决策树分类及实例
本文介绍机器学习中最基础最简单的决策树分类
参考:
- https://zhuanlan.zhihu.com/p/133838427
- https://zhuanlan.zhihu.com/p/30059442
- https://www.kaggle.com/prashant111/decision-tree-classifier-tutorial/notebook
一. 理论
1.决策树的介绍
决策树算法是最流行的机器学习算法之一。它使用树状结构及其可能的组合来解决特定的问题。它属于监督学习算法的一类,可以用于分类和回归目的。
决策树是一种包含根节点、分支和叶节点的结构。每个内部节点表示对一个属性的测试,每个分支表示测试的结果,每个叶节点保存一个类标签。树中最顶端的节点是根节点。
2.分类和回归树(CART)
CART是一个二叉树,也是回归树,同时也是分类树,CART的构成简单明了。CART只能将一个父节点分为2个子节点。CART用GINI指数来决定如何分裂。
回归解析用来决定分布是否终止。理想地说每一个叶节点里都只有一个类别时分类应该停止,但是很多数据并不容易完全划分,或者完全划分需要很多次分裂,必然造成很长的运行时间,所以CART可以对每个叶节点里的数据分析其均值方差,当方差小于一定值可以终止分裂,以换取计算成本的降低。
3.熵增和基尼系数
熵
熵度量给定数据集中的杂质。在物理学和数学中,熵指的是随机变量x的随机性或不确定性。在信息论中,熵指的是一组例子中的杂质。信息增益是熵的减少。信息增益是根据给定的属性值计算数据集分割前的熵值与分割后的平均熵值的差值。
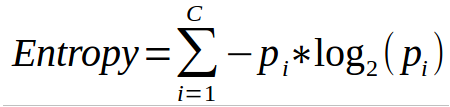
c是类的个数pi是第i类的概率。
ID3 (Iterative Dichotomiser)决策树算法使用熵来计算信息增益。因此,通过计算每个属性的熵减,我们可以计算出它们的信息增益。选择信息增益最高的属性作为节点的分割属性。
基尼系数
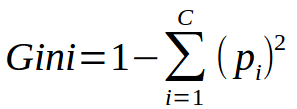
c是类的个数pi是第i类的概率。
基尼指数表示,如果我们从总体中随机选择两项,它们必须属于同一类如果总体是纯的,概率为1。
它与分类目标变量“成功”或“失败”一起工作。它只执行二进制分割。基尼系数越高,同质性越高。CART (Classification and Regression Tree)使用基尼方法创建二进制分割。
计算分割Gini的步骤
- 计算子节点的Gini,使用公式成功和失败概率的平方和(p2 + q2)。
- 使用该分割的每个节点的加权基尼值计算分割的基尼值。
- 对于离散值属性,给出所选属性的最小基尼指数的子集被选为分割属性。对于连续值属性,该策略是选择每一对相邻值作为可能的分割点,并选择基尼指数较小的点作为分割点。选择基尼指数最小的属性作为分割属性。
4.过拟合
在建立决策树模型时,过拟合是一个实际问题。当算法不断深入以减少训练集误差而导致测试集误差增大时,考虑过拟合问题。因此,我们模型的预测精度下降了。当我们由于数据中的异常值和不规则性而构建许多分支时,通常会发生这种情况。
有两种方法可以用来避免过拟合:
-
Pre-Pruning
在Pre-Pruning中,我们提前一点停止树的构造。如果节点的优度度量值低于阈值,我们不希望拆分节点。但是很难选择一个合适的停靠点。 -
Post-Pruning
在Post-Pruning中,我们在树中越走越深,以构建一个完整的树。如果树显示过拟合问题,那么剪枝作为后剪枝步骤进行。我们使用交叉验证数据来检查修剪的效果。使用交叉验证数据,我们测试扩展一个节点是否会导致改进。如果它显示了改进,那么我们可以继续扩展该节点。但如果它显示了准确性的下降,那么它就不应该扩大。因此,节点应该被转换为叶节点。
二. 实践
数据预览
本例所用数据为汽车的分类。输入features如下,输出分为acc, noacc, good 3个等级
这里的doors和persons并不一定是数字,有5more和more代表车具有更多的车门和座位
本例通过sklearn来做决策树
导入库和数据:
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
import matplotlib.pyplot as plt
df = pd.read_csv('car_evaluation.csv')
预处理(编码):
FEATURES_NEED_ENCODE = ['buying', 'maint', 'doors', 'persons','lug_boot', 'safety', 'class']
for feature in FEATURES_NEED_ENCODE:
le = preprocessing.LabelEncoder()
le.fit(df[feature].unique())
df[feature] = le.transform(df[feature])
X = df.drop(['class'], axis=1)
y = df['class']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
训练:
clf_gini = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=0)
clf_gini.fit(X_train, y_train)
print('Prediction Accuracy:', (clf_gini.score(X_test, y_test) * 100), '%')
画出决策树:
tree.plot_tree(clf_gini)
plt.show()
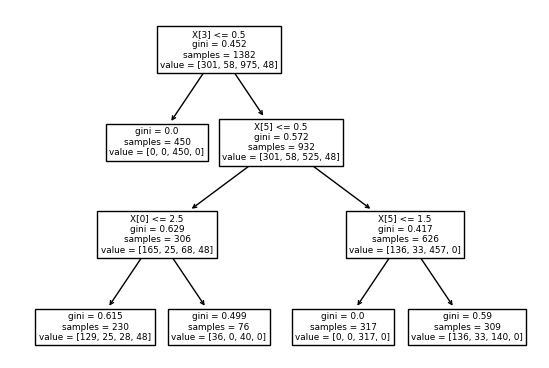
如果用熵增来做:
clf_en = DecisionTreeClassifier(criterion='entropy', max_depth=3, random_state=0)
clf_en.fit(X_train, y_train)
print('Prediction Accuracy:', (clf_en.score(X_test, y_test) * 100), '%')
tree.plot_tree(clf_gini)
plt.show()
关于DecisionTreeClassifier的参数详见:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号