

InstructGPT 论文略读:三步走,让大模型真正听懂人话
摘要:
InstructGPT 论文略读:三步走,让大模型真正听懂人话 摘要 (Introduction) 大语言模型(LLM),如 GPT-3,无疑开启了自然语言处理的新纪元。它们强大的零样本和少样本学习能力,让我们看到了通用人工智能的一丝曙光。然而,任何与 GPT-3 有过深入“交流”的开发者或研究员都 阅读全文
posted @ 2025-10-06 09:47 GlenTt 阅读(253) 评论(0) 推荐(0)
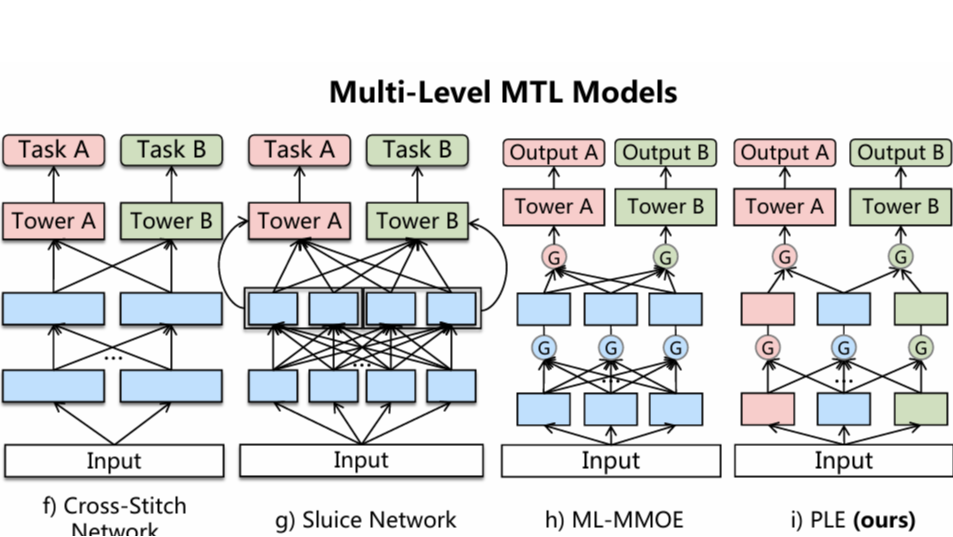 从MMoE到PLE:读懂多任务学习架构的渐进式演化 引言 在多任务学习(MTL)领域,MMoE(Multi-gate Mixture-of-Experts)无疑是一个里程碑式的模型,它通过巧妙的软参数共享机制,极大地提升了工业界推荐、广告等系统的多目标优化能力。然而,在面对任务间关系愈发复杂、甚至相
从MMoE到PLE:读懂多任务学习架构的渐进式演化 引言 在多任务学习(MTL)领域,MMoE(Multi-gate Mixture-of-Experts)无疑是一个里程碑式的模型,它通过巧妙的软参数共享机制,极大地提升了工业界推荐、广告等系统的多目标优化能力。然而,在面对任务间关系愈发复杂、甚至相  浙公网安备 33010602011771号
浙公网安备 33010602011771号