

ESMM 核心总结笔记
ESMM 核心总结笔记
背景
在电商推荐场景下,我们的最终目标是让用户在看到商品(曝光)后完成下单(转化)。如果直接把这个“曝光→转化”的联合概率当成一个单一的预测目标(CTCVR)来训练,正样本——也就是既被曝光又产生了转化的记录——在海量用户行为日志里极度稀少,模型很难从如此稀疏的数据中学到有用特征,训练往往会陷入梯度稀疏、收敛缓慢甚至不稳定的困境。以及随着归因分析的趋势,开始对CVR建模,CVR能够反映详情页、价格和促销等因素的说服力在哪里出现问题。
传统 CVR 模型只在点击样本上训练,导致训练空间与实际预测空间不一致(样本选择偏差)以及存在数据稀疏的问题;ESMM 用 CTCVR loss 把监督信号扩展到了整个曝光空间,让 CVR 在不可监督的样本上也能通过乘积 loss 间接受到梯度更新,解决了样本选择偏差和缓解数据稀疏的问题。
CTR 任务可以利用所有曝光样本进行训练,样本量大、正负比例平衡,模型能快速学习到哪些内容最吸引点击;CVR 任务则聚焦在点击样本上,通过共享底层表示和在联合概率乘积损失中间接受到曝光样本的信号,既保持了对“点击→转化”环节的精细刻画,也让 CVR 在整个曝光空间中得到隐含的训练支持,从而消除传统 CVR 模型因只在点击样本上训练而产生的样本选择偏差。
这种拆解不仅提升了模型在稀疏转化场景下的训练效率和稳定性,还带来了更强的业务可解释性:CTR 输出可以帮助我们判断封面、标题和推荐位是否足够吸引人,CVR 输出则反映详情页、价格和促销等因素的说服力在哪里出现问题。通过对这两者的联合优化——在总损失中既有 CTR 的交叉熵,又有基于 CTR×CVR 的 CTCVR 交叉熵——我们既能最大化最终的曝光转化率,又能在产品和运营层面深入诊断和迭代,从而实现点击量与成交量的双赢。
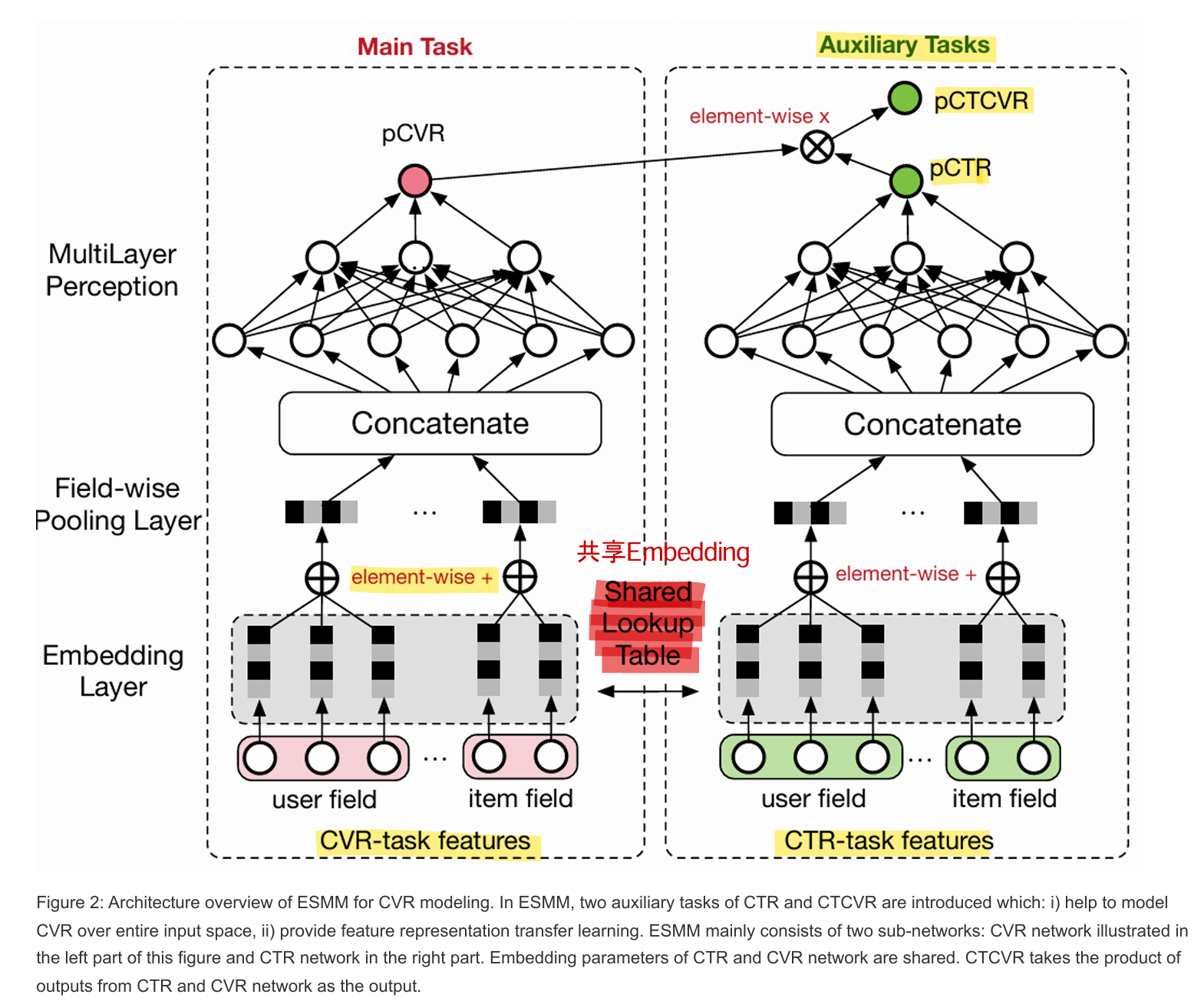
一、三种预测任务的定义
| 预测任务 | 定义公式 | 含义 | 预测目标 |
|---|---|---|---|
| CTR | \(P(y=1 \mid x)\) | 用户是否点击广告 | 预测点击率 |
| CVR | \(P(z=1 \mid y=1, x)\) | 用户点击后是否转化 | 预测转化率(条件) |
| CTCVR | \(P(y=1, z=1 \mid x) = P(y=1 \mid x) \cdot P(z=1 \mid y=1, x)\) | 用户曝光后最终转化的概率 | 预测点击转化率 |
二、三种任务的训练样本(正负样本)
| 样本条件 | CTR 是否训练 | CTR Label | CVR 是否训练 | CVR Label | CTCVR 是否训练 | CTCVR Label |
|---|---|---|---|---|---|---|
| 曝光 + 点击 + 转化 | ✅ | 1 | ✅ | 1 | ✅ | 1 |
| 曝光 + 点击 + 未转化 | ✅ | 1 | ✅ | 0 | ✅ | 0 |
| 曝光 + 未点击 | ✅ | 0 | ❌ | 无 | ✅ | 0 |
✅ 说明:
- CTR 训练样本:所有曝光样本,正样本是点击,负样本是未点击
- CVR 训练样本:只有点击样本,正样本是转化,负样本是未转化
- CTCVR 训练样本:所有曝光样本,正样本是点击+转化,其他都是负样本(包括未点击的)
三、ESMM 的训练损失函数(原文)
✅ 特点:
- 没有直接计算 CVR loss(可以考虑加入点击样本的CVR loss)
- CVR 通过 CTCVR 的乘积 loss 被间接训练
四、核心机制 & 技巧
1. 为什么不直接训练 CVR?
传统 CVR 模型只在点击样本上训练,会有以下问题:
- 训练空间和预测空间不一致(训练时在点击空间,预测时要泛化到曝光空间)
- CVR预估模型的本质,不是预测“item被点击,然后被转化”的概率(CTCVR),而是“假设item被点击,那么它被转化”的概率(CVR)。
它与CTR没有绝对的关系,很多人有一个先入为主的认知,即若user对某item的点击概率很低,则user对这个item的转化概率也肯定低,这是不成立的。
这就是不能直接使用全部样本训练CVR模型的原因,因为不知道那些unclicked的item,假设他们被点击了,是否会被转化。如果直接使用0作为它们的label,会很大程度上误导CVR模型的学习。 - 但是CTCVR是已知的,因为未点击,CTCVR的标签肯定为0
2. ESMM 的设计解决了什么?
-
用 CTCVR 的目标(点击 + 转化的联合概率)替代了 CVR 的目标
-
训练时:
- 在所有曝光样本上训练 CTR 和 CTCVR
- 虽然 CVR 在未点击样本上没有 label,但它的输出参与了乘积,仍然被训练
- CVR 通过共享底层网络和乘积梯度反向传播,被“间接”训练
-
推理时:
- pCTR × pCVR 得到最终的 CTCVR(曝光转化率)
五、关键疑问及解答整理
| 疑问 | 解答 |
|---|---|
| 未点击样本怎么处理? | 虽然 CVR 没有 label,但它的输出 PCVR 会被用于计算 pCTR × pCVR;再通过 loss 反向传播给 CVR |
| 没点击就没转化,为什么可以构造 CTCVR label? | 因为 y=0 时,y∧z 一定为 0,label 是可靠的,能作为监督信号 |
| CVR 输出是否为 0? | 不一定,但 y=0 时的 z label 是 undefined,所以不能训练 CVR;只能通过 CTCVR loss 间接训练 |
| 为什么不直接训练 CTCVR? | 实际上 ESMM 就是这样做的!通过 CTR 和 CTCVR 两个子任务建模整个转化流程(曝光 → 点击 → 转化) |
六、一句话总结 ESMM 的亮点
ESMM 通过构造 CTCVR 的监督目标,把 CVR 的训练空间扩展到了全曝光空间,同时避免了训练推理不一致和样本选择偏差的问题,是一种结构简单却效果极强的多任务建模方法。
✅ 负采样策略 + CVR 标签处理注意事项(ESMM)
一、为什么需要负采样?
在只有“点击样本”的训练数据中:
- CTR 没有负样本 → 模型只能学习点击的特征,无法区分点击/未点击
- CTCVR 没有负样本 → 模型无法学习“曝光未转化”的分布
- CVR 仍可训练(只在点击样本上)
解决方法:
→ 引入曝光未点击的样本作为负采样样本
二、负采样方法
从召回候选集中随机或策略性采样用户曝光但未点击的样本。
采样样本也需构造完整标签字段结构:
| 字段 | 说明 |
|---|---|
is_click |
点击标记(设为 0) |
is_convert |
转化标记(设为 0 或 None) |
CTR_label |
= is_click |
CTCVR_label |
= is_click & is_convert |
CVR_label |
= is_convert(仅用于点击样本训练) |
三、训练时的 label 使用逻辑
| 任务 | 计算范围(哪些样本参与) | 使用的 label |
|---|---|---|
| CTR | 所有样本 | is_click |
| CTCVR | 所有样本 | is_click & is_convert |
| CVR | 仅点击样本(is_click=1) | is_convert |
🚫 未点击样本的
CVR_label不参与任何 loss 计算
四、验证和测试时的 CVR 评估
-
验证阶段评估 CVR 时,仅使用点击样本
-
可以计算:
- AUC(CVR)
- LogLoss(CVR)
-
此时
CVR_label有效使用
✅ 实践建议:
- ✅ 构造样本时可统一填入
CVR_label=0,但训练中不能直接计算负样本的cvr loss - ✅ 负采样比例控制建议在 1:1 ~ 1:4 之间(正:负)
- ✅ 尽量从实际曝光日志或召回结果中采样,避免完全随机采样带来的分布偏差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号