吴恩达深度学习课程五:自然语言处理 第二周:词嵌入(六)情绪分类和词嵌入除偏
此分类用于记录吴恩达深度学习课程的学习笔记,目前已完结,点击进入全集目录
课程相关信息链接如下:
- 原课程视频链接:[双语字幕]吴恩达深度学习deeplearning.ai
- github课程资料,含课件与笔记:吴恩达深度学习教学资料
- 课程配套练习(中英)与答案:吴恩达深度学习课后习题与答案
本篇为第五课的第二周内容,2.2、2.9和2.10内容,同时也是本周理论部分的最后一篇。
本周为第五课的第二周内容,与 CV 相对应的,这一课所有内容的中心只有一个:自然语言处理(Natural Language Processing,NLP)。
应用在深度学习里,它是专门用来进行文本与序列信息建模的模型和技术,本质上是在全连接网络与统计语言模型基础上的一次“结构化特化”,也是人工智能中最贴近人类思维表达方式的重要研究方向之一。
这一整节课同样涉及大量需要反复消化的内容,横跨机器学习、概率统计、线性代数以及语言学直觉。
语言不像图像那样“直观可见”,更多是抽象符号与上下文关系的组合,因此理解门槛反而更高。
因此,我同样会尽量补足必要的背景知识,尽可能用比喻和实例降低理解难度。
本周的内容关于词嵌入,是一种相对于独热编码,更能保留语义信息的文本编码方式。通过词嵌入,模型不再只是“记住”词本身,而是能够基于语义关系进行泛化,在一定程度上实现类似“举一反三”的效果。词嵌入是 NLP 领域中最重要的基础技术之一。
本篇的内容关于情绪分类和词嵌入除偏,是对本周内容的最后补充。
1. 词向量的使用
在介绍完前面的内容后,你会发现,我们使用各种模型和技术,最终的目的都是为了得到可以合理刻画文本信息间语义关系的词向量。
而一旦这些词向量被训练出来,它们的价值并不会随着训练任务的结束而消失,反而真正的用武之地才刚刚开始。
实际上,在词向量的使用中,最常见、也是最直接的方式,就是将训练好的词向量作为下游任务的输入表示。
在文本分类、情绪分析、问答系统等任务中,我们不再使用独热编码这种“只区分身份、不包含语义”的表示方式,而是通过查表的方式,将每个词映射为一个稠密的词向量,再送入分类器或序列模型中进行处理。
也正是这种连续、可度量的语义空间,使得模型在还没有接触具体任务之前,就已经拥有了一定程度的语言理解能力。
而且,你会发现这其实是一种非常典型的迁移学习思想:
词向量模型在大规模语料上学习到的是一种通用的语言结构与语义分布,而下游任务只需要在此基础上进行少量参数调整,就可以完成更具体的目标。
更重要的是, NLP 中对词向量的迁移学习和我们之前介绍的 CV 内容有所不同,在 CV 任务中,迁移效果往往高度依赖于任务之间的相似性,例如用自然图片上训练得到的模型参数去处理医学影像,效果未必理想。
而在 NLP 领域中,由于语言本身具有极强的通用性,只要任务使用的是同一语言,将预训练词向量作为嵌入层矩阵的初始化方式,往往是一种“用了就不亏”的选择。
最终,从模型结构上看,这相当于模型的第一层不再从完全随机的参数开始学习,而是直接站在了一个已经组织好语义结构的空间中,再去完成具体任务。
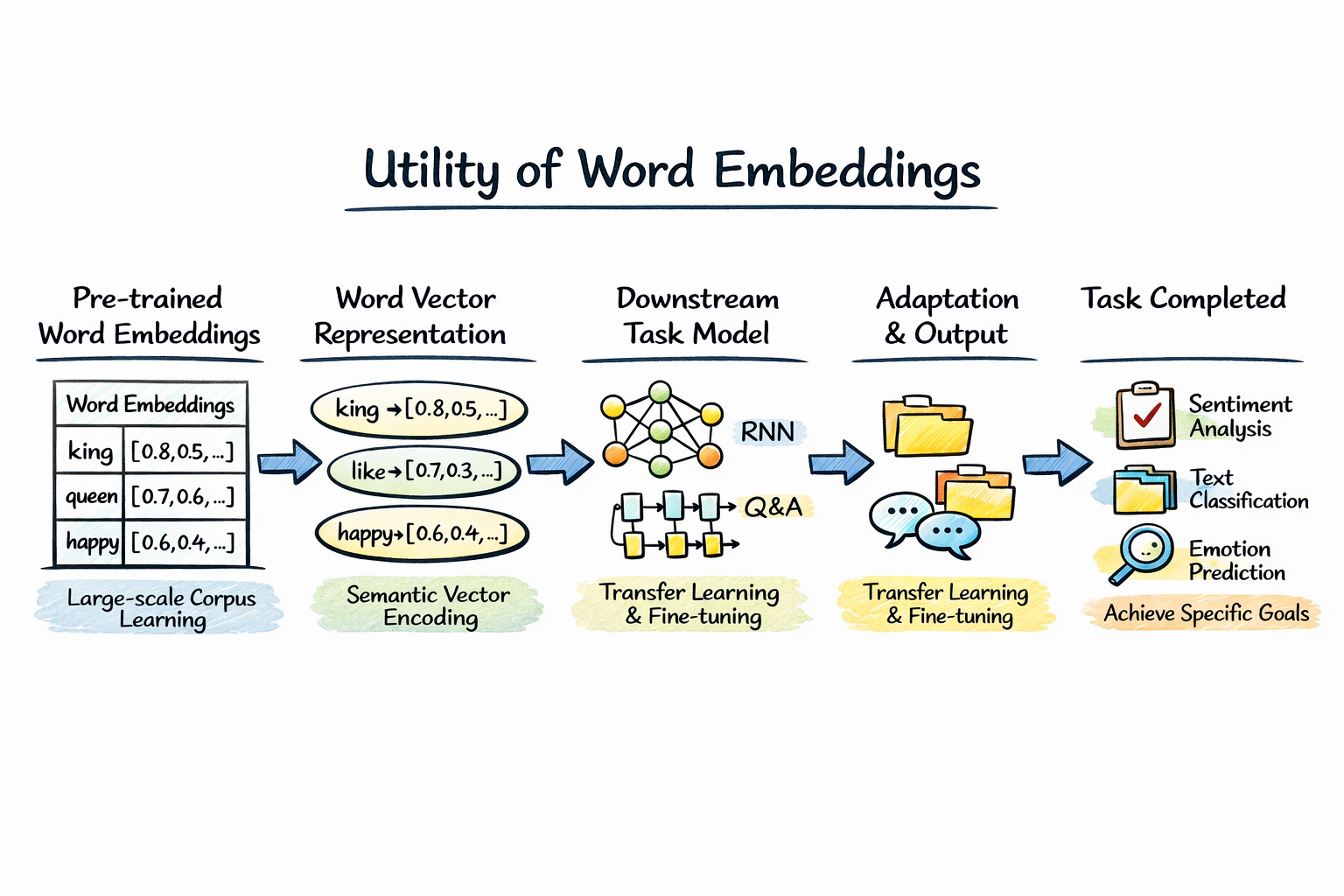
也正是在这样的背景下,NLP 的各种应用百花齐放,其中最经典的应用之一,就是下面要介绍的情绪分类。
2. 情绪分类(Sentiment Classification)
2.1 情绪分类原理
情绪分类是自然语言处理领域中最早被系统研究、同时也最具代表性的任务之一。
其基本形式并不复杂:给定一段文本,判断其情绪倾向,例如正面、负面,或更细粒度的多类别情绪。
简单举个例子:
对于两条酒店评论 “拉完了” 和 “夯爆了”,我们可以在不同的情绪粒度下,对它们给出不同形式的分类结果。
- 正负二分类:在最粗粒度的情绪分类任务中,我们只关心文本所表达的整体态度是正面还是负面。
- “拉完了” → 负面情绪
- “夯爆了” → 正面情绪
在这一设定下,模型的目标非常明确:只需判断“喜欢”还是“不喜欢”,而不关心情绪强度或细节差异。
2. 星级五分类:如果进一步提高情绪刻画的精细程度,就可以将任务扩展为多类别分类,例如常见的 1~5 星评分预测。
- “拉完了” → ★☆☆☆☆
- “夯爆了” → ★★★★★
在这一情况下,模型不仅需要识别情绪的正负,还需要理解情绪的强烈程度,相比二分类任务,五分类对语义表示的要求明显更高。

可以看出,情绪分类任务的核心难点并不在于模型结构本身,而在于如何让模型“理解”文本所蕴含的情绪语义。
而这恰恰正是词向量发挥作用的地方:只有当“拉完了”“夯爆了”这样的词语在向量空间中被映射到合理的位置,后续的分类模型才有可能做出稳定、可靠的判断。
而在句子中,情绪本身并不是由单个词独立决定的,而是由多个词在语义空间中的组合关系共同构成。
同样举例来说明,比如:
- “好” 和 “棒” 在语义空间中彼此接近。
- “糟糕” 和 “失望” 会聚集在另一片区域。
因此,当文本被表示为一组词向量后,模型实际上是在判断:这些向量整体更靠近“正面情绪区域”,还是“负面情绪区域”。
这也是为什么,在情绪分类任务中,词向量的质量往往直接决定了模型的上限。
了解了基本原理后,我们来看看如何实现情绪分类。
2.2 情绪分类 1.0 :平均词向量输入分类器
在最早期、也是最朴素的情绪分类实现中,我们并不会引入复杂的序列模型,而是采用一种几乎不关心词序的做法:将一句话中所有词的词向量取平均,作为整句文本的表示。
具体来说,假设一句话由 \(n\) 个词组成,其对应的词向量分别为 :\(\mathbf{w}_1, \mathbf{w}_2, \dots, \mathbf{w}_n\),那么句向量可以直接定义为:
这个 \(\mathbf{s}\) 就被视为整段文本在语义空间中的“位置”,随后只需要将它送入一个简单的分类器(如全连接层 + softmax),即可完成情绪预测。
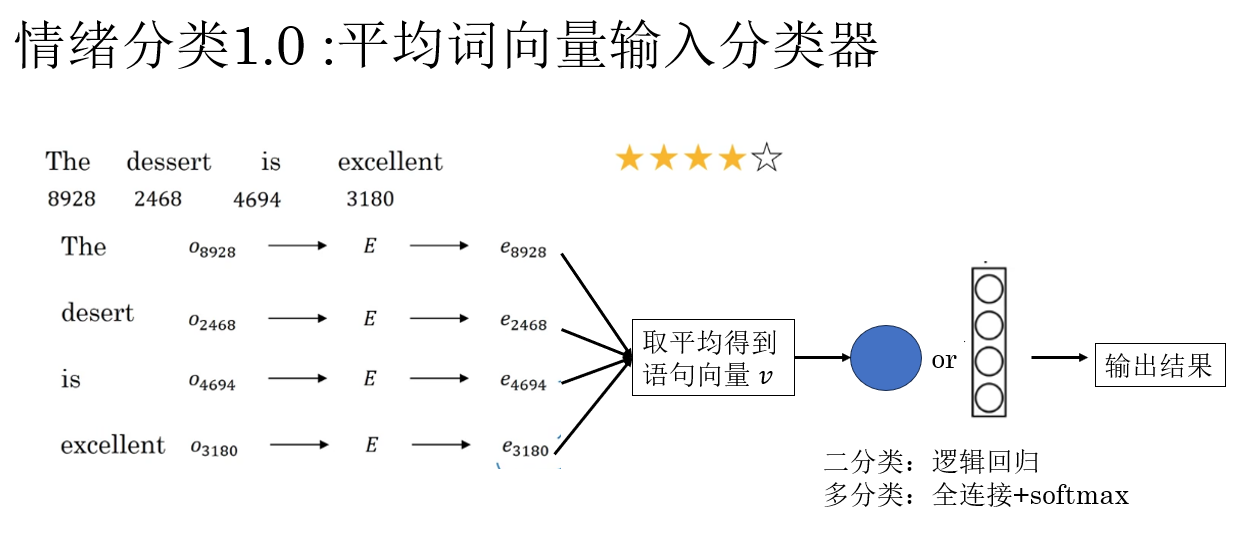
这种方法理解起来很直观:这句话里,所有词语的“情绪方向”加起来,更偏向哪一边?
如果一句话中大多数词的向量都靠近“正面情绪区域”,那么平均后的结果自然也会偏向正面;反之亦然。
它的优点是实现简单,计算开销极低;不依赖复杂模型,对小数据集也较为友好,而且通过这种简单的方式也可以直观体现词向量质量对下游任务的影响。
但它的缺点非常突出,我们常说:语言是有顺序的,这种方法完全忽略了词序信息,只看孤立的语义方向的堆叠,便极有可能产生相应的误解。
例如:“缺少好的服务,好的环境和好的餐食。”
这句话很明显是负面评价,分类器却可能因为出现了很多“好”而将其判断为正面评价。
因此,平均词向量 + 分类器 只是情绪分类任务的入门解法,我们知道有这种方式即可。
2.3 情绪分类 2.0 :使用循环神经网络
与直接取平均不同,RNN 会按顺序逐词读取文本,并在每一步将当前词的信息与历史上下文进行融合。
而回顾之前介绍的语言模型内容就会发现,不同于我们之前演示使用的命名实体识别,情绪分类是在读取完整句信息后输出一个分类结果,它是一个多对一模型,这类模型反而更符合我们的直觉,来看它的传播过程:
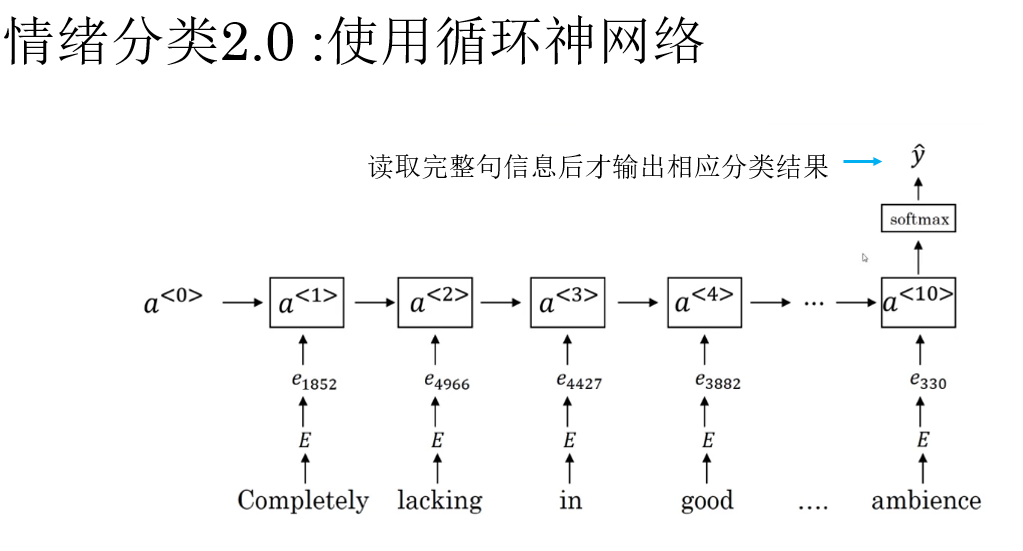
对于一个词序列 \(w_1, w_2, \dots, w_n\),RNN 的核心计算可以抽象为:
其中,\(\mathbf{a}_t\) 表示模型在读到第 \(t\) 个词时,对“当前语义状态”的综合理解。
我们使用最后一个隐藏状态 \(\mathbf{a}_n\) 作为整句文本的表示,再将得到的句向量输入分类器进行预测,得到最终的分类结果。
这种方式带来的最大改变在于:情绪不再是词向量的简单叠加,而是一个随阅读过程逐步演化的结果。
举例来说:
- 在读到“好”的时候,模型的情绪倾向可能偏正。
- 但当随后读到“不”时,隐藏状态会被重新调整。
- 最终输出的表示能够体现“否定”对整体情绪的修正。
因此,RNN 在对语义的理解能力上明显优于简单的平均向量方法。当然,这也带来了梯度问题和训练成本的提升。
情绪分类的相关技术同样在不断进步,如今,以 BERT 为代表的双向 Transformer 通过大规模语料预训练,能够捕获更精细的上下文语义关系,在情绪分类等判别任务上显著超越传统模型,而更前沿的做法是直接利用指令微调的大语言模型,通过 prompt 或少量样本即可完成情绪判断。
情绪分类正逐步从“专用模型任务”内化为“通用语言理解能力”的自然体现。
下面,我们补充最后一部分内容:
3. 词嵌入除偏(Word Embedding Debiasing)
我们知道,词向量并不是从真空中学到的,它们来源于真实语料。而真实语料,本身就不可避免地携带着各种社会偏见和统计偏向。
由于词向量的训练目标是捕捉词与词的共现关系,如果某些刻板印象在语料中频繁出现,那么它们就会被“如实地”编码进向量空间中。
例如,在大量文本中,如果:
- “医生” 、“工程师”更频繁地与男性词汇共现。
- “护士” 、“保姆”更频繁地与女性词汇共现。
那么训练出来的词向量空间中,就可能形成一条明显的“性别方向”,并在无意中强化这些关联。
从模型角度看,这种行为是完全合理的统计学习结果,但从应用角度看,这种偏见在情绪分析、招聘筛选、推荐系统等场景中,可能带来严重问题。
这便是词嵌入除偏的目标:在尽量保留语义信息的前提下,削弱或移除特定维度上的偏见成分。
2016 年, 论文 Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings 中,首次对词嵌入中的社会偏见进行了清晰的建模,并提出了一套可操作的除偏方法。它的主要观点是:偏见并不是“到处都是”的,而是主要集中在某些可解释的方向上。
我们分点来看看这一方法的实现逻辑:
3.1 定义偏见方向(Bias Direction)
论文的第一步,是显式地定义什么是“偏见方向”。
以性别偏见为例,我们并不凭主观判断去找偏见,而是构造一组成对的性别词,例如:
- (he, she)
- (man, woman)
- (king, queen)
对于每一组词对,都可以在词向量空间中计算其差向量。将这些差向量进行平均,便可得到一个代表“性别差异”的方向向量,就像这样:
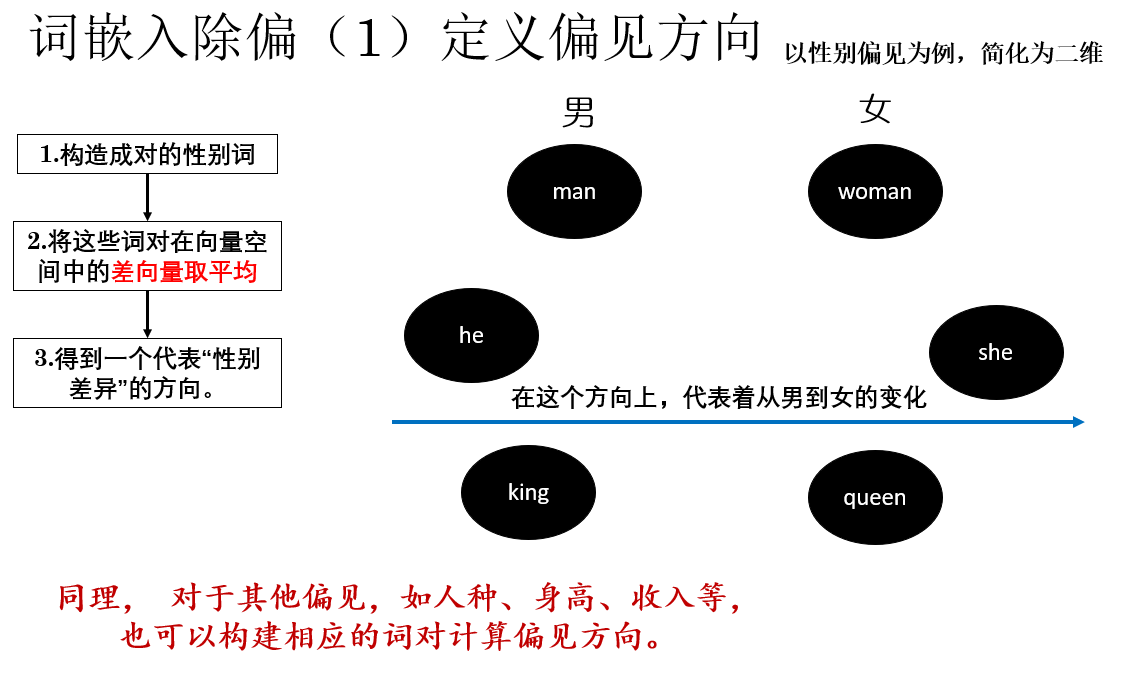
假定词向量拟合度较高,那么对于这个方向就可以理解为:沿着这条方向移动,语义主要在“男性 ↔ 女性”之间变化,而与其他语义因素关系不大。
这一步的意义在于将原本模糊、抽象的“偏见”问题,转化为向量空间中一个可操作的几何方向。,就像射击前需要先确定靶心一样,只有明确了偏见方向,后续才能有针对性地削弱或移除某些词在该方向上所携带的偏见成分。
3.2 区分中性词与性别词
同样以性别偏见为例:接下来,我们将词汇分为两类:
- 性别中性词:如 doctor, nurse, homeworker,它们不应天然带有性别信息。
- 性别特定词:如 man, woman, she, he,要保留合理的性别信息。
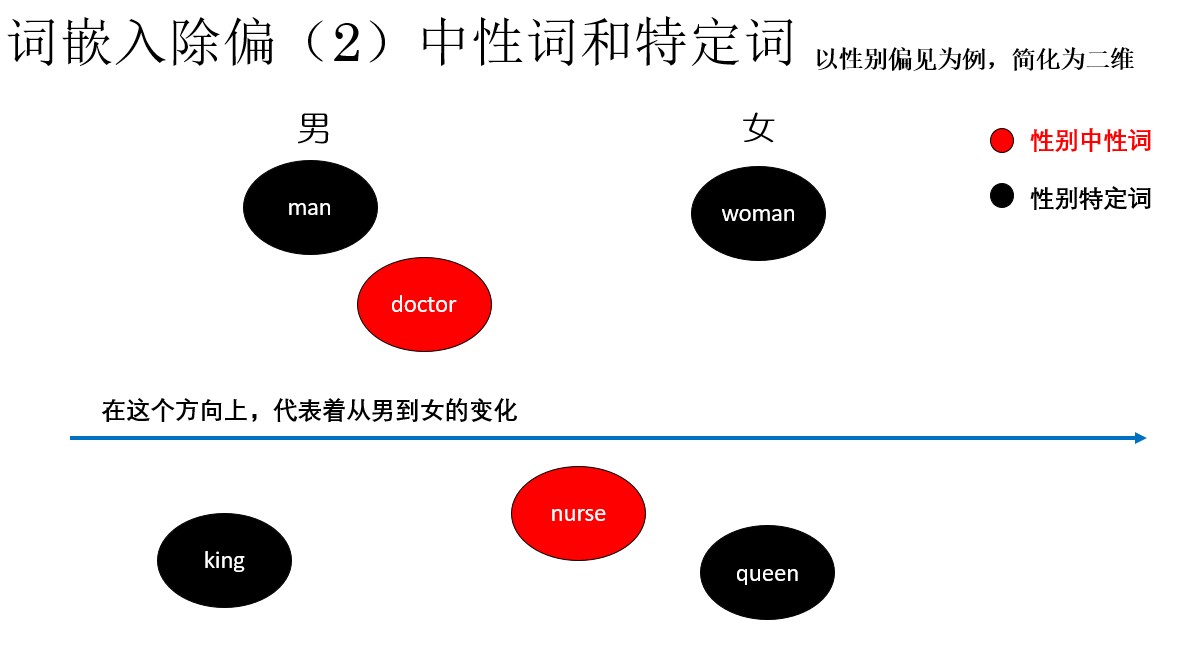
注意,这样区分并不代表我们不对特定词进行处理,而是对不同类型的词采取不同策略:
- 对语义上应当与性别无关的中性词,应移除其性别方向上偏见。
- 对本身就包含性别差异的词对,则在保留性别信息的前提下,强制其在性别维度上对称、在其他语义维度上对齐,从而避免偏见被不合理地放大。
下面就来看看如何实现这些策略:
3.3 硬除偏(Hard Debias)
其实并不难理解,首先,我们处理中心词,这一步我们称之为去投影(Neutralize):将中性词向量在性别方向上的分量直接移除,使其在该方向上的投影为 0。
就像这样:
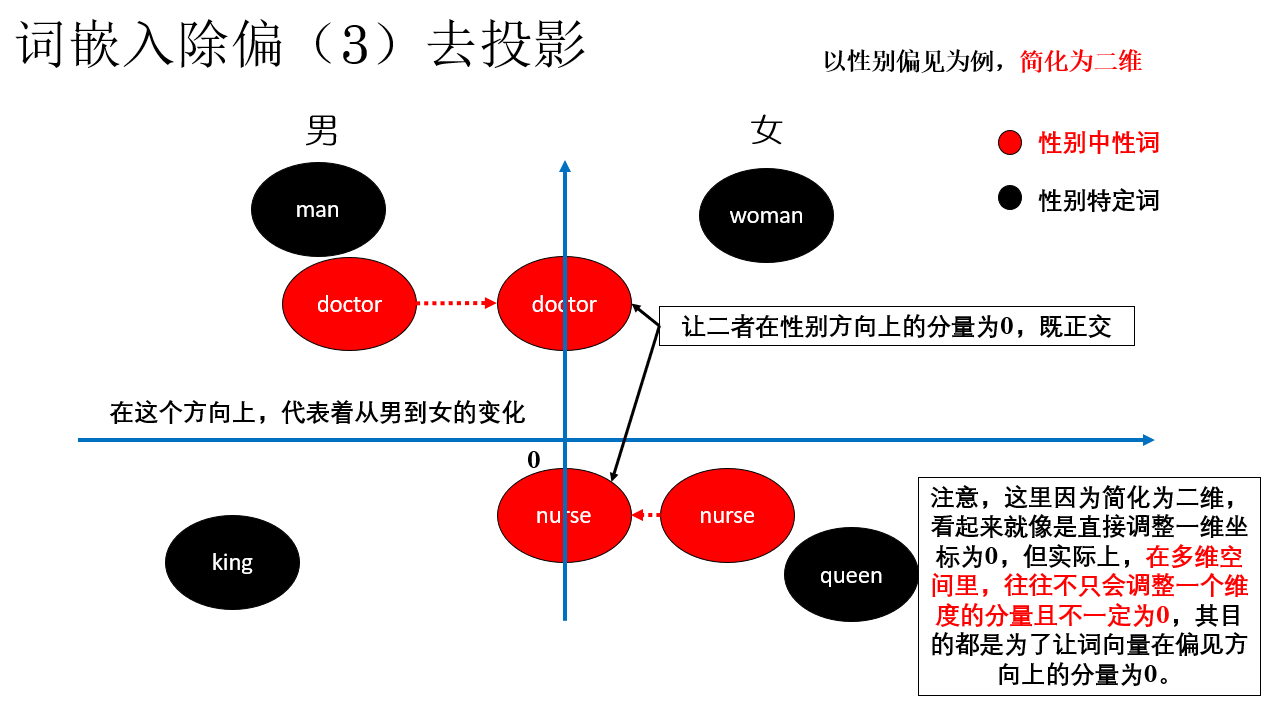
通过这样调整词向量,让中性词在性别方向上的分量消失,自然就不会因为这个方向上的语义差异而产生偏见。
继续,我们处理特定词,而这部分我们称为等距化(Equalize):对于这类本应只在性别上不同的词对,强制它们在性别方向上的距离对称,而在其他语义维度上保持一致。
就像这样:
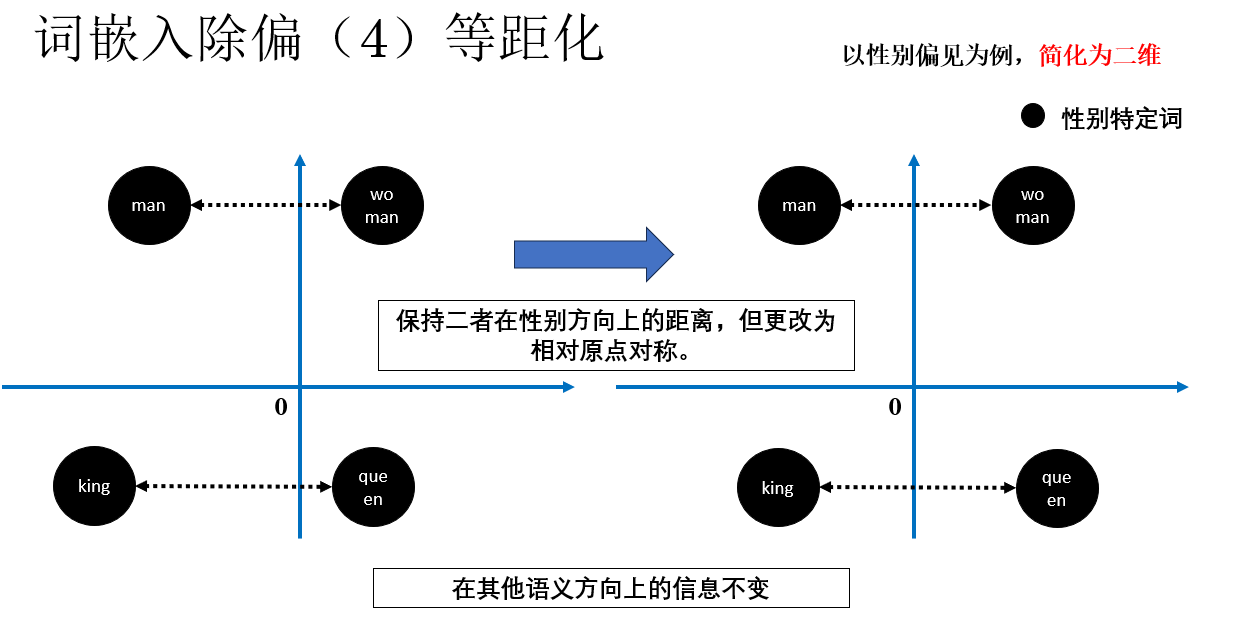
这样做的道理很直观:对于“男”和“女”,在语义空间里,我们不希望出现“男只有一点点男性特征,而女则非常女性化”的不对称情况。
如果特定词在性别方向上不对称,不仅会模糊性别边界,还可能降低词向量的整体质量。
通过等距化,特定词对在“性别以外”的语义上保持等价,但在性别方向上依然可以清晰区分,从而既消除偏见,又保留必要的性别信息。
此外,既然有硬除偏,自然也有软除偏,在明白了硬除偏后,软除偏便不难理解:
简单来讲,软除偏只针对中性词,其处理逻辑和硬除偏也大体相同,不同的是软除偏将每类偏见中“让中性词在偏见方向上的分量最小化”的逻辑加入神经网络损失函数中作为一项进行迭代优化。
这种方法更符合我们在深度学习领域的直觉,实际上在现代技术中也有继承软除偏思想、更先进的词嵌入除偏方法,这里就不再专门展开了。
4. 总结
| 概念 | 原理 | 理解 |
|---|---|---|
| 词向量使用 | 将训练好的词向量作为下游任务输入,捕捉语义关系,支持迁移学习。 | 模型第一层不再从零开始,而是“站在已整理好的语义空间上”。 |
| 情绪分类(Sentiment Classification) | 给定文本判断情绪倾向,可二分类(正/负)或多分类(如 1~5 星)。 | 文本中的词语向量整体靠近“正面区域”还是“负面区域”。 |
| 平均词向量 + 分类器 | 将句子中所有词向量取平均作为整句表示,再送入分类器。 | 词语的“情绪方向”堆叠,哪边多就偏向哪边。 |
| RNN 情绪分类 | 按顺序逐词读取文本,将当前词与历史上下文融合,输出最后隐藏状态作为句向量。 | 情绪随着阅读过程逐步演化,如“好” → 正面,但遇到“不”被修正。 |
| 词嵌入偏见问题 | 词向量从真实语料中学习共现关系,容易捕捉社会偏见(如性别刻板印象)。 | 统计规律“如实反映”,但可能强化偏见。 |
| 偏见方向(Bias Direction) | 构造成对词(he/she, man/woman),计算差向量并平均得到偏见方向。 | 在向量空间中,沿此方向语义主要在“男性 ↔ 女性”之间变化。 |
| 区分中性词与特定词 | 中性词移除偏见方向成分;特定词保持性别信息并等距化。 | 中性词去除偏见就像去掉不必要的色彩,特定词对保持对称,就像男女形象保持平衡。 |
| 硬除偏(Hard Debias) | 对中性词去投影使性别方向为 0,对特定词做等距化保持对称。 | 用“刀子”切掉中性词性别成分,同时调整特定词对保持对称。 |
| 软除偏(Soft Debias) | 只针对中性词,将“最小化偏见方向分量”的目标加入损失函数,通过迭代优化实现减弱偏见。 | 温和压低偏见方向,而不是完全切掉,保留语义空间结构。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号