(MariaDB)开窗函数用法
在使用GROUP BY子句时,总是需要将筛选的所有数据进行分组操作,它的分组作用域是整张表。分组以后,为每个组只返回一行。而使用基于窗口的操作,类似于分组,但却可以对这些"组"(即窗口)中的每一行进行计算,所以可以为每"组"返回多行。
窗口函数也称为分区函数,在Oracle中称为分析函数,因为开窗函数是对分区中的数据进行个各种分析、计算。
MySQL直到MySQL 8才千呼万唤般开始支持窗口函数。MariaDB 10.2之后开始支持window function。
本文将简单介绍开窗函数的使用方法,并给出一些经典示例,同时还会给出使用子查询实现开窗函数的功能。由此来说明开窗函数相比子查询的简洁、高效率。
MariaDB开窗函数官方手册:https://mariadb.com/kb/en/library/window-functions/
我翻译的window functions overview:https://mariadb.com/kb/zh-cn/window-functions-overview/
1.1 窗口和开窗函数简介
在如图所示的成绩表中,包含了6名学生的3科成绩,共18行记录。按照学号sid进行划分,每名学生都可以被看成是一个窗口(或称为分区),18行成绩共有6个窗口。可以基于每个窗口中的数据进行排序和聚合操作,如在 sid=1 的窗口进行一次升序排序,编号从1开始。当到其他窗口时,编号又重新从1开始。当然也可以按课程定义窗口,有3门课程,因此可以分为3个窗口。

窗口函数的特征是使用OVER()关键字。"开窗函数"这一名词描述了窗口变化后重新打开其它窗口进行计算的动作。窗口计算主要是对每组数据进行排序或聚合计算,因此开窗函数可以分为排名开窗函数和聚合开窗函数。
之所以提出窗口的概念,是因为这种基于窗口或分区的重新计算能简化很多问题。在不支持该技术时,很多情况下处理基于窗口重新计算的问题时,语句的编写相对复杂许多。窗口的提出,提供了一种简单而又高效的问题解决方式。在本文中也会演示不使用这些基于窗口计算的替代语句,熟悉这些替代语句后,才能更好的体会这种技术的简单和高效。
1.2 OVER()语法和执行位置
在逻辑执行顺序上,OVER()子句的执行位置在WHERE、GROUP BY和HAVING子句之后,在ORDER BY子句之前。如下:
SELECT (11)<DISTINCT> (5)select_list (9)<OVER()> ( 1)FROM ( 3) JOIN ( 2) ON ( 4)WHERE ( 6)GROUP BY ( 7)WITH ROLLUP ( 8)HAVING (10)ORDER BY (12)LIMIT
因此,where子句无法筛选来自开窗计算得到的结果集。
OVER()子句的使用语法如下:
function (expression) OVER ( [ PARTITION BY expression_list ] [ ORDER BY order_list ] ) function: A valid window function expression_list: expression | column_name [, expr_list ] order_list: expression | column_name [ ASC | DESC ] [, ... ]
MariaDB支持以下window function:
- 排名函数:ROW_NUMBER(),RANK(),DENSE_RANK(),PERCENT_RANK(),CUME_DIST(),NTILE()
- 聚合函数:COUNT(),SUM(),AVG(),BIT_OR(),BIT_AND(),BIT_XOR()
- 不支持带有DISTINCT的聚合函数,例如COUNT(DISTINCT X)
- 其他一些窗口分析函数,例如lag(),lead()。具体见官方手册。
PARTITION BY子句用于划分窗口(分区),也就是另类的GROUP BY。如果不指定PARTITION BY子句,则默认整张表是一个分区,即对所有行进行窗口函数的计算。这里的所有行不是FROM后面表的所有行,而是经过WHERE、GROUP BY、和HAVING运行之后的所有行。
ORDER BY子句用于对分区内的行进行排序。在MariaDB中可以省略该子句,表示不对分区内数据做任何排序。
在SQL Server中ORDER BY不可省略,SQL Server认为无顺序的区内数据由于不知道顺序而无法使用开窗函数。实际上,SQL Server通过特殊的ORDER BY子句,也能实现不对分区做任何排序,例如 over(order by (select 1)) ,其中1可以替换为任意其他常量。
无论如何,over()中不使用order by子句的结果中,顺序是不可预测的,因此在涉及任何排名的时候,都建议使用order by进行排序,除非你知道自己在做什么。
之所以不支持带有DISTINCT的聚合函数,是因为DISTINCT的执行过程在OVER()之后。开窗之后再DISTINCT没有意义,且消耗额外的资源。如果想先去重再OVER(),可以使用GROUP BY替代DISTINCT的功能。
1.3 row_number()对分区排名
row_number()函数用于给每个窗口内的行排名,且排名连续不断开的。例如,2个学生90分,一个学生89分,那么两个90分的学生将给定排名1和2,89分的学生给定排名3。至于谁是1谁是2,由物理存储顺序决定,也就是说当排名依据大小重复时,row_number()的排名将是不可预测的。
给定tscore表和相关数据:每个sid有3门课程以及对应的成绩,共6个sid
create or replace table tscore(sid int,subject char(10),score int); insert into tscore values (1,'Java',74),(1,'Linux',67),(1,'SQL',57), (2,'Java',67),(2,'Linux',63),(2,'SQL',68), (3,'Java',90),(3,'Linux',79),(3,'SQL',82), (4,'Java',50),(4,'Linux',68),(4,'SQL',59), (5,'Java',98),(5,'Linux',65),(5,'SQL',67), (6,'Java',66),(6,'Linux',96),(6,'SQL',95); select * from tscore; +------+---------+-------+ | sid | subject | score | +------+---------+-------+ | 1 | Java | 74 | | 1 | Linux | 67 | | 1 | SQL | 57 | | 2 | Java | 67 | | 2 | Linux | 63 | | 2 | SQL | 68 | | 3 | Java | 90 | | 3 | Linux | 79 | | 3 | SQL | 82 | | 4 | Java | 50 | | 4 | Linux | 68 | | 4 | SQL | 59 | | 5 | Java | 98 | | 5 | Linux | 65 | | 5 | SQL | 67 | | 6 | Java | 66 | | 6 | Linux | 96 | | 6 | SQL | 95 | +------+---------+-------+
按照sid分区,计算出每个sid 3科成绩的分数排名。例如sid=1的学生,Java课程分数最高,Linux课程次之,SQL分数最低,所以给定排名Java:1、Linux:2、SQL:3。sid=2的学生分数从高到低依次是SQL、Java、Linux,给定排名SQL:1、Java:2、Linux:3。依次类推。
由于是按照sid分区,所以over()子句中使用 partition by sid ,由于每个分区内部按照score降序排序,因此over()子句中使用 order by score desc 。所以,完整的SQL语句如下:
select row_number() over(partition by sid order by score desc) as rnum, sid, subject, score from tscore;
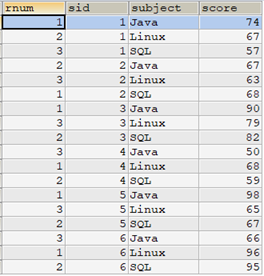
从查询结果中,可以看到每个sid都按照score的高低为相关课程给定了排名号。但是,最后返回的结果却不那么易读,每个sid对应的rnum的顺序是乱的。因此,如果为了易读性,可以考虑在select语句中使用order by子句,对sid和rnum进行排序。如下:
select row_number() over(partition by sid order by score desc) as rnum, tscore.* from tscore order by sid,rnum;
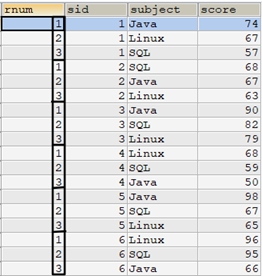
如何使用子查询的方式实现以上row_number()的排名效果?参考如下语句:
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查询 */ (select count(*)+1 from tscore t2 where t2.sid=t1.sid and t2.score>t1.score) as rnum2, t1.* from tscore t1 order by sid,rnum1;
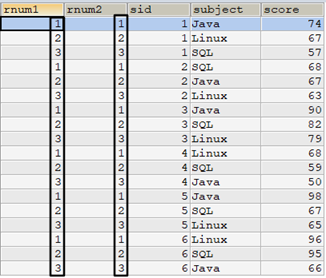
如果窗口中排序依据score的值有重复呢?row_number()如何为它们排名?如何使用子查询实现row_number()相同的效果?
/* 给定score重复的值 */ create table tscore_tmp like tscore; insert into tscore_tmp select * from tscore; update tscore_tmp set score=67 where sid=1 and subject='Java';
此时sid=1的学生Java和Linux两课程的分数都是67。
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查询 */ (select count(*)+1 from tscore_tmp t2 where t2.sid=t1.sid and t2.score>t1.score) as rnum2, t1.* from tscore_tmp t1 order by sid,rnum1;
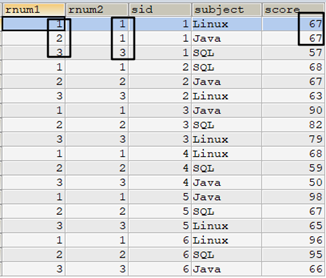
从结果中可看出row_number()对重复值会继续向后排名。但上面的子查询却并非如此,其实读一读子查询语句就能明白为何如此。
那么如何使用子查询实现row_number()相同的结果呢?也简单,只需添加一个决胜条件即可。
select /* 使用row_number() */ row_number() over(partition by t1.sid order by t1.score desc) as rnum1, /* 使用子查询 */ (select count(*)+1 from tscore_tmp t2 where t2.sid=t1.sid and (t2.score>t1.score or (t2.score=t1.score and t2.subject>t1.subject))) as rnum2, t1.* from tscore_tmp t1 order by sid,rnum1;
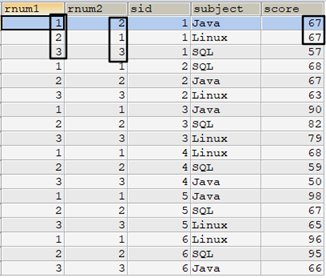
尽管rnum1和rnum2的排名结果不一样,但这无所谓,只要能为重复值排名实现row_number()函数的效果即可。
1.4 rank()和dense_rank()
前面介绍了ROW_NUMBER(),ROW_NUMBER()的作用更像是用于编号而不是排名。例如,前面将sid=1的学生的Java课程的score改为67后,由于Java和Linux两门课程分数都是67,使用ROW_NUMBER()时得到的结果就有两种方案可供选择:一种是Java排第一位,Linux排第二位,另一种是Java第二位而Linux第一位。这两种方案都是可能的,但是正因为如此,它具有不确定性。
相比于编号,排名则具有确定性,相同的值总是被分配相同的排名值。Java和Linux都是67分,它们应当都排在第一位,也就是并列第一位。但是它们接下来的SQL课程的排名值呢?是2还是3?SQL课程前面已经有两门课程排在前面,那么SQL应该排在第3位,但是从Java和Linux并列排第一位的角度来看,它们之后的SQL应当是第二位。
MariaDB中使用RANK()和DENSE_RANK()来对应这两种排名方式,RANK()的排名方式是SQL课程的排序值是第3位,DENSE_RANK()则是第2位。DENSE_RANK()的排名方式称之为密集排名,因为它的名次之间没有间隔。
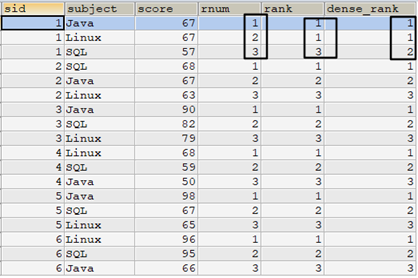
例如,下面的语句中使用ROW_NUMBER()、RANK()和DENSE_RANK()三种排名函数作比较。可以看到ROW_NUMBER()、RANK()和DENSE_RANK()三者的区别。
select t.*, /* 使用ROW_NUMBER()的方式排名 */ row_number() over(partition by sid order by score desc) as rnum, /* 使用RANK()的方式排名 */ rank() over(partition by sid order by score desc) as rank, /* 使用DENSE_RANK()的方式排名 */ dense_rank() over(partition by sid order by score desc) as dense_rank from tscore_tmp t order by t.sid,rnum;
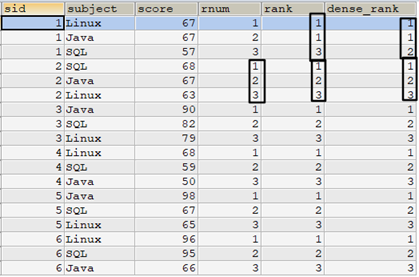
如果使用子查询实现rank()和dense_rank()的排名效果,参考如下语句:
也可以使用子查询的方式实现排名计算。参考下面的语句。ROW_NUMBER()的子查询实现方式前文已经介绍过。相比ROW_NUMBER(),RANK()的实现只需要比较内外两表t1和t2的score大小即可,而DENSE_RANK()则需要去除重复的score值,使用 COUNT(DISTINCT score) 实现。
select t1.*, /* 使用ROW_NUMBER()的方式排名 */ (select count(*) + 1 from tscore_tmp AS t2 where t2.sid = t1.sid and (t2.score > t1.score or (t2.score = t1.score and t2.subject > t1.subject))) as rnum, /* 使用RANK()方式排名 */ (select count(*) + 1 from tscore_tmp t2 where t2.sid = t1.sid and t2.score > t1.score) as rank, /* 使用DENSE_RANK()方式排名 */ (select count(distinct score) + 1 from tscore_tmp t2 where t2.sid = t1.sid and t2.score > t1.score) as dense_rank from tscore_tmp t1 order by sid,rnum;
1.5 percent_rank()和cume_dist()
percent_rank()函数用于计算分组中某行的相对排名。
cume_dist()函数用于计算分组中某排名的相对比重。
percent_rank()的计算方式:(窗口中rank排名-1)/(窗口行数-1) cume_dist()的计算方式:(窗口中小于或等于当前行的行数)/窗口行数,即(<=当前rank值的行数)/窗口行数
通过这样的相对位置计算,我们可以获取分区中最前、中间和最后的排名。
仍然使用上面的tscore_tmp表的数据做测试。
select t1.*, row_number() over(partition by sid order by score desc) as rnum, rank() over(partition by sid order by score desc) as rank, percent_rank() over(partition by sid order by score desc) as pct_rank, cume_dist() over(partition by sid order by score desc) as cume_dist from tscore_tmp t1 order by sid,rnum;
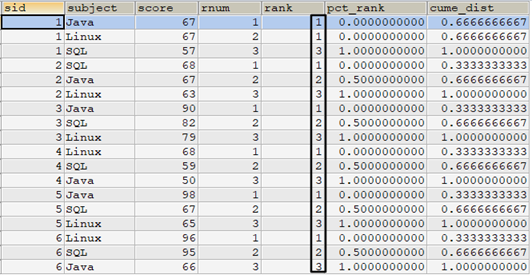
其中:
- pct_rank列是根据每个窗口中,rank列的值计算的。例如sid=1,score=67的两行记录,它们的rank值都是1,窗口中的行数位3,所以计算方式为(1-1)/(3-1)=0。
- cume_dist列计算的是每个窗口中某个rank值所占排名比重。例如sid=1,score=67的两行记录,这两行的rank值都为1,窗口中3行,所以计算方式为2/3=0.67。
如果不进行分区。
select t1.*, row_number() over(order by score desc) as rnum, rank() over(order by score desc) as rank, percent_rank() over(order by score desc) as pct_rank, cume_dist() over(order by score desc) as cume_dist from tscore_tmp t1 order by rnum;
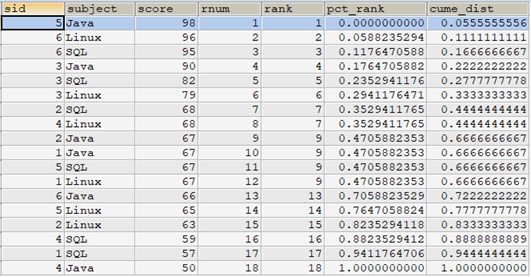
以rnum=10那一行记录为例。该行rank=9,所以:
- pct_rank=(9-1)/(18-1)=8/17=0.47
- cume_dist=12/18=0.67
即使我们所取的行为rnum=10,但rnum=11和rnum=12的rank值也都为9,所以cume_dist的分子为12。即分区中(所有行)小于或等于rank=9的行共有12行。
因此,percent_rank()函数计算的是分区中某个rank排名的相对位置,cume_dist()函数计算的是分区中某个rank排名在分区中的比重。
1.6 ntile()数据分组
NTILE()的功能是进行"均分"分组,括号内接受一个代表要分组组数量的参数,然后以组为单位进行编号,对于组内每一行数据,NTILE都返回此行所在组的组编号。简单的说就是NTILE函数将每一行数据关联到组,并为每一行分配一个所属组的编号。
假设一个表的某列值为1到10的整数,要将这10行分成两组,则每个组都有5行,表示方式为NTILE(2)。如果表某列是1到11的整数,这11行要分成3组的表示方式为NTILE(3),但是这时候无法"均分",它的分配方式是先分成3组,每组3行数据,剩下的两行数据从前向后均分,即第一组和第二组都有4行数据,第三组只有3行数据。
可以使用上述方法计算每组中记录的数量,但是要注意分组的时候是按指定顺序分组的。例如1到11的整数分3组时,三个组的值分别是(1、2、3、4)、(5、6、7、8)和(9、10、11),而不是真的将均分后剩下的两个值10、11插会前两组,即(1、2、3、10)、(4、5、6、11)、(7、8、9)是错误的分组。
下面的语句指定将tscore表按score的升序排列分成4组,mark值从最低到最高共18个值,NTILE(4)的结果是前2组有5行数据,后2组只有4行数据。
SELECT tscore.*, row_number() over (ORDER BY score) AS rnum, ntile(4) over (ORDER BY score) AS ntile FROM tscore ORDER BY rnum;
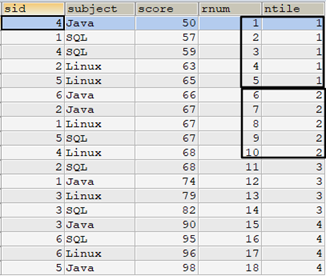
在进行NTILE()函数分组时,逻辑上会依赖ROW_NUMBER()函数。例如上面的示例,逻辑上先进行ROW_NUMBER()编号,要查询的共有18行,请求分成4组,那么编号1到5的行分配到第一组,6到10分配到第二组,依此类推,直到最后的4行被分配结束。
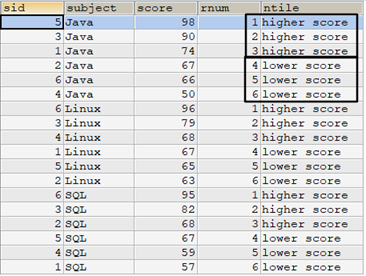
上面的示例是对整张表进行NTILE()操作,也可以先分区,再在每个分区中进行NTILE()。例如,对tscore表,按subject分成3个区,然后按每门课程分成高低两组。可以看出,每个区有6个学生的成绩,分成2组,每组3行数据。
select t.*, row_number() over(partition by subject order by score desc) as rnum, case ntile(2) over(partition by subject order by score desc) when 1 then 'higher score' when 2 then 'lower score' end as ntile from tscore t order by subject,rnum;
1.7 取相邻行数据:lag()函数和lead()函数
lag()和lead()函数可以在同一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列。
这种操作可以代替表的自联接,并且lag()和lead()有更高的效率。
语法:
LAG (expr[, offset]) OVER ( [ PARTITION BY partition_expression ] < ORDER BY order_list > ) LEAD (expr[, offset]) OVER ( [ PARTITION BY partition_expression ] [ ORDER BY order_list ] )
其中offset是偏移量,表示取出当前行向前或向后偏移N行后的行,默认值为1。
例如某个分区中order by排序后,当前行是第3行,lag(id,2)表示取出当前分区中的第1行(3-2),所取内容为id字段。
如以下示例:对subject分区,分区中按照score降序排序
select t.subject,t.score, row_number() over(partition by subject order by score desc) as rnum, lag(sid,1) over(partition by subject order by score desc) as lag, t.sid, lead(sid,1) over(partition by subject order by score desc) as lead from tscore t order by subject,rnum;
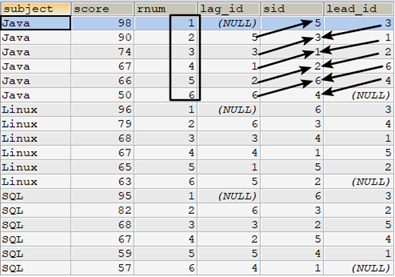
以subject='Java'分区为例:
- 对于rnum=1的行,它表示score最高,lag(sid,1)表示取该行前一行的sid字段,由于没有前一行,所以lag_id的值为NULL,lead(sid,1)表示取该行后一行的sid字段,该行后一行为rnum=2的行,对应sid=3,所以lead_id的值为3。
- 对于rnum=2的行,按照score排序,它的前一行为rnum=1的行,对应sid=5,所以lag_id的值为5。它的后一行为rnum=3的行,对应sid=1,所以lead_id的值为1。
依次类推。
1.8 窗口聚合函数
聚合函数的要点就是对一组值进行聚合,聚合函数传统上一直以GROUP BY查询作为操作的上下文。对数据进行分组以后,查询为每个组只返回一行。而使用窗口聚合函数,以窗口作为操作对象,不再使用GROUP BY分组后的组作为操作对象。
由于开窗函数运行在逻辑上比较后执行的SELECT阶段,不像GROUP BY的逻辑执行阶段比较靠前,因此很多操作比GROUP BY方便的多。比如可以在SELECT选择列表中随意选择返回列,这样就能够同时返回某一行的数据列和聚合列,也就是说可以为非分组数据进行聚合计算。甚至如果没有分组后的HAVING筛选子句时,可以使用聚合窗口函数替代GROUP BY分组,所做的仅仅是将GROUP BY替换为PARTITION BY分组。
在进行窗口聚合计算时,OVER()子句中不再要求ORDER BY子句,因此,使用方法简化为如下:
OVER([PARTITION BY expression])
OVER()括号内的内容省略时表示对所有筛选后的行数据进行聚合。
下面的语句进行了不分区(整张表作为输入数据)和分区的平均分计算。
select t.*, avg(score) over() as sum_avg, avg(score) over(partition by sid) as sid_avg from tscore t;
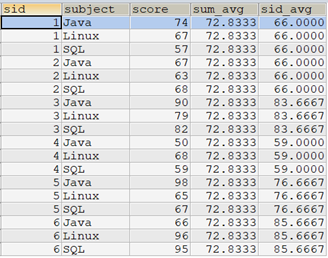
如果需要使用子查询的方式达到和示例一样的结果,则需要使用联接的方式。
要计算sum_avg这一列,参考下面的语句:
select t1.*,t2.sum_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) as t2;
由于"sum_avg"是全部学生所有课程分数的聚合计算,它不需要先分组,因此可以将 AVG(score) OVER() 理解成子查询 SELECT AVG(score) FROM tscore ,但是它们在性能上是有差距的。
要计算"sid_avg"这一列,参考下面的语句:
select t1.*,t3.sid_avg from tscore t1 left join (select sid,avg(score) as sid_avg from tscore group by sid) as t3 on t3.sid=t1.sid;
将上述两个子查询联接,就得到与使用OVER()子句相同的返回结果。参考下面的语句。
select t1.*,t2.sum_avg,t3.sid_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) t2 left join (select sid,avg(score) as sid_avg from tscore group by sid) as t3 on t1.sid=t3.sid;
可以看出,使用OVER()子句比使用联接的方式简洁了许多,并且当语句中包含多个分区聚合时(示例中包含两个分区聚合操作),使用OVER()子句拥有更大的优势,因为使用联接的方式会涉及到多个联接,将会多次扫描需要联接的表。
使用OVER()子句另一个优点在于可以在表达式中混合使用基本列和聚合列值,而使用group by分组聚合时这是不允许的。下面两条语句在返回结果上等价的,第一条语句使用OVER()子句,第二条语句则使用联接的方式。
select t1.*, avg(score) over() as sum_avg, score - avg(score) over() as diff_avg from tscore t1; /* 使用联接的方式 */ select t1.*,sum_avg,score - t2.sum_avg as diff_avg from tscore t1 cross join (select avg(score) as sum_avg from tscore) as t2;
对于在相同的分区进行的多种聚合计算,不会影响性能。例如,下面第一条语句仅包含一个OVER()子句,而第二条语句包含4个OVER()子句,但是它们的性能几乎是一样的。
SELECT t1.*, AVG(score) OVER(PARTITION BY sid) FROM tscore t1 /* 下面的查询和上面的查询性能一样 */ SELECT t1.*, AVG(score) OVER(PARTITION BY sid) AS Avgscore, SUM(score) OVER(PARTITION BY sid) AS Sumscore, MAX(score) OVER(PARTITION BY sid) AS Maxscore, MIN(score) OVER(PARTITION BY sid) AS Minscore FROM tscore t1;
第二条语句使用子查询的替代语句如下。
select t1.*,Avgscore,Sumscore,Maxscore,Minscore from tscore t1 left join (select sid, AVG(score) Avgscore, SUM(score) Sumscore, MAX(score) Maxscore, MIN(score) Minscore from tscore group by sid) as t2 on t1.sid=t2.sid;
1.9 开窗函数的性能
使用窗口函数往往效率会比一般的SQL语句高的多的多,特别是数据较大时。以下是一个性能差异比较统计结果:其中regularSQL指的是使用了一个相关子查询实现需求的SQL语句。(仅为说明性能差距,不具有代表性)
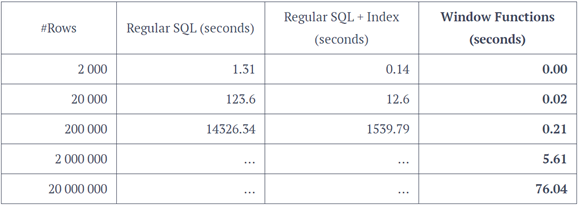
从表中可以看出,随着行数每增大10倍,regularSQL和regularSQL+index的时间都成100倍增加,而开窗函数计算的时间相比它们则少的多。
此外,一个SQL语句中如果使用了多个OVER()子句,这些OVER()子句的内容完全一致,那么很多时候只会做一次分区,这一个分区可以提供给多个开窗函数计算分析。正如上窗口聚合函数中所说:对于在相同的分区进行的多种聚合计算,不会影响性能。
总而言之,窗口函数为编写SQL语句带来了极大的便利性,且性能优越。如果能使用窗口函数解决问题,应尽量使用窗口函数。
Linux系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
Shell系列文章:https://www.cnblogs.com/f-ck-need-u/p/7048359.html
网站架构系列文章:http://www.cnblogs.com/f-ck-need-u/p/7576137.html
MySQL/MariaDB系列文章:https://www.cnblogs.com/f-ck-need-u/p/7586194.html
Perl系列:https://www.cnblogs.com/f-ck-need-u/p/9512185.html
Go系列:https://www.cnblogs.com/f-ck-need-u/p/9832538.html
Python系列:https://www.cnblogs.com/f-ck-need-u/p/9832640.html
Ruby系列:https://www.cnblogs.com/f-ck-need-u/p/10805545.html
操作系统系列:https://www.cnblogs.com/f-ck-need-u/p/10481466.html
精通awk系列:https://www.cnblogs.com/f-ck-need-u/p/12688355.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号