MLP神经网络理论及实践
本文介绍MLP(Multi-Layer Perception的理论以及实践)
参考:
https://zhuanlan.zhihu.com/p/63184325
https://en.wikipedia.org/wiki/Multilayer_perceptron
一. 理论
MLP是最基本的神经网络模型。
最典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
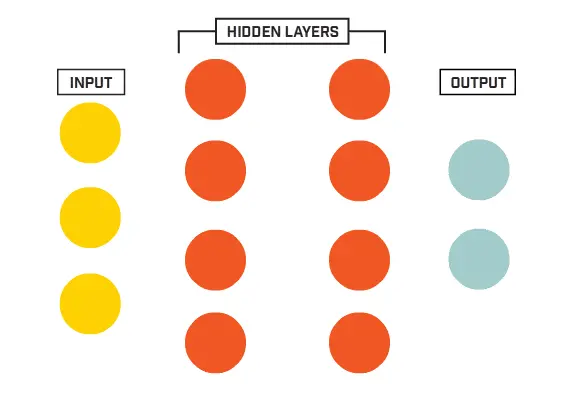
神经网络
神经网络其实是对生物神经元的模拟和简化,生物神经元由树突、细胞体、轴突等部分组成。树突是细胞体的输入端,其接受四周的神经冲动;轴突是细胞体的输出端,其发挥传递神经冲动给其他神经元的作用,生物神经元具有兴奋和抑制两种状态,当接受的刺激高于一定阈值时,则会进入兴奋状态并将神经冲动由轴突传出,反之则没有神经冲动。
神经元使用特征向量来表示的前馈神经网络,它是一种二元分类器,把矩阵上的输入(实数值向量)映射到输出值上(一个二元的值)。

w是实数的表示权重的向量,w·x是点积。b是偏置,一个不依赖于任何输入值的常数。
神经网络主要有三个基本要素:权重、偏置和激活函数
- 权重:神经元之间的连接强度由权重表示,权重的大小表示可能性的大小
- 偏置:偏置的设置是为了正确分类样本,是模型中一个重要的参数,即保证通过输入算出的输出值不能随便激活。
- 激活函数:起非线性映射的作用,其可将神经元的输出幅度限制在一定范围内
激活函数
激活函数主要有以下几种:
- sigmoid
- tanh
- ReLU
sigmoid

其可将(-∞,+∞)的数映射到(0~1)的范围内。

tanh

tanh是Sigmoid函数的变形,tanh的均值是0,在实际应用中有比Sigmoid更好的效果
ReLU

ReLU是近来比较流行的激活函数,当输入信号小于0时,输出为0;当输入信号大于0时,输出等于输入
神经网络用例
MLP的最经典例子就是数字识别,有个非常值得学习的视频课:
https://www.youtube.com/watch?v=aircAruvnKk&t=2s
二. 实践
Sklearn包括了MLPClassifier和MLPRegressor可以使用MLP做分类和拟合。
参数
下面介绍MLPClassifier的一些参数:
- hidden_layer_sizes :元祖格式,长度=n_layers-2, 默认(100,),第i个元素表示第i个隐藏层的神经元的个数。
即通过这个参数,可以设置神经网络层数和每层神经元个数 - activation :{‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, 默认‘relu
- ‘identity’: no-op activation, useful to implement linear bottleneck,
- ‘logistic’:the logistic sigmoid function, returns f(x) = 1 / (1 + exp(-x)).
- ‘tanh’:the hyperbolic tan function, returns f(x) = tanh(x).
- ‘relu’:the rectified linear unit function, returns f(x) = max(0, x)
- solver : {‘lbfgs’, ‘sgd’, ‘adam’}, 默认 ‘adam’,用来优化权重
- lbfgs:quasi-Newton方法的优化器
- sgd:随机梯度下降
- adam: Kingma, Diederik, and Jimmy Ba提出的机遇随机梯度的优化器
注意:默认solver ‘adam’在相对较大的数据集上效果比较好(几千个样本或者更多),对小数据集来说,lbfgs收敛更快效果也更好。
- alpha :float,可选的,默认0.0001,正则化项参数
- batch_size : int , 可选的,默认‘auto’,随机优化的minibatches的大小,如果solver是‘lbfgs’,分类器将不使用minibatch,当设置成‘auto’,batch_size=min(200,n_samples)
- learning_rate :{‘constant’,‘invscaling’, ‘adaptive’},默认‘constant’,用于权重更新,只有当solver为’sgd‘时使用
- ‘constant’: 有‘learning_rate_init’给定的恒定学习率
- ‘incscaling’:随着时间t使用’power_t’的逆标度指数不断降低学习率 learning_rate_ ,effective_learning_rate = learning_rate_init / pow(t, power_t)
- ‘adaptive’:只要训练损耗在下降,就保持学习率为’learning_rate_init’不变,当连续两次不能降低训练损耗或验证分数停止升高至少 tol 时,将当前学习率除以5.
- max_iter : int,可选,默认200,最大迭代次数。
- random_state :int 或RandomState,可选,默认None,随机数生成器的状态或种子。
- shuffle : bool,可选,默认True,只有当solver=’sgd’或者‘adam’时使用,判断是否在每次迭代时对样本进行清洗。
- tol :float, 可选,默认1e-4,优化的容忍度
- learning_rate_int :double,可选,默认0.001,初始学习率,控制更新权重的补偿,只有当solver=’sgd’ 或’adam’时使用。
- power_t : double, optional, default 0.5,只有solver=’sgd’时使用,是逆扩展学习率的指数.当learning_rate=’invscaling’,用来更新有效学习率。
- verbose : bool, optional, default False,是否将过程打印到stdout
- warm_start : bool, optional, default False,当设置成True,使用之前的解决方法作为初始拟合,否则释放之前的解决方法。
- momentum : float, default 0.9,Momentum(动量) for gradient descent update. Should be between 0 and 1. Only used when solver=’sgd’.
- nesterovs_momentum : boolean, default True, Whether to use Nesterov’s momentum. Only used when solver=’sgd’ and momentum > 0.
- early_stopping : bool, default False,Only effective when solver=’sgd’ or ‘adam’,判断当验证效果不再改善的时候是否终止训练,当为True时,自动选出10%的训练数据用于验证并在两步连续爹迭代改善低于tol时终止训练。
- validation_fraction : float, optional, default 0.1,用作早期停止验证的预留训练数据集的比例,早0-1之间,只当early_stopping=True有用
- beta_1 : float, optional, default 0.9,Only used when solver=’adam’,估计一阶矩向量的指数衰减速率,[0,1)之间
- beta_2 : float, optional, default 0.999,Only used when solver=’adam’估计二阶矩向量的指数衰减速率[0,1)之间
- epsilon : float, optional, default 1e-8,Only used when solver=’adam’数值稳定值。
属性说明:
- classes_ :每个输出的类标签
- loss_ :损失函数计算出来的当前损失值
- coefs_ :列表中的第i个元素表示i层的权重矩阵
- intercepts_ :列表中第i个元素代表i+1层的偏差向量
- n_iter_ :迭代次数
- n_layers_ :层数
- n_outputs_ :输出的个数
- out_activation_ :输出激活函数的名称。
方法说明: - fit(X,y) :拟合
- get_params([deep]) :获取参数
- predict(X) :使用MLP进行预测
- predic_log_proba(X) :返回对数概率估计
- predic_proba(X) :概率估计
- score(X,y[,sample_weight]) :返回给定测试数据和标签上的平均准确度
- set_params(**params) :设置参数。
SKLearn实例
下面介绍使用SKLearn MLP分类器的一个实例
数据来源:https://www.kaggle.com/datasets/kamilpytlak/personal-key-indicators-of-heart-disease
通过一组特征来分类是否患有心脏疾病
数据预览:
import pandas as pd
import numpy as np
df = pd.read_csv('./heart_2020_cleaned.csv')
df.head()

空值分析发现没有空值
import missingno as msno
msno.matrix(df)
特征工程:
大概就是把数据的一些string项转化为int分类
df = df.replace('Yes', 1)
df = df.replace('No', 0)
df['Sex'] = df['Sex'].replace(['Female', 'Male'], [0, 1])
age_category_map = {
'18-24': 1,
'25-29': 2,
'30-34': 3,
'35-39': 4,
'40-44': 5,
'45-49': 6,
'50-54': 7,
'55-59': 8,
'60-64': 9,
'65-69': 10,
'70-74': 11,
'75-79': 12,
'80 or older': 13
}
df['AgeCategory'] = df['AgeCategory'].map(age_category_map).round(0)
race_map = {
'White': 0,
'Hispanic': 1,
'Black': 2,
'Other': 3,
'Asian': 4,
'American Indian/Alaskan Native': 5
}
df['Race'] = df['Race'].map(race_map).round(0).astype(int)
gen_health_map = {
'Poor': 1,
'Fair': 2,
'Good': 3,
'Very good': 4,
'Excellent': 5
}
df['GenHealth'] = df['GenHealth'].map(gen_health_map).round(0).astype(int)
df['Diabetic'] = df['Diabetic'].replace(['No, borderline diabetes', 'Yes (during pregnancy)'], [2,3])
df.describe()

数据分割:
y = df['HeartDisease']
X = df.drop('HeartDisease', axis=1)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
MLP分类:
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(random_state=1, max_iter=500, hidden_layer_sizes=(200, 100)).fit(X_train, y_train)
model.score(X_test, y_test)
大概准确率91%左右,和RF等集成学习模型差不多
Kaggle Notebook:
https://www.kaggle.com/code/asprant/heart-disease-with-rf-and-mlp-classification/notebook?scriptVersionId=93341744

 浙公网安备 33010602011771号
浙公网安备 33010602011771号