python 数据可视化 -- 读取数据
从 CSV 文件中读取数据(CSV)
import sys import csv # python 内置该模块 支持各种CSV文件 file_name = r"..\ch02_data\ch02-data.csv" # r 指明字符串不用转义 data = [] try: with open(file_name) as f: # 打开文件 reader = csv.reader(f) # 获取 reader 对象,通过对该对象的遍历获取文件的所有内容,默认分隔符为“,” 可以通过 dialect 指定分隔符 header = next(reader) # 读取文件头 data = [row for row in reader] # 读取文件内容,并存放到列表中 except csv.Error as e: print("Error reading CSV file at line %s: %s" %(reader.line_num, e)) sys.exit(-1) if header: print(header) print("===========================") for datarow in data: print(datarow)

读取 tab 分隔的文件(csv)
也可以通过传统的 split("\t") 来进行分隔
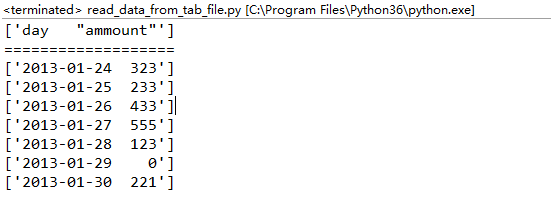
import csv import sys filename = r'../ch02_data/ch02-data.tab' data = [] try: with open(filename) as f: reader = csv.reader(f, dialect = csv.excel_tab) # 指定 tab 分隔符 header = next(reader) data = [row for row in reader] # 将文件内容读入列表 except csv.Error as e: print("Error reading CSV file at line %s: %s" % (reader.line_num, e)) sys.exit(1) if header: print(header) print('===================') for datarow in data: print(datarow)
从 Excel 中读取数据
www.python-excel.org 项目提供的软件包可以方便 python 处理 excel 文件。
该项目提供的 package 有:openpyxl xlsxwriter xlrd xlwt xlutils
安装方法:以管理员方式打开 cmd --> pip install xlrd


import xlrd ## 专门读取 excel 的 package # from pprint import pprint file = r"..\ch02_data\ch02-xlsxdata.xlsx" wb = xlrd.open_workbook(filename = file) # 读取 excel 文件,返回 xlrd.book.Book 类的实例对象 ws = wb.sheet_by_name("Sheet1") # 根据 sheet name 读取 sheet 中的数据,返回 xlrd.sheet.Sheet 类的实例对象 data_set = [] for r in range(ws.nrows): # sheet 的行数 col = [] for c in range(ws.ncols): # sheet 的列数 col.append(ws.cell(r, c).value) # 获取指定的 Cell 的实例对象,通过 value 属性获取值 data_set.append(col) # pprint(data_set) for i in data_set: print(i)

从定宽数据文件导入数据(struct)
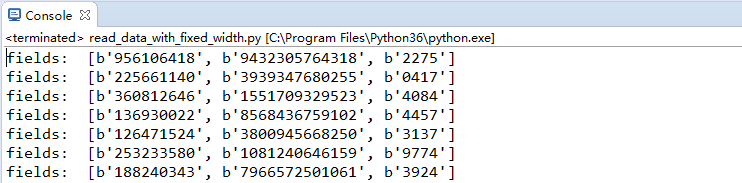
import struct # 该 module 执行 python 值和 C 结构体之间的转换,从而形成 python 字节对象 datafile = r"../ch02_data/ch02-fixed-width-1M.data" # mask = bytes('9s15s5s', encoding = 'utf-8') # bytes 内置函数返回一个新的 bytes 对象。 mask = '9s15s5s' with open(datafile, 'rb') as f: # 以二进制格式打开一个文件用于只读 for line in f: fields = struct.Struct(mask).unpack_from(line) # 根据 mask 描述的格式,将 bytes 反向解析出来,返回一个元组 print('fields: ', [field.strip() for field in fields])
从数据库读写数据
import sqlite3 import sys from builtins import str # 向数据库中写入数据 if len(sys.argv) < 2: print("Error: You must supply at least SQL script.") print("Usage: %s table.db ./sql-dump.sql" % (sys.argv[0])) sys.exit(1) script_path = sys.argv[2] # sql脚本文件 if len(sys.argv)== 3: db = sys.argv[1] # 写入的数据库文件 else: db = ":memory:" try: con = sqlite3.connect(db) # 返回一个 sqlite3.Connection 对象实例 with con: cur = con.cursor() # 返回一个 sqlite3.Cursor 对象实例 with open(script_path, 'rb') as f: cur.executescript(f.read().decode()) except sqlite3.Error as err: print("Error occured: %s" % err) # 从数据库中读取数据 db = sys.argv[1] try: con = sqlite3.connect(db) with con: cur = con.cursor() # 得到一个游标对象,用于遍历数据库放回的结果集中的记录 query = 'SELECT ID, Name, Population FROM City ORDER BY Population DESC LIMIT 10' con.text_factory = str # 该属性控制返回对象的数据类型 cur.execute(query) # 执行查询语句 resultset = cur.fetchall() # 获取查询结果集汇总所有的记录,返回一个列表,每个查询记录是一个元组 col_names = [cn[0] for cn in cur.description] # description 属性提供了列的描述信息,每列的描述是一个7个元素的元组 print("%10s %30s %10s" % tuple(col_names)) print("="*(10 + 1+ 30 + 1 + 10)) for row in resultset: print("%10s %30s %10s" % row) except sqlite3.Error as err: print("[ERROR]: ", err)

sql 脚本文件
DROP TABLE IF EXISTS 'City'; CREATE TABLE `City` ( `ID` int(11) NOT NULL , `Name` char(35) NOT NULL , `CountryCode` char(3) NOT NULL , `District` char(20) NOT NULL , `Population` int(11) NOT NULL , PRIMARY KEY (`ID`) ); INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000); INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500); INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800); INSERT INTO `City` VALUES (4,'Mazar-e-Sharif','AFG','Balkh',127800); INSERT INTO `City` VALUES (5,'Amsterdam','NLD','Noord-Holland',731200); INSERT INTO `City` VALUES (6,'Rotterdam','NLD','Zuid-Holland',593321); INSERT INTO `City` VALUES (7,'Haag','NLD','Zuid-Holland',440900); INSERT INTO `City` VALUES (8,'Utrecht','NLD','Utrecht',234323); INSERT INTO `City` VALUES (9,'Eindhoven','NLD','Noord-Brabant',201843); INSERT INTO `City` VALUES (10,'Tilburg','NLD','Noord-Brabant',193238); INSERT INTO `City` VALUES (11,'Groningen','NLD','Groningen',172701); INSERT INTO `City` VALUES (12,'Breda','NLD','Noord-Brabant',160398); INSERT INTO `City` VALUES (13,'Apeldoorn','NLD','Gelderland',153491); INSERT INTO `City` VALUES (14,'Nijmegen','NLD','Gelderland',152463); INSERT INTO `City` VALUES (15,'Enschede','NLD','Overijssel',149544);
读取图片
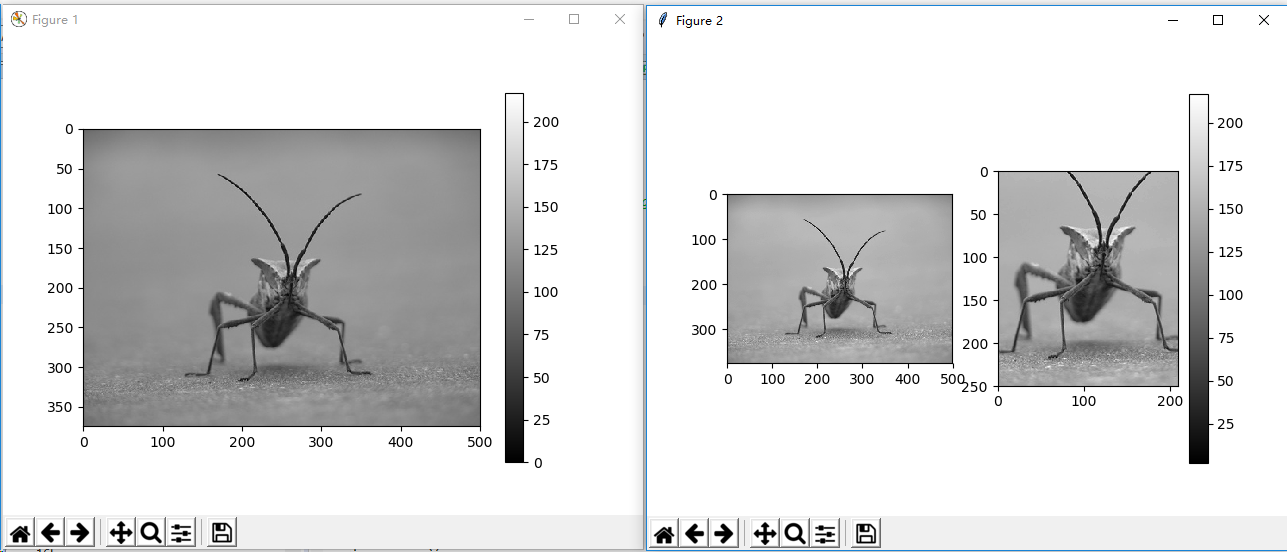
import matplotlib.pyplot as plt import scipy.misc bug = scipy.misc.imread('stinkbug.png') plt.figure(1) plt.gray() plt.imshow(bug) plt.colorbar() plt.figure(2) bug = bug[:,:,0] plt.subplot(121) plt.imshow(bug) zbug = bug[100:350, 140:350] plt.subplot(122) plt.imshow(zbug) plt.colorbar() plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号