NOIP2025 题解
T1
宝宝题,10min 秒了。
赛后:你妈怎么没判 sigma x > m,跳了
T2
赛时怎么被这道煞笔题创飞了,加训计数。
正难则反,考虑不优的方案数。
首先充要条件很好推,先从大到小排序,观察样例 1 发现当且仅当存在 \(w_i=2, w_j=1, w_k=1\) 使得 \(2a_j > a_i, a_j < a_i, a_k < a_j, a_j + a_k < a_i\) 且考虑到 \(j\) 的时候只剩 \(m - 2\) 元了。这样的话最优应该是买 \(i\) 而不是 \(j\) 和 \(k\),注意到 \(k\) 是可以不存在的,但是不用特判。
考虑枚举 \(i, j\), 那么 \(x \ge j\) 的 \(x\) 的 \(w\) 可以是 \(1\) 或 \(2\),除了 \(i\) 需要是 \(2\) 以外其余都可以随便填,再令 \(k\) 为最小的满足条件的 \(k\),则 \([i + 1, k - 1]\) 都得是 \(2\) 不然不会考虑到 \(k\),最后一段的贡献是 \(2^{n - k + 1}\),没有 \(k\) 满足时是 \(1\),所以不用特判。
再看前面,任选 \(1, 2\) 使得总花费是 \(m - 2\),范德蒙德卷积得方案为 \(\dbinom{j - 2}{m - i - 1}\)。前后乘一起即可。
时间复杂度 \(\mathcal{O}(\sum n^2)\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
// typedef __int128 i128;
typedef pair<int, int> pii;
const int N = 5e3 + 10, mod = 998244353;
template<typename T>
void dbg(const T &t) { cout << t << endl; }
template<typename Type, typename... Types>
void dbg(const Type& arg, const Types&... args) {
cout << arg << ' ';
dbg(args...);
}
int C[N][N], pw[N];
namespace Loop1st {
int n, m, a[N];
void add(ll &x, ll y) { x += y; if (x >= mod) x -= mod; }
void main() {
cin >> n >> m;
ll ans = 0;
for (int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + n + 1, greater<int>());
for (int i = 1; i < n; i++) {
int k = 1;
for (int j = n; j > i; j--) if (a[j] < a[i] && 2 * a[j] > a[i]) {
while (k <= n && a[j] + a[k] >= a[i]) k++;
if (m - i - 1 > j - 2 || m - 1 < i || j < 2) continue;
add(ans, (ll)C[j - 2][m - i - 1] * pw[n - k + 1] % mod);
}
}
cout << (pw[n] - ans + mod) % mod << '\n';
}
}
int main() {
// freopen("data.in", "r", stdin);
// freopen("data.out", "w", stdout);
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
pw[0] = 1;
C[0][0] = 1;
for (int i = 1; i < N; i++) {
pw[i] = pw[i - 1] * 2 % mod;
C[i][0] = C[i][i] = 1;
for (int j = 1; j < i; j++) {
C[i][j] = (C[i - 1][j] + C[i - 1][j - 1]) % mod;
}
}
int c, T; cin >> c >> T;
while (T--) Loop1st::main();
return 0;
}
T3
无敌了赛时一直在做这个。
::::info[记号说明]
\(\text{subtree}_u\):\(u\) 的子树内(不包括 \(u\))的点组成的集合。
\(\text{son}_u\):\(u\) 的子节点组成的集合。
\(\text{path}_{u, v}\):树上 \(u\) 到 \(v\) 的简单路径上的点组成的集合。
::::
以下内容参考了其它题解。
记每个点填的数为 \(a_u\),答案为 \(b_u\),另记 \(x = \text{mex}_{v\in \text{subtree}_u} a_v\),称 \(a_u=x\) 的点为黑点,否则为白点。显然,\(a_u \ge x\)。
白点的作用一定是为黑点产生贡献,可以理解成是将一个白点分配给一个唯一的黑点,让这个黑点的贡献 \(+1\)。
容易设计出一个状态:\(f_{u, i, j}\) 表示 \(u\) 子树内(不包括 \(u\) 本身) \(x = i\),有 \(j\) 个白点的最大价值和。转移即枚举 \(b_u\) 与 \(\max_{v \in son_u} {b_v}\) 的差,表示将这么多个白点分给 \(u\),再枚举一个取到 \(\max b_v\) 的 \(v\),可以做到 \(\mathcal{O}(n^4)\) 或 \(\mathcal{O}(n^3)\)。
我们考虑这个取到最大值的儿子 \(v\),我们令其为重儿子(和重链剖分没有关系),那么树就被剖分成了若干链,且每次 \(b_u \leftarrow b_u + 1\),都会使 \(u\) 到该链的链顶这些点 \(b + 1\) 即分一个白点给 \(u\) 的贡献为 \(\text{dep}_u\)。注意这里的 \(\text{dep}_u\) 是指其到链顶的路径上的点数。
考虑 \(f_{u, i, j}\) 表示 \(u\) 所在链的长度为 \(i\),\(\text{dep}_u=j\) 的答案(\(\text{dep}_u\) 定义同上)。这个的转移是 \(\mathcal{O}(nm^2)\) 的。
考虑优化,发现其实 \(j = 1\) 和 \(j = i\) 的情况就足够了:\(f_{u, i}\) 表示 \(u\) 就是其所在链的链顶,链长为 \(i\) 的答案,\(g_{u, i}\) 表示 \(u\) 是其所在链链底,链长为 \(i\) 的答案。
初始时 \(f_{u, i}, g_{u, i}\) 都为 \(i \times sz_u\)。
\(g\) 的转移:
\(f\) 的转移:考虑枚举一个与 \(u\) 距离为 \(i - 1\) 的后代 \(v\) 代表链底,有转移:
后面这一坨代表这些链被截了,\(i(i - 1)\) 是 \(b_u\)。
枚举 \(v\) 的复杂度是 \(\mathcal{O}(nm)\) 的,因为每个点最多有 \(m\) 个祖先。
使用树状数组即可做到 \(\mathcal{O}(nm \log n)\)。
T4
看的 @IvanZhang2009 老师的题解,太深刻了。
考虑分治,对于每次询问,用 solve(x, y) 处理 \(x \le l \le i \le r \le y\) 的答案,其中 \(r - l + 1 \in [L, R]\)。
令区间中点为 \(mid\),考虑 \(i \le mid\) 这一边,另一边同理,\(r \le mid\) 的会分治处理,所以考虑 \(r > mid\)。枚举 \(l\),合法的 \(r\) 是一个区间,对于每个 \(l\) 单调队列/ST 表就行。每个 \(l\) 可以贡献到的 \(i\) 是所有 \(i \in [l, mid]\),做一个前缀 \(\max\) 即可。
这样分治一次时间复杂度是 \(\mathcal{O}(\min(R, y - x + 1))\) 的。另外如果 \(y - x + 1 < L\) 直接停掉。
那么每次分治带个 \(\log\),总复杂度是 \(\mathcal{O}(nq \log n)\) 的,常数有点大,应该过不去。
到这里为止这题就是一个正常的下位紫。发现不太好优化了。
考虑观察性质 DE,发现非常奇怪,那么这俩性质肯定有用。
观察 D 性质,发现每个合法的 \([l, r]\) 区间都会过中点,分治一层就结束了。观察 E 性质,两层结束。
发现了什么?
我们来画一下分治的区间,和线段树差不多:
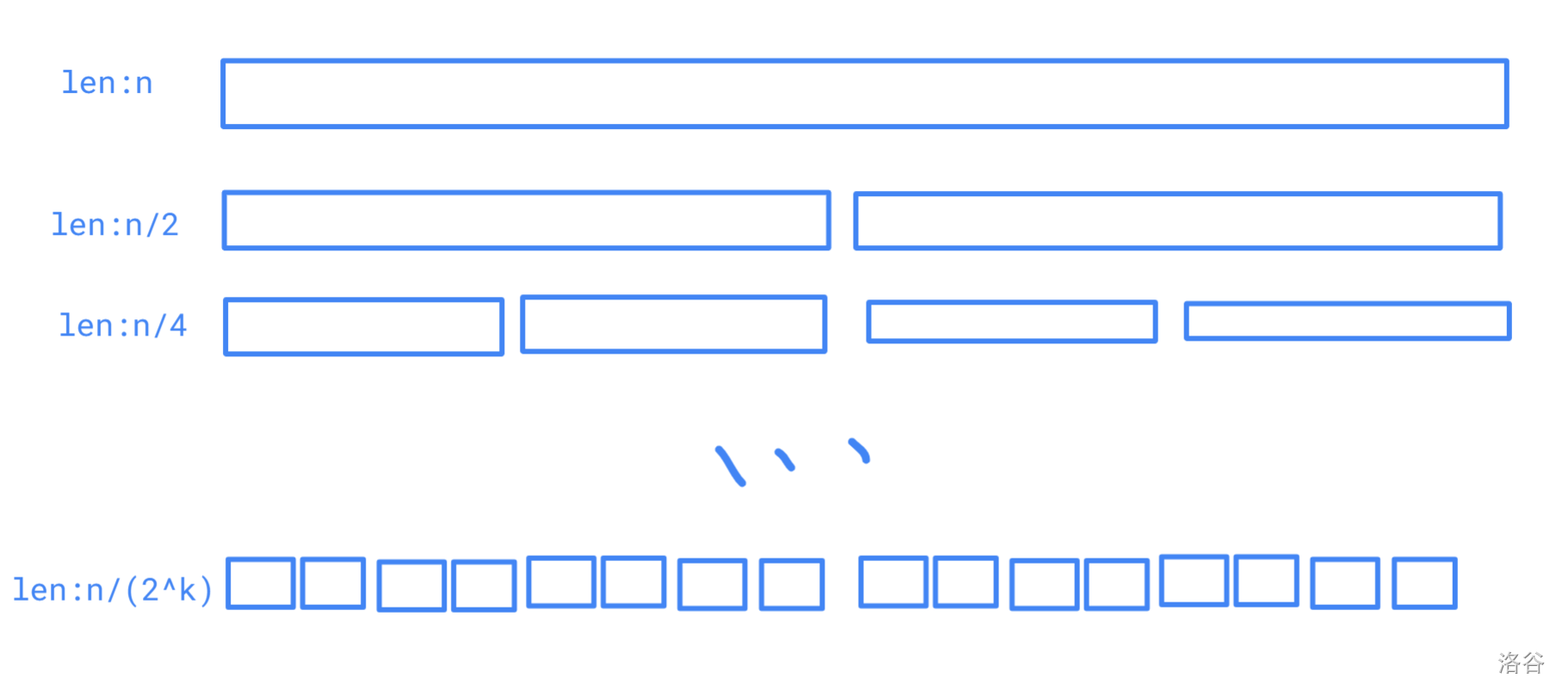
其中 \(k\) 是最大的使得 \(\frac{n}{2^k} \ge L\) 的 \(k\)。
每层的区间个数有一个性质:第 \(t\) 层 \(2^{t-1}\) 个,前 \(t\) 层一共 \(2^{t}-1\) 个。第 \(k\) 层的区间有 \(\mathcal{O}(\frac{n}{L})\) 个,由于前 \(k - 1\) 层的区间个数不超过第 \(k\) 层的区间个数,所以前 \(k\) 层的区间一共有 \(\mathcal{O}(\frac{n}{L})\) 个。
正常的分治是用 \(\sum\limits_{x, y} y - x + 1\) 计算复杂度的,每层 \(\sum y - x + 1 = n\) 故复杂度为 \(\mathcal{O}(n \log n)\)。
另外地,如果计算一个区间的复杂度有下界,那么也可以是区间个数 \(\times\) 下界,本题中下界为 \(R\)。这种方式算出来是 \(\mathcal{O}(\frac{n}{L}R)\) 的。
当 \(\frac{R}{L} = \mathcal{O}(1)\) 时,分治的复杂度是 \(\mathcal{O}(\frac{n}{L}R) = \mathcal{O}(n)\) 的。线性分治神奇不??
接下来就需要凑出这样的 \(L, R\) 了。观察到 \([L, R]\) 拆成若干区间后每个区间分别处理没有问题,所以我们可以拆成若干个 \(L' = 2^i, R' = 2^{i + 1} - 1\),这样的分治是线性的,就像分块一样,散块直接暴力分治,整块可以预处理并使用 ST 表。
时间复杂度 \(\mathcal{O}(n \log^2 n + nq)\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号