Tensorflow(三) 自动微分
本章学习TensorFlow中的自动微分:
https://tensorflow.google.cn/guide/autodiff
自动微分的含义
参考:
深度学习中的反向传播的实现借助于自动微分。 让计算机实现微分功能, 有以下四种方式:
- 手工计算出微分, 然后编码进代码
- 数值微分 (numerical differentiation)
- 符号微分 (symbolic differentiation)
- 自动微分
自动微分是将一个复杂的数学运算过程分解为一系列简单的基本运算, 每一项基本运算都可以通过查表得出来。自动微分有两种形式
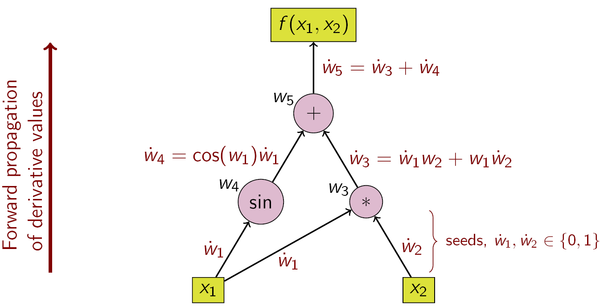
- 前向模式 (forward mode)
前向模式是在计算图前向传播的同时计算微分。
- 反向模式 (reverse mode)
反向模式需要对计算图进行一次正向计算, 得出输出值,再进行反向传播
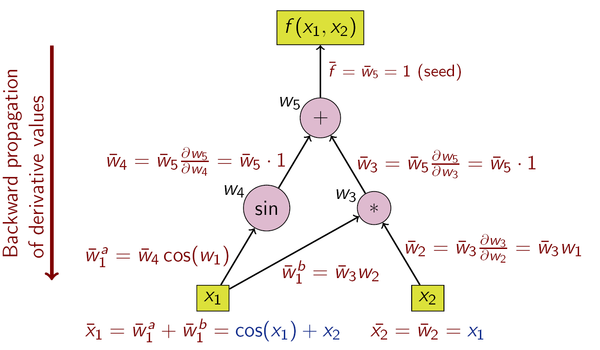
前向模式的一次正向传播能够计算出输出值以及导数值, 而反向模式需要先进行正向传播计算出输出值, 然后进行反向传播计算导数值,所以反向模式的内存开销要大一点, 因为它需要保存正向传播中的中间变量值,这些变量值用于反向传播的时候计算导数。
当输出的维度大于输入的时候,适宜使用前向模式微分;当输出维度远远小于输入的时候,适宜使用反向模式微分。、
从矩阵乘法次数的角度来看,前向模式和反向模式的不同之处在于矩阵相乘的起始之处不同。当输出维度小于输入维度,反向模式的乘法次数要小于前向模式。
TensorFlow中的自动微分
自动微分对于实现机器学习算法非常有用,例如用于训练神经网络的反向传播。
为了自动区分,TensorFlow 需要记住在正向传递期间以什么顺序发生的操作。然后,在向后传递期间,TensorFlow 以反向顺序遍历此操作列表以计算梯度。
Gradient tapes
TensorFlow 提供了 tf.GradientTapeAPi来实现自动微分。对与数据输入(通常是tf.Variable),TensorFlow会将其操作记录记录到TensorFlow的 tf.GradientTape库中的tape里。然后,TensorFlow使用该tape使用反向模式微分来计算“记录”计算的梯度。
示例:
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
记录完一些操作后,使用 GradientTape.gradient(target,source)计算某个目标相对于某个Source(通常是模型的Variable)的梯度(通常是Loss):
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
dy_dx.numpy()
6.0
用于二维的Tensor:
w = tf.Variable(tf.random.normal((3, 2)), name='w')
b = tf.Variable(tf.zeros(2, dtype=tf.float32), name='b')
x = [[1., 2., 3.]]
with tf.GradientTape(persistent=True) as tape:
y = x @ w + b
loss = tf.reduce_mean(y**2)
以下两种写法进行梯度计算:
# list
[dl_dw, dl_db] = tape.gradient(loss, [w, b])
# dictionary
my_vars = {
'w': w,
'b': b
}
grad = tape.gradient(loss, my_vars)
grad['b']
用于Model
通常将 tf.Variables 收集到 tf.Module 或其子类之一(layers.Layer、keras.Model)中,用于设置检查点和导出。
在大多数情况下,需要计算相对于模型的可训练变量的梯度。 由于 tf.Module 的所有子类都在 Module.trainable_variables 属性中聚合其变量,可以用几行代码计算这些梯度:
layer = tf.keras.layers.Dense(2, activation='relu')
x = tf.constant([[1., 2., 3.]])
with tf.GradientTape() as tape:
# Forward pass
y = layer(x)
loss = tf.reduce_mean(y**2)
# Calculate gradients with respect to every trainable variable
grad = tape.gradient(loss, layer.trainable_variables)
for var, g in zip(layer.trainable_variables, grad):
print(f'{var.name}, shape: {g.shape}')
dense/kernel:0, shape: (3, 2)
dense/bias:0, shape: (2,)
tape监视
默认情况下,可以访问训练 tf.Variable后记录所有运算。原因如下:
- tape需要知道在前向传递中记录哪些运算,以计算后向传递中的梯度。
- 梯度带包含对中间输出的引用,因此应避免记录不必要的操作。
- 最常见用例涉及计算损失相对于模型的所有可训练变量的梯度。
# A trainable variable
x0 = tf.Variable(3.0, name='x0')
# Not trainable
x1 = tf.Variable(3.0, name='x1', trainable=False)
# Not a Variable: A variable + tensor returns a tensor.
x2 = tf.Variable(2.0, name='x2') + 1.0
# Not a variable
x3 = tf.constant(3.0, name='x3')
with tf.GradientTape() as tape:
y = (x0**2) + (x1**2) + (x2**2)
grad = tape.gradient(y, [x0, x1, x2, x3])
for g in grad:
print(g)
tf.Tensor(6.0, shape=(), dtype=float32)
None
None
None
可以使用 GradientTape.watched_variables 方法列出梯度带正在监视的变量:
[var.name for var in tape.watched_variables()]
tf.GradientTape 提供了hook,让用户可以控制被监视或不被监视的内容。
要记录相对于 tf.Tensor 的梯度,您需要调用 GradientTape.watch(x):
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x**2
# dy = 2x * dx
dy_dx = tape.gradient(y, x)
print(dy_dx.numpy())
6.0
相反,要停用监视所有 tf.Variables 的默认行为,需要在创建gradient tape时设置 watch_accessed_variables=False。此计算使用两个变量,但仅连接其中一个变量的梯度:
x0 = tf.Variable(0.0)
x1 = tf.Variable(10.0)
with tf.GradientTape(watch_accessed_variables=False) as tape:
tape.watch(x1)
y0 = tf.math.sin(x0)
y1 = tf.nn.softplus(x1)
y = y0 + y1
ys = tf.reduce_sum(y)
# dys/dx1 = exp(x1) / (1 + exp(x1)) = sigmoid(x1)
grad = tape.gradient(ys, {'x0': x0, 'x1': x1})
print('dy/dx0:', grad['x0'])
print('dy/dx1:', grad['x1'].numpy())
dy/dx0: None
dy/dx1: 0.9999546
用于控制流
GradientTape同样适用于具有if和while这样有条件语句的情况,下面是一个例子:
x = tf.constant(1.0)
v0 = tf.Variable(2.0)
v1 = tf.Variable(2.0)
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
if x > 0.0:
result = v0
else:
result = v1**2
dv0, dv1 = tape.gradient(result, [v0, v1])
print(dv0)
print(dv1)
dx = tape.gradient(result, x)
print(dx)
tf.Tensor(1.0, shape=(), dtype=float32)
None
None
性能相关
- 在梯度带上下文内进行运算会有一个微小的开销。对于大多数 Eager Execution 来说,这一成本并不明显,但是您仍然应当仅在需要的地方使用梯度带上下文。
- 梯度带使用内存来存储中间结果,包括输入和输出,以便在后向传递中使用。
- 为了提高效率,某些运算(例如 ReLU)不需要保留中间结果,而是在前向传递中进行剪枝。不过,如果在梯度带上使用
persistent=True,则不会丢弃任何内容,并且峰值内存使用量会更高。
中间结果
还可以请求输出相对于 tf.GradientTape 上下文中计算的中间值的梯度。
x = tf.constant(3.0)
with tf.GradientTape() as tape:
tape.watch(x)
y = x * x
z = y * y
# Use the tape to compute the gradient of z with respect to the
# intermediate value y.
# dz_dy = 2 * y and y = x ** 2 = 9
print(tape.gradient(z, y).numpy())
18.0
默认情况下,只要调用 GradientTape.gradient 方法,就会释放 GradientTape 保存的资源。要在同一计算中计算多个梯度,请创建一个 persistent=True的梯度带。这样一来,当梯度带对象作为垃圾回收时,随着资源的释放,可以对 gradient 方法进行多次调用。例如:
x = tf.constant([1, 3.0])
with tf.GradientTape(persistent=True) as tape:
tape.watch(x)
y = x * x
z = y * y
print(tape.gradient(z, x).numpy()) # 108.0 (4 * x**3 at x = 3)
print(tape.gradient(y, x).numpy()) # 6.0 (2 * x)
[ 4. 108.]
[2. 6.]
使用GradientTape和Optimizer求最小值
转载自:https://github.com/lyhue1991/eat_tensorflow2_in_30_days/blob/master/2-3,自动微分机制.md
# 求f(x) = a*x**2 + b*x + c的最小值
# 使用optimizer.apply_gradients
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for _ in range(1000):
with tf.GradientTape() as tape:
y = a*tf.pow(x,2) + b*x + c
dy_dx = tape.gradient(y,x)
optimizer.apply_gradients(grads_and_vars=[(dy_dx,x)])
tf.print("y =",y,"; x =",x)
y = 0 ; x = 0.999998569
# 求f(x) = a*x**2 + b*x + c的最小值
# 使用optimizer.minimize
# optimizer.minimize相当于先用tape求gradient,再apply_gradient
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
#注意f()无参数
def f():
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
y = a*tf.pow(x,2)+b*x+c
return(y)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
for _ in range(1000):
optimizer.minimize(f,[x])
tf.print("y =",f(),"; x =",x)
y = 0 ; x = 0.999998569
# 在autograph中完成最小值求解
# 使用optimizer.apply_gradients
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
@tf.function
def minimizef():
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
for _ in tf.range(1000): #注意autograph时使用tf.range(1000)而不是range(1000)
with tf.GradientTape() as tape:
y = a*tf.pow(x,2) + b*x + c
dy_dx = tape.gradient(y,x)
optimizer.apply_gradients(grads_and_vars=[(dy_dx,x)])
y = a*tf.pow(x,2) + b*x + c
return y
tf.print(minimizef())
tf.print(x)
0
0.999998569
# 在autograph中完成最小值求解
# 使用optimizer.minimize
x = tf.Variable(0.0,name = "x",dtype = tf.float32)
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
@tf.function
def f():
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
y = a*tf.pow(x,2)+b*x+c
return(y)
@tf.function
def train(epoch):
for _ in tf.range(epoch):
optimizer.minimize(f,[x])
return(f())
tf.print(train(1000))
tf.print(x)
0
0.999998569

 浙公网安备 33010602011771号
浙公网安备 33010602011771号