持久化数据结构
所谓持久化,就是可以保留每一个历史版本,并且支持操作的不可变特性。例如对于线段树而言,持久化意味着它可以保留多个历史版本的线段树,并且支持对历史版本的访问与修改。
本文将介绍几种常见数据结构的持久化方式。
1 持久化线段树
1.1 基本思想
保存每一个历史版本的线段树本身是简单的,直接开一堆线段树就行,但是显然这样做空间会爆炸。
我们考虑当我们进行一次单点修改的时候,实际上只有原树上的一条链被修改了权值。换句话说,当我们新建一个版本的时候,只需要新建一条链的信息,剩下的采用原版本信息即可。这样我们每次新增的节点就达到了 \(O(\log n)\) 个,可以接受。
例如下图即为修改 \(1\) 时新建节点情况:
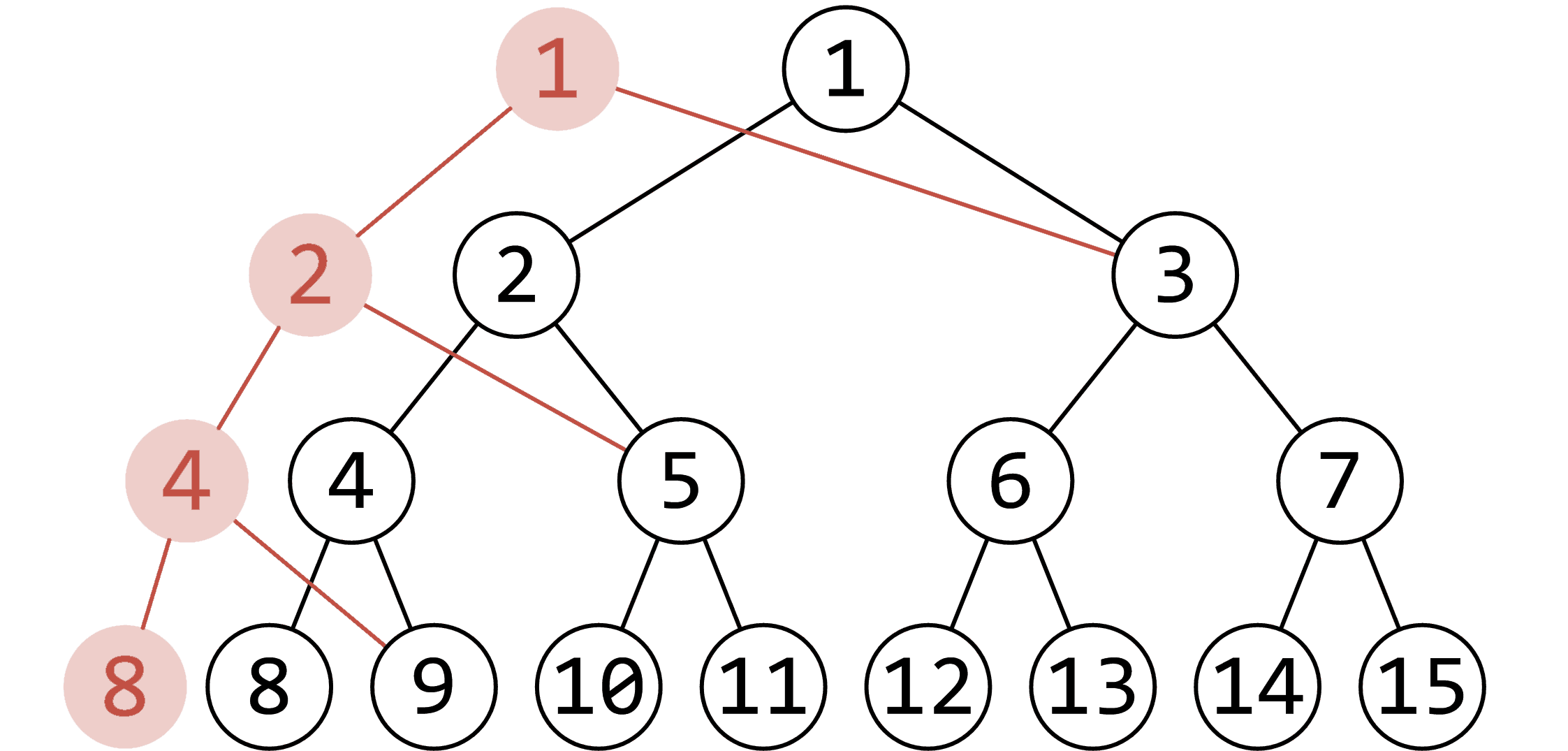
自然,由于每一次会复用原来的节点,所以左右儿子不能用朴素的 \(2\times p,2\times p+1\) 来存储,需要采用类似动态开点的方式存储。
上面我们讲的是单点修改的持久化线段树,那么区间修改应该如何做呢?
考虑普通线段树怎样进行区间修改,不难想到就是下放标记、上传合并。但是由于持久化线段树上有复用的节点,所以无法下放懒标记,也无法上传合并信息。这个时候我们想到了标记永久化,通过标记永久化我们就可以不用下放和上传操作,并且仍然只需要修改 \(O(\log n)\) 个节点的信息。如此便可在正确的时空复杂度内完成持久化线段树的区间修改。
这种思想成为路径复制,在持久化数据结构中应用相当广泛,下文依然会有所提及。
1.2 例题
例 1 【模板】可持久化线段树 2
题意: 求静态区间第 \(k\) 小。
先考虑对于全局求第 \(k\) 小怎么做,这个用权值线段树是显然的。先对原数组离散化,然后建一颗权值线段树。我们在线段树上遍历,如果左子树的数字总个数小于 \(k\),则说明目标在右子树内,遍历右子树即可;否则去遍历左子树。
现在如果要求区间 \([l,r]\) 的第 \(k\) 小值,实际上只需要知道 \([l,r]\) 这段区间内所有数字构成的权值线段树上的信息即可。考虑运用前缀和的思想,我们单次插入数组中的一个元素,建立一颗主席树,则主席树上每一个节点存储的就是 \([1,r]\) 内所有数字的信息。如果要求 \([l,r]\) 内的信息,用 \([1,r]\) 内的信息减去 \([1,l-1]\) 内的信息即可。
代码如下:
#include <bits/stdc++.h>
using namespace std;
const int Maxn = 2e5 + 5;
const int Inf = 2e9;
int n, m, a[Maxn], t[Maxn], tot;
int rt[Maxn];
namespace Sgt {
struct node {
int l, r, sum;
}t[Maxn << 5];
#define lp t[p].l
#define rp t[p].r
int tot = 0;
void build(int &p, int l, int r) {
p = ++tot;
t[p].sum = 0;
if(l == r) return ;
int mid = (l + r) >> 1;
build(lp, l, mid), build(rp, mid + 1, r);
}
int mdf(int p, int l, int r, int x) {//p 为上一版本树上节点
int rt = ++tot;//建新节点
t[rt] = t[p];
t[rt].sum++;
if(l == r) return rt;
int mid = (l + r) >> 1;
if(x <= mid) t[rt].l = mdf(lp, l, mid, x);
else t[rt].r = mdf(rp, mid + 1, r, x);
return rt;
}
int query(int p, int q, int l, int r, int k) {
if(l == r) return l;
int mid = (l + r) >> 1, res = t[t[q].l].sum - t[t[p].l].sum;//前缀和相减
if(res < k) return query(t[p].r, t[q].r, mid + 1, r, k - res);
else return query(t[p].l, t[q].l, l, mid, k);
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n >> m;
for(int i = 1; i <= n; i++) {
cin >> a[i];
t[++tot] = a[i];
}
sort(t + 1, t + tot + 1);
tot = unique(t + 1, t + tot + 1) - t - 1;
for(int i = 1; i <= n; i++) {
a[i] = lower_bound(t + 1, t + tot + 1, a[i]) - t;
}
Sgt::build(rt[0], 1, tot);
for(int i = 1; i <= n; i++) {
rt[i] = Sgt::mdf(rt[i - 1], 1, tot, a[i]);
}
while(m--) {
int l, r, k;
cin >> l >> r >> k;
int pos = Sgt::query(rt[l - 1], rt[r], 1, tot, k);
cout << t[pos] << '\n';
}
return 0;
}
例 2 [SDOI2013] 森林
题意: 维护一个森林,支持合并两个连通块、求两点间权值第 \(k\) 小。
看到维护第 \(k\) 小不难想到主席树,但是这是一个树上问题,那么自然的将序列前缀和转化为树上前缀和即可。因此在主席树上跑的时候,当前权值区间的信息应该是用 \(u\) 处的信息加上 \(v\) 处的信息,减去 \(\text{lca}\) 和 \(\text{lca}\) 的父亲处的信息。
现在的问题就是怎样合并连通块,由于强制在线,除了暴力合并我们似乎没有什么更好的方式。那么就考虑启发式合并,每一次将节点数量小的合并到大的上面,然后暴力重构小的连通块中每一个点在主席树上的信息即可。这样做的复杂度是 \(O(n\log ^2 n)\) 的,完全可以通过。
当然由于我们还需要在合并后求 \(\text{lca}\),所以树剖肯定不可行,只能使用倍增,在暴力重构的时候一起更新倍增数组即可。
例 3 [AHOI2017 / HNOI2017] 影魔
首先考虑这个贡献的含义:假设区间 \((l,r)\) 的最大值是 \(c\),当 \(c<k_l\) 且 \(c<k_r\) 时产生 \(p_1\) 贡献;否则当 \(c<k_l\) 或 \(c<k_r\) 时产生 \(p_2\) 贡献。
那么这就说明要产生贡献肯定有一个端点是最大值,那么考虑枚举 \(c\) 所在位置 \(i\),并预处理出 \(i\) 左侧和右侧第一个大于 \(c\) 的数的位置,记作 \(L_i,R_i\)。此时根据上面所述的贡献,会发现贡献分为如下类型:
- 当 \(L_i\) 在 \([a,b]\) 中时,所有 \(x\in(i,\min(R_i,b + 1))\) 的 \(x\) 可以与 \(L_i\) 一起产生 \(p_2\) 贡献。
- 当 \(R_i\) 在 \([a,b]\) 中时,所有 \(x\in(\max(a-1,L_i),i)\) 的 \(x\) 可以与 \(R_i\) 一起产生 \(p_2\) 贡献。
- 当 \(L_i,R_i\) 均在 \([a,b]\) 中时,\(L_i,R_i\) 可以一起产生 \(p_1\) 贡献。
- 对于任意 \((i,i+1)\) 点对,它们可以一起产生 \(p_1\) 贡献。
我们以第一个举例说明如何维护。当我们遇到一个 \(L_i\) 时,将 \((i,R_i)\) 这个区间中的数全部 \(+p_2\) 的贡献,然后对于一组询问 \([a,b]\),我们直接查询 \([a,b]\) 中所有数的和即可满足 \(x\in(i,\min(R_i,b + 1))\) 这个要求。但是此时还没有满足 \(L_i\in[a,b]\) 这个要求,不难发现运用一次前缀和之后用在 \(b\) 处求得的答案减去在 \(a-1\) 处求得的答案即可满足该条件,所以利用主席树维护上述信息即可。剩余三个操作是同理的。
代码如下:
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int Maxn = 2e5 + 5;
const int Maxm = 1.6e7 + 5;
const int Inf = 2e9;
int n, m, p1, p2;
int a[Maxn];
int pre[Maxn], nxt[Maxn], s[Maxn], top;
int rt[Maxn];
namespace Sgt {
struct node {
int l, r;
ll sum, tag;
}t[Maxm];
#define lp t[p].l
#define rp t[p].r
int tot = 0;
void build(int &p, int l, int r) {
p = ++tot;
if(l == r) return ;
int mid = (l + r) >> 1;
build(lp, l, mid), build(rp, mid + 1, r);
}
int mdf(int p, int l, int r, int pl, int pr, int v) {//区间修改
int rt = ++tot;
t[rt] = t[p];
t[rt].sum += 1ll * (min(pr, r) - max(pl, l) + 1) * v;//直接修改区间和
if(pl <= l && r <= pr) {
t[rt].tag += v;//打标记
return rt;
}
int mid = (l + r) >> 1;
if(pl <= mid) t[rt].l = mdf(lp, l, mid, pl, pr, v);
if(pr > mid) t[rt].r = mdf(rp, mid + 1, r, pl, pr, v);
return rt;
}
ll query(int p, int l, int r, int pl, int pr, ll tag/*当前增加的标记*/) {//区间查询
if(pl <= l && r <= pr) {
return t[p].sum + 1ll * (r - l + 1) * tag;//加上一路上走过来的标记
}
int mid = (l + r) >> 1;
ll res = 0;
if(pl <= mid) res += query(lp, l, mid, pl, pr, tag + t[p].tag);
if(pr > mid) res += query(rp, mid + 1, r, pl, pr, tag + t[p].tag);
return res;
}
}
struct node {
int l, r, v;
};
vector <node> V[Maxn];
signed main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n >> m >> p1 >> p2;
for(int i = 1; i <= n; i++) cin >> a[i];
for(int i = 1; i <= n; i++) {
while(top && a[s[top]] <= a[i]) top--;
if(top) pre[i] = s[top];
else pre[i] = 0;
s[++top] = i;
}
top = 0;
for(int i = n; i >= 1; i--) {
while(top && a[s[top]] <= a[i]) top--;
if(top) nxt[i] = s[top];
else nxt[i] = n + 1;
s[++top] = i;
}
for(int i = 1; i <= n; i++) {
V[pre[i]].push_back((node){i + 1, nxt[i] - 1, p2});
V[nxt[i]].push_back((node){pre[i] + 1, i - 1, p2});
V[pre[i]].push_back((node){nxt[i], nxt[i], p1});
V[i].push_back((node){i + 1, i + 1, p1});
}
Sgt::build(rt[0], 0, n + 1);
for(int i = 1; i <= n; i++) {
bool flg = 0;
for(auto p : V[i]) {
if(!flg) {
rt[i] = Sgt::mdf(rt[i - 1], 0, n + 1, p.l, p.r, p.v);
flg = 1;
}
else {
rt[i] = Sgt::mdf(rt[i], 0, n + 1, p.l, p.r, p.v);
}
}
}
while(m--) {
int l, r;
cin >> l >> r;
cout << Sgt::query(rt[r], 0, n + 1, l, r, 0) - Sgt::query(rt[l - 1], 0, n + 1, l, r, 0) << '\n';
}
return 0;
}
例 4 [国家集训队] middle
题意: 求出 \(l\in [a,b],r\in [c,d]\) 的所有区间 \([l,r]\) 的中位数的最大值。强制在线。
考虑区间中位数的求法,在此题中最合适且最常见的套路就是二分答案。我们二分中位数 \(mid\),然后看怎样判断其与答案的大小关系。不难想到的是,此时如果 \(\ge mid\) 的数的数量不比 \(<mid\) 的数的数量少,那么 \(mid\) 应该是小于等于最后答案的,否则应该大于最后答案。
将上述条件转化如下:将当前数列中所有 \(\ge mid\) 的数改为 \(-1\),\(< mid\) 的数改为 \(1\),若当前区间的和 \(\le 0\),则说明 \(mid\) 小于等于最终答案。
回到原题,我们二分出 \(mid\) 之后,自然是希望 \(mid\) 比最终答案小,也就是说我们要尽可能找到一个合法区间 \([l,r]\),使它的权值和 \(\le 0\),也就是要让它的和尽可能小。考虑到最后选出的 \([l,r]\) 实际上是从区间 \([a,d]\) 中,删去一个 \([a,b]\) 的前缀与 \([c,d]\) 的后缀得到的,由于 \([a,d]\) 的权值和一定,所以只需要让 \([a,b]\) 的前缀、\([c,d]\) 的后缀分别最大即可。这个显然可以直接用线段树维护出来。
最后的问题就是怎样构建出每个数对应的 \(1,-1\) 序列,如果每一次都暴力建线段树肯定不行。考虑从大到小建树,这样每一次由 \(1\) 改为 \(-1\) 的位置总数只有 \(n\),所以每一次修改用主席树维护即可。
例 5 [FJOI2016] 神秘数
题意: 令一个可重数字集合 \(S\) 的神秘数为最小的不能被 \(S\) 的子集和表示的正整数。给定一个序列,求集合 \(\{a_i\mid i\in[l,r]\}\) 的神秘数。
首先需要发现一个性质。如果当前可重集可以表示出 \([1,lim]\) 的所有正整数,那么如果下一个加入的数字 \(a \le lim+1\),则可重集可表示的数字会扩展到 \([1,lim+a]\);否则该可重集的神秘数就是 \(lim+1\)。
证明如下:
当前可重集可以表示 \([1,lim]\) 的所有正整数,那么加入 \(a\) 后可以表示的正整数就应该是 \([1,lim]\cup [a,lim+a]\)。如果 \(a\le lim+1\),则上面的集合就是 \([1,lim+a]\);否则中间就会存在无法被表示的正整数,而这其中最小的就是 \(lim+1\)。
对于每一个询问,考虑暴力扩展当前的可重集。设当前可重集中包含了值域在 \([1,res]\) 中的所有数,它们可以表示所有在 \([1,lim]\) 中的正整数,那么下一次可以加入的数的范围应该是 \([res+1,lim+1]\)。设值域在这个区间中的所有数的和为 \(sum\),若 \(sum=0\),答案就是 \(lim+1\);否则当前可重集的值域范围会扩展至 \([1,lim+1]\),而它能表示的正整数范围则会扩大至 \([1,lim+sum]\)。
不难发现上面的过程中需要求解区间 \([l,r]\) 中值域在 \([res+1,lim+1]\) 的数的总和,这个就可以用主席树来实现了。最后的问题就是暴力扩展的时间复杂度,我们考虑 \(lim\) 的最大值是题目中给出的 \(10^9\),而每一次加上的 $sum $ 的最小值是 \(res+1\)。根据手玩可以发现,最后 \(sum\) 前的系数是一个类似斐波那契数列的东西,而斐波那契数列的数量级是 \(2^n\) 的,所以暴力扩展的复杂度是 \(O(\log \sum A_i)\),总复杂度 \(O(m\log n\log \sum A_i)\),可以通过。
例 6 [BZOJ4771] 七彩树
我们在这里介绍一下区间数颜色的基本方式,常见的有两种:
- 记录每个节点的 \(pre\),表示该节点颜色上一次出现的位置。对于区间 \([l,r]\),我们只计算区间中第一次出现的颜色,那么这些颜色对应的位置一定满足 \(pre_i< l\)。所以我们相当于求出 \(i\in[l,r],pre_i\in[0,l)\) 的点的个数,二维数点即可。
- 换一种思路,我们用扫描线和区间加法来做。当从 \(r\to r+1\) 的时候,区间 \((pre_{r+1},r+1]\) 这一段的颜色数量会加 \(1\),我们此时求的是后缀和,所以在 \(r+1\) 处加一,\(pre_{r+1}\) 处减一。再用树状数组维护后缀和即可。
对于此题来讲,第一种方法不是很好做,考虑第二种方法。我们按照 \(dep\) 来建立持久化线段树(也就是第 \(k\) 个线段树维护 \(dep\le k\) 的点的信息),当增加一个点的时候,我们找到当前颜色中已经被插入的点按 DFS 序排名后该点的前驱和后继。根据 DFS 序的优良性质,可以知道这两个点和当前点的 \(\text{lca}\) 中更深的那个节点就是第一个会受到影响的节点,按照上面所说的第二种方式,我们在当前节点处加一,\(\text{lca}\) 处减一,最后求出子树和即可。
复杂度是 \(O(n\log n)\),可以通过。
1.3 拓展
我们在上面已经实现了持久化线段树,实际上就是实现了一个持久化数组。那么按照这个理论,所有使用数组的数据结构应该都能用持久化线段树来维护。那么我们就有了另一种持久化数据结构——持久化并查集。
由于要持久化,所以肯定不能路径压缩了,我们只能用按秩合并。开一个持久化数组维护 \(fa\) 和 \(siz\) 信息,然后查询和修改时正常操作,记录新版本编号即可。由于按秩合并的复杂度是 \(O(\log n)\) 的,加上线段树自己的 \(O(\log n)\),总复杂度即为 \(O(n\log^2 n)\)。
2 持久化平衡树
2.1 概述
在这里需要对若干持久化平衡树的误区进行一些说明:
-
带旋转操作的平衡树(例如 Treap、Splay、WBLT)不能持久化。
实际上这是完全错误的。如果平衡树复杂度不基于均摊分析,那么最坏情况下我们采用持久化数组也可以在多一个 \(\log\) 的情况下维护持久化平衡树。而实际上旋转操作也可以通过新建节点的方式来持久化。所以只有 FHQ 才能持久化的说法也是错误的。
-
FHQ 是推荐学习的持久化平衡树。
事实上 FHQ 除了容易实现(代码短)之外几乎没有什么突出的优势,同时 FHQ 在做区间复制的时候复杂度是错误的,原因在于 FHQ 的合并复杂度是 \(O(\log (siz_x+siz_y))\) 的,并且在实际题目中可以被卡掉,具体表现为树高远超出 \(\log n\) 范围。所以虽然 FHQ 可以实现一些持久化操作,但是在区间复制问题上无法胜任。
那么综上所述,我们可以使用的持久化平衡树还剩下 WBLT、AVL 等平衡树。本文将介绍 WBLT 的持久化操作。
2.2 基本思想
2.2.1 普通平衡树的持久化
普通平衡树涉及到修改的部分只有插入和删除,那么类似于持久化线段树,我们采用路径复制的方法,对于每个经过的节点,将他复制一个点出来,然后对这个点进行操作即可。然后在 rotate 的时候,我们只需要复制一下需要旋转的点以及其父亲即可,这样不会影响原树结构。容易发现单次操作新增的节点个数是 \(O(\log n)\) 的。代码如下:
il void copy(int &p) {t[++tot] = t[p]; p = tot;}
il void rotate(int &p, int d) {
copy(p), copy(son(p, d));
swap(ls(p), rs(p));
swap(ls(son(p, d ^ 1)), rs(son(p, d ^ 1)));
swap(son(son(p, d ^ 1), d ^ 1), son(p, d));
pushup(son(p, d ^ 1)), pushup(p);
}
然后在插入删除的时候传递引用即可修改节点,完整代码如下:
#include <bits/stdc++.h>
#define il inline
using namespace std;
const int N = 5e5 + 5;
const int Inf = 2147483647;
template <typename T> il void chkmin(T &x, T y) {x = min(x, y);}
template <typename T> il void chkmax(T &x, T y) {x = max(x, y);}
bool Beg;
namespace My_Space {
struct IO {
static const int Size = (1 << 21);
char buf[Size], *p1, *p2; int st[105], Top;
~IO() {clear();}
il void clear() {fwrite(buf, 1, Top, stdout); Top = 0;}
il char gc() {return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, Size, stdin), p1 == p2) ? EOF : *p1++;}
il void pc(const char c) {Top == Size && (clear(), 0); buf[Top++] = c;}
il IO &operator >> (char &c) {while(c = gc(), c == ' ' || c == '\n' || c == '\r'); return *this;}
template <typename T> il IO &operator >> (T &x) {
x = 0; bool f = 0; char ch = gc();
while(!isdigit(ch)) {if(ch == '-') f = 1; ch = gc();}
while(isdigit(ch)) x = (x << 1) + (x << 3) + (ch ^ 48), ch = gc();
f ? x = -x : 0; return *this;
}
il IO &operator << (const char c) {pc(c); return *this;}
template <typename T> il IO &operator << (T x) {
if(x < 0) pc('-'), x = -x;
do st[++st[0]] = x % 10, x /= 10; while(x);
while(st[0]) pc('0' + st[st[0]--]);
return *this;
}
il IO &operator << (const char *s) {for(int i = 0; s[i]; i++) pc(s[i]); return *this;}
}fin, fout;
int n, rt[N];
namespace WBLT {
struct node {
int ls, rs, siz, val;
}t[N * 30];
#define son(p, x) ((x) ? t[p].rs : t[p].ls)
#define ls(p) t[p].ls
#define rs(p) t[p].rs
int tot;
il int newnode(int k) {t[++tot] = {0, 0, 1, k}; return tot;}
il int rnk(int p, int k) {
int cnt = 0;
while(1) {
if(t[p].siz == 1) return cnt + 1;
else if(k <= t[ls(p)].val) p = ls(p);
else cnt += t[ls(p)].siz, p = rs(p);
}
}
il int kth(int p, int k) {
while(1) {
if(t[p].siz == 1) return t[p].val;
else if(k <= t[ls(p)].siz) p = ls(p);
else k -= t[ls(p)].siz, p = rs(p);
}
}
il int pre(int p, int k) {return kth(p, rnk(p, k) - 1);}
il int nxt(int p, int k) {return kth(p, rnk(p, k + 1));}
il void pushup(int p) {
t[p].siz = t[ls(p)].siz + t[rs(p)].siz;
t[p].val = t[rs(p)].val;
}
il void copy(int &p) {t[++tot] = t[p]; p = tot;}
il void rotate(int &p, int d) {
copy(p), copy(son(p, d));
swap(ls(p), rs(p));
swap(ls(son(p, d ^ 1)), rs(son(p, d ^ 1)));
swap(son(son(p, d ^ 1), d ^ 1), son(p, d));
pushup(son(p, d ^ 1)), pushup(p);
}
il void maintain(int &p) {
if(t[p].siz == 1) return ;
int d;
if(t[ls(p)].siz * 4 < t[p].siz) d = 1;
else if(t[rs(p)].siz * 4 < t[p].siz) d = 0;
else return ;
if(t[son(son(p, d), d ^ 1)].siz * 3 >= t[son(p, d)].siz * 2)
rotate(son(p, d), d ^ 1);
rotate(p, d);
}
il void ins(int &p, int k) {
copy(p);
if(t[p].siz == 1) {
int x = newnode(t[p].val), y = newnode(k);
if(t[x].val > t[y].val) swap(x, y);
ls(p) = x, rs(p) = y;
return pushup(p);
}
ins(k <= t[ls(p)].val ? ls(p) : rs(p), k);
pushup(p); maintain(p);
}
il void del(int &p, int k) {
copy(p);
if(k <= t[ls(p)].val) {
if(t[ls(p)].siz == 1) return t[ls(p)].val != k ? 0 : p = rs(p), void();
else del(ls(p), k);
}
else {
if(t[rs(p)].siz == 1) return t[rs(p)].val != k ? 0 : p = ls(p), void();
else del(rs(p), k);
}
pushup(p), maintain(p);
}
il void Init() {
rt[0] = newnode(Inf), rs(rt[0]) = newnode(Inf), ls(rt[0]) = newnode(-Inf);
t[rt[0]].siz = 2;
}
}
il void main() {
fin >> n; WBLT::Init();
for(int i = 1; i <= n; i++) {
int v, opt, x; fin >> v >> opt >> x;
rt[i] = rt[v];
switch(opt) {
case 1: {WBLT::ins(rt[i], x); break;}
case 2: {WBLT::del(rt[i], x); break;}
case 3: {fout << WBLT::rnk(rt[i], x) - 1 << '\n'; break;}
case 4: {fout << WBLT::kth(rt[i], x + 1) << '\n'; break;}
case 5: {fout << WBLT::pre(rt[i], x) << '\n'; break;}
case 6: {fout << WBLT::nxt(rt[i], x) << '\n'; break;}
}
}
}
}
il void File() {freopen(".in", "r", stdin); freopen(".out", "w", stdout);}
bool End;
il void Usd() {cerr << (&Beg - &End) / 1024.0 / 1024.0 << "MB " << (double)clock() * 1000.0 / CLOCKS_PER_SEC << "ms\n";}
int main() {
My_Space::main();
Usd();
return 0;
}
2.2.2 区间平衡树的持久化
WBLT 实现区间操作的核心在于合并和分裂操作,因此我们对这两个操作进行持久化即可。首先看合并,显然的一点是我们对于原先要删除的废节点现在需要保留下来。
同时在 \(x,y\) 不能直接合并的时候,我们原先会直接将两棵树合并到 \(x\) 上,现在我们需要新建一个节点作为根来满足持久化。修改后的代码如下:
il int merge(int x, int y) {
if(!x || !y) return x + y;
int sum = t[x].siz + t[y].siz;
if(min(t[x].siz, t[y].siz) * 4 >= sum) {
int p = newnode(); ls(p) = x, rs(p) = y;
return pushup(p), p;
}
if(t[x].siz >= t[y].siz) {
copy(x), pushdown(x);//新建根节点
if(t[ls(x)].siz * 4 >= sum) return rs(x) = merge(rs(x), y), pushup(x), x;
int p = rs(x); pushdown(p);
ls(x) = merge(ls(x), ls(p)), rs(x) = merge(rs(p), y);
return pushup(x), x;
}
else {
copy(y), pushdown(y);//新建根节点
if(t[rs(y)].siz * 4 >= sum) return ls(y) = merge(x, ls(y)), pushup(y), y;
int p = ls(y); pushdown(p);
rs(y) = merge(rs(p), rs(y)), ls(y) = merge(x, ls(p));
return pushup(y), y;
}
}
然后由于 WBLT 的分裂是基于合并的,所以我们不用进行额外操作。只需要注意废节点依然需要保留下来即可。代码如下:
il void split(int p, int k, int &x, int &y) {
if(!k) return x = 0, y = p, void();
if(t[p].siz == 1) return x = p, y = 0, void();
pushdown(p);
if(k <= t[ls(p)].siz) split(ls(p), k, x, y), y = merge(y, rs(p));
else split(rs(p), k - t[ls(p)].siz, x, y), x = merge(ls(p), x);
}
然后可持久化文艺平衡树的模板题中还需要进行插入删除操作,所以将上文普通平衡树的代码搬过来即可。完整代码如下:
#include <bits/stdc++.h>
#define il inline
using namespace std;
typedef long long ll;
const int N = 2e5 + 5;
const int Inf = 2e9;
template <typename T> il void chkmin(T &x, T y) {x = min(x, y);}
template <typename T> il void chkmax(T &x, T y) {x = max(x, y);}
bool Beg;
namespace My_Space {
struct IO {
static const int Size = (1 << 21);
char buf[Size], *p1, *p2; int st[105], Top;
~IO() {clear();}
il void clear() {fwrite(buf, 1, Top, stdout); Top = 0;}
il char gc() {return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, Size, stdin), p1 == p2) ? EOF : *p1++;}
il void pc(const char c) {Top == Size && (clear(), 0); buf[Top++] = c;}
il IO &operator >> (char &c) {while(c = gc(), c == ' ' || c == '\n' || c == '\r'); return *this;}
template <typename T> il IO &operator >> (T &x) {
x = 0; bool f = 0; char ch = gc();
while(!isdigit(ch)) {if(ch == '-') f = 1; ch = gc();}
while(isdigit(ch)) x = (x << 1) + (x << 3) + (ch ^ 48), ch = gc();
f ? x = -x : 0; return *this;
}
il IO &operator << (const char c) {pc(c); return *this;}
template <typename T> il IO &operator << (T x) {
if(x < 0) pc('-'), x = -x;
do st[++st[0]] = x % 10, x /= 10; while(x);
while(st[0]) pc('0' + st[st[0]--]);
return *this;
}
il IO &operator << (const char *s) {for(int i = 0; s[i]; i++) pc(s[i]); return *this;}
}fin, fout;
int n;
int rt[N];
namespace WBLT {
struct node {
int ls, rs, siz, tag;
ll sum;
}t[N * 100];
#define ls(p) t[p].ls
#define rs(p) t[p].rs
#define son(p, x) ((x) ? t[p].rs : t[p].ls)
int tot;
il int newnode(int k = 0) {t[++tot] = {0, 0, 1, 0, k}; return tot;}
il void pushup(int p) {
t[p].siz = t[ls(p)].siz + t[rs(p)].siz;
t[p].sum = t[ls(p)].sum + t[rs(p)].sum;
}
il void copy(int &p) {t[++tot] = t[p]; p = tot;}
il void pushtag(int &p) {copy(p); t[p].tag ^= 1; swap(ls(p), rs(p));}
il void pushdown(int p) {
if(!t[p].tag) return ;
pushtag(ls(p)), pushtag(rs(p));
t[p].tag = 0;
}
il void rotate(int &p, int d) {
copy(son(p, d)), pushdown(son(p, d));
swap(ls(p), rs(p));
swap(ls(son(p, d ^ 1)), rs(son(p, d ^ 1)));
swap(son(son(p, d ^ 1), d ^ 1), son(p, d));
pushup(son(p, d ^ 1)), pushup(p);
}
il void maintain(int &p) {
if(t[p].siz == 1) return ;
int d;
if(t[ls(p)].siz * 4 < t[p].siz) d = 1;
else if(t[rs(p)].siz * 4 < t[p].siz) d = 0;
else return ;
copy(son(p, d)), pushdown(son(p, d));
if(t[son(son(p, d), d ^ 1)].siz * 3 >= t[son(p, d)].siz * 2)
rotate(son(p, d), d ^ 1);
rotate(p, d);
}
il void ins(int &p, int k, int v) {
copy(p); pushdown(p);
if(t[p].siz == 1) {
int x = newnode(t[p].sum), y = newnode(v);
ls(p) = x, rs(p) = y;
return pushup(p);
}
if(k <= t[ls(p)].siz) ins(ls(p), k, v);
else ins(rs(p), k - t[ls(p)].siz, v);
pushup(p), maintain(p);
}
il void del(int &p, int k) {
copy(p); pushdown(p);
if(k <= t[ls(p)].siz) {
if(t[ls(p)].siz == 1) return p = rs(p), void();
else del(ls(p), k);
}
else {
if(t[rs(p)].siz == 1) return p = ls(p), void();
else del(rs(p), k - t[ls(p)].siz);
}
pushup(p); maintain(p);
}
il int merge(int x, int y) {
if(!x || !y) return x + y;
int sum = t[x].siz + t[y].siz;
if(min(t[x].siz, t[y].siz) * 4 >= sum) {
int p = newnode(); ls(p) = x, rs(p) = y;
return pushup(p), p;
}
if(t[x].siz >= t[y].siz) {
copy(x), pushdown(x);
if(t[ls(x)].siz * 4 >= sum) return rs(x) = merge(rs(x), y), pushup(x), x;
int p = rs(x); pushdown(p);
ls(x) = merge(ls(x), ls(p)), rs(x) = merge(rs(p), y);
return pushup(x), x;
}
else {
copy(y), pushdown(y);
if(t[rs(y)].siz * 4 >= sum) return ls(y) = merge(x, ls(y)), pushup(y), y;
int p = ls(y); pushdown(p);
rs(y) = merge(rs(p), rs(y)), ls(y) = merge(x, ls(p));
return pushup(y), y;
}
}
il void split(int p, int k, int &x, int &y) {
if(!k) return x = 0, y = p, void();
if(t[p].siz == 1) return x = p, y = 0, void();
pushdown(p);
if(k <= t[ls(p)].siz) split(ls(p), k, x, y), y = merge(y, rs(p));
else split(rs(p), k - t[ls(p)].siz, x, y), x = merge(ls(p), x);
}
il ll query(int p, int l, int r, int pl, int pr) {//WBLT 的特点:可以采用类似线段树的查询方式以减少分裂合并产生的常数
if(pl <= l && r <= pr) return t[p].sum;
pushdown(p);
int mid = l + t[ls(p)].siz - 1; ll res = 0;
if(pl <= mid) res += query(ls(p), l, mid, pl, pr);
if(pr > mid) res += query(rs(p), mid + 1, r, pl, pr);
return res;
}
il void Reverse(int &p, int l, int r) {
int x, y, z;
split(p, r, x, z); split(x, l - 1, x, y);
pushtag(y); p = merge(merge(x, y), z);
}
il ll Query(int p, int l, int r) {return query(p, 1, t[p].siz, l, r);}
}
il void main() {
fin >> n; rt[0] = WBLT::newnode(-Inf);
ll lst = 0;
for(int i = 1; i <= n; i++) {
int v, opt; fin >> v >> opt;
rt[i] = rt[v];
switch(opt) {
case 1: {
ll x, v; fin >> x >> v; x ^= lst, v ^= lst;
WBLT::ins(rt[i], x + 1, v);
break;
}
case 2: {
ll x; fin >> x; x ^= lst;
WBLT::del(rt[i], x + 1);
break;
}
case 3: {
ll l, r; fin >> l >> r; l ^= lst, r ^= lst;
WBLT::Reverse(rt[i], l + 1, r + 1);
break;
}
case 4: {
ll l, r; fin >> l >> r; l ^= lst, r ^= lst;
fout << (lst = WBLT::Query(rt[i], l + 1, r + 1)) << '\n';
break;
}
}
}
}
}
il void File() {freopen(".in", "r", stdin); freopen(".out", "w", stdout);}
bool End;
il void Usd() {cerr << (&Beg - &End) / 1024.0 / 1024.0 << "MB " << (double)clock() * 1000.0 / CLOCKS_PER_SEC << "ms\n";}
signed main() {
My_Space::main();
Usd();
return 0;
}
2.3 区间复制
最后我们来到 FHQ 的折戟之地——区间复制操作,来看两道例题。
例 1 HDU6087 Rikka with Sequence
很显然核心是操作 \(2\),意思是将 \([l-k,l-1]\) 这个区间不断复制直到填满 \([l-k,r]\)。直接暴力复制复杂度肯定不正确,一个常用的套路是利用倍增,每次将区间长度扩大一倍直到超出边界,将超出的部分再删除即可。很显然复制的时候两棵树会有重复节点,所以用持久化平衡树维护即可。
这里就体现出来 WBLT 的优势了,由于 WBLT 合并的复杂度为 \(O(\log \frac{siz_x}{siz_y})\),而我们复制的时候两个树的大小是相同的,因此单次合并复杂度是 \(O(1)\) 的,复制的复杂度就为 \(O(\log n)\),非常优秀。而 FHQ 由于两棵树随机值完全相同,直接合并会导致大量随机值相同破坏平衡;而如果每次合并都用随机值判断可以卡过一些题,但是构造数据下依然是爆炸的。
然后对于 WBLT 的复制有一个优化:如果保证序列长度不超过 \(O(n)\),我们可以每 \(O(\frac{n}{\log n})\) 次操作重构一次,因为每次操作最多增加 \(O(\log n)\) 个节点,这样可以控制空间复杂度为 \(O(n)\),时间复杂度依然不变,为 \(O(n\log n)\)。这样可以轻松通过此题。
例 2 P8263 [Ynoi Easy Round 2020] TEST_8
这道题也是一道区间复制的模板题。与上面不同的是我们要求复制 \(k\) 次,依然考虑倍增的思路,处理出复制了 \(2^0,2^1,\cdots,2^i\) 次后的平衡树,然后按照二进制合并即可。对于第二个需要进行翻转的复制,维护一下原本的树和翻转后的树,打翻转标记后进行合并即可。复杂度是 \(O(n\log n)\) 的。
给一下这道题的代码:
#include <bits/stdc++.h>
#define il inline
using namespace std;
const int N = 2e5 + 5, M = 2e7 + 5;
const int Inf = 2e9;
template <typename T> il void chkmin(T &x, T y) {x = min(x, y);}
template <typename T> il void chkmax(T &x, T y) {x = max(x, y);}
bool Beg;
namespace My_Space {
struct IO {
static const int Size = (1 << 21);
char buf[Size], *p1, *p2; int st[105], Top;
~IO() {clear();}
il void clear() {fwrite(buf, 1, Top, stdout); Top = 0;}
il char gc() {return p1 == p2 && (p2 = (p1 = buf) + fread(buf, 1, Size, stdin), p1 == p2) ? EOF : *p1++;}
il void pc(const char c) {Top == Size && (clear(), 0); buf[Top++] = c;}
il IO &operator >> (char &c) {while(c = gc(), c == ' ' || c == '\n' || c == '\r'); return *this;}
template <typename T> il IO &operator >> (T &x) {
x = 0; bool f = 0; char ch = gc();
while(!isdigit(ch)) {if(ch == '-') f = 1; ch = gc();}
while(isdigit(ch)) x = (x << 1) + (x << 3) + (ch ^ 48), ch = gc();
f ? x = -x : 0; return *this;
}
il IO &operator >> (string &s) {
s = ""; char c = gc();
while(c == ' ' || c == '\n' || c == '\r') c = gc();
while(c != ' ' && c != '\n' && c != '\r' && c != EOF) s += c, c = gc();
return *this;
}
il IO &operator << (const char c) {pc(c); return *this;}
template <typename T> il IO &operator << (T x) {
if(x < 0) pc('-'), x = -x;
do st[++st[0]] = x % 10, x /= 10; while(x);
while(st[0]) pc('0' + st[st[0]--]);
return *this;
}
il IO &operator << (const char *s) {for(int i = 0; s[i]; i++) pc(s[i]); return *this;}
}fin, fout;
int n, m;
string s;
int rt;
namespace WBLT {
struct node {
int ls, rs, tag, siz, sum;
}t[M];
#define ls(p) t[p].ls
#define rs(p) t[p].rs
#define son(p, x) ((x) ? t[p].rs : t[p].ls)
int tot;
il void copy(int &p) {t[++tot] = t[p]; p = tot;}
il void pushtag(int &p) {copy(p); t[p].tag ^= 1; swap(ls(p), rs(p));}
il void pushdown(int p) {
if(!t[p].tag) return ;
pushtag(ls(p)), pushtag(rs(p));
t[p].tag = 0;
}
il void pushup(int p) {
t[p].siz = t[ls(p)].siz + t[rs(p)].siz;
t[p].sum = t[ls(p)].sum + t[rs(p)].sum;
}
il int merge(int x, int y) {
if(!x || !y) return x + y;
int sum = t[x].siz + t[y].siz;
if(min(t[x].siz, t[y].siz) * 4 >= sum) {
int p = ++tot; ls(p) = x, rs(p) = y;
return pushup(p), p;
}
if(t[x].siz > t[y].siz) {
copy(x), pushdown(x);
if(t[ls(x)].siz * 4 >= sum) return rs(x) = merge(rs(x), y), pushup(x), x;
int p = rs(x); pushdown(p);
ls(x) = merge(ls(x), ls(p)), rs(x) = merge(rs(p), y);
return pushup(x), x;
}
else {
copy(y), pushdown(y);
if(t[rs(y)].siz * 4 >= sum) return ls(y) = merge(x, ls(y)), pushup(y), y;
int p = ls(y); pushdown(p);
ls(y) = merge(x, ls(p)), rs(y) = merge(rs(p), rs(y));
return pushup(y), y;
}
}
il void split(int p, int k, int &x, int &y) {
if(k == 0) return x = 0, y = p, void();
if(t[p].siz == 1) return x = p, y = 0, void();
pushdown(p);
if(k <= t[ls(p)].siz) split(ls(p), k, x, y), y = merge(y, rs(p));
else split(rs(p), k - t[ls(p)].siz, x, y), x = merge(ls(p), x);
}
il int kth(int p, int k) {
if(k > t[p].sum) return -1;
int cnt = 0;
while(1) {
if(t[p].siz == 1) return cnt + 1;
pushdown(p);
if(k <= t[ls(p)].sum) p = ls(p);
else k -= t[ls(p)].sum, cnt += t[ls(p)].siz, p = rs(p);
}
}
il void build(int &p, int l, int r) {
p = ++tot;
if(l == r) return t[p].siz = 1, t[p].sum = s[l - 1] - '0', void();
int mid = (l + r) >> 1;
build(ls(p), l, mid), build(rs(p), mid + 1, r);
pushup(p);
}
int rot[30];
il void Copy1(int l, int r, int k) {
int a, b, c, i = 1;
split(rt, r, b, c); split(b, l - 1, a, b);
rot[0] = b; b = 0;
for(; (1 << i) <= k; i++) rot[i] = merge(rot[i - 1], rot[i - 1]);
for(; i >= 0; i--) if((k >> i) & 1) b = merge(b, rot[i]);
rt = merge(merge(a, b), c);
}
int rot2[30];
il void Copy2(int l, int r, int k) {
int a, b, c, i = 1;
split(rt, r, b, c); split(b, l - 1, a, b);
rot[0] = rot2[0] = b; pushtag(rot2[0]); b = 0;
for(; (1 << i) <= k; i++) {
rot[i] = merge(rot[i - 1], rot2[i - 1]), rot2[i] = merge(rot2[i - 1], rot[i - 1]);
}
int cnt = 0;
for(; i >= 0; i--) {
if((k >> i) & 1) {
if(cnt == 0) b = merge(b, rot[i]);
else b = merge(b, rot2[i]);
cnt ^= 1;
}
}
rt = merge(merge(a, b), c);
}
il void Delete(int l, int r) {
int a, b, c;
split(rt, r, b, c), split(b, l - 1, a, b);
rt = merge(a, c);
}
}
il void main() {
fin >> n >> s >> m;
WBLT::build(rt, 1, n);
while(m--) {
int opt, l, r, k; fin >> opt;
switch(opt) {
case 1: {
fin >> l >> r >> k;
WBLT::Copy1(l, r, k);
break;
}
case 2: {
fin >> l >> r >> k;
WBLT::Copy2(l, r, k);
break;
}
case 3: {
fin >> l >> r;
WBLT::Delete(l, r);
break;
}
case 4: {
fin >> k;
fout << WBLT::kth(rt, k) << '\n';
break;
}
}
}
}
}
il void File() {freopen(".in", "r", stdin); freopen(".out", "w", stdout);}
bool End;
il void Usd() {cerr << (&Beg - &End) / 1024.0 / 1024.0 << "MB " << (double)clock() * 1000.0 / CLOCKS_PER_SEC << "ms\n";}
int main() {
My_Space::main();
Usd();
return 0;
}
在最后给出本人实现的 WBLT 和 FHQ 在所有平衡树题目上的时空对比:
| 题目 | WBLT | FHQ-Treap |
|---|---|---|
| 普通平衡树(P3369) | \(158\text{ms},6.14\text{MB}\) | \(211\text{ms},6.23\text{MB}\) |
| 文艺平衡树(P3391) | \(401\text{ms},8.18\text{MB}\) | \(429\text{ms},4.44\text{MB}\) |
| 可持久化平衡树(P3835) | \(1.04\text{s},143.64\text{MB}\) | \(2.04\text{s},463.36\text{MB}\) |
| 可持久化文艺平衡树(P5055) | \(2.55\text{s},219.55\text{MB}\) | \(6.68\text{s},573.00\text{MB}\) |
| 区间复制(HDU6087) | \(483\text{ms},50080\text{KB}\) | \(904\text{ms},26048\text{KB}\) |
3 持久化字典树
3.1 基本思想
持久化字典树的思想和上面两种数据结构依然一致,容易发现,当我们插入一个字符串的时候,我们只会修改这条路径上节点的信息,而别的地方我们不会加以理睬。所以对于没有修改的地方,我们直接复用上一次的节点即可。
大部分情况下,持久化字典树使用的都是 \(\text{0-1 Trie}\),当然也有例外。
3.2 例题
例 1 [BZOJ3261] 最大异或和
容易将区间的异或转化为两个前缀异或和的异或。也就是 \(s_{p-1}\oplus s_n\oplus x\)。发现后面的值是定值,所以实际上就是查询区间 \([l-1,r-1]\) 中 \(s_p\) 异或 \(s_n\oplus x\) 的最大值。
考虑到没有区间限制的时候,我们就是每一次尽可能往与当前位不同的那一位上走。现在有了区间的限制,我们就需要知道这个区间内所有数构成的字典树上的信息。考虑运用主席树的思想,每一次插入一个数后建持久化字典树,然后两个点之间作差就可以知道当前节点在这个区间内的出现次数,以此来判断能不能走到该节点然后求答案即可。
代码如下:
#include <bits/stdc++.h>
using namespace std;
const int Maxn = 6e5 + 5;
const int Inf = 2e9;
int n, q, a[Maxn];
int sum[Maxn];
int rt[Maxn];
namespace Trie {
struct node {
int son[2], siz;
}t[Maxn * 25];
int tot = 0;
int insert(int p, int x) {//在上一个版本的基础上建字典树
int rt = ++tot, ret = rt;
for(int i = 25; i >= 0; i--) {
int ch = (x >> i) & 1;
t[rt] = t[p];
t[rt].siz++;
t[rt].son[ch] = ++tot;
rt = t[rt].son[ch];
p = t[p].son[ch];
}
t[rt] = t[p];
t[rt].siz++;
return ret;
}
int query(int p, int q, int x) {//两颗字典树作差得到当前区间的字典树
int ans = 0;
for(int i = 25; i >= 0; i--) {
int ch = (x >> i) & 1;
if(t[t[q].son[ch ^ 1]].siz - t[t[p].son[ch ^ 1]].siz) {//有节点才能跳
ans += (1 << i);
p = t[p].son[ch ^ 1];
q = t[q].son[ch ^ 1];
}
else {
p = t[p].son[ch];
q = t[q].son[ch];
}
}
return ans;
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0), cout.tie(0);
cin >> n >> q;
rt[0] = Trie::insert(rt[0], 0);//先插入 0
for(int i = 1; i <= n; i++) {
cin >> a[i];
sum[i] = sum[i - 1] ^ a[i];
rt[i] = Trie::insert(rt[i - 1], sum[i]);
}
while(q--) {
char opt;
int l, r, x;
cin >> opt;
switch(opt) {
case 'A': {
cin >> x;
a[++n] = x;
sum[n] = sum[n - 1] ^ a[n];
rt[n] = Trie::insert(rt[n - 1], sum[n]);
break;
}
case 'Q': {
cin >> l >> r >> x;
l--, r--;
if(!l) cout << Trie::query(0, rt[r], sum[n] ^ x) << '\n';
else cout << Trie::query(rt[l - 1], rt[r], sum[n] ^ x) << '\n';
break;
}
}
}
return 0;
}
例 2 [BZOJ2741] Fotile 模拟赛 L
最大异或和仍然可以考虑上一题的方式,但是如果直接暴力枚举并求解的话复杂度是 \(O(nm\log V)\),难以通过。
考虑序列没有修改操作,所以可以进行预处理,这时可以想到分块。预处理出 \(mx(l,r)\) 表示区间端点在第 \(l\) 个块到 \(r\) 位置之间的最优答案。转移显然可以从 \(mx(l,r-1)\) 转移过来,用持久化字典树求出以 \(r\) 为右端点的最优答案即可。
查答案的时候只需要对散块暴力查询即可,仍然运用持久化字典树。设块长为 \(B\),复杂度为 \(O(n\cdot \dfrac nB\cdot \log V+mB\log V)\)。取 \(B=\sqrt{n}\) 即可,复杂度为 \(O(n\sqrt n\log V)\)。
例 3 [THUSC2015] 异或运算
发现这居然是求矩阵中的第 \(k\) 大值,那么直接考虑二分。我们先想想对于一个固定的 \(x\),找出一段区间内的 \(y\) 与 \(x\) 异或后的第 \(k\) 大值怎么做,显然可以在持久化字典树上二分,每次判断一下当前位取到 \(1\) 的大小并与 \(k\) 比较即可。复杂度 \(O(\log V)\)。
然后考虑给出了一段 \(x\) 之后怎么做,不难发现题目中的 \(x\) 只有 \(1000\) 个,所以暴力枚举后跑多重根的二分即可,复杂度 \(O(pn\log V)\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号