输出
高端处理器处理 280 万行数据的串行处理时间为 9 分钟 5 秒。
100% 2845342/2845342 [09:05<00:00, 5724.25it/s]
CPU times: user 8min 14s, sys: 53.6 s, total: 9min 7s
Wall time: 9min 5s
多进程
有多种方法可以并行处理文件,我们将学习所有这些方法。multiprocessing是一个内置的 Python 包,通常用于并行处理大文件。
我们将创建一个包含8 个工作线程的多进程Pool,并使用map函数来启动处理。为了显示进度条,我们使用tqdm。
map 函数由两个部分组成。第一部分需要函数,第二部分需要一个参数或参数列表。
了解更多信息,请阅读文档。
%%time
p = mp.Pool(n_workers)
df['Description'] = p.map(clean_text,tqdm(df['Description']))
输出
我们将处理时间提高了近3 倍。处理时间从9 分钟 5 秒减少到3 分钟 51 秒。
100% 2845342/2845342 [02:58<00:00, 135646.12it/s]
CPU times: user 5.68 s, sys: 1.56 s, total: 7.23 s
Wall time: 3min 51s
并行
我们现在将学习另一个 Python 包来执行并行处理。在这一部分,我们将使用 joblib 的Parallel和delayed来模拟map函数。
-
Parallel 需要两个参数:n_jobs = 8 和 backend = multiprocessing。
-
然后,我们将把clean_text添加到delayed函数中。
-
创建一个循环一次处理一个值。
下面的过程相当通用,你可以根据需要修改你的函数和数组。我已经用它处理了成千上万的音频和视频文件,没有遇到任何问题。
推荐: 使用try:和except:添加异常处理
def text_parallel_clean(array):
result = Parallel(n_jobs=n_workers,backend="multiprocessing")(
delayed(clean_text)
(text)
for text in tqdm(array)
)
return result
将“Description”列添加到text_parallel_clean()中。
%%time
df['Description'] = text_parallel_clean(df['Description'])
输出
我们的函数比使用Pool的多进程慢了 13 秒。即便如此,Parallel比serial处理快了 4 分钟 59 秒。
100% 2845342/2845342 [04:03<00:00, 10514.98it/s]
CPU times: user 44.2 s, sys: 2.92 s, total: 47.1 s
Wall time: 4min 4s
并行批处理
有一种更好的方法来处理大文件,即将其拆分为批次并进行并行处理。让我们从创建一个批处理函数开始,该函数将在一批值上运行clean_function。
批处理函数
def proc_batch(batch):
return [
clean_text(text)
for text in batch
]
将文件拆分为批次
下面的函数将根据工作线程的数量将文件拆分为多个批次。在我们的案例中,我们得到 8 个批次。
def batch_file(array,n_workers):
file_len = len(array)
batch_size = round(file_len / n_workers)
batches = [
array[ix:ix+batch_size]
for ix in tqdm(range(0, file_len, batch_size))
]
return batches
batches = batch_file(df['Description'],n_workers)
>>> 100% 8/8 [00:00<00:00, 280.01it/s]
运行并行批处理
最后,我们将使用Parallel和delayed来处理批次。
注意: 要获取单个值数组,我们必须运行列表推导式,如下所示。
%%time
batch_output = Parallel(n_jobs=n_workers,backend="multiprocessing")(
delayed(proc_batch)
(batch)
for batch in tqdm(batches)
)
df['Description'] = [j for i in batch_output for j in i]
输出
我们已经改进了处理时间。这种技术因处理复杂数据和训练深度学习模型而闻名。
100% 8/8 [00:00<00:00, 2.19it/s]
CPU times: user 3.39 s, sys: 1.42 s, total: 4.81 s
Wall time: 3min 56s
tqdm 并发
tqdm 将多进程处理提升到了一个新的水平。它简单且强大。我会向每位数据科学家推荐它。
查看文档以了解更多关于多进程的信息。
process_map 需要:
-
函数名称
-
数据框列
-
max_workers
-
chucksize 类似于批大小。我们将使用工作数量来计算批大小,或者你可以根据个人喜好添加数量。
%%time
from tqdm.contrib.concurrent import process_map
batch = round(len(df)/n_workers)
df["Description"] = process_map(
clean_text, df["Description"], max_workers=n_workers, chunksize=batch
)
输出
只需一行代码,我们就能获得最佳结果。
100% 2845342/2845342 [03:48<00:00, 1426320.93it/s]
CPU times: user 7.32 s, sys: 1.97 s, total: 9.29 s
Wall time: 3min 51s
结论
你需要找到一个平衡点,选择最适合你情况的技术。可以是串行处理、并行处理或批处理。如果你处理的是较小且复杂性较低的数据集,并行处理可能会适得其反。
在这个迷你教程中,我们学习了各种 Python 包和技术,这些技术允许我们并行处理数据函数。
如果你仅处理表格数据集并希望提升处理性能,我建议你尝试Dask、datatable和RAPIDS
参考
Abid Ali Awan (@1abidaliawan) 是一位认证的数据科学专业人士,热爱构建机器学习模型。目前,他专注于内容创作,并撰写有关机器学习和数据科学技术的技术博客。Abid 拥有技术管理硕士学位和电信工程学士学位。他的愿景是利用图神经网络为有心理疾病困扰的学生开发 AI 产品。
主题更多

获取免费的电子书《伟大的自然语言处理入门》和《数据科学备忘单的完整合集》,以及有关数据科学、机器学习、人工智能和分析的领先新闻通讯,直接送到你的收件箱。
订阅即表示你接受 KDnuggets 的 隐私政策
最新文章
|
热门文章
|
© 2024 Guiding Tech Media | 关于 | 联系 | 广告合作 | 隐私政策 | 服务条款
发表时间:2023 年 2 月 21 日,作者:Abid Ali Awan
并行化 Python 代码
评论
由 Dawid Borycki,生物医学研究员和软件工程师 & Michael Galarnyk,数据科学专家
Python 非常适合用于训练机器学习模型、执行数值模拟和快速开发概念验证解决方案,而无需设置开发工具和安装多个依赖项。在执行这些任务时,你还希望尽可能多地使用底层硬件以获得快速结果。并行化 Python 代码可以实现这一点。然而,使用标准 CPython 实现意味着你无法充分利用底层硬件,因为全局解释器锁(GIL)阻止了字节码在多个线程中同时运行。
本文回顾了几种常见的并行化 Python 代码的选项,包括:
-
专门的库
对于每种技术,本文列出了一些优点和缺点,并展示了代码示例,帮助你理解使用它的感觉。
如何并行化 Python 代码
并行化 Python 代码有几种常见的方法。你可以启动多个应用程序实例或脚本以并行执行作业。这种方法非常适合当你不需要在并行作业之间交换数据时。否则,在进程之间共享数据会显著降低性能,特别是在汇总数据时。
在同一进程内启动多个线程可以更有效地在作业之间共享数据。在这种情况下,基于线程的并行化可以将一些工作卸载到后台。然而,标准 CPython 实现的全局解释器锁(GIL)阻止了字节码在多个线程中同时运行。
以下示例函数模拟复杂计算(旨在模仿激活函数)
iterations_count = round(1e7)
def complex_operation(input_index):
print("Complex operation. Input index: {:2d}".format(input_index))
[math.exp(i) * math.sinh(i) for i in [1] * iterations_count]
complex_operation 执行多次以更好地估计处理时间。它将长时间运行的操作分成一批较小的操作。它通过将输入值划分为多个子集,并从这些子集中并行处理输入来实现这一点。
这是运行 complex_operation 多次(输入范围为十)的代码,并使用 timebudget 包测量执行时间:
@timebudget
def run_complex_operations(operation, input):
for i in input:
operation(i)
input = range(10)
run_complex_operations(complex_operation, input)
执行 这个脚本后,你将获得类似于下面的输出:

如你所见,在本教程中使用的笔记本电脑上执行此代码大约花费了 39 秒。让我们看看如何改进这个结果。
基于进程的并行 ism
第一种方法是使用基于进程的并行 ism。通过这种方法,可以同时启动多个进程。这种方式可以使它们并行地执行计算。
从 Python 3 开始,multiprocessing 包 已经预装,并且为我们提供了启动并发进程的便捷语法。它提供了 Pool 对象,该对象自动将输入划分为子集,并在多个进程中分配它们。
这是一个示例 展示了如何使用 Pool 对象启动十个进程:
import math
import numpy as np
from timebudget import timebudget
from multiprocessing import Pool
iterations_count = round(1e7)
def complex_operation(input_index):
print("Complex operation. Input index: {:2d}\n".format(input_index))
[math.exp(i) * math.sinh(i) for i in [1] * iterations_count]
@timebudget
def run_complex_operations(operation, input, pool):
pool.map(operation, input)
processes_count = 10
if __name__ == '__main__':
processes_pool = Pool(processes_count)
run_complex_operations(complex_operation, range(10), processes_pool)
每个进程并行执行复杂的操作。因此,理论上代码可以将总执行时间减少最多十倍。然而,下面的代码输出仅显示了大约四倍的改进(上一节的 39 秒 vs 本节的 9.4 秒)。

改进效果没有达到十倍的原因有几个。首先,能够同时运行的最大进程数取决于系统中的 CPU 数量。你可以通过使用os.cpu_count()方法来查看系统中的 CPU 数量。
import os
print('Number of CPUs in the system: {}'.format(os.cpu_count()))

本教程中使用的机器有八个 CPU。
改进效果没有更好的原因是,本教程中的计算相对较小。最后,需要注意的是,进行并行计算时通常会有一些开销,因为需要通信的进程必须利用进程间通信机制。这意味着对于非常小的任务,并行计算往往比串行计算(普通 Python)要慢。如果你对了解更多关于 multiprocessing 的内容感兴趣,Selva Prabhakaran 有一篇优秀的博客 ,这篇博客启发了本教程的这一部分。如果你想了解更多关于并行/分布式计算的权衡,可以查看这个教程。

专用库
像 NumPy 这样的专用库的许多计算不受 GIL 影响 ,能够使用线程和其他技术进行并行计算。本教程的这一部分讲解了结合 NumPy 和 multiprocessing 的好处。
为了展示原始实现和基于 NumPy 的实现之间的差异,需要实现一个额外的函数:
def complex_operation_numpy(input_index):
print("Complex operation (numpy). Input index: {:2d}".format(input_index))
data = np.ones(iterations_count)
np.exp(data) * np.sinh(data)
代码现在使用 NumPy 的 exp 和 sinh 函数对输入序列进行计算。然后,代码使用进程池执行 complex_operation 和 complex_operation_numpy 十次,以比较它们的性能:
processes_count = 10
input = range(10)
if __name__ == '__main__':
processes_pool = Pool(processes_count)
print(‘Without NumPy’)
run_complex_operations(complex_operation, input, processes_pool)
print(‘NumPy’)
run_complex_operations(complex_operation_numpy, input, processes_pool)
以下输出显示了使用和不使用 NumPy 的性能对比,针对 这个脚本。

NumPy 提供了显著的性能提升。在这里,NumPy 将计算时间减少到原始时间的大约 10%(859ms 对比 9.515 秒)。它更快的原因之一是因为 NumPy 中的大部分处理都是向量化的。通过向量化,底层代码有效地被“并行化”,因为操作可以一次计算多个数组元素,而不是逐一循环处理。如果你对了解更多内容感兴趣,Jake Vanderplas 进行了一次很好的讲座,可以在这里观看。

IPython Parallel
IPython shell 支持在多个 IPython 实例之间进行交互式并行和分布式计算。IPython Parallel 几乎是与 IPython 一起开发的。当 IPython 被更名为 Jupyter 时,它们将 IPython Parallel 分离成了一个独立的包。IPython Parallel 有许多优势,但也许最大的优势是它使得并行应用程序可以以交互的方式开发、执行和监控。在使用 IPython Parallel 进行并行计算时,你通常会从 ipcluster 命令开始。
ipcluster start -n 10
最后的参数控制要启动的引擎(节点)数量。上述命令在 安装 ipyparallel Python 包后变得可用。以下是一个示例输出:

下一步是提供应该连接到 ipcluster 并启动并行作业的 Python 代码。幸运的是,IPython 提供了一个方便的 API 来实现这一点。代码看起来像是基于 Pool 对象的进程并行:
import math
import numpy as np
from timebudget import timebudget
import ipyparallel as ipp
iterations_count = round(1e7)
def complex_operation(input_index):
print("Complex operation. Input index: {:2d}".format(input_index))
[math.exp(i) * math.sinh(i) for i in [1] * iterations_count]
def complex_operation_numpy(input_index):
print("Complex operation (numpy). Input index: {:2d}".format(input_index))
data = np.ones(iterations_count)
np.exp(data) * np.sinh(data)
@timebudget
def run_complex_operations(operation, input, pool):
pool.map(operation, input)
client_ids = ipp.Client()
pool = client_ids[:]
input = range(10)
print('Without NumPy')
run_complex_operations(complex_operation, input, pool)
print('NumPy')
run_complex_operations(complex_operation_numpy, input, pool)
在终端中新标签页中执行的代码生成了如下输出:

对于 IPython Parallel,使用和不使用 NumPy 的执行时间分别为 13.88 毫秒和 9.98 毫秒。注意,标准输出中没有包含日志,但可以通过额外的命令进行评估。

Ray
类似于 IPython Parallel,Ray 可以用于并行 和 分布式计算。Ray 是一个快速、简单的分布式执行框架,使得扩展应用程序和利用最先进的机器学习库变得容易。使用 Ray,你可以将顺序运行的 Python 代码转化为分布式应用程序,代码修改最小。

虽然这个教程简要讲解了 Ray 如何简化普通 Python 代码的并行化,但值得注意的是,Ray 及其生态系统也使得并行化现有库变得容易,如 scikit-learn、XGBoost、LightGBM、PyTorch 等等。
使用 Ray 时,需要 ray.init() 来启动所有相关的 Ray 进程。默认情况下,Ray 为每个 CPU 核心创建一个工作进程。如果你想在集群上运行 Ray,你需要传入类似 ray.init(address='insertAddressHere') 的集群地址。
ray.init()
下一步是创建一个 Ray 任务。这可以通过使用 @ray.remote 装饰器装饰一个普通的 Python 函数来完成。这会创建一个可以在你的笔记本电脑的 CPU 核心(或 Ray 集群)上调度的任务。下面是对之前创建的 complex_operation_numpy 的一个示例:
@ray.remote
def complex_operation_numpy(input_index):
print("Complex operation (numpy). Input index: {:2d}".format(input_index))
data = np.ones(iterations_count)
np.exp(data) * np.sinh(data)
在最后一步,在 Ray 运行时执行这些函数,如下所示:
@timebudget
def run_complex_operations(operation, input):
ray.get([operation.remote(i) for i in input])
执行 这个脚本 后,你将得到类似以下的输出:

使用和不使用 NumPy 的 Ray 执行时间分别为 3.382 秒和 419.98 毫秒。重要的是要记住,当执行长时间运行的任务时,Ray 的性能优势会更加明显,如下图所示。

当运行更大规模的任务时,Ray 的好处更为明显 (image source)
如果你想了解 Ray 的语法,可以在 这里 查阅介绍教程。

其他 Python 实现
一个最终的考虑是,你可以使用其他 Python 实现来应用多线程。例如,IronPython 用于 .NET,Jython 用于 Java。在这种情况下,你可以使用底层框架的低级线程支持。如果你已经有 .NET 或 Java 的多处理经验,这种方法会非常有利。
结论
这篇文章回顾了通过代码示例并突出一些优缺点来并行化 Python 的常见方法。我们使用简单的数值数据进行了基准测试。重要的是要记住,并行化的代码通常会引入一些开销,并且并行化的好处在处理较大的任务时更为明显,而不是在本教程中的短期计算。
请记住,并行化对于其他应用可能更为强大。尤其是在处理典型的基于 AI 的任务时,你必须对模型进行重复的微调。在这种情况下,Ray 由于其丰富的生态系统、自动扩展、容错能力和使用远程机器的能力,提供了最佳支持。
Dawid Borycki 是生物医学研究员和软件工程师,书籍作者和会议讲者。
Michael Galarnyk 是数据科学专业人士,并在 Anyscale 从事开发者关系工作。
原文。已获得许可重新发布。
相关内容:
-
如何加速 Scikit-Learn 模型训练
-
使用 Ray 编写你的第一个分布式 Python 应用程序
-
Dask 和 Pandas:数据量再多也不为过
我们的前三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织 IT
更多相关话题
数据科学家的帕累托原则
原文:
www.kdnuggets.com/2019/03/pareto-principle-data-scientists.html
评论
作者:Pradeep Gulipalli,Tiger Analytics
一个多世纪前,政治经济学教授维弗雷多·帕累托发布了他关于社会财富分配的研究结果。他观察到的剧烈不平等现象,如 20%的人拥有 80%的财富,令经济学家、社会学家和政治学家感到惊讶。在过去的一个世纪中,许多领域的先驱观察到这种不成比例的分配,包括商业。少数关键投入/原因(例如 20%的投入)直接影响大多数输出/效果(例如 80%的输出)的理论被称为帕累托原则,也称为 80-20 法则。

来源:威廉·利波夫斯基
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
帕累托原则是一个非常简单却极其强大的管理工具。企业高管们长期以来一直用它来进行战略规划和决策。比如,20%的商店产生了 80%的收入,20%的软件漏洞导致了 80%的系统崩溃,20%的产品特性驱动了 80%的销售等,这些观察结果非常普遍,分析能力强的企业试图在其业务中发现这样的帕累托。这样,他们能够进行计划和优先排序。事实上,今天,数据科学在筛选大量复杂数据以帮助识别未来的帕累托中扮演着重要角色。
虽然数据科学有助于预测企业的新帕累托,但数据科学也可以通过内部视角来受益,寻找内部的帕累托。利用这些可以使数据科学显著更高效、更有效。在这篇文章中,我将分享作为数据科学家,我们如何利用帕累托原则的力量来指导我们日常活动的一些方法。
项目优先排序
如果你是数据科学领域的领导者/经理,你不可避免地需要帮助制定组织的分析策略。虽然不同的业务领导者可以分享他们的需求,你必须将所有这些组织(或业务单元)的需求进行阐述,并将它们优先排序为分析路线图。一种简单的方法是量化每个分析需求的解决价值,并按价值降序排序。你会发现,前几个问题/用例通常具有不成比例的高价值(帕累托原则),应该优先于其他问题。实际上,更好的方法是量化解决/实施每个问题/用例的复杂性,并根据价值与复杂性之间的权衡来进行优先排序(例如,通过将价值放在 y 轴上、复杂性放在 x 轴上的图示来进行排序)。
问题范围定义
业务问题往往模糊且结构不明确,而数据科学家的工作涉及确定正确的范围。范围定义通常需要关注问题最重要的方面,并降低较低价值方面的优先级。首先,查看输出/效果与输入/原因的分布将帮助我们理解问题空间中是否存在高层次的帕累托分布。随后,我们可以选择只关注某些输入/输出或原因/效果。例如,如果 20%的商店产生了 80%的销售额,我们可以将其余的商店分组为一个集群进行分析,而不是逐个评估它们。
范围定义还涉及评估风险——更深入的评估通常会告诉我们,最重要的项目可能会带来显著更高的风险,而较低的重要性项目发生的可能性非常小(帕累托原则)。我们可以优先将时间和精力集中在少数关键风险上,而不是解决所有风险。
数据规划
复杂的业务问题需要的数据超出分析数据集市中易得的数据范围。我们需要请求访问、购买、获取、抓取、解析、处理和整合来自内部/外部来源的数据。这些数据形态、规模、健康状况、复杂性、成本等各不相同。等待整个数据计划完全到位可能会导致项目延迟,而这些延迟不在我们的控制范围内。一种简单的方法是根据数据对最终解决方案的价值将数据需求进行分类,例如绝对必须的、希望有的和可选的(帕累托原则)。这将帮助我们专注于绝对必须的数据,而不会被可选项目分散注意力或拖延。此外,考虑数据获取的成本、时间和努力方面将帮助我们更好地优先排序我们的数据规划工作。
分析
据说工匠使用仅 20%的工具完成 80%的工作。对我们数据科学家来说也是如此。我们往往在工作中使用少量的分析和模型(帕累托原则),而其他技术则使用得较少。典型的探索分析例子包括变量分布、异常检测、缺失值填补、相关矩阵等。建模阶段的例子包括 k 折交叉验证、实际与预测图、误分类表、超参数调优分析等。构建小型自动化(如库、代码片段、可执行文件、用户界面)来使用/访问/实施这些分析可以显著提高分析过程的效率。
建模
在建模阶段,我们通常能在过程中较早地得出一个合理的工作模型。此时大部分的准确度提升已经完成(帕累托原则)。其余的过程主要是对模型进行微调,以争取逐步的准确度提升。有时,这些逐步的准确度提升是使解决方案对业务可行所必需的。在其他情况下,模型的微调对最终的洞察/提案贡献不大。作为数据科学家,我们需要对这些情况保持意识,以便知道在哪里适当划定界限。
商业沟通
当今的数据科学生态系统是高度多学科的。团队包括业务分析师、机器学习科学家、大数据工程师、软件开发人员和多个业务利益相关者。这类团队成功的关键驱动因素之一是沟通。作为一个努力工作的人,你可能会被诱惑去传达所有的工作——挑战、分析、模型、洞察等。然而,在信息过载的今天,这种方法不会有帮助。我们需要意识到有“有用的很多,但至关重要的少数”(帕累托原则),并利用这一理解简化我们沟通的信息量。同样,我们展示和强调的内容也需要根据目标受众(业务利益相关者与数据科学家)进行定制。
帕累托原则是我们工具箱中的一个强大工具。使用得当,它可以帮助我们理顺并优化我们的活动。
 简介: Pradeep Gulipalli 是 Tiger Analytics 的联合创始人,目前负责印度的团队。在过去的十年里,他与财富 100 强公司和初创公司客户合作,以推动他们组织中的科学决策。他帮助设计了复杂商业环境的分析路线图,并架构了众多数据科学解决方案框架,包括定价、预测、异常检测、个性化、优化、行为模拟。
简介: Pradeep Gulipalli 是 Tiger Analytics 的联合创始人,目前负责印度的团队。在过去的十年里,他与财富 100 强公司和初创公司客户合作,以推动他们组织中的科学决策。他帮助设计了复杂商业环境的分析路线图,并架构了众多数据科学解决方案框架,包括定价、预测、异常检测、个性化、优化、行为模拟。
相关:
-
关于数据科学职位申请的那些你不知道的事
-
如何识别适合你团队的数据科学家?
-
为意外情况做准备
更多相关话题
全栈数据科学的路径
原文:
www.kdnuggets.com/2021/09/path-full-stack-data-science.html
评论
作者:Jawwad Shadman Siddique,德州理工大学研究生。
全栈数据科学已经成为计算机科学领域最热门的行业之一。从传统数学到数据工程等高级概念,这个行业要求广泛的知识和专业技能。它的需求在在线资源、书籍和教程中呈指数级增长。对初学者来说,这简直是令人不知所措。大多数初学者要么从 Python 课程、机器学习课程或一些基础数学课程开始。但许多人往往不知道从哪里入手。面对如此众多的资源,他们常常在各大平台之间游移,浪费了很多时间。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT

涉及数据科学的学科领域。
本文的目标 不是列出所需的课程大纲,而是列出在端到端数据科学领域中,每个学科领域的一些突出的在线资源。它将帮助初学者在不浪费宝贵时间的情况下开始他们的数据科学之旅。我尽量将资源按顺序排列。但这可能会根据个人的专业知识和需求有很大差异。本文的重点仅仅是列出一些深入且全面的在线课程和教程,涉及到全栈数据科学的领域。我尽力将列表保持尽可能简短,以帮助初学者开始学习,而无需过多选择。
以下领域的资源
-
数学 — 线性代数、微积分、概率、统计和凸优化
-
Python 编程 — 基础、面向对象的概念、算法、数据结构和数据科学应用
-
R 编程 — 基础、数据科学和网络应用
-
核心数据科学概念— 数据库编程、机器学习、深度学习、自然语言处理、计算机视觉、强化学习、数据可视化、模型部署、大数据
-
C/C++ 编程— 基础、问题解决、面向对象编程概念、算法和数据结构
-
计算机科学基础— 介绍、算法、数据结构、离散数学、操作系统、计算机体系结构、数据库概念、Git 和 GitHub
数学
线性代数
-
讲师:Grant Sanderson / 频道:3Blue1Brown
课程: 线性代数的精髓
-
讲师:Prof. Gilbert Strang / MIT OpenCourseWare
-
讲师:Kaare Brandt Petersen & Michael Syskind Pedersen
书籍: 矩阵代数
微积分
-
讲师:Grant Sanderson / 频道:3Blue1Brown
课程: 微积分的精髓
-
讲师:Prof. David Jerison / MIT OpenCourseWare
-
讲师:Prof. Denis Auroux / MIT OpenCourseWare
课程: 多变量微积分 / YouTube
概率与统计
-
讲师:Khan Academy
课程: 概率论
-
讲师:Khan Academy
课程: 统计学
-
讲师:Joshua Starmer
课程: 统计学基础
-
讲师:Prof. John Tsitsiklis / MIT OpenCourseWare
课程: 概率方法
-
讲师:Allen B. Downey
书籍: 统计思维
注:在完成 Python 和统计学基础后使用此书
凸优化(高级概念)
-
讲师:Prof. Stephen Boyd / Stanford
课程: 凸优化简介
Python 编程
Python 基础
算法与面向对象编程(OOP)与 Python
Python 数据科学
-
Python 数据科学手册:书籍
-
数据科学与 Python:freecodecamp 课程
-
计算思维与数据科学导论:课程
-
应用数据科学与 Python:课程
R 编程
数据库编程
-
数据库系统基础:书籍
-
完整的数据库设计课程:教程
-
使用 MySQL 的 SQL:课程
-
PostgreSQL:课程
-
PostgreSQL for Everybody:课程
-
使用 Python 的 SQLite:课程
-
流行的数据库:教程
数据可视化
-
Edureka 的 Power BI 完整课程:课程
-
Simplilearn 的 Power BI 完整课程:课程
-
Edureka 的完整 Tableau 课程:课程
-
Simplilearn 的完整 Tableau 课程:课程
-
freecodecamp.org 的 Tableau 速成课程:课程
机器学习
初学者课程
-
教授:Andrew Ng
-
讲师:Krish Naik
-
MIT 的人工智能:课程
使用 Python 的应用机器学习课程
实践机器学习书籍
深度学习
专业课程
-
讲师:Krish Naik
-
讲师:Yann Le’Cun
-
讲师:MIT
使用 Python 和 TensorFlow 的应用深度学习
-
深度学习 A-Z: 实践人工神经网络:课程
-
freecodecamp.org 的 TensorFlow 完整课程:课程
-
AI TensorFlow 开发者专业证书:课程
-
TensorFlow 数据与部署:课程
实践深度学习书籍
自然语言处理
计算机视觉
强化学习
Web 开发
-
Corey Schafer 的 Django 教程: 课程
-
Django for Everybody: 课程
-
Corey Schafer 的 Flask 教程: 课程
-
全栈 Web 开发指南: 教程
-
面向每个人的网页设计: 课程
-
面向每个人的 Web 应用程序: 课程
Git & Github
-
freecodecamp.org 的速成课程: 课程
-
Traversy Media 的速成课程: 课程
-
Edureka 的完整课程: 课程
-
Mosh 的 Git 入门教程: 课程
-
Amigoscode 的 Git 和 Github 教程: 课程
AWS
-
AWS 认证: 教程
-
AWS 入门教程: 课程
-
AWS 基础知识入门: 课程
-
AWS 认证云计算从业者培训: 课程
-
AWS 认证解决方案架构师 — 助理培训: 课程
-
AWS 认证开发者 — 助理培训: 课程
-
AWS SysOps 管理员-助理培训: 课程
模型部署
-
教师: Krish Naik
-
教师: Daniel Bourke
-
实时端到端模型部署: 教程
-
使用 Amazon Sagemaker 进行模型部署:教程
-
使用 Azure 进行模型部署:教程
大数据
-
CrashCourse 的大数据导论:教程
-
Edureka 的大数据导论:教程
-
Simplilearn 的大数据介绍:教程
-
Edureka 的大数据与 Hadoop:课程
-
Edureka 的 Apache Spark:课程
C/C++编程与问题解决
教程与课程
-
Mike 的完整 C 教程:课程
-
Caleb Curry 的完整 C++教程:课程
-
Suldina Nurak 的完整 C++教程:课程
-
C++面向对象编程概念:课程
-
使用 C++进行问题解决与面向对象编程:课程
-
C++中的指针:课程
-
使用 C++的 STL:课程
-
使用 C/C++的数据结构:课程
书籍
算法与数据结构
计算机科学基础
-
计算机科学的缺失学期:课程
-
CMU 的计算机系统架构:课程
-
MIT 的计算机系统架构: 课程
-
Neso Academy 的操作系统课程: 课程
-
UC Berkeley 的操作系统: 课程
-
软件工程基础: 课程
我尝试提供一些具体的资源(课程/教程/书籍),这些资源深入且在网络上非常知名,对大量数据科学学习者非常有帮助。我尽量提供了我熟悉的资源。毋庸置疑,还有许多优秀的资源被遗漏。因此,这份列表不应被视为专家指南。相反,它挑选了一些突出的课程,以便让初学者的学习旅程更加轻松。我将最后提供一些最受欢迎的 YouTube 频道,这些频道有大量的学习材料和关于该主题的很好的指导。
顶级 YouTube 数据科学频道
原文. 经许可转载。
相关:
更多相关内容
学习人工智能的路径
原文:
www.kdnuggets.com/2017/05/path-learning-artificial-intelligence.html
评论
由 Kirill Eremenko 和 Hadelin de Ponteves 提供,Super Data Science。
学习人工智能的路径通常被复杂的数学和技术话题所压倒。但不必如此……我们想通过创建一个直观而令人兴奋的课程来打破这种趋势,该课程将引导你进入蓬勃发展的人工智能世界,同时享受乐趣:
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织在 IT 领域
点击这里加入人工智能在线课程 [链接: bit.ly/2BuildAI ]
就在此刻,我们正在进行一个 Kickstarter 项目,以创建一个革命性的人工智能培训项目。在这篇博客中,我们将描述课程结构背后的秘密,以便即使你还没有准备好加入培训——你也可以在自己的学习计划中复制这些步骤。

图. 人工智能、机器学习与深度学习
在这次人工智能之旅中,我们将实现四个层级的人工智能,从简单到高级:
- 人工智能等级 1: Q 学习
最简单的 AI 算法之一是 Q 学习。简单但强大,我们将使用它来训练像 R2D2 这样的机器人找到迷宫的出口。这将是我们在课程中制作的第一个 AI,只是为了热身,同时享受乐趣。
- 人工智能等级 2 – 深度 Q 学习
然后我们将通过研究深度 Q 学习(DQN)将事情提升到下一个层级。通过 DQN,我们将能够解决一个更具挑战性的问题:征服流行的游戏《打砖块》!为了完成这个挑战,我们的输入将是编码值的向量,所有这些都描述了环境的一个状态,即:球的位置坐标、球的运动方向向量坐标,以及每个砖块是否存在的二进制值,其中 1 表示砖块仍在,0 表示砖块已不存在。

图. 人工智能玩《打砖块》
深度 Q 学习的理念是将 Q 学习算法与神经网络结合起来。我们的输入是编码向量。它们进入一个神经网络,输出将是要执行的动作。
这已经是一个更高级的人工智能,但我们可以更进一步:如果输入不是一些编码向量,而是游戏中我们看到的实际图像呢?这就引出了 AI 级别
- AI 第 3 级 – 深度卷积 Q 学习
开始吧!通过这个,我们将构建一个非常接近人类玩游戏的人工智能。由于编码向量无法保留图像的空间结构,这不是描述状态的最佳形式。空间结构确实很重要,因为它为我们提供了更多的信息来预测下一个状态,而预测下一个状态对于人工智能了解正确的下一步至关重要。因此,我们需要保留空间结构,为此,我们的输入必须是 3D 图像(2D 的像素数组加上一个额外的颜色维度)。在这种情况下,输入就是屏幕上的图像,与人类玩游戏时看到的完全相同。按照这个类比,人工智能的行为像人类:它观察游戏时屏幕的输入图像,输入图像进入一个卷积神经网络(相当于人类的大脑),该网络将检测每张图像中的状态,然后通过 Q 学习预测下一个状态,人工智能/人类将预测最佳动作。而这个动作再次是神经网络的输出。
我们将构建这个高度先进的人工智能,挑战在非常受欢迎的游戏《毁灭战士》中通过一个关卡。
- AI 第 4 级 – 异步演员-评论员代理(A3C)
如果环境中有多个代理需要训练呢?在这种情况下,最佳的人工智能是 A3C,这是人工智能领域的热门话题,由 Google DeepMind 去年推出。我们希望在同一地图上实现多个自动驾驶汽车的 AI。我们将训练汽车避免相互碰撞并避开障碍物。这将是结束这段 AI 之旅的一个非常激动人心的挑战!

加入我们
这是我们在全新人工智能课程中将采用的方法。如果你想为自己的学习计划构建类似的内容,可以随意复制……但与他人一起学习会更加令人兴奋。
我们的 Kickstarter 项目已经得到了超过 1,500 名学生的支持。距离截止日期仅剩几天——快来加入我们,获取课程及大量早鸟奖励!
了解如何构建人工智能 [链接: bit.ly/2BuildAI ]
人工智能是一项每个人都应该可以掌握的技能,这不仅是学习 AI 的机会,也是站在下一个工业革命前沿的机会。
此致敬礼,
Hadelin de Ponteves & Kirill Eremenko
注:图片 #1 和 #3 的版权归 SuperDataScience Pty Ltd 所有。KDNuggets 在本博客及任何相关宣传媒体中的使用已获批准。
作者简介: Kirill Eremenko 是一位多语言企业家,在教育领域有 3 年的经验,在数据科学领域有 7 年的经验。而Hadelin de Ponteves 是 Google 的数据工程师。
相关:
-
什么是人工智能?智能的组成成分
-
人工智能与深度学习的进展:DeepMind、Facebook 和 OpenAI
-
人工智能简史
更多相关主题
Fidelity 如何找到量体裁衣的独角兽数据科学家
原文:
www.kdnuggets.com/2020/02/paw-find-tailor-fit-unicorn-data-scientist.html
赞助帖子。
| Fidelity Investments 的 Victor Lo 将在 PAW Financial 2020金融服务预测分析世界上发表主题演讲,会议将于 2020 年 5 月 31 日至 6 月 4 日在拉斯维加斯举行,荣幸地邀请到 Fidelity Investments 人工智能和数据科学卓越中心领导者 Victor Lo:题目为:“如何为金融服务找到量体裁衣的‘独角兽’数据科学家”。
我们的前 3 大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业道路。 2. 谷歌数据分析专业证书 - 提升你的数据分析技能! 3. 谷歌 IT 支持专业证书 - 支持你组织的 IT 需求
使用代码 KDNUGGETS 获取预测分析世界门票 15% 的折扣。
如何为金融服务找到量体裁衣的“独角兽”数据科学家随着数据科学家背景和经验的多样化,如何确定你真正需要哪种类型的数据科学家来满足你的业务需求?数据科学家有多少种类型?你可以在哪里找到他们?他们能为金融服务行业提供什么样的分析?Victor Lo 将结合超过 25 年的行业经验以及 20 多年的管理经验,介绍数据科学家的分类框架,并提出这些人才与各种项目类型之间的映射方案。
| Victor Lo AI 和数据科学卓越中心负责人,职场投资富达投资 | Victor S.Y. Lo 是一位经验丰富的大数据、市场营销、风险和金融领域的领导者,拥有超过 25 年的广泛咨询和企业经验,致力于在各种商业领域应用数据驱动的解决方案。他积极从事因果推断,是 Uplift/True-lift 建模的先驱,这是数据科学的一个关键子领域。在学术服务方面,Victor 曾在本特利大学担任访问研究员和企业驻校执行官。他还曾在波士顿运筹学与管理科学学会(INFORMS)分会的指导委员会和两个学术期刊的编辑委员会中服务。他还是国家统计科学研究所(NISS)的选举董事会成员。Victor 获得了运筹学硕士学位和统计学博士学位,并曾在管理科学领域担任博士后研究员。他曾合著了一本研究生级别的计量经济学书籍,并在数据挖掘、市场营销、统计学、分析学和管理科学领域发表了众多文章,目前正在完成一本关于商业中因果推断的研究生级别书籍。 |
金融服务预测分析世界 (拉斯维加斯 2020 年 5 月 31 日至 6 月 4 日 ) 汇聚了强大的演讲者阵容。现在就计划参加这场领先的跨供应商会议,涵盖银行、保险公司、信用卡公司、投资公司及其他金融机构在机器学习部署方面的应用。
PAW 金融 2020 年其他重要演讲
| 
 | “大海捞针”——缺陷和欺诈检测案例研究 Richard Lee -数据科学总监,美国 EOIT 高级分析与人工智能 - 宏利 |
| “大海捞针”——缺陷和欺诈检测案例研究 Richard Lee -数据科学总监,美国 EOIT 高级分析与人工智能 - 宏利 |
| 
 |
| Jen Gennai -**负责任创新全球事务负责人 - Google |
| 
 | 从自动驾驶到欺诈检测——Lyft 如何简化机器学习的部署
| 从自动驾驶到欺诈检测——Lyft 如何简化机器学习的部署
Gil Arditi -**产品负责人,机器学习 - Lyft |
早鸟价格截至 2 月 21 日 查看完整议程 | 立即注册 |
| 机器学习周的一部分(前身为 Mega-PAW)——“一个活动五个会议”PAW Financial 是机器学习周(前身为 Mega-PAW)的一部分——包括五个(5)平行会议,共有八个(8)专题: PAW Business, PAW Financial, PAW Healthcare, PAW Industry 4.0, 和 深度学习世界。
钻石赞助商

铂金赞助商


金牌赞助商


媒体合作伙伴




|
 |
|---|
| 会议主办单位: Rising Media 和 Prediction Impact |
更多相关主题
统计学、因果关系及难以接受的论点:Judea Pearl 辩论 Kevin Gray
原文:
www.kdnuggets.com/2018/06/pearl-gray-statistics-causality-claims-difficult-swallow.html
评论
最近,著名计算机科学家和人工智能研究员Judea Pearl 发布了他与 Dana Mackenzie 共同编著的新书《因果之书:因果关系的新科学》。虽然这本书迅速成为畅销书,但也引起了部分读者的共鸣。
在发布后,市场营销科学家和分析顾问(以及常驻 KDnuggets 的撰稿人)Kevin Gray 撰写了对这本书的评论和反驳,该评论在 KDnuggets 上发表。Pearl 随后回应了 Gray,Gray 又做出了回应,然后 Pearl 再次回应……你懂的。
我们的前 3 大课程推荐
1. Google 网络安全证书 - 加速你的网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT

图片来源:虚假相关
本文包括了从 Kevin 原始回应文章引发的辩论。虽然 KDnuggets 没有表态,我们呈现了这场信息丰富且尊重的辩论,因为我们认为它对我们的读者有价值。我们希望你同意。
读者 Carlos Cinelli 指出,Judea Pearl 回复了 Kevin Gray 的文章,回复内容见下文。
Kevin 预测许多统计学家可能会认为我的观点“奇怪或夸张”是准确的。这正是我在过去 30 年与统计学家进行的众多对话中发现的。然而,如果你更仔细地审视我的观点,你会发现它们并不像初看时那样异想天开或草率。
当然,许多统计学家会挠头问:“这不正是我们多年来一直在做的事情,只是名字不同或者根本没有名字吗?”这就是我观点的本质。以非正式的方式,在不同的名字下进行,同时避免用统一的符号进行数学化处理,对因果推断的进展产生了毁灭性的影响,无论是在统计学中,还是在许多依赖统计学指导的学科中。最好的证据是,直到今天,只有一小部分实践中的统计学家能够解决《为何之书》中提出的因果玩具问题。
例如:
选择足够的协变量来控制混杂因素
明确假设以便能够一致地估计因果效应
查找这些假设是否可被检验
估计因果的原因(而不是因果的效果)
逐渐增多。
《为何之书》的每一章都带来了一系列统计学家深切关注的问题,他们多年来一直在努力解决这些问题,尽管用错了名字(例如 ANOVA 或 MANOVA)“或者根本没有名字”。结果是许多深层次的问题却没有解决方案。
在这一点上,一个有效的问题是,是什么让我如此大胆地断言在 1980 年代之前,没有统计学家(实际上没有科学家)能够正确解决这些玩具问题。怎么能如此确信没有某位聪明的统计学家或哲学家找到解决辛普森悖论的正确方法或区分直接效应与间接效应的正确方式?答案很简单:我们可以从科学家在 20 世纪使用的方程式的语法中看出这一点。要正确定义因果问题,更不用说解决它们,需要一种超出概率论语言的词汇。这意味着所有使用联合密度函数、相关分析、列联表、ANOVA 等的聪明和杰出的统计学家,如果没有用图示或反事实符号丰富这些工具,都是在徒劳地工作——与问题正交——如果没有提问的词汇,就无法回答问题。(《为何之书》,第 10 页)
正是这种符号化的试金石让我有信心支持《为何之书》中您所引述的每一个声明。此外,如果您仔细观察这一试金石,您会发现它不仅是符号化的,还有概念上的和实际的。例如,费舍尔使用 ANOVA 来估计直接效应的错误仍然困扰着当今的中介分析师。其他许多例子在《为何之书》中有所描述,我希望您认真考虑每一个例子传达的教训。
是的,你的许多朋友和同事会挠头说:“嗯……这不是我们多年来一直在做的事情吗,虽然可能用不同的名字,或者根本没有名字?”我希望你在阅读《为什么的书》后,能够抓住一些让人挠头的问题,并告诉他们:“嘿,在你进一步挠头之前,你能解决《为什么的书》中的任何一个玩具问题吗?”你会对结果感到惊讶——我确实是!
对我来说,解决问题是理解的测试,而不是挠头。这就是我写这本书的原因。
Kevin Gray 随后注意到了Judea Pearl 的回复,并在下面提供了跟进的回应。
我很感激 Judea Pearl 花时间阅读并回应我的博客文章。我也感到受宠若惊,因为我多年来一直是 Pearl 的仰慕者和追随者。由于某种原因——这种情况以前发生过——我在使用 Disqus 时遇到了困难,并请 Matt Mayo 代表我发布这篇(确实写得很仓促的)回应。
简而言之,我认为 Pearl 对我帖子评论的实质性不强,因为他基本上重复了我在文章中质疑的观点。
他开篇评论的建议是我对他的观点只了解皮毛。显然,我不觉得是这样。此外,文章中我没有将 Pearl 的观点描述为异想天开或轻率。我非常认真对待这些观点,否则我不会费心写博客文章。
像许多其他统计学家,包括学术界人士,我觉得他对统计学家的描述不准确,而且他对谨慎的处理方法过于简单。这就是我的观点的本质(正如我所说,我并不孤单)。对于这些差异的许多可能原因,我在这里不会猜测为什么。????
“你没有词汇来提问就无法回答问题”这确实是对的。实践中的统计学家——与专注于理论的学术人员相对——与他们的客户紧密合作,而这些客户是特定领域的专家。该领域的语言在很大程度上定义了特定语境中使用的因果关系语言。这就是为什么没有普遍的因果框架,以及为什么心理学、医疗保健和经济学等领域的统计学家有不同的方法,并且经常使用不同的语言和数学。我自己结合了这三者以及 Pearl 的观点。在我 30 多年经验中,每种方法的实用性都是个案情况。此外,还有一些临时方法(有些值得怀疑)。
他声称“……即使到今天,只有一小部分从业统计学家能解决《为什么的书》中提出的因果玩具问题”,但没有提供证据。这些问题并不难,声明并不是证据。此外,他在《为什么的书》的每一章中给出的统计学失败的例子,通常并不令人信服,且这些例子本身就是文章写作的动机之一。
西蒙斯悖论的各种形式是几代研究人员和统计学家被训练去警惕的内容。我们确实如此。它并没有什么神秘之处。(关于西蒙斯的辩论,发表于 2014 年的《美国统计学家》,我在文章中提供了链接,希望对不是 ASA 会员的读者可见。)
调解,常常与调节混淆,可能是一个难题。简单的路径图或包含少量变量的 DAG 往往是不够的,并且可能严重误导我们。在统计学家的实际工作中,通常存在大量潜在的相关变量,包括那些我们无法观察到的变量。还有一些关键变量由于各种原因没有包含在我们可以使用的数据中,并且无法获得。测量误差可能是相当大的——这并不罕见——而且不同类别的主体(例如,消费者)可能存在不同的因果机制。这些类别通常是未观察到的,对我们来说是未知的。
我应该明确表示,我非常赞赏 Pearl 将因果分析引入公众视野的努力。我会建议统计学家阅读他的著作,但也要咨询(就像我做的那样)其他资深从业者和学者对他的著作和因果分析的看法。因果关系有许多种方法来处理,Pearl 的方法只是其中之一。正如 Pearl 自己也意识到的那样,直到今天,哲学家们对因果关系是什么仍然存在分歧,因此在我看来,建议他找到了答案是不现实的。真正的统计学家知道寻找“万能钥匙”是不切实际的。
Pearl 随后回应了这一回复:
亲爱的 Kevin,
我并不是在暗示你只是对我的工作有肤浅的了解。实际上,你对我的了解比我们部门的大多数统计学家要深得多,我非常感激你花时间评论《为什么的书》。你向我展示了其他有类似视角的读者会如何看待这本书,以及他们会发现哪些观点没有依据或难以接受。因此,让我们直接进入这两个要点(即,没有依据和难以接受)并进行深入的探讨。
你说我没有提供支持我说法的证据:“即使在今天,只有一小部分实践中的统计学家能解决《为何之书》中提出的任何因果玩具问题。”我相信我确实提供了这样的证据,在每一章中,而这一说法是有效的,只要我们对“解决”的含义达成一致。
让我们以你提到的第一个例子——Simpson 悖论为例,它在《为何之书》第六章中处理,并且每个热血的统计学家都很熟悉。我用这些话描述了这个悖论:“它困扰了统计学家超过六十年——直到今天仍然令人困扰”(第 201 页)。正如你正确地注意到的,这是一种委婉的说法:“即使在今天,大多数统计学家无法解决 Simpson 悖论”,这一事实我坚信是正确的。
你觉得这个说法很难接受,因为:“几代研究人员和统计学家已经被训练去留意它[Simpson 悖论]”,这一观察似乎与我的说法相矛盾。但我恳请你注意,“被训练去留意它”并不能使研究人员能够“解决它”,即在数据中出现悖论时决定该怎么做。
这种区别在 2014 年《美国统计学家》上的辩论中表现得非常明显,而这是你我引用的期刊。然而,尽管你将辩论中的分歧视为统计学家解决 Simpson 悖论的多种方式的证据,我却认为这是他们甚至没有接近正确答案的证据。换句话说,其他参与者没有提出一种方法来决定是聚合数据还是分离数据能正确回答“治疗是否有帮助或有害”的问题。
请特别注意 Keli Liu 和 Xiao-Li Meng 的文章,他们都来自哈佛大学统计系(Xiao-Li 是资深教授和系主任),所以不能被指责扭曲 2014 年统计知识的现状。请仔细阅读他们的论文,并自行判断它是否能帮助你决定在辩论中提供的任何示例中,治疗是否有效。
绝对不会!!我怎么知道?我在听他们的结论:
- 他们否认与因果关系的任何关联(第 18 页),并且
- 他们最终得出了错误的结论。引用:“当 Simpson 悖论出现时,较少的条件设定最有可能导致严重偏差。”(第 17 页)Simpson 本人举了一个例子,说明条件设定会导致更多偏差,而不是更少。
我不责怪 Liu 和 Meng 在这一点上的错误,这不完全是他们的错(Rosenbaum 和 Rubin 也犯了同样的错误)。解决 Simpson 困境的正确方法依赖于后门准则,而没有 DAG 几乎不可能阐明这一点。正如你可能知道的,DAG 在哈佛大学周围 5 英里禁飞区内是禁止进入的。
所以,我们来到了这里。大多数统计学家认为每个人都知道如何“留意”辛普森悖论,而那些寻求“我们应该治疗还是不治疗?”答案的人意识到,“留意”远非“解决”。此外,他们还意识到,没有走出统计分析的舒适区,进入因果关系和图形模型的禁忌之地,就没有解决方案。
我同意你的一点——你对因果革命的不切实际的警告。引用:“直到今天,哲学家们对于因果关系是什么存在分歧,因此,建议他找到了答案是不切实际的。”确实,不切实际的是,特别是一个半外部者,找到了银弹。这很难接受。这也是我如此兴奋于因果革命的原因,也是我写这本书的原因。这本书并没有为所有存在的因果问题提供银弹,但它为一类问题提供了解决方案,而这些问题几个世纪以来的统计学家和哲学家尝试过但未能破解。我同意这不切实际,但它发生了。发生的原因不是因为我更聪明,而是因为我认真对待了 Sewall Wright 的想法,并尽可能将其推导到逻辑结论。
我冒着相当大的风险,显得自负地称这一发展为因果革命。我认为这是必要的。现在我请你花几分钟时间,自己判断证据是否足以证明这样的冒险性描述是合理的。
如果我们能提醒那些深度投入统计语言的统计学家,21 世纪甚至可能出现范式转变,那就太好了,并且几个世纪的无效争论并不会使这样的转变变得不可能。
你对范式转变的必要性表示怀疑和不信是对的,任何负责任的科学家都会这样做。下一步是让社区进行探索:
- 多少统计学家能真正回答辛普森的问题,以及
- 如何让那个数字达到 90%。
我相信《因果之书》已经把那个数字翻倍了,这算是一种进展。实际上,这是我在过去三十年里通过与我们时代的主要统计学家的艰苦讨论无法做到的事情。
这是一些进展,让我们继续,
Judea
最新的消息是,Gray 在发布时向我们提供了以下内容。
再次感谢你抽出时间回复我的博客文章和早期的回复。也感谢你的好评,特别是考虑到 UCLA 在 SEM 和 AI 方面处于前沿。那里没有禁飞区。
我觉得我们是在为同一个问题而战,尽管方式不同、角度不同、往往对抗的“敌人”也不同。我告诉别人我对因果关系情有独钟,但不知其所以然。???? 我从应用市场研究员和“数据科学家”(这是我不太舒服且自己也不完全理解的术语)的角度来看待这场战斗。为了让你了解我“来自何处”,让我重现一下我刚刚在 LinkedIn 上发布的一条帖子:
关于因果关系的更多想法…
了解“谁、什么、何时、何地、如何、多久一次”等信息在市场营销和市场研究中至关重要。预测分析在许多情况下和许多组织中也很有用。
然而,了解“为什么”也往往至关重要,这有助于我们更好地理解和预测“谁、什么、何时、何地、如何、多久一次”等问题。
然而,因果关系的分析非常具有挑战性,有些人会说几乎是不可能的。
传统观念认为,最佳的方法是通过随机实验。虽然我同意这一点,但在许多情况下,实验是不可行或不道德的。实验也可能出现错误,或过于人为,以至于无法推广到真实世界条件中。它们也可能无法复制。它们不是魔法。
在许多情况下,非实验性研究可能是我们唯一的选择。但这并不意味着数据挖掘或其他不靠谱的研究方式。进行非实验性研究有更好和更差的方法。这就是问题所在——这并不容易做到正确,错误可能非常昂贵。
我觉得最后一点最为重要。一些人似乎误解了你的著作,认为理论和判断无关紧要,计算机能够自动找到“最佳模型”。这是现代形式的“散弹枪经验主义”…这种情况因点选和拖拽的软件而加剧,这些软件可以说比微软 Word 更易于使用。散弹枪(有时还有 DAG)在孩子手中…
在大数据时代,我这种角色有时需要确定成千上万变量的相对重要性,有时是针对每个消费者单独进行。一般认为这不是因果分析。在另一极端,基于少数几个焦点小组有时会得出广泛的因果推论。同样,这也经常不被认为是因果研究。
关于辛普森悖论,我会让你继续与学术同行争论。我会根据手头的数据和研究目标逐案处理这个问题。显然,一些应该知道更好的人在这方面犯了错误。要明确的是,我指的是实际解决方案,而不是理论数学解决方案。虽然我与孟教授并不熟识,但我看过他在 YouTube 上的几次讲座,并阅读过他的一些论文。他在讨论常见的大数据谬误方面有很多见解。
在应用领域,我确实注意到一些拥有出色数学和编程技能的人,尽管如此,他们在使用统计学解决现实世界问题方面却不尽如人意。这不是一个原创的观察。也许 ASA、RSS 和其他专业组织会对定期技能评估感兴趣,这完全是自愿的,旨在专业发展?
我设想一个在线测验,包含少量应用统计学问题——不是数学问题,除非是某些重要领域。这将是保密的。作为激励,参与者在完成测试后将看到正确答案。随着时间的推移,参与者将能够了解他们在哪些方面表现强劲,哪些方面需要改进。我们还将拥有一些实证证据(即使不是来自真正具有代表性的样本)来了解实践统计学家和研究人员在关键领域的技能水平,这将是可以发表的。我希望你能贡献一些问题!
对于任何领域具有良好统计学背景的统计学家和研究人员,我认为《因果关系》是必读书目。我也觉得《为什么的书》有价值,正如我所提到的。你当然会熟悉概率图模型(Koller 和 Friedman),我了解到 Fenton 教授和 Neil 教授将出版《风险评估与决策分析》的新版本。由于你为第一版撰写了前言,你显然也认为这本优秀的书值得阅读。
再次感谢你在漫长而卓越的职业生涯中对许多领域所做的诸多贡献。不幸的是,对我来说,现在是时候戴上安全帽,回到工作中了。
此致,
凯文
相关:
-
为什么的书
-
为什么的书:因果关系的新科学
-
更好的统计学 101
更多相关话题
《使用 RetinaNet 进行航拍图像中的行人检测》
原文:
www.kdnuggets.com/2019/03/pedestrian-detection-aerial-images-retinanet.html
评论
由 Priyanka Kochhar,深度学习顾问
介绍
航拍图像中的物体检测是一个具有挑战性且有趣的问题。随着无人机成本的降低,生成的航拍数据量激增。拥有能够从航拍数据中提取有价值信息的模型将非常有用。RetinaNet 是最著名的单阶段检测器,在这篇博客中,我想测试它在来自 斯坦福无人机数据集 的行人和骑车人的航拍图像上的表现。见下图。这是一个具有挑战性的问题,因为大多数物体宽度只有几个像素,有些物体被遮挡,而阴影中的物体更难检测。我阅读了几篇关于航拍图像中物体检测的博客,特别是在行人检测方面的链接较少,这尤其具有挑战性。
 斯坦福无人机数据集中的航拍图像 — 行人用粉色标记,骑车人用红色标记
斯坦福无人机数据集中的航拍图像 — 行人用粉色标记,骑车人用红色标记
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 部门
RetinaNet
RetinaNet 是一种单阶段检测器,使用特征金字塔网络 (FPN) 和焦点损失进行训练。特征金字塔网络 是一种用于多尺度物体检测的结构,介绍于这篇 论文 中。它通过自上而下的路径和横向连接将低分辨率、语义强的特征与高分辨率、语义弱的特征结合在一起。最终结果是,它在网络的多个层次上生成不同尺度的特征图,这有助于分类器和回归器网络。
Focal Loss 旨在解决单阶段目标检测问题中的不平衡问题,在这种问题中,背景类别的数量非常大,而前景类别则很少。这导致训练效率低下,因为大多数位置都是容易的负例,不提供有用的信号,而这些大量的负例会淹没训练并降低模型性能。Focal Loss 基于交叉熵损失,如下所示,通过调整 gamma 参数,我们可以减少来自已分类示例的损失贡献。
 Focal Loss 解释
Focal Loss 解释
在这个博客中,我想谈谈如何在 Keras 上训练一个 RetinaNet 模型。我没有充分阐述 RetinaNet 背后的理论。我使用了这个链接来了解该模型,并强烈推荐它。我的第一个训练模型在检测目标方面表现很好,如下面的视频所示。我还在我的Github 链接上开源了代码。
 Retina Net 在人和骑车人的航空图像上的效果
Retina Net 在人和骑车人的航空图像上的效果
斯坦福无人机数据集
斯坦福无人机数据集是一个由无人机在斯坦福校园上空收集的大量航空图像数据集。该数据集非常适合用于目标检测和跟踪问题。它包含约 60 个航空视频。每个视频都有 6 个类别的边界框坐标——“行人”、“骑车人”、“滑板车手”、“推车”、“汽车”和“公交车”。该数据集在人和骑车人方面非常丰富,这两个类别覆盖了约 85%-95%的标注。
在斯坦福无人机数据集上训练 RetinaNet
为了训练 Retina Net,我使用了Keras 中的这个实现。它文档齐全且没有错误。非常感谢 Fizyr 开源他们的实现!
我遵循的主要步骤是:
-
从庞大的斯坦福无人机数据集中选择样本图像以构建模型。我取了大约 2200 张训练图像,带有 30,000+个标注,并保留了大约 1000 张图像用于验证。我已经将我的图像数据集上传到 Google Drive 这里,供有兴趣跳过这一步的人使用。
-
生成 Retina Net 所需格式的标注。Retina Net 要求所有标注都符合该格式。
path/to/image.jpg,x1,y1,x2,y2,class_name
我将斯坦福标注转换为这种格式,我的训练和验证标注已上传到我的Github。
- 调整锚点尺寸:Retina Net 的默认锚点尺寸为 32、64、128、256、512。这些锚点尺寸适用于大多数物体,但由于我们处理的是空中图像,一些物体可能小于 32。这些库提供了一个方便的工具来检查现有锚点是否足够。下图中绿色的注释被现有的锚点覆盖,红色的注释被忽略。如图所示,相当一部分注释对于最小的锚点尺寸来说仍然太小。
 使用默认锚点的 Retina Net
使用默认锚点的 Retina Net
因此,我调整了锚点,去掉了最大的 512 并添加了一个大小为 16 的小锚点。这带来了明显的改进,如下所示:
 添加一个小锚点后
添加一个小锚点后
- 有了这些准备,我们已经可以开始训练了。我保留了大部分其他默认参数,包括 Resnet50 主干,并开始了训练:
keras_retinanet/bin/train.py --weights
snapshots/resnet50_coco_best_v2.1.0.h5 --config config.ini
csv train_annotations.csv labels.csv --val-annotations
val_annotations.csv
这里的权重是 COCO 权重,可以用于启动训练。训练和验证的注释是输入数据,config.ini 中有更新后的锚点尺寸。所有文件也在我的 Github 仓库 中。
就这些!模型训练速度较慢,我整晚都在训练。我通过检查测试集上的 平均精度 (MAP) 来测试训练模型的准确性。如下所示,第一个训练模型的 MAP 达到了 0.63,表现非常好。尤其在汽车和公交车类别上表现优异,因为这些类别在空中比较容易识别。Biker 类的 MAP 较低,因为它经常被行人混淆。我目前正在进一步提高 Biker 类的准确性。
Biker: 0.4862
Car:0.9363
Bus: 0.7892
Pedestrian: 0.7059
Weighted: 0.6376
结论
Retina Net 是一个强大的模型,使用了特征金字塔网络。它能够在一个非常具有挑战性的数据集上进行空中物体检测,该数据集中的物体尺寸非常小。我在半天的工作时间内训练了一个 Retina Net。第一个版本的训练模型性能相当不错。我仍在探索如何进一步调整 Retina Net 架构,以提高空中检测的准确性。有关内容将在我的下一篇博客中介绍。
希望你喜欢这篇博客,也尝试自己训练模型。
我有自己的深度学习咨询公司,喜欢处理有趣的问题。我帮助了许多初创公司部署创新的 AI 解决方案。请访问我们的 网站 了解更多。
你也可以查看我的其他文章: deeplearninganalytics.org/blog
如果你有一个可以合作的项目,请通过我的网站或邮件 priya.toronto3@gmail.com 联系我。
参考文献
个人简介: Priyanka Kochhar 已有 10 年以上的数据科学经验。她现在拥有自己的深度学习咨询公司,并热衷于解决有趣的问题。她曾帮助多家初创公司部署创新的 AI 解决方案。如果你有一个可以合作的项目,请通过 priya.toronto3@gmail.com 联系她。
原创。经许可转载。
相关:
-
使用深度学习进行人员跟踪
-
Keras 深度学习入门
-
Keras 四步工作流程
更多相关话题
同行评审数据科学项目
原文:
www.kdnuggets.com/2020/04/peer-reviewing-data-science-projects.html
评论
作者:Shay Palachy,数据科学顾问。
同行评审是任何创意活动中重要的一部分。它在研究中使用——无论是在学术界还是在学术界之外——以确保结果的正确性、遵循科学方法和输出的质量。在工程领域,它用于提供外部审查,并在技术开发过程的早期捕捉到昂贵的错误。在各个领域,它都用于改进决策。
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道
2. Google 数据分析专业证书 - 提升你的数据分析能力
3. Google IT 支持专业证书 - 支持你所在组织的 IT
我们在科技行业工作的人员都熟悉一个特别重要的同行评审实例——代码审查过程。如果你曾经接受过审查,你应该知道尽管这会稍微让人不适——因为将我们的创作放在审查下总是令人不安——但它可以非常有价值。这个过程迫使我们提前准备,从而在审查之前就发现了许多改进点。这通常会提出一些小但重要的问题,这些问题可能被我们忽视,但对外部人员来说却很容易发现,有时它还可以提供非常深刻的见解。
本文的目标是建议一个布局,用于为数据科学项目执行类似功能的流程。这是作为对 我个人观点 的一个部分,关于小规模数据科学项目的运行方式,这个话题我在之前的博客文章中已经涉及过:数据科学项目流程。你可以在下面找到这个工作流程的图示。
这个框架也基于我作为首席数据科学家、团队领导的经验,以及作为 独立顾问 目睹了我咨询过的各种公司遵循的工作模式。我还依赖于许多领导团队或数据科学家小组的朋友们的经验。

图 1:数据科学项目流程(来源:作者)。
根据我对项目流程的看法,我建议针对我认为最需要同行审查的两个阶段:研究阶段和模型开发阶段,采用两种不同的同行评审过程。
目标是为这两个阶段提供一个同行评审过程的一般框架,该框架将:
-
使过程正式化并提供结构。
-
鼓励数据科学家提出问题并提供同行评审。
-
降低高成本错误的风险。
我将讨论这两个过程的动机、目标和结构,并为每个过程提供一个独特的问题和问题检查列表。
类似于项目流程,这些过程是在考虑小团队从事应用数据科学的情况下编写的。然而,较大的团队甚至研究小组可能会发现下面的一些想法有用。
致谢: 模型开发 审查清单 是 Philip Tannor的创作,他是一位出色的数据科学家,也是一个更好的人。
数据科学研究阶段审查
为了帮助你记忆,我们称“研究阶段”为在数据探索和文献回顾之间进行迭代往返的过程(可以包括审查现有代码和实现)。这一阶段还包括描绘可能的方法论方法的空间,以框定和解决当前问题,并形成我们对前进最佳方式的推荐,同时列出每个选择固有的优缺点。

图 2:研究阶段的三项检查(来源:作者)。
请注意,在这一阶段进行三种类型的检查以验证自然影响力选择的方法:
-
技术有效性检查,通常与支持项目的数据/软件工程师一起进行,旨在确保建议的方法可以成功部署并得到工程支持。
-
研究审查,同行帮助数据科学家验证他的过程和建议。我们将在稍后深入探讨。
-
范围和 KPI 有效性检查,与负责产品的人一起进行,以确保推荐的方法仍在项目范围内,并且看起来能够满足项目的 KPI。
动机
我认为数据科学家对项目研究阶段进行同行评审的主要动机是防止他们在项目的早期阶段选择错误的方法或方向。这些错误——在 DS 工作流程 中称为 方法失败——是 非常 昂贵的,并且会阻碍项目在其余生命周期中的进展。
如果我们幸运的话,我们在经过几个模型开发迭代后发现方法失败,这会浪费宝贵的数据科学家工作时间。这种情况是指方法失败导致使用我们选择的指标进行跟踪和优化时性能下降。
然而,在某些情况下,由于方法失败导致的性能差异可能更加微妙,并且在使用大量生产数据验证模型性能之前可能极其难以识别,有时甚至需要用户/客户反馈来发现这一行为,从而在模型投入生产后才发现失败。其代价显著更高:数据科学家、工程师和产品人员的数月工作,客户满意度下降,潜在的客户流失,甚至收入减少。
这就是为什么模型基准测试不能是我们希望发现过程和决策中方法论错误的唯一方式;我们必须明确假设这些错误可能会被这些手段遗漏,并尝试通过检查过程本身、其逻辑以及支持它们的主张和数据来从方法论上发现这些错误。
目标
显然,这里的主要目标是及早发现代价高昂的错误,如前所述,通过明确检验过程的核心方面,同时对几个常见问题进行基本的合理性检查。
然而,这里可以陈述两个额外的子目标:首先,提高数据科学家在即将到来的产品/业务评审过程中解释和辩护她决策的能力。其次,更好地准备将研究阶段的成果展示给团队其他成员,这是大多数数据科学团队/小组中非常常见且重要的实践。
结构
准备评审的步骤有三:
-
被评审的数据科学家准备一个关于他所经历的研究过程的演示(不一定是幻灯片)。
-
被评审的数据科学家与评审员安排了一个长时间的会议(至少 60 分钟;上次我们花了两个小时)。
-
评审员在会议前检查清单。
在他的演示中,被评审的数据科学家尝试涉及以下七个要点:
-
提醒:项目范围和产品需求。
总是从这里开始,因为评审的主要一点是估计过程的遵循情况以及做出的选择是否满足项目范围和需求。
-
初步的指导方针和关键绩效指标(KPIs)。
在许多情况下,这将是评审数据科学家第一次看到产品需求转化为技术 KPIs 的过程,这是一种很好的机会来暴露这一点接受同行审查。覆盖问题特征和限制。
-
做出的假设。
我们都对数据格式、可用性、可接受的错误和常见产品使用模式等方面做出强烈假设。将这些假设明确化。
-
使用的数据及其探索方式。
数据探索结果可以证明一些假设和选择的方法,因此请清楚地呈现它们。
-
得出的可能方法/解决方案列表。
研究阶段的第一个主要成果:解决方案地图,详细说明每个方案的优缺点——包括假设——并可能还描绘了它们的起源和相互关系(如果相关的话)。
-
未来选择的方法及其理由。
你的推荐。这是这一阶段最显著的成果,但请记住,要绘制路线图,你首先必须拥有地图。解决方案地图提供的背景应使你能够向评审者解释选择,同时排除其他选项。
-
什么可能的失败会导致替代选择?
我认为,这一常被忽视的研究阶段产物不亚于你的推荐。你现在正通过应急计划来增强它,明确分享如何对研究驱动项目固有的风险进行对冲和计算。
最后,这里是审查会议的建议结构:
-
待审查的 DS: 研究阶段演示
-
评审者: 一般反馈
-
评审者: 检查清单 (见下方)
-
评审者: 批准或拒绝
-
共同: 结果行动点
检查清单
该列表关注于在研究阶段应解决的问题。我将其分为十个类别:
-
数据属性
-
方法假设
-
过去的经验
-
目标对齐
-
实施情况
-
扩展
-
组合/拆分能力
-
信息要求
-
领域适应
-
噪声/偏差/缺失数据的韧性
让我们回顾一下问题。记住,这只是我提出的初步建议,并没有全面覆盖需要考虑的所有内容。
数据属性
关于初始数据集:
-
生成是如何完成的?样本是如何选择的?是否进行了更新?
例如,上个月 10%的数据是从现有五个客户中的每一个均匀采样的。
-
这引入了什么噪声、采样偏差和缺失数据?
例如,其中一个客户仅在两周前才与我们的服务整合,这在数据集中引入了对其数据的下采样偏差。
-
你能否修改采样/生成以减少或消除噪声?采样偏差?缺失数据?
例如,将样本量不足的客户增加一倍,或者仅使用过去两周的数据用于所有客户。
-
你能否独立于某种方法来显式建模噪声?
-
如果数据集有标签,它是如何标记的?
-
这引入了什么标签偏差?可以测量吗?
例如,标签可能来自半关注的用户。通过专家/分析师手动标记一个非常小(但具有代表性)的集合可能是可行的,并且将使我们能够测量这个集合上的标签偏差/错误。
-
你能否修改或增强标记过程以补偿现有的偏差?
-
初始数据集在生产中预期的输入数据、结构和模式上有多相似?
例如,某些项目的内容在生产中动态变化。或者可能不同领域缺失,取决于创建时间或源领域,之后被补全或推断。
-
初始数据集对生产数据的代表性如何?
例如,客户之间的数据分布不断变化。或者可能是采样覆盖了两个春季月,但模型将在冬季开始时出现问题。或者可能是在集成了一个重要的客户/服务/数据源之前收集的。
-
你能期望的最佳训练数据集是什么?
-
非常明确地定义它。
-
估算:它将改善性能多少?
-
生成的可能性和成本有多大?
例如,使用三个标注员标记 20,000 条帖子情感,并给出每条帖子的模式/平均分数作为标签。这将需要 400 人小时,预计成本为两到三千美元,并预计将提高至少 5% 的准确率(这个数字通常很难提供)。
-
方法假设
-
每种方法对数据/数据生成过程/研究现象做出了什么假设?
-
对你的问题做出这些假设是否合理?在多大程度上?
-
你如何期望适用性与这些假设的违反情况相关联?例如,10% 违反 → 性能降低 10%?
-
这些假设可以独立验证吗?
-
是否存在违反这些假设的边缘/极端情况?
示例: 为了确定飞机票价格的变化是否驱动了你服务的使用增加,你可能希望使用一些经典的因果推断统计方法对这两个值的时间序列进行分析。或者,你可以使用像 ARIMA 这样的常见模型来预测下个月的飞机票价格。
许多此类方法不仅有时隐含地假设输入时间序列是平稳随机过程的实现,而且也没有提供时间序列的平稳度度量或其违反假设的程度的度量。最后,当这种假设在任何程度上被违反时,它们没有提供误差的上界或发生误差的概率。
因此,这是这些方法的一个显著缺点,应该明确呈现并加以说明。在这种情况下,平稳性实际上可以被测试,与使用的方法无关,因此可以在做出选择之前确认某些方法的有效性。
以下是一些方法所做的非常强且通常隐含的假设示例:
-
每个特征遵循高斯分布。
-
时间序列是平稳过程的实现。
-
特征是严格独立的(例如,朴素贝叶斯假设这一点)。
-
系统中不同组件的测量可分离性。
过去经验
-
你在应用这种方法方面有什么经验,无论是一般的还是针对类似问题的?
-
你是否发现任何已发布的(例如,在博客文章或文章中)将这种方法应用于类似问题的成功/失败案例?
-
你是否向同行询问过他们的经验?
-
从上述内容中可以学习到哪些教训?
-
如果这个项目是试图在现有解决方案的基础上进行迭代和改进:迄今为止使用了什么解决方案来解决这个问题?它们的优点是什么,它们遇到了什么问题?
目标对齐
对于基于优化的监督学习方法:
-
在拟合模型参数时可以使用哪些损失函数?它们与项目 KPIs 的关系如何?
-
可以使用哪些指标进行模型选择/超参数优化?它们与项目 KPIs 的关系如何?
-
应该添加哪些硬性约束以反映 KPIs?
对于无监督学习方法:
-
该方法优化了什么指标?
-
这与 KPIs 有何关联?
例如,最大化平均词向量的可分离性与寻找一组捕捉不同意见的文章的近似效果如何?
-
有哪些边缘案例满足指标但不符合 KPI?
对于无监督表示学习:
- 为什么假任务(例如,在Word2Vec中预测一个词的邻居)预计能促进输入表示的学习,这将有利于执行实际任务的模型?
实现
-
目前在你的生产环境中使用的语言中是否有这种方法的实现?
-
实现是否是最新的?是否得到持续支持?是否被广泛使用?
-
有类似公司/组织成功使用这种具体实现的案例吗?这些问题是否与您的类似?
扩展性
-
计算/训练时间如何随着数据点的增加而变化?
-
随着特征数量的增加?
-
存储如何随着数据点/特征的增加而扩展?
组合/拆解能力
-
如果需要,不同领域(类别/客户/国家)的模型可以以合理的方式组合吗?
-
或者,它们的结果是否可以以有意义的方式整合?
-
一般模型是否可以分解为每个领域的模型?可以识别和利用这些模型的每个领域相关的内部组件吗?

图 3:模型的可组合性可能是一个要求,并且有不同的形式(来源:作者)。
示例: 假设我们正在开发一个主题动态播放列表生成系统,作为音乐流媒体服务的一部分。这意味着我们想自动生成和更新围绕“新独立”、“英国新浪潮”、“女性主义音乐”或“俗气情歌”等主题的播放列表。为了增加复杂性,我们可能还希望允许主题组合的播放列表,例如“女性主义新浪潮”或“新忧郁独立”。或者,也许我们希望能够为每个听众个性化每个播放列表。最终,如果我们有一个为主题播放列表排名歌曲的模型和另一个通过特定用户喜欢的可能性排名歌曲的个性化模型,我们可能希望能够结合这两个模型的结果。*
不同的方法可以以不同的方式支持这些场景。例如,如果我们将每个人/主题建模为所有歌曲的概率分布,其中播放列表通过重复采样(无重复)动态生成,那么可以很容易地将这些模型组合成一个单一的概率分布,然后可以使用相同的过程生成适应性的播放列表。然而,如果我们使用某些机器学习模型通过评分对歌曲进行排序,我们可能需要制定一种方法使不同模型的评分可比,或者使用通用的方法将多个排序结果整合到相同的项目集合中。
信息需求
-
每种方法在多大程度上依赖于可用的信息量?少量信息对性能的预期影响是什么?
-
这与当前可用的信息量以及未来的信息可用性是否一致?
例如,从头开始训练基于神经网络的序列模型进行文本分类通常需要大量信息,如果不能依赖于预训练模型或词嵌入。例如,如果我们正在为代码文件构建一个脚本或模块分类器,这可能正是我们面临的情况。在这种情况下,假设每种编程语言代表一个独立的领域,神经网络模型可能在非常稀有的编程语言或我们拥有很少标签的语言上表现不好。
冷启动与领域适应
-
新客户/类别/国家/领域预计需要多长时间才能达到每种方法的最低信息需求?
-
一般模型是否可以预期在这些领域表现良好,至少作为起点?
-
是否有办法将已经拟合的模型适应到新领域?这是否预期会比从头开始训练获得更好的性能?这样做是否比从头开始训练更快/更便宜?
示例: 假设我们正在为我们在线市场中的产品建立推荐系统,这些产品由许多商家使用,新商家每天都会加入并开始销售他们的产品。使用基于神经网络的模型,该模型在某些代表商家的数据上学习商家及/或其产品的嵌入,对于这些新商家,通过将他们映射到嵌入空间中与类似现有商家接近的位置,然后借用已经学习到的现有商家中不同购物者购买某些产品的可能性,这样的模型可能表现出意想不到的好效果。
噪声/偏差/缺失数据的弹性
该方法如何处理数据中的噪声?如何处理?
-
这是否针对特定模型?
-
如果适用,请考虑:噪声模型对你问题中的噪声生成过程的适用性如何?
-
对于异常/预测/因果关系/动态:该方法是否对系统中的外生变量进行建模?
对于监督和半监督方法:
-
每种方法对标签偏差的敏感性如何?
-
在你的案例中,偏置模型的影响是什么?
-
泛型偏差修正技术是否适用于该方法?
对于所有方法:
-
每种方法如何处理缺失数据(如果有的话)?
-
在每种情况下,随着缺失数据的增加,性能预计会恶化到什么程度?
数据科学模型开发阶段审查
再次回顾一下,我所称的模型开发阶段是数据科学项目的一个部分,在这个阶段,进行了大量的数据处理(包括特征生成,如果使用的话),实际模型应用于实际数据——在监督情境下,它们被训练或拟合——并使用一些预定的指标进行基准测试,通常是在留出的测试/验证集上。
你可以把整个过程看作是一个大的迭代——无论检查了多少种方法——但我更倾向于将其视为几个迭代,每个迭代专注于单一方法。这些迭代要么并行进行,要么按研究阶段末尾概述的排名顺序进行,在这种情况下,方法失败——即模型子性能估计由于当前方法与问题的不匹配或基本不适用——将导致对下一个最佳方法的模型开发迭代。

图 4:模型开发阶段的两个检查点(来源:作者)。
与所有其他阶段类似,最终检查点是与负责的产品经理进行联合讨论,以验证即将部署的模型是否满足项目 KPI。然而,在此之前,还需要由同事进行另一次审查。
动机与目标
正如在研究审查中一样,这里的动机是模型开发阶段的错误也可能代价高昂。这些错误几乎总是在生产中发现,可能需要主动模型监控来捕捉。否则,它们会在产品化阶段晚些时候被发现,这可能需要开发人员/数据工程师,并暴露出在工程能力或生产环境方面做出的隐性假设之间的差距;研究阶段末的技术有效性检查旨在减轻一些这些错误。然而,由于许多错误是(1)技术性的,(2)基于实现的,以及(3)特定于模型的,它们通常只能在此阶段及之后进行检查,因此模型开发评审也会处理这些问题。
因此,目标是相同的:首先,为模型开发阶段提供一个结构化的评审过程,将其正式纳入项目流程中以增加同行审查的严谨性。其次,通过审查准备好的问题和问题清单来减少成本高昂的错误风险,这些问题和问题基于其他数据科学家的宝贵经验。
结构
准备审查时需要遵循三个简单的步骤:
-
被评审的数据科学家准备模型开发过程的演示(不一定是幻灯片)。
-
被评审的数据科学家安排一个详细的会议(至少 60 分钟)与评审的数据科学家。
-
评审的数据科学家在会议前检查清单。
被评审的数据科学家在其演示中应涵盖以下要点:
-
提醒:项目范围和产品需求
-
研究阶段后的选定方法
-
模型选择的指标 + 软约束和硬约束
-
使用的数据、预处理和特征工程
-
检查的模型、训练方案、超参数优化。
-
选择的模型、备选方案及其优缺点。
-
后续步骤:自动化、产品化、性能优化、监控等。
这里建议的审查会议结构如下:
-
被评审的数据科学家: 模型开发阶段演示
-
评审者: 一般反馈
-
评审者: 检查清单 (见下文)
-
评审者: 批准或拒绝
-
共同: 结果行动点
检查清单
再次, Philip Tannor 创建了一个审查模型开发阶段时使用的问题和问题清单,分为以下几个类别:
-
数据假设
-
预处理
-
漏洞
-
因果关系
-
损失/评估指标
-
过拟合
-
运行时间
-
笨蛋错误
-
微不足道的问题
在这里重复清单没有意义,尤其是因为 Philip 计划维护它,所以直接去阅读 他的博客文章。
原文。经许可转载。
简介:Shay Palachy在担任过ZenCity的首席数据科学家、Neura的数据科学家,以及英特尔和Ravello(现为 Oracle Cloud)的开发人员之后,现在作为机器学习和数据科学顾问工作。Shay 还创办并管理了NLPH,这是一个旨在促进希伯来语开放 NLP 工具的倡议。
相关:
相关文章
为什么大多数人无法学会编程?
原文:
www.kdnuggets.com/2022/03/people-fail-learn-programming.html

图片由 Fotis Fotopoulos 提供,来源于 Unsplash
介绍
当我第一次想进入数据科学领域时,一个主要的障碍是学习编程。
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT
尽管花了几个小时参加在线编程教程,但当我需要编写自己的程序来从零开始构建项目时,我完全迷失了方向。
在决定职业道路时,我坚决选择了一个不需要编程的领域。我觉得我不适合成为程序员。
然而,当 Covid-19 大流行爆发时,我被困在家里,手上有很多空闲时间。因为没有其他事情可做,我决定给自己另一个学习编程的机会。
这一次,我决定研究一下为什么我发现编程如此困难。是否真的有些人天生比其他人更擅长编程?我是否缺少某种可以让我一夜之间成为更好程序员的秘密成分?
我花了无数小时阅读其他人学习编程的经历。我与高级开发人员和数据科学家进行了交谈。
我花了一些时间,但我意识到是我自己的态度阻碍了我学习编程。
你看,我的问题不是我不够聪明以成为程序员。问题在于我没有拥有正确的心态。
我把编程当作了学校里的其他科目。我试图学习太多,太快。这样做时,我忘记了学习曲线的存在。每当我的代码运行失败时,我很容易感到沮丧。我不断地与其他更有经验的程序员进行比较,而我无法理解他们的代码。
一旦我意识到自己做错了什么,我决定这次以不同的方式做事。我每天编码,并允许自己在过程中犯错误。起初,简单的问题需要我花大约 4–5 小时来解决。随着不断练习,我能够更快地解决更复杂的问题。慢慢地,我发现自己变得更好了。
今天,我绝不是一个熟练的程序员。然而,我能够完成日常工作的任务,执行数据科学工作流,并担任需要编程的自由职业角色。每次解决一个新问题,我的编程技能都会得到提高。
在这篇文章中,我将提供一些关于如何学习编程的建议。这里提供的见解基于我自己的编程经历,以及我多年从有经验的编码者那里收集的建议。
建议 #1:避免教程陷阱
我们几乎都上过编程在线课程。教程是学习编程的一个好方法,因为它们教你基本的编程概念和语法。
然而,大多数人从未停止学习教程。
我跟随了至少 10 个编程 YouTube 视频,并购买了超过 5 个不同语言的在线课程。
我一直这样做,期待每次上不同的在线课程时都能学到新的东西。
不幸的是,我没有。
我上过的每一门课程都教给我我已经知道的相同编程基础知识。
然而,由于我没有将这些概念应用于实践中,我总是无法提出自己的代码来解决问题。
这是一种糟糕的情况。每次上一个新教程时,我感觉自己学到了新的东西。但当我尝试自己创建一个项目时,我根本不知道从哪里开始。
许多程序员称之为 教程陷阱。
如果这种情况对你来说很熟悉,那就该打破它了。
一旦你上过入门课程来学习基本的编程概念,就开始将你的知识付诸实践。
我建议使用编程挑战网站来磨练你的技能。我注册了一个名为 Hackerrank 的平台。他们以各种不同的语言提供编程问题,难度也各不相同。
从最基本的挑战开始,然后逐步攻克更困难的挑战。
起初,我通常需要花费大约 3–4 小时来解决即使是最基本的问题。我会查看其他编码者对这个问题的解决方案,然后将他们的思维过程重新构建成自己的代码。
这样,我逐渐摆脱了仅仅复制粘贴代码的做法。我能够理解不同人的思维过程,并将其重构以匹配自己的思维。
这样做会提升你的编程技能,因为你会意识到有很多不同的方式来解决同一个问题。
建议 #2:改变你的心态
学习编程就像骑自行车一样。你需要愿意摔倒多次,才能最终掌握它。
当我刚开始学习编码时,我缺乏耐心。花了几个小时学习一个新的编程概念后,我期待能够成功地将其付诸实践。每次遇到错误时,我都会感到沮丧。我开始失去信心。慢慢地,我放弃了。
我们生活在一个大多数结果都是瞬时的世界中。我们期望快速的成果,而在这个过程中,往往忘记了学习曲线的存在。
我犯的另一个错误是总是拿自己与他人比较。当我阅读其他程序员复杂且难以理解的代码时,我常常觉得自己永远达不到他们的水平。似乎我永远无法像他们那样优秀,这再次降低了我的自信。
我花了一段时间才意识到,没有实践就无法成为一名熟练的编码者。我认识的每一位优秀程序员都有多年的经验。他们每天都在电脑屏幕前待上数小时。
通过与他们交谈,我意识到他们都面临着与我相同的问题。即使在这个领域拥有多年的经验,他们仍然会遇到需要几天甚至几周才能解决的错误。在需要转向不同框架时,他们也会遇到困难,并且在阅读其他人的代码时会感到困惑。
编码并不容易。即使是经验丰富的程序员也会面临看似无法解决的问题。他们在编码时也会感到沮丧。随着经验的增加,他们需要完成的任务的复杂性也会增加。
建议 #3:创建项目
在解决编码挑战网站上的问题并克服思维障碍后,开始从事你热爱的项目。
构建一个全面的项目是将你学到的所有技能付诸实践的好方法。
我目前的大部分知识来源于我所创建的项目——无论是在工作中还是自己动手做的。
此外,当你创建一个项目时,你超越了在在线课程和教程中学习的工具栈。你需要扩展到不同的框架,甚至可能需要使用多种语言来完成最终产品。
这将大大提升你的编程技能。当你进入行业工作时,即使需要使用不同的工具来解决手头的问题,你也能更快地上手。
如果你想构建你的第一个数据科学项目但没有任何创意,你可以看看我的之前的工作来寻找灵感。
结论
学习编码需要实践、耐心,以及在你变得半途而废之前允许自己失败多次的能力。
最重要的是,这需要巨大的思维方式转变。
许多人期望自己在完成在线课程后成为专家程序员。当他们感到困惑时,他们过早放弃问题,觉得自己不够聪明或准备不足以学习编程。
这种“这实在太难了”的感觉让许多有志的数据科学家放弃了,转而选择了其他职业道路。
为了克服这个问题,你需要理解,没有大量编程时间就无法成为一名体面的程序员。你需要大量练习,还需要学会多次失败。
花时间在编码挑战平台上。如果你感到卡住,查看其他程序员发布的现有解决方案。尝试复制他们的思路。不断重复这个过程,直到你对自己的编码能力充满信心。
最后,从零开始创建自己的实践项目。确保给自己足够的时间去学习、失败和成长。如果你有朋友也在同样的旅程中,可以与他们一起工作。这样,你们可以分享想法,互相激励,一起持续学习。
Natassha Selvaraj 是一位自学成才的数据科学家,热衷于写作。你可以通过LinkedIn与她联系。
相关主题
人工智能人员管理:构建高效能 AI 团队
原文:
www.kdnuggets.com/2022/03/people-management-ai-building-highvelocity-ai-teams.html
本文描述了如何将机器学习基础设施、人员和流程融合在一起,以实现适合您组织的 MLOps。它为希望建立高效能 AI 团队的经理和主管提供了实际的建议。
我们在这篇文章中分享的建议基于 Provectus AI 团队的经验,该团队与多个客户在不同阶段的 AI 旅程中合作。
什么是平衡的 AI 团队?
仅仅几年前,大部分 AI/ML 项目由数据科学家负责。虽然一些团队依赖于更高级的角色和工具组合,但数据科学家在笔记本中处理模型仍然是行业常态。
如今,仅雇用一个数据科学家不足以快速、高效、大规模地将可行的 AI/ML 项目交付到生产中。它需要一个跨职能、高效能的团队,每个角色处理其自己的机器学习基础设施和 MLOps。
在现代团队中,数据科学家或公民数据科学家仍然是不可或缺的成员。数据科学家是理解数据以及业务的主题专家。他们在数据挖掘、数据建模和数据可视化方面亲自参与。他们还关注数据质量和数据偏见问题,分析实验和模型输出,验证假设,并为机器学习工程路线图做出贡献。
平衡的 AI 团队还应包括一个机器学习工程师,其技能与数据科学家不同。他们应该在特定的 AI 和 ML 应用程序和用例方面拥有深厚的专业知识。例如,如果您构建一个计算机视觉应用程序,机器学习工程师应该拥有有关计算机视觉的最先进深度学习模型的广泛知识。
注意: 每个机器学习工程师都应该具备 MLOps 专业知识,但 MLOps 基础设施本身,包括其工具和组件,应该由专门的 MLOps 专业人员负责。
项目经理也应接受培训以执行机器学习和 AI 项目。传统的 Scrum 或 Kanban 项目工作流程不适用于机器学习项目。例如,在 Provectus,我们有一种特定的方法来管理机器学习项目的范围和时间表,并设定其业务利益相关者的期望。
我们将更详细地探讨这些(和其他)角色,并解释它们如何映射到机器学习基础设施、MLOps 赋能过程和机器学习交付。这里的主要信息是,AI 团队需要平衡的组成,以实现 MLOps 并加速 AI 采用。
进一步阅读: Provectus 和 GoCheck Kids 如何构建用于改善视力筛查可用性的 ML 基础设施
建立 AI 团队的管理挑战
除了实际的团队组成外,有效的管理对于使 AI 团队与 ML 基础设施和 MLOps 基础保持同步至关重要。
从管理的角度来看,典型的组织结构包括:
-
向工程副总裁报告的业务部门和传统软件工程师
-
向基础设施副总裁报告的 DevOps 专业人员和基础设施专家
-
数据科学家处理数据,并通常直接与业务利益相关者合作。
-
数据工程师负责构建系统,将原始数据转换为数据科学家和业务分析师可以使用的信息。

这种结构产生了大量的跨部门孤岛和其他挑战。
-
由于公司对 ML 工作流程和 AI 项目管理的理解有限,上述群体中的任何人都无法完全理解如何将业务目标转化为投入生产的 AI 产品。因此,项目的范围和 KPI 管理变得不可能,导致未能满足业务利益相关者的期望。
-
一些公司试图将 AI 项目委托给现有的数据科学团队,这些团队历史上在自己的孤岛中工作,并依赖于不适用于 AI/ML 项目的数据科学方法。结果,他们最终得到的是未完成的产品和无法投入生产的项目。
-
其他公司通常将 AI 项目分配给传统的 Java 和.NET 开发人员,或利用第三方 ML API。这种方法也往往失败,因为你仍然需要深入了解数据及其底层算法,才能有效地使用这些 API。结果,他们会面临不断增长的技术债务,即无法投入生产的数据科学代码。
解决这些挑战的办法在于找到人员与工具之间的正确平衡。在本文的背景下,这意味着一个平衡的 AI 团队利用端到端的 MLOps 基础设施来进行协作和迭代。
请记住,你不能仅仅通过聘请一个 MLOps 专家或购买一个 MLOps 平台来解决问题。你需要的是一个强大的基础设施和一个平衡的人工智能团队来启动你的 AI/ML 项目。
平衡的 AI 团队和 MLOps 基础设施如何协同工作
在平衡的人工智能团队和 MLOps 基础设施中,特定角色的协同效应可以被形象化为一个三级生态系统:
![AI 人员管理:构建高效能 AI 团队]()
-
第一层是MLOps 的基础设施骨干,由云与安全专业人员和 DevOps 支持。此层托管基础设施组件,如访问、网络、安全和 CI/CD 管道。
-
第二层是MLOps 的共享和重用资产。此层由 ML 工程师和 MLOps 专业人员管理,包括带有各种图像、内核和模板的笔记本;包含组件和库的管道被视为共享资产;实验;数据集和特征;以及模型。此层的每个资产可以被不同团队使用和重用,加速 AI 开发和采用。
-
第三层是AI 项目,由数据科学家、全栈软件开发人员和项目经理负责。此层独立于其他两层,但受到它们的支持。
请注意,云与安全、DevOps、ML 工程师和 MLOps 角色被置于层级之间,并对每个层级做出贡献。例如:
-
云与安全拥有基础设施骨干,同时也负责重用资产层,确保所有组件和检查到位。
-
DevOps 专业人员处理底层两个层级的自动化部分,从自动构建到环境管理。
-
ML 工程师具备 MLOps 基础设施和项目专业知识。他们负责重用资产层的各个组件。
-
MLOps 专家与 ML 工程师紧密合作,但他们负责整个基础设施(例如 Amazon SageMaker,Kubeflow)。他们的终极目标是将一切整合在一起。
与此同时,公民数据科学家可以优先实现特定的 AI/ML 项目,主要在笔记本中工作。他们可以负责 ML 管道的某个部分,但不需要深入 MLOps 的细节。全栈工程师可以处理 AI 产品的常规软件部分,从 UI 到 API。接受 ML 训练的项目经理负责产品的实施。
当然,这只是一个抽象的表示。下面是展示基础设施骨干的参考基础设施。
![AI 的人才管理:构建高效能 AI 团队]()
在这里,我们可以看到数据科学家拥有处理原始数据、在笔记本中进行数据分析和验证假设的工具。他们可以在ML 工程师管理的实验环境中轻松运行实验。实验环境由共享和重用的组件组成,如特征存储、数据集生成、模型训练、模型评估和预配置的数据访问模式。这使得繁琐、易出错的任务自动化,同时不会让数据科学家脱离舒适区。
ML 工程师 负责将 ML 模型投入生产,这意味着他们准备算法代码和数据预处理代码,以在生产环境中使用。他们还建立和运营各种实验环境中的管道。
DevOps 专业人员 帮助高效管理所有基础设施组件。例如,在我们的参考架构中,从一到四的数字演示了由 DevOps 处理的 CI 工作流。
总结一下
MLOps 的实现需要时间和资源。最重要的是,它需要理解 MLOps 既涉及人和流程,也涉及实际的技术。如果您能组织具体的角色和职能,将它们匹配到机器学习基础设施的相应组件上,就不会过于复杂。记住:人 + 基础设施 = MLOps。
在 Provectus,我们帮助企业构建最先进的 AI/ML 解决方案,同时培养高效的 AI 团队,支持 强大的 MLOps 基础设施。请与我们联系,开始评估您组织的选项!
如果您对构建高效的 AI 团队和 MLOps 感兴趣,我们建议您还可以申请 这个按需网络研讨会。它是免费的!
Stepan Pushkarev 是 Provectus 的 CEO、CTO 和联合创始人,Provectus 是一家 AI 顾问和解决方案提供商,帮助企业加速 AI 采用并推动增长。在 Provectus,Pushkarev 领导行业特定 AI 解决方案的愿景,重新构想企业的运营、竞争和客户价值交付方式。Pushkarev 是一位在机器学习、云计算和分布式数据处理系统方面具有深厚专业知识的思想领袖,拥有成功建立专业服务业务和创办 SaaS 初创公司的记录。
更多相关话题
-
-


如何使用 Python 进行运动检测
原文:
www.kdnuggets.com/2022/08/perform-motion-detection-python.html

来源:gfycat
概述
我们的三大课程推荐
1. 谷歌网络安全证书 - 快速开启网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT 工作
使用 Python 进行运动检测很简单,因为 Python 编程语言提供了多种开源库。运动检测有许多现实世界的应用。例如,它可以用于在线考试监控或用于商店、银行等的安全目的。
介绍
Python 编程语言是一个富含开源库的语言,为用户提供了大量应用,并且拥有众多用户。因此,它在市场上迅速增长。由于其简单的语法、易于发现错误和快速的调试过程,使得 Python 语言更具用户友好性,其优点无穷无尽。
为什么你应该学习 Python?图示:

Python 于 1991 年设计,由 Python 软件基金会开发。Python 有许多版本,其中 python2 和 python3 最为著名。目前,python3 被广泛使用,python3 的用户正在迅速增加。在这个项目或脚本中,我们将使用 python3。
什么是运动检测?
根据物理学,当物体静止且没有速度时,它被认为处于静止状态;相反,当物体没有完全静止,并在某个方向上有一定的运动或速度时,无论是左右、前后还是上下,它就被认为处于运动状态。在这篇文章中,我们将尝试检测这一点。

来源:gtycat
运动检测有许多实际应用,例如使用网络摄像头进行在线考试监考(我们将在本文中实现),作为保安等。
在这篇文章中,我们将尝试实现一个脚本,通过它我们将使用桌面或笔记本电脑的网络摄像头来检测运动。其思路是我们将拍摄两个视频帧,并尝试找到它们之间的差异。如果两个帧之间有某种差异,那么很明显在摄像头前面有物体的移动,这会产生差异。
重要库
在我们开始代码实现之前,让我们看看在通过网络摄像头进行运动检测时会用到的一些模块或库。正如我们讨论过的,库在 Python 的流行中扮演着重要角色,接下来我们来了解一下我们需要哪些:
-
OpenCV
-
Pandas
上述提到的库,OpenCV 和 Pandas 完全基于 Python,免费且开源,我们将与 Python3 版本的 Python 编程语言一起使用它们。
1. OpenCV
OpenCV 是一个开源库,可以与多种编程语言(如 C++、Python 等)一起使用。它用于处理图像和视频,通过将其与 Python 的 Pandas/NumPy 库集成,我们可以充分利用 OpenCV 的功能。
2. Pandas:
如我们所讨论的,“pandas” 是一个 Python 的开源库,提供了丰富的内置数据分析工具,因此在数据科学和数据分析领域被广泛使用。Pandas 提供了以数据结构形式存在的数据框,这对操作和存储二维表格数据非常有用。
上述两个模块不是 python 的内置模块,我们必须先安装它们才能使用。除此之外,还有两个模块我们将在项目中使用。
-
Python 日期时间模块
-
Python 时间模块
这两个模块是 Python 的内置模块,不需要后续安装。它们分别处理与日期和时间相关的功能。
代码实现
到目前为止,我们已经看到了我们将在代码中使用的库,现在让我们开始实现,前提是视频只是许多静态图像或帧的组合,而所有这些帧结合在一起形成一个视频:
导入所需的库
在这一部分,我们将导入所有库,如 pandas 和 panda。然后我们从 DateTime 模块导入 cv2、time 和 DateTime 函数。
# Importing the Pandas libraries
import pandas as panda
# Importing the OpenCV libraries
import cv2
# Importing the time module
import time
# Importing the datetime function of the datetime module
from datetime import datetime
初始化我们的数据变量
在这一部分,我们初始化了一些将在代码中进一步使用的变量。我们将初始状态定义为“None”,并将跟踪到的运动存储在另一个变量 motionTrackList 中。
我们定义了一个列表“motionTime”来存储检测到运动的时间,并使用 Pandas 模块初始化了 dataFrame 列表。
# Assigning our initial state in the form of variable initialState as None for initial frames
initialState = None
# List of all the tracks when there is any detected of motion in the frames
motionTrackList= [ None, None ]
# A new list ‘time’ for storing the time when movement detected
motionTime = []
# Initialising DataFrame variable ‘dataFrame’ using pandas libraries panda with Initial and Final column
dataFrame = panda.DataFrame(columns = ["Initial", "Final"])
主要捕获过程
在这一部分,我们将执行主要的运动检测步骤。让我们一步一步理解它们:
-
首先,我们将使用 cv2 模块捕捉视频,并将其存储在 video 变量中。
-
然后,我们将使用无限的 while 循环捕获视频中的每一帧。
-
我们将使用 read() 方法读取每一帧,并将它们存储到各自的变量中。
-
我们定义了一个变量 motion,并将其初始化为零。
-
我们使用 cv2 函数 cvtColor 和 GaussianBlur 创建了两个变量 grayImage 和 grayFrame,以发现运动中的变化。
-
如果我们的 initialState 为 None,则将当前的 grayFrame 分配给 initialState,否则使用 ‘continue’ 关键字中止下一步处理。
-
在下一部分,我们计算了当前迭代中初始帧和灰度帧之间的差异。
-
然后我们将使用 cv2 threshold 和 dilate 函数突出显示初始帧和当前帧之间的变化。
-
我们将从当前图像或帧中的移动物体中找到轮廓,并通过使用矩形函数创建绿色边界来标识移动物体。
-
之后,我们将通过将当前检测到的元素添加到 motionTrackList 中来更新我们的列表。
-
我们使用 imshow 方法显示了所有的帧,如灰度帧和原始帧等。
-
此外,我们使用 cv2 模块的 witkey() 方法创建了一个键以结束过程,我们可以通过使用 ‘m’ 键来结束过程。
# starting the webCam to capture the video using cv2 module
video = cv2.VideoCapture(0)
# using infinite loop to capture the frames from the video
while True:
# Reading each image or frame from the video using read function
check, cur_frame = video.read()
# Defining 'motion' variable equal to zero as initial frame
var_motion = 0
# From colour images creating a gray frame
gray_image = cv2.cvtColor(cur_frame, cv2.COLOR_BGR2GRAY)
# To find the changes creating a GaussianBlur from the gray scale image
gray_frame = cv2.GaussianBlur(gray_image, (21, 21), 0)
# For the first iteration checking the condition
# we will assign grayFrame to initalState if is none
if initialState is None:
initialState = gray_frame
continue
# Calculation of difference between static or initial and gray frame we created
differ_frame = cv2.absdiff(initialState, gray_frame)
# the change between static or initial background and current gray frame are highlighted
thresh_frame = cv2.threshold(differ_frame, 30, 255, cv2.THRESH_BINARY)[1]
thresh_frame = cv2.dilate(thresh_frame, None, iterations = 2)
# For the moving object in the frame finding the coutours
cont,_ = cv2.findContours(thresh_frame.copy(),
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for cur in cont:
if cv2.contourArea(cur) < 10000:
continue
var_motion = 1
(cur_x, cur_y,cur_w, cur_h) = cv2.boundingRect(cur)
# To create a rectangle of green color around the moving object
cv2.rectangle(cur_frame, (cur_x, cur_y), (cur_x + cur_w, cur_y + cur_h), (0, 255, 0), 3)
# from the frame adding the motion status
motionTrackList.append(var_motion)
motionTrackList = motionTrackList[-2:]
# Adding the Start time of the motion
if motionTrackList[-1] == 1 and motionTrackList[-2] == 0:
motionTime.append(datetime.now())
# Adding the End time of the motion
if motionTrackList[-1] == 0 and motionTrackList[-2] == 1:
motionTime.append(datetime.now())
# In the gray scale displaying the captured image
cv2.imshow("The image captured in the Gray Frame is shown below: ", gray_frame)
# To display the difference between inital static frame and the current frame
cv2.imshow("Difference between the inital static frame and the current frame: ", differ_frame)
# To display on the frame screen the black and white images from the video
cv2.imshow("Threshold Frame created from the PC or Laptop Webcam is: ", thresh_frame)
# Through the colour frame displaying the contour of the object
cv2.imshow("From the PC or Laptop webcam, this is one example of the Colour Frame:", cur_frame)
# Creating a key to wait
wait_key = cv2.waitKey(1)
# With the help of the 'm' key ending the whole process of our system
if wait_key == ord('m'):
# adding the motion variable value to motiontime list when something is moving on the screen
if var_motion == 1:
motionTime.append(datetime.now())
break
完成代码
在关闭循环后,我们将数据从 dataFrame 和 motionTime 列表中添加到 CSV 文件中,并最终关闭视频。
# At last we are adding the time of motion or var_motion inside the data frame
for a in range(0, len(motionTime), 2):
dataFrame = dataFrame.append({"Initial" : time[a], "Final" : motionTime[a + 1]}, ignore_index = True)
# To record all the movements, creating a CSV file
dataFrame.to_csv("EachMovement.csv")
# Releasing the video
video.release()
# Now, Closing or destroying all the open windows with the help of openCV
cv2.destroyAllWindows()
过程总结
我们已经创建了代码,现在让我们简要讨论一下过程。
首先,我们使用设备的网络摄像头捕获了一个视频,然后将输入视频的初始帧作为参考,并不时检查后续帧。如果发现与第一帧不同的帧,则表示存在运动。这将在绿色矩形中标记。
结合代码
我们在不同部分查看了代码。现在,让我们将其结合起来:
# Importing the Pandas libraries
import pandas as panda
# Importing the OpenCV libraries
import cv2
# Importing the time module
import time
# Importing the datetime function of the datetime module
from datetime import datetime
# Assigning our initial state in the form of variable initialState as None for initial frames
initialState = None
# List of all the tracks when there is any detected of motion in the frames
motionTrackList= [ None, None ]
# A new list 'time' for storing the time when movement detected
motionTime = []
# Initialising DataFrame variable 'dataFrame' using pandas libraries panda with Initial and Final column
dataFrame = panda.DataFrame(columns = ["Initial", "Final"])
# starting the webCam to capture the video using cv2 module
video = cv2.VideoCapture(0)
# using infinite loop to capture the frames from the video
while True:
# Reading each image or frame from the video using read function
check, cur_frame = video.read()
# Defining 'motion' variable equal to zero as initial frame
var_motion = 0
# From colour images creating a gray frame
gray_image = cv2.cvtColor(cur_frame, cv2.COLOR_BGR2GRAY)
# To find the changes creating a GaussianBlur from the gray scale image
gray_frame = cv2.GaussianBlur(gray_image, (21, 21), 0)
# For the first iteration checking the condition
# we will assign grayFrame to initalState if is none
if initialState is None:
initialState = gray_frame
continue
# Calculation of difference between static or initial and gray frame we created
differ_frame = cv2.absdiff(initialState, gray_frame)
# the change between static or initial background and current gray frame are highlighted
thresh_frame = cv2.threshold(differ_frame, 30, 255, cv2.THRESH_BINARY)[1]
thresh_frame = cv2.dilate(thresh_frame, None, iterations = 2)
# For the moving object in the frame finding the coutours
cont,_ = cv2.findContours(thresh_frame.copy(),
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for cur in cont:
if cv2.contourArea(cur) < 10000:
continue
var_motion = 1
(cur_x, cur_y,cur_w, cur_h) = cv2.boundingRect(cur)
# To create a rectangle of green color around the moving object
cv2.rectangle(cur_frame, (cur_x, cur_y), (cur_x + cur_w, cur_y + cur_h), (0, 255, 0), 3)
# from the frame adding the motion status
motionTrackList.append(var_motion)
motionTrackList = motionTrackList[-2:]
# Adding the Start time of the motion
if motionTrackList[-1] == 1 and motionTrackList[-2] == 0:
motionTime.append(datetime.now())
# Adding the End time of the motion
if motionTrackList[-1] == 0 and motionTrackList[-2] == 1:
motionTime.append(datetime.now())
# In the gray scale displaying the captured image
cv2.imshow("The image captured in the Gray Frame is shown below: ", gray_frame)
# To display the difference between inital static frame and the current frame
cv2.imshow("Difference between the inital static frame and the current frame: ", differ_frame)
# To display on the frame screen the black and white images from the video
cv2.imshow("Threshold Frame created from the PC or Laptop Webcam is: ", thresh_frame)
# Through the colour frame displaying the contour of the object
cv2.imshow("From the PC or Laptop webcam, this is one example of the Colour Frame:", cur_frame)
# Creating a key to wait
wait_key = cv2.waitKey(1)
# With the help of the 'm' key ending the whole process of our system
if wait_key == ord('m'):
# adding the motion variable value to motiontime list when something is moving on the screen
if var_motion == 1:
motionTime.append(datetime.now())
break
# At last we are adding the time of motion or var_motion inside the data frame
for a in range(0, len(motionTime), 2):
dataFrame = dataFrame.append({"Initial" : time[a], "Final" : motionTime[a + 1]}, ignore_index = True)
# To record all the movements, creating a CSV file
dataFrame.to_csv("EachMovement.csv")
# Releasing the video
video.release()
# Now, Closing or destroying all the open windows with the help of openCV
cv2.destroyAllWindows()
结果
运行上述代码后得出的结果将类似于下面所示的内容。

在这里,我们可以看到视频中男子的动作已被跟踪。因此,输出可以相应地显示出来。
然而,在这段代码中,跟踪将通过围绕移动物体的矩形框进行,类似于下面所示的内容。值得注意的是,视频是安全摄像头的录像,检测已在其上完成。

结论
-
Python 编程语言是一个开源的、功能丰富的库语言,为用户提供了许多应用。
-
当一个物体静止且没有速度时,它被认为是静止的,反之,当一个物体不完全静止时,它被认为是运动中的。
-
OpenCV 是一个开源库,可与多种编程语言一起使用,通过将其与 Python 的 pandas/NumPy 库集成,我们可以最大限度地利用 OpenCV 的功能。
-
主要的观点是,每个视频实际上是由许多静态图像(称为帧)组合而成,而帧之间的差异用于检测。
Vaishnavi Amira Yada 是一名技术内容编写者。她掌握 Python、Java、数据结构与算法(DSA)、C 等知识。她发现自己喜欢写作,并且热爱这份工作。
更多相关话题
如何在 Python 中进行单元测试?
原文:
www.kdnuggets.com/2023/01/perform-unit-testing-python.html

图片由作者提供
介绍
验证代码的独立性是确保我们的代码符合质量标准并按预期工作的重要步骤。在制作简单的食谱时,我们会在各个阶段品尝并相应调整味道。将这一概念扩展到代码中,我们不断审视代码以验证其正确性。在测试方面,我们可以进行手动测试或自动测试,但手动测试是一项繁琐且耗时的过程。自动化测试涉及由脚本而非人工执行测试。自动化测试中有各种测试类型,如单元测试、集成测试、压力测试等,但本教程将重点关注单元测试。
单元测试的重要性
单元测试是一种分析单个单元是否存在错误的技术,以使你的代码稳定并具备未来适应性。这些单元可能是单独的函数、完整的类或整个模块。在大多数情况下,这些单元与代码的其他部分没有依赖关系。它的重要性在于,这些单元是你应用程序的基本构建块,如果它们有缺陷,你的应用程序就会崩溃。它还提升了开发者的生产力,并鼓励模块化编程。
UnitTest
许多测试运行器可用于 Python,例如
-
Unittest
-
Pytest
-
Nose2
-
Testify
-
DocTest
在本教程中,我们将使用 unittest,这是 Python 标准库中的内置测试框架。它包含测试框架和测试运行器,提供了从测试自动化、将测试聚合到集合中的功能,到测试与报告框架独立的各种特性。它具有以下要求:
-
每个单元测试可以创建为扩展 TestCase 类的方法,并在方法前加上 "test" 以通知测试运行器测试方法
-
使用特殊的断言方法序列来确定测试用例是否通过或失败。以下是一些最常用的断言方法:
| 方法 | 描述 |
|---|---|
| .assertEqual(a, b) | a == b |
| .assertNotEqual(a, b) | a != b |
| .assertTrue(x) | bool(x) 为 True |
| .assertFalse(x) | bool(x) 为 False |
| .assertIs(a, b) | a 是 b |
| .assertIs(a, b) | a 不是 b |
| .assertIsNone(x) | x 是 None |
| .assertIsNotNone(x) | x 不是 None |
| .assertIn(a,b) | a 在 b 中 |
| .assertNotIn(a,b) | a 不在 b 中 |
| .assertIsInstance(a, b) | isinstance(a, b) |
| .assertNotIsInstance(a, b) | not isinstance(a, b) |
来源: unittest 官方文档
使用 UnitTest 执行单元测试的步骤
-
在 Python 文件中编写你想要测试的代码,例如 example.py。
-
创建一个新的 Python 文件用于你的单元测试,文件名以 test 开头,例如 test_example.py。
-
导入 unittest 模块 和 example.py。
-
创建一个扩展 unittest.TestCase 类的类。
-
编写以 test_functionName(self) 开头的测试方法,并使用 assert 方法来验证正在测试的代码的行为。
-
在终端中运行命令 python -m unittest test_example.py,或者在测试文件中调用 unittest 的主方法,并运行 python test_example.py。
示例
创建一个名为 calc.py 的文件,用于计算矩形的面积。
def calc_rectangle_area(length, width):
return length * width
创建一个测试文件 test_calc.py 并编写以下代码:
import unittest
import calc
class TestRectangleArea(unittest.TestCase):
def test_area_calculation(self):
self.assertEqual(calc.calc_rectangle_area(2, 4), 8, "Incorrect area for a rectangle with length 2 and width 4")
self.assertEqual(calc.calc_rectangle_area(3, 5), 15, "Incorrect area for a rectangle with length 3 and width 5")
self.assertEqual(calc.calc_rectangle_area(10, 10), 100, "Incorrect area for a rectangle with length 10 and width 10")
if __name__ == '__main__':
unittest.main()
在终端中运行 python test_calc.py。将显示以下输出:
-----------------------------------------------------------
Ran 1 test in 0.001s
OK
现在,修改矩形计算的公式以验证我们的测试用例。
def calc_rectangle_area(length, width):
return length * width * 2
再次在终端中运行 python test_calc.py。
self.assertEqual(calc.calc_rectangle_area(2, 4), 8, "Incorrect area for a rectangle with length 2 and width 4")
AssertionError: 16 != 8: Incorrect area for a rectangle with length 2 and width 4
-----------------------------------------------------------
Ran 1 test in 0.001s
FAILED (failures=1)
你还可以扩展此代码以处理如除零错误等问题。
结论
虽然 unittest 模块为我们提供了编写和运行单元测试的基本工具,但也有第三方库提供更高级的功能。然而,单元测试仍然是软件开发生命周期的重要组成部分,并能帮助你及早发现错误,从而编写出更可靠和易于维护的代码。希望你喜欢这篇文章。欢迎在评论区分享你的想法或反馈。
Kanwal Mehreen 是一位有志的软件开发者,对数据科学和人工智能在医学中的应用充满兴趣。Kanwal 被选为 2022 年 APAC 区域的谷歌新生代学者。Kanwal 喜欢通过撰写关于热点话题的文章来分享技术知识,并且热衷于提高女性在科技行业的代表性。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速入门网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关内容
你应该了解的更多分类问题性能评估指标
原文:
www.kdnuggets.com/2020/04/performance-evaluation-metrics-classification.html
评估模型是构建有效机器学习模型的关键部分。我们使用的最常见分类评估指标应该是准确率。你可能会认为当准确率达到 99%时模型很好!然而,这并不总是准确的,并且在某些情况下可能会误导。我将在本文中解释如下 4 个方面:
-
2 类分类问题的混淆矩阵
-
关键分类指标:准确率、召回率、精准率和 F1 分数
-
召回率和精准率在特定情况下的区别
-
决策阈值和接收者操作特征(ROC)曲线
机器学习模型的流程
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析水平
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 工作
在任何二分类任务中,我们的模型只能得到两种结果:正确或不正确。假设我们现在有一个分类任务,要预测一张图像是狗还是猫。在监督学习中,我们首先在训练数据上拟合/训练一个模型,然后在测试数据上测试该模型。一旦我们从X_test数据中获得模型的预测结果,我们将其与真实的 y_values(正确标签)进行比较。

在模型预测之前,我们将狗的图像输入到我们训练好的模型中。模型预测这是一只狗,然后我们将预测结果与正确标签进行比较。如果我们将预测结果与“狗”的标签进行比较,则预测正确。然而,如果预测结果是这张图像是一只猫,那么与正确标签的比较将是不正确的。
我们对 X 测试数据中的所有图像重复这一过程。最终,我们将获得正确匹配的数量和错误匹配的数量。关键的认识是,并非所有的错误或正确匹配在现实中都具有相同的价值。因此,单一指标不能全面反映情况。
如前所述,准确率是分类问题中的常见评估指标,即正确预测的总数除以数据集上做出的总预测数。当目标类别平衡良好时,准确率是有用的,但对于不平衡的类别就不太适用。想象一下我们有 99 张狗的图片和只有 1 张猫的图片在训练数据中,我们的模型将只是一个总是预测狗的线,因此得到了 99%的准确率。现实中数据总是失衡的,如垃圾邮件、信用卡欺诈和医疗诊断。因此,如果我们想全面了解模型评估,还应考虑其他指标,如召回率和精准度。
混淆矩阵
对分类模型性能的评估基于模型正确和错误预测的测试记录计数。混淆矩阵提供了一个更有洞察力的图景,它不仅展示了预测模型的性能,还显示了哪些类别被正确和错误预测,错误类型是什么。为了说明这一点,我们可以看到四个分类指标(TP、FP、FN、TN)是如何计算的,并且在下面的混淆矩阵表中,我们的预测值与实际值的对比被清晰地呈现出来。

可能的分类结果:TP、FP、FN、TN。
混淆矩阵对于测量召回率(也称为敏感性)、精准度、特异性、准确率以及最重要的 AUC-ROC 曲线非常有用。
读表格时你感到困惑吗?这是正常的。我之前也是如此。让我用怀孕类比来解释 TP、FP、FN 和 TN 的术语。这样我们可以理解召回率、精准度、特异性、准确率,更重要的是 AUC-ROC 曲线。

四个关键分类指标的公式

召回率与精准度

精准度 是模型预测的所有正样本中真实正样本的比例。
低精准度:模型预测的假阳性越多,精准度越低。
召回率(敏感性) 是数据集中所有正样本中真实正样本的比例。
低召回率:模型预测的假阴性越多,召回率越低。
召回率和精准度的概念似乎很抽象。让我通过三个实际案例来说明差异。

-
TP 的结果是 COVID-19 居民被诊断为 COVID-19。
-
TN 的结果是健康的居民身体健康。
-
FP 的结果是那些实际上健康的居民被预测为 COVID-19 居民。
-
FN 的结果是那些实际的 COVID-19 居民被预测为健康居民。
在情况 1 中,你认为哪个场景的成本会最高?
想象一下,如果我们将 COVID-19 居民预测为健康患者,而他们不需要隔离,这将导致大量的 COVID-19 感染。假阴性的成本要远高于假阳性的成本。

-
TP 的结果是垃圾邮件被放入垃圾邮件文件夹。
-
TN 的结果是重要的电子邮件被收到。
-
FP 的结果是重要的电子邮件被放入垃圾邮件文件夹。
-
FN 的结果是垃圾邮件被收到。
在情况 2 中,你认为哪个场景的成本会最高?
嗯,由于错过重要的电子邮件显然比收到垃圾邮件更严重,我们可以说,在这种情况下,FP 的成本会高于 FN。

-
TP 的结果是坏贷款被正确预测为坏贷款。
-
TN 的结果是好贷款被正确预测为好贷款。
-
FP 的结果是(实际的)好贷款被错误预测为坏贷款。
-
FN 的结果是(实际的)坏贷款被错误预测为好贷款。
在情况 3 中,你认为哪个场景的成本会最高?
如果实际的坏贷款被预测为好贷款,银行将损失大量资金,因为贷款无法偿还。另一方面,如果实际的好贷款被预测为坏贷款,银行将无法获得更多收入。因此,假阴性的成本要远高于假阳性的成本。想象一下吧。
总结

在实际应用中,假阴性的成本与假阳性的成本不同,这取决于具体情况。显然,我们不仅应计算准确率,还应使用其他指标来评估我们的模型,例如 召回率 和 精确率。
结合精确率和召回率
在上述三个情况中,我们希望在牺牲另一个指标的情况下,最大化召回率或精确率。例如,在好贷款或坏贷款分类的情况下,我们希望减少 FN 以提高召回率。然而,在我们希望找到精确率和召回率的最佳结合的情况下,我们可以通过使用 F1 分数 将这两个指标结合起来。

F-Measure 提供了一个综合精确率和召回率的单一评分。一个好的 F1 分数意味着你有低假阳性和低假阴性,因此你能正确识别实际威胁,并且不会被虚假警报所干扰。当 F1 分数为 1 时,表示模型完美;而当 F1 分数为 0 时,表示模型完全失败。

决策阈值
ROC 是呈现分类模型性能的主要可视化技术。它总结了使用不同概率阈值时预测模型的真正率(tpr)和假正率(fpr)之间的权衡。

tpr 和 fpr 的公式。
真正率(tpr)是召回率,而假正率(FPR)是误报的概率。
ROC 曲线绘制了真正率(tpr)与假正率(fpr)之间的关系,作为模型分类正例的阈值函数。考虑到c是称为决策阈值的常数,下图 ROC 曲线表明默认 c=0.5,当 c=0.2 时,tpr 和 fpr 都增加;当 c=0.8 时,tpr 和 fpr 都减少。一般来说,tpr 和 fpr 随着 c 的减少而增加。在极端情况下,当 c=1 时,所有案例被预测为负例;tpr=fpr=0。而当 c=0 时,所有案例被预测为正例;tpr=fpr=1。

ROC 图。
最终,我们可以通过 ROC 曲线下的面积(AUC)来评估模型的性能。作为经验法则,0.9–1=优秀;0.8-0.9=良好;0.7–0.8=中等;0.6–0.7=差;0.50–0.6=失败。
摘要
-
二分类问题的混淆矩阵
-
主要分类指标:准确率、召回率、精准率和 F1 分数
-
召回率与精准率在特定情况下的区别
-
决策阈值和接收者操作特征(ROC)曲线
Clare Liu 是一位在香港金融科技行业的 数据科学家。热衷于解决关于数据科学和机器学习的难题。加入我,一起踏上自学之旅。
更多相关话题
如何评估你的机器学习模型的性能
原文:
www.kdnuggets.com/2020/09/performance-machine-learning-model.html
评论
作者 Saurabh Raj,印度理工学院贾穆。
为什么评估是必要的?
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业轨道。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你在组织中的 IT 工作
让我从一个非常简单的例子开始。
罗宾和萨姆都开始为工程学院的入学考试做准备。他们共享一个房间,并在解决数值问题时付出了相同的努力。他们几乎每天都学习相同的小时数,并参加了最终考试。令人惊讶的是,罗宾通过了,而萨姆没有。经过询问,我们了解到他们准备策略中有一个不同点,“测试系列。”罗宾参加了一个测试系列,他通过这些考试来测试自己的知识和理解,然后进一步评估自己的不足之处。但萨姆很自信,他只是继续训练自己。
以同样的方式,如上所述,一个机器学习模型可以通过许多参数和新技术进行广泛的训练,但只要你忽视其评估,你就无法信任它。
如何阅读混淆矩阵?
一个混淆矩阵是模型预测与数据点实际类别标签之间的关联。

二分类的混淆矩阵。
假设你正在构建一个模型来检测一个人是否患有糖尿病。在训练-测试分割后,你得到了一个长度为 100 的测试集,其中 70 个数据点标记为正例(1),30 个数据点标记为负例(0)。现在,让我绘制一下你的测试预测矩阵:

在 70 个实际正例数据点中,你的模型预测了 64 个点为正例,6 个点为负例。在 30 个实际负例数据点中,它预测了 3 个点为正例,27 个点为负例。
注意: 在这些符号中,真正例、真负例、假正例和假负例,注意第二个术语(正例或负例)表示你的预测,而第一个术语表示你预测的正确性。
基于上述矩阵,我们可以定义一些非常重要的比率:
-
TPR(真正阳性率)=(真正阳性 / 实际阳性)
-
TNR(真正负性率)=(真正负性 / 实际负性)
-
FPR(假阳性率)=(假阳性 / 实际负例)
-
FNR(假阴性率)=(假阴性 / 实际阳性)
对于我们糖尿病检测模型的情况,我们可以计算这些比例:
TPR = 91.4%
TNR = 90%
FPR = 10%
FNR = 8.6%
如果你想让你的模型变得智能,你的模型必须准确预测。这意味着你的真正阳性和真正负性 应该尽可能高,同时,你需要尽量减少你的错误,即假阳性和假阴性 应该尽可能低。同时,在比例方面,你的TPR & TNR 应该非常高,而FPR & FNR 应该非常低。
一个智能模型: TPR ↑,TNR ↑,FPR ↓,FNR ↓
一个糟糕的模型: 任何其他组合的 TPR、TNR、FPR、FNR。
有人可能会争辩说,不可能对所有四个比例进行平等处理,因为最终没有模型是完美的。那么我们应该怎么做?
是的,这是真的。这就是为什么我们在构建模型时要考虑领域的原因。有些领域要求我们将特定的比例作为主要优先级,即使其他比例较差也是如此。例如,在癌症诊断中,我们不能以任何代价漏掉任何一个阳性患者。因此,我们应该将 TPR 保持在最大值,而 FNR 接近 0。即使我们将任何健康患者预测为已诊断,仍然可以接受,因为他们可以进行进一步检查。
准确率
准确率就是其字面意义上所说的,衡量你的模型有多准确。
准确率 = 正确预测 / 总预测
通过使用混淆矩阵,准确率 = (TP + TN)/(TP + TN + FP + FN)
准确率是我们可以使用的最简单的性能指标之一。但我需要警告你,准确率有时会让你对模型产生错误的幻想,因此你应该首先了解你的数据集和使用的算法,然后决定是否使用准确率。
在讨论准确率的失败案例之前,让我先介绍两种数据集:
-
平衡数据集: 一个包含几乎所有标签/类别都有相等条目的数据集。例如,在 1000 个数据点中,600 个是正例,400 个是负例。
-
不平衡数据集: 一个包含偏向特定标签/类别的条目的数据集。例如,在 1000 个条目中,990 个是正例,10 个是负例。
非常重要:处理不平衡测试集时,永远不要使用准确率作为衡量标准。
为什么?
假设你有一个不平衡的测试集,包含 1000 个条目,其中990 (+ve)和10 (-ve)。假如你创建了一个糟糕的模型,由于不平衡的训练集,该模型总是预测“+ve”。现在,当你预测测试集标签时,它将总是预测“+ve”。所以,在 1000 个测试集点中,你得到 1000 个“+ve”预测。然后你的准确率将是,
990/1000 = 99%
哇!太棒了!你很高兴看到如此出色的准确度评分。
但是,你应该知道你的模型实际上很差,因为它总是预测“+ve”标签。
非常重要:另外,我们不能比较两个返回概率分数并且具有相同准确度的模型。
有些模型提供每个数据点属于特定类别的概率,就像逻辑回归中的那样。让我们来看看这种情况:

表 1。
正如你所看到的,如果 P(Y=1) > 0.5,它预测类别 1。 当我们计算 M1 和 M2 的准确度时,结果是相同的,但很明显M1 是比 M2 更好的模型,看看概率分数就可以看出来。
Log Loss很好地解决了这个问题,我将在博客中进一步解释。
精确度与召回率
精确度: 它是实际正例(TP)与所有正例预测的比例。基本上,它告诉我们你的正例预测中有多少次实际上是正例。

召回率: 这就是上面解释的 TPR(真正阳性率)。它告诉我们所有正例中有多少被预测为正例。

F-Measure: 精确度和召回率的调和平均数。

为了理解这一点,我们来看一个例子:当你在 Google 中查询时,它返回了 40 页结果,但只有 30 页是相关的。然而,你的朋友,一个 Google 的员工,告诉你总共有 100 页相关的结果。所以,它的精确度是 30/40 = 3/4 = 75%,而召回率是 30/100 = 30%。所以,在这个例子中,精确度是“搜索结果的有用性”,而召回率是“结果的完整性”。
ROC 与 AUC
接收者操作特征曲线(ROC):
这是一个TPR(真正阳性率)与 FPR(假阳性率)的绘图,通过从模型给出的概率分数的逆序列表中取多个阈值计算得出。

典型的 ROC 曲线。
那么,我们如何绘制 ROC 曲线?
为了回答这个问题,让我带你回到上面的表 1。只考虑 M1 模型。你会看到,对于所有 x 值,我们都有一个概率分数。在这个表中,我们将分数大于 0.5 的数据点分配为类别 1。现在按概率分数的降序排列所有值,一一取等于所有概率分数的阈值。然后我们会得到阈值 = [0.96,0.94,0.92,0.14,0.11,0.08]。对应每个阈值,预测类别,并计算 TPR 和 FPR。你将得到 6 对 TPR 和 FPR。将它们绘制出来,你将得到 ROC 曲线。
注意:由于最大 TPR 和 FPR 值为 1,ROC 曲线下的面积(AUC)介于 0 和 1 之间。
蓝色虚线下的面积是 0.5。AUC = 0 表示模型很差,AUC = 1 表示完美模型。只要你的模型的 AUC 分数超过 0.5,模型就是有意义的,因为即使是随机模型也可以获得 0.5 的 AUC。
非常重要: 即使在不平衡数据集生成的简单模型中,你也可以获得很高的 AUC。因此,处理不平衡数据集时一定要小心。
注意: 只要顺序保持一致,AUC 与数值概率分数无关。只要所有模型在基于概率分数排序后给出相同的数据点顺序,所有模型的 AUC 都将相同。
对数损失
这个性能指标检查数据点的概率分数与临界分数的偏差,并赋予一个与偏差成比例的惩罚。
对于二分类中的每个数据点,我们使用下面的公式计算它的对数损失,

二分类对数损失公式。
其中 p = 数据点属于类别 1 的概率,y 是类别标签(0 或 1)。
假设某些 x_1 的 p_1 是 0.95,某些 x_2 的 p_2 是 0.55,且类别 1 的合格概率是 0.5。那么两者都符合类别 1,但 p_2 的对数损失将远高于 p_1 的对数损失。

从曲线中可以看到,对数损失的范围是 0, 无穷)。
对于多分类中的每个数据点,我们使用下面的公式计算它的对数损失,
![
多分类对数损失公式。
其中 y(o,c) = 1 如果 x(o,c) 属于类别 1。其余的概念是相同的。
决定系数
它用R²表示。在预测测试集的目标值时,我们遇到了一些误差(e_i),这是预测值与实际值之间的差异。
假设我们有一个包含 n 个条目的测试集。我们知道,所有的数据点都有一个目标值,比如 [y1,y2,y3…….yn]。让我们将测试数据的预测值取为 [f1,f2,f3,……fn]。
计算残差平方和,这是所有误差(e_i)平方的总和,使用这个公式,其中 fi 是模型为第 i 个数据点预测的目标值。

总平方和。
取所有实际目标值的均值:

然后计算总平方和,它与测试集目标值的方差成正比:

如果你观察平方和的两个公式,你会发现唯一的区别是第二项,即 y_bar 和 fi。总平方和在某种程度上给了我们一个直觉,即它与残差平方和是一样的,只不过预测值为 [ȳ, ȳ, ȳ, ……ȳ ,n 次]。是的,你的直觉是对的。假设有一个非常简单的均值模型,它每次都给出目标值的平均预测,无论输入数据是什么。
现在我们将 R² 公式化为:

如你所见,现在 R² 是用来将你的模型与每次返回目标值平均值的非常简单均值模型进行比较的指标。比较有 4 种情况:
案例 1: SS_R = 0
(R² = 1) 完美模型,没有任何错误。
案例 2: SS_R > SS_T
(R² < 0) 模型甚至比简单均值模型还要差。
案例 3: SS_R = SS_T
(R² = 0) 模型与简单均值模型相同。
案例 4: SS_R < SS_T
(0< R² <1) 模型还可以。
摘要
总之,你应该非常了解你的数据集和问题,然后你可以始终创建一个混淆矩阵,检查其准确性、精确性、召回率,并绘制 ROC 曲线,找出 AUC 以满足你的需求。但如果你的数据集不平衡,绝不要使用准确率作为衡量标准。如果你想更深入地评估你的模型,以便概率评分也被考虑,可以使用对数损失。
记住,始终评估你的训练!
原文. 经许可转载。
相关:
更多相关主题
在 Python 中执行 T 检验

图片由编辑提供
主要要点
我们的前三个课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT 工作
-
t 检验是一种统计检验方法,用于确定两个独立样本的均值是否存在显著差异。
-
我们通过使用鸢尾花数据集和 Python 的 Scipy 库来说明如何应用 t 检验。
t 检验是一种统计检验方法,用于确定两个独立样本的均值是否存在显著差异。在本教程中,我们演示了 t 检验的最基本版本,我们假设两个样本具有相等的方差。其他高级版本的 t 检验包括 Welch 的 t 检验,它是 t 检验的一种改编,更适用于两个样本方差不等且可能样本量不等的情况。
t 检验的基本公式
t 统计量或 t 值的计算方法如下:

其中  是样本 1 的均值,
是样本 1 的均值, 是样本 2 的均值,
是样本 2 的均值, 是样本 1 的方差,
是样本 1 的方差, 是样本 2 的方差,
是样本 2 的方差, 是样本 1 的样本量,和
是样本 1 的样本量,和  是样本 2 的样本量。
是样本 2 的样本量。
使用鸢尾花数据集的示例
为了说明 t 检验的使用,我们将使用鸢尾花数据集展示一个简单的例子。假设我们观察到两个独立的样本,例如花萼长度,我们需要考虑这两个样本是否来自同一总体(例如,相同的花卉物种或两个具有相似花萼特征的物种)或两个不同的总体。
t 检验量化了两个样本算术均值之间的差异。p 值量化了在假设原假设(即样本来自均值相同的总体)为真的情况下获得观察结果的概率。p 值大于选择的阈值(例如 5% 或 0.05)表示我们的观察结果不太可能偶然发生。因此,我们接受均值相等的原假设。如果 p 值小于我们的阈值,则我们有证据反对均值相等的原假设。
T 检验输入
执行 t 检验所需的输入或参数包括:
- 包含样本 1 和样本 2 数据的两个数组 a 和 b
T 检验输出
t 检验返回如下结果:
-
计算得到的 t 统计量
-
p 值
使用等样本大小的 Python 实现
导入必要的库
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
加载鸢尾花数据集
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
计算样本均值和样本方差
mu1 = np.mean(a_1)
mu2 = np.mean(b_1)
np.std(a_1)
np.std(b_1)
实现 t 检验
stats.ttest_ind(a_1, b_1, equal_var = False)
输出
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
输出
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
输出
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)
观察结果
我们观察到使用“true”或“false”作为“equal-var”参数并不会显著改变 t 检验结果。我们还观察到交换样本数组 a_1 和 b_1 的顺序会得到负的 t 检验值,但不会改变 t 检验值的大小,正如预期的那样。由于计算得到的 p 值远大于阈值 0.05,我们可以拒绝均值相等的原假设。这表明样本 1 和样本 2 的萼片长度来自相同的总体数据。
使用不等样本大小的 Python 实现
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
计算样本均值和样本方差
mu1 = np.mean(a_1)
mu2 = np.mean(b_1)
np.std(a_1)
np.std(b_1)
实现 t 检验
stats.ttest_ind(a_1, b_1, equal_var = False)
输出
stats.ttest_ind(a_1, b_1, equal_var = False)
观察结果
我们观察到使用不等大小的样本不会显著改变 t 统计量和 p 值。

总结一下,我们展示了如何使用 Python 的 scipy 库实现一个简单的 t 检验。
本杰明·O·塔约 是一位物理学家、数据科学教育者和作家,同时也是 DataScienceHub 的所有者。此前,本杰明曾在中央俄克拉荷马大学、大峡谷大学和匹兹堡州立大学教授工程学和物理学。
相关主题
香水、计算机编程与哈佛
原文:
www.kdnuggets.com/2014/10/perfume-computer-programming-harvard.html
 品牌力量的经典例子是香水——昂贵的香水生产成本可能只需几美元,但由于品牌的声望,可以以超过$100 的价格出售。
品牌力量的经典例子是香水——昂贵的香水生产成本可能只需几美元,但由于品牌的声望,可以以超过$100 的价格出售。
大卫·马兰在哈佛的计算机科学课程,CSCI E-50,在教育领域提供了一个有趣的平行示例。它可以通过 EdX 免费获取,或者你可以支付$75 获得 EdX 完成证书(前提是你成功完成课程)。或者你可以支付$2200 获得哈佛学分。
这才是重点——在所有这三种情况下,学生的课程体验完全相同。唯一的区别,除了价格,还有是否有证书,以及如果有证书,则颁发证书的组织名称。
不是什么秘密,常春藤联盟的证书在教育质量之外还具有无形的价值。MOOC 时代生动地说明了这种品牌溢价——在固定产品的情况下,消费者似乎愿意为哈佛的名字支付 2800%的溢价,而不是 EdX 的证书。有点像香水。
Statistics.com 还提供了一个针对数据科学家需求的编程入门课程,使用 R、Python 和 SQL。小班授课,教师和助教提供个性化关注。详见:
www.statistics.com/r-prog-intro-1/
彼得·布鲁斯是 Statistics.com 的总裁。
相关:
-
谁主导了分析就业市场?
-
统计教育指南
-
独家采访:彼得·布鲁斯,Statistics.com 总裁
-
开始文本分析
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT 需求
更多相关话题
顶尖数据科学家克劳迪娅·佩利奇谈数据科学中的最大问题
原文:
www.kdnuggets.com/2016/09/perlich-biggest-issues-data-science.html
评论
由克劳迪娅·佩利奇,Dstillery.

感谢: O'Reilly.
我们的前三大课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你的组织 IT 需求
首先,让我声明我认为不是问题的地方:数据科学家将 80%的时间花在数据准备上。这就是他们的工作!如果你在数据准备方面不擅长,你就不是一个优秀的数据科学家。这并不是 Steve Lohr 所激起的清洁工问题。任何分析的有效性几乎完全依赖于数据准备。你最终使用的算法几乎无关紧要。抱怨数据准备就像一个农民抱怨只想做收割工作,希望其他人处理烦人的浇水、施肥、除草等工作。
话虽如此——数据准备可能因原始数据收集过程而变得困难。设计一个收集数据的系统,使其对数据科学有用且易于消化是一门高超的艺术。向数据科学提供数据如何精确流入系统的完全透明度也是另一门艺术。它涉及到考虑采样、数据注释、匹配等过程,而不是替换缺失值和过度归一化。创建一个有效的数据环境需要数据科学的参与,不能完全由工程团队主导。数据科学通常无法详细规范这样的系统需求,从而实现清晰的交接。
但从更大的角度来看,还有更重要的事情需要考虑。我看到的最大问题是数据科学在解决无关的问题。这是巨大的时间和精力浪费。原因通常是问题的提出者缺乏数据科学的理解,甚至无法表达问题,而数据科学家最终解决了他们理解的可能是问题的内容,最终创建了一个并不真正有用的解决方案(通常也过于复杂)。典型的情况是“定义不清”的任务:“在这个数据集中寻找可操作的见解!” 好吧 - 大多数数据科学家不知道可以采取哪些行动。他们也不知道哪些见解是平凡的还是有趣的。所以让他们去追逐无用的目标真的没有意义。
“解决错误问题”的现象普遍存在,部分原因是数据科学在决策过程中没有充分参与(感谢 Meta 让我澄清这个问题)。现在 - 不是每个数据科学家都能也应该被期望既能定义问题又能解决问题(回到独角兽问题),但团队中至少应该有一个数据科学家能够做到这一点。然而,更大的问题并不是数据科学方面能力/意愿的缺乏(虽然确实有很多人只是喜欢解决有趣的问题,不管它的相关性),而是企业文化中分析、IT 等部门被视为“执行”职能。管理层决定需要什么,然后其他人去做。
在个人层面和特定(值得做的)问题上,我会将缺乏数据理解、数据直觉和最终的怀疑态度归咎为效率的主要限制因素。这些因素之所以导致低效率,并不是因为得到答案需要更长时间(事实上,缺乏这三者通常会导致更快的结果),而是因为得到一个(几乎)正确答案所需的时间较长。
Dstillery 是一家数据分析公司,利用机器学习和预测建模为品牌营销及其他商业挑战提供智能解决方案。我们从独特的 360 度视角出发,结合数字、实体和离线活动的数据,生成关于个体和特定群体行为的见解和预测。
原文。已获许可转载。
相关:
-
自动化数据摄取:3 个重要部分
-
第二名:数字广告中的自动化数据科学和机器学习
-
激发灵感的数据科学家想法
更多相关内容
个性化 AI 简单易用:您的无代码 GPT 适配指南
原文:
www.kdnuggets.com/personalized-ai-made-simple-your-no-code-guide-to-adapting-gpts

图片来自 OpenAI GPT 的主要视图。
在我们快速发展的数字世界中,人工智能 (AI) 不再只是一个流行词,而是正在重塑我们与技术互动方式的革命性力量。
自从 ChatGPT 首次推出以来,没有一个星期没有在 AI 领域取得重大进展。
就在一周前,我拿到了 OpenAI 的全新玩具 GPT(个性化 ChatGPT 版本),在最新的 OpenAI DevDay 上揭晓。
错过了活动?没关系!
这里有个快速介绍:GPT 是这些很酷的、可定制的 ChatGPT 版本,你可以在不写一行代码的情况下创建。
所以跟我一起,试着一起探索这些新功能吧。
1. 使用 OpenAI 的 GPT 开始
我将带你进行一个 DIY 之旅,制作属于你自己的 GPT,非常适合那些希望利用 AI 提升生产力的人。
对于 ChatGPT Plus 订阅者,这项功能正在逐步推出中。
OpenAI 最近推出的可定制生成预训练变换器 (GPTs) 标志着 AI 向以用户为中心设计迈出了重要一步。
随着这些发展,创建一个个性化的 ChatGPT 实例不再是复杂的任务——现在人人都能访问,开启了量身定制 AI 互动的无限可能。
更新后,ChatGPT 展现了全新面貌,涵盖了如网页浏览、DALL-E 和代码解释器等功能,全都在 GPT-4 的框架下。
唯一遗漏的功能是插件,它们仍然是单独的选项。

图片来源:作者
新的 GPTs 功能可以在“探索”按钮中找到。
所以按下按钮,然后……
2. 让我们开始构建!
在这里,你将找到所有你创建的 GPT 版本,可以选择“创建一个 GPT”来创建全新的 GPT,或从 OpenAI 的库中选择 OpenAI 制作的 GPT。

图片来源:作者
准备好制作你的 GPT 了吗?
然后点击“创建一个 GPT”在“我的 GPTs”部分,瞧——这将展开一个用户友好的编辑器,分为两部分:GPT Builder 和你的创作的实时预览。
这个互动设置允许你直接与 GPT Builder 对话,将你的 AI 设想实时变为现实。

图片来源:作者
3. 微调你的 AI 伴侣
配置你的 ChatGPT 不仅仅是给它命名。你将获得许多选项来个性化它的行为、目的甚至外观。
你有两种主要方式来做到这一点:
-
选择“配置”选项,在那里你可以手动自定义你的 GPT。
-
与 GPT 构建器进行直接对话。这种方法涉及直接传达你对 ChatGPT 实例的具体需求和要求,让魔法发生。
那么……你应该决定接下来做什么。为了进一步理解两种处理方式,我将分别解释。
过程 1. 从头开始创建
如果我们选择“配置”选项,将会转到一个详细介绍创建 GPT 步骤的页面。主要的部分包括:
-
为这个个性化 GPT 版本选择一个头像。
-
一个名称和描述,赋予你的 GPT 一个身份。
-
指令以概述其高级行为。
-
用对话引导语来设定初始提示的语调。
-
用自定义文件来增强知识。
-
添加网页浏览、DALL-E 或编码技能的能力。
-
行动以集成外部 API 或数据。

作者图片
因此,在这种情况下,你可以一步步填写所需的所有信息。
当然,你可以利用 ChatGPT 的能力来帮助你撰写之前的大部分信息。
这引出了第二个过程……
过程 2. 利用 GPT 构建器
与其手动输入所有所需信息以生成个性化的 ChatGPT 实例,你可以直接与 GPT 构建器对话,让魔法发生。
因此,在这种情况下,假设我需要一个可以简化复杂数据科学概念的技术顾问。我可以描述这个假设的 GPT 实例,以便 GPT 构建器生成第一个版本。

作者图片
就这样……魔法发生了,GPT 构建器为我们完成了一切!

作者图片
4. 超越基础
要将你的 GPT 提升到市场准备的水平,并使其具有独特性,可以通过丰富其专业知识和行动来实现,例如,融入有价值的资源或集成 API 以获取实时数据。
知识
GPTs 具有知识功能,允许我们上传数据文件以便它们“扩展”其知识。
向你的 GPT 添加有价值的文件,比如包含相关信息的 CSV 文件,以便它执行任务。
不过,请注意这些文件的内容在聊天过程中是可见的,因此要小心其他可能复制你创意的人。
行动
当创建一个需要将外部数据纳入用户请求的 GPT 时,必须集成一个能够提供这些数据的 API。
这种整合涉及定义特定的端点、参数和指令,以便模型能利用这些信息。
虽然动作的概念乍看之下可能令人畏惧,但它们是一个重要的工具,可以增强你 GPT 的独特性和盈利能力。鉴于这一特性的复杂性和重要性,我们将很快开发一个专门的指南,以提供更详细的见解。
5. 测试你的新 AI 伴侣
关于提示工程,生成你自己的 GPT 实例是一个迭代过程。这意味着你需要测试你的全新模型,检查其行为是否符合预期,并尝试改进你可能发现的错误。
使用预览选项进行实验,当你对结果满意时,继续保存或更新。
6. 让你的 GPT 变为现实
一旦你将 ChatGPT 调整到你喜欢的样子,就该把它带到数字世界了。
通过简单的保存和发布操作,你的 AI 伴侣就准备好与人互动、学习和进化,提供专为你量身定制的独特体验。

图片由作者提供
个性化 AI 的黎明
OpenAI 最新推出的 GPTs 不仅仅是技术上的进步;它是我们感知和互动 AI 的范式转变。
这款新工具不仅提升了用户体验,还预示着个性化数字助理的新纪元。
无论是用于商业、教育还是个人用途,将 AI 定制到我们的具体需求中是一个巨大的进步。
那么,为什么要等待呢?
深入个性化 ChatGPT 的世界,亲身体验 AI 定制的未来。
Josep Ferrer**** 是来自巴塞罗那的分析工程师。他毕业于物理工程,目前在应用于人类流动的数据科学领域工作。他是数据科学和技术方面的兼职内容创作者。Josep 写关于 AI 的所有内容,涵盖该领域持续爆炸性增长的应用。
更多相关主题
关于实时机器学习,没有人告诉你的事
原文:
www.kdnuggets.com/2015/11/petrov-real-time-machine-learning.html
评论由 Dmitry Petrov,FullStackML。
在今年,我听到并阅读了很多关于实时机器学习的内容。人们通常在讨论信用卡欺诈检测系统时提供这种引人注目的商业场景。他们说他们可以实时地持续更新信用卡欺诈检测模型(参见 “什么是 Apache Spark?”、“...实时用例...” 和 “实时机器学习”)。这看起来很棒,但对我来说不切实际。这个场景中缺少一个重要细节——模型重训练并不需要连续流动的事务数据。相反,你需要的是连续流动的标记(或预标记为欺诈/非欺诈)的事务数据。

机器学习过程
创建标记数据可能是大多数机器学习系统中最慢且最昂贵的步骤。机器学习算法通过标记数据学习检测欺诈交易,类似于人们的学习方式。 让我们看看它在欺诈检测场景中的工作方式。
1. 创建模型
对于训练信用卡模型,你需要大量的交易示例,并且每个交易都应标记为欺诈或非欺诈。这些标签必须尽可能准确!这就是我们的标记数据集。这个数据集是监督机器学习算法的输入。基于标记数据,算法训练欺诈检测模型。该模型通常表现为一个二分类器,具有真实(欺诈)或虚假(非欺诈)类别。
标记数据集在此过程中起着核心作用。更改算法的参数,如特征归一化方法或损失函数,非常容易。例如,我们可以将算法本身从逻辑回归更改为 SVM 或随机森林。然而,你不能更改标记数据集。这些信息是预定义的,你的模型应预测你已经拥有的标签。
2. 数据标记过程需要多长时间?
我们如何标注最新的交易?如果客户报告欺诈交易或信用卡被盗,我们可以立即将交易标记为“欺诈”。我们该如何处理其余的交易?我们可以假设未报告的交易为“非欺诈”。我们应该等多久才能确认它们不是欺诈?上次我朋友丢了信用卡,她说:“我暂时不会报告丢失的信用卡。明天我会去我最后去过的商店,问问他们是否找到了我的信用卡。”幸运的是,商店找到了并归还了她的信用卡。我不是信用卡欺诈领域的专家(我只是一个好卡用户),但根据我的经验,我们应该等待至少几天再将交易标记为“非欺诈”。
相反,如果有人报告了欺诈交易,我们可以立即将这笔交易标记为“欺诈”。报告欺诈的人可能在丢失几小时或几天后才意识到欺诈,但这是我们能做的最好事情。
这样一来,我们的“最新”标注数据集将受到限制,只有几个“欺诈”交易存在几小时或几天的延迟,以及很多“非欺诈”交易在 2-3 天的延迟内。
3. 尝试加快标注过程
我们的目标是获得“最新”的标注数据。事实上,我们只有“最新欺诈”标签。对于“非欺诈”标签,我们必须等待几天。仅使用“最新欺诈”标注数据构建模型可能看起来是个好主意。然而,我们应该理解这份标注数据集存在偏差,这可能会导致模型出现很多问题。
让我们假设昨天开了一家新的大型购物中心,我们收到了一份关于这家店的一次交易的欺诈报告。我们的标注数据集将只包含这家商店的一次交易,标记为“欺诈”。这家店的所有其他交易尚未标注。算法可能会认为这家商店是一个强有力的欺诈预测指标,所有来自这家店的交易都会被错误地立即“实时”标记为“欺诈”。实时性的优势也带来了实时性的问题。
结论
如我们所见,信用卡欺诈检测业务场景似乎不是实时监督学习的最佳场景。此外,我无法从其他业务领域中想象出一个好的场景。我希望看到实时机器学习的好场景。如果你有任何信息或想法与社区分享,请告知。
另见 Reddit 上的有趣讨论 讨论了本文中的一些想法。
简介: Dmitry Petrov,博士,现为微软的数据科学家。他曾是某大学的研究员。
原文。
相关:
-
流实时分析的模式
-
实时分析中的 Spark SQL
-
访谈:Ted Dunning,MapR 讲述大数据中实时的真正含义
我们的三大课程推荐
1. Google 网络安全证书 - 快速进入网络安全职业生涯。
2. Google 数据分析专业证书 - 提升你的数据分析技能
3. Google IT 支持专业证书 - 支持你的组织的 IT
更多相关主题
Phi-2: 小型语言模型正在做大事
原文:
www.kdnuggets.com/phi-2-small-lms-that-are-doing-big-things

作者提供的图片
在我们深入了解 Phi-2 的惊人之处之前。如果你还没有了解 phi-1.5,我建议你快速浏览一下微软几个月前的有效的小型语言模型:微软的 13 亿参数 phi-1.5。
我们的前三个课程推荐
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
2. 谷歌数据分析专业证书 - 提升你的数据分析技能
3. 谷歌 IT 支持专业证书 - 支持你所在组织的 IT
现在你已经了解了基础,我们可以继续学习更多关于 Phi-2 的内容。微软一直在努力发布一系列名为“Phi”的小型语言模型(SLMs)。这系列模型已被证明能够取得显著的性能,就像大型语言模型一样。
微软的第一个模型是Phi-1,具有 13 亿参数,然后是Phi-1.5。
我们已经看到了 Phi-1、Phi-1.5,现在我们有了Phi-2。
什么是 Phi-2?
Phi-2 变得更大、更好。更大,更好。它是一个 27 亿参数的语言模型,已被证明在推理和语言理解能力上表现出色。
对于如此小的语言模型,这真是惊人,不是吗?
Phi-2 已被证明在性能上超越了大 25 倍的模型。这都归功于模型的扩展和训练数据的策划。小巧、紧凑且性能卓越。由于其规模,Phi-2 适用于研究人员探索解释能力、微调实验以及深入安全改进。它可以在 Azure AI Studio 模型目录中获得。
Phi-2 的创建
微软的训练数据是合成数据集的混合,这些数据集用于教授模型常识,例如一般知识、科学、心智理论和日常活动。
训练数据经过精心挑选,以确保其经过优质内容的筛选,并具有教育价值。凭借这种可扩展性,他们将 1.3 亿参数的 Phi-1.5 模型提升到了 2.7 亿参数的 Phi-2。

图片来源:微软 Phi-2
微软对 Phi-2 进行了测试,因为他们意识到当前模型评估的挑战。他们在测试用例中将 Phi-2 与 Mistral 和 Llama-2 进行了比较。结果显示,Phi-2 在某些情况下超越了 Mistral-7B,而 70 亿参数的 Llama-2 模型在某些情况下超越了 Phi-2,如下所示:

图片来源:微软 Phi-2
Phi-2 的局限性
不过,尽管如此,Phi-2 仍然有其局限性。例如:
-
不准确性:该模型在生成错误代码和事实方面存在一些局限,用户应对此保持谨慎,将这些输出视为起点。
-
限制的代码知识:Phi-2 的训练数据基于 Python 及常见包,因此生成其他语言和脚本的结果需要进行验证。
-
指令:该模型尚未经过指令微调,因此可能难以真正理解用户提供的指令。
Phi-2 还有其他局限性,例如语言限制、社会偏见、毒性和冗长。
尽管如此,每个新产品或服务都有其局限性,而 Phi-2 仅发布了一周左右。因此,微软需要将 Phi-2 推广到公众手中,以帮助改进服务并克服当前的局限性。
总结
微软以一个小型语言模型结束了这一年,这个模型可能会成为 2024 年最受关注的模型。既然如此,我们应该对 2024 年的语言模型世界有什么期待呢?
Nisha Arya 是一位数据科学家、自由职业技术作家,以及 KDnuggets 的编辑和社区经理。她特别关注提供数据科学职业建议或教程,以及围绕数据科学的理论知识。Nisha 涵盖了广泛的话题,并希望探索人工智能如何有利于人类生命的长寿。作为一个热衷学习者,Nisha 寻求扩展她的技术知识和写作技能,同时帮助指导他人。
更多相关内容
Phishytics – 检测网络钓鱼网站的机器学习
原文:
www.kdnuggets.com/2020/03/phishytics-machine-learning-detecting-phishing-websites.html
评论
作者 Faizan Ahmad,弗吉尼亚大学
几乎每周你都会看到关于网络钓鱼的新闻。在过去的一周里,黑客们正在向 Disney+ 用户发送网络钓鱼邮件,‘Shark Tank’ 明星巴巴拉·科克伦在网络钓鱼骗局中损失了近 40 万美元,某银行发布了网络钓鱼警告,而且现在几乎四分之三的网络钓鱼网站都使用 SSL。由于网络钓鱼在网络安全领域是一个如此广泛的问题,让我们来深入探讨一下机器学习在网络钓鱼网站检测中的应用。尽管已有许多关于此主题的文章和研究论文[恶意 URL 检测] [通过视觉白名单检测网络钓鱼网站] [检测网络钓鱼的新技术],它们并不总是提供开源代码并深入分析。本文旨在填补这些空白。我们将使用一个大规模的网络钓鱼网站语料库,并应用一些简单的机器学习方法来获得高精度的结果。
数据
解决这个问题的最佳部分是有良好收集的网络钓鱼网站数据集,其中一个由马来西亚沙捞越大学的研究人员收集。这个‘钓鱼数据集 – 钓鱼与合法数据集用于快速基准测试’数据集包含 30,000 个网站,其中 15,000 个是钓鱼网站,15,000 个是合法网站。数据集中的每个网站都包含 HTML 代码、whois 信息、URL 以及网页中嵌入的所有文件。这对那些希望应用机器学习进行钓鱼检测的人来说是一个宝贵的资源。这个数据集有几种使用方式。我们可以通过查看 URL 和 whois 信息来尝试检测钓鱼网站,并像之前的一些研究那样手动提取特征[1]。然而,我们将使用网页的原始 HTML 代码来看看是否可以通过构建机器学习系统有效对抗钓鱼网站。在 URL、whois 信息和 HTML 代码中,HTML 代码是最难被混淆或更改的,如果攻击者试图阻止系统检测其钓鱼网站,因此我们在系统中使用 HTML 代码。另一种方法是将三种来源结合起来,这应该能提供更好、更稳健的结果,但为了简化起见,我们将仅使用 HTML 代码,并证明仅靠它即可获得有效的钓鱼网站检测结果。关于数据集的最后一点:由于计算限制,我们将仅使用 20,000 个样本。我们还将仅考虑用英语编写的网站,因为其他语言的数据稀缺。
HTML 代码的字节对编码
对于一个初学者来说,HTML 代码看起来并不像一种简单的语言。此外,开发者在编写代码时常常不遵循所有良好的实践。这使得解析 HTML 代码和提取词汇/标记变得困难。另一个挑战是 HTML 代码中许多词汇和标记的稀缺性。例如,如果一个网页使用了一个复杂名称的特殊库,我们可能在其他网站上找不到这个名称。最后,由于我们希望将系统部署到实际环境中,可能会有新的网页使用我们模型之前未见过的完全不同的库和代码实践。这使得使用简单的语言标记器并根据空格或其他标签或字符将代码拆分为标记变得更加困难。幸运的是,我们有一个叫做字节对编码(BPE)的算法,它根据频率将文本拆分为子词标记,并解决了未知词汇的问题。在 BPE 中,我们首先将每个字符视为一个标记,并根据最高频率迭代合并标记。例如,如果出现了一个新词“googlefacebook”,BPE 会将其拆分为“google”和“facebook”,因为这些词在语料库中可能会频繁出现。BPE 已被广泛应用于最近的深度学习模型 [2]。
训练 BPE 的库有很多。我们将使用一个很棒的库,叫做tokenizer,由Huggingface提供。按照这个库的github 仓库中的说明非常简单。我们在原始 HTML 数据上用10,000 tokens的词汇量训练 BPE。BPE 的优点是它可以自动将 HTML 关键词如“tag”、“script”、“div”分离成单独的标记,即使这些标签在 HTML 文件中大多是用括号书写的,例如

 浙公网安备 33010602011771号
浙公网安备 33010602011771号