做题记录(OI)
注:题号前打星的为非独立做出的题。

Subtangle Game
E1
对于第 \(i\) 轮,必败态是容易确定的。那么设 \(f(i, x, y)\) 表示第 \(i\) 轮走 \((x, y)\) 的位置是否必胜。
转移:如果对于任意 \(x' > x, y' > y\),\(f(i + 1, x', y')\) 都必败,那么 \(f(i, x, y)\) 必胜。这样是 \(O(n^2)\) 的,可以记 \(g(i, x, y)\) 表示上述条件是否满足,这样就是 \(O(1)\) 的。
E2
把 E1 用 bitset 优化即可。不知道为何出题人没卡这种做法。虽然我还没卡过去。
Salyg1n and Array
E1
读题不完整,自己两行泪。
按 \(k\) 个为一块分块。对于整块,直接问即可。手玩一下,可以发现散块可以一个一个元素问。形式化的:设散块长度为 \(l = n \bmod k\),按 \(n - l - k + 2 \to n - k + 1\) 的顺序问即可。
为什么对?因为此时 \([n - l - k + 2, n - k]\) 里面的元素会向后平移,而 \(l\) 为偶数,所以这些元素会被消掉。
*E2
E1 一个一个问是没有必要的。观察 E1 的问法中 \(a\) 的变化,可知直接问 \(n - \dfrac{l}{2} - k + 1, n - k + 1\) 也是对的。手模一下即知正确性。
*Scammy Game Ad
这题实际上可以贪心。首先显然要把全部增加的人放到同一边。我们把加法看作 \(\times 1\)。
在走第 \(i\) 道门时,先算出来总共增加多少人。然后往后面扫,如果左边的倍率多于右边,那就放到左边;否则放到右边。如果比不出来,那就跳过。
为什么对?因为每次新增的人都是独立的。
3-2
把 \([0, 2^n)\) 的 0-1 Trie 建出来,设每个节点的权值为它在 \([0, 2^n)\) 中出现的次数。询问的位置为 \(u\) 时,把包含 \(u\) 的同色连通块的权值和算出来,即为答案。
*Long Common Subsequence
在 \(S_1 + S_1\) 中,前半部分有 \(N\) 个 \(\texttt{0}\),后半部分有 \(N\) 个 \(\texttt{1}\)。所以考虑 \(\texttt{00} \cdots \texttt{01} \cdots \texttt{11}\),但是长度不够。发现在选完这些字符后,一定会有一个 \(\texttt{0}\) 在最后,所以 \(S_1 + S_1\) 的答案就是 \(\texttt{00} \cdots \texttt{01} \cdots \texttt{110}\)。
发现 \(S_2 + S_2, S_3 + S_3\) 同理,所以答案就是 \(\texttt{00} \cdots \texttt{01} \cdots \texttt{110}\)。
*Job Completion
进行了反悔贪心的学习。
容易发现,当 \(s_1 + t_1 < s_2 + t_2\) 时,选前者更好。所以按 \(s_i + t_i\) 升序选择。设当前用时为 \(t\),如果 \(t > s_i\),那就让当前工作替换做过的工作中用时最长的。
*取模
高明的诈骗题。
在已知 \(m\) 时,可以 \(O(n \log n)\) 算出答案。枚举 \(a_i\),找到最大的 \(< m - a_i\) 的 \(a_j\),然后用 \(a_i + a_j\) 更新答案。还可能是两个最大值,也要用这个更新答案。可以加一个优化:把重复的跳过。
我们倒序枚举 \(a_i\),如果答案 \(\ge a_i\) 就停止。实际上这样只会枚举 \(O(\log V)\) 个,因为跳过了重复的数。
*Genius Acm
算 SPD 时一定是最大的和最小的作差,次大的和次小的作差,以此类推。
考虑贪心。维护已经分好段的部分 \([1, l)\),找最大的合法的 \([l, r]\),把它分成一段。如何找?容易发现 \(r\) 有单调性,所以可以二分。
但是二分是 \(O(n \log^2 n)\) 的,极难优化。发现二分可以换成倍增:每次找最大的合法的 \(2^i\),然后 \(r \gets r + 2^i\)。在算 SPD 时,不需要每次都重新排序,只需把无序部分排序,然后归并到一起,即为 \(O(n \log n)\)。
想到没前途的做法时要及时换思路。
*奶龙大战暴暴龙
有解时 \(n = m\),故设 \(n = m\)。判无解是容易的。
先进行离散化,把 \(a_i\) 用它在 \(a'\) 中的下标代替,这样就变成了排序问题。
先把 \(1\) 和 \(2\) 放到最前面,可以暴力模拟。我们可以平移 \((1, 2)\) 到 \(3\) 的前面,把 \(3\) 拼到一起;然后再平移 \((1, 2, 3)\) 到 \(4\) 的前面,把 \(4\) 拼到一起,以此类推。容易发现这样的操作数是 \(n\) 次。
实现时,记录每个元素的位置 \(p_i\) 与当前平移区间的位置 \([l, r]\)。发现 \(a_i\) 在未选中的点中的下标就是 \(i - d_i\),其中 \(d_i\) 为 \(i\) 之前选中的点。所以开一个树状数组维护 \(d_i\)。平移到 \(a_i\) 时,令 \(l \gets i - d_i\),然后 \(d_i \gets d_i + 1\) 即可。
建议画图辅助理解。
*配对
发现 \(\sum c_i\) 为奇数时有一个点没用,我们把这个点删去。交换两个 \(c_i\) 相当于删一个点再加一个点。
先做 \(\sum c_i\) 为偶数且无交换。考虑以 \(u\) 为根的子树,设当前子树中有 \(s_i\) 个 \(1\),且 \(u\) 的父亲为 \(f_s\)。若 \(s_i\) 为偶数,那么这个子树内可以两两操作;否则就要有一个和子树外的一个点操作。所以当 \(s_i\) 为奇数时,\(\{ f_s, s \}\) 的边要选。
那其他情况怎么办呢?考虑 DP,令 \(f_{i, j, k}\) 表示在以 \(i\) 为根的子树中,删了 \(j \in [0, 2]\) 个点,新增了 \(k \in [0, 1]\) 个点。当 \(2 \nmid s_i - j + k\) 时就要把 \(\{ f_s, s \}\) 的边选上,以此转移,类似树上背包。
*图排列
发现最短路径一定是简单路径,否则可以把环去掉,这样一定不劣。
特殊性质 F
只需判定有没有只走 \([1, 2, 3, 4, 5]\) 的路径,如果有答案就是 \(1\),否则是 \(2\)。
特殊性质 G
此时权值只有 \(6\) 种,\(S_{\mathrm{path}}\) 只有 \(2^6 = 64\) 种。所以对每一种 \(S_{\mathrm{path}}\),分别判定可不可能只走 \(S_{\mathrm{path}}\) 以内的边抵达,然后更新答案。注意把不封闭的 \(S_{\mathrm{path}}\) 排除掉。
正解
权值有 \(5! = 120\) 种时,封闭的 \(S_{\mathrm{path}}\) 有多少种呢?打表发现只有 \(156\) 种。那么把性质 G 的做法套用过来即可。
如何打表?随机一个子集,然后把它填充到封闭。重复 \(10^5\) 次。
*Target Practice
容易发现,矩形的右上角要分给 \(s_i > 0\) 的奶牛,右下角要分给 \(s_i < 0\) 的奶牛。
考虑二分距离,发现难以 check,所以分别二分两个端点。check 是容易的,但是需要知道矩形的左上角和左下角分别分给哪种奶牛。发现越靠下的点越要给 \(s_i < 0\) 的奶牛,越靠上的点越要给 \(s_i > 0\) 的奶牛。按这个原则分配即可。
*Med-imize
考虑二分答案。设当前要 check 中位数 \(m\)。令 \(b_i = [a_i \ge m]\),则答案 \(\ge m\) 当且仅当有一种操作序列满足剩下的 \(1\) 严格多于剩下的 \(0\)。
那么怎么样求出最多剩下多少 \(1\) 呢?设最后剩下 \(l\) 个下标 \(r_i = i\)。那么可以将 \(r\) 的后缀 \(+kx\) 获得另一种方案。注意到无论怎么加,\(r_i \equiv i \pmod k\)。
那么可以 DP。设前 \(i\) 个最多剩下 \(f_i\) 个 \(1\),则:
*Minimax Problem
设下标从 \(0\) 开始。
二分答案,设当前 check 的答案为 \(k\)。因为 \(m \le 8\),所以可以令 \(b_i = \sum \limits_{j = 0}^{m - 1} [a_{i, j} \ge m] \cdot 2^j\),发现不同的 \(b_i\) 只有 \(2^m \le 256\) 种,所以开桶记录每种 \(b_i\) 的位置。我们需要找到 \((i, j)\) 满足 \(b_i \lor b_j = 2^m - 1\),那么 \(O(4^m)\) 枚举一下即可。
*序列
给定长度为 \(n\) 的数列 \(A\)。你可以交换 \(A_i\) 和 \(A_j\),当且仅当 \(A_i \cap A_j = 0\)。给出做任意次操作后,字典序最小的数组。可以不做操作。
\(1 \le n \le 10^6\),\(1 \le A_i < 2^{20}\)。
把所有满足 \(A_i \cap A_j = 0\) 的 \((i, j)\) 连边。发现同一个连通块内的元素可以排序,连通块间的元素无法交换。用并查集维护可以做到 \(O(n^2)\)。
问题在于边太多了。设 \(V = 2^{20}, y' = V - 1 - y\),考虑转化条件:\(x \cap y = 0 \iff x \subseteq y'\)。所以把 \(A_i\) 和 \(V - 1 - A_i\) 连无向边,\(V - 1 - A_i\) 和它的子集连有向边。在这个图上跑 SCC 即可。
连边时不需要枚举子集,只需要去掉一位然后连边即可。并且连无向边时不要直接把 \(A_i\) 和 \(V - 1 - A_i\) 连边,要连 \(i + V \leftrightarrow V - 1 - A_i\) 与 \(A_i \to i + V\)。
*Coins
错解
先令所有人选择自己的最大值,然后按最大值与次大值的差值升序排序。按顺序枚举,如果当前选择的超了人数,那就改选次大值。对于次大值和最小值重复以上操作。
为什么不对?在有两个重复的次大值时,并不知道选哪个更优,所以这样贪心是错误的。
正解
令所有人都选择金币,设当前的答案为 \(S\)。若第 \(i\) 个人改选银币,则 \(S \gets S + B_i - A_i\),铜币同理。
于是设 \(P_i = B_i - A_i, Q_i = C_i - A_i\)。现在相当于在所有 \((P_i, Q_i)\) 当中选 \(Y\) 个 \(P_i\),\(Z\) 个 \(Q_i\)。这是经典贪心。把二元组按 \(P_i - Q_i\) 降序排序,则一定能找到一个分界点 \(k\),使得选 \(P_i\) 的下标都 \(\le k\),选 \(Q_i\) 的下标都 \(> k\)。
那么预处理:前 \(i\) 个中前 \(Y\) 大的 \(P_i\) 的和,与后 \(i\) 个中前 \(Z\) 大的 \(Q_i\) 的和,使用优先队列可以做到 \(O(n \log n)\)。然后枚举分界点并更新答案即可。
*Rotate Columns (easy version)
转化一下操作:
- 任意旋转每一列。
- 在每一行中选择一个数,最大化它们的和。
那么可以 DP。令 \(f_{i, S}\) 表示:考虑前 \(i\) 列,第 \(j\) 行(\(j \in S\))选出了一个数时的答案。随便转移即可。
*道路修复
看这个标题应该就知道我啥时候补出来的了。
48 pts
\(O(2^k)\) 枚举每个额外点选不选,然后把这些边加进去跑 Kruskal。边数为 \(E = m + nk\),故总时间复杂度为 \(O(2^k E \log E)\)。
80 pts
注意到原有的边不用全部保留,只需要保留最小生成树即可。\(O(2^k nk \log nk + m \log m)\)。
100 pts
与 P10455 类似。可以提前把每个额外点的边排好序。每次枚举选哪些额外点时,不需要先把所有边加进去再排序,可以直接归并。\(O(2^k nk + m \log m + kn \log n)\)。
*MEX of LCM
发现答案 \(\le n^2 + 1\),那么只需要维护 \(\le n^2 + 1\) 的 \(\operatorname{lcm}\)。
从前往后扫右端点,拿 set 维护一下。每次把上次的 \(\operatorname{lcm}\) 用 \(a_i\) 更新一下,然后全扔到一个大 set 即可。
Li Hua and Array
与 CF992E 类似,发现每个数最多被修改 \(\log\) 次。那么每次暴力修改叶子,如果当前区间全部是 \(1\),那就跳过。
如何合并区间?记录区间会变成哪个数 \(t\) 以及修改的次数 \(c\) 以及长度 \(s\)。设左右区间的信息分别为 \((t_l, c_l, s_l)\) 和 \((t_r, c_r, s_r)\),当前区间的信息为 \((t, c, s)\),合并时:
- \(s \gets s_l + s_r\)。
- \(t \gets F(t_l, t_r)\),其中 \(F(x, y)\) 表示 \(x, y\) 可以变成的同一个数的最大值。
- \(c \gets s_l \cdot L(t_l, t_r) + s_r \cdot R(t_l, t_r) + c_l + c_r\),其中 \(L(x, y), R(x, y)\) 分别表示 \(x, y\) 变成 \(F(x, y)\) 的过程中,\(x, y\) 做了多少次操作。
*Kevin and Binary String (Easy Version)
错解
把 ARC205C 的做法搬到这里。因为 1 的相对位置不变,所以把每个 1 算出它要去的下标。然后把向左的 1 的连续段拿出来统一挪到最左边,向右的 1 的连续段拿出来统一挪到最右边。
但是没想清楚如何实现,导致没做出来。
正解
考虑增量构造。假设 \(s[1, i] = t[1, i]\) 且 \(s_{i + 1} \neq t_{i + 1}\),那么把 \(t_{i + 1}\) 所在的连续段的右端点求出来,设为 \(r_1\)。然后求出最小的 \(r_2\),使得 \(\sum_{i = l}^{r_2} [s_i = t_l] = r_1 - l + 1\)。把 \(s[l, r_2]\) 挪到 \(s[l, r_1]\),然后继续往后构造即可。
*寻雾启示
错解
贪心。
90 pts
DP,设 \(f_i\) 表示到达第 \(i\) 格并回到起点的最短时间。转移为:
为什么是 \(\max(f_j, i \cdot k)\)?因为发现生成 \(i\) 个铁需要 \(i \cdot k\) 的时间,所以在这个时间后一定能拿到 \(i\) 个铁。
100 pts
把转移式子变形:
使用值域线段树维护 \(f_i \to f_i + (t_2 - t_1) \cdot i\) 的映射。查询 \([i \cdot k, V]\) 的最小值与最大的 \(\le i \cdot k\) 的下标,转移即可。\(V \le (k + t_1) \cdot m \le 2 \cdot 10^{14}\),需要动态开点线段树。
Traps
发现跳过陷阱后要后缀 \(+1\) 很难受,那就从答案入手。把答案表示出来:设跳过了第 \(b_1, b_2, \cdots, b_k\) 个陷阱,则答案为:
展开得:
发现有 \(a_{b_i} + b_i\),尝试凑一个相同的形式:
把常数忽略,发现只需把 \(a_i + i\) 中最大的 \(k\) 个跳过即可。
魔法
首先要把 \(b_i \ge 0\) 的做了。按 \(t_i\) 升序排序,然后一个一个做即可。
接下来是 \(b_i < 0\) 的。考虑何时任务 \(i\) 优于任务 \(j\)。 具体的,考虑何时会发生:做完 \(i\) 后可以做 \(j\),但做完 \(j\) 后无法做 \(i\)。设当前时间为 \(T\),则此时 \(T + b_i > t_j, T + b_j \le t_i\)。两式相加得 \(b_i + t_i > b_j + t_j\),于是按 \(b_i + t_i\) 降序做任务即可。
*Nezuko in the Clearing
错解
考虑贪心。能走就走,不能走就休息。
但是打表发现“两步一休”(两次移动 + 一次休息)的方法可能是更优的,所以这样不对。
正解
考虑最优解的性质。 发现最优解中不会连续休息。那么考虑休息次数的性质,发现休息次数有单调性。那么尝试二分休息次数。
如何 check?设休息了 \(m\) 次,那么有 \(m + 1\) 段移动区间。很明显,移动区间越平均越好。那么可以计算出移动区间的长度,然后计算出消耗生命值并与 \(h + m\) 比较即可。
*Count Seconds
发现第 \(i\) 个点流完的时间就是它上游流完的时间加上它本来的流量。但是在上游有 \(a_i = 0\) 时会出问题。如何让上游没有 \(a_i = 0\)?发现手动模拟前 \(n\) 秒后就没问题了,因为 \(n\) 秒后所有点都会被流到。
*Traffic Lights
DP。设 \(f(i, j)\) 表示在第 \(i\) 秒位于点 \(j\) 的最小休息时间。转移分两种:
- 不走:\(f(i, j) + 1 \to f(i + 1, j)\)。
- 走:\(f(i, j) \to f(i + 1, j')\),其中 \(j'\) 是 \(j\) 的第 \(i \bmod \operatorname{deg}(j) + 1\) 个邻居。
最小总时间即为最小的 \(i\) 满足 \(f(i, n) < \infty\),此时 \(f(i, n)\) 是最小休息时间。
实现时不要尝试直接从 \(u \to v\),不然转移顺序极难确定。
*The Boss's Identity
核心矛盾在于 \(a_i\) 太多。考虑如何减少 \(a_i\) 的数量。打表可以发现如下规律:
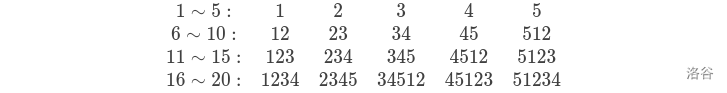
(图中 \(n = 5\),其中每一位指 \([1, 5]\) 中的一个下标。)
于是发现在第 \(n\) 行往后的值不会再变。
但是考虑按位或的性质:在把一堆数一个一个或起来时,因为只有 \(\log V\) 位且每一位只变 \(\le 1\) 次,所以最多只有 \(\log V\) 个中间值。
那么预处理到 \(\log V\) 行即可。往后找不一样的值可以用 ST 表优化。
*夕阳西下几时回
考虑乡愁度的性质。 发现它一定 \(\le \lfloor n / 2 \rfloor\),因为 \(\forall 1 \le i < j \le n, \gcd(i, j) \le \lfloor n / 2 \rfloor\)。考虑如何达到上界,发现 \(1, 2, 4, \cdots, 3, 6, 12, \cdots, 5, 10, 20, \cdots\) 是可行的。现在考虑令 \(\gcd \in [1, k]\)。把 \([2k + 1, n]\) 提到最前面即可。
*Face The Right Way
首先一定要枚举 \(K\)。那么如何操作?直接从前到后操作即可,这样可以保证前 \(N - K\) 个一定朝前,剩下的就看造化了。翻转用异或差分优化即可。
*Two Sets
设 \(a \ge b\)。每次在没匹配的序列中找到最小值 \(x\),若 \(a - x\) 没匹配,就把这俩匹配上;否则尝试匹配 \(b - x\),失败了就无解。
在 \(a - x\) 和 \(b - x\) 同时可以匹配时这样为什么对?因为如果此时 \(x\) 匹配 \(b - x\),那么 \(a - x \notin A\),那么 \(a - x \in B\),那么 \(b - (a - x) = x + (b - a) \in B\)。但是 \(x + (b - a) < x\),与 \(x\) 为最小值矛盾。
*Help Yourself
先把线段按左端点升序排序。
显然要 DP。设 \(f_i\) 为前 \(i\) 个线段的答案。如何转移?考虑加入第 \(i\) 条线段对答案的贡献。发现对于所有与第 \(i\) 条线段不交的子集答案都 \(+1\)。设与第 \(i\) 条线段不交的子集的个数为 \(c_i\),则有
树状数组统计 \(c_i\) 并转移即可。
*Deforestation
先离散化。设 \(S_i\) 表示前 \(i\) 棵树中还剩几棵。那么我们有
变形一下:
建图跑差分约束即可。
*Compressed Tree
设根为 \(1\)。发现不断删叶子相当于先保留一棵子树,再删去这棵子树的一些子树。最终压缩完的树其实就是保留所有度数 \(\neq 2\) 的点。
那么树形 DP。令 \(f_i\) 表示以 \(i\) 为根的子树的答案,发现这样会有问题,因为从 \(j\) 转移到 \(i\) 时,\(f_j\) 假定 \(j\) 没有父亲,但实际上它有。所以令 \(f_i, g_i\) 分别表示 \(i\) 有 / 无父亲时,以 \(i\) 为根的子树的答案。
转移时需要讨论一下 \(i\) 最终的度数。注意:这里需要强制子树非空。
*Cave Paintings
发现如果填上 \((i, j)\),那么它在第 \([i, n]\) 行的连通块中的每一格都要填上。这启示我们从下往上做,用并查集维护连通块 \(u\) 内的方案数 \(f_u\)。合并 \(u\) 和 \(v\) 时就把 \(f_u\) 乘上 \(f_v\)。
那么对于一行,要先往上面一行合并,然后在上面一行内部合并(此时没有考虑到选择上面一行),最后给每个连通块的方案数 \(+1\)(考虑选择上面一行)。
*Dance Mooves
解法 1
考虑记录每个人经过的点。
首先可以把每一轮操作做的变换求出来,直接模拟即可。假设 \(i\) 经过一轮操作后到了 \(p_i\)。
然后发现从同一个点出发的人,每一轮走的路径也相同。所以可以把每个人一轮走的路径求出来,也是模拟即可。假设从 \(i\) 出发一轮操作走的路径为 \(q_i\)。
那么发现把 \(i\) 和 \(p_i\) 连边,就构成了许多环。对于每个环,把每个人走的路径合并到一起,就是这个环上每个点的答案。
使用并查集维护即可。但是赛时的我太唐了,tmd 用的 bitset。但是如果开 512 MB 还真能过。
解法 2
实际上可以反过来,记录每个点有哪些人经过。发现如果有人可以经过某个点,那么它所在环的其他点也能经过那个点。
那么使用并查集维护即可。
*Range Connect MST
先忽略原有点(前 \(N\) 个点)和新加点(后 \(Q\) 个点)之间的连通性。我们可以把 \((C_i, L_i, R_i)\) 转化成在 \([L_i, R_i]\) 中相邻两个点之间连一条边。
那么在 Kruskal 的时候,只需把没连上边的点连边即可。那么用线段树维护相邻两个点有没有连边即可。
*Road Blocked
删边很困难,但加边很简单。那我们离线下来倒着做不就行了。
首先肯定要跑 Floyd。假设加入边 \((u, v, w)\),那么我们更新 \(d(i, j)\):
因为会多出 \(i \to u \to v \to j\) 和 \(i \to v \to u \to j\) 两条路径。
MST Query
考虑如何给 MST 加边。加上一条边后会形成一个环,我们需要断掉环上最大的边,来维持树的结构。
如何找到环上最大的边?因为值域只有 \(10\),所以我们开 \(10\) 个并查集,第 \(i\) 个维护只有 \(\ge i\) 的边的 MST。对于加边 \((u, v)\),找到最小的 \(w\) 满足 \(u, v\) 在第 \(w\) 个并查集连通,那么 \(w\) 就是环上最大的边。
那还要断边呢,这该怎么做啊?实际上不需要断边,因为非 MST 上的边一定会被忽略,如果没被忽略就说明它在 MST 上。
*Gift
首先,对于一个生成树 \(T \subseteq E\),它需要 \(G \max(g_i) + S \max(s_i)\) 块钱。
但有两个变量怎么办?固定变量法!MO 学多了。 我们固定 \(\max(g_i) = g_{\max}\),那么只需要最小化 \(\max(s_i)\)。把 \(\le g_{\max}\) 的边拿出来跑 MST 即可。
这还是太慢了。发现 \(g_{\max}\) 增加,相当于给 MST 加边,每次加完边后把环上的最大值断掉即可。
*Minimum spanning tree for each edge
唐完了。
显然要先把 MST 求出来。对于“强制选第 \(i\) 条边”的限制,我们把这条边加入 MST,然后把环上最大的边(不能是第 \(i\) 条边)断掉。
显然断边会超时,但是我们不需要把它真断掉,直接拿它的权值算一下即可。使用倍增算环上最大的边的权值即可。
Weights Distributing
先把 \(p\) 排序。
考虑 \(a \to b \to c\) 的路径是什么样的。显然,\(a \to b\) 需要走边数最短的路径(因为可以自己指定边权),\(b \to c\) 同理。
但是可能会有下图一样的情况,所以我们枚举 \(i\),给 \(i \to b\) 的路径赋上 \(p\) 的最小值,剩下的往后赋,然后更新答案。
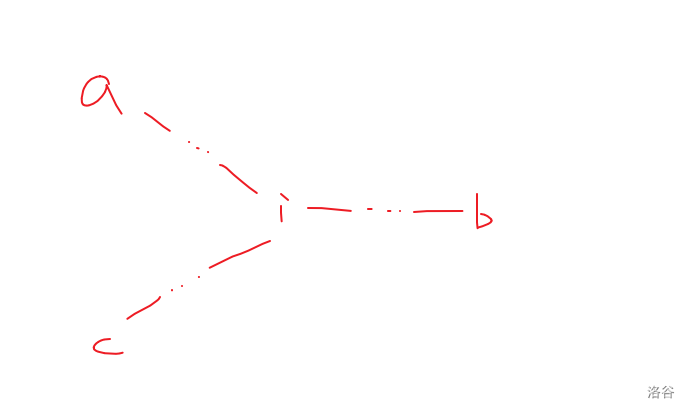
实际上我们只需要路径的边数,不需要知道路径本身。所以分别从 \(a, b, c\) 出发跑 BFS 预处理最短路即可。
*Intervals
错解
尝试推一维 DP。设 \(f_i\) 为考虑前 \(i\) 位的答案,那么难以保证每个区间只被触发一次。设 \(f_i\) 为考虑右端点 \(\le i\) 的答案,那很难转移。
正解
步子迈太大了,先搞二维 DP。 设 \(f_{i, j}\) 表示最后一个 1 在第 \(j\) 位且右端点 \(\le i\) 的答案。
来进行转移。首先 \(f_i\) 应该从 \(f_{i - 1}\) 转移过来,所以转移时只考虑右端点 \(= i\) 的区间,因为前面的都被考虑过了。下文的“区间”都指右端点 \(= i\) 的区间。
在 \(j = i\) 时,每一个区间都被触发,且前面的 1 可以随便取,所以有
在 \(j < i\) 时,所有左端点 \(\le j\) 的区间都被触发,且这些 1 不能移动,因为还没算完答案,所以有
拼到一起就是转移方程。显然可以压掉第一维,那么如何优化呢?发现 \(j < i\) 时,\(\sum \limits_{r_k = i, l_k \le j} a_k = C\) 的 \(j\) 形成一个区间,且不同的区间最多只有 \(n\) 个,所以直接上线段树。
大魔法师
显然要把 \((A_i, B_i, C_i)\) 打包成矩阵
但是操作 \(4 \sim 6\) 又该如何应对?所以我们加一个辅助的 \(1\):
这样就可以维护了。
Q. 为何可以区间乘?
A. 定义 \((A + B)_{ij}\) 为 \(A_{ij} + B_{ij}\),则 \((A + B)C = AC + BC\)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号