Python - opencv (八) OCR
(Optical Character Recognition,光学字符识别)技术,将图片、照片上的文字内容,直接转换为文本。opencv不自带ocr,即使从cv4.4以后的external中包含cv::text识别文字,也需要用户先预装tesseract。
Tesseract是最主流的OCR开源库,安装:
1. Windows:
有Binary安装文件可以即装即用,但是只是个可执行文件不能用来开发,开发的话可以源码安装,路径https://github.com/tesseract-ocr/tesseract/,cmake以后用vs打开,但是这玩意依赖太多,没成功。
推荐方法:安装sw和vcpkg,然后命令:
.\vcpkg install tesseract:x64-windows
2. Mac:
brew install tesseract
3. Ubuntu
sudo add-apt-repository ppa:alex-p/tesseract-ocr sudo apt-get update sudo apt-get install tesseract-ocr
安装好后可装Python库:
pip install pytesseract
训练集需要另外下载,地址:https://github.com/tesseract-ocr/tessdata
下载好后,Windows默认放在编译路径下的tessdata文件夹里,Mac默认路径:
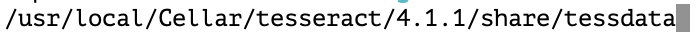
测试:
图片

代码:
1 import cv2 2 import pytesseract 3 4 if __name__ == '__main__': 5 6 # Read image path from command line 7 imPath = "../pics/2.jpg" 8 9 # Uncomment the line below to provide path to tesseract manually 10 # pytesseract.pytesseract.tesseract_cmd = '/usr/bin/tesseract' 11 12 # Define config parameters. 13 # '-l eng' for using the English language 14 # '--oem 1' for using LSTM OCR Engine 15 config = ('-l eng --oem 1 --psm 3') 16 17 # Read image from disk 18 im = cv2.imread(imPath, cv2.IMREAD_COLOR) 19 20 # Run tesseract OCR on image 21 text = pytesseract.image_to_string(im, config=config, output_type=pytesseract.Output.DICT) 22 23 # Print recognized text 24 print(text)
输出:
{'text': 'WORLD FAMOUS BRAND\nPOP FASHION\nINSTLTUTIONS OF\nOUR DREAM AND HOPE\n\x0c'}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号